/














































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































Автор: Ульман Дж. Гарсиа-Молина Г. Уидом Дж.
Теги: компьютерные технологии программное обеспечение базы данных
ISBN: 5-8459-0384-X
Год: 2003




Текст
Г"
\
V-
J
^
;
rJ
-J
&
C7
c1-
с
(i
Системы баз данных
Полный курс
Database Systems
The Complete Book
Hector Garcia-Molina
Jeffrey D. Ullman
Jennifer Widom
Department of Computer Science
Stanford University
Prentice
Hall
Prentice Hall
Upper Saddle River, New Jersey 07458
Системы баз данных
Полный курс
Гектор Гарсиа-Молина
Джеффри. Д. Ульман
Дженнифер Уидом
Отделение компьютерных наук
Станфордского университета
Москва • Санкт-Петербург • Киев
2003
ББК 32.973.26-018.2.75
Г21
УДК 681.3.07
Издательский дом "Вильяме"
Зав. редакцией А. В. Слепцов
Перевод с английского и редакция канд.техн.наук А. С. Варакина
По общим вопросам обращайтесь в Издательский дом "Вильяме" по адресу:
info@williamspublishlng.com, http://www.williamspublishing.com
Гарсиа-Молина, Гектор, Ульман, Джеффри, Д., Уидом, Дженнифер
Г21 Системы баз данных. Полный курс. : Пер. с англ. — М. : Издательский дом
"Вильяме", 2003. — 1088 с. : ил. — Парал. тит. англ.
ISBN 5-8459-0384-Х (рус.)
Книга известного специалиста в области компьютерных наук Дж. Ульмана
и его именитых коллег по Станфордскому университету является уникальным
учебным и справочным пособием, которое отличается беспрецедентными широтой
и глубиной охвата предмета и представляет несомненный интерес для всех, кто по
роду своей профессиональной деятельности сталкивается с проблемами
проектирования и использования современных систем баз данных.
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми марками
соответствующих фирм.
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в
какой бы то ни было форме и какими бы то ни было средствами, будь то электронные или
механические, включая фотокопирование и запись на магнитный носитель, если на это нет
письменного разрешения издательства Prentice Hall, Inc.
Authorized translation from the English language edition published by Prentice-Hall, Inc.,
Copyright © 2002
All rights reserved. No part of this book may be reproduced or transmitted in any form or by any
means, electronic or mechanical, including photocopying, recording or by any information storage
retrieval system, without permission from the Publisher.
Russian language edition published by Williams Publishing House according to the Agreement with
R&I Enterprises International, Copyright © 2002
ISBN 5-8459-0384-Х (рус.) © Издательский дом "Вильяме", 2002
ISBN 0-1303-1995-3 (англ.) © Prentice Hall, Inc., 2002
Оглавление
Глава 1. Мир баз данных 31
Глава 2. Модель данных "сущность-связь" 51
Глава 3. Реляционная модель 87
Глава 4. Другие модели данных 149
Глава 5. Реляционная алгебра 203
Глава 6. Язык SQL 249
Глава 7. Ограничения и триггеры 317
Глава 8. Системные аспекты SQL 349
Глава 9. Объектная ориентация и языки запросов 419
Глава 10. Логические языки запросов 453
Глава 11. Принципы хранения информации 489
Глава 12. Представление элементов данных 549
Глава 13. Структуры индексов 583
Глава 14. Многомерные и точечные индексы 637
Глава 15. Выполнение запросов 683
Глава 16. Компиляция и оптимизация запросов 753
Глава 17. Профилактика системных отказов и устранение их последствий 837
Глава 18. Управление параллельными заданиями 879
Глава 19. Дополнительные аспекты управления транзакциями 949
Глава 20. Интеграция информации 1003
Послесловие редактора перевода 1049
Именной указатель 1051
Предметный указатель 1055
Содержание
Об авторах 27
Предисловие 28
Как работать с книгой 28
Предварительные условия 28
Упражнения 29
Ресурсы в World Wide Web 29
Благодарности 29
Глава 1. Мир баз данных 31
1.1. Эволюция систем баз данных 32
1.1.1. Первые СУБД 32
1.1.2. Системы реляционных баз данных 34
1.1.3. Уменьшение и удешевление систем 35
1.1.4. Тенденции роста систем 36
1.1.5. Системы "клиент/сервер" и многоуровневые архитектуры 37
1.1.6. Данные мультимедиа 38
1.1.7. Интеграция информации 38
1.2. Обзор структуры СУБД 39
1.2.1. Команды языка определения данных 40
1.2.2. Обработка запросов 40
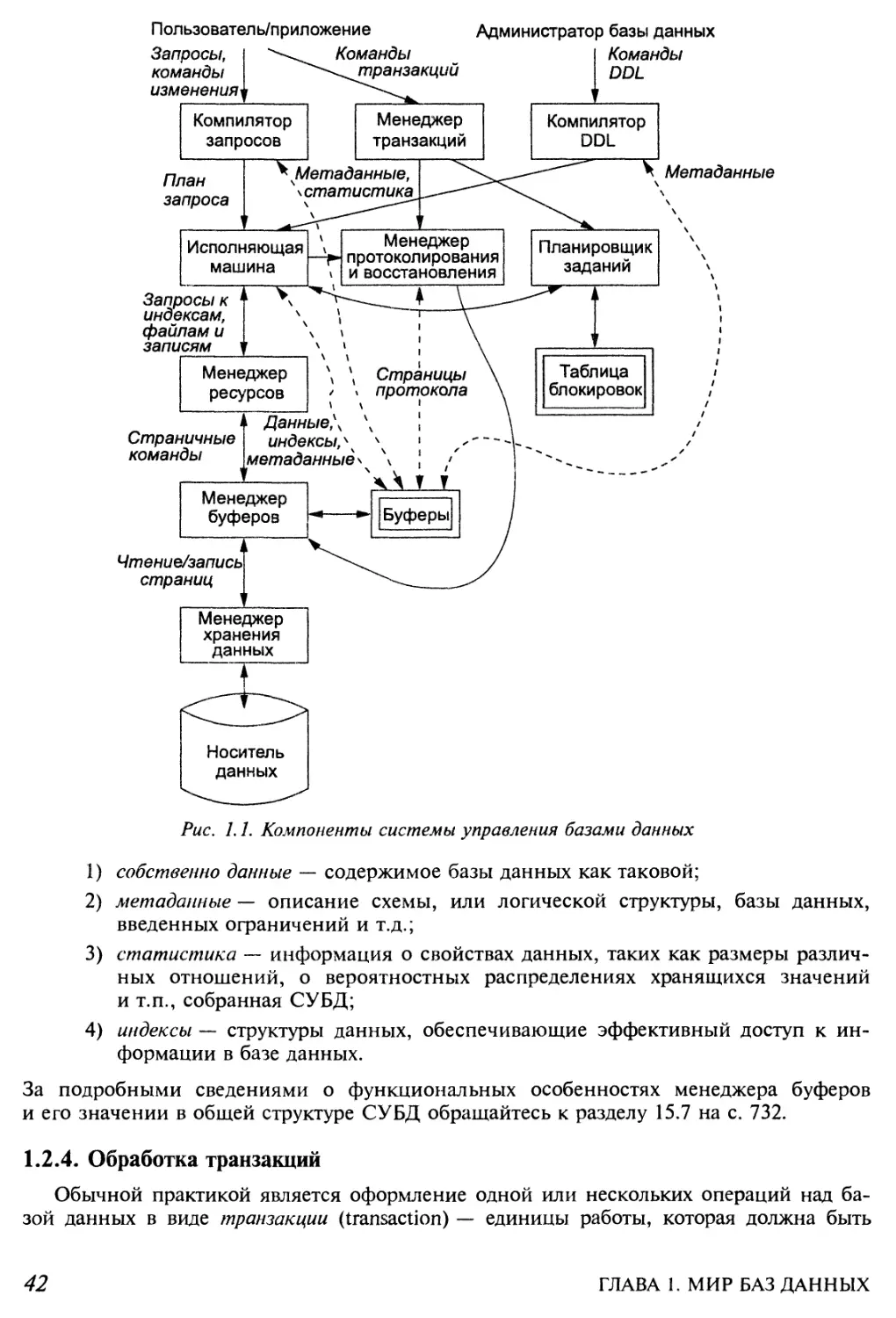
1.2.3. Менеджеры буферов и хранения данных 41
1.2.4. Обработка транзакций 42
1.2.5. Процессор запросов 43
1.3. Обзор технологий СУБД 45
1.3.1. Проектирование баз данных 45
1.3.2. Программирование приложений баз данных 45
1.3.3. Реализация систем баз данных 47
1.3.4. Интеграция информации 48
1.4. Резюме 49
1.5. Литература 50
Глава 2. Модель данных "сущность-связь" 51
2.1. Элементы ER-модели 52
2.1.1. Множества сущностей 52
2.1.2. Атрибуты 53
2.1.3. Связи 53
2.1.4. Диаграммы сущностей и связей 53
2.1.5. Экземпляры ER-диаграммы 54
2.1.6. Множественность бинарных связей 55
2.1.7. Многосторонние связи 56
2.1.8. Связи и роли 57
2.1.9. Связи и атрибуты 59
2.1.10. Преобразование многосторонних связей в бинарные 60
2.1.11. Подклассы в ER-модели 61
2.1.12. Упражнения к разделу 2.1 63
2.2. Принципы проектирования 66
2.2.1. Достоверность 66
2.2.2. Отсутствие избыточности 67
2.2.3. Простота 67
2.2.4. Выбор подходящих связей 67
2.2.5. Использование элементов адекватных типов 69
2.2.6. Упражнения к разделу 2.2 71
2.3. Моделирование ограничений 74
2.3.1. Классификация ограничений 74
2.3.2. Ключи и ER-моделирование 75
2.3.3. Представление ключей в ER-модели 77
2.3.4. Ограничения уникальности 77
2.3.5. Ограничения ссылочной целостности 78
2.3.6. Ссылочная целостность и ER-диаграммы 79
2.3.7. Ограничения других видов 79
2.3.8. Упражнения к разделу 2.3 80
2.4. Слабые множества сущностей 81
2.4.1. Примеры использования слабых множеств сущностей 81
2.4.2. Требования к слабым множествам сущностей 82
2.4.3. Система обозначений слабых множеств сущностей 84
2.4.4. Упражнения к разделу 2.4 85
2.5. Резюме 85
2.6. Литература 86
Глава 3. Реляционная модель 87
3.1. Основы реляционной модели 87
3.1.1. Атрибуты 88
3.1.2. Схемы 88
3.1.3. Кортежи 88
3.1.4. Домены 89
3.1.5. Формы представления отношений 89
3.1.6. Экземпляры отношения 89
3.1.7. Упражнения к разделу 3.1 90
3.2. От ER-диаграмм к реляционным схемам 91
3.2.1. От множеств сущностей к отношениям 91
3.2.2. От ER-связей к отношениям 93
3.2.3. Объединение отношений 95
3.2.4. Преобразование слабых множеств сущностей 96
3.2.5. Упражнения к разделу 3.2 99
3.3. Преобразование структур подклассов в отношения 100
3.3.1. Преобразование в стиле "сущность—связь" 101
3.3.2. Объектно-ориентированный подход 102
3.3.3. Значения "null" и объединение отношений 103
8
СОДЕРЖАНИЕ
3.3.4. Сравнение стратегий 103
3.3.5. Упражнения к разделу 3.3 104
3.4. Функциональные зависимости 106
3.4.1. Определение функциональной зависимости 106
3.4.2. Ключи отношений 108
3.4.3. Суперключи 109
3.4.4. Выбор ключей для отношения 109
3.4.5. Упражнения к разделу 3.4 111
3.5. Правила использования функциональных зависимостей 112
3.5.1. Правила разделения/объединения 113
3.5.2. Тривиальные функциональные зависимости 114
3.5.3. Замыкание множества атрибутов 115
3.5.4. Обоснование алгоритма вычисления замыкания 116
3.5.5. Правило транзитивности 118
3.5.6. Замкнутые множества функциональных зависимостей 119
3.5.7. Проецирование функциональных зависимостей 120
3.5.8. Упражнения к разделу 3.5 121
3.6. Проектирование реляционных схем 123
3.6.1. Аномалии 123
3.6.2. Декомпозиция отношений 124
3.6.3. Нормальная форма Бойса—Кодда 126
3.6.4. Декомпозиция в BCNF 128
3.6.5. Реконструкция данных из отношений декомпозиции 132
3.6.6. Третья нормальная форма 134
3.6.7. Упражнения к разделу 3.6 136
3.7. Многозначные зависимости 137
3.7.1. Независимость атрибутов как причина избыточности 137
3.7.2. Определение многозначной зависимости 138
3.7.3. Правила использования многозначных зависимостей 139
3.7.4. Четвертая нормальная форма 141
3.7.5. Декомпозиция в 4NF 141
3.7.6. Взаимоотношения нормальных форм 143
3.7.7. Упражнения к разделу 3.7 143
3.8. Резюме 145
3.9. Литература 146
Глава 4. Другие модели данных 149
4.1. Обзор понятий объектно-ориентированного проектирования 150
4.1.1. Система поддержки типов 150
4.1.2. Классы и объекты 151
4.1.3. Идентификационный номер объекта 151
4.1.4. Методы 151
4.1.5. Иерархии классов 152
4.2. Введение в язык ODL 152
4.2.1. Объектно-ориентированное проектирование 153
4.2.2. Объявление класса 154
4.2.3. Атрибуты 154
4.2.4. Связи 155
СОДЕРЖАНИЕ
9
4.2.5. Обратные связи 156
4.2.6. Множественность связей 158
4.2.7. Методы 159
4.2.8. Типы в ODL 161
4.2.9. Упражнения к разделу 4.2 163
4.3. Другие понятия ODL 164
4.3.1. Многосторонние связи 164
4.3.2. Подклассы 165
4.3.3. Множественное наследование 166
4.3.4. Экземпляры 167
4.3.5. Ключи 168
4.3.6. Упражнения к разделу 4.3 170
4.4. От ODL-проектов к реляционным схемам 171
4.4.1. От ODL-атрибутов к атрибутам отношений 172
4.4.2. Неатомарные атрибуты классов 172
4.4.3. Представление атрибутов типа множеств 173
4.4.4. Представление атрибутов других составных типов 175
4.4.5. Представление связей 177
4.4.6. А если ключей просто нет? 178
4.4.7. Упражнения к разделу 4.4 179
4.5. Объектно-реляционная модель 180
4.5.1. От отношений к объектам-отношениям 181
4.5.2. Вложенные отношения 182
4.5.3. Ссылки 183
4.5.4. Объектно-ориентированный и объектно-реляционный
подходы: за и против 184
4.5.5. От ODL-проектов к объектно-реляционным решениям 185
4.5.6. Упражнения к разделу 4.5 186
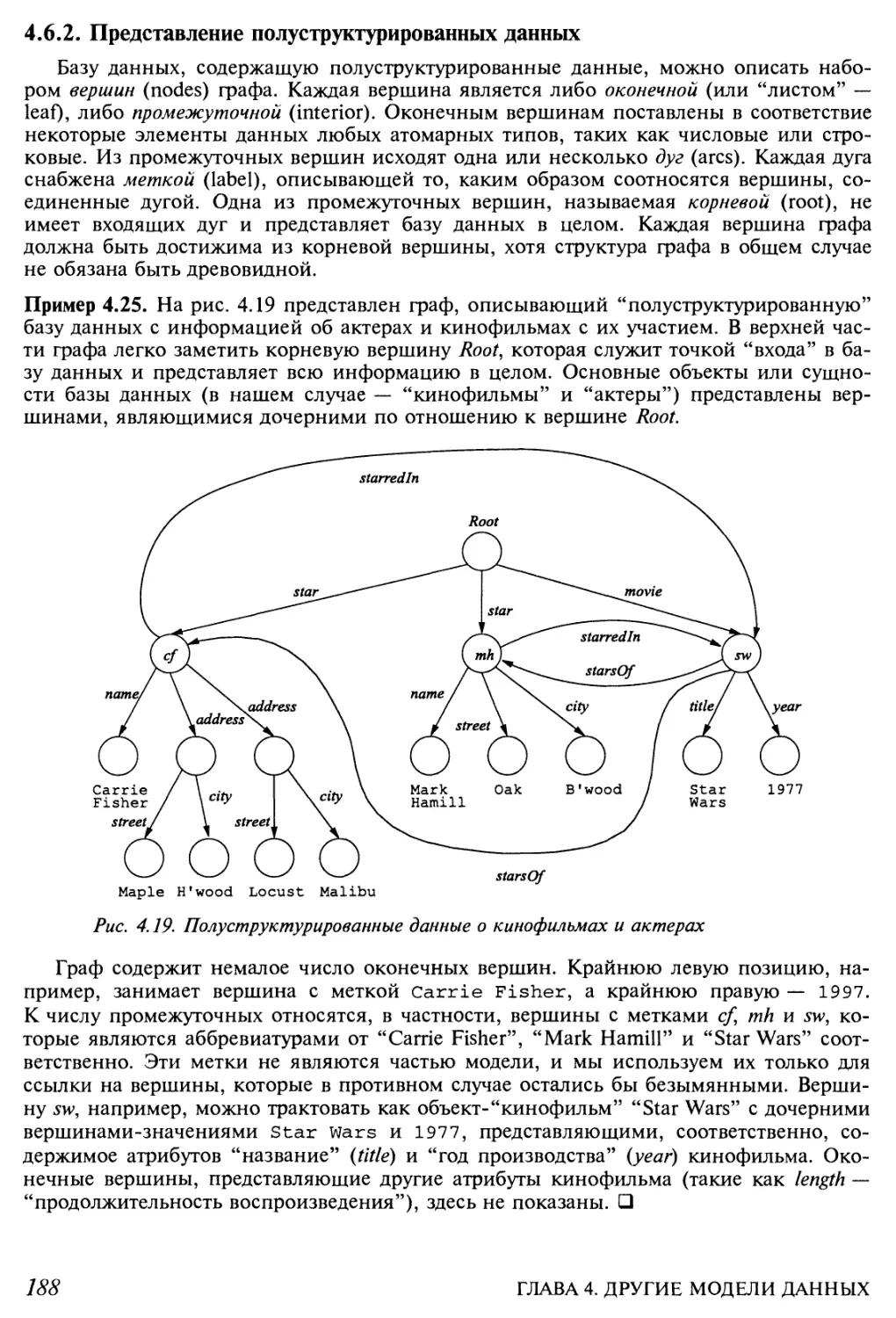
4.6. Полуструктурированные данные 187
4.6.1. Обоснование модели полуструктурированных данных 187
4.6.2. Представление полуструктурированных данных 188
4.6.3. Интеграция информации с помощью модели
полу структурированных данных 189
4.6.4. Упражнения к разделу 4.6 191
4.7. Язык и модель данных XML 192
4.7.1. Семантические тэги 192
4.7.2. Правильные XML-документы 193
4.7.3. Определения типа документа 194
4.7.4. Использование DTD 195
4.7.5. Списки атрибутов 196
4.7.6. Упражнения к разделу 4.7 199
4.8. Резюме 199
4.9. Литература 200
Глава 5. Реляционная алгебра 203
5.1. Пример схемы базы данных 204
5.2. Алгебра реляционных операций 205
5.2.1. Основы реляционной алгебры 206
5.2.2. Теоретико-множественные операции над отношениями 207
10
СОДЕРЖАНИЕ
5.2.3. Проекция 208
5.2.4. Выбор 209
5.2.5. Декартово произведение 210
5.2.6. Естественное соединение 211
5.2.7. Тета-соединение 212
5.2.8. Наборы операций и формирование запросов 214
5.2.9. Переименование атрибутов 215
5.2.10. Зависимые и независимые операции 216
5.2.11. Алгебраические выражения в линейном представлении 217
5.2.12. Упражнения к разделу 5.2 218
5.3. Реляционные операции над мультимножествами 225
5.3.1. Зачем нужны мультимножества 226
5.3.2. Объединение, пересечение и разность мультимножеств 227
5.3.3. Проекция мультимножеств 228
5.3.4. Выбор из мультимножеств 229
5.3.5. Декартово произведение мультимножеств 230
5.3.6. Операции соединения мультимножеств 230
5.3.7. Упражнения к разделу 5.3 231
5.4. Дополнительные операторы реляционной алгебры 232
5.4.1. Удаление дубликатов 233
5.4.2. Операторы агрегирования 234
5.4.3. Группирование 234
5.4.4. Оператор группирования 235
5.4.5. Оператор расширенной проекции 236
5.4.6. Оператор сортировки 238
5.4.7. Внешние соединения 238
5.4.8. Упражнения к разделу 5.4 241
5.5. Отношения и ограничения 241
5.5.1. Реляционная алгебра как язык описания ограничений 242
5.5.2. Ограничения ссылочной целостности 242
5.5.3. Другие ограничения 243
5.5.4. Упражнения к разделу 5.5 245
5.6. Резюме 246
5.7. Литература 247
Глава 6. Язык SQL 249
6.1. Простые запросы на языке SQL 250
6.1.1. Проекция в SQL 251
6.1.2. Выбор в SQL 253
6.1.3. Сравнение строк 254
6.1.4. Значения даты и времени в SQL 256
6.1.5. Значение null и операции сравнения с null 258
6.1.6. Значение unknown 259
6.1.7. Упорядочение результатов 260
6.1.8. Упражнения к разделу 6.1 261
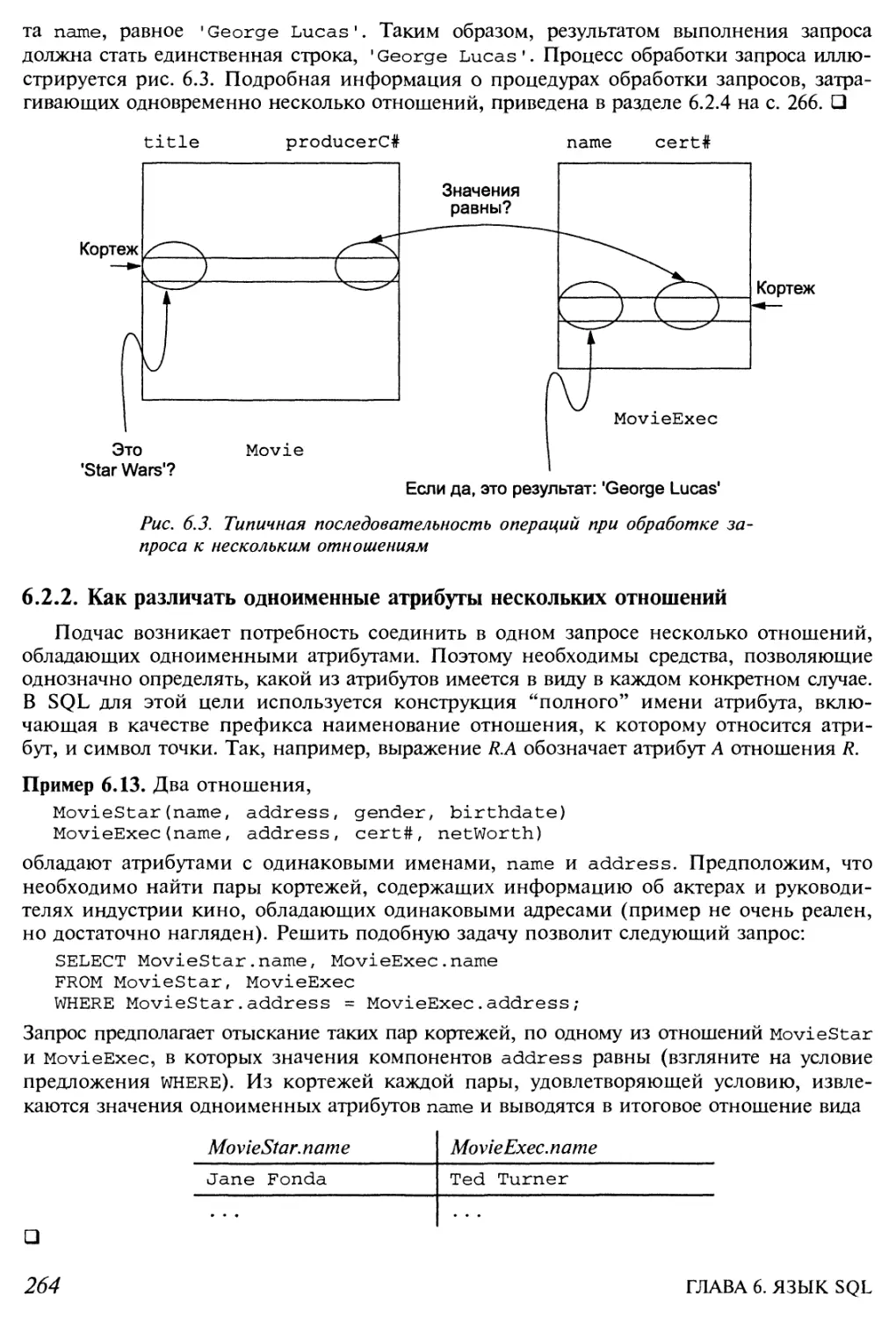
6.2. Запросы к нескольким отношениям 263
6.2.1. Декартово произведение и соединение в SQL 263
6.2.2. Как различать одноименные атрибуты нескольких отношений 264
6.2.3. Переменные кортежей и псевдонимы отношений 265
6.2.4. Интерпретация запросов к нескольким отношениям 266
СОДЕРЖАНИЕ
77
6.2.5. Объединение, пересечение и разность запросов
6.2.6. Упражнения к разделу 6.2 270
6.3. Подзапросы 271
6.3.1. Подзапросы для вычисления скалярных значений 272
6.3.2. Условия уровня отношения 273
6.3.3. Условия уровня кортежа 273
6.3.4. Коррелированные подзапросы 275
6.3.5. Подзапросы в предложениях FROM 276
6.3.6. Выражения соединения в SQL 277
6.3.7. Естественное соединение 278
6.3.8. Внешние соединения 279
6.3.9. Упражнения к разделу 6.3 280
6.4. Операции над отношениями 283
6.4.1. Удаление кортежей-дубликатов 283
6.4.2. Дубликаты в объединениях, пересечениях и разностях
отношений 284
6.4.3. Группирование и агрегирование в SQL 285
6.4.4. Операторы агрегирования 285
6.4.5. Группирование 286
6.4.6. Предложения having 287
6.4.7. Упражнения к разделу 6.4 289
6.5. Модификация базы данных 291
6.5.1. Вставка кортежей 291
6.5.2. Удаление кортежей 293
6.5.3. Обновление данных 294
6.5.4. Упражнения к разделу 6.5 295
6.6. Определение схем отношений в SQL 296
6.6.1. Типы данных 296
6.6.2. Простые объявления схем отношений 297
6.6.3. Модификация реляционных схем 298
6.6.4. Значения по умолчанию 299
6.6.5. Индексы 299
6.6.6. Знакомство с технологиями выбора индексов 301
6.6.7. Упражнения к разделу 6.6 304
6.7. Виртуальные таблицы 305
6.7.1. Объявление виртуальной таблицы 305
6.7.2. Запросы к виртуальным таблицам 306
6.7.3. Переименование атрибутов 307
6.7.4. Модификация виртуальных таблиц 308
6.7.5. Интерпретация запросов к виртуальным таблицам 310
6.7.6. Упражнения к разделу 6.7 312
6.8. Резюме 314
6.9. Литература 315
Глава 7. Ограничения и триггеры 317
7.1. Ключи отношений 318
7.1.1. Объявление первичного ключа 318
7.1.2. Объявление ключа unique 319
7.1.3. Соблюдение ограничений ключей 320
12
СОДЕРЖАНИЕ
7.1.4. Объявление внешнего ключа
7.1.5. Обеспечение ссылочной целостности
7.1.6. Отложенная проверка ограничений
7.1.7. Упражнения к разделу 7.1
7.2. Ограничения уровня атрибутов и кортежей
7.2.1. Ограничения not null
7.2.2. Ограничения check уровня атрибута
7.2.3. Ограничения check уровня кортежа
7.2.4. Упражнения к разделу 7.2
7.3. Модификация ограничений
7.3.1. Именование ограничений
7.3.2. Модификация ограничений и команда alter table
7.3.3. Упражнения к разделу 7.3
7.4. Ограничения уровня схемы и триггеры
7.4.1. Ограничения "общего вида"
7.4.2. Правила "событие—условие—действие"
7.4.3. Триггеры в SQL
7.4.4. Триггеры instead of
7.4.5. Упражнения к разделу 7.4
7.5. Резюме
7.6. Литература
Глава 8. Системные аспекты SQL
8.1. SQL в среде программирования
8.1.1. Проблема согласования моделей данных
8.1.2. Интерфейс взаимодействия SQL и базового языка
8.1.3. Секция объявления
8.1.4. Использование общих переменных
8.1.5. Команды выбора единственного кортежа
8.1.6. Курсоры
8.1.7. Модификация данных посредством курсоров
8.1.8. Защита данных курсора от внешних воздействий
8.1.9. Изменение порядка просмотра содержимого курсора
8.1.10. Динамический SQL
8.1.11. Упражнения к разделу 8.1
8.2. Хранимые процедуры и функции
8.2.1. Создание хранимых процедур и функций
8.2.2. Простые формы выражений
8.2.3. Ветвления
8.2.4. Запросы
8.2.5. Циклы LOOP
8.2.6. Циклы for
8.2.7. Исключения
8.2.8. Использование хранимых процедур и функций
8.2.9. Упражнения к разделу 8.2
8.3. Среда SQL
8.3.1. Среды
8.3.2. Схемы
322
324
327
328
328
329
330
332
334
334
334
335
336
336
339
339
343
344
347
348
349
350
350
352
352
353
354
355
358
359
360
361
362
364
364
366
367
368
369
370
372
374
374
376
377
378
СОДЕРЖАНИЕ
8.3.3. Каталоги
8.3.4. Клиенты и серверы в среде SQL 380
8.3.5. Соединения 380
8.3.6. Сеансы 381
8.3.7. Модули 381
8.4. Интерфейс уровня вызовов 382
8.4.1. Введение в SQL/CLI 383
8.4.2. Обработка команд 385
8.4.3. Извлечение данных 386
8.4.4. Передача аргументов в SQL-команды 388
8.4.5. Упражнения к разделу 8.4 389
8.5. Java Database Connectivity 390
8.5.1. Введение в JDBC 390
8.5.2. Создание объектов SQL-команд 390
8.5.3. Операции с курсорами 392
8.5.4. Передача аргументов в SQL-команды 393
8.5.5. Упражнения к разделу 8.5 393
8.6. Транзакции и SQL 393
8.6.1. Последовательное выполнение операций 394
8.6.2. Атомарность 396
8.6.3. Транзакции 398
8.6.4. Транзакции "только для чтения" 399
8.6.5. "Чтение мусора" 400
8.6.6. Другие уровни изоляции 403
8.6.7. Упражнения к разделу 8.6 404
8.7. Безопасность и авторизация пользователей в SQL 405
8.7.1. Привилегии доступа 406
8.7.2. Создание привилегий 407
8.7.3. Контроль привилегий 408
8.7.4. Назначение привилегий 409
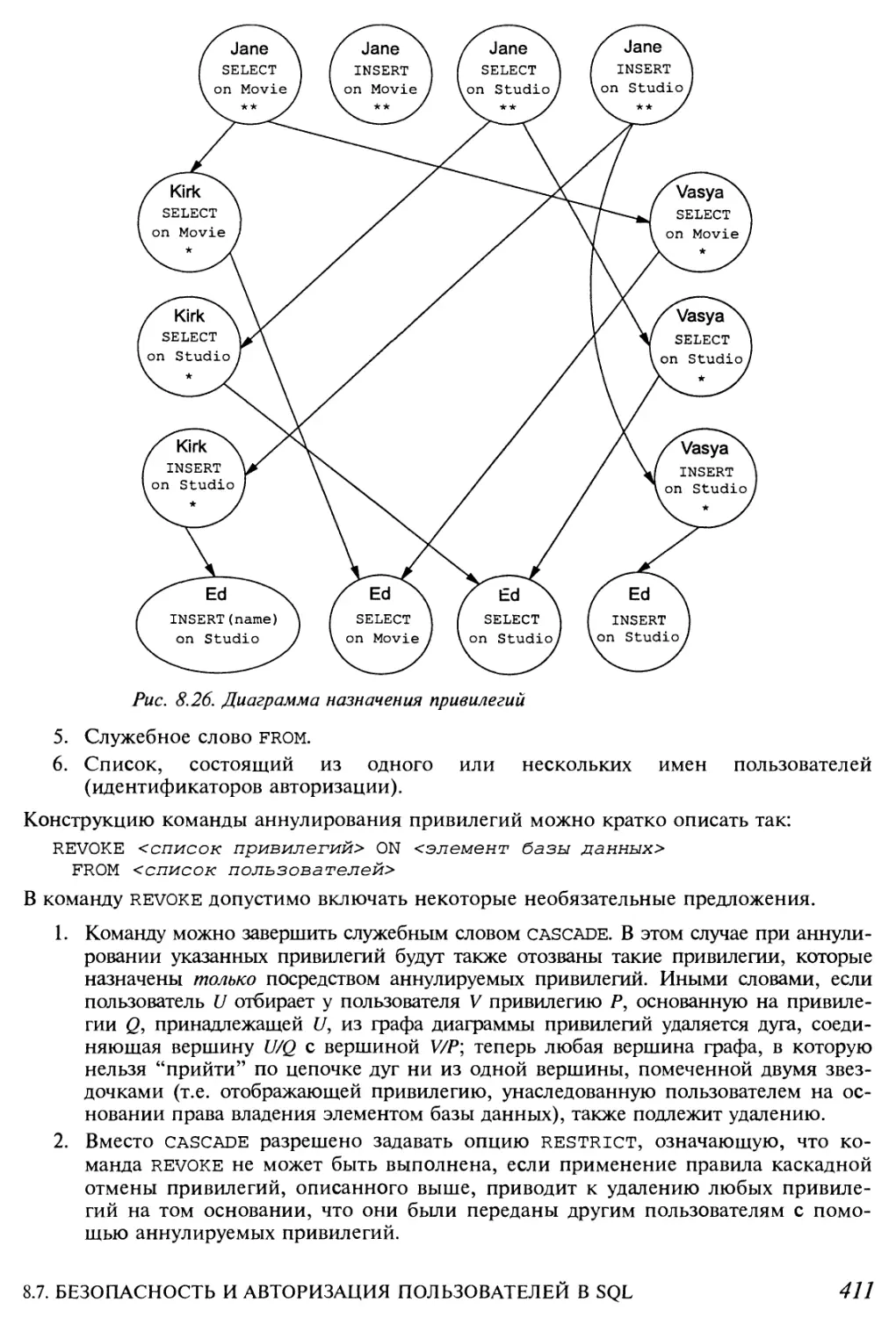
8.7.5. Диаграммы назначения привилегий 411
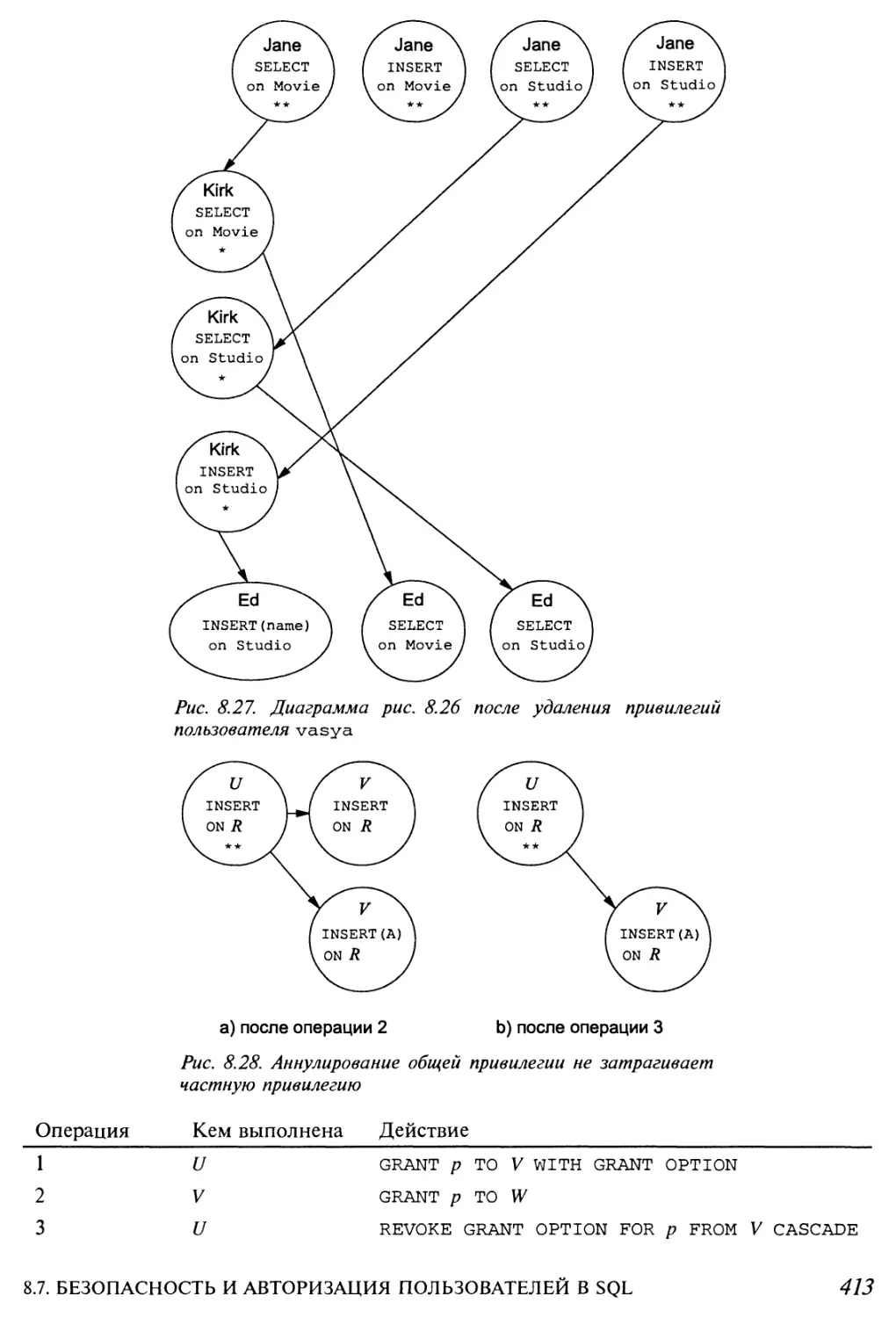
8.7.6. Аннулирование привилегий 411
8.7.7. Упражнения к разделу 8.7 415
8.8. Резюме 416
8.9. Литература 418
Глава 9. Объектная ориентация и языки запросов 419
9.1. Введение в язык OQL 419
9.1.1. Пример объектно-ориентированной базы данных 420
9.1.2. Описание зависимости между объектами и их членами 420
9.1.3. Выражения "select—from—where" 421
9.1.4. Изменение типа результата запроса 423
9.1.5. Сложные типы выходных данных 424
9.1.6. Подзапросы 424
9.1.7. Упражнения к разделу 9.1 425
9.2. Дополнительные формы выражений OQL 429
9.2.1. Логические множественные условия 429
9.2.2. Выражения с операторами агрегирования 430
14
СОДЕРЖАНИЕ
9.2.3. Выражения с оператором группирования 430
9.2.4. Предложения having 432
9.2.5. Операторы объединения, пересечения и разности 433
9.2.6. Упражнения к разделу 9.2 434
9.3. Создание и присваивание объектов в OQL 435
9.3.1. Присваивание значений переменным базового кода 435
9.3.2. Извлечение элементов единичных коллекций 435
9.3.3. Получение элементов произвольных коллекций 436
9.3.4. Константы в OQL 437
9.3.5. Создание объектов 438
9.3.6. Упражнения к разделу 9.3 439
9.4. Типы данных SQL, определяемые пользователем 440
9.4.1. Определение типов в SQL 440
9.4.2. Методы в пользовательских типах 441
9.4.3. Объявление схем отношений с помощью пользовательских
типов 442
9.4.4. Ссылочные типы 442
9.4.5. Упражнения к разделу 9.4 444
9.5. Операции над объектно-реляционными данными 445
9.5.1. Обращение по ссылке 445
9.5.2. Доступ к компонентам пользовательских типов 446
9.5.3. Генерирование объектов и модификация компонентов 446
9.5.4. Сопоставление объектов пользовательских типов 448
9.5.5. Упражнения к разделу 9.5 449
9.6. Резюме 451
9.7. Литература 452
Глава 10. Логические языки запросов 453
10.1. Логика отношений 453
10.1.1. Предикаты и атомы 453
10.1.2. Арифметические атомы 454
10.1.3. Правила и запросы Datalog 454
10.1.4. Интерпретация правил Datalog 455
10.1.5. Экстенсиональные и интенсиональные предикаты 458
10.1.6. Правила Datalog для мультимножеств 459
10.1.7. Упражнения к разделу 10.1 460
10.2. От реляционной алгебры к языку Datalog 460
10.2.1. Пересечение 460
10.2.2. Объединение 461
10.2.3. Разность 461
10.2.4. Проекция 462
10.2.5. Выбор 462
10.2.6. Декартово произведение 464
10.2.7. Соединения 464
10.2.8. Представление наборов операций средствами Datalog 466
10.2.9. Упражнения к разделу 10.2 467
10.3. Рекурсивное программирование на языке Datalog 468
10.3.1. Рекурсивные правила Datalog 469
СОДЕРЖАНИЕ
15
10.3.2. Вычисление рекурсивных правил Datalog 469
10.3.3. Отрицание в рекурсивных правилах 474
10.3.4. Упражнения к разделу 10.3 477
10.4. Рекурсия в SQL 478
10.4.1. Определение интенсиональных отношений в SQL 479
10.4.2. Изолированная рекурсия в SQL 480
10.4.3. Проблемы реализации рекурсии в SQL 482
10.4.4. Упражнения к разделу 10.4 485
10.5. Резюме 486
10.6. Литература 487
Глава 11. Принципы хранения информации 489
11.1. Пример системы баз данных 490
11.1.1. Особенности реализации 490
11.1.2. Как СУБД выполняет запросы 491
11.1.3. Что плохого в нашей системе? 492
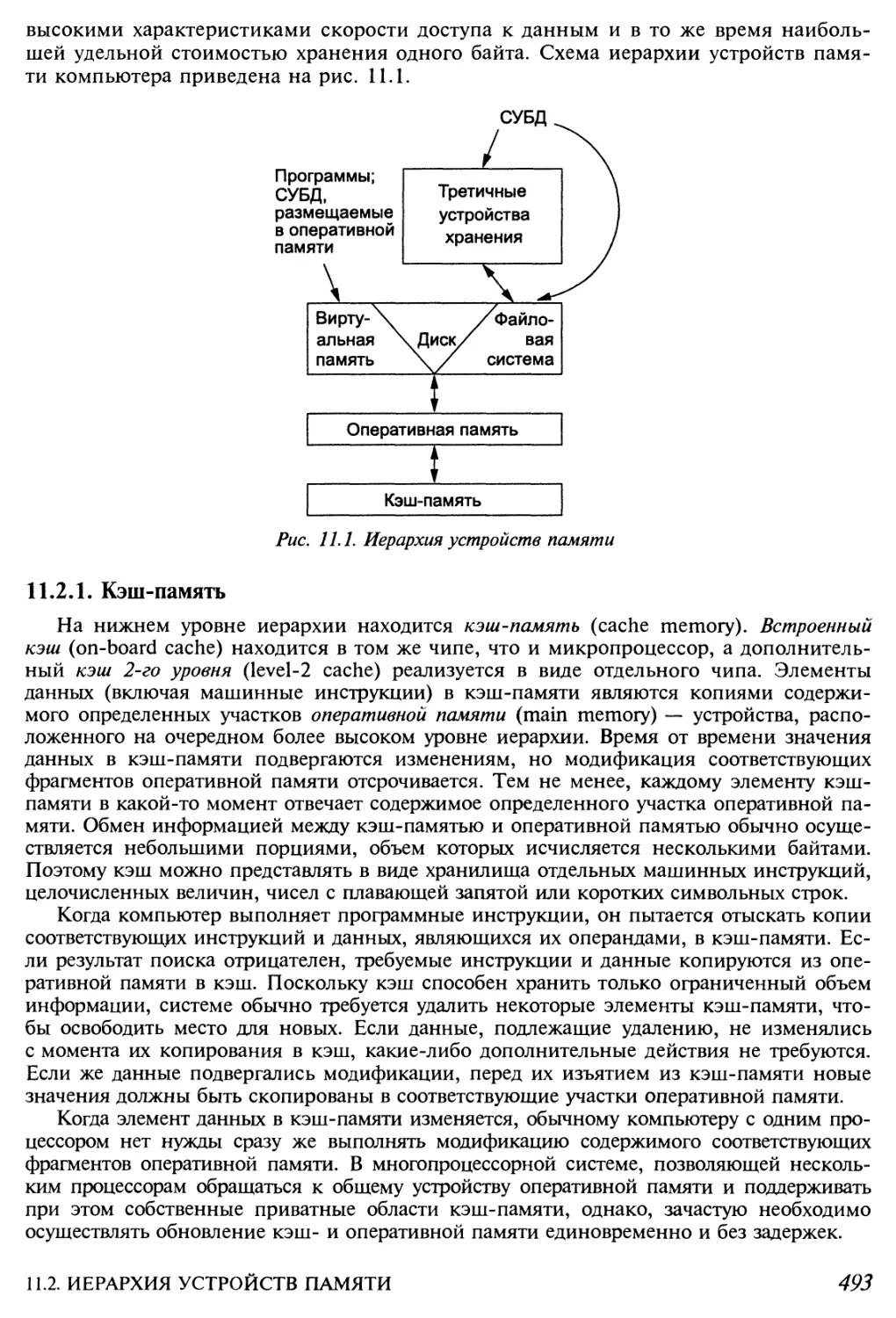
11.2. Иерархия устройств памяти 492
11.2.1. Кэш-память 493
11.2.2. Оперативная память 494
11.2.3. Виртуальная память 494
11.2.4. Вторичные устройства хранения 495
11.2.5. Третичные устройства хранения 497
11.2.6. Энергозависимые и энергонезависимые устройства памяти 499
11.2.7. Упражнения к разделу 11.2 500
11.3. Диски 500
11.3.1. Внутренние механизмы дисковых накопителей 500
11.3.2. Контроллер дисков 502
11.3.3. Общие параметры дисков 503
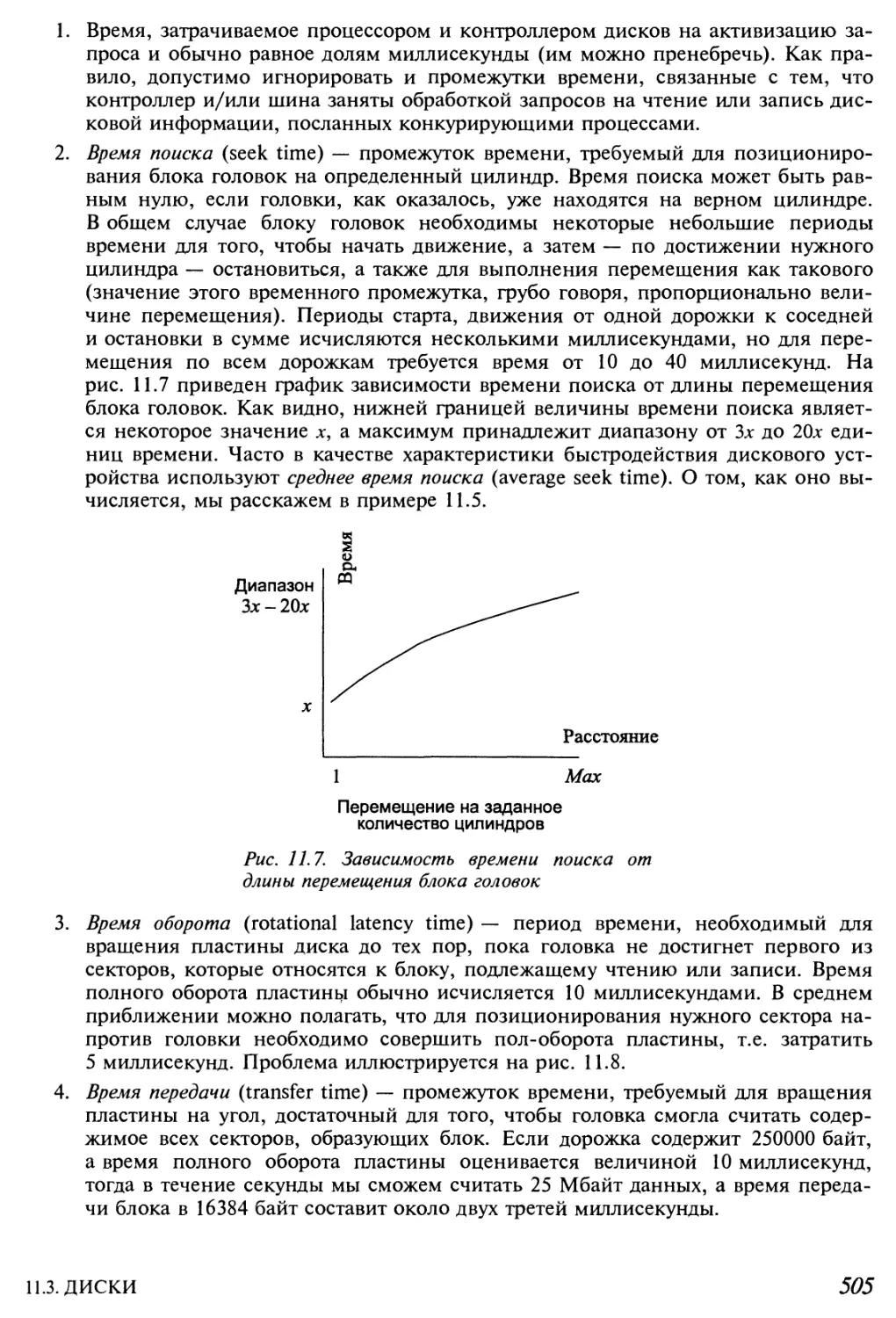
11.3.4. Параметры доступа 504
11.3.5. Запись блоков 508
11.3.6. Модификация содержимого блоков 508
11.3.7. Упражнения к разделу 11.3 509
11.4. Использование вторичных устройств хранения 510
11.4.1. Модель вычислений с функциями ввода-вывода 510
11.4.2. Сортировка данных во вторичных хранилищах 511
11.4.3. Сортировка слиянием 512
11.4.4. Сортировка двухфазным многокомпонентным слиянием 513
11.4.5. Многокомпонентное слияние и сверхбольшие отношения 516
11.4.6. Упражнения к разделу 11.4 517
11.5. Повышение эффективности дисковых операций 518
11.5.1. Группирование данных по цилиндрам диска 519
11.5.2. Использование нескольких дисковых устройств 521
11.5.3. Создание зеркальных копий дисков 522
11.5.4. Упорядочение дисковых операций и "алгоритм лифта" 523
11.5.5. Предварительное считывание и крупномасштабная
буферизация данных 526
11.5.6. Приемы оптимизации дисковых операций: за и против 527
11.5.7. Упражнения к разделу 11.5 529
16
СОДЕРЖАНИЕ
11.6. Отказы дисковых устройств 530
11.6.1. Перемежающиеся отказы 531
11.6.2. Контрольные суммы 531
11.6.3. "Устойчивые хранилища" 532
11.6.4. Устранение последствий ошибок 533
11.6.5. Упражнения к разделу 11.6 534
11.7. Восстановление данных при полном отказе диска 534
11.7.1. Модель отказов дисковых устройств 534
11.7.2. Зеркальные диски как средство резервирования 535
11.7.3. Блоки четности 536
11.7.4. Массивы RAID уровня 5 539
11.7.5. Восстановление данных после отказа нескольких дисков 540
11.7.6. Упражнения к разделу 11.7 543
11.8. Резюме 546
11.9. Литература 548
Глава 12. Представление элементов данных 549
12.1. Элементы данных и поля 549
12.1.1. Представление элементов реляционных баз данных 550
12.1.2. Представление объектов 550
12.1.3. Представление элементов данных 551
12.2. Записи 554
12.2.1. Конструирование записей постоянной длины 554
12.2.2. Заголовки записей 556
12.2.3. Группирование записей постоянной длины в блоках 557
12.2.4. Упражнения к разделу 12.2 558
12.3. Представление адресов записей и блоков 558
12.3.1. Системы "клиент/сервер" 559
12.3.2. Логические и структурированные адреса 560
12.3.3. "Подмена" указателей 561
12.3.4. Сохранение блоков на диске 565
12.3.5. "Закрепленные" записи и блоки 566
12.3.6. Упражнения к разделу 12.3 567
12.4. Элементы данных и записи переменной длины 569
12.4.1. Записи с полями переменной длины 569
12.4.2. Записи с повторяющимися полями 570
12.4.3. Записи переменного формата 571
12.4.4. Записи крупного объема 573
12.4.5. Объекты BLOB 574
12.4.6. Упражнения к разделу 12.4 575
12.5. Модификация записей 576
12.5.1. Вставка 576
12.5.2. Удаление 577
12.5.3. Обновление 579
12.5.4. Упражнения к разделу 12.5 579
12.6. Резюме 580
12.7. Литература 582
17
Глава 13. Структуры индексов 583
13.1. Индексы для последовательных файлов 584
13.1.1. Последовательные файлы 584
13.1.2. Плотные индексы 585
13.1.3. Разреженные индексы 586
13.1.4. Многоуровневые индексы 588
13.1.5. Дубликаты ключевых значений 589
13.1.6. Управление индексами при модификации данных 592
13.1.7. Упражнения к разделу 13.1 598
13.2. Вторичные индексы 599
13.2.1. Проектирование вторичных индексов 599
13.2.2. Применение вторичных индексов 600
13.2.3. Дополнительные уровни во вторичных индексах 601
13.2.4. Поиск документов и обращенные индексы 603
13.2.5. Упражнения к разделу 13.2 607
13.3. В-деревья 609
13.3.1. Структура В-дерева 609
13.3.2. Применение В-деревьев 612
13.3.3. Поиск в В-деревьях 613
13.3.4. Запросы в диапазонах значений 614
13.3.5. Вставка элементов в В-дерево 615
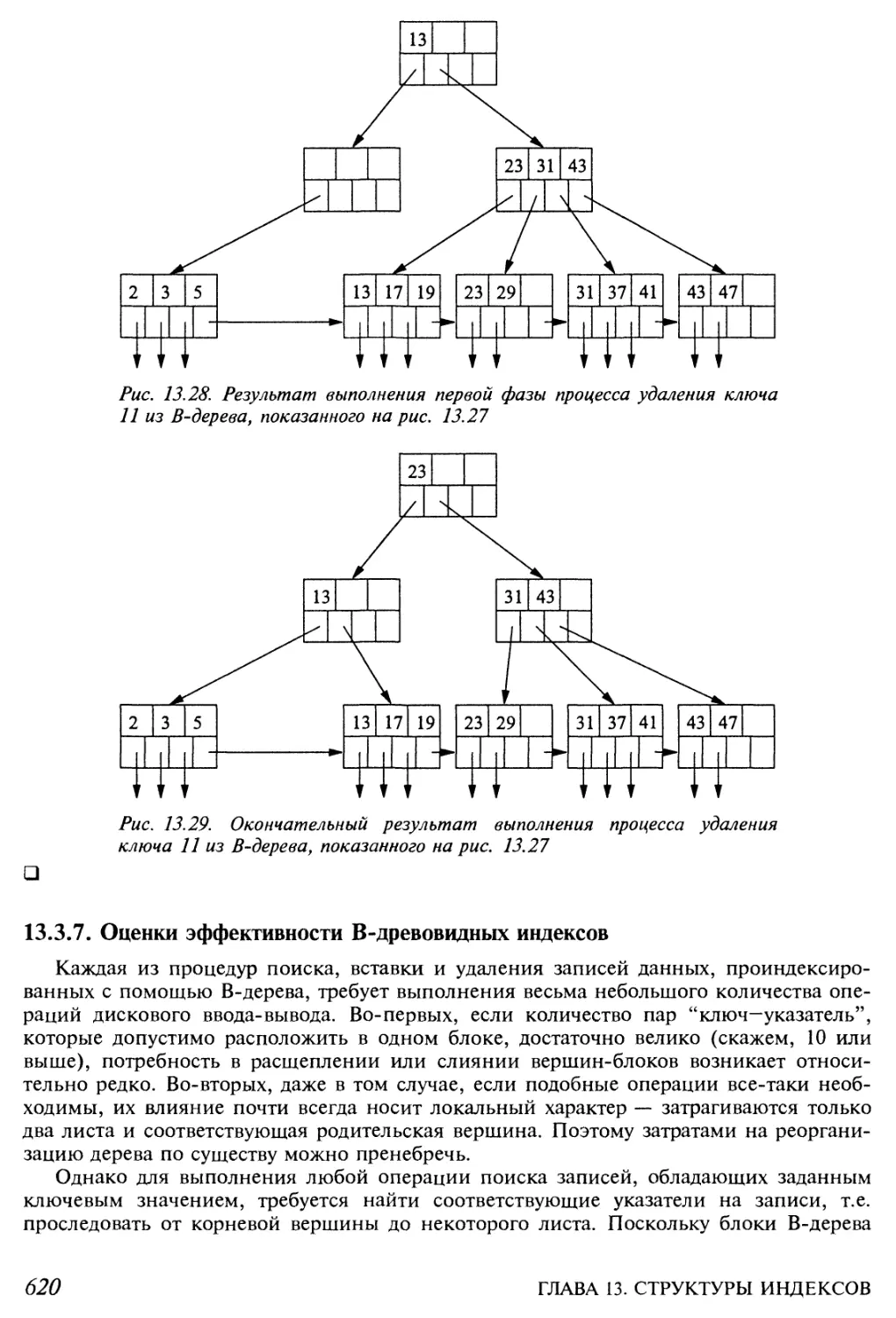
13.3.6. Удаление элементов из В-дерева 617
13.3.7. Оценки эффективности В-древовидных индексов 620
13.3.8. Упражнения к разделу 13.3 621
13.4. Хеш-таблицы 624
13.4.1. Хеш-таблицы для данных во вторичных хранилищах 624
13.4.2. Вставка записей в хеш-таблицу 625
13.4.3. Удаление записей из хеш-таблицы 626
13.4.4. Оценки эффективности хешированных индексов 626
13.4.5. Расширяемые хеш-таблицы 627
13.4.6. Вставка записей в расширяемую хеш-таблицу 627
13.4.7. Линейные хеш-таблицы 629
13.4.8. Вставка записей в линейную хеш-таблицу 631
13.4.9. Упражнения к разделу 13.4 633
13.5. Резюме 634
13.6. Литература 635
Глава 14. Многомерные и точечные индексы 637
14.1. Приложения модели многомерных данных 638
14.1.1. Географические информационные системы 638
14.1.2. Кубы данных 639
14.1.3. SQL-запросы к многомерным данным 640
14.1.4. Запросы в диапазонах значений с использованием
традиционных индексов 641
14.1.5. Поиск ближайших соседних объектов с использованием
традиционных индексов 643
14.1.6. Другие офаничения традиционных структур индексов 644
14.1.7. Обзор структур индексов для многомерных данных 645
14.1.8. Упражнения к разделу 14.1 645
18
СОДЕРЖАНИЕ
14.2. Хеш-подобные структуры для многомерных данных 646
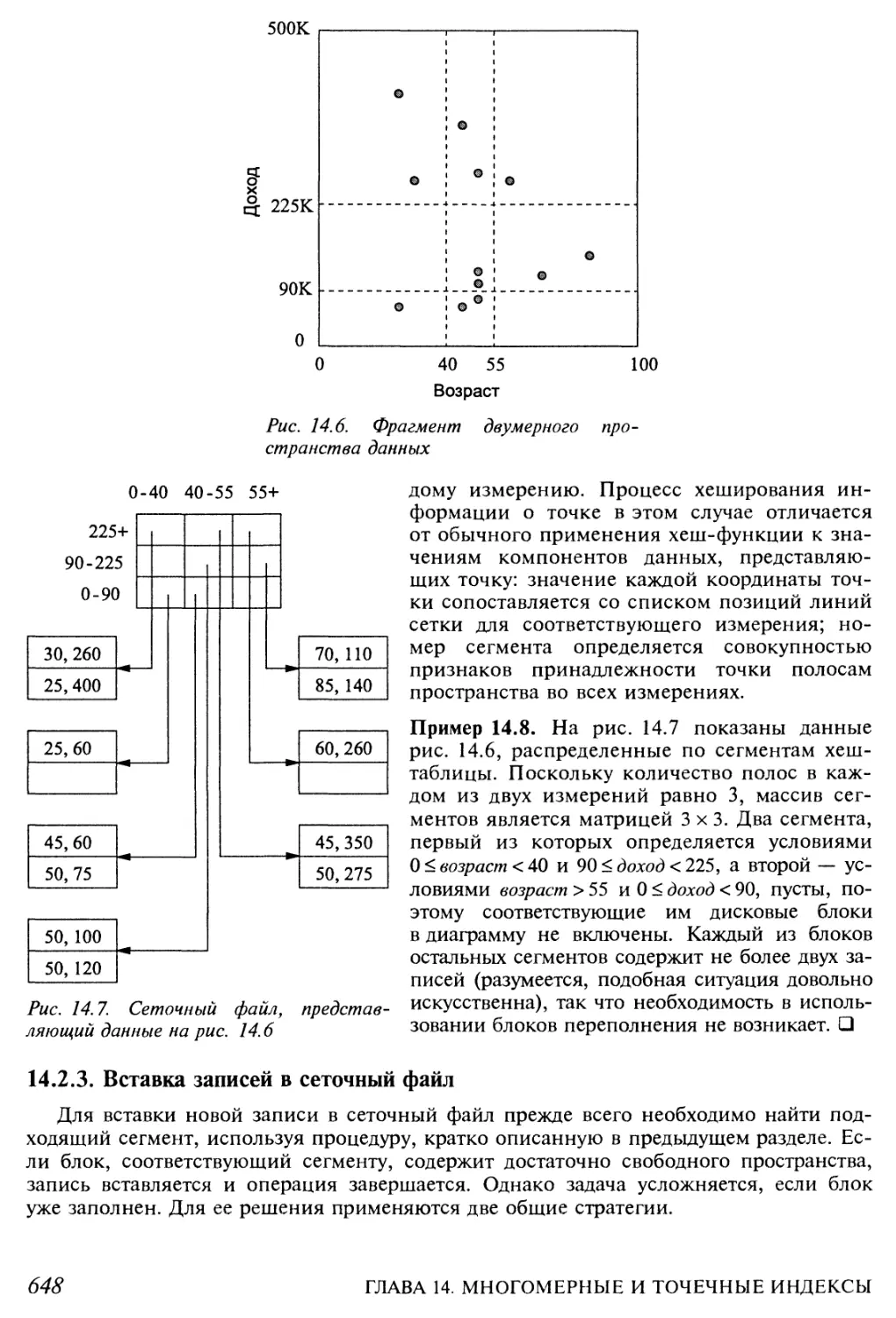
14.2.1. Сеточные файлы 647
14.2.2. Поиск записей в сеточном файле 647
14.2.3. Вставка записей в сеточный файл 648
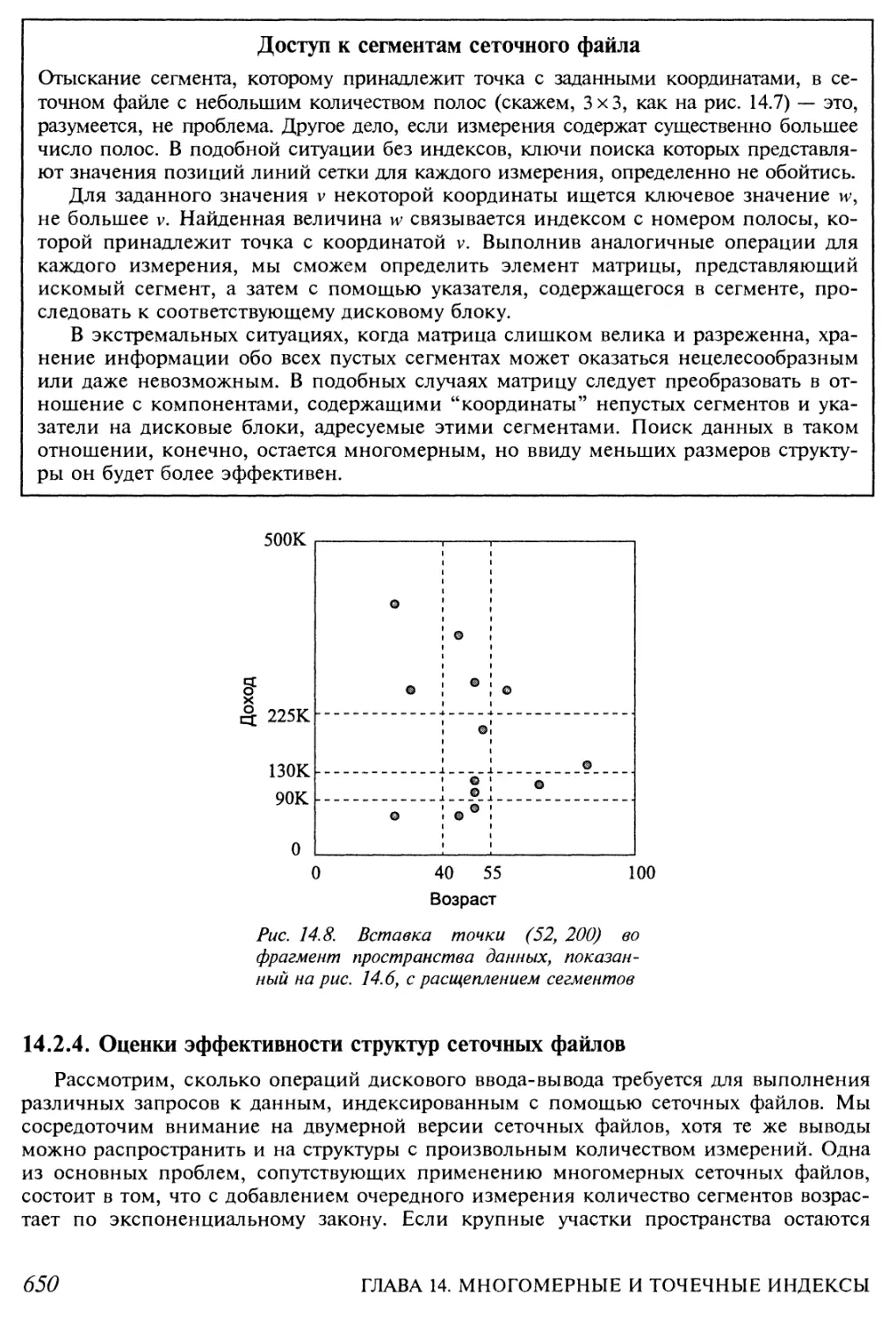
14.2.4. Оценки эффективности структур сеточных файлов 650
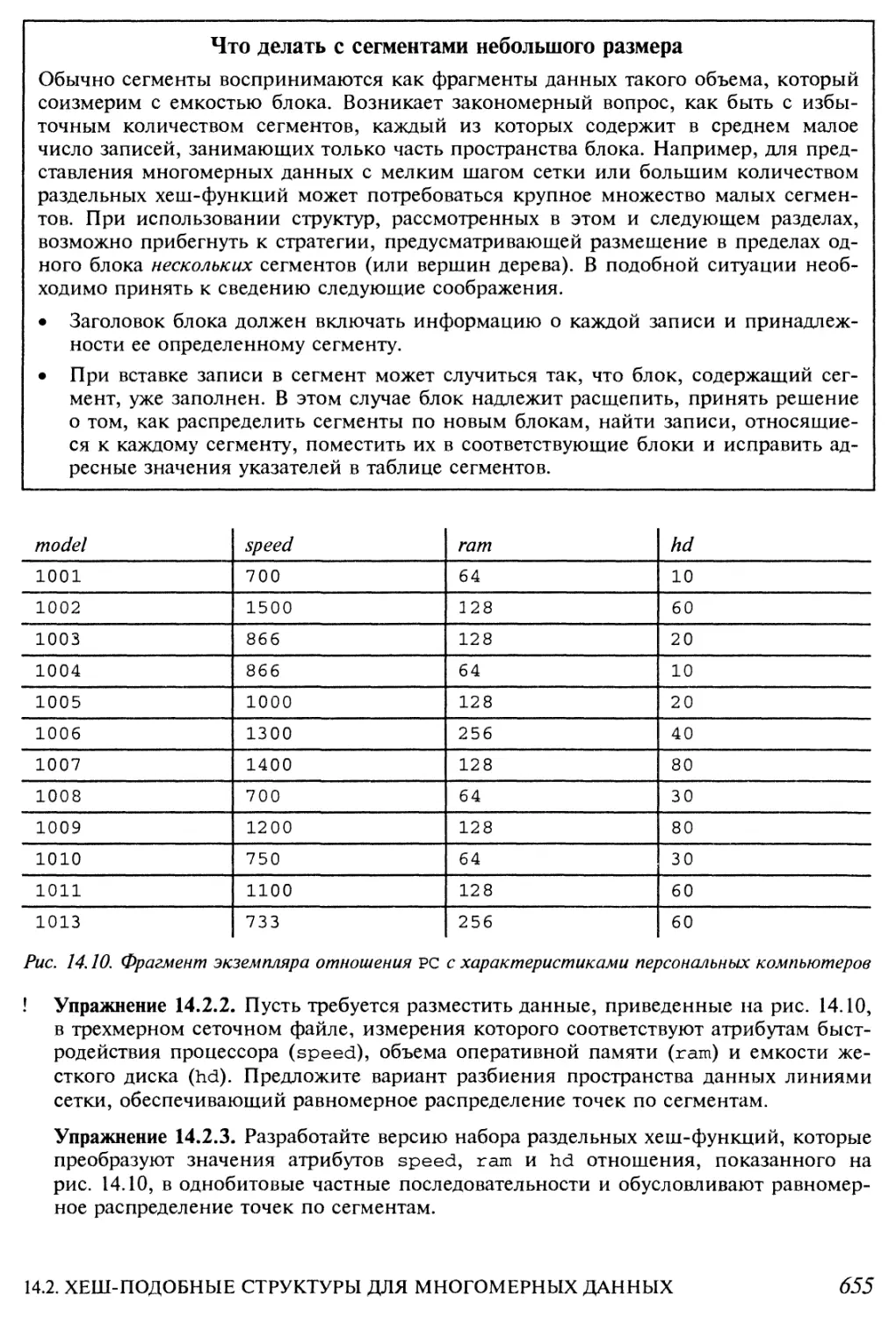
14.2.5. Раздельные хеш-функции 652
14.2.6. Сравнение структур сеточных файлов и раздельных хеш-таблиц 654
14.2.7. Упражнения к разделу 14.2 654
14.3. Древовидные структуры для многомерных данных 657
14.3.1. Индексы с несколькими ключами 657
14.3.2. Оценки эффективности структур индексов с несколькими
ключами 659
14.3.3. kd-деревья 659
14.3.4. Операции с kd-деревьями 660
14.3.5. kd-деревья и данные во вторичных хранилищах 663
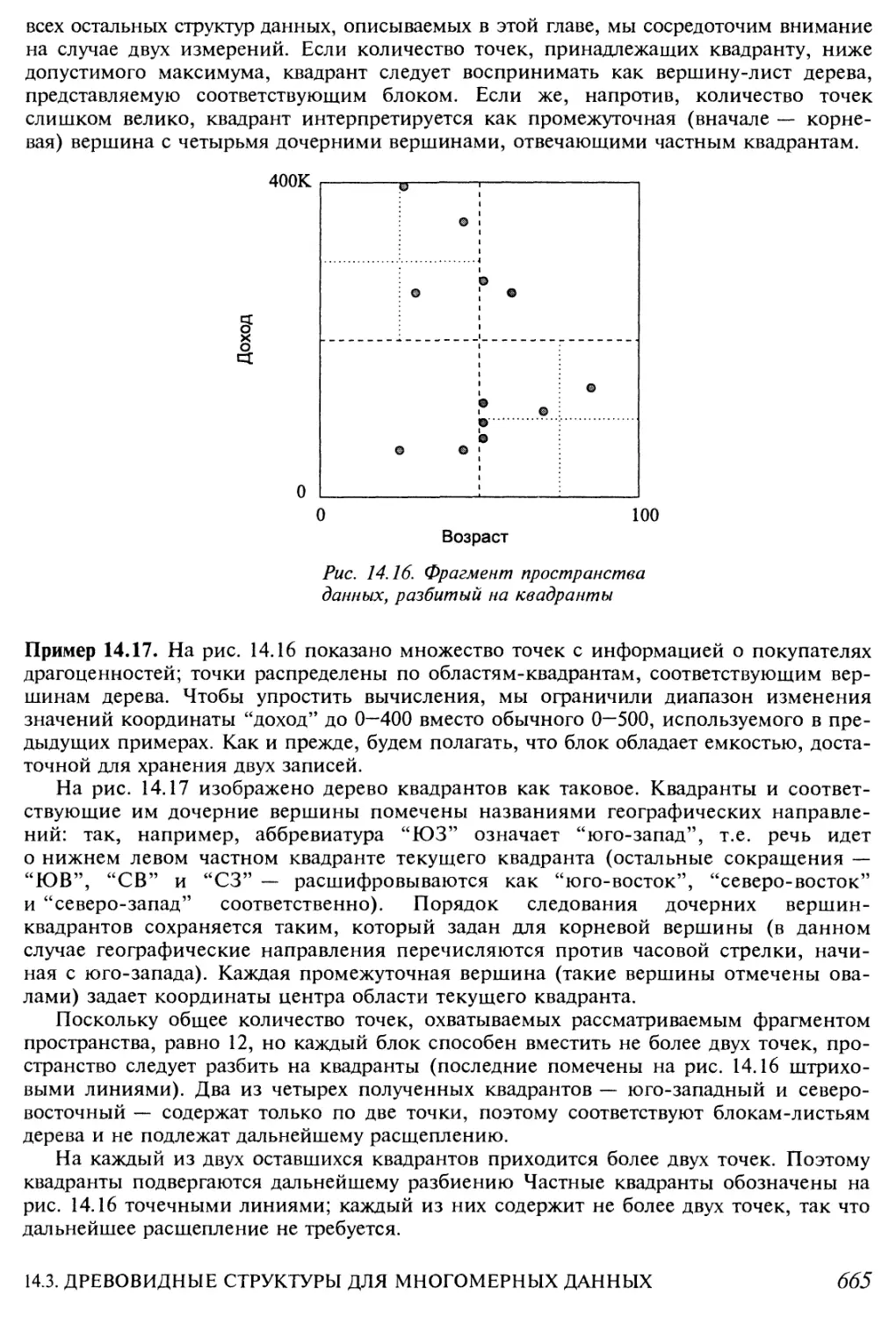
14.3.6. Деревья квадрантов 664
14.3.7. R-деревья 666
14.3.8. Операции с R-деревьями 667
14.3.9. Упражнения к разделу 14.3 669
14.4. Точечные индексы 671
14.4.1. Зачем нужны точечные индексы 672
14.4.2. Сжатые точечные индексы 673
14.4.3. Операции со сжатыми битовыми векторами 675
14.4.4. Управление точечными индексами 676
14.4.5. Упражнения к разделу 14.4 678
14.5. Резюме 679
14.6. Литература 680
Глава 15. Выполнение запросов 683
15.1. Знакомство с операторами физического плана запроса 684
15.1.1. Сканирование таблиц 685
15.1.2. Сортировка в процессе сканирования таблиц 686
15.1.3. Модель вычислений операторов физического плана 686
15.1.4. Критерии эффективности физических операторов 687
15.1.5. Оценки затрат на ввод-вывод для операторов сканирования 688
15.1.6. Реализация физических операторов с помощью итераторов 689
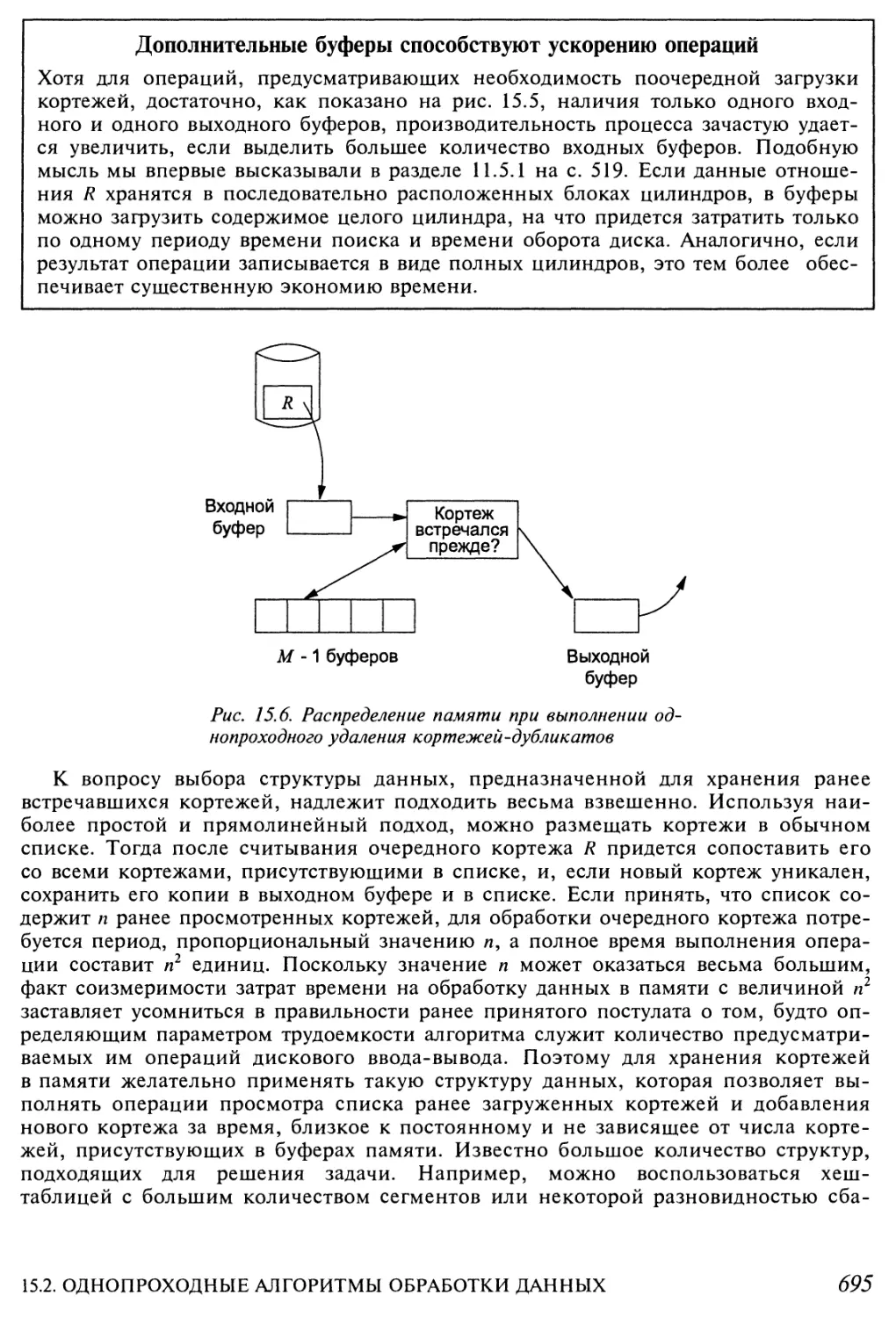
15.2. Однопроходные алгоритмы обработки данных 692
15.2.1. Однопроходные алгоритмы для унарных операций над
отдельными кортежами 693
15.2.2. Однопроходные алгоритмы для унарных операций над
полными отношениями 694
15.2.3. Однопроходные алгоритмы для бинарных операций над
полными отношениями 697
15.2.4. Упражнения к разделу 15.2 700
15.3. Реализация соединений посредством вложенных циклов 702
15.3.1. Соединение посредством вложенных циклов с загрузкой
отдельных кортежей 702
15.3.2. Итератор для соединения посредством вложенных циклов с
загрузкой отдельных кортежей 702
19
15.3.3. Соединение посредством вложенных циклов с загрузкой
блоков данных 702
15.3.4. Анализ алгоритмов соединения посредством вложенных
циклов 704
15.3.5. Сводка характеристик однопроходных и циклических
алгоритмов 705
15.3.6. Упражнения к разделу 15.3 705
15.4. Двухпроходные алгоритмы, основанные на сортировке 706
15.4.1. Алгоритм удаления кортежей-дубликатов 706
15.4.2. Алгоритм группирования и агрегирования 709
15.4.3. Алгоритм объединения 709
15.4.4. Алгоритмы пересечения и разности 710
15.4.5. Простой алгоритм соединения 712
15.4.6. Анализ простого алгоритма соединения 713
15.4.7. Более эффективный алгоритм соединения 714
15.4.8. Сводка характеристик алгоритмов, основанных на
сортировке 715
15.4.9. Упражнения к разделу 15.4 716
15.5. Двухпроходные алгоритмы, основанные на хешировании 717
15.5.1. Распределение содержимого отношений по сегментам хеш-
таблицы 718
15.5.2. Алгоритм удаления кортежей-дубликатов 718
15.5.3. Алгоритмы группирования и агрегирования 719
15.5.4. Алгоритмы объединения, пересечения и разности 719
15.5.5. Алгоритм соединения 720
15.5.6. Сокращение затрат на дисковый ввод-вывод 721
15.5.7. Сводка характеристик алгоритмов, основанных на
хешировании 723
15.5.8. Упражнения к разделу 15.5 724
15.6. Алгоритмы, основанные на индексировании 725
15.6.1. Группирующие индексы 725
15.6.2. Алгоритм выбора 726
15.6.3. Алгоритм соединения с использованием индекса 728
15.6.4. Алгоритмы соединения посредством сортировки и
индексирования 729
15.6.5. Упражнения к разделу 15.6 731
15.7. Управление буферизацией 732
15.7.1. Архитектура менеджера буферов 732
15.7.2. Стратегии управления буферизацией 734
15.7.3. Выбор физических операторов и проблемы управления
буферизацией 735
15.7.4. Упражнения к разделу 15.7 737
15.8. Многопроходные алгоритмы 738
15.8.1. Многопроходные алгоритмы, основанные на сортировке 738
15.8.2. Характеристики многопроходных алгоритмов, основанных
на сортировке 739
15.8.3. Многопроходные алгоритмы, основанные на хешировании 739
15.8.4. Характеристики многопроходных алгоритмов, основанных
на хешировании 740
15.8.5. Упражнения к разделу 15.8 741
20
СОДЕРЖАНИЕ
15.9. Параллельные алгоритмы для реляционных операторов 741
15.9.1. Архитектуры параллельных вычислительных систем 741
15.9.2. Параллельные алгоритмы для операций над отдельными
кортежами 744
15.9.3. Параллельные алгоритмы для операций над полными
отношениями 745
15.9.4. Характеристики параллельных алгоритмов 746
15.9.5. Упражнения к разделу 15.9 748
15.10. Резюме 749
15.11. Литература 751
Глава 16. Компиляция и оптимизация запросов 753
16.1. Синтаксический анализ 754
16.1.1. Синтаксический анализ и деревья разбора 754
16.1.2. Грамматика простого подмножества языка SQL 755
16.1.3. Препроцессор 759
16.1.4. Упражнения к разделу 16.1 759
16.2. Алгебраические законы и планы запросов 760
16.2.1. Коммутативный и ассоциативный законы 760
16.2.2. Законы выбора 762
16.2.3. Продвижение операторов выбора по дереву выражений 765
16.2.4. Законы проекции 766
16.2.5. Законы соединения и декартова произведения 769
16.2.6. Законы, касающиеся удаления кортежей-дубликатов 769
16.2.7. Законы группирования и агрегирования 770
16.2.8. Упражнения к разделу 16.2 772
16.3. От деревьев разбора к логическим планам запросов 774
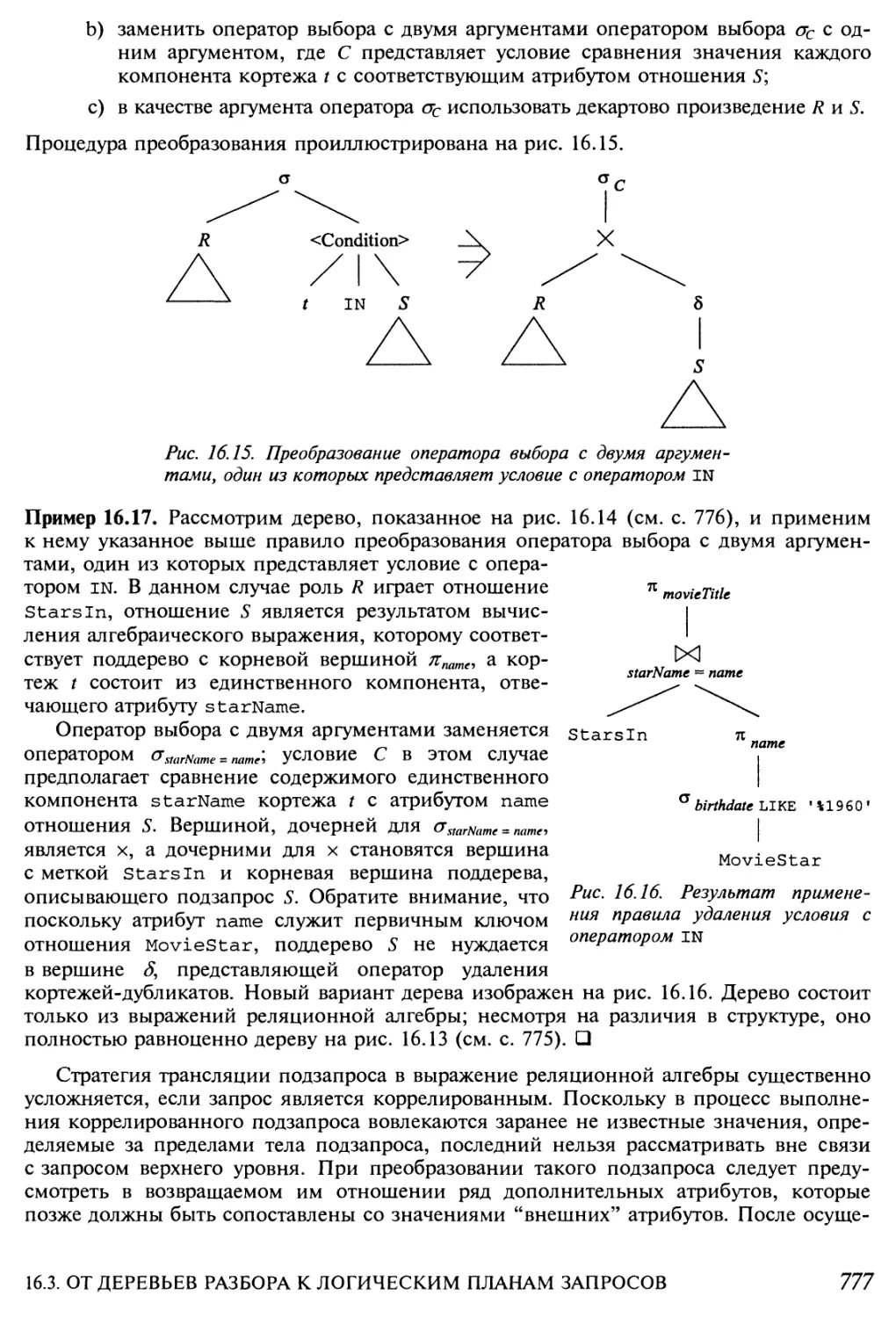
16.3.1. От дерева разбора к дереву выражений реляционной
алгебры 774
16.3.2. Изъятие подзапросов из условий 775
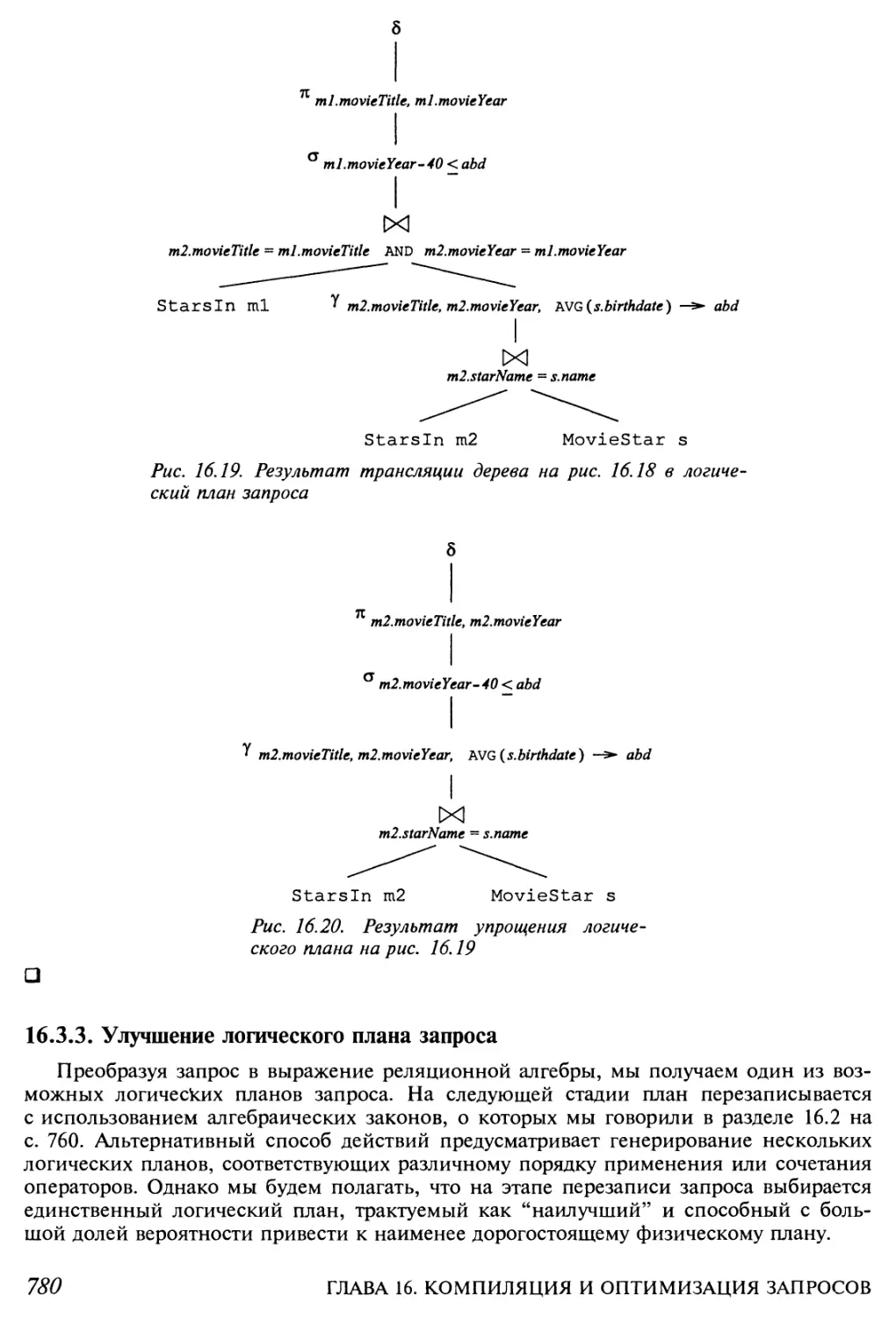
16.3.3. Улучшение логического плана запроса 780
16.3.4. Группирование ассоциативно-коммутативных операторов 781
16.3.5. Упражнения к разделу 16.3 782
16.4. Анализ стоимости операций 783
16.4.1. Оценка размеров промежуточных отношений 784
16.4.2. Оценка размера результата оператора проекции 785
16.4.3. Оценка размера результата оператора выбора 785
16.4.4. Оценка размера результата оператора соединения 788
16.4.5. Естественное соединение отношений с несколькими
общими атрибутами 791
16.4.6. Соединение нескольких отношений 792
16.4.7. Оценка размеров результатов выполнения других операторов 794
16.4.8. Упражнения к разделу 16.4 796
16.5. Выбор планов с учетом их стоимости 797
16.5.1. Статистические характеристики данных 798
16.5.2. Вычисление статистик 801
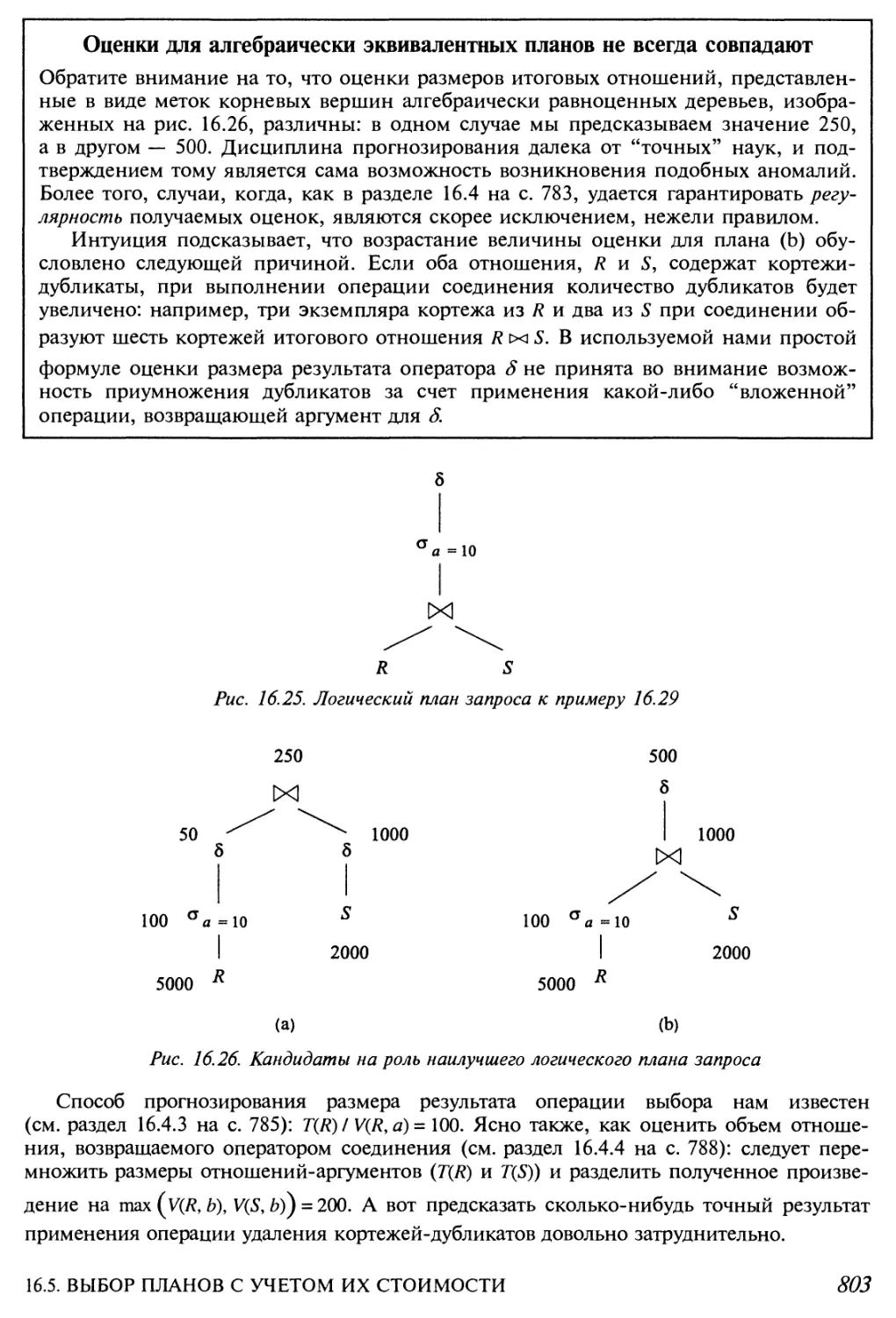
16.5.3. Эвристические правила сокращения стоимости
логических планов 802
СОДЕРЖАНИЕ
21
16.5.4. Способы сопоставительного анализа физических планов 804
16.5.5. Упражнения к разделу 16.5 807
16.6. Выбор порядка соединения 809
16.6.1. Различия между левыми и правыми операндами соединения 809
16.6.2. Деревья соединения 809
16.6.3. Левосторонние деревья соединения 810
16.6.4. Динамическое программирование и выбор порядка
соединения 814
16.6.5. Динамическое программирование и уточненные функции
стоимости 819
16.6.6. "Жадный" алгоритм выбора порядка соединения 819
16.6.7. Упражнения к разделу 16.6 821
16.7. Завершение формирования физического плана запроса 822
16.7.1. Поиск метода выбора 822
16.7.2. Поиск метода соединения 824
16.7.3. Организация каналов и материализация: за и против 825
16.7.4. Каналы и унарные операции 826
16.7.5. Каналы и бинарные операции 827
16.7.6. Система представления физических планов запросов 830
16.7.7. Упорядочение физических операторов 832
16.7.8. Упражнения к разделу 16.7 833
16.8. Резюме 834
16.9. Литература 836
Глава 17. Профилактика системных отказов и устранение их последствий 837
17.1. Модели живучести систем баз данных 838
17.1.1. Режимы отказов 838
17.1.2. Подробнее о транзакциях 839
17.1.3. Условия выполнения транзакций 841
17.1.4. Базовые операции транзакций 842
17.1.5. Упражнения к разделу 17.1 845
17.2. Протоколирование в режиме "undo" 846
17.2.1. Записи протокола 846
17.2.2. Правила протоколирования в режиме "undo" 847
17.2.3. Восстановление с применением протокола "undo" 850
17.2.4. Введение контрольных точек 852
17.2.5. Динамическое введение контрольных точек 854
17.2.6. Упражнения к разделу 17.2 857
17.3. Протоколирование в режиме "redo" 858
17.3.1. Правило протоколирования в режиме "redo" 859
17.3.2. Восстановление с применением протокола "redo" 860
17.3.3. Введение контрольных точек в режиме "redo" 861
17.3.4. Восстановление на основе протокола "redo"
с контрольными точками 863
17.3.5. Упражнения к разделу 17.3 864
17.4. Протоколирование в режиме "undo/redo" 865
17.4.1. Правила протоколирования в режиме "undo/redo" 865
17.4.2. Восстановление с применением протокола "undo/redo" 866
22
СОДЕРЖАНИЕ
17.4.3. Введение контрольных точек в режиме "undo/redo" 867
17.4.4. Упражнения к разделу 17.4 869
17.5. Защита от отказа дискового устройства 870
17.5.1. Архив 871
17.5.2. Динамическое архивирование 872
17.5.3. Восстановление с применением архива и протокола 874
17.5.4. Упражнения к разделу 17.5 875
17.6. Резюме 875
17.7. Литература 876
Глава 18. Управление параллельными заданиями 879
18.1. Последовательные и условно-последовательные расписания 880
18.1.1. Расписания 880
18.1.2. Последовательные расписания 881
18.1.3. Условно-последовательные расписания 882
18.1.4. О важности конкретной семантики транзакций 884
18.1.5. Система обозначений для представления транзакций
и расписаний 885
18.1.6. Упражнения к разделу 18.1 886
18.2. Условно-последовательное упорядочение с учетом
конфликтов 887
18.2.1. Конфликты 887
18.2.2. Графы предшествования и расписания, условно-
последовательные с учетом конфликтов 888
18.2.3. Обоснование корректности процедуры проверки графа
предшествования 891
18.2.4. Упражнения к разделу 18.2 892
18.3. Последовательные расписания и механизмы блокирования 894
18.3.1. Блокировки 894
18.3.2. Архитектура простого планировщика с блокированием 897
18.3.3. Двухфазное блокирование 897
18.3.4. Обоснование корректности условия двухфазного
блокирования 898
18.3.5. Упражнения к разделу 18.3 900
18.4. Системы с несколькими режимами блокирования 901
18.4.1. Общие и монопольные блокировки 902
18.4.2. Матрицы совместимости 904
18.4.3. Повышение уровня блокирования 905
18.4.4. Обновляемые блокировки 906
18.4.5. Инкрементные блокировки 908
18.4.6. Упражнения к разделу 18.4 910
18.5. Архитектура планировщика с блокированием 912
18.5.1. Планировщик заданий и вставка инструкций блокирования 912
18.5.2. Таблица блокировок 915
18.5.3. Упражнения к разделу 18.5 918
23
18.6. Управление иерархиями элементов базы данных 918
18.6.1. Блокировки с множеством степеней детализации 918
18.6.2. Предупреждающие блокировки 919
18.6.3. Фантомные кортежи и корректная обработка
операций вставки 923
18.6.4. Упражнения к разделу 18.6 924
18.7. Протокол блокирования древовидных структур 924
18.7.1. Модель блокирования древовидных структур 924
18.7.2. Правила доступа к элементам древовидных структур 925
18.7.3. Обоснование корректности протокола блокирования
древовидных структур 927
18.7.4. Упражнения к разделу 18.7 929
18.8. Хронометраж действий транзакций 930
18.8.1. Хронологические признаки 931
18.8.2. Физически неосуществимые расписания 931
18.8.3. Операции "чтения мусора" 932
18.8.4. Правила упорядочения действий с помощью механизма
хронометража 934
18.8.5. Множественные версии элементов и хронологических
признаков 936
18.8.6. Хронометраж и блокирование: за и против 938
18.8.7. Упражнения к разделу 18.8 939
18.9. Проверка достоверности действий транзакций 939
18.9.1. Архитектура планировщика с функциями проверки
достоверности действий транзакций 939
18.9.2. Правила проверки достоверности действий транзакций 940
18.9.3. Упражнения к разделу 18.9 943
18.10. Сравнение схем управления параллельными заданиями 944
18.11. Резюме 945
18.12. Литература 947
Глава 19. Дополнительные аспекты управления транзакциями 949
19.1. Последовательное упорядочение операций
и восстановление данных 949
19.1.1. Проблема "чтения мусора" 950
19.1.2. Каскадный откат 952
19.1.3. Восстановимые расписания 952
19.1.4. Расписания без каскадного отката 953
19.1.5. Управление процедурами отката с помощью схем
блокирования 954
19.1.6. Групповая фиксация 956
19.1.7. Логическое протоколирование 957
19.1.8. Восстановление данных с помощью логического протокола 959
19.1.9. Упражнения к разделу 19.1 961
19.2. Условно-последовательное упорядочение с учетом
источников данных 962
19.2.1. Эквивалентность расписаний с учетом источников данных 962
19.2.2. Теоретико-графовая модель расписаний, условно-
последовательных с учетом источников данных 964
24
СОДЕРЖАНИЕ
19.2.3. Обоснование корректности процедуры проверки графа
предшествования 967
19.2.4. Упражнения к разделу 19.2 968
19.3. Разрешение взаимоблокировок 968
19.3.1. Обнаружение взаимоблокировок по истечении лимита
времени 968
19.3.2. Графы ожидания 969
19.3.3. Предотвращение взаимоблокировок за счет упорядочения
элементов данных 971
19.3.4. Выявление взаимоблокировок с помощью механизма
хронометража 972
19.3.5. Сравнение методов обнаружения и предотвращения
взаимоблокировок 975
19.3.6. Упражнения к разделу 19.3 976
19.4. Распределенные базы данных 977
19.4.1. Концепция распределенных данных 977
19.4.2. Распределенные транзакции 979
19.4.3. Репликация данных 979
19.4.4. Распределенная оптимизация запросов 980
19.4.5. Упражнения к разделу 19.4 981
19.5. Распределенная фиксация 981
19.5.1. Поддержка распределенной атомарности 982
19.5.2. Двухфазная фиксация 982
19.5.3. Восстановление распределенных транзакций 985
19.5.4. Упражнения к разделу 19.5 986
19.6. Распределенное блокирование 987
19.6.1. Централизованное блокирование 988
19.6.2. Модель трудоемкости алгоритмов распределенного
блокирования 988
19.6.3. Блокирование реплицированных элементов 989
19.6.4. Режим блокирования "главной копии" 990
19.6.5. Глобальные блокировки на основе локальных блокировок 991
19.6.6. Упражнения к разделу 19.6 992
19.7. Длинные транзакции 993
19.7.1. Проблемы использования длинных транзакций 993
19.7.2. Хроники 995
19.7.3. Уравновешивающие транзакции 996
19.7.4. Обоснование корректности модели уравновешивающих
транзакций 997
19.7.5. Упражнения к разделу 19.7 998
19.8. Резюме 999
19.9. Литература 1001
Глава 20. Интеграция информации 1003
20.1. Обзор технологий интеграции информации 1003
20.1.1. Проблемы интеграции информации 1004
20.1.2. Федеративные базы данных 1005
СОДЕРЖАНИЕ
25
20.1.3. Хранилища данных 1007
20.1.4. Медиаторы 1009
20.1.5. Упражнения к разделу 20.1 1010
20.2. Компоненты-оболочки 1012
20.2.1. Шаблоны запросов 1012
20.2.2. Генераторы оболочек 1013
20.2.3. Фильтры 1014
20.2.4. Другие функции оболочек 1015
20.2.5. Упражнения к разделу 20.2 1017
20.3. Медиаторы и оптимизация с учетом возможностей
источников данных 1017
20.3.1. Проблема ограниченных возможностей источника данных 1018
20.3.2. Классификация возможностей источника данных 1019
20.3.3. Выбор плана запроса с учетом возможностей источника
данных 1020
20.3.4. Дополнительная оптимизация планов с учетом их стоимости 1022
20.3.5. Упражнения к разделу 20.3 1022
20.4. Оперативная аналитическая обработка данных 1023
20.4.1. Приложения OLAP 1024
20.4.2. Многомерная модель данных OLAP 1025
20.4.3. Схема "звезды" 1026
20.4.4. Рассечение и расслоение куба исходных данных 1028
20.4.5. Упражнения к разделу 20.4 1030
20.5. Кубы данных 1031
20.5.1. Оператор CUBE 1031
20.5.2. Реализация куба на основе материализованных
представлений 1033
20.5.3. Сетки представлений 1036
20.5.4. Упражнения к разделу 20.5 1037
20.6. Разработка данных 1039
20.6.1. Приложения разработки данных 1039
20.6.2. Отыскание часто встречающихся наборов объектов 1042
20.6.3. Априорный алгоритм анализа рыночной корзины 1043
20.6.4. Упражнения к разделу 20.6 1045
20.7. Резюме 1046
20.8. Литература 1047
Послесловие редактора перевода 1049
Именной указатель 1053
Предметный указатель 1057
26
СОДЕРЖАНИЕ
Об авторах
Джеффри Д. Ульман (Jeffrey D. Ullman), профессор компьютерных наук Станфорд-
ского университета. Автор и соавтор 16 книг, включая, например, Elements of ML
Programming (Prentice Hall, 1998). Сфера научных интересов — технологии анализа
и "разработки" информации, интеграции данных и электронного обучения. Член
Национальной академии инженерных наук США, обладатель стипендии Guggenheim
Fellowship, лауреат премий Karl V. Karlstrom Outstanding Educator Award, SIGMOD
Contributions Award и Knuth Prize.
Дженнифер Уидом (Jennifer Widom), адъюнкт-профессор компьютерных наук
и электротехники Станфордского университета. Сфера научных интересов —
обработка запросов к потокам данных, кэширование и репликация информации,
полуструктурированные данных и XML, хранилища данных. Обладатель стипендии Guggenheim
Fellowship и член многочисленных комитетов, советов и редакционных коллегий.
Гектор Гарсия-Молина (Hector Garcia-Molina), профессор компьютерных наук
и электротехники, заведующий отделением компьютерных наук Станфордского
университета. Сфера научных интересов — цифровые библиотеки, интеграция данных и
приложения баз данных для Internet. Лауреат премии SIGMOD Innovations Award и член
Совета по информационным технологиям при Президенте США.
Предисловие
В Станфордском университете учебный период делится на четверти. Наше введение
в технологии баз данных охватывает два курса. Первый, обозначаемый в соответствии
с учебным планом специальности "Компьютерные науки" как CS145, предназначен для
тех слушателей, которые в период профессиональной деятельности собираются
использовать базы данных, но не обязательно участвовать в реализации СУБД — систем управ-
ления базами данных. Этот курс служит основой другого курса, CS245, охватывающего
проблематику реализации СУБД. Студенты, желающие углубить знания в области
систем баз данных, могут далее перейти к курсам CS345 (теория), CS346 (проект
реальной СУБД) и CS347 (обработка транзакций и распределенные базы данных).
За четыре последних года мы опубликовали две книги: A First Course in Database
Systems содержала сведения, имеющие отношение к курсу CS145, a Database System
Implementation была посвящена вопросам, которые обычно находят отражение в курсах
CS245 и, частично, CS346. Поскольку многие университеты придерживаются
семестровой модели преподавания и сочетают оба вводных курса в одном, мы почувствовали
насущную потребность в объединении материала этих книг. В то же время эволюция
систем баз данных породила целый ряд новых тем, относящихся к сфере
программирования приложений и заслуживающих внимания при написании современного
учебного пособия: так, например, мы постарались осветить вопросы обработки объектно-
реляционных данных, применения средств SQL/PSM, обеспечивающих возможности
создания хранимых программ, а также SQL/CLI и JDBC — стандартов интерфейсов
C/SQL и Java/SQL соответственно.
Как работать с книгой
Мы рекомендуем посвятить изучению книги две учебные четверти. Если следовать
подходу, принятому в Станфорде, на протяжении первой четверти целесообразно
рассмотреть начальные десять глав, а во второй четверти — заключительные главы. Если
же вы предпочтете охватить материал книги в течение одного семестра, вам, вероятно,
придется исключить какие-то ее части. По нашему мнению, более пристальное
внимание следует уделить главам 2—7, 11—13 и 17—18, хотя и в них имеются отдельные
фрагменты, которые при необходимости можно опустить.
Если вы захотите предложить студентам подробные сведения по вопросам
программирования приложений баз данных и продемонстрировать соответствующий
реальный проект (при изложении курса CS145 мы сами поступаем именно так), вам,
возможно, потребуется определенным образом переупорядочить материал, чтобы
раздел, касающийся инструкций языка SQL, был рассмотрен несколько раньше.
Изучение других тем, таких как зависимости данных, напротив, до определенного момента
может быть отложено, хотя, разумеется, для реализации проекта студентам
потребуются знания о нормализации данных.
Предварительные условия
Слушателями курса, охватываемого нашей книгой, являются студенты-
выпускники. Ниже перечислены дисциплины, без знания которых, формально
говоря, ее освоение будет затруднено; 1) структуры данных, алгоритмы и основы дискрет-
ной математики; 2) системы и языки программирования. Важно, чтобы студенты
прошли хотя бы элементарную предварительную подготовку в таких областях, как
алгебраические законы и выражения, логика высказываний, базовые структуры
данных (деревья поиска, графы и т.д.), концепции объектно-ориентированного
программирования и среды программирования. Впрочем, мы имеем основания надеяться, что
соответствующими знаниями обладают даже те студенты, которые завершили только
начальный курс обучения по типовой программе специальности "Компьютерные науки".
Упражнения
Почти все разделы книги содержат большое количество упражнений. Более
трудные задания или их части помечены в тексте одним восклицательным знаком (!),
а самые серьезные — двумя.
Отдельные упражнения либо их фрагменты снабжены символом звездочки (*),
который свидетельствует о том, что решение упражнения приведено (либо будет
приведено в ближайшее время) в тексте Web-страницы нашей книги. Подобные решения
открыты для широкого доступа и могут быть использованы вами для самоконтроля.
Примите к сведению, что в нескольких случаях некоторое упражнение В
предусматривает доработку или исправление решения упражнения А. Если для определенных
частей упражнения Л предлагаются решения, вы вправе ожидать, что таковые должны
существовать и для соответствующих фрагментов упражнения В.
Ресурсы в World Wide Web
Web-страница книги размещена по следующему адресу:
http://www-db.Stanford.edu/~ullman/dscb.html
На ней приводятся решения упражнений, текст которых помечен в книге символом
звездочки (*), информация об ошибках, включаемая по мере ее поступления,
и вспомогательный материал. Мы также предлагаем конспекты курсов CS145
и CS245 в том виде, в каком их преподаем, домашние задания, условия курсовых
работ и экзаменационные вопросы.
Благодарности
В процессе работы над книгой нам помогало множество людей, которые
рецензировали отдельные части текста и сообщали об обнаруженных ошибках и недочетах.
Мы искренне рады назвать и поблагодарить всех, кто способствовал улучшению ее
качеств: Марк Абромовиц (Marc Abromowitz), Джозеф Адамски (Joseph Adamski), Брэд
Эделберг (Brad Adelberg), Глеб Ашимов (Gleb Ashimov), Дональд Эйнгуэрт (Donald
Aingworth), Джонатан Беккер (Jonathan Becker), Маргарет Бенитез (Margaret Benitez),
Ларри Бонем (Larry Bonham), Филип Боннет (Phillip Bonnet), Давид Броко (David
Brokaw), Эд Бернз (Ed Burns), Карен Батлер (Karen Butler), Кристофер Чан
(Christopher Chan), Сударшан Чават (Sudarshan Chawathe), Пер Кристенсен (Per
Christensen), Эд Чанг (Ed Chang), Сураджит Чоудхури (Surajit Chaudhuri), Кен Чен
(Ken Chen), Рада Киркова (Rada Chirkova), Нитин Чопра (Nitin Chopra), Бобби Кок-
рин (Bobbie Cochrane), Артуро Кресло (Arturo Crespo), Линда де Мишелл (Linda
DeMichiel), Том Динстбьер (Tom Dienstbier), Пэл д'Соуза (Pearl D'Souza), Оливер
Душка (Oliver Duschka), Ксавье Фаз (Xavier Faz), Грег Фихтенголц (Greg Fichtenholtz),
Барт Фишер (Bart Fisher), Джерл Фрайис (Jarl Friis), Джон Фрай (John Fry), Чи-пинь
Фу (Chi-Ping Fu), Трейси Фудзиеда (Tracy Fujieda), Маниш Годара (Manish Godara),
Мередит Голдсмит (Meredith Goldsmith), Луис Гравано (Luis Gravano), Жерар Гилль-
метт (Gerard Guillemette), Рафаэль Эрнандес (Rafael Hernandez), Антти Хьелт (Antti
ПРЕДИСЛОВИЕ
29
Hjelt), Бен Голыдман (Ben Holtzman), Стив Хантсбери (Steve Huntsberry), Леонард
Джекобсон (Leonard Jacobson), Туласираман Джейяраман (Thulasiraman Jeyaraman),
Дуайт Джо (Dwight Joe), Сет Катц (Seth Katz), Ен-пинь Ко (Yeong-Ping Koh), Дьердь Ковач
(Gyirrgy Kovacs), Филип Коза (Phillip Koza), Брайан Калман (Brian Kulman), Сань Хо Ли
(Sang Ho Lee), Оливье Лобри (Olivier Lobry), Лю Чао-Джун (Lu Chao-Jun), Арун Марат
(Arun Marathe), Ли-вей Mo (Le-Wei Mo), Фабьен Модо (Fabian Modoux), Питер Морк
(Peter Mork), Марк Мортенсен (Mark Mortensen), Рампракаш Нарайянасвами
(Ramprakash Narayanaswami), Нанк-юнь На (Nankyung Na), Мэри Нильссон (Marie
Nillson), Торбьерн Норби (Torbjorn Norbye), Чань-мин О (Chang-Min Oh), Мегул Пател
(Mehul Patel), Берт Портер (Bert Porter), Лимбек Река (Limbek Reka), Пракаш Раманан
(Prahash Ramanan), Кен Росс (Ken Ross), Тим Рафгартен (Tim Roughgarten), Мема Рос-
сопулос (Mema Roussopoulos), Ричард Скерл (Richard Scherl), Кэтрин Торнабин
(Catherine Tornabene), Андерс Уль (Anders Uhl), Джонатан Ульман (Jonathan Ullman),
Майанк Упадхьяй (Mayank Upadhyay), Вассилис Вассалос (VassiHs Vassalos), Кьянь Уанг
(Qiang Wang), Кристиан Виджайа (Kristian Widjaja), Дженет By (Janet Wu), Сундар Йа-
муначари (Sundar Yamunachari), Такеши Иокукава (Takeshi Yokukawa), Мин-си Юн
(Min-Sig Yun), Торбен Заль (Torben Zahle) и Сэнди Занг (Sandy Zhang).
Исключительную ответственность за ошибки, оставшиеся в тексте книги, несем
мы, ее авторы.
30
ПРЕДИСЛОВИЕ
Глава 1
Мир баз данных
Современные технологии баз данных являются одним из определяющих факторов
успеха в любой отрасли бизнеса, обеспечивая хранение корпоративной информации,
представление данных для пользователей и клиентов в среде World Wide Web и
поддержку многих других процессов. Помимо того, базы данных составляют основу
разнообразных научных проектов. Они позволяют накапливать информацию, собранную
астрономами, исследователями генотипа человека, биохимиками, изучающими
свойства протеинов, и специалистами многих других отраслей знания.
Мощь баз данных зиждется на результатах исследований и технологических
разработок, полученных на протяжении нескольких последних десятилетий, и заключена
в специализированных программных продуктах, которые принято называть системами
управления базами данных (СУБД) (Database Management Systems — DBMS), или
просто системами баз данных (database systems). СУБД — это эффективный инструмент
сбора больших порций информации и действенного управления ими, позволяющий
сохранять данные в целости и безопасности на протяжении длительного времени.
СУБД относятся к категории наиболее сложных программных продуктов, имеющихся
на рынке в настоящее время. СУБД предлагают пользователям функциональные
возможности, перечисленные ниже.
1. Средства постоянного хранения данных. СУБД, подобно файловым системам,
поддерживают возможности хранения чрезвычайно больших фрагментов
данных, которые существуют независимо от каких бы то ни было процессов их
использования. СУБД, однако, значительно превосходят файловые системы в
отношении гибкости представления информации, предлагая структуры,
обеспечивающие эффективный доступ к большим порциям данных.
2. Интерфейс программирования. СУБД позволяет пользователю или прикладной
программе обращаться к данным и изменять их посредством команд развитого
языка запросов. Преимущества СУБД в сравнении с файловыми системами
проявляются и в том, что первые дают возможность манипулировать данными
самыми разнообразными способами, гораздо более гибкими, нежели обычные
операции чтения и записи файлов.
3. Управление транзакциями. СУБД поддерживают параллельный доступ к данным,
т.е. возможность единовременного обращения к одной и той же порции данных
со стороны нескольких различных процессов, называемых транзакциями
(transactions). Чтобы избежать некоторых нежелательных последствий
подобного обращения, СУБД реализуют механизмы обеспечения изолированности
(isolation) транзакций (транзакции выполняются независимо одна от другой,
как если бы они активизировались строго последовательно), их атомарности
(atomicity) (каждая транзакция либо выполняется целиком, либо не
выполняется вовсе) и устойчивости (durability) (системы содержат средства надежного
сохранения результатов выполнения транзакций и самовосстановления после
различного рода ошибок и сбоев) .
1.1. Эволюция систем баз данных
Что такое база данных? По существу, это не что иное, как набор порций
информации, существующий в течение длительного периода времени (возможно,
исчисляемого годами или даже десятилетиями). Термином база данных (database) в
соответствии с принятой традицией обозначают набор данных, находящийся под контролем
СУБД. Добротная СУБД обязана обеспечить реализацию следующих требований.
1. Позволять пользователям создавать новые базы данных и определять их схемы
(schemata) (логические структуры данных) с помощью некоторого
специализированного языка, называемого языком определения данных (Data Definition
Language — DDL).
2. Предлагать пользователям возможности задания запросов (queries) (слово
"запрос", в данном случае обладающее известным жаргонным оттенком,
означает вопрос, затрагивающий те или иные аспекты информации, хранящейся
в базе данных) и модификации данных средствами соответствующего языка за-
просов (query language), или языка управления данными (Data Manipulation
Language — DML).
3. Поддерживать способность сохранения больших объемов информации —- до
многих гигабайтов и более — на протяжении длительных периодов времени,
предотвращая опасность несанкционированного доступа к данным и
гарантируя эффективность операций их просмотра и изменения.
4. Управлять единовременным доступом к данным со стороны многих пользователей,
исключая возможность влияния действий одного пользователя на результаты,
получаемые другим, и запрещая совместное обращение к данным, чреватое их порчей.
1.1.1. Первые СУБД
Появление первых коммерческих систем управления базами данных датируется
концом 1960-х годов. Непосредственными предшественниками таких систем были
файловые системы, удовлетворявшие только некоторым из требований,
перечисленных выше (см. п. 3). Файловые системы действительно пригодны для хранения
обширных фрагментов данных в течение длительного времени, но они не способны
гарантировать, что данные, не подвергшиеся резервному копированию, не будут
испорчены или утеряны, и не поддерживают эффективные инструменты доступа
к элементам данных, положение которых в определенном файле заранее не известно.
Файловые системы не отвечают и условиям п. 2, т.е. не предлагают языка
запросов, подходящего для обращения к данным внутри файла. Обеспечиваемая ими
реализация требований п. 1, предполагающих наличие возможности создания схем
данных, ограничена способностью определения структур каталогов. Наконец, файловые
системы совершенно не удовлетворяют условиям п. 4. Даже если система и не
препятствует параллельному доступу к файлу со стороны нескольких пользователей или
процессов, она не в состоянии предотвратить возникновение ситуаций, когда,
например, два пользователя в один и тот же момент времени пытаются внести изменения
в один файл: результаты действий одного из них наверняка будут утрачены.
32
ГЛАВА 1. МИР БАЗ ДАННЫХ
К числу первых серьезных программных приложений СУБД относились те, в
которых предполагалось, что данные состоят из большого числа элементов малого
объема; для обработки таких элементов требовалось выполнять множество элементарных
запросов и операций модификации. Ниже кратко рассмотрены некоторые из ранних
приложений баз данных.
Системы бронирования авиабилетов
Система подобного типа имеет дело со следующими элементами данных:
1) сведениями о резервировании конкретным пассажиром места на
определенный авиарейс, включая информацию о номере места и обеденном меню;
2) информацией о полетах — аэропортах отправления и назначения для
каждого рейса, сроках отправки и прибытия, принадлежности воздушных судов
тем или иным компаниям, экипажах и т.п.;
3) данными о ценах на авиабилеты, поступивших заявках и наличии
свободных мест.
В типичных запросах требуется выяснить, какие рейсы из одного заданного аэропорта
в другой близки по времени отправления к указанному календарному периоду,
имеются ли свободные места и какова стоимость билетов. К числу характерных операций
по изменению данных относятся бронирование места на рейс, определение номера
места и выбор обеденного меню. В любой момент к одним и тем же элементам
данных могут обращаться несколько операторов-кассиров. СУБД обязана обеспечить
подобную возможность, но исключить любые потенциальные проблемы, связанные,
например, с продажей нескольких билетов на одно место, а также предотвратить
опасность потери записей данных, если система внезапно выйдет из строя.
Банковские системы
Базы данных банковских систем содержат информацию об именах и адресах
клиентов, лицевых счетах, кредитах, остатках и оборотах денежных средств, а также
о связях между элементами бухгалтерской и персональной информации, т.е. о том,
кто из клиентов владеет теми или иными счетами, кредитами и т.п. Весьма
распространенными являются запросы об остатке на счете, а также операции по изменению
его состояния, связанные с приходом или расходом средств.
Как и в ситуации с системой бронирования авиабилетов, вполне естественной
выглядит возможность одновременного доступа к информации со стороны
многочисленных клиентов и служащих банка, пользующихся локальными терминалами,
банкоматами или средствами Web. В этой связи жизненно важное значение приобретает
требование о том, чтобы единовременное обращение к одному и тому же банковскому
счету ни при каких условиях не приводило к потере отдельных транзакций. Какие бы
то ни было ошибки в данном случае совершенно не допустимы. Как только,
например, деньги со счета выданы банкоматом, система должна немедленно сохранить
информацию о выполненной расходной операции — даже тогда, когда в тот же момент
внезапно отключилось электропитание. Соответствующие решения, обладающие
требуемым уровнем надежности, далеко не очевидны и могут быть отнесены к разряду
"фигур высшего пилотажа" в сфере технологий СУБД.
Корпоративные системы
Многие из ранних приложений баз данных были предназначены для хранения
корпоративной информации — записей о продажах и закупках, данных об остатках на
счетах внутреннего бухгалтерского учета или персональных сведений о служащих
компании (их именах, адресах проживания, уровнях фиксированной заработной
платы, надбавках, отчислениях и т.д.). Запросы к таким базам данных позволяют полу-
1.1. ЭВОЛЮЦИЯ СИСТЕМ БАЗ ДАННЫХ
33
чать информацию о состоянии счетов, выплатах сотрудникам и т.п. Каждая операция
купли/продажи, прихода/расхода, приема сотрудника на работу, его продвижения по
службе или увольнения приводит к изменению соответствующих элементов данных.
Самые первые СУБД, во многом унаследовавшие свойства файловых систем,
оказывались способными представлять результаты запросов практически только в том
виде, который соответствовал структуре хранения данных. В подобных системах баз
данных находили применение несколько различных моделей описания структуры
информации — в основном, "иерархическая" древовидная и "сетевая" графовая. В
конце 1960-х годов последняя получила признание и нашла отражение в стандарте
CODASYL (Committee on Data Systems and Languages).1
Одной из основных проблем, препятствовавших распространению и
использованию таких моделей и систем, было отсутствие поддержки ими высокоуровневых
языков запросов. Например, язык запросов CODASYL для перехода от одного элемента
данных к другому предусматривал необходимость просмотра вершин графа,
представляющего элементы и связи между ними. Совершенно очевидно, что в таких условиях
для создания даже самых простых запросов требовались весьма серьезные усилия.
1.1.2. Системы реляционных баз данных
После опубликования в 1970 году знаменитой статьи Э.Ф. Кодда (E.F. Codd)2
системы баз данных претерпели существенные изменения. Д-р Кодд предложил схему
представления данных в виде таблиц, называемых отношениями (relations). Структуры
таблиц могут быть весьма сложными, что не снижает скорости обработки самых
различных запросов. В отличие от ранних систем баз данных, рассмотренных выше,
пользователю реляционной базы данных вовсе не требуется знать об особенностях
организации хранения информации на носителе. Запросы к такой базе данных
выражаются средствами высокоуровневого языка, позволяющего значительно повысить
эффективность работы программиста.
Различным аспектам реляционной модели, положенной в основу многих
современных СУБД, посвящен материал большинства глав нашей книги, начиная с главы 3
(см. с. 87), в которой изложены основные концепции модели. В главе 6 (см. с. 249)
и нескольких следующих главах мы расскажем о языке SQL (Structured Query
Language — язык структурированных запросов) — наиболее важном и мощном
представителе семейства языков запросов. Впрочем, дабы продемонстрировать читателю
простоту и изящество модели, уже сейчас имеет смысл изложить краткие сведения об
отношениях и привести наглядный пример использования SQL, который позволил бы
показать, каким образом реляционная модель создает благоприятные условия для
применения высокоуровневых запросов и позволяет избежать необходимости
"копания" в недрах базы данных.
Пример 1.1. Отношения — это таблицы. Каждый столбец таблицы озаглавлен
посредством атрибута (attribute), описывающего природу элементов столбца.
Например, отношение Accounts, содержащее данные о номерах банковских счетов
(accountNo), их типах (type) и величине остатков (balance), могло бы
выглядеть следующим образом:
accountNo balance type
12345 1000.00 savings
67890 223322.99 checking
1 CODASYL Data Base Task Group April 1971 Report, ACM, New York.
2 Codd E.F. A relational model for large shared data banks, Comm. ACM, 13:6 (1970), p. 377-387.
34
ГЛАВА 1. МИР БАЗ ДАННЫХ
Столбцы таблицы озаглавлены следующими атрибутами: accountNo, type и balance.
Под строкой атрибутов расположены строки данных, или кортежи (tuples). Здесь явно
показаны два кортежа отношения, а многоточия в последней строке указывают на
тот факт, что отношение может включать большее число кортежей, по одному на
каждый счет, открытый в банке. Первый кортеж свидетельствует о том, что на счете
с номером 12345 содержится остаток, равный 1000 денежных единиц, и счет
относится к категории накопительных (savings). Второй кортеж соответствует чековому
(checking) счету с номером 67890 и остатком 223322.79.
Пусть необходимо узнать величину остатка на счете с номером 67890.
Соответствующий запрос, оформленный по правилам языка SQL, может выглядеть так:
SELECT balance
FROM Accounts
WHERE accountNo = 67890;
Рассмотрим другой пример. Чтобы получить список номеров накопительных счетов
с отрицательным остатком, достаточно выполнить следующий запрос:
SELECT accountNo
FROM Accounts
WHERE type = 'savings' AND balance < 0;
Разумеется, мы не вправе ожидать, что двух приведенных примеров будет достаточно,
чтобы превратить новичка в эксперта по программированию на языке SQL, но они
вполне способны донести до читателя смысл инструкции SQL "select—from—where"
("выбрать—из—при_условии"). Каждое из рассмотренных выражений SQL по
существу заставляет СУБД выполнить следующие действия:
1) проверить все кортежи отношения Accounts, упомянутого в
предложении from;
2) выбрать те кортежи, которые удовлетворяют некоторому критерию,
описанному предложением where;
3) возвратить в качестве результата определенные атрибуты выбранных
кортежей, перечисленные в предложении select.
В реальной ситуации система бывает способна "оптимизировать" запрос, чтобы
отыскать некоторый более эффективный способ выполнения поставленного задания, —
даже в том случае, если размеры отношений, участвующих в запросе, чрезвычайно велики. □
До 1990-х годов системы реляционных баз данных занимали главенствующее
положение. Однако технологии СУБД продолжают интенсивно развиваться, и на
арене с завидной регулярностью появляются новые теоретические и
технологические решения проблемы управления данными. Нам хотелось бы быть
последовательными, поэтому мы должны уделить внимание некоторым современным
тенденциям развития систем баз данных.
1.1.3. Уменьшение и удешевление систем
Изначально СУБД представляли собой крупные и дорогие программные
комплексы, ориентированные на использование больших компьютеров. Обширные "размеры"
компьютера были необходимым условием работоспособности СУБД, имевших дело
с гигабайтами информации. Сегодня многие гигабайты данных способны уместиться
на единственном маленьком дисковом устройстве, поэтому вполне закономерным
итогом развития технологий стала возможность установки СУБД на персональных
компьютерах. Системы баз данных, основанные на реляционной модели, теперь
доступны для использования на самых малых машинах и становятся обычным
компонентом вычислительных систем — во многом подобно тому, как в свое время та же
счастливая участь постигла приложения текстовых процессоров и электронных таблиц.
1.1. ЭВОЛЮЦИЯ СИСТЕМ БАЗ ДАННЫХ
35
1.1.4. Тенденции роста систем
Гигабайт — это в действительности далеко не самый большой объем информации.
Размеры корпоративных баз данных зачастую исчисляются сотнями гигабайтов.
Помимо того, с удешевлением носителей информации человек получает в свое
распоряжение новые возможности хранения все возрастающих массивов данных. Например,
базы данных, обслуживающие пункты розничной продажи, нередко включают
терабайты (I терабайт равен 1000 гигабайт, или 1012 байт) информации, фиксирующей
каждую операцию продажи на протяжении длительного периода времени, что
позволяет более эффективным образом планировать оптовые поставки товаров (подобные
вопросы мы осветим в разделе 1.1.7 на с. 38).
Помимо того, современные базы данных способны хранить не только простые
элементы данных, такие как целые числа и короткие строки символов. Они позволяют
накапливать графические изображения, аудио- и видеозаписи и чрезвычайно крупные
фрагменты данных других типов. Например, для хранения видеоматериалов часовой
продолжительности воспроизведения требуется участок носителя емкостью в один
гигабайт. Базы данных, предназначенные для хранения графической информации,
полученной со спутников, могут охватывать петабайты (1000 терабайт, или 1015 байт) данных.
Задача обслуживания крупных баз данных требует неординарных технологических
решений. Базы данных даже относительно скромных размеров сегодня обычно
размещают на дисковых массивах, называемых вторичными устройствами хранения
(secondary storage devices) — в отличие от оперативной памяти (main memory), которая
служит ипервичным " хранилищем информации. Нередко говорят и о том, что наиболее
существенной особенностью, отличающей СУБД от других программных продуктов,
является их способность к долговременному хранению данных на внешних носителях
и загрузке требуемых порций информации в оперативную память по мере
необходимости. Технологические решения, кратко рассмотренные ниже, позволяют СУБД
эффективно справляться с неуклонно возрастающими потоками данных.
Третичные устройства хранения
Для нормального функционирования самых крупных баз данных, используемых
в настоящее время, возможностей, предлагаемых обычными дисковыми
накопителями, уже не достаточно. Поэтому разрабатываются различные типы третичных
устройств хранения (tertiary storage devices) данных. Такое устройство, способное к
сохранению терабайтов информации, требует гораздо большего времени для доступа к
конкретному элементу данных, нежели диск. Если период обращения к данным на диске
исчисляется, как правило, 10—20 миллисекундами, на выполнение аналогичной
операции третичным устройством хранения может уйти несколько секунд. Третичные
устройства хранения предполагают наличие какого-либо роботизированного
транспортного средства, способного перемещать носитель, на котором расположен
запрошенный элемент данных, к устройству чтения данных.
Функции отдельных носителей данных в третичных устройства хранения могут
выполнять компакт-диски (CD) либо диски формата DVD (digital versatile disk). Захват
робота передвигается к определенному диску, выбирает его, перемещает к устройству
чтения и загружает в последний.
Параллельные вычисления
Способность системы сохранять громадные объемы данных, разумеется, важна, но
она вряд ли будет востребована, если производительность такой системы недостаточно
высока. Поэтому СУБД, обрабатывающие чрезмерно большие фрагменты
информации, нуждаются в реализации решений, позволяющих повысить скорость
вычислений. Один из важнейших подходов к проблеме связан с использованием структур
индексов (indexes) — мы упомянем их в разделе 1.2.2 на с. 40 и рассмотрим более полно
36
ГЛАВА 1. МИР БАЗ ДАННЫХ
в главе 13 (см. с. 583). Другой способ достижения поставленной цели — обработать
больше данных в течение промежутка времени заданной продолжительности —
предполагает обращение к средствам распараллеливания вычислений. Параллелизм
вычислений реализуется в нескольких направлениях.
Поскольку скорость считывания данных, расположенных на определенном диске,
заведомо низка и измеряется несколькими мегабайтами в секунду, ее можно
увеличить, если использовать множество дисков и выполнять операции чтения данных
с них параллельно (такой подход приемлем даже в том случае, если в системе
применяется третичное устройство хранения, так как данные, прежде чем поступить в
распоряжение СУБД, в любом случае "кэшируются" на дисках). Такие диски могут
служить частью специальным образом спроектированной параллельной вычислительной
машины либо компонентами распределенной системы, состоящей из нескольких
машин, каждая иэ которых ответственна за поддержку определенного звена базы данных
и при необходимости допускает обращение при посредничестве
высокопроизводительного сетевого соединения.
Разумеется, способность системы к быстрому перемещению данных — равно как
и возможность хранения больших объемов информации — сама по себе еще не
служит гарантией того, что результаты запросов будут получены достаточно быстро.
Независимо от применяемых аппаратных средств, безусловно необходимы реализации
соответствующих алгоритмов, позволяющих "дробить" множества запросов на части
таким образом, чтобы позволить параллельным компьютерам или распределенным
сетям компьютеров эффективно использовать все имеющиеся вычислительные ресурсы.
Параллельное и распределенное управление сверхбольшими базами данных остается
сферой активных исследований и технологических разработок; более серьезное
внимание этой теме мы уделим в разделе 15.9 на с. 741.
1.1*5. Системы "клиент/сервер" и многоуровневые архитектуры
Огромный пласт современного программного обеспечения поддерживает
архитектуру клиент/сервер (client/server), в соответствии с которой запросы, сформированные
одним процессом {клиентом), отсылаются для обработки другому процессу {серверу).
Системы баз данных в этом смысле -— не исключение: обычной практикой является
разделение функций СУБД между процессом сервера и одним или несколькими
клиентскими процессами.
Простейший вариант архитектуры "клиент/сервер" предполагает, что СУБД
целиком представляет собой сервер, за исключением интерфейсов запросов, которые
взаимодействуют с пользователем и отсылают запросы и другие команды на сервер
с целью их выполнения. Например, в реляционных системах для представления
запросов клиентов к серверу используются инструкции языка SQL. Результаты
выполнения запросов сервером возвращаются клиентам в форме таблиц, или отношений.
Взаимосвязь клиента и сервера может быть гораздо более сложной, особенно в тех
случаях, когда результаты выполнения запросов обладают сложной структурой или
большим объемом. Более подробно мы рассмотрим этот вопрос в следующем разделе.
Существует и тенденция к тому, чтобы изрядную часть функций оставлять за
клиентом, если серверное звено в общей структуре системы является "узким местом" ввиду
того, что сервер базы данных из-за большого числа единовременных подключений
испытывает чрезмерную нагрузку. В последнее время широкое распространение получили
многоуровневые архитектуры, в которых СУБД отводится роль поставщика динамически
генерируемого содержимого Web-сайтов. СУБД продолжает действовать как сервер базы
данных, но его клиентом теперь служит сервер приложений (application server), который
управляет подключениями к базе данных, транзакциями, авторизацией и иными
процессами. Клиентами серверов приложений в свою очередь могут являться Web-серверы,
обслуживающие конечных пользователей, и другие программные приложения.
1.1. ЭВОЛЮЦИЯ СИСТЕМ БАЗ ДАННЫХ
37
1.1.6. Данные мультимедиа
Другая важная тенденция развития современных СУБД связана с поддержкой
данных мультимедиа. Употребляя термин мультимедиа (multimedia), мы имеем в виду
информацию, представляющую сигнал определенного вида. К числу наиболее
распространенных разновидностей данных мультимедиа относятся аудио- и видеозаписи, сигналы,
полученные от радаров, спутниковые изображения, а также документы и графика
различных форматов. Общим свойством элементов данных мультимедиа является большой
объем, способный изменяться в широких пределах, что отличает их от традиционных
единиц представления информации — целых чисел, строк фиксированной длины и т.п.
Потребность в хранении данных мультимедиа способствует развитию технологий
СУБД в нескольких направлениях. Например, общепринятые операции, применимые
в отношении простых элементов данных, не приемлемы в контексте проблемы
обработки информации мультимедиа. Хотя задача поиска в базе данных всех номеров
банковских счетов с отрицательным сальдо, предполагающая сравнение значений
остатков с вещественным числом 0.0, является вполне правомерной, совершенно не
уместной будет выглядеть попытка отыскания в базе данных фотографических
изображений лиц, "похожих" на определенную физиономию.
Чтобы обеспечить возможность выполнения манипуляций сложной информацией
(например, операций по обработке графических изображений), СУБД должны
позволять пользователям определять новые функции, которые необходимы в той или иной
ситуации. Расширение функционального потенциала систем зачастую осуществляется
на основе объектно-ориентированного подхода — даже в контексте сугубо
реляционных СУБД, которые после подобной "доработки" становятся "объектно-
реляционными" (object-relational). Аспекты объектно-ориентированного
программирования приложений баз данных мы будем рассматривать неоднократно — в
частности, в главах 4 (см. с. 149) и 9 (см. с. 419).
Большие размеры объектов данных мультимедиа вынуждают разработчиков СУБД
модифицировать функции менеджеров хранения данных, чтобы обеспечить
возможность размещения в базе данных объектов или кортежей объемом в гигабайт и более.
Одна из серьезных проблем, возникающих вследствие непомерного роста объема
элементов данных, связана с доставкой клиенту результатов отправленного им запроса.
В контексте традиционной реляционной базы данных результатом выполнения
запроса служит набор кортежей, которые возвращаются клиенту как единое целое. А теперь
предположим, что результатом выполнения запроса является видеоклип объемом
в один гигабайт. Вполне очевидно, что задача доставки клиенту элемента данных
размером в гигабайт в виде единого целого не может считаться безусловно корректной.
Во-первых, фрагмент данных настолько велик, что попытка его пересылки
воспрепятствует обработке сервером всех других запросов, ожидающих обслуживания. Во-вторых,
пользователь может быть заинтересован в получении только небольшой части клипа, но
он лишен возможности точно сформулировать цель запроса, не взглянув, например, на
начальный фрагмент материала. В-третьих, даже в том случае, если пользователь
абсолютно убежден в необходимости получения всего клипа, надеясь просмотреть его
целиком, вполне достаточно передавать информацию частями с фиксированной скоростью
в течение одного часа (промежутка времени, необходимого для воспроизведения
гигабайта сжатых видеоданных). Таким образом, подсистема хранения данных СУБД,
поддерживающей форматы мультимедиа, должна предлагать интерактивный режим
обслуживания запросов, чтобы пользователь смог указать, желает ли он получать фрагменты
данных по дополнительному требованию либо непрерывно с фиксированной частотой.
1.1.7. Интеграция информации
По мере повышения роли информации в жизни общества изменяются и развиваются
способы использования существующих информационных источников. В качестве
примера рассмотрим компанию, желающую обладать электронным каталогом всех собст-
38
ГЛАВА 1. МИР БАЗ ДАННЫХ
венных товаров, чтобы потенциальные клиенты получили возможность просматривать
каталог средствами Web-броузера, выбирать нужные товары и оформлять электронные
заказы. Крупные компании состоят из многих подразделений. Каждое независимое
подразделение вправе создавать собственные базы данных о товарах и применять при этом
различные СУБД, различные структуры данных и даже употреблять различные
наименования одной и той же вещи либо один термин для обозначения нескольких вещей.
Пример 1.2. Рассмотрим компанию, производящую компьютерные диски и
состоящую из нескольких филиалов. В каталоге продукции одного филиала скорость
вращения дисков представлена, скажем, в виде значения количества оборотов в секунду,
а в каталоге другого филиала в качестве единицы измерения того же параметра
выбрано количество оборотов в минуту. Третий каталог вовсе не содержит упоминаний
о скорости вращения дисков. В каталоге филиала, производящего гибкие диски, для
обозначения продукции употребляется термин "диск". То же название товара
используется и в подразделении, занимающемся разработкой жестких дисков. В одном
случае дорожки диска могут быть названы "треками", а в другом — "цилиндрами". □
Строгую централизацию управления не всегда можно считать приемлемым
решением рассмотренной проблемы. Подразделения компании, возможно, инвестировали
большие средства в создание собственных баз данных еще до того момента, когда на
повестке дня возник вопрос о целесообразности интеграции информации в рамках
всей компании. Также вполне допустимо, что какое-либо подразделение, обладающее
собственной базой данных, вошло в состав компании совсем недавно. Исходя из
подобных и иных причин так называемые унаследованные базы данных (legacy databases)
подразделений не могут (и не должны) непосредственно заменяться единой
центральной базой данных компании. Более разумно построить "поверх" существующих
унаследованных баз новую информационную структуру, способную представить всю
продукцию компании в согласованном и последовательном виде.
Один из самых популярных подходов к решению такой задачи связан с
использованием технологий хранилищ данных (data warehouses), которые предполагают копирование
информации из унаследованных баз данных с соответствующей трансляцией и
последующим сохранением в центральной базе данных. При изменении состояния
унаследованной базы данных необходимые исправления вносятся и в содержимое хранилища, хотя
не обязательно автоматически и немедленно. Весьма часто репликацию данных
осуществляют ночью, когда вероятность загрузки унаследованных баз данных наиболее низка.
Унаследованная база данных, таким образом, продолжает выполнять все обычные
функции, предусмотренные в период ее проектирования, а новые, такие как
поддержка электронных каталогов в Web, возлагаются на хранилище данных. Содержимое
хранилищ данных используется также в целях планирования и анализа: аналитики
компании получают возможность обращаться к хранилищу данных с запросами,
позволяющими, например, выявить тенденции продаж продукции, чтобы
оптимизировать ее ассортимент и спланировать дальнейшее развитие производства. Хранилища
данных открывают перспективы применения новейших технологий "разработки " (или
"добычи ") данных (data mining) -~ поиска любопытных и необычных образцов
информации и использования их для оптимизации бизнес-процессов. Эти и другие вопросы
интеграции данных мы обсудим в главе 20 (см. с. 1003).
1.2. Обзор структуры СУБД
На рис. 1.1 приведена структурная схема типичной системы управления базами
данных. Прямоугольниками из одинарных линий обозначены компоненты системы,
а фигурами из двойных линий — структуры данных, организованные в памяти.
Непрерывные отрезки со стрелками указывают направление потоков управляющих
инструкций и данных, а пунктирными линиями отмечены только потоки данных. По-
1.2. ОБЗОР СТРУКТУРЫ СУБД
39
скольку схема достаточно сложна, мы будем рассматривать ее поэтапно. Начнем
с того, что в верхней части рисунка изображены два различных источника
управляющих инструкций, направляемых системе:
1) рядовые пользователи и прикладные программы, запрашивающие или
изменяющие данные;
2) администратор базы данных (database administrator — DBA) — лицо или
группа лиц, ответственных за поддержку и развитие структуры, или схемы,
базы данных.
1.2.1. Команды языка определения данных
Относительно более простым является множество команд, поступающих от
администратора базы данных (их поток изображен в правой верхней части рис. 1.1). В
качестве примера рассмотрим базу данных факультета университета. Администратор
может включить в ее состав таблицу (отношение), строки (кортежи) которой
представляют информацию о студентах — их имена и фамилии, номера курсов и курсовые
отметки. Администратор вправе ограничить множество допустимых отметок,
выставляемых студентам по окончании курса, скажем, значениями А, В, С, D и F. Структура
создаваемой таблицы и вводимая информация об ограничениях становятся частью
схемы базы данных. Чтобы выполнить задуманное, администратор должен обладать
специальными полномочиями по выполнению команд, затрагивающих схему базы
данных, поскольку таковые оказывают самое серьезное влияние на структуру
хранения информации. Подобные команды определения данных — их называют командами
языка DDL (Data Definition Language — язык определения данных) — подвергаются
лексической обработке с помощью компилятора DDL (DDL compiler) и передаются для
выполнения исполняющей машине (execution engine), которая при посредничестве
менеджера ресурсов (resource manager) изменяет метаданные (metadata — "данные о
данных"), т.е. информацию, описывающую схему базы данных.
1.2.2. Обработка запросов
Большая часть обращений к базе данных инициируется пользователями и
приложениями (соответствующие потоки команд и данных изображены в левой части
рис. 1.1). Подобные действия не оказывают влияния на схему базы данных, но
затрагивают содержимое последней (если команда предусматривает внесение
изменений) либо предполагают чтение данных (если команда содержит запрос). В разделе 1.1
на с. 32 мы уже писали о том, что такие команды оформляются с помощью языка
управления данными (Data Manipulation Language — DML), или, проще говоря, языка
запросов (query language). Существует множество различных языков управления
данными, но самым распространенным и мощным из них является SQL, упоминавшийся
нами в примере 1.1 (см. с. 34). Инструкции языка DML обрабатываются двумя
отдельными подсистемами СУБД, описанными ниже.
Получение ответа на запрос
Запрос анализируется и оптимизируется компилятором запросов (query compiler).
Сформированный компилятором план запроса (query plan), или последовательность
действий, подлежащих выполнению системой с целью получения ответа на запрос,
передается исполняющей машине. Исполняющая машина направляет группу запросов
на получение небольших порций данных -— как правило, строк (кортежей) таблицы
(отношения) — менеджеру ресурсов, который "осведомлен" об особенностях
размещения информации в файлах данных (data files), содержащих таблицы, о форматах и
размерах записей в этих файлах и о структурах индексных файлов (index files),
обеспечивающих существенное ускорение процессов поиска запрошенных данных.
40
ГЛАВА 1. МИР БАЗ ДАННЫХ
Запросы на получение данных транслируются в адреса страниц и пересылаются
менеджеру буферов (buffer manager). О роли менеджера буферов мы поговорим ниже,
но здесь уместно кратко отметить, что его задачей является обращение к
соответствующим порциям данных на носителях вторичных устройств хранения (обычно,
дисках), где они располагаются постоянно, с последующим переносом данных в
буферы, размещаемые в оперативной памяти, и наоборот. Единицами потоков обмена
данными между буферами в памяти и диском являются страница или "дисковый блок".
Чтобы получить информацию с диска, менеджеру буферов приходится обращаться
к услугам менеджера хранения данных (storage manager), который, решая возложенные
на него задачи, может вызывать команды операционной системы, но чаще всего
непосредственно инициирует инструкции дискового контроллера.
Обработка транзакций
Запросы и другие команды языка управления данными группируются в транзакции
(transactions) — процессы, которые должны выполняться атомарным образом
(atomically) и изолированно (in isolation) друг от друга. Зачастую каждый отдельный
запрос или операция по изменению данных является самостоятельной транзакцией.
Транзакция обязана обладать свойством устойчивости (durability). Это значит, что
результат каждой завершенной транзакции должен быть зафиксирован в базе данных
даже в тех ситуациях, когда после окончания транзакции система по той или иной
причине выходит из строя. На рис. 1.1 процессор транзакций (transaction processor)
представлен в виде двух основных компонентов:
1) планировщика заданий (scheduler), или менеджера параллельных заданий
(concurrency-control manager), ответственного за обеспечение атомарности
и изолированности транзакций;
2) менеджера протоколирования и восстановления (logging and recovery manager),
гарантирующего выполнение требования устойчивости транзакций.
Указанные компоненты будут подробно рассмотрены в разделе 1.2.4 на с. 42.
1.2.3. Менеджеры буферов и хранения данных
Информация, хранимая в базе данных, обычно располагается на носителях
вторичных устройств хранения. Термин вторичное устройство хранения (secondary storage
device), употребляемый применительно к современной компьютерной системе,
обычно означает магнитный диск. Однако, чтобы выполнить любую сколько-нибудь
полезную операцию над данными, необходимо перенести их в оперативную память.
Задача управления размещением информации на диске и обмена ею между диском
и оперативной памятью возлагается на менеджер хранения данных (storage manager).
В простой системе баз данных роль менеджера хранения может быть поручена
непосредственно файловой системе, обслуживаемой соответствующей операционной
системой. Впрочем, из соображений обеспечения эффективности вычислений СУБД
обычно (по меньшей мере, при определенных обстоятельствах) самостоятельно
управляет размещением данных на дисках. В ответ на запрос со стороны менеджера буферов
менеджер хранения данных определяет положение файлов на диске и получает набор
блоков диска, содержащих требуемый файл или его часть. Отметим, что поверхность
диска обычно разделена на дисковые блоки (disk blocks) — непрерывные участки,
способные сохранять большое число байтов информации, до 212 или 214 (4096 или 16384).
Менеджер буферов (buffer manager) ответствен за разбиение доступной оперативной
памяти на буферы (buffers) — участки-страницы (pages), куда может быть помещено
содержимое дисковых блоков. Все компоненты СУБД, обращающиеся к дисковой
информации, взаимодействуют с буферами и менеджером буферов — либо
непосредственно, либо при помощи исполняющей машины. Данные, требуемые компонентами
системы, могут относиться к одной из следующих категорий:
1.2. ОБЗОР СТРУКТУРЫ СУБД
41
Пользователь/приложение
Запросы,
команды
изменения4
Команды
транзакций
Администратор базы данных
Команды
DDL
Компилятор
запросов
План
запроса
Менеджер
транзакций
^ ^Метаданные,
^\статистика
Исполняющая
машина
Запросы к
индексам,
файлам и
записям
Менеджер
протоколирования
и восстановления
Менеджер
ресурсов
1Данные,\
индексы,^
метаданные^
Менеджер
буферов
Чтение/записц
страниц
Менеджер
хранения
данных
Носитель
данных
Компилятор
DDL
\ Метаданные
Планировщик
заданий
Таблица i
блокировок
Рис. 1.1. Компоненты системы управления базами данных
1) собственно данные — содержимое базы данных как таковой;
2) метаданные — описание схемы, или логической структуры, базы данных,
введенных ограничений и т.д.;
3) статистика — информация о свойствах данных, таких как размеры
различных отношений, о вероятностных распределениях хранящихся значений
и т.п., собранная СУБД;
4) индексы — структуры данных, обеспечивающие эффективный доступ к
информации в базе данных.
За подробными сведениями о функциональных особенностях менеджера буферов
и его значении в общей структуре СУБД обращайтесь к разделу 15.7 на с. 732.
1.2.4. Обработка транзакций
Обычной практикой является оформление одной или нескольких операций над
базой данных в виде транзакции (transaction) — единицы работы, которая должна быть
42
ГЛАВА 1. МИР БАЗ ДАННЫХ
выполнена атомарным образом и изолированно от других транзакций. Кроме того, СУБД
обязана удовлетворять требованию устойчивости транзакций: результат выполнения
завершенной транзакции не должен быть утрачен ни при каких условиях. Менеджер
транзакций (transaction manager) воспринимает от приложения команды транзакций (transaction
commands), которые свидетельствуют о начале и завершении транзакции, а также
передают информацию о предпочтениях приложения в отношении параметров транзакции
(приложение, например, может отказаться от свойства атомарности транзакции).
Процессор транзакций (transaction processor) выполняет функции, рассмотренные ниже.
1. Протоколирование (logging). С целью удовлетворения требования устойчивости
(durability) транзакций каждое изменение в базе данных фиксируется в
специальных дисковых файлах. Менеджер протоколирования (logging manager) в своей
работе руководствуется одной из нескольких стратегий, призванных исключить
вредные последствия системных сбоев во время выполнения транзакции, а
менеджер восстановления (recovery manager) в случае возникновения подобных
ситуаций способен считать протокол изменений и привести базу данных в
некоторое сообразное состояние. Информация протокола изначально сохраняется
в буферах; затем менеджер протоколирования в определенные моменты
времени взаимодействует с менеджером буферов, дабы убедиться, что содержимое
буферов действительно сохранено на диске (где данные находятся под
надежной защитой в момент возможного краха системы).
2. Управление параллельными заданиями (concurrency control). Транзакции обязаны
выполняться в полной изоляции друг от друга. Горькая истина, однако,
заключается в том, что в реальных системах одновременно могут действовать
несколько процессов-транзакций. Планировщик заданий (scheduler), или менеджер
параллельных заданий (concurrency-control manager), должен обеспечить такой
режим работы системы, чтобы результат выполнения отдельных
перемежающихся во времени операций многочисленных транзакций оказался таким, как
если бы транзакции в действительности инициировались, протекали и
полностью завершались в строгой очередности, не "пересекаясь" одна с другой.
Типичный планировщик заданий добивается поставленной перед ним цели,
устанавливая признаки блокировки (lock) на соответствующие фрагменты
содержимого базы данных. Блокировки препятствуют возможности единовременного
обращения нескольких транзакций к порции данных такими способами,
которые плохо согласуются друг с другом. Признаки блокировки обычно хранятся
в таблице блокировок (lock table), размещаемой в оперативной памяти, как
показано на рис. 1.1 (см. с. 42). Планировщик заданий воздействует на процесс
выполнения запросов и других операций, запрещая исполняющей машине
обращаться к блокированным порциям данных.
3. Разрешение взаимоблокировок (deadlock resolution). Поскольку транзакции
состязаются за ресурсы, которые могут быть блокированы планировщиком заданий,
возможно возникновение таких обстоятельств, когда ни одна из транзакций не
в состоянии продолжить работу ввиду того, что ей необходим ресурс,
находящийся в ведении другой транзакции. Менеджер транзакций обладает
прерогативой вмешиваться в ситуацию и прерывать (откатывать — "rollback") одну
или несколько транзакций, чтобы позволить остальным продолжить работу.
1.2.5. Процессор запросов
Подсистема, в наибольшей степени определяющая показатели производительности
СУБД, видимые, что называется невооруженным глазом, носит название процессора
запросов (query processor). На рис. 1.1 (см. с. 42) процессор запросов представлен
двумя компонентами, рассмотренными ниже.
1.2. ОБЗОР СТРУКТУРЫ СУБД
43
ACID: свойства транзакций
Принято говорить, что правильным образом реализованные транзакции
удовлетворяют "условиям ACID":
• А представляет свойство "atomicity" (атомарность) — транзакция
осуществляется в соответствии с принципом "все или ничего", т.е. должна быть выполнена
либо вся целиком, либо не выполнена вовсе;
• /служит сокращением термина "isolation" (изолированность) — процесс протекает
таким образом, словно в тот же период времени других транзакций не существует;
• D определяет требование под названием "durability" (устойчивость) — результат
выполнения завершенной транзакции не должен быть утрачен ни при каких условиях.
Оставшаяся буква аббревиатуры, С, обозначает свойство "consistency"
(согласованность). Все базы данных вводят те или иные ограничения (constraints),
обусловливающие особенности различных элементов данных и их взаимную
согласованность (так, например, сумма бухгалтерской проводки не может быть
отрицательной). Транзакции обязаны сохранять согласованность данных. О том, каким
образом ограничения определяются в схеме базы данных, мы расскажем в главе 7
(см. с. 317), а вопросы, касающиеся поддержки системой требования
согласованности данных, будут освещены в разделе 18.1 на с. 880.
1. Компилятор запросов (query compiler) транслирует запрос во внутренний формат
системы — 1ыан запроса (query plan). Последний описывает последовательность
инструкций, подлежащих выполнению. Часто инструкции плана запроса
представляют собой реализации операций "реляционной алгебры" (мы расскажем о ней
в разделе 5.2 на с. 205). Компилятор запросов состоит из трех основных частей:
a) синтаксического анализатора запросов (query parser), создающего на основе
текста запроса древовидную структуру данных;
b) препроцессора запросов (query preprocessor), выполняющего семантический
анализ запроса (проверку того, все ли отношения и их атрибуты,
упомянутые в тексте запроса, действительно существуют) и функции преобразования
дерева, построенного анализатором, в дерево алгебраических операторов,
отвечающих исходному плану запроса;
c) оптимизатора запросов (query optimizer), осуществляющего трансформацию
плана запроса в наиболее эффективную последовательность фактических
операций над данными.
Компилятор запросов, принимая решение о том, какая из последовательностей
операций с большей вероятностью окажется самой оптимальной по
быстродействию, пользуется метаданными и статистической информацией, накопленной СУБД.
Например, наличие индекса (index) — специальной структуры данных,
обслуживающей процессы доступа к информации отношений посредством хранения
определенных значений, которые соответствуют порциям содержимого отношения, —
способно существенным образом повлиять на выбор наиболее эффективного плана.
2. Исполняющая машина (execution engine) несет ответственность за осуществление
каждой из операций, предусмотренных выбранным планом запроса. В процессе
своей работы она взаимодействует с большинством других компонентов
СУБД — либо напрямую, либо при посредничестве буферов данных. Чтобы
получить возможность обрабатывать данные, исполняющая машина обязана
считать их с носителя и перенести в буферы. При этом ей необходимо "общаться"
с планировщиком заданий, чтобы избежать опасности обращения к блокиро-
44
ГЛАВА 1. МИР БАЗ ДАННЫХ
ванным порциям информации, а также с менеджером протоколирования,
обеспечивающим гарантии того, что все изменения, внесенные в базу данных,
должным образом зафиксированы в протоколе.
1.3. Обзор технологий СУБД
Вопросы, имеющие отношение к проблематике создания систем баз данных,
можно поделить на три категории, описанные ниже.
1. Проектирование баз данных. Как разрабатывать полезные базы данных?
Информация каких разновидностей должна быть включена в базу данных? Как надлежит
структурировать данные? Какие предположения следует выдвигать относительно
типов и значений элементов данных? Как обеспечить взаимосвязь этих элементов?
2. Программирование приложений баз данных. Каковы средства представления
запросов и других операций над содержимым базы данных? Каким образом следует
использовать другие возможности СУБД, такие как транзакции или ограничения,
в конкретном программном приложении? Как соотносится и сочетается
программирование баз данных с программированием обычных приложений?
3. Реализация систем баз данных. Что необходимо сделать, чтобы реализовать
конкретную СУБД, включая и такие ее функции, как обработка запросов,
управление транзакциями и эффективная организация хранения данных?
1.3.1. Проектирование баз данных
В главе 2 на с. 51 мы рассмотрим абстракцию процесса проектирования базы
данных, называемую ER-моделью, или моделью "сущность—связь" (entity-relationship
model). Глава 3 на с. 87 познакомит вас с реляционной моделью (relational model),
лежащей в основе большинства наиболее распространенных коммерческих СУБД
(некоторые особенности реляционной модели мы кратко освещали в разделе 1.1.2 на
с. 34). Мы покажем, как конкретный образец ER-модели транслируется в
соответствующую реляционную схему базы данных. Позже, в разделе 6.6 на с. 296, будут
изложены сведения о том, как реляционная схема базы данных может быть описана
средствами подмножества языка SQL, которое имеет отношение к определению данных.
В главе 3 рассматривается и понятие зависимостей (dependencies), формально
выражающее предположения о взаимоотношениях кортежей отношения. Использование
аппарата определения зависимостей позволяет улучшить качество проекта реляционной
базы данных в ходе процесса, известного как нормализация (normalization) отношений.
В главе 4 на с. 149 мы изложим сведения об объектно-ориентированных подходах к
проектированию баз данных. Здесь рассмотрены особенности языка ODL (Object Definition
Language — язык определения объектов), позволяющего описывать базы данных
высокоуровневыми объектно-ориентированными средствами. Мы расскажем также о способах
сочетания инструментов объектно-ориентированного проектирования с реляционным
моделированием, что подведет вас к пониманию "объектно-реляционной" (object-relational)
парадигмы. В главе 4 затрагиваются и вопросы использования "полуструктурированных"
данных (semistructured data) — особенно гибкой модели представления информации —
и современной реализации этой модели в виде языка описания документов XML.
1.3.2. Программирование приложений баз данных
В главах 5—10 на с. 203—487 излагаются основы программирования приложений,
ориентированных на использование баз данных. Главу 5 мы начнем с рассмотрения
абстрактной трактовки запросов в рамках реляционной модели, введя семейство
операторов, применяемых в контексте отношения, которые составляют существо
реляционной алгебры (relational algebra).
1.3. ОБЗОР ТЕХНОЛОГИЙ СУБД
45
Как создаются индексы
Вы, читатель, возможно, уже изучали курс структур данных и осведомлены о том, что
хеш-таблицы (hash tables) — это весьма многообещающее средство создания
индексов. В ранних СУБД хеш-таблицы использовались особенно интенсивно. Но сегодня
наиболее распространенной структурой данных, применяемой для создания
индексов, является В-дерево (B-tree; буква В служит сокращением термина "balanced" —
сбалансированное). Структура В-дерева представляет собой обобщение так
называемого сбалансированного бинарного дерева поиска (balanced binary search tree): если
вершина бинарного дерева обладает, самое большее, двумя дочерними вершинами,
вершина В-дерева может иметь произвольное число дочерних вершин. Если принять во
внимание, что данные В-дерева обычно размещаются на диске, а не в оперативной
памяти, структура проектируется таким образом, чтобы информация о каждой ее
вершине занимала отдельный блок диска. Поскольку обычный размер блока
достигает 212 (4096) байт, в одном блоке вполне возможно хранить данные о сотнях
дочерних вершин дерева. Таким образом, при поиске данных по В-дереву
необходимость обращения к более чем нескольким блокам возникает сравнительно редко.
Трудоемкость дисковых операций пропорциональна количеству запрашиваемых
блоков диска. Поэтому поиск по В-дереву, затрагивающий, как правило, всего
несколько блоков диска, существенно более эффективен, нежели бинарный поиск,
в процессе выполнения которого приходится посещать вершины дерева,
относящиеся к многим различным блокам. Указанное различие между деревьями
бинарного поиска и В-деревьями — это один из характерных примеров того, что
структуры данных, наиболее подходящие для хранения данных в оперативной памяти,
не обязательно столь же эффективны, если данные располагаются на диске.
Главы 6—8 на с. 249—418 посвящены технологиям программирования на языке
SQL. Как мы говорили прежде, SQL преобладает на современном рынке языков
запросов. Глава 6 познакомит вас с базовыми понятиями, касающимися представления
запросов и схем баз данных на языке SQL. Глава 7 на с. 317 охватывает аспекты SQL,
связанные с заданием ограничений (constraints) и построением триггеров (triggers).
Глава 8 на с. 349 дает ответы на некоторые более сложные вопросы применения
SQL. Простейшая модель программирования на SQL предусматривает обособленное
употребление элементов "чистого" интерфейса языка, но в большинстве реальных
ситуаций фрагменты SQL-кода используются в контексте крупных программных проектов,
написанных на традиционных языках, таких как С. В главе 8 мы расскажем о том, как
правильно применять выражения SQL внутри кода других программ, а также
переносить информацию из базы данных в переменные программы и наоборот. В той же
главе приводятся сведения об использовании в прикладных программах механизмов
поддержки транзакций, подключения клиентов к серверам и авторизации доступа к
информации со стороны пользователей, не являющихся владельцами объектов базы данных.
В главе 9 на с. 419 мы сосредоточим внимание на двух направлениях объектно-
ориентированного программирования приложений баз данных. Первое из них связано
с применением языка OQL (Object Query Language — язык объектных запросов),
появление которого можно рассматривать как тенденцию к пополнению СН-4- и других
объектно-ориентированных языков общего назначения инструментами,
удовлетворяющими требованиям концепции высокоуровневого программирования с
ориентацией на использование баз данных. Второе направление, имеющее отношение к
недавно принятым нововведениям, которые касаются объектно-ориентированных
"расширений" стандарта SQL, выглядит, с другой стороны, как попытка обеспечения
совместимости реляционной парадигмы и языка SQL с моделью объектно-
ориентированного программирования.
46
ГЛАВА 1. МИР БАЗ ДАННЫХ
Наконец, в главе 10 на с. 453 мы вновь вернемся к теме абстрактных языков
запросов, рассмотрение которой начато в главе 5 (см. с. 203). Мы расскажем о
логических языках запросов (logical query languages) и об использовании их с целью
расширения возможностей современных диалектов SQL.
1.3.3. Реализация систем баз данных
Третья часть книги посвящена технологиям реализации СУБД, которые можно
условно поделить на три категории, перечисленные ниже.
1. Управление процессами хранения данных— использование вторичных устройств
хранения для обеспечения эффективного доступа к информации.
2. Обработка запросов — оптимальное обслуживание запросов, оформленных
средствами высокоуровневых языков, подобных SQL.
3. Управление транзакциями — поддержка транзакций, обеспечивающая
выполнение условий ACID (см. раздел 1.2.4 на с. 42).
Каждой из названных тем отведено несколько глав книги.
Управление процессами хранения данных
В главе 11 на с. 489 рассматривается иерархия устройств памяти. Поскольку
вторичные устройства хранения данных, в частности диски, являются наиболее важным
средством сбережения информации в рамках СУБД, мы уделим повышенное
внимание способам хранения данных на диске и доступа к ним. Вашему вниманию будет
предложена "блоковая модель" размещения данных на диске, оказывающая влияние
почти на все стороны "деятельности" СУБД.
В главе 12 на с. 549 обсуждаются вопросы хранения отдельных элементов данных —
отношений, кортежей, значений атрибутов и равнозначных им сущностей, принятых
в других моделях представления информации, —- в соответствии с требованиями
блоковой модели дисковых данных. Далее мы уделим внимание основным структурам
данных, находящим применение при конструировании индексов. Уместно напомнить, что
индекс — это структура данных, обеспечивающая эффективный доступ к информации
на диске. Глава 13 на с. 583 содержит сведения о важных одномерных (one-dimensional)
индексных структурах данных — последовательных файлах (sequential files), В-деревьях
(B-trees) и хеш-таблицах (hash tables). Подобные индексы широко используются в СУБД
для оптимизации запросов, предполагающих поиск группы кортежей, которые
удовлетворяют заданному значению некоторого атрибута. В-деревья применяются также для
доступа к содержимому отношения, отсортированного в порядке убывания или
возрастания определенного атрибута. В главе 14 на с. 637 рассматриваются многомерные
(multidimensional) индексы, представляющие собой структуры данных, используемые
при создании специализированных разновидностей баз данных (например,
предназначенных для хранения географической информации), запросы к которым обычно
предполагают поиск элементов данных, отвечающих нескольким критериям. Подобные
индексные структуры хорошо приспособлены для удовлетворения сложных SQL-
запросов, в которых ограничения накладываются1 на целую группу атрибутов, и
некоторые из таких структур уже обрели поддержку со стороны ряда коммерческих СУБД.
Обработка запросов
В главе 15 на с. 683 излагаются сведения о процессах выполнения запросов. Мы
представим вашему вниманию большое количество алгоритмов, позволяющих
эффективно реализовать множество операций реляционной алгебры. Алгоритмы
спроектированы таким образом, чтобы оптимизировать действия с дисковыми данными,
и в некоторых случаях довольно существенно отличаются от аналогов,
предназначенных для обработки информации, размещенной в оперативной памяти.
1.3. ОБЗОР ТЕХНОЛОГИЙ СУБД
47
Глава 16 на с. 753 содержит сведения об архитектуре компилятора запросов (query
compiler) и оптимизатора запросов (query optimizer). Сначала мы рассмотрим процессы
лексического анализа запросов и их семантической проверки. Затем будет рассказано
о преобразовании запросов SQL в наборы инструкций реляционной алгебры и критериях
выбора логического плана запроса (logical query plan), т.е. алгебраического выражения,
которое представляет определенные операции, подлежащие выполнению, и необходимые
ограничения, затрагивающие порядок следования операций. Наконец, мы обсудим вопросы
конструирования физического плана запроса (physical query plan), который, учитывая
конкретный порядок выполнения операций, задает алгоритм реализации каждой операции.
Управление транзакциями
В главе 17 на с. 837 мы ответим на вопросы, каким образом СУБД обеспечивает
устойчивость (durability) транзакций. Основной подход к решению проблемы связан
с ведением протокола, регистрирующего все изменения в базе данных. При сбое
системы (возникающем, например, из-за отключения электропитания) информация,
расположенная в оперативной памяти, но не зафиксированная на диске, будет утрачена.
Поэтому весьма важно, чтобы операции по перемещению данных из буферов памяти
на диск выполнялись своевременно и в соответствующем порядке и чтобы изменения,
затрагивающие непосредственно базу данных и протокол, вносились синхронно.
Существует несколько стратегий ведения протоколов, но каждый из них каким-либо
образом ограничивает свободу действий над данными.
В главе 18 на с. 879 мы затронем тему управления параллельным доступом к
данным, способного обеспечить поддержку свойств атомарности (atomicity) и
изолированности (isolation) транзакций. Транзакции представляются в виде последовательностей
операций чтения и записи элементов содержимого базы данных. Основное внимание
в главе уделено тому, как следует обращаться с блокировками (locks) элементов
данных. Здесь рассмотрены различные типы блокировок и допустимые методы установки
блокировок параллельными транзакциями и освобождения их. Помимо того, мы
предоставим сведения о способах обеспечения свойств атомарности и изолированности
транзакций без использования механизмов блокирования.
Глава 19 на с. 949 завершает обсуждение проблем обработки транзакций. Мы
расскажем о взаимном соотношении требований протоколирования, рассмотренных
в главе 17 на с. 837, и условий, обеспечивающих параллельное выполнение
транзакций (этой теме посвящена глава 18 на с. 879). Особое внимание мы уделим
технологии разрешения взаимоблокировок (deadlock resolution) — одной из важнейших функций
менеджера транзакций. В главе 19 также изложены сведения об управлении
параллельными транзакциями в условиях распределенной вычислительной среды
(distributed environment) и инструментах обслуживания длинных ("long") транзакций,
продолжительность выполнения которых измеряется часами или даже сутками вместо
привычных секунд или долей секунды. Длинная транзакция не в состоянии
блокировать элементы данных, не причиняя ущерба интересам других потенциальных
пользователей тех же данных, что приводит к необходимости переосмысления подходов
к проектированию приложений, предусматривающих применение транзакций.
1.3.4. Интеграция информации
Немалая часть современных исследований в сфере технологий баз данных
направлена на обеспечение возможностей сочетания в единое целое различных источников
данных (data sources), среди которых могут быть как привычные базы данных, так
и информационные ресурсы, не относящиеся к ведению СУБД. Подобные проблемы
кратко освещались в разделе 1.1.7 на с. 38. Заключительная, 20-я, глава (см. с. 1003)
содержит сведения о важнейших аспектах интеграции данных. Здесь мы расскажем об
основных режимах интеграции, включая использование транслированных и
объединенных копий источников информации в рамках хранилищ данных (data warehouses)
48
ГЛАВА 1. МИР БАЗ ДАННЫХ
и создание виртуальных баз данных (virtual databases) на основе фупп источников
информации, которое выполняется средствами профаммных компонентов, называемых
медиаторами (mediators).
1.4. Резюме
♦ Системы управления базами данных. СУБД отличаются способностью к
эффективному выполнению операций обработки больших массивов информации,
хранимых на протяжении длительных периодов времени. В СУБД реализована
поддержка мощных языков запросов и устойчивых транзакций, которые могут
выполняться атомарным образом и независимо от других параллельных транзакций.
♦ СУБД и файловые системы. Традиционные файловые системы не являются
полноценной альтернативой СУБД, поскольку они не в состоянии обеспечить
реализацию высокопроизводительных функций поиска, возможность эффективной
модификации небольших элементов информации, поддержку сложных
запросов, гибкую буферизацию требуемых данных в оперативной памяти и
атомарное и изолированное выполнение транзакций.
♦ Системы реляционных баз данных. Большинство современных СУБД основано на
реляционной модели представления данных, в соответствии с которой
информация организуется в виде таблиц. В подобных системах в качестве языка
запросов наиболее часто применяется SQL.
♦ Вторичные и третичные устройства хранения данных. Крупные базы данных
размещают на вторичных устройствах хранения (как правило, дисках). Наиболее
обширные базы данных требуют использования третичных устройств хранения, которые
на несколько порядков более емки, но во много раз менее производительны.
♦ Системы "клиент/сервер". СУБД обычно поддерживают архитектуру
"клиент/сервер", предусматривающую размещение основных компонентов системы
на сервере и предоставляющую пользователю необходимый клиентский интерфейс.
♦ Языки баз данных. Существует ряд языков или языковых компонентов для
определения структур данных (языки определения данных) и описания запросов и
инструкций по изменению элементов информации (языки управления данными).
♦ Компоненты СУБД. К числу наиболее важных компонентов системы
управления базами данных относятся менеджер хранения данных, процессор запросов
и менеджер транзакций.
♦ Менеджер хранения данных — компонент СУБД, ответственный за размещение
и хранение на диске основной информации базы данных, метаданных
(сведений о схеме, или логической структуре, данных), индексов (структур,
ускоряющих доступ к информации) и протоколов (записей, фиксирующих изменения
в базе данных). Важнейшей частью подсистемы хранения данных является
менеджер буферов, обеспечивающий перенос порций дисковой информации
в буферы оперативной памяти и обратно.
♦ Процессор запросов — элемент СУБД, осуществляющий лексический и
семантический разбор запроса, его оптимизацию, выбор соответствующего плана
запроса и последующее выполнение плана применительно к реальным данным.
♦ Менеджер транзакций — часть СУБД, реализующая функции ведения протокола
изменений с целью обеспечения возможности восстановления данных после сбоев
системы, а также управляющая процессами протекания параллельных транзакций
и гарантирующая их атомарность (транзакция выполняется либо целиком и до
конца, либо не выполняется вовсе) и изолированность (каждая транзакция
обслуживается таким образом, словно других конкурирующих транзакций не существует).
1.4. РЕЗЮМЕ
49
♦ Будущее систем баз данных. Основные тенденции в развитии СУБД связаны
с поддержкой сверхбольших объектов мультимедиа-данных (таких как видео-
или аудиозаписи) и интеграцией информации из многих разнородных
источников в единую базу данных.
1.5. Литература
Сегодня, в эпоху существования электронных библиографических каталогов,
открытых для доступа с помощью средств Internet и содержащих, в частности, ссылки
на все свежие информационные источники, относящиеся к сфере технологий баз
данных, совершенно нецелесообразно пытаться привести на страницах книги
исчерпывающий список литературы, достойной цитирования. Здесь уместно упомянуть
только те печатные работы, которые важны с точки зрения исторической
перспективы, указать основные гиперссылки на соответствующие ресурсы Web и отметить
некоторые полезные обзоры. Один из каталогов, охватывающих библиографию результатов
исследований по проблемам управления базами данных, в свое время был создан
и содержится в актуальном состоянии Михелем Леем (Michael Ley) [5]. Альф-
Кристиан Ахилл (Alf-Christian Achilles) поддерживает каталог каталогов информации,
относящихся к предметной области систем баз данных [1].
Хотя существенные успехи были достигнуты при реализации многих проектов
СУБД, наибольшую известность получили два из них — System R, осуществленный
в исследовательском центре IBM Almaden Research Center [3], и INGRES,
выполненный в Калифорнийском университете в Беркли [7]. Каждый из проектов
предусматривал создание систем реляционных баз данных и способствовал становлению этой
разновидности систем в качестве главного участника рынка технологий баз данных.
Большое количество результатов исследований нашло отражение в обзоре [6].
Одним из самых свежих в серии отчетов по результатам научных изысканий и
технологических разработок в области СУБД является отчет [4], который содержит
ссылки на многие более ранние информационные источники подобного рода.
За дополнительными сведениями по теории систем баз данных, не нашедшими
отражения в литературе, названной выше, обращайтесь к работам [2], [8] и [9].
1. http://liinwww.ira.uka.de/bibliography/Database.
2. Abiteboul S., Hull R., and Vianu V. Foundations of Databases, Addison-Wesley, Reading, MA, 1995.
3. Astrahan M.M. et al. System R: a relational approach to database management, ACM Trans, on
Database Systems, 1:2 (1976), p. 97-137.
4. Bernstein P.A. et al. The Asilomar report on database research
(http://www.acm.org/sigmod/record/issues/9812/asilomar.html).
5. http://www.informatik.uni-trier.de/-ley/db/index.html. Адрес зеркального
сайта: http://www.acm.org/sigmod/dblp/db/index.html.
6. Stonebraker M., Hellerstein J.M. (eds.) Readings in Database Systems, Morgan-Kaufmann,
San Francisco, 1998.
7. Stonebraker M., Wong E., Kreps P., and Held G. The design and implementation of INGRES,
ACM Trans, on Database Systems, 1:3 (1976), p. 189-222.
8. Ullman J.D. Principles of Database and Knowledge-Base Systems, Volume I, Computer Science
Press, New York, 1988.
9. Ullman J.D. Principles of Database and Knowledge-Base Systems, Volume II, Computer Science
Press, New York, 1989.
50
ГЛАВА 1. МИР БАЗ ДАННЫХ
Глава 2
Модель данных
"сущность-связь"
Процесс проектирования базы данных начинается с анализа того, какого рода
информация должна быть в ней представлена и каковы взаимосвязи между элементами этой
информации. Структура, или схема (schema), базы данных определяется средствами
различных языков или систем обозначений, пригодных для описания проектов. По
завершении этапа уточнений и согласований проект преобразуется в форму, которая
может быть воспринята СУБД, и база данных начинает собственную жизнь.
В книге рассматривается несколько систем описания проектов баз данных. Эта
глава посвящена изучению ER-модели, или модели "сущность—связь" (entity-relationship
model), ставшей традиционной и наиболее популярной. По своей природе модель
является графической: прямоугольники отображают элементы данных, а линии
(возможно, со стрелками) указывают на связи между ними.
В главе 3 на с. 87 мы сосредоточим внимание на реляционной модели (relational
model), представляющей данные об окружающем мире в виде набора таблиц.
Множество структур, которые могут быть описаны средствами реляционной модели,
разумеется, ограниченно, но этот факт не способен преуменьшить ее значение: модель
чрезвычайно проста и плодотворна и является основой большинства современных
коммерческих СУБД. Процесс проектирования базы данных обычно начинается
с разработки ее схемы посредством инструментов, предлагаемых ER-моделью либо
некоторой объектной моделью, с последующей трансляцией схемы в реляционную
модель, подлежащую физической реализации.
Альтернативные модели описания данных рассмотрены в главе 4 на с. 149. Раздел
4.2 на с. 152 предлагает введение в язык ODL (Object Definition Language — язык
определения объектов) — стандарт средств описания объектно-ориентированных баз
данных. Затем мы проследим, как идеи объектно-ориентированного проектирования,
сочетаясь с реляционной моделью представления данных, трансформируются в модель,
называемую объектно-реляционной (object-relational model).
В разделе 4.6 на с. 187 описан другой подход к моделированию, основанный на
концепции "полуструктурированных" данных (semistructured data). Последняя
предоставляет неограниченную свободу выбора структурных форм, в которые может быть
облечена информация. В разделе 4.7 на с. 192 мы обсудим стандарт XML,
позволяющий моделировать данные в виде иерархически структурированных документов,
используя "тэги" (подобные тэгам HTML), которые определяют роль и функции тексто-
вых элементов. XML представляет собой блестящее практическое воплощение модели
"полуструктурированных" данных.
Рис. 2.1 иллюстрирует, каким образом ER-модели используются при проектировании
баз данных. Обычно принято начинать с изучения понятий и описаний информации,
подлежащей моделированию, а затем пытаться отобразить их в рамках ER-модели. Затем ЕЯ-
проект преобразуется в реляционную схему, выраженную средствами языка определения
данных для конкретной СУБД. В большинстве случаев СУБД основываются на
реляционной модели. Если дело обстоит именно так, в ходе довольно прямолинейного процесса,
детали которого мы обсудим в разделе 3.2 на с. 91, абстракция обретает конкретную
осязаемую форму, называемую реляционной схемой базы данных (relational database schema).
Понятия и ER- Реляционная Реляционная
описания проект схема СУБД
Рис. 2.1. Процесс моделирования и реализации базы данных
Важно отметить, что в то время как в СУБД подчас находят применение модели,
отличные от реляционных или объектно-реляционных, систем баз данных, способных
реализовать ER-модель непосредственно, попросту не существует. Причина заключается
в том, что эта модель недостаточно удовлетворительно согласовывается с эффективными
структурами данных, на основе которых должна создаваться "реальная" база данных.
2.1. Элементы ER-модели
Наиболее распространенным средством абстрактного представления структур баз
данных является ER-модель, или модель "сущность—связь" (entity-relationship model).
В ER-модели структура данных отображается графически, в виде диаграммы сущностей
и связей (entity-relationship diagram), состоящей из элементов трех основных типов:
a) множеств сущностей;
b) атрибутов;
c) связей.
Ниже подробно рассмотрен каждый из типов элементов диаграммы сущностей и связей.
2.1.1. Множества сущностей
Сущность (entity) — это абстрактный объект определенного вида. Набор
однородных сущностей образует множество сущностей (entity set). Понятие сущности обладает
определенным сходством с понятием объекта (object) (если трактовать последнее так,
как это принято делать в объектно-ориентированном проектировании). Примерно
таким же образом соотносятся множество сущностей и класс объектов. ER-модель,
однако, отображает статические объекты — она имеет дело со структурами данных, но
не с операциями над данными. Поэтому предполагать, что в ней могут содержаться
описания неких "методов", соответствующих множествам сущностей и аналогичных
методам класса, нет никаких оснований.
Пример 2.1. На протяжении многих глав книги мы будем рассматривать и развивать
пример, касающийся базы данных о кинофильмах, участвующих в них актерах, студиях,
осуществивших съемку, и т.п. Каждый из фильмов представляет собой сущность, а
коллекция всех фильмов образует множество сущностей. Актеры, снимающиеся в фильмах,
также являются сущностями, но другого вида, и их множество — это множество
сущностей. Киностудия — это сущность еще одного вида, а перечень киностудий формирует
третье множество сущностей, которое будет использоваться в дальнейших примерах. □
52
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
Разновидности ER-модели
В некоторых версиях ER-модели атрибуты могут относиться к следующим типам:
1) атомарный, как в версии, рассматриваемой нами;
2) "struct", как в языке С, или кортеж с фиксированным числом атомарных
компонентов;
3) множество значений одного типа — атомарного либо "struct".
Например, в качестве типа атрибута в подобной модели может быть задано
множество пар, каждая из которых состоит из целого числа и строки.
2.1.2. Атрибуты
Множеству сущностей отвечает набор атрибутов (attributes), являющихся
свойствами сущностей множества. Например, множеству сущностей Movies ("кинофильмы")
могут быть поставлены в соответствие такие атрибуты, как title ("название") и length
("продолжительность" — значение периода времени воспроизведения, выраженное
в минутах). В версии ER-модели, рассматриваемой в этой книге, мы предполагаем,
что атрибуты представляют собой атомарные значения (например, строки, целые
или вещественные числа и т.д.). Существуют и такие варианты модели, в которых
понятие типа атрибута трактуется иным образом (см. врезку "Разновидности ER-
модели", приведенную выше).
2.1.3. Связи
Связи (relationships) — это соединения между двумя или большим числом множеств
сущностей. Если, например, Movies ("кинофильмы") и Stars ("актеры") — это два
множества сущностей, вполне закономерно наличие связи Stars-in ("актеры-
участники", снявшиеся в фильме), которая соединяет множества сущностей Movies
и Stars: сущность т множества Movies соединена с сущностью s множества Stars
посредством связи Stars-in, если актер s снялся в фильме т. Хотя наиболее
распространена разновидность бинарных связей (binary relationships), соединяющих два множества
сущностей, ER-модель допускает наличие связей, охватывающих произвольное
количество множеств сущностей. Обсуждение вопросов, касающихся многосторонних связей
(multiway relationships), мы отложим до раздела 2.1.7 на с. 56.
2.1.4. Диаграммы сущностей и связей
Диаграмма сущностей и связей (entity—relationship diagram), или ER-диаграмма
(ER-diagram), — это графическое представление множеств сущностей, их
атрибутов и связей. Элементы названных видов описываются вершинами графа, и для
задания принадлежности элемента к определенному виду используется
специальная геометрическая фигура:
• прямоугольник — для множеств сущностей;
• овал — для атрибутов;
• ромб — для связей.
Ребра графа соединяют множества сущностей с атрибутами и служат для
представления связей между множествами сущностей.
Пример 2.2. На рис. 2.2 приведена ER-диаграмма, представляющая структуру простой базы
данных, содержащей информацию о кинофильмах. В составе диафаммы имеется три
множества сущностей: Movies ("кинофильмы"), Stars ("актеры") и Studios ("киностудии").
2.1. ЭЛЕМЕНТЫ ER-МОДЕЛИ
53
Множество сущностей Movies обладает четырьмя атрибутами: title ("название"),
year ("год производства"), length ("продолжительность") и film Type ("тип пленки") —
"color" ("цветная") или "blackAndWhite" ("черно-белая"). Два других множества
сущностей, Stars и Studios, содержат по паре однотипных атрибутов, пате ("имя" или
"название") и address ("адрес"), смысл которых вполне очевиден без дополнительных
разъяснений. На диаграмме представлены две связи, описанные ниже.
1. Stars-in ("актеры-участники", снявшиеся в фильме) — это связь, соединяющая
каждую сущность-"кинофильм" с сущностями-"актерами", принимавшими
участие в съемках фильма. Связь Stars-in, рассматриваемая в противоположном
направлении, в свою очередь соединяет актеров с кинофильмами.
2. Связь Owns ("владеет") соединяет каждую сущность-"кинофильм" с
сущностью-"студией", выпустившей фильм и владеющей правами на него. Стрелка,
задающая направление от связи Owns к множеству сущностей Studios,
свидетельствует о том, чго каждый фильм является собственностью одной и только
одной киностудии. Подобные ограничения уникальности (uniqueness constraints)
будут рассмотрены в разделе 2.1.6 на с. 55.
Рис. 2.2. Диаграмма сущностей и связей для базы данных о
кинофильмах
2.1.5. Экземпляры ER-диаграммы
ER-диаграммы представляют собой инструмент описания схем (schemata), или
структур, баз данных. Базу данных, соответствующую определенной ER-диаграмме
и содержащую конкретный набор данных, принято называть экземпляром базы данных
(database instance). Каждому множеству сущностей в экземпляре базы данных отвечает
некоторый частный конечный набор сущностей, а каждая из таких сущностей
обладает определенными значениями каждого из атрибутов. Уместно отметить, что
информация о сущностях, атрибутах и связях носит строго абстрактный характер:
содержимое ER-модели не может быть сохранено в базе данных непосредственно. Однако
представление о том, что такие данные будто бы реально существуют, помогает на
начальной стадии проекта — пока мы не перейдем к отношениям и структуры данных
не приобретут физическую форму.
54
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ1
Экземпляр базы данных включает также определенные экземпляры связей,
описываемых диаграммой. Связи R, которая соединяет п множеств сущностей Еь Е2,..., Еп,
соответствует экземпляр, состоящий из конечного множества списков (еи еъ ..., еп), где
каждый элемент <?, выбран из числа сущностей, присутствующих в текущем
экземпляре множества сущностей £,. Мы говорим, что элементы каждого из таких списков,
охватывающих п сущностей, "соединены" посредством связи R.
Указанное множество списков называют множеством данных связи (relationship set)
для текущего экземпляра связи R. Зачастую оказывается полезным представлять
множество данных связи в виде таблицы. Столбцы этой таблицы озаглавлены
наименованиями множеств сущностей, охватываемых связью, а каждому списку соединенных
сущностей отводится одна строка таблицы.
Пример 2.3. Экземпляр связи Stars-in ("актеры-участники") легко описать таблицей
пар данных, которая может иметь следующий вид:
Movies Stars
Basic Instinct Sharon Stone
Total Recall Arnold Schwarzenegger
Total Recall Sharon Stone
Члены множества данных связи — это строки таблицы. Например,
("Basic Instinct", "Sharon Stone")
представляет собой кортеж множества данных для текущего экземпляра связи Stars-in. □
2.1.6. Множественность бинарных связей
Бинарная связь (binary relationship) в общем случае способна соединять любой член
одного множества сущностей с любым членом другого множества сущностей. Однако
весьма распространены ситуации, в которых свойство "множественности" связи
некоторым образом ограничивается. Предположим, что R — связь, соединяющая
множества сущностей Е и F. Тогда возможно выполнение одного из нескольких условий,
перечисленных ниже.
• Если каждый член множества Е посредством связи R может быть соединен не
более чем с одним членом F, принято говорить, что R представляет связь типа
"многие к одному" (many-one relationship), направленную от Е к F. В этом случае
каждая сущность множества /'допускает соединение с многими членами Е.
Если же член F посредством связи R может быть соединен не более чем с одним
членом Е, мы говорим, что R — это связь "многие к одному", направленная от
F к Е (или, что то же самое, связь типа "один ка многим"(one-many relationship),
направленная от Е к F).
• Если связь R в обоих направлениях, от Е к F и от F к Е, относится к типу
"многие к одному", говорят, что R — это связь типа "один к одному'' (one-one
relationship). В этом случае каждый элемент одного множества сущностей
допускает соединение не более чем с одним элементом другого множества сущностей.
• Если связь R ни в одном из направлений — ни от Е к F и ни от F к Е — не
относится к типу "многие к одному", имеет место связь типа "многие ко многим "
(many-many relationship).
Как мы уже отмечали в примере 2.2 (см. с. 53), стрелки в ER-диаграмме
используются для отображения факта множественности связей. Если связь относится к типу
"многие к одному" и соединяет множество сущностей Е с множеством сущностей F,
она отображается в виде стрелки, направленной к F. Стрелка указывает, что каждая из
2.1. ЭЛЕМЕНТЫ ER-МОДЕЛИ
55
сущностей множества Е связана не более чем с одной сущностью множества F. Если
при этом линия не снабжена противоположной стрелкой, обращенной к Е, сущность
множества F допускает связь со многими сущностями множества Е.
Пример 2.4. Если следовать рассмотренной логике, связь типа "один к одному" между
множествами сущностей Е и F должна представляться на диаграмме двунаправленной
стрелкой, один конец которой обращен в сторону множества Е, а другой — в сторону F.
На рис. 2.3 показаны два множества сущностей, Studios ("киностудии") и Presidents
("президенты"), соединенные связью Runs ("возглавляет") (атрибуты сущностей для
краткости опущены). Уместно предположить, что каждый президент вправе
руководить только одной студией, а каждая студия может возглавляться только одним
президентом. Поэтому связь Runs следует отнести к типу "один к одному" и соединить на
диаграмме с множествами сущностей Studios и Presidents посредством двух стрелок, по
одной на каждое множество (так, как показано на рис. 2.3).
Studios
Runs
Presidents
Рис. 2.3. Связь типа "один к одному"
Следует помнить: стрелка означает, что в связи участвует "не более чем один"
элемент множества сущностей, на которое она указывает. При этом обязательное
наличие такого элемента в составе множества не гарантируется. Рассматривая диафамму
рис. 2.3, мы вправе полагать, что некий "президент" обязательно связан с
определенной студией — иначе на каком основании он мог бы величать себя президентом?
Однако студия в какой-то период времени может обходиться без руководителя, так что
стрелка, направленная от Runs к Presidents, на самом деле означает именно "не более
чем один", но не "в точности один". Указанное различие мы проясним позже, в
разделе 2.3.6 на с. 79. □
2.1.7. Многосторонние связи
ER-модели вполне по силам отображать связи, охватывающие более двух множеств
сущностей. В реальных ситуациях тернарные связи (ternary relationships), соединяющие
три множества, или связи, представляющие взаимоотношения еще большего числа
множеств сущностей, сравнительно редки, но иногда они все-таки находят
применение, помогая воссоздать в модели истинное положение вещей. Многосторонние связи
(multiway relationships) отображаются на ER-диафамме линиями, соединяющими ромб
связи с каждым из соответствующих прямоугольников множеств сущностей.
Пример 2.5. На рис. 2.4 изображена связь Contracts ("контракты"), которая соединяет
между собой множества сущностей Studios ("киностудии"), Stars ("актеры") и Movies
("кинофильмы"). Связь отображает факт заключения контракта между киностудией и
определенным актером, обязующимся принять участие в съемках конкретного
кинофильма. Значение некоторой связи в ER-модели, вообще говоря, можно
воспринимать в виде соответствующего множества кортежей, компонентами которых являются
Рис. 2.4. Тернарная связь
56
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
Взаимоотношения типов связей
Следует отметить, что связь типа "многие к одному" является частным случаем
связи типа "многие ко многим", а связь "один к одному" — это частный случай
связи "многие к одному". Другими словами, любое свойство связей "многие ко
многим" характерно и для связей "многие к одному", а некоторое свойство связей
"многие к одному" сохраняется в силе для связей "один к одному". Например,
структура данных, представляющая связь "многие к одному", способна адекватно
отображать связи "один к одному", хотя в общем случае она непригодна для
поддержки связей типа "многие ко многим".
сущности из множеств, соединяемых этой связью (мы говорили об этом в разделе
2.1.5 на с. 54). Таким образом, связь Contracts может быть описана набором
кортежей вида
(studio, star, movie).
В многосторонних связях стрелка, обращенная к некоему множеству сущностей Е,
означает следующее: если мы выберем по одной сущности из всех остальных
множеств сущностей, охватываемых связью, эти сущности могут быть связаны не более
чем с одним элементом множества Е. (Обратите внимание, что это правило является
обобщением того, которое относится к бинарным связям типа "многие к одному".)
На рис. 2.4 стрелка направлена к множеству сущностей Studios, свидетельствуя о том,
что для каждой пары актеров и кинофильмов существует только одна студия, с
которой этот актер заключил контракт на участие в съемках определенного кинофильма.
Однако стрелки, которые были бы обращены к множествам сущностей Stars и Movies,
не заданы: любая студия вправе пригласить для участия в фильме несколько актеров,
а любой актер может быть связан со студией контрактом, предусматривающим
участие в съемках нескольких кинофильмов. □
2.1.8. Связи и роли
Вполне вероятна ситуация, когда одно и то же множество сущностей упоминается
в контексте единственной связи многократно. Если дело обстоит именно так, в ER-
диаграмме задается столько линий, соединяющих связь с множеством сущностей,
сколько требуется. Каждая линия, направленная к множеству сущностей,
представляет отдельную роль (role), в которой множество выступает в конкретном случае. Линии,
соединяющие связь и множество сущностей, принято обозначать текстовыми
метками, описывающими определенные роли.
Пример 2.6. На рис. 2.5 изображена связь Sequel-of ("продолжение кинофильма"),
соединяющая множество сущностей Movies Orw'nal
("кинофильмы") само с собой. Каждый конкретный
экземпляр связи соединяет два кинофильма, один из
которых служит продолжением другого. Чтобы
различить два фильма, участвующих в связи, одна из ее
линий помечена ролью Original ("исходный"), а
другая — Sequel ("продолжение"). Мы
подразумеваем, что некий фильм может иметь несколько
продолжений, но для каждого продолжения существует
только один "исходный" фильм. Таким образом, Рис. 2.5. Связь и ее роли
связь Sequel-of, соединяющая фильмы Sequel с
фильмами Original, относится к типу "многие к одному" (этот факт на диаграмме
рис. 2.5 отмечен стрелкой). □
2.1. ЭЛЕМЕНТЫ ER-МОДЕЛИ
57
Стрелки в многосторонних связях
Если связь охватывает три или более множеств сущностей, для адекватного
описания каждой возможной ситуации средствами ER-диаграмм уже не достаточно
ответить на вопрос, снабжать стрелкой соответствующую линию или нет. Для примера
вновь обратимся к диаграмме рис. 2.4. Некоторая студия напрямую связана
с определенным кинофильмом, а не с актером и кинофильмом, рассматриваемыми
совместно, поскольку производством фильмов занимается именно студия. Однако
используемая нами система обозначений не позволяет отличить эту ситуацию от
случая, когда в тернарной связи одно множество сущностей в действительности
является функцией двух других множеств. В разделе 3.4 на с. 106 мы рассмотрим
строгую систему, основанную на задании функциональных зависимостей и
позволяющую описать все мыслимые ситуации, в которых связи одного множества
сущностей с другими обособлены друг от друга.
Пример 2.7. В качестве завершающего примера, иллюстрирующего как
многосторонние связи, так и связи с несколькими ролями, на рис. 2.6 приведен более сложный
вариант связи Contracts ("контракты"), рассмотренной выше, в примере 2.5 (см. с. 56).
Теперь связь Contracts затрагивает уже две киностудии, актера и кинофильм. Смысл
состоит в том, что одна студия, заключившая контракт с актером (вообще говоря, не
обязательно связанный со съемками конкретного фильма), может подписать контракт
с другой студией, который позволил бы актеру участвовать в работе над новым
фильмом. Таким образом, связь теперь описывается набором кортежей следующего вида:
(studio 1, studio2, star, movie).
Имеется в виду, что студия "studio2" заключает контракт со студией "studiol",
оговаривающий условия привлечения актера студии "studiol" на съемки фильма "movie",
который выпускается студией "studio2".
Стрелки, изображенные на рис. 2.6,
характеризуют две роли киностудии,
относящейся к множеству сущностей Studios:
"студия-владелец актера" (Studio-of-Star) и
"студия-продюсер кинофильма"
(Producing-Studio). Доводы таковы. Для
каждого определенного актера, фильма и
студии, которая занимается съемкой этого
фильма, существует только одна студия,
"владеющая" актером. (Предполагается,
что актер заключил долговременный
контракт только с одной студией.)
Аналогично, конкретный фильм снимается только
одной студией, так что обладая
информацией об актере, фильме и студии, к
которой относится этот актер, мы сможем определить уникальную сущность,
соответствующую студии, осуществляющей съемку. Обратите внимание, что в обоих случаях
для определения уникальной сущности нам необходимо только одно из остальных
множеств сущностей — например, для отыскания конкретной студии-продюсера
достаточно определить кинофильм, снимаемый ею, — но этот факт не меняет общей
картины множественности соединений в многосторонней связи.
Стрелок, которые были бы обращены к множествам Movies ("кинофильмы")
и Stars ("актеры"), однако, не существует. Заданной тройке значений — имени
актера и названиям студии-владельца и студии-продюсера — может соответство-
Stars
0
^tudio - [
f-Star \
Contracts
Studios
Movies
\ Producing-
1 Studio
Рис. 2.6. Четырехсторонняя связь
58
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ
вать несколько контрактов, позволяющих актеру сниматься в различных фильмах.
Поэтому такой набор данных кортежа не обязательно соответствует уникальному
кинофильму. Аналогично, студия-продюсер вправе заключить контракт с другой
студией на привлечение к съемкам фильма сразу нескольких актеров, так что имя
актера в общем случае не может быть определено на основании данных трех
других компонентов связи. □
2.1.9. Связи и атрибуты
Подчас бывает удобно или даже, как кажется, настоятельно необходимо
ассоциировать атрибут со связью, а не с некоторым множеством сущностей, охватываемых
этой связью. Вновь вернемся к примеру связи, показанной на рис. 2.4 (см. с. 56),
которая представляет множество контрактов между актерами и студиями.3 Пусть нам
необходимо зафиксировать на диаграмме атрибут "размер заработной платы" (salary)
актера (Stars), установленный в соответствии с контрактом (Contracts). Мы не вправе
связывать подобный атрибут непосредственно с актером: последний за участие в
съемках различных фильмов может получать различные суммы вознаграждения. Исходя из
подобных соображений, не имеет смысла ассоциировать атрибут "размер заработной
платы" и с множествами сущностей "киностудии" (Studios) (студии по-разному
оплачивают работу различных актеров) и "кинофильмы" (Movies) (различные актеры за
участие в съемках одного и того же фильма могут получать различную зарплату).
Однако уместно ассоциировать атрибут salary с кортежем
(star, movie, studio)
из множества данных, соответствующего связи Contracts. На рис. 2.7 приведена
диаграмма рис. 2.4 (см. с. 56), дополненная атрибутами множеств сущностей Movies, Stars
и Studios (эти атрибуты приводились на рис. 2.2 — см. с. 54), а также атрибутом salary,
соединенным со связью Contracts.
Рис. 2.7. Связь с атрибутом
Впрочем, злоупотреблять возможностью размещения атрибутов на связях не
следует. В ка-честве альтернативы можно предложить следующее: ввести в диаграмму новое
множество сущностей с тем же атрибутом, соединить это множество со связью и уда-
3 Здесь мы рассматриваем исходную, тернарную, редакцию связи Contracts, соответствующую
примеру 2.5 на с. 56, а не ее четырехстороннюю версию, упоминавшуюся в примере 2.7 на с. 58.
2.1. ЭЛЕМЕНТЫ ER-МОДЕЛИ
59
лить атрибут связи. Но иногда мы все-таки будем использовать атрибуты,
ассоциированные со связями напрямую, если такое решение в конкретной ситуации окажется
более целесообразным и наглядным.
Пример 2.8. Давайте исправим ER-диаграмму рис. 2.7, на которой атрибутом salary
("размер заработной платы") снабжена связь Contracts ("контракты"). Создадим
множество сущностей Salaries ("заработная плата") с одноименным атрибутом salary.
Salaries станет четвертым множеством сущностей, соединенным со связью Contracts.
Результат показан на рис. 2.8. □
2.1.10. Преобразование многосторонних связей в бинарные
Существуют некоторые модели представления данных, такие как язык ODL (Object
Definition Language — язык определения объектов), рассматриваемый в разделе 4.2 на
с. 152, которые ограничивают число "сторон", охватываемых связью, до двух, т.е.
предполагают использование только бинарных связей (binary relationships). Поскольку
ER-модели подобные ограничения не присущи, полезно знать о том, что любая связь,
соединяющая более двух множеств сущностей, может быть преобразована в набор
бинарных связей типа "многие к одному" (many-one relationships). С этой целью вводится
новое множество сущностей, элементы которого являются кортежами множества
данных для рассматриваемой многосторонней связи. Множество сущностей, подобное
вводимому, называют соединяющим множеством сущностей (connecting entity set).
Затем в диаграмму включаются связи типа "многие к одному", "сплачивающие"
соединяющее множество сущностей с каждым из множеств сущностей, элементы которых
служат компонентами кортежей множества данных для исходной многосторонней
связи. (Читатель, если вы это поняли, вы поймете и все остальное. — Прим. перев.)
Если некоторое множество сущностей в контексте связи обладает несколькими
ролями, каждая роль преобразуется отдельно.
Рис. 2.8. Передача атрибута связи множеству сущностей
Пример 2.9. Четырехсторонняя связь Contracts ("контракты"), изображенная на
рис. 2.6 (см. с. 58), может быть заменена соединяющим множеством сущностей,
которое уместно назвать тем же именем, Contracts. Результат показан на рис. 2.9. Множе-
60
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ
ство сущностей Contracts принимает участие в четырех связях. Если в составе
множества данных, соответствующего связи Contracts, имеется кортеж
(studio 1, studio2, star, movie),
можно считать, что множество сущностей Contracts содержит некоторую сущность е,
соединенную связью Star-of с сущностью star множества сущностей Stars ("актеры"),
связью Movie-of— с сущностью movie множества сущностей Movies ("кинофильмы"),
а также с сущностями studio 1 и studio2 множества сущностей Studios ("киностудии")
посредством связей Studio-of-Star и Producing-Studio соответственно.
Здесь мы подразумеваем, что соединяющее множество сущностей Contracts не
содержит атрибутов, а все другие множества таковыми обладают, хотя на рис. 2.9 они не
показаны. Однако ничто не мешает снабдить подходящими атрибутами — например,
таким как date-of-signing ("дата подписания") — и множество Contracts. □
2.1.11. Подклассы в ER-модели
Нередки ситуации, когда множество сущностей содержит определенные сущности,
которые обладают специальными свойствами, не присущими остальным членам
множества. В подобных случаях подчас оказывается полезным создавать специальные
множества сущностей — или подклассы (subclasses) — каждое из которых обладает
собственными набором атрибутов и/или связями. Для соединения "полного" множества
сущностей — базового класса (superclass) — с его подклассами используются связи,
называемые isa (от "is а" — есть) (например, утверждение "А есть Я" выражает наличие
связи isa, направленной от множества сущностей А к множеству сущностей В).
Связь isa имеет особый смысл, и чтобы отличить ее от других, мы применяем
специальное обозначение: каждая связь isa на ER-диаграмме представляется
треугольником. Одна из сторон треугольника соединяется с подклассом, а
противоположная вершина — с базовым классом. Каждая связь isa относится к типу "один
к одному", но, в отличие от других связей типа "один к одному", стрелки на ее
линиях не проставляются.
Рис. 2.9. Замена многосторонней связи
соединяющим множеством сущностей и
набором бинарных связей
2.1. ЭЛЕМЕНТЫ ER-МОДЕЛИ
61
Пример 2.10. В "кинематографической" базе данных, рассматриваемой нами, может
храниться информация о фильмах, относящихся к различным жанрам:
мультипликация, "боевик", приключения, комедия и т.д. Для каждого из жанров вполне
правомерно определить соответствующий подкласс множества сущностей Movies
("кинофильмы"). Рассмотрим для примера два подкласса — Cartoons
("мультипликация") и Murder-Mysteries ("боевики"). Множество сущностей
"мультипликация", помимо атрибутов и связей, унаследованных от базового класса
"кинофильмы", участвует в дополнительной связи Voices ("голоса"), которая
определяет подмножество актеров, участвовавших в озвучивании фильма, но не
появлявшихся на экране непосредственно. Фильмы, не относящиеся к жанру
мультипликации, не обладают подобной связью. Для кинофильмов-"боевиков" характерно
наличие атрибута weapon ("оружие"). Взаимоотношения множеств сущностей Movies,
Cartoons и Murder-Mysteries иллюстрируются диаграммой рис. 2.10. G
К множеству
сущностей
Stars
[length) С title J Г year
filmType
Movies
weapon
Cartoons
Murder-
Mysteries
Рис. 2.10. Связи isa на ER-диаграмме
Хотя, вообще говоря, набор множеств сущностей, соединенных связями isa, может
обладать структурой любой топологии, мы сосредоточим внимание на гораздо более
распространенных древовидных (tree-like) /^-структурах, обладающих одним корневым
(root) множеством сущностей (таким как Movies на рис. 2.10), из которого
"произрастают" и "ветвятся" множества более частного характера.
Рассмотрим дерево множеств сущностей, соединенных связями isa. Некоторая
сущность состоит из компонентов (components), относящихся к одному или
нескольким указанным множествам сущностей, если эти компоненты принадлежат поддереву
(subtree) исходного дерева, включающему корневую вершину. Другими словами, если
некоторая сущность е обладает компонентом с из множества сущностей Е и
родительским по отношению к Е в дереве является множество F, то е обладает также
некоторым компонентом d из F. Кроме того, end должны быть представлены в виде пары
во множестве данных для связи isa, направленной от Е к F. Сущность е имеет те же
атрибуты, которыми обладает любой из ее компонентов, и участвует в тех же связях,
к которым имеет отношение любой из этих компонентов.
Пример 2.11. Обратимся к рис. 2.10. Сущность-"кинофильм", которая не относится
ни к жанру мультипликации (Cartoons), ни к числу "боевиков" (Murder-Mysteries),
будет обладать только таким компонентом, который принадлежит корневому множеству
сущностей Movies ("кинофильмы"). Всем сущностям Movies поставлены в соответствие
четыре атрибута (length ("продолжительность"), title ("название"), year ("год
производства") и filmType ("тип пленки")) и две связи (Stars-in ("актеры-участники") и Owns
("владеет") — последние на рис. 2.10 не показаны).
62
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
Различия параллельных связей
На рис. 2.10 иллюстрируется одна тонкая особенность ER-связей, требующая
дополнительного разъяснения. Диаграмма содержит две различные связи, Studio-of-
Star ("студия-владелец актера") и Producing-Studio ("студия-продюсер
кинофильма"), и каждая из них соединяет одни и те же множества сущностей — Contracts
("контракты") и Studios ("киностудии"). Мы, однако, не вправе ожидать, что из
факта "параллель-ности" связей следует идентичность множеств данных,
соответствующих этим связям. Действительно, в рассматриваемом здесь случае
совершенно неправомочно полагать, что обе связи представляют один и тот же "контракт",
относящийся к некоторой сущности-"киностудии", поскольку иначе студия
должна заключать контракт сама с собой.
В более общем плане можно утверждать, что в ER-диаграмме, содержащей
связи, которые соединяют одинаковые множества сущностей, нет ничего
противоестественного. В базе данных конкретные экземпляры этих связей при нормальных
условиях всегда окажутся различными, подтверждая особый смысл каждой из связей.
Если же множества данных для двух или более связей, как предусматривается,
должны совпадать, такие связи по существу сводятся к единственной связи, и нет
никаких причин отображать их отдельно под разными именами.
Сущность-"мультфильм", не являющаяся "боевиком", обладает двумя
компонентами, один из которых относится к множеству Movies, а другой — к Cartoons. Поэтому
она получит не только четыре упомянутых выше атрибута множества Movies, но
и связь Voices ("голоса"). Аналогичным образом, сущность-"боевик", не являющаяся
"мультфильмом", также обладает двумя компонентами, один из которых относится
к множеству Movies, а другой — к Murder-Mysteries, и поэтому характеризуется пятью
атрибутами, включая weapon ("оружие").
Наконец, сущности-"кинофильмы" (подобные "Roger Rabbit"), которые относятся
к жанрам мультипликации и "боевика" одновременно, обладают компонентами всех
трех множеств — Movies, Cartoons и Murder-Mysteries. Компоненты соединяются в
целостную сущность благодаря связям isa. Рассматриваемые совместно, эти компоненты
поставят в соответствие тому же "Roger Rabbit" все четыре атрибута множества
сущностей Movies плюс атрибут weapon множества Murder-Mysteries плюс связь Voices
множества Cartoons. □
2.1.12. Упражнения к разделу 2.1
* Упражнение 2.1.1. Рассмотрим проект базы данных банка, содержащей
информацию о клиентах (назовем это множество сущностей Customers) и состоянии их
счетов {Accounts). Данные о клиенте включают его имя {пате), адрес {address), номер
телефона {phone) и код полиса социального страхования {ssnumber). Счет
описывается атрибутами номера {number), типа (например, "накопительный", "чековый"
и т.п.) {type) и остатка {balance). Необходимо также отразить в базе данных факт
принадлежности счета определенному клиенту. Начертите ER-диаграмму,
соответствующую такой базе данных. Не забудьте там, где необходимо, использовать
стрелки, чтобы однозначно описать тип той или иной связи.
Упражнение 2.1.2. Исправьте решение упражнения 2.1.1 следующим образом:
a) измените диаграмму в предположении, что счет может принадлежать только
одному клиенту;
b) измените диаграмму, предусматривая, что клиент может открыть в банке
только один счет;
2.1. ЭЛЕМЕНТЫ ER-МОДЕЛИ
63
Подклассы в объектно-ориентированных системах
Имеется значительное сходство между связью isa, соединяющей множества
сущностей в ER-модели, и отношением подкласса (subclass) к базовому классу в объект-
но-ориентиро-ванном языке. Впрочем, между двумя подходами существует и
фундаментальное различие: сущности в ER-модели могут обладать компонентами,
представляющими другие вершины дерева множеств сущностей, в то время как
объекты относятся к конкретному классу.
Чтобы прояснить указанное различие, рассмотрим сущность-"кинофильм"
"Roger Rabbit", которую мы упоминали в примере 2.11. Если применить объектно-
ориентированный подход, для описания этой сущности нам пришлось бы
образовать новое множество сущностей, что-то вроде Cartoons-Murder-Mysteries ("
мультипликационные боевики"), и придать ему все атрибуты и связи множеств Movies
("кинофильмы"), Cartoons ("мультипликация") и Murder-Mysteries ("боевики"). В ER-
модели, однако, тот же эффект достигается "распределением" компонентов
сущности "Roger Rabbit" по множествам сущностей Cartoons и Murder-Mysteries.
! с) измените исходную диаграмму, полученную в результате решения
упражнения 2.1.1, в предположении, что клиент может иметь несколько адресов,
описываемых кортежами вида "улица—город—страна", и множество номеров
телефонов. Имейте в виду, что в рамках ER-модели вы не вправе использовать
атрибуты типов, таких как множества, не являющихся атомарными;
! d) выполните дальнейшую модификацию диаграммы, предусматривая, что
клиент может иметь несколько адресов, а за каждым адресом закреплено
множество номеров телефонов.
Упражнение 2.1.3. Представьте в виде ER-диаграммы структуру "футбольной" базы
данных, охватывающей информацию о командах, об игроках и о болельщиках,
включая следующие атрибуты:
1) для каждой команды — название, перечень имен игроков, имя капитана
(из числа игроков), цвета формы;
2) для каждого игрока — имя;
3) для каждого болельщика — имя, название команды, имя любимого игрока
и предпочитаемый цвет.
Не забывайте, что множество не является допустимым типом атрибута. Как обойти
это ограничение при описании цветов формы команды?
Упражнение 2.1.4. Предположим, что в диаграмме решения упражнения 2.1.3
следует предусмотреть связь Led-by ("играл под руководством"), соединяющую двух
игроков и команду. Множество данных для связи Led-by состоит из кортежей вида
(playerl, player2, team),
свидетельствующих о том, что игрок "playerl" играл в команде "team" в тот
период, когда игрок "player2" был ее капитаном.
a) Внесите в ER-диаграмму необходимые изменения.
b) Замените тернарную связь Led-by новым множеством сущностей и набором
бинарных связей.
! с) Совпадают ли новые бинарные связи с какими-либо из ранее
существовавших связей? Мы полагаем, что две сущности вида "игрок", соединяемые
64
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ
связью Led-by, различны, т.е. капитан команды не может играть под своим
собственным руководством.
Упражнение 2.1.5. Дополните диаграмму решения упражнения 2.1.3 информацией
о том, в каких командах игрок выступал прежде, включая даты зачисления в состав
каждой команды и увольнения из нее.
! Упражнение 2.1.6. Рассмотрим задачу описания генеалогического дерева семьи.
Нам понадобится одно множество сущностей, People ("люди"). Информация,
которую необходимо отобразить в модели, включает атрибут пате ("имя") и
следующие связи: MotherOf ("является матерью"), FatherOf ("является отцом") и ChildOf
("является ребенком"). Постройте ER-диаграмму, состоящую из множества
сущностей People и при-соединенных к нему связей MotherOf, FatherOf и ChildOf He
забудьте воспользоваться ролями, если множество сущностей в контексте связи
участвует многократно.
! Упражнение 2.1.7. Измените проект базы данных, созданный вами при решении
упражнения 2.1.6, включив в него описание следующих специальных множеств
сущностей "человек":
1) Females ("женщины");
2) Males ("мужчины");
3) Parents ("родители").
Можете усложнить задание и создать другие частные подклассы множества People,
воспользовавшись требуемыми связями.
Упражнение 2.1.8. Альтернативный способ решения задания упражнения 2.1.6
состоит в применении тернарной связи Family ("семья") в предположении, что
кортеж множества данных для Family выглядит как
(person, mother, father),
где сущности "mother" и "father" представляют данные о матери и отце человека
"person" соответственно.
* а) Начертите диаграмму, пометив стрелками необходимые связи.
Ь) Замените тернарную связь Family множеством сущностей и набором
бинарных связей. Вновь разместите стрелки соответствующим образом,
отмечая типы связей.
Упражнение 2.1.9. Спроектируйте структуру, адекватно описывающую
университетскую базу данных, которая должна включать информацию о студентах,
факультетах, профессорах, курсах, а также о том, какие студенты слушают какие курсы
и какие профессора преподают эти курсы, какие курсы читаются на том или ином
факультете, об отметках студентов и лучших достижениях студентов по каждому
курсу. Вы вправе представить на диаграмме и другие данные, которые покажутся
вам уместными и значимыми. Это задание предусматривает большую свободу
действий, нежели предыдущие, и при его выполнении вам придется принимать
самостоятельные решения, касающиеся свойств множественности связей, выбора их типов
и даже того, какого рода информация достойна представления в базе данных.
! Упражнение 2.1.10. Мы вправе неформально утверждать, что две ER-диаграммы
"равнозначны по смыслу", если в контексте реальной ситуации экземпляры этих
диаграмм могут быть "приведены" одна к другой путем вычислений. Вновь для
примера обратимся к диаграмме рис. 2.6 (см. с. 58). Четырехсторонняя связь
Contracts ("контракты") может быть заменена тернарной и бинарной связями на
основании того факта, что для каждого фильма из множества сущностей Movies
2.1. ЭЛЕМЕНТЫ ER-МОДЕЛИ
65
имеется в точности одна киностудия (Studios), которая снимает этот фильм.
Начертите ER-диаграмму, равнозначную представленной на рис. 2.6, не используя
четырехстороннюю связь.
2.2. Принципы проектирования
Нам с вами предстоит рассмотреть еще немало аспектов модели "сущность-
связь", но уже сейчас уместно обсудить ряд принципиальных вопросов, касающихся
того, что представляет собой хороший проект базы данных и чего в процессе дизайна
желательно избегать. В этом разделе мы предложим вашему вниманию сведения об
основных принципах проектирования.
2.2.1. Достоверность
Прежде всего, проект обязан достоверно представлять спецификацию базы
данных. Другими словами, множества сущностей и их атрибуты должны соответствовать
реальным требованиям. Вы не вправе, например, ассоциировать с множеством
сущностей Stars ("актеры") атрибут number-of-cylinders ("количество цилиндров"), хотя
последний вполне применим по отношению к множеству Automobiles ("автомобили").
Прежде чем вводить в модель новое множество сущностей, атрибут или связь,
надлежит задаться вопросом, а все ли доподлинно известно о той части реального мира,
которая должна быть смоделирована.
Пример 2.12. Если вновь присмотреться к связи Stars-in ("актеры-участники"),
соединяющей множества сущностей Stars ("актеры") и Movies ("кинофильмы"), станет
очевидным, что она должна относиться к типу "многие ко многим". Причины
бесспорны: здравый смысл, основанный на элементарном понимании моделируемых
сущностей, подсказывает, что актеры вправе участвовать в съемках нескольких фильмов,
а в каждом фильме могут быть заняты одновременно несколько актеров. Совершенно
неправомерно считать, что связь Stars-in в любом направлении может представлять
отношение "многие к одному" или, более того, "один к одному". □
Пример 2.13. Подчас, однако, далеко не очевидно, как именно те или иные объекты
реального мира должны соотноситься в рамках ER-модели. Рассмотрим для примера
множества сущностей Courses ("учебные курсы") и Instructors ("преподаватели"),
соединенные связью Teaches ("обучает"). Действительно ли Teaches представляет связь
типа "многие к одному" в направлении от Courses к Instructors? Ответ зависит от
корпоративной политики и традиций конкретного учебного заведения. Вполне возможно,
что за каждым курсом закреплен в точности один преподаватель. Даже в том случае,
если несколько преподавателей ведут курс совместно, не исключено, что в
соответствии с внутренними требованиями организации в базе данных должен быть указан
только один из преподавателей, "ответственный" за курс. В любом из подобных
случаев мы имеем право утверждать, что связь Teaches, соединяющая множества
сущностей Courses и Instructors, должна относиться к типу "многие к одному" (если
рассматривать ее в указанном направлении).
С другой стороны, в учебном заведении может быть принят такой порядок, когда
несколько преподавателей способны заменять друг друга при чтении определенного
курса без каких бы то ни было ограничений. Либо изначальный смысл связи Teaches
заключается не в том, чтобы отобразить зависимость между курсом и преподавателем,
ведущим его в данный момент, а зафиксировать хронологию ведения курса
различными преподавателями или просто описать множество преподавателей, готовых
к чтению этого курса (наименование связи Teaches само по себе не раскрывает ее
истинного смысла). В любом из названных случаев уместно считать, что связь Teaches
должна относиться к типу "многие ко многим". □
66
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ
2.2.2. Отсутствие избыточности
Мы обязаны тщательно следить за тем, чтобы объекты структуры не повторяли
друг друга. Пусть, например, сущности Movies ("кинофильмы") и Studios
("киностудии") соединены связью Owns ("владеет"). Мы можем также снабдить
множество сущностей Movies атрибутом studioName ("название студии"). Хотя такое
решение на первый взгляд вполне приемлемо, оно таит в себе ряд опасностей.
1. Повторение описания студии-владельца кинофильма приводит к
дополнительному расходу памяти при хранении атрибута в базе данных.
2. При продаже кинофильма мы можем изменить название студии, которая им
владела, на новое, определяемое связью Owns, но забыть исправить содержимое
атрибута studioName — или умудриться сделать наоборот. Конечно, можно
утверждать, что подобные ошибки вряд ли вероятны, но на практике они, к
несчастью, случаются, и, пытаясь описать некий объект несколькими различными
способами, мы заранее ставим себя, мягко говоря, в невыгодное положение.
Подобные ситуации мы опишем более подробно в разделе 3.6 на с. 123, где расскажем
и о некоторых конкретных инструментах устранения избыточности в схемах баз данных.
2.2.3. Простота
Включайте в проект только те структурные элементы, без которых совершенно
нельзя обойтись.
Пример 2.14. Предположим, что вместо непосредственной связи между множествами
сущностей Movies ("кинофильмы") и Studios ("киностудии") мы считаем
целесообразным использовать новое "промежуточное" множество сущностей Holdings ("права
владения"), описывающее факт принадлежности конкретного фильма определенной
студии. Между каждым фильмом и сущностью "права владения" может быть установлена
связь Represents ("представляет") типа "один к одному". Общую картину,
иллюстрируемую рис. 2.11, завершает связь типа "многие к одному", соединяющая множества
сущностей Holdings и Studios.
Movies
Studios
Рис. 2.11. Неудачный пример: в диаграмму включено избыточное
множество сущностей
Если говорить формально, структура, приведенная на рис. 2.11, совершенно верно
отображает реальные зависимости, поскольку она позволяет "проследовать" от
конкретного кинофильма к студии, которая им владеет, при посредничестве множества
сущностей Holdings. Последнее, однако, не выполняет никаких уникальных функций,
и его вполне можно исключить. Не сделав этого, при создании базы данных и
соответствующих программных приложений мы затратим усилия и время на реализацию
более сложных зависимостей и поиск дополнительных вероятных ошибок, а также
израсходуем лишнее дисковое пространство. □
2.2.4. Выбор подходящих связей
Множества сущностей могут быть соединены посредством связей разными
способами. Однако включение в проект первых попавшихся связей — это не самое хорошее
решение. Во-первых, оно способно привести к избыточности схемы, когда одни и те же
соотношения множеств сущностей выражаются несколькими цепочками соединений.
2.2. ПРИНЦИПЫ ПРОЕКТИРОВАНИЯ
67
Во-вторых, реализация подобной модели потребует дополнительного расхода дискового
пространства, а задача внесения изменений в схему базы данных существенно
усложнится, поскольку исправление одной связи повлечет необходимость модификации
многих других. Указанные проблемы по существу схожи с теми, о которых мы
говорили в разделе 2.2.2 на с. 67, хотя причины возникновения тех и других различаются.
Чтобы проиллюстрировать проблемы и описать средства их разрешения, мы
воспользуемся двумя примерами: в первом несколько связей представляют одну и ту же
информацию, а во втором одна связь может быть получена на основании нескольких других.
Пример 2.15. Вернемся к диаграмме рис. 2.7 (см. с. 59), на которой множества
сущностей Movies ("кинофильмы"), Stars ("актеры") и Studios ("киностудии") соединены
с помощью тернарной связи Contracts ("контракты"). Здесь опущены две бинарные
связи, Stars-in ("актеры-участники") и Owns ("владеет"), введенные в диаграмму
ранее, на рис. 2.2 (см. с. 54). Возникает закономерный вопрос, действительно ли связи
Stars-in (между Movies и Stars) и Owns (между Movies и Studios) все еще необходимы
при наличии связи Contracts! Ответ таков: "не известно; решение зависит от того,
какой смысл мы вкладываем в каждую из трех рассматриваемых связей".
Вполне возможно получить связь, аналогичную Stars-in, на основании связи
Contracts. Если актер появляется в фильме только при наличии соответствующего
контракта, в котором упоминаются сам актер, студия и производимый ею фильм, тогда
действительно необходимость в использовании связи Stars-in отпадает: для определения
всех пар вида "актер—кинофильм" для заданных сущностей "актер" и "кинофильм"
достаточно просмотреть кортежи "актер—кинофильм—киностудия" множества данных,
отвечающего связи Contracts, и выбрать нужные, ограничившись компонентами "актер"
и "кинофильм". Если, однако, актер может сниматься в фильме, не подписав
контракт — или, что более вероятно с практической точки зрения, не имея контракта,
который был бы зафиксирован в нашей базе данных, — тогда во множестве данных связи
Stars-in могут существовать такие пары вида "актер—кинофильм", которые не являются
частью кортежей "актер—кинофильм—киностудия" множества данных связи Contracts. В этой
ситуации связь Stars-in обладает самостоятельным значением и должна быть сохранена.
Подобные соображения применимы и по отношению к связи Owns. Если для каждой
сущности "кинофильм" имеется по меньшей мере один "контракт", в который
вовлечены как она сама, так и соответствующие сущности "киностудия"-владелец кинофильма
и некоторый "актер", связью Owns без какого-либо ущерба можно пренебречь. Если же,
напротив, существует вероятность того, что студия владеет кинофильмом и при этом
актеры не связаны контрактом на участие в этом фильме либо такой контракт не
зарегистрирован в базе данных, связь Owns следует оставить в неприкосновенности.
Если подытожить сказанное, мы не можем дать пригодного на все случаи жизни совета
по поводу того, как определить, является конкретная связь избыточной или нет. Вы
должны получить нужные сведения от тех, для кого предназначена проектируемая база
данных, и на этом основании самостоятельно принять единственно правильное решение. □
Пример 2.16. Давайте вновь обратимся к диаграмме рис. 2.2 (см. с. 54). На ней нет
каких-либо прямых связей между множествами сущностей Stars ("актеры") и Studios
("киностудии"). Но мы можем получить необходимую соединяющую цепочку,
используя свойства связей Stars-in ("актеры-участники") и Owns ("владеет"), поскольку
некоторый "актер" связан посредством Stars-in с определенными "кинофильмами",
а те, в свою очередь, благодаря связи Owns соединены с соответствующими
сущностями-"киностудиями". Таким образом, можно говорить, что актер связан со студией,
владеющей фильмом, в котором этот актер снимался.
Имеет ли смысл включать в диаграмму дополнительную связь — что-то вроде
Works-for ("работает" на киностудию) — между множествами сущностей Stars
и Studios, как показано на рис. 2.12? И вновь, как и прежде, мы не можем ответить на
68
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
Рис. 2.12. Включение в диаграмму
дополнительной связи
этот вопрос однозначно, не обладая нужными
сведениями. Самое главное, каково истинное
назначение этой связи? Если ее смысл таков,
что "актер снялся, по меньшей мере, в одном
фильме, выпущенном студией", тогда,
вероятно, веских причин для использования
подобной связи нет, так как аналогичная
информация может быть получена на основе
существующих связей, Stars-in и Owns.
Однако вполне вероятна ситуация, что
имеется некая иная информация (возможно,
совершенно уникальная) об особенностях работы
актеров со студиями, которая не отражена
в цепочке связей Stars-in и Owns. В этом
случае связь, соединяющая множества
сущностей Stars и Studios напрямую, может оказаться
полезной и не восприниматься как
избыточная. Например, такая связь должна представить
тот факт, что актер связан со студией неким общим контрактом, который не имеет
отношения к конкретному кинофильму. Кроме того, как мы упоминали в примере 2.7
(см. с. 58), отнюдь не невероятно, что актер, заключивший контракт с одной студией,
принимает участие в фильме, выпускаемом другой студией. В подобных ситуациях
новая связь Works-for никак не зависит от связей Stars-in и Owns и определенно не
будет считаться излишней. □
2.2.5. Использование элементов адекватных типов
Иногда при выборе типа элемента модели, используемого для отображения
реального объекта, возможно наличие нескольких альтернатив дальнейших действий. Во
многих случаях приходится поразмышлять, чему отдать предпочтение — атрибутам или
сочетаниям множеств сущностей и связей. Вообще говоря, атрибут реализовать гораздо
проще, нежели множество сущностей или связь. Однако крайности всегда вредны —
необоснованное повсеместное применение атрибутов способно привести к неприятностям.
Пример 2.17. Обратимся к рис. 2.2 (см. с. 54) и рассмотрим одну частную проблему.
Насколько здравым было наше решение о представлении объектов "киностудия"
отдельным множеством сущностей Studios? Может быть, следовало передать атрибуты
"название студии" и "адрес студии" множеству сущностей Movies ("кинофильмы")
и исключить Studios вовсе? Если поступить так, как мы сказали, придется повторять
адрес студии в наборе данных о каждом кинофильме. Это еще один пример избыточности,
подобный тем, которые упоминались в двух предыдущих разделах. Помимо издержек,
связанных с избыточностью данных, мы столкнемся со следующей опасностью: если
в базе данных будут отсутствовать сведения о каких бы то ни было фильмах, снятых
определенной студией, информация об этой студии как таковой окажется утраченной.
С другой стороны, если потребность в хранении адреса студии не возникает,
никакого вреда не принесет то, что наименование студии в качестве атрибута будет
поставлено в соответствие каждому фильму. Теперь об избыточности из-за
многократного повторения адреса студии речь не идет, а то, что наименование студии, такое
как, скажем, "Disney", указывается для каждого фильма, снятого этой студией, не
может рассматриваться как излишняя информация, поскольку авторские права студии
должны быть отражены так или иначе. □
Теперь попробуем абстрагировать выводы, к которым мы пришли,
рассматривая пример 2.17, чтобы более строго описать обстоятельства, позволяющие
предпочесть атрибут множеству сущностей. Пусть Е — это некоторое множество сущ-
2.2. ПРИНЦИПЫ ПРОЕКТИРОВАНИЯ
69
ностей. Ниже перечислены условия, которым должно удовлетворять множество Е,
чтобы его было целесообразно заменить атрибутом или набором атрибутов
нескольких других множеств сущностей.
1. Все связи, в которые вовлечено множество Е, обладают стрелками,
указывающими на Е. Другими словами, множеству Е должна отводиться роль
компонента "один" во всех связях типа "многие к одному" или их обобщениях для
случаев многосторонних связей.
2. Атрибуты множества Е в совокупности обязаны однозначно определять любую
сущность множества. Чаще всего имеется только один такой атрибут, и в этом
случае условие определенно удовлетворяется. Если же множество обладает
несколькими атрибутами, ни один из них не должен зависеть от остальных (таким
образом, как, например, атрибут address ("адрес") множества сущностей Studios
("киностудии") зависит от атрибута пате ("название") того же множества).
3. Ни в одной из связей множество Е не должно участвовать многократно.
Если все указанные условия удовлетворены, множество сущностей Е может быть
заменено другими элементами одним из следующих способов:
a) если существует связь R типа "многие к одному", направленная от
некоторого множества сущностей F к множеству Е, следует удалить R и передать
атрибуты Е множеству F, выполнив при необходимости их переименование,
если F уже содержит атрибуты с теми же именами; в результате каждая
сущность множества F получит в качестве атрибута наименование уникальной
связанной с ней сущности множества Е 4 (как, например, в случае, когда
сущностям "кинофильм" передается атрибут "название студии", а атрибут
"адрес студии" исключается).
b) если существует многосторонняя связь R, содержащая стрелку,
направленную к Е, целесообразно передать атрибуты Е связи R и удалить стрелку,
соединяющую R с Е\ примером может служить возврат от диаграммы рис. 2.8
(см. с. 60), где было введено новое множество сущностей Salaries, к
исходной версии диаграммы с аналогичным атрибутом salary, относящимся
к элементу связи Contracts (см. рис. 2.7 на с. 59).
Пример 2.18. Проанализируем ситуацию, предполагающую выбор компромиссного
решения — использовать многостороннюю связь или предпочесть соединяющее
множество сущностей и набор из нескольких бинарных связей. В разделе 2.1.8 на с. 57 мы
рассматривали четырехстороннюю связь Contracts ("контракты"), соединяющую
сущности "актер" (из множества Stars), "кинофильм" (Movies) и две сущности
"киностудия" (Studios) (см. рис. 2.6 на с. 58). На диаграмме рис. 2.9 (см. с. 61) в
предыдущем разделе эта структура была "механически" преобразована в одноименное
соединяющее множество сущностей Contracts с несколькими дополнительными
бинарными связями. Возникает вопрос, насколько принципиален подобный выбор.
Если говорить о задаче в том виде, как мы ее представили, можно считать
приемлемым любое из двух решений. Если, однако, изменить постановку задачи хотя бы
незначительно, мы почти во всех случаях будем вынуждены отдать предпочтение
варианту, предполагающему применение соединяющего множества сущностей.
Допустим, например, что в контракте упоминаются один актер, некоторый фильм, но
любое подмножество студий. (Подобная ситуация более сложна по сравнению с той, ко-
4 В ситуации, где F-сущность не связана ни с какой £-сущностью, новым атрибутам
множества F будут присвоены специальные значения пи/1, свидетельствующие об отсутствии
подходящей Е-сущности. Подобное замечание применимо и к случаю передачи атрибутов множества Е
связи R, который рассматривается в п. (Ь).
70
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
торая отображена на диаграмме рис. 2.6 (см. с. 58), где контракт охватывает две
студии, "играющие" определенные роли.) Теперь мы имеем дело с произвольным
числом студий, одна из которых, например, занимается собственно производством
фильма, другая осуществляет монтаж спецэффектов, третья несет ответственность за
маркетинг и рекламу и т.д., и роли студиям присвоить уже нельзя.
Чтобы модель адекватно описывала условия поставленной задачи, множество
данных связи Contracts должно состоять из кортежей вида
(star, movie, set-of-studios),
и связь Contracts как таковая будет охватывать не только привычные множества
сущностей Stars и Movies, но и новое множество сущностей, элементами которого
являются множества студий ("set-of-studios"). Хотя в рассматриваемой ситуации такого
результата, как кажется, избежать нельзя, похоже, не совсем естественно воспринимать
множества студий в виде элементарных сущностей, и поэтому мы не рекомендуем
применять указанный подход.
Более предпочтительным представляется решение, в котором контракты описываются
множеством сущностей. На диаграмме рис. 2.9 (см. с. 61) сущность "контракт"
соединяется с сущностями "актер", "кинофильм" и двумя сущностями "киностудия", но сейчас
ограничение на количество киностудий, подписывающих контракт, должно быть снято.
Связь между множествами Contracts и Studios приобретает свойство "многие ко многим",
а не относится к типу "многие к одному", как в том случае, когда Contracts является
"подлинным" соединяющим множеством сущностей. Новая версия диаграммы
приведена на рис. 2.13. Еще раз подчеркнем, что теперь контракт соединяет по одной
сущности вида "актер" и "кинофильм" с произвольным числом сущностей "киностудия". □
Рис. 2.13. Контракт соединяет актера и кинофильм
с произвольным множеством киностудий
2.2.6. Упражнения к разделу 2.2
* Упражнение 2.2.1. На рис. 2.14 представлена диаграмма, описывающая структуру
базы данных банка, в которой предусматривается хранение информации о
клиентах {Customers) и их счетах {Accounts). Поскольку в общем случае клиент вправе
открыть в банке несколько счетов, а счетом могут совместно распоряжаться
несколько клиентов, клиентам ставятся в соответствие "наборы счетов" {AcctSets), и
каждый счет может быть членом {Member-of) одного или нескольких "наборов счетов".
Мы полагаем, что смысл всех остальных связей и атрибутов, приведенных на
диаграмме, внятно определяется их названиями {owner-address — "адрес владельца",
Has— "обладает", пате— "имя", number— "номер счета", balance— "размер
остатка на счете", Lives-at — "проживает", Addresses — "адреса", address — "адрес").
Изучите схему и попытайтесь выдвинуть собственные критические замечания. Ка-
2.2. ПРИНЦИПЫ ПРОЕКТИРОВАНИЯ
71
кие правила проектирования, по вашему мнению, нарушены? Почему? Какие
изменения вы предложили бы внести?
* Упражнение 2.2.2. При каких условиях два множества сущностей — Studios
("киностудии") и Presidents ("президенты") — и связь Runs ("возглавляет"),
образующие диаграмму рис. 2.3 (см. с. 56) (с учетом атрибутов, которые для краткости
опущены), могут быть заменены единственным множеством сущностей с
соответствующими атрибутами?
Упражнение 2.2.3. Предположим, что атрибут address ("адрес") множества
сущностей Studios ("киностудии") на диаграмме рис. 2.7 (см. с. 59) удален. Покажите,
каким образом множество Studios теперь может быть заменено некоторым атрибутом.
Как именно следовало бы расположить этот атрибут?
Рис. 2.14. Неудачный пример: ЕЯ-
диаграмма банковской базы данных
Упражнение 2.2.4. Выберите атрибуты для перечисленных ниже множеств
сущностей диаграммы рис. 2.13, что позволит заменить каждое из этих множеств
некоторым атрибутом:
a) Stars ("актеры");
b) Movies ("кинофильмы");
! с) Studios ("киностудии").
!! Упражнение 2.2.5. В этом и следующих примерах мы рассмотрим два альтернативных
проектных решения, касающихся возможности описания события рождения
человека. С фактом рождения связана одна сущность "младенец" (событие рождения
близнецов может быть отображено набором отдельных кортежей данных), сущность
"мать" и произвольные наборы сущностей "медсестра" и "врач". Предположим
далее, что имеются множества сущностей Babies ("младенцы"), Mothers ("матери"),
Nurses ("медсестры") и Doctors ("врачи"), а также связь Births ("роды"), соединяющая
названные множества сущностей так, как показано на диаграмме рис. 2.15.
Примите к сведению, что кортеж множества данных связи Births имеет следующий вид:
(baby, mother, nurse, doctor).
Если родовспоможением занимается более одной медсестры и/или врача, будут
существовать несколько кортежей для одних и тех же компонентов данных "младенец"
72
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ
("baby") и "мать" ("mother") — по одному на
каждую комбинацию компонентов
"медсестра" ("nurse") и "врач" ("doctor").
Существует несколько дополнительных
предположений, перечисленных ниже, которые
могут быть учтены при построении модели.
Рассмотрев каждое из них, ответьте, следует ли
для его реализации добавить в диаграмму
какие-либо стрелки связей или другие элементы,
и если да, то какие именно.
a) Каждой сущности "младенец"
соответствует уникальная сущность "мать".
b) Каждому сочетанию сущностей "младенец
ветствует уникальная сущность "мать".
Рис. 2.15. Представление события
"роды " с помощью многосторонней связи
'медсестра" и "доктор" соот-
Births
Babies
Mothers
Doctors
Nurses
Рис. 2.16. Представление события "роды" посредством
множества сущностей
с) Каждой комбинации сущностей "младенец" и
кальная сущность "доктор".
мать соответствует уни-
! Упражнение 2.2.6. Другой подход к решению проблемы, описанной в упражнении
2.2.5, состоит в соединении множеств сущностей Babies ("младенцы"), Mothers
("матери"), Nurses ("медсестры") и Doctors ("врачи") с множеством сущностей
Births ("роды") посредством четырех отдельных связей, как показано на рис. 2.16.
Используя стрелки (с целью констатации, что соответствующая связь относится
к типу "многие к одному"), обеспечьте реализацию следующих условий:
d) каждая сущность "младенец" связана с уникальной сущностью "роды"
и каждая сущность "роды" связана с уникальной сущностью "младенец";
e) в дополнение к условию (а), каждой сущности "младенец" соответствует
уникальная сущность "мать";
f) в дополнение к условиям (а) и (Ь), каждой сущности "роды" соответствует
уникальная сущность "врач".
Какие ошибки дизайна вы можете назвать в каждом из случаев?
!! Упражнение 2.2.7. Изменим постановку задачи, добавив требование о том, что
модель должна отображать факт рождения близнецов непосредственно, а не в
виде набора кортежей, по одному на каждую сущность "младенец". Каким
образом представить условие, что каждой сущности "младенец" соответствует
уникальная сущность "мать", используя подходы, рассмотренные в
упражнениях 2.2.5 и 2.2.6?
2.2. ПРИНЦИПЫ ПРОЕКТИРОВАНИЯ
73
2.3. Моделирование ограничений
До сих пор мы говорили о том, как моделировать "срез" реального мира средствами
множеств сущностей, атрибутов и связей. Однако существуют некоторые другие аспекты
действительности, для адекватного представления которых возможностей инструментов
моделирования, изученных нами, уже не достаточно. Дополнительная информация об
объектах окружающего мира зачастую бывает облечена в форму определенных
ограничений (constraints), которые никак не связаны со структурными и "типовыми"
ограничениями, сопутствующими описанию конкретных множеств сущностей, атрибутов и связей.
2.3.1. Классификация ограничений
Следующий перечень представляет некую грубую классификацию наиболее
распространенных ограничений. В этом разделе мы не намереваемся давать их
исчерпывающее описание. Дополнительный материал, касающийся ограничений, изложен
в разделе 5.5 на с. 241 в терминах реляционной алгебры, а в главе 7 на с. 317 — в
контексте модели программирования на языке SQL.
1. Ключ (key) — атрибут или подмножество атрибутов, уникальным образом
определяющие некоторую сущность в составе множества сущностей. Никакие две
сущности в пределах множества сущностей не могут обладать одинаковыми
комбинациями значений атрибутов, составляющих ключ. Впрочем, совпадение
отдельных, но не всех одновременно, значений ключевых атрибутов любых двух
сущностей вполне допустимо.
2. Ограничение уникальности (single-value constraint): определенное значение в
некотором контексте должно быть уникальным. Ключи — это основной
"поставщик" ограничений уникальности, поскольку наличие ключа предполагает, что
каждая сущность во множестве сущностей обладает уникальными значениями
атрибутов, в совокупности образующих ключ. Есть и другие источники,
"порождающие" ограничения уникальности, — например, связи типа "многие к одному".
3. Ограничение ссылочной целостности (referential integrity constraint): некоторое
значение, на которое ссылается другой объект, должно существовать в базе
данных. Ограничение ссылочной целостности аналогично запрету на
использование в обычных программах "висящих" указателей или иных элементов,
ссылающихся на нечто отсутствующее.
4. Ограничение домена (domain constraint): значение атрибута должно выбираться
из некоего конечного множества значений или принадлежать определенному
диапазону изменения.
5. Ограничение общего вида (general constraint): произвольное требование, которое
должно быть зафиксировано в базе данных, — например, такое как "каждой
сущности кинофильм должно быть поставлено в соответствие не более десяти
сущностей актер". За сведениями об инструментах описания ограничений
общего вида обращайтесь к разделам 5.5 на с. 241 и 7.4 на с. 336.
Назовем несколько причин, обусловливающих важность механизма задания
ограничений в рамках модели базы данных. Ограничения дают возможность выразить
некоторые особые свойства моделируемых сущностей реального мира. Так, например,
ключи позволяют однозначно распознавать элементы множества однородных
сущностей. Если, скажем, мы знаем, что атрибут пате ("название") служит ключом для
множества сущностей Studios ("киностудии"), тогда при обращении к сущности
"киностудия" по ее названию обеспечиваются гарантии выбора уникального элемента
множества. Помимо того, при сохранении уникального значения экономятся время
и дисковое пространство; отдельное значение занести в базу данных проще, нежели
множество значений — даже в том случае, если множество состоит из единственного
74
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ
члена.5 Применение ключей и ограничений ссылочной целостности также
способствует оптимизации структур данных, что приводит к увеличению скорости доступа к
информации (об этом мы расскажем в главе 13 на с. 583).
2.3.2. Ключи и ER-моделирование
Говоря более строго, ключ (key) для множества сущностей Е — это множество К,
состоящее из одного или более атрибутов множества Е, такое, что при выборе из Е
любых двух различных сущностей е{ и е2 последние не могут обладать одинаковыми
значениями атрибутов, относящихся к множеству К. Если К состоит из нескольких
элементов, допустимо равенство отдельных, но не всех, атрибутов сущностей ех и е2.
Надлежит запомнить важные положения, перечисленные ниже.
• Каждое множество сущностей должно обладать определенным ключом.
• Ключ может состоять более чем из одного атрибута (соответствующая
иллюстрация приведена в примере 2.19).
• Для каждого множества сущностей допускается наличие нескольких ключей
(мы обсудим подобную ситуацию в примере 2.20). Целесообразно, однако,
выбрать один их них в качестве "первичного ключа" (primary key) и далее
обращаться с множеством таким образом, словно оно обладает единственным ключом.
• Если некоторое множество сущностей вовлечено в иерархию связей isa, следует
обеспечить, чтобы корневое множество сущностей обладало всеми атрибутами,
необходимыми для формирования ключа, и ключ для каждой сущности мог
быть найден на основе ее компонентов, относящихся к корневому множеству
сущностей, — независимо от того, какое число множеств, участвующих в
иерархии, располагает соответствующими компонентами.
Пример 2.19. Рассмотрим множество сущностей Movies ("кинофильмы"). На первый
взгляд, на роль ключа подходит атрибут title ("название"). Однако нетрудно привести
целый ряд примеров названий, которые употреблялись для обозначения двух и более
различных кинофильмов (скажем, "King Kong"). Поэтому выбор атрибута title в
качестве самодостаточного ключа — это, очевидно, не самое дальновидное решение. Если
все же поступить именно так, в дальнейшем мы не сможем различить в базе данных
те кинофильмы, которые волею случая получили одно и то же название.
Более уместно создать ключ на основе двух атрибутов — title и year ("год
производства"). Разумеется, вероятность выхода в одном и том же году двух кинофильмов
с одинаковым названием (в базе данных нельзя будет представить сведения об одном
и другом одновременно) все еще существует, но она, надо признать, довольно мала.
Решение о выборе ключей для двух других основных множеств сущностей,
представляющих рассматриваемую нами "кинематографическую" базу данных, должно
быть не менее взвешенным. Функции ключа для множества сущностей Studios
("киностудии") имеет смысл возложить на атрибут пате ("название"), поскольку двух
студий с одинаковым названием определенно быть не может. Однако столь же
категорично утверждать, что сущность "актер" однозначно определяется атрибутом "имя",
мы бы не стали, поскольку различить людей только по имени-фамилии в общем
случае нельзя. Впрочем, актеры довольно часто выбирают для себя броские "сценические"
псевдонимы, поэтому атрибут пате ("имя") может рассматриваться как претендент на
роль ключа множества сущностей Stars ("актеры"). Более универсальным, однако, могло
бы оказаться решение, предполагающее создание ключа на основе пары атрибутов,
пате и address ("адрес"), — если, конечно, вы не столкнетесь с тем редким случаем,
когда два актера с одинаковым именем проживают по одному и тому же адресу. □
5 Аналогично, в программе на языке С, например, гораздо проще представить отдельное
целочисленное значение, чем связанный список таких значений, пусть даже этот список состоит
из единственного элемента.
2.3. МОДЕЛИРОВАНИЕ ОГРАНИЧЕНИЙ
75
Ограничения как часть схемы базы данных
При изучении содержимого некоторой базы данных легко впасть в заблуждение
и принять решение о выборе ключевых атрибутов лишь на том, довольно зыбком,
основании, что в данный момент времени никакие из сущностей рассматриваемого
множества не обладают одинаковыми значениями этих атрибутов (скажем, в базу
данных до сих пор не заносились сведения о кинофильмах с одинаковыми
названиями). Таким образом, для множества сущностей Movies ("кинофильмы") ключ
может быть ошибочно сформирован, например, из единственного атрибута title
("название"). К чему это способно привести, подробно пояснять, вероятно, не
нужно: если база данных проектируется с учетом того, что title является
уникальным ключом множества сущностей Movies, в дальнейшем в нее нельзя будет внести
информацию о нескольких одноименных кинофильмах (таких как "King Kong").
Таким образом, ограничения, касающиеся ключей, — впрочем, и ограничения
всех других категорий — в процессе реализации базы данных становятся частью ее
схемы, наряду со всеми остальными структурными элементами, такими как
множества сущностей и связи. После того как ограничение объявлено, любые
операции по пополнению или изменению содержимого базы данных, нарушающие
условие этого ограничения, будут запрещены.
Хотя частный экземпляр базы данных может заведомо удовлетворять некоторым
ограничениям, "подлинными" следует считать только те из них, которые
определены проектировщиком базы данных и справедливы для всех ее экземпляров,
верно отображающих особенности моделируемых сущностей.
Пример 2.20. Предыдущий пример мог утвердить вас во мнении, что, дескать, задача
выбора подходящих ключей, гарантирующих уникальность представляемых данных,
всегда и заведомо сложна. В действительности обычно все гораздо проще. В реальных
ситуациях, подлежащих моделированию, при выборе ключевых атрибутов множеств
сущностей зачастую применяются непрямолинейные подходы. Например, во многих
компаниях принято присваивать всем служащим уникальный идентификационный
код, и одна из целей подобных мер состоит в том, чтобы облегчить введение
информации о служащих в корпоративные базы данных и гарантировать возможность
различения записей даже в тех случаях, когда несколько служащих имеют одинаковые
имена и фамилии. Таким образом, в качестве ключа множества сущностей,
описывающего служащих, используется атрибут идентификационного кода.
В США является нормой, когда каждый сотрудник компании обладает также
собственным номером полиса социального страхования (Social Security number). Если в
базе данных предусмотрен соответствующий атрибут для отображения номера полиса
социального страхования служащих, он также вполне пригоден для использования в
качестве ключевого. Заметим, что в наличии нескольких альтернативных вариантов
ключей для одного и того же множества сущностей — например, самостоятельных
ключевых атрибутов идентификационного кода и номера полиса социального
страхования служащих — нет ничего предосудительного.
Практика создания специальных атрибутов, единственным назначением которых
является поддержка ключевых признаков сущности во множестве однородных
сущностей, достаточно распространена. Аналогично идентификаторам служащих, во многих
университетах каждому студенту также присваивают уникальный идентификационный
код. В базах данных Государственной автомобильной инспекции в качестве ключевых
атрибутов множеств сущностей, представляющих сведения о водителях и
транспортных средствах, используются, соответственно, номера водительских удостоверений и
регистрационные номера транспортных средств. Любой читатель при желании сможет
привести и другие примеры определения специальных атрибутов, предназначенных
для использования в качестве ключевых. □
76
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ!
2.3.3. Представление ключей в ER-модели
Используемая нами система обозначений предусматривает, что атрибуты множеств
сущностей, объявленные как ключевые, на ER-диаграмме выделяются подчеркиванием.
На рис. 2.17 воспроизведена диаграмма рис. 2.2 (см. с. 54), которая отображает
структуру базы данных, содержащей сведения о кинофильмах {Movies), киностудиях
(Studios) и актерах (Stars). Ключевые атрибуты названных множеств сущностей
подчеркнуты. В качестве ключевых атрибутов для множеств Stars и Studios выбраны атрибуты
пате ("имя" или "название") — это решение мы обсуждали в примере 2.19 на с. 75.
Рис. 2.17. На ER-диаграмме атрибуты-ключи отмечаются
подчеркиванием
Ключ для множества сущностей Movies сформирован на основе совокупности
атрибутов title ("название") и year ("год производства"). Атрибуты, наименования
которых подчеркнуты, являются членами ключа. Для описания ситуации, когда множество
сущностей снабжено несколькими альтернативными ключами, специальных
обозначений, однако, не существует; мы подчеркиваем только первичные ключи (primary
keys). Следует упомянуть и тот довольно необычный случай, когда атрибуты,
образующие ключ для некоторого множества сущностей, не обязательно принадлежат
этому множеству (подобные вопросы, имеющие отношение к так называемым слабым
множествам сущностей (weak entity sets), мы обсудим в разделе 2.4 на с. 81).
2.3.4. Ограничения уникальности
Важным свойством некоторого объекта базы данных зачастую является то, что он
может описываться не более чем одним значением. Так, например, конкретной
сущности "кинофильм" соответствуют строго определенные значения атрибутов
"название", "год производства", "продолжительность" и "тип", а "владеет"
кинофильмом только одна "киностудия".
Существует несколько ситуаций, в которых ограничения уникальности (single-value
constraints) проявляют себя в рамках ER-модели.
1. Некоторый атрибут множества сущностей обладает единственным значением.
Иногда допускается отсутствие значения атрибута для отдельных сущностей
множества, и в подобных случаях приходится "изобретать" какое-то "нулевое"
значение, используемое по умолчанию. Для примера можно представить ситуацию,
2.3. МОДЕЛИРОВАНИЕ ОГРАНИЧЕНИЙ
77
когда для некоторых кинофильмов, сведения о которых занесены в базу данных,
информация о продолжительности их воспроизведения неизвестна. Значением
атрибута length в таком случае могло бы быть, скажем, —1. С другой стороны,
допускать отсутствие значений ключевых атрибутов, таких как title ("название")
и year ("год производства"), нельзя. Требование о том, что некоторый атрибут
не может иметь неопределенных значений вида null, в ER-модели не имеет
специальных средств представления. Если необходимо описать подобное
ограничение, можно снабдить атрибут дополнительным текстовым пояснением.
2. Связь R типа "многие к одному", соединяющая множества сущностей Е и F
в направлении от Е к F, подразумевает наличие ограничения уникальности.
Другими словами, для каждой сущности е множества Е имеется не более одной
связанной с ней сущности / множества F. Или, в общем случае, если R
представляет собой многостороннюю связь, тогда каждая из стрелок, "выходящая"
из R, выражает ограничение уникальности. В частности, если существует
стрелка, соединяющая связь R с множеством сущностей Е, в составе Е имеется не
более одной сущности, ассоциированной с определенным набором сущностей
из всех остальных множеств, охватываемых связью R.
2.3.5. Ограничения ссылочной целостности
Если ограничения уникальности (single-value constraints) декларируют возможность
существования не более одного значения, выступающего в определенной роли,
ограничения ссылочной целостности (referential integrity constraints) подразумевают наличие
в точности одного такого значения. Требование о том, чтобы атрибут обладал
единственным возможным значением, отличным от null, можно рассматривать как
разновидность ограничений ссылочной целостности, но чаще последние используются для
описания свойств связей между множествами сущностей.
Рассмотрим связь Owns ("владеет"), соединяющую множества сущностей Movies
("кинофильмы") и Studios ("киностудии") так, как показано на рис. 2.2 (см. с. 54).
Связь Owns относится к типу "многие к одному" и предполагает только то, что ни
один из кинофильмов не может принадлежать нескольким студиям одновременно.
Связь — в том виде, как она задана — отнюдь не подразумевает, что кинофильмом
определенно должна владеть какая-либо студия, а если это даже и так, студия вовсе не
обязана быть представлена во множестве сущностей Studios.
Ограничение ссылочной целостности в контексте связи Owns предусматривает, что
для каждой сущности "кинофильм" в базе данных должна присутствовать
соответствующая сущность "киностудия", на которую "кинофильм" ссылается. Существует
несколько способов поддержки условий ссылочной целостности. Мы рассмотрим их
ниже на примере связи Owns.
1. Если база данных пополняется новой сущностью "кинофильм", обязана
существовать (или должна быть добавлена) и соответствующая сущность
"киностудия". Помимо того, если значение экземпляра связи Owns (ссылка
на множество сущностей Studios) для конкретного "кинофильма"
изменяется, необходимо гарантировать, что новое значение ссылки также является
сущностью множества Studios.
2. Следует запретить удаление сущностей множества Studios, адресуемых
сущностями множества Movies. Другими словами, некоторая сущность "киностудия"
не может быть удалена до тех пор, пока имеются сущности "кинофильм",
которые на нее ссылаются.
3. Если сущность множества Studios подлежит принудительному удалению, должны
быть удалены также все сущности множества Movies, ссылающиеся на нее.
78
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
Аспекты практической реализации ограничений ссылочной целостности относятся
к компетенции определенной СУБД или конкретного проекта базы данных, поэтому
здесь мы не будем останавливаться на них подробно.
2.3.6. Ссылочная целостность и ER-диаграммы
Правила применения стрелок в ER-диаграммах могут быть расширены с целью
обеспечения возможности отображения ограничений ссылочной целостности связей
в одном или нескольких направлениях. Предположим, что R — это связь,
соединяющая множества сущностей Е и F в направлении от Е к F. Тогда полукруглая стрелка,
указывающая на F, не только свидетельствует о том, что связь, соединяющая
множества Е и F, относится к типу "многие к одному" или "один к одному", но и
отображает требование обязательного наличия в F сущности, на которую ссылается
определенная сущность из Е. Те же соображения применимы и к случаю, когда R соединяет
между собой более двух множеств сущностей.
Пример 2.21. На рис. 2.18 обозначены несколько ограничений ссылочной
целостности, заданных для связей Owns ("владеет") и Runs ("возглавляет"), которые соединяют
множества сущностей Movies ("кинофильмы"), Studios ("киностудии") и Presidents
("президенты"). Названные связи и множества сущностей были впервые введены на
диаграммах рис. 2.2 (см. с. 54) и 2.3 (см. с. 56). Полукруглая стрелка, соединяющая
связь Owns с множеством сущностей Studios, выражает ограничение ссылочной
целостности, которое подразумевает, что каждым кинофильмом должна владеть одна
определенная студия и соответствующая сущность "киностудия" обязана
присутствовать в составе множества Studios.
Presidents
Рис. 2.18. ER-диаграмма с обозначениями ограничений ссылочной
целостности
Аналогично, полукруглая стрелка, указывающая на множество Studios со стороны
связи Runs, обозначает ограничение ссылочной целостности, которое заключается в том,
что каждый президент возглавляет одну студию и соответствующая сущность
"киностудия" должна наличествовать во множестве Studios.
Обратите внимание, связь Runs по-прежнему соединена с множеством сущностей
Presidents обычной (а не полукруглой) стрелкой, поскольку она отображает вполне
естественную закономерность взаимоотношений сущностей "президент" и
"киностудия". Если студия прекращает свое существование, ее президент более не может
занимать свой пост, и поэтому резонно ожидать, что соответствующая сущность
"президент" должна быть удалена из множества Presidents', здесь проявляет себя
ограничение ссылочной целостности. С другой стороны, удаление сущности "президент",
как подсказывает здравый смысл, не должно оказывать влияния на содержимое
множества Studios, поскольку в какие-то периоды времени студия может обходиться без
руководителя. Поэтому связь Runs и множество сущностей Presidents соединены
обычной стрелкой: каждая студия может возглавляться не более чем одним президентом,
а в каких-то случаях президента может не быть вовсе. □
2.3.7. Ограничения других видов
В начале раздела 2.3, помимо ключей, ограничений уникальности и ссылочной
целостности, мы упоминали и другие ограничения, которые могут быть предусмотрены
в схеме базы данных. Здесь мы только вкратце остановимся на вопросах задания
произвольных ограничений и более подробно осветим их в главе 7 на с. 317.
2.3. МОДЕЛИРОВАНИЕ ОГРАНИЧЕНИЙ
79
Ограничения домена (domain constraints) предполагают, что значения атрибута
должны выбираться из определенного конечного множества или принадлежать
ограниченному диапазону изменения. Простой пример использования ограничений
домена связан с объявлением типа атрибута. Более строгое ограничение предусматривает
определение некоторого перечислимого типа атрибута либо диапазона значений. Так,
например, значение атрибута length ("продолжительность") множества сущностей
Movies было бы уместно задавать в виде целого числа, выраженного в минутах и
принадлежащего интервалу от 0 до 240. ER-модель не содержит специальных
выразительных средств, позволяющих описать ограничения домена, но не запрещает размещать
на диаграмме вместе с атрибутом необходимые текстовые примечания.
Существуют и иные разновидности ограничений, которые нельзя отнести ни к
одной из категорий, рассмотренных выше. Вполне вероятна, например, такая ситуация,
когда следует ограничить количество возможных сочетаний сущностей множеств,
охватываемых определенной связью (скажем, одна сущность "кинофильм" должна быть
соединена не более чем с десятью сущностями "актер"). ER-модель позволяет включить в
диаграмму соответствующее ограничивающее значение, поместив его в
непосредственной близости от линии, соединяющей связь и множество сущностей, как на рис. 2.19.
Movies
<=10
Stars
Рис. 2.19. Так обозначается ограничение на
количество сущностей- "актеров", сея-
занных с определенной
сущностью-"кинофильмом "
Пример 2.22. На рис. 2.19 показан пример ограничения на число сущностей
множества Stars ("актеры"), связанных с определенной сущностью множества Movies
("кинофильмы"). Развивая мысль, мы могли бы сказать, что обычная стрелка между
связью типа "... к одному" и множеством сущностей равнозначна ограничению вида
"<= 1", а полукруглая стрелка (см. рис. 2.18), применяемая для обозначения условий
ссылочной целостности, —- ограничению "= 1". □
2.3.8. Упражнения к разделу 2.3
Упражнение 2.3.1. Обратившись к ER-диаграммам, построенным вами при
решении заданий из упражнений
*а) 2.1.1 (см. с. 63);
b) 2.1.3 (см. с. 64);
c) 2.1.6 (см. с. 65),
выполните следующее:
i) выберите и обозначьте ключевые атрибуты для каждого множества сущностей;
и) отметьте ограничения ссылочной целостности, если таковые необходимы.
! Упражнение 2.3.2. Вполне допустимо представить, что связи в ER-модели
способны обладать ключами точно так же, как и множества сущностей. Пусть R является
связью, соединяющей множества сущностей Еь Ег,..., Еп. Тогда ключ для R — это
множество К атрибутов, выбранных из наборов атрибутов множеств Е[у £2,..., Еп таким
образом, что если (eh еь ..., еп) и (/i,/2, ...,/л) представляют собой два различных
кортежа множества данных связи R, то совпадение этих кортежей во всех атрибутах К
невозможно. Пусть также для каждого i tf, представляет множество атрибутов,
служащих ключами множества сущностей £,. Теперь предположим, что п = 2, т.е. R
является бинарной связью. Создайте наименьший возможный ключ для R при условии, что
80
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ
a) R относится к типу "многие ко многим";
* b) R представляет связь типа "многие к одному" от Ех к Е2\
c) R представляет связь типа "многие к одному" от Е2 к Е{;
d) R относится к типу "один к одному".
!! Упражнение 2.3.3. Вновь рассмотрим задание упражнения 2.3.2, но теперь
позволим параметру п принимать произвольные значения, а не только значение 2.
Обладая информацией о том, какие линии от R к Е{ снабжены стрелками, покажите,
каким образом найти наименьший возможный ключ К для R в терминах К,.
! Упражнение 2.3.4. Приведите реальные образцы атрибутов (отличные от
упомянутых в примере 2.20 на с. 76), которые созданы преимущественно для
использования в роли ключей множеств сущностей.
2.4. Слабые множества сущностей
Изредка обстоятельства складываются так, что ключ для некоторого множества
сущностей (его называют слабым — weak entity set) приходится формировать на основе
атрибутов, которые полностью или частично принадлежат другому множеству сущностей.
2.4.1. Примеры использования слабых множеств сущностей
Существуют два основных источника, порождающих необходимость использования
слабых множеств сущностей. Во-первых, иногда множества сущностей участвуют
в иерархии, построенной на принципах, не имеющих отношения к связям isa (см.
раздел 2.1.11 на с. 61). Если сущности множества Е представляют собой единицы более
"крупных" сущностей множества F, вполне вероятна ситуация, когда атрибуты
сущностей Е, претендующие на роль ключевых, не будут обладать свойством
уникальности до тех пор, пока во внимание не приняты атрибуты сущностей F, которым
"подчиняются" сущности Е. Проблема иллюстрируется несколькими примерами.
Пример 2.23. Киностудия может состоять из нескольких творческих объединений.
Пусть объединениям (назовем их Crews) в рамках киностудии даны условные
названия, такие как, скажем, "crew 1", "crew 2" и т.д. Но в другой киностудии для
нумерации объединений может быть принята совершенно такая же схема, так что атрибут
number ("номер") уже нельзя считать ключевым. Чтобы обеспечить уникальность
названия объединения среди подразделений всех киностудий, необходимо, наряду с его
номером, учесть и наименование (пате) студии, которой это объединение
принадлежит. Ситуация смоделирована на рис. 2.20. Ключом для слабого множества сущностей
Crews служит совокупность двух атрибутов — собственного атрибута number множества
Crews и атрибута пате уникальной сущности-"киностудии", с которой сущность-
"объединение" соотносится посредством связи Unit-of ("подразделение").6 □
Рис. 2.20. Так отображаются слабые множества
сущностей и соответствующие связи
6 Правила употребления в ER-диаграммах двойных прямоугольников и ромбов разъяснены
в разделе 2.4.3 на с. 84.
2.4. СЛАБЫЕ МНОЖЕСТВА СУЩНОСТЕЙ
81
Пример 2.24. Биологический вид принято обозначать совокупностью имен рода, к
которому принадлежит этот вид, и собственного имени вида. Например, человек как
биологическое существо относится к виду Homo sapiens, где Homo ("человек") — название
рода, a sapiens ("разумный") — название вида. Род в общем случае состоит из
нескольких видов, и полное наименование каждого из них включает название рода и
уточняется названием вида. Названия видов, рассматриваемые отдельно, к сожалению, не
уникальны. В составе двух или нескольких родов могут встретиться виды с
одинаковыми собственными названиями. Поэтому для обеспечения уникальности сущности
"вид" во множестве сущностей Species ("биологические виды") необходимо
пользоваться полными именами видов, состоящими из собственного имени вида и названия
соответствующей сущности "род" из множества сущностей Genera ("биологические роды"),
с которой "вид" соединен связью Belongs-to ("принадлежит") (см. рис. 2.21). Таким
образом, Species — это слабое множество сущностей, в состав ключа которого введен
атрибут множества Genera, находящегося на более "высокой" ступени иерархии. □
>
Genera
Рис. 2.21. Еще одна ER-диаграмма,
представляющая слабое множество сущностей
Другая причина применения слабых множеств сущностей связана с механизмом
соединяющих множеств сущностей (connecting entity sets) (см. раздел 2.1.10 на с. 60),
который позволяет преобразовать ER-диаграмму, устраняя многосторонние связи.7
Соединяющие множества сущностей зачастую не содержат собственных атрибутов,
поэтому ключи для таких множеств формируются на основе ключевых атрибутов
других, связанных с ними множеств.
Пример 2.25. На рис. 2.22 изображено соединяющее множество сущностей Contracts
("контракты"),, заменяющее собой одноименную тернарную связь, которая была
рассмотрена в примере 2.5 на с. 56. Множество Contracts обладает собственным
атрибутом salary ("размер заработной платы"), который, однако, не участвует в
формировании ключа. Уникальная сущность "контракт" определяется совокупностью
значений ключевых атрибутов пате ("имя" или "название") множеств Stars
("актеры") и Studios ("киностудии"), а также title ("название") и year ("год
производства") множества Movies ("кинофильмы"). □
2.4.2. Требования к слабым множествам сущностей
К проблеме выбора ключевых атрибутов для слабых множеств сущностей надлежит
подходить аккуратно и взыскательно. Если Е представляет собой слабое множество
сущностей, его ключ может быть образован из
1) подмножества (возможно, пустого) собственных атрибутов;
2) ключевых атрибутов множеств сущностей, которые могут быть достигнуты
посредством цепочки связей типа "многие к одному", соединяющих множество Е
с другими множествами; подобные связи принято называть поддерживающими
связями (supporting relationships) для множества Е.
7 ER-модель не содержит жестких требований относительно того, что многосторонние связи
непременно должны быть преобразованы, хотя подобные условия предусмотрены в некоторых
других моделях, применяемых для проектирования баз данных.
82
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
Рис. 2.22. Соединяющие множества сущностей "слабы"
Чтобы некоторую связь R типа "многие к одному", соединяющую множества
сущностей Е и F в направлении от Е к F, можно было отнести к числу поддерживающих
связей для множества £", должны выполняться условия, перечисленные ниже.
1. Связь R должна быть бинарной связью типа "многие к одному"8,
направленной от Е к F.
2. Связь R обязана предусматривать реализацию ограничения ссылочной
целостности в направлении от Е к F. Другими словами, для каждой Е-сущности
следует обеспечить наличие в базе данных соответствующей F-сущности, с которой
Е-сущность соотносится посредством связи R, т.е. присутствие на диаграмме
полукруглой стрелки, соединяющей R с F, должно быть подтверждено фактически.
3. Атрибуты, предоставляемые множеством F для образования ключа множества Е,
должны быть ключевыми для F.
4. Если F, в свою очередь, также является слабым множеством сущностей, тогда
некоторые или все ключевые атрибуты, поставляемые множеству Е, должны
быть ключевыми атрибутами одного или нескольких множеств сущностей G,
с которыми множество F соединено посредством поддерживающих связей. Если
и G относится к числу слабых множеств, ключевые атрибуты по цепочке связей
заимствуются у других множеств и т.д.
5. Если существует несколько различных поддерживающих связей, направленных со
стороны Е к F, каждая связь для формирования ключа множества Е поставляет
собственную копию ключевых атрибутов множества F. Заметим, что некоторая
сущность е множества Е может быть связана с несколькими различными
сущностями множества F посредством различных поддерживающих связей, направленных
otEkF. Таким образом, сущность е множества Е может определяться
ключевыми значениями, полученными от нескольких различных сущностей множества F.
8 Заметим, что связь "один к одному" является частным случаем связи типа "многие к
одному". Когда мы говорим о том, что некоторая связь должна относиться к типу "многие к
одному", мы подразумеваем и равную возможность существования связи "один к одному".
2.4. СЛАБЫЕ МНОЖЕСТВА СУЩНОСТЕЙ
83
Интуитивные доводы в пользу необходимости принятия названных условий
таковы. Рассмотрим некоторую сущность, принадлежащую слабому множеству сущностей,
такому как, скажем, Crews ("объединения") (см. пример 2.23 на с. 81). Каждая
сущность "объединение" должна быть уникальной, чтобы ее можно было отличить от
другой даже в том случае, если "объединения" обладают одним порядковым номером,
но относятся к разным "киностудиям". Одного номера для решения задачи, однако,
не достаточно. Следует провести поиск дополнительных значений, способных
обеспечить уникальность сущностей множества Crews. К числу уникальных значений, тем
или иным образом связанных с сущностями "объединение", относятся:
1) значения атрибутов самого множества Crews]
2) значения, которые можно получить на основе связей множества Crews с
другими множествами; каждая подобная связь должна относиться к типу "многие
к одному" (или, в частном случае, "один к одному") и соединять множество
Crews с некоторым множеством F, а заимствованные множеством Crews
атрибуты обязаны участвовать в образовании ключа множества F.
2.4.3. Система обозначений слабых множеств сущностей
При обозначении на ER-диаграмме слабых множеств сущностей, их ключевых
атрибутов и поддерживающих связей мы действуем в соответствии со
следующими правилами.
1. Если множество сущностей является слабым, его принято изображать в виде
двойного прямоугольника. Примерами могут служить множества
сущностей Crews ("объединения") (см. рис. 2.20 на с. 81) и Contracts ("контракты")
(см. рис. 2.22 на с. 83).
2. Поддерживающие связи типа "многие к одному" для слабых множеств
сущностей обозначают двойными ромбами. В качестве примеров можно
упомянуть связь Unit-of ("подразделение") (см. рис. 2.20) и все три связи
диаграммы рис. 2.22.
3. Если в формировании ключа слабого множества сущностей участвуют его
собственные атрибуты, их наименования подчеркиваются. На диаграмме рис. 2.20
атрибут number ("номер") является частью ключа множества сущностей Crews,
хотя этим состав ключа не исчерпывается.
Те же правила, но в лаконичной форме, могут быть представлены так.
• "Если множество Е на диаграмме обозначено двойным прямоугольником, оно
является слабым. Атрибуты множества £, отмеченные подчеркиванием (если
таковые есть), в совокупности с ключевыми атрибутами тех множеств сущностей,
с которыми Е соединено посредством связей типа "многие к одному",
обозначенных двойными ромбами, образуют ключ множества Е\
Следует напомнить, что двойные ромбы применяются только для обозначения
поддерживающих связей. Вполне возможно наличие в диаграмме связей типа "многие
к одному", охватывающих слабые множества сущностей, но не относящихся к категории
поддерживающих связей; такие связи отмечаются обычными (не двойными) ромбами.
Пример 2.26. Изображенную на ER-диаграмме рис. 2.22 (см. с. 83) связь Studio-of не
обязательно следует считать поддерживающей связью для множества сущностей
Contracts ("контракты"), поскольку каждой сущности "кинофильм" соответствует
строго определенная сущность "киностудия", определяемая не показанной здесь
связью Owns ("владеет"), которая соединяет множества сущностей Movies
("кинофильмы") и Studios ("киностудии"). Поэтому для каждой конкретной пары сущностей
84
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ"
"актер—кинофильм" существует не более одного контракта с любой студией,
оговаривающего условия участия актера в съемках фильма, и для обозначения связи Studio-of
более уместно было бы вместо двойного ромба использовать обычный, одинарный. □
2.4.4. Упражнения к разделу 2.4
* Упражнение 2.4.1. Один из способов представления сведений о студентах и
оценках, полученных ими по завершении изучения тех или иных курсов, связан с
созданием множеств сущностей "студенты", "курсы" и "регистрационные записи".
Сущности "регистрационные записи" формируют множество, "соединяющее"
множества "студенты" и "курсы", которое может быть использовано не только для
регистрации того факта, что определенный студент сдал экзамен по конкретному
курсу, но и для хранения данных о полученных студентами оценках. Начертите
ER-диаграмму, представляющую описанную ситуацию, и отметьте на ней слабые
множества сущностей и ключи для всех множеств. Является ли атрибут "оценка"
частью ключа для множества сущностей "регистрационные записи"?
Упражнение 2.4.2. Дополните решение упражнения 2.4.1 таким образом, чтобы
обеспечить хранение промежуточных оценок, получаемых студентом в процессе
изучения курса. Вновь отметьте на диаграмме слабые множества сущностей
и ключи для всех множеств.
Упражнение 2.4.3. Обратившись к ER-диаграммам, представляющим решения
заданий упражнения 2.2.6 (а)—(с) (см. с. 73), отметьте слабые множества сущностей,
поддерживающие связи и ключи.
Упражнение 2.4.4. Постройте ER-диаграммы, описывающие ситуации с участием
слабых множеств сущностей, перечисленные ниже. Отметьте на каждой диаграмме
ключи для всех множеств сущностей.
а) Даны множества сущностей Courses ("курсы") и Departments ("факультеты").
Каждый курс читается на строго определенном факультете, но обладает
единственным атрибутом number ("номер"). Различные факультеты вправе
предлагать курсы с одинаковыми номерами. Каждому факультету
соответствует уникальное значение атрибута пате ("название").
*! Ь) Даны множества сущностей Leagues ("лиги"), Teams ("команды") и Players
("игроки"). Лиги обладают уникальными названиями. В составе лиги нет
двух команд с одинаковыми наименованиями, а в команде — игроков с
одним и тем же номером. Однако в пределах нескольких команд могут
совпадать номера игроков, а в нескольких лигах допускается наличие команд
с одинаковыми наименованиями.
2.5. Резюме
♦ Модель "сущность—связь", или ER-модель, используется для представления
множеств сущностей, связей между ними, а также атрибутов множеств и связей.
♦ Диаграмма сущностей и связей. При построении диаграммы сущностей и связей,
или ER-диаграммы, для описания множеств сущностей, связей и атрибутов
применяются соответственно прямоугольники, ромбы и овалы.
♦ Множественность связей. Бинарные связи могут относиться к типам "один
к одному", "многие к одному" или "многие ко многим". Связь "один к
одному" соединяет некоторую сущность множества не более чем с одной сущностью
другого множества. Связь "многие к одному" соединяет любую сущность
множества, указанного на стороне "многие", не более чем с одной сущностью
множества, заданного на противоположной стороне соединения. Связи типа
2.5. РЕЗЮМЕ
85
"многие ко многим' не ограничивают свойство множественности
взаимоотношений соединяемых множеств сущностей.
♦ Ключи. Ключом для множества сущностей называется набор атрибутов,
значения которых уникальным образом определяют сущность во множестве
однородных сущностей.
♦ Принципы проектирования. Чтобы достичь успеха при проектировании базы
данных, следует обеспечить достоверность представления сведений об объектах
реального мира, выбрать подходящие инструменты моделирования (т.е. верно
использовать элементы множеств сущностей, связей и атрибутов) и избежать
избыточности (представления некоторых сущностей дважды либо описания их
неоднозначными и сложными средствами).
♦ Ссылочная целостность. Ограничение ссылочной целостности подразумевает,
что сущность, на которую ссылается некоторая другая сущность, обязана
присутствовать в базе данных.
♦ Подклассы. ER-модель предлагает возможность использования связей
специальной разновидности, isa, для представления того факта, что одно множество
сущностей является некоторым подмножеством другого. Множества сущностей,
соединенные связями isa, могут образовывать древовидную иерархию, а их
элементы — обладать компонентами, принадлежащими любому поддереву дерева
иерархии, включающему корневую вершину.
♦ Слабые множества сущностей. ER-модель позволяет представлять такие множества
сущностей, ключи которых полностью или частично основаны на ключевых
атрибутах других, связанных, множеств. Для описания слабых множеств сущностей в ER-
диаграммах применяются специальные обозначения — двойные прямоугольники.
2.6. Литература
Самое первое описание модели "сущность—связь" приведено в работе [2].
Современные достижения в области ER-моделирования отражены в книгах [1] и [3].
1. Batini Carlo, Ceri S., Navathe S.B., and Batini Carol. Conceptual Database Design: an
Entity/Relationship Approach, Addison-Wesley, Reading, MA, 1991.
2. Chen P.P. The entity-relationship model: toward a unified view of data, ACM Trans, on
Database Systems, 1:1 (1976), p. 9-36.
3. Thalheim B. Fundamentals of Entity-Relationship Modeling, Springer- Verlag, Berlin, 2000.
86
ГЛАВА 2. МОДЕЛЬ ДАННЫХ "СУЩНОСТЬ-СВЯЗЬ1
Глава 3
Реляционная модель
Хотя подход к проектированию баз данных, который связан с моделью "сущность-
связь" (ее называют также ER-моделью), рассмотренной в главе 2 на с. 51, предлагает
простые и адекватные средства описания структур данных, современные образцы баз
данных почти всецело основываются на иных принципах, в совокупности называемых
реляционной моделью (relational model). Реляционная модель крайне проста и
плодотворна, поскольку основана чуть ли не на единственном основном понятии
отношения (relation). Отношение — это двумерная таблица, предназначенная для
упорядоченного хранения данных. В главе 6 на с. 249 будет рассказано о том, как в рамках
реляционной модели поддерживается весьма высокоуровневый язык
программирования, сокращенно называемый SQL (от Structured Query Language — язык
структурированных запросов). Благодаря языку SQL можно создавать простые, но чрезвычайно
мощные программы, позволяющие манипулировать данными, хранящимися в
отношениях, самыми различными способами. ER-модель, напротив, нельзя считать
пригодной для использования в качестве основы какого-либо языка управления данными.
С другой стороны, проектировать базы данных зачастую легче именно в терминах
ER-модели. Таким образом, наша первая задача состоит в том, чтобы рассказать, как
проект базы данных, оформленный по правилам ER-моделирования, может быть
преобразован в набор отношений. Затем вы узнаете, что реляционная модель реализует
собственную теорию проектирования. Эта теория, обычно сводимая к правилам нормализации
(normalization) отношений, основывается преимущественно на концепции
функциональных зависимостей (functional dependencies), которая включает и расширяет понятие
ключа (key), рассмотренное нами неформально в разделе 2.3.2 на с. 75. Практическое
применение правил нормализации позволяет существенно улучшить структуру
отношений, представляющих конкретную предметную область, подлежащую моделированию.
3.1. Основы реляционной модели
Реляционная модель предусматривает единственный способ представления
данных — в виде набора двумерных таблиц, называемых отношениями (relations). На
рис. 3.1 приведен пример отношения. Наименование отношения — Movies, и
предназначено оно для хранения информации об элементах множества сущностей Movies
("кинофильмы"), рассматриваемого в контексте знакомого вам по главе 2 (см. с. 51)
проекта "кинематографической" базы данных, который мы будем развивать и далее.
Каждая строка отношения Movies отвечает одной сущности "кинофильм", а каждый
столбец — одному из атрибутов множества сущностей Movies. Впрочем, отношения
позволяют отображать не только множества сущностей, и об этом мы расскажем ниже.
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
filmType
color
color
color
Рис. 3.1. Отношение Movies
3.1.1. Атрибуты
В верхней части таблицы-отношения задается перечень наименований атрибутов
(attributes): так, на рис. 3.1 атрибутами являются title, year, length и filmType.
Атрибуты отношения выполняют функцию наименований его столбцов и содержательно
описывают смысл и назначение элементов данных, располагаемых в соответствующих
ячейках. Например, в столбце с атрибутом length хранятся целочисленные данные
о продолжительности воспроизведения каждого кинофильма, выраженной в минутах.
Обратите внимание, что атрибуты отношения Movies, представленного на
рис. 3.1, — это те же атрибуты, которыми обладает множество сущностей Movies.
Позже мы покажем, что преобразование некоторого множества сущностей в
отношение с тем же набором атрибутов — это весьма распространенная операция. В общем
случае, однако, требований о том, чтобы атрибуты некоторого отношения обязательно
соответствовали определенным компонентам ER-модели, не существует.
3.1.2. Схемы
Наименования отношения и атрибутов этого отношения в совокупности называют
схемой (schema) отношения. Схема отношения представляется в виде имени
отношения, за которым следует список имен атрибутов, заключенный в круглые скобки.
Например, схема отношения Movies, изображенного на рис. 3.1, может выглядеть так:
Movies(title, year, length, filmType).
Атрибуты схемы отношения образуют на самом деле множество, а не упорядоченный
список. Однако, чтобы облегчить работу с отношениями, часто бывает полезно
принять некий "стандартный" порядок следования их атрибутов. Поэтому всякий раз,
когда приводится схема отношения со списком атрибутов (как в примере выше), мы
подразумеваем определенный "стандартный" порядок перечисления атрибутов,
позволяющий однозначно задавать любые кортежи данных этого отношения.
Проект базы данных, выполненный в рамках реляционной модели, включает одну
или несколько схем отношений. Набор схем отношений называют реляционной схемой
базы данных (relational database schema), или просто схемой базы данных (database schema).
3.1.3. Кортежи
Строки отношения, отличные от той, которая представляет наименования
атрибутов, называют кортежами (tuples). Кортеж содержит по одному компоненту
(component) для каждого атрибута отношения. Например, первый из трех кортежей
отношения Movies, изображенных на рис. 3.1, включает четыре компонента, star
Wars, 1977, 124 и color, которые соответствуют атрибутам title, year, length
и filmType. Если необходимо описать кортеж отдельно, вне контекста отношения,
принято заключать его в круглые скобки и разделять компоненты символом запятой.
Первый кортеж отношения Movies можно задать следующим образом:
(Star Wars, 1977, 124, color).
88
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Если кортеж представляется так, как показано выше, видимая связь компонентов
с атрибутами утрачивается, поэтому следует непременно указывать, к какому
отношению принадлежит данный кортеж, и перечислять его компоненты в том "стандартном"
порядке, который зафиксирован в схеме отношения.
3.1.4. Домены
Одно из требований, выдвигаемых реляционной моделью, гласит, что каждый
компонент кортежа должен быть атомарным, т.е. относиться к некоторому базовому типу,
такому как целочисленный или строковый. В качестве значений компонентов кортежа
не разрешается использовать записи, множества, списки, массивы или иные
составные объекты, которые допускают естественное разбиение на более мелкие элементы.
Помимо того, предполагается, что с каждым атрибутом отношения ассоциирован
определенный домен (domain), т.е. некоторый базовый тип. Значения компонентов
всех кортежей должны принадлежать соответствующим доменам, определяемым
каждым из атрибутов отношения. Вновь для примера обратимся к отношению Movies,
показанному на рис. 3.1. Первые компоненты всех кортежей отношения Movies
должны быть строками, вторые и третьи — целыми числами, а четвертые обязаны
содержать одну из двух допустимых строковых констант, color или blackAndWhite.
Домены являются частью схемы отношения (мы отложим обсуждение вопросов,
касающихся средств описания доменов в схемах отношений, до раздела 6.6.2 на с. 297).
3.1.5. Формы представления отношений
Отношения — это множества (но не упорядоченные списки!) кортежей. Порядок,
в котором кортежи перечисляются в пределах отношения, не существен. Вполне
возможно, например, переставить кортежи отношения Movies, показанного на рис. 3.1, любым
из шести различных способов, но это никоим образом не повлияет на его содержимое.
Более того, допускается без каких-либо последствий изменять и порядок задания
атрибутов отношения. Если, однако, реляционная схема отношения подвергается
упорядочению, необходимо помнить, что наименования атрибутов являются заголовками
столбцов отношения. Поэтому, изменяя порядок перечисления атрибутов, мы должны
позаботиться и о соответствующем упорядочении столбцов отношения. При
перемещении столбцов изменится и взаимное положение компонентов кортежей. В результате
каждый компонент кортежа займет то же место, что и соответствующий ему атрибут.
На рис. 3.2 показан один из многочисленных вариантов представления отношения
Movies, получаемых при перемещении его строк и столбцов. Все возможные версии
таблицы рис. 3.1 (включая и ту, которая изображена на рис. 3.2) по существу
являются различными формами, в которых допустимо изображать отношение Movies.
year
1991
1992
1977
title
Mighty Ducks
Wayne's World
Star Wars
film Type
color
color
color
length
104
95
124
Рис. 3.2. Другая форма представления отношения Movies
3.1.6. Экземпляры отношения
Отношение, содержащее информацию о кинофильмах, по своей природе не
является статичным; этому и большинству других отношений со временем свойственно
меняться. Изменения обычно затрагивают содержимое отношения: в базу данных
помещаются новые кортежи (например, представляющие сведения о новинках кинема-
3.1. ОСНОВЫ РЕЛЯЦИОННОЙ МОДЕЛИ
89
тографии), а также модифицируются (при поступлении дополнительной уточняющей
информации) или удаляются (по самым разным причинам) существующие.
Гораздо менее вероятны такие изменения, которые затрагивают схему отношения.
Однако ситуации, связанные с необходимостью добавления, изменения или удаления
атрибутов отношения, иногда все же возникают. Операции по изменению схемы
реальных баз данных обычно весьма дорогостоящи, поскольку подразумевают просмотр
и модификацию миллионов кортежей. Например, при добавлении нового атрибута
задача отыскания подходящих значений для новых компонентов существующих
кортежей может оказаться весьма трудоемкой или даже вовсе неразрешимой.
Конкретное множество кортежей отношения называют экземпляром (instance)
отношения. Например, набор из трех кортежей, показанный на рис. 3.1 (см. с. 88),
образует некоторый экземпляр отношения Movies. Ясно, что отношение, подобное
Movies, могло претерпевать изменения раньше и будет подвержено изменениям
впредь. Скажем, в 1980 году отношение Movies не могло содержать кортежей для таких
кинофильмов, как Mighty Ducks или Wayne ' s World (их просто еще не было).
Традиционные системы баз данных обычно поддерживают только одну версию любого
отношения: набор кортежей, которые содержатся в отношении "в данный момент".
Такой экземпляр отношения принято называть текущим экземпляром (current instance).
3.1.7. Упражнения к разделу 3.1
Упражнение 3.1.1. На рис. 3.3 показаны два отношения — Accounts ("счета")
и Customers ("клиенты"), — которые могут служить частью базы данных банка.
Назовите или изобразите следующее:
a) атрибуты каждого отношения;
b) кортежи каждого отношения;
c) компоненты одного кортежа из каждого отношения;
d) реляционную схему каждого отношения;
e) схему базы данных;
f) домен, соответствующий каждому атрибуту;
g) альтернативный способ представления каждого отношения.
acctNo
12345
23456
34567
type
savings
checking
savings
balance
12000
1000
25
Отношение Accounts
firstName
Robbie
Lena
Lena
lastName
Banks
Hand
Hand
idNo
901-222
805-333
805-333
account
12345
12345
23456
Отношение Customers
Рис. 3.3. Два отношения банковской базы данных
!! Упражнение 3.1.2. Каким числом способов (зависящих от порядка следования
атрибутов и кортежей) может быть представлен экземпляр отношения, если он включает:
90
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
* а) три атрибута и три кортежа (подобно отношению Accounts, изображенному
на рис. 3.3)?
b) четыре атрибута и пять кортежей?
c) п атрибутов и т кортежей?
3.2. От ER-диаграмм к реляционным схемам
Рассмотрим процесс создания новой базы данных, подобной рассматриваемой
нами базе данных о кинофильмах. На первой стадии процесса, связанной с
проектированием, необходимо сформулировать следующие вопросы и найти ответы на них:
какая информация должна быть представлена в базе данных; каким образом элементы
данных соотносятся друг с другом; какие ограничения (например, ключи и условия
ссылочной целостности) должны быть введены и т.д. Эта стадия может протекать
в течение длительного времени, пока все альтернативные варианты не будут
рассмотрены и сопоставлены, а все мнения — учтены и согласованы.
За стадией проектирования следует стадия реализации, предусматривающая
использование инструментов конкретной системы управления базами данных. Поскольку
подавляющее большинство коммерческих систем баз данных основано на реляционной модели,
уместно предположить, что в ходе проектирования было бы целесообразно применять ту
же модель, а не модель "сущность—связь" или любые другие средства проектирования.
На практике, однако, зачастую проще приступить к проектированию, пользуясь ER-
или другой аналогичной моделью, осуществить задуманное, а затем преобразовать
результат в реляционную модель. Основной довод в пользу такого подхода связан с тем,
что реляционная модель, основанная на единственном понятии "отношения", а не на
совокупности различных взаимодополняющих понятий (таких как "множество
сущностей" и "связь" в ER-модели), обладает определенными ограничениями в смысле
гибкости, которые проще "обойти" уже по завершении начальной стадии проектирования.
В первом приближении процесс "превращения" ER-диаграммы в реляционную
схему довольно прямолинеен:
• преобразовать каждое множество сущностей в отношение с тем же набором
атрибутов;
• заменить каждую связь отношением, атрибуты которого являются ключами
множеств сущностей, соединяемых этой связью.
Хотя названные правила охватывают изрядную часть предмета, существует несколько
особых ситуаций, с которыми приходится считаться.
1. Слабые множества сущностей (weak entity sets) не могут быть преобразованы
в отношения непосредственно.
2. Связи isa и подклассы (subclasses) требуют специального подхода.
3. Иногда целесообразно объединить в составе одного отношения два других —
например, отношение для множества сущностей Е с отношением для связи
типа "многие к одному", которая соединяет Е с другими множествами.
3.2.1. От множеств сущностей к отношениям
Вначале рассмотрим множества сущностей, не относящиеся к категории слабых.
(О том, как справляться со слабыми множествами сущностей, мы расскажем в разделе
3.2.4 на с. 96.) Для каждого множества сущностей, не являющегося слабым, можно
создать отношение с теми же именем и набором атрибутов. Такое отношение не будет
содержать каких бы то ни было сведений о связях, в которых участвует исходное
множество сущностей; информация о связях отображается в отдельных отношениях
(этот вопрос освещен в разделе 3.2.2 на с. 93).
3.2. ОТ ER-ДИАГРАММ К РЕЛЯЦИОННЫМ СХЕМАМ
91
Схемы и экземпляры
Давайте не будем забывать об основном различии между схемой отношения и
экземпляром отношения. Схема включает наименование и перечень атрибутов и
считается относительно более устойчивым объектом. Экземпляр состоит из набора
кортежей отношения и, как правило, подвержен частым изменениям.
В процессе моделирования данных различия между схемой и экземпляром
отношения отчетливо себя проявляют. Описания множеств сущностей и связей —
это средства представления схемы в ER-модели, а множества сущностей и данных
связей как таковые — это экземпляры схемы. Экземпляр базы данных не является
частью ее дизайна: в процессе проектирования мы можем только предполагать,
какие конкретные образцы данных будут в ней храниться.
Пример 3.1. Рассмотрим три множества сущностей — Movies ("кинофильмы"), Stars
("актеры") и Studios ("киностудии") — ER-диаграммы рис. 2.17 (см. с. 77), которая
в том же виде воспроизведена на рис. 3.4. Атрибутами множества Movies, например,
являются title ("название"), year ("год производства"), length ("продолжительность")
и film Type ("тип пленки"). Отношение Movies может выглядеть так, как оно
представлено на рис. 3.1 (см. с. 88).
Рис. 3.4. ER-диаграмма базы данных о кинофильмах
Теперь обратимся к другому множеству сущностей, Stars. Оно обладает двумя
атрибутами, пате ("имя") и address ("адрес"). Схема соответствующего
отношения Stars может быть представлена как Stars (name, address), а его типичный
экземпляр — как
пате
Carrie Fisher
Mark Hamill
Harrison Ford
address
123 Maple St., Hollywood
456 Oak Rd., Brentwood
789 Palm Dr., Beverly Hills
□
92 ГЛАВА З. РЕЛЯЦИОННАЯ МОДЕЛЬ
Замечание по поводу качества примеров данных :—)
Пытаясь представить примеры реальных данных в настолько точном виде,
насколько это возможно, мы, тем не менее, вынуждены покривить душой, когда речь
идет об адресах и другой информации личного характера, касающейся
упоминаемых нами актеров. Не судите строго — мы не можем и не должны разглашать
конфиденциальные сведения о людях, которые и без того у всех на виду.
3.2.2. От ER-связей к отношениям
Связи ER-модели также представляются отношениями. Отношение для заданной
связи R должно охватывать атрибуты, перечисленные ниже.
1. В схему отношения для связи R заносятся ключевые атрибуты каждого из
множеств сущностей, соединяемых связью R.
2. Если связь обладает собственными атрибутами, они также вводятся в набор
атрибутов отношения для этой связи.
Если одно и то же множество сущностей в контексте связи упоминается многократно,
в различных "ролях", каждый из его ключевых атрибутов вводится в отношение столько
раз, в скольких ролях он участвует. При этом во избежание конфликтов имена атрибутов
должны быть изменены. Переименование атрибутов выполняется, вообще говоря, в тех
случаях, когда атрибуты с одинаковым именем встречаются в наборе атрибутов самой
связи или среди атрибутов тех множеств сущностей, которые охватываются этой связью.
Пример 3.2. Рассмотрим связь Owns ("владеет") ER-диаграммы рис. 3.4 (см. с. 92),
соединяющую множества сущностей Movies ("кинофильмы") и Studios ("киностудии").
В схему отношения Owns для связи Owns мы введем ключевые атрибуты множеств
сущностей, соединяемых связью Owns: title ("название") и year ("год производства")
множества Movies и пате ("название") — множества Studios (наименование атрибута
пате для ясности уместно изменить, скажем, на studioName). Схема отношения Owns
примет следующий вид:
Owns(title, year, studioName).
А так может выглядеть типичный экземпляр отношения Owns:
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
studioName
Fox
Disney
Paramount
□
Пример 3.3. Связь Stars-in ("актеры-участники") ER-диаграммы рис. 3.4 подобным
образом может быть преобразована в отношение с атрибутами title и year
(служащими ключом для множества сущностей Movies) и атрибутом starName
(аналогичным ключевому атрибуту пате множества Stars). На рис. 3.5 показан
простой экземпляр отношения Stars-in.
Поскольку названия кинофильмов в столбце title на рис. 3.5 выглядят как
уникальный ключ, может показаться, что атрибут year избыточен. Однако, если в базу
данных попадет информация о нескольких фильмах с одним и тем же названием (таким,
например, как "King Kong"), атрибут year приобретет существенное значение, поскольку
позволит определить, в каких именно версиях фильма снимался тот или иной актер. □
3.2. ОТ ER-ДИАГРАММ К РЕЛЯЦИОННЫМ СХЕМАМ
93
title
Star Wars
Star Wars
Star Wars
Mighty Ducks
Wayne's World
Wayne's World
year
1977
1977
1977
1991
1992
1992
starName
Carrie Fisher
Mark Hamill
Harrison Ford
Emilio Estevez
Dana Carvey
Mike Meyers
Рис. 3.5. Экземпляр отношения Stars-in
Stars
Studio- 1
of-Star \
Contracts
Studios
Movies
\ Producing-
1 Studio
Рис. З.6. Связь Contracts
Пример 3.4. Многосторонние связи также могут быть легко преобразованы в
отношения. Рассмотрим четырехстороннюю связь Contracts ("контракты") диаграммы рис. 2.6
(см. с. 58), вновь воспроизведенной на рис. 3.6. Связь охватывает сущности "актер"
(Stars), "кинофильм" (Movies) и две сущности "киностудия" (Studios). Роль Studio-of-
Star отображает долговременный контракт актера с некоторой студией, a Producing-
Studio — контракт, оговаривающий условия участия актера в съемках фильма,
выпускаемого какой-либо другой студией. Связь Contracts представляется в виде отношения
Contracts, схема которого состоит из следующих ключевых атрибутов:
1) атрибута starName, соответствующего ключу пате множества Stars;
2) атрибутов title и year ключа множества Movies;
3) атрибута studioofstar, содержащего название студии-"владельца" актера;
напомним, что атрибут "название" мы выбрали в качестве ключа множества
сущностей Studios;
4) атрибута producingStudio, содержащего название студии, которая
выпускает фильм с участием приглашенного актера.
Схема отношения Contracts, таким образом, примет вид
Contracts(starName, title, year, studioOfStar, producingStudio).
Обратите внимание — мы совершенно свободны в выборе имен атрибутов
отношения: так, мы постарались избежать использования имени name, поскольку в
противном случае было бы далеко не очевидно, на какой объект оно указывает — на имя
актера или на название киностудии (тем более, что схема предусматривает задание
двух атрибутов-названий киностудии). Кроме того, если рассматривать вариант
многосторонней связи Contracts с собственными атрибутами — такой, например, как
изображенный на диаграмме рис. 2.7 (см. с. 59), — эти атрибуты (в данном случае,
salary) пришлось бы ввести и в схему отношения Contracts. □
94
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
3.2.3. Объединение отношений
Иногда отношения, получаемые в результате прямых преобразований из множеств
сущностей или связей, нельзя считать наилучшей формой представления
определенных элементов данных. Один из распространенных вариантов подобных ситуаций
таков. Имеется множество сущностей Е, соединенное посредством связи R типа "многие
к одному" с множеством F в направлении от Е к F. Реляционные схемы каждого из
отношений, полученных на основе множества Е и связи R, будут содержать ключ
множества Е. Кроме того, в схему отношения для множества Е будут введены также
атрибуты £, не относящиеся к ключевым, а в схему отношения для связи R —
собственные атрибуты R и ключевые атрибуты множества F. Поскольку связь R относится
к типу "многие к одному", все указанные атрибуты обладают значениями, которые
однозначным образом определяются на основе ключа множества Е, и их можно
объединить в одной схеме отношения, состоящей из:
1) всех атрибутов множества Е;
2) ключевых атрибутов множества F;
3) собственных атрибутов связи R.
В кортеже для сущности е множества Е, которая не связана ни с одной сущностью
множества F, компоненты, отвечающие атрибутам, названным в пп. 2, 3, получат
некоторые "нулевые" (null) значения. О значениях null как о средстве представления
ситуации, когда содержательное значение компонента кортежа неизвестно или утрачено,
мы неформально уже говорили (см. раздел 2.3.4 на с. 77). Понятие "значение пи1Г не
является частью реляционной модели, но в языке SQL для его обозначения применяется
специальное служебное слово, null, и мы будем пользоваться им по мере
необходимости,, если в ходе изложения нам потребуется сослаться на "неопределенное" значение.
Пример 3.5. Возвращаясь к примеру "кинематографической" базы данных, отметим,
что Owns — это связь типа "многие к одному", соединяющая множества сущностей
Movies ("кинофильмы") и Studios ("киностудии") в направлении от Movies к Studios.
Процесс "превращения" связи Owns в отношение рассматривался в примере 3.2 на
с. 93, а преобразование множества сущностей Movies мы иллюстрировали в примере
3.1 на с. 92. Теперь мы вправе объединить полученные решения в общую
реляционную схему отношения. Пример экземпляра такого отношения приведен на рис. 3.7.
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
frim Type
color
color
color
studioName
Fox
Disney
Paramount
Рис. 3.7. Объединение отношений Movies и Owns
□
Стоит объединять отношения таким образом или нет — это вопрос,
заслуживающий обсуждения. Сочетание всех атрибутов, зависящих от ключа множества
сущностей Е, в едином отношении, в определенных случаях сулит дополнительные
преимущества — даже тогда, когда существует сразу несколько связей типа "многие к
одному", направленных от Е к другим множествам. Зачастую, например, гораздо проще
получить ответ на запрос, касающийся данных, которые размещены в одном
отношении, нежели обращаться за теми же данными одновременно к нескольким
отношениям. Действительно, некоторые системы проектирования баз данных, основанные на
ER-модели, выполняют подобное объединение автоматически.
3.2. ОТ ER-ДИАГРАММ К РЕЛЯЦИОННЫМ СХЕМАМ
95
С другой стороны, вероятно, не следует серьезно рассматривать возможность
объединения отношения для множества Е с отношением для связи R, которая охватывает
Е, но не является связью типа "многие к одному", направленной от Е к каким-либо
другим множествам. Подобная операция довольно рискованна, поскольку нередко
приводит к избыточности данных (эту тему мы обсудим в разделе 3.6 на с. 123).
Пример 3.6. Чтобы продемонстрировать, чем отличается плохое решение от хорошего,
рассмотрим объединение отношения, представленного на рис. 3.7, с отношением,
полученным для связи Stars-in типа "многие ко многим" (см. рис. 3.5 на с. 94).
Результат может выглядеть так, как показано на рис. 3.8.
title
Star Wars
Star Wars
Star Wars
Mighty Ducks
Wayne's World
Wayne's World
year
1911
1977
1977
1991
1992
1992
length
124
124
124
104
95
95
film Type
color
color
color
color
color
color
studio Name
Fox
Fox
Fox
Disney
Paramount
Paramount
starName
Carrie Fisher
Mark Hamill
Harrison Ford
Emilio Estevez
Dana Carvey
Mike Meyers
Рис. 3.8. Отношение Movies, включающее сведения об актерах
Поскольку в кинофильме могут сниматься несколько актеров, в кортежи для каждого
из них приходится вводить одну и ту же информацию о кинофильме. Нетрудно
заметить, например, что значение атрибута length ("продолжительность") — равно как и
содержимое всех остальных атрибутов сущности-"кинофильма" "Star Wars" —
повторяются три раза, по числу актеров, принимавших участие в съемках фильма. Подобные
излишества явно нежелательны, и одна из целей, которые ставились при разработке
теории проектирования реляционных баз данных, как раз и состоит в устранении
информационной избыточности (за подробностями обращайтесь к разделу 3.6 на с. 123). □
3.2.4. Преобразование слабых множеств сущностей
Для преобразования слабого множества сущностей в отношение необходимо
принять во внимание следующее.
1. Отношение для слабого множества сущностей W как такового должно включать
не только собственные атрибуты W, но и ключевые атрибуты всех других
множеств, содействующих в формировании ключа множества W. Подобные
"вспомогательные" множества на ER-диаграмме легко различимы, поскольку
они соединяются с W посредством поддерживающих связей, которые
обозначаются двойными ромбами.
2. В отношении для любой связи, с которой соединено слабое множество
сущностей W, должны быть отражены все ключевые атрибуты множества W, в том
числе и те, которые "получены" им от других множеств.
3. Поддерживающая связь R, соединяющая слабое множество сущностей W с другим
множеством, помогающим в образовании ключа для W, однако, вовсе не
нуждается в преобразовании. Причина заключается в том, что (как упоминалось в
предыдущем разделе ) атрибуты отношения для связи R типа "многие к одному" либо
уже присутствуют в отношении для множества W, либо (если речь идет о
собственных атрибутах R) могут быть объединены со схемой отношения для множества W.
Разумеется, при формировании ключа слабого множества сущностей на основе
дополнительных атрибутов надлежит позаботиться о том, чтобы не использовать одно
96
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
и то же имя атрибута дважды. При необходимости некоторые или все подобные
атрибуты следует переименовать.
Пример 3.7. Рассмотрим слабое множество сущностей Crews ("объединения") ER-
диаграммы рис. 2.20 (см. с. 81), которая воспроизведена на рис. 3.9. На основе
диаграммы мы можем получить три отношения, схемы которых выглядят так:
Studios(name, addr)
Crews(number, studioName)
Unit-of(number, studioName, name)
Первое отношение, studios, создано непосредственно на основе одноименного
множества сущностей, предназначенного для хранения информации о киностудиях.
Второе отношение, Crews, соответствует слабому множеству сущностей Crews,
представляющему творческие подразделения киностудий. Атрибутами Crews служат
ключевые атрибуты множества Crews; если бы Crews обладало собственными неключевыми
атрибутами, их также пришлось бы ввести в схему отношения Crews. Атрибут
studioName отношения Crews суть атрибут пате множества сущностей Studios.
Рис. 3.9. Пример ER-диаграммы со слабым
множеством сущностей
Третье отношение, Unit-of, соответствует связи Unit-of. Связь в реляционной
модели, как мы говорили выше, представляется отношением, в схему которого вводятся
ключевые атрибуты множеств, соединяемых этой связью. В нашем случае схема
отношения Unit-of включает атрибуты number й studioName, образующие ключ
слабого множества сущностей Crews, и атрибут name — аналог атрибута пате множества
Studios. Однако, поскольку связь Unit-of относится к типу "многие к одному",
атрибуты studioName и name фактически совпадают.
Предположим для примера, что "Disney-crew-#3" — это одно из творческих
подразделений студии "Disney". Тогда во множестве данных для связи Unit-of должен
существовать кортеж
("Disney-crew-#3", "Disney"),
которому соответствует кортеж
(3, Disney, Disney)
отношения Unit-of. Обратите внимание, что компоненты этого кортежа,
соответствующие атрибутам studioName и name, одинаковы, поэтому вполне допустимо
осуществить их "слияние", что позволит получить более простую схему:
Unit-of(number, name).
Впрочем, теперь необходимость в использовании отношения Unit-of вовсе
исключается, поскольку его схема полностью совпадает со схемой отношения Crews. □
Пример 3.8. Обратимся к слабому множеству сущностей Contracts ("контракты"),
которое рассматривалось в примере 2.25 и было представлено на ER-диаграмме рис. 2.22
(см. с. 83). Та же диаграмма приведена и на рис. 3.10. Схема соответствующего
отношения Contracts выглядит так:
Contracts(starName, studioName, title, year, salary).
3.2. ОТ ER-ДИАГРАММ К РЕЛЯЦИОННЫМ СХЕМАМ
97
Подмножества схем отношений
Изучая пример 3.7, вы могли бы сделать вывод о том, что коль скоро одно
отношение (назовем его R) обладает набором атрибутов, являющимся подмножеством
множества атрибутов другого отношения, 5, отношение R может быть исключено
из рассмотрения. В общем случае такое утверждение неверно. Отношение R
способно содержать информацию, которой нет в S, поскольку дополнительные
атрибуты S не позволяют перейти от кортежа R непосредственно к кортежу S.
Пусть, например, налоговая служба пытается (:-). — Прим. перев.) создать
отношение People (name, ss#) ("люди"), которое содержит информацию об именах
потенциальных налогоплательщиков и их кодах полисов социального страхования (или
каких-либо иных идентификационных кодах) и охватывает даже такую ситуацию,
когда человек не имеет доходов и его налоги прежде еще не фиксировались. Службе,
вероятно, потребуется и отношение Taxpayers (name, ss#, amount
("налогоплательщики"), в котором отражаются суммы налогов, выплаченные каждым
человеком в текущем году. Как нетрудно убедиться, схема отношения People является
подмножеством схемы отношения Taxpayers, но смысл в хранении
идентификационных номеров лиц, не "замеченных" в уплате налогов, т.е. упомянутых в People,
но отсутствующих в Taxpayers, для вас, тем не менее, должен быть очевиден.
На самом деле даже совершенно одинаковые наборы атрибутов отношений
могут обладать различной семантикой, так что говорить о возможности замены
одного отношения другим в общем случае нельзя. Примером могут служить
отношения Stars (name, address) и Studios (name, address), представляющие
объекты знакомой вам "кинематографической" базы данных. Хотя схемы выглядят
одинаково, мы не имеем права превращать кортежи, описывающие информацию
об актерах, в кортежи, содержащие данные о киностудиях, и наоборот.
С другой стороны, если два отношения создаются на основе одной и той же
конструкции с участием слабого множества сущностей, то из них, в котором
меньше атрибутов, не будет иметь самостоятельного значения. Причина
заключается в том, что кортежи отношения, соответствующего поддерживающей связи
множества, однозначно совпадают с кортежами отношения, отображающего слабое
множество сущностей как таковое. Таким образом, отношение для
поддерживающей связи может быть безболезненно отброшено.
Атрибуты starName и studioName — это переименованные ключевые атрибуты
пате ("имя" или "название") множеств сущностей Stars ("актеры") и Studios
("киностудии") соответственно, title ("название") и year ("год производства") —
ключевые атрибуты множества Movies ("кинофильмы"), a salary ("размер заработной
платы") — собственный атрибут слабого множества сущностей Contracts. Создание
отношений для поддерживающих связей Star-of, Studio-ofw Movie-of лишено смысла, поскольку
их схемы представляют собой соответствующие подмножества схемы Contracts.
Между прочим, обратите внимание, что построенное отношение совершенно
совпадает с тем, какое мы могли бы получить, если бы взяли за основу ER-диаграмму
рис. 2.7 (см. с. 59). Напомним, что последняя трактует контракты как трехсторонние
связи между "актерами", "кинофильмами" и "киностудиями", а атрибут salary
относится непосредственно к связи Contracts. □
Явление, проиллюстрированное в примерах 3.7 и 3.8 — связи,
"поддерживающие" слабые множества сущностей, не нуждаются в создании соответствующих
отношений, — носит универсальный характер. Ниже приведена новая версия
правила преобразования в отношения тех множеств сущностей, которые относятся
к категории слабых.
98
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Рис. 3.10. Слабое множество сущностей Contracts
1. Если W является слабым множеством сущностей, построить отношение для W,
схема которого включает следующее:
a) все атрибуты множества W;
b) все атрибуты поддерживающих связей для множества W;
c) все ключевые атрибуты каждого из множеств сущностей Е, соединенных
с множеством W посредством поддерживающих связей типа "многие к
одному" в направлении от W к Е\
2. Не создавать отношения, соответствующие любым поддерживающим связям
для слабого множества W.
3.2.5. Упражнения к разделу 3.2
* Упражнение 3.2.1. Преобразуйте ER-диаграмму рис. 3.11 в реляционную схему
базы данных, имея в виду следующую семантику наименований множеств сущностей
и атрибутов: Bookings— "заказы на билеты", row— "ряд", seat— "место",
Customers — "пассажиры", SSNo — "код полиса социального страхования", phone —
"номер телефона", addr — "адрес", пате — "имя", Flights — "рейсы", number —
"номер", aircraft — "самолет", day— "дата вылета".
! Упражнение 3.2.2. Возможен иной вариант представления ER-диаграммы
рис. 3.11 в части, касающейся слабого множества сущностей Bookings ("заказы
на билеты"). Заметим, что сущность-"заказ" однозначно задается номером
рейса, датой вылета и номерами ряда и места; для идентификации заказа
информация о пассажире не нужна.
a) Исправьте диаграмму рис. 3.11, чтобы отразить в ней указанные условия.
b) Преобразуйте диаграмму, полученную при выполнении задания п. (а), в
набор отношений и проверьте, совпадает ли он с тем, который вы построили,
решая упражнение 3.2.1.
3.2. ОТ ER-ДИАГРАММ К РЕЛЯЦИОННЫМ СХЕМАМ
99
Рис. 3.11. ER-диаграмма базы данных системы
бронирования авиабилетов
Упражнение 3.2.3. ER-диаграмма рис. 3.12
представляет базу данных о кораблях (Ships). Корабли
называют однотипными (sister), если они строятся
по одним чертежам. Преобразуйте диаграмму в
реляционную схему.
Упражнение 3.2.4. Преобразуйте в реляционные
схемы баз данных следующие ER-диаграммы:
a) диаграмму рис. 2.22 (см. с. 83);
b) результат решения упражнения 2.4.1 (см. с. 85);
c) результат решения упражнения 2.4.4 (а)
(см. с. 85);
d) результат решения упражнения 2.4.4 (Ь).
Рис. 3.12. ER-диаграмма,
представляющая данные об
однотипных кораблях
3.3. Преобразование структур подклассов в отношения
Имея дело с иерархией множеств сущностей, соединенных связями isa, мы вправе
выбрать одну из нескольких возможных стратегий преобразования ER-диаграмм в
реляционные схемы. Напомним ряд положений.
• Существует корневое множество сущностей иерархии.
• Корневое множество сущностей обладает ключом, который используется для
идентификации любой сущности из множеств, входящих в иерархию.
• Сущность может содержать компоненты, принадлежащие множествам
сущностей любого поддерева иерархии, если только это поддерево включает корневое
множество.
Основные стратегии преобразования таковы.
1. Применить подход "сущность—связь ". Для каждого множества сущностей Е
иерархии создать отношение, содержащее ключевые атрибуты корневого
множества сущностей и все атрибуты, принадлежащие Е.
2. Трактовать сущности как объекты одного класса. Для каждого возможного
поддерева, включающего корневое множество сущностей, создать одно
отношение, схема которого содержит все атрибуты всех множеств сущностей,
принадлежащих поддереву.
100
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
3. Использовать значения null. Создать одно отношение, включающее все атрибуты
всех множеств сущностей, входящих в иерархию. Каждая сущность
представляется одним кортежем, и компоненты кортежа, соответствующие тем атрибутам,
которых сущность не имеет, принимают значения null.
Указанные стратегии рассмотрены в следующих разделах.
3.3.1. Преобразование в стиле "сущность—связь"
Первый из подходов к проблеме преобразования иерархии множеств сущностей,
соединенных связями isa, в реляционную схему состоит в создании отношений для
каждого множества сущностей (до сих пор мы так и поступали). Если множество
сущностей Е не является корневым, отношение для Е должно содержать ключевые
атрибуты корневого множества и все собственные атрибуты Е. Если, помимо того,
множество Е соединено связью с другими множествами, ключевые атрибуты
используются для идентификации сущностей из Е в отношении, представляющем эту связь.
Заметим, однако, что, называя связь isa именно связью, мы, тем не менее,
подразумеваем ее принципиальное отличие от других связей, поскольку связь isa соединяет
компоненты единой сущности, а не различные сущности. Поэтому отдельные
отношения для связей isa не создаются.
К множеству
сущностей
Stars
Рис. 3.13. Иерархия множеств сущностей,
основанная на связях isa
Пример 3.9. Рассмотрим ER-диаграмму рис. 2.10 (см. с. 62), заново воспроизведенную
на рис. 3.13. Схемы отношений, необходимых для представления множеств
сущностей, входящих в иерархию — Movies ("кинофильмы"), Cartoons ("мультипликация")
и Murder-Mysteries ("боевики"), — указаны ниже.
1. Movies (title, year, length, filmType). Экземпляр этого отношения мы
приводили на рис. 3.1 (см. с. 88). Каждый фильм может быть однозначно
представлен кортежем отношения Movies.
2. MurderMysteries (title, year, weapon). Два первых атрибута— title
и year — это ключ множества сущностей Movies, а последний, weapon, —
собственный атрибут множества Murder-Mysteries. Сущности-"боевики"
описываются кортежами отношений MurderMysteries и Movies.
3. Cartoons (title, year). Отношение описывает множество сущностей-
"мультфильмов" и не содержит, помимо title и year, никаких других
атрибутов; дополнительная информация о мультфильмах может быть получена на ос-
3.3. ПРЕОБРАЗОВАНИЕ СТРУКТУР ПОДКЛАССОВ В ОТНОШЕНИЯ
101
нове связи Voices ("голоса"), соединяющей множества сущностей Cartoons
и Stars ("актеры"). Сущности-"мультфильмы" описываются кортежами
отношений Cartoons и Movies.
Сущности-"кинофильмы", относящиеся к жанру "мультипликационного боевика",
описываются кортежами всех трех названных отношений одновременно.
Нам необходимо, помимо перечисленных выше, и отношение Voices
(title, year, starNarne), соответствующее связи Voices, которая соединяет
множества сущностей Cartoons и Stars (последнее на диаграмме не показано). Первые два
атрибута, title и year, являются ключом множества Cartoons, а последний, starNarne
("имя актера"), — это переименованный ключ множества Stars.
Например, кинофильм "Roger Rabbit", который относится к жанру
"мультипликационного боевика", будет представлен кортежами во всех четырех отношениях.
Основные сведения о нем должны храниться в отношении Movies, информация об
оружии (weapon) -~ в MurderMysteries, а данные об актерах, принимавших участие
в озвучивании, — в Voices.
Обратите внимание, что схема отношения Cartoons является подмножеством схемы
отношения Voices. Во многих ситуациях было бы уместно отбрасывать отношения,
подобные Cartoons, поскольку в них нет такой информации, которая отсутствует в более
"полном" отношении (в данном случае — Voices). Однако вполне резонно
предположить существование "немых" мультфильмов, сведения о которых необходимо сохранить.
Удаляя из схемы базы данных отношение Cartoons, мы рискуем утратить информацию
о том, что подобные фильмы относятся к жанру мультипликации, если не предусмотрим
возможность присваивания атрибуту starNarne отношения Voices значения null. □
3.3.2. Объектно-ориентированный подход
Другая стратегия преобразования шг-иерархии в отношения предполагает
перечисление всех возможных поддеревьев ER-диаграммы, включающих корневое множество
сущностей, с последующим созданием отношений, представляющих сущности,
которые обладают всеми компонентами каждого поддерева. Схема отношения должна
включать все атрибуты любого множества сущностей, принадлежащего поддереву. Мы
называем подобный подход "объектно-ориентированным", поскольку трактуем
сущности как "объекты" одного и только одного "класса".
Пример 3.10. Вновь рассмотрим иерархическую диаграмму рис. 3.13. В ней можно
различить четыре поддерева, включающих корневую вершину и содержащих
следующие множества сущностей:
1) Movies;
2) Movies и Cartoons;
3) Movies и Murder-Mysteries;
4) Movies, Cartoons и Murder-Mysteries.
Нам предстоит создать отношения для всех четырех перечисленных "классов".
Поскольку только множество Murder-Mysteries обладает собственным особым атрибутом,
выделяющим сущности "боевик" среди других, схемы отношений будут содержать
преимущественно повторяющиеся атрибуты:
Movies (title, year, length, filrnType)
MoviesC (title, year, length, filrnType)
MoviesMM(title, year, length, filrnType, weapon)
MoviesCMM(title, year, length, filrnType, weapon)
Теперь, вероятно, без серьезного ущерба мы можем объединить отношения Movies
и MoviesC (т.е. создать одно отношение, представляющее все "кинофильмы", не отно-
102
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
сящиеся к жанру "боевика"), а также MoviesMM и MoviesCMM (создать отношение для
хранения данных обо всех кинофильмах-"боевиках"), хотя в последнем случае
информация о том, какие фильмы относятся к жанру "мультипликации", будет утрачена.
Помимо того, следует подумать, как быть со связью Voices, соединяющей множества
сущностей Cartoons и Stars в направлении от первого ко второму. Если бы Voices
относилась к типу "многие к одному", мы могли бы добавить атрибут voice в схемы
отношений MoviesC и MoviesCMM, чтобы как-то отобразить информацию связи Voices (это
действие привело бы и к побочному эффекту — все четыре отношения стали бы
различными). Voices, однако, принадлежит к категории связей "многие ко многим", поэтому для нее
надлежит создать отдельное отношение. Схема отношения Voices — это очевидно —
должна содержать ключевые атрибуты множеств сущностей, соединяемых связью Voices:
Voices(title, year, starName).
Вполне правомерен вопрос, не следовало ли вместо одного создать два таких
отношения: одно, отображающее связь "мульфильмов", не являющихся "боевиками", с
множеством "актеров", и второе, содержащее информацию об актерах, озвучивавших
"мультипликационные боевики". В нашем случае, однако, подобное решение не
способно обеспечить получение каких бы то ни было дополнительных преимуществ. □
3.3.3. Значения "null" и объединение отношений
Существует еще один подход к описанию иерархии множеств сущностей,
соединенных связями isa. Если допустить возможность использования неопределенных
значений вида null (так обозначаются значения null в языке SQL), можно "уместить"
все множества в единственном отношении, которое охватывает все атрибуты всех
множеств сущностей иерархии. Произвольная сущность любого множества в этом
случае представляется одним кортежем, компонентам которого присваиваются значения
nu£l, если соответствующий атрибут не определен для рассматриваемой сущности.
Пример 3.11. Применяя указанный подход к иерархии множеств сущностей,
показанной на рис. 3.13 (см. с. 101), мы получим отношение, схема которого такова:
Movie(title, year, length, filmType, weapon).
Компоненты weapon кортежей для тех сущностей-"кинофильмов", которые не
являются "боевиками", получат значения mull. Как и в примере ЗЛО, следует создать
также дополнительное отношение voices, представляющее информацию об актерах,
озвучивавших "мультфильмы".
3.3.4. Сравнение стратегий
Каждый из трех рассмотренных выше подходов к проблеме преобразования
иерархических структур подклассов в отношения — "ER-подобный", "объектно-
ориентированный" и "нулевой" — обладает как несомненными преимуществами, так
и очевидными недостатками, рассмотренными ниже.
1. Обработка запросов, охватывающих информацию из нескольких отношений,
значительно упрощается, если та же информация размещена в пределах единственного
отношения. Подход с использованием значений null предполагает создание только
одного отношения, так что в этом контексте он обладает безусловными
преимуществами. Два других подхода сулят выгоды при выполнении запросов иных видов.
а) Для удовлетворения запроса, подобного такому как "Какие фильмы
продолжительностью свыше 150 минут были выпущены в 1999 году?", вполне достаточно
информации отношения Movies, созданного в соответствии со стратегией
"сущность—связь" (см. пример 3.9 на с. 101). Однако при использовании
"объектно-ориентированного" подхода для ответа на тот же вопрос нам при-
3.3. ПРЕОБРАЗОВАНИЕ СТРУКТУР ПОДКЛАССОВ В ОТНОШЕНИЯ
103
шлось бы проверить содержимое всех четырех отношений — Movies, MoviesC,
MoviesMM и MoviesCMM, — поскольку киноленты продолжительностью свыше
150 минут, выпущенные в 1999 году, могут относиться к любому из жанров.9
Ь) С другой стороны, применив подход "сущность—связь", мы столкнемся
с неприятностями при получении запроса, подобного следующему: "Какое
оружие применялось персонажами мультфильмов продолжительностью свыше
150 минут?" Для отыскания ответа нам придется выполнить такие действия:
обратиться к отношению Movies и найти все кинофильмы указанной
продолжительности; просмотреть кортежи отношения Cartoons, чтобы выбрать из
числа найденных кинофильмов только те, которые относятся к жанру
мультипликации; обратившись к отношению MurderMysteries, определить типы
оружия, применявшегося персонажами каждого из фильмов, удовлетворяющих
двум предыдущим требованиям. Если же применить
"объектно-ориентированный" подход, мы сможем свести задачу к просмотру единственного
отношения, MoviesCMM, в котором содержится вся необходимая информация.
2. Разумеется, нам не хотелось бы иметь слишком много отношений. Подход,
предусматривающий использование значений null, выглядит в этом смысле
наиболее многообещающим, поскольку предполагает создание единственного
отношения. Два других подхода принципиально отличны. Прямолинейная
стратегия "сущность—связь" требует создания отношений для каждого
множества иерархии. Применяя "объектно-ориентированный" подход, мы вынуждены
рассматривать Т различных классов сущностей и создавать столько же
отношений для иерархии, состоящей из корневого и п "дочерних" множеств сущностей.
3. При проектировании базы данных необходимо минимизировать расход
дискового пространства и избежать повторения одних и тех же порций информации.
Поскольку при использовании "объектно-ориентированного" подхода каждой
сущности соответствует единственный кортеж и последний содержит
компоненты только для тех атрибутов, которые имеют смысл для рассматриваемой
сущности, этот подход позволяет расходовать дисковое пространство наиболее
экономно. Стратегия, допускающая применение значений null, также
предполагает создание одного кортежа для каждой из сущностей, но кортежи в этом
случае становятся слишком "длинными", т.е. содержат компоненты для всех
атрибутов — независимо от того, требуются они для описания конкретной
сущности или нет. Если иерархия охватывает много множеств сущностей, а каждое
из них содержит изрядное количество атрибутов, при использовании
"нулевого" подхода немалая часть дискового пространства будет истрачена, что
называется, впустую. Подход "сущность—связь" допускает создание нескольких
кортежей для каждой сущности, но повторяться в них будут только ключевые
атрибуты. Поэтому в каких-то ситуациях он может оказаться более
предпочтительным в сравнении с "нулевым" подходом, а в других — проигрышным.
3.3.5. Упражнения к разделу 3.3
* Упражнение 3.3.1. Преобразуйте ER-диаграмму рис. 3.14 в реляционную схему
базы данных, используя следующие стратегии:
a) "сущность—связь";
b) "объектно-ориентированную";
c) допускающую использование значений null.
9 Даже если четыре названных отношения будут "слиты" в два (так, как показано в примере
3.10), все равно для ответа на запрос мы все еще будем вынуждены обращаться к двум
отношениям, а не к одному равноценному отношению.
104
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Семантика наименований множеств сущностей и атрибутов диафаммы рис. 3.14 такова:
Courses— "учебные курсы", number— "номер", тот — "аудитория", Lab-Courses —
"лабораторные работы", computer-allocation — "компьютерный класс", GivenBy — "кем
читается", Depts — "факультеты", пате — "название", chair — "декан".
number
Croomj-
С chair )
Courses
А*
Lab-
Courses
rcomputer\
, allocation j
Рис. 3.14. ER-диаграмма к упражнению 3.3.1
address^
People
Рис. 3.15. ER-диаграмма к упражнению 3.3.2
Упражнение 3.3.2. Преобразуйте ER-диафамму рис. 3.15 в реляционную схему
базы данных, используя следующие стратегии:
a) "сущность-связь";
b) "объектно-ориентированную";
c) допускающую использование значений null.
3.3. ПРЕОБРАЗОВАНИЕ СТРУКТУР ПОДКЛАССОВ В ОТНОШЕНИЯ
105
Семантика наименований множеств сущностей и атрибутов диаграммы рис. 3.15
такова: People — "люди", пате — "имя", address — "адрес", Children — "дети", Child Of —
"является ребенком", Fathers— "отцы", FatherOf — "является отцом", Mothers —
"матери", MotherOf— "является матерью", Married— "женаты".
Упражнение 3.3.3. Преобразуйте ER-диаграмму, полученную вами при решении
задания упражнения 2.1.7 (см. с. 65), в реляционную схему базы данных, используя
следующие стратегии:
a) "сущность—связь";
b) "объектно-ориентированную";
c) допускающую использование значений null.
! Упражнение 3.3.4. Пусть задана /ш-иерархия, охватывающая е множеств
сущностей. Каждое множество обладает а атрибутами, к из которых относятся к
корневому множеству и образуют ключ для всех множеств сущностей. Предложите
формулы вычисления
i) минимального и максимального количества используемых отношений;
и) минимального и максимального количества компонентов, включаемых
в кортеж(и) для одной сущности,
если используется одна из следующих стратегий преобразования ER-диаграммы
в реляционную схему базы данных:
* а) "сущность—связь";
b) "объектно-ориентированная";
c) допускающая использование значений null
3.4. Функциональные зависимости
В разделах 3.2 (см. с. 91) и 3.3 (см. с. 100) мы показали, как выполнять
преобразование ER-диаграмм в реляционные схемы. Вполне возможно также создать
реляционную схему непосредственно на основе спецификации базы данных, минуя стадию
ER-моделирования, хотя такой подход может оказаться довольно трудоемким.
Независимо от того, каким образом создается реляционная схема, зачастую представляется
возможным повысить качество проекта, реализуя определенные типы ограничений.
К наиболее важным типам ограничений, применяемых в контексте проекта
реляционной базы данных, относится ограничение уникальности, называемое
функциональной зависимостью (functional dependency ~- FD). Реализация ограничений этого типа
жизненно важна для обеспечения возможности внесения изменений в схему базы
данных с целью устранения информационной избыточности (этот вопрос будет
освещен в разделе 3.6 на с. 123). Существуют и иные разновидности ограничений,
способных улучшить реляционную схему базы данных: здесь достаточно упомянуть
многозначные зависимости (multivalued dependencies), рассмотренные в разделе 3.7 на
с. 137, и ограничения ссьшочной целостности (referential integrity constraints), о которых
мы подробно расскажем в разделе 5.5 на с. 241.
3.4.1. Определение функциональной зависимости
Функциональная зависимость (functional dependency — FD) для отношения R — это
утверждение следующего вида: "Если два кортежа отношения R совпадают в атрибутах
Al9A2,...,An (т.е. кортежи обладают одинаковыми значениями компонентов для
каждого из названных атрибутов), то они должны совпадать и в другом атрибуте, /?".
106
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Формально такая FD записывается как А{А2 ■ •Л„-~> В и свидетельствует, что
"Аг,А2, -., Ап функционально обусловливают В".
Если несколько атрибутов, АьА2,...,Ап, функционально обусловливают более
одного атрибута, т.е.
А1А2-Ап-*В1
А, А2 •• Ап -» В2
А1А2-Ап->Вт,
позволяется использовать следующее сокращенное представление набора таких FD:
А1А2-Ая->В1В2-Вт.
На рис. 3.16 представлена диаграмма, изображающая функциональную зависимость
на примере двух кортежей t и и отношения R.
-*- Атрибуты А +~
:
-*- Атрибуты В -***
Если f и и они должны
совпадают здесь, совпадать и здесь
Рис. 3.16. Эффект функциональной
зависимости двух кортежей
Пример 3.12. Рассмотрим отношение
Movies(title, year, length, filmType, studioName, starNarne),
экземпляр которого изображен на рис. 3.8 (см. с. 96) и воспроизведен на рис. 3.17.
Нетрудно указать несколько функциональных зависимостей, которым подчиняется
отношение Movies ("кинофильмы"). Например, мы имеем основания утверждать, что
title year —> length
title year —> filmType
title year —> studioName
title
Star Wars
Star Wars
Star Wars
Mighty Ducks
Wayne's World
Wayne's World
year
1977
1977
1977
1991
1992
1992
length
124
124
124
104
95
95
film Type
color
color
color
color
color
color
studioName
Fox
Fox
Fox
Disney
Paramount
Paramount
starNarne
Carrie Fisher
Mark Hamill
Harrison Ford
Emilio Estevez
Dana Carvey
Mike Meyers
Рис. 3.17. Экземпляр отношения Movies (title, year, length, filmType, studioName,
starNarne)
Поскольку левая часть всех трех FD одинакова, title year, их можно кратко
представить так:
title year —> length filmType studioName.
3.4. ФУНКЦИОНАЛЬНЫЕ ЗАВИСИМОСТИ 107
Если говорить неформально, рассматриваемый набор функциональных зависимостей
свидетельствует, что если два отношения обладают попарно одинаковыми значениями
компонентов title и year, они должны содержать одни и те же значения в
компонентах length, f ilrnType и studioName. Это утверждение справедливо, если принять
во внимание изначальный смысл реальных объектов, которые моделируются
отношением Movies. Атрибуты title ("название") и year ("год производства") образуют ключ
множества сущностей Movies. Таким образом, подразумевается, что конкретные
значения атрибутов title и year однозначно определяют сущность-"кинофильм", которой
соответствуют строго определенные значения атрибутов length ("продолжительность")
и f ilmType ("тип пленки"). Кроме того, существует связь типа "многие к одному",
соединяющая множества сущностей Movies и Studios ("киностудии"). Следовательно,
каждой сущности-"кинофильму" соответствует только одна сущность "киностудия".
С другой стороны, выражение
title year —> starName
неверно, поскольку не является функциональной зависимостью для отношения
Movies. Каждой сущности-"кинофильму" в базе данных, вообще говоря, может
соответствовать сразу несколько сущностей-"актеров". □
3.4.2. Ключи отношений
Говорят, что множество вида [AhA2,...,An], состоящее из одного или нескольких
атрибутов, является ключом отношения R, если выполняются следующие условия:
1) атрибуты АиАъ..., Л„ функционально обусловливают все остальные атрибуты
отношения; ситуация, когда два различных кортежа R совпадают во всех
атрибутах Аь Аъ..., Ап, невозможна;
2) ни одно из допустимых подмножеств множества {АьА2,...,Ап} атрибутов не
является функциональным обоснованием всех остальных атрибутов
отношения R, т.е. ключ минимален (minimal).
Если ключ состоит из одного атрибута А, вместо громоздкого обозначения {А} мы
будем пользоваться кратким — А.
Пример 3.13. Атрибуты {title, year, starName} образуют ключ для отношения
Movies в той его редакции, которая приведена на рис. 3.17. Первым делом мы
обязаны показать, что эти атрибуты функционально обусловливают все остальные
атрибуты. Предположим, что существуют два кортежа, которые совпадают во всех трех
атрибутах — title ("название"), year ("год производства") и starName ("имя актера").
Как мы упоминали в примере 3.12, поскольку эти кортежи обладают, в частности,
одинаковыми значениями атрибутов title и year, должны попарно совпадать
значения и всех остальных атрибутов — length ("продолжительность"), filmType ("тип
пленки"), studioName ("название киностудии") и starName ("имя актера"). Вывод
справедлив только в отношении первых трех атрибутов — length, filmType
и studioName. Двух кортежей, у которых одновременно равны значения атрибутов
title, year и starName, быть не может, т.е. исходное предположение неверно, и
атрибуты {title, year, starName} действительно формируют ключ отношения Movies.
Теперь надлежит доказать, что ни одно из подмножеств множества
{title, year, starName} атрибутов не в состоянии функционально обусловить все
остальные атрибуты. Начнем с того, что на основании {title, year} нельзя однозначно
определить значение starName, так как в одном кинофильме могут участвовать
несколько актеров. Поэтому {title, year} нельзя считать ключом.
Подмножество {year, starName} также не является ключом, поскольку актер может
сняться в нескольких фильмах, выпущенных в течение одного года. Поэтому выражение
year starName —> title
108
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Функциональные зависимости как свойства схемы
Напомним, что функциональная зависимость, как и любое другое ограничение, —
это некоторое предположение относительно структуры схемы отношения, не
связанное с конкретными экземплярами этого отношения. Экземпляр отношения сам по
себе не дает оснований делать какие-либо выводы, касающиеся взаимозависимостей
данных. Например, глядя на частный экземпляр отношения, приведенный на
рис. 3.17, можно подумать, будто отношение само по себе поддерживает такую FD,
как, скажем, title —> filrnType, поскольку два любых его кортежа, совпадающих
в значениях атрибута title, как кажется, всегда совпадают и в значениях f ilrnType.
Мы, однако, не вправе декларировать справедливость этой FD. Случись так, что
в базу данных попадет информация о двух версиях кинофильма (скажем, какого-
нибудь "King Kong"), одна из которых снята на цветной пленке (color), а
другая — на черно-белой (blackAnaWhite), и все наши умозаключения просто рухнут.
не относится к числу функциональных зависимостей для рассматриваемого
отношения Movies. Наконец, мы можем утверждать, что и подмножество {title, starNarne}
не может быть ключом, так как вероятны случаи, когда один и тот же актер в разные
годы участвует в съемках фильмов с одинаковыми названиями.10 □
Подчас для отношения может быть создано несколько ключей. В такой ситуации,
как правило, одному из них отводится роль первичного ключа (primary key). В
коммерческих системах баз данных выбор первичного ключа способен воздействовать на
определенные свойства реализации (например, на то, каким образом отношение
хранится на диске). Вот одно полезное правило, которому следуем мы сами.
• "В тексте схемы отношения атрибуты первичного ключа надлежит подчеркивать".
3.4.3. Суперключи
Множество атрибутов, содержащее ключ в качестве подмножества, называют
суперключом (superkey). Каждый ключ, очевидно, является и суперключом. Некоторые
суперключи, однако, не обладают свойством минимальности, хотя каждый суперключ
удовлетворяет первому требованию, предъявляемому к ключам: он функционально
обусловливает все остальные атрибуты отношения.
Пример 3.14. Для отношения Movies, рассмотренного в примере 3.13, можно указать
несколько суперключей. Суперключом является не только ключ
{title, year, starNarne},
но и любое его надмножество, такое, как, скажем,
{title, year, starNarne, length, studioNarne}.
□
3.4.4. Выбор ключей для отношения
Когда реляционная схема создается путем преобразования ER-диаграммы в набор
отношений, зачастую структуру ключа определенного отношения можно предсказать
заранее. Первое правило, касающееся выбора ключей отношения, звучит так.
• "Если отношение получено на основе множества сущностей, ключ отношения
формируется из ключевых атрибутов множества сущностей".
10 Приводя этот пример в предыдущих книгах, мы не могли найти подлинные образцы
подобных совпадений, но получили их от нескольких коллег и читателей. Вообще говоря, это
забавно — отыскать реальных актеров, которые умудрились сняться в нескольких версиях
одного и того же кинофильма.
3.4. ФУНКЦИОНАЛЬНЫЕ ЗАВИСИМОСТИ
109
Минимальность ключей
Требование, касающееся минимальности ключей, в ER-модели не выдвигается, но,
имея дело с реляционной моделью, мы вынуждены ему подчиняться. Опытный
дизайнер, работая с ER-моделью, вряд ли станет добавлять в ключи избыточные
атрибуты, но модель сама по себе не дает возможности проверить, действительно ли
каждый из ключей минимален. Только используя некий формализм, подобный
функциональным зависимостям, мы можем, по меньшей мере, грамотно поставить
вопрос, является ли определенное множество атрибутов "минимальным"
множеством, пригодным для применения в качестве ключа.
Позвольте напомнить о смысловом различии между минимальным ключом
(из него нельзя удалить какой бы то ни было атрибут) и ключом, наименьшим
среди всех возможных. Минимальный ключ, вообще говоря, не обязательно обладает
наименьшим количеством атрибутов в сравнении с другими, альтернативными,
ключами для того же отношения. Может случиться, например, что А В С и D Е
одновременно являются ключами некоторого отношения (разумеется,
минимальными), но только D Е обладает наименьшей "размерностью" среди всех остальных.
Пример 3.15. В примере 3.1 на с. 92 мы рассказывали о том, как преобразовать
множества сущностей Movies ("кинофильмы") и Stars ("актеры") в отношения. Ключами
указанных множеств сущностей являются, соответственно, множества [title, year)
и [пате]. Они будут и ключами отношений Movies и stars, схемы которых можно
представить следующим образом:
Movies (title, year, length, filrnType)
Stars(name, address)
где ключевые атрибуты выделены подчеркиванием. □
Второе правило выбора ключей отношения касается бинарных связей. Если
отношение R создается на основе связи, на состав множества ключей отношения
оказывает влияние свойство множественности связи. Существуют три варианта
правила, перечисленных ниже.
• "Если связь относится к типу "многие ко многим", ключами отношения R
становятся ключевые атрибуты обоих множеств сущностей, соединяемых связью".
• "Если связь относится к типу "многие к одному" и соединяет множества
сущностей Е{ и Е2 в направлении от Ех к Еъ ключами отношения R должны быть
ключевые атрибуты множества Е{ (но не Е2у\
• "Если связь относится к типу "один к одному", ключевыми атрибутами
отношения R могут быть ключи любого из соединяемых множеств".
Пример 3.16. В примере 3.2 на с. 93 мы обсуждали свойства связи Owns ("владеет"),
соединяющей множества сущностей Movies ("кинофильмы") и Studios ("киностудии")
и относящейся к типу "многие к одному". Ключ отношения Owns в соответствии
с рассмотренным выше правилом должен состоять из атрибутов title и year,
которые являются ключом множества сущностей Movies. Схема отношения Owns с
подчеркнутыми ключевыми атрибутами выглядит так:
Owns (title, year, studioNarne).
В примере 3.3 на с. 93 речь шла о связи Stars-in типа "многие ко многим",
соединяющей множества сущностей Movies и Stars ("актеры"). Все атрибуты отношения
Stars-in(title, year, starName)
no
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Что есть "функционального" в функциональных зависимостях?
Выражение АХА2~-Ап —>В называют "функциональной" зависимостью благодаря
тому, что по существу оно определяет "функцию", которая в качестве
"параметров" принимает список значений, по одному на каждый из атрибутов
АЪА2, ...,Ап, и возвращает строго определенное значение (либо не возвращает
никакого значения вовсе) для атрибута В. Изучая, например, отношение Movies, мы
можем предположить существование функции, которая воспринимает строку
(скажем, "Star Wars") и целочисленное значение (такое как 1977), а затем
возвращает в виде результата определенное значение атрибута length (а именно, 124)
из содержимого отношения Movies. Рассматриваемая функция, однако, не
относится к категории обычных математических функций, поскольку не предполагает
каких-либо "вычислений" в привычном смысле этого слова: мы не можем
выполнить некие "операции" над строкой "Star Wars" и числом 1977, чтобы получить
на их основе число 124. Процесс "вычислений" заключается в просмотре
отношения и поиске в нем необходимых данных: отыскивается кортеж, содержащий для
атрибутов title и year заданные значения "Star Wars" и 1977 соответственно,
а затем из него извлекается содержимое атрибута length.
должны быть ключевыми. Единственный способ предотвратить введение всех
атрибутов отношения связи в состав ключевых состоит в том, чтобы снабдить связь
собственным атрибутом. Тогда атрибуты множеств сущностей, охватываемых связью,
можно будет изъять из набора ключевых атрибутов отношения связи. □
В завершение вкратце упомянем многосторонние связи. Поскольку в подобных
случаях, вообще говоря, с помощью одних только стрелок нельзя описать все
допустимые взаимозависимости соединяемых множеств сущностей, возможны ситуации,
когда состав ключа или ключей отношения связи трудно определить, если тщательно
не поразмыслить о том, каким именно образом те или иные сущности
функционально обусловливают содержимое других сущностей. Впрочем, справедливость одного
утверждения мы все-таки можем гарантировать.
• "Если многосторонняя связь R содержит стрелку, направленную к множеству
сущностей £, существует по меньшей мере один ключ для соответствующего
отношения, который противоречит ключу £".
3.4.5. Упражнения к разделу 3.4
Упражнение 3.4.1. Рассмотрим отношение, которое представляет сведения о
гражданах США, включая их имена, номера полисов социального страхования, почтовые
адреса, названия городов и штатов проживания, почтовые коды, телефонные коды
и номера. Какие функциональные зависимости следовало бы учесть? Каковы ключевые
атрибуты такого отношения? Чтобы ответить на эти вопросы, необходимо знать о том,
каким образом указанные параметры соотносятся друг с другом и как их значения
присваиваются объектам (людям, городам и т.д.). Например, может ли один телефонный
код охватывать два штата или один почтовый код соответствовать нескольким
телефонным кодам? Могут ли два человека обладать полисами социального страхования
с одним номером? Могут ли люди иметь один почтовый адрес или номер телефона?
* Упражнение 3.4.2. Рассмотрим отношение, представляющее текущие позиции
молекул вещества, размещенного в ограниченном сосуде. Пусть в число атрибутов
входят идентификатор id молекулы, ее координаты х, у и z, а также значения
скоростей vx, vy и vz в направлении осей х, у и г. Какие функциональные
зависимости необходимо предусмотреть? Как может выглядеть ключ отношения?
3.4. ФУНКЦИОНАЛЬНЫЕ ЗАВИСИМОСТИ
111
К вопросу о терминах
В отдельных книгах и статьях при обозначении ключей отношения употребляется
особая терминология. В одних ситуациях "ключом" называют то, что мы трактуем как
"суперключ", т.е. множество атрибутов, функционально обусловливающих значе-ния
всех других атрибутов отношения (при этом требование минимальности ключа не
выдвигается). В других источниках для ссылки на минимальный ключ используется
выражение "candidate key" — мы же в подобном случае применяем термин "ключ" ("key").
! Упражнение 3.4.3. В упражнении 2.2.5 на с. 72 мы выдвигали три различных
предположения относительно свойств связи Births ("роды"). Постройте для каждого из
них схему соответствующего отношения и укажите ключевые атрибуты.
* Упражнение 3.4.4. Обратитесь к реляционной схеме базы данных, построенной
вами при решении задания упражнения 3.2.1 (см. с. 99), и определите наборы
ключевых атрибутов для каждого отношения.
Упражнение 3.4.5. Укажите множества ключевых атрибутов для отношений, созданных
вами при решении каждого из четырех вариантов задания упражнения 3.2.4 (см. с. 100).
!! Упражнение 3.4.6. Предположим, что R — это отношение с атрибутами Ль Аъ..., Ап.
Ответьте, каким количеством суперключей, выраженным в виде функции от л,
обладает отношение R, если отдельными ключами являются:
* а) атрибут А\\
b) атрибуты Ах и А2\
c) множества атрибутов {Аь А2} и {A3>Ai};
d) множества атрибутов {АиА2} и {ЛьЛз}-
3.5. Правила использования функциональных зависимостей
В этом разделе мы постараемся рассказать, как следует воспринимать
функциональные зависимости (functional dependencies — FD) — например, тогда, когда нам говорят,
что некоторый набор FD удовлетворяет определенному отношению. Зачастую в
процессе анализа можно прийти к выводу, что тому же отношению должны
удовлетворять и некоторые другие FD. Способность к выявлению дополнительных
функциональных зависимостей особенно важна, если мы стремимся отыскать самые удачные
схемы отношений (эта тема освещена в разделе 3.6 на с. 123).
Пример 3.17. Если известно, что отношение R с атрибутами А, В и С удовлетворяет
функциональным зависимостям А —> В и В —> С, можно утверждать, что R также
удовлетворяет FD A —> С. Как мы пришли к такому выводу? Чтобы доказать
справедливость выражения А —> С, мы должны рассмотреть два кортежа отношения R, которые
совпадают в атрибуте А, и доказать, что они совпадают также в атрибуте С.
Пусть (а, Ьи с{) и (д, Ъъ с2) — два кортежа, в которых значения атрибута А
совпадают. Мы подразумеваем, что порядок следования атрибутов в кортежах таков: А, В, С.
Так как R удовлетворяет FD А —> В и кортежи совпадают в атрибуте А, они должны
совпадать и в атрибуте В. Другими словами, Ъх - Ь2 и поэтому кортежи фактически
выглядят как {a, b, ci) и (а, Ь, с2), где Ъ — это одновременно и Ьи и Ь2. Аналогично, поскольку
R удовлетворяет В —> С и кортежи совпадают в атрибуте В, они должны совпадать и в
атрибуте С. Таким образом, сх - с2, т.е. кортежи совпадают в значениях атрибута С. Мы
доказали, что любые два кортежа отношения R, совпадающие в атрибуте А, также
совпадают и в атрибуте С, так что А —> С — это верная функциональная зависимость для R. □
112
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Функциональные зависимости нередко могут быть представлены несколькими
различными способами при условии, что набор существующих экземпляров отношения
остается неизменным. Говорят, что:
• два множества FD S и Т являются эквивалентными (equivalent), если множество
экземпляров отношения, удовлетворяющих S, в точности совпадает с
множеством экземпляров отношения, удовлетворяющих Г;
• множество FD S следует из множества FD Г, если каждый экземпляр отношения,
удовлетворяющий всем FD множества Г, также удовлетворяет всем FD множества S.
Заметим, что два множества FD S и Т являются эквивалентными, если и только если
S следует из Г и Г следует из S.
Ниже мы приведем несколько полезных правил использования функциональных
зависимостей. Правила дают возможность, например, заменять одно множество FD
другим, эквивалентным, множеством или добавлять в множество другие FD, которые
следуют из существующих FD. Пример 3.17, рассмотренный выше, иллюстрирует
правило транзитивности (transitive rule), которое позволяет следовать по цепочке
взаимосвязанных FD. Кроме того, мы предложим алгоритм, способный дать ответ на общий
вопрос, следует ли заданная FD из одной или нескольких других FD.
3.5.1. Правила разделения/объединения
В разделе 3.4.1 на с. 106 мы упоминали о том, что функциональная зависимость вида
А1А2-Ая->В1В2...Вт
представляет собой сокращенное представление множества FD:
АХА2-Ап->ВХ
А1А2~Ап->В2
AiA2-An-^Bm.
Другими словами, мы имеем право разделить множество атрибутов, перечисленных
в правой части сокращенного выражения FD, на элементы и поместить каждый из
них в правую часть новой отдельной FD. И наоборот, допустимо заменить набор FD,
обладающих одинаковой левой частью, единственной FD с той же левой частью,
а в правой части этой FD указать все "правосторонние" атрибуты исходных FD,
объединенные в множество. В любом из двух случаев новые функциональные зависимости
полностью равноценны исходным. Изложим каждое из правил формально.
• Преобразование FD вида А{ А2 •• • А„ —> В{ В2 ••• Вт в множество FD, таких что
Ах А2 — Ап —> Bh где /=1,2,..., т, называют правилом разделения (splitting rule).
• Преобразование множества FD вида АХА2 — Ап —> Bh где /=1,2,..., w, в FD
Ах А2 •• • Ап —> Вх В2 •• • Вт, называют правилом объединения (combining rule).
В качестве иллюстрации приведем множество FD, рассмотренное в примере 3.12 на с. 107,
title year —> length
title year —> filmType
title year —> studioName,
которое эквивалентно единственной FD:
title year —> length filmType studioName.
У читателя может возникнуть вопрос, нельзя ли правило разделения,
справедливое в отношении правых частей FD, применять и к их левым частям? Правила
разделения левых частей FD, увы, не существует; соответствующая иллюстрация
приведена в следующем примере.
3.5. ПРАВИЛА ИСПОЛЬЗОВАНИЯ ФУНКЦИОНАЛЬНЫХ ЗАВИСИМОСТЕЙ
113
Пример 3.18. Рассмотрим одну из функциональных зависимостей для отношения
Movies ("кинофильмы"), упоминавшихся в примере 3.12 на с. 107,
title year —> length.
Если попытаться применить правило разделения к ее левой части, мы получим две
неверные FD:
title —> length
year —> length.
Атрибут title не является функциональным обоснованием атрибута length,
поскольку могут существовать два фильма с одинаковым названием (таким как,
например, "King Kong"), но разной продолжительностью воспроизведения. Атрибут year
также не способен функционально обусловить атрибут length, так как определенно
существует множество кинофильмов, вышедших на экран в одном и том же году, но
имеющих разные значения продолжительности. □
3.5.2. Тривиальные функциональные зависимости
Говорят, что функциональная зависимость А\ А2 -• Ап —> В является тривиальной
(trivial), если атрибут В совпадает с любым из атрибутов Ah /=1,2,..., п. Например, FD
title year —> title
относится к категории тривиальных.
Тривиальная FD справедлива для любого отношения, поскольку она гласит, что
"два кортежа, совпадающие во всех атрибутах АХ,А2, ...,А„, совпадают также в одном из
них". Таким образом, тривиальная FD может быть принята к рассмотрению без
обоснования ее истинности применительно к другим FD, справедливость которых в
контексте отношения сомнений не вызывает.
Приводя исходное определение функциональной зависимости, мы не
предполагали возможность создания тривиальных FD. Расширение определения на случай
тривиальных FD, однако, не только не вредоносно, но и полезно: тривиальные FD
заведомо истинны и в некоторых ситуациях позволяют упростить толкование правил.
Допуская существование тривиальных FD, мы должны признать возможность
применения и таких FD, в которых некоторое подмножество атрибутов правой части
присутствует и в левой части. Принято утверждать, что FD вида Ах А2 •• Ап -> Вх В2 - Вт
относится к категории
• тривиальных (trivial), если множество {Вх, В2,..., Вт) является подмножеством
множества {Ah A2,..., Ап};
• нетривиальных (nontrivial), если по меньшей мере один из атрибутов Bt не
является элементом множества {АЬА2,..., А„);
• полностью нетривиальных (completely nontrivial), если ни один из атрибутов В, не
является элементом множества [АиА2, -,Ап}.
Поэтому функциональная зависимость
title year —> year length
является нетривиальной, но не полностью нетривиальной. Если удалить из ее правой
части атрибут year, FD станет полностью нетривиальной.
Мы всегда вправе изъять из правой части любой FD те атрибуты, которые
присутствуют в левой ее части. Иными словами,
• функциональная зависимость вида Ах А2 •• • Ап —> Вх B2 • • Вт равносильна следующей:
AlA2-An->Ci C2- Сь
114
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
i 1
i 1
г*- Атрибуты А 4—►
i i
i i^—
i i
i i
i
i
i
i
г* Атрибуты С^
-Атрибуты В -+>
где {Сь Съ..., Ck} представляет собой подмножество множества {Вь Въ..., Вт),
такое, что ни один из его элементов не является членом множества {АЬА2,..., Ап).
Это правило, называемое правилом тривиальной зависимости (trivial-dependency rule),
проиллюстрировано на рис. 3.18.
3.5.3. Замыкание множества атрибутов
Прежде чем перейти к изложению остальных правил обращения с
функциональными зависимостями, рассмотрим основной принцип, лежащий в основе всех этих
правил. Предположим, что {Ai,A2> —,Ап} — это множество атрибутов, a S — множество
функциональных зависимостей. Замыканием (closure) множества {Аь А2,..., Ап] при
условии выполнения FD множества S называют
множество В атрибутов, такое что для каждого
отношения, которому удовлетворяют все FD
множества S, справедлива и FD А1А2~Ап~^В.
Другими словами, FD А{ А2 •• • Ап —> В следует из
FD множества S. Замыкание множества
{Аь А2,..., А„} атрибутов обозначают как
{АЬА2,..., Ап}+. Чтобы упростить обсуждение
аспектов вычисления замыканий множеств
атрибутов, мы разрешим возможность
использования тривиальных FD, полагая, что АьА2,...,Ап
всегда являются членами {Аь А2,..., Ап}+.
На рис. 3.19 схематически изображен
процесс вычисления замыкания множества
атрибутов. Некоторое заданное множество
атрибутов последовательно расширяется по мере
добавления в него атрибутов правых частей
функциональных зависимостей, атрибуты
левых частей которых уже присутствуют в
множестве. На определенном шаге процедуры дальнейшее расширение множества окажется
невозможным, и ее результатом будет искомое замыкание множества. Ниже приведено
более подробное описание алгоритма вычисления замыкания множества {AhA2,...,An}
атрибутов по отношению к некоторому множеству FD.
1. Пусть переменная X представляет множество атрибутов, подлежащее расширению
до момента достижения замыкания. X инициализируется значением {АЬА2,...,Ап}.
2. Выполняется поиск некоторой FD Вх В2 — Вт —> С, такой, что все атрибуты
Вь В2,..., Вт принадлежат множеству X, а С — нет. Если указанная FD
существует, С добавляется в множество X.
3. Шаг 2 повторяется до тех пор, пока существуют соответствующие FD, атрибуты
которых подлежат включению в множество X. Поскольку X допускает только
расширение и количество атрибутов, охватываемых любой реляционной
схемой, конечно, на определенной итерации процесса множество атрибутов,
которые могут быть добавлены в X, будет исчерпано.
4. После завершения процедуры расширения множество X содержит искомое
значение замыкания, {Ль А2,...,Ап}+.
Если / им они должны
совпадают в Л, совпадать и в В,
а также
совпадать в С
Рис. 3.18. Правило тривиальной
зависимости
Пример 3.19. Рассмотрим отношение с атрибутами А, В, С, D, Е и F.
Предположим, что отношению удовлетворяют следующие функциональные зависимости:
А В -^ С, В С ~> A D, D -» £ и С F -» В. Что представляет собой замыкание
множества [А, В], т.е. [А,В}+?
3.5. ПРАВИЛА ИСПОЛЬЗОВАНИЯ ФУНКЦИОНАЛЬНЫХ ЗАВИСИМОСТЕЙ 115
Вначале положим Х={А, В]. Обратите внимание, что атрибуты левой части FD
А В —> С присутствуют в X, поэтому в X может быть добавлен и атрибут С правой части
этой FD. Таким образом, после первой итерации шага 2 алгоритма получим Х- {А, В, С].
Теперь X содержит атрибуты левой части FD
В С-^А D, так что мы имеем право добавить в X
атрибуты ее правой части, А и D.11 Атрибут А уже
является членом множества X, но атрибут D — нет,
поэтому его следует включить. Множество X
приобретет вид {А, В, С, D]. Далее мы можем воспользоваться
функциональной зависимостью D —> Е, чтобы
добавить в X атрибут Е: {А, В, С, D, Е). Дальнейшее
расширение X невозможно. В частности, мы не вправе
рассматривать FD С Т7 —> В, поскольку атрибут F из
ее левой части не является элементом множества X.
Итак, [А, В}+= {А, В, С, D,E]. □
Коль скоро нам известно, как вычислять
замыкание любого множества атрибутов, мы можем
проверить, следует ли любая заданная FD Ах А2 ■• • Ап —> В
из множества FD S. Вначале получим замыкание
{АиА2,...,Ап}+, используя множество FD S. Если В
Рис. 3.19. Вычисление замыкания является членом {АьА2,...,Ап}+, FD АХА2 — Ап—> В
множества атрибутов следует из S, а если В не входит в состав
{AhA2,...,An}+, FD не следует из S. В более общем
случае допустимо проверять, следует ли из множества FD S некоторая FD, правая
часть которой охватывает сразу несколько атрибутов, поскольку подобное выражение,
как мы неоднократно говорили, служит сокращением записи множества FD. Другими
словами, FD вида А\ А2 — Ап —> Вх В2 — Вт следует из множества FD S, если и только
если все атрибуты Въ В2,..., Вт являются членами замыкания {Аь Аъ ..., Ап}+.
Пример 3.20. Рассмотрим отношение и функциональные зависимости примера 3.19.
Предположим, что необходимо проверить, следует ли из множества этих зависимостей
FD А В -» D. В примере 3.19 мы уже вычислили замыкание [А, В}+ = {А, В, С, Д Е].
Поскольку атрибут D является его членом, мы имеем основания заключить, что FD
А В —> D действительно следует из множества заданных FD.
Теперь рассмотрим FD D—>А. Чтобы проверить, следует ли эта FD из множества
исходных FD, необходимо вначале вычислить {D}+. Для этого положим Х- {D}.
Просматривая имеющиеся FD, мы вправе добавить в X атрибут Е, поскольку существует
FD D —> Е. Дальнейшее расширение X, однако, оказывается невозможным, так как
более нельзя найти ни одной FD, атрибуты левой части которой содержались бы
в Х= {D,E}. Поэтому {D}+= {D, Е]. Поскольку атрибут А не является членом множества
{А Е), мы приходим к выводу, что FD D —> А не следует из множества заданных FD. □
3.5.4. Обоснование алгоритма вычисления замыкания
В этом разделе мы покажем, почему алгоритм вычисления замыкания множества
атрибутов действительно позволяет верно определить, следует некоторая FD
AiA2 — An-*B из множества FD S или нет. Доказательство состоит из двух частей.
1. Необходимо доказать, что алгоритм вычисления замыкания принимает во
внимание только верные FD, т.е. если FD А\ А2 — Ап —> В подтверждается проверкой
11 Напомним, что В С-+AD — это сокращенная запись, обозначающая пару FD, BC-+A
и В С -> D. Каждая из этих функциональных зависимостей при необходимости может
рассматриваться отдельно.
ив
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
(В принадлежит замыканию {Ль А2,..., Ап}+), FD А1 А2 — Ап —> В удовлетворяет
любому отношению, которому удовлетворяет множество S заданных FD.
2. Следует доказать, что алгоритм действительно находит каждую FD, которая
следует из множества S заданных FD.
Почему алгоритм вычисления замыкания подтверждает только верные FD
Докажем по индукции (по числу операций расширения исходного множества,
выполняемых на шаге 2 алгоритма), что для каждого атрибута D из X условие FD Ах А2 - Ап —> D
выполняется (в частном случае, когда D является элементом множества {AhA2,...,An}, эта
FD тривиальна). Другими словами, каждое отношение R, которому удовлетворяют все
FD множества S, также удовлетворяется функциональной зависимостью Ах А2 -• Ап —> D.
Базис. Базисный случай имеет место, если выполняется нулевое количество шагов
алгоритма. Тогда атрибут D должен быть одним из атрибутов AhA2,...,An, и FD
Ах А2 — Ап —> D определенно справедлива для любого отношения, поскольку она
относится к категории тривиальных.
Индукция. Предположим по индукции, что атрибут D был добавлен в множество,
когда рассматривалась FD BlB2--Bm~^D. На основании гипотезы индукции мы можем
утверждать, что отношению R удовлетворяют FD АХА2- Ап-^>В{ для всех /=1,2,..., т.
Иными словами, два произвольных кортежа R, совпадающие во всех А1,А2,...,А„,
должны совпадать и во всех Ви Въ..., Вт. Поскольку R удовлетворяется FD
BiB2 — Bm-> D, мы также уверены, что эти кортежи совпадают и в атрибуте D. Таким
образом, FD Ах А2 •■ • Ап —> D удовлетворяет отношению R.
Почему алгоритм вычисления замыкания находит все верные FD
Предположим, что А{ А2 ••■ Ля-»В — это FD, отвергнутая алгоритмом по той
причине, что она не следует из множества S, т.е. замыкание множества
[Аь А2, ..., Ап], вычисленное с использованием множества FD S, не содержит В.
Мы должны показать, что FD Ах А2 • ■ Ап —> В действительно не следует из FD
множества S: существует по меньше один экземпляр отношения, которому
удовлетворяют все FD из S и не удовлетворяет FD Ах А2 ••• Ап —> В.
Подобный экземпляр отношения (назовем его /) легко создать; он показан на
рис. 3.20. / содержит только два кортежа, t и s. Эти кортежи совпадают во всех
атрибутах замыкания [АиАъ ..., А„}+, но не совпадают во всех других атрибутах. Вначале
необходимо показать, что экземпляру / удовлетворяют все FD из S, а затем то, что FD
А{ А2 •• • А„ —> В не удовлетворяет экземпляру /.
г.
s:
{ЛЬЛ2,...,ЛЛ
111-11
111-11
Другие атрибуты
000-00
111-11
Рис. 3.20. Экземпляру I удовлетворяют все FD множества S, но не удовлетворяет FD
А\ А2 •••Ап —> В
Предположим, что в S существует некоторая FD C\C2-Ck—> D, которая не
удовлетворяет экземпляру /. Поскольку / содержит только два кортежа, именно они обязаны
нарушать условие СхС2-Ск—> D, т.е., совпадая во всех атрибутах множества
{Q, С2,..., Q}, кортежи не должны совпадать в D. Из рис. 3.20 становится ясно, что все
атрибуты СХ,СЪ..., Ск должны принадлежать множеству {AhA2, ...,Ап}+, так как именно
в них совпадают кортежи t и s. Атрибут D, с другой стороны, должен относиться к числу
атрибутов, в которых кортежи t и s не совпадают. Но тогда замыкание множества было
3.5. ПРАВИЛА ИСПОЛЬЗОВАНИЯ ФУНКЦИОНАЛЬНЫХ ЗАВИСИМОСТЕЙ 117
вычислено неверно: следовало учесть FD Сх С2 — Ck-^D на том этапе, когда X равнялось
{Ах,А2,...,Ап}, чтобы включить в состав X атрибут D. Мы приходим к выводу, что FD
С\ Сг -' Q—> D существовать не может, т.е. множество FD S удовлетворяет экземпляру /.
Теперь мы должны показать, что FD АХА2-Ап-^В не удовлетворяет экземпляру /.
Впрочем, эта часть доказательства более проста. Атрибуты АЪАЪ ...,An безусловно
относятся к числу тех, в которых кортежи t и s совпадают. Помимо того, мы знаем, что
В не принадлежит множеству {Ль Аг,..., А„}+, так что В является одним из тех
атрибутов, в которых кортежи t и s не совпадают. Таким образом, FD Ах А2 — Ап —> В
действительно не удовлетворяет экземпляру /.
Нам остается заключить, что алгоритм вычисления замыкания находит те и только
те FD, которые следуют из S.
3.5.5. Правило транзитивности
Правило транзитивности (transitive rule) позволяет соединять функциональные
зависимости в логическую цепочку.
• Если для отношения R справедливы FD Ах А2 ■•• А„ —> Вх В2 ■■ ■ Вт
и Вх В2 — Вт -» С\ С2 •■■ Q, то справедлива и FD Ах А2 ••• Ап -» Сх С2 ■•• Ск.
Если некоторые из элементов Сь С2,..., Ск содержатся во множестве {Аь А2,..., Ап], их
можно удалить из правой части FD, применяя правило тривиальной зависимости.
Нетрудно удостовериться в справедливости правила транзитивности, если
применить алгоритм проверки, который был рассмотрен в разделе 3.5.3 на с. 115. Чтобы
определить, выполняется ли условие Ах А2 — Ап —> С\ С2 - Ск, необходимо вычислить
замыкание {АХ,А2,..., А„}+ с учетом двух заданных FD.
FD Ах А2 - Ап —> Вх В2 - Вт позволяет утверждать, что все атрибуты Bh Въ ..., Вт
являются членами множества {Ль А2, ...,Ап}+. Значит, принимая во внимание справедливость FD
ВХВ2- Вт->СХС2- Сь мы вправе включить в состав [АЪАЬ ...,А„}+ и атрибуты Съ С2,..., Ск.
Поскольку теперь все Сь С2,..., Ск принадлежат множеству {Аь А2,..., А„}+, мы
заключаем, что FD Ах А2 — Ап -~> Сх С2 ■■■ Ск удовлетворяет любому отношению, которому
одновременно удовлетворяют FD Ах А2 - Ап -^ Вх В2 - Вт и ^i ^2 - &т -> Ci C2 ••• Q.
Пример 3.21. Обратимся к варианту отношения Movies (см. рис. 3.7 на с. 95), который
был создан в примере 3.5 с целью представления четырех атрибутов множества
сущностей Movies ("кинофильмы") в совокупности с атрибутами отношения, представляющего
связь Owns ("владеет"), которая соединяет множества сущностей Movies и Studios
("киностудии"). Экземпляр этого отношения может выглядеть следующим образом:
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
film Type
color
color
color
studioName
Fox
Disney
Paramount
Предположим, что возникла необходимость размещения некоторой информации
о киностудии-"владельце" фильма в пределах того же отношения. Для простоты
ограничим внимание сведениями о городе, в котором находится студия. Теперь
отношение будет выглядеть так, как показано ниже.
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
filmType
color
color
color
studioName
Fox
Disney
Paramount
studioAddr
Hollywood
Buena Vista
Hollywood
118 ГЛАВА З. РЕЛЯЦИОННАЯ МОДЕЛЬ
Замыкания и ключи
Заметим, что {АЬА2, ...,А„}+ является множеством всех атрибутов отношения, если
и только если атрибуты АЬА2, ..., А„ образуют суперключ этого отношения. Отсюда, по
меньшей мере, следует, что атрибуты АьАъ...,Ап функционально обусловливают все
другие атрибуты отношения. Чтобы определить, формируют ли атрибуты АиА2,...,А„
ключ отношения, достаточно вначале убедиться, что множество {АЬА2,..., А„}+
содержит все атрибуты, а затем показать, что ни для одного множества X, получаемого
удалением одного атрибута из {АЬА2,..., А„}, Х+ не является множеством всех атрибутов.
Мы можем указать две функциональные зависимости, которые определенно
справедливы:
title year —> studioNarne
studioNarne —> studioAddr.
Корректность первой из них обусловлена тем, что связь Owns относится к типу "многие
к одному", а вторая FD верна ввиду того, что адрес (studioAddr) является атрибутом
множества Studios, а наименование студии (studioNarne) — это ключевой атрибут Studios.
Правило транзитивности позволяет объединить две названные выше FD и на их
основе получить новую функциональную зависимость:
title year —> studioAddr,
которая гласит, что атрибуты "название" и "год производства" сущности "кинофильм"
однозначно определяют содержимое атрибута "адрес" сущности "киностудия". □
3.5.6. Замкнутые множества функциональных зависимостей
Как мы показали, на основании заданного множества FD зачастую возможно
вывести некоторые другие FD, включая тривиальные и нетривиальные. В следующих
разделах нам понадобится различать заданные (given) FD, справедливость которых
в контексте определенного отношения провозглашается изначально, и производные
(derived) FD, получаемые путем логического вывода на основании заданных FD с
помощью рассматриваемых здесь правил и изложенного выше алгоритма вычисления
замыкания множества атрибутов.
Иногда существует возможность выбора одного из альтернативных наборов FD,
пригодных для представления полного множества FD конкретного отношения. Любое
множество функциональных зависимостей отношения, из которых допустимо вывести
все другие FD, называют базисом (basis) отношения. Если ни одно из подмножеств
базиса не может быть, в свою очередь, использовано для получения полного множества
FD отношения, принято говорить, что базис является минимальным (minimal).
Пример 3.22. Рассмотрим отношение R(A, В, Q, такое, что каждый из его атрибутов
функционально обусловливает два других атрибута. Таким образом, полное множество
производных FD для отношения R будет включать шесть FD с одним атрибутом в
левой и правой частях: А-»#, Д-»С, #-»А, #-»С, С-»АиС-»#. В состав множества
входят также три нетривиальных FD с двумя атрибутами в левой части: А В —> С,
АС-^>В и ВС-^А. Помимо того, возможно использовать сокращенные записи для
представления пар FD, такие как А —> В С, либо рассматривать тривиальные FD
(например, А-^А) или FD вида А В —> В С, которые не относятся к категории
полностью нетривиальных (хотя в соответствии со строгим определением FD мы не
обязаны перечислять тривиальные или частично тривиальные (нетривиальные) FD либо
приводить зависимости с несколькими атрибутами в правой части).
3.5. ПРАВИЛА ИСПОЛЬЗОВАНИЯ ФУНКЦИОНАЛЬНЫХ ЗАВИСИМОСТЕЙ 119
Отношение R и его FD обладают несколькими минимальными базисами. Один из,
например, выглядит как
а другой — так:
{А->#, #->С, С->А}.
Для отношения R можно привести много других базисов (даже минимальных), и
задачу их отыскания мы оставляем читателю в качестве упражнения. □
3.5.7. Проецирование функциональных зависимостей
При изучении аспектов дизайна реляционных схем нам потребуется получить ответ на
следующий вопрос. Предположим, что имеется некоторое отношение R с множеством FD
F и мы "проецируем" R, удаляя некоторые атрибуты его схемы. Пусть S — это
отношение, полученное из R путем отбрасывания компонентов, соответствующих всем
удаленным атрибутам, во всех кортежах R. Поскольку S является множеством, совпадающие
кортежи в нем заменяются одной копией. Какие FD останутся справедливыми и для 5?
Ответ состоит в вычислении всех FD, которые
a) следуют из F\
и
b) включают атрибуты, принадлежащие только S.
Поскольку таких FD может быть много, а некоторые из них, вполне вероятно,
излишни (т.е. следуют из других FD), при необходимости мы вправе упростить
множество этих FD. Сложность алгоритма поиска FD для отношения S в худшем случае
оценивается экспоненциальной функцией от числа атрибутов S.
Пример 3.23. Пусть отношение R(A, В, С, D) обладает FD А -> В, В -> С и С -> D.
Предположим также, что нам необходимо отбросить атрибут В, перейдя от схемы
R(A, В, С, D) к схеме S(A, С, D). Чтобы найти FD, удовлетворяющие S, нам по существу
требуется вычислить замыкание для всех восьми подмножеств множества {A,C,D},
используя полное множество FD, включающее и те зависимости, в которые вовлечен
атрибут В. Однако имеется возможность применить ряд очевидных упрощений.
• Замыкания пустого множества и множества всех атрибутов не способны
приводить к получению нетривиальных FD.
• Если известно, что замыкание некоторого множества X содержит все его атрибуты,
построение замыканий для надмножеств X не приведет к нахождению новых FD.
Поэтому мы имеем право начать с построения замыканий для единичных множеств,
а затем при необходимости перейти к рассмотрению множеств с двумя элементами. Для
каждого замыкания некоторого множества X можно добавить FD вида X —> Е, где
Е — это каждый из атрибутов, который присутствует в Х+ и в схеме S, но отсутствует в X.
Во-первых, {А}+= {А, В, С, D]. Поэтому FD А-^С и A-^D справедливы для S.
Заметьте, что FD А —> В верна в контексте отношения R, но для S она не имеет смысла,
так как В не относится к числу атрибутов S.
Во-вторых, принимая во внимание, что [С}+= [С, D], мы можем получить для S
дополнительную FD, C-^>D. Наконец, поскольку {D}+= {D}, дополнительные FD добавить уже
нельзя, и рассмотрение единичных множеств атрибутов можно считать завершенным.
Ввиду того, что {А}+ включает все атрибуты S, обращаться к надмножествам {А}
нецелесообразно. Причина состоит в том, что какую бы FD мы ни выявили
(например, AC-^D), согласно частному случаю правила расширения FD (обратитесь
к упражнению 3.5.3 (а)) она будет следовать из тех FD, которые найдены прежде при
120
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Полное множество правил вывода
Если необходимо установить, следует ли определенная FD из некоторой другой FD,
ответ всегда может быть получен с помощью рассмотренного в разделе 3.5.3 (см. с. 115)
алгоритма вычисления замыкания множества. Однако небезынтересно отметить,
что существует множество правил, называемых аксиомами Армстронга (Armstrong's
axioms), которые путем логического вывода позволяют получить любую производную
FD, следующую из множества заданных FD. Аксиомы Армстронга перечислены ниже.
1. Рефлективность (reflexivity). Если {Ви В2,..., Вт] q {АЬА2, ...,Ап], то
Ах А2 — Ап —> #! В2 ■■■ Вт. Полученные зависимости, в соответствии с нашими
определениями, будут тривиальными.
2. Расширение (augmentation). Если Ах А2 - Ап -» Вх В2 - Вт, то
А, А2 ». Ап d С2 ». Q -4 Вх В2 .. Вт С, С2 ••• Q
для любого множества {Сь Съ ..., Q}.
3. Транзитивность (transitivity). Если
Ах А2.» А„ -4 Я, Я2.» Вт и ^! Я2... Вт -4 d C2 ••• Q,
то Aj А2 " К -> Ci C2 ••• Q.
условии, что А является единственным атрибутом левой части. Поэтому
единственным множеством с двумя атрибутами, замыкание которого подлежит рассмотрению,
является {C,D}: {С, D}+ = {С, D). Это условие также не позволяет отыскать какие-либо
новые FD. Итак, с замыканиями покончено, и набор найденных FD, справедливых
для, отношения S, таков: А—> С, А—> D и С—> D.
Если присмотреться, нетрудно заметить, что FD А —> D по правилу транзитивности
может быть получена из двух других итоговых FD. Поэтому более простое
эквивалентное множество FD, удовлетворяющих отношению S, выглядит так: А—> С и С —> D. □
3.5.8. Упражнения к разделу 3.5
* Упражнение 3.5.1. Рассмотрим схему отношения R(A, В, С, D) и следующий набор
FD:AS->C,C->DhD-4A.
a) Каковы все нетривиальные FD, которые следуют из заданных FD?
Ограничьтесь рассмотрением FD с единственным атрибутом в правой части.
b) Каковы все ключи отношения Я?
c) Каковы все суперключи R, не являющиеся ключами?
Упражнение 3.5.2. Выполните задания упражнения 3.5.1 для следующих схем
отношений и наборов FD:
i) S(A, В, С, D) с FD А -» В, В ~> С и В -» D.
ii) Т(А, В, С, D) с FD А В -» С, В С -» £>, С D -» А и А £> -» Я.
iii) [/(A, fi,CD)cFDA->fi,fi->C,C->DHD-^A.
Упражнение 3.5.3. Докажите справедливость следующих правил, используя
алгоритм вычисления замыкания множества, рассмотренный в разделе 3.5.3 на с. 115.
* а) Расширение левых частей (augmenting left sides). Если выполняется
условие FD А1А2 — Ап->В и С является еще одним атрибутом, выполняется
и АХА2 -■■ Ап С-^В.
3.5. ПРАВИЛА ИСПОЛЬЗОВАНИЯ ФУНКЦИОНАЛЬНЫХ ЗАВИСИМОСТЕЙ 121
b) Полное расширение (full augmentation). Если выполняется условие FD
Ах А2 •• • Ап —> В и С является еще одним атрибутом, выполняется
и А{ А2 ••• Ап С —> В С. На основании этого правила легко доказать
справедливость аксиомы расширения Армстронга в той редакции, которая приведена
в тексте врезки "Полное множество правил вывода" на с. 121.
c) Псевдотранзитивность (pseudotransitivity). Предположим, что выполняются FD
Ах А2 - Ап —> Вх В2 - Вт и С\ С2 - Q —> D, причем все Bh B2,..., Вт принадлежат
множеству {Сь С2,..., С*}. Тогда имеет место AlA2-AnElE2~Ej-^D, где EhE2,...,Ej
представляют собой те Сь С2,..., Q, которые не совпадают ни с одним Вь Въ..., Вт.
d) Сложение (addition). Если справедливы FD А\А2 —Ап-*ВХВ2 —Вт
и С\ С2 — Ск —> Dx D2 — Dj, справедлива и FD
Л! А2 .. А„ С, С2 ••• Ск -» Вх В2 - Вт Dx D2 - Dj.
Если некоторые из атрибутов АьА2,...,Ап и Сь С2,..., Q либо ВиВ2,...,Вт
и Du Оъ..., Dj попарно совпадают, необходимо удалить одинаковые
элементы, оставив единственную копию каждого из них.
! Упражнение 3.5.4. Докажите, что каждое из приведенных ниже утверждений не
является верным правилом вывода на основе заданных FD, и предъявите экземпляр
отношения, который удовлетворяет заданным FD (перечисленным после слова
"если"), но не удовлетворяет производным FD (указанным после слова "то").
* а) Если А -^ В, то В -»А.
b) Если АВ-^>СнА-^ С, то В-* С.
c) Если А В -4 С, то А -^ С или В -4 С.
! Упражнение 3.5.5. Докажите, что если некоторое отношение не обладает
атрибутами, которые функционально обусловлены всеми другими атрибутами, то для этого
отношения не существует нетривиальных FD.
! Упражнение 3.5.6. Пусть X и Y — множества атрибутов. Докажите, что если
X с Y, тоХ+сК+ при условии, что замыкания вычислены применительно к тем
же множествам FD.
! Упражнение 3.5.7. Докажите, что (Х+)+ = Х+.
!! Упражнение 3.5.8. Говорят, что множество X атрибутов замкнуто (closed) по
отношению к заданному набору FD, если Х+ = Х. Рассмотрим схему отношения
R(A, В, С, D) и неопределенное множество FD. Если будет известно, какие
множества атрибутов замкнуты, мы сможем выявить все FD. Каковы эти FD, если
* а) все множества четырех атрибутов замкнуты;
b) замкнутые множества — это 0 и {А, В, С, D};
c) замкнутые множества — это 0, {А, В] и {А, В, С, D].
! Упражнение 3.5.9. Найдите все минимальные базисы для множества FD и
отношения, которые были рассмотрены в примере 3.22 на с. 119.
! Упражнение 3.5.10. Пусть дано отношение R(A, В, С, D, Е) с некоторым набором
FD и необходимо отыскать FD, справедливые для отношения, которое получено
проецированием R на схему S(A, В, С). Найдите FD, удовлетворяющие S, если
наборы FD для R таковы:
* a) AB-+DE, С-^Е, О^СиЕ-^А;
Ъ) A-^D, В D-^E, АС->£и££->#;
122
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
c) A#->D, AC->£, #C->D, D->A и £->#;
d) A->#, #->C, C-^D, D-^E и E-^A.
В каждом из случаев достаточно предъявить минимальный базис для полного
множества FD, справедливых для S.
!! Упражнение 3.5.11. Докажите, что если некоторая FD F следует из определенных
заданных FD, то можно обосновать ее справедливость на основе этих FD,
используя аксиомы Армстронга (см. врезку "Полное множество правил вывода" на
с. 121). Воспользуйтесь следующим советом: обратитесь к алгоритму вычисления
замыкания множества атрибутов (см. раздел 3.5.3 на с. 115) и покажите, каким
образом каждый шаг алгоритма может быть сымитирован путем вывода некоторых
FD с применением аксиом Армстронга.
3.6. Проектирование реляционных схем
Небрежный выбор реляционной схемы базы данных способен повлечь за собой
немалые проблемы. Например, в примере 3.6 на с. 96 было показано, что
произойдет, если объединить отношение для связи типа "многие ко многим" с отношением
для одного из множеств сущностей, соединяемых этой связью. Основной изъян,
который мы обозначили, связан с избыточностью данных, когда одно и то же
содержимое некоего атрибута повторяется в нескольких кортежах. Факт возникновения
избыточности мы проиллюстрировали на рис. 3.17 (см. с. 107), который
воспроизводится ниже в виде рис. 3.21: значения атрибутов length ("продолжительность")
wfilmType ("тип пленки") для сущностей-"кинофильмов" с названиями (title)
"Star Wars" и "Wayne's World" повторяются неоднократно.
В этом разделе мы обсудим некоторые аспекты проектирования добротных
реляционных схем баз данных, придерживаясь такой последовательности изложения.
1. Подробно рассмотрим аномалии (anomalies), возникающие при выборе
неправильного подхода к проектированию.
2. Введем понятие декомпозиции (decomposition), определяющее способ разбиения
реляционной схемы (т.е. множества атрибутов) на две более "мелкие" схемы.
3. Дадим определение так называемой нормальной формы Бойса-Кодда (Воусе-
Codd normal form — BCNF) — условия, которое исключает аномалии
реляционной схемы.
4. Объединим все рассмотренные положения и поясним, как добиться
выполнения условия BCNF посредством декомпозиции реляционных схем.
title
Star Wars
Star Wars
Star Wars
Mighty Ducks
Wayne's World
Wayne's World
year
1977
1977
1977
1991
1992
1992
length
124
124
124
104
95
95
film Type
color
color
color
color
color
color
studioName
Fox
Fox
Fox
Disney
Paramount
Paramount
starName
Carrie Fisher
Mark Hamill
Harrison Ford
Emilio Estevez
Dana Carvey
Mike Meyers
Рис. 3.21. Экземпляр отношения Movies, представляющий аномалии
3.6.1. Аномалии
Проблемы, подобные избыточности, которая возникает при попытке
"заталкивания" в единственное отношение слишком большого числа атрибутов, принято назы-
3.6. ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ СХЕМ
123
вать аномалиями (anomalies). Разновидности аномалий, с которыми приходится иметь
дело наиболее часто, перечислены ниже.
1. Избыточность (redundancy). Одинаковые элементы информации повторяются
многократно в нескольких кортежах. Примером может служить содержимое
атрибутов length ("продолжительность") и filmType ("тип пленки") экземпляра
отношения Movies, приведенного на рис. 3.21.
2. Аномалии изменения (update anomalies). Один и тот же фрагмент данных
изменяется в одном кортеже, но остается нетронутым в другом. Если, например, вдруг
выяснится, что подлинное значение продолжительности воспроизведения
кинофильма "Star Wars" равно 125 минутам, а не 124, как считалось прежде,
вполне возможно, не проявив аккуратности, изменить его в одном кортеже
отношения Movies (см. рис. 3.21), но забыть сделать то же самое в двух других
кортежах. Вы, разумеется, вправе возразить, что вряд ли, дескать, найдется
столь неосмотрительный человек, способный на подобные "подвиги". Тем не
менее лучше исправить структуру отношения, дабы полностью исключить
вероятность появления таких ошибок.
3. Аномалии удаления (deletion anomalies). Если множество значений становится
пустым, это косвенным образом может привести к потере некоторой другой
информации. Например, удалив из отношения Movies (см. рис. 3.21) данные
об актере Эмилио Эстевезе (Emilio Estevez), участвовавшем в работе над
фильмом "Mighty Ducks", мы лишимся какой бы то ни было информации об
актерах, связанных с этим фильмом. Более того, единственный кортеж отношения,
представляющий сведения о фильме "Mighty Ducks", попросту пропадет вместе
со всей информацией о фильме, включая данные о годе его производства,
продолжительности, типе пленки и названии киностудии.
3.6.2. Декомпозиция отношений
Один из наиболее приемлемых способов устранения аномалий, рассмотренных
выше, состоит в декомпозиции (decomposing) отношений. Декомпозиция отношения R
предполагает разбиение множества атрибутов R с целью построения схем двух новых
отношений с последующим занесением в эти отношения определенных кортежей
отношения R. После описания процесса декомпозиции как такового мы сосредоточим
внимание на критериях выбора такого варианта композиции, который позволяет
избавиться от аномалий исходного отношения.
Заданное отношение R со схемой {Аь А2,..., Ап] может быть подвергнуто
декомпозиции в два отношения S и Т, которым соответствуют схемы {Вь В2,..., Вт]
и {Сь С2,..., Q}, удовлетворяющие перечисленным ниже условиям.
1. {Ль А2,..., Ап) = {Вь В2,..., Вт) U {Сь С2,..., С*}.
2. Кортежи отношения S являются проекциями (projections) всех кортежей
отношения R на множество атрибутов {Вь В2,..., Вт]. Другими словами, в каждом кортеже
t текущего экземпляра R выбираются компоненты, соответствующие атрибутам
Bh B2,..., Вт. Эти компоненты образуют новый кортеж, который становится
принадлежностью текущего экземпляра отношения S. Однако отношения являются
множествами, и при проецировании двух различных кортежей R на схему S могут
быть получены идентичные кортежи отношения S. В подобных случаях
следует помещать в S только одну копию кортежа из набора одинаковых кортежей.
3. Аналогично, кортежи отношения Т являются проекциями всех кортежей
текущего экземпляра отношения R на множество атрибутов {Сь С2,..., С*}.
124
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Пример 3.24. Выполним декомпозицию отношения Movies, экземпляр которого
изображен на рис. 3.21. Вначале осуществим декомпозицию схемы. Наш выбор,
достоинства которого освещены в следующем разделе, состоит в получении на основе
отношения Movies двух отношений:
1) Moviesl, в схему которого входят все атрибуты отношения Movies, за
исключением starNarne;
2) Movies2, схема которого состоит из трех атрибутов — title, year и starNarne.
Теперь рассмотрим процесс декомпозиции экземпляра отношения Movies на
примере набора данных, приведенных на рис. 3.21. Построим проекцию экземпляра
Movies на множество атрибутов схемы Moviesl,
{title, year, length, f ilrnType, studioNarne}.
Три первых кортежа экземпляра отношения Moviesl обладают одинаковыми
значениями во всех пяти атрибутах:
(Star Wars, 1977, 124, color, Fox).
Четвертый кортеж содержит другие значения тех же атрибутов, а пятый и шестой
кортежи вновь совпадают во всех пяти атрибутах. Итоговый экземпляр Moviesl после
удаления повторяющихся кортежей показан на рис. 3.22.
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
film Type
color
color
color
studioNarne
Fox
Disney
Paramount
Рис. 3.22. Экземпляр отношения Moviesl
Теперь рассмотрим проекцию экземпляра отношения Movies (см. рис. 3.21) на
схему Movies2. Каждый из шести кортежей отношения Movies в этом случае
отличается от других по меньшей мере в одном из атрибутов title, year или starNarne.
Результат проецирования изображен на рис. 3.23.
title
Star Wars
Star Wars
Star Wars
Mighty Ducks
Wayne's World
Wayne's World
year
1977
1977
1977
1991
1992
1992
starNarne
Carrie Fisher
Mark Harnill
Harrison Ford
Ernilio Estevez
Dana Carvey
Mike Meyers
Рис. 3.23. Экземпляр отношения Movies2
□
Обратим ваше внимание на то, каким образом рассмотренный процесс
декомпозиции ликвидирует аномалии, о которых мы говорили в разделе 3.6.1 на с. 123.
Избыточность устранена полностью: скажем, значение продолжительности воспроизведения
(length) каждого кинофильма включено в экземпляр отношения Moviesl только
единожды. Опасность возникновения аномалии изменения также предотвращена: значение
продолжительности воспроизведения (length) кинофильма "Star Wars", например,
может быть модифицировано только в одном месте, и нам никак не удастся задать две
различных величины length для одной и той же сущности "кинофильм". Наконец,
3.6. ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ СХЕМ
125
мы избавились и от вероятной аномалии удаления: если, скажем, изъять данные обо
всех актерах, снявшихся в фильме "Mighty Ducks", это приведет к исчезновению
соответствующих кортежей из отношения Movies2, но все другие сведения о фильме
"Mighty Ducks", хранящиеся в отношении Movies 1, останутся в неприкосновенности.
Может показаться, что экземпляр отношения Movies2 все еще избыточен,
поскольку, дескать, одни и те же пары значений атрибутов title и year повторяются
несколько раз. Эти атрибуты, однако, образуют ключ множества сущностей Movies
("кинофильмы"), и более лаконичного способа идентификации сущности-"кинофильма" в данном
случае не существует. Кроме того, отношение Movies2 не предрасположено к
возникновению аномалии изменения. Например, можно было бы допустить, что, изменив
(скажем, на 2003) значение атрибута year в кортеже, которому отвечает значение
"Carrie Fisher" атрибута starName, и оставив без изменения значения атрибута year
в двух других кортежах, представляющих фильм "Star Wars", мы тем самым спровоцируем
появление аномалии изменения. Однако в предусмотренных нами функциональных
зависимостях нет ничего такого, что препятствовало бы включению в отношение Movies2
кортежа, описывающего другой фильм "Star Wars", снятый в 2003 году при участии той
же Кэрри Фишер. Поэтому запрещать возможность изменения содержимого атрибута
year неправомерно, поскольку результат вовсе не обязательно окажется ошибочным.
3.6.3. Нормальная форма Бойса—Кодда
Цель декомпозиции состоит в замене одного отношения несколькими другими, не
содержащими аномалий. Существует простое условие, при выполнении которого
полностью гарантируется отсутствие аномалий. Это условие называют нормальной формой
Бойса—Кодда (Boyce-Codd normal form — BCNF).
• Отношение R удовлетворяет BCNF, если и только если выполняется следующее
требование: всякий раз, когда для отношения R существует некоторая
нетривиальная FD АХА2-■ Ап—> В, соответствующее множество {Аи А2щ..., Ап]
представляет суперключ для R.
Другими словами, атрибуты левой части любой нетривиальной FD должны
образовывать суперключ. Напомним, что суперключ может быть не обязательно минимальным.
Поэтому равноценное определение условия BCNF выглядит так: левая часть каждой
нетривиальной FD должна содержать ключ.
Если найдена FD, преступающая условие BCNF, иногда возможно отступить от
простой схемы полной декомпозиции исходного отношения в отношения,
удовлетворяющие BCNF, если попробовать расширить правую часть этой FD, включив в нее
атрибуты правых частей всех других FD с той же левой частью, независимо от того, нарушают
они условие BCNF или нет. Ниже приведено альтернативное определение BCNF,
подразумевающее отыскание некоего множества функциональных зависимостей с общей
левой частью, таких что по меньшей мере одна из этих FD является нетривиальной.
• Отношение R удовлетворяет BCNF, если и только если выполняется следующее
требование: всякий раз, когда для отношения R существует некоторая
нетривиальная FD Ах А2 — Ап —> В{ В2 — Вт, соответствующее множество {Аь А2,..., Ап)
представляет суперключ для R.
Это определение BCNF равносильно исходному. Напомним, что FD вида
А1А2-Ап-^В1В2-Вт-~ это сокращенная запись множества FD АХА2-Ап-* Bh где
/= 1, 2,..., т. Поскольку должен существовать по меньшей мере один атрибут Bh не
принадлежащий множеству {АЬА2, ...,Ап) (в противном случае FD AlA2~An-^>BlB2-Bm
становится тривиальной), FD АХА2- • Ап—> Я, представляет случай совпадения с
исходным определением.
126
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Пример 3.25. Отношение Movies, экземпляр которого приведен на рис. 3.21 (см. с. 123), не
удовлетворяет условию BCNF. Чтобы понять, почему, для начала мы должны
определить, какие множества атрибутов являются ключами. В примере 3.13 на с. 108 мы
обосновали, что ключом этого отношения служит множество атрибутов {title, year, starName}.
Поэтому любое множество, содержащее указанные атрибуты, является суперключом.
Доводы, приведенные в примере 3.13, могут быть использованы и для объяснения того,
почему ни одно из множеств, которое не охватывает одновременно все три атрибута —
title, year и starName, — не может быть суперключом. Мы вправе утверждать,
что {title, year, starName} — это единственный ключ для отношения Movies.
Рассмотрим, однако, FD
title year —> length filmType studioName,
которая удовлетворяет отношению Movies (об этом мы говорили в том же примере
3.13). К несчастью, левая часть этой FD не является суперключом: в частности, нам
известно, что атрибуты title и year не способны функционально обусловить шестой
атрибут отношения, starName. Поэтому наличие этой FD свидетельствует, что
отношение Movies не удовлетворяет требованию BCNF. Кроме того, согласно исходному
определению BCNF, в соответствии с которым FD должна содержать единственный
атрибут в правой части, мы можем привести более частные примеры нарушения
BCNF, такие как title year —> length. □
Пример 3.26. Напротив, отношение Movies 1, экземпляр которого представлен на
рис. 3.22 (см. с. 125), удовлетворяет условию BCNF. Поскольку для этого отношения FD
title year —> length filmType studioName
справедлива и мы доказали, что ни один из атрибутов title и year отдельно не в
состоянии функционально обусловить все другие атрибуты, единственным ключом для
отношения Moviesl будет {title, year}. Помимо того, нетривиальные FD должны
обладать, как минимум, атрибутами title и year в левой части, и поэтому
множества "левосторонних" атрибутов обязаны быть суперключами. Итак, отношение
Moviesl удовлетворяет требованию BCNF. □
Пример 3.27. Мы вправе утверждать, что любое отношение, содержащее два атрибута,
удовлетворяет условию BCNF. Чтобы это доказать, необходимо проверить все
возможные нетривиальные FD с единственным атрибутом в правой части. Подобных
вариантов на самом деле не так уж много, поэтому мы просто их перечислим.
Обозначим атрибуты отношения как А и В.
1. Нетривиальных FD не существует. Можно безусловно утверждать, что
требование BCNF удовлетворяется, поскольку нарушить его в состоянии только какая-
либо нетривиальная FD. Заметим, между прочим, что единственный ключ в
таком случае — это {Л, В].
2. А —> В выполняется, а В —> А — нет. В этом случае А — единственный ключ,
и каждая нетривиальная FD должна содержать А в левой части (на самом деле,
в левой части будет присутствовать только А). Условие BCNF не нарушается.
3. В —> А выполняется, а А —> В — нет. Случай симметричен по отношению
к предыдущему.
4. Имеют место обе FD, А —> В и В —>А. Как А, так и В являются ключами. Любая
FD определенно должна содержать в левой части по меньшей мере один из
них, поэтому условие BCNF не нарушается.
Полезно обратить внимание на следствие, вытекающее из случая (4): для
отношения может быть создано несколько ключей. Условие BCNF гласит, что левая часть
3.6. ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ СХЕМ
127
любой нетривиальной FD должна содержать некоторый ключ, а не все ключи.
Заметьте также, что отношение с двумя атрибутами, каждый из которых взаимно
обусловливает другой, не так уж и неправдоподобно. Например, компания вправе назначать
своим служащим уникальные идентификационные коды и наряду с ними сохранять
в базе данных номера полисов социального страхования. В отношении с атрибутами
ernpiD ("код служащего") и ssNo ("номер полиса социального страхования") каждый
из них будет служить функциональным обоснованием другого. Иными словами,
каждый из атрибутов является ключом, и мы не вправе ожидать, что найдем в отношении
два кортежа, которые совпадают в каком-либо атрибуте. □
3.6.4. Декомпозиция в BCNF
Последовательно выбирая подходящие варианты декомпозиции, мы можем разбить
любую реляционную схему на коллекцию подмножеств ее атрибутов, каждое из
которых обладает указанными ниже важными свойствами.
1. Подмножества являются схемами отношений, удовлетворяющих условию BCNF.
2. Данные исходного отношения достоверно представляются отношениями,
полученными в результате декомпозиции (этот аспект более подробно обсуждается
в разделе 3.6.5 на с. 132). Грубо говоря, необходимо обеспечить возможность
точной реконструкции экземпляра исходного отношения на основании
экземпляров отношений, служащих итогом декомпозиции.
Рассмотренный выше пример 3.27 предлагает, как может показаться, одно из верных
решений проблемы: все, что следует сделать, — это разбить схему исходного
отношения на подмножества, состоящие из двух атрибутов, и все итоговые отношения
определенно будут удовлетворять условию BCNF. Подобный прямолинейный подход,
однако, в общем случае не удовлетворяет требованию (2) (что будет показано в разделе
3.6.5). В действительности следует поступать более гибко и осмотрительно, используя
в качестве ориентира, подсказывающего направление дальнейших действий по
декомпозиции, те FD, которые нарушают условие BCNF для конкретного отношения.
Стратегия декомпозиции, которой мы собираемся следовать, состоит в поиске
нетривиальной FD А{А2 • • Ап—> В{ В2 ■• - Вт, попирающей условие BCNF; множество
{AhA2,...,An} в этом случае не является суперключом. В качестве эвристического
правила можно предложить добавлять в правую часть FD все те атрибуты, которые
функционально обусловлены атрибутами множества {АьА2,...,Ап}. На рис. 3.24 показано,
как множество атрибутов разбивается на две перекрывающиеся реляционные схемы.
Одна из них содержит все атрибуты, охватываемые "нарушающей" FD, а другая —
атрибуты левой части этой FD в совокупности со всеми атрибутами, которые не входят
в состав FD (т.е. все атрибуты отношения, за исключением тех Ви Въ ..., Вт, которые
не совпадают ни с одним из Аь А2, ..., Ап).
Другие атрибуты [ Атрибуты А Атрибуты В
Рис. 3.24. Стратегия декомпозиции реляционной
схемы, принимающая во внимание FD, которая
нарушает условие BCNF
128
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Пример 3.28. Рассмотрим отношение Movies, экземпляр которого изображен на
рис. 3.21 (см. с. 123). В примере 3.25 на с. 127 говорилось, что FD
title year -» length filrnType studioNarne
нарушает условие BCNF. В этом конкретном случае правая часть FD уже содержит
все атрибуты, функционально обусловливаемые атрибутами title и year, так что мы
можем воспользоваться этой FD непосредственно, чтобы осуществить декомпозицию
отношения Movies в две схемы, охватывающие:
1) все атрибуты FD, т.е.
{title, year, length, filrnType, studioNarne};
2) все атрибуты отношения Movies, за исключением трех, входящих в правую
часть FD, т.е.
{title, year, starNarne}.
Заметьте, что это те же схемы, которые были выбраны для отношений Movies 1
HMovies2, рассмотренных в примере 3.24 на с. 125. В примере 3.26 на с. 127 мы
показали, что обе схемы удовлетворяют условию BCNF. □
title
Star Wars
Mighty Ducks
Wayne's World
Addarns Family
year
1977
1991
1992
1991
length
124
104
95
102
filrnType
color
color
color
color
studioNarne
Fox
Disney
Paramount
Paramount
studioAddr
Hollywood
Buena Vista
Hollywood
Hollywood
Рис. 3.25. Экземпляр отношения MovieStudio
Пример 3.29. Рассмотрим отношение, с которым вы познакомились в примере 3.21 на
с. 118. Это отношение (назовем его MovieStudio) хранит информацию о фильмах,
студиях-владельцах этих фильмов и адресах студий. Экземпляр отношения
MovieStudio приведен на рис. 3.25.
Заметим, что MovieStudio содержит избыточные данные. Поскольку к
привычному набору кортежей мы добавили еще один, описывающий другой фильм, снятый на
киностудии "Paramount", адрес этой студии (значение атрибута studioAddr)
сохраняется дважды. Однако источник проблемы отнюдь не тот же, о каком мы говорили
раньше. В нескольких предыдущих примерах избыточность была обусловлена тем, что
информация о связи типа "многие ко многим" (об актерах, снявшихся в
определенном фильме) сохранялась вместе с данными о самом фильме. Здесь же о
множественности связи речь не идет: представляются сведения о кинофильме (title, year,
length и filrnType), строго определенной киностудии (studioNarne), осуществившей
съемку этого фильма, и адресе студии (studioAddr).
В нашем случае трудность связана с наличием транзитивной зависимости (transitive
dependency). Иными словами, как упоминалось в примере 3.21 на с. 118, для
отношения MovieStudio справедливы следующие FD:
title year —> studioNarne
studioNarne —> studioAddr.
Применив правило транзитивности, мы можем получить на их основе новую FD:
title year —> studioAddr.
То есть значения атрибутов title ("название") и year ("год производства")
"кинофильма" (ключи множества сущностей Movies) функционально обусловливают
значение "адреса" (studioAddr) студии, владеющей этим кинофильмом. Поскольку
title year —> length filrnType
3.6. ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ СХЕМ
129
является еще одной очевидной функциональной зависимостью, мы приходим к
заключению, что {title, year} представляет собой ключ отношения, причем этот ключ
является единственным.
С другой стороны, FD
studioNarne —> studioAddr,
которая использовалась выше в качестве "операнда" правила транзитивности,
нетривиальна, но атрибуты ее левой части не образуют суперключ. Этот вывод
свидетельствует о том, что отношение Moviestudiо не удовлетворяет условию BCNF. Решим
проблему, следуя той же стратегии декомпозиции. Первая из схем отношений,
получаемых в результате разбиения исходной схемы, должна содержать все атрибуты FD
как таковой, т.е. {studioNarne, studioAddr}, а вторая схема — все атрибуты
отношения Moviestudio, за исключением studioAddr, который используется в правой
части FD, "провоцирующей" декомпозицию:
{title, year, length, filmType, studioNarne}.
Проецируя экземпляр отношения, показанный на рис. 3.25, на указанные схемы,
получим два отношения (назовем их MovieStudiol и MovieStudio2), приведенные
на рис. 3.26 и 3.27 соответственно. Каждое из отношений удовлетворяет условию
BCNF. В разделе 3.5.7 на с. 120 мы говорили, что для каждого из отношений,
полученных в результате декомпозиции схемы на ряд частных схем, необходимо
определить набор FD, удовлетворяющих отношению, посредством вычисления (на основе
полного множества заданных FD) замыкания для соответствующего подмножества
атрибутов. В общем случае сложность этой задачи оценивается экспоненциальной
функцией от количества атрибутов в частных схемах, но, как мы упоминали в том же
разделе 3.5.7, возможно использование ряда упрощений.
В нашем случае нетрудно убедиться, что базисом для функциональных
зависимостей отношения MovieStudiol служит FD
title year —> length filmType studioNarne,
а для отношения Movies tudi o2 единственной нетривиальной FD является
studioNarne —> studioAddr.
Таким образом, единственные ключи для отношений MovieStudiol и MovieStudio2 —
это {title, year} и {studioNarne} соответственно. В каждом из случаев
нетривиальных FD, в левой части которых отсутствовали бы указанные ключевые
атрибуты, не существует.
title
Star Wars
Mighty Ducks
Wayne's World
Addarns Family
year
1977
1991
1992
1991
length
124
104
95
102
filmType
color
color
color
color
studioNarne
Fox
Disney
Paramount
Paramount
Рис. 3.26. Экземпляр отношения MovieStudiol
studioNarne
Fox
Disney
Paramount
studioAddr
Hollywood
Buena Vista
Hollywood
Рис. 3.27. Экземпляр отношения Moviestudio2
□
130
ГЛАВА З. РЕЛЯЦИОННАЯ МОДЕЛЬ
В предыдущих примерах одной удачной итерации декомпозиции оказывалось
достаточно для получения набора отношений, удовлетворяющих условию BCNF. В
общем случае, разумеется, не все так просто.
Пример 3.30. Обобщим условия примера 3.29 на случай цепочки функциональных
зависимостей. Рассмотрим отношение с такой схемой:
{title, year, studioName, president, presAddr}.
Другими словами, каждый кортеж отношения включает данные о кинофильме,
студии, на которой он снят, а также о президенте этой студии и адресе его проживания.
Мы подразумеваем, что отношению удовлетворяют три FD:
title year —> studioName
studioName —> president
president —> presAddr.
Единственный ключ отношения — это {title, year}. Поэтому две последние FD из
трех, указанных выше, нарушают условие BCNF. Предположим, что в качестве
отправного пункта декомпозиции выбрана FD
studioName —> president.
Для начала следует добавить в правую часть этой FD любые другие атрибуты из
замыкания {studioName}. В соответствии с правилом транзитивности, применяемым по
отношению к FD studioName —> president и president —> presAddr, получим:
studioName —> presAddr.
Объединение двух FD с атрибутом studioName в левой части даст в результате
studioName —> president presAddr.
Эта FD обладает максимально расширенной правой частью, поэтому мы можем
приступить к декомпозиции схемы исходного отношения в две следующие схемы:
{title, year, studioName},
{studioName, president, presAddr}.
Следуя алгоритму проецирования, рассмотренному в разделе 3.5.7 на с. 120,
определим, что FD для первого отношения обладают базисом
title year —> studioName,
а для второго — базисом
studioName —> president
president —> presAddr.
Поэтому {title, year} — единственный ключ первого отношения, и, следовательно,
оно удовлетворяет условию BCNF. Второе отношение обладает ключом
{studioName}, но для него имеет место дополнительная функциональная зависимость
president —> presAddr,
которая преступает условие BCNF. Необходимо выполнить еще одну итерацию
декомпозиции. Итоговые реляционные схемы, удовлетворяющие требованию BCNF, таковы:
{title, year, studioName}
{studioName, president}
{president, presAddr}.
□
Вообще говоря, декомпозицию следует проводить столько раз, сколько требуется,
и до тех пор, пока все отношения не будут удовлетворять условию BCNF. Мы можем
быть уверены в безусловной "сходимости" процесса, поскольку всякий раз, когда
правило декомпозиции применяется для некоторого отношения R, два итоговых отношения
3.6. ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ СХЕМ
131
будут обладать заведомо меньшим числом атрибутов, нежели R. Как было показано
в примере 3.27 на с. 127, если на некотором этапе процесса получено отношение с
двумя атрибутами, оно гарантированно удовлетворяет BCNF; часто встречаются ситуации,
когда требованию BCNF соответствуют и отношения с большим количеством атрибутов.
3.6.5. Реконструкция данных из отношений декомпозиции
Теперь сосредоточим внимание на вопросе, действительно ли алгоритм
декомпозиции, рассмотренный в предыдущем разделе, сохраняет всю информацию исходного
отношения. Иными словами, можно ли, воспользовавшись "проекциями" данных
отправного отношения на реляционные схемы, полученные в результате декомпозиции,
"объединить" эти данные, чтобы получить именно те и только те кортежи, которые
содержались в экземпляре исходного отношения?
Чтобы упростить обсуждение, рассмотрим некоторое отношение /?(Л, В, Q и FD
В _> с, нарушающую условие BCNF. Возможно, скажем, что (как в примере 3.29 на
с. 129) существует цепочка транзитивных зависимостей, включающая другую FD,
А —>Я. В этом случае {Л} представляет собой единственный ключ, и левая часть FD
В _> с, очевидно, не является суперключом. Другая альтернатива связана с тем, что
В _> с может оказаться единственной нетривиальной FD, и в такой ситуации
единственным ключом будет {А, В]. И вновь левая часть FD В —> С не является суперключом.
В любом случае декомпозиция, основанная на FD В —> С, разделит атрибуты
исходного отношения на схемы [А, В] и {В, С].
Пусть г — это кортеж R. Мы можем записать, что г - (а, Ь, с), где а, Ъ и с —
компоненты кортежа г, отвечающие атрибутам А, В и С. Кортеж t проецируется как {а, Ь) на
схему отношения {А, В] и как (Ь, с) — на схему отношения [В, С].
Возможно соединить (join) кортеж отношения {А, В] с кортежем отношения {В, С],
учитывая, что они совпадают в компоненте В. В частности, (а, Ь) соединяется с (Ь, с),
давая в результате исходный кортеж г = (а, Ь, с). Таким образом, независимо от того,
какой именно кортеж г рассматривался, всегда удастся осуществить соединение его
проекций, чтобы получить кортеж t вновь.
Однако гарантии восстановления каждого отдельного кортежа еще не достаточно,
дабы поручиться, что исходное отношение R верно представляется экземплярами
отношений, служащими результатом декомпозиции. Что произойдет, например, если
в R существуют два кортежа, г- (а, Ь, с) и v = (d, b, е)? Проецируя t на {А, В], мы получим
и - (а, Ь), а результатом проекции v на {В, С) будет w = (b, е), как показано на рис. 3.28.
Кортежи и и w допускают соединение, так как они совпадают в компонентах В.
Результатом окажется кортеж х = (а, Ь, е). Возможно ли, чтобы х не был действительным
кортежем отношения R?
Поскольку мы предполагаем, что FD В -> С справедлива для отношения R, ответ на
вопрос отрицателен. Эта FD, напомним, подразумевает, что любые два кортежа
отношения R, совпадающие в компонентах В, должны совпадать и в компонентах С. Так
как г и v совпадают в компонентах В (компонент В обоих кортежей содержит значение
Ь), они совпадают и в компонентах С. Отсюда следует, что с = е, т.е. два значения,
которые воспринимались нами как различные, на самом деле равны. Поэтому (а, Ь, е) —
это в действительности не что иное, как {а, Ь, с), т.е. х = t.
Поскольку / принадлежит R, значит, и х принадлежит /?. Иными словами, если FD
В —> С имеет место, соединение двух кортежей-проекций не способно привести
к получению недействительного кортежа. Напротив, каждый кортеж, получаемый
в результате соединения, безусловно содержится в R.
Приведенные нами доводы остаются в силе и в общем случае. Мы подразумевали,
будто Л, В и С — это отдельные атрибуты, но ничто не мешает использовать те же
аргументы, если трактовать Л, В и С как произвольные множества атрибутов. Иными
132
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
словами, мы находим любую подходящую FD, нарушающую условие BCNF,
интерпретируем В как множество атрибутов ее левой части,
правой части, отсутствующих в левой, а А — как
множество атрибутов, которых нет ни в правой части
FD, ни в левой. Итоговое правило приведено ниже.
• Если декомпозиция проводится в соответствии
с алгоритмом, описанным в разделе 3.6.4 на
с. 128, исходное отношение может быть
реконструировано совершенно точно посредством
соединения кортежей отношений,
представляющих результат декомпозиции, независимо
от того, какие конкретные варианты
декомпозиции были выбраны.
Если осуществлять декомпозицию, не принимая во
внимание FD, преступающие условие BCNF,
возможность адекватного восстановления исходного
отношения в обшем случае не гарантируется. Вот пример.
Пример 3.31. Предположим, что, как и прежде,
имеется отношение R(A, В, С), но FD 5->Сна сей раз не
выполняется. Тогда отношение R может состоять из
двух следующих кортежей:
С
как множество атрибутов
А В С
Рис. 3.28. Соединение двух
тежей отношений-проекций
кор-
А
1
4
В
2
2
С
3
5
Проекции R на отношения со схемами {А, В) и {В, С] можно представить как
А
1
4
В
2
2
В
2
2
С
3
5
соответственно. Поскольку во всех четырех кортежах присутствует одно и то же
значение компонента В, 2, каждый кортеж одного отношения допускает соединение с
любым из кортежей другого отношения. Поэтому, попытавшись восстановить
исходный экземпляр отношения /?, мы получим
А
1
1
4
4
В
2
2
2
2
С
3
5
3
5
Очевидно, что результат "намного превосходит" тот, который мы ожидали: здесь
присутствуют кортежи (1, 2, 5) и (4, 2, 3), которых не было в исходном отношении R. □
3.6. ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ СХЕМ
133
Другие нормальные формы
Если есть "третья нормальная форма", что же стряслось с первыми двумя? Не
сомневайтесь, в свое время определили и их, но сегодня они находят ограниченное
применение. Первая нормальная форма (first normal form) устанавливает простое
условие: каждый компонент каждого кортежа должен содержать атомарное значение.
Вторая нормальная форма (second normal form) — это менее жесткий вариант
третьей нормальной формы, который допускает наличие транзитивных FD, но
запрещает существование нетривиальной FD с левой частью, представляющей собой
подмножество ключа. Существует и четвертая нормальная форма (fourth normal form),
с которой вы познакомитесь в разделе 3.7 на с. 137.
3.6.6. Третья нормальная форма
Иногда можно встретить отношение с соответствующими FD, которые не
удовлетворяют условию BCNF, но декомпозиция отношения, тем не менее, считается
нецелесообразной или даже неправомочной. Следующий пример представляет довольно
типичную ситуацию.
Пример 3.32. Предположим, что имеется отношение Bookings ("заказы на билеты")
с такими атрибутами:
1) title — название кинофильма;
2) theater — наименование кинотеатра, где демонстрируется фильм;
3) city — город, в котором расположен кинотеатр.
Кортеж (т, t, с) представляет кинофильм т, который демонстрируется в кинотеатре t,
расположенном в городе с.
Предположим, что справедливы следующие FD:
theater —> city-
title city —> theater.
Первая FD гласит, что некий кинотеатр расположен в одном строго определенном
городе. Вторая же FD не столь очевидна, но она основывается на том предположении,
что обычно билет на определенный фильм в двух кинотеатрах, расположенных в
одном городе, не заказывают (ладно, эта гипотеза довольно зыбка; считайте, что вторая
FD введена нами просто в методических целях).
Первым делом найдем ключи. Ни один из атрибутов, рассматриваемых отдельно, не
пригоден на роль ключа. Атрибут title, например, не является ключом, поскольку
один и тот же фильм может одновременно демонстрироваться в нескольких кинотеатрах
и нескольких городах.13 Атрибут theater сам по себе также не может быть ключевым,
так как, несмотря на то, что theater функционально обусловливает city, существуют
кинотеатры с несколькими залами, в которых в тот или иной момент времени
обычно показывают разные кинофильмы. Поэтому theater не служит функциональным
обоснованием title. Наконец, city не может быть ключом, поскольку в городе, как
правило, есть несколько кинотеатров, а в них обычно "идут" разные кинофильмы.
С другой стороны, два из трех возможных множеств, состоящих из двух атрибутов,
определенно могут выполнять функцию ключей. Вполне очевидно, что {title, city}
является ключом на основании FD, гласящей, что эти атрибуты функционально
обусловливают третий, theater.
12 В этом примере мы полагаем, что двух "свежих" кинофильмов с одним и тем же
названием не существует, хотя, как мы говорили прежде, вполне возможно совпадение названий
фильмов, выпущенных в разные годы.
134
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
Также правда и то, что ключом служит множество {theater, title}. Чтобы
понять, почему, обратимся к заданной FD theater —> city. На основании частного
случая правила расширения, рассмотренного в упражнении 3.5.3 (а) (см. с. 121),
справедлива и FD theater title -> city. Интуитивно ясно, что если атрибут theater,
взятый отдельно, функционально обусловливает значение атрибута city, то
множество атрибутов {theater, title} и подавно удовлетворяет этому предположению.
Оставшаяся пара атрибутов, city и theater, не в состоянии функционально
обусловить title, и поэтому она не может быть ключом. Таким образом, мы пришли
к заключению, что существуют только два ключа:
{title, city},
{theater, title).
Теперь факт нарушения условия BCNF становится явным, и виновник этого
"происшествия" — FD theater —> city, "левосторонний" атрибут которой,
theater, не является суперключом. Можно было бы, взяв за основу указанную F.D,
попытаться осуществить декомпозицию отношения в две реляционные схемы:
{theater, city},
{theater, title}.
Однако такой вариант декомпозиции приводит к проблеме, связанной с FD
title city —> theater.
Могут существовать экземпляры отношений, полученных в результате декомпозиции,
которые удовлетворяют условию FD theater —> city (это может быть проверено в
отношении {theater, city}), но после объединения приводят к экземпляру отношения, не
верному в смысле FD title city —> theater. Например, два экземпляра отношения,
theater
Guild
Park
city
Menlo Park
Menlo Park
и
theater
Guild
Park
title
The Net
The Net
вполне допустимы с точки зрения соответствующих им FD, но при объединении
дадут в результате два кортежа,
theater
Guild
Park
city
Menlo Park
Menlo Park
title
The Net
The Net
которые противоречат FD title city -» theater. □
Решение рассмотренной выше проблемы состоит в незначительном смягчении
условия BCNF, допускающем возможность практического использования реляционной
схемы (подобной схеме примера 3.32), которую нельзя подвергнуть декомпозиции
в отношения, удовлетворяющие BCNF, не теряя возможности проверить
справедливость каждой FD применительно к одному отношению. Это ослабленное условие
называют третьей нормальной формой (third normal form — 3NF).
• Отношение R удовлетворяет 3NF, если выполняется следующее требование:
всякий раз, когда для отношения R существует некоторая нетривиальная FD
Ах А2 - Ап -» #, соответствующее множество {Ль А2,..., Ап] представляет супер-
ключ для R либо В является членом некоторого ключа.
3.6. ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННЫХ СХЕМ
135
Атрибут, принадлежащий некоторому ключу, часто называют первичным (prime).
Поэтому условие 3NF можно сформулировать и так: "Для каждой нетривиальной FD
должно выполняться одно из условий — либо атрибуты ее левой части представляют
суперключ, либо атрибуты правой части являются первичными".
Заметим, что различие между формами BCNF и 3NF обусловлено присутствием
в последней дополнительного предложения, "либо В является членом некоторого
ключа" (т.е. относится к категории первичных атрибутов). Это предложение и
позволяет "оправдать" FD, подобные theater-» city из примера 3.32, где
"правосторонний" аргумент city и в самом деле является первичным.
Доказательство того, что условие 3NF действительно адекватно выполняет
возложенные на него функции, выходит за рамки предмета нашей книги. Мы, однако,
всегда можем, не рискуя потерять информацию, осуществить декомпозицию
отношения в схемы, которые удовлетворяют условию 3NF и позволяют проверить
справедливость всех FD. Если при этом отношения не отвечают требованию BCNF, остается
вероятность их некоторой избыточности.
3.6.7. Упражнения к разделу 3.6
Упражнение 3.6.1. Для каждого из следующих отношений и наборов FD:
* а) /?(Л, В, С, D) с FD А В -> С, С -> D и D -» А;
* b) R(A, В, С, D) с FD В -» С и В -> D;
c) R(A,B,C,D) с FDA Я-> С, BC-^D, CD-^AnAD-^B;
d) R(A, В, С, D) с FD A -» В, В -> С, С -» D и D -» А;
e) R(A, В, С, D, Е) с FD А В -> С, D Е -> С, и В -> D;
f) R(A, В, С, D, Е) с FD А В -> С, С -> D, D -> В и D -> Е
выполните действия, указанные ниже:
i) отметьте все FD, нарушающие условие BCNF (приводить FD с несколькими
атрибутами в правой части не нужно); не забудьте рассмотреть те FD,
которые не относятся к множеству заданных, но могут быть выведены из них;
ii) если необходимо, выполните декомпозицию отношений в наборы схем,
удовлетворяющих BCNF;
iii) укажите все FD, нарушающие условие 3NF;
iv) если необходимо, выполните декомпозицию отношений в наборы схем,
удовлетворяющих 3NF.
Упражнение 3.6.2. В разделе 3.6.4 на с. 128 мы говорили о том, что желательно, если
это возможно, расширять правую часть FD, нарушающей условие BCNF. Впрочем,
делать это не обязательно. Рассмотрим отношение R со схемой {Л, В, С, £>}, которому
соответствуют FD А-^В и А-^С. Любая из названных FD преступает условие BCNF,
поскольку единственный ключ для отношения R — это {A, D]. Предположим, что
процесс декомпозиции выполняется с учетом FD А —> В. Получим ли мы совершенно тот
же результат, если сначала расширим эту FD до А —> В С? Почему да или почему нет?
! Упражнение 3.6.3. Пусть R — то же отношение, что и в упражнении 3.6.2, но к числу
FD, которые ему удовлетворяют, теперь относятся А —> В и В —> С. Вновь
сопоставьте результаты декомпозиции, основанной на FD A —> В, а затем на FD A —> В С.
! Упражнение 3.6.4. Пусть R — это отношение со схемой R(A, В, Q и FD А -> В.
Предположим, что R подвергается декомпозиции в схемы S(A, В) и Т(В, Q. Приведите
экземпляр отношения R, который после проецирования на 5 и Г не может быть
реконструирован посредством алгоритма объединения, рассмотренного в разделе 3.6.5 на с. 132.
136
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
3.7. Многозначные зависимости
Многозначная зависимость (multivalued dependency ~ MVD) — это утверждение
о том, что два атрибута или множества атрибутов независимы друг от друга. Это
условие, как будет показано позже, является обобщением понятия функциональной
зависимости (factional dependency — FD) в том смысле, что каждая FD подразумевает
справедливость соответствующей MVD. Существуют ситуации, в которых независимость
множеств атрибутов, однако, не может быть выражена в терминах FD. В этом разделе
мы постараемся рассказать об "истоках" многозначных зависимостей и
продемонстрировать примеры их применения в проектах баз данных.
3.7.1. Независимость атрибутов как причина избыточности
Встречаются ситуации, когда реляционная схема удовлетворяет условию BCNF, но
отношение все еще избыточно, и причина этого явления не связана с FD. Весьма
часто избыточность в схемах BCNF возникает при попытке представить в рамках одного
отношения данные нескольких связей типа "многие ко многим".
Пример 3.33. Вернемся к примеру "кинематографической" базы данных и предположим,
что актер вправе иметь несколько адресов проживания. Адрес может быть разбит на два
компонента — "номер дома и название улицы" (street) и "город" (city). Наряду с
именами (name) и адресами (street и city) актеров мы включим в отношение обычную
информацию связи Stars-in ("актеры-частники"), представляющую сведения о
кинофильмах — "название" (title) и "год производства" (year), — в которых актер снимался. На
рис. 3.29 представлен типичный экземпляр такого отношения.
На рис. 3.29 отображена информация о двух вымышленных адресах Кэрри Фишер
и трех широко известных кинофильмах с ее участием. Повода ассоциировать некоторый
адрес с одним кинофильмом и не делать этого для другого кинофильма нет.
Единственный способ описать тот факт, что "адреса" и "кинофильмы" — это независимые
свойства сущности "актер", состоит в том, чтобы представить каждое значение "адрес"
совместно с каждым значением "кинофильм". Однако построение всех комбинаций
"адрес—кинофильм" приводит к очевидной избыточности. Например, на рис. 3.29
каждый адрес Кэрри Фишер повторяется трижды (для каждого из кинофильмов, в
которых снялась актриса), а название каждого кинофильма — дважды (по числу адресов).
пате
С. Fisher
С. Fisher
С. Fisher
С. Fisher
С. Fisher
С. Fisher
street
123 Maple St.
5 Locust Ln.
123 Maple St.
5 Locust Ln.
123 Maple St.
5 Locust Ln.
city
Hollywood
Malibu
Hollywood
Malibu
Hollywood
Malibu
title
Star Wars
Star Wars
Empire Strikes Back
Empire Strikes Back
Return to the Jedi
Return to the Jedi
year
1977
1977
1980
1980
1983
1983
Рис. 3.29. Множество адресов не зависит от множества кинофильмов
Тем не менее отношение рис. 3.29 не нарушает условия BCNF. В
действительности оно вовсе не содержит каких бы то ни было нетривиальных FD. Например,
атрибут city функционально не обусловливается ни одним из четырех остальных
атрибутов. Некий "актер" может владеть двумя домами в разных городах, расположенными
на улицах с одним и тем же названием. Поэтому вполне допустимо существование
двух кортежей, которые совпадают во всех атрибутах, кроме city. Таким образом, FD
name street title year —> city
3.7. МНОГОЗНАЧНЫЕ ЗАВИСИМОСТИ
137
в контексте рассматриваемого отношения не справедлива. Задачу обоснования того,
что ни один из пяти других атрибутов функционально не обусловливается четырьмя
оставшимися, мы оставляем читателю. Поскольку нетривиальных FD не существует,
отсюда следует, что все пять атрибутов образуют единственный ключ и каких-либо
нарушений условия BCNF нет. □
3.7.2. Определение многозначной зависимости
Многозначная зависимость (multivalued dependency — MVD) — это утверждение
о том, что некоторое множество атрибутов отношения R не зависит от другого
множества атрибутов. Если говорить несколько строже, многозначная зависимость
Л,Л2
Я, #2
Вт
для отношения R имеет место тогда, когда выполняется следующее условие: если мы
сосредоточим внимание на кортежах R, которые в каждом из атрибутов АХ,АЪ..., А„
содержат определенные значения, то множество значений атрибутов Bh В2, ..., Вт не
зависит от множества значений атрибутов, не относящихся ни к АиА2,..., А„, ни
к Ви Въ ..., Вт. Еще более строгая формулировка условия MVD приведена ниже.
• Для каждой пары кортежей г и и отношения R, которые совпадают во всех
атрибутах АЬАЪ ...,А„, можно найти в R некоторый кортеж v, совпадающий:
a) с кортежами гимв атрибутах Аь А2, ..., Ап\
b) с кортежем г в атрибутах Вь Въ .,., Вт\
c) с кортежем и во всех атрибутах отношения R, которые не принадлежат ни
множеству {Аь А2,..., А„}, ни множеству {Вь Въ..., Вт).
Заметьте, что атрибуты t и и в контексте правила взаимозаменяемы; это позволяет
обосновать существование четвертого кортежа w, который совпадает смв атрибутах ВЬВЪ ...,Вт
и с t — в других атрибутах. Как следствие, для любых фиксированных значений
атрибутов АЬА2, ...,Ап связанные с ними значения Вь В2,..., Вт и других атрибутов
располагаются в любых возможных сочетаниях различных кортежей. На рис. 3.30 показано,
как кортеж v может соотноситься с кортежами г и и, сохраняя в силе условие MVD.
Атриб^
-I— А
т
»i
а\
ai
а\
А
Л7
)ибуты
В ~~+
*\ "
bl
h
Другие
-* атрибуты -►
ci
с2
с2
Рис, 3.30. Многозначная зависимость
гарантирует существование кортежа v
В общем случае можно полагать, что множества {Аь А2,..., Ап} и {Вь Въ..., Вт) (левая
и правая части MVD) не пересекаются. Однако, как и в случае с FD, допустимо при
необходимости добавлять некоторые из атрибутов AhA2,...,An в правую часть MVD.
Заметим также, что, в отличие от FD, которые допускают наличие в правой части
и отдельных атрибутов, и их множеств, представляющих сокращенную запись
нескольких FD, MVD позволяют изначально задавать в правой части только множества
138
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
атрибутов. Как мы покажем в примере 3.35 на с. 140, осуществить разбиение правой
части MVD на отдельные атрибуты удается не всегда.
Пример 3.34. В примере 3.33 мы рассматривали MVD, выражение которой с учетом
принятых нами обозначений можно записать так:
name -» street city.
Иными словами, для каждого значения name имени актера набор адресов (street и city)
представляется в совокупности с описанием каждого из кинофильмов с участием
этого актера. В качестве примера практического применения определения MVD
рассмотрим первый и четвертый кортежи отношения, показанного на рис. 3.29 (см. с. 137).
пате
С. Fisher
С. Fisher
street
123 Maple St.
5 Locust Ln.
city
Hollywood
Malibu
title
Star Wars
Empire Strikes Back
year
1977
1980
Если воспринимать первый кортеж как кортеж /, а второй — как м, в соответствии
с определением MVD отношение R должно включать также кортеж, атрибут name
которого содержит значение "С. Fisher", атрибуты street и city ~- значения, которые
хранятся в одноименных атрибутах первого кортежа, а остальные атрибуты (title
и year) — значения тех же атрибутов второго кортежа. Такой кортеж действительно
существует; это третий кортеж отношения рис. 3.29.
Аналогично, мы можем трактовать второй кортеж приведенного выше отношения
как кортеж /, а первый — как и. Тогда, в соответствии с определением MVD, в
отношении R должен существовать кортеж, который совпадает со вторым кортежем в атрибутах
name, street и city и с первым кортежем — в атрибутах name, title и year. Такой
кортеж (второй по счету в отношении, приведенном на рис. 3.29) также существует. □
3.7.3. Правила использования многозначных зависимостей
Существует набор правил использования MVD, подобных аналогам для FD, о
которых мы говорили в разделе 3.5 на с. 112. Например, для MVD справедливы правила,
рассмотренные ниже.
• Правило тривиальной зависимости (trivial dependency rule): если для некоторого
отношения выполняется условие MVD
АХА2-Ап-»ВХВ2-Вш
должно выполняться и условие Ах А2 — Ап -» Сх С2 — Сь где {Сь С2,..., Ск] — это
{Вх, Въ..., Вт] плюс один или несколько атрибутов АХ,АЪ ...,Ап. И наоборот, мы
можем также удалить атрибуты из {Вх, В2,..., Вт], если они совпадают
с Ах, Аъ ..., Ап, и получить MVD Ах А2 - Ап -» Dx D2 - Dn если Dx, D2,..., Dr
совпадают с теми Вх, В2,..., Впп которых нет среди Ль А2,..., Ап.
• Правило транзитивности (transitive rule): если для некоторого отношения
справедливы MVD АХА2 - Ап -» Вх В2 ••• Вт и Вх В2 - Вт -» Сх С2 - Сь должно
выполняться и условие
АхА2-Ап~*СхС2-Ск.
Однако каждый из атрибутов Сх, С2,..., Q, который также принадлежит
{Вх, Въ ..., Вт), должен быть удален из правой части MVD.
Впрочем, многозначные зависимости не поддерживают ту часть правила
разделения/объединения, которая касается разделения атрибутов, и этот аспект
иллюстрируется следующим примером.
3.7. МНОГОЗНАЧНЫЕ ЗАВИСИМОСТИ
139
Пример 3.35. Вновь обратимся к отношению рис. 3.29 (см. с. 137). Для него
справедлива MVD
name -» street city.
Применив к последней правило разделения, мы могли бы ожидать, что MVD
name ~» street
также имеет место. Эта MVD гласит, что значение атрибута street сущности "актер"
не зависит от других атрибутов, включая city. На самом деле это не так. Рассмотрим
для примера два первых кортежа отношения рис. 3.29. Указанная гипотетическая
MVD могла бы привести нас к выводу, будто значения атрибутов street этих
кортежей взаимозаменяемы:
пате
С. Fisher
С. Fisher
street
5 Locust Ln.
123 Maple St.
city
Hollywood
Malibu
title
Star Wars
Star Wars
year
1977
1977
Но такие кортежи не соответствуют действительности, так как, скажем, дом
номер 5 по Locust Lane находится не в Голливуде, а в Малибу. □
Многозначные зависимости подчиняются и некоторым другим правилам, которые
заслуживают того, чтобы их упомянуть.
• Каждая FD является одновременно и MVD. Другими словами, если
Ах А2 - Ап -> В{ В2.» Вт, то А{ А2 - Ап -» Вх В2 - Вт.
Чтобы понять, почему так происходит, предположим, что R — некоторое
отношение, для которого выполняется FD AlA2-An-^BlB2--Bm, a t и и — это кортежи R,
совпадающие в атрибутах АЬАЪ ...,An. Дабы обосновать справедливость условия MVD
АХА2 •• • Ап -» Вх В2 .. Вт, следует доказать, что R также содержит некоторый кортеж v,
который совпадает с г и и в Ah Аъ ..., Ап, с г — в Вь В2,..., Вт и с и — во Bqex других
атрибутах. Но кортеж v может оказаться и кортежем и. Кортеж v (читай и) определенно
совпадает с t и и в AhA2, ...,An, поскольку мы начали с предположения о том, что эти
два кортежа совпадают в атрибутах Аь А2,..., Ап. Условие FD Ах А2 ••• Ап -» BY B2 — Вт
гарантирует, что и совпадает с г в Ви Въ ..., Вт. И, разумеется, кортеж и совпадает сам
с собой во всех других атрибутах. Таким образом, если выполняется условие FD,
справедливо и соответствующее условие MVD.
Второе достойное внимания правило, которое, однако, не имеет аналогов в
контексте FD, называют правилом дополнения (complementation rule).
• Если Л! А2 •• • А„ -» Вх В2 •• Вт — MVD, справедливая для отношения /?, тогда
отношению R также удовлетворяет MVD Ах А2 •• • Ап -» Сх С2 ••• Q, где Сь С2,..., Ск —
это атрибуты, не принадлежащие ни {Аь А2> —,Ап], ни {Вь Въ ..., Вт].
Пример 3.36. И еще раз обратимся к отношению рис. 3.29 (см. с. 137), для которого
имеет место MVD
name -» street city.
Согласно правилу дополнения, MVD вида
name -» title year
также должна удовлетворять этому отношению, поскольку title и year — это
атрибуты, которые не упоминались в исходной MVD. MVD name-» title year означает,
что каждому актеру соответствует множество кинофильмов, в которых тот принимал
участие, и значения этой связи не зависят от содержимого атрибутов адреса актера. □
140
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
3.7.4. Четвертая нормальная форма
Избыточность, обусловленная многозначной зависимостью (см. раздел 3.7.1 на
с. 137), может быть устранена, если использовать эту зависимость в качестве
отправного пункта в другом алгоритме декомпозиции отношений. В этом разделе мы
рассмотрим еще одну "нормальную форму", которую называют четвертой нормальной
формой (fourth normal form — 4NF). 4NF предполагает изъятие всех "нетривиальных"
(в том смысле, о котором будет рассказано ниже) MVD наряду со всеми FD,
нарушающими условие BCNF. Отношения, полученные в результате декомпозиции, будут
избавлены от избыточности, причиной которой служат как FD, рассмотренные в
разделе 3.6.1 на с. 123, так и MVD, о которых мы говорили в разделе 3.7.1.
MVD Ах А2 • -Ап -» Вх В2 • • Вт для отношения R является нетривиальной (nontrivial), если:
1) ни один из атрибутов Вх, В2,..., Вт не совпадает с Аь А2,..., Ап\
2) не все атрибуты R принадлежат {Аь А2> —,Ап} и {Вь Въ ..., Вт].
Условие четвертой нормальной формы суть условие BCNF, но применяется
к MVD, а не к FD. Вот его формальное определение.
• Отношение R удовлетворяет 4NF, если выполняется следующее требование:
всякий раз, когда для отношения R существует некоторая нетривиальная MVD
А1А2-Ап~»В1В2-Вт,
соответствующее множество {Аь А2,..., Ап] представляет суперключ для R.
Иными словами, если отношение удовлетворяет условию 4NF, каждая нетривиальная
многозначная зависимость фактически является функциональной зависимостью с
суперключом в левой части. Заметьте, что понятия "ключ" и "суперключ" основаны на
определении FD; при рассмотрении MVD их смысл не меняется.
Пример 3.37. Отношение, приведенное на рис. 3.29 (см. с. 137), нарушает условие
4NF. Например, MVD
name -» street city
является нетривиальной, но атрибут name сам по себе не образует суперключ. На
самом деле, единственный ключ этого отношения — множество всех атрибутов. □
4NF представляет собой обобщение BCNF. В предыдущем разделе, напомним,
утверждалось, что каждая FD есть также MVD. Поэтому при каждом нарушении
условия BCNF нарушается и условие 4NF. Другими словами, каждое отношение,
удовлетворяющее 4NF, удовлетворяет также BCNF.
Напротив, можно привести примеры отношений, которые поддерживают
требование BCNF, но противоречат условию 4NF (см., скажем, рис. 3.29 на с. 137).
Единственным ключом упомянутого отношения служит множество всех атрибутов, а
нетривиальных FD нет вовсе, поэтому отношение определенно удовлетворяет BCNF.
Однако оно не отвечает условию 4NF — мы показали это в примере 3.37.
3.7.5. Декомпозиция в 4NF
Алгоритм 4NF^eKOMno3HUHH аналогичен алгоритму BCNF-декомпозиции.
Нарушение условия 4NF означает, что существует некоторая нетривиальная MVD
Ах А2 ••• Ап -» Вх В2 ••• Вт, такая, что множество {Ль А2,..., Ап] не является суперключом.
Заметим, что эта MVD может быть определена явно либо выведена из соответствующей
FD Ах А2 — Ап —> Вх В2 ••• Вт, поскольку каждая FD суть MVD. Затем схема отношения R,
в которой замечено нарушение условия 4NF, разбивается на две схемы, содержащие:
3.7. МНОГОЗНАЧНЫЕ ЗАВИСИМОСТИ
141
Проецирование многозначных зависимостей
Выполняя декомпозицию отношения в 4NF, мы должны найти те MVD, которые
справедливы для отношений, полученных в результате декомпозиции. Хотелось бы,
разумеется, облегчить эту задачу. Однако простого алгоритма, схожего
с вычислением замыкания множества атрибутов относительно некоторой FD
(см. раздел 3.5.3 на с. 115), в данном случае не существует. На самом деле, даже
краткое изложение полного множества правил использования наборов FD и MVD
является достаточно трудоемким делом и выходит за рамки нашей книги. Вы
сможете ближе познакомиться с предметом, если обратитесь к дополнительным
литературным источникам, перечисленным в разделе 3.9 на с. 146.
К счастью, MVD, которые справедливы для одного или нескольких отношений,
служащих результатом декомпозиции, зачастую можно получить с помощью
правил транзитивности (transitive rule), дополнения (complementation rule) и пересечения
(intersection rule), которые рассмотрены в упражнении 3.7.7 (Ь) на стр. 144. Мы
рекомендуем читателю попытаться применить их на практике.
1) множества атрибутов [Аь А2,..., Ап} и {Вь Въ..., Вт}\
2) множество атрибутов {АЪАЪ ,..,Ап) и все атрибуты R, которые не
принадлежат ни {Аь Аъ..., А„}, ни [Bh Въ ..., Вт].
Пример 3.38. Продолжим рассмотрение примера 3.37. Мы установили, что MVD
name -» street city
преступает условие 4NF. Правило декомпозиции MVD велит нам заменить схему
с пятью атрибутами двумя схемами, одна из которых содержит три атрибута,
охватываемые указанной выше MVD, а другая включает "левосторонний" атрибут name
MVD и атрибуты, которые в MVD не участвуют (т.е. title и year). Результатом
декомпозиции окажутся схемы
{name, street, city},
{name, title, year}.
В каждой из названных схем нетривиальных многозначных (или функциональных)
зависимостей не существует, поэтому схемы удовлетворяют условию 4NF. Заметим,
что для отношения со схемой {name, street, city} справедлива MVD
name -» street city,
но она является тривиальной, поскольку охватывает все атрибуты этого отношения.
Аналогично, тривиальной является и MVD
name -» title year,
рассматриваемая в контексте отношения {name, title, year}. Если одна или
несколько схем, полученных в результате декомпозиции, по-прежнему не удовлетворяют
условию 4NF, процесс декомпозиции надлежит продолжить. □
Как и при BCNF-декомпозиции, каждая итерация 4NF-декомпозиции приводит
к получению схем со все меньшим количеством атрибутов, так что на некотором этапе
процесса мы определенно придем к набору схем, которые далее "дробить" не
целесообразно, поскольку они удовлетворяют условию 4NF. Помимо того, доводы,
обосновывающие корректность алгоритма декомпозиции в BCNF (см. раздел 3.6.5 на с. 132),
остаются в силе и в случае 4NF-декомпозиции. При декомпозиции отношения
применительно к многозначной зависимости Ах А2 •• • Ап -» Вх В2 • •• Вт мы вправе утверждать, что
данные исходного отношения при необходимости могут быть точно
реконструированы на основе экземпляров частных отношений, служащих результатом декомпозиции.
142
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
3.7.6. Взаимоотношения нормальных форм
Как упоминалось выше, справедливость 4NF подразумевает выполнение
BCNF, a BCNF предполагает, что удовлетворяется условие 3NF. Множества
реляционных схем (вместе с соответствующими зависимостями), удовлетворяющие
трем указанным здесь нормальным формам, можно графически представить так,
как это сделано на рис. 3.31. Иными словами, если отношение с определенными
зависимостями удовлетворяет условию 4NF, оно удовлетворяет также условиям
BCNF и 3NF. Если же отношение с зависимостями поддерживает требование
BCNF, оно отвечает и требованию 3NF.
Другой способ сопоставления нормальных форм
связан с рассмотрением "свойств" отношений,
получаемых в результате декомпозиции исходного
отношения с учетом требований той или иной
формы. Итоговые выводы приведены на рис. 3.32.
Условия BCNF и 4NF позволяют устранить
избыточность и другие аномалии, проявляющиеся
в контексте функциональных зависимостей, в то
время как только форма 4NF способна избавить
отношение от дополнительной избыточности,
вызванной наличием нетривиальных MVD, которые не
являются FD. Часто подобную избыточность удается
устранить, приведя отношение в соответствие с
условием 3NF, однако существуют примеры,
доказывающие, что в общем случае такой меры может
оказаться не достаточно. Чтобы сохранить в силе уело- Рис. 3.31. 4NF => BCNF => 3NF
вия FD, всегда может быть выбрана декомпозиция
в 3NF; в итоговых ЗЫР-отношениях условия исходных FD заведомо поддерживаются (хотя
на этом вопросе мы подробно останавливаться не будем). Форма BCNF в общем
случае не обеспечивает сохранения условий FD; что же касается MVD, то их
справедливость для итоговых отношений декомпозиции не гарантируется ни одной из
нормальных форм (впрочем, в типичных примерах все зависимости могут оставаться в силе).
Свойство
Отсутствие избыточности
из-за FD
Отсутствие
избыточности из-за MVD
Сохранение условий FD
Сохранение условий MVD
Обеспечивается ли
b3NF
В большинстве
случаев
Нет
Да
Не всегда
Обеспечивается
ли в BCNF
Да
Нет
Не всегда
Не всегда
Обеспечивается
ли в 4NF
Да
Да
Не всегда
Не всегда
Рис. 3.32. Свойства нормальных форм и соответствующих результатов декомпозиции
3.7.7. Упражнения к разделу 3.7
* Упражнение 3.7.1. Пусть имеется отношение R(A, В, Q с MVD Л -» В. Если известно,
что в текущем экземпляре отношения содержатся кортежи (a. bh сО, (а, Ьъ с2) и (а, Ь3, с3),
какие другие кортежи также должны присутствовать в том же экземпляре R?
* Упражнение 3.7.2. Предположим, что дано отношение, предназначенное для
хранения информации о человеке, включающей его имя, номер полиса социального
3.7. МНОГОЗНАЧНЫЕ ЗАВИСИМОСТИ
143
страхования, дату рождения, те же сведения для каждого из детей этого человека,
а также данные о номере и марке каждого автомобиля, которым человек владеет.
Кортеж отношения выглядит как
(п, s, b, en, cs, cb, as, am),
где: п — имя человека, s — номер полиса социального страхования, Ъ — дата
рождения, сп — имя ребенка, cs — номер полиса социального страхования
ребенка, cb — дата рождения ребенка, as — номер автомобиля, am — марка
автомобиля.
Для заданного отношения:
a) укажите функциональные и многозначные зависимости, которым, по
вашему мнению, оно должно отвечать;
b) предложите вариант декомпозиции в 4NF.
Упражнение 3.7.3. Для каждого из следующих отношений с зависимостями:
* а) R(A, В, С, D) с MVD Д-»виЛ^С;
b) R(A, В, С, D) с MVD А-»#и#-»С£;
c) R(A, В, С, D) с MVD A#-»ChFD#->D;
d) Я(А, В, С, Д Е) с MVD А -» Я, A#-»ChFDA->D, А Я -> £
выполните такие действия:
i) найдите все случаи нарушения условия 4NF;
ii) выполните декомпозицию отношений в наборы схем, удовлетворяющих
условию 4NF.
! Упражнение 3.7.4. В упражнении 2.2.5 на с. 72 мы приводили несколько различных
предположений относительно смысла связи Births ("роды"). Рассмотрите отдельно
каждое из них и укажите MVD (отличные от FD), которые должны выполняться
в соответствующем отношении.
Упражнение 3.7.5. Используя неформальные доводы, ответьте, почему любой из
пяти атрибутов отношения, рассмотренного в примере 3.33 на с. 137, не может
быть функционально обусловлен ни одним из остальных четырех атрибутов.
! Упражнение 3.7.6. Основываясь на определении MVD, докажите справедливость
правила дополнения.
! Упражнение 3.7.7. Докажите справедливость перечисленных ниже правил
использования MVD.
* а) Правило объединения (union rule). Если X, Y и Z — множества атрибутов
и имеют место зависимости X -» Y и X -» Z, справедлива и MVD X -» (У U Z).
b) Правило пересечения (intersection rule). Если X, Y и Z — множества атрибутов
и имеют место зависимости X -» Y и X -» Z, справедлива и MVD X -» (У П Z).
c) Правило вычитания (difference rule). Если X, У и Z — множества атрибутов
и имеют место зависимости X-» У и X -» Z, справедлива и MVD X -» (У- Z).
d) Тривиальные MVD. Если X с У, то MVD X -» У выполняется в любом отношении.
144
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
e) Другой источник тривиальных FD. Если X U У — полное множество атрибутов
отношения R, то для R справедлива MVD X -» Y.
f) Удаление атрибутов, общих для левой и правой частей. Если выполняется
X-» Y, имеет место иХ-^(У-Х).
! Упражнение 3.7.8. Предоставьте контрпримеры отношений, чтобы доказать, почему
не выполняются следующие правила, касающиеся MVD и FD:
* а) если А -» В С, то Л -» В;
b) если Л -» В, то Л —> В;
c) если Л В -» С, то Л -» С.
3.8. Резюме
♦ Реляционная модель. Отношение — это таблица, представляющая информацию.
Столбцы таблицы озаглавлены названиями атрибутов; каждому атрибуту
поставлен в соответствие определенный домен, или тип данных. Строки таблицы
называют кортежами, и каждый кортеж обладает компонентами — по одному
на соответствующий атрибут таблицы-отношения.
♦ Схемы. Наименование отношения в совокупности с названиями его
атрибутов образует схему отношения. Множество схем отношений представляет
схему базы данных. Определенный набор данных отношения или
множества отношений называют, соответственно, экземпляром отношения и
экземпляром базы данных.
♦ Преобразование множеств сущностей в отношения. Отношение,
построенное для множества сущностей, обладает теми же атрибутами, что и
исходное множество сущностей. Исключение составляют слабые множества
сущностей Е, отношения для которых должны содержать также ключевые
атрибуты других множеств, способствующих возможности различения
сущностей каждого множества Е.
♦ Преобразование связей в отношения. Отношение, построенное для ER-связи,
обладает атрибутами, соответствующими ключевым атрибутам каждого из
множеств сущностей, охватываемых этой связью. Если, однако, связь является
поддерживающей связью для некоторого слабого множества сущностей,
необходимости в построении отдельного отношения для этой связи нет.
♦ Преобразование иерархий isa- связей в отношения. Один из способов реализации
подобного преобразования предполагает распределение сущностей по
различным множествам иерархии и состоит в создании отношения со всеми
необходимыми атрибутами для каждого множества сущностей, подчиняющихся
иерархии. Другой способ связан с созданием отношений для каждого возможного
подмножества множеств сущностей иерархии; каждой сущности отводится
отдельный кортеж отношения, построенного именно для того множества, к
которому принадлежит сущность. Третий подход предусматривает создание только
одного отношения для представления всех множеств сущностей и
использование значений null для тех атрибутов, которые не применимы к сущности,
представляемой данным кортежем.
♦ Функциональные зависимости. Функциональная зависимость — это утверждение
о том, что два кортежа отношения, совпадающие в некоторых атрибутах,
должны совпадать и в других определенных атрибутах.
3.8. РЕЗЮМЕ
145
♦ Ключи отношения. Суперключ отношения — это множество атрибутов, которые
функционально обусловливают все другие атрибуты отношения. Ключ — это
суперключ, ни одно из подмножеств которого не в состоянии функционально
обосновать все другие атрибуты отношения.
♦ Использование функциональных зависимостей. Существуют правила,
позволяющие логически обосновать справедливость некоторой FD X—>А
применительно к любому экземпляру отношения, если этому отношению
удовлетворяет определенный набор других FD. Простейший способ проверки
выполнения условия FD X —> А связан с вычислением замыкания множества X
посредством использования заданных FD для расширения X до тех пор,
пока оно не будет включать А.
♦ Декомпозиция отношений. Схема отношения допускает декомпозицию в две
другие схемы без потери информации, если атрибуты, общие для двух схем,
образуют суперключ по меньшей мере для одного из отношений, получаемых
в результате декомпозиции.
♦ Нормальная форма Бойса—Кодда. Отношение удовлетворяет условию BCNF,
если единственная нетривиальная FD гласит, что некоторый суперключ
функционально обусловливает один из других атрибутов. Возможно
осуществить декомпозицию любого отношения в набор отношений,
удовлетворяющих условию BCNF, без потери информации. Основное
преимущество условия BCNF состоит в устранении избыточности, возникающей с
введением FD.
♦ Третья нормальная форма. Декомпозиция в BCNF не всегда обеспечивает
сохранность условий определенных FD. Ослабленный вариант BCNF,
называемый 3NF, допускает выполнение условия X—>А даже в том случае,
если X не является суперключом, но А служит членом некоторого ключа. Хотя
3NF в общем случае не гарантирует устранения избыточности,
возникшей из-за условий FD, зачастую избыточности в 3NF-OTHOineHHH все-таки
можно избежать.
♦ Многозначные зависимости. Многозначная зависимость — это
утверждение о том, что два множества атрибутов отношения обладают наборами
значений, которые могут присутствовать в отношении во всех возможных
сочетаниях.
♦ Четвертая нормальная форма. Причиной появления избыточности часто
служат многозначные зависимости. 4NF подобна BCNF, но запрещает
наличие нетривиальных MVD (если только они фактически не являются FD,
которые допускаются в BCNF). Возможно осуществить декомпозицию
отношения в набор отношений, удовлетворяющих условию 4NF, без потери
информации.
3.9. Литература
Классическое описание реляционной модели содержится в работе [4]. В ней
введены понятие функциональной зависимости и общая концепция отношений. Здесь
же приведены характеристики третьей нормальной формы, а нормальная форма
Бойса—Кодда рассмотрена в более поздней работе [5].
Определения многозначной зависимости и четвертой нормальной формы даны
в статье [7]. Впрочем, первые результаты, касающиеся многозначных зависимостей,
получены "независимо" и изложены также в работах [6] и [9].
146
ГЛАВА 3. РЕЛЯЦИОННАЯ МОДЕЛЬ
У. Армстронг (W.W. Armstrong) был первым, кто начал изучать правила
логического вывода функциональных зависимостей [1]. Правила использования FD
и MVD, рассмотренные в этой главе (включая и те, которые мы называем
"аксиомами Армстронга"), берут начало из результатов исследований,
представленных в докладе [2]. Алгоритм проверки FD с вычислением замыкания
множества атрибутов заимствован из [3].
Существует большое число алгоритмов и доказательств их корректности,
оставшихся за пределами нашей книги, включая, например, те, которые относятся к
проблемам логического вывода многозначных зависимостей, проецирования MVD на
схемы, полученные в результате декомпозиции, а также декомпозиции отношений
в 3NF с сохранением возможности проверки функциональных зависимостей. Эти
и другие аспекты использования зависимостей изложены в книге [8].
1. Armstrong W.W. Dependency structures of database relationships, Proc. of the 1974 IFIP
Congress, p. 580—583.
2. Beeri C, Fagin R., Howard J.H. A complete axiomatization for functional and multivalued
dependencies, ACM SIGMOD Intl. Conf. on Management of Data (1977), p. 47-61.
3. Bernstein P.A. Synthesizing third normal form relations from functional dependencies, ACM
Trans, on Database Systems, 1:4 (1976), p. 277-298.
4. Codd E.F. A relational model for large shared data banks, Comm. ACM, 13:6 (1970), p. 377—
387.
5. Codd E.F. Further normalization of the database relational model, in Database Systems
(R. Rustin, ed.), Prentice Hall, Englewood Cliffs, NJ, 1972.
6. Delobel C. Normalization and hierarchical dependencies in the relational data model, ACM
Trans, on Database Systems, 3:3 (1978), p. 201-222.
7. iFagin R. Multivalued dependencies and a new normal form for relational databases, ACM Trans,
on Database Systems, 2:3 (1977), p. 262-278.
8. Ullman J.D. Principles of Database and Knowledge-Base Systems, Volume I, Computer Science
Press, New York, 1988.
9. Zaniolo C, Melkanoff M.A. On the design of relational database schemata, ACM Trans, on
Database Systems, 6:1 (1981), p. 1-47.
3.9. ЛИТЕРАТУРА
147
Глава 4
Другие модели данных
Модель "сущность—связь" и реляционная модель — это только часть множества
современных инструментов представления данных. В этой главе мы познакомим вам
с другими моделями, важность которых по мере их становления неуклонно возрастает.
Глава начинается с рассмотрения объектно-ориентированных моделей данных.
Один из подходов к обеспечению совместимости систем баз данных с парадигмой
объектно-ориентированного проектирования связан с расширением системы понятий,
лежащей в основе объектно-ориентированных языков программирования, таких как
C++ или Java, в направлении поддержки средств постоянного хранения данных.
В традиционном программировании подразумевается, что после завершения цикла
работы программы ее объекты безвозвратно утрачиваются, в то время как
принципиальное условие работы любой СУБД состоит в том, что объекты должны храниться
неограниченно долгое время, пока не будут изменены или удалены принудительно,
как это происходит в файловых системах. Мы изучим "чистую" объектно-
ориентированную модель представления данных, называемую ODL (Object Definition
Language — язык определения объектов), которая в свое время была стандартизована
исследовательской группой Object Data Management Group (ODMG).
Далее мы сосредоточим внимание на модели, называемой объектно-реляционнои
(object-relational model). Эта модель является частью самого последнего стандарта SQL,
называемого SQL-99 (или SQL: 1999, а также SQL3), и представляет собой вариант
расширения обычной реляционной модели (см. главу 3 на с. 87) за счет формализации
многих общепринятых концепций объектно-ориентированного проектирования.
Указанный стандарт служит основой для построения объектно-реляционных систем баз
данных, каковые сегодня выпускаются всеми основными поставщиками коммерческих
СУБД. Эти системы, однако, значительно различаются в деталях практической
реализации исходных концепций. Дальнейшему обсуждению объектно-реляционной модели
в том виде, как она описывается стандартом SQL-99, посвящена глава 9 на с. 419.
В заключение мы расскажем о модели "полуструктурированных" данных
(semistructured data) — одном из последних достижений, призванных разрешить
большое число актуальных проблем технологий СУБД, включая, например, необходимость
объединения традиционных баз данных с другими источниками информации, такими
как Web-страницы самой разнообразной структуры. В то время как объектно-
ориентированные или объектно-реляционные системы предполагают использование
фиксированных схем для каждого класса или отношения, модель
полуструктурированных данных отличается намного более высокой гибкостью представления компонен-
тов информации: например, в каждом конкретном случае сущность "кинофильм" может
быть описана по-иному, в соответствии с текущими требованиями (одни фильмы,
скажем, существуют в различных версиях с неодинаковыми длительностями
воспроизведения, другие снабжены текстовыми аннотациями, третьи содержат субтитры и т.д.).
Наиболее ярким практическим воплощением модели полуструктурированных
данных является XML (extensible Markup Language — расширяемый язык разметки). XML
по своей сути — это спецификация описания "документов", представляющих собой
наборы вложенных элементов данных, функции которых определяются
соответствующими тэгами. Мы уверены, что поддержка XML со временем станет важнейшим
компонентом систем, осуществляющих посреднические функции между
разнородными источниками данных, и даже, что очень возможно, послужит целям гибкого
представления информации в базах данных.
4.1. Обзор понятий объектно-ориентированного проектирования
Прежде чем приступить к изучению объектно-ориентированных моделей баз данных,
рассмотрим основные понятия объектно-ориентированного проектирования как
таковые. Объектно-ориентированное проектирование и программирование заслужили
широкое признание как инструмент повышения качества программных проектов и
увеличения степени надежности их реализации. Парадигма объектно-ориентированного
программирования, впервые воплощенная в языке Smalltalk, пережила бурный рост
и приобрела всеобщую популярность с появлением языка C++; многие почувствовали
тогда и насущную необходимость переноса на C++ огромного пласта программного
обеспечения, ранее написанного на языке С. В последние годы прокатилась новая
волна интереса к объектно-ориентированному программированию, и ее причиной
послужило распространение языка Java — мощного и удобного инструмента создания
программных приложений, ориентированных на использование в среде World Wide Web.
Мир баз данных также не остался в стороне от столбовой дороги прогресса:
сегодня внимание разработчиков СУБД привлечено к вопросам использования концепций
объектно-ориентированного программирования в качестве инструментов
моделирования и расширения функционального потенциала существующих реляционных систем.
В этом разделе мы обсудим следующие понятия, лежащие в основе объектно-
ориентированной парадигмы:
1) система поддержки типов (types);
2) класс (class) — тип, которому соответствует набор объектов (objects);
3) идентификационный номер объекта (object identity) — значение, однозначно
удостоверяющее подлинность объекта и позволяющее различить его среди других
объектов того же класса и всех других классов независимо от содержимого объекта;
4) наследование (inheritance) — способ иерархической организации классов, при
которой каждый "дочерний" класс наследует свойства "родительского" класса.
4.1.1. Система поддержки типов
Объектно-ориентированный язык программирования предлагает пользователю
обширный набор типов (types), который включает в том числе и атомарные типы (atomic
types), представляющие целые и вещественные числа, булевы значения и строки
символов. Программист вправе создавать новые типы, используя специальные
конструкции языка, которые позволяют описать разновидности данных, перечисленные ниже.
1. Структуры записей (record structures). На основе заданных списка типов
ТьТ2,...,Тп и списка соответствующих наименований полей (fields) (называемых
в Smalltalk переменными экземпляра — instance variables) fbf2, ...,fn создается тип
записи, состоящей из п компонентов. На компонент / типа Г, ссылаются по
150
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
имени/. Структуры записей — это именно то, что в С и C++ принято
обозначать служебным словом "struct", и при необходимости мы будем пользоваться
этим термином без дополнительных разъяснений.
2. Типы коллекций (collection types). На основе типа Т посредством оператора
коллекции (collection operator) создается новый тип коллекции. В разных языках
применяются различные операторы коллекции, но существуют и некоторые
общие для всех языков операторы, позволяющие создавать массивы, списки
и множества элементов данных: если Т представляет собой, например,
атомарный целочисленный тип, то, используя соответствующий оператор коллекции,
можно сконструировать такие типы, как "массив целых чисел", "список целых
чисел" или "множество целых чисел".
3. Ссылочные типы (reference types). Ссылка на объект типа Т — это переменная
такого типа, значения которого удобно применять для задания местоположения
содержимого объектов типа Т. В языках С и C++ ссылка — это "указатель" на
значение, содержащий адрес этого значения в виртуальной памяти машины.
Структуры записей и операторы коллекции, разумеется, допускают "вложение"
с целью построения сложных составных типов. Например, в банковских программных
приложениях может найти применение тип структуры записи, первый компонент
которой, customer, относящийся к строковому типу, служит для определения имени
клиента, а второй, accounts, типа "множество целых чисел" — для представления
номеров счетов. Подобный составной тип является удобным инструментом для
задания связи между именами клиентов и наборами принадлежащих им счетов.
4.1.2. Классы и объекты
Класс (class) — это тип, способный содержать в своем составе одну или несколько
функций или процедур (называемых методами (methods); см. раздел 4.1.4), которые
выполняются в контексте объектов этого класса. Объект (object) класса — это либо
значение соответствующего типа (называемое неизменяемым объектом — immutable object),
либо переменная, содержащая значение такого типа {изменяемый объект — mutable
object). Например, для класса С типа "множество целых чисел" значение вида {2,5,7}
будет являться неизменяемым объектом этого класса, а соответствующим образом
объявленная переменная s, которой присвоено значение {2, 5, 7}, — изменяемым объектом.
4.1.3. Идентификационный номер объекта
Каждый объект должен обладать собственным идентификационным номером (object
identity — OID). Никакие два объекта не могут иметь одинаковый OID, и ни одному
объекту нельзя поставить в соответствие два различных OID. В модели данных
идентификационному номеру объекта отводится особая роль. Важно, например, чтобы
множество сущностей обладало ключом, образованным из атрибутов этого множества
или иных множеств, которые с ним связаны (как в случае слабых множеств
сущностей). В контексте класса, однако, необходимо уметь различать даже такие объекты,
которые обладают совершенно одинаковыми значениями атрибутов, и эта задача
решается посредством использования идентификационных номеров объектов, поскольку
их уникальность гарантируется.
4.1.4. Методы
С классом связан набор функций, называемых методами (methods). Метод класса С
обладает, самое меньшее, одним аргументом, представляющим "текущий" объект класса
С; впрочем, метод может использовать и другие аргументы самых различных типов,
втом числе и типа С. Например, для класса, представляющего "множество целых чисел",
4.1. ОБЗОР ПОНЯТИЙ ОБЪЕКТНО-ОРИЕНТИРОВАННОГО ПРОЕКТИРОВАНИЯ 151
уместно предусмотреть методы для суммирования элементов заданного множества,
получения объединения двух множеств или определения того, является ли множество пустым.
В некоторых случаях классы объявляются как "приватные типы данных" —
имеется в виду, что такие классы инкапсулируют (encapsulates) содержимое объектов таким
образом, чтобы изменять его непосредственно могли только методы того же класса.
Цель подобного ограничения состоит в поддержке возможности модификации
объектов класса именно такими способами, которые предусмотрены автором класса.
Инкапсуляция служит одним из основных инструментов повышения уровня надежности
программного обеспечения.
4.1.5. Иерархии классов
Вполне допустимо объявить некоторый класс С в виде подкласса (subclass), или
производного класса (derived class), класса D. В этом случае класс С наследует (inherits) все
характеристики базового класса (superclass) D, включая тип последнего и любые его
свойства. Классу С, тем не менее, позволяется иметь и собственные дополнительные свойства.
Например, класс С может обладать новыми методами, которые изменяют поведение
методов, унаследованных от класса D, или полностью их замещают. Возможно также
расширить тем или иным способом структуру данных типа D. В частности, если D
представляет собой один из типов структур записей, мы можем пополнить его
определениями новых полей, которые будут "видимы" только в объектах производного класса С.
Пример 4.1. Рассмотрим класс, представляющий банковские счета. Структуру данных
этого класса можно описать неформально следующим образом:
CLASS Account = { accountNo: integer;
balance: real;
owner: REF Customer;
}
Тип класса Account представляет структуру записи с тремя полями — целочисленным
номером счета (accountNo), вещественным значением остатка (balance) и ссылкой
owner на объект класса Customer, задающего информацию о клиенте-владельце счета
(Customer — это еще один класс, который необходимо определить в базе данных, но
его описание здесь не приведено).
Уместно было бы, вероятно, предусмотреть в составе класса некоторые методы.
Так, например, само собой "напрашивается" определение метода
deposit(a: Account, m: real),
который позволяет складывать текущее значение остатка balance на счете-объекте а
класса Account с величиной т, представляющей сумму операции прихода.
Наконец, в каких-то ситуациях могут потребоваться классы, производные от
Account. Например, класс, служащий для описания срочных вкладов (назовем его
TimeDeposit), целесообразно было бы снабдить дополнительным полем dueDate для
хранения даты, по истечении которой суммы вклада и начисленных процентов могут
быть получены клиентом, а также методом
penalty(a: TimeDeposit),
принимающим в качестве параметра объект класса TimeDeposit и вычисляющим
значение пени (взимаемой из суммы процентов при досрочном расторжении договора
вклада) как функции от разности значений поля dueDate и текущей даты (последняя
может быть получена при помощи соответствующего системного вызова). □
4.2. Введение в язык ODL
ODL (Object Definition Language — язык определения объектов) — это
стандартизованный язык, служащий для описания структур баз данных в терминах объектно-
152
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
ориентированного проектирования. ODL представляет собой расширение IDL
(Interface Description Language — язык описания интерфейса) — компонента
архитектуры CORBA (Common Object Request Broker Architecture), определяющей стандарт
распределенных объектно-ориентированных вычислительных систем.
4.2.1. Объектно-ориентированное проектирование
В процессе объектно-ориентированного проектирования реальный мир,
подлежащий моделированию, воспринимается так, будто он состоит из объектов (objects),
представляющих сущности тех или иных разновидностей. Например, в определенных
ситуациях в качестве объектов могут выступать люди, банковские счета, авиарейсы,
учебные курсы в университете, здания и т.п. Подразумевается, что каждому из них
поставлен в соответствие уникальный идентификационный номер объекта (object
identity — 01D), который позволяет отличить объект от всех других (мы говорили об
этом в разделе 4.1.3 на с. 151).
Для упрощения задачи организации информации объекты, обладающие сходными
свойствами, обычно группируют в классы (classes). Говоря о "сходных свойствах"
объектов определенного класса в контексте объектно-ориентированного проекта,
оформленного по правилам ODL, мы будем иметь в виду одно из двух следующих условий.
• Сущности реального мира, которые представляются объектами класса,
являются однородными. Например, имеет смысл сгруппировать все объекты,
описывающие клиентов банка, в один класс, а объекты-счета, принадлежащие
клиентам, — в другой класс. Напротив, было бы совершенно неправильно относить
объекты клиентов и счетов к одному классу, поскольку соответствующие им
сущности в реальной банковской системе выполняют абсолютно разные функции.
Номер счета
Остаток
acctNo
balance
tcOwner
Ссылка на объект класса
Customer
Объект класса Account
Рис. 4.1. Объект, представляющий банковский счет
• Свойства объектов класса должны быть одинаковы. Программируя на
объектно-ориентированном языке, мы часто трактуем объекты в виде записей,
подобных той, которая, изображена на рис. 4.1. Объекты содержат поля, в которых
хранятся конкретные значения. Эти значения могут относиться к одинаковым
типам, таким как целочисленный или строковый, или представлять собой
ссылки на другие объекты.
Определяя класс на языке ODL, мы обязаны описать характеристики объектов
этого класса, относящиеся к трем следующим категориям:
1) атрибуты (attributes) — значения, описывающие характеристики объекта;
о допустимых типах атрибутов ODL будет рассказано в разделе 4.2.8 на с. 161;
2) связи (relationships) — соединения между объектом текущего класса и
другими объектами;
3) методы (methods) — функции, которые допускают применение в контексте
объекта класса.
Атрибуты, связи и методы класса в совокупности принято называть свойствами
(properties).
4.2. ВВЕДЕНИЕ В ЯЗЫК ODL
153
4.2.2. Объявление класса
Объявление класса в ODL в своей простой форме состоит из следующих частей:
1) служебного слова class;
2) наименования класса;
3) списка свойств класса, заключенного в фигурные скобки (в качестве свойств
могут быть заданы описания атрибутов, связей и/или методов,
перечисленные в произвольном порядке).
Иными словами, объявление класса может выглядеть так:
class Наименование {
Список свойств
}
4.2.3. Атрибуты
Атрибут (attribute) — это простейший вид свойства. Атрибут описывает
определенную характеристику объекта класса и содержит некоторое значение
фиксированного типа. Например, объекты класса, представляющего сведения о людях, могут
содержать атрибут name строкового типа, предназначенный для хранения имени
человека. В составе того же класса может быть предусмотрен атрибут birthdate, состоящий
из тройки целочисленных полей (т.е. являющийся структурой записи), в которые
заносятся значения дня, месяца и года рождения человека.
В языке ODL, в отличие от модели "сущность—связь", атрибуты не обязательно
должны относиться к атомарным типам, таким как целочисленный или строковый.
Упомянутый атрибут birthdate служит примером атрибута структурного типа. Другой пример —
атрибут phone, содержащий значение номера телефона, которое может быть представлено
набором строк. Здесь мы назвали только самые простые варианты структурных типов —
вполне допустимо пользоваться определениями типов произвольной сложности.
Подробные сведения о системе типов, поддерживаемой ODL, приведены в разделе 4.2.8 на с. 161.
Пример 4.2. На рис. 4.2 приведено объявление класса, служащего для представления
сущностей-"кинофильмов". Объявление не является исчерпывающим — мы будем
пополнять его по мере изложения. Строка 1 свидетельствует о том, что Movie — это
класс. Ниже заданы объявления четырех атрибутов, которыми должны обладать все
объекты класса Movie.
1) class Movie {
2) attribute string title;
3) attribute integer year;
4) attribute integer length;
5) attribute enum Film {color, blackAndWhite} filrnType;
};
Рис. 4.2. Объявление класса Movie на языке ODL
Первый атрибут, объявление которого расположено в строке 2, назван как title.
Его тип — это string (строка символов произвольной длины). Предусматривается, что
значениями атрибута title любого объекта класса Movie будут строки, содержащие
названия кинофильмов. Два следующих атрибута, year и length, объявленные в строках
3 и 4, относятся к целочисленному типу (integer) и предназначены соответственно для
хранения значений года, в котором был выпущен кинофильм, и продолжительности
154
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
воспроизведения фильма, выраженной в минутах. В строке 5 содержится
объявление еще одного атрибута, f ilrnType, который представляет сведения о том, на
какой пленке снят фильм — цветной или черно-белой. Атрибут относится к
перечислимому (enumerative) типу с названием Film. Значения перечислимого типа
выбираются из множества литералов (literals) — в нашем примере это color и blackAndWhite.
Объект объявленного выше типа Movie можно представить в виде кортежа,
состоящего из четырех компонентов, по одному на каждый атрибут:
("Gone With the Wind", 1939, 231, color). □
Пример 4.3. В объявлении класса Movie, рассмотренном в примере 4.2, все атрибуты
относятся к атомарным типам. Ниже приведен образец объявления, в котором
предусмотрено использование составного типа. Класс star служит для описания сущно-
стей-"актеров":
1) class Star {
2) attribute string name;
3) attribute Struct Addr
{string street, string city} address;
};
Строка 2 указывает, что атрибут name ("имя" актера) относится к типу string.
В строке 3 содержится объявление другого атрибута, address ("адрес"). Типом этого
атрибута является структура записи (record structure). Наименование структуры —
Addr, а ее тип определен как набор из двух строковых полей — street и city.
Структура записи объявляется в ODL в виде конструкции, состоящей из служебного
слова struct, за которым следует список названий полей и соответствующих им
типов, заключенный в фигурные скобки.
Подобно перечислимым типам, каждый структурный тип также может быть снабжен
именем, которое позволяет ссылаться на ранее созданный тип и избежать
необходимости его повторного определения. □
4.2.4. Связи
Подчас важная информация об объекте заключена не только в его атрибутах, но
и в том, каким образом он соотносится с другими объектами того же или иного класса.
Пример 4.4. Предположим, что возникла необходимость пополнить объявление класса
Movie, которое было приведено в примере 4.2 на с. 154, определением нового свойства,
описывающего множество актеров, снявшихся в фильме. Если говорить более точно, мы
хотели бы связать каждый объект класса Movie, представляющий конкретный
кинофильм, с множеством объектов класса star, которые соответствуют актерам-участникам
съемок этого фильма. Наилучший способ задания подобной зависимости между
классами Movie и Star — это определение связи (relationship). Соответствующую связь
нетрудно описать, если включить в объявление класса Movie следующую строку:
relationship Set<Star> starsOf;
Эта строка может быть вставлена в текст объявления класса Movie после любой из
строк с номерами от 1 до 5. Она гласит, что в каждом объекте класса Movie
содержится множество ссылок на объекты класса star. Это множество ссылок обозначено как
starsOf. Служебное слово relationship указывает на то, что starsOf представляет
связь объекта текущего класса с другими объектами, а служебное слово Set,
предшествующее конструкции <star>, свидетельствует, что определяется не
единственная ссылка на объект другого класса (в данном случае —- star), а единовременно целое
4.2. ВВЕДЕНИЕ В ЯЗЫК ODL
155
Зачем именовать перечислимые и структурные типы
Наименование Film перечислимого типа, указанное в строке 5 листинга рис. 4.2,
на первый взгляд не так уж необходимо. Однако, присвоив этому типу конкретное
имя, мы сможем позже сослаться на него вне контекста объявления класса Movie.
В подобных ситуациях применяется конструкция полного имени вида
Movie::Film. Например, при создании класса, предназначенного для описания
сущностей-"кинокамер", мы могли бы воспользоваться ранее определенным типом
Film, чтобы не объявлять его заново:
attribute Movie::Film uses
Эта строка представляет объявление атрибута с именем uses, который относится
к перечислимому типу Movie: : Film, содержащему литералы color и blackAndWhite.
Еще один довод в пользу именования перечислимых (как, впрочем, и
структурных) типов состоит в том, что их можно определять внутри "модуля" за пределами
конструкции объявления какого бы то ни было класса, чтобы сделать доступными
для всех классов, описанных в модуле.
множество таких ссылок. Вообще говоря, объявление типа, представляющего собой
множество элементов некоторого другого типа Г, в ODL оформляется с помощью
служебного слова Set, за которым следует наименование типа Г, заключенное в
угловые скобки < и >. □
4.2.5. Обратные связи
В предыдущем разделе мы показали, как определить связь некоторого кинофильма
с множеством актеров; точно таким же образом можно объявить связь, которая
позволяет зафиксировать множество кинофильмов, в съемках которых принял участие тот или
иной актер. Чтобы ввести подобную информацию в объекты класса star, следует
поместить в объявление этого класса, рассмотренное в примере 4.3 на с. 155, такую строку:
relationship Set<Movie> starredln;
В этой конструкции и аналогичной ей, присутствующей в объявлении класса Movie,
однако, не нашел отражения весьма важный аспект взаимоотношений между
объектами "кинофильмов" и "актеров". Предусматривается, что если объект-"актер" S
принадлежит множеству ссылок starsOf для некоторого объекта-"кинофильма" М, то
М должен быть включен в множество ссылок starredln объекта S. Подобная
обоюдная зависимость между связями starsOf и starredln выражается следующим
образом: в объявление каждой связи надлежит включить служебное слово inverse и
сопроводить его наименованием соответствующей "обратной" связи. Если обратная
связь принадлежит некоторому другому классу (что обычно и происходит),
указывается полное имя этой связи, состоящее из наименования класса, двух символов
двоеточия (: :) и собственного названия связи.
Пример 4.5. Если необходимо декларировать, что связи starredln класса Star
и starsOf класса Movie являются взаимно обратными, следует исправить объявления
этих классов так, как показано на рис. 4.3 (здесь также присутствует объявление
класса studio, к которому мы обратимся позже). Строка 6 содержит объявление связи
starsOf класса Movie и свидетельствует, что эта связь является обратной по
отношению к связи Star:: starredln. Поскольку связь starredln объявлена в другом
классе, ее имени здесь предшествуют название класса (star) и два символа
двоеточия. Напомним, что два символа двоеточия всегда используются в ODL при
необходимости задания ссылки на член другого класса.
156
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Объявление другой связи, starredln, приведено в строке И. В нем также
зафиксирован факт наличия обратной связи: inverse Movie: : starsOf. Так и должно
быть, поскольку взаимообратные связи всегда объединяются в пары. □
Рассмотрим общее правило: если некоторая связь R класса С ставит в соответствие
объекту х класса С набор объектов у\,у2, ...,уп класса D, то связь, обратная по
отношению к R, должна соединять каждый из объектов у, с объектом х (возможно, наряду
с другими объектами). Иногда оказывается полезным отобразить связь R класса С
с классом D в виде списка пар значений, или кортежей, некоторого отношения. Такой
список по смыслу аналогичен множеству данных связи, о котором мы говорили при
описании связей в модели "сущность—связь" (см. раздел 2.1.5 на с. 54). Каждый
кортеж состоит из наименований объекта х класса С и объекта у класса D:
С
Х\
*2
D
У\
Уг
Тогда связь, обратная по отношению к R, может быть представлена таким множеством
кортежей:
D
У\
Уг
С
*\
*2
1)
г)
3)
4)
5)
8)
9)
10)
11)
12)
13)
14)
15)
class Movie {
attribute string title;
attribute integer year;
attribute integer length;
attribute enurn Film {color, blackAndWhite} filrnType;
relationship Set<Star> starsOf
inverse Star::starredln;
relationship Studio ownedBy
inverse Studio::owns;
};
class Star {
attribute string name;
attribute Struct Addr
{string street, string city} address;
relationship Set<Movie> starredln
inverse Movie::starsOf;
};
class Studio {
attribute string name;
attribute string address;
relationship Set<Movie> owns
inverse Movie::ownedBy;
};
Рис. 4.З. Некоторые классы с объявлениями связей
4.2. ВВЕДЕНИЕ В ЯЗЫК ODL
157
Заметим, что рассмотренное правило применимо даже в том случае, когда С и D
представляют собой один и тот же класс. Ситуации, в которых связь соединяет два объекта
одного и того же класса, вполне правдоподобны — достаточно назвать связь "является
ребенком" для класса "люди".
4.2.6. Множественность связей
Подобно бинарным связям в модели "сущность—связь", пара обратных связей
в ODL может быть отнесена к одному из типов — "многие ко многим" (many-many),
"многие к одному" (many-one) или "один к одному" (one-one) — в любом
направлении. Тип связи задается способом ее объявления.
1. Если между классами С и D существует связь "многие ко многим", в классе С тип
этой связи должен быть определен как Set<JD>, а в классе D — как Set<C>.13
2. Если связь относится к типу "многие к одному" в направлении от С к D,
в классе С выражение, определяющее ее тип, должно выглядеть как дав
классе D — как Set<C>.
3. Если связь относится к типу "многие к одному" в направлении от D к С, этот
случай симметричен тому, который описан в п. 2.
4. Если же тип связи — "один к одному", в классе С тип связи задается как д
а в классе D — как С.
Заметим, что, как и в ER-модели, связи "многие к одному" и "один к одному" в ODL
охватывают и такую ситуацию, когда для некоторых объектов слово "один" на самом
деле означает "ничего". Например, в некоторых объектах класса С, соединяемых
связью "многие к одному" с объектом класса D, значение соответствующей ссылки
может быть равно "null" или просто отсутствовать. С другой стороны, поскольку
объекты класса D допускают соединение с любым подмножеством объектов класса С, для
некоторого объекта D такое подмножество может быть и пустым.
Пример 4.6. В тексте листинга, приведенного на рис. 4.3, содержатся объявления трех
классов — Movie, Star и studio. Два первых класса были рассмотрены в примерах
4.2 (см. с. 154) и 4.3 (см. с. 155). Особенности пары связей starsOf и starredin
также нами уже обсуждались. Поскольку в объявлении каждой из них присутствует
служебное слово Set, ясно, что эти объявления представляют связь типа "многие ко
многим", соединяющую объекты классов Movie и Star.
Объекты класса Studio обладают атрибутами name и address (соответствующие
объявления заданы в строках 13 и 14). Заметим, что атрибут address в данном случае
относится к строковому типу, в отличие от одноименного атрибута класса star
(строка 10), который представляет собой структуру. Нет ничего предосудительного
в том, что в различных классах объявлены разнотипные атрибуты с одним именем.
В строке 7 содержится объявление связи ownedBy, соединяющей объект класса
Movie с объектом класса studio. Поскольку тип связи — это studio, а не
Set<Studio, подразумевается, что для каждого кинофильма существует только одна
студия, которая им владеет. Связь owns, обратная связи ownedBy, объявлена в
строке 15. Она соединяет объект класса studio с объектами класса Movie и относится
к типу Set<Movie>, свидетельствуя о том, что каждая студия может обладать правами
на произвольное число кинофильмов. □
13 В действительности служебное слово Set в конструкции объявления связи может быть
заменено названием любого другого "типа коллекции", поддерживаемого в ODL, — такого, например,
как List или Bag (подробные сведения о типах ODL приведены в разделе 4.2.8 на с. 161). Впрочем,
здесь мы вправе ограничиться предположением, что все коллекции относятся к типу множеств (sets).
158
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
4.2.7. Методы
Третья категория свойств классов ODL — это методы (methods). Как и в других
объектно-ориентированных языках программирования, метод в ODL — это фрагмент
исполняемого кода, который может быть выполнен в контексте объекта класса.
В ODL объявление (declaration) метода содержит его наименование совместно с типами
параметров и типом возвращаемого значения. Объявление такого рода, подобное
объявлению функции в программе на языке С или C++, принято называть сигнатурой
(signature), в отличие от определения (definition) функции, в которое, помимо
сигнатуры, входит код реализации метода. Код метода может быть написан на другом языке
и не является частью текста ODL.
Объявления методов включаются в объявление класса точно так же, как и
определения атрибутов и связей. Как и в других объектно-ориентированных языках, каждый
метод связан с некоторым классом и вызывается в контексте объекта этого класса.14
Ссылка на текущий объект присутствует в объявлении метода в виде "скрытого"
параметра. При таком подходе одно и то же название метода может быть использовано
в нескольких различных классах, поскольку семантика метода определяется
конкретным объектом, которому этот метод принадлежит. Подобные методы принято
называть перегруженными (overloaded).15
Синтаксис объявления метода ODL подобен тому, который принят для объявления
функций на языке программирования С, но предусматривает две важные особенности.
1. Параметры метода определяются с помощью служебных слов-квалификаторов in,
out и inout, означающих, соответственно, что параметр является входным,
выходным и входным/выходным одновременно. Содержимое параметров,
помеченных как out или inout, может быть модифицировано в процессе выполнения
кода метода; параметры in, однако, подобного изменения не допускают.
Параметры out и inout передаются по ссылке, а параметры in — по значению.
Заметим, что метод, помимо того, способен возвращать в код-инициатор значение
определенного типа, что дает возможность получать результат работы метода
непосредственно, а не с помощью присваивания значений параметрам out или inout.
2. Методам позволяется генерировать исключения (exceptions), которые
представляют собой дополнительный механизм коммуникации, отличный от обычной
схемы передачи параметров и получения возвращаемых значений.
Сгенерированное исключение обычно служит свидетельством возникновения
ненормальной или неожиданной ситуации, которая должна быть обработана кодом-
инициатором (возможно, после возврата по целой цепочке вызовов). Примером
условия, которое должно восприниматься как исключительное, может служить
деление на нуль. В объявлении метода на языке ODL допустимо использовать
служебное слово raises с заключенным в круглые скобки списком
исключений, которые могут генерироваться методом.
Пример 4.7. На рис. 4.4 представлен усовершенствованный вариант объявления класса
Movie, ранее упоминавшегося в листинге рис. 4.3 на с. 157. Рассмотрим каждый из
методов, определенных в тексте объявления класса.
14 В составе классов, написанных, например, на языках C++ и Java, могут быть объявлены
и так называемые статические (static) методы, которые не принадлежат какому бы то ни было
объекту класса. — Прим. перев.
15 В традиционных объектно-ориентированных языках программирования перегруженными
обычно называют такие одноименные методы с различными сигнатурами, которые принадлежат
одному классу или иерархии классов. — Прим. перев.
4.2. ВВЕДЕНИЕ В ЯЗЫК ODL
159
Зачем нужны сигнатуры
Ценность аппарата сигнатур методов заключается в том, что при реализации схемы
на конкретном языке программирования проверка того, отвечает ли такая
реализация параметрам проекта, описанным в схеме, выполняется автоматически.
Разумеется, подобная проверка не в состоянии дать конкретный ответ на вопрос, верно
ли реализовано "сущест-во" операций, но позволяет, по меньшей мере, убедиться
в том, соответствуют ли типы и количество параметров метода тем, которые
предусмотрены спецификацией проекта.
Строка 8 содержит объявление метода lengthlnHours. Как предполагается, метод
должен возвращать величину продолжительности воспроизведения кинофильма,
который представляется текущим объектом Movie, преобразованную из значения,
выраженного в минутах (и равного содержимому атрибута length), в значение с
плавающей запятой, выраженное в часах. Метод не предусматривает передачи каких бы то
ни было аргументов. Методу, однако, всегда передается "скрытый" аргумент,
представляющий собой ссылку на текущий объект Movie, в контексте которого метод
вызывается, и с помощью этой ссылки код реализации метода способен, в частности,
определить значение атрибута length, подлежащее преобразованию.16
Метод lengthlnHours способен генерировать исключение, обозначенное как
noLengthFound. Это исключение должно вызываться в том случае, если объект
Movie содержит неопределенное или неверное (например, отрицательное) значение
атрибута length.
1) class Movie {
2) attribute string title;
3) attribute integer year;
4) attribute integer length;
5) attribute enum Film {color, blackAndWhite} filmType;
6) relationship Set<Star> starsOf
inverse Star::starredln;
7) relationship Studio ownedBy
inverse Studio::owns;
8) float lengthlnHours() raises(noLengthFound);
9) void starNames(out Set<String>);
10) void otherMovies(in Star, out Set<Movie>)
raises(noSuchStar);
};
Рис. 4.4. Объявление методов класса Movie
В строке 9 приведена сигнатура другого метода класса, starNames. Метод не
возвращает значений, но обладает выходным (out) параметром, тип которого представляет
собой множество строк. Содержимое параметра — набор строковых значений атрибута
name объектов класса Star, с которыми связан текущий объект Movie, — вычисляется
в теле метода. Впрочем, сигнатура метода сама по себе, как и во всех других случаях,
не дает возможности судить о том, какой именно должна быть реализация метода.
Для ссылки на текущий объект класса Movie, в контексте которого вызван метод, в теле
метода используется специальное служебное слово self.
160
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Наконец, строка 10 содержит объявление третьего метода класса Movie —
otherMovies. Методу передается входной (in) параметр типа star. Рассмотрим
особенности возможной реализации метода otherMovies. Можно предположить, что
сначала метод проверяет, входит ли актер, представляемый объектом-аргументом класса
star, в число актеров, принимавших участие в съемках кинофильма, которому
соответствует текущий объект Movie. Если ответ отрицателен, метод генерирует исключение
типа noSuchStar. В случае положительного результата проверки выходному (out)
параметру Set<Movie> присваивается набор ссылок на все другие объекты класса Movie,
с которыми связан переданный объект Star. Другими словами, метод возвращает
информацию обо всех остальных фильмах, в которых принимал участие конкретный актер. □
4.2.8. Типы в ODL
Язык ODL предлагает в распоряжение проектировщика баз данных систему
определения типов, аналогичную тем, которые реализованы в С и других традиционных
языках программирования. Система основана на наборе существующих базовых типов
(basic types) и предусматривает возможность использования некоторых рекурсивных
правил, позволяющих создавать сложные типы из более простых. К категории
базовых относятся типы ODL, указанные ниже.
1. Атомарные типы (atomic types): integer (целое число), float (вещественное
число с плавающей запятой), character (символ), string (строка символов),
boolean (бинарное логическое значение) и перечислимые типы (enumerations).
Последние представляют собой списки имен, обозначающих абстрактные
значения. Примером перечислимого типа может служить тип Film, объявление
которого приведено в строке 5 на рис. 4.3 (см. с. 157).
2: Классы (classes), такие как Movie или Star, — типы, по существу являющиеся
структурами, которые содержат компоненты для каждого атрибута или связи,
представленных в объявлении класса.
Из названных базовых типов могут быть образованы составные типы; для этого
применяются следующие конструкторы типов (type constructors).
1. Set (множество). Пусть Т— произвольный тип; тогда выражение Set<T>
представляет тип, значениями которого являются конечные множества элементов
типа Т. Примеры объявлений этого типа содержатся в строках 6, 11 и 15 рис. 4.3.
2. Bag (мультимножество). Пусть Т — произвольный тип; тогда выражение Вад<т>
представляет тип, значениями которого являются конечные мультимножества
элементов типа Т. Мультимножество допускает возможность включения
одинаковых элементов. Например, {1,2, 1} представляет собой мультимножество, но
не множество, поскольку элемент 1 присутствует дважды.
3. List (список). Пусть Т— произвольный тип; тогда выражение List<T>
представляет тип, значениями которого являются конечные списки, состоящие из
нулевого или любого другого количества элементов типа Т. Для обозначения
типа List<char> существует сокращенная форма записи — string.
4. Array (массив). Пусть Т — произвольный тип и i — целое число; тогда
Array<T\ i> представляет тип, значениями которого являются массивы из /
элементов типа Т. Например, выражение Array<char, 10> обозначает строки,
состоящие из 10 символов.
5. Dictionary (словарь). Пусть Т и S — произвольные типы; тогда
Dictionary<T\ s> представляет тип, значениями которого являются конечные
множества пар вида ключ/значение (ключи относятся к типу Г, а значения — к
4.2. ВВЕДЕНИЕ В ЯЗЫК ODL
161
Множества, мультимножества и списки
Чтобы облегчить понимание различий между множествами, мультимножествами
и списками, напомним, что множество — это неупорядоченный набор элементов,
и каждый элемент может присутствовать во множестве только единожды.
Мультимножество допускает наличие нескольких одинаковых элементов, и порядок их
следования, как и для множества, не определен. В список, как и в
мультимножество, может включаться несколько одинаковых элементов, но элементы списка
упорядочиваются. Так, например, {1,2, 1} и {2, I, 1} — это одинаковые
мультимножества, но (1, 2, 1) и (2, 1, 1) — различные списки.
типу 5). Словарь не должен содержать двух пар с одинаковым ключом. Словари
реализуются таким образом, чтобы операция поиска значения типа S по
заданному ключу типа Т выполнялась эффективно.
6. Structure (структура). Пусть ТЬТ2, ...,Тп — произвольные типы, a Fb F2,..., Fn —
наименования полей; тогда выражение
Struct N {Tt F1# T2 F2, . . . , Т„ F„}
представляет тип с именем N, элементами которого являются структуры,
состоящие из п полей. Поле с номером / обозначается как F, и относится к типу
Г/. Например, строка 10 рис. 4.3 (см. с. 157) содержит объявление структуры
Addr с двумя полями типа string, названными как street и city.
Пять типов — Set, Bag, List, Array и Dictionary — называют типами коллекций
(collection types). Существует несколько правил относительно того, какие типы могут
быть поставлены в соответствие атрибутам, а какие — связям.
• В качестве типа связи используется либо тип класса, либо конструктор типа
коллекции, однократно примененный по отношению к типу класса.
• Тип атрибута может быть определен на основе атомарного типа или нескольких
типов. В конструкциях объявления атрибутов используются и типы классов, но
обычно такие, которые находят применение в виде "структур", подобных Addr
из примера 4.3, приведенного на с. 155. Для соединения классов, как правило,
предпочтительно использовать двусторонние связи, поскольку в этом случае
существенно облегчается оформление запросов к базе данных. От объектов
можно "проследовать" к их атрибутам, но не наоборот. Отталкиваясь от
атомарных типов или типов класса, при необходимости мы можем применять
к ним и конструкторы типов коллекций, причем столько раз, сколько требуется.
Пример 4.8. Вот как могут выглядеть некоторые типы атрибутов:
1) integer;
2) Struct N {string fieldl, integer field2};
3) List<real>;
4) Array<Struct N {string fieldl, integer field2}, 10>.
Строка 1 содержит описание атомарного типа, строка 2 представляет структуру,
построенную на основе двух атомарных типов, строка 3 служит примером коллекции
(списка) значений атомарного типа, а строка 4 определяет коллекцию (массив)
значений структурного типа, который, в свою очередь, образован из атомарных типов.
Предположим, что Movie и star — это существующие базовые типы классов. На
их основе можно построить типы связей, такие как, скажем, Movie или Bag<Star>.
Ниже приведены примеры типов, которые нельзя использовать для объявления связей:
162
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
1) Struct N {Movie fieldl, Star field2}; в качестве типа связи не
допускается использовать структуры;
2) Set<integer>; в объявлении типа связи не могут участвовать атомарные типы;
3) Set<Array<star, 10>>; при объявлении типа связи не разрешается
применять конструктор типа коллекции более одного раза.
□
4.2.9. Упражнения к разделу 4.2
* Упражнение 4.2.1. В упражнении 2.1.1 на с. 63 предлагалось неформальное описание
банковской базы данных. Реализуйте проект такой базы данных средствами ODL.
Упражнение 4.2.2. Исправьте полученное вами решение упражнения 4.2.1 в
соответствии с рекомендациями, которые были даны в упражнении 2.1.2 на с. 63.
Опишите внесенные изменения, не создавая полную схему заново.
Упражнение 4.2.3. Преобразуйте решение упражнения 2.1.3 (см. с. 64) в проект на
языке ODL. Почему проблема представления множества цветов формы команды
средствами модели "сущность—связь" легко преодолевается при обращении к ODL?
*! Упражнение 4.2.4. Пусть необходимо обеспечить представление генеалогического
дерева семьи с использованием единственного класса Person ("человек").
Информация, подлежащая хранению, охватывает атрибут "имени" (name) каждого из
членов семьи и следующие связи: "мать" (rnotherOf), "отец" (fatherOf) и "ребенок"
(childOf). Представьте класс Person в виде проекта, оформленного средствами
ODL. Не забудьте включить в него связи, обратные по отношению к rnotherOf,
fatherOf и childOf и соединяющие класс Person сам с собой. Совпадает ли
связь, обратная к rnotherOf, со связью childOf? Почему да или почему нет?
Опишите прямые и обратные связи в виде множества пар связей.
! Упражнение 4.2.5. Добавим в проект, полученный при решении упражнения 4.2.4,
атрибут education ("образование"). Значением этого атрибута, как
предполагается, должна быть коллекция строк, описывающих уровни образования каждого
человека с указанием специальностей и полученных квалификаций (например,
"бакалавр в области компьютерных наук"), наименований учебных заведений и дат
их окончания. Названная коллекция структур может относиться к любому из
следующих типов: множество, мультимножество, список или массив. Опишите
преимущества и недостатки каждой из указанных альтернатив. Какая информация будет
приобретена или утрачена при выборе каждого конкретного типа коллекции?
Действительно ли потерянная информация так уж важна с практической точки зрения?
Упражнение 4.2.6. На рис. 4.5 приведены объявления двух классов — ship
("корабль") и TG (от task group — "флотилия"). Семантика наименований
атрибутов и связей классов такова: name — "название", yearLaunched — "год выпуска",
assignedTo — "приписан", unitsOf — "являются единицами", number —
"номер", commander — "командующий". В текст необходимо внести некоторые
изменения. Каждое изменение можно описать, упомянув номера строк,
нуждающихся в определенном исправлении или добавлении после них новых строк.
Приведите описания, отвечающие следующим изменениям.
a) Типом атрибута commander должна стать пара строк, первая из которых
содержит наименование воинского звания, а вторая — имя.
b) Корабль может быть приписан к нескольким флотилиям одновременно.
c) Корабли называют однотипными (sister), если они строятся по одним
чертежам. Для каждого корабля необходимо предусмотреть возможность пред-
4.2. ВВЕДЕНИЕ В ЯЗЫК ODL
163
ставления множества однотипных судов, исключая рассматриваемый
корабль. Можно полагать, что каждому из однотипных судов соответствует
объект класса ship.
1) class Ship {
2) attribute string name;
3) attribute integer yearLaunched;
4) relationship TG assignedTo inverse TG::unitsOf;
};
5) class TG {
6) attribute real number;
7) attribute string commander;
8) relationship Set<Ship> unitsOf
inverse Ship::assignedTo;
};
Рис. 4.5. Объявления классов судов и флотилий
*!! Упражнение 4.2.7. При каких обстоятельствах связь может оказаться обратной
самой себе? Примите к сведению следующий совет: воспринимайте связь в виде
множества пар значений (об этом мы говорили в разделе 4.2.5 на с. 156).
4.3. Другие понятия ODL
Язык ODL предлагает немалое число иных возможностей, которые заслуживают
внимания, если нам хотелось бы научиться выражать с помощью понятий ODL все
то, что подвластно изобразительным средствам модели "сущность—связь". В этом
разделе мы сосредоточим внимание на следующих вопросах.
1. Представление многосторонних связей. Заметим, что все связи в ODL
трактуются как бинарные, и для описания связей, охватывающих большее число
"сторон", необходимо предпринять дополнительные усилия — в отличие от
ER-модели, где подобная задача решается сравнительно более просто.
2. Подклассы и наследование.
3. Ключи.
4. Экземпляры — наборы объектов определенного класса, существующих в базе
данных. Экземпляры аналогичны по смыслу множествам сущностей или
экземплярам отношений, и их не следует путать с классом как таковым, который по
своей природе является схемой.
4.3.1. Многосторонние связи
Язык ODL поддерживает непосредственно только бинарные связи. Однако
существует трюк (мы рассказывали о нем в разделе 2.1.7 на с. 56), предполагающий замену
многосторонней связи несколькими бинарными связями типа "многие к одному".
Предположим, что задана многосторонняя связь R между классами или множествами
сущностей Сь С2,..., Сп. Связь R подлежит замене некоторым классом Сип бинарными
связями типа "многие к одному", которые соединяют С с каждым из С,. Каждый
объект класса С можно трактовать как кортеж t во множестве данных связи R. Объект t
посредством п связей типа "многие к одному" соединен с объектами классов С,-.
164
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Пример 4.9. Рассмотрим, каким образом может быть представлена средствами ODL
тернарная связь Contracts ("контракты"), показанная на ER-диаграмме рис. 2.7
(см. с. 59). Начнем с определений классов Movie, star и studio, соединяемых
связью Contracts (см. рис. 4.3 на с. 157).
Необходимо создать класс Contract, соответствующий трехсторонней связи Contracts.
Связи, соединяющие класс Contract с тремя названными классами, обозначим как
theMovie, theStar и theStudio. На рис. 4.6 приведено объявление класса Contract.
1) class Contract {
2) attribute integer salary;
3) relationship Movie theMovie
inverse ... ;
4) relationship Star theStar
inverse ... ;
5) relationship Studio theStudio
inverse ... ;
};
Рис. 4.6. Класс Contract представляет тернарную связь Contracts
Класс Contract содержит единственный атрибут, salary ("размер заработной
платы"), совпадающий с одноименным атрибутом связи Contracts и ассоциированный с
объектом-"контрактом", а не с одним из объектов трех других классов. Напомним, что при
рассмотрении ER-диаграммы рис. 2.7 мы приняли аналогичное решение о придании
атрибута salary именно связи, а не одному из соединяемых ею множеств сущностей. Остальные
свойства класса Contract — это три упомянутые связи, замещающие исходную связь.
В тексте объявлений связей theMovie, theStar и theStudio обратные связи не
обозначены — вначале необходимо исправить объявления классов Movie, star
и studio, включив в них определения связей, соединяющих эти классы с классом
Contract. Пусть, например, связь, обратная по отношению к theMovie, названа как
contractsFor. Тогда строку 3 на рис. 4.6 можно заменить такой:
3) relationship Movie theMovie
inverse Movie::contractsFor;
а в текст объявления класса Movie добавить выражение
relationship Set<Contract> contractsFor
inverse Contract::theMovie;
Обратите внимание, что последняя инструкция объявляет связь contractsFor в виде
множества "контрактов", поскольку условия производства кинофильма действительно
могут быть оговорены несколькими контрактами одновременно. Каждый подобный
контракт по существу представляет собой кортеж, содержащий ссылки на объекты
Movie, Star и studio, а также значение атрибута salary, которое представляет
размер гонорара, выплаченного соответствующей студией определенному актеру за
участие в съемках конкретного кинофильма. □
4.3.2. Подклассы
Вспомним материал, посвященный подклассам в ER-модели, который мы
приводили в разделе 2.1.11 на с. 61. Язык ODL предлагает схожие возможности объявления
одного класса (скажем, С) в виде подкласса (subclass) другого класса (например, D).
В таком случае в объявлении класса С после его имени необходимо указать служебное
слово extends ("расширяет") и название базового (superclass) класса D.
4.3. ДРУГИЕ ПОНЯТИЯ ODL
165
Пример 4.10. Возвратимся к примеру 2.10 на с. 62, где множество сущностей Cartoons
("мультипликация") трактуется как подкласс множества сущностей Movies
("кинофильмы") и участвует в дополнительной связи Voices ("голоса"), которая
определяет подмножество множества сущностей-"актеров" Stars, участвовавших в
озвучивании фильма. Объявление класса Cartoon, служащего подклассом класса Movie, на
языке ODL может выглядеть так:
class Cartoon extends Movie {
relationship Set<Star> voices;
};
Здесь мы не приводим наименование связи, обратной по отношению к voices, хотя,
строго говоря, обязаны это сделать.
Подкласс наследует (inherits) все свойства базового класса. Так, например, каждый
объект класса Cartoon обладает атрибутами title ("название"), year ("год
производства"), length ("продолжительность") и filrnType ("тип пленки"),
унаследованными от класса Movie (обратитесь к рис. 4.3 на с. 157), а также получает от Movie две
связи, starsOf и ownedBy, в дополнение к собственной связи voices.
В примере 2.10 рассматривался еще один подкласс множества Movies — множество
сущностей Murder-Mysteries ("боевики") с атрибутом weapon ("оружие"). Приведем
объявление аналогичного по смыслу класса ODL:
class MurderMystery extends Movie {
attribute string weapon;
};
Класс MurderMystery, как и класс Cartoon, будучи подклассом класса Movie,
наследует все свойства последнего. □
4.3.3. Множественное наследование
Подчас возникает необходимость создания класса, который является подклассом
сразу нескольких базовых классов. Примером может служить класс,
предназначенный для представления в базе данных таких объектов-"кинофильмов" (подобных
"Roger Rabbit"), которые относятся к жанрам "боевика" и мультипликации
одновременно. В ER-модели сущность "Roger Rabbit" может быть представлена
компонентами всех трех множеств сущностей — Movies,
Movie Cartoons и Murder-Mysteries, — участвующих
в иерархии связей isa (см. рис. 2.10 на с. 62).
Однако один из принципов объектно-
ориентированной парадигмы заключается в том,
Cartoon MurderMystery что объект может принадлежать одному и только
одному классу. Поэтому для представления
объектов-"кинофильмов", относящихся к жанрам
"боевика" и мультипликации, нам понадобится
CartoonMurderMystery определить еще один класс.
Рис. 4.7. Диаграмма, представ- Класс CartoonMurderMystery должен унасле-
ляющая пример множественного Довать свойства и класса Cartoon, и класса
наследования MurderMystery, как показано на рис. 4.7. Таким
образом, объект класса CartoonMurderMystery
будет обладать всеми свойствами класса Movie, а также связью voices и
атрибутом weapon.
В ODL-объявлении класса, расширяющего одновременно несколько базовых
классов, после служебного слова extends перечисляются имена этих классов, разделен-
166
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
ные символом двоеточия.17 Поэтому объявление класса CartoonMurderMystery
может выглядеть так:
class CartoonMurderMystery
extends MurderMystery : Cartoon;
Если некоторый класс С наследует свойства нескольких базовых классов, возникает
потенциальная опасность конфликтов имен этих свойств. Два и более классов, базовых
по отношению к С, могут обладать одноименными, но различными по смысловому
содержанию свойствами, относящимися к различным типам или даже к одному типу.
Класс CartoonMurderMystery, однако, избавлен от подобной проблемы, поскольку
общими для классов Cartoon и MurderMystery являются только такие свойства,
которые унаследованы от класса Movie, и в обоих случаях смысл этих свойств идентичен.
Ниже приведен пример ситуации, когда обстоятельства складываются не столь удачно.
Пример 4.11. Пусть имеются подклассы класса Movie, названные как Romance
("любовная история") и Courtroom ("судебный процесс"). Предположим также, что в составе
каждого из классов определен атрибут ending ("финал"). Атрибут ending класса
Romance относится к перечислимому типу {happy, sad} ("счастливый" и
"печальный"), в то время как одноименный атрибут класса Courtroom принимает значения
перечислимого типа {guilty, notGuilty} ("виновен" и "невиновен"). Если создать
класс Courtroom-Romance, производный от классов Courtroom и Romance, нам не
удастся однозначно определить тип унаследованного атрибута ending. □
Стандарт ODL не содержит каких-либо рекомендаций относительно того, как
разрешать подобные конфликты. Мы, тем не менее, можем назвать несколько
возможных способов преодоления проблемы.
1. Полностью отказаться от применения механизма множественного
наследования. Разумеется, такое решение весьма существенно ограничит возможности
проектирования.
2. Явно указать в объявлении подкласса, какому из конфликтующих свойств
базовых классов следует отдать предпочтение. В примере 4.11 мы могли бы решить,
что для кинофильмов жанра "любовная история на фоне судебного процесса"
более важно сохранить информацию о том, как завершилась история —
"счастливо" или "печально", — а не о вердикте суда. В таком случае нам
пришлось бы оговорить, что класс Courtroom-Romance наследует атрибут ending
от базового класса Romance, а не от класса Courtroom.
3. В объявлении производного класса дать одному из конфликтующих свойств,
унаследованных от базовых классов, новое имя. Если, скажем, класс
Courtroom-Romance наследует атрибут ending от базового класса Romance, мы
вправе указать, что класс Courtroom-Romance обладает дополнительным
атрибутом (назовем его verdict), который является переименованной версией
атрибута ending, унаследованного от класса Courtroom.
4.3.4. Экземпляры
Когда класс, определенный средствами ODL, становится частью базы данных,
необходимо уметь различать объявление класса как таковое и объекты этого класса, су-
Строго говоря, второе и все последующие имена типов, подлежащих множественному
расширению, должны соответствовать интерфейсам, а не обычным классам. Если не вдаваться
в детали, интерфейс (interface) в ODL — это объявление класса, для которого не существует
объектов или экземпляров (extents). О различии между классами и интерфейсами мы расскажем
подробно в разделе 4.3.4.
4.3. ДРУГИЕ ПОНЯТИЯ ODL
167
шествующие в заданный момент времени, — точно так же, как мы различаем схему
отношения и его экземпляр (последние, однако, допускают обращение по имени
отношения, и смысл этого имени зависит от контекста). Та же проблема возникает при
рассмотрении ER-модели, когда следует обособить определение множества сущностей
от конкретных наборов сущностей, отвечающих этому определению.
В ODL различие между классом и его экземпляром (extent), т.е. множеством
существующих объектов этого класса, становится вполне ощутимым, поскольку они
получают разные имена. Таким образом, наименование класса относится к схеме класса,
а экземпляру присваивается другое имя. Имя экземпляра класса задается в
объявлении класса в виде выражения, заключенного в круглые скобки и содержащего
служебное слово extent, за которым следует выбранное имя.
Пример 4.12. Мы действуем в соответствии со следующим соглашением об именах
классов и их экземпляров: в качестве имен классов используются существительные
в единственном числе, а для названий экземпляров классов употребляются те же
существительные во множественном числе. Если придерживаться подобного правила,
экземпляр класса Movie надлежит обозначить как Movies.
Объявление класса Movie с экземпляром Movies может выглядеть так:
class Movie (extent Movies) {
attribute string title;
};
В свое время, в ходе рассмотрения языка объектных запросов OQL, предназначенного
для обращения к данным, которые описаны средствами ODL, мы расскажем о том, что
при выполнении запроса на получение информации о кинофильмах, хранящейся в базе
данных в настоящий момент, следует ссылаться на экземпляр Movies, но не на класс
Movie. Напомним, что жесткого регламента именования экземпляров классов не
существует; правило, касающееся использования существительных множественного числа,
предложено нами и используется в этой книге из соображений удобства и простоты. □
4.3.5. Ключи
Язык ODL отличается от моделей и способов описания данных, которые мы
рассматривали до сих пор, тем, что объявлять и использовать ключи в ODL не
обязательно. В ER-модели ключи необходимы для того, чтобы различать элементы
множества сущностей один от другого. В реляционной модели, где отношения являются
множествами, все атрибуты отношения образуют ключ — если эта функция явно не
передана какому-либо подмножеству атрибутов. В любом случае отношение должно
обладать по меньшей мере одним ключом.
Объекты классов, однако, обладают уникальным идентификационным номером (object
identity ~ OID) (мы говорили об этом в разделе 4.1.3 на с. 151). Поэтому в определении
дополнительных ключей объектов, вообще говоря, необходимости нет. Вполне
допустима ситуация, когда несколько объектов класса внешне совершенно не отличаются друг
от друга, поскольку значения всех их свойств совпадают, но система все еще способна
распознать каждый из объектов по их внутренним идентификационным номерам.
Для присваивания одному или нескольким атрибутам класса статуса ключевых
в ODL используется служебное слово key или keys (не имеет значения, какое
именно), вслед за которым указывается имя нужного атрибута. Если в
формировании ключа должно участвовать несколько атрибутов, список их имен заключается
в круглые скобки. Конструкция объявления ключа в целом также обрамляется
круглыми скобками наряду с объявлением экземпляра и помещается в заголовок
объявления класса после имени класса.
168
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Интерфейсы
Язык ODL предусматривает возможность определения интерфейсов (interfaces) —
классов, в объявлении которых отсутствует конструкция со служебным словом
extent, обозначающая имя экземпляра класса. Поскольку интерфейсу не ставится
в соответствие имя экземпляра, создание его объектов не предусматривается. Мы
впервые упомянули интерфейсы в разделе 4.3.3 на с. 166, где речь шла о механизме
множественного наследования. Интерфейсы оказываются полезными и в том
случае, если несколько классов обладают различными экземплярами, но
совпадающими свойствами; подобная ситуация аналогична той, когда несколько отношений
с одной и той же схемой содержат различные множества кортежей.
Определив интерфейс /, мы вправе объявить несколько классов, наследующих
свойства /. Каждому из таких классов может соответствовать особый экземпляр, так
что нам удастся разместить в базе данных несколько наборов объектов одного
и того же типа; наборы объектов, однако, будут принадлежать различным классам.
Пример 4.13. Чтобы определить атрибуты title и year класса Movie как ключевые,
достаточно изменить начало текста объявления класса так, как показано ниже.
class Movie
(extent Movies key (title, year))
{
attribute string title;
Вместо key допустимо применять служебное слово keys — даже в том случае, если
функцию ключа должен выполнять только один атрибут.
Аналогично, если роль ключа отводится атрибуту name класса star, объявление
последнего следует изменить так:
class Star
(extent Stars key name)
{
attribute string name;
□
Вполне допустимо объявить для класса несколько независимых множеств
ключевых атрибутов. В этом случае после служебного слова key (или keys) вводятся списки
ключей, разделенные символом запятой. Список атрибутов, образующих каждый
отдельный ключ, задается в круглых скобках, поэтому случаи использования одного
ключа, состоящего из нескольких атрибутов, и нескольких ключей, каждый из
которых сформирован на основе одного атрибута, легко различимы.
Пример 4.14. В качестве примера ситуации, когда для класса желательно создать
несколько ключей, рассмотрим класс Employee ("служащий") (здесь мы не будем
приводить полный набор атрибутов и связей этого класса). Предположим, что в составе
класса имеются атрибуты empiD ("идентификатор") и ssNo ("номер полиса
социального страхования"). Каждый из них пригоден на роль ключа, поэтому заголовок
объявления класса будет выглядеть так:
class Employee
(extent Employees key empID, ssNo)
Поскольку список атрибутов, следующих после слова key, не заключен в круглые
скобки, каждый из атрибутов интерпретируется как самостоятельный ключ. Если бы
список атрибутов выглядел как (empID, ssNo), системе пришлось бы трактовать его
4.3. ДРУГИЕ ПОНЯТИЯ ODL
169
как выражение объявления единственного ключа, образованного из двух атрибутов.
Таким образом, конструкция
class Employee
(extent Employees key (empID, ssNo))
предполагает, что ни для каких служащих не могут совпасть одновременно
идентификатор и номер полиса социального страхования, хотя равенство значений этих
атрибутов, рассматриваемых отдельно, допустимо. □
Стандарт ODL позволяет формировать ключи не только из атрибутов, но и из
других свойств. Не случится ничего предосудительного, если в роли ключа или его
части выступит связь или метод класса. Нетрудно представить ситуацию, когда в
качестве ключа задается имя такого метода, который, как предполагается, в контексте
различных объектов должен возвращать гарантированно уникальные значения.
Поскольку в ODL определение ключей не считается обязательным, ответ на вопрос, будут ли
получены некие дополнительные преимущества за счет их использования, относится
к сугубой компетенции конкретной системы баз данных.
Если функция ключа возлагается на связь типа "многие к одному", эффект
аналогичен тому, который обусловлен применением слабых множеств сущностей в ER-
модели. Вполне возможно объявить, что объект Ои адресуемый некоторым объектом
02, расположенным на стороне "многие" связи, совместно с другими свойствами Оъ
которые, возможно, участвуют в образовании ключа, уникален для каждого
конкретного объекта 02. Впрочем, необходимо помнить о том, что создавать ключи для
классов вовсе не обязательно; нас никто не заставляет каким-то специальным образом
трактовать классы, лишенные ключевых атрибутов, как это делается, например, в
отношении слабых множеств сущностей.
Пример 4.15. Рассмотрим пример со слабым множеством сущностей Crews
("объединения"), которое изображено на ER-диаграмме рис. 2.20 на с. 81. Напомним
о том, что, как мы предполагали, сущность-"объединение" однозначно определяется
ее номером (number) и наименованием (пате) "киностудии", в состав которой входит
это "объединение", хотя две студии могут содержать объединения с одинаковыми
номерами. Объявление класса Crew может выглядеть так, как показано на рис. 4.8.
Связи unitof класса Crew должна соответствовать обратная связь crewsOf, которую
следует включить в состав класса studio.
class Crew
(extent Crews key (number, unitOf))
{
attribute integer number;
relationship Studio unitOf
inverse Studio::crewsOf;
};
Рис. 4.8. Объявление класса Crew
Ключ класса Crew в том виде, как он определен, исключает возможность
существования двух объектов класса Crew, содержащих одинаковые значения атрибута
number и одновременно связанных с одним и тем же объектом класса studio. Это
предположение совпадает с тем, которое выдвигалось нами прежде относительно
взаимозависимостей множеств сущностей Crews и Studios на ER-диаграмме рис. 2.20. □
4.3.6. Упражнения к разделу 4.3
* Упражнение 4.3.1. Дополните схему ODL, построенную вами при решении
упражнения 4.2.1 (см, с. 163), подходящими объявлениями экземпляра и ключей.
170
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Упражнение 4.3.2. Дополните схему ODL, построенную при решении упражнения
4.2.3 (см. с. 163), подходящими объявлениями экземпляра и ключей.
! Упражнение 4.3.3. Обратимся к решению упражнения 4.2.4 (см. с. 163), где
рассматривался класс Person ("человек"), представляющий генеалогию семьи, со
связями motherOf ("мать"), fatherOf ("отец'') и childof ("ребенок"), и
предположим, что его требуется дополнить. Следует обеспечить представление подклассов
Males ("мужчины"), Females ("женщины") и People ("люди"), описывающих
людей-родителей. Помимо того, связи motherOf, fatherOf и childOf должны
действовать между "наиболее частными" классами, для которых допустимы все
возможные экземпляры каждой из связей. Вы можете определить и другие классы,
а также использовать механизм множественного наследования, если все это
покажется вам необходимым. Приведите объявления классов.
Упражнение 4.3.4. Существует ли ключ, пригодный для определения в составе
класса Contract, текст объявления которого приведен на рис. 4.6 (см. с. 165)?
Если да, то как должен выглядеть такой ключ?
Упражнение 4.3.5. В упражнении 2.4.4 на с. 85 рассматривались две ситуации, в
которых особая роль отводилась слабым множествам сущностей. Опишите решения
упражнения 2.4.4 средствами ODL и не забудьте упомянуть в объявлениях классов
определения экземпляров и подходящих ключей.
Упражнение 4.3.6. Оформите с помощью ODL проект университетской базы
данных, рассмотренной в упражнении 2.1.9 на с. 65.
4.4. От ODL-проектов к реляционным схемам
Как мы говорили выше, на этапе реализации проекта в виде конкретной базы
данных ER-модель подлежит преобразованию в некоторую другую модель — например,
реляционную. Но язык ODL, в свою очередь, изначально задуман как средство
определения спецификаций баз данных с ориентацией на конкретные объектно-
ориентированные СУБД. Однако ODL, как и другие объектно-ориентированные
системы проектирования баз данных, может применяться также для создания эскизных
решений-прототипов, которые к моменту практической реализации должны быть
преобразованы в наборы отношений. В этом разделе мы расскажем о том, как
осуществлять подобное преобразование. Процесс превращения проекта ODL в
реляционную схему во многом напоминает получение реляционной схемы из ER-диаграммы.
Вместе с тем, ему присущи некоторые особенности, перечисленные ниже.
1. Множества сущностей должны быть снабжены ключами, но для классов ODL
это условие не является обязательным. Поэтому при построении отношения
для заданного класса в некоторых случаях приходится "изобретать" новый
атрибут класса, специально предназначенный для выполнения функций ключа.
2. Атрибуты ER-модели и отношения обязаны быть атомарными, в то время как
для атрибутов ODL такое требование не выдвигается. Процесс преобразования
атрибутов ODL, относящихся, например, к типам коллекций, в атрибуты
отношения зачастую непрост и непрямолинеен; помимо того, его результатом нередко
оказываются ненормализованные отношения, подлежащие дальнейшей
трансформации с помощью приемов, которые были рассмотрены в разделе 3.6 на с. 123.
3. ODL позволяет объявлять методы в виде неотъемлемой части проекта, но
способов их непосредственного преобразования в реляционные схемы не
существует. К вопросам использования методов в контексте реляционных схем мы
обратимся в разделе 4.5.5 на с. 185, а затем в главе 9 (см. с. 419), освещающей
4.3. ДРУГИЕ ПОНЯТИЯ ODL
171
особенности стандарта SQL-99. В данный момент мы будем полагать, что в
составе классов, которые должны быть преобразованы в реляционные схемы,
объявления методов отсутствуют.
4.4.1. От ODL-атрибутов к атрибутам отношений
Для начала предположим, что основной целью преобразования является получение
одного отношения для каждого класса и одного атрибута отношения для каждого свойства
класса. Позже мы расскажем о различных способах изменения подобного подхода, но
в данный момент целесообразно ограничить рассмотрение простейшим случаем, когда
возможность прямого преобразования класса в отношение и свойства класса в атрибут
отношения заведомо гарантируется. Предположим, что выполняются следующие условия:
1) все свойства класса относятся к категории атрибутов (не связей и не методов);
2) типы всех атрибутов являются атомарными (не составными).
Пример 4.16. На рис. 4.9 приведено объявление класса Movie, удовлетворяющее
указанным выше ограничениям. Кроме четырех атрибутов, объявление не содержит
каких-либо иных свойств. Все атрибуты относятся к атомарным типам: тип атрибута
title — это string; year и length являются целочисленными (integer); атрибут
f ilmType принимает значения перечислимого типа Film.
class Movie (extent Movies) {
attribute string title;
attribute integer year;
attribute integer length;
attribute enum Film {color, blackAndWhite} filmType;
};
Рис. 4.9. Атрибуты класса Movie
Отношение, создаваемое на основе класса, получает имя экземпляра класса,
указанное в его объявлении (в нашем случае — Movies). Отношение Movies должно
содержать четыре атрибута, по одному на каждый атрибут исходного класса Movie. Для
атрибутов отношения могут быть сохранены имена соответствующих атрибутов
класса. Таким образом, схема отношения Movies примет следующий вид:
Movies(title, year, length, filmType).
Каждому объекту в экземпляре Movies класса Movie отвечает один кортеж
отношения Movies, обладающий компонентами для каждого из четырех атрибутов класса,
и значения этих компонентов совпадают со значениями атрибутов объекта. □
4.4.2. Неатомарные атрибуты классов
Даже в том случае, когда все свойства класса относятся к категории атрибутов,
преобразование класса в отношение, к сожалению, все еще может быть сопряжено
с некоторыми трудностями. Причина состоит в том, что для атрибутов ODL
допускается задавать сложные типы, такие как Set (множество), Bag (мультимножество) или
List (список). С другой стороны, один из основополагающих принципов
реляционной модели предполагает возможность определения только таких атрибутов, которые
относятся к атомарным типам, подобным числовым или строковым. Поэтому нам
предстоит изыскать средства представления в контексте реляционной модели таких
типов, которые не являются атомарными.
Наиболее простой вариант состоит в использовании структур записей, поля
которых относятся к атомарным типам. В этом случае достаточно просто расширить
определение структуры и создать по одному дополнительному атрибуту отношения для каж-
172
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
дого из ее полей. Единственная потенциальная опасность связана с тем, что в
нескольких структурах могут встретиться одноименные поля; в этом случае придется
переименовать некоторые из полей, чтобы названия атрибутов отношения стали уникальными.
class Star (extent Stars) {
attribute string name;
attribute Struct Addr
{string street, string city} address;
};
Рис. 4.10. Класс с атрибутом структурного типа
Пример 4.17. На рис. 4.10 приведено объявление класса star, свойствами которого
являются только атрибуты. Атрибут name относится к атомарному типу string, но
типом атрибута address служит структура, состоящая из двух полей, street и city.
Класс star может быть описан отношением с тремя атрибутами. Первый атрибут
отношения, name, соответствует одноименному атрибуту класса. Второй и третий
атрибуты отношения мы обозначили как street и city; они отвечают двум полям
структуры address и в совокупности представляют значение адреса. Результат
преобразования класса в отношение таков:
Stars(name, street, city).
На рис. 4.11 для примера приведено несколько кортежей полученного отношения. Q
пате
Carrie Fisher
Mark Hamill
Harrison Ford
street
123 Maple St.
456 Oak Rd.
7 89 Palm Dr.
city
Hollywood
Brentwood
Beverly Hills
Рис. 4.11. Экземпляр отношения Stars
4.4.3. Представление атрибутов типа множеств
Структуры записей — это не самый сложный тип атрибутов, которые
употребляются в объявлениях ODL-классов. Значения атрибутов могут относиться к составным
типам, которые строятся средствами конструкторов типов Set, Bag, List, Array
и Dictionary (мы вкратце упоминали о них в разделе 4.2.8 на с. 161).
Преобразование значений каждого из названных типов для представления их в рамках
реляционной модели сопряжено с особыми проблемами. Наиболее подробно мы остановимся
на том, как выполнять преобразование значений типа Set, поскольку этот тип
находит самое широкое применение.
Один из способов представления множества значений атрибута А заключается
в создании отдельного кортежа отношения для каждого значения множества. Для всех
остальных атрибутов, помимо А, кортеж должен содержать одни и те же
соответствующие значения. Вначале приведем пример, в котором такой подход проявляет себя
с выгодной стороны, а затем рассмотрим его недостатки.
class Star (extent Stars) {
attribute string name;
attribute Set<
Struct Addr {string street, string city}
> address;
};
Рис. 4.12. Каждый актер обладает множеством адресов
4.4. ОТ ODL-ПРОЕКТОВ К РЕЛЯЦИОННЫМ СХЕМАМ
173
Пример 4.18. Пусть класс star объявлен таким образом, чтобы каждому объекту-
"актеру" соответствовало множество адресов, как на рис. 4.12. Предположим также,
что актрисе Кэрри Фишер посчастливилось приобрести дом в тихом переулке
курортного городка, второй по счету, но каждый из двух других актеров, упомянутых на
рис. 4.11, по-прежнему владеет только одним домом. Теперь можно создать два
кортежа, атрибут name которых содержит значение "Carrie Fisher", как показано на
рис. 4.13. Другие кортежи экземпляра отношения рис. 4.11 остаются без изменений. □
пате
Carrie Fisher
Carrie Fisher
Mark Hamill
Harrison Ford
street
123 Maple St.
5 Locust Ln.
456 Oak Rd.
7 89 Palm Dr.
city
Hollywood
Malibu
Brentwood
Beverly Hills
Рис. 4.13. Так выглядит экземпляр отношения для класса star с множествами адресов
Подобный прием преобразования объекта с одним или несколькими атрибутами
типа Set в набор кортежей, по одному на каждую комбинацию значений атрибутов,
к сожалению, приводит к получению ненормализованных отношений, нарушающих
условия, рассмотренные в разделе 3.6 на с. 123. На самом деле наличие в составе
класса даже одного атрибута типа Set способно привести к нарушению требований
BCNF, и следующий пример служит тому подтверждением.
class Star (extent Stars) {
attribute string name;
attribute Set<
Struct Addr {string street, string city}
> address;
attribute Date birthdate;
};
Рис. 4.14. Класс Star с дополнительным атрибутом birthdate
Пример 4.19. Предположим, что в состав класса star введен новый атрибут
birthdate ("дата рождения"). Соответствующий вариант объявления класса
изображен на рис. 4.14; он отличается от исходного, приведенного на рис. 4.12, наличием
атрибута birthdate типа Date — последний входит в число атомарных типов ODL.
Атрибут birthdate подлежит включению в отношение stars наряду с остальными
атрибутами, так что схема отношения приобретает следующий вид:
Stars(name, street, city, birthdate).
Теперь изменим содержимое экземпляра отношения, представленного на рис. 4.13.
Поскольку множество адресов в частном случае может оказаться пустым,
предположим, что в нашей базе данных отсутствует информация об адресах проживания актера
Гаррисона Форда. Исправленная версия экземпляра отношения изображена на
рис. 4.15. Произошли два неприятных события.
1. Дата рождения Кэрри Фишер повторяется в двух кортежах, что явно излишне.
Имя актрисы также повторяется, но считать это характерным признаком
избыточности данных нельзя, так как, не будь ее имени в обоих кортежах, мы не
смогли бы определить, что оба адреса принадлежат именно Кэрри Фишер.
2. Поскольку в базе данных нет информации об адресах Гаррисона Форда, вся
остальная информация об этом актере также будет утрачена. Подобная ситуация
служит примером аномалии удаления (см. раздел 3.6.1 на с. 123).
174
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Атомарные значения: недостаток или благо?
Может показаться, что реляционная модель воздвигает на пути к достижению
цели ничем не обоснованные препятствия, в то время как язык ODL,
позволяющий использовать в определениях свойств структурные типы, является
более гибким инструментом. Поэтому сам собой напрашивается решительный
вывод о полном отказе от реляционной модели ввиду ее вопиющей
"примитивности" в сравнении с более "элегантными" и мощными объектно-
ориентированными подходами, подобными ODL. Однако реальность такова,
что на сегодняшнем рынке СУБД доминируют именно те системы, которые
основаны на реляционной модели. Одна из причин такого положения вещей
заключается в том, что простота реляционной модели делает возможным
применение мощных языков программирования, среди которых наибольшую
популярность завоевал SQL (за подробностями обращайтесь к главе 6 на с. 249).
пате
Carrie Fisher
Carrie Fisher
Mark Hamill
street
123 Maple St.
5 Locust Ln.
456 Oak Rd.
city
Hollywood
Malibu
Brentwood
birthdate
9/9/99
9/9/99
8/8/88
Рис. 4.15. Экземпляр отношения Stars с атрибутом birthdate
Хотя атрибут name служит ключом для класса star, необходимость представления
в отношении stars нескольких адресов, соответствующих одному объекту star,
означает, что name не может считаться ключом для отношения. На самом деле ключ
отношения stars должен быть таким: {name, street, city}. Поэтому наличие
функциональной зависимости
name —> birthdate
провоцирует нарушение условия BCNF. Этот факт объясняет причину возникновения
аномалий, упомянутых выше. □
Существует ряд способов обращения с атрибутами типа Set, присутствующими
в объявлении класса наряду с другими атрибутами. Во-первых, мы вправе
включить все атрибуты класса — не важно, атомарных или составных типов — в схему
отношения и затем прибегнуть к приемам нормализации, рассмотренным в
разделах 3.6 (см. с. 123) и 3.7 (см. с. 137), с целью устранения причин возможных
нарушений требований BCNF и 4NF. Заметим, что включение в отношение
атрибута типа Set совместно с атомарными атрибутами приводит к нарушению условия
BCNF. Введение в состав отношения двух атрибутов типа Set чревато
невыполнением требований 4NF. Второй подход состоит в разделении каждого атрибута
типа Set таким образом, будто существует связь типа "многие ко многим" между
объектами класса и множеством значений атрибута типа Set (подробнее об
этом — в разделе 4.4.5 на с. 177).
4.4.4. Представление атрибутов других составных типов
Помимо структур записей и множеств, для определения атрибутов в составе
классов ODL могут применяться и другие типы, такие как Bag (мультимножество),
List (список), Array (массив) и Dictionary (словарь). Чтобы представить
значение типа мультимножества, в котором каждый элемент может повторяться п раз, мы
не вправе внести в экземпляр отношения п одинаковых кортежей непосредствен-
4.4. ОТ ODL-ПРОЕКТОВ К РЕЛЯЦИОННЫМ СХЕМАМ
175
но.18 Вместо этого можно добавить в схему отношения дополнительный атрибут
count ("счетчик"), содержащий число экземпляров каждого различного элемента
мультимножества. Предположим, например, что в объявлении класса star
(см. рис. 4.12 на с. 173) атрибут address относится к типу Bag, а не Set. Тот факт,
что значение адреса {"123 Maple St. ", "Hollywood"} актрисы Кэрри Фишер
повторяется, скажем, дважды, а адрес ее второго дома, {"5 Locust Ln.", "Malibu"}, —
трижды (зачем — это другой вопрос), может быть отображен так:
пате
Carrie Fisher
Carrie Fisher
street
123 Maple St.
5 Locust Ln.
city
Hollywood
Malibu
count
2
3
Список (List) адресов нетрудно представить с помощью дополнительного
атрибута position ("позиция"), задающего положение элемента в списке. В этом случае
информация об адресах домов Кэрри Фишер (первого — в Голливуде, а второго —
в Малибу) в экземпляре отношения stars сохраняется следующим образом:
пате
Carrie Fisher
Carrie Fisher
street
123 Maple St.
5 Locust Ln.
city
Hollywood
Malibu
position
1
2
Чтобы представить адреса, заданные в виде массива фиксированной длины
(Array), достаточно создать атрибут отношения для каждого элемента массива. Если
бы, например, атрибут address класса star (см. рис. 4.12 на с. 173) представлял
собой массив, состоящий из двух структур вида "street—city", объекты класса можно
было бы оформить в виде отношения, подобного следующему:
пате
Carrie Fisher
street!
123 Maple St.
cityl
Hollywood
street2
5 Locust Ln.
city2
Malibu
Наконец, словарь (Dictionary) также допускает представление в виде множества,
но с атрибутами для компонентов ключей и значений, образующих пары, которые
являются элементами словаря. Предположим, что помимо обычных адресов актеров
необходимо сохранить в базе данных сведения о владельцах закладных на каждый из
домов. Подобную информацию легко отобразить в виде словаря, где функцию ключа
выполняет содержимое атрибута address, а значениями являются наименования
компаний или банков. Вот пример:
пате
Carrie Fisher
Carrie Fisher
street
123 Maple St.
5 Locust Ln.
city
Hollywood
Malibu
mortgage-holder
Bank of Burbank
Torrance Trust
Разумеется, при определении составного типа атрибута ODL может быть
использовано единовременно несколько конструкторов. Если типом атрибута служит результат
18 Точнее говоря, это запрещено с точки зрения абстрактной реляционной модели,
рассмотренной в главе 3. Но конкретные SQL-ориентированные реляционные СУБД, напротив,
обычно позволяют размещать в отношениях повторяющиеся кортежи; т.е. с точки зрения
SQL отношения представляют х;обой не множества, а мультимножества (за подробностями
обращайтесь к разделам 5.3 и 6.4 на с. 225 и 283 соответственно). Если при обращениях к
базе данных часто запрашиваются значения количеств кортежей того или иного вида, мы
рекомендуем применять рассматриваемый здесь подход даже тогда, когда используемая вами
СУБД разрешает вводить одинаковые кортежи.
176
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
применения конструктора любого типа коллекции (кроме Dictionary) к структуре
(например, множество структур), следует воспользоваться приемами, о которых было
рассказано в этом и предыдущем разделах: вначале структура трактуется как
атомарный тип, а затем каждому полю структуры ставится в соответствие отдельный атрибут
(в примерах, рассмотренных выше, мы поступали именно так, поскольку адрес
представлял собой структуру из двух полей). Случай применения к структуре конструктора типа
Dictionary аналогичен, и его изучение мы оставляем читателю в качестве упражнения.
Имеется немало причин для снижения сложности типов атрибутов при
проектировании конкретных баз данных; на наш взгляд, целесообразно ограничиться структурами
либо, самое большее, составными типами, служащими результатом применения к структурам
конструкторов коллекций. В разделе 2.1.1 на с. 52 упоминалось о том, что некоторые
версии ER-модели допускают именно такой уровень обобщения, хотя мы сами ограничили
рассмотрение атомарными типами ER-атрибутов. Если вы собираетесь использовать
ODL-проекты с целью их дальнейшего преобразования в реляционные схемы, мы
рекомендуем придерживаться тех же ограничений. Вопросы использования атрибутов ODL,
относящихся к некоторым более сложным типам, вынесены в раздел 4.4.7 на с. 179.
4.4.5. Представление связей
Классы ODL часто содержат объявления связей, соединяющих объекты этих
классов с объектами других классов. Как и в ER-модели, для каждой связи ODL может
быть построено отдельное отношение, объединяющее ключевые атрибуты связанных
классов. Связи ODL, однако, отвечает обратная связь, и пара связей должна быть
представлена только одним отношением.
class Movie
(extent Movies key(title, year))
attribute string title;
attribute integer year;
attribute integer length;
attribute enum Film {color, blackAndWhite} filmType;
relationship Set<Star> starsOf
inverse Star::starredln;
relationship Studio ownedBy
inverse Studio::owns;
};
class Studio
(extent Studios key name)
{
attribute string name;
attribute string address;
relationship Set<Movie> owns
inverse Movie::ownedBy;
};
Рис. 4.16. Полные объявления классов Movie и Studio
Пример 4.20. Рассмотрим объявления классов Movie и studio, приведенные на
рис. 4.16. Атрибуты title и year формируют ключ класса Movie, а атрибут name —
ключ класса studio. Построим отношение для пары связей owns и ownedBy. Имя
такого отношения может быть произвольным; мы выберем studioOf. Схема отношения
StudioOf должна содержать ключевые атрибуты title и year класса Movie и ключ
name (мы переименуем его в studioName) класса Studio:
StudioOf(title, year, studioName).
4.4. ОТ ODL-ПРОЕКТОВ К РЕЛЯЦИОННЫМ СХЕМАМ
777
А так может выглядеть типичный экземпляр отношения studioOf:
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
studioName
Fox
Disney
Paramount
□
Если связь относится к типу "многие к одному", существует возможность объединить
отношение, которое ей соответствует, с отношением, построенным для класса,
"расположенного" на стороне "многие" связи. Сделав это, мы получим такой же эффект,
какой дает объединение двух отношений с общим ключом (см. раздел 3.2.3 на с. 95).
Подобный прием не нарушает условие BCNF и поэтому находит широкое применение.
Пример 4.21. Вместо построения отношения StudioOf для пары связей owns
и ownedBy классов Movie и studio, как предлагалось в примере 4.20, мы можем
расширить схему отношения Movies, дополнив ее атрибутом studioName,
представляющим ключ класса studio:
Movies(title, year, length, filmType, studioName).
Вот один из возможных экземпляров такого отношения:
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
film Type
color
color
color
studioName
Fox
Disney
Paramount
Обратите внимание, что {title, year}, ключ класса Movie, остается ключом и для
отношения Movies в указанной выше редакции, поскольку каждый объект-
"кинофильм" обладает строго определенными значениями атрибутов length,
filmType и studioName. □
Полезно заметить, что связь типа "многие ко многим" в процессе преобразования ее
в отношение можно трактовать так же, как и связь "многие к одному" (см. пример 4.21),
но делать так не стоит. В примере 3.6 на с. 96 мы уже показывали, что произойдет,
если попытаться "сплотить" отношение для связи Stars-in типа "многие ко многим",
соединяющей множества сущностей Movies и Stars, с отношением для множества
Movies с целью получения отношения со следующей схемой:
Movies(title, year, length, filmType, studioName, starName).
Отношение нарушает условие BCNF, поскольку ключом является множество
атрибутов {title, year, starName}, но значения length, filmType и studioName по-
прежнему функционально обусловлены только содержимым атрибутов title и year.
Если объединяются отношение для связи типа "многие к одному" и отношение для
класса, этот класс должен быть "прицеплен" к связи со стороны "многие". Напротив,
объединение отношения для пары связей owns и ownedBy с отношением Studios,
например, приведет к нарушению требований BCNF (см. упражнение 4.4.4 на с. 179).
4.4.6. А если ключей просто нет?
Поскольку задание ключей в ODL не обязательно, вполне возможна ситуация,
когда имеющиеся в наличии атрибуты класса С не способны представлять его объекты
совершенно однозначно, и это грозит проблемами, если класс С вовлечен в одну или
несколько связей.
178
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
В подобных случаях мы рекомендуем создать новый атрибут, выполняющий
функцию "сертификата" объектов класса С в реляционном проекте, — во многом подобно
тому, как скрытый идентификационный номер объекта (OID) позволяет отличить
последний от всех других объектов в объектно-ориентированной системе. Сертификат
становится дополнительным атрибутом отношения для класса С и представляет его
объекты в каждом отношении, которое создается на основе связей с участием класса
С. Заметим, что на практике объекты многих важных классов различаются именно
при посредничестве сертификатов — уникальных идентификаторов служащих,
номеров водительских удостоверений и т.п.
Пример 4.22. Предположим, что для однозначного различения объектов-"актеров"
одного атрибута имени (name) не достаточно. Поэтому каждому объекту ставится в
соответствие уникальный "номер-сертификат". Схема соответствующего отношения
stars приобретет следующий вид:
Stars(cert#, name, street, city, birthdate).
Если затем нам понадобится представить в виде отношения stars in связь типа "многие
ко многим", соединяющую классы Movie и star, в схему отношения достаточно будет
включить наряду с атрибутами title и year класса Movie атрибут cert# класса Star:
Starsln(title, year, cert#).
□
4.4.7. Упражнения к разделу 4.4
Упражнение 4.4.1. Преобразуйте в реляционные схемы ODL-проекты, созданные
вами при решении следующих упражнений:
*а) 4.2.1 (см. с. 163);
b) 4.2.2 (см. с. 163);
c) 4.2.3 (см. с. 163);
* d) 4.2.4 (см. с. 163);
е) 4.2.5 (см. с. 163).
Упражнение 4.4.2. Преобразуйте в реляционную схему классы ODL, приведенные
на рис. 4.5 (см. с. 164). Каким образом повлияют на результат три предположения,
указанные в упражнении 4.2.6?
! Упражнение 4.4.3. Пусть дан атрибут типа "словаря" (Dictionary), ключи и
значения которого представляются структурами, содержащими элементы атомарных
типов. Покажите, как преобразовать в отношение класс с атрибутом названного типа.
* Упражнение 4.4.4. Мы утверждали, что если объединить отношение для класса
studio, объявленного в том виде, как показано на рис. 4.16 (см. с. 177), с
отношением для пары связей owns и ownedBy, это приведет к нарушению условия BCNF.
Выполните объединение и покажите на примере факт подобного нарушения.
Упражнение 4.4.5. Выше мы говорили, что если атрибуты класса относятся к типу,
более замысловатому, нежели коллекция структур, задача преобразования такого класса
в отношение приобретает дополнительную сложность: в частности, приходится
рассматривать некие промежуточные типы данных и создавать для них вспомогательные
отношения. В списке заданий, приведенных ниже, предлагаются типы
возрастающей степени сложности и формулируются условия преобразования их в отношения.
* а) Игральная карта card может быть представлена в виде экземпляра структуры
с полями rank ("достоинство"), принимающим значения из множества 2, 3, ...,
4.4. ОТ ODL-ПРОЕКТОВ К РЕЛЯЦИОННЫМ СХЕМАМ
179
10, Jack ("валет"), Queen ("дама"), King ("король"), Асе ("туз"), и suit
("масть"), которому отвечает перечислимый тип {Clubs, Diamonds,
Hearts, Spades} (соответственно, "трефы", "бубны", "черви", "пики").
Дайте формальное определение типа Card, не зависящее от объявлений
каких-либо иных классов, но доступное для обращений извне.
* Ь) Рассмотрим набор карт hand, находящихся в руках одного из игроков.
Количество карт в таком наборе может изменяться. Предложите объявление
класса Hand, объекты которого описывают наборы hand, т.е. содержат некоторый
атрибут theHand типа hand.
*!с) Преобразуйте в реляционную схему класс Hand, объявление которого
создано вами при выполнении задания п. (Ь).
d) Poker hand — это набор из пяти карт. Выполните задания пп. (Ь), (с)
применительно к наборам вида poker hand.
*!е) Deal — это множество пар, каждая из которых состоит из имени игрока
и набора карт вида hand. Объявите класс Deal, объекты которого
представляют множества deal, т.е. содержат некоторый атрибут theDeal типа deal.
f) Выполните задание п. (е) при условии, что наборы карт относятся к виду
poker hand.
g) Выполните задание п. (е), используя для представления множеств deal тип
Dictionary и полагая, что имена игроков, сохраняемые в множествах deal,
уникальны.
*!!h) Преобразуйте в реляционную схему класс, объявление которого создано
вами при выполнении задания п. (е).
*!i) Предположим, что deal означает множество наборов карт вида hand, но
с каждым набором hand не сопоставлено имя игрока. Допустимо
представить множество deal в виде следующей реляционной схемы:
Deals(deallD, card),
где карта card является элементом одного из наборов hand в множестве deal,
которому отвечает определенный номер deal id. Что плохого в подобном
представлении? Как исправить недостатки, если таковые действительно есть?
Упражнение 4.4.6. Пусть дано объявление класса С вида
class С (key a) {
attribute string a;
attribute T b;
};
где Т — некоторый тип. Представьте реляционные схемы отношений для класса С
и укажите их ключевые атрибуты в предположении, что Т представляет собой один
из следующих типов:
a) Set<Struct S {string f, string g}>;
*! b) Bag<Struct S {string f, string g}>;
!c) List<Struct S (string f, string g}>;
! d) Dictionary<Struct К {string f, string g}, Struct R {string i,
string j}>.
4.5. Объектно-реляционная модель
Реляционная модель и объектно-ориентированная модель, описываемая
средствами ODL, представляют собой два важнейших инструмента проектирования баз дан-
180
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
ных. На протяжении длительного периода времени на рынке коммерческих СУБД
предпочтение отдавалось системам баз данных, созданным на основе реляционной
модели. В 90-х годах некоторое развитие получили так называемые объектно -
ориентированные СУБД (object-oriented DBMS's), но ныне подобные проекты
находятся на грани полного краха. Вместо перехода от реляционных к "чистым" объектно-
ориентированным системам, предсказываемого в начале 90-х годов, производители
реляционных систем сделали ставку на развитие существующих решений за счет
пополнения их новыми инструментами, предлагаемыми языком ODL и другими технологиями
объектно-ориентированных баз данных. В итоге многие программные продукты, ранее
называвшиеся "реляционными", теперь приобрели статус "объектно-реляционных".
В главе 9 на с. 419 будет рассмотрен новейший стандарт SQL, регламентирующий
характеристики объектно-реляционных СУБД (object-relational DBMS's). В этом разделе
мы, однако, обсудим предмет с более абстрактных позиций. Раздел 4.5.1 познакомит вас
с понятием объектов-отношений (object-relations), а в разделе 4.5.2 на с. 182 мы
расскажем об одном из самых ранних нововведений — вложенных отношениях (nested relations).
Аппарат ODL-подобных ссылок (references) на объекты-отношения обсуждается в
разделе 4.5.3 на с. 183, а в разделе 4.5.4 на с. 184 мы проведем сравнительный анализ
объектно-реляционной модели и "чистого" объектно-ориентированного подхода.
4.5.1. От отношений к объектам-отношениям
Оставаясь фундаментальной концепцией, реляционная модель получила развитие
и превратилась в объектно-реляционную модель (object-relational model) за счет
пополнения следующими новшествами.
1. Структурные типы атрибутов. Помимо атомарных типов, объектно-
реляционные системы поддерживают систему типов, подобную той, которая
применяется в ODL: структурные типы, построенные на основе атомарных,
и конструкторы типов, позволяющие создавать множества (sets),
мультимножества (bags) и т.п. Особенно важное значение отводится типу,
представляющему множество19 структур, т.е. по существу описывающему обычное
отношение. Отсюда естественно следует, что компонент кортежа одного отношения
способен, в свою очередь, сохранять целиком другое отношение.
2. Методы. Позволяется определять специальные операции, подлежащие
выполнению над данными некоторого типа, объявленного пользователем. Мы еще не
касались вопроса, как манипулировать значениями или кортежами в
реляционной или объектно-ориентированной модели, но позже, в главе 5 на с. 203,
когда мы приступим к рассмотрению предмета, вы познакомитесь с некоторыми
любопытными вещами. Например, значения числовых типов могут
обрабатываться традиционными арифметическими и логическими операторами, такими
как "плюс" (+) или "меньше" (<). Объектно-реляционная модель, однако,
предлагает дополнительную возможность определения специализированных
операторов, учитывающих особенности конкретных типов (достаточно вспомнить
ODL-объявление класса Movie в примере 4.7 на с. 159, где предусматривался
ряд методов, ориентированных на применение в контексте объектов Movie).
3. Идентификаторы кортежей. В объектно-релядионных системах кортежи
выполняют функцию объектов. Поэтому в некоторых ситуациях полезно снабдить
каждый кортеж уникальным идентификатором, позволяющим отличать один
кортеж от другого даже тогда, когда кортежи обладают совершенно
одинаковыми значениями во всех компонентах. Такой идентификатор, схожий с иденти-
19 Если быть более точным, мультимножество (bag), а не множество (set), поскольку
коммерческие реляционные СУБД обычно поддерживают отношения с повторяющимися кортежами.
4.5. ОБЪЕКТНО-РЕЛЯЦИОННАЯ МОДЕЛЬ
181
фикационным номером объекта (OID) в ODL, обычно невидим с точки зрения
пользователя, хотя возможны и такие обстоятельства, когда имеет смысл
наделить пользователя объектно-реляционной системы способностью обращаться
к идентификатору кортежа непосредственно.
4. Ссылки. В то время как реляционная модель не предусматривает каких бы то ни
было механизмов формирования ссылок или указателей на кортежи
отношения, объектно-реляционные системы позволяют использовать такие ссылки,
причем самыми различными способами.
В следующих разделах мы рассмотрим каждую из перечисленных возможностей более
подробно.
4.5.2. Вложенные отношения
В соответствии с условиями п. 1, отношения могут быть вложенными (nested
relations). Другими словами, позволяется определять атрибуты отношения таких
типов, которые не являются атомарными; в частности, в роли типа атрибута может
выступать реляционная схема. Результатом подобных рассуждений служит рекурсивное
определение типов атрибутов и типов (схем) отношений, приведенное ниже.
Базис. Допустимыми типами атрибута являются атомарные типы (целочисленный,
числовой вещественный, строковый и т.п.).
Индукция. Допустимым типом отношения может служить любая схема,
включающая имена одного или нескольких атрибутов любых допустимых типов.
Рассматривая реляционную модель, мы явно не оговаривали, какой именно атомарный
тип поставлен в соответствие тому или иному атрибуту отношения, поскольку различия
между типами не имели "отношения" к обсуждаемым проблемам, связанным, например,
с функциональными зависимостями или нормализацией. Мы будем по-прежнему
игнорировать подобные различия, но при описании схемы отношения, содержащего вложенные
отношения, нам придется оговаривать, какие атрибуты относятся к типам схем
отношений. Подобные типы мы будем представлять в виде имени вложенного отношения со
списком его атрибутов, заключенным в круглые скобки. Атрибуты вложенного отношения
также, в свою очередь, способны хранить вложенные отношения, и глубина вложения
отношений может быть настолько большой, насколько это действительно необходимо.
Пример 4.23. Рассмотрим схему отношения stars с атрибутом movies, который для
каждого объекта-"актера" содержит соответствующий экземпляр отношения,
представляющего информацию о кинофильмах с участием этого актера. Схема отношения атрибута
movies включает знакомые вам атрибуты title, year и length, описывающие объекты-
" кинофильмы". Схема отношения stars, помимо атрибута movies, содержит атрибуты
name, address и birthdate. Атрибут address также относится к типу схемы отношения,
атрибутами которой являются street и city. Схема отношения stars выглядит так:
Stars(name, address(street, city), birthdate,
movies(title, year, length)).
Экземпляр отношения stars показан на рис. 4.17. Экземпляр содержит два
кортежа, один из которых представляет сведения об актрисе Кэрри Фишер, а другой —
об актере Марке Хэмилле. Значения компонентов для удобства отображения
несколько сокращены; штриховые линии, разделяющие кортежи, служат только для
облегчения восприятия данных и не несут никакой смысловой нагрузки.
Кортеж с информацией о Кэрри Фишер содержит ее имя (атомарное значение), за
которым следует отношение, представляющее адреса актрисы. Это вложенное
отношение описывается двумя атрибутами, street и city, и включает два кортежа,
соответствующие двум домам, которыми владеет Кэрри Фишер. Далее приведено атомар-
182
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
ное значение атрибута birthdate. Наконец, значением атрибута movies служит
вложенное отношение, представляющее сведения о кинофильмах с участием Кэрри
Фишер. Схема этого отношения состоит из атрибутов title, year и length,
описывающих характеристики кинофильмов; экземпляр отношения содержит кортежи,
соответствующие трем наиболее известным фильмам, в которых снялась актриса.
Fisher
Hamill
address
street
Maple
Locust
city
H'wood
Malibu
street
Oak
city
B'wood
birthdate
9/9/99
8/8/88
title
Star Wars
Empire
Return
year
1977
1980
1983
length
124
127
133
title
Star Wars
Empire
Return
year
1977
1980
1983
length
124
127
133
Рис. 4.17. Отношение Stars с вложенными отношениями
Второй кортеж, содержащий сведения о Марке Хэмилле, обладает теми же
компонентами. Отношение для атрибута address состоит из одного кортежа, поскольку,
как мы полагаем, актер владеет только одним домом. Отношение для атрибута
movies, однако, выглядит точно так же, как и для Кэрри Фишер, так как по стечению
обстоятельств артисты снимались в одних и тех же фильмах. Заметим, что эти
отношения являются компонентами различных кортежей и совпали просто случайно —
точно так же, как могут совпасть обычные целочисленные величины или строки текста. □
4.5.3. Ссылки
Тот факт, что кортежи (например, соответствующие фильму "Star Wars")
вложенных отношений атрибута movies повторяются неоднократно, служит причиной
избыточности данных. Схема отношения stars, рассмотренная в примере 4.23, нарушает
условие BCNF. Обычные приемы декомпозиции, однако, не способны устранить
подобную избыточность. Тем не менее нам необходимо добиться, чтобы информация
о каждом кинофильме появлялась не более одного раза.
Для достижения цели объекты-отношения должны быть наделены способностью
поддерживать ссылки одного кортежа t на другой кортеж s вместо непосредственного
включения s в t. Поэтому модель следует пополнить новым правилом, допускающим
рекурсивное применение: типом атрибута может быть ссылка на кортеж заданной схемы.
Если атрибут А относится к типу, который представляет собой ссылку на
единственный кортеж реляционной схемы /?, этот факт записывается как A(*R). Заметим, что
указанный случай совпадает с тем, когда ODL-связь А обладает тем же типом R, т.е.
указывает на единственный объект типа R. Если атрибут А представляет множество ссылок на
кортежи схемы R, определение его типа в контексте реляционной схемы выглядит так:
А({*Я}). Эта ситуация аналогична той, когда ODL-связь Л относится к типу Set<R>.
Пример 4.24. Один из приемлемых способов устранения избыточности в отношении
рис. 4.17 состоит в использовании двух отношений, одно из которых содержит инфор-
4.5. ОБЪЕКТНО-РЕЛЯЦИОННАЯ МОДЕЛЬ
183
мацию об актерах, а другое — о кинофильмах с их участием. Отношение Movies
оказывается в этом случае обычным отношением с той же схемой, каковой обладал атрибут
movies в примере 4.23. Схема отношения stars почти не изменяется — за
исключением атрибута movies, типом которого теперь служит множество ссылок на кортежи
схемы Movies. Ниже приведены схема отношения Movies и новая редакция схемы stars.
Movies(title, year, length)
Stars(name, address(street, city), birthdate,
movies({*Movies}))
Fisher
Hamill
address
street
Maple
Locust
city
H1wood
Malibu
street
Oak
city
В'wood
birthdate movies
9/9/99
8/8/88
title
Star Wars
Empire
Return
year
1977
1980
1983
length
124
127
133
Stars
Рис. 4.18. Множества ссылок как значения атрибута
Movies
Вариант экземпляра отношения stars рис. 4.17, преобразованный в соответствии
с рассмотренным выше подходом, приведен на рис. 4.18. Поскольку теперь каждому
кинофильму отвечает единственный кортеж, можно считать, что проблема
избыточности, которая упоминалась в примере 4.23, решена. □
4.5.4. Объектно-ориентированный и объектно-реляционный подходы: за и против
Объектно-ориентированная модель данных, описываемая средствами языка ODL,
и объектно-реляционная модель, рассматриваемая в этом разделе, весьма схожи.
Ниже обсуждаются и сопоставляются наиболее характерные особенности каждой из них.
Объекты и кортежи
Содержимым объекта является структура с компонентами для атрибутов и связей
класса. Стандарт ODL не содержит предписаний относительно того, как должна
представляться информация о связях, но можно предположить, что объект соединяется
с другими объектами посредством определенного набора указателей. Кортеж также
описывается структурой, но в традиционной реляционной модели предусматривается,
что кортеж обладает только компонентами атрибутов. Связи представляются
кортежами других отношений (см. раздел 3.3.2 на с. 102). Объектно-реляционная модель,
однако, позволяет рассматривать множества ссылок в виде компонентов кортежей, и
поэтому допускает включение информации связей непосредственно в кортежи,
представляющие "объекты" или "сущности".
Экземпляры классов и отношения
В языке ODL все объекты класса трактуются в контексте экземпляра (extent)
класса. Объектно-реляционная модель допускает возможность существования нескольких
различных отношений с одной и той же схемой, так что должны быть предусмотрены
и более развитые средства различения членов одного и того же класса. ODL, однако,
позволяет определять интерфейсы (interfaces) — по существу, те же классы, но без
184
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
объявления экземпляра (см. врезку "Интерфейсы" на с. 169). Помимо того, в ODL
предусмотрена возможность определения произвольного числа классов с различными
экземплярами, наследующих один и тот же интерфейс.
Методы
Мы не говорим о возможности использования методов как о неотъемлемой части
объектно-реляционной модели. На практике, однако, это вполне допустимо, поскольку
в стандарте SQL-99 и реализациях объектно-реляционной модели предусмотрены средства
объявления и определения методов в составе классов, аналогичные инструментам ODL.
Системы типов
Системы типов в объектно-ориентированной и объектно-реляционной моделях
весьма схожи. Каждая из них основана на множестве атомарных типов и
предусматривает средства создания новых типов из существующих с помощью конструкторов
структурных типов и типов коллекций. Набор доступных типов коллекций в каждом
конкретном случае может отличаться, но во всех реализациях предлагаются, как
минимум, конструкторы типов множеств (sets) и мультимножеств (bags). В обоих
моделях типам множеств (или мультимножеств) структур отводится особая роль: речь идет
о типах классов в ODL и типах отношений в объектно-реляционной модели.
Ссылки и идентификационные номера объектов
В "чистой" объектно-ориентированной модели каждый объект снабжен
уникальным идентификационным номером (OID), который скрыт от пользователя и не может
быть просмотрен или запрошен. Объектно-реляционная модель позволяет
использовать ссылки в определениях типов, и поэтому в некоторых обстоятельствах
пользователю разрешается видеть значения ссылок и даже манипулировать ими. Вы можете
расценить эту возможность либо как заведомо вредоносную, либо, наоборот, как
нечто совершенно выдающееся (в зависимости от конкретной точки зрения), но на
практике все это мало что значит.
Обратная совместимость
Принимая во внимание незначительную степень различий между двумя моделями,
любопытно узнать, почему объектно-реляционные системы завоевали всеобщее
признание на рынке СУБД, а объектно-ориентированные — нет. Главная причина, по
нашему мнению, заключается в том, что к тому моменту, когда объектно-
ориентированные системы получили сколько-нибудь серьезное развитие,
реляционные СУБД уже существовали в тысячах или даже миллионах экземпляров. По мере
включения объектно-ориентированных инструментов в реляционные коммерческие
продукты их производители тщательно заботились об обеспечении обратной
совместимости. Иными словами, новейшие версии систем все еще оказывались способными
поддерживать весь имеющийся в наличии код и схемы баз данных — даже в том случае,
если пользователь, выполняя обновление системы, принимал решение об отказе от
каких бы то ни было объектно-ориентированных возможностей. С другой стороны,
переход от реляционной к "чистой" объектно-ориентированной системе потребовал бы
глубокого пересмотра существующих работоспособных решений. Поэтому, какие бы
соблазнительные перспективы объектно-ориентированная модель ни сулила, все они
меркнут в сравнении с теми потенциальными трудностями, которые пришлось бы
преодолеть на пути превращения реляционной базы данных в объектно-ориентированную.
4.5.5. От ODL-проектов к объектно-реляционным решениям
В разделе 4.4 на с. 171 мы рассматривали процесс преобразования проектов,
оформленных средствами ODL, в схемы, отвечающие требованиям реляционной мо-
4.5. ОБЪЕКТНО-РЕЛЯЦИОННАЯ МОДЕЛЬ
185
дели. Трудности, о которых мы говорили, обусловлены преимущественно наличием
в ODL более широких изобразительных возможностей, касающихся, в частности,
поддержки неатомарных типов атрибутов, связей и методов непосредственно в
контексте класса. При переходе от ODL-дизайна к объектно-реляционному проекту
некоторые из подобных проблем устраняются, хотя, увы, не полностью и далеко не все.
В зависимости от особенностей конкретной объектно-реляционной модели (в главе 9 на
с. 419 рассмотрена одна из наиболее известных реализаций модели, основанная на
стандарте SQL-99), может оказаться возможным преобразование большинства неатомарных
типов ODL непосредственно в соответствующие объектно-реляционные типы; к этой
категории относятся, например, все разновидности типов struct, Set, Bag, List и Array.
Если тип, используемый в ODL-проекте, не доступен в конкретной реализации
объектно-реляционной модели, можно прибегнуть к технике преобразования типов,
рассмотренной в разделах 4.4.2—4.4.4 (начиная со страницы 172). Приемы
представления связей в ODL и объектно-реляционной модели по существу одинаковы
(см. раздел 4.4.5 на с. 177), хотя в определенных случаях вместо ключей удобно
предпочесть ссылки. Наконец, несмотря на то что способов представления ODL-классов,
содержащих объявления методов, в виде наборов обычных отношений попросту не
существует, большинство реализаций объектно-реляционной модели позволяет
определять методы, так что и это ограничение может быть преодолено.
4.5.6. Упражнения к разделу 4.5
Упражнение 4.5.1. Используя систему обозначений, принятую для описания
вложенных отношений и отношений со ссылками, представьте одну или несколько
реляционных схем отношений, пригодных для хранения указанной ниже
информации. В каждом из случаев вам предлагается некоторая свобода выбора атрибутов,
подлежащих включению в схему отношения, но постарайтесь, тем не менее,
придерживаться того набора атрибутов, который присутствует в рассматриваемом нами
примере "кинематографической" базы данных. Отметьте, являются ли полученные
вами схемы избыточными, и если да, то какие меры следует предпринять, чтобы
разрешить эту проблему. Итак, что необходимо сделать, чтобы представить в виде
отношений следующую информацию:
* а) о кинофильмах (с обычными атрибутами) и обо всех актерах-участниках
съемок (также с обычными атрибутами)?
*!Ь) о студиях, обо всех фильмах, выпущенных каждой студией, и об актерах,
принявших участие в работе над каждым из фильмов, включая все атрибуты
студий, кинофильмов и актеров?
с) о кинофильмах, соответствующих студиях и об актерах (с обычными
атрибутами)?
* Упражнение 4.5.2. Представьте проект банковской базы данных, который
рассматривался в упражнении 2.1.1 на с. 63,в терминах объектно-реляционной модели.
Убедитесь, что решение позволяет для заданного кортежа-"клиента" легко
отыскать все кортежи-"счета", связанные с клиентом, а для каждого кортежа-
"счета" — кортежи, описывающие всех клиентов, имеющих право распоряжаться
счетом. Помимо того, попытайтесь избежать избыточности данных.
! Упражнение 4.5.3. Изменим условие упражнения 4.5.2 таким образом, чтобы
правом владения счетом мог обладать только один клиент банка (как в задании (а)
упражнения 2.1.2 на с. 63). Как в этом случае упростить решение упражнения 4.5.2?
! Упражнение 4.5.4. Представьте проект "футбольной" базы данных (охватывающей
сведения о командах, об игроках и о болельщиках), который предлагался в
качестве упражнения 2.1.3 на с. 64, в виде объектно-реляционной модели.
186
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
! Упражнение 4.5.5. Преобразуйте в объектно-реляционную модель полученное
вами решение упражнения 2.1.6 (см. с. 65), касающееся описания
генеалогического дерева семьи.
4.6. Полуструктурированные данные
Модели полуструктурированных данных (semistructured data) в системах баз данных
отводится особая роль.
1. Модель выполняет функцию удобного средства интеграции (integration) данных,
т.е. описания с помощью одних и тех же терминов схожей информации,
которая содержится в нескольких базах данных, обладающих различными схемами
(подробнее — в главе 20 на с. 1003).
2. Модель пригодна для представления документов в инструментальных системах,
подобных XML (см. раздел 4.7 на с. 192), которые используются для
обеспечения доступа к данным в среде Web.
В этом разделе мы познакомим вас с основными идеями, лежащими в основе
концепции "полуструктурированных данных", и расскажем о том, почему с ее помощью
информация может быть представлена гораздо более гибко, нежели средствами других
моделей, о которых говорилось выше.
4.6.1. Обоснование модели полуструктурированных данных
Вначале упомянем ER-модель и два основополагающих понятиях — "множество
сущностей" и "связь", — на которых она зиждется. Напомним также, что
реляционная модель имеет дело с данными только одной разновидности — отношениями,
а множества сущностей и связи допускают преобразование в отношения (см. раздел
3.2 На с. 91). Наличие двух понятий обеспечивает несомненные преимущества:
работая над ER-проектом, моделирующим реалии окружающего мира, в тех или иных
ситуациях мы можем пользоваться или множествами сущностей, или связями — в
зависимости от того, что из них наиболее близко природе объектов, подлежащих
воспроизведению в рамках модели. Имеются и определенные выгоды от замены двух
понятий одним: изобразительные средства проектирования существенно упрощаются
и унифицируются, а способы повышения эффективности запросов могут применяться
без оглядки на особенности тех или иных разновидностей данных. Преимущества
реляционной модели станут более очевидными, когда, начиная с главы 11 на с. 489, мы
приступим к изучению технологий реализации СУБД.
Сейчас давайте вернемся к объектно-ориентированной модели, о которой мы
рассказывали в разделе 4.2 на с. 152. Она основана на двух понятиях — "класс"
(с "экземпляром") и "связь". Аналогично, объектно-реляционная модель (см. раздел
4.5 на с. 180) вводит в обиход два схожих понятия — "тип атрибута" (охватывающее
понятие "класс") и "отношение".
Модель полуструктурированных данных можно представить в виде сочетания двух
концепций — "класс и связь" или "класс и отношение" — во многом подобно тому,
как в рамках реляционной модели сближаются понятия множества сущностей и
связи. Доводы в пользу слияния понятий, однако, в каждом из случаев различны. В то
время как реляционная модель обязана своим успехом возможностям эффективной
практической реализации, интерес к модели полуструктурированных данных
обусловлен преимущественно ее гибкостью. Все модели, о которых мы рассказывали до сих
пор, находят выражение в виде схем — ER-диаграмм, схем отношений или ODL-
объявлений, — но модель полуструктурированных данных не укладывается в рамки
какой бы то ни было "схемы". Данные сами по себе несут информацию о том, как их
следует представлять, и подобная "схема" способна изменяться произвольно, как со
временем, так и в контексте конкретной базы данных.
4.5. ОБЪЕКТНО-РЕЛЯЦИОННАЯ МОДЕЛЬ
187
4.6.2. Представление полуструктурированных данных
Базу данных, содержащую полуструктурированные данные, можно описать
набором вершин (nodes) графа. Каждая вершина является либо оконечной (или "листом" —
leaf), либо промежуточной (interior). Оконечным вершинам поставлены в соответствие
некоторые элементы данных любых атомарных типов, таких как числовые или
строковые. Из промежуточных вершин исходят одна или несколько дуг (arcs). Каждая дуга
снабжена меткой (label), описывающей то, каким образом соотносятся вершины,
соединенные дугой. Одна из промежуточных вершин, называемая корневой (root), не
имеет входящих дуг и представляет базу данных в целом. Каждая вершина графа
должна быть достижима из корневой вершины, хотя структура графа в общем случае
не обязана быть древовидной.
Пример 4.25. На рис. 4.19 представлен граф, описывающий "полуструктурированную"
базу данных с информацией об актерах и кинофильмах с их участием. В верхней
части графа легко заметить корневую вершину Root, которая служит точкой "входа" в
базу данных и представляет всю информацию в целом. Основные объекты или
сущности базы данных (в нашем случае — "кинофильмы" и "актеры") представлены
вершинами, являющимися дочерними по отношению к вершине Root.
Maple H'wood Locust Malibu
Рис. 4.19. Полуструктурированные данные о кинофильмах и актерах
Граф содержит немалое число оконечных вершин. Крайнюю левую позицию,
например, занимает вершина с меткой Carrie Fisher, а крайнюю правую — 1997.
К числу промежуточных относятся, в частности, вершины с метками cf, mh и sw,
которые являются аббревиатурами от "Carrie Fisher", "Mark HamiH" и "Star Wars"
соответственно. Эти метки не являются частью модели, и мы используем их только для
ссылки на вершины, которые в противном случае остались бы безымянными.
Вершину sw, например, можно трактовать как объект-"кинофильм" "Star Wars" с дочерними
вершинами-значениями star wars и 1977, представляющими, соответственно,
содержимое атрибутов "название" (title) и "год производства" (year) кинофильма.
Оконечные вершины, представляющие другие атрибуты кинофильма (такие как length —
"продолжительность воспроизведения"), здесь не показаны. □
188
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Метки, которыми обозначены дуги графа, выполняют две функции, объединяя
информацию, содержащуюся в объявлениях классов и связях. Предположим, что дуга,
соединяющая вершины N и М в направлении от N к М, снабжена меткой L.
1. Вершину N можно интерпретировать как объект или структуру, а М — как один
из атрибутов объекта или одно из полей структуры. Тогда L представляет имя
атрибута или поля соответственно.
2. С другой стороны, вершины N и М можно трактовать как объекты, a L — как
связь, соединяющую объект N с объектом М.
Пример 4.26. Вновь обратимся к рис. 4.19. Вершину графа, помеченную как sf можно
воспринимать как объект класса star, соответствующий дктрисе Кэрри Фишер. Из
вершины исходит дуга, обозначенная меткой пате и представляющая атрибут name;
дуга приводит нас к вершине, "содержащей" имя актрисы — Carrie Fisher. Из
вершины (/также исходят две дуги с метками address, направленные к безымянным
вершинам, которые представляют два известных адреса Кэрри Фишер. Дуги в
совокупности соответствуют атрибуту address типа Set (см. рис. 4.12 на с. 173).
Каждый из двух адресов Кэрри Фишер представляет собой структуру, состоящую
из двух полей — street и city. Поэтому из обеих безымянных вершин-"адресов"
исходят по две дуги, помеченные как street и city и обозначающие названия полей
структуры. Каждая из дуг направлена к собственной оконечной вершине,
представляющей соответствующее атомарное значение поля структуры.
Граф рис. 4.19 содержит также такие дуги, которые могут быть интерпретированы
как связи объектов. Например, дуга с меткой starredin соединяет вершины cf и sw
в направлении от cf к sw. Из вершины mh исходит такая же дуга, а из вершины sw —
дуги с метками stars Of, направленные к вершинам cf и mh. Дуги starredin представляют
элементы данных одноименной связи класса star, а дуги starsOf— обратной связи
starsOf класса Movie (см. рис. 4.3 на с. 157). □
4.6.3. Интеграция информации с помощью модели
полуструктурированных данных
В отличие от других ранее рассмотренных моделей, данные в
"полуструктурированной" модели самодостаточны: схема представления данных содержится в них
самих. Другими словами, каждая вершина графа (за исключением корневой) обладает
одной или несколькими входящими дугами, и метка, которой снабжена дуга,
указывает на функцию, выполняемую вершиной по отношению к вершине на другом
конце дуги. Во всех других моделях данные подчиняются фиксированной схеме,
описываемой отдельно и загодя, и функции каждого элемента данных неявно
регламентируются схемой как таковой.
Кого-то может удивить (и это естественно), что база данных без схемы, якобы
допускающая ввод "первых попавшихся" элементов информации и отнесение их к тому
или иному типу так, как "Бог на душу положит", может обладать хоть какими-то
преимуществами. На самом деле, однако, существуют образцы реальных
мелкомасштабных информационных систем, таких как Lotus Notes, в которых реализован именно
такой подход: данные говорят сами за себя. Когда же речь идет о проектах баз
данных, предназначенных для хранения больших порций информации, принято считать,
что выгоды от определения фиксированной схемы намного перевешивают тот
выигрыш в гибкости, который обеспечивается "самоуверенным" подходом к
представлению данных. Схема, оговоренная заранее, позволяет, например, предусмотреть для
хранения тех или иных элементов информации такие структуры данных, которые
гарантируют высокую эффективность процессов обработки запросов (мы коснемся этой
темы в начале главы 13 на с. 583).
4.6. ПОЛУСТРУКТУРИРОВАННЫЕ ДАННЫЕ
189
Гибкость модели полуструктурированных данных, однако, важна, по меньшей
мере, в приложениях двух категорий. В разделе 4.7 на с. 192 будет рассказано о
применении модели как средстве описания документов, но здесь мы сосредоточим
внимание на особенностях ее использования в качестве инструмента интеграции
информации. По мере роста числа баз данных возникает естественное желание добиться того,
чтобы информация, хранимая в нескольких базах данных, поддавалась обработке
настолько же эффективно, как если бы она была размещена в единственной базе
данных. Компаниям, например, присущи тенденции к взаимному слиянию и
поглощению; в каждой из них, как правило, поддерживаются собственные базы данных,
содержащие сведения о персонале, выпускаемой продукции, остатках на складах, ценах
и т.п. Если базы данных со схожей информацией обладают еще и одинаковыми
схемами, тогда задача их интеграции, вероятно, сравнительно проста: достаточно
объединить в одном отношении кортежи всех отношений, обладающих одинаковыми
схемой и смысловым назначением.
Увы, жизнь — не простая штука. Почти невероятно, чтобы схемы баз данных,
разрабатываемые в разное время разными людьми, вдруг совпали — даже в тех простых
случаях, когда речь идет о базе данных отдела кадров: в одной из них, например,
предусмотрен обязательный ввод сведений о семейном положении сотрудника, в
другой — нет; одна предлагает возможность сохранения нескольких почтовых или
электронных адресов и телефонных номеров служащего, другая — нет; одна база данных
является реляционной, а другая — объектно-ориентированной.
Это еще "цветочки". Базы данных со временем "обрастают" таким гигантским
числом самых разнородных приложений, что становится совершенно невозможным
приостановить их работу на время копирования или трансляции информации из
одних баз данных в другие, — даже в том случае, если вы удосужитесь отыскать самый
эффективный способ преобразования схем. Подобную ситуацию часто называют
проблемой унаследованных баз данных (legacy databases): если база данных активно
используется в течение длительного периода времени, затея с ее трансформацией заранее
обречена на неудачу, и база данных просто обязана поддерживаться в исходном виде.
Одно из возможных решений проблемы унаследованных баз данных
иллюстрируется диаграммой рис. 4.20. Две унаследованные базы данных связаны в единое целое
с помощью некоторого интерфейса (в действительности таких баз данных может
гораздо больше). Каждая из систем, тем не менее, остается в неприкосновенности, так
что они по-прежнему могут быть использованы традиционными приложениями.
Пользователь
Традиционные
приложения
Унаследованная
база данных
Традиционные
приложения
Унаследованная
база данных
Рис. 4.20. Интеграция двух унаследованных баз данных
посредством интерфейса, поддерживающего модель
полуструктурированных данных
190
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
Для обеспечения гибкости интеграции интерфейс должен поддерживать модель
полуструктурированных данных; и пользователю предоставляется возможность
обращаться к интерфейсу с запросами, которые оформляются средствами языка запросов,
соответствующего природе этих данных. Полуструктурированные данные могут быть
получены путем трансляции информации из баз-источников с помощью специальных
компонентов, называемых оболочками (wrappers).
С другой стороны, поддержка интерфейсом модели полуструктурированных
данных в общем случае не является обязательной. Пользователь направляет интерфейсу
запросы точно так же, как если бы тот действительно обеспечивал представление
полуструктурированных данных, а интерфейс, в свою очередь, адресует источникам
собственные запросы, преобразованные из исходных таким образом, чтобы особенности
схем каждой из унаследованных баз данных были непременно учтены.
Пример 4.27. Рис. 4.19 (см. с. 188) можно трактовать и как иллюстрацию результата
объединения информации об актерах, "собранной" из различных источников.
Обратите внимание, что информация об адресе актрисы Кэрри Фишер обладает типом
address (так помечены дуги, исходящие из вершины с/), и адрес представлен в виде
структуры {street, city) (полям структуры соответствуют одноименные вершины графа).
Поддерево, состоящее из вершины cf и дочерних вершин, грубо говоря, отвечает
схеме, включающей вложенную схему: Stars (name, address (street, city) ).
Адрес актера Марка Хэмилла (взгляните на вершину mh), однако, изображен в
виде пары независимых дочерних вершин street и city. Такое представление соответствует
схеме stars (name, street, city), в которой возможность хранения нескольких
адресов одного и того же актера не предусмотрена. Мы не смогли показать на
небольшом рисунке все мыслимые варианты схем, но, поверьте, их окажется очень
много, если допустить, что информация действительно поступает из самых
разнородных источников. □
4.6.4. Упражнения к разделу 4.6
Упражнение 4.6.1. Поскольку модель полуструктурированных данных не
предусматривает задания какой бы то ни было определенной схемы, мы не будем
призывать вас к созданию схем, описывающих те или иные ситуации. Напротив, в
следующих примерах от вас потребуется предложить способы организации данных
с целью отображения определенных фактов.
* а) Отобразите в диаграмме рис. 4.19 (см. с. 188) такие факты: режиссером
кинофильма "Star Wars" является Джордж Лукас, а продюсером — Гэри Куртц.
b) Пополните диаграмму рис. 4.19 информацией о кинофильмах "Empire
Strikes Back" и "Return of the Jedi" и сведениями о том, что в обеих лентах
снялись Кэрри Фишер и Марк Хэмилл.
c) Включите в решение задания п. (Ь) данные о киностудии, выпустившей оба
фильма ("Fox"), и об адресе этой студии ("Hollywood").
* Упражнение 4.6.2. Предложите способ представления в рамках модели
полуструктурированных данных типичной информации о банках и их клиентах
(см. упражнение 2.1.1 на с. 63).
Упражнение 4.6.3. Предложите способ представления в рамках модели
полуструктурированных данных типичной информации о футбольных командах, об игроках
и о болельщиках (см. упражнение 2.1.3 на с. 64).
Упражнение 4.6.4. Предложите способ представления в рамках модели
полуструктурированных данных типичной информации о генеалогическом дереве семьи
(см. упражнение 2.1.6 на с. 65).
4.6. ПОЛУСТРУКТУРИРОВАННЫЕ ДАННЫЕ
191
*! Упражнение 4.6.5. И ER-модель, и модель полуструктурированных данных
являются "графическими" по своей природе — в том смысле, что в обеих "носителем"
информации служат вершины графа, соединяющие их дуги и текстовые метки.
Вместе с тем, модели существенно различаются. Чем именно?
4.7. Язык и модель данных XML
XML (extensible Markup Language — расширяемый язык разметки) — это система
обозначений, основанная на тэгах (tags) и используемая для "разметки" документов. Язык
XML во многом напоминает повсеместно популярный HTML и менее известный
SGML. Документ (document) — это не что иное, как файл, содержащий набор символов.
Однако тэги HTML описывают способы представления информации, содержащейся
в документе, — например, обозначают, какие ее элементы должны быть отображены
курсивным шрифтом или включены в состав маркированного списка, — в то время
как тэги XML определяют смысловое значение тех или иных строк текста документа.
В этом разделе мы расскажем об истоках XML и продемонстрируем, как документ
XML в линейной форме выражает ту же структуру данных, которая представляется
графом модели полуструктурированных данных (см. предыдущий раздел). В
частности, можно утверждать, что тэги XML выполняют те же функции, что и метки,
которыми снабжены дуги графа полуструктурированных данных. Затем вы познакомитесь
с понятием определения типа документа (document type definition — DTD), которое
обозначает гибкую разновидность схемы, допускающую применение по отношению
к целым группам документов XML.
4.7.1. Семантические тэги
Тэги (tags) XML — это строки текста, заключенные в угловые скобки < и > (как
и в HTML). Тэги XML — в этом они также напоминают тэги HTML — определяются
парами: начальному тэгу, такому, как, скажем, <F00>, соответствует ч завершающий
тэг, содержащий тот же текст, что и начальный тэг, с предшествующим символом
косой черты (в нашем случае — </F00>). В HTML, однако, в некоторых случаях
позволяется использовать тэги, подобные <р> (начало нового абзаца), для которых задавать
завершающий тэг не обязательно, но в XML такая возможность исключается. Пара тэгов
определяет элемент (element) документа. Элементы могут быть вложены друг в друга.
Так, например, в промежутке между тэгами <F00> и </F00> допускается присутствие
любого числа пар других тэгов, но если в некотором интервале находится открывающий
тэг какой-либо пары, то здесь же должен быть расположен и ее завершающий тэг.
XML спроектирован в расчете на применение в одном из двух — до некоторой
степени различных — "режимов".
1. Правильный (well-formed) документ XML позволяет автору изобретать
собственные тэги, подобные меткам дуг в графе полуструктурированных данных. Этот
режим в большой мере соответствует модели полуструктурированных данных,
в которой предварительное определение каких бы то ни было схем не требуется:
в документе могут содержаться любые тэги, включаемые по усмотрению автора.
2. Действительный (valid) документ XML предусматривает наличие DTD; DTD
регламентирует номенклатуру доступных для применения тэгов и правила их
взаимного "вложения" и интерпретации. Категорию действительных XML-
документов можно считать неким компромиссом между моделями, такими как
реляционная или ODL, предполагающими задание жестких схем, и моделью
полуструктурированных данных, в которой схемы как таковые не применяются
вовсе. Как будет показано в разделе 4.7.3 на с. 194, определения типа
документа, вообще говоря, обеспечивают гораздо более высокую степень гибкости
192
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
представления данных, нежели традиционные схемы: в DTD, например,
допускается задание таких полей, которые в дальнейшем могут не использоваться.
(Все действительные ХМ L-доку менты являются правильными, но не все
правильные — действительными. — Прим. перев.)
4.7.,2. Правильные XML-документы
Чтобы документ XML можно было считать правильным (well-formed), в его начале
должны присутствовать инструкция объявления XML (XML declaration) с последующим
корневым элементом (root element), между начальным и завершающим тэгами которого
заключено содержимое всего документа. Таким образом, правильный XML-документ
может быть описан структурой следующего вида:
<? XML VERSION = "1.0й STANDALONE = "yes" ?>
<BODY>
</BODY>
Первая строка свидетельствует о том, что речь идет о документе XML. Параметр
standalone = "yes" гласит, что в документе не используются какие бы то ни было
(внешние. — Прим. перев.) DTD, т.е. документ относится к категории правильных, но
не действительных. Объявление XML обрамлено специальными маркерами, <? и ?>.
<? XML VERSION = "1.0" STANDALONE = "yes" ?>
<STAR-MOVIE-DATA>
<STAR><NAME>Carrie Fisher</NAME>
<ADDRESS><STREET>12 3 Maple St.</STREET>
<CITY>Hollywood</CITYx/ADDRESS>
<ADDRESS><STREET>5 Locust Ln.</STREET>
<CITY>Malibu</CITY></ADDRESS>
</STAR>
<STAR><NAME>Mark Hamill</NAME>
<STREET>456 Oak Rd.</STREET>
<CITY>Brentwood</CITY>
</STAR>
<MOVIE>
<TITLE>Star Wars</TITLE><YEAR>1977</YEAR>
</MOVIE>
</STAR-MOVIE-DATA>
Puc. 4.21. XML-документ со сведениями о кинофильмах и актерах
Пример 4.28. На рис. 4.21 приведен текст XML-документа, который соответствует
графу полуструктурированных данных, изображенному на рис. 4.19 (см. с. 188).
Корневой элемент документа отмечен тэгами <star-movie-data> и </star-movie-
data>. Он содержит два элемента star, обозначенных парами тэгов <star> и </star>.
Внутри каждого элемента star имеется элемент name, задающий имя актера. Элемент
STAR, содержащий сведения об актрисе Кэрри Фишер, обладает двумя вложенными
элементами address, каждый из которых описывает адрес дома, принадлежащего
актрисе. Элемент star, предлагающий информацию об актере Марке Хэмилле,
включает только отдельные элементы street и city, описывающие названия улицы и
города, и не использует для их группирования элемент address более высокого уровня.
Различия между элементами star рассматриваемого ХМL-документа аналогичны
различиям между вершинами cf и mh графа полуструктурированных данных,
изображенного на рис. 4.19.
Заметьте, что в документе на рис. 4.21 не представлена информация о связях
между актерами и кинофильмами. Сведения о том, в каком кинофильме снимался
4.7. ЯЗЫК И МОДЕЛЬ ДАННЫХ XML
193
тот или иной актер, можно было бы поместить в элемент STAR, соответствующий
этому актеру, например:
<STAR><NAME>Mark Hamill</NAME>
<STREET>456 Oak Rd.</STREET><CITY>Brentwood</CITY>
<MOVIE><TITLE>Star Wars</TITLE><YEAR>1977</YEARx/MOVIE>
<MOVIE><TITLE>Empire</TITLE><YEAR>1980</YEARx/MOVIE>
</STAR>
Такой подход, однако, приводит к аномалии избыточности данных, поскольку вся
информация о кинофильме повторяется вновь и вновь для каждого из актеров,
участвовавших в съемках одного и того же кинофильма (впрочем в нашем примере
задаются только сведения о названии фильма и годе его выпуска — значения ключевых
атрибутов сущности "кинофильм", — которые, вообще говоря, нельзя считать
избыточными). В разделе 4.7.5 на с. 196 мы покажем, как XML справляется с проблемой,
возникающей из-за того, что вложенные элементы образуют древовидную структуру. □
4.7.3. Определения типа документа
Для обеспечения возможностей автоматической обработки XML-документов
необходимо ввести некоторое понятие "схемы" документа, т.е. каким-либо образом
регламентировать множество пригодных для использования тэгов и способы их взаимного
"вложения". Описание схемы документа XML оформляется в соответствии с набором
грамматических правил, называемым определением типа документа (document type
definition — DTD). Если компании или сообщества собираются осуществлять обмен
ХМL-данными, каждая из них должна создать наборы DTD, определяющих формы
представления документов и правила семантического толкования используемых в них
тэгов. Например, XML-описания структур протеинов должны подчиняться одним
DTD, документы, посвященные проблемам купли-продажи запасных частей для
автомобилей, — другим DTD и т.д.
Структура DTD выглядит следующим образом:
<!DOCTYPE корневой_элемент [
<!ELEMENT элемент (компоненты)>
Другие элементы
]>
Корневой элемент (root element), обрамленный соответствующими начальным и
завершающим тэгами, представляет все содержимое документа, отвечающего условиям
рассматриваемого DTD. Элемент (element) описывается именем, совпадающим с
именами начального и завершающего тэгов, которые охватывают этот элемент, и
представляет часть документа. После имени элемента задается список компонентов
(components), заключенный в круглые скобки. Компоненты — это элементы, которые
могут или должны быть вложены в определяемый элемент. О том, как именно
определяются компоненты в списке элемента, мы расскажем чуть ниже.
Существует один важный частный случай задания списка элемента. Выражение
(# pcdata), следующее в DTD после имени элемента, означает, что значением
элемента служит фрагмент текста и элемент не содержит вложенных элементов.
Пример 4.29. На рис. 4.22 приведено DTD, регламентирующее правила описания
информации об актерах.20 Имя корневого элемента — stars (язык XML, как и HTML,
не чувствителен к регистру символов). Определение первого элемента гласит, что в
промежутке между тэгами <stars> и </stars> допускается задавать нулевое или
большее число элементов star (символ * после star означает "нуль или больше",
т.е. произвольное количество элементов), каждый из которых служит для
представления информации об одном актере.
20 Требованиям этого DTD документ, представленный на рис. 4.21, не отвечает.
194
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
<!DOCTYPE Stars [
<
<
<
<
<
<
<
<
<
<
]>
ELEMENT STARS (STAR*)>
ELEMENT STAR (NAME, ADDRESS+, MOVIES)>
ELEMENT NAME (#PCDATA)>
ELEMENT ADDRESS (STREET, CITY)>
ELEMENT STREET (#PCDATA)>
ELEMENT CITY (#PCDATA)>
ELEMENT MOVIES (MOVIE*)>
ELEMENT MOVIE (TITLE, YEAR)>
ELEMENT TITLE (#PCDATA)>
ELEMENT YEAR (#PCDATA)>
Рис. 4.22. DTD для представления XML-документов об актерах
Второй элемент, star, охватывает элементы трех видов — name, address
и movies. Они должны следовать в заданном порядке, и каждый из них обязан быть
в наличии. Символ + после имени элемента address означает "один или больше",
т.е. для каждого актера может быть задано произвольное количество адресов, но один
адрес должен присутствовать в любом случае. Элемент name определен посредством
строки PCDATA, т.е. в нем будет представлен обычный текст. Четвертый элемент
определения свидетельствует, что элемент address состоит из полей-элементов street
и city, которые должны задаваться в указанном здесь порядке.
Далее определяется элемент movies: он может содержать нуль или больше элементов
типа movie (символ *, как и прежде, означает "произвольное число элементов"). Элемент
movie должен состоять из полей-элементов title и year, представляющих строки текста.
На рис. 4.23 приведен документ XML, удовлетворяющий требованиям DTD рис. 4.22. □
Элемент Е в общем случае может содержать другие элементы. Они должны
присутствовать в промежутке между тэгами <Е> и <JE> и следовать в том порядке,
который определен в DTD. Ниже рассмотрены операторы, позволяющие задавать
количество "вложений" элемента в другой элемент и регламентировать содержимое элемента.
1. Оператор * означает, что элемент может повторяться произвольное количество
раз или вовсе отсутствовать.
2. Оператор + означает, что элемент должен присутствовать не менее одного раза.
3. Оператор ? означает, что элемент может отсутствовать или быть использован
только однократно.
4. Оператор |, разделяющий наименования отдельных элементов или групп имен
элементов, заключенных в круглые скобки, означает, что допускается
присутствие элементов, расположенных либо слева от оператора, либо справа от него,
но не обеих групп элементов одновременно. Например, выражение
(#pcdata | (street, city)), помещенное в объявление элемента address,
означало бы, что компонентами адреса могут быть либо фрагмент обычного
текста, либо элементы street и city.
4.7.4. Использование DTD
Если документ обязан удовлетворять требованиям некоторого DTD, у нас есть две
альтернативы:
1) включить DTD в начало текста документа;
2) в первой строке документа, следующей за объявлением XML, указать ссылку
на DTD, которое может храниться в виде файла, доступного для обращения
из приложения, выполняющего обработку документа.
4.7. ЯЗЫК И МОДЕЛЬ ДАННЫХ XML
195
<STARS>
<STAR><NAME>Carrie Fisher</NAME>
<ADDRESS><STREET>12 3 Maple St.</STREET>
<CITY>Hollywood</CITYx/ADDRESS>
<ADDRESS><STREET>5 Locust Ln.</STREET>
<CITY>Malibu</CITYx/ADDRESS>
<MOVIES>
<MOVIExTITLE>Star Wars</TITLE>
<YEAR>1977</YEARx/MOVIE>
<MOVIExTITLE>Empire Strikes Back</TITLE>
<YEAR>19 80</YEARx/MOVIE>
<MOVIExTITLE>Return of the Jedi</TITLE>
<YEAR>1983</YEARx/MOVIE>
</MOVIES>
</STAR>
<STAR><NAME>Mark Hamill</NAME>
<ADDRESS><STREET>456 Oak Rd.</STREET>
<CITY>Brentwood</CITYx/ADDRESS>
<MOVIES>
<MOVIExTITLE>Star Wars</TITLE>
<YEAR>1977</YEARx/MOVIE>
<MOVIExTITLE>Empire Strikes Back</TITLE>
<YEAR>19 80</YEARx/MOVIE>
<MOVIExTITLE>Return of the Jedi</TITLE>
<YEAR>1983</YEARx/MOVIE>
</MOVIES>
</STAR>
</STARS>
Рис. 4.23. Пример документа, соответствующего требованиям DTD на рис. 4.22
Пример 4.30. Ниже показано, как можно пополнить начало документа,
представленного на рис. 4.23, конструкцией, гласящей, что документ должен соответствовать
условиям, предусмотренным в DTDHa рис. 4.22.
<? XML VERSION = "1.0" STANDALONE = "no" ?>
<!DOCTYPE Stars SYSTEM "star.dtd">
Параметр standalone = "no" означает, что в документе могут содержаться ссылки
на внешние файлы, и если такие ссылки действительно присутствуют, они должны
быть корректно обработаны. Напомним, что прежде мы присваивали параметру
standalone значение "yes", поскольку не предусматривали задания ссылок на
внешние DTD. Местоположение DTD определяется содержимым последующего
предложения ! doctype: после служебного слова system, определяющего один из
возможных вариантов прав доступа, задано имя файла DTD. □
4.7.5. Списки атрибутов
Между документами XML и графами полуструктурированных данных
прослеживается строгое взаимное соответствие. Предположим, что элементу Т ХМL-документа,
обрамленному тэгами <7> и <JT>, отвечает вершина п графа. Если S — это элемент XML-
документа, вложенный непосредственно в элемент Т (т.е. таких пар тэгов, которые были
бы вложенными в элемент Т и содержали бы элемент S внутри себя, не существует), мы
вправе включить в граф дугу с меткой S, направленную от вершины п к вершине,
соответствующей элементу S. Полученный в результате фрагмент полуструктурированных
данных будет обладать совершенно такой же структурой, что и элемент Г документа XML.
К сожалению, то подмножество изобразительных средств языка XML, которое мы
рассматривали до сих пор, не дает возможности сделать связь между документом XML
и соответствующим графом полуструктурированных данных еще более тесной. Необ-
196
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
ходимо снабдить XML инструментами, которые позволили бы отобразить в документе
тот факт, что вершина графа может обладать несколькими входящими дугами, а не
одной. Совершенно очевидно, что одна и та же пара тэгов не может быть вложена
одновременно в несколько других пар тэгов; поэтому для представления вершины с
несколькими дочерними вершинами мощи механизма взаимного вложения элементов
XML-документа явно не достаточно. К. дополнительным средствам языка, которые
позволяют описать в ХМL-документе любые полуструктурированные данные,
относятся атрибуты (attributes), идентификаторы (identifiers — ID's) и ссылки на
идентификаторы (identifier references — IDREF's).
Открывающий тэг может содержать атрибуты (по аналогии с конструкцией
<а href=. . .> HTML. Служебное слово iattlist позволяет определить в DTD
список атрибутов и их типов, соответствующий конкретному элементу. Один из широко
распространенных способов использования атрибутов предполагает задание для
элемента строго определенного значения. Это еще один вариант объявления элементов,
содержащих обычный текст (альтернативный применению служебной константы PCDATA).
Другое, более важное назначение атрибутов тэгов состоит в представлении
полуструктурированных данных, графы которых не относятся к категории деревьев.
Атрибуты элементов типа Е, объявленных в виде id, получают значения, которые
уникальным образом определяют каждую часть документа, окруженную тэгами <Е>
и </Е>. Если пользоваться терминами модели полуструктурированных данных, id
обеспечивает получение уникального имени вершины графа.
Некоторые атрибуты могут быть объявлены в виде idref. Их значениями служат
ссылки на идентификаторы id других тэгов. Присваивая одному экземпляру тэга
(соответствующему вершине в графе полуструктурированных данных) id со значением у,
а другому — idref с тем же значением у, мы тем самым задаем ссылку (или дугу в
графе), соединяющую последний с первым. Следующий пример иллюстрирует как
синтаксис объявления идентификаторов и ссылок на идентификаторы тэгов, так и важность их
использования для представления полуструктурированных данных произвольного вида.
<!DOCTYPE Stars-Movies [
<!ELEMENT STARS-MOVIES (STAR*, MOVIE*)>
<!ELEMENT STAR (NAME, ADDRESS+)>
<IATTLIST STAR
starld ID
starredln IDREFS>
<!ELEMENT NAME (# PCDATA)>
<!ELEMENT ADDRESS (STREET, CITY)>
<!ELEMENT STREET (#PCDATA)>
<!ELEMENT CITY (#PCDATA)>
<!ELEMENT MOVIE (TITLE, YEAR)>
<IATTLIST MOVIE
movield ID
starsOf IDREFS>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT YEAR (#PCDATA)>
]>
Puc. 4.24. DTD с использованием ID и IDREF для представления XML-документов об
актерах и фильмах
Пример 4.31. На рис. 4.24 показана исправленная и дополненная версия DTD, в
которой "актеры" и "кинофильмы" представляются в виде элементов, обладающих
одинаковым взаимным статусом, и для описания связей типа "многие ко многим" между
сущностями-"актерами" и сущностями-"кинофильмами" используются пары
идентификаторов id и соответствующих им ссылок idref. Аналогичную роль играют дуги
starredln и starsOfв графе пол у структурированных данных, изображенном на рис. 4.19
4.7. ЯЗЫК И МОДЕЛЬ ДАННЫХ XML
197
(см. с. 188). Наименование корневого элемента DTD изменено на stars-movies,
поскольку сущности-"кинофильмы" теперь не "подчинены" сущностям-"актерам".
Актеру не ставится в соответствие набор кинофильмов, как предусматривалось в DTD
на рис. 4.22 (см. с. 195). Элемент star XML-документа сейчас должен содержать
только вложенные элементы name и address, но в начальном тэге <star> могут быть
заданы атрибуты star id и starredin; значением последнего служит список
идентификаторов тех элементов-"кинофильмов", которые связаны с рассматриваемым
элементом-"актером". Обратите внимание, что в объявлении атрибута starredin указан
тип idrefs, а не idref. Дополнительный символ s свидетельствует о том, что
атрибуту starredin может быть поставлен в соответствие список ссылок на
идентификаторы элементов (в данном примере — элементов movie), а не одна ссылка (как было
бы в случае задания типа idref). Как упоминалось выше, тэг <star> содержит также
атрибут stand. Поскольку star id объявлен как id, другие элементы документа
(в частности, movie) могут содержать ссылки на соответствующие элементы star.
Таким образом, содержимым атрибутов starredin элементов STAR могут служить
списки значений атрибутов movieid элементов movie (что соответствует дугам starredin
в графе полуструктурированных данных на рис. 4.19) — и наоборот, в качестве
содержимого атрибутов starsOf элементов movie могут быть заданы списки значений
атрибутов star id элементов star (подобные связи представляются дугами stars Орграфа).
На рис. 4.25 приведен пример XML-документа, удовлетворяющего требованиям
определения DTD, показанного на рис. 4.24. Документ почти полностью
соответствует графу полуструктурированных данных, изображенному на рис. 4.19. Он содержит
даже больше данных — в нем содержатся описания трех кинофильмов вместо одного.
Единственное отличие состоит в том, что все элементы star документа включают
вложенные элементы address, в то время как вершине mh графа соответствуют
дочерние вершины, описывающие компоненты street и city непосредственно. □
<stars-movies>
<STAR starld = "cf" starredin = "sw, esb, rj">
<NAME>Carrie Fisher</NAME>
<ADDRESS><STREET>123 Maple St.</STREET>
<CITY>Hollywood</CITY></ADDRESS>
<ADDRESS><STREET>5 Locust Ln.</STREET>
<CITY>Malibu</CITY></ADDRESS>
</STAR>
<STAR starld = "mh" starredin = "sw, esb, rj">
<NAME>Mark Hamill</NAME>
<ADDRESS><STREET>456 Oak Rd.</STREET>
<CITY>Brentwood</CITYx/ADDRESS>
</STAR>
<MOVIE movieid = "sw" starsOf = "cf, mh">
<TITLE>Star Wars</TITLE^
<YEAR>1977</YEAR>
</MOVIE>
<MOVIE movieid = "esb" starsOf = "cf, mh">
<TITLE>Empire Strikes Back</TITLE>
<YEAR>19 8 0 </YEAR>
</MOVIE>
<MOVIE movieid = "rj" starsOf = "cf, mh">
<TITLE>Return of the Jedi</TITLE>
<YEAR>1983</YEAR>
</MOVIE>
</STARS-MOVIES>
Puc. 4.25. Пример документа, соответствующего
требованиям определения DTD, которое показано на рис. 4.24
198
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
4.7.6. Упражнения к разделу 4.7
Упражнение 4.7.1. Включите в текст ХМL-документа, представленного на рис. 4.25,
описания следующих фактов:
* а) Гаррисон Форд участвовал в съемках всех трех упомянутых фильмов, а
также фильма "Witness" (1985);
b) Кэрри Фишер также снялась в фильме "Hannah and Her Sisters" (1985);
c) Лайэм Нисон — член съемочной группы фильма "The Phantom Menace" (1999).
* Упражнение 4.7.2. Предложите способ представления в рамках DTD типичной
информации о банках и их клиентах (см. упражнение 2.1.1 на с. 63).
Упражнение 4.7.3. Предложите способ представления в рамках DTD типичной
информации о футбольных командах, об игроках и о болельщиках (см. упражнение
2.1.3 на с. 64).
Упражнение 4.7.4. Предложите способ представления в рамках DTD типичной
информации о генеалогическом дереве семьи (см. упражнение 2.1.6 на с. 65).
4.8. Резюме
♦ Язык определения объектов. Язык ODL представляет собой систему
обозначений, соответствующую требованиям объектно-ориентированной парадигмы
и позволяющую формально описывать схемы баз данных. Средствами ODL
определяются классы, в составе которых могут содержаться объявления свойств
следующих категорий: атрибуты, связи и методы.
♦ Связи в ODL. Связь в объявлении ОDL-класса должна быть бинарной. В
соединяемых классах объявляется пара взаимно обратных связей. Связи могут
относиться к типам "многие ко многим", "многие к одному" и "один к одному",
в зависимости от того, какие типы заданы в объявлениях пары обратных
связей — ссылка на единственный объект класса или набор таких ссылок.
♦ Система типов ODL. Система типов ODL допускает расширение: новые типы
определяются на основе имен ранее объявленных классов и стандартных
атомарных типов, таких как integer или string, с помощью конструкторов
типов структур (Struct), а также составных типов Set (множество), Bag
(мультимножество), List (список), Array (массив) и Dictionary (словарь).
♦ Экземпляры классов. Каждому классу может быть поставлен в соответствие
экземпляр, представляющий собой множество объектов этого класса,
существующих в базе данных в текущий момент времени. Экземпляр класса ODL
соответствует экземпляру отношения в реляционной модели, а объявление класса
сродни схеме отношения.
♦ Ключи в ODL. В объявлениях ODL-классов задание ключей не является
обязательным. Независимо от того, определены ключи или нет, система,
интерпретирующая код ODL, всегда в состоянии различить объекты класса (даже если
они обладают совершенно одинаковыми значениями атрибутов), поскольку
каждому объекту ставится в соответствие скрытый идентификационный номер.
♦ Преобразование ODL-проектов в отношения. Простейший способ
преобразования ODL-проектов в отношения заключается в создании схемы отношения для
каждого из классов, содержащей те же атрибуты, какие определены для класса,
и схем отношений для каждой из пар взаимно обратных связей. Впрочем,
отношения для связи типа "многие к одному" и класса, "расположенного" на
4.8. РЕЗЮМЕ
199
стороне "многие" этой связи, можно объединить. Если класс не содержит
ключевых атрибутов, в схеме отношения надлежит определить дополнительные
атрибуты, которым отводится роль ключевых.
♦ Объектно-реляционная модель. Альтернативой "чистым"
объектно-ориентированным моделям баз данных, подобным ODL, является подход, предполагающий
расширение реляционной модели за счет включения в нее функций,
реализующих основные концепции объектно-ориентированной парадигмы. К числу
подобных "расширений" относятся поддержка вложенных отношений, т.е.
атрибутов отношений, типами которых служат схемы других отношений, иных
сложных типов атрибутов, методов, определяемых для типов, и возможности
создания в пределах кортежа отношения ссылок, указывающих на другие кортежи.
♦ Полуструктурированные данные. "Носителем" информации в модели
полуструктурированных данных служит граф. Вершины графа соответствуют объектам
классов и значениям их атрибутов, а дуги, обозначенные метками, соединяют
объект со значениями его атрибутов и с другими объектами, с которыми он
соотносится посредством связей.
♦ XML. extensible Markup Language (расширяемый язык разметки) — это
стандарт, разработанный сообществом WWW Consortium и реализующий модель
полуструктурированных данных в применении к задаче описания текстовых
документов. Вершины графа полуструктурированных данных соответствуют в
документе элементам текста, а некоторые помеченные дуги представляются
парами начальных и завершающих тэгов.
♦ Идентификаторы и ссылки в документах XML. Для представления информации
графов, не относящихся к категории деревьев, XML предусматривает
возможность задания (в тексте начальных тэгов элементов) атрибутов типов id и idref
(или idrefs). Таким образом, с тэгом (соответствующим вершине графа
полуструктурированных данных) сопоставляется идентификатор, на который можно
ссылаться из других тэгов (в графе подобная ссылка представляется в воде дуги).
4.9. Литература
Полное описание языка ODL приведено в руководстве [6], выпущенном
исследовательской группой Object Data Management Group (ODMG). Подробную
информацию об истории развития объектно-ориентированных систем баз данных можно
найти в работах [4], [5] и [8].
Модель полуструктурированных данных базируется на результатах проектов
TSIMMIS и LORE, выполненных в Станфордском университете. Исходное описание
модели содержится в [9]. Система LORE, в том числе и используемый в ней язык
запросов, рассмотрены в [3]. К числу обзоров недавних результатов в области
разработки систем, основанных на модели полуструктурированных данных, относятся [1], [2]
и [10]. Обширная библиография, посвященная вопросам применения и развития
модели полуструктурированных данных, приведена в [7].
XML — это стандарт, разработанный специалистами сообщества World Wide Web
Consortium. Ссылка [11] содержит адрес Web-сайта сообщества.
1. Abiteboul S. Quering semi-structured data, Proc. Intl. Conf. on Database Theory (1997),
Lecture Notes in Computer Science 1187 (F. Afrati and P. Kolaitis, eds.), Springer-Verlag,
Berlin, p. 1-18.
2. Abiteboul S., Suciu D., Buneman P. Data on the Web: From Relations to Semistructured Data
and Xml, Morgan-Kaufmann, San Francisco, 1999.
3. Abiteboul S., Quass D., McHugh J., Widom J., and Weiner J.L. The LOREL query language
for semistructured data, J. Digital Libraries, 1:1 (1997).
200
ГЛАВА 4. ДРУГИЕ МОДЕЛИ ДАННЫХ
4. Bancilhon F., Delobel C, and Kanellakis P. Building an Object-Oriented Database System,
Morgan-Kaufmann, San Francisco, 1992.
5. Cattell R.G.G. Object Data Management, Addison-Wesley, Reading, MA, 1994.
6. Cattell R.G.G. (ed.) The Object Database Standard: ODMG-99, Morgan-Kaufmann,
San Francisco, 1999.
7. Faulstich L.C.
(http://www.inf.fu-berlin.de/~faulstic/bib/semistruct/).
8. Kim W. (ed.) Modern Database Systems: The Object Model, Interoperability, and Beyond,
ACM Press, New York, 1994.
9. Papakonstantinou Y., Garcia-Molina H., Widom J. Object exchange across heterogeneous
information sources, IEEE Intl. Conf. on Data Engineering (March 1995), p. 251-260.
10. Suciu D. (ed.) SIGMOD Record, 26:4 (1997), специальный выпуск, посвященный
проблемам использования полуструктурированных данных.
11. World Wide Web Consortium (http: //www.w3 .org/XML/).
4.9. ЛИТЕРАТУРА
201
Глава 5
Реляционная алгебра
В этой главе мы приступим к изучению аспектов программирования баз данных и
расскажем о том, каким образом пользователь может обращаться к базе данных с запросами
и выполнять команды изменения ее содержимого. Здесь мы сосредоточим внимание на
реляционной модели — в частности, на системе обозначений, принятой для описания
запросов к содержимому отношений и называемой реляционной алгеброй (relational algebra).
В то время как язык ODL предлагает возможность использования методов,
пригодных для выполнения любых операций над данными, а ER-модель вовсе не
предусматривает каких-либо способов манипуляции информацией, реляционная модель содержит
совершенно конкретный набор "стандартных" операторов, применяемых в контексте
отношений. Что удивительно, этот набор не является функционально полным по Тьюрингу
(Turing complete), хотя обычные языки программирования этому требованию отвечают.
Поэтому средствами реляционной алгебры MOiyr быть описаны далеко не все
возможные операции, которые, однако, поддаются реализации при программировании методов
ODL-классов с помощью, скажем, языка C++. Впрочем, такое положение вещей
нельзя считать признаком слабости или несовершенства реляционной модели и
реляционной алгебры, — наоборот, в этом есть свои преимущества: упрощение множества
операторов позволяет существенно оптимизировать выражения запросов к базе
данных, которые в этом случае могут быть написаны на высокоуровневых языках,
подобных SQL (за подробной информацией о языке SQL обращайтесь к главе 6 на с. 249).
Вначале мы познакомим вас с операциями реляционной алгебры. Операции
применяются к множествам кортежей, или отношениям. Коммерческие СУБД, однако,
обычно основываются на несколько иной модели отношений, где отношение
представляется мультимножеством кортежей (множеством с повторяющимися
элементами), а не обычным множеством. Хотя зачастую удобнее воспринимать алгебру
отношений как алгебру множеств, мы должны уметь предвидеть возможные эффекты
дублирования кортежей в отношениях, получаемых в результате выполнения операций
реляционной алгебры. В заключительном разделе главы будет показано, как
использовать средства реляционной алгебры для описания тех или иных ограничений,
касающихся содержимого отношений.
В последующих главах мы рассмотрим дополнительные возможности, предлагаемые
современными коммерческими СУБД. Все операции реляционной алгебры находят то или
иное выражение в языке SQL, к изучению которого мы приступим в главе 6 на с. 249. Те
же алгебраические операции поддерживаются и языком объектных запросов OQL,
основанным на модели ODL (за сведениями о языке OOL обращайтесь к главе 9 на с. 419).
5Л. Пример схемы базы данных
Мы переходим к изучению вопросов программирования баз данных в контексте
реляционной модели, и поэтому полезно составить некоторую схему базы данных,
пригодную для дальнейшего использования в примерах и упражнениях. Мы вновь
прибегнем к схеме "кинематографической" базы данных, содержащей сведения
о фильмах, актерах и киностудиях. Возьмем за основу нормализованные версии
отношений, построенные в разделе 3.6 на с. 123. В редакцию схемы, которой мы будем
придерживаться, однако, включены дополнительные атрибуты и новое отношение
MovieExec. Цель внесения указанных изменений состоит в том, чтобы облегчить
демонстрацию различных типов данных и приемов представления информации. Схема
базы данных приведена на рис. 5.1.
Movie(
TITLE: string,
YEAR: integer,
length: integer,
inColor: boolean,
studioName: string,
producerC#: integer)
Starsln(
MOVIETITLE: string,
MOVIEYEAR: integer,
STARNAME: string)
MovieStar(
NAME: string,
address: string,
gender: char,
birthdate: date)
MovieExec(
name: string,
address: string,
CERT#: integer,
netWorth: integer)
Studio(
NAME: string,
address: string,
presC#: integer)
Рис. 5.1. Пример схемы базы данных о фильмах,
актерах и киностудиях
Схема базы данных охватывает пять отношений. Схема каждого из отношений
содержит перечень атрибутов с указанием доменов, к которым должны принадлежать значения
атрибутов. Наименования ключевых атрибутов набраны в верхнем регистре, хотя, как
и прежде, мы можем ссылаться на них посредством строк в нижнем регистре. Ключ
отношения stars in, например, образован совокупностью всех трех атрибутов — movietitle,
MOVIEYEAR и STARNAME. Отношение Movie содержит шесть атрибутов, два из которых —
title и year — как и раньше, формируют ключ. Атрибут title, например, относится
к строковому типу (string), а атрибут year — к целочисленному (integer).
Ниже перечислены основные изменения, которым подверглась схема с того
момента, когда мы последний раз к ней обращались.
204
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
• Для обозначения "руководителей" индустрии кино — президентов студий
и продюсеров фильмов — введено понятие сертификационного номера (certificate
number). Сертификационный номер содержит уникальное целочисленное
значение, которое, как мы полагаем, присваивается каждому президенту и
продюсеру неким профессиональным советом или творческим союзом.
• Для различения руководящих персон используются сертификационные номера,
хотя актеры по-прежнему обозначаются в отношении Movies tar только именем
и фамилией (ключевым атрибутом name). Подобное половинчатое решение,
очевидно, не совсем правильно с практической точки зрения, поскольку включение
в базу данных сведений об актерах с одинаковыми фамилиями и именами вполне
вероятно, но мы выбрали такой путь только с той целью, чтобы
проиллюстрировать различные варианты представления данных и способов их обработки.
• В схему отношения Movie введен дополнительный атрибут producerC# —
сертификационный номер продюсера кинофильма. Продюсеры наряду с
президентами киностудий относятся к категории "руководителей", и информация о них
представляется отношением MovieExec.
• Атрибут f ilmType отношения Movie переименован в inColor и теперь
относится не к перечислимому типу, а к булевому: атрибут получает значение true,
если фильм снят на цветной пленке, и false — если на черно-белой.
• В отношение Movies tar добавлен атрибут gender ("пол") типа char,
принимающий значение *м* ("male"), если актер — мужчина, и *f* ("female") —
если женщина. Введен также атрибут birthdate ("дата рождения") типа date,
который принадлежит к категории специальных типов, поддерживаемых многими
коммерческими СУБД, или, если необходимо, описывается обычной строкой.
• Все атрибуты address ("адрес") теперь относятся к строковому типу вместо
структурного, представляющего отдельно сведения о названиях улицы и города.
Это облегчает задачу сопоставления и обработки адресов.
5.2. Алгебра реляционных операций
Чтобы приступить в рассмотрению различных операций, которые могут
выполняться над отношениями, целесообразно сначала рассказать об особенностях
специальной алгебры, называемой реляционной алгеброй (relational algebra), которая служит
для формального описания способов конструирования новых отношений на основе
заданных. Заданные отношения хранят информацию, а вновь создаваемые содержат
ответы на запросы относительно тех или иных свойств такой информации.
Развитие алгебры отношений имеет свою историю, и в ходе изложения мы
постараемся придерживаться хронологии введения тех или иных понятий и операций.
Изначально реляционная алгебра была разработана Э.Ф. Коддом (E.F. Codd) в виде
совокупности операторов, выполняемых над множествами кортежей (т.е. отношениями)
и обеспечивающих возможности выражения типичных запросов, касающихся
содержимого отношений. Алгебра охватывала пять операций над множествами: объединение
(union), разность (difference), декартово произведение (Cartesian product) (с ними вы,
возможно, уже знакомы), а также две нетрадиционные операции — выбор (selection)
и проекция (projection). Затем в нее вошли другие операции, которые можно выразить
в терминах операций из исходного набора (наиболее важными из них являются
различные варианты операции соединения —join).
С появлением первых СУБД, основанных на реляционной модели, операторы
реляционной алгебры были реализованы в языках запросов. Однако с целью повышения
эффективности обработки запросов было принято решение рассматривать отношения
как мультимножества (bags) кортежей, а не обычные множества (sets). Иными слова-
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИИ
205
Почему мультимножества более эффективны, нежели множества
В качестве простого примера, иллюстрирующего тот факт, что модель
мультимножеств способна увеличить степень эффективности реализации СУБД, рассмотрим
следующую ситуацию: если выполняется объединение отношений, не
предусматривающее удаления кортежей-дубликатов, мы можем просто скопировать их
содержимое в одно итоговое отношение. Если же результатом обязательно должно
оказаться множество, нам придется отсортировать данные или выполнить какую-
либо настолько же трудоемкую операцию, чтобы выявить совпадающие кортежи
отношений, подлежащих слиянию.
ми, если условие удаления повторяющихся кортежей не оговаривается явно, в
отношения позволяется включать кортежи-дубликаты. В разделе 5.3 на с. 225 мы
рассмотрим соответствующие варианты операций над отношениями как мультимножествами
и покажем, в чем состоит их отличие.
В ходе развития коммерческих реляционных СУБД алгебру отношений понадобилось
пополнить целым рядом новых операций, наиболее важные из которых связаны с
выполнением функций агрегирования (aggregation), т.е. нахождения суммарных, средних,
максимальных, минимальных и иных значений в определенном столбце таблицы-отношения.
Дополнительные операции реляционной алгебры рассмотрены в разделе 5.4 на с. 232.
5.2.1. Основы реляционной алгебры
Некоторая алгебра, вообще говоря, состоит из набора операторов, применяемых
к атомарным операндам. Например, в алгебре арифметики атомарные операнды
представляют собой переменные вида х и константы, подобные 15, а операторами служат
обычные арифметические операторы сложения, вычитания, умножения и деления.
Любая алгебра позволяет создавать выражения (expressions) путем применения
операторов к операндам и/или другим выражениям, допустимым в контексте этой алгебры.
Для группирования операторов и операндов обычно применяются круглые скобки.
В алгебре арифметики, скажем, вполне приемлемыми считаются выражения,
подобные таким, как (jc + у) * z или ((* + 7) / (у - 3)) + х.
Реляционная алгебра — это просто еще одна частная разновидность алгебр. В ней
поддерживаются следующие виды атомарных операндов:
1) переменные, обозначающие отношения;
2) константы, являющиеся конечными отношениями.
Как мы уже упоминали, в классической реляционной алгебре все операнды и
результаты вычисления выражений являются множествами. Операции реляционной алгебры
относятся к четырем классам, перечисленным ниже.
1. Обычные операции над множествами -— объединение (union), пересечение
(intersection) и разность (difference), — применяемые к отношениям.
2. Операции удаления частей отношения: операция выбора (selection) приводит
к отбрасыванию некоторых кортежей (строк), а операция проекции
(projection) — к устранению атрибутов (столбцов).
3. Операции сочетания кортежей двух отношений: например, операция декартова
произведения (Cartesian product) позволяет совместить в пределах кортежей
итогового отношения все возможные комбинации кортежей двух исходных
отношений, а различные разновидности операции соединения (join) применяются
для избирательного слияния кортежей.
4. Операция переименования (renaming) атрибутов или отношения целиком
(операция не оказывает влияния на содержимое отношения, но изменяет его схему).
206
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
Выражения реляционной алгебры принято называть запросами (queries). Хотя до
сих пор мы еще не вводили специальных обозначений для описания большинства
выражений реляционной алгебры, операции группы (1), тем не менее, должны быть вам
знакомы. Примером характерного выражения реляционной алгебры может служить
R U S, где R и S — атомарные операнды, представляющие отношения с произвольными
множествами кортежей. Указанный запрос предполагает вычисление объединения
множеств кортежей отношений R и S.
5.2.2. Теоретико-множественные операции над отношениями
К числу наиболее известных и употребительных операций теории множеств
относятся объединение (union), пересечение (intersection) и разность (difference). Смысл
каждой из операций пояснен ниже (мы полагаем, что все они хорошо вам знакомы).
• R\JS, объединение множеств R и S, — множество элементов, присутствующих в R,
S или в обоих множествах одновременно. Каждый элемент включается в итоговое
множество только один раз — даже в том случае, если он является членом и R, и S.
• R П S, пересечение множеств R и S, — множество элементов, присутствующих
в множествах R и S одновременно.
• R-S, разность множеств R и S, — множество элементов, являющихся членами
R, но отсутствующих в S. Заметим, что R-S — это не то же самое, что S-R\
последняя операция вычисляет множество элементов, которые входят в состав S,
но не принадлежат R.
Если R и S представляют собой множества кортежей (отношения), они должны
удовлетворять следующим требованиям:
1) обладать схемами с идентичными наборами атрибутов, типы (домены)
которых обязаны попарно совпадать;
2) атрибуты (столбцы) должны следовать в одном и том же порядке.
Иногда приходится вычислять объединение, пересечение или разность отношений,
атрибуты которых относятся к совпадающим типам, но обладают различными
названиями. В подобных случаях необходимо предварительно применить оператор
переименования (обратитесь к разделу 5.2.9 на с. 215), чтобы изменить схему одного или
обоих отношений, обеспечив их идентичность.
пате
Carrie Fisher
Mark Hamill
address
123 Maple St., Hollywood
456 Oak Rd., Brentwood
gender
F
M
birthdate
9/9/99
8/8/88
Отношение R
name
Carrie Fisher
Harrison Ford
address
123 Maple St., Hollywood
789 Palm Dr., Beverly Hills
gender
F
M
birthdate
9/9/99
7/7/77
Отношение S
Puc. 5.2. Пример двух отношений
Пример 5.1. Пусть даны отношения R и S, которые представляют собой экземпляры
отношения MovieStar (см. раздел 5.1 на с. 204), изображенные на рис. 5.2. Результат
объединения отношений R и S (R U S) выглядит так:
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ
207
name
Carrie Fisher
Mark Hamill
Harrison Ford
address
123 Maple St., Hollywood
456 Oak Rd., Brentwood
789 Palm Dr., Beverly Hills
gender
F
M
M
birthdate
9/9/99
8/8/88
7/7/77
Заметим, что два кортежа, соответствующие актрисе Кэрри Фишер и присутствующие
одновременно в R и S, в итоговом отношении заменены одним кортежем.
Операция пересечения в применении к отношениям R и S (R П S) даст следующее:
пате
Carrie Fisher
address
123 Maple St., Hollywood
gender
F
birthdate
9/9/99
Итоговое отношение содержит единственный кортеж, представляющий сведения
о Кэрри Фишер, поскольку только он одновременно присутствует и в R, и в S.
Наконец, в результате выполнения операции разности R и S (R-S) мы получим
такое отношение:
пате
Mark Hamill
address
456 Oak Rd., Brentwood
gender
M
birthdate
8/8/88
Кандидатами на включение в R- S являются кортежи R, соответствующие
Кэрри Фишер и Марку Хэмиллу, но первый является также членом S, поэтому из R - S
он изымается. □
5.2.3. Проекция
Оператор проекции (projection) применяется к отношению R с целью получения
нового отношения, которое содержит только некоторые из атрибутов R. Значением
выражения л:А л л (R) служит отношение, содержащее явно перечисленные атрибуты
Г 2"'" п
АЪАЪ ...,А„ отношения R. Схема итогового отношения охватывает множество
атрибутов {AhA2,..., Ап), отображаемых в указанном порядке.
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
in Color
true
true
true
studioName
FOX
Disney
Paramount
producerCtt
12345
67890
99999
Рис. 5.3. Экземпляр отношения Movie
Пример 5.2. Рассмотрим отношение Movie со схемой, представленной в разделе 5.1
на с. 204. Экземпляр отношения изображен на рис. 5.3. Операция проекции
отношения Movie в новое отношение, содержащее три первых атрибута исходного,
записывается в виде выражения
Я title, year, length (Movi в).
Результатом выполнения операции служит отношение
title
Star Wars
Mighty Ducks
Wayne's World
year
1977
1991
1992
length
124
104
95
208
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
Другой пример — это проекция отношения Movie в отношение с атрибутом
inColor, которая может быть представлена в виде выражения л1пСЫог(Movie). В итоге
будет получено отношение с одним атрибутом
in Color
true
Обратите внимание, что оно содержит только один кортеж, поскольку все три кортежа
исходного отношения рис. 5.3 обладают одинаковыми значениями компонентов для
атрибута inColor, а в соответствии с требованиями реляционной алгебры множеств
кортежи-дубликаты удаляются. □
5.2.4. Выбор
Оператор выбора (selection), будучи примененным к отношению R, дает в
результате новое отношение, содержащее подмножество кортежей R, удовлетворяющих
некоторому заданному условию С, которое накладывается на атрибуты отношения R.
Операцию выбора принято обозначать как crc(R). Схемы итогового и исходного
отношений совпадают и порядок следования атрибутов в них сохраняется.
С — это условное выражение, подобное тем, которые применяются в традиционных
языках программирования (например, после служебного слова if в коде, написанном
на C++ или Java). Единственная особенность выражения С связана с тем, что его
операндами служат или константы, или названия атрибутов отношения R. Выражение С
вычисляется для каждого кортежа t отношения R путем замены всех атрибутов А,
вовлеченных в выражение С, содержимым соответствующих компонентов кортежа г. Если
после выполнения замены условие С становится истинным, тогда t включается в итоговый
набор кортежей отношения сгс(Д); в противном случае кортеж t в результат не попадает.
Пример 5.3. Вновь обратимся к экземпляру отношения Movie, приведенному на рис. 5.3.
Результатом вычисления выражения crlengthzwo(Movie) окажется следующее отношение:
title
Star Wars
Mighty Ducks
year
1977
1991
length
124
104
in Color
true
true
studioName
Fox
Disney
producerC#
12345
67890
Первый кортеж удовлетворяет условию length > 100, поскольку после замены
"переменной" length значением 124, которое содержится в компоненте кортежа,
отвечающем атрибуту length, условие преобразуется в 124 > 100 и становится истинным.
Поэтому кортеж включается в итоговое отношение. С помощью тех же доводов легко
объяснить, почему в результат заносится и второй кортеж отношения Movie.
Компонент length третьего кортежа содержит значение 95, поэтому после замены
атрибута length значением 95 условие выбора примет вид 95 > 100, что, разумеется,
ложно. Поэтому последний кортеж Movie в отношение crlength>l00(Movie) не включается. □
Пример 5.4. Предположим, что необходимо выбрать из экземпляра отношения Movie
в редакции, показанной на рис. 5.3, только такие кортежи, которые представляют
сведения о кинофильмах, снятых на студии "Fox" и обладающих длительностью
воспроизведения не менее 100 минут. Критерий выбора описывается более сложным
условием, в котором два условных выражения соединяются с помощью оператора and
("логическое И"). Выражение выбора принимает следующий вид:
Оlength > 100 AND studioName = • Fox • (MOVi e).
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ
209
Указанному условию удовлетворяет только один кортеж отношения Movie:
title
Star Wars
year
1977
length
124
inColor
true
studio Name
Fox
producerC#
12345
5.2.5. Декартово произведение
Декартово произведение (Cartesian product) двух множеств R и S представляет собой
множество пар элементов, таких что первым элементом пары является любой элемент
множества R, а вторым — любой элемент множества S. Операция обозначается так:
RxS. Когда в роли R и S выступают отношения, существо операции не меняется.
Однако, поскольку членами R и S являются кортежи, обычно состоящие более чем из
одного компонента, результатом сочетания кортежа отношения R с кортежем
отношения S окажется более длинный кортеж с компонентами, соответствующими
компонентам обоих исходных кортежей. Порядок следования атрибутов в итоговом
отношении таков: сначала указываются атрибуты отношения R, а затем — отношения S.
Схема отношения-результата RxS является объединением схем отношений R и S.
Если так случится, что отношения R я S обладают одноименными атрибутами,
необходимо переименовать по меньшей мере один атрибут из каждой пары одинаковых
атрибутов. Чтобы различить атрибуты А, присутствующие в схемах отношений R и S, мы
будем использовать обозначение R.A для атрибута схемы R и S.A — для атрибута схемы S.
А
1
3
В
2
4
В
2
4
9
С
5
7
10
D
6
8
11
Отношение S
А
1
1
1
3
3
3
R.B
2
2
2
4
4
4
S.B
2
4
9
2
4
9
С
5
7
10
5
7
10
D
6
8
11
6
8
11
Отношение RxS
Рис. 5.4. Два отношения и их декартово произведение
Пример 5.5. Рассмотрим абстрактный пример, иллюстрирующий применение
операции декартова произведения. Пусть даны отношения R и S со схемами и кортежами,
показанными на рис. 5.4. Отношение RxS, изображенное в нижней части рисунка,
содержит шесть кортежей, соответствующих всем возможным парам, образованным из
двух кортежей отношения R и трех кортежей отношения S. Поскольку схемы исход-
210
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
ных отношений содержат одноименные атрибуты Я, в схеме отношения R x S эти
атрибуты обозначены как R.B и S.B. Имена других атрибутов не совпадают и поэтому
в итоговом отношении они не изменились. □
5.2.6. Естественное соединение
Полезность операции декартова произведения несомненна, но гораздо чаще
возникает потребность в соединении (join) двух отношений, т.е. формировании пар таких
их кортежей, которые удовлетворяют определенному критерию. Простейшая
разновидность операции соединения двух отношений R и S, которую называют
естественным соединением (natural join) и обозначают как
RxS,
предусматривает включение в итоговое отношение тех кортежей из R и S, которые
совпадают в атрибутах, общих для схем R a S. Чтобы быть более точными, обозначим
как ЛЬЛ2» -»^и все атрибуты, которые определены одновременно в схемах отношений
R и S. Тогда кортежи г из R и s из S допускают соединение, если и только если г и s
совпадают в каждом из атрибутов Ль А2,..., Ап.
Если кортежи г и s успешно соединены, результат пред- R
ставляет собой кортеж, называемый соединенным кортежем S
(joined tuple) и содержащий по одному компоненту для ка-
ждого из атрибутов схемы, полученной в результате
объединения схем R и S. Соединенный кортеж совпадает с
кортежем г в каждом из атрибутов схемы R и с кортежем s
в каждом из атрибутов схемы S. Поскольку г и s успешно
соединены, итоговый кортеж совпадает с обоими
исходными кортежами во всех их общих атрибутах. Процесс
получения соединенного кортежа иллюстрируется рис. 5.5.
Заметим, что рассмотренная операция соединения
совпадает с той, которую мы использовали в разделе 3.6.5
на с. 132 для реконструкции отношений, подвергнутых Рис. 5.5.
процедуре декомпозиции, с целью получения доказа- тежей
тельств того, что декомпозиция BCNF верна. В разделе
5.2.8 на с. 214 будет показан еще один пример применения операций естественного
соединения: речь пойдет о сочетании двух отношений таким образом, чтобы
облегчить создание единого запроса, затрагивающего атрибуты обоих отношений.
Пример 5.6. Результатом операции естественного соединения отношений R и S,
изображенных на рис. 5.4, окажется следующий экземпляр отношения:
г
s
соединенный кортеж
Соединение кор-
А
1
3
В
2
4
С
5
7
D
6
8
Единственный атрибут, общий для отношений R и S, — это В. Поэтому для успешного
соединения кортежей достаточно их совпадения в атрибуте В. Соединенный кортеж
обладает такими атрибутами: А (из схемы R), В (из R или S), С (из S) и D (также из S).
Первый кортеж отношения R успешно сочетается только с первым кортежем
отношения S; кортежи совпадают в единственном общем атрибуте В. В результате мы
получаем первый кортеж итогового отношения: (1,2,5,6). Второй кортеж R образует
пару только со вторым кортежем S, и эта операция дает в итоге кортеж (3, 4, 7, 8).
Обратите внимание, что третий кортеж S не совпадает в атрибуте В ни с одним кортежем
R и поэтому в расчет не принимается. Кортежи одного отношения, которые в
процессе соединения не в состоянии образовать пару ни с одним кортежем другого
отношения, называют висящими (dangling tuples). □
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ
211
Пример 5.7. В предыдущем примере не нашли отражения все ситуации, которые могут
возникнуть при выполнении естественного соединения: например, ни один из
кортежей отношения не допускал сочетания более чем с одним кортежем другого
отношения, и отношения обладали только одним общим атрибутом.
На рис. 5.6 приведены два других отношения, U и V, которые обладают двумя
общим атрибутами — В и С. Один кортеж каждого отношения может быть соединен
с несколькими кортежами другого отношения. Чтобы кортежи отношений U и V
позволяли соединение, они должны совпадать и в атрибуте Б, и в атрибуте С; поэтому
первый кортеж U успешно сочетается с двумя первыми кортежами V, в то время как
второй и третий кортежи U образуют пары с третьим кортежем V. Итоговое
отношение показано в нижней части рис. 5.6.
А
1
6
9
В
2
7
7
С
3
8
8
Отношение U
В
2
2
7
С
3
3
8
D
4
5
10
Отношение V
А
1
1
6
9
В
2
2
7
7
С
3
3
8
8
D
4
5
10
10
Отношение UxV
Рис. 5.6. Два отношения и их естественное соединение
□
5.2.7. Тета-соединение
Естественное соединение кортежей двух отношений основано на частном условии
равенства содержимого компонентов, которые соответствуют атрибутам, общим для
обоих отношений. Хотя подобная ситуация, несомненно, является весьма
распространенной, подчас желательно иметь возможность соединения кортежей отношений на
основе иных критериев. И такая операция, называемая тета-соединением (theta-join),
действительно существует. По традиции для обозначения произвольного условия
используется прописная буква © (тета) греческого алфавита, но мы для удобства
заменим ее прописной латинской С.
Операция тета-соединения отношений R и S в соответствии с условием С
обозначается как
RxS
с
и выполняется следующим образом:
1) вычисляется декартово произведение R и 5;
212
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
2) из результата произведения выбираются те кортежи, которые удовлетворяют
заданному условию С.
Как и при выполнении операции декартова произведения, схема итогового
отношения представляет собой объединение схем отношений R и S. При необходимости
наименование атрибута снабжается префиксом "/?." или "5.", указывающим на
"происхождение" атрибута.
Пример 5.8. Рассмотрим операцию Ua^dV в применении к отношениям U и V,
низанным на рис. 5.6. Нам придется перебрать все девять возможных пар кортеже,
и проверить, действительно ли значение компонента А кортежа U меньше значения
компонента D кортежа V. Первый кортеж U, компонент А которого содержит значение 1,
успешно сочетается с каждым из кортежей отношения V. Однако второй и третий
кортежи U с компонентами А, равными, соответственно, 6 и 9, способны образовать
пары только с третьим кортежем V. Поэтому в итоговое отношение будут включены
пять кортежей. Результат показан на рис. 5.7.
А
1
1
1
6
9
U.B
2
2
2
7
7
U.C
3
3
3
8
8
V.B
2
2
7
7
7
V.C
3
3
8
8
8
D
4
5
10
10
10
Рис. 5.7. Отношение Ua<dV
□
Обратите внимание, что схема отношения рис. 5.7 содержит все шесть атрибутов,
и названия атрибутов В и С, общих для отношений U и V, предварены префиксами
"U." и "К", позволяющими различить одноименные атрибуты исходных отношений.
Таким образом, операции тета-соединения и естественного соединения
различаются — при выполнении последней общие атрибуты представляются единственной
копией. В случае естественного соединения подобный подход, разумеется, оправдан,
поскольку кортежи не смогли бы образовать пару, если бы не совпали в значениях
общих атрибутов. Операция тета-соединения, однако, не гарантирует, что
сопоставляемые атрибуты вообще смогут совпасть, так как вполне возможно, что они
просто не допускают сравнения посредством оператора =.
Пример 5.9. Рассмотрим операцию тета-соединения тех же отношений U и V,
предусматривающую выполнение более сложного условия:
U х V.
А < D AND U.B* V.B
Теперь для успешного соединения кортежей условия превосходства значения
компонента D кортежа V над значением компонента А кортежа U уже не достаточно: необходимо
также, чтобы кортежи различались содержимым компонентов В. Поэтому
единственным кортежем, удовлетворяющим одновременно обоим условиям, окажется следующий:
А
1
U.B
2
U.C
3
V.B
1
V.C
8
D
10
Указанное отношение является результатом операции тета-соединения
отношений U и V в соответствии с условием А < D and U.B Ф V.B. □
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ
213
5.2.8. Наборы операций и формирование запросов
Если бы наши возможности сводились к написанию запросов, предусматривающих
выполнение отдельных операций над одним или двумя отношениями, реляционную
алгебру нельзя было бы считать настолько мощным инструментом, каковым она
является в действительности. Однако реляционная алгебра, как и все другие алгебры,
позволяет создавать выражения произвольной степени сложности и применять
операторы не только к исходным отношениям, но и к отношениям, полученным в результате
выполнения других операторов.
Выражения реляционной алгебры могут содержать операторы, применяемые к
более частным выражениям, и скобки, задающие порядок группирования операндов.
Допускается представлять выражения в виде деревьев частных выражений; подобная
форма зачастую более легка для восприятия, хотя и менее удобна в сравнении с
линейной записью, предназначенной для программного выполнения.
Пример 5.10. Рассмотрим отношение Movies из примера 3.24 на с. 125 (здесь мы
назовем это отношение как Movie21). Пусть необходимо выяснить названия и даты
выпуска кинофильмов компании "Fox", продолжительность воспроизведения которых
составляет не менее 100 минут. Один из способов получения ответа на вопрос таков:
1) выбрать из отношения Movie те кортежи, которые удовлетворяют
условию length > 100;
2) выбрать из отношения Movie те кортежи, которые удовлетворяют условию
studioName = * Fox *;
3) вычислить пересечение множеств-отношений, полученных при
выполнении пп. 1, 2;
4) осуществить проекцию итогового отношения п. 3 на атрибуты title и year.
На рис. 5.8 частные операции, указанные выше,
изображены в виде дерева выражений. Вершины,
задающие операции выбора (о), соответствуют
пп. 1, 2, вершина, описывающая операцию
пересечения (П), — п. 3, а вершина, представляющая
операцию проекции (л), — п. 4.
То же выражение нетрудно представить в виде
традиционной линейной формулы со скобками:
Я title, year {& length > 100 (Movie) fl OstudioName = 'Fox1 (Movie)).
Зачастую один и тот же алгоритм вычислений
допускает представление посредством нескольких
различных выражений реляционной алгебры.
Например, запрос, рассмотренный выше, можно
записать, заменив два оператора выбора (о), связанные
оператором пересечения (0), единственным
оператором выбора с оператором "логического И" (and) в его условии:
Яtitle, year \ & length > 100 AND studioName = • Fox' (MO VI ©) ) •
title, year
n
length > 100
Movie
studioName = ' Fox'
Movie
Рис. 5.8. Дерево частных
выражений реляционной алгебры
21 Обратим ваше внимание на то, что отношение в названном примере обладает иной
схемой, нежели отношение Movie, рассмотренное в разделе 5.1 на с. 204 и используемое
в примерах 5.2, 5.3 и 5.4.
214
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
Эквивалентные выражения и оптимизация запросов
Все СУБД содержат в своем составе подсистемы обработки запросов, многие из
которых поддерживают языки, сравнимые по мощи изобразительных средств с
реляционной алгеброй. Запрос, сформированный пользователем, зачастую может быть
представлен в виде нескольких эквивалентных выражений (т.е. выражений, дающих в
результате вычисления один и тот же результат для одинаковых операндов-отношений),
но некоторые из них поддаются обработке более эффективно, нежели другие. Одна
из основных функций оптимизатора запросов, который кратко упоминался в разделе
1.2.5 на с. 43, состоит в замене одного выражения реляционной алгебры другим,
допускающим более эффективную реализацию. Подробные сведения о процессе
оптимизации выражений реляционной алгебры приведены в разделе 16.2 на с. 760.
Пример 5.11. Операция естественного соединения может быть использована для
реконструкции отношения, подвергшегося декомпозиции в отношения, удовлетворяющие
требованиям BCNF. Обратимся к отношениям Moviesl и Movies2 (здесь мы будем
называть их как Moviel и Movie2 соответственно), полученным в результате
декомпозиции отношения Movies в примере 3.24 на с. 125; схемы отношений выглядят так:
{title, year, length, filmType, studioName}
{title, year, starName}
Пусть необходимо составить выражение следующего запроса: "Найти фамилии актеров,
принимавших участие в съемках кинофильмов продолжительностью не менее
100 минут". В контексте этого запроса атрибут starName отношения Movie2 должен
быть "связан" с атрибутом length отношения Moviel. Чтобы построить такую "связь",
достаточно выполнить операцию соединения двух отношений. Операция естественного
соединения, примененная к отношениям Moviel и Movie2, успешно сгруппирует в
пары только такие кортежи, которые совпадают в атрибутах title и year, т.е.
описывают одни и те же кинофильмы. В результате выполнения выражения Moviel cxMovie2
будет получено отношение, которое в примере 3.24 мы называли Movies. Отношение,
схема которого включает все шесть атрибутов схем отношений Moviel и Movie2,
нарушает условие BCNF, поскольку будет содержать несколько кортежей с описанием
одного и того же кинофильма, если в съемках фильма участвовало несколько актеров.
К результату соединения отношений Moviel и Movie2 следует применить
оператор выбора, учитывающий заданное условие, которое ограничивает снизу величину
продолжительности кинофильма (length > 100), а затем выполнить проекцию
полученного отношения на атрибут starName:
Л starName {^length> 100 (Moviel CX Movie2)).
□
5.2.9. Переименование атрибутов
В процессе конструирования отношений посредством применения операторов
реляционной алгебры часто возникает потребность в явном задании имен отношений и их
атрибутов. Для переименования отношения R используется оператор pS(A А А }(R).
12 п
Итоговое отношение обладает теми же кортежами, что и R, но получает имя 5, а его
атрибуты — имена Аь Аъ ..., Ап в порядке слева направо. Если необходимо изменить
только имя отношения, сохранив за его атрибутами прежние названия, заданные
в схеме R, употребляется сокращенная запись ps(R)-
Пример 5.12. В примере 5.5 на с. 210 мы демонстрировали применение операции
декартова произведения к отношениям R и 5, представленным на рис. 5.4 (см. с. 210),
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ
215
и приняли соглашение, в соответствии с которым одноименные атрибуты
итогового отношения, общие для исходных отношений-операндов, переименовываются
с использованием имен отношений в качестве префиксов. Экземпляры отношений
R и S вновь воспроизведены на рис. 5.9.
Предположим, однако, что более уместным было бы не обозначать оба атрибута
В итогового отношения как R.B и S.B, а сохранить за первым из них имя В и
присвоить атрибуту В, ранее принадлежавшему схеме 5, название X. Результат выполнения
операции переименования Ps(x,c,d)(S) — это отношение, названное 5, которое
выглядит почти так же, как отношение S на рис. 5.4, за исключением того, что его первый
атрибут обозначен как X вместо В.
А
1
3
В
2
4
В
2
4
9
С
5
7
10
D
6
8
11
Отношение S
А
1
1
1
3
3
3
в
2
2
2
4
4
4
X
2
4
9
2
4
9
С
5
7
10
5
7
10
D
6
8
11
6
8
11
Отношение Rxps(x,c, D) (S)
Рис. 5.9. Вычисление декартова произведения отношений с
предварительным переименованием атрибута одного из них
Теперь при вычислении декартова произведения отношения R и отношения S с
переименованным атрибутом конфликты имен не возникают, поэтому в дальнейшем
изменении названий атрибутов необходимости нет. Иными словами, результат применения
выражения Rxpsa,c,D)(S), показанный в нижней части рис. 5.9, совпадает с отношением
R х S из примера 5.4 — за тем исключением, что атрибуты названы как Л, В, X, С и D.
Другой возможный вариант вычислений состоит в использовании оператора
декартова произведения (что мы и делали в примере 5.5) с последующим применением к
полученному результату оператора переименования. Выражение Prs(a,b,x,c,d)(RxS)
даст то же итоговое отношение, которое показано на рис. 5.9, но отношение получит
имя RS, в то время как отношение рис. 5.9 было безымянным. □
5.2.10. Зависимые и независимые операции
Некоторые из ранее рассмотренных операций реляционной алгебры могут быть
выражены в терминах других операций. Например, операция пересечения допускает
замену парой операций разности:
RП S = R~(R- S).
216
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
Иными словами, если R и S представляют собой отношения с одинаковыми схемами,
их пересечение можно вычислить в два этапа: вначале определить разность R и 5, т.е.
некоторое отношение Г, содержащее все кортежи R, которых нет в S, а затем вычесть
Т из R, оставив в итоговом отношении кортежи R, присутствующие в S.
Обе формы оператора соединения также могут быть выражены средствами других
операторов. Операцию тета-соединения легко представить в виде сочетания операций
декартова произведения и выбора:
RxS=ac(RxS).
с
Чтобы отыскать результат естественного соединения отношений R и 5, можно начать
с вычисления их декартова произведения, R x S, а затем применить к последнему
оператор выбора, предусматривающий выполнение условия С вида
R.A^S.Ai AND R.A2 = S.A2 AND - AND R.An = S.An9
где АЬАЪ ...,Ап — это все атрибуты, одновременно присутствующие в схемах R и S.
В завершение необходимо осуществить операцию проекции, чтобы выбрать по одной
копии из каждой пары совпадающих атрибутов. Пусть L представляет собой список
атрибутов схемы R, за которыми следуют атрибуты 5, отсутствующие в R. Тогда
полное выражение приобретет следующий вид:
RxS^7rL(crc(RxS)).
Пример 5.13. Операцию естественного соединения отношений U и V на рис. 5.6
(см. с. 212) можно выразить в терминах декартова произведения, выбора и проекции:
Я A, U.B, U.C, D В = V.BbNDU.C= V.C
(UxV)).
Вначале вычисляется декартово произведение UxV. Затем выбираются кортежи,
удовлетворяющие условию равенства одноименных атрибутов В и С отношений U и V.
Наконец, выполняется операция проекции, исключающая по одному "лишнему"
атрибуту В и С: мы приняли решение удалить атрибуты В и С схемы V.
Чтобы продемонстрировать еще один пример, перепишем выражение операции
тета-соединения из примера 5.9 на с. 213:
°А < D AND U.B * V.B iJJ X Ю-
Другими словами, мы вправе вначале вычислить декартово произведение отношений
U и V, а затем к полученному результату применить оператор выбора с тем же
условием, которое использовалось в операторе тета-соединения. □
Указанные выше формулы представляют все возможные зависимости между
операторами реляционной алгебры. Шесть операций — объединения, разности, выбора,
проекции, декартова произведения и переименования — являются независимыми,
и каждую из них нельзя выразить в терминах остальных пяти.
5.2.11. Алгебраические выражения в линейном представлении
В разделе 5.2.8 на с. 214 мы показали, как выражения реляционной алгебры
представляются в виде деревьев. Другой способ состоит в обозначении промежуточных
отношений, соответствующих вершинам дерева, временными именами и формировании
последовательности выражений присваивания с использованием этих имен. Порядок
следования частных выражений присваивания обязан соответствовать логике
исходного выражения реляционной алгебры (или дерева): так, например, отношения,
представляемые вершинами, дочерними для вершины N, должны быть вычислены прежде,
чем может быть сформировано выражение присваивания, соответствующее вершине N.
Выражение присваивания состоит из следующих частей:
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ
217
1) имени отношения и списка имен его атрибутов, заключенного в скобки;
имя Answer в соответствии с принятым соглашением используется для
обозначения итогового отношения, представляющего результат выполнения
всех операций и отвечающего корневой вершине дерева;
2) оператора присваивания :=;
3) любого выражения реляционной алгебры; обычно присваиванию подлежит
результат выполнения единственного оператора, и в этом случае для каждой
промежуточной вершины дерева должно быть создано отдельное выражение
присваивания; впрочем, в правой части выражения присваивания допустимо
задавать комбинации алгебраических операторов, и вы вправе, если
посчитаете это удобным, воспользоваться такой возможностью.
Пример 5.14. Рассмотрим дерево выражений реляционной алгебры, показанное на
рис. 5.8 (см. с. 214). Один из вариантов представления его в виде последовательности
выражений присваивания таков:
R(t,
S(t,
T(t,
Answ
У, 1, i.
У, 1, i.
У, 1/ i/
er (title,
s, p)
s, p)
s, p)
year)
= <rlength* loo (Movie);
= G'studioName = • Fox' (MoV^ e) »
= Rfls;
= ^,.v(T)'
Первый шаг состоит в получении отношения, соответствующего промежуточной
вершине дерева на рис. 5.8, обозначенной как <х^,Л>юо, а на втором шаге вычисляется
отношение, отвечающее вершине о^шломте =-fo^- Обратите внимание, что за возможность
переименования мы не "платим" ничего: в левой части выражения присваивания допустимо
задавать любые имена отношений и атрибутов. Два оставшихся выражения, реализующих
операции пересечения и проекции, вполне очевидны без дополнительных разъяснений.
Как мы уже говорили, в правой части выражения присваивания позволяется
объединять несколько операторов. Например, мы вправе преобразовать два последних
выражения в одно:
= ^length* 100 (Movie);
= G'studioName = 'Fox' (Movie);
= ^,v(RflS).
R(t, y, 1, i,
S(t, y, 1, i,
Answer(title,
s, p)
s, p)
year)
5.2.12. Упражнения к разделу 5.2
Упражнение 5.2.1. Здесь мы познакомим вас с примером реляционной схемы базы
данных и экземплярами отношений, к которым будем неоднократно обращаться в
дальнейшем.22 База данных состоит из четырех отношений, схемы которых выглядят так:
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
Отношение Product ("продукты") представляет информацию о производителях
(maker), номерах моделей (model) и типах (type) различных образцов
компьютерного оборудования — персональных компьютеров ('рс'), переносных компьютеров
('laptop') и принтеров ('printer'). Мы подразумеваем, что номера моделей про-
22 Источники информации: Web-сайты компаний, производящих компьютерное
оборудование, и http: //www. amazon. com.
218
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
дуктов различных типов, выпускаемых разными производителями, следуют одному
формату; строго говоря, такое допущение далеко от действительности, и в реальных
базах данных в номер модели обычно включается определенный код производителя.
Отношение рс ("персональные компьютеры") для каждой модели (model)
компьютера содержит значения быстродействия процессора (speed) в мегагерцах, объема
оперативной памяти (ram) в мегабайтах, емкости жесткого диска (hd) в гигабайтах,
скорости и типа привода съемных дисков (rd) — CD или DVD, а также цены
(price) в долларах США. Схема отношения Laptop ("переносные компьютеры")
почти аналогична схеме отношения PC, за исключением того, что вместо атрибута
rd в ней предусмотрен атрибут screen, предназначенный для хранения данных
о размере экрана в дюймах. Отношение Printer ("принтеры") для каждой модели
(model) принтера содержит информацию о том, является ли принтер цветным
(color) (true, если да, и false — в противном случае), о типе (type) технологии,
поддерживаемой принтером ('laser' — лазерный, 'ink-jet' — струйный,
•bubble' — пузырьковый), а также о его цене (price).
Экземпляр отношения Product показан на рис. 5.10, а экземпляры трех остальных
отношений — на рис. 5.11. Наименования производителей и номера моделей
упрощены и унифицированы, но остальные данные вполне реальны и отражают
номенклатуру рынка и уровни цен на конец 2001 года.
Напишите выражения реляционной алгебры, способные дать ответы на
перечисленные ниже запросы. Если хотите, можете применить линейную форму представления
запросов в виде наборов операторов присваивания (см. раздел 5.2.11). Для
иллюстрации результатов используйте информацию из экземпляров отношений рис. 5.10
и 5.11. (Разумеется, ваши решения должны справляться с произвольными данными,
а не только с содержимым этих или иных частных экземпляров отношений.)
* а) Какие модели персональных компьютеров обладают процессорами с
быстродействием не ниже 1000 МГц?
b) Какие производители выпускают переносные компьютеры с жесткими
дисками емкостью не ниже 1 Гбайт?
c) Найти номера моделей и цены всех продуктов (любых типов), выпускаемых
производителем ' в'.
d) Найти номера моделей всех цветных лазерных принтеров.
e) Найти тех производителей, которые выпускают только переносные, но не
персональные компьютеры.
*! f) Найти те значения емкости жесткого диска, которые характерны для двух
или более персональных компьютеров.
! g) Найти такие пары моделей персональных компьютеров, которые обладают
одинаковыми значениями быстродействия процессора и объема
оперативной памяти; каждая пара должна упоминаться только один раз — если
найдена пара (/,/), пару (/, /) следует исключить.
*!! h) Найти производителей, выпускающих по меньшей мере две различных
модели компьютеров (персональных или переносных) с быстродействием
процессора не ниже 700 МГц.
!! i) Найти производителей компьютеров (персональных или переносных) с
наивысшим быстродействием процессора.
!! j) Найти производителей, выпускающих персональные компьютеры по
меньшей мере с тремя различными уровнями быстродействия процессора.
!! к) Найти производителей, выпускающих три различные модели персональных
компьютеров.
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ 219
maker
A
A
A
A
A
A
В
В
В
В
В
В
С
С
С
С
С
С
С
D
D
D
D
Е
Е
Е
F
F
G
Н
model
1001
1002
1003
2004
2005
2006
1004
1005
1006
2001
2002
2003
1007
1008
2008
2009
3002
3003
3006
1009
1010
1011
2007
1012
1013
2010
3001
3004
3005
3007
type
рс
рс
рс
laptop
laptop
laptop
рс
рс
рс
laptop
laptop
laptop
рс
рс
laptop
laptop
printer
printer
printer
pc
pc
pc
laptop
pc
pc
laptop
printer
printer
printer
printer
Рис. 5.10. Экземпляр отношения Product
Упражнение 5.2.2. Постройте деревья частных выражений для каждого из
выражений реляционной алгебры, полученных вами при выполнении заданий
упражнения 5.2.1.
Упражнение 5.2.3. Преобразуйте каждое из выражений реляционной алгебры,
полученных при выполнении заданий упражнения 5.2.1, в набор операторов
присваивания (см. раздел 5.2.11 на с. 217), если вы не сделали этого раньше.
220
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
model
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
1011
1012
1013
speed
700
1500
866
866
1000
1300
1400
700
1200
750
1100
350
733
ram
64
128
128
64
128
256
128
64
128
64
128
64
256
hd
10
60
20
10
20
40
80
30
80
30
60
7
60
rd
4 8xCD
12xDVD
8xDVD
12xDVD
12xDVD
16xDVD
12xDVD
2 4xCD
16xDVD
40xCD
16xDVD
48xCD
12xDVD
price
799
2499
1999
999
1499
2119
2299
999
1699
699
1299
799
2499
(а) Экземпляр отношения PC
model
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
speed
700
800
850
550
600
800
850
650
750
366
ram
64
96
64
32
64
96
128
64
256
64
hd
5
10
10
5
6
20
20
10
20
10
screen
12.1
15.1
15.1
12.1
12.1
15.7
15.0
12.1
15.1
12.1
price
1448
2584
2738
999
2399
2999
3099
1249
2599
1499
(b) Экземпляр отношения Laptop
model
3001
3002
3003
3004
3005
3006
3007
color
true
true
false
true
true
true
false
type
ink-jet
ink-jet
laser
ink-jet
bubble
laser
laser
price
231
267
390
439
200
1999
350
(с) Экземпляр отношения Printer
Рис. 5.11. Экземпляры отношений к упражнению 5.2.1
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ
221
Упражнение 5.2.4. Вашему вниманию предлагается еще один пример, который мы
будем развивать по мере необходимости. Пример касается базы данных с
информацией о боевых судах, участвовавших во второй мировой войне. База данных
охватывает следующие отношения:
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
Однотипные суда сгруппированы по "классам", и имя класса совпадает с названием
первого построенного корабля этого класса. Отношение Classes ("классы судов")
содержит значения имени (name) класса, его типа (type) — bb (от "battleship" —
линейный корабль, или линкор) или be (от "battlecruiser" — крейсер), названия страны
(country), выпустившей корабли класса, количества главных орудий (numGuns), их
калибра (bore) в дюймах и водоизмещения судов (displacement) в тоннах.
Отношение Ships ("суда") предусматривает хранение информации о названии (name)
судна, имени класса (class), к которому оно относится, и годе спуска судна на воду
(launched). Отношение Battles ("морские сражения") предлагает сведения о
названиях (name) и датах (date) (в формате "месяц/день/год") проведения военных
операций с участием кораблей, описанных в отношении Ships, а отношение
Outcomes ("потери") содержит данные о том, каким результатом (result)
завершилось участие корабля (ship) в том или ином сражении (battle) — ok ("невредим"),
damaged ("поврежден") или sunk ("потоплен").
На рис. 5.12 и 5.13 показаны экземпляры четырех вышеназванных отношений.23
Заметим, что, в отличие от условия упражнения 5.2.1 (см. с. 218), приведенные
отношения содержат ряд "висящих" кортежей (например, в Ships отсутствует
информация о некоторых судах, упомянутых в Outcomes).
Напишите выражения реляционной алгебры, способные дать ответы на
перечисленные ниже запросы. Для иллюстрации результатов используйте информацию
из экземпляров отношений рис. 5.12 и 5.13. (Разумеется, ваши решения должны
справляться с произвольными данными, а не только с содержимым этих или иных
частных экземпляров отношений.)
a) Найти имена классов судов и названия стран, в которых они были
построены, для кораблей, способных нести орудия с калибром не менее 16 дюймов.
b) Найти суда, построенные до 1921 года.
c) Найти суда, потопленные в северной Атлантике ('North Atlantic').
d) Союзнический договор, подписанный в Вашингтоне в 1921 году, запрещал
строительство военных кораблей водоизмещением свыше 35000 тонн. Найти
суда, построенные в нарушение условий договора.
e) Найти названия, объемы водоизмещения и количества орудий судов,
участвовавших в сражении у острова Гуадалканал ('Guadalcanal').
f) Создать список всех судов, упомянутых в базе данных (имейте в виду, что
отношение Ships содержит сведения не обо всех судах, которые описаны
в других отношениях).
! g) Найти все классы, которые содержат по одному судну-члену класса.
23 Источники информации: 1) Westwood J.N. Fighting Ships of World War II, Follett Publishing,
Chicago, 1975; 2) Stern R.C. US Battleships in Action, Squadron/Signal Publications, Carrollton, TX,
1980. (В работе [1] содержатся сведения о нескольких кораблях ВМФ СССР времен Великой
Отечественной войны, не нашедшие отражения в оригинальной версии книги; некоторые из
них включены в русское издание. — Прим. перев.)
222
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
! h) Найти все страны, в которых строились и линкоры, и крейсеры.
! i) Найти все суда, которые, получив повреждения в одном сражении,
впоследствии участвовали в других.
class
Bismarck
Iowa
Kongo
North Carolina
Renown
Revenge
Tennessee
Yamato
Октябрьская революция
type
bb
bb
be
bb
be
bb
bb
bb
bb
country
Germany
USA
Japan
USA
Gt. Britain
Gt. Britain
USA
Japan
USSR
пит Guns
8
9
8
9
6
8
12
9
12
bore
15
16
14
16
15
15
14
18
13
displacement
42000
46000
32000
37000
32000
29000
32000
65000
25000
(а) Экземпляр отношения Classes
name
North Atlantic
Guadalcanal
North Cape
Surigao Strait
date
5/24-27/41
11/15/42
12/26/43
10/25/44
(b) Экземпляр отношения Battles
ship
Bismarck
California
Duke of York
Fuso
Hood
King George V
Kirishima
Prince of Wales
Rodney
Scharnhorst
South Dakota
Tennessee
Washington
West Virginia
Yamashiro
battle
North Atlantic
Surigao Strait
North Cape
Surigao Strait
North Atlantic
North Atlantic
Guadalcanal
North Atlantic
North Atlantic
North Cape
Guadalcanal
Surigao Strait
Guadalcanal
Surigao Strait
Surigao Strait
result
sunk
ok
ok
sunk
sunk
ok
sunk
damaged
ok
sunk
damaged
ok
ok
ok
sunk
(с) Экземпляр отношения Outcomes
Рис. 5.12. Экземпляры отношений к упражнению 5.2.4
5.2. АЛГЕБРА РЕЛЯЦИОННЫХ ОПЕРАЦИЙ 223
name
California
Haruna
Hiei
Iowa
Kirishima
Kongo
Missouri
Musashi
New Jersey
North Carolina
Ramillies
Renown
Repulse
Resolution
Revenge
Royal Oak
Royal Sovereign
Tennessee
Washington
Wisconsin
Yamato
Октябрьская революция
Парижская коммуна
Марат
class
Tennessee
Kongo
Kongo
Iowa
Kongo
Kongo
Iowa
Yamato
Iowa
North Carolina
Revenge
Renown
Renown
Revenge
Revenge
Revenge
Revenge
Tennessee
North Carolina
Iowa
Yamato
Октябрьская революция
Октябрьская революция
Октябрьская революция
launched
1921
1915
1914
1943
1915
1913
1944
1942
1943
1941
1917
1916
1916
1916
1916
1916
1916
1920
1941
1944
1941
1914
1914
1914
Рис. 5.13. Экземпляр отношения Ships
Упражнение 5.2.5. Постройте деревья частных выражений для каждого из выражений
реляционной алгебры, полученных вами при решении заданий упражнения 5.2.4.
Упражнение 5.2.6. Преобразуйте каждое из выражений реляционной алгебры,
полученных при решении заданий упражнения 5.2.4, в набор операторов
присваивания (см. раздел 5.2.11 на с. 217).
* Упражнение 5.2.7. В чем состоит различие между естественным соединением R ex S
и тета-соединением R^S, где условие С предполагает выполнение равенства
R.A = S.A для каждого атрибута А, общего для схем R и 5?
! Упражнение 5.2.8. Оператор реляционной алгебры называют монотонным (monotone),
если при добавлении кортежа в один из его операндов-отношений результат будет
по-прежнему содержать все кортежи, присутствовавшие в нем до добавления
нового кортежа, и, возможно, некоторые другие дополнительные кортежи. Какие из
операторов, рассмотренных в разделе 5.2, можно отнести к категории монотонных?
Объясните, почему тот или иной оператор является монотонным, либо предъявите
контрпример, подтверждающий, что оператор нельзя считать монотонным.
224
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
! Упражнение 5.2.9. Пусть отношения R и S содержат, соответственно, по п и т
кортежей. Дайте нижнюю и верхнюю оценки количества кортежей в отношениях,
служащих результатами выполнения следующих операций:
*а) R\JS;
b) RxS;
c) ac(R) х S, где С — некоторое условие;
d) лL (R) - 5, где L — некоторый список атрибутов.
*! Упражнение 5.2.10. Полусоединение (semijoin) отношений R и S, обозначаемое как
RxS, — это мультимножество таких кортежей / из R, что существует по меньшей
мере один кортеж из S, который совпадает с / во всех атрибутах, общих для R и S.
Напишите три различных выражения реляционной алгебры, эквивалентных RxS.
! Упражнение 5.2.11. Обратное полусоединение (antisemijoin) RxS — это
мультимножество кортежей / отношения R, которые не совпадают ни с одним из кортежей
отношения S в атрибутах, общих для R и S. Напишите выражение реляционной
алгебры, эквивалентное RxS.
!! Упражнение 5.2.12. Пусть R — это отношение со схемой (АъАъ...,Ап,ВьВ2,...,Вт),
a S — отношение со схемой (Ви Въ ..., Вт), т.е. атрибуты S образуют подмножество
множества атрибутов R. Частное (quotient) R и 5, обозначаемое как R ч- 5, — это
множество кортежей с компонентами для АЬА2, ..., А„ (т.е. для атрибутов R, не
являющихся атрибутами 5), таких, что для каждого кортежа s в S кортеж ts,
состоящий из компонентов кортежа t для AhA2,..., Ап и компонентов кортежа s для
Въ В2,..., Вт, является членом R. Используя операторы, ранее определенные в этом
разделе, напишите выражение реляционной алгебры, эквивалентное R + S.
5.3. Реляционные операции над мультимножествами
Хотя множество кортежей (т.е. отношение) — это наиболее простая и
естественная модель представления информации в базе данных, реализации коммерческих
СУБД чрезвычайно редко основываются исключительно на модели множеств
(вообще говоря, подобные примеры и подыскать-то довольно трудно). Во многих
ситуациях отношениям — в том виде, как они представлены в реальных базах
данных, — позволяется хранить повторяющиеся кортежи. Напомним, что множество
(set), допускающее наличие дубликатов элементов, принято называть
мультимножеством (bag). В этом разделе мы рассмотрим операции над отношениями, которые
являются мультимножествами кортежей, т.е. позволяют многократное включение
одного и того же кортежа. Говоря о множестве кортежей, мы будем иметь в виду
отношения, не допускающие повторения кортежей, а термин "мультимножество"
применять для обозначения отношений, которые могут содержать (хотя и не
обязательно) кортежи-дубликаты.
Пример 5.15. Экземпляр отношения, показанный на рис. 5.14, представляет собой
мультимножество кортежей: кортеж (1, 2) присутствует в нем троекратно, а кортеж
(3,4) — один раз. Если бы речь шла об отношении-множестве, нам пришлось бы
удалить два "лишних" кортежа (1, 2). В отношениях-мультимножествах повторение
одинаковых кортежей, однако, допускается, и, как в случае отношений-множеств,
порядок следования кортежей несуществен.
5.3. РЕЛЯЦИОННЫЕ ОПЕРАЦИИ НАД МУЛЬТИМНОЖЕСТВАМИ
225
A
1
3
1
1
В
2
4
2
2
Рис. 5.14. Экземпляр отношения-мультимножества
□
5.3.1. Зачем нужны мультимножества
Говоря об эффективной реализации отношений в рамках СУБД, можно привести
несколько доводов в пользу модели мультимножеств против модели множеств. В
начале раздела 5.2 на с. 205 мы уже упоминали о том, как производительность операции
объединения двух отношений повышается за счет того, что в отношениях позволяется
сохранять повторяющиеся кортежи. В качестве другого примера достаточно назвать
операцию проекции отношения на список атрибутов, допускающую наличие в
итоговом отношении кортежей-дубликатов (даже если исходное отношение является
множеством) и позволяющую рассматривать каждый полученный кортеж независимо.
Если принять условие, что итоговое отношение должно быть множеством, нам придется
сопоставить каждый кортеж отношения-проекции со всеми другими кортежами, дабы
убедиться, что ни один из них не повторяется. Если же предположить, что результат
операции проекции может быть мультимножеством, достаточно выполнить проекцию
каждого кортежа и не заботиться о сравнении его с другими кортежами.
Пример 5.16. Отношение-мультимножество рис. 5.14 можно рассматривать как
результат проекции экземпляра отношения рис. 5.15 на атрибуты А и В, допускающий
наличие повторяющихся кортежей — в частности (1, 2).
А
1
3
1
1
В
2
4
2
2
С
5
6
7
8
Рис. 5.15. Отношение-мультимножество к примеру 5.16
Применив обычный оператор проекции, предполагающий удаление из результата
кортежей-дубликатов, мы получили бы такое отношение:
А
1
3
В
CNJ
4
Заметим, что итоговое отношение-мультимножество, несмотря на больший размер,
может быть получено существенно быстрее, поскольку необходимости в сравнении
кортежей (1,2)и(3,4)с ранее полученными кортежами нет.
Помимо того, если проекция выполняется с целью последующего вычисления
какой-либо функции агрегирования (например, среднего арифметического значений
атрибута А отношения рис. 5.15), применение модели отношений-множеств вообще
недопустимо. Если рассматривать результат проекции как множество, средним арифме-
226
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
тическим окажется значение 2, поскольку в столбце А содержатся только два
различных значения — 1 и 3 — и их среднее равно 2. Если же трактовать набор значений
атрибута А кортежей отношения рис. 5.15 как мультимножество {1, 3,1,1} (что и
следует делать), мы получим верное значение среднего арифметического, равное 14. □
5.3.2. Объединение, пересечение и разность мультимножеств
При объединении двух отношений-мультимножеств количества вхождений
каждого кортежа складываются, т.е. если R — мультимножество, в котором кортеж t
присутствует п раз, a S — мультимножество с т экземплярами кортежа t, тогда в
отношение-мультимножество R\JS кортеж / будет включен п + т раз. Заметим, что
соотношение справедливо и для тех случаев, когда п, т или п и т одновременно равны нулю.
При пересечении двух отношений-мультимножеств R и S с п и т экземплярами
кортежа t соответственно в отношение Rf]S кортеж / будет включен min(n, m) раз, а при
вычислении разности тех же отношений в результат R-S кортеж t включается тах{0, п-т)
раз: если количество экземпляров кортежа t в R (т.е. п) превосходит число вхождений
кортежа t в S (т), тогда в R-S этот кортеж будет представлен п-т раз; если же в R
кортеж t присутствует не большее число раз, нежели в S, в R - S он не будет включен вовсе
(интуитивно ясно, что каждое вхождение t в S "съедает" по одному экземпляру t в R).
Пример 5.17. Пусть R — отношение-мультимножество, представленное на рис. 5.14
и содержащее три экземпляра кортежа (1, 2) и один — кортежа (3, 4). Предположим,
что S — это отношение
А
1
3
3
5
В
2
4
4
6
Тогда результат выполнения операции объединения мультимножеств, R\JS, будет
содержать четыре экземпляра кортежа (1, 2) (три из R и один из S), три экземпляра
кортежа (3, 4) (один из R и два из S) и один кортеж (5, 6) (из S).
Результат операции пересечения отношений-мультимножеств, R П S, — это отношение
А
1
3
В
2
4
содержащее по одному вхождению кортежей (1, 2) и (3, 4): отношение R включает три
экземпляра кортежа (1, 2), a S — один, так что /иш(3, 1)= 1; аналогично, кортеж (3, 4)
должен присутствовать в Rf] S шш(1, 2) = 1 раз, а кортеж (5, 6), который в S содержится
в единственном экземпляре, а в R вовсе отсутствует, — /иш(0, 1) = 0 раз.
Результатом операции вычисления разности мультимножеств, R - S, окажется
отношение
А
1
1
В
2
2
5.3. РЕЛЯЦИОННЫЕ ОПЕРАЦИИ НАД МУЛЬТИМНОЖЕСТВАМИ
227
Операции над мультимножествами в применении к множествам
Пусть даны два множества, R и S. Множество можно трактовать и как частный
случай мультимножества, в котором по стечению обстоятельств оказалось по одному
экземпляру каждого различного кортежа. Предположим, что выполняется операция
пересечения R П S, но R и S воспринимаются нами как мультимножества, и для них
действует правило пересечения мультимножеств. В итоге будет получено то же
отношение, что и в случае, когда R и S интерпретируются как обычные множества.
Иными словами, если рассматривать R n S как мультимножества, число
экземпляров кортежа / в отношении Rf]S должно равняться минимуму из количеств
вхождений этого кортежа в R и S. Но поскольку R и S на самом деле являются
множествами, кортеж t может присутствовать в них только один или нуль раз. Совершенно
не важно, каким правилом пересечения мы пользуемся — мультимножеств или
множеств, — кортеж t будет включен в R П S не более одного раза (даже если он
содержится одновременно в R и S). Аналогично, при использовании правила
вычисления разности мультимножеств результаты операций R-S или S-R окажутся
такими же, как если бы применялось правило вычисления разности множеств.
Правило объединения, однако, действует по-разному, в зависимости от того,
что в конкретном случае подразумевается под R и S — мультимножества или
множества. Если при вычислении R(JS, где R и S являются множествами, следовать
правилу объединения мультимножеств, результат не обязательно окажется
множеством. В частности, если t присутствует и в R, и в S, тогда, применяя правило
объединения мультимножеств, в R U S его придется включить дважды. Если в той же
ситуации используется правило объединения множеств, кортеж t заносится в
отношение R U S в единственном экземпляре. Поэтому, обращаясь к операции объединения,
мы обязаны тщательно оговаривать, какое из правил следует использовать.
Чтобы понять, почему, заметьте, что в R содержатся три экземпляра кортежа (1, 2),
а в S — один, так что в R-S должны быть включены тах(0, 3-1) = 2 таких кортежа.
Кортеж (3, 4) присутствует в R один раз, а в S — дважды, поэтому в R-S он должен
быть представлен числом экземпляров, равным тах(Оу 1 - 2) = 0. Других кортежей
в R нет, поэтому их не будет и в R - S.
В качестве еще одного примера рассмотрим разность мультимножеств S-R:
А
3
5
В
4
6
Кортежи (3, 4) и (5, 6) включены в результат по одному разу, поскольку тах(0у 2 - 1) = 1
и тах(0, 1 - 0) = 1 соответственно. В данном случае итоговое мультимножество является
множеством. □
5.3.3. Проекция мультимножеств
Мы уже иллюстрировали операцию проекции мультимножеств — как было сказано
в примере 5.16, при выполнении подобной проекции каждый кортеж обрабатывается
независимо от других. Если обозначить как R отношение-мультимножество на
рис. 5.15, а затем выполнить операцию 7rAtB(R), в результате будет получено
отношение, показанное на рис. 5.14.
228
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
Алгебраические законы для мультимножеств
Алгебраический закон — это тождество двух выражений (реляционной) алгебры;
аргументами таких выражений служат переменные, обозначающие отношения.
Результатом вычисления выражений всегда служит одно и то же отношение, и
тождество выполняется независимо от того, какие именно частные экземпляры
отношений подставлены вместо переменных. Широко известен, например,
коммутативный закон объединения множеств: R(JS = S\JR. Закон сохраняет силу, когда
переменные R и S обозначают и множества, и мультимножества. Однако существует
целый ряд других законов, которые выполняются для отношений-множеств, но
перестают быть справедливыми для мультимножеств. Одним из простых примеров
является дистрибутивный закон разности в применении к объединению множеств:
(R U S) - Т= (R - Г) U (S - 7). Закон выполняется для множеств, но не для
мультимножеств. Чтобы понять, почему так происходит, предположим, что отношения-
мультимножества R, S и Т имеют по одной копии кортежа /. Тогда выражение
левой части будет содержать один экземпляр t, а выражение правой части — ни
одного. Если трактовать R, S и Т как множества, в отношениях, соответствующих
левой и правой частям выражения, кортежи t не будут присутствовать вовсе. За
информацией о некоторых других алгебраических законах для отношений-
мультимножеств обращайтесь к упражнениям 5.3.4 (см. с. 232) и 5.3.5.
Если в процессе выполнения проекции (устранения нескольких атрибутов)
некоторые кортежи становятся одинаковыми, такие кортежи не удаляются из итогового
отношения-мультимножества. Так, например, в результате выполнения проекции
отношения R рис. 5.15 на подмножество атрибутов {Л, В) кортежи (1,2,5), (1,2,7)
и (1, 2, 8) превратятся в три экземпляра одного и того же кортежа (1, 2). Если
действовать в соответствии с правилом проекции мультимножеств, все эти экземпляры
следует включить в итоговое отношение; если же использовать правило проекции
множеств, кортежи-дубликаты надлежит удалить.
5.3.4. Выбор из мультимножеств
При выполнении выбора кортежей отношения-мультимножества условие выбора
применяется к каждому кортежу независимо, и, как обычно бывает при
использовании мультимножеств, повторяющиеся кортежи из отношения-результата не удаляются.
Пример 5.18. Если R представляет собой отношение
А
1
3
1
1
В
2
4
2
2
С
5
6
7
7
тогда результатом операции выбора <хс>6(Я) послужит отношение
А
3
1
1
В
4
2
2
С
6
7
7
5.3. РЕЛЯЦИОННЫЕ ОПЕРАЦИИ НАД МУЛЬТИМНОЖЕСТВАМИ
229
Как нетрудно убедиться, условию С>6 удовлетворяют все кортежи отношения R,
кроме первого. Два последних (одинаковых) кортежа R включаются в результат
независимо друг от друга. □
5.3.5. Декартово произведение мультимножеств
Правило выполнения операции декартового произведения
отношений-мультимножеств вполне предсказуемо: каждый кортеж одного отношения образует пару
с каждым кортежем другого — независимо от того, повторяются кортежи или нет.
Если кортеж г присутствует в R т раз, а кортеж s в S — п раз, тогда кортеж rs должен
быть включен в итоговое отношение RxS т*п раз.
Пример 5.19. Пусть R и S представляют собой отношения-мультимножества,
изображенные на рис. 5.16 (а) и (Ь). Тогда декартово произведение RxS будет состоять из
шести кортежей, как показано на рис. 5.16 (с). Обратите внимание, что принятое
нами соглашение об именовании атрибутов отношений-множеств столь же успешно
применимо и к мультимножествам: имена атрибутов В, содержащихся в схемах R и 5,
в итоговом отношении RxS помечены префиксами "/?." и "5.".
А
1
1
В
2
2
(а) Отношение R
В
2
4
4
С
3
5
5
(Ь) Отношение S
А
1
1
1
1
1
1
R.B
2
2
2
2
2
2
S.B
2
2
4
4
4
4
С
3
3
5
5
5
5
(с) Отношение RxS
Рис. 5.16. Вычисление декартова произведения
отношений -мультимножеств
□
5.3.6. Операции соединения мультимножеств
Соединение мультимножеств также не таит каких-либо сюрпризов. Каждый
кортеж одного отношения сопоставляется с каждым кортежем другого отношения, и если
кортежи способны образовать пару, такая пара создается и включается в итоговое
отношение. Повторяющиеся кортежи из отношения-результата не удаляются.
230
ГЛАВА 5, РЕЛЯЦИОННАЯ АЛГЕБРА
Пример 5.20. Результат выполнения операции естественного соединения RxS
отношений R и S, показанных на рис. 5.16 (а) и (Ь), выглядит так:
А
1
1
В
2
2
С
3
3
Кортеж (1, 2) отношения R успешно сочетается с кортежем (2,3) отношения S.
Поскольку в R имеются две копии кортежа (1, 2), а в S — один экземпляр кортежа (2,3),
существуют две пары кортежей (1, 2) и (2,3), которые в результате соединения
сформируют два одинаковых кортежа (1, 2, 3). Никакие другие кортежи R и S не в
состоянии образовать допустимые пары.
Еще один пример с использованием тех же отношений R и S — это операция тета-
соединения
R х 5,
R.B<S.B
которая дает в результате отношение-мультимножество
А
1
1
1
1
R.B
2
2
2
2
S.B
4
4
4
4
С
5
5
5
5
Процесс вычислений протекает следующим образом. Кортеж (1, 2) отношения R и кортеж
(4, 5) отношения S удовлетворяют условию соединения. Поскольку каждый из них
присутствует в исходном отношении в двух копиях, количество соединенных
кортежей в итоговом отношении равно 2*2 = 4. Кортежи другой пары, (1, 2) в R и (2, 3) в 5,
не удовлетворяют условию соединения и поэтому в результат не включаются. □
5.3.7. Упражнения к разделу 5.3
* Упражнение 5.3.1. Рассмотрим отношение рс рис. 5.11 (а) на с. 221 и
предположим, что необходимо вычислить результат проекции тг^^СРС). Как будет выглядеть
итоговое отношение-множество? А мультимножество? Каковы средние значения
быстродействия процессоров, вычисленные на основании содержимого
компонентов speed таблицы 7rspeed(iPC), если трактовать ее как множество и мультимножество?
Упражнение 5.3.2. Выполните задания упражнения 5.3.1 применительно к
результатам операции проекции 7rhd(iPC).
Упражнение 5.3.3. Обратимся к отношениям базы данных о боевых судах
(см. упражнение 5.2.4 на с. 222).
а) В результате вычисления выражения ттЬоге (classes) будет получено
отношение с единственным атрибутом bore, представляющим значения калибра
главных орудий судов различных классов. Как может выглядеть такое
отношение в виде множества и мультимножества?
! Ь) Напишите выражение реляционной алгебры, позволяющее получить
мультимножество значений калибров орудий отдельных судов (не классов);
иными словами, если п судов обладает орудиями калибра Ь, результат должен
содержать п кортежей, содержащих значение Ь.
5.3. РЕЛЯЦИОННЫЕ ОПЕРАЦИИ НАД МУЛЬТИМНОЖЕСТВАМИ
231
! Упражнение 5.3.4. Некоторые алгебраические законы, перечисленные ниже и
справедливые для отношений-множеств, также остаются в силе для отношений-
мультимножеств. Объясните, почему так происходит.
* а) Ассоциативный закон объединения: (R(JS)\JT=R\J(S\JT).
b) Ассоциативный закон пересечения: (R П S) П Т = R П (S Г) 7).
c) Ассоциативный закон естественного соединения:
(R сх S) сх T= R сх (S сх 7).
d) Коммутативный закон объединения: (R U S) = (S U R)-
e) Коммутативный закон пересечения: (R П S) = (S Г) R)-
О Коммутативный закон естественного соединения:
(R сх 5) = (S сх Я).
g) /rL (/? U 5) = ^ (/?) U nl (S), где L — произвольный список атрибутов.
* h) Дистрибутивный закон объединения применительно к пересечению:
R\J(SnT) = (R\JS)f](Rl)T).
О ^candd (R) = <тс(/?)Г) crD(R), где С и D— произвольные условия относительно
содержимого компонентов кортежей отношения R.
!! Упражнение 5.3.5. Следующие алгебраические законы выполняются для
отношений-множеств, но утрачивают силу для отношений-мультимножеств. Объясните,
почему они справедливы для множеств, и приведите контрпримеры,
доказывающие невозможность их использования для мультимножеств.
*а) (Rf]S)-T=Rf](S-T).
b) Дистрибутивный закон пересечения в применении к объединению:
R П (S U Т) = (R П S) U (R П 7).
c) &cord(R) = crc(R) U crD(R), где С и D— произвольные условия относительно
содержимого компонентов кортежей отношения R.
5.4. Дополнительные операторы реляционной алгебры
В разделе 5.2 на с. 205 рассмотрен классический аппарат реляционной алгебры,
а в разделе 5.3 на с. 225 мы познакомили вас с альтернативными вариантами
алгебраических операторов и законов, которые предусматривают возможность интерпретации
отношений-операндов в виде мультимножеств. Материал этих разделов можно
воспринимать как фундамент, на котором зиждется большинство современных языков
запросов. Однако конкретные языки, подобные SQL, предлагают целый ряд дополнительных
инструментальных средств, которые доказали свою состоятельность при использовании
в реальных приложениях. Хотелось бы представить вашему вниманию настолько полный
обзор реляционных операций, насколько это возможно, и поэтому нам никак не
обойтись без рассмотрения других операторов, что мы и намереваемся сделать в этом разделе.
1. Оператор удаления кортежей-дубликатов (duplicate-elimination operator) £
преобразует отношение-мультимножество в множество путем отбрасывания всех
копий каждого кортежа, за исключением одной.
232
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
2. Операторы агрегирования (aggregation operators), предназначенные, например,
для нахождения суммарных, средних, максимальных и минимальных значений
в определенном столбце таблицы-отношения, строго говоря, не относятся
к компетенции реляционной алгебры как таковой, но используются в контексте
оператора группирования, который описан ниже.
3. В процессе группирования (grouping) множество кортежей-строк отношения
разбивается на "группы" в соответствии с содержимым одного или нескольких
компонентов. Затем к атрибутам-столбцам внутри каждой группы, как правило,
применяется определенный оператор агрегирования. Это дает возможность
формировать самые разные запросы, которые нельзя выразить в рамках
традиционной реляционной алгебры. Оператор группирования (grouping operator)
^сочетает в себе возможности группирования и агрегирования.
4. Оператор сортировки (sorting operator) г преобразует отношение в список кортежей,
упорядоченных в соответствии с некоторым критерием, учитывающим содержимое
одного или нескольких их компонентов. Оператор т следует применять
осмотрительно, поскольку все другие операторы реляционной алгебры способны
обращаться только с множествами или мультимножествами (но не со списками) кортежей.
Поэтому оператор т может использоваться только на заключительной стадии
формирования выражения, состоящего из нескольких "вложенных" операторов.
5. Оператор проекции (projection operator) n может быть наделен расширенными
полномочиями. Помимо обычной проекции отношения на список атрибутов,
оператор п в его общей форме способен выполнять дополнительные функции
над атрибутами-столбцами отношения с целью получения новых атрибутов.
6. Оператор внешнего соединения (outerjoin operator) — это вариант оператора
соединения, позволяющий избежать потери висящих (dangling) кортежей.
Висящие кортежи включаются в итоговое отношение, и соответствующие
компоненты их заполняются значениями null.
5.4.1. Удаление дубликатов
Иногда возникает потребность в преобразовании отношения-мультимножества
в множество. Для выполнения подобной функции используется оператор S(R),
возвращающий множество кортежей отношения R, в котором каждый различный кортеж
представлен не более чем одной копией.
Пример 5.21. Пусть R — это отношение
А
1
3
1
1
В
2
4
2
2
заимствованное из рис. 5.14 на с. 226. Тогда S(R) будет выглядеть как
А
1
3
В
сч
4
Обратите внимание, что кортеж (1, 2), который присутствовал в R в трех экземплярах,
в S(R) включен только один раз. □
5.4. ДОПОЛНИТЕЛЬНЫЕ ОПЕРАТОРЫ РЕЛЯЦИОННОЙ АЛГЕБРЫ
233
5.4.2. Операторы агрегирования
Существует ряд операторов, применяемых к множествам или мультимножествам
атомарных значений одноименных компонентов кортежей с целью получения
некоторых "агрегированных", т.е. общих, значений. Поэтому подобные операторы носят
название операторов агрегирования (aggregation operators). К числу широко
употребительных операторов агрегирования принадлежат следующие:
1) SUM — возвращает сумму значений в определенном столбце числового типа;
2) AVG — вычисляет среднее арифметическое значений в определенном столбце
числового типа;
3) min и мах — вычисляют, соответственно, минимальное и максимальное
значения в определенном столбце числового типа; если операторы
применяются к столбцам строкового типа, они возвращают, соответственно,
первое и последнее значения из списка строк, отсортированного в
лексикографическом (алфавитном) порядке;
4) COUNT — возвращает количество значений (не обязательно различных) в
определенном столбце или, что то же самое, число кортежей в отношении,
включая дубликаты.
Пример 5.22. Рассмотрим отношение
А
1
3
1
1
В
2
4
2
2
Вот результаты применения к столбцам-атрибутам этого отношения некоторых
операторов агрегирования:
1) SUM(£) = 2 + 4 + 2 + 2 = 10;
2) AVG(A) = (l+3+l + l)/4=1.5;
3) MIN(A) = 1;
4) МАХ(Я)=4;
5) C0UNT(A) = 4.
□
5.4.3. Группирование
Зачастую возникает необходимость применения операторов агрегирования не ко
всему столбцу отношения, а к некоторой его части. В этом случае следует
рассматривать кортежи отношения в виде групп, сформированных по определенному критерию,
учитывающему содержимое одного или нескольких компонентов кортежей, а затем
применять функции агрегирования внутри каждой отдельной группы. В качестве
примера предположим, что необходимо подсчитать общую продолжительность
воспроизведения кинофильмов, выпущенных каждой студией, т.е. получить отношение вида
studio
Disney
MGM
sum Of Lengths
12345
54321
234
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
Рассмотрим отношение
Movie(title, year, length, inColor, studioName, producerC#)
из "кинематографической" базы данных в редакции, предложенной в разделе 5.1 на
с. 204. Необходимо сгруппировать кортежи отношения в соответствии с содержимым
компонентов studioName. Затем следует просуммировать значения атрибута length
для кортежей внутри каждой группы. Иными словами, можно представить, что
кортежи отношения Movie сгруппированы так, как показано на рис. 5.17, и оператор
SUM (length) применяется к каждой группе значений независимо.
studioName
Disney
Disney
Disney
MGM
MGM
О
О
О
Рис. 5.17. Отношение с воображаемыми группами
кортежей
5.4.4. Оператор группирования
Рассмотрим оператор, позволяющий группировать кортежи отношения и
применять к атрибутам кортежей групп функции агрегирования.
Нижний индекс оператора ^задает список L элементов, каждый из которых может
относиться к любой из следующих категорий:
a) атрибуты отношения R, к которым применяется у\ каждый подобный
атрибут участвует в определении критерия группирования R; в этом случае
элемент называют группирующим атрибутом (grouping attribute);
b) операторы агрегирования, применяемые к атрибутам отношения; имя
результата агрегирования задается после стрелки, следующей за оператором
агрегирования; атрибут, выступающий в роли операнда функции
агрегирования, называют агрегируемым атрибутом (aggregated attribute).
Отношение, возвращаемое оператором /l(R), строится в соответствии со
следующим алгоритмом.
1. Разбить множество кортежей отношения R на группы. Каждая группа включает
все кортежи, содержащие определенные значения группирующих атрибутов из
списка L. Если группирующие атрибуты не заданы, отношение R целиком
рассматривается как единая группа,
2. Для каждой группы создать по одному кортежу, состоящему из:
a) значений группирующих атрибутов, соответствующих группе;
b) результатов агрегирования, вычисленных по агрегируемым атрибутам всех
кортежей группы, заданным в списке L.
Пример 5.23. Пусть дано отношение
Starsln(title, year, starName),
5.4. ДОПОЛНИТЕЛЬНЫЕ ОПЕРАТОРЫ РЕЛЯЦИОННОЙ АЛГЕБРЫ
235
Оператор 5 — частный случай оператора у
Строго говоря, оператор £ избыточен. Для отношения R(AUA2, ...,Ап) выражение
S(R) эквивалентно выражению уА >А ..д (R). Иными словами, чтобы удалить из
отношения R кортежи-дубликаты, достаточно выполнить функцию группирования по
всем атрибутам отношения, не используя агрегирующие операторы. Тогда каждая
группа будет соответствовать кортежу, который присутствует в R в одном или
нескольких экземплярах. Поскольку итоговое отношение Уа ,а2,...,ап(К) содержит
в точности по одному кортежу в каждой группе, эффект группирования
равнозначен удалению кортежей-дубликатов. Впрочем, оператор S настолько широко
употребителен и важен, что при обсуждении алгебраических законов и алгоритмов
обработки запросов мы будем свободно на него ссылаться.
С другой стороны, оператор у можно рассматривать как расширенную версию
оператора проекции в применении к множествам. Иными словами, если R является
отношением-множеством, выражения Уага2,...,ап(К) и Яа{,а2,...,апW эквивалентны.
Если же R представляет собой мультимножество, использование оператора у приведет
к удалению повторяющихся кортежей, а оператора тс— нет. По этой причине результат
применения оператора /часто называют обобщенной проекцией (generalized projection).
представляющее сведения об актерах, и для каждого актера, принявшего участие
в съемках не менее трех кинофильмов, необходимо определить год выпуска самого
раннего кинофильма, в котором тот снимался. Первый шаг состоит в построении
групп кортежей с использованием атрибута starName ("имя") в качестве
группирующего. Очевидно, что затем для каждой группы следует вычислить значение оператора
агрегирования MlN(year). Помимо того, чтобы определить, какие группы
удовлетворяют условию, касающемуся участия актера в съемках не менее трех кинофильмов,
для каждой группы надлежит вычислить значение оператора count (title).
Начнем с построения выражения группирования:
У starName, MIN (year) —» minYear, COUNT (title) —> ctTitle \b\L3.TS 1TL).
Два первых столбца результата (starName и minYear) должны быть включены в
итоговое отношение. Третий столбец, отвечающий дополнительному атрибуту ctTitle,
необходим только для определения того, в каком числе фильмов снялся тот или иной
актер. К полученному отношению следует применить оператор выбора crctTi,ie>3, а
затем оператор проекции 7rstarName^minYear- Дерево выражений, представляющее
рассмотренный запрос, показано на рис. 5.18. □
5.4.5. Оператор расширенной проекции
Вновь обратимся к оператору проекции 7TL(R), сведения о котором приводились
в разделе 5.2.3 на с. 208. В контексте классической реляционной алгебры L
представляет список (некоторых) атрибутов отношения R. Рассмотрим более развитую версию
оператора, предусматривающую наряду с выбором атрибутов возможность
выполнения манипуляций с содержимым компонентов кортежей. В операторе расширенной
проекции (extended projection), также обозначаемом посредством 7TL(R), список L может
содержать элементы следующих типов:
1) отдельный атрибут отношения R;
2) выражение вида х —> у, где х и у — наименования атрибутов; элемент х —> у
списка L предусматривает переименование атрибута х отношения R в у, т.е.
именем атрибута в схеме итогового отношения должно стать у\
236
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
starName, minYear
ctTitle > 3
У starName, МЩуеаг) -^ minYear, COUNT( title) -^ ctTitle
Starsln
Рис. 5.18. Дерево выражений,
SQL-запрос из примера 5.23
представляющее
3) выражение вида £-»z, где Е— выражение, включающее наименования
атрибутов отношения R, константы и арифметические и строковые операторы,
a z — новое имя атрибута, получаемого в результате вычисления выражения
Е\ например, выражение а + Ь —> х, выступающее в роли элемента списка L,
представляет атрибут с именем х, содержащий сумму значений атрибутов а
и Ь, а элемент с \ \ d —> е — атрибут, названный как е, который содержит
результат сцепления (конкатенации) строковых значений атрибутов end.
В процессе вычисления оператора расширенной проекции каждый кортеж
отношения R рассматривается отдельно. Элементы списка L замещаются
соответствующими значениями компонентов кортежа и к последним применяются предусмотренные
списком арифметические и/или строковые операторы. Результатом служит отношение
с атрибутами, упомянутыми в списке L (с учетом вариантов их переименования).
Каждому кортежу R отвечает кортеж итогового отношения. Если R содержит
повторяющиеся кортежи, соответствующие кортежи-дубликаты определенно появятся и в
отношении-результате; впрочем, отношение, возвращаемое оператором расширенной
проекции, может содержать повторяющиеся кортежи даже тогда, когда в исходном
отношении R таковые отсутствуют.
Пример 5.24. Пусть R — это отношение
А
0
0
3
в
1
1
4
С
2
2
5
Тогда результатом операции лЛчВ + С-*х(К) окажется отношение
А IX
О JT
О |3
3 ГТ
Схема итогового отношения включает два атрибута, А (первый атрибут отношения R,
который не был переименован) и X, содержащий сумму компонентов кортежа,
соответствующих атрибутам В и С отношения R.
5.4. ДОПОЛНИТЕЛЬНЫЕ ОПЕРАТОРЫ РЕЛЯЦИОННОЙ АЛГЕБРЫ
237
В качестве другого примера рассмотрим операцию 7Tb_a_+x,c-b-+y(R)i которая
приводит к получению отношения
X [y
1 I 1
"l I 1
Обратите внимание, как в процессе вычислений, предусмотренных списком оператора
расширенной проекции, различные кортежи, (0, 1, 2) и (3, 4, 5), преобразуются в
одинаковые, (1, 1), которые в итоговом отношении повторяются трижды. □
5.4.6. Оператор сортировки
Встречаются ситуации, когда кортежи отношения подлежат сортировке по значениям
одного или нескольких атрибутов. Часто желательно представить результат обработки
запроса в виде упорядоченного набора данных: так, например, итоговое отношение со
сведениями о том, в каких кинофильмах сыграл Шен Коннери, удобно отсортировать
по названиям, чтобы облегчить поиск того или иного фильма. В разделе 15.4 на с. 706
будет рассказано о том, как повысить эффективность выполнения запроса системой
баз данных, если предварительно упорядочить отношения тем или иным образом.
Результатом вычисления выражения tl(R), где R — некоторое отношение, a L —
список определенных атрибутов R, является то же отношение /?, но его кортежи
переставлены в таком порядке, который задан посредством списка L. Если L представляет
собой список А ЬЛ2, —,Л» кортежи вначале упорядочиваются по значениям
компонентов Ах. Затем кортежи, обладающие одинаковыми значениями Ль упорядочиваются
с учетом содержимого компонентов Л2. Если существуют кортежи, совпадающие в
атрибутах А{ и Л2, они сортируются по значениям А3> и т.д. После того как кортежи,
совпадающие в атрибутах ЛЬЛ2,..., Ап_и упорядочены по содержимому Ап, значения
остальных атрибутов во внимание не принимаются, и порядок их следования в
кортежах может быть произвольным.
Пример 5.25. Если R представляет собой отношение со схемой R(A, В, Q, тогда
оператор ?"с в (Ю выполнит сортировку кортежей R по содержимому компонентов С, а затем
кортежи, обладающие одинаковыми значениями атрибута С, будут упорядочены в
соответствии с содержимым компонентов В. Кортежи, совпадающие в атрибутах С и В,
располагаются в произвольном порядке. □
Оператор т принципиально отличается от всех других операторов реляционной
алгебры тем, что результатом его выполнения является не множество, а список
кортежей. Если говорить о порядке следования операторов в выражении реляционной
алгебры, оператор т имеет смысл использовать только как самый "внешний". Если
после т применяется другой оператор, отношение, служащее результатом вычисления
г, интерпретируется как множество или мультимножество кортежей и какой бы то ни
было порядок их следования во внимание не принимается.24
5.4.7. Внешние соединения
Оператору соединения присуща способность оставлять некоторые кортежи
отношения "висящими" (dangling), если они не совпадают в атрибутах, общих для двух
отношений, ни с одним кортежем другого отношения. Информация висящих кортежей ни-
24 Впрочем, как будет показано в главе 15, сортировка промежуточных результатов в
некоторых случаях способна привести к повышению скорости обработки запросов.
238
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
как не отражается в отношении, служащем результатом операции соединения, и
поэтому оно воспроизводит данные исходных отношений с недостаточной степенью полноты.
В тех случаях, когда подобный исход нежелателен, применяется специальная
разновидность оператора соединения, называемая внешним соединением (outerjoin), которая
приобрела широкое признание и поддерживается в большинстве коммерческих СУБД.
Вначале обратимся к операции естественного соединения (natural join), позволяющей
связать кортежи отношений, обладающих некоторыми общими атрибутами, на
основании равенства значений этих атрибутов. Результат операции внешнего соединения RxS
формируется из отношения RxS с последующим включением всех висящих кортежей
отношений R и S. В итоговом отношении компонентам висящих кортежей R для
атрибутов, отсутствующих в R, и компонентам висящих кортежей S для атрибутов,
отсутствующих в S, присваиваются специальные значения null, обозначаемые символом I.25
Пример 5.26. Обратимся к экземплярам отношений U и V, показанным на рис. 5.19.
Кортеж (1, 2, 3) отношения U успешно соединяется с кортежами (2, 3, 10) и (2, 3, 11)
отношения V, так что эти три кортежа висящими не являются. Однако все другие
кортежи — (4, 5, 6) и (7, 8, 9) из отношения U и (6, 7, 12) из отношения V — относятся к
категории висящих, поскольку ни для одного из них не существует какого бы то ни
было кортежа другого отношения, с которым кортеж совпал бы в атрибутах В и С,
общих для U и V. В U х V висящие кортежи снабжаются значениями 1 для тех
атрибутов, которых они не имеют, — для атрибута D в кортежах U и атрибута А в кортеже V. □
Существует ряд вариантов операции естественного внешнего соединения.
Оператор левого внешнего соединения (left outerjoin), RxLS, аналогичен Rx S, но
предусматривает пополнение символами 1 и включение в итоговое отношение только тех
висящих кортежей, которые принадлежат отношению R — левостороннему аргументу
оператора. Оператор правого внешнего соединения (right outerjoin), R xR 5, напротив,
подразумевает возможность включения в отношение соединения только висящих
кортежей отношения S — правостороннего операнда.
Пример 5.27. Если U и V представляют собой экземпляры отношений, показанные на
рис. 5.19, тогда в результате выполнения операции UxL V будет получено отношение
А
1
1
4
7
В
2
2
5
8
С
3
3
6
9
D
10
11
1
1
а итогом операции U xR V окажется отношение
А
1
1
1
В
2
2
6
С
3
3
7
D
10
11
12
□
25 В языке SQL для представления значений null используется служебное слово NULL. Если
хотите, можете применять его вместо символа 1.
5.4. ДОПОЛНИТЕЛЬНЫЕ ОПЕРАТОРЫ РЕЛЯЦИОННОЙ АЛГЕБРЫ
239
A
1
4
7
В
2
5
8
С
3
6
9
Отношение (/
5
2
2
6
С
3
3
7
D
10
11
12
А
1
1
4
7
1
5
2
2
5
8
6
С
3
3
6
9
7
D
10
11
1
1
12
Отношение UtxV
Рис. 5.19. Внешнее соединение отношений
Для каждого из трех операторов естественного внешнего соединения существует
аналогичный вариант оператора тета-соединения. Так, например, в результате
выполнения операции внешнего тета-соединения (theta-outerjoin) вида R cA S будет получено
отношение, содержащее кортежи обычного тета-соединения R ex S в совокупности
с теми кортежами отношений R и S, которые не удовлетворяют условию С
(отсутствующим атрибутам висящих кортежей присваивается значение 1).Оператор ml
служит для обозначения левого внешнего тета-соединения (left theta-outerjoin), а
оператор схд — правого внешнего тета-соединения (right theta-outerjoin).
Пример 5.28. Рассмотрим экземпляры отношений U и V на рис. 5.19 и операцию
U & V.
А> V.C
Каждый из кортежей (4, 5, 6) и (4, 5, 6) отношения U удовлетворяет условию А > V.C
применительно к кортежам (2, 3, 10) и (2, 3, 11) отношения V. Поэтому ни один из
четырех упомянутых кортежей не является висящим. Однако все другие кортежи —
(1, 2, 3) из отношения U и (б, 7, 12) из отношения V — относятся к категории
висящих, поскольку ни для одного из них не существует какого бы то ни было кортежа
другого отношения, такого, что условие соединения выполняется. В итоговом
отношении, показанном на рис. 5.20, висящие кортежи снабжаются значениями 1 для тех
атрибутов, которых они не имеют.
240
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
A
4
4
7
7
1
1
U.B
5
5
8
8
2
1
£/.C
6
6
9
9
3
1
V.B
2
2
2
2
1
6
КС
3
3
3
3
1
7
D
10
11
10
11
1
12
Pwc. 5.20. Результат операции внешнего тета-соединения
5.4.8. Упражнения к разделу 5.4
Упражнение 5.4.1. Даны два отношения, представленные в виде следующих
множеств кортежей:
Л(А, В): {(0, 1), (2, 3), (0, 1), (2, 4), (3, 4)},
S(B, Q: «0, 1), (2, 4), (2, 5), (3, 4), (0, 2), (3, 4)}.
Вычислите выражения: *а) кА + ВчА2%Bi(R)\ b) ягя+1,с_!(/?); *с) г5м(Я); d) гя,с(5);
*е) <?(*); 0 *(«; *g) Гд,зим(*)(Я); h) ^,AVG(C)(5); !i) МЛ); U) Гл.мах<с)(Л х S);
*k) R^LS\ 1) /?йл5; ш)/?м5; n) # >< 5.
/?.В < S.B
! Упражнение 5.4.2. Унарный оператор / называют идемпотентным (idempotent),
если для любого отношения R справедливо условие /(/"(/?)) =/(/?)• Иными
словами, применяя оператор несколько раз, вы получите тот же результат, как если
бы оператор использовался однократно. Какие из следующих операторов
являются идемпотентными? Объясните, почему, или приведите контрпримеры,
подтверждающие отрицательный ответ.
*а) S; *Ь) ttl; с) <тс; d) yL\ e) г.
*! Упражнение 5.4.3. Одна из возможностей, отличающих оператор расширенной
проекции от исходной версии оператора проекции (см. раздел 5.2.3 на с. 208),
заключается в том, что первый позволяет дублировать столбцы итогового отношения.
Например, применяя оператор 7rAA(R) к отношению /?(А, В), мы получим кортеж
(а, а) для каждого кортежа (а, Ь) отношения R. Можно ли добиться подобного
результата, используя только классические операторы реляционной алгебры,
рассмотренные в разделе 5.2 на с. 205? Поясните собственное решение.
5.5. Отношения и ограничения
Реляционная алгебра содержит средства, позволяющие описывать ограничения
(constraints) общего вида, подобные ограничениям ссылочной целостности,
рассмотренным в разделе 2.3 на с. 74. На самом деле реляционная алгебра, как будет
показано ниже, предлагает инструменты, удобные для выражения ограничений и многих
других типов — например, функциональных зависимостей (обратитесь к примеру 5.31
на с. 243). Ограничениям отводится весьма важная роль в программировании баз
данных, и в главе 7 на с. 317 мы покажем, каким образом в SQL-совместимых СУБД
поддерживается аппарат задания различных ограничений, которые могут быть
определены средствами реляционной алгебры.
5.5. ОТНОШЕНИЯ И ОГРАНИЧЕНИЯ
241
5.5.1. Реляционная алгебра как язык описания ограничений
Существуют две формы представления ограничений с помощью выражений
реляционной алгебры.
1. Если R — выражение реляционной алгебры, то R = 0 — ограничение следующего
вида: "Отношение R не должно содержать кортежей (обязано быть пустым)".
2. Если R и S — выражения реляционной алгебры, то RqS — ограничение
следующего вида: "Каждый кортеж отношения R должен также присутствовать в
отношении 5". Отношение S, разумеется, может содержать кортежи, которых нет в R.
Указанные формы выражения ограничений по существу равнозначны, хотя подчас
удобнее и проще использовать одну, а не другую. Ограничение R с S может быть записано
как R-S = 0. Нетрудно убедиться, что если каждый кортеж R обязан присутствовать
в S, множество, получаемое в результате выполнения операции R-S, определенно должно
оказаться пустым. И наоборот, если отношение R - S не содержит кортежей, каждый
кортеж R должен быть членом S (иначе он принадлежал бы отношению R-S). С другой
стороны, первую форму ограничений, R = 0, легко преобразовать во вторую, R с 0. Строго
говоря, 0 не является выражением реляционной алгебры, но поскольку существуют вполне
"законные" выражения (скажем, R-R), которые в результате вычисления обращаются
в 0, нет ничего предосудительного в том, что 0 интерпретируется в виде обычного
выражения реляционной алгебры. Заметим, что указанные примеры тождественности
различных форм ограничений остаются в силе и в том случае, если R и S являются
мультимножествами (в предположении, что соотношение R с S трактуется так: каждый
кортеж t представлен в S, по меньшей мере, таким же числом экземпляров, что и в R).
В следующих разделах мы продемонстрируем, как представлять различные
ограничения в любой из двух названных форм. Как будет показано в главе 7 на с. 317, первая из
форм, представляющая равенство значения пустому множеству, в программировании
на языке SQL используется наиболее часто. Однако мы вправе пользоваться обеими
формами одинаково свободно и при необходимости переходить от одной к другой.
5.5.2. Ограничения ссылочной целостности
Ограничения одной широко употребительной разновидности, называемые
ограничениями ссылочной целостности (referential integrity constraints) (мы упоминали их
в разделе 2.3 на с. 74), подразумевают, что если значение присутствует в одном
контексте, оно обязано присутствовать и в другом, связанном, контексте. Как уже
говорилось, ограничения ссылочной целостности помогают "придать смысл" связям между
множествами сущностей, объектами или отношениями. Так, если объект А связан с
объектом #, последний обязан существовать. Например, пользуясь терминами ODL, можно
утверждать: если связь в объекте Л физически реализована в виде указателя,
соответствующее ограничение ссылочной целостности подразумевает, что значение указателя
не может быть равно null, т.е. указатель обязан адресовать вполне осязаемый объект.
В реляционной модели ограничения ссылочной целостности выглядят несколько
иначе: если v является значением определенного атрибута некоторого кортежа
отношения /?, то, руководствуясь выбранным проектным решением, мы вправе ожидать,
что и должно быть значением определенного атрибута некоторого кортежа отношения
S. В качестве примера покажем, как ограничение ссылочной целостности может быть
выражено средствами реляционной алгебры.
Пример 5.29. Вернемся к схеме "кинематографической" базы данных и рассмотрим
два отношения:
Movie(title, year, length, inColor, studioName, producerC#)
MovieExec(name, address, cert#, netWorth)
242
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
Будет вполне справедливым полагать, что информация о продюсере кинофильма,
описываемого кортежем отношения Movie, должна присутствовать и в отношении
MovieExec, содержащем сведения о "руководителях", наделенных властными
полномочиями, — президентах кинокомпаний и продюсерах. В противном случае мы как
пользователи системы хотели бы иметь гарантии того, что СУБД, по меньшей мере,
проинформирует нас об отсутствии данных в одном отношении, ссылка на которые
присутствует в другом отношении.
Если говорить более точно, значению компонента producerC# каждого кортежа
отношения Movie должно соответствовать равное значение компонента cert# некоторого
кортежа отношения MovieExec. Поскольку все "руководители" обозначены уникальными
сертификационными номерами, мы вправе надеяться, что информация о каждом
продюсере, упомянутом в отношении Movie, может быть найдена в отношении MovieExec.
Подобное ограничение нетрудно представить в форме "подмно-жества множества":
7iProducerC#(Movie) с ncertU(MovieExec).
Значением оператора левой части выражения служит множество всех
сертификационных номеров, содержащихся в компонентах producerC# кортежей отношения Movie,
а результатом вычисления оператора правой части — множество всех номеров,
содержащихся в компонентах cert# кортежей отношения MovieExec. Выражение
ограничения гласит, что каждый из элементов множества левой части должен быть членом
множества правой части.
То же ограничение может быть выражено в форме равенства значения пустому
множеству:
Прожегся (Movie) - ncert# (MovieExec) = 0.
□
Пример 5.30. Аналогичным образом могут быть выражены такие ограничения
ссылочной целостности, в которых "адресуемое значение" представляется одновременно
несколькими атрибутами. Например, мы имеем все основания считать, что любому
кинофильму, упомянутому в отношении
Starsln(movieTitle, movieYear, starName)
должен соответствовать кортеж отношения
Movie(title, year, length, inColor, studioName, producerC#)
"Кинофильм" в каждом из отношений представляется парой значений "название-
год" (ранее мы уже согласились с тем, что одного атрибута для однозначного
описания кинофильма явно не достаточно). Сформулированное выше ограничение
ссылочной целостности можно выразить так:
Л movieTitle, movieYear (Stars In) С ЛМе, year (Movie).
□
5.5.3. Другое ограничения
Та же система обозначений позволяет описывать не только ограничения
ссылочной целостности, но и ограничения других видов. Например, в виде выражения
реляционной алгебры можно представить любую функциональную зависимость (functional
dependency — FD), хотя и не столь изящно, как это делается традиционными
средствами описания FD (см. раздел 3.4 на с. 106).
Пример 5.31. Попробуем представить FD
name —> address,
справедливую для отношения
MovieStar(name, address, gender, birthdate),
5.5. ОТНОШЕНИЯ И ОГРАНИЧЕНИЯ
243
в форме ограничения, выраженного средствами реляционной алгебры. Основная идея
состоит в том, что если построить все возможные пары кортежей (th t2) отношения
MovieStar, не должно быть ни одной пары, кортежи которой совпали бы в атрибутах
name и не совпали в атрибутах address. Для построения множества пар кортежей мы
используем оператор декартова произведения, а для поиска пар, нарушающих условие
FD, — оператор выбора. Результат сопоставляется со значением 0.
Поскольку аргументами оператора декартова произведения служат две копии
одного и того же отношения, необходимо переименовать хотя бы одну из них, чтобы
получить возможность свободно различать их атрибуты. Чтобы избежать недомолвок,
мы введем, однако, сразу два новых имени отношения MovieStar — MSI и MS2.
Рассматриваемая функциональная зависимость может быть описана ограничением
в форме следующего алгебраического выражения:
&MSl.name = MS2.name AND MSI.address * MS2.address (MS1 X MS2 ) = 0.
Операцию переименования отношения MovieStar в MSI легко представить так:
Pt4Sl{name, address, gender, birthdate) (MovieS tar).
Переименование MovieStar в MS2 выполняется аналогично. □
Средствами реляционной алгебры можно выразить также ограничения домена.
Зачастую ограничение домена предполагает, что значения некоторого атрибута должны
относиться к определенному типу данных, такому как, например, целочисленный или
строковый с длиной в 30 символов. Не менее часто ограничение домена
предусматривает, что атрибуту могут быть присвоены строго определенные значения. Если
множество приемлемых значений допускает возможность описания в виде условного
выражения конкретного языка, соответствующее ограничение домена может быть
оформлено как алгебраическое выражение.
Пример 5.32. Как мы говорили прежде, допустимыми значениями атрибута gender
("пол") отношения MovieStar являются символьные константы 'F' (от female —
женщина) и 'М' (male — мужчина). Это ограничение домена может быть
представлено в виде следующего выражения реляционной алгебры:
Cgender* .F. июgender* -м- (MovieStar) = 0.
Иными словами, множество кортежей отношения MovieStar, компоненты gender
которых обладают значениями, отличными от • f • и ' м', должно быть пустым. □
Наконец, встречаются ситуации, когда возникает необходимость в задании
ограничений, которые нельзя отнести ни к одной из категорий, рассмотренных в разделе 2.3
на с. 74, и ни к числу функциональных (FD) или многозначных (MVD) зависимостей
(см. разделы 3.4 и 3.7 на с. 106 и 137 соответственно). Реляционная алгебра позволяет
справиться с подобными задачами. Один из примеров приведен ниже.
Пример 5.33. Предположим, что требуется ввести ограничение, в соответствии с
которым президентом кинокомпании может стать человек, обладающий совокупным
годовым доходом (атрибут netWorth отношения MovieExec) в размере не менее
10 миллионов долларов. Такое ограничение нельзя отнести к категории ограничений
домена или ссылочной целостности. Однако его все же удастся описать средствами
реляционной алгебры. Во-первых, необходимо выполнить тета-соединение двух отношений
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
используя условие равенства значений атрибутов presC# отношения studio и cert#
отношения MovieExec. В результате операции будет получено множество пар
кортежей, каждая из которых представляет сведения о студии и о руководителе,
занимающем пост президента этой студии. Если выбрать из полученного отношения те корте-
244
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
жи, компонент netWorth которых содержит значение, меньшее 10000000 (что,
собственно, и служит предметом рассматриваемого ограничения), множество таких
кортежей обязано быть пустым. Вот как может выглядеть искомое выражение:
<*network< looooooo (Studio ex MovieExec) = 0.
precC# = certfF
Другой способ представления того же ограничения заключается в сопоставлении
множества сертификационных номеров президентов киностудий с множеством
номеров руководителей, обладающих совокупным годовым доходом в размере не менее
10 миллионов долларов; первое должно быть подмножеством второго:
яРге*с#(Studio) с ncert#(crnerWorth> юоооооо(MovieExec)).
□
5.5.4. Упражнения к разделу 5.5
Упражнение 5.5.1. Представьте в виде выражений реляционной алгебры указанные
ограничения, касающиеся содержимого отношений, которые описаны в
упражнении 5.2.1 (см. с. 218) и воспроизведены ниже.
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
Можете воспользоваться любой из форм задания выражений — в виде равенства
значения пустому множеству или подмножества множества. Изучите экземпляры
отношений, приведенные на рис. 5.10 и 5.11 (см. с. 220 и 221), и найдите в них
примеры нарушений ограничений.
* а) Персональные компьютеры (рс) с быстродействием процессора (speed)
ниже 1000 МГц не должны иметь цену (price), превышающую 1500 долларов.
Ь) Переносные компьютеры (Laptop) с размером экрана (screen) менее
14 дюймов должны обладать диском с емкостью (hd) не менее 10 Гбайт либо
стоить (price) менее 2000 долларов.
! с) Ни один из производителей (maker) персональных компьютеров (PC) не
должен выпускать также переносные компьютеры (Laptop).
*!! d) Каждый производитель (maker) персональных компьютеров (рс) обязан
выпускать и переносные компьютеры (Laptop) с таким же или более высоким
быстродействием процессора (speed).
! е) Если переносной компьютер (Laptop) обладает большим объемом
оперативной памяти (ram), нежели персональный (РС), переносной компьютер
должен иметь и более высокую цену (price).
Упражнение 5.5.2. Представьте в виде выражений реляционной алгебры указанные
ограничения, касающиеся содержимого отношений, которые описаны в
упражнении 5.2.4 (см. с. 222) и воспроизведены ниже.
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
Можете воспользоваться любой из форм задания выражений — в виде равенства
значения пустому множеству или подмножества множества. Изучите экземпляры
отношений, приведенные на рис. 5.12 и 5.13 (см. с. 223 и 224), и найдите в них
примеры нарушений ограничений.
5.5. ОТНОШЕНИЯ И ОГРАНИЧЕНИЯ
245
a) Суда ни одного из классов (classes) не могут быть оснащены главными
орудиями калибра (bore), превышающего 16 дюймов.
b) Если на судах некоторого класса (Classes) установлено более 9 (numGuns)
главных орудий, их калибр (bore) не должен превышать 14 дюймов.
! с) Ни один из классов (class) не может включать более 2 судов (ships).
! d) Ни одна из стран (country) не должна выпускать одновременно линкоры
и крейсеры (им соответствуют значения 'bb' и 'be' атрибута type).
!! е) Ни одно судно (ship) с более чем 9 (numGuns) главными орудиями не
должно было сражаться с судном, обладавшим меньшим числом орудий
и оказавшимся потопленным (этот факт представляется значением ' sunk'
атрибута result).
! Упражнение 5.5.3. Даны отношения R и S. Пусть С — ограничение ссылочной
целостности, предусматривающее выполнение следующего условия: всякий раз,
когда в R содержится кортеж с некоторыми значениями vb v2,..., vn определенных
атрибутов ДЬА2, ...,АП, в S должен существовать кортеж с теми же значениями
vi, v2,..., vn атрибутов Въ Въ ..., Вп. Покажите, каким образом ограничение С может
быть выражено средствами реляционной алгебры.
! Упражнение 5.5.4. Предположим, что R — некоторое отношение, а А{ А2 • •• Ап -> В —
функциональная зависимость (FD), справедливая в контексте этого отношения.
Представьте указанную FD в виде выражения реляционной алгебры.
!! Упражнение 5.5.5. Предположим, что R — некоторое отношение, а
А1А2-Ап-»В1В2-Вт
является многозначной зависимостью (MVD), справедливой в контексте этого
отношения. Представьте указанную MVD в виде выражения реляционной алгебры.
5.6. Резюме
♦ Классическая реляционная алгебра. Эта алгебра лежит в основе большинства
систем баз данных и языков запросов, реализующих реляционную модель. К числу
основных операторов реляционной алгебры относятся операторы объединения,
пересечения, разности, выбора, проекции, декартова произведения,
естественного соединения, тета-соединения и переименования.
♦ Выбор и проекция. Оператор выбора возвращает отношение, содержащее все
кортежи отношения-операнда, которые удовлетворяют заданному критерию.
Оператор проекции сохраняет в итоговом отношении только те атрибуты
отношения-операнда, которые указаны явно.
♦ Соединения. В процессе соединения двух отношений выполняется сочетание их
кортежей. Оператор естественного соединения дает в результате множество всех
пар кортежей, которые совпадают в атрибутах, общих для двух отношений-
операндов. Оператор тета-соединения обеспечивает сочетание тех кортежей,
которые удовлетворяют заданному критерию.
♦ Отношения-мультимножества. В коммерческих системах баз данных
отношения трактуются как мультимножества, т.е. допускают наличие нескольких
одинаковых кортежей. Операции реляционной алгебры, справедливые для
отношений-множеств, как правило, поддаются обобщению на случай отношений-
мультимножеств, хотя существует ряд алгебраических законов, которые в такой
ситуации утрачивают силу.
246
ГЛАВА 5. РЕЛЯЦИОННАЯ АЛГЕБРА
♦ Дополнительные операторы реляционной алгебры. Для расширения возможностей
SQL и удовлетворения потребностей иных языков запросов классическая
реляционная алгебра нуждается в пополнении новыми операторами, к числу
которых относятся операторы сортировки, расширенной проекции, группирования,
агрегирования и внешних соединений.
♦ Группирование и агрегирование. Операторы агрегирования позволяют вычислять
различные общие показатели, касающиеся содержимого того или иного столбца
отношения: суммы, минимальные, максимальные и средние значения, а также
количества кортежей. Оператор группирования обеспечивает возможность
разбиения множества кортежей на группы в соответствии с содержимым тех или
иных атрибутов и обычно используется в сочетании с операторами агрегирования.
♦ Внешние соединения. Процесс внешнего соединения двух отношений начинается
с вычисления "обычного" соединения. Затем в результат включаются висящие
кортежи (т.е. кортежи, не способные к соединению ни с одним кортежем
другого отношения) одного или обоих отношений (это зависит от типа
конкретного оператора внешнего соединения), и их компоненты, которые отвечают
отсутствующим атрибутам, заполняются значениями null.
♦ Ограничения в форме выражений реляционной алгебры. Ограничения самых
различных типов (например, функциональные зависимости или ограничения
ссылочной целостности) могут быть оформлены в виде алгебраических выражений,
представляющих подмножество множества или равенство некоторого значения
пустому множеству.
5.7. Литература
Реляционная алгебра — это еще одна область, ощутимый вклад в которую внесла
фундаментальная статья Э.Ф. Кодда (E.F. Codd) [1], посвященная реляционной
модели. Расширенные варианты оператора проекции, позволяющие выполнять функции
группирования и агрегирования, описаны в работе [2]. Возможность представления
ограничений в виде выражений запросов впервые рассмотрена в [3].
1. Codd E.F. A relational model for large shared data banks, Comm. ACM, 13:6 (1970), p. 377-387.
2. Gupta A., Harinarayan V., and Quass D. Aggregate-query processing in data warehousing
environments, Proc. Intl. Conf. on Very Large Databases (1995), p. 358—369.
3. Nicolas J.-M. Logic for improving integrity checking in relational databases, Acta Informatica,
18:3 (1982), p. 227-253.
5.7. ЛИТЕРАТУРА
247
Глава 6
Язык SQL
Запросы (queries) относительно содержимого базы данных и команды его изменения
наиболее часто описываются средствами языка, сокращенно называемого SQL (от
Structured Query Language — язык структурированных запросов', аббревиатуру принято
произносить как "сикуэл"). Подмножество SQL, поддерживающее функции
определения запросов, по своим возможностям весьма близко реляционной алгебре с
дополнительными операторами (см. раздел 5.4 на с. 232). Помимо того, SQL предлагает
инструменты, позволяющие изменять содержимое базы данных (например, добавлять
в отнршения новые кортежи и удалять существующие) и определять ее схему. SQL,
таким образом, способен выполнять функции как языка управления данными (Data
Manipulation Language — DML), так и языка определения данных (Data Definition
Language — DDL), а также обеспечивать стандартное представление многих других
команд управления базами данных (за полной информацией о подобных командах
обращайтесь к главам 7 на с. 317 и 8 на с. 349).
Существует множество различных диалектов SQL. Прежде всего, имеются три
основных стандарта языка. Первый разработан ANSI.26 Обновленная версия стандарта
принята в 1992 году и носит название SQL-92, или SQL2. Самый последний стандарт,
SQL-99 (или SQL3), расширяет SQL2 за счет включения в состав языка объектно-
реляционных инструментов и большого числа иных новейших функциональных
возможностей. Кроме того, существуют версии языка, предлагаемые основными
поставщиками коммерческих СУБД. Все они, как правило, удовлетворяют требованиям
исходного стандарта ANSI SQL и реализуют многие возможности, описываемые
стандартом SQL2, хотя каждая обладает теми или иными отклонениями и расширениями,
в том числе и такими, которые предусмотрены в стандарте SQL-99.
В этой и двух следующих главах мы рассмотрим вопросы использования SQL в
качестве языка запросов. Текущая глава посвящена изложению сведений о базовом
интерфейсе SQL (generic SQL interface). Здесь мы проанализируем особенности SQL как
самостоятельного языка запросов, позволяющего вводить с терминала запросы о
содержимом базы данных и получать ответы на них, а также выполнять модификацию
базы данных (например, вставлять в отношения новые кортежи).
Следующая глава (см. с. 317) предлагает информацию об ограничениях (constraints)
и триггерах (triggers) — еще одном механизме управления состоянием базы данных.
American National Standards Institute — Американский институт национальных стандартов,
неправительственная организация, создающая промышленные стандарты, не обязательные
к применению. — Прим. перев.
В главе 8 на с. 349 освещены аспекты создания приложений баз данных на
традиционных языках программирования. В этой и двух следующих главах мы будем
придерживаться требований стандарта SQL-99, привлекая ваше внимание и к таким
функциональным возможностям SQL, которые оговорены в ранних стандартах языка
и реализованы в большинстве коммерческих СУБД.
Цель, поставленная нами при изложении материала этих глав, которые, как нам
кажется, должны быть больше "учебником", нежели "руководством", состоит в том, чтобы
дать читателю почувствовать смысл и "вкус" SQL. Поэтому мы сосредоточим внимание
только на наиболее общих функциональных средствах языка. В разделе 6.9 на с. 315
приведены ссылки на источники, где вы сможете получить дополнительную
информацию о специальных возможностях SQL и об особенностях его различных диалектов.
6.1. Простые запросы на языке SQL
Вероятно, простейшей формой SQL-запроса является такая, которая предполагает
выбор из некоторого отношения группы кортежей, удовлетворяющих определенному
условию. Подобный запрос аналогичен операции выбора в реляционной алгебре. При
его написании используются три служебных слова SQL — select ("выбрать"), FROM
("из") и where ("при условии"), — применяемые в большинстве запросов SQL.
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
Рис. 6.1. Пример схемы базы данных
Пример 6.1. В этом и следующих примерах мы воспользуемся схемой
"кинематографической" базы данных в той ее редакции, которая приведена в разделе
5.1 на с. 204 и воспроизведена на рис. 6.1. В разделе 6.6 на с. 296 будет показано, как
информация схемы базы данных определяется средствами SQL, но сейчас достаточно
полагать, что отношения, представленные на рис. 6.1, с указанными атрибутами,
относящимися к требуемым типам данных (доменам), уже созданы.
Для начала рассмотрим запрос к отношению
Movie(title, year, length, inColor, studioName, producerC#),
предусматривающий выбор данных обо всех кинофильмах, снятых на студии "Disney"
в 1990 году. На языке SQL такой запрос записывается следующим образом:
SELECT *
FROM Movie
WHERE studioName = 'Disney' AND year = 1990;
Запрос следует форме "выбрать—из—при_условии", характерной для большинства
типичных SQL-запросов.
• В предложении from перечислены наименования отношений, к которым
обращен запрос. В данном случае нас интересует информация, содержащаяся в
отношении Movie.
• Предложение where задает условие, аналогичное условию С оператора выбора
<ус в реляционной алгебре. Выбираемые кортежи обязаны удовлетворять
условию where. В данном случае условие предполагает, что компонент studioName
должен содержать значение 'Disney', а компонент year— значение 1990.
Кортежи, для которых оба равенства выполняются одновременно,
удовлетворяют условию в целом, а все остальные кортежи — нет.
250
ГЛАВА 6. ЯЗЫК SQL
Совет по поводу восприятия и записи запросов
Обычно проще всего начинать изучение запроса вида "выбрать—из—при_условии"
с предложения from, чтобы понять, какие отношения базы данных охватываются
запросом. Затем целесообразно сосредоточить внимание на предложении where,
где указаны критерии, которым должны удовлетворять выбираемые кортежи.
Наконец, следует перейти к предложению select, определяющему форму
представления итоговых данных. Того же порядка обращения к предложениям SQL-
запроса — from ("из"), where ("при условии") и select ("выбрать") — удобно
придерживаться и при написании собственных запросов.
• Предложение select оговаривает, какие атрибуты кортежей, принадлежащих
отношениям из from и удовлетворяющих условию where, должны быть
включены в отношение, служащее результатом обработки запроса.
Один из способов интерпретации запроса состоит в последовательном просмотре
каждого кортежа отношения, упомянутого в предложении from (в нашем примере —
Movie), и проверке, выполняется ли для него условие предложения where. Если
говорить более точно, наименование каждого атрибута, упомянутого в условии where,
заменяется значением соответствующего компонента кортежа. Затем полученное
условное выражение вычисляется, и, если результат оказывается истинным, значения
компонентов кортежа, перечисленных в предложении select, включаются в очередной
кортеж итогового отношения. В результате обработки рассматриваемого запроса будет
получено множество кортежей, представляющих сведения о фильмах, выпущенных
компанией "Disney" в 1990 году (например, о ленте "Pretty Woman"). Процессор
запросов SQL, встретив кортеж отношения Movie
title
Pretty Woman
year
1990
length
119
in Color
true
studio Name
Disney
producerC#
999
(999 — это вымышленный сертификационный номер продюсера кинофильма),
заменит в условии where название атрибута studioName значением 'Disney', а имя
атрибута year — значением 1990. Предложение where примет следующий вид:
WHERE 'Disney' = 'Disney' AND 1990 = 1990
Поскольку это условие явно справедливо, проверка кортежа с информацией о фильме
"Pretty Woman" завершается успехом и кортеж включается в итоговое отношение. □
6.1.1. Проекция в SQL
При необходимости мы можем удалить некоторые из атрибутов выбранных
кортежей, т.е. осуществить проекцию отношения, полученного в результате обработки
SQL-запроса, на определенное подмножество атрибутов. Для решения подобной
задачи в предложении select вместо символа звездочки (*) следует задать список
атрибутов отношения, упомянутого в предложении from, которые подлежат
включению в итоговое отношение.27
Пример 6.2. Пусть необходимо исправить текст запроса из примера 6.1 таким образом,
чтобы в итоговое отношение включались только наименования кинофильмов и
значения длительности их воспроизведения. Запрос может выглядеть так:
27 Служебное слово select в SQL наиболее близко по смыслу (но не по названию)
оператору проекции (projection) я в реляционной алгебре, в то время как оператор выбора (selection) or,
используемый в реляционной алгебре, соответствует предложению WHERE в SQL-запросах.
6.1. ПРОСТЫЕ ЗАПРОСЫ НА ЯЗЫКЕ SQL
251
SELECT title, length
FROM Movie
WHERE studioName = 'Disney' AND year = 1990;
Результатом его выполнения окажется таблица с двумя столбцами, озаглавленными
как title и length, и строками, содержащими наименования кинофильмов,
выпущенных студией "Disney" в 1990 году, и значения их продолжительности. Вот пример
экземпляра итогового отношения с одним кортежем:
title
Pretty Woman
length
119
□
Подчас в результате обработки запроса требуется получить отношение,
наименования столбцов которого должны отличаться от названий атрибутов отношения,
упомянутого в предложении from. Предложение select позволяет сопроводить имя атрибута
служебным словом as и псевдонимом (alias), который должен стать заголовком
соответствующего столбца итоговой таблицы. Служебное слово as, вообще говоря, задавать не
обязательно; в этом случае имя и псевдоним атрибута должны быть разделены только
символом пробела — размещение между ними других знаков пунктуации не разрешается.
Пример 6.3. Чтобы обеспечить замену заголовков таблицы, получаемой в результате
обработки запроса из примера 6.2, с title и length на name и duration,
необходимо дополнить текст запроса следующим образом:
SELECT title AS name, length AS duration
FROM Movie
WHERE studioName = 'Disney' AND year = 1990;
Содержимое итогового отношения не изменится, но его столбцы будут озаглавлены
по-новому — как name и duration:
пате
Pretty Woman
duration
119
□
Еще одна возможность, предусмотренная синтаксисом предложения select,
связана с использованием на месте имен атрибутов вычисляемых выражений. Иными
словами, список предложения select способен выполнять те же функции, что и
список оператора расширенной проекции л в реляционной алгебре (см. раздел 5.4.5 на
с. 236). В разделе 6.4 на с. 283 показано, что в список select допустимо включать
и агрегирующие функции — такие же, какие применяются в операторе
группирования у, рассмотренном в разделе 5.4.4 на с. 235.
Пример 6.4. Предположим, что при выполнении запроса необходимо обеспечить
получение такого же результата, как в примере 6.3, но с условием, что значения
продолжительности воспроизведения кинофильмов должны быть выражены не в минутах,
а в часах. Для достижения цели предложение select следует исправить, скажем, так:
SELECT title AS name, length*0.016667 AS lengthlnHours
В процессе обработки запроса будут выбраны те же кортежи отношения Movie, но
значениями второго столбца итоговой таблицы, озаглавленного как lengthlnHours,
окажутся результаты умножения содержимого компонентов length на
константу 0.016667:
252
ГЛАВА 6. ЯЗЫК SQL
name
Pretty Woman
length In Hours
1.98334
□
Пример 6.5. В качестве элементов списка предложения select разрешается
использовать даже постоянные величины. Как может показаться, это лишено особого смысла,
но в некоторых случаях возможность включения в итоговую таблицу каких-либо
дополнительных слов или строк оказывается достаточно полезной. Так, например, в
результате выполнения запроса
SELECT title AS name, length*0.016667 AS length, 'hrs.' AS inHours
FROM Movie
WHERE studioName = 'Disney' AND year = 1990;
будет получено отношение вида
name
Pretty Woman
length
1.98334
inHours
hrs.
Таблица пополнилась новым столбцом, и названия второго и третьего столбцов
логически связаны друг с другом — впрочем, так же, как их компоненты: каждый кортеж
содержит в третьей ячейке одну и ту же константу 'hrs. ' ("час"), указывающую, что
продолжительность воспроизведения кинофильма задана в часах. □
6.1.2. Выбор в SQL
Возможности оператора выбора <т, используемого в реляционной алгебре,
реализуются и значительно расширяются предложением where SQL. Условные выражения,
следующие за служебным словом where, во многом схожи с теми, которые
используются в программном коде, написанном на традиционных языках, подобных С или Java.
Условные выражения могут создаваться на основе шести общеупотребительных
операторов сравнения: = ("равно"), <> ("не равно"), < ("меньше"), > ("больше"), < =
("меньше или равно", или "не больше") и >= ("больше или равно", или "не
меньше"). Операторы обладают той же семантикой, что и в языке С, но в С для
обозначения оператора "не равно" используется пара символов ! =.
В роли операндов, сопоставляемых посредством операторов сравнения, могут
выступать константы и идентификаторы-имена атрибутов отношений, упомянутых в
предложении from. Перед сравнением числовых значений допустимо применять к ним
различные арифметические операторы, такие как +, * и т.д. Например, выражение
(year - 193 0) * (year - 193 0) < 100 окажется истинным для тех (целочисленных)
значений "переменной" year, которые заключены в интервале от 1921 до 1939. К
строковым операндам может применяться оператор сцепления, или конкатенации, | |:
например, результатом операции 'Здесь был ' || 'Вася Сидорчук' будет строка
'Здесь был Вася Сидорчук'.
В примере 6.1 на с. 250 вы уже видели образец операции сравнения:
studioName = 'Disney'
В этом случае проверяется условие равенства содержимого компонента studioName
кортежа отношения Movie с константой 'Disney'. Константа относится к строковому типу;
строки в текстах SQL заключаются в одинарные кавычки. В SQL, разумеется, допустимо
применять и числовые константы, как целочисленные (например, -12 или 34), так и
вещественные (в обеих общепринятых формах написания — скажем, -12 .34 и 1.23Е45).
6.1. ПРОСТЫЕ ЗАПРОСЫ НА ЯЗЫКЕ SQL
253
SQL-тексты и чувствительность к регистру
Тексты запросов и команд SQL не чувствительны к регистру (case insensitive)
набора. Это значит, что компилятор запросов SQL трактует одноименные буквы
верхнего и нижнего регистров как одинаковые: например, мы вправе, ничем не рискуя,
представить слово FROM как From, from или даже From (хотя в соответствии с
устоявшейся традицией служебные слова SQL принято записывать символами верхнего
регистра). Имена атрибутов, псевдонимов, отношений и т.п. также не
чувствительны к регистру. Компилятор различает буквы верхнего и нижнего регистров только
тогда, когда они набраны в составе строки, заключенной в кавычки. Поэтому
•FROM' и ' from' воспринимаются системой как различные строки (разумеется, ни
одна из них не имеет ничего общего со служебным словом from).
Результатом операции сравнения служит значение булева типа — true либо
false.28 Булевы значения могут объединяться в выражения с помощью логических
операторов and ("И"), or ("ИЛИ") и not ("HE"), смысл которых достаточно
очевиден. Например, в примере 6.1 два условных выражения связываются в логическое
с помощью оператора and, и условие предложения where становится истинным
(true), если и только если истинны результаты вычисления обоих операторов
сравнения, т.е. значением компонента studioName действительно служит строка 'Disney',
а в компоненте year хранится число 1990. Ниже приведено несколько примеров
запросов с более сложными условиями where.
Пример 6.6. Следующий запрос предполагает поиск информации обо всех
кинофильмах, вышедших на экран после 1970 года и снятых на черно-белой пленке:
SELECT title
FROM Movie
WHERE year > 197 0 AND NOT inColor;
В предложении where два условия вновь соединены оператором and: первое из них — это
обычное выражение сравнения, а второе представляет собой значение атрибута inColor,
к которому применен оператор отрицания NOT. Подобное обращение к отдельному
значению inColor вполне оправданно, поскольку атрибут относится к булеву типу.
Рассмотрим еще одну конструкцию SQL:
SELECT title
FROM Movie
WHERE (year > 197 0 OR length < 90) AND studioName = *MGM';
Запрос предусматривает выбор названий таких кинофильмов, которые сняты
киностудией "MGM" и либо выпущены после 1970 года, либо обладают продолжительностью
воспроизведения, меньшей 90 минут. Выражения сравнения сгруппированы с
помощью круглых скобок. Здесь скобки играют существенную роль, поскольку приоритеты
выполнения логических операторов в SQL те же, что и в большинстве других языков
программирования: оператор and обладает более высоким приоритетом, нежели OR,
a not по уровню приоритета превосходит и and, и or. □
6.1.3. Сравнение строк
Две строки считаются равными, если они состоят из одинаковых символов,
следующих в одном и том же порядке. SQL, однако, позволяет использовать различные
строковые типы — например, символьные массивы фиксированной длины или спи-
" Помимо двух названных, в SQL поддерживается еще одно логическое значение, unknown
(обратитесь к разделу 6.1.6 на с. 259).
254
ГЛАВА 6. ЯЗЫК SQL
SQL-запросы и реляционная алгебра
Простые SQL-запросы, которые рассматривались нами до сих пор, следуют
такой схеме:
SELECT L
FROM Л
WHERE С
где L — некоторый список выражений, R — отношение, а С — условие. Подобный
запрос аналогичен по смыслу выражению реляционной алгебры
KL(crc(R)),
которое вычисляется для отношения-аргумента R (предложение from): к каждому
кортежу R применяется условие С (предложение where), и результат выбора
проецируется на список L атрибутов и/или выражений (предложение select).
ски, состоящие из произвольного количества символов.29 Поэтому мы вправе ожидать,
что существуют и строгие правила их взаимного преобразования.
Например, последовательность символов f oo может сохраняться в виде строки
постоянной длины, равной 10 (в этом случае в строку будет добавлено 7 символов-
"заполнителей"), либо строки переменной длины. Независимо от формы
представления, содержимое обеих строк должно трактоваться как одинаковое и равное
постоянному значению ' f oo *. За дополнительной информацией о способах хранения
символьных строк на физическом уровне обращайтесь к разделу 12.1.3 на с. 551.
При сравнении строк посредством любого из операторов — <, <=, > или >= —
проверяется, должна ли одна строка предшествовать другой, если их поместить в список,
отсортированный в лексикографическом (алфавитном) порядке. Иными словами, если
две строки выглядят как последовательности символов аха2 — ап и b{b2 — bm, первая из
них, например, окажется "меньше" (<) второй, если либо а{<Ь{, либо а{ = Ь{ и а2<Ьъ
либо ах = Ъъ а2 = Ь2 и а3 < Ьъ^ и т.д. Условие ах а2 — ап < b{ b2 — bm выполняется и в том
случае, если n<mw аха2 ••• ап = Ь{ Ь2 — Ьп, т.е. первая строка представляет собой префикс
второй. Например, вполне очевидна справедливость соотношения ' fodder' < ' foo',
поскольку два первых символа (fo) обеих строк совпадают, но третий символ (d)
строки ' fodder' предшествует в алфавите третьему символу (о) строки ' foo'.
Выполняется и условие 'bar' < 'bargain', так как строка 'bar' служит префиксом
строки 'bargain'. Как и при сопоставлении строк с помощью оператора равенства,
предполагается, что перед сравнением строки различных типов приводятся к одному
типу на основании строгих правил преобразования.
Язык SQL предлагает также возможность сравнения строк с образцом. В этом
случае выражение сравнения выглядит как
s LIKE p,
где s — это тестируемая строка, ар— образец, т.е. строка, которая может содержать
необязательные символы-шаблоны — % и _. Обычные символы в р сопоставляются
с аналогичными символами в s, но символ % в р отвечает нулевому или большему
количеству любых символов в 5, а символ __ — в точности одному произвольному
символу в s. Значением выражения служит true, если и только если строка s удовлетворяет
образцу р. Напротив, выражение s not like p обращается в true, если и только
если строка s не совпадает с образцом р.
29 Так, по меньшей мере, мы можем воспринимать значения строковых типов. Как они
сохраняются в базе данных на самом деле — ответ на этот вопрос зависит от особенностей реализации и
относится к компетенции конкретной СУБД, поскольку никак не регламентируется стандартом SQL.
6.1. ПРОСТЫЕ ЗАПРОСЫ НА ЯЗЫКЕ SQL
255
Представление строк битов
Строка битов задается в виде последовательности символов 0 и 1, заключенной
в одинарные кавычки, с предшествующим символом в. Так, например, в'011'
представляет строку, описывающую значения трех битов, первый из которых
содержит 0, а два остальных — 1. Чтобы представить в виде строки
последовательность шестнадцатеричных цифр, описываемых десятичными цифрами 0—9 и
латинскими буквами а—/, следует заключить последовательность в одинарные
кавычки, но предпослать ей префикс х. Например, строка x'7ff описывает
шестнадцатеричное значение, эквивалентное последовательности из 12 бит, первый
из которых равен 0, а остальные одиннадцать — 1 (каждая шестнадцатеричная
цифра представляет четыре бита, причем ведущие нулевые биты не подавляются).
Пример 6.7. Предположим, что нам удалось вспомнить только первую часть названия
фильма, "Star", и то, что следующее слово состоит из четырех букв. Как может
называться такой фильм? Чтобы извлечь из базы данных все подобные названия фильмов,
достаточно выполнить запрос
SELECT title
FROM Movie
WHERE title LIKE 'Star ';
Запрос предполагает поиск кортежей-"фильмов", названия которых состоят из девяти
символов, причем первыми пятью являются star и пробел. Последние четыре символа
могут быть любыми, поскольку каждому из четырех символов-шаблонов _ отвечает один
произвольный символ. В итоговое отношение будут включены все названия,
удовлетворяющие критерию выбора, — такие, как, например, "Star Wars" и "Star Trek". □
Пример 6.8. Пусть необходимо выбрать все англоязычные названия, в которых
употребляется частица 's притяжательного падежа. Следует выполнить такой запрос:
SELECT title
FROM Movie
WHERE title LIKE '%' 's% ' ;
Чтобы понять смысл используемого образца, следует обратить внимание, что символ
апострофа в SQL выполняет служебную функцию разграничения строк и поэтому не
может представлять сам себя непосредственно. Существует соглашение, в
соответствии с которым два апострофа подряд трактуются системой как символ апострофа как
таковой, а не как признак завершения строки. Таким образом, подстрока ' ' s образца
как раз и отвечает искомой частице 's притяжательного падежа.
Два символа % в начале и в конце строки образца представляют любые
последовательности символов (в том числе и нулевой длины). Поэтому заданному образцу
удовлетворяет любое название, в котором присутствуют символы 's, — например,
"Logan's Run" или "Alice's Restaurant". □
6.1.4. Значения даты и времени в SQL
В конкретных реализациях SQL значениям даты и времени обычно соответствуют
специальные типы данных. Подобные величины, как правило, допускают
возможность записи в самых различных форматах, таких как 5/14/1948, 14 May 1948 и т.п.
Здесь мы рассмотрим только тот весьма ограниченный круг форматов, который
оговорен стандартом SQL.
Константы, представляющие даты, вводятся с помощью служебного слова date,
за которым следует строка специального формата, заключенная в кавычки.
Подобному требованию отвечает, например, такая запись: date '1948-05-14*. Первые четыре
256
ГЛАВА 6. ЯЗЫК SQL
Выражения like с символами escape
Как быть в том случае, если строка образца, подлежащая сравнению со значениями из
базы данных, должна содержать значимые (а не служебные) символы % или _? Вместо
того чтобы придать определенным символам постоянный статус управляющих (escape)
(каковым, например, наделен символ обратной косой черты — backslash — в
большинстве команд UNIX), SQL позволяет в каждом отдельном выражении like
определять собственный escape-символ: выражение like сопровождается служебным
словом escape, после которого вводится выбранный символ, заключенный в одинарные
кавычки. Если в строке образца встречается символ % или _, которому предшествует
назначенный нами escape-символ, такой символ (% или _) теперь интерпретируется
системой не как служебный, обозначающий, соответственно, произвольную строку
или любой отдельный символ, а как литеральный, представляющий сам себя
"буквально". Например, в выражении
s LIKE 'x%%x%' ESCAPE 'x'
символ х обозначен как управляющий. Поэтому пара символов х% трактуется как
единственный литеральный символ %. С указанным образцом будут совпадать
любые строки, в начале и в конце которых расположен символ %. Обычную функцию
шаблона, представляющего "произвольную строку", в образце выполняет только
средний символ %.
цифры в строке определяют значение года. Затем вводятся символ дефиса и две цифры
номера месяца (в нашем примере номер месяца состоит из одной цифры 5 с начальным
нулем). Наконец, задаются еще один символ дефиса и две цифры дня месяца. Как
и при наборе номера месяца, если номер дня месяца включает только одну цифру, ей
следует предпослать ведущий символ нуля.
Для ввода временнб/х констант используется схожая схема, предполагающая
задание служебного слова time со строкой строго определенного формата. Первые две
цифры строки представляют значение часов по 24-часовой шкале. Затем вводятся
двоеточие, две цифры значения минут, еще одно двоеточие и две цифры значения
секунд. Если требуется указать и доли секунды, вводятся десятичная точка и столько
десятичных разрядов дробной части, сколько необходимо. Например, запись
time '15:00:03.1415* представляет момент времени, к которому все студенты
обычно успевают покинуть аудиторию, если лекция заканчивается в 3 часа пополудни.
Значение момента времени может быть задано также в виде положительного или
отрицательного смещения относительно времени нулевого меридиана (Greenwich
Mean Time — GMT). Так, например, выражение time * 12 .-00:00-8: 00*
соответствует полудню в городах западного побережья США и Канады, относящихся к часовому
поясу тихоокеанского стандартного времени, time '12:00:00+3:00' обозначает
полдень в Москве, a time '12:00: 00+0 : 00 ' — в Лондоне.
Для представления даты и времени в виде единого значения используется
служебное слово timestamp, сопровождаемое строками даты и времени, которые
форматируются в соответствии с рассмотренными выше правилами и разделяются
символом пробела. Так, запись timestamp '1948-05-14 12:00:00* соответствует
полудню 14 мая 1948 года.
Для сопоставления значений дат и времени применяются те же операторы
сравнения, что и для чисел и строк. Получение истинного (true) результата
вычисления выражения с оператором "меньше" (<) означает, например, что левосторонний
операнд представляет более ранние дату либо момент времени в пределах суток,
нежели правосторонний.
6.1. ПРОСТЫЕ ЗАПРОСЫ НА ЯЗЫКЕ SQL
257
6Л.5. Значение null и операции сравнения с null
SQL позволяет присваивать атрибутам специальные значения null. Значения null
интерпретируются различными способами и используются в нескольких типичных
ситуациях, перечисленных ниже.
1. Значение не известно: "Атрибуту (например, birthdate — "дата рождения")
должно быть присвоено значение, но не известно, какое именно".
2. Значение не применимо: "Не существует подходящих значений, которые в
конкретной ситуации имеют смысл". Если бы, например, отношение MovieStar
содержало атрибут spouse ("супруг"), в соответствующие компоненты
кортежей, представляющих сведения об актерах (актрисах), не состоящих в браке,
пришлось бы ввести значение null — не потому, что имя жены (мужа) не
известно, а из-за того, что таковой(ого) просто нет.
3. Значение умалчивается: "Точная информация не подлежит разглашению".
Примером может служить значение номера телефона (атрибут phone),
отсутствующее в общедоступном справочнике.
В разделе 5.4.7 на с. 238 мы уже говорили о том, как и почему в процессе
выполнения операции внешнего соединения (outerjoin) некоторые компоненты кортежей,
образующих пары, заполняются значениями null. Язык SQL, в свою очередь, также
поддерживает операцию внешнего соединения, где значения null находят аналогичное
применение (за полной информацией обращайтесь к разделу 6.3.8 на с. 279).
Встречаются и другие ситуации, в которых используются значения null (например, в
процессе вставки в отношение таких кортежей, не все компоненты которых заданы; об
этом рассказано в разделе 6.5.1 на с. 291).
Конструируя предложение where запроса, мы должны быть готовы к тому, что
некоторые из тестируемых компонентов кортежей могут принимать значения null.
Следует помнить о двух важных правилах обращения со значениями null.
1. Если значение null, наряду с любым другим значением (также, возможно,
равным null), является аргументом бинарного арифметического оператора,
подобного * или +, результатом всегда окажется null.
2. При сопоставлении значения null с любым другим значением (включая null)
посредством операторов сравнения, таких как = или >, в итоге будет получено
значение unknown, относящееся, подобно true и false, к логическому трехзначному
типу (подробные сведения о значении unknown приведены в следующем разделе).
Необходимо понимать, что null не относится к числу констант. Хотя указанные
правила применимы в тех случаях, когда выражения содержат значения NULL,
непосредственно использовать NULL в качестве операнда нельзя.
Пример 6.9. Пусть х содержит значение null. Значением выражения х + 3 также будет
NULL. Но null + 3 не является допустимым выражением SQL. Результатом
вычисления оператора сравнения х = 3 окажется значение unknown, поскольку мы не вправе
утверждать, равно содержимое х (null) числу 3 или нет. Аналогично, фраза NULL = 3
не относится к числу допустимых выражений SQL. □
Чтобы проверить, содержит ли х значение null, надлежит использовать
специальную логическую конструкцию SQL x is null. Выражение обращается в true,
если содержимое х действительно "равно" null, и в false — в противном случае.
Напротив, выражение х is not null в результате вычисления дает true, если
значением х не является NULL.
258
ГЛАВА 6. ЯЗЫК SQL
Как избежать ошибок при использовании значений null
Значению null в SQL, как кажется, всегда правомерно придавать следующий
смысл: "Значение, нам не известное, но определенно существующее". Однако
нетрудно привести примеры, когда подобное утверждение попросту не соответствует
действительности. Предположим, что х — это компонент некоторого кортежа и что
доменом компонента служит множество целых чисел. Можно полагать, что
значением произведения 0*х является 0, поскольку результат умножения любого числа
(независимо от его конкретного значения) на 0 всегда равен 0. Если же, однако, х
содержит значение null, для вычисления результата следует применить правило (1) из
раздела 6.1.5: произведение 0 и null есть null. Аналогично, здравый смысл
подсказывает, что выражение х-х обращается в 0, поскольку, дескать, операция вычитания
одинаковых значений всегда приводит к получению нуля. Но если допустить,
что х может содержать null, и применить то же правило, результатом окажется null.
6.1.6. Значение unknown
В разделе 6.1.2 на с. 253 говорилось, что результатом операции сравнения служит
одно из двух значений — true или false, — и такие значения могут объединяться
в более сложные логические выражения посредством операторов and, OR и NOT.
В предыдущем разделе было показано, что в тех случаях, когда аргументы операторов
сравнения содержат значения null, результатом оказываются значения unknown.
Поскольку множество логических значений пополнилось еще одним, unknown, следует
пересмотреть и правила применения к ним операторов and, or и not. Проще всего
запомнить эти правила, если воспринимать true как 1 (т.е. как нечто "полностью"
истинное), false — как 0 ("заведомо" ложное) и unknown — как Ч или иное значение
из промежутка между "истиной" и "ложью".
1. Результатом операции хШОу является минимальное из значений х и у:
выражение равно false, если любой из операндов, х или у, равен false, unknown —
если ни х, ни у не равны false и по меньшей мере один из операндов равен
unknown, и true — если и х, и у равны true.
2. Результатом операции xORy является максимальное из значений х и у:
выражение равно true, если любой из операндов, х или у, равен true, unknown —
если ни х, ни у не равны true и по меньшей мере один из операндов равен
unknown, и false — если их, иу равны false.
3. Операция отрицания (not) значения х дает в результате значение 1 -х, т.е.
выражение not х равно true, если х равно false, false — если х равно true,
и unknown — если х равно unknown.
На рис. 6.2 приведены значения логических выражений на основе операторов and, or
и not в применении ко всем возможным сочетаниям значений операндов (значения
выражения NOT* зависят только от содержимого аргументах).
Условие, задаваемое в предложении where SQL-запроса "выбрать—из—
при_условии", применяется к каждому кортежу некоторого отношения, заданного
в предложении from, и для каждого кортежа вычисляется одно из трех возможных
значений — true, false или unknown. В итоговое отношение, однако, включаются
компоненты только тех кортежей, которым отвечает значение true, — кортежи, для
которых результатом вычисления условия являются false или unknown, во внимание
не принимаются. Подобное поведение системы чревато сюрпризами, аналогичными
тем, которые рассмотрены в тексте врезки "Как избежать ошибок при использовании
значений null", и следующий пример содержит красноречивую иллюстрацию.
6.1. ПРОСТЫЕ ЗАПРОСЫ НА ЯЗЫКЕ SQL
259
X
TRUE
TRUE
TRUE
UNKNOWN
UNKNOWN
UNKNOWN
FALSE
FALSE
FALSE
У
TRUE
UNKNOWN
FALSE
TRUE
UNKNOWN
FALSE
TRUE
UNKNOWN
FALSE
x&NDy
TRUE
UNKNOWN
FALSE
UNKNOWN
UNKNOWN
FALSE
FALSE
FALSE
FALSE
xORy
TRUE
TRUE
TRUE
TRUE
UNKNOWN
UNKNOWN
TRUE
UNKNOWN
FALSE
NOT*
FALSE
FALSE
FALSE
UNKNOWN
UNKNOWN
UNKNOWN
TRUE
TRUE
TRUE
Рис. 6.2. Таблица истинности трехзначной логики
Пример 6.10. Рассмотрим следующий запрос, обращенный к отношению
Movie(title, year, length, inColor, studioName, producerC#)
из "кинематографической" базы данных:
SELECT *
FROM Movie
WHERE length <= 12 0 OR length > 120;
Как может показаться на первый взгляд, в результате обработки запроса система
возвратит отношение Movie целиком, поскольку продолжительность воспроизведения
кинофильма, что совершенно очевидно, всегда либо не больше (<=) 120 минут, либо
больше (>) 120 минут.
Предположим, однако, что в Movie существуют кортежи со значением NULL в
компонентах length. Тогда при вычислении обоих операторов сравнения, length <= 120
и length > 12 0, будут получены значения UNKNOWN. В соответствии с данными
рис. 6.2, выражение unknown or unknown также равно unknown. Таким образом, для
каждого кортежа, содержащего null в компоненте length, условие предложения
where обратится в unknown. А это значит, что кортеж не будет включен в итоговое
отношение. Поэтому истинный смысл запроса, по существу, таков: "Выбрать все
кинофильмы с известными значениями продолжительности воспроизведения".□
6.1.7. Упорядочение результатов
Зачастую необходимо, чтобы кортежи итогового отношения были упорядочены
в соответствии с некоторым критерием. Порядок сортировки может определяться
значениями нескольких атрибутов: вначале кортежи упорядочиваются по значениям
компонентов первого атрибута; кортежи, совпадающие в компонентах первого
атрибута, упорядочиваются по содержимому компонентов второго атрибута, и т.д. (как
в операторе сортировки г, рассмотренном в разделе 5.4.6 на с. 238). Чтобы получить
итоговое отношение с кортежами, отсортированными в нужном порядке, необходимо
пополнить конструкцию "select—from—where" предложением
ORDER BY <список__атрибутов>
По умолчанию значения каждого атрибута, упомянутого в списке, сортируются по
возрастанию. Чтобы изменить порядок сортировки на обратный, следует указать после
имени атрибута служебное слово DESC. Для явного задания порядка сортировки по
возрастанию может быть использовано служебное слово ASC, но делать это необязательно.
Пример 6.11. Ниже приведен дополненный вариант запроса, рассмотренного в
примере 6.1 на с. 250 и предусматривавшего поиск информации о кинофильмах,
выпущенных компанией "Disney" в 1990 году.
260
ГЛАВА 6. ЯЗЫК SQL
SELECT *
FROM Movie
WHERE studioName = 'Disney' AND year = 1990
ORDER BY length, title;
В результате обработки запроса будет получено отношение, в котором кортежи-
"кинофильмы" вначале упорядочены по возрастанию значений продолжительности
воспроизведения (length), а затем фильмы, обладающие одинаковой
продолжительностью, отсортированы по названиям (title). □
6.1.8. Упражнения к разделу 6.1
* Упражнение 6.1.1. Пусть предложение select SQL-запроса задано в виде
SELECT А В
Как это понимать? А и В являются названиями атрибутов или В — псевдоним
атрибута Л?
Упражнение 6.1.2. Сформулируйте следующие SQL-запросы к "кинематографической"
базе данных со схемами отношений рис. 6.1 (см. с. 250), воспроизведенными ниже:
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
* а) Найти адрес (address) киностудии (Studio) "MGM".
b) Определить дату рождения (birthdate) актрисы (MovieStar) Сандры Баллок.
* с) Найти всех актеров (Starsln), каждый из которых снимался либо в
фильме, выпущенном (movieYear) в 1980 году, либо в фильме, в названии
(movieTitle) которого присутствует слово "Love".
d) Найти информацию обо всех руководителях (MovieExec), обладающих
совокупным годовым доходом (netWorth) в размере не менее 10 миллионов долларов.
e) Найти всех актеров (MovieStar), каждый из которых либо мужчина
(значение 'М' атрибута gender), либо живет в Малибу (строка 'Malibu'
является частью адреса — address).
Упражнение 6.1.3. Сформулируйте следующие SQL-запросы к базе данных со схемами
отношений, рассмотренными в упражнении 5.2.1 на с. 218 и воспроизведенными ниже:
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.10 (см. с. 220) и 5.11 (см. с. 221).
* а) Найти номера моделей (model) и значения быстродействия процессора
(speed) и емкости диска (hd) всех персональных компьютеров (PC) с ценой
(price) ниже 1200 долларов.
* Ь) Выполнить задание п. (а), переименовав столбцы speed и hd итогового
отношения в megahertz и gigabytes соответственно.
c) Найти всех производителей (maker) принтеров (значение 'printer'
атрибута type).
6.1. ПРОСТЫЕ ЗАПРОСЫ НА ЯЗЫКЕ SQL
261
d) Найти номера моделей (model) и значения объема оперативной памяти
(ram) и размера экрана (screen) всех переносных компьютеров (Laptop)
с ценой (price) выше 2000 долларов.
* е) Найти все кортежи отношения Printer, представляющие сведения о
цветных принтерах (значение true атрибута color булева типа).
f) Найти номера моделей (model) и значения быстродействия процессора
(speed) и емкости диска (hd) всех персональных компьютеров (PC) с ценой
(price), не превышающей 2000 долларов, которые обладают 12- или 16-
скоростным приводом DVD (значениями *12xDVD' или '16xDVD' атрибута
rd строкового типа).
Упражнение 6.1.4. Сформулируйте следующие SQL-запросы к базе данных со
схемами отношений, рассмотренными в упражнении 5.2.4 на с. 222 и
воспроизведенными ниже:
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.12 (см. с. 223) и 5.13 (см. с. 224).
a) Найти названия классов (class) и стран (country) выпуска для всех
кораблей, на которых установлено не менее 10 (numGuns) главных орудий.
b) Найти названия (name) всех кораблей (Ships), спущенных на воду
(launched) до 1918 года, и переименовать столбец name итогового
отношения в shipName.
c) Найти названия (ship) судов, потопленных (значение ' sunk' атрибута
result) в морских сражениях, и наименования (battle) этих сражений.
d) Найти все суда (ships) с названиями (name), совпадающими с
наименованиями классов (class), к которым принадлежат эти суда.
e) Найти названия (name) всех судов (ships), начинающиеся с буквы "R".
! f) Найти названия (name) всех судов (ships), состоящие из трех и более слов
(например, "King George V").
Упражнение 6.1.5. Предположим, что а и b — целочисленные атрибуты,
допускающие присваивание значений null. Рассмотрев каждое из указанных ниже условий
предложения where, опишите точный состав множества кортежей (я, /?),
удовлетворяющих условию, включая случаи, когда а и/или b равны NULL:
* а) а = 10 or b = 20;
b) a = 10 AND b = 20;
c) а < 10 OR a >= 10;
*! d) a = b;
! e) a <= b.
! Упражнение 6.1.6. В примере 6.10 на с. 260 рассматривался запрос
SELECT *
FROM Movie
WHERE length <= 12 0 OR length >12 0;
262
ГЛАВА 6. ЯЗЫК SQL
который "ведет себя" неожиданным образом, если допустить, что атрибут length
может принимать значение null. Найдите более простой вариант запроса с
единственным выражением сравнения в предложении where (без операторов and и/или OR),
позволяющий получить тот же результат.
6.2. Запросы к нескольким отношениям
Мощь реляционной алгебры во многом обусловлена предоставляемыми ею
возможностями сочетания нескольких отношений с помощью операций соединения,
декартова произведения, объединения, пересечения и разности. Те же операции могут
быть описаны и средствами SQL. Теоретико-множественные операции —
объединения, пересечения и разности — реализованы непосредственно в языке SQL (за
подробностями обращайтесь к разделу 6.2.5 на с. 268). Однако вначале мы рассмотрим,
как в рамках конструкции запроса "select—from—where" осуществить декартово
произведение и соединение отношений.
6.2.1. Декартово произведение и соединение в SQL
SQL позволяет простым и естественным образом сочетать в одном запросе
обращения к нескольким отношениям одновременно: достаточно перечислить
наименования отношений в предложении FROM, после чего можно обращаться к их атрибутам
в предложениях select и where.
Пример 6.12. Пусть необходимо определить имя продюсера кинофильма "Star Wars".
Чтобы получить результат, необходимо воспользоваться двумя следующими
отношениями из "кинематографической" базы данных:
Movie(title, year, length, inColor, studioName, producerC#)
MovieExec(name, address, cert#, netWorth)
Сертификационный номер продюсера хранится в отношении Movie в виде значения
атрибута producerC#, и для его отыскания достаточно обратиться к Movie с простым
запросом. Затем, зная номер продюсера, мы можем выполнить запрос к отношению MovieExec,
принимая во внимание, что семантика атрибутов producerC# и cert# одинакова.
Однако в определенных ситуациях удобнее совместить два этапа процедуры поиска
в одном и адресовать отношения Movie и MovieExec единовременно:
SELECT name
FROM Movie, MovieExec
WHERE title = 'Star Wars' AND producerC# = cert#;
Запрос предусматривает рассмотрение всех пар кортежей, по одному из отношений Movie
и MovieExec. Условия сочетания кортежей в пары задаются предложением WHERE30:
1) компонент title кортежа отношения Movie обязан содержать значение
'Star Wars';
2) значения компонентов producerC# кортежа Movie и cert# кортежа
MovieExec должны быть равны.
Если пара кортежей, удовлетворяющих обоим условиям, найдена, ответом на запрос
будет значение компонента name кортежа отношения MovieExec. Если информация
введена в базу данных правильно, кортежи совпадут лишь в том случае, когда компонент
title отношения Movie содержит строку ' Star Wars ', а компонент producerC# —
такое число, совпадающее с cert# в MovieExec, которому отвечает значение компонен-
При отсутствии предложения WHERE мы получили бы конструкцию декартова
произведения отношений. — Прим. перев.
6.1. ПРОСТЫЕ ЗАПРОСЫ НА ЯЗЫКЕ SQL
263
та name, равное ' George Lucas'. Таким образом, результатом выполнения запроса
должна стать единственная строка, ■ George Lucas •. Процесс обработки запроса
иллюстрируется рис. 6.3. Подробная информация о процедурах обработки запросов,
затрагивающих одновременно несколько отношений, приведена в разделе 6.2.4 на с. 266. □
title producerC# name cert#
Значения
равны?
Это Movie I
•Star Wars'? '
Если да, это результат: 'George Lucas'
Рис. 6.3. Типичная последовательность операций при обработке
запроса к нескольким отношениям
6.2.2. Как различать одноименные атрибуты нескольких отношений
Подчас возникает потребность соединить в одном запросе несколько отношений,
обладающих одноименными атрибутами. Поэтому необходимы средства, позволяющие
однозначно определять, какой из атрибутов имеется в виду в каждом конкретном случае.
В SQL для этой цели используется конструкция "полного" имени атрибута,
включающая в качестве префикса наименование отношения, к которому относится
атрибут, и символ точки. Так, например, выражение R.A обозначает атрибут А отношения R.
Пример 6.13. Два отношения,
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
обладают атрибутами с одинаковыми именами, name и address. Предположим, что
необходимо найти пары кортежей, содержащих информацию об актерах и
руководителях индустрии кино, обладающих одинаковыми адресами (пример не очень реален,
но достаточно нагляден). Решить подобную задачу позволит следующий запрос:
SELECT MovieStar.name, MovieExec.name
FROM MovieStar, MovieExec
WHERE MovieStar.address = MovieExec.address;
Запрос предполагает отыскание таких пар кортежей, по одному из отношений MovieStar
и MovieExec, в которых значения компонентов address равны (взгляните на условие
предложения where). Из кортежей каждой пары, удовлетворяющей условию,
извлекаются значения одноименных атрибутов name и выводятся в итоговое отношение вида
MovieStar.name
Jane Fonda
MovieExec.name
Ted Turner
□
264 ГЛАВА 6. ЯЗЫК SQL
Переменные кортежей и имена отношений
Строго говоря, ссылка на атрибут отношения в предложениях select и where
всегда указывает на некоторую переменную кортежа. Если, однако, в предложении
from определенное отношение упомянуто только один раз, функцию переменной
кортежа выполняет имя отношения (в этом случае имя R отношения в
предложении from можно трактовать как сокращенный вариант выражения R as R). Как мы
говорили выше, если конфликтов имен атрибутов нет, при ссылке на них названия
отношений (переменные кортежей) могут быть опущены.
Конструкцию "полного" имени атрибута вполне позволительно применять даже
тогда, когда опасности совпадения имен атрибутов нет. Так, например, можно было
бы переписать текст запроса из примера 6.12 на с. 263:
SELECT MovieExec.name
FROM Movie, MovieExec
WHERE Movie.title = 'Star Wars'
AND Movie.producerC# = MovieExec.cert#;
В подобных запросах, где затрагиваются отношения, не имеющие одноименных
атрибутов, разрешается обозначать полными именами любые атрибуты либо не включать
названия отношений в имена атрибутов вовсе.
6.2.3. Переменные кортежей и псевдонимы отношений
Прием использования полных имен с целью различения атрибутов работает
удовлетворительно, если в запросе сочетается несколько различных отношений. Но нередко
возникает необходимость соединения нескольких кортежей одного и того же отношения.
Отношение R может быть упомянуто в предложении from столько раз, сколько
необходимо, но "копии" отношения R каким-то образом надлежит различать. SQL
позволяет сопроводить каждый экземпляр имени отношения R в предложении from
уникальным псевдонимом (alias) отношения, или переменной кортежа (tuple variable). Имя
и псевдоним отношения в предложении from разделяются (необязательным)
служебным словом AS (в дальнейшем мы будем его опускать).
Если отношению поставлен в соответствие псевдоним, он может быть31
использован вместо имени отношения во всех случаях — например, для ссылки на
(одноименные) атрибуты в предложениях select и where.
Пример 6.14. В примере 6.13 рассматривалась процедура поиска кортежа,
соответствующего актеру и руководителю, которые обладают одинаковым адресом, а здесь мы
обратимся к аналогичной задаче, предполагающей отыскание информации о двух
актерах, проживающих по одному адресу. Структура запроса — вы убедитесь в этом
чуть позже — по существу сохраняется, но теперь нам предстоит соединить два
кортежа одного и того же отношения Movies tar. Создадим псевдонимы для двух копий
отношения Movies tar и перепишем текст запроса следующим образом:
SELECT Starl.name, Star2.name
FROM MovieStar Starl, MovieStar Star2
WHERE Starl.address = Star2.address
AND Starl.name < Star2.name;
В некоторых реализациях одновременное использование в контексте запроса имени
отношения и его псевдонима, коль скоро таковой определен, не допускается. Иными словами, если
псевдоним создан, его надлежит употреблять вместо имени отношения. Помимо того, псевдонимы
отношений могут задаваться в любых ситуациях — не обязательно связанных с необходимостью
упоминания в предложении FROM нескольких "копий" одного отношения (например, для
упрощения текста запроса, если наименование отношения слишком велико). — Прим. перев.
6.2. ЗАПРОСЫ К НЕСКОЛЬКИМ ОТНОШЕНИЯМ
265
Предложение from содержит определения двух псевдонимов (переменных кортежа),
Starl и Star2, указывающих на отношение MovieStar. Псевдонимы используются
в предложении SELECT для ссылки на компоненты name двух кортежей MovieStar,
а в предложении WHERE — для выражения того факта, что два кортежа MovieStar,
представляемые переменными starl и star2, содержат одинаковые значения в
компонентах address и различаются в компонентах name.
Обратите внимание на второе выражение сравнения в предложении where,
Starl.name < Star2.name, которое подразумевает, что имена, хранимые в первом
и втором кортежах, должны быть упорядочены по алфавиту. Не будь этого условия,
мы столкнулись бы с ситуацией, когда переменные starl и star2 указывают на один
и тот же кортеж. Разумеется, условие равенства адресов позволило бы отыскать такой
кортеж (если он действительно существует), но в соответствующий кортеж итогового
отношения были бы включены два одинаковых имени.32 Помимо того, условие
Starl.name < Star2.name заставляет систему включить в результат только одну
пару "имен" с одинаковыми "адресами", упорядоченную по алфавиту. Если вместо
оператора < (или >) применить оператор неравенства, о, это приведет к выбору двух
взаимно "обратных" пар, как показано в таблице:
Starl.name
Alec Baldwin
Kim Basinger
Starl.name
Kim Basinger
Alec Baldwin
□
6.2.4. Интерпретация запросов к нескольким отношениям
Существует несколько способов толкования смысла рассмотренных выше SQL-
конструкций вида "select—from—where". Все способы равноценны в том смысле, что
приводят к одинаковому результату для каждого запроса, обращенного к одним и тем
же экземплярам отношений.
Вложенные циклы
Демонстрируя примеры SQL-запросов, мы неявно пользовались семантикой
переменных кортежа. Напомним, что множеством значений переменной кортежа служит
набор кортежей соответствующего отношения. Имя отношения, не снабженное
псевдонимом, также можно трактовать как переменную кортежа (см. врезку "Переменные
кортежей и имена отношений" на с. 265). Если существует несколько переменных
кортежа, можно представить, будто с каждой из них связан определенный цикл, в
теле которого переменная "пробегает" по всем кортежам соответствующего отношения.
Осуществляя "присваивание" переменной очередного кортежа, система проверяет,
удовлетворяется ли условие предложения where. Если да, конструируется кортеж,
состоящий из значений выражений, указанных в предложении select. При
вычислении выражений select учитываются значения компонентов "текущего" кортежа,
представляемого переменной. Рассмотренный алгоритм иллюстрируется рис. 6.4.
Параллельное присваивание
Существует и несколько иной подход к восприятию процесса обработки запроса, не
предусматривающий конструирования вложенных циклов для переменных кортежа.
Вместо этого в произвольном порядке (или параллельно) рассматриваются все возможные
32 Аналогичная проблема возникает и при выполнении запроса из примера 6.13 на с. 264,
если один и тот же человек является актером и продюсером (или президентом киностудии)
одновременно; для ее решения следует включить в предложение where такое же условие.
266
ГЛАВА 6. ЯЗЫК SQL
комбинации операций присваивания кортежей отношений соответствующим переменным.
При выполнении каждого присваивания проверяется истинность условия предложения
where. Операция присваивания, обращающая условие в true, пополняет итоговое
отношение одним кортежем; кортеж конструируется из результатов вычисления
выражений предложения select с учетом значений кортежа, участвовавшего в операции.
Объявить переменные кортежей для отношений Rlf R2, ..., Rn,
упомянутых в предложении FROM
FOR (ДЛЯ) каждого кортежа t{ отношения R{ (ВЫПОЛНИТЬ) DO
FOR (ДЛЯ) каждого кортежа t2 отношения R2 (ВЫПОЛНИТЬ) DO
FOR (ДЛЯ) каждого кортежа tn отношения Rn (ВЫПОЛНИТЬ) DO
IF (ЕСЛИ) условие предложения WHERE выполняется
при подстановке значений
из кортежей tbt2,...,tn, (ТОГДА) THEN
Вычислить выражения предложения SELECT
в соответствии с содержимым кортежей t{, t2, ..., tn
и включить полученный кортеж в результат.
Рис. 6.4. Алгоритм обработки простого SQL-запроса на основе вложенных циклов
Преобразование в выражение реляционной алгебры
Третий подход к проблеме интерпретации смысла SQL-запросов предусматривает
использование аппарата реляционной алгебры. Вначале рассматриваются переменные
кортежа из предложения from и вычисляется декартово произведение
соответствующих отношений. Если две переменные ссылаются на одно отношение, такое
отношение включается в произведение дважды, и его одноименные атрибуты во избежание
недоразумений переименовываются. По той же причине подлежат переименованию
и одноименные атрибуты, принадлежащие различным отношениям.
К полученному декартову произведению следует применить оператор выбора с тем
же условием, которое задано в предложении where запроса. Точнее говоря, каждая
ссылка на атрибут в where заменяется наименованием соответствующего атрибута
отношения, служащего результатом декартова произведения. Наконец, на основе
предложения select создается список выражений оператора (расширенной) проекции.
Как и при преобразовании выражения where, каждая ссылка на атрибут трактуется
как название соответствующего атрибута декартова произведения.
Пример 6.15. Пусть необходимо преобразовать в выражение реляционной алгебры
запрос, рассмотренный в примере 6.14 на с. 265. Предложение from содержит две
переменные кортежа, и обе ссылаются на отношение MovieStar. Основой выражения
должен служить результат вычисления декартова произведения
MovieStar x MovieStar.
Итоговое отношение включает восемь атрибутов, первые четыре из которых
соответствуют атрибутам name, address, gender и birthdate первой копии отношения
MovieStar, а вторые четыре — тем же атрибутам второй копии. Разумеется, для каждой
из копий можно было бы определить псевдоним (скажем, starl и star2) и ссылаться
сего помощью на одноименные атрибуты отношений (например, starl.gender), но
для краткости мы переименуем все атрибуты как AhA2,...,A%, так что А\ соответствует
Starl. name, А5 — Star2 . name, A2 — Starl. address, A6 — Star2 . address и т.д.
Условие выбора, заданное в предложении where, в терминах новых имен
атрибутов выглядит как A2 = A6ANDA{ <A5, а список оператора проекции — как АЬА$. Итак,
рассматриваемому запросу соответствует следующее выражение реляционной алгебры:
62. ЗАПРОСЫ К НЕСКОЛЬКИМ ОТНОШЕНИЯМ
267
Скрытые следствия семантики SQL
Предположим, что R, S и Т — отношения, каждое из которых обладает
единственным атрибутом А, и необходимо найти все значения А, присутствующие в R и либо
в 5, либо в Т, либо в 5 и Г одновременно. Иными словами, требуется вычислить
R П (S U Т). Как кажется, с задачей должен справиться запрос следующего вида:
SELECT R.A
FROM R, S, T
WHERE R.A = S.A OR R.A = Т.А;
А что произойдет, если отношение Т окажется пустым? Поскольку в этом случае
условие R.A = ТА не выполнится никогда, руководствуясь соображениями здравого
смысла и интуитивным пониманием того, как действует оператор or, можно
считать, что система возвратит результат пересечения R П S. Однако, какой из трех
рассмотренных выше подходов к интерпретации смысла запроса ни избрать, нам
придется признать, что итоговое отношение оказывается пустым — независимо от
того, каким количеством общих значений обладают отношения R и S. Если
прибегнуть к алгоритму на основе вложенных циклов, приведенному на рис. 6.4,
нетрудно убедиться, что цикл для переменной кортежа Т выполнится ни много ни
мало 0 раз, поскольку из-за отсутствия кортежей в Т переменной цикла просто
некуда "деваться". По этой причине вложенное условие if. . .then не выполнится
ни разу и, естественно, ни один из кортежей в результат не попадет. Если
попытаться применить прием, связанный с параллельным присваиванием, результат
вновь окажется отрицательным, поскольку не существует способов присвоить
переменной Т то, чего нет. Наконец, применив алгебраический подход,
предполагающий вычисление декартова произведения RxSxT, мы вновь придем к пустому
множеству, поскольку Т по определению пусто.
ЛГА А (0ГА =А ahdA <А (/9М(А А А А }(MOVieStar)X
15х 2 6 1 5х v 1 2 3 4'
PN(A a a A)(MovieStar))).
□
6.2.5. Объединение, пересечение и разность запросов
Иногда возникает необходимость в сочетании отношений посредством теоретико-
множественных операций реляционной алгебры, таких как объединение (union),
пересечение (intersection) и разность (difference). В языке SQL предусмотрены
соответствующие операторы, применяемые к результатам запросов в предположении, что запросы
возвращают отношения с совпадающими списками атрибутов и атрибуты относятся
к одинаковым доменам. Операторам объединения (U), пересечения (П) и разности (-)
соответствуют служебные слова union, intersect и except. Каждое из них
располагается между текстами двух запросов, заключенными в круглые скобки.
Пример 6.16. Пусть необходимо отыскать имена и адреса всех актрис, которые
одновременно являются президентами киностудий или продюсерами, обладающими
совокупным годовым доходом в размере свыше 10 миллионов долларов. Запрос к отношениям
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
может выглядеть так, как показано на рис. 6.5. Результатом выполнения строк 1—3
окажется отношение со схемой (name, address), кортежи которого представляют
имена и адреса всех актрис.
268
ГЛАВА 6. ЯЗЫК SQL
1) (SELECT name, address
2) FROM MovieStar
3) WHERE gender = 'F')
4) INTERSECT
5) (SELECT name, address
6) FROM MovieExec
7) WHERE netWorth > 10000000);
Рис. 6.5. "Пересечение"актрис с богатыми чиновниками
Строки 5—7 позволяют "вычислить" тех "руководящих товарищей", которые
умудрились сколотить капитал, превосходящий 10 миллионов долларов. Этот запрос также
возвратит отношение со схемой (name, address). Поскольку схемы отношений
идентичны, ничто не запрещает осуществить их пересечение — эту функцию
выполняет оператор intersect, размещенный в строке 4. □
Пример 6.17. Аналогичным образом может быть вычислена разность двух множеств
кортежей. Запрос
(SELECT name, address FROM MovieStar)
EXCEPT
(SELECT name, address FROM MovieExec)
возвратит имена и адреса тех актеров (независимо от их пола и размера
годового дохода), которые не являются одновременно продюсерами или президентами
киностудий. □
В двух предыдущих примерах атрибуты отношений, к которым адресовались
запросы, заведомо совпадали. Если подобное условие не выполняется, можно
переименовать атрибуты принудительно — так, как показано в примере 6.3 на с. 252.
Пример 6.18. Предположим, что требуется выбрать названия и даты выпуска
кинофильмов, которые упоминаются в любом из отношений
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
"кинематографической" базы данных.
(Разумеется, случай совпадения обоих множеств кинофильмов идеален. В
действительности отношения, содержащие схожие данные, зачастую различаются составом
этих данных: например, вполне реальна ситуация, когда для значения-
"кинофильма" из отношения Movie нет соответствующих значений-"актеров" в
отношении Starsln либо кортеж в starsln ссылается на такой "кинофильм",
сведения о котором отсутствуют в Movie.33)
Искомый запрос может выглядеть так:
SELECT title, year FROM Movie)
UNION
(SELECT movieTitle AS title, movieYear AS year FROM Starsln);
Результатом выполнения запроса окажется набор кортежей со сведениями о
кинофильмах, упомянутых либо в Movie, либо в Starsln, либо в обоих отношениях
одновременно. Схема итогового отношения включает атрибуты title и year. □
33 Существует ряд способов предотвращения подобных несоответствий; за дополнительной
информацией обращайтесь к разделу 7.1.4 на с. 321.
6.2. ЗАПРОСЫ К НЕСКОЛЬКИМ ОТНОШЕНИЯМ 269
Как создавать удобочитаемые SQL-запросы
Обычно текст SQL-запросов структурируется так, чтобы особо важные служебные
слова — например, from или where — и следующие за ними аргументы размещались
в новой строке. В этом случае восприятие запроса значительно облегчается. Если
же запрос или подзапрос краток, иногда его удобно расположить в одной строке
целиком (см. пример 6.17) — удобочитаемость текста от этого никак не пострадает.
6.2.6. Упражнения к разделу 6.2
Упражнение 6.2.1. Используя схемы отношений
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
из "кинематографической" базы данных, сформулируйте средствами SQL
перечисленные ниже запросы.
* а) Кто из актеров-мужчин (значение 'М' атрибута gender) участвовал в
съемках фильма "Terms of Endearment"?
b) Какие актеры снимались в фильмах, выпущенных киностудией "MGM"
в 1995 году?
c) Кто занимает пост президента киностудии "MGM"?
*! d) Какие из кинофильмов превосходят по продолжительности воспроизведения
фильм "Gone With the Wind"?
! e) Кто из руководителей индустрии кино обладает большим состоянием,
нежели Мервин Гриффин?
Упражнение 6.2.2. Сформулируйте следующие SQL-запросы к базе данных со схемами
отношений, рассмотренными в упражнении 5.2.1 на с. 218 и воспроизведенными ниже:
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.10 (см. с. 220) и 5.11 (см. с. 221).
* а) Найти наименования производителей (maker) и значения быстродействия
процессора (speed) тех переносных компьютеров (Laptop), которые
обладают диском с емкостью (hd) не ниже 30 Гбайт.
* Ь) Найти номера моделей (model) и значения цены (price) всех продуктов
(любых типов), выпускаемых производителем (maker) ' в '.
с) Найти наименования тех производителей (maker), кто выпускает
переносные (Laptop), но не персональные (рс) компьютеры.
! d) Найти те значения емкости дисков (hd), которые характерны для двух или
более персональных компьютеров (рс).
! е) Найти пары моделей (model) персональных компьютеров (РС) с
совпадающими значениями быстродействия процессора (speed) и объема
оперативной памяти (ram), исключив при этом "обратные" пары (т.е. если найдена
пара значений (*,у), пару (/, /) рассматривать не следует).
270
ГЛАВА 6. ЯЗЫК SQL
!! О Найти наименования производителей (maker), каждый из которых
выпускает по меньшей мере две различные модели компьютеров —
персональных (PC) или переносных (Laptop) — с быстродействием процессора
(speed) не ниже 1000 МГц.
Упражнение 6.2.3. Сформулируйте следующие SQL-запросы к базе данных со схемами
отношений, рассмотренными в упражнении 5.2.4 на с. 222 и воспроизведенными ниже:
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.12 (см. с. 223) и 5.13 (см. с. 224).
a) Найти все суда (ships) с водоизмещением (displacement) свыше 35 тонн.
b) Найти наименования (name) и значения водоизмещения (displacement)
и количества главных орудий (numGuns) для тех судов (ship), которые
принимали участие в сражении у острова Гуадалканал (значение
'Guadalcanal' атрибута battle).
c) Получить список всех судов, упомянутых в базе данных (имейте в виду, что
отношение ships содержит сведения не обо всех судах, которые описаны
в других отношениях).
! d) Найти все страны (country), в которых строились и линкоры, и крейсеры
(им соответствуют значения ' bb' и ' be ' атрибута type).
! е) Найти все суда (ship), которые, получив повреждения (значение • damaged'
атрибута result) в одном сражении (battle), впоследствии участвовали в других.
! f) Найти названия (name) сражений (Battles), в которых участвовало не
менее трех кораблей одной страны (country).
*! Упражнение 6.2.4. Общая форма представления SQL-запроса в терминах
реляционной алгебры такова:
7TL(crc(RlxR2x-xRn)),
где L — произвольный список атрибутов и С — некоторое условие. Список
Rb R2,.., Rn может включать несколько экземпляров имени одного и того же
отношения; подразумевается, что в подобных случаях к элементам R, списка
применяется соответствующий оператор переименования. Покажите, как представить
средствами SQL любой запрос, отвечающий указанным условиям.
! Упражнение 6.2.5. Еще одна форма записи запроса с помощью операторов
реляционной алгебры выглядит так:
Яь (ос {R\ tx R2 x — х Rn)).
Предположим, что оговорены те же требования, которые перечислены в
упражнении 6.2.4 (единственное отличие состоит в использовании оператора естественного
соединения вместо оператора декартова произведения). Покажите, как представить
средствами SQL любой запрос, отвечающий указанным условиям.
6.3. Подзапросы
Язык SQL позволяет использовать один запрос в качестве вспомогательного при
вычислении результатов другого. Запрос, служащий частью более "крупного" запроса,
принято называть подзапросом (subquery). Степень взаимной вложенности запросов не
Офаничивается и может быть произвольной. Вы уже знакомы с примерами подзапро-
6.3. ПОДЗАПРОСЫ
271
сов — в разделе 6.2.5 на с. 268 было показано, как с помощью операторов
объединения (union), пересечения (intersect) и разности (except) осуществляется слияние
двух подзапросов с целью получения результата общего запроса. Существуют и другие
способы использования подзапросов, перечисленные ниже.
1. Запрос возвращает единственное значение, которое сравнивается с другим
значением в условии предложения where.
2. Запрос возвращает отношение, используемое в предложении where с той или
иной целью.
3. Запрос оперирует отношениями, перечисленными в предложении from.
6.3.1. Подзапросы для вычисления скалярных значений
Атомарное значение, способное выступать в роли содержимого одного компонента
кортежа отношения, называют скаляром (scalar). Запросы вида "select—from—where" могут
возвращать отношения с любым числом атрибутов и произвольным количеством
кортежей. Однако зачастую требуется получить набор значений единственного атрибута.
Более того, нередко результатом запроса является единственное значение, представляющее
некоторый итог, вычисленный на основании содержимого целой группы компонентов.
Если запрос возвращает единственное значение, он может быть использован в
качестве подзапроса, заключенного в круглые скобки и располагаемого в любом месте
предложения where, где допустимо задать константу или имя атрибута .В этом случае
операндом выражения сравнения будет значение, возвращаемое подзапросом.
Пример 6.19. Вновь обратимся к заданию из примера 6.12 на с. 263, где требуется найти
имя продюсера киноленты "Star Wars". Мы вынуждены адресовать сразу два отношения,
Movie(title, year, length, inColor, studioName, producerC#)
MovieExec(name, address, cert#, netWorth),
поскольку только в первом из них имеется информация о названиях кинофильмов
и только во втором — сведения об именах продюсеров. Элементы информации
связаны посредством значений "сертификационных номеров". Каждый продюсер обладает
уникальным номером. Прежнее решение выглядело так:
SELECT name
FROM Movie, MovieExec
WHERE title = 'Star Wars' AND producerC# = cert#;
Можно взглянуть на задачу и под другим углом. Отношение Movie необходимо
только для получения сертификационного номера продюсера кинофильма "Star Wars". Как
только номер найден, его можно использовать при обращении к MovieExec для
отыскания имени человека, обладающего этим номером. Первая часть задачи, связанная
с поиском сертификационного номера, решается с помощью подзапроса, а его
результат, который, как мы полагаем, представляет собою единственное значение,
используется "основным" запросом. Текст запроса в новой редакции приведен на рис. 6.6.
Итог операции окажется таким же, как при использовании прежнего запроса.
1) SELECT name
2) FROM MovieExec
3) WHERE cert# =
4) (SELECT producerC#
5) FROM Movie
6) WHERE title = 'Star Wars'
);
Рис. 6.6. Использование подзапроса для отыскания единственного значения
272
ГЛАВА 6. ЯЗЫК SQL
Строки 4—6 рис. 6.6 содержат текст подзапроса. Если рассматривать его отдельно,
вполне очевидно, что результатом окажется отношение с одним атрибутом,
producerC#, и, как можно полагать, единственным кортежем. Кортеж может
выглядеть как, скажем, (12345), т.е. содержать некоторое целочисленное значение, которое
поставлено в соответствие Джорджу Лукасу — продюсеру фильма "Star Wars". Если бы
подзапрос возвратил более одного кортежа или не возвратил ничего, такая ситуация
была бы воспринята системой как ошибка периода выполнения (runtime error).
После того как подзапрос, указанный в строках 4—6, успешно обработан, в правую
часть оператора сравнения в предложении where подставляется результат подзапроса
(например, число 12345) и начинает выполняться "основной" запрос (см. строки 1—
3). Иными словами, на этом этапе текст запроса может быть представлен как
SELECT name
FROM MovieExec
WHERE cert# = 12345;
Если информация базы данных верна, результатом его выполнения окажется строка
'George Lucas'. □
6.3.2. Условия уровня отношения
В SQL предусмотрен ряд операторов, которые применяются к некоторому
отношению R в целом и возвращают булево значение. В данном случае мы говорим об R как об
итоге выполнения определенного подзапроса вида "select—from—where". Некоторые из
упомянутых операторов — in, all и any — вначале рассмотрены в их простой форме,
когда подзапрос возвращает скалярное значение s. В этой ситуации подразумевается, что
отношение R содержит только один атрибут. Определения операторов даны ниже.
1. Условие exists R равно true, если и только если R не пусто.
2. Условие s in R равно true, если и только если s равно одному из значений в R.
Напротив, условие s NOT IN R обращается в true, если и только если s не равно
ни одному из значений в R. За сведениями о расширенных версиях операторов
IN и not IN, допускающих наличие в R нескольких атрибутов (тогда s — вместо
s мы будем использовать обозначение t — представляет собой не отдельное
значение, а кортеж), обращайтесь к разделу 6.3.3.
3. Условие s > all R равно true, если и только если s превосходит все значения
в R. Оператор > может быть заменен любым из пяти других операторов
сравнения (=, >=, <, <= и <>); соответственно изменится и смысл условия в целом:
например, условие s < all R равно true, если и только если s меньше всех
значений в R. Выражения s о all R и s not in R эквивалентны.
4. Условие s > any R равно true, если и только если s превосходит по меньшей
мере одно значение в R. Оператор > может быть заменен любым из пяти других
операторов сравнения. Выражения s = any R и s in R эквивалентны.
Выражения с операторами exists, all и any, как и все другие булевы выражения,
могут использоваться в качестве аргументов оператора отрицания, not. Так,
например, выражение not exists/? обращается в true, если и только если R пусто,
требование not s > all R выполняется, если и только если s не является максимальным
значением в R, а условие not s > any R справедливо, если и только если s равно
минимальному значению в R. Примеры, иллюстрирующие приемы использования
перечисленных операторов, рассмотрены ниже.
6.3.3. Условия уровня кортежа
Кортеж в SQL представляется списком скалярных значений, заключенным в
круглые скобки. Примерами могут служить (123, 'foo') и (name, address, netWorth):
6.3. ПОДЗАПРОСЫ
273
в первом случае компонентами кортежа являются константы, а во втором — атрибуты.
Допустима и смешанная форма представления — скажем, (name, address, 10000000).
Если кортеж / обладает компонентами, соответствующими атрибутам отношения R,
допустимо сопоставлять / с R с помощью операторов, рассмотренных в разделе 6.3.2. В
качестве примеров можно привести выражения tiNR и к> anyR (последнее означает, что в R
имеется по меньшей мере один кортеж, отличный от г). Для обеспечения корректности
операции сравнения кортежа t с кортежами отношения R необходимо, чтобы порядок
следования компонентов в t соответствовал принятому порядку перечисления атрибутов R.
1) SELECT name
2) FROM MovieExec
3) WHERE cert# IN
4) (SELECT producerC#
5) FROM Movie
6) WHERE (title, year) IN
7) (SELECT movieTitle, movieYear
8) FROM Starsln
9) WHERE starName = 'Harrison Ford'
)
) ;
Рис. 6.7. Поиск имен продюсеров кинофильмов, в которых
снимался конкретный актер
Пример 6.20. На рис. 6.7 приведен текст запроса с использованием трех отношений из
"кинематографической" базы данных,
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieExec(name, address, cert#, netWorth),
предполагающего поиск имен продюсеров всех кинофильмов, в съемках которых
принимал участие актер Гаррисон Форд. Запрос содержит два подзапроса, вложенных
один в другой.
Запрос, содержащий иерархию вложенных подзапросов, следует анализировать
"изнутри наружу". Поэтому рассмотрим вначале "самый" внутренний подзапрос,
описываемый строками 7—9. Запрос проверяет кортежи отношения starsln, выбирает те из
них, в компонентах starName которых содержится значение 'Harrison Ford', и
возвращает значения компонентов movieTitle и movieYear выбранных кортежей.
Напомним, что ключом отношения Movie служат атрибуты title ("название") и year ("год
производства"), а не один атрибут title, как могло бы показаться, поскольку он один
не в состоянии обеспечить уникальность кортежей. Результат, который возвращается
подзапросом, описанным в строках 7—9, может выглядеть так, как показано на рис. 6.8.
Теперь обратимся к "среднему" подзапросу (см. строки 4—6). Он предусматривает
просмотр отношения Movie с целью отыскания кортежей, компоненты title и year которых
содержат те же значения, что и кортежи отношения, возвращенного вложенным запросом.
Из каждого кортежа, найденного в Movie, извлекается значение компонента producerC#.
Результатом "среднего" запроса окажется отношение с одним атрибутом, содержащее
набор сертификационных номеров продюсеров фильмов с участием Гаррисона Форда.
Наконец, исследуем "основной" запрос, определенный в строках 1—3. Запрос
предполагает поиск таких кортежей отношения MovieExec, компоненты cert#
которых содержат значения, присутствующие в отношении, полученном при выполнении
"среднего" запроса. Из каждого найденного кортежа считывается значение
компонента имени (name) продюсера и помещается в итоговое отношение. □
274
ГЛАВА 6. ЯЗЫК SQL
title
Star Wars
Raiders of the Lost Ark
The Fugitive
year
1977
1981
1993
Рис. 6.8. Экземпляр отношения, возвращаемого "средним"
подзапросом SQL-запроса на рис. 6.7
Стоит заметить, что запрос с подзапросами, представленный на рис. 6.7, как и
многие другие запросы, допускает представление в виде "плоского" выражения "select-from-
where", в предложении from которого перечислены все отношения, упомянутые в тексте
основного запроса и его подзапросов. Связи in заменяются условиями равенства,
размещаемыми в предложении where. Например, запрос, показанный на рис. 6.7, может
быть заменен равноценным запросом, демонстрируемым на рис. 6.9. Однако для
последнего случая характерна одна особенность, касающаяся обработки кортежей,
соответствующих одному и тому же продюсеру, и мы расскажем о ней в разделе 6.4.1 на с. 283.
SELECT name
FROM MovieExec, Movie, Starsln
WHERE cert# = producerC# AND
title = movieTitle AND
year = movieYear AND
starName = 'Harrison Ford';
Рис. 6.9. Запрос без подзапросов для решения задачи из упражнения 6.20
6.3.4. Коррелированные подзапросы
Подзапросы самых простых типов могут выполняться только один раз, и их
результаты используются во "внешних" запросах. В более сложных случаях подзапрос
должен обрабатываться многократно, по одному разу для каждого значения,
получаемого подзапросом извне. Подобные подзапросы принято называть коррелированными
(correlated subquery). Рассмотрим пример, иллюстрирующий сказанное.
Пример 6.21. Пусть требуется найти все кинофильмы, названия которых повторяются
два раза и более. Начнем с построения внешнего запроса, который предполагает
просмотр всех кортежей отношения
Movie(title, year, length, inColor, studioName, producerC#).
Для каждого из кортежей выполняется подзапрос, призванный определить, существуют
ли другие кинофильмы с тем же названием и датой выпуска, превосходящей значение
даты для текущего кортежа-"кинофильма". Полный текст запроса показан на рис. 6.10.
Как и в других случаях, рассмотрим вначале внутренний запрос, определенный
в строках 4—6. Если мысленно заменить атрибут Old. title конкретным строковым
значением, таким как ' King Kong', станет ясно, что подзапрос предполагает поиск
значений года выпуска всех кинофильмов с названием "King Kong", но отличается от
подзапроса, описанного в строках 7—9 рис. 6.7, тем, что точное значение Old. title
заранее не известно. Однако по мере просмотра кортежей Movie в процессе
обработки внешнего запроса (см. строки 1—3) каждый из них предоставляет значение
Old. title для использования во вложенном запросе с целью вычисления условия
предложения where, охватывающего строки 3—6.
Условие, заданное в строке 3, выполняется, если любой кинофильм с названием,
совпадающим с содержимым Old. title, обладает большим значением year, нежели
63. ПОДЗАПРОСЫ
275
то, которое хранится в кортеже, представляемом текущим значением переменной
кортежа old. Условие сохраняет значение true, если только содержимое компонента
year переменной кортежа old не равно максимальной из дат выпуска кинофильмов с
тем же названием. Следовательно, при выполнении строк 1—3 запроса будет
возвращено количество копий определенного названия, на единицу меньшее34 общего
количества фильмов с этим названием: строка, использованная в качестве названия
фильмов дважды, будет выведена один раз, одинаковое название трех фильмов в итоговом
отношении будет упомянуто два раза и т.д.35 □
1) SELECT title
2) FROM Movie Old
3) WHERE year < ANY
4) (SELECT year
5) FROM Movie
6) WHERE title = Old.title
);
Рис. 6.10. Пример коррелированного подзапроса
При написании коррелированного подзапроса важно помнить о контекстах имен.
Обычно атрибут, упоминаемый в подзапросе, принадлежит одной из переменных
кортежа, перечисленных в предложении from подзапроса, если атрибут является частью
схемы отношения, соответствующего этой переменной. В противном случае атрибут
должен принадлежать одному из запросов более высокого уровня. Поэтому year
в строке 4 и title в строке 6 рис. 6.10 указывают на атрибуты переменной кортежа,
соответствующей копии отношения Movie, "объявленной" в строке 5.
Чтобы явно задать принадлежность атрибута той или иной переменной кортежа,
следует предварить его имя названием этой переменной и символом точки. Вот
почему во внешнем запросе мы ввели в обращение псевдоним Old отношения Movie
и используем этот псевдоним в строке 6. Если бы отношения, указанные в обоих
предложениях from (cm. строки 2 и 5), оказались различными, потребность в
использовании псевдонима просто не возникла бы и мы могли бы непосредственно
обращаться из текста подзапроса к атрибутам отношения, указанного в строке 2.
6.3.5. Подзапросы в предложениях from
Подзапросы могут использоваться и в роли отношений, перечисляемых в
предложении from внешнего запроса. В этом случае текст подзапроса заключается в круглые
скобки и помещается в список имен отношений предложения from. Поскольку
итоговое отношение, получаемое в результате обработки подзапроса, заведомо
безымянно, его следует снабдить соответствующим псевдонимом. Это даст возможность
ссылаться на кортежи отношения, возвращаемого подзапросом, точно так же, как при
обращении к обычным отношениям из списка from.
Пример 6.22. Рассмотрим задание из примера 6.20 на с. 274, связанное с отысканием
данных о продюсерах фильмов, в которых снимался актер Гаррисон Форд. Предполо-
Точнее говоря, меньшее на число, равное количеству одноименных кинофильмов с
одинаковым максимальным значением года выпуска, если допустить, что в одном году могут быть
сняты несколько фильмов с одним и тем же названием (т.е. атрибуты title и year не
образуют ключ, достаточный для однозначного описания кинофильма). — Прим. перев.
35 Пример предоставляет удачную возможность напомнить, что отношения в SQL по своему
существу являются мультимножествами, а не множествами. SQL предлагает различные способы
удаления кортежей-дубликатов — более подробно эта тема освещена в разделе 6.4.1 на с. 283.
276
ГЛАВА 6. ЯЗЫК SQL
жим, что имеется запрос, способный возвратить отношение, которое содержит
сертификационные номера всех этих продюсеров. Связав отношение с отношением
MovieExec, мы сможем легко определить имена продюсеров. Текст соответствующего
запроса приведен на рис. 6.11.
1) SELECT name
2) FROM MovieExec, (SELECT producerC#
3) FROM Movie, Starsln
4) WHERE title = movieTitle AND
5) year = MovieYear AND
6) starName = 'Harrison Ford'
7) ) Prod
8) WHERE cert# = Prod.producerC#;
Рис. 6.11. Пример SQL-запроса с подзапросом в предложении FROM
Строки 2—7 содержат описание предложения from внешнего запроса. Список
FROM, наряду с отношением MovieExec, содержит текст подзапроса, заключенный
в круглые скобки. Подзапрос соединяет отношения Movie и starsln посредством
сравнения содержимого их атрибутов (строки 3—5), оговаривает имя актера (строка 6)
и возвращает отношение с множеством сертификационных номеров продюсеров,
обозначенное как Prod. Условие равенства сертификационных номеров (строка 8)
обеспечивает соединение отношений MovieExec и Prod. Запрос возвращает множество
значений атрибута name отношения MovieExec, которым соответствуют значения
атрибута producerC# отношения Prod. □
6.3.6. Выражения соединения в SQL
SQL позволяет использовать различные варианты оператора соединения (join) двух
отношений с целью конструирования новых отношений. Речь идет об операторах
декартова произведения (Cartesian product), естественного соединения (natural join), mema-
соединения (theta-join) и внешнего соединения (outerjoin). Операторы могут применяться
как в виде самостоятельных запросов, так и в контексте подзапросов в предложениях
from конструкций "select—from—where".
Простейшая форма выражения соединения в SQL носит название перекрестного
соединения (cross join); термин является синонимом декартова произведения
(см. раздел 5.2.5 на с. 210). Например, при необходимости получения декартова
произведения двух отношений
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
можно написать
Movie CROSS JOIN Starsln;
и результатом окажется отношение с девятью столбцами-атрибутами отношений-
операндов Movie и starsln, кортежи которого представляют собой все возможные
пары кортежей из Movie и Starsln.
Атрибуты отношения перекрестного соединения могут быть обозначены как R.A, где
R — название одного из соединенных отношений, а А — любой из его атрибутов. Если
атрибут А присутствует в схеме только одного из отношений, участвующих в операции
соединения, префикс "/?.", как обычно, опускается. В нашем примере отношения
Movie и Starsln не содержат одноименных атрибутов, поэтому атрибуты итогового
отношения будут обозначены теми же именами, что и в отношениях-операндах.
6.3. ПОДЗАПРОСЫ
277
Декартово произведение в его "чистом" виде, однако, используется относительно
редко. Более широкое применение находит операция тета-соединения, обозначаемая с
помощью служебного слова on: между именами отношений-аргументов R и S задается
служебное слово join, а затем, после слова on, формулируется требуемое условие соединения.
Смысл конструкции R join S ON С состоит в вычислении декартова произведения
R х S с последующим применением операции выбора по критерию С, заданному после on.
Пример 6.23. Пусть необходимо соединить отношения
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
в предположении, что слиянию подлежат только такие кортежи, которые ссылаются
на один и тот же "кинофильм". Иными словами, соединяемые кортежи должны
обладать одинаковыми значениями компонентов title (movieTitle) и year
(movieYear). Запрос можно записать как
Movie JOIN StarsIN ON
title = movieTitle AND year = movieYear;
Результатом вновь окажется отношение с девятью столбцами, обозначенными их
исходными именами. Согласно заданному условию, кортеж Movie будет соединен с некоторым
кортежем starsln, однако, только в том случае, если кортежи совпадают в значениях
компонентов "названия" и "года производства". В итоге два столбца итогового
отношения окажутся избыточными, поскольку пары компонентов title/movieTitle
и у ear/mo vieYear содержат заведомо одинаковые значения. Если подобные
избыточные данные не нужны, выражение соединения следует поместить в виде подзапроса
в предложение from конструкции "select—from" и перечислить в предложении select
только те атрибуты, которые вас интересуют. Так, в результате обработки запроса
SELECT title, year, length, inColor, studioName,
producerC#, starName
FROM Movie JOIN StarsIN ON
title = movieTitle AND year = movieYear;
будет получено отношение с семью столбцами, содержащее сведения о каждом
кинофильме и актере, принимавшем участие в съемках этого кинофильма. □
6.3.7. Естественное соединение
Как мы говорили в разделе 5.2.6 на с. 211, естественное соединение (natural join)
отличается от операции тета-соединения тем, что:
1) единственное условие соединения двух отношений состоит в равенстве
значений компонентов их одноименных атрибутов;
2) один атрибут каждой пары одноименных атрибутов удаляется из итогового
отношения.
Операция естественного соединения выполняется в SQL точно так же, как в
реляционной алгебре, и аналогом оператора х является пара служебных слов
NATURAL JOIN.
Пример 6.24. Пусть необходимо выполнить естественное соединение отношений
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth).
В результате должно быть получено отношение с атрибутами name и address, а также
всеми остальными атрибутами исходных отношений. Кортеж итогового отношения,
как предполагается, представляет сведения о людях, которые одновременно являются
278
ГЛАВА 6. ЯЗЫК SQL
актерами и президентами киностудий либо продюсерами, — их имена (name), адреса
(address), пол (gender), даты рождения (birthdate), сертификационные номера
(cert#) и значения совокупного годового дохода (netWorth). Для получения такого
отношения достаточно выполнить следующий запрос:
MovieStar NATURAL JOIN MovieExec;
□
6.3.8. Внешние соединения
Операторы внешнего соединения (outerjoins), которые мы уже рассматривали прежде
(см. раздел 5.4.7 на с. 238), предназначены для пополнения итогового отношения
информацией висящих кортежей (dangling tuples). В процессе естественного соединения
некоторые кортежи одного из пары отношений (скажем, R) остаются "висящими",
если они не совпадают в атрибутах, общих для двух отношений, ни с одним кортежем
другого отношения, S. В итоговом отношении компонентам висящих кортежей R для
атрибутов, отсутствующих в R, и компонентам висящих кортежей S для атрибутов,
отсутствующих в S, присваиваются специальные значения null. Для ссылки на значения
null в SQL используется служебное слово null.
Пример 6.25. Предположим, что требуется выполнить внешнее соединение отношений
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth).
В SQL операцию внешнего соединения, предполагающую включение в итоговое
отношение висящих кортежей из обоих отношений-операндов, принято называть полным
внешним соединением (full outerjoin). Ее синтаксис не таит в себе ничего неожиданного:
MovieStar NATURAL FULL OUTER JOIN MovieExec
В результате будет получено отношение с теми же шестью атрибутами, что и при
выполнении запроса, рассмотренного в примере 6.24. Кортежи отношения, однако,
можно отнести к трем различным категориям. Всем лицам, являющимся
одновременно актерами и президентами киностудий (продюсерами), соответствуют кортежи, все
шесть компонентов которых отличны от null (это именно те кортежи, которые
составляют содержимое итогового отношения из примера 6.24).
Ко второй категории относятся кортежи, содержащие сведения об актерах, не
упомянутых в числе руководящих лиц. Значения компонентов name, address, gender
и birthdate таких кортежей заимствованы из MovieStar, а остальные компоненты
(cert# и netWorth), отвечающие атрибутам схемы MovieExec, содержат значения NULL.
Третью категорию составляют кортежи с информацией о руководителях, которые
не совмещают свою деятельность с актерским ремеслом. В этих кортежах значения
компонентов name, address, cert# и netWorth взяты из соответствующих кортежей
MovieExec, а компонентам gender и birthdate, относящимся к схеме MovieStar,
присвоены значения null. Экземпляр отношения, показанный на рис. 6.12,
представляет кортежи всех трех названных категорий. □
пате
Mary Tyler Moore
Tom Hanks
George Lucas
address
Maple St.
Cherry Ln.
Oak Rd.
gender
,F.
■M'
NULL
birthdate
9/9/99
8/8/88
NULL
cert#
12345
NULL
23456
netWorth
$100...
NULL
$200. . .
Puc. 6.12. Три кортежа из результата полного внешнего соединения отношений MovieStar
иMovieExec
6.3. ПОДЗАПРОСЫ
279
Все разновидности операции внешнего соединения, упоминавшиеся в разделе 5.4.7
на с. 238, также доступны и в SQL. Если необходимо выполнить процедуру левого
(left) (правого — right) внешнего соединения, full следует заменить служебным
словом left (right). Например, при выполнении операции
MovieStar NATURAL LEFT OUTER JOIN MovieExec
в итоговое отношение будут включены только первые два кортежа рис. 6.12, но не
третий. Напротив, в результате обработки запроса
MovieStar NATURAL RIGHT OUTER JOIN MovieExec
будет получено отношение с кортежами, аналогичными первому и третьему кортежам
рис. 6.12, но не второму.
Теперь рассмотрим операцию внешнего тета-соединения (theta-outerjoin). В этом
случае из SQL-выражения изымается слово natural, но включается конструкция on,
содержащая требуемое логическое условие. Если выражение внешнего тета-
соединения содержит служебное слово full, речь идет о полном внешнем тета-
соединении (full theta-outerjoin). Если же вместо full в нем упоминается слово left
(right), имеется в виду левое (left) (правое — right) внешнее тета-соединение.
Пример 6.26. Вновь обратимся к примеру 6.23 (см. с. 278), в котором рассматривается
задача соединения кортежей отношений Movie и Stars In при условии попарного
равенства компонентов title/movieTitle и year/movieYear. При выполнении
операции полного внешнего соединения,
Movie FULL OUTER JOIN Stars In ON
title = movieTitle AND year = movieYear;
в итоговое отношение будут включены не только кортежи Movie для фильмов с
участием актеров, упомянутых в stars In, но и висящие кортежи Movie для фильмов,
сведения о которых отсутствуют в Stars In (компонентам movieTitle, movieYear
и starName присваиваются значения NULL), а также висящие кортежи Stars In для
актеров, не принимавших участия в съемках фильмов, описанных в Movie (значения NULL
присваиваются компонентам, соответствующим всем шести атрибутам схемы Movie). □
Если в запросе, рассмотренном в примере 6.26, full заменить на left,
Movie LEFT OUTER JOIN Stars In ON
title = movieTitle AND year = movieYear;
итоговое отношение будет содержать те же кортежи, что и прежде, за исключением
висящих кортежей из stars in. Напротив, операция правого внешнего тета-соединения
Movie RIGHT OUTER JOIN Starsln ON
title = movieTitle AND year = movieYear;
позволит исключить висящие кортежи отношения Movie.
6.3.9. Упражнения к разделу 6.3
Упражнение 6.3.1. Сформулируйте перечисленные ниже запросы к отношениям
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
базы данных, рассмотренной в упражнении 5.2.1 на с. 218. Каждый из запросов
обязан содержать, самое меньшее, один подзапрос и должен быть оформлен двумя
различными способами (например, с применением разных наборов операторов
EXISTS, IN, ALL И ANY).
280
ГЛАВА 6. ЯЗЫК SQL
* а) Найти производителей (maker) персональных компьютеров (рс) с
быстродействием процессора (speed) не ниже 1200 МГц.
b) Найти информацию о принтерах (Printer) с максимальным значением
цены (price).
! с) Найти информацию о переносных компьютерах (Laptop), быстродействие
процессора (speed) которых ниже, нежели у любого персонального
компьютера (PC).
! d) Найти номер модели (model) продукта — персонального (рс) или
переносного (Laptop) компьютера либо принтера (printer) — с наивысшим
значением цены (price).
! е) Найти производителя (maker) цветного (значение true атрибута color)
принтера (Printer) с самой низкой ценой (price).
!! f) Найти производителей (maker) персональных компьютеров (РС),
обладающих самым быстродействующим (speed) процессором среди тех
компьютеров, которые оснащены оперативной памятью самого низкого объема (ram).
Упражнение 6.3.2. Сформулируйте перечисленные ниже запросы к отношениям
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
базы данных, рассмотренной в упражнении 5.2.4 на с. 222. Каждый из запросов
обязан содержать, самое меньшее, один подзапрос и должен быть оформлен двумя
различными способами (например, с применением разных наборов операторов
EXISTS, IN, ALL И ANY).
a) Найти наименования стран (country), строивших корабли с наибольшим
количеством (numGuns) главных орудий.
*! Ь) Найти классы (class) судов, по меньшей мере один из которых оказался
потопленным (значение 'sunk' атрибута result) в сражении.
c) Найти названия (name) судов (Ships), обладающих орудиями калибра
(bore) 16 дюймов.
d) Найти названия (name) морских сражений (Battles), в которых принимали
участие корабли класса (class) ' Kongo '.
!! е) Найти названия (name) кораблей (Ships), количество (numGuns) главных орудий
которых было наибольшим среди судов с орудиями того же калибра (bore).
! Упражнение 6.3.3. Перепишите запрос, приведенный на рис. 6.10 (см. с. 276), не
пользуясь какими бы то ни было подзапросами.
! Упражнение 6.3.4. Рассмотрим выражение ttl(RiXR2x-xRn) реляционной
алгебры, где L — список атрибутов, таких, что все они принадлежат отношению Rx.
Покажите, что выражение можно сформулировать в виде SQL-запроса, пользуясь
только подзапросами. Иными словами, представьте запрос, ни одно из
предложений from которого не содержит более одного названия отношения.
! Упражнение 6.3.5. Заново сформулируйте следующие запросы, не используя
операторы пересечения или разности:
* а) запрос рис. 6.5 (см. с. 269), иллюстрирующий операцию пересечения;
b) запрос из примера 6.17 (см. с. 269), демонстрирующего операцию
вычисления разности.
6.3. ПОДЗАПРОСЫ
281
!! Упражнение 6.3.6. Определенные операторы SQL допустимо трактовать как
избыточные, поскольку их всегда можно заменить другими операторами. Например, в
разделе 6.3.2 на с. 273 утверждалось, что выражения s in/? и 5 = any/? являются
эквивалентными. Докажите избыточность операторов exists и not exists,
продемонстрировав, как любое из выражений вида exists R или not exists R можно заменить
выражением без служебного слова exist (за исключением тех экземпляров этого
слова, которые, возможно, присутствуют в выражении R как таковом). Воспользуйтесь
советом: не забывайте, что в предложении select разрешено использовать константы.
Упражнение 6.3.7. Опишите категории кортежей отношений
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
"кинематографической" базы данных, которые будут присутствовать в итоговых
отношениях, полученных в результате выполнения следующих запросов:
a) Studio CROSS JOIN MovieExec;;
b) Starsln NATURAL FULL OUTER JOIN MovieStar;;
c) Starsln FULL OUTER JOIN MovieStar ON name = starName;.
*! Упражнение 6.З.8. Используя схемы отношений
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
базы данных, рассмотренной в упражнении 5.2.1 на с. 218, напишите SQL-запрос,
способный представить полную информацию обо всех продуктах — персональных
компьютерах (PC), переносных компьютерах (Laptop) и принтерах (Printer), —
включая сведения о производителе (maker) (если таковые существуют), а также
любые имеющиеся данные о продукте (т.е. такие, которые можно найти в
соответствующем отношении).
Упражнение 6.3.9. Используя схемы отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
базы данных, рассмотренной в упражнении 5.2.4 на с. 222, напишите SQL-запрос,
способный представить полную информацию о судах (ships), включая сведения,
имеющиеся в отношении Classes. Если судов, упомянутых в Classes, в Ships
нет, использовать подобные кортежи Classes не следует.
! Упражнение 6.3.10. Выполните задание упражнения 6.3.9, обеспечив включение
в итоговое отношение информации о судах, название которых совпадает с именем
С класса, если класс С не упоминается в отношении ships.
! Упражнение 6.3.11. Операторы соединения (join), не относящиеся к категории
операторов внешнего соединения (outerjoin), о которых мы рассказали выше, допустимо
трактовать как избыточные, поскольку их всегда можно заменить
соответствующими выражениями вида "select—from—where". Поясните, каким образом можно
переписать в форме конструкций "select—from—where" следующие выражения:
* a) r cross join s;;
b) R NATURAL JOINS;;
c) r join s ON С;, где С — некоторое условие.
282
ГЛАВА 6. ЯЗЫК SQL
6.4. Операции над отношениями
В этом разделе мы сосредоточим внимание на операциях, которые выполняются
над отношениями в целом, а не над отдельными кортежами или их сочетаниями (как,
например, при соединении кортежей нескольких отношений). Вначале следует
обратить внимание на тот факт, что в SQL отношения трактуются как мультимножества,
а не множества, и любой кортеж может быть включен в отношение многократно.
В разделе 6.4.1 будет показано, как обеспечить преобразование отношения-
мультимножества в множество, а в разделе 6.4.2 (см. с. 284) — напротив, как
предотвратить возможное удаление кортежей-дубликатов в тех ситуациях, когда системой
предусмотрено именно такое поведение.
Затем мы расскажем о том, как в SQL поддерживается оператор группирования
и агрегирования у (см. раздел 5.4.4 на с. 235). В языке SQL реализованы целый ряд
операторов агрегирования и предложение group by, позволяющее осуществлять
группирование кортежей. Имеется и специальное предложение having,
обеспечивающее возможность выбора групп как единых сущностей.
6.4.1. Удаление кортежей-дубликатов
Как утверждалось в разделе 6.3.4 на с. 275, понятие отношения в SQL отличается
от абстрактной модели отношений (см. главу 3 на с. 87), в соответствии с которой
отношение-множество не способно содержать более одной копии каждого кортежа.
В процессе создания отношения как результата обработки запроса SQL-система
обычно не удаляет кортежи-дубликаты, поэтому каждый различный кортеж может
повторяться в отношении несколько раз.
В разделе 6.2.4 на с. 266 мы говорили, что один из равноценных способов
интерпретации SQL-конструкции "select-from-where" связан с вычислением декартова
произведения отношений, упомянутых в предложении from. Для каждого кортежа
произведения проверяется, удовлетворяется ли условие предложения where; если ответ
положителен, кортеж подвергается операции проекции на выражения предложения select
и включается в итоговое отношение. В результате проекции различные кортежи могут
быть преобразованы в одинаковые. Более того, поскольку SQL не запрещает
дублирование кортежей и в исходных отношениях, служащих операндами декартова
произведения, количество повторяющихся кортежей в итоговом отношении еще более возрастает.
Если дублирования кортежей необходимо избежать, после слова select
указывается служебное слово distinct, аналогичное по смыслу оператору 8 реляционной
алгебры (см. раздел 5.4.1 на с. 233).
Пример 6.27. Вновь рассмотрим запрос, приведенный на рис. 6.9 (см. с. 275), где речь
идет о поиске продюсеров тех фильмов, в которых снимался актер Гаррисон Форд.
В результате выполнения такого варианта запроса строка, подобная 'George Lucas*,
будет присутствовать в итоговом отношении многократно. Если необходимо, чтобы
имя каждого продюсера включалось в отношение только один раз, предложение
select запроса можно изменить так:
1) SELECT DISTINCT name
Теперь, прежде чем возвратить итоговое отношение, система осуществит
принудительное удаление всех кортежей-дубликатов.
Выполнение запроса с подзапросами, представленного на рис. 6.7 (см. с. 274), между
прочим, вовсе не обязательно приводит к получению "лишних" кортежей. Да,
разумеется, подзапрос в строке 4 может вернуть несколько копий сертификационного номера
одного и того же продюсера (такого как Джордж Лукас). Однако в "основном" запросе
каждый кортеж отношения MovieExec просматривается только один раз. Если полагать,
6.4 ОПЕРАЦИИ НДД ОТНОШЕНИЯМИ
283
Во что обходится удаление кортежей-дубликатов
Как может показаться на первый взгляд, включение служебного слова distinct
в заголовок любого запроса не сулит ничего плохого. Но на самом деле операция
удаления из отношения повторяющихся кортежей весьма дорогостояща.
Отношение подлежит предварительной сортировке или разбиению, чтобы идентичные
кортежи оказались соседними (подобные алгоритмы рассмотрены в разделе 15.2.2 на
с. 694). Только после такого группирования система в состоянии определить,
требуется ли удалять тот или иной кортеж. Время, затрачиваемое на сортировку
отношения, зачастую многократно превышает время, необходимое для обработки
запроса. Поэтому, если мы хотим получать результаты выполнения запроса
настолько быстро, насколько возможно, служебное слово distinct следует использовать
только в тех ситуациях, где без него действительно не обойтись.
что тому же Джорджу Лукасу соответствует всего один кортеж в MovieExec (так и
должно быть), именно этот кортеж и удовлетворит условию where в строке 3. Следовательно,
имя каждого продюсера будет помещено в итоговое отношение только однократно. □
6.4.2. Дубликаты в объединениях, пересечениях и разностях отношений
В отличие от выражения select, при обработке которого удаление кортежей-
дубликатов по умолчанию не предусмотрено и может быть инициировано только
заданием служебного слова DISTINCT, операции объединения (union), пересечения
(intersection) и разности (difference) отношений, рассмотренные в разделе 6.2.5 на с. 268,
обычно предполагают предварительное удаление повторяющихся кортежей. Иными
словами, отношения-мультимножества преобразуются в множества и только потом
к ним применяется та или иная операция. Чтобы предотвратить действия по удалению
кортежей-дубликатов, каждое из служебных слов union, intersect и except следует
сопроводить служебным словом all. В этом случае операции будут выполняться по
правилам обработки мультимножеств, рассмотренным в разделе 5.3.2 на с. 227.
Пример 6.28. Вновь обратимся к выражению соединения отношений из примера 6.18
(см. с. 269), но дополним его служебным словом all:
(SELECT title, year FROM Movie)
UNION ALL
(SELECT movieTitle AS title, movieYear AS year FROM Starsln);
Теперь каждая пара значений названия кинофильма и года его выпуска будет
включена в итоговое отношение столько раз, сколько она упоминается в отношениях
Movie и starsln вместе. Например, если сведения о некотором фильме с участием
трех актеров описаны одним кортежем отношения Movie и тремя кортежами
Starsln, в отношении, получаемом в результате объединения, название этого фильма
и дата его выпуска будут повторяться четыре раза. □
Как и в случае объединения, выражения intersect all и except all
обозначают операции над мультимножествами. Если R и S — некоторые отношения,
результатом выполнения выражения
R intersect all S
окажется отношение, которое содержит такое количество копий некоторого кортежа г,
которое равно минимуму из количеств экземпляров этого кортежа в отношениях R и S.
В результате вычисления выражения
REXCEPT ALL S
284
ГЛАВА 6. ЯЗЫК SQL
будет получено отношение с таким числом копий кортежа t, которое равно разности
между количествами экземпляров этого кортежа в отношениях R и S (если такая
разность положительна). Каждое из указанных определений соответствует семантике
операций над мультимножествами, рассмотренной в разделе 5.3.2 на с. 227.
6.4.3. Группирование и агрегирование в SQL
В разделе 5.4.4 на с. 235 вы познакомились с оператором группирования и
агрегирования (grouping and aggregation) у, который делит кортежи отношения на "группы"
(см. раздел 5.4.3 на с. 234) в соответствии со значениями одного или нескольких
атрибутов, а затем выполняет те или иные операции агрегирования над определенными
компонентами кортежей групп. SQL реализует те же возможности, что и оператор у,
предоставляя в распоряжение пользователя специальное предложение group by и
позволяя задавать операторы агрегирования в контексте предложения select.
6.4.4. Операторы агрегирования
В SQL применяются пять операторов агрегирования (aggregation) — SUM, AVG, min,
max и count (аналогичные операторы реляционной алгебры упоминались в разделе
5.4.2 на с. 234). Операторы задаются в списке предложения select и в качестве
аргументов используют скалярные выражения — как правило, названия атрибутов
отношения, которые принято называть агрегируемыми (aggregated attributes). Исключение
составляет оператор count (*), который вычисляет количество кортежей в
отношении, создаваемом на основе отношений, перечисленных в предложении from,
и с учетом условий предложения where.
Существует возможность исключения значений-дубликатов из столбца, подлежащего
агрегированию. С этой целью аргумент оператора агрегирования обозначается
признаком distinct. Так, например, выражение count (distinct x) означает, что в столбце
х подсчитываться должны только различные (distinct) значения. Аналогичный синтаксис
формально поддерживается и остальными операторами агрегирования, но выражения,
подобные такому, как sum (distinct x), находят существенно меньшее применение,
поскольку вряд ли кому-либо потребуется вычислять сумму различных значений атрибута х.
Пример 6.29. Следующий запрос позволяет найти среднее значение годового дохода
всех руководящих лиц мира кино:
SELECT AVG(netWorth)
FROM MovieExec;
Обратите внимание, что в данном случае предложение where опущено, т.е.
просматриваться должны все кортежи отношения
MovieExec(name, address, cert#, netWorth),
а точнее — содержимое всех компонентов, соответствующих атрибуту netWorth. При
выполнении запроса значения netWorth складываются (независимо от того,
существуют ли совпадающие значения), а затем полученная сумма делится на количество
кортежей. Если отношение не содержит кортежей-дубликатов (как, собственно, и должно
быть в данном случае), запрос вернет вполне корректное среднее значение. В
противном случае величина дохода некоторого руководящего лица, которому
соответствует п кортежей, при вычислении среднего значения будет учтена п раз. □
Пример 6.30. Запрос
SELECT COUNT(*)
FROM Starsin;
позволяет подсчитать количество кортежей в отношении stars in. Аналогичный запрос
6.4. ОПЕРАЦИИ НАД ОТНОШЕНИЯМИ
285
SELECT COUNT(starName)
FROM StarsIn;
возвратит количество значений в столбце starName того же отношения. Поскольку
операция проекции, описываемая предложением SELECT COUNT (starName), сама по
себе не приводит к удалению значений-дубликатов, результаты этого и предыдущего
запросов окажутся одинаковыми.
Если же каждое различное значение должно быть учтено не более одного раза,
агрегируемый атрибут-операнд следует пометить признаком distinct:
SELECT COUNT(DISTINCT starName)
FROM StarsIn;
В этом случае каждый актер будет учтен только единожды, независимо от того, в
каком количестве фильмов он снимался. □
6.4.5. Группирование
Для группирования (grouping) в SQL используется предложение group by,
следующее в конструкции "select—from—where" за предложением where. После пары
служебных слов GROUP BY задается список группирующих атрибутов (grouping attributes).
В самой простой ситуации предложение from запроса содержит только одно название
отношения, и кортежи этого отношения делятся на группы в соответствии со
значениями группирующих атрибутов. Если предложение select содержит какие-либо
операторы агрегирования, при наличии предложения group by они применяются
только к значениям внутри каждой отдельной группы.
Пример 6.31. Задача вычисления сумм длительностей воспроизведения всех
кинофильмов, выпущенных каждой студией, решается с помощью одного запроса,
обращенного к отношению
Movie(title, year, length, inColor, studioName, producerC#).
Текст запроса приведен ниже.
SELECT studioName, SUM(length)
FROM Movie
GROUP BY studioName;
Чтобы облегчить восприятие текста запроса, можно полагать, что все кортежи
отношения Movie, содержащие в компонентах studioName значение 'Disney*,
собраны в одном месте, за ними следуют кортежи со значениями 'MGM* и т.д.
(см. рис. 5.17 на с. 235). Для каждой группы кортежей значения компонентов
length складываются, и полученные суммы вместе с содержимым компонентов
studioName выводятся в итоговое отношение. □
Обратите внимание на категории выражений, перечисленных в предложении
select запроса, рассмотренного в примере 6.31:
1) операторы агрегирования (в данном случае — sum (length)), применяемые
к атрибутам или выражениям, составленным из названий атрибутов, и
вычисляемые для кортежей каждой группы отдельно;
2) атрибуты (такие как studioName), упомянутые в предложении GROUP BY;
в предложении select выражения с конструкцией group by вне
операторов агрегирования допустимо указывать только такие атрибуты, которые
перечислены в списке group by.
Хотя обычно в предложения select запросов с конструкциями group by включаются
как выражения агрегирования, так и группирующие атрибуты, упомянутые в списке
286
ГЛАВА 6. ЯЗЫК SQL
group BY, формальных требований задавать одновременно те и другие не существует.
Например, вполне правомочен запрос
SELECT studioName
FROM Movie
GROUP BY studioName;
При выполнении запроса система осуществляет группирование кортежей в соответствии
с содержимым компонентов studioName и выводит в итоговое отношение единственное
значение studioName для каждой группы, независимо от количества кортежей,
содержащих такое значение. Указанный запрос по своему существу равнозначен такому:
SELECT DISTINCT studioName
FROM Movie;
Допустимо использовать предложения group by и в таких запросах, которые
охватывают одновременно несколько отношений. Подобные запросы интерпретируются
системой согласно следующему алгоритму.
1. Создать отношение R, представляющее собой декартово произведение
отношений, перечисленных в предложении from, с применением оператора выбора по
критерию, заданному в предложении where.
2. Сгруппировать кортежи R в соответствии с содержимым компонентов
атрибутов, перечисленных в предложении group by;
3. Возвратить в качестве результата значения атрибутов и выражений
агрегирования, указанных в предложении select, как если бы R было обычным
отношением, хранимым в базе данных.
Пример 6.32. Предположим, что требуется получить информацию о суммарных
значениях продолжительности воспроизведения кинофильмов, снятых каждым
продюсером, воспользовавшись отношениями
Movie(title, year, length, inColor, studioName, producerC#)
MovieExec(name, address, cert#, netWorth).
Начнем с вычисления тета-соединения, основанного на равенстве значений атрибутов
сертификационных номеров, producer с # и cert#. В результате получим отношение,
представляющее пары кортежей, такие, что каждый кортеж MovieExec соединяется со
всеми кортежами Movie, содержащими то же значение сертификационного номера.
Заметим, что кортежи со сведениями о тех руководителях, которые не являются
продюсерами, по понятным причинам в соединении не участвуют, и эти данные в итоговом
отношении представлены не будут. Теперь кортежи, выбранные на предыдущем шаге
процедуры, могут быть сфуппированы в соответствии со значением имени продюсера
(name). Наконец, следует вычислить суммы длительностей воспроизведения (length)
кинофильмов, относящихся к каждой группе. Текст запроса приведен на рис. 6.13. □
SELECT name, SUM(length)
FROM MovieExec, Movie
WHERE producerC# = cert#
GROUP BY name;
Рис. 6.13. Пример группирования и агрегирования данных из нескольких отношений
6.4.6. Предложения having
Предположим, что, решая задание из примера 6.32, мы не хотели бы включать
в итоговое отношение информацию обо всех продюсерах. Разумеется, можно было
бы ограничить набор кортежей до выполнения группирования, чтобы сделать
группы, которые не следует принимать во внимание, пустыми. Например, если все, что не
6.4. ОПЕРАЦИИ НАД ОТНОШЕНИЯМИ
287
Группирование, агрегирование и значения null
Если вы собираетесь использовать функции группирования и/или агрегирования,
а некоторые компоненты кортежей обладают значениями null, надлежит принять
во внимание следующие соображения.
• В процессе агрегирования значения null игнорируются. Они не учитываются
ни при вычислении сумм (sum), средних значений (avg) и количеств (count),
ни при подсчете минимальных (min) и максимальных (мах) величин.
Например, оператор count (*) всегда возвращает общее количество кортежей в
отношении, но count (А) — это число кортежей, значения компонентов Л
которых ОТЛИЧНЫ ОТ NULL.
• Напротив, при группировании значение null в компоненте кортежа,
соответствующем группирующему атрибуту, трактуется системой как обычное значение,
отличное от других (не null). Например, если по меньшей мере один кортеж
отношения R содержит в компоненте атрибута а значение null, при
выполнении запроса select a, AVG(b) FROM R GROUP BY а; будет создана отдельная
группа кортежей, отвечающих условию a is null, и в итоговом отношении
появится кортеж со значением null для а и некоторым значением AVG(b).
обходимо, — это вычислить значения продолжительности воспроизведения
кинофильмов, снятых продюсерами, которые обладают годовым доходом свыше
10 миллионов долларов, — достаточно было бы заменить третью строку рис. 6.13 такой:
WHERE producerC# = cert# AND netWorth >10000000
Подчас, однако, требуется выбирать группы, учитывая некоторые свойства групп
как таковых. В подобных случаях конструкция "select ... group by" пополняется
специальным предложением having, оговаривающим определенные условия включения
групп в итоговое отношение.
Пример 6.33. Пусть необходимо вычислить суммарные значения длительностей
воспроизведения кинофильмов только тех продюсеров, которые выпустили по меньшей
мере один фильм до 1930 года. Текст запроса, показанный на рис. 6.13, можно
дополнить следующим предложением:
HAVING MIN(year) < 193 0;
(естественно, удалив из строки group by символ точки с запятой).
При выполнении запроса, приведенного на рис. 6.14, из итогового отношения будут
удалены все группы, каждый кортеж которых содержит в компоненте year значение
года, большее или равное 1930. □
SELECT name, SUM(length)
FROM MovieExec, Movie
WHERE producerC# = cert#
GROUP BY name
HAVING MIN(year) < 193 0;
Рис. 6.14. Пример группирования с применением предложения HAVING
При использовании предложения having следует придерживаться перечисленных
ниже правил.
• Оператор агрегирования в предложении having применяется к кортежам групп
только при их тестировании.
288
ГЛАВА 6. ЯЗЫК SQL
Порядок следования предложений в SQL-запросах
Теперь вы знакомы со всеми шестью предложениями, которые могут быть
использованы в контексте SQL-выражения вида "select—from—where": select, from,
where, group by, having и order by. Обязательными для применения являются
только два первых, select и from; помимо того, having нельзя задавать в
отсутствие предложения group by. Какие предложения вы ни использовали бы в каждом
конкретном случае, они должны следовать в том порядке, который указан выше.
• Любые атрибуты отношений, упомянутых в предложении from, могут быть
агрегированы в предложении having, но вне операторов агрегирования в having
можно ссылаться только на те атрибуты, которые перечислены в предложении
group BY (аналогичное правило регламентирует использование неагрегируемых
атрибутов в списке select конструкции, содержащей group by).
6.4.7. Упражнения к разделу 6.4
Упражнение 6.4.1. Сформулируйте каждый из запросов, созданных вами при
решении заданий упражнения 5.2.1 (см. с. 218), средствами SQL и обеспечьте удаление
кортежей-дубликатов.
Упражнение 6.4.2. Сформулируйте каждый из запросов, созданных при решении
заданий упражнения 5.2.4 (см. с. 222), средствами SQL и обеспечьте удаление
кортежей-дубликатов.
! Упражнение 6.4.3. Обратитесь к решениям заданий упражнения 6.3.1 (см. с. 280)
и определите, содержат ли итоговые отношения, получаемые при обработке
каждого из запросов, повторяющиеся кортежи. Если ответ положителен, перепишите
запросы таким образом, чтобы гарантировать удаление дубликатов. В противном
случае предложите равноценные варианты запросов без использования подзапросов.
! Упражнение 6.4.4. Предложите решения заданий упражнения 6.4.3 в применении
к результатам из упражнения 6.3.2 (см. с. 281).
*! Упражнение 6.4.5. В примере 6.27 на с. 283 говорилось о том, что различные
варианты запроса "найти всех продюсеров фильмов с участием Гаррисона Форда"
способны давать различные итоговые отношения-мультимножества — даже в том
случае, если отношения-множества одинаковы. Обратитесь к версии запроса,
рассмотренной в примере 6.22 (см. с. 276), где использовался подзапрос,
размещенный в предложении from. Может ли отношение, получаемое в результате
обработки этого запроса, содержать кортежи-дубликаты? Почему да или почему нет?
Упражнение 6.4.6. Сформулируйте следующие SQL-запросы к базе данных со схемами
отношений, рассмотренными в упражнении 5.2.1 на с. 218 и воспроизведенными ниже:
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.10 (см. с. 220) и 5.11 (см. с. 221).
* а) Найти среднее значение быстродействия процессоров (speed) персональных
компьютеров (PC).
6.4. ОПЕРАЦИИ НАД ОТНОШЕНИЯМИ
289
b) Найти среднее значение быстродействия процессоров (speed) переносных
компьютеров (Laptop) с ценой (price), превышающей 2000 долларов.
c) Найти среднее значение цены (price) персональных компьютеров (PC),
выпускаемых производителем (maker) ' А'.
! d) Найти среднее значение цены (price) персональных (рс) и переносных
(Laptop) компьютеров, выпускаемых производителем (maker) ' D'.
е) Найти среднее значение цены (price) для каждой группы персональных
компьютеров (PC) с одинаковыми уровнями быстродействия процессоров (speed).
*! f) Найти среднее значение размера экрана (screen) переносных компьютеров
(Laptop), выпускаемых каждым производителем (maker).
! g) Найти производителей (maker), выпускающих по меньшей мере три
различных модели (model) персональных компьютеров (рс).
! h) Найти максимальное значение цены (price) персональных компьютеров
(РС), выпускаемых каждым производителем (maker).
*! i) Найти среднее значение цены (price) для каждой группы персональных
компьютеров (РС) с быстродействием процессора (speed), превышающим 800 МГц.
!! j) Найти среднее значение емкости диска (hd) тех персональных компьютеров
(РС), производители (maker) которых выпускают также и принтеры
(значение 'printer' атрибута type отношения Product).
Упражнение 6.4.7. Сформулируйте следующие SQL-запросы к базе данных со
схемами отношений, рассмотренными в упражнении 5.2.4 на с. 222 и
воспроизведенными ниже:
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.12 (см. с. 223) и 5.13 (см. с. 224).
a) Найти количество классов (class) линкоров (значение 'ЬЬ' атрибута type).
b) Найти среднее количество главных орудий (numGuns) для классов (class)
линкоров (значение 'ЬЬ* атрибута type).
! с) Найти среднее количество главных орудий (numGuns) на линкорах
(значение 'ЬЬ' атрибута type). Обратите внимание на отличие этого
задания от предыдущего; оказывает ли влияние на результат последнего
количество кораблей в классе?
! d) Найти для каждого класса (class) значение даты (year) спуска на воду
первого корабля этого класса.
! е) Найти для каждого класса (class) количество кораблей этого класса,
потопленных (значение 'sunk' атрибута result) в морских сражениях.
!! f) Найти для каждого класса (class), насчитывающего не менее трех судов,
количество кораблей этого класса, потопленных (значение ' sunk' атрибута
result) в морских сражениях.
!! g) Масса (в фунтах) гильзы от снаряда морского орудия приблизительно равна
половине значения калибра (bore) (в дюймах), возведенного в куб. Найти
среднее значение массы гильзы снаряда для групп судов, построенных
каждой из стран (country).
290
ГЛАВА 6. ЯЗЫК SQL
Упражнение 6.4.8. В примере 5.23 на с. 235 рассматривалось выражение реляционной
алгебры с оператором y реализующее запрос "для каждого актера, принявшего участие
в съемках не менее трех кинофильмов, найти год выпуска самого раннего
кинофильма, в котором снимался этот актер". Создайте аналогичный запрос средствами SQL.
*! Упражнение 6.4.9. Оператор /реляционной алгебры не обладает средствами,
предоставляемыми предложением having в SQL. Возможно ли имитировать функция
предложения having с помощью операторов реляционной алгебры, и если да, то как именно?
6.5. Модификация базы данных
До сих пор мы сосредоточивали внимание на конструкциях SQL-запросов вида
"select—from—where". Язык SQL позволяет применять и множество других выражений,
которые не возвращают результатов, но изменяют состояние базы данных. В этом
разделе мы рассмотрим три разновидности выражений, предназначенных для
1) вставки (insertion) новых кортежей в отношения;
2) удаления (deletion) определенных кортежей из отношений;
3) обновления (updating) значений некоторых компонентов в определенных
существующих кортежах отношений.
Все указанные операции в совокупности называют модификацией (modification)
базы данных.
6.5.1. Вставка кортежей
Основная синтаксическая форма выражения вставки (insertion) кортежа в
отношение состоит из следующих частей:
1) пары служебных слов insert into;
2) имени R отношения;
3) списка атрибутов отношения R в круглых скобках;
4) служебного слова values;
5) выражения-кортежа — заключенного в круглые скобки списка значений, по
одному на каждый атрибут списка, заданного в п. 3.
Иными словами, базовый вариант выражения вставки выглядит так:
INSERT INTO R(AuA2,...,An) VALUES (vb v2, ..., v„);
Кортеж, подлежащий вставке в отношение R, создается из значений v,
компонентов Л/, /= 1, 2,..., п. Если заданный список атрибутов не охватывает все атрибуты
отношения R, всем компонентам кортежа для атрибутов, отсутствующих в списке,
присваиваются соответствующие значения, принятые по умолчанию. Наиболее общим
значением, предлагаемым по умолчанию, является null, но существуют возможности
задания иных значений (за полной информацией обращайтесь к разделу 6.6.4 на с. 299).
Пример 6.34. Предположим, что требуется пополнить отношение stars in
информацией о том, что актер Сидней Гринстрит участвовал в съемках фильма "The Maltese
Falcon". Для достижения цели достаточно ввести команду
1) INSERT INTO Starsln(movieTitle, movieYear, starName)
2) VALUES('The Maltese Falcon *, 1942, 'Sydney Greenstreet') ;
В результате ее выполнения в отношение starsln будет вставлен кортеж с
компонентами, указанными в строке 2. Поскольку все атрибуты отношения starsln перечис-
6.5. МОДИФИКАЦИЯ БАЗЫ ДАННЫХ
291
лены в строке 1, потребность в использовании значений по умолчанию не возникает.
Значения строки 2 ставятся в соответствие атрибутам отношения stars in в таком
порядке, который указан в строке 1. Так, компоненту атрибута movieTitle присваивается
значение 'The Maltese Falcon', компоненту movieYear — значение 1942 и т.д. □
Если список атрибутов в выражении вставки содержит все атрибуты отношения
(как в примере 6.34), этот список разрешено опускать. Поэтому команду,
рассмотренную в примере 6.34, можно упростить:
1) INSERT INTO Starsln
2) VALUES('The Maltese Falcon', 1942, 'Sydney Greenstreet');
В этом случае, однако, необходимо гарантировать, что значения в предложении
values перечислены в соответствии со "стандартным" порядком следования
атрибутов отношения. В разделе 6.6 на с. 296 вы познакомитесь с SQL-инструкциями
определения схем отношений и с тем, каким образом в них задается порядок
перечисления атрибутов. Если конструкция insert не содержит список атрибутов,
подразумевается, что компонентам вставляемого кортежа значения присваиваются в том
порядке, который определен при создании схемы отношения.
• Если при использовании команды insert точный порядок следования
атрибутов отношения не известен, наилучшим решением будет явно перечислить их
в соответствии с предложением values.
Инструкция insert в ее простейшей форме, рассмотренная выше, позволяет
поместить в отношение только один кортеж. Вместо предложения values, задающего
конкретные значения компонентов кортежа, в SQL разрешено использовать
подзапрос, возвращающий целое множество кортежей, подлежащих вставке.
Пример 6.35. Пусть необходимо пополнить отношение
Studio(name, address, presC#)
названиями студий, упомянутыми в отношении
Movie(title, year, length, inColor, studioName, producerC#),
но отсутствующими в studio. Поскольку адреса и имена президентов студий, названных
в Movie, не известны, при вставке кортежей в отношение studio нам придется
согласиться с тем, что компонентам address и presC# будут присвоены значения NULL,
предусмотренные по умолчанию. Текст соответствующей команды SQL приведен на рис. 6.15.
1) INSERT INTO Studio(name)
2) SELECT DISTINCT studioName
3) FROM Movie
4) WHERE studioName NOT IN
5) (SELECT name
6) FROM Studio);
Рис. 6.15. Конструкция INSERT с подзапросом
Как и во всех других случаях, связанных с использованием вложенных SQL-
конструкций, текст рис. 6.15 целесообразно рассматривать "изнутри наружу". Строки
5, 6 генерируют набор кортежей с названиями студий, содержащимися в отношении
Studio, а в строке 4 проверяется, не совпадает ли значение компонента studioName
кортежа Movie с одним из этих названий.
Запрос, описанный в строках 2—6, возвращает множество названий студий,
которые найдены в Movie, но отсутствуют в studio. Использование в строке 2
служебного слова distinct гарантирует, что каждое название будет включено в итоговое от-
292
ГЛАВА 6. ЯЗЫК SQL
Об упорядочении операций вставки во времени
Рис. 6.15 иллюстрирует один из тонких аспектов семантики выражений SQL.
Вообще говоря, обработка строк 2—6 команды должна быть завершена прежде, чем
система выполнит фактическую инструкцию вставки, определяемую строкой 1.
Поэтому возможность влияния кортежа, вновь вставленного в studio командой
строки 1, на результат вычисления условия, заданного в строке 4, как правило,
отсутствует. Однако совершенно не исключено, что в какой-либо реализации с целью
повышения эффективности работы системы не будет предусмотрено такое ее
поведение, когда изменения вносятся в состав отношения studio сразу после
отыскания новых названий студий, т.е. непосредственно в процессе выполнения строк 2—6.
Если говорить о SQL-команде на рис. 6.15, на самом деле не важно,
приостанавливается выполнение процедуры вставки на время обработки подзапроса или
нет. Однако нетрудно привести другие образцы конструкций, где результат
существенным образом зависит от того, когда именно выполняются инструкции вставки.
Предположим, что из строки 2 удалено служебное слово distinct. Если
выполнение вставки кортежей откладывается до момента завершения обработки строк 2—6,
название студии, отсутствующее в Studio, но содержащееся в Movie в нескольких
копиях, будет включено в отношение, служащее результатом подзапроса, а затем
вставлено в studio столько же раз. Если же вставка новых названий студий в
отношение studio осуществляется по мере их отыскания в Movie, т.е. в процессе
выполнения подзапроса, ни одна из строк названий не будет повторяться дважды: после
вставки первой копии названия любая попытка вставки того же названия окажется
безуспешной, поскольку условие, заданное в строках 4—6, перестанет выполняться.
ношение только однократно, независимо от того, сколько раз оно упоминается в
компонентах studioName отношения Movie. Наконец, инструкция строки 1 осуществляет
вставку каждого из названий, найденных при вычислении подзапроса, в отношение studio,
с заполнением компонентов address и presC# новых кортежей значениями NULL. □
6.5.2. Удаление кортежей
Выражение удаления (deletion) кортежа из отношения состоит из следующих частей:
1) пары служебных слов delete from;
2) имени R отношения;
3) служебного слова where;
4) условия С выбора кортежей, подлежащих удалению.
Иными словами, выражение удаления можно представить так:
DELETE FROM R WHERE С;
В результате выполнения команды каждый кортеж отношения R, удовлетворяющий
условию С, будет удален.
Пример 6.36. Чтобы удалить из отношения
Starsln(movieTitle, movieYear, starName)
информацию о том, что актер Сидней Гринстрит участвовал в съемках фильма
"The Maltese Falcon", достаточно выполнить команду
DELETE FROM Starsln
WHERE movieTitle = 'The Maltese Falcon' AND
movieYear = 1942 AND
starName = 'Sydney Greenstreet'/
6.5. МОДИФИКАЦИЯ БАЗЫ ДАННЫХ
293
Заметьте, что, в отличие от выражения вставки, рассмотренного в примере 6.34 на
с. 291, мы не можем просто указать значения компонентов кортежа, подлежащего
удалению, — условия, которым должен удовлетворять удаляемый кортеж, надлежит
описать с помощью предложения where. □
Пример 6.37. Рассмотрим еще один пример удаления кортежей. На сей раз мы
собираемся избавить отношение
MovieExec(name, address, cert#, netWorth)
от целой группы кортежей, которые удовлетворяют определенному условию. При
выполнении команды
DELETE FROM MovieExec
WHERE netWorth < 10000000;
из отношения MovieExec будет удалена информация обо всех президентах
киностудий и продюсерах, кто, по нашему мнению, "мелко плавает", т.е. обладает годовым
доходом менее 10 миллионов долларов. □
6.5.3. Обновление данных
Хотя термин обновление (updating), как кажется, вполне применим для обозначения
и операций вставки кортежей, и функций их удаления, в SQL ему придается строго
определенный смысл: значения заданных компонентов в группе существующих
кортежей отношения подлежат замене. Выражение обновления данных отношения
состоит из следующих частей:
1) служебного слова update;
2) имени R отношения;
3) служебного слова set;
4) списка инструкций присваивания, в левой части каждой из которых
указывается название атрибута отношения R, а в правой — соответствующее
вычисляемое выражение, название атрибута или константа;
5) условия С выбора кортежей, подлежащих обновлению.
Иными словами, выражение обновления данных отношения можно представить так:
UPDATE R SET А,= vhA2 = v2, ...,АЯ = vn WHERE С;
В процессе выполнения команды система отыскивает в отношении R все кортежи,
удовлетворяющие условию С, вычисляет выражения v, и присваивает их компонентам
атрибутов Л, найденных кортежей.
Пример 6.38. Пусть необходимо изменить содержимое отношения
MovieExec(name, address, cert#, netWorth)
таким образом, чтобы имени каждого руководителя, который является президентом
киностудии, предшествовал префикс "Pres. ". Условие выбора кортежей, подлежащих
обновлению, состоит в том, чтобы сертификационный номер лица (значение
компонента cert#) присутствовал в компоненте presC# одного из кортежей отношения
studio. Соответствующая команда update может выглядеть так:
1) UPDATE MovieExec
2) SET name = 'Pres. ' || name
3) WHERE cert# IN (SELECT presC# FROM Studio);
В строке З выполняется проверка, действительно ли содержимое компонента
cert# кортежа MovieExec присутствует в качестве значения компонента presC#
одного из кортежей отношения studio.
294
ГЛАВА 6. ЯЗЫК SQL
Напомним, что оператор | | осуществляет сцепление (конкатенацию) строковых
аргументов. Строка 2 содержит инструкцию присваивания; при ее выполнении в
компонент name каждого кортежа заносится префикс ' Pres. ', сопровождаемый
строкой, которая хранилась в этом компоненте прежде. □
6.5.4. Упражнения к разделу 6.5
Упражнение 6.5.1. Сформулируйте следующие команды модификации базы данных
со схемами отношений, рассмотренными в упражнении 5.2.1 на с. 218 и
воспроизведенными ниже:
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.10 (см. с. 220) и 5.11 (см. с. 221).
а) Применив две команды insert, сохранить в базе данных информацию
о том, что производителем (maker) 'С выпущена модель (model) "1100"
персонального компьютера (рс), обладающая процессором с
быстродействием (speed) 1800 МГц, оперативной памятью объемом (ram) 256 Мбайт,
диском емкостью (hd) 80 Гбайт, 20-скоростным приводом DVD (rd) и
ценой (price) в 2499 долларов.
! Ь) Обеспечить вставку кортежей, представляющих тот факт, что каждому
персональному компьютеру (рс) соответствует переносной компьютер (Laptop),
выпускаемый тем же производителем (maker) и обладающий аналогичными
значениями быстродействия процессора (speed), объема оперативной памяти (ram)
и емкости диска (hd), а также 15-дюймовым экраном (screen); номер модели
(model) переносного компьютера больше номера соответствующей модели
персонального компьютера на 1100, а его цена (price) выше на 500 долларов.
c) Удалить данные обо всех персональных компьютерах (рс) с дисками
емкостью (hd) менее 20 Гбайт.
d) Удалить сведения обо всех переносных компьютерах (Laptop) от таких
производителей (maker), которые не выпускают принтеры (значение 'printer*
атрибута type отношения Product).
e) Компания-производитель (maker) *A* приобрела компанию • в*. Заменить
все ссылки на компанию * в * ссылками на компанию • а *.
f) Для каждого персонального компьютера (рс) удвоить значение объема
оперативной памяти (ram) и увеличить на 20 Гбайт значение емкости диска
(hd) (напомним, что с помощью одной команды update можно изменить
значения нескольких компонентов кортежа одновременно).
! g) Для каждого переносного компьютера (Laptop), выпускаемого
производителем (maker) ' в', увеличить на один дюйм значение размера экрана
(screen) и снизить на 100 долларов значение цены (price).
Упражнение 6.5.2. Сформулируйте следующие команды модификации базы данных
со схемами отношений, рассмотренными в упражнении 5.2.4 на с. 222 и
воспроизведенными ниже:
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
6.5. МОДИФИКАЦИЯ БАЗЫ ДАННЫХ
295
Для иллюстрации результатов используйте информацию из экземпляров
отношений рис. 5.12 (см. с. 223) и 5.13 (см. с. 224).
* а) Два британских (country) линкора (значение 'ЬЬ' атрибута type) класса
(class) "Nelson" — собственно, "Nelson", а также "Rodney" — были
спущены на воду (launched) в 1927 году и оба обладали девятью (numGuns)
16-дюймовыми (bore) орудиями и водоизмещением (displacement) 34 тыс.
тонн. Обеспечить вставку кортежей, представляющих эти факты.
Ь) Два из трех линкоров (значение 'ЬЬ' атрибута type) класса (class)
"Vittorio Veneto", построенных в Италии (country), — "Vittorio Veneto"
и "Italia" — впервые покинули доки (launched) в 1940 году; третье судно
класса, "Roma", было спущено на воду в 1942 году. Каждый из кораблей
обладал водоизмещением (displacement) в 41 тыс. тонн и был оснащен
девятью (numGuns) 15-дюймовыми (bore) орудиями. Обеспечить вставку
кортежей, представляющих эти факты.
* с) Удалить из отношения Ships сведения о кораблях, потопленных (значение
' sunk' атрибута result) в морских сражениях.
* d) В отношении classes преобразовать значения калибра (bore) корабельных
орудий в сантиметры (1 дюйм равен 2,54 сантиметра), а значения
водоизмещения (displacement) — в метрические тонны (1 метрическая тонна
равна 1,1 "малой"(пе1) тонны).
е) Удалить информацию обо всех классах (class), насчитывающих в своем
составе менее трех судов.
6.6. Определение схем отношений в SQL
В этом разделе мы приступим к обсуждению вопросов, связанных с определением
данных (data definition), т.е. описанием структуры хранения информации в базе данных
средствами SQL. Напротив, то подмножество языка, которое рассматривалось нами до сих пор
и использовалось для конструирования выражений запросов к базе данных и ее
модификации, принято относить к категории средств управления данными (data manipulation).36
Предметом настоящего раздела являются конструкции объявления, изменения и
удаления схем хранимых отношений, или таблиц (tables) (как их принято называть
в SQL). В разделе 6.7 на с. 305 рассмотрены средства определения виртуальных таблиц
(virtual tables), или представлений (views), которые не сохраняются в базе данных
подобно обычным таблицам; более сложные темы, связанные с заданием ограничений
уровня отношения и его атрибутов, вынесены в главу 7 на с. 317.
6.6.1. Типы данных
Для начала рассмотрим основные атомарные типы данных, поддерживаемые
большинством реляционных СУБД. (Каждому атрибуту любого отношения должен
быть поставлен в соответствие тот или иной тип данных.)
1. Строки символов постоянной или переменной длины. Тип CHAR(n) обозначает
строку постоянной длины (fixed-length string), содержащую п символов. Иными
36 Вообще говоря, материал этого раздела в большей степени относится к проблематике
проектирования реляционных баз данных, и, как кажется, его уместно было бы рассмотреть
в одной из предыдущих глав — по аналогии с языком ODL, применяемым в объектно-
ориентированных системах. Однако мы полагаем, что в данном случае более целесообразно
отступить от собственных правил, чтобы получить возможность осветить все аспекты языка SQL
последовательно и единообразно.
296
ГЛАВА 6. ЯЗЫК SQL
словами, если некоторый атрибут относится к типу CHAR(n), любой компонент
кортежа, соответствующий этому атрибуту, представляет собой строку из п
символов. Тип VARCHAR(n) служит для определения строки переменной длины
(varying-length string). Компоненты атрибутов этого типа могут содержать
строки с количеством символов от 0 до п. SQL предусматривает очевидные
возможности взаимного преобразования значений строковых типов. Если в компонент
строкового типа постоянной длины помещается более короткая строка, она
дополняется соответствующим количеством символов пробела. Например, если
компоненту типа CHAR(5) присваивается строка 'foo', его значением
становится строка 'foo * (с двумя замыкающими символами пробела). При
сравнении строк (см. раздел 6.1.3 на с. 254) дополнительные пробелы игнорируются.
2. Строки битов постоянной или переменной длины. Подобные типы аналогичны
обычным строковым типам постоянной и переменной длины, но вместо
произвольных символов в них могут сохраняться только символьные представления
битов — ' 0 ' или ' 1 *. Выражение bit (N) обозначает тип битовых строк
постоянной длины п, a bit varying (n) — тип атрибутов, способных содержать от
О до л символов ' 0 * или * 1'.
3. Логические значения. Атрибутам, которые по своей природе являются
логическими (logical), ставится в соответствие тип boolean, допустимыми
значениями которого являются true, false и — для Джорджа Буля (G. Bool) это
наверняка оказалось бы сюрпризом! — unknown.
4. Целочисленные значения. Обычные целочисленные значения (integer values) относят
к типу int, или integer (это слова-синонимы). Более "короткие"
целочисленные величины можно обозначать как short int; тип short int, как правило,
допускает возможность хранения меньшего числа битов (конкретные детали
зависят от реализации). Типы int и shortint в SQL соотносятся между собой
примерно так же, как типы int и short int в языке С.
5. Числовые значения с плавающей запятой. Такие значения представляются в SQL
разнообразными способами. "Обычные" числа с плавающей запятой
(floatingpoint numbers) можно обозначать как float, или real (это синонимы). Тип
double precision позволяет хранить числа с большим количеством знаков
дробной части. Различия между указанными типами приблизительно такие же,
как между типами с плавающей запятой в языке С. В SQL также определены
стандартные типы, предназначенные для хранения чисел с фиксированной
длиной мантиссы и дробной части. Например, тип decimal(n, d) служит для
описания числовых величин, состоящих из п десятичных разрядов в целом
и дробной части длиной в d разрядов. В качестве значения, подходящего для
присваивания атрибуту типа decimal (6, 2), можно указать, скажем, такое:
1234.56. Тип numeric обычно немногим отличается от decimal, хотя ему могут
быть присущи и некоторые особенности, зависящие от реализации.
6. Значения дат и времени. Для представления подобных значений в SQL
используются типы date и time соответственно (см. раздел 6.1.4 на с. 256). Значения
типов date и time по существу являются символьными строками,
представленными в специальном формате. Язык позволяет преобразовывать их в
обычные строки и, наоборот, "превращать" строки символов, удовлетворяющие
требованиям записи дат и времени, в значения date и TIME.
6.6.2. Простые объявления схем отношений
Конструкция объявления таблицы в своей простейшей форме состоит из пары
служебных слов create table, после которой задаются наименование отношения, подлежащего
созданию, и список пар названий атрибутов и их типов, заключенный в круглые скобки.
6.6. ОПРЕДЕЛЕНИЕ СХЕМ ОТНОШЕНИЙ В SQL
297
Пример 6.39. Выражение объявления реляционной схемы отношения Movies tar,
неформально описанное в разделе 5.1 на с. 204, может быть выражено в виде конструкции
на языке SQL так, как показано на рис. 6.16. Атрибуты name и address, как
предполагается, должны относиться к строковым типам. Для представления имени актера (name)
мы решили воспользоваться строковым типом char (30) постоянной длины: если длина
имени меньше 30 символов, оно будет дополнено пробелами, а если больше — усечено
до 30 символов. Адрес (address) проживания актера, напротив, описан в виде
строкового значения переменной длины varchar(255) ,37 Мы не настаиваем на том, что
выбранные типы в наилучшей степени соответствуют ситуации — они используются
только в методических целях, для иллюстрации различных доступных нам альтернатив.
Атрибут gender ("пол") объявлен как строка единичной длины, CHAR (1),
предназначенная для хранения одного из двух допустимых символов — ■ м' (от male — "мужчина")
или • F' (от female — "женщина"). Наконец, атрибуту birthdate ("дата рождения")
разумно поставить в соответствие тип date. Если тип date не поддерживается конкретной
СУБД, вместо него можно использовать тип char (10), позволяющий сохранить восемь
цифр номеров дня, месяца и года, а также два символа-разделителя (например, дефиса). □
1) CREATE TABLE MovieStar (
2 ) name CHAR(30),
3) address VARCHAR(255) ,
4) gender CHAR(1) ,
5) birthdate DATE
) ;
Рис. 6.16. SQL-объявление реляционной схемы отношения MovieStar
6.6.3. Модификация реляционных схем
Чтобы удалить (drop) отношение R из базы данных, достаточно выполнить команду
DROP TABLE R ;
После обработки команды отношение R перестанет быть частью схемы базы данных,
и в дальнейшем никто не сможет обратиться к его кортежам.
Гораздо чаще, однако, возникает необходимость изменения (altering) схемы
существующего отношения. С этой целью используется команда вида alter table,
содержащая наименование отношения, схема которого подлежит изменению, и одно из
дополнительных предложений, наиболее важными из которых являются следующие:
1) ADD, с именем А атрибута и обозначением его типа ("добавить атрибут А");
2) drop, с именем А атрибута ("удалить атрибут А").
Пример 6.40. Чтобы пополнить схему отношения MovieStar атрибутом phone ("номер
телефона") строкового типа постоянной длины, равной 10, достаточно выполнить команду
ALTER TABLE MovieStar ADD phone CHAR(16);
После обработки команды схема отношения MovieStar будет содержать уже пять
атрибутов, четыре из которых были определены ранее (см. рис. 6.16), а пятый, phone,
добавлен сейчас. Каждый существующий кортеж отношения пополнится компонен-
Число 255 не следует воспринимать так, будто оно представляет некую "типичную" длину
адресов. В одном байте можно хранить целое число от 0 до 255, поэтому строку переменной
длины, способную содержать до 255 символов, можно представить в виде единственного байта-
счетчика символов и последовательности байтов, содержащих символы строки как таковые.
Впрочем, в коммерческих СУБД поддерживается возможность определения строк произвольной длины.
298
ГЛАВА 6. ЯЗЫК SQL
том, соответствующим атрибуту phone, но поскольку реальные значения, подходящие
для размещения в этих компонентах, не известны, вместо них система присвоит
каждому компоненту значение null, предусмотренное по умолчанию. За информацией
о том, как на этапе проектирования отношения выбирать для атрибутов иные,
отличные от null, значения, предлагаемые по умолчанию и уместные в каждом
конкретном случае, обращайтесь к разделу 6.6.4 на с. 299.
Для удаления из схемы отношения MovieStar атрибута birthdate следовало бы
применить команду
ALTER TABLE MovieStar DROP birthdate;
□
6.6.4. Значения по умолчанию
Иногда в момент создания или модификации кортежа значения некоторых его
компонентов не известны. В примере 6.40 рассматривалась ситуация, связанная с
добавлением в схему отношения нового атрибута. Если отношение уже содержит
кортежи, система не "знает" о том, какие конкретные значения следует присвоить вновь
созданным компонентам этих кортежей, и предлагает воспользоваться значениями
null. Аналогичная ситуация возникает и при выполнении команды вставки кортежа
в отношение studio, когда известно только название киностудии, а ее адрес и
сертификационный номер президента — нет (см. пример 6.35 на с. 292).
Для преодоления подобных проблем в SQL используется значение null,
автоматически присваиваемое любому компоненту, точное значение которого в данный момент не
известно, — за исключением некоторых ситуаций, когда null применять нельзя
(см. раздел 7.1 на с. 318). Однако подчас было бы целесообразно предпочесть иное
значение, которое должно предлагаться системой по умолчанию (default value), если никакие
другие значения, подходящие для присваивания конкретному компоненту, не известны.
Вообще говоря, любую инструкцию, в которой определяется название атрибута
и его тип, можно сопроводить служебным словом default и соответствующим
значением. В качестве значения допустимо вводить null или какую-либо константу
(в некоторых случаях система предлагает и иные варианты — например, значение
текущего момента времени).
Пример 6.41. Вновь обратимся к заданию из примера 6.39 (см. с. 298). При
определении схемы отношения MovieStar можно предусмотреть, чтобы для компонентов
атрибута gender в качестве значения, предлагаемого по умолчанию, использовалась
строка ' ? ■, а для компонентов атрибута birthdate — выражение DATE • 0000-00-00 ',
интерпретируемое системой как "нулевая" дата. Строки 4, 5 на рис. 6.16 (см. с. 298),
таким образом, приобретут следующий вид:
4 ) gender CHAR(1) DEFAULT '?' ,
5) birthdate DATE DEFAULT DATE '0000-00-00 *
Еще один пример. Определение атрибута phone, добавляемого в схему отношения
MovieStar (см. пример 6.40), можно было бы снабдить предложением,
оговаривающим, что каждому "пустому" компоненту phone в качестве значения по умолчанию
должна присваиваться строка "Номер неизвестен":
ALTER TABLE MovieStar ADD phone CHAR(16) DEFAULT 'Номер неизвестен';
□
6.6.5. Индексы
Индекс (index) атрибута А некоторого отношения R — это структура данных,
позволяющая повысить эффективность процедуры отыскания некоторого конкретного
значения, хранимого в компонентах атрибута А. Наличие индекса обычно способно при-
6.6. ОПРЕДЕЛЕНИЕ СХЕМ ОТНОШЕНИЙ В SQL
299
вести к существенному уменьшению времени обработки запросов, в которых
значения атрибута А сравниваются с константами посредством выражений, таких, как,
скажем, Л = 3 или даже Л<3. Технологиям создания индексов для крупных отношений
в процессе реализации СУБД отводится весьма важная роль. Подобной проблематике
целиком посвящена глава 13 на с. 583.
С увеличением размера отношения задача просмотра всех его кортежей с целью
отыскания группы кортежей (возможно, очень ограниченной), удовлетворяющих
определенному условию, все более усложняется. Для примера обратимся к самому
первому запросу, рассмотренному в этой главе (см. пример 6.1 на с. 250):
SELECT *
FROM Movie
WHERE studioName = 'Disney' AND year = 1990;
Вполне вероятно, что отношение studioName может содержать, этак, 10000 кортежей, из
которых только 200 представляют данные о кинофильмах, выпущенных в 1990 году. Было
бы наивным полагать, что компьютерная система с некоторым "достаточно высоким"
уровнем аппаратного быстродействия сможет "моментально" просмотреть все 10000
кортежей и для каждого из них проверить справедливость условия, заданного в предложении
where. Эффективность поиска существенно возросла бы, будь у нас некоторое средство
быстрого предварительного "отсеивания" кортежей, компоненты year которых содержат
значение, отличное от 1990, — нам осталось бы проверить справедливость условия
studioName = 'Disney' только для 200 кортежей. Обработка запроса потребовала бы
еще меньше времени, если бы система обладала возможностью непосредственного
получения какого-нибудь десятка кортежей, удовлетворяющих одновременно обоим
условиям, т.е. представляющих кинофильмы, выпущенные студией "Disney" в 1990 году.
Хотя технологии создания индексов не регламентируются ни одним стандартом SQL
(включая и SQL-99), в большинстве коммерческих СУБД предусмотрены средства,
позволяющие "заставить" систему сконструировать индекс для определенного атрибута
конкретного отношения. Предположим, что необходимо создать индекс для атрибута year
отношения Movie. Вот как может выглядеть типичная синтаксическая форма такой команды:
CREATE INDEX Year Index ON Movie(year) ;
В результате ее выполнения для атрибута year отношения Movie будет создан индекс
с наименованием Yearindex. Впоследствии все SQL-запросы, в условиях WHERE
которых упоминается атрибут year, будут выполняться системой значительно быстрее,
поскольку процессор запросов сможет сузить область поиска до группы кортежей,
содержащих в компоненте year значение, удовлетворяющее заданному условию.
Нередко СУБД позволяют создавать единые индексы для нескольких атрибутов.
Подобные индексы позволяют системе быстро находить кортежи с целым набором
заданных значений атрибутов.
Пример 6.42. Поскольку атрибуты title и year формируют ключ отношения Movie,
можно полагать, что в запросах, обращенных к Movie, как правило, будут задаваться
значения обоих атрибутов одновременно — либо они не будут задаваться вовсе. Следующее
выражение представляет пример инструкции создания индекса для двух атрибутов:
CREATE INDEX Keylndex ON Movie(title, year);
Поскольку пара атрибутов (title, year) образует ключ, всякий раз, когда
задаются конкретные значения этих атрибутов, мы можем быть уверены, что индекс
позволит найти только один кортеж, и это будет именно тот кортеж, который требовалось
отыскать. Если же в запросе фигурируют те же значения title и year, но в
распоряжении системы имеется индекс Yearindex, созданный для одного атрибута year,
лучшее, что она сможет сделать — это извлечь из отношения группу кортежей,
содержащих заданное значение year, и только потом, просмотрев каждый из них, найти
кортеж с нужным значением title.
300
ГЛАВА 6. ЯЗЫК SQL
Если, как это часто бывает, ключ индекса, созданного для нескольких атрибутов, по
существу представляет собой строку, сцепленную из значений этих атрибутов в
некотором порядке, индекс может использоваться для отыскания всех кортежей, содержащих
значение, заданное для первого из атрибутов индекса. Таким образом, важным этапом
процесса проектирования индекса для нескольких атрибутов является выбор порядка
перечисления этих атрибутов в команде создания индекса. Если вы полагаете, что
значения title будут задаваться в запросах чаще, чем значения year, следует
предпочесть такой порядок перечисления атрибутов, который указан выше; если же более
вероятным уместно считать задание значений year, порядок следования атрибутов
в инструкции создания индекса необходимо изменить на обратный, (year, title). □
Если индекс необходимо удалить, следует применить команду, подобную такой:
DROP INDEX Year Index;
6.6.6. Знакомство с технологиями выбора индексов
Выбор подходящих индексов относится к категории задач, бросающих вызов
проектировщику базы данных и во многом определяющих производительность последней
и даже ее дальнейшую судьбу. При выборе индексов следует принять во внимание два
важных фактора, указанных ниже.
• Наличие индекса для определенного атрибута приводит к существенному
повышению скорости обработки запросов, в которых задаются значения этого
атрибута, и в некоторых случаях позволяет также ускорить операции соединения
с участием атрибута.
• С другой стороны, присутствие в базе данных любого индекса, созданного для
атрибутов отношения, способно усложнить и замедлить процедуры вставки,
удаления и обновления кортежей отношения.
Выбор адекватных индексов — одна из самых сложных стадий процесса
проектирования, и для ее успешного "прохождения" желательно получить достоверный ответ
на вопрос, какова номенклатура типовых запросов и иных команд, с которыми
пользователи будут обращаться к базе данных в дальнейшем. Если запросы к отношению,
как можно полагать, должны выполняться чаще, нежели команды его модификации,
целесообразно рассмотреть возможность создания индексов для самых "популярных"
атрибутов отношения. Индексы наиболее полезны в тех ситуациях, когда
соответствующие атрибуты часто сравниваются с константами в контексте предложений where
или присутствуют в условиях соединения отношений.
Пример 6.43. Обратимся к рис. 6.3 (см. с. 264), иллюстрирующему типичную
процедуру построения пар кортежей в ходе вычисления соединения отношений. Индекс для
атрибута Movie, title помог бы системе быстро отыскать кортеж Movie с описанием
кинофильма "Star Wars", а затем, после извлечения из найденного кортежа
содержимого компонента producerC#, другой индекс, созданный для атрибута
MovieExec . cert#, обеспечил бы ускорение процесса поиска соответствующего
кортежа в отношении MovieExec. □
Если база данных подвержена частым модификациям, к вопросу создания
индексов следует подходить весьма взвешенно, хотя и в этом случае выигрыш от создания
индексов для наиболее "употребительных" атрибутов достаточно вероятен. Впрочем,
даже если в некоторых командах модификации нередко используются подзапросы
(например, конструкции "select—from—where" в командах insert или предложения
where в инструкциях delete), следует очень тщательно проанализировать
относительную частоту использования операций модификации и запросов.
6.6. ОПРЕДЕЛЕНИЕ СХЕМ ОТНОШЕНИЙ В SQL
301
До сих пор мы еще не знакомили вас с деталями — например, касающимися того,
как обычно хранятся данные на физическом уровне и как реализуются индексы, —
необходимыми для понимания целостной картины происходящего. Однако
следующий пример, возможно, позволит вам разобраться хотя бы в некоторых проблемах.
Следует иметь в виду, что любое сколько-нибудь "приличное" отношение
размещается во многих дисковых блоках, и основные вычислительные затраты в процессе
выполнения команды модификации или запроса часто определяются тем, какое
количество блоков диска при этом приходится считывать в оперативную память (за
подробностями обращайтесь к разделу 11.4.1 на с. 510). Поэтому при наличии индекса
система сможет найти требуемый кортеж, не просматривая все отношение, а это
сэкономит немало времени. Однако индексы как таковые также должны храниться на
диске (по меньшей мере, частично), поэтому при использовании и изменении
индексов системе приходится тратить определенное время и на выполнение дисковых
операций. Команды модификации данных, предполагающие необходимость одного
обращения к диску для чтения информации и еще одного — для сохранения внесенных
изменений, примерно вдвое более трудоемки, нежели операции, осуществляющие
доступ к индексу или содержимому отношений при выполнении запросов.
Пример 6.44. Рассмотрим отношение
Starsln(movieTitle, movieYear, starName).
Предположим, что операции с базой данных (запросы Q и процедуры вставки /),
затрагивающие отношение starsln, относятся к трем перечисленным ниже категориям.
Q{. Найти названия и даты выпуска кинофильмов, в съемках которых принимал
участие конкретный актер:
SELECT movieTitle, movieYear
FROM Starsln
WHERE starName = s;
где s — некоторая константа.
Q2. Найти имена актеров, принимавших участие в съемках конкретного кинофильма:
SELECT starName
FROM Starsln
WHERE movieTitle = t AND movieYear = y;
где t и у — некоторые константы.
/. Вставить в отношение Starsln новый кортеж:
INSERT INTO Starsln VALUES (t, у, s);
где t, у и s — некоторые константы.
Предположим также, что выполняются следующие условия.
1. Отношение starsln занимает 10 дисковых блоков, так что трудоемкость
операции просмотра всего отношения оценивается величиной 10.
2. В среднем каждый актер принимает участие в съемках 3 фильмов, а в каждом
фильме снимаются 3 актера.
3. Поскольку вполне вероятно, что кортежи, в которых упоминаются
определенные кинофильм или актер, могут быть распределены по всем 10 блокам,
охватываемым отношением Starsln, для отыскания (в среднем) 3-х кортежей,
отвечающих заданному кинофильму или актеру, потребуется выполнить
3 обращения к диску — даже при наличии индексов для атрибута starName
и пары атрибутов movieTitle и movieYear.
302
ГЛАВА 6. ЯЗЫК SQL
4. Для отыскания кортежей с заданными значениями индексированного атрибута
или двух атрибутов требуется выполнить одно обращение к диску всякий раз,
когда необходимо считать блок индекса. Если блок индекса подлежит
модификации (как в случае вставки кортежа), требуется выполнить еще одну дисковую
операцию для сохранения измененного блока.
5. Аналогично, при выполнении вставки кортежа одна дисковая операция нужна
для считывания блока, в который будет помещен новый кортеж, а другая — для
сохранения этого блока. Мы подразумеваем, что даже в отсутствие индекса
система способна отыскать блок, в который надлежит поместить дополнительный
кортеж, без необходимости просмотра всего отношения.
Операция
Qi
I
Индексов нет
10
10
2
2 + 8р{ + 8р2
Индекс для
starName
4
10
4
4 + 6р2
Индекс для
movieTitle и
movieYear
10
4
4
4 + 6/7!
Оба индекса
4
4
6
6~2р{-2р2
Рис. 6.17. Функции трудоемкости операций, зависящие от множества выбранных инде ксов
Рис. 6.17 иллюстрирует зависимости трудоемкости каждой из операций — Q{
(поиск фильмов с участием определенного актера), Q2 (поиск актеров, снявшихся
в определенном фильме) и / (вставка кортежа) — от того, какие индексы созданы.
Если индексов нет, при выполнении операций Qx и Q2 системе придется просмотреть
отношение целиком (значение трудоемкости равно 10), а при вставке (/) — обратиться
к пустому блоку и сохранить в нем содержимое нового кортежа (трудоемкость
оценивается величиной 2, так как, в соответствии с нашим предположением, подходящий
блок может быть найден без использования индекса). Эти значения показаны в
первых трех ячейках столбца с заголовком "Индексов нет".
Если создан индекс только для атрибута starName, операция Q2 все еще потребует
просмотра всего отношения (10). Однако ответ на запрос Q{ теперь может быть получен
посредством выбора одного индексного блока, позволяющего найти три кортежа,
соответствующих заданному имени актера, и трех дополнительных обращений к диску для
извлечения из этих кортежей искомой информации о кинофильмах (итоговое значение
трудоемкости — 4). При выполнении операции вставки (/) система будет вынуждена считать и
записать и блок индекса, и блок с данными кортежа, т.е. выполнить 4 обращения к диску.
Случай, связанный с наличием индекса, созданного только для пары атрибутов
movieTitle и movieYear, симметричен по отношению к предыдущему.
Наконец, если созданы оба индекса — как для атрибута starName, так и для пары
атрибутов movieTitle и movieYear, — для получения ответов на запросы Q{ и Q2
системе придется обратиться к диску 4 раза (соответствующие доводы приведены
выше), но при выполнении операции вставки кортежа (/) потребуется считать и записать
по блоку для каждого из двух индексов, а также произвести считывание и запись
блока данных (т.е. осуществить 6 обращений к диску).
В последней строке рис. 6.17 указаны средние суммарные значения трудоемкости
выполнения всех трех операций, основанные на предположении, что доли времени,
затрачиваемого системой на обработку запросов Q{ и Q2, равны рх и р2 соответственно;
тогда на выполнение операции вставки / остается 1 -р\-р2 единиц времени.38
38 Для столбца "Индексов нет" получим: 10pi + 10р2 + 2(1 -р\ -pi) = 2 + 8pi + %р2\ остальные
значения последней строки на рис. 6\17 вычисляются аналогично. — Прим. перев.
6.6. ОПРЕДЕЛЕНИЕ СХЕМ ОТНОШЕНИЙ В SQL
303
В зависимости от конкретных величин рх и р2, нетрудно определить, какая
комбинация индексов является наилучшей в той или иной ситуации. Например, если
положить рх =р2 = 0,1, тогда наименьшей окажется величина трудоемкости 2 + 8рх + 8р2, т.е.
наиболее предпочтительным будет решение не создавать индексы вовсе.
(Действительно, поскольку чаше всего выполняются операции вставки и
относительно более редко — запросы, индексы не нужны.) Если же р{ = р2 = 0,4, наименьшим из
четырех окажется значение 6-2р{-2р2; в этом случае целесообразно создать оба
индекса. (К тому же выводу можно прийти и интуитивно: если количество запросов Q{
и Q2, существенно превышает число операций вставки / и оба запроса примерно
одинаково "популярны", желательно иметь оба индекса.)
Если предположить, что р{ = 0,5, а р2 = 0,\, минимум трудоемкости достигается
в значении 4 + 6р2, т.е. имеет смысл создать индекс только для атрибута starName.
Если же, наоборот, р, =0,1, а /?2 = 0,5, минимальным становится значение 4 + 6/?2, а это
свидетельствует о том, что необходимо предпочесть индекс для пары атрибутов
movieTitle и movieYear. Очевидно, что если один из запросов выполняется гораздо
чаще, нежели другой, следует выбрать компромиссное решение, связанное с
созданием только одного индекса. □
6.6.7. Упражнения к разделу 6.6
* Упражнение 6.6.1. В разделе 6.6 мы рассмотрели команду создания только одной
схемы отношения из "кинематографической" базы данных — MovieStar. Дайте
соответствующие SQL-определения четырех остальных отношений:
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#).
Упражнение 6.6.2. Ниже воспроизведены неформальные описания схем отношений
из базы данных, рассмотренной в упражнении 5.2.1 на с. 218:
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
Дайте соответствующие SQL-определения отношений:
a) Product;
b) pc;
* c) Laptop;
d) Printer.
Сформулируйте команды изменения схемы отношения:
e) Printer (см. п. (d)) — с целью удаления атрибута color;
* 0 Laptop (см. п. (с)) — с целью добавления атрибута cd (необходимо
предусмотреть значение по умолчанию ' нет', которое должно использоваться
системой, если переносной компьютер не обладает приводом компакт-дисков).
Упражнение 6.6.3. Ниже воспроизведены неформальные описания схем отношений
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222:
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
304
ГЛАВА 6. ЯЗЫК SQL
Дайте соответствующие SQL-определения отношений:
a) Classes;
b) Ships;
c) Battles;
d) Outcomes.
Сформулируйте команды изменения схемы отношения:
e) classes (см. п. (а)) — с целью удаления атрибута bore;
f) Ships (см. п. (с)) — с целью добавления атрибута yard для хранения
названия верфи, на которой был построен корабль.
! Упражнение 6.6.4. Поясните различия между командами drop table r и
DELETE FROM R.
Упражнение 6.6.5. Обратимся к примеру 6.44 на с. 302 и предположим, что
отношение Stars In занимает не 10 дисковых блоков, а 100, но все другие условия
сохраняются в силе. Предоставьте формулы средней суммарной трудоемкости
выполнения операций Qu Q2 и / в терминах значений р{ и р2 для всех рассмотренных
комбинаций индексов.
6.7. Виртуальные таблицы
Отношение, определенное с помощью команды вида create table, физически
существует в базе данных и может находиться в одном и том же состоянии
неограниченно долгое время, пока не будет изменено командами insert, delete, update
либо удалено инструкцией drop (cm. раздел 6.5 на с. 291).
В SQL поддерживается возможность определения отношений и другой категории,
которые, в отличие от "обычных" отношений, не создаются на физическом уровне.
Такие отношения принято называть виртуальными таблицами (virtual tables), или
представлениями (views). К виртуальным таблицам можно обращаться с запросами, а в
некоторых случаях — и с командами модификации.
6.7.1. Объявление виртуальной таблицы
Выражение объявления виртуальной таблицы в своей простейшей форме состоит
из следующих частей:
1) пары служебных слов create view;
2) названия R виртуальной таблицы;
3) служебного слова as;
4) запроса Q, служащего определением виртуальной таблицы; при обращении
к таблице с некоторым запросом система выполняет запрос Q, а затем
использует его результат для обработки заданного запроса.
Иными словами, выражение создания виртуальной таблицы можно представить так:
CREATE VIEW R AS Q;
Пример 6.45. Пусть необходимо создать виртуальную таблицу, представляющую часть
отношения
Movie(title, year, length, inColor, studioName, producerC#),
а именно значения компонентов title и year тех кортежей, которые содержат
информацию о кинофильмах, снятых на студии "Paramount". Для решения задачи
достаточно выполнить следующую команду:
6.7. ВИРТУАЛЬНЫЕ ТАБЛИЦЫ
305
Отношения, таблицы и представления
Программисты, использующие язык SQL, вместо термина "отношение" склонны
употреблять термин "таблица" — вероятно, так легче различать хранимые
отношения, или "таблицы", и виртуальные отношения, или "представления". Теперь вы
осведомлены об этих различиях, и мы будем использовать термин "отношение"
только тогда, когда ими можно пренебречь. Если необходимо подчеркнуть, что
в какой-либо ситуации речь идет именно о хранимом отношении, подчас мы будем
ссылаться на него как на "базовое отношение" или "базовую таблицу".
Существует и третья категория отношений — они содержат промежуточные
результаты (например, получаемые при выполнении подзапроса), которые нельзя
отнести ни к базовым таблицам, ни к представлениям. Подобные временные
таблицы также называют "отношениями".
1) CREATE VIEW ParamountMovie AS
2) SELECT title, year
3) FROM Movie
4) WHERE studioName = 'Paramount';
Строка 1 содержит название виртуальной таблицы, ParamountMovie. Интересующие
нас атрибуты отношения Movie — title и year — перечислены в предложении
select, а критерий выбора кортежей задан в предложении where; полная
конструкция определения виртуальной таблицы приведена в строках 2—4. □
6.7.2. Запросы к виртуальным таблицам
Отношение ParamountMovie, команда создания которого рассмотрена в примере
6.45, не содержит кортежей в привычном смысле этого слова. Если обратиться
к ParamountMovie с запросом, система вначале выполнит запрос к Movie, указанный в
определении ParamountMovie. Если выполнить один и тот же запрос к ParamountMovie
дважды, полученные результаты могут оказаться различными. Причина состоит в
следующем: несмотря на то, что определение ParamountMovie как таковое остается
прежним, содержимое "базовой" таблицы Movie с течением времени способно изменяться.
Пример 6.46. К виртуальной таблице ParamountMovie позволено обращаться с
запросами точно таким же образом, как и к любой хранимой таблице, например:
SELECT title
FROM ParamountMovie
WHERE year = 1979;
В процессе анализа запроса к виртуальной таблице система преобразует его в аналог,
обращенный к базовой таблице (в данном случае — Movie) (о том, как это делается,
рассказано в разделе 6.7.5 на с. 310). Рассматриваемый здесь запрос, однако,
настолько прост, что проследить ход его обработки совершенно не трудно. Отношение
ParamountMovie отличается от Movie в двух аспектах (о том, что ParamountMovie не
"хранит" кортежи, мы уже не говорим — это подразумевается):
1) ParamountMovie содержит только два атрибута схемы Movie, title и year;
2) выражение studioName = 'Paramount' автоматически включается в
предложение WHERE любого запроса, обращенного к ParamountMovie.
Поскольку в запросе предусматривается получение только компонентов title, это
обстоятельство согласуется с условием (1). Для завершения преобразования запроса
к ParamountMovie в запрос к Movie достаточно заменить ParamountMovie на Movie
306
ГЛАВА 6. ЯЗЫК SQL
в предложении from и, учитывая условие (2), с помощью оператора and добавить
выражение studioName = ' Paramount' в предложение WHERE. В результате обработки запроса
SELECT title
FROM Movie
WHERE studioName = 'Paramount' AND year = 1979;
будут получены те же данные, что и при выполнении исходного запроса, обращенного
к виртуальной таблице ParamountMovie. Напомним еще раз, что все обязанности по
преобразованию запросов из одной формы в другую возлагаются на СУБД. □
Пример 6.47. Вполне допустимо в контексте одного запроса объединять обращения
к виртуальным таблицам и базовым отношениям. Вот пример:
SELECT DISTINCT starName
FROM ParamountMovie, StarsIn
WHERE title = movieTitle AND year = movieYear;
Запрос предполагает получение сведений обо всех актерах, когда-либо
принимавших участие в съемках кинофильмов, выпущенных студией "Paramount".
Служебное слово distinct гарантирует, что каждый актер будет упомянут в итоговом
отношении не более одного раза, независимо от того, в каком количестве фильмов
студии "Paramount" он снимался. □
Пример 6.48. Рассмотрим более сложный образец запроса, используемого при
определении виртуальной таблицы. Цель состоит в создании отношения MovieProd,
содержащего названия и даты выпуска кинофильмов в совокупности с именами их
продюсеров. Запрос охватывает отношение
Movie(title, year, length, inColor, studioName, producerC#),
из которого можно извлечь сертификационный номер продюсера, и отношение
MoVieExec(name, address, cert#, netWorth),
подлежащее соединению с Movie для получения имени продюсера. Чтобы создать
виртуальную таблицу MovieProd, обладающую требуемыми свойствами, достаточно
выполнить команду
CREATE VIEW MovieProd AS
SELECT title, name
FROM Movie, MovieExec
WHERE producerC# = cert#;
Теперь можно обращаться к MovieProd с запросами, как к любому хранимому
отношению. Например, чтобы найти имя продюсера фильма "Gone With the Wind",
следует ввести запрос:
SELECT name
FROM MovieProd
WHERE title = 'Gone With the Wind';
Как и во всех других случаях, запрос интерпретируется системой так, как если бы
он представлял собой эквивалентный запрос, обращенный к базовым таблицам Movie
и MovieExec:
SELECT name
FROM Movie, MovieExec
WHERE producerC# = cert# AND title = 'Gone With the Wind';
□
6.7.3. Переименование атрибутов
Подчас более предпочтительно дать атрибутам виртуальной таблицы другие названия,
отличные от исходных, "наследуемых" из схем базовых отношений. Чтобы переименовать
атрибуты виртуальной таблицы, следует задать список новых названий, заключенный
6.7. ВИРТУАЛЬНЫЕ ТАБЛИЦЫ
307
в круглые скобки, непосредственно после имени таблицы в инструкции ее объявления.
Объявление, рассмотренное в примере 6.48, можно переписать следующим образом:
CREATE VIEW MovieProd (movieTitle, prodName) AS
SELECT title, name
FROM Movie, MovieExec
WHERE producerC# = cert#;
Виртуальная таблица по своему существу не изменится, но ее столбцы получат новые
названия — movieTitle (вместо title) и prodName (вместо name).
6.7.4. Модификация виртуальных таблиц
При выполнении определенных, хотя и довольно жестких, условий допустимо
обращаться к виртуальной таблице с командами вставки (insert), удаления (delete)
и обновления (update) кортежей. Впрочем, сама идея внесения подобных изменений
вряд ли имеет серьезный смысл, поскольку способ существования виртуальных
таблиц отличается от того, как "живут" в базе данных хранимые (базовые) отношения.
Что может означать, например, желание вставить в виртуальную таблицу новый
кортеж? Куда именно следует поместить кортеж и каким образом система должна
зафиксировать факт его наличия в виртуальной таблице?
Для большой части разновидностей виртуальных таблиц ответ на подобные
вопросы однозначен: "Это сделать нельзя". Если говорить о некоторых сравнительно
простых виртуальных таблицах — их принято называть обновляемыми (updatable), —
системе вполне под силу преобразовать команду модификации такой таблицы в
эквивалентную инструкцию изменения содержимого базовой таблицы. Стандарт SQL
содержит формальное определение условий, способствующих возможности
модификации виртуальных таблиц. Эти правила достаточно сложны, но в грубом
приближении их можно изложить так: виртуальная таблица допускает внесение изменений,
если она определена на основе запроса, предполагающего выбор (select — не
select distinct) значений некоторых атрибутов одного отношения R (которое,
в свою очередь, также может быть виртуальной таблицей, отвечающей аналогичным
требованиям). Помимо того, существуют и определенные технические нюансы:
• предложение where не должно содержать R в составе какого бы то ни было
подзапроса;
• список предложения select обязан охватывать достаточное количество атрибутов,
чтобы при попытке вставки кортежа в виртуальную таблицу система смогла
присвоить остальным атрибутам значения null или иные значения, предусмотренные
по умолчанию при создании базовой таблицы, и сохранить в последней
"полноценный" кортеж, соответствующий кортежу, вставляемому в виртуальную таблицу.
Пример 6.49. Предположим, что осуществляется попытка вставки в виртуальную
таблицу Paramountview, рассмотренную в примере 6.45 на с. 305, нового кортежа:
INSERT INTO ParamountMovie
VALUES('Star Trek *, 1979);
Таблица Paramountview удовлетворяет формальным требованиям стандарта SQL,
которые оговаривают возможность обновления виртуальных таблиц, так как в ее запросе
предусмотрен выбор значений только некоторых атрибутов определенных
компонентов одной базовой таблицы:
Movie(title, year, length, inColor, studioName, producerC#).
Единственная проблема связана с тем, что, поскольку атрибут studioName отношения
Movie не входит в набор атрибутов Paramountview, компоненту studioName кортежа,
вставляемого в Movie, будет присвоено значение NULL, а не ' Paramount', как того хоте-
308
ГЛАВА 6. ЯЗЫК SQL
лось бы. Кортеж, таким образом, не будет содержать информацию о том, что фильм
выпущен именно студией "Paramount". Чтобы исправить этот недочет, достаточно ввести
в предложение SELECT определения таблицы Par amount View атрибут studioName (хотя
при использовании таблицы в качестве источника информации компоненты studioName
окажутся явно лишними, поскольку все они будут содержать одно и то же значение
■ Paramount'). Обновленная версия инструкции создания таблицы приведена ниже:
CREATE VIEW ParamountMovie AS
SELECT studioName, title, year
FROM Movie
WHERE studioName = 'Paramount';
Теперь команда вставки кортежа в ParamountMovie должна выглядеть так:
INSERT INTO ParamountMovie
VALUES('Paramount', 'Star Trek', 1979);
Система преобразует ее в инструкцию вставки кортежа в базовое отношение Movie,
полагая, что компонент studioName содержит значение 'Paramount', компонент title —
строку 'Star Trek', а компонент year— число 1979. Три других атрибута— length,
inColor и producerC#, — отсутствующие в ParamountMovie, определенно существуют
в схеме Movie, однако при вставке кортежа значения их компонентов не известны.
Поэтому компонентам присваиваются значения, предлагаемые по умолчанию, — либо
null, либо некоторые константы, предусмотренные в конструкции определения
схемы Movie. Если бы, например, строка определения атрибута length выглядела как
length INT DEFAULT 0,
а определения атрибутов inColor и producerC# остались без изменений, в
отношение Movie был бы вставлен следующий кортеж, соответствующий команде INSERT,
указанной выше:
title
Star Trek
year
1979
length 1 inColor
0 j NULL
studioName
Paramount
producerC#
NULL
Обновляемые виртуальные таблицы допускают и возможность удаления кортежей.
Подобные команды транслируются системой в инструкции удаления соответствующих
кортежей базового отношения R.
Пример 6.50. Предположим, что необходимо удалить из виртуальной таблицы
ParamountMovie все кортежи с описанием кинофильмов, в названии которых
присутствует слово "Trek". С этой целью достаточно применить команду
DELETE FROM ParamountMovie
WHERE title LIKE '%Trek%';
Последняя преобразуется в эквивалентную инструкцию удаления кортежей базового
отношения Movie, которая отличается тем, что содержит в предложении WHERE
дополнительное условие из определения виртуальной таблицы ParamountMovie:
DELETE FROM Movie
WHERE title LIKE '%Trek%' AND studioName = 'Paramount';
□
Аналогично, команды обновления виртуальной таблицы (если таковые вообще
допустимы) транслируются в инструкции изменения содержимого соответствующих
кортежей базовой таблицы.
Пример 6.51. Команда обновления виртуальной таблицы,
UPDATE ParamountMovie
SET year = 1979
WHERE title = 'Star Trek the Movie';
6.7. ВИРТУАЛЬНЫЕ ТАБЛИЦЫ
309
Почему некоторые виртуальные таблицы не поддаются модификации
Обратимся к виртуальной таблице MovieProd, рассмотренной в примере 6.48 на
с. 307 и связывающей информацию о кинофильмах с именами их продюсеров.
Согласно правилам, изложенным в стандарте SQL, таблица не допускает
возможности изменения, поскольку в предложении from ее определения упоминаются
сразу два базовых отношения — Movie и MovieExec. Предположим, однако, что
предпринята попытка вставки в MovieProd нового кортежа
('Greatest Show on Earth', 'Cecil В. DeMille').
Системе придется позаботиться о вставке соответствующих кортежей в оба базовых
отношения. Для инициализации компонентов, подобных length или address,
система могла бы воспользоваться значениями по умолчанию, но что делать с
компонентами producerC# и cert#, обязанными содержать заведомо равные
сертификационные номера продюсера Сесиль де Милл, которые на самом деле не известны?
Как кажется, для этих компонентов подошло бы значение null, однако при
соединении отношений система не сможет расценить значения null как взаимно равные
(см. раздел 6.1.5 на с. 258). Таким образом, значения 'Greatest Show on Earth'
и 'Cecil В. DeMille' нельзя соединить в кортеж виртуальной таблицы
MovieProd, и команда вставки этого кортежа выполнена не будет.
преобразуется системой в соответствующую инструкцию, воздействующую на
базовую таблицу:
UPDATE Movie
SET year = 1979
WHERE title = 'Star Trek the Movie' AND
studioName = 'Paramount';
□
Наконец, еще одна команда модификации — это удаление виртуальной таблицы.
Ее можно выполнять независимо от того, является таблица обновляемой или нет.
Типичное выражение удаления виртуальной таблицы выглядит так:
DROP VIEW ParamountMovie;
Обратите внимание, что после выполнения подобной команды определение
виртуальной таблицы перестает существовать, так что обращаться к ней с запросами
или инструкциями модификации больше нельзя. Команда удаления виртуальной
таблицы, однако, нисколько не влияет на базовую таблицу (в нашем примере —
Movie). Но инструкция
DROP TABLE Movie;
воздействует не только на отношение Movie — после ее применения таблица
ParamountMovie также становится недоступной, поскольку определенный в ней
запрос ссылается на несуществующее базовое отношение Movie.
6.7.5. Интерпретация запросов к виртуальным таблицам
Чтобы получше разобраться с тем, что представляют собой виртуальные таблицы,
целесообразно рассмотреть способы их интерпретации системой. Предмет более
подробно освещен в разделе 16.2 на с. 760, в котором изложены общие аспекты
процессов обработки запросов.
Основная идея иллюстрируется рис. 6.18. Запрос Q представляется
соответствующим деревом выражений реляционной алгебры. Некоторые виртуальные таблицы яв-
310
ГЛАВА 6. ЯЗЫК SQL
ляются оконечными вершинами дерева. Положим, что существуют две такие
вершины, V и W. Чтобы интерпретировать запрос Q в терминах базовых отношений, следует
обратиться к определениям V и W. Эти определения также, в свою очередь, можно
описать деревьями выражений реляционной алгебры. Каждую оконечную вершину
в дереве Q, представляющую виртуальную таблицу, следует заменить копией дерева
выражений, описывающего определение этой таблицы. Так, на рис. 6.18 вершины V
и W подлежат замещению соответствующими деревьями запросов-определений.
Итоговое дерево представляет запрос к базовым таблицам, эквивалентный исходному
запросу, обращенному к виртуальным таблицам.
^>
Рис. 6.18. Замена определений виртуальных
таблиц ссылками на эти таблицы
Пример 6.52. Рассмотрим объявление виртуальной таблицы Paramountview и запрос
из примера 6.46 (см. с. 306). Команда объявления вопроизведена ниже.
CREATE VIEW ParamountMovie AS
SELECT title, year
FROM Movie
WHERE studioName = 'Paramount';
Дерево выражений реляционной алгебры, представляющее запрос определения
таблицы ParamountMovie, изображено на рис. 6.19.
Запрос Q,
SELECT title
FROM ParamountMovie
WHERE year = 1979;
предусматривает поиск кортежей с информацией о кинофильмах студии "Paramount",
снятых в 1979 году. Дерево выражений, описывающее этот запрос, показано на
рис. 6.20 (оконечная вершина представляет виртуальную таблицу ParamountMovie).
' title, year
studioName = 'Paramount'
Movie
Рис. 6.19. Дерево выражений
для виртуальной таблицы
ParamountMovi e
' title
year =1979
ParamountMovie
Рис. 6.20. Дерево выражений,
описывающее запрос к виртуальной
таблице ParamountMovie
Система интерпретирует запрос Q, подставляя на место оконечной вершины
ParamountMovie дерева, изображенного на рис. 6.20, дерево из рис. 6.19. В результате
будет получено дерево выражений, приведенное на рис. 6.21.
6.7. ВИРТУАЛЬНЫЕ ТАБЛИЦЫ
311
Дерево на рис. 6.21 по существу верно, но избыточно. Системе придется
преобразовать его к такому виду, который соответствовал бы запросу, рассмотренному в
примере 6.46 на с. 306:
SELECT title
FROM Movie
WHERE studioName = 'Paramount' AND year = 1979;
Если говорить более точно, разумно, например, расположить вершину, отвечающую
операции проекции лм^утп над вершиной, представляющей операцию выбора crygar=l919.
Это, как нетрудно догадаться, не окажет влияния на результат выражения. Теперь
две операции проекции я следуют одна
за другой: первая предполагает изъятие
всех столбцов отношения, кроме title
и year, а вторая оставляет в
отношении только столбец title. Ясно, что
первая операция избыточна и может
быть исключена из рассмотрения.
Таким образом, две операции проекции
заменяются одной, тгши.
' title
year-
= 1979
' title, year
studioName
'Paramount'
Movie
Рис. 6.21. Дерево
выражений запроса к
ParamountMovie в
терминах базовой таблицы
• title
year =1979 AND studioName = 'Paramount'
Movie
Рис. 6.22. Упрощенное дерево
выражений запроса к базовой таблице
Две последовательные операции выбора а могут быть объединены в одну
посредством сочетания их условий с помощью оператора and. Итоговое дерево выражений
показано на рис. 6.22.
Это именно то дерево, которое соответствует эквивалентному запросу, обращенному
к базовой таблице Movie:
SELECT title
FROM Movie
WHERE studioName = 'Paramount' AND year = 1979;
□
6.7.6. Упражнения к разделу 6.7
Упражнение 6.7.1. Используя неформальные определения схем отношений
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
из "кинематографической" базы данных, представьте команды создания
следующих виртуальных таблиц:
* a) RichExec, содержащей сведения об именах (name), адресах (address),
сертификационных номерах (cert#) и уровнях годового дохода (netWorth) всех
руководящих лиц (MovieExec), обладающих доходом не менее 10 миллионов долларов;
312
ГЛАВА 6. ЯЗЫК SQL
b) StudioPres, содержащей сведения об именах (name), адресах (address)
и сертификационных номерах (cert#) всех руководителей (MovieExec),
являющихся президентами киностудий (studio);
c) ExecutiveStar, содержащей сведения об именах (name), адресах (address),
половой принадлежности (gender), датах рождения (birthdate),
сертификационных номерах (cert#) и уровнях годового дохода (netWorth) всех
лиц, занимающих руководящие посты (MovieExec) и одновременно
являющихся актерами (MovieStar).
Упражнение 6.7.2. Какие из виртуальных таблиц, созданных вами при решении
заданий упражнения 6.7.1, являются обновляемыми?
Упражнение 6.7.3. Сформулируйте перечисленные ниже запросы, пользуясь
исключительно виртуальными таблицами, созданными в процессе решения заданий
упражнения 6.7.1.
а) Найти имена женщин (значение ' F ' атрибута gender), являющихся
одновременно актрисами и руководящими сотрудниками.
* Ь) Найти имена тех руководящих товарищей, кто является президентом
киностудии и обладает годовым доходом в размере не менее 10 миллионов
долларов.
! с) Найти имена тех президентов киностудий, одновременно являющихся
актерами, кто обладает годовым доходом в размере не менее 50 миллионов
долларов.
*! Упражнение 6.7.4. Обратитесь к виртуальной таблице и запросу, рассмотренным
в примере 6.48 на с. 307, и выполните следующие задания.
a) Создайте дерево выражений для виртуальной таблицы.
b) Создайте дерево выражений для запроса.
c) Используя решения заданий (а) и (Ь), создайте выражение запроса в
терминах базовых отношений.
d) Объясните, как изменить выражение, созданное при решении задания
(с), чтобы оно оказалось эквивалентным выражению, предложенному в
примере 6.48.
! Упражнение 6.7.5. Для каждого из запросов, созданных в процессе решения
заданий упражнения 6.7.3, представьте запрос и определение соответствующей
виртуальной таблицы в виде выражения реляционной алгебры, замените обращения
к виртуальным таблицам ссылками на базовые отношения и упростите полученные
выражения способом, наилучшим из возможных. Создайте SQL-запросы,
соответствующие итоговым выражениям реляционной алгебры.
Упражнение 6.7.6. Используя схемы отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222, выполните
следующие задания.
а) Представьте команду создания виртуальной таблицы BritishShips,
содержащей сведения о классе (class), типе (type), количестве главных
орудий (numGuns), их калибре (bore), водоизмещении (displacement)
6.7. ВИРТУАЛЬНЫЕ ТАБЛИЦЫ
313
и годе спуска на воду (launched) для каждого судна, построенного в
Великобритании.
Ь) Создайте запрос к виртуальной таблице, полученной в результате решения
задания (а), который возвращает информацию о количестве орудий и
водоизмещении всех британских линкоров (значение 'bb' атрибута type),
построенных до 1919 года.
! с) Представьте определение виртуальной таблицы и запрос, созданные вами
при решении заданий (а) и (Ь), в виде выражений реляционной алгебры,
замените обращения к виртуальным таблицам ссылками на базовые
отношения и упростите полученное выражение способом, наилучшим из
возможных.
! d) Создайте SQL-запрос, соответствующий итоговому выражению реляционной
алгебры, полученному при решении задания (с).
6.8. Резюме
♦ SQL. Язык SQL представляет собой основной инструмент создания запросов
в системах реляционных баз данных. Современный стандарт языка носит
название SQL-99, или SQL3. Коммерческие системы зачастую реализуют те или
иные расширения стандарта.
♦ Запросы вида "select—from—where". Наиболее общая форма SQL-запросов
описывается последовательностью предложений "select—from—where". Подобные
запросы позволяют вычислять декартовы произведения нескольких отношений,
указанных в предложении FROM, выбирать кортежи в соответствии с условиями
предложения where и осуществлять проекцию полученных результатов на
множество выражений, перечисленных в предложении select.
♦ Подзапросы. Запросы вида "select—from—where" могут использоваться в качестве
подзапросов, вызываемых из предложений where или from других запросов.
Для представления логических условий, касающихся итоговых отношений,
получаемых при вызове подзапросов из предложения where, применяются
операторы EXISTS, IN, ALL И ANY.
♦ Теоретико-множественные операции над отношениями. Допустимо выполнять
операции объединения, пересечения и разности отношений, сочетая эти
отношения или запросы, посредством которых они создаются, с помощью
операторов union, intersect и except соответственно.
♦ Выражения соединения. SQL предоставляет различные операторы соединения,
подобные natural join, которые могут применяться к отношениям либо
непосредственно, либо в контексте предложений from.
♦ Значения null. В SQL предусмотрено использование специальных значений
null в тех ситуациях, когда точное значение компонента кортежа не известно.
Обработка значений null в контексте арифметических и логических
выражений выполняется по особым правилам. Результатом сравнения с null любого
значения (даже null) является значение unknown. Значение unknown в
логических выражениях "ведет" себя так, будто представляет "промежуточную"
величину между булевыми значениями true и false.
♦ Внешние соединения. В SQL предусмотрен оператор outer join, который
позволяет соединять отношения и включать в них "висящие" кортежи одного или
обоих отношений-операндов. Определенным компонентам висящих кортежей
автоматически присваиваются значения null.
314
ГЛАВА 6. ЯЗЫК SQL
♦ Модель отношений-мультимножеств. В SQL отношения трактуются как
мультимножества, а не множества, кортежей. Удаление кортежей-дубликатов
обеспечивается применением служебного слова distinct, а служебное слово all,
напротив, в некоторых случаях позволяет изменить поведение системы,
предусмотренное по умолчанию, и гарантировать включение повторяющихся
кортежей в итоговое отношение.
♦ Группирование и агрегирование. К значениям, присутствующим в столбце
отношения, могут быть применены операторы агрегирования — суммирования (SUM),
вычисления среднего арифметического (avg), получения максимального (мах)
и минимального (min) значений, а также подсчета (count). Перед
выполнением агрегирования кортежи допускают группирование в соответствии с
требованиями предложения GROUP by. Для удаления определенных групп используется
предложение having.
♦ Команды модификации отношений. SQL позволяет выполнять инструкции
модификации отношений — вставлять новые кортежи (insert), удалять
определенные существующие кортежи (delete) и обновлять содержимое отдельных
компонентов кортежей (update).
♦ Определение данных. SQL предлагает средства определения элементов схемы
базы данных. Команда create table служит для создания хранимых отношений
(называемых таблицами) с указанием наименований атрибутов, их типов и
значений, предусмотренных по умолчанию.
♦ Изменение реляционных схем. Для изменения свойств реляционных схем —
например, для добавления или удаления атрибутов — используются команды
семейства alter. Команды drop применяются с целью удаления элементов
схемы базы данных.
♦ Индексы. Коммерческие СУБД позволяют определять индексы для тех или
иных групп атрибутов отношений (хотя эти функции не регламентируются
стандартами SQL). Наличие индекса способно привести к существенному
снижению времени обработки запросов, в которых упоминаются значения
индексированных атрибутов.
♦ Виртуальные таблицы. Определение виртуальной таблицы содержит запрос
к тем или иным базовым таблицам. К виртуальным таблицам можно
обращаться с запросами точно так же, как и к любым хранимым таблицам, и в процессе
обработки подобных запросов система преобразует их в эквивалентные
запросы, адресованные соответствующим базовым таблицам.
6.9. Литература
Стандарты SQL2 и SQL-99 опубликованы в Web, и для их получения следует
обратиться по адресу ftp://jerry.ece.umassd.edu/isowg3/dbl/BASEdocs. Авторы не
гарантируют, что упомянутая ссылка будет доступна к тому моменту, когда читатель
решит ею воспользоваться. За свежей информацией39 обращайтесь на сайт со
сведениями об оригинальной версии книги; адрес сайта указан в предисловии.
Мы могли бы назвать немалое число публикаций, содержащих дополнительные
данные о тех или иных аспектах программирования на языке SQL. К числу книг,
предпочитаемых лично нами, относятся [2], [4] и [6]. Руководство [5] содержит одно
из первых "толкований" стандарта SQL-99.
39 Помимо указанной, в оригинале приведены и другие ftp-ссылки, но все они, увы, не
работоспособны. Обещания авторов не выполнены — "свежей" информации на сайте, посвященном
книге, нет (по меньшей мере, не было в период подготовки русского издания). — Прим. ред.
6.9. ЛИТЕРАТУРА
315
Язык SQL был впервые упомянут в работе [3] и реализован как часть
System R [1] — одного из первых прототипов промышленных систем
реляционных баз данных.
1. Astrahan M.M. et al. System R: a relational approach to data management, ACM Trans, on
Database Systems, 1:2 (1976), p. 97-137.
2. Celko J. SQL for Smarties, Morgan-Kaufmann, San Francisco, 1999.
3. Chamberlin D.D. et al. SEQUEL 2: a unified approach to data definition, manipulation, and
control, IBM J. Research and Development, 20:6 (1976), p. 560-575.
4. Date C.J., Darwen H. A Guide to the SQL Standard, Addison-Wesley, Reading, MA, 1997.
5. Gulutzan P., Pelzer T. SQL-99 Complete, Really, R&D Books, Lawrence, KA, 1999.
6. Melton J., Simon R. Understanding the New SQL: A Complete Guide, Morgan-Kaufmann,
San Francisco, 1993.
316
ГЛАВА 6. ЯЗЫК SQL
Глава 7
Ограничения и триггеры
В этой главе мы сосредоточим внимание на тех средствах SQL, которые позволяют
создавать так называемые "активные" элементы. Активный элемент (active element) —
это выражение или команда, которые, будучи объявленными и сохраненными в базе
данных, выполняются по мере необходимости в определенные моменты времени
и в связи с наступлением событий, подобных вставке кортежа в то или иное
отношение или изменению состояния базы данных, при которых некоторое логическое
условие приобретает значение true.
Одна из серьезных проблем, с которыми сталкиваются разработчики приложений
баз данных, связана с тем, что при обновлении элементов информации последние
оказываются неверными или вступают в противоречие с другими элементами.
Зачастую подобные ошибки возникают в процессе "ручного" ввода данных или
преобразования их из одной формы представления в другую. Наиболее прямолинейный способ
предотвращения возможности попадания в базу данных новых кортежей, содержащих
ущербную информацию, или искажения существующей информации состоит в том,
чтобы прикладная программа сама "заботилась" о корректности данных, предваряя
каждую операцию вставки, удаления или обновления соответствующей проверкой. К
сожалению, зачастую критерии, которым необходимо подчиняться, весьма сложны; помимо
того, одни и те же операции проверки обычно следует повторять вновь и вновь.
Теперь о приятном: SQL предлагает множество способов выражения
ограничений целостности данных и представления их в виде неотъемлемой части схемы базы
данных. В этой главе мы рассмотрим основные из них. Вначале будет рассказано об
ограничениях, предусматривающих создание первичных ключей (primary keys),
содержащих в своем составе один или несколько атрибутов отношения. Затем мы
познакомим вас с такими формами выражения требований ссылочной целостности,
которые связаны с определением так называемых внешних ключей (foreign keys),
предполагающих, что если некоторые компоненты атрибутов одного отношения
(например, presC# таблицы studio) содержат определенные значения, те же
значения должны присутствовать в компонентах атрибутов другого отношения
(соответственно cert# таблицы MovieExec).
Далее мы покажем, как определять ограничения уровня отдельного атрибута,
кортежа и отношения в целом, а также ограничения "общего вида" (assertions),
и приведем сведения о триггерах (triggers) — разновидности активных элементов,
вызываемых системой в ответ на определенные события, такие как вставка кортежа
в заданное отношение.
7.1. Ключи отношений
Возможно, наиболее важным является такое ограничение, которое позволяет
сформулировать утверждение о том, что некоторое подмножество атрибутов
определенного отношения формирует ключ этого отношения. Если подмножество S
атрибутов является ключом отношения /?, любые два кортежа R должны различаться в
значениях компонентов хотя бы одного из атрибутов S. Это правило остается в силе
и в применении к кортежам-дубликатам: если схема отношения R содержит
объявление ключа, в R не могут быть помещены повторяющиеся кортежи.
Ограничение ключа, как и многие другие виды ограничений, формулируется в
контексте SQL-команды create table. Существуют два схожих способа определения
ключей: первый предусматривает использование пары служебных слов primary key, а
второй — служебного слова unique. Для каждого отношения может быть определен только
один первичный ключ (primary key), но любое количество "уникальных " (unique) ключей.
Термин "ключ" употребляется в SQL и для обозначения ограничений ссылочной
целостности, называемых ограничениями внешних ключей (foreign-key constraints),
которые предусматривают, что если некоторые значения присутствуют в определенных
компонентах одного отношения, они должны наличествовать и в компонентах
первичного ключа некоторого кортежа другого отношения (за подробностями
обращайтесь к разделу 7.1.4 на с. 321).
7.1.1. Объявление первичного ключа
Отношение может содержать только один первичный ключ (primary key).
Существуют два способа объявления первичного ключа в рамках выражения create table:
1) дополнить особым признаком определение атрибута в списке атрибутов
реляционной схемы;
2) добавить в список элементов объявления схемы (до сих пор мы говорили
о том, что такой список может содержать только определения атрибутов)
специальное предложение, свидетельствующее о том, что атрибут или
несколько атрибутов должны образовать первичный ключ.
При использовании первого способа следует присоединить к определению атрибута
в списке элементов схемы отношения пару служебных слов primary key; второй способ
предоставляет возможность вставки в этот список предложения primary key со
списком ключевых элементов, заключенным в круглые скобки. Если ключ должен состоять
из нескольких атрибутов, для его определения можно применять только второй способ.
Результат объявления подмножества S атрибутов в качестве ключа отношения R
следует трактовать так:
1) два произвольных кортежа R не могут совпадать в значениях компонентов всех
ключевых атрибутов одновременно; любая попытка вставки нового кортежа
или обновления содержимого существующего кортежа, приводящая к
нарушению этого правила, будет отвергнута системой как недопустимая операция;
2) компоненты ключевых атрибутов S не могут содержать значения null.
Пример 7.1. Обратимся к схеме отношения Movies tar ("актеры") (см. рис. 6.16 на с. 298).
Ключом отношения является атрибут name ("имя"). Этот факт следует отразить в
инструкции объявления отношения. Дополненный вариант объявления приведен на рис. 7.1.
Можно воспользоваться и таким вариантом определения первичного ключа,
который предполагает включение в список элементов схемы отношения MovieStar
отдельного предложения primary key (name). Соответствующая версия объявления
показана на рис. 7.2.
318
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
1) CREATE TABLE MovieStar (
2) name CHAR(30) PRIMARY KEY,
3) address VARCHAR(255) ,
4) gender CHAR(1) ,
5) birthdate DATE
) ;
Рис. 7.1. Придание атрибуту name статуса первичного ключа
1) CREATE TABLE MovieStar (
2) name CHAR(30),
3) address VARCHAR(255) ,
4) gender CHAR(l),
5) birthdate DATE,
6) PRIMARY KEY (name)
) ;
Рис. 7.2. Объявление первичного ключа в виде отдельного предложения
□
В примере 7.1 приемлемой можно считать любую из двух альтернативных форм
определения первичного ключа, поскольку тот состоит только из одного атрибута.
Если же необходимо создать ключ на основе нескольких атрибутов, следует пользоваться
вторым вариантом, предусматривающим применение отдельного предложения
(см. рис. 7.2). Например, при объявлении схемы отношения Movie, ключом которого
(мы неоднократно говорили об этом прежде) является пара атрибутов title и year,
после списка атрибутов нам пришлось бы включить строку вида
PRIMARY KEY (title, year)
7.1.2. Объявление ключа unique
Еще один способ объявления ключа отношения связан с использованием
служебного слова unique. Слово unique можно употреблять в тех же "местах" конструкции
create table, что и выражение primary key, т.е. после имен атрибута и его типа
в списке атрибутов либо в виде отдельного предложения. Смысл объявления со
словом unique почти аналогичен значению выражения primary key; существуют,
однако, два исключения, указанные ниже.
1. Отношение может обладать несколькими ключами unique, но только одним
первичным ключом.
2. В то время как компонентам атрибутов ключа primary key запрещено
присваивать значения null, это разрешено для компонентов ключа unique. Кроме того,
правило, запрещающее совпадение содержимого компонентов ключевых
атрибутов нескольких кортежей, в ключе unique может быть нарушено, если этим
компонентам присвоены значения null (допустима даже такая ситуация, когда все
компоненты ключа unique нескольких кортежей содержат значения null).
Разработчику СУБД предоставлена возможность задавать дополнительные условия,
касающиеся различий между ключами primary key и unique. Например, в
конкретной реализации системы может быть предусмотрено автоматическое построение
индекса для ключа, объявленного в качестве первичного (даже в том случае, если такой
ключ состоит из нескольких атрибутов), но с учетом того, что иные индексы, если та-
7.1. КЛЮЧИ ОТНОШЕНИИ
319
ковые необходимы, должны создаваться дополнительно. В другом случае система
способна сортировать отношение по значениям компонентов ключевых атрибутов и далее
поддерживать его именно в таком виде.
Пример 7.2. Строку 2 рис. 7.1 допустимо изменить так:
2) name CHAR(30) UNIQUE,
Помимо того, строка 3, например, может быть представлена в следующем виде:
3) address VARCHAR(255) UNIQUE,
если нам кажется, что адреса актеров обязаны быть уникальными (хотя такая
"догадка", вероятно, сомнительна). Аналогичным образом при необходимости можно
изменить и строку 6 рис. 7.2:
6) PRIMARY KEY (name)
□
7.1.3. Соблюдение ограничений ключей
Давайте вновь обратимся к теме раздела 6.6.5 (см. с. 299), где, рассказывая об
индексах, мы говорили о том, что хотя необходимость в их создании не
регламентируется ни одним стандартом SQL, каждая реализация СУБД предусматривает те или иные
средства конструирования индексов как части определения схемы базы данных. Если
система предлагает создать индекс для первичного ключа отношения, это естественно
и объяснимо — вполне вероятно, что запросы, предполагающие задание значений
ключевых атрибутов, окажутся наиболее "популярными". Иногда целесообразно также
создать индексы для других атрибутов, которые объявлены как unique. Если предложение
where запроса содержит условие равенства ключевого атрибута определенному
значению (например, name = 'Audrey Hepburn' для отношения MovieStar, упомянутого
в примере 7.1 на с. 318), при наличии подобного индекса система сможет отыскать
подходящий кортеж чрезвычайно быстро, не просматривая все отношение целиком.
Во многих реализациях SQL предлагается возможность включения в команду
создания индекса служебного слова unique, что позволяет придать атрибуту статус ключа
и одновременно сконструировать индекс для этого атрибута. Например, выражение
CREATE UNIQUE INDEX Yearlndex ON Movie(year);
выполняет не только функцию создания индекса, о чем говорилось в разделе 6.6.5, но
и содержит объявление ограничения уникальности значений атрибута year отношения
Movie (разумеется, в данном случае это не вполне правильно, поскольку уникальными
должны быть пары значений title и year, но сейчас мы преследуем иную цель —
продемонстрировать синтаксис и обсудить семантические особенности такой команды).
Рассмотрим вкратце, каким образом система следит за соблюдением ограничения
ключа. Вообще говоря, условие такого ограничения подлежит проверке перед каждой
попыткой изменения содержимого базы данных. Впрочем, понятно, что ограничение
ключа отношения R подвергается опасности нарушения только в том случае, если R
каким-либо образом модифицируется. Если говорить более точно, операция удаления
кортежа из R не способна привести к нарушению условия ограничения — этим
чреваты команды вставки новых кортежей и обновления существующих кортежей. Поэтому
обычно SQL-системы осуществляют проверку условия ограничения ключа только при
обработке команд insert и update.
Наличие индекса для атрибутов, объявленных как ключевые, жизненно важно в том
смысле, что система может эффективно следить за соблюдением ограничений ключей.
Всякий раз, когда выполняется вставка кортежа или обновление значений ключевых
атрибутов существующего кортежа, система использует индекс для быстрого просмотра содер-
320
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
жимого отношения в поисках кортежа с теми же значениями ключевых атрибутов. Если
такой кортеж уже существует, система обязана предотвратить модификацию отношения.
Если индекс для ключевых атрибутов не создан, соблюдение ограничения ключа
все еще необходимо и возможно. Процедуру поиска удастся упростить, отсортировав
отношение по ключевым атрибутам. Однако в отсутствие какой бы то ни было
отправной точки поиска при попытке отыскания кортежа с заданными значениями
компонентов системе придется проверить все отношение. Подобный процесс
настолько трудоемок, что задача модификации отношения с большим количеством
кортежей становится попросту неразрешимой.
7.1.4. Объявление внешнего ключа
Ограничения, относящиеся ко второй важнейшей разновидности, призваны
гарантировать, что значения заданных атрибутов отношения имеют строго определенный смысл.
Например, атрибут presC# отношения studio должен содержать ссылку на элемент
информации с описанием конкретного руководящего лица. Рассматриваемое ограничение
ссылочной целостности предполагает, что если в компоненте presc# некоторого кортежа
отношения studio содержится сертификационный номер с, этот номер должен
принадлежать реальному лицу. Таким "реальным" лицом может быть только человек, сведения
о котором представлены в отношении MovieExec, или, иными словами, в MovieExec
должен существовать кортеж, компонент cert# которого содержит тот же номер с.
SQL позволяет объявить атрибут или несколько атрибутов отношения как внешний
ключ (foreign key), ссылающийся (references) на некоторые атрибуты другого (или того
же самого) отношения. Результат объявления внешнего ключа следует трактовать так.
1. Атрибуты, адресуемые внешним ключом, должны быть объявлены как unique или
primary key. Если это требование не выполняется, внешний ключ не будет создан.
2. Значения атрибутов внешнего ключа должны присутствовать в компонентах
адресуемых атрибутов некоторого кортежа. Если говорить более точно, положим,
что внешний ключ F ссылается на множество атрибутов G определенного
отношения. Положим также, что некоторый кортеж t отношения с внешним
ключом обладает отличными от null значениями во всех компонентах атрибутов F;
обозначим список этих значений как t[F]. Тогда в отношении, адресуемом
внешним ключом, должен существовать некоторый кортеж s, который
совпадает с t[F] во всех атрибутах G, т.е. удовлетворяет условию s[G] = t[F].
Как и в случае объявления первичного ключа, внешний ключ допускает две
формы объявления.
1. Если внешний ключ содержит единственный атрибут, объявление последнего
можно сопроводить предложением, свидетельствующим о том, что атрибут
"ссылается" (references) на определенный атрибут (обязанный быть
ключом — первичным или "уникальным") некоторой таблицы:
REFERENCES <таблица>{<атрибут>)
2. Другой способ объявления предполагает включение в список элементов
команды create table отдельного предложения с утверждением о том, что
некоторое подмножество атрибутов таблицы является внешним ключом
(foreign key), ссылающимся (references) на множество ключевых атрибутов
той же или другой таблицы:
FOREIGN KEY <атрибуты> REFERENCES <таблица>(<атрибуты>)
Пример 7.3. Пусть необходимо объявить отношение
Studio(name, address, presC#),
7.1. КЛЮЧИ ОТНОШЕНИИ
321
обладающее первичным ключом name и внешним ключом presC#, ссылающимся на
атрибут cert# отношения
MovieExec(name, address, cert#, netWorth).
Тот факт, что атрибут presC# ссылается на атрибут cert#, можно описать
непосредственно в строке определения presC#:
CREATE TABLE Studio (
name CHAR(30) PRIMARY KEY,
address VARCHAR(255),
presC# INT REFERENCES MovieExec(cert#)
) ;
Альтернативная форма объявления такова:
CREATE TABLE Studio (
name CHAR(30) PRIMARY KEY,
address VARCHAR(255),
presC# INT,
FOREIGN KEY (presC#) REFERENCES MovieExec(cert#)
);
Заметьте, что адресуемый атрибут cert# должен быть (впрочем, так оно и есть)
ключом отношения MovieExec. Смысл любой из двух конструкций состоит в том, что
любое значение, присваиваемое компоненту presC# кортежа studio, должно
присутствовать в компоненте cert# некоторого кортежа отношения MovieExec.
Единственное исключение связано с присваиванием компоненту presC# значения null —
требование наличия NULL в cert# не выдвигается (атрибут cert# и не может содержать
null, поскольку является первичным ключом). □
7.1.5. Обеспечение ссылочной целостности
Теперь вы знаете, как объявлять внешние ключи, и осведомлены о том, что любая
комбинация значений компонентов внешнего ключа, ни одно из которых не равно
null, должна присутствовать и в компонентах соответствующих атрибутов
отношения, адресуемого внешним ключом. Однако возникает закономерный вопрос, каким
образом система может поддерживать подобные ограничения при осуществлении
операций модификации базы данных. Разработчику базы данных предоставляется
возможность выбора одной из альтернативных стратегий, рассмотренных ниже.
Стратегия по умолчанию: отмена операции
По умолчанию система всегда отвергает операцию модификации, нарушающую
условие ограничения ссылочной целостности. Обратимся к примеру 7.3, в котором
предполагается, что любое значение атрибута presC# отношения studio должно
присутствовать также в числе значений атрибута cert# отношения MovieExec. Каждое из
перечисленных ниже действий будет отменено системой, т.е. вызовет исключение
периода выполнения либо приведет к появлению сообщения об ошибке.
1. Попытка вставки (insert) в studio нового кортежа, компонент presC#
которого содержит значение, отличное от null и не совпадающее ни с одним
значением компонентов cert# кортежей MovieExec. Операция вставки
отвергается системой, и подобный кортеж не будет включен в состав отношения studio.
2. Попытка присваивания (update) компоненту presC# любого из существующих
кортежей studio значения, отличного от null и не совпадающего ни с одним
значением компонентов cert# кортежей MovieExec. Операция обновления
отвергается системой, и содержимое компонента presC# кортежа отношения
Studio не изменяется.
322
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
возникает проблема. Причина состоит в том, что в MovieExec не существует кортежа,
который содержал бы сертификационный номер 23456 (мы полагаем, что это личный
номер Билла Клинтона), и поэтому ограничение внешнего ключа явно нарушается.
Одно из возможных решений состоит в том, чтобы для начала попробовать
вставить кортеж с описанием студии "Redlight Studios", не вводя сертификационный
номер ее президента:
INSERT INTO Studio(name, address)
VALUES('Redlight', 'New York');
Это позволит предотвратить нарушение ограничения, поскольку компоненту presC#
кортежа с информацией о студии "Redlight Studios" будет присвоено значение null,
а при наличии null в компонентах внешнего ключа проверка кортежей отношения,
адресуемого внешним ключом, не выполняется. Однако, прежде чем можно будет
выполнить команду обновления,
UPDATE Studio
SET presC# = 23456
WHERE name = 'Redlight';
нам все-таки придется вставить кортеж со сведениями о Билле Клинтоне в отношение
MovieExec. Если этого не сделать, операция обновления также приведет к
нарушению ограничения ссылочной целостности.
Разумеется, если упорядочить операции вставки во времени (вначале поместить
кортеж с информацией о Билле Клинтоне в отношение MovieExec, а затем кортеж
с описанием студии "Redlight Studios" в studio), это определенно исключит всякую
возможность нарушений. Однако существуют ситуации, когда из-за наличия так
называемых циклических ограничений (circular constraints) проблему их возможного
нарушения нельзя решить простым упорядочением операций модификации базы данных.
Пример 7.5. Предположим на время, что множество "руководителей'4 состоит только из
президентов киностудий. В этом случае ничто не мешает объявить атрибут cert#
отношения MovieExec как внешний ключ, ссылающийся на атрибуг presC# отношения Studio;
при этом, разумеется, придется снабдить атрибут presC# признаком unique,
предусматривая, что ни одно лицо не может быть президентом двух киностудий одновременно.
Теперь окажется, что невозможно пополнить базу данных ни кортежем с
описанием новой киностудии, ни кортежем с информацией о новом президенте: операция
вставки в отношение studio кортежа с уникальным значением presC# приводит к
нарушению ограничения внешнего ключа, связывающего presC# с MovieExec (cert#),
а операция вставки в MovieExec кортежа с уникальным значением cert# влечет
нарушение условия внешнего ключа, соединяющего cert# со Studio (presC#). □
Проблема, освещенная в примере 7.5, поддается решению, но для этого следует
прибегнуть к средствам SQL, которые до сих пор нами не рассматривались.
1. Требуется наличие способа группирования нескольких команд SQL (в данном
случае двух инструкций вставки кортежей: одного — в отношение studio, а
другого — в MovieExec) в неделимую логическую единицу работы, называемую
транзакцией (transaction) (за подробностями обращайтесь к разделу 8.6 на с. 393).
2. Необходимо иметь возможность указать системе, что условие определенного
ограничения не должно проверяться до тех пор, пока транзакция не будет
выполнена полностью, т.е. ее результаты не будут зафиксированы (committed)
в базе данных.
Некие способы объявления транзакций действительно существуют — сейчас вы
можете просто принять это на веру, — но относительно второго условия следует
высказать два соображения.
7.1. КЛЮЧИ ОТНОШЕНИИ
325
"Висящие" кортежи и стратегии модификации
Кортеж, значения атрибутов внешнего ключа которого отсутствуют в отношении,
адресуемом этим ключом, называют висящим (dangling tuple). Напомним, что
кортежи, не способные принять участие в соединении двух отношений, также
называют "висящими". Обе ситуации весьма схожи. Если значение, на которое
ссылается компонент внешнего ключа, отсутствует, кортеж с неверной ссылкой не будет
соединен ни с одним кортежем адресуемого отношения.
Статус "висящих" приобретают те кортежи, которые нарушают условие
ссылочной целостности для конкретного ограничения внешнего ключа.
• Стратегия, предлагаемая по умолчанию в случае удаления или обновления
кортежей, на которые ссылаются компоненты внешнего ключа, предусматривает
запрет на выполнение подобных операций, если и только если они приводят к
возникновению висящих кортежей в отношении, содержащем внешний ключ.
• Стратегия каскадной модификации предполагает удаление или обновление
висящих кортежей отношения, содержащего внешний ключ, в соответствии с теми
изменениями, которые претерпевает отношение, адресуемое внешним ключом.
• Стратегия set-null предусматривает присваивание значений null компонентам
внешнего ключа каждого из висящих кортежей.
1) CREATE TABLE Studio (
2) name CHAR(30) PRIMARY KEY,
3) address VARCHAR(255),
4) presC# INT REFERENCES MovieExec(cert#)
5) ON DELETE SET NULL
6) ON UPDATE CASCADE
) ;
Рис. 7.3. Выбор стратегий соблюдения ограничения ссылочной целостности
В данном случае стратегия set-null предпочтительна для операций удаления, в то
время как стратегия каскадной модификации — для операций обновления.
Справедливо полагать, что если, например, президент киностудии уволен или ушел на пенсию
(кортеж отношения MovieExec удален), студия продолжает существовать и некоторое
время обходится без президента (значение компонента presC# кортежа отношения
studio равно NULL). Однако изменение сертификационного номера президента
студии, вероятно, может быть связано только с какими-либо бюрократическими
манипуляциями: студия продолжает работать, президент на месте, так что наиболее уместно
подчиниться предложенному решению и внести соответствующее изменение и в
содержимое компонента presC# кортежа отношения studio. □
7.1.6. Отложенная проверка ограничений
Вновь обратимся к примеру 7.3 на с. 321, где речь идет о том, что атрибут presC#
отношения studio является внешним ключом, ссылающимся на атрибут cert# отношения
MovieExec, и предположим, что небезызвестный Билл Клинтон, завершив карьеру
президента Соединенных Штатов, решил потрудиться на киностудии "Redlight Studios" —
естественно, на посту ее президента. При попытке выполнения операции вставки,
INSERT INTO Studio
VALUES('Redlight', 'New York', 23456);
324 ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
возникает проблема. Причина состоит в том, что в MovieExec не существует кортежа,
который содержал бы сертификационный номер 23456 (мы полагаем, что это личный
номер Билла Клинтона), и поэтому ограничение внешнего ключа явно нарушается.
Одно из возможных решений состоит в том, чтобы для начала попробовать
вставить кортеж с описанием студии "Redlight Studios", не вводя сертификационный
номер ее президента:
INSERT INTO Studio(name, address)
VALUES('Redlight', 'New York');
Это позволит предотвратить нарушение ограничения, поскольку компоненту presC#
кортежа с информацией о студии "Redlight Studios" будет присвоено значение null,
а при наличии null в компонентах внешнего ключа проверка кортежей отношения,
адресуемого внешним ключом, не выполняется. Однако, прежде чем можно будет
выполнить команду обновления,
UPDATE Studio
SET presC# = 23456
WHERE name = 'Redlight';
нам все-таки придется вставить кортеж со сведениями о Билле Клинтоне в отношение
MovieExec. Если этого не сделать, операция обновления также приведет к
нарушению ограничения ссылочной целостности.
Разумеется, если упорядочить операции вставки во времени (вначале поместить
кортеж с информацией о Билле Клинтоне в отношение MovieExec, а затем кортеж
с описанием студии "Redlight Studios" в Studio), это определенно исключит всякую
возможность нарушений. Однако существуют ситуации, когда из-за наличия так
называемых циклических ограничений (circular constraints) проблему их возможного
нарушения нельзя решить простым упорядочением операций модификации базы данных.
Пример 7.5. Предположим на время, что множество "руководителей'4 состоит только из
президентов киностудий. В этом случае ничто не мешает объявить атрибут cert#
отношения MovieExec как внешний ключ, ссылающийся на атрибуг presC# отношения Studio;
при этом, разумеется, придется снабдить атрибут presC# признаком unique,
предусматривая, что ни одно лицо не может быть президентом двух киностудий одновременно.
Теперь окажется, что невозможно пополнить базу данных ни кортежем с
описанием новой киностудии, ни кортежем с информацией о новом президенте: операция
вставки в отношение studio кортежа с уникальным значением presc# приводит к
нарушению ограничения внешнего ключа, связывающего presC# с MovieExec (cert#),
а операция вставки в MovieExec кортежа с уникальным значением cert# влечет
нарушение условия внешнего ключа, соединяющего cert# со studio (presC#). □
Проблема, освещенная в примере 7.5, поддается решению, но для этого следует
прибегнуть к средствам SQL, которые до сих пор нами не рассматривались.
1. Требуется наличие способа группирования нескольких команд SQL (в данном
случае двух инструкций вставки кортежей: одного — в отношение studio, а
другого — в MovieExec) в неделимую логическую единицу работы, называемую
транзакцией (transaction) (за подробностями обращайтесь к разделу 8.6 на с. 393).
2, Необходимо иметь возможность указать системе, что условие определенного
ограничения не должно проверяться до тех пор, пока транзакция не будет
выполнена полностью, т.е. ее результаты не будут зафиксированы (committed)
в базе данных.
Некие способы объявления транзакций действительно существуют — сейчас вы
можете просто принять это на веру, — но относительно второго условия следует
высказать два соображения.
7.1. КЛЮЧИ ОТНОШЕНИЙ
325
1. Ключ, внешний ключ или любое другое ограничение, о которых мы будем
говорить ниже, могут быть объявлены с использованием любого из двух
предложений — deferable или not deferable. Последнее, подразумеваемое по
умолчанию, означает, что всякий раз, когда содержимое базы данных подвергается
модификации, система сразу выполняет все необходимые проверки, если таковые
предусмотрены. Если же ограничение объявлено как deferable, система, прежде
чем осуществить проверку, должна дождаться завершения текущей транзакции,
2. Если объявление ограничения содержит служебное слово deferable, вслед за
ним можно указать также любую из двух пар служебных слов —
INITIALLY DEFERRED ИЛИ INITIALLY IMMEDIATE. В первом Случае проверка
выполнения условия ограничения должна быть отложена до момента
окончания обработки текущей транзакции, если только команда возобновления
проверки этого ограничения не задана принудительно. Если же ограничение
объявлено с применением предложения initially immediate, проверка
ограничения изначально будет осуществляться непосредственно перед внесением
любых изменений, но с условием, что команда приостановки проверки может
быть введена в любой момент.
Пример 7.6. На рис. 7.4 приведено объявление отношения studio,
предусматривающее, что операции проверки ограничения внешнего ключа должны быть отложены до
завершения каждой соответствующей транзакции. Помимо того, атрибут presC#
помечен как unique, чтобы его можно было использовать в качестве объекта внешней
ссылки со стороны других отношений (в частности, MovieExec).
CREATE TABLE Studio (
name CHAR(30) PRIMARY KEY,
address VARCHAR(255) ,
presC# INT UNIQUE
REFERENCES MovieExec(cert#)
DEFERRABLE INITIALLY DEFERRED
);
Рис. 7.4. Использование инструкции отложенной
проверки ограничения внешнего ключа
Объявив аналогичным образом предусмотренное примером 7.5 ограничение
внешнего ключа, связывающее атрибут MovieExec (cert#) с атрибутом Studio (presC#),
мы смогли бы сформировать транзакцию, охватывающую операции вставки кортежей
в оба отношения, и тогда процедуры проверки ограничений внешних ключей
приостанавливались бы системой до тех пор, пока обе операции вставки не были бы завершены.
Таким образом, при пополнении базы данных сведениями о новых президенте и
киностудии можно было бы не беспокоиться о возможных нарушениях внешних ключей. □
Существуют два дополнительных обстоятельства, которые следует иметь в виду при
использовании механизма отложенной проверки ограничений:
• ограничению любого типа может быть присвоено наименование (за
подробностями обращайтесь к разделу 7.3.1 на с. 334);
• если ограничение deferrable снабжено именем (скажем, MyConstraint), для
перехода с режима непосредственной (immediate) проверки на режим
отложенной (deferred) проверки необходимо выполнить SQL-команду
SET CONSTRAINT MyConstraint DEFERRED;
а в противном случае — команду
SET CONSTRAINT MyConstraint IMMEDIATE;
326
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
7.1.7. Упражнения к разделу 7.1
* Упражнение 7.1.1. Отношения из "кинематографической" базы данных в редакции,
впервые рассмотренной в разделе 5.1 на с. 204, обладают следующими ключами,
отмеченными подчеркиванием:
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
Дополните определениями первичных ключей объявления вида create table,
которые были сконструированы вами при решении упражнения 6.6.1 (см. с. 304)
(учтите, что ключом отношения starsln служат все три его атрибута).
Упражнение 7.1.2. Предложите объявления следующих ограничений ссылочной
целостности для отношений "кинематографической" базы данных, имея в виду
наличие в них ключей, созданных при решении упражнения 7.1.1.
* а) Продюсер кинофильма должен быть одним из тех лиц, кто упомянут в
отношении MovieExec. Операции модификации MovieExec, нарушающие это
условие, должны быть отвергнуты.
b) Повторите решение задания п. (а) с учетом того, что в результате
возможного нарушения ограничения компоненту producerC# отношения Movie
должно быть присвоено значение null.
c) Повторите решение задания п. (а) с учетом того, что в результате
возможного нарушения ограничения соответствующий кортеж Movie обязан быть
удален или обновлен.
d) Кинофильм, упомянутый в Starsln, должен быть описан и в Movie.
Операции, нарушающие это ограничение, подлежат отмене.
e) Информация об актере, упомянутом в starsln, должна присутствовать
и в Movies tar. В случае нарушения этого ограничения соответствующие
кортежи starsln следует удалить.
*! Упражнение 7.1.3. Рассмотрим ограничение, предполагающее, что каждый
кинофильм, сведения о котором представлены в отношении Movie, должен быть
упомянут по меньшей мере в одном кортеже отношения starsln. Возможно ли
представить это условие в виде ограничения внешнего ключа? Почему да или почему нет?
Упражнение 7.1.4. Предложите объявления подходящих первичных ключей для
отношений
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
из базы данных, рассмотренной в упражнении 5.2.1 на с. 218. Дополните
определениями первичных ключей объявления вида create table, которые были
сконструированы вами при решении заданий (a)—(d) упражнения 6.6.2 (см. с. 304).
Упражнение 7.1.5. Предложите объявления подходящих первичных ключей для
отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
7.1. КЛЮЧИ ОТНОШЕНИЙ
327
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222. Дополните
определениями первичных ключей объявления вида create table, которые были
сконструированы вами при решении заданий (a)—(d) упражнения 6.6.3 (см. с. 304).
Упражнение 7.1.6. Сформулируйте следующие ограничения ссылочной целостности
для отношений из базы данных о судах, упомянутой в упражнении 7.1.5. Примите
к сведению ранее принятые вами решения, касающиеся выбора первичных ключей
отношений, и учтите, что в результате возможного нарушения ограничений
компонентам внешних ключей должны быть присвоены значения null.
* а) Каждый класс, упомянутый в Ships, должен быть описан в Classes.
b) Каждое сражение, упомянутое в Outcomes, должно быть представлено
кортежем в Battles.
c) Сведения о каждом судне, упомянутом в Outcomes, должны
присутствовать в Ships.
7.2. Ограничения уровня атрибутов и кортежей
Вы уже знакомы с ограничениями ключей, предполагающими, что определенные
атрибуты всех кортежей отношений должны содержать различные значения, и
внешними ключами, устанавливающими ограничения ссылочной целостности между
атрибутами двух отношений. Теперь пришло время рассмотреть третью важную
разновидность ограничений, в соответствии с которыми компоненты определенных атрибутов
отношения могут обладать только такими значениями, которые относятся к заранее
оговоренному подмножеству допустимых значений. Каждое из подобных ограничений
может быть выражено одним из следующих способов:
1) как ограничение конкретного атрибута, заданное в определении этого
атрибута в контексте объявления схемы отношения;
2) как ограничение уровня кортежа в целом; такое ограничение является
частью объявления отношения и оформляется в виде отдельного предложения,
не относящегося к каким бы то ни было атрибутам.
В разделе 7.2.1 мы расскажем о простом типе ограничений уровня атрибута,
предполагающем, что компоненты атрибута не могут содержать значения null, а в разделе
7.2.2 — о базовой синтаксической форме подобных ограничений (об ограничениях
check уровня атрибута). Сведения об ограничениях check уровня кортежа приведены
в разделе 7.2.3 на с. 330.
Существует и иная, наиболее общая разновидность ограничений (см. раздел 7.4
на с. 336), которые способны препятствовать внесению определенных изменений
как в отдельные компоненты или кортежи, так и в отношения целиком или даже
в группы отношений.
7.2.1. Ограничения NOT null
Одно из самых простых ограничений уровня отдельного атрибута позволяет
запретить присваивание компонентам атрибутов значений null. Ограничение объявляется
с помощью пары служебных слов not null, располагаемых после имени и
обозначения типа атрибута в конструкции create table.
Пример 7.7. Предположим, что следует запретить возможность присваивания
значений null компонентам presC# отношения studio. Чтобы реализовать замысел,
достаточно дополнить строку 4 рис. 7.3 (см. с. 324) следующим образом:
4) presC# INT REFERENCES MovieExec(cert#) NOT NULL
328
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
Последствия внесения подобного изменения таковы:
• вставка в отношение studio нового кортежа, содержащего только значения
названия (name) и адреса (address) киностудии, окажется невозможной, поскольку
система предпримет попытку присвоить компоненту presC# кортежа значение null;
• мы не сможем применить стратегию set-null в тех ситуациях (взгляните на
строку 5 рис. 7.3), когда во избежание нарушения ограничения внешнего ключа
система обязана занести в компонент presc# значение null.
□
7.2.2. Ограничения check уровня атрибута
Более сложное ограничение уровня атрибута включается в определение последнего
с помощью служебного слова check, за которым следует условное выражение в
круглых скобках, описывающее множество допустимых значений атрибута. Обычно
подобные ограничения используются для задания перечислимых множеств значений или
границ изменения значений. Впрочем, строго говоря, в качестве условия может быть
использовано любое выражение, которое разрешается применять в контексте
предложения where SQL-запроса. Для ссылки на атрибут, значения которого должны быть
ограничены, в выражении условия используется имя этого атрибута. Если, однако,
условие распространяется на какое-либо другое отношение или его атрибуты, такое
отношение должно быть указано в предложении from подзапроса (даже в том случае,
если проверяемый атрибут принадлежит схеме того же отношения).
Ограничение check уровня атрибута проверяется всякий раз, когда компонент
кортежа, относящийся к этому атрибуту, получает новое значение — либо в процессе
выполнения операции update, либо при вставке (insert) кортежа. Если новое значение
компонента нарушает ограничение, операция отменяется. В примере 7.9 будет рассмотрена
ситуация, когда условие check уровня атрибута не проверяется, если операция модификации
не затрагивает значение этого атрибута непосредственно, что способно привести к
нарушению ограничения. Впрочем, для начала мы обратимся к более простому примеру.
Пример 7.8. Пусть необходимо обеспечить выполнение следующего условия:
сертификационные номера президентов киностудий должны включать не менее шести цифр.
Для решения задачи достаточно заменить строку 4 рис. 7.3 (см. с. 324),
представляющего объявление схемы отношения
Studio(name, address, presC#),
строкой
4) presC# INT REFERENCES MovieExec(cert#)
CHECK (presC# >= 100000)
Еще один пример. Атрибут gender схемы отношения
MovieStar(name, address, gender, birthdate),
объявление которой приведено на рис. 6.16 (см. с. 298), не только относится к типу
char(1), но и, как мы полагаем, способен принимать одно из двух значений — ' F'
(от female — "женщина") или 'М' (от male — "мужчина"). Указанное ограничение
можно выразить, дополнив строку 4 рис. 6.16 предложением check:
4) gender CHAR(l) CHECK (gender IN ('F', 'M')),
Список ( • f ' , ' м' ) представляет собой экземпляр отношения с двумя кортежами-
компонентами, и условие gender IN ( ' F ' , 'М' ) гласит, что любой компонент
атрибута gender может содержать только одно из двух значений — ' F ' или ' м'. □
7.2. ОГРАНИЧЕНИЯ УРОВНЯ АТРИБУТОВ И КОРТЕЖЕЙ
329
Условие, задаваемое в предложении check, может содержать ссылки на другие
атрибуты или кортежи того же отношения или даже адресовать другие отношения, но для
этого требуется использовать конструкцию подзапроса. Как мы говорили выше, в
качестве условия check позволено использовать любое выражение, разрешенное для
применения в контексте предложения where запроса "select—from—where". Однако следует
иметь в виду, что при проверке ограничения тестируются только значения того
атрибута, к которому относится предложение check, но не остальных атрибутов, упомянутых
в предложении. Поэтому в некоторых случаях к отрицательному (false) результату
проверки сложного условного выражения может привести изменение не того компонента,
который, собственно, и подлежит проверке, а какого-либо другого элемента выражения.
Пример 7.9. Как кажется, можно имитировать ограничение ссылочной целостности,
предполагающее существование значения, адресуемого внешним ключом, с помощью
ограничения check уровня атрибута. Ниже рассмотрен пример ошибочной попытки
представления посредством ограничения check такого условия, которое
предусматривает, что значение компонента presC# кортежа отношения
Studio(name, address, presC#)
обязано присутствовать в компоненте cert# некоторого кортежа отношения
MovieExec(name, address, cert#, netWorth).
Предположим, что строка 4 рис. 7.3 (см. с. 324) изменена следующим образом:
4) presC# INT CHECK
(presC# IN (SELECT cert# FROM MovieExec(cert#) )
С формальной точки зрения в такой конструкции нет ничего плохого, но давайте
проанализируем ее более внимательно.
• При попытке вставки (insert) в отношение studio нового кортежа,
компонент presC# которого содержит такое значение сертификационного номера,
какого нет среди значений компонентов cert# отношения MovieExec*,
операция, как и ожидалось, будет отменена.
• Операция замены (update) содержимого компонента presc# некоторого
кортежа studio значением, отсутствующим в столбце cert# отношения
MovieExec, также будет отвергнута.
• Если, однако, модифицировать отношение MovieExec (например, удалить
кортеж, соответствующий президенту какой-либо киностудии), ограничение check,
объявленное для атрибута отношения studio, никак на подобное изменение не
отреагирует. Таким образом, операция удаления кортежа, нарушающая
рассматриваемое ограничение check, воспринимается системой как вполне допустимая.
В разделе 7.4.1 на с. 336 показано, как та же задача может быть решена с
использованием более мощных разновидностей ограничений. □
7.2.3. Ограничения check уровня кортежа
Для того чтобы определить ограничение, регламентирующее состав кортежей
отношения R, в объявление create table после списка атрибутов, ключей и внешних
ключей следует поместить предложение check и сопроводить его условным
выражением, заключенным в круглые скобки. Выражение должно следовать тем же
правилам, в соответствии с которыми оформляются предложения where. Выражение check
интерпретируется как условие уровня кортежа отношения R; для ссылки на атрибуты
R употребляются их имена. Однако, как и в случае ограничений check уровня
атрибута, условное выражение посредством подзапросов способно адресовать другие
отношения или иные кортежи того же отношения R.
330
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
Как создавать правильные ограничения
Во многих случаях ограничения должны предотвратить появление кортежей,
удовлетворяющих нескольким условиям (как в примере 7.10, где необходимо исключить
возможность существования кортежей, отвечающих условию "актер является
мужчиной и его имя начинается с заданного префикса"; условие запрета состоит их двух
операндов, "актер является мужчиной" и "имя актера начинается с заданного
префикса", соединенных оператором (союзом) and ("и")). Следующее за check условие-
"разрешение", получаемое на основании исходного условия запрета, можно
представить в виде оператора or, примененного к операндам-"отрицаниям": согласно
одному из законов Моргана, отрицание (not) выражения and равнозначно оператору or
с теми же операндами, что и в выражении and, к каждому из которых применен
оператор отрицания. Так, первым операндом выражения запрета в примере 7.10 является
условие "актер является мужчиной". Поэтому в выражение check мы вправе
включить его отрицание— gender = ' F' (возможно, выражение gender о 'М'
оказалось бы более понятным). Второй операнд выражения запрета, "строка name
начинается с символов 'Ms . ' ", в форме отрицания выглядит так: name not like 'Ms . % '.
Условие, лежащее в основе ограничения check уровня кортежа, проверяется перед
каждой операцией вставки в R нового кортежа или обновления одного из
существующих кортежей. Если содержимое компонентов кортежа таково, что условие
обращается в false, это значит, что ограничение нарушено и операция вставки или
обновления, спровоцировавшая нарушение, подлежит отмене. Если, однако, в условии
посредством подзапроса адресуется некоторое отношение (даже то же R) и модификация
этого отношения приводит к тому, что для некоторого кортежа R условие обращается
в false, это не препятствует успешному завершению операции. Иными словами, как
и в случае ограничений check уровня атрибута, ограничения check уровня кортежа
не реагируют на изменения, вносимые в другие отношения.
Хотя с помощью ограничений check уровня кортежа может быть представлена
весьма сложная логика поведения системы, особенно изощренные условия зачастую лучше
выражать посредством офаничений "общего вида" (assertions), о которых рассказано
в разделе 7.4.1 на с. 336. Причина состоит в том, что, как мы упоминали, при некоторых
обстоятельствах система не в состоянии верно отреагировать на нарушения ограничений
check уровня кортежа. Впрочем, если в условии ограничения упоминаются только
компоненты проверяемого кортежа и оно не содержит подзапросов, такое ограничение
гарантированно поддерживается системой во всех случаях. Ниже приведен пример
простого ограничения check, которое охватывает несколько компонентов одного кортежа.
Пример 7.10. Обратимся к примеру 6.39 (см. с. 298), где содержится объявление схемы
отношения MovieStar. Объявление воспроизведено на рис. 7.5 и дополнено
определениями ключа и одного из возможных ограничений "целостности", которые, как мы
полагаем, целесообразно ввести. Ограничение предусматривает, что в строке имени
актера не должен присутствовать префикс "Ms.", если актер является мужчиной.
1) CREATE TABLE MovieStar (
2) name CHAR(30) PRIMARY KEY,
3) address VARCHAR(255),
4) gender CHAR(1),
5) birthdate DATE,
6) CHECK (gender = 'F' OR name NOT LIKE 'Ms.%')
);
Рис. 7.5. Простой пример ограничения CHECK уровня кортежа
7.2. ОГРАНИЧЕНИЯ УРОВНЯ АТРИБУТОВ И КОРТЕЖЕЙ
331
Неполная проверка ограничений check: недостаток или благо?
Может показаться сфанным, почему офаничения check уровня афибута
и кортежа допускают возможность нарушения в тех случаях, когда они содержат
ссылки на другие отношения или другие кортежи того же отношения. Причина
состоит в том, что офаничения такого рода могут (и должны) быть реализованы
более эффективно, нежели мощные офаничения "общего вида" (assertions) (см. раздел
7.4.1 на с. 336). Имея дело с офаничениями уровня атрибута или кортежа, системе
достаточно проверить выполнение их условий только для тех кортежей, которые
подлежат вставке или обновлению. Если же речь идет об Офаничении "общего
вида", система обязана выполнять проверку всякий раз, когда модификации
подвергается любое из отношений, упомянутых в условии этого офаничения. Грамотный
проектировщик базы данных должен обращаться к офаничениям уровня афибута
или кортежа только в тех случаях, когда заведомо известно, что они не могут быть
нарушены ни при каких обстоятельствах, и использовать иные механизмы, такие
как офаничения "общего вида" или фиггеры (см. раздел 7.4.2 на с. 339), если
задачу нельзя решить более простыми средствами.
Сфока 2 содержит объявление, гласящее, что афибут name является первичным
ключом отношения. В сфоке 6 сформулировано рассмафиваемое офаничение. Условие
офаничения обращается в true для каждого кортежа, содержащего информацию о любой ак-
фисе либо о любом актере, чье имя не начинается с префикса "Ms.". Напротив, кортеж
об актере-мужчине, имя которого содержит префикс "Ms.", считается недопустимым. □
7.2.4. Упражнения к разделу 7.2
Упражнение 7.2.1. Сформулируйте перечисленные ниже офаничения, касающиеся
содержимого афибутов отношения
Movie(title, year, length, inColor, studioName, producerC#).
* а) Значение афибута year не должно быть меньше 1985.
b) Значение афибута length обязано принадлежать интервалу 60—250.
* с) Допустимыми значениями афибута name являются такие, как "Disney",
"Fox", "MGM" или "Paramount".
Упражнение 7.2.2. Сформулируйте перечисленные ниже офаничения, касающиеся
содержимого афибутов отношений
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
из базы данных, рассмофенной в упражнении 5.2.1 на с. 218.
a) Значение бысфодействия процессора (speed) переносного компьютера
(Laptop) не должно быть менее 800 Мгц.
b) В качестве устройства (rd), работающего со съемными дисками, в
персональных компьютерах (рс) могут использоваться 32- или 40-скоростные
приводы компакт-дисков ('32xCD' или '40xCD') либо 12- или 16-скоростные
приводы DVD ('12 xDVD' или '16xDVD').
c) Допустимыми значениями типа (type) принтера (Printer) являются ' laser'
("лазерный"), 'ink-jet' ("сфуйный") и 'bubble' ("пузырьковый").
332
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
d) Допустимыми значениями типа (type) продукта (Product) являются 'рс'
("персональный компьютер"), 'laptop' ("переносной компьютер")
и 'printer' ("принтер").
! е) Номер модели (model) продукта (Product) должен быть номером модели
(model) персонального компьютера (PC), переносного компьютера (Laptop)
либо принтера (Printer).
Упражнение 7.2.3. В примере 7.13 на с. 337 утверждается, что ограничение check
уровня кортежа, приведенное на рис. 7.7 (см. с. 338), выполняет только
"половину" функций ограничения "общего вида", текст которого показан на
рис. 7.6. Сформулируйте ограничение check, касающееся отношения MovieExec
и гарантирующее осуществление всех остальных функций.
Упражнение 7.2.4. Сформулируйте перечисленные ниже условия в виде
ограничений check уровня кортежа, каждое из которых определяется в контексте
объявления одного из отношений
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
"кинематографической" базы данных. Если ограничение в действительности
должно охватывать два отношения, введите по одному ограничению в объявление
каждой из таблиц таким образом, чтобы они (ограничения) проверялись для
каждой операции вставки или обновления кортежей отношений. Операции удаления
кортежей рассматривать не следует, поскольку в общем случае ограничения уровня
кортежа не способны гарантировать корректность и целостность одних порций
данных при удалении других.
* а) Кинофильм (Movie) не мог быть снят на цветной пленке (значение true
атрибута color), если он выпущен до (year) 1939 года.
Ь) Актер (MovieStar) не мог сняться в фильме (starsln), вышедшем на экран
(movieYear) до момента рождения (birthdate) самого актера.
! с) Никакие две студии (studio) не могут быть расположены по одному адресу
(address).
*! d) Значение атрибута name отношения MovieStar не может присутствовать
в одноименных компонентах отношения MovieExec.
! е) Каждое название (name) студии (Studio) должно присутствовать
(studioName) по меньшей мере в одном кортеже отношения Movie.
!! f) Если продюсер кинофильма является еще и президентом киностудии, он
должен быть президентом той студии, которая выпустила этот кинофильм.
Упражнение 7.2.5. Сформулируйте перечисленные ниже условия в виде
ограничений check уровня кортежа для отношений PC и Laptop, схемы которых
воспроизведены в упражнении 7.2.2.
a) Персональный компьютер (PC), оснащенный процессором с
быстродействием (speed) менее 1200 МГц, не должен продаваться по цене (price),
превосходящей 1500 долларов.
b) Переносной компьютер (Laptop) с экраном размером менее 15 дюймов
обязан обладать диском (hd) с емкостью не менее 20 Гбайт либо должен
продаваться по цене (price) менее 2000 долларов.
7.2. ОГРАНИЧЕНИЯ УРОВНЯ АТРИБУТОВ И КОРТЕЖЕЙ 333
Упражнение 7.2.6. Сформулируйте перечисленные ниже ограничения check,
касающиеся содержимого кортежей отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222.
a) Суда ни одного из классов (Classes) не могут быть оснащены главными
орудиями калибра (bore), превышающего 16 дюймов.
b) Если суда класса (Classes) оснащены более чем 9 орудиями (numGuns), их
калибр (bore) не должен превосходить 14 дюймов.
! с) Ни одно из судов (Ships) не могло участвовать в сражении (Battles),
происходившем прежде (date), чем судно было спущено на воду (launched).
7.3. Модификация ограничений
Вполне возможно добавить, изменить или удалить то или иное ограничение в любой
момент. Способ модификации зависит от того, к какому "объекту" относится
ограничение — атрибуту, таблице или (как в разделе 7.4.1 на с. 336) к схеме базы данных в целом.
7.3.1. Именование ограничений
Чтобы получить возможность изменения или удаления существующего
ограничения, последнему необходимо присвоить имя. Для этого достаточно предпослать
объявлению ограничения служебное слово constraint и соответствующую строку имени.
Пример 7.11. Чтобы обозначить именем ограничение первичного ключа, приведенное
в строке 2 рис. 7.1 (см. с. 319), следует изменить строку, скажем, так:
2) name CHAR(30) CONSTRAINT NamelsKey PRIMARY KEY,
Аналогичным образом можно присвоить подходящее имя и ограничению check
уровня атрибута, рассмотренному в примере 7.8 на с. 329:
4) gender CHAR(l) CONSTRAINT NoAndro
CHECK (gender IN ('F\ 'M')),
Наконец, конструкция
6) CONSTRAINT RightTitle
CHECK (gender = * F* OR name NOT LIKE 'Ms^')
является уточненной редакцией ограничения check уровня кортежа (см. рис. 7.5
на с. 331). □
7.3.2. Модификация ограничений и команда alter table
В разделе 7.1.6 на с. 324 мы упоминали, каким образом с помощью команды
set constraint изменить режим обработки ограничения с "непосредственного"
(immediate) на "отложенный" (deferred) и наоборот. Команда alter table
позволяет выполнять другие действия по модификации ограничений. В разделе 6.6.3 на
с. 298 уже приводились примеры использования этой команды с целью добавления
и удаления атрибутов.
С помощью команды alter table можно воздействовать как на ограничения
check уровня атрибута, так и на ограничения уровня кортежа. Чтобы удалить
ограничение, следует ввести предложение drop, содержащее имя ограничения. Для добавле-
334
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
ния ограничения используется служебное слово add, после которого дается
определение ограничения. Заметьте, что ограничение добавить нельзя, если в текущем
экземпляре базы данных существует одноименное ограничение.
Пример 7.12. Покажем, каким образом с помощью команды alter table можно
удалить и добавить ограничения, касающиеся отношения MovieStar (см. пример 7.11).
Для удаления ограничений следует использовать команды
ALTER TABLE MovieStar DROP CONSTRAINT NamelsKey;
ALTER TABLE MovieStar DROP CONSTRAINT NoAndro;
ALTER TABLE MovieStar DROP CONSTRAINT RightTitle;
Если ограничения требуется восстановить, достаточно изменить схему отношения
MovieStar, добавив одноименные ограничения:
ALTER TABLE MovieStar ADD CONSTRAINT NamelsKey
PRIMARY KEY (name);
ALTER TABLE MovieStar ADD CONSTRAINT NoAndro
CHECK (gender IN ('F', 'M'));
ALTER TABLE MovieStar ADD CONSTRAINT RightTitle
CHECK (gender = 'F' OR name NOT LIKE 'Ms.%');
Вновь созданные ограничения относятся к категории ограничений уровня кортежа —
придать им статус ограничений уровня атрибута уже нельзя.
При воссоздании ограничений давать им имена не обязательно (но весьма
желательно). Однако мы не вправе полагаться на то, что система каким-либо образом
"помнит" о ранее удаленных ограничениях. Поэтому при необходимости добавления
в схему ранее существовавшего ограничения следует объявить его заново и целиком. □
7.3.3. Упражнения к разделу 7.3
Упражнение 7.3.1. Покажите, каким образом следует модифицировать схемы
отношений
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
из "кинематографической" базы данных, чтобы реализовать перечисленные ниже
ограничения.
* а) Атрибуты title и year образуют первичный ключ отношения Movie.
b) Продюсер (producerC#) каждого кинофильма (Movie) должен быть
упомянут в отношении MovieExec.
c) Значение атрибута length отношения Movie обязано принадлежать
интервалу 60—250.
*! d) Значение атрибута name отношения MovieStar не может присутствовать
в одноименных компонентах отношения MovieExec (операции удаления
кортежей рассматривать не следует).
! е) Никакие две студии (studio) не могут быть расположены по одному
адресу (address).
Упражнение 7.3.2. Покажите, каким образом следует модифицировать схемы
отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
7.3. МОДИФИКАЦИЯ ОГРАНИЧЕНИЙ
335
Почему ограничениям желательно давать имена
Помните о том, что каждое из определяемых ограничений целесообразно снабдить
подходящим именем — даже в том случае, если, как вы полагаете, на него не
придется ссылаться в дальнейшем. Если ограничение объявлено без имени и требуется
внести в ограничение какие-либо изменения, дать ему имя вы уже не сможете.
Впрочем, если подобная ситуация все-таки произошла, не забывайте, что
используемая вами СУБД, вероятно, предоставляет возможность запросить список всех
ограничений, объявленных в базе данных: ограничениям, определенным без
указания имени, система обычно присваивает собственные внутренние имена, на
каждое из которых при необходимости можно сослаться.
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222, чтобы реализовать
перечисленные ниже условия в виде ограничений уровня кортежа.
a) Атрибуты class и country образуют первичный ключ отношения Classes.
b) Каждое судно (ship), упомянутое в отношении Outcomes, должно быть
описано кортежем в ships.40
c) Ни одно из судов не должно быть оснащено более чем 14 орудиями (numGuns).
! d) Ни одно из судов (ships) не могло участвовать в сражении (Battles),
происходившем прежде (date), чем судно было спущено на воду (launched).
7.4. Ограничения уровня схемы и триггеры
Возможности наиболее "мощных" активных элементов в SQL не ограничены
уровнем кортежа или отдельного атрибута кортежа отношения. Подобные элементы
(ограничения "общего вида" и триггеры) являются частью схемы базы данных —
наравне с хранимыми отношениями и виртуальными таблицами.
• Ограничение "общего вида" (assertion) — это булево SQL-выражение, значением
которого всегда должно быть true.
• Триггер (trigger) — последовательность команд, поставленная в соответствие
определенному событию (такому как вставка кортежа в заданное отношение)
и выполняемая в ответ на это событие.
Ограничения "общего вида", предполагающие задание некоторого условия,
выполнение которого система обязана гарантировать, более просты для программирования.
Триггеры, которые принято относить к категории активных элементов общего
назначения, однако, находят более широкое применение. Причина состоит в том, что
ограничения "общего вида" с трудом поддаются эффективной реализации: всякий раз,
когда выполняется модификация содержимого базы данных, система обязана
самостоятельно проследить, не повлияет ли результат операции на истинность условия
ограничения. Текст триггера, с другой стороны, совершенно точно сообщает системе,
что именно необходимо делать в том или ином случае.
7.4.1. Ограничения "общего вида"
В стандарте SQL предусмотрена возможность задания ограничений "общего вида"
(assertions), позволяющих оговорить любое условие (в формате, принятом для
описания предложений where), подлежащее выполнению. Подобно другим элементам схе-
40 Задание (Ь) в оригинале содержит ошибочное условие и поэтому здесь опущено. Номера
остальных заданий соответствующим образом "сдвинуты". — Прим. перев.
336
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
мы базы данных, ограничения "общего вида" объявляются с помощью конструкции,
содержащей служебное слово create. Объявление ограничения "общего вида"
состоит из следующих частей:
1) пары служебных слов create assertion;
2) названия А ограничения;
3) служебного слова check;
4) условия С, заключенного в круглые скобки.
Иными словами, выражение создания ограничения "общего вида" можно представить так:
CREATE ASSERTION A CHECK (С);
Условие С ограничения должно равняться значению true в момент выполнения
команды и обязано оставаться истинным и в дальнейшем; любая операция
модификации базы данных, чреватая нарушением условия, подлежит отмене. (Напомним, что
некоторые из рассмотренных выше ограничений check допускают возможность
нарушения, если они содержат подзапросы.)
Способы оформления ограничений check уровня кортежа и ограничений "общего
вида" различаются. Ограничение уровня кортежа способно свободно ссылаться на
атрибуты того отношения, к схеме которого относится само ограничение. Например,
в строке 6 рис. 7.5 (см. с. 331) атрибуты gender и name адресуются напрямую, без
указания на то, схеме какого отношения они принадлежат, и ссылаются на
компоненты кортежа, подлежащего вставке или обновлению в MovieStar (это единственное
отношение, упомянутое в рассматриваемой конструкции create table).
При создании ограничения "общего вида" мы лишены подобных привилегий. Любые
атрибуты, на которые необходимо сослаться, должны быть однозначно описаны — как
правило, с упоминанием соответствующих отношений в выражении вида "select—from—
where". Поскольку выражение в целом должно относиться к булеву типу, результат
вычисления выражения некоторым образом агрегируется и приводится к единственной
величине, способной принимать значения true или false. Например, условие может выглядеть
как выражение, возвращающее отношение, к которому применяется оператор not exists;
иными словами, ограничение состоит в том, что отношение всегда обязано быть
пустым. В другом случае к столбцу отношения можно применить оператор агрегирования
(подобный sum) и сопоставить его результат с некоторой константой, т.е. предусмотреть,
что сумма определенных значений, скажем, не должна превышать заданной границы.
Пример 7.13. Предположим, что требуется реализовать ограничение "общего вида",
согласно которому лицо не может стать президентом киностудии, если оно не
обладает совокупным годовым доходом в размере не менее 10 миллионов долларов.
Ограничение по сути равнозначно утверждению о том, что множество киностудий,
президенты которых являются владельцами состояний с размером менее 10 миллионов
долларов, пусто. В ограничение вовлечены два отношения:
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#).
Текст ограничения приведен на рис. 7.6.
CREATE ASSERTION RichPres CHECK
(NOT EXISTS
(SELECT *
FROM Studio, MovieExec
WHERE presC# = cert# AND netWorth < 10000000
)
) ;
Рис. 7.6. Пример ограничения "общего вида"
7.4. ОГРАНИЧЕНИЯ УРОВНЯ СХЕМЫ И ТРИГГЕРЫ 337
Между прочим, рассмотренное ограничение "общего вида", затрагивающее два
отношения, можно заменить парой ограничений check уровня кортежа, объявленных
в составе тех же отношений. Например, нетрудно ввести в объявление отношения
Studio (см. пример 7.3 на с. 321) конструкцию CHECK, показанную на рис. 7.7.
CREATE TABLE Studio (
name CHAR(30) PRIMARY KEY,
address VARCHAR(255),
presC# INT REFERENCES MovieExec(cert#),
CHECK (presC# NOT IN
(SELECT cert# FROM MovieExec
WHERE netWorth < 10000000)
)
) ;
Рис. 7.7. Попытка замены ограничения "общего вида "
ограничением CHECK уровня атрибута
Необходимо заметить, что ограничение, показанное на рис. 7.7, будет проверяться
только при изменении содержимого "родного" отношения studio. Система не может
выявить, например, такую ситуацию, когда значение компонента netWorth кортежа
MovieExec с информацией о президенте какой-либо студии снижается и становится
меньше заветных 10 миллионов долларов. Чтобы получить решение, которое можно
было бы считать полноценной альтернативой ограничению "общего вида", приведенному
на рис. 7.6, в составе отношения MovieExec надлежит объявить дополнительное
ограничение CHECK, гласящее, что значение компонента netWorth не должно быть
меньше 10000000, если руководящее лицо является президентом какой-либо киностудии. □
Пример 7.14. Рассмотрим еще один образец ограничения "общего вида". Оно
касается отношения
Movie(title, year, length, inColor, studioName, producerC#)
и гласит, что значение общей продолжительности воспроизведения кинофильмов,
выпущенных одной студией, не должно превышать 10000 минут:
CREATE ASSERTION SumLength CHECK (10000 >= ALL
(SELECT SUM(length) FROM Movie GROUP BY studioName)
) ;
Поскольку указанное ограничение "общего вида" относится только к Movie, его можно
выразить в виде ограничения CHECK уровня кортежа и объявить в контексте схемы Movie.
Другими словами, следует пополнить объявление отношения Movie конструкцией
CHECK (10000 >= ALL
(SELECT SUM(length) FROM Movie GROUP BY studioName));
Указанное условие применяется к каждому кортежу отношения Movie. Однако оно не
содержит явных ссылок на атрибуты кортежа, и основная доля "обязанностей"
возлагается на подзапрос.
Обратите внимание, что если условие представлено в форме ограничения check
уровня кортежа, оно не будет проверяться системой при удалении кортежей из Movie.
В данном случае такое поведение не опасно, поскольку если ограничение
выполнялось до операции удаления кортежа, оно определенно останется в силе и после
удаления. Однако, если заменить условие на обратное, т.е. установить не верхнюю границу
суммарной продолжительности воспроизведения кинофильмов, а нижнюю,
использование ограничения check уровня кортежа вместо аналогичного ограничения "общего
вида" грозит неприятностями, поскольку при удалении кортежей в какой-то момент
времени условие может быть нарушено, а система никак на это не отреагирует. □
338
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
О классификации ограничений по функциональным возможностям
В следующей таблице представлены основные различия между ограничениями
CHECK уровня атрибута, уровня кортежа и ограничениями "общего вида".
Вид ограничения
Ограничение check
уровня атрибута
Ограничение check
уровня кортежа
Ограничение
"общего вида"
Контекст
объявления
Объявление
атрибута
Объявление
схемы
отношения
Схема базы
данных
Когда проверяется
При вставке кортежа или
обновлении атрибута
При вставке или
обновлении кортежа
При любой модификации
одного из упомянутых
отношений
Гарантии
выполнения
Да, если не
используются
подзапросы
Да, если не
используются 1
подзапросы
Да
Наконец, стандарт SQL предусматривает возможность удаления ограничений
"общего вида". Соответствующая команда сродни другим командам удаления
элементов схемы базы данных:
DROP ASSERTION Л;
где Л — наименование ограничения.
7.4.2. Правила "событие—условие—действие"
Триггеры (triggers), или, как их еще называют, правила "событие—условие—действие"
(event—condition—action rules — ECA rules), отличаются от других ограничений,
рассмотренных выше, в трех аспектах.
1. Триггер "срабатывает" только при наступлении определенного события (event),
описание которого содержится в тексте триггера. К числу допустимых событий
обычно относят операции вставки, удаления и обновления кортежа указанного
отношения. Во многих СУБД "событием", на которое способен отреагировать
триггер, разрешено считать и факт завершения транзакции. В разделе 7.1.6 на
с. 324 мы уже вкратце рассказывали о транзакциях; за подробностями
обращайтесь к разделу 8.6 на с. 393.
2. Вместо того чтобы сразу отвергнуть операцию, вызвавшую его срабатывание,
триггер выполняет проверку условия (condition). Если результат проверки равен
значению false, работа триггера завершается.
3. Если же условие, сформулированное в тексте триггера, справедливо, СУБД
выполняет действие (action), поставленное в соответствие событию, — например,
препятствует продолжению операции либо наряду с ней выполняет другие
операции. Под действием понимается последовательность операций с базой
данных, отвечающая логике определенного события.
7.4.3. Триггеры в SQL
Синтаксис и семантика выражения триггера в SQL предоставляют программисту
множество разнообразных возможностей, касающихся реализации каждой из частей
конструкции — "событие", "условие" и "действие". Основные особенности
конструкции объявления триггера перечислены ниже.
1. Действие может выполняться либо до, либо после события триггера.
7.4. ОГРАНИЧЕНИЯ УРОВНЯ СХЕМЫ И ТРИГГЕРЫ 339
2. При выполнении действия триггер способен ссылаться как на прежние (old),
так и на новые (new) значения компонентов кортежа, операция модификации
которого рассматривается как событие, повлекшее срабатывание триггера.
3. События обновления данных могут быть ограничены операциями над
отдельным компонентом или множеством компонентов.
4. Условие может задаваться с помощью предложения when; действие
выполняется при наступлении события и только в том случае, если в этот момент условие
оставалось справедливым.
5. Действие может выполняться в одном из двух возможных режимов:
a) один раз для каждого модифицируемого кортежа;
b) единожды для всех кортежей, которые подверглись изменению при
выполнении одной операции.
Прежде чем приступить к изложению строгих синтаксических правил, рассмотрим
пример, который поможет прояснить наиболее существенные аспекты
программирования триггеров. Подразумевается, что триггер выполняется один раз для каждого
кортежа, подлежащего модификации.
Пример 7.15. Пусть необходимо создать триггер, реагирующий на событие обновления
(update) компонента networth кортежа отношения
MovieExec(name, address, cert#, netWorth).
Триггер обязан воспрепятствовать любой попытке снижения текущего значения
годового дохода руководящего лица.41 Объявление триггера приведено на рис. 7.8.
1) CREATE TRIGGER NetWorthTrigger
2) AFTER UPDATE OF netWorth ON MovieExec
3) REFERENCING
4) OLD ROW AS OldTuple,
5) NEW ROW AS NewTuple
6) FOR EACH ROW
7) WHEN (OldTuple.netWorth > NewTuple.netWorth)
8) UPDATE MovieExec
9) SET netWorth = OldTuple.netWorth
10) WHERE cert# = NewTuple.cert#;
Рис. 7.8. Пример триггера уровня кортежа
Строка 1 содержит заголовок объявления (create trigger) триггера с указанием
его наименования. Строка 2 описывает событие триггера — а именно факт
обновления (UPDATE) компонента netWorth кортежа отношения MovieExec. В строках 3—5
регламентируется способ, посредством которого фрагменты кода триггера,
отвечающие за реализацию "условия" и "действия", способны обращаться к кортежу и в его
прежнем (old) состоянии (т.е. до выполнения операции обновления), и в новом (new)
(после операции). Эти кортежи названы для ясности как OldTuple и NewTuple
соответственно. Во фрагментах кода "условия" и "действия" триггера эти имена могут
использоваться совершенно так же, как и переменные кортежа, объявляемые в
предложении from обычного SQL-запроса.
41 Ах, если бы проблема похудания кошелька исчерпывалась определением триггера в базе
данных! — Прим. перев.
340
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
Строка 6, содержащая предложение for each row, выражает требование о том,
что код триггера должен выполняться по одному разу для каждого кортежа,
подвергшегося обновлению. Если бы эта фраза была опущена или заменена альтернативной,
for each statement, предусмотренной по умолчанию, триггер срабатывал бы
единожды для SQL-команды целиком, независимо от того, какое количество связанных
с ней операций обновления должно быть выполнено. В подобном случае вместо
псевдонимов кортежей, old row и new row, можно было бы определить псевдонимы
таблиц, OLD TABLE И NEW TABLE (о Последних — НИЖе).
Строка 7 представляет "условие" триггера, которое гласит, что последующее
"действие" должно выполняться только в том случае, если новое значение
компонента networth меньше, нежели прежнее.
Строки 8—10 содержат порцию кода триггера, описывающую "действие",
которое подлежит выполнению, если "условие" справедливо. В данном случае
"действие" представляет собой заурядную команду update, которая призвана
восстановить прежнее содержимое компонента networth, т.е. то значение, которое
хранилось в компоненте до выполнения операции обновления, вызвавшей
срабатывание триггера. Как может показаться на первый взгляд, "восстановлению"
способен поддаться любой кортеж MovieExec, но на самом деле операция затронет
только тот, в котором, как предусмотрено предложением where, содержится
соответствующее значение cert#. □
Разумеется, в рамках одного простого примера нам удалось проиллюстрировать
только некоторые из множества возможностей, предусмотренных механизмом SQL-
триггеров. Ниже кратко перечислены иные важные аспекты практического
использования триггеров.
• Строка 2 рис. 7.8 гласит, что "действие" триггера должно выполняться после
(after) возникновения его "события". Служебное слово after может быть
заменено словом before (до) — это будет означать, что условие предложения
when должно проверяться до внесения изменения, спровоцировавшего
срабатывание триггера. Если условие верно, вначале выполняется код "действия"
триггера, а затем операция, которая активизировала триггер, — независимо от
того, справедливо условие или нет.
• Помимо update, к категории допустимых (т.е. способных привести к
срабатыванию триггера) относятся события-операции insert и delete. Предложение of
(см. строку 2 рис. 7.8) при описании события update задавать не обязательно.
Если служебное слово of присутствует, после него перечисляются наименования
атрибутов, операции обновления которых расцениваются как событие триггера.
Предложение of нельзя использовать для определения событий insert
и delete, поскольку последние связаны с модификацией кортежа в целом.
• Предложение when не является обязательным. В его отсутствие "действие"
выполняется всякий раз после срабатывания триггера без учета каких бы то ни
было условий.
• Код "действия" триггера может состоять из произвольной42 последовательности
SQL-команд, завершаемых символом точки с запятой; последовательность
размещается между служебными словами begin и end.
42 В секции "действия" текста триггера разрешено использовать далеко не все команды SQL:
так, например, возбраняется применять команды управления транзакциями (подобные commit
и rollback), организации соединения между клиентом и сервером базы данных (скажем,
connect и disconnect), создания (create), изменения (alter) и удаления (drop) элементов
схемы, определения параметров сеанса (set) и пр. — Прим. перев.
7.4. ОГРАНИЧЕНИЯ УРОВНЯ СХЕМЫ И ТРИГГЕРЫ
341
• Если событие триггера связано с операцией обновления (update), существует
возможность адресовать варианты обновляемого кортежа, соответствующие
состоянию базы данных до и после выполнения операции: с помощью
предложений old row AS и new row AS кортежам могут быть присвоены имена, как это
сделано в строках 4, 5 рис. 7.8. Если событие триггера обусловлено операцией
вставки (insert), на кортеж, подлежащий вставке, разрешено ссылаться
посредством предложения new row as, а предложение old row as использовать
запрещено. В случае события-удаления (delete) допустимо ссылаться на
удаляемый кортеж с помощью предложения old row as, а предложение
new row as, напротив, применять возбраняется.
• Если опустить предложение for each ROW, триггер уровня кортежа (row-level
trigger) (см. строку 6 рис. 7.8) "превратится" в триггер уровня команды
(statement-level trigger). Триггер уровня команды выполняется один раз для
команды модификации соответствующего типа, независимо от того, какое
именно количество кортежей подлежит обновлению, вставке или удалению.
Например, при задании инструкции обновления, затрагивающей множество
кортежей таблицы, триггер уровня команды срабатывает один раз, в то время
как триггер уровня кортежа должен выполняться для каждого кортежа,
подлежащего обновлению. В тексте триггера уровня команды ссылаться на
прежнюю и новую версии кортежа, как показано в строках 4 и 5, запрещено.
Однако любому триггеру — и уровня кортежа, и уровня команды —
позволено адресовать множества "старых" (old) кортежей (удаляемых кортежей либо
прежних версий обновляемых кортежей) и/или "новых" (new) кортежей
(вставляемых кортежей либо новых версий обновляемых кортежей): с этой
целью применяются предложения, подобные таким, как
OLD TABLE AS OldStuff И NEW TABLE AS NewStuff.43
Пример 7.16. Предположим, что необходимо предотвратить возможность уменьшения
среднего значения годового дохода руководящих лиц ниже отметки в 500 тыс.
долларов. К подобному результату способна привести команда вставки в отношение
MovieExec(name, address, cert#, netWorth)
нового кортежа, а также удаления любого существующего кортежа либо обновления
его компонента netWorth. Один из тонких моментов связан с тем, что единственная
команда insert или update может предусматривать вставку или обновление
нескольких кортежей MovieExec, и в процессе ее выполнения среднее значение дохода
будет то падать ниже заданной границы, то возрастать, пока процедура обработки
команды не завершится полностью. Поэтому триггер обязан отреагировать на результат
команды в целом (если, разумеется, условие триггера обратится в true).
Необходимо создать отдельный триггер для каждого из трех возможных событий —
вставка (insert), удаление (delete) и обновление (update). На рис. 7.9 приведен
текст триггера, запускаемого системой в ответ на событие обновления кортежа
отношения MovieExec. Код двух других триггеров аналогичен и несколько более прост.
В строках 3—5 содержатся объявления псевдонимов olds tuff и NewStuff,
позволяющих ссылаться на отношения со "старыми" и "новыми" кортежами, которые
затрагиваются в процессе выполнения операции обновления, вызывающей срабатыва-
В дополнительных пунктах списка стоило бы упомянуть синтаксическую форму команды
удаления триггера (drop trigger Г, где Т — наименование триггера), а также вкратце осветить
еще один важный аспект, который касается правил, регламентирующих последовательность
запуска нескольких триггеров, если таковые определены для одних и тех же события и таблицы.
За подробностями обращайтесь к стандарту SQL-99 (см. раздел 6.9 на с. 315) и к документации
из комплекта поставки конкретной СУБД. — Прим. перев.
342
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
ние триггера. Единственная команда модификации способна повлиять на состояние
многих кортежей, и поэтому столько же кортежей будет помещено системой в каждое
из отношений Olds tuff и News tuff.
Если речь идет об операции обновления (как в нашем примере), в отношения
Olds tuff и News tuff заносятся прежние и новые версии обновляемых кортежей.
Если рассмотреть аналогичный триггер, реагирующий на событие удаления, удаляемые
кортежи будут помещены в отношение oldstuff (предложение вида
NEW table AS NewStuf f, однако, в этом случае использовать нельзя). При
написании триггера для события вставки, напротив, можно предусмотреть предложение
NEW table AS NewStuf f, которое позволит ссылаться на отношение с вновь
вставленными кортежами, но отношение вида Oldstuff, по понятным причинам, в этом
случае системой поддерживаться не будет.
1) CREATE TRIGGER AvgNetWorthTrigger
2) AFTER UPDATE OF netWorth ON MovieExec
3) REFERENCING
4) OLD TABLE AS OldStuff,
5) TABLE AS NewStuff
6) FOR EACH STATEMENT
7) WHEN (500000 > (SELECT AVG(netWorth) FROM MovieExec))
8) BEGIN
9) DELETE FROM MovieExec
10) WHERE (name, address, cert#, netWorth) IN NewStuff;
11) INSERT INTO MovieExec
12) (SELECT * FROM OldStuff);
13) END;
Рис. 7.9. Пример триггера уровня команды
Строка 6 свидетельствует о том, что триггер должен выполняться один раз для
каждой команды обновления в целом, независимо от того, какое именно количество
кортежей подлежит обновлению. Строка 7 представляет условие, которое
удовлетворяется, если среднее значение, вычисленное на основе содержимого компонентов
netWorth после их обновления, меньше 500000.
Порция кода "действия" триггера, охватывающая строки 8—13, выполняется,
если условие предложения when обращается в true, и состоит из двух команд: первая
(см. стро-ки 9, 10) предполагает удаление из MovieExec всех "новых" (т.е. уже
обновленных) кортежей, а вторая (см. строки 11, 12) — восстановление кортежей
в том состоянии, в котором они пребывали до операции update, вызвавшей
срабатывание триггера. □
7.4.4. Триггеры instead of
Существует весьма многообещающая разновидность триггеров, которая не
описана в стандарте SQL-99, но активно обсуждалась в период его разработки
и была реализована во многих коммерческих СУБД. В подобных триггерах
разрешается заменять предложения before (до) и after (после) предложением
instead of (вместо), означающим, что всякий раз при срабатывании триггера
код "действия" последнего должен выполняться вместо той операции, которая
спровоцировала запуск триггера.
7.4. ОГРАНИЧЕНИЯ УРОВНЯ СХЕМЫ И ТРИГГЕРЫ
343
Это средство мало что дает, если речь идет о хранимых отношениях44, но в полной
мере проявляет все свои качества в применении к виртуальным таблицам (views),
поскольку последние редко допускают возможность непосредственной модификации
(см. раздел 6.7.4 на с. 308). Триггер instead of способен "распознать" попытку
изменения содержимого виртуальной таблицы и вместо этого выполнить другую
операцию, уместную в конкретном случае. Рассмотрим пример.
Пример 7.17. Вновь обратимся к определению виртуальной таблицы
CREATE VIEW ParamountMovie AS
SELECT title, year
FROM Movie
WHERE studioName = 'Paramount';
из примера 6.45 (см. с. 305), представляющей информацию обо всех кинофильмах,
выпущенных студией "Paramount". Как было показано в примере 6.49 на с. 308,
содержимое таблицы ParamountMovie, вообще говоря, поддается обновлению, но при
этом возникает одна неприятность: при вставке кортежа система не в состоянии
определить, что в компонент studioName всегда должна заноситься строка
'Paramount' (хотя для нас с вами это очевидно), и поэтому присваивает компоненту
значение null, предусмотренное по умолчанию.
Более изящное решение проблемы связано с использованием триггера
instead of, текст которого показан на рис. 7.10. Большая часть кода триггера не таит
никаких сюрпризов. Однако полезно обратить внимание на строку 2, содержащую
предложение instead of, которое свидетельствует, что любая операция вставки
кортежа в таблицу ParamountMovie должна быть отменена.
Строки 5, 6 содержат описание "действия" триггера: вставить соответствующий
кортеж в хранимое отношение Movie. Содержимое всех компонентов кортежа,
подлежащего вставке в Movie, известно: значения title и year взяты из кортежа, команда
вставки которого в таблицу ParamountMovie вызвала срабатывание триггера (мы
ссылаемся на них с помощью псевдонима NewRow, определенного в строке 3), а
значением компонента studioName служит знакомая константа 'Paramount' (в составе
исходного кортежа она не задавалась).
1) CREATE TRIGGER Paramountlnsert
2) INSTEAD OF INSERT ON ParamountMovie
3) REFERENCING NEW ROW AS NewRow
4) FOR EACH ROW
5) INSERT INTO Movie(title, year, studioName)
6) VALUES(NewRow.title, NewRow.year, 'Paramount');
Рис. 7.10. Пример триггера INSTEAD OF
□
7.4.5. Упражнения к разделу 7.4
Упражнение 7.4.1. Создайте триггеры, упомянутые в примере 7.16 на с. 342,
которые обязаны реагировать на события вставки кортежа в отношение MovieExec
и удаления кортежа из этого отношения.
Подобное утверждение слишком категорично — достаточно взглянуть на примеры триггеров,
приведенные на рис. 7.8 и 7.9: применение модели триггеров instead of позволило бы существенно
снизить издержки, связанные с тем, что системе вначале приходится выполнять команды,
вызвавшие срабатывание триггера, а затем (after) фактически отменять их результаты. — Прим. перев.
344
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
Упражнение 7.4.2. Сформулируйте перечисленные ниже условия, касающиеся
содержимого атрибутов отношений
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
из базы данных, рассмотренной в упражнении 5.2.1 на с. 218, в форме триггеров
или ограничений "общего вида", предусматривая необходимость запрета или
отмены операции, если таковая нарушает заданное условие.
* а) При обновлении значения цены (price) компьютера (рс) гарантировать,
что компьютеров с более низкой ценой и тем же уровнем быстродействия
процессора (speed) не существует.
* Ь) Ни один из производителей (maker) персональных компьютеров
(значение ' рс ' атрибута type) не должен выпускать переносные
компьютеры (' laptop ').
*! с) Производитель (maker) персональных компьютеров обязан выпускать
переносные компьютеры по меньшей мере с таким же уровнем быстродействия
процессора (speed).
d) При вставке кортежа с информацией о новом принтере (Printers)
убедиться, что номер модели (model) присутствует в отношении Product.
! е) При выполнении любой операции модификации содержимого отношения
Laptop обеспечить сохранение следующего условия: среднее значение цены
(price) переносных компьютеров, выпускаемых каждым производителем
(maker), не должно быть ниже 2000 долларов.
! 0 При обновлении значений объема оперативной памяти (ram) и емкости
диска (hd) персонального компьютера (рс) гарантировать, что величина hd
по меньшей мере в 100 раз превышает значение ram.
! g) Если переносной компьютер (Laptop) обладает большим объемом
оперативной памяти (ram), нежели персональный компьютер (РС), его цена
(price) также должна быть выше.
! h) При вставке кортежа с информацией о новом персональном компьютере
(РС), переносном компьютере (Laptop) или принтере (Printers) убедиться,
что заданный номер модели (model) не совпадает ни с одним из
существующих номеров.
! i) Если отношение Product содержит кортеж с определенными значениями
номера модели (model) и типа продукта (type), тот же номер модели
должен присутствовать в отношении, соответствующем типу продукта.
Упражнение 7.4.3. Сформулируйте перечисленные ниже условия, касающиеся
содержимого атрибутов отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222, в форме триггеров
или ограничений "общего вида", предусматривая необходимость запрета или
отмены операции, если таковая нарушает заданное условие.
7.4. ОГРАНИЧЕНИЯ УРОВНЯ СХЕМЫ И ТРИГГЕРЫ
345
* а) При вставке кортежа с информацией о новом классе судов (classes)
обеспечить вставку кортежа со сведениями о судне (ships), название (name)
которого совпадает с наименованием (class) класса; дату спуска судна на воду
(launched) принять равной NULL.
b) При вставке кортежа с данными о классе судов (classes)
водоизмещением (displacement) свыше 35000 тонн заменить значение
displacement на 35000.
c) Ни один из классов (class) не должен включать более 2 судов (ships).
! d) Ни одна из стран (country) не может владеть как линкорами (значение
'bb' атрибута type), так и крейсерами ('be').
! е) Ни одно из судов (ship) с более чем 9-ю главными орудиями (numGuns)
не могло участвовать в сражении (battle) наряду с потопленным
(значение 'sunk' атрибута result) судном, обладавшим орудиями в
количестве, меньшем 9.
! 0 При вставке кортежа в отношение Outcomes убедиться, что заданные
значения названия (name) судна и наименования (battle) сражения
присутствуют в отношениях ships и Battles соответственно; в противном случае
обеспечить вставку в последние подходящих кортежей, при необходимости
используя значения null.
! g) При вставке кортежа в отношение ships или обновлении компонента
class существующего кортежа ships гарантировать, что ни одна из стран
(country) не обладает более чем 20-ю судами.
! h) Ни одно из судов (ships) не могло быть спущено на воду (launched)
прежде, чем флагманский корабль, давший имя (class) классу, к
которому относится судно.
! i) Для каждого класса (class) должно существовать одноименное (name)
судно (ships).
!! j) При всех обстоятельствах, способных привести к нарушению условия,
обеспечить выполнение этого условия, состоящего в том, что ни одно из судов
(ship) не должно было участвовать в сражении (Battles), состоявшемся
позже (date) другого сражения, в котором судно оказалось потопленным
(значение 'sunk' атрибута result).
Упражнение 7.4.4. Сформулируйте перечисленные ниже условия, касающиеся
содержимого атрибутов отношений
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
из "кинематографической" базы данных, в форме триггеров или ограничений
"общего вида", предусматривая необходимость запрета или отмены операции,
если таковая нарушает заданное условие. Следует полагать, что до момента
изменения содержимого базы данных каждое из условий выполняется. При поиске
решений необходимо отдавать предпочтение тем из них, которые
предусматривают не отмену операций модификации, а выполнение их — пусть даже ценой
вставки кортежей со значениями, предлагаемыми по умолчанию (скажем, null).
346
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
a) Каждому актеру, информация о котором присутствует в отношении
Stars In, должен соответствовать кортеж отношения MovieStar.
b) Каждый "руководитель" должен быть либо президентом киностудии, либо
продюсером, участвовавшим в съемках хотя бы одного кинофильма, либо
тем и другим одновременно.
c) В каждом фильме должны сниматься хотя бы один актер и по меньшей мере
одна актриса.
d) Количество кинофильмов, выпущенных каждой киностудией в любом году,
не должно превышать 120.
e) Средняя продолжительность воспроизведения кинофильмов, снятых в
течение каждого года, не должна превышать 120 минут.
7,5, Резюме
♦ Ограничения ключа. Чтобы описать тот факт, что атрибут или подмножество
атрибутов образуют ключ отношения, достаточно воспользоваться одной из
синтаксических форм предложений unique или primary key, размещаемых
в контексте объявления реляционной схемы.
♦ Ограничения ссылочной целостности. Ограничение, в соответствии с
которым значения компонентов атрибута или подмножества атрибутов одного
отношения обязаны присутствовать в соответствующих компонентах
ключевых атрибутов некоторого кортежа другого отношения, выражается
посредством предложений references или foreign key, включаемых в
объявление схемы отношения.
♦ Ограничения CHECK уровня атрибута. Чтобы ограничить множество
допустимых значений атрибута некоторым условием, достаточно снабдить
определение атрибута в схеме отношения служебным словом check и указать
соответствующее условие.
♦ Ограничения CHECK уровня кортежа. Объявление отношения может содержать
отдельные предложения check, описывающие условия, которым должны
удовлетворять кортежи отношения.
♦ Модификация ограничений. Ограничение CHECK уровня кортежа легко добавить
и удалить с помощью команды alter table, предусматривающей изменение
схемы соответствующей таблицы.
♦ Ограничения "общего вида". Ограничение "общего вида" объявляется как
элемент схемы базы данных с помощью команды create assertion со
служебным словом check и соответствующим условием. Условие может охватывать
отдельные атрибуты или кортежи как одного отношения, так и нескольких
отношений одновременно.
♦ Проверка условий ограничений. Условие ограничения "общего вида" подлежит
проверке при любом изменении, вносимом в одно из отношений,
упомянутых в условии. Условие ограничения check уровня атрибута или кортежа
проверяется только в том случае, если отношение, к схеме которого
относится ограничение, изменяется командами вставки или обновления. Если
ограничение check содержит подзапрос, система не способна гарантировать
поддержку этого ограничения.
♦ Триггеры. Триггер — это фрагмент кода, хранимый в схеме базы данных,
который активизируется системой при наступлении определенного события (как
7.5. РЕЗЮМЕ
347
правило, при вставке, обновлении или удалении кортежа заданного
отношения). После запуска триггера система проверяет его условие; если условие
справедливо, выполняется заданная последовательность SQL-команд, таких как
запросы или инструкции модификации.
7,6. Литература
За информацией о возможности получения стандартов SQL2 и SQL-99
обращайтесь к разделу 6.9 на с. 315. В работах [4] и [5] представлены подробные обзоры
всего того, что относится к проблематике активных элементов баз данных. Доклад
[1] предлагает оригинальную трактовку понятия активных элементов в контексте
SQL-99 и будущих стандартов. Статьи [2] и [3] содержат сведения о HiPAC — одном
из ранних прототипов систем баз данных, реализующих возможность определения
активных элементов.
1. Cochrane R.J., Pirahesh H., and Mattos N. Integrating triggers and declarative constraints in
SQL database systems, Intl. Conf. on Very Large Database Systems (1996), p. 567—579.
2. Dayal U. et al. The HiPAC project: combining active databases and timing constraints, SIGMOD
Record, 17:1 (1988), p. 51-70.
3. McCarthy D.R., Dayal U. The architecture of an active database management system, Proc.
ACM SIGMOD Intl. Conf. on Management of Data (1989), p. 215-224.
4. Paton N.W., Diaz O. Active database systems, Computing Surveys, 31:1 (March, 1999), p. 63-103.
5. Widom J., Ceri S. Active Database Systems, Morgan-Kaufmann, San Francisco, 1996.
348
ГЛАВА 7. ОГРАНИЧЕНИЯ И ТРИГГЕРЫ
Глава 8
Системные аспекты SQL
В предыдущей главе мы рассмотрели основные средства SQL, и сейчас уместно
обратиться к вопросу о том, каким образом фрагменты SQL-кода могут использоваться
в полноценной среде программирования. В разделе 8.1 будут продемонстрированы
способы "внедрения " (embedding) команд SQL в программы, создаваемые на
традиционных языках программирования, таких как С. Особое внимание мы уделим тому,
как осуществляется обмен данными между реляционными структурами SQL и
переменными программы, написанной на базовом, или "включающем"(host), языке.
Раздел 8.2 (см. с. 364) посвящен изложению сведений о другом направлении
совместного использования SQL и технологий программирования общего
назначения, предусматривающем создание хранимых модулей (stored modules) —
фрагментов исполняемого кода, размещаемых в схеме базы данных и вызываемых по
команде внешней программы или пользователя. В разделе 8.3 на с. 376
рассмотрены дополнительные системные аспекты SQL, такие как поддержка модели
вычислений "клиент/сервер".
Третий подход к проблеме сочетания SQL и базовых языков предполагает
использование так называемого интерфейса уровня вызовов (call-level interface — CLI):
в программе, написанной на традиционном языке, для доступа к базе данных
используются специализированные библиотеки функций. В разделе 8.4 на с. 381 мы
расскажем о стандартной библиотеке функций SQL, называемой SQL/CLI, которая
позволяет обращаться к средствам SQL из среды программы на языке С. Раздел 8.5
(см. с. 389) посвящен JDBC (от Java Database Connectivity) — альтернативному
интерфейсу уровня вызовов, который предоставляет стандартные средства
программирования приложений баз данных на языке Java.
В разделе 8.6 на с. 393 мы познакомим вас с понятием транзакции (transaction) —
неделимой единицы работы. Во многих приложениях баз данных (например,
связанных с банковской деятельностью) в качестве непременного условия выдвигается
требование о том, что определенные последовательности операций с данными должны
выполняться атомарным образом, как единое целое — даже в том случае, если
одновременно с ними система обслуживает множество параллельных операций. Язык SQL
содержит средства описания транзакций, а СУБД, как правило, поддерживают
механизмы, гарантирующие, что каждая транзакция действительно выполнится целиком
либо не будет выполнена вовсе. Наконец, в разделе 8.7 на с. 404 мы сосредоточим
внимание на том, каким образом на уровне языка SQL и СУБД обеспечивается
управление доступом (access control) к данным.
SQL и языки программирования общего назначения
Реализации систем на основе стандарта SQL обязаны поддерживать возможность
взаимодействия по меньшей мере с одним из следующих семи традиционных
языков программирования: ADA, С, Cobol, Fortran, M (прежнее название — Mumps),
Pascal и PL/I. Почти все они знакомы большинству студентов, обучающихся по
специальности "Компьютерные науки" (возможно, за исключением М — этот язык
применяется преимущественно для создания программных приложений в сфере
медицины). В наших примерах мы будем обращаться к языку С.
8.L SQL в среде программирования
До сих пор, демонстрируя образцы кода SQL, мы имели в виду использование
базового интерфейса SQL (generic SQL interface), предполагающего наличие
самостоятельного интерпретатора, который принимает и обрабатывает различные запросы и
команды, написанные в соответствии с синтаксическими правилами языка SQL. Хотя
подобный режим работы поддерживается большинством коммерческих СУБД,
в "чистом" виде он используется сравнительно редко. В действительности команды
SQL оформляются в составе более крупных единиц кода. Гораздо чаще приходится
иметь дело с программой, написанной на одном из базовых (host) языков, которая
содержит отдельные фрагменты, которые по существу являются командами SQL. В этом
разделе мы осветим один из способов взаимодействия традиционной программы с
реляционной СУБД, поддерживающей язык SQL.
Схема типовой среды программирования, допускающей возможность обращения
к средствам SQL, представлена на рис. 8.1. Программист создает приложение с
использованием одного из базовых языков, по мере необходимости "внедряя" в текст
специальные SQL-выражения, не являющиеся конструкциями базового языка.
Программа передается для обработки препроцессору, который преобразует внедренные
(embedded) команды SQL в форму директив, удовлетворяющих синтаксическим
требованиям базового языка. Представление SQL-команды может оказаться настолько же
простым, как и обычный вызов функции, которая принимает команду в качестве
строкового аргумента, а затем ее выполняет.
После обработки препроцессором программа компилируется обычным образом.
Поставщик СУБД обычно предлагает в составе системы все необходимые библиотеки
функций, которые позволяют приложению работать как единой целое. Рис. 8.1 иллюстрирует
и другую возможность: программист пишет код на базовом языке, вызывая
библиотечные функции непосредственно. Такой подход, связанный с использованием интерфейса
уровня вызовов (call-level interface — CLI), подробно описан в разделе 8.4 на с. 381.
8.1.1. Проблема согласования моделей данных
Основная проблема, препятствующая эффективному сочетанию директив SQL
и инструкций традиционного языка в рамках единого программного приложения,
связана с тем, что модель данных, поддерживаемая в SQL, решительным образом
отличается от моделей, принятых в других языках. Как вы знаете, ядром SQL является
реляционная модель данных. Однако, обращаясь к С или любому другому языку
программирования общего назначения, программист имеет дело с данными, представленными
в самых разнообразных форматах, — с целочисленными величинами, числами с
плавающей запятой, символами, строками, указателями, структурами записей, массивами
и т.д. Ни С, ни иные языки, как правило, не обеспечивают непосредственную
поддержку множеств (sets) элементов данных, a SQL, в свою очередь, не позволяет использовать
указатели, а также создавать циклы, ветвления и другие вычислительные конструкции,
привычные и употребительные в традиционном программировании. Поэтому решение
350
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
задачи обмена данными между порциями кода SQL и базового языка не столь
прямолинейно, как хотелось бы, и требует привлечения особых механизмов и технологий.
Может показаться, будто проще и целесообразнее выбрать что-то одно — либо
выполнять все вычисления на SQL, либо позабыть о SQL и сосредоточить силы на
программировании средствами традиционного языка. Впрочем, попытавшись написать любое
сколько-нибудь серьезное приложение баз данных без использования SQL, вы быстро
откажетесь от этой пагубной идеи. Реляционные СУБД просто-таки вынуждают программиста
применять SQL — наиболее мощное и высокоуровневое средство описания операций над
данными. Всю ответственность за реализацию тонких особенностей хранения информации
и механизмов обеспечения эффективного доступа к ней SQL принимает на себя.
???
Базовый язык
+
внедренный" SQL
Препроцессор
Базовый язык
+
вызовы функций
Компилятор
базового
языка
Библиотека SQL
Объектный код
Рис. 8.1. Обработка программного кода с
инструкциями SQL
С другой стороны, существует множество важных вещей, с которыми SQL просто
не в состоянии справиться. Попробуйте, например, описать средствами SQL
процедуру вычисления факториала числа п — я! = л*(л-1)* — *2*1, — простенький этюд для
программиста, использующего С или другой подобный язык.45 Еще один пример: SQL
не дает возможности представить результат запроса в иной удобной для восприятия
форме, которая отличается от табличной, — скажем, в виде графика. Таким образом,
при программировании приложений баз данных чаще всего целесообразно
использовать и SQL, и один из традиционных языков, называемый в подобной ситуации
базовым, или включающим (host language).
45 Здесь необходимо сделать оговорку. Существуют различные "расширения" ядра SQL,
такие как "рекурсивный SQL" (recursive SQL) (см. раздел 10.4 на с. 478) или стандарт SQL/PSM
(обратитесь к разделу 8.2 на с. 364), которые, будучи "полными по Тьюрингу" (Turing complete),
позволяют реализовать любые вычислительные операции, поддающиеся описанию средствами
традиционных языков программирования. Подобные расширения SQL, однако, не
предназначены для выполнения "любых" операций, и их не принято относить к категории языков
программирования общего назначения.
8.1. SQL В СРЕДЕ ПРОГРАММИРОВАНИЯ
351
8.1.2. Интерфейс взаимодействия SQL и базового языка
Обмен информацией между базой данных, доступ к которой реализуется только
с помощью директив SQL, и программой на базовом языке осуществляется
посредством переменных программы, которые могут считываться и записываться командами
SQL. Подобные общие переменные (shared variables) обозначаются префиксом-
двоеточием, если они используются в контексте инструкции SQL; при ссылке на
переменную в базовом коде префикс опускается.
Выражение SQL может быть "внедрено" в текст программы на базовом языке
с помощью директивы exec SQL, предшествующей выражению. В обычной
системе такие выражения подвергаются обработке препроцессором, который
заменяет их вызовами соответствующих функций SQL-библиотеки, удовлетворяющей
требованиям базового языка.
В стандарте SQL предусмотрена специальная переменная, называемая sqlstate,
которая предназначена для обмена системной информацией между программой на
базовом языке и СУБД. Тип переменной sqlstate — это массив из пяти символов.
При вызове функции SQL-библиотеки система помещает в переменную специальный
код, который свидетельствует о том, каким образом завершился вызов. Программа на
базовом языке способна считывать содержимое переменной sqlstate и принимать
соответствующие решения, руководствуясь тем, какой именно код возвращен
системой. В стандарте SQL описаны множество допустимых значений кодов sqlstate и их
семантические особенности. Например, строка '00000' (пять нулей) означает, что
процесс обработки SQL-команды завершен успешно, а код ' 02 000 ' гласит, что
некоторый запрошенный кортеж не может быть найден. Позже мы проиллюстрируем
смысл, которым обладает значение '02000': в теле базовой программы может быть
создан цикл для пошаговой проверки кортежей некоторого отношения; при
получении значения ' 02000 ' выполнение цикла подлежит завершению.
8.1.3. Секция объявления
Объявления общих переменных располагаются между следующими директивами
SQL, "внедряемыми" в текст базовой программы:
EXEC SQL BEGIN DECLARE SECTION;
EXEC SQL END DECLARE SECTION;
и образуют так называемую секцию объявления (declare section). Форма
представления объявлений переменных внутри секции объявления обусловлена
требованиями конкретного базового языка. Имеет смысл объявлять переменные только
таких типов, с которыми смогут справиться и базовая программа, и команды
SQL, — чаще всего используются целочисленные величины, вещественные
значения, символьные строки и массивы.
Пример 8.1. Вот как может выглядеть, скажем, объявление переменных в
контексте функции на языке С, предназначенной для модификации содержимого
отношения studio:
EXEC SQL BEGIN DECLARE SECTION;
char studioName[31], studioAddr[256j;
char SQLSTATE[ 6 j ;
EXEC SQL END DECLARE SECTION;
Первое и последнее выражения представляют собой обязательные конструкции,
обрамляющие секцию объявления. Между ними размещены два объявления: первое
определяет две строковые переменные, studioName и studioAddr, предназначенные
352
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
для хранения наименования и адреса киностудии соответственно и образующие
кортеж, подлежащий вставке в отношение studio; второе представляет переменную
sqlstate как массив, состоящий из шести символов.46 □
8.1.4. Использование общих переменных
Общие переменные (shared variables) разрешено использовать в тех "местах"
выражений SQL, где допустимы константы. Напомним, что при обращении к общей
переменной в контексте инструкции SQL наименованию (идентификатору) переменной
следует предпослать префикс-двоеточие. Ниже рассмотрен образец кода, в котором
переменные, объявленные в примере 8.1, используются как компоненты кортежа,
подлежащего вставке в отношение studio.
Пример 8.2. На рис. 8.2 приведен "эскиз" С-функции getstudio, которая
запрашивает у пользователя название и адрес студии, считывает полученные ответы, формирует
на их основе новый кортеж и вставляет его в отношение studio. Строки 1—4
содержат объявления, которые уже знакомы вам по примеру 8.1. Код на языке С,
предназначенный для вывода строк-приглашений и считывания ответов на них в
переменные studioName и studioAddr, опущен.
Строки 5, 6 представляют "внедренное" выражение SQL, обеспечивающее вставку
(insert) кортежа. Выражению предшествует директива exec sql, свидетельствующая
о том, что последующий текст действительно является командой SQL, а не кодом на
языке С (между прочим, не верным с точки зрения грамматики С). Препроцессор
(см. рис. 8.1 на с. 351), обрабатывая код программы, отыскивает предложения
exec SQL и преобразует их в правильные вызовы функций С.
Значения, содержащиеся в SQL-предложении values, не являются константами,
как в командах SQL (см. пример 6.34 на с. 291), которые мы рассматривали прежде, —
здесь речь идет об общих переменных, значения которых служат компонентами
вставляемого кортежа. □
Помимо команды insert, существует много других видов выражений SQL,
которые, будучи "внедренными" в код программы, написанной на некотором базовом
языке, способны пользоваться интерфейсом общих переменных. Каждая
"внедренная" инструкция SQL, снабженная предложением exec SQL, вправе
содержать общие переменные вместо констант. Допускается "внедрение" в базовый код
любых выражений SQL, которые не возвращают результат (т.е. не являются
запросами). В качестве примеров таких выражений можно назвать команды удаления и
обновления кортежей отношений, а также создания, изменения и изъятия элементов
схемы базы данных (таких как отношения или виртуальные таблицы).
Выражения SQL вида "select—from—where", однако, не допускается "внедрять"
в базовый код напрямую ввиду несогласованности моделей данных (об этой проблеме
мы говорили в разделе 8.1.1 на с. 350). Запросы возвращают в качестве результата
множества кортежей — ни один из распространенных базовых языков не
поддерживает подобные структуры данных непосредственно. Поэтому для обработки результата
"внедренного" SQL-запроса в базовой программе приходится применять один из двух
дополнительных механизмов, указанных ниже.
Хотя, как мы говорили выше, содержимое переменной SQLSTATE состоит из пяти
символов, объявление предусматривает возможность хранения шести символов. В последующих
примерах программ на языке С для проверки значений SQLSTATE используется стандартная
функция С strcmp, которая предполагает, что строка завершается специальным "нулевым"
символом, ' \0'. В последнюю позицию строки переменной SQLSTATE символ ' \0' следует заносить
принудительно, но эту операцию присваивания в дальнейшем мы будем опускать.
8.1. SQL В СРЕДЕ ПРОГРАММИРОВАНИЯ
353
void getStudio() {
1) EXEC SQL BEGIN DECLARE SECTION;
2) char studioName[31], studioAddr[256];
3) char SQLSTATE[6];
4) EXEC SQL END DECLARE SECTION;
/* Вывести на экран строки-приглашения и
считать введенные пользователем значения
в переменные studioName и studioAddr */
5) EXEC SQL INSERT INTO Studio(name, address)
6) VALUES (:studioName, :studioAddr);
}
Рис. 8.2. Пример использования общих переменных для вставки кортежа
1. Результат запроса, возвращающего единственный кортеж, можно сохранить
в наборе общих переменных, по одной на каждый компонент кортежа. С этой
целью применяется специальная разновидность конструкции "select—from—
where", называемая командой выбора единственного кортежа (single-row select).
2. Чтобы получить возможность "внедрения" в базовый код таких SQL-запросов,
которые способны возвращать более одного кортежа, следует применить
механизм объявления курсора (cursor), соответствующего запросу. Курсор позволяет
"перемещаться" по всем кортежам итогового отношения, поочередно извлекать
(fetch) значения компонентов текущего кортежа и присваивать их
соответствующим общим переменным.
Каждый из названных механизмов подробно рассмотрен в следующих разделах.
8.1.5. Команды выбора единственного кортежа
Синтаксическая форма команды выбора единственного кортежа (single-row select)
аналогична обычной конструкции "select—from—where" — за исключением того, что
в ней предусмотрено использование дополнительного предложения into, следующего
за предложением select и содержащего список идентификаторов общих переменных.
Как и во всех других случаях, наименования общих переменных, перечисленные
в списке, помечаются префиксом-двоеточием. Если результатом обработки запроса
является единственный кортеж, значения его компонентов присваиваются
соответствующим переменным; если же запрос возвращает более одного кортежа или не
возвращает кортежей вовсе, операции присваивания значений общим переменным не
выполняются и в переменную SQL state заносится надлежащий код ошибки.
Пример 8.3. Рассмотрим код функции на языке С, которая обязана предложить
пользователю ввести наименование киностудии, найти в базе данных величину годового
дохода президента студии и вывести это значение на экран. Эскизный вариант
функции приведен на рис. 8.3. Строки 1—5 содержат секцию объявления общих
переменных. Далее следуют инструкции (здесь они опущены), позволяющие вывести на экран
строку приглашения и считать в общую переменную studioName наименование
киностудии, введенное пользователем со стандартной консоли.
В строках 6—9 приведена команда выбора единственного кортежа. Она достаточно
схожа с теми "внедренными" конструкциями, которые мы рассматривали до сих пор.
Два принципиальных отличия таковы: значение системной переменной studioName
используется на месте константы в тексте условия предложения where в строке 9;
существует дополнительное предложение into (см. строку 7), которое указывает систе-
354
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
ме, куда поместить результат обработки запроса. В нашем примере, как мы полагаем,
при нормальном исходе система должна возвратить отношение с единственным
кортежем, содержащим один компонент, netWorth, — это значение подлежит
присваиванию общей переменной presNetWorth.
void printNetWorth() {
1) EXEC SQL BEGIN DECLARE SECTION;
2) char studioName[31];
3) int presNetWorth;
4) char SQLSTATE[6];
5) EXEC SQL END DECLARE SECTION;
/* Вывести на экран строку-приглашение и
считать введенное пользователем значение
в переменную studioName */
6) EXEC SQL SELECT netWorth
7) INTO .-presNetWorth
8) FROM Studio, MovieExec
9) WHERE presC# = cert# AND
10) Studio.name = :studioName;
/* Сравнить содержимое SQLSTATE с константой '00000';
если результат сравнения успешен, вывести на экран
содержимое переменной presNetWorth */
}
Рис. 8.3. Пример использования команды выбора единственного кортежа
8.1.6. Курсоры
Наиболее универсальный способ объединения фрагментов кода базового языка
с инструкциями SQL связан с объявлением курсора (cursor), позволяющего
последовательно "просматривать" кортежи отношения. Отношением в данном случае может
быть хранимая таблица или набор данных, сгенерированный системой в результате
обработки запроса. Чтобы воспользоваться механизмом курсора, необходимо
выполнить ряд действий, указанных ниже.
1. Объявить курсор. Простейшая форма объявления курсора состоит из
следующих частей:
a) начального предложения exec SQL, используемого для "внедрения"
инструкций SQL в код базовой программы;
b) служебного слова declare;
c) наименования С курсора;
d) пары служебных слов cursor for;
e) выражения Q, представляющего собой наименование отношения или текст
запроса вида "select—from—where", возвращающего отношение. Будучи
объявленным и открытым (opened), курсор предоставляет возможность
"перемещения" по кортежам отношения Q — после выполнения
программой инструкции извлечения (fetch) кортежа курсор будет содержать ссылку на
текущий кортеж отношения.
8.1. SQL В СРЕДЕ ПРОГРАММИРОВАНИЯ
355
Иными словами, выражение объявления курсора можно представить так:
EXEC SQL DECLARE С CURSOR FOR Q;
2. Открыть курсор. Инструкция открытия курсора С выглядит следующим образом:
EXEC SQL OPEN С;
После открытия курсор инициализируется и его внутренний "указатель"
устанавливается таким образом, чтобы курсор давал возможность извлечь первый
кортеж отношения.
3. Выполнить одну или несколько команд извлечения (fetch) кортежа. Назначение
команды состоит в получении очередного кортежа отношения, которое указано
в объявлении курсора. Если на некотором шаге множество кортежей
оказывается исчерпанным, т.е. команда извлечения не способна возвратить очередной
кортеж, в переменную SQL state заносится код '02000', означающий, что
"кортеж не найден". Команда извлечения кортежа состоит из следующих частей:
a) служебных слов exec sql fetch from;
b) наименования С курсора;
c) служебного слова into;
d) списка L общих переменных. Если кортеж, подлежащий извлечению,
существует, содержимое компонентов кортежа присваивается переменным в
соответствии с порядком следования их в списке.
Другими словами, команду извлечения кортежа можно представить так:
EXEC SQL FETCH FROM C INTO Ц
4. Закрыть курсор. Инструкция закрытия курсора С выглядит следующим образом:
EXEC SQL CLOSE С;
После закрытия курсор не способен реагировать на команды извлечения
кортежей. Впрочем, вполне допустимо открыть курсор вновь, после чего он
приобретает прежние функциональные качества.
Пример 8.4. Пусть требуется получить статистику распределения значений годовых
доходов руководителей индустрии кино в зависимости от количества цифр в каждом
значении. Запрос, который мы собираемся создать, призван обеспечить извлечение
содержимого компонентов netWorth всех кортежей отношения MovieExec в
специальную общую переменную (назовем ее worth). Помощь в "перемещении" по
указанным кортежам с одним компонентом должен оказать курсор (обозначим его как
execCursor). При извлечении значения компонента очередного кортежа необходимо
подсчитать количество цифр в значении и увеличить на единицу содержимое
соответствующего элемента массива статистических показателей counts.
Текст С-функции worthRanges показан на рис. 8.447. Строка 2 содержит объявления
некоторых переменных, которые будут использоваться только в коде С (не во
"внедренных" выражениях SQL). Массив counts предназначен для хранения количеств
значений различной длины, переменная digits используется для подсчета длины
отдельного значения дохода, a i выполняет роль счетчика элементов массива counts.
Строки 3—6 содержат секцию объявления общих переменных worth и SQLSTATE,
а строки 7—8 — объявление курсора execCursor, который .должен обеспечить
возможность просмотра содержимого отношения, возвращаемого запросом, описанным
в строке 8. Запрос, весьма простой по форме, предполагает выбор значений
компонентов netWorth всех кортежей отношения MovieExec. Строка 9 представляет
директиву открытия курсора, а строка 10 завершает процесс инициализации — в ней
элементам массива counts присваиваются нулевые значения.
Необходимые директивы #include для краткости авторами опущены. — Прим. перев.
356
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
1) void worthRanges () {
2) int i, digits, counts[15];
3) EXEC SQL BEGIN DECLARE SECTION;
4) int worth;
5) char SQLSTATE[6];
6) EXEC SQL END DECLARE SECTION;
7) EXEC SQL DECLARE execCursor CURSOR FOR
8) SELECT netWorth FROM MovieExec;
9) EXEC SQL OPEN execCursor;
10) for(i = 0; i < 15; i++) counts[i] = 0;
11) while(l) {
12) EXEC SQL FETCH FROM execCursor INTO .-worth;
13) if (NO_MORE_TUPLES) break;
14) digits = 1;
15) while((worth /= 10) > 0) digits++;
16) if (digits <= 14) counts[digits]++;
}
17) EXEC SQL CLOSE execCursor;
18) for(i = 0; i < 15; i++)
19) printf("%с!-значный доход: количество начальников =
%d\n",
i, counts[i]);
}
Рис. 8.4. Пример использования курсора для чтения и обработки данных
Основные обязанности возлагаются на цикл, приведенный в строках 11—16. При
выполнении строки 12 извлекается (fetch) очередной кортеж отношения, возвращенного
запросом, и значение компонента netWorth присваивается общей переменной worth.
Поскольку в рассматриваемом случае кортежи итогового отношения содержат по одному
кортежу, нам необходима только одна общая переменная, хотя, вообще говоря, количество
переменных должно совпадать с числом компонентов. В строке 13 проверяется, успешно
ли завершилась операция извлечения кортежа. При этом используется макрос
no_more_tuples, который, как мы полагаем, может быть объявлен следующим образом:
#define NO_MORE_TUPLES !(strcmp(SQLSTATE, "02000"))
Напомним, что строка "02000м представляет код sqlstate, означающий, что
"кортеж не найден". В строке 13, таким образом, анализируется условие, существуют
ли кортежи итогового отношения, пригодные для извлечения. Если таких кортежей
нет (условие макроса справедливо), выполняется инструкция break, прерывающая
цикл и передающая управление строке 17.
Если кортеж извлечен успешно, в строке 14 инициализируется переменная
digits, предназначенная для хранения количества разрядов в текущем значении
worth. Строка 15 содержит цикл, в процессе выполнения которого значение worth
делится на 10; после сравнения остатка от деления с нулем содержимое digits
увеличивается на единицу. Как только остаток обращается в нуль, это значит, что
переменная digits содержит верное количество цифр в текущем значении worth.
Наконец, в строке 16 выполняется приращение соответствующего элемента массива
counts на единицу. Мы полагаем, что значение дохода не может содержать более
14 десятичных разрядов. Если это условие не выполняется, ни один из элементов
8.1. SQL В СРЕДЕ ПРОГРАММИРОВАНИЯ
357
массива counts не изменяется — значения дохода, выходящие за рамки заданного
диапазона, просто отбрасываются.
Строка 17 содержит инструкцию закрытия курсора, а строки 18, 19 — функции
вывода статистических показателей на экран. □
8.1.7. Модификация данных посредством курсоров
Если курсор открыт для базовой таблицы (а не для виртуальной таблицы либо
отношения, возвращаемого в результате обработки запроса), с его помощью вполне
допустимо не только считывать и обрабатывать содержимое кортежей, но и удалять
(delete) или обновлять (update) их. Синтаксические формы команд удаления и
обновления кортежей посредством курсора почти ничем не отличаются от тех, которые
были рассмотрены в разделе 6.5 на с. 291. Единственное исключение связано с
конструкцией предложения where. При использовании команд модификации в контексте
курсора предложение where принимает вид
WHERE CURRENT OF С
где С — наименование курсора. Разумеется, в тексте программы на базовом языке
могут быть предусмотрены произвольные критерии предварительного отбора
кортежей, подлежащих удалению или обновлению.
Пример 8.5. На рис. 8.5 приведен текст функции на языке С, которая позволяет
поочередно считывать все кортежи отношения MovieExec и удалять или обновлять их,
принимая во внимание значения компонентов netWorth. Строки 3, 4 содержат
объявления общих переменных, отвечающих всем четырем атрибутам отношения
MovieExec, а также объявление системной переменной SQLSTATE. В строке 6
объявляется курсор exec Curs or, предназначенный для "перемещения" по кортежам
отношения MovieExec как такового. Напомним, что операции модификации данных
посредством курсора могут быть выполнены только в том случае, если курсор
"ссылается" на хранимое отношение, подобное MovieExec.
1) void changeWorth() {
2) EXEC SQL BEGIN DECLARE SECTION;
3) int certNo, worth;
4) char execName[31], execAddr[256], SQLSTATE[6];
5) EXEC SQL END DECLARE SECTION;
6) EXEC SQL DECLARE execCursor CURSOR FOR MovieExec;
7) EXEC SQL OPEN execCursor;
8) while(l) {
9) EXEC SQL FETCH FROM execCursor INTO :execName,
:execAddr, icertNo, :worth;
10) if (NO_MORE_TUPLES) break;
11) if (worth < 1000)
12) EXEC SQL DELETE FROM MovieExec
WHERE CURRENT OF execCursor;
13) else
14) EXEC SQL UPDATE MovieExec
SET netWorth = 2* netWorth
WHERE CURRENT OF execCursor;
}
15) EXEC SQL CLOSE execCursor;
}
Рис. 8.5. Пример использования курсора для модификации данных
358
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Строки 8—14 формируют цикл, в котором "указатель" курсора execCursor
"проходит" по всем кортежам отношения MovieExec. Строка 9 содержит инструкцию
извлечения (fetch) текущего кортежа и присваивания значений его компонентов
соответствующим общим переменным; обратите внимание, что далее фактически
используется только переменная worth. В строке 10 проверяется, не исчерпалось ли
множество кортежей MovieExec, доступных для чтения. С этой целью мы вновь
используем макрос no_more_tuples, который содержит условие сравнения текущего
значения переменной sqlstate с константой "02 000", обозначающей отсутствие
кортежей, подлежащих извлечению.
В строке 11 содержимое общей переменной worth сопоставляется с константой
1000. Если величина дохода "руководителя" действительно меньше 1000 долларов,
соответствующий кортеж удаляется из отношения MovieExec командой DELETE,
расположенной в строке 12. Стоит заметить, что предложение where ссылается на курсор
как таковой, поэтому из MovieExec изымается текущий кортеж, только что
считанный командой FETCH. Если же значение worth не ниже заданной границы, в
строке 14 выполняется операция обновления (UPDATE) текущего кортежа MovieExec —
величина компонента netWorth удваивается. □
8.1.8. Защита данных курсора от внешних воздействий
Предположим, что во время выполнения функции worthRanges (см. рис. 8.4 на
с. 357), вычисляющей распределение значений доходов руководящих лиц, некоторый
другой процесс, протекающий параллельно, модифицирует содержимое того же
отношения MovieExec. Проблемы, связанные с одновременным доступом к базе данных
нескольких процессов, мы сможем обсудить гораздо более обстоятельно, когда в
разделе 8.6 на с. 393 приступим к изучению технологий управления транзакциями. Но
сейчас давайте примем следующую ситуацию как должное: существует некий
"сторонний" процесс, пытающийся модифицировать отношение в тот момент, когда
наша программа использует данные этого отношения для собственных нужд.
Что можно предпринять в подобном случае? Как кажется, почти ничего. Получив
статистические данные, мы, вероятно, будем пребывать в счастливом неведении, даже
не догадываясь о том, что некоторые кортежи, которые, как мы полагаем, наша
программа с успехом обработала, на самом деле были удалены другим приложением. На
первый взгляд, остается просто доверять той информации, которую способен
возвратить созданный нами курсор.
Ну а если возможность воздействия на результаты работы программы со стороны
внешних процессов предотвратить все-таки крайне необходимо? Можно потребовать,
чтобы данные выбирались из отношения так, будто его содержимое "зафиксировано"
в определенный момент времени. Разумеется, мы не в состоянии доподлинно знать,
каким операциям модификации подвергалось отношение MovieExec до того, как
к нему обратилась наша программа, но вправе ожидать, что все подобные операции
либо уже завершились, либо будут выполнены по окончании сеанса работы функции
worthRanges. Чтобы получить такие гарантии, достаточно включить в конструкцию
объявления курсора признак нечувствительности (insensibility) к возможным
изменениям информации в базе данных, вносимым параллельными процессами.
Пример 8.6. Заменим строки 7, 8 рис. 8.4 (см. с. 357) следующими:
7) EXEC SQL DECLARE execCursor INSENSITIVE CURSOR FOR
8) SELECT netWorth FROM MovieExec;
Если курсор execCursor объявить так, как показано, система сможет гарантировать,
что все изменения, вносимые в отношение MovieExec в период времени между
открытием и закрытием курсора, не будут воздействовать на множество кортежей,
"видимых" из функции worthRanges с помощью этого курсора. □
8.1. SQL В СРЕДЕ ПРОГРАММИРОВАНИЯ
359
Использование нечувствительных курсоров, однако, сопряжено с немалыми
издержками — системе приходится тратить время на дополнительные операции
управления информацией, которые, собственно, и придают курсору требуемые качества.
Здесь нам не хотелось бы погружаться в детали — отложим их до раздела 8.6 на с. 393.
Впрочем, достаточно упомянуть хотя бы самый простой способ поддержки свойства
нечувствительности курсора: система вправе просто приостановить любые процессы,
которые пытаются модифицировать отношение, находящееся в "поле зрения"
курсора, до тех пор, пока курсор не будет закрыт.
Имеется возможность определять и такие курсоры, предназначенные "только для
чтения" отношения /?, о которых можно с уверенностью говорить, что они не
способны повлиять на содержимое отношения R. Любой подобный курсор можно смело
открывать наряду с обычным ("чувствительным") курсором для /?, не опасаясь, что на
результатах работы последнего скажутся какие-либо изменения. Если снабдить курсор
признаком for read only, с его помощью нельзя будет выполнить какую бы то ни
было операцию модификации отношения R.
Пример 8.7. Если после строки 8 в объявлении курсора, представленном на рис. 8.4,
вставить предложение
FOR READ ONLY;
любая попытка модификации содержимого отношения MovieExec посредством
курсора execCursor будет отвергнута. □
8.1.9. Изменение порядка просмотра содержимого курсора
Курсор может быть снабжен механизмом, позволяющим выбирать способ
"перемещения" по кортежам отношения, лежащего в основе определения курсора. По
умолчанию (и это удобно в большинстве ситуаций) система предлагает начать
просмотр содержимого курсора с первого кортежа и извлекать кортежи в естественном
порядке их следования, вплоть до достижения завершающего кортежа. В некоторых
ситуациях требуется изменять порядок обработки либо на протяжении сеанса
открытия курсора обращаться к одним и тем кортежам несколько раз.48 Чтобы
воспользоваться подобными возможностями, надлежит выполнить два действия.
1. Включить в конструкцию объявления курсора (непосредственно перед словом
cursor) служебное слово scroll, свидетельствующее о том, что курсор должен
позволять "пролистывание" его содержимого в произвольном порядке,
отличном от линейного, предлагаемого по умолчанию.
2. Сопроводить служебное слово fetch в одноименной команде одним из
перечисленных ниже слов, соответствующих требуемому режиму "перемещения"
внутри курсора:
a) next или prior — для перемещения соответственно к следующему или
предыдущему кортежу относительно текущего; если ни одно из служебных слов,
указывающих "направление" перемещения, не задано, по умолчанию, как
наиболее уместный, подразумевается режим next;
b) first или last — для перемещения соответственно к первому или
последнему кортежу;
c) relative п (где п — целое значение) — для перемещения на п позиций
вперед (если п положительно) или на п позиций назад (если п отрицательно)
Важно отметить, что все это приобретает практический смысл только в том случае, если
отношение, "обслуживаемое" курсором, получено при выполнении запроса, содержащего
предложение ORDER BY, либо является хранимой таблицей, принудительно отсортированной по
определенному критерию. — Прим. перев.
360
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
относительно текущего кортежа; например, relative 1 — это синоним
NEXT, a RELATIVE -1 — СИНОНИМ PRIOR;
d) absolute п (где п — целое значение) — для перемещения на п позиций вперед,
начиная с нулевой (если п положительно), или на п позиций назад, начиная
с позиции, следующей за завершающим кортежем (если п отрицательно);
например, ABSOLUTE 1 — ЭТО СИНОНИМ FIRST, a ABSOLUTE -1 — СИНОНИМ LAST.
Пример 8.8. Пусть необходимо переписать текст функции changeWorth, показанный
на рис. 8.5, так, чтобы вначале обрабатывался последний кортеж, затем
предпоследний и т.д. Первым делом следует изменить объявление курсора execCursor, снабдив
его признаком scroll:
6) EXEC SQL DECLARE execCursor SCROLL CURSOR FOR MovieExec;
Помимо того, перед выполнением цикла надлежит установить "указатель" курсора на
последний кортеж с помощью команды fetch last, а внутри цикла использовать
команду fetch prior. Исправленный фрагмент кода рис. 8.5, охватывающий строки
8—14, показан на рис. 8.6. (Однако не следует полагать, что изменение порядка
просмотра кортежей на обратный49 способно предоставить какие-либо дополнительные
преимущества — в данном случае мы преследуем только методические цели.) □
8.1.10. Динамический SQL
До сих пор, говоря о "внедрении" команд SQL в код программы, написанной на
базовом языке, мы полагали, что текст SQL известен заранее. Альтернативный
подход, более гибкий и многообещающий, предусматривает, что
EXEC SQL FETCH LAST FROM execCursor INTO :execName,
:execAddr, :с er tNo, :wor th;
while(1) {
/* Те же строки 10-14 */
EXEC SQL FETCH PRIOR FROM execCursor INTO :execName,
: exec Addr, rcertNo, -.worth;
}
Рис. 8.6. Пример процедуры просмотра кортежей в "обратном " порядке
выражения SQL создаются и выполняются динамически в процессе работы
программы. Эти выражения не известны в период компиляции программы, поэтому
обработке препроцессором они не подвергаются.
Примером подобной программы может служить приложение, которое
запрашивает текст команды SQL у пользователя, а затем считывает и выполняет ее. На
протяжении главы 6 (см. с. 249—316)мы подразумевали именно такой режим работы:
многие коммерческие СУБД содержат в своем составе приложения, позволяющие
вводить и выполнять произвольные команды SQL. Команда, введенная
пользователем, подлежит синтаксическому анализу, а затем система выбирает наиболее
целесообразный способ ее выполнения.
Программа должна сообщить системе о том, что строку символов, введенную
пользователем или полученную иным образом, следует считать, преобразовать в команду
SQL, а затем выполнить. Подобные действия можно осуществить с помощью двух
команд, рассмотренных ниже.
49 В данной ситуации трудно судить о том, что представляет собой "обратный" порядок,
поскольку курсор открыт на основе обычной хранимой таблицы. Порядок следования кортежей
в отношениях "обычному" пользователю, вообще говоря, не известен. — Прим. перев.
8.1. SQL В СРЕДЕ ПРОГРАММИРОВАНИЯ
361
1. EXEC SQL PREPARE V FROM £, где V — переменная SQL, a E — общая
переменная или выражение строкового типа. Выражение Е считывается и
анализируется (подготавливается — prepare), но не выполняется: найденный системой
план (plan) выполнения присваивается переменной V.
2. exec SQL execute V. Содержимое переменной V трактуется как команда SQL
и выполняется.
Обе стадии можно объединить в одну, если воспользоваться директивой
EXEC SQL EXECUTE IMMEDIATE E
где £, как и прежде, представляет общую переменную или выражение строкового
типа. Недостаток такого подхода проявляется в тех ситуациях, когда выражение один
раз "подготавливается", а затем многократно выполняется: при использовании
инструкции execute immediate системе каждый раз приходится осуществлять
подготовку одного и того же выражения к выполнению, а это обходится недешево — в том
смысле, что требует немалых вычислительных затрат.
Пример 8.9. На рис. 8.7 приведен "набросок" программы на языке С, которая
осуществляет чтение текста, введенного пользователем со стандартной консоли, в общую
переменную query, подготавливает SQL-команду, сформированную на основе
содержимого query, а затем выполняет ее.
1) void readQuery() {
2) EXEC SQL BEGIN DECLARE SECTION;
3) char *query;
4) EXEC SQL END DECLARE SECTION;
5) /* Вывести на экран приглашение,
выделить участок памяти (скажем, используя функцию
malloc) для хранения введенной пользователем строки
запроса и присвоить указателю :query адрес первого
символа строки */
6) EXEC SQL PREPARE SQLquery FROM :query;
7) EXEC SQL EXECUTE SQLquery;
..}
Рис. 8.7. Пример подготовки и выполнения SQL-команды, полученной динамически
Поскольку в данном случае, как мы полагаем, команда должна выполнять только
один раз, строки 6 и 7 можно заменить одной:
6) EXEC SQL EXECUTE IMMEDIATE :query;
8.1.11. Упражнения к разделу 8.1
Упражнение 8.1.1. Представьте перечисленные ниже задания, касающиеся отношений
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
из базы данных, рассмотренной в упражнении 5.2.1 на с. 218, в виде "внедренных"
SQL-команд. Для написания базовых программ можете воспользоваться любым
языком программирования общего назначения, который вам знаком. Если хотите,
замените детали реализации кода базовых программ внятными комментариями.
362
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
* а) Запросить у пользователя значение цены и найти информацию —
наименование производителя (maker), номер модели (model) и уровень
быстродействия процессора (speed) — о персональном компьютере (рс) с ценой
(price), наиболее близкой к заданной.
Ь) Запросить у пользователя минимальные значения быстродействия процессора
(speed), объема оперативной памяти (ram), емкости диска (hd) и размера
экрана (screen) переносного компьютера (Laptop) и найти информацию обо всех
таких компьютерах, которые удовлетворяют заданным критериям поиска.
Вывести на экран полные спецификации компьютеров (значения всех компонентов
кортежей отношения Laptop), включая сведения об их производителях (maker).
! с) Запросить у пользователя строку наименования производителя (maker).
Найти и вывести на экран информацию обо всех продуктах, выпускаемых
указанным производителем, включая номера моделей (model) и значения
типов (type), а также полные спецификации каждого продукта, взятые из
соответствующих отношений.
!! d) Запросить у пользователя значение допустимого "бюджета" (в расчете на
покупку персонального компьютера и принтера), а также минимальное
значение быстродействия процессора (speed). Найти самую дешевую "систему"
(компьютер плюс принтер), которая "укладывается" в заданные рамки
бюджета и ограничения быстродействия процессора. Если возможно, обеспечить
выбор цветного (значение true атрибута color) принтера. Вывести номера
моделей (model) компонентов выбранной системы.
е) Запросить у пользователя значения параметров нового персонального
компьютера (PC) — кода производителя (maker), номера модели (model),
быстродействия процессора (speed), объема оперативной памяти (ram), емкости диска (hd),
типа привода съемных дисков (rd), а также цены (price). Убедиться, что в базе
данных отсутствует информация о персональном компьютере с аналогичным
номером модели, и вставить (INSERT) в отношения Product и PC
соответствующие кортежи; в противном случае вывести на экран сообщение об ошибке.50
*! f) Уменьшить значение цены (price) всех персональных компьютеров (рс) на
100 долларов. Гарантировать, что цена компьютеров, сведения о которых могут
вводиться в базу данных в период работы вашей программы, не будет изменена.
Упражнение 8.1.2. Представьте перечисленные ниже задания, касающиеся отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222, в виде "внедренных"
SQL-команд.
а) Значение "огневой мощи" судна примерно пропорционально количеству
главных орудий (numGuns), умноженному на величину их калибра (bore),
возведенную в куб. Найти класс (class) судов, обладающих наивысшей огневой мощью.
! Ь) Запросить у пользователя строку названия (name) морского сражения
(Battles). Найти наименования стран (country), корабли которых
принимали участие в указанном сражении. Вывести названия стран, понесших
наибольшие потери из-за того, что их суда были потоплены (значение
' sunk' атрибута result) и повреждены (' damaged').
' В оригинале задание содержит некорректное условие, которое здесь изменено. — Прим. перев.
8.1. SQL В СРЕДЕ ПРОГРАММИРОВАНИЯ
363
Запросить у пользователя наименование класса (class) и значения других
компонентов кортежа отношения Classes. Затем запросить список пар
значений, представляющих название (name) судна, относящегося к указанному
классу, и дату его спуска на воду (launched) (пользователю не нужно
заново повторять ввод названия класса). Собранную информацию вставить
(INSERT) в отношения Classes и Ships.
Проверить отношения Battles, Outcomes и Ships на предмет присутствия
в них ошибочных сведений о судах, которые принимали участие в
сражениях раньше (date), нежели были построены (launched). Для каждого из
подобных судов, если они найдены, предложить пользователю ввести на выбор
новые значения даты сражения или даты спуска судна на воду и внести
соответствующие изменения в базу данных.
*! Упражнение 8.1.3. Цель состоит в отыскании среди множества кортежей отношения
PC(model, speed, ram, hd, rd, price)
сведений о таких персональных компьютерах, для которых существуют по
меньшей мере два более дорогих (price) компьютера с тем же уровнем быстродействия
процессора (speed). Задача может быть решена разнообразными способами, но
необходимо выбрать тот, который предполагает использование курсора,
допускающего (scroll) изменение порядка просмотра содержимого. Обеспечьте чтение
кортежей отношения PC, отсортированного по значениям speed и price.
Воспользуйтесь советом: считав очередной кортеж, пропустите два следующих, а затем
проверьте, изменилось ли значение speed.
8.2. Хранимые процедуры и функции
В этом разделе вы познакомитесь с недавним стандартом, называемым Persistent,
Stored Modules (SQL/PSM, или PSM-96, или просто PSM) — "постоянно хранимые
модули". Каждая коммерческая СУБД предлагает те или иные способы написания
и сохранения в схеме базы данных некоторых функций и/или процедур, к которым
допустимо обращаться из SQL-запросов или других SQL-выражений. Подобные
фрагменты кода создаются с использованием простого языка общего назначения,
позволяющего описывать самые разнообразные вычислительные конструкции, которые
нельзя выразить средствами языка SQL как такового. В этой книге мы сосредоточили
внимание на стандарте SQL/PSM, который обусловливает основные направления
развития технологий хранимого кода; эти сведения при необходимости помогут вам
разобраться в особенностях конкретных реализаций.
Опираясь на стандарт PSM, программист создает модули (modules), содержащие
наборы определений процедур и функций, объявлений временных таблиц и иных
элементов схемы базы данных. О модулях будет рассказано в разделе 8.3.7 на с. 381,
а здесь мы остановимся на хранимых процедурах и функциях.
8.2.1. Создание хранимых процедур и функций
Объявление хранимой процедуры в своей базовой форме выглядит так:
CREATE PROCEDURE <имя> (<параметры>)
<объявления локальных леременных>
<тело лроцедуры>;
Подобная конструкция наверняка знакома вам по многим языкам
программирования; она состоит из пары служебных слов create procedure, имени
процедуры, списка параметров, заключенного в круглые скобки, ряда объявлений
локальных переменных и фрагмента исполняемого кода, который, собственно, и яв-
364
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
ляется "ядром" процедуры. Хранимая функция определяется почти аналогично;
отличия связаны с использованием вместо слова procedure служебного слова
function и наличием обязательного предложения, задающего тип возвращаемого
функцией значения. Иными словами, конструкцию объявления хранимой
функции можно представить следующим образом:
CREATE FUNCTION <имя> (<параметры>) RETURNS <тип>
<объявления локальных переменных>
<тело функции>;
Параметрами процедуры являются тройки вида "режим—идентификатор—тип", во
многом схожие с параметрами методов ODL, о которых мы говорили в разделе 4.2.7
на с. 159. Для обозначения параметра следует указать не только его имя-
идентификатор и тип, как это принято в традиционных языках программирования, но
и дополнительный квалификатор, определяющий "режим " (mode) использования
параметра — in ("входной"), оит ("выходной") и inout ("выходной/выходной").
Квалификатор IN, предусмотренный по умолчанию, разрешено не задавать.
Параметры хранимой функции, однако, могут использоваться только в режиме in.
Другими словами, стандарт PSM запрещает хранимой функции возвращать значения
каким бы то ни было способом, отличным от традиционного, описываемого командой
RETURN (см. раздел 8.2.2 на с. 366). Определяя параметры функций, квалификатор in
мы будем опускать; в объявлениях процедур, однако, его все-таки полезно задавать.
Пример 8.10. Хотя мы еще не познакомили вас с внутренним "устройством"
типичной хранимой процедуры или функции, одна из категорий конструкций,
которые допустимо применять в их теле, вас отнюдь не удивит: речь идет о
выражении SQL. Ограничения, которым должно отвечать такое выражение, аналогичны
тем, что приняты для "внедряемых" SQL-выражений (см. раздел 8.1.4 на с. 353):
здесь разрешено использовать команды выбора единственного кортежа и
конструкции на основе курсоров. На рис. 8.8 приведен пример процедуры, которая
в качестве параметров принимает два адреса, "старый" и "новый", находит все
кортежи отношения MovieStar с компонентами address, содержащими
"старый" адрес, и заменяет их новым значением адреса.
1) CREATE PROCEDURE Move(
2) IN oldAddr VARCHAR(255),
3) IN newAddr VARCHAR(2 55)
)
4) UPDATE MovieStar
5) SET address = newAddr
6) WHERE address = oldAddr;
Рис. 8.8. Пример простой хранимой процедуры
Строка 1 содержит заголовок объявления процедуры и ее имя, Move. Строки 2, 3
представляют описания параметров: оба параметра являются входными и относятся
к строковому типу переменной длины 255. Заметим, что эти определения согласуются
с объявлением атрибута address в схеме отношения MovieStar (см. рис. 6.16 на
с. 298). В строках 4—6 приведена обычная команда update. Обратите внимание, что
идентификаторы параметров используются так же, как если бы вместо них задавались
константы. В отличие от общих переменных, которые формируют интерфейс между
базовым кодом и "внедренными" SQL-командами и помечаются префиксом-
двоеточием (см. раздел 8.1.2 на с. 352), параметры и локальные переменные хранимых
процедур и функций в обозначении с помощью двоеточия не нуждаются. □
8.2. ХРАНИМЫЕ ПРОЦЕДУРЫ И ФУНКЦИИ
365
8.2.2. Простые формы выражений
Начнем с попурри, составленного из простейших синтаксических форм
выражений, которые, как нам кажется, вы сможете освоить очень быстро.
1. Вызов процедуры:
CALL <имя процедуры> (<список аргументов>) ;
Служебное слово call сопровождается именем процедуры и списком
аргументов, заключенным в круглые скобки (как и во многих других языках).
Подобным вызовом, однако, можно пользоваться в различных контекстах:
a) внутри программы, написанной на базовом языке; примером может служить
конструкция
EXEC SQL CALL Foo(:x, 3);
b) внутри другой хранимой процедуры или функции;
c) как интерпретируемой командой базового интерфейса SQL; например, вызов
CALL Foo(1, 3);
заставляет систему обратиться к хранимой процедуре Foo, передав ей в
качестве аргументов значения 1 и 3.
Заметим, что с помощью call можно вызывать только процедуры, но не
функции. Вызов функции в PSM выполняется так же, как и в С — имя функции
и список аргументов обычно являются частью более крупного выражения.
2. Возврат значения:
RETURN <выражение>;
Эту команду разрешено использовать только в теле хранимой функции.
Выражение, служащее аргументом команды, вычисляется, и полученный результат
трактуется как значение, подлежащее возврату в код-инициатор, откуда
функция была вызвана. В отличие от обычных языков программирования, команда
return в PSM не завершает выполнение кода функции. Управление передается
следующему выражению, если таковое существует, и поэтому в процессе
работы функции возвращаемое значение может неоднократно изменяться.
3. Объявление локальной переменной. Выражение вида
DECLARE <имя> <тип>;
представляет объявление переменной с заданными именем и типом.
Переменная является локальной — это значит, что система не сохраняет информацию
о ней по завершении выполнения процедуры или функции. Выражения
объявления локальных переменных должны предшествовать любым исполняемым
инструкциям в теле процедуры или функции.
4. Оператор присваивания:
SET <переменная> = <выражение>;
Оператор присваивания в PSM весьма схож с аналогичными конструкциями
в других языках (необычным, пожалуй, является только наличие служебного слова
set). Вначале система вычисляет значение выражения в правой части оператора,
а затем полученный результат становится значением переменной, указанной в
левой части. К числу допустимых выражений правой части относятся null, а также
запрос вида "select—from—where", если таковой возвращает единственное значение.
5. Блоки кода. Список выражений, размещенный между парой служебных слов
begin и end, интерпретируется системой как единое выражение, которое
может использоваться в любом месте кода, где допускается присутствие отдель-
366
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
ного выражения. В частности, тело процедуры или функции также
воспринимается системой как единое выражение.
6. Метки. Метка состоит из имени и суффикса-двоеточия. В разделе 8.2.5 на
с. 369 мы рассмотрим одну из ситуаций, в которых применение меток
необходимо и оправданно.
8.2.3. Ветвления
Теперь перейдем к более сложным выражениям PSM и для начала рассмотрим
условное выражение if, которое отличается от аналогичных конструкций других языков
(таких как С) в двух аспектах:
1) выражение завершается предложением END if;;
2) выражения if, вложенные в предложения ELSE других выражений if,
вводятся с помощью служебного слова elseif.
Синтаксическая форма условного выражения if PSM приведена на рис. 8.9. В
качестве "условий" могут задаваться любые выражения (подобные таким, как в
предложении where SQL-запроса), возвращающие значения булева типа. Каждый "список
выражений" состоит из ряда выражений, завершаемых символом точки с запятой
(использовать блоки кода, обрамленные служебными словами begin и end,
необязательно). Предложения elseif и else также не являются обязательными, т.е.
приемлемой считается и конструкция вида if. . .then. . .end if.
IF <условие> THEN
<список выражений>
ELSEIF <условие> THEN
<список выражений>
ELSEIF
ELSE <список выражений>
END IF;
Рис. 8.9. Синтаксис условного выражения IF
Пример 8.11. Пусть необходимо создать хранимую функцию, которая принимает в
качестве параметров значение года у и название киностудии s и возвращает булево
значение, равное true в том и только в том случае, если студия s на протяжении года у
выпустила по меньшей мере один черно-белый кинофильм либо не выпускала
фильмы вовсе. Код функции приведен на рис. 8.10.
1) CREATE FUNCTION BandW(y INT, s CHAR(30)) RETURNS BOOLEAN
2) IF NOT EXISTS(
3) SELECT * FROM Movie WHERE year = у AND studioName = s)
4) THEN RETURN TRUE;
5) ELSEIF 1 <=
6) (SELECT COUNT(*) FROM Movie WHERE year = у AND
studioName = s AND NOT inColor)
7) THEN RETURN TRUE;
8) ELSE RETURN FALSE;
9) END IF;
Puc. 8.10. Пример хранимой функции с условным выражением IF
8.2. ХРАНИМЫЕ ПРОЦЕДУРЫ И ФУНКЦИИ
367
Строка 1 содержит заголовок функции со списком параметров и типом
возвращаемого значения. Квалификаторы "режима" использования параметров не задаются,
поскольку в хранимых функциях всегда подразумевается режим IN. В строках 2, 3
проверяется условие "студия s в течение года у не выпустила ни одного фильма"; если
условие справедливо, в строке 4 в качестве значения, подлежащего возврату,
устанавливается true. Напомним, что инструкция return сама по себе не завершает
выполнение функции — в данном случае управление передается строке 9, а поскольку та
является последней, работа функции прекращается естественным образом.
Если в отношении Movie все-таки есть какая-то информация о кинофильмах,
выпущенных студией s в году у, в строках 5, 6 проверяется, существует ли среди
множества этих фильмов хотя бы один, который снят на черно-белой пленке. При
положительном ответе в строке 7 задается возвращаемое значение, равное true. Если же все
фильмы, снятые на киностудии s на протяжении года у, оказались цветными, в
строке 8 устанавливается возвращаемое значение, равное false. □
8.2.4. Запросы
Существует несколько способов использования запросов вида "select—from—where"
в коде PSM; все они перечислены ниже.
1. Подзапросы разрешено применять в контексте условий (или, вообще говоря,
в любом "месте", где это позволительно с точки зрения правил SQL). Образцы
подзапросов можно видеть, например, в строках 3 и 6 рис. 8.10.
2. Запросы, возвращающие единственное значение, могут быть использованы
в правых частях операторов присваивания.
3. В PSM находят применение и команды выбора единственного кортежа
(см. раздел 8.1.5 на с. 354). Напомним, что подобная команда select Содержит
предложение into, перечисляющее имена переменных, которым должны быть
присвоены значения соответствующих компонентов выбранного кортежа. В
качестве переменных предложения into в PSM можно использовать локальные
переменные и параметры (последние — только в процедурах).
4. В теле хранимых процедур и функций допустимо использовать курсоры (в том
виде, о котором мы говорили в разделе 8.1.6 на с. 355). Форматы объявления
курсора и команд open, fetch и close аналогичны прежним, но с учетом
нескольких исключений:
a) не задается префикс exec SQL;
b) при ссылке на переменные не используется двоеточие.
CREATE PROCEDURE SomeProc(IN studioName CHAR(30))
DECLARE presNetWorth INTEGER;
SELECT netWorth
INTO presNetWorth
FROM Studio, MovieExec
WHERE presC# = cert# AND Studio.name = studioName;
Рис. 8.11. Пример процедуры с командой выбора единственного кортежа
Пример 8.12. На рис. 8.11 приведена команда выбора единственного кортежа,
рассмотренная нами ранее (см. рис. 8.3 на с. 355), которая изменена по правилам PSM
и помещена в объявление гипотетической хранимой процедуры. Поскольку
возвращаемый кортеж в данном случае содержит только один компонент, запрос можно
расположить в правой части оператора присваивания:
368 ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
SET presNetWorth = (SELECT
FROM Studio, MovieExec
WHERE presC# = cert# AND Studio.name = studioName);
О правилах использования курсоров в контексте хранимых процедур и функций мы
расскажем в следующем разделе, когда рассмотрим циклические конструкции PSM. □
8.2.5. Циклы LOOP
Базовая конструкция цикла в PSM выглядит так:
LOOP
<список выражений>
END LOOP;
Часто заголовок цикла loop снабжают меткой, что дает возможность прервать
выполнение цикла командой
LEAVE <метка ЬООР>;
Если цикл используется для последовательного извлечения (fetch) кортежей
средствами курсора, прерывать цикл обычно необходимо в ситуации, когда кортежи,
подлежащие считыванию, отсутствуют. В подобных случаях полезное применение находит
конструкция условного наименования (condition name) для значения переменной
sqlstate (напомним, что код условия "кортеж не найден" равен ' 02000 ')•
DECLARE Not_Found CONDITION FOR SQLSTATE ' 02000 ' ;
Вообще говоря, можно определить условное наименование для любого значения
переменной sqlstate, если воспользоваться командой следующего формата:
DECLARE <наименование> CONDITION FOR SQLSTATE <значение>;
Теперь вы готовы к восприятию примера, иллюстрирующего особенности
использования циклов и курсоров в хранимых процедурах и функциях.
Пример 8.13. На рис. 8.12 приведен текст хранимой процедуры, которая принимает в
качестве "входного" параметра строку s названия студии и возвращает в "выходные"
параметры mean и variance соответственно величины среднего арифметического и дисперсии
значений продолжительности воспроизведения кинофильмов, выпущенных студией s.
Строки 1—4 содержат заголовок объявления процедуры с указанием ее параметров.
Строки 5—8 представляют объявления локальных переменных. В строке 5
определено условное наименование Not_Found, отвечающее ситуации, когда команда FETCH
не в состоянии извлечь очередной кортеж. В строке 6 задано объявление курсора
MovieCursor, который возвращает множество значений продолжительности
воспроизведения фильмов, снятых на студии s. Строки 7, 8 содержат объявления двух
вспомогательных локальных целочисленных переменных: переменная newLength
предназначена для хранения содержимого компонента length текущего кортежа,
возвращенного командой fetch, а переменная movieCount представляет собой счетчик
кортежей, значение которого по завершении цикла обработки будет использовано для
вычисления искомых величин среднего арифметического и дисперсии.
Остальные строки образуют собственно тело процедуры. Параметры mean и variance
используются и в роли "временных" переменных, и для "возврата" итоговых значений
среднего арифметического и дисперсии. В строках 9-11 переменные mean, variance
и movieCount инициализируются нулевыми значениями. Строка 12 содержит
инструкцию открытия курсора, а строки 13-19 — основной цикл, снабженный меткой movieLoop.
В строке 14 предпринимается попытка извлечения (fetch) очередного кортежа,
а в строке 15 проверяется, успешен ли результат операции. В строках 16—18
аккумулируются полученные данные: в movieCount накапливается количество обработанных
кортежей, в mean — сумма значений компонентов length, а в variance — сумма
квадратов этих значений.
8.2. ХРАНИМЫЕ ПРОЦЕДУРЫ И ФУНКЦИИ
369
После того как все кортежи отношения, возвращенного запросом курсора,
просмотрены, выполнение цикла прерывается командой leave в строке 15 и управление
передается строке 20. Здесь "выходному" параметру mean присваивается итоговое
значение среднего арифметического: текущее содержимое mean делится на количество
кортежей, сохраненное в movieCount. В строке 21 вычисляется величина дисперсии:
накопленная в variance сумма квадратов значений делится на их количество, а затем
из полученного частного вычитается квадрат среднего арифметического. За
сведениями о том, почему параметры среднего арифметического и дисперсии вычисляются
именно так, а не иначе, обращайтесь к упражнению 8.2.4 на с. 376. В строке 22
курсор закрывается, и выполнение процедуры завершается. □
1) CREATE PROCEDURE MeanVar(
2) IN s CHAR(30),
3 ) OUT mean REAL,
4) OUT variance REAL
)
5) DECLARE Not_Found CONDITION FOR SQLSTATE '02000';
6) DECLARE MovieCursor CURSOR FOR
SELECT length FROM Movie WHERE studioName = s;
7) DECLARE newLength INTEGER;
8) DECLARE movieCount INTEGER;
BEGIN
9) SET mean = 0.0;
10) SET variance = 0.0;
11) SET movieCount = 0;
12) OPEN MovieCursor;
13) movieLoop: LOOP
14) FETCH MovieCursor INTO newLength;
15) IF Not_Found THEN LEAVE movieLoop END IF;
16) SET movieCount = movieCount + 1;
17) SET mean = mean + newLength;
18) SET variance = variance + newLength * newLength;
19) END LOOP;
20) SET mean = mean / movieCount;
21) SET variance = variance / movieCount - mean * mean;
22) CLOSE MovieCursor;
END;
Рис. 8.12. Вычисление среднего арифметического и дисперсии значений с
помощью цикла LOOP
8.2.6. Циклы FOR
Стандарт PSM предлагает возможность использования циклов и других видов.
Цикл FOR, например, находит единственное применение — для "перемещения"
в пределах курсора. Синтаксическая форма цикла FOR такова:
FOR <имя цикла> AS <имя курсора> CURSOR FOR
<запрос>
DO
<список выражений>
END FOR;
370
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Другие конструкции циклов PSM
В стандарте PSM предусмотрены формы циклов while и repeat, по
' минающие циклические конструкции языка С "while" и "do-
но. Синтаксис цикла while выглядит так:
WHILE <условие> DO
<список выражений>
END WHILE;
а цикла repeat — так:
REPEAT
<список выражений>
UNTIL <условие>
END REPEAT;
Между прочим, если необходимо снабдить меткой любой из
-while
циклов
смыслу
напо-
соответствен-
— LOOP
, FOR,
while или repeat, — метку можно размещать и непосредственно после
соответствующей команды END (скажем, end loop). Подобный стиль
позволяет быстро определять, где завершается тот или иной
использования
цикл;
ПОМИМО
меток
того,
интерпретатор PSM получает возможность выявлять некоторые синтаксические
ошибки, обусловленные отсутствием предложений END.
Указанная конструкция не только содержит объявление курсора, но и делает вместо
нас с вами много "черновой" работы, связанной с открытием (open) и закрытием
(close) курсора, а также с операциями извлечения (fetch) кортежей и проверкой
условий их завершения. Однако поскольку управление операциями извлечения
кортежей в данном случае выходит за рамки нашей компетенции, мы не в состоянии явно
определить переменные, в которые следует заносить содержимое компонентов
считываемых кортежей. Поэтому интерпретатор PSM сохраняет для локальных переменных,
используемых им для этой цели, те же имена и типы, с которыми объявлены
соответствующие атрибуты отношения, служащего результатом запроса.
Пример 8.14. Заменим цикл loop в примере процедуры, показанной на рис. 8.12,
конструкцией цикла for. Результат преобразования показан на рис. 8.13. Многое
осталось неизменным: например, сохранились заголовок процедуры в строках 1—4 и
объявление локальной переменной movieCount (см. строку 5).
Теперь, однако, в секции объявлений нам не требуется определять курсор и условное
наименование Not_Found. Строки 6—8 содержат прежние инструкции инициализации
локальных переменных. Строка 9 представляет заголовок цикла FOR с объявлением того же
курсора MovieCursor. Строки 11—13 образуют тело цикла. Обратите внимание, что в
строках 12, 13 для ссылки на значение длительности воспроизведения кинофильма, считанное
из извлеченного курсора, мы используем имя атрибута length, а не newLength, как
прежде, — локальная переменная newLength в этой версии процедуры не используется.
В строках 15, 16, как и в прежней версии процедуры, вычисляются итоговые значения
среднего арифметического и дисперсии. □
8.2.7. Исключения
Система уведомляет об исключительных ситуациях, или исключениях (exceptions),
встреченных ею в процессе выполнения SQL-команд, присваивая переменной
sqlstate соответствующие символьные представления последовательностей из пяти
десятичных цифр (код '00000' означает, что ошибок нет). Один из примеров кодов
ошибок вы уже видели: '02 000' — "кортеж не найден". В качестве другого примера
можно привести код • 21000 ', свидетельствующий о том, что команда выбора
единственного кортежа возвратила более одного кортежа.
8.2. ХРАНИМЫЕ ПРОЦЕДУРЫ И ФУНКЦИИ
371
1) CREATE PROCEDURE MeanVar(
2) IN s CHAR(30),
3) OUT mean REAL,
4) OUT variance REAL
)
5) DECLARE movieCount INTEGER;
BEGIN
6) SET mean = 0.0;
7) SET variance = 0.0;
8) SET movieCount = 0;
9) FOR movieLoop AS MovieCursor CURSOR FOR
SELECT length FROM Movie WHERE studioName = s;
10) DO
11) SET movieCount = movieCount + 1;
12) SET mean = mean + length;
13) SET variance = variance + length * length;
14) END FOR;
15) SET mean = mean / movieCount;
16) SET variance = variance / movieCount - mean * mean;
END;
Рис. 8.13. Вычисление среднего арифметического и дисперсии значений с
помощью цикла FOR
Стандарт PSM предусматривает возможность объявления специального фрагмента
кода, называемого обработчиком исключений (exception handler), который вызывается
всякий раз, когда любое значение из списка заданных кодов ошибок присваивается
системой переменной sqlstate в процессе выполнения команд текущего блока кода.
Каждый обработчик исключений ассоциируется с определенным блоком кода вида
begin. . .end (а именно с тем, которому принадлежит сам обработчик) и
ограничивает свое "влияние" только содержимым этого блока.
Компонентами конструкции обработчика исключений служат:
1) список условий исключений, провоцирующих вызов обработчика;
2) фрагмент кода, подлежащего выполнению, если сгенерировано одно из
указанных исключений;
3) одно из служебных слов, указывающих на то, куда следует передать
управление по завершении выполнения кода обработчика.
Выражение определения обработчика исключения можно описать следующим образом:
DECLARE <куда идти> HANDLER FOR <кто виноват>
<что делать>
Альтернативные варианты ответа на вопрос "куда идти" таковы:
a) continue — после выполнения выражения "что делать" перейти к
очередному выражению текущего блока кода begin. . .end;
b) exit — по завершении выражения "что делать" покинуть текущий блок
кода и передать управление выражению, следующему за блоком;
c) UNDO — вариант, аналогичный exit, за "исключением" того, что все
изменения, которые затронули содержимое базы данных и локальных перемен-
372
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Зачем циклам for имена?
Обратите внимание на строку 9 рис. 8.13: имена movieLoop и MovieCursor
объявлены, но никак не используются в тексте процедуры. Несмотря на это, создавая
цикл for, мы вынуждены изобретать подходящие имена и для цикла как такового,
и для курсора, лежащего в основе цикла. Причина состоит в том, что
интерпретатор PSM обязан преобразовать затейливую конструкцию for в обычный цикл, во
многом напоминающий цикл loop, который показан на рис. 8.12, а в таком коде
оба имени находят серьезное применение.
ных в период выполнения команд текущего блока кода до момента
возникновения исключительной ситуации, подлежат отмене, будто эти
команды не выполнялись вовсе.
Секция "кто виноват" представляет собой список условий исключений, разделенных
запятыми. В качестве условий чаще используются условные наименования, подобные
Not_Found, объявленному в строке 5 рис. 8.12.
Пример 8.15. Рассмотрим функцию, которая должна принимать в качестве параметра
строку наименования кинофильма и возвращать дату создания последнего. Если
фильма с заданным названием нет либо таких фильмов несколько, функция обязана
возвратить null. Код функции показан на рис. 8.14.
Строки 2, 3 содержат объявления условных наименований кодов исключений;
вообще говоря, их можно было и не объявлять — тогда в строке пришлось бы
перечислить коды непосредственно. Строки 4—6 образуют блок выражений, первым из
которых объявлен обработчик, реагирующий на две исключительные ситуации — "кортеж
не найден" ('02000') и "слишком много кортежей" ('21000'). Секция "действия"
обработчика (строка 5) содержит единственный оператор возврата значения null.
1) CREATE FUNCTION GetYear(t VARCHAR(255)) RETURNS INTEGER
2) DECLARE Not_Found CONDITION FOR SQLSTATE '02000';
3) DECLARE Too_Many CONDITION FOR SQLSTATE '21000';
BEGIN
4) DECLARE EXIT HANDLER FOR Not_Found, Too_Many
5) RETURN NULL;
6) RETURN (SELECT year FROM Movie WHERE title = t);
END;
Рис. 8.14. Пример использования обработчика исключений
Строка 6 является "ядром" функции GetYear, выполняющим основную работу.
В ней содержится команда возврата единственного значения, получаемого в
результате выполнения запроса вида "select—from—where"; тип (в данном случае —- integer)
возвращаемого значения обязан совпадать с тем, который указан в предложении
RETURNS заголовка объявления функции. Если в отношении Movie существует
единственный кортеж, компонент title которого содержит значение t, переданное
функции в виде аргумента, запрос, как и ожидается, возвратит значение компонента year
этого кортежа. Если же при выполнении запроса система генерирует исключение,
связанное либо с отсутствием кортежа для фильма с указанным названием, либо
с тем, что таких кортежей несколько, вызывается обработчик исключений, который
в качестве значения, подлежащего возврату, устанавливает null. Помимо того,
поскольку в объявлении обработчика задан режим exit, управление передается за
пределы текущего блока кода, но поскольку после инструкции end никаких команд
больше нет, функция завершает работу, возвращая значение null. □
8.2. ХРАНИМЫЕ ПРОЦЕДУРЫ И ФУНКЦИИ
373
8.2.8. Использование хранимых процедур и функций
Как говорилось в разделе 8.2.2 на с. 366, к хранимой процедуре или функции
можно обратиться из программы, написанной на традиционном языке
программирования, из кода другой процедуры или функции PSM либо средствами базового
интерфейса SQL. Способы использования хранимых процедур и функций мало чем
отличаются от технологий программирования на "обычных" языках — процедуры PSM
вызываются с помощью служебного слова call, а функции чаще применяются в
составе более крупных выражений (например, в качестве правосторонних операндов
операторов присваивания). Ниже мы покажем, как хранимая функция может быть
вызвана из среды базового интерфейса SQL.
Пример 8.16. Предположим, что в составе схемы "кинематографической" базы данных
имеется модуль, содержащий определение функции GetYear, приведенное на рис. 8.14.
Предположим также, что средствами базового интерфейса SQL необходимо
зафиксировать в базе данных тот факт, что актер Дензел Вашингтон — член творческой группы,
принимавшей участие в съемках кинофильма "Remember the Titans". Значение года
выпуска кинофильма, однако, нам не известно. Если такой фильм действительно
существует и информация о нем присутствует в отношении Movie, нам нет
необходимости выполнять предварительный запрос, чтобы узнать недостающие сведения.
Проще сразу выполнить следующую команду вставки кортежа в отношение stars in:
INSERT INTO Starsln(movieTitle, movieYear, starName)
VALUES('Remember the Titans', GetYear('Remember the Titans'),
'Denzel Washington');
Поскольку функция GetYear способна возвратить NULL, если кортежа с информацией
о фильме "Remember the Titans" нет либо если таких кортежей несколько, возможна
ситуация, когда компоненту mo vie Year кортежа, вставляемого в starsln, будет
присвоено значение null. □
8.2.9. Упражнения к разделу 8.2
Упражнение 8.2.1. Используя схемы отношений
Movie(title, year, length, inColor, studioName, producerC#)
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
MovieExec(name, address, cert#, netWorth)
Studio(name, address, presC#)
из "кинематографической" базы данных, создайте хранимые процедуры или
функции для выполнения следующих заданий.
* а) Для заданного названия (name) киностудии найти и возвратить значение
годового дохода (netWorth) ее президента.
* Ь) Для заданных значений имени (name) и адреса (address) человека возвратить
значение 1, если тот является актером, но не руководящим лицом, 2 — если
человек, напротив, является руководителем, но не относится к числу актеров,
3 — если человек совмещает обе профессии, и 4 — если человека с
указанными именем и адресом нет ни в когорте актеров, ни в обойме руководителей.
*! с) Для заданной строки названия (studioName) студии найти и присвоить
выходным параметрам процедуры строки названий (title) двух самых
продолжительных (length) кинофильмов, снятых на этой студии. Присвоить
одному или обоим параметрам значения null, если таких фильмов нет
(например, если на киностудии был снят всего один фильм,
зафиксированный в базе данных, либо студия не выпустила ни одного фильма).
374
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
! d) Для заданного имени (starName) актера найти и возвратить значение года
выпуска (year) самого раннего из кинофильмов продолжительностью
(length) свыше 120 минут с участием этого актера. Если подходящих
фильмов нет, возвратить значение 0.
е) Для заданной строки адреса (address) актера найти и возвратить его имя
(name). Если по указанному адресу никто не проживает либо адрес
соответствует нескольким актерам, возвратить значение null.
0 Для заданного имени актера удалить соответствующие кортежи из
отношений MovieStar и starsln, а также всю информацию о кинофильмах с
участием этого актера из отношения Movie.
Упражнение 8.2.2. Используя схемы отношений
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
Laptop(model, speed, ram, hd, screen, price)
Printer(model, color, type, price)
из базы данных, рассмотренной в упражнении 5.2.1 на с. 218, создайте хранимые
процедуры или функции для выполнения следующих заданий.
* а) Передать в качестве аргумента значение цены и возвратить номер модели
(model) того персонального компьютера (PC), цена (price) которого
наиболее близка к заданной.
Ь) Передать в качестве аргументов значения кода производителя (maker) и номера
модели (model) и возвратить значение цены (price) продукта указанной модели
из отношения (PC, Laptop или Printer), соответствующего типу продукта.51
! с) Передать в качестве аргументов значения номера модели (model),
быстродействия процессора (speed), объема оперативной памяти (ram), емкости
диска (hd), типа привода съемных дисков (rd) и цены (price)
персонального компьютера и вставить соответствующий кортеж в отношение PC. Если
кортеж с указанным номером модели существует (подразумевается, что при
попытке вставки кортежа, нарушающего ограничение ключа, генерируется
исключение с кодом '23000', присваиваемым переменной sqlstate),
выполнять ту же операцию, последовательно увеличивая значение номера
модели на единицу до тех пор, пока ограничение ключа не будет удовлетворено.
! d) Для заданного значения цены (price) найти и возвратить количество
моделей персональных компьютеров (PC), переносных компьютеров (Laptop)
и принтеров (Printer), продаваемых по более высокой цене.
Упражнение 8.2.3. Используя схемы отношений
Classes(class, type, country, numGuns, bore, displacement)
Ships(name, class, launched)
Battles(name, date)
Outcomes(ship, battle, result)
из базы данных, рассмотренной в упражнении 5.2.4 на с. 222, создайте хранимые
процедуры или функции для выполнения следующих заданий.
а) Значение "огневой мощи" судна примерно пропорционально количеству
главных орудий (numGuns), умноженному на величину их калибра (bore),
возведенную в куб. Для заданного класса (class) судов возвратить
значение огневой мощи.
51 В оригинале задание содержит ошибочное условие, которое здесь изменено. — Прим. перев.
8.2. ХРАНИМЫЕ ПРОЦЕДУРЫ И ФУНКЦИИ
375
! b) Для заданного названия (name) сражения найти и возвратить названия двух
стран (country), корабли которых принимали участие в этом сражении.
Если в сражении участвовало меньше или больше стран, обеспечить возврат
двух значений null.
с) Передать в качестве аргументов значения названия нового класса (class),
типа (type), наименования страны (country), количества главных орудий
(numGuns), калибра (bore) и водоизмещения (displacement). Ввести
указанную информацию в отношение Classes и добавить кортеж с названием
флагманского корабля класса в отношение ships. (Обеспечить обработку
исключительных ситуаций с кодом '23000', связанных с нарушением
ограничений ключа при вставке кортежей. — Прим. перев.)
! d) Для заданного названия (ship) судна определить, существует ли в базе
данных ошибочная информация о том, что судно принимало участие в
сражениях (Battles) прежде (date), чем оно было спущено на воду (launched).
При положительном результате поиска заменить соответствующие даты
сражений и завершения строительства судна значениями 0.
Упражнение 8.2.4. В тексте процедуры MeanVar (см. рис. 8.12 на с. 370) для
подсчета дисперсии последовательности значений хь х2, ..., хп мы использовали
специальную формулу. Напомним, что дисперсия ряда чисел представляет собой
усредненную сумму квадратов отклонений этих чисел от среднего значения. Другими
словами, дисперсия — это (2^/=1С*,- -*)2) /п , где X есть (У™ xt) /п. Докажите,
что формула ^ '~ '
Iw/»- ь
V^
/л
использованная при вычислении дисперсии в примере 8.12, дает тот же результат.
8.3. Среда SQL
В этом разделе мы попробуем рассмотреть СУБД и поддерживаемые ими базы
данных и профаммные приложения с наиболее общих позиций. Мы покажем, каким
образом базы данных определяются и организуются в виде кластеров (clusters),
каталогов (catalogs) и схем (schemata), а также как приложения получают доступ к
необходимым данным. Многие детали существенным образом зависят от особенностей
конкретных реализаций, поэтому мы сосредоточим внимание на тех общих идеях и
подходах, которые нашли свое отражение в стандарте SQL. В разделах 8.4 (см. с. 381)
и 8.5 (см. с. 389) будет показано, как те же концепции выглядят в контексте
интерфейсов уровня вызовов (call-level interfaces).
8.3.1. Среды
Среда SQL (SQL environment) — это рабочее окружение, в котором данные
способны существовать, а SQL-операции их обработки — выполняться. Среду SQL можно
воспринимать как установленный и действующий экземпляр СУБД. Пусть, например,
компания ABC приобрела лицензию, позволяющую установить СУБД Megatron 2002
на нескольких собственных компьютерах. О системе, работающей на этих машинах,
можно говорить как о среде SQL.
Все элементы базы данных, о которых мы уже говорили — базовые отношения,
виртуальные таблицы, триггеры, хранимые процедуры и т.д., — определяются в среде SQL
и формируют иерархию структур, каждой из которых отводится особая роль.
Подобные структуры изображены на рис. 8.15 в том виде, как они описаны в стандарте SQL.
376
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Если говорить кратко, среда SQL состоит из структур, перечисленных ниже.
1. Схемы52 — коллекции хранимых отношений, виртуальных таблиц, офаничений
"общего вида", триггеров, модулей PSM; схемы могут содержать и элементы
данных других видов, задача сколько-нибудь полного освещения которых
выходит за рамки нашей книги (впрочем, обратитесь к врезке "Другие элементы
схемы" на с. 379). Схема — это основная структурная единица, наиболее
близкая к тому, что обычно воспринимается как "база данных", хотя последнее
понятие, как будет показано в п. 3 ниже, является более широким.
2. Каталоги — коллекции схем. Каждый каталог содержит одну или несколько
"обычных" схем (имена которых внутри каталога должны быть уникальными)
и одну специальную схему, называемую information_schema, которая
описывает все другие схемы каталога.
3. Кластеры — коллекции каталогов. Каждому пользователю ставится в
соответствие определенный кластер — множество доступных каталогов (за сведениями
о том, как управлять доступом к каталогам и другим элементам среды,
обращайтесь к разделу 8.7 на с. 404). Хотя стандарт SQL не содержит точного
определения того, что именно представляет собой кластер, последний можно
воспринимать как наиболее широкий контекст, в котором допустимо выполнить
команду SQL, т.е. с точки зрения конкретного пользователя понятия "кластер"
и "база данных" выглядят как идентичные.
Рис. 8.15. Иерархия структурных элементов среды SQL
8.3.2. Схемы
Простейшая синтаксическая форма объявления схемы (schema) состоит из
следующих элементов:
1) пары служебных слов create schema;
52 Здесь мы говорим о схемах баз данных, а не о схемах отношений.
8.3. СРЕДА SQL 377
2) имени схемы;
3) списка объявлений элементов схемы, таких как базовые отношения,
виртуальные таблицы и ограничения "общего вида".
Выражение объявления схемы можно описать так:
CREATE SCHEMA <имя схемы> <список объявлений элементов>
При объявлении элементов схемы следует придерживаться правил, рассмотренных
выше (за подробностями обращайтесь, например, к разделам 6.6 на с. 296, 6.7.1 на
с. 305, 7.4.3 на с.339 и 8.2.1 на с. 364).
Пример 8.17. На рис. 8.16 представлен "эскиз" объявления схемы
"кинематографической" базы данных, содержащей пять знакомых вам базовых отношений и некоторые
другие созданные ранее элементы, такие как виртуальные таблицы.
CREATE SCHEMA MovieSchema
CREATE TABLE MovieStar <далее как на рис. 7.5 (см. с. 331)>
«Объявления остальных четырех базовых таблиц>
CREATE VIEW MovieProd <далее как в примере 6.48 на с. 307>
«Объявления других виртуальных таблиц>
CREATE ASSERTION RichPres <далее как в примере 7.13 на с. 337>
«Объявления других ограничений "общего вида">
CREATE TRIGGER NetWorthTrigger <далее как на рис. 7.8 (см. с. 340)>
«Объявления других триггеров>
«Объявления других элементов>
Рис. 8.16. Пример объявления схемы
□
Вовсе не обязательно объявлять схему целиком и сразу — со временем наверняка
потребуется что-то добавить (create), изменить (alter) или удалить (drop). Существует,
однако, одна проблема — системе необходимо "знать", какая именно схема подлежит
модификации. Если мы собираемся изменить или удалить таблицу либо другой элемент
схемы, необходимо, чтобы указанное имя определяло элемент однозначно, поскольку две
схемы могут содержать одноименные, но совершенно различные по смыслу элементы.
Существует понятие текущей (current) схемы. Для задания текущей схемы
используется команда
SET SCHEMA <имя схемы>;
Например, введя инструкцию SET SCHEMA MovieSchema, мы "перейдем" к схеме,
текст команды создания которой приведен на рис. 8.16. Все дальнейшие команды
модификации будут адресованы текущей схеме MovieSchema.
8.3.3. Каталоги
Подобно тому как элементы схемы (скажем, таблицы) создаются в контексте
схемы, схемы объявляются и модифицируются в контексте каталога (catalog). Как
кажется, справедливо ожидать, что процесс создания и пополнения каталогов должен
быть аналогичен процедуре объявление и модификации схем. К сожалению, стандарт
SQL не предусматривает возможности использования схожей команды
CREATE CATALOG <имя каталога> <список объявлений схем>
Однако стандарт рекомендует для применения команду
SET CATALOG <имя каталога>;
задания "текущего" каталога, после выполнения которой новые схемы будут
создаваться в контексте указанного каталога, а инструкции модификации элементов схем
адресоваться определенным схемам каталога, а не их "однофамильцам", относящимся
к другому каталогу.
378
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Другие элементы схемы
В тех или иных ситуациях в схемы допустимо включать элементы других
категорий, на которых, однако, мы не будем останавливаться подробно.
• Домены (domains) — наборы значений или описания типов данных. В настоящее
время домены находят ограниченное применение, поскольку современные
объектно-реляционные СУБД предлагают более совершенные механизмы создания
типов (за подробностями обращайтесь к разделу 9.4 на с. 440).
• Наборы символов (character sets) — упорядоченные множества символов и методы
их кодирования. Примером наиболее известного набора символов может
служить ASCII, но конкретные реализации SQL способны поддерживать
множество других наборов — скажем, для различных иностранных языков.
• Методы сопоставления строк (collations). В разделе 6.1.3 на с. 254 мы говорили
о том, что строки символов сравниваются в лексикографическом порядке,
подразумевая, что любые два символа можно сопоставить между собой с помощью
оператора < ("меньше"). Конкретный метод сопоставления определяет, какие символы
следует считать "меньшими", нежели другие: например, в одной ситуации удобно
придерживаться порядка следования символов, предусмотренного стандартом
ASCII, в другой — трактовать буквы нижнего и верхнего регистра как идентичные
и исключать при сравнении любые символы, не относящиеся к буквам, и т.п.
• Привилегии доступа (grant statements) — описания прав доступа конкретных
пользователей или групп пользователей к тем или иным элементам схемы
(подробнее — в разделе 8.7 на с. 404).
8.3.4. Клиенты и серверы в среде SQL
Среда SQL — это не просто коллекция каталогов и схем. Она содержит и такие
элементы, назначение которых связано с поддержкой операций над базой или базами
данных, представляемыми каталогами и схемами. В контексте среды SQL существуют
процессы двух специальных категорий — SQL-клиенты (SQL clients) и SQL-серверы
(SQL servers). Процесс сервера обеспечивает выполнение операций над элементами
базы данных, а процесс клиента позволяет пользователю подсоединиться к серверу
и активизировать требуемые прикладные операции. Подразумевается, что процесс
сервера функционирует на мощном компьютере, на котором хранится база данных,
а процесс клиента выполняется на другом компьютере — как правило, на удаленной
рабочей станции. Впрочем, вполне возможна ситуация, когда и сервер, и клиент
сосуществуют на одном и том же компьютере.
8.3.5. Соединения
При необходимости запуска программы, предполагающей выполнение SQL-
команд, на компьютере, где функционирует процесс клиента, обычно требуется
открыть соединение (connection) между клиентом и сервером посредством инструкции
CONNECT ТО <имя сервера> AS <имя соединения>
AUTHORIZATION <имя и пароль пользователя>
Имя сервера — это параметр, обычно определяемый на этапе установки СУБД. Вместо
имени сервера допустимо вводить служебное слово default — в такой ситуации клиент
будет подключен к тому серверу, который в конкретной среде SQL трактуется как сервер,
предлагаемый "по умолчанию". Предложение authorization содержит строки имени
и пароля пользователя и описывает способ авторизации пользователя процессом сервера
(в некоторых случаях предложение может содержать дополнительную информацию).
8.3. СРЕДА SQL
379
Полные имена элементов схемы
Говоря формально, имя элемента схемы, такого как таблица, в общем случае
состоит из имен каталога и схемы, к которым относится элемент, и собственного
имени элемента, разделенных символами точки. Так, например, для ссылки на
таблицу Movie, принадлежащую схеме Movie Schema, которая содержится в
каталоге MovieCatalog, допустимо использовать полное имя
MovieCatalog.MovieSchema.Movie
Если каталог является текущим или предлагаемым по умолчанию, имя каталога
можно опустить. Если, в свою очередь, и схема является текущей или
подразумеваемой по умолчанию, ее имя также разрешается не задавать — в этом случае полное
имя сводится к собственному имени элемента (до сих пор мы адресовали элементы
схем именно так). Если же необходимо подчеркнуть, что тот или иной элемент
относится к определенным схеме и каталогу, надлежит указывать его полное имя.
Имя соединения обычно используется для ссылки на объект соединения после его
открытия, если система позволяет пользователю создавать одновременно несколько
соединений, только одно из которых может быть активным (active) в каждый момент
времени. Для перехода от одного соединения к другому применяется команда вида
SET CONNECTION <имя соединения>;
и соединение, пребывавшее в активном состоянии до выполнения этой команды,
становится пассивным (dormant) — до тех пор, пока оно не будет принудительно
активизировано соответствующей командой set connection.
Имя соединения может быть использовано и для закрытия соединения:
DISCONNECT <имя соединения>;
Указанное соединение закрывается и далее не может быть активизировано вновь.
Если, как мы полагаем, на объект соединения в дальнейшем ссылаться не
придется, предложение AS команды connect to открытия соединения можно опустить.
Более того, в некоторых ситуациях, когда система способна создавать соединения,
предусматриваемые по умолчанию, командой connect to можно не пользоваться вовсе.
Рис. 8.17. Взаимодействие между процессами клиента
и сервера в среде SQL
380
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
8.3.6. Сеансы
Операции SQL, выполняемые посредством открытого соединения, в совокупности
образуют сеанс (session). Сеанс совпадает во времени с периодом активности
соединения, с помощью которого сеанс формируется. Если, например, соединение переходит
в пассивный режим, сеанс также становится пассивным, а активизация соединения
посредством команды set connection приводит к возобновлению соответствующего
сеанса. Поэтому, как показано на рис. 8.17, соединение и сеанс — это два аспекта
связи, установленной между клиентом и сервером.
Каждый сеанс ассоциирован с текущим каталогом и текущей схемой .внутри
каталога. Как было показано в разделах 8.3.2 (см. с. 377) и 8.3.3 (см. с. 378), для задания
текущих схемы и каталога применяются команды set schema и set catalog
соответственно. Каждый сеанс связан также с определенным пользователем,
авторизованным системой (подробнее об этом — в разделе 8.7 на с. 404).
8.3.7. Модули
В SQL термином модуль (module) принято обозначать прикладную программу.
Стандарт SQL предусматривает возможность определения модулей трех различных
категорий, перечисленных ниже, но оговаривает, что в конкретной реализации СУБД
могут использоваться модули не всех категорий.
1. Базовый интерфейс SQL (generic SQL interface). Пользователь получает
возможность ввода команд SQL с целью их непосредственного выполнения сервером.
В этом режиме каждая команда является отдельным модулем. Демонстрируя
примеры "чистого" кода SQL, мы подразумевали использование именно этого
режима, хотя на практике он используется относительно редко.
2. "Внедренные" команды SQL (embedded SQL). Режиму использования
"внедренных" команд SQL посвящен раздел 8.1 на с. 350. Предполагается, что
команды SQL "встраиваются" в текст программы, написанной на одном из
базовых языков, с помощью специальных директив exec SQL. Препроцессор
трансформирует "внедренные" команды SQL в вызовы соответствующих библиотечных
функций, удовлетворяющих синтаксическим требованиям базового языка.
Откомпилированная версия программы на базовом языке является отдельным модулем.
3. Модули общего вида (generalized modules). Наиболее широкое применение
находит технология программирования, предполагающая использование и
прикладных программ на базовом языке с "внедренными" командами SQL, и хранимых
процедур и функций. Фрагменты кода взаимодействуют друг с другом
посредством передачи аргументов и с помощью общих переменных. Примером модулей
такой категории являются модули PSM, рассмотренные в разделе 8.2 на с. 364.
Процесс выполнения модуля SQL принято называть SQL-агентом (SQL agent). На
рис. 8.17 модуль и SQL-агент показаны как единое целое. Однако следует понимать,
что модуль отличается от SQL-агента точно так же, как программа от процесса:
программа — это код, а процесс — это набор динамических характеристик выполняемого
кода в тот или иной момент времени.
8.4. Интерфейс уровня вызовов
В этом разделе мы вновь обратимся к теме, связанной с особенностями
взаимодействия SQL-команд и программ, написанных на одном из базовых, или
"включающих" (host), языков. О "внедренных" командах SQL (embedded SQL) мы
говорили в разделе 8.1 на с. 350, а о хранимых процедурах и функциях (stored procedures and
functions), удовлетворяющих стандарту PSM, — в разделе 8.2 на с. 364. Ниже мы
сосредоточим внимание на третьей, альтернативной технологии SQL-програм-
8.4. ИНТЕРФЕЙС УРОВНЯ ВЫЗОВОВ
381
мирования, предполагающей использование интерфейса уровня вызовов (call-level
interface — CLI), который позволяет создавать код на базовом языке и использовать
библиотеки функций, обеспечивающих возможности подключения приложения к базе
данных, выполнения SQL-команд и получения результатов.
Различия между интерфейсом уровня вызовов и технологией "внедренных"
команд SQL в определенном смысле незначительны. Если присмотреться к тому, каким
образом препроцессор преобразует "внедренные" выражения SQL в вызовы
соответствующих библиотечных функций, нетрудно убедиться, что результаты его работы во
многом напоминают код с использованием стандартной библиотеки SQL/CLI. Однако
функции SQL/CLI передают команды SQL на сервер базы данных непосредственно,
за счет чего достигается более высокий уровень системной независимости. Иными
словами, одно и то же приложение на базовом языке в принципе способно к
взаимодействию с различными СУБД, если таковые следуют рекомендациям стандарта SQL
(хотя, к сожалению, это требование выполняется далеко не всегда), без
необходимости использования специальным образом спроектированного препроцессора.
Мы собираемся рассмотреть два примера интерфейсов уровня вызовов. Текущий
раздел посвящен изложению сведений о стандарте SQL/CLI, о котором можно
говорить как о модифицированной версии стандарта ODBC — Open Database Connectivity.
В разделе 8.5 на с. 389 мы обсудим особенности JDBC (Java Database Connectivity) —
аналогичного стандарта, позволяющего подключать к базам данных объектно-
ориентированные приложения, написанные на языке Java. В обоих случаях,
разумеется, мы не в состоянии дать исчерпывающее описание стандартов — предпочтение
будет отдано изложению основных идей, лежащих в их основе.
8.4.1. Введение в SQL/CLI
Программа, написанная на языке С и предполагающая использование интерфейса
SQL/CLI (в дальнейшем — просто CLI), должна содержать директиву включения
заголовочного файла (header file) sqlcli.h, в котором приведены объявления всех
функций, типов, структур и именованных констант библиотеки CLI. В этом случае
программа сможет создавать и использовать записи (records) (в терминологии С —
структуры) четырех различных категорий, перечисленных ниже.
1. Среды (environments). Запись этого типа создается прикладной (клиентской)
программой с целью подготовки к открытию одного или нескольких соединений
с сервером базы данных.
2. Соединения (connections). Каждая из записей подобного типа создается для
подключения приложения к базе данных. Соединение существует в контексте
определенной среды.
3. Команды (statements). Прикладная программа вправе создать одну или
несколько записей команды, каждая из которых предназначена для хранения
информации об одной SQL-команде (и о соответствующем курсоре, если команда
представляет собой запрос). На протяжении периода выполнения программы одна
и та же запись команды может представлять различные SQL-команды. Каждая
запись команды существует в контексте определенного соединения.
4. Описания (descriptions). Подобные записи содержат информацию о кортежах или
параметрах. Прикладная программа или сервер базы данных заполняют
компоненты записей, сохраняя в них имена и типы атрибутов и/или их значения. При
выполнении каждой команды неявно создаются одна или несколько структур
описаний; при необходимости программа способна создавать подобные записи
принудительно. В ходе изложения явно ссылаться на структуры описаний мы не будем.
Запись любого из названных типов представляется в прикладной программе с
помощью соответствующего указателя (handle). Заголовочный файл sqlcli.h содержит
382
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
объявления типов указателей на записи среды (sqlhenv), соединения (sqlhdbc),
команды (sqlhstmt) и описания (sqlhdesc), каждый из которых для простоты можно
воспринимать как некоторый целочисленный адрес. В дальнейших примерах мы
будем использовать и другие типы, объявленные в sqlcli.h; среди них существуют
и такие, как sql_char и sql_integer, смысл которых достаточно очевиден без
дополнительных разъяснений.
Мы не будем вдаваться в детали, связанные с созданием и использованием
структур описаний, но о трех остальных категориях записей рассказать обязаны. Для
создания записей среды, соединения и команды с инициализацией соответствующих
указателей применяется функция
SQLAllocHandle(/z7>/?*>, hln, hOut).
Назначение каждого из параметров функции рассмотрено ниже.
1. hType — тип указателя на запись, подлежащую созданию: sql_handle_env —
запись среды, sql_handle_dbc — запись соединения, sql_handle_stmt —
запись команды.
2. hln — указатель на "родительскую" запись более высокого уровня, в контексте
которой должна быть создана новая запись. Если необходима новая запись среды, на
месте hln следует задать именованную константу sql_null_handle, означающую,
что подходящей "родительской" записи нет; если создается запись соединения,
здесь надлежит ввести имя указателя соответствующей записи среды, а если
требуется новая запись команды, следует задать имя подходящей записи соединения.
3. hOut — адрес переменной, которой должен быть присвоен указатель на запись,
созданную функцией.
Функция SQLAllocHandle возвращает значение перечислимого типа sqlreturn — О,
если ошибок нет, и определенное ненулевое значение, если при выполнении
операции возникла некоторая ошибка.
Пример 8.18. Рассмотрим, каким образом, используя CLI, можно переписать текст
функции worthRanges (см. рис. 8.4 на с. 357), созданной в соответствии с
технологией "внедренных" команд SQL. Напомним, что функция предназначена для получения
статистики распределения значений годовых доходов руководителей индустрии кино
в зависимости от количества цифр в каждом значении и использует данные базовой
таблицы MovieExec из "кинематографической" базы данных. Начальный фрагмент
преобразованной версии функции приведен на рис. 8.18.
1) #include sqlcli.h
2) SQLHENV myEnv;
3) SQLHDBC myCon;
4) SQLHSTMT execStat;
5) SQLRETURN errorCodel, errorCode2, errorCode3;
6) errorCodel = SQLAllocHandle(SQL_HANDLE_ENV,
SQL_NULL_HANDLE, &myEnv) ;
7) if (!errorCodel)
8) errorCode2 = SQLAllocHandle(SQL_HANDLE_DBC,
myEnv, &myCon);
9) if (!errorCode2)
10) errorCode3 = SQLAllocHandle(SQL_HANDLE_STMT,
myCon, &execStat);
Рис. 8.18. Объявление и создание записей среды, соединения и команды
8.4. ИНТЕРФЕЙС УРОВНЯ ВЫЗОВОВ
383
Что содержится в записях среды и соединения?
Мы не собираемся давать исчерпывающее описание содержимого записей среды
и соединения. Впрочем, в некоторых полях этих записей может храниться достаточно
любопытная информация, которая, однако, зачастую не соответствует стандарту
и во многом зависит от особенностей конкретной реализации. В качестве примера
можно указать, что запись среды обязана содержать признак, свидетельствующий
о том, каким образом представляются строки символов (например, как наборы
символов постоянной длины, как последовательности, завершаемые символом ' \0 ', и т.д.).
Строки 2—4 содержат объявления указателей на записи среды (myEnv), соединения
(myCon) и команды (execStat) соответственно. Мы полагаем, что переменная
exec Stat должна представлять SQL-запрос
SELECT netWorth FROM MovieExec;
аналогичный запросу в объявлении курсора на рис. 8.4, но пока этот запрос к
переменной никак не "привязан". В строке 5 объявлены три переменные типа sqlreturn,
которым предполагается присваивать возвращаемые функцией SQLAllocHandle коды
ошибок (0 означает, что вызов завершен успешно).
В строке 6 вызывается функция SQLAllocHandle с целью создания записи среды
(первый аргумент равен sql_handle_env). Второй аргумент вызова содержит нулевой
указатель sql_null_handle, поскольку для записи среды не нужно задавать
"родительскую" запись. Третий аргумент — это адрес переменной myEnv, по которому
должен быть размещен указатель, сгенерированный в результате выполнения функции.
Если вызов функции в строке 6 завершается успешно, в строках 7, 8 указатель на запись
среды используется для получения указателя (myCon) на запись соединения. Если и этот
вызов успешен, в строках 9, 10 запрашивается указатель (execStat) на запись команды. □
8.4.2. Обработка команд
Текст программы, приведенной на рис. 8.18, завершается созданием записи
команды, на которую указывает значение execStat. Однако запись все еще не "связана"
ни с одной "реальной" командой SQL, подлежащей обработке. Процесс "связывания"
SQL-команды с записью и ее последующего выполнения в программе с использованием
CLI аналогичен ситуации, предполагающей применение технологии динамического
"внедрения" SQL-команды в базовый код (см. раздел 8.1.10 на с. 361), где текст
SQL-команды в процессе "подготовки" (prepare) ассоциируется с тем, что мы называли
"переменной SQL", а затем выполняется с помощью "внедренной" инструкции execute.
В программе CLI все происходит примерно так же, если в роли "переменной SQL"
выступает указатель на запись команды. С этой целью применяется функция
SQLPrepare(s/z, st, si),
в качестве параметров принимающая следующие значения:
a) sh — указатель на запись команды;
b) st — указатель на строку SQL-команды;
c) si — значение длины строки символов, на которую указывает st; если длина
неизвестна, при задании в качестве si именованной константы sql_nts,
свидетельствующей о том, что строка завершается символом '\0' ("nuU-terminated
string" — NTS), функция обязана определить длину строки самостоятельно.
После выполнения функции SQLPrepare запись команды, адресуемая переменной sh,
будет "ссылаться" на строку st.
384
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Вызов другой функции CLI,
SQLExecute(sZz),
приводит к выполнению SQL-команды, на которую указывает аргумент sh. Результат
обработки таких SQL-команд, которые связаны, например, со вставкой или
обновлением кортежей, вполне предсказуем. Итог выполнения функции, однако, менее
очевиден, если аргумент sh указывает на строку запроса. Как будет показано в разделе
8.4.3, в подобной ситуации система создает "скрытый" курсор, который является
частью записи команды; можно полагать, что после выполнения запроса все кортежи
итогового отношения "где-то" хранятся и готовы для чтения. Их можно извлечь
(fetch) с помощью скрытого курсора — во многом подобно тому, как это делается
посредством "реального" курсора, специальным образом объявляемого для этой цели
(см. разделы 8.1 на с. 350 и 8.2 на с. 364).
Пример 8.19. Продолжим рассмотрение CLI-версии функции worthRanges, начатое
в примере 8.18. на с. 383. С помощью двух следующих вызовов функций нам
удастся "связать" запрос
SELECT netWorth FROM MovieExec;
с записью команды, адресуемой указателем execs tat:
11) SQLPrepare(execStat, "SELECT netWorth FROM MovieExec",
SQL_NTS);
12) SQLExecute(execStat);
Указанные строки можно вставить в текст рис. 8.18 непосредственно после строки 10.
Напомним, что константа sql_nts, использованная в качестве третьего аргумента
в вызове функции SQLPrepare, сообщает, что строка команды, заданная вторым
аргументом, ограничена символом ' \ 0 ', и ее длина подлежит вычислению. □
Как и в случае динамического "внедрения" команд SQL в код программы на
базовом языке, процедуры подготовки (prepare) и выполнения (execute) SQL-команды
можно объединить; для этого применяется функция SQLExecDirect. Приведенные
выше строки 11, 12 функции worthRanges легко заменить одной строкой:
11) SQLExecDirect(execStat, "SELECT netWorth FROM MovieExec",
SQL_NTS);
8.4.3. Извлечение данных
Команде fetch, используемой в программах с "внедренным" кодом SQL и в
хранимых модулях PSM, в CLI соответствует функция
SQLFetch(sZz),
где sh — указатель на запись команды. Мы полагаем, что к моменту вызова SQLFetch
запрос SQL, адресуемый переменной sh, уже выполнен, иначе вызов приведет к ошибке.
Функция SQLFetch, как и все другие функции CLI, возвращает значение типа sqlreturn,
которое свидетельствует о том, насколько успешно завершен вызов. При использовании
функции SQLFetch особое внимание следует обратить на возвращаемый код ошибки,
обозначаемый именованной константой sql_no_data, который гласит, что в отношении,
служащем итогом выполнения запроса, кортежи, подлежащие извлечению,
отсутствуют. Как и в ранее рассмотренных примерах извлечения данных посредством курсоров,
это значение необходимо использовать для прерывания цикла просмотра кортежей.
Возникает закономерный вопрос: куда "деваются" извлекаемые кортежи, если
после успешного выполнения функции SQLExecute в примере 8.19 один или несколько
8.4. ИНТЕРФЕЙС УРОВНЯ ВЫЗОВОВ
385
раз вызывается функция SQLFetch? Вот ответ: содержимое компонентов кортежей
заносится в соответствующие структуры описаний, связанные с записью команды, на
которую указывает аргумент функции. Чтобы ассоциировать некоторый компонент
с переменной базового кода, достаточно перед обращением к SQLFetch выполнить
специальную функцию связывания (binding)
SQLBindCol (s/г, colNo, colType, pVar, varSize, varlnfo),
семантика параметров которой такова:
1) sh — указатель на запись команды-запроса;
2) colNo — номер компонента, подлежащего связыванию;
3) colType — символическое обозначение типа переменной, которой
присваивается значение компонента; заголовочный файл sqlcli.h содержит
полный перечень констант, описывающих допустимые типы; в качестве
примеров можно назвать sql_char (массивы символов и строки)
и SQL_integer (целые числа);
4) pVar — адрес переменной, в которую будет помещено содержимое компонента;
5) varSize — длина (в байтах) значений переменной, на которую указывает pVar\
6) varlnfo — адрес целочисленной переменной, в которую функция может
помещать дополнительную информацию о считанном значении компонента.
Пример 8.20. Вновь вернемся к функции worthRanges (см. рис. 8.4 на с. 357), чтобы
заменить "внедренные" команды SQL вызовами соответствующих функций CLI.
Воспользуемся начальным фрагментом кода, представленным на рис. 8.18 (см. с. 383), но
для краткости опустим операторы проверки значений, возвращаемых всеми
функциями, за исключением SQLFetch — последняя способна возвратить код ошибки
SQL_no_data ("кортеж не найден"), игнорировать который просто нельзя. Полный
текст CLI-версии функции worthRanges приведен на рис. 8.19.
Строка 3 содержит объявления тех же локальных переменных, которые
использовались в версии функции с "внедренными" командами SQL, а в строках 4—7
объявлены дополнительные локальные переменные, относящиеся к типам CLI,
определенным в файле sqlcli .h. Строки 4—6 взяты из текста рис. 8.18, а строка 7 представляет
новые переменные: worth соответствует одноименной общей переменной из
предыдущей версии функции (см. рис. 8.4), a worthlnfo позже передается при вызове
функции SQLBindCol, но реально не используется.
В строках 8—10 создаются необходимые записи и инициализируются указатели на
них, как в начальном фрагменте кода, приведенном на рис. 8.18, а в строках 11, 12
"подготавливается" (prepare) и "выполняется" (execute) заданная SQL-команда (мы
говорили об этом в примере 8.19). Строка 13 содержит инструкцию "связывания"
(binding) первого (и единственного) столбца отношения, получаемого в результате
обработки запроса, с переменной worth. Первый аргумент вызова функции
SQLBindCol — это указатель (execStat) на запись SQL-команды, второй — номер
интересующего нас компонента кортежа (в данном случае — 1), третий —
символическое наименование типа компонента (sql_integer), четвертый — адрес переменной
worth, которой следует присвоить значение компонента, пятый — размер значений
переменной worth в байтах, шестой — адрес переменной worthlnfo, которая
предназначена для хранения дополнительной информации, размещаемой функцией
SQLBindCol (эта информация нами не используется53).
В данном случае вместо адреса worthlnfo в функцию можно было бы передать "нулевой"
указатель NULL. — Прим. перев.
386
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
1) #include sqlcli.h
2) void worthRanges() {
3) int i, digits, counts[15];
4) SQLHENV myEnv;
5) SQLHDBC myCon;
6) SQLHSTMT execStat;
7) SQL_INTEGER worth, worthlnfo;
8 ) SQLA11ocHandle(SQL_HANDLE_ENV,
SQL_NULL_HANDLE, &myEnv);
9) SQLAllocHandle(SQL_HANDLE_DBC, myEnv, &myCon);
10) SQLAllocHandle(SQL_HANDLE_STMT, myCon, &execStat);
11) SQLPrepare(execStat,
"SELECT netWorth FROM MovieExec", SQL_NTS);
12) SQLExecute(execStat);
13) SQLBindCol(execStat, 1, SQL_INTEGER, &worth,
sizeof(worth), &worthInfo);
14) while(SQLFetch(execStat)) != SQL_NO_DATA) {
15) digits = 1;
16) while((worth /= 10) > 0) digits++;
17) if (digits <= 14) counts[digits]++;
}
18) for(i = 0; i < 15; i++)
19) printf("%с1-значный доход: количество начальников =
%d\n", i, counts[i]);
. .)
Рис. 8.19. Пример приложения с использованием функций СЫ
Основная часть кода функции схожа со строками 11—19 рис. 8.4. "Главный" цикл
while на рис. 8.19 охватывает строки 14—17. Обратите внимание, что операция
извлечения (fetch) очередного кортежа и проверка корректности полученных данных
совмещены в заголовке цикла. Если условие цикла выполняется, т.е. кортеж успешно
извлечен, в строках 15—17 определяется количество цифр в значении компонента,
"связанного" с переменной worth, и содержимое соответствующего счетчика
(элемента массива counts [ ]) увеличивается на единицу. По завершении цикла
while, когда все кортежи итогового отношения, возвращенного функцией
SQLExecute в строке 12, просмотрены, с помощью цикла for в строках 18, 19
результаты отображаются на стандартной консоли вывода. □
8.4.4. Передача аргументов в SQL-команды
Технология "внедрения" (embedding) команд SQL в код, написанный на одном из
базовых языков, предоставляет возможность выполнения команд с учетом текущих
значений общих переменных. Аналогичные, но несколько более сложные средства
существуют и в CLI. Чтобы воспользоваться ими, необходимо выполнить следующие действия.
1. Вызвать функцию SQLPrepare с целью "подготовки" текста команды, отдельные
фрагменты которого, называемые параметрами, заменены символами
вопросительного знака: /-й символ вопросительного знака соответствует /-му параметру.
8.4. ИНТЕРФЕЙС УРОВНЯ ВЫЗОВОВ
387
Извлечение компонентов посредством SQLGetData
Вместо предварительного "связывания" (binding) переменной программы с одним
из компонентов отношения, получаемого в результате выполнения запроса,
допустимо извлекать (fetch) кортежи и присваивать значения их компонентов
переменным только по мере необходимости. С этой целью используется функция
SQLGetData, принимающая такие же аргументы, как и SQLBindCol. Функция,
однако, присваивает значение компонента переменной только однократно, и поэтому
должна вызываться после каждой операции SQLFetch, если необходимо добиться
такого же эффекта, который дает функция SQLBindCol.
2. Обратиться к функции SQLBindParameter для "связывания" параметров
с конкретными значениями. Функция предполагает задание десяти аргументов
(мы рассмотрим только основные из них).
3. Выполнить команду, связанную с набором значений, посредством вызова
функции SQLExecute. Если команду необходимо выполнить вновь, а значения
параметров изменились, следует повторить процедуру их "связывания".
Процесс иллюстрируется примером; попутно мы отметим наиболее важные
параметры функции SQLBindParameter.
Пример 8.21. Вновь обратимся к фрагменту кода с "внедренной" командой SQL,
показанному на рис. 8.2 (см. с. 354), где предполагается получить значения переменных
studioName и studioAddr и использовать их в качестве содержимого компонентов
кортежа, вставляемого в отношение studio с помощью "внедренной" команды
insert. На рис. 8.20 показан "скелет" функции CLI, решающей ту же задачу (детали,
связанные с объявлениями переменных studioName и studioAddr, их
инициализацией и созданием записи команды с указателем myStat, опущены).
Строка 1 содержит инструкцию "подготовки" записи, указывающей на
команду вставки с двумя параметрами (вопросительными знаками), к выполнению.
В строках 2, 3 вызывается функция SQLBindParameter с целью "связывания"
параметров с текущим содержимым переменных studioName и studioAddr
соответственно. Наконец, в строке 4 выполняется команда вставки. Если всю
рассмотренную последовательность операций, включая не видимые здесь
манипуляции с целью получения значений переменных studioName и studioAddr
(и исключая строку 1 с вызовом функции SQLPrepare, которую достаточно
выполнить один раз. — Прим. перев.), поместить внутрь цикла, тогда на каждом его
шаге программа сможет вставлять в отношение studio кортежи с новыми
значениями компонентов name и address.
/* Получить значения переменных studioName и studioAddr */
1) SQLPrepare(myStat,
"INSERT INTO Studio(name, address) VALUES(?, ?)",
SQL_NTS);
2) SQLBindParameter(myStat, 1, . . . , studioName, ...);
3) SQLBindParameter(myStat, 2, . . . , studioAddr, ...);
4) SQLExecute(myStat);
Рис. 8.20. Пример передачи аргументов в SQL-команду в программе СЫ
□
388
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
8.4.5. Упражнения к разделу 8.4
Упражнение 8.4.1. Выполните задания упражнения 8.1.1 на с. 362, используя язык
программирования С и библиотеку функций SQL/CLI.
Упражнение 8.4.2. Выполните задания упражнения 8.1.2 на с. 363, используя язык
программирования С и библиотеку функций SQL/CLI.
8.5. Java Database Connectivity
Java Database Connectivity (JDBC) — это набор инструментальных средств,
аналогичный CLI и позволяющий создавать приложения реляционных баз данных на языке
программирования Java. Основные приемы использования JDBC схожи с методами
применения CLI, хотя объектно-ориентированный характер Java естественным
образом проявляется и в JDBC.
8.5.1. Введение в JDBC
Чтобы воспользоваться инструментами JDBC, надлежит выполнить следующие
предварительные действия.
1. Загрузить драйвер (driver), соответствующий конкретной СУБД. Существо
операции, как правило, зависит от особенностей реализации и установки системы.
В результате создается объект класса DriverManager. Объект во многом
напоминает запись среды, указатель на которую необходимо получить при
обращении к функциям CLI.
2. Установить соединение (connection) с базой данных. Метод getConnection
класса DriverManager возвращает объект типа Connection.
Выражение на языке Java, позволяющее установить соединение с базой данных,
выглядит так:
Connection myCon = DriverManager.getConnection(<URL>,
<name>, <password>);
Метод getConnection54 принимает в качестве параметров универсальный локатор
ресурсов (CTRL), указывающий на базу данных, с которой необходимо соединиться, имя
пользователя (name), его пароль (password) и возвращает объект типа Connection,
присваиваемый переменной myCon того же типа. Обратите внимание, что синтаксис
Java позволяет объявлять и инициализировать переменную в едином выражении.
Объект соединения аналогичен записи среды в CLI и выполняет схожие функции.
Вызывая соответствующие методы объекта соединения, такого как myCon, мы вправе
создавать объекты команд, "размещать" в них необходимые выражения SQL, связывать
значения с параметрами этих выражений, инициировать выполнение SQL-команд и
последовательно считывать кортежи итоговых отношений. Поскольку различия между JDBC и CLI
относятся скорее к сфере синтаксиса, нежели семантики, нам остается только бегло
рассмотреть каждую из названных стадий программирования с использованием JDBC.
8.5.2. Создание объектов SQL-команд
Существуют два метода интерфейса Connection, предназначенных для создания
объектов SQL-команд в Java-программе.
54 Существуют и иные перегруженные варианты этого и других методов Java, упоминаемых
ниже. За справками обращайтесь к комплекту документации Java™ 2 Platform Standard
Edition v.1.3 или его более новым версиям (http: //Dava.sun.com/). — Прим. перев.
8.5. JAVA DATABASE CONNECTIVITY
389
1. Метод createstatement() возвращает объект типа Statement, с которым не
связана конкретная команда SQL. Метод createStatement () можно считать
аналогом CLI-функции SQLAllocHandle, которая принимает в качестве
параметра указатель на запись соединения и возвращает указатель на запись команды.
2. Метод preparestatement(Q) (Q ~ строка, содержащая текст SQL-команды)
возвращает объект типа PreparedStatement. Существует определенная
аналогия между использованием метода preparestatement (Q) в JDBC и
вызовами двух функций CLP. первая, SQLAllocHandle, возвращает указатель на
запись команды, а вторая, SQLPrepare, "подготавливает" запись команды к
выполнению SQL-выражения Q.
В JDBC предлагается четыре метода55, предусматривающих выполнение SQL-команд.
Как и при создании объектов команд, методы различаются тем, какие аргументы им
передаются. Помимо того, методы "чувствительны" к типу SQL-команд, подлежащих
выполнению. В JDBC SQL-команды разделяются на две категории — запросы (Query)
и "иные" выражения, обобщенно называемые командами обновления (Update). К числу
последних относятся все команды модификации содержимого базы данных (insert,
update и delete) и ее схемы (create, alter и drop). Методы перечислены ниже.
1. Метод executeQuery(Q) объекта Statement принимает в качестве параметра
строку SQL-выражения Q, описывающего запрос, и возвращает объект типа
ResultSet, который представляет мультимножество кортежей, полученное
в результате обработки запроса Q. За сведениями о способах доступа к
отдельным кортежам итогового отношения обращайтесь к разделу 8.5.3 на с. 391.
2. Метод executeQuery() объекта PreparedStatement не предусматривает
задание аргументов, поскольку SQL-запрос, подлежащий выполнению, с
объектом PreparedStatement уже ассоциирован. Метод также возвращает объект
типа ResultSet.
3. Метод executeUpdate(£/) объекта Statement принимает в качестве параметра
строку SQL-выражения U, описывающего инструкцию "обновления", и
выполняет ее. Результат вызова сказывается только на содержимом базы данных или
ее схемы; никакие наборы данных не возвращаются.
4. Метод executeUpdate() объекта PreparedStatement не предполагает задание
аргументов и выполняет ту SQL-команду, которая была поставлена в
соответствие объекту PreparedStatement при его создании. Разумеется, SQL-команда
не должна относиться к категории запросов.
Пример 8.22. Предположим, что создан объект соединения (Connection) myCon и
необходимо выполнить запрос
SELECT netWorth FROM MovieExec;
Один из способов достижения цели связан с созданием объекта команды (Statement)
execStat и использованием его для выполнения запроса. Итоговое мультимножество
кортежей, как мы предусматриваем, должно быть помещено в объект worths типа
ResultSet. О том, как извлекать кортежи и значения их отдельных компонентов
(в данном случае — netWorth), рассказано в разделе 8.5.3 на с. 391. Соответствующий
фрагмент кода Java может выглядеть так:
Statement execStat = myCon.createStatement();
ResultSet worths = execStat.executeQuery(
"SELECT netWorths FROM MovieExec");
Имеется ряд других методов семейства execute аналогичного назначения, которые здесь
не рассмотрены. — Прим. перев.
390
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Альтернативный подход состоит в том, чтобы вначале подготовить (prepare)
запрос, а затем выполнить (execute) его. Такое решение окажется более
предпочтительным, если, как и в случае использования технологии CLI, один и тот же
запрос необходимо выполнять неоднократно. Последовательность необходимых
действий показана ниже.
PreparedStatement execStat = myCon.prepareStatement(
"SELECT netWorths FROM MovieExec");
ResultSet worths = execStat.executeQuery();
□
Пример 8.23. Если необходимо выполнить SQL-команду, не относящуюся к
категории запросов и не предусматривающую задания параметров, можно выполнить
действия, аналогичные рассмотренным в примере 8.22. В данном случае, разумеется,
никакой набор данных возвращен не будет. Предположим для примера, что
требуется отразить в "кинематографической" базе данных тот факт, что актер Дензел
Вашингтон участвовал в съемках фильма "Remember the Titans", выпущенного на
экран в 2000 году. Операция вставки (insert) кортежа в отношение stars In может
быть осуществлена двумя способами:
Statement starStat = myCon.createStatement();
starStat.executeUpdate("INSERT INTO Starsln VALUES(" +
"'Remember the Titans', 2000, 'Denzel Washington')");
либо
PreparedStatement starStat = myCon.prepareStatement(
"INSERT INTO Starsln VALUES('Remember the Titans'," +
"2000, 'Denzel Washington')");
starStat.executeUpdate();
Обратите внимание, какое удобное применение находит оператор сцепления
(конкатенации) строк (+) Java. С его помощью легко разбить длинные выражения со
строковыми операндами на несколько более коротких. □
8.5.3. Операции с курсорами
После выполнения запроса и получения итогового набора данных естественно
задаться вопросом, каким образом эти данные могут быть просмотрены и обработаны.
Тип ResultSet содержит весьма полезные методы манипуляции курсором,
извлечения содержимого компонентов кортежей и их модификации. Ниже перечислены
только некоторые из них.
1. next() — перемещает "указатель" внутреннего курсора к очередному кортежу
отношения, служащего результатом обработки запроса (при первом вызове — к
первому кортежу), и возвращает значение false, если множество кортежей исчерпано.
2. getString(Z), getlnt(/), getFloat(Z) и аналогичные методы,
соответствующие типам данных, поддерживаемым в SQL, — возвращают содержимое /-го
компонента текущего кортежа отношения, "обслуживаемого" внутренним
курсором. Для извлечения значения компонента должен выбираться метод,
соответствующий типу компонента.
Пример 8.24. Получив итоговый набор значений worths, как показано в примере
8.22, мы приобретаем возможность последовательного просмотра кортежей.
Напомним, что кортежи итогового отношения в данном случае содержат по одному
целочисленному компоненту, соответствующему атрибуту netWorth базовой таблицы
MovieExec. Пример простого цикла показан ниже.
8.5. JAVA DATABASE CONNECTIVITY
391
/* ... */
while(worths.next() ) {
worth = worths.getlnt(1);
/* ... */
}
□
8.5.4. Передача аргументов в SQL-команды
Технология JDBC (как и CLI) допускает возможность задания SQL-команд,
отдельные фрагменты которых, называемые параметрами, заменены символами
вопросительного знака, с последующим "связыванием" (binding) этих параметров с
конкретными значениями. Для этого необходимо создать объект типа
PreparedStatement, а затем связать параметры описываемой им SQL-команды с
реальными значениями посредством вызовов методов вида setstring(/, v),
setlnt(/, v) и т.п., подразумевая, что значение v соответствует /-му параметру, а
выбранный метод отвечает требуемому типу значения.
Пример 8.25. Вновь обратимся к CLI-коду, рассмотренному в примере 8.21 на с. 388, где
предполагается выполнить команду вставки (insert) нового кортежа с
параметризованными значениями компонентов названия и адреса киностудии в отношение studio,
и покажем, как та же задача может быть решена с помощью языка Java и технологии
JDBC. Соответствующий фрагмент кода приведен на рис. 8.21. Мы по-прежнему
полагаем, что объект myCon класса Connection уже создан и готов для использования.
В строках 1, 2 создается объект типа PreparedStatement, содержащий
"подготовленное" SQL-выражение. Параметры, соответствующие значениям
компонентов названия и адреса киностудии и подлежащие дальнейшему уточнению, помечены
символами вопросительного знака. После строки 2 можно было бы вставить заголовок
цикла, на каждом шаге которого пользователю предлагается ввести подходящие
значения параметров, которые присваиваются строковым переменным studioName
и studioAddr (эти действия не показаны и замены комментарием); в строках 3, 4
параметры SQL-команды связываются с текущим содержимым переменных studioName
и studioAddr соответственно; наконец, в строке 5 выполняется команда вставки кортежа
с учетом значений параметров. По завершении строки 5, как можно полагать,
выполнение цикла должно быть возобновлено, начиная со строки, помеченной комментарием.
1) PreparedStatement studioStat = myCon.prepareStatement(
2) "INSERT INTO Studio(name, address) VALUES(?, ?)");
/* Получить значения переменных studioName и studioAddr */
3) studioStat.setString(1, studioName);
4) studioStat.setString(2, studioAddr);
5) studioStat.executeUpdate();
Рис. 8.21. Пример передачи аргументов в SQL-команду в программе JDBC
8.5.5. Упражнения к разделу 8.5
Упражнение 8.5.1. Выполните задания упражнения 8.1.1 на с. 362, используя язык
программирования Java и функции JDBC.
Упражнение 8.5.2. Выполните задания упражнения 8.1.2 на с. 363, используя язык
программирования Java и функции JDBC.
392
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
8.6. Транзакции и SQL
До сих пор, говоря об операциях с базой данных, мы подразумевали, что с запросами
и командами модификации к базе данных обращается только один пользователь,
операции выполняются последовательно (serially) и поодиночке в любой момент времени, а по
окончании каждой из них база данных остается в согласованном и корректном
состоянии. Помимо того, мы полагали, что все операции завершаются целиком (атомарным
образом — atomically), т.е. не считали возможным, что операция может быть прервана
ввиду аппаратного или программного сбоя, способного привести базу данных в такое
состояние, которое не может восприниматься как результат какой-либо штатной операции.
Перефразируя известное поэтическое изречение, уместно напомнить, что жизнь,
увы, не столь прекрасна, сколь удивительна. Вначале мы попытаемся "удивить" вас
неприятно, продемонстрировав совершенно реальные ситуации, чреватые
нарушением состояния базы данных, а затем (это уже хорошие новости) расскажем о средствах
SQL, помогающих избежать подобных потрясений.
8.6.1. Последовательное выполнение операций
С помощью приложений, связанных с банковской деятельностью или
бронированием авиабилетов, к базам данных каждую секунду могут обращаться сотни и тысячи
пользователей — клиентов банкоматов, бухгалтеров банков, сотрудников
туристических агентств, операторов билетных касс и просто владельцев Web-броузеров. Вполне
вероятно, что в каждый момент времени несколько операций могут затрагивать один
и тот же банковский счет или место в самолете. Разумеется, с этим необходимо как-то
"бороться". Ниже приведен пример ситуации, когда база данных неминуемо придет
в негодность, если в СУБД не предусмотрены какие бы то ни было ограничения,
касающиеся порядка выполнения операций во времени. Мы подчеркиваем, что реальные
системы баз данных при обычных обстоятельствах, конечно, так не работают, и если вы
собрались "сбить с толку" серьезную коммерческую СУБД, вам это вряд ли удастся.
Пример 8.26. Предположим, что требуется написать функцию на языке С с
"внедренными" выражениями SQL, которая в состоянии извлечь информацию об авиарейсе,
определить, свободно ли указанное место, и забронировать его в случае
положительного результата проверки. Отношение, к которому должна обращаться функция,
носит название Flights ("авиарейсы") и содержит четыре атрибута: fltNum ("номер
рейса"), f ltDate ("дата вылета"), fltSeat ("номер места") и occupied ("занято").
Набросок текста функции приведен на рис. 8.22.
Строки 9—11 содержат команду выбора единственного кортежа, в результате
выполнения которой общей переменной осе присваивается значение 1 или 0 (true или
false) в зависимости от того, свободно указанное место (seat) на рейс номер flight
с датой вылета date или нет. В строке 12 осуществляется проверка, свободно ли место,
и если да, значение компонента occupied кортежа, соответствующего этому месту,
должно быть изменено с false ("свободно") на true ("занято"). Операция обновления
выполняется командой update, расположенной в строках 13—15. В строке 16
забронированное место закрепляется за клиентом, который его запросил. (На практике
информацию о бронировании конкретных мест, разумеется, следовало бы вынести в отдельное
отношение, чтобы избежать дублирования данных.) Наконец, если место, интересующее
заказчика, занято, фрагмент кода, представленный комментарием в строке 17, должен
обеспечить возможность ввода другого номера места и повторения операции.
Напомним, что функция chooseSeat () может вызываться одновременно
несколькими пользователями системы. Предположим для краткости, что два оператора
билетных касс пытаются забронировать одно и то же место на определенные рейс и дату
вылета примерно в один и тот же момент времени, как показано на рис. 8.23. Оба
процесса единовременно достигают строки 9 функции, и обеим копиям локальной
8.6. ТРАНЗАКЦИИ И SQL
393
переменной осе присваивается значение 0 ("свободно"). Затем, после выполнения
проверки в строке 12, каждый процесс принимает решение о присваивании
компоненту occupied одного и того же кортежа значения TRUE, свидетельствующего о том,
что место забронировано. Обе операции обновления (update) безболезненно
выполняются (вероятно, одна за другой), и строка 16 сообщает обоим счастливым
заказчикам, что желанное место принадлежит каждому из них безраздельно.
1) EXEC SQL BEGIN DECLARE SECTION;
2) int flight; /* номер рейса */
3) char date[10]; /* дата вылета (в формате SQL) */
4) char seat[3]; /* номер места -- две цифры и буква */
5) int осе; /* флаг: 1 -- место занято, 0 -- свободно */
6) EXEC SQL END DECLARE SECTION;
7) void chooseSeat() {
/* Бронирование авиабилета на указанное место */
8) /*С-код: запросить у клиента номер рейса,
дату вылета, номер места и сохранить значения
в переменных flight, date и seat соответственно */
9) EXEC SQL SELECT occupied INTO :occ
10) FROM Flights
11) WHERE fltNum = :flight AND fltDate =
.-date AND fltSeat = :seat;
12) if (!occ) {
13) EXEC SQL UPDATE Flights
14) SET occupied = TRUE
15) WHERE fltNum = :flight
AND fltDate = -.date
AND fltSeat = :seat;
16) /* С- и SQL-код: сохранить заказ и информировать клиента */
}
17) else { /*С-код: уведомить клиента о том, что место занято,
и предложить выбрать другое место */ }
..}
Рис. 8.22. Пример функции бронирования авиабилета
Пользователь 1 определяет,
что место свободно
Пользователь 2 определяет,
что то же место свободно
Пользователь 1 бронирует место
Пользователь 2 бронирует то же место
Рис. 8.23. Пример коллизии, связанной с одновременным бронированием
одного места двумя пользователями
□
394
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Как мы показали в примере 8.26, вполне возможна ситуация, когда каждая отдельная
операция выполняется корректно, но общий результат неверен: оба заказчика
полагают, что они владеют правом занять одно и то же место. Проблема допускает
решение с помощью нескольких механизмов SQL, которые обеспечивают
последовательную обработку процессов, связанных с выполнением функции chooseSeat (). Говорят,
что процессы, затрагивающие один и тот же элемент содержимого базы данных,
протекают последовательно (serially), если один из них полностью завершается прежде, чем
начинает выполняться другой; процессы можно считать условно-последовательными
(serializable), если они способны "вести себя" так, как при последовательной
обработке, — даже в тех случаях, когда в действительности они перекрываются во времени.
Теперь ясно, что для устранения проблемы достаточно обеспечить строго
последовательную обработку вызовов функций chooseSeat (). Один из вызовов всегда
окажется первым. Соответствующий пользователь найдет свободное место и забронирует
его. Второму пользователю останется убедиться, что место уже занято. Кто из
пользователей окажется "проворнее" — это уж как Бог даст; главное, что одно и то же место
теперь будет забронировано только один раз.
8.6.2. Атомарность
Помимо проблемы, касающейся возможности одновременного обращения к одним
и тем же порциям данных со стороны нескольких процессов, не упорядоченных во
времени, существует и иная опасность: база данных может оказаться в неприемлемом
состоянии, если в период выполнения единственной операции случится аппаратный
или программный сбой. Соответствующий пример рассмотрен ниже. Как и прежде,
мы хотели бы напомнить, что коммерческие СУБД в подавляющем большинстве
случаев способны справляться с последствиями подобных неприятностей и
восстанавливать базу данных в согласованном виде.
Пример 8.27. Теперь обрисуем другую весьма распространенную разновидность баз
данных. Речь пойдет о базах данных, связанных с банковской деятельностью. Для
дальнейшего изложения нам достаточно простенького отношения Accounts ("счета")
с двумя атрибутами — acctNo ("номер счета") и balance ("остаток").
Пусть необходимо написать функцию, которая считывает номера двух счетов
и размер денежной суммы, подлежащей переводу с одного счета на другой, проверяет,
содержит ли "первый" счет остаток, достаточный для совершения расходной
операции, и если условие справедливо, выполняет операцию, вычитая заданное значение
суммы из остатка на "первом" счете и прибавляя его к остатку на "втором" счете.
Эскиз функции transfer () приведен на рис. 8.24.
Процесс вычислений, предусмотренный функцией, прямолинеен и прост. Строки 8—
10 содержат запрос, позволяющий выяснить размер остатка на "первом" счете. В
строке 11 проверяется, достаточно ли велик остаток для выполнения расходной части
требуемой операции перевода. Если условие удовлетворяется, в строках 12—14 выполняется
команда обновления (update), соответствующая "приходу" суммы на "второй" счет,
а в строках 15—17 аналогичная команда update осуществляет "расход" с "первого"
счета. Если же размер остатка на "первом" счете слишком мал, перевод средств выполнить
нельзя, и строка 18 выводит на консоль соответствующее предупреждающее сообщение.
Теперь рассмотрим, что случится, если непосредственно после выполнения
команды обновления в строке 14 произойдет сбой системы (причины могут быть самыми
разными — ошибка операционной системы, нарушение электропитания, поломка
устройства компьютера или выход из строя сетевого оборудования). База данных
останется в таком состоянии, когда сумма "пришла" на один счет, но не была "снята"
с другого. Деньги не могут взяться из ниоткуда и пропасть в никуда — пострадавшей
стороной окажется банк. □
8.6. ТРАНЗАКЦИИ И SQL
395
Как обеспечивается последовательное протекание процессов
На практике требование обязательного строго последовательного упорядочения
процессов во времени чаще всего неправомочно — их может быть просто
слишком много, и поэтому без некоторого параллелизма обойтись не удастся. СУБД
поддерживают собственные механизмы, гарантирующие последовательное
протекание отдельных фаз процессов; если процессы и не являются подлинно
последовательными, для пользователей они выглядят так, будто других
конкурирующих процессов не существует вовсе.
Один из общих подходов связан с использованием средств блокирования (locking)
элементов базы данных, так что две функции не смогут обратиться к ним
единовременно. (В разделе 1.2.4 на с. 42 мы уже кратко останавливались на этом вопросе; за
подробными сведениями обращайтесь к той части главы 18, которая начинается
с раздела 18.3 на с. 894.) Если бы, скажем, функция chooseSeat (), рассмотренная
в примере 8.26 на с. 393, предусматривала задание признаков блокирования
соответствующего кортежа отношения Flights либо отношения целиком, процессы, не
затрагивающие это отношение, могли бы протекать параллельно, но единовременное
выполнение нескольких "экземпляров" функции chooseSeat () было бы запрещено.
Проблема, рассмотренная в примере 8.27, заключается в том, что определенные
комбинации операций с базой данных, подобные двум командам update в функции,
приведенной на рис. 8.24, обязаны выполняться атомарным образом (atomically) —
либо все вместе, либо ни одна из них поодиночке.
1) EXEC SQL BEGIN DECLARE SECTION;
2) int acctl, acct2; /* номера счетов */
3) int balancel; /* остаток на 1-м счете */
4) int amout; /* сумма, подлежащая переводу */
5) EXEC SQL END DECLARE SECTION;
6) void transfer() {
7) /* С-код: запросить номера счетов и размер суммы перевода;
сохранить значения в переменных acctl, acct2
и amount соответственно */
8) EXEC SQL SELECT balance INTO .-balancel
9) FROM Accounts
10) WHERE acctNo = :acctl;
11) if (balancel >= amount) {
12) EXEC SQL UPDATE Accounts
13) SET balance = balance + :amount
14) WHERE acctNo = :acct2;
15) EXEC SQL UPDATE Accounts
16) SET balance = balance - :amount
17) WHERE acctNo = :acctl;
}
18) else { /* С-код: вывести сообщение о том,
что размер остатка на счете слишком мал */ }
..}
Рис. 8.24. Пример функции перевода денежной суммы с одного счета на другой
396
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Одно из возможных и самых простых решений состоит в том, чтобы сохранять все
промежуточные результаты в "отдельном месте" и фиксировать (commit) их в
основных таблицах базы данных только после того, как все операции успешно завершены.
8.6.3. Транзакции
Общее и наиболее совершенное решение проблем, рассмотренных в разделах 8.6.1
и 8.6.2, связано с группированием операций, применяемых к базе данных, в
транзакции (transactions). Транзакция — это набор, состоящий из одной или нескольких
операций над базой данных, которые обязаны выполняться атомарным образом
(atomically); иными словами, допустимы два варианта действий — либо целиком
выполняются все операции набора, либо не выполняется ни одна из них. Помимо того,
SQL по умолчанию предусматривает, что транзакции должны выполняться
последовательно (serially). СУБД обычно позволяют пользователю задавать менее жесткие
ограничения, касающиеся возможности перекрытия операций двух или более транзакций
во времени (об этом будет рассказано в следующих разделах).
При использовании базового интерфейса SQL (generic SQL interface) каждая
команда SQL, как правило, расценивается как самостоятельная транзакция.56 Однако
при написании прикладного кода с использованием "внедренных" конструкций SQL,
библиотек CLI или JDBC обычно требуется явное задание директив управления
транзакциями. Транзакции запускаются на выполнение автоматически с каждой командой
запроса либо модификации содержимого или схемы базы данных. При необходимости
с той же целью может быть введена команда start transaction.
В базовом интерфейсе при отсутствии инструкции start transaction
транзакция завершает выполнение вместе с командой, которая ее вызвала. В остальных
случаях транзакция может быть завершена двумя способами, указанными ниже.
1. SQL-команда commit приводит к успешному завершению транзакции. Все
изменения, вызванные командами текущей транзакции, окончательно фиксируются
(commit) в базе данных и приобретают необратимый характер. До
выполнения команды commit такие изменения трактуются как "предварительные" или
"временные" и могут быть доступными или недоступными для других
параллельных транзакций.
2. SQL-команда rollback влечет прерывание транзакции. Любые изменения,
внесенные командами текущей транзакции, отменяются, или откатываются
(rollback), и никак не отражаются в базе данных.
Существует одно исключение из указанных правил. Если при завершении
транзакции некоторые ограничения, подлежащие отложенной проверке (см. раздел 7.1.6 на
с. 324), нарушаются, результаты транзакции не будут зафиксированы даже в том случае,
если команда commit задана явно. Изменения, вызванные командами транзакции,
отменяются, и переменной SQLSTATE присваивается соответствующий код ошибки, с
помощью которого приложение в состоянии определить истинную причину происшедшего.
Пример 8.28. Пусть необходимо обеспечить выполнение функции transfer(), текст
которой приведен на рис. 8.24 (см. с. 396), в виде единой транзакции. Начало
транзакции уместно обозначить в строке 8, где выполняется запрос, касающийся размера
остатка на счете, для которого предполагается выполнить расходную операцию. Если
результат проверки в строке 11 успешен, посредством двух команд update осуществляется
5 Следует отметить, что процессы выполнения кода триггеров, активизируемых SQL-
командой, являются частью той же транзакции. В некоторых системах позволено использовать
триггеры, которые способны провоцировать срабатывание других триггеров; все эти действия
также относятся к текущей транзакции.
8.6. ТРАНЗАКЦИИ И SQL
397
О состоянии базы данных в ходе выполнения транзакции
В различных системах баз данных механизм поддержки транзакций реализуется
по-разному. Возможна ситуация, когда по мере протекания транзакции последняя
сохраняет предварительные результаты непосредственно в базе данных. Если такая
транзакция прерывается, ее промежуточные итоги могут оказаться доступными для
других транзакций. Наиболее общее решение предполагает использование функций
блокирования элементов данных, подвергающихся изменениям, до момента
выполнения команды commit или rollback — с тем, чтобы предотвратить доступ
к временным данным со стороны других транзакций. Блокирование или иной
аналогичный механизм определенно можно использовать и в том случае, когда
транзакции выполняются строго последовательно.
Далее, начиная с раздела 8.6.4, мы обсудим иные средства SQL, касающиеся
возможности различной интерпретации промежуточных результатов транзакций.
Допустима ситуация, когда изменяемые порции данных не блокируются и
становятся достоянием других процессов даже в том случае, если позже
соответствующие операции модификации отменяются командой rollback. Право принятия
решения о том, запретить доступ к изменяемым элементам информации или нет,
предоставляется программисту, создающему код транзакции.
операция перевода, по завершении которой изменения следует зафиксировать в базе
данных. С этой целью после строки 17 в блок кода if надлежит вставить SQL-команду
EXEC SQL COMMIT;
Если же условие в строке 11 не выполняется (величина остатка на счете слишком
мала), транзакцию уместно прервать. Это можно сделать, поместив в конец блока else
в строке 18 команду
EXEC SQL ROLLBACK;
Впрочем, делать это вовсе не обязательно, поскольку в блоке else изменение
Содержимого базы данных не предусмотрено, поэтому фиксировать или отменять просто нечего. □
8.6.4. Транзакции "только для чтения"
В примерах 8.26 (см. с. 393) и 8.27 (см. с. 395) по существу рассматриваются
транзакции, предполагающие считывание и, возможно, сохранение некоторой
информации в базе данных. Для такого рода транзакций характерно возникновение проблем,
связанных с порядком выполнения операций. Пример 8.26 служит иллюстрацией
того, что может случиться, если два процесса одновременно вызывают функцию
бронирования одного и того же места на авиарейс, а пример 8.27 демонстрирует
последствия, которые способен повлечь сбой системы в период выполнения функции. Если,
однако, транзакция только считывает данные, но не изменяет их, она может
выполняться параллельно с другими транзакциями гораздо более свободно.57
Пример 8.29. Пусть необходимо написать функцию, которая должна обращаться к
базе данных системы бронирования авиабилетов с запросом о том, свободно ли
указанное место. Текст функции может выглядеть точно так же, как фрагмент
(ограниченный строками 1—11) исходного кода, приведенного на рис. 8.22 (см. с. 394).
В этом контексте нетрудно заметить определенное сходство между транзакциями и
курсорами. В разделе 8.1.8 на с. 359 мы упоминали, например, о том, что курсоры, предназначенные
"только для чтения" (READ ONLY), допускают большую степень параллелизма в сравнении
с "обычными" курсорами. С другой стороны, транзакции "только для чтения" могут
выполняться наряду с другими транзакциями относительно независимо, но транзакции,
предусматривающие возможность модификации данных, в этом смысле гораздо более ограниченны.
398
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Кому генерировать команды rollback — приложению или системе?
Говоря о транзакциях, мы предполагали, что решение о том, фиксировать
результаты транзакции или отменять их, принимается на уровне приложения, которое
активизирует транзакцию. Так, в примерах 6.28 и 6.30 после выполнения ряда
действий их результаты могут быть явно зафиксированы с помощью команды commit
либо отменены посредством инструкции rollback. Система, однако, также
наделена правом осуществлять откат транзакций, чтобы обеспечить их атомарное
выполнение, удовлетворить требованиям заданного уровня изоляции (isolation level)
транзакции при наличии параллельных транзакций либо гарантировать
сохранность данных в случае системного сбоя. Если система прерывает транзакцию, она
обычно генерирует определенный код ошибки или исключения. Если приложение
обязано добиться успешного завершения транзакции, программист должен
позаботиться об "отлове " (catch) "выброшенных " (thrown) системой исключений (с помощью
проверки содержимого переменной sqlstate) и повторном выполнении транзакции.
Подобная функция может вызываться одновременно многими процессами без какого
бы то ни было риска, связанного с опасностью приведения базы данных в
несогласованное состояние. В самом худшем случае может случиться то, что в момент, когда
запрос свидетельствует о наличии (отсутствии) места, другая параллельно
выполняемая функция бронирует (освобождает) то же место. Таким образом, ответ на запрос —
"свободно" или "занято" — будет зависеть от какого-то ничтожно малого "сдвига"
процесса, выполняющего запрос, во времени, но корректность этого ответа в каждый
конкретный момент сомнению не подлежит. □
Если сообщить системе о том, что конкретная транзакция относится к категории
транзакций "только для чтения" (read-only), которые не способны изменять базу
данных, вполне вероятно, что система сможет извлечь из этой информации
определенные выгоды. Вообще говоря, допустима ситуация, когда несколько параллельных
транзакций "только для чтения" в некоторый момент времени обращаются к одному
и тому же элементу данных; если же транзакции наделены правом модифицировать базу
данных, в единовременном доступе к любой порции информации им будет отказано.
Дабы указать, что следующей будет выполняться транзакция "только для чтения",
достаточно выполнить команду
SET TRANSACTION READ ONLY;
Эта инструкция должна быть задана до начала транзакции. Рассмотрим
гипотетическую функцию, включающую строки 1—11 рис. 8.22 (см. с. 394). Если необходимо,
чтобы запрос в строке 9 выполнялся в режиме "только для чтения", непосредственно
перед этой строкой следует вставить инструкцию
EXEC SQL SET TRANSACTION READ ONLY;
Если транзакция начата, изменить ее статус уже нельзя.
Имеется и команда отмены признака "только для чтения" для очередной транзакции,
SET TRANSACTION READ WRITE;
но эта опция предлагается по умолчанию, и использовать команду явно обычно нет
необходимости.
8.6.5. "Чтение мусора"
"Чтение мусора" (dirty reads) — это термин, принятый для обозначения
возможности считывания одной транзакцией временных данных, сохраненных другой
транзакцией. Опасность, связанная с "чтением мусора", заключается в том, что выполнение
транзакции, служащей источником таких данных, может быть прервано. В подобной
8.6. ТРАНЗАКЦИИ И SQL
399
ситуации данные будут удалены, и все приложения, как можно полагать,
впоследствии должны действовать так, будто этих данных не было вовсе. Если же временные
данные считываются другой транзакцией, они способны косвенным образом повлиять
на решения, принимаемые в процессе выполнения этой транзакции.
Подчас риск "чтения мусора" имеет значение, подчас — нет. Зачастую с
негативными последствиями "чтения мусора" можно смириться, если учесть, что этот режим
дает возможность избежать
1) лишних вычислительных затрат с целью предотвращения вероятности
"чтения мусора";
2) потери параллелизма ввиду того, что системе приходится ожидать моментов,
когда несколько транзакций смогут выполняться одновременно, не рискуя
"захватить" временные данные "соседей".
Ниже на нескольких примерах мы покажем, что может случиться, если транзакциям
позволено считывать незафиксированные данные других транзакций.
Пример 8.30. Вновь обратимся к проблеме перевода денежных сумм с одного
банковского счета на другой, рассмотренной в примере 8.27 на с. 395, но предположим, что
операция перевода осуществляется программой Р в соответствии с алгоритмом,
указанным ниже.
1. Добавить сумму перевода на "второй" счет.
2. Проверить, достаточно ли велик остаток на "первом" счете, чтобы операция
перевода могла быть выполнена.
a) Если нет, вычесть сумму, добавленную при выполнении п. 1, из остатка на
"втором" счете и завершить операцию.58
b) В противном случае вычесть сумму из остатка на "первом" счете и
завершить операцию.
Если программа Р выполняется последовательно, решение о временном зачислении
суммы на "второй" счет не может иметь никаких вредоносных последствий. Ни
одна из параллельных транзакций результата этого действия не "увидит" (таких
транзакций просто нет), и в случае нехватки денег на "первом" счете операция перевода
будет благополучно отменена.
Теперь предположим, что разрешен режим "чтения мусора". Представим, что
существуют три счета — Ль А2 и Л3 — с остатками, равными 100, 200 и 300 долларам
соответственно. Пусть транзакция Тх выполняет программу Р с целью перевода суммы в
150 долларов со счета А{ на счет Аъ а примерно в то же самое время транзакция Т2
осуществляет попытку перевода суммы в 250 долларов со счета А2 на счет Л3. Ниже
рассмотрена возможная последовательность событий.
1. Т2 выполняет п. 1 алгоритма и прибавляет 250 долларов к остатку на счете А3;
остаток становится равным 550.
2. Т{ выполняет п. 1 алгоритма и прибавляет 150 долларов к остатку на счете А2;
остаток становится равным 350.
3. Т2 выполняет проверку, предусмотренную в п. 2 алгоритма, и находит, что
остаток на счете А2 достаточно велик (350) для того, чтобы можно было
перевести 250 долларов с А2 на Л3-
58 Обратите внимание, что здесь программа Р выполняет такое действие, какие обычно
возлагаются на СУБД. В частности, если программе, как в этом случае, требуется восстановить
состояние базы данных и прервать транзакцию, для этого достаточно просто вызвать команду
rollback; система самостоятельно осуществит откат результатов операций, выполненных с
момента начала транзакции, избавив программу от лишних "забот".
400
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
4. Тх выполняет аналогичную проверку и находит, что остаток на счете Л,
недостаточен (100) для того, чтобы можно было перевести 150 долларов с Л! на Л2.
5. Т2 выполняет п. 2Ь алгоритма: из остатка на счете А2 вычитается 250 долларов;
остаток становится равным 100; транзакция завершается.
6. Тх выполняет п. 2а алгоритма: из остатка на счете А2 вычитается 150 долларов;
остаток становится равным —50; транзакция завершается.
Общая сумма остатков на трех счетах не изменилась и по-прежнему равна 600. Но
поскольку при выполнении п. 3 последовательности, указанной выше, транзакция Т2
считывает незафиксированные данные ("мусор"), внесенные транзакцией Ти мы не
в состоянии противостоять присваиванию остатку счета А2 отрицательного значения. □
Пример 8.31. Рассмотрим новый вариант функции выбора свободного места на
авиарейс, которая обсуждалась в примере 8.26 на с. 393. Предположим, что реализован
следующий подход.
1. Найти свободное место и забронировать его присваиванием значения true
компоненту occupied соответствующего кортежа отношения Flights. Если
свободных мест нет, завершить функцию.
2. Запросить у клиента согласие на приобретение билета. Если согласие получено,
зафиксировать обновление командой commit. В противном случае отменить
результат операции присваиванием значения FALSE компоненту occupied того
же кортежа и повторить п. 1 с целью отыскания другого свободного места.
Если в один и тот же момент времени к функции обращаются две транзакции,
возможна ситуация, когда одна из них забронирует некоторое место S, от которого позже
клиент откажется. Если вторая транзакция выполняет п. 1 в тот момент, когда место S
помечено первой транзакцией как занятое, клиент, обслуживаемый второй
транзакцией, будет лишен возможности претендовать на место S.
Как и в примере 8.30, проблема связана с тем, что одной транзакции позволено
считывать "мусор", оставленный другой: "вторая" транзакция "видит" значение
компонента кортежа, свидетельствующее, что место занято, хотя позже место
освобождается "первой" транзакцией. □
Насколько важен тот факт, что данные, считанные транзакцией, оказались
"мусором"? В примере 8.30 он чрезвычайно важен, поскольку приводит к
присваиванию компоненту кортежа (недопустимого) отрицательного значения вопреки
предпринятым мерам безопасности. В примере 8.31, напротив, проблема не выглядит
столь серьезной: да, с первой попытки клиент, возможно, получит отказ в ответ на
просьбу продать ему билет на любимое место либо услышит, что мест нет вовсе, но
затем, при повторении транзакции, недоразумение будет наверняка устранено и
вожделенный билет продан. Поэтому нет ничего плохого в том, чтобы реализовать
функцию выбора мест на авиарейсы именно таким образом: это даст возможность
увеличить среднюю производительность обработки заказов.
SQL позволяет явно задавать режим выполнения транзакции, открывающий доступ
к нефиксированным данным других транзакций. С этой целью используется команда
set transaction, упоминавшаяся в разделе 8.6.4 на с. 398. Параметры транзакции,
рассмотренной в примере 8.31, можно задать так:
1) SET TRANSACTION READ WRITE
2) ISOLATION LEVEL READ UNCOMMITTED;
Команда выполняет две функции:
1) строка 1 содержит объявление, гласящее, что транзакция способна
модифицировать данные;
8.6. ТРАНЗАКЦИИ И SQL
401
Взаимодействие между транзакциями различных уровней изоляции
Необходимо подчеркнуть один тонкий аспект: уровень изоляции транзакции
оказывает влияние только на то, какие данные способна "видеть" эта транзакция,
и никоим образом не воздействует на характеристики других транзакций. Если
транзакция Т выполняется на уровне изоляции "последовательный", этот процесс
выглядит так, будто все другие транзакции либо полностью прекращают работу до
момента старта Г, либо активизируются после завершения Т. Однако если
некоторые из этих транзакций используют другой уровень изоляции, они могут "видеть"
результаты работы транзакции Г, сохраненные в базе данных: например, если
транзакции поставлен в соответствие уровень изоляции "чтение мусора", она будет
способна считывать и нефиксированные данные, оставленные транзакцией Т.
2) строка 2 свидетельствует, что транзакция наделяется правом чтения
нефиксированных данных (read-uncommitted), или "мусора", и ей ставится в
соответствие одноименный уровень изоляции (isolation level); до сих пор мы
сталкивались с двумя уровнями изоляции — "последовательный " (serial) и "чтение
нефиксированных данных" (read-uncommitted); сведения о двух других уровнях
изоляции приведены в разделе 8.6.6.
Обратите внимание, что если транзакция не относится к категории транзакций
"только для чтения" (read only) (т.е. способна модифицировать базу данных) и
соответствует уровню изоляции read uncommitted, ее следует явно обозначить как
read write. Напомним (обратитесь к разделу 8.6.4 на с. 398), что по умолчанию
система снабжает транзакции признаком read write. Однако в случае использования
режима "чтения мусора" (read uncommitted) по умолчанию предполагается, что
транзакция помечена как read only, поскольку сочетание опций read uncommitted
и read write, как было показано выше, чревато опасностями.
8.6.6. Другие уровни изоляции
В SQL различаются четыре уровня изоляции (isolation level). О двух из них мы уже
говорили— "последовательный" (serial) и "чтение нефиксированных данных" (read-
uncommitted), а два оставшихся — это "чтение фиксированных данных" (read-
committed) и "повторяемое чтение" (repeatable-read). Чтобы обозначить конкретную
транзакцию признаком "чтение фиксированных данных" или "повторяемое чтение",
достаточно выполнить одну из команд —
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
или
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
соответственно. Для каждого из этих уровней изоляции по умолчанию предлагается
режим read write, так что в том случае, если транзакция должна действовать в
режиме "только для чтения", в конструкцию set transaction следует включить
опцию read only. SQL позволяет задать и команду вида
set transaction isolation level serializable;
но уровень изоляции "последовательный" предусмотрен по умолчанию, поэтому
необходимость в использовании такой команды вряд ли возникнет.
Уровень изоляции "чтение фиксированных данных" (read-committed), как следует из
его названия, запрещает чтение нефиксированных данных, или "мусора". Однако
в этом случае транзакция может выполнять один и тот же запрос многократно, но
получать различные результаты, если таковые зависят от изменений, вносимых
параллельными транзакциями.
402
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Пример 8.32. Вновь обратимся к обновленному варианту функции выбора места на
авиарейс, рассмотренному в примере 8.31 на с. 401, и предположим, что транзакция,
предусмотренная функцией, выполняется на уровне изоляции "чтение
фиксированных данных". Тогда в процессе поиска свободного места (п. 1 алгоритма) транзакция
не будет "видеть", что некоторые места помечены другими транзакциями как
занятые, если эта информация еще не зафиксирована в базе данных.59 Если, однако,
транзакция выполняет запрос на поиск свободных мест неоднократно, вполне вероятно,
что всякий раз она будет получать различные наборы данных, поскольку в то же
самое время могут выполняться параллельные транзакции, бронирующие или
освобождающие те или иные места. □
Теперь остановим внимание на уровне изоляции "повторяемое чтение" (г ереаХаЫе-
read). Термин до некоторой степени неточен, поскольку система не может
гарантировать, что запрос, неоднократно выполняемый транзакцией с таким уровнем изоляции,
всякий раз будет возвращать один и тот же результат. Однако если при использовании
уровня изоляции "повторяемое чтение" некоторый кортеж возвращен запросом один
раз, можно быть уверенным, что при повторении запроса идентичный кортеж также
будет найден. При этом возможно получение и других (фантомных — phantom)
кортежей, которых не было в итоговом отношении, возвращенном первым запросом, —
такие кортежи могут быть вставлены в отношение параллельными транзакциями.
Пример 8.33. Продолжим изучение проблемы бронирования мест на авиарейс в той ее
версии, которая рассматривалась в примерах 8.31 и 8.32. Если выполнять функцию
посредством транзакции, помеченной признаком "повторяемое чтение", место,
которое при первом выполнении п. 1 оказалось свободным, будет трактоваться как
"свободное" и всеми последующими запросами.
Теперь предположим, что в отношение Flights добавлены новые кортежи
(скажем, на рейс назначен более вместительный самолет). Транзакции,
функционирующие на уровне изоляции "повторяемое чтение", смогут обнаружить новые места
и воспользоваться ими. □
8.6.7. Упражнения к разделу 8.6
Упражнение 8.6.1. В этом и следующих упражнениях мы обратимся к отношениям
Product(maker, model, type)
PC(model, speed, ram, hd, rd, price)
из базы данных, впервые рассмотренной в упражнении 5.2.1 на с. 218. Напишите
следующие программы, используя один из базовых языков по выбору
и "внедренные" инструкции SQL. He забудьте использовать директивы commit
и rollback и применить признак read only там, где это необходимо.
а) Передать функции в качестве аргументов значения быстродействия
процессора (speed) и объема оперативной памяти (ram) и найти номера моделей
(model) и уровни цен (price) персональных компьютеров (PC) с заданными
параметрами speed и ram.
* b) Удалить из отношений PC и Product информацию о персональном
компьютере указанной модели (model).
5 То, что в действительности происходит в подобных случаях, на первый взгляд может
показаться чем-то таинственным, ведь мы еще не говорили об алгоритмах выбора уровней изоляции,
уместных в каждом конкретном случае. Вполне возможен следующий вариант развития событий:
если две транзакции обнаружат одно и то же свободное место и попытаются забронировать его,
системе придется выполнить откат одной из транзакций, чтобы прервать состояние
взаимоблокировки (см. врезку "Кому генерировать команды ROLLBACK — приложению или системе?" на с. 399).
8.6. ТРАНЗАКЦИИ И SQL
403
Уменьшить на 100 долларов значение цены (price) персонального
компьютера (PC) указанной модели (model).
Запросить значения параметров нового персонального компьютера (рс) — кода
производителя (maker), номера модели (model), быстродействия процессора
(speed), объема оперативной памяти (ram), емкости диска (hd), типа привода
съемных дисков (rd), а также цены (price). Убедиться, что в базе данных
отсутствует информация о персональном компьютере с аналогичным
номером модели, и вставить (INSERT) в отношения Product и PC
соответствующие кортежи; в противном случае вывести на экран сообщение об ошибке.
! Упражнение 8.6.2. Рассмотреть каждое из решений заданий упражнения 8.6.1
и изучить проблемы, связанные с возможным нарушением принципа атомарности
транзакции ввиду системного сбоя, возникающего при ее выполнении.
! Упражнение 8.6.3. Предположим, что транзакция Т выполняет одну из функций,
предназначенных для решения заданий упражнения 8.6.1, и примерно в то же
время функционируют параллельные транзакции, вызывающие ту же или другие
указанные функции. С какими ситуациями, которых не было бы в том случае,
когда все транзакции используют уровень изоляции serializable, способна
столкнуться транзакция Г, если все транзакции действуют на уровне изоляции
read uncommitted? Рассмотрите отдельно каждый случай, когда Т вызывает
функции, созданные при решении заданий (a)—(d) упражнения 8.6.1.
*!! Упражнение 8.6.4. Предположим, что транзакция Т в "бесконечном" цикле ежечасно
вызывает функцию, которая проверяет, существует ли информация о персональном
компьютере (рс) с уровнем быстродействия процессора (speed) не менее 1500 МГц
и ценой (price) ниже 1000 долларов. Если соответствующие кортежи найдены,
функция выводит информацию на экран, и транзакция завершается. В период
работы транзакции Т могут действовать другие транзакции, которые обращаются к
функциям, предназначенным для решения заданий упражнения 8.6.1. Опишите
возможные последствия выбора для транзакции Т каждого из четырех уровней
изоляции — SERIALIZABLE, REPEATABLE READ, READ COMMITTED И READ UNCOMMITTED.
8.7. Безопасность и авторизация пользователей в SQL
В SQL предусмотрено, что пользователи базы данных обладают уникальными
идентификаторами авторизации (authorization ID's), или, проще говоря, именами.
В SQL поддерживается и специальный идентификатор авторизации public, к
которому вправе обратиться любой пользователь. Идентификатору авторизации может
быть поставлен в соответствие определенный набор привилегий (privileges) доступа,
во многом схожий с теми, которые используются для ограничения доступа к
объектам файловой системы и поддерживаются операционными системами. Например,
система UNIX обычно контролирует три категории привилегий, связанных с
возможностью чтения (read), записи (write) и исполнения кода (execute). Подобный
список привилегий хорошо согласуется с особенностями файловой системы и теми
операциями, которые обычно выполняются над ее объектами. Базы данных, однако,
гораздо более сложны, нежели файловые системы; соответственно намного более
сложна и номенклатура операций SQL, которые должны регламентироваться теми
или иными привилегиями.
В этом разделе вначале будут рассмотрены привилегии доступа к базам данных,
поддерживаемые в SQL. Затем мы расскажем о том, как следует назначать
привилегии и удалять их.
404
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
8.7.1. Привилегии доступа
В стандарте SQL определены девять типов привилегий (privileges) доступа: select,
INSERT, DELETE, UPDATE, REFERENCES, USAGE, TRIGGER, EXECUTE И UNDER. Первые
четыре регламентируют права доступа к отношению — базовой или виртуальной
таблице. Как свидетельствуют их названия, владельцу привилегий предоставляется
возможность выполнения запросов, а также вставки, удаления и обновления кортежей
отношения соответственно.
Модуль, содержащий выражение SQL, не может быть запущен на выполнение,
если пользователь не обладает надлежащей привилегией доступа к этому
выражению; так, например, чтобы обратиться к выражению "select—from—where", требуется
иметь привилегию select для каждого из отношений, которые упомянуты в тексте
запроса. О том, как кратко описать права на использование модуля, мы расскажем
ниже. В определения привилегий select, insert и update могут быть включены
названия конкретных атрибутов— скажем, SELECT (name, addr). В этом случае
пользователю предоставляется право обращаться к компонентам только тех
атрибутов, которые указаны явно, т.е. видеть их в отношениях, получаемых в результате
выполнения запросов, задавать при вставке или изменять при обновлении
кортежей. При назначении подобных привилегий они ассоциируются с определенным
отношением, так что совершенно очевидно, какому именно отношению
принадлежат указанные атрибуты (такие как name и addr).
Привилегия references также относится к конкретному отношению и дает
пользователю право указывать это отношение в описании ограничений целостности,
которые могут быть выражены в любой приемлемой форме (мы говорили об этом в главе
7 на с. 317) — как ограничения "общего вида", ограничения check уровня атрибута
или кортежа либо ограничения ссылочной целостности. В описании привилегии
references могут быть перечислены названия конкретных атрибутов; в этом случае
пользователь имеет право ссылаться в любом ограничении целостности,
затрагивающем рассматриваемое отношение, только на те атрибуты отношения, которые
оговорены явно. Ограничение не будет проверяться, если владелец схемы, к которой оно
относится, не обладает привилегией создания ссылок (references) на все элементы
данных, вовлеченные в ограничение.
usage — это разновидность привилегий, применимых к различным элементам
схемы базы данных, отличных от отношений и ограничений "общего вида"
(см. раздел 8.3.2 на с. 377); привилегия usage предоставляет пользователю право на
использование элемента в собственных объявлениях. Привилегия trigger для
конкретного отношения означает право на создание триггеров для этого отношения.
Привилегия execute — это право на выполнение той или иной порции кода, такой
как хранимая процедура или функция. Наконец, under — привилегия, позволяющая
создавать новые типы на основе указанного типа (обсуждение этого предмета мы
отложим до главы 9 на с. 419, где подробно рассмотрены объектна-ориентированные
возможности языков запросов).
Пример 8.34. Рассмотрим, какие привилегии необходимы для выполнения команды
вставки кортежей (insert), текст которой приведен на рис. 6.15 (см. с. 292) и
воспроизведен на рис. 8.25. Во-первых, коль скоро речь идет о вставке кортежей в
отношение studio, необходима привилегия INSERT для таблицы studio. Поскольку при
вставке задаются только значения компонентов name, приемлемыми могут считаться
обе формы привилегии — как INSERT, так и INSERT (name). Последняя позволяет
задавать только значения компонентов name кортежей, подлежащих вставке, и
предусматривать для остальных компонентов значения, принятые по умолчанию
(например, null) (что, собственно, и делается командой рис. 8.25).
8.7. БЕЗОПАСНОСТЬ И АВТОРИЗАЦИЯ ПОЛЬЗОВАТЕЛЕЙ В SQL
405
Триггеры и привилегии
На первый взгляд не совсем ясно, каким образом можно регламентировать доступ
к триггерам. Если пользователь обладает привилегией trigger для отношения, он
вправе попытаться создать любой триггер, касающийся этого отношения. Однако
поскольку фрагменты "условия" и "действия" кода триггера обычно представляют
собой запросы и/или команды обновления, создатель триггера должен иметь
необходимые права на их выполнение. Если другой пользователь осуществляет
операции, которые приводят к срабатыванию триггера, ему необязательно обладать
правами, регламентирующими доступ к порциям "условия" и "действия" кода
триггера, — триггер выполняется с учетом привилегий его автора.
1) INSERT INTO Studio(name)
2) SELECT DISTINCT studioName
3) FROM Movie
4) WHERE studioName NOT IN
5) (SELECT name
6) FROM Studio);
Рис. 8.25. Пример команды, нуждающейся
в задании привилегий на ее выполнение
Обратите внимание, что команда вставки содержит два подзапроса; начало одного
из них указано в строке 2, а другого — в строке 5. Для выполнения подзапросов
необходимо иметь соответствующие права; в частности, требуются привилегии select для
отношений Movie и studio, упомянутых в обоих предложениях FROM. Заметьте, что
наличие привилегии INSERT для Studio отнюдь не означает, что мы автоматически
получим и привилегию select для studio, и наоборот. Каждая привилегия должна
быть назначена явно. Поскольку подзапросы предусматривают выбор только
некоторых атрибутов отношений Movie и Studio, вполне достаточными окажутся
"ограниченные" привилегии: SELECT (studioName) для отношения Movie
и SELECT (name) для Studio (либо любые их варианты, в которых интересующие нас
атрибуты перечислены в составе списков атрибутов). □
8.7.2. Создание привилегий
Мы уже рассказали о том, что представляют собой привилегии в SQL, и о
необходимости владения ими для выполнения тех или иных операций над базой данных.
Теперь имеет смысл перейти к следующей теме: каким образом пользователь получает
определенные привилегии. Существуют два аспекта проблемы — как привилегии
создаются изначально и как они передаются одним пользователем другому. На первый
вопрос мы ответим ниже, а на второй — в разделе 8.7.4 на с. 408.
Элементы, которыми принято оперировать в SQL, такие как схемы или модули, имеют
владельцев. Владелец элемента обладает всеми привилегиями, связанными с этим
элементом. Можно указать три события, имеющие отношение к установлению факта владения.
1. При создании схемы последняя вместе со всем ее содержимым поступает
в полное владение пользователя-автора. Пользователь наделяется
исчерпывающим набором привилегий, относящихся ко всем элементам схемы.
2. При выполнении команды CONNECT для инициализации соединения (connection)
и открытия сеанса (session) существует возможность задания идентификатора
авторизации пользователя с помощью дополнительного предложения
authorization. Например, команда
406
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
CONNECT TO Starfleet-sql-server AS connl
AUTHORIZATION kirk;
позволяет создать соединение connl с сервером, обозначенным именем
Starfleet-sql-server, для пользователя kirk. Для того чтобы проверить,
действительно ли пользователь является тем, за кого себя выдает, СУБД обычно
требует ввести пароль (password). Возможно включение пароля наряду с именем
пользователя в предложение authorization (cm. раздел 8.3.5 на с. 379). Такой
подход, однако, небезопасен, поскольку в момент ввода команды за плечом
неосторожного Кирка может стоять некто любопытный или даже злонамеренный.
3. В команду создания модуля может быть включено предложение
authorization с именем автора. Если, например, предложение выглядит как
AUTHORIZATION vasya;
владельцем созданного модуля станет пользователь vasya. Имя владельца
можно и не задавать; в этом случае обратиться к модулю сможет любой
пользователь (public), но привилегии, необходимые для выполнения команд,
содержащихся в модуле, должны быть определены из какого-либо другого источника —
скажем, на основании имени пользователя, связанного с соединением и
сеансом, посредством которых модуль был создан.
8.7.3. Контроль привилегий
Как говорилось выше, с любыми модулем, схемой или сеансом связан
определенный пользователь, или, выражаясь в терминах SQL, с каждым из названных
элементов ассоциирован некоторый идентификатор авторизации (authorization ID). С каждой
из операций SQL соотнесены "объекты" двух категорий:
1) элементы базы данных, к которым применяется операция;
2) SQL-агент (agent), провоцирующий выполнение операции.
SQL-агент получает соответствующий набор доступных привилегий на основании
конкретного идентификатора авторизации, называемого текущим идентификатором
авторизации (current authorization ID). В качестве текущего выступает один из
следующих идентификаторов:
a) идентификатор авторизации модуля — если модуль, выполняемый SQL-
агентом, обладает таковым;
b) идентификатор авторизации сеанса — в противном случае.
Право выполнения SQL-команды предоставляется в том случае, если текущий
идентификатор авторизации дает возможность получения всех привилегий, необходимых
для обращения к элементам базы данных, которые затрагиваются командой.
Пример 8.35. Чтобы продемонстрировать механизм контроля привилегий, вновь
обратимся к команде, рассмотренной в примере 8.34 на с. 405. Предположим, что таблицы
Movie и Studio, адресуемые командой, являются частью схемы MovieSchema,
созданной пользователем jane и находящейся в ее владении. Пользователь jane, таким
образом, приобретает все привилегии, касающиеся указанных таблиц и любых других
элементов схемы MovieSchema, и, более того, способна передавать некоторые
привилегии другим пользователям, используя механизм, о котором мы расскажем в разделе
8.7.4. Но сейчас будем считать, что никто, кроме jane, никакими привилегиями не
обладает. Существует несколько сценариев выполнения команды insert из примера
8.34, если рассматривать ее в контексте механизма контроля привилегий.
8.7. БЕЗОПАСНОСТЬ И АВТОРИЗАЦИЯ ПОЛЬЗОВАТЕЛЕЙ В SQL
407
1. Операция вставки может быть выполнена как часть модуля, созданного
пользователем jane с указанием предложения authorization jane. Идентификатор
авторизации, если таковой задан при создании модуля, всегда выбирается в
качестве текущего. Тогда и модуль в целом, и содержащаяся в нем команда
INSERT будут снабжены именно теми привилегиями, которыми обладает jane,
включая полные права на манипуляции таблицами Movie и studio.
2. Команда insert является частью модуля, авторство которого не
зафиксировано. Пользователь jane открывает соединение, введя в команду CONNECT
предложение authorization jane. Теперь идентификатор авторизации jane вновь
становится текущим, так что для выполнения команды INSERT у jane есть
полный набор привилегий.
3. Пользователь jane передает все привилегии, касающиеся таблиц Movie и studio,
пользователю ed или пользователю public (т.е. любому пользователю).
Команда вставки является частью модуля, созданного с применением опции
authorization ed. Поскольку теперь текущим идентификатором авторизации
является ed и этот пользователь обладает всеми необходимыми привилегиями,
команда insert может быть выполнена и в этом случае.
4. Как и в п. 3, jane передала все требуемые привилегии пользователю ed. Команда
вставки, размещенная в модуле, владелец которого не определен, выполняется во
время сеанса, открытого командой connect, содержавшей предложение
authorization ed. Текущим идентификатором авторизации является ed, что
дает пользователю все привилегии, необходимые для выполнения операции вставки.
□
Пример 8.35 иллюстрирует ряд моментов, которые имеет смысл обобщить.
Требуемые привилегии доступны, если:
• владельцем данных является тот пользователь, идентификатор авторизации
которого выступает в роли текущего; этому случаю соответствуют сценарии 1 и 2;
• пользователь, идентификатор авторизации которого является текущим, получил
привилегии от владельца данных либо таковые были переданы пользователю
public (см. сценарии 3 и 4);
• выполняется модуль, обладает которым владелец данных или некто,
получивший привилегии от другого пользователя; разумеется, для выполнения модуля
необходимо иметь привилегию execute, относящуюся к этому модулю
(см. сценарии 1 и 3);
• модуль, открытый для пользователя public, выполняется во время сеанса,
идентификатор авторизации которого совпадает с идентификатором
пользователя, обладающего необходимыми привилегиями (см. сценарии 2 и 4).
8.7.4. Назначение привилегий
В примере 8.35 было показано, насколько важно для пользователя (т.е. для
идентификатора авторизации) обладать привилегиями, требуемыми для выполнения той
или иной операции. Но до сих пор мы полагали, что единственный способ
приобретения привилегий связан с созданием элемента данных и его владением. В SQL
предусмотрена команда GRANT, которая позволяет одному пользователю назначать, или
"даровать" (grant), определенные права другому. "Даритель", тем не менее,
привилегий не лишается; речь, таким образом, идет о передаче "копии" привилегии.
Между назначением и копированием привилегий существует одно принципиальное
различие. С каждой привилегией ассоциировано право передачи (grant option). Например,
408
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
один пользователь обладает привилегией, подобной SELECT для таблицы Movie, с
правом ее передачи, в то время как другому пользователю "дарована" та же привилегия, но
без права передачи. Тогда первый пользователь способен назначить привилегию select
для таблицы Movie третьему пользователю, причем либо предоставить ему право
передавать привилегию, либо нет. Однако второй пользователь, который лишен права
передачи привилегии SELECT для таблицы Movie, назначить ее кому-либо еще не сможет.
Если так случится, что третий пользователь со временем приобретет ту же привилегию,
но уже с правом ее передачи, он получит возможность при необходимости назначить ее
четвертому пользователю — и вновь либо с правом передачи, либо без такового — и т.д.
Ниже перечислены составные части команды назначения привилегии.
1. Служебное слово grant.
2. Список, включающий описание одной или нескольких привилегий, таких как
SELECT или INSERT (name). Вместо списка привилегий допускается задавать
предложение all privileges, означающее, что "даритель" назначает
получателю все привилегии, относящиеся к элементу базы данных, упомянутому
после служебного слова on (см. п. 4).
3. Служебное слово on.
4. Название элемента базы данных (обычно базового отношения или виртуальной
таблицы). Допустимо задавать привилегии, касающиеся доменов и иных
элементов схемы, которые мы подробно рассматривать не будем (см. врезку "Другие
элементы схемы" на с. 379), однако в подобных ситуациях название элемента, как
правило, предваряется соответствующим служебным словом (таким как domain).
5. Служебное слово то.
6. Список, состоящий из одного или нескольких имен пользователей
(идентификаторов авторизации).
7. Необязательное предложение with grant option.
Конструкцию команды назначения привилегий можно кратко описать так:
GRANT <список привилегий> ON олемент базы данных>
ТО <список пользователей [WITH GRANT OPTION]
где в квадратные скобки заключено предложение, не обязательное для использования.
Чтобы выполнение команды завершилось успешно, пользователь, который ее
активизирует, должен обладать всеми привилегиями, которые поддерживаются
соответствующими правами передачи. "Даритель" может обладать и привилегиями более
общего характера (разумеется, с опцией права передачи) в сравнении с теми, которые
он назначает. Например, обладание привилегией insert для таблицы studio
с правом передачи позволяет пользователю назначить кому-либо другому
привилегию INSERT (name) для той же таблицы.
Пример 8.36. Предположим, что пользователь jane, являющаяся владельцем схемы
MovieSchema, которая содержит таблицы
Movie(title, year, length, inColor, studioName, producerC#)
Studio(name, address, presC#)
назначает привилегии insert и select для таблицы studio и привилегию select
для Movie пользователям kirk и vasya, причем с правом передачи. Соответствующие
команды могут выглядеть так:
GRANT SELECT, INSERT ON Studio TO kirk, vasya
WITH GRANT OPTION;
GRANT SELECT ON Movie TO kirk, vasya
WITH GRANT OPTION;
8.7. БЕЗОПАСНОСТЬ И АВТОРИЗАЦИЯ ПОЛЬЗОВАТЕЛЕЙ В SQL
409
Пусть теперь пользователь vasya назначает пользователю ed те же привилегии, но
уже без права их передачи. Василию придется выполнить следующие команды:
GRANT SELECT, INSERT ON Studio TO ed;
GRANT SELECT ON Movie TO ed;
Пользователь kirk, в свою очередь, вознамерился облагодетельствовать пользователя ed
набором привилегий, более узким, но тем не менее достаточным для выполнения SQL-
инструкции, приведенной на рис. 8.25 (см. с. 406), а именно SELECT и INSERT (name)
для Studio и SELECT для Movie. Команды их назначения таковы:
GRANT SELECT, INSERT(name) ON Studio TO ed;
GRANT SELECT ON Movie TO ed;
Заметьте, что пользователь ed получил привилегии SELECT для Movie и studio из двух
источников. Привилегия INSERT (name) также назначена дважды: пользователем kirk
непосредственно и пользователем vasya —- в виде более общей привилегии INSERT. □
8.7.5. Диаграммы назначения привилегий
Поскольку в процессе назначения привилегий и передачи прав на них привилегии
зачастую перекрываются и зависимости между "дарителями" и получателями
привилегий становятся все более сложными, структуры привилегий полезно представлять
в виде графов, называемых диаграммами назначения (grant diagrams). СУБД
поддерживают внутреннее представление подобных диаграмм с целью отслеживания событий
назначения и получения привилегий; такая информация используется в случае
возможного аннулирования (revoke) привилегий (обращайтесь к разделу 8.7.6).
Вершины графа соответствуют пользователям и привилегиям. Одна и та же
привилегия с опцией права передачи и без таковой должна представляться различными
вершинами. Если пользователь U назначает привилегию Р пользователю V и если эта
операция выполняется на том основании, что U обладает привилегией Q (где Q — это
привилегия Р с правом передачи либо некоторое обобщение привилегии Р, опять же
с правом передачи), в граф включается дуга, соединяющая вершину U/Q с вершиной V/P.
Пример 8.37. На рис. 8.26 изображена диаграмма назначения привилегий,
иллюстрирующая результаты выполнения последовательности команд grant, рассмотренных
в примере 8.36. Граф соответствует следующим соглашениям: символом звездочки (*)
обозначены привилегии с опцией права передачи; двумя звездочками (**) помечены
привилегии, унаследованные пользователем на основании права владения элементом
базы данных, а не полученные им от других пользователей. Это различие проявляется
в ситуации, связанной с аннулированием (revoke) привилегий (см. раздел 8.7.6).
Привилегии, обозначенные двумя звездочками, автоматически включают право передачи. □
8.7.6. Аннулирование привилегий
Назначенные привилегии могут быть в любой момент отозваны. Аннулирование
(revoke) одной привилегии нередко связано с выполнением ряда каскадных действий
по отмене иных привилегий: если отзывается привилегия, назначенная другим
пользователям с правом передачи, она должна быть отобрана и у этих пользователей.
Ниже перечислены составные части команды аннулирования привилегии.
1. Служебное слово revoke.
2. Список, включающий описание одной или нескольких привилегий.
3. Служебное слово on.
4. Название элемента базы данных (см. п. 4 описания составных частей команды
GRANT в разделе 8.7.4 на с. 408).
410
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Рис. 8.26. Диаграмма назначения привилегий
5. Служебное слово from.
6. Список, состоящий из одного или нескольких имен пользователей
(идентификаторов авторизации).
Конструкцию команды аннулирования привилегий можно кратко описать так:
REVOKE <список привилегий> ON олемент базы данных>
FROM <список пользователей
В команду revoke допустимо включать некоторые необязательные предложения.
1. Команду можно завершить служебным словом cascade. В этом случае при
аннулировании указанных привилегий будут также отозваны такие привилегии, которые
назначены только посредством аннулируемых привилегий. Иными словами, если
пользователь U отбирает у пользователя V привилегию Р, основанную на
привилегии Q, принадлежащей U, из графа диаграммы привилегий удаляется дуга,
соединяющая вершину U/Q с вершиной V/P; теперь любая вершина графа, в которую
нельзя "прийти" по цепочке дуг ни из одной вершины, помеченной двумя
звездочками (т.е. отображающей привилегию, унаследованную пользователем на
основании права владения элементом базы данных), также подлежит удалению.
2. Вместо cascade разрешено задавать опцию restrict, означающую, что
команда revoke не может быть выполнена, если применение правила каскадной
отмены привилегий, описанного выше, приводит к удалению любых
привилегий на том основании, что они были переданы другим пользователям с
помощью аннулируемых привилегий.
8.7. БЕЗОПАСНОСТЬ И АВТОРИЗАЦИЯ ПОЛЬЗОВАТЕЛЕЙ В SQL
411
Служебное слово revoke допустимо заменять предложением
revoke grant option for, означающим, что отмене подлежат не привилегии как
таковые, а права на их передачу другим пользователям. Эта форма команды revoke
также может быть пополнена предложениями cascade или restrict.
Пример 8.38. Вернемся к примеру 8.36 на с. 409 и предположим, что пользователь
jane с помощью указанных ниже команд аннулирует привилегии, назначенные ею
пользователю vasya:
REVOKE SELECT, INSERT ON Studio FROM vasya CASCADE;
REVOKE SELECT ON Movie FROM vasya CASCADE;
Это значит, что из графа диаграммы назначения привилегий, изображенной на
рис. 8.26, необходимо удалить дуги, соединяющие вершины-привилегии jane с
вершинами, соответствующими привилегиям пользователя vasya. Поскольку команды
включают опцию cascade, требуется убедиться (и это нетрудно сделать), что
вершины vasya недостижимы по цепочке дуг ни из одной вершины, помеченной двумя
звездочками (это было бы не так, если бы Вася удосужился получить аналогичные
привилегии и от другого пользователя). Вершина, отвечающая привилегии
INSERT ON Studio для пользователя ed, также становится недостижимой и должна
быть удалена наряду с вершинами-привилегиями vasya.
Обратите внимание, что вершины-привилегии SELECT ON Movie, SELECT ON Studio
и INSERT (name) ON Studio, назначенные пользователю ed, каскадному удалению
в данном случае не подлежат, поскольку все они соединены дугами с вершинами
jane при посредничестве вершин kirk. Диаграмма, соответствующая структуре
привилегий после выполнения рассмотренных команд revoke, изображена на рис. 8.27. □
Пример 8.39. Существует несколько тонких моментов, связанных с процессами
аннулирования привилегий, и для их иллюстрации мы прибегнем к нескольким
абстрактным примерам. Прежде всего, если удаляется общая привилегия /?, это не значит, что
должна быть отозвана и назначенная привилегия, являющаяся частным случаем р.
Рассмотрим ситуацию, когда пользователь U, владеющий отношением /?,
вначале назначает пользователю V общую привилегию insert для /?, а затем более
частную привилегию, insert (А), для того же отношения R.
Операция Кем выполнена Действие
1 U GRANT INSERT ON R TO V
2 U GRANT INSERT(A) ON R TO V
3 U REVOKE INSERT ON R FROM V RESTRICT
Когда пользователь U аннулирует привилегию insert у V, привилегия insert (A)
остается в силе. Диаграммы назначения привилегий после выполнения операций 2
и 3 показаны на рис. 8.28.
Обратите внимание, что после операции 2 граф содержит две схожие, но отдельные
вершины, соответствующие привилегиям, полученным пользователем V. Примите к
сведению и то, что опция restrict не препятствует аннулированию, поскольку
пользователь V не передавал полученные им привилегии кому бы то ни было еще (впрочем, он
и не смог бы этого сделать, поскольку получил привилегии без права передачи). □
Пример 8.40. Теперь рассмотрим ситуацию, когда пользователь U назначает
пользователю V привилегию р с правом ее передачи, а затем аннулирует только это право,
но не привилегию как таковую. В этом случае нам придется отразить на диаграмме
факт потери права передачи, а также удалить дуги, которые исходят из вершины V/p
и иллюстрируют возможные операции передачи пользователем V привилегии р
каким-либо другим пользователям. Примерная последовательность операций может
выглядеть так, как показано в таблице.
412
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Рис. 8.27. Диаграмма рис. 8.26 после удаления привилегий
пользователя vasya
INSERT \_
ON R Г
Ji INSERT ]
V ON R )
I INSERT
V ON R
V
INSERT(A)
ON R
Операция
а) после операции 2 b) после операции 3
Рис. 8.28. Аннулирование общей привилегии не затрагивает
частную привилегию
Кем выполнена Действие
U
V
U
GRANT p TO V WITH GRANT OPTION
GRANT p TO W
REVOKE GRANT OPTION FOR p FROM V CASCADE
8.7. БЕЗОПАСНОСТЬ И АВТОРИЗАЦИЯ ПОЛЬЗОВАТЕЛЕЙ В SQL
413
Операция 1 предполагает назначение пользователем U пользователю V
привилегии р с правом ее передачи. Выполняя операцию 2, пользователь V передает
привилегию р пользователю W. Соответствующая диаграмма назначения привилегий
приведена на рис. 8.29(a).
а) после операции 2 Ь) после операции 3
Рис. 8.29. Аннулирование права передачи не отменяет привилегию
При выполнении операции 3 пользователь U аннулирует право передачи
привилегии р пользователем V, но не отбирает саму привилегию р. Символ звездочки,
которым помечена вершина V/p, теперь необходимо изъять. Вершина, не обозначенная
таким символом (*), не может выступать в качестве источника ("дарителя")
привилегий, поэтому исходящие из нее дуги (в частности, дуга, связывающая V/p с W/p) также
должны быть удалены. Теперь к вершине W/p нельзя "добраться" из вершины U/p,
помеченной двумя звездочками, поэтому W/p подлежит удалению. Вершина V/p, однако,
остается на месте — правда, уже без звездочки, поскольку право передачи привилегии
аннулировано. Итоговая диаграмма назначения привилегий показана на рис. 8.29(b). □
8.7.7. Упражнения к разделу 8.7
Упражнение 8.7.1. Ответьте, какие привилегии необходимы для выполнения
перечисленных ниже операций. В каждом случае укажите наиболее частные и общие
варианты привилегий, достаточные для достижения цели.
a) Запрос на рис. 6.5 (см. с. 269).
b) Запрос на рис. 6.7 (см. с. 274).
* с) Команда вставки на рис. 6.15 (см. с. 292).
d) Команда удаления из примера 6.36 на с. 293.
e) Команда обновления из примера 6.38 на с. 294.
О Ограничение check уровня кортежа на рис. 7.5 (см. с. 331).
g) Ограничение "общего вида" из примера 7.13 на с. 337.
* Упражнение 8.7.2. Начертите диаграммы назначения привилегий после
выполнения операций 4—6 из таблицы, показанной на рис. 8.30 (предполагается, что
пользователь А является владельцем отношения, к которому относится привилегия р).
Операция Кем выполнена Действие
1 A GRANT p ТО В WITH GRANT OPTION
2 A GRANT p TO С
3 В GRANT p TO D WITH GRANT OPTION
4 D GRANT p TO В, С, Е WITH GRANT OPTION
5 В REVOKE p FROM D CASCADE
6 A REVOKE p FROM С CASCADE
Puc. 8.30. Последовательность операций к упражнению 8.7.2
414
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
Упражнение 8.7.3. Начертите диаграммы назначения привилегий после
выполнения операций 5, 6 из таблицы, показанной на рис. 8.31 (предполагается, что
пользователь А является владельцем отношения, к которому относится привилегия р).
Операция Кем выполнена Действие
1 A GRANT p ТО В, Е WITH GRANT OPTION
2 В GRANT p TO С WITH GRANT OPTION
3 С GRANT p TO D WITH GRANT OPTION
4 E GRANT p TO С
5 E GRANT p TO D WITH GRANT OPTION
6 A REVOKE GRANT OPTION FOR p FROM В CASCADE
Puc. 8.31. Последовательность операций к упражнению 8.7.3
! Упражнение 8.7.4. Начертите итоговую диаграмму назначения привилегий после
выполнения операций из таблицы, показанной ниже (предполагается, что
пользователь А является владельцем отношения, к которому относится привилегия р).
Операция Кем выполнена Действие
1 A GRANT p ТО В WITH GRANT OPTION
2 В GRANT p TO В WITH GRANT OPTION
3 A REVOKE p FROM В CASCADE
8.8. Резюме
♦ "Внедренные " инструкции SQL. Вместо базового интерфейса SQL, позволяющего
вводить и выполнять команды SQL, зачастую удобнее и эффективнее
"внедрять" инструкции SQL в код программ, написанных с помощью
традиционных языков программирования, называемых в этом случае базовыми.
Препроцессор преобразует "внедренные" выражения SQL в вызовы функций
библиотеки базового языка.
♦ Проблема согласования моделей данных. Модель данных SQL существенным
образом отличается от соответствующих моделей, принятых в традиционных
языках программирования. Поэтому обмен информацией между фрагментами кода
SQL и кода, написанного на базовом языке, осуществляется с помощью общих
переменных, которые способны представлять содержимое компонентов
кортежей, полученных в результате выполнения запросов или подлежащих вставке,
обновлению или удалению.
♦ Курсоры. Курсор — это переменная SQL-программы, позволяющая получить
доступ к кортежу указанного отношения, а также "перемещаться" по кортежам
отношения в том или ином направлении. Если курсор открыт в программе,
написанной на базовом языке, содержимое компонентов текущего кортежа счи-
тывается в общие переменные и далее может быть обработано средствами
программы так, как это необходимо.
♦ Динамический SQL. Вместо "внедрения" в код программы на базовом языке
заранее известных SQL-конструкций, можно создавать программы, которые
формируют и выполняют строки SQL-выражений динамически.
8.8. РЕЗЮМЕ
415
♦ Хранимые модули. Существует технология создания коллекций процедур
и функций, хранимых в виде неотъемлемой части схемы базы данных. Такие
фрагменты кода пишутся на специальном языке, содержащем все необходимые
управляющие конструкции и совместимом с языком SQL. Для вызова
хранимых процедур и функций используются средства "внедренных" инструкций
SQL и базового интерфейса SQL.
♦ Среда SQL. При установке реляционной СУБД и вводе ее в эксплуатацию
создается среда SQL. В контексте среды SQL элементы базы данных (например,
отношения) группируются в схемы, каталоги и кластеры. Каталог представляет
собой набор схем, а кластер является самой крупной коллекцией элементов,
доступной для пользователя.
♦ Системы "клиент/сервер ". Когда SQL-клиент подключается к SQL-серверу,
создаются соединение (связь между двумя процессами) и сеанс
(последовательность операций). Код, выполняемый в течение сеанса,
размещается в модулях, а процесс выполнения модуля называют SQL-агентом.
♦ Интерфейс уровня вызовов. Существует стандартная библиотека функций,
называемая SQL/CLI или ODBC и используемая при написании программ на
языке С. Интерфейс SQL/CLI предоставляет возможности, аналогичные тем,
которыми обладает механизм "встроенных" инструкций SQL, но не требует
применения препроцессора.
♦ JDBC Java Database Connectivity — интерфейс, подобный SQL/CLI и применяемый
для создания приложений баз данных с помощью языка программирования Java.
♦ Управление параллельными процессами. SQL предлагает два механизма,
позволяющих предотвратить взаимное влияние параллельно выполняемых
процессов, — транзакции и курсоры с ограничениями. Допустимо включать в
конструкцию объявления курсора признак нечувствительности к возможным
изменениям информации в базе данных, вносимым параллельными процессами.
♦ Транзакции. SQL позволяет группировать выражения в транзакции —
неделимые единицы работы, — результаты выполнения которых допускают фиксацию
или откат (отмену). Откат может выполняться или приложением, или системой
с целью поддержки атомарности или заданного уровня изоляции.
♦ Уровни изоляции. SQL предоставляет возможность выполнять транзакции с
учетом одного из четырех уровней изоляции; мы кратко перечислим их ниже,
начиная с наиболее строгого и заканчивая самым "либеральным":
"последовательный" (транзакция может выполняться либо до начала любых других
транзакций, либо после их полного завершения); "повторяемое чтение" (каждый
кортеж, полученный в результате выполнения запроса, будет гарантированно
возвращен, если запрос вновь активизируется той же транзакцией); "чтение
фиксированных данных" (транзакция способна "видеть" только те данные,
которые зафиксированы другими транзакциями); "чтение нефиксированных
данных" (набор данных, которые может считывать транзакция, не ограничен).
♦ Курсоры и транзакции "только для чтения ". Любой курсор или транзакция могут
быть помечены признаком "только для чтения". Подобное объявление
информирует СУБД о том, что курсор или транзакция не изменяют базу данных и не
способны оказывать влияние на другие курсоры или транзакции, нарушая их
свойства чувствительности, порядка выполнения и т.д.
♦ Привилегии. С целью обеспечения безопасности СУБД позволяют задавать
различные привилегии доступа к тем или иным элементам базы данных. В число
подобных привилегий входят права на чтение отношений, вставку, обновление
и удаление кортежей, упоминание отношений в контексте ограничений
целостности, создание триггеров и т.п.
416
ГЛАВА 8. СИСТЕМНЫЕ АСПЕКТЫ SQL
♦ Диаграммы назначения привилегий. Пользователи-владельцы элементов базы
данных могут назначать привилегии другим конкретным пользователям и
пользователю public (т.е. любым пользователям). Одновременно с получением
привилегии пользователь может приобретать и право на ее передачу.
Назначенные привилегии при необходимости могут быть аннулированы. Существует
удобный способ графического представления привилегий в виде диаграмм,
позволяющий наглядно описать последовательность назначения и аннулирования
привилегий, а также взаимозависимости между их источниками и получателями.
8.9. Литература
За сведениями о том, как и где получить информацию о стандартах SQL,
обращайтесь к разделу 6.9 на с. 315. Описание стандарта PSM приведено в документе [4],
а [5] — это исчерпывающий учебник и справочник по хранимым процедурам и
функциям. Популярное введение в технологии JDBC содержится в [6].
Доклад [1] посвящен обсуждению ряда проблем управления транзакциями и
курсорами. За полной информацией о транзакциях и способах их практической реализации
обращайтесь к библиографическим ссылкам, упомянутым в разделе 18.11 на с. 945.
Общие подходы к проблеме организации системы привилегий впервые описаны
в работах [2] и [3].
1. Berenson H., Bernstein PA, Gray J.N., Melton J., O'NeU E., and O'NeU P. A critique of ANSI SQL
isolation levels, Proc. of ACM SIGMOD Intl. Conf. on Management of Data (1995), p. 1—10.
2. Fagin R. On an authorization mechanism, ACM Trans, on Database Systems, 3:3 (1978),
p. 310-319.
3. Griffiths-Selinger P., Wade B.W. An authorization mechanism for a relational database system,
ACM Trans, on Database Systems, 1:3 (1976), p. 242-255.
4. ISO/IEC Report 9075-4, 1996.
5. Melton J. Understanding SQL's Stored Procedures: A Complete Guide to SQL/PSM, Morgan-
Kaufmann, San Francisco, 1998.
6. White S., Fisher M., Cattell R.G.G., Hamilton G., and Hapner M. JDBC API Tutorial and
Reference, Addison-Wesley, Boston, 1999.
8.9. ЛИТЕРАТУРА
417
Глава 9
Объектная ориентация
и языки запросов
В этой главе мы обсудим два способа сочетания технологий объектно-
ориентированного программирования и языков запросов. OQL (Object Query
Language — язык объектных запросов) — это стандартизованный язык запросов,
предназначенный для использования в контексте объектно-ориентированных баз данных.
Он поддерживает и высокоуровневые декларативные средства SQL, и инструменты
объектно-ориентированного программирования. Язык OQL позволяет
манипулировать данными, описанными с помощью ODL (Object Definition Language) — языка
определения объектов, с которым вы знакомились в разделе 4.2 на с. 152.
Если OQL надлежит рассматривать как попытку перенесения лучших инструментов
SQL в мир объектно-ориентированного программирования, то разделы стандарта SQL-99,
посвященные относительно новым объектно-ориентированным средствам SQL, можно
трактовать как пример усилий, направленных на совершенствование SQL за счет
привлечения парадигмы объектно-ориентированного проектирования. Если мысленно
соединить материк реляционных баз данных с континентом объектных технологий
гипотетическим мостом, оба языка, о которых мы здесь говорим, могли бы "встретиться" на его
середине. Каждому из двух подходов, разумеется, присущи определенные достоинства
и недостатки, и некоторые вещи легче описать средствами одного языка, нежели другого.
Основное различие в подходах по существу заключается в ответе на вопрос о том,
насколько в действительности важна концепция отношения (relation). С точки зрения
апологетов объектно-ориентированного программирования, сосредоточенных на
технологиях ODL и OQL, ответ таков: "не слишком важна" — OQL способен оперировать
объектами самых разнообразных типов, и множества или мультимножества структур
(т.е. отношения) — это только частные примеры таких типов. Приверженцы "чистого"
SQL по-прежнему продолжают считать модель отношения краеугольным камнем систем
баз данных. Объектно-реляционный подход, о котором мы говорили в разделе 4.5 на
с. 180, предусматривает расширение реляционной модели посредством включения
в нее более сложных типов кортежей отношений и их атрибутов: модель пополняется
классами и объектами, но последние интерпретируются в контексте отношений.
9.1. Введение в язык OQL
OQL (Object Query Language — язык объектных запросов) позволяет представлять
запросы с помощью системы обозначений, совместимой с SQL, и, как предполагается, должен
использоваться в качестве инструмента "расширения" изобразительных средств базовых,
или "включающих" (host), объектно-ориентированных языков общего назначения (скажем,
C++, Smalltalk и Java), позволяющего обращаться к одним и тем же объектам и в запросах
(OQL), и в контексте выражений базового языка. Возможность "смешивания" запросов
и конструкций базового языка, исключающая необходимость применения общих
переменных или иных средств взаимного обмена данными между разнородными порциями
кода, демонстрирует несомненные преимущества OQL в сравнении с технологией
"внедрения" выражений SQL в базовый код, о которой мы говорили в разделе 8.1 на с. 350.
9.1.1. Пример объектно-ориентированной базы данных
Чтобы проиллюстрировать приемы использования OQL, целесообразно
воспользоваться добротным примером базы данных. Мы обратимся к знакомым вам классам
Movie, Star и Studio в той редакции, которая показана на рис. 4.3 (см. с. 157), и
пополним их объявления определениями ключей (keys) и экземпляров (extents). Класс
Movie содержит также объявления методов, заимствованные из текста рис. 4.4 на
с. 160. Полные объявления классов Movie, Star и Studio приведены на рис. 9.1.
9.1.2. Описание зависимости между объектами и их членами
Доступ к компонентам объектов и структур OQL осуществляется с помощью
оператора точки (.), схожего с аналогичными операторами традиционных языков
программирования, таких как С, C++ или Java, и языка SQL. Общее правило
использования оператора точки в OQL таково: если а — объект класса С, а р — некоторое
свойство (property) класса (атрибут, связь или метод), тогда выражение а.р обозначает
результат "применения" р к а. Иными словами,
1) если р — атрибут, а.р — значение атрибута р объекта а\
2) если р — связь, а.р — объект или коллекция объектов, соединенных с а
посредством связи р\
3) если р — метод (возможно, с параметрами), а.р(—) — результат вызова
метода р объекта а.
Пример 9.1. Обозначим как myMovie объект класса Movie. В этом случае:
• myMovie. length — это значение продолжительности воспроизведения
кинофильма, т.е. содержимое атрибута length объекта myMovie класса Movie;
• myMovie. lengthlnHours () — это значение продолжительности
воспроизведения кинофильма, выраженное в часах и возвращаемое методом lengthlnHours
объекта myMovie;
• myMovie. starsOf — множество (set) объектов класса star, соединенных
посредством связи starsOf с объектом myMovie;
• выражение myMovie. star Names (my Stars) означает вызов метода starNames;
метод не возвращает значения напрямую (поскольку помечен как void), но
делает это косвенным образом, присваивая "выходному" (out) параметру
myStars множество строк, содержащих имена актеров, принимавших участие
в съемках кинофильма, которому соответствует объект myMovie класса Movie.
□
В пределах одного выражения OQL допускается использовать несколько
операторов точки. Например, если myMovie обозначает объект класса Movie, тогда
выражение myMovie.ownedBy соответствует объекту класса Studio, отвечающему
киностудии, которая владеет фильмом myMovie, a myMovie.ownedBy .name — строке
наименования этой студии.
420
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
class Movie
(extent Movies key (title, year))
{
attribute string title;
attribute integer year;
attribute integer length;
attribute enum Film {color, blackAndWhite} filmType;
relationship Set<Star> starsOf
inverse Star::starredln;
relationship Studio ownedBy
inverse Studio::owns;
float lengthlnHours() raises(noLengthFound);
void starNames(out Set<String>);
void otherMovies(in Star, out Set<Movie>)
raises(noSuchStar);
};
class Star
(extent Stars key name)
{
attribute string name;
attribute Struct Addr
{string street, string city} address;
relationship Set<Movie> starredln
inverse Movie::starsOf;
};
class Studio
(extent Studios key name)
{
attribute string name;
attribute string address;
relationship Set<Movie> owns
inverse Movie::ownedBy;
};
Рис. 9.1. Объявления классов объектно-ориентированной
"кинематографической " базы данных
9.1.3. Выражения "select—from—where"
В языке OQL для описания запросов вида "select—from—where" используется
синтаксис, схожий с тем, который принят в SQL. Ниже приведен пример OQL-запроса,
предполагающего отыскание информации о дате выпуска кинофильма "Gone With the Wind":
SELECT m.year
FROM Movies m
WHERE m.title = "Gone With the Wind"
Обратите внимание, что конструкция вполне может "сойти" за SQL-запрос, если
двойные кавычки, обрамляющие содержимое строки, заменить одинарными и
завершить текст символом точки с запятой.
Выражение "select—from—where" в OQL содержит перечисленные ниже
составные части.
1. Служебное слово select со списком выражений.
2. Служебное слово from, за которым указывается список объявлений
переменных; объявление переменной включает:
а) выражение, значение которого относится к типу коллекций (например,
Set или Bag);
9.1. ВВЕДЕНИЕ В ЯЗЫК OQL
421
Операторы стрелки (->) и точки (.)
В языке OQL оператор стрелки (->) трактуется как синоним оператора точки (.).
Это соглашение в определенном смысле соответствует правилу использования
одноименных операторов в языке С, где и тот и другой используются для доступа
к компонентам структур. В языке С указанные операторы, однако, различаются
следующим образом: выражение вида а. f подразумевает, что а — это структура,
в то время как в выражении p->f переменная р обозначает указатель на структуру,
хотя обе конструкции открывают доступ к полю f структуры.
b) необязательное служебное слово as;
c) имя (идентификатор) переменной.
Обычно выражение, упомянутое в п. (а), представляет собой наименование
экземпляра (extent) некоторого класса: так, в нашем примере Movies является
экземпляром класса Movie (см. рис. 9.1). Экземпляр класса, таким образом,
служит аналогом отношения в предложении from SQL-запроса. Однако в контексте
объявления переменной вполне возможно использовать любое выражение,
относящееся к типу коллекций, — например, вложенный запрос "select—from—where".
3. Служебное слово where с логическим выражением. Операндами выражения
where, как и выражения select, могут служить константы и только те
переменные, которые объявлены в предложении from. Операторы сравнения
аналогичны операторам, применяемым в SQL, за исключением оператора "не
равно": в OQL он обозначается парой символов ! =, а в SQL — о. К выражениям
сравнения допустимо применять логические операторы and ("И"), or ("ИЛИ")
и not ("HE"), идентичные операторам SQL.
Запрос возвращает мультимножество (bag) объектов. То же мультимножество
можно вычислить с помощью вложенных циклов, в каждом из которых
просматриваются все возможные значения определенной переменной, упомянутой в
предложении from. Если некоторая комбинация значений переменных удовлетворяет
условию, заданному в предложении where, соответствующий объект, структура
которого описана предложением select, включается в мультимножество объектов,
служащее результатом обработки запроса.
Пример 9.2. Ниже приведен более сложный OQL-запрос:
SELECT s.name
FROM Movies m# m.starsOf s
WHERE m.title = "Casablanca"
Запрос предусматривает поиск имен актеров, принимавших участие в съемках
кинофильма "Casablanca". Обратите внимание на последовательность элементов
предложения from. Первым делом мы указываем, что переменная m представляет
произвольный объект класса Movie, принадлежащий экземпляру (т.е. множеству объектов)
Movies класса, а затем для каждого объекта m полагаем, что s является объектом
множества m.starsOf "актеров", участвовавших в съемках "фильма" т. Процесс
обработки запроса можно представить в виде двух циклов, один из которых вложен
в другой; циклы позволяют получить множество всех пар вида (m, s), таких, что m —
некоторый "кинофильм", as — "актер", занятый в этом кинофильме:
FOR (ДЛЯ) каждого m в Movies (ВЫПОЛНИТЬ) DO
FOR (ДЛЯ) каждого s в m.starsOf (ВЫПОЛНИТЬ) DO
IF (ЕСЛИ) m. title = "Casablanca" (ТОГДА) THEN
Добавить s.name в итоговое мультимножество объектов
422
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
Другая форма списка в предложении from
Помимо SQL-подобного синтаксиса, где каждый элемент представляется
наименованием типа коллекции, за которым следует идентификатор переменной этого типа,
OQL позволяет использовать совершенно равноценную, более логичную, но менее
схожую на SQL форму представления предложения from: каждый элемент списка
описывается идентификатором, служебным словом in и наименованием типа коллекции.
Предложение from запроса из примера 9.2 можно переписать, например, и так:
FROM m IN Movies, s IN m.starsOf
Условие предложения where позволяет сузить область поиска до множества пар,
компоненты m которых представляют объект Movie с атрибутом title, содержащим
строку "Casablanca". При выполнении предложения SELECT формируется
мультимножество (в данном случае — множество) значений атрибутов name объектов s из пар
(m, s), отвечающих условию предложения where, т.е. набор значений атрибутов name
объектов класса star, образующих подмножество mc.starsOf, где тс — объект класса
Movie, содержащий сведения о кинофильме "Casablanca". □
9.1.4. Изменение типа результата запроса
Запрос, рассмотренный в примере 9.2, возвращает мультимножество (bag) строк.
В OQL, так же как и в SQL, удаление дубликатов по умолчанию не
предусматривается, если только подобное требование не оговорено особо. Если необходимо, можно
указать, что в результате обработки запроса должны быть возвращены множество (set)
либо список (list) объектов.
• Если требуется получить множество объектов, следует сопроводить слово
select служебным словом distinct, как и в SQL.
• Чтобы представить итоговый набор объектов в виде списка, надлежит
пополнить текст запроса предложением order by (вновь, как в SQL).
Пример 9.3. Пусть необходимо получить множество имен актеров, участвовавших
в работе над кинофильмами, выпущенными студией "Disney". Следующий запрос
позволяет решить задачу, обеспечивая удаление повторяющихся имен в тех случаях,
когда актер снимался в нескольких фильмах компании "Disney".
SELECT DISTINCT s.name
FROM Movies m, m.starsOf s
WHERE m.ownedBy.name = "Disney"
Запрос по своей структуре напоминает тот, который был рассмотрен в примере 9.2.
Процесс его обработки вновь можно представить в виде вложенных циклов, в которых
"просматриваются" все пары "кинофильмов" и "актеров", участвовавших в съемках
этих фильмов. Но теперь критерием отбора пар вида (m, s) служит наличие в атрибуте
name объекта Studio, соединенного с объектом m связью ownedBy, строки "Disney". □
Предложение order by в OQL совершенно аналогично одноименному
предложению SQL. После пары служебных слов order и by задается список выражений.
Первое из выражений вычисляется для каждого объекта в итоговом мультимножестве
объектов, и объекты упорядочиваются в соответствии с полученными значениями.
Объекты, обладающие одинаковыми значениями для первого выражения списка
order by, сортируются по значениям второго выражения, если таковое задано, и т.д.
По умолчанию предлагается порядок сортировки по возрастанию (asc), но его можно
изменить на противоположный (по убыванию), если, как и в SQL, дополнить
соответствующий элемент списка служебным словом desc.
9.1. ВВЕДЕНИЕ В ЯЗЫК OQL
423
Пример 9.4. Предположим, что требуется получить список "кинофильмов" студии
"Disney", упорядоченный по значениям продолжительности их воспроизведения (length),
а фильмы, обладающие одинаковой продолжительностью, должны быть отсортированы
в алфавитном порядке следования их названий (title). Текст запроса представлен ниже.
SELECT m
FROM Movies m
WHERE m.ownedBy.name = "Disney"
ORDER BY m.length, m. title
При выполнении первых трех строк запроса рассматривается каждый объект m класса
Movie. Если названием (name) студии, владеющей (ownedBy) правами на фильм т,
является "Disney", объект m включается в итоговое мультимножество. Четвертая
строка указывает, что объекты т, выбранные в процессе обработки запроса, должны быть
упорядочены вначале по значениям продолжительности воспроизведения (m. length),
а затем, если какие-либо объекты m обладают одинаковым содержимым атрибутов
length, — в алфавитном порядке следования названий (m. title). В результате будет
получен список объектов-"кинофильмов". □
9.1.5. Сложные типы выходных данных
В качестве элементов списка предложения select в OQL-запросах вида "select—
from—where" могут задаваться не только простые переменные, но и выражения, в том
числе построенные с помощью конструкторов типов (type constructors). Например,
вполне допустимо применить к нескольким выражениям конструктор типа struct, чтобы
получить в результате выполнения запроса множество или мультимножество структур.
Пример 9.5. Пусть необходимо сформировать множество пар объектов-"актеров"
(Star), проживающих по одному и тому же адресу (address). Для этого достаточно
выполнить запрос:
SELECT DISTINCT Struct(starl: si, Star2: s2)
FROM Stars si, Stars s2
WHERE sl.address = s2.address AND si.name < s2.name
В процессе выполнения запроса рассматриваются все пары актеров sl и s2.
Предложение where задает критерий их выбора: во-первых, актеры должны обладать
одинаковым адресом; во-вторых, имя актера sl должно предшествовать имени актера s2
в списке, отсортированном по алфавиту, так что в результат не будут включены пары,
в которых одно и то же имя повторяется дважды, и пары, перечисляющие одинаковые
имена в различном порядке.
Для каждой пары имен, удовлетворяющей условию предложения where, создается
структура. Тип структуры представляет собой запись с двумя полями, названными как
starl и star2. Тип каждого из полей — это класс star, поскольку переменные sl
и s2, значения которых сохраняются в записи, относятся именно к типу star.
Формально говоря, типом рассматриваемой структуры является
Struct{starl: Star, star2: Star},
а тип результата выполнения запроса — это множество таких структур, т.е.
Set<Struct{starl: Star, star2: Star}>.
□
9.1.6. Подзапросы
Выражение "select—from—where" допускается использовать в любом "месте"
конструкции OQL, где возможно задание значения типа коллекции. Здесь мы приведем
только один пример, связанный с размещением подзапросов в предложении from.
Остальные варианты применения подзапросов рассмотрены в разделе 9.2 на с. 429.
424
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
Особый случай: список select с одним элементом
Необходимо отметить, что если список предложения select OQL-запроса
содержит только одно выражение, результат обработки запроса относится к типу
коллекции значений, каждое из которых обладает типом выражения. Если же
список select включает более одного выражения, результат представляется
в виде коллекции структур, неявным образом формируемых на основе
компонентов, соответствующих выражениям. Даже если бы предложение select запроса
из примера 9.5 выглядело просто как
SELECT DISTINCT starl: si, Star2: s2
типом результата все равно оказалось бы множество структур
Set<Struct{starl: Star, star2: Star}>.
Запрос из примера 9.3 на с. 423, однако, возвращает результат, типом которого
является Set<String>, а не Set<Struct{name: String}>.
Подзапросы в предложениях from способны возвращать коллекции объектов,
и областью допустимых значений переменной, представляющей коллекцию, является
множество значений членов коллекции.
Пример 9.6. Вернемся к запросу из примера 9.3 на с. 423, где предусматривается
отыскание информации об актерах, участвовавших в съемках кинофильмов, выпущенных
студией "Disney". Прежде всего, для получения множества объектов-"кинофильмов"
студии "Disney" целесообразно использовать запрос из примера 9.4 на с. 424:
SELECT m
FROM Movies m
WHERE m.ownedBy.name = "Disney"
Этот запрос можно применить в качестве подзапроса, определяющего множество
значений переменной d, которая представляет фильмы студии "Disney":
SELECT DISTINCT s.name
FROM (SELECT m
FROM Movies m
WHERE m.ownedBy.name = "Disney") d,
d.starsOf s
Подобная форма запроса не намного более пространна, нежели та, которая приведена
в примере 9.3, но, вероятно, более "содержательна". Предложение from можно
описать в виде двух вложенных циклов: переменная d внешнего цикла "проходит" по
всем "фильмам" студии "Disney", множество которых возвращается подзапросом,
а диапазон изменения переменной s внутреннего цикла определяется множеством
"актеров", снимавшихся в "фильме" d. Обратите внимание, что надобность в
использовании предложения where в тексте "основного" запроса не возникает. □
9.1.7. Упражнения к разделу 9.1
Упражнение 9.1.1. На рис. 9.2 приведена ODL-версия схемы базы данных
"компьютерных продуктов", впервые рассмотренной в упражнении 5.2.1 на с. 218.
Классы PC, Laptop и Printer, отвечающие трем типам продуктов, представлены
в виде подклассов (subclasses) базового (superclass) класса Product. Следует обратить
внимание, что значение типа конкретного продукта может быть получено
двояко—с помощью атрибута type и непосредственно из факта принадлежности
объекта продукта к одному из трех производных классов. Разумеется, мы не считаем
такое решение безукоризненным, поскольку, строго говоря, оно не препятствует
9.1. ВВЕДЕНИЕ В ЯЗЫК OQL
425
возможности присваивания объекту неверного значения атрибута type — скажем,
объекту класса рс значения "laptop" или "printer". Однако такой подход сулит
ряд любопытных возможностей представления запросов.
Поскольку атрибут type наследуется классом Printer от базового класса
Product, мы вынуждены переименовать собственный атрибут type класса
Printer, скажем, в printerType. Атрибут printerType служит для обозначения
типа технологии, поддерживаемой принтером ("laser" — лазерный, "ink-jet" —
струйный, "bubble" — пузырьковый) , а атрибут type класса Product содержит
значение типа продукта ("рс", "laptop" или "printer").60
Добавьте в ODL-объявления классов, указанные на рис. 9.2, сигнатуры методов
(см. раздел 4.2.7 на с. 159), позволяющих выполнять перечисленные ниже функции.
* а) Уменьшить значение цены (price) продукта (Product) на х, полагая, что л;
передается методу в виде входного (in) параметра.
* Ь) Возвратить значение быстродействия процессора (speed) продукта
(Product), если тот является персональным ("рс") или переносным
("laptop") компьютером, а в противном случае сгенерировать исключение
типа notComputer.
c) Установить значение размера экрана (screen) переносного компьютера
(Laptop) равным содержимому входного (in) параметра х.
! d) Для продукта р, заданного в виде входного (in) параметра, определить,
обладает ли продукт q, которому отвечает текущий объект, большим
быстродействием процессора (speed) и меньшей ценой (price), нежели р.
Обеспечить выбрасывание исключения типа badinput, если р не является
продуктом, обладающим атрибутом speed, т.е. не относится ни к персональным
(РС), ни к переносным (Laptop) компьютерам, и исключения типа noSpeed,
если тем же атрибутом не обладает объект q.
Упражнение 9.1.2. Используя ODL-схему, рассмотренную в упражнении 9.1.1
и представленную на рис. 9.2, напишите OQL-запросы, позволяющие решить
следующие задания.
* а) Найти номера моделей (model) всех продуктов (Product), являющихся
персональными компьютерами (значение "рс" атрибута type), которые
обладают ценой (price), меньшей 2000 долларов.
Ь) Найти номера моделей (model) всех персональных компьютеров (рс) с
объемом оперативной памяти (ram) не ниже 128 Мбайт.
*! с) Найти производителей (maker), выпускающих по меньшей мере две
различные модели (model) лазерных (значение "laser" атрибута printerType)
принтеров (Printer).
d) Сформировать множество пар вида (г, /г), соответствующих персональным
(рс) и переносным (Laptop) компьютерам, обладающим оперативной
памятью объемом (ram) r Мбайт и диском емкостью (hd) h Гбайт.
e) Создать список персональных компьютеров (рс) (объектов, а не номеров
моделей), упорядоченный по возрастанию значений быстродействия
процессора (speed).
60 Еще одно отличие схем отношений из упражнения 5.2.1 от структур классов,
приведенных на рис. 9.2, состоит в том, что последние наследуют от базового класса Product атрибут
maker. — Прим. перев.
426
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
! f) Создать список номеров моделей (model) переносных компьютеров
(Laptop) с оперативной памятью объемом (ram) не менее 64 Мбайт,
упорядоченный по убыванию размера экрана (screen).
class Product
(extent Products key model)
{
attribute integer model;
attribute string maker;
attribute string type;
attribute real price;
};
class PC extends Product
(extent PCs)
{
attribute integer speed;
attribute integer ram;
attribute integer hd;
attribute string rd;
};
class Laptop extends Product
(extent Laptops)
{
attribute integer speed;
attribute integer ram;
attribute integer hd;
attribute real screen;
};
class Printer extends Product
(extent Printers)
{
attribute boolean color;
attribute string printerType;
};
Рис. 9.2. ODL-схема базы данных "компьютерных продуктов"
Упражнение 9.1.3. На рис. 9.3 представлены ODL-объявления классов базы данных
с информацией о судах и морских сражениях. Добавьте в состав классов сигнатуры
методов, позволяющих выполнять перечисленные ниже функции.
a) Вычислить значение "огневой мощи" судна, равное количеству главных орудий
(numGuns), умноженному на величину их калибра (bore), возведенную в куб.
b) Найти суда, однотипные (sister) по отношению к заданному судну.
Обеспечить выбрасывание исключения типа noSisters, если судно является
единственным представителем своего класса (class).
c) Для объекта Ь, представляющего морское сражение (Battle) и задаваемого
в качестве входного (in) параметра, найти множество судов (ship),
потопленных (значение sunk атрибута status) в сражении Ь, при условии, что
судно, описываемое текущим объектом s класса ship, участвовало в том же
сражении. Обеспечить выбрасывание исключения типа
didNotParticipate, если судно s не принимало участия в сражении Ь.
d) Добавить объект-"судно" со значениями имени (name) и года спуска на воду
(launched), заданными в качестве входных (in) параметров, в состав
текущего класса (class) судов.
9.1. ВВЕДЕНИЕ В ЯЗЫК OQL
427
class Class
(extent Classes key name)
{
attribute string name;
attribute string type;
attribute string country;
attribute integer numGuns;
attribute integer bore;
attribute integer displacement;
relationship Set<Ship> ships inverse Ship::classOf;
};
class Ship
(extent Ships key name)
{
attribute string name;
attribute integer launched;
relationship Class classOf inverse Class::ships;
relationship Set<Outcome> inBattles
inverse Outcome::theShip;
};
class Battle
(extent Battles key name)
{
attribute string name;
attribute Date dateFought;
relationship Set<Outcome> results
inverse Outcome::theBattle;
};
class Outcome
(extent Outcomes)
{
attribute enum Stat {ok, sunk, damaged} status;
relationship Ship theShip inverse Ship::inBattles;
relationship Battle theBattle inverse Battle::results;
};
Рис. 9.3. ODL-схема "морской " базы данных
! Упражнение 9.1.4. Повторите решение заданий упражнения 9.1.2, используя в
каждом из запросов по меньшей мере один подзапрос.
Упражнение 9.1.5. Используя ODL-схему, рассмотренную в упражнении 9.1.3
и представленную на рис. 9.3, напишите OQL-запросы, позволяющие решить
следующие задания.
a) Найти названия классов (class) судов с количеством главных орудий
(numGuns), не меньшим девяти.
b) Найти суда (ship) (объекты, а не названия), обладающие не менее чем
девятью главными орудиями (numGuns).
c) Сформировать список названий судов водоизмещением (displacement)
ниже 30 тыс. тонн, упорядоченный по возрастанию значений года спуска
судов на воду (launched), а для судов-"одногодков" — в алфавитном
порядке следования их названий (name).
d) Найти пары объектов-"судов" (не названий), относящихся к одному
классу (class).
428
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
! е) Найти названия (name) сражений (Battle), в которых были потоплены
(значение sunk атрибута status) суда не менее двух стран (country).
!! f) Найти названия (name) сражений (Battle), в которых ни одно из судов не
было повреждено (значение damaged атрибута status).
9.2. Дополнительные формы выражений OQL
Выше мы уже рассказывали об OQL-выражениях вида "select-from-where". В этом
разделе будут рассмотрены другие формы операторов, позволяющих создавать
конструкции языка OQL, в том числе логические множественные условия (logical quantifiers)
вида for all и exists, операторы агрегирования (aggregation), оператор группирования
group by и теоретико-множественные операторы объединения (union), пересечения
(intersection) и разности (difference).
9.2.1. Логические множественные условия
Язык OQL позволяет формулировать логические множественные условия (logical
quantifiers), которые дают возможность проверить, во-первых, все ли члены х коллекции
S удовлетворяют определенному условию С(х) и, во-вторых, существует ли по меньшей
мере один член х коллекции 5, для которого заданное условие С(х) справедливо. Первое
логическое множественное условие записывается в виде следующего OQL-выражения:
FOR ALL x IN S : С(х),
результат вычисления которого равен true, если каждый элемент х коллекции S
удовлетворяет условию С(х), и false — в противном случае. Аналогично, выражение
второго логического условия,
EXISTS x IN S : С(х),
обращается в true, если в составе коллекции S существует по меньшей мере один
элемент х, для которого условие С(х) выполняется, и в false — в противном случае.
Пример 9.7. Другой вариант оформления рассмотренного ранее запроса,
предполагающего необходимость отыскания всех актеров, снимавшихся в кинофильмах,
выпущенных студией "Disney", представлен на рис. 9.4. Здесь мы сосредоточиваем внимание на
актере s и задаемся вопросом, участвовал ли он в съемках некоторого фильма т, правами
на который владеет студия "Disney". Строка 3 заставляет систему обратиться к каждому из
объектов-"кинофильмов" m множества s.starredln, представляющего набор
кинофильмов с участием актера s. Строка 4 задает условие, гласящее, что атрибут name объекта m
должен содержать строку "Disney". Если хотя бы один такой объект m существует,
выражение exists в строках 3, 4 обращается в true, а в противном случае — в false.
1) SELECT s
2) FROM Stars s
3) WHERE EXISTS m IN s.starredln :
4) m.ownedBy.name = "Disney"
Рис. 9.4. Пример использования логического множественного условия EXISTS
□
Пример 9.8. Рассмотрим способ применения логического условия FOR ALL в
контексте OQL-запроса, предусматривающего поиск всех актеров, участвовавших в съемках
только тех кинофильмов, которые выпущены студией "Disney". Текст запроса показан
на рис. 9.5. Строго говоря, результат выполнения запроса охватывает и тех "актеров",
которые вообще не снимались ни в одном кинофильме (если таковые представлены
9.2. ДОПОЛНИТЕЛЬНЫЕ ФОРМЫ ВЫРАЖЕНИЙ OQL
429
в экземпляре базы данных). Разумеется, можно дополнить предложение where
специальным условием, оговаривающим, что актер должен был участвовать в съемках хотя
бы одного фильма, но мы возлагаем эту обязанность на читателя.
SELECT S
FROM Stars S
WHERE FOR ALL m IN s.starredln :
m.ownedBy.name = "Disney"
Рис. 9.5. Пример использования логического множественного условия FOR ALL
□
9.2.2. Выражения с операторами агрегирования
В OQL используются те же операторы агрегирования (aggregation), что и в SQL: AVG,
count, sum, min и max, позволяющие вычислять среднее арифметическое, количество,
сумму, минимальное и максимальное значения соответственно. В SQL эти операторы
допускают применение к определенным столбцам отношений, а в OQL — к любым
коллекциям элементов подходящих типов. Говоря о "подходящих" типах, мы имеем в виду, что
оператор count разрешено применять к любым коллекциям без ограничений, операторы
AVG и SUM — к коллекциям элементов числовых типов (например, integer), a min
и мах — к коллекциям объектов, допускающих сравнение (таких как числа или строки).
Пример 9.9. Для вычисления средней продолжительности воспроизведения всех
кинофильмов вначале следует создать мультимножество значений продолжительности
(length). Заметьте, что нас интересует именно мультимножество, а не множество —
в последнем случае два кинофильма с одинаковой продолжительностью были бы
восприняты как один. Искомый запрос может выглядеть так:
AVG(SELECT m.length FROM Movies m)
Иными словами, к результату подзапроса, возвращающего мультимножество значений
продолжительности воспроизведения всех кинофильмов, применяется оператор AVG,
вычисляющий среднее значение. □
9.2.3. Выражения с оператором группирования
Предложение group by перекочевало в OQL из SQL, но приобрело одну
любопытную особенность. Предложение group by в OQL-запросе содержит
перечисленные ниже составные части.
1. Служебные слова group by.
2. Список, состоящий из одного или нескольких группирующих атрибутов (partition
attributes), перечисленных через запятую. Каждый элемент списка состоит из:
a) имени атрибута (поля);
b) символа двоеточия;
c) выражения.
Синтаксическую форму предложения group by OQL-запроса можно кратко описать так:
GROUP BY fx:eXl f2:e2, . . . , fn:en
Предложения group by применяются в контексте запросов вида "select—from—
where". В выражениях еь еъ..., еп допустимо ссылаться на переменные, упомянутые
в предложении from. Чтобы упростить обсуждение особенностей оператора
группирования в OQL, ограничим внимание случаем, когда предложение from содержит толь-
430
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
ко одну переменную х. Пусть областью допустимых значений переменной д: служит
множество элементов некоторой коллекции С. Для каждого элемента / коллекции С,
удовлетворяющего условию предложения where, вычисляются выражения
предложения GROUP by; полученную группу значений можно представить как e{(i), e2(i),..., en(i).
Промежуточная коллекция
При вычислении предложения group by возвращается множество структур,
которое мы называем промежуточной коллекцией (intermediate collection). Каждый член
промежуточной коллекции представляет собой структуру
Struct (fi:vu f2:v2, ..., fn-vn, partition :P).
Первые п полей обозначают группу, т.е. выражение (vb v2,..., vn) является списком
значений (ex(i), e2(i),..., е„(0) Для каждого элемента / коллекции С, удовлетворяющего
условию выражения where.
Последнее поле носит специальное имя partition. Значением Р служит
мультимножество структур вида struct (x:i), где х — переменная из предложения from.
Итоговая коллекция
В предложении select OQL-запроса "select—from—where", содержащего
предложение group by, разрешено ссылаться только на поля структур промежуточной
коллекции, а именно на/ь/2? • ••■>/« и partition. При посредничестве partition мы
получаем доступ к полю х, присутствующему в структурах, являющихся членами
мультимножества Р — значения partition. На переменную х предложения from
допустимо ссылаться только внутри некоторого оператора агрегирования,
применяемого по отношению ко всем членам мультимножества Р. Результат выполнения
предложения select мы называем итоговой коллекцией (output collection).
Пример 9.10. Пусть необходимо построить таблицу, содержащую значения суммарной
продолжительности воспроизведения кинофильмов, выпущенной каждой студией
в каждом году. Фактически требуется построить мультимножество структур, каждая из
которых содержит три поля, соответствующих названию студии, году и значению
суммарной продолжительности кинофильмов, снятых на указанной киностудии в
течение заданного года. Текст OQL-запроса приведен на рис. 9.6.
SELECT stdo, yr, sumLength: SUM(SELECT p.m.length
FROM partition p)
FROM Movies m
GROUP BY stdo: m.ownedBy.name, yr: m.year
Рис. 9.6. Пример использования предложения GROUP BY
Чтобы разобраться в существе запроса, вначале обратимся к предложению from.
Здесь указана переменная т, областью допустимых значений которой является
множество всех объектов класса Movie. Переменная т в данном случае играет роль
переменной х, которая использовалась в выкладках, приведенных выше. Предложение group by
содержит два поля, stdo и уг, соответствующие выражениям m. ownedBy .name и m.year.
Рассмотрим кинофильм "Pretty Woman", снятый на киностудии "Disney"
в 1990 году. Когда т "достигает" объекта Movie, отвечающего этому фильму,
значением m.ownedBy.name становится "Disney", а значением m.year— 1990. Одним из
членов промежуточной коллекции окажется структура
Struct(stdo:"Disney", yr11990, partition:P),
где Р — множество структур; Р содержит, в частности, структуру
Struct {m:mpw),
9.2. ДОПОЛНИТЕЛЬНЫЕ ФОРМЫ ВЫРАЖЕНИЙ OQL
431
где mpw —- объект класса Movie, отвечающий кинофильму "Pretty Woman". В состав
множества Р, помимо того, входят однокомпонентные структуры, поле m каждой из которых
соответствует одному из остальных фильмов, выпущенных студией "Disney" в 1990 году.
Теперь подвергнем анализу предложение select. Для каждой структуры
промежуточной коллекции создается одна структура итоговой коллекции. Первым компонентом
каждой структуры итоговой коллекции является stdo, значением которого служит содержимое
одноименного поля соответствующей структуры промежуточной коллекции. Аналогично,
вторым компонентом структуры итоговой коллекции является поле с идентификатором уг
и значением одноименного поля структуры промежуточной коллекции. Третьим
компонентом каждой структуры итоговой коллекции является поле sumLength со значением
SUM(SELECT p.m.length FROM partition p).
Следует понимать, что областью допустимых значений переменной р служит
множество структур, отображаемых полем partition члена промежуточной коллекции.
Напомним, что каждое значение р — это структура вида struct (m: о), где о —
некоторый объект класса Movie. Выражение р.т, таким образом, указывает на объект о,
a p.m. length обозначает продолжительность воспроизведения кинофильма,
соответствующего объекту р.т класса Movie. Рассматриваемое выражение "select—from"
возвращает мультимножество значений продолжительности объектов-"кинофильмов",
принадлежащих одной группе. Если, например, значением поля stdo является
"Disney", а значением уг — 1990, результатом обработки подзапроса "select—from"
окажется мультимножество величин продолжительности воспроизведения кинофильмов,
выпущенных студией "Disney" в 1990 году. Применяя к этому мультимножеству
оператор sum, мы получаем значение общей продолжительности объектов-"кинофильмов",
принадлежащих группе. Один из членов итоговой коллекции мог бы выглядеть так:
Struct(stdo:"Disney", уг:1990, sumLength:1234),
если полагать, что число 1234 действительно представляет общую продолжительность
воспроизведения кинофильмов студии "Disney", вышедших на экраны в 1990 году. □
Оператор group by и предложения from с несколькими переменными
Случай, когда предложение from OQL-запроса, содержащего предложение
group BY, включает несколько переменных, требует отдельного рассмотрения, хотя
изложенные выше принципы, касающиеся интерпретации предложения from с
единственной переменной, остаются в силе. Обозначим переменные, перечисленные
в предложении from, как^!,^, ...,**. Тогда:
1) все переменные хих2, ...,-** могут использоваться в выражениях еь е2, ...,еп
предложения group by;
2) структуры мультимножества, служащего значением поля partition,
обладают полями хи х2,..., **;
3) если обозначить как ih i2, ...,*"* значения переменных х\, х2,..., хк, обращающие
условие предложения WHERE в true, to в промежуточной коллекции
существует структура вида
Struct t/i:*i(/i, i*2, -, /*)# • • • / fn'-en(ii, i2, -., k)> partition:F)
и в мультимножестве Р существует структура
Stuct Ui: i'i , x2:i2, . . . , xk: ik).
9.2.4. Предложения having
В OQL-запросе предложение group by можно сопроводить предложением having,
которое имеет тот же смысл, что и в SQL. Иными словами, предложение вида
HAVING С,
432
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
где С — некоторое условие, служит цели "фильтрации" и удаления некоторых групп,
созданных при выполнении предложения group by. Условие С применяется к
значению поля partition каждой структуры промежуточной коллекции (intermediate
collection). Если условие обращается в true, структура далее обрабатывается так, как
показано в разделе 9.2.3, и становится частью итоговой коллекции (output collection);
в противном случае структура в итоговую коллекцию не включается.
Пример 9.11. Обратимся к примеру 9.10 и предположим, что необходимо найти сумму
длительностей воспроизведения фильмов, выпущенных только такими студиями,
в "арсенале" которых имеется по меньшей мере один фильм продолжительностью
свыше 120 минут. Текст соответствующего запроса приведен на рис. 9.7. Обратите
внимание, что предложение having содержит тот же запрос, что select, и запрос
позволяет получить мультимножество сумм длительностей кинофильмов,
соответствующих определенным названию студии и значению года. В предложении having,
однако, в соответствии с постановкой задачи вычисляется максимальное из значений
таких сумм и сопоставляется с величиной 120.
SELECT stdo, yr, sumLength: SUM(SELECT p.m.length
FROM partition p)
FROM Movies m
GROUP BY stdo: m.ownedBy.name, yr: m.year
HAVING MAX(SELECT p.m.length FROM partition p) > 120
Рис. 9.7. Пример использования предложения HAVING
□
9.2.5. Операторы объединения, пересечения и разности
Операторы объединения (union), пересечения (intersection) и разности (difference)
применяются в OQL к двум объектам типа множества или мультимножества. Как
и в SQL, операторы представляются с помощью служебных слов union, intersect
и except соответственно.
1) (SELECT DISTINCT m
2) FROM Movies m, m.starsOf s
3) WHERE s.name = "Harrison Ford")
4) EXCEPT
5) (SELECT DISTINCT m
6) FROM Movies m
7) WHERE m.ownedBy.name = "Disney")
Рис. 9.8. Запрос с использованием оператора разности двух множеств
Пример 9.12. Чтобы найти множество кинофильмов с участием актера Гаррисона
Форда, которые не снимались на киностудии "Disney", достаточно, как показано на
рис. 9.8, вычислить разность множеств, получаемых в результате обработки двух
запросов вида "select—from—where". Запрос, расположенный в строках 1—3, позволяет
найти множество кинофильмов, в которых снимался Гаррисон Форд, а запрос,
состоящий из строк 5—7, — множество кинофильмов, выпущенных киностудией "Disney".
Оператор except, размещенный в строке 4, вычисляет разность двух множеств. □
Следует обратить внимание на служебные слова distinct, употребленные в
строках 1 и 5. Они гарантируют, что в результате выполнения запросов должны быть
получены множества (sets) объектов; в отсутствие distinct итоговые наборы объектов
будут относиться к типу мультимножеств. В OQL операторы union, intersect
и except применимы как к множествам, так и к мультимножествам. Если оба аргу-
9.2. ДОПОЛНИТЕЛЬНЫЕ ФОРМЫ ВЫРАЖЕНИЙ OQL 433
мента оператора являются множествами, тот трактуется как оператор,
предназначенный для работы с множествами. Если же оба или один аргумент относятся к типу
мультимножеств, используется и соответствующая "версия" оператора. (Об
особенностях операторов объединения, пересечения и разности в применении к
мультимножествам мы говорили, напомним, в разделе 5.3.2 на с. 227.)
В частном случае, который проиллюстрирован на рис. 9.8, тот или иной объект-
"кинофильм" может быть включен в результат выполнения любого из двух запросов
не более одного раза, так что результат останется прежним независимо от того,
используется служебное слово distinct или нет. Тип результата, однако, способен
изменяться. Если слово DISTINCT задано, результат относится к типу Set<Movie>, но
если признак distinct исключить из одного или обоих запросов, итоговый набор
объектов окажется мультимножеством, т.е. будет относиться к типу Bag<Movie>.
9.2.6. Упражнения к разделу 9.2
Упражнение 9.2.1. Используя ODL-схему, рассмотренную в упражнении 9.1.1
(см. с. 425) и представленную на рис. 9.2 (см. с. 427), напишите OQL-запросы,
позволяющие решить следующие задания.
* а) Найти производителей (maker), выпускающих одновременно персональные
компьютеры (значение "рс" атрибута type) и принтеры ("printer").
* b) Найти производителей (maker) персональных компьютеров (рс), все модели
которых обладают дисками емкостью (hd) не менее 20 Гбайт.
с) Найти производителей (maker), выпускающих персональные ("рс"), но не
переносные ("laptop") компьютеры.
* d) Найти среднее значение быстродействия процессора (speed) всех
персональных компьютеров (рс).
* е) Для каждой группы персональных компьютеров (рс) с определенным типом
привода (rd) съемных дисков (CD или DVD) найти среднее значение
объема оперативной памяти (ram).
! f) Найти производителей (maker), выпускающих компьютеры с объемом
оперативной памяти (ram) не менее 64 Мбайт, а также продукты с ценой
(price) ниже 1000 долларов.
!! g) Для каждого производителя (maker), выпускающего персональные
компьютеры (рс) со средним значением быстродействия процессора (speed) не
менее 1200 МГц, найти максимальный объем оперативной памяти (ram),
которой комплектуются компьютеры этого производителя.
Упражнение 9.2.2. Используя ODL-схему, рассмотренную в упражнении 9.1.3
(см. с. 427) и представленную на рис. 9.3 (см. с. 428), напишите OQL-запросы,
позволяющие решить следующие задания.
a) Найти классы судов (class), такие, что все суда класса были спущены на
воду (launched) до 1919 года.
b) Найти максимальное значение водоизмещения (displacement) судов всех
классов (Class).
! с) Для каждой группы значений калибра (bore) главных орудий найти
минимальное значение года выпуска (launched) судов, относящихся к этой группе.
*!! d) Для каждого класса (class), по меньшей мере одно из судов которого было
спущено на воду (launched) до 1919 года, найти количество кораблей этого
класса, потопленных (значение sunk атрибута status) в сражениях.
! е) Найти среднее количество судов (Ship) в классах (class).
434
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
! f) Найти среднее значение водоизмещения (displacement) судов (ship).
!! g) Найти сражения (Battle) (объекты, а не названия), в каждом из которых
принимал участие по меньшей мере один британский (country) корабль
и было потоплено (значение sunk атрибута status) не менее двух кораблей.
! Упражнение 9.2.3. В примере 9.8 на с. 429 упоминалось о том, что запрос,
приведенный на рис. 9.5, способен возвращать информацию и о тех актерах, которые
вообще не снимались в фильмах, хотя запрос, строго говоря, предусматривает
поиск актеров, участвовавших в съемках только тех фильмов, которые выпущены
киностудией "Disney". Перепишите текст запроса, чтобы устранить указанный изъян.
! Упражнение 9.2.4. Возможно ли, чтобы условие for all х in S : С(х) равнялось
true одновременно с обращением в false условия exists x in S : С(х)?
Поясните ход своих рассуждений.
9.3. Создание и присваивание объектов в OQL
В этом разделе будет показано, каким образом выражения OQL могут сочетаться
с кодом, написанным на одном из базовых (host) языков. В качестве иллюстрации мы
воспользуемся языком C++, хотя те же правила и приемы легко распространить на
другие объектно-ориентированные языки общего назначения (скажем, Java).
9.3.1. Присваивание значений переменным базового кода
В отличие от языка SQL, который при совместном использовании с языками
общего назначения требует применения общих переменных для взаимного обмена
данными между разнородными порциями кода, OQL "вписывается" в среду программы
на базрвом объектно-ориентированном языке совершенно естественно.
Рассмотренные нами выражения OQL, подобные конструкциям "select—from—where", возвращают
значения, представленные в виде объектов, и поэтому вполне правомочно
присваивать их переменным базового кода, относящимся к соответствующим объектным типам.
Пример 9.13. OQL-запрос
SELECT DISTINCT m
FROM Movies m
WHERE m.year < 1920
возвращает множество объектов, отвечающих кинофильмам, выпущенным до 1920
года. Тип результата — Set<Movie>. Если в программе, написанной на C++ с
использованием соответствующих средств OQL, объявлена, например, переменная
oldMovies того же типа, мы вправе написать:
oldMovies = SELECT DISTINCT m
FROM Movies m
WHERE m.year < 1920;
и переменной будет присвоено итоговое множество объектов класса Movie,
полученное в результате обработки запроса. □
9.3.2. Извлечение элементов единичных коллекций
Поскольку и запросы "select—from—where", и выражения "group—by" возвращают
коллекции (множества, мультимножества или списки), при необходимости
извлечения отдельного элемента коллекции приходится предпринимать дополнительные
действия — даже в том случае, когда коллекция является единичной (singleton), т.е.
содержит только один элемент. Для преобразования единичной коллекции в
соответствующий элемент этой коллекции в OQL применяется оператор element.
9.3. СОЗДАНИЕ И ПРИСВАИВАНИЕ ОБЪЕКТОВ В OQL
435
Пример 9.14. Предположим, что требуется присвоить переменной gwtw типа Movie объект,
представляющий кинофильм "Gone With the Wind". Результатом выполнения запроса
SELECT m
FROM Movies m
WHERE m.title = "Gone With the Wind"
служит мультимножество, содержащее искомый объект. Мы не вправе осуществить
присваивание мультимножества переменной gwtw непосредственно, поскольку это приведет
к ошибке несоответствия типов. Если, однако, применить оператор element,
gwtw = ELEMENT(SELECT m
FROM Movies m
WHERE m.title = "Gone With the Wind"
);
типы переменной и выражения совпадут, и операция присваивания окажется
возможной. □
9.3.3. Получение элементов произвольных коллекций
Задача извлечения отдельных элементов произвольного итогового множества или
мультимножества, возвращаемого в результате выполнения OQL-запроса вида "select—
from—where", более сложна, но она, однако, все еще проще, нежели манипуляции
с курсорами SQL. Первым делом необходимо преобразовать множество
(мультимножество) в список (list). Для этого следует снабдить выражение запроса
предложением order by (в разделе 9.1.4 на с. 423, напомним, мы говорили о том, что
результатом обработки OQL-запроса с предложением order by является именно список).
Пример 9.15. Пусть требуется получить список всех объектов класса Movie.
Ключевыми атрибутами, позволяющими различать объекты-"кинофильмы", являются title
("название") и year ("год производства"). Выражение
movieList = SELECT m
FROM Movies m
ORDER BY m.title, m.year;
означает, что переменной movieList базового кода присваивается список,
содержащий все объекты Movie и отсортированный по значениям title и year. □
Как только список (неважно, отсортированный или нет) получен, к его
элементам допустимо обращаться по номерам-индексам: /-му элементу списка L
соответствует выражение Д/-1]. Обратите внимание, что элементы списков и массивов
в OQL нумеруются, начиная с нуля (как в С, C++ и многих других языках
программирования общего назначения).
Пример 9.16. Предположим, что необходимо написать функцию на языке C++,
которая позволяет вывести на консоль значения названия (title), года выпуска (year)
и продолжительности воспроизведения (length) каждого кинофильма. Набросок
функции приведен на рис. 9.9.
В строке 1 множество объектов Movie сортируется, и результат присваивается
переменной movieList, а в строке 2 с помощью OQL-оператора count вычисляется
мощность множества. Строки 3—5 содержат конструкцию цикла for, в теле которого
целочисленный индекс i принимает значения всех позиций элементов списка. Для удобства
i-й элемент списка присваивается переменной movie типа Movie, а затем значения
атрибутов title, year и length объекта movie выводятся на стандартную консоль.61 □
Объявления переменных movieList и movie авторами опущены. Помимо того, более
очевидный вариант применения оператора COUNT в строке 2 таков: COUNT (movieList). — Прим. перев.
436
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
1) movieList = SELECT m
FROM Movies m
ORDER BY m. title, m.year;
2) int numberOfMovies = COUNT(Movies);
3) for(int i = 0; i < numberOfMovies; i++) {
4) movie = movieList[i];
5) cout << movie.title « " " « movie.year « " "
« movie.length « "\n";
}
Рис. 9.9. Пример функции, позволяющей извлечь содержимое каждого элемента
коллекции
9.3.4. Константы в OQL
Константы (constants) в OQL — иногда их называют неизменяемыми объектами
(immutable objects) — создаются с помощью соответствующих конструкторов теми же
способами, что и типы ODL.
1. Значения базовых (basic) типов:
a) атомарные (atomic) величины — целые числа (integer), значения с
плавающей запятой (float), символы (character), строки (string) и булевы
значения (boolean) — используются в соответствии с теми же правилами,
что и в SQL, за исключением строк, которые, в отличие от строк SQL,
заключаются в двойные кавычки;
b) значения перечислимых типов (enumerations) объявляются средствами ODL
и могут использоваться в качестве констант.
2. Значения составных (complex) типов создаются с помощью следующих
конструкторов типов:
a) set(•••);
b) Bag (•••);
c) List (•••);
d) Array (•••);
e) Struct (•••).
Первые четыре типа относятся к категории типов коллекций (collection types).
Конструкторы типов коллекций и struct могут применяться к любым
значениям подходящих типов, простых или составных. При использовании
конструктора struct, однако, требуется задавать названия полей и соответствующие
значения, разделяя их символом двоеточия, а пары "имя—значение" —
символом запятой. Аналогичные конструкторы типов применяются и в ODL, но
в OQL вместо угловых скобок, о, используются круглые, ().
Пример 9.17. Выражение Bag (2, 1, 2) обозначает мультимножество значений, в
котором элемент 2 присутствует дважды, а 1 — один раз. Выражение
Struct(too: Bag(2, 1, 2), bar: "baz")
соответствует структуре с двумя полями: поле f оо в качестве значения содержит
мультимножество, рассмотренное выше, а поле bar — строку "baz". □
9.3. СОЗДАНИЕ И ПРИСВАИВАНИЕ ОБЪЕКТОВ В OQL
437
9.3.5. Создание объектов
Мы уже показывали, как OQL-выражения, подобные запросам вида "select—from—
where", позволяют создавать новые объекты. Вполне допустимо также конструировать
объекты на основе констант и выражений с помощью конструкторов коллекций
и структур. Скажем, в примере 9.5 на с. 424 строка
SELECT DISTINCT Struct(starl: si, star2: s2)
указывает, что результат запроса должен представлять собой множество объектов
типа Struct {starl: star, star2: star}. Для обозначения полей структуры
используются идентификаторы starl и star2, а типам полей соответствует тип
переменных si и s2 (star).
Пример 9.18. Процесс конструирования констант, о котором рассказывалось в разделе
9.3.4, может быть совмещен с присваиванием результатов переменным — теми же
способами, какие приняты в других языках программирования. Рассмотрим для
примера последовательность операций присваивания, указанную ниже:
х = Struct(a: 1, b: 2);
у = Вад(х, х, Struct(а: 3, Ь: 4));
В первой строке переменной х присваивается значение типа
Struct(a: integer, b: integer),
представляющего структуру, которая содержит два целочисленных поля, а и Ь.
Значения этого типа можно задавать в виде пар целых чисел, опуская названия полей:
например, (1,2). Вторая строка содержит оператор присваивания переменной у значения
типа мультимножества, элементами которого служат структуры того же типа, что и х.
Структура (1,2) включена в мультимножество дважды, а (3, 4) — один раз. □
Экземпляры классов и других типов создаются с помощью конструкторов-функций
(constructor functions). Классы обычно содержат конструкторы-функции нескольких
форм, различающихся способами инициализации атрибутов и использования значений,
принятых по умолчанию. Например, методы не инициализируются, атрибуты, как
правило, получают некоторые исходные значения, а связям изначально могут быть
присвоены пустые множества, которые позже заменяются конкретными значениями.
Имена конструкторов-функций совпадают с именем класса; конструкторы
различаются количеством и типами аргументов. Детали, связанные с объявлением и
использованием конструкторов-функций, зависят от синтаксических особенностей базового языка.
Пример 9.19. Рассмотрим, как может выглядеть конструктор-функция для создания
объектов класса Movie. Мы полагаем, что функция принимает в качестве параметров
значения, соответствующие атрибутам title, year, length и связи ownedBy, и создает
объект Movie с заданными значениями указанных членов класса, значением атрибута
f ilmType, предусмотренным по умолчанию, и пустым множеством объектов-"актеров",
отвечающим связи starsof. Если допустить, что переменная mgm содержит объект
класса studio, представляющий информацию о киностудии "MGM", объект Movie,
соответствующий кинофильму "Gone With the Wind", можно было бы сконструировать так:
gwtw = Movie( title: "Gone With the Wind",
year: 1939,
length: 239,
ownedBy: mgm);
Выражение выполняет две функции:
1) создает новый объект класса Movie, который становится частью экземпляра
(extent) Movies;
2) присваивает созданный объект переменной gwtw базового кода.
□
438
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
9.3.6. Упражнения к разделу 9.3
Упражнение 9.3.1. Напишите выражения присваивания переменной х базового кода
следующих констант:
* а) множества {1, 2, 3};
b) мультимножества {1, 2, 3, 1};
c) списка (1,2,3, 1);
d) структуры, первое поле, а, которой представляет собой множество {1,2},
а второе, Ь, — мультимножество {1, 1};
e) мультимножества структур с двумя целочисленными полями а и Ь,
состоящего из пар значений (1,2), (2, 1) и (1,2).
Упражнение 9.3.2. Используя ODL-схему, рассмотренную в упражнении 9.1.1
(см. с. 425) и представленную на рис. 9.2 (см. с. 427), напишите выражения на
языке C++ (или ином базовом языке, поддерживающем OQL), позволяющие
решить следующие задания.
* а) Присвоить переменной х базового кода объект, представляющий
персональный компьютер (рс) с номером модели (model), равным 1000.
b) Присвоить переменной у базового кода множество объектов,
соответствующих переносным компьютерам (Laptop), которые обладают оперативной
памятью объемом (ram) не менее 64 Мбайт.
c) Присвоить переменной z базового кода значение среднего быстродействия
процессоров (speed) персональных компьютеров (рс) с ценой (price) ниже
1500 долларов.
! d) Найти все объекты, представляющие лазерные (значение "laser" атрибута
printerType) принтеры (Printer), и вывести список номеров моделей
(model) и значений цен (price), а также номер модели, соответствующий
принтеру с наиболее низкой ценой.
!! е) Вывести таблицу, представляющую информацию о наименьшей и
наибольшей цене персональных компьютеров (рс), выпускаемых каждым
производителем (maker).
Упражнение 9.3.3. В этом примере мы обратимся к ODL-схеме, рассмотренной
в упражнении 9.1.3 (см. с. 427) и представленной на рис. 9.3 (см. с. 428). Положим,
что для каждого из классов схемы определен одноименный конструктор-функция,
принимающий в качестве аргументов значения всех атрибутов и единичных связей
(многозначные связи инициализируются пустыми множествами). Помимо того,
пусть для каждой единичной связи, указывающей на другой класс, существует
переменная базового кода, содержащая подходящий объект. Обеспечьте создание
перечисленных ниже объектов и присваивание их переменным базового кода.
* а) Линкор (значение "bb" атрибута type) "Colorado" класса (class)
"Maryland" был спущен на воду (launched) в 1923 году.
b) Линкор "Graf Spee" класса "Liitzow" был построен в 1936 году.
c) Корабль "Prince of Wales" был потоплен (значение sunk атрибута status)
в сражении у берегов Малайи.
d) Сражение (Battle) у берегов Малайи произошло 10 декабря 1941 года.
e) Британские (country) крейсеры (значение "be" атрибута type) класса
"Hood" обладали 15-дюймовыми (bore) орудиями и водоизмещением
(displacement) в 41 тыс. тонн.
9.3. СОЗДАНИЕ И ПРИСВАИВАНИЕ ОБЪЕКТОВ В OQL
439
9.4. Типы данных SQL, определяемые пользователем
В этом разделе мы рассмотрим, каким образом в стандарте SQL-99
регламентировано использование объектно-ориентированных средств. СУБД, поддерживающие
подобные нововведения, часто называют объектно-реляционными (object-relational).
Многие из концепций, лежащих в основе объектно-реляционных систем, обсуждались
с абстрактной точки зрения в разделе 4.5 на с. 180. Сейчас же подошло время изучить
все эти вещи более предметно и обстоятельно.
В OQL понятие отношения никак не поддерживается — язык позволяет
оперировать множествами (или мультимножествами) структур. Но в SQL концепция
отношения настолько важна, что она сохранена в неприкосновенности и в объектных
расширениях языка. Аналогом классов ODL в SQL служат типы, определяемые
пользователем, или просто пользовательские типы (user-defined types — UDT). Пользовательские
типы SQL выполняют две различные функции:
1) используются в качестве типов таблиц;
2) определяют типы атрибутов таблицы.
9.4.1. Определение типов в SQL
Конструкция определения пользовательского типа в SQL схожа с объявлением
класса ODL, но обладает некоторыми отличиями. Во-первых, объявления ключей
отношения, определенного посредством пользовательского типа, являются частью
схемы отношения как такового, а не типа; иными словами, один и тот же тип может
быть применен для определения нескольких отношений, которые, однако, обладают
различными ключами и другими ограничениями. Во-вторых, в SQL связи не
интерпретируются как свойства (properties) — каждая связь, как было показано в разделе
4.4.5 на с. 177, должна быть представлена отдельным отношением. Простое
определение пользовательского типа включает следующие составные части:
1) служебные слова create type;
2) наименование типа;
3) служебное слово as;
4) список разделенных запятыми пар идентификаторов атрибутов и их типов,
заключенный в круглые скобки;
5) список разделенных запятыми объявлений методов с указанием типов
аргументов и возвращаемых значений.
Синтаксическую форму определения пользовательского типа Т можно кратко
представить так:
CREATE TYPE T AS <объявления атрибутов и методов>;
Пример 9.20. Покажем, как создается пользовательский тип, служащий для
представления информации об объектах-"актерах" и аналогичный классу Star из ODL-схемы,
показанной на рис. 9.1 (см. с. 421). Сейчас мы не в состоянии непосредственно
описать множество объектов-"кинофильмов", в которых снимался актер, в виде
некоторого поля кортежа star. Поэтому начнем с определения компонентов name ("имя")
и address ("адрес") кортежа.
Следует обратить внимание, что адрес в свою очередь также представляется
кортежем, содержащим компоненты street и city. Поэтому необходимо создать два
определения типа — одно для компонента адреса, а второе — для описания объекта-
"актера" в целом. Определения приведены на рис. 9.10.
440
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
CREATE TYPE AddressType AS (
street CHAR(50),
city CHAR(20)
);
CREATE TYPE StarType AS (
name CHAR(30),
address AddressType
);
Рис. 9.10. Примеры определений пользовательских типов
Кортеж типа AddressType содержит два компонента, соответствующие атрибутам
street и city; типы атрибутов — строки фиксированной длины в 50 и 20 символов
соответственно. Кортеж типа StarType также содержит два компонента: первый — атрибут
name типа char(30) , а второй — атрибут address определенного выше пользовательского
типа AddressType, представляемого кортежем с двумя компонентами, street и city. □
9.4.2. Методы в пользовательских типах
Объявление метода в составе пользовательского типа SQL напоминает способ
создания хранимой функции PSM (см. раздел 8.2.1 на с. 364) — аналогов хранимых процедур
среди методов пользовательских типов, однако, не существует, поскольку метод обязан
возвращать значение некоторого типа. В то время как объявление (declaration) и
определение (definition) функции PSM совмещаются в пределах единой конструкции, метод
пользовательского типа нуждается как в объявлении, размещаемом непосредственно в тексте
определения типа, так и отдельном определении с помощью выражения create method.
Объявление метода выглядит подобно заголовку объявления хранимой функции,
если пару служебных слов create function заменить одним — method. Методы
пользовательских типов SQL обычно не имеют параметров и применяются к
кортежам — точно так же, как методы ODL применяются к объектам. Если в тексте
определения метода необходимо сослаться на текущий кортеж явно, для этого
используется указатель, обозначаемый служебным словом self.
Пример 9.21. Расширим определение пользовательского типа AddressType,
приведенного на рис. 9.10, за счет включения метода houseNumber, предназначенного для
извлечения из компонента street порции информации, содержащей номер дома.
Если, например, компонент street содержит строку '123 Maple St. ', метод должен
вернуть строку ' 123 '. Дополненная версия определения типа такова:
CREATE TYPE AddressType AS (
street CHAR(50),
city CHAR(20)
)
METHOD houseNumber () RETURNS CHAR (10);
В объявлении метода за служебным словом method следуют наименование метода и
заключенный в скобки список пар идентификаторов параметров и их типов, разделенных
запятыми. В нашем случае метод не предполагает задания аргументов, но скобки,
обрамляющие пустой список, все равно необходимы. (Если бы аргументы потребовались, их
можно было бы перечислить, скажем, так: (a INT, b char(5)).) Завершает объявление
предложение returns, содержащее описание типа возвращаемого методом значения. □
Помимо объявления, необходимо создать определение метода. Определение метода
пользовательского типа в своей простой форме содержит следующие составные части:
1) служебные слова create method;
2) имя метода, список параметров и предложение returns, как в конструкции
объявления метода;
9.4. ТИПЫ ДАННЫХ SQL, ОПРЕДЕЛЯЕМЫЕ ПОЛЬЗОВАТЕЛЕМ
441
3) служебное слово for с наименованием пользовательского типа, к которому
относится метод;
4) текст тела метода, который пишется на том же диалекте, что и хранимые
функции PSM.
Определение метода houseNumber, объявленного в примере 9.21, может выглядеть
следующим образом:
CREATE METHOD houseNumber() RETURNS CHAR(10)
FOR AddressType
BEGIN
END;
Текст тела метода мы опускаем, поскольку задача извлечения части строки street
адреса не вполне тривиальна, а нам не хотелось бы отвлекаться на детали, не
относящиеся к обсуждаемой теме.
9.4.3. Объявление схем отношений с помощью пользовательских типов
Обладая объявлением некоторого пользовательского типа, можно использовать его
для объявления схем одного или нескольких отношений — имея в виду, что к
указанному типу должны относиться кортежи этих отношений. Форма объявления схемы
отношения аналогична той, которая приводилась в разделе 6.6.2 на с. 297, но вместо
списка атрибутов следует задавать предложение
OF <наименование типа>
При необходимости в конструкцию объявления отношения могут быть добавлены
другие элементы, такие как объявления первичных и/или внешних ключей,
ограничения уровня кортежа и т.д., но все они будут относиться к схеме отношения, а не
к его типу как таковому.
Пример 9.22. Дабы объявить, что отношение MovieStar должно содержать кортежи
типа star Туре, достаточно ввести команду
CREATE TABLE MovieStar OF StarType;
Полученная в результате схема таблицы MovieStar включает два атрибута, name
и address, первый из которых, name, — это обычная строка, а второй, address, —
относится к другому пользовательскому типу, AddressType. □
Обычно каждому отношению ставится в соответствие отдельный пользовательский
тип, и отношение можно воспринимать как экземпляр (extent) (в том смысле, о
котором говорилось в разделе 4.3.4 на с. 167) класса, соответствующего этому типу.
Впрочем, ничто не запрещает использовать один и тот же тип для объявления нескольких
схем отношений либо не обращаться к нему вовсе.
9.4.4. Ссылочные типы
Функцию идентификационного номера объекта (object identity) — концепции,
поддерживаемой в объектно-ориентированных языках программирования общего
назначения, — в SQL выполняет понятие ссылки (reference). Таблица, созданная с применением
пользовательского типа, способна содержать ссылочный атрибут, или столбец (reference
column), выступающий в роли "идентификатора" кортежей таблицы. Ссылочным
столбцом может быть первичный ключ таблицы, если таковой определен, либо атрибут,
компоненты которого генерируются системой автоматически и получают гарантированно
уникальные значения. Обсуждение вопросов, касающихся определения ссылочных столбцов,
мы отложим до момента знакомства с приемами их практического использования.
442
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
Чтобы получить возможность обращения к кортежам таблицы по значениям
компонентов ссылочного столбца, следует отнести соответствующий атрибут таблицы
к типу, который является ссылкой на другой тип. Если Т — некоторый
пользовательский тип, тогда ref(jT) — тип ссылки на кортеж типа Т. Ссылка может быть
ограничена контекстом (scope) — отношением, на кортежи которого она направлена.
Атрибут А, значения которого являются ссылками на кортежи отношения R, объявленного
с заданием пользовательского типа Г, допустимо объявить следующим образом:
A REF(D SCOPE R
Если контекст ссылки не задан, с ее помощью можно адресовать любое отношение типа Т.
Пример 9.23. Применения механизма ссылочных атрибутов не достаточно для
представления в отношении Movies tar множества всех фильмов, в съемках которых
принимал участие тот или иной актер, но сохранить информацию об одном из фильмов
(скажем, наиболее "удачном") все-таки возможно. Предположим, что схема
отношения Movie создана с помощью пользовательского типа MovieType; определения типа
MovieType и отношения Movie даны на рис. 9.11. Приведем новую версию
объявления типа starType, включающую атрибут bestMovie ссылочного типа:
CREATE TYPE StarType AS (
name CHAR(30),
address AddressType,
bestMovie REF(MovieType) SCOPE Movie
)/
Если придать отношению MovieStar "усовершенствованный" тип StarType, каждый
кортеж отношения, представляющий сведения об актере, будет содержать компонент,
ссылающийся на соответствующий кортеж отношения Movie — "лучшую" роль,
сыгранную актером. □
Мало объявить атрибут отношения как ссылочный — необходимо позаботиться
о том, чтобы другое, адресуемое (referenceable), отношение (такое как Movie в
примере 9.23) содержало соответствующий атрибут, на который должна указывать ссылка.
Конструкция объявления таблицы, create table, созданная на основе
пользовательского типа, может быть пополнена предложением следующего вида:
REF IS <имя атрибута> <способ получения значений>
Параметр <имя атрибута > определяет атрибут, которому отводится роль
"идентификатора" кортежей отношения. Параметр <способ получения значений>
обычно задается одним из двух способов:
1) system generated — ответственность за присваивание компонентам
атрибута гарантированно уникальных значений возлагается на СУБД;
2) derived — для получения значений компонентов атрибута СУБД должна
использовать содержимое первичного ключа отношения.
Пример 9.24. На рис. 9.11 приведены объявления пользовательского типа MovieType
и схемы таблицы Movie; последняя получает статус адресуемой. Строки 1—4 содержат
конструкцию объявления типа MovieType; созданный тип используется для
определения схемы таблицы Movie (см. строки 5—7). В строке 7 задано объявление
первичного ключа таблицы, формируемого из атрибутов title и year.
В строке 6 указано имя movie id атрибута-"идентификатора" кортежей отношения
Movie. Этот атрибут автоматически добавляется к исходным трем — title, year
и inColor (здесь мы вновь обратились к той редакции SQL-схемы отношения Movie,
которая приведена в разделе 6.1 на с. 250, но ограничились только тремя ее
атрибутами) — и может использоваться наряду с ними в любых запросах. Строка 6 также гла-
9.4. ТИПЫ ДАННЫХ SQL, ОПРЕДЕЛЯЕМЫЕ ПОЛЬЗОВАТЕЛЕМ
443
сит, что обязанность по получению уникального значения компонента movie ID
очередного кортежа, подлежащего вставке в отношение Movie, возлагается на СУБД.
Если заменить предложение system generated значением derived, системе придется
вычислять содержимое компонента movie ID на основе значений компонентов title
и year первичного ключа того же кортежа.
1) CREATE TYPE MovieType AS (
2) title CHAR(30),
3) year INTEGER,
4) inColor BOOLEAN
);
5) CREATE TABLE Movie OF MovieType (
6) REF IS movieID SYSTEM GENERATED,
7) PRIMARY KEY (title, year)
) ;
Рис. 9.11. Пример объявлений пользовательского типа
и схемы адресуемой таблицы
□
Пример 9.25. Теперь рассмотрим, каким образом, используя ссылочные типы, можно
представить связь типа "многие ко многим", соединяющую объекты-"кинофильмы"
с объектами-"актерами". Прежде для этой цели мы использовали отношение
Stars In, содержащее ключевые атрибуты отношений Movie и MovieStar. Теперь
имеется возможность объявить схему отношения stars In, воспользовавшись
ссылками на оба соединяемых отношения.
Первым делом необходимо снабдить объявление таблицы MovieStar признаком ref:
CREATE TABLE MovieStar OF StarType (
REF IS StarID SYSTEM GENERATED
);
Теперь мы можем объявить отношение stars In, включив в его схему два ссылочных
атрибута, один из которых адресует кортежи отношения MovieStar, а другой —
отношения Movie:
CREATE TABLE StarsIn (
star REF(StarType) SCOPE MovieStar,
movie REF(MovieType) SCOPE Movie
);
Можно было бы объявить и соответствующий пользовательский тип, включив в него те
же ссылочные атрибуты, а затем на его основе определить схему таблицы stars In. □
9.4.5. Упражнения к разделу 9.4
Упражнение 9.4.1. Создайте объявления следующих пользовательских типов:
a) NameType, предназначенного для представления имени, состоящего из строк
обращения (скажем, 'г-н', 'д-р', 'проф. ' и т.п.), собственно имени,
отчества и фамилии;
*b) PersonType, содержащего имя человека и ссылки на людей, являющихся
его матерью и отцом; требуется применить тип, полученный в результате
решения задания (а);
с) MarriageType, включающего дату бракосочетания и ссылки на людей,
являющихся мужем и женой.
444
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
Упражнение 9.4.2. Пересмотрите схему базы данных "компьютерных продуктов",
впервые рассмотренную в упражнении 5.2.1 на с. 218; создайте и примените
пользовательские типы и ссылочные атрибуты там, где сочтете возможным и целесообразным.
В частности, объявите атрибуты model в схемах отношений PC, Laptop и Printer
как ссылочные, адресующие соответствующие кортежи отношения Product.
! Упражнение 9.4.3. В упражнении 9.4.2 вам было предложено объявить атрибуты
model отношений PC, Laptop и Printer как ссылочные, с помощью которых
можно адресовать кортежи отношения Product. Удастся ли в свою очередь
представить компоненты атрибута model таблицы Product как ссылки на кортежи
отношений, соответствующих типу конкретного продукта? Почему да или почему нет?
* Упражнение 9.4.4. Пересмотрите схему "морской" базы данных, впервые
рассмотренную в упражнении 5.2.4 на с. 222; создайте и примените пользовательские типы
и ссылочные атрибуты там, где сочтете возможным и целесообразным. Примите к
сведению решения, предложенные в ODL-версии схемы на рис. 9.3 (см. с. 428).
Обратите внимание на связи вида "многие к одному" и попытайтесь представить
их с помощью атрибутов ссылочных типов.
9.5. Операции над объектно-реляционными данными
Все рассмотренные ранее операторы SQL применимы также к отношениям,
объявленным с помощью пользовательских типов или содержащим атрибуты подобных
типов. С введением пользовательских типов появляется возможность применения
операторов новых видов, позволяющих, например, выполнять обращение по ссылке
(reference following). Помимо того, некоторые из традиционных операторов (скажем,
связанные с обеспечением доступа к столбцам, объявленным с привлечением
пользовательских типов, или модификацией их содержимого) приобретают новый синтаксис.
9.5.1. Обращение по ссылке
Предположим, что х — значение типа ref(jT) . Это значит, что х ссылается на
некоторый кортеж / типа Т. Существуют два оператора, позволяющих получить кортеж /
или его отдельные компоненты:
1) оператор ->, обладающий такой же семантикой, что и одноименный
оператор, используемый в языках С и C++; если х представляет собой ссылку на
кортеж t и а — некоторый атрибут кортежа /, выражение х->а возвращает
значение компонента а кортежа /;
2) оператор deref, применяемый к значению ссылочного типа и
возвращающий адресуемый кортеж.
Пример 9.26. Обратимся к отношению stars In из примера 9.25, чтобы найти
информацию о кинофильмах с участием актера Мэла Гибсона. Напомним, что схема
отношения выглядит как
Starsln(star, movie),
где star и movie — атрибуты ссылочных типов, адресующие кортежи отношений
MovieStar и Movie соответственно. Запрос может быть оформлен следующим образом:
1) SELECT DEREF(movie)
2) FROM Starsln
3) WHERE star->name = 'Mel Gibson';
Выражение star->name в строке З возвращает значение компонента name кортежа
MovieStar, адресуемое компонентом star любого кортежа starsln. Условие предло-
9.5. ОПЕРАЦИИ НАД ОБЪЕКТНО-РЕЛЯЦИОННЫМИ ДАННЫМИ
445
жения where позволяет "отфильтровать" те кортежи stars In, компоненты star
которых служат ссылками на кортеж отношения Movies tar, содержащий сведения о Мэле
Гибсоне. При обработке предложения select строки 1 система возвратит кортежи
отношения Movie, адресуемые компонентами movie кортежей Stars In, выбранных с
учетом условия WHERE, и выведет на экран содержимое атрибутов title, year и inColor.
Если заменить строку 1 строкой
1) SELECT movie
помимо значений "обычных" атрибутов, система возвратит внутренние
идентификационные номера кортежей, которые для непосвященного могут выглядеть, мягко
говоря, не очень привлекательно (разумеется, в большинстве ситуаций в получении
подобной информации необходимости нет). □
9.5.2. Доступ к компонентам пользовательских типов
Если объявление схемы отношения создано на основе пользовательского типа,
кортежи отношения следует воспринимать как отдельные объекты, а не просто как
списки компонентов, соответствующих атрибутам, которые упомянуты в определении
типа. Вновь обратимся к объявлению отношения Movie, приведенному на рис. 9.11.
Объявление сконструировано на основе пользовательского типа MovieType, который
охватывает определения трех атрибутов — title, year и inColor. Однако кортеж /
отношения Movie содержит только один компонент, а не три, и компонент является
отдельным объектом. Если "проникнуть" внутрь этого объекта, можно извлечь
компоненты трех атрибутов, упомянутых в объявлении типа MovieType, а также
воспользоваться методами, если таковые определены. К компоненту атрибута
пользовательского типа нельзя обращаться напрямую, поскольку он не является принадлежностью
кортежа. С этой целью следует применять соответствующий метод-обозреватель
(observer method), который неявным образом определяется для каждого атрибута в
составе пользовательского типа. Метод-обозреватель для атрибута х носит то же
название — х(). Метод можно использовать совершенно так же, как и любой другой, —
достаточно присоединить конструкцию его вызова, .*(), к выражению, возвращающему
объект соответствующего типа. Если / — переменная пользовательского типа Т, а х —
атрибут, объявленный в составе этого типа, тогда выражение t.xQ возвратит значение
компонента х кортежа-объекта, обозначенного переменной /.
Пример 9.27. Рассмотрим запрос, призванный найти в отношении Movie и возвратить
значения дат выпуска кинофильмов с названием "King Kong". Один из возможных
вариантов текста запроса приведен ниже:
SELECT m.year()
FROM Movie m
WHERE m.title() = 'King Kong';
Хотя переменную кортежа m, как может показаться, использовать не обязательно,
такая переменная, значениями которой служат объекты типа MovieType, лежащего
в основе определения схемы отношения Movie, все-таки нужна. В условии предложения
WHERE константа 'King Kong' сопоставляется с содержимым компонента title,
извлекаемым с помощью метода-обозревателя title(). Аналогичная конструкция
используется и в предложении select — для получения значения компонента year
вызывается метод-обозреватель year (), применяемый к текущему кортежу-объекту т. □
9.5.3. Генерирование объектов и модификация компонентов
Для конструирования объектов пользовательских типов и модификации
содержимого их компонентов используются методы двух категорий, создаваемые системой
автоматически наряду с методами-обозревателями, рассмотренными выше.
446
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
1. Метод-генератор (generator method). Метод наследует имя пользовательского
типа, которому принадлежит, и не имеет параметров. Методу-генератору присуще
одно необычное свойство — его можно вызывать вне контекста какого бы то ни
было объекта типа. Иными словами, если Т — пользовательский тип,
выражение Г() возвращает "пустой" объект типа Г, не инициализируя его компоненты.
2. Методы-модификаторы (mutator methods). Для каждого атрибута х
пользовательского типа Т существует метод-модификатор x(v), который, будучи
примененным к объекту типа Г, изменяет текущее значение компонента х объекта на
v. Заметьте, что метод-обозреватель и метод-модификатор атрибута х обладают
одинаковым именем, х, но различаются тем, что последнему при вызове
передается соответствующий аргумент.
Пример 9.28. Рассмотрим хранимую процедуру, соответствующую стандарту PSM,
которая в качестве параметров принимает значения компонентов name, street и city
и вставляет (insert) в отношение MovieStar (пользовательского типа starType,
созданного в примере 9.20 на с. 440) объект, сконструированный на основе этих
значений с помощью соответствующих метода-генератора и методов-модификаторов.
Напомним, что объект пользовательского типа StarType обладает строковым
компонентом name, а его компонент address в свою очередь является объектом
пользовательского типа AddressType. Текст процедуры приведен на рис. 9.12.
Строки 2—4 содержат объявления входных (in) параметров s, с и п,
представляющих заданные значения компонентов названия улицы (street), города (city) и
имени актера (name) соответственно. В строках 5, 6 объявляются две локальные
переменные, newAddr и newStar, которым в строках 7, 8 присваиваются пустые объекты
пользовательских типов AddressType и StarType, создаваемые с помощью
надлежащих методов-генераторов.
В строках 9, 10 компонентам street и city объекта newAddr с помощью методов-
модификаторов присваиваются значения названий улицы и города, переданные
процедуре в виде параметров. Строка 11 содержит аналогичный оператор присваивания,
который заносит в компонент name объекта newStar содержимое параметра п —
значение имени актера. В строке 12 объект newAddr целиком присваивается компоненту
address объекта newStar. Наконец, строка 13 содержит директиву вставки
полностью инициализированного объекта newStar в отношение MovieStar. Напомним
еще раз, что кортеж отношения, объявленного с применением пользовательского
типа, следует трактовать как отдельный объект — даже тогда, когда, как в нашем
примере, он состоит из нескольких атрибутов.
Чтобы вставить кортеж со сведениями об актере в отношение MovieStar,
достаточно вызвать хранимую процедуру insert star и передать ей подходящие значения
аргументов, например:
CALL InsertStar('345 Spruce St.1, 'Glendale', 'Gwyneth Paltrow');
□
Задача вставки объектов-кортежей в отношение, созданное с привлечением
пользовательских типов, значительно упрощается, если СУБД предоставляет возможность
создания метода-генератора, который принимает в качестве параметров значения
атрибутов и возвращает полностью инициализированный объект. Например, если бы
существовали методы-генераторы AddressType (s, с) и StarType(п, а),
возвращающие полноценные объекты одноименных типов, операцию вставки (insert)
в примере 9.28 можно было бы представить более естественным и очевидным
образом, избежав необходимости применения методов-модификаторов:
INSERT INTO MovieStar VALUES(
StarType('Gwyneth Paltrow1,
AddressType('345 Spruce St.', 'Glendale')));
9.5. ОПЕРАЦИИ НАД ОБЪЕКТНО-РЕЛЯЦИОННЫМИ ДАННЫМИ
447
1) CREATE PROCEDURE InsertStar (
2) IN S CHAR(50),
3) IN С CHAR(20),
4) IN n CHAR(30)
)
5) DECLARE newAddr AddressType;
6) DECLARE newStar StarType;
BEGIN
7) SET newAddr = AddressType();
8) SET newStar = StarType();
9) newAddr.street(s) ;
10) newAddr.с i ty(с);
11) newStar.name(n);
12) newStar.address(newAddr);
13) INSERT INTO MovieStar VALUES(newStar);
END;
Рис. 9.12. Пример использования методов-генераторов и
методов-модификаторов
9.5.4. Сопоставление объектов пользовательских типов
Объекты, созданные на основе пользовательских типов, до некоторой степени
абстрактны — в том смысле, что прямых способов сопоставления двух объектов одного
и тот же пользовательского типа на предмет их "равенства" или "неравенства", не
существует. Даже в том случае, когда два объекта обладают идентичными значениями
всех компонентов, объекты все равно нельзя считать равными, если только не
предусмотрены необходимые средства их сопоставления. По той же причине отсутствуют
способы непосредственной сортировки кортежей отношения, сконструированного
с помощью пользовательского типа, — необходимо позаботиться о создании
специальной функции, которая в состоянии определить, каким именно образом объекты
должны предшествовать друг другу в упорядоченном списке.
Имеется и немало других операторов SQL, которые предполагают необходимость
выполнения проверки условий "равенства" или "неравенства" объектов. Например,
нельзя удалить кортежи-дубликаты, не зная, на каком основании кортежи можно
воспринимать как равные; нельзя осуществлять группирование кортежей по значениям
атрибутов пользовательских типов в отсутствие корректного критерия равенства этих
значений; нельзя использовать предложение order by и операторы сравнения,
подобные <, в предложении where, если правила сравнения не установлены.
Для задания критериев сопоставления и упорядочения SQL позволяет
использовать команду create ordering, относящуюся к определенному пользовательскому
типу. Существует целый ряд синтаксических форм этой команды, но мы рассмотрим
только две наиболее простые.
1. Выражение
CREATE ORDERING FOR T EQUALS ONLY BY STATE;
гласит, что два объекта пользовательского типа Т должны трактоваться как равные,
если попарно равны значения всех их одноименных компонентов. Другие
операторы сравнения, такие как <, в контексте типа Т по-прежнему не "действуют".
2. Выражение
448
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
CREATE ORDERING FOR T
ORDERING FULL BY RELATIVE WITH F;
свидетельствует о том, что к объектам пользовательского типа Т допустимо
применять все шесть операторов сравнения: <, <=, >, >=, = и о. Для
сопоставления двух объектов хх и х2 типа Т к ним следует применить функцию F.
Функция должна быть написана так, чтобы возвращать значение F(xh x2) < 0 всякий
раз, когда, как следует полагать, х{ <лу, результат F(xx,x2) = 0 обязан
соответствовать условию х{ -хъ a F(xu х2) > 0 — условию х{ >х2. Если заменить предложение
ordering full предложением equals only, результат F(xbx2) = 0 будет
означать, что х{=х2, а любое другое значение F(xbx2)— что ххФх2\ осуществлять
сравнение посредством других операторов, подобных <, в этом случае нельзя.
Пример 9.29. Рассмотрим возможности упорядочения объектов пользовательского
типа starType, о котором мы говорили в примере 9.20 на с. 440. Если достаточно
применения оператора равенства объектов, следует воспользоваться командой
CREATE ORDERING FOR StarType EQUALS ONLY BY STATE;
которая гласит, что два объекта типа StarType считаются равными, если и только если
попарно совпадают их строковые компоненты name и компоненты address
пользовательского типа AddressType. Очевидная проблема заключается в том, что до тех пор,
пока мы не определим критерий упорядочения объектов AddressType, объект этого
типа (и, как следствие, типа StarType) нельзя будет считать равным даже самому себе.
Поэтому необходимо оговорить также по меньшей мере одно правило сопоставления
объектов типа AddressType. Простой способ достижения цели состоит в задании
объявления, свидетельствующего о том, что два объекта типа AddressType равны тогда и только
тогда, когда попарно совпадает содержимое их строковых компонентов street и city.
CREATE ORDERING FOR AddressType EQUALS ONLY BY STATE;
В качестве альтернативы можно было бы определить исчерпывающее правило
упорядочения объектов типа AddressType. Один из очевидных подходов заключается в том,
чтобы вначале отсортировать в алфавитном порядке значения компонентов city, а
затем, при их равенстве, — значения компонентов street, также в алфавитном порядке.
С этой целью необходимо определить функцию (назовем ее AddrLEG), которая
принимает в качестве параметров два объекта типа AddressType и возвращает отрицательное,
нулевое и положительное значения, если соответственно первый объект "меньше"
второго, объекты "равны" и первый объект "больше" второго. Инструкция задания
"полного" критерия сопоставления объектов типа AddressType может выглядеть так:
CREATE ORDERING FOR AddressType
ORDER FULL BY RELATIVE WITH AddrLEG;
Код функции AddrLEG приведен на рис. 9.13. Обратите внимание, что факт
достижения строки 7 означает, что компоненты city объектов равны, поэтому имеет смысл
сопоставлять содержимое компонентов street. Аналогично, по достижении строки 9
очевидно, что единственной комбинацией, оставшейся нерассмотренной, является
такая: компоненты city равны и первая строка street "больше" второй. □
9.5.5. Упражнения к разделу 9.5
Упражнение 9.5.1. Используя схемы отношений Stars in и Movies tar (см. пример
9.25 на с. 444), а также Movie (см. рис. 9.11 на с. 444), выразите средствами SQL
запросы, перечисленные ниже.
* а) Найти имена актеров, снявшихся в кинофильме "Ishtar".
*! b) Найти значения названий и дат выпуска всех кинофильмов с участием
актеров, по меньшей мере один из которых проживает в Малибу.
9.5. ОПЕРАЦИИ НАД ОБЪЕКТНО-РЕЛЯЦИОННЫМИ ДАННЫМИ
449
с) Найти все кинофильмы (объекты типа MovieType), в съемках которых
принимала участие актриса Мелани Гриффит.
! d) Найти значения названий и дат выпуска всех кинофильмов, в которых
снималось не менее пяти актеров.
1) CREATE FUNCTION AddrLEG(
2) xl AddressType,
3) x2 AddressType
4) ) RETURNS INTEGER
5) IF xl.cityO < x2.city() THEN RETURN(-l)
6) ELSEIF xl.cityO > x2.city() THEN RETURN(l)
7) ELSEIF xl.Street() < x2.street() THEN RETURN(-1)
8) ELSEIF xl.street() = x2.street() THEN RETURN(0)
9) ELSE RETURN(l)
END IF;
Рис. 9.13. Пример функции, определяющей порядок сортировки объектов
пользовательских типов
Упражнение 9.5.2. Используя схему базы данных "компьютерных продуктов",
созданную вами при решении упражнения 9.4.2 на с. 445, напишите SQL-запросы,
перечисленные ниже. Не забудьте воспользоваться ссылочными типами в тех
ситуациях, где это целесообразно или необходимо.
a) Найти производителей (maker), выпускающих персональные компьютеры
(рс), которые оснащены дисками емкостью, превышающей 60 Гбайт.
b) Найти производителей (maker) лазерных (значение 'laser' атрибута type)
принтеров (Printer).
! с) Вывести таблицу, содержащую для каждого номера модели (model)
переносного компьютера (Laptop) значение номера модели аналогичного
компьютера, выпускаемого тем же производителем и обладающего наивысшим
быстродействием процессора (speed).
Упражнение 9.5.3. Используя схему "морской" базы данных, созданную вами
при решении упражнения 9.4.4 на с. 445, напишите SQL-запросы,
перечисленные ниже. Не забудьте воспользоваться ссылочными типами в тех ситуациях,
где это целесообразно или необходимо. Постарайтесь избежать применения
операций соединения (т.е. подзапросов или нескольких переменных кортежей
в предложениях from).
* а) Найти суда (ships) водоизмещением (displacement), превышающим
35 тыс. тонн.
Ь) Найти морские сражения (Battles), в которых было потоплено (значение
' sunk' атрибута result) не менее одного судна.
! с) Найти классы (classes) судов, в состав которых входили суда (Ships),
спущенные на воду (launched) после 1930 года.
!! d) Найти морские сражения (Battles), в которых было повреждено
(значение 'damaged' атрибута result) по меньшей мере одно судно
ВМС США (country).
450
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
Упражнение 9.5.4. Предполагая, что функция AddrLEG, рассмотренная в примере
9.29 на с. 449, доступна для использования, напишите функцию, позволяющую
сравнивать объекты пользовательского типа StarType, и объявите эту функцию
в качестве инструмента упорядочения объектов StarType.
*! Упражнение 9.5.5. Напишите код процедуры, которая принимает в качестве
параметра строку имени актера и удаляет из отношений stars In и MovieStar все
кортежи, связанные с этим актером.
9.6. Резюме
♦ Выражения "select—from—where" в OQL. Язык OQL позволяет создавать
выражения формата "select—from—where", схожие с аналогичными конструкциями
SQL. В предложениях from разрешается задавать переменные, области
допустимых значений которых охватывают множества элементов определенных
коллекций, включая экземпляры классов (аналоги отношений) и коллекции
значений атрибутов объектов.
♦ Общеупотребительные операторы OQL. Язык OQL поддерживает логические
множественные условия for all и exists, а также операторы объединения,
пересечения, разности и агрегирования, схожие с теми, которые используются
в SQL. Агрегирование в OQL, однако, всегда выполняется в применении к
коллекции, а не к значениям столбца отношения.
♦ Предложение group by в OQL. В конструкциях "select—from—where" OQL, как
и в SQL, допустимо использовать предложения group by. В OQL, однако,
доступ к коллекции объектов каждой группы осуществляется посредством
специального поля partition.
♦ Извлечение элементов OQL-коллекций. Для преобразования единичной коллекции
в собственный элемент используется оператор element. Доступ к элементам
коллекции, содержащей несколько членов, осуществляется посредством
преобразования ее в список (для этого выражение "select—from—where" пополняется
предложением order by) с последующим применением конструкции цикла в
основном коде, позволяющей обратиться к каждому отдельному элементу списка.
♦ Пользовательские типы SQL. Объектно-ориентированные инструменты SQL
основаны на концепции типа, определяемого пользователем. В SQL
предусмотрена специальная команда объявления типа, требующая перечисления
атрибутов типа и позволяющая задавать другую информацию. Тип может
содержать определения методов.
♦ Схемы таблиц на основе пользовательских типов. Вместо традиционной команды
определения схемы отношения может использоваться конструкция, в которой
список атрибутов заменен ссылкой на пользовательский тип. Кортежи
подобного отношения обладают одним компонентом, который является объектом
соответствующего пользовательского типа.
♦ Ссылочные типы. В качестве типа атрибута может задаваться ссылка на тип,
определенный пользователем. Компоненты подобного атрибута по существу являются
указателями на соответствующие объекты заданного пользовательского типа.
♦ Идентификационные номера объектов пользовательских типов. При создании
отношения с привлечением пользовательского типа объявляется атрибут,
компоненты которого являются ссылками на соответствующие объекты-
кортежи отношения и служат их "идентификаторами". В отличие от "чистых"
объектно-ориентированных систем, объектно-реляционные системы позво-
9.6. РЕЗЮМЕ
451
ляют свободно обращаться к компонентам-идентификаторам, хотя подобная
возможность используется сравнительно редко.
♦ Доступ к компонентам пользовательского типа. SQL позволяет использовать
метод-обозреватель и метод-модификатор, автоматически создаваемые для
каждого атрибута пользовательского типа, с целью считывания и изменения
значений атрибута текущего объекта этого типа.
9.7. Литература
Наиболее полным источником информации об OQL (и об ODL) является
справочное пособие [1]. Материалы, касающиеся объектно-реляционных средств SQL,
перечислены в разделе 6.9 на с. 315.
1. Cattell R.G.G. (ed.) The Object Database Standard: ODMG-99, Morgan-Kaufmann,
San Francisco, 1999.
452
ГЛАВА 9. ОБЪЕКТНАЯ ОРИЕНТАЦИЯ И ЯЗЫКИ ЗАПРОСОВ
Глава 10
Логические языки запросов
Некоторые языки запросов, соответствующие требованиям реляционной модели,
обладают в большей степени логическим, нежели алгебраическим (в том смысле, о
котором мы говорили в разделе 5.2 на с. 205) характером. Языки, основанные на логике,
однако, как показывает опыт, многим программистам кажутся более трудными для
освоения. Поэтому мы и отложили обсуждение логических языков до того момента, пока
изложение материала, касающегося языков запросов, не будет полностью завершено.
Здесь мы познакомим вас с Datalog — простейшим представителем семейства
логических языков, разработанных для реляционной модели. В своей нерекурсивной форме
Datalog обладает теми же выразительными средствами, что и классическая реляционная
алгебра. Аппарат рекурсии Datalog, однако, позволяет представлять такие запросы,
которые не могут быть описаны с помощью SQL2 (если не принимать во внимание
инструменты создания хранимых процедур, подобные PSM). Мы подробно рассмотрим
сложные ситуации, с которыми приходится сталкиваться при совместном применении
средств рекурсии и операторов отрицания, а в завершение раздела покажем, как
решения, положенные в основу Datalog, использованы для реализации возможностей
рекурсивных вычислений с помощью средств, регламентируемых стандартом SQL-99.
10.1. Логика отношений
В качестве альтернативного средства описания запросов вместо абстрактных языков,
основанных на реляционной алгебре, допустимо применять определенные логические
формы. Язык логических запросов Datalog (от Database Logic) состоит из правил вида
"if—then" ("если—то"). Каждое из правил служит для выражения некоторого факта,
состоящего в том, что на основе определенной комбинации кортежей заданных
отношений можно сделать заключение о наличии определенного кортежа в некотором другом
отношении или итоговом наборе данных, возвращаемом в результате обработки запроса.
10.1.1. Предикаты и атомы
Отношения в контексте Datalog представляются с помощью предикатов
(predicates). Каждый предикат обладает фиксированным количеством аргументов;
предикат с аргументами называют атомом (atom). Синтаксис описания атомов
напоминает форму вызова функции в традиционном языке программирования: например,
Р(хь х2,..., хп) — это предикат Р с аргументами xh x2,..., хп.
По существу предикат — это имя функции, возвращающей значение булева типа.
Если R представляет собой отношение с п атрибутами, перечисленными в некотором
определенном порядке, R можно трактовать как предикат, соответствующий
отношению. Атом R(ah a2,..., ап) обладает значением TRUE, если список (ah a2,..., ап) является
кортежем отношения R; в противном случае атому отвечает значение false.
Пример 10.1. Пусть R — это отношение
А
1
3
В
2
4
Тогда атомы /?(1,2) и /?(3, 4) обладают значением true. Для всех других хну атому
R(x, у) соответствуют значения false. □
В качестве аргументов атомы способны воспринимать не только константы, но
и переменные. Если аргументами атома являются одна или несколько переменных,
атом представляет собой функцию, которая получает значения этих переменных
и возвращает величины true или false.
Пример 10.2. Если R — предикат из примера 10.1, тогда R(x, у) — это функция, которая
для любых значений х и у проверяет, содержится ли кортеж (х, у) в отношении R. Для
экземпляра /?, приведенного в примере 10.1, R(x, у) возвратит true, если выполняется
любое из условий:
1) х=\ AND ("И") у = 2;
2) х=3 AND у = 4.
Во всех остальных случаях R(x, у) вернет false. Еще один короткий пример,
касающийся экземпляра R из примера 10.1: атом R(\,z) возвратит true, если z = 2,
и false — в противном случае. □
10.1.2. Арифметические атомы
Существует отдельная разновидность атомов, которым в языке Datalog придается
особое значение, — речь идет об арифметических атомах (arithmetic atoms).
Арифметический атом представляет собой оператор сравнения двух арифметических
выражений, например: х<у или x+\>y + 4*z. (Атомы, рассмотренные в разделе 10.1.1,
с другой стороны, называют реляционными (relational); там, где различия между обоими
типами атомов несущественны, мы будем употреблять термин атом.)
И реляционные, и арифметические атомы принимают в качестве аргументов
значения переменных, упоминаемых в их контексте, и возвращают одно из булевых
значений — true или false. Операторы сравнения арифметических выражений, такие
как < или >, подобны именам отношений, содержащих все допустимые пары
значений кортежей, удовлетворяющих заданному условию. Поэтому можно полагать, будто
"отношение" < содержит все кортежи, например, (1,2) и (-1.5,65.4), в которых
значение первого компонента меньше значения второго. Однако следует помнить, что
"реальные" отношения в базах данных всегда содержат конечное количество кортежей
и обычно подвержены изменениям во времени, а отношения, моделирующие условия
сравнения (скажем, <) арифметических значений, бесконечны и неизменяемы.
10.1.3. Правила и запросы Datalog
Операторы, подобные тем, которые составляют ядро классической реляционной
алгебры (см. раздел 5.2 на с. 205), в языке Datalog описываются с помощью правил
(rules), каждое из которых включает следующие компоненты:
1) реляционный атом, называемый заголовком (head);
454
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
2) символ <-, который часто трактуют как условие "if ("если");
3) тело (body), состоящее из одного или нескольких атомов, называемых
подцелями (subgoals), которые могут быть как реляционными, так и
арифметическими атомами; подцели объединяются посредством операторов and ("И"),
и каждой из них может предшествовать оператор логического отрицания not.
Пример 10.3. Datalog-правило
LongMovie (t, у) <— Movie (t, у, 1, с, s, p) AND l > 100
ссылается на схему отношения Movie вида
Movie(title, year, length, inColor, studioName, producerC#)
и определяет множество "кинофильмов", продолжительность воспроизведения
которых превышает 100 минут. Заголовок правила представляется атомом LongMovie(t,y),
а тело состоит из двух подцелей, рассмотренных ниже.
1. Первая подцель — это предикат Movie с шестью аргументами,
соответствующими атрибутам отношения Movie. Каждый аргумент описан определенной
переменной: так, атрибуту title отвечает переменная /, year — у, length — / и т.д.
Подцель можно представить следующим высказыванием: пусть (/, у, /, с, s, p) —
кортеж текущего экземпляра отношения Movie. Если говорить более точно,
подцель обращается в true в том случае, когда шесть переменных-аргументов
ее атома соответствуют содержимому соответствующих компонентов некоторого
кортежа отношения Movie.
2. Вторая подцель, /> 100, равна true, если компонент length некоторого
кортежа Movie содержит значение, не меньшее 100.
Правило в целом можно описать таким образом: LongMovie(t, у) обращается в TRUE,
если и только если в отношении Movie существует такой кортеж, что:
a) значения / и у совпадают с содержимым двух первых компонентов, title
и year;
b) значение / (соответствующее содержимому компонента length) не меньше 100;
c) значения остальных компонентов произвольны.
Полезно отметить, что рассматриваемое правило эквивалентно следующему
выражению присваивания в реляционной алгебре:
LongMovie := п,ШчУеаг(<7length> loo (Movie)).
□
Запрос (query) в Datalog — это набор из одного или нескольких правил. Если в
заголовке правила присутствует ссылка только на одно отношение, содержимое этого отношения
трактуется как ответ на запрос. Так, в примере 10.3 атом LongMovie является результатом
обработки запроса. Если в заголовках правил содержатся ссылки на несколько
отношений, только одно из них будет интерпретировано как итог выполнения запроса, а все
остальные — как вспомогательные данные, используемые для получения результата. Автор
запроса обязан оговорить, какое именно отношение следует воспринимать как
итоговое; с этой целью отношение можно снабдить специальным именем, таким как Answer.
10.1.4. Интерпретация правил Datalog
Пример 10.3 дает только намек на то, как следует трактовать правила языка Data-
log. Если говорить более точно, представим, что переменные, упоминаемые в тексте
правила, "пробегают" по множествам всех допустимых значений. Всякий раз, когда
10.1. ЛОГИКА ОТНОШЕНИЙ
455
Анонимные переменные
Зачастую в правилах Datalog некоторые переменные упоминаются только
однократно. Имена, используемые для таких переменных, особого смысла не имеют. Об
употреблении того или иного имени следует заботиться только в том случае, если
на переменную приходится ссылаться несколько раз. Если же переменная
присутствует в списке аргументов только одного атома, ее принято заменять символом
подчеркивания (_). Все экземпляры символа подчеркивания служат для
обозначения различных переменных. Правило из примера 10.3 можно переписать так:
LongMovie(t, у) *- Movie(t, у, 1, _, _, _) AND l > 100.
Поскольку каждая из переменных с, s и р упоминается только один раз, мы вправе
заменить ее символом _, но в отношении остальных переменных ту же операцию
сделать нельзя — все они присутствуют в выражении правила дважды.
переменные получают значения, в совокупности удовлетворяющие всем подцелям,
определяется содержимое атома-заголовка правила для текущей комбинации значений
переменных и соответствующий кортеж добавляется в итоговое отношение, на
которое ссылается заголовок.
Представим, что шесть переменных правила, рассмотренного в примере 10.3,
последовательно принимают все возможные значения. Единственная комбинация значений,
доставляющая всем подцелям результат true, такова, что значения переменных из
списка (/, у, I, с, 5, р) совпадают в заданном порядке с содержимым всех компонентов
некоторого кортежа отношения Movie. Поскольку, в частности, должна удовлетворяться и
подцель /> 100, кортеж обязан быть таким, что содержимое переменной /, отвечающей
компоненту length, содержит число, не меньшее 100. Как только указанная комбинация
значений найдена, кортеж (/, у) помещается в отношение LongMovie заголовка правила.
Существуют некоторые ограничения, касающиеся способов использования
переменных в правилах и предполагающие, что результатом вычисления правила должно
служить конечное отношение и правила с использованием арифметических атомов-
подцелей и подцелей с отрицанием (т.е. атомов, являющихся операндами оператора
not) обязаны обладать интуитивно ясным смыслом. Эти ограничения можно кратко
выразить посредством так называемого условия безопасности (safety condition):
• любая переменная, адресуемая в правиле Datalog, должна упоминаться и в
контексте некоторой реляционной подцели этого правила, не подвергаемой
операции отрицания.
В частности, каждая переменная, являющаяся элементом атома-заголовка,
реляционной подцели с отрицанием или арифметической подцели, должна присутствовать
также в некоторой реляционной подцели без оператора отрицания.
Пример 10.4. Вновь вернемся к правилу
LongMovie(t, у) <r- Movie(t, у, 1, _, _, _) AND 1 > 100
из примера 10.3 на с. 455. Первая подцель, которая является реляционной и не
содержит оператора отрицания, охватывает все переменные, упоминаемые в тексте
правила. В частности, переменные х и у из заголовка правила присутствуют также
и в первой подцели его тела. Аналогично, переменная / является элементом
арифметической подцели, но ссылка на нее есть и в первой подцели. □
Пример 10.5. Правило
Р(х, у) <— Q(x, z) AND NOT R(w, x, z) AND x < у
содержит три примера нарушения условия безопасности.
456
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
1. Переменная у присутствует в заголовке, но ее нет в Q — единственной
реляционной подцели, не помеченной оператором отрицания. Заметьте, что факт наличия
у в арифметической подцели х<у не помогает ограничить круг возможных
значений у конечным множеством. Пусть даже удастся найти значения а, Ь и с
переменных w, х и z соответственно, удовлетворяющие двум первым подцелям, нам
придется включить в отношение Р заголовка бесконечное множество кортежей (b, d),
каждый из которых удовлетворяет условию b<d, что, разумеется, невозможно.
2. Переменная w упоминается только в реляционной подцели R, являющейся
аргументом оператора отрицания, и ссылок на нее нет больше нигде (в частности,
нет и в реляционной подцели Q, не подвергаемой операции отрицания).
3. Ссылка на переменную у содержится в арифметической подцели, но в Q —
единственной реляционной подцели без оператора отрицания — ссылок на у нет.
Таким образом, указанное правило Datalog не отвечает условию безопасности и
использоваться не может. □
Существует и иной способ интерпретации правил Datalog. Вместо перебора всех
возможных комбинаций значений переменных следует обратить внимание на множества
кортежей отношений, соответствующих реляционным подцелям без операторов
отрицания. Если кортежи, назначаемые таким подцелям, образуют согласованный (consistent)
набор — в том смысле, что одноименным переменным присваиваются одни и те же
значения, — далее необходимо рассмотреть значения всех переменных правила (если
правило действительно удовлетворяет условию безопасности, определенное значение
получит каждая переменная правила): для любого согласованного набора следует проверить,
обращаются ли все реляционные подцели без отрицания и арифметические подцели
в true при подстановке значений из набора в переменные этих подцелей. Заметьте, что
значение подцели с отрицанием равно true, если значение подцели как таковой равно
false. Если набор данных доставляет всем подцелям значения true, необходимо
выяснить, какой вид принимает кортеж заголовка правила с учетом значений набора,
и включить этот кортеж в итоговое отношение, соответствующее предикату заголовка.
Пример 10.6. Рассмотрим Datalog-правило
Р(х, у) <- Q(x, z) AND R(z, y) AND NOT Q(x, y)
Предположим, что экземпляр отношения Q содержит кортежи (1,2) и (1,3), а
экземпляр отношения R — кортежи (2, 3) и (3, 1). Правило включает две реляционные
подцели без отрицания, Q(x, z) и R(z, у), поэтому следует проанализировать все варианты
присваивания кортежей отношений Q и R указанным подцелям. Существует четыре
комбинации присваивания, и все они изображены на рис. 10.1.
1)
2)
3)
4)
Кортеж для
Q(x, z)
(1,2)
(1,2)
(1,3)
(1,3)
Кортеж для
R(z, у)
(2,3)
(3,1)
(2,3)
(3,1)
Набор
согласован?
Да
Нет: z = 2, 3
Нет: z = 3, 2
Да
NOT Q(x, у)
равно true?
Нет
-
-
Да
Значение
заголовка
-
-
-
Р(1 1)
Рис. 10.1. Все возможные варианты присваивания кортежей подцелям Q(x, z) и R(z, у)
Вторая и третья комбинации кортежей не являются согласованными:
переменной z присваиваются различные значения. Поэтому дальнейшее рассмотрение этих
вариантов нецелесообразно.
10.1. ЛОГИКА ОТНОШЕНИЙ
457
Первый вариант, предполагающий присваивание подцели Q(x, z) кортежа (1,2),
а подцели R(z, у) — кортежа (2, 3), приводит к получению согласованного набора
данных: переменным х, у и z доставляются значения 1, 3 и 2 соответственно. Поэтому
имеет смысл провести анализ значений других подцелей — реляционных с
отрицанием и арифметических (в данном случае имеется одна такая подцель — not q(x, у)).
С учетом содержимого переменных хну подцель приобретает вид not q (l, 3).
Поскольку (1, 3) является кортежем отношения <2, подцель обращается в false, и
поэтому соответствующий кортеж в заголовок не включается.
Остается рассмотреть четвертую комбинацию. Она, как и первая, согласованна:
переменным х, у и z присваиваются значения 1, 1 и 3 соответственно. Подцель not q(x, у)
принимает форму not q(1, 1). Поскольку кортеж (1,1) не входит в число кортежей
отношения Q, значением этой подцели становится true. Все подцели истинны, поэтому
мы вправе вычислить значение заголовка Р(х, у) правила: Р(1, 1). Таким образом, кортеж
(1,1) включается в состав отношения Р. Поскольку множество всех возможных
сочетаний кортежей исчерпано, отношение Р будет содержать единственный кортеж — (1,1). □
10.1.5. Экстенсиональные и интенсиональные предикаты
Полезно подчеркнуть различие между двумя категориями предикатов:
• экстенсиональными (extensional) (соответствующие отношения хранятся в базе
данных);
• интенсиональными (intensional) (отношения вычисляются посредством
применения одного или нескольких правил Data log),
аналогичное различию между операндами выражения реляционной алгебры, которые
"экстенсиональны" в том смысле, что определяются посредством текущих
"экземпляров" (extents) соответствующих отношений, и отношениями, получаемыми
в процессе или в результате вычисления выражения реляционной алгебры, —
"интенсиональными", т.е. определяемыми "намерениями" (intents) программиста.62
Говоря о правилах языка Datalog, мы будем называть отношение, отвечающее
предикату, "интенсиональным" или "экстенсиональным", если соответственно
интенсионален или экстенсионален сам предикат. Помимо того, мы будем пользоваться
терминами IDB (от Intensional Database — "интенсиональная база данных") и EDB
(от Extensional Database — "экстенсиональная база данных") для обозначения
интенсиональных/экстенсиональных предикатов и/или отвечающих им отношений. Так,
в примере 10.3 отношение Movie является EDB-отношением, а предикат Movie —
EDB-предикатом, в то время как и предикат, и отношение LongMovie интенсиональны.
EDB-предикат не может упоминаться в заголовке правила, хотя в теле правила его
присутствие вполне допустимо. ID В-предикаты, напротив, могут употребляться как
в теле или заголовке, так и в обеих частях правила одновременно. Для
конструирования отношения могут использоваться несколько правил с одним и тем же предикатом
заголовка (соответствующую иллюстрацию вы увидите в примере 10.10 на с. 461, где
рассматривается операция объединения (union) двух отношений).
Используя последовательность интенсиональных предикатов, можно
конструировать все более сложные функции, применяемые к EDB-отношениям. Процесс
подобен созданию выражений реляционной алгебры с помощью нескольких операторов.
62 Здесь авторы слишком вольно и своеобразно трактуют традиционные этимологию и
семантику понятий интенсиональности и экстенсиональности, принятых в логике вообще и в
математической логике в частности. Строго говоря, интенсиональностъ (от лат. intensio —
усиление) — термин логики, характеризующий зависимость истинностного значения
высказывания не только от значений составляющих его более простых высказываний, но и от
различных смысловых оттенков этих высказываний; антипод экстенсиональности (от лат. extensio —
протяжение, расширение). — Прим. перев.
458
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
10.1.6. Правила Datalog для мультимножеств
Язык Datalog основан на логике множеств (sets). Однако если исключить из
рассмотрения реляционные подцели с отрицанием, способы вычисления правил Datalog
применительно к множествам можно распространить и на случай мультимножеств
(bags). Если отношения являются мультимножествами, с концептуальной точки
зрения проще применять второй из рассмотренных в разделе 10.1.4 подходов к
интерпретации правил Datalog, который, напомним, предусматривает обращение к каждой
реляционной подцели без отрицания с последующим подбором кортежей отношения,
соответствующего предикату подцели. Если комбинация кортежей, выбранных для
каждой подобной подцели, такова, что набор значений всех переменных правила
является согласованным и все арифметические подцели обращаются в true63, надлежит
вычислить кортеж заголовка правила и включить его в итоговое отношение.
Поскольку здесь речь идет о мультимножествах, выполнение операции удаления
дубликатов из отношения заголовка правила не предусматривается. Более того, так
как мы обязаны проверить все комбинации кортежей реляционных подцелей, кортеж,
упоминаемый в отношении подцели п раз, должен рассматриваться столько же раз
в сочетании со всеми кортежами отношений других подцелей.
Пример 10.7. Рассмотрим правило
Н(х, z) <r- R(x, у) AND S(y, z)
при условии, что экземпляр отношения R(A, В) содержит кортежи
А
1
1
В
2
2
а экземпляр отношения S(B, Q
в
— кортежи
2
4
4
С
3
5
5
Единственная ситуация, приводящая к получению согласованного набора значений
переменных (в данном случае — к присваиванию переменной у одинакового значения
в каждой из подцелей), связана с назначением подцели R(x,y) кортежа (1, 2), а подцели
S(y, z) — кортежа (2, 3). Поскольку отношение R содержит кортеж (1, 2) дважды, a S —
один экземпляр кортежа (2, 3), существуют две комбинации кортежей, приводящие
к присваиванию переменным х, у и z значений 1, 2 и 3 соответственно. Каждой из
комбинаций соответствуют два одинаковых кортежа (x,z) отношения-заголовка Н— (1,3).
Таким образом, результатом вычисления правила является экземпляр отношения
1 13
1 13
Если бы кортеж (1, 2) присутствовал в R п раз, а кортеж (2, 3) в S
был бы включен в отношение Н т*п раз. □
т раз, кортеж (1,3)
63 Заметим, что правило Datalog, допускающее использование мультимножеств, не должно
включать реляционные подцели, служащие аргументами операторов отрицания. В контексте
модели мультимножеств смысл произвольного правила, содержащего реляционные подцели
с отрицанием, не определен.
10.1. ЛОГИКА ОТНОШЕНИЙ
459
Если некоторое отношение определено посредством нескольких Datalog-правил,
общим итогом окажется мультимножество, являющееся объединением наборов
кортежей, получаемых в результате вычисления всех правил.
Пример 10.8. Рассмотрим отношение Н, описываемое двумя правилами,
Н(х, у) <r- S(x, у) AND х > 1,
Н(х, у) <- S(x, у) AND у < 5,
где отношение S(B, Q представлено тем же экземпляром, что и в примере 10.7, т.е.
5= {(2, 3), (4, 5), (4, 5)}. Руководствуясь первым правилом, мы должны поместить в Н
все кортежи S, поскольку содержимое первого компонента каждого из них превышает
значение 1. Второе правило ограничивает множество кортежей, включаемых в Я,
кортежем (2, 3), поскольку кортежи (4, 5) не удовлетворяют условию у < 5. Поэтому
итоговый экземпляр Я будет содержать по две копии каждого из кортежей — (2, 3) и (4, 5). □
10.1.7. Упражнения к разделу 10.1
Упражнение 10.1.1. Сформулируйте каждый из запросов, перечисленных в качестве
заданий упражнения 5.2.1 на с. 218, средствами Datalog. Следует применять только
такие правила, которые отвечают условию безопасности, но можно
воспользоваться несколькими IDB-предикатами, соответствующими отдельным частям сложных
выражений реляционной алгебры.
Упражнение 10.1.2. Сформулируйте каждый из запросов, перечисленных в качестве
заданий упражнения 5.2.4 на с. 222, средствами Datalog. Вновь, как и в задании
10.1.1, надлежит применять только такие правила, которые отвечают условию
безопасности, но разрешено пользоваться несколькими IDB-предикатами,
соответствующими отдельным частям сложных выражений реляционной алгебры.
!! Упражнение 10.1.3. Выполнения условия безопасности правила Datalog достаточно,
дабы гарантировать, что предикату заголовка будет соответствовать конечное
отношение, если конечны отношения, отвечающие реляционным подцелям. Это
требование, однако, чересчур строго. Приведите пример Datalog-правила, нарушающего
условие, хотя отношение его заголовка является конечным независимо от того, какие
конечные отношения ставятся в соответствие реляционным предикатам-подцелям.
10.2. От реляционной алгебры к языку Datalog
Поведение каждого из операторов реляционной алгебры, рассмотренных в разделе
5.2 на с. 205, можно смоделировать с помощью одного или нескольких Datalog-
правил, и о том, как это сделать, будет рассказано ниже. Затем мы обсудим способы
сочетания правил с целью имитации сложных алгебраических выражений.
10.2.1. Пересечение
Теоретико-множественная операция пересечения (intersection), применяемая к двум
отношениям, может быть представлена посредством правила, содержащего подцели,
соответствующие обоим отношениям, причем для описания аргументов подцелей
используются одинаковые переменные.
Пример 10.9. Рассмотрим отношения R:
пате
Carrie Fisher
Mark Hamill
address
123 Maple St., Hollywood
456 Oak Rd., Brentwood
gender
F
M
birthdate
9/9/99
8/8/88
460 ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
и S:
name
Carrie Fisher
Harrison Ford
address
123 Maple St.
789 Palm Dr. ,
, Hollywood
Beverly Hills
gender
F
M
birthdate
9/9/99
8/8/88
Пересечение отношений Rw S можно описать с помощью следующего правила Datalog:
1(11, а, д, b) <— R(n, а, д, b) AND S(n, а, д, Ъ)
Здесь / представляет IDB-предикат, которому соответствует отношение Rf]S: чтобы
некоторый кортеж (п, a, g, b) мог быть включен в итоговое отношение /, он должен
доставлять обеим подцелям значение true, т.е. принадлежать отношениям R и S
одновременно. В нашем случае такой кортеж, хотя и единственный, действительно существует:
('Carrie Fisher', '123 Maple St., Hollywood', 'F', 9/9/99)
□
10.2.2. Объединение
Операцию объединения (union) двух отношений можно смоделировать посредством
двух Datalog-правил, каждое из которых содержит единственную подцель,
соответствующую одному (различному) отношению из числа двух заданных, и одинаковые
IDB-предикаты заголовков. Помимо того, списки аргументов заголовков и подцелей
в обоих правилах также должны совпадать.
Пример 10.10. Чтобы вычислить результат объединения отношений R и S,
рассмотренных в примере 10.9, достаточно воспользоваться двумя следующими правилами:
1) U(n, a, g, b) <- R(n, а, д, Ь);
2) U(n, а, д, b) <- S(n, а, д, Ь).
Правило 1 гласит, что каждый кортеж R должен быть включен в IDB-отношение U.
Правило 2 аналогичным образом предполагает, что отношение U обязано содержать все
кортежи S. Таким образом, правила, рассматриваемые совместно, предусматривают
необходимость включения в U каждого кортежа отношения R U S. Если другие правила, в
заголовках которых упоминается отношение V, не определены, причин и способов
пополнения U какими-либо иными кортежами не существует, поэтому можно заключить,
что содержимое U точно совпадает с набором данных R U S.64 Заметим, что, в отличие от
операции пересечения, которая применяется только к множествам, рассматриваемая
пара правил может трактоваться и в контексте мультимножеств — в зависимости от того,
каким образом воспринимается объединение результатов вычисления каждого из
правил. Если не оговорено иное, подразумевается "множественный" вариант объединения. □
10.2.3. Разность
Теоретико-множественная разность (difference) отношений R и S вычисляется
с помощью единственного правила, содержащего подцель с оператором отрицания:
точнее говоря, отношению R отвечает подцель без отрицания, а отношению S —
подцель с отрицанием. Обе подцели и заголовок правила должны обладать одинаковыми
списками аргументов атомов.
64 В каждом из примеров этого раздела мы подразумеваем, что кроме тех правил, которые
заданы явно, других правил, регламентирующих состав тех же IDB-отношений, нет. Если
допустить возможность существования дополнительных правил, гарантировать результат тех или
иных операций сколько-нибудь точно не удастся.
10.2. ОТ РЕЛЯЦИОННОЙ АЛГЕБРЫ К ЯЗЫКУ DATALOG
461
Переменные правила локальны
Необходимо заметить, что идентификаторы, используемые для описания
переменных в контексте правила, могут выбираться совершенно произвольно и вне какой
бы то ни было связи с переменными, используемыми в других правилах: каждое
правило вычисляется отдельно и независимо от других. Поэтому правило 2 в
примере 10.10 можно заменить, скажем, таким:
U(w, х, у, z) <r- S(w, х, у, z),
оставив первое правило без изменений, но на конечный результат (R U S) это
никоим образом не повлияет. Если, однако, переменная а заменяется переменной Ь
внутри одного правила, следует осуществить замену всех экземпляров
идентификатора я, причем до выполнения операции в тексте правила не должно быть
ссылок на переменную Ь.
Пример 10.11. Если R и S представляют собой отношения, рассмотренные в примере
10.9, правило
D(n, a, g, b) <- R(n, a, д, b) AND NOT S(n, a, g, b)
определяет D как разность отношений R и S, т.е. R-S. □
10.2.4. Проекция
Для вычисления проекции (projection) отношения R достаточно правила,
содержащего единственную подцель с предикатом R, который снабжен списком аргументов-
переменных, отвечающих всем атрибутам отношения. Заголовком правила является
атом с переменными, соответствующими атрибутам, которые подлежат включению
в список проекции в указанном порядке.
Пример 10.12. Пусть необходимо осуществить проекцию отношения
Movie(title, year, length, inColor, studioName, producerC#)
на список атрибутов (title, year, length). Для этого достаточно применить правило
P(t, у, 1) <- Movie(t, у, 1, с, s, p),
определяющее отношение Р как искомый результат проекции. □
10.2.5. Выбор
Операции выбора (selection) несколько более сложны для описания средствами
языка Datalog. В простейшем случае критерий выбора определяется одним или
несколькими выражениями сравнения, связанными операторами and ("И"), и правило
должно содержать следующие компоненты:
1) реляционную подцель, соответствующую отношению, к которому
применяется операция выбора; в атом подцели следует включить аргументы-
переменные, отвечающие каждому атрибуту отношения;
2) арифметические подцели для каждого выражения сравнения, содержащие
вместо имен атрибутов переменные в порядке их соответствия,
установленном реляционной подцелью.
Пример 10.13. Оператор выбора
Оlength > 100 AND studioName = ■ Fox' (МО V1 e)
из примера 5.4 на с. 209 можно представить в виде следующего Datalog-правила:
S(t, у, 1, с, s, p) <r- Movie (t, у, 1, с, s, p) AND 1 > 100 AND s = 'Fox'.
462
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
Результатом выполнения правила окажется отношение S. Обратите внимание, что /
И5— идентификаторы переменных, отвечающих атрибутам length и studioName
отношения Movie, и порядок соответствия задан реляционной подцелью Movie. □
Теперь рассмотрим варианты выбора с применением операторов OR ("ИЛИ").
Подобные задачи не обязательно сводятся к написанию единственного правила Datalog.
Операция выбора с учетом двух условий, связанных посредством or, например,
эквивалентна двум операциям выбора по каждому условию, рассматриваемым отдельно,
с последующим объединением (union) результатов. Вообще говоря, если операторами
or соединены п выражений сравнения, критерий выбора следует представлять в
форме п правил, содержащих одинаковые атомы заголовков.
Пример 10.14. Рассмотрим иную версию запроса из примера 10.13, заменив
оператор and на or:
alength> 100OR studioName = -Fox1 (Movie),
т.е. предполагая необходимость выбора сведений о тех кинофильмах, которые либо
обладают продолжительностью воспроизведения, не меньшей 100 минут, либо сняты
на киностудии "Fox". Каждое из условий можно описать отдельным правилом,
1) S(t, у, 1, с, s, р) <- Movie(t, у, 1, с, s, p) AND 1 > 100,
2) S(t, у, 1, с, s, р) <— Movie (t, у, 1, с, s, p) AND s = 'Fox',
которые, будучи восприняты в совокупности, дают искомый результат: правило 1
регламентирует выбор кинофильмов продолжительностью не менее 100 минут, а
правило 2 — кинофильмов, выпущенных студией "Fox". □
Более сложные условия выбора могут быть трансформированы в конструкции,
содержащие логические операторы and, or и not, с помощью широко известного алгоритма
(мы не будем останавливаться на нем подробно) преобразования логического выражения в
так называемую дизъюнктивную нормальную дЬорму (disjunctive normal form), содержащую
дизъюнкцию (or) "конъюнктов". Конъюнкт (conjunct) представляет собой выражение,
состоящее из "литералов", соединенных операторами and, а литерал (literal), в свою
очередь, — это либо выражение сравнения, либо выражение сравнения с отрицанием (not).65
Каждый литерал легко представить в виде подцели (возможно, с оператором not),
причем если подцель является арифметической, оператор отрицания, если таковой
присутствует, можно "встроить" непосредственно в оператор сравнения. Например,
выражению not х > 100 соответствует аналог х < 100, не содержащий отрицания.
Далее каждый конъюнкт следует оформить в виде правила Datalog, в котором
каждому выражению сравнения отвечает определенная подцель. Наконец, каждая
дизъюнктивная нормальная форма может быть представлена набором правил, по одному на
каждый конъюнкт. Рассматриваемые в совокупности, результаты вычисления правил
образуют дизъюнкцию (or) конъюнктов.
Пример 10.15. Простой образец применения указанного алгоритма рассмотрен в
примере 10.14. Усложним задание, снабдив условие отбора оператором отрицания,
^NOT (length > 100 OR studioName = ' Fox ■) (MOVie),
и полагая, что выбору подлежат все кинофильмы, кроме тех, которые либо
обладают продолжительностью воспроизведения, не меньшей 100 минут, либо выпущены
киностудией "Fox".
65 За дополнительной информацией обращайтесь, например, к работе Aho A.V., Ullman J.D.
Foundations of Computer Science, Computer Science Press, New York, 1992.
10.2. ОТ РЕЛЯЦИОННОЙ АЛГЕБРЫ К ЯЗЫКУ DATALOG
463
Здесь оператор not применяется к выражению, которое само по себе не является
простым сравнением. Чтобы "избавиться" от оператора not, воспользуемся законом
Моргана (Morgan's law) в той его редакции, которая гласит, что отрицание
дизъюнкции (or) равносильно конъюнкции (and) отрицаний:
^(NOT {length > 100)) AND (NOT (studioName = ' Fox •)) (MOviв),
а затем "упрячем" операторы not, изменив условия выражений сравнения на
противоположные:
&length < 100 AND studioName Ф ' Fox ■ (МО Vi в).
Это выражение реляционной алгебры представляется в виде Datalog-правил а вполне
естественным образом:
S(t, у, 1, с, s, p) <r- Movie(t, у, 1, с, s, p) AND 1 < 100 AND s Ф 'Fox'.
□
Пример 10.16. Рассмотрим схожее условие, в котором, однако, отрицанию (not)
подвергается конъюнкция (and) двух выражений сравнения:
^"not (length > 100 AND studioName = • Fox') (MOV1e)?
т.е. предполагается выбор всех кинофильмов, кроме тех, которые обладают
продолжительностью воспроизведения, не меньшей 100 минут, и выпущены киностудией
"Fox". В этом случае уместно применить вторую форму закона Моргана, согласно
которой отрицание конъюнкции эквивалентно дизъюнкции (or) отрицаний:
^(NOT (length > 100)) OR (NOT (studioName = • Fox')) (MO vi e).
Вновь, чтобы "отбросить" операторы not, достаточно инвертировать условия сравнения:
&length < 100 OR studioName * ■ Fox' (MOVlв).
Наконец, каждое условие следует представить в виде отдельного Datalog-правила:
1) S(t, у, 1, с, s, р) <- Movie (t, у, 1, с, s, p) AND 1 < 100;
2) S(t, у, 1, с, s, р) <— Movie (t, у, 1, с, s, p) AND s Ф 'Fox'.
□
10.2.6. Декартово произведение
Декартово произведение (Cartesian product) двух отношений R и S (/? х S) можно
представить в виде Datalog-правила, содержащего две подцели, по одной для отношений R и 5.
Каждая подцель должна содержать переменные, соответствующие атрибутам отношения
(R или S), а ШВ-атом заголовка — список переменных, упоминаемых в обоих подцелях,
причем переменные подцели R должны предшествовать в списке переменным подцели S.
Пример 10.17. Рассмотрим отношения R и S из примера 10.9 на с. 460, каждое из
которых содержит по четыре атрибута. Правило
Р(а, Ь, с, d, w, х, у, z) <— R(a, b, с, d) AND S(w, x, y, z)
определяет отношение Р как результат операции RxS. Для обозначения переменных,
соответствующих атрибутам отношений R и S, мы использовали по четыре буквы из
начала и конца алфавита, и все они присугствуют в заголовке правила в заданном порядке. □
10.2.7. Соединения
Datalog-правило для выражения естественного соединения (natural join) двух
отношений R и S (R х S) во многом схоже с правилом, отвечающим декартову произведению.
Различие состоит в том, что при конструировании правила вычисления RxS одно-
464
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
именные атрибуты отношений должны быть представлены и одноименными
переменными (например, в качестве идентификаторов переменных можно использовать
названия атрибутов), В IDB-атом заголовка каждая переменная включается по одному разу.
Пример 10.18. Рассмотрим отношения со схемами R(A, В) и S(B, С, D). Операцию их
естественного соединения можно выразить в виде правила
J(a, b, с, d) <- R(a, b) AND S(b, c, d).
Заметьте, что идентификаторы переменных в подцелях соответствуют названиям
атрибутов отношений. □
Средствами Datalog можно описать и операцию тета-соединения (theta-join) двух
отношений. Напомним (см. раздел 5.2.10 на с. 216), что тета-соединение может быть
представлено в виде последовательности операций декартова произведения и выбора.
Если условие выбора является конъюнкцией (and) нескольких выражений сравнения,
достаточно начать с построения правила для декартова произведения, а затем
присовокупить к нему дополнительные подцели, по одной на каждое выражение сравнения.
Пример 10.19. Обратимся к отношениям U(A, В, Q и V(B, С, D) из примера 5.9 на с. 213,
где рассматривалась операция тета-соединения
U х V.
А < D AND и.ВФ V.B
Ей соответствует Datalog-правило
J (a, ub, uc, vb, vc, d) <— U(a, ub, uc) AND V(vb, vc, d) AND
a < d AND ub Ф vb.
Переменные ub и uc использованы для обозначения атрибутов Ь и с отношения (У,
а переменные vb и vc — одноименных атрибутов отношения V, хотя с тем же успехом
мы могли бы выбрать шесть совершенно различных идентификаторов. Первые две
подцели, являющиеся реляционными, отвечают отношениям U и V, подлежащим
соединению, а вторые две, арифметические, — двум операциям сравнения, образующим
критерий соединения. □
Если условие тета-соединения не является конъюнкцией, его следует привести
к дизъюнктивной нормальной форме с помощью алгоритма, который обсуждался
в разделе 10.2.5 на с. 462, а затем сконструировать по одному Datalog-правилу для
каждого конъюнкта, начиная с подцелей, соответствующих декартовому произведению
отношений, и добавляя подцели для описания литералов конъюнкта. Заголовки всех
правил должны быть идентичными и обязаны содержать по одному аргументу для
каждого атрибута соединяемых отношений.
Пример 10.20. Незначительно исправим условие примера 10.19, заменив and оператором
OR. Выражение не содержит операторов отрицания, пребывает в дизъюнктивной
нормальной форме и содержит два конъюнкта, каждый из которых состоит из одного литерала:
U х V.
А < Dor и.ВФ v.b
Используя ту же схему именования переменных, что и в примере 10.19, создадим два
Datalog- правила:
1) J (a, ub, uc, vb, vc, d) <— U(a, ub, uc) AND V(vb, vc, d) AND a < d;
2) J(a, ub, uc, vb, vc, d) <— U(a, ub, uc) AND V(vb, vc, d) AND ub Ф vb.
Оба правила содержат одни и те же реляционные подцели лпя отношений,
участвующих в операции, и по одной подцели, соответствующей одному из двух условий
соединения -~ А < D или и.ВфУ.В. □
10.2. ОТ РЕЛЯЦИОННОЙ АЛГЕБРЫ К ЯЗЫКУ DATALOG
465
10.2.8. Представление наборов операций средствами Datalog
С помощью правил языка Datalog могут быть описаны не только отдельные
операции реляционной алгебры, но и целые алгебраические выражения, составленные из
нескольких операторов. Для этого следует рассмотреть дерево частных выражений,
соответствующее выражению реляционной алгебры, и создать по одному ID В-атому
для каждой промежуточной и оконечной вершин дерева. Существо правила или
нескольких правил, отвечающих IDB-атому, определяется характером оператора,
используемого на определенной вершине дерева. Экстенсиональные операнды (т.е. те,
которые соответствуют хранимым отношениям) представляются EDB-атомами, а
операнды, описывающие промежуточные вершины, — IDB-атомами.
Пример 10.21. Вновь обратимся к алгебраическому выражению
fttitle,year\O'lengthbW0№ovie) О О'studioName = -Fox' (Movie))
из примера 5.10 на с. 214, дерево которого изображено на рис. 5.8 и воспроизведено
на рис. 10.2. Дерево содержит четыре вершины, для которых следует создать IDB-
атомы. Каждый IDB-атом может быть представлен одним правилом (см. рис. 10.3).
title, year
n
length > 100
Movie
studioName = ' Fox'
Movie
Рис. 10.2. Дерево частных выражений
реляционной алгебры
1) W(t, у, 1, с, s, р) <- Movie(t, у, 1, с, s, p) AND 1 > 100
2) X(t, у, 1, с, s, p) <r- Movie (t, у, 1, с, s, p) AND s = 'Fox'
3) Y(t, у, 1, с, s, p) <r- W(t, у, 1, с, s, p) AND X(t, у, 1, с, s, p)
4) Z(t, у) <r- Y(t, у, 1, с, s, p)
Рис. 10.3. Правила Datalog для описания набора алгебраических операций
Две промежуточные вершины нижнего уровня отображают операции выбора
кортежей из EDB-отношения Movie, и им соответствуют IDB-предикаты W и X. Правила
1 и 2 содержат описания этих операций. Например, правило 1 определяет, что
отношение W должно включать такие кортежи, которые представляют информацию о
кинофильмах с длительностью воспроизведения, не меньшей 100 минут.
Правило 3 гласит, что отношение Y является результатом пересечения отношений
W и X, и следует форме, о которой мы рассказывали в разделе 10.2.1 на с. 460.
Наконец, правило 4 определяет предикат Z как итог выполнения операции проекции
отношения Y на атрибуты title и year (здесь мы использовали прием имитации
операции проекции средствами Datalog, о котором говорилось в разделе 10.2.4 на с. 462).
Предикат Z представляет окончательный "ответ" на запрос; независимо от конкрет-
466
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
ного состава набора данных отношения Movie, отношение Z по существу совпадает
с результатом выполнения исходного алгебраического выражения.
Поскольку предикат Y представлен единственным правилом (3), подцель Y в теле
правила 4 можно заменить телом правила 3, а затем вместо подцелей W и X
подставить тела правил 1 и 2 соответственно. Поскольку реляционная подцель Movie
содержится в телах обоих правил, одну из ее копий можно исключить. В результате набор
из четырех правил можно свести к единственному правилу:
Z(t, у) <- Movie (t, у, 1, с, s, p) AND 1 > 100 AND s = 'Fox'.
Разумеется, такая ситуация, когда сложное выражение реляционной алгебры
допускает возможность описания посредством единственного Datalog-правила,
отнюдь не типична. □
10.2.9. Упражнения к разделу 10.2
Упражнение 10.2.1. Рассмотрите три отношения со схемами R(a, b, с), S(a, b, с) и Т(а, Ь, с).
Создайте по одному или несколько Datalog-правил, позволяющих представить
результаты вычисления следующих выражений реляционной алгебры:
a) R\JS;
b) ЯП5;
c) R-S',
* d) (R U S) - Г;
!е) (R-S)fMR-T);
0 **.*(*);
*\g) ^b(R)npU(a,b)(^b,c(S)).
Упражнение 10.2.2. Рассмотрите отношение со схемой R(x, у, z). Создайте по одному
или несколько Datalog-правил, реализующих операции crc(R) выбора, где С
соответствует каждому из приведенных ниже условий:
а) х = у;
* Ъ) х<у and y<z\
c) х<у OR y<z\
d) NOT (x<y OR x>y)',
*! e) not ((x<y or x>y) and y<z);
! f) NOT ((x<y OR x<z) AND y<z).
Упражнение 10.2.3. Рассмотрите три отношения со схемами R(a, b, с), S{b, c,d) и T(d, e).
Создайте по одному Datalog-правилу, реализующему каждую из указанных ниже
операций естественного соединения:
a) RxS;
b) SxT-
c) (RxS)xT (примите к сведению, что операция естественного соединения
ассоциативна и коммутативна, поэтому порядок соединения отношений
значения не имеет).
10.2. ОТ РЕЛЯЦИОННОЙ АЛГЕБРЫ К ЯЗЫКУ DATALOG
467
Упражнение 10.2.4. Рассмотрите два отношения со схемами R(x, у, z) и S(x, у, z).
Создайте по одному или несколько Datalog-правил, реализующих операции R\xS тета-
соединения, где С соответствует каждому из условий, приведенных в упражнении
10.2.2. Воспринимайте эти условия таким образом, будто левая часть каждого
оператора сравнения представляет атрибут отношения R, а правая — атрибут
отношения S (например, х < у соответствует условию R.x < S.y).
! Упражнение 10.2.5. Вполне возможно обратное преобразование Datalog-правил
в эквивалентные выражения реляционной алгебры. Хотя общую методику
подобных действий мы не обсуждали, с некоторыми простыми примерами вам
наверняка удастся справиться самостоятельно. Создайте выражения реляционной алгебры,
определяющие те же отношения, которые представлены в заголовках каждого из
Datalog-правил, перечисленных ниже:
* а) Р(х, у) f- Q(x, z) AND R(z, у);
b) P(x, y) <r- Q(x, z) AND Q(z, y) ;
C) P(x, y) <- Q(x, z) AND R(z, y) AND x < y.
10.3. Рекурсивное программирование на языке Datalog
Аппарат реляционной алгебры позволяет представить множество самых разных
операций над отношениями, но, к сожалению, далеко не все. Характерным примером
операций, не поддающихся описанию средствами реляционной алгебры, может служить
рекурсивная обработка неограниченной последовательности однотипных выражений.
Пример 10.22. Зачастую нашумевшие кинофильмы имеют продолжение (sequel); если
серия продолжения также завоевывает успех, снимается очередная серия и т.д. Таким
образом, один кинофильм может служить прародителем долгой последовательности
других. Предположим, что дано отношение SequelOf (movie, sequel), содержащее пары
значений, представляющих названия фильма (movie) и его непосредственного
продолжения (sequel). Один из возможных экземпляров отношения SequelOf показан ниже.
movie
Naked Gun
Naked Gun 2Vi
sequel
Naked Gun 2Vi
Naked Gun 3 3^
Можно предложить обобщенное понятие продолжения кинофильма, серия (follow-
on), которое обозначает любую ленту из последовательности продолжений
кинофильма. В приведенном выше экземпляре отношения кинофильм "Naked Gun 33V3"
является серией ленты "Naked Gun", но не непосредственным ее продолжением. Понятие
серии позволяет не сохранять в отношении всю последовательность продолжений
кинофильма и получать ее только в случае необходимости. В рассматриваемом примере
экономия исчисляется только одним кортежем, но если бы нам пришлось описывать
последовательности из пяти кинофильмов "Rocky" или восемнадцати лент "Friday
the 13th", выигрыш оказался бы весьма ощутимым — 6 и 136 кортежей соответственно.
Впрочем, задача вычисления отношения, содержащего информацию о сериях
кинофильма, на основе отношения SequelOf не столь очевидна, как может показаться.
Чтобы определить, какие ленты являются продолжениями продолжений, следует
соединить (join) отношение SequelOf с собой. Пример соответствующего выражения
реляционной алгебры, где в результате переименования атрибутов соединение
превращается в естественное соединение, приведен ниже:
л first, third (A? (first, second) (SequalOf) ex Ps (second, third) (SequalOf)).
468
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
Здесь атрибуты отношения Sequalof подвергаются переименованию дважды — один
раз в first и second, а затем — в second и third. Таким образом, в результате
естественного соединения кортежей (т{, га2) и (w3, w4) должны быть получены кортежи
(ть т4), такие, что т2 = т3. Заметьте, что т4 представляет "продолжение продолжения" тх.
Аналогичным образом могут быть соединены три копии кортежей отношения
Sequelof с целью получения продолжений продолжений продолжений кинофильмов
(например, "Rocky" и "Rocky IV"). Для вычисления /-го продолжения для каждого
фиксированного / следует соединить отношение Sequelof с собой /-1 раз.
Объединение (union) Sequelof с конечной последовательностью результатов соединения
даст в итоге набор всех продолжений вплоть до определенного фиксированного
уровня. Но вот чего нельзя сделать средствами реляционной алгебры, так это
осуществить объединение "бесконечной" последовательности выражений,
возвращающих множества /-х продолжений для /= 1, 2,... . Напомним, что оператор объединения
в реляционной алгебре применим только к двум отношениям, но отнюдь не к
бесконечному количеству отношений. Употребляя оператор объединения в контексте
выражения реляционной алгебры определенное количество раз, мы сможем вычислить
результат объединения соответствующего (но не бесконечного) количества отношений. □
10.3.1. Рекурсивные правила Datalog
Используя один и тот же IDB-предикат как в заголовке, так и в теле правила,
можно выразить средствами Datalog операцию объединения бесконечного количества
отношений. Вначале мы продемонстрируем пример выражения рекурсии в Datalog,
а затем, в разделе 10.3.2, обсудим алгоритм, позволяющий определить содержимое
отношений, соответствующих IDB-предикатам набора правил. Для вычисления
рекурсивных правил требуется новый подход, поскольку тот, который мы рассматривали
в разделе 10.1.4 на с. 455, предусматривает, что всем предикатам тела правила должны
отвечать фиксированные отношения.
Пример 10.23. IDB-отношение FollowOn, представляющее информацию о сериях
кинофильмов (см. пример 10.22), можно описать двумя следующими правилами:
1) FollowOn(х, у) <— Sequelof(х, у),
2) FollowOn(х, у) <— Sequelof (х, z) AND FollowOn (z, у).
Правило 1 представляет собой базисное утверждение и гласит, что каждое
продолжение (sequel) является серией (follow-on). Правило 2 свидетельствует, что любая серия
продолжения фильма х является также серией фильма х\ более точно, если z —
продолжение х и v — серия z, то у — серия х. □
10.3.2. Вычисление рекурсивных правил Datalog
При вычислении IDB-атомов рекурсивных Datalog-правил мы придерживаемся такого
принципа: решение о том, что некоторый кортеж принадлежит ID В-отношению, не
принимается, если только к этому не вынуждает необходимость применения правил в
соответствии с тем, как это изложено в разделе 10.1.4 на с. 455. Иными словами, следует:
1) положить, что всем ID В-предикатам соответствуют пустые отношения;
2) выполнить ряд итераций, на каждой из которых для IDB-предикатов
конструируются все более крупные отношения, причем в телах правил
используются IDB-отношения, полученные на предыдущей итерации, и правила
применяются для получения новых, уточненных вариантов отношений;
3) если правила отвечают условию безопасности, ни один кортеж IDB-
отношения не может содержать значение компонента, отсутствующее в не-
10.3. РЕКУРСИВНОЕ ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ DATALOG
469
котором EDB-отношении; поэтому существует конечное количество
кортежей, которые подлежат включению во все ID В-отношения, и на некоторой
итерации непременно возникнет такая ситуация, когда ни в одно из IDB-
отношений новые кортежи добавлены быть не могут; в этом случае процесс
надлежит завершить, полагая, что искомый ответ получен.
Пример 10.24. Рассмотрим, как применить изложенный выше алгоритм для
вычисления содержимого отношения FollowOn с помощью правил, приведенных в примере
10.23, если экземпляр отношения Sequelof содержит три кортежа:
movie
Коску-
Коску II
Rocky III
sequel
Rocky II
Rocky III
Rocky IV
На первой итерации положим, что отношение FollowOn пусто. Поэтому в
соответствии с правилом 2 в FollowOn никакие кортежи добавлены быть не могут. Однако
правило 1 гласит, что всякий кортеж Sequelof является и кортежем FollowOn.
Поэтому по завершении итерации 1 содержимое отношений FollowOn и Sequelof
окажется идентичным. Соответствующий промежуточный экземпляр отношения
FollowOn изображен на рис. 10.4 (а).
На второй итерации в качестве текущего используется экземпляр FollowOn,
показанный на рис. 10.4 (а). Применим к отношениям Sequelof и FollowOn оба правила.
Первое дает те же три кортежа, которые в FollowOn уже включены: собственно
говоря, нетрудно убедиться, что, действуя в соответствии с правилом 1, мы не сможем
отыскать никакие кортежи, кроме трех, найденных на первой итерации. Применяя
правило 2, мы должны найти кортежи Sequelof, вторые компоненты которых
совпадают с первыми компонентами некоторых кортежей FollowOn. Так, мы вправе
соединить кортеж (Rocky, Rocky II) из Sequelof с кортежем
(Rocky II, Rocky III) из FollowOn, чтобы получить новый кортеж
(Rocky, Rocky III), подлежащий включению в FollowOn. Аналогично, на основе
кортежа (Rocky II, Rocky III) из Sequelof и кортежа (Rocky III, Rocky IV)
из FollowOn можно "добыть" еще один новый кортеж для FollowOn —
(Rocky II, Rocky IV). Однако никакие другие кортежи отношений Sequelof
и FollowOn соединены быть не могут. Поэтому по завершении итерации 2 процесса
экземпляр FollowOn будет выглядеть так, как показано на рис. 10.4 (Ь).
На третьей итерации мы принимаем за основу экземпляр отношения FollowOn,
приведенный на рис. 10.4 (Ь), и вновь вычисляем тело правила 2, получая не только все
кортежи, которые уже включены в отношение FollowOn, но и еще один: операция соединения
кортежа (Rocky, Rocky II) из Sequelof и кортежа (Rocky II, Rocky IV) из
FollowOn приводит к формированию нового допустимого кортежа, (Rocky, Rocky IV).
На рис. 10.4 (с) изображен экземпляр отношения FollowOn по окончании итерации 3.
Четвертая итерация не приносит новой "добычи", поэтому процесс необходимо
завершить. Итоговый вариант отношения FollowOn показан на рис. 10.4 (с). □
Существует один важный аспект, способный значительно облегчить вычисление
рекурсивных Datalog-правил вообще и тех, что рассмотрены выше, в частности:
• на любой итерации новые кортежи, подлежащие включению в любые IDB-
отношения, могут быть получены только в результате применения таких правил,
в которых по меньшей мере одна из IDB-подцелей сводится к некоторому
кортежу, добавленному в соответствующее отношение на предыдущей итерации.
470
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
X
Коску-
Коску II
Rocky III
У
Rocky II
Rocky III
Rocky IV
(а) после итерации 1
X
Rocky
Rocky II
Rocky III
Rocky
Rocky II
У
Rocky II
Rocky III
Rocky IV
Rocky III
Rocky IV
(b) после итерации 2
X
Rocky
Rocky II
Rocky III
Rocky
Rocky II
Rocky
У
Rocky II
Rocky III
Rocky IV
Rocky III
Rocky IV
Rocky IV
(с) после итерации З и по завершении процесса
Рис. 10.4. Иллюстрация процесса вычисления рекурсивных Datalog-правил
Чтобы доказать справедливость этого утверждения, достаточно отметить следующее:
если к "старым" кортежам сводятся одновременно все подцели, это значит, что
кортежи, подлежащие включению в отношение заголовка, уже добавлены в него на
предыдущей итерации. В двух следующих примерах мы проиллюстрируем этот вопрос
подробнее; там же будут продемонстрированы и более сложные образцы рекурсии.
Пример 10.25. Можно привести множество примеров рекурсии, если обратиться к
задачам, связанным с поиском путей в графах. На рис. 10.5 показан граф,
представляющий информацию о рейсах, выполняемых самолетами двух (вымышленных)
авиакомпаний — "Untried Airlines" (ua) и "Arcane Airlines" (aa) — между городами Сан-
Франциско (sf), Денвер (den), Даллас (dal), Чикаго (chi) и Нью-Йорк (ny).
Предположим, что сведения о рейсах хранятся в EDB-отношении
Flights(airline, from, to, departs, arrives),
где airline — "авиакомпания", from — "откуда", to — "куда", departs — "время
вылета", arrives — "время прибытия". Экземпляр отношения, соответствующий
графу на рис. 10.5, приведен на рис. 10.6.
Один из простых вопросов, допускающих рекурсивное решение, таков: "Для каких
пар (х,у) городов существует последовательность авиарейсов, позволяющая добраться
из х в у?" Для получения отношения Reaches (x, у), содержащего искомый набор
кортежей, можно применить следующие правила:
1) Reaches (х, у) <— Flights (а, х, у, d, r),
2) Reaches (х, у) <— Reaches (x, z) AND Reaches (z, у).
10.3. РЕКУРСИВНОЕ ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ DATALOG 471
Другие формы рекурсии
В примере 10.23 на с. 469 демонстрировалась право-рекурсивная (right-recursive)
форма выражения, в соответствии с которой рекурсивное IDB-отношение
FollowOn размещается в теле правила после EDB-отношения Sequelof. Если
предикаты поменять местами, мы получим лево-рекурсивную (left-recursive) форму:
1) FollowOn(x, у) <— SequelOf (х, у),
2) FollowOn(х, у) <r- FollowOn(x, z) AND SequelOf(z, у).
Говоря неформально, у есть серия (follow-on) x, если у является либо продолжением
(sequel) x, либо продолжением серии х.
Рекурсивное отношение может быть упомянуто в теле правила даже дважды,
как в нелинейной рекурсивной (nonlinear recursive) форме:
1) FollowOn(x, у) <r- SequelOf(х, у),
2) FollowOn(х, у) <r- FollowOn(x, z) AND FollowOn(z, у).
Этот набор правил следует трактовать так: у есть серия х, если у является либо
продолжением х, либо серией серии х. Все три формы рекурсии позволяют получить
один и тот же набор кортежей отношения FollowOn — множество пар (х, у), таких,
что у является продолжением продолжения... (и так некоторое количество раз) х.
Рис. 10.5. Граф, представляющий авиарейсы между
несколькими городами
airline
UA
АА
UA
UA
АА
АА
АА
UA
from
SF
SF
DEN
DEN
DAL
DAL
CHI
CHI
to
DEN
DAL
CHI
DAL
CHI
NY
NY
NY
departs
930
900
1500
1400
1530
1500
1900
1830
arrives
1230
1430
1800
1700
1730
1930
2200
2130
Рис. 10.6. Экземпляр отношения Flights
472
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
Правило 1 гласит, что отношение Reaches содержит кортежи для таких пар
городов, для которых существует прямой рейс из первого города (х) во второй (у);
значения переменных а ("авиакомпания"), d ("время вылета") и г ("время прибытия")
могут быть произвольными. Правило 2 свидетельствует, что если существуют рейсы из х
в z, а также из z в у, то можно добраться и из х в у. Обратите внимание, что здесь
применена нелинейная рекурсивная форма, о которой мы упоминали в тексте врезки
"Другие формы рекурсии" на с. 472. Использование именно этой формы оправдано
тем, что при обращении к отношению Flights вместо Reaches нам пришлось бы
указывать три переменные (a, d и г), которые в данной ситуации просто излишни.
Для вычисления содержимого отношения Reaches следует выполнить
итеративный процесс, аналогичный тому, который рассматривался в примере 10.24. Начнем
с того, что на основании правила 1 включим в состав Reaches следующие кортежи:
(SF, DEN), (SF, DAL), (DEN, CHI) , (DEN, DAL), (DAL, CHI), (DAL, NY)
и (CHI, NY). Все они представлены дугами графа, изображенного на рис. 10.5.
На следующей итерации применяется рекурсивное правило 2, позволяющее
объединить пары дуг таким образом, что конец (стрелка) одной дуги совпадает с началом другой.
В результате получим три дополнительных кортежа: (sf, chi), (den, ny) и (sf, ny).
Третья итерация могла бы позволить объединить пути, состоящие из одной или двух дуг,
в пути, содержащие от трех до четырех дуг, но в графе на рис. 10.5 таких
последовательностей дуг просто нет, поэтому ни один новый кортеж в отношение Reaches добавлен
не будет. Это значит, что процесс надлежит завершить. Таким образом, отношение
Reaches должно содержать десять кортежей вида (х, у), таких, что город у "достижим" из
города х с учетом данных диаграммы, изображенной на рис. 10.5. Граф построен таким
образом, что к числу допустимых кортежей относятся только такие, в которых
компоненту у соответствует вершина, расположенная "правее" относительно вершины х. □
Пример 10.26. Более сложное условие, позволяющее соединить две дуги графа,
представляющего авиарейсы, в единую последовательность, состоит в том, чтобы момент
времени вылета (departs) второго рейса не менее чем на один час превышал момент
времени прибытия (arrives) первого. Для обозначения итогового отношения
воспользуемся IDB-атомом Connects(х, у, d, r), полагая, что компоненты х и у
должны содержать названия аэропортов отправления и назначения, a d и г —
значения времени вылета из х и прибытия в у.
Правила вычисления содержимого отношения Connects таковы:66
1) Connects(х, у, d, г) <— Flights(а, х, у, d, r),
2) Connects(х, у, d, г) <— Connects(x, z, d, tl) AND
Connects(z, y, t2, r) AND
tl < t2 - 100.
На первой итерации процесса правило 1 позволяет включить в отношение Connects
восемь первых кортежей, показанных на рис. 10.7. Каждый из кортежей соответствует
одному рейсу, отмеченному дугой графа на рис. 10.5 (дуга, соединяющая вершины
CHI и NY, представляет два различных рейса).
На второй итерации для соединения кортежей используется правило 2. Так,
например, могут быть соединены второй и пятый кортежи, и в результате мы получим
кортеж (SF, CHI, 90 0, 1730). Второй и шестой кортежи, однако, соединить
нельзя, поскольку моменты прибытия рейса из Сан-Франциско в Даллас (143 0) и вылета
из Далласа в Нью-Йорк (15 0 0) разделяет промежуток времени, равный всего лишь
66 Правила действуют в предположении, что авиарейсы, подлежащие соединению в "цепочки",
выполняются в течение одних календарных суток.
10.3. РЕКУРСИВНОЕ ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ DATALOG
473
получасу. После выполнения второй итерации в отношение Connects, показанное на
рис. 10.7, будет добавлена группа из шести новых кортежей.
Выполняя третью итерацию, мы должны были бы, вообще говоря, просмотреть все
четырнадцать ранее полученных кортежей и проанализировать, способны ли они
выполнять роль двух экземпляров кортежей Connects, упоминаемых в теле правила 2.
Если, однако, оба кортежа относятся к первой группе из восьми кортежей, они
должны были быть рассмотрены на предыдущей итерации и поэтому сейчас не в
состоянии дать ни одного нового соединенного кортежа. Единственный вариант,
позволяющий получить нечто действительно новое, таков: по меньшей мере один из
рассматриваемых кортежей должен относиться к группе из шести кортежей, добавленных на
предыдущей итерации. Действуя в соответствии с этой стратегией, мы можем выявить
еще три кортежа, которые показаны в нижней части рис. 10.7.
Четвертая итерация не приводит к получению новых кортежей, и процесс должен
быть завершен. Итоговое отношение изображено на рис. 10.7. □
10.3.3. Отрицание в рекурсивных правилах
Подчас возникает необходимость использования операторов отрицания и в
наборах рекурсивных правил, причем существуют "опасные" и безопасные способы
сочетания аппарата рекурсии и операторов отрицания. Вообще говоря, приемлемым
считается применение операторов отрицания только таким образом, чтобы они не
принимали непосредственного участия в процессе рекурсивных вычислений. Дабы
продемонстрировать различия между "опасными" и безопасными подходами, мы
приведем два примера и покажем, что совместно с рекурсией можно свободно
пользоваться только изолированными (stratified) операторами отрицания (точное значение
термина будет разъяснено после рассмотрения примеров).
X
SF
SF
DEN
DEN
DAL
DAL
CHI
CHI
SF
SF
SF
DEN
DAL
DAL
SF
SF
SF
У
DEN
DAL
CHI
DAL
CHI
NY
NY
NY
CHI
CHI
DAL
NY
NY
NY
NY
NY
NY
d
930
900
1500
1400
1530
1500
1900
1830
900
930
930
1500
1530
1530
900
900
930
г
1230
1430
1800
1700
1730
1930
2200
2130
1730
1800
1700
2200
2130
2200
2130
2200
2200
Рис. 10.7. Экземпляр отношения Connects к примеру 10.26
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
Пример 10.27. Предположим, что необходимо найти такие пары (х, у) вершин графа,
изображенного на рис. 10.5, что добраться из х в у (возможно, через другие города)
удастся только посредством рейсов авиакомпании UA. Предикат UAreaches можно
определить рекурсивным образом так же, как и предикат Reaches в примере 10.25, но
в итоговое множество следует включать только такие кортежи, которые содержат
информацию о рейсах компании ua:
1) UAreaches(x, у) <— Flights (UA, х, у, d, r),
2) UAreaches(х, у) <— UAreaches(x, z) AND UAreaches(z, у).
Аналогично определяются правила для вычисления содержимого отношения
AAreaches, которое должно включать кортежи (х, у) с описанием рейсов,
выполняемых компанией аа и позволяющих долететь из города х в город у:
1) AAreaches(х, у) <- Flights (UA, x, у, d, r),
2) AAreaches (х, у) <— AAreaches (x, z) AND AAreaches (z, у).
Теперь для нахождения кортежей, представляющих города, которые связаны друг
с другом только рейсами авиакомпании UA, достаточно создать отношение UAonly,
применив следующее нерекурсивное правило:
UAonly (х, у) <r- UAreaches (х, у) AND NOT AAreaches (x, у).
Правило реализует операцию разности множеств UAreaches и AAreaches.
Отношение UAreaches, вычисленное на основе данных, представленных на рис. 10.5
и 10.6, с помощью алгоритма, рассмотренного в разделе 10.3.2, содержит кортежи
(SF, DEN), (SF, DAL), (SF, CHI) , (SF, NY) , (DEN, DAL), (DEN, CHI) , (DEN, NY)
И (CHI, NY), а отношение AAreaches — кортежи (SF, DAL), (SF, CHI), (SF, NY),
(DAb, chi), (dal, NY) и (CHI, ny). Вычислив разность двух множеств, получим:
(SF, DEN), (DEN, DAL), (DEN, CHI) И (DEN, NY) — именно ЭТИ кортежи ДОЛЖНЫ
быть включены в отношение UAonly. □
Пример 10.28. Теперь рассмотрим абстрактный и до некоторой степени
парадоксальный пример, в котором, мягко говоря, не все так гладко, как в предыдущем. Пусть
даны единственный EDB-предикат R, унарный (т.е. обладающий одним аргументом)
и содержащий кортеж (0), и два IDB-предиката, Ри<2, которые также унарны.
Предикаты связаны между собой следующими правилами:
1) Р(х) <- R(x) AND NOT Q(x),
2) Q(x) <- R(x) AND NOT P(x).
Правила гласят, что элемент х, принадлежащий /?, содержится также либо в Р, либо
в <2, но не в Р и Q одновременно. Предикаты Р и Q определены рекурсивным образом
друг через друга.
В разделе 10.3.2 на с. 469, говоря о вычислении рекурсивных правил, мы имели
в виду необходимость отыскания IDB-отношений, содержащих наименьшее число
всех таких кортежей, которые можно получить на основании этих правил. В нашем
случае правило 1 является единственным правилом, определяющим состав отношения
Р, и свидетельствует о том, что P = R-Q. Аналогично, из правила 2 следует, что Q = R-
Р. Поскольку по определению R содержит единственный кортеж, (0), мы знаем, что
только этот кортеж может принадлежать либо Р, либо Q. В каком именно
отношении — Р или Q — присутствует кортеж (0)? Он не может не принадлежать одному из
отношений, поскольку в этом случае равенства соблюдены не будут: из условия P-R-
Q, например, последует, что 0 = {(0)} - 0, а это, разумеется, неверно.
Если положить Р= {(0)} и <2 = 0, оба равенства удовлетворяются: P = R-Q
обращается в {(0)} = {(0)} -0, что верно, aQ = R-P — в0= {(0)} - {(0)}, что также верно.
10.3. РЕКУРСИВНОЕ ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ DATALOG
475
Впрочем, с тем же правом мы можем полагать, что Р=0и<2={(О)}, ив этом случае
равенства также сохраняются в силе. Таким образом, у нас есть два равноправных решения:
a) Р={(0)} Q = 0,
b) Р = 0 (2=1(0)},
минимальных в том смысле, что если каким-либо образом изменить состав любого из
отношений, это приведет к нарушению соответствующего правила; таким образом,
мы не в состоянии отдать предпочтение какому-либо одному решению. □
Пример 10.28 служит неплохим образцом того, как перестают действовать
"обычные" процедуры вычисления Datalog-правил, если механизмы рекурсии
и отрицания переплетаются слишком тесно. В подобных ситуациях процесс
вычисления правил способен приводить к получению нескольких решений,
противоречащих друг другу. Было бы неплохо иметь иные способы толкования смысла
рекурсивных правил с отрицанием, но, к сожалению, общего соглашения,
позволяющего это делать, просто нет.
Поэтому принято ограничивать рассмотрение только такими рекурсивными
правилами, в которых операторы отрицания являются изолированными (stratified).
Аналогичное ограничение, касающееся использования механизмов рекурсии в SQL (мы
расскажем о них в разделе 10.4 на с. 478), предусмотрено и в стандарте SQL-99. Как
будет показано ниже, если операторы отрицания изолированы, существует алгоритм
вычисления "минимальных" множеств кортежей IDB-заголовков каждого правила,
которые вполне удовлетворяют всем заданным условиям и не противоречат друг другу.
Свойство изолированности отрицания (или, если угодно, изолированности рекурсии)
можно определить, выполнив следующие действия.
1. Создать граф, вершины которого соответствуют IDB-предикатам набора правил.
2. Соединить вершину А с вершиной В дугой, помеченной знаком минус (~) и
называемой отрицательной (negative), если правило с заголовком-предикатом А
содержит подцель-предикат В с оператором отрицания.
3. Соединить вершину А с вершиной В обычной дугой, если правило с
заголовком-предикатом А содержит подцель-предикат В без оператора отрицания.
Если граф не содержит ни одного цикла, в который входили бы одна или несколько
отрицательных дуг, рекурсия является изолированной. В противном случае считать
изолированной рекурсию нельзя. ШВ-предикаты графа изолированной рекурсии можно
разбить на группы, называемые слоями (strata). Слою, к которому относятся
предикаты, подобные А, ставится в соответствие значение максимального количества
отрицательных дуг в путях, которые начинаются с вершины Л.
Если рекурсия изолирована, ШВ-предикаты могут быть вычислены в порядке
следования их слоев, начиная со слоя с наименьшим значением. Придерживаясь этой
стратегии, мы сможем получить одно из "минимальных" допустимых решений, причем,
что важно, это "верное" решение всегда будет иметь очевидный смысл. Напротив,
как было показано в примере 10.28, применение рекурсии, не являющейся
изолированной, способно привести к тому, что ни одно из "верных" решений получено
не будет — даже в том случае, когда, как кажется, есть из чего выбирать.
Пример 10.29. На рис. 10.8 изображен граф, соответствующий набору рекурсивных
правил, рассмотренному в примере 10.27 на с. 475. Вершины-предикаты AAreaches
и UAreaches относятся к слою 0, поскольку ни один из путей, который с них
начинается, не содержит отрицательных дуг. Предикат UAonly относится к слою 1 —
дуга, соединяющая UAonly с AAreaches, отрицательна, но путей, исходящих из
UAonly и охватывающих большее количество отрицательных дуг, не существует. Та-
476
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
ким образом, прежде чем приступить к
вычислению отношения UAonly, следует
полностью завершить обработку предикатов
AAreaches и UAreaches.
Теперь обратимся к примеру 10.28.
Соответствующий граф представлен на рис. 10.9.
Поскольку правило 1 с заголовком-предикатом
Р содержит подцель-предикат Q с оператором
отрицания, граф должен содержать
отрицательную дугу, соединяющую Р с Q. Правило 2
с заголовком Q, в свою очередь, содержит
подцель Р с оператором отрицания, так что дуга,
связывающая вершины графа в
противоположном направлении, также отрицательна. Имеем
цикл, содержащий отрицательные дуги,
поэтому набор рекурсивных правил нельзя считать
изолированным. □
10.3.4. Упражнения к разделу 10.3
Упражнение 10.3.1. Если в граф, показанный на рис. 10.5 (см. с. 472), добавить
дополнительные дуги или удалить какие-либо из существующих дуг, это может
привести к изменению содержимого отношения Reaches из примера 10.25 на с. 471,
отношения Connects из примера 10.26 на с. 473 или отношений UAreaches
и AAreaches из примера 10.27 на с. 475. Модифицируйте указанные отношения
соответствующим образом, если граф подвергается следующим изменениям:
* а) добавлена дуга с меткой аа 1900-2100, соединяющая CHI с sf в указанном
направлении;
b) добавлена дуга с меткой ua 900-1100, соединяющая NY с den;
c) добавлены одновременно две дуги, указанные в пп. (а), (Ь);
d) удалена дуга, соединявшая den с dal.
Упражнение 10.3.2. Сформулируйте правила Datalog (обращаясь к средствам
изолированной рекурсии, если необходимы операторы отрицания), которые
позволяют вычислить перечисленные ниже предикаты, расширяющие понятия
"продолжения" и "серии" кинофильма, введенные в примере 10.22 на с. 468.
Если нужно, воспользуйтесь EDB-отношением SequelOf и ШВ-отношением
FollowOn из примера 10.23 на с. 469.
* а) Р(х, у) — у есть серия, но не продолжение х.
b) Q(x, у) — у есть серия х, причем у не является ни продолжением, ни
продолжением продолжения х.
! с) R(x) — х обладает по меньшей мере двумя сериями, причем обе могут
служить продолжениями, но не должны быть одна продолжением, а другая —
продолжением продолжения х.
!! d) s (x, у) — у есть серия х, но у обладает не более чем одной серией.
Упражнение 10.3.3. ODL-классы и связи между ними могут быть описаны с
помощью отношения вида Rel (class, rclass, mult). Атрибут mult представляет
свойство множественности связей и способен принимать значение multi, если на
стороне класса class связь относится к типу "многие", и значение single —
в противном случае. Атрибуты class и rclass представляют связываемые классы,
UAonly
I AAreaches
UAreaches ]
Рис. 10.8. Пример графа изолированной
рекурсии
Рис. 10.9. Пример графа
неизолированной рекурсии
10.3. РЕКУРСИВНОЕ ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ DATALOG
477
т.е. подразумевается, что связь направлена от class к rclass. Экземпляр
отношения Rel, представляющий связи между тремя ODL-классами
"кинематографической" базы данных, приведен на рис. 10.10.
class
Star
Movie
Movie
Studio
rclass
Movie
Star
Studio
Movie
mult
multi
multi
single
multi
Рис. 10.10. Представление ODL-связей посредством
реляционных данных
Связи между ODL-классами можно описать также с помощью графа, в котором
вершины соответствуют классам, а дуги — связям между классами, причем метки дуг,
multi или label, указывают на тип связи. На рис. 10.11 изображен граф,
отвечающий данным отношения, показанного на рис. 10.10.
Сформулируйте правила Datalog (обращаясь
к средствам изолированной рекурсии, если
необходимы операторы отрицания), которые позволяют
вычислить перечисленные ниже предикаты. Если
нужно, воспользуйтесь EDB-отношением Rel.
Проиллюстрируйте каждую итерацию процесса
вычислений на примере данных из экземпляра отношения
Rel, приведенного на рис. 10.10.
multi
single
Star
Studio
multi
multi
Рис. 10.11. Представление ODL-
связей в виде графа
а) Р(class, eclass) — в графе, представляющем связи классов, существует
путь67, который соединяет класс class с классом eclass.
*! b) S(class, eclass) и M(class, eclass); предикат S подразумевает, что
существует путь, который соединяет class с eclass, причем все его дуги
снабжены метками single; предикат М выражает факт существования пути,
соединяющего class с eclass посредством дуг, по меньшей мере одна из
которых обозначена меткой multi.
с) Р(class, eclass) — существует путь, который соединяет class с eclass,
причем ни одна из его дуг не помечена признаком single; если требуется,
воспользуйтесь IDB-предикатами из предыдущих заданий этого упражнения.
10.4. Рекурсия в SQL
Стандарт SQL-99 содержит ряд положений, регламентирующих способы
использования в SQL рекурсивных конструкций, аналогичных рекурсивным правилам языка
Datalog, которые рассматривались нами в разделе 10.3 на с. 468. Хотя подобные
возможности не относятся к ядру языка и нельзя ожидать, что они будут реализованы
в каждой коммерческой СУБД без исключения, можно назвать по меньшей мере одну
весьма популярную систему баз данных — DB2 от IBM, — в которой эта часть
рекомендаций стандарта SQL-99 нашла свое конкретное воплощение. Впрочем, последнее
отличается от того, о чем мы будем говорить ниже, в двух аспектах:
1) допускается только линейная (linear) рекурсия, т.е. каждое из
соответствующих Datalog-правил может содержать не более одной рекурсивной подцели;
Мы полагаем, что путь не может быть "пустым".
478
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
далее мы будем игнорировать подобное ограничение, но при обращении
к конкретным реализациям СУБД эту возможность следует иметь в виду;
2) требование изолированности (stratification) операций, которое обсуждалось
применительно к операторам отрицания в разделе 10.3.3 на с. 474,
распространяется на другие конструкции SQL (такие как операторы
агрегирования), способные провоцировать возникновение аналогичных проблем.
10.4.1. Определение интенсиональных отношений в SQL
Эквивалент IDB-отношения можно определить в SQL с помощью выражения
with, которое в своей простейшей форме выглядит так:
WITH R AS <определение отношения R> oanpoc с участием R>
и означает, что временное отношение R вначале определяется, а затем упоминается
в тексте некоторого запроса. Вообще говоря, в контексте одного выражения with
разрешается указывать несколько различных отношений, разделяя их определения
запятыми. Любое из таких определений может быть рекурсивным. Более того,
допускается взаимная рекурсия — каждое из отношений позволяется определять
в терминах других отношений; определение отношения может содержать также
рекурсивные ссылки на самое себя. Любое отношение, вовлеченное в рекурсию,
должно быть помечено признаком recursive. Итак, говоря более строго,
выражение WITH должно содержать следующие составные части:
1) служебное слово with;
2) одно или несколько определений, разделенных запятыми; каждое
определение состоит из
a) необязательного служебного слова recursive, которое требуется
задавать, если определяемое отношение участвует в рекурсии;
b) наименования отношения;
c) служебного слова as;
d) запроса, служащего определением отношения;
3) текст запроса, который способен содержать ссылки на любое из указанных
выше определений и возвращает результат выражения with в целом.
Важно отметить, что, в отличие от других схожих SQL-конструкций, определения,
размещенные внутри выражения with, разрешено адресовать только в контексте этого
выражения. Если необходимо создать хранимое отношение, его следует определить
в схеме базы данных вне какого бы то ни было выражения with.
Пример 10.30. Вернемся к примеру 10.25 на с. 471, в котором рассматривалось отношение68
Flights(airline, frm, to, departs, arrives)
с информацией об авиарейсах. Граф, представляющий схему рейсов, и экземпляр
отношения Flights приведены на рис. 10.5 и 10.6 соответственно (см. с. 472).
В примере 10.25 мы обсуждали способ вычисления IDB-отношения Reaches,
содержащего информацию о таких упорядоченных парах городов, которые могут быть
связаны последовательностью авиарейсов, перечисленных в EDB-отношении Flights.
Напомним Datalog-правила, позволяющие выявить набор кортежей отношения Reaches:
1) Reaches (x, у) <— Flights (а, х, у, d, r),
2) Reaches (х, у) <— Reaches (x, z) AND Reaches (z, у).
68 Название атрибута from изменено на frm во избежание совпадения с одноименным
служебным словом SQL.
10.4. РЕКУРСИЯ В SQL
479
Опираясь на эти правила, можно сконструировать SQL-запрос, способный возвратить
искомое отношение Reaches. В примере 10.25 результат вычислений представлял
собой отношение Reaches целиком, но теперь в рамках выражения WITH мы можем
сформулировать дополнительный запрос — например, потребовать информацию о
городах, "достижимых" посредством последовательности авиарейсов из Денвера.
1) WITH RECURSIVE Reaches(frm, to) AS
2) (SELECT frm, to FROM Flights)
3) UNION
4) (SELECT Rl.frm, R2.to
5) FROM Reaches Rl, Reaches R2
6) WHERE Rl.to = R2.frm)
7) SELECT * FROM Reaches;
Рис. 10.12. Пример простого рекурсивного SQL-запроса
На рис. 10.12 приведена конструкция with, позволяющая вычислить IDB-
отношение Reaches средствами SQL. Строка 1 содержит заголовок определения
отношения Reaches, а определение как таковое расположено в строках 2—6.
Определение представляет собой объединение (union) двух запросов,
соответствующих приведенным выше Datalog-правилам. Первый аргумент оператора union —
запрос в строке 2 — соответствует первому (базисному) правилу и гласит, что в состав
Reaches должны входить те же кортежи, что содержатся в отношении Flights,
"урезанные" до двух компонентов, frm и to.
Запрос в строках 4—6 соответствует второму, индуктивному, правилу. Две подцели
Reaches правила представлены в предложении from запроса псевдонимами R1 и R2,
заданными для одного и того же отношения Reaches. Первый компонент кортежа
отношения R1 совпадает с переменной х правила, а второй компонент кортежа отношения R2
отвечает переменной у. Переменная z правила описывается вторым компонентом кортежа R1
и первым компонентом кортежа R2, условие равенства которых декларируется в строке 6.
Наконец, строка 7 содержит текст запроса, возвращающего отношение Reaches
как итог выполнения конструкции WITH в целом. Если заменить строку 7 следующей,
7) SELECT to FROM Reaches WHERE frm = 'DEN';
запрос вернет данные о том, в какие города можно попасть из Денвера, если
воспользоваться авиарейсами, информация о которых содержится в отношении Flights. □
10.4.2. Изолированная рекурсия в SQL
В качестве конструкций определений рекурсивных отношений можно
использовать далеко не любые SQL-запросы — следует соблюдать определенные ограничения,
наиболее важным из которых является требование о том, чтобы операторы отрицания
во взаимно рекурсивных отношениях были изолированы (stratified) (см. раздел 10.3.3 на
с. 474). В разделе 10.4.3 на с. 482 мы покажем, как принцип изолированности
распространяется на другие конструкции SQL (такие как операторы агрегирования).
Пример 10.31. Вновь обратимся к примеру 10.27 на с. 475, где обсуждается задача
поиска таких пар (х, у) городов, что из х в у можно попасть только посредством авиарейсов,
совершаемых самолетами компании ua, но не компании АА. Чтобы выразить
указанное требование формально, необходимо прибегнуть к средствам рекурсии. Оператор
отрицания в этом случае выполняется изолированно от процесса рекурсивных
вычислений: разность отношений UAreaches и AAreaches определяется только после того,
как их состав полностью определен.
480
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
Взаимная рекурсия
Существует теоретико-графовый способ определения того, являются ли взаимно
рекурсивными два отношения или предиката. Конструируется граф зависимостей
(dependency graph), вершины которого соответствуют отношениям (или
предикатам, если речь идет о Datalog-правилах); вершина А должна быть связана с
вершиной В направленной дугой, если определение В содержит непосредственную ссылку
на определение А (обычно в контексте предложения from или, что также
возможно, в виде аргумента оператора объединения, пересечения или разности) либо
предикат А присутствует в теле правила, в заголовке которого находится предикат В.
Если граф содержит цикл, в который вовлечены вершины R и 5, отношения
(предикаты) R к S трактуются как взаимно рекурсивные (mutually recursive). Весьма
типична ситуация, когда цикл, исходящий из вершины R, замыкается на R —
отношение (предикат) R содержит рекурсивные ссылки на самое себя.
Следует обратить внимание, что граф зависимостей по структуре и способу
построения напоминает граф изолированной (неизолированной) рекурсии (см. раздел
10.3.3 на с. 474); основное отличие последнего состоит в наличии помеченных
(отрицательных) дуг, но в графе зависимостей метки дугам не присваиваются.
Аналогичную стратегию можно применить и при создании запроса SQL, призванного
решить ту же задачу. Чтобы продемонстрировать альтернативные возможности, мы,
однако, определим как рекурсивное только одно отношение, Reaches (airline, frm, to),
каждый кортеж (a,fit) которого означает, что из города / в город / можно добраться
(возможно, с несколькими пересадками), пользуясь авиарейсами только одной
авиакомпании, а. Помимо того, нам придется воспользоваться нерекурсивным отношением
Triples (airline, frm, to), которое представляет собой проекцию исходного
отношения Flights на три указанных атрибута. Текст запроса показан на рис. 10.13.
Определение отношения Reaches, приведенное в строках 3—9, состоит из двух
запросов, объединяемых оператором union. Базовому Datalog-правилу соответствует
запрос к отношению Triples в строке 4, а индуктивному — запрос в строках 6—9,
вычисляющий соединение (j°in) отношений Triples и Reaches.
Выражение, возвращающее искомое множество кортежей, расположено в строках
10—12. Запрос в строке 10 определяет кортежи, которые представляют пары городов,
соединяемых авиарейсами компании UA, а запрос в строке 12 позволяет выбрать
аналогичные кортежи с информацией, относящейся к компании аа. Оператор except
в строке 11 вычисляет разность двух множеств кортежей.
1) WITH
2) Triples AS SELECT airline, frm, to FROM Flights,
3) RECURSIVE Reaches(airline, frm, to) AS
4) (SELECT * FROM Triples)
5) UNION
6) (SELECT Triples.airline, Triples.frm, Reaches.to
7) FROM Triples, Reaches
8) WHERE Triples.to = Reaches.frm AND
9) Triples.airline = Reaches.airline)
10) (SELECT frm, to FROM Reaches WHERE airline = 'UA')
11) EXCEPT
12) (SELECT frm, to FROM Reaches WHERE airline = 'AA');
Рис. 10.13. Пример SQL-запроса с изолированной рекурсией
□
10.4. РЕКУРСИЯ В SQL
481
Пример 10.32. Оператор отрицания, реализуемый оператором except в строке 11
выражения SQL, представленного на рис. 10.13, полностью изолирован, поскольку
применяется к итоговому результату выполнения рекурсивного процесса, описываемого
строками 3—9. С другой стороны, если изучить возможность преобразования набора
Datalog-правил, рассматриваемого в примере 10.28 на с. 475, в эквивалентную
конструкцию SQL, нам придется поместить оператор except непосредственно в код
определения взаимно рекурсивных отношений. Один из вариантов подобной
прямолинейной трансляции приведен на рис. 10.14. Запрос предусматривает поиск значения Р, хотя
можно было бы заняться отысканием значений Q или некоторых функций от Р и Q.
1)
2)
3)
4)
5)
6)
7)
8)
9)
Ю)
WITH
RECURSIVE P(x) AS
(SELECT *
EXCEPT
(SELECT *
RECURSIVE Q(x) AS
(SELECT *
EXCEPT
(SELECT *
SELECT * FROM P;
FROM
FROM
FROM
FROM
R)
Q),
R)
P)
Рис. 10.14. Пример неизолированной рекурсии, недопустимой в SQL
Операторы except в строках 4 и 8 рис. 10.14 на самом деле применять нельзя,
поскольку в обоих случаях определяемые отношения и отношения, упоминаемые в виде
вторых аргументов операторов except, являются взаимно рекурсивными. Эту
проблему не удастся решить средствами SQL — да, собственно говоря, решать и не
следует, — так как рассматриваемый образец рекурсии не способен определить содержимое
отношений Р и Q совершенно однозначно. □
10.4.3. Проблемы реализации рекурсии в SQL
В примере 10.32 приведен образец неверного применения оператора except в
контексте рекурсивного выражения, нарушающий требование изолированности отрицания.
Однако существуют и такие неприемлемые формы рекурсивных SQL-запросов, в
которых оператор except не используется. Например, конструкцию отрицания можно
описать посредством оператора not in, заменив строки 2—5 рис. 10.14 следующими:
RECURSIVE Р(х) AS
SELECT x FROM R WHERE x NOT IN Q
но и в этом случае рекурсия все еще остается неизолированной и потому некорректной.
С другой стороны, применение оператора not в предложениях where (скажем,
not х = у, что всегда можно переписать как х о у) вовсе не обязательно приводит
к нарушению условия изолированности отрицания. Резонно задаться вопросом,
каково общее правило конструирования SQL-выражений, предназначенных для
определения рекурсивных отношений.
Коротко говоря, SQL-выражение рекурсии является верным, если определение
рекурсивного отношения R содержит только такие ссылки на взаимно рекурсивное
отношение S, которые сохраняют свойство монотонности (monotonicity). Определение S
является монотонным, если добавление в S произвольного кортежа влечет пополнение
R одним или несколькими кортежами либо не вызывает какого бы то ни было
изменения R вообще, но никогда не приводит к удалению кортежей из R.
482
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
Это правило приобретает особый смысл в контексте процесса вычисления
"минимальных" множеств кортежей IDB-отношений, рассмотренного в разделе 10.3.2
на с. 469. Напомним, процесс начинается с того, что рекурсивно определяемые IDB-
отношения считаются пустыми, а затем на каждой итерации в них добавляются
кортежи, удовлетворяющие условиям соответствующих Datalog-правил. Если при
добавлении кортежа на очередной итерации мы вынуждены удалить некоторый кортеж на
следующей итерации, возникает опасность, что процесс может не обладать свойством
сходимости. В следующих примерах мы приведем образцы рекурсивных SQL-
выражений, поведение которых не отличается монотонностью, что служит доводом
против их практического применения.
Пример 10.33. Рис. 10.14 представляет конструкцию SQL, реализующую набор Data-
log-правил, рассмотренных в примере 10.28 на с. 475, которые не удовлетворяют
требованию изолированности рекурсии, поскольку допускают возможность получения
двух совершенно разных равноправных "минимальных" множеств кортежей IDB-
отношений Р и Q. Как и можно было ожидать, определения Р и Q не обладают
свойством монотонности. Обратимся для примера к определению отношения Р в
строках 2—5. Р зависит от Q посредством взаимной рекурсии, но добавление кортежа
в Q способно привести к удалению кортежа из Р. Чтобы понять, почему,
предположим, что R содержит кортежи (а) и (fc), a Q — кортежи (а) и (с). Тогда Р= {(b)}.
Однако, если добавить (Ь) в Q, Р становится пустым. Таким образом, добавление
кортежа в Q провоцирует удаление кортежа из Р — мы имеем дело с немонотонной
и поэтому неприемлемой конструкцией.
Отсутствие монотонности непосредственно сказывается на том, что процесс
вычисления "минимальных" множеств кортежей отношений Р и Q приобретает
"колебатель-ный" характер.69 Предположим, например, что R состоит из двух
кортежей, {(a), (b)}, a P и Q изначально пусты. Тогда на первой итерации, действуя в
соответствии с инструкциями в строках 3—5 рис. 10.14, мы получим для Р
множество кортежей {(а), (Ь)}\ в результате вычисления строк 7—9 те же кортежи будут
добавлены и в Q, поскольку запрос в строке 9 возвратит в качестве содержимого Р
исходное — пустое — множество.
Теперь все отношения — Р, Q и R — содержат одинаковое множество кортежей,
{(а), (Ь)}. Следующая итерация процесса, предусматривающая повторное
выполнение строк 3—5 и 7—9, приведет к тому, что отношения Р и Q окажутся пустыми. На
третьей итерации они вновь приобретут то же множество кортежей, {(а), (Ь)}.
Процесс может продолжаться до бесконечности: оба отношения становятся пустыми
после выполнения каждой четной итерации и получают значения {(а), (Ь)} по
завершении каждой нечетной итерации. Таким образом, некий "итоговый" результат
получить не удастся. □
Пример 10.34. К нарушению свойства монотонности способно привести и
применение некоторых операций агрегирования, хотя причины и следствия в этом случае
могут оказаться не столь очевидными. Предположим, что даны унарные (обладающие
одним атрибутом) отношения Р и Q, определяемые следующими условиями:
1) Р есть объединение (union) Q и некоторого EDB-отношения /?;
2) Q содержит один кортеж, представляющий сумму компонентов Р.
69 Если рекурсия не является монотонной, общий итог процесса может зависеть от порядка
вычисления отношений, определяемых в выражении WITH (в противном случае порядок вычисления
влияния на результат не оказывает). В этом и следующем примерах мы полагаем, что на каждой
итерации процесса отношения Р и Q рассматриваются "параллельно", так что при выполнении
следующей итерации учитывается "старое" содержимое отношений, полученное на предыдущей
итерации (обратитесь к врезке "Порядок вычисления взаимно рекурсивных отношений" на с. 485).
10.4. РЕКУРСИЯ В SQL
483
Указанные условия можно представить в виде SQL-выражения with — к сожалению,
нарушающего требование монотонности. Текст конструкции показан на рис. 10.15;
запрос обязан возвратить содержимое отношения Р.
1) WITH
2) RECURSIVE P(x) AS
3) (SELECT * FROM R)
4) UNION
5) (SELECT * FROM Q),
6) RECURSIVE Q(x) AS
7) SELECT SUM(x) FROM P
8) SELECT * FROM P;
Рис. 10.15. Пример немонотонного рекурсивного
агрегирования, недопустимого в SQL
Пусть R содержит кортежи (12) и (34), а Р и Q, как того требует процесс
вычисления "минимальных" множеств кортежей IDB-отношений, изначально пусты. На
рис. 10.16 представлены результаты, вычисленные в процессе выполнения первых
шести итераций процесса. Напомним, что мы придерживаемся стратегии, согласно
которой для определения содержимого отношений на одной итерации используются
итоги, достигнутые на предыдущей итерации. Поэтому по завершении первой
итерации отношение Р должно содержать те же кортежи, что и R, a Q — оставаться пустым,
поскольку запрос в строке 7 адресуется к исходному, пустому, отношению Р.
После второй итерации содержимое Р, вычисляемое как объединение результатов,
возвращаемых запросами в строках 3 и 5, остается прежним, Р= {(12), (34)}, но
трактуется как "новое" значение. Тот же, но "старый", набор кортежей Р используется для
вычисления содержимого отношения Q, которое становится равным {(46)}, поскольку
46 — сумма значений 12 и 34.
На третьей итерации получаем Р= {(12), (34), (46)}, но Q сохраняет прежнее значение,
{(46)}, поскольку оно вычисляется на основе "старого" содержимого Р, {(12), (34)}.
Итерация
о
2)
3)
4)
5)
6)
Р
{(12), (34)}
{(12), (34)}
{(12), (34), (46)}
{(12), (34), (46)}
{(12), (34), (92)}
{(12), (34), (92)}
Q
0
{(46)}
{(46)}
{(92)}
{(92)}
{(138)}
Рис. 10.16. Иллюстрация рекурсивных вычислений с
использованием немонотонного агрегирования
На четвертой итерации содержимое Р= {(12), (34), (46)} остается без изменений, но
Q получает значение {(92)}, поскольку 12 + 34 + 46 = 92. Обратите внимание, что Q
теряет кортеж (46), но приобретает вместо него кортеж (92), т.е. добавление в Р кортежа
(46) приводит к удалению некоторого (в данном случае, того же самого) кортежа из Q.
Вообще говоря, на 2/-й итерации отношение Р будет содержать кортежи (12), (34)
и (46/-46), a Q— единственный кортеж (46/). Поведение процесса отличается ярко
выраженным немонотонным характером, а это свидетельствует о том, что
конструкция SQL, приведенная на рис. 10.15, неверна. □
484
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
Порядок вычисления взаимно рекурсивных отношений
Вполне закономерен вопрос, почему при вычислении содержимого отношений Q
в примерах 10.33 и 10.34 на очередной итерации мы обращаемся к "старому", а не
"новому" значению Р, полученному на той же итерации. Если предположить, что
запросы действительно корректны и на очередной итерации используются самые
"свежие" значения отношений, результаты процесса должны существенным
образом зависеть от порядка перечисления определений рекурсивных предикатов-
отношений в контексте выражения with: в примере 10.33 выбор одного из двух
возможных наборов данных отношений Р и Q будет определяться порядком их
перечисления, а в примере 10.34 условие сходимости процесса останется по-
прежнему проблематичным, но содержимое отношений будет изменяться на
каждой итерации, а не на каждой второй итерации.
10.4.4. Упражнения к разделу 10.4
Упражнение 10.4.1. В примере 10.23 на с. 469 рассматривались отношение
SequelOf(movie, sequel),
содержащее информацию о кинофильмах и их непосредственных "продолжениях",
а также IDB-отношение FollowOn, каждый кортеж (х, у) которого представляет тот
факт, что у является "серией" х, т.е. продолжением л; либо продолжением
продолжения л; и т.д. Опишите средствами SQL следующие конструкции:
a) рекурсивное определение FollowOn;
b) рекурсивный запрос, возвращающий множество таких пар вида (х, у), что у
является серией х, но не продолжением х;
c) рекурсивный запрос, возвращающий множество таких пар вида (х, у), что
у является серией х, но не продолжением хине продолжением продолжения х;
! d) рекурсивный запрос, возвращающий множество таких кортежей вида (х), что
л; обладает по меньшей мере двумя сериями, причем обе могут служить
продолжениями, но не должны быть одна продолжением, а другая —
продолжением продолжения х;
! е) рекурсивный запрос, возвращающий множество таких пар вида (х, у), что
у является серией х, но у обладает не более чем одной серией.
Упражнение 10.4.2. В упражнении 10.3.3 на с. 477 мы обсуждали отношение
Rel(class, rclass, mult),
представляющее сведения о связях между ODL-классами: наличие кортежа (с, d, m)
свидетельствует о том, что определение класса с содержит связь с классом d, причем на стороне
класса class связь относится к типу "многие", если т= 'multi', и к типу "один" —
если т= 'single'. В том же упражнении говорилось, что содержимое отношения Rel
можно описать графом, вершины которого соответствуют классам, а дуга,
соединяющая вершину с с вершиной d и обозначенная меткой т, — кортежу (с, d, т) отношения.
Напишите рекурсивные SQL-запросы, возвращающие множества пар (с, d), таких, что:
а) в графе существует путь, соединяющий вершины с и d;
* b) в графе существует путь, соединяющий вершины с и d, причем каждая дуга
пути обозначена меткой single;
*! с) в графе существует путь, соединяющий вершины с и d, причем по меньшей
мере одна дуга пути обозначена меткой multi;
10.4. РЕКУРСИЯ В SQL
485
d) в графе существует путь, соединяющий вершины с и d, причем ни одна из
дуг пути не обозначена меткой single;
! е) в графе существует путь, соединяющий вершины с и d, причем по мере
перехода от одной дуги пути к другой значения меток попеременно
изменяются с single на multi и с multi на single;
f) в графе существуют пути, соединяющие вершины с и d, а также d и с,
причем каждая дуга путей обозначена меткой single.
10.5. Резюме
♦ Язык Datalog. Datalog относится к семейству логических языков и позволяет
создавать запросы к данным, представление которых соответствует требованиям
реляционной модели. Запросы оформляются в виде наборов правил; предикат-
отношение заголовка правила определяется в терминах предикатов-подцелей,
образующих тело правила.
♦ Атомы. Заголовок и подцели правила являются атомами; каждый атом состоит
из предиката (возможно, с оператором отрицания) и списка аргументов.
Предикаты способны представлять отношения или выражения сравнения
арифметических значений.
♦ Интенсиональные и экстенсиональные предикаты. Предикаты, соответствующие
хранимым отношениям, называют экстенсиональными (EDB).
Интенсиональные (IDB) предикаты определяются посредством правил.
Экстенсиональные предикаты нельзя использовать в заголовках правил.
♦ Условие безопасности Datalog-правил. Принято ограничивать правила Datalog
условием, которое заключается в том, что любая переменная правила должна
упоминаться и в контексте некоторой реляционной подцели этого правила, не
подвергаемой операции отрицания. Условие безопасности гарантирует, что если
EDB-отношения конечны, конечными будут и вычисляемые ID В-отношения.
♦ Язык Datalog и реляционная алгебра. Все запросы, поддающиеся описанию
средствами реляционной алгебры, можно выразить с помощью языка Datalog.
И наоборот, если правила безопасны и нерекурсивны, им может быть
поставлен в соответствие определенный набор выражений реляционной алгебры.
♦ Рекурсивные Datalog-правила. Правило Datalog способно содержать рекурсивное
определение IDB-отношения в терминах того же отношения. Существует
алгоритм вычисления рекурсивных Datalog-правил без отрицания, подразумевающий
поиск "минимальных" множеств кортежей IDB-заголовков каждого правила,
которые удовлетворяют всем заданным условиям и не противоречат друг другу.
♦ Изолированное отрицание. Если в рекурсивных определениях отношений
используются операторы отрицания, уникальность решения, доставляемого
алгоритмом вычисления "минимальных" множеств кортежей IDB-заголовков
правил, не гарантируется, а в некоторых случаях приемлемых решений не
существует вовсе. Поэтому применение операторов отрицания внутри рекурсивных
выражений запрещается — операторы отрицания должны быть изолированы.
♦ Рекурсивные SQL-запросы. Стандарт SQL-99 предусматривает возможность
рекурсивного определения интенсиональных отношений таким же образом, как
это позволяется в Datalog.
♦ Требование изолированности в SQL. Рекурсивные SQL-определения с
использованием операторов отрицания и агрегирования должны быть монотонными (это
обобщение требования изолированности отрицания в Datalog).
486
ГЛАВА 10. ЛОГИЧЕСКИЕ ЯЗЫКИ ЗАПРОСОВ
10.6. Литература
В одной из ранних работ, [4], посвященных реляционной модели, Э.Ф. Кодд
(E.F. Codd) предложил логическую модель, названную реляционным исчислением
(relational calculus). Реляционное исчисление — это язык, во многом схожий с
реляционной алгеброй; факт эквивалентности изобразительных средств реляционной
алгебры и реляционного исчисления доказан в [4].
Интерес к языку Datalog, в еще большей степени приближенному к логике, возник
благодаря появлению и развитию языка программирования Prolog. Datalog,
обладающий средствами описания рекурсии, более выразителен, нежели реляционное
исчисление. В книге [6] нашли отражение результаты исследований в области логических
языков запросов, а в [2] проблемы рассмотрены в контексте систем баз данных.
Понятие изолированности рекурсии было введено в статье [3], хотя приемы
использования этого подхода для вычисления Datalog-правил рассматривались отдельно
в работах [1], [8] и [10]. Дополнительную информацию об изолированности
операторов отрицания, о связях между реляционной алгеброй, языком Datalog и
реляционным исчислением, а также о способах вычисления Datalog-правил, как с отрицанием,
так и без такового, можно найти в книге [9].
Статья [7] представляет обзор логических языков запросов. Отчет [5] содержит
рекомендации, положенные в основу разделов стандарта SQL-99, которые посвящены
вопросам реализации рекурсии в SQL.
1. Apt K.R., Blair H., and Walker A. Towards a theory of declarative knowledge, in Foundations of
Deductive Databases and Logic Programming (J. Minker, ed.), Morgan-Kaufmann,
San Francisco, 1988, p. 89-148.
2. Bancilhon F., Ramakrishnan R. An amateur's introduction to recursive query-processing
strategies, ACM SIGMOD Intl. Conf. on Management of Data (1986), p. 16-52.
3. Chandra A.K., Harel D. Structure and complexity of relational queries, J. Computer and System
Sciences, 25:1 (1982), p. 99-128.
4. Codd E.F. Relational completeness of database sublanguages, in Database Systems (R. Rustin,
ed.), Prentice Hail, Englewood Cliffs, NJ, 1972.
5. Finkelstein S.J., Mattos N., Mumick I.S., and Pirahesh H. Expressing recursive queries in SQL,
ISO WG3 Report X3H2-96-075, March, 1996.
6. Gallaire H., Minker J. Logic and Databases, Plenum Press, New York, 1978.
7. Liu M. Deductive database languages: problems and solutions, Computing Surveys, 31:1 (March,
1999), p. 27-62.
8. Naqvi S. Negation as failure for first-order queries, Proc. 5th ACM Symp. on Principles of
Database Systems (1986), p. 114-122.
9. Ullman J.D. Principles of Database and Knowledge-Base Systems, Volume I, Computer Science
Press, New York, 1988.
10. Van Geider A. Negation as failure using tight derivations for general logic programs, in
Foundations of Deductive Databases and Logic Programming (J. Minker, ed.), Morgan-
Kaufmann, San Francisco, 1988, p. 149-176.
10.6. ЛИТЕРАТУРА
487
Глава 11
Принципы хранения
информации
Эта глава открывает раздел книги, посвященный технологиям реализации систем баз
данных. Вначале целесообразно остановиться на том, каким образом СУБД
справляются с большими объемами информации. Проблему можно свести к двум
основополагающим вопросам.
1. Как компьютерная система сохраняет данные и управляет ими?
2. Какие формы представления и структуры данных наилучшим образом
способствуют повышению эффективности операций по обработке данных?
Здесь мы постараемся дать ответ на первый вопрос, а в главах 12—14 на с. 549—
681 — на второй.
Ниже мы расскажем об устройствах, используемых для хранения крупных
массивов информации (в частности, о дисках), рассмотрим иерархию устройств
памяти в целом и продемонстрируем, каким образом быстродействие алгоритмов
обработки хранимых данных зависит от способов перемещения порций
информации между оперативной памятью и вторичными (secondary storage devices) (обычно
дисками) или даже третичными (tertiary storage devices) устройствами хранения
(роботизированными комплексами, обеспечивающими доступ к большому числу
сменных оптических дисков или кассет с магнитной лентой). Наиболее
эффективные механизмы использования устройств, образующих иерархию памяти,
основаны на алгоритме сортировки двухфазным многокомпонентным слиянием (two-
phase, multiway merge sort).
В разделе 11.5 на с. 518 мы уделим серьезное внимание изучению различных
приемов снижения временных затрат на операции чтения данных с диска и их
записи, а в двух последних разделах обсудим методы повышения надежности
дисковых систем, позволяющие справляться с ошибками чтения-записи,
возникающими периодически, и даже с ситуациями полного "отказа", когда данные на
диске недоступны для чтения постоянно.
Начнем с рассмотрения примера, демонстрирующего особенности некоей
вымышленной СУБД, в основу которой положены неверные проектные решения, не
соответствующие общепринятой практике.
11.1. Пример системы баз данных
Если вы доселе уже пользовались какой-либо СУБД, вам, возможно, покажется, что
реализация подобных систем особого труда не составляет (тем более, если присмотреться
к Megatron 2002 Database Management System — недавнему достижению инженерной
мысли, воплощенному в жизнь в стенах Megatron Systems Inc.70). Эта система относится
к категории реляционных, поддер-живает SQL и распространяется в виде отдельных
версий для многих операционных систем, включая UNIX.
11.1.1. Особенности реализации
Для начала следует упомянуть, что в базовой версии Megatron 2002 для хранения
отношений используется файловая система UNIX. Так, например, отношение
Students (name, id, dept) может быть представлено в виде файла /usr/db/
Students. Каждая запись в файле students соответствует одному кортежу. Значения
компонентов кортежа хранятся в виде строк, разделенных специальными символами-
маркерами #. Содержимое файла /usr/db/students может выглядеть, скажем, так:
Smith#123#CS
Vasya Sidorchuk#522#EE
Описание схемы базы данных размещается в специальном файле /usr/db/schema.
Каждому отношению базы данных отвечает одна строка файла schema, которая
начинается с названия отношения и далее содержит пары имен атрибутов и их типов. Все
элементы строки разделяются символами #. Файл /usr/db/schema способен
содержать следующие строки:
Students#name#STR#id#INT#dept#STR
Depts#name#STR#office#STR
Здесь мы полагаем, что файл schema включает описания отношения
Students (name, id, dept) со строковыми (str) атрибутами name и dept и
целочисленным (int) атрибутом id, а также отношения Depts (name, office).
Пример 11.1. Рассмотрим, как протекает обычный сеанс взаимодействия с СУБД
Megatron 2002. Предположим, что мы работаем на компьютере с именем dbhost,
активизируем СУБД командой megatron2 002 уровня операционной системы,
dbhost> megatron2002
и получаем строку приветствия
WELCOME TO MEGATRON 2 002!
Теперь нам дано право обращаться к пользовательскому интерфейсу Megatron 2002,
вводя необходимые команды SQL в ответ на приглашение (&) системы. Текст запроса
завершается символом #. Так, запрос
& SELECT * FROM Students #
способен возвратить следующую таблицу:
пате
Smith
Vasya Sidorchuk
id
123
522
dept
cs
ЕЕ
70 Возможные совпадения с реальными названиями торговых марок просим считать случайными.
490 ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
СУБД Megatron 2002 позволяет также сохранять результаты выполнения запросов
в новых файлах: с этой целью текст команды следует сопроводить символом
вертикальной черты и именем файла. Например, при выполнении команды
& SELECT * FROM Students WHERE id >= 5 00 | Highld #
будет создан файл /usr/db/Highld, содержащий одну строку:
Vasya Sidorchuk#522#EE
□
11.1.2. Как СУБД выполняет запросы
Рассмотрим типовую форму SQL-запроса:
SELECT * FROM R WHERE <условие>
В ответ на подобный запрос Megatron 2002 предпринимает следующее:
1) обращается к файлу schema за информацией об атрибутах отношения R
и их типах;
2) проверяет, верно ли заданное <условие> с точки зрения семантики
отношения R;
3) передает на экран компьютера пользователя заголовок результата запроса
с наименованиями атрибутов, подчеркнутый линией;
4) считывает файл, соответствующий отношению R, и для каждой строки-записи
a) проверяет <условие>;
b) если <условие> верно, выводит на экран строку-кортеж.
При выполнении команды вида
SELECT * FROM R WHERE <условие> | Т
Megatron 2002 осуществляет такие действия:
1) обрабатывает запрос таким же образом, как и прежде, но пропускает действия,
предусмотренные в п. 3, т.е. не генерирует заголовок итогового отношения;
2) сохраняет результат в новом файле /usr/db/т;
3) добавляет в файл /usr/db/schema строку с описанием отношения Г,
аналогичную строке со сведениями о схеме отношения /?; таким образом, схемы
отношений Т и R совпадают.
Пример 11.2. Рассмотрим более сложный запрос, предполагающий соединение (join)
кортежей двух упомянутых выше отношений, students и Depts:
SELECT office
FROM Students, Depts
WHERE Students .name = 'Smith' AND
Students.dept = Depts.name #
Запрос заставляет систему осуществить соединение отношений students и Depts, т.е.
рассмотреть каждую пару кортежей, по одному из названных отношений, и определить:
a) содержат ли компоненты Students .dept и Depts .name одну и ту же строку
названия факультета;
b) является ли именем студента (students .name) строка ' Smith'.
Алгоритм может быть неформально описан следующим образом:
11.1. ПРИМЕР СИСТЕМЫ БАЗ ДАННЫХ
491
FOR (ДЛЯ) каждого кортежа s в Students (ВЫПОЛНИТЬ) DO
FOR (ДЛЯ) каждого кортежа d в Depts (ВЫПОЛНИТЬ) DO
IF (ЕСЛИ) 5 и d удовлетворяют условию WHERE (ТОГДА) THEN
Отобразить значение компонента office кортежа d;
□
11.1.3. Что плохого в нашей системе?
Хочется надеяться, для вас не окажется сюрпризом то, что "настоящие" СУБД
реализуются совершенно не так, как выдуманная нами Megatron 2002. Можно
назвать множество причин, не позволяющих считать систему адекватной тем
требованиям, которые выдвигаются в связи с возрастанием объемов данных и/или
количества одновременно подключенных к системе пользователей. Перечислим только
некоторые из множества проблем.
• Методика размещения кортежей на диске не отличается гибкостью,
необходимой для выполнения операций модификации. Если, например, в одном из
кортежей отношения students требуется изменить значение компонента dept
с ее на econ, системе придется перезаписать весь файл, сдвигая каждый
последующий символ на две позиции "вниз".
• Операции поиска чрезмерно трудоемки. Система всегда обязана просматривать
отношение целиком — даже в тех ситуациях, когда, как в запросе из примера
11.2, заданы одно или несколько значений, позволяющих сосредоточить
внимание только на ограниченной группе кортежей.
• Обработка запросов осуществляется "в лоб", хотя имеется множество гораздо более
эффективных способов выполнения операций, подобных соединению отношений.
Например, для обслуживания запроса из примера 11.2 вовсе не обязательно
просматривать все пары кортежей отношений, участвующих в соединении, — даже
в том случае, если бы имя студента (' Smith') не было задано в условии запроса.
• Система не предполагает возможности буферизации отдельных "полезных"
фрагментов данных в оперативной памяти; всякий раз, когда возникает потребность
в получении той или иной информации, последняя считывается с диска заново.
• В системе не предусмотрены средства управления параллельными заданиями.
Несколько пользователей способны единовременно модифицировать один и тот
же файл, что чревато непредсказуемыми последствиями.
• Система ненадежна; в случае сбоя данные могут быть утеряны, а
операции — прерваны.
В оставшейся части книги мы расскажем о технологиях, позволяющих
эффективно разрешать указанные проблемы. Надеемся, это знакомство окажется
ненавязчивым и приятным.
11,2. Иерархия устройств памяти
Типичная компьютерная система содержит в своем составе ряд компонентов,
предназначенных для хранения данных. Компоненты различаются емкостью и
скоростью доступа к данным, и степень различий значений этих параметров
оценивается, самое меньшее, семью порядками. Величины стоимости хранения байта
информации в компонентах также разнятся, но не столь серьезно — стоимость самых
дешевых компонентов на три порядка ниже в сравнении с наиболее дорогими. Нет
ничего удивительного в том, что устройства наименьшей емкости обладают самыми
492
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
высокими характеристиками скорости доступа к данным и в то же время
наибольшей удельной стоимостью хранения одного байта. Схема иерархии устройств
памяти компьютера приведена на рис. 11.1.
Программы;
СУБД,
размещаемые
в оперативной
памяти
\
Вирту-\ /Файло-
альная \ Диск/ вая
память \ / система
Оперативная память
\
Кэш-память
Рис. 11.1. Иерархия устройств памяти
11.2.1. Кэш-память
На нижнем уровне иерархии находится кэш-память (cache memory). Встроенный
кэш (on-board cache) находится в том же чипе, что и микропроцессор, а
дополнительный кэш 2-го уровня (level-2 cache) реализуется в виде отдельного чипа. Элементы
данных (включая машинные инструкции) в кэш-памяти являются копиями
содержимого определенных участков оперативной памяти (main memory) — устройства,
расположенного на очередном более высоком уровне иерархии. Время от времени значения
данных в кэш-памяти подвергаются изменениям, но модификация соответствующих
фрагментов оперативной памяти отсрочивается. Тем не менее, каждому элементу
кэшпамяти в какой-то момент отвечает содержимое определенного участка оперативной
памяти. Обмен информацией между кэш-памятью и оперативной памятью обычно
осуществляется небольшими порциями, объем которых исчисляется несколькими байтами.
Поэтому кэш можно представлять в виде хранилища отдельных машинных инструкций,
целочисленных величин, чисел с плавающей запятой или коротких символьных строк.
Когда компьютер выполняет программные инструкции, он пытается отыскать копии
соответствующих инструкций и данных, являющихся их операндами, в кэш-памяти.
Если результат поиска отрицателен, требуемые инструкции и данные копируются из
оперативной памяти в кэш. Поскольку кэш способен хранить только ограниченный объем
информации, системе обычно требуется удалить некоторые элементы кэш-памяти,
чтобы освободить место для новых. Если данные, подлежащие удалению, не изменялись
с момента их копирования в кэш, какие-либо дополнительные действия не требуются.
Если же данные подвергались модификации, перед их изъятием из кэш-памяти новые
значения должны быть скопированы в соответствующие участки оперативной памяти.
Когда элемент данных в кэш-памяти изменяется, обычному компьютеру с одним
процессором нет нужды сразу же выполнять модификацию содержимого соответствующих
фрагментов оперативной памяти. В многопроцессорной системе, позволяющей
нескольким процессорам обращаться к общему устройству оперативной памяти и поддерживать
при этом собственные приватные области кэш-памяти, однако, зачастую необходимо
осуществлять обновление кэш- и оперативной памяти единовременно и без задержек.
/
СУБД.
Третичные
устройства
хранения
11.2. ИЕРАРХИЯ УСТРОЙСТВ ПАМЯТИ
493
Единицы измерения объемов памяти
Стало традицией говорить о значениях емкости компьютерных компонентов памяти
так, как если бы они измерялись степенями числа 10 — мегабайты, гигабайты и т.д.
На самом деле, поскольку наиболее целесообразно проектировать устройства памяти
(скажем, полупроводниковые чипы) таким образом, чтобы обеспечить возможность
хранения количества битов, равного степени числа 2, все эти понятия трактуются как
соглашения, удобные для обозначения ближайших степеней 2. Поскольку величина
2ю = 1024 весьма незначительно отличается от тысячи, принято считать, что 2ю = 1000,
и употреблять для сокращения записи 2ю префикс "кило", 220 — "мега", 230 — "гига",
240 _ "тера" и 250 — "пета", хотя те же префиксы в областях, далеких от
информационных технологий, означают соответственно 103, 106, 109, 1012 и 1015. По мере роста
значений величина несоответствия между тем, что говорится и подразумевается
в действительности, также растет: 1 гигабайт — это приблизительно 1,074 * 109 байт.
Для обозначения префикса "кило" используется стандартное сокращение "К",
"мега" - "М", "гига" - "Г", "тера" - "Т" и "пета" - "П". Например,
16 Гбайт — это шестнадцать гигабайтов, или, строго говоря, 234 байт. Поскольку
иногда возникает необходимость представлять значения объемов памяти в виде
степеней числа 10, в этих случаях принято обходиться без применения приставок
"кило", "мега" и т.п. Например, "один миллион байтов" — это 1000000 байт,
а "один мегабайт" — 1048576 байт.
В компьютерах, выпускавшихся в 2001 году, емкость устройств кэш-памяти
достигала 1 Мбайт. Время обмена данными между кэш-памятью и процессором
определяется частотой процессора и на сегодняшний день исчисляется несколькими
наносекундами (1 наносекунда равна 10~9 секунд). С другой стороны, промежуток времени,
требуемый для передачи инструкции или элемента данных из оперативной памяти
в кэш и обратно, более велик и достигает 100 наносекунд.
11.2.2. Оперативная память
В центре событий, происходящих внутри компьютера, находится оперативная
память (main memory). Все действия, выполняемые компьютером, так или иначе
связаны с программными инструкциями и данными, расположенными в оперативной
памяти (хотя, если говорить более точно, информация, подлежащая обработке, вначале
перемещается в область кэш-памяти, о которой мы говорили в разделе 11.2.1).
Компьютеры, производившиеся в 2001 году, оснащались оперативной памятью,
средний объем которой составлял около 100 Мбайт (108 байт). Разумеется, существуют
и машины, обладающие гораздо большими размерами оперативной памяти, до
10 Гбайт (10ю байт) и выше.
Устройства оперативной памяти обеспечивают произвольный доступ (random access)
к ячейкам, а это значит, что на получение любого байта данных требуется одно и то
же время71 — обычно оно исчисляется значениями из диапазона 10—100 наносекунд
(10"8-10~7 секунд).
11.2.3. Виртуальная память
При выполнении программы данные, которыми она оперирует, — переменные,
значения, считанные из файлов, и т.п. — располагаются в пространстве адресов
виртуальной памяти (virtual memory). Инструкции программы также располагаются по опреде-
71 Некоторые современные компьютеры обладают оперативной памятью, разделяемой
несколькими процессорами таким образом, что значения скорости доступа к памяти для каждого
процессора различны (подчас они разнятся даже втрое).
494
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
ленным адресам. Многие компьютеры поддерживают 32-разрядное адресное пространство,
т.е. позволяют обращаться по различным адресам, общее количество которых составляет
232 (или около 4 миллиардов). Поскольку каждый байт нуждается в собственном адресе,
можно считать, что типичная виртуальная память обладает объемом, равным 4 Гбайт.
Так как пространство виртуальной памяти намного превышает размер оперативной
памяти обычного компьютера, большая часть содержимого виртуальной памяти на
самом деле размещается на диске. Операции с диском мы обсудим в разделе 11.3 на
с. 500, но сейчас достаточно иметь в виду только то, что диск делится на логические
единицы, называемые блоками (blocks). Размер блока диска обычно находится в
пределах от 4 Кбайт до 56 Кбайт (4—56 килобайт). Пересылка данных между диском
и оперативной памятью в рамках виртуальной памяти осуществляется целыми
блоками, которые в контексте оперативной памяти называют страницами (pages).
Аппаратное обеспечение и операционная система компьютера позволяют размещать страницы
виртуальной памяти в любой части оперативной памяти и обеспечивают корректное
отображение каждого байта внутри блока посредством адресов виртуальной памяти.
Часть схемы на рис. 11.1 (см. с. 493), касающаяся виртуальной памяти,
представляет то, каким образом последняя трактуется обычными программными приложениями,
и не имеет отношения к способам управления информацией в системах баз данных.
В настоящее время проявляется растущий интерес к СУБД, размещаемым в
оперативной памяти (main-memory DBMS's), которые на самом деле управляют данными
посредством механизма страничной пересылки информации в
оперативную память, поддерживаемого на уровне операционной системы. Системы
баз данных, размещаемые в оперативной памяти, как и большинство "обычных"
приложений, демонстрируют наибольшую эффективность в тех случаях, когда размер
данных, которыми они оперируют, настолько мал, что данные могут оставаться в
оперативной памяти на протяжении всего сеанса работы, и необходимость в их подкачке
(swapping) средствами операционной системы отсутствует. Если компьютер обладает
32-разрядным адресным пространством, подобные системы баз данных целесообразно
применять в тех случаях, когда требование единовременного размещения в памяти
информации объемом свыше 4 Гбайт (или менее, если адресное пространство не так
велико) не выдвигается. 32 разрядов адресного пространства обычно достаточно для
многих "обычных" программ, но отнюдь не для серьезных приложений систем баз
данных. Управление информацией в крупномасштабных СУБД не обходится без
участия дисков, и размеры баз данных в таких системах ограничены только емкостью
всех доступных дисковых и других устройств хранения данных.
11.2.4. Вторичные устройства хранения
Практически каждый компьютер оснащен теми или иными вторичными
устройствами хранения (secondary storage devices) информации, которые обладают существенно
большей емкостью и менее высоким быстродействием в сравнении с оперативной
памятью; каждое такое устройство обеспечивает возможность произвольного доступа
к элементам данных, и его производительность мало зависит от положения
конкретных элементов на носителе (за более подробной информацией о подобных
зависимостях обращайтесь к разделу 11.3 на с. 500). В современных компьютерных системах
роль вторичных устройств хранения отводится дискам (disks) — обычно магнитным
(magnetic), хотя применение находят также приводы оптических (optical) или
магнитооптических (magneto-optical) дисков. Последние обычно более дешевы, но подчас они
обеспечивают ограниченную поддержку режима записи либо не позволяют
осуществлять перезапись данных вовсе и поэтому выполняют функции хранилищ архивной
информации, изменять которую не требуется.
На рис. 1.1 (см. с. 493) показано, что диск осуществляет поддержку как
виртуальной памяти, так и файловой системы: в то время когда одни блоки диска содержат
11.2. ИЕРАРХИЯ УСТРОЙСТВ ПАМЯТИ
495
Закон Мура
Гордон Мур (Gordon Moore) много лет назад обратил внимание на то, что
параметры интегральных схем непрерывно улучшаются в соответствии с
экспоненциальным законом и их значения удваиваются каждые 18 месяцев. Вот некоторые из
параметров, подчиняющихся "закону Мура":
1) быстродействие процессора, т.е. количество инструкций, выполняемых им в
течение секунды, а также отношение быстродействия процессора к его стоимости;
2) стоимость оперативной памяти в пересчете на один бит и количество битов,
размещаемых в одном чипе;
3) стоимость диска в пересчете на один бит и емкость самых вместительных
моделей дисков.
С другой стороны, существует целый ряд иных важных характеристик,
поведение которых не отвечает закону Мура, — их значения, если и возрастают, то весьма
медленно: например, время доступа к данным в оперативной памяти и скорость
вращения диска. Из-за недостаточно быстрого увеличения значений этих
параметров их "запаздывание" прогрессирует. Другими словами, разрыв между скоростями
вычисления и перемещения данных к устройствам, принадлежащим различным
уровням иерархии памяти, все более усугубляется. Поэтому, как можно ожидать,
производительность оперативной памяти со временем будет все быстрее отставать
от производительности кэш-памяти процессора, а расхождение между уровнями
быстродействия дисков и процессоров будет увеличиваться еще более
угрожающими темпами. Не стоит обольщаться насчет отдаленности этого "будущего" —
проблемы обострились уже в 2001 году.
страницы области виртуальной памяти программного приложения, другие
обеспечивают сохранность (частей) файлов. Обмен файловыми данными между диском и
оперативной памятью выполняется блоками под управлением операционной системы
или СУБД. Перемещение блока с диска в оперативную память называют чтением
дисковых данных (disk read), а обратную операцию, связанную с сохранением блока из
памяти на диске, — записью дисковых данных (disk write). Обе операции в
совокупности принято обозначать термином дисковый ввод-вывод (disk I/O). Некоторые фрагменты
оперативной памяти используются для буферизации (buffering) дисковых файлов, т.е. для
временного хранения отдельных блоков этих файлов. Например, если файл открывается
для чтения, операционная система вправе зарезервировать блок оперативной памяти
размером в 4 Кбайт в качестве буфера, соответствующего файлу (мы подразумеваем, что
объем одного блока диска равен 4 килобайтам). Изначально в буфер копируется
первый блок файла. После того как прикладная программа выполнит необходимые
действия по обработке считанных данных, в буфер может быть помещен очередной блок
файла, замещающий прежний. Процесс, проиллюстрированный на рис. 11.2,
продолжается до тех пор, пока файл не будет полностью обработан или принудительно закрыт.
X
Буфер
Рис. 11.2. Файл и соответствующий буфер
оперативной памяти
496
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
СУБД способны управлять перемещением дисковых блоков между оперативной
памятью и вторичными устройствами хранения самостоятельно, не полагаясь на
средства менеджера файлов операционной системы. Функции управления и
сопутствующие им проблемы, однако, не меняются. Время, необходимое для осуществления
типичной операции чтения или записи дискового блока, исчисляется 10—30
миллисекундами (ОД—0,3 секунды). В течение промежутка времени такой продолжительности
современный процессор в состоянии выполнить несколько миллионов машинных
инструкций. В результате возникает ситуация, когда затраты на чтение-запись дискового
блока намного превосходят тот ресурс времени, который требуется для обработки
содержимого этого блока. Поэтому жизненно важной оказывается реализация
следующего условия: в любых ситуациях, когда это возможно, дисковый блок, содержимое
которого подлежит обработке, должен загодя присутствовать в буфере оперативной
памяти. Если условие выполняется, системе не приходится тратить драгоценное время
на трудоемкие операции дискового ввода-вывода. Мы вернемся к этой проблеме
в разделах 11.4 (см. с. 510) и 11.5 (см. с. 518), где приведем примеры проектных
решений, позволяющих снизить общие затраты на пересылку данных между устройствами,
относящимися к различным уровням иерархии компьютерной памяти.
В 2001 году значения емкости магнитного диска достигли отметки в 100 Гбайт
и даже превзошли ее. Поскольку компьютер может быть оснащен несколькими
дисковыми устройствами, речь идет о сотнях гигабайт дискового пространства, доступных
в пределах одной системы. Хотя вторичная память на пять порядков менее
производительна, нежели оперативная, емкость дисковых устройств обычно в несколько сотен
раз выше объема оперативной памяти компьютера. Удельная стоимость хранения
одного байта дисковых данных намного ниже в сравнении с аналогичным показателем
устройств оперативной памяти: в 2001 году цены в пересчете на 1 Мбайт емкости
дисков колебались от 1 до 2 центов, в то время как стоимость хранения того же
мегабайта данных в оперативной памяти составляла 1—2 доллара.
11.2.5. Третичные устройства хранения
Каким бы емким ни оказался набор дисков, установленных на одной машине,
реальные базы данных со временем могут становиться куда более обширными — подчас
их не удается разместить на вторичных устройствах хранения одного или даже целой
группы мощных компьютеров. Например, магазины розничной продажи ежегодно
накапливают многие терабайты данных с описанием совершенных покупок, а объемы
информации, получаемой со спутников, исчисляются петабайтами.
Для удовлетворения подобных непомерных "аппетитов" были разработаны
третичные устройства хранения (tertiary storage devices) данных, обычные величины
емкости которых измеряются в терабайтах. Третичным устройствам присущи существенно
более низкие показатели производительности операций чтения-записи и менее
высокие значения удельной стоимости хранения данных в сопоставлении с магнитными
дисками. В то время как устройства оперативной памяти обеспечивают совершенно
однородные характеристики доступа к любому элементу хранимых данных, а для
дисковых накопителей время доступа к тому или иному элементу зависит от положения
этого элемента на носителе весьма незначительно, для третичных устройств величина
периода времени, необходимого для обнаружения и получения нужного фрагмента
информации, способна изменяться в очень широких пределах, в зависимости от того,
насколько близка головка чтения-записи устройства к нужному участку носителя.
Ниже перечислены основные разновидности третичных устройств хранения данных.
1. Магнитные ленты, устанавливаемые по требованию (ad hoc tape storage).
Простейший — и на протяжении многих прошедших лет единственный — подход
к организации третичных хранилищ информации связан с записью данных на
бобины или кассеты с магнитной лентой и размещением последних на стойках -
11.2. ИЕРАРХИЯ УСТРОЙСТВ ПАМЯТИ
497
стеллажах. При необходимости извлечения порции информации с третичного
носителя человек-оператор отыскивает нужную ленту и устанавливает ее в
привод. Привод перематывает ленту к нужному участку, после чего считываемый
с ленты фрагмент данных копируется на вторичное устройство хранения или
в оперативную память. Для записи данных на третичный носитель выбирается
требуемая лента, на ленте отыскивается нужный участок, и копирование
информации производится в обратном направлении.
2. Автоматические приводы оптических дисков (optical disk jukeboxes).
Роботизированный автоматический привод обслуживает стойки, на которых размещены
оптические компакт-диски CD-ROM. Каждому биту информации соответствует
участок поверхности диска, окрашенный, условно говоря, в "черный" или
"белый" цвет, и привод считывает биты, определяя, отражается пучок света
лазера от того или иного фрагмента носителя либо нет. Выбор требуемого диска
осуществляется автоматически, и диск устанавливается в устройство чтения
с помощью робота, после чего содержимое диска или его часть копируется на
вторичное устройство хранения.
3. Ленточные бункеры (tape silos). Бункер — это специальным образом
оборудованное помещение, в котором располагаются стойки с магнитными лентами. Робот
обращается к нужной кассете с лентой и посредством захвата устанавливает ее в
любом из доступных приводов. Таким образом, бункер можно рассматривать как
автоматизированный вариант упомянутого выше хранилища магнитных лент,
устанавливаемых по требованию. Поскольку процессами поиска и выбора лент
управляет компьютер, производительность системы возрастает в сравнении с
хранилищами, обслуживаемыми человеком-оператором, по меньшей мере, на порядок.
Средняя емкость кассеты с лентой в 2001 году оценивалась величиной в 50 Гбайт.
Ленточные бункеры позволяют справляться с объемами информации, исчисляемыми
многими терабайтами. Емкость стандартного оптического компакт-диска CD-ROM
составляет около двух третей гигабайта, но все большую популярность завоевывают
носители стандарта DVD (digital versatile disk) — диски нового поколения, способные
сохранять до 2,5 Гбайт данных. Современные модели автоматических приводов оптических
дисков способны обслуживать массивы дисков общей емкостью в несколько терабайт.
Для доступа к заданному элементу данных на носителе третичного устройства
хранения может потребоваться период времени продолжительностью от нескольких
секунд до нескольких минут. Захват робота в автоматических приводах оптических
дисков и ленточных бункерах способен найти и установить нужный диск или кассету за
несколько секунд, но человеку-оператору для выполнения тех же действий
потребуются, вероятно, уже минуты. Как только диск установлен в привод, любая порция
хранящихся на нем данных может быть получена за доли секунды. Поиск требуемого
фрагмента информации на ленте, однако, сопряжен с трудоемкими операциями
перемотки; поэтому на считывание данных с ленты системе придется затратить несколько
дополнительных секунд или даже минут.
Подводя итог, можно сказать, что время доступа к данным на носителях третичных
устройств хранения примерно в 1000 раз превышает аналогичные характеристики
вторичных устройств (исчисляется секундами против миллисекунд). Если сопоставить среднюю
емкость третичных и вторичных устройств, по этому показателю первые превосходят
вторые в те же 1000 раз (речь идет о сотнях терабайтов против сотен гигабайтов). График,
приведенный на рис. 11.3, демонстрирует логарифмические зависимости между
показателями быстродействия и емкости устройств, относящихся ко всем четырем рассмотренным
уровням иерархии компьютерной памяти. Мы решили включить в него и сведения о
широко распространенных приводах, работающих с гибкими дисками (дискетами) и дисками
формата "Zip", хотя их нельзя отнести к типичным вторичным устройствам хранения,
используемым в системах баз данных. Горизонтальная — временная — ось градуирована
498
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
значениями степеней числа 10: так, —3 означает 10~3 секунд, или 1 миллисекунду.
Вертикальная ось представляет величины емкости в байтах и также градуирована значениями
экспоненты по основанию 10 (например, 8 означает 100 Мбайт).
8
13
12
11
10
9
8
7
6
5
о
Третичные устройства
Вторичные устройства
О Диски Zip
О Гибкие диски
Оперативная память
о
Кэш-память
2 1 0-1-2-3 -4 -5 -6 -7 -8 -9
Время
Рис. 11.3. Зависимости значений времени доступа к
данным и емкости устройств, относящихся к
различным уровням иерархии памяти
11.2.6. Энергозависимые и энергонезависимые устройства памяти
Дополнительный критерий сопоставления различных устройств компьютерной
памяти связан с их зависимостью от внешних источников электропитания. Энергозависимое
(volatile) устройство при выключении или сбое питания "забывает" все, что в нем
хранилось. Энергонезависимое (nonvolatile) устройство, напротив, как следует из его
названия, способно поддерживать хранимые в нем данные в целости на протяжении долгих
периодов пребывания в отключенном состоянии или отсутствия питания. Важность аспекта
независимости от электропитания не подлежит сомнению, поскольку одна из
ключевых характеристик СУБД обусловлена способностью поддерживать целостность данных
при возникновении сбоев и отказов (в частности, связанных с нарушением питания).
Магнитные материалы сохраняют свое физическое состояние и в отсутствие
внешнего источника электроэнергии, поэтому устройства памяти с магнитными
носителями, такие как диски и ленты, относятся к категории энергонезависимых. Оптические
свойства материалов компакт-дисков также не подвержены изменению в зависимости
от того, помещен диск в работающий привод или нет, — матрица "белых" и "черных"
точек на поверхности оптического диска, сохраненная в момент его записи и
представляющая значения битов данных, остается нетронутой (в действительности многие
разновидности оптических дисков просто не допускают возможности перезаписи ни
при каких условиях). Поэтому практически все вторичные и третичные устройства
хранения информации являются энергонезависимыми.
С другой стороны, устройства оперативной памяти большей частью энергозависи-
мы. Дело в том, что дизайн схемы чипа памяти существенно упрощается, а удельная
стоимость хранения одного бита значительно уменьшается, если допускается
возможность снижения потенциалов ячеек, ответственных за хранение значений битов
данных, в течение ограниченного промежутка времени, равного примерно одной минуте:
электрический заряды, представляющие значения битов, постепенно "утекают".
Поэтому подобные чипы динамической памяти с произвольным доступом (dynamic random-
11.2. ИЕРАРХИЯ УСТРОЙСТВ ПАМЯТИ
499
access memory — DRAM) нуждаются в периодическом считывании и перезаписи их
содержимого. Если ввиду отключения электропитания операция регенерации (refresh)
данных не выполняется, чип быстро теряет всю информацию, которая в нем хранилась.
Система баз данных, функционирующая на компьютере, оснащенном
энергозависимой оперативной памятью, обязана неотложно фиксировать на диске все внесенные
изменения — иначе в случае сбоя электропитания возникает серьезная опасность
потери данных. Как следствие, при выполнении операций модификации системе
приходится обращаться к диску множество раз; подобного повышения нагрузки удалось бы
избежать, если бы требование сохранять на диске "все и немедленно" было снято.
Одно из решений состоит в применении особых разновидностей устройств
оперативной памяти, являющихся энергонезависимыми. В качестве примера можно назвать
модули флэш-памяти (flash memory), которые разрабатываются уже достаточно долгое
время и постепенно становятся более дешевыми и экономичными. Еще одна
альтернатива — создание на основе чипов оперативной памяти так называемых виртуальных
дисков (RAM disks) с дополнительным питанием от аккумуляторных батарей.
11.2.7. Упражнения к разделу 11.2
Упражнение 11.2.1. Предположим, что в 2001 году типичная конфигурация
компьютерной системы предусматривала наличие процессора с частотой 1500 МГц, диска
емкостью 40 Гбайт и модулей оперативной памяти объемом 100 Мбайт. Положим
также, что закон Мура, в соответствии с которым значения указанных характеристик
удваиваются каждые 18 месяцев, будет оставаться в силе неограниченно долго.
* а) К какому году "типичными" станут диски емкостью в 1 Тбайт?
b) Когда следует ожидать массового производства устройств оперативной
памяти объемом в 1 Гбайт?
c) Через какое время обиходными станут процессоры с частотой 1 ТГц?
d) Каковой будет обычная конфигурация (процессор, диск, оперативная
память) компьютера в 2008 году?
! Упражнение 11.2.2. Командор Дейта, человекоподобный робот из киноленты "Star
Trek: The Next Generation", действие которой разворачивается в 24-м столетии,
однажды с гордостью признался, что его собственный процессор способен выполнять
1012 операций в секунду. Хотя количество операций в секунду и частота
процессора — это, строго говоря, не одно и то же, будем считать, что командор имел в виду
именно значение частоты, и полагать, что закон Мура будет по-прежнему
справедлив в течение следующих 300 лет. Выясните, слукавил ли тов. Дейта? Какой
должна была бы оказаться частота его процессора в действительности?
11.3. Диски
То, каким образом в СУБД используются вторичные устройства хранения, в
значительной степени определяет жизненно важные функциональные характеристики
этих систем. Роль вторичных устройств хранения практически всецело отдана
накопителям на магнитных дисках. Поэтому, прежде чем приступить к обоснованному
изложению сведений о технологиях реализации СУБД, целесообразно подробно изучить,
что происходит внутри дискового устройства.
11.3.1. Внутренние механизмы дисковых накопителей
На рис. 11.4 показаны два основных подвижных элемента дискового привода —
блок дисков (disk assembly) и блок головок (head assembly). Блок дисков состоит из
одной или нескольких круглых пластин (platters), вращающихся вокруг центрального
500
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
шпинделя. Верхняя и нижняя поверхности пластин покрыты тонким слоем
магнитного материала, предназначенного для хранения битов информации. Нулевое
значение бита представляется одним направлением ориентации элемента (домена)
магнитного слоя, а единичное значение — противоположным. Обычный диаметр пластин
диска составляет 3,5 дюйма, хотя выпускаются и диски с пластинами диаметром от
одного дюйма до нескольких футов.72
Блок головок
Цилиндр
Пластина
с двумя поверхностями
Рис. 11.4. Схема внутреннего устройства
привода магнитных дисков
Участки намагниченной поверхности пластин организованы в виде дорожек
(tracks), представляющих собой концентрические окружности. Дорожки занимают
большую часть поверхности, за исключением области, прилегающей к шпинделю (как
показано на рис. 11.5, представляющем вид пластины сверху). Каждая дорожка
состоит из множества элементов, способных сохранять значения отдельных битов данных.
Дорожки разбиты на секторы (sectors) посредством областей зазоров (gaps),
лишенных магнитного слоя.73 Сектор является неделимой единицей емкости диска — как
с точки зрения операций считывания и записи, так и в отношении устойчивости
устройства к возможным повреждениям. Если некоторый участок магнитного слоя по
той или иной причине приходит в негодность, т.е. далее не способен сохранять
информацию, считается неработоспособным целый сектор, которому принадлежит этот
участок. Зазоры используются для идентификации начала секторов; суммарная
площадь зазоров обычно составляет около 10% от площади дорожки. Дисковые блоки
(blocks), о которых мы говорили в разделе 11.2.3 на с. 494, являются логическими
единицами измерения объемов фрагментов данных, перемещаемых между диском и
оперативной памятью, и состоят из одного или нескольких секторов.
Теперь вкратце рассмотрим, что представляет собой блок головок. Головки (heads)
закреплены на рычаге, движущемся поступательно. Каждой поверхности пластин
соответствует собственная головка, перемещающаяся в непосредственной близости от
пластины, не касаясь ее. Если головка по какой-либо причине входит в
соприкосновение с поверхностью диска, она разрушается и дисковое устройство портится. Головка
способна определять заряд находящихся вблизи от нее элементов магнитного слоя, т.е.
считывать биты данных, и изменять заряд элементов с целью сохранения информации.
72 1 дюйм = 2,54 см; 1 фут = 12 дюймов = 30,48 см. — Прим. перев.
73 На рис. 11.5 каждая дорожка состоит из одинакового количества секторов. Однако, как
будет показано в примере 11.3 на с. 503, этот параметр может варьироваться — внешние
дорожки способны содержать большее количество секторов, нежели внутренние.
11.3. ДИСКИ
501
Дорожки
Сектор
Зазор
Рис. 11.5. Структура поверхности пластины
диска: вид сверху
11.3.2. Контроллер дисков
Одно или несколько дисковых устройств компьютера управляются контроллером
дисков (disk controller) — небольшим специализированным процессором,
выполняющим перечисленные ниже функции.
1. Управление электромеханическим исполнительным приводом, который
перемещает блок головок на требуемую линейную величину таким образом, чтобы
поблизости от каждой головки оказалась определенная дорожка
соответствующей поверхности пластины, доступная для чтения или записи данных.
Совокупность дорожек» находящихся в один и тот же момент времени под/над
каждой головкой, принято называть цилиндром (cylinder).
2. Выбор поверхности пластины и определенного сектора этой поверхности
(с учетом текущего углового положения вращающегося шпинделя) с целью
осуществления операций считывания или записи информации.
3. Передача считываемых с сектора битовых данных в оперативную память и
запись в нужный сектор тех данных, которые получены из оперативной памяти.
На рис. 11.6 показана схема простой однопроцессорной компьютерной системы.
Процессор посредством шины данных (data bus) взаимодействует с оперативной
памятью и контроллером дисков. Контроллер дисков способен управлять одновременно
несколькими дисковыми устройствами (на схеме изображены три таких устройства).
Процессор
г
Оперативная
память
-
1
Контроллер
дисков
Шина данных
Диски
Рис. 11.6. Укрупненная схема простой
компьютерной системы
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Секторы и блоки
Напомним, что сектор — это физическая структурная единица поверхности диска,
а блок — логическая единица объема дисковых данных, используемая для передачи
информации от диска к операционной системе или к СУБД и обратно. Мы уже
говорили, что обычный блок может соответствовать по объему одному или
нескольким секторам, хотя нет ничего противоестественного в том, если величина блока
окажется меньше емкости сектора и в сектор смогут "уместшъся" несколько
блоков (в некоторых устаревших системах использовался именно такой подход).
11.3.3. Общие параметры дисков
В угоду потребностям в эффективном хранении возрастающих объемов
информации технологии создания дисковых устройств непрерывно совершенствуются. Ниже
перечислены основные критерии оценки и средние значения, соответствующие
образцам таких устройств, выпускавшихся в 2001 году.
• Скорость вращения блока дисков: 5400 об./мин., т.е. примерно один оборот
каждые 11 миллисекунд, хотя существуют диски с большей или меньшей
скоростью вращения.
• Количество пластин. Обычное дисковое устройство включает 5 пластин
(10 поверхностей). Однако гибкий диск (дискета) или диск формата "Zip"
состоит из одной пластины с двумя поверхностями, и выпускаются модели
приводов, позволяющие использовать до 30 поверхностей.
• Количество дорожек на поверхности. Поверхность обычной пластины диска
способна содержать до 20000 дорожек, хотя для дискет этот показатель
существенно ниже (см. пример 11.4 на с. 504).
• Количество байтов на дорожке. Обычная дорожка может хранить около
миллиона байтов, но дорожки на поверхности пластины дискеты обладают намного
меньшей емкостью. Как упоминалось выше, дорожки разбиты на секторы. На
рис. 11.5 показаны 12 секторов в дорожке, хотя на самом деле дорожки
современных моделей дисков способны содержать до 500 секторов. Емкость одного
сектора исчисляется несколькими тысячами байтов.
Пример 11.3. Рассмотрим характеристики гипотетической модели дискового
устройства "Megatron 747" — лучшего представителя семейства высокопроизводительных
приводов магнитных дисков, выпускавшихся в 2001 году74:
• 8 пластин, или 16 поверхностей;
• 214, или 16384 дорожек на пластине;
• в среднем 27, или 128 секторов в дорожке;
• 212, или 4096 байт в секторе.
Для вычисления общей емкости дисковых пластин привода "Megatron 747"
достаточно перемножить значения 16 (поверхностей), 16384 (дорожек), 128 (секторов)
и 4096 (байтов). В результате получим 237 байт, или 128 Гбайт. Одна дорожка способна
хранить 128 * 4096 байт, или 512 Кбайт. Если размер блока равен 214, или 16384 байт,
один блок может содержать данные из четырех последовательных секторов, и тогда на
одну дорожку будет приходиться 128 / 4 = 32 блока.
74 Авторы иронизируют, проводя аналогию с надоедливой рекламой популярного аэробуса
Boeing-747. — Прим. перев.
11.3. ДИСКИ
503
Диаметр пластин дисков "Megatron 747" составляет 3,5 дюйма. Дорожки занимают
внешнюю часть поверхности пластины шириной в 1 дюйм, а внутренняя часть
шириной 0,75 дюйма остается свободной. Удельная плотность записи в радиальном
направлении составляет 16384 бит на дюйм, поскольку таково количество дорожек.
Плотность записи в пределах дорожки, однако, существенно выше. Предположим,
что каждая дорожка содержит в среднем по 128 секторов, а зазоры занимают
10% площади дорожки, так что упомянутые выше 512 Кбайт (или 4 Мбит) должны
быть распределены на 90% площади дорожки. Длина внешней дорожки равна 3,5я;
или около 11 дюймов. Данные объемом 4 Мбит сохраняются на участках дорожки
общей длиной около 9,9 дюйма (90% от 11 дюймов), поэтому плотность записи на
внешней дорожке составляет приблизительно 420000 бит на дюйм.
Внутренняя дорожка, однако, обладает диаметром, равным только 1,5 дюйма, так
что те же 4 Мбит данных должны уместиться на фрагментах дорожки длиной
0,9 * 1,5 * я; или 4,2 дюйма. Плотность записи на внутренней дорожке составляет,
таким образом, около 1 Мбит на дюйм.
Поскольку в случае однородного распределения секторов по дорожкам значения
плотности записи на внешней и внутренней дорожках весьма существенно
различаются, в "Megatron 747", как и в других современных моделях дисковых устройств,
поддерживается конструктивное решение, в соответствии с которым внешние дорожки
содержат большее количество секторов, нежели внутренние: например, множество
дорожек можно было бы поделить в радиальном направлении на три части и полагать, что
"внутренние" дорожки содержат по 96, "средние" — по 128, а "внешние" — по
160 секторов. Тогда значения плотности записи будут варьироваться уже не столь
широко — от 530000 бит до 742000 бит в направлении от внешних дорожек к внутренним. □
Пример 11.4. Если устройства на магнитных дисках упорядочить по значениям
емкости их носителей и разместить на гипотетической оси, поблизости от нулевой отметки
особняком расположится группа приводов стандартных 3,5-дюймовых дискет. Дискета
состоит из одной пластины с двумя поверхностями, каждая из которых содержит по
40 дорожек. Общая емкость дискеты в формате PC или MAC составляет около
1,5 Мбайт, или 150000 бит (18750 байт) в пересчете на одну дорожку. Около четверти
площади поверхности пластины отводится под зазоры и другие служебные области,
независимо от способа форматирования. □
11.3.4. Параметры доступа
При изучении технологий СУБД необходимо понимать не только то, как
сохраняются дисковые данные, но и разобраться в механизмах манипуляции этими данными.
Поскольку в процессах вычислений непосредственное участие принимает только
такая информация, которая находится в оперативной памяти или кэш-памяти,
единственный аспект, соотносящий эти процессы с дисками, связан с функциями передачи
блоков данных между дисками и оперативной памятью. Как мы упоминали в разделе
11.3.2 на с. 502, операции считывания и записи блоков (или последовательных
секторов диска, отвечающих блокам) осуществляются при выполнении следующих условий:
a) головки позиционированы на цилиндре, содержащем дорожку, где
расположены нужные секторы;
b) секторы поверхности вращающейся пластины, подлежащие считыванию или
записи, находятся непосредственно под/над головкой.
Промежуток времени, отделяющий момент активизации запроса на чтение или
запись дискового блока от момента, к которому содержимое блока оказывается в
оперативной памяти или сохраняется на диске, принято называть временем задержки
(latency time) диска. Время задержки складывается из периодов, перечисленных ниже.
504
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
1. Время, затрачиваемое процессором и контроллером дисков на активизацию
запроса и обычно равное долям миллисекунды (им можно пренебречь). Как
правило, допустимо игнорировать и промежутки времени, связанные с тем, что
контроллер и/или шина заняты обработкой запросов на чтение или запись
дисковой информации, посланных конкурирующими процессами.
2. Время поиска (seek time) — промежуток времени, требуемый для
позиционирования блока головок на определенный цилиндр. Время поиска может быть
равным нулю, если головки, как оказалось, уже находятся на верном цилиндре.
В общем случае блоку головок необходимы некоторые небольшие периоды
времени для того, чтобы начать движение, а затем — по достижении нужного
цилиндра — остановиться, а также для выполнения перемещения как такового
(значение этого временного промежутка, грубо говоря, пропорционально
величине перемещения). Периоды старта, движения от одной дорожки к соседней
и остановки в сумме исчисляются несколькими миллисекундами, но для
перемещения по всем дорожкам требуется время от 10 до 40 миллисекунд. На
рис. 11.7 приведен график зависимости времени поиска от длины перемещения
блока головок. Как видно, нижней границей величины времени поиска
является некоторое значение х, а максимум принадлежит диапазону от Зд; до 20*
единиц времени. Часто в качестве характеристики быстродействия дискового
устройства используют среднее время поиска (average seek time). О том, как оно
вычисляется, мы расскажем в примере 11.5.
о
Диапазон
Зд: - 20*
х
1 Мах
Перемещение на заданное
количество цилиндров
Рис. 11.7. Зависимость времени поиска от
длины перемещения блока головок
3. Время оборота (rotational latency time) — период времени, необходимый для
вращения пластины диска до тех пор, пока головка не достигнет первого из
секторов, которые относятся к блоку, подлежащему чтению или записи. Время
полного оборота пластины обычно исчисляется 10 миллисекундами. В среднем
приближении можно полагать, что для позиционирования нужного сектора
напротив головки необходимо совершить пол-оборота пластины, т.е. затратить
5 миллисекунд. Проблема иллюстрируется на рис. 11.8.
4. Время передачи (transfer time) — промежуток времени, требуемый для вращения
пластины на угол, достаточный для того, чтобы головка смогла считать
содержимое всех секторов, образующих блок. Если дорожка содержит 250000 байт,
а время полного оборота пластины оценивается величиной 10 миллисекунд,
тогда в течение секунды мы сможем считать 25 Мбайт данных, а время
передачи блока в 16384 байт составит около двух третей миллисекунды.
Расстояние
11.3. ДИСКИ
505
Текущее
-+ положение
головки
Требуемый ^ ^Щ^^^^^^Х/
сектор —HZIZI--—^
Рис. 11.8. Позиционирование сектора напротив головки
Пример 11.5. Попробуем оценить время, необходимое для чтения блока данных
размером в 16384 байт с диска модели "Megatron 747" (см. пример 11.3 на с. 503). Прежде
всего необходимо принять к сведению следующие временное характеристики устройства.
• Блок дисков вращается со скоростью 7200 об./мин., т.е. совершает один оборот
за 8,33 миллисекунды.
• Блок головок на старт, перемещение на расстояние в 1000 цилиндров и
остановку затрачивает по одной миллисекунде. Поэтому головки передвигаются от
дорожки к дорожке за 1,001 миллисекунды, а от внутренней дорожки к
внешней (с учетом того, что общее число дорожек равно 16384) — за время,
приблизительно равное 17,38 миллисекунды.
Вычислим максимальное, минимальное и среднее время, требуемое для чтения блока
размером в 16384 байт. Минимальное время чтения блока за вычетом величин
возможных периодов занятости контроллера и/или шины, которыми можно пренебречь, по
существу сводится к времени передачи: в наилучшем случае головка может оказаться
непосредственно напротив нужных дорожки и первого сектора блока, подлежащего чтению.
Поскольку славный "Megatron 747" способен сохранять 4096 байт в пересчете на
дорожку, блок занимает четыре сектора. Для чтения блока головка, таким образом, должна
"пройти" над четырьмя секторами и тремя разделяющими их зазорами. Напомним, что
суммарные площади зазоров и секторов составляют соответственно около 10% и 90% от
площади дорожки. Дорожка на пластине привода "Megatron 747" содержит
128 секторов и столько же зазоров. Поскольку зазоры в сумме покрывают угол
в 36 градусов, а секторы — в 324 градуса, величина центрального угла дуги,
охватывающей 4 сектора и 3 зазора, равна 36 * (3 /128) + 324 * (4 /128) = 10,97 градуса. Поэтому
время передачи составит (10,97/360) * 0,00833 = 0,000253 секунды, или около четверти
миллисекунды, где 10,97/360 — доля полного угла поворота, обеспечивающая возможность
чтения блока, а 0,00833 секунды — время, затрачиваемое на полный оборот пластины.
Теперь оценим максимально возможную длительность промежутка времени,
требуемого для чтения дискового блока. В худшем случае можно полагать, что головка
расположена над самым внутренним цилиндром, а чтению подлежат секторы,
принадлежащие самому внешнему цилиндру (или наоборот). Первое, что должен
выполнить контроллер, — это переместить блок головок. Как упоминалось выше, для
перемещения головок привода "Megatron 747" по всем цилиндрам необходимо затратить
17,38 секунды — это наибольшее значение времени поиска.
Худшее, что может произойти после того, как головка прибыла к нужному
цилиндру, — это возникновение ситуации, когда головка расположена непосредственно
после первого сектора требуемого блока. Поскольку блок должен считываться с первого
506
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Тенденции развития архитектур контроллеров дисков
С резким падением стоимости комплектующих цифрового электронного
оборудования контроллеры дисков становятся все более похожи на небольшие
компьютеры, оснащенные процессорами общего назначения и емкими устройствами
оперативной памяти с произвольным доступом. При наличии подобного мощного
аппаратного обеспечения контроллеры приобретают возможность выполнения самых
разнообразных дополнительных функций — например, считывания и сохранения
в собственной области памяти содержимого дорожки целиком (даже в тех случаях,
когда запрос предусматривает чтение единственного блока). Это позволяет
значительно уменьшить значение среднего времени чтения, если последовательно
запрашиваемые блоки принадлежат одной и той же дорожке. В разделе 11.5.1 на
с. 519 мы обсудим некоторые области применения операций считывания и записи
полных дорожек и цилиндров.
сектора, нам придется подождать 8,33 миллисекунды, пока пластина не выполнит
полный оборот, чтобы начало блока оказалось в непосредственной близости от
головки. Как только это произошло, блок считывается в течение времени передачи,
равного 0,25 миллисекунды. Таким образом, время задержки диска в наихудшем случае
составит 17,38 + 8,33 + 0,25 = 25,96 миллисекунды.
Наконец, вычислим среднее время чтения блока. Средние значения времени
оборота и времени передачи подсчитать довольно легко: первое, как и прежде,
составляет приблизительно четверть миллисекунды, а второе — это временной
промежуток, необходимый для поворота пластины на 180 градусов и равный
4,17 миллисекунды. Можно было бы предположить, что среднее время поиска —
это просто период, в течение которого головка в состоянии "пробежать" в
радиальном направлении через половину дорожек. Такая гипотеза, однако, не вполне
верна, поскольку более вероятно, чго изначально головки позиционированы где-то
поближе к середине пластины, поэтому для перемещения к нужному цилиндру им
в среднем требуется совершить более короткий путь.
Более точную оценку среднего количества дорожек, через которые должна
переместиться головка прежде, чем она попадет на искомую дорожку, можно получить
следующим образом. Предположим, что в начальный момент времени головка может
находиться с равной вероятностью на любом из 16384 цилиндров. Если это цилиндры с
номерами 1 или 16384, тогда средняя величина окажется равной (1 + 2 + - + 16383)/16384, или
около 8192. Если головка изначально находится на среднем цилиндре с номером 8192,
тогда для перемещения к нужному цилиндру в любом направлении ей потребуется
"пройти" четверть (4096) общего количества цилиндров. Таким образом, если исходная
позиция головки варьируется в пределах от 1 до 8192, среднее расстояние уменьшается с
8192 до 4096 по квадратичному закону. Аналогично, если начальное положение головки
изменяется от 8192 до 16384, среднее расстояние также оценивается квадратичной
функцией, возрастающей от 4096 до 8192 (график функции показан на рис. 11.9).
Если суммировать полученные результаты, нетрудно прийти к выводу, что
среднее расстояние, которое проходит головка вдоль диска в радиальном
направлении, равно одной трети от общего количества дорожек, или 5461. Таким
образом, среднее время поиска, состоящее из суммы величин периодов старта и
перемещения по трети дорожек диска, равно 1+5461/1000 = 6,46 миллисекунды75,
75 Стоит заметить, что здесь мы не учитываем вероятность такого события, когда головка не
должна перемещаться вовсе, но в предположении равновероятного распределения запросов на
выборку блоков это событие будет возникать только в одном из 16384 случаев. С другой
стороны, как будет показано в разделе 11.5 на с. 518, модель запросов на выборку случайных блоков
не вполне адекватна тому, что происходит в действительности.
11.3. ДИСКИ
507
а среднее время задержки диска, включающее значения трех компонентов —
среднего времени поиска, среднего времени оборота и среднего времени
передачи, — 6,46 + 4,17 + 0,25 = 10,88 миллисекунды.
8192 L у
Среднее ^v s^
перемещение \^ ^^
4096 ^ --^^^
0 I
0 8192 16384
Начальная позиция
Рис. 11.9. Парабола величины среднего
перемещения головок как функции значения
их начальной позиции
□
11.3.5. Запись блоков
Процесс записи блоков в его простой форме аналогичен функции чтения
блоков. Головка позиционируется на требуемую дорожку, а затем проходит
определенный период времени, необходимый для поворота пластины на такой угол, чтобы
напротив головки оказался нужный сектор. Но вместо чтения содержимого
секторов, образующих блок, происходит запись данных в секторы. Минимальное,
максимальное и среднее значения времени записи блока данных совпадают с
одноименными параметрами процесса чтения блока.
Процедура несколько усложняется, если по завершении записи требуется
выполнить функцию проверки (verifying) корректности сохраненной информации. В этом
случае после следующего поворота пластины содержимое обновленных секторов счи-
тывается и сопоставляется с исходным блоком. Один из простых способов проверки
сохраненных данных связан с использованием контрольных сумм, и о нем мы
расскажем в разделе 11.6.2 на с. 531.
11.3.6. Модификация содержимого блоков
Модифицировать содержимое блока непосредственно на диске не представляется
возможным. Даже в том случае, когда изменению подлежат всего несколько байтов
блока (например, значение компонента одного из кортежей отношения), надлежит
выполнить следующие действия:
1) осуществить чтение блока в оперативную память;
2) внести необходимые изменения в содержимое копии блока в
оперативной памяти;
3) сохранить блок на диске;
4) произвести, если требуется, проверку корректности записанных данных.
Таким образом, значение общего времени модификации содержимого блока
определяется суммой длительностей периодов чтения, обновления данных в памяти
508
ГЛАВА И. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
(этим компонентом ввиду его существенно малой величины в сравнении с
продолжительностью дисковых операций можно пренебречь) и записи, а также, если
выполняется проверка корректности данных, времени полного оборота диска и
дополнительной операции чтения.76
11.3.7. Упражнения к разделу 11.3
Упражнение 11.3.1. Дисковый привод "Megatron 777" обладает следующими
параметрами:
• десять поверхностей, по 10000 дорожек на каждой;
• каждая дорожка содержит в среднем 1000 секторов емкостью 512 байт;
• зазоры занимают 20% площади дорожки;
• пластины вращаются со скоростью 10000 об./мин.;
• время перемещения головки через п дорожек оценивается величиной в 1 + 0,001л
миллисекунд.
Дайте ответы на перечисленные ниже вопросы, касающиеся характеристик устройства.
* а) Какова общая емкость дисков привода?
Ь) Если принять, что все дорожки состоят из одинакового количества секторов,
какова удельная плотность записи в пределах сектора дорожки?
* с) Каково максимальное значение времени поиска?
* d) Каково максимальное значение времени оборота?
е) Если предположить, что блок содержит 16384 байт, т.е. охватывает
32 сектора, каково время передачи такого блока?
! 0 Каково среднее значение времени поиска?
g) Каково среднее значение времени оборота?
! Упражнение 11.3.2. Предположим, что головка привода "Megatron 747" (см. пример
11.3 на с. 503) находится на дорожке с номером 2048, т.е. на расстоянии от края
пластины, равном 1/8 ее радиуса. Предположим также, что очередной запрос
предусматривает необходимость чтения блока с любой произвольной дорожки.
Вычислите значение среднего времени выполнения подобной операции чтения.
*!! Упражнение 11.3.3. В конце примера 11.5 на с. 506 мы рассказывали о том, как
вычисляется среднее расстояние, которое головка проходит от одной наудачу
выбранной дорожки до другой, и определили, что эта дистанция равна 1/3 от общего
количества дорожек. Предположим, однако, что количество секторов в дорожке
пропорционально ее длине (или радиусу), так что плотность записи сохраняется
одинаковой для всех дорожек. Предположим также, что головка перемещается от
одного случайно выбранного сектора к другому. Поскольку внешние дорожки
содержат большее количество секторов, нежели внутренние, можно ожидать, что
среднее расстояние перемещения головки окажется меньшим 1/3 от общего
количества дорожек. Имея в виду, что, как и в случае с приводом "Megatron 747",
76 Естественно задаться вопросом, не равно ли время записи только что считанного блока
времени, необходимому для выполнения "случайной" записи блока. Если головки остаются на
месте, все, что требуется для осуществления операции записи, — это дождаться полного
оборота диска (время поиска равно нулю). Но поскольку контроллер не осведомлен о том, когда
именно приложение завершит формирование нового содержимого блока, подлежащего записи,
до момента получения запроса на запись блока головки могут быть перемещены к другому
цилиндру с целью выполнения операций ввода-вывода, инициированных иным процессом.
11.3. ДИСКИ
509
дорожки занимают внешнюю часть поверхности пластины шириной в 1 дюйм,
а внутренняя часть шириной 0,75 дюйма остается свободной, вычислите значение
среднего количества дорожек, которые необходимо "пройти" головке, чтобы
переместиться от одного произвольным образом заданного сектора к другому.
!! Упражнение 11.3.4. В примере 11.3 на с. 503 упоминалось о том, что максимальную
плотность записи на дорожках удастся уменьшить, если поделить дорожки на три
группы в зависимости от количества секторов в них. Если пойти дальше и
предположить, что значения ширины трех групп дорожек также могут варьироваться
с учетом единственного ограничения, касающегося общей емкости (8 Гбайт) всех
(16384) дорожек, какие значения пяти параметров (двух радиусов, делящих полосу
дорожек на три группы, а также количеств секторов в дорожках каждой из групп)
способны минимизировать максимальную плотность записи для любой дорожки?
11.4. Использование вторичных устройств хранения
В большинстве случаев при исследовании алгоритмов обработки данных
предполагается, что информация размещена в оперативной памяти и на доступ к одному элементу
данных приходится затрачивать не больше и не меньше времени, чем на обращение к
любому другому элементу. Подобную схему действий принято называть моделью
вычислений с произвольным доступом к данным (random-access computation model). Если же
речь идет о разработке СУБД, в качестве непременного постулата надлежит принять
положение о том, что какой бы емкой ни оказалась оперативная память, в общем случае
заведомо не удастся разместить в ней все требуемые данные целиком. В этой ситуации
при проектировании эффективных алгоритмов манипуляции данными нельзя не
учитывать необходимость в обращении ко вторичным и даже к третичным устройствам
хранения. Наилучшие алгоритмы обработки информации сверхбольших объемов
зачастую серьезным образом отличаются от аналогов, ориентированных на решение тех
же проблем в рамках модели вычислений с произвольным доступом к данным.
В этом разделе мы сосредоточим внимание преимущественно на способах
эффективного взаимодействия устройств оперативной и вторичной памяти и в частности
продемонстрируем, что наибольшим преимуществом обладает тот или иной алгоритм,
обеспечивающий минимизацию количества обращений к диску, — даже в том случае,
если с точки зрения модели вычислений в оперативной памяти такой алгоритм не
является самым эффективным. Схожий принцип применим к каждому уровню
иерархии устройств памяти: например, весьма удачный алгоритм, ориентированный на
обработку данных в оперативной памяти, возможно, удастся улучшить в контексте
модели кэш-памяти, если учесть, что информация, перемещаемая в кэш-память,
отвечает тенденции многократного использования. Аналогично, рассматривая
взаимодействие вторичного и третичного устройств хранения, следует обратить внимание на
величины объемов перемещаемых данных и предпринять усилия по минимизации
этих объемов — даже ценой увеличения нагрузки на устройства, относящиеся к более
низким уровням иерархии.
11.4.1. Модель вычислений с функциями ввода-вывода
Рассмотрим простой компьютер с одним процессором, контроллером и диском, на
котором работает СУБД, обслуживающая большое количество пользователей,
обращающихся к ней как с запросами, так и с командами модификации данных. Предположим,
что база данных настолько велика, что не может быть загружена в оперативную
память целиком. Некоторые основные части базы данных допускают буферизацию
в оперативной памяти, но, вообще говоря, каждый фрагмент запрашиваемых или
модифицируемых данных должен быть первоначально извлечен непосредственно с диска.
510
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
При наличии большого числа одновременно работающих пользователей, каждый
из которых часто отсылает запросы на выполнение операций дискового ввода-вывода,
контроллер дисков нередко вынужден организовывать очередь запросов; очередь, как
мы полагаем, устроена по принципу "первым пришел — первым обслужен " (first-in, first-
out — FIFO). Поэтому каждый запрос, посланный определенным пользователем,
можно считать случайным (в том смысле, что перед началом обработки запроса
головка диска с равной вероятностью может оказаться в любой позиции — даже если
пользователь считывает блоки, относящиеся к одному и тому же отношению базы
данных, а само отношение хранится на одном цилиндре диска). Ниже в этом разделе
мы обсудим различные способы повышения производительности такой системы,
придерживаясь следующего правила, которое определяет сущность модели вычислений
с функциями ввода-вывода (I/O computation model).
• Презумпция снижения затрат на операции ввода-вывода. Если необходимо
обработать блок дисковых данных, время, требуемое для выполнения операций
ввода-вывода, существенным образом превышает время, затрачиваемое на
манипуляции данными в оперативной памяти. Поэтому производительность
алгоритмов большей частью зависит от количества обращений к диску для чтения
и записи, и последнее должно быть минимизировано.
В последующих примерах мы будем полагать, что размер блока данных равен
16 Кбайт, и подразумевать использование модели дискового устройства
"Megatron 747", времениые характеристики которого (в частности, среднее время
считывания и записи блока, равное приблизительно 11 миллисекундам) определены
в примере 11.5 на с. 506.
Пример 11.6. Пусть в нашей базе данных имеется отношение R и запрос предполагает
отыскание в R кортежа, обладающего определенным ключевым значением к. Было бы
крайне желательно (позже мы расскажем об этом подробнее) создать индекс для R,
который позволял бы идентифицировать дисковый блок, содержащий кортеж с
заданным значением к. Однако в общем случае совершенно не важно, в состоянии ли
индекс "подсказать", в каком месте блока расположен искомый кортеж. Причина
состоит в том, что на операцию чтения дискового блока размером в 16 Кбайт необходимо
затратить 11 миллисекунд, а за то же время современный микропроцессор способен
выполнить миллионы инструкций. При этом на поиск значения к в блоке, который
уже находится в оперативной памяти, придется затратить всего пару тысяч
элементарных инструкций — даже в том случае, если используется "глупейшая" стратегия
линейного поиска. Таким образом, промежуток времени, необходимый для поиска
значения в оперативной памяти, пренебрежимо мал в сравнении с периодом времени
считывания дискового блока. □
11.4.2. Сортировка данных во вторичных хранилищах
В качестве примера, иллюстрирующего необходимость изменения алгоритмов
обработки данных при переходе к модели вычислений с функциями ввода-вывода,
рассмотрим проблему сортировки данных, общий объем которых намного превышает
емкость оперативной памяти. Для начала конкретизируем задачу сортировки и дадим
описание характеристик компьютера, на котором она должна выполняться.
Пример 11.7. Предположим, что мы имеем дело с крупноразмерным отношением R,
насчитывающим 10000000 кортежей. Каждый кортеж представляется записью с
несколькими полями, одно из которых является полем ключа сортировки (sort key), или
просто ключевым (key) полем, если это не противоречит возможности существования
ключей иных разновидностей. Цель, которая ставится перед алгоритмом сортировки,
состоит в упорядочении записей по возрастанию значений ключа сортировки.
ПА ИСПОЛЬЗОВАНИЕ ВТОРИЧНЫХ УСТРОЙСТВ ХРАНЕНИЯ
511
Ключ сортировки может или может не быть "ключом" в том смысле, который
придается в SQL понятию первичного ключа (primary key), гарантирующего, что
значения его компонентов в пределах всех кортежей отношения являются уникальными.
Если возможность дублирования значений ключа сортировки допускается, считается
приемлемым любой порядок следования записей с одинаковым содержимым ключа
сортировки. Для простоты будем полагать, что значения ключа сортировки уникальны.
Множество записей (кортежей) отношения R распределяется по дисковым блокам
размером в 16384 байт. Предположим, что в один блок умещаются 100 записей (каждая
запись обладает объемом около 160 байт). Если учесть, что вместе с записями как
таковыми в блоке должна сохраняться дополнительная информация служебного характера
(за подробностями обратитесь к разделу 12.2 на с. 554), 100 записей указанного
размера — это как раз то, для чего подойдет один блок в 16384 байт. Таким образом,
отношение R должно занимать 100000 блоков общей емкостью около 1,64 миллиарда байт.
Компьютер, на котором выполняется сортировка, оснащен одним дисковым
приводом модели "Megatron 747" (см. пример 11.3 на с. 503) и оперативной памятью,
100 Мбайт которой доступны для буферизации блоков, представляющих кортежи
отношения R. Фактический объем оперативной памяти более велик, но часть ее
используется системой. Количество блоков, которые можно разместить в 100 Мбайт памяти
(а это, напомним, 100 * 220 байт), равно 100 * 220 / 214, или 6400. □
Если данные, подлежащие сортировке, умещаются в оперативной памяти целиком,
их можно упорядочить с помощью разнообразных алгоритмов77, самыми
эффективными из которых являются варианты алгоритма быстрой сортировки (quick sort). Одна
из предпочтительных версий алгоритма быстрой сортировки предусматривает
упорядочение только ключевых полей, сохраняя вместе с ними указатели на полные записи.
К сожалению, эти алгоритмы утрачивают многие достоинства, если данные
приходится размещать во вторичных хранилищах. Если информация, подлежащая
сортировке, располагается преимущественно вне оперативной памяти, целесообразно
применять такой подход, который предполагает выполнение минимального количества
перемещений блоков данных из вторичной памяти в оперативную. Часто подобные
алгоритмы предусматривают осуществление нескольких проходов (passes), и в течение
одного прохода каждый блок однократно считывается с диска в оперативную память и
сохраняется на диске. В разделе 11.4.4 на с. 513 мы рассмотрим один из таких
алгоритмов более подробно.
11.4.3. Сортировка слиянием
Возможно, вы уже знакомы с широко известным алгоритмом сортировки слиянием
(merge sort), который позволяет объединять отсортированные списки в более крупные
отсортированные списки: алгоритм предполагает циклическое сопоставление
наименьших ключей, по одному из каждого списка, перемещение записи, соответствующей
найденному наименьшему ключу, в итоговый список, и повторение операций до тех пор,
пока один из исходных списков не будет исчерпан; затем к итоговому списку
добавляется оставшаяся часть одного из списков; в результате будет получен полный список
записей из двух исходных списков, отсортированный по возрастанию значений ключей.
Пример 11.8. Пусть даны два отсортированных списка с четырьмя записями в каждом.
Для простоты будем полагать, что структура записи содержит только ключевой
элемент целочисленного типа. Списки таковы: (1,3,4,9) и (2,5,7,8). Итерации процесса
слияния проиллюстрированы на рис. 11.10.
77 Наиболее подробные сведения по этим вопросам можно найти в книге Knuth D.E. The Art
of Computer Programming, Vol. 3: Sorting and Searching, 2nd Edition, Addison-Wesley, Reading, MA,
1998. [Имеется перевод: Кнут Д.Э. Искусство программирования, т. 3. Сортировка и поиск, 2-е
изд. — М.: Издательский дом "Вильяме", 2000.]
512
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
На первой итерации сопоставляются наименьшие элементы, 1 и 2, двух списков.
Поскольку 1 < 2, элемент 1 изымается из первого списка и становится начальным
элементом итогового списка. На второй итерации сравниваются элементы 3 и 2;
элемент 2 "побеждает" и переносится в итоговый список. Процесс продолжается
аналогичным образом до тех пор, пока на итерации 7 второй список не будет исчерпан,
после чего оставшаяся часть первого списка (в данном случае — единственный элемент)
переносится в конец итогового списка, и слияние завершается. Обратите внимание,
что элементы объединенного списка, как и требуется, следуют в возрастающем
порядке, поскольку на каждой итерации выбирается наименьший из оставшихся элементов.
Итерация
начало
1)
2)
3)
4)
5)
6)
7)
8)
Список 1
1, 3, 4, 9
3,4,9
3,4,9
4,9
9
9
9
9
пуст
Список 2
2, 5, 7, 8
2, 5, 7, 8
5, 7, 8
5, 7, 8
5,7,8
7, 8
8
пуст
пуст
Итоговый список
пуст
1
1,2
1,2,3
1, 2, 3, 4
1, 2, 3, 4, 5
1, 2, 3, 4, 5, 7
1, 2, 3, 4, 5, 7, 8
1, 2, 3, 4, 5, 7, 8, 9
Л/с. 77.7ft Слияние двух отсортированных списков в один
□
Время слияния списков в оперативной памяти линейным образом зависит от
суммы их длин: поскольку исходные списки заранее отсортированы, претендентами на
включение в итоговый список являются только элементы на первой позиции списков
и каждая операция их сравнения выполняется в течение постоянного промежутка
времени. Классический вариант алгоритма сортировки слиянием, выполняющийся
рекурсивно за log2« итераций (если сортировке подлежат п элементов), может быть
описан следующим образом.
Базис. Если существует список, состоящий из одного элемента и подлежащий
сортировке, ничего не предпринимать, поскольку список уже отсортирован.
Индукция. Если существует список, состоящий более чем из одного элемента
и подлежащий сортировке, поделить список произвольным образом на два списка
с одинаковыми либо различающимися на единицу длинами (если исходный список
содержит нечетное количество элементов). Рекурсивно отсортировать оба подсписка,
а затем осуществить их слияние в один отсортированный список.
Аналитические оценки качеств этого алгоритма хорошо известны, и способ их
получения в данном случае не особенно важен. Коротко говоря, время Т(п), необходимое
для сортировки п элементов, можно оценить как сумму произведения некоторой
константы на п (времени, затрачиваемого на разбиение списка и слияние полученных
отсортированных списков) и времени, требуемого для сортировки двух списков
размерности п /2, т.е. Т(п) - 2Т(п I 2) + an для некоторой константы а. Решением этого
рекурсивного выражения окажется Т(п) = 0(п log п), т.е. величина, пропорциональная и log я.
11.4.4. Сортировка двухфазным многокомпонентным слиянием
Рассмотрим, как воспользоваться алгоритмом сортировки двухфазным
многокомпонентным слиянием (two-phase, multiway merge sort — TPMMS) с целью упорядочения
отношения R, рассмотренного в примере 11.7 на с. 511, на компьютере, параметры которого
11.4. ИСПОЛЬЗОВАНИЕ ВТОРИЧНЫХ УСТРОЙСТВ ХРАНЕНИЯ
513
заданы в том же примере. TPMMS, один из наиболее популярных алгоритмов,
применяемый во многих приложениях баз данных, можно кратко описать следующим образом.
• Фаза 1. Выполнить сортировку произвольного количества списков данных
суммарным объемом, равным доступной емкости оперативной памяти.
• Фаза 2. Осуществить слияние отсортированных подсписков, полученных на
предыдущей фазе, в единый отсортированный список.
Если, как мы полагаем, данные большого объема размещены во вторичном
хранилище, приступать к их сортировке, начиная с базиса рекурсии, в соответствии с
которым следует рассматривать только одну или несколько записей, не имеет смысла —
когда данные, подлежащие упорядочению, умещаются в оперативной памяти,
алгоритм сортировки слиянием демонстрирует меньшую эффективность, нежели
некоторые другие алгоритмы. Поэтому целесообразно начинать рекурсию, заполнив
данными всю доступную область оперативной памяти целиком и используя более
быстродействующие инструменты упорядочения, подобные алгоритму быстрой сортировки.
Следует повторить перечисленные ниже итерации столько раз, сколько необходимо:
1) заполнить свободную область оперативной памяти блоками,
представляющими содержимое отношения, подлежащее сортировке;
2) отсортировать записи в оперативной памяти;
3) сохранить отсортированный подсписок в новом участке вторичной памяти.
По завершении первой фазы, рассмотренной выше, все записи исходного отношения
будут однократно считаны в оперативную память и включены в отсортированные
подсписки, сохраненные на диске.
Пример 11.9. Рассмотрим отношение R из примера 11.7 на с. 511. Как было
установлено, оперативная память компьютера с параметрами, указанными в том же примере,
способна вместить 6400 из общего количества блоков, равного 100000. Поэтому для
выполнения первой фазы нам придется 16 раз заполнять оперативную память
считываемыми блоками, сортировать записи, а затем сохранять отсортированные подсписки
на диске. Последний подсписок более краток — он охватывает только 4000, а не
6400 блоков, как каждый из 15 предыдущих подсписков.
Естественно задаться вопросом, насколько продолжительной окажется первая
фаза. Нам придется однократно считать и заново записать 100000 блоков, т.е. выполнить
200000 операций дискового ввода-вывода. Для примера можно полагать, что блоки
размещаются на диске в случайном порядке (хотя, как будет показано в разделе 11.5
на с. 518, существуют более эффективные способы организации хранения дисковых
данных). В этом случае продолжительность каждой операции считывания и записи
составляет 11 миллисекунд. Поэтому только на операции ввода-вывода, выполняемые
в ходе первой фазы, необходимо затратить 2200 секунд, или около 37 минут (свыше
2 минут на ввод-вывод данных каждого подсписка). Поскольку за одну секунду
процессор способен выполнить сотни миллионов инструкций, временем сортировки
информации в оперативной памяти уместно пренебречь. Таким образом, можно считать,
что длительность первой фазы процесса сортировки составляет около 37 минут. □
Теперь рассмотрим процедуру слияния отсортированных подсписков, полученных
в результате выполнения первой фазы. Следуя классической стратегии сортировки
слиянием, можно было бы осуществлять последовательное объединение каждой пары
подсписков, но в этом случае нам пришлось бы считывать и записывать каждый из
блоков данных 2 log2 n раз, где п — количество отсортированных подсписков,
полученных после первой фазы. Так, для слияния 16 отсортированных подсписков, о которых
говорилось в примере 11.9, необходимо считать и сохранить блоки каждой пары
подсписков с целью формирования 8 объединенных отсортированных подсписков, затем
514
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
последовательно повторить то же самое для получения 4 и 2 более крупных подсписков
и наконец выполнить слияние двух подсписков в единый итоговый отсортированный
список. Поэтому на каждый блок приходится по 8 операций дискового ввода-вывода.
Более удачный подход подразумевает необходимость считывания первых блоков
каждого из отсортированных подсписков во входные буферы оперативной памяти.
Если исходное отношение настолько объемно, что после выполнения первой фазы
процесса количество подсписков слишком велико, может случиться, что не удастся
считать в оперативную память даже по одному блоку из каждого подсписка (эта
проблема обсуждается в разделе 11.4 5 на с. 516). Впрочем, для отношения R из примера
11.7, как говорилось выше, будет создано всего 16 подсписков, поэтому в данном
случае указанная опасность нам не грозит.
Еще один (выходной) буфер оперативной памяти используется для хранения
блока, содержащего текущую порцию данных итогового отсортированного списка, и
объем буфера должен быть настолько велик, насколько это возможно. Изначально
выходной буфер пуст. Схема организации процесса вычислений с участием входных
и выходного буферов приведена на рис. 11.11. Чтобы осуществить слияние
отсортированных подсписков в единый отсортированный список, необходимо выполнить
действия, перечисленные ниже.
Входные буферы,
по одному на каждый отсортированный подсписок
Указатели
на первые
невыбранные
записи
Выбор
^минимального/
\ ключа /
Выходной
буфер
Рис. 11.11. Схема вычислений при выполнении
второй фазы сортировки многокомпонентным слиянием
1. Среди ключей первых элементов всех подсписков найти ключ с минимальным
значением. Поскольку необходимые операции сравнения выполняются в оперативной
памяти, вполне достаточно применить алгоритм линейного поиска,
эффективность которого пропорциональна количеству подсписков. Впрочем, при большом
желании можно использовать метод отыскания минимального элемента
подсписков, основанный на модели очередей с приоритетами (priority queues)78 и
обладающий трудоемкостью, пропорциональной логарифму от количества подсписков.
2. Переместить найденный минимальный элемент на первую доступную позицию
списка в выходном буфере.
78 За деталями обращайтесь к книге Aho A.V., Ullman J.D. Foundations of Computer Science,
Computer Science Press, New York, 1992.
11.4. ИСПОЛЬЗОВАНИЕ ВТОРИЧНЫХ УСТРОЙСТВ ХРАНЕНИЯ
575
Насколько велики должны быть блоки?
Изучая характеристики дискового привода "Megatron 747", мы подразумевали, что
размер блока составляет 16 Кбайт. Однако можно привести аргументы в пользу
выбора блока большего объема. В примере 11.5 на с. 506, напомним, мы
установили, что время передачи блока длиной в 16 Кбайт составляет около четверти
секунды, но средние значения времени поиска и времени оборота составляют в
сумме 10,63 миллисекунды. Если размер блока удвоить, нам удастся в два раза снизить
количество операций дискового ввода-вывода, необходимых для выполнения
алгоритмов обработки данных, подобных TPMMS. При этом время передачи блока
возрастет всего до 0,50 миллисекунды. Таким образом, общее время сортировки
уменьшится приблизительно в два раза. Если увеличить размер блока до 512 Кбайт
(т.е. до величины объема целой дорожки диска "Megatron 747"), время передачи
возрастет до 8 миллисекунд, а общее время чтения блока — до 20 миллисекунд, но
для осуществления двух фаз сортировки того же массива данных, который
рассматривается в примере 11.9 на с. 514, нам придется выполнить всего 12500 операций с
блоками, что позволит уменьшить общее время сортировки более чем в 17 раз.
Впрочем, существуют и доводы против увеличения размера блока. Во-первых,
если блок охватывает несколько дорожек, предложить эффективные способы
использования подобных блоков проблематично. Во-вторых, отношения небольшого
размера могут занимать только часть блока, что приведет к излишнему расходу
дисковой памяти. Помимо того, для организации хранения информации на
носителях вторичных устройств используются специальные структуры данных,
характеристики которых отличаются повышенной эффективностью, если данные
распределены между большим количеством блоков, т.е. размеры блоков не слишком
велики. Как будет показано в разделе 11.4.5 на с. 516, чем крупнее блоки, тем
меньшее количество записей может быть отсортировано с помощью алгоритма
TPMMS. Тем не менее по мере роста производительности процессоров и емкости
дисковых устройств существует тенденция и к увеличению размеров блоков.
3. Если выходной буфер заполнен, сохранить его содержимое на диске и заново
инициализировать тот же буфер для хранения очередной порции данных.
4. Если блок, из которого был извлечен минимальный элемент, исчерпан,
осуществить чтение очередного блока того же отсортированного подсписка в тот же
входной буфер. Если исчерпан и подсписок, оставить буфер пустым и в
процессе выбора минимального элемента к этому буферу более не обращаться.
В отличие от первой фазы, при выполнении второй фазы алгоритма блоки считыва-
ются в произвольном порядке, поскольку заранее не известно, какой из блоков будет
исчерпан первым. Однако достаточно обратить внимание, что каждый блок,
содержащий записи одного из отсортированных подсписков, считывается с диска только один
раз. Поэтому, как и на первой фазе, общее количество операций чтения блоков составит
100000. Аналогично, каждая запись однократно помещается в выходной буфер,
содержимое которого позже сохраняется на диске, поэтому количество операций записи блоков
также оценивается величиной 100000. Поскольку и в этом случае временем вычислений в
оперативной памяти уместно пренебречь, можно заключить, что на выполнение второй
фазы сортировки требуются те же 37 минут. Общее время сортировки составит 74 минуты.
11.4.5. Многокомпонентное слияние и сверхбольшие отношения
Рассмотренный выше алгоритм сортировки двухфазным многокомпонентным
слиянием позволяет обрабатывать и чрезвычайно крупные множества записей. Чтобы
получить числовые оценки допустимых объемов данных, введем следующие
обозначения (все величины измеряются в байтах):
516
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
1) В — размер блока;
2) М — объем оперативной памяти, доступной для буферизации блоков;
3) R — размер записи.
Количество буферов, которые удастся разместить в оперативной памяти, равно
Ml В. При выполнении второй фазы алгоритма все буферы, кроме одного, можно
использовать для считывания блоков отсортированных подсписков, а оставшийся
буфер — для хранения выходного блока. Поэтому максимальное количество
отсортированных подсписков, создаваемых на первой фазе, оценивается величиной {М1В)-\.
Этим числом определяется и количество стадий заполнения оперативной памяти
записями, подлежащими сортировке. На каждой стадии будет сортироваться максимум
МIR записей. Поэтому верхняя граница количества записей, которые можно
отсортировать, равна (МI /?)((М / В) - l), или приблизительно М21RB.
Пример 11.10. Если принять к сведению значения параметров, заданные в примере
11.7 на с. 511, получим Л/= 104857600, В- 16384 и R- 160. Верхняя граница количества
записей, которые могут быть отсортированы, составит в этом случае М21RB = 4,2
миллиарда, и для их хранения потребуется 0,67 Тбайт. Отношение подобного объема
нельзя разместить на носителях привода "Megatron 747". □
Если требуется отсортировать большее количество записей, можно пополнить
процесс третьей фазой: вначале, воспользовавшись алгоритмом TPMMS, создать на
основе групп из М21RB записей отсортированные подсписки, а затем осуществить слияние
(МI В)-\ таких подсписков в итоговый отсортированный список.
Третья фаза позволяет сортировать приблизительно МъIRB2 записей, занимающих
М3/В3 блоков. С учетом данных из примера 11.7 эти параметры получат значения
27 триллионов (записей) и 4,3 (Пбайт) соответственно, по нынешним временам просто
неслыханные. Поскольку емкость современных вторичных устройств хранения далека
даже от предела в 0,67 Тбайт, устанавливаемого алгоритмом TPMMS, можно полагать,
что двухфазной версии алгоритма с лихвой хватит для решения любых реальных задач.
11.4.6. Упражнения к разделу 11.4
Упражнение 11.4.1. Насколько продолжительным окажется процесс сортировки
двухфазным многокомпонентным слиянием отношения R из примера 11.7 на с. 511,
если дисковый привод "Megatron 747" заменить устройством "Megatron 777",
характеристики которого заданы в упражнении 11.3.1 на с. 509, оставив все
остальные параметры компьютера и данных, подлежащих сортировке, без изменения?
Упражнение 11.4.2. Сколько операций ввода-вывода потребуется выполнить для
сортировки с помощью алгоритма TPMMS отношения R из примера 11.7 на с. 511,
если значения отдельных параметров отношения и конфигурации компьютера
изменены так, как указано ниже?
* а) Количество кортежей отношения R удвоено и равно 20000000.
Ь) Длина кортежа увеличена в два раза и составляет 320 байт.
* с) Размер блока удвоен (32768 байт).
d) Объем свободной области оперативной памяти увеличен до 200 Мбайт.
! Упражнение 11.4.3. Предположим, что количество кортежей отношения R из
примера 11.7 на с. 511 достигло отметки, предельно допустимой, но все еще
гарантирующей возможность сортировки с применением алгоритма TPMMS на
компьютере, параметры которого заданы в том же примере. Предположим также, что
coll A ИСПОЛЬЗОВАНИЕ ВТОРИЧНЫХ УСТРОЙСТВ ХРАНЕНИЯ
517
ответствующим образом увеличен и объем диска компьютера, но все остальные
параметры диска, компьютера в целом и отношения R оставлены без изменения.
Сколько времени понадобится для сортировки отношения /??
* Упражнение 11.4.4. Вновь обратимся к отношению R из примера 11.7 на с. 511, но
предположим, что его кортежи хранятся в упорядоченном виде в соответствии со
значениями ключа сортировки, который к тому же является ключом в обычном
смысле, т.е. позволяет идентифицировать кортежи однозначно. Предположим
также, что отношение R размещено в последовательности блоков, положение которых
на диске заранее известно: иными словами, для любого наперед заданного /
возможно определить местонахождение /-го блока R и извлечь его с помощью
единственной операции дискового ввода-вывода. Для заданного значения К ключа можно
найти кортеж, соответствующий этому значению, используя стандартную
процедуру бинарного поиска. Каково максимальное количество операций дискового ввода-
вывода, необходимых для отыскания кортежа по ключу КР.
!! Упражнение 11.4.5. Предположим, что мы имеем дело с той же ситуацией, которая
описана в примере 11.4.4, но следует отыскать кортежи по 10 заданным значениям
ключа. Каково максимальное количество операций дискового ввода-вывода,
необходимых для отыскания всех 10 кортежей?
* Упражнение 11.4.6. Пусть дано отношение, содержащее п кортежей, длина каждого
из которых равна R байт, и параметры компьютера — объем М оперативной памяти
и размер В дискового блока — как раз и позволяют отсортировать кортежи
отношения с помощью алгоритма TPMMS. Как необходимо изменить и, сохранив все
другие условия в силе, если удвоить значение: (а) В; (b) R; (с) М?
! Упражнение 11.4.7. Выполните задания упражнения 11.4.6, если для
упорядочения кортежей подходит только алгоритм сортировки трехфазным
многокомпонентным слиянием.
*! Упражнение 11.4.8. Как представить количество записей, которые можно упорядочить
с помощью алгоритма сортировки £-фазным многокомпонентным слиянием, в виде
функции от параметров R, М и В (см. упражнение 11.4.6) и целочисленного значения к!
11.5. Повышение эффективности дисковых операций
В разделе 11.4.4 на с. 513, проводя анализ производительности алгоритмов
сортировки дисковых данных, мы полагали, что информация хранится на единственном
диске и блоки считываются с произвольных позиций. Подобная гипотеза уместна
в том случае, если речь идет о системе, выполняющей одновременно множество
запросов, затрагивающих небольшие фрагменты данных. Но когда в какой-либо период
задача системы сводится только к сортировке крупного отношения, можно
существенно снизить расходы времени на выполнение дисковых операций, если
позаботиться о строгом порядке размещения блоков данных, вовлеченных в сортировку, на
носителе. На самом деле, даже в том случае, когда показатель загрузки системы
определяется большим числом не связанных между собой запросов, затрагивающих
"случайные" блоки диска, нам вполне по силам предпринять ряд перечисленных
ниже действий, позволяющих ускорить обработку запросов и/или выполнять большее их
количество в единицу времени (т.е. увеличить "пропускную способность" системы).
• Разместить блоки, которые должны обрабатываться совместно, на одном
цилиндре, что позволит уменьшить до нуля значения времени поиска и,
возможно, времени оборота.
518
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
• Расположить информацию на нескольких дисках меньшего объема вместо того,
чтобы использовать один диск той же емкости. При наличии нескольких
блоков головок, перемещающихся независимо, объем данных, которые могут быть
считаны/записаны в течение единицы времени, возрастает пропорционально
количеству дисковых устройств.
• Создать "зеркальные" копии одних и тех же данных на нескольких дисках. Это
позволит не только обезопасить данные в случае выхода из строя одного из дисковых
устройств, но и (как в рассмотренном выше случае распределения данных по
нескольким дискам меньшего объема) увеличить пропускную способность системы.
• Использовать алгоритмы уровня операционной системы, СУБД или
контроллера дисков, служащие для упорядочения запросов к блокам диска во времени.
• Применить стратегии предварительного считывания определенных порций
дисковых данных в оперативную память, предвосхищающие потребность в
использовании этих данных.
Ниже мы будем обращать ваше внимание на возможный прирост
производительности системы в тех ситуациях, когда та способна хотя бы на время полностью
"отдаться" решению определенной задачи, подобной операции сортировки,
рассмотренной в примере 11.7 на с. 511. Впрочем, существуют, по меньшей мере, две другие
точки зрения на то, как следует измерять пропускную способность систем в целом и
устройств вторичного хранения данных в частности.
1. Как должна вести себя система, обслуживающая большое количество
одновременно поступающих запросов? Примером может служит система бронирования
авиабилетов, которая принимает запросы на информацию об авиарейсах и
заказы на билеты от множества агентов, функционирующих параллельно.
2. Как надлежит поступать, если бюджет, предусматривающий возможность
модернизации компьютерной системы, ограничен либо пользователь вынужден
выполнять "смесь" запросов в настроенной и работающей системе,
конфигурацию которой нелегко изменить?
Мы затронем эти вопросы в разделе 11.5.6 на с. 527, но вначале обсудим указанные
выше возможности увеличения производительности вторичных устройств хранения данных.
11.5.1. Группирование данных по цилиндрам диска
Поскольку время поиска отнимает чуть ли не половину среднего времени
считывания/записи блока, нетрудно назвать немало разновидностей приложений, в которых
целесообразно предусмотреть возможность размещения данных (таких как
содержимое отношений), с определенной долей вероятности обрабатываемых совместно,
в пределах одного цилиндра. Если емкость одного цилиндра недостаточно велика,
можно воспользоваться несколькими смежными цилиндрами.
Если все блоки одной дорожки или одного цилиндра считываются последовательно,
мы вправе пренебречь всеми составляющими времени чтения, кроме первого периода
поиска, необходимого для перемещения блока головок к нужному цилиндру, первого
промежутка времени оборота до достижения начального сектора последовательности блоков и,
разумеется, времени передачи. В такой ситуации нам удастся приблизиться к
теоретическому пределу скорости перемещения данных между диском и оперативной памятью.
Пример 11.11. Вновь проанализируем производительность алгоритма сортировки
двухфазным многокомпонентным слиянием, рассмотренного в разделе 11.4.4 на
с. 513. В примере 11.5 на с. 506, напомним, мы определили, что средние значения
времени передачи, поиска и оборота для дискового привода "Megatron 747"
составляют 0,25, 6,46 и 4,17 миллисекунды соответственно. Помимо того, было установлено,
11.5. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ДИСКОВЫХ ОПЕРАЦИЙ
519
что процедура сортировки содержимого отношения, состоящего из 10000000 записей
и занимающего около 1 Гбайта дискового пространства, выполняется за 74 минуты,
причем это время делится на четыре равных промежутка, необходимых для
осуществления функций чтения и записи блоков для двух фаз алгоритма.
Попробуем ответить на вопрос, поможет ли упорядочение данных по цилиндрам
уменьшить общее время сортировки. Первая стадия процесса связана с чтением
исходных блоков в оперативную память. В примере 11.9 на с. 514 мы установили, что
оперативная память заполняется данными объемом в 6400 блоков 16 раз.
Вполне возможно предусмотреть хранение 100000 блоков данных на
последовательных цилиндрах. Каждый из 16384 цилиндров привода "Megatron 747" способен
хранить около 8 Мбайт информации в 512 блоках; разумеется, это число является
средним, поскольку внутренние дорожки менее емки, нежели внешние, поэтому для
простоты будем полагать, что все дорожки и цилиндры обладают одним — средним —
объемом. Таким образом, для размещения исходных данных потребуется
196 цилиндров, причем для однократного заполнения оперативной памяти нам
придется обращаться к 13 цилиндрам.
На чтение данных с одного цилиндра требуется один период времени поиска. Мы
можем даже не учитывать время оборота, необходимое для размещения головки над
определенным блоком цилиндра, так как порядок чтения данных при выполнении
первой фазы не существен. Головки потребуется перемещать от одного соседнего
цилиндра к другому 12 раз, и, как было показано в примере 11.5, на передвижение блока
головок на одну дорожку тратится по 1 миллисекунде. Таким образом, время,
необходимое для однократного считывания исходных данных в оперативную память,
определяется суммой следующих компонентов:
1) 6,46 миллисекунды (среднее время одной операции поиска);
2) 12 миллисекунд (время поиска каждого из 12 соседних цилиндров);
3) 1,6 секунды (время передачи 6400 блоков).
Двумя первыми компонентами можно без ущерба пренебречь. Поскольку заполнять
оперативную память данными приходится 16 раз, общее время считывания данных на
первой фазе процесса составляет приблизительно 26 секунд. Напомним (см. пример
11.9 на с. 514), что при "случайном" размещении блоков на ту же операцию
пришлось бы затратить около 18 минут. Для сохранения данных 16 отсортированных
подсписков, получаемых в ходе выполнения первой фазы алгоритма, могут
использоваться другие 196 соседних цилиндров, и временнб/е параметры процесса записи окажутся
аналогичными: один период "случайного" поиска цилиндра, 12 промежутков времени
для перемещения головки от одного цилиндра к другому и время передачи 6400 блоков
для каждого из 16 отсортированных подсписков. Поэтому общее время записи данных
на первой фазе алгоритма также составляет 26 секунд, а время выполнения первой
фазы целиком — 52 секунды (сравните это число с 37 минутами, требуемыми для
осуществления тех же действий в условиях "случайного" расположения блоков).
С другой стороны, приемы организации хранения данных на последовательных
цилиндрах не способны уменьшить продолжительность протекания второй фазы
сортировки. Напомним, что в ходе выполнения второй фазы блоки считываются с первых
позиций 16 отсортированных подсписков в том порядке, который обусловлен свойствами
данных как таковых и, в частности, тем, какой из блоков каждого из подсписков и
какие подсписки в целом будут исчерпаны прежде других. Выходные блоки итогового
отсортированного списка сохраняются по одному, перемежаясь операциями чтения.
Поэтому для выполнения второй фазы алгоритма потребуется тот же промежуток времени
длительностью 37 минут. Таким образом, упорядочение данных по цилиндрам способно
уменьшить продолжительность процесса сортировки вдвое, и лучшего результата без
использования дополнительных альтернативных подходов достичь не удастся. □
520
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
11.5.2. Использование нескольких дисковых устройств
Зачастую пропускную способность системы удается существенно повысить, если
заменить один дисковый привод с блоком головок, "связанных" в единое целое,
несколькими. Подобная архитектура схематически показана на рис. 11.6 (см. с. 502), где
один контроллер дисков управляет одновременно тремя накопителями. Поскольку
производительность контроллера, шины данных и оперативной памяти несравнимо
выше, общее время осуществления дисковых операций при подобном подходе
уменьшается пропорционально количеству дисковых устройств. Проиллюстрируем
сказанное следующим примером.
Пример 11.12. Предположим, что дисковое устройство "Megatron 737" обладает теми
же характеристиками, что и модель "Megatron 747", рассмотренная в примерах 11.3 на
с. 503 и 11.5 на с. 506, но содержит только две пластины с четырьмя поверхностями,
позволяя сохранять до 32 Гбайт данных. Предположим также, что конфигурация
компьютерной системы изменена таким образом, что один привод "Megatron 747"
заменен четырьмя накопителями "Megatron 737". Проанализируем, как поведет себя в этих
условиях алгоритм сортировки двухфазным многокомпонентным слиянием в
применении к тому же отношению R, содержащему 100000 блоков по 16384 байт в каждом.
Прежде всего, множество записей отношения R уместно разделить между четырьмя
дисками, причем так, чтобы на каждом диске данные хранились на 196 соседних
цилиндрах. В этом случае мы сможем воспользоваться преимуществами группирования
данных по цилиндрам, рассмотренными в примере 11.11 на с. 519, когда значения времени
поиска и времени оборота по существу сводятся к нулю. При заполнении оперативной
памяти в ходе осуществления первой фазы под данные, считываемые с каждого из
дисков, следует отводить 1/4 часть памяти. На операцию чтения 1600 блоков с каждого
диска, достаточных для загрузки четверти объема оперативной памяти, потребуется только
400 миллисекунд, но поскольку система способна обслуживать четыре диска одновременно
без видимой потери производительности, на заполнение 100 Мбайт памяти уйдет, таким
образом, 0,4 секунды вместо 1,6 секунды при использовании единственного диска.
Аналогично, выполняя в ходе первой фазы запись данных, мы можем
распределить содержимое любого из отсортированных подсписков по четырем дискам
и 13 соседним цилиндрам каждого диска, сохранив тот же четырехкратный выигрыш
в скорости. Таким образом, на выполнение первой фазы в целом потребуется
13 секунд вместо 52, характерных для случая применения только одной стратегии
группирования данных по цилиндрам (см. раздел 11.5.1 на с. 519), и 37 минут,
требуемых при использовании самого прямолинейного подхода, предусматривающего
"случайное" размещение блоков (см. пример 11.9 на с. 514).
Теперь исследуем параметры второй фазы алгоритма. Нам по-прежнему необходимо
считывать блоки с первых позиций отсортированных подсписков в некотором порядке,
близком к "случайному" и диктуемом характеристиками данных как таковых. Если при
выполнении центральной части второй фазы алгоритма — выбора наименьшего из
оставшихся элементов, принадлежащих 16 подспискам, — требуется, чтобы все 16 списков
были представлены блоками, полностью загруженными в оперативную память, тогда
наличие четырех дисков вместо одного преимуществ не обеспечивает. Каждый раз по
исчерпании блока требуется ждать, пока в тот же подсписок не будет считан очередной
блок. Поэтому в каждый момент времени будет использоваться только один диск.
Однако, если написать код приложения более тщательно, можно добиться
возобновления операций сравнения наименьших 16 элементов подсписков
непосредственно после того, как первый элемент нового блока окажется в оперативной памяти.79
79 Следует отметить, что за реализацию подобного подхода надлежит браться в случае крайней
необходимости, заранее предвидя все преимущества, которые удастся получить, и продумывать
детали весьма тщательно. Одна из потенциальных опасностей, которую можно назвать сразу, связана
с попыткой обращения к записи в тот момент, когда она еще не считана в оперативную память.
11.5. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ДИСКОВЫХ ОПЕРАЦИЙ
521
В такой ситуации блоки нескольких подсписков могут загружаться в память
одновременно, а поскольку они расположены на разных дисках, параллельные операции
чтения дисковых блоков будут выполняться в один и тот же момент времени, помогая
приблизиться к порогу четырехкратного ускорения процессов чтения данных на
второй фазе. Разумеется, мы все еще ограничены в своих возможностях из-за того, что
порядок считывания блоков носит случайный характер; например, если два очередных
блока, подлежащих загрузке, размещены на одном диске, процесс обработки данных
в оперативной памяти будет приостановлен до тех пор, пока по меньшей мере первый
элемент второго блока не будет считан.
Часть второй фазы, связанная с записью данных, поддается оптимизации
значительно легче. Для каждого из четырех дисков можно создать собственный выходной буфер,
который, будучи заполненным, должен "сбрасываться" в строгом порядке на соседние
цилиндры соответствующего диска. Таким образом, заполнение одного из буферов
может продолжаться во время записи на диски содержимого трех остальных буферов.
Тем не менее мы не сможем сохранить на дисках полный отсортированный список
быстрее, нежели осуществить считывание данных из 16 промежуточных подсписков.
Как говорилось выше, невозможно гарантировать, что четыре диска будут
функционировать параллельно в течение всего периода сортировки, так что возможный
прирост производительности оценивается приближенным коэффициентом из интервала
2—3. Впрочем, и это вовсе неплохо: если принять, что значение коэффициента равно
2, экономия составит 18 минут. Таким образом, замена одного диска четырьмя и
использование стратегии группирования данных по цилиндрам в совокупности дают
возможность снизить общее время сортировки с 74 минут до 18 минут 13 секунд. □
11.5.3. Создание зеркальных копий дисков
Встречаются ситуации, когда уместно и целесообразно хранить на двух или
нескольких дисках идентичные копии одних и тех же данных. Такие диски принято называть
зеркальными (mirror). Один из доводов в пользу применения зеркальных дисков состоит
в том, что в случае выхода из строя одного диска данные удастся считать с диска-копии.
Помимо основного предназначения, связанного с повышением уровня надежности
хранения информации, зеркальные диски нередко выполняют функции увеличения
пропускной способности системы. Давайте вспомним ту часть примера 11.12, в
которой обсуждались характеристики второй фазы алгоритма сортировки TPMMS и
говорилось о том, что при тщательном программировании процесса загрузки данных в
оперативную память удастся приблизиться к порогу, когда единовременно считываются
блоки из четырех различных отсортированных подсписков в случае исчерпания текущих
блоков этих списков. Однако мы не можем гарантировать, какие именно четыре списка
должны получать новые блоки. Нельзя исключить ситуацию, когда, к нашему
несчастью, на одном диске расположены данные двух или даже трех таких списков.
Если мы можем позволить себе приобретение четырех дисковых устройств
(скажем, "Megatron 747") вместо одного, система окажется способной выполнять по
четыре операции чтения блоков одновременно. Иными словами, независимо от того,
какие именно четыре блока нужны в тот или иной момент, нам удастся считать
каждый требуемый блок с любого из четырех дисков.
Вообще говоря, имея п копий данных, мы сможем считывать параллельно любые п
блоков. Более того, если единовременной загрузке подлежат менее п блоков, появляется
возможность увеличения скорости работы системы путем тщательного выбора диска,
с которого данные могут быть считаны быстрее: достаточно, например, проанализировать,
головки какого из дисков, не занятых в данный момент выполнением других операций,
находятся наиболее близко к тому цилиндру, где расположена требуемая информация.
Применение зеркальных дисков не позволяет ускорить процессы записи, хотя
замедления работы в сравнении с теми ситуациями, когда используется единственный
диск, также не наблюдается. Записываемый блок сохраняется сразу на всех дисках, но
поскольку операции записи выполняются параллельно, они требуют примерно того
522
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
же времени, что и в системе с единственным диском. Конечно, абсолютно точной
синхронности операций записи на зеркальные диски достичь вряд ли удастся,
поскольку головки одного диска, например, могут быть расположены "невыгодно", т.е.
непосредственно после сектора, начиная с которого следует записывать блок, а
головки другого диска вдруг окажутся именно там, где нужно. Впрочем, подобные различия
в периодах времени оборота в среднем довольно малы; если наряду с созданием
зеркальных копий дисков применяется и стратегия группирования данных по цилиндрам
(см. раздел 11.5.1 на с. 519), этими различиями можно просто пренебречь.
11.5.4. Упорядочение дисковых операций и "алгоритм лифта"
Еще один способ повышения пропускной способности системы связан с
применением алгоритмов (мы будем говорить об алгоритмах уровня контроллера дисков, хотя
здесь этот аспект не имеет принципиального значения), позволяющих упорядочивать
(schedule) запросы на выполнение дисковых операций во времени и выбирать, какие
из них должны обрабатываться первыми. Такая возможность не особенно полезна,
если, как в рассматриваемом нами примере, связанном с сортировкой данных
отношения, системе приходится считывать и записывать дисковые блоки в определенной
последовательности. Но в тех ситуациях, когда система выполняет единовременно
множество запросов, затрагивающих небольшие порции данных, средства построения
динамических расписаний обслуживания запросов могут прийтись весьма кстати.
Один из простых и эффективных способов упорядочения запросов к диску во
времени носит название алгоритма лифта (elevator algorithm). Вполне правомочно
полагать, что блок головок привода совершает перемещения от внутреннего к внешнему
цилиндру и обратно точно так же, как лифт высотного здания, движущийся
вертикально вверх и вниз. Если один или несколько запросов предусматривают обращение
к одному цилиндру, головки перемещаются к этому цилиндру и выполняют требуемые
операции чтения и/или записи. Затем головки продолжают движение в том же
направлении до достижения очередного запрошенного цилиндра. Если среди поступивших
запросов нет таких, которые предусматривали бы обращение к следующим по порядку
цилиндрам, направление перемещения блока головок изменяется на противоположное.
Пример 11.13. Пусть с помощью алгоритма лифта необходимо упорядочить обращения
к диску модели "Megatron 747", средние временнь/е параметры которого, напомним
(см. пример 11.5 на с. 506), таковы: время поиска — 6,46, время оборота — 4,17 и время
передачи — 0,25 (все значения даны в миллисекундах). Предположим, что к некоторому
(нулевому) моменту времени поступили три запроса, предусматривающие обращение
к блокам данных, размещенным на цилиндрах с номерами 2000 6000 и 14000, а блок
головок расположен напротив цилиндра 2000. Помимо того, предположим, что в скором
времени должны поступить еще три запроса. Параметры всех шести запросов
представлены на рис. 11.12 (например, запрос, предполагающий необходимость обращения
к цилиндру с номером 4000, поступает в момент времени 10 (миллисекунд)).
Номер
цилиндра
2000
6000
14000
4000
16000
10000
Момент поступления
0
0
0
10
20
30
Рис. 11.12. Данные, иллюстрирующие применение
алгоритма лифта
11.5. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ДИСКОВЫХ ОПЕРАЦИЙ
523
Согласимся с тем, что время передачи составляет 0,25 миллисекунды, а время
оборота — 4,17 миллисекунды, т.е. для выполнения одной операции с блоком требуется
период времени, равный 4,42 миллисекунды плюс соответствующее время поиска
конкретного цилиндра. Время поиска легко вычислить, пользуясь правилом,
изложенным в примере 11.5: 1 плюс количество дорожек, поделенное на 1000. Рассмотрим
действие алгоритма лифта. Для обработки запроса, обращенного к цилиндру 2000,
выполнять поиск не требуется, поскольку блок головок находится уже здесь. Поэтому
к моменту 4,42 этот запрос будет полностью обработан. Запрос к цилиндру 4000 еще не
поступил, поэтому головки перемещаются к цилиндру 6000. Интервал времени перехода
с цилиндра 2000 к цилиндру 6000 равен 5 миллисекундам, поэтому обработка второго
запроса начинается в момент 9,42 и завершается по прошествии 4,42 миллисекунды, т.е.
к моменту 13,84. Теперь запрос, обращенный к цилиндру 4000, уже активизирован, но
головки "проскочили" этот цилиндр в момент времени 7,42 и не вернутся к нему до тех
пор, пока не будут обработаны все запросы к "дальним" цилиндрам.
Сейчас настал черед обслуживания запроса к цилиндру 14000, и на перемещение
к нему будет затрачено 9 миллисекунд, а на считывание блока — еще
4,42 миллисекунды. Таким образом, обработка третьего запроса завершится к моменту
27,26. Сейчас уже поступил запрос к цилиндру 16000, поэтому движение головок
в выбранном направлении продолжается. Время поиска составит 3 миллисекунды, так
что операция будет полностью завершена к моменту 27,26 + 3 + 4,42 = 34,68.
Теперь "прибыл" и запрос к цилиндру 10000, так что остаются необработанными
всего два запроса, адресованные к цилиндрам 10000 и 4000, и запросов к цилиндрам
с более высокими номерами нет. Поэтому направление перемещения головок
изменяется, и последовательно обслуживаются два оставшихся запроса . На рис. 11.13
показаны моменты завершения обработки всех запросов.
Номер
цилиндра
2000
6000
14000
16000
10000
4000
Момент завершения
4,42
13,84
27,26
34,68
46,10
57,52
Рис. 11.13. Расписание обслуживания запросов согласно
алгоритму лифта
Теперь попытаемся сопоставить производительность системы, обеспечиваемую
алгоритмом лифта, с той, которую можно получить, применяя прямолинейную
стратегию "первым пришел — первым обслужен" (FIFO). Три первых запроса
удовлетворяются точно так же, как и прежде, если полагать, что порядок их следования таков:
2000, 6000 и 14000. После обработки третьего запроса, однако, мы переходим к
запросу, предусматривающему обращение к цилиндру с номером 4000, поскольку этот
запрос успел поступить четвертым. Время поиска цилиндра (перехода от цилиндра
14000) составит 11 миллисекунд. Для выполнения пятого запроса, адресованного
к цилиндру 16000, требуется время поиска в 13 миллисекунд, а на возврат к цилиндру
с номером 10000 с целью обслуживания последнего запроса уйдет 7 миллисекунд. На
рис. 11.14 представлено расписание обработки запросов в соответствии с алгоритмом
"первым пришел — первым обслужен" (FIFO).
Различие между полученными результатами на первый взгляд не очень
значительно — всего 14 миллисекунд, но не следует забывать, что количество запросов в
нашем примере очень мало (6) и, более того, три из них в обоих случаях
обрабатывались в одном и том же порядке.
524
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Номер
цилиндра
2000
6000
14000
4000
16000
10000
Момент завершения
4,42
13,84
27,26
42,68
60,10
71,52
Рис. 11.14. Расписание обработки запросов в
соответствии со стратегией "первым пришел — первым
обслужен " (FIFO)
□
Если среднее количество запросов, ожидающих обработки, возрастает,
соответственно увеличивается и относительная эффективность алгоритма лифта. Если,
например, размер множества ожидающих запросов равен количеству цилиндров, длина
каждого перемещения головок может уменьшиться на несколько цилиндров, а значение
среднего времени поиска — снизиться до теоретического минимума. Если количество
запросов, ожидающих обслуживания, возрастет еще больше, это будет означать, что
на каждый цилиндр приходится в среднем более одного запроса. В такой ситуации
контроллер дисков способен переставить запросы, относящиеся к одному цилиндру,
в соответствии с порядком следования адресуемых ими блоков "вдоль" длины
дорожки, чтобы наряду с уменьшением среднего времени поиска оптимизировать еще
и среднее время оборота. Если, однако, множество запросов становится чрезмерно
большим, время, затрачиваемое на ожидание обслуживания каждого запроса, в
среднем также возрастает. Ситуация иллюстрируется следующим примером.
Пример 11.14. Предположим, что мы вновь вознамерились поэксплуатировать
многострадальный "Megatron-747" с его 16384 цилиндрами. Представим, что обработки
ожидают 1000 запросов на дисковые операции. Для простоты допустим, что все запросы
предусматривают обращение к различным цилиндрам, равноотстоящим друг от друга на
величину 16. Если начать движение блока головок с крайнего цилиндра, для обработки
каждого из 1000 запросов понадобится чуть более 1 миллисекунды времени поиска,
4,17 миллисекунды времени оборота и 0,25 миллисекунды времени передачи. Таким
образом, каждый запрос может быть удовлетворен за время 5,42 миллисекунды, примерно
вдвое меньшее 10,88 миллисекунды — среднего времени обслуживания запросов к блокам,
размещенным случайным образом. Однако для обработки всех 1000 запросов потребуется
5,42 секунды, так что средняя величина задержки обслуживания каждого отдельного
запроса составит половину этого значения, т.е. 2,71 секунды, а это не так уж и мало.
Теперь допустим, что размер множества запросов возрастает до 32768.
Предположим для простоты, что к каждому цилиндру адресуются по два запроса. В этом случае
каждый период времени поиска равен 1 миллисекунде (по 0,5 миллисекунды на
каждый запрос) и, разумеется, время передачи по прежнему составляет
0,25 миллисекунды. Поскольку с каждого цилиндра считываются по два блока,
среднее время оборота пластины, достаточное для считывания более "дальнего" из
двух блоков, составляет 2/3 от периода полного оборота, равного 8,33 миллисекунды
(см. пример 11.5 на с. 506). Доказательство этой оценки довольно хитро и вкратце
изложено в тексте врезки "Немного теории вероятностей". Поэтому среднее время оборота
для достижения каждого из двух блоков равно половине от 2/3 периода полного
оборота, т.е. 0,5 * 0,667 * 8,33 = 2,78 миллисекунды, так что общее среднее время
обработки блока удастся уменьшить до 0,5 + 0,25 + 2,78 = 3,53 миллисекунды, что составляет
11.5. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ДИСКОВЫХ ОПЕРАЦИЙ
525
Немного теории вероятностей
Предположим, что существуют два блока, занимающих случайные позиции в
пределах одного цилиндра. Пусть эти позиции представляются величинами хх и хъ
принимающими значения дробных долей длины окружности из промежутка от 0 до 1.
Вероятность того, что значения хх и х2 одновременно меньше некоторого числа у из
промежутка 0—1, оценивается величиной у2. Поэтому плотность вероятности для у —
это производная от у2, или 2у. Иными словами, вероятность того, что у примет заданное
значение, возрастает линейно с увеличением значения от 0 до 1. Среднее значение у —
это интеграл от произведения у и плотности вероятности для у, т.е. J 2y2, или 2/3.
около трети среднего времени доступа к блоку в случае применения алгоритма
"первым пришел — первым обслужен" (FIFO). С другой стороны, на обработку всех
32768 запросов уйдет 116 секунд, так что среднее время задержки обслуживания
каждого запроса будет достигать почти 1 минуты. □
11.5.5. Предварительное считывание и крупномасштабная буферизация данных
Последняя из рассматриваемых нами методик повышения эффективности
использования вторичных устройств хранения связана с предварительным считыванием (data
prefetching), или крупномасштабной буферизацией (large-scale buffering), данных. В
некоторых приложениях удается заранее предвидеть порядок, в соответствии с которым
блоки должны считываться с диска. Если дело обстоит именно так, можно загрузить
дисковые данные в оперативную память еще до того момента, когда потребность в них
действительно возникнет. Одно из получаемых в этом случае преимуществ обусловлено
тем, что качество расписания обслуживания обращений к диску в соответствии с тем же
алгоритмом лифта может быть повышено за счет уменьшения среднего времени
обработки блока. Нам удастся достичь того же прироста производительности, о котором
говорилось в примере 11.14, без длительных задержек в обслуживании запросов.
Пример 11.15. Для того чтобы продемонстрировать выигрыш, получаемый при
использовании стратегии предварительного считывания данных, вновь рассмотрим
вторую фазу алгоритма сортировки двухфазным многокомпонентным слиянием.
Напомним (см. пример 11.9 на с. 514), что в процессе слияния в оперативную память считы-
вается по одному блоку из каждого отсортированного подсписка, общее количество
которых равно 16. Если предположить, что подсписков настолько много, что
множество очередных считываемых блоков каждого из них заполняет оперативную память
целиком, ничего лучшего, разумеется, добиться уже нельзя. Но в нашем примере
изрядная область памяти остается свободной. Поэтому вполне правомочно создать для
каждого подсписка не один, а два буфера, и заполнять один из них в то время, пока
другой "поставляет" данные, подлежащие слиянию. Если один буфер исчерпан,
достаточно без каких бы то ни было задержек "переключиться" на другой. □
Конечно, схема, предложенная в примере 11.15, сама по себе не позволяет
уменьшить общее время, требуемое для считывания всех 100000 блоков отсортированных
подсписков. Можно было бы объединить стратегии предварительного считывания
с группированием данных по цилиндрам, если:
• сохранять отсортированные подсписки на последовательных цилиндрах,
придерживаясь такого же порядка следования блоков на каждой дорожке и на
дорожках в пределах цилиндра, какой задается подсписком;
• осуществлять чтение дорожек или цилиндров, представляющих данные того
или иного подсписка, целиком.
526
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Пример 11.16. Вновь обратимся ко второй фазе алгоритма TPMMS (см. пример 11.9
на с. 514). Количество свободной оперативной памяти позволяет организовать по два
буфера объемом, равным емкости дорожки, для каждого из 16 отсортированных
подсписков. Напомним, что дорожка диска "Megatron-747" позволяет сохранять
512 Кбайт банных, поэтому объем требуемой области оперативной памяти составляет
16 Мбайт. Можно начинать считывание дорожки с любого сектора, так что время,
необходимое для загрузки данных всей дорожки, по существу состоит из одного периода
среднего времени поиска и времени полного оборота диска, или 6,46 + 8,33 = 14,79
миллисекунды. Поскольку для считывания данных всех 16 отсортированных
подсписков требуется обратиться к 3136 дорожкам 196 цилиндров, общее время загрузки
информации в оперативную память составит 46 секунд.
Показатели производительности можно улучшить еще больше, если использовать
для каждого из подсписков по два буфера объемом, равным емкости цилиндра.
Поскольку цилиндр в приводе "Megatron-747" содержит 16 дорожек, нам потребуются
32 буфера по 4 Мбайт каждый, т.е. 128 Мбайт. Прежде мы говорили, что размер
свободной области оперативной памяти нашего подопытного компьютера составляет,
однако, только 100 Мбайт, хотя 128 Мбайт — это и более реальное число с
практической точки зрения, и, разумеется, более выгодное.
При использовании буферов объемом с цилиндр потребуется только один период
времени поиска в расчете на один цилиндр. Общее время поиска и считывания
данных с 16 дорожек цилиндра, таким образом, составит 6,46 + 16 * 8,33 = 140
миллисекунд, а время загрузки данных со всех 196 цилиндров — 27 секунд. □
Рассмотренные приемы чтения данных применимы и для выполнения операций
записи. Действуя в духе "предварения" реальной потребности в информации, мы
можем задерживать "сброс" содержимого буферов оперативной памяти на диск до
момента их заполнения, если, конечно, необходимость в непосредственном повторном
использовании этих буферов отсутствует. Подобная стратегия позволит избежать
задержек с обслуживанием запросов к диску, предусматривающих запись блоков данных.
Еще более продуктивной окажется концепция создания крупномасштабных
выходных буферов объемом с дорожку или цилиндр диска. Если параметры системы
и характер приложения позволяют осуществлять запись данных такими крупными
порциями, это поможет по существу свести к нулю периоды времени поиска и оборота
и достичь теоретически максимальной скорости передачи данных на диск. Если,
например, предусмотреть, что во время выполнения второй фазы процесса сортировки
используются два выходных буфера объемом по 4 Мбайт, мы смогли бы "сбрасывать"
на цилиндр отсортированные данные из одного буфера параллельно с заполнением
второго. В этом случае время записи составило бы 27 секунд — как время чтения в
примере 11.16, — а вторую фазу целиком удалось бы завершить менее чем за 1 минуту
(как и улучшенный вариант первой фазы, рассмотренный в примере 11.11 на с. 519).
Продуманное сочетание и удачная реализация технологий группирования данных по
цилиндрам, предварительного считывания и крупномасштабной выходной буферизации
способны привести к тому, что на сортировку рассматриваемого массива данных нам
потребуется менее 2 минут (вспомните о 74 минутах, которые пришлось бы затратить на
решение той же задачи при использовании "стратегии" "как Бог на душу положит").
11.5.6. Приемы оптимизации дисковых операций: за и против
Мы познакомили вас с пятью подходами, позволяющими повысить
производительность дисковых систем:
1) группирование данных по цилиндрам диска;
2) использование нескольких дисковых устройств;
3) создание зеркальных копий дисков;
11.5. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ДИСКОВЫХ ОПЕРАЦИЙ
527
4) упорядочение дисковых операций посредством алгоритма лифта;
5) предварительное считывание и крупномасштабная буферизация данных,
и рассмотрели примеры их применения в двух до некоторой степени
противоположных ситуациях:
i) выполнение первой фазы алгоритма TPMMS, где блоки считываются и
записываются в заранее известной последовательности и в один и тот же
момент времени к диску способен обращаться только один процесс;
ii) активизация отдельных процессов, связанных, скажем, с бронированием
авиабилетов или выполнением банковских операций; процессы
протекают параллельно, используют одни и те же дисковые устройства и не
допускают возможности сколько-нибудь адекватного предсказания их
характеристик.
Ниже кратко описаны преимущества и недостатки каждого из подходов.
Группирование данных по цилиндрам диска
• Преимущество: проявляет прекрасные показатели для приложений типа (i), где
порядок обращений к диску известен заранее и в каждый момент времени
с диском работает только один процесс.
• Недостаток: не в состоянии оптимизировать время выполнения приложений
типа (ii), где режим использования диска непредсказуем.
Использование нескольких дисковых устройств
• Преимущество: увеличивает скорость обслуживания запросов на чтение/запись
дисковых данных в приложениях обоих типов.
• Проблема: запросы на чтение/запись данных, предполагающие обращение
к одному и тому же диску, не могут выполняться одновременно, поэтому
коэффициент повышения производительности может оказаться ниже, нежели
коэффициент увеличения количества дисков.
• Недостаток: стоимость нескольких дисковых устройств выше стоимости одного
устройства той же суммарной емкости.
Создание зеркальных копий дисков
• Преимущество: увеличивает скорость обслуживания запросов на чтение/запись
дисковых данных в приложениях обоих типов; не вызывает проблемы
снижения производительности, характерной для технологии использования
нескольких "обычных" (не "зеркальных") дисков.
• Преимущество: обеспечивает повышение степени надежности хранения данных.
• Недостаток: при повышенной стоимости нескольких дисковых устройств
фактически используется объем только одного из них.
Упорядочение дисковых операций посредством алгоритма лифта
• Преимущество: сокращает среднее время считывания/записи блоков
в ситуациях, когда порядок запросов к диску непредсказуем.
• Проблема: алгоритм проявляет наибольшую эффективность в тех случаях, когда
существует множество необработанных запросов; при этом, однако, возрастает
среднее время ожидания обслуживания каждого запроса.
528
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Предварительное считывание и крупномасштабная буферизация данных
• Преимущество: снижает общее время выполнения дисковых операций, если порядок
считывания/записи данных известен заранее, хотя характеристики процесса
зависят от свойств данных (как при выполнении второй фазы алгоритма TPMMS).
• Недостаток: требует наращивания объема оперативной памяти для создания
дополнительных буферов; не доставляет ощутимой выгоды, если поток запросов
к диску случаен.
11.5.7. Упражнения к разделу 11.5
Упражнение 11.5.1. Предположим, что необходимо упорядочить процесс обработки
запросов (перечисленных на рис. 11.15) к дисковому приводу модели "Megatron-
747" при условии, что в начальный момент времени блок головок расположен
напротив цилиндра с номером 8000. Постройте расписания обслуживания запросов:
a) в соответствии с алгоритмом лифта (в качестве начального направления
перемещения блока головок можно выбрать любое);
b) согласно стратегии "первым пришел — первым обслужен" (FIFO).
Номер цилиндра
2000
12000
1000
10000
Момент поступления
0
1
10
20
Рис. 11.15. Данные к упражнению 11.5.1
*! Упражнение 11.5.2. Пусть два дисковых привода "Megatron-747" используются для
хранения зеркальных копий данных. Предположим, что вместо того, чтобы блоки
данных могли считываться с любого диска, головкам первого диска разрешено
перемещаться только по внутренней половине цилиндров, а головкам второго
диска — по внешней. Имея в виду, что запросы на чтение адресованы к случайным
блокам, а операции записи не выполняются вовсе, ответьте на следующие вопросы.
a) Каково среднее время обработки одного запроса?
b) Насколько отличается среднее время чтения блока в том случае, если
указанное ограничение, касающееся возможности перемещения блоков головок
зеркальных дисков, снято?
c) Какие недостатки, обусловленные введением ограничения, вы можете назвать?
! Упражнение 11.5.3. Попробуем исследовать взаимосвязи между значениями
времени поступления запросов, производительностью алгоритма лифта и средним
временем задержки обслуживания запросов. Чтобы упростить задачу, введем
следующие предположения.
1. Головки всегда перемещаются от самого внутреннего цилиндра к внешнему
или наоборот — даже в тех случаях, когда запросы к "крайним" цилиндрам
отсутствуют.
2. После начала движения головок в определенном направлении удовлетворяются
только те запросы, которые успели поступить до момента старта, а
обслуживание запросов, "прибывающих" в период до момента смены направления дви-
11.5. ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ДИСКОВЫХ ОПЕРАЦИЙ
529
жения, откладывается — даже тогда, когда головки проходят над цилиндрами,
к которым адресуются "запоздавшие" запросы.80
3. Во время любого из периодов перемещения головок в одном направлении
исключается возможность поступления двух запросов, адресующих один и тот же цилиндр.
Пусть А — величина среднего промежутка времени между поступлением запросов
на обработку дисковых блоков. Предположим, что система, оснащенная дисковым
приводом "Megatron-747", пребывает в стабильном состоянии, т.е. принимает и
обслуживает запросы в течение длительного периода. Выразите в виде функции от Л:
* а) среднее время прохода головок в одном направлении;
b) количество запросов, обслуживаемых в процессе выполнения одного прохода;
c) среднее время ожидания обслуживания одного запроса.
*!! Упражнение 11.5.4. В примере 11.12 на с. 521 было показано, как распределение
данных, подлежащих сортировке, по четырем дискам дает возможность считывагь
более одного блока в каждый момент времени. Полагая, что в процессе
выполнения фазы слияния генерируются запросы на считывание блоков, размещенных по
дискам случайным образом, и все эти запросы удовлетворяются без задержек, если
только они не обращены к диску, который в тот же момент занимается
обслуживанием другого запроса, ответьте, каково среднее количество дисков,
обрабатывающих запросы в каждый момент времени. Примите к сведению следующие
дополнительные соображения, позволяющие упростить задачу.
1. Если запрос на чтение блока не может быть обработан, процесс слияния
должен быть приостановлен, поскольку данные, требуемые для пополнения
исчерпанного подсписка, не получены.
2. Как только процесс слияния может быть продолжен, он генерирует запрос на
чтение, так как время обработки данных в оперативной памяти пренебрежимо
мало в сравнении с периодом, требуемым для обслуживания запроса к диску.
! Упражнение 11.5.5. Если необходимо обработать запросы на чтение к блоков,
случайно распределенных в пределах некоторого цилиндра, каково среднее время
оборота, достаточное для считывания этих блоков?
11.6. Отказы дисковых устройств
В этом и следующем разделах мы обсудим ситуации, связанные с отказами дисковых
приводов, и способы преодоления возможных последствий. Ниже перечислены
различные категории отказов, классифицированные в порядке возрастания степени их тяжести.
1. Перемежающийся отказ (intermittent failure) — возникает периодически и
выражается в том, что одна попытка чтения/записи сектора оказывается
безуспешной, но при ее повторении операцию удается выполнить.
2. Отказ записи (write failure) — часто возникает из-за сбоев электропитания
в ъмомент выполнения операции записи сектора и проявляется в
невозможности записи информации и считывания прежнего содержимого сектора.
3. Разрушение носителя (media decay) — часть сектора приходит в негодность, так
что операция считывания данных из сектора не может быть выполнена ни при
каких обстоятельствах и независимо от количества попыток.
80 Введение подобного ограничения позволяет избежать возможных различий между первым
и всеми остальными проходами головок в соответствии с алгоритмом лифта. Анализ изменения
параметров плотности распределения запросов, поступающих в период одного прохода головок,
представляет собой отдельную любопытную задачу.
530
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
4. Полный отказ диска (disk crash) — внезапная поломка, при которой дальнейшая
эксплуатация устройства не представляется возможной.
Ниже мы остановимся на простой модели отказов дисков, рассмотрим технологии
контроля четности (parity check), позволяющие выявлять ситуации перемежающихся
отказов, и разберем политику организации устойчивых хранилищ (stable storage),
предотвращающую возможность потери данных при возникновении отказов записи и разрушении
носителя. Раздел 11.7 на с. 534 посвящен технологиям, которые в совокупности
обозначаются аббревиатурой RAID и позволяют преодолеть последствия полного отказа диска.
11.6.1. Перемежающиеся отказы
Секторы диска обычно содержат дополнительные избыточные биты. Их значения
позволяют определить, корректна информация, считанная из сектора или записанная
в сектор, либо нет.
Одна из удобных моделей операции считывания дисковых данных предполагает,
что функция чтения возвращает пару (w, s) значений, где w — собственно данные,
которые были запрошены, as— бит индикации состояния (status bit),
свидетельствующий о том, успешен ли результат операции, т.е. можно ли полагать, что w верно
представляет содержимое сектора. В случае возникновения перемежающихся отказов
функция чтения способна возвращать "ложный" бит индикации состояния несколько
раз, но если повторять операцию достаточно долго (обычный предел — 100 раз), со
временем, возможно, функция вернет "истинный" бит, удостоверяющий, что
считанная информация корректна. Как будет показано в разделе 11.6.2, нельзя исключать
ситуацию, когда бит индикации содержит значение "истина", но считанные данные
на самом деле не верны. Приняв соответствующие меры, связанные с использованием
в пределах сектора дополнительных избыточных битов, можно снизить вероятность
появления такого события настолько, насколько это необходимо.
Бит индикации состояния полезен и при выполнении операций записи. Как
упоминалось в разделе 11.3.5, для проверки корректности результата записи информации
в секторы можно осуществить повторное чтение и сопоставить считанный блок с тем,
который был записан. Однако вместо осуществления всеобъемлющей проверки
контроллер дисков вправе, выполнив чтение, проверить содержимое бита индикации
состояния: если значением бита является "истина", можно полагать, что операция
записи была завершена успешно; в противном случае вероятен неверный результат, так
что запись надлежит повторить. Следует отметить, что, как и при выполнении чтения,
"истинное" значение бита индикации состояния еще не служит полной гарантией
правильности результата записи, и для снижения вероятности возникновения
подобных явлений должны приниматься адекватные меры, о которых рассказано ниже.
11.6.2. Контрольные суммы
На первый взгляд, задача проверки "качества" данных в секторе при выполнении их
чтения выглядит неразрешимой. Однако дела обстоят гораздо проще: в современных
дисковых устройствах каждому сектору носителя отвечают несколько дополнительных
битов, называемых контрольной суммой (checksum); их значения устанавливаются в
зависимости от содержимого битов данных, сохраняемых в секторе. Если функция чтения
обнаруживает несоответствие данных контрольной сумме, она возвращает состояние
"ложь", а в противном случае — "истина". Однако существует небольшая вероятность
появления такого события, когда биты данных считаны неверно, но их контрольная
сумма совпадает с той, которая соответствует корректным битам (и поэтому
неправильный результат воспринимается как "истинный"). Эту вероятность удается снизить до
любого приемлемого значения путем увеличения количества битов контрольной суммы.
11.6. ОТКАЗЫ ДИСКОВЫХ УСТРОЙСТВ
531
Контрольная сумма в своей простой форме основывается на свойстве четности
(parity) всех битов сектора. Если в наборе битов данных присутствует нечетное (odd)
количество единиц, бит четности принимает значение 1. Если же количество единиц
четно (even), биту четности присваивается значение 0. Имеет место следующее правило:
• количество единиц в наборе битов данных, включая бит четности, всегда четно.
Выполняя запись данных в сектор, контроллер дисков способен вычислить
значение бита четности и присовокупить его к последовательности битов, подлежащих
записи. Таким образом, каждый сектор будет содержать четное количество битов.
Пример 11.17. Предположим, что в секторе следует сохранить последовательность
битов данных 01101000; количество единиц в последовательности нечетно, поэтому биту
четности надлежит присвоить значение 1. Присоединив полученный бит четности
к исходной последовательности, получим 011010001. Если бы изначально
последовательность имела вид 11101110, бит четности оказался бы нулевым: 111011100.
Обратите внимание, что каждая из итоговых последовательностей, полученных добавлением
соответствующего бита четности, содержит четное количество единиц. □
Любая ошибка, связанная с искажением значения одного из битов
последовательности данных с битом четности, приводит к получению набора битов с нечетным
количеством единиц. В такой ситуации контроллеру дисков не составляет труда
вычислить количество единиц в полной порции считанных данных и определить, четно ли
это количество, т.е. верен ли результат.
Разумеется, может быть повреждено и несколько битов сектора единовременно.
В этой ситуации с вероятностью 50% количество единиц в секторе окажется четным
и ошибка не будет выявлена. Чтобы гарантировать возможность обнаружения
ошибок, затрагивающих сразу несколько битов, набор битов четности следует расширить.
Например, можно предусмотреть восемь битов четности, по одному на
соответствующий бит каждого байта данных в секторе. В таком случае вероятность того, что ни
один из битов четности не окажется способным подтвердить наличие ошибки,
оценивается уже существенно меньшей величиной, равной 1/256. Вообще говоря, если
использовать п независимых битов четности, вероятность возникновения незамеченной
ошибки составляет 1/2п. Например, если отвести под контрольную сумму четыре
байта, ошибка останется необнаруженной только в одном из 4 миллиардов случаев.
11.6.3. "Устойчивые хранилища"
Хотя механизм контрольных сумм практически всегда позволяет обнаруживать
сбойные участки носителя и ошибки операций чтения/записи, он не в состоянии обеспечить
возможность исправления ошибок. Вполне правдоподобна ситуация, когда после
выполнения попытки записи выясняется, что прежнее содержимое сектора уже утеряно,
а новое считать повторно не удается. Представьте, в какую проблему все это может
обратиться, если речь идет, например, об изменении остатка на банковском счете, когда
оказываются утраченными оба значения остатка, старое и новое. Если бы можно было
с уверенностью утверждать, что сектор содержит старое (или новое) значение, это
позволило бы сделать вывод о некорректности (или правильности) результата записи.
Для преодоления указанной проблемы на основе одного или нескольких дисков
можно организовать так называемое устойчивое хранилище (stable storage). Общая идея
состоит в том, что секторы диска (дисков) объединяются в пары, и каждая пара
представляет содержимое X одного сектора. Мы будем ссылаться на секторы пары как на
"левый" (XL) и "правый" (XR) и полагать, что оба сектора содержат достаточное
количество битов четности, способных гарантировать практическую невозможность
возникновения ситуаций, когда испорченное содержимое сектора выглядит как правильное.
Поэтому будем подразумевать, что если для сектора XL или XR функция чтения возвращает
532
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
значение w и "истинный" бит индикации состояния, значит, w верно отображает X.
Алгоритм записи данных в устойчивое хранилище можно представить следующим образом.
1. Сохранить значение X в XL. Проверить, действительно ли бит индикации
состояния содержит значение "истина", т.е. биты четности сохраненной копии
данных верны. Если нет, повторить операцию. Если после нескольких попыток
сохранить X в XL по-прежнему не удается, принять, что сектор поврежден, и
заменить сектор XL другим.
2. Повторить действия п. 1 для сектора XR.
Процедура считывания данных из устойчивого хранилища такова.
1. Считать значение X из XL. Если функция возвращает "ложное" значение бита
индикации состояния, несколько раз повторить операцию. Если на некоторой
итерации возвращается "истинное" значение бита индикации состояния,
принять, что считанные данные являются значением X.
2. Если попытки чтения из XL оказались безуспешными, повторить действия п. 1
применительно к сектору XR.
11.6.4. Устранение последствий ошибок
Стратегии увеличения степени надежности хранения данных, рассмотренные
в разделе 11.6.3, способны обеспечить возможность устранения последствий ошибок,
относящихся к нескольким перечисленным ниже категориям.
1. Разрушение носителя (media decay). Если после сохранения данных X в секторах
XL и XR один из них приходит в негодность из-за разрушения носителя и
становится нечитаемым, восстановить значение X удастся всегда, обратившись
к другому — уцелевшему — сектору. Если сектор XR испорчен, a XL — нет, в
соответствии с алгоритмом чтения данные следует извлечь из XL, даже не
обращаясь к XR; факт выхода XR из строя будет обнаружен при очередной попытке
записи нового значения X. Если же, напротив, разрушен только сектор XL, нам не
удастся получить значение "истина" бита индикации состояния при любом
количестве попыток чтения X из XL (мы подразумеваем, напомним, что функция,
обращающаяся к разрушенному сектору, всегда возвращает "ложь", хотя в
действительности мизерная вероятность получения значения "истина" из-за
совпадения содержимого битов контрольной суммы с ожидаемым значением все-
таки существует). Поэтому, переходя к п. 2 алгоритма, следует считать X из
сектора XR. Если, наконец, одновременно разрушены оба сектора, значение X будет
утрачено, но вероятность возникновения подобного события ничтожно мала.
2. Отказ записи (write failure). Предположим, что в момент записи значения X
произошел кратковременный сбой системы (например, в результате потери
электропитания). Вероятна ситуация, когда значение X в оперативной памяти
отсутствует, а его копия повреждена в момент сохранения на диске: например,
в половине сектора содержится часть нового значения X, а в другой половине —
прежнее содержимое. После запуска системы нам удастся восстановить либо
старое, либо новое значения X. Возможные ситуации таковы:
а) сбой произошел в процессе записи XL, поэтому значением бита индикации
состояния для XL окажется "ложь"; поскольку до момента сбоя новые данные X в
сектор XR еще не записывались, состояние этого сектора "истинно" (разумеется,
если XR вдруг не оказался разрушенным, но вероятность подобного совпадения
чрезвычайно мала), поэтому из XR можно извлечь старое значение X; для
восстановления состояния сектора XL в него следует скопировать данные из XR;
11.6. ОТКАЗЫ ДИСКОВЫХ УСТРОЙСТВ
533
b) сбой системы случился после завершения операции записи XL; можно
полагать, что состояние XL "истинно", поэтому XL содержит новое значение X,
которое при необходимости может быть успешно считано; независимо от
состояния сектора XR в него следует скопировать содержимое XL.
11.6.5. Упражнения к разделу 11.6
Упражнение 11.6.1. Вычислите значения бита четности для следующих битовых
последовательностей:
*а) 00111011;
b) 00000000;
c) 10101101.
Упражнение 11.6.2. Для каждой из битовых последовательностей, указанных
в упражнении 11.6.1, определите значения двух битов четности, первый из
которых соответствует битам на нечетных позициях последовательности, а второй —
битам на четных позициях.
11.7. Восстановление данных при полном отказе диска
В этом разделе мы рассмотрим наиболее серьезную разновидность отказов, когда
дисковое устройство приходит в негодность, скажем, из-за соприкосновения головки
с поверхностью пластины. Если информация не была предварительно скопирована на
другой носитель — например, на резервную магнитную ленту или зеркальный диск
(см. раздел 11.5.3 на с. 522), — она безвозвратно утрачивается. Для многих приложений
СУБД, таких как банковские и иные финансовые системы, системы управления
полетами, бронирования билетов, ведения складского учета и т.п., это означает полный крах.
К настоящему моменту разработано немало стратегий, призванных снизить
опасность потери данных из-за поломок дисковых приводов. Все они. как правило,
предусматривают использование той или иной модели избыточности, расширение
концепции контроля четности (см. раздел 11.6.2 на с. 531) либо применение технологий
дублирования секторов (см. раздел 11.6.3 на с. 532) и обозначаются общим термином
RAID (от Redundant Array of Independent Disks — "резервированный массив
независимых дисков").81 Ниже мы сосредоточим внимание преимущественно на трех схемах
дисковых массивов — RAID уровней 4, 5 и 6. Эти схемы, помимо своего основного
предназначения (восстановление данных в случае полного отказа диска), позволяют
устранять последствия ошибочных ситуаций, рассмотренных в разделе 11.6 на с. 530
и связанных с разрушением носителя и порчей данных в отдельных секторах из-за
кратковременных сбоев системы.
11.7.1. Модель отказов дисковых устройств
Прежде чем приступить к обсуждению ситуаций полного отказа дисковых
приводов, полезно рассмотреть статистику подобных отказов. Простейшая единица
измерения частоты возникновения этих явлений известна как среднее время наработки на
отказ (mean time to failure) и представляет собой промежуток времени, в продолжение
которого 50% экземпляров дисковых устройств определенной модели полностью
выходят из строя. Для современных моделей приводов магнитных дисков среднее время
наработки на отказ составляет около 10 лет.
Чтобы упростить восприятие этого параметра, можно полагать, что одна десятая
всех дисковых устройств приходит в негодность в течение одного года, и в этом случае
81 Прежде аббревиатура RAID переводилась как "Redundant Array of Inexpensive Disks"
("избыточный массив недорогих дисков"), и это толкование иногда встречается в литературе и поныне.
534
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
процент живучести (survival) представим в виде экспоненциально убывающей функции.
На практике, однако, кривая живучести больше похожа на ту, которая изображена на
рис. 11.16. Как и для большинства разновидностей электронного оборудования, большая
часть отказов дисковых устройств происходит в самом начале периода их эксплуатации
из-за незначительных технологических дефектов. Обнадеживает тот факт, что
большинство изделий с теми или иными нарушениями отбраковывается еще на стадии
технического контроля и тестирования, но отдельные изъяны, к несчастью, остаются
незамеченными и могут не проявлять себя в течение месяцев. Диск, который не вышел из
строя в начале эксплуатации, с большой долей вероятности успешно послужит многие
годы. Но ближе к концу жизненного цикла устройства начинает сказываться негативное
влияние таких факторов, как старение материалов, износ трущихся частей и
накапливание мельчайших частиц пыли, что увеличивает вероятность поломки.
Процент
живучести
Время —►
Рис. 11.16. Кривая живучести дисковых
устройств
Среднее время наработки на отказ — это, однако, не то же самое, что среднее
время возникновения события потери данных, поскольку применение схем RAID
позволяет сохранять информацию в целости даже при выходе дисков из строя. Ниже мы
подробно рассмотрим особенности наиболее распространенных схем, но сейчас
уместно вкратце остановиться на том, что их объединяет. Каждая из схем предполагает
использование одного или нескольких дисков данных (data disks) в совокупности с
одним или несколькими резервными дисками (redundant disks), предназначенными для
хранения служебной информации, состав которой полностью определяется
содержимым дисков данных. При поломке диска данных или резервного служебного диска
для восстановления информации используется содержимое остальных дисков массива,
так что невосполнимой потери данных удается избежать.
11.7.2. Зеркальные диски как средство резервирования
Простейший подход к решению задачи повышения степени надежности хранения
информации состоит в использовании резервных дисков, содержащих зеркальные (mirror)
копии содержимого дисков данных; в этом случае диски данных и резервные диски
полностью взаимозаменяемы. Технология использования зеркальных дисков как средства
предотвращения потери данных, которую часто называют схемой RAID уровня 1 (RAID
level 1), обеспечивает значительно более высокое значение среднего времени
возникновения события потери данных в сравнении со средним временем наработки на отказ, и
следующий пример служит тому иллюстрацией. Важно подчеркнуть, что единственная
ситуация, способная привести к утрате данных при использовании зеркальных дисков и
некоторых других вариантов схем RAID, связана с возможной поломкой второго диска массива
в тот период, когда происходит восстановление данных первого отказавшего диска.
Пример 11.18. Предположим, что каждый из дисков характеризуется 10-летним
средним периодом времени наработки на отказ, а это значит, что вероятность его поломки
11.7. ВОССТАНОВЛЕНИЕ ДАННЫХ ПРИ ПОЛНОМ ОТКАЗЕ ДИСКА
535
в любом году составляет 10%. Если диски зеркальны, при выходе из строя одного из
них достаточно осуществить замену диска и скопировать данные с работоспособного
диска — система окажется восстановленной в своем прежнем состоянии.
Единственная неприятность, которая может произойти (хотя вероятность ее, как будет
показано ниже, чрезвычайно мала), связана с поломкой диска с полноценными данными в
момент их копирования на новый диск. В этом случае информация окажется утраченной
полностью или частично без какой бы то ни было возможности ее восстановления.
Насколько вероятно появление именно такой цепочки событий? Положим, что
процесс замены отказавшего диска длится 3 часа, т.е. восьмую часть суток, или
1/2920 года. Поскольку, как мы считаем, полный отказ диска происходит в среднем
раз в 10 лет, вероятность того, что зеркальный диск выйдет из строя в момент
копирования данных, которые на нем хранятся, оценивается величиной
(1/10) * (1/2920)= 1/29200. Если среднее время наработки на отказ одного диска
составляет 10 лет, один из двух дисков может прийти в негодность в среднем раз в 5 лет,
причем только один из 29200 подобных отказов способен повлечь потерю данных.
Таким образом, среднее время наработки на отказ, приводящий к утрате данных в
системе с двумя зеркальными дисками, составляет 5 * 29200 = 146000 лет. □
11.7.3. Блоки четности
Хотя технология использования зеркальных дисков служит эффективным
средством снижения вероятности утраты данных в связи с полным отказом одного из
устройств, ее недостатком является то, что для дублирования каждого диска данных
требуется отдельный резервный диск. Другой подход, называемый схемой RAID уровня 4
(RAID level 4), предусматривает использование только одного резервного служебного
диска независимо от количества дисков данных. Будем полагать, что все диски
идентичны, так что их блоки можно условно пронумеровать от 1 до некоторого числа п.
Разумеется, все блоки всех дисков содержат одинаковое количество битов; так,
например, блоки размером в 16384 байт, используемые для обращения к знакомому вам
дисковому приводу "Megatron-747", содержат по 8 * 16384= 131072 бит. Блок с
номером i резервного диска состоит из битов четности для i-x блоков всех дисков данных.
Точнее говоря, последовательность j-x битов i-x блоков всех дисков, включая
резервный, должна содержать четное количество единиц, и это правило может быть
удовлетворено выбором подходящего (0 или 1) значения у-го бита /-го блока резервного
диска (см. пример 11.17 на с. 532): если в наборе j-x битов i-x блоков дисков данных
содержится нечетное количество единиц, у-му биту /-го блока резервного диска
присваивается значение 1, а в противном случае — значение 0. В основе этого
правила лежит операция вычисления суммы по модулю 2 (modulo-2 sum). Сумма по
модулю 2 значений битов равна 0, если среди этих значений имеется четное количество
единиц, и равна 1, если число единиц нечетно.
Пример 11.19. Рассмотрим чрезвычайно упрощенный случай, когда каждый блок
содержит всего по одному байту (8 бит). Предположим, что массив состоит из трех
дисков данных (будем называть их как "диск 1", "диск 2" и "диск 3") и одного
резервного диска ("диск 4"). Сосредоточим внимание, скажем, на первых блоках всех
дисков. Если в них сохраняются битовые последовательности
диск 1: 11110000
диск 2: 10101010
дискЗ: 00111000
тогда первый блок резервного диска должен содержать соответствующие биты четности:
диск 4: 01100010
536
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Обратите внимание, что все восемь 4-битовых последовательностей, соответствующих
каждой позиции блоков трех дисков данных и резервного диска, содержат по четному
количеству единиц: две единицы на позициях 1, 2, 4, 5 и 7, четыре — на позиции 3
и ни одной единицы — на позициях 6 и 8. □
Считывание
Операция считывания блоков с дисков данных массива RAID уровня 4 ничем не
отличается от аналогичных процедур, применяемых по отношению к обычным
дискам. Считывать содержимое резервного служебного диска, как правило,
нецелесообразно, хотя формально не запрещено. В определенных обстоятельствах некоторый
выигрыш может быть получен от единовременного выполнения двух запросов на
чтение, адресованных к одному и тому же диску данных, хотя сочетание условий, при
которых это оказывается выгодным, возникает относительно редко.
Пример 11.20. Предположим, что во время считывания некоторого блока с первого
диска данных поступает запрос на чтение другого блока (скажем, блока номер 1)
с того же диска данных. Если действовать в традиционной манере, прежде чем
приступить к обработке второго запроса, мы должны были бы дождаться завершения
обслуживания первого. Однако если ни один из остальных дисков массива в этот
момент не занят, вполне правомочно осуществить чтение блоков 1 с каждого диска,
кроме первого диска данных, а затем вычислить содержимое искомого блока 1
первого диска данных с помощью операции суммирования по модулю 2. Если, в
частности, диски массива и их первые блоки отвечают условиям примера 11.19, можно
осуществить чтение блоков второго и третьего дисков данных и резервного диска:
диск 2: 10101010
дискЗ: 00111000
диск 4: 01100010
а затем, применив операции сложения по модулю 2 к битам каждой позиции,
получить ту же последовательность битов, которая хранится в блоке первого диска:
диск 1: 11110000
□
Запись
При выполнении операции записи нового блока на диск данных следует изменить
не только этот блок, но и соответствующий блок резервного диска, чтобы тот по-
прежнему содержал верные биты четности, отвечающие битам одноименных блоков
всех дисков данных. Тривиальный и прямолинейный подход предполагает считывание
соответствующих блоков п дисков данных, вычисление сумм по модулю 2 битовых
последовательностей для каждого разряда блоков и сохранение полученного результата
в виде блока резервного диска. В этом случае придется выполнить операции записи
исходного блока, чтения п - 1 блоков с остальных дисков данных и записи блока на
резервный диск, т.е. в целом п + 1 операций ввода-вывода.
Более эффективный способ предусматривает манипуляции только со старым и
новым содержимым записываемого /-го блока диска данных и блока резервного диска.
Если вычислить сумму по модулю 2 старого и нового значений записываемого блока,
мы сможем определить, в каких последовательностях битов для каждой позиции /-х
блоков дисков данных изменилось количество единиц. Поскольку количества могут
изменяться только на 1, четное количество единиц становится нечетным. Если
изменить содержимое соответствующих битов /-го блока резервного диска, тогда
количество единиц во всех последовательностях вновь станет четным. Для выполнения этих
действий достаточно выполнить четыре дисковые операции:
11.7. ВОССТАНОВЛЕНИЕ ДАННЫХ ПРИ ПОЛНОМ ОТКАЗЕ ДИСКА
537
Алгебра сложения по модулю 2
Для понимания механизмов контроля четности полезно знать об алгебраических
законах, справедливых в отношении операций сложения по модулю 2,
применяемых к битовым векторам. Оператор сложения по модулю 2 принято обозначать
символом ©: в качестве примера можно указать соотношение 1100© 1010 = 0110.
Ниже перечислены некоторые из наиболее употребительных правил алгебры
сложения по модулю 2:
• коммутативный закон: х © у - у © х',
• ассоциативный закон: х © (у © z) = (х © у) © z;
• сложение любого вектора с нулевым, 0, вектором (вектором, содержащим только
нулевые биты): x©0 = 0©jc = jc;
• собственная инверсия: х © х = 0; одно из следствий: если х © у = z, тогда из
x®x®y = x®z вытекает у = х © z.
1) считать старое содержимое блока данных, подлежащего записи;
2) считать значение соответствующего блока резервного диска;
3) записать новый блок данных;
4) произвести вычисления и сохранить измененный блок резервного диска.
Пример 11.21. Пусть первые блоки трех дисков выглядят так же, как в примере
11.19 нас. 536:
диск 1: 11110000
диск 2: 10101010
дискЗ: 00111000
Предположим, что значение блока диска 2 подлежит изменению с 10101010 на 11001100.
Сложение по модулю 2 старого и нового значений блока дает в результате
последовательность битов 01100110, которая свидетельствует, что в первом блоке резервного диска
надлежит изменить значения битов на позициях 2, 3, 6 и 7. Блок резервного диска
следует считать: 01100010, — а затем заменить новым блоком, содержащим изменения
в указанных позициях; для получения нового значения блока фактически достаточно
суммировать по модулю 2 прежнее содержимое блока, 01100010, с результатом сложения
по модулю 2 старого и нового значений блока данных, 01100110, что даст в итоге
00000100. В нашем примере после записи блока на второй диск данных и модификации
блока резервного диска блоки всех дисков приобретут следующий вид:
диск 1: 11110000
диск 2: 11001100
дискЗ: 00111000
диск 4: 00000100
Обратите внимание, что все последовательности битов для каждой позиции блоков
по-прежнему содержат по четному количеству единиц.
Стоит заметить, что при выполнении рассмотренной процедуры записи блока (как
и в любых других ситуациях, связанных с записью блоков на диски массива RAID
уровня 4) необходимо осуществить четыре операции дискового ввода-вывода.
Упомянутый выше прямолинейный подход, предполагающий считывание блоков всех
дисков данных, кроме диска, подлежащего модификации, в данном случае также требует
выполнения четырех операций ввода-вывода — двух для считывания блоков с первого
и третьего дисков данных и двух для записи блоков на второй диск данных и резерв-
538
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
ный диск. Если, однако, количество дисков данных возрастает, количество операций
ввода-вывода, выполняемых в этом случае, также линейно увеличивается, но для
рассмотренного "эффективного" способа записи оно остается неизменным. □
Восстановление данных после отказа диска
Теперь рассмотрим, что может быть сделано для восстановления данных после
полного отказа одного из дисков массива RAID уровня 4. Если вышел из строя резервный
диск, достаточно установить новое устройство, последовательно считать одноименные
блоки всех дисков, вычислить контрольные суммы для битовых последовательностей
каждой позиции и сохранить полученные результаты в виде блоков резервного диска.
Если потерпел аварию один из дисков данных, достаточно заменить его новым
приводом и вычислить данные на основании информации всех остальных дисков. Правило
вычисления потерянных данных достаточно просто и действует независимо от того,
какой из дисков — резервный или диск данных — пришел в негодность. Поскольку
известно, что количество единичных битов в каждой последовательности, отвечающей
определенной позиции блоков дисков, должно быть четным, правило формулируется так:
• значение бита блока одного диска равно сумме по модулю 2 битов,
расположенных на той же позиции блоков всех остальных дисков.
Если сумма по модулю 2 значений соответствующих битов равна 1, т.е. количество
единиц нечетно, восстанавливаемому биту следует присвоить значение 1; если же
количество единиц четно, значит, искомое значение бита должно быть равно 0.
Пример 11.22. Обратимся к тому же массиву дисков, что и в примере 11.19 на с. 536,
и предположим, будто вышел из строя диск 2. Рассмотрим, как выглядят первые
блоки всех четырех дисков:
диск 1: 11110000
диск 2: ????????
дискЗ: 00111000
диск 4: 01100010
Вычислив суммы по модулю 2 последовательностей битов для каждой позиции блоков
первого, третьего и четвертого дисков, получим недостающий блок второго диска
в его первозданном виде: 10101010. □
11.7.4. Массивы RAID уровня 5
Схема RAID уровня 4, которой мы уделили внимание в разделе 11.7.3, эффективно
справляется с задачей обеспечения сохранности данных до момента единовременного
выхода из строя нескольких дисков массива. Узкое место модели RAID уровня 4,
однако, легко обнаружить, если внимательнее изучить процесс записи нового блока
данных. Какой бы алгоритм обновления блока любого из дисков данных мы ни выбрали,
нам, помимо того, всегда придется считывать и сохранять блок резервного диска. Если
количество дисков данных равно п, число операций записи на резервный диск будет в п
раз превышать среднее количество операций записи на любой из дисков данных.
Однако, как было показано в примере 11.22, правило восстановления данных
одинаково как для дисков данных, так и для резервного диска, и сводится к вычислению
сумм по модулю 2 битовых последовательностей для соответствующих позиций
блоков дисков. Напрашивается вывод о том, что трактовать один диск как служебный,
а остальные — как "обычные" вовсе не обязательно: каждый из дисков способен
выполнять роль резервного применительно к определенным наборам блоков. Именно
эта идея и положена в основу схемы дискового массива RAID уровня 5 (RAID level 5).
Например, если существует набор из п + 1 дисков, пронумерованных от 0 до п,
можно интерпретировать i-й цилиндр у-го диска как резервный в том случае, когда j
есть остаток от деления / на п + 1.
11.7. ВОССТАНОВЛЕНИЕ ДАННЫХ ПРИ ПОЛНОМ ОТКАЗЕ ДИСКА
539
Пример 11.23. Обратимся к массиву из 4 дисков, впервые рассмотренному в примере
11.19 на с. 536, и положим я = 3. Диск с номером 0 способен выполнять функцию
резервного для цилиндров с номерами 4, 8, 12 и т.д., поскольку остаток от деления этих
номеров на значение общего количества дисков (4) равен нулю. Аналогично, диск 1
может служить резервом для цилиндров 1, 5, 9 и т.д., диск 2 — для цилиндров 2, 6, 10
и т.д., а диск 3 — для цилиндров 3, 7, 11 и т.д. В результате коэффициент загрузки
всех дисков окажется одинаковым. Если операции записи всех блоков выполняются
с равной частотой, вероятность того, что операция обращена к определенному диску,
составляет 1/4. Если же операция адресована другому диску, тот с вероятностью 1/3
окажется резервным для сохраняемого блока. Таким образом, каждый из четырех
дисков будет вовлечен в любую из операций записи с вероятностью 1А + % * Yz - ¥2. □
11.7.5. Восстановление данных после отказа нескольких дисков
Технологии восстановления информации после отказа нескольких дисков
(резервных или дисков данных) массива, реализованные в схеме RAID наивысшего
уровня —RAID уровня 6 (RAID level 6), — основаны на теории кодов с исправлением
ошибок (error-correcting codes) и позволяют справиться с последствиями аварий любой
степени тяжести — лишь бы количество резервных дисков оказалось достаточным.
Здесь мы рассмотрим только краткий пример, связанный с единовременным отказом
двух дисков и использованием стратегии восстановления данных на основе
простейшего кода с исправлением ошибок, известного как код Хемминга (Hamming code).
Обратимся к массиву, состоящему из семи дисков, пронумерованных от 1 до 7.
Первые четыре из них являются дисками данных, а дискам 5~7 отводится функция
резервных. Взаимосвязи между дисками данных и резервными дисками массива
описываются бинарной матрицей размерами 3x7, представленной на рис. 11.17.
Обратите внимание на следующее:
a) матрица содержит все возможные 3-битовые последовательности единиц
и нулей, кроме набора из трех нулей;
b) столбцы, соответствующие резервным дискам, включают по одной единице;
c) столбцы, отвечающие дискам данных, содержат по две единицы.
Номер диска
1
1
1
1
диски
данных
2
1
1
0
3
1
0
1
4
0
1
1
резервные
диски
5 6 7
1 0 0
0 1 0
0 0 1
Рис. 11.17. Матрица резервирования
для системы, допускающей
восстановление после единовременного отказа
двух дисков
Смысл каждой из трех строк матрицы таков. Если взглянуть на биты,
соответствующие каждому из семи дисков массива, и ограничить внимание теми дисками,
которые в рассматриваемой строке помечены единицами, сумма по модулю 2 значений
битов для этих дисков должна быть равна нулю. Иными словами, диски, которым
отвечают единицы в каждой из строк матрицы, трактуются так, будто они объединены
в массив RAID уровня 4. Поэтому для вычисления битов одного из резервных дисков
540
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
достаточно найти строку матрицы, в которой этот диск обозначен единицей, и
осуществить сложение по модулю 2 значений соответствующих битов других дисков,
помеченных единицами в той же строке.
Если обратиться к матрице рис. 11.17, указанное правило означает следующее:
1) биты диска 5 — это суммы по модулю 2 соответствующих битов дисков 1, 2 и 3;
2) биты диска 6 — суммы по модулю 2 соответствующих битов дисков 1, 2 и 4;
3) биты диска 7 — суммы по модулю 2 соответствующих битов дисков 1, 3 и 4.
Ниже мы покажем, как конкретный набор битов матрицы указывает простой способ
восстановления информации после единовременного отказа любых двух дисков системы.
Считывание
Данные с любого из дисков массива могут считываться обычным образом.
Считывать информацию с резервных дисков с целью использования в прикладных задачах
нецелесообразно, хотя формально это не возбраняется.
Запись
Способы записи аналогичны тем, которые упоминались в разделе 11.7.4 на с. 539, но
в данном случае операция записи может затрагивать несколько резервных дисков. Чтобы
записать блок на любой из дисков данных, необходимо сложить по модулю 2 прежнее и
новое содержимое блока, подлежащего обновлению, а затем полученный результат прибавить
(по модулю 2) к значениям соответствующих блоков всех резервных дисков,
помеченных единицей в строках, в которых модифицируемый диск также обозначен единицей.
Пример 11.24. Вновь рассмотрим массив RAID уровня 6, состоящий из семи дисков,
с матрицей резервирования, показанной на рис. 11.17, и положим, что блоки
обладают длиной 8 бит. Предположим также, что первые блоки всех семи дисков выглядят
так, как показано на рис. 11.18. Заметьте, что блок диска 5 является суммой по
модулю 2 блоков первых трех дисков, строка 6 представляет собой результат сложения по
модулю 2 строк 1, 2 и 4, а последняя строка — это сумма по модулю 2 строк 1, 3 и 4.
Пусть новым значением первого блока диска 2 должен стать байт 00001111. Выполнив
сложение по модулю 2 этой битовой последовательности с прежним содержимым блока,
10101010, получим 10100101. Если обратиться к столбцу матрицы на рис. 11.17,
отвечающему диску 2, легко видеть, что он содержит единицы в первых двух строках. Поскольку
в строках 1 и 2 единицами обозначены резервные диски 5 и 6, надлежит сложить по
модулю 2 содержимое первых блоков дисков 5 и 6 с вычисленным выше байтом 10100101, т.е.
изменить значения битов этих блоков на позициях 1, 3, 6 и 8 на противоположные.
Результат показан на рис. 11.19. Обратите внимание, что новое содержимое всех блоков по-
прежнему удовлетворяет требованиям матрицы на рис. 11.17: суммы по модулю 2
значений блоков дисков, обозначенных единицей в каждой из строк матрицы, равны нулю.
Диск
1)
2)
3)
4)
5)
6)
7)
Содержимое
11110000
10101010
00111000
01000001
01100010
00011011
10001001
Рис. 11.18. Значения первых блоков всех дисков
11.7. ВОССТАНОВЛЕНИЕ ДАННЫХ ПРИ ПОЛНОМ ОТКАЗЕ ДИСКА
541
Диск
1)
2)
3)
4)
5)
6)
7)
Содержимое
11110000
00001111
00111000
01000001
11000111
10111110
10001001
Рис. 11.19. Значения первых блоков всех
дисков после обновления содержимого 2-го диска
данных и соответствующих резервных дисков
□
Восстановление данных после единовременного отказа двух дисков
Теперь рассмотрим, каким образом схема резервирования данных, рассмотренная
выше, позволяет совладать с последствиями единовременного отказа двух дисков.
Обозначим диски, вышедшие из строя, как а и Ъ. Поскольку все столбцы матрицы,
представленной на рис. 11.17 (см. с. 540), различны, необходимо найти некоторую
строку г, в которой содержимое ячеек столбцов а и Ъ не совпадает. Предположим, что на
пересечении строки г со столбцом а находится 0, а в ячейке с координатами г и b — 1.
Для вычисления утраченного значения блока диска Ъ следует попарно сложить по
модулю 2 биты блоков всех дисков, кроме Ь, содержащих единицы в строке г
матрицы. Заметим, что среди этих дисков диска а нет, так что все блоки окажутся
доступными. Поскольку каждый столбец матрицы содержит единицы по меньшей мере
в одной строке, можно воспользоваться одной из этих строк для вычисления
содержимого блока диска а, определив сумму по модулю 2 значений блоков тех дисков
(кроме а), которые в этой строке помечены единицей.
Диск
1)
2)
3)
4)
5)
6)
7)
Содержимое
11110000
999?????
00111000
01000001
99999999
10111110
10001001
Рис. 11.20. Значения первых блоков всех
дисков после отказа дисков 2 и 5
Пример 11.25. Предположим, что приблизительно в один и тот же момент времени
диски 2 и 5 вышли из строя. Обратившись к матрице, изображенной на рис. 11.17
(см. с. 540), определим, что значения в ячейках столбцов, соответствующих дискам 2
и 5, различаются в строке 2, где диск 2 помечен единицей, а диск 5 — нулем. Поэтому
для восстановления блока данных диска 2 мы можем прибегнуть к сложению по
модулю 2 блоков трех других дисков, обозначенных единицей в строке 2, — дисков 1, 4 и 6.
542
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Дополнительные соображения по поводу схемы RAID уровня 6
1. Вполне возможно объединить идеи, положенные в основу схем RAID уровней 5
и 6, чтобы распределить функции резервирования по номерам блоков или
цилиндров во избежание избыточной нагрузки на выделенные резервные диски,
чем страдает схема, рассмотренная в разделе 11.7.5.
2. Схема RAID уровня 6 не ограничена четырьмя дисками данных. Общее
количество дисков может быть на единицу меньше требуемой степени числа 2 —
скажем, 2*- 1, где к дисков являются резервными, а остальные 2к-к- 1 — это диски
данных, так что степень резервирования возрастает приблизительно как
логарифм от количества дисков данных. Для любого к нетрудно построить матрицу,
подобную представленной на рис. 11.17, столбцы которой содержат все
различные ^-битовые последовательности нулей и единиц, за исключением набора из к
нулей, причем столбцы с единственной единицей соответствуют резервным
дискам, а все остальные — дискам данных.
Обратите внимание, что ни один из этих дисков не относится к числу пострадавших.
Если предположить, что первые блоки всех дисков изначально выглядели так, как
показано на рис. 11.19, ситуацию после отказа дисков 2 и 5 можно схематически
представить в виде таблицы рис. 11.20.
Если сложить по модулю 2 значения блоков дисков 1, 4 и 6 (11110000, 01000001
и 10111110 соответственно), будет получен недостающий байт 00001111 диска 2. Как
легко видеть, он совпадает с тем, который содержится во второй строке рис. 11.19.
Теперь ситуация выглядит так, как показано на рис. 11.21.
Диск
1)
2)
3)
4)
5)
6)
7)
Содержимое
11110000
00001111
00111000
01000001
????????
10111110
10001001
Рис. 11.21. Значения первых блоков всех
дисков после восстановления диска 2
Обратим внимание, что диск 5 помечен единицей в строке 1 матрицы на
рис. 11.17. Поэтому для восстановления блока данных диска 5 следует сложить по
модулю 2 значения блоков трех других дисков, обозначенных единицей в строке 1, —
дисков 1, 2 и 3. Искомая сумма равна 11000111. Вновь, как нетрудно заметить, она
совпадает с исходным содержимым блока 5-го диска, показанным на рис. 11.19. □
11.7.6. Упражнения к разделу 11.7
Упражнение 11.7.1. Предположим, что используется схема создания зеркальных
дисков, аналогичная приведенной в примере 11.18 на с. 535, причем вероятность
поломки каждого диска в любом году составляет 4%, а на замену вышедшего из
строя диска требуется 8 часов. Каково в этом случае среднее время наработки на
отказ, приводящий к утрате данных?
11.7. ВОССТАНОВЛЕНИЕ ДАННЫХ ПРИ ПОЛНОМ ОТКАЗЕ ДИСКА
543
Коды с исправлением ошибок и массивы RAID уровня 6
Выбор подходящей матрицы резервирования, подобной той, которая показана на
рис. 11.17 (см. с. 540), осуществляется на основе теории кодов с исправлением
ошибок (error-correcting codes). Код (code) длины п — это множество битовых векторов
длины п, называемых кодовыми словами (code words). Расстоянием Хемминга
(Hamming distance) между двумя кодовыми словами называют количество позиций,
в которых содержимое битов слов различается, а минимальное расстояние (minimum
distance) кода — это наименьшее расстояние Хемминга между двумя любыми
различными кодовыми словами.
Если С — произвольный код длины п, мы вправе потребовать, чтобы
соответствующие биты блоков п дисков образовывали последовательности, являющиеся
словами кода С. В качестве простейшего примера можно назвать систему из двух
зеркальных дисков, где п = 2; в этом случае можно использовать код С ={00, 11}, т.е.
одноименные биты блоков обоих дисков должны быть одинаковыми. Другой
пример: матрица на рис. 11.17 задает фрагмент кода, состоящего из 16 битовых
векторов длины 7, которые содержат произвольные биты на первых четырех позициях,
а значения оставшихся трех битов определяются на основе правил,
регламентирующих содержимое трех резервных дисков.
Если минимальное расстояние кода равно d, система, диски которой содержат
биты, образующие слова кода, способна устоять против единовременного отказа d-
1 дисков, поскольку, если рассмотреть d - 1 позиций слова и учесть, что
существуют два различных способа заполнения этих позиций для получения кодового слова,
тогда два кодовых слова могли бы различаться, самое большее, в d-\ позициях
и код не обладал бы минимальным расстоянием, равным d. Матрица на рис. 11.17
по существу определяет широко известный код Хемминга (Hamming code) с
минимальным расстоянием 3. Поэтому система, удовлетворяющая этой матрице,
способна справиться с двумя единовременными отказами дисков.
*! Упражнение 11.7.2. Пусть диск может прийти в негодность на протяжении
определенного года с вероятностью F и на его замену необходимо затратить Н часов.
a) Если используется механизм зеркальных дисков, каково среднее время
возникновения события потери данных как функция от F и Я?
b) Если применяется массив RAID уровня 4 или 5, содержащий N дисков, каково
среднее время возникновения события потери данных как функция от F, Н и N?
!! Упражнение 11.7.3. Предположим, что группа зеркальных дисков состоит из трех
устройств, т.е. каждый из них содержит идентичную информацию. Если значение
вероятности выхода одного диска из строя в любом году равно F, а на его замену
требуется Н часов, каково среднее время возникновения события потери данных?
Упражнение 11.7.4. Рассмотрим массив RAID уровня 4 с четырьмя дисками данных
и одним резервным диском. Предположим, как в примере 11.19 на с. 536, что
каждый блок любого из дисков состоит из одного байта. Найдите содержимое блока
резервного диска, если соответствующие блоки дисков данных таковы:
* а) 01010110, 11000000, 00111011 и 11111011;
Ь) 11110000, 11111000, 00111111 и 00000001.
Упражнение 11.7.5. Обратимся к массиву RAID уровня 4, удовлетворяющему
условиям упражнения 11.7.4, и предположим, что вышел из строя диск 1. Выполните
восстановление содержимого блока этого диска, учитывая следующие требования:
544
ГЛАВА И. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
* а) диски 2—4 содержат блоки 01010110, 11000000 и 00111011 соответственно,
а резервный диск — блок 11111011;
Ь) диски 2—4 содержат блоки 11110000, 11111000 и 00111111 соответственно,
а резервный диск — блок 00000001.
Упражнение 11.7.6. Предположим, что содержимое блока первого диска массива,
рассмотренного в упражнении 11.7.4, изменено на 10101010. Как надлежит
модифицировать блоки других дисков?
Упражнение 11.7.7. Пусть дан массив RAID уровня 6, созданный в соответствии со
схемой, рассмотренной в примере 11.24 на с. 541, и блоки четырех дисков данных
массива содержат байты 00111100, 11000111, 01010101 и 10000100 соответственно.
a) Как должны выглядеть соответствующие блоки резервных дисков?
b) Если значение блока третьего диска изменено на 10000000, какие действия
по модификации содержимого остальных дисков следует предпринять?
Упражнение 11.7.8. Опишите действия, подлежащие выполнению с целью
восстановления данных в массиве RAID уровня 6 с семью дисками, рассмотренном
в примере 11.24 на с. 541, при выходе из строя следующих дисков:
* а) 1 и 7;
b) 1 и 4;
c) 3 и 6.
Упражнение 11.7.9. Предложите схему массива RAID уровня 6 с 15 дисками,
четыре из которых являются резервными, обобщив матрицу Хемминга для 7 дисков,
изображенную на рис. 11.17 (см. с. 540).
Упражнение 11.7.10. Перечислите 16 кодовых слов кода Хемминга длиной 7.
Иными словами, каковы 16 последовательностей битов, которые могли бы
использоваться в качестве содержимого блоков семи дисков массива RAID уровня 6 с
матрицей резервирования, изображенной на рис. 11.17 (см. с. 540)?
Упражнение 11.7.11. Предположим, что имеется массив из четырех дисков, первый
и второй из которых являются дисками данных, а третий и четвертый —
резервными дисками. Диск 3 содержит зеркальную копию данных диска 1, а диск 4 —
биты четности соответствующих пар битов дисков 2 и 3.
а) Создайте матрицу битов четности, аналогичную изображенной на рис. 11.17
(см. с. 540).
!! Ь) Рассматриваемый массив позволяет восстановить информацию при
единовременном выходе из строя двух дисков только в некоторых, но не во всех
ситуациях. Определите, при отказе каких пар дисков спасти положение
можно, а в каких случаях — нельзя.
*! Упражнение 11.7.12. Пусть дан массив, содержащий восемь дисков данных
(пронумерованных от 1 до 8) и три резервных диска (9, 10 и 11). Диск 9 содержит
блоки четности для дисков 1—4, а диск 10 — аналогичные блоки для дисков 5—8.
Если вероятность единовременного отказа любых пар дисков одинакова и
необходимо максимизировать вероятность того, что данные удастся восстановить при выходе
из строя двух дисков, блоки четности каких дисков должен содержать диск 11?
!! Упражнение 11.7.13. Предложите схему массива RAID уровня 6 с десятью дисками,
такую, которая позволяла бы восстанавливать информацию при единовременном
выходе из строя любых трех дисков (количество дисков данных с учетом заданного
предела, равного десяти, должно быть максимальным).
11.7. ВОССТАНОВЛЕНИЕ ДАННЫХ ПРИ ПОЛНОМ ОТКАЗЕ ДИСКА
545
11.8. Резюме
♦ Иерархия устройств памяти. В компьютерных системах находят применение
различные устройства хранения информации, во много раз различающиеся по
быстродействию, емкости и удельной стоимости хранения одного бита.
Перечислим их, начиная с самых малоемких/дорогих и заканчивая наиболее
вместительными/дешевыми: кэш-память, оперативная память, вторичные (диски)
и третичные устройства хранения.
♦ Третичные устройства хранения. К основным разновидностям третичных
устройств хранения данных относятся отдельные накопители на магнитных
лентах, ленточные бункеры (автоматизированные хранилища кассет с магнитной
лентой) и автоматические приводы оптических дисков (роботизированные
комплексы, обслуживающие стойки с архивами оптических дисков). Подобные
системы обладают наивысшей емкостью, исчисляемой многими терабайтами,
но самым низким быстродействием.
♦ Вторичные устройства хранения (диски). К категории вторичных устройств
хранения относятся преимущественно накопители на магнитных дисках, емкость
которых может доходить до сотен гигабайт. Дисковый привод состоит, в
частности, из нескольких круглых пластин, покрытых слоем магнитного материала.
Поверхность каждой пластины разделена на концентрические дорожки,
позволяющие сохранять биты данных. Пластины вращаются вокруг центрального
шпинделя. Множество дорожек с одним радиусом, отсчитываемым от центра
всех пластин, формирует цилиндр.
♦ Блоки и секторы. Дорожки разбиты на секторы, отделенные друг от друга
зазорами — полосами немагнитного материала. Секторы представляют собой
физические структурные единицы носителя. Блоки — это логические единицы
объема данных, передаваемых от дисков в оперативную память и обратно. Блок
обычно охватывает несколько секторов.
♦ Контроллеры дисков. Контроллер дисков — это специализированный процессор,
способный управлять одним или несколькими дисковыми устройствами и
ответственный за перемещение блока головок привода на соответствующий
цилиндр с целью считывания или записи запрошенных секторов дорожки, а также
за составление и выполнение расписания обслуживания параллельных запросов
и буферизацию данных, подлежащих считыванию или записи.
♦ Время задержки диска — это промежуток времени, отделяющий момент
активизации запроса на чтение или запись дискового блока от момента,
к которому содержимое блока оказывается в оперативной памяти или
сохраняется на диске. Величина времени задержки по существу
определяется тремя факторами: временем поиска для перемещения головок на
требуемый цилиндр, временем оборота до момента совпадения головок с
запрошенным сектором и временем передачи блока с диска в оперативную
память или обратно.
♦ Закон Мура. Наблюдается устойчивая тенденция к удвоению значений
некоторых основных параметров компьютерного оборудования, таких как
быстродействие процессора и емкость диска или оперативной памяти, каждые
18 месяцев. Однако значения других параметров, подобных времени задержки
диска, по мере развития технологий улучшаются весьма незначительно либо
не изменяются вовсе.
♦ Стратегии использования вторичной памяти. Когда порции информации
настолько объемны, что не могут быть сохранены в оперативной памяти целиком,
546
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
используются специальные алгоритмы манипуляции данными, учитывающие
тот факт, что операции обмена информацией между диском и оперативной
памятью отнимают во много раз большее время, нежели то, которое требуется для
обработки той же информации в оперативной памяти. Поэтому решающим
параметром, обусловливающим эффективность подобных алгоритмов, служит
количество операций дискового ввода-вывода.
♦ Сортировка двухфазным многокомпонентным слиянием. Этот алгоритм
сортировки предназначен для обработки огромных объемов информации, хранящейся на
диске, использует только по две операции чтения и записи в расчете на каждый
элемент дисковых данных и применяется в большинстве СУБД.
♦ Повышение эффективности дисковых операций. Существуют определенные
приемы, позволяющие значительно ускорить выполнение дисковых
операций в тех или иных условиях: распределение данных по нескольким дискам
(для обеспечения возможности параллельного доступа), создание
зеркальных дисков (для хранения нескольких копий одних и тех же данных и для
ускорения доступа), группирование взаимосвязанных данных по дорожкам
и цилиндрам, предварительное считывание и крупномасштабная
буферизация информации (считывание и сохранение данных целыми дорожками или
цилиндрами).
♦ Алгоритм лифта. Для ускорения дисковых операций применяется алгоритм
упорядочения запросов на чтение/запись блоков данных, предусматривающий,
что блок головок движется поступательно в одном, а затем в другом
направлении, а не изменяет его при необходимости обслуживания очередного запроса.
♦ Отказы дисковых устройств. Во избежание потери данных системы обязаны
поддерживать средства преодоления последствий сбоев и отказов. К
основным типам отказов дисковых накопителей относятся перемежающийся
отказ (при неоднократном повторении неудачной попытки выполнения
чтения/записи операцию удается успешно завершить), разрушение носителя
(данные на диске утрачиваются из-за частичного повреждения магнитного
слоя) и полный отказ (устройство выходит из строя, и информация,
хранящаяся на нем, становится недоступной).
♦ Контрольные суммы. Наличие бита четности (дополнительного бита, имеющего
целью обеспечить сохранение четного количества единиц в битовой
последовательности) позволяет выявлять (но не устранять) факты перемежающихся
и частичных отказов ввиду разрушения носителя.
♦ "Устойчивые хранилища". Сохранение двух копий данных и тщательное
соблюдение порядка их записи дает возможность противостоять почти всем
нарушениям отдельных секторов дисковых носителей.
♦ Массивы RAID. Специальные схемы совместного использования дисковых
устройств позволяют восстанавливать информацию после полного отказа
одного или нескольких из них. Массив RAID уровня 1 — это система с
зеркальными дисками; массив уровня 4 предполагает наличие дополнительного
резервного диска, содержащего контрольные биты для битов данных всех
остальных дисков; в массиве уровня 5 функции резервирования распределены
между всеми дисками с целью снижения нагрузки на отдельные компоненты
системы; массив уровня 6 реализует концепцию кодов с исправлением
ошибок и позволяет восстанавливать информацию после единовременного отказа
нескольких дисковых устройств.
11.8. РЕЗЮМЕ
547
11.9. Литература
Схемы RAID основаны на модели попеременного распределения блоков данных по
нескольким дискам (disk striping) [6], а название технологии (RAID) и
предусматриваемые ею механизмы исправления ошибок впервые упомянуты в докладе [5].
Информация о модели отказов дисковых устройств заимствована из
неопубликованного отчета [4].
Имеется ряд любопытных обзоров, охватывающих результаты исследований в
областях, затронутых в этой главе: в [2] обсуждаются направления развития дисковых систем;
в [1] приведены подробные сведения о схемах RAID; статья [7] содержит описания
алгоритмов эффективного использования вторичных устройств хранения данных.
В докладе [3] освещены важные принципы оптимизации систем, включающих
процессор, оперативную память и диск, для решения конкретных задач.
1. Chen P.M. et al. RAID: high-performance, reliable secondary storage, Computing Surveys, 26:2
(1994), p. 145-186.
2. Gibson G.A. et al. Strategic directions in storage I/O issues in large-scale computing, Computing
Surveys, 28:4 (1996), p. 779-793.
3. Gray J.N., Putzolo F. The five minute rule for trading memory for disk accesses and the 10 byte
rule for trading memory for CPU time, Proc. ACM SIGMOD Intl. Conf. on Management of
Data (1987), p. 395-398.
4. Lampson В., Sturgis H. Crash recovery in a distributed data storage system, Technical Report,
Xerox Palo Alto Research Center, 1976.
5. Patterson D.A., Gibson G.A., and Katz R.H. A case for redundant arrays of inexpensive disks,
Proc. ACM SIGMOD Intl. Conf. on Management of Data (1988), p. 109-116.
6. Salem K., Garcia-Molina H. Disk striping, Proc. 2nd Intl. Conf. on Data Engineering
(1986), p. 336-342.
7. Vitter J.S. External memory algorithms, Proc. 17th Annual ACM Symp. on Principles of
Database Systems (1998), p. 119-128.
548
ГЛАВА 11. ПРИНЦИПЫ ХРАНЕНИЯ ИНФОРМАЦИИ
Глава 12
Представление элементов
данных
В этой главе мы продолжим обсуждение модели блоков (blocks) данных, размещаемых
на носителях вторичных устройств хранения (secondary storage devices), — но теперь на
более высоком структурном уровне. Начнем с изучения того, каким образом во
вторичных хранилищах представляются отношения или множества объектов.
• Атрибуты (attributes) отображаются в виде байтовых последовательностей
постоянной или переменной длины, называемых полями (fields).
• Поля, в свою очередь, объединяются в наборы данных постоянной или
переменной длины, обозначаемые термином запись (record) и соответствующие
кортежам или объектам.
• Записи сохраняются в физических блоках (blocks). Для формирования блоков
используются различные структуры данных, особенно полезные в тех
ситуациях, когда содержимое базы данных подвергается изменениям.
• Наборы записей, отвечающие отношениям или экземплярам (extents) классов,
сохраняются в виде коллекций блоков, называемых файлами (files).82 Для
обеспечения возможностей эффективной обработки запросов и команд
модификации таких коллекций файлам ставятся в соответствие одна или
несколько структур индексов (index) (за подробными сведениями обращайтесь
к главам 13 на с. 583 и 14 на с. 637).
12.1. Элементы данных и поля
Для начала покажем, как значения атрибутов (attributes) — отправные элементы
информации, хранимой в базах данных, управляемых реляционными или объектно-
ориентированными системами, — представляются в виде полей (fields), а позже
остановимся на способах объединения полей в более крупные структуры — записи, блоки и файлы.
82 Термин файл в контексте СУБД получает более широкое толкование, нежели
одноименное понятие, употребляемое в операционных системах. Хотя файл базы данных может
представлять собой и неструктурированный поток байтов, гораздо чаще такие файлы состоят
из наборов блоков, организованных в строго определенном порядке и допускающих
индексирование и применение эффективных специализированных методов доступа к их
содержимому. Подобные вопросы освещены в главе 13.
12.1.1. Представление элементов реляционных баз данных
Предположим, что в контексте реляционной базы данных средствами SQL-
команды create table, представленной на рис. 6.16 (см. с. 298) и воспроизведенной
с некоторыми дополнениями на рис. 12.1, объявлено отношение с именем
MovieStar. Задача структурирования и сохранения отношения, описываемого
командой, возлагается на соответствующую СУБД. Поскольку отношение является
множеством кортежей, а кортежи по определению схожи с записями или "структурами"
(в смысле, принятом в языках программирования С и C++), можно предположить,
что каждый кортеж будет сохранен на диске в виде отдельной записи. Запись
занимает некоторый дисковый блок или его часть, а внутри записи значению каждого
компонента кортежа отвечает определенное поле.
1) CREATE TABLE MovieStar (
2) name CHAR(30) PRIMARY KEY,
3) address VARCHAR(255),
4 ) gender CHAR(1) ,
5) birthdate DATE
) ;
Рис. 12.1. Пример SQL-объявления отношения
Хотя на первый взгляд все выглядит просто и прозрачно, на самом деле здесь, как
говорится, "черт ногу сломит", так что давайте наберемся терпения и постараемся
ответить на целый ряд вопросов.
1. Как представляются в виде полей значения типов данных SQL?
2. Как кортежи сохраняются в форме записей?
3. Как наборы записей или кортежей отображаются в физических блоках памяти?
4. Как отношения оформляются и сохраняются в виде коллекций блоков?
5. Что делать, если кортежам соответствуют записи различной длины либо записи
точно не умещаются в пределах блоков?
6. Что происходит, если после обновления содержимого некоторого поля размер
записи изменяется? Как отыскать необходимое пространство внутри блока,
особенно в тех ситуациях, когда длина записи увеличивается?
Первой проблеме посвящен текущий раздел. Два следующих вопроса освещены в
разделе 12.2 на с. 554, а два последних — в разделах 12.4 на с. 569 и 12.5 на с. 576
соответственно. Четвертая тема, затрагивающая такие способы преставления отношений,
которые обеспечивают возможности эффективного доступа к кортежам этих
отношений, изучается в главе 13 на с. 583.
Заслуживают внимания и методы низкоуровневого представления данных некоторых
специальных разновидностей, активно применяемых в современных объектно-
реляционных и объектно-ориентированных системах, а именно идентификаторов
объектов (или указателей на записи) и объектов типа "BLOB" (от Binary Large Objects —
"крупные двоичные объекты") — например, видеофрагментов формата MPEG объемом
в несколько гигабайтов. Об этом мы расскажем в разделах 12.3 на с. 558 и 12.4 на с. 569.
12.1.2. Представление объектов
В некотором приближении объект можно воспринимать как кортеж, а его поля —
как компоненты атрибутов. Кортежи в объектно-реляционных базах данных весьма
напоминают кортежи "обычных" (реляционных) баз данных. Однако существуют два
особых обстоятельства, о которых мы не упоминали в разделе 12.1.1.
550
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
1. Объекту могут ставиться в соответствие специальные ассоциированные с ним
функции, называемые методами (methods). Код методов является частью схемы
класса, к которому относится объект.
2. Каждый объект обычно обладает собственным идентификационным номером
(object identity — О ID), который можно трактовать как определенный адрес
в некотором глобальном адресном пространстве, однозначно определяющий
этот объект. Объекты нередко связываются с другими объектами, и подобные
связи описываются указателями или списками указателей.
Код методов сохраняется в схеме и поэтому принадлежит базе данных в целом,
а не отдельным объектам. Для обеспечения возможности обращения к методу, однако,
необходимо, чтобы запись, представляющая объект, содержала поле,
свидетельствующее о том, к какому классу относится этот объект.
Способы представления адресов — будь то идентификационный номер объекта
или ссылка на другой объект — обсуждаются в разделе 12.3 на с. 558. Связи — в том
виде, как они рассматриваются в языке ODL, — являются принадлежностью объекта,
и информация о них также должна каким-то образом сохраняться в базе данных.
Поскольку количество взаимосвязанных объектов, подлежащих созданию, заранее не
известно (по меньшей мере, в тех случаях, когда речь идет об объектах, соединенных
связями типа "многие ко многим" или относящихся к стороне "многие" связей вида
"многие к одному"), для описания связей приходится пользоваться записями
переменной длины (подробнее об этом — в разделе 12.4 на с. 569).
12.1.3. Представление элементов данных
Начнем с изучения способов хранения элементов данных, относящихся к основным
типам SQL и представляемых в виде полей записей. Важно понимать, что все данные
описываются последовательностями байтов. Например, значение атрибута типа integer
обычно отображается в виде двух или четырех байтов, а для хранения величин типа float
требуется от четырех до восьми байтов. Целые и вещественные числа представляются
наборами битов, которые интерпретируются аппаратным обеспечением компьютера таким
образом, чтобы сделать возможным выполнение традиционных арифметических операций.
Символьные строки постоянной длины
Простейшая разновидность строк символов описывается SQL-типом char(h) ,
определяющим множество строк постоянной длины п. Поле, соответствующее атрибуту
подобного типа, представляет собой массив из п байтов.83 Если значением атрибута
оказывается более короткая строка, в каждую "лишнюю" позицию поля заносится
специальный незначащий (pad) символ, 8-битовый код которого не совпадает с кодом
любого другого символа из числа тех, которые разрешено включать в строки SQL.
Пример 12.1. Если объявление атрибута А указывает на его принадлежность к типу
char (5), поля, отвечающие атрибуту во всех кортежах, будут представлять собой
массивы из пяти символов. Если компонент атрибута А в одном из кортежей должен
содержать значение, подобное ' cat', массив будет выглядеть как
с a t 1 1
Здесь _1_ представляет незначащий символ-заполнитель, код которого заносится в
четвертый и пятый байты-элементы массива. Обратите внимание, что символы
одинарных кавычек, применяемые для обозначения строк в SQL-программах, в значение
строки не включаются и в соответствующем поле не сохраняются. □
Утверждение справедливо только в том случае, если символы относятся к одному из
традиционных 8-битовых наборов (скажем, ASCII или EBCDIC). Символ Unicode представляется
шестнадцатью битами, или двумя байтами. — Прим. перев.
12.1. ЭЛЕМЕНТЫ ДАННЫХ И ПОЛЯ
551
Замечание по поводу терминологии
Если вы имеете опыт работы с файловыми системами, программируете на
традиционных языках, подобных С, или на языках реляционных баз данных (в частности,
SQL) либо знакомы с инструментами объектно-ориентированного программирования
(скажем, Smalltalk, C++, OQL и т.п.), вам, возможно, знакомы различные
термины, обозначающие по существу одни и те же понятия. В приведенной ниже
таблице мы попытались суммировать эти термины, проследив их родство и различия.
Файлы
С
SQL
OQL
Элемент данных
Поле
Поле
Атрибут
Атрибут, связь
Запись
Запись
Структура
Кортеж
Объект
Коллекция
Файл
Массив, файл
Отношение
Экземпляр класса
Мы будем употреблять преимущественно такие термины, которые имеют
отношение к файловым системам — поле и запись, — если только не подразумевается
необходимость их специального толкования в контексте реляционных или объектно-
ориентированных приложений баз данных.
Символьные строки переменной длины
Подчас длина строковых значений компонентов определенного атрибута
отношения может изменяться в широких пределах. В таких случаях атрибуты обычно относят
к типу varchar(/i ). Впрочем, при реализации подобных типов под значение может
отводиться п + 1 байт независимо от истинного размера строки. Поэтому SQL-тип
varchar на самом деле представляет поле фиксированной длины, хотя размер
содержимого может варьироваться. Особенности полей и записей данных переменной
длины мы подробно обсудим в разделе 12.4 на с. 569, а здесь кратко упомянем два общих
способа представления строк типа varchar.
1. Длина плюс содержимое. Система организует массив из п+ 1 байт. В первом байте
в виде 8-битового целого числа сохраняется количество байтов в строке. Длина
строки не может превысить п, а величина п, в свою очередь, должна быть не больше
значения 255 — в противном случае длину строки нельзя представить с помощью
одного байта.84 Второй и последующие байты отображают символы
содержимого строки. Если строка состоит из меньшего количества символов,
оставшиеся байты массива не могут интерпретироваться как часть содержимого (поскольку
первый байт указывает, где именно завершается строка) и игнорируются.
2. Строки, завершаемые символом null. В этом случае также формируется массив из
п + 1 байт. Массив заполняется символами строки, а в элемент, следующий за
последним байтом содержимого строки, заносится специальный символ null, не
совпадающий ни с одним из символов, которые разрешено использовать внутри
строк SQL. Как и в предыдущем случае, оставшиеся байты массива
игнорируются, поскольку символ null задает признак конца строки; символ null, помимо того,
обеспечивает совместимость строк SQL-типа varchar, реализуемых подобным
образом, со строковым типом данных, применяемым в языке программирования С.
84 Разумеется, могут существовать реализации, в которых под описание длины строки
отводится большее количество байтов.
552
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
Пример 12.2. Предположим, что объявление атрибута А содержит указание на тип
varchar(IO). В записях, представляющих кортежи отношения с атрибутом А,
создаются поля-массивы длиной в 11 байт, предназначенные для хранения содержимого
компонентов атрибута А. Пусть значением одного из компонентов является строка
'cat'. Тогда в соответствии с первым подходом в начальный байт массива
помещается число 3, представляющее длину строки, а в следующие три байта — символы
содержимого строки. Значения остальных семи байтов не важны. В подобном случае
массив можно описать так:
3 с a t
Заметьте, что здесь "3" — это 8-битовое целое число (т.е. 00000011), а не символ ' 3 '.
Руководствуясь вторым подходом, система заполнит три первых байта массива
символами содержимого строки, а в четвертый занесет символ null (для представления
символа null — как и для описания "незначащих" символов — мы применяем обозначение 1):
с a t 1
□
Значения дат и времени
Значения дат обычно представляются в виде символьных строк постоянной длины
(мы упоминали об этом в разделе 6.1.4 на с. 256) и принципиально ничем не
отличаются от обычных строк символов подобного формата. Времешше величины
допускают аналогичное представление. В стандарте SQL, однако, предусмотрен и тип time,
позволяющий сохранять значения времени с точностью до дробных долей секунды.
Формат значений time относится к категории строк произвольной длины. Таким
образом, имеются два альтернативных средства описания значений времени.
1. Система способна ограничивать точность представления временнб/х величин,
как если бы они относились к типу varchar(/i), где п — максимально
допустимая длина строки с описанием значения времени.
2. Временные значения могут сохраняться и использоваться в виде строк
действительно переменной длины (за подробностями обращайтесь к разделу 12.4 на с. 569).
Битовые последовательности
Последовательности битов, описываемые значениями SQL-типа В1Т(л), обычно
делятся на группы по 8 бит в каждой, которые упаковываются в байты. Если п не делится
на 8 нацело, неиспользуемые биты последнего байта игнорируются. Например, битовую
последовательность 010111110011 легко описать двумя байтами— 01011111 и 00110000;
последние четыре нуля второго байта не являются частью значения поля. В частном
случае байт можно использовать для задания булевой величины, т.е. содержимого
единственного бита — скажем, как 10000000 (true) и 00000000 (false). В некоторых
ситуациях более удобным оказывается такое представление булева значения, когда величины
true и false различаются во всех битах байта — соответственно 11111111 и 00000000.
Перечислимые типы
Подчас удобное применение находят такие атрибуты, содержимое которых
должно выбираться из фиксированных множеств значений. Подобным значениям
присваиваются символические имена; тип, в объявлении которого указывается
набор символических имен, называют перечислимым (enumerative type). В качестве
примеров перечислимых типов можно назвать множества названий дней недели,
{SUN, MON, TUE, WED, THU, FRI, SAT}, ИЛИ цветов, {RED, GREEN, BLUE, YELLOW}.
Значения перечислимых типов допустимо представлять посредством
целочисленных кодов с использованием требуемого количества байтов. Например, для описания
12.1. ЭЛЕМЕНТЫ ДАННЫХ И ПОЛЯ
553
Группирование полей в одном байте
Бытует мнение о неких преимуществах размещения нескольких полей,
представляющих значения "небольших" перечислимых типов или булевых величин, в пределах
одного байта. Например, в пространстве байта удалось бы расположить
одновременно булеву величину, а также значения дня недели и одного из четырех цветов, отведя
под каждый компонент один, три и два бита соответственно (и еще "целых" два бита
остались бы невостребованными). Выполнять такие трюки формально не
возбраняется, но следует иметь в виду, что задача считывания или обновления содержимого
подобных полей заметно более сложна и чревата недоразумениями и даже
серьезными ошибками. К приемам упаковки нескольких полей в один байт следует
прибегать только в тех случаях, когда удельная стоимость хранения единицы
информации действительно высока, но сегодня трудно назвать области, в которых
применение подобного подхода можно было бы считать безусловно оправданным.
значения RED можно выбрать число 0, значению green поставить в соответствие 1,
blue — 2 и yellow — 3. Для представления подобного множества целых чисел
достаточно двух битов — соответственно 00, 01, 10 и 11. Впрочем, даже в тех случаях, когда
множество значений перечислимого типа мало, удобнее использовать целые байты,
а не их части. При таком подходе значению yellow, например, будет соответствовать
байт 00000011. Вообще говоря, с помощью единственного байта можно представить до
256 различных значений перечислимого типа. Если перечислимый тип охватывает
большее количество значений, для их описания выбирается более "широкий"
целочисленный тип (скажем, shortint) и т.д.
12.2. Записи
Теперь поговорим о способах формирования записей (records), представляющих
собой группы полей. Смежные вопросы затрагиваются также в разделе 12.4 на с. 569,
где рассматриваются поля и записи переменной длины.
Вообще говоря, каждому типу записи, применяемому в контексте базы данных,
должна быть поставлена в соответствие определенная хранимая схема (schema). Схема
содержит описания имен и типов данных полей, а также величины их смещения
(offset) от начала записи. Информация схемы используется системой при
необходимости обращения к компонентам записи.
12.2.1. Конструирование записей постоянной длины
Кортежи отношений представляются записями, состоящими из полей различных
типов (некоторые из них мы перечислили в разделе 12.1.3 на с. 551). В простейшем
случае, когда все поля обладают постоянной длиной, запись можно получить
простым сцеплением полей.
Пример 12.3. Обратимся к объявлению отношения MovieStar, приведенному на
рис. 12.1. Оно включает четыре поля:
1) name — 30-байтовая строка символов;
2) address — символьная строка типа VARCHAR (255), представляемая
массивом из 256 байтов в соответствии с одной из схем, рассмотренных
в примере 12.2 на с. 553;
3) gender — единственный байт, содержащий код одного из двух допустимых
символов — ' f ' или ' м';
4) birthdate — величина типа DATE (подразумевается, что здесь используется
10-байтовое представление значений дат SQL).
554
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
Таким образом, общая длина записи типа Moviestar составляет 30 + 256+1 + 10 = 297
байт. Запись схематически изображена на рис. 12.2. В нижней части рисунка указаны
значения смещения — количество байтов от начала записи — для каждого поля. Так,
смещение поля name равно 0 (первый байт записи имеет номер 0), начало поля address
отстоит от начала записи на 30 байт, gender — на 286 байт, a birthdate — на 287 байт.
gender birthdate
name
address
0 30 286 287
Рис. 12.2. Запись типа MovieStar
297
□
Некоторые архитектуры компьютеров поддерживают более эффективные
алгоритмы считывания и записи элементов данных, если последние размещаются в
оперативной памяти по адресам с номерами, кратными 4 (или 8, если компьютер оснащен
64-битовым процессором). Для определенных типов данных, таких как целые числа,
требование размещения по адресам, кратным 4, может оказаться обязательным, а для
других (скажем, чисел с плавающей запятой), возможно, столь же неукоснительно
должно выполняться условие "привязки" к адресам с множителем 8.
Хотя кортежи отношения постоянно хранятся на диске, а не в оперативной памяти, не
учитывать подобные обстоятельства нельзя, поскольку при считывании дискового блока
в оперативную память первый байт блока будет определенно размещен по адресу,
кратному 4 либо являющемуся более высокой степенью 2 (скажем, 212, если блоки и
страницы имеют длину, равную 4096 = 212). Таким образом, требование расположения полей
данных по строго определенным адресам памяти, кратным 4, 8 и т.д., можно
трактовать как условие смещения этих полей от начала блока на соответствующую величину.
Для простоты предположим, что все поля данных должны размещаться по адресам
оперативной памяти, кратным 4. Для удовлетворения этого требования достаточно
выполнения следующих условий:
a) каждая запись смещена от начала блока на величину, кратную 4;
b) значение смещения каждого поля от начала записи также кратно 4.
Иными словами, мы округляем длины всех полей и записей до ближайшего значения,
кратного 4.
Пример 12.4. Предположим, что кортежи отношения MovieStar должны
представляться в памяти в соответствии с указанным выше требованием, т.е. каждое поле
записи обязано начинаться с байта, номер которого является множителем 4. Тогда
значения смещений полей от начала записи будут такими: 0, 32, 288 и 292. Общая длина
записи составит 304 байта. Формат записи показан на рис. 12.3.
gender birthdate
address
z
32
288 292
304
Рис. 12.3. Расположение полей кортежей MovieStar со
смещениями, кратными 4
12.2. ЗАПИСИ
555
Зачем нужны схемы записей
Вас может удивить, почему мы так подробно рассматриваем схемы записей, ведь до
сих пор речь шла только о записях фиксированного формата. Например, смещения
полей структур вида "struct", используемых в С и других подобных языках
программирования общего назначения, вычисляются только при компиляции кода
прикладных программ и более нигде не хранятся.
Однако нетрудно привести по меньшей мере несколько причин,
обусловливающих необходимость принудительного хранения схем записей и обеспечения
возможностей доступа к ним со стороны СУБД. Первая и самая главная — схемы
отношений (и, как следствие, схемы записей, представляющих кортежи
отношений) подвержены изменениям. Для обработки запросов система должна быть
"осведомлена" о структуре текущей схемы. В определенных случаях эту
информацию нельзя получить непосредственно на основе структуры хранения кортежей на
носителе, поскольку иногда допускается размещение разнотипных кортежей
нескольких отношений в пределах одного и того же блока.
Длина первого поля, name, составляет 30 байт, но второе поле, address, не
должно начинаться непосредственно после первого — его следует сместить до ближайшей
отметки, кратной 4, — это значение 32. Размер поля address равен 256, поэтому
смещение третьего поля, gender, должно составить 288. Поле gender требует всего
одного байта, но отвести для его хранения менее 4 байт нельзя, поэтому смещение
следующего поля, birthdate, окажется равным 292. Поле birthdate имеет длину
10 байт и завершается элементом под номером 301, поэтому общая длина записи
должна была бы составить 302 байта (вновь напомним, что первый байт записи
обладает номером 0), но поскольку значение длины записи также должно быть кратным 4,
запись следует дополнить двумя "лишними" байтами. Уместно ввести эти байты в
состав поля birthdate, чтобы их нельзя было случайно использовать для иных целей. □
12.2.2. Заголовки записей
Существует еще одна проблема, с которой приходится сталкиваться при
проектировании структур записей. Нередко в записи необходимо хранить порции
дополнительной информации, не относящиеся ни к одному из полей, например:
1) данные о схеме записи либо указатель на то место, где СУБД сохраняет
схему записи данного типа;
2) сведения об общей длине записи;
3) данные о моменте последнего обращения к записи с целью ее считывания
или модификации.
Поэтому во многих случаях в структуру записи включается заголовок (record header),
состоящий, как правило, из небольшого количества байтов с дополнительными
данными того или иного вида.
СУБД, напомним, сохраняет и поддерживает в актуальном состоянии информацию
схемы отношения, которая по существу отображает содержимое соответствующей
команды CREATE TABLE'.
1) перечень названий атрибутов;
2) список типов атрибутов;
3) порядок следования компонентов атрибутов в кортеже;
4) ограничения, касающиеся отдельных атрибутов и/или отношения в целом
(например, сведения о первичном ключе либо ограничения принадлежности
значений некоторому допустимому диапазону или множеству).
556
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
Разумеется, располагать подобную информацию в каждой записи кортежа отношения
заведомо неразумно — достаточно включить в запись указатель на то место, где
система сможет легко найти все, что ей потребуется. С другой стороны, хотя длину
кортежа нетрудно получить на основе схемы отношения, иногда более удобно сохранять
это значение непосредственно в самой записи, чтобы избежать необходимости
обращения к схеме (и выполнения дополнительных операций ввода-вывода) и получить
возможность быстрого отыскания начала следующей записи.
Пример 12.5. Дополним структуру записи, рассмотренной в примере 12.4 на с. 555,
заголовком длиной в 12 байт. Первые четыре байта заголовка предназначены для
хранения указателя, задающего величину смещения в области файла базы данных, где
представлена информация о схеме отношения. Следующие четыре байта представляют
целочисленное значение длины записи, а оставшиеся четыре байта — целочисленную
величину, определяющую момент времени вставки или обновления кортежа. Теперь
длина записи составляет 316 байт. Структура записи представлена на рис. 12.4.
Указатель на схему
Длина записи
Время вставки/обновления
I7
gender birthdate
address
t : t
z
12
44
300 304 316
Заголовок
Рис. 12.4. Запись типа Movies tar с заголовком
12.2.3. Группирование записей постоянной длины в блоках
Записи, представляющие кортежи отношения, хранятся в дисковых блоках и
перемещаются в оперативную память (в составе соответствующих блоков) при
необходимости их считывания или обновления. Структура блока, содержащего записи
отношения, приведена на рис. 12.5.
Заголовок
Запись 1
Запись 2
Запись п
77/
Рис. 12.5. Структура типичного блока записей
Блок может быть снабжен необязательным заголовком (block header), способным
содержать следующую информацию:
1) ссылки на один или несколько других блоков, являющихся частью сети
блоков, которая используется для создания структур индексов,
облегчающих доступ к кортежам отношения (за подробными сведениями
обращайтесь к главе 13 на с. 583);
2) сведения о функции, выполняемой блоком в составе подобной сети блоков;
3) данные о том, кортежи какого отношения представляются записями
текущего блока;
4) таблицу со значениями смещения каждой записи от начала блока;
5) "идентификатор" блока (подробнее — в разделе 12.3 на с. 558);
12.2. ЗАПИСИ
557
6) значения моментов времени последнего обращения к блоку и/или его
модификации.
В простейшем случае блок содержит записи, отвечающие кортежам одного
отношения, и формат этих записей фиксирован. Поэтому вслед за заголовком в блоке
располагается такое количество записей, которое удается уместить; оставшееся
пространство блока не используется.
Пример 12.6. Пусть необходимо упаковать в блоки размером 4096 байт содержимое
отношения MovieStar; каждый кортеж отношения представляется записью, структура
которой показана на рис. 12.4. Длина записи составляет 316 байт. Под заголовок
блока отводится, скажем, 12 байт; 4084 байта могут использоваться для размещения
12 записей, и 292 байта остаются свободными. □
12.2.4. Упражнения к разделу 12.2
* Упражнение 12.2.1. Предположим, что запись состоит из следующих полей,
перечисленных в требуемом порядке: строка из 15 символов, целое размером в 2 байта,
строка даты формата SQL и строка времени формата SQL (без дробных долей
секунды). Какова длина такой записи, если:
a) смещения полей произвольны;
b) значения смещения каждого поля кратны 4;
c) значения смещения каждого поля кратны 8.
Упражнение 12.2.2. Выполните задания упражнения 12.2.1 при условии, что список
полей таков: вещественное число размером в 8 байт, строка из 17 символов,
отдельный байт и дата в формате SQL.
* Упражнение 12.2.3. Выполните задания упражнения 12.2.1, полагая, что список
полей тот же, но каждая запись снабжена заголовком, состоящим из двух 4-байтовых
указателей и символа.
Упражнение 12.2.4. Выполните задания упражнения 12.2.2 с учетом того, что
каждая запись содержит заголовок, включающий 8-байтовый указатель и десять 2-
байтовых целочисленных значений.
* Упражнение 12.2.5. Предположим, что структура записи соответствует условиям
упражнения 12.2.3 и необходимо упаковать в блоки размером 4096 байт
максимально возможное количество записей, учитывая, что заголовок блока содержит
десять 4-байтовых целых чисел. Сколько записей удастся поместить в блок в
каждой из трех ситуаций, связанных с выравниванием полей относительно начала
записи в соответствии с правилами, упомянутыми в заданиях упражнения 12.2.1?
Упражнение 12.2.6. Выполните задания упражнения 12.2.5 применительно к структуре
записи, указанной в упражнении 12.2.4, и с учетом того, что размер блока составляет
16384 байт и блок снабжен заголовком, состоящим из трех 4-байтовых целых чисел
и таблицы смещений, содержащей по 2 байта данных в расчете на каждую запись блока.
12.3. Представление адресов записей и блоков
Прежде чем приступить к рассмотрению принципов формирования записей более
сложных структур, следует изучить способы отображения адресов, указателей и
ссылок на записи и блоки, поскольку таковые часто выступают в роли составных частей
других записей. Существуют и иные причины, обусловливающие необходимость
понимания методов описания адресов во вторичных хранилищах данных. Позже (в главе
558
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
13 на с. 583), рассказывая об эффективных структурах представления отношений
и файлов, мы приведем ряд важных примеров использования адресов записей и блоков.
После загрузки блока в буфер оперативной памяти адреса блока и отдельной
записи внутри блока можно воспринимать как соответствующие адреса первых байтов
блока и записи в виртуальной памяти. Но если блок еще не считан и находится на
диске вторичного устройства хранения, он не является частью пространства адресов
виртуальной памяти. В этом случае местоположение блока в базе данных,
управляемой СУБД, описывается определенной последовательностью байтов, содержащей
сведения об идентификаторе дискового устройства, номере цилиндра и т.д., а запись
внутри блока определяется смещением ее первого байта относительно начала блока.
Задача представления адресов еще более усложняется с появлением тенденций
к использованию "брокеров объектов", позволяющих многим программным агентам
создавать отдельные объекты совершенно независимо. Такие объекты трактуются как
записи, служащие частью базы данных, управляемой объектно-ориентированной
системой, хотя, не теряя основной идеи, их можно воспринимать просто как кортежи
отношений. Тем не менее возможность свободного создания объектов или записей
существенно усложняет механизм, ответственный за поддержку их адресов.
Этот раздел мы начнем с обсуждения особенностей адресных пространств в том
смысле, как они представляются в архитектуре "клиент/сервер", затем расскажем
о различных способах описания адресов и познакомим вас с методами "подмены"
указателей, т.е. их преобразования при передаче информации с сервера базы данных
прикладным программам-клиентам.
12.3.1. Системы "клиент/сервер"
Типичная СУБД функционирует в виде процесса сервера (server), обслуживающего
запросы на получение данных из вторичных устройств хранения, поступающие от
процессов клиентов (clients) — приложений-потребителей информации базы данных.
Процессы сервера и клиентов могут работать как на одном компьютере, так и в пределах
распределенной сети компьютеров (мы уже упоминали об этом в разделе 8.4.3 на с. 380).
Клиентские приложения обычно используют 32-разрядное виртуальное адресное
пространство, содержащее свыше 4 миллиардов различных адресов. Операционная
система или СУБД принимает решение о том, какие части адресного пространства
в тот или иной момент времени следует разместить в оперативной памяти, а
аппаратное обеспечение несет ответственность за установление взаимно однозначного
соответствия между виртуальными адресами и физическими адресами оперативной
памяти. Мы не станем погружаться в детали преобразования виртуальных адресов в
физические и будем воспринимать адресное пространство клиента так, будто оно целиком
располагается в оперативной памяти.
Информация сервера "обитает" в адресном пространстве базы данных (database
address space). Адреса в таком пространстве указывают на блоки и, возможно, на
смещения внутри блоков. Существует несколько способов представления подобных адресов.
1. Физические адреса (physical addresses) — наборы байтов, позволяющие
определить местонахождение блока или записи на носителе вторичного устройства
хранения. Физический адрес включает следующие компоненты:
a) адрес компьютера, к которому подключено устройство хранения (если база
данных распределена между несколькими компьютерами);
b) идентификатор (дискового) устройства хранения, на котором расположен
искомый блок данных;
c) номер цилиндра диска;
d) номер дорожки цилиндра (если устройство содержит пластины с
несколькими поверхностями);
12.3. ПРЕДСТАВЛЕНИЕ АДРЕСОВ ЗАПИСЕЙ И БЛОКОВ
559
Логический
адрес
Физический
адрес
Рис. 12.6. Таблица соответствий для
трансляции логических адресов в
физические
e) номер блока в пределах дорожки;
f) смещение первого байта записи от начала блока (если адресуется запись).
2. Логические адреса (logical addresses). Каждый блок или запись обладает
логическим адресом — произвольной последовательностью байтов некоторой
фиксированной длины. Логические адреса транслируются в физические посредством
таблицы соответствий (map table), хранящейся в определенном месте диска.
Таблица соответствий схематически изображена на рис. 12.6.
Заметим, что физические адреса отличаются большими размерами. Восемь
байтов — это тот минимум, при котором в адрес удастся включить хотя бы некоторые
из перечисленных выше компонентов, и в некоторых системах под каждый
физический адрес отводится до 16 байт. Вообразим
для примера базу данных объектов, которая
спроектирована таким образом, чтобы
обеспечить возможность использования в течение
100 лет. Предположим, что в будущем система
дорастет до таких размеров, что ее придется
распределить по миллиону компьютеров,
каждый из которых обладает расширенным
адресным пространством и настолько
производителен, что способен создавать по одному объекту
в течение каждой наносекунды. Такая система
будет способна хранить до 277 объектов, и для
представления каждого из их адресов
потребуется явно не менее десяти байтов, а поскольку
в каждый адрес потребуется включить ссылку на компьютер, идентификатор
устройства хранения и наверняка еще целый ряд компонентов, размер адреса
значительно превысит исходный 10-байтовый предел.
12.3.2. Логические и структурированные адреса
Закономерен вопрос, каково назначение логических адресов. Всю необходимую
информацию о физических адресах можно "выудить" из таблицы соответствий, и для
того, чтобы проследовать по логическим ссылкам, указывающим на записи,
достаточно обратиться к таблице соответствий и найти требуемые физические адреса. Однако
уровень опосредования, заложенный в таблицу соответствий, обеспечивает
значительные преимущества в гибкости. Например, при использовании различных форм
организации данных требуется осуществлять перемещение записей — как внутри блока, так
и от одного блока к другому. При использовании таблицы соответствий внешние
указатели ссылаются только на ее ячейки, и все, что необходимо сделать для перемещения
или удаления записи, — это изменить определенный элемент таблицы соответствий.
Находят применение и схемы представления так называемых структурированных
адресов (structured addresses), предлагающие те или иные возможности совмещения
физических и логических адресов. Например, вполне правдоподобна ситуация, когда
для ссылки на блок (но не на смещение внутри блока) используется физический
адрес, который сопровождается ключевым значением искомой записи. Тогда блок
отыскивается по "физической" части адреса, а затем для нахождения требуемой записи
анализируется заданное ключевое значение.
Разумеется, для просмотра записей внутри блока необходимо обладать достаточной
информацией, позволяющей определять местонахождение записей и различать их.
В простейшем случае записи относятся к известному типу постоянной длины и
обладают ключевыми полями, расположенными со строго определенным смещением.
Тогда остается обратиться к элементу заголовка блока, содержащему значение счетчика
560
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
записей, принадлежащих блоку, — и мы точно узнаем, где искать ключевые поля,
содержимое одного из которых задано в виде части адреса. Однако блоки могут
формироваться и многими другими способами (мы расскажем о них несколько ниже),
позволяющими выделять записи внутри блока.
Схожий и весьма удобный вариант сочетания физических и логических адресов
предполагает хранение в составе каждого блока специальной таблицы смещений (offset
table), которая содержит значения смещения от начала блока для каждой записи,
принадлежащей блоку. Схема блока с таблицей смещений показана на рис. 12.7.
Обратите внимание, что таблица смещений наращивается от начала блока к его концу, а
записи заносятся в блок в обратном направлении. Подобный подход особенно удобен,
если длина записей не обязательно одинакова. Мы не можем знать заранее, какое
количество записей удастся разместить в блоке, и поэтому не в состоянии изначально
выделить какую-либо фиксированную часть блока под его заголовок.
j-«- Заголовок -►!
i Таблица i Свободная
i смещений! область
шш
Запись 4
4
Запись 3
А
Запись
2
А
Запись 1
А
Рис. 12.7. Схема блока с таблицей смещений записей
В этом случае адрес записи определяется физическим адресом блока и значением
соответствующего элемента таблицы смещений. Подобный уровень опосредования
значений адресов сулит немалые выгоды в сравнении с моделью логических адресов
и исключает необходимость использования глобальной таблицы соответствий.
• При изменении положения записи внутри блока достаточно модифицировать
содержимое элемента таблицы смещений; значения внешних указателей на
запись в исправлении не нуждаются.
• Если размерность элементов таблицы смещений достаточна для хранения
"длинных" адресов, запись может быть перемещена даже в другой блок.
• При удалении записи существует возможность пометить соответствующий элемент
таблицы смещений специальным признаком- "обелиском " (tombstone),
свидетельствующим о факте изъятия записи. До удаления записи в базе данных могут
существовать внешние указатели, ссылающиеся на запись. Если запись удалена, следуя по
значениям указателей, система отыщет признак-"обелиск" и будет вынуждена
присвоить указателям нулевые значения либо изменить структуры данных таким
образом, чтобы исключить ссылки на несуществующую запись. В отсутствие признака-
"обелиска" возникает опасность, связанная с тем, что указатели смогут адресовать
совершенно "посторонние" записи, а это чревато неприятностями и ошибками.
12.3.3. "Подмена" указателей
Зачастую в состав записей включаются указатели или адреса. Подобную ситуацию
нельзя назвать типичной для записей, представляющих кортежи отношений, но она
достаточно распространена, если речь идет об объектах. Помимо того, современные
объектно-реляционные системы баз данных позволяют использовать атрибуты типа
12.3. ПРЕДСТАВЛЕНИЕ АДРЕСОВ ЗАПИСЕЙ И БЛОКОВ
561
Кому принадлежат адресные пространства памяти?
В этом разделе мы будем придерживаться такой точки зрения на процессы обмена
данными между оперативной памятью и вторичными хранилищами, в соответствии
с которой каждый клиент владеет собственным пространством адресов памяти, а
адресное пространство базы данных находится в совместном пользовании. Подобная
модель точно соответствует реалиям объектно-ориентированных СУБД. В реляционных
системах, однако, пространство адресов памяти распределяется между всеми
агентами, что обеспечивает возможности восстановления данных и управления
параллельными процессами (за подробностями обращайтесь к главам 17 на с. 837 и 18 на с. 879).
Существует удобное компромиссное решение: адресное пространство делится
между агентами на стороне сервера, и соответствующие части пространства
копируются на стороны клиентов. В этом случае возможности восстановления данных
и управления параллельными заданиями сохраняются, и в то же время система
допускает гибкое распределение и масштабирование функций: чем больше клиентов
обращается к системе, тем большее количество вычислительных ресурсов
вовлекается в процессы обработки запросов и команд.
указателя (называемые ссылками), так что необходимость описания указателей в
контексте записей возникает даже в реляционной среде. Наконец, на основе блоков,
связанных между собой с помощью указателей, формируются структуры индексов (за
деталями обращайтесь к главе 13 на с. 583). Поэтому нам просто нельзя не обсудить
проблемы управления указателями при перемещении блоков из вторичных хранилищ
данных в оперативную память и обратно, что мы и собираемся сделать ниже.
Как мы упоминали прежде, каждый блок, запись, объект или иной адресуемый
элемент данных обладает адресами двух типов.
1. Адрес в базе данных (database address) — адрес в пространстве адресов сервера
базы данных, содержащий обычно около восьми байтов и задающий
местоположение элемента данных во вторичном хранилище.
2. Адрес памяти (memory address) — адрес в виртуальном адресном пространстве
после буферизации элемента в виртуальной памяти, состоящий, как правило,
из четырех байтов.
Если элемент находится в базе данных, ссылаться на него следует, используя адрес
в базе данных. Если же элемент считан в оперативную память, он допускает
возможность обращения как по адресу в базе данных,
так и по адресу памяти. Применяя для ссылки
на элемент, расположенный в виртуальной
памяти, указатель, удобнее использовать адрес
памяти, поскольку проследовать по значению
такого указателя удастся с помощью единственной
машинной инструкции.
Употребление адресов в базе данных,
напротив, сопряжено со значительными
вычислительными издержками, связанными с
использованием таблицы, которая транслирует
"базовые" адреса всех элементов, находящихся
в данный момент в виртуальной памяти, в
адреса памяти. Подобная таблица трансляции
(translation table), схематически изображенная на рис. 12.8, напоминает таблицу
соответствий (см. рис. 12.6 на с. 560), выполняющую преобразование логических
адресов в физические. Однако необходимо иметь в виду следующее:
Адрес
в базе данных
Адрес
памяти
Рис. 12.8. Таблица трансляции для
преобразования адресов в базе данных в
адреса памяти
562
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
a) и логические, и физические адреса являются формами представления
адресов в базе данных; с другой стороны, адреса памяти, перечисленные в
таблице трансляции, указывают на копии объектов в виртуальной памяти;
b) таблица соответствий содержит строки для всех адресуемых элементов базы
данных, но в таблице трансляции упоминаются адреса только тех элементов,
которые загружены в виртуальную память.
Для уменьшения накладных расходов, связанных с необходимостью
непрерывного повторения процедур трансляции адресов в базе данных в адреса памяти,
разработан ряд приемов, которые в совокупности принято обозначать термином
"подмена" указателей (pointer swizzling). Основная идея состоит в том, что при
перемещении блока данных из вторичного хранилища в оперативную память
указатели внутри блока "подменяются", т.е. их содержимое преобразуется из пространства
адресов базы данных в виртуальное адресное пространство. Указатель в этом случае
должен содержать следующие компоненты:
1) бит, свидетельствующий о том, что указатель содержит адрес в базе данных
либо ("подмененный") адрес памяти;
2) адрес в базе данных либо адрес памяти — то, что необходимо в конкретном
случае; для хранения адреса отводится одинаковое пространство независимо
от его типа (разумеется, если используется адрес памяти, который обычно
короче адреса в базе данных, часть пространства не используется).
Пример 12.7. На рис. 12.9 проиллюстрирована простая ситуация: блок 1 содержит запись
с указателями, первый из которых ссылается на другую запись того же блока, а
второй — на запись в блоке 2. При копировании блока 1 в оперативную память указатель,
адресующий запись внутри этого блока, подвергается "подмене", после чего он должен
будет содержать ссылку на адрес памяти, по которому расположена искомая запись.
Диск Память
Загрузка
в память ' '
ч "Подмена"
Блок1
Указатель не "подменен"
Блок 2
Рис. 12.9. Пример использования механизма
"подмены "указателей
Блок 2, однако, по-прежнему остается на диске, так что "подменить" второй
указатель блока 1 не удастся — он, как и раньше, обязан ссылаться на адрес записи в
базе данных. Если предположить, что позже блок 2 также будет считан в оперативную
память, в этом случае, вероятно, система получит возможность "подменить" и второй
12.3. ПРЕДСТАВЛЕНИЕ АДРЕСОВ ЗАПИСЕЙ И БЛОКОВ
563
указатель в записи блока 1 — все зависит от используемой стратегии "подмены"
(например, от того, поддерживается ли системой список указателей, ссылающихся на
записи, которые размещены во вторичном хранилище). □
Существует несколько стратегий применения механизма "подмены" указателей.
Автоматическая "подмена"
Как только блок считывается в оперативную память, в его записях отыскиваются
все указатели и адреса и вводятся в таблицу трансляции (если это не было сделано
прежде). К их числу относятся как указатели, ссылающиеся из записей блока вовне,
так и адреса блока как такового и/или записей внутри блока, если эти элементы
относятся к категории адресуемых. Необходим соответствующий механизм, позволяющий
находить подобные указатели в блоке.
1. Если блок содержит записи с известными схемами, последние помогут
отыскать в структуре записей любые элементы (в частности, и указатели).
2. Если блок используется в структуре индекса (об этом мы расскажем в главе 13
на с. 583), местоположение указателей известно заранее.
3. Заголовок блока способен содержать специальный список, задающий значения
адресов размещения указателей внутри блока.
При вставке в таблицу трансляции адресов блока и/или его записей, только что
скопированных в память, положение блока в буфере памяти уже известно. Поэтому
включить в таблицу трансляции адреса памяти для загруженных элементов
несложно. Возможна ситуация, когда при попытке внесения в таблицу трансляции адреса
А базы данных выясняется, что этот адрес уже присутствует в таблице, поскольку
блок с адресом А загружался ранее. В этом случае достаточно заменить содержимое
указателя на Л в блоке, только что считанном в память, соответствующим адресом
памяти и присвоить биту "подмены" значение "истина". Если же адрес А еще не
вносился в таблицу трансляции, значит, блок с этим адресом прежде не считывался.
Поэтому указатель на А "подменить" нельзя и его адрес должен, как и раньше,
относиться к категории адресов в базе данных.
Если при попытке следования по указателю Р из некоторого блока выясняется, что
этот указатель не "подменен", т.е. ссылается на адрес в базе данных, необходимо
проверить, загружен ли в память блок Я, содержащий элемент, на который ссылается
указатель Р (иначе как "добраться" до адресуемого элемента?). Для этого надлежит
обратиться к таблице трансляции и удостовериться, поставлен ли в соответствие адресу Р
в базе данных определенный эквивалент оперативной памяти. Если нет, следует
скопировать блок В в буфер оперативной памяти, после чего "подменить" указатель Р,
заместив адрес в базе данных равнозначным адресом памяти.
"Подмена" по требованию
Альтернативный подход к использованию механизма "подмены" указателей
состоит в том, что после первоначальной загрузки блока в оперативную память содержимое
указателей остается прежним. В таблицу трансляции вносятся элементы,
представляющие адреса в базе данных и в памяти для блока, записей в блоке и указателей
в записях. Если требуется проследовать по адресу памяти, задаваемому некоторым
указателем Р, этот указатель преобразуется точно таким же образом, как и в случае
использования автоматической "подмены".
Различие между стратегиями автоматической трансляции и "подмены" по
требованию состоит в том, что первая подразумевает выполнение преобразования
содержимого всех указателей при загрузке блока в оперативную память. Возможная
экономия, получаемая при единовременной трансляции всех указателей в блоке, вероятно,
564
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
уравновешивается тем обстоятельством, что далеко не все "подмененные" указатели
будут использованы в дальнейшем. Иными словами, речь идет о лишних затратах
времени на преобразования, результаты которых просто не нужны.
Имеется и одна любопытная возможность, связанная с принятием соглашения о том,
чтобы адреса в базе данных трактовались как неверные адреса памяти. В этом случае
можно позволить системе обращаться по любому указателю, как если бы тот ссылался
на адрес памяти. Если указатель окажется не "подмененным", ссылка на неверный
адрес вызовет аппаратное прерывание. Если СУБД позволяет использовать функцию,
активизируемую прерыванием, и эта функция способна "подменить" указатель так, как
говорилось выше, системе удастся быстро проследовать по требуемому адресу,
осуществляя действия по трансляции адресов только тогда, когда это действительно необходимо.
Запрет "подмены"
Разумеется, можно не обращаться к механизму "подмены" указателей вовсе.
В этой ситуации таблица трансляции, однако, все еще необходима, и проследовать по
указателям можно и в их "обычной" (не "подмененной") форме. Подобный подход
обладает тем преимуществом, что позволяет избежать возможности появления
записей, "закрепленных" в памяти (подробнее об этом — в разделе 12.3.5 на с. 566), и
необходимости принятия решений о форме представления указателей.
Программное управление механизмом "подмены" указателей
В некоторых ситуациях программист, создающий приложение, может загодя знать
о том, когда и какие указатели в блоке будут востребованы, и позаботиться об их
принудительной "подмене" в процессе загрузки блока в оперативную память либо по
специальному требованию. Например, если заранее известно, что информация
загружаемого блока (скажем, корневого блока В-дерева — за подробностями обращайтесь
к разделу 13.3 на с. 609) будет активно использоваться, указатели наверняка удобнее
"подменить" сразу. Однако указатели в блоках, которые после считывания
используются только однократно, вероятно, имеет смысл оставлять в исходном виде и
транслировать исключительно при необходимости.
12.3.4. Сохранение блоков на диске
Если блок данных в памяти необходимо сохранить на диске, содержимое всех
указателей внутри блока следует преобразовать в "обратном" направлении, т.е. адреса
памяти заменить соответствующими адресами в базе данных. Таблица трансляции,
связывающая адреса обоих типов, может использоваться, разумеется, и для отыскания
адресов в базе данных по задаваемым адресам памяти. Однако было бы
нецелесообразно осуществлять просмотр таблицы трансляции целиком при необходимости
выполнения каждой операции, обратной по отношению к "подмене" указателей. Хотя
мы еще не обсуждали варианты реализации таблицы трансляции, в данном случае
достаточно полагать, что таблица, аналогичная приведенной на рис. 12.8 (см. с. 562),
обладает соответствующими индексами. Если воспринимать таблицу трансляции в
виде отношения, задача отыскания адреса памяти по заданному адресу х в базе данных
может быть сведена к обработке запроса
SELECT memAddr
FROM TranslationTable
WHERE dbAddr = x;
В этом случае подходящим решением было бы создание индекса по атрибуту dbAddr
в форме хеш-таблицы, в которой функцию ключей выполняют адреса в базе данных
(в главе 13 на с. 583 вы познакомитесь и со многими другими структурами данных,
применяемыми при конструировании индексов).
12.3. ПРЕДСТАВЛЕНИЕ АДРЕСОВ ЗАПИСЕЙ И БЛОКОВ
565
Если необходимо, чтобы система эффективно поддерживала и обратные запросы вида
SELECT dbAddr
FROM TranslationTable
WHERE memAddr = y;
уместным окажется индекс по атрибуту memAddr. В разделе 12.3.5 мы расскажем
о структурах связанных списков, которые при некоторых обстоятельствах могут
успешно применяться для поиска по значению адреса памяти всех указателей в буферах
оперативной памяти, ссылающихся на этот адрес.
12.3.5. "Закрепленные" записи и блоки
Говорят, что блок "закреплен" (pinned) в памяти, если его нельзя безопасно
сохранить на диске, не предпринимая дополнительных действий. В заголовке блока может
быть предусмотрен специальный бит, свидетельствующий о том, "закреплен" блок
или нет. Причины, обусловливающие возможность "закрепления" блока в памяти,
разнообразны; в качестве примера можно назвать необходимость поддержки
требований, выдвигаемых подсистемой восстановления данных (подробнее — в главе 17 на
с. 837). Другим немаловажным основанием для "закрепления" некоторого блока
является наличие ссылок на элементы этого блока со стороны "подмененных" указателей
(см. раздел 12.3.3 на с. 561) других блоков.
Если блок Вх содержит "подмененный" указатель, адресующий некоторый элемент
данных блока Въ к вопросу перемещения на диск блока В2 и очистки принадлежащего
ему буфера оперативной памяти следует подходить весьма взвешенно. Если не
принять защитных мер, указатель в Вх (если вдруг придется им воспользоваться) приведет
систему к буферу, в котором блока В2 уже нет — последствия могут оказаться далеко
идущими и самыми печальными. Таким образом, блок (подобный В2), адресуемый
извне, приобретает статус "закрепленного".
Предпринимая попытку сохранения блока памяти на диске, необходимо не только
транслировать обратно принадлежащие блоку "подмененные" указатели, но и
удостовериться в том, что блок не является "закрепленным". Если блок "закреплен",
следует либо устранить причины, которые привели блок в это состояние, либо оставить
блок на месте (разумеется, согласившись с тем, что буфер памяти, отведенный под
блок, нельзя будет использовать для других целей). Чтобы избавить блок от признака
"закрепления", установленного в связи с наличием внешних "подмененных"
указателей, ссылающихся на элементы блока, необходимо осуществить обратное
преобразование содержимого этих указателей. Следовательно, в таблице трансляции для
каждого адреса в базе данных, которому отвечает определенный элемент в памяти,
следует сохранять и адреса памяти, по которым размещены "подмененные" указатели,
адресующие этот элемент. С этой целью применяются два подхода.
1. Поддерживать перечень ссылок на адреса памяти в виде связанного списка,
поставленного в соответствие тому или иному элементу таблицы трансляции.
2. Если адреса памяти существенно короче адресов в базе данных, создать
связанный список в пространстве, используемом для размещения указателя, т.е.
расположить в области указателя на адрес в базе данных
a) "подмененный" указатель;
b) другой указатель, являющийся частью связанного списка указателей,
ссылающихся на один адрес памяти.
На рис. 12.10 проиллюстрирован способ связывания в список всех указателей,
ссылающихся на адрес у памяти, начиная с элемента таблицы трансляции, ставящего
в соответствие адресу х в базе данных адрес у.
566
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
Таблица трансляции
Рис. 12.10. Представление связанного
списка указателей, адресующих один
адрес памяти
12.3.6. Упражнения к разделу 12.3
* Упражнение 12.3.1. Если необходимо представить физические адреса структурных
элементов носителей дискового привода модели "Megatron 747" (см. пример 11.3
на с. 503), выделив отдельные байты для описания каждого цилиндра, дорожки
цилиндра и блока внутри цилиндра, сколько байтов для этого может
потребоваться? Примите к сведению максимально возможное количество блоков в дорожке
и учтите, что соотношение числа секторов в расчете на одну дорожку варьируется.
Упражнение 12.3.2. Выполните задание упражнения 12.3.1 применительно к
параметрам дискового устройства "Megatron 777", которые представлены в упражнении
11.3.1 нас. 509.
Упражнение 12.3.3. Если наряду с описанием адресов блоков необходимо
представить адреса записей внутри блоков, потребуются дополнительные байты. Полагая,
что, как и в упражнении 12.3.1, рассматривается дисковое устройство
"Megatron 747", ответьте, сколько байтов следует отвести для адресов записей, если:
* а) в состав физического адреса включить номер байта внутри блока;
Ь) для ссылки на записи использовать структурированные адреса, полагая, что
каждой записи ставится в соответствие ключ, задаваемый в виде 4-байтового
целого числа.
Упражнение 12.3.4. Для представления адреса компьютера в соответствии с
требованиями протокола IP в его сегодняшней версии требуется 4 байта.
Предположим, что адрес блока дисковых данных в системе, открытой для доступа из
Internet, состоит из IP-адреса компьютера, номера дискового устройства из
интервала 1—1000 и адреса блока на конкретном устройстве (речь идет о дисковом
приводе модели "Megatron 747" — см. пример 11.3 на с. 503). Насколько
длинным окажется полный адрес блока?
Упражнение 12.3.5. В соответствии с условиями протокола IP версии 6 размер IP-
адреса компьютера составляет 16 байт. Требуется обращаться не только к
дисковым блокам, но и к отдельным записям переменной длины, которые могут
располагаться внутри блоков произвольным образом. Помимо того, допускается, что
дисковые устройства способны обладать собственными IP-адресами, что исключает
необходимость представления устройства как составной части компьютерной
системы. Сколько байтов необходимо для описания адресов записей дисковых блоков,
расположенных на носителях дисковых приводов "Megatron 747"?
12.3. ПРЕДСТАВЛЕНИЕ АДРЕСОВ ЗАПИСЕЙ И БЛОКОВ
567
! Упражнение 12.3.6. Предположим, что адреса блоков данных на носителях
дискового устройства "Megatron 747" следует представлять логическим образом, т.е.
используя идентификаторы размером к байт (для некоторого целочисленного к),
и сохранять на диске таблицу соответствий (подобную приведенной на рис. 12.6 —
см. с. 560), которая содержит пары логических и физических адресов. Блоки,
отводимые под таблицу соответствий, не являются частью базы данных и поэтому не
имеют в таблице соответствий собственных логических адресов. Полагая, что
физические адреса состоят из минимально допустимого количества байтов (вы
должны были определить это значение в упражнении 12.3.1) и длина логических
адресов также настолько мала, насколько это возможно, ответьте, сколько блоков
объемом 4096 байт потребуется для хранения таблицы соответствий?
*! Упражнение 12.3.7. Рассмотрим блок размером в 4096 байт, в котором требуется
хранить записи длиной 100 байт. Заголовок блока состоит из таблицы смещений
(см. рис. 12.7 на с. 561), содержащей 2-байтовые указатели на записи внутри блока.
Предположим, что в продолжение одного дня в среднем две записи добавляются
в блок и одна удаляется из блока. После удаления записи соответствующий
указатель в таблице смещений заменяется признаком-"обелиском", чтобы внешние
указатели (если таковые имеются), ссылающиеся на запись, не стали "висящими".
Будем считать, что операция удаления всегда выполняется перед операциями
вставки. Если изначально блок пуст, по истечении какого количества дней он
заполнится настолько, что осуществить вставку новой записи не удастся?
! Упражнение 12.3.8. Выполните задание упражнения 12.3.7 при условии, что
ежедневно в блок вставляется в среднем 1,1 записи и одна запись удаляется.
Упражнение 12.3.9. Выполните задание упражнения 12.3.7 при условии, что вместо
удаления осуществляется операция перемещения записи в другой блок, в ячейку
таблицы смещений заносится "длинный" 8-байтовый адрес и
! а) каждый элемент таблицы смещений занимает максимальный требуемый объем;
!! Ь) длина элементов таблицы смещений способна варьироваться с сохранением
возможности отыскания и корректной интерпретации любого элемента.
* Упражнение 12.3.10. Предположим, что процесс автоматической "подмены"
указателей занимает половину времени, которое потребовалось бы в том случае,
если бы каждый указатель "подменялся" отдельно и независимо от других. Если
вероятность того, что указатель в памяти будет востребован по меньшей мере один
раз, равна р, при каких значениях р процесс автоматической "подмены" окажется
более эффективным в сравнении с механизмом "подмены" по требованию?
! Упражнение 12.3.11. Распространим условие упражнения 12.3.10 на тот случай,
когда "подмена" указателей может быть запрещена. Пусть продолжительность
выполнения основных операций исчисляется следующими значениями,
выраженными в некоторых условных единицах:
i) "подмена" указателя по требованию — 30;
и) автоматическая "подмена" в расчете на один указатель — 20;
ш) обращение по "подмененному" указателю — 1;
iv) обращение по указателю, который не был "подменен", — 10.
Предположим, что каждый указатель должен быть востребован к раз с
вероятностью р либо не использован вовсе (вероятность — 1 -р). При каких значениях к и р
стратегии автоматической "подмены", "подмены" по требованию и запрета
"подмены" демонстрируют наивысшую среднюю эффективность?
568
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
12.4. Элементы данных и записи переменной длины
До сих пор мы следовали упрощенным предположениям, будто каждый элемент
данных обладает неизменной длиной, все записи описываются фиксированными
схемами и каждая запись представляет собой список полей постоянного размера. На
практике, однако, все далеко не так гладко. Вполне правдоподобны ситуации, когда
приходится иметь дело со следующими объектами и условиями.
1. Элементы данных переменного размера. Например, на рис. 12.1 (см. с. 550)
приводилось объявление отношения MovieStar с атрибутом-полем address, длина
которого способна достигать 255 байт. Некоторые строки адресов действительно
могут быть настолько длинны, но в подавляющем большинстве случаев их
размер составит, вероятно, 50 байт или менее. Если отводить под каждый адрес
ровно столько байт, сколько требуется, нам удастся более чем вдвое сократить
пространство, необходимое для хранения содержимого отношения.
2. Повторяющиеся поля. При необходимости представления в рамках записи,
отвечающей некоторому объекту, связи вида "многие ко многим" следует сохранять
в записи такое количество ссылок, какое соответствует числу объектов,
адресуемых текущим объектом.
3. Записи переменного формата. В определенных ситуациях предварительная
информация о количестве экземпляров полей в записи или номенклатуре полей
заведомо отсутствует. Например, некоторые киноактеры одновременно являются и
режиссерами, поэтому, возможно, потребуется пополнить записи со сведениями об
актерах ссылками на снятые ими кинофильмы. Помимо того, нередки случаи, когда
актеры выполняют и функции продюсеров или руководителей киностудий —
подобная информация также не окажется лишней. Поскольку, однако, большинство
актеров все-таки не являются ни режиссерами, ни продюсерами/руководителями,
резервировать соответствующее пространство под подобную информацию в
каждой записи, представляющей данные об актере, разумеется, не целесообразно.
4. Поля типа "BLOB". Современные СУБД поддерживают атрибуты, значениями
которых могут быть весьма крупные порции данных. Например, в каких-то
случаях уместным окажется включение в схему отношения MovieStar атрибута
picture, предназначенного для хранения фотографии актера в формате GIF.
Запись со сведениями о кинофильме вполне способна содержать поле с
данными объемом в несколько гигабайт, представляющими кодированную версию
кинофильма в формате MPEG. Подобные поля настолько велики, что модель,
предполагающая возможность размещения нескольких записей в пределах
блока, подлежит кардинальному пересмотру.
12.4.1. Записи с полями переменной длины
Если одно или несколько полей записи обладают переменной длиной, запись, тем
не менее, должна содержать информацию, необходимую и достаточную для
отыскания любого из полей. Одна из простых и вместе с тем эффективных схем
предусматривает размещение всех полей постоянного размера в начале записи, а всех других
полей — в конце. Заголовок записи должен содержать:
1) значение длины записи;
2) адреса (смещения) первых байтов всех полей переменного размера; если
такие поля всегда располагаются в пределах записи в одном и том же порядке,
первое из них не нуждается в указателе — ясно, что оно следует
непосредственно после группы полей постоянной длины.
12.4. ЭЛЕМЕНТЫ ДАННЫХ И ЗАПИСИ ПЕРЕМЕННОЙ ДЛИНЫ
569
Пример 12.8. Рассмотрим запись, представляющую сведения об имени (name),
адресе (address), половой принадлежности (gender) и дате рождения (birthdate)
актера. Будем полагать, что gender и birthdate являются полями постоянной
длины — 1 и 12 байт соответственно. Под атрибуты name и address, однако, уместно
отводить поля такой длины, какая необходима в каждом конкретном случае. На
рис. 12.11 показана схема, иллюстрирующая запись указанного формата. Если поле
имени всегда располагать перед полем адреса, можно обойтись без указателя на
первый байт имени, поскольку в соответствии с принятым нами соглашением поля
переменной длины располагаются непосредственно после постоянной части записи.
Другая информация заголовка
Длина записи
Смещение поля address
gender
ЫтЫ
birthdate1 name
address
J
□
Рис. 12.11. Запись типа MovieStar с компонентами name
и address, реализованными в виде полей переменной длины
12.4.2. Записи с повторяющимися полями
Ситуация, схожая с рассмотренной в разделе 12.4.1, имеет место и в том случае,
если запись содержит переменное количество экземпляров поля некоторого типа F,
но само это поле обладает фиксированным размером. Удобно объединить все
вхождения поля F в одну группу и включить в заголовок записи указатель, адресующий
первый элемент группы. Для отыскания произвольного экземпляра поля F достаточно
выполнить следующее. Обозначим количество байтов, отводимых для поля F, как L,
а значение смещения группы полей F — как S. Тогда смещение экземпляра поля
с номером к, где к = О, 1, 2,..., равно S + к* L.
Другая информация заголовка
1
1 : 1
Дли
' : '
на записи
Смещение поля address
Смещение группы повторяющихся полей
1
И1
И ;
• name • address •
t f
1 i
Указатели на записи Movie
Рис. 12.12. Пример записи с группой повторяющихся полей
Пример 12.9. Пусть необходимо изменить структуру записи типа MovieStar таким
образом, чтобы сохранить поля name и address и обеспечить представление информации
о кинофильмах с участием актера. На рис. 12.12 приведена схема, иллюстрирующая один
из способов компоновки подобной записи. Заголовок записи содержит указатели на
первый байт поля address (мы полагаем, что поле name размещается непосредственно
570
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
Представление значений null
Кортежи отношений нередко содержат компоненты со значениями null. Эти
значения удобно представлять в формате записи, показанном на рис. 12.11. Если в
поле, подобное address, надлежит занести значение null, достаточно разместить
в поле заголовка с указателем на address нулевой указатель — область под
содержимое address не понадобится вовсе и затраты будут связаны только с
необходимостью хранения указателя в заголовке. Подобный подход обеспечивает
существенную экономию в среднем — он обладает преимуществами даже в тех случаях,
когда поле address обладает постоянной длиной, но его содержимое зачастую
оказывается неопределенным.
после заголовка и поэтому в указателе не нуждается) и на первый из указателей,
адресующих записи типа Movie, — известное значение длины записи позволяет
вычислить их количество. □
Альтернативный подход состоит в сохранении постоянной части записи в ее
изначальном виде и перемещении варьируемой порции данных — полей переменной длины и/или
группы повторяющихся полей — в отдельный блок. Исходная запись должна содержать
1) адреса каждого из "вынесенных" полей;
2) количество подобных полей либо, если поля различны, значения их длин.
На рис. 12.13 показан иной вариант компоновки записи, рассмотренной в примере
12.9: поля name и address переменной длины, а также группа повторяющихся полей-
указателей на записи Movie перенесены в отдельный блок или несколько блоков.
Рассмотренный прием, предусматривающий распределение постоянной и
переменной частей записи по различным блокам, обладает как преимуществами, так
и недостатками:
• равенство длин записей позволяет ускорить процессы поиска, уменьшить
размеры заголовков и упростить задачи перемещения записей внутри блоков
и между различными блоками;
• хранение переменных частей записей в отдельных блоках, однако, приводит
к увеличению количества операций ввода-вывода, необходимых для просмотра
содержимого каждой записи в целом.
Компромиссное решение заключается в том, чтобы выделить в рамках порции
записи постоянной длины такую область, емкости которой достаточно для представления
1) некоторого "разумного" количества копий повторяющихся полей;
2) указателя, адресующего место размещения дополнительных экземпляров полей;
3) счетчика дополнительных экземпляров полей.
Если количество полей окажется меньшим, чем было предусмотрено, некоторая часть
области просто не будет использована по назначению. Если же число дополнительных
полей возрастает, указателю в основной записи присваивается соответствующее
ненулевое значение, задающее адрес размещения полей во внешнем блоке.
12.4.3. Записи переменного формата
Значительно более сложная ситуация связана с использованием записей, структура
которых не отвечает заранее оговоренной постоянной схеме: например, размерности
полей и/или порядок их следования в пределах записей не полностью определяются
12.4. ЭЛЕМЕНТЫ ДАННЫХ И ЗАПИСИ ПЕРЕМЕННОЙ ДЛИНЫ
571
объявлениями отношения или класса, кортежи или объекты которых представляются
такими записями. В простейшем варианте записи переменного формата для описания
каждого поля предусматривается применение последовательности тэгов (tagged fields),
каждый из которых предназначен для хранения
1) сведений о функциональном назначении поля, как-то:
a) имя поля или атрибута;
b) наименование типа поля, если эти данные нельзя получить на основе
других элементов схемы;
c) значение длины поля, если это значение непосредственно не определяется
информацией о типе поля;
2) значения поля.
Информация заголовка
Указатель на поле name
Длина поля name
Указатель на поле address
Длина поля address
Адрес группы указателей
Количество указателей
Дополнительное пространство
Указатели на записи Movie
Рис. 12.13. Схема распределения постоянной и переменной частей
записи по разным блокам
Можно указать по меньшей мере две причины, обусловливающие целесообразность
использования полей тэгов.
1. Распространенность приложений интеграции информации. Нередко отношения
конструируются на основе традиционных источников информации
разнообразных типов (за подробностями обращайтесь к разделу 20.1 на с. 1003). Например,
сведения о кинофильмах и актерах, поступающие в централизованную базу
данных, могут быть получены от различных поставщиков информации, одни из
которых предусматривают необходимость хранения данных о датах рождения
актеров, другие это требование игнорируют, третьи предоставляют сведения об
адресах в произвольном формате, а четвертые придерживаются четко оговоренной
структуры и т.д. Если полей не много, возможно, удобнее заполнять значениями
null те из них, содержимое которых не определено. Если же количество и
номенклатура типов полей чрезмерно велики, значения null придется использовать
572
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
слишком часто — лучше сэкономить пространство и воспользоваться структурой
полей тэгов, представляющих только такие значения, которые отличны от null.
2. Использование записей свободного формата. Если запись содержит большое
количество полей и многие из них часто не используются либо перечисляются
в произвольном порядке, структуры полей тэгов обладают существенными
преимуществами: например, в личных карточках пациентов медицинских
учреждений может содержаться информация о различных тестах и анализах, количество
разновидностей таких тестов исчисляется тысячами, но только некоторые из
них применяются при обследовании каждого конкретного пациента.
Пример 12.10. Предположим, что наряду с обычными сведениями об актерах имеются
отдельные порции информации о том, в каких фильмах тот или иной актер выступал
в амплуа режиссера, как звали прежних жен (мужей) актеров (актрис), каким
бизнесом занимаются актеры (являются ли они, например, владельцами ресторанов или
магазинов) и т.п. На рис. 12.14 изображен фрагмент гипотетической записи
переменного формата с использованием тэгов. Подразумевается, что имена полей и названия
их типов описываются однобайтовыми кодами. На схеме показаны два поля с
соответствующими тэгами; оба поля относятся к строковому типу.
Код имени
| Код строкового типа
(Длина
I
Код ресторанного бизнеса
| Код строкового типа
(Длина
I
14
Clint Eastwood
16
Hog's Breath Inn
Рис. 12.14. Структура записи с полями тэгов
12.4.4. Записи крупного объема
Теперь мы обсудим проблему иного рода, значимость которой возрастает по мере
распространения СУБД, поддерживающих крупноформатные типы данных: мы
расскажем о способах представления значений, размер которых заведомо превышает
объем блока. Типичные примеры таких данных — фрагменты аудио- или видеозаписей.
Зачастую элементы подобной информации обладают еще и переменной длиной, но
даже если длина фиксирована, все равно для представления таких значений требуются
особые приемы. В этом разделе мы сосредоточим внимание на модели связанных
записей — удобном механизме управления записями, которые не умещаются в пределах
блоков. Вопросам представления записей сверхбольших размеров, исчисляемых
мегабайтами или гигабайтами, посвящен раздел 12.4.5.
Модель связанных записей обладает преимуществами и в тех случаях, когда
размеры записей не превышают объем блока, но при группировании записей в блоки
теряются большие фрагменты пространства памяти. В примере 12.6 (см. с. 558) в
аналогичной ситуации, связанной с размещением записей в блоке, размер неиспользуемой
области составлял около 7% от общего объема блока, но если предположить, что
длина записи ненамного превосходит половину размера блока (в блок удается поместить
только одну запись), потери будут приближаться к отметке 50%.
Для преодоления указанных выше проблем желательно иметь возможность
расщепления записей по нескольким блокам. Записи, состоящие из фрагментов,
разнесенных по нескольким блокам, принято называть связанными (spanned records).
Если записи допускают связывание, для описания каждой записи и ее отдельных
фрагментов требуется включить в их заголовки дополнительную информацию:
12.4. ЭЛЕМЕНТЫ ДАННЫХ И ЗАПИСИ ПЕРЕМЕННОЙ ДЛИНЫ
573
1) заголовок каждой записи и фрагмента должен хранить отдельный бит,
удостоверяющий, является ли порция данных фрагментом записи;
2) заголовок фрагмента следует пополнить битами, свидетельствующими
о том, что фрагмент является первым (последним) в цепочке связанных
фрагментов записи;
3) заголовок фрагмента записи обязан содержать указатели на предыдущий
и/или следующий фрагменты.
Пример 12.11. На рис. 12.15 показана схема распределения трех записей по двум
блокам (размер одной записи составляет около 60% от объема блока). Заголовок
фрагмента 2а записи 2 содержит бит-индикатор фрагмента, бит, указывающий на то, что
фрагмент является первым, и указатель на второй (2Ь) фрагмент записи 2.
Аналогично, заголовок фрагмента 2Ь включает бит-индикатор фрагмента, бит-признак
завершающего фрагмента и указатель на первый (2а) фрагмент записи 2.
Заголовок блока
Заголовок записи
Запись 1
Запись
2а
Запись
2Ь
Запись 3
Блок 1 Блок 2
Рис. 12.15. Пример распределения связанных записей по блокам
12.4.5. Объекты BLOB
Теперь рассмотрим способы представления записей или полей сверхбольших
размеров. Примерами подобных данных могут служить графические изображения
различных форматов (скажем, GIF или JPEG), фрагменты видеозаписей (например,
в кодировке MPEG), разнообразная аудиоинформация, сигналы радаров и т.д.
Элементы такой информации принято обозначать аббревиатурой BLOB (от Binary Large
Objects — "крупные двоичные объекты"). Прежде чем приступать к работе с
объектами BLOB, следует переосмыслить подходы к решению по меньшей мере двух
основных задач, рассмотренных ниже.
Хранение объектов BLOB
Объект BLOB должен сохраняться в виде последовательности блоков. Зачастую
предпочтительно размещать блоки, относящиеся к одному объекту, на одном цилиндре
или нескольких соседних цилиндрах, чтобы оптимизировать операции считывания
данных. Впрочем, вполне возможно хранить объект и в виде связанного списка блоков.
В определенных ситуациях объект BLOB должен считываться настолько быстро
(например, для обеспечения возможности воспроизведения видеофильма в
реальном масштабе времени), что при размещении его на одном дисковом устройстве
приемлемой скорости достичь не удается. Одним из решений такой проблемы
является попеременное распределение соседних блоков объекта по нескольким дискам
(disk striping). В этом случае группа блоков может считываться одновременно,
и скорость операции возрастает, грубо говоря, пропорционально количеству
используемых дисковых устройств.
574
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
Извлечение объектов BLOB
Естественное требование о том, что блок данных, запрошенный клиентом, должен
возвращаться системой целиком, при возрастании размеров элементов данных подлежит
радикальному пересмотру: можно полагать, что система должна передавать
единовременно и полностью только "небольшие" значения полей записей и позволять клиенту
запрашивать отдельные блоки объекта BLOB, по одному в каждый момент времени и
независимо от наличия оставшихся блоков. Например, если объект BLOB представляет
двухчасовой кинофильм и клиент выдает запрос на его воспроизведение, система должна
считывать и передавать клиенту последовательные блоки объекта с достаточной скоростью.
Во многих случаях важно, чтобы клиенту была предоставлена возможность
считывания отдельных порций данных (скажем, титров кинофильма или финальной части
аудиоклипа) независимо от порядка их расположения "внутри" объекта и без
необходимости загрузки объекта целиком. Если система поддерживает подобные операции,
ей, вероятно, требуются удобные структуры индексных значений (например,
указывающих на начало каждого секундного фрагмента видеофильма).
12.4.6. Упражнения к разделу 12.4
* Упражнение 12.4.1. Предположим, что карточка пациента лечебного учреждения
включает дату рождения, номер полиса социального страхования и
идентификатор — под каждое поле фиксированного размера отводится по 10 байт. Запись
содержит также поля переменной длины, предназначенные для хранения строк
имени, адреса и сведений об истории болезни. Если каждый указатель внутри записи
и счетчик длины записи занимают по 4 байта, а требование выравнивания полей
не выдвигается, каким окажется размер записи без учета области, необходимой для
хранения содержимого полей переменной длины?
* Упражнение 12.4.2. Предположим, что структура записи отвечает условиям
упражнения 12.4.1, но размеры содержимого полей переменной длины равномерно
распределены в следующих интервалах: имя — 10—50 байтов, адрес — 20—80 байтов, история
болезни — 0—1000 байтов. Какова средняя длина записи с информацией о пациенте?
Упражнение 12.4.3. Предположим, что структура записи со сведениями о пациенте
лечебного учреждения, рассмотренная в упражнении 12.4.1, дополнена
повторяющимися полями, отображающими результаты анализов на наличие холестерина в крови.
Каждое такое поле требует 16 байт для представления даты проведения и
целочисленного результата анализа. Предложите варианты компоновки карточки пациента, если
a) повторяющиеся поля с результатами анализов содержатся непосредственно
в самой записи;
b) результаты сохраняются в отдельных блоках, а в запись включаются
указатели на них.
Упражнение 12.4.4. Пусть в запись со структурой, предложенной в упражнении
12.4.1, необходимо добавить поля с описанием названий анализов, дат их
проведения и полученных результатов. Каждая тройка полей, представляющих данные
одного анализа, занимает 40 байт. Предположим, что вероятность прохождения
каждым пациентом любого из тестов равна р.
a) Если для хранения указателя и целого значения требуется по 4 байта, а все
данные анализов сохраняются внутри записи в виде полей переменной
длины, каково среднее количество байтов, отводимых под описания
анализов одного пациента?
b) Выполните задание п. (а), если результаты анализов хранятся вне записи,
а запись содержит соответствующие указатели.
12.4. ЭЛЕМЕНТЫ ДАННЫХ И ЗАПИСИ ПЕРЕМЕННОЙ ДЛИНЫ
575
! с) Предположим, что используется компромиссное решение: в записи отведена
область, достаточная для хранения результатов к анализов, а информация
о дополнительных анализах, если таковые проводятся, располагается в
дополнительных блоках, адреса которых описываются указателями внутри основной
записи. При каком значении к, выраженном в виде функции от р, достигается
минимум объема памяти, необходимой для хранения результатов анализов?
!! d) Минимизация величины области памяти, требуемой для хранения
повторяющихся полей с результатами анализов, — это не единственная проблема.
Предположим, что целевой функционал, подлежащий минимизации, представляет
собой количество байтов с учетом штрафа в 10000 единиц, если результат
отдельного анализа приходится выносить вовне (что влечет необходимость
выполнения лишней операции ввода-вывода для доступа к дополнительному
блоку). Каково оптимальное значение функции к, зависящей от р, в этом случае?
*!! Упражнение 12.4.5. Предположим, что в каждом блоке имеется свободная область
размером 1000 байт, доступная для размещения записей фиксированной длины г,
где 500 < г < 1000. В значение г включена длина заголовка записи, но если запись
расщепляется на связанные фрагменты, каждый из них требует дополнительно по
16 байт под собственный заголовок. При каких значениях г достигается оптимум
функции расходования пространства памяти?
!! Упражнение 12.4.6. Объем видеофильма в формате MPEG составляет около 1 Гбайт
в пересчете на один час воспроизведения. Если тщательно продумать способ
размещения данных нескольких фильмов на носителях дискового привода
"Megatron 747" (сведения о котором приведены в примере 11.5 на с. 506), сколько
фильмов можно воспроизводить одновременно с минимальной задержкой (скажем,
100 миллисекунд), считывая информацию с одного такого устройства? Предложите
соответствующий вариант компоновки данных.
12.5. Модификация записей
Операции вставки, удаления и обновления записей данных создают
специфические проблемы, заслуживающие особого внимания. Проблемы приобретают наиболее
серьезный характер, если изменяется длина записей, хотя подчас возникают и тогда,
когда записи и поля имеют постоянные размеры.
12.5.1. Вставка
Для начала рассмотрим операцию вставки новых кортежей в отношение (или, что
почти то же самое, объектов в текущий экземпляр класса). Если записи,
представляющие содержимое отношения, хранятся в произвольном порядке, достаточно
просто найти некоторый блок со свободной областью, достаточной для размещения
дополнительных записей, либо, если такового нет, затребовать новый блок. Обычно
системы баз данных поддерживают некий механизм эффективного поиска всех блоков,
содержащих кортежи определенного отношения или объекты указанного класса, но
обсуждение тонких моментов такого механизма мы отложим до раздела 13.1 на с. 584.
Проблема усугубляется, если кортежи должны следовать в некотором заданном
порядке (таком, какой обеспечивается, например, сортировкой отношения по значениям
компонентов первичного ключа). Существует немало серьезных доводов в пользу
хранения записей в упорядоченном виде, поскольку в этом случае существенно
упрощается обработка запросов определенных категорий (подробнее — в том же разделе 13.1
на с. 584). При необходимости вставки новой записи система должна прежде всего
определить местонахождение блока, в который следовало бы поместить эту запись,
в надежде, что блок содержит требуемую свободную область. Поскольку записи долж-
576
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
ны удовлетворять заданному порядку следования, системе, возможно, придется
сдвинуть записи внутри блока, чтобы освободить пространство достаточного объема.
Если необходимо осуществить сдвиг записей внутри блока, структура,
предложенная на рис. 12.7 и воспроизведенная на рис. 12.16, придется весьма кстати. Напомним
один из аспектов, о котором мы говорили в разделе 12.3.2 на с. 560: в заголовок блока
может быть включена таблица смещений (offset table), содержащая указатели на первые
байты каждой записи внутри блока. Если указатель ссылается на запись за пределами
блока, он должен содержать структурированный адрес (structured address), состоящий
из адреса другого блока и адреса элемента заголовка этого блока, в котором хранится
значение смещения требуемой записи.
j-*- Заголовок -►:
Таблица
; смещений
Свободная
область
ш
ш
Запись 4
*
Запись 3
1
Запись
2
А
Запись 1
i
Рис. 12.16. Таблица смещений облегчает задачу передвижения
записей внутри блока с целью освобождения места для новой записи
Если пространства для новой записи в текущем блоке достаточно, записи
сдвигаются и указатели в таблице смещений получают обновленные адресные значения,
после чего запись вставляется в освобожденное место блока и в таблицу смещений
добавляется новый указатель, ссылающийся на адрес первого байта вставленной записи.
Если же места для новой записи в блоке нет, подыскивается позиция для ее вставки
за пределами блока. Существуют два основных подхода к решению подобной задачи
и ряд их комбинированных вариантов.
1. Найти место в "ближайшем" блоке. Например, если в соответствии с заданным
порядком следования записей новая запись подлежит вставке в блок Яь а
достаточного свободного пространства в нем нет, надлежит обратиться к очередному по
порядку блоку В2. Если блок В2 обладает свободным фрагментом требуемого размера,
следует переместить одну или несколько записей с наивысшими номерами из
блока Вх в Въ сдвинуть записи в обоих блоках и присвоить указателям в таблице
смещений Яь ссылавшимся на записи, перенесенные в блок Въ "длинные"
структурированные адреса соответствующих элементов таблицы смещений блока В2.
В этом случае, разумеется, размер области таблицы смещений блока Вх возрастает.
2. Создать блок переполнения. В заголовке каждого блока В следует предусмотреть
место для специального указателя, адресующего дополнительный блок
переполнения (overflow block), предназначенный для хранения записей, которые должны
были бы принадлежать блоку В, но в нем не уместились. Один блок
переполнения, связанный с блоком В, способен ссылаться на следующий блок
переполнения и т.д. Структура показана на рис. 12.17.
12.5.2. Удаление
При удалении записи появляется возможность повторного использования
освобождаемого фрагмента пространства блока. Если применяется структура блока,
показанная на рис. 12.16, и записи способны сдвигаться в пределах блока, системе удастся
легко оптимизировать расположение записей, чтобы очистить область в середине блока.
12.5. МОДИФИКАЦИЯ ЗАПИСЕЙ
577
J—
J
Блок В Блок переполнения
для блока В
Рис. 12.17. Основной блок и
соответствующий блок переполнения
Если сдвиг записей выполнять нельзя, система должна поддерживать некий список
неиспользуемых фрагментов блока, дабы при вставке новой записи было ясно,
обладает ли блок достаточным свободным пространством и, если ответ положителен, где
именно расположены доступные участки и насколько они велики. Список свободных
областей не обязательно следует хранить в заголовке блока — достаточно разместить
здесь только головной элемент-указатель связанного списка, а остальные элементы
располагать непосредственно в свободных областях — во многом подобно тому, как
показано на рис. 12.10 (см. с. 567).
Удаление записи иногда приводит к тому, что надобность в использовании блока
переполнения отпадает. Если запись изымается из блока В либо из любого блока,
принадлежащего цепочке связанных блоков переполнения, относящихся к блоку Я,
система вправе подсчитать общий объем используемых областей всех блоков цепочки.
Если для размещения записей удастся использовать меньшее количество блоков,
система способна принять решение о реорганизации структуры блоков.
Однако какая из схем представления записей в блоках ни была бы выбрана, не
следует забывать об одной проблеме, всегда сопутствующей операции удаления
записей. Вполне возможно наличие внешних указателей, адресующих удаляемую запись,
и если подобные указатели действительно существуют, было бы неправильным
оставить их в неопределенном ("висящем") состоянии либо позволить ссылаться на
новую запись, которая, вероятно, со временем будет вставлена в блок взамен удаленной.
Обычная практика, о которой мы вкратце рассказывали в разделе 12.3.2 на с. 560,
предусматривает размещение специального признака- "обелиска " (tombstone) на
позиции, которую занимала удаленная запись. Признак должен находиться здесь до
момента полной реконструкции базы данных.
Где именно располагается признак-"обелиск" — это зависит от природы
указателей на запись. Если указатели адресуют некоторые фиксированные позиции, на
которых размещаются другие указатели, ссылающиеся на запись, признаки-"обелиски"
размещают на названных фиксированных позициях. Рассмотрим два примера.
1. Как упоминалось в разделе 12.3.2 на с. 560, если используется схема блока
с таблицей смещений записей (см. рис. 12.16 на с. 577), роль "обелиска" может
выполнять нулевой указатель в таблице смещений, поскольку внешние
указатели ссылаются именно сюда, а не на адрес записи непосредственно.
2. Если для трансляции логических адресов в физические применяется таблица
соответствий (см. рис. 12.6 на с. 560), признак-"обелиск" в виде нулевого
указателя располагается на месте физического адреса удаленной записи.
Если необходимо заменить признаком-"обелиском" саму запись, а не ссылку на нее,
целесообразно в самом начале заголовка записи предусмотреть специальный бит-
"обелиск", присваивая ему значение 0, если запись не удалена, и 1 — в противном
случае. После удаления записи бит должен оставаться на месте, но все последующие
байты освобожденного участка блока могут быть использованы для вставки новой
записи (как показано на рис. 12.18).85 Если система проследует по содержимому внеш-
Если поля записи подлежат выравниванию (см. раздел 12.2.1 на с. 554), одним байтом,
содержащим бит-"обелиск", отделаться не удастся — возможно, придется пожертвовать
четырьмя или более байтами.
578
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
него указателя, адресовавшего удаленную запись, первым делом она "увидит"
"обелиск", свидетельствующий о том, что запись удалена и считывать последующие
байты просто бессмысленно.
Запись 1
Запись 2
Рис. 12.18. При удалении записи 1 остается признак- "обелиск ";
запись 2 не помечена этим признаком и поэтому при обращении извне
может быть успешно считана
12.5.3. Обновление
Операция обновления содержимого записи постоянной длины не оказывает
влияния на структуру хранения, поскольку новые данные должны занимать то же
пространство, что и прежние. Однако при изменении значения записи переменной
длины система встретится с теми же проблемами (разве что за исключением
необходимости использования признаков-"обелисков"), которые сопутствуют операциям вставки
новых и удаления существующих записей.
Если объем нового содержимого записи превышает ранее установленные границы,
может потребоваться расширение свободной области блока за счет сдвига записей
внутри блока либо создания и использования блока переполнения. Если фрагменты
записи переменной длины сохраняются в отдельном блоке, как показано на рис. 12.13
(см. с. 572), системе, возможно, придется упорядочить элементы этого блока или
создать новый блок, предназначенный для хранения варьируемой порции данных
записи. Если же, напротив, объем содержимого записи уменьшается, система получает те
же возможности консолидации и повторного использования свободного пространства
блока либо удаления блоков переполнения, что и при удалении записи.
12.5.4. Упражнения к разделу 12.5
Упражнение 12.5.1. Предположим, что записи упорядочены по соответствующим
ключевым полям сортировки и в этой последовательности распределены по блокам.
Каждому блоку отвечает заранее известный диапазон значений ключей сортировки —
примером подобной ситуации может служить применение структуры разреженного
индекса (sparse index) (за подробностями обращайтесь к разделу 13.1.3 на с. 586).
Внешние указатели, способные адресовать записи, отсутствуют, поэтому при
необходимости записи могут свободно перемещаться внутри блоков и между блоками. Ниже
перечислены различные варианты реализации операций вставки и удаления записей.
i) При переполнении блока выполнить перераспределение записей по блокам
и соответствующим образом изменить диапазоны значений ключей
сортировки для каждого блока.
ii) Сохранять диапазоны значений ключей сортировки для каждого блока в
неизменном виде и в случае необходимости использовать цепочку блоков
переполнения. В каждом основном блоке и блоке переполнения поддерживать
таблицы смещений записей, принадлежащих этому блоку.
ш) То же, что в п. (ii), но общую таблицу смещений записей основного блока
и всех относящихся к нему блоков переполнения поддерживать в основном
блоке. Если для таблицы смещений требуется дополнительное пространство,
перенести запись из основного блока в блок переполнения.
12.5. МОДИФИКАЦИЯ ЗАПИСЕЙ
579
iv) To же, что в п. (ii), но в таблицах смещений наряду с указателями хранить
значения ключей сортировки.
v) To же, что в п. (iii), но в общей таблице смещений наряду с указателями
хранить значения ключей сортировки.
Выполните следующие задания.
* а) Сопоставьте варианты (i) и (ii) на предмет среднего количества операций
дискового ввода-вывода, необходимых для считывания записи, если
основной блок (или один из блоков переполнения), содержащий запись,
соответствующую заданному значению ключа сортировки, уже найден. Существуют
ли какие-либо недостатки, присущие выбранному вами варианту, которому
соответствует меньшее среднее число операций дискового ввода-вывода?
Ь) Сравните варианты (ii) и (iii) по критерию среднего количества операций
дискового ввода-вывода в расчете на одну процедуру считывания записи,
выразив результаты в виде функции от значения Ь, представляющего общее
количество блоков в цепочке. Примите к сведению, что таблицы смещений
занимают в данном случае 10% пространства блока, а записи располагаются
в оставшейся области блока.
! с) Выполните задание п. (Ь) применительно к вариантам (iv) и (v), полагая, что
размер ключа сортировки составляет 1/9 от объема записи. (Учтите, что
ключ сортировки не следует хранить в записи, если он уже присутствует
в таблице смещений.) Поэтому, как следствие, таблица смещений занимает
20% пространства блока, а оставшиеся 80% отводятся под записи.
Упражнение 12.5.2. Работая с системами реляционных баз данных, всегда
предпочтительнее, если это возможно, пользоваться кортежами постоянной длины.
Приведите три довода в доказательство этого утверждения.
12.6. Резюме
♦ Поля — элементарные структурные единицы представления данных. Многие из
них, такие как целочисленные значения или символьные строки постоянной
длины, сохраняются на носителях вторичных устройств в виде определенных
байтовых последовательностей фиксированного размера. Строка переменной
длины представляется как набор байтов с завершающим символом null либо как
последовательность байтов, в начале которой содержится значение длины строки.
♦ Записи — структуры, состоящие из нескольких полей и заголовка. Заголовок
содержит дополнительную информацию о записи — значения даты и времени
последнего обновления и длины записи, данные о ее схеме и т.д.
♦ Записи переменной длины. Если запись содержит одно или несколько полей
переменной длины либо произвольное количество экземпляров того или иного
поля, необходимы дополнительные структурные решения. Для отыскания внутри
записи полей переменного размера могут применяться группы указателей в
составе заголовка записи. Допустимо выносить поля и за пределы записи; в этом
случае в запись включаются указатели, содержащие внешние адреса полей.
♦ Блоки. Записи сохраняются внутри блоков. Блок обычно содержит заголовок,
представляющий информацию как о самом блоке, так и о записях,
принадлежащих блоку.
♦ Связанные записи. Запись, как правило, размещается в пределах одного блока.
Однако, если размер записи превышает объем блока либо необходимо эффек-
580 ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
тивнее использовать свободное пространство внутри блоков, допустимо
расщеплять записи на несколько связанных фрагментов, по одному на каждый блок.
Каждый фрагмент снабжается собственным заголовком с указателями,
позволяющими адресовать последующий и/или предыдущий фрагменты цепочки.
♦ Объекты BLOB. Сверхбольшие значения, представляющие, например,
графические изображения, видеофильмы или фрагменты аудиозаписей, принято
обозначать аббревиатурой BLOB. Для их хранения обычно требуются длинные
последовательности дисковых блоков. В зависимости от требований, касающихся
скорости доступа к дисковой информации, блоки объекта BLOB располагаются
в пределах одного или нескольких соседних цилиндров либо попеременно
распределяются по цилиндрам нескольких дисковых устройств — последнее
позволяет осуществлять загрузку данных параллельно.
♦ Таблицы смещений. Для упрощения операций вставки и удаления записей,
а также процедур обновления записей переменной длины заголовок блока
может быть снабжен таблицей смещений, содержащей указатели на первые байты
всех записей, принадлежащих блоку.
♦ Блоки переполнения. Для обеспечения гибкости операций вставки и обновления,
приводящих к изменению размеров записей, используется механизм
связывания основного блока с цепочкой блоков переполнения, предназначенных для
хранения записей, которые логически относятся к основному блоку.
♦ Физические и логические адреса в базе данных. Данные, которыми управляет СУБД,
распределены по различным устройствам хранения (для этой цели обычно
используются магнитные диски). Система отыскивает в хранилище требуемые
блоки и записи, пользуясь их физическими адресами, которые содержат описания
идентификатора конкретного устройства, а также номеров цилиндра, дорожки,
сектора и (изредка) байта внутри сектора. Находят применение и логические
адреса, которые представляются в виде произвольных символьных строк и
транслируются в физические адреса на основании специальной таблицы соответствий.
♦ Структурированные адреса. Для доступа к записям внутри блоков иногда
применяются составные адреса, содержащие физический адрес требуемого блока
и дополнительную информацию (скажем, значение ключа записи или адрес
в таблице смещений, по которому расположен указатель на начало записи),
необходимую для отыскания записи в пределах блока.
♦ "Подмена " указателей. При считывании дисковых блоков в оперативную
память и обращении по указателю, ссылающемуся на элемент одного из блоков,
соответствующий адрес элемента в базе данных должен транслироваться в
адрес памяти. Подобное преобразование называется "подменой" указателей
и выполняется автоматически (непосредственно в процессе загрузки блоков
в оперативную память) либо по требованию (для каждого запрашиваемого
элемента данных отдельно).
♦ Признаки-"обелиски ". Если запись удаляется, внешние указатели, которые ее
адресуют, становятся "висящими". Специальный признак-обелиск,
располагаемый на месте (части) записи, уведомляет систему о том, что запись отсутствует.
♦ "Закрепленные " блоки. Встречаются ситуации, когда по определенным причинам
(например, из-за наличия в блоке "подмененных" указателей) нельзя безопасно
сохранить на диске блок данных из памяти, не предпринимая дополнительных
действий. Подобные блоки называют "закрепленными". Если основанием для
"закрепления" блока в памяти послужило присутствие в нем "подмененных"
указателей, сохранить блок на диске удастся только после выполнения
обратной трансляции содержимого таких указателей.
12.6. РЕЗЮМЕ
581
12.7. Литература
Нельзя не назвать классический труд [2], охватывающий, в частности, и
проблематику структур данных. В книге [4] представлена дополнительная информация о
структурах, близких к тем, которые обсуждаются в этой и следующей главах.
Концепция признаков-"обелисков", реализуемая в процессах удаления записей,
заимствована из статьи [3]. В работе [1] можно найти дополнительный материал по
вопросам представления элементов данных при использовании объектно-
ориентированных СУБД.
1. Cattell R.G.G. Object Data Management, Addison-Wesley, Reading, MA, 1994.
2. Knuth D.E. Tlie Art of Computer Programming, Vol. 1, Fundamental Algorithms, 3rd Edition,
Addison-Wesley, Reading, MA, 1997. [Имеется перевод: Кнут Д.Э. Искусство
программирования, т. 1. Основные алгоритмы, 3-е изд. — М.: Издательский дом "Вильяме", 2000.]
3. Lomet D. Scheme for invalidating free references, IBM J. Research and Development, 19:1
(1975), p. 26-35.
4. Wiederhold G. File Organization for Database Design, McGraw-Hill, New York, 1987.
582
ГЛАВА 12. ПРЕДСТАВЛЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ
Глава 13
Структуры индексов
В предыдущей главе (см. с. 549) были рассмотрены способы хранения полей и
записей — теперь же самое время изучить, как представляются отношения и
экземпляры классов в целом. Если вы думаете, что достаточно ограничиться распределением
записей, содержащих данные кортежей или объектов экземпляра класса, по
произвольным дисковым блокам, это, смеем вас заверить, глубокое заблуждение. Чтобы
было ясно, почему, попросим ответить, как вы представляете себе процесс обработки
простейшего запроса вида select * from r, обращенного к отношению R, записи
которого "разбросаны" по всему диску. Бедной системе в подобной ситуации придется
проверять каждый блок данных во вторичном хранилище в надежде, что заголовки
блоков и записей содержат достаточно информации для того, чтобы определить, где каждая
запись блока начинается, где заканчивается и какому отношению принадлежит.
Несколько лучшее решение состоит в резервировании для каждого отношения
определенного количества блоков — возможно, даже целых цилиндров диска. Как
можно полагать, все блоки таких цилиндров предназначены для хранения информации
кортежей одного отношения. Теперь в процессе поиска блоков содержимого
отношения системе удастся избежать, по меньшей мере, необходимости сканирования всего
пространства дискового хранилища. Однако подобный способ организации данных
уже не в состоянии упростить задачу обработки несколько более сложного запроса —
скажем, select * from r where a = 10. В разделе 6.6.6 на с. 301 мы обращали ваше
внимание на важность создания и выбора индексов (indexes) отношения, позволяющих
ускорить поиск таких кортежей, определенные компоненты которых обладают
значениями, удовлетворяющими заданному условию. Как показано на рис. 13.1, индекс —
это некоторая структура данных, которая в качестве "параметра" принимает заданное
"свойство" записей (обычно значения одного или нескольких полей) и "быстро"
находит записи, обладающие этим свойством. Удачный индекс позволяет отыскать
требуемую запись, обращаясь только к весьма небольшой части полного множества
записей (в идеале — непосредственно к группе искомых записей). Поля, на основе
значений которых индекс конструируется, называют ключом поиска (search key), или просто
"ключом", если из контекста ясно, что речь идет об индексе.
В качестве индексов могут использоваться самые разнообразные структуры
данных. Ниже мы рассмотрим следующие варианты индексов:
1) простые индексы для упорядоченных файлов;
2) вторичные индексы для неупорядоченных файлов;
Ключи... еще ключи...
Термин ключ (key) имеет множество значений, различных по смыслу. В разделе
7.1.1 на с. 318 он использовался нами для обозначения первичного ключа (primary
key) отношения. В разделе 11.4.4 на с. 513 упоминалось о ключах сортировки (sort
keys) — атрибутах, по значениям которых упорядочивается файл записей. Ниже
мы будем говорить о ключах поиска (search keys) — атрибутах, заданные значения
которых используются в качестве критерия поиска (с применением индекса)
определенных групп кортежей отношений. Если смысл термина "ключ" в том или ином
контексте неясен, мы будем добавлять соответствующие уточняющие определения
или дополнения — "первичный ключ", "ключ сортировки" или "ключ поиска".
Однако, как будет показано в разделах 13.1.2 на с. 585 и 13.1.3 на с. 586, зачастую
все три категории ключей сводятся к одной.
3) В-деревья — модель, применяемую с целью организации индексов для
произвольных файлов;
4) хеш-таблицы — альтернативную и широко употребительную структуру
представления индексов.
Искомые
записи
Рис. 13.1. Индекс позволяет найти записи,
удовлетворяющие заданному критерию поиска
13.1. Индексы для последовательных файлов
Начнем знакомство с индексами с наиболее простого варианта структуры:
отсортированному файлу данных (data file) поставлен в соответствии файл индекса (index
file), состоящий из пар вида ключ—указатель. Значение К ключа поиска в файле
индекса ассоциировано с указателем, ссылающимся на запись файла данных,
обладающую значением К. Подобная индексная структура может быть плотной (dense) (в том
смысле, что каждой записи файла данных отвечает определенный элемент файла
индекса) или разреженной (sparse) — файл индекса содержит указатели только на
некоторые записи файла данных (скажем, один элемент в расчете на каждый блок данных).
13.1.1. Последовательные файлы
Одна из простейших индексных структур основывается на файле, отсортированном
по значениям атрибутов индекса. Подобный файл называют последовательным
(sequential file). Структура индекса для последовательного файла особенно полезна в тех
случаях, когда ключ поиска совпадает с первичным ключом отношения. На рис. 13.2
схематически изображено отношение, представленное в виде последовательного файла.
Кортежи отношения, хранимого в форме последовательного файла, отсортированы
по значениям первичного ключа. Рисунок соответствует ситуации, когда ключами
являются целочисленные значения; здесь показаны только ключевые поля и выдвинуто
довольно нетипичное предположение о том, что каждый блок способен содержать
Значения
584
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
только две записи. Например, в первом блоке размещены записи с ключами 10 и 20.
Помимо того, в этом и многих следующих примерах в качестве ключевых значений
используются последовательные целые числа, кратные 10, хотя, разумеется, на
практике подобное требование не ставится — равно как и то, чтобы в индексе и файле
данных присутствовали все значения, кратные 10, из определенного интервала.
13.1.2. Плотные индексы
После того как записи файла данных отсортированы, можно создать на их основе
плотный индекс (dense index), который представляет собой последовательность блоков,
содержащих только ключи записей данных и указатели на эти записи (под указателями
понимаются адреса — в том смысле, о котором говорилось в разделе 12.3 на с. 558).
Плотным называют индекс, содержащий ключи для каждой записи файла данных.
Разреженные (sparse) индексы (мы расскажем о них в разделе 13.1.3 на с. 586), напротив,
обычно хранят по одному ключевому элементу для каждого блока файла данных.
Записи файла плотного индекса упорядочиваются таким же образом, как и записи
файла данных. Поскольку ключи и указатели занимают существенно меньшее
пространство, нежели полные записи, можно ожидать, что для хранения индекса потребуется гораздо
меньше дисковых блоков. Преимущества индексного файла особенно ощутимы в
ситуации, когда он может быть загружен в оперативную память целиком, а соответствующий
файл данных — нет. С помощью подобного индекса удастся отыскать требуемую запись
данных по заданному ключу посредством единственной операции дискового ввода-вывода.
Пример 13.1. На рис. 13.3 изображены начальные блоки файла индекса для
последовательного файла, приведенного на рис. 13.2. Для удобства мы полагаем, что значения
ключей кратны 10, хотя на практике подобная закономерность встречается, конечно,
весьма редко. Мы подразумеваем также, что блоки индексного файла содержат по
четыре пары вида "ключ—указатель". Надо сказать, что и эта гипотеза далека от
реальности — в типичном дисковом блоке могут уместиться сотни подобных пар.
10
20
30
40
50
60
70
80
90
100
10
20
30
40
90
100
ПО
120
50
60
70
80
Файл индекса
Н 10
Н 20
30
40
50
60
70
80
90
100
Файл данных
Рис. 13.2. Пример
последовательного файла
Рис. 13.3. Плотный индекс (слева) для
последовательного файла данных (справа)
13.1. ИНДЕКСЫ ДЛЯ ПОСЛЕДОВАТЕЛЬНЫХ ФАЙЛОВ
585
Первый блок индекса содержит указатели на четыре начальные записи данных,
второй блок — на следующие четыре записи и т.д. На практике иногда целесообразно
заполнять блоки индексного файла не полностью — доводы в пользу подобного
решения приведены в разделе 13.1.6 на с. 592. □
Плотный индекс позволяет системе с успехом обрабатывать запросы, в которых
предполагается отыскание записей по заданному значению ключа. Система
просматривает блоки индекса в поисках значения К ютюча, а затем, когда запись индекса
с ключом К найдена, обращается по указателю, адресующему запись данных с тем же
ключевым значением. На первый взгляд может показаться, что для отыскания записи
индекса с ключом К системе придется просмотреть каждый блок индекса (или в
среднем — половину блоков), но существует ряд факторов, которые дают возможность
значительно увеличить производительность операций поиска по индексу.
1. Размер файла индекса обычно существенно меньше объема файла данных.
2. Поскольку ключи хранятся в упорядоченном виде, для отыскания значения К
уместно использовать алгоритм бинарного поиска. Если индекс содержит п блоков,
системе придется обратиться только к \og2n из них.
3. Индекс может быть настолько мал, что его удастся целиком зафузить в
оперативную память и хранить здесь в течение такого промежутка времени, какой
требуется; в этом случае для отыскания ключа поиска К достаточно выполнить
ряд операций в оперативной памяти, не обращаясь к диску.
Пример 13.2. Пусть дано отношение, содержащее 1000000 кортежей, причем для
хранения каждых десяти кортежей требуется один 4096-байтовый блок, а общий объем
данных отношения составляет, таким образом, примерно 400 мегабайт — это,
вероятно, слишком много, чтобы зафузить информацию в оперативную память целиком.
Предположим, что длина ключевого поля равна 30 байтам, а размер указателя —
8 байтам. Тогда в один 4096-байтовый блок (с учетом расходов на заголовок блока)
удастся поместить 100 пар "ключ—указатель". Для построения плотного индекса
потребуется 10000 блоков, или 40 Мбайт. Такой индекс при определенных
обстоятельствах может быть зафужен в буферы оперативной памяти — все зависит от ее общего
объема и размеров области, свободной от других данных. Поскольку log2 (10000)
составляет около i3, для отыскания нужного ключа придется выполнить 13 или 14
обращений к блокам индекса. Так как при использовании любого варианта бинарного
поиска адресуется только небольшое подмножество всех блоков (например, блок в
середине списка, далее блоки на позициях 1/4 и 3/4, затем на позициях 1/8, 3/8, 5/8,
7/8 и т.д.), даже в том случае, если разместить весь индекс в памяти нельзя, зафузить
основные блоки все-таки удастся, и поэтому для извлечения записи с любым ключом
гюфебуется значительно меньше 14-ти операций дискового ввода-вывода. □
13.1.3. Разреженные индексы
Если плотный индекс оказывается слишком большим, иногда целесообразно
воспользоваться схожей структурой разреженного индекса (sparse index), позволяющей уменьшить
размер файла ценой вероятного увеличения промежутка времени, необходимого для
отыскания записи по заданному значению ключа. Как показано на рис. 13.4, разреженный
индекс содержит только по одному указателю на каждый блок файла данных, а
ключами индекса являются ключевые значения первых записей каждого блока данных.
Пример 13.3. Как и в примере 13.1 на с. 585, будем полагать, что файл данных
отсортирован, значениями ключа служат целые числа, кратные 10, и каждый блок
индекса содержит по четыре пары вида "ключ-указатель". Поэтому первый блок индекса
включает элементы, соответствующие начальным записям первых четырех блоков
586
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Определение местоположения блоков индекса
Мы подразумеваем, что система использует некий механизм определения точного
положения блока индекса, что позволяет быстро находить отдельные кортежи (если
индекс является плотным) или блоки (если индекс разрежен) файла данных.
Существует целый ряд способов обнаружения блоков индекса. Например, если файл
индекса мал, его можно хранить в зарезервированной области диска. Если размер файла
достаточно велик, иногда уместно создать индекс более высокого уровня
(подробнее — в разделе 13.1.4 на с. 588) и содержать в специальной области диска
именно этот, дополнительный, индекс. Развитие подхода, связанного с
конструированием многоуровневых индексов, нашло воплощение в модели В-дерева (за полной
информацией обращайтесь к разделу 13.3 на с. 609), которая позволяет находить
требуемый ключ на основе информации о положении одного — корневого — блока.
данных, т.е. 10, 30, 50 и 70. Аналогично, второй индексный блок содержит значения
ключа для первых записей блоков данных с номерами 5—8, а это 90, 110, 130 и 150.
На рисунке изображен и третий блок индекса, указатели которого ссылаются на
первые записи гипотетических блоков данных 9—12.
10
30
50
70
90
ПО
130
150
3S
170
190
210
230
■—-
-—>
-—».
—
10
20
30
40
50
60
70
80
90
100
□
Рис. 13.4. Разреженный индекс для
последовательного файла данных
Пример 13.4. Разреженный индекс обычно занимает намного меньше дискового
пространства, нежели плотный. Если вновь обратиться к условиям примера 13.2 (см. с. 586),
где данные размещались в 100000 блоков, а на каждый блок индекса приходилось по
100 пар "ключ—указатель", и вместо плотного индекса создать разреженный, для
хранения последнего потребуются только 1000 блоков и всего 4 мегабайта
пространства — такой объем данных определенно поместится в буферах оперативной памяти.
С другой стороны, плотный индекс позволяет системе обрабатывать запросы вида
"существует ли запись с ключевым значением А?", не требуя загрузки всего блока с
искомой записью. Тот факт, что значение К присутствует в ключевом поле плотного индекса,
13.1. ИНДЕКСЫ ДЛЯ ПОСЛЕДОВАТЕЛЬНЫХ ФАЙЛОВ
587
служит гарантией существования записи данных с ключом К. При обработке того же
запроса с участием разреженного индекса системе придется выполнить дисковую операцию
ввода-вывода для загрузки блока, который (возможно!) содержит запись с ключом К. □
Чтобы с помощью разреженного индекса отыскать запись данных с ключом К,
следует найти запись индекса с наибольшим ключевым значением, меньшим или
равным К. Поскольку файл индекса отсортирован по ключу, указанный элемент
индекса нетрудно обнаружить, применив модифицированный вариант алгоритма
бинарного поиска. Указатель, соответствующий найденному ключу, адресует определенный
блок данных. Обратившись к этому блоку, система должна найти в нем запись с
ключом К. Форматы описания блока и записи данных, разумеется, должны предоставлять
соответствующую информацию, достаточную для идентификации записи внутри
блока и отдельных элементов содержимого самой записи (за справками обращайтесь
к разделам 12.2 на с. 554 и 12,4 на с. 569).
13.1.4. Многоуровневые индексы
Как было показано в примерах 13.2 (см. с. 586) и 13.4, индекс сам по себе может
оказаться достаточно объемным. Даже в том случае, если для отыскания элемента
индекса используется алгоритм бинарного поиска, системе зачастую все еще приходится
выполнять немалое количество операций дискового ввода-вывода. Для ускорения
просмотра индексного файла можно создать дополнительный индекс второго
уровня — "индекс для индекса".
На рис. 13.5 приведена заимствованная из рис. 13.4 схема, которая дополнена
индексом второго уровня (вновь, как и прежде, в качестве значений ключа мы для
простоты используем числа, кратные 10). Можно пойти дальше и попытаться создать,
если это необходимо, индексы третьего уровня, четвертого и т.д. Однако такому подходу
присущи определенные внутренние ограничения — при необходимости
конструирования индексов нескольких уровней предпочтительнее обращаться к структуре В-
дерева (подробнее — в разделе 13.3 на с. 609).
10
90
170
250
330
410
490
570
—->
-—.,
—
—
—*
"^
\
\
\
\
—i».
10
30
50
70
90
ПО
130
150
170
190
210
230
—^
—.
.—^
•—..
—.
X
k\
ч
V
1—**
J
10
20
™ !
40
50
60
70
80
90
100
Рис. 13.5. Пример двухуровневого разреженного индекса
588
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
В данном случае индекс первого уровня является разреженным, хотя для этого
уровня можно было бы создать и плотный индекс. Однако индексы всех уровней,
кроме первого, с возрастанием номера уровня всегда должны быть все более
разреженными, поскольку в противном случае система не получит никаких преимуществ —
индекс будет содержать столько же элементов, сколько и "соседний" индекс
меньшего уровня, и занимать то же дисковое пространство.
Пример 13.5. Продолжим изучение гипотетического отношения, рассмотренного
в примере 13.4, и предположим, что к разреженному индексу первого уровня добавлен
индекс второго уровня. Поскольку индекс первого уровня занимает 1000 блоков и
позволяет "упаковать" по 100 пар вида "ключ—указатель" в каждый блок, для индекса
второго уровня потребуются 10 блоков. Весьма вероятно, что эти 10 блоков удастся
загрузить в буферы оперативной памяти. Тогда для отыскания записи данных с
заданным ключевым значением К первым делом следует просмотреть индекс второго
уровня, чтобы найти в нем запись с наибольшим ключевым значением, меньшим или
равным К. Соответствующий указатель приведет к некоторому блоку В индекса
первого уровня, откуда система определенно получит доступ к искомой записи данных,
но для начала следует считать блок В в оперативную память (если это не было сделано
ранее); заметим, что пока это первая выполненная операция дискового ввода-вывода.
Теперь система обязана просмотреть блок В в поисках наибольшего ключевого
значения, меньшего или равного К, и элемент индекса с этим ключом непосредственно
укажет на блок данных, содержащий запись с ключевым значением К — конечно,
если таковая существует. Для считывания найденного блока данных потребуется
выполнить вторую, и последнюю, операцию дискового ввода-вывода. □
13.1.5. Дубликаты ключевых значений
До сих пор мы полагали, что ключ поиска, для которого создается индекс,
совпадает с ключом отношения, т.е. каждому значению ключа соответствует не более одной
записи данных. Однако зачастую индексы конструируются для атрибутов, не
образующих первичный ключ, так что вполне допустима ситуация, когда одно и то же
ключевое значение присутствует в нескольких записях. Если записи сортируются по
ключу поиска, причем порядок следования записей с одинаковыми ключами
произволен, все ранее рассмотренные подходы вполне пригодны и для случая, когда ключ
поиска не является ключом отношения.
Вероятно, простейший вариант расширения прежней модели состоит в создании
плотного индекса, в котором для каждой записи файла данных со значением ключа
поиска К существует элемент с тем же ключом К. Другими словами, в файле индекса
допускается присутствие дубликатов значений ключа поиска. Задача отыскания всех
записей данных, содержащих заданный ключ поиска К, проста: идентифицировать
в файле индекса первый экземпляр записи с ключом К, найти все другие экземпляры
(они должны следовать непосредственно после первого) и проследовать по адресам
указателей на записи данных с ключевым значением К.
Несколько более эффективный вариант подразумевает включение в файл плотного
индекса по одной записи для каждого значения ключа поиска К. Указатель в этой
записи адресует первую из записей данных с ключевым значением К. Чтобы найти
остальные записи данных с тем же значением ключа, достаточно считывать последующие
записи данных до момента изменения содержимого ключевого поля — поскольку файл
данных отсортирован по ключевому полю, записи с одинаковыми значениями поля
окажутся собранными в отдельные группы. Идея проиллюстрирована на рис. 13.6.
Пример 13.6. Предположим, что необходимо отыскать такие записи файла данных,
изображенного на рис. 13.6, которые содержат значение ключа поиска, равное 20.
Система обнаруживает в файле индекса элемент с ключом 20 и, следуя по адресному
значению указателя, находит первую запись данных с ключом поиска 20. Затем необ-
13.1. ИНДЕКСЫ ДЛЯ ПОСЛЕДОВАТЕЛЬНЫХ ФАЙЛОВ
589
ходимо просмотреть следующие записи файла данных. Поскольку текущей является
последняя запись второго блока, система переходит к третьему блоку.86 Здесь
ключевым значением 20 обладает первая запись, но вторая содержит ключ 30. Поэтому
процесс поиска завершается, поскольку записей с ключом 20 больше нет. Таким образом,
система находит две записи со значением ключа поиска, равным 20.
10
20
30
40
10
10
10
20
50
...
20
30
30
30
40
50
Рис. 13.6. Плотный индекс для файла с
дубликатами значений ключа поиска
□
На рис. 13.7 показан вариант разреженного индекса для того же файла данных, что
и на рис. 13.6. Этот индекс выглядит как обычно: он содержит пары ""ключ—указатель",
соответствующие значениям ключа поиска первых записей блоков данных.
Чтобы найти записи с заданным значением К ключа поиска в такой структуре,
необходимо отыскать элемент индекса (назовем его Ех) с наибольшим номером,
обладающий значением ключа, меньшим или равным К. Затем надлежит перемещаться
к началу индекса до тех пор, пока не будет достигнут первый элемент индекса либо
элемент Е2 со значением ключа, строго меньшим К (в частном случае, когда Ех уже
содержит значение ключа, строго меньшее К, Е2 совпадает с Ех). Блоки данных,
способные содержать записи со значением К ключа поиска, адресуются элементами
индекса с номерами из интервала от Е2 до Ех включительно.
Пример 13.7. Предположим, что в структуре, представленной на рис. 13.7, необходимо
найти записи данных со значением ключа поиска, равным 20. Роль Ех в этом случае
будет выполнять третья запись первого блока индекса — это элемент с наибольшим
номером, такой, что значение его ключа не превышает заданную границу 20.
Очередной элемент, более близкий к началу индекса, содержит значение ключа (10), строго
меньшее 20. Поэтому элементом Е2 окажется вторая запись первого блока индекса.
Указатели в записях Е2 и Ех индекса ограничивают искомый диапазон файла данных
вторым и третьим блоками -~ именно здесь должны располагаться записи данных со
значением ключа поиска, равным 20.
86 Мы полагаем, что блоки файла данных организованы в форме связанного списка:
заголовок каждого блока содержит указатель на следующий блок.
590
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
10
10
20
30
40
...
—h
10
10
10
20
20
30
30
30
40
50
Рис. 13.7. Разреженный индекс, элементы кото-
рого содержат наименьшие значения ключа в
каждом блоке данных
Рассмотрим еще один краткий пример. Если принять АГ= 10, тогда элемент Е{ —
это вторая запись первого блока индекса, а элемента Е2 попросту не существует,
поскольку ключа с меньшим значением в составе индекса нет. Поэтому для отыскания
записей данных с ключевым значением 10 необходимо воспользоваться указателями
в первом и втором элементах индекса, адресующими два первых блока данных. □
10
20
30
30
40
10
10
10
20
20
30
30
30
40
50
Рис. 13.8. Разреженный индекс, элементы
которого содержат наименьшие новые значения ключа
в каждом блоке данных
13.1. ИНДЕКСЫ ДЛЯ ПОСЛЕДОВАТЕЛЬНЫХ ФАЙЛОВ
Несколько иная схема организации индекса показана на рис. 13.8. Здесь элемент
индекса, соответствующий блоку данных, содержит наименьшее новое (new) значение
ключа поиска, т.е. такое, которого не было в предыдущем блоке. Если в блоке данных
нет новых значений ключа (все записи обладают одинаковым — "старым" —
ключом), в соответствующий элемент индекса заносится именно это значение. Система
сможет найти записи данных со значением К ключа поиска, если обратится к первому
элементу индекса, ключевое значение которого
a) равно К
либо
b) меньше К, но следующий ключ больше К,
а затем проследует по адресу, на который ссылается указатель в этом элементе. Если
найденный блок данных содержит по меньшей мере одну запись с ключом К,
остальные записи с тем же ключом (коль скоро они существуют) удастся отыскать,
просмотрев содержимое следующих блоков.
Пример 13.8. Обратимся к структуре, приведенной на рис. 13.8, и предположим, что
К = 20. На основании указанного выше правила выбирается второй элемент индекса —
его указатель приводит к первому блоку данных, содержащему запись с ключом 20
(это блок с номером 2). Перейдя к следующему блоку данных, система сможет найти
еще одну запись с ключом 20.
Если принять # = 30, правило заставит обратиться к третьему элементу индекса,
указатель которого адресует третий блок данных, содержащий первый экземпляр
записи с ключом 30 (дальнейшие действия очевидны). Наконец, если положить AT =25,
придется воспользоваться пунктом (Ь) правила и считать второй элемент индекса,
указатель которого ссылается на второй блок данных. Если бы файл данных содержал
записи со значением ключа поиска, равным 25, по меньшей мере одна из них должна
была бы присутствовать в этом блоке, поскольку, как нам известно, "новое" значение
ключа в третьем блоке равно 30. Так как записей с ключом 25 в файле данных нет,
процедура поиска завершается безуспешно. □
13.1.6. Управление индексами при модификации данных
До сих пор мы полагали, что файлы данных и индексов представляют собой
последовательности блоков, плотно заполненных записями соответствующих типов. Поскольку с
течением времени информация подвергается изменениям, можно ожидать, что пользователи
системы наверняка будут обращаться к файлам данных с командами вставки, удаления
и обновления записей, и поэтому вовсе не обязательно, что сегодняшнее содержимое
блоков структуры, подобной последовательному файлу, в неизменном виде сохранится
и завтра. Для реорганизации файлов данных используются методы и приемы, о которых
говорилось в разделе 12.5 на с. 576. Мы считаем уместным напомнить основные из них.
1. Создание блоков переполнения (overflow blocks) при нехватке места в
существующих блоках данных и удаление блоков переполнения при освобождении
крупных областей в блоках после удаления групп записей. Разреженный индекс
не содержит элементов, указывающих на блоки переполнения, — последние
трактуются как расширения основных блоков.
2. Иногда существует возможность вместо блоков переполнения создавать новые
основные блоки данных, размещая их в соответствующих позициях
последовательности блоков файла. В этой ситуации добавленным блокам данных должны
соответствовать новые элементы разреженного индекса. Необходимо иметь в виду, что при
изменении индекса могуг возникать те же проблемы, касающиеся общей
компоновки файла, какие сопутствуют операциям вставки, удаления и обновления запи-
592
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
сей файла данных. При создании новых блоков индекса система должна
размещать их настолько "удачным" образом, насколько это возможно.
3. Если при попытке вставки записи в блок данных выясняется, что внутри блока
нет свободных областей достаточной длины, подчас возможно осуществить
перемещение записей в соседние блоки с целью освобождения требуемого
пространства. Если же, напротив, после удаления записей соседние блоки оказываются
заполненными не плотно, иногда их данные удается объединить в один блок.
Изменение файла данных зачастую приводит к необходимости соответствующей
модификации файла индекса, причем выбор подхода зависит от принадлежности
индекса к числу плотных или разреженных и от того, какие из перечисленных выше
методов используются в процессе изменения файла данных. Однако существует один
общий принцип, справедливый в любой ситуации.
• Файл индекса является последовательным; пары вида "ключ—указатель" можно
воспринимать как записи, отсортированные по значениям ключа поиска.
Поэтому все стратегии, используемые для поддержки процедур модификации
последовательных файлов данных, применимы и к файлам индексов.
На рис. 13.9 перечислены все действия, предпринимаемые в отношении файлов
разреженных и плотных индексов при выполнении каждой из семи различных операций
над файлами данных — создания/удаления пустых блоков переполнения или блоков
последовательного файла, а также вставки, удаления и перемещения записей. Мы
полагаем, что создаваться или изыматься могут только пустые блоки. В частности, если
удалению подлежит блок, содержащий записи, прежде всего следует "избавиться" от
записей этого блока — либо удалить их, либо перенести в другой блок.
Действие
Создание пустого блока переполнения
Удаление пустого блока переполнения
Создание пустого последовательного
блока
Удаление пустого последовательного
блока
Вставка записи
Удаление записи
Перемещение записи
Плотный индекс
-
-
—
—
Вставка
Удаление
Обновление
Разреженный индекс
-
-
Вставка
Удаление
Обновление(?)
Обновление(?)
Обновление(?)
Рис. 13.9. Как действия в отношении последовательного файла данных влияют на файл индекса
Рассмотрим содержимое таблицы более подробно.
• Операции создания или удаления пустого блока переполнения не оказывают
воздействия на индексы обоих типов: элементы плотного индекса указывают на
отдельные записи; элементы разреженного индекса адресуют только основные
блоки данных, а не блоки переполнения.
• Операции создания или удаления блока последовательного файла не влияют на
плотный индекс по той же причине — его элементы ссылаются на записи, а не
на блоки. Если же индекс является разреженным, при создании или
обновлении блока данных система обязана соответственно вставить в файл индекса или
изъять из него определенный элемент.
13.1. ИНДЕКСЫ ДЛЯ ПОСЛЕДОВАТЕЛЬНЫХ ФАЙЛОВ
593
Как предвосхитить результаты эволюции данных
Поскольку отношениям и экземплярам классов присуща устойчивая тенденция
к возрастанию объемов хранимой в них информации, зачастую разумно заранее
снабдить блоки данных и индексов дополнительными свободными областями. Если
к моменту начала активной эксплуатации базы данных заполнено до 75%
пространства блоков, можно надеяться, что какое-то время удастся обойтись без
создания блоков переполнения и перемещения записей между блоками. Если
количество блоков переполнения сведено к минимуму, каждая процедура извлечения
записи потребует в среднем только одной операции дискового ввода-вывода. Чем больше
блоков переполнения, тем выше затраты на поиск записи с заданным ключом.
• При вставке или удалении записи данных подвергается воздействию и плотный
индекс — в него надлежит вставить соответствующую пару вида "ключ-
указатель" либо удалить такую пару. Подобная операция, однако, обычно не
оказывает влияния на разреженный индекс. Единственное исключение связано
с ситуацией, когда затрагивается первая запись в блоке данных, — в этом
случае подлежит обновлению и соответствующее ключевое значение в файле
разреженного индекса. Поэтому три последних элемента столбца "Разреженный
индекс" таблицы помечены символом вопросительного знака — операция
обновления индекса, возможно, потребуется, но далеко не всегда.
• Аналогично, операция перемещения записи (как внутри блока, так и между
блоками) приводит к необходимости обновления соответствующего элемента
плотного индекса, но затрагивает разреженный индекс только в том случае, когда
перемещаемая запись занимала либо должна занять первую позицию в блоке данных.
Для иллюстрации особенностей алгоритмов, применяемых в перечисленных выше
ситуациях, мы приведем ряд примеров, где рассмотрим и плотные/разреженные
индексы, и технику перемещения записей и использования блоков переполнения-
Пример 13.9. Для начала рассмотрим операцию удаления записи из блока
последовательного файла данных при наличии плотного индекса. Обратимся к структуре, изображенной
на рис. 13.3 (см. с. 585), и предположим, что удалению подлежит запись с ключом 30.
На рис. 13.10 показан фрагмент той же структуры после выполнения операции удаления.
10
20
40
У///У//Л X УЩ//ШШЛ
50
60
70
80
10
20
40
50
60
70
80
Рис. 13.10. Результат удаления записи с
ключом 30 из структуры с плотным индексом,
показанной на рис. 13.3
594
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Вначале из последовательного файла данных удаляется запись с ключом 30. Вполне
возможно существование внешних указателей, ссылающихся на оставшуюся запись блока,
и поэтому передвигать ее в начало блока нецелесообразно — на месте удаленной записи
система способна "воздвигнуть" признак- "обелиск " (tombstone) (см. раздел 12.5.2 на с. 577).
Далее из индекса изымается пара "ключ—указатель" со значением ключа 30.
Внешние указатели на записи индекса наверняка отсутствуют и необходимости в
использовании "обелиска" нет. Поэтому имеет смысл переместить оставшиеся записи в
блоке индекса на одну позицию "вверх", чтобы консолидировать свободные участки
внутри блока (если их несколько) в единую более крупную область. □
Пример 13.10. Теперь продемонстрируем, как выполняются операции удаления двух
записей из последовательного файла данных, снабженного разреженным индексом.
Возьмем за основу структуру, изображенную на рис. 13.4 (см. с. 587), и предположим,
что первой должна быть удалена запись с ключом 30. Помимо того, будем считать, что
перемещению записей между блоками ничего не препятствует — либо заведомо
известно, что внешние указатели, которые могли бы ссылаться на записи внутри блока,
отсутствуют, либо для поддержки операций передвижения записей между блоками
используется таблица смещений, аналогичная представленной на рис. 12.16 (см. с. 577).
Результат удаления записи данных с ключом 30 схематически изображен на
рис. 13.11. После удаления записи с ключом 30 следующая запись блока, обладающая
ключом 40, смещена "вверх" с целью укрупнения свободной области внутри блока.
Поскольку запись с ключом 40 теперь занимает первую позицию во втором блоке
данных, необходимо обновить содержимое элемента ключа, ссылающегося на этот
блок. На рис. 13.11 показано, что значение ключа, которому отвечает указатель,
адресующий второй блок данных, изменено с 30 на 40.
10
40
50
70
90
ПО
130
150
-—■>
-—">!
.—^
—
10
20
40
У///У//////////Л
50
60
70
80
Рис. 13.11. Результат удаления записи данных
с ключом 30 из структуры с разреженным индексом,
показанной на рис. 13.4
Пусть теперь необходимо удалить и запись данных с ключом 40. Итог операции
приведен на рис. 13.12. Второй блок данных становится пустым. Если
последовательный файл хранится в произвольных блоках (а не в смежных блоках цилиндра, что
было бы также вполне возможно), освободившийся блок может быть включен в список
неиспользуемых областей дискового пространства.
Чтобы завершить операцию, необходимо модифицировать и файл индекса.
Поскольку второго блока данных уже нет, соответствующий элемент индекса следует
исключить. Записи индекса, как показано на рис. 13.12, могут быть смещены к началу
блока, хотя это действие не обязательно.
13.1. ИНДЕКСЫ ДЛЯ ПОСЛЕДОВАТЕЛЬНЫХ ФАЙЛОВ
595
10
10
50
70
////
////
90
ПО
130
150
1—^.
—►
20
У//У//////////А
У/Л//////////А
50
60
70
80
Рис. 13.12. Результат удаления записи данных с
ключом 40 из структуры, показанной на рис. 13.11
□
Пример 13.11. Сосредоточим внимание на операции вставки записи данных. Обратимся
к рис. 13.11, иллюстрирующему ситуацию, когда запись с ключом 30 только что удалена
из файла данных с разреженным индексом, но запись, содержащая ключ 40, остается на
месте. Предположим, что необходимо произвести вставку записи с ключом 15.
Обратившись к файлу разреженного индекса, определим, что запись с ключом 15 должна
принадлежать первому блоку данных. Но этот блок заполнен — в нем уже находятся
записи с ключами 10 и 20. Один из вариантов дальнейших действий связан с поиском
ближайшего блока данных, в котором есть незанятая область подходящего размера.
В нашем случае поиск приводит ко второму блоку. Запись с ключом 20 переносится из
первого блока во второй, освобождая место для записи с ключом 15. Результат приведен
на рис. 13.13. Для размещения записи 20 во втором блоке запись 40 необходимо
сдвинуть на одну позицию "вниз", дабы сохранить установленный порядок сортировки.
На последнем шаге надлежит модифицировать содержимое индекса. При
определенных обстоятельствах могла бы возникнуть ситуация, когда нам пришлось бы обновить
содержимое поля ключа в соответствующем элементе индекса, но в данном случае
этого делать не нужно, поскольку вставленная запись не является первой записью
блока. Следует, однако, модифицировать ключ во втором элементе индекса, так как
значение ключа в первой записи второго блока данных изменилось с 40 на 20. □
Пример 13.12. Подход, представленный в примере 13.11, не сопряжен с проблемами
только в том случае, если свободную область удается найти непосредственно в
соседнем блоке данных. Если бы запись с ключом 30 не оказалась предварительно
удаленной, процесс поиска участка, подходящего для вставки новой записи, не был бы столь
краток — для освобождения места под новую запись пришлось бы последовательно
смещать все записи, начиная с "20-й", к концу файла и создавать дополнительный блок.
Если файл содержит большое число записей, такая стратегия, разумеется, чревата
серьезными издержками, и поэтому нередко разумнее воспользоваться
альтернативным механизмом создания блоков переполнения. На рис. 13.14 показан результат
вставки записи с ключом 15 в блок переполнения, добавленный в структуру, которая
приведена на рис. 13.11. В первом блоке данных свободной области, достаточной для
вставки новой записи, нет. Вместо перемещения записи с ключом 20 во второй блок
создается блок переполнения для первого основного блока. На рис. 13.14 каждый
блок данных помечен справа дополнительным прямоугольным "выступом",
символически представляющим то место в заголовке блока, где может быть расположен
указатель на соответствующий блок переполнения. К одному блоку переполнения таким
596
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
10
20
50
70
10
15
90
ПО
130
150
—.
-—.
-ч
—
20
40
50
60
70
80
Рис. 13.13. Результат вставки записи данных с
ключом 15 в структуру с разреженным индексом,
показанную на рис. 13.11
же образом легко присовокупить другой, к другому третий и т.д. Цепочка блоков
переполнения для основного блока образует связанный список.
Итак, запись с ключом 15 вставляется в соответствующую позицию блока после
записи, содержащей ключ 10, а запись с ключом 20, освобождающая требуемое
пространство в блоке, перемещается во вновь созданный блок переполнения. Изменять
индекс не требуется, поскольку первая запись второго блока данных остается в
неприкосновенности. Обратите внимание, что отдельный элемент индекса для блока
переполнения не создается — тот трактуется как расширение основного блока данных,
а не как самодостаточный блок последовательного файла.
10
40
50
70
90
ПО
130
150
■ -ч
—
,
—
i
\ L
1—►
^
10
15
40
У/А
У/////////Л
50
60
70
80
1
~1
"1
20
~1
Рис. 13.14. Операция вставки записи данных,
предусматривающая использование блока переполнения
13.1. ИНДЕКСЫ ДЛЯ ПОСЛЕДОВАТЕЛЬНЫХ ФАЙЛОВ
597
13.1.7. Упражнения к разделу 13.1
* Упражнение 13.1.1. Предположим, что в блок умещаются три записи данных либо
десять пар вида "ключ—указатель". Выразите в виде функции от числа п записей
данных количество блоков, требуемых для хранения файла данных и
a) плотного индекса;
b) разреженного индекса.
Упражнение 13.1.2. Выполните задание упражнения 13.1.1, если каждый блок способен
содержать до 30 записей данных или 200 индексных элементов "ключ—указатель", но
ни блоки данных, ни блоки индекса не должны быть заполнены более чем на 80%.
! Упражнение 13.1.3. Выполните задание упражнения 13.1.1, если предполагается
конструирование такого количества уровней индекса, при котором верхний
уровень индекса будет содержать только один блок.
*!! Упражнение 13.1.4. Предположим, что, как и в упражнении 13.1.1, каждый блок
позволяет размещение трех записей данных или десяти пар вида "ключ-
указатель", но допускается существование дубликатов значений ключа поиска. Для
примера допустим, что 1/3 всех ключей представлены в файле данных в одном
экземпляре, 1/3 — в двух и 1/3 — в трех экземплярах. Предположим также, что
имеется плотный индекс, но для каждого различного значения ключа существует
только один элемент индекса, указывающий на первую по порядку запись
данных, обладающую этим ключом. Если изначально ни один из блоков в
оперативную память не загружен, вычислите среднее количество дисковых операций
ввода-вывода, требуемых для отыскания всех записей данных с заданным
значением К ключа поиска. Можно считать, что положение блока индекса, содержащего
элемент с ключом К, на диске известно заранее.
! Упражнение 13.1.5. Выполните задание упражнения 13.1.4 при наличии:
a) плотного индекса, содержащего соответствующую пару "ключ—указатель"
для каждой записи, включая и те, которые обладают повторяющимися
значениями ключа;
b) разреженного индекса, элементы которого адресуют записи с наименьшими
значениями ключа в каждом блоке данных, как на рис. 13.7 (см. с. 591);
c) разреженного индекса, элементы которого ссылаются на записи с наименьшими
новыми значениями ключа в каждом блоке данных, как на рис. 13.8 (см. с. 591).
! Упражнение 13.1.6. Если имеется плотный индекс для атрибута первичного ключа
отношения, возможно адресовать извне элементы индекса, а не записи, на
которые указывают эти элементы. Каковы преимущества каждого из подходов?
Упражнение 13.1.7. Обратитесь к структуре, приведенной на рис. 13.13, и
продолжите процесс модификации данных, предусматривающий удаление записей
данных с ключами 60, 70 и 80 с последующей вставкой записей с ключами 21, 22
и т.д. вплоть до записи, содержащей ключ 29, полагая, что необходимое
дополнительное пространство запрашивается следующим образом:
* а) созданием блоков переполнения для файла данных либо файла индекса;
b) перемещением записей "вниз" и созданием дополнительных блоков в конце
файла данных или файла индекса;
c) вставкой новых блоков данных или индексных блоков в середину
соответствующего файла.
598
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
*! Упражнение 13.1.8. Предположим, что в процессе вставки п записей в файл данных
допустимо создание необходимых блоков переполнения. Допустим также, что
изначально блоки данных заняты в среднем наполовину. Если вставлять новые
записи случайным образом, сколько подобных операций придется выполнить до того
момента, когда среднее количество блоков данных (включая, если необходимо,
блоки переполнения), к которым придется обращаться в процессе поиска записи
с заданным значением ключа, достигнет 2?
13.2. Вторичные индексы
Структуры, о которых мы говорили в разделе 13.1 на с. 584, принято называть
первичными индексами (primary indexes) — они определяют местоположение
индексированных записей в файле данных, отсортированном по ключу поиска. В разделе 13.4 на
с. 624 рассмотрены первичные индексы и другой общеупотребительной
разновидности — хеш-таблицы (hash tables), в которых ключ поиска определяет сегмент (bucket),
которому принадлежит определенная запись.
Зачастую возникает необходимость создания нескольких индексов для одного
и того же отношения, позволяющих ускорить обработку запросов различных
категорий. Например, первичным ключом отношения MovieStar (см. рис. 12.1 на с. 550)
является атрибут name ("имя"), поэтому можно создать первичный индекс на основе
значений этого атрибута, полагая, что в немалом количестве запросов будет задаваться
имя актера. Предположим, однако, что информация отношения MovieStar часто
используется и для подготовки поздравительных посланий актерам в связи с их
юбилеями. Для этого используются запросы вида
SELECT name, address
FROM MovieStar
WHERE birthdate = DATE '1952-01-01';
Для повышения эффективности процессов обработки подобных запросов
уместным окажется вторичный индекс (secondary index) для атрибута birthdate. В SQL-
системе для создания такого индекса используется команда
CREATE INDEX BDIndex ON MovieStar (birthdate) ;
Вторичный индекс выполняет те же функции, что и любой другой индекс, — он
представляет собой структуру, облегчающую поиск записей по заданным значениям
одного или нескольких полей. Однако вторичный индекс отличается от первичного
тем, что он не определяет, а только указывает позиции записей в файле данных — для
задания взаимного положения записей может использоваться первичный индекс для
некоторого другого атрибута. Важное следствие, обусловленное различиями между
первичными и вторичными индексами, таково:
• создавать разреженные (sparse) вторичные индексы не имеет смысла; поскольку
вторичный индекс не оказывает воздействия на физическое положение записей
в файле данных и его нельзя использовать как инструмент предсказания
позиции произвольной записи, ключ которой не упомянут в файле индекса явно;
вторичные индексы всегда должны быть плотными (dense).
13.2.1. Проектирование вторичных индексов
Вторичный индекс — это плотный индекс, обычно содержащий дубликаты
ключевых значений. Как и прежде, индекс состоит из пар значений вида "ключ-
указатель"; "ключ" в данном случае — это ключ поиска, и требование его
уникальности не выдвигается. Элементы файла индекса отсортированы по значениям ключа —
это позволяет ускорить поиск требуемого элемента. Если необходимо дополнить
структуру индекса вторым уровнем, тот должен быть разреженным —
соответствующие доводы мы приводили в разделе 13.1.4 на с. 588.
13.2. ВТОРИЧНЫЕ ИНДЕКСЫ
599
Пример 13.13. На рис. 13.15 приведена типичная структура данных, содержащая
вторичный индекс. В соответствии с принятым нами соглашением блоки файла данных
содержат по две записи; на рисунке изображены только значения ключевых полей
записей и эти значения, как прежде, кратны 10. Заметьте, что, в отличие от файлов
данных, которые рассматривались в разделе 13.1.5 на с. 589, файл данных в данном
случае не отсортирован по ключу поиска.
10
10
20
20
\
\
20
40
10
20
20
30
40
50
/'
50
30
10
50
50
60
////
Ш
////
У//,
60
20
Рис. 13.15. Пример структуры со вторичным
индексом
Однако элементы файла индекса отсортированы по значениям ключа. В результате
указатели в записях одного блока вторичного индекса способны адресовать самые
разные блоки данных, а не один или несколько последовательных блоков, как при
использовании первичного индекса. Например, чтобы извлечь все записи данных
с ключом 20, придется не только обратиться к двум блокам индекса, но и
проследовать по соответствующим значениям указателей к трем различным блокам данных.
Таким образом, применение вторичных индексов в общем случае сопряжено с
необходимостью выполнения намного большего количества операций дискового ввода-
вывода в сравнении с тем, когда то же количество записей данных упорядочено с
помощью первичного индекса. К сожалению, помощи ждать неоткуда: мы не вправе
надеяться на то, что порядок следования записей данных окажется именно тем, который
необходим, поскольку он может быть обусловлен значениями других атрибутов.
Вполне возможно снабдить структуру, подобную приведенной на рис. 13.15,
вторым уровнем индекса. Этот — разреженный — индекс должен содержать элементы,
адресующие наименьшие или наименьшие новые значения ключей каждого блока
данных (об этом мы упоминали в разделе 13.1.4 на с. 588). □
13.2.2. Применение вторичных индексов
Помимо обеспечения возможности быстрой обработки различных запросов к
отношениям (или экземплярам классов), организованным в виде последовательных
файлов, вторичные индексы способны выполнять полезные функции и при
использовании со структурами иных типов, такими как "куча" (heap), где записи данных
располагаются в произвольном порядке.
600
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Вторичные индексы нередко используют и для оптимизации доступа к структурам
другой общеупотребительной категории, называемым компактно сгруппированными
файлами (clustered files). Рассмотрим отношения R и S, соединенные связью типа
"многие к одному", направленной от R к S. В некоторых ситуациях имеет смысл
хранить каждый кортеж R совместно со связанным кортежем S, а не упорядочивать R по
первичному ключу. Проиллюстрируем сказанное с помощью реального примера.
Пример 13.14. Обратимся к знакомым отношениям "кинематографической" базы данных:
Movie(title, year, length, inColor, studioName, producerC#)
Studio(name, address, presC#)
Предположим, что одним из наиболее "популярных" запросов является следующий:
SELECT title, year
FROM Movie, Studio
WHERE presC# = zzz AND Movie.studioName = Studio.name;
где zzz представляет некоторый конкретный сертификационный номер президента
киностудии. Таким образом, речь идет об отыскании информации обо всех фильмах,
снятых на киностудии, президентом которой является лицо, обладающее заданным
сертификационным номером.
Если указанный запрос действительно относится к числу самых типичных, тогда
вместо упорядочения кортежей отношения Movie по значениям первичного ключа
(title, year) целесообразнее создать структуру компактно сгруппированного файла,
объединяющего информацию отношений studio и Movie так, как показано на
рис. 13.16. За каждым кортежем отношения studio, описывающим данные о
некоторой киностудии, следует группа кортежей отношения Movie, представляющих
сведения обо всех кинофильмах, выпущенных этой студией.
Студия 1
Студия 2
Студия 3
Студия 4
Фильмы
студии 1
Фильмы
студии 2
Фильмы
студии 3
Фильмы
студии 4
Рис. 13.16. Пример компактно сгруппированного файла
Если создать индекс для отношения studio по ключу поиска presC#, это
позволит быстро находить кортеж с информацией о киностудии для любого заданного
значения zzz. Более того, все кортежи-записи Movie, содержимое компонентов
studioName которых совпадает со значением компонента name кортежа studio,
располагаются в компактно сгруппированном файле непосредственно после
соответствующей записи studio. Поэтому для получения данных о кинофильмах, выпущенных
определенной студией, будет достаточно выполнить такое количество операций
дискового ввода-вывода, которое близко к теоретическому минимуму. □
13.2.3. Дополнительные уровни во вторичных индексах
Использование структуры, приведенной на рис. 13.15, подчас сопряжено с
излишними (и немалыми) затратами дискового пространства. Если значение ключа поиска
присутствует в файле данных п раз, оно столько же раз включается и в файл индекса.
Было бы более разумно сохранять только одну копию значения ключа совместно со
всеми указателями, адресующими записи данных, обладающие этим ключом.
Чтобы избежать необходимости повторения ключевых значений, можно
разместить между вторичным индексом и файлом данных дополнительный уровень индекса,
состоящий из групп-сегментов (buckets) указателей. Как показано на рис. 13.17,
каждому существующему значению К ключа поиска соответствует единственный элемент
13.2. ВТОРИЧНЫЕ ИНДЕКСЫ
601
вторичного индекса, указатель которого адресует определенную позицию в "файле
сегментов", где расположена группа указателей, отвечающих ключу К.
20
40
10
20
50
30
10
50
60
20
Файл индекса
Сегменты
Файл данных
Рис. 13.17. Дополнительный уровень опосредования во
вторичном индексе позволяет экономить дисковое пространство
Пример 13.15. Обратимся к структуре, изображенной на рис. 13.17, и проследуем от
элемента индекса с ключом поиска 50 в направлении указателя до соответствующей
позиции в промежуточном "файле сегментов". Так случилось, что на этой позиции
расположен указатель на запись данных, занимающий последнее место в блоке файла
сегментов. Очередной указатель той же группы размещен в начале второго блока
файла сегментов, а далее следует указатель, связанный с другим элементом (содержащим
ключ 60) индексного файла. Таким образом, файл сегментов содержит группу из двух
указателей, ссылающихся на записи данных со значением ключа поиска, равным 50. □
Схема, приведенная на рис. 13.17, позволяет сэкономить пространство на диске
только в том случае, если значения ключа поиска требуют больше места, нежели
содержимое указателей, и повторяются в среднем не менее двух раз. Дополнительный
уровень опосредования между вторичным индексом и файлом данных, однако, сулит
немаловажные преимущества и тогда, когда достичь существенной экономии памяти
не удается: зачастую указатели в файле сегментов в состоянии помочь системе
обработать запрос с минимальным количеством обращений к файлу данных. В частности,
если запрос содержит несколько условий и каждому из них соответствует
определенный вторичный индекс, посредством операции поиска пересечения множеств
указателей в памяти можно обнаружить указатели, удовлетворяющие одновременно всем
условиям, и ограничить набор считываемых записей только теми, которые адресуются
указателями итогового множества. Поэтому системе удастся избежать затрат,
связанных с загрузкой записей, удовлетворяющих некоторым, но не всем, условиям.87
87 Трюк с пересечением множеств указателей можно использовать и в том случае, если
указатели размещены в файле индекса, а не в промежуточных группах-сегментах. Однако наличие
файла сегментов часто снижает расходы на операции дискового ввода-вывода, поскольку
указатели менее объемны, нежели пары "ключ—указатель" индекса.
602
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Пример 13.16. Рассмотрим отношение
Movie(title, year, length, inColor, studioName, producerC#)
из "кинематографической" базы данных. Предположим, что созданы вторичные
индексы с промежуточными сегментами для значений атрибутов studioName и year
и необходимо получить ответ на запрос
SELECT title
FROM Movie
WHERE studioName = 'Disney' AND year = 1995;
предполагающий отыскание информации обо всех кинофильмах, выпущенных
студией "Disney" в 1995 году.
На рис. 13.18 приведена схема действий, необходимых для обработки запроса
с привлечением имеющихся вторичных индексов. С помощью индекса для атрибута
studioName можно быстро найти указатели на все записи, соответствующие
кинофильмам студии "Disney" (заметьте, что речь пока идет только об указателях — ни
одна из записей еще не загружалась в оперативную память). В свою очередь, индекс
для атрибута year окажет содействие в обнаружении указателей на записи с
описанием всех кинофильмов, вышедших на экраны в 1995 году. Теперь достаточно
выполнить операцию пересечения двух множеств указателей, чтобы выявить именно те из
них, которые соответствуют записям о кинофильмах студии "Disney", снятых
в 1995 году, а затем загрузить в память все блоки данных (и только такие блоки),
содержащие записи, адресуемые указателями итогового множества.
Сегменты для
studioName
Кортежи
отношения
Movie
Сегменты для
year
Индекс для Индекс для
studioName year
Рис. 13.18. Пересечение множеств указателей в
оперативной памяти
13.2.4. Поиск документов и обращенные индексы
На протяжении длительного времени сообщество потребителей информации было
озабочено проблемами эффективного поиска документов по заданному множеству
ключевых слов. С пришествием технологий World Wide Web, обеспечивающих
возможности доступа к документам в режиме on-line, проблемы приобретают все более острый
характер и заслуживают повышенного внимания. Для отыскания подходящих доку-
13.2. ВТОРИЧНЫЕ ИНДЕКСЫ
603
ментов пользователи применяют самые разнообразные запросы; наиболее простую
и распространенную форму подобных запросов можно представить следующим образом.
• Информация, описывающая документ, трактуется как кортеж некоторого
отношения Doc. Отношение обладает весьма большим количеством атрибутов, по
одному на каждое слово в документе. Каждый атрибут относится к булеву типу;
компонент атрибута удостоверяет, присутствует ли соответствующее слово в
документе или нет. Пример схемы отношения Doc выглядит так:
Doc(hasCat, hasDog, ...),
где компонент, подобный has Cat, обладает значением true, если и только
если документ содержит по меньшей мере один экземпляр соответствующего
слова (в данном случае — "cat").
• Каждый атрибут отношения Doc снабжен вторичным индексом, причем индекс
состоит только из таких элементов, которые соответствуют значениям true
ключа поиска, т.е. указывают на документы, содержащие определенное слово.
• Все индексы сочетаются в одном, обращенном (inverted), индексе. Обращенный
индекс используется совместно с промежуточным уровнем групп-сегментов
указателей (см. раздел 13.2.3 на с. 601).
Пример 13.17. Способ применения обращенного индекса проиллюстрирован на
рис. 13.19. На месте файла с записями данных используется коллекция документов,
каждый из которых хранится в одном или нескольких дисковых блоках. Обращенный
индекс состоит из множества пар вида "слово—указатель"; слова выполняют функцию
значений ключа поиска. Обращенный индекс, как и любой другой индекс,
содержится в последовательных блоках. Однако в приложениях, связанных с поиском
документов, информация более статична, нежели содержимое обычных баз данных, поэтому
ситуации, предусматривающие необходимость создания блоков переполнения или
изменения индекса, возникают реже.
cat
dog
I—**"
i—**
Обращенный
индекс
С
Сегмент*
^
э1
...When
the cat
is away,
the mice
will play
. . .as
a cat
with
a dog...
...Barking
dogs
seldom
bite... |
Документы
Рис. 13.19. Поиск документов с помощью
обращенного индекса
604
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Немного о поиске информации по ключевым словам
Существует целый ряд приемов, способствующих повышению эффективности
процедур поиска документов по ключевым словам. Хотя сколько-нибудь полное
освещение предмета выходит за рамки нашей книги, стоит упомянуть, по меньшей
мере, два полезных метода.
1. Выделение корневой основы слов (stemming). До включения в индекс каждое слово
подвергается обработке, предусматривающей удаление приставок, суффиксов
и окончаний, а также выполнение иных необходимых действий. Например,
существительные множественного числа приводятся к форме единственного числа
(этот прием определенно применен в структуре, изображенной на рис. 13.19,
поскольку процесс поиска по ключевому слову "dog" приводит к получению
документов, содержащих не только слово "dog", но и соответствующий вариант
множественного числа —"dogs").
2. Отбрасывание слов-разделителей (stop words). Часто употребляемые союзы,
частицы, артикли, междометия и иные подобные слова, не несущие особой
смысловой нагрузки и присутствующие практически в любом документе, из
обращенного индекса обычно исключаются. Удаление слов-разделителей не
сказывается на качестве результатов поиска и позволяет существенно снизить
размеры файла индекса и время, требуемое для его просмотра.
Указатели в элементах индекса адресуют позиции "файла сегментов". На
рис. 13.19, например, указатель записи индекса с ключевым словом "cat" ссылается на
начало группы указателей, адресующих документы, которые содержат в своем составе
слово "cat". На рисунке символически представлены некоторые из таких документов.
Аналогично, элемент с ключом "dog" приводит к группе указателей, ссылающихся на
документы со словом "dog". □
Файл сегментов способен содержать:
1) указатели на документы в целом;
2) указатели, ссылающиеся на экземпляры ключевого слова внутри документа;
в этом случае указатель может состоять из двух частей — адреса первого
блока документа и целочисленного номера слова в документе.
При использовании второго варианта, предусматривающего использование
указателей, адресующих отдельные вхождения ключевого слова в тексте документа, модель
файла сегментов может быть расширена за счет включения дополнительной
информации о каждом экземпляре ключевого слова внутри документа. Теперь файл сегментов
сам по себе становится коллекцией записей достаточно сложной структуры. Ранние
реализации подобной модели позволяли различать образцы ключевого слова,
присутствующие в названии, аннотации и теле документа. С развитием технологий описания
Web-документов средствами HTML, XML и иных языков разметки стало возможным
задавать и различные признаки форматирования ключевых слов, подлежащих
отысканию. Теперь система способна совершенно независимо распознавать слова,
присутствующие в названиях, заголовках, таблицах, фрагментах "обычного" текста или
строках гиперссылок, набранные с помощью определенных шрифтов либо
отформатированные с применением тех или иных признаков.
Пример 13.18. На рис. 13.20 изображен файл сегментов, позволяющий находить
экземпляры слов в документах формата HTML. Ячейка первого столбца описывает тип
слова — принадлежность экземпляра слова определенной составной части
документа, признаки форматирования слова и т.п. Значения во втором и третьем столбцах
13.2. ВТОРИЧНЫЕ ИНДЕКСЫ
605
Файлы сегментов: операции вставки и удаления элементов
Структуру файлов сегментов принято изображать (как это сделано, скажем, на
рис. 13.19) в виде массивов элементов. В реальности группы-сегменты состоят из
записей с единственным полем указателя и сохраняются в блоках, как и любые
другие коллекции записей. Поэтому при модификации файлов сегментов,
предполагающей вставку и удаление указателей, допустимо использовать любые приемы,
рассмотренные выше: предварительное распределение записей по блокам, при
котором блоки остаются заполненными не до конца, что упрощает расширение
файла в будущем, применение блоков переполнения и перемещение записей внутри
блоков и между блоками (в последнем случае необходимо позаботиться и о
соответствующем изменении содержимого указателей в обращенном индексе,
ссылающихся на перемещаемые записи файла сегментов).
в совокупности образуют указатель на экземпляр слова в документе: третья ячейка
содержит ссылку на документ, а вторая представляет номер слова в документе.
Подобная структура данных дает возможность получать ответы на различные
запросы, касающиеся содержимого документов, не требуя подробного изучения каждого
документа. Предположим, например, что необходимо найти документы, посвященные
собакам и содержащие упоминания о кошках. Если не вчитываться в каждый
документ подробно, получение точного ответа на подобный запрос довольно
проблематично. Впрочем, неплохую основу для дальнейшего анализа нетрудно обеспечить,
если попытаться найти документы, в которых
a) слово "dog" ("собака") упоминается в названии;
b) слово "cat" ("кошка") содержится в областях текста, служащих
гиперссылками (которые, как можно надеяться, указывают на документы,
посвященные кошкам).
Тип Номер
dog
title
header
anchor
text
title
title
5
10
3
57
100
12
\l
\ 1
-"|
docl
doc2
doc3
Puc. 13.20. Обращенный индекс с дополнительной
информацией об экземплярах ключевых слов
Чтобы получить ответ на запрос, достаточно осуществить операцию пересечения
множеств указателей. Указатель в файле индекса, соответствующий ключевому слову "cat",
позволяет определить группу указателей, адресующих экземпляры этого слова в
документах. Среди указателей группы-сегмента необходимо выбрать такие, которые
относятся к типу "anchor" (область текста гиперссылки). Затем отыскивается группа указателей,
606
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
ссылающихся на экземпляры слова "dog" в документах, и в ней выбираются указатели
типа "title" (название). Операция пересечения двух множеств указателей даст в
результате набор ссылок на документы, удовлетворяющие одновременно обоим условиям: слова
"dog" присутствуют в названиях, а слова "cat" — в областях текста гиперссылок. □
13.2.5. Упражнения к разделу 13.2
* Упражнение 13.2.1. По мере осуществления операций вставки записей в файл
данных и удаления записей в соответствующем обновлении нуждается и файл
вторичного индекса. Предложите стратегии поддержки вторичного индекса в
актуальном состоянии при изменении файла данных.
! Упражнение 13.2.2. Предположим, что, как и в упражнении 13.1.1 на с. 598, каждый
блок способен содержать три записи данных либо десять элементов "ключ—указатель"
вторичного индекса для ключа поиска К. Для каждого значения v ключа К, которое
представлено в файле индекса, существуют одна, две или три записи данных,
содержащих v в поле К, причем 1/3 всех значений v присутствует в файле данных в одном
экземпляре, 1/3 — в двух, а 1/3 — в трех экземплярах. Предположим далее, что все блоки
данных и блоки индекса хранятся на диске, но существует структура, позволяющая
для любого значения v ключа К получить указатели на все блоки индекса,
содержащие по одной или несколько записей со значением v ключа поиска (допустим, что
речь идет о втором уровне индекса, размещенном в оперативной памяти). Вычислите
среднее количество операций дискового ввода-вывода, необходимых для
отыскания и извлечения всех записей данных, соответствующих значению v ключа поиска.
*! Упражнение 13.2.3. Рассмотрим структуру компактно сгруппированного файла,
подобную приведенной на рис. 13.16 (см. с. 601), и предположим, что в один блок
умещаются десять записей данных, представляющих кортежи отношений Movie
либо Studio. Предположим также, что количество фильмов, соответствующих
студии, равномерно распределено в интервале от 1 до т. Как выглядит функция от т,
выражающая среднее число операций дискового ввода-вывода, необходимых для
получения информации о киностудии и всех выпущенных ею фильмах? Какой
окажется эта величина, если допустить, что информация о кинофильмах
распределена по дисковым блокам случайным образом?
Упражнение 13.2.4. Предположим, что каждый блок способен хранить три записи
данных, десять пар вида "ключ—указатель" либо пятьдесят указателей и
предусматривается использование схемы с промежуточным уровнем групп-сегментов
(см. рис. 13.17 на с. 602).
* а) Если каждое значение ключа поиска содержится в среднем в 10 записях,
сколько блоков потребуется для хранения 3000 записей данных и
соответствующей структуры вторичного индекса? Сколько блоков пришлось бы
отвести при отсутствии файла сегментов?
! Ь) Если ограничений на количество записей данных с определенным
значением ключа поиска нет, каковы минимальная и максимальная оценки
количества необходимых блоков?
! Упражнение 13.2.5. Если принять условия задания (а) упражнения 13.2.4, каковы
оценки среднего количества операций дискового ввода-вывода, необходимых для отыскания
и загрузки десяти записей данных с заданным значением ключа поиска при
использовании структуры файла сегментов и без такового? Следует полагать, что изначально все
данные расположены на диске, но для определения местонахождения блоков индекса
и файла сегментов дополнительные операции ввода-вывода (помимо тех, которые
предназначены для считывания этих блоков в оперативную память) не требуются.
13.2. ВТОРИЧНЫЕ ИНДЕКСЫ
607
Упражнение 13.2.6. Предположим, что, как и в упражнении 13.2.4, в блоке можно
сохранить три записи данных, десять пар вида "ключ—указатель" либо пятьдесят
указателей. Допустим, что, как в примере 13.16 на с. 603, отношение Movie
обеспечено вторичными индексами для атрибутов studioName и year. Предположим
также, что отношение содержит информацию о 51 кинофильме студии "Disney"
и 101 кинофильме, выпущенном в 1995 году, причем только один из фильмов
этого года принадлежит студии "Disney". Определите количество операций
дискового ввода-вывода, необходимых для получения ответа на запрос, рассмотренный
в примере 13.16 (речь идет, напомним, об отыскании сведений о кинофильмах
студии "Disney", вышедших на экраны в 1995 году), если:
* а) оба вторичных индекса снабжены промежуточными файлами сегментов,
и система, извлекая из соответствующих групп-сегментов требуемые
указатели и выполняя пересечение множеств этих указателей в оперативной
памяти, способна непосредственно обнаружить единственную запись о
кинофильме студии "Disney", снятом в 1995 году;
b) файлы сегментов не используются, с помощью индекса для studioName
отыскиваются указатели на записи с описанием кинофильмов студии
"Disney", записи загружаются в оперативную память и среди них
выбираются те, которые соответствуют фильмам, выпущенным в 1995 году (следует
полагать, что никакие две записи с информацией о фильмах студии
"Disney" не принадлежат одному блоку);
c) то же, что и в п. (Ь), но применяется индекс для атрибута year (с условием,
что ни один блок не содержит более одной записи с данными о фильмах,
выпущенных в 1995 году).
Упражнение 13.2.7. Представим, что имеется хранилище, содержащее 1000 документов,
и необходимо сконструировать обращенный индекс, охватывающий 10000 слов. Блок
способен вместить десять пар вида "слово—указатель" либо пятьдесят указателей,
адресующих документы или позиции внутри документов. Частотное распределение
слов подчиняется функции Зипфа (G.K. Zipf) (за дополнительной информацией
обращайтесь к тексту врезки "Распределение Зипфа" на с. 787): среднее количество
экземпляров /-го по частоте встречаемости слова в массиве из п выбранных
наудачу слов оценивается величиной п IV/ , где / = 1, 2,..., п (в нашем случае п = 10000).
* а) Каково среднее количество слов в документе?
* Ь) Предположим, что обращенный индекс содержит ссылки только на такие
слова, которые присутствуют во всех документах. Каково максимальное
количество блоков, требуемых для хранения такого индекса?
c) Допустим, что обращенный индекс содержит указатели на каждый экземпляр
каждого слова. Сколько блоков понадобится отвести для подобного индекса?
d) Выполните задание (Ь) при условии, что из индекса исключены
400 наиболее употребительных слов (слов-разделителей).
e) Выполните задание (с) при условии, что из индекса исключены
400 наиболее употребительных слов.
Упражнение 13.2.8. Расширенный вариант обращенного индекса, подобный
приведенному на рис. 13.20 (см. с. 606), позволяет выполнять запросы различных видов.
Ответьте, как можно использовать этот индекс для отыскания документов, в которых
* а) слова "cat" и "dog" чередуются на пяти соседних позициях в текстовом
фрагменте одного типа — например, "title" (название), "text" ("обычный"
текст) или "anchor" (область текста гиперссылки);
608
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
b) за словом "dog" следуют произвольное слово и слово "cat";
c) слова "dog" и "cat" присутствуют в названии документа.
13.3. В-деревья
Хотя многоуровневые индексы считаются неплохим инструментом ускорения
процессов обработки запросов, существует более общая, гибкая и эффективная разновидность
структур, находящих самое широкое применение в коммерческих СУБД. Речь идет
о семействе структур, называемых В-деревъями (B-tree); наиболее распространенный
вариант В-дерева известен как В -дерево (B+-tree). Основные особенности В-деревьев таковы:
• автоматическая поддержка необходимого количества уровней индексации,
отвечающего размеру индексируемого файла данных;
• эффективное управление размером свободных областей внутри блоков (уровень
заполнения блоков колеблется от 50% до 100%) и исключение потребности
в использовании блоков переполнения.
Ниже мы будем обсуждать такие характеристики В-деревьев, которые полностью
справедливы для В+-деревьев. Сведения о В-деревьях иных типов вынесены в упражнения.
13.3.1. Структура В-дерева
Как следует из названия структуры В-дерева, ее блоки организованы в виде
древовидного графа (tree-like graph). В-дерево является сбалансированным (balanced) — в том смысле,
что длины всех путей от корневой (root) вершины до любой из вершин-листьев (leaves)
равны. Типичное В-дерево содержит три уровня: корневую вершину, промежуточные
вершины и листья, — хотя способно включать и произвольное количество уровней. Чтобы
получить начальное представление о В-деревьях, взгляните на рис. 13.21 и 13.22,
описывающие отдельные вершины, и на рис. 13.23, изображающий небольшое полное В-дерево.
Каждому В-древовидному индексу поставлен в соответствие параметр л,
определяющий свойства компоновки блоков В-дерева. Каждый блок обладает
пространством, достаточным для размещения п значений ключа поиска и п + 1 указателей. Блок
В-дерева по существу схож с индексными блоками, рассмотренными в разделе 13.1 на
с. 584, за исключением того, что наряду с п парами вида "ключ—указатель" он
содержит дополнительный, п + 1-й, указатель. Величина п выбирается таким образом, чтобы
обеспечить возможность хранения в блоке п + 1 указателей и п ключевых значений.
Пример 13.19. Пусть дисковый блок имеет размер 4096 байт. Предположим также, что
функцию ключей выполняют 4-байтовые целочисленные значения, а под каждый
указатель отводится по 8 байт. Если считать, что блоки не содержат заголовков, наибольшим
целым значением п, удовлетворяющим условию An + 8(л + 1) < 4096, окажется 340. □
Существует ряд важных правил, регламентирующих состав содержимого
блоков В-дерева.
• Ключевые значения, указанные в вершинах-листьях, являются копиями ключей
записей файла данных. Ключи распределены по вершинам-листьям слева
направо в порядке возрастания значений.
• Корневая вершина содержит, самое меньшее, два указателя, адресующих
блоки-вершины следующего уровня В-дерева.88
88 Строго говоря, возможна ситуация, когда файл данных содержит только одну запись и
поэтому В-дерево состоит из единственной вершины, обладающей одной парой "ключ—указатель"
и являющейся одновременно корнем и листом. Подобный вырожденный случай в дальнейшем
мы будем игнорировать.
13.3. В-ДЕРЕВЬЯ
609
Последний указатель вершины-листа ссылается на очередную вершину-лист
справа, т.е. на блок, содержащий следующую по порядку порцию ключевых
значений. По меньшей мере [_(п + 1) / 2J из п указателей в блоке-листе
используются для ссылки на записи данных, а остальные считаются свободными и
интерпретируются так, будто они обладают значениями null; /-й указатель, если он
используется, адресует запись с /-м ключом.
Все п + 1 указателей в промежуточной вершине могут применяться для ссылки
на блоки очередного уровня В-дерева, хотя реально должны использоваться по
меньшей мере [(п+\)/2] из них (напомним, что, независимо от величины п,
корневая вершина может содержать не менее 2 указателей, используемых по
назначению).89 Если действующими являются у указателей, им соответствуют у-
1 ключей (скажем, Кх, Къ ..., #)-i). Первый указатель адресует ту часть В-дерева,
которая позволяет отыскать записи с ключевыми значениями, меньшими К\.
Второй указатель ссылается на фрагмент дерева, ответственный за обнаружение
записей со значениями ключа, не меньшими Кх и строго меньшими К2, и т.д.
Наконец, j-Pi указатель приводит к ветви дерева, которая соответствует записям
с ключевыми значениями, равными или большими Kj.\. Заметим, что записи
с ключами, намного меньшими К\ и далеко превышающими £у_ь из текущего
блока, возможно, не достижимы — в таком случае им должны соответствовать
определенные соседние блоки, относящиеся к тому же уровню дерева.
К следующему
листу
К записи К записи К записи
с ключом с ключом с ключом
57 81 95
Рис. 13.21. Так выглядит типичная
вершина-лист В-дерева
Пример 13.20. В этом и следующих примерах, касающихся В-деревьев, мы будем
полагать, что п = 3, т.е. каждый блок способен содержать три ключевых значения и
четыре указателя, представляющих собой небольшие (это допущение не вполне
правдоподобно) целые числа. На рис. 13.21 показана вершина-лист, все указатели которой
используются по назначению. Блок вершины содержит три ключа — 57, 81 и 95.
Первые три указателя адресуют записи данных с названными ключами, а последний (как
и в любом листе В-дерева) ссылается на соседний лист справа от текущего; если
текущая вершина-лист является последней, указателю присваивается значение null.
Мы уже говорили, что допустимо не заполнять блок-лист до конца, но в нашем
случае (при условии п = 3) блок обязан содержать, как минимум, две пары вида
"ключ—указатель" (в схеме на рис. 13.21 ключ 95 и соответствующий ему указатель,
снабженный меткой "К записи с ключом 95", например, могут отсутствовать).
На рис. 13.22 изображена обычная промежуточная вершина В-дерева. Она
содержит три ключа (мы выбрали те же90 значения, что и в образце вершины-листа,
приведенном на рис. 13.21, — 57, 81 и 95) и четыре указателя. Первый указатель ссылается на
89 Выражения [_х\ и \х] означают "наибольшее целое, меньшее х" (выделение целой части х)
и "наименьшее целое, большее х" (округление х до ближайшего большего целого)
соответственно. — Прим. перев.
90 Несмотря на совпадение ключевых значений, лист на рис. 13.21 и промежуточная
вершина на рис. 13.22 никак между собой не связаны; более того, вполне возможно, что они никогда
не будут одновременно представлены в одном и том же В-дереве.
610
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
ветвь дерева, позволяющую обращаться к записям с ключами, меньшими 57. Второй
указатель способен привести к записям с ключевыми значениями из промежутка от 57
(включительно) до 81, третий — к записям с ключами из интервала от 81
(включительно) до 95, а четвертый — к записям, значения ключей которых не меньше 95.
К ключам К ключам К ключам К ключам
К<57 51<К<Ъ\ Ъ\<К<95 К>95
Рис. 13.22. Пример промежуточной вершины
В-дерева
Как и в рассмотренном выше примере листа В-дерева, вовсе не обязательно, чтобы
были заняты все "ячейки", предназначенные для хранения ключей и указателей.
Однако в случае п = 3 промежуточная вершина должна содержать по меньшей мере один
ключ и два указателя. Наиболее "экстремальным" вариантом оказался бы такой, когда
блок содержит ключ 57 и только два начальных указателя: первый из них адресует
ключи, меньшие 57, а второй — ключи, большие или равные 57. □
13
/
^
\
2 |3 |5
f f ?
ft 111
Рис. 13.23. Пример В-дерева
23
Т
291
т
Пример 13.21. На рис. 13.23 изображено полное трехуровневое В-дерево,
содержащее вершины, образцы которых были рассмотрены в примере 13.20.
Подразумевается, что файл данных состоит из записей, ключевые значения которых представляют
собой простые числа в интервале от 2 до 47. Обратите внимание, что на уровне
вершин-листьев каждый ключ упоминается однократно, и ключи упорядочены по
возрастанию от "левых" вершин к "правым". Каждый блок-лист содержит от двух
до трех пар "ключ—указатель", а также указатель, адресующий очередной лист
последовательности.
Корневая вершина содержит только два указателя (минимально возможное
количество), хотя могла бы включать до четырех. Единственный ключ корневой вершины
делит множество ключей на две части: одна доступна через посредничество первого
указателя, а другая — второго; ключи со значениями 2—11 (не 2—12, как кажется, по-
13.3. В-ДЕРЕВЬЯ
611
скольку в соответствии с нашим соглашением ключи являются простыми числами)
могут быть найдены в левом поддереве относительно корневой вершины, а ключи со
значениями 13 и выше — в правом.
Первая (левая) дочерняя вершина корневой вершины, содержащая ключ 7, также
обладает двумя указателями, первый из которых ссылается на ключи, меньшие 7,
а второй — на ключи, большие или равные 7. Заметьте, что второй указатель
позволяет обратиться к ключам 7 и 11, а не ко всем ключам, не меньшим 7 (скажем 13), —
остальные ключи достижимы из соседней промежуточной вершины дерева.
Наконец, вторая (правая) дочерняя вершина содержит все четыре указателя.
Первый адресует подмножество ключей, меньших 23 (а именно — 13, 17 и 19), второй
ссылается на ключи К, удовлетворяющие условию 23 < К < 31, третий позволяет найти
ключи, такие, что 31 < АГ< 43, а четвертый приводит к подмножеству ключей К>АЪ. □
13.3.2. Применение В-деревьев
Модель В-дерева является мощным инструментом конструирования индексов.
Последовательность указателей на записи, содержащихся в вершинах-листьях, способна
выполнять те же функции, что и любое подмножество указателей в "традиционных"
индексных файлах, о которых мы говорили в разделах 13.1 (см. с. 584) и 13.2 (см. с. 599).
Приведем несколько примеров.
1. Ключ поиска в В-дереве является первичным ключом файла данных и индекс
относится к категории плотных. Иными словами, блоки-листья индекса
содержат по одной паре "ключ—указатель" для каждой записи данных. Файл данных
может быть (или может не быть) отсортирован по первичному ключу.
2. Файл данных отсортирован по первичному ключу и В-дерево представляет
собой разреженный индекс, листья которого содержат по одной паре "ключ-
указатель" для каждого блока данных.
3. Файл данных отсортирован по значениям атрибута, не являющегося первичным
ключом, и этот атрибут служит ключом поиска в В-дереве. Для каждого
ключевого значения К, присутствующего в записях данных, в некотором блоке-листе
существует одна пара "ключ—указатель", и указатель адресует первую из
записей, обладающих значением К.
Варианты В-деревьев, допускающие наличие дубликатов значений ключа
поиска91, также находят широкое применение. Пример подобного В-дерева представлен
на рис. 13.24 и служит иллюстрацией расширенной модели В-деревьев, которая
аналогична схеме "обычных" индексов с повторяющимися значениями ключа
(см. раздел 13.1.5 на с. 589).
Если ключ В-дерева допускает наличие значений-дубликатов, необходимо слегка
пересмотреть способ интерпретации ключей, принадлежащих промежуточным
вершинам (мы говорили об этом в разделе 13.3.1 на с. 609). Предположим, что
промежуточная вершина содержит ключевые значения КЬК2,..., Кп. Тогда Kt должно быть
наименьшим новым значением, наличествующим в той части поддерева, которая
доступна при посредничестве /+1-го указателя. Слово "новый" подразумевает, что
экземпляры Kj отсутствуют в части дерева, расположенной слева от /+ 1-го поддерева,
но это поддерево содержит по меньшей мере один экземпляр Кг В некоторых
ситуациях такого значения может и не быть, и тогда К} трактуется как null. Однако
соответствующий указатель все еще необходим, поскольку он адресует значительную часть
дерева, которая оказалась связанной с единственным ключевым значением.
91 Напомним, что термин "ключ поиска" не обязательно подразумевает свойство
уникальности ключевых значений.
612
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
17
Л
V
Ч
2 |3 |5
? ¥ ¥
7 | |
АЛ 1
7
¥
131
f
13
¥
17
¥ {
23
23
f
23 J
f
23
f
37
¥ {
41
n
Рис. 13.24. В-дерево с дубликатами значений ключа
Пример 13.22. На рис. 13.24 приведено В-дерево, схожее с изображенным на
рис. 13.23, но допускающее повторение значений ключа (в частности, значение 11
заменено на 13, а 19, 29 и 31 — на 23). В результате ключевым значением корневой
вершины становится 17 (вместо 13). Причина заключается в том, что хотя 13 и служит
минимальным ключом правого поддерева, это значение не является новым, поскольку
присутствует также в левом поддереве.
Не обошлась без модификации и правая промежуточная вершина. Значение второго
ключа изменено с 31 на 37, поскольку именно это число стало наименьшим новым
ключом в пятом слева листе. Но более всего любопытно, что первый ключ правой
промежуточной вершины приобрел значение null, поскольку четвертый слева лист вообще
не имеет новых ключей. Другими словами, если процесс поиска приводит к правой
дочерней вершине корневой вершины, продолжать поиск с четвертого листа
бессмысленно: если необходимо найти ключ 23 или меньший, необходимо так или иначе
обратиться к третьему листу. Помимо того, следует принять во внимание такие обстоятельства.
• Если необходимо найти ключ 13, из корневой вершины надлежит обратиться
к левой (а не к правой) дочерней вершине.
• Если предполагается отыскание ключей из промежутка 24—36, придется
проследовать к третьему листу, но при отрицательном результате поиска
обращаться к листьям справа, очевидно, не требуется. Например, если бы в блоках-
листьях требовалось найти ключ 24, тот мог бы располагаться либо в четвертом
листе (и в такой ситуации ключ null правой промежуточной вершины должен
был бы принять значение 24), либо в пятом (но тогда на 24 следовало бы
изменить значение 37 ключа промежуточной вершины).
□
13.3.3. Поиск в В-деревьях
Вернемся к исходному предположению, в соответствии с которым вершины-листья
В-дерева не способны содержать повторяющиеся значения ключа, и будем считать, что
В-древовидный индекс является плотным — каждое ключевое значение, присутствующее
в файле данных, должно быть представлено в блоках-листьях дерева. Подобные
допущения позволяют значительно упростить обсуждение особенностей операций с В-деревьями
и тем не менее не затрагивают существа этих операций. В свою очередь, процедуры
модификации разреженных В-деревьев аналогичны тем, которые применяются по
отношению к "обычным" индексам для последовательных файлов (см. раздел 13.1.3 на с. 586).
13.3. В-ДЕРЕВЬЯ
613
Пусть с помощью В-древовидного индекса необходимо найти запись данных,
обладающую значением К ключа поиска. Процесс поиска выполняется рекурсивно — он
начинается с корневой вершины дерева и завершается по достижении вершины-листа.
Базис. Если достигнута некоторая вершина-лист, просмотреть принадлежащие ей
значения ключа. Если /-е значение равно К, /-й указатель адресует искомую запись данных.
Индукция. Если достигнута некоторая промежуточная вершина, содержащая ключи
Кь К2,..., Кп, для определения очередной дочерней вершины, к которой надлежит
перейти, руководствоваться правилами, изложенными в разделе 13.3.1 на с. 609.
Существует единственная дочерняя вершина, из которой удастся достичь записи данных
с ключом К: если К<Ки следует перейти к первой дочерней вершине, если
Кх < К < К2 — ко второй и т.д. Продолжать поиск рекурсивно от найденной вершины.
Пример 13.23. Предположим, что требуется найти запись с ключом 40 в структуре В-
дерева, приведенной на рис. 13.23 (см. с. 611). Начнем процесс поиска с корневой
вершины, содержащей единственный ключ, 13. Так как 13<40, проследуем по
направлению второго указателя, который адресует промежуточную вершину с ключами
23, 31 и 43. Здесь определяем, что 31 < 40 < 43, поэтому воспользуемся третьим
указателем, который приводит к вершине-листу с ключами 31, 37 и 41. Если бы в файле
данных существовала запись с ключом 40, найденный лист позволил бы ее отыскать,
но поскольку ключ 40 в составе блока-листа отсутствует, приходится сделать вывод,
что записи с ключом 40 в файле данных нет.
Если бы ставилась задача найти запись с ключом 37, процесс поиска привел бы
к тому же листу дерева. Так как значение 37 присутствует среди ключей этого листа,
соответствующий указатель (второй по счету) адресует искомую запись данных. □
13.3.4. Запросы в диапазонах значений
В-древовидные индексы находят полезное применение не только при
необходимости отыскания единственного значения ключа, но и в тех ситуациях, когда запрос
предусматривает поиск записей, удовлетворяющих диапазону значений, т.е. содержит
предложение where с операторами сравнения, отличными от = ("равно") и <> ("не
равно"). Подобный запрос к отношению R с атрибутом к, выполняющим роль ключа
поиска, может выглядеть, например, как
SELECT *
FROM R
WHERE R.k > 40;
либо как
SELECT *
FROM R
WHERE R.k >= 10 AND R.k <= 25;
Если в блоках-листьях В-дерева необходимо найти все ключи, принадлежащие
(закрытому) диапазону [а, Ь], следует задаться целью найти лист с ключом а.
Независимо от того, существует ключ а как таковой или нет, процесс поиска приведет
к листу, в котором этот ключ мог бы находиться, что позволит найти ключи, не
меньшие а и не большие Ъ. С каждым подобным ключом связан определенный
указатель, адресующий запись данных, ключ которой удовлетворяет заданному диапазону.
Если в текущем блоке-листе нет ключей, превышающих Ь, с помощью указателя
осуществляется переход к следующему по очереди листу; здесь вновь последовательно
проверяется принадлежность каждого ключа установленному диапазону, и если
условие удовлетворяется, используется соответствующий указатель, ссылающийся на
искомую запись данных. Процесс повторяется до тех пор, пока не будет найден ключ,
значение которого превышает Ь.
614
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Если Ь = +00, т.е. задана только нижняя граница диапазона, просматриваются все
блоки-листья, начиная от блока, содержащего ключ а, и завершая последним блоком
в цепочке. Если же а = -°° (задана только верхняя граница диапазона), поиск
начинается с первого листа дерева и продолжается так, как описано выше, т.е. до
достижения ключа, значение которого превосходит Ъ.
Пример 13.24. Предположим, что в В-дереве, изображенном на рис. 13.23, необходимо
отыскать ключи, принадлежащие (открытому) диапазону (10,25). Попытка найти
ключ 10 приведет ко второму листу. Первый ключ, 7, меньше 10, но второй, 11,
принадлежит заданному диапазону. Указатель позволяет найти соответствующую запись
данных и включить ее в итоговое множество.
Набор ключей второго блока-листа исчерпан, поэтому мы переходим к третьему
листу, содержащему ключи 13, 17 и 19. Все они строго меньше верхней границы диапазона,
равной 25, что дает основание обратиться с помощью указателей к соответствующим
записям и ввести эти записи в состав итогового множества. Наконец, после перемещения
к четвертому листу множество пополнится записью с ключом 23. Очередной ключ листа,
однако, обладает значением 29, превышающим 25, и поэтому поиск завершается. Таким
образом, итоговое множество будет содержать записи с ключами 11, 13, 17, 19 и 23. Q
13.3.5. Вставка элементов в В-дерево
Одно из преимуществ модели В-деревьев в сравнении с более простой схемой
многоуровневых индексов, рассмотренной в разделе 13.1.4 на с. 588, связано с
упрощением операций вставки новых ключевых элементов. Вставка записей в файл
данных, индексированный посредством В-дерева, осуществляется с помощью любого из
методов, упомянутых в разделе 13.1 на с. 584; здесь же мы сосредоточим внимание на
том, каким изменениям в ответ на вставку записи данных подвергается В-
древовидный индекс. Процесс по своему характеру рекурсивен.
♦ Найти в соответствующем блоке-листе свободное место, подходящее для
размещения новой пары "ключ—указатель", и вставить пару, если такое место существует.
♦ Если свободное место в листе отсутствует, расщепить лист на два листа и
распределить между ними исходное множество ключей и указателей поровну
(либо, если количество ключей нечетно, поместить в один блок на одну пару
"ключ—указатель" меньше или больше).
♦ Расщепление вершины дерева на одном уровне приводит к необходимости
вставки новой пары "ключ—указатель" в соответствующую вершину
следующего более высокого уровня. С этой целью применяется та же стратегия: если
места достаточно, вставить пару; в противном случае расщепить вершину на две
и продолжить процесс вверх по дереву.
♦ Единственное исключение связано с ситуацией, когда при попытке вставки
новой пары "ключ—значение" в корневую вершину обнаруживается, что
свободного места нет. В этому случае корневая вершина расщепляется на две
промежуточные и создается новая корневая вершина. Напомним, что, независимо от
количества п "ячеек" для хранения ключей в пределах вершины, корневой
вершине позволяется содержать всего один ключ и два указателя.
Аспект, связанный с расщеплением вершины и вставкой новой пары "ключ-
указатель" в родительскую вершину, заслуживает особого внимания. Предположим, что
предпринимается попытка вставки /г+1-й пары "ключ—указатель" в вершину-лист N,
максимальное количество ключей которой равно п. Создается новая соседняя вершина-
лист М, расположенная справа от N и имеющая ту же родительскую вершину, что и N.
Первые Г(л+ 1) / 2~] пар "ключ—указатель" сохраняются в вершине N, а остальные пары
13.3. В-ДЕРЕВЬЯ
615
перемещаются в М\ порядок следования ключей в N и М сберегается. Обе вершины, N
и М, получают достаточное количество пар "ключ—указатель", не меньшее [_(п + l)/2j.
Теперь предположим, что N •— промежуточная вершина, содержащая п ключей и п +1
указателей, и из-за расщепления дочерней вершины была осуществлена попытка
добавления в N новой пары "ключ—указатель". Необходимо предпринять следующие действия.
1. Создать новую вершину М того же уровня, что и N, расположенную
непосредственно справа от N и имеющую ту же родительскую вершину.
2. Сохранить в N первые [(п + 2) / 2] указателей и перенести в М оставшиеся
[_(л + 2) / 2J указателей, сберегая порядок их следования.
3. Сохранить в N первые \п12\ ключей и перенести в М оставшиеся [_п12J ключей.
Один из ключей К, расположенный в середине последовательности, всегда
оказывается лишним и не присваивается ни N, ни М. Ключ К является
наименьшим ключом, доступным из первой вершины, дочерней для М. Хотя К явно не
включается ни в N, ни в М, он ассоциируется с М (в том смысле, что
представляет наименьший ключ, доступный из М) и используется в вершине,
родительской по отношению к N и М, как критерий деления текущей ветви дерева на
поддеревья, соответствующие вершинам N и М.
Пример 13.25. Рассмотрим процесс вставки ключа 40 в В-дерево, приведенное на
рис. 13.23 (см. с. 611). Для отыскания блока-листа, подходящего для вставки нового
ключа, используется процедура, рассмотренная в разделе 13.3.3 на с. 613. Как
показано в примере 13.23 на с. 614, модификации подлежит пятый блок-лист. Поскольку
л = 3, а лист должен содержать уже четыре пары "ключ—указатель" со значениями
ключей 31, 37, 40 и 41, его надлежит расщепить. Первая фаза, проиллюстрированная
на рис. 13.25, состоит в создании нового листа и переносе в него двух последних
ключей, 40 и 41, с соответствующими указателями.
13
/.]
N
\
2 | 3 | 5
I j | | | | | | Т f |—I
—•*
31
?
Г
371
f
4о| 4
т |
I43
Г~Н 1
1 т
1 1
47|
т
Рис. 13.25. Результат выполнения первой фазы процесса вставки
ключа 40 в В-дерево, показанное на рис. 13.23
em
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Хотя на первый взгляд может показаться, что новый вариант дерева содержит
четыре уровня, их на самом деле по-прежнему три — нижний уровень состоит из семи
вершин-листьев, соединенных в цепочку слева направо.
Теперь промежуточную вершину с ключами 23, 31 и 43 необходимо снабдить
указателем, адресующим новый лист, содержащий ключи 40 и 41. Помимо того,
указателю следует поставить в соответствие ключ 40 — минимальный ключ, достижимый
посредством нового листа. К сожалению, вершина с ключами 23, 31 и 43, родительская
по отношению к расщепленному листу, заполнена — в ней нет места для
дополнительной пары "ключ—указатель". Поэтому она также нуждается в расщеплении.
Рассмотрим указатели, адресующие пять последних листьев, и первые ключи — 23,
31, 40 и 43 — четырех последних листьев, "разделяющие" эти указатели. Первые три
указателя и первые два ключа остаются в расщепленной промежуточной вершине,
а последние два указателя и последний ключ переносятся в новую промежуточную
вершину. Оставшийся ключ, 40, является наименьшим ключом, доступным при
посредничестве новой вершины.
Рис. 13.26 служит иллюстрацией второй, заключительной, фазы операции вставки
ключа 40. Корневая вершина обладает уже тремя дочерними вершинами; две
последние представляют результат расщепления второй исходной промежуточной вершины.
Обратите внимание, что ключ 40, являющийся минимальным ключом, достижимым
из новой промежуточной вершины, заносится в корневую вершину и разделяет
"правое" подмножество ключей между второй и третьей промежуточными вершинами.
13
I40!
2 [3 [5
Т Т ¥
7
f
ll|
f
7
13 17 19
TTT W TfT T T i—'
23
f
29 [
▼ Г
I
J
31
37
t t
h
40^
T f
I43
r-^H |
f
r
11 1
47l
f
a
Рис. 13.26. Окончательный результат процесса вставки ключа 40 в В-
дерево, показанное на рис. 13.23
13.3.6. Удаление элементов из В-дерева
При необходимости удаления записи с заданным ключом К прежде всего следует
определить местонахождение этого ключа в одной из вершин-листьев В-дерева. Эта
часть процесса удаления по существу связана с поиском и описана в разделе 13.3.3 на
с. 613. После того как запись данных найдена, она удаляется; затем удалению
подлежит соответствующая пара "ключ—указатель" В-дерева.
13.3. В-ДЕРЕВЬЯ
617
Если вершина N В-дерева, затрагиваемая процедурой удаления, все еще содержит
такой набор пар "ключ—указатель", количество которых не меньше допустимого
минимума, никакие дополнительные действия выполнять не требуется.92 Однако
возможна ситуация, когда вершина N хранит наименьшее возможное количество пар
"ключ—указатель", так что удаление одной из них приведет к нарушению
ограничения. В подобных случаях необходимо предпринять одно из перечисленных ниже
действий (возможно, с рекурсивным обновлением вершин вверх по дереву).
1. Если хотя бы одна из двух ближайших к N вершин того же уровня, имеющих
общую с N родительскую вершину, обладает таким количеством ключей
и указателей, которое выше минимального, одна из пар "ключ—указатель"
такой вершины может быть перемещена в N с сохранением порядка
следования ключей. Вполне вероятно, что в таком случае потребуется изменить
значения ключей и в вершине, родительской по отношению к N. Например, если
N получает пару "ключ—указатель" от соседней вершины справа (назовем ее
М), ключ этой пары обязан быть наименьшим среди всех ключей М. В
вершине, родительской для N и М, существует ключ, являющийся минимальным
ключом, достижимым из М; значение этого ключа должно быть увеличено.
Если же пара "ключ—указатель" перемещается в N из соседней вершины М
слева, ключ этой пары должен быть наибольшим среди ключей М, и значение
минимального ключа в родительской вершине подлежит уменьшению.
2. Ситуация оказывается более серьезной, если ни одна из ближайших соседних
вершин, относящихся к той же родительской вершине, не в состоянии
"выручить" вершину N, предоставив той недостающую пару "ключ—указатель".
В подобном случае, однако, одна из двух смежных вершин (имеются в виду N
и одна из сопредельных с ней вершин) обладает минимальным количеством
ключей, а другая содержит на единицу меньшее число ключей. Поэтому обе
вершины в совокупности имеют не больше пар вида "ключ—указатель", чем
разрешено для одной вершины (вот почему в качестве минимально
допустимого был выбран половинный уровень заполнения вершин В-дерева). Поэтому
можно осуществить слияние содержимого таких вершин, удалив одну из них,
после чего придется исправить значения ключей родительской вершины и
удалить в ней одну пару "ключ—указатель". Если степень заполнения
родительской вершины остается удовлетворительной, операция удаления завершается;
в противном случае процесс рекурсивным образом повторяется для вершин все
более высоких уровней дерева вплоть до достижения корневой вершины.
Пример 13.26. Вновь обратимся к В-дереву, изображенному на рис. 13.23 (см. с. 611),
и предположим, что удалению подлежит запись данных с ключевым значением 7.
Соответствующий ключ принадлежит второму листу дерева. Ключ надлежит изъять, а
затем удалить соответствующий указатель и запись данных, на которую тот ссылается.
К сожалению, после удаления второй лист будет содержать только одну пару "ключ-
указатель", а необходимо не менее двух. Но ситуацию спасает наличие "лишнего"
ключа в левой смежной (первой) вершине-листе. Поэтому наибольший ключ этой вершины
(5) вместе с соответствующим указателем можно перенести во второй лист. Итоговый
вариант В-дерева представлен на рис. 13.27. Поскольку наименьшим ключом во втором
листе теперь является 5, значение ключа в родительской вершине изменено с 7 на 5.
92 Если удаляемая запись данных обладает ключом, значение которого является
минимальным для вершины-листа, имеется возможность увеличения значения соответствующего ключа
в одной из родительских вершин, хотя делать это не обязательно — работоспособность
процедур поиска никоим образом не пострадает.
618
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
13
л
X
213
f ¥
5
f
11J
T
5
13 17 19
23
f
29|
у
31
f
37
T \
41
43
f
471
f
ft?
Pwc. 7J.27. Результат удаления ключа 7 из В-дерева, показанного на
рис. 13.23
Пусть далее необходимо удалить ключ 11. Операция вновь оказывает аналогичное
воздействие на второй лист дерева — количество пар "ключ—указатель" уменьшается
ниже допустимого минимума. На сей раз позаимствовать недостающие данные из
первого листа не удастся — тот содержит предельно малое количество ключей.
Ситуация усугубляется тем, что листа справа, относящегося к той же родительской
вершине, который к тому же обладал бы "лишними" указателями, нет.93 Поэтому
принимается решение о слиянии содержимого первой и второй вершин-листьев.
Три оставшиеся пары "ключ—указатель" первых двух листьев способны
уместиться в одном, поэтому пара с ключом 5 переносится в первый лист, а второй
лист удаляется. Далее подлежит уточнению и содержимое родительской вершины:
два прежних указателя заменяются одним (адресующим оставшийся первый лист),
а ключ 5 как не отвечающий действительности изымается. Эта фаза процесса
удаления проиллюстрирована на рис. 13.28.
К несчастью, удаление листа оказало неблагоприятное воздействие на
родительскую вершину — левую дочернюю вершину относительно корневой: как видно из
рис. 13.28, вершина не содержит ни одного ключа и обладает единственным
указателем. Поэтому надлежит предпринять попытку заимствования необходимой пары
"ключ—указатель" из соседней вершины того же уровня с общей родительской
вершиной. В нашем случае такая возможность имеется: правая промежуточная вершина
готова предоставить левой свой минимальный ключ с соответствующим указателем.
Сложившаяся ситуация отображена на рис. 13.29. Указатель на лист с ключами 13, 17
и 19 перенесен из правой промежуточной вершины в левую. Подверглись изменению
и некоторые ключи промежуточных и корневой вершин. Ключ 13, который
располагался в корневой вершине и представлял наименьшее ключевое значение, доступное
посредством только что перемещенного указателя, теперь необходим для первой
промежуточной вершины. С другой стороны, ключ 23, разделявший подмножества ключей
второй и третьей вершин-листьев, в данный момент является минимальным ключом,
доступным в правом поддереве. Поэтому он переносится в корневую вершину.
93 Заметьте, что правый (третий) лист, обладающий ключами 13, 17 и 19, имеет совершенно
другую родительскую вершину. Строго говоря, можно было бы заполучить пару "ключ-
указатель" и из этого листа, но тогда пришлось бы применять более сложный алгоритм
исправления значений ключей в вершинах, "разбросанных" по всему дереву. Этот вариант мы
предоставляем читателю в качестве упражнения.
13.3. В-ДЕРЕВЬЯ
619
2
f
3
f \
5
^
13
f
n]
f \
19
TT? IT TT? I I
43
f
471
f
Рис. 13.28. Результат выполнения первой фазы процесса удаления ключа
11 из В-дерева, показанного на рис. 13.27
13
\
31
| 431
\
ч
2 |з
5
f '
г '
'
13j п\ 19
1
II
1
\\
23
?
29 j
т
31
f
37
f \
41
43
f
471
f
Рис. 13.29. Окончательный результат выполнения процесса удаления
ключа 11 из В-дерева, показанного на рис. 13.27
□
13.3.7. Оценки эффективности В-древовидных индексов
Каждая из процедур поиска, вставки и удаления записей данных,
проиндексированных с помощью В-дерева, требует выполнения весьма небольшого количества
операций дискового ввода-вывода. Во-первых, если количество пар "ключ—указатель",
которые допустимо расположить в одном блоке, достаточно велико (скажем, 10 или
выше), потребность в расщеплении или слиянии вершин-блоков возникает
относительно редко. Во-вторых, даже в том случае, если подобные операции все-таки
необходимы, их влияние почти всегда носит локальный характер — затрагиваются только
два листа и соответствующая родительская вершина. Поэтому затратами на
реорганизацию дерева по существу можно пренебречь.
Однако для выполнения любой операции поиска записей, обладающих заданным
ключевым значением, требуется найти соответствующие указатели на записи, т.е.
проследовать от корневой вершины до некоторого листа. Поскольку блоки В-дерева
620
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
только считываются, число операций дискового ввода-вывода складывается из
количества уровней дерева и одной (при поиске) или двух (при вставке или удалении)
операций, необходимых для манипуляций с записью данных как таковой. Возникает
закономерный вопрос: сколько уровней содержит В-дерево в том или иной случае?
Если принять во внимание "типичные" размеры ключей, указателей и блоков, трех
уровней дерева окажется достаточно для всех баз данных, кроме особо крупных.
Поэтому 3 — эта та цифра, которой обычно характеризуют количество уровней В-деревьев.
Ответ на вопрос, почему все складывается именно так, дает следующий пример.
Пример 13.27. Напомним результаты анализа, проведенного в примере 13.19 на с. 609,
где было установлено, что один блок "обычного" размера (4096 байт) способен
содержать 340 пар "ключ—указатель". Предположим, что значение уровня заполнения блока
определяется серединой промежутка между минимальной и максимальной границами
(340/2 + 340/4), т.е. блок содержит 255 указателей. Таким образом, корневая вершина
адресует 255 промежуточных вершин, которые в совокупности ссылаются на 2552 = 65025
листьев, а каждый лист указывает на 255 записей, что дает возможность обращаться
к 2553, или 16,6 миллиона записей. Иначе говоря, если количество записей не
превышает 16,6 миллиона, для индексации такого файла достаточно 3-уровневого В-дерева. □
Однако на практике количество операций дискового ввода-вывода, необходимых
для прохода по дереву, может быть даже меньше трех. Корневой блок В-дерева —
прекрасный кандидат для постоянного размещения в буфере оперативной памяти.
Такое решение дает возможность сократить число обращений к диску в процессе
просмотра дерева до двух. При некоторых обстоятельствах имеет смысл буферизовать
в памяти даже блоки вершин второго уровня В-дерева, что позволит уменьшить
количество операций дискового ввода-вывода еще на одну единицу.
13.3.8. Упражнения к разделу 13.3
Упражнение 13.3.1. Предположим, что дисковый блок способен хранить 10 записей
данных либо 99 ключей и 100 указателей. Допустим также, что блок вершины В-
дерева заполнен в среднем на 70%, т.е. содержит только 69 ключей
и 70 указателей. В-деревья можно использовать как составную часть различных
структур. Полагая, что никакая информация изначально в оперативную память не
загружена и ключ поиска является одновременно первичным ключом записей
данных, для каждой из описанных ниже структур следует определить (i) общее
количество блоков, требуемых для хранения файла с 1000000 записей, и (И) среднее
число операций дискового ввода-вывода, необходимых для извлечения записи,
обладающей заданным значением ключа поиска.
* а) Данные размещены в последовательном файле, отсортированном по ключу
поиска, и каждый блок состоит из 10 записей. В-древовидный индекс
является плотным.
b) То же, что и в п. (а), но записи файла данных не упорядочены.
c) То же, что и в п. (а), но В-дерево является разреженным.
! d) Листья В-дерева содержат не указатели на записи данных, а записи как
таковые. Блок способен вместить 10 записей, но блок-лист заполнен в
среднем на 70%, т.е. хранит 7 записей.
* е) Файл данных является последовательным, а В-дерево — разреженным, но
каждому основному блоку данных поставлен в соответствие блок
переполнения. Каждый основной блок в среднем полон, а область блока
переполнения используется на 50%. Записи в основных блоках и блоках переполнения
не упорядочены.
13.3. В-ДЕРЕВЬЯ
621
Необходимо ли удалять вершины В-дерева?
Существуют такие реализации модели В-древовидных индексов, в которых
операции удаления элементов не предусмотрены вовсе. Если лист дерева содержит всего
несколько пар "ключ—указатель", позволено оставлять все как есть. Довод
заключается в том, что большинство файлов данных со временем расширяются, и если
в один момент времени операция удаления приводит к уменьшению количества
ключей ниже установленного минимума, то в другой вероятная операция вставки
восстанавливает нарушенный баланс.
Помимо того, если запись данных адресуется не только из вершины В-дерева, но
и извне, при удалении такой записи на ее месте обычно требуется оставлять признак-
"обелиск" (см. раздел 12.5.2 на с. 577). В этом случае разговор об изъятии указателя
В-дерева, который ссылается на подобную запись, лишен особого смысла. В
некоторых ситуациях, когда гарантируется, что все возможные обращения к удаленной
записи выполняются только при посредничестве В-древовидного индекса,
признак-"обелиск" можно перенести из записи данных на место указателя в
соответствующем листе дерева, что позволит использовать область записи данных повторно.
Упражнение 13.3.2. Выполните задания упражнения 13.3.1 в предположении, что
диапазон запроса охватывает 1000 записей.
Упражнение 13.3.3. Допустим, что размер указателя составляет 4 байта, а длина
ключа — 12 байт. Сколько пар "ключ—указатель" удастся "втиснуть" в блок
объемом 16384 байт?
Упражнение 13.3.4. Каковы минимальные количества ключей и указателей,
которые могут храниться в (i) промежуточных вершинах и (и) листьях В-дерева, если:
* а) п = 10, т.е. блок способен содержать 10 ключей и 11 указателей;
Ь) п=\\ (максимальные количества ключей и указателей в блоке равны 11 и 12
соответственно).
Упражнение 13.3.5. Выполните перечисленные ниже операции применительно
к структуре В-дерева, приведенной на рис. 13.23 (см. с. 611). Опишите изменения,
которые требуется внести в структуру при осуществлении операций модификации.
a) Поиск записи с ключом 41.
b) Поиск записи с ключом 40.
c) Поиск всех записей со значениями ключа в диапазоне 20—30.
d) Поиск всех записей со значениями ключа, меньшими 30.
e) Поиск всех записей со значениями ключа, большими 30.
f) Вставка записи с ключом 1.
g) Вставка записей со значениями ключа в диапазоне 14—16.
h) Удаление записи с ключом 23.
i) Удаление всех записей со значениями ключа, не меньшими 23.
! Упражнение 13.3.6. В примере 13.20 на с. 610 мы упоминали о том, что экземпляры
вершины-листа и промежуточной вершины В-дерева, изображенные на рис. 13.21
и 13.22, вполне возможно, никогда не будут одновременно представлены в одном
и том же В-дереве. Объясните, почему.
Упражнение 13.3.7. Если допустить возможность наличия в вершинах В-дерева
повторяющихся значений ключа поиска, рассмотренные выше алгоритмы поиска,
622
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
вставки и удаления ключей нуждаются в пересмотре. Опишите необходимые
изменения и добавления для алгоритмов
* а) поиска;
b) вставки;
c) удаления.
! Упражнение 13.3.8. В примере 13.26 на с. 618 упоминалось о том, что вполне возможно
заполучить требуемую пару "ключ—указатель" из левой/правой соседней вершины,
которая не обладает той же родительской вершиной, если использовать более сложный
алгоритм исправления значений ключей в вершинах дерева. Опишите приемлемый
алгоритм, позволяющий сохранить баланс дерева при заимствовании данных из
соседних вершин и действующий независимо от того, являются эти вершины
"соседями" вершины с избыточным или недостаточным количеством пар "ключ—указатель".
Упражнение 13.3.9. Предположим, что, как и в рассмотренных выше примерах,
вершины В-дерева содержат по 3 ключа и 4 указателя. Каково количество
различных В-деревьев, если файл данных состоит из
*! а) 6 записей;
!! Ь) 10 записей;
!! с) 15 записей.
*! Упражнение 13.3.10. Пусть существует В-дерево, вершины-блоки которого, как
и прежде, обладают пространством, достаточным для размещения трех ключей
и четырех указателей. Предположим, что при расщеплении листа с избыточным
количеством данных указатели распределяются по блокам поровну, а при
расщеплении промежуточной вершины три указателя попадают в первую (левую)
вершину, а остальные два — во вторую (правую). Начнем с листа, содержащего
указатели, которые адресуют записи с ключами 1, 2 и 3, а затем будем последовательно
добавлять записи с ключами 4, 5, 6 и т.д. При вставке какого ключа В-дерево из 3-
уровневого превратится в 4-уровневое?
!! Упражнение 13.3.11. Рассмотрим индекс, организованный в виде В-дерева.
Допустим, что вершины-листья содержат указатели, которые ссылаются в совокупности
на N записей, а каждый из блоков, образующих индекс, имеет в своем составе т
указателей. Мы хотели бы выбрать такое значение т, которое обеспечивает
минимизацию времени поиска данных, хранимых на диске системы, обладающей
перечисленными ниже характеристиками (за справками о параметрах доступа дисковых
устройств обращайтесь к разделу 11.3.4 на с. 504).
• Время, необходимое для считывания заданного блока в оперативную память,
оценивается величиной 70 + 0,05т миллисекунд, где 70 миллисекунд — это
сумма компонентов времени поиска цилиндра и времени оборота, а 0,05т
миллисекунд — время передачи: чем выше значение т, т.е. крупнее блок, тем
большее время требуется для считывания блока в оперативную память.
• Как только блок загружен в память, для отыскания в нем требуемого указателя
применяется процедура бинарного поиска. Поэтому время обработки блока
данных в памяти составляет a + b\og2m миллисекунд, где а и b — некоторые константы.
• Значение константы а существенно меньше суммы времени поиска цилиндра
и времени оборота, составляющей 70 миллисекунд.
• Индекс полон, так что количество блоков, подлежащих просмотру при
выполнении одной операции поиска ключа, равно \ogmN.
13.3. В-ДЕРЕВЬЯ
623
Дайте ответы на следующие вопросы.
a) Какое значение т доставляет минимум функции времени поиска записи по
заданному значению ключа?
b) Что произойдет в случае снижения суммы (70 миллисекунд) времени поиска
цилиндра и времени оборота? Если, например, эта константа уменьшится
вдвое, как изменится оптимальное значение ш?
13.4. Хеш-таблицы
Существует ряд полезных структур индексов, реализующих модель хеш-таблиц
(hash tables). Мы полагаем, что читатель знаком с вариантами применения хеш-таблиц
как средства организации данных в оперативной памяти. Каждой подобной структуре
ставится в соответствие некоторая хеш-функция (hash function), принимающая в
качестве параметра значение ключа поиска (в данном случае уместно называть его хеш-
ключом — hash key) и вычисляющая число в интервале от 0 до В - 1, где В —
количество сегментов (buckets). Элементы массива сегментов (bucket array) проиндексированы
от 0 до В -1 и содержат заголовки связанных списков (их количество равно В), по
одному на каждый элемент-сегмент массива. Если запись обладает значением К ключа
поиска, она присоединяется к списку сегмента с номером h(K), где h — хеш-функция.
13.4.1. Хеш-таблицы для данных во вторичных хранилищах
Хеш-таблица, содержащая настолько большое количество записей, что их
приходится располагать преимущественно во вторичном хранилище, отличается от варианта
хеш-таблицы, предназначенной для структурирования данных в оперативной памяти,
в нескольких важных аспектах. Прежде всего, массив сегментов должен состоять из
блоков, а не отдельных указателей на заголовки связанных списков. Перемешиваемые
записи относятся хеш-функцией к определенным сегментам и размещаются в блоках,
соответствующих этим сегментам. Если сегмент переполняется (в том смысле, что его
блок более не в состоянии содержать все записи, принадлежащие сегменту,
одновременно), к основному блоку сегмента присоединяется цепочка блоков переполнения
(overflow blocks), позволяющих сохранять дополнительные записи.
Будем считать, что местоположение основного блока /-го
сегмента может быть найдено непосредственно по номеру /.
Например, допустимо хранить в оперативной памяти массив указателей °
на блоки сегментов, индексированный по номерам сегментов.
Альтернативный способ связан с размещением основных блоков всех .
сегментов в фиксированных последовательных позициях диска.
Пример 13.28. На рис. 13.30 приведен образец хеш-таблицы.
Чтобы упростить дальнейшее обсуждение, будем полагать, что
каждый блок способен хранить не более двух записей и В = 4, т.е.
хеш-функция h возвращает значения в интервале 0—3. Таблица 3
содержит несколько записей с ключами, обозначенными буквами
от а до /. Подразумевается, что h(d) = 0, h(c) = h(e)=l, h(b) = 2
и h(a) = h(f) = 3. Поэтому шесть записей распределены по блокам ^ис- 13.30. Пример
именно так, как показано на рисунке. □ хеш-таблицы
Обратите внимание, что на рис. 13.30 каждый блок помечен справа
дополнительным прямоугольным "выступом", символически представляющим то место в
заголовке блока, где, например, может быть расположен указатель на соответствующий блок
переполнения. В разделе 13.4.5 на с. 627 и далее мы будем использовать подобные
"выступы" и для представления иной важной информации о блоке.
d
е
с
Ъ
а
f
J
J
J
J
624
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Как выбирать хеш-функцию
Хеш-функция призвана "перемешивать" ключи таким образом, чтобы
возвращаемое ею целочисленное значение представляло собой близкую к случайной
величину, зависящую от ключа-аргумента. Подобная функция обладает тенденцией к
равномерному распределению записей по сегментам таблицы, что (как показано в
разделе 13.4.4 на с. 626) приводит к снижению временнь/х затрат на доступ к записям.
Помимо того, хеш-функция должна быть легко вычислимой, поскольку
пользоваться ею приходится весьма часто.
• Обычный вариант хеш-функции, ключи-аргументы которой представляют собой
целые числа, предполагает вычисление остатка от деления К/ В, где К —
значение ключа, а В — количество сегментов. Часто в качестве В выбирается одно из
простых чисел, хотя существуют доводы в пользу принятия В равным степени
числа 2 (за подробностями обращайтесь к разделу 13.4.5 на с. 627).
• Если в роли ключей выступают строки символов, нередко каждый из символов
трактуется как целое число, все числа, соответствующие символам строки,
складываются, а затем вычисляется остаток от деления полученной суммы на
количество сегментов В.
13.4.2. Вставка записей в хеш-таблицу
При необходимости вставки в хеш-таблицу записи со значением К ключа поиска
следует вычислить хеш-функцию h(K). Если в блоке сегмента с номером h(K) имеется
свободное пространство, достаточное для размещения записи, запись вставляется в блок
этого сегмента. Если основной блок заполнен, запись сохраняется в одном из
соответствующих блоков переполнения. Если же ни в основном блоке, ни в любом из блоков
переполнения места нет, к цепочке блоков переполнения присоединяется новый блок.
Пример 13.29. Пусть в хеш-таблицу, представленную на рис. 13.30, требуется вставить
запись с ключом g, и h(g) = 1. Запись подлежит размещению в блоке сегмента с
номером 1. Блок, однако, уже заполнен. Необходимо создать новый блок переполнения
и соединить его с основным блоком сегмента 1. Запись с ключом g располагается во
вновь добавленном блоке, как показано на рис. 13.31.
d
е
с
Ъ
а
f
J
J
J
Рис. 13.31. Результат вставки записи
с ключом g в хеш-таблицу,
показанную на рис. 13.30
13.4. ХЕШ-ТАБЛИЦЫ
625
13.4.3. Удаление записей из хеш-таблицы
d
е
g
Ь
f
J
J
J
J
Рис. 13.32.
Результат удаления
записей с ключами с
и а из
хеш-таблицы, показанной на
рис. 13.31
Процедура удаления записи или нескольких записей с ключом К
выполняется по вполне предсказуемой схеме: необходимо перейти к
сегменту с номером h(K), отыскать в его блоках записи со значением
ключа поиска К и удалить их. Если имеется возможность
перемещения записей между блоками, после удаления записей допустимо
консолидировать оставшиеся записи в меньшем множестве блоков.94
Пример 13.30. На рис. 13.32 отображен результат удаления записи
с ключом с из хеш-таблицы, приведенной на рис. 13.31.
Напомним, что h(c) = 1, поэтому надлежит обратиться к сегменту с
номером 1 и просмотреть все принадлежащие ему блоки в поисках
записи (или нескольких записей, если ключ поиска не является
одновременно первичным ключом) с ключом с. Запись находится
в основном блоке сегмента 1. После ее удаления освобождается
область блока, достаточная для размещения записи с ключом g,
расположенной в блоке переполнения. Поэтому при желании
запись можно перенести, а блок переполнения — удалить
(рис. 13.32 отвечает именно такому варианту действий).
Заодно из хеш-таблицы удалена и запись с ключом а, что позволяет
перенести запись с ключом / из конца блока сегмента 3 в его начало. □
13.4.4. Оценки эффективности хешированных индексов
В идеальном случае содержимое каждого из сегментов хеш-таблицы умещается
в одном блоке, и тогда процедура поиска записи потребует выполнения единственной
операции дискового ввода-вывода, а процедуры вставки/удаления записей — двух
операций. Эта оценка значительно превосходит показатели эффективности, которыми
обладают "обычные" разреженные/плотные или В-древовидные индексы., хотя
последние поддерживают возможность "быстрой" обработки запросов в диапазонах
значений (см. раздел 13.3.4 на с. 614), а традиционные варианты хеш-таблиц — нет.
Однако по мере возрастания размеров файла неизбежно возникает ситуация, когда
для хранения содержимого типичного сегмента приходится использовать достаточно
длинную цепочку блоков. В этом случае в процессе поиска необходимо осуществлять
по одной операции дискового ввода-вывода для обращения к каждому из блоков
цепочки. Поэтому надлежит стремиться к тому, чтобы соотношение количества блоков
в расчете на один сегмент оставалось настолько низким, насколько это возможно.
До сих пор мы говорили о статических хеш-таблицах (static hash tables), имея в виду,
что значение параметра В (количества сегментов) остается неизменным. Однако
активное применение находят и различные варианты структур динамических хеш-таблиц
(dynamic hash tables), где значение параметра В позволено варьировать соразмерно
частному от деления общего количества записей на наибольшее число записей в одном
блоке, т.е. с целью обеспечения возможности размещения содержимого сегмента
в пределах единственного блока. Ниже мы сосредоточим вниманием на двух подобных
моделях: в разделе 13.4.5 рассмотрены способы расширяемого хеширования, а раздел
13.4.7 на с. 629 посвящен схемам линейного хеширования. Обе модели
предусматривают увеличение значения параметра В с ростом количества записей: в первом случае
значение В при необходимости удваивается, а во втором увеличивается на единицу.
94 Недостаток такого решения проявляется в тех случаях, когда чередующиеся операции
вставки и удаления записей приводят к необходимости попеременного выполнения трудоемких
процедур создания новых и уничтожения "лишних" блоков.
626
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
13.4.5. Расширяемые хеш-таблицы
Первый из рассматриваемых нами вариантов динамического хеширования связан
с использованием расширяемых хеш-таблиц (extensible hash tables); их основные
отличия от модели статических хеш-таблиц перечислены ниже.
1. Вводится новый уровень опосредования: сегмент представляется массивом
указателей на блоки, а не списком блоков как таковых.
2. Массив указателей способен к расширению. Его длина всегда сохраняется
равной степени числа 2, так что на очередном шаге увеличения массива
количество сегментов таблицы удваивается.
3. Каждому сегменту не обязательно ставится в соответствие отдельный блок: если
суммарное количество записей в нескольких сегментах не превышает
допустимого числа записей в блоке, сегменты могут владеть блоком совместно.
4. Хеш-функция h вычисляет для каждого ключа последовательность из к битов,
где к — определенное достаточно большое целое число (например, 32). Однако
для номеров сегментов будет использоваться некоторое меньшее количество
битов (скажем, /), выбираемых из начала последовательности. Таким образом,
длина массива сегментов составит 2' для любого / < к.
0
1
1 = 1
/'
0001
1001
1100
J]
Jj
Сегменты Блоки данных
Рис. 13.33. Пример расширяемой
хеш-таблицы
Пример 13.31. На рис. 13.31 представлена небольшая
расширяемая хеш-таблица. Для простоты положим
к = 4: хеш-функция возвращает битовые
последовательности длины 4. Допустим, что в данный момент
для обозначения номеров сегментов используется
только один бит (как гласит метка /= 1,
расположенная над массивом сегментов), т.е. массив состоит
всего из двух элементов.
Элементы массива сегментов ссылаются на два
блока. Первый содержит все имеющиеся в данный момент
записи, ключи поиска которых хешированы в битовые
последовательности с нулем в первой позиции, а
второй — записи с битовыми хеш-кодами,
начинающимися с единицы. Для наглядности ключи представлены в виде полных последовательностей
битов, возвращаемых хеш-функцией: так, верхний блок состоит из одной записи с ключом
поиска, хешированным в 0001, а нижний — из двух записей с хеш-кодами 1001 и 1100. □
Следует обратить внимание на единицы, проставленные в прямоугольных
"выступах", которыми помечен каждый блок на рис. 13.33. Это число, которое могло
бы действительно присутствовать в заголовке блока, указывает на то, сколько битов
последовательности, возвращаемой хеш-функцией, используется для определения
принадлежности записи текущему блоку. В ситуации, рассмотренной в примере 13.31,
для всех блоков и записей принимается во внимание только один бит, но, как будет
показано ниже, по мере увеличения объема таблицы это значение для различных
блоков может варьироваться. Иными словами, размер массива сегментов определяется
максимальным количеством битов, используемых в данный момент (для некоторых
блоков, возможно, потребуется меньшее количество битов).
13.4.6. Вставка записей в расширяемую хеш-таблицу
Начальные фазы процессов вставки записей в расширяемую и статическую хеш-
таблицы по существу совпадают. Чтобы осуществить вставку записи с ключом К,
надлежит вычислить значение функции h(K), вычленить из полученной
последовательности первые / битов и обратиться к элементу массива сегментов, обладающему индек-
13.4. ХЕШ-ТАБЛИЦЫ
627
сом, который равен значению этих / битов. Конкретную величину / определить легко,
поскольку она хранится в виде неотъемлемой части структуры хеш-таблицы.
Указатель, хранящийся в найденном элементе массива сегментов, ссылается на
некоторый блок В. Если блок содержит свободную область достаточной длины, запись
вставляется и процесс успешно завершается. Если же такой области в блоке В нет,
существуют две альтернативы дальнейших действий, и выбор одной из них зависит
от величины j, определяющей, какое количество битов последовательности,
возвращенной хеш-функцией, используется для определения принадлежности записи
блоку В (напомним, что именно это значение указано в прямоугольных "выступах",
которыми помечен каждый блок на рис. 13.33—13.35).
1. Если j < /, массив сегментов модификации не требует. Достаточно выполнить
следующее:
a) расщепить блок В на два блока;
b) распределить записи, принадлежавшие блоку В, по двум блокам,
руководствуясь значением j + 1-го бита хеш-кода; записи с нулем в указанной
позиции хеш-кода оставить в блоке В, а остальные переместить в новый блок;
c) снабдить "выступ" каждого из двух полученных блоков значением j + 1;
d) исправить значения указателей в элементах массива сегментов так, чтобы
указатели, ранее адресовавшие блок В, теперь ссылались на В либо на новый
блок — в зависимости от значения^ + 1-го бита хеш-кода.
Заметьте, что однократное расщепление блока В, возможно, не решит
проблему, поскольку достаточно вероятно, что все записи, пребывавшие в В, целиком
переместятся в один из новых блоков, на которые В был расщеплен. В этом
случае необходимо повторить процесс расщепления переполненного блока,
вновь увеличив значение j на единицу.
2. Если же j = /, увеличению на единицу подлежит значение /. При этом длина
массива сегментов удваивается и становится равной 2/+1. Предположим, что w —
последовательность из / битов, являвшаяся индексом одного из элементов прежнего
массива сегментов. В новом массиве элементы с индексами иЮ и wl (числами,
полученными из w добавлением 0 и 1) адресуют тот же блок, на который
ссылался указатель элемента с индексом w. Иными словами, два новых элемента
владеют одним блоком совместно, но блок как таковой изменению не подвергается.
Принадлежность записей этому блоку все еще может быть установлена посредством
последовательности с тем же количеством битов, что и прежде. Далее блок В следует
расщепить, как и в случае, описанном в п. 1
(теперь условие j < i выполняется).
Пример 13.32. Пусть в хеш-таблицу,
представленную на рис. 13.33, требуется вставить запись с
ключом, хешированным в битовую последовательность
1010. Поскольку значение первого бита
последовательности равно 1, запись должна принадлежать
второму (нижнему) блоку. Блок, однако, уже
заполнен, поэтому нуждается в расщеплении. В нашем
случае j = i = l, так что первым делом необходимо
удвоить размер массива сегментов, как показано на
рис. 13.34 (здесь же присутствует метка / = 2).
Обратите внимание, что два элемента массива Рис Ш4 Р тат встадки за_
с нулями в первой позиции индексов указывают на тси с хеш.кодом то в расши.
блок с записями, хеш-коды которых начинаются ряемую хеш.таблицУг показанную
с нуля, и блок в своем "выступе" все еще содержит на рис. 13.33
00
01
10
11
1=2
yf
0001
1001
1010
1100
_и
2J
1\
628
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
единицу, свидетельствующую, что для определения принадлежности записи блоку
достаточно одного первого бита хеш-кода. Блок с записями, хеш-коды которых
начинаются с единицы, однако, подлежит расщеплению, так что множество записей
разбивается на два подмножества: одни записи обладают хеш-кодами с префиксами 10, а хеш-
коды других записей начинаются с пары битов 11.
Метка 2 в "выступе" каждого из двух блоков
удостоверяет, что для установления факта членства
записи в блоке используются два бита хеш-кода.
К счастью, результат расщепления оказался
успешным: поскольку каждый из двух новых блоков
получил по одной записи, необходимости
дальнейшего рекурсивного расщепления удалось избежать.
Теперь предположим, что требуется пополнить
таблицу записями с ключами, хешированными
в битовые последовательности 0000 и 0111. Обе
записи должны быть помещены в первый (верхний)
блок, что вызывает его переполнение. Поскольку
в качестве признака принадлежности записей
этому блоку используется только один бит при i = 2,
изменять организацию массива сегментов не
требуется. Достаточно просто расщепить блок, оставив
в его исходной части записи с хеш-кодами 0000
и 0001 и переместив в новый блок запись с хеш-
кодом 0111. Указатель "ОГ'-го элемента массива
сегментов получает в качестве значения адрес
нового блока. И вновь нам повезло: записи не
"перешли" в один из новых блоков все целиком,
поэтому потребности в дальнейшем рекурсивном
расщеплении блоков нет.
Наконец, рассмотрим процедуру вставки записи с хеш-кодом 1000. Блок, на
который указывает "10"-й элемент массива сегментов, переполняется. Поскольку факт
членства записей в этом блоке определяется двумя битами хеш-кода, но / = 2, настал
черед увеличения значения параметра / (/ = 3) и удвоения емкости массива сегментов.
Результат приведен на рис. 13.35. Блок для записей с хеш-кодами, начинающимися
с 10, расщеплен на блоки 100 и 101, а принадлежность записей остальным блокам по-
прежнему определяется двумя битами. □
000
001
010
011
100
101
по
111
1=3
/
У
\
S
N>
\
л
</
/
\
^х
\ч
Nk
0000
0001
0111
1000
1001
1010
1100
2}
1\
1\
jU
2\
Рис. 13.35. Результат вставки
записей с хеш-кодами 0000, 0111 и
1000 в расширяемую хеш-таблицу,
показанную на рис. 13.34
13.4.7. Линейные хеш-таблицы
Модель расширяемых хеш-таблиц, рассмотренная в двух предыдущих разделах,
обладает рядом важных преимуществ, наиболее существенным из которых является тот
факт, что при поиске записи по заданному значению ключа приходится обращаться
не более чем к одному блоку данных. Разумеется, необходимо также просматривать
содержимое элементов массива сегментов, но если тот настолько мал, что может
храниться в оперативной памяти, необходимости выполнения трудоемких операций
дискового ввода-вывода в этом случае удастся избежать. Однако нельзя не упомянуть
и о серьезных недостатках, снижающих ценность модели расширяемых хеш-таблиц.
1.
2.
Процедура удвоения размера массива сегментов связана с немалыми
вычислительными затратами (если значение параметра / велико) и приводит к
приостановке процессов обработки запросов к файлу данных на относительно
продолжительные периоды времени.
Резкое увеличение длины массива сегментов способно привести к тому, что
массив более не сможет сохраняться в оперативной памяти, не вытесняя из нее
13.4. ХЕШ-ТАБЛИЦЫ
629
другие ценные порции информации, в результате чего системе,
демонстрировавшей дотоле нормальные показатели быстродействия, внезапно придется
осуществлять существенно большее количество операций дискового ввода-
вывода, что негативным образом скажется на ее производительности.
3. Если емкость блока мала, необходимость расщепления блоков возникает чаще,
чем это требовалось бы при других обстоятельствах. Например, если каждый блок
способен хранить по две записи (как в рассмотренных выше примерах),
возможна ситуация, когда три записи обладают хеш-кодами, совпадающими в первых
20 битах, хотя общее количество записей гораздо ниже 220. В подобном случае
придется полагать / = 20 и использовать массив сегментов с миллионом
элементов — даже тогда, когда количество блоков существенно меньше миллиона.
Иная стратегия, связанная с использованием линейных хеш-таблиц (linear hash
tables), позволяет наращивать количество сегментов более плавно. Основные новшества
модели линейного хеширования таковы.
• Количество п сегментов хеш-таблицы всегда выбирается так, чтобы отношение
среднего числа записей в блоке к максимально допустимому оставалось
постоянным (например, 80%).
• Поскольку расщепление блоков не всегда возможно, допустимо применять
блоки переполнения, хотя среднее удельное количество блоков переполнения
в расчете на один сегмент таблицы существенно меньше единицы.
• Количество битов, используемых для нумерации элементов массива сегментов,
составляет |~log2п\, где п — текущее количество сегментов. Биты выбираются из
младших разрядов (правой части) последовательности, возвращаемой хеш-функцией.
• Предположим, что для нумерации элементов массива сегментов используются /
битов последовательностей, получаемых в результате выполнения хеш-
функции, и запись с ключом К подлежит размещению в сегменте с номером
аха2 — ах, т.е. ах а2 ••• а-х — это / младших битов последовательности,
возвращенной функцией h{K). Допустим, что последовательность ах а2 — at трактуется как
/-разрядное двоичное целое число, равное десятичному значению т. Если т < п,
это значит, что сегмент с номером т существует и запись может быть сохранена
в этом сегменте. Если п<т<21, сегмента т нет, так что запись размещается
в сегменте т-2'"1, т.е. в сегменте, который можно получить, изменив значение
ах (которое должно быть равно 1) на 0.
Пример 13.33. На рис. 13.36 представлена линейная хеш-таблица, удовлетворяющая
условию п = 2. Для определения принадлежности записей сегментам в данный момент
используется только один бит. Как и в примере 13.31 на с. 627, для простоты будем
полагать, что хеш-функция h возвращает битовые
последовательности длиной 4 бита, и для представления
хеш-кодов записей используются все 4 бита.
Таблица состоит из двух сегментов, каждый из
которых содержит по одному блоку. Сегменты
пронумерованы как 0 и 1. Все записи с младшим нулевым
разрядом хеш-кода попадают в первый (верхний) сегмент,
а записи с единицей в младшем разряде — во второй.
Частью структуры являются параметры / (количество
используемых в данный момент битов
последовательности, возвращаемой хеш-функцией), п (текущее количество сегментов) и г (текущее
число записей, хранимых в хеш-таблице). Отношение г In ограничивается таким
образом, чтобы для хранения одного сегмента требовался в среднем один дисковый блок.
1 = 1
/1=2
г = 3
0
1
Рис. 13.36. П
0000
1010
1111
Пример
линет
3
J
юй
хеш-таблицы
630
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Мы придерживаемся такой политики выбора значения п, в соответствии с которой
файл содержал бы не более 1,7л записей, т.е. г < 1,7л. Иными словами, поскольку
в блок умещаются только две записи, средний уровень заполнения сегментов не
должен превышать 85% от емкости блока. □
13.4.8. Вставка записей в линейную хеш-таблицу
При необходимости вставки в хеш-таблицу новой записи для определения
подходящего сегмента таблицы используется алгоритм, рассмотренный в разделе 13.4.7.
Вначале для заданного значения К ключа поиска записи вычисляется хеш-функция
h(K), и в качестве искомого номера т сегмента используются / младших битов
последовательности h(K). Если т < л, запись заносится в сегмент т\ если же т > п, запись
размещается в сегменте т-2'"1. Если в выбранном сегменте нет свободного места,
создается блок переполнения, который присоединяется к цепочке блоков сегмента.
При выполнении каждой операции вставки значение соотношения г/п
анализируется с учетом возросшего количества г записей; если соотношение становится
чрезмерно большим, в таблицу добавляется новый сегмент. Заметим, что добавляемый
сегмент не имеет отношения к тому, в который вставляется очередная запись. Если
бинарным представлением номера добавленного сегмента является
последовательность 1 a2 — ah расщепляется сегмент 0а2-^; записи заносятся в один из двух
полученных сегментов в зависимости от значений битов аг Заметим, что все эти записи
должны обладать хеш-кодами, завершающимися последовательностью а2 — ah и
варьироваться будет только значение /-го бита справа.
Еще один важный аспект связан с ситуацией, когда значение л превышает 2'. В этом
случае текущее содержимое / увеличивается на единицу и в начало битового
представления номера каждого сегмента заносится дополнительный 0; по существу ничего не
меняется, поскольку битовые последовательности, интерпретируемые как целые
десятичные числа, остаются прежними.
Пример 13.34. Продолжим рассмотрение структуры, представленной на рис. 13.36,
и предположим, что в нее необходимо вставить запись с ключом, хешированным
в битовую последовательность 0101. Поскольку последним битом является 1, запись
должна быть помещена во второй (нижний) сегмент. Так как сегмент обладает
достаточным свободным пространством, блок переполнения не создается.
Теперь, однако, 4 записи располагаются в 2
сегментах, т.е. заданное отношение 1,7 превышено, и мы
обязаны увеличить значение п до 3. Поскольку flog2 3"| = 2,
номерами сегментов вместо 0 и 1 становятся значения
00 и 01, но структура данных остается прежней.
Таблица дополняется новым сегментом с номером 10. Затем
сегмент с номером 00 (отличающимся от номера вновь
созданного сегмента только одним битом)
расщепляется. При этом запись с хеш-кодом 0000 остается в
сегменте 00 (хеш-код завершается битами 00), а запись
с хеш-кодом 1010 по аналогичной причине
переносится в сегмент 10. Результат приведен на рис. 13.37.
Далее рассмотрим операцию вставки записи с хеш-
кодом 0001. Два последних бита кода — это 01,
поэтому запись подлежит размещению в существующем
сегменте с номером 01. К сожалению, сегмент уже заполнен, и к нему присоединяется
блок переполнения. Три записи распределяются по двум блокам сегмента в
соответствии с числовым порядком следования их хеш-кодов (впрочем, выбор определенного
порядка не столь важен). Поскольку отношение количества записей к числу сегментов
i = 2
00
01
10
0000
0101
1111
1010
J
J
J
Рис. 13.37. Результат
вставки записи с хеш-кодом 0101
и добавления сегмента в
линейную хеш-таблицу,
показанную на рис. 13.36
13.4. ХЕШ-ТАБЛИЦЫ
631
таблицы нынче равно 5/3, т.е. меньше 1,7, новый сегмент создавать не требуется.
Результат отображен на рис. 13.38.
Наконец, опишем последовательность действий, необходимых для вставки записи
с ключом, хешированным в 0111. Последние два бита хеш-кода, 11, указывают номер
сегмента, в который надлежит поместить запись, но такого сегмента в таблице нет.
Поэтому запись направляется в сегмент 01, номер которого отличается нулем в
первом бите. Запись занимает свободное место в блоке переполнения сегмента 01.
i = 2
л = 3
00
01
10
0000
0001
0101
1010
J
J
1111
Рис. 13.38. Результат вставки записи с хеш-кодом
0001 и добавления блока переполнения в хеш-
таблицу, показанную на рис. 13.37
1 = 2
л = 4
г=6
ии
U1
10
и
0000
0001
0101
1010
0111
1111
J
J
J
J
Рис. 13.39. Результат вставки записи с хеш-кодом
0111 и добавления сегмента в хеш-таблицу,
показанную на рис. 13.38
Однако теперь отношение количества записей к числу сегментов хеш-таблицы уже
превышает порог 1,7, поэтому надлежит создать новый сегмент с очередным номером,
11. Так случилось, что это как раз тот сегмент, в который следовало поместить новую
запись. Записи с хеш-кодами 0001 и 0101, принадлежащие сегменту 01, остаются на
месте, а две другие (0111 и 1111) переносятся в новый сегмент. Поскольку сегмент 01
сейчас содержит только две записи, блок переполнения оказывается лишним и
удаляется. Итоговая структура представлена на рис. 13.39.
Заметим, что очередная возможная операция вставки записи в хеш-таблицу на
рис. 13.39 приведет к превышению порога 1,7 и повлечет необходимость увеличения
значений п и / до 5 и 3 соответственно. □
Пример 13.35. Поиск в линейных хеш-таблицах выполняется в соответствии
с описанной выше процедурой, используемой при выборе сегмента, в который
следует поместить вставляемую запись. Если искомой записи в выбранном сегменте нет, ее
не может быть больше нигде. Чтобы проиллюстрировать сказанное, обратимся
к структуре хеш-таблицы, приведенной на рис. 13.37, где / = 2 и п = 3.
Для начала зададимся целью найти запись с ключом, хешированным в битовую
последовательность 1010. Поскольку / = 2, следует обратить внимание на два послед-
632
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
них бита хеш-кода записи, 10, которые, будучи интерпретированными в виде целого
десятичного числа, означают т = 2. Так как т<п, сегмент 10 существует и за записью
следует обратиться именно к нему. Обратите внимание, что факт отыскания записи
с хеш-кодом 1010 еще не означает, что это искомая запись; для пущей уверенности
надлежит проверять полное значение ключа записи.
Теперь рассмотрим процесс поиска записи с хеш-кодом 1011. На сей раз
необходимо обратиться к сегменту с номером 11. Поскольку значение 11, трактуемое в виде
целого десятичного числа, есть т = 3, имеем т>п, а это значит, что сегмента 11 в
таблице нет. Заменив начальную единицу номера на нуль, следует перейти к сегменту 01.
Однако в этом сегменте нет записи с хеш-кодом 1011, и мы можем быть уверены, что
ее нет и в таблице в целом. □
13.4.9. Упражнения к разделу 13.4
Упражнение 13.4.1. Поясните, как повлияют на содержимое сегментов хеш-
таблицы, приведенной на рис. 13.30 (см. с. 624), перечисленные ниже операции
вставки и замены записей с заданными ключами.
a) Записи g—j вставляются в сегменты 0~3 соответственно.
b) Записи а и b удаляются.
c) Записи к—п вставляются в сегменты 0—3 соответственно.
d) Записи cud удаляются.
Упражнение 13.4.2. Особенности операций удаления записей из расширяемых
и линейных хеш-таблиц нами не рассматривались. Механизм определения
местоположения записей, подлежащих удалению, однако, очевиден. Какой вариант
метода удаления вы смогли бы предложить? В частности, в чем состоят
преимущества и недостатки подходов, предполагающих реструктуризацию таблицы, если после
удаления отдельных записей данные могут быть консолидированы?
! Упражнение 13.4.3. На протяжении всего раздела мы неявно подразумевали, что
значения ключей поиска являются уникальными. Дабы обеспечить возможность
использования рассмотренных алгоритмов поиска, вставки и удаления записей при
наличии ключей-дубликатов, алгоритмы необходимо незначительным образом
видоизменить. Внесите собственные предложения по поводу необходимых
изменений и сформулируйте основные проблемы, сопряженные с присутствием
повторяющихся ключевых значений в
* а) простой хеш-таблице;
b) расширяемой хеш-таблице;
c) линейной хеш-таблице.
! Упражнение 13.4.4. Характеристики поведения некоторых хеш-функций далеки от
теоретического оптимума. Предположим, что ключи / записей хеш-таблицы
являются целочисленными значениями и хеш-функция выглядит как h(i) = i2 mod В, где
В — количество сегментов хеш-таблицы.
* а) В чем состоят недостатки хеш-функции при условии В = 10?
b) Насколько удачен выбор функции при В =16?
c) Существуют ли конкретные значения В, при которых хеш-функцию можно
считать вполне благополучной?
Упражнение 13.4.5. Какова вероятность того, что при вставке записи в
расширяемую хеш-таблицу с блоками, способными хранить до п записей, переполнение
блока повлечет необходимость рекурсивного расщепления ввиду переноса всех
записей исходного блока в один из вновь созданных блоков?
13.4. ХЕШ-ТАБЛИЦЫ
633
Упражнение 13.4.6. Предположим, что ключи записей хешируются в 4-битовые
последовательности (как и во всех примерах расширяемого и линейного
хеширования, рассмотренных выше). Допустим, однако, что блоки обладают емкостью,
достаточной для хранения трех (а не двух, как прежде) записей, и рассмотрим хеш-
таблицу с двумя пустыми блоками (с номерами 0 и 1). Покажите, как будет
выглядеть структура после вставки записей со следующими хеш-кодами:
* а) 0000, 0001, ..., 1111; хеш-таблица является расширяемой;
b) 0000, 0001, ..., 1111; хеш-таблица является линейной с предельным
значением отношения количества записей к числу сегментов, равным 100%;
c) 1111, 1110, ..., 0000; хеш-таблица является расширяемой;
d) 1111, 1110, ..., 0000; хеш-таблица является линейной с предельным
значением отношения количества записей к числу сегментов, равным 75%.
* Упражнение 13.4.7. Предположим, что существуют ссылки извне, адресующие
записи, которые хранятся в блоках расширяемой или линейной хеш-таблицы.
Наличие внешних указателей не позволяет свободно перемещать записи между
блоками. Предложите несколько способов преодоления указанной проблемы.
!! Упражнение 13.4.8. В схеме линейного хеширования, предусматривающей
использование блоков, каждый из которых способен содержать к записей, задается
пороговая константа с, связывающая текущие количества п сегментов и г записей
соотношением г = скп (скажем, в примере 13.33 на с. 630 использовались значения
к = 2 и с = 0,85, так что на каждый сегмент приходилось 1,7 записи, т.е. г= 1,7л).
e) Для простоты предположим, что количество экземпляров записи с
определенным значением ключа известно заранее. Выразите в виде функции от с, к
и п количество блоков (включая блоки переполнения), необходимых для
хранения подобной структуры.
f) Количества записей с заданным значением ключа (либо суффикса ключа)
распределены по закону Пуассона, т.е. если Л — ожидаемое количество
записей с заданным суффиксом ключа, реальное количество окажется
равным i с вероятностью е"ЛХ'//!. Выразите в виде функции от с, к и п
количество требуемых блоков.
*! Упражнение 13.4.9. Пусть имеется файл данных с 1000000 записей, которые
необходимо хешировать в таблицу с 1000 сегментов. Один блок способен вместить
100 записей, и требуется поддерживать настолько высокий уровень заполнения
блоков, насколько это возможно, учитывая, что блоки не должны находиться в
совместном пользовании у нескольких сегментов. Каковы минимальное и
максимальное количества блоков, достаточные для хранения указанной структуры?
13.5. Резюме
♦ Последовательные файлы. Простая схема организации файлов,
предусматривающая сортировку записей по некоторому ключу и использование
соответствующего индекса.
♦ Плотные индексы — индексы, содержащие по одной паре вида "ключ-
указатель" для каждой записи файла данных. Пары отсортированы по
ключевым значениям.
♦ Разреженные индексы — индексы, содержащие по одной паре вида "ключ-
указатель" для каждого блока файла данных. Пара с указателем, адресующим
некоторый блок, содержит ключ, совпадающий с ключом первой записи блока.
634
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
♦ Многоуровневые индексы. Иногда оказывается полезным создавать
дополнительные уровни индексации поверх исходного индекса. Индексы верхних уровней
должны быть разреженными.
♦ Вторичные индексы. Допустимо создавать индексы по некоторому ключу поиска
К даже в том случае, если файл данных не отсортирован по значениям К.
Подобные индексы должны быть плотными.
♦ Обращенные индексы. Взаимосвязь между документами и наборами слов,
которые в них содержатся, часто представляют с помощью индексной структуры,
образованной из пар вида "слово—указатель". Указатель адресует позицию
в файле сегментов, где расположен список указателей, ссылающихся на
экземпляры слова в документах.
♦ В-деревья. Подобные структуры по существу являются многоуровневыми
индексами, снабженными гибкими инструментами наращивания. Блоки, содержащие
по п ключей ип+1 указателей, формируют древовидную структуру, вершины-
листья которой адресуют физические записи данных. Уровень заполнения всех
блоков (кроме корневого) колеблется от половинного до максимального.
♦ Запросы в диапазонах значений. Для повышения эффективности процессов
обработки запросов, которые предусматривают необходимость отыскания записей
по значениям ключа, принадлежащим заданному диапазону, используются
структуры индексированных последовательных файлов в совокупности с
В-древовидными индексами.
♦ Хеш-таблицы. Структуры хеш-таблиц находят применение не только для
организации данных в оперативной памяти, но и для индексирования дисковой
информации. Хеш-функция транслирует значения ключа поиска в хеш-коды и
позволяет распределять записи по небольшим группам-сегментам. Каждому сегменту
ставятся в соответствие основной блок и, возможно, цепочка блоков переполнения.
♦ Динамическое хеширование. Поскольку с увеличением количества записей в
расчете на один сегмент показатели производительности хеш-таблиц снижаются,
для сохранения баланса следует увеличивать количество сегментов. Два
основных метода, реализующих подобный подход, носят название расширяемого
и линейного хеширования. Оба метода предусматривают необходимость
хеширования значений ключа поиска в длинные битовые строки и использования
варьируемого количества битов для обнаружения сегмента, подходящего для
размещения тех или иных записей.
♦ Расширяемое хеширование. Метод позволяет удваивать количество сегментов
в тех случаях, когда уровень заполнения любого из них становится чрезмерно
высоким. Расширяемая хеш-таблица содержит массив указателей, которые
ссылаются на блоки, представляющие сегменты таблицы. Дабы избежать
использования слишком большого количества блоков, несколько сегментов могут
обращаться к одному и тому же блоку.
♦ Линейное хеширование. При превышении заданного порога отношения числа
записей к числу сегментов количество сегментов линейной хеш-таблицы
увеличивается на единицу. В некоторых ситуациях для наращивания содержимого
отдельных сегментов используются блоки переполнения.
13.6. Литература
Модель В-дерева основана на результатах, изложенных в работе [2], где, в отличие
от рассмотренной нами схемы В+-дерева, предполагается возможность размещения
указателей на записи данных не только в листьях дерева, но и в его промежуточных
вершинах. Статья [3] содержит обзор различных вариантов В-деревьев.
13.6. ЛИТЕРАТУРА
635
Идея использования механизма хеширования как средства структурирования
данных впервые сформулирована в [8]. Модель расширяемого хеширования восходит
к результатам [4], а схема линейного хеширования заимствована из [7]. Монография
[6] содержит массу информации о различных структурах данных, включая описание
приемов выбора хеш-функций, проектирования хеш-таблиц и использования самых
различных версий В-деревьев.
Технологии использования вторичных индексов и других средств оптимизации
процедур поиска документов подробно изложены в [9]. В работах [1] и [5]
предлагаются обзоры методов индексирования текстовых документов.
1. Baeza-Yates R. Integrating contents and structure in text retrieval, SIGMOD Record, 25:1
(1996), p. 67-79.
2. Bayer R., McCreight E.M. Organization and maintenance of large ordered indexes, Acta Infor-
matica, 1:3 (1972), p. 173-189.
3. Comer D. The ubiquitous B-tree, Computing Surveys, 11:2 (1979), p. 121-137.
4. Fagin R., Nievergelt J., Pippenger N., and Strong H.R. Extendible hashing — a fast access
method for dynamic files, ACM Trans, on Database Systems, 4:3 (1979), p. 315—334.
5. Faloutsos C. Access methods for text, Computing Surveys, 17:1 (1985), p. 49-74.
6. Knuth D.E. The Art of Computer Programming, Vol. 3: Sorting and Searching, 2nd Edition, Ad-
dison-Wesley, Reading, MA, 1998. [Имеется перевод: Кнут Д.Э. Искусство
программирования, т. 3. Сортировка и поиск; 2-е изд. — М.: Издательский дом "Вильяме"', 2000]
7. Litwin W. Linear hashing: a new tool for file and table addressing, Proc. Intl. Conf. on Very
Large Databases (1980), p. 212-223.
8. Peterson W.W. Addressing for random access storage, IBM J. Research and Development, 1:2
(1957), p. 130-146.
9. Salton G. Introduction to Modern Information Retrieval, McGraw-Hill, New York, 1983.
636
ГЛАВА 13. СТРУКТУРЫ ИНДЕКСОВ
Глава 14
Многомерные и точечные
индексы
Все ранее рассмотренные структуры индексов являются одномерными (one-
dimensional), т.е. подразумевают наличие единственного ключа поиска и позволяют
обнаруживать записи данных, удовлетворяющие заданным значениям этого ключа. До
сих пор мы полагали, что функцию ключа поиска выполняет отдельный атрибут или
поле. К категории одномерных могут относиться и такие индексы, ключ поиска
которых образуется на основе нескольких полей. Если необходим одномерный индекс
с ключом поиска, сформированным из списка полей (Fb F2,..., Fk), содержимое ключа
допустимо представлять в виде цепочки связанных воедино значений полей Fb F2
и т.д., разделяемых специальными символами.
Пример 14.1. Если поле Fx относится к строковому типу, а поле F2 — к
целочисленному и в роли разделителя выступает символ #, который в данном случае запрещено
использовать внутри строковых значений, комбинацию величин F{= 'abed' и F2 = 12 3
можно оформить как строку 'abcd#123 '. □
В главе 13 на с. 583 мы упоминали о следующих преимуществах одномерного
пространства значений ключа поиска.
• Эффективность В-деревьев и индексов для последовательных файлов
обусловлена тем, что ключевые значения располагаются в упорядоченном виде.
• Поиск по хеш-таблице оказывается возможным только в том случае, если значение
ключа поиска достоверно известно. Если ключ образован на основе нескольких
полей и содержимое одного из них не определено, хеш-функцию применить не
удастся — вместо этого придется просматривать содержимое всех сегментов таблицы.
Существует целый ряд приложений, требующих, чтобы данные трактовались
в контексте 2-, 3- или даже «-мерных пространств. Некоторые из таких приложений
поддерживаются традиционными СУБД, но разработаны и специализированные
системы, которые ориентированы на обслуживание приложений, взаимодействующих
с многомерными данными. Одна из основных особенностей подобных систем связана
с поддержкой ими таких структур данных, которые делают возможной обработку
некоторых разновидностей запросов, не типичных для традиционных приложений SQL.
В разделе 14.1 представлены некоторые образцы запросов, эффективность обслужива-
ния которых существенно возрастает при использовании индексов для многомерных
данных. Разделы 14.2 на с. 646 и 14.3 на с. 657 посвящены обсуждению характеристик
перечисленных ниже структур данных.
1. Сеточные файлы (grid files) — многомерная версия хеш-таблиц.
2. Раздельные хеш-функции (partitioned hash functions) — альтернативный способ
реализации механизма хеш-таблиц в применении к многомерным данным.
3. Индексы с несколькими ключами (multiple-key indexes) — структуры, в которых
индексные значения одного ключа связаны со значениями ключа индексов
следующего уровня и т.д.
4. kd-деревья (Ы-trees) — обобщение модели В-дерева в приложении к
множествам точек.
5. Деревья квадрантов (quad trees) — деревья, каждая дочерняя вершина которых
представляет один из квадрантов площади, описываемой родительской вершиной.
6. Я-деревья (/?-trees) — обобщение модели В-дерева для представления множеств
областей пространства.
Наконец, в разделе 14.4 на с. 671 изучаются особенности структур точечных
индексов (bitmap indexes), содержащих краткие коды, описывающие положение записей
с заданными значениями в определенных полях. Механизмы поддержки точечных
индексов реализуются во многих популярных коммерческих СУБД с целью оптимизации
процессов обработки запросов как к одномерным, так и к многомерным данным.
14.1. Приложения модели многомерных данных
В этом разделе рассмотрены два класса приложений, реализующих модель
многомерных данных. Один связан с географическими информационными системами,
где элементы данных описывают сущности двумерного (иногда трехмерного) мира.
В приложениях другого класса понятие измерения трактуется более абстрактно:
каждый атрибут отношения можно интерпретировать как некоторое измерение; тогда
кортежи уместно воспринимать как определенные точки в пространстве,
ограниченном атрибутами-измерениями.
Помимо того, мы проанализируем способы применения традиционных индексов,
таких как В-деревья, для поддержки запросов к многомерным данным. В некоторых
случаях подобный подход целесообразен и эффективен, хотя в других гораздо
разумнее использовать определенные структуры специального назначения.
14.1.1. Географические информационные системы
Типичная географическая информационная система (geographic information system)
имеет дело с объектами двумерного (реже — трехмерного) пространства. Зачастую в
базах данных подобных систем представлена картографическая информация,
описывающая положение и взаимную ориентацию сооружений, дорог, мостов, трубопроводов
и многих других физических объектов. Пример подобной карты приведен на рис. 14.1.
Существуют и многие другие области применения подобных систем. Например,
сборка интегральной схемы выглядит как набор двумерных карт прямоугольных
областей, выполненных из специальных материалов и организованных в виде "слоев".
Окна и пиктограммы на экране компьютера также можно трактовать как объекты
двумерного пространства.
Запросы, обслуживаемые географическими информационными системами, нельзя
отнести к традиционной сфере использования SQL, хотя при определенных условиях
их все-таки удается выразить средствами SQL. Ниже перечислены некоторые из
разновидностей подобных запросов.
638
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
100
4.
Школа
ул. Дерибасовская
ДомМ
У
л.
К
Р
р
щ
а
т
и
к
Дом N2
Бейкер-стрит
0 100
Рис. 14.1. Несколько объектов двумерного
пространства
Запросы к данным с совпадением отдельных координат (partial match queries): задаются
значения координат одного или нескольких измерений и возвращается
информация обо всех точках пространства данных, удовлетворяющих критерию поиска.
Запросы в диапазонах значений (range queries): указываются диапазоны значений
для одного или нескольких измерений и запрашиваются данные о точках,
координаты которых относятся к этим диапазонам (примером может служить
запрос, предполагающий отыскание всех двумерных геометрических фигур,
которые частично или полностью принадлежат указанным областям плоскости).
Подобные запросы являются обобщением модели одномерных запросов в
диапазонах значений, о которой мы рассказывали в разделе 13.3.4 на с. 614.
Поиск ближайших соседних объектов (nearest-neighbor search). В качестве
примера достаточно упомянуть запрос, предусматривающий обнаружение точки,
ближайшей к заданной. Если точки представляют города, одним из подобных
запросов может быть такой: найти город с населением, превышающим заданную
границу численности, который наиболее близок к указанному городу.
Определение местонахождения объекта ("where-am-I" queries): задается точка
и запрашиваются сведения о принадлежности точки тем или иным фигурам,
областям или объектам. Характерным примером может служить задача
определения положения курсора относительно экранных объектов в момент
щелчка кнопкой мыши.
14.1.2. Кубы данных
Одно из недавних достижений в области технологий баз данных, реализованное
в ряде коммерческих СУБД, связано с поддержкой модели кубов данных (data cubes),
где информация интерпретируется в контексте многомерного пространства. Более
детальные сведения о модели приводятся в разделе 20.5 на с. 1031, а здесь мы вкратце
осветим ее основные идеи. Многие корпорации заняты сбором многомерных данных,
используемых в приложениях поддержки принятия решений (decision-support), которые
позволяют, например, проанализировать показатели хозяйственной деятельности
предприятия на основе информации о продажах производимых товаров, включающей:
14.1. ПРИЛОЖЕНИЯ МОДЕЛИ МНОГОМЕРНЫХ ДАННЫХ
639
1) дату и время сделки;
2) наименование пункта продажи;
3) название товара, его цвет, артикул, размер и т.п.
Обычно данные принято интерпретировать в форме отношения, которое содержит
по одному атрибуту для описания каждого свойства некоторой сущности. Атрибуты
отношения можно воспринимать как отдельные измерения многомерного
пространства, или "куба данных", а каждый кортеж — как точку в этом пространстве. Аналитики
вводят запросы, группирующие данные по определенным измерениям, а затем
суммируют результаты, полученные для групп, посредством функций агрегирования. Вот
типичный пример подобного запроса: "Насколько велики объемы продаж оранжевых
галстуков артикула 223-322 в каждом из магазинов сети по месяцам 1998 года?"
14.1.3. SQL-запросы к многомерным данным
Каждое из перечисленных выше приложений можно сформулировать в виде SQL-
запроса, обращенного к реляционной базе данных традиционной структуры.
Рассмотрим несколько примеров.
Пример 14.2. Предположим, что необходимо выполнять серии запросов,
предполагающих поиск ближайших соседних точек двумерного пространства. Информацию
о точках можно представить в виде отношения, содержащего пары вещественных чисел:
Points(х, у).
Иными словами, схема отношения Points включает атрибуты х и у, компоненты которых
содержат координаты х и у точек плоскости. В состав отношения могут входить и
дополнительные атрибуты, предназначенные для хранения значений других свойств точек.
Пусть требуется определить точку, ближайшую к точке с координатами
(10.0, 20.0). Соответствующий запрос, текст которого приведен на рис. 14.2,
определяет, существует ли для каждой точки р некоторая точка q, расположенная ближе
к заданной точке, нежели р. В сравнении участвуют значения расстояний,
вычисляемые как суммы квадратов разностей координат х и у точки (10.0,20.0)
и "текущей" точки, рассматриваемой в данный момент. Обратите внимание, что
для уменьшения времени обработки запроса действительные расстояния между
точками (квадратные корни сумм квадратов значений) не вычисляются: сравнение
квадратов величин даст тот же результат, что и сопоставление самих величин.
SELECT *
FROM POINTS p
WHERE NOT EXISTS(
SELECT *
FROM POINTS q
WHERE (q.x-10.0)*(q.x-10.0) + (q.y-20.0)*(q.y-20.0) <
(p.x-10.0)*(p.x-10.0) + (p.y-20.0)*(p.y-20.0)
);
Рис. 14.2. Пример запроса, позволяющего найти точку, ближайшую к заданной
□
Пример 14.3. Объектами географических информационных систем весьма часто служат
прямоугольные фигуры. Прямоугольник на плоскости может быть описан несколькими
способами; один из наиболее употребительных предусматривает задание координат
нижнего левого (lower left) и верхнего правого (upper right) углов. Коллекцию прямоугольников
легко представить в форме отношения Rectangles с атрибутами идентификатора фигуры
и значений координат ее углов (а также любыми другими атрибутами, соответствующими
требованиям конкретной ситуации). В этом примере мы будем пользоваться схемой
Rectangles(id, xll, yll, xur, yur),
640 ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
атрибуты которой предназначены для хранения идентификатора (id)
прямоугольника, а также абсцисс и ординат его нижнего левого (xll и у 11) и верхнего
правого (xur и yur) углов.
На рис. 14.3 приведен текст запроса, позволяющего найти прямоугольники,
охватывающие точку с координатами (10.0, 20.0). Условие предложения where достаточно
очевидно: чтобы точка (10.0, 20.0) принадлежала некоторому прямоугольнику, значение
абсциссы нижнего левого угла последнего должно быть не больше 10,0, а величина
ординаты — не больше 20,0; помимо того, значения абсциссы и ординаты верхнего
правого угла обязаны быть не меньше 10,0 и 20,0 соответственно.
SELECT id
FROM Rectangles
WHERE xll <= 10.0 AND yll <= 20.0 AND
xur >= 10.0 AND yur >= 20.0;
Рис. 14.3. Пример запроса, позволяющего найти
прямоугольники, охватывающие заданную точку
□
Пример 14.4. Информация в системах, реализующих модель кубов данных, обычно
организована в виде таблицы фактических значений (fact table), представляющей
базовые элементы хранимых данных (скажем, сведения о каждой операции продажи),
и набора размерностных таблиц (dimension tables), описывающей свойства базовых
значений по каждому измерению. Например, если одним из измерений служит
параметр, определяющий место совершения сделки продажи (магазин), атрибутами раз-
мерностной таблицы, соответствующей этому параметру, должны быть адрес, номер
телефона и имя управляющего магазином.
Размерностями таблицы фактических значений
Sales(day, store, item, color, article)
являются параметры, упомянутые в разделе 14.1.2 на с. 639. Текст запроса,
предусматривающего получение суммарной информации об объемах продаж оранжевых
галстуков по каждому из магазинов и по датам, может выглядеть так, как показано на
рис. 14.4. Здесь роль группирующих атрибутов (см. раздел 6.4.5 на с. 286) выполняют
размерностные атрибуты day и store, а данные всех других измерений агрегируются
посредством оператора count. Мы сосредоточиваем внимание только на тех точках
куба данных, которые отвечают условию предложения where, т.е. представляют
сведения о галстуках оранжевого цвета.
SELECT day, store, COUNT(*) AS totalSales
FROM Sales
WHERE item = 'tie' AND color = 'orange'
GROUP BY day, store;
Рис. 14.4. Пример запроса, возвращающего суммарную
информацию о продажах товаров
□
14.1.4. Запросы в диапазонах значений с использованием традиционных индексов
Теперь исследуем степень повышения эффективности процессов обработки
запросов в диапазонах значений (range queries) при использовании структур индексов,
рассмотренных в главе 13 на с. 583. Для простоты предположим, что речь идет о
двумерном пространстве свойств представляемых сущностей. При наличии вторичных
индексов, сконструированных для каждого из измерений х и у, особенно полезным для
14.1. ПРИЛОЖЕНИЯ МОДЕЛИ МНОГОМЕРНЫХ ДАННЫХ
641
отыскания значений, принадлежащих заданным диапазонам этих измерений,
окажется В-древовидный индекс. Вначале листья В-дерева дают возможность получить
множество указателей на записи данных, удовлетворяющие диапазону измерения х. Затем
В-дерево используется для обнаружения указателей на записи, соответствующие
точкам, координаты у которых относятся к диапазону измерения у. Наконец, с помощь
приема, описанного в разделе 13.2.3 на с. 601, вычисляется пересечение множеств
указателей. Если указатели размещены в оперативной памяти, общее количество
операций дискового ввода-вывода определяется числом листьев В-дерева, подлежащих
просмотру, и включает несколько дополнительных операций, необходимых для
перемещения по дереву (см. раздел 13.3.7 на с. 620). К этому числу надлежит добавить те
дисковые операции, которые требуются для считывания записей данных, удовлетворяющих
критерию поиска (следует иметь в виду, что таких записей может оказаться немало).
Пример 14.5. Рассмотрим гипотетическое множество из 1000000 точек,
распределенных случайным образом в двумерном пространстве и обладающих координатами х и у,
которые принимают значения из диапазонов 0—1000. Предположим также, что в один
дисковый блок умещаются 100 записей с информацией о точках и лист В-дерева
содержит в среднем 200 пар вида "ключ—указатель" (напомним, что в каждый момент
времени заняты не обязательно все ячейки блоков-вершин дерева). Будем считать, что
для измерений х и у созданы отдельные В-древовидные индексы.
Представим, что требуется получить ответ на запрос, предусматривающий
отыскание точек, принадлежащих квадрату со стороной 100, который расположен в центре
исходного квадрата 1000x1000. Иными словами, координаты точек должны
удовлетворять условиям 450 <лс< 550 и 450 < у < 550. Используя В-дерево для атрибута х,
нетрудно найти указатели на записи, соответствующие точкам, абсциссы которых
относятся к заданному диапазону. Таких указателей окажется примерно 100000, и
требуется, чтобы все они уместились в буферах оперативной памяти. Аналогично, с помощью
В-дерева для атрибута у отыскиваются указатели (их вновь будет около 100000) на
записи со значениями у в нужном диапазоне. Операция пересечения множеств
указателей даст в результате множество, содержащее приблизительно 10000 указателей на
записи, удовлетворяющие обоим условиям одновременно.
Теперь попытаемся оценить количество операций дискового ввода-вывода,
необходимых для получения ответа на запрос. Прежде всего, как упоминалось в разделе
13.3.7 на с. 620, во многих случаях весьма продуктивным окажется решение,
предусматривающее хранение корневой вершины В-дерева в оперативной памяти.
Поскольку необходимо отыскать в каждом из двух В-деревьев соответствующий диапазон
значений ключа поиска (имея в виду, что указатели в листьях деревьев упорядочены
по величинам ключей), для доступа к 100000 указателей в каждом измерении
надлежит обратиться к одной промежуточной вершине и ко всем листьям, содержащим
требуемые указатели. Мы полагаем, что один лист содержит около 200 пар "ключ-
указатель", поэтому в каждом из деревьев придется просмотреть по 500 блоков-
листьев. Если учесть процедуру считывания блока промежуточной вершины каждого
дерева, общее количество операций дискового ввода-вывода составит 1002.
Наконец, необходимо загрузить блоки, содержащие 10000 искомых записей. Если
записи распределены случайно, нам придется иметь дело почти с 10000 различных
блоков. Поскольку, как мы считаем, 1000000 записей файла распределены по
10000 блоков, речь идет о необходимости просмотра в среднем каждого блока файла
данных. Таким образом, традиционные индексы (по меньшей мере в этом случае)
вряд ли сослужат сколько-нибудь полезную службу при получении ответа на запрос
в диапазонах значений. Разумеется, если бы диапазоны были покороче, операция
пересечения множеств указателей позволила бы сузить область поиска до небольшой
части блоков файла данных. Q
642
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
14.1.5. Поиск ближайших соседних объектов с использованием
традиционных индексов
Для отыскания объектов, ближайших по отношению к заданному, как кажется на
первый взгляд, подойдет практически любая индексная структура: достаточно,
например, определить подходящие диапазоны в каждом измерении, выполнить запрос,
подобный рассмотренному в предыдущем разделе, и выбрать точку, удовлетворяющую
всем диапазонам и наиболее близкую к заданной. Подобный подход, к сожалению, не
учитывает две вероятные ситуации:
1) выбранные диапазоны не содержат нужную точку;
2) ближайшая точка, удовлетворяющая ограничениям диапазонов, не является
ближайшей в строгом смысле этого слова.
Проанализируем обе проблемы в контексте запроса из примера 14.2 на с. 640, считая,
что, как и в примере 14.5, каждый из атрибутов х и у снабжен определенным индексом.
Если бы мы имели достаточные основания полагать, что на расстоянии d от точки
(10.0, 20.0) существует по меньшей мере одна точка, мы смогли бы воспользоваться В-
деревом для получения указателей на все записи, представляющие точки с абсциссами
х, принадлежащими диапазону от 10-d до 10 + d. Аналогично, В-дерево для атрибута у
позволило бы обнаружить указатели на записи с информацией о точках, ординаты
которых находятся внутри промежутка [20-d, 20+ d]. Если бы в результате пересечения
множеств указателей были получены одна или несколько точек (ключами, хранимыми
вместе с указателями, в этом случае являются значения координат х и у), мы смогли
бы определить, какая из точек является ближайшей к точке (10.0,20.0), выполнив
загрузку всего одной записи. К сожалению, гарантий того, что хотя бы одна точка
находится на расстоянии d от заданной, не существует, поэтому весь процесс придется
повторить (возможно, неоднократно) для некоторого большего значения d.
Впрочем, даже если по меньшей мере одна точка в выбранном диапазоне и
существует, при определенных обстоятельствах ближайшая точка, принадлежащая
диапазону, окажется дальше от заданной, нежели некоторая точка, лежащая вне диапазона.
Ситуация проиллюстрирована на рис. 14.5. В этом случае надлежит расширить диапазон
и повторить поиск, дабы удостовериться, что более близких точек нет: если ближайшая
точка, относящаяся к выбранному диапазону, находится на расстоянии d' от заданной
точки и d' > d, мы обязаны провести поиск вновь, используя вместо d значение d'.
Ближайшая
точка
в диапазоне
°"*\^ Самая близкая точка
(вне диапазона)
Рис. 14.5. Точка принадлежит выбранному
диапазону, но не является ближайшей по
отношению к заданной
Пример 14.6. Вновь обратимся к набору данных и индексам, рассмотренным в
примере 14.5 на с. 642, и допустим, что необходимо отыскать точку, ближайшую к точке
Р = (10.0, 20.0). Положим, что d=l. Поскольку в каждом квадрате единичной площади
14.1. ПРИЛОЖЕНИЯ МОДЕЛИ МНОГОМЕРНЫХ ДАННЫХ
643
располагается в среднем одна точка, в квадрат со стороной 2, в центре которого
находится точка Р, с определенной долей вероятности "попадут" четыре точки.
Анализ содержимого листьев В-дерева для ключевых атрибутов-координат х со
значениями в диапазоне 9.0<х< 11.0 дает возможность получить около 2000 точек; для этого
придется обратиться, самое меньшее, к 10 блокам (вероятнее всего, даже к 11, поскольку
вряд ли начальным ключевым значением первого блока окажется х = 9.0). Как и в
примере 14.5, корневую вершину В-дерева целесообразно хранить в оперативной памяти,
что даст возможность сократить количество операций дискового ввода-вывода до 12:
одна операция необходима для считывания блока промежуточной вершины и 11 — для
обращения к блокам-листьям. Еще 12 операций потребуются для обнаружения в другом
В-дереве таких ключей-координат у, которые принадлежат диапазону 9.0 <у < 11.0.
Выполнив пересечение двух множеств с общим количеством указателей, примерно
равным 4000, мы найдем, вероятно, четыре таких указателя, которые адресуют точки,
являющиеся наиболее подходящими кандидатами на роль ближайших "соседей"
точки Р. Чтобы найти единственную искомую точку, достаточно извлечь связанные
с указателями значения ключей хну, вычислить расстояния, сравнить их и загрузить
соответствующую запись. Таким образом, в процессе обработки запроса придется
выполнить в общей сумме 25 операций дискового ввода-вывода. Если же квадрат со
стороной 2 (при d= 1) не содержит ни одной точки и точка, ближайшая к заданной,
находится за пределами этого квадрата, поиск надлежит повторить для большего значения d. □
Напрашивается следующий вывод: хотя традиционные структуры индексов в
некоторых случаях пригодны для обслуживания запросов, предполагающих поиск объекта,
ближайшего по отношению к заданному, они тем не менее требуют выполнения
существенно большего количества операций дискового ввода-вывода, нежели в тех
ситуациях, когда с помощью В-дерева необходимо найти запись по заданному значению
ключа (на что, вероятно, понадобится не более двух-трех операций). Методы,
рассматриваемые в следующих разделах этой главы, способны обеспечить гораздо более
высокий уровень производительности системы и потому находят широкое
применение в СУБД, ориентированных на поддержку многомерных данных.
14.1.6. Другие ограничения традиционных структур индексов
Упомянутые ранее индексные структуры демонстрируют себя не с лучшей стороны
и при выполнении запросов в диапазонах значений, и при поиске объекта,
ближайшего к заданному. Подход, используемый в примере 4.6 для решения задачи
отыскания ближайшего объекта, фактически сводится к запросу в диапазонах значений
и предположению о том, что небольшие размеры этих диапазонов окажутся
достаточными для обнаружения хотя бы одного объекта. Однако нетрудно представить, что
произойдет, если диапазоны станут более обширными, — количество операций
дискового ввода-вывода, необходимых для извлечения всех указателей на записи с
информацией об объектах, являющихся потенциальными кандидатами на роль "ближайшего
соседа", возрастет многократно.
Качество поддержки запросов с многомерным агрегированием, аналогичных
рассмотренному в примере 14.4 на с. 641, средствами традиционных индексов также не
впечатляет. При наличии индексов для атрибутов item и color мы, разумеется, в
состоянии найти указатели на все записи, представляющие уровни продаж галстуков
и предметов одежды оранжевого цвета, и выполнить пересечение множеств этих
указателей по той же схеме, что и в примере 14.6. Однако малейшее изменение
структуры запроса (скажем, добавление в предложение where условия, касающегося какого-
либо иного атрибута) потребует создания дополнительного индекса.
Что еще хуже, упорядочив файл данных по одному из пяти атрибутов, мы не
можем одновременно поддерживать порядок сортировки и по двум атрибутам. Поэтому
644
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
для выполнения большинства запросов, схожих по форме с рассмотренным в примере
14.4, потребуется обращаться если не ко всем, то почти ко всем блокам файла данных.
Если данные размещаются на носителях вторичных устройств хранения, издержки
становятся непомерно большими.
14.1.7. Обзор структур индексов для многомерных данных
Большинство индексных структур, пригодных для поддержки запросов к
многомерным данным, можно отнести к одной из двух категорий:
1) хеш-подобные структуры;
2) древовидные структуры.
Перечислим те характеристики индексов для одномерных структур, рассмотренных в главе
13 на с. 583, с которыми приходится расстаться при переходе к многомерным данным.
• Хеш-подобные схемы — сеточные файлы (grid files) и раздельные хеш-функции
(partitioned hash functions) (подробнее — в разделе 14.2) — не обеспечивают
гарантий того, что для получения ответа на запрос потребуется обратиться только
к одному сегменту; каждая из структур позволяет ограничить область поиска
некоторым подмножеством сегментов.
• Древовидные схемы утрачивают по меньшей мере одно из следующих свойств:
a) баланс дерева, при котором все вершины-листья относятся к одному уровню;
b) однозначное соответствие между вершинами дерева и дисковыми блоками;
c) возможность быстрой модификации данных.
Как будет показано в разделе 14.3 на с. 657, ветви деревьев индексов,
сконструированных для многоуровневых данных, часто обладают различной длиной: более
пространные ветви нередко представляют области, содержащие большее количество
объектов. Помимо того, довольно распространенной является ситуация, когда объем
информации, описывающей одну вершину дерева, намного меньше емкости
дискового блока, что вызывает необходимость группирования вершин по блокам.
14.1.8. Упражнения к разделу 14.1
Упражнение 14.1.1. Используя схему отношения
Rectangles(id, xll, yll, xur, yur),
описанную в примере 14.3 на с. 640, сформулируйте следующие SQL-запросы.
* а) Найти множество прямоугольников, пересекающихся с прямоугольником,
нижний левый и верхний правый углы которого расположены в точках с
координатами (10.0, 20.0) и (40.0, 30.0) соответственно.
b) Найти пары пересекающихся прямоугольников.
c) Найти прямоугольники, охватывающие прямоугольник с координатами
углов, указанными в п. (а).
d) Найти прямоугольники, расположенные внутри прямоугольника с
координатами углов, указанными в п. (а).
! е) Найти кортежи отношения Rectangles с информацией, которая не может
представлять реально существующие прямоугольники.
Укажите, какие индексы, если таковые действительно необходимы,
поспособствуют эффективному выполнению каждого из запросов.
14.1. ПРИЛОЖЕНИЯ МОДЕЛИ МНОГОМЕРНЫХ ДАННЫХ
645
Упражнение 14.1.2. Используя схему отношения
Sales(day, store, item, color, article),
описанную в примере 14.4 на с. 641, сформулируйте следующие SQL-запросы.
* а) Найти значения объемов продаж мужских сорочек (значение 'shirt'
атрибута item) определенных цветов (color), превышающие 1000.
b) Найти значения объемов продаж мужских сорочек, сгруппированные по
магазинам (store) и цветам изделий.
c) Найти значения объемов продаж всех изделий, сгруппированные по
магазинам и цветам изделий.
! d) Для каждой пары значений атрибутов item ("вид изделия") и color
("цвет") найти магазин (store) с наивысшим объемом продаж изделий
этого вида/цвета.
Укажите, какие индексы, если таковые действительно необходимы,
поспособствуют эффективному выполнению каждого из запросов.
Упражнение 14.1.3. Выполните задание из примера 14.5 (см. с. 642), полагая, что
запрос предусматривает отыскание точек, принадлежащих квадрату со стороной п,
который расположен в центре исходного квадрата 1000x1000, где 1<жЮ00.
Сколько операций дискового ввода-вывода потребуется осуществить для
получения ответа? При каких значениях п индексы традиционных структур способны
снизить трудоемкость обслуживания запроса?
* Упражнение 14.1.4. Выполните задание упражнения 14.1.3, если записи файла
данных отсортированы по значениям х.
!! Упражнение 14.1.5. Предположим, что, как и в примере 14.6 на с. 643, необходимо
выполнить запрос, предусматривающий поиск точки, ближайшей к заданной,
среди множества равномерно распределенных точек. Речь идет о поиске точек,
принадлежащих квадрату со стороной 2d (при некотором выбранном значении d),
центр которого совпадает с исходной точкой. Результат поиска считается
успешным, если внутри квадрата найдена хотя бы одна точка, расположенная на
расстоянии от исходной точки, меньшем или равном d.
* а) Если на единицу площади приходится в среднем по одной точке, выразите в
виде функции от d вероятность того, что результат поиска окажется успешным.
Ь) Если поиск безуспешен, процесс надлежит повторить при большем
значении d. Для простоты предположим, что в подобных ситуациях значение d
удваивается и вычислительные затраты, сопряженные с новой итерацией
поиска, также возрастают вдвое. Если вновь допустить, что на единицу площади
приходится в среднем по одной точке, какое исходное значение d обеспечит
минимум функции затрат?
14.2. Хеш-подобные структуры для многомерных данных
В этом разделе мы сосредоточим внимание на двух структурах, обобщающих
классическую схему хеш-таблиц, предусматривающую использование единственного
ключа. В каждой из структур номер сегмента, отвечающего точке, является функцией всех
атрибутов или измерений. Первая структура, называемая сеточным файлом (grid file),
обычно не предусматривает "перемешивания" (hash) значений по измерениям, но
разделяет измерения посредством сортировки относящихся к ним значений. Схема
раздельных хеш-функций (partitioned hash functions), напротив, предполагает
хеширование значений измерений таким образом, что каждое измерение вносит в номер
сегмента собственную составляющую.
646
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
14.2.1. Сеточные файлы
Одна из простейших схем индексации, которая зачастую превосходит по
эффективности традиционные индексы, применяемые для обработки запросов к
многомерным данным, носит название сеточного файла (grid file). Модель сеточного файла
можно представлять так, будто пространство точек-объектов разбивается на части
воображаемой сеткой (grid). Линии сетки (grid lines), параллельные осям каждого
измерения, делят пространство на полосы (stripes). Точки, принадлежащие линии, которая
является нижней границей определенной полосы, относятся к этой полосе.
Количество линий сетки по различным измерениям допустимо варьировать; более того,
ширина полос также может быть различной — даже в пределах одного измерения.
Пример 14.7. Рассмотрим запрос (мы будем обращаться к нему неоднократно на
протяжении всей главы), который можно кратко сформулировать так: "Кому по карману
приобретение драгоценностей?" Вообразим, что существует база данных с
информацией о клиентах ювелирных магазинов, содержащая самые различные сведения о
каждом клиенте — его имя, адрес, номер телефона и т.п. Однако для простоты
ограничим внимание всего двумя атрибутами, компоненты которых сохраняют значения
возраста клиента и его годового дохода, выраженного в тысячах (К) долларов.95
Предположим, что база данных содержит информацию о двенадцати клиентах,
представленную в форме пар вида "возраст—доход":
(25, 60)
(50, 120)
(25, 400)
(45, 60)
(70, ПО)
(45, 350)
(50, 75)
(85, 140)
(50, 275)
(50, 100)
(30, 260)
(60, 260)
На рис. 14.6 показаны 12 точек, распределенных в двумерном пространстве.
Каждое измерение поделено на полосы несколькими линиями сетки. В данном случае мы
использовали по две линии для каждого измерения, что привело к разбиению
пространства на девять прямоугольных областей, хотя никаких особых доводов в пользу
выбора одинакового количества линий сетки для всех измерений не существует.
Линии расположены так, что полосы обладают различной шириной. Вертикальные
полосы, соответствующие измерению "возраст", например, имеют ширину 40, 15 и 45.
В нашем примере ни одна из точек не располагается непосредственно на линии
сетки, хотя в общем случае в соответствующий прямоугольник включаются такие
точки, которые принадлежат его нижней или левой (но не верхней или правой)
границам. Например, центральный прямоугольник на рис. 14.6 представляет точки,
координаты которых удовлетворяют условиям 40 < возраст < 55 и 90 < доход < 225. □
14.2.2. Поиск записей в сеточном файле
Каждую из прямоугольных областей, получаемых в результате пересечения полос
пространства, можно трактовать как сегмент (bucket) хеш-таблицы (hash table): точки,
принадлежащие области, представляются записями, размещаемыми в блоке (block),
который относится к соответствующему сегменту. Если для хранения информации
обо всех точках области емкости одного блока недостаточно, создаются необходимые
блоки переполнения (overflow blocks).
В отличие от одномерного массива сегментов, используемого в традиционных хеш-
таблицах, сеточный файл содержит массив сегментов, количество размерностей которого
совпадает с числом измерений файла данных. Чтобы выявить факт принадлежности точки
определенному сегменту, необходимо обладать списками позиций линий сетки по каж-
Данные соответствуют реалиям США. — Прим. перев.
14.2. ХЕШ-ПОДОБНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
647
500K
I
90K
О
© ; ;
! © !
I © !
© , , ©
! ! ©
! • ! ©
;___•:____:
о
40 55
Возраст
100
Рис. 14.6. Фрагмент двумерного
пространства данных
0-40 40-55 55+
225+
90-225
0-90
30, 260
25,400
25,60
45,60
50,75
50, 100
50,120
70,110
85, 140
60, 260
45, 350
50, 275
Рис. 14.7. Сеточный файл,
представляющий данные на рис. 14.6
дому измерению. Процесс хеширования
информации о точке в этом случае отличается
от обычного применения хеш-функции к
значениям компонентов данных,
представляющих точку: значение каждой координаты
точки сопоставляется со списком позиций линий
сетки для соответствующего измерения;
номер сегмента определяется совокупностью
признаков принадлежности точки полосам
пространства во всех измерениях.
Пример 14.8. На рис. 14.7 показаны данные
рис. 14.6, распределенные по сегментам хеш-
таблицы. Поскольку количество полос в
каждом из двух измерений равно 3, массив
сегментов является матрицей 3x3. Два сегмента,
первый из которых определяется условиями
0 < возраст < 40 и 90 < доход < 225, а второй —
условиями возраст > 55 и 0 < доход < 90, пусты,
поэтому соответствующие им дисковые блоки
в диаграмму не включены. Каждый из блоков
остальных сегментов содержит не более двух
записей (разумеется, подобная ситуация довольно
искусственна), так что необходимость в
использовании блоков переполнения не возникает. □
14.2.3. Вставка записей в сеточный файл
Для вставки новой записи в сеточный файл прежде всего необходимо найти
подходящий сегмент, используя процедуру, кратко описанную в предыдущем разделе.
Если блок, соответствующий сегменту, содержит достаточно свободного пространства,
запись вставляется и операция завершается. Однако задача усложняется, если блок
уже заполнен. Для ее решения применяются две общие стратегии.
648
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
1. Добавить блок переполнения. Подобный подход неплох только в тех
ситуациях, когда цепочка блоков переполнения не слишком длинна. В
противном случае количество операций дискового ввода-вывода, необходимых для
выполнения процедур поиска, вставки и удаления записей, становится
неприемлемо большим.
2. Реорганизовать структуру путем добавления линий сетки или их
перемещения. Прием напоминает технологию динамического хеширования, о
которой мы рассказывали в разделе 13.4 на с. 624, но проблема усугубляется
тем, что содержимое сегментов в пределах измерения взаимосвязано.
Иными словами, добавление новой линии сетки приводит к расщеплению всех
областей-сегментов, которые она пересекает. Выбор линии, "удачной" для
всех сегментов без исключения, может оказаться невозможным. Например,
если уровень заполнения некоторого сегмента слишком высок, вполне
вероятна ситуация, когда попросту не удастся найти измерение, подлежащее
расщеплению, или точку, вблизи которой следует "провести" линию сетки,
не создавая слишком большого количества пустых сегментов и не оставляя
другие сегменты чрезмерно заполненными.
Пример 14.9. Предположим, что активным покупателем драгоценностей является лицо
52 лет от роду, обладающее годовым доходом, равным 200 тыс. долларов. Точка,
соответствующая этому клиенту, обязана принадлежать центральной прямоугольной
области пространства, изображенного на рис. 14.6. После добавления точки сегмент
должен будет содержать уже три записи. Для размещения новой записи можно создать
блок переполнения. Если же сегмент необходимо расщепить, нам потребуется
выбрать, во-первых, одно из двух измерений и, во-вторых, позицию линии сетки внутри
сегмента. Существуют три варианта размещения линии сетки, обеспечивающего
расщепление центрального сегмента таким образом, чтобы две точки остались по одну
сторону от линии, а третья — по другую.
1. Вертикальная линия с координатой возраст = 51, отделяющая две точки с
координатой возраст = 50 от точки с координатой возраст = 52. Множества точек
верхнего и нижнего сегментов, соответствующих тому же условию
40 < возраст < 55, не затрагиваются, поскольку все точки одного и другого
остаются по левую сторону от новой линии сетки.
2. Горизонтальная линия, отделяющая точку с координатой доход = 200 от двух
других точек с меньшими координатами (100 и 120). Значение координаты
доход линии сетки может быть выбрано равным, скажем, 130, что приведет
к расщеплению множества точек правого сегмента, удовлетворяющего условиям
возраст > 55 и 90 < доход < 225.
3. Горизонтальная линия, отделяющая точку с координатой доход = 100 от двух
других точек с большими координатами (120 и 200). В качестве значения
координаты доход линии сетки теперь может быть выбрано число, равное,
например, 115, и это вновь повлечет необходимость расщепления
множества точек правого сегмента.
Вариант 1, вероятно, нельзя назвать самым лучшим, поскольку при его
использовании содержимое иных сегментов, помимо центрального, не расщепляется и
создаются лишние пустые сегменты. Варианты 2 и 3, как кажется, одинаково
хороши, но второй, возможно, более предпочтителен, поскольку линия сетки
с координатой доход = 130 проходит ближе к середине диапазона 90—225.
Результат показан на рис. 14.8. □
14.2. ХЕШ-ПОДОБНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
649
Доступ к сегментам сеточного файла
Отыскание сегмента, которому принадлежит точка с заданными координатами, в
сеточном файле с небольшим количеством полос (скажем, 3x3, как на рис. 14.7) — это,
разумеется, не проблема. Другое дело, если измерения содержат существенно большее
число полос. В подобной ситуации без индексов, ключи поиска которых
представляют значения позиций линий сетки для каждого измерения, определенно не обойтись.
Для заданного значения v некоторой координаты ищется ключевое значение w,
не большее v. Найденная величина w связывается индексом с номером полосы,
которой принадлежит точка с координатой v. Выполнив аналогичные операции для
каждого измерения, мы сможем определить элемент матрицы, представляющий
искомый сегмент, а затем с помощью указателя, содержащегося в сегменте,
проследовать к соответствующему дисковому блоку.
В экстремальных ситуациях, когда матрица слишком велика и разреженна,
хранение информации обо всех пустых сегментах может оказаться нецелесообразным
или даже невозможным. В подобных случаях матрицу следует преобразовать в
отношение с компонентами, содержащими "координаты" непустых сегментов и
указатели на дисковые блоки, адресуемые этими сегментами. Поиск данных в таком
отношении, конечно, остается многомерным, но ввиду меньших размеров
структуры он будет более эффективен.
500К
9
130К
90К
О
© ; ;
! © !
I © !
4. А-
! ©!
I i •
J.__Jr_Jl
I © I
© I © I
40 55
Возраст
100
Рис. 14.8. Вставка точки (52, 200) во
фрагмент пространства данных,
показанный на рис. 14.6, с расщеплением сегментов
14.2.4. Оценки эффективности структур сеточных файлов
Рассмотрим, сколько операций дискового ввода-вывода требуется для выполнения
различных запросов к данным, индексированным с помощью сеточных файлов. Мы
сосредоточим внимание на двумерной версии сеточных файлов, хотя те же выводы
можно распространить и на структуры с произвольным количеством измерений. Одна
из основных проблем, сопутствующих применению многомерных сеточных файлов,
состоит в том, что с добавлением очередного измерения количество сегментов
возрастает по экспоненциальному закону. Если крупные участки пространства остаются
650
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
пустыми, матрица оказывается разреженной. С той же ситуацией можно столкнуться
даже при использовании двух измерений. Допустим, что значения возраста и дохода
в высокой степени коррелированны; тогда (см. рис. 14.6 на с. 648) большинство точек
будет сосредоточено поблизости от диагонали матрицы, и, независимо от позиций
линий сетки, сегменты за пределами диагонали окажутся пустыми. Если, однако,
распределение точек близко к равномерному и файл данных не слишком велик, положение
линий сетки можно выбрать так, чтобы обеспечить выполнение следующих условий.
1. Количество сегментов настолько мало, что индексный файл удается разместить
в оперативной памяти. Это позволяет исключить необходимость выполнения
операций дискового ввода-вывода при доступе к сегментам индекса и
добавлении полос в случае вставки новых линий сетки.
2. Индексы для значений позиций линий сетки по каждому измерению также
хранятся в оперативной памяти (см. врезку "Доступ к сегментам сеточного
файла" выше) либо потребность в использовании индексов исключается вовсе за
счет применения соответствующих процедур бинарного поиска таких значений.
3. Типичный сегмент содержит не более нескольких блоков переполнения, что
дает возможность избежать лишних затрат при обращении к сегменту.
Теперь проанализируем, как ведут себя сеточные файлы, удовлетворяющие указанным
условиям, при обработке запросов нескольких основных категорий.
Поиск заданной точки
Координаты точки непосредственно хешируются в номер сегмента, содержащего
указатель на блок, и для доступа к последнему требуется одна дисковая операция
ввода-вывода. При вставке/удалении записи необходима дополнительная дисковая
операция. Процедура вставки, приводящая к созданию блока переполнения, увеличивает
количество дисковых операций еще на единицу.
Запросы к данным с совпадением отдельных координат
Примерами подобных запросов могут служить такие, как "найти информацию обо
всех 50-летних клиентах" или "возвратить сведения о покупателях с доходом в 200
тыс. долларов". В подобных случаях приходится обращаться ко всем сегментам,
принадлежащим определенной полосе пространства. Если полоса содержит много
непустых сегментов, количество операций дискового ввода-вывода существенно возрастает.
Запросы в диапазонах значений
Запрос в диапазоне значений определяет прямоугольную область сетки, и ответом
на него будет множество точек, принадлежащих сегментам, которые покрывают эту
область (за исключением некоторых точек в сегментах, примыкающих к границе
области поиска). Например, при необходимости отыскания сведений о покупателях в
возрасте 35—45 лет, обладающих доходом в пределах 50—100 тыс. долларов, придется
обратиться к четырем сегментам в нижней левой части рис. 14.6 (см. с. 648). В этом
случае ни один из сегментов не принадлежит области поиска целиком, так что
изрядную часть точек из итогового ответа, вероятно, придется исключить. Если же область
поиска охватывает большое количество сегментов, многие из них оказываются внутри
области, так что все их точки заведомо удовлетворяют критерию поиска. Поскольку
обработка запросов в диапазонах значений зачастую сопряжена с просмотром многих
сегментов, количество операций дискового ввода-вывода может оказаться весьма
значительным. Однако ввиду того, что в результате выполнения подобных запросов
обычно возвращаются крупные порции данных, затраты на считывание блоков файла
исходных данных соизмеримы с расходами, связанными с записью блоков (если
таковая предусматривается) с итоговой информацией.
14.2. ХЕШ-ПОДОБНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
651
Поиск ближайших соседних объектов
Поиск точек, ближайших по отношению к некоторой заданной точке Р,
начинается с определения сегмента, которому принадлежит Р. Если сегмент содержит по
меньшей мере еще одну точку Q, ее можно рассматривать как потенциального
кандидата на роль искомой точки. Впрочем, возможны случаи, когда точки в смежных
сегментах находятся ближе к Р, нежели точка Q из того же сегмента; примером может
служить рис. 14.5 на с. 643. Поэтому необходимо убедиться, не меньше ли расстояние
от точки Р до границы сегмента, к которому она относится, нежели дистанция между
точками Р и Q. Если ситуация именно такова, следует проанализировать и
местоположение точек соответствующего сопредельного сегмента. Более того, если
прямоугольники-сегменты слишком вытянуты в одном измерении и чрезмерно узки в
другом, не исключено, что потребуется обратиться не только к ближайшим, но и к более
отдаленным "соседям" сегмента с точкой Р.
Пример 14.10. Пусть в структуре, изображенной на рис. 14.6 (см. с. 648), необходимо
найти точку, ближайшую по отношению к точке Р = (45, 200). Самая близкая точка,
принадлежащая тому же сегменту, обладает координатами (50, 120) и отстоит от Р на
расстояние 80,2. Ни одна из точек трех нижних сегментов не может быть более близкой,
поскольку верхней границей этих сегментов служит линия сетки с координатой
доход = 90, поэтому 200-90 > 80,2, и сегменты можно не рассматривать. Пять оставшихся
сегментов, однако, определенно заслуживают внимания, и наши усилия окажутся не
напрасными: здесь мы найдем две точки с координатами (30, 260) и (60, 260), которые
расположены на одинаковом расстоянии от точки Р, равном 61,8. Вообще говоря,
процедура поиска ближайшего соседнего объекта обычно ограничивается несколькими
сегментами и поэтому требует выполнения небольшого числа операций дискового ввода-
вывода. Впрочем, поскольку сегменты, ближайшие по отношению к исходному, могут
оказаться пустыми, верхнюю границу трудоемкости поиска заранее предугадать нельзя. □
14.2.5. Раздельные хеш-функции
Хеш-функции в качестве аргумента способны принимать списки значений
атрибутов, хотя обычно хешированию подвергаются значения одного атрибута. Например,
если а и Ъ — целочисленный и строковый атрибуты соответственно, для вычисления
номера сегмента хеш-таблицы, используемой в качестве индекса для пар значений
(а, Ь), можно сложить величину а с ASCII-кодами всех символов строки Ь, поделить
полученную сумму на количество сегментов и взять остаток от деления. Подобная
хеш-таблица, однако, может использоваться только в таких запросах, в которых
одновременно оговариваются значения атрибутов а и Ъ. Предпочтительнее же
проектировать хеш-функцию таким образом, чтобы она возвращала определенное количество
битов (скажем, к), которые распределяются между п атрибутами, где &, бит хеш-кода
вычисляется на основе значения /-го атрибута и \ к — к • Если говорить более
точно, хеш-функция h в действительности представляет собой список (hh h2,..., hn)
хеш-функций, где функция Л, применяется к значению /-го атрибута и возвращает
последовательность из kj бит. Номер сегмента индекса, из которого адресуется кортеж со
значениями (vb v2,..., vn) n атрибутов, вычисляется посредством сцепления частных
битовых последовательностей: hi(vi)h2(v2)--hn(vn).
Пример 14.11. Предположим, что имеется кортеж, компонент а которого содержит
значение А, а компонент Ъ — значение В (другие компоненты в хешировании участия
не принимают). Пусть сегменты хеш-таблицы обладают 10-битовыми номерами, т.е.
таблица может содержать до 1024 сегментов, и четыре бита отводятся атрибуту а, а
остальные шесть — атрибуту Ъ. Функция ha, связанная с атрибутом а, хеширует значение
652
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
А и возвращает четыре бита (скажем, 0101), а функция hb, поставленная в соответствие
атрибуту Ь, на основе значения В вычисляет последовательность из шести битов
(например, 111000). Таким образом, кортежу (А, В) будет отвечать сегмент хеш-
таблицы, обладающий номером 0101111000, который составлен из двух частных
битовых последовательностей, полученных для значений А и В.
Подобное раздельное хеширование обладает тем преимуществом, что позволяет
использовать известные значения любых одного или нескольких компонентов,
вносящих свой вклад в итоговый хеш-код. Например, если дано значение А атрибута а,
которое с помощью вызова функции ha(A) хешируется в битовую последовательность
0101, мы можем быть уверены, что ссылки на любые кортежи, содержащие в
компонентах а значения А, следует искать только в пределах 64 сегментов, номера которых
описываются битовыми последовательностями формата 0101—, где многоточие
обозначает шесть произвольных битов. Аналогично, если известно значение В атрибута Ь,
это дает возможность ограничить область поиска 16-ю сегментами, номера которых
завершаются битовой последовательностью hb(B)= 111000. □
Пример 14.12. Предположим, что данные о покупателях драгоценностей,
рассмотренные в примере 14.7 на с. 647, необходимо представить в форме раздельной хеш-
таблицы с 8-ю сегментами, отводя для номера сегмента по три бита (один
соответствует атрибуту возраста, а два — атрибуту дохода). Как и прежде, будем считать, что
блок способен содержать не более двух записей.
Допустим, что хеш-функция для атрибута "возраст" вычисляет результат деления
значения возраста по модулю 2; иными словами, содержимое кортежа "возраст-
доход" при четном значении возраста хешируется в битовую последовательность вида
Оху с некоторыми битами х и у, а при нечетном — в последовательность 1ху. Хеш-
функция для атрибута "доход" аналогичным образом определяет результат деления
значения дохода, выраженного в тысячах, по модулю 4. Например, при величине
дохода, подобной 57К, которая делится на 4 с остатком 1, пара значений "возраст-
доход" хешируется в последовательность вида z01 с некоторым битом z.
000
001
010
011
100
101
по
111
/
\
\
\
30, 260
50, 100
70,110
50,75
50, 275
25,60
25, 400
45, 350
J
J
J
50, 120
60, 260
45,60
85, 140
J
J
Puc. 14.9. Пример раздельной хеш-таблицы
На рис. 14.9 показан результат раздельного хеширования данных из примера 14.7
в соответствии с указанным выше алгоритмом. Обратите внимание на следующее об-
14.2. ХЕШ-ПОДОБНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
653
стоятельство: поскольку большинство выбранных значений возраста и дохода делится
на 10, хеш-функция оказывается неспособной обеспечить достаточно равномерное
распределение точек по сегментам. Два из восьми сегментов содержат по четыре
записи и нуждаются в блоках переполнения, а три сегмента остаются пустыми. □
14.2.6. Сравнение структур сеточных файлов и раздельных хеш-таблиц
Показатели производительности структур индексов, рассмотренных в этом
разделе, заметно различаются. Ниже перечислены основные сопоставительные оценки
эффективности структур сеточных файлов и таблиц, получаемых в результате
раздельного хеширования.
• Для целей поиска ближайших соседних объектов и обработки запросов в
диапазонах значений раздельные хеш-таблицы менее полезны, нежели сеточные
файлы, поскольку значения физических расстояний между точками не находят
отображения в близости номеров сегментов, которым принадлежат эти точки.
Разумеется, можно было бы спроектировать хеш-функцию для некоторого атрибута а
таким образом, чтобы для минимального значения а генерировалась битовая строка,
представляющая наименьшее число, т.е. содержащая все нулевые биты,
следующему по величине значению а ставилось в соответствие большее число вида 00-01
и т.д., но тогда мы вновь невольно пришли бы к структуре сеточного файла.
• Удачно выбранные раздельные хеш-функции способны обеспечить
распределение точек пространства по сегментам индекса, близкое к равномерному.
Сеточные файлы, однако, "склонны" оставлять большое количество сегментов
пустыми (особенно при большом числе размерностей). Причина кроется в том, что
при наличии многих атрибутов по меньшей мере некоторые из них в большой
степени коррелированны, поэтому изрядные области пространства оказываются
незаполненными. Например, в разделе 14.2.4 на с. 650 мы упоминали о том,
что фактор корреляции значений возраста и дохода обусловливает размещение
большинства точек фрагмента пространства, показанного на рис. 14.6
(см. с. 648), вдоль диагонали матрицы. Как следствие, при использовании
раздельной хеш-таблицы удастся обойтись меньшим количеством сегментов
и блоков переполнения, нежели в случае применения сеточного файла.
Таким образом, если речь идет преимущественно о выполнении запросов к
данным с совпадением отдельных координат, где задаются значения одних атрибутов
и игнорируются другие, раздельная хеш-таблица с большой долей вероятности
превзойдет по производительности индекс на основе сеточного файла. Напротив, если
в системе чаще выполняются поиск ближайших соседних объектов или запросы
в диапазонах значений, предпочтение следует отдавать структурам сеточных файлов.
14.2.7. Упражнения к разделу 14.2
Упражнение 14.2.1. На рис. 14.10 приведены спецификации 12 из 13 персональных
компьютеров, упомянутых на рис. 5.11 (см. с. 221). Пусть необходимо создать индекс
для атрибутов быстродействия процессора (speed) и емкости жесткого диска (hd).
* а) Выберите позиции пяти линий сетки (речь идет об общем количестве линий
для двух измерений) сеточного файла, обеспечивающие "попадание" в
каждый сегмент не более двух точек.
! Ь) Возможно ли выполнить задание, указанное в п. (а), используя только
четыре линии сетки? Приведите доводы за или против.
! с) Предложите вариант раздельного хеширования, при котором каждый из
четырех сегментов будет содержать не более четырех точек.
654
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
Что делать с сегментами небольшого размера
Обычно сегменты воспринимаются как фрагменты данных такого объема, который
соизмерим с емкостью блока. Возникает закономерный вопрос, как быть с
избыточным количеством сегментов, каждый из которых содержит в среднем малое
число записей, занимающих только часть пространства блока. Например, для
представления многомерных данных с мелким шагом сетки или большим количеством
раздельных хеш-функций может потребоваться крупное множество малых
сегментов. При использовании структур, рассмотренных в этом и следующем разделах,
возможно прибегнуть к стратегии, предусматривающей размещение в пределах
одного блока нескольких сегментов (или вершин дерева). В подобной ситуации
необходимо принять к сведению следующие соображения.
• Заголовок блока должен включать информацию о каждой записи и
принадлежности ее определенному сегменту.
• При вставке записи в сегмент может случиться так, что блок, содержащий
сегмент, уже заполнен. В этом случае блок надлежит расщепить, принять решение
о том, как распределить сегменты по новым блокам, найти записи,
относящиеся к каждому сегменту, поместить их в соответствующие блоки и исправить
адресные значения указателей в таблице сегментов.
model
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
1011
1013
speed
700
1500
866
866
1000
1300
1400
700
1200
750
1100
733
ram
64
128
128
64
128
256
128
64
128
64
128
256
hd
10
60
20
10
20
40
80
30
80
30
60
60
Рис. 14.10. Фрагмент экземпляра отношения PC с характеристиками персональных компьютеров
! Упражнение 14.2.2. Пусть требуется разместить данные, приведенные на рис. 14.10,
в трехмерном сеточном файле, измерения которого соответствуют атрибутам
быстродействия процессора (speed), объема оперативной памяти (ram) и емкости
жесткого диска (hd). Предложите вариант разбиения пространства данных линиями
сетки, обеспечивающий равномерное распределение точек по сегментам.
Упражнение 14.2.3. Разработайте версию набора раздельных хеш-функций, которые
преобразуют значения атрибутов speed, ram и hd отношения, показанного на
рис. 14.10, в однобитовые частные последовательности и обусловливают
равномерное распределение точек по сегментам.
14.2. ХЕШ-ПОДОБНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
655
Упражнение 14.2.4. Предположим, что данные, приведенные на рис. 14.10,
оформлены в виде сеточного файла с двумя измерениями, отвечающими атрибутам speed
и ram. Линии сетки для оси speed имеют координаты 720, 950, 1150 и 1350, а линии
сетки для измерения ram размещены на позициях 100 и 200. Допустим также, что
блок сегмента способен содержать не более двух записей. Предложите оптимальные
варианты расщепления сегментов при необходимости вставки точек с координатами:
* a) speed = 1000, ram = 192;
b) speed = 800, ram = 128 и speed = 833, ram = 96.
Упражнение 14.2.5. Допустим, что отношение R(x, у) представлено в виде сеточного
файла. Диапазоны изменения значений обоих атрибутов равны 0—1000. Линии
сетки распределены по осям равномерно: шаг сетки для атрибута х составляет
20 единиц (т.е. координаты х линий равны 20, 40, 60 и т.д.), а для атрибута у —
50 единиц (координаты у линий сетки равны 50, 100, 150 и т.д.).
a) К какому количеству сегментов придется обратиться системе при обработке
запроса в диапазонах значений, приведенного ниже:
SELECT *
FROM R
WHERE 310 < x AND x < 400 AND 520 < у AND у < 730;
*!b) Предположим, что требуется найти точку, ближайшую по отношению к
точке (ПО, 205). При просмотре сегмента, нижний левый угол которого обладает
координатами (100,200), а верхний правый — координатами (120,250) (точка
(110,205) принадлежит этому сегменту), обнаруживается, что ближайшая
точка имеет координаты (115,220). Какие другие сегменты надлежит
проверить, дабы убедиться, что найденная точка является искомой?
! Упражнение 14.2.6. Допустим, что имеется двумерный сеточный файл с тремя
линиями сетки (т.е. четырьмя полосами) в каждом измерении и точки (л\ у)
распределены по закону, указанному ниже. Найдите максимально возможное количество
непустых сегментов, если:
* а) все точки принадлежат одной прямой, т.е. их координаты х и у
удовлетворяют уравнению у = ах + Ъ для некоторых констант а и Ь;
b) координаты х и у точек связаны квадратичной зависимостью, т.е.
удовлетворяют уравнению у = ах2 + Ъх + с для некоторых констант а, Ъ и с.
Упражнение 14.2.7. Предположим, что отношению R(x, у, z) поставлена в
соответствие раздельно хешированная таблица с 1024 сегментами (т.е. обладающая 10-
битовыми адресами сегментов). В запросах, обращенных к R, задается значение
только одного атрибута, и вероятность задания каждого из трех атрибутов
одинакова. Если составляющая номера сегмента, отвечающая атрибуту х, содержит 5 бит,
а для представления значений атрибутов у и z отводится по 3 и 2 бита
соответственно, каково среднее количество сегментов, подлежащих просмотру в процессе
обработки произвольного запроса?
!! Упражнение 14.2.8. Пусть имеется хеш-таблица, сегменты которой пронумерованы
числами от 0 до 2п - 1, т.е. адрес сегмента состоит из п бит. Необходимо
представить в таблице содержимое некоторого отношения с двумя атрибутами, х и у. В
запросах задаются либо значение х, либо значение у, но не оба одновременно,
причем вероятность задания значения х равна р.
а) Предположим, что в последовательности, возвращаемой раздельной хеш-
функцией, т бит отводится значению х и п-т бит — значению у. Выразите
656
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
в виде функции от т, пир количество сегментов, подлежащих просмотру
в процессе обработки некоторого запроса.
Ь) При каком значении ш, выраженном в виде функции от п и р, достигается
минимум количества сегментов, к которым требуется обращаться при выполнении
запроса? (Не беспокойтесь, если т не удается представить в виде целого числа.)
*! Упражнение 14.2.9. Пусть дано отношение R(x, у), содержащее значения координат
равномерно распределенных точек плоскости. Диапазоны изменения значений
обоих атрибутов равны 0—1000. В один блок умещаются 100 кортежей отношения.
В качестве индексной структуры используется сеточный файл с линиями сетки,
следующими в обоих измерениях с шагом, равным т. Требуется выбрать значение
т, которое обеспечивает минимум количества операций дискового ввода-вывода,
необходимых для просмотра сегментов в процессе обработки запроса в диапазонах
протяженностью 50 единиц в каждом измерении. Можно считать, что стороны
квадрата, задающего область поиска, не совпадают с линиями сетки. Если принять
в качестве т слишком большое число, каждому сегменту будет соответствовать
длинная цепочка блоков переполнения, и окажется, что сегмент, охватывающий
область поиска, содержит много "лишних" точек. Если же, напротив, выбрать
чересчур малое значение т, это приведет к возрастанию количества сегментов
и снижению уровня заполнения блоков. Каково наилучшее значение т?
14.3. Древовидные структуры для многомерных данных
Теперь рассмотрим ряд индексных структур, особенно полезных при обработке
запросов в диапазонах значений и поиске объектов, ближайших по отношению к заданному:
1) индексы с несколькими ключами (multiple-key indexes);
2) kd-деревъя (kd-trees);
3) деревья квадрантов (quad trees);
4) R-деревья (R-trees).
Три первые структуры предназначены для представления множеств точек. R-деревья
обычно используются с целью описания множеств областей пространства, хотя
находят применение и для отображения множеств точек.
14.3.1. Индексы с несколькими ключами
Предположим, что схема отношения содержит атрибуты, представляющие
значения координат элементов данных многомерного пространства, и необходимо
обеспечить эффективную поддержку запросов в диапазонах значений (range queries)
координат либо процедур поиска объектов, наиболее близких к заданному (nearest-neighbor
search). Одно из простых решений связано с использованием индекса индексов или,
говоря в более общем смысле, древовидной схемы, в которой вершины каждого
уровня являются индексами для определенного атрибута.
Основная идея проиллюстрирована на рис. 14.11 на примере двух атрибутов.
"Корнем дерева" служит индекс для первого атрибута. В подобной роли может
выступать индекс любого из традиционных типов, таких как В-дерево или хеш-таблица.
Индекс связывает значение ключа поиска (содержимое компонента первого атрибута)
с указателем на некоторый индекс для другого атрибута. Если V — содержимое
компонента первого атрибута, отыскав элемент со значением V ключа поиска в первом
индексе и проследовав в "направлении" указателя, связанного с этим элементом, мы
"придем" к индексу, представляющему подмножество точек, первые координаты
которых равны V, а вторые содержат произвольные значения.
14.3. ДРЕВОВИДНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
657
Пример 14.13. На рис. 14.12 схематически изображен индекс с несколькими ключами
(multiple-key index), который отвечает рассматриваемому нами примеру, касающемуся
сведений о любителях драгоценностей: "первым" атрибутом в данном случае служит
"возраст", а "вторым" — "доход". "Корневой" индекс, соответствующий атрибуту
возраста, расположен в левой части рисунка. Здесь мы не уточняем детали реализации
этого индекса — семь его пар "ключ—указатель", например, могут быть распределены
по вершинам-листьям В-дерева. Более важно то, что индекс содержит только такие
ключевые значения возраста, которым соответствует одна или несколько
существующих точек пространства данных, и позволяет легко найти указатель, связанный с
определенным значением ключа.
Индекс для
первого атрибута
Индексы для
второго атрибута
Рис. 14.11. Пример
многоуровневого индекса с несколькими
ключами
25
30
45
50
60
70
85
/
/'
\,
Л
\
\ \
\ \
\ ч
60
400
260
60
350
75
100
120
275
260
ПО
140
Рис. 14.12. Индексы с несколькими
ключами для двумерного
пространства данных "возраст—доход"
В правой части рис. 14.12 расположены семь индексов, обеспечивающих доступ
непосредственно к записям данных. Например, обратившись к (корневому) индексу
с ключом "возраст" и проследовав по адресному значению указателя, связанного со
значением координаты возраста, равным 50, мы придем к подчиненному индексу
с ключом "доход", четыре элемента которого представляют значения координаты
дохода точек, удовлетворяющих условию возраст = 50. (И вновь мы не акцентируем
внимание на особенностях реализации подобных индексов — достаточно наличия пар
вида "ключ—значение".) Указатели в элементах индекса, соответствующие каждому из
четырех ключевых значений дохода (75, 100, 120 и 275), адресуют конкретные записи
данных (например, указатель, связанный со значением ключевой координаты
доход - 100, позволяет найти запись, представляющую лицо 50 лет от роду, обладающее
годовым доходом в размере 100 тыс. долларов). □
В структурах индексов с несколькими ключами индексы второго или более
высоких уровней подчиненности могут иметь очень малый объем. Например, четыре из
семи индексов второго уровня, представленных на рис. 14.12, содержат по одному
элементу. Такие индексы уместно реализовывать в виде простых таблиц, упакованных
в один общий блок (схожая ситуация обсуждалась во врезке "Что делать с сегментами
небольшого размера" на с. 655).
658
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
14.3.2. Оценки эффективности структур индексов с несколькими ключами
Рассмотрим характеристики поведения индексов с несколькими ключами (multiple-
key indexes) в применении к различным категориям запросов в контексте
многомерных данных. Мы сосредоточим внимание на структурах с двумя атрибутами, хотя все
выводы легко обобщить на случай произвольного количества атрибутов.
Запросы к данным с совпадением отдельных координат
Если в запросе задается значение атрибута, соответствующего корневому индексу,
индексная структура проявляет высокую эффективность. Корневой индекс
используется для отыскания одного из подчиненных индексов, который в свою очередь
приводит к искомой точке. Например, если корневой индекс оформлен в виде В-дерева, для
перехода к определенному подчиненному индексу потребуется выполнить две или три
операции дискового ввода-вывода, а для просмотра найденного частного индекса
и загрузки искомой записи данных — еще несколько подобных операций. С другой
стороны, если значение атрибута, служащего ключом поиска в корневом индексе,
в запросе не оговаривается, системе придется обращаться к каждому подчиненному
индексу, что, вероятно, потребует немалых затрат времени и вычислительных ресурсов.
Запросы в диапазонах значений
При выполнении запросов в диапазонах значений индекс с несколькими ключами
демонстрирует добротные показатели производительности — разумеется, если
входящие в его состав частные индексы (например, В-деревья или "обычные" индексы для
последовательных файлов) в свою очередь поддерживают запросы в диапазонах
изменения значений соответствующих атрибутов. Диапазон значений ключа поиска
корневого индекса в совокупности с диапазонами изменения ключей подчиненных
индексов дают возможность обнаружить все искомые точки пространства.
Пример 14.14. Обратимся к структуре индекса с несколькими ключами, показанной на
рис. 14.12, и предположим, что необходимо выполнить запрос в следующих диапазонах
значений: 35 < возраст < 55 и 100 < доход < 120. При просмотре элементов корневого индекса
удается обнаружить два ключа (45 и 55), удовлетворяющих заданному диапазону
изменения значений атрибута "возраст". Связанные с найденными ключами указатели адресуют
два подчиненных индекса для ключа поиска "доход". Индекс для координаты возраст = 45
не содержит значений дохода в заданном диапазоне, но индекс, соответствующий
условию возраст = 55, обладает двумя подходящими элементами — 100 и 120. Таким образом,
результатом поиска окажутся две точки с координатами (50,100) и (50,120). □
Поиск ближайших соседних объектов
Поиск объектов, ближайших по отношению к заданному, с помощью индекса с
несколькими ключами выполняется в соответствии с той же стратегией, что и почти все
остальные запросы, рассматриваемые в этой главе. Для отыскания ближайшей
"соседки" точки (х0, у0) выбирается расстояние d, покрывающее область с центром
в (ль, у0), которая, как можно ожидать, содержит по меньшей мере одну точку. Затем
выполняется запрос в диапазонах x0-d<x<x0 + duy0-d<y<y0 + d значений координат.
Если запрос оказывается безрезультатным либо возвращает точку, которая расположена на
расстоянии от (х0, у0), превышающем d (последнюю ситуацию мы обсуждали в разделе
14.1.5 на с. 643), надлежит увеличить значение d и повторить процедуру поиска.
14.3.3. kd-деревья
kd-depeeo (Ы-tree, или /:-dimensional search tree) — это структура, служащая для
представления информации в оперативной памяти и обобщающая модель бинарных
деревьев поиска на случай многомерных данных. Вначале мы обсудим основные ха-
14.3. ДРЕВОВИДНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
659
рактеристики схемы kd-дерева, а затем расскажем об особенностях ее реализации
в контексте модели блоковых вторичных хранилищ данных, kd-дерево представляет
собой бинарное дерево, с корневой и промежуточными вершинами которого
ассоциированы атрибут а, представляющий некоторую размерность данных, и определенное
значение V этого атрибута, расщепляющее множество точек данных на два
подмножества: точкам одного подмножества отвечают значения атрибута а, меньшие V, а
точкам другого — значения а, равные или большие V. Атрибуты в пределах одного уровня
дерева одинаковы, а в соседних уровнях — различны: при движении от корневой
вершины дерева "вниз" по уровням промежуточных вершин все атрибуты-
размерности циклически замещают друг друга.
В классическом kd-дереве, как и в дереве бинарного поиска, с вершинами связаны
точки данных. Мы, однако, незначительно изменим схему таким образом, чтобы
адаптировать ее к особенностям модели блокового хранилища данных:
1) каждой промежуточной вершине поставлены в соответствие некоторый
атрибут, конкретное "разделяющее" значение этого атрибута и указатели-дуги,
адресующие левую и правую дочерние вершины;
2) листья дерева представляют блоки, способные содержать такое количество
записей, какое обусловлено физическим объемом блока.
Пример 14.15. На рис. 14.13 приведено kd-дерево, которое представляет двенадцать
точек-записей из рассматриваемого нами примера, касающегося сведений
о "ценителях" драгоценностей. Для простоты емкость блока ограничена двумя
записями. Подобные блоки вместе с их содержимым изображены в виде прямоугольных
вершин-листьев. Промежуточные вершины имеют форму овалов, в которых указаны
название одного из двух атрибутов-размерностей ("доход" или "возраст") и
соответствующее значение этого атрибута. Например, корневая вершина расщепляет
множество точек на два подмножества в зависимости от значения атрибута "доход": все точки-
записи, удовлетворяющие условию доход < 150, относятся к левому поддереву, а
остальные точки (соответствующие условию доход > 150) — к правому.
Вершины второго уровня используются для дальнейшего разбиения подмножеств точек
в соответствии со значениями атрибута "возраст". Например, левая дочерняя вершина
расщепляет множество точек в зависимости от выполнения условия возраст < 60:
координаты точек, описываемых левым поддеревом, удовлетворяют требованиям возраст < 60
и доход < 150, а точки, относящиеся к правому поддереву, соответствуют условиям
возрасти60 и доход< 150. На рис. 14.14 изображена схема разбиения пространства точек
по блокам-листьям, соответствующая графу, приведенному на рис. 14.13. Например,
горизонтальная прямая с координатой доход = 150 представляет корневую вершину дерева.
Область пространства под прямой разбивается вертикальным лучом возраст = 60
(соответствующим левой дочерней вершине), а область над прямой подвергается
расщеплению вертикальным лучом возраст = 47 (представляющим правую дочернюю вершину). □
14.3.4. Операции с kd-деревьями
Процедура отыскания точки (записи) по заданным значениям координат-
компонентов выполняется в kd-дереве так же, как и в бинарном дереве поиска: на
каждой промежуточной вершине принимается решение о том, по какой ветви
надлежит проследовать дальше, вплоть до достижения единственной вершины-листа,
представляющей блок с искомыми данными.
Операция вставки точки (записи) предполагает необходимость обращения к
процедуре поиска подходящего блока, описанной выше. Если блок, соответствующий
найденному листу дерева, обладает достаточным свободным пространством, запись
помещается в блок и операция успешно завершается. В противном случае на месте
660
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
вершины-листа создается новая промежуточная вершина, ей ставятся в соответствие
подходящие атрибут и "разделяющее" значение этого атрибута96, блок листа
расщепляется на два новых и его содержимое распределяется между блоками в соответствии
с выбранным значением атрибута.
"Доход 150"
(Возраст 47
(^Доход 8(Р)
(Возрастж)
25,60
70,110
85,140
50,100
50,120
45,60
50,75
С^Доход ЗСКГ)
30,260
25,400
45,350
60,260
Рис. 14.13. Пример kd- дерева
500К
!
100
Возраст
Рис. 14.14. Разбиение пространства
точек посредством kd-дерева,
приведенного на рис. 14.13
Пример 14.16. Предположим, что с помощью kd-дерева в базу данных с информацией
о покупателях драгоценностей необходимо внести сведения о 35-летнем человеке,
обладающем годовым доходом в размере 500 тыс. долларов. Условие, задаваемое корневой
вершиной (доход = 150), заставляет проследовать к правой дочерней вершине (доход > 150).
Здесь значение 35 сопоставляется с "разделяющим" значением возраста (47): поскольку
96 Возможна следующая проблема: все точки, принадлежащие блоку, обладают равными
значениями определенной координаты, так что расщепить блок по значениям этой
координаты не удается. В подобной ситуации можно попытаться выбрать другую координату либо
создать блок переполнения.
14.3. ДРЕВОВИДНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
661
35 < 47, следует перейти к левой дочерней вершине. Вершины третьего уровня дерева вновь
соответствуют координате "доход". Так как 500 > 300, мы достигаем листа, содержащего
точки (25,400) и (45,350), — сюда же надлежит поместить и точку (35,500). Блок, однако,
целиком заполнен, поэтому его необходимо расщепить. Вершины четвертого уровня
дерева должны соответствовать координате "возраст", и нам предстоит выбрать такое
значение координаты, которое позволило бы распределить записи по двум новым блокам
настолько равномерно, насколько это возможно. Удачным, как нам представляется,
было бы значение 35, поэтому лист заменяется промежуточной вершиной с условием
возраст = 35. В левый лист-блок переносится точка (25,400), а в правый — точки (35, 500)
и (45, 350). Результат операции вставки показан на рис. 14.15.
Доход 150
(Возраст 47
(Возраст
25,60
Доход 80^)
тз|)
70,110
85,140
50,100
50,120
45,60
50,75
С^Доход 3(Ю
30,260
(§озр
25,400
г 35)
35,500
45,350
Рис. 14.15. kd-дерево (см. рис. 14.13 на с. 661) после
вставки точки (35, 500)
а
Модель kd-деревьев поддерживает возможность выполнения и более сложных
операций. Основные идеи и алгоритмы рассмотрены ниже.
Запросы к данным с совпадением отдельных координат
Если значения некоторых атрибутов заданы, это дает возможность перемещения по
дереву от уровня, которому отвечает один из атрибутов с известным значением. Если же
текущая вершина относится к такому уровню, для которого значение соответствующего
атрибута не определено, придется осуществить проверку условий обеих дочерних вершин.
Для примера рассмотрим, как обрабатывается запрос, предполагающий отыскание всех
точек с координатой возраст = 50 с помощью kd-дерева, показанного на рис. 14.13
(см. с. 661). Поскольку корневой вершине соответствует координата "доход", а не
"возраст", необходимо проанализировать условия обеих вершин, дочерних по отношению
к корневой: значению возраст = 50 удовлетворяют левая ветвь левой вершины и правая
ветвь правой. Далее надлежит проследовать по обеим выбранным ветвям, проверяя на
каждом уровне все альтернативы, вплоть до достижения всех вершин-листьев,
содержащих точки, координаты которых удовлетворяют заданному условию возраст = 50 (всего
таких точек четыре — (50,75), (50,100), (50,120) и (50,275)). Если kd-дерево сбалансировано,
количество проверяемых вершин-листьев составит не более Vh от общего числа п листьев.
Запросы в диапазонах значений
Иногда заданный диапазон таков, что позволяет перемещаться от текущей
вершины kd-дерева непосредственно к одной дочерней вершине, но если "разделяющее"
значение атрибута текущей вершины находится внутри диапазона, приходится рас-
662
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
сматривать обе дочерние вершины. Вновь обратимся к kd-дереву, изображенному на
рис. 14.13 (см. с. 661), и предположим, что запрос предусматривает поиск точек,
координаты которых принадлежат диапазонам 35 < возраст < 55 и 100 < доход < 200.
Диапазон значений дохода включает "разделяющее" значение (150) атрибута "доход"
корневой вершины, поэтому следует обратить внимание на обе вершины, дочерние по
отношению к корневой. Начнем с левой дочерней вершины. Заданный диапазон
значений возраста "лежит" левее "разделяющей" величины (60) координаты "возраст",
что дает возможность переместиться к левой дочерней вершине доход = 80. Поскольку
заданный диапазон дохода находится целиком правее, мы переходим к блоку-листу
с точками-записями (50, 100) и (50, 120); координаты точек удовлетворяют обоим
диапазонам. Теперь вернемся к правой дочерней вершине относительно корневой.
"Разделяющее" значение возраст = 47 находится внутри заданного диапазона значений
"возраст", поэтому приходится анализировать обе дочерние вершины.
Переместившись к вершине доход = 300, далее мы можем двигаться только влево: координаты
точки (30, 260) не удовлетворяют ни одному из диапазонов. Правой дочерней вершиной
относительно вершины возраст = 47 является лист с двумя записями-точками, но их
координаты не соответствуют диапазонам, оговоренным в условии запроса.
Поиск ближайших соседних объектов
Обработка запросов, предусматривающих отыскание с помощью kd-дерева точек,
ближайших к заданной, выполняется по той же схеме, о которой мы говорили в
разделе 14.3.2 на с. 659: задача сводится к выполнению запроса в определенном
диапазоне значений; если результат не достигнут, диапазон расширяется.
14.3.5. kd-деревья и данные во вторичных хранилищах
Пусть необходимо проиндексировать файл данных с помощью kd-дерева с п
вершинами-листьями. Средняя длина пути от корня до некоторого листа kd-дерева, как
и в любом бинарном дереве, оценивается величиной \og2n. Если вершине
соответствует один блок, в процессе перемещения по дереву надлежит выполнять по одной
операции дискового ввода-вывода для считывания данных каждой вершины. Например,
при п = 1000 типичная процедура поиска записи в kd-дереве потребует осуществления
около 10 дисковых операций, что намного превышает трудоемкость (2—3 операции)
аналогичной процедуры поиска в существенно более крупном В-древовидном файле.
Помимо того, поскольку промежуточные вершины kd-дерева представляют относительно
малые фрагменты информации, большинство блоков дерева окажется незаполненным.
Задачи уменьшения средней длины пути в дереве и оптимизации уровней
заполнения блоков взаимозависимы — добиться обеих целей одновременно не удастся. Тем
не менее ниже мы представим на ваш суд два подхода, которые позволяют достичь
некоторого прироста производительности системы.
Множественное ветвление
Корневую и промежуточные вершины kd-дерева можно трактовать таким же
образом, как и вершины В-дерева, содержащие подмножества пар данных вида "ключ-
указатель". Если вершине поставить в соответствие не одно, а п ключевых значений,
это дало бы возможность расщеплять значения атрибута а на п + 1 диапазонов и
обращаться только к одному из п + 1 поддеревьев, соответствующему подмножеству точек
со значениями атрибута а из требуемого диапазона.
При попытке реорганизации вершин с целью равномерного распределения записей
и обеспечения баланса (как обычно поступают с В-деревьями), правда, могут
возникать некоторые проблемы. Предположим для примера, что расщеплению подлежит
вершина kd-дерева, соответствующая атрибуту "возраст", и необходимо осуществить
слияние ее дочерних вершин, каждая из которых представляет некоторое "разделяющее"
14.3. ДРЕВОВИДНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
663
"Ничто не вечно под луной..."
Операции модификации любой из структур данных, упомянутых в этой главе,
носят частный характер. Последствия подобных локальных изменений в конечном
итоге приводят к потере баланса (например, сеточный файл приобретает чрезмерно
большое количество пустых сегментов либо одни ветви kd-дерева становятся
слишком протяженными в сравнении с другими).
Обычной практикой является периодическое выполнение процедуры
реструктуризации базы данных. Осуществляя выгрузку содержимого базы данных в
промежуточные файлы с последующей загрузкой их во вновь создаваемые структуры,
администратор имеет возможность перестроить и индексы, чтобы возвратить им
утраченное свойство баланса и обеспечить максимально высокую степень
эффективности дальнейшего использования (хотя бы на некоторое время, до
внесения очередных существенных изменений). Затраты на реструктуризацию
(разумеется, если таковая выполняется не слишком часто) обычно компенсируются
выигрышем в производительности. Однако существует одно условие — на период
реструктуризации база данных становится недоступной для обращений извне.
Существенно такое ограничение или нет — это зависит от особенностей конкретных
базы данных и пользующихся ею приложений (подобные профилактические
работы нередко проводят в ночное время, когда к системе никто не обращается).
значение атрибута "доход". Мы не можем создать новую вершину, просто объединив
диапазоны атрибута "доход" дочерних вершин, поскольку эти диапазоны обычно
перекрываются. Обратите внимание, насколько упростилась бы задача, если бы (как
в В-дереве) обе дочерние вершины служили дальнейшему уточнению диапазонов того
же атрибута "возраст", который соответствует родительской вершине.
Группирование промежуточных вершин по блокам
Допустим и иной подход, при котором условие принадлежности вершине только
двух дочерних вершин остается в силе, но информация с описанием нескольких
вершин упаковывается в один дисковый блок. Чтобы минимизировать количество
операций дискового ввода-вывода, выполняемых в процессе следования от корневой
вершины дерева до определенного листа, уместно предпринять попытку сохранения
данных этой вершины и всех ее "наследников" вплоть до определенного уровня
в пределах одного блока. В этом случае, загрузив блок, соответствующий вершине, мы
можем быть уверены, что блок содержит данные еще нескольких уровней вершин,
дочерних по отношению к текущей, и для их просмотра дополнительные дисковые
операции не потребуются. Предположим для примера, что объем блока достаточен для
размещения информации о трех ("овальных") вершинах: скажем, корневую и две
дочерние вершины дерева, представленного на рис. 14.13 (см. с. 661), можно описать
с помощью одного блока, вершину доход = 80 с ее левой дочерней вершиной
поместить в другой блок, а вершину доход = 300 — в третий (вероятно, второй и третий
блоки удалось бы совместить в одном, хотя подобное объединение чревато немалыми
издержками при необходимости модификации дерева). Таким образом, для отыскания
записи (25, 60), например, потребуется обратиться всего к двум блокам со сведениями
о корневой и промежуточных вершинах, хотя общее количество таких вершин,
подлежащих просмотру в процессе поиска, равно четырем.
14.3.6. Деревья квадрантов
В дереве квадрантов (quad tree) каждая промежуточная вершина соответствует
определенному квадранту пространства данных — прямоугольной двумерной области либо к-
мерному параллелепипеду, если количество измерений равно к. Как и при рассмотрении
664
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
всех остальных структур данных, описываемых в этой главе, мы сосредоточим внимание
на случае двух измерений. Если количество точек, принадлежащих квадранту, ниже
допустимого максимума, квадрант следует воспринимать как вершину-лист дерева,
представляемую соответствующим блоком. Если же, напротив, количество точек
слишком велико, квадрант интерпретируется как промежуточная (вначале —
корневая) вершина с четырьмя дочерними вершинами, отвечающими частным квадрантам.
400К
!
© I
: © ! ©
! ©
I © ;
©
©
© © I
100
Возраст
Рис. 14.16. Фрагмент пространства
данных, разбитый на квадранты
Пример 14.17. На рис. 14.16 показано множество точек с информацией о покупателях
драгоценностей; точки распределены по областям-квадрантам, соответствующим
вершинам дерева. Чтобы упростить вычисления, мы ограничили диапазон изменения
значений координаты "доход" до 0—400 вместо обычного 0—500, используемого в
предыдущих примерах. Как и прежде, будем полагать, что блок обладает емкостью,
достаточной для хранения двух записей.
На рис. 14.17 изображено дерево квадрантов как таковое. Квадранты и
соответствующие им дочерние вершины помечены названиями географических
направлений: так, например, аббревиатура "ЮЗ" означает "юго-запад", т.е. речь идет
о нижнем левом частном квадранте текущего квадранта (остальные сокращения —
"ЮВ", "СВ" и "СЗ" — расшифровываются как "юго-восток", "северо-восток"
и "северо-запад" соответственно). Порядок следования дочерних вершин-
квадрантов сохраняется таким, который задан для корневой вершины (в данном
случае географические направления перечисляются против часовой стрелки,
начиная с юго-запада). Каждая промежуточная вершина (такие вершины отмечены
овалами) задает координаты центра области текущего квадранта.
Поскольку общее количество точек, охватываемых рассматриваемым фрагментом
пространства, равно 12, но каждый блок способен вместить не более двух точек,
пространство следует разбить на квадранты (последние помечены на рис. 14.16
штриховыми линиями). Два из четырех полученных квадрантов — юго-западный и
северовосточный — содержат только по две точки, поэтому соответствуют блокам-листьям
дерева и не подлежат дальнейшему расщеплению.
На каждый из двух оставшихся квадрантов приходится более двух точек. Поэтому
квадранты подвергаются дальнейшему разбиению Частные квадранты обозначены на
рис. 14.16 точечными линиями; каждый из них содержит не более двух точек, так что
дальнейшее расщепление не требуется.
14.3. ДРЕВОВИДНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
665
50,75
50,100
85,140
50,120
70,110
30,260
25,400
45,350
Рис. 14.17. Дерево квадрантов для фрагмента пространства данных,
показанного на рис. 14.16
а
Поскольку корневая и каждая промежуточная вершина /г-мерного дерева
квадрантов обладают 2* дочерними вершинами, существуют определенные значения к, при
которых информация вершины "вписывается" в дисковый блок. Если, например,
блок способен вместить 128 = 27 указателей, тогда к = 1 — "удачное" количество
размерностей. В двумерном случае, однако, ситуация не намного лучше, нежели при
использовании kd-деревьев: корневая и промежуточные вершины содержат всего по
четыре дочерние вершины. Более того, если в kd-дереве выбор "разделяющего"
значения атрибута вершины ничем не ограничен, вершина в дереве квадрантов всегда
представляет центр текущей области пространства, подлежащей разбиению на
частные квадранты, по которым более или, что гораздо хуже, менее равномерно
распределяются точки области. Если количество размерностей велико, следует ожидать
появления немалого числа "нулевых" указателей, адресующих пустые квадранты. Разумеется,
имея дело с многомерным деревом квадрантов, можно позаботиться о его более
экономичном представлении за счет исключения нулевых указателей и принятия особых мер,
позволяющих различить, какому квадранту соответствует тот или иной указатель.
Мы не будем останавливать ваше внимание на деталях, касающихся выполнения
стандартных операций (подобных тем, которые рассмотрены в разделе 14.3.4 на с. 660
применительно к kd-деревьям) с деревьями квадрантов: выводы, полученные для kd-
деревьев, вполне применимы и к модели деревьев квадрантов.
14.3.7. R-деревья
R-дерево (R-tree, или region tree — дерево областей) — это структура данных,
наследующая многие свойства модели В-дерева в применении к многомерной
информации. Напомним, что вершина В-дерева содержит подмножество значений ключа,
делящих числовую ось на сегменты так, как показано на рис. 14.18. Каждая точка
оси может принадлежать только одному сегменту.
Отыскание заданной точки в В-дереве труда не составляет:
так как точка расположена на оси, представляемой
вершиной В-дерева, мы можем определить единственный
сегмент (дочернюю вершину), которые позволят сузить
область поиска и в конце концов либо найти точку,
либо убедиться, что ее не существует.
R-дерево, с другой стороны, представляет
информацию в виде 2- или к-мерных областей данных (data
regions). Корневая (или промежуточная) вершина R-дерева соответствует
некоторой внутренней области (interior region), или просто "области", которая обычно не
является областью данных. Вообще говоря, область может иметь любую форму,
хотя на практике, как правило, используются области прямоугольных или иных
Рис. 14.18. Вершина В-
дерева распределяет
значения ключа поиска по оси и
разделяет последнюю на
сегменты
666
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
простых форм. Вершина R-дерева вместо ключевых |. ~~]
значений содержит подобласти (subregions), описы- ;• ■
вающие содержимое дочерних вершин. На рис. 14.19 : \
изображена вершина R-дерева, которая ассоциирована • ■ :
с большим прямоугольником, отмеченным сплошной : \'"\ :
линией. Внутренние прямоугольники, ограниченные • !.. • :
отрезками точечных линий, представляют подобласти, ; " -;у:' \\
поставленные в соответствие четырем дочерним вер- • ;.: •
шинам. Обратите внимание, что подобласти не покры- ' :: ■"'
вают область в целом — это нормально. Помимо того, Рис. 14.19. Область верши-
области могут пересекаться, хотя степень подобных ны R-дерева, охватывающая
совпадений желательно уменьшать. подобласти дочерних вершин
14.3.8. Операции с R-деревьями
Типичным примером запроса, при обработке которого R-дерево оказывается особенно
полезным, может служить запрос, предполагающий определение местонахождения
объекта ("where-am-I" query): задается некоторая точка Р и запрашиваются сведения о
принадлежности точки тем или иным областям. Вначале рассматривается корневая вершина
дерева, с которой связана самая крупная область. Затем проверяется каждая подобласть
корневой вершины и устанавливается, какие вершины, дочерние по отношению к
корневой, ассоциированы с внутренними областями, содержащими точку Р. Таких областей
может быть одна или несколько (либо может не быть вовсе). Если областей нет,
операция завершается: Р не принадлежит ни одной области данных. Если, напротив,
существует по меньшей мере одна внутренняя область, охватывающая точку Р, следует
осуществить рекурсивный просмотр вершин, соответствующих каждой из областей, которым
принадлежит Р. По достижении одной или нескольких вершин-листьев мы обнаружим
искомые области данных в виде полных записей либо указателей на такие записи.
При вставке новой области R в R-дерево необходимо обратиться к корневой
вершине и попытаться найти некоторую подобласть, пригодную для размещения в ней
области R* Если подобных областей несколько, следует выбрать одну область, перейти
к соответствующей ей дочерней вершине дерева и повторить процесс далее. Если
подобластей, способных содержать R, нет, одну из подобластей придется расширить.
Решение о том, какую из подобластей надлежит выбрать с целью расширения,
зачастую не очевидно. Интуиция подсказывает, что воздействие на существующие области
следовало бы свести к минимуму, поэтому уместно задаться вопросом, какая из
подобластей дочерних вершин допускает наименьшее увеличение, достаточное для
размещения в ней области R, соответствующим образом изменить границы найденной
области и внести рекурсивные изменения в структуру дерева.
Со временем мы достигнем вершины-листа, куда и потребуется вставить область R.
Если в области, соответствующей листу, для R места нет, лист надлежит расщепить; как
именно — это особый вопрос. Вообще говоря, хотелось бы, чтобы две подобласти
оказались настолько малы, насколько возможно, но все еще покрывали все области данных
исходного листа. При расщеплении листа область и указатель на лист, располагаемые
в вершине, родительской по отношению к листу, заменяются парой областей и
указателей, соответствующих двум новым листьям. Если блок родительской вершины обладает
достаточным свободным пространством, процедура благополучно завершается. В
противном случае, как и при выполнении аналогичной операции в В-дереве, рекурсивным
образом расщепляются вершины уровней, все более близких к корневой вершине.
Пример 14.18. Рассмотрим операцию вставки нового объекта во фрагмент двумерного
пространства, показанный на рис. 14.1 (см. с. 639). Предположим, что блок листа R-
дерева позволяет хранить описания шести областей. Допустим также, что шесть
областей-объектов рис. 14.1 представлены в одном листе, область которого отмечена на
рис. 14.20 прямоугольником, ограниченным отрезками сплошной линии.
14.3. ДРЕВОВИДНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
667
100
1
1
1
J
Школа
1 ул. Дерибасовская |
i
i
i
i
Дом N1 .
У
л.
кг
pL
е 1
щ
а
т
и
к
Музей
Дом N2
Бейкер-стрит 1! \
о
100
Рис. 14.20. Расщепление множества объектов
Теперь предположим, что неподалеку от объектов, изображенных на карте, открыт
новый музей. Поскольку седьмая область данных не может быть сохранена в том же
листе дерева, лист подлежит расщеплению: четыре области относятся к одному вновь
созданному листу, а три — к другому. Количество возможных альтернатив
расщепления велико, но мы выбрали такую (на рис. 14.20 подобласти обозначены штриховыми
прямоугольниками), которая минимизирует степень перекрытия областей и
обеспечивает равномерное распределение объектов между ними.
На рис. 14.21 показано, как два новых листа заносятся в R-дерево. Родительская
вершина содержит указатели на оба листа и связанные с ними значения координат
нижнего левого и верхнего правого углов прямоугольных областей, описываемых листьями.
/
((0,0),(60,50)) [/J ((20,20),(100,80))
ул. Дерибасовская ул. Крещатик Дом N1
Школа Дом N2 Бейкер-стрит Музей
Рис. 14.21. Пример R-depeea
а
Пример 14.19. Предположим, что в правую нижнюю часть карты на рис. 14.20
необходимо внести информацию о построенном доме. Координаты нижнего левого и
верхнего правого углов прямоугольника "дом N3" равны (70, 5) и (80, 15) соответственно.
Поскольку объект целиком не умещается ни в одну из областей, отвечающих листьям
дерева, необходимо выбрать область, подлежащую расширению. Если расширить
нижнюю левую область, соответствующую левому листу R-дерева, приведенного на
рис, 14.21, площадь области увеличится на 1000 квадратных единиц (горизонтальный
размер области возрастет на 20 единиц). Если же расширить правую верхнюю область,
668
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
переместив ее нижнюю границу на 15 единиц вниз, это приведет к увеличению
площади области на 1200 квадратных единиц. Мы выбираем первый вариант; результат
показан на рис. 14.22. Описание области в корневой вершине дерева на рис. 14.21
надлежит изменить с ((0, 0), (60, 50)) на ((0, 0), (80, 50)).
100
Школа
Музей
ул. Дерибасовская
ДомМ
Дом N2
Бейкер-стрит
Дом N3
Рис. 14.22. Расширение области
включения нового объекта
100
с целью
а
14.3.9. Упражнения к разделу 14.3
Упражнение 14.3.1. Изобразите структуру индекса с несколькими ключами для
данных, приведенных на рис. 14.10 (см. с. 655), если порядок подчиненности
индексов таков:
a) speed, ram;
b) ram, hd;
c) speed, ram, hd.
Упражнение 14.3.2. Представьте данные, показанные на рис. 14.10 (см. с. 655),
в виде kd-дерева, подразумевая, что блок способен хранить не более двух записей,
и для вершин каждого уровня выберите "разделяющие" значения атрибутов,
обеспечивающие настолько равномерное распределение данных, насколько возможно,
если атрибуты ставятся в соответствие уровням дерева от корня в направлении
листьев в указанном ниже порядке:
a) speed и ram, попеременно;
b) speed, ram и hd, попеременно;
c) на каждом уровне выбирается такой атрибут, который обеспечивает
наиболее равномерное распределение данных.
Упражнение 14.3.3. Пусть дано отношение R(x,y, z), пары значений компонентов х и у
которого образуют ключ. Диапазоны изменения значений атрибутов х и у равны 1—100,
и 1—1000 соответственно. Для каждого значения х существуют записи со 100
различными значениями у, а каждому значению у отвечают записи с 10 различными
14.3. ДРЕВОВИДНЫЕ СТРУКТУРЫ ДЛЯ МНОГОМЕРНЫХ ДАННЫХ
669
значениями х (таким образом, отношение R содержит 10000 кортежей-записей).
Необходимо создать структуру индекса с несколькими ключами, которая
позволила бы оптимизировать процессы обработки SQL-запросов вида
SELECT z
FROM R
WHERE x = С AND у = D;
где С и D — некоторые константы. Предположим, что в каждый блок умещаются по
10 пар "ключ—указатель". Допустим также, что индексы на каждом уровне в свою
очередь могут быть многоуровневыми, причем верхние подуровни разрешено
оставлять разреженными (самый верхний подуровень способен содержать
единственный блок), но индексы нижних подуровней обязаны быть плотными. Помимо того,
будем считать, что изначально все блоки данных и индекса расположены на диске.
* а) Сколько операций дискового ввода-вывода необходимо выполнить для
получения ответа на запрос, если первым создан индекс для атрибута х?
Ь) То же, что и в п. (а), но на верхнем уровне находится индекс для атрибута у.
! с) Предположим, что позволено буферизовать в оперативной памяти до
11 блоков. Какие блоки следует буферизовать и какой из индексов (для х
или у) надлежит выбрать в качестве индекса верхнего уровня, чтобы
минимизировать количество дополнительных дисковых операций, требуемых для
получения результата запроса?
Упражнение 14.3.4. Сколько операций дискового ввода-вывода требуется
выполнить для получения ответа на запрос в диапазонах значений 20<д:<35
и 200 < у < 350 при наличии структуры, указанной в п. (а) упражнения 14.3.3?
Примите к сведению, что распределение данных однородно, т.е. внутри любого
наперед заданного диапазона можно найти предсказуемое количество точек.
Упражнение 14.3.5. Приведите примеры новых точек, которые должны быть
вставлены в следующие блоки дерева, показанного на рис. 14.13 (см. с. 661):
* а) блок с точкой (30, 260);
Ь) блок с точками (50, 100) и (50, 120).
Упражнение 14.3.6. Изобразите варианты дерева, представленного на рис. 14.15
(см. с. 662), после вставки точки (20, ПО), а затем точки (40, 400).
Упражнение 14.3.7. Выше упоминалось о том, что если kd-дерево является
полностью сбалансированным, при выполнении запроса к данным с совпадением
отдельных координат, в котором задается значение одного из двух атрибутов,
достаточно просмотреть Vrt от общего количества п листьев.
a) Объясните, почему.
b) Если уровни дерева попеременно содержат "разделяющие" значения для d
атрибутов-измерений и в запросе задаются значения т атрибутов, какую
часть от общего количества листьев потребуется просмотреть для получения
ответа на запрос?
c) Сопоставьте характеристики производительности структуры, описанной
в п. (Ь), и варианта индекса на основе раздельных хеш-функций.
Упражнение 14.3.8. Представьте данные, показанные на рис. 14.10 (см. с. 655), в виде
дерева квадрантов с размерностями speed и ram, подразумевая, что диапазоны
изменения значений атрибутов speed и ram равны 100—500 и 0—256 соответственно.
Упражнение 14.3.9. Выполните задание упражнения 14.3.8 при добавлении третьего
измерения, hd, с диапазоном изменения значений, равным 0—32.
670
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
*! Упражнение 14.3.10. Если бы центральную точку текущего квадранта позволялось
размещать в любом его месте, удалось бы гарантировать возможность разбиения
квадранта на частные квадранты с равным количеством точек (либо с наиболее
близким к равному, если количество точек в исходном квадранте не делится на 4
нацело)? Обоснуйте ответ.
! Упражнение 14.3.11. Предположим, что база данных содержит информацию
о 1000000 областей, которые могут, перекрываться. Каждая вершина (блок)
R-дерева способна содержать описания 100 областей с соответствующими
указателями. Область, представляемая любой вершиной, содержит 100 подобластей,
и степень перекрытия последних такова, что их общая площадь составляет 150% от
площади родительской области. Сколько блоков придется загрузить в процесс
обработки запроса, предполагающего выявление факта принадлежности точки с
заданными координатами тем или иным областям?
! Упражнение 14.3.12. Предположим, что новая область, вставляемая в R-дерево,
представленное на рис. 14.22 (см. с. 669), может быть помещена в подобласть,
охватывающую объект "школа", либо в подобласть, содержащую объект "дом N3".
Укажите области, которые получают выигрыш от того, что новая область
располагается в подобласти с объектом "школа" (т.е. подобный выбор минимизирует
увеличение размеров подобласти).
14.4. Точечные индексы
Теперь обратимся к разновидности индексов, которые довольно серьезно
отличаются от всех, рассмотренных нами ранее. Представим, что записи файла данных
снабжены фиксированными номерами 1,2,..., п и существует структура, позволяющая
легко отыскать /-ю запись по заданному номеру /.
Точечный индекс (bitmap index) для некоторого поля F — это коллекция битовых
векторов длины п, по одному на каждое возможное значение поля F. Вектор,
отвечающий значению v, обладает единицей в /-м разряде, если компонент поля F в /-й
записи содержит значение v, и нулем — в противном случае.
Пример 14.20. Предположим, что записи файла данных состоят из двух полей, F и G,
целочисленного и строкового типа соответственно, и текущий экземпляр файла
содержит шесть записей, пронумерованных от 1 до 6 и обладающих парами значений
(30, f оо), (30, bar), (40, baz), (50, f oo), (40, bar) и (30, baz).
Точечный индекс для первого поля, F, включает три битовых вектора длины 6.
Вектор, соответствующий значению 30, имеет вид 110001, так как это значение
присутствует в компонентах F записей с номерами 1, 2 и 6. Вектор 001010 отвечает
значению 40, а вектор 000100 — значению 50.
Точечный индекс для поля G также содержит три битовых вектора, поскольку
количество различных строковых значений, присваиваемых компонентам этого
поля, равно трем:
Значение
foo
bar
baz
Вектор
100100
010010
001001
Единицы в битовых векторах свидетельствуют о том, в каких записях файла
присутствует то или иное строковое значение. Q
14.4. ТОЧЕЧНЫЕ ИНДЕКСЫ
671
14.4.1. Зачем нужны точечные индексы
Как может показаться на первый взгляд, точечные индексы требуют излишних
затрат дискового пространства — особенно в тех случаях, когда поле способно
содержать много различных значений. Общее количество битов в индексе вычисляется как
произведение числа записей в файле на число различных значений, хранимых в
определенном поле. Например, если поле является первичным ключом и количество
записей равно п, общая длина всех битовых векторов составит п2. Однако, как будет
показано в разделе 14.4.2 на с. 673, существуют способы сжатия точечных индексов,
позволяющие приблизить объем индекса к пороговому значению п независимо от
количества различных значений поля.
Справедливо задаться вопросом, не возникнут ли проблемы, связанные с
управлением точечными индексами. Содержимое индекса, например, "привязано" к текущему
количеству записей в файле данных. Как, скажем, отыскать i-ю запись, если файл
пополняется или сокращается? Определенное значение поля может то появляться в файле,
то исчезать. Как эффективно находить ключ индекса, соответствующий заданному
значению поля? Эти и подобные им вопросы обсуждаются в разделе 14.4.4 на с. 676.
Возможные неудобства в использовании точечных индексов с лихвой
компенсируются тем, что подобные индексы во многих случаях позволяют весьма эффективно
обрабатывать запросы к данным с совпадением отдельных координат — в том смысле,
о котором говорилось в примере 13.16 на с. 603, где нам удалось отыскать кортежи
отношения Movie с заданными значениями нескольких атрибутов, не прибегая
к предварительной загрузке всех записей с совпадающими значениями в каждом
отдельном атрибуте. Проиллюстрируем сказанное следующим примером.
Пример 14.21. Обратимся к примеру 13.16 на с. 603, посвященному изучению одного
из способов ускорения обработки запроса
SELECT title
FROM Movie
WHERE studioName = 'Disney' AND year = 1995;
Предположим, что существуют точечные индексы для атрибутов studioName и year.
Мы вправе выполнить пересечение битовых векторов, соответствующих значениям
year = 1995 и studioName = 'Disney'; иными словами, осуществив в применении
к векторам операцию побитового "И" (bitwise AND), получим вектор, содержащий 1
в /-й позиции в том и только в том случае, если f-й кортеж отношения Movie
представляет сведения о кинофильме, выпущенном студией "Disney" в 1995 году.
Если допустимо извлечение кортежей Movie по их номерам, нам придется загружать
только такие дисковые блоки, которые содержат по одному или несколько кортежей
с найденным ключом поиска (буквально то же самое мы делали и в примере 13.16).
Чтобы вычислить результат пересечения битовых векторов, их надлежит загрузить в
память, а это потребует одной операции дискового ввода-вывода в расчете на каждый
блок, в котором присутствует один из двух векторов. Позже мы рассмотрим подробнее
обе проблемы: в разделе 14.4.4 на с. 676 обсуждаются способы доступа к записям по их
номерам, а в разделе 14.4.2 на с. 673 — методы уменьшения объемов битовых индексов. □
Точечные индексы находят полезное применение и при обработке запросов в
диапазонах значений. Следующий пример иллюстрирует одновременно особенности
использования точечных индексов при выполнении запросов в диапазонах значений
и приемы употребления побитовых операций and и or с целью получения искомого
ответа на запрос таким способом, который предполагает загрузку только нужных
(и никаких других) записей.
Пример 14.22. Вновь обратимся к базе данных со сведениями о покупателях
драгоценностей, впервые рассмотренной в примере 14.7 на с. 647. Предположим, что двенадцать
точек пространства представлены в виде набора записей, пронумерованных от 1 до 12:
672
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
1:
5:
9:
(25, 60)
(50, 120)
(25, 400)
2:
6:
10:
(45, 60)
(70, ПО)
(45, 350)
3:
7:
11:
(50, 75)
(85, 140)
(50, 275)
4:
8:
12:
(50, 100)
(30, 260)
(60, 260)
Компоненты атрибута "возраст" содержат семь различных значений, так что
точечный индекс для этого атрибута состоит из семи битовых векторов:
25:
50:
85:
100000001000
001110000010
000000100000
30:
60:
000000010000
000000000001
45:
70:
010000000100
000001000000
Количество различных значений атрибута "доход" равно десяти, поэтому
соответствующий точечный индекс включает десять битовых векторов:
60:
ПО:
260:
400:
110000000000
000001000000
000000010001
000000001000
75:
120:
275:
001000000000
000010000000
000000000010
100:
140:
350:
000100000000
000000100000
000000000100
Предположим, что требуется отыскать информацию о покупателях, возраст которых
относится к диапазону 45—55 лет, а годовой доход составляет 100—200 тыс. долларов.
Первым делом найдем битовые векторы, отвечающие значениям возраста из
указанного диапазона; в данном случае таких векторов два — 010000000100 и 001110000010
для значений 45 и 50 соответственно. Если применить к векторам оператор
побитового "ИЛИ" (bitwise OR), будет получен новый вектор, содержащий 1 в /-м разряде
в том и только в том случае, если /-я запись содержит в поле "возраст" значение,
принадлежащее указанному диапазону. Итоговый вектор выглядит как 011110000110.
Далее необходимо отыскать битовые векторы, которые связаны со значениями
атрибута "доход", принадлежащими диапазону 100—200. Таких значений четыре — 100,
ПО, 120 и 140, — и результатом операции побитового "ИЛИ", примененной к
соответствующим битовым векторам, является вектор 000111100000.
Наконец, выполним операцию побитового "И" (bitwise AND) над векторами,
полученными выше:
011110000110 AND 000111100000 = 000110000000
Таким образом, условиям 45 < возраст < 55 и 100 < доход < 200 удовлетворяют только
четвертая, (50, 100), и пятая, (50, 120), записи. □
14.4.2. Сжатые точечные индексы
Предположим, что для некоторого поля F создан точечный индекс и файл данных
содержит п записей и т различных значений поля F. Тогда общая длина всех битовых
векторов индекса равна тп. Если объем дискового блока исчисляется, скажем,
4096 байтами, в одном блоке удастся разместить 32768 бит, и общее количество
требуемых блоков составит тп 132768. Эта величина может оказаться заметно меньшей
в сравнении с числом блоков, необходимых для хранения файла данных как такового,
но чем выше значение т, тем большее пространство занимает файл индекса.
С возрастанием т единицы в битовых векторах будут встречаться все реже; если
выразиться более точно, вероятность появления единицы в любом наудачу взятом
разряде вектора оценивается величиной 1 / т. Если единицы действительно редки,
появляется возможность закодировать битовые векторы таким образом, чтобы сущест-
14.4. ТОЧЕЧНЫЕ ИНДЕКСЫ
673
Бинарные числа и периодическое кодирование
Предположим, что для описания периода, состоящего из / нулей и единицы,
используется бинарное представление числа /. Рассмотрим для примера вектор
000101, состоящий из двух периодов с длинами, равными 3 и 1. Эти числа в
бинарном представлении выглядят как 11 и 1, так что периодическим кодом вектора
будет 111. Применив аналогичную схему вычислений к вектору 010001, мы
получим, однако, совершенно такой же кодированный вектор 111. Тем же кодом
описывается и вектор 010101. Таким образом, код 111 не является однозначным
представлением какого-то одного исходного битового вектора.
венно уменьшить их длину относительно исходного значения п. Общий подход,
называемый периодическим кодированием (run-length encoding), предусматривает
представление периода (run), т.е. последовательности из / нулей, завершаемой единицей,
посредством некоторого кода, соответствующего целому числу /. Осуществив
последовательное сцепление кодов, отвечающих каждому периоду, воедино, мы получим
кодовую последовательность, описывающую исходный вектор.
Легко впасть в соблазн и вообразить, будто для кодирования значения / достаточно
воспользоваться представлением / в виде двоичного (бинарного) числа. Подобная
тривиальная схема, однако, не работает, поскольку не дает возможности расчленить
последовательность кодов на составляющие, представляющие длины отдельных периодов
исходного битового вектора (подробнее об этом — выше во врезке "Бинарные числа
и периодическое кодирование"). Поэтому код числа /, задающего длину каждого
периода битового вектора, не может быть столь же простым, как бинарное представление /.
Здесь мы рассмотрим один из множества различных вариантов кодирования
битовых векторов; существуют и иные, более совершенные и сложные, алгоритмы,
способные увеличить степень сжатия данных (иногда даже в 2 раза), но при условии, что
типичный период обладает большой длиной. В используемой нами схеме вначале
определяется длина бинарного представления числа /. Эта величина, j, приблизительно
равная log2 /, выражается в "унарном" виде с помощью j - 1 единиц и единственного
нуля; затем к ней добавляется бинарное представление Z.97
Пример 14.23. Если /=13, тогда у = 4, т.е. бинарное представление числа / содержит
4 бита. Код / начинается с префикса 1110, а затем к нему добавляется бинарное
представление /, 1101. Поэтому число 13, закодированное в соответствии с предложенной
схемой, будет выглядеть как 11101101.
Код / = 1 равен 01, а код / = 0 — 00: в обоих случаях j = 1, так что префикс
вырождается в 0, а за префиксом следует бинарное представление / (1 или 0). □
После сцепления кодов периодов битового вектора в единую последовательность
мы всегда сможем восстановить набор длин периодов, а затем — и исходный вектор.
Предположим, что после просмотра некоторого количества битов кодированной
последовательности достигнуто начало фрагмента, представляющего некоторое целое /.
Переместившись далее по направлению к концу последовательности до первого нуля,
мы определим значение у; иными словами, j равно количеству битов, считанных до
достижения первого нуля (нуль включается в это количество). Поскольку j уже
известно, далее необходимо считать j очередных битов, которые служат бинарным
представлением / — длины периода. Теперь мы находимся в начале фрагмента,
содержащего описание следующего периода, и вправе повторить процесс.
За исключением случая j = 1 (т.е. / = 0 или /= 1), можно с уверенностью утверждать, что
двоичное представление числа i начинается с единицы. Если опустить первый единичный
бит и пользоваться оставшимися j - 1 битами, это даст возможность сэкономить один бит
почти на каждом числе.
674
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
Пример 14.24. Попытаемся декодировать последовательность 11101101001011. Первый
нуль расположен на четвертой позиции, поэтому у = 4. Четыре следующих бита, 1101,
являются бинарным представлением десятичного числа 13. Теперь осталось расшифровать
фрагмент 001011. Поскольку первый бит содержит 0, это значит, что следующий бит
представляет число как таковое (число равно 0). К этому моменту мы получили
последовательность из двух чисел — 13 и 0, — и декодированию подлежит набор битов 1011.
Первый нуль занимает вторую позицию, и это позволяет заключить, что два финальных
бита, 11, служат бинарной записью десятичного числа 3. Найденные значения (13, 0
и 3) длин периодов позволяют реконструировать сам вектор: 0000000000000110001. □
Говоря формально, любой вектор, дешифрованный подобным образом, должен
завершаться единицей — заключительные нули, если они присутствовали в исходном
векторе, при декодировании не восстанавливаются. Поскольку количество записей
в файле всегда известно, реконструированный вектор можно дополнить нужным
числом нулей. Однако поскольку нулевой бит в векторе свидетельствует о том, что
соответствующая запись не содержит определенное значение в поле ключа поиска,
заключительные нули вектора допустимо игнорировать, что избавляет от необходимости
знать общее количество записей.
Пример 14.25. Попробуем преобразовать в периодические коды некоторые из битовых
векторов, рассмотренных в примере 14.22 на с. 672. Векторы для первых трех
значений атрибута "возраст", 25, 30 и 45, напомним, выглядят как 100000001000,
000000010000 и 010000000100 соответственно. Длины периодов первого вектора
образуют последовательность (0,7). Код 0 есть 00, а код 7 — 110111. Битовый вектор
100000001000 для значения возраст = 25, таким образом, преобразуется в
кодированную форму 00110111.
Аналогичным образом выясняется, что битовый вектор для значения возраст - 30
состоит из единственного периода, содержащего семь нулей, т.е. код принимает вид
110111. Битовый вектор, отвечающий условию возраст = 45, включает два периода
с длинами (1,7). Поскольку код 1 равен 01, а код 7, как было установлено выше, —
110111, код вектора в целом можно записать как 01110111. □
Степень сжатия данных, продемонстрированную в примере 14.25, нельзя назвать
впечатляющей. Впрочем, истинные достоинства метода в ситуациях, когда количество
записей, п, остается малым, проявляют себя слабо. Чтобы проиллюстрировать
ценность рассмотренного алгоритма кодирования более наглядно, предположим, что
т = л, т.е. каждое значение поля, для которого сконструирован точечный индекс,
уникально. Заметьте, что код для периода длины / содержит около 21og2 / бит. Если
каждый битовый вектор включает единственную единицу, значит, он состоит из одного
периода, длина которого не может превысить /г. Поэтому в рассматриваемом случае
верхней границей длины кода битового вектора будет 21og2/x. Поскольку индекс
содержит п битовых векторов (т = п), общая длина всех векторов индекса составит,
самое большее, 2/xlog2/x, а без использования кодирования/сжатия она достигла бы п2
бит. При п > 4 имеем 2n\og2 n<n2, и с ростом п степень различий между значениями
2n\og2nun2 становится все более ощутимой.
14.4.3. Операции со сжатыми битовыми векторами
При необходимости выполнения побитовых операций "И" (bitwise AND) или
"ИЛИ" (bitwise OR) над кодированными битовыми векторами без восстановления
последних в исходном виде не обойтись, но острой потребности в полном
единовременном декодировании векторов-операндов нет. Используемая нами схема сжатия
позволяет последовательно дешифровать по одному периоду векторов и определять, в какой
позиции каждого из них располагается очередная единица. Если применяется опера-
14.4. ТОЧЕЧНЫЕ ИНДЕКСЫ
675
тор OR, наличие единицы в определенной позиции любого из векторов дает
основание поместить единицу в тот же разряд вектора, представляющего результат операции.
При вычислении выражения с оператором AND единица заносится в определенную
позицию итогового вектора в том и только в том случае, если очередные единицы
в обоих операндах размещаются на той же позиции. Алгоритм довольно громоздок, но
следующий пример, мы надеемся, позволит прояснить основную идею.
Пример 14.26. Рассмотрим процесс выполнения операции побитового "ИЛИ" в
применении к кодированным векторам 00110111 и 110111, полученным в примере 14.25
для представления значений 25 и 30 атрибута "возраст". Первые периоды векторов
дешифруются очевидным образом; в результате мы получим значения их длин,
равные 0 и 7 соответственно. Иными словами, первая единица в битовом векторе для
значения 25 занимает позицию 1 (это дает основание поместить 1 в первый разряд
вектора результата), а первая единица в векторе для значения 30 — позицию 8.
Далее необходимо декодировать второй период вектора, отвечающего значению 25,
поскольку вполне вероятно получение единиц в разрядах с номерами, меньшими 8.
Однако длина этого периода, как выясняется, равна 7, т.е. ближайшая единица
занимает позицию 9. Теперь мы с полным правом можем включить в результат шесть
нулей и поместить единицу (из вектора для значения 30) в позицию 8. Вектор,
связанный со значением 30, исчерпан. На позиции 9 итогового вектора располагается
единица из одноименного разряда вектора, соответствующего значению 25. Теперь
использованы и все единицы вектора для 25.
Итак, получен битовый вектор 100000011. Если обратиться к исходным векторам
длины 12 (см. пример 14.22 на с. 672) и выполнить ту же операцию побитового
"ИЛИ", легко убедиться, что вектор "почти" верен: в нем отсутствуют три
завершающих нуля. Поскольку общее количество записей в файле известно и составляет 12,
дополнить вектор недостающими тремя нулями нетрудно. Впрочем, делать это вовсе
не обязательно, поскольку интерес представляют только такие записи, которым
соответствуют единичные разряды векторов индекса. □
14.4.4. Управление точечными индексами
До сих пор мы обсуждали особенности точечных индексов, не затрагивая три
важных вопроса.
1. Какова эффективная процедура поиска
a) битового вектора для заданного значения атрибута?
b) набора битовых векторов, которые соответствуют значениям,
принадлежащим определенному диапазону?
2. Если множество записей данных, удовлетворяющих критерию поиска,
определено, что необходимо сделать для их быстрого отыскания?
3. Каким образом следует изменять элементы точечного индекса при вставке или
удалении записей данных?
Поиск битовых векторов
Для получения ответа на первый вопрос необходимо прибегнуть к приемам, о
которых мы уже говорили. Каждый битовый вектор следует воспринимать как запись
с ключом, равным значению, которому соответствует этот вектор (хотя само значение
в подобной "записи" отсутствует). Тогда вектор, отвечающий заданному значению,
легко найти с помощью вторичного индекса любой разновидности. На эту роль,
например, вполне подойдет В-дерево, вершины-листья которого содержат пары вида
"ключ—указатель", где указатель адресует битовый вектор, связанный со значением
676
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
ключа. Зачастую В-дерево является наилучшим выбором, поскольку обеспечивает
надежную и эффективную поддержку запросов в диапазонах значений, хотя в некоторых
ситуациях не стоит пренебрегать и моделями хеш-таблиц или индексированных
последовательных файлов.
Приходится заботиться и о надлежащем хранении битовых векторов. Наиболее
целесообразно трактовать битовые векторы как записи переменной длины (см. раздел
12.4 на с. 569), поскольку по мере пополнения файла данных новыми записями
должны "вырастать" и элементы точечного индекса. Если битовые векторы (предположим,
сжатые) обладают длиной, меньшей емкости блока, уместно изучить возможность
упаковки нескольких векторов в один блок и перемещения их между блоками по мере
необходимости. Если же длина типичного битового вектора превосходит размер блока,
следует воспользоваться схемой хранения векторов в виде цепочек связанных блоков.
Поиск записей данных
Теперь обратимся ко второму вопросу: если установлено, что необходима некая
запись к файла данных, как до нее добраться? И вновь мы вправе использовать методы,
рассмотренные ранее. Запись к можно интерпретировать так, будто она снабжена
значением к ключа поиска (хотя такое значение в запись не включается), и создать для
файла данных вторичный индекс с ключом поиска, представляющим номера записей.
Если неоспоримых доводов в пользу усложнения структуры файла нет, можно
использовать номера записей в роли значений ключа поиска для первичного индекса
(см. раздел 13.1 на с. 584). В этом случае схема организации файла особенно проста,
поскольку номера записей никогда не меняются (даже при удалении записей) и новые
записи могут добавляться в конец файла данных. Поэтому возникает возможность
плотного заполнения блоков данных и удается обойтись без резервирования
свободных областей в середине файла, предназначенных для вставки новых записей в
будущем (что, как мы говорили в разделе 13.1.6 на с. 592, требуется при использовании
индексированных последовательных файлов в самом общем случае).
Отображение изменений файла данных в индексе
Существуют два аспекта проблемы воспроизведения изменений, вносимых в файл
данных, в файле точечного индекса:
1) номера записей после назначения должны оставаться неизменными;
2) результаты модификации файла данных обязаны отображаться в
содержимом точечного индекса.
При удалении записи / ее номер проще всего оставлять в неприкосновенности,
а на месте записи в файле данных размещать признак- "обелиск" (tombstone)
(см. раздел 12.5.2 на с. 577). В этой ситуации подлежит изменению и точечный
индекс, поскольку /-й бит каждого вектора, содержавший единицу, должен быть заменен
нулем. Заметьте, что найти соответствующие векторы нетрудно, если "запомнить"
ключевое значение записи / перед ее удалением.
Теперь рассмотрим операцию вставки новой записи данных. (Система в состоянии
следить за тем, каким очередным доступным номером следует снабдить вставленную
запись.) Для каждого точечного индекса необходимо определить значение, которым
обладает соответствующее поле новой записи, и дополнить битовый вектор для этого
значения единицей. Строго говоря, все другие векторы индекса также следовало бы
модифицировать, добавив в конец каждого из них по нулю, но если векторы сжаты
в соответствии с алгоритмом, подобным рассмотренному в разделе 14.4.2 на с. 673, их
значения изменять не обязательно.
Особого внимания заслуживает ситуация, когда в индексированном поле новой
записи данных содержится значение, которое ранее еще не встречалось. В подобном
14.4. ТОЧЕЧНЫЕ ИНДЕКСЫ
677
случае требуется создать новый вектор и вставить его вместе с соответствующим
значением в структуру вторичного индекса, которая используется для отыскания вектора
по заданному содержимому ключевого поля.
В завершение упомянем о том, как осуществляется операция модификации /-й
записи файла данных, предусматривающая изменение значения поля, для которого
создан точечный индекс, с v на w. Надлежит найти битовый вектор, соответствующий
значению v, и изменить содержимое бита на позиции / с 1 на 0. Если вектор для
значения w существует, в нем значение /-го бита изменяется, напротив, с 0 на 1. Если же
значение w встречается в индексированном поле впервые, т.е. в составе индекса
соответствующего вектора еще нет, такой вектор необходимо создать, выполнив
дополнительные действия, указанные в предыдущем абзаце.
14.4.5. Упражнения к разделу 14.4
Упражнение 14.4.1. Продемонстрируйте содержимое точечных индексов (в
исходной и сжатой форме) для атрибутов
* a) speed;
b) ram;
c) hd
экземпляра отношения, показанного на рис. 14.10 (см. с. 655), используя алгоритм
кодирования/сжатия, приведенный в разделе 14.4.2 на с. 673.
Упражнение 14.4.2. Используя битовые векторы, указанные в примере 14.22 на
с. 672, найдите записи, соответствующие диапазонам координат 20 < возраст < 40
и 0<доход< 100.
Упражнение 14.4.3. Пусть дан файл, состоящий из 1000000 записей данных, в поле
F которых встречается т различных значений.
a) Выразите в виде функции от т общий объем точечного индекса для поля F.
! Ь) Предположим, что каждые т записей файла, пронумерованных от 1 до
1000000, содержат в поле F определенное значение, отличное от других
значений. Сколько байт потребуется для хранения сжатого точечного индекса?
!! Упражнение 14.4.4. В разделе 14.4.2 на с. 673 упоминалось о том, что вполне
возможно уменьшить количество битов, затрачиваемых для кодирования числа /,
с 21og2/ (чем мы пользовались) до log2/. Покажите, как приблизиться к этому
пределу настолько тесно, насколько необходимо, при больших значениях /. (Мы
применяли "унарный" способ представления бинарного выражения длины i периода.
Можно ли описывать длину участков бинарного кода в бинарном виде?)
Упражнение 14.4.5. Используя алгоритм, рассмотренный в разделе 14.4.2 на с. 673,
выполните кодирование следующих битовых векторов:
*а) 0110000000100000100;
b) 10000010000001001101;
c) 0001000000000010000010000.
*! Упражнение 14.4.6. Как говорилось выше, объем сжатого точечного индекса для
файла с п записями может достигать 2/xlog2/x. Насколько соизмеримо это значение
с количеством битов, требуемым для хранения В-древовидного индекса
аналогичного назначения? (Напомним, что объем файла В-дерева зависит от размеров
ключей и указателей, а также (в небольшой мере) от величины блоков. Проводя вы-
678
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
числения, примите в расчет некоторые "разумные" оценки значений этих
параметров.) На каком основании можно отдать предпочтение В-древовидному индексу даже
в том случае, если он занимает большее пространство, нежели точечный индекс?
14.5. Резюме
♦ Многомерные данные. Во многих приложениях, связанных, например, с
географическими информационными системами, с обработкой сведений о продажах
или с учетом товаров на складах, элементы данных могут трактоваться как
точки в пространстве двух или нескольких измерений.
♦ Запросы к многомерным данным. В числе разновидностей запросов,
используемых в контексте многомерных данных, можно выделить запросы к данным
с совпадением отдельных координат ("найти все точки с заданными
значениями координат в некоторых измерениях"), запросы в диапазонах значений
("найти точки, координаты которых принадлежат указанным диапазонам"),
а также запросы, предусматривающие поиск ближайших соседних объектов
и определение факта принадлежности объекта одной или нескольким областям.
♦ Поиск ближайших соседних объектов. Во многих случаях задача отыскания точки,
ближайшей по отношению к заданной, сводится к выполнению запроса в
диапазоне значений, охватывающем заданную точку, с возможностью расширения
диапазона в тех случаях, когда запрос оказывается нерезультативным. Следует иметь
в виду, что факт наличия точки в прямоугольном диапазоне, вообще говоря, не
означает, что вне диапазона не может быть точки, более близкой к заданной.
♦ Сеточные файлы. Сеточный файл расчленяет пространство в каждом измерении
на полосы заданной ширины. Позиции линий сетки и их количество могут
быть произвольными. Если данные распределены относительно равномерно,
сеточные файлы обеспечивают эффективную поддержку запросов в диапазонах
значений, запросов к данным с совпадением отдельных координат и процедур
поиска ближайших соседних объектов.
♦ Раздельные хеш-таблицы. Раздельные хеш-функции возвращают номер сегмента
таблицы в виде набора битов, сформированного с учетом данных каждого
измерения, и находят удачное применение при обработке запросов к данным с
совпадением отдельных координат, причем показатели эффективности подобных
индексных структур не зависят от степени однородности распределения данных.
♦ Индексы с несколькими ключами — многоуровневые (и многомерные) структуры,
в которых элементы "корневого" индекса для одного атрибута связаны с
подчиненными индексами для другого атрибута, а те в свою очередь — с
индексами для третьего атрибута и т.д. Полезны при обслуживании запросов в
диапазонах значений и при поиске ближайших соседних объектов.
♦ kd-деревья — структуры, подобные деревьям бинарного поиска, но
отличающиеся тем, что критериями ветвления на различных уровнях служат значения
различных атрибутов. Оказывают эффективную помощь при выполнении
запросов к данным с совпадением отдельных координат, запросов в диапазонах
значений и процедур поиска ближайших соседних объектов. Для повышения
производительности операций с данными во вторичных хранилищах вершины
kd-деревьев подлежат распределению по дисковым блокам в соответствии со
специальными правилами.
♦ Деревья квадрантов — позволяют рекурсивным образом делить многомерные
пространства данных на параллелепипеды-квадранты меньшего объема и
поддерживают возможность эффективного выполнения запросов к данным с сов-
14.5. РЕЗЮМЕ
679
падением отдельных координат, запросов в диапазонах значений и операций
поиска ближайших соседних объектов.
♦ R-деревья — обеспечивают представление коллекций областей в виде иерархий
областей возрастающих размеров, находят применение с целью определения
факта принадлежности точки тем или иным областям и используются при
обработке запросов иных разновидностей, рассмотренных в этой главе (в
частности, если области интерпретируются как точки).
♦ Точечные индексы. Для оптимизации запросов к многомерным данным
используются индексы, в которых позиции записей с заданными значениями
определенного атрибута представляются с помощью битовых векторов. Подобные
индексы оказывают помощь при обработке запросов в диапазонах значений,
запросов к данным с совпадением отдельных координат и при выполнении
операций поиска ближайших соседних объектов.
♦ Сжатые битовые векторы. С целью экономии дискового пространства
точечные индексы, содержащие битовые векторы с малым количеством единиц,
подвергаются сжатию в соответствии со схемами периодического кодирования.
14.6. Литература
Большинство образцов структур данных, рассмотренных в этой главе, является
продуктом исследований, проведенных в конце 1970-х и начале 1980-х годов. Модель
kd-дерева впервые представлена в [2], а ее модификации, учитывающие особенности
вторичных хранилищ данных, разработаны в [3] и [13]. Схема раздельного
хеширования с приемами ее использования для обработки запросов к данным с совпадением
отдельных координат заимствована из [5] и [12], а идея, лежащая в основе условий
упражнения 14.2.8 (см. с. 656), — из [14].
Схема сеточных файлов впервые упомянута в [9], а модель деревьев квадрантов
восходит к результатам, изложенным в [6]. Структура R-дерева описана в [8], а две ее
наиболее известные модификации — в [1] и [15].
Появлению структуры точечных индексов сопутствовала любопытная история.
Когда-то существовала компания Nucleus, основанная неким Теодором Глейзером
(Ted Glaser). Компания запатентовала основную идею и разработала СУБД, в которой
структура точечного индекса использовалась и как собственно индексная структура, и
как форма представления данных. В конце 1980-х годов фирма потерпела крах, но ее
достижения оказались востребованными и нынче реализованы в нескольких основных
коммерческих системах баз данных. Первой опубликованной работой, посвященной
модели точечных индексов, был доклад [10]. Результаты, развивающие исходную
идею, приведены в сравнительно недавней статье [11].
Опубликован целый ряд обзоров, касающихся проблематики многомерных
структур хранения данных: одним из самых ранних является [4], а более свежую
информацию по теме можно найти в [7] и [16]. Книга [16] содержит обзоры и по другим
важным аспектам технологий баз данных.
1. Beckmann N., Kriegel H.-P., Schneider R., and Seeger В. The TC-tree: an efficient and robust
access method for points and rectangles, Proc. ACM SIGMOD Intl. Conf. on Management of
Data (1990), p. 322-331.
2. Bentley J.L. Multidimensional binary search trees used for associative searching, Comm. ACM,
18:9 (1975), p. 509-517.
3. Bentley J.L. Multidimensional binary search trees in database applications, IEEE Trans, on
Software Engineering, SE-5:4 (1979), p. 333-340.
680
ГЛАВА 14. МНОГОМЕРНЫЕ И ТОЧЕЧНЫЕ ИНДЕКСЫ
4. Bentley J.L., Friedman J.H. Data structures for range searching, Computing Surveys, 13:3
(1979), p. 397-409.
5. Burkhard W.A. Hashing and tree algorithms for partial match retrieval, ACM Trans, on
Database Systems, 1:2 (1976), p. 175-187.
6. Finkel R.A., Bentley J.L. Quad trees, a data structure for retrieval on composite keys, Acta
Informatica, 4:1 (1974), p. 1-9.
7. Gaede V., Gunther O. Multidimensional access methods, Computing Surveys, 30:2 (1998),
p. 170-231.
8. Guttman A. R-trees: a dynamic index structure for spatial searching, Proc. ACM SIGMOD Intl.
Conf. on Management of Data (1984), p. 47-57.
9. Nievergelt J., Hinterberger H., and Sevcik K. The grid file: an adaptable, symmetric, multikey
file structure, ACM Trans, on Database Systems, 9:1 (1984), p. 38-71.
10. O'Neil P. Model 204 architecture and performance, Proc. 2nd Intl. Workshop on High
Performance Transaction Systems, Springer-Verlag, Berlin, 1987.
11. O'Neil P., Quass D. Improved query performance with variant indexes, Proc. ACM SIGMOD
Intl. Conf. on Management of Data (1997), p. 38-49.
12. Rivest R.L. Partial match retrieval algorithms, SIAM J. Computing, 5:1 (1976), p. 19-50.
13. Robinson J.T. The K-D-B-tree: a search structure for large multidimensional dynamic indexes,
Proc. ACM SIGMOD Intl. Conf. on Management of Data (1981), p. 10-18.
14. Rothnie J.B. (Jr.), Lozano T. Attribute based file organization in a paged memory environment,
Comm. ACM, 17:2 (1974), p. 63-69.
15. Sellis Т.К., Roussopoulos N., and Faloutsos С The 1С-tree: a dynamic index for
multidimensional objects, Proc. Intl. Conf. on Very Large Databases (1987), p. 507—518.
16. Zaniolo C, Ceri S., Faloutsos C, Snodgrass R.T., Subrahmanian V.S., and Zicari R.
Advanced Database Systems, Morgan-Kaufmann, San Francisco, 1997.
14.6. ЛИТЕРАТУРА
681
Глава 15
Выполнение запросов
В предыдущих главах мы рассказали о структурах, обеспечивающих эффективное
выполнение основных операций (таких как поиск кортежей по заданному значению
ключа поиска) с базами данных. Теперь вы готовы к использованию подобных
структур в эффективных алгоритмах обработки запросов. Текущая и следующая главы
посвящены обширной теме, связанной с технологиями обработки запросов. Процессор
запросов (query processor) представляет собой группу компонентов СУБД, которые
преобразуют вводимые пользователем запросы и команды в последовательности операций
с базой данных и выполняют эти операции. Поскольку SQL предоставляет возможность
описания команд в виде высокоуровневых абстракций, процессор запросов обязан
позаботиться о реализации большого количества деталей, регламентирующих самые
разные свойства процесса обработки. Неудачный выбор стратегии обработки запроса
способен привести к неоправданно высоким расходам системных ресурсов и времени.
На рис. 15.1 представлена укрупненная функциональная схема процессора
запросов, блоки которой снабжены ссылками на главы нашей книги, где они подробно
рассмотрены. Здесь мы сосредоточим внимание на особенностях выполнения запросов
(query execution), т.е. на алгоритмах манипуляции информацией, выраженных в форме
наборов операторов расширенной реляционной алгебры (extended relational algebra)
(см. раздел 5.4 на с. 232). Поскольку в языке SQL данные трактуются в соответствии
с требованиями модели мультимножеств (bags), мы будем воспринимать отношения
как мультимножества и использовать соответствующие "мультимножественные"
версии операторов реляционной алгебры, рассмотренных в разделе 5.3 на с. 225.
Мы собираемся осветить основополагающие методы выполнения операторов
реляционной алгебры. Методы различаются используемыми в них базовыми
стратегиями—к числу наиболее важных относятся сканирование (scanning), хеширование
(hashing), сортировка (sorting) и индексирование (indexing). Другой критерий
различения методов связан с их потребностями в свободной оперативной памяти. В
некоторых алгоритмах предусматривается, что объем доступной памяти должен быть
достаточным для хранения по меньшей мере одного из отношений, принимающих участие
в операции. В других ставка делается на то, что аргументы оператора слишком велики
для размещения в памяти целиком. Поэтому структуры и показатели
производительности алгоритмов существенным образом разнятся.
Краткий обзор технологий компиляции запросов
Процесс компиляции запроса, как показано на рис. 15.2, можно представить в
виде трех основных этапов.
Запрос
\
Компиляция
запроса
(глава 16)
Метаданные
План запроса
Выполнение
запроса
(глава 15)
Данные
Рис. 15.1. Главные функции
процессора запросов
1. Синтаксический анализ (parsing) — конструирование дерева разбора (parse tree),
описывающего запрос и его структуру.
2. Перезапись запроса (query rewrite) —
реформирование дерева разбора в начальный
логический план запроса, который обычно
отображается в виде алгебраического
представления запроса, а затем преобразуется
в эквивалентный более эффективный план.
3. Генерация физического плана (physical plan
generation) — превращение абстрактного
логического плана запроса (logical query
plan), полученного на этапе 2, в физический
план запроса (physical query plan)
посредством выбора алгоритмов, реализующих
каждый оператор логического плана, и задания
порядка выполнения этих операторов.
Физический план, подобно результату
синтаксического анализа и логическому плану,
представляется в форме дерева выражений.
Помимо того, физический план содержит
описания деталей реализации, которые,
например, регламентируют способы доступа
к отношениям, упомянутым в запросе, или определяют условия и очередность
сортировки содержимого отношений.
Этапы 2 и 3, часто в совокупности называемые оптимизацией запроса (query
optimization), являются наиболее трудоемкой фазой процесса компиляции запроса.
Проблематике оптимизации запросов посвящена глава 16 (см. с. 753); в ней мы расскажем
о том, как выбирается "план запроса", требующий минимально возможного времени
выполнения. Чтобы осуществить наилучший выбор, надлежит дать ответы на
следующие вопросы и принять соответствующие решения.
1. Какие из алгебраически эквивалентных форм запроса позволяют
воспользоваться наиболее эффективными алгоритмами получения результата?
Какие алгоритмы следует выбрать для реализации каждой операции,
предусмотренной в плане запроса?
Каким образом следует организовать передачу данных от одного оператора к
другому (скажем, посредством каналов, буферов оперативной памяти или диска)?
Выбор каждой из альтернатив во многом обусловлен содержимым метаданных
(metadata), описывающих базу данных. К числу метаданных, доступных для
использования оптимизатором запросов, относятся размеры каждого из отношений,
статистические зависимости (такие как оценки количеств и частот встречаемости различных
значений тех или иных атрибутов), сведения о наличии определенных индексов
и схемы распределения данных по блокам диска.
2.
3.
15.1. Знакомство с операторами физического плана запроса
Физический план запроса (physical query plan) конструируется из операторов,
каждый из которых отвечает за выполнение одного из этапов плана. Нередко операторы
физического плана представляют собой определенные реализации операторов
реляционной алгебры. Впрочем, для выполнения некоторых функций используются и такие
физические операторы, которые не имеют отношения к операторам реляционной
алгебры. Например, зачастую возникает потребность в сканировании (scanning) таблицы,
684
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
т.е. загрузке в оперативную память каждого кортежа отношения, которое служит
операндом некоторого выражения реляционной алгебры. В этом разделе мы
сосредоточим внимание на базовых "кирпичиках", из которых строятся физические планы
запросов, а в последующих расскажем о более сложных алгоритмах эффективной
реализации операторов реляционной алгебры; подобные алгоритмы также являются
немаловажной частью физических планов запросов. Помимо того, мы изложим
концепцию итератора (iterator) — важной схемы, в рамках которой операторы,
составляющие физический план, способны осуществлять взаимный обмен данными.
SQL-запрос
_J
Оптимизация
запроса
Синтаксический
анализ
запроса
/\ Дерево выражений запроса
Выбор
логического
плана запроса
/ \ Дерево логического плана запроса
Выбор
физического
плана запроса
/\ Дерево физического плана запроса
Выполнение плана
Рис. 15.2. Диаграмма процесса компиляции запроса
15.1.1. Сканирование таблиц
Вероятно, одна из наиболее употребительных функций, предусматриваемых
физическими планами запросов, связана с чтением полного содержимого (сканированием —
scanning) некоторого отношения R. Потребность в ее выполнении возникает,
например, при вычислении объединения (union) или соединения (join) отношения R с другим
отношением. Возможны такие варианты оператора сканирования, в которых задается
определенный предикат, оговаривающий условия, которым должны удовлетворять
кортежи отношения R, подлежащие считыванию. Существуют два основных подхода
к задаче обнаружения кортежей отношения R.
1.
2.
Во многих случаях кортежи отношения R компактным образом размещаются
в определенной группе блоков вторичной дисковой памяти. Адреса блоков
известны, и система в состоянии загружать блоки один за другим. Подобная
операция носит название табличного сканирования (table-scan).
Если для некоторого атрибута отношения R сконструирован индекс, его можно
использовать для извлечения всех кортежей отношения. Например, в разделе
13.1.3 на с. 586 мы упоминали о том, что разреженный индекс для атрибута
отношения способен "привести" ко всем блокам, содержащим данные
отношения, — даже в том случае, если иная информация о местоположении блоков
отсутствует. Такую операцию принято называть индексным сканированием (index-scan).
15.1. ЗНАКОМСТВО С ОПЕРАТОРАМИ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА
685
К операции индексного сканирования мы вернемся в разделе 15.6.2 на с. 726, где
расскажем об особенностях реализации оператора выбора (selection) <х. Однако более
важным обстоятельством является то, что индекс можно использовать не только для
получения всех кортежей соответствующего отношения, но и с целью загрузки только
таких кортежей, которые обладают определенными значениями (либо относятся к
заданным диапазонам значений) компонентов атрибута или нескольких атрибутов,
образующих ключ поиска индекса.
15.1.2. Сортировка в процессе сканирования таблиц
Можно привести целый ряд доводов, обосновывающих целесообразность
сортировки данных отношения при их считывании. Во-первых, запрос может содержать
предложение order by, требующее, чтобы отношение было отсортировано в
соответствии с заданным критерием. Во-вторых, различные алгоритмы, реализующие
операции реляционной алгебры, предусматривают необходимость сортировки отношений-
операндов (подобные алгоритмы обсуждаются, в частности, в разделе 15.4 на с. 706).
Оператор сканирования с сортировкой (sort-scan), относящийся к числу операторов
физического плана запроса, принимает в качестве параметров отношение R и
спецификации атрибутов, определяющих критерий сортировки, и возвращает отношение R
в отсортированном виде. Существует несколько способов реализации оператора
сканирования с сортировкой.
1. Если необходимо отсортировать отношение R с учетом значений атрибута а и
либо существует В-древовидный индекс для я, либо R хранится в
индексированном последовательном файле, упорядоченном в соответствии со значениями
компонентов а, оператор индексного сканирования позволит получить кортежи
R в требуемом порядке.
2. Если отношение R, подлежащее загрузке в отсортированном виде, настолько
мало, что допускает размещение в буферах оперативной памяти, кортежи
отношения могут быть загружены с помощью оператора табличного или
индексного сканирования, а затем упорядочены посредством любого из вариантов
эффективных алгоритмов сортировки данных в памяти.
3. Если же отношение R не может быть загружено в оперативную память
целиком, для его обработки подойдет алгоритм сортировки двухфазным
многокомпонентным слиянием, рассмотренный в разделе 11.4.4 на с. 513. Однако вместо
сохранения итоговой отсортированной версии отношения R на диске в данном
случае уместно предусмотреть возможность последовательного получения
отдельных блоков отсортированного отношения R по мере возникновения
потребности в использовании кортежей из этих блоков.
15.1.3. Модель вычислений операторов физического плана
Запрос обычно сводится к набору из нескольких операций реляционной алгебры,
и физический план, соответствующий запросу, формируется из ряда физических
операторов. Зачастую физические операторы представляют собой некоторые реализации
операторов реляционной алгебры, но существуют и иные операторы физического
плана (мы говорили об этом в разделе 15.1.1), отвечающие таким операциям
(подобным сканированию), которые не имеют аналогов в реляционной алгебре.
Поскольку способность к разумному выбору операторов физического плана — это
существенный критерий качества процессора запросов, необходимо иметь возможность
получения оценок эффективности ("стоимости") каждого применяемого оператора.
В качестве меры эффективности оператора мы будем использовать количество
предусматриваемых им операций дискового ввода-вывода. Это решение вполне согласуется
с выводами, к которым мы пришли ранее (см. раздел 11.4.1 на с. 510): процедуры извле-
686
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
чения информации с диска заведомо более продолжительны, нежели любые
манипуляции данными, загруженными в оперативную память. Единственное заслуживающее
внимания исключение связано с ситуацией, когда обработка запроса предполагает
передачу данных по сети. О том, как оценивать эффективность процессов
распределенной обработки запросов, мы расскажем в разделах 15.9 (см. с. 741) и 19.4.4 (см. с. 980).
При сопоставлении алгоритмов, реализующих одну и ту же операцию, мы будем
придерживаться следующего положения, которое на первый взгляд может показаться
несколько необычным:
• аргументы-данные любого оператора располагаются на диске, но результат его
выполнения сохраняется в оперативной памяти.
Если оператор возвращает итоговый ответ на запрос и результат в самом деле
сохраняется на диске, стоимость подобной операции зависит только от объема данных результата,
но не от того, каким образом тот был получен: достаточно просто присовокупить
значение затрат, связанных с выполнением завершающей операции записи информации на
диск, к общей стоимости обработки запроса. Во многих приложениях, однако, результат
не сохраняется на диске вовсе — он или выводится на экран, на принтер и т.п., или
передается для обработки в какую-либо форматирующую программу. В этом случае
затраты на сохранение итоговых данных на диске либо сводятся к нулю, либо зависят
от заранее не известных параметров некоей сторонней прикладной программы.
Зачастую не подлежат сохранению на диске и результаты работы промежуточных
операторов, ответственных за выполнение отдельных "внутренних" частей запроса.
В разделе 15.1.6 на с. 689 мы расскажем об "итераторах" — схемах организации
вычислений, в которых результат выполнения одного оператора конструируется в
оперативной памяти (возможно, по частям) и передается в виде аргумента другому
оператору. В подобных случаях промежуточные итоги никогда не сохраняются на диске, что
позволяет избежать затрат, связанных с загрузкой данных, которые являются
аргументами' операторов, пользующихся "услугами" других операторов. Как не упустить шанс
получения подобной экономии — это одна из тех задач, на решение которых должны
быть направлены основные "усилия" оптимизатора запросов.
15.1.4. Критерии эффективности физических операторов
Здесь мы познакомим вас с критериями (иногда их называют статистиками —
statistics), используемыми для выражения эффективности (или "стоимости") того или
иного оператора. Оценки стоимости оказывают решающее влияние на то, какой из
множества эквивалентных планов будет выбран оптимизатором запросов. Вопросам анализа и
практического применения оценок стоимости операторов посвящен раздел 16.5 на с. 797.
Прежде всего, необходимы параметры, представляющие размеры аргумента (или
аргументов) оператора и потребности самого оператора в ресурсах оперативной
памяти. Предположим, что оперативная память поделена на буферы того же объема, что
и дисковые блоки. Обозначим через М количество буферов памяти, доступных для
использования конкретным оператором. При получении оценок стоимости
выполнения оператора мы не будем учитывать расходы ресурсов оперативной памяти и
затраты на дисковые операции, которые непосредственно связаны с процедурами вывода
результата; поэтому в М включаются только те буферы, которые требуются для
загрузки входных и хранения промежуточных данных оператора.
Подчас М можно воспринимать как количество буферов, для размещения которых
используется вся (или почти вся) оперативная память (именно это мы имели в виду
в разделе 11.4.4 на с. 513). Однако много более реальны ситуации, когда память
распределяется между несколькими процессами, так что значение М оказывается
существенно более низким. Как будет показано в разделе 15.7 на с. 732, количество буферов,
доступных для некоторого оператора, чаще всего не является некоей заранее
предсказуемой константой и может быть определено только в процессе выполнения
оператора в зависимости от номенклатуры и количества параллельно действующих процессов.
15.1. ЗНАКОМСТВО С ОПЕРАТОРАМИ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА
687
В подобных случаях М следует трактовать только как приближенную оценку. Если
оценка слишком груба, реальное время выполнения оператора может значительно
отличаться от того, которое предусматривалось оптимизатором запросов. Если
оптимизатор настолько "разумен", что способен предсказать истинное распределение
буферов в будущем, эти "знания" могут повлиять на выбор физического плана запроса.
Теперь рассмотрим параметры измерения стоимости доступа к отношениям,
являющимся аргументами оператора. Подобные параметры, позволяющие оценить
размер и характеристики распределения данных отношения, во многих случаях
вычисляются оптимизатором запросов периодически, что помогает выбрать адекватные
физические операторы. Мы будем придерживаться упрощенного предположения о том,
что данные считываются с диска последовательно, по одному блоку в каждый момент
времени. На практике, однако, используются различные приемы (мы рассказывали
о них в разделе 11.5 на с. 518) ускорения процессов загрузки, когда единовременно
считывается целое множество последовательно расположенных дисковых блоков.
Существуют три семейства параметров — назовем их #, Т и V, — применяемых для
описания характеристик отношений-аргументов физических операторов.
• При описании размера отношения R чаще всего имеет смысл обращать
внимание на количество блоков, необходимых для хранения всех кортежей R. Эту
величину мы будем обозначать как B(R), или просто В, если из контекста
понятно, что подразумевается R. Обычно предполагается, что данные отношения R
компактно сгруппированы (clustered) в В (или приблизительно в В) блоков. Как
упоминалось в разделе 13.1.6 на с. 592, иногда небольшую часть каждого блока,
содержащего данные отношения /?, оставляют свободной в расчете на
возможные будущие операции вставки кортежей в R. В любом случае В часто является
достаточно добротной приближенной оценкой количества дисковых блоков,
которые требуется загрузить для получения полного содержимого отношения /?,
и поэтому мы будем воспринимать параметр В именно в таком качестве
независимо от конкретных обстоятельств.
• Подчас полезно знать также количество кортежей отношения R; эта величина
обозначается в виде Г(/?), или просто Г, если предполагается, что речь идет об
отношении R. Если требуется вычислить количество кортежей /?, которые
способны уместиться в пределах одного блока, достаточно воспользоваться
соотношением TIB. Далее, возможны ситуации, когда содержимое отношения R
распределено по блокам, в которых размещаются также кортежи других
отношений. В подобных случаях уместно воспользоваться упрощенным подходом
и полагать, что для загрузки каждого кортежа R применяется отдельная
дисковая операция, т.е. трактовать Т как оценку количества операций дискового
ввода-вывода, необходимых для считывания данных отношения /?.
• Наконец, нередко требуется знать количество V(R, а) различных значений в
пределах определенного столбца-атрибута а отношения R. В более общем случае, если
(аь а2,..., ап) — некоторый список атрибутов отношения /?, тогда к(/?, (аъ аъ ..., aS) —
количество различных наборов значений атрибутов аь а2,..., ап, или, говоря
формально, количество кортежей в 8(ка ч(1 а (/?)).
15.1.5. Оценки затрат на ввод-вывод для операторов сканирования
В качестве простого примера использования перечисленных выше критериев
эффективности физических операторов рассмотрим оценки количества операций дискового
ввода-вывода, выполняемых каждым из упомянутых операторов сканирования. Если
содержимое отношения R сгруппировано по блокам компактным образом, для его
загрузки оператору табличного сканирования (table-scan) понадобится выполнить
приблизительно В операций дискового ввода-вывода. Аналогично, если отношение R может быть
688
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
загружено в оперативную память целиком, для реализации оператора сканирования
с сортировкой (sort-scan) достаточно предусмотреть считывание R и выполнение
сортировки его содержимого в памяти, что вновь потребует осуществления В дисковых операций.
Если отношение R хранится компактно, но его упорядочение сопряжено с
использованием алгоритма сортировки двухфазным многокомпонентным слиянием, тогда, как
упоминалось в разделе 11.4.4 на с. 513, системе придется произвести ЪВ дисковых
операций — по В операций на каждую из трех процедур: считывание содержимого R в
подсписки, сохранение отсортированных подсписков на диске и их повторная загрузка
в память. Заметьте, что здесь не учитываются затраты на дисковые операции, связанные
с записью окончательного результата (равно как и расходы памяти для хранения этого
результата). Напротив, мы полагаем, что каждый итоговый блок непосредственно
передается в распоряжение очередного оператора (в частном случае — сохраняется на диске).
Если же распределение содержимого R по блокам нельзя считать компактным,
количество необходимых дисковых операций, вообще говоря, может быть существенно
большим. Если наряду с кортежами R блоки содержат данные других отношений, для
выполнения табличного сканирования /?, возможно, придется обращаться к такому
количеству блоков, которое равно числу кортежей /?, т.е. затраты на операции дискового
ввода-вывода будут оцениваться величиной Т. Аналогично, если отношение R подлежит
упорядочению, причем его размеры позволяют загрузку в память целиком, тогда Т вновь
послужит хорошей оценкой расходов, связанных с дисковыми операциями. Наконец,
если расположение кортежей R не является компактным и для упорядочения данных R
предполагается применение алгоритма сортировки двухфазным многокомпонентным
слиянием, для формирования исходных подсписков понадобится Т дисковых операций.
Однако поскольку далее данные можно (и нужно) хранить в компактном виде, две
другие процедуры — сохранение упорядоченных подсписков на диске и их повторная
загрузка в память — потребуют в общей сумме только 2В операций дискового ввода-
вывода. Поэтому общие затраты на выполнение сканирования крупномасштабного
некомпактного отношения с его сортировкой можно оценить функцией Т + 2В.
Наконец, исследуем стоимость операции индексного сканирования. Вообще
говоря, произвольный индекс для отношения R занимает намного меньше B(R) блоков.
Поэтому сканирование отношения R целиком, требующее, как минимум, В дисковых
операций, существенно более трудоемко в сравнении с просмотром полного индекса
для этого отношения. Хотя для выполнения индексного сканирования приходится
обращаться к блокам и отношения, и индекса, можно полагать следующее:
• в качестве оценок затрат на доступ к содержимому компактного и
некомпактного отношения посредством индекса правомерно использовать величины В и Т
соответственно.
Если, однако, требуется только часть данных отношения /?, нередко удается избежать
необходимости просмотра и всего отношения, и всего индекса. Анализ подобных
примеров использования индексов мы отложим до раздела 15.6.2 на с. 726.
15.1.6. Реализация физических операторов с помощью итераторов
Многие физические операторы допускают реализацию в виде схемы итератора
(iterator), предусматривающей использование группы из трех функций, которые
позволяют потребителю результата работы физического оператора получать по одному
кортежу в каждый момент времени.
1. Функция Open дает начало процессу получения кортежей, но фактически кортежи
не передает. Она инициализирует структуры данных, необходимые для
выполнения операции, и вызывает функции Open соответствующих аргументов оператора.
2. Функция GetNext возвращает очередной кортеж, модифицирует значения во
внутренних структурах данных, обеспечивая возможность получения после-
15.1. ЗНАКОМСТВО С ОПЕРАТОРАМИ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА 689
дующих кортежей, и обычно один или несколько раз вызывает функции
GetNext аргументов оператора. Если множество кортежей исчерпано, GetNext
возвращает специальное значение NotFound, которое, как предполагается,
нельзя спутать с обычным кортежем.
3. Функция Close завершает итеративный процесс получения данных и обычно
вызывает функции Close аргументов оператора.
Итераторы и их функции мы будем воспринимать так, будто каждому типу итератора
(т.е. каждому типу физического оператора, реализуемого в виде итератора) соответствует
некий "класс", и экземпляры этого класса поддерживают методы Open, GetNext и Close.
Пример 15.1. Вероятно, простейшим является итератор, обеспечивающий выполнение
оператора табличного сканирования. Такой итератор можно представить в виде класса
TableScan, и оператор табличного сканирования в физическом плане запроса является
экземпляром этого класса, параметризованным посредством аргумента-отношения R,
подлежащего сканированию. Предположим, что содержимое отношения R компактно
размещено в определенной группе блоков, которые допускают последовательное
обращение традиционным образом, т.е. функция "получить следующий блок /?" легко
реализуется системой хранения и не нуждается в подробном описании. Помимо того, будем
считать, что заголовок блока содержит каталог записей (кортежей), позволяющий быстро
"добраться" до очередной записи блока либо удостовериться, что достигнут конец блока.
Open() {
b := первый блок R;
t := первый кортеж блока Ь;
}
GetNext() {
IF (t указывает на позицию после завершающего кортежа блока Ь) {
Увеличить Ь, присвоив адрес следующего блока;
IF (следующего блока нет)
RETURN NotFound;
ELSE /* b — новый блок */
t := первый кортеж блока Ь;
} /* Теперь можно возвратить t и увеличить t */
oldt := t;
Увеличить t, присвоив адрес следующего кортежа блока Ь;
RETURN oldt;
}
Close() {}
Рис. 15.3. Функции итератора для оператора табличного сканирования в применении
к отношению R
На рис. 15.3 представлены эскизные варианты трех функций подобного итератора.
Предположим, что существуют указатель Ъ на блок и указатель / на кортеж внутри
блока, адресуемого указателем Ъ, и эти указатели способны ссылаться на позиции за
пределами последнего блока и последнего кортежа в блоке соответственно, причем факт
возникновения любой из двух ситуаций возможно идентифицировать. Заметьте, что тело
функции Close в данном случае пусто. На практике функция Close итератора способна
очищать внутренние структуры СУБД и выполнять дополнительные обязанности —
например, информировать модуль менеджера буферов (buffer manager) о том, что
определенные буферы более не используются, и уведомлять менеджер параллельных заданий
(concurrency-control manager) о завершении операции считывания данных отношения. □
690
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Зачем нужны итераторы
Как будет показано в разделе 16.7 на с. 822, схемы итераторов (iterators),
компонуемые в рамках плана запроса, способны существенно повысить эффективность
выполнения запроса. Антиподом итератора является стратегия материализации
(materialization), в соответствии с которой результат каждого оператора
конструируется полностью, а затем либо сохраняется на диске, либо оставляется в
оперативной памяти. При использовании итераторов в каждый момент времени в активном
состоянии пребывает сразу несколько операций; по мере необходимости операции
обмениваются данными, что сокращает потребность в обращениях к диску.
Разумеется, как будет рассказано ниже, далеко не все физические операторы в равной
мере успешно поддерживают схему итераторов, или каналов (pipelines). В
некоторых случаях львиная доля обязанностей возлагается на функцию Open, и такая
схема становится равноценной стратегии материализации.
Пример 15.2. Теперь обратимся к варианту итератора, большая часть обязанностей
которого возложена на функцию Open. Итератор реализует операцию сканирования
с сортировкой, считывая кортежи отношения R и возвращая их в определенном
порядке. Предположим, что отношение R настолько велико, что для его упорядочения
приходится применять алгоритм сортировки двухфазным многокомпонентным
слиянием (подробности — в разделе 11.4.4 на с. 513).
Итератор не вправе вернуть даже первый считанный кортеж до тех пор, пока не
будут загружены и проанализированы все остальные кортежи отношения R. Поэтому
функция open обязана выполнять по меньшей мере следующее:
1) последовательно загрузить все кортежи R порциями объемом, равным
емкости доступной области оперативной памяти, выполняя сортировку кортежей
и сохранение их на диске;
2) инициализировать структуры данных, необходимые для осуществления
второй фазы алгоритма, связанной со слиянием, и загрузить первый блок
каждого отсортированного подсписка в буферы оперативной памяти.
Далее вступает в действие функция GetNext. Она сопоставляет значения
компонентов первых кортежей в заголовках всех упорядоченных подсписков; если блок
выбранного подсписка оказывается исчерпанным, GetNext выполняет "подкачку"
данных с диска в буфер. □
Пример 15.3. Наконец, рассмотрим простой образец сочетания нескольких итераторов
в единую цепочку. Здесь мы не пытаемся показать, насколько много итераторов могут
быть активными одновременно, но это подождет — прежде нам придется обсудить
алгоритмы выполнения физических операторов, подобных операторам выбора (select)
и соединения Coin), которые лучше других поддаются сочетанию.
Обратимся к операции объединения мультимножеств (bag union) R\JS, которая
вначале предполагает считывание всех кортежей /?, а затем — всех кортежей S (вместе
с возможными дубликатами). Обозначим как 7Z и Sитераторы, служащие для
получения отношений R и S соответственно и являющиеся "наследниками" оператора
объединения в плане запроса, реализующем операцию R (J S. В качестве итераторов 7Z и S
могут выступать операторы табличного сканирования, применяемые к отношениям R
и S, либо итераторы, обращающиеся по сети к другим итераторам с запросами на
вычисление R и S. Независимо от истинной природы итераторов 7Z и S, важно то, что
они предоставляют в распоряжение системы соответствующие функции Open,
15.1. ЗНАКОМСТВО С ОПЕРАТОРАМИ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА
691
GetNext и Close. Набросок функций итератора, реализующего объединение
отношений R и S, представлен на рис. 15.4. Стоит обратить внимание на один тонкий
момент: функции используют общую переменную CurRel, которая представляет собой
итератор К либо итератор S— в зависимости от того, сканирование какого из
отношений (R или S) осуществляется в данный момент времени.
Open() {
R.Open();
CurRel := R;
}
GetNext() {
IF (CurRel = R) {
t := R.GetNext();
IF (to NotFound) /* Содержимое R не исчерпано */
RETURN t;
ELSE /* Содержимое R исчерпано */ {
S.Open();
CurRel := S;
}
}
/* Здесь необходимо выполнить чтение из S */
RETURN S.GetNext();
/* Если содержимое S исчерпано, S.GetNextO возвращает
NotFound, что является допустимым результатом
текущей функции GetNext() */
}
Close() {
R.Close();
S.Close();
}
Рис. 15.4. Конструирование итератора объединения на основе итераторов 7Z и S
□
15.2. Однопроходные алгоритмы обработки данных
Приступим к изучению весьма важного раздела теории и практики оптимизации
запросов к базам данных, позволяющего дать ответ на следующий общий вопрос:
каким образом следует выполнять отдельные операции — скажем, соединение или
выбор — логического плана запроса? Подбор алгоритмов с целью реализации каждого
оператора — значимая часть процесса преобразования логического плана запроса
в физический план. Разработано целое множество альтернативных алгоритмов
операторов, и все они могут быть отнесены к одному из трех обширных классов:
1) алгоритмы, основанные на сортировке (sort-based algorithms) (обсуждаются
преимущественно в разделе 15.4 на с. 706);
2) алгоритмы, основанные на хешировании (hash-based algorithms) (упоминаются,
в частности, в разделах 15.5 на с. 717 и 15.9 на с. 741);
3) алгоритмы, основанные на индексировании (index-based algorithms)
(рассматриваются в разделе 15.6 на с. 725).
Помимо того, алгоритмы физических операторов можно классифицировать по
критерию трудоемкости.
692
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
1. Некоторые методы предусматривают возможность считывания данных с диска
только один раз. Такие алгоритмы, называемые однопроходными (one-pass
algorithms), являются предметом настоящего раздела. Обычно однопроходные
схемы вычислений допускают реализацию только в тех случаях, когда по
меньшей мере одно из отношений, служащих аргументами операции, может
быть загружено в оперативную память целиком, хотя существуют и отдельные
исключения, наиболее характерные для операций выбора и проекции
(подробнее — в разделе 15.2.1 на с. 693).
2. Определенные методы способны работать с данными, объем которых
превышает размер свободной области оперативной памяти, но они не приемлемы для
обработки особо крупных наборов данных. Примером подобных методов
служит алгоритм сортировки двухфазным многокомпонентным слиянием,
исследованный в разделе 11.4.4 на с. 513. Такие двухпроходные алгоритмы (two-pass
algorithms) характерны тем, что предусматривают необходимость считывания
данных с диска, манипуляций ими в памяти, сохранения всей (или почти всей)
информации на диске с последующей повторной загрузкой с целью обработки
в процессе выполнения второго прохода. С подобными алгоритмами вы
встретитесь в разделах 15.4 на с. 706 и 15.5 на с. 717.
3. Существует и ряд методов, которые не накладывают ограничений на объем
входных данных. Такие методы достигают цели с помощью трех или большего
количества проходов и являются естественными рекурсивными обобщениями
соответствующих двухпроходных версий. О многопроходных алгоритмах
(multipass algorithms) мы расскажем в разделе 15.8 на с. 738.
В этом разделе рассмотрены однопроходные алгоритмы выполнения физических
операторов. Здесь и далее мы будем разделять операторы на три класса.
1. Унарные операции над отдельными кортежами (tuple-at-a-time, unary operations),
к которым относятся операции сг {выбор — selection) и л; {проекция — projection),
не требуют наличия в оперативной памяти содержимого всего отношения или
его крупных частей и предполагают необходимость считывания с диска
отдельных блоков данных, использования одного буфера оперативной памяти и
последовательного вывода результатов.
2. Унарные операции над полными отношениями (full-relation, unary operations)
предусматривают выполнение загрузки всех или большей части кортежей
отношения в оперативную память, поэтому однопроходные алгоритмы, реализующие
подобные операции, способны работать только с такими отношениями,
содержимое которых может быть сохранено в М доступных буферах оперативной
памяти. Мы будем рассматривать две операции этого класса — 8 (удаление
кортежей-дубликатов — duplicate elimination) и у {группирование — grouping).
3. Бинарные операции над полными отношениями (full-relation, binary operations);
к этому классу относятся все остальные операции: объединение (union),
пересечение (intersection), разность (difference), варианты соединения (join) и декартова
произведения (Cartesian product) в версиях для множеств (sets) и
мультимножеств (bags). При использовании однопроходных алгоритмов во всех случаях,
за исключением оператора объединения мультимножеств, требуется, чтобы
размер хотя бы одного аргумента был ограничен величиной М.
15.2.1. Однопроходные алгоритмы для унарных операций над отдельными
кортежами
Для унарных операций cr(R) {выбор — selection) и ж{К) {проекция — projection),
предполагающих необходимость единовременной загрузки отдельных кортежей
отношения /?, существуют очевидные алгоритмы, не зависящие от того, умещается содер-
15.2. ОДНОПРОХОДНЫЕ АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ
693
жимое R в буферы оперативной памяти или нет: достаточно считать очередной блок R
во входной буфер, выполнить операцию над каждым кортежем загруженной порции
данных и переместить выбранные или спроецированные кортежи в выходной буфер,
как показано на рис. 15.5. Поскольку выходной буфер способен служить входным
буфером для некоторого другого оператора либо средством пересылки данных
пользователю или стороннему приложению, при подсчете размера требуемой области
оперативной памяти он не учитывается. Таким образом, операции требуют наличия М > 1
буферов, независимо от величины В.
Количество процедур дискового ввода-вывода, необходимых для выполнения
унарных операций над отдельными кортежами, обусловлено только тем, в каком виде
представляется аргумент R. Если отношение R изначально размещено на диске,
затраты на выполнение операций, очевидно, совпадают со стоимостью табличного или
индексного сканирования R (эти величины исследовались в разделе 15.1.5 на с. 688
и обычно равны В, если R хранится компактно, и Г — в противном случае).
Входной
буфер
Выходной
буфер
Рис. 15.5. Процесс выполнения операторов выбора
или проекции данных отношения R
Целесообразно вновь напомнить о важном исключении, связанном с операцией
выбора, предполагающей сопоставление значений атрибута с определенной константой
и возможность использования индекса. В подобном случае индекс позволяет
ограничить внимание только некоторым подмножеством блоков, содержащих данные
отношения #, и сулит немалый выигрыш в производительности.
15.2.2. Однопроходные алгоритмы для унарных операций над полными
отношениями
Теперь обсудим особенности операций, выполняемых над отношениями в целом, а
не над их отдельными кортежами. Речь пойдет об операциях S (удаление кортежей-
дубликатов — duplicate elimination) и у (группирование — grouping).
Удаление кортежей-дубликатов
Для удаления дубликатов блоки с данными отношения R могут считываться
последовательно, но при загрузке очередного кортежа необходимо принять следующие решения:
1) если кортеж ранее не встречался, его надлежит скопировать в выходной буфер;
2) если аналогичный кортеж прежде уже загружался, его следует игнорировать.
Чтобы реализовать подобные требования, достаточно, как показано на рис. 15.6,
обеспечить хранение в оперативной памяти каждого уникального считанного кортежа.
Один (входной) буфер используется для хранения "текущего" загруженного блока
с данными отношения R, а оставшиеся М - 1 буферов — для содержания копий всех
ранее просмотренных уникальных кортежей.
694
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Дополнительные буферы способствуют ускорению операций
Хотя для операций, предусматривающих необходимость поочередной загрузки
кортежей, достаточно, как показано на рис. 15.5, наличия только одного
входного и одного выходного буферов, производительность процесса зачастую
удается увеличить, если выделить большее количество входных буферов. Подобную
мысль мы впервые высказывали в разделе 11.5.1 на с. 519. Если данные
отношения R хранятся в последовательно расположенных блоках цилиндров, в буферы
можно загрузить содержимое целого цилиндра, на что придется затратить только
по одному периоду времени поиска и времени оборота диска. Аналогично, если
результат операции записывается в виде полных цилиндров, это тем более
обеспечивает существенную экономию времени.
Входной
буфер
М -1 буферов
Выходной
буфер
Рис. 15.6. Распределение памяти при выполнении
однопроходного удаления кортежей-дубликатов
К вопросу выбора структуры данных, предназначенной для хранения ранее
встречавшихся кортежей, надлежит подходить весьма взвешенно. Используя
наиболее простой и прямолинейный подход, можно размещать кортежи в обычном
списке. Тогда после считывания очередного кортежа R придется сопоставить его
со всеми кортежами, присутствующими в списке, и, если новый кортеж уникален,
сохранить его копии в выходном буфере и в списке. Если принять, что список
содержит п ранее просмотренных кортежей, для обработки очередного кортежа
потребуется период, пропорциональный значению п, а полное время выполнения
операции составит п2 единиц. Поскольку значение п может оказаться весьма большим,
факт соизмеримости затрат времени на обработку данных в памяти с величиной п2
заставляет усомниться в правильности ранее принятого постулата о том, будто
определяющим параметром трудоемкости алгоритма служит количество
предусматриваемых им операций дискового ввода-вывода. Поэтому для хранения кортежей
в памяти желательно применять такую структуру данных, которая позволяет
выполнять операции просмотра списка ранее загруженных кортежей и добавления
нового кортежа за время, близкое к постоянному и не зависящее от числа
кортежей, присутствующих в буферах памяти. Известно большое количество структур,
подходящих для решения задачи. Например, можно воспользоваться хеш-
таблицей с большим количеством сегментов или некоторой разновидностью сба-
15.2. ОДНОПРОХОДНЫЕ АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ
695
лансированного бинарного дерева поиска.98 Применение каждой из таких
структур сопряжено, правда, с дополнительными расходами памяти: например, хеш-
таблицы требуют наличия массива сегментов и областей для хранения указателей,
адресующих кортежи в сегменте. Подобные расходы, однако, несоизмеримо малы
с теми, которые обусловлены необходимостью хранения кортежей как таковых.
Поэтому вполне правомочно упростить анализ, полагая, что дополнительных
затрат нет вовсе, и сосредоточить внимание только на том, какой объем
оперативной памяти требуется для хранения содержимого отношения R.
В М - 1 буферах оперативной памяти можно расположить столько кортежей /?,
сколько умещается в М - 1 блоках. Чтобы в памяти удалось сохранить каждый
уникальный кортеж /?, значение #(#(/?)) не должно превышать М- 1. Поскольку можно
полагать, что М намного превосходит 1, уместно упростить оценку следующим образом:
• B(S(R))<M.
Заметьте, что, вообще говоря, нельзя определить размер S(R), не вычислив само
выражение S(R). Если мы недооценим величину S(R) и она в действительности окажется большей
М, это повлечет серьезные издержки, связанные с необходимостью частого "сбрасывания"
блоков с отобранными уникальными кортежами на диск и их повторной загрузки.
Группирование
Оператор группирования yL задает список L, представляющий нуль или большее
количество группирующих атрибутов (grouping attributes) и один или несколько
агрегируемых атрибутов (aggregated attributes) (см. раздел 5.4.4 на с. 235). Если в
оперативной памяти создается по одному элементу для каждой группы — т.е. для каждого
набора значений группирующих атрибутов, — кортежи отношения R можно сканировать
последовательно, по одному блоку в каждый момент времени. Элемент (entry) для
группы состоит из значений группирующих атрибутов и аккумулируемых значений
для каждого агрегируемого атрибута. Алгоритмы накопления значений, за
исключением одного случая, достаточно очевидны.
• Для функций MiN(a) и мах (а) — сравнить значение компонента атрибута а
загруженного кортежа с хранимым минимальным (максимальным) значением;
если текущее значение а меньше (больше) минимального (максимального),
сохранить его в виде минимального (максимального) значения.
• Для функции count — увеличить значение счетчика на единицу для каждого
кортежа, относящегося к рассматриваемой группе.
• Для функции sum (а) — прибавить значение компонента атрибута а
загруженного кортежа к накапливаемой сумме значений а группы.
• Процесс вычисления функции AVG(a) более сложен. Требуется поддерживать
два аккумулируемых значения — счетчик количества кортежей в группе и
сумму значений компонентов а этих кортежей. Каждое из значений вычисляется
так, как указано выше в описании агрегирующих функций count и sum coot-
98 За информацией о подобных структурах данных, ориентированных на обработку
информации в оперативной памяти, обращайтесь, скажем, к книге Aho A.V., Hopcroft J.E., and Ull-
man J.D. Data Structures and Algorithms, Addison-Wesley, Reading, MA, 1984. [Имеется перевод:
Ахо А., ХопкрофтДж., Ульман Дж. Структуры данных и алгоритмы.— М.: Издательский дом
"Вильяме", 2000.] В частности, для обработки п элементов данных с использованием методов
хеширования требуется в среднем 0(п) единиц времени, а трудоемкость алгоритмов,
основанных на модели сбалансированных деревьев, пропорциональна 0(n\ogn). Вторую зависимость
в данном случае можно считать близкой к линейной.
696
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
ветственно. После того как все кортежи R загружены, следует получить частное
от деления суммы на содержимое счетчика.
По завершении считывания всех кортежей отношения R во входной буфер и
вычисления агрегируемых значений для групп результат оформляется в виде отношения,
содержащего по одному кортежу для каждой из групп. Заметьте, что до тех пор, пока
не обработан последний исходный кортеж, итог выполнения оператора у получить
нельзя. Следовательно, рассмотренные алгоритмы не вполне соответствуют модели
итератора (см. раздел 15.1.6 на с. 689): основная обязанность возлагается на функцию
Open, которая должна осуществить полное группирование прежде, чем функция
GetNext сможет извлечь первый кортеж.
Для повышения эффективности обработки кортежей в оперативной памяти
необходимо использовать структуру данных, позволяющую находить элемент для каждой
группы по заданным значениям группирующих атрибутов. Как и в рассмотренной
выше ситуации, связанной с выполнением оператора S, для этой цели подойдут
общеупотребительные структуры данных, ориентированные на обработку информации
в оперативной памяти, — такие как хеш-таблицы или сбалансированные деревья
поиска. Однако следует помнить, что роль ключа поиска в версиях структур,
применяемых в подобных случаях, могут выполнять только группирующие атрибуты.
Количество операций дискового ввода-вывода, подлежащих выполнению при
использовании рассматриваемых однопроходных алгоритмов, оценивается величиной В
(как и должно быть для любого однопроходного алгоритма, реализующего унарный
оператор). Между количеством требуемых буферов памяти (М) и значением В какой-либо
простой зависимости не существует, хотя обычно М меньше В. Проблема состоит в том,
что элементы рля групп могут оказаться более короткими или более протяженными,
нежели кортежи /?, а количество групп способно исчисляться любым значением, не большим
количества кортежей R. Впрочем, на практике размер элементов групп, как правило, не
превосходит длину кортежей, а количество групп намного меньше числа кортежей.
15.2.3. Однопроходные алгоритмы для бинарных операций над полными
отношениями
Здесь мы рассмотрим, как выполняются бинарные операции — объединение (union),
пересечение (intersection), разность (difference), декартово произведение (Cartesian
product) и соединение (join). Поскольку в определенных случаях следует различать версии
операторов, предназначенные для работы с множествами (sets) и мультимножествами
(bags), в обозначениях операторов будут применяться соответствующие подстрочные
индексы — S для операций над множествами и В — над мультимножествами: так,
например, \JB — это объединение мультимножеств, а -5 — разность множеств. Чтобы
упростить обсуждение особенностей выполнения операций соединения, мы
сосредоточим внимание только на операторе естественного соединения (natural join).
Соединение посредством равенства (equijoin) может быть реализовано тем же образом, после
соответствующего переименования атрибутов, а процедуры тета-соединения (theta-
join) сводятся к операциям декартова произведения или соединения посредством
равенства, сопровождаемым операцией выбора кортежей в соответствии с условиями,
которые не могут быть выражены в форме соединения посредством равенства.
Для вычисления объединения мультимножеств может быть использован весьма
простой однопроходный алгоритм. Чтобы определить результат R{JBS, достаточно, как было
показано в примере 15.3 на с. 691, скопировать в выходной буфер каждый кортеж
отношения /?, а затем все кортежи отношения S. Количество операций дискового ввода-вывода
в этом случае, что совершенно очевидно, определяется величиной B(R) + B(S), а расход
ресурсов памяти оценивается значением М - 1, которое не зависит от размеров R и S.
15.2. ОДНОПРОХОДНЫЕ АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ
697
Операции над некомпактными данными
Напомним, что все приводимые нами выкладки, касающиеся количества операций
дискового ввода-вывода, требуемых для выполнения того или иного физического
оператора, основаны на предположении о том, что содержимое отношений,
служащих аргументами операции, компактно сгруппировано (clustered). В тех (как правило,
редких) случаях, когда содержимое отношения R располагается на диске
некомпактно, для его считывания потребуется выполнить не #(/?), a T(R) операций ввода-вывода.
Заметим, однако, что любое отношение, являющееся результатом работы некоторого
оператора, можно трактовать как компактно сгруппированное, поскольку нет
никаких оснований сохранять промежуточные итоги, что называется, "как попало".
Для реализации других бинарных операций требуется считать в буферы
оперативной памяти содержимое меньшего из операндов R и S и сконструировать подходящую
структуру данных (см. раздел 15.2.2), обеспечивающую быструю вставку кортежей
и их эффективный поиск. Как и прежде, наиболее удачными альтернативами
оказываются хеш-таблицы и сбалансированные деревья поиска. Помимо пространства для
хранения кортежей, структуры требуют небольших затрат памяти для служебных
целей — этим обстоятельством обычно можно пренебречь. Дабы бинарная операция над
отношениями R и S могла быть реализована посредством однопроходного алгоритма,
должно выполняться следующее условие:
• min (#(/?), B(S)) < М.
Правило подразумевает, что один буфер потребуется для считывания блоков более
крупного отношения, в то время как приблизительно М буферов необходимы для
сохранения в памяти содержимого меньшего отношения и поддержания
соответствующей ему структуры данных.
Теперь обсудим особенности отдельных операторов. Во всех случаях будем
полагать, что R — более крупное из двух отношений, a S (меньшее отношение) подлежит
загрузке в память целиком.
Объединение множеств
Содержимое S считывается в М - 1 буферов оперативной памяти, и конструируется
структура данных, ключом поиска которой является целый кортеж. Копии всех
кортежей S также направляются в итоговое отношение. Затем блоки отношения R по
очереди загружаются в М-й буфер. Для каждого кортежа t отношения R проверяется,
существует ли аналогичный кортеж в S. Если ответ отрицателен, кортеж t включается
в итоговое отношение; в противном случае t пропускается.
Пересечение множеств
Как и при объединении множеств, содержимое S загружается в М-1 буферов,
и создается структура данных, значениями ключа поиска которой являются полные
кортежи. Блоки R последовательно считываются в оставшийся буфер, и для каждого
кортежа / отношения R проверяется, существует ли t в S; если да, t копируется в
итоговое отношение; иначе t игнорируется.
Разность множеств
Поскольку оператор разности не коммутативен, выражения R-SS и S-SR надлежит
различать (мы по-прежнему полагаем, что R — более крупное из двух отношений).
В обоих случаях содержимое S считывается в М -1 буферов, и конструируется
структура данных, ключом поиска которой является целый кортеж.
698
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Для вычисления R-SS считывается каждый блок R и проверяется наличие
кортежей t отношения R в S\ если кортеж t присутствует в S, он пропускается; в противном
случае / направляется в итоговое отношение.
В процессе вычисления S-SR, как и прежде, после загрузки очередного блока
отношения R проверяется, существует ли каждый кортеж t в отношении S. Если t
содержится в S, t удаляется из копии S в оперативной памяти; если же t в S нет, никакие
действия не предпринимаются. По завершении просмотра всех кортежей R кортежи S,
оставшиеся в памяти, переносятся в итоговое отношение.
Пересечение мультимножеств
Содержимое отношения S считывается в М-\ буферов оперативной памяти,
и с каждым различным кортежем ассоциируется счетчик количества экземпляров
этого кортежа, присутствующих в 5: вместо одинаковых копий кортежа t сохраняются
его единственный экземпляр и соответствующее значение счетчика.
Если дубликатов немного, подобная структура данных требует несколько большего,
нежели #(£), количества блоков памяти, хотя часто область, отводимую под S, удается
сократить. Поэтому, как и раньше, мы вправе полагать, что B(S) < М является достаточным
(правда, приближенным) условием возможности применения однопроходного алгоритма.
Далее считываются блоки отношения R и для каждого кортежа t проверяется,
существует ли в 5 аналогичный кортеж. Если нет, кортеж t игнорируется — он не может
быть введен в результат пересечения. Если кортеж t присутствует в S и значение
связанного с ним счетчика положительно, t заносится в итоговое отношение и величина
счетчика уменьшается на единицу. Наконец, если t содержится в S, но значение
счетчика достигло нуля, t более не рассматривается — в итоговое отношение уже
включено такое количество копий кортежа t, какое наличествует в S.
Разность мультимножеств
Для вычисления S -B R по мере загрузки блоков S в оперативную память подсчиты-
вается количество экземпляров каждого различного кортежа S (как и при выполнении
операции пересечения мультимножеств). Затем при считывании блоков R для каждого
кортежа t проверяется, присутствует ли t в S] при утвердительном ответе значение
соответствующего счетчика уменьшается на единицу. В завершение операции в итоговое
отношение включается такое количество экземпляров каждого кортежа, которое равно
положительному значению счетчика.
В процессе вычисления R-bS, как и прежде, в оперативную память загружаются
блоки S и в соответствующих счетчиках фиксируется количество экземпляров каждого
различного кортежа. Значение с счетчика числа копий кортежа / можно воспринимать
как с доводов против включения t в итоговое отношение. Иными словами, по мере
просмотра содержимого отношения R проверяется, существует ли кортеж / в S. Если
нет, / выводится в результат. Если / присутствует в S, анализируется текущее значение
с счетчика. При с = 0 кортеж / переносится в итоговое отношение; если же о 0, / в
результат не включается и значение с уменьшается на единицу.
Декартово произведение
Содержимое отношения S считывается в М- 1 буферов оперативной памяти,
причем применения какой-либо специальной структуры данных не требуется. Затем по
мере загрузки блоков отношения R выполняется сцепление каждого кортежа / с
каждым кортежем S, хранимым в памяти, и объединенные кортежи перенаправляются
в итоговое отношение.
Алгоритм требует значительных затрат процессорного времени на сцепление кортежей
R с каждым из кортежей S, занимающих М -1 буферов, но поскольку итоговое
отношение велико, удельная стоимость каждой операции сцепления остается приемлемой.
15.2. ОДНОПРОХОДНЫЕ АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ
699
Как быть, если объем доступной памяти заранее не известен?
До сих пор, рассматривая алгоритмы выполнения физических операторов, мы
считали, что величина М, представляющая количество свободных блоков оперативной
памяти, фиксирована и загодя определена, хотя на практике точное значение М чаще
всего предсказать нельзя (разумеется, этот вывод не распространяется на самые
грубые и очевидные оценки, связанные, скажем, с общим объемом чипов памяти,
которыми оснащен конкретный компьютер). Поэтому оптимизатор запросов,
осуществляя выбор между однопроходной и двухпроходной версиями алгоритма, обязан
оценить значение М. Если оценка окажется чересчур завышенной или чрезмерно
заниженной, это приведет к необходимости "сбрасывания" буферов на диск с их
повторным считыванием либо к выполнению ненужных проходов соответственно.
Существует ряд алгоритмов, способных изящно приспосабливаться к ситуации
нехватки памяти. Например, вначале, когда памяти достаточно, такие алгоритмы
действуют в соответствии с однопроходной схемой, а затем, если свободное
пространство памяти исчерпывается, начинают работать как двухпроходные. Некоторые
из подобных подходов обсуждаются в разделах 15.5.6 на с. 721 и 15.7.3 на с. 735.
Естественное соединение
При рассмотрении этого и других алгоритмов, реализующих операции соединения,
будем полагать, что соединению подлежат отношения R(X, Y) и S(Y, Z), где Y
представляет все атрибуты, общие для R и S, X соответствует атрибутам /?, отсутствующим
в схеме S, a Z — атрибутам S, которых нет в схеме R. Пусть, как и
прежде, S является меньшим из двух отношений. Для вычисления оператора
естественного соединения надлежит выполнить следующие действия.
1. Загрузить все кортежи отношения S и сформировать в оперативной памяти
структуру, ключ поиска которой образуют атрибуты Y (как и в других случаях,
удачными примерами таких структур являются хеш-таблица или
сбалансированное дерево поиска). Использовать для этих целей М-\ блоков памяти.
2. Последовательно считывать блоки отношения R в оставшийся буфер памяти
и с помощью поисковой структуры для каждого кортежа / из R находить
кортежи S, совпадающие с / во всех атрибутах К; формировать на основе каждой
пары согласующихся кортежей новый соединенный кортеж и перемещать его
в итоговое отношение.
Как и всем другим однопроходным алгоритмам, реализующим бинарные операции, для
загрузки содержимого отношений-операндов рассмотренному алгоритму понадобится
выполнить B(R) + B(S) операций дискового ввода-вывода и израсходовать B(S)<M- 1 (или
приблизительно B(S) < М) блоков памяти. Как и прежде, здесь не учитываются
дополнительные затраты памяти, связанные с поддержкой поисковой структуры данных.
Мы не будем подробно рассматривать другие разновидности операций соединения.
Достаточно напомнить, что соединение посредством равенства (equijoin) может быть
реализовано тем же образом, что и естественное соединение, с учетом возможности
переименования "приравниваемых" атрибутов, а процедуры тета-соединения (theta-join) с
условиями, выходящими за рамки равенств, сводятся к операциям декартова произведения
или соединения посредством равенства, сопровождаемым операцией выбора кортежей.
15.2.4. Упражнения к разделу 15.2
Упражнение 15.2.1. Для каждой из указанных операций сконструируйте итератор,
реализующий один из рассмотренных выше алгоритмов:
700
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
* а) проекция (я);
* b) удаление кортежей-дубликатов (S);
с) группирование (yL);
* d) объединение множеств (Us);
e) пересечение множеств (П$);
О разность множеств (-5);
g) пересечение мультимножеств (Пя);
h) разность мультимножеств (-в);
[) декартово произведение (х);
j) естественное соединение (х).
Упражнение 15.2.2. Для каждого из операторов, перечисленных в упражнении
15.2.1, ответьте на вопрос, является ли оператор блокирующим (blocking) (имеется
в виду, что никакая часть итогового отношения не может быть получена до тех
пор, пока не будет целиком загружено содержимое операндов). Другими словами,
в любой допустимой реализации блокирующего оператора посредством схемы
итератора основные обязанности должны возлагаться на функцию Open.
Упражнение 15.2.3. На рис. 15.9 (см. с. 705) представлена суммарная информация
о требованиях относительно количества необходимых операций дискового ввода-
вывода и объема свободной оперативной памяти, выдвигаемых алгоритмами,
которые исследованы в этом и следующем разделах. Подразумевается, однако, что
содержимое отношений-операндов является компактно сгруппированным (clustered).
Как изменятся оценки, если один или оба аргумента окажутся некомпактными?
! Упражнение 15.2.4. Предложите варианты однопроходных алгоритмов,
реализующих каждую из перечисленных ниже версий оператора соединения:
* a) RxS, причем R умещается в памяти (определение оператора полусоединения
(sernijoin) приведено в упражнении 5.2.10 на с. 225);
* b) RxS, S умещается в памяти;
c) RxS, R умещается в памяти (определение оператора обратного
полусоединения (antisemijoin) приведено в упражнении 5.2.11 на с. 225);
d) RxS, S умещается в памяти;
* е) RxLS, R умещается в памяти (определения версий оператора внешнего
соединения (outerjoin) приведены в разделе 5.4.7 на с.238);
f) R xL S, S умещается в памяти;
g) RxRS, R умещается в памяти;
h) R xR S, S умещается в памяти;
i) Rx S, R умещается в памяти.
15.2. ОДНОПРОХОДНЫЕ АЛГОРИТМЫ ОБРАБОТКИ ДАННЫХ
701
15.3. Реализация соединений посредством вложенных циклов
Перед тем как приступить к изучению более сложных алгоритмов, обратим
внимание на семейство алгоритмов, реализующих операторы соединения посредством
вложенных циклов (nested-loop join). Подобные алгоритмы по существу выполняются за
"полтора" прохода, поскольку кортежи одного из отношений-аргументов считываются
один раз, а загрузка содержимого другого отношения производится дважды.
Алгоритмы, обеспечивающие выполнение операции соединения с помощью вложенных
циклов, применимы к отношениям любого размера и не предусматривают обязательного
условия, в соответствии с которым по меньшей мере одно из отношений должно
умещаться в оперативной памяти.
15.3.1. Соединение посредством вложенных циклов с загрузкой отдельных кортежей
Простейший вариант алгоритма соединения с помощью вложенных циклов
предусматривает циклическое обращение к отдельным кортежам отношений, вовлеченных
в операцию (tuple-based nested-loop join). Подобный алгоритм позволяет вычислить
результат соединения R(Xy Y)txS(Y,Z) следующим образом:
FOR (ДЛЯ) каждого кортежа s отношения S (ВЫПОЛНИТЬ) DO
FOR (ДЛЯ) каждого кортежа г отношения R (ВЫПОЛНИТЬ) DO
IF (ЕСЛИ) г и s допускают соединение
с образованием кортежа t (ТОГДА) THEN
Включить t в итоговое отношение;
Если не позаботиться о надлежащей буферизации блоков отношений R и S, алгоритм
потребует выполнения T(R)T(S) операций дискового ввода-вывода. Во многих случаях,
однако, затраты удается существенно снизить за счет соответствующей модификации
схемы вычислений. Одним из примеров подобных ситуаций является возможность
использования индекса для атрибутов Y отношения /?, который позволяет находить
кортежи R, согласующиеся с заданным кортежем S, не требуя просмотра всего отношения R.
Версии алгоритма соединения на основе индексирования (index-based join) обсуждаются
в разделе 15.6.3 на с. 728. Другой вариант повышения производительности алгоритма
связан с загрузкой кортежей отношений R и S в виде блоков и использованием всей
доступной области памяти, что приводит к снижению количества дисковых операций при
выполнении внутреннего цикла. Алгоритм соединения посредством вложенных циклов
с загрузкой блоков данных (block-based nested-loop join) приведен в разделе 15.3.3 на с. 702.
15.3.2. Итератор для соединения посредством вложенных циклов с загрузкой
отдельных кортежей
Одно из преимуществ алгоритмов реализации операторов соединения с помощью
вложенных циклов состоит в том, что такие алгоритмы удачно укладываются в схему
итераторов и поэтому, как будет показано в разделе 16.7.3 на с. 825, в определенных
ситуациях позволяют избежать необходимости сохранения промежуточных результатов на
диске. Итератор для RtxS легко сконструировать на основе итераторов для R и S,
поддерживающих функции Open, GetNext и Close, рассмотренные в разделе 15.1.6 на
с. 689. Код соответствующих функдий итератора, реализующего операцию соединения
посредством вложенных циклов, представлен на рис. 15.7. Мы полагаем, что ни одно
из отношений R и S не является пустым.
15.3.3. Соединение посредством вложенных циклов с загрузкой блоков данных
Рассмотренный в разделе 15.3.1 на с. 702 алгоритм соединения посредством
вложенных циклов с загрузкой отдельных кортежей (tuple-based nested-loop join) поддается
улучшению, если при вычислении оператора RtxS
702
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Open() {
R.Open();
S.Open();
s := S.GetNextO ;
}
GetNextO {
REPEAT {
r := R.GetNextO ;
IF (r = NotFound) { /* Содержимое R исчерпано
для текущего s */
R.CloseO ;
s := S.GetNextO ;
IF (s = NotFound) RETURN NotFound; /* Исчерпаны R и S */
R.Open();
r := R.GetNextO ;
}
}
UNTIL(г и s способны к соединению);
RETURN (соединение г и s) ;
}
Close() {
R. Close() ;
S.Close();
}
Рис. 15.7. Функции итератора для операции соединения отношений R и S посредством
вложенных циклов с загрузкой отдельных кортежей
1) организовать доступ к блокам обоих отношений-операндов;
2) для хранения кортежей отношения S, просматриваемых во внешнем цикле,
использовать всю доступную оперативную память.
Условие, указанное в п. 1, гарантирует, что для загрузки кортежей отношения R во
внутреннем цикле будет применено минимально допустимое количество операций
дискового ввода-вывода. Требование, упомянутое в п. 2, позволяет анализировать
возможность соединения каждого считываемого кортежа R не с одним —
"текущим" — кортежем S, а сразу с таким количеством кортежей S, которые способны
разместиться в свободной области памяти.
Как и в разделе 15.2.3 на с. 697, будем полагать B(S) <B(R), но, помимо того,
допустим, что B(S) > М, т.е. ни одно из двух отношений не может быть загружено в
оперативную память целиком. Содержимое отношения S считывается в буферы памяти
порциями по М-\ блоков. Для кортежей 5, присутствующих в памяти, создается
структура с ключом поиска, охватывающим атрибуты, общие для отношений R и S.
Далее в оставшийся буфер последовательно загружаются все блоки R, и на каждом
шаге процедуры все кортежи "текущего" блока R сопоставляются с кортежами из
блоков S, наличествующих в памяти. Для кортежей R и S, способных к соединению,
создается соединенный кортеж, который выводится в итоговое отношение. Структура
вложенных циклов алгоритма в формализованном виде описана на рис. 15.8.
Текст, приведенный на рис. 15.8, как кажется, содержит три вложенных цикла.
Однако, если взглянуть на код под более "правильным" углом зрения, основных
циклов на самом деле два. Внешний цикл описывает процесс загрузки содержимого
отношения S. Два вложенных цикла предполагают просмотр кортежей отношения R.
Мы используем именно два цикла с той целью, дабы подчеркнуть, что порядок
обращения к кортежам R не является произвольным: первый внутренний цикл указывает,
15.3. РЕАЛИЗАЦИЯ СОЕДИНЕНИЙ ПОСРЕДСТВОМ ВЛОЖЕННЫХ ЦИКЛОВ 703
что кортежи R загружаются в память блоками, а второй свидетельствует, что до
перехода к следующему блоку R все кортежи текущего блока R должны быть просмотрены
и сопоставлены со всеми кортежами порции содержимого отношения S,
присутствующей в памяти в данный момент.
FOR (ДЛЯ) каждой порции из М-\ блоков отношения S (ВЫПОЛНИТЬ) DO
BEGIN
Загрузить порцию блоков в буферы оперативной памяти;
сохранить кортежи в виде структуры с ключом поиска,
охватывающим атрибуты, общие для R и S;
FOR (ДЛЯ) каждого блока b отношения R (ВЫПОЛНИТЬ) DO BEGIN
Загрузить блок в буфер оперативной памяти;
FOR (ДЛЯ) каждого кортежа t блока b (ВЫПОЛНИТЬ) DO BEGIN
Найти в буферах памяти все кортежи 5,
пригодные для соединения с /;
включить в итоговое отношение все соединенные кортежи;
END;
END;
END;
Рис. 15.8. Алгоритм соединения посредством вложенных циклов с загрузкой блоков данных
Пример 15.4. Пусть #(/0=1000, Д5) = 500 и М=101. Предположим, что содержимое
отношения S зафужается в буферы оперативной памяти порциями по 100 блоков, так что
при использовании алгоритма, приведенного на рис. 15.8, потребуется выполнить пять
итераций внешнего цикла. На каждой итерации для считывания порции данных S
необходимо произвести 100 операций дискового ввода-вывода, а во внутреннем цикле
посредством 1000 дисковых операций надлежит полностью загрузить данные отношения R.
Таким образом, общее количество операций дискового ввода-вывода составит 5500.
Если отношения R и S поменять местами, т.е. во внешнем цикле считывать порции
содержимого R, a во внутреннем — блоки S, число дисковых операций возрастет до 6000:
на каждой из десяти итераций внешнего цикла придется выполнять по 600 операций.
Вообще говоря, подход, в соответствии с которым во внешнем цикле считываются
данные менее крупного отношения, обладает определенным преимуществом. □
Алгоритм соединения с загрузкой блоков данных (block-based nested-loop join) является
наиболее популярной разновидностью схемы соединения посредством вложенных циклов.
15.3.4. Анализ алгоритмов соединения посредством вложенных циклов
Выводы, полученные в примере 15.4, нетрудно распространить в применении
к произвольным величинам B(R), B(S) и М. Если S является меньшим из двух
отношений, количество порций данных S, или итераций внешнего цикла, равно B{S) I (М- 1).
На каждой итерации подлежат загрузке М - 1 блоков S и B(R) блоков R. Поэтому общее
количество операций дискового ввода-вывода составит (B(S) / (М- 1))(м- 1 + #(/?)),
или B(S) + B(S)B(R) I (M - 1). Если принять, что значения М, B(S) и B(R) велики и М
является наименьшим из них, полученную оценку можно свести к более простой
приближенной формуле B(S)B(R) IM. Другими словами, трудоемкость операции
пропорциональна произведению размеров отношений, деленному на значение объема
доступной оперативной памяти. Если оба отношения слишком велики, иные алгоритмы
соединения способны обеспечить более высокую производительность. Но для
небольших экземпляров отношений, подобных рассмотренным в примере 15.4,
стоимость соединения посредством вложенных циклов не намного выше затрат,
предусматриваемых однопроходным алгоритмом соединения (см. раздел 15.2.3 на с. 697):
704
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
при использовании последнего в применении к данным примера 15.4 необходимо
осуществить 1500 операций дискового ввода-вывода. Если же B(S) < М- 1,
производительность обоих алгоритмов соединения уравнивается.
Хотя алгоритм соединения посредством вложенных циклов нельзя считать
наиболее удачным вариантом реализации соединения, уместно заметить, что в некоторых
ранних образцах реляционных СУБД он был единственным доступным средством
и даже сегодня в некоторых ситуациях (например, когда одно значение атрибута, по
которому осуществляется соединение, является общим для большого количества
кортежей обоих отношений-операндов) используется в виде подпрограммы более
эффективными алгоритмами соединения. Пример, иллюстрирующий важность алгоритма
соединения посредством вложенных циклов, приведен в разделе 15.4.5 на с. 712.
15.3.5. Сводка характеристик однопроходных и циклических алгоритмов
Требования к объему ресурса свободной оперативной памяти и количеству
операций дискового ввода-вывода, предъявляемые алгоритмами, которые рассмотрены
в разделах 15.2 (см. с. 692) и 15.3, суммированы в таблице, показанной на рис. 15.9.
Оценки объемов памяти, необходимой для работы алгоритмов, реализующих
операторы у и 8, на самом деле более сложны, и М - В — это только довольно грубое
приближение: для /значение М увеличивается с возрастанием количества групп, а для 8 —
с расширением множества различных кортежей.
Операторы
<т, к
Ъ*
U, П, -, х, tx
X
Оценка объема
памяти в единицах М
1
В
min (#(/?), B{S))
любое М > 2
Оценка количества
дисковых операций
В
В
B(R) + B(S)
B(R)B(S) 1М
Номер
раздела книги
15.2.1
15.2.2
15.2.3
15.3.3
Номер
страницы
693
694
697
702
Рис. 15.9. Оценки затрат ресурсов памяти и дисковых операций для однопроходных
алгоритмов и алгоритмов на основе вложенных циклов
15.3.6. Упражнения к разделу 15.3
Упражнение 15.3.1. Предложите варианты трех функций итератора, реализующего
версию алгоритма соединения посредством вложенных циклов с загрузкой блоков данных.
* Упражнение 15.3.2. Пусть B(R) = B(S)= 10000 и М- 1000. Вычислите количество
операций дискового ввода-вывода, требуемых для выполнения соединения
содержимого отношений R n S посредством вложенных циклов.
Упражнение 15.3.3. Какое значение М окажется достаточным для вычисления
соединения содержимого отношений R и S, удовлетворяющих условиям упражнения
15.3.2, посредством вложенных циклов, если количество дисковых операций не
должно превышать а) 100000; !Ь) 25000; !с) 15000?
! Упражнение 15.3.4. Если содержимое отношений R и S хранится не компактно,
в первом приближении можно полагать, что алгоритм соединения посредством
вложенных циклов потребует выполнения около T(R)T(S) I M операций
дискового ввода-вывода.
а) Каким образом удастся значительно уменьшить эти затраты?
15.3. РЕАЛИЗАЦИЯ СОЕДИНЕНИЙ ПОСРЕДСТВОМ ВЛОЖЕННЫХ ЦИКЛОВ 705
b) Если одно из двух отношений не является компактным, как надлежит
осуществлять их соединение посредством вложенных циклов? Исследуйте оба
случая, когда некомпактно большее (меньшее) отношение.
! Упражнение 15.3.5. Итератор, текст которого приведен на рис. 15.7 (см. с. 703), не
действует должным образом, если любое из отношений R и S пусто. Перепишите
функции итератора так, чтобы тот смог работать в ситуации, когда одно или оба
отношения являются пустыми.
15.4. Двухпроходные алгоритмы, основанные на сортировке
Теперь приступим к изучению многопроходных алгоритмов (multipass algorithms),
предназначенных для реализации операторов реляционной алгебры в условиях, когда
отношения-операнды настолько велики, что не могут быть обработаны с помощью
однопроходных алгоритмов, рассмотренных в разделе 15.2 на с. 692. Мы сосредоточим
усилия на двухпроходных алгоритмах (two-pass algorithms), предусматривающих
загрузку содержимого отношений-аргументов в оперативную память, определенные
действия по обработке данных в памяти, сохранение их на диске и повторное считывание
с диска с целью завершения операции. Схему нетрудно распространить на
произвольное количество проходов, при выполнении которых данные сохраняются на диске
и загружаются в оперативную память многократно. Впрочем, вполне уместно
ограничить внимание двухпроходными версиями алгоритмов, поскольку:
1) выполнения двух проходов обычно достаточно для обработки даже весьма
крупных отношений;
2) обобщение выкладок и оценок на случай нескольких проходов довольно
прозрачно (за подробностями обращайтесь к разделу 15.8 на с. 738).
В этом разделе механизм сортировки рассматривается как средство реализации
операций над отношениями. Основная идея такова. Если размер B(R) отношения R
превышает количество М доступных буферов оперативной памяти, надлежит
циклически выполнять следующие действия:
1) загрузить М блоков отношения R в оперативную память;
2) упорядочить содержимое считанных блоков в памяти, используя один из
эффективных алгоритмов сортировки, на выполнение которого требуется
время, "почти" линейно зависящее от количества кортежей в оперативной
памяти и заведомо меньшее в сравнении с времениыми затратами,
связанными с дисковыми операциями;
3) сохранить отсортированный подсписок в М дисковых блоках.
По завершении первого прохода все алгоритмы, рассматриваемые ниже,
предусматривают применение второго прохода с целью "слияния" отсортированных подсписков
некоторым образом, соответствующим природе оператора.
15.4.1. Алгоритм удаления кортежей-дубликатов
Для выполнения операции 8{R) (удаление кортежей-дубликатов — duplicate
elimination) в два прохода кортежи отношения R распределяются по отсортированным
подспискам так, как указано выше. Затем все доступные буферы оперативной памяти
используются для последовательной загрузки по одному блоку из каждого подсписка
(аналогичные действия предусматриваются алгоритмом сортировки двухфазным
многокомпонентным слиянием — см. раздел 11.4.4 на с. 513). Однако вместо сортировки
кортежей, считываемых из подсписков, каждый уникальный кортеж копируется
в итоговое отношение, а другие идентичные кортежи игнорируются. Процесс
схематически проиллюстрирован на рис. 15.10.
706
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Отсортированные
подсписки
с кортежами R
М буферов
Те же М буферов
Рис. 15.10. Двухпроходный алгоритм удаления
кортежей-дубликатов
Если говорить более формально, просматриваются первые кортежи каждого блока
и среди них отыскивается первый (скажем, t) в порядке сортировки. Одна копия t
перенаправляется в итоговое отношение, а остальные удаляются из блоков подсписков.
Если в этот момент некоторый блок исчерпывается, в буфер считывается очередной
блок того же подсписка; если во вновь загруженном блоке существуют экземпляры
кортежа t, они также удаляются.
Пример 15.5. Для простоты предположим, что кортеж отношения R состоит из
компонента единственного целочисленного атрибута, и в блок умещаются только два
кортежа. Пусть также М = 3, т.е. свободная область памяти ограничена тремя блоками.
Рассмотрим экземпляр R, содержащий 17 кортежей:
2,5,2, 1,2,2,4,5,4,3,4,2, 1,5,2, 1,3
Вначале первые шесть кортежей считываются в три буфера памяти, сортируются и
сохраняются на диске в виде подсписка R{. Затем аналогичным образом загружаются,
сортируются и записываются на диск кортежи с 7-го по 12-й, образующие подсписок
R2. Наконец, те же действия с последними пятью кортежами приводят к получению
отсортированного подсписка R3.
Второй проход начинается с загрузки в оперативную память первого блока (двух
кортежей) каждого из трех подсписков. Схема распределения данных выглядит так:
Подсписок
tff.
R2:
R3:
В памяти
1 2
23
1 1
На диске
2 2, 2 5
4 4, 4 5
2 3,5
При проверке первых кортежей трех блоков памяти обнаруживается, что 1 —
это первый кортеж, соответствующий порядку сортировки. Одна копия
кортежа 1 выводится в итоговое отношение, а все остальные удаляются из блоков
памяти. В процессе удаления блок подсписка R3 исчерпывается, поэтому в память
загружается следующий блок этого подсписка, содержащий кортежи 2 и 3. (Если
бы среди загруженных оказались кортежи 1, их, разумеется, пришлось бы также
удалить.) Теперь ситуация такова:
15.4. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА СОРТИРОВКЕ
707
Подсписок
Я,:
Я2:
Я3:
В памяти
2
2 3
2 3
На диске
2 2, 2 5
4 4, 4 5
5
В начале каждого из блоков в памяти располагаются кортежи 2. Одна копия
кортежа сохраняется в итоговом отношении, а другие удаляются. Блок подсписка RY
истощается, и поэтому в память считывается следующий блок того же подсписка.
Новый блок целиком состоит из кортежей 2, подлежащих удалению, так что и он быстро
исчерпывается. Загружается третий блок подсписка R{; в нем также присутствует
кортеж 2, который требуется удалить. В результате мы приходим к следующей схеме:
Подсписок
Я,:
R2:
Я3:
В памяти
5
3
3
На диске
4 4, 4 5
5
Сейчас уже наименьшим кортежем, отвечающим порядку сортировки, является
кортеж 3, одна копия которого включается в итоговое отношение, а другая удаляется. При
этом блоки подсписков R2 и Я3 оказываются пустыми — с диска загружаются новые блоки:
Подсписок
Я,:
Я2:
Я3:
В памяти
5
44
5
На диске
45
При выборе кортежа 4 изымается большая часть подсписка Я2. Теперь каждый блок
включает по кортежу 5, один из которых выводится в итоговое отношение, а два других
удаляются. Списки исчерпаны, и операция завершена — ее результат очевиден. □
Суммарное количество операций дискового ввода-вывода, выполняемых в
процессе работы алгоритма, состоит (как всегда, без учета затрат на формирование итогового
отношения) из следующих компонентов:
1) B(R) — загрузка блоков Я при создании отсортированных подсписков;
2) B(R) — сохранение содержимого подсписков на диске;
3) B(R) — считывание блоков по мере формирования итогового отношения.
Таким образом, общая трудоемкость двухпроходного алгоритма удаления кортежей-
дубликатов составляет 3#(Я) против B(R) для однопроходной версии, рассмотренной
в разделе 15.2.2 на с. 694.
С другой стороны, двухпроходный алгоритм позволяет обрабатывать существенно
более крупные файлы, нежели однопроходный. Если доступны М блоков оперативной
памяти, можно создать отсортированные подсписки, каждый из которых состоит из М
блоков. При выполнении второго прохода требуется хранить в памяти по одному
блоку каждого подсписка, так что подсписков может быть не более М. Поэтому при
использовании двухпроходного алгоритма затраты памяти оцениваются величиной
В<М2 (напомним, что аналогичная оценка для однопроходного алгоритма выглядит
как В<М). Иными словами, для вычисления S(R) с помощью двухпроходного
алгоритма необходимо наличие только V#(tf) (вместо #(Я)) блоков оперативной памяти.
708
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
15.4.2. Алгоритм группирования и агрегирования
Двухпроходный алгоритм, реализующий операцию yL(R) (группирование —
grouping), достаточно схож с алгоритмом выполнения операции S(R), рассмотренным в
разделе 15.4.1, и может быть описан следующим образом.
1. Загрузить кортежи отношения R в оперативную память порциями по М блоков;
отсортировать каждые М блоков, используя в качестве ключа сортировки
группирующие атрибуты, указанные в списке L; сохранить каждый
отсортированный подсписок на диске.
2. Каждому отсортированному подсписку поставить в соответствие один буфер
памяти и изначально загрузить в буферы первые блоки каждого подсписка.
3. Циклическим образом находить среди первых доступных кортежей в блоках
наименьшее значение v ключа сортировки (группирующих атрибутов),
определяющее очередную группу, для которого:
a) осуществить подготовку к вычислению всех агрегируемых значений для группы
на основе списка L (для определения среднего арифметического, как и в
алгоритме из раздела 15.2.2 на с. 694, использовать накапливаемые счетчик и сумму);
b) просмотреть каждый кортеж с ключом сортировки v и аккумулировать
требуемые агрегируемые значения;
c) при исчерпании буфера загрузить очередной блок того же отсортированного
подсписка.
Если кортежей с ключом сортировки v больше нет, вывести в итоговое
отношение кортеж, состоящий из группирующих атрибутов L и связанных с ними
агрегируемых значений, вычисленных для группы.
Как и для алгоритма, реализующего операцию S, двухпроходный алгоритм
выполнения оператора у требует осуществления 3B(R) операций дискового ввода-вывода
и наличия V#(fi) блоков оперативной памяти.
15.4.3. Алгоритм объединения
Для реализации оператора объединения мультимножеств (bag union) (Us)
необходимость в использовании двухпроходного алгоритма не возникает — однопроходный
алгоритм, рассмотренный в разделе 15.2.3 на с. 697 и предполагающий простое
копирование в итоговое отношение содержимого обоих отношений-операндов, одинаково
хорошо справляется с исходными данными любого объема. Однопроходный алгоритм
для оператора объединения множеств (set union) (Us)» однако, способен работать только
в том случае, когда размер по меньшей мере одного из двух отношений меньше
объема свободной области оперативной памяти. Если указанное ограничение не
удовлетворяется, необходимо, разумеется, прибегнуть к двухпроходной версии алгоритма.
Представленная ниже стратегия, как будет показано в разделе 15.4.4, применима
и при реализации операций пересечения и разности множеств и мультимножеств.
Чтобы вычислить R Us S, достаточно выполнить следующие действия.
1. Считывать в оперативную память содержимое отношения R порциями по М
блоков, сортировать кортежи и сохранять получаемые отсортированные
подсписки на диске.
2. Аналогичным образом создать отсортированные подсписки с кортежами
отношения S.
15.4. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА СОРТИРОВКЕ
709
3. Каждому отсортированному подсписку с данными отношений R и S поставить
в соответствие один буфер памяти и изначально загрузить в буферы первые
блоки каждого подсписка.
4. Циклическим образом находить во всех блоках кортежи t, первые по порядку
сортировки, копировать t в итоговое отношение и удалять из всех блоков копии
/ (если R и S являются множествами, в них, очевидно, может быть не больше
двух экземпляров каждого кортежа t). Если буфер становится пустым, загрузить
в него очередной блок соответствующего подсписка.
Нетрудно убедиться, что каждый кортеж отношений R и S дважды считывается
в оперативную память (при загрузке исходных данных с целью создания подсписков
и в процессе формирования итогового отношения), а также один раз сохраняется на
диске (при формировании соответствующего подсписка). Поэтому затраты, связанные
с выполнением операций дискового ввода-вывода, оцениваются величиной 3 (#(/?) + 5(5)).
Алгоритм способен нормально работать при условии, что общее количество
подсписков с данными отношений R и S не превышает М, поскольку каждому подсписку
отводится один буфер оперативной памяти. Так как каждый подсписок состоит не
более чем из М блоков, это значит, что суммарный размер двух отношений не должен
превосходить М2, т.е. B(R) + B(S) <M2.
15.4.4. Алгоритмы пересечения и разности
Алгоритмы реализации операций пересечения (intersection) и разности (difference) по
существу аналогичны алгоритму объединения (union), рассмотренному в разделе 15.4.3,
и практически не зависят от того, являются отношения множествами или
мультимножествами (единственное различие связано с тем, как обрабатываются копии кортежа t
в головных частях отсортированных подсписков). Во всех случаях выполняются
следующие действия: создать для каждого из отношений-операндов, R и S, отсортированные
подсписки путем считывания порций содержимого отношений по М блоков в каждой,
сортировки данных в памяти и сохранения их на диске; для каждого подсписка использовать
по одному буферу памяти и изначально загрузить в буферы первые блоки подсписков.
Затем во всех блоках циклическим образом отыскиваются кортежи г, первые по
порядку сортировки, и под считывается количество копий t в отношениях R и S. Если
при этом какой-либо блок исчерпывается, в соответствующий буфер загружается
очередной блок того же подсписка. Ниже приведены правила, определяющие, следует ли
включать кортеж t в итоговое отношение, и если да, то сколько раз.
• Для пересечения множеств (R fls S) — вывести кортеж t в итоговое отношение,
если тот присутствует в R и S.
• Для пересечения мультимножеств (R fls S) — включить в результат минимальное
из количеств копий t, содержащихся в двух отношениях. Если значение одного
из двух счетчиков t равно нулю, т.е. кортеж t отсутствует либо в R, либо в S, t
в итоговое отношение не выводить.
• Для разности множеств (R -5 S) — направить кортеж t в итоговое отношение,
если и только если тот наличествует в R, но отсутствует в S.
• Для разности мультимножеств (R -B S) — включить кортеж t в результат столько
раз, каково количество копий t в R за вычетом числа экземпляров / в 5; если
последнее не меньше первого, t в итоговое отношение не выводить.
Пример 15.6. Как и в примере 15.5 на с. 707, будем полагать, что М=3, каждый
кортеж состоит из единственного целочисленного компонента и в блок умещаются два
710
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
кортежа. Позаимствуем из примера 15.5 и данные, но поскольку здесь
рассматриваются операторы с двумя аргументами, допустим, что отношению R принадлежат первые
12 из 17 кортежей, а отношению S — оставшиеся 5 кортежей. Поскольку свободная
область памяти допускает загрузку шести кортежей, на первом проходе получим два
отсортированных подсписка с кортежами отношения R (назовем их RY и R2) и один
подсписок (Si) с содержимым отношения S." После создания подсписков и считывания
в память их первых блоков схема распределения данных выглядит следующим образом:
Подсписок
Я,:
R2:
5,:
В памяти
1 2
23
1 1
На диске
2 2, 2 5
4 4, 4 5
2 3, 5
Пусть требуется вычислить результат операции разности мультимножеств, R-BS.
Первым по порядку сортировки среди кортежей, загруженных в буферы памяти,
является кортеж 1, поэтому надлежит подсчитать количество копий этого кортежа в
подсписках отношений R и S. Нетрудно удостовериться, что кортеж присутствует в одном
экземпляре в подсписке R{ и в двух — в подсписке SY. Поскольку количество копий
кортежа 1 в R не больше, чем в S, ни одна из копий в итоговое отношение не
включается. При подсчете кортежей 1 блок подсписка SY исчерпывается, так что приходится
загрузить следующий блок Sx:
Подсписок
Д,:
R2:
Si:
В памяти
2
2 3
23
На диске
2 2, 2 5
4 4, 4 5
5
Теперь первым по порядку является кортеж 2. При вычислении количества копий
кортежа обнаруживается, что в отношении R их пять (четыре в подсписке RY и одна —
в R2), а в S — одна. Поэтому кортеж 2 выводится в итоговое отношение четыре раза.
По мере подсчета буфер подсписка RY дважды истощается и вновь заполняется:
Подсписок
Rx:
R2:
Si:
В памяти
5
3
3
На диске
4 4, 4 5
5
Далее рассматривается кортеж 3. Отношения R и S содержат по одной копии
кортежа, которые в результат не включаются и просто удаляются из подсписков:
Подсписок
R{:
R2:
Si:
В памяти
5
44
5
На диске
45
99 Поскольку содержимое отношения S может быть считано в оперативную память целиком,
в данном случае уместно было бы прибегнуть к однопроходной версии алгоритма,
рассмотренной в разделе 15.2.3 на с. 697, но мы, преследуя методические цели, тем не менее, обратимся
к двухпроходному алгоритму.
15.4. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА СОРТИРОВКЕ
711
Кортеж 4 наличествует в R в трех экземплярах, а в S отсутствует, поэтому в
результат направляются три копии кортежа 4. Наконец, отношение R содержит две копии
кортежа 5, a S — одну, что дает основание включить кортеж 5 в итоговое отношение
один раз. Общий результат таков: 2, 2, 2, 2, 4, 4, 4, 5. □
Характеристики рассмотренного семейства алгоритмов аналогичны тем, которые
получены в разделе 15.4.3 (см. с. 709) для алгоритма объединения множеств:
• 3 (#(/?) + 5(5)) — количество дисковых операций;
• B(R) + B(S) < M2 — ограничение объема свободной области оперативной памяти.
15.4.5. Простой алгоритм соединения
Существует несколько способов использования механизма сортировки с целью
реализации оператора соединения (sort-based join) крупных отношений. Прежде чем перейти
к описанию конкретных алгоритмов соединения, обсудим одну проблему, присущую
процессу соединения отношений и не характерную для других бинарных операторов,
рассмотренных выше. При вычислении соединения кортежи двух отношений-операндов
с общими значениями совпадающих атрибутов должны присутствовать в оперативной
памяти одновременно, но их объем способен превысить размер свободной области
памяти. Один из "экстремальных" примеров таков: имеется единственный набор
значений совпадающих атрибутов, и каждый кортеж одного отношения подлежит
соединению с каждым кортежем другого отношения. В подобном случае реальной альтернативы
применению алгоритма соединения посредством вложенных циклов не существует.
Чтобы справиться с подобной ситуацией, можно попытаться уменьшить расход
ресурсов оперативной памяти для других элементов алгоритма, предоставив большее
количество буферов для хранения кортежей с определенным значением совпадающего
атрибута. Ниже рассмотрен алгоритм, который предусматривает вьщеление для этой цели
максимально возможного числа буферов. В разделе 15.4.7 на с. 714 представлен другой
алгоритм с использованием механизма сортировки, который предполагает выполнение
меньшего количества операций дискового ввода-вывода, но чреват проблемами, если
кортежей с одинаковым значением совпадающего атрибута оказывается слишком много.
Для соединения отношений R(X, Y) и S(Y, Z) при наличии М блоков свободной
оперативной памяти надлежит выполнить следующие действия.
1. С помощью алгоритма сортировки двухфазным многокомпонентным слиянием
(см. раздел 11.4.4 на с. 513) упорядочить данные отношения R, используя в
качестве ключа сортировки атрибуты Y.
2. Аналогичным образом отсортировать кортежи отношения S.
3. Осуществить слияние содержимого отсортированных отношений R и S,
используя два буфера, по одному для хранения текущих блоков R к S. Циклически
выполнять перечисленные ниже операции.
a) Найти наименьшие значения у совпадающих атрибутов Y среди кортежей
в головных частях блоков R и S, загруженных в буферы памяти.
b) Если у наличествуют в кортежах одного отношения, но отсутствуют в
кортежах другого отношения, удалить кортежи с ключом сортировки у.
c) В противном случае идентифицировать все кортежи с ключом сортировки
у в обоих отношениях. При необходимости загружать новые блоки
отсортированных отношений R и S до тех пор, пока не будут считаны все кортежи
со значениями у (для этой цели предоставляются М буферов памяти).
d) Вывести в итоговое отношение все соединенные кортежи, сформированные
на основе кортежей R n S с общими значениями у атрибутов Y.
e) Если буфер какого-либо отношения исчерпан, загрузить новый блок данных
этого отношения.
712
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Пример 15.7. Обратимся к отношениям R и S из примера 15.4 на с. 704. Напомним,
что под содержимое отношений отводится 1000 и 500 блоков соответственно, а
количество буферов оперативной памяти равно М=101. При использовании алгоритма
сортировки двухфазным многокомпонентным слиянием на каждый блок данных
затрачивается по четыре операции дискового ввода-вывода (по две в каждой из фаз).
Поэтому для сортировки содержимого отношений R и S потребуются 4(#(Я) + 5(5)),
или 6000, дисковых операций.
При слиянии отсортированных отношений R и S с целью отыскания соединяемых
кортежей каждый блок R и S считывается еще один раз, т.е. выполняются
1500 дополнительных операций дискового ввода-вывода. В процессе слияния
используются, вообще говоря, только два из М буферов памяти. Однако при необходимости
для хранения кортежей R и S с общими значениями у совпадающих атрибутов Y могут
быть отведены все буферы. Поэтому ни для одного набора значений у не должно быть
такого количества кортежей, которые занимали бы более М блоков.
Заметим, что суммарное количество дисковых операций, предусматриваемых
рассмотренным алгоритмом, в данном случае составляет 7500 против 5500 (см. пример 5.4),
которые требуются при использовании процедуры соединения посредством вложенных
циклов. Однако алгоритм с применением вложенных циклов, вообще говоря, отличается
квадратичной сложностью, поскольку время его работы соразмерно величине B(R)B(S),
а затраты на выполнение алгоритма, основанного на механизме сортировки,
оцениваются линейной функцией, пропорциональной B(R) + B(S). Циклический алгоритм может
оказаться более предпочтительным (как в нашем примере) только в частных случаях,
когда размеры каждого из отношений лишь в 5—10 раз превышают объем выделенной
области оперативной памяти. Более того, как будет показано в разделе 15.4.7 на с. 714,
обычно оказывается возможным выполнять соединение с помощью сортировки,
используя только з(#(Я) + #(£)) операций дискового ввода-вывода (в нашем случае — 4500, что
заведомо ниже стоимости процедуры соединения посредством вложенных циклов). □
Если количество кортежей с общими значениями у совпадающих атрибутов Y
настолько велико, что для их размещения М буферов памяти не хватает, алгоритм
нуждается в изменении.
1. Если кортежи со значениями у, принадлежащие одному из отношений (скажем,
R), способны уместиться в М-1 буферов памяти, загрузить соответствующие
блоки R в буферы и по очереди считывать блоки S с аналогичными кортежами
в оставшийся буфер (речь по существу идет о выполнении однопроходного
алгоритма соединения, рассмотренного в разделе 15.2.3 на с. 697, в применении
к множествам кортежей с компонентами У, содержащими значения у).
2. Если количество кортежей со значениями у в каждом из двух отношений
настолько велико, что их нельзя загрузить в М-1 буферов, использовать все М
буферов для соединения этих кортежей посредством вложенных циклов.
Заметим, что в обоих случаях не исключен вариант, когда придется загрузить
блоки одного отношения, чтобы затем пренебречь ими и позже вновь загрузить те же
блоки. Например, может случиться так, что вначале считываются блоки отношения S с
кортежами, обладающими значениями у, и обнаруживается, что общий объем таких
кортежей чрезмерно велик, но при загрузке аналогичных кортежей отношения R выясняется,
что они свободно умещаются в М - 1 буферах памяти.
15.4.6. Анализ простого алгоритма соединения
Как упоминалось в примере 15.7, алгоритм предполагает выполнение пяти
операций дискового ввода-вывода в расчете на каждый блок данных отношений-
аргументов. Исключением является ситуация, когда количество кортежей с оди-
15.4. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА СОРТИРОВКЕ
713
наковыми значениями у совпадающих атрибутов Y слишком велико, что
вынуждает применять одну из специальных схем вычислений. В подобных случаях число
дополнительных дисковых операций зависит от того, одно или оба отношения
содержат избыточно большое количество кортежей с общими значениями
совпадающих атрибутов, требующее применения более чем М - 1 буферов. Здесь мы не
станем подробно останавливаться на всех этих частностях — анализ таких случаев
предлагается читателю в виде упражнений.
Следует обратить внимание и на то, насколько большой должна быть величина М,
чтобы "простой" алгоритм соединения с помощью сортировки мог успешно
выполнять свои функции. Основное ограничение состоит в обеспечении возможности
осуществления сортировки содержимого отношений R и S двухфазным
многокомпонентным слиянием: как указывалось в разделе 11.4.4 на с. 513, для этого необходимо
выполнение условий B(R)<M2 и B(S)<M2. Если указанные требования удовлетворяются,
буферов памяти будет достаточно, хотя — мы говорили об этом выше — если кортежи
с общими значениями у совпадающих атрибутов не умещаются в М буферов, от схемы
"обычного" слияния приходится отступать. Подводя итог, можно сказать, что при
отсутствии отклонений от "нормы" характеристики простого алгоритма соединения
с применением механизма сортировки таковы:
• 5 (#(/?) + 5(5)) — количество дисковых операций;
• B(R) < М2 и B(S) < М2 — ограничения объема свободной области оперативной памяти.
15.4.7. Более эффективный алгоритм соединения
Если заботиться о возможном наличии слишком большого количества кортежей
с общими значениями совпадающих атрибутов оснований нет, можно сэкономить на
выполнении двух операций дискового ввода-вывода в расчете на один блок, объединив
вторую фазу сортировки с процедурой соединения как таковой. Мы называем этот
алгоритм соединением с сортировкой (sort-join); в литературе употребляются и такие его
названия, как соединение со слиянием (merge-join) или даже соединение с сортировкой и
слиянием (sort-merge-join). Для вычисления оператора R(X, Y) x S(Y, Z) в соответствии с
рассматриваемым здесь алгоритмом соединения с сортировкой (мы считаем, как и прежде, что
доступны М буферов оперативной памяти) надлежит выполнить следующие действия.
1. Для отношений R и S создать отсортированные подсписки размера М,
используя в качестве ключа сортировки атрибуты У.
2. Загрузить первый блок каждого подсписка в соответствующий буфер (можно
полагать, что количество подсписков не превышает М).
3. Циклическим образом находить в блоках всех подсписков кортежи, содержащие
минимальные значения у совпадающих атрибутов Y. Идентифицировать все
кортежи обоих отношений с компонентами у и для хранения этих кортежей по
возможности использовать некоторые из М доступных буферов, если
количество подсписков меньше М. Выводить в итоговое отношение все соединенные
кортежи, созданные на основе допустимых сочетаний кортежей R и S с общими
компонентами у. В случае исчерпания буфера пополнять его очередным блоком
того же подсписка, считанным с диска.
Пример 15.8. Вновь обратимся к задаче, сформулированной в примере 15.4 на с. 704:
осуществить соединение отношений R и S, содержащих 1000 и 500 блоков
соответственно, при наличии 101 буфера оперативной памяти. Отношение R делится на
10 отсортированных подсписков длины 100, а отношение S — на пять подобных под-
714
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
списков.100 Для загрузки текущих блоков всех подсписков используются 15 буферов.
При возникновении ситуации, связанной с наличием многих кортежей с
одинаковыми значениями совпадающих атрибутов У, для хранения таких кортежей можно
использовать оставшиеся 86 буферов. Если же количество кортежей, подлежащих
соединению, слишком велико, надлежит обращаться к специальным алгоритмам,
упомянутым в разделе 15.4.5 на с. 712.
Если не рассматривать "экстремальные" случаи, на каждый блок данных приходится
по три операции дискового ввода-вывода: две из них используются для создания
отсортированных подсписков, а третья — для считывания блоков в процессе
многокомпонентного слияния. Таким образом, общее количество дисковых операций составляет 4500. □
Алгоритм соединения с сортировкой более эффективен в сравнении с "простым"
алгоритмом, о котором мы говорили в разделе 15.4.5 на с. 712. Как указывалось
в примере 15.8, количество операций дискового ввода-вывода, предусматриваемых
алгоритмом соединения с сортировкой, оценивается величиной з(#(Я) + 5(5)). Объемы
данных, к которым могут применяться оба алгоритма, вполне сопоставимы. Размеры
отсортированных подсписков равны М, ив двух списках может быть, самое большее,
М блоков. Поэтому оценка B(R) + B(S) <M2 остается в силе.
Естественно задаться вопросом, удастся ли в данном случае избежать неприятностей,
связанных с наличием большого количества кортежей, обладающих одинаковыми
значениями совпадающих атрибутов Y. Некоторые важные соображения перечислены ниже.
1. Иногда отсутствие потенциальных проблем можно предсказать заранее.
Например, если Y служит первичным ключом R, любые наборы значений у атрибутов
Y окажутся уникальными. Отыскав кортеж R, содержащий компоненты у,
нетрудно соединить его со всеми совпадающими кортежами S. Если в процессе
соединения блоки подсписков S истощаются, в буферы загружаются очередные
блоки тех же подсписков и необходимость в дополнительном пространстве
памяти никогда не возникает, независимо от того, насколько велико количество
кортежей S с компонентами у. Разумеется, аналогичные доводы применимы
и к случаю, когда Y является первичным ключом отношения S.
2. Если B(R) + B(S) много меньше М2, незанятые буферы могут использоваться для
временного сохранения кортежей с компонентами у (мы упоминали об этом
в примере 15.8).
3. Если же количество кортежей с общими значениями у чрезмерно велико, для
соединения таких кортежей, как указывалось в разделе 15.4.5 на с. 712, следует
применять, скажем, алгоритм на основе вложенных циклов — задача будет
решена, хотя и ценой дополнительных дисковых операций.
15.4.8. Сводка характеристик алгоритмов, основанных на сортировке
На рис. 15.11 приведена таблица, представляющая суммарные требования к объему
ресурса свободной оперативной памяти и количеству операций дискового ввода-
вывода, предъявляемые алгоритмами, которые рассмотрены в разделе 15.4. Как
упоминалось в разделах 15.4.5 (см. с. 712) и 15.4.7, если отношения-операнды содержат
чрезмерно большое количество кортежей с одинаковыми наборами значений
совпадающих атрибутов, оценки объемов памяти и количества дисковых операций
подлежат корректировке.
юо Строго говоря, можно использовать и подсписки, содержащие по 101 блоку (последние
подписки R и S в этом случае получат по 91 и 96 блоков соответственно), но затраты
окажутся равнозначными.
15.4. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА СОРТИРОВКЕ
715
Операторы
г, s
и,а-
IX
X
Оценка объема
памяти в единицах М
VF
V B(R) + B(S)
V max (#(tf), B(S))
V B(R) + B(S)
Оценка количества
дисковых операций
ЪВ
3(B(R) + B(S))
5(B(R) + B(S))
3(B(R) + B(S))
Номер раздела
книги
15.4.1, 15.4.2
15.4.3, 15.4.4
15.4.5
15.4.7
Номер
страницы
706, 709
709 710
712
714
Рис. 15.11. Оценки затрат ресурсов памяти и дисковых операций для алгоритмов, основанных
на сортировке
15.4.9. Упражнения к разделу 15.4
Упражнение 15.4.1. Используя условия примера 15.5 (см. с. 707) (блок содержит два
кортежа и М- 3), выполните следующие задания.
a) Опишите поведение двухпроходного алгоритма удаления кортежей-
дубликатов в применении к набору из тридцати однокомпонентных кортежей,
в которых последовательность значений 0, 1, 2, 3, 4 повторяется шесть раз.
b) Проанализируйте действия двухпроходного алгоритма группирования при
вычислении оператора уа,Ачсф)(Ю, если отношение R(a,b) состоит из
тридцати кортежей t0... t29, и компонент группирующего атрибута а кортежа ff-
содержит значение / mod 5, а компонент атрибута b — число /.
Упражнение 15.4.2. Для каждого из перечисленных ниже операторов создайте
итератор, реализующий соответствующий алгоритм, рассмотренный в разделе 15.4:
* а) удаление кортежей-дубликатов {8)\
b) группирование ())\
* с) пересечение множеств (П$);
d) разность мультимножеств (-в);
e) естественное соединение (ix).
Упражнение 15.4.3. Если B(R) = B(S) - 10000 и М=1000, укажите количество
операций дискового ввода-вывода, требуемых для выполнения следующих операторов:
а) объединение множеств (R (JB S);
* b) соединение (RtxS) с помощью простого алгоритма на основе сортировки,
рассмотренного в разделе 15.4.5 на с. 712;
c) соединение с помощью более эффективного алгоритма из раздела 15.4.7
на с. 714.
! Упражнение 15.4.4. Предположим, что при выполнении второго прохода
алгоритмов, описанных в разделе 5.4, не все М буферов памяти оказываются
востребованными, поскольку количество отсортированных подсписков меньше М. Каким
образом можно сократить количество операций дискового ввода-вывода за счет
использования свободных буферов?
716
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
! Упражнение 15.4.5. В примере 15.7 на с. 713 рассматривалась операция соединения
отношений R и S, содержащих 1000 и 500 блоков данных соответственно, при
условии М- 101. Мы отмечали, что в случае, если оба отношения содержат
избыточно большое количество кортежей с одинаковыми значениями совпадающих
атрибутов У, что препятствует возможности размещения этих кортежей в буферах
памяти, потребуются дополнительные операции дискового ввода-вывода. Вычислите
общее количество дисковых операций, если:
* а) существуют только два различных набора значений атрибутов У, по одному
на каждую половину множеств кортежей отношений R и S;
b) кортежи обоих отношений содержат по пять равновероятных наборов
значений У;
c) кортежи обоих отношений содержат по десять равновероятных наборов
значений У.
! Упражнение 15.4.6. Выполните задания упражнения 15.4.5 в применении к более
эффективному алгоритму соединения с сортировкой, рассмотренному в разделе
15.4.7 на с. 714.
Упражнение 15.4.7. Сколько буферов памяти потребуется для работы двухпроход-
ного алгоритма, основанного на сортировке и реализующего операцию
* а) удаления кортежей-дубликатов (S);
b) группирования (у);
c) соединения (х) или объединения (U),
если отношения-операнды содержат по 10000 блоков данных?
Упражнение 15.4.8. Приведите описание двухпроходного алгоритма, основанного
на сортировке и предназначенного для реализации каждого из операторов
соединения, указанных в упражнении 15.2.4 на с. 701.
! Упражнение 15.4.9. Предположим, что размер записи превышает емкость блока,
т.е. приходится прибегать к помощи модели связанных записей (см. раздел 12.4.4
на с. 573). Каким образом в подобном случае изменятся требования к объемам
свободных областей оперативной памяти, необходимых для работы двухпроходных
алгоритмов, основанных на сортировке?
!! Упражнение 15.4.10. Подчас количество операций дискового ввода-вывода удается
сократить, если сохранить в памяти отсортированный подсписок, созданный
последним. Для получения преимуществ от использования подобного решения,
возможно, целесообразно конструировать подсписки с объемом, меньшим М.
Насколько большой выигрыш может быть получен в этом случае?
!! Упражнение 15.4.11. Язык OQL позволяет группировать объекты (см. раздел 9.2.3 на
с. 430) в соответствии с произвольными функциями объектов, определенными
пользователем. Например, допускается группирование кортежей по значениям сумм
компонентов двух атрибутов. Каким образом с помощью механизма сортировки может быть
реализован подобный оператор группирования, применяемый к множеству объектов?
15.5. Двухпроходные алгоритмы, основанные на хешировании
Для решения проблем, рассмотренных в разделе 15.4 на с. 706, разработано и
целое семейство алгоритмов, использующих механизм хеширования (hash-based
algorithms). Эти алгоритмы основаны на следующей идее. Если данные настолько объем-
15.5. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА ХЕШИРОВАНИИ 717
ны, что не умещаются в буферы оперативной памяти, следует хешировать кортежи
отношений-операндов с помощью подходящей хеш-функции. Для всех
общеупотребительных операций существует способ выбора ключа хеширования таким образом,
чтобы все кортежи, которые должны рассматриваться совместно при выполнении
операции, обладали одним хеш-кодом.
В ходе выполнения операции в каждый момент времени используется один
сегмент (bucket) (или пара сегментов с одинаковым хеш-кодом, если операция
бинарна). В результате удается уменьшить размеры операндов во столько раз, каково
количество сегментов. Если доступны М буферов памяти, число М может быть
выбрано в качестве количества сегментов. Заметим, что алгоритмы из раздела 15.4 на
с. 706, основанные на сортировке, на подготовительном этапе также делят
исходный объем данных на М частей, но подходы, связанные с сортировкой и
хешированием, позволяют достичь схожих целей разными средствами.
15.5.1. Распределение содержимого отношений по сегментам хеш-таблицы
Для начала рассмотрим способ распределения данных отношения R по М -1
сегментам примерно равного объема с привлечением М буферов. Будем полагать, что
хеш-функция h принимает в качестве аргументов полные кортежи R (т.е. хеш-код
формируется на основе значений всех атрибутов). Каждому сегменту ставится в
соответствие один буфер. Оставшийся буфер предназначен для хранения в каждый момент
времени одного блока данных R. Кортеж t блока хешируется в номер сегмента h(t)
и копируется в соответствующий буфер. Если буфер заполнен, он "сбрасывается" на
диск, и для того же сегмента инициализируется новый блок. В завершение процедуры
на диске сохраняются последние блоки каждого сегмента, если они не пусты. Более
подробно алгоритм описан на рис. 15.12. Мы полагаем, что кортежи могут иметь
переменную длину, но они не настолько велики, чтобы не уместиться в пустой буфер.
Инициализировать М-\ сегментов с использованием М-\ буферов;
FOR (ДЛЯ) каждого блока b отношения R (ВЫПОЛНИТЬ) DO BEGIN
Загрузить блок b в М-й буфер;
FOR (ДЛЯ) каждого кортежа t в блоке b (ВЫПОЛНИТЬ) DO BEGIN
IF (ЕСЛИ) в буфере сегмента h{t) нет места для t (ТОГДА) THEN
BEGIN
Сохранить содержимое буфера на диске;
инициализировать новый пустой блок для буфера;
END;
Скопировать t в буфер сегмента h{t);
END;
END;
FOR (ДЛЯ) каждого сегмента (ВЫПОЛНИТЬ) DO
IF (ЕСЛИ) буфер сегмента не пуст (ТОГДА) THEN
Сохранить содержимое буфера на диске;
Рис. 15.12. Распределение данных отношения R по М - 1 сегментам
15.5.2. Алгоритм удаления кортежей-дубликатов
Теперь приступим к подробному изучению алгоритмов с хешированием,
предназначенных для реализации различных операторов реляционной алгебры в условиях,
когда одного прохода недостаточно. Для начала рассмотрим алгоритм вычисления
оператора S(R), выполняющего удаление кортежей-дубликатов (duplicate elimination).
С помощью процедуры, текст которой приведен на рис. 15.12, содержимое отношения
R распределяется по М - 1 сегментам. Заметим, что копии одного и того же кортежа t
помещаются в один сегмент. Поэтому оператор 8 можно применять к каждому
сегменту отдельно от других сегментов и получать итоговое отношение в виде
объединения частных отношений £(/?,-), где Rx — подмножество кортежей R, направляемых в /-й
718
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
сегмент. Для удаления кортежей-дубликатов из каждого подмножества Rt можно
применять однопроходный алгоритм, представленный в разделе 15.2.2 на с. 694.
Подобный подход окажется уместным только в том случае, если фрагменты данных Я,
достаточно малы, чтобы уместиться в свободных буферах памяти, — это естественное условие
работоспособности всех однопроходных алгоритмов. Поскольку, как мы полагаем, хеш-
функция h разносит элементы содержимого R по сегментам примерно равного объема,
каждому подмножеству кортежей Я, будут отводиться приблизительно B(R)/(M-l)
блоков памяти. Если это число не превышает величину М, т.е. B(R)<M(M- 1), двухпроход-
ный алгоритм, основанный на хешировании, способен к работе. Как упоминалось
в разделе 15.2.2 на с. 694, решающим условием является то, чтобы различные кортежи,
принадлежащие одному сегменту, смогли уместиться в М буферах оперативной памяти,
хотя на практике нельзя с уверенностью утверждать, что дубликаты вообще существуют.
Упрощенная оценка, в которой значения МиМ-1 считаются равными, выглядит как
B(R)<M2, т.е. совпадает с характеристикой двухпроходного алгоритма удаления
кортежей-дубликатов, основанного на сортировке (см. раздел 15.4.1 на с. 706). Количество
операций дискового ввода-вывода, предусматриваемых обоими алгоритмами, также
одинаково. Один раз каждый блок данных отношения R считывается с целью
хеширования, затем записывается в соответствующий сегмент хеш-таблицы на диске и,
наконец, вновь загружается однопроходным алгоритмом, удаляющим дубликаты из
подмножества кортежей, хранимых в сегменте (напомним, что, как и прежде, мы не
учитываем затраты, связанные с формированием итогового отношения). Таким образом,
общее количество дисковых операций оценивается величиной 3B(R).
15.5.3. Алгоритмы группирования и агрегирования
Для выполнения операции группирования (grouping), yL(R), вначале следует хеширо-
вать все кортежи отношения R по М - 1 сегментам. Однако для получения гарантий
того, что все кортежи определенной группы попадут в один и тот же сегмент,
надлежит выбрать такую хеш-функцию, которая принимает во внимание только
компоненты группирующих атрибутов из списка L.
После распределения данных R по сегментам для манипуляций содержимым
каждого отдельного сегмента можно использовать однопроходный алгоритм вычисления
оператора у, рассмотренный в разделе 15.5.2 на с. 718. Как указывалось в подразделе
раздела 15.5.2, посвященном оператору удаления кортежей-дубликатов (S), каждый
сегмент может быть обработан в оперативной памяти при условии B(R) <М2.
Однако при выполнении второго прохода, связанного с обработкой данных каждого
сегмента, требуется получить по одной записи для каждой группы. Поэтому даже в том
случае, если размер сегмента превосходит М, сегмент удастся обслужить за один проход
при условии, что записи, представляющие все группы в сегменте, занимают не более М
буферов. Обычно записи групп не бывают длиннее кортежей R. В таком случае более
точная верхняя граница величины B(R) в М2 раз превышает среднее количество
кортежей в группе. Как следствие, при наличии малого количества групп алгоритм на самом
деле способен обрабатывать намного более крупные отношения R, нежели те, размер
которых регламентируется правилом B(R)<M2. С другой стороны, если М превосходит
число групп, все сегменты заполнить не удастся. Поэтому в действительности
ограничение размера R зависит от М довольно сложным образом, и имеет смысл
пользоваться более простой оценкой B(R)<M2. Наконец, отметим, что алгоритм вычисления
оператора у, как и алгоритм для S, требует выполнения 3B(R) дисковых операций.
15.5.4. Алгоритмы объединения, пересечения и разности
При реализации алгоритма, основанного на механизме хеширования и
предназначенного для вычисления бинарного оператора, для распределения кортежей обоих
отношений-операндов по сегментам следует использовать одну и ту же хеш-функцию.
15.5. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА ХЕШИРОВАНИИ 719
Например, для получения результата операции R(JSS необходимо хешировать
содержимое отношений R и S по равному количеству сегментов, М-1, — скажем,
/?ь /?2, •••> Rm-\ и S,, 52,..., SM_V Затем надлежит выполнить объединение Rk с S, для всех /
и вывести результаты в итоговое отношение. Заметим, что если некоторый кортеж t
присутствует одновременно в R и S, тогда он окажется в сегментах Я, и S, для
определенного /. Поэтому при вычислении объединения множеств (set union) (R (Js S)
кортежей, принадлежащих этим сегментам, в результат направляется только одна копия t,
и вероятность попадания в итоговое отношение кортежей-дубликатов полностью
исключается. Если речь идет об объединении мультимножеств (bag union) (R(JBS),
наиболее предпочтительным является однопроходный алгоритм, описанный в разделе 15.2.3
на с. 697, и никакие другие реализации оператора не требуются.
Для вычисления пересечения (intersection) (П) или разности (difference) (-)
отношений R и S, как и при выполнении оператора объединения, создаются 2(М- 1)
сегментов, и для обработки содержимого каждой пары сегментов Я, и S, применяется
соответствующий однопроходный алгоритм. Напомним, что все упомянутые алгоритмы
требуют использования B(R) + B(S) операций дискового ввода-вывода. К этому
количеству следует прибавить по две операции в расчете на каждый блок, необходимые для
хеширования кортежей обоих отношений и сохранения данных в сегментах на диске,
так что оценка обретет вид 3(#(/?) + 5(5)).
Для обеспечения работоспособности алгоритмов надлежит гарантировать возможность
выполнения однопроходных алгоритмов объединения, пересечения и разности частных
отношений Rj и Sh размеры которых оцениваются приближенными значениями B(R)/(M-
1) и B(S)/ (М- 1) соответственно. Напомним, что однопроходные алгоритмы,
реализующие эти операции, требуют, чтобы меньшее из двух отношений-аргументов занимало не
более М-\ блоков. Таким образом, размер доступной области оперативной памяти,
необходимой для выполнения двухпроходных алгоритмов объединения, пересечения
и разности, основанных на хешировании, должен отвечать условию min {b(R), B{S))<M2.
15.5.5. Алгоритм соединения
При вычислении оператора R(X, Y) tx S(Y, Z) с помощью двухпроходного алгоритма
соединения с хешированием (hash-join)101 выполняются практически те же действия, что и для
других бинарных операций, рассмотренных в разделе 15.5.4. Единственное отличие
состоит в том, что в качестве ключа хеширования должны использоваться только совпадающие
атрибуты, Y, — это гарантирует размещение кортежей R n S, подлежащих соединению,
в соответствующих сегментах Я, и St для некоторого /. Завершает операцию однопроходный
алгоритм из раздела 15.2.3 на с. 697, соединяющий кортежи из пар сегментов Я, и Sh
Пример 15.9. Вновь обратимся к условиям примера 15.4 на с. 704, где рассматриваются
отношения R и S, занимающие 1000 и 500 блоков соответственно, и используется
101 буфер оперативной памяти. Можно осуществить хеширование кортежей каждого
отношения по 100 сегментам, так что средний размер сегмента составит 10 блоков для R
и 5 блоков — для S. Поскольку минимальное из двух значений, 5, намного меньше
количества доступных буферов, можно ожидать, что однопроходное соединение кортежей
каждой пары сегментов удастся выполнить без сколько-нибудь ощутимых проблем.
101 Иногда термин hash-join отводят для обозначения вариантов однопроходного алгоритма
соединения, представленного в разделе 15.2.3 на с. 697, где хеш-таблица выполняет функцию
поисковой структуры данных в оперативной памяти. В таких ситуациях обсуждаемый здесь
двухпроходный алгоритм соединения с хешированием сокращенно называют partition hash-join.
720
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Общее количество предполагаемых операций дискового ввода-вывода состоит из трех
компонентов: 1500 (чтение кортежей R и S с целью их хеширования), 1500 (сохранение
содержимого всех сегментов на диске) и 1500 (повторная загрузка данных каждой пары
сегментов в оперативную память в процессе выполнения однопроходного соединения
соответствующих кортежей). Таким образом, рассматриваемый здесь алгоритм с
хешированием и эффективный алгоритм соединения на основе сортировки (см. пример 15.8
на с. 714) требуют применения одинакового количества дисковых операций, 4500. □
Выводы, полученные в примере 15.9, дают основание представить характеристики
алгоритма соединения с хешированием следующим образом:
• 3(#(/?) + 5(5)) — количество дисковых операций;
• min (B(R), 5(5)) < М2 — ограничение объема свободной области оперативной памяти.
Доводы в пользу последнего утверждения те же, что и для алгоритмов с
хешированием, реализующих другие бинарные операции: содержимое одного сегмента из каждой
пары сегментов должно умещаться в М - 1 буферах памяти.
15.5.6. Сокращение затрат на дисковый ввод-вывод
Если при выполнении первого прохода алгоритма, основанного на хешировании,
доступно больше буферов памяти, нежели необходимо для хранения одного блока
сегмента, появляется возможность уменьшить количество дисковых операций. Одна
из альтернатив связана с использованием нескольких блоков для каждого сегмента
и сохранением их в виде группы в последовательных блоках диска. Строго говоря,
этот прием не служит сокращению количества операций дискового ввода-вывода —
речь идет о более быстром их выполнении за счет уменьшения периодов времени
поиска и оборота диска в процессе записи и последующего считывания данных.
Однако существует целый ряд "трюков", позволяющих избежать необходимости
записи некоторых сегментов на диск и их последующего считывания. Наиболее
эффективный из подобных инструментов, называемый гибридным соединением с
хешированием (hybrid hash-join), действует следующим образом. Предположим, что для
вычисления оператора RtxS, где S является меньшим по объему отношением, требуется
создать к сегментов, причем к много меньше М. При хешировании данных отношения S
можно принять решение о хранении в оперативной памяти содержимого т из к
сегментов целиком и только первых блоков всех оставшихся к-т сегментов. Основанием для
такого шага служит то, что ожидаемый общий объем полных сегментов в совокупности
с размерами отдельных блоков остальных сегментов не превышает значения М, т.е.
(mB(S) /к) + к-т<м (15.1)
(средний размер одного сегмента составляет B(S) / к, а общее количество сегментов,
размещаемых в памяти, как мы условились, равно /и).
При считывании кортежей другого отношения, R, (с целью их хеширования) в
памяти должны сохраняться
a) данные т сегментов отношения S, которые не "сбрасывались" на диск;
b) по одному блоку для каждого из к-т сегментов отношения R,
соответствующих тем сегментам 5, которые частично (за исключением отдельных
блоков каждого сегмента) записывались на диск.
Если кортеж г отношения R хешируется в один из первых т сегментов, система вправе
предпринять попытку его непосредственного соединения с кортежами из
соответствующего сегмента S, расположенного в памяти (буквально как при использовании од-
15.5. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА ХЕШИРОВАНИИ 721
нопроходного алгоритма соединения), и направить соединенные кортежи в итоговое
отношение. Чтобы облегчить операцию, необходимо организовать каждый из
сегментов S, находящихся в памяти, в виде эффективной поисковой структуры. Если же
кортеж t отношения R в результате хеширования распределяется в один из сегментов,
которым отвечают сегменты S, расположенные на диске, t направляется в блок
памяти, принадлежащий этому сегменту, и со временем перемещается на диск, как в двух-
проходном алгоритме соединения с хешированием.
Во время выполнения второго прохода кортежи соответствующих сегментов R и S
соединяются традиционным образом. Однако необходимости в обработке пар сегментов,
охватывающих сегменты S, расположенные в памяти, нет — кортежи таких сегментов
уже подвергались соединению и результаты этих операций зафиксированы в итоговом
отношении.
Экономия количества дисковых операций исчисляется двумя операциями в расчете
на каждый блок сегмента отношения S, оставляемого в памяти, и соответствующего
сегмента R. Поскольку в памяти сохраняется (т/к)-я часть сегментов, выигрыш
оценивается величиной 2(т/ £)(#(#) + 5(5)). Уместно задаться вопросом, как
максимизировать значение ml к с учетом ограничения (15.1), указанного на с. 721. Ответ
довольно любопытен: выбрать т = 1 и уменьшить к настолько, насколько возможно.
Интуитивно ясно, что все буферы, кроме к-т буферов, могут использоваться для хранения
кортежей S в оперативной памяти, и чем больше таких кортежей, тем меньше
количество дисковых операций. Поэтому целесообразно минимизировать общее
количество к сегментов. Этого можно достичь, увеличив размеры сегментов до
максимума М, откуда k = B{S)l М. В памяти остается место только для одного сегмента, т.е. т- 1.
На самом деле следует создавать сегменты с размером, несколько меньшим
B(S) IM, иначе в памяти не удастся разместить одновременно один полный сегмент и
по одному блоку для к -1 других сегментов. Если для простоты допустить, что
к = B(S) IM и т =1, экономия количества дисковых операций составит
{lM I B(S))(B(R) + B(S)), а общая оценка примет вид (з - 2МI B(S))(B(R) + B(S)).
Пример 15.10. В соответствии с условиями примера 15.4 на с. 704, соединению подлежат
кортежи отношений R и S, занимающих 1000 и 500 блоков соответственно, а объем
свободной области оперативной памяти составляет М = 101. При использовании алгоритма
гибридного соединения с хешированием необходимо выбрать значение количества к
сегментов, близкое к 500/101. Предположим, что принято к = 5. Тогда каждый сегмент S
должен содержать 100 блоков. Если попытаться разместить в памяти один из таких
сегментов целиком и по одному блоку каждого из четырех оставшихся сегментов, для этого
потребуются 104 буфера, что противоречит исходному ограничению М- 101.
Приходится выбрать к = 6. Теперь при хешировании кортежей S во время первого
прохода в наличии окажется пять буферов для пяти отдельных блоков сегментов и до
96 буферов для одного полного сегмента, размер которого равен 500/6, или 83.
Количество дисковых операций, требуемых для обработки содержимого S на первом
проходе, составляет 500 (для чтения всех кортежей S) плюс 500-83 = 417 (для записи пяти
сегментов на диск). В процессе обработки данных R на первом проходе придется
применить 1000 дисковых операций для загрузки кортежей в память и 833 операции
для сохранения пяти из шести сегментов на диске.
При выполнении второго прохода следует загрузить содержимое всех сегментов,
сохраненных на диске, т.е. осуществить 417 + 833 = 1250 дополнительных дисковых
операций. Таким образом, общее количество операций дискового ввода-вывода
составляет 1500 (считывание содержимого R и S) плюс 1250 (запись на диск 5/6 от
общего числа всех кортежей) плюс 1250 (повторная загрузка сохраненных кортежей),
или 4000. Уместно сопоставить это значение с величиной 4500, описывающей количе-
722
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
ство дисковых операций, которые придется выполнить для обработки тех же данных
с помощью "прямолинейных" алгоритмов соединения, основанных на механизмах
хеширования или сортировки. □
15.5.7. Сводка характеристик алгоритмов, основанных на хешировании
На рис. 15.13 представлены оценки ресурсов свободной оперативной памяти
и операций дискового ввода-вывода, требуемых алгоритмами, которые рассмотрены
в разделе 15.5. Результаты, полученные для алгоритмов с хешированием, реализующих
операторы у и S, следует воспринимать как весьма приближенные (то же справедливо
и для иных алгоритмов, обеспечивающих вычисление тех же операторов), поскольку
в действительности оценки в большей степени зависят от количества кортежей-
дубликатов и групп соответственно, а не от числа кортежей в отношении-аргументе.
Операторы
Y>S
ua-
IX
IX
Оценка объема
памяти в единицах М
4F
JB(S)
V#(S)
V#(S)
Оценка количества
дисковых операций
ЪВ
з(я(Д) + B(S))
3(B(R) + B(S))
(3 - 2М / B(S))(B(R) + B(S))
Номер
раздела книги
15.5.2,
15.5.3
15.5.4
15.5.5
15.5.6
Номер
страницы
718, 719
719
720
721
Рис. 15.13. Оценки затрат ресурсов памяти и дисковых операций для алгоритмов, основанных
на хешировании (для бинарных операций подразумевается, что B(S) < B(R))
Обратите внимание, что характеристики алгоритмов с хешированием и
соответствующих им алгоритмов, основанных на сортировке, почти совпадают. Наиболее
важные различия перечислены ниже.
1. Требования к объему свободной области памяти, которые выдвигаются
алгоритмами с использованием механизма хеширования, предназначенными для
реализации бинарных операций, зависят только от размера меньшего из
отношений-операндов, а не от суммы размеров обоих отношений, как для
аналогичных алгоритмов, основанных на сортировке.
2. Алгоритмы с применением аппарата сортировки нередко позволяют получать
итоговое отношение в упорядоченном виде и позже извлекать из этого факта
определенные выгоды — результат может быть использован другим алгоритмом
с сортировкой либо способен служить ответом на запрос, требующий
упорядочения итогового отношения.
3. Поведение алгоритмов на основе хеширования зависит от равенства размеров
сегментов. Поскольку зачастую эти размеры могут незначительно различаться,
практически невозможно полагаться на то, что объем используемых сегментов окажется
равным в среднем М блокам — надлежит ограничить его некоторой меньшей
величиной. Этот эффект особенно ярко проявляется в тех ситуациях, когда
количество различных хеш-кодов мало, что может быть связано с выполнением
запроса с группированием при наличии малого числа групп либо с соединением
отношений при небольшом количестве различных значений совпадающих атрибутов.
4. Если структура хранения дисковых данных организована соответствующим
образом, при выполнении алгоритмов с сортировкой упорядоченные подсписки
15.5. ДВУХПРОХОДНЫЕ АЛГОРИТМЫ, ОСНОВАННЫЕ НА ХЕШИРОВАНИИ 723
могут сохраняться в последовательных блоках или дорожках. Поэтому при
чтении блоков подсписков удастся уменьшить периоды времени поиска и оборота,
что позволит осуществлять обращения к диску быстрее, нежели при
использовании аппарата хеширования.
5. Более того, если значение М намного превосходит количество отсортированных
подсписков, это даст возможность считывать единовременно несколько
последовательных блоков списка, что является еще одним резервом сокращения
периодов времени поиска и оборота диска.
6. С другой стороны, если при использовании алгоритма с хешированием выбрать
количество сегментов, меньшее М, это позволит сохранять на диске
единовременно несколько блоков сегмента и даст выигрыш для операции записи хеши-
рованных данных, аналогичный тому, который может быть получен для
операции повторного чтения в алгоритме на основе сортировки (см. п. 5).
Аналогично, если организовать структуру хранения дисковых данных таким образом,
чтобы обеспечить размещение содержимого сегментов в последовательных
блоках или дорожках, при чтении сегментов (как и отсортированных подсписков —
см. п. 4) удастся сократить периоды времени поиска и оборота диска.
15.5.8. Упражнения к разделу 15.5
Упражнение 15.5.1. Идея, лежащая в основе процедуры гибридного соединения
с хешированием и предусматривающая сохранение одного полного сегмента в
оперативной памяти, может быть распространена и на алгоритмы, предназначенные
для реализации других операторов. Покажите, каким образом можно избежать
необходимости записи и считывания одного сегмента данных каждого отношения
при выполнении двухпроходного алгоритма с хешированием для следующих
операций: *а) 8\ Ь) у\ с) П*; d) -s.
Упражнение 15.5.2. Если B(S) = B(R) = 10000 и М- 1000, каково количество операций
дискового ввода-вывода, требуемых для выполнения алгоритма гибридного
соединения с хешированием?
Упражнение 15.5.3. Создайте итераторы, реализующие двухпроходные алгоритмы
с хешированием для следующих операторов: а) 8\ Ь) у\ с) {\в\ d) -s\ e) х-
*! Упражнение 15.5.4. Предположим, что к отношению R удовлетворительного
размера (т.е. B(R)<M2) применяется операция группирования, реализуемая посредством
двухпроходного хеширования. Однако количество групп настолько мало, что
объемы некоторых групп превышают М, т.е. содержимое группы не может быть
загружено в оперативную память целиком. Какие изменения следует внести (если
действительно следует) в алгоритм группирования с хешированием (см. раздел 15.5.3
на с. 719), чтобы обеспечить его работоспособность?
! Упражнение 15.5.5. Предположим, что используется дисковое устройство,
обладающее следующими параметрами доступа к данным: время перемещения головки
к блоку равно 100 миллисекундам, а время передачи (считывания) блока —-
1/2 миллисекунды. Как только головка позиционирована на нужный сектор, для
считывания к последовательно расположенных блоков потребуется к/2
миллисекунд. Допустим, что с помощью двухпроходного алгоритма с хешированием
необходимо вычислить оператор RxS при условиях #(/?) = 1000, 5(5) = 500 и М =101.
Для ускорения операции хотелось бы использовать настолько малое количество
сегментов, насколько возможно (предполагая, что кортежи распределены по
сегментам равномерно), и последовательно считывать/записывать возможно большее
724
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
количество блоков. Таким образом, если принять, что на доступ к произвольному
блоку диска расходуется 100,5 миллисекунд, а на считывание/запись к
последовательно расположенных блоков — 100 + /:/2 миллисекунд,
a) какова общая продолжительность операций дискового ввода-вывода?
b) сколько времени необходимо для выполнения дисковых операций при
использовании алгоритма гибридного соединения с хешированием?
c) насколько продолжительной окажется операция, если для ее выполнения
применить алгоритм соединения на основе сортировки,
предусматривающий возможность сохранения упорядоченных подсписков в
последовательных блоках диска?
15.6. Алгоритмы, основанные на индексировании
Возможность создания индекса для одного или нескольких атрибутов отношения
позволяет использовать специальные алгоритмы. Алгоритмы, основанные на индексировании
(index-based algorithms), особенно полезны при реализации оператора выбора (selection), но
наличие индексов доставляет преимущества и другим бинарным операторам (скажем,
соединения — join). В этом разделе мы сосредоточим внимание именно на таких
алгоритмах. Помимо того, мы продолжим обсуждение особенностей оператора индексного
сканирования для доступа к данным хранимых таблиц, начатое в разделе 15.1.1 на с. 685.
Чтобы облегчить изучение многих вопросов, для начала целесообразно отвлечься от
основной темы и рассмотреть так называемые группирующие (clustering) индексы.
15.6.1. Группирующие индексы
Напомним (см. раздел 15.1.4 на с. 687), что отношение является компактно
сгруппированным (clustered), если его кортежи упакованы в минимально возможное
количество блоков. Во всех предыдущих выкладках подразумевалось, что содержимое
отношений сохраняется компактным образом.
Заслуживает особого внимания и модель группирующих индексов (clustering indexes):
все кортежи с фиксированным значением ключа поиска, определяемого индексом,
располагаются в минимально возможном количестве блоков. Заметим, что отношение,
не являющееся компактно сгруппированным, не в состоянии обладать группирующим
индексом,102 но если отношение и компактно, оно может иметь индексы, не
принадлежащие к категории группирующих.
Пример 15.11. Отношение R(a,b), кортежи которого отсортированы по значениям
атрибута а и упакованы в блоки именно в таком порядке, определенно является
компактно сгруппированным. Индекс, созданный для атрибута а, относится к числу
группирующих, поскольку все кортежи, содержащие некоторое значение ах атрибута
а, располагаются последовательно. Кортежи с ах упакованы в последовательно
расположенные блоки и занимают их полностью (возможно, за исключением первого и
последнего блоков) (см. рис. 15.14). Индекс для атрибута Ь, однако, почти наверняка не
будет группирующим (все кортежи с определенным значением Ъ окажутся
"разбросанными" по всему файлу), если только содержимое атрибутов а и Ъ не
слишком тесно коррелированно. □
102 Строго говоря, если ключом индекса служит первичный ключ отношения, т.е. все
значения ключа индекса различны, такой индекс относится к категории "группирующих", даже если
отношение и не является компактно сгруппированным. Однако при наличии единственного
кортежа отношения для каждого значения ключа индекса свойство "группирования" индекса не
дает никаких преимуществ, и характеристики поведения системы при использовании подобного
индекса ничем не отличаются от ситуации, в которой индекс не трактуется как группирующий.
15.6. АЛГОРИТМЫ, ОСНОВАННЫЕ НА ИНДЕКСИРОВАНИИ
725
Все кортежи с а^
Рис. 15.14. Кортежи, содержащие одинаковые
значения ключа группирующего индекса,
упакованы в такое количество блоков, которое близко
к минимально возможному
15.6.2. Алгоритм выбора
В разделе 15.1.1 на с. 685 упоминалось о реализации оператора выбора (selection),
crc(R), посредством считывания всех кортежей отношения R, проверки условия выбора
С и вывода в итоговое отношение таких кортежей, которые удовлетворяют этому
условию. Если индексы для R не созданы, подобный подход — это, вероятно, лучшее,
что можно предложить; для выполнения процедуры потребуются B(R) операций
дискового ввода-вывода — или даже T(R), если отношение R не является компактно
сгруппированным (clustered).103 Предположим, однако, что условие С имеет вид a = v,
где а — определенный атрибут, для которого создан индекс, a v — значение этого
атрибута. Тогда для отыскания всех кортежей R с компонентами атрибута а,
содержащими значение v, достаточно просмотреть элементы индекса и проследовать по
адресам, задаваемым соответствующими указателями. Такие кортежи как раз и образуют
искомое множество cra = v (/?), и все, что остается сделать, — это извлечь их с диска.
Если индекс для R.a является группирующим, количество операций дискового
ввода-вывода, требуемых для считывания данных, образующих множество <ra = v(R),
составляет в среднем B(R) I V(Ry а). Реальное значение может оказаться несколько более
высоким по следующим причинам.
1. Зачастую индекс не загружен в оперативную память целиком, и поэтому для
просмотра его элементов необходимы дополнительные дисковые операции.
2. Даже если все кортежи, отвечающие условию a = v, способны разместиться в b
блоках, для их хранения обычно требуются b + 1 блоков, поскольку начало
последовательности кортежей с a = v может совпасть с началом блока только случайно.
3. Несмотря на то что индекс является группирующим, кортежи с компонентами
а - v могут быть распределены по нескольким дополнительным блокам, так как
a) блоки не обязательно заполняются максимально плотно — зачастую полезно
намеренно оставлять в них свободные области, предусматривая возможность
расширения содержимого отношения в будущем (об этом мы упоминали
в тексте врезки "Как предвосхитить результаты эволюции данных" на с. 594);
b) кортежи R иногда хранятся совместно с кортежами других отношений —
например, в соответствии с требованиями модели компактно сгруппированных
файлов (clustered files) (см. раздел 13.2.2 на с. 600).
Более того, надлежит, разумеется, округлять дробное частное от деления
B(R) I V(R, а) до ближайшего целого. Но наиболее важным обстоятельством
является то, что если а служит первичным ключом отношения Я, значение V(Ry a) - T(R)
заведомо намного превосходит величину B(R), так что системе определенно
придется выполнять одну дисковую операцию в расчете на кортеж с ключевым
значением v плюс необходимые операции ввода-вывода для доступа к элементам индекса.
103 Напомним (см. раздел 15.1.4 на с. 687), что означают используемые здесь функции:
T(R) — количество кортежей в отношении R; B(R) — количество блоков, содержащих данные R;
V(R, L) — число различных кортежей в отношении nL(R).
726
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
О понятиях компактного группирования данных
К настоящему моменту вы уже встречались с тремя достаточно различными, хотя
и взаимосвязанными, понятиями, в названиях которых присутствует слово
"сгруппированный " (clustered) или "группирующий " (clustering).
1. В разделе 13.2.2 на с. 600 упоминалась модель компактно сгруппированных
файлов (clustered files), предусматривающая возможность размещения кортежей
отношения R совместно со связанными по смыслу кортежами некоторого другого
отношения S; примером может служить группирование кортежей,
представляющих сведения о кинофильмах, с кортежами, содержащими информацию
о студиях, которыми выпущены эти кинофильмы.
2. В разделе 15.1.4 на с. 687 мы говорили о компактно сгруппированном
отношении (clustered relation), имея в виду, что кортежи отношения размещаются
в блоках, выделенных исключительно или преимущественно для хранения
данных этого отношения.
3. В разделе 15.6.1 на с. 725 введено понятие группирующего индекса (clustering
index), представляющего кортежи, содержащие одинаковые значения ключа и
собранные в последовательных блоках; кортежи с другими значениями ключа
могут присутствовать только в первом и последнем блоках последовательности.
Структура компактно сгруппированного файла — один из примеров организации
компактного отношения, в блоках которого могут содержаться данные и других
отношений. Предположим, что в рамках сгруппированного файла один кортеж
отношения S ассоциирован со многими кортежами отношения R. В этом случае
блоки файла нельзя считать выделенными исключительно для данных /?, хотя они
содержат "преимущественно" кортежи Я, так что отношение R можно трактовать как
компактное. С другой стороны, отношение S, вероятно, не является компактным,
поскольку его кортежи хранятся в блоках, большая часть объема которых
предназначена для хранения кортежей отношения R.
Теперь рассмотрим, что произойдет, не будь индекс для R.a группирующим. В
первом приближении можно полагать, что каждый извлекаемый кортеж относится к
отдельному блоку, так что для считывания всех кортежей системе придется выполнить
T(R) I V(R, а) операций дискового ввода-вывода. Это значение в действительности
может оказаться большим, поскольку с диска требуется загружать и блоки данных
индекса, или меньшим, так как вполне вероятно, что некоторые кортежи, подлежащие
загрузке, уже находятся в блоке, который ранее считывался в буфер памяти.
Пример 15.12. Допустим, что B(R) = 1000 и T(R) = 20000, т.е. 20000 кортежей отношения
R упакованы в 1000 блоков по 20 в каждом. Предположим, что для одного из
атрибутов отношения R — а — создан индекс и необходимо вычислить оператор аа = 0 (R).
Ниже рассмотрены некоторые возможные ситуации и приведены оценки требуемого
количества дисковых операций в худшем случае (затраты, связанные с обращением
к блокам индекса, не учитываются).
1. Если R компактно сгруппировано, но индекс не используется, расходы
составляют 1000 дисковых операций, т.е. загрузке подлежит каждый блок R.
2. Если R не является компактным и индекс по-прежнему не используется, для
выполнения процедуры придется выполнить 20000 операций дискового ввода-вывода.
3. Если V(R, a) - 100 и индекс относится к категории группирующих, алгоритм,
использующий индекс, требует выполнения 1000/100= 10 дисковых операций.
15.6. АЛГОРИТМЫ, ОСНОВАННЫЕ НА ИНДЕКСИРОВАНИИ
727
4. Если V(R< a) - 10 и индекс не является группирующим, алгоритму, основанному
на индексировании, придется осуществить 20000/10 = 2000 обращений к диску.
Заметьте, что в этом случае затраты выше, нежели при сканировании полного
компактного отношения без применения индекса (см. п. 1).
5. Если V(R, a) - 20000, т.е. а служит первичным ключом /?, алгоритму с
индексированием понадобится выполнить одну дисковую операцию (независимо от того,
является индекс группирующим или нет) и понести расходы, связанные с
доступом к индексу.
□
Индексное сканирование как метод доступа к данным способно оказать помощь
при выполнении некоторых других вариантов оператора выбора.
1. Существуют индексы (скажем, В-древовидные), позволяющие эффективно
отыскивать кортежи, значения ключа поиска которых принадлежат заданному
диапазону. Если для атрибута а отношения R сконструирован именно такой индекс, его
уместно использовать для непосредственного обращения к кортежам /?,
удовлетворяющим условиям выбора операторов, подобных cra>]0(R) или даже cra>]0Mma<20(R).
2. Оператор выбора а со сложным условием С подчас удобно реализовать
посредством индексного сканирования, к результатам которого применяется другой
алгоритм выбора. Если условие С имеет вид а - v and С, где С — иное
произвольное условие, оператор выбора можно представить в форме
последовательности из двух операторов: при выполнении первого проверяется только условие
а - v, а в ходе вычисления второго — условие С. Первый оператор — удачный
образец для реализации посредством индексного сканирования. Подобный
прием расщепления операции выбора на частные операции — одна из многих
альтернатив, к которым способен прибегнуть оптимизатор запросов с целью
улучшения качества логического плана запроса (более подробно эта тема
освещена в разделе 16.7.1 на с. 822).
15.6.3. Алгоритм соединения с использованием индекса
При реализации всех рассмотренных ранее бинарных операторов, а также унарных
операторов над полными отношениями, таких как 8 (удаление кортежей-дубликатов —
duplicate elimination) и у (группирование — grouping), удачное применение индексов
может оказаться весьма плодотворным. Разработку большинства подобных вариантов
алгоритмов мы оставляем читателю в качестве упражнений, а для примера сосредоточим
внимание на операции соединения (join). Обратимся, в частности, к оператору
естественного соединения R(X, Y)txS(Y,Z); напомним, что X, У и Z мы трактуем как подмножества
атрибутов, хотя для простоты их можно воспринимать и как отдельные атрибуты.
Рассматривая первый алгоритм соединения на основе индексирования (index-based
join), предположим, что отношение S обладает индексом для атрибутов У. Один из
способов вычисления соединения состоит в просмотре каждого блока данных R и
каждого кортежа t внутри текущего блока. Обозначим как tY компоненты кортежа t,
соответствующие атрибутам Y. Для отыскания всех кортежей S, обладающих
компонентами tY атрибутов У, естественно воспользоваться существующим индексом. Это как
раз те кортежи, которые подлежат соединению с кортежем t отношения R;
соединенные кортежи, представляющие результат операции, выводятся в итоговое отношение.
Количество дисковых операций, предусматриваемых таким алгоритмом, зависит от
нескольких факторов. Прежде всего, если принять, что отношение R компактно
сгруппировано, для извлечения всех его кортежей надлежит загрузить B(R) блоков.
Если же R не является компактным, могут потребоваться до T(R) дисковых операций.
728
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Для каждого кортежа t отношения R следует считать в среднем T(S) I V(S, У)
кортежей S. Если индекс для S.Y не является группирующим, количество операций
дискового ввода-вывода, необходимых для загрузки кортежей S, оценивается величиной
T(R)T(S) I V(S, У); в противном случае будет достаточно осуществить только
T(R)B(S) I V(S, У) обращений к диску.104 В любом из случаев к этим величинам нужно
прибавить по несколько единиц дисковых операций в расчете на каждый различный набор
значений атрибутов Y — речь идет о стоимости доступа к блокам индекса как такового.
Независимо от того, является отношение R компактно сгруппированным или нет,
затраты на извлечение кортежей S существенно превалируют. Итак, если пренебречь
стоимостью загрузки данных R, количество дисковых операций, необходимых для
соединения отношений R(X, У) и S(Y,Z) при наличии индекса для атрибута S. У, составляет
T(R)T(S) I V(S, У), если индекс не является группирующим, и Г(#)(тах (l, B(S) I V(Sy У))) — в
противном случае.
Пример 15.13. В очередной раз обратимся к условиям примера 15.4 на с. 704, где
рассматриваются отношения R(X, У) и S(Y, Z), занимающие 1000 и 500 блоков
соответственно. Предположим, что в одном блоке умещаются десять кортежей каждого
отношения, т.е. T(R)= 10000 и Щ) = 5000. Примем V(S9 У) =100— кортежи S содержат
100 различных наборов значений атрибутов У.
Допустим, что отношение R компактно и существует группирующий индекс для
S.Y. Тогда примерное количество операций дискового ввода-вывода (за исключением
тех, которые требуются для доступа к блокам индекса) равно 1000 (для чтения блоков
R — прежде этой составляющей мы пренебрегали) плюс 10000 * 500/100 = 50000.
Полученная величина значительно превосходит значения затрат, связанных с
использованием других рассмотренных выше алгоритмов применительно к тем же данным. Если
отношение R не компактно либо индекс для S. У не является группирующим,
стоимость операции окажется еще более высокой. □
После знакомства с примером 15.13 вам может показаться, что алгоритм
соединения, основанный на индексировании, не просто не заслуживает внимания, — он
весьма плох. Не торопитесь с выводами — в других ситуациях он вполне способен
проявить свои лучшие качества. Вот один из примеров: отношение R очень мало
в сравнении с S, a V(S, У) — велико. В упражнении 15.6.5 на с. 731 обсуждается
довольно типичный запрос, в котором операция выбора, предшествующая соединению,
кардинальным образом сокращает исходный объем данных R. В такой ситуации к
подавляющей части кортежей S алгоритм соединения с индексированием не будет
обращаться вовсе, поскольку большинство значений атрибутов У в R просто отсутствует.
Однако алгоритмы соединения, основанные на сортировке и хешировании, обязаны
просмотреть каждый кортеж S по меньшей мере один раз.
15.6.4. Алгоритмы соединения посредством сортировки и индексирования
Если индекс представляет собой В-дерево или иную структуру, позволяющую
легко извлекать кортежи отношения в отсортированном виде, использование такого
индекса сулит немало разнообразных альтернатив. Вероятно, простейшим примером
является следующий: имеется индекс для атрибутов У отношения R или S и вычислению
подлежит оператор R(Xy Y)xS(Y,Z). Для достижения цели можно воспользоваться
обычной процедурой соединения с сортировкой (sort-join), но при наличии индекса
необходимости в выполнении промежуточного этапа, связанного с сортировкой
одного из отношений по ключу У, нет.
104 Напомним (см. раздел 15.6.2 на с. 726), что если частное B(S)/V(SyY) меньше единицы,
его следует округлить до единицы.
15.6. АЛГОРИТМЫ, ОСНОВАННЫЕ НА ИНДЕКСИРОВАНИИ
729
Представим крайнюю ситуацию, когда индексы созданы одновременно для
атрибутов R. У и S. У: в этом случае для получения результата достаточно выполнить только
завершающий шаг "простого" алгоритма соединения на основе сортировки,
рассмотренного в разделе 15.4.5 на с. 712. Подобный вариант алгоритма иногда называют
зигзагообразным соединением (zig-zag join), поскольку он предусматривает попеременное
обращение к индексам обоих отношений с целью отыскания общих значений совпадающих
атрибутов У. Заметим, что кортежи R со значениями У, отсутствующими в S, и кортежи
S, обладающие компонентами У, которых нет в R, в загрузке не нуждаются.
Пример 15.14. Предположим, что отношения R(X,Y) и S(Y,Z), подлежащие
соединению, обладают индексами для атрибутов У. Рассмотрим небольшие экземпляры
отношений и допустим, что значениями ключа поиска (атрибутов У) для кортежей R
являются 1, 3, 4, 4, 4, 5 и 6, а для кортежей S — 2, 2, 4, 4, 6 и 7. Вначале обратимся к
первым ключам R и S — 1 и 2 соответственно. Поскольку 1 < 2, первый ключ R следует
пропустить и перейти ко второму, 3. Теперь текущий ключ S меньше текущего ключа
R, так что, миновав два значения 2 ключа S, мы переходим к значению 4. В этот
момент ключ 3 R меньше ключа 4 S, поэтому приходится перейти к очередному ключевому
значению R, 4. Сейчас оба текущих ключа равны 4: необходимо проследовать по
адресным значениям указателей, связанных со всеми ключами 4 обоих отношений, извлечь
соответствующие кортежи и соединить их. (Обратите внимание, что до момента
достижения одинаковых ключевых значений ни один кортеж отношений не загружался.)
Покончив с ключами 4, перейдем к ключам 5 (R) и 6 (S). Поскольку 5 < 6, обратимся к
следующему ключу R, 6. Теперь ключи совпали вновь — это значит, что требуется найти
соответствующие кортежи и выполнить их соединение. Так как множество
ключей R исчерпано, ясно, что кортежей, которые удалось бы соединить, больше нет. □
Если индексы являются В-деревьями, достаточно просматривать вершины-листья
обоих деревьев в направлении слева направо, пользуясь встроенными указателями,
которые связывают один лист с другим (процесс схематически отображен на
рис. 15.15). Если отношения R и S компактны, для извлечения всех кортежей с
заданным значением ключа потребуется количество операций дискового ввода-вывода,
пропорциональное числу таких кортежей. В экстремальных ситуациях, когда
количество кортежей с общими значениями совпадающих атрибутов У отношений R и S
настолько велико, что эти кортежи нельзя загрузить в оперативную память
одновременно, надлежит воспользоваться одной из дополнительных схем вычислений,
упомянутых в разделе 15.4.5 на с. 712.
Пример 15.15. Продолжим рассмотрение примера 15.13 (см. с. 729), чтобы
продемонстрировать способ применения алгоритма зигзагообразного соединения, сочетающего
механизмы сортировки и индексирования. Пусть
существует индекс для S. У, позволяющий извлекать
кортежи S в порядке следования значений У.
Предположим также, что оба отношения компактны, а индекс
является группирующим. Будем считать, что в
данный момент индекс для отношения R отсутствует.
101 блок свободной области оперативной памяти
можно использовать для создания 10 сортированных
подсписков с данными 1000 блоков отношения R.
Для считывания и записи всего содержимого R
потребуются 2000 операций дискового ввода-вывода.
Во время выполнения второго прохода находят
применение 11 буферов памяти - 10 для загрузки под- Рис 1515 Процесс зигзагообраз-
списков R и 1 — для хранения блока кортежей S, ного соединения с использованием
найденных посредством индекса, а для считывания двух индексов
шт
730
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
содержимого R и S понадобится 1500 дисковых операций. (Здесь мы не учитываем
дисковые операции и затраты памяти, необходимые для манипуляций блоками индекса, но
если индекс относится к категории В-древовидных, эти величины заведомо малы.) Таким
образом, общее количество операций дискового ввода-вывода составляет 3500, что
существенно меньше, нежели при использовании других алгоритмов, исследованных ранее.
Теперь предположим, что индексами для атрибутов Y снабжены оба отношения,
R и S. Необходимость в сортировке какого-либо из отношений уже не возникает —
достаточно осуществить не более 1500 дисковых операций для считывания блоков
отношений R и S при посредничестве индексов. В действительности, если на основании
информации индексов обнаружится, что изрядная часть отношения R (S) не содержит
кортежей, совпадающих в компонентах Y с кортежами отношения S (R), общая
стоимость операции значительно снизится. □
15.6.5. Упражнения к разделу 15.6
Упражнение 15.6.1. Предположим, что отношение R снабжено индексом для атрибута а.
Поясните, каким образом этот индекс может быть использован для повышения
производительности алгоритмов, реализующих перечисленные ниже операторы:
* a) R Us S (подразумевается, что R и S не содержат кортежей-дубликатов, но
совпадающие кортежи, принадлежащие различным отношениям, могут существовать);
b) RdsS;
c) S(R).
При каких обстоятельствах алгоритм с индексированием окажется более
эффективным, нежели алгоритмы, основанные на сортировке или хешировании?
Упражнение 15.6.2. Пусть B(R) - 10000 и T(R) = 500000. Предположим, что существует
индекс для R.a, причем V(R, а) = к для некоторого к. Выразите стоимость операции
о[,г()(Л) в виде функции от к, принимая во внимание следующие дополнительные
условия (дисковыми операциями, требуемыми для доступа к блокам индекса как
такового, можно пренебречь):
* а) индекс является группирующим;
b) индекс не относится к категории группирующих;
c) отношение R компактно и индекс не используется.
Упражнение 15.6.3. Выполните задания упражнения 15.6.2, если операция
представляет собой запрос в диапазоне значений <7c<rtANDa<D(#) (можете полагать, что С и D
являются константами, обеспечивающими попадание в диапазон C<a<D (к/ 10)-й
части значений атрибута а).
! Упражнение 15.6.4. Если отношение R компактно, но индекс для атрибута R.a не
является группирующим, значение к (см. упражнение 15.6.2) способно определить
выбор в пользу табличного сканирования R либо использования индекса. При
каких значениях к целесообразно предпочесть алгоритм, основанный на
индексировании, если речь идет об отношении и запросе из
a) упражнения 15.6.2;
b) упражнения 15.6.3.
* Упражнение 15.6.5. Рассмотрим SQL-запрос
SELECT birthdate
FROM Starsln, MovieStar
WHERE movieTitle = 'King Kong' AND starName = name;
15.6. АЛГОРИТМЫ, ОСНОВАННЫЕ НА ИНДЕКСИРОВАНИИ
731
адресуемый к отношениям
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
из "кинематографической" базы данных. Если преобразовать запрос в выражение
реляционной алгебры, последнее по существу сводится к вычислению соединения
посредством равенства (equijoin) между отношениями
& movieTitle = 'King Kong' (Starsln)
и Movies tar, которое может быть реализовано практически так же, как
естественное соединение RxS. Поскольку в базе данных, как мы полагаем, имеются
сведения только о двух кинофильмах с названием "King Kong", значение T(R) (R
соответствует отношению starsln) весьма мало. Допустим, что отношение Movies tar
(оно выполняет роль S) обладает индексом для атрибута name. Сопоставьте
стоимости вычисления подобного оператора R tx S с помощью алгоритмов, основанных
на индексировании, сортировке и хешировании.
Упражнение 15.6.6. В примере 15.15 на с. 730 обсуждались характеристики
алгоритма вычисления оператора соединения RxS при условии, что одно или оба
отношения R и S снабжены индексами для совпадающих атрибутов. Алгоритм,
однако, не способен справляться с ситуациями, когда количество кортежей,
обладающих одинаковыми значениями атрибутов соединения, чрезмерно велико. Каково
предельное число блоков, занимаемых такими кортежами, при котором без
выполнения дополнительных операций дискового ввода-вывода все еще можно обойтись?
Ввод-вывод
Заявки
15.7. Управление буферизацией
До сих пор мы полагали, что при выполнении каждой операции над отношениями
доступны М буферов оперативной памяти, которые могут быть использованы для
хранения необходимых данных. На практике буферы редко выделяются системой загодя,
и значение М, как правило, серьезным образом
зависит от условий, в которых система пребывает
в конкретный момент времени. Обязанности по
предоставлению процессам (скажем, таким, ко-
Буферы I I I I I I I I I I I I I I торые обрабатывают запросы к базе данных)
буферов оперативной памяти требуемого объема
и минимизации задержек в обслуживании заявок
возлагается на менеджер буферов (buffer manager).
Роль менеджера буферов в структуре системы баз
данных проиллюстрирована на рис. 15.16.
1
J
1
\
1
Менеджер |
(
5у
Ф
ер
ОЕ
3
А*
Рис. 15.16. Менеджер буферов служит
промежуточным звеном между оперативной памятью и
дисковыми устройствами и обрабатывает заявки на
распределение областей памяти
15.7.1. Архитектура менеджера буферов
Существуют две широко распространенные архитектуры менеджеров буферов.
1. Менеджер буферов управляет оперативной памятью напрямую (как в
большинстве современных реляционных СУБД).
732
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Управление памятью при обработке запросов
Мы полагаем, что менеджер буферов выделяет для выполнения некоторого оператора
М буферов оперативной памяти, где значение М зависит от текущих условий, в
которых работает система (в частности, от количества и номенклатуры параллельно
обрабатываемых запросов и команд), и может варьироваться в широких пределах.
Получив в свое распоряжение М буферов, процесс, обслуживающий оператор, может
использовать одни для загрузки дисковых страниц данных, другие — для считывания
блоков индексов, а третьи — для хранения результатов сортировки или хеширования.
В некоторых СУБД оперативная память не распределяется из единого источника
{пула — pool), но существуют самостоятельные пулы памяти, управляемые
собственными менеджерами буферов и предназначенные для совершенно различных целей.
Например, процессу могут быть предоставлены D буферов из пула, служащего для
размещения страниц дисковых данных, S буферов из отдельной области памяти,
выделяемых для сортировки, и Н буферов, предуготовленных для создания хеш-
таблицы. Подобный подход допускает более широкие возможности для настройки
и тонкой "доводки" тех или иных параметров системы, но, вероятно, не может
считаться наилучшим с точки зрения использования общего пространства памяти.
2. Менеджер буферов выделяет буферы в пространстве виртуальной памяти,
позволяя операционной системе решать, какие буферы в каждый момент времени
в самом деле размещаются в оперативной памяти, а какие — в дисковом файле
подкачки, который находится в ведении операционной системы. Подобным
образом действуют многие СУБД, размещаемые в оперативной памяти (main-memory
DBMS's), и объектно-ориентированные (object-oriented) системы баз данных.
Какой из подходов ни применялся бы в каждом конкретном случае,
сопутствующие проблемы схожи: менеджер буферов обязан ограничивать количество буферов,
находящихся в пользовании, таким образом, чтобы обеспечить возможность их
размещения в доступной области оперативной памяти. Если менеджер буферов управляет
оперативной памятью непосредственно и заявки на ресурс памяти в совокупности
превышают текущий доступный объем ресурса, менеджер способен освободить
некоторые буферы, возвратив их содержимое на диск. Если буферизованный блок данных
после его загрузки с диска не модифицировался, он может быть просто удален из
памяти; если же содержимое блока претерпело изменения, его надлежит вернуть в то же
место диска. При выделении области пространства виртуальной памяти менеджер
буферов имеет возможность зарезервировать больше буферов, чем может быть размещено
в оперативной памяти. Однако если все эти буферы будут находиться в активном
пользовании, возникает общая проблема уровня операционной системы, связанная с
необходимостью попеременного "сбрасывания" многих блоков памяти в дисковый файл
подкачки и их последующей повторной загрузки. В подобной ситуации система может
проводить большую часть времени, занимаясь суетными операциями по "перетасовке"
блоков, а не продуктивной деятельностью, направленной на решение задачи.
Обычно количество буферов определяется значением определенного параметра,
устанавливаемым в момент старта и инициализации системы. Уместно считать, что это
значение позволяет использовать всю доступную область оперативной памяти,
независимо от того, где именно размещаются буферы — в оперативной памяти как
таковой или в виртуальном адресном пространстве. Ниже мы не будем касаться того,
какой из режимов буферизации применяется в каждом конкретном случае; достаточно
полагать, что существует пул буферов (buffer pool) фиксированного объема —
множество буферов, которые доступны для использования процессами, обслуживающими
запросы и другие команды манипуляции содержимым базы данных.
15.7. УПРАВЛЕНИЕ БУФЕРИЗАЦИЕЙ
733
15.7.2. Стратегии управления буферизацией
Один из основополагающих вопросов, решение которого является прерогативой
менеджера буферов, заключается в том, какой из буферов должен быть освобожден
при поступлении заявки на размещение нового блока данных в условиях, когда пул
буферов исчерпан. Механизмы, подобные стратегиям замещения буферов (buffer-
replacement strategies), возможно, знакомы вам по другим приложениям,
предполагающим составление расписаний выполнения процессов или использования ресурсов
(к таким приложениям относятся, например, операционные системы). Наиболее
употребительные стратегии замещения буферов рассмотрены ниже.
"Самое давнее время использования" (LRU)
В соответствии с критерием "самого давнего времени использования" (least-recently
used — LRU) на диск "сбрасывается" блок, к которому система не обращалась для
чтения или записи в продолжение наиболее длительного времени. При использовании
подобной стратегии требуется, чтобы менеджер буферов поддерживал в актуальном
состоянии специальную таблицу, содержащую сведения о моментах времени
последнего доступа к блокам данных в каждом буфере. Таким образом, менеджер обязан
фиксировать в таблице информацию, связанную со всеми обращениями к элементам
базы данных, что требует немалых затрат. Тем не менее LRU следует признать
достаточно эффективной стратегией: интуитивно ясно, что к буферам, не востребованным
в течение долгого времени, система будет обращаться с меньшей вероятностью,
нежели к тем, которые использовались сравнительно недавно.
"Первым пришел — первым обслужен" (FIFO)
При использовании стратегии "первым пришел — первым обслужен" (first-in, first-
out — FIFO) замещению новым содержимым подлежит буфер, занятый одним и тем
же блоком на протяжении самого обширного периода времени. В этом случае
менеджер буферов должен быть осведомлен только о том, когда блок, занимающий буфер,
был загружен в этот буфер. Поэтому данные в специальной таблице обновляются
менеджером лишь в моменты загрузки блоков в буферы — изменять элементы таблицы
при последующих обращениях к буферам не требуется. Стратегия FIFO менее
обременительна, нежели LRU, но зато чревата большим количеством неадекватных
решений: например, блок, используемый периодически (скажем, блок, отвечающий
корневой вершине В-древовидного индекса), со временем наверняка станет "долгожителем"
и подвергнется принудительному вытеснению на диск, хотя через короткое время его
вновь придется загружать, но, вероятнее всего, уже в другой буфер.
Алгоритм часов
Алгоритм часов (clock algorithm) — это часто используемая эффективная версия
стратегии LRU. Представим, что буферы упорядочены по кругу и напоминают
циферблат часов, как показано на рис. 15.17. "Указатель" адресует один из буферов
и вращается по часовой стрелке при необходимости отыскания буфера, в который
надлежит поместить очередной считываемый блок дисковых данных. Каждому
буферу поставлен в соответствие "флаг", принимающий одно из двух значений — О
или 1. Буферы с нулевым значением флага не защищены от возможности
"сбрасывания" их содержимого на диск, а буферы, которым отвечает единичный
флаг, напротив, обладают "иммунитетом". При загрузке блока данных в буфер
флагу этого буфера присваивается значение 1. Та же операция выполняется и при
обращении к содержимому буфера.
Если менеджер буферов испытывает потребность в буфере, подходящем для
размещения нового блока, он, вращая "указатель" по часовой стрелке, предпринимает
попытку найти буфер с нулевым флагом. В процессе вращения "указателя" все
встреть
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
ченные им единичные значения флагов заменяются
нулевыми. Таким образом, буфер может быть освобожден
только в том случае, если он остается невостребованным
в течение периода времени, пока "указатель" не
совершит полный оборот для установки флага этого буфера в О
и еще один оборот до момента повторного достижения
этого буфера, по-прежнему обладающего нулевым
флагом. Рис. 15.17 соответствует ситуации, когда при
необходимости загрузки нового блока должны быть выполнены
следующие действия: вращение "указателя" по часовой
стрелке на одну позицию, замена значения флага с 1 на
О, вращение еще на одну позицию (здесь обнаруживается
нулевой флаг, свидетельствующий о том, что
соответствующий буфер может быть освобожден), очистка буфера
с возможной выгрузкой хранимого в нем блока на диск,
считывание в найденный буфер нового блока и
присваивание флагу буфера значения 1.
Корректировка стратегий со стороны других компонентов системы
Процессор запросов или иные компоненты системы наделены правом вмешательства в
"дела" менеджера буферов, что позволяет избежать решений (принимаемых в соответствии
с алгоритмами "часов", LRU или FIFO), которые могут оказаться некорректными с учетом
определенных "высших" соображений. Например, в разделе 12.3.5 на с. 566
рассматривались обстоятельства, препятствующие возможности непосредственного перемещения
блока данных из оперативной памяти на диск без предварительной модификации
содержимого определенных других блоков, ссылающихся на блок, подлежащий вытеснению.
Такой блок * называют "закрепленным " (pinned); любой менеджер буферов обязан соизмерять
используемую стратегию замещения буферов с принятой политикой "закрепления"
блоков, дабы избежать опасности вредоносного воздействия на работоспособность других
компонентов системы. Чтобы, скажем, справиться с упомянутой выше проблемой
периодического "сбрасывания" на диск корневого блока В-древовидного индекса при
использовании стратегии FIFO, достаточно "закрепить" этот блок, гарантируя его
неприкосновенность. Аналогичным образом, используя алгоритм, подобный однопроходному
соединению, основанному на хешировании, процессор запросов вправе "закрепить"
блоки меньшего из двух отношений, дабы поручиться, что эти данные будут оставаться
в памяти столько времени, сколько необходимо для завершения всей операции.
15.7.3. Выбор физических операторов и проблемы управления буферизацией
Одной из основных функций оптимизатора запросов является выбор множества
физических операторов, позволяющих реализовать заданный запрос. В процессе выбора
оптимизатор вправе полагать, что при выполнении каждого из операторов доступно
определенное количество М буферов оперативной памяти. Однако, как мы говорили выше,
менеджер буферов далеко не всегда способен гарантировать наличие М буферов к
моменту фактического выполнения запроса. Можно назвать по меньшей мере два аспекта,
связанных с буферизацией и оказывающих влияние на выбор физических операторов.
1. Способен ли алгоритм, реализующий оператор, адаптировать свое поведение
при изменении количества М свободных буферов оперативной памяти?
2. Если предусмотренное значение М не достигается и определенные блоки,
которые, как ожидалось, должны были бы находиться в буферах оперативной
памяти, на самом деле оказались "сброшенными" на диск, насколько серьезно
стратегия замещения буферов связана с необходимостью выполнения
дополнительных операций дискового ввода-вывода?
0
0
□
□
ш
ш
Рис. 15.17. Алгоритм часов
предусматривает
циклический просмотр флагов
буферов с заменой единиц нулями
и наоборот
15.7. УПРАВЛЕНИЕ БУФЕРИЗАЦИЕЙ
735
Нюансы алгоритма часов
Алгоритм часов, выбирая свободные буферы и изменяя содержимое флагов, не
ограничен в своих действиях схемой, в соответствии с которой флаги способны
принимать одно из двух значений, 0 или 1. Например, флагу буфера, содержащего
какую-то важную страницу данных, может быть присвоено значение, большее 1, —
всякий раз по мере прохождения "стрелки часов" мимо этого буфера значение его
флага должно уменьшаться на единицу. Концепцию "закрепленных" блоков
нетрудно реализовать в самом алгоритме часов — достаточно снабдить флаг
соответствующего буфера "бесконечно" большим значением и позволить менеджеру
буферов изменять это значение до нуля при необходимости освобождения блока.
Пример 15.16. Чтобы проиллюстрировать сказанное, рассмотрим алгоритм соединения
посредством вложенных циклов с загрузкой блоков данных (block-based nested-loop join),
представленный на рис. 15.8 (см. с. 704). Алгоритм по существу не принимает во
внимание величину М, хотя его производительность зависит от М. Поэтому достаточно
определить значение М непосредственно перед выполнением оператора.
Вполне допустима ситуация, когда величина М изменяется на разных итерациях
внешнего цикла: всякий раз при загрузке в оперативную память порции данных
отношения S (оно фигурирует во внешнем цикле), можно использовать все свободные
в этот момент времени буферы памяти, кроме одного, который резервируется для
блока R, загружаемого во внутреннем цикле. Поэтому фактическое количество
итераций внешнего цикла зависит от среднего числа буферов, доступных на каждой
итерации. Впрочем, если значение М выдерживается в среднем, выводы, полученные в
результате анализа стоимостных характеристик алгоритма (см. раздел 15.3.4 на с. 704),
остаются в силе. При самых благоприятных условиях на первой итерации внешнего
цикла могут оказаться свободными столько буферов, что их общего объема хватит для
загрузки содержимого отношения S в целом — в этом случае алгоритм соединения с
использованием вложенных циклов изящным образом превращается в однопроходный
алгоритм, упомянутый в разделе 15.2.3 на с. 697.
Если "закрепить" М-\ блоков отношения S, используемых на одной итерации
внешнего цикла, это позволит гарантировать, что данные не будут вытеснены на диск.
С другой стороны, на протяжении итерации буферы могут освобождаться — система
в состоянии использовать их для хранения большего количества блоков данных
отношения R, хотя, если не принять соответствующих мер, наличие дополнительных
буферов не поспособствует уменьшению общего времени работы алгоритма.
Предположим для примера, что менеджер буферов использует стратегию замещения
буферов LRU и существуют к буферов, доступных для хранения блоков
отношения R. Блоки R загружаются один за другим, и по окончании текущей итерации
внешнего цикла в буферах остаются к последних блоков R. На следующей итерации внешнего
цикла М -1 буферов для S заполняются новыми блоками 5, и процесс считывания
блоков R осуществляется вновь. Если приступить к загрузке блоков от начала R,
содержимое к буферов для R потребуется заменить, что явно расточительно, особенно при к>\.
Более эффективная реализация алгоритма соединения посредством вложенных
циклов при использовании стратегии замещения буферов LRU предполагает поочередную
смену направления просмотра блоков R с целью их загрузки: на первой итерации
внешнего цикла блоки R считываются в направлении от начала последовательности к концу,
на второй итерации — от конца к началу и т.д. В этом случае удается сэкономить к
операций дискового ввода-вывода для каждой итерации, кроме первой. Иными словами,
вторая и все следующие итерации внешнего цикла для считывания содержимого R
потребуют выполнения только B(R) - к дисковых операций. Заметим, что даже в случае к - 1
(т.е. при отсутствии дополнительных буферов для Я), небольшая экономия (одна
дисковая операция в расчете на итерацию внешнего цикла) все-таки достигается. □
736
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Возможности изменения значения М в процессе выполнения оператора и
использования менеджером буферов различных стратегий замещения воздействуют на
поведение и других алгоритмов. Некоторые важные соображения приведены ниже.
• Алгоритм на основе сортировки, предназначенный для реализации
произвольного оператора, вполне возможно адаптировать к изменению величины М. Если
М уменьшается, допустимо изменить размер подсписка, поскольку
рассмотренные нами алгоритмы, использующие механизм сортировки, не выдвигают
требования равенства длин подсписков. Основное ограничение связано с тем, что
при снижении значения М может возникнуть такая ситуация, когда количество
подсписков станет настолько большим, что при выполнении их слияния
выделить по одному буферу для каждого подсписка уже не удастся.
• Сортировка содержимого подсписков в оперативной памяти может выполняться
самыми различными способами. Поскольку алгоритмы, подобные сортировке
слиянием (merge sort) или быстрой сортировке (quick sort), по своей природе
рекурсивны, большую часть времени они довольствуются малыми фрагментами
памяти, так что эти компоненты алгоритмов, основанных на сортировке, слабо
зависят от применяемой менеджером буферов стратегии замещения.
• При использовании алгоритмов, основанных на хешировании, со снижением
значения М можно уменьшать количество сегментов и увеличивать их размеры —
разумеется, в таких пределах, чтобы каждый сегмент не оказался настолько
большим, когда его уже нельзя разместить в памяти. Однако в отличие от алгоритмов,
использующих механизм сортировки, алгоритмы с хешированием не способны
адаптироваться к изменениям величины М в процессе работы: как только
количество сегментов выбрано, оно остается фиксированным на протяжении всего времени
выполнения первого прохода, и если все буферы оказываются заполненными,
блоки, принадлежащие некоторым сегментам, должны быть вытеснены на диск.
15.7.4- Упражнения к разделу 15.7
Упражнение 15.7.1. Предположим, что необходимо осуществить операцию
соединения RtxS в условиях, когда размер доступной области оперативной памяти
варьируется в пределах от М до Ml 2. Опишите в терминах М, B(R) и B(S) условия,
при выполнении которых можно гарантировать работоспособность следующих
алгоритмов, реализующих указанную операцию соединения:
* а) однопроходного соединения;
* Ь) двухпроходного соединения, основанного на хешировании;
c) двухпроходного соединения с использованием механизма сортировки.
! Упражнение 15.7.2. Каким образом можно уменьшить количество операций
дискового ввода-вывода, необходимых для выполнения соединения посредством
вложенных циклов, если доступны дополнительные буферы памяти и менеджером
буферов применяется одна из следующих стратегий замещения:
d) "первым пришел — первым обслужен" (FIFO);
e) алгоритм часов.
!! Упражнение 15.7.3. В примере 15.16 на с. 736 упоминалось о том, что при
выполнении алгоритма соединения возможно извлечь дополнительные
преимущества из факта наличия дополнительных буферов, если резервировать
для блоков R более одного буфера и осуществлять поочередную смену
направления просмотра блоков R от одной итерации внешнего цикла к другой.
J5.7. УПРАВЛЕНИЕ БУФЕРИЗАЦИЕЙ
737
Допустимо применять и альтернативный подход, поддерживая только один
буфер для R и увеличивая количество буферов для S. Какой вариант действий
позволяет уменьшить количество операций дискового ввода-вывода?
15.8. Многопроходные алгоритмы
Хотя двух проходов вычислений достаточно в большинстве случаев, для полноты
картины мы обязаны рассмотреть обобщенные версии основных алгоритмов из
разделов 15.4 на с. 706 и 15.5 на с. 717, позволяющие обрабатывать отношения
произвольного размера. Ниже представлены расширенные варианты алгоритмов, использующих
механизмы сортировки и хеширования.
15.8.1. Многопроходные алгоритмы, основанные на сортировке
В разделе 11.4.5 на с. 516 упоминалось о том, каким образом алгоритм
сортировки многокомпонентным двухфазным слиянием может быть расширен на случай
трех фаз. Простой рекурсивный механизм позволяет либо сортировать содержимое
отношения в целом, либо создать п отсортированных подсписков для любого
наперед заданного значения п.
Допустим, что существуют М буферов оперативной памяти, доступных для
использования с целью сортировки данных отношения R, которое, как мы полагаем,
является компактно сгруппированным (clustered). Для сортировки R надлежит выполнить
следующие действия.
Базис. Если содержимое R способно уместиться в М блоков (т.е. B(R) <M), загрузить
кортежи R в буферы оперативной памяти, упорядочить посредством одного из
общеизвестных алгоритмов сортировки и сохранить результат на диске.
Индукция. Если R нельзя считать в оперативную память целиком, разделить блоки
R на М групп, /?ь /?2,.., Rm- Рекурсивным образом сортировать группы блоков Rh
/= 1, 2,..., М. По завершении осуществить слияние М отсортированных подсписков
таким образом, как указано в разделе 11.4.4 на с. 513.
Если задача сводится не просто к сортировке кортежей Я, а к осуществлению
некоей унарной операции, подобной группированию (?) или удалению кортежей-
дубликатов (S), достаточно на завершающей стадии слияния предусмотреть
выполнение соответствующей операции применительно к кортежам, расположенным в
головных частях отсортированных подсписков. Иными словами,
• для операции S— включить в итоговое отношение по одной копии каждого
кортежа, пропуская все другие копии;
• для операции у— выполнив сортировку по компонентам группирующих
атрибутов, распределить кортежи по группам с учетом значений этих атрибутов, как
указано в разделе 15.4.2 на с. 709.
При необходимости выполнения бинарной операции (такой, как пересечение или
соединение) используется по существу аналогичный подход — единственное
исключение связано с тем, что содержимое обоих отношений вначале распределяется в
общей сумме по М подспискам; затем каждый подсписок упорядочивается так, как
описано выше; наконец, данные каждого из М подсписков считываются в отдельный
буфер, и операция выполняется в соответствии с рекомендациями раздела 15.4 на с. 706.
М буферов оперативной памяти распределяются между отношениями R и S так, как
требуется в конкретном случае. Однако, чтобы минимизировать количество проходов,
следует предоставлять буферы пропорционально количеству блоков, принадлежащих
отношению: так, например, отношение R получит М * B(R) I (в(К) + В($)) буферов,
a S — оставшиеся буферы.
738
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
15.8.2. Характеристики многопроходных алгоритмов, основанных на сортировке
Исследуем взаимозависимости между размерами вовлеченных в операцию
отношений, количеством требуемых операций дискового ввода-вывода и объемом
свободной области оперативной памяти. Обозначим как s(M, к) максимальный размер
отношения, которое может быть отсортировано с использованием М буферов памяти
и к проходов алгоритма. Значение s(M, к) может быть вычислено следующим образом.
Базис. Если &= 1, т.е. позволен только один проход, необходимо выполнение
условия B(R) < М, или, иными словами, s(M, 1) = М.
Индукция. Предположим, что к> 1. Кортежи отношения R разделяются на М
фрагментов, каждый из которых должен допускать возможность сортировки за к - 1
проходов. Если B(R) = s(M, к), тогда значение s(M, к) IМ размера каждого из М фрагментов R
не должно превосходить величину s(M, к - 1), т.е. s(M, k) = M s(M, k-\).
Представленное рекурсивное правило нетрудно записать в виде единой формулы:
s(M, k) = M s(M, к - 1) = М2 5(М, к - 2) = - = Мк"1 j(Af, 1)
Поскольку 5(М, 1) = М, заключаем, что s(Myk) = Mk. Другими словами, посредством к
проходов можно отсортировать отношение R в том случае, если B(R) < s(M, к), или
B(R) <Mk: если требуется упорядочить кортежи R за к проходов, минимальное
количество буферов памяти, которыми придется воспользоваться, составляет М = (#(/?)) llk.
На каждом проходе алгоритма сортировки все кортежи отношения
загружаются в память и сохраняются на диске. Поэтому £-проходный алгоритм требует
выполнения 2kB(R) операций дискового ввода-вывода.
Теперь рассмотрим стоимость многопроходного соединения R(X, Y) х S(Y, Z),
которое можно считать характерным образцом бинарных операций над отношениями.
Обозначим как j(M, к) наибольшее количество блоков, подлежащих обработке в
процессе соединения посредством к проходов при использовании М буферов оперативной
памяти, т.е. подразумевается, что B(R) + B(S) <j(M, к).
На последнем проходе осуществляется слияние М отсортированных подсписков двух
отношений. Каждый из подсписков сортируется за к -1 проходов, так что он не может
быть длиннее s(M,k- l) = Mk~\ а все списки в совокупности — Мs(M, к- \) = Мк. Т.е.
значение B(R) + B(S) не должно превышать Мк, или, иными словами, j(M,k) = Мк. Если
взглянуть на оценку с другой стороны, можно заключить, что для вычисления
оператора соединения R(Xy Y) x S(Y, Z) посредством к проходов требуется (b(R) + B(S)^) l/k
буферов оперативной памяти.
При определении количества дисковых операций, необходимых для выполнения
многопроходных алгоритмов, реализующих соединения или иные операторы
реляционной алгебры, следует иметь в виду, что, в отличие от сортировки, стоимость
сохранения итогового отношения не учитывается. Для сортировки подсписков требуются
2(к- 1)(#(#) + #(S)) операций дискового ввода-вывода; дополнительные B(R) + B(S)
операций необходимы для считывания упорядоченных подсписков на последнем проходе.
Общее количество дисковых операций, таким образом, составляет (2к- 1)(#(Я) + 5(5)).
15.8.3. Многопроходные алгоритмы, основанные на хешировании
Соответствующий рекурсивный подход применяется и при использовании
механизма хеширования для реализации операций над крупными отношениями.
Содержимое отношения или отношений хешируется в М- 1 сегментов, где М представляет
количество свободных буферов оперативной памяти. Если операция унарна, далее она
15.8. МНОГОПРОХОДНЫЕ АЛГОРИТМЫ
739
применяется к каждому сегменту отдельно. При выполнении бинарной операции,
подобной соединению, рассматриваются пары связанных сегментов обоих отношений.
Общим итогом операции — такой как удаление кортежей-дубликатов, группирование,
объединение, пересечение, разность, естественное соединение или соединение
посредством равенства — служит объединение частных результатов, полученных для
отдельных сегментов. Рекурсивное описание алгоритма выглядит следующим образом.
Базис. Для унарной операции: если содержимое отношения способно уместиться в М
блоков, загрузить его в оперативную память и осуществить операцию. Для бинарной
операции: если данные любого из отношений могут быть размещены в М- 1 буферах,
выполнить операцию, загрузив содержимое соответствующего отношения в оперативную память
и последовательно считывая по одному блоку второго отношения в М-и буфер.
Индукция. Если ни одно из отношений не может быть загружено в оперативную память
целиком, хешировать кортежи каждого отношения в М -1 сегментов таким образом, как
указано в разделе 15.5.1 на с. 718. Рекурсивно выполнять операцию над каждым
сегментом или каждой парой связанных сегментов, аккумулируя получаемые результаты.
15.8.4. Характеристики многопроходных алгоритмов, основанных на
хешировании
Будем полагать, что в процессе хеширования кортежи распределяются по
сегментам настолько равномерно, насколько это возможно. На практике для приближения
к подобному результату следует выбирать хеш-функцию, которая возвращает
значения, близкие к случайным, хотя, разумеется, абсолютного совпадения размеров
сегментов достичь вряд ли удастся.
Прежде всего рассмотрим характеристики алгоритмов для унарных операций —
группирования (у) или удаления кортежей-дубликатов (S), — применяемых к
отношению R при наличии М буферов оперативной памяти. Обозначим как и(М, к)
количество блоков наибольшего отношения, которое может быть обработано ^-проходным
алгоритмом на основе хеширования с использованием М буферов. Вот как выглядит
рекурсивное определение м(М, к).
Базис. и(М, 1) = М, поскольку содержимое R должно уместиться в М буферов,
т.е. B(R)<M.
Индукция. Предположим, что вначале кортежи R распределяются поМ-1
сегментам равного размера. Значение м(М, к) можно вычислить следующим образом.
Сегменты обязаны быть настолько малы, чтобы их можно было обработать за к -1 проходов,
т.е. размер каждого сегмента равен и(М, к- 1). Поскольку R делится на М- 1 сегментов,
должно выполняться условие и(Му к) = (М- 1) и(М, к- 1).
Приведя указанное рекурсивное правило к единой формуле, получим и(М9 к) = М(М-
I)*"1, или, полагая, что М сравнительно велико, и(М,к)~Мк. Иными словами, унарную
операцию над отношением R можно осуществить за к проходов с использованием М
буферов оперативной памяти при выполнении условия Л/>(#(/?)) 1/Л.
Аналогичный анализ нетрудно провести и для алгоритмов, реализующих бинарные
операции. Как и в разделе 15.8.2 на с. 739, ограничим внимание операцией
соединения. Обозначим как j(M, к) верхнюю границу размера меньшего из двух отношений R
и S, вовлеченных в операцию R(X, Y) tx S(Y, Z). Здесь, как и прежде, М представляет
количество свободных буферов оперативной памяти, а к — число проходов алгоритма.
Базис. j(M9 1) = M-1, т.е. при использовании однопроходного алгоритма
соединения, как указывалось в разделе 15.2.3 на с. 697, одно из двух отношений, R или 5,
должно содержать не более М - 1 блоков.
740
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Индукция. j(M,k) = (M-l)j(M,k-\y, другими словами, на первом из к проходов
можно поделить содержимое каждого отношения на М-1 сегментов таким образом,
чтобы размер каждого сегмента составлял (1 / (М- 1))-ю часть от объема всего
отношения, причем каждая пара соответствующих сегментов должна допускать возможность
соединения за к - 1 проходов.
Приведение рекурсивного правила к единой формуле позволяет заключить, что
j(Myk)-(M-\)k. Вновь, полагая значение М относительно большим, правомерно
утверждать, что j(M,k)~Mk. Иными словами, операцию соединения R(X, Y) tx S(Y, Z)
можно осуществить за к проходов с использованием М буферов оперативной памяти
при выполнении условия Мк > min (b(R), #(£)).
15.8.5. Упражнения к разделу 15.8
Упражнение 15.8.1. Допустим, что B(R) = 20000, B(S) = 50000 и М= 101. Опишите
поведение следующих алгоритмов вычисления оператора RtxS:
* а) трехпроходного алгоритма, основанного на сортировке;
b) трехпроходного алгоритма, использующего механизм хеширования.
! Упражнение 15.8.2. Ранее мы обсуждали ряд "трюков", позволяющих повысить
производительность двухпроходных алгоритмов. Можно ли использовать
перечисленные ниже приемы применительно к многопроходным алгоритмам, и
если да, то каким образом?
c) Гибридное соединение с хешированием (см. раздел 15.5.6 на с. 721).
d) Версия алгоритма на основе сортировки, улучшенная за счет хранения блоков
на последовательных дорожках и цилиндрах диска (см. раздел 15.5.7 на с. 723).
e) Версия алгоритма на основе хеширования, улучшенная за счет хранения блоков
на последовательных дорожках и цилиндрах диска (см. раздел 15.5.7 на с. 723).
15.9. Параллельные алгоритмы для реляционных операторов
Операции с базами данных, часто весьма продолжительные и охватывающие
большие порции информации, определенно выигрывают при наличии средств параллельной
обработки. В этом разделе представлен обзор основных архитектур параллельных систем
(parallel systems). Особое внимание уделено архитектуре компьютера с обособленными
ресурсами (shared nothing), которая выглядит наиболее убедительной и эффективной
в тех случаях, когда применяется для поддержки СУБД, хотя в других ситуациях,
вероятно, не всегда способна проявить все свои лучшие качества. Для большинства
операторов реляционной алгебры разработаны простые расширенные варианты
алгоритмов, позволяющие использовать практически все возможности, предоставляемые
механизмами параллельных вычислений: в частности, промежуток времени выполнения
операции на компьютере с р процессорами составляет "почти" (1/р)-ю часть от
периода времени, требуемого для решения той же задачи на однопроцессорной машине.
15.9.1. Архитектуры параллельных вычислительных систем
Ядром параллельного компьютера является набор процессоров. Нередко количество р
процессоров, устанавливаемых в компьютерной системе, исчисляется сотнями и даже
тысячами. Будем полагать, что каждый процессор Р обладает собственным модулем
кэшпамяти (на приводимых ниже диаграммах эти модули не показаны). В большинстве архи-
15.9. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ ДЛЯ РЕЛЯЦИОННЫХ ОПЕРАТОРОВ
741
тектур процессоры также снабжены устройствами локальной оперативной памяти
(последние обозначены на рисунках буквой М). Что наиболее важно с точки зрения
обработки данных, наряду с массивами процессоров параллельные системы содержат
множества дисковых устройств — возможно, по одному или более на каждый
процессор, — а в некоторых структурах диски открыты для доступа со стороны всех процессоров.
М
М
М
<t> fCt> <±>
Рис. 15.18. Система с общей памятью
Помимо того, все параллельные системы снабжены коммуникационными
средствами, позволяющими осуществлять взаимный обмен информацией между
процессорами. На наших диаграммах эти средства показаны в виде общей шины,
соединяющей элементы системы. На практике, однако, традиционные шины не в состоянии
обеспечить поддержку такого количества процессоров и иных модулей, которыми
обладают наиболее крупные системы, поэтому во многих случаях подсистема
межпроцессорного взаимодействия представляет собой мощный концентратор, возможно,
расширенный посредством шин, соединяющих подмножества процессоров в
локальные кластеры (clusters).
Ниже кратко описаны три наиболее важных класса параллельных
вычислительных систем.
1. Системы с общей памятью (shared memory). В таких системах (см. рис. 15.18)
каждый процессор имеет доступ к модулям памяти всех других процессоров.
Другими словами, в системе поддерживается единое пространство физических
адресов памяти, а не отдельные пространства для каждого процессора.
Диаграмма на рис. 15.18 отображает крайнюю ситуацию, когда процессоры лишены
собственных устройств памяти вовсе — хотя каждый процессор обладает
локальной памятью, он при необходимости вправе адресовать и фрагменты
памяти, поставленные в соответствие всем остальным процессорам. Крупные
системы подобного класса относятся к типу NUMA (nonuniform memory access —
"неоднородный доступ к памяти") — это значит, что процессору приходится
расходовать большее время на обращение к данным в памяти,
"принадлежащей" другим процессорам, нежели к информации в "собственной"
памяти или памяти, ассоциированной с процессорами того же локального
кластера. Однако различия в скоростях доступа к тем или иным участкам памяти
в современных архитектурах становятся все менее значительными. Впрочем,
существенно более весомы расхождения между уровнями производительности
оперативной и кэш-памяти — поистине ключевым является вопрос, находятся
ли данные, в которых нуждается процессор, в его собственной кэш-памяти.
742
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
V V т
м
м
м
3.
Рис. 15.19. Система с общими дисками
Системы с общими дисками (shared disks). В архитектуре, схематически показанной
на рис. 15.19, каждый процессор обладает собственной памятью, недоступной для
других процессоров, но диски посредством коммуникационной шины
предоставляются в общее пользование. Параллельные конкурирующие запросы к дисковым
ресурсам, поступающие от различных процессоров, обрабатываются контроллерами
дисков. Количество дисков не обязательно совпадает с числом процессоров, хотя
на рис. 15.19 для простоты представлен частный случай подобного совпадения.
Системы с обособленными ресурсами (shared nothing). В системах подобного класса,
как показано на рис. 15.20, модули памяти и группы дисков находятся
в безраздельном владении определенных процессоров. Межпроцессорное
взаимодействие обеспечивается коммуникационной шиной. Например, если процессору
Р необходимо обратиться к кортежам отношения, которое хранится на диске,
пребывающем в ведении процессора Q, процессор Р отсылает процессору Q
соответствующее сообщение-запрос. Процессор Q считывает данные с собственного диска
и отправляет их по шине в виде ответного сообщения, получаемого процессором Р.
ЛЛ^ЛХ,Л>
м
м
м
Рис. 15.20. Система с обособленными ресурсами
Как упоминалось в вводной части этого раздела на с. 741, архитектура с
обособленными ресурсами находит наиболее широкое применение для поддержки
высокопроизводительных систем баз данных. Компьютеры с обособленными ресурсами
относительно недороги. В то же время при разработке алгоритмов, учитывающих особенности
подобных структур, следует иметь в виду, что процедуры межпроцессорного обмена
информацией (наряду, как обычно, с дисковым вводом-выводом) являются "узким ме-
15.9. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ ДЛЯ РЕЛЯЦИОННЫХ ОПЕРАТОРОВ
743
стом" системы. Обычно данные пересылаются от процессора к процессору в форме
сообщений, что обусловливает значительный уровень накладных расходов. Оба процессора
должны выполнять приложение, поддерживающее прием/передачу сообщений, а запросы
к коммуникационной шине зачастую конкурируют друг с другом и задерживаются.
"Стоимость" пересылки сообщения обычно можно представить в виде суммы крупной
постоянной составляющей и относительно небольшого компонента, зависящего от
количества передаваемых байтов. Поэтому при проектировании паратлельного алгоритма
значительный выигрыш может быть получен в том случае, если данные пересылаются
крупными порциями. Например, имеет смысл буферизовать сразу несколько блоков данных,
обрабатываемых процессором Р, и отправлять их единым сообщением процессору Q.
Если процессор не нуждается в данных "сию секунду", намного разумнее "накопить"
сколько-нибудь обширную порцию информации и только затем отослать ее получателю.
15.9.2. Параллельные алгоритмы для операций над отдельными кортежами
Начнем обсуждение параллельных алгоритмов для систем с обособленными
ресурсами с алгоритма, предназначенного для реализации оператора выбора. Прежде всего
следует обратить внимание на проблему оптимального хранения данных. Как
упоминалось в разделе 11.5.2 на с. 521, полезно распределять данные по возможно
большему количеству дисковых устройств. Для простоты будем полагать, что с каждым
процессором связан один диск. Таким образом, в случае наличия в системе р процессоров
речь идет о равномерном разделении множеств кортежей любого отношения R между
дисками, соответствующими всем р процессорам.
Для вычисления оператора crc (R) целесообразно поручить каждому процессору
анализ того подмножества кортежей R, которое хранится на диске, связанном с этим
процессором. Процессор обязан отыскать кортежи, удовлетворяющие условию С,
и скопировать их в итоговое отношение. Чтобы избежать необходимости в обмене
данными между процессорами, кортежи-копии / отношения-результата <jc(R) следует
сохранять на том же диске, где расположены исходные кортежи /, т.е. распределять
содержимое crc(R) по дискам таким же образом, как это сделано для отношения R.
Поскольку crc{R) может выполнять роль отношения-аргумента другого оператора
(причем, разумеется, хотелось бы уменьшить время простоя процессоров, доведя
коэффициент их использования до максимально высокого уровня), оптимальной оказалась
бы ситуация, когда кортежи crc(R) разделены между дисками процессоров равномерно.
Что касается, например, операции проекции, количества кортежей в порциях итогового
отношения kl(R), сохраняемых на дисках процессоров, остаются равными размерам
фрагментов исходного отношения R, которые располагаются на тех же дисках. Иными
словами, если содержимое R распределено по дискам равномерно, настолько же
равномерным окажется и разбиение nL(R). Оператор выбора, однако, способен
радикальным образом изменить характер распределения данных итогового отношения.
Пример 15.17. Рассмотрим оператор выбора <xa=10(fi), предполагающий отыскание всех
кортежей R, компоненты а которых (предполагается, что а является атрибутом R)
содержат значение 10. Допустим также, что кортежи R распределены по дискам в
соответствии со значениями компонентов а. Тогда все кортежи /?, удовлетворяющие
условию а- 10, окажутся на одном диске, и на тот же диск будет целиком помещено
содержимое итогового отношения cra = 10 {R). □
Чтобы избежать проблем, аналогичных указанной в примере 15.17, следует
весьма тщательно продумывать политику распределения кортежей хранимых отношений
по дискам процессоров. Вероятно, лучшим решением окажется применение хеш-
функции h, которая принимает во внимание значения всех компонентов кортежа /,
так что незначительное изменение содержимого одного из них способно привести
744
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Алгоритмы для других архитектур параллельных систем
При использовании вычислительных систем с общими дисками — так же как
и систем с обособленными ресурсами — предпочтительны более объемные
сообщения. Если обмен данными осуществляется при посредничестве диска, следует
перемещать данные порциями объемом в блок, а если к тому же дисковые данные,
подлежащие передаче, сохраняются на последовательных дорожках или цилиндрах,
это, как указывалось в разделе 11.5.1 на с. 519, позволяет получить существенную
экономию за счет уменьшения периодов времени поиска и времени оборота диска.
С другой стороны, машины с общей памятью позволяют организовать процесс
обмена данными между процессорами ~- что неудивительно — через оперативную
память. В этом случае нет необходимости в применении специального программного
обеспечения для приема/передачи сообщений, и стоимость считывания/записи
данных в оперативной памяти пропорциональна количеству обрабатываемых байтов.
Поэтому системы с общей памятью предпочтительны при использовании
алгоритмов, предусматривающих частый и быстрый межпроцессорный обмен короткими
сообщениями. Что любопытно — подобные алгоритмы находят широкое
применение в самых различных ситуациях, но в системах баз данных почти не востребованы.
к тому, что результатом вызова h{t) может оказаться любой допустимый номер
сегмента.105 Если, например, необходимо использовать В сегментов, можно каким-то
образом преобразовать значение каждого компонента в целое число из интервала от
О до В- 1, сложить полученные величины, разделить сумму на В и использовать
остаток от деления в качестве номера сегмента. Если количество процессоров также
равно В (самый удачный вариант), уместно сохранить содержимое каждого сегмента
на диске соответствующего процессора.
15.9.3. Параллельные алгоритмы для операций над полными отношениями
Дли начала рассмотрим одну из менее типичных операций над полными
отношениями, связанную с удалением кортежей-дубликатов, S(R). Если для распределения
кортежей R по дискам процессоров употребить такую хеш-функцию, о которых
говорилось в конце предыдущего раздела, каждая группа кортежей-дубликатов попадет
в ведение одного и того же процессора. Таким образом, для получения итогового
отношения S(R) достаточно параллельного применения стандартного "однопроцессорного"
алгоритма (см., например, разделы 15.4.1 на с. 706 или 15.5.2 на с. 718) к фрагменту
данных R на диске каждого процессора. Аналогично, если использовать одинаковые
хеш-функции для распределения кортежей отношений R и S, это позволит применять
алгоритмы вычисления операторов объединения, пересечения и разности параллельно
к порциям данных R и S на каждом диске.
Предположим, однако, что для распределения кортежей отношений R и S
использованы различные хеш-функции и требуется вычислить оператор объединения
(union).106 В подобной ситуации вначале надлежит скопировать все кортежи R и S
и распределить их по сегментам посредством единой хеш-функции h.[07
105 В частности, мы не рекомендуем использовать в такой ситуации раздельные хеш-функции
(см. раздел 14.2.5 на с. 652), поскольку в результате их выполнения кортежи с заданным
значением определенного атрибута (скажем, а - 10) окажутся распределенными по крайне малому
подмножеству сегментов.
106 Вообще говоря, рассматриваемый ниже алгоритм применг/м к объединению и множеств
(set union), и мультимножеств (bag union). Но поскольку простой алгоритм объединения
мультимножеств, представленный в разделе 15.2.3 на с. 697, вполне способен работать в
параллельном режиме, его и предпочтительнее применять.
107 Проще, разумеется, загодя использовать для распределения кортежей R и S одну и ту же
хеш-функцию.
15.9. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ ДЛЯ РЕЛЯЦИОННЫХ ОПЕРАТОРОВ
745
Кортежи отношений R и S, хранимые на дисках всех процессоров, параллельно
хешируются посредством функции h. Процесс хеширования выполняется так, как
указано в разделе 15.5.1 на с. 718, но если буфер, соответствующий сегменту / в области
памяти процессора j заполняется, вместо перемещения на диск j содержимое буфера
передается процессору /. Если в памяти удается сохранять несколько блоков каждого
сегмента, появляется возможность дождаться заполнения некоторого количества
буферов с кортежами сегмента / и только затем переслать их процессору /. Таким
образом, процессор / получает все кортежи отношений R и S, принадлежащие сегменту /.
На второй стадии алгоритма каждый процессор выполняет объединение кортежей R и
S из одного сегмента. Кортежи итогового отношения R (J S разносятся по дискам всех
процессоров. Если порядок распределения данных по сегментам, обеспечиваемый
хеш-функцией h, действительно близок к случайному, можно ожидать, что на дисках
всех процессоров окажется примерно одинаковое количество кортежей результата.
Операции пересечения (intersection) и разности (difference) могут быть
выполнены аналогично операции объединения, причем алгоритмы не зависят от того,
являются аргументы операторов множествами или мультимножествами. Операции
соединения (join) и группирования/агрегирования (grouping/aggregation) заслуживают
особого внимания.
• Для вычисления оператора соединения R(X, У) х 5(У, Z) кортежи отношений R и S
хешируются в сегменты, общее количество которых совпадает с числом
процессоров. Применяемая хеш-функция, однако, должна зависеть только от
значений атрибутов Y, а не от содержимого всех компонентов, чтобы кортежи обоих
отношений, допускающие соединение, всегда направлялись в один и тот же
сегмент. Как и при выполнении объединения, кортежи сегмента / передаются
процессору I. Соединение кортежей на диске каждого процессора
осуществляется в соответствии с любым из "однопроцессорных" алгоритмов соединения,
рассмотренных ранее.
• Для выполнения оператора группирования и агрегирования yL(R) кортежи
отношения R распределяются по сегментам посредством хеш-функции h, которая
зависит только от группирующих атрибутов, указанных в списке L. Если на
диске каждого процессора хранятся все кортежи определенного сегмента,
оператор yL может быть применен к этим кортежам локальным образом с
помощью любого "однопроцессорного4' алгоритма вычисления у.
15.9.4. Характеристики параллельных алгоритмов
Сопоставим время, затрачиваемое параллельным алгоритмом, работающим на р-
процессорном компьютере, с уровнем производительности алгоритма, решающего ту
же задачу в условиях однопроцессорной системы. При переходе к системе с
несколькими процессорами снижения количества дисковых операций и циклов вычислений,
разумеется, ожидать нельзя, но поскольку р процессоров одновременно
взаимодействуют с р дисками, общее время выполнения операции в абсолютном исчислении
многократно уменьшится.
Унарные операции, подобные ac(R), могут быть завершены за (1/р)-ю часть
времени, требуемого для получения того же результата в однопроцессорной
системе, если кортежи отношения R распределены по дискам р процессоров равномерно
(об этом упоминалось в разделе 15.9.2 на с. 744). Количество операций дискового
ввода-вывода по существу сохраняется неизменным. Единственное отличие связано
с тем, что при хранении кортежей R на р дисках количество блоков, занятых напо-
746
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
ловину, возрастает в среднем от 1 до р, за счет чего незначительно увеличивается
и количество дисковых операций.
Теперь рассмотрим бинарные операции — скажем, соединение R(Xy Y) x S(Y, Z).
Хеш-функция, учитывающая значения совпадающих атрибутов Y, направляет каждый
кортеж в один из р сегментов, где р — количество процессоров. Для пересылки
кортежей /-го сегмента /-му процессору для всех значений / требуется загрузить кортежи
с диска в оперативную память, вычислить значения хеш-функции и отправить все
кортежи по назначению (за исключением одного из каждых р кортежей, который, как можно
ожидать, попадет для обработки на процессор с номером, совпадающим с вычисленным
номером сегмента). Таким образом, для определения сегментов, в которые следует
поместить кортежи, необходимо осуществить B(R) + B(S) операций дискового ввода-вывода.
Затем ((р- 1)/р) (#(/?) + 5(5)) блоков данных подлежат отправке по внутренней
коммуникационной шине системы с целью доставки к тем или иным процессорам —
только в среднем (1 /р)-я часть всех кортежей сразу окажется в ведении нужного
процессора и поэтому пересылки не потребует. Стоимость перемещения данных по шине
может оказаться более или менее высокой в сравнении с затратами на выполнение
равного количества дисковых операций — все зависит от архитектуры конкретной
системы. Однако вполне правомерно полагать, что пересылать данные по
коммуникационной шине все-таки гораздо дешевле, нежели считывать с диска в оперативную
память, — хотя бы потому, что межпроцессорный обмен, в отличие от запросов
к диску, не связан с эффектами механического движения.
Вообще говоря, можно считать, что процессор-получатель должен сохранить
принятые кортежи на собственном диске, а затем подвергнуть их локальному
соединению. Например, если каждый процессор выполняет двухпроходное соединение на
основе сортировки, прямолинейный алгоритм распараллеливания потребует
осуществления каждым процессором з(/?(/0 + B(S)j Ip операций дискового ввода-вывода,
поскольку объемы групп кортежей R и 5, принадлежащих одному сегменту,
составляют приблизительно B(R) I p и B(S) I р, и при подобном подходе к соединению на
каждый блок данных отношений-операндов расходуется по три дисковые операции.
К этой величине следует прибавить еще 2(b{R) + #(5)) I р операций в расчете на
каждый процессор, чтобы принять во внимание затраты на первоначальное считывание
каждого кортежа и сохранение кортежей в ходе их хеширования и распределения по
сегментам. Не мешало бы учесть и стоимость межпроцессорного обмена данными, но,
как мы условились ранее, подобные значения можно считать пренебрежимо малыми
в сравнении с издержками, обусловленными операциями дискового ввода-вывода
данных аналогичного объема.
Результаты проведенного анализа демонстрируют важность модели
многопроцессорной обработки. Хотя абсолютное число дисковых операций возрастает — с трех до пяти
в расчете на один блок данных, — общее время работы алгоритма, определяемое
количеством обращений к диску со стороны каждого процессора, снижается с 3(#(/?) + 5(5))
до 5 (#(/?) + 5(5)) /р, и выигрыш возрастает с увеличением количества процессоров р.
Более того, существуют способы усовершенствования рассматриваемого
параллельного алгоритма, позволяющие сохранить общее количество операций дискового
ввода-вывода на том же уровне, который характерен для версии алгоритма,
ориентированной на однопроцессорные системы. Поскольку каждый процессор имеет дело
с небольшими частями отношений, становится возможным применение алгоритмов
локального соединения, нуждающихся в существенно меньшем количестве дисковых
операций. Например, если даже отношения R и 5 настолько велики, что в условиях
однопроцессорной системы требуют применения двухпроходного алгоритма, для об-
15.9. ПАРАЛЛЕЛЬНЫЕ АЛГОРИТМЫ ДЛЯ РЕЛЯЦИОННЫХ ОПЕРАТОРОВ
747
работки каждой (1 /р)-й порции, возможно, удастся употребить однопроходный
алгоритм. Помимо того, не исключен вариант экономии на двух дисковых операциях
в расчете на каждый блок данных, если при получении блока, предназначенного для
размещения в соответствующем сегменте, процессор в состоянии сразу
воспользоваться содержимым этого блока, не "сбрасывая" его на диск. Большинство известных
алгоритмов, реализующих соединение и другие реляционные операторы, допускают
подобный режим работы, и в этом случае параллельный алгоритм выглядит
совершенно так же, как и многопроходный алгоритм, на первом проходе которого
используется техника хеширования, упомянутая в разделе 15.8.3 на с. 739.
Пример 15.18. Вновь обратимся к оператору соединения R(X, Y)xS(Y, Z) отношений R
и S, содержащих 1000 и 500 блоков данных соответственно. Предположим, что
каждый из 10 процессоров многопроцессорной системы имеет возможность адресовать по
101 буферу оперативной памяти. Допустим также, что кортежи R и S распределены по
дискам процессоров равномерно.
Начнем с процедуры разнесения кортежей R и S по 10 сегментам посредством хеш-
функции h, зависящей только от значений совпадающих атрибутов Y. Каждый сегмент
связан с определенным процессором, и кортежи в ходе хеширования направляются
в распоряжение соответствующего процессора. Общее количество дисковых операций,
необходимых для считывания кортежей R и S, составляет 1500, или 150 в расчете на
один процессор. К каждому процессору попадают 135 блоков данных,
предназначенных для пересылки девяти другим процессорам. Общее количество перемещаемых
блоков, таким образом, равно 1350.
Будем полагать, что процессоры передают вначале блоки с данными S, а затем R.
Так как каждый процессор получает около 50 блоков с кортежами S, он в состоянии
разместить эти кортежи в структурах оперативной памяти, расходуя 50 из
101 доступных блоков. Затем, при поступлении кортежей R, процессор сопоставляет
каждый из них с кортежами S, находящимися в буферах памяти, и при совпадении
значений компонентов общих атрибутов включает соединенный кортеж в итоговое
отношение. В этом случае общие затраты на выполнение процедуры соединения
определяются полутора тысячами дисковых операций, что намного меньше в сравнении
с любым другим методом, рассмотренным в этой главе. Более того, период времени,
требуемый для завершения соединения, состоит из компонентов времени
обслуживания 150 обращений к диску со стороны каждого процессора, а также времени обмена
данными между процессорами и вычислений в оперативной памяти. Заметьте, что
временнб/е затраты на выполнение 150 дисковых операций меньше 1/10-й доли
времени работы алгоритма на однопроцессорном компьютере: выигрыш обусловлен не
только параллельным функционированием 10 процессоров, но и тем, что в
распоряжение процессоров выделены 1010 буферов оперативной памяти.
Разумеется, вполне правомочно утверждать, что имей однопроцессорная система
1010 буферов памяти, она также смогла бы справиться с задачей за один проход с
помощью 1500 операций дискового ввода-вывода. Однако поскольку для
многопроцессорных систем обычно характерно однозначное соответствие между объемом памяти и
количеством процессоров, это дает возможность воспользоваться двумя
преимуществами таких систем одновременно — дополнительными процессорами и возросшим
ресурсом памяти, позволяющим применить более быстрый алгоритм. □
15.9.5. Упражнения к разделу 15.9
Упражнение 15.9.1. Предположим, что продолжительность дисковой операции
составляет 100 миллисекунд. Пусть B(R)= 100, так что на обращения к диску при
вычислении оператора crc{R) на однопроцессорном компьютере придется затратить
около 10 секунд. Насколько быстрее удастся выполнить ту же операцию выбора на
многопроцессорной машине с р процессорами, если: *а) р - 8; Ь) р - 100; с) р = 1000?
748
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
Поберегись!
При использовании алгоритмов на основе хеширования с целью распределения
данных по процессорам и реализации операций (как в примере 15.18) не стоит
злоупотреблять применением одной и той же хеш-функции. Предположим для
примера, что в ходе выполнения операции соединения отношений R и S для разнесения
их кортежей по процессорам используется хеш-функция п. Можно поддаться
искушению впоследствии воспользоваться той же функцией h для локального
хеширования кортежей S при выполнении однопроходного соединения на каждом
отдельном процессоре. Если поступить именно так, все кортежи будут направлены
в один и тот же сегмент, и процедура соединения в оперативной памяти,
обсуждаемая в примере 15.18, окажется чрезвычайно неэффективной.
! Упражнение 15.9.2. В примере 15.18 описана процедура параллельного вычисления
соединения R x S, предполагающая распределение кортежей по процессорам
посредством хеширования с последующим использованием однопроходного
алгоритма соединения на каждом процессоре. Используя параметры размеров B(R) и B(S)
отношений R и S, числа р процессоров и количества М буферов оперативной
памяти, доступных для каждого процессора, выразите условие, при выполнении
которого алгоритм функционирует успешно.
15.10. Резюме
♦ Обработка запросов. Запросы, получаемые системой, вначале компилируются
и оптимизируются, а затем выполняются. При изучении процесса выполнения
запросов необходимо ознакомиться с методами реализации операторов
реляционной алгебры, учитывающими особенности и возможности SQL.
♦ Планы запросов. На основе текста запроса конструируется логический план
запроса, во многом напоминающий выражение реляционной алгебры, который
затем преобразуется в физический план запроса посредством выбора способа
реализации каждого оператора и порядка выполнения соединений, а также
принятия иных решений (подробнее ~- в главе 16 на с. 753).
♦ Сканирование таблиц. Существует ряд физических операторов,
позволяющих обращаться к кортежам отношений. Оператор табличного
сканирования обеспечивает возможность последовательного считывания блоков
с кортежами отношения, оператор индексного сканирования для отыскания
кортежей использует индекс, а оператор сканирования с сортировкой
возвращает отношение в упорядоченном виде.
♦ Измерение стоимости физических операторов. Доминирующей компонентой
суммарных затрат, связанных с выполнением физического оператора,
служит, как правило, количество требуемых операций дискового ввода-вывода.
В нашей модели учитываются только время осуществления дисковых
операций, а также объем буферов оперативной памяти, предназначенных для
считывания аргументов операции, но не затраты, обусловленные
необходимостью сохранения результатов.
♦ Итераторы. Последовательность операторов, вовлеченных в процесс
выполнения запроса, воспринимается проще в контексте модели итератора,
предусматривающей наличие трех функций, которые предназначены для открытия
конструкции, представляющей отношение, считывания очередного кортежа и
закрытия конструкции.
15.10. РЕЗЮМЕ
749
♦ Однопроходные алгоритмы. Если размер одного из отношений-аргументов
оператора достаточно мал, чтобы кортежи этого отношения можно было уместить
в буферы оперативной памяти целиком, при выполнении оператора следует
считать меньшее из отношений в память, а затем последовательно загружать
блоки другого отношения.
♦ Соединение посредством вложенных циклов —■ простой алгоритм соединения,
действующий даже в тех случаях, когда содержимое ни одного из отношений-
операндов не может быть загружено в оперативную память единовременно:
в память считывается возможно более крупная порция данных меньшего
отношения, и кортежи из этой порции последовательно сопоставляются со всеми
кортежами другого отношения; процесс продолжается до тех пор, пока в
памяти не "побывает" каждый кортеж меньшего отношения.
♦ Двухпроходные алгоритмы. За исключением процедур, использующих вложенные
циклы, большинство алгоритмов, предназначенных для реализации реляционных
операций в условиях, когда размеры отношений-аргументов превышают объем
свободной области оперативной памяти, выполняются в два прохода и
основываются на механизмах сортировки, хеширования или индексирования.
♦ Алгоритмы на основе сортировки: содержимое отношений-операндов
распределяется по отсортированным подспискам с длиной, равной объему доступной
области оперативной памяти; затем при слиянии подсписков выполняются
действия, отвечающие природе оператора.
♦ Алгоритмы на основе хеширования: с помощью хеш-функции кортежи отношений-
аргументов разносятся по сегментам; далее обрабатывается содержимое отдельных
сегментов (для унарных операций) или пар сегментов (для бинарных операций).
♦ Хеширование против сортировки. Алгоритмы, основанные на хешировании,
зачастую превосходят по эффективности аналоги, предусматривающие
использование механизма сортировки, поскольку требуют, чтобы только одно из
отношений-операндов было достаточно "мало". Алгоритмы с сортировкой, с другой
стороны, являются более предпочтительными в ситуациях, когда имеются
дополнительные основания для упорядочения определенных порций данных.
♦ Алгоритмы на основе индексирования. Применение индексов — прекрасный
способ ускорения операции выбора в тех случаях, когда в условии выбора атрибуты
индекса сопоставляются с константами. Алгоритмы соединения на основе
хеширования удобны в ситуациях, когда одно из отношений достаточно мало,
а другое снабжено индексом для атрибутов соединения.
♦ Менеджер буферов. Доступ к областям памяти контролируется менеджером
буферов. При поступлении заявки на буфер памяти менеджер буферов, используя
одну из стратегий замещения, освобождает занятый буфер, при необходимости
"сбрасывая" его содержимое на диск, и предоставляет в распоряжение
процесса, инициировавшего заявку. Зачастую количество буферов, доступных для
оператора, нельзя предсказать заранее, поэтому алгоритм, реализующий оператор,
должен "уметь" адаптироваться к конкретным условиям.
♦ Многопроходные алгоритмы. Двухпроходным алгоритмам, основанным на
сортировке и хешировании, соответствуют рекурсивные аналоги, позволяющие
использовать три или большее количество проходов для обработки данных особо
крупного объема.
♦ Параллельные вычислительные системы. Современные многопроцессорные
компьютеры относятся к трем категориям в зависимости от критерия
распределения ресурсов по процессорам: с общей памятью, с общими дисками и с обо-
750
ГЛАВА 15. ВЫПОЛНЕНИЕ ЗАПРОСОВ
собленными ресурсами. Для приложений баз данных наиболее эффективной
является архитектура систем с обособленными ресурсами.
♦ Параллельные алгоритмы. При использовании алгоритмов, реализующих
операторы реляционной алгебры в среде многопроцессорной системы, уровень
производительности повышается почти пропорционально количеству процессоров.
Обычно предпочтение отдается алгоритмам, осуществляющим хеширование
кортежей отношений-операндов по сегментам с последующими рассылкой
данных подходящим процессорам и параллельным выполнением операции над
локальными данными, находящимися в ведении каждого процессора.
15.11. Литература
Обзоры технологий оптимизации запросов представлены в работах [2J и [6]. Статья
[8] посвящена проблематике распределенной оптимизации и обработки запросов.
Ранние результаты, достигнутые в области разработки методов соединения,
приведены в [5]. Доклад [3] содержит результаты анализа и обзор алгоритмов управления
буферизацией данных.
Алгоритмы, основанные на сортировке, впервые описаны в [1]. Преимущества
алгоритмов, использующих механизм хеширования для вычисления соединения,
доказаны в работах [4] и [7]; доклад [4] содержит и первое упоминание о технике
гибридного соединения с хешированием. Методы применения хеширования с целью
реализации соединения и других реляционных операторов в условиях многопроцессорных
систем предлагались и развивались неоднократно; наиболее ранней известной работой
в этой области является диссертация [9].
1. Blasgen M.W., Eswaran К.P. Storage access in relational databases, IBM Systems J., 16:4
(1977), p. 363-378.
2. Chaudhuri S. An overview of query optimization in relational systems, Proc. 17th Annual ACM
Symp. on Principles of Database Systems (1998), p. 34—43.
3. Chou H.-T., DeWitt D.J. An evaluation of buffer management strategies for relational database
systems, Proc. Intl. Conf. on Very Large Databases (1985), p. 127-141.
4. DeWitt D.J., Katz R.H., Olken F., Shapiro L.D., Stonebraker M., and Wood D. Implementation
techniques for main-memory database systems, Proc. ACM SIGMOD Intl. Conf. on
Management of Data (1984), p. 1-8.
5. Gotlieb L.R. Computing joins of relations, Proc. ACM SIGMOD Intl. Conf. on Management
of Data (1975), p. 55-63.
6. Graefe G. Query evaluation techniques for large databases, Computing Surveys, 25:2
(1993), p. 73-170.
7. Kitsuregawa M., Tanaka H., and Moto-oka T. Application of hash to database machine and its
architecture, New Generation Computing, 1:1 (1983), p. 66—74.
8. Kossman D. The state of the art in distributed query processing, Computing Surveys, 32:4
(2000), p. 422-469.
9. Shaw D.E. Knowledge-based retrieval on a relational database machine, Ph. D. Thesis, Dept.
of CS, Stanford Univ. (1980).
15.11. ЛИТЕРАТУРА
751
Глава 16
Компиляция и оптимизация
запросов
После изучения базовых алгоритмов выполнения операторов физического плана
запроса (см. главу 15 на с. 683) вы готовы к восприятию сведений об архитектуре
компилятора и оптимизатора запросов. Как мы отмечали на рис. 15.2 (см. с. 685),
процессор запросов, осуществляя компиляцию запроса, обязан выполнить
следующие операции.
1. Запрос, написанный на языке, подобном SQL, подвергается синтаксическому
анализу (parsing) и преобразуется в дерево разбора (parse tree), представляющее
структуру запроса в определенном виде, удобном для дальнейшего использования .
2. Дерево разбора реформируется в дерево выражений реляционной алгебры (или
сходной системы обозначений), которое называют логическим планом запроса
(logical query plan).
3. Логический план запроса превращается в физический план запроса (physical
query plan), который фиксирует не только отдельные операции, но и
регламентирует порядок их следования, задает алгоритмы, применяемые на
каждом шаге, и определяет способы получения данных и взаимообмена
информацией между операторами.
Первая стадия, связанная с синтаксическим разбором, служит предметом
обсуждения в разделе 16.1 на с. 754. Результатом ее выполнения является дерево разбора
запроса. Две другие стадии предполагают выбор из множества альтернатив. При
конструировании наилучшего логического плана запроса имеются возможности
применения множества самых различных алгебраических операторов. В разделе 16.2 на с. 760
законы реляционной алгебры рассматриваются с абстрактной точки зрения. Раздел
16.3 на с. 774 посвящен проблемам преобразования дерева разбора в начальный
логический план запроса с демонстрацией способов применения алгебраических законов,
упомянутых в разделе 16.2, для улучшения качества начального логического плана.
В процессе создания физического плана на основе логического плана надлежит
оценивать "стоимость" каждого возможного варианта действий. Стоимостной анализ
является самостоятельной областью исследований, и примеры использования методов
оценки затрат, связанных с выполнением тех или иных реляционных операторов,
приведены в разделе 16.4 на с. 783. В разделе 16.5 на с. 797 показано, как применять
оценки стоимости затрат для сопоставления планов, а в разделе 16.6 на с. 809
исследованы специальные проблемы выбора порядка соединения (join) нескольких
отношений. Наконец, раздел 16.7 на с. 822 освещает стратегии избрания алгоритмов
физического плана запроса и содержит сведения о преимуществах и недостатках схем
организации каналов (pipelining) и материализации (materialization).
16.1. Синтаксический анализ
Ряд начальных стадий процесса компиляции
запроса показан на рис. 16.1. Четыре элемента
диаграммы соответствуют двум первым блокам
укрупненной структуры, приведенной на рис. 15.2
(см. с. 685). Препроцессор (preprocessor), о котором мы
расскажем в разделе 16.1.3 на с. 759, выделен
в отдельный блок, занимающий место между
синтаксическим анализатором (parser) и генератором
логического плана запроса (logical query plan generator).
В этом разделе мы обсудим вопросы
синтаксического разбора текстов на языке SQL и познакомим вас
с основами соответствующей грамматики (grammar),
а в разделе 16.2 на с. 760 ненадолго отступим от темы,
связанной с компиляцией SQL-запросов, чтобы
подробно рассмотреть различные законы и способы
преобразований, применимые к выражениям
реляционной алгебры. Раздел 16.3 (см. с. 774) вновь возвратит
нас в лоно теории и практики компиляции запросов:
мы расскажем, как дерево синтаксического разбора
превращается в выражение реляционной алгебры,
которое становится начальным логическим планом
запроса, а затем продемонстрируем, как способы
преобразований, упомянутые в разделе 16.2,
используются для улучшения плана запроса.
16.1.1. Синтаксический анализ и деревья разбора
Задача синтаксического анализатора (parser) состоит в преобразовании текста,
написанного на языке, подобном SQL, в дерево разбора (parse tree). Каждая вершина
дерева разбора представляет одну из следующих сущностей:
1) атомы (atoms) — лексические единицы, такие как служебные слова
(например, select), наименования атрибутов или отношений, константы,
скобки, операторы (скажем, + или <) и иные элементы схемы;
2) синтаксические категории (syntactic categories) — символические обозначения
семейств частей запроса, выполняющих одинаковые функции; обычно
задаются в виде имен, заключенных в угловые скобки (например, для описания
любого запроса в общеупотребительной форме "select—from—where"
используется аббревиатура <SFW>, а категория <Condition> (условие) служит для
представления любого выражения, которое играет роль условия, т.е.
употребляется в контексте предложения where SQL-запроса).
Если вершина дерева разбора является атомом, она не может иметь дочерних
вершин. Если же вершина представляет синтаксическую категорию, дочерние вершины
описываются посредством одного из правил (rules) грамматики языка. Все эти понятия
мы разъясним с помощью примеров. Подробности, касающиеся проектирования
Запрос
Синтаксический
анализатор
Препроцессор
Раздел 16.1
Генератор
логического
плана запроса
Переписчик
логического
плана запроса
Раздел 16.3
Предпочтительный
логический
план запроса
Рис. 16.1. От запроса к
логическому плану запроса
754
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
формальных грамматик конкретного языка и особенностей процесса синтаксического
разбора, т.е. превращения программного кода или текста запроса в соответствующее
дерево разбора, должны изучаться в рамках отдельного курса компиляции.108
16.1.2. Грамматика простого подмножества языка SQL
Проиллюстрируем процесс синтаксического разбора, воспользовавшись рядом
правил, действующих в контексте языка запросов, который является ограниченным
подмножеством SQL. По ходу изложения мы будем ссылаться на дополнительные
правила, необходимые в той ситуации, когда речь могла бы идти о конструировании
функционально полной грамматики языка SQL.
Запросы
Синтаксическая категория <Query> (запрос) предназначена для представления
любых правильных (well-formed) запросов SQL. Вот некоторые из правил с "участием"
этой категории:
<Query> ::= <SFW>
<Query> ::= ( <Query> )
Символ : : = используется нами в значении "может быть выражено как". Первое из
указанных правил гласит, что запрос способен принимать форму "select—from—where"
(о правилах, касающихся категории <sfw>, мы поговорим ниже). В соответствии со
вторым правилом текст запроса может быть заключен в круглые скобки. В полной
грамматике SQL нам также понадобились бы правила, позволяющие в качестве
запроса использовать наименования отдельных отношений или выражения с привлечением
имен отношений и операторов, подобных union и join.
Формы "select-from-where"
Категорию <sfw> мы опишем только одним правилом:
<SFW> ::= SELECT <SelList> FROM <FromList> WHERE <Condition>
Это правило представляет самую общую форму SQL-запросов и не учитывает
возможность использования различных необязательных предложений, таких как
group by, having или order by, а также дополнительных опций внутри
предложений (скажем, distinct в select). Обратим ваше внимание на то, что грамматика
конструкции "select—from—where", определяющая полный перечень языковых средств
и вариантов их применения, намного сложнее. Заметим также, что в соответствии
с принятым нами соглашением служебные слова вводятся в верхнем регистре.
Синтаксические категории <SelList> и <FromList>, несколько подробнее
описанные ниже, представляют форматы списков, сопровождающих служебные слова
SELECT и FROM соответственно. Категория <Condition> описывает структуру условия
SQL (выражения, способного возвращать значения true или false); некоторые
упрощенные правила для этой категории мы рассмотрим чуть позже.
СПИСКИ SELECT
<SelList> ::= <Attribute> , <SelList>
<SelList> ::= <Attribute>
Правила гласят, что список предложения select может состоять из единственного
атрибута (описываемого синтаксической категорией <Attribute>) или перечня атрибутов,
108 Всем, кто не знаком с предметом, советуем обратиться к книге Aho A.V., Sethi R., and
Ullman J.D. Compilers: Principles, Techniques, and Tools, Reading, MA, 1986, хотя примеров из
раздела 16.1.2, вообще говоря, вполне достаточно, чтобы осознать место и роль синтаксического
анализатора в структуре процессора запросов.
16.1. СИНТАКСИЧЕСКИЙ АНАЛИЗ
755
разделяемых символом запятой. При рассмотрении полной грамматики SQL нам
пришлось бы добавить правила, регламентирующие использование в предложении select
выражений и агрегирующих функций, а также псевдонимов для атрибутов и выражений.
СПИСКИ FROM
<FromList> ::= <Relation> , <FromList>
<FromList> ::= <Relation>
Здесь список предложения from определяется как упорядоченный набор
наименований отношений (<Relation>), разделяемых запятыми. Для простоты мы не
рассматриваем варианты списков from, содержащих выражения (скажем, R join S) или
вложенные конструкции "select—from—where". В полной грамматике SQL следовало бы
также учесть правила использования псевдонимов отношений (переменных кортежа).
Условия
Некоторые правила конструирования SQL-условий таковы:
<Condition> ::= <Condition> AND <Condition>
<Condition> ::= <Tuple> IN <Query>
<Condition> ::= <Attribute> = <Attribute>
<Condition> ::= <Attribute> LIKE <Pattern>
Хотя в сравнении с другими синтаксическими категориями набор правил для категории
условия (<Condition>) более внушителен, это не должно вводить вас в заблуждение:
здесь мы только слегка "копнули" гигантский кладезь многообразных форм задания
условий в SQL — за пределами нашего внимания остались правила применения
операторов OR, not и exists, операторов сравнения, отличных от "равно" (=) и like,
употребления операндов-констант и т.д. Помимо того, хотя в SQL существует целый ряд
вариантов описания структур кортежей (<Tuple>), мы будем пользоваться только одним
правилом, удостоверяющим, что кортеж может представляться единственным атрибутом:
<Tuple> ::= <Attribute>
Базовые синтаксические категории
Синтаксические категории <Attribute> (атрибут), <Relation> {отношение)
и <Pattern> {образец) имеют специальное значение и отличаются от остальных тем,
что определяются не грамматическими правилами, а правилами, установленными для
соответствующих атомов. Например, вершина <Attribute> в дереве разбора
способна иметь только одну дочернюю вершину, представляющую последовательность
символов, которая выполняет функцию наименования атрибута и однозначно определяет
атрибут в текущей схеме базы данных. Аналогично, вершине <Relation> отвечает
символьная строка, задающая имя отношения, а вершине <Pattern> — строка в
одинарных кавычках, описывающая образец сравнения.
Пример 16.1. В процессе изучения стадий синтаксического разбора и перезаписи
запроса мы будем неоднократно обращаться к двум версиям запроса, адресующего отношения
Starsln(movieTitle, movieYear, starName)
MovieStar(name, address, gender, birthdate)
из "кинематографической" базы данных. Обе версии запроса предполагают отыскание
сведений о названиях кинофильмов (movieTitle), в съемках которых принимали
участие по меньшей мере один актер или одна актриса, родившиеся (birthdate)
в 1960 году. Для идентификации кортежей с информацией об актерах, появившихся
на свет в 1960 году, мы будем пользоваться оператором like, проверяющим,
завершается ли строка компонента birthdate константой • I960 '.
756
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Один из способов решения задачи состоит в использовании подзапроса к
отношению Movies tar с целью получения множества имен (name) актеров 1960 года
рождения и выполнении проверки принадлежности этому множеству компонента starName
каждого кортежа stars in. Полный текст запроса приведен на рис. 16.2.
SELECT movieTitle
FROM Starsln
WHERE starName IN (
SELECT name
FROM MovieStar
WHERE birthdate LIKE
'%1960'
);
Рис. 16.2. Запрос, возвращающий наименования
кинофильмов с участием актеров I960 года рождения
Дерево разбора запроса, сконструированное с учетом рассмотренного выше
ограниченного набора грамматических правил, показано на рис. 16.3. Корневую вершину
представляет синтаксическая категория <Query> — так и должно быть при
построении деревьев разбора для любых SQL-запросов. Если прошествовать по дочерним
вершинам дерева, нетрудно убедиться, что запрос задан в форме "select—from—where";
список <SelList> состоит только из одного атрибута, movieTitle, а список
<FromList> включает название единственного отношения, starsln (на этом и
следующих рисунках с изображением деревьев синтаксические категории обозначены
обычным шрифтом — в отличие от основного текста, где они набраны <вот так>).
<Query>
<SFW>
SELECT <SelList> FROM <FromList> WHERE <Condition>
/ / ^V\
<Attribute> <RelName> <Tuple> IN <Query>
I I / ^7\
movieTitle Starsln <Attribute> ( <Query> )
i /
starName <SFW>
SELECT <SelList> FROM <FromList> WHERE <Condition>
<Attribute> <RelName> <Attribute> LIKE <Pattern>
name MovieStar birthdate '%1960'
Рис. 16.3. Дерево разбора для запроса на рис. 16.2
Условие, заданное в предложении where внешнего запроса, более сложно:
конструкция содержит служебное слово in с подзапросом, заключенным в круглые скобки
(скобками в SQL следует обрамлять любые вложенные запросы). Подзапрос в свою
16.1. СИНТАКСИЧЕСКИЙ АНАЛИЗ
757
очередь также представлен в форме "select—from—where", обладает собственными од-
нокомпонентными списками select и from и содержит простое условие с
оператором like в предложении where. □
Пример 16.2. Теперь рассмотрим другую версию того же запроса, но на сей раз без
вложенных запросов: мы применяем операцию соединения посредством равенства
(equijoin), сопоставляющую данные отношений stars In и Movies tar с помощью
условия starName = name, которое гарантирует, что кортежи обоих отношений
представляют информацию об одном и том же актере (starName является атрибутом
отношения Starsln, a name — MovieStar). Текст запроса приведен на рис. 16.4.109
Дерево разбора, соответствующее версии запроса на рис. 16.4, показано на
рис. 16.5. Многие ветви дерева сконструированы с использованием тех же правил, что
и на рис. 16.3. Однако обратите внимание на способы представления списка FROM,
содержащего несколько имен отношений, и условия, состоящего из нескольких "мелких"
условий, которые соединены логическим оператором (в данном случае — and).
SELECT movieTitle
FROM Starsln, MovieStar
WHERE starName = name AND
birthdate LIKE '%1960';
Puc. 16.4. Другой вариант запроса,
предусматривающего поиск названий кинофильмов с
участием актеров, родившихся в I960 году
<Query>
<SFW>
SELECT <SelList> FROM <FromList> WHERE <Condition>
<Attribute> <RelName> , <FromList>
movieTitle Starsln <RelName> / AND
<Condition>
\
<Attribute> = < Attributed <Attribute> LIKE <Pattern>
starName name birthdate
Рис. 16.5. Дерево разбора для запроса на рис. 16.4
'%1960'
109 Запросы незначительно различаются тем, что вариант на рис. 16.4 способен возвращать
кортежи-дубликаты в тех ситуациях, когда в некотором фильме снимались несколько актеров 1960 года
рождения. Строго говоря, следовало бы снабдить список предложения SELECT служебным словом
DISTINCT, но применяемая нами упрощенная грамматика такой возможности не предоставляет.
758
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
16.1.3. Препроцессор
Компонент компилятора запросов, который на рис. 16.1 (см. с. 754) обозначен как
препроцессор (preprocessor), выполняет ряд важных функций. Если отношение,
упоминаемое в тексте запроса, на самом деле является виртуальной таблицей (virtual table),
или представлением (view), каждая ссылка на это отношение в контексте предложения
FROM должна быть заменена деревом разбора текстовой конструкции, описывающей
соответствующую виртуальную таблицу: такое дерево конструируется на основе
определения таблицы, которое по существу является запросом.
Препроцессор также ответствен за проведение семантического контроля (semantic
checking). Если запрос верен с синтаксической точки зрения, это не значит, что
возможность нарушения им одного или нескольких семантических правил употребления имен
полностью исключена. Некоторые из обязанностей препроцессора перечислены ниже.
1. Контроль употребления имен отношений. Каждое имя, упомянутое в
предложении FROM запроса, должно представлять существующие отношение или
виртуальную таблицу, зарегистрированные в текущей схеме базы данных, к которой
адресован запрос. Например, проверяя дерево разбора, показанное на рис. 16.3,
препроцессор должен удостовериться, что оба имени (stars In и Movies tar),
заданные в списке предложения from запроса, принадлежат реальным
отношениям "кинематографической" базы данных.
2. Контроль использования имен атрибутов и их разрешение. Каждое имя атрибута,
указанное в предложениях select и where, должно обозначать существующий
атрибут одного из отношений, адресуемых в текущем контексте; в противном
случае компилятор обязан свидетельствовать об ошибке. Например, атрибут
movieTitle в предложении SELECT основного запроса на рис. 16.3 может быть
отнесен только к контексту отношения Stars In; к счастью, movieTitle
действительно является атрибутом stars in, так что результат его проверки
препроцессором оказывается положительным. Типичный препроцессор в такой ситуации
осуществляет разрешение имени атрибута, добавляя к нему, если это не было
сделано явно, имя соответствующего отношения (скажем, starsln.movieTitle).
Если препроцессор обнаруживает неоднозначность, связанную с тем, что
несколько схем отношений из текущего контекста содержат один и тот же атрибут,
ссылку на который нельзя разрешить, выдается сообщение об ошибке.
3. Контроль типов. Способ использования каждого атрибута должен
соответствовать типу этого атрибута. Например, атрибут birthdate в запросе на рис. 16.3
употребляется в контексте оператора сравнения like, который требует, чтобы
аргументы относились к одному из строковых типов либо к типам,
допускающим очевидное преобразование в строковые типы. Поскольку birthdate
обладает типом date, а значения дат в SQL обычно могут трактоваться в виде
строк, итог проверки будет позитивным. Аналогично, операторы в свою очередь
проверяются на предмет совместимости со значениями своих аргументов.
Дерево разбора, успешно прошедшее все стадии контроля, называют
действительным (valid). Далее дерево, модифицированное за счет возможной вставки
поддеревьев виртуальных таблиц и разрешения имен атрибутов, передается генератору
логического плана запроса. Если же дерево разбора оказывается недействительным,
компилятор осуществляет необходимую диагностику и завершает работу.
16.1.4. Упражнения к разделу 16.1
Упражнение 16.1.1. Пополните или измените набор правил для синтаксической
категории <SFW>, чтобы обеспечить возможность представления более развитых
форм запросов вида "select—from—where":
16.1. СИНТАКСИЧЕСКИЙ АНАЛИЗ
759
* а) со средствами удаления дубликатов с помощью опции distinct
предложения select;
b) с предложениями group by и having;
c) с предложениями order by;
d) без предложений where.
Упражнение 16.1.2. Введите дополнительные правила, позволяющие расширить
синтаксическую категорию <Condition> с целью представления:
* а) логических операторов OR и not;
b) операторов сравнения, отличных от = ("равно");
c) условий, заключенных в скобки;
d) выражений со служебным словом exists.
Упражнение 16.1.3. Используя ограниченную грамматику SQL, описанную выше,
сконструируйте деревья разбора для следующих запросов, адресующих отношения
R(a, b) и S(b, с):
a) SELECT а, с FROM R, S WHERE R.b = S.b;
b) SELECT a FROM R WHERE b IN
(SELECT a FROM R, S WHERE R.b = S.b);
16.2. Алгебраические законы и планы запросов
Мы вернемся к теме компиляции запросов в разделе 16.3 на с. 774, где обсудим
процесс преобразования дерева разбора в выражение, целиком или преимущественно
состоящее из операторов расширенной реляционной алгебры, которые
рассматривались в разделах 5.2 на с. 205 и 5.4 на с. 232. В разделе 16.3 также освещаются
эвристические приемы использования законов преобразования выражений реляционной
алгебры, позволяющие улучшить качество начального логического плана запроса и
получить равноценное дерево выражений, для которого можно построить более
эффективный физический план. Но для начала следует познакомить вас с
алгебраическими законами как таковыми, что мы и намереваемся сделать в этом разделе.
Обсуждаемые ниже правила преобразования применяются в процессе выполнения
стадии перезаписи запроса, результатом которой является логический план запроса.
Затем оптимизатор запросов, принимая серию решений, касающихся особенностей
реализации операторов, превращает логический план запроса в физический план.
(Проблемы конструирования физических планов затрагиваются, начиная с раздела
16.4 на с. 783.) Альтернативный, хотя и менее употребительный на практике, подход
состоит в том, что на стадии перезаписи запроса генерируется сразу несколько примерно
равнозначных по качеству логических планов, последние преобразуются в физические
планы и только затем из ряда физических планов выбирается один наилучший.
16.2.1. Коммутативный и ассоциативный законы
Для упрощения алгебраических выражений самых разных типов наиболее широко
применяются коммутативный и ассоциативный законы. Коммутативный закон
(commutative law) для некоторого оператора гласит, что в каком бы порядке ни
задавались аргументы оператора, результат оказывается одинаковым. Например, к
коммутативным арифметическим операторам относятся операторы сложения (+) и
умножения (*): если говорить формально, для любых числовых величин х и у справедливы
соотношения х + у = у + х и х*у = у*х. С другой стороны, оператор вычитания (-) не
коммутативен: х - у ф у - х.
760
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Ассоциативный закон (associative law) разрешает группирование аргументов
нескольких одноименных операторов. Те же арифметические операторы + и * являются
ассоциативными: для любых числовых значений х, у и z имеют место тождества
(х + у) + z = х + (у + z) и (х*у)* z = x*(y*z). Оператор вычитания, напротив, не
ассоциативен: (x-y)-z*x-(y-z). Если оператор одновременно коммутативен и
ассоциативен, его результат не изменяется при любом мыслимом упорядочении и/или
группировании аргументов: например, ((н> + х) + у) + z = (у + х) + (z + w).
Некоторые операторы реляционной алгебры являются как коммутативными, так
и ассоциативными, а именно:
• Rx S = S х R; (Rx S) х T = Rx (S x 7);
• R\xS = S\xR; (RtxS)\xT=Rx(SxT);
• R(JS = S(JR; (R(JS)UT=R(J(S(JT)',
• Rns = snR'ARriS)nT = Rn(snT).
Заметим, что указанные законы справедливы для операторов, работающих и с
множествами, и с мультимножествами.
Мы не будем строго доказывать каждый из этих законов, хотя один пример
подобного доказательства все-таки приведем. Общий метод проверки справедливости
выражения реляционной алгебры, претендующего на роль "закона", таков: надлежит
убедиться в том, что каждый кортеж, получаемый с помощью выражения из левой части,
также возвращается в результате вычисления выражения правой части и наоборот.
Пример 16.3. Попытаемся доказать справедливость коммутативного закона для
оператора соединения Ooin): Rx S = Stx R. Прежде всего, предположим, что в отношении,
служащем итогом операции Rex S из левой части выражения, присутствует кортеж г.
Иными словами, должны существовать кортежи г в R и s в S, которые согласуются с /
в каждом общем атрибуте. Поэтому при вычислении оператора из правой части
выражения, S х R, те же кортежи s и г дадут возможность образовать кортеж г.
Правомерно спросить, не будут ли компоненты t следовать в различном порядке
при вычислении операторов из левой и правой частей. Формально говоря, в контексте
реляционной алгебры порядок перечисления компонентов кортежей не существен —
как упоминалось в разделе 3.1.5 на с. 89, мы вольны при необходимости переставлять
компоненты кортежей, не забывая соответствующим образом упорядочивать
заголовки столбцов таблицы-отношения.
Наше доказательство пока не завершено. Поскольку реляционная алгебра — это,
вообще говоря, алгебра мультимножеств, а не множеств, следует убедиться, что если
кортеж / присутствует в итоговом отношении левой части выражения п раз, количество
экземпляров / в отношении из правой части также должно быть равно п и наоборот. Пусть
отношение из левой части содержит п копий кортежа t. Тогда следует признать, что
кортеж г из R, согласующийся с /, присутствует в отношении RtxS из левой части в
некотором количестве nR экземпляров, а кортеж s из S, также совпадающий с / в общих
атрибутах, — в ns экземплярах, причем nR ns = п. При вычислении оператора S x R правой части
обнаруживается, что количество копий кортежа s из S по-прежнему равно ns, а
количество копий кортежа г из R — nR, что дает возможность получить nsnR, или и, копий г.
Строго говоря, доказательство все еще не полно — рассмотрена та его часть, которая
гласит, что все кортежи, присутствующие в отношении из левой части выражения,
должны наличествовать и в правой части, но, помимо того, следовало бы доказать и
обратное утверждение — если кортеж содержится в отношении правой части выражения,
он обязан пребывать в составе отношения левой части. Ввиду очевидной симметрии все
доводы сохраняют силу, так что повторять те же рассуждения нецелесообразно. □
16.2. АЛГЕБРАИЧЕСКИЕ ЗАКОНЫ И ПЛАНЫ ЗАПРОСОВ
767
Законы для "множественных" и "мультимножественных" версий операторов
Пытаясь применять законы, справедливые для множеств, к отношениям-
мультимножествам, следует быть особо внимательным. Приведем пример. Вам,
возможно, известен так называемый дистрибутивный закон (distributive law)
пересечения множеств, формально записываемый как Л DsC^UsQ = (АГ\$В) UsC^flsO-
Этот закон выполняется только для множеств, но не для мультимножеств.
Предположим, что каждое из мультимножеств Л, В и С равно [х]. Тогда
А Г\в (В Ub Q = М Пв U х] = [х]. Но (Л Г\в В) 1)в (А Пв Q = W \JB М = [х, х] - это,
разумеется, отнюдь не то же самое, что результат вычисления левой части выражения, {х}.
Мы не причисляем к категории коммутативно-ассоциативных оператор тета-
соединения (theta-join), и вот почему. Несомненно, оператор коммутативен:
• R\xS = SxR.
с с
Более того, если условия С сохраняют смысл при различном группировании
аргументов, операция тета-соединения является ассоциативной. Однако существуют примеры,
подобные приведенному ниже, где ассоциативный закон утрачивает силу ввиду того,
что условия операторов не допускают применения к атрибутам отношений,
подвергающихся тета-соединению.
Пример 16.4. Предположим, что даны отношения R(a, b), S(b, с) и Т(с> d), и выражение
(R х S) х Т
R.b > S.b a<d
преобразуется посредством применения гипотетического ассоциативного закона
в следующее:
R х (Sex T).
R.b > S.b a<d
Однако отношения S и Т нельзя соединить на основе условия а < d, поскольку а не
является атрибутом ни S, ни Т (и, более того, d присутствует только в Т). Поэтому
ассоциативный закон не может применяться к произвольным выражениям с операторами
тета-соединения. □
16.2.2. Законы выбора
Порядок выполнения операций выбора (selection) весьма значим с точки зрения
оптимизации запросов. Поскольку при осуществлении выбора кортежей размеры
отношений способны существенным образом уменьшаться, одно из важнейших правил
повышения эффективности обработки запросов состоит в смещении операторов
выбора вниз по дереву выражений настолько "глубоко", насколько это возможно без
изменения семантики выражения в целом. В ранних версиях оптимизаторов запросов
варианты подобных преобразований использовались в качестве основной стратегии
поиска наилучших логических планов. Как будет показано ниже, трансформации вида
"продвинуть операторы выбора вниз по дереву", однако, не вполне универсальны, но
сама идея "перемещения операторов выбора" остается плодотворной.
В этом разделе мы рассмотрим алгебраические законы, касающиеся оператора а.
Для начата отметим полезность разбиения фомоздких условий выбора, включающих
логические операторы AND или OR, на составные части. Доводы в пользу подобной
стратегии таковы: оператор выбора с более простым условием, охватывающим
меньшее количество атрибутов, может быть перемещен в такое место дерева, куда
исходный оператор со сложным условием продвинуть просто нельзя. Вот как выглядят
законы расщепления (splitting rules) условий оператора выбора:
762
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
• 0c x and c2 (R) = °cx (<Усг (Ю);
• ere, orс2 (Ю = (crCi (Я)) Us Ос, (#))•
Второй закон, регламентирующий расщепление условия с оператором OR,
выполняется только в том случае, если отношение R является множеством. Если бы R оказалось
мультимножеством, оператор объединения множеств осуществил бы некорректные
действия по удалению дубликатов.
Заметьте, что порядок задания частных условий Q и С2 несуществен. Правую часть
первого из законов расщепления, например, вполне правомочно записать так: <тс (<тс (/?)).
Если говорить в более общем смысле, допустимо задавать любой порядок
перечисления операторов выбора:
• crcx(°c2(R)) = °c2(crcx(RJ)-
Пример 16.5. Рассмотрим отношение R(a,b,c). Оператор cr(azzX0Ra = 3)MJDb<c(R) на
основании первого закона расщепления можно преобразовать к виду o,a=lORa^3(^crb<c(R)y
Далее, применив закон расщепления условий выбора, содержащих оператор or,
получим <тя = 1 (<T£<f(/?)) U ^ = з(^<с№)-В данной ситуации кортеж не может
единовременно удовлетворять условиям а-\ и д = 3, и поэтому преобразование справедливо
независимо от того, является R множеством или мультимножеством и используется ли
для объединения оператор \JB. В общем же случае при расщеплении условий выбора,
содержащих OR, требуется, чтобы к аргументу-множеству применялся оператор Ц>.
С другой стороны, можно начать преобразование, сделав аь<с внешним
оператором: аь<с(<тя=10КЯ = 3(#))• Выполнив расщепление условия, содержащего OR, получим
равноценное, но несколько иное выражение: ab<c (<r,;=1(#)U <r„ = 3W)- ^
Теперь рассмотрим семейство законов, регламентирующих порядок
преобразования операторов выбора, операндами которых служат бинарные операторы декартова
произведения (Cartesian product), объединения (union), пересечения (intersection), разности
(difference) и соединения Qoin). Законы подразделяются на три типа в зависимости от
того, обязательно ли следует применять оператор выбора к одному или обоим
аргументам "вложенного" бинарного оператора.
1. Для объединения — оператор выбора должен применяться к обоим аргументам.
2. Для разности — оператор следует применять к первому и (необязательно) ко
второму аргументам.
3. Для остальных операторов — требуется, чтобы оператор выбора был применен
по меньшей мере к одному аргументу. Что касается соединения и декартова
произведения, применение оператора к обоим аргументам может оказаться
либо возможным, либо нет, поскольку не исключено, что то или иное
отношение-аргумент не обладает атрибутами, оговоренными в условии выбора. Если
применение оператора выбора к обоим аргументам и допустимо, улучшение
качества плана запроса в результате принятия подобного решения не
гарантируется (за подробностями обратитесь к упражнению 16.2.1 на с. 772).
Закон, связывающий операторы выбора и объединения, выглядит так:
• а с (R U S) = а с (R) U сгс (5).
16.2. АЛГЕБРАИЧЕСКИЕ ЗАКОНЫ И ПЛАНЫ ЗАПРОСОВ
763
В данном случае оператор выбора продвигается "вниз" по обеим ветвям дерева.
А вот один из вариантов закона для оператора разности:
• ac(R-S) = ac(R)-S.
Возможно, однако, применить оператор выбора и к обоим аргументам разности
одновременно:
• crc(R-S) = crc(R)-crc(S).
Другие бинарные операторы позволяют применять оператор выбора к одному или
обоим аргументам. Аргументом оператора выбора ас может быть только такое
отношение, которое содержит все атрибуты, упомянутые в условии С. В приведенных
ниже законах подразумевается, что отношение R обладает всеми атрибутами,
присутствующими в условии С:
• crc(RxS) = crc(R)xS;
• ac(RtxS) = ac(R)txS;
• ac(R х S) = crc(R) tx S;
• crc(RnS) = crc(R)ns.
Если в условии С упоминаются только атрибуты 5, можно, напротив, воспользоваться
соотношением
• ac(RxS) = Rxac(S)
и подобными ему зависимостями, соответствующими операторам х, х и П- Если всеми
атрибутами из С обладают оба отношения, R и S, становится справедливым закон вида
• а с (R х S) = а с (R) х <тс (5).
Заметим, что такой закон невыполним для операций хим, поскольку схема
итогового отношения RxS (или R x S) представляет собой объединение схем
отношений R и S и все их атрибуты строго различаются. С другой стороны, аналогичный
закон для оператора П имеет место, если схемы R и S совпадают.
Пример 16.6. Рассмотрим отношения R(a, b), S(b, с) и выражение
^"(Л = 1 OR а = 3) AND b<c\R X Л).
Условие Ъ < с может быть применено только к данным отношения S, ад=1сжд = 3 —
только к кортежам R. Поэтому уместно начать с расщепления условия с оператором
AND (мы делали подобное в начале примера 16.5):
^ а - 1 OR а = 3
Далее, продвигая оператор аь<с "внутрь" R x S с применением к отношению 5, получим:
w а = 1 OR а = з
Наконец, применим "внешний" оператор а к аргументу R: cra:sl0Ra=:3(R)tx crb<c(S).
Можно было бы также расщепить условие с оператором or, как показано в примере
16.5, но получение каких-либо преимуществ, обусловленных подобным решением,
заранее гарантировать нельзя. □
764
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Некоторые тривиальные законы
Разумеется, мы не собираемся подтверждать или опровергать справедливость
каждого закона реляционной алгебры. Тем не менее читатель должен быть осведомлен,
в частности, о действии законов в некоторых "экстремальных" случаях: примерами
могут служить применение оператора к пустому множеству, использование
операторов выбора или тета-соединения с условием, которое всегда истинно или всегда
ложно, или проекция отношения на список всех атрибутов. Вот несколько из
многих возможных вариантов законов для частных случаев:
• результат операции выбора из пустого отношения является пустым отношением;
• если некоторое условие С справедливо всегда (скажем, х> 10 OR jt< 10 для
отношения, где х IS NOT NULL), тогда ос(R)-R\
• если R = 0, то R U S = S.
16.2.3. Продвижение операторов выбора по дереву выражений
Как было показано в примере 6.52 на с. 311, перемещение операторов выбора вниз
по дереву выражений, т.е. замена левой части одного из соотношений, рассмотренных
в разделе 16.2.2, выражением правой части, — это один из наиболее мощных
инструментов в арсенале оптимизатора запросов. Долгое время считалось, что применять
законы для оператора а с целью оптимизации запросов можно только в таком
направлении. Однако с появлением коммерческих систем баз данных, поддерживающих
модель виртуальных таблиц, обнаружилось, что в некоторых ситуациях гораздо
целесообразнее вначале переместить оператор выбора вверх по дереву на максимально
допустимое количество уровней, чтобы затем "охватить" им наибольшее возможное
число ветвей. Проиллюстрируем подобный подход на конкретном примере.
Пример 16.7. Обратимся к отношениям
Starsln(title, year, starName)
Movie(title, year, length, inColor, studioName, producerC#)
из "кинематографической" базы данных. Обратим ваше внимание на то, что для
упрощения дальнейших выкладок атрибуты movieTitle и movieYear отношения Starsln
намеренно переименованы в title и year соответственно. Определим виртуальную
таблицу MoviesOf 1996, представляющую данные о кинофильмах, выпущенных в 1996 году:
CREATE VIEW MoviesOfl996 AS
SELECT *
FROM Movie
WHERE year = 1996;
Теперь для получения сведений о том, какие актеры работали на тех или иных
студиях в 1996 году, достаточно выполнить запрос
SELECT starName, studioName
FROM MoviesOfl996 NATURAL JOIN Starsln;
Определению виртуальной таблицы MoviesOf 1996 соответствует следующее
выражение реляционной алгебры:
^W=1996(M°vie)-
Запрос, представляющий собой естественное соединение результата указанного
выражения и отношения Starsln с последующей проекцией на атрибуты starName
и studioName, описывается выражением, или "логическим планом запроса",
показанным на рис. 16.6.
16.2. АЛГЕБРАИЧЕСКИЕ ЗАКОНЫ И ПЛАНЫ ЗАПРОСОВ
765
В этом выражении единственный оператор выбора уже занимает самую "нижнюю"
допустимую позицию в дереве, так что "продвигать операторы выбора по
дереву вниз" возможности нет. Ничто не запрещает, однако, применять правило
а с (R х S) = а с (R) x S и в "обратном" направлении, чтобы разместить ау1
над
оператором соединения на рис. 16.6. Затем, поскольку year является атрибутом и Movie,
и stars in, мы получаем право продвинуть оператор выбора в направлении обеих вершин,
дочерних по отношению к х. Итоговый логический план запроса приведен на рис. 16.7.
Вполне вероятно, что это решение позволит получить определенные выгоды, поскольку
количество кортежей отношения Stars In уменьшается до выполнения их соединения
с множеством кортежей-"кинофильмов", соответствующих условию уеаг= 1996.
starName, studio Name
X
starName, studioName
I
year** 1996
Starsln
'year =1996
year= 1996
Movie
Рис. 16.6. Логический план
запроса, сконструированный на
основе определений запроса и
виртуальной таблицы
Movie
Рис. 16.7.
Starsln
Улучшение качества
логического плана за счет
перемещения операторов выбора вверх
и вниз по дереву выражений
□
16.2.4. Законы проекции
Операторы проекции (projection), как и операторы выбора (см. разделы 16.2.2,
16.2.3), допускают возможность "продвижения" вниз по дереву выражений.
Продвижение операторов проекции, однако, отличается от перемещения операторов выбора
тем, что зачастую первые остаются на месте, а где-либо "ниже" в дереве создаются
вершины, отвечающие новым операторам проекции.
Техника продвижения операторов проекции довольно полезна, хотя и не в такой
степени, как перемещение операторов выбора. Причина очевидна: применение
операторов выбора часто приводит к многократному снижению количества кортежей
отношения, но оператор проекции, не влияя на число кортежей, только уменьшает их длину.
Более того, при использовании оператора расширенной проекции (extended projection)
(см. раздел 5.4.5 на с. 236) длина кортежей на самом деле способна даже возрасти.
Для описания алгебраических законов расширенной проекции нам понадобятся
некоторые новые термины. Рассмотрим элемент Е—>х списка проекции, где Е
представляет собой атрибут или выражение, состоящее из атрибутов и констант. Все
атрибуты, упомянутые в составе Е, мы будем называть входными (input), а атрибут х —
выходным (output). Если элемент списка является отдельным атрибутом, такой атрибут
будет одновременно входным и выходным. Заметим, что иные формы выражений без
стрелки и переименования, отличные от представления отдельного атрибута,
недопустимы — это позволяет охватить все возможные случаи.
Если список проекции состоит только из отдельных атрибутов и не включает
элементы со стрелками и иные выражения, такую проекцию мы будем называть простой
(simple). Все операторы проекции, рассматриваемые в рамках классической
реляционной алгебры, являются простыми.
766
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Пример 16.8. Оператор проекции na,b,c{R) относится к категории простых — атрибуты
a, b и с являются одновременно входными и выходными. С другой стороны, оператор
ла + ь->х,с(Ю нельзя считать простым; a, b и с служат входными , а х и с — выходными
атрибутами. □
Основной принцип, лежащий в основе законов проекции, таков:
• оператор проекции можно размещать в любом месте дерева, если он удаляет
только такие атрибуты, которые не используются ни в одном из операторов,
расположенных "выше" по дереву, и не присутствуют в отношении, служащем
итогом вычисления выражения в целом.
В большинстве основных форм законов проекции операторы проекции трактуются
как простые, хотя в некоторых случаях (например, в используемых ниже операторах
со списком L) это условие выполняется не всегда.
• nL(RxS) = Яь(ям№) х kn(S)), где М — список всех атрибутов R, которые
являются либо общими атрибутами R и S, либо входными атрибутами L, а N —
список атрибутов S, принадлежащих либо к числу общих атрибутов R и S, либо
к категории входных атрибутов L.
• aL(RxS) = nL(яи(R) хnN(S)), где М — список всех атрибутов R, которые
являются либо атрибутами тета-соединения R и S, упомянутыми в условии С,
либо входными атрибутами L, а N — список атрибутов S, принадлежащих либо
к числу атрибутов тета-соединения R и S, либо к категории входных атрибутов L.
• ^(/?х5) = ^(%Wх%(5)), где М и N— списки всех атрибутов R и S
соответственно, являющихся входными атрибутами L.
Пример 16.9. Рассмотрим отношения R(a, b, с), 5(с, d, ё) и выражение
7Ta + e^x,b-+y(R xS). Входные атрибуты проекции — a, b и е, а с — единственный
общий атрибут соединяемых отношений R и S. На основании соответствующего закона
имеем право применить к отношениям R и S (аргументам соединения) операторы
проекции со списками, учитывающими номенклатуру атрибутов R и S:
Заметьте, что оператор яа,ь,с(Ю тривиален — он выполняет проекцию на все атрибуты
отношения R. Удаление этого оператора приводит к третьей эквивалентной форме
выражения, n0 + e^Xyb^y(R х #f,Д5)), которая отличается от исходной тем, что предполагает
удаление атрибута d отношения S непосредственно перед выполнением соединения. □
Помимо того, допустимо заменять проекцию "мультимножественной" версии
объединения отношений объединением отношений-проекций:
• ях (R Us S) = nL (R) Us tzl (5).
Аналогичные преобразования операций объединения множеств, а также пересечения
и разности (в версиях для множеств и мультимножеств), напротив, применять нельзя.
Пример 16.10. Допустим, что отношение R(a,b) содержит единственный кортеж
{(1,2)}, а отношение S(a, Ь) — единственный кортеж {(1,3)}. Тогда
ла(R П S) = яг„(0) = 0. Однако na(R) П яа(S) = {(1)} П {(1)} = {(1)}. □
Если проецирование сопряжено с выполнением определенных вычислений
и входные атрибуты некоторого элемента списка проекции целиком принадлежат
одному из аргументов оператора соединения (или декартова произведения), служащего
16.2. АЛГЕБРАИЧЕСКИЕ ЗАКОНЫ И ПЛАНЫ ЗАПРОСОВ
767
операндом проекции, есть возможность (но не обязанность) осуществить вычисления
непосредственно над аргументом. Проиллюстрируем сказанное примером.
Пример 16.11. Вновь обратимся к отношениям R(a,b,c), S(c,d,e) и рассмотрим
следующую операцию проекции, применяемую к результату соединения: /ra + b^Xfd+e^y(RtxS).
Допустимо применить операции суммирования а + Ъ и переименования суммы в х
непосредственно к отношению R, а аналогичные операции получения суммы d + e и ее
переименования в у —- к отношению S. Эквивалентное выражение примет вид
Один из заслуживающих внимания частных случаев связан с совпадением с с х или у.
В подобной ситуации переименовать сумму в с нельзя, поскольку отношение не
может иметь два атрибута с именем с. Поэтому следует воспользоваться новым
временным именем и выполнить соответствующее переименование в условии "внешнего"
оператора проекции. Например, выражение /ra + b^Cfd + e^y(R\xS) в преобразованном
виде можно было бы записать как я^-*^ (#<, + *-» *,<■(/?) х #</ + <?->>>, с (£))• Q
Допустимо также применение нового оператора проекции к аргументу
"внутреннего" оператора выбора.
• ^(^cW) = Ях(<7с(#л/(Я)))» где М— список всех атрибутов, которые либо
являются входными атрибутами из списка L, либо упоминаются в условии С.
Как и в примере 16.11, имеется возможность выполнения вычислений над списком М
вместо L — при условии, что в С не упоминаются входные атрибуты из L,
вовлеченные в процесс вычислений.
Зачастую целесообразно продвигать операторы проекции вниз по дереву
выражений — даже если при этом исходный оператор проекции остается на месте, поскольку
при проецировании удается уменьшить размеры кортежей и, таким образом,
сократить количество дисковых блоков, занимаемых промежуточным отношением.
Впрочем, подобные действия нельзя выполнять безоглядно, так как в определенных
ситуациях перенос операторов проекции вниз по дереву выражений сопряжен с
дополнительными времени ыми затратами.
Пример 16.12. Рассмотрим запрос, обращаемый к отношению
StarsIn(movieTitle, movieYear, starName) и предполагающий отыскание
сведений об актерах, которые снимались в фильмах, вышедших на экраны в 1996 году:
SELECT starName
FROM StarsIn
WHERE movieYear = 1996;
Результат прямой трансляции запроса в логический план показан на рис. 16.8.
Перед выполнением операции выбора можно осуществить операцию проекции на
следующие атрибуты:
1) starName — требуемый для включения в схему итогового отношения;
2) movieYear — необходимый для условия выбора.
Итог приведен на рис. 16.9.
Если бы отношение stars in было не хранимой таблицей, а результатом другой
операции, такой как соединение, план, представленный на рис. 16.9, имел бы очевидный
смысл: нам удалось бы передавать результат проекции по "каналу" (pipeline)
(подробности — в разделе 16.7.3 на с. 825) по мере генерирования кортежей в процессе
768
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
соединения, опуская "лишний" атрибут movieTitle. Однако starsln является
хранимым отношением. Применение оператора проекции 7tstarNam^movieYear в действительности
способно повлечь необоснованные затраты времени, особенно в том случае, если
атрибут movieYear снабжен индексом. В физическом плане, сконструированном на основе
исходного логического плана на рис. 16.8, напротив, тот же индекс удалось бы
использовать для выбора только таких кортежей Starsln (их наверняка оказалось бы не
много), значения компонентов movieYear которых равны 1996. Но если первой выполнять
операцию проекции (как на рис. 16.9), придется считывать (а затем проецировать) каждый
кортеж Starsln. Что еще хуже, индекс, созданный для атрибута movieYear отношения
Starsln, окажется абсолютно бесполезным при работе с совершенно другим отношением
^flrMimr,movi<ri>ar(Starsin), так что для выполнения оператора выбора придется применять
полномасштабное сканирование всех кортежей результата "вредоносной" проекции.
starName
I
71 starName a movieYear = 1996
I I
G movieYear - 1996 n starName, movieYear
i i
Starsln Starsln
Рис. 16.8. Логический план запроса рис. J6.9. Результат добавления
к примеру 16.12 оператора проекции
16.2.5. Законы соединения и декартова произведения
В разделе 16.2.1 на с. 760 уже упоминались весьма важные коммутативный и
ассоциативный законы, действующие в отношении операторов соединения (join) и
декартова произведения (Cartesian product). Существует и несколько других законов (мы уже
говорили о них в разделе 5.2.10 на с. 216), вытекающих непосредственно из
определения операции соединения:
• R\xS=crc(RxSy,
• RtxS = ;tl(<tc(/?xS)), где С— условие сравнения значений одноименных
атрибутов отношений R и S, a L — список, содержащий по одному атрибуту из
каждой пары одноименных атрибутов, а также все остальные атрибуты R и S
(или, как мы говорили в разделе 5.2.10, список атрибутов схемы R, за которыми
следуют атрибуты S, отсутствующие в R).
На практике указанные правила обычно применяются в направлении справа налево.
Другими словами, декартово произведение, к результату которого применяется
оператор выбора, трактуется как определенная разновидность соединения. Доводы в пользу
такого подхода состоят в том, что алгоритмы вычисления соединений, вообще говоря,
выполняются намного быстрее, нежели алгоритмы, реализующие декартово
произведение, а затем выбор из (обычно весьма объемного) результата произведения.
16.2.6. Законы, касающиеся удаления кортежей-дубликатов
Оператор S, осуществляющий удаление кортежей-дубликатов (duplicate elimination),
может быть продвинут "внутрь" многих, но не всех операторов. Вообще говоря,
перемещение оператора S вниз по дереву выражений позволяет уменьшить размеры промежуточ-
16.2. АЛГЕБРАИЧЕСКИЕ ЗАКОНЫ И ПЛАНЫ ЗАПРОСОВ
769
ных отношений и потому сулит определенные выгоды. Более того, подчас имеет смысл
размещать оператор S на таких позициях, где он, строго говоря, вообще не нужен,
поскольку заведомо известно, что отношение-операнд не содержит кортежей-дубликатов:
• S(R) = R, если R не имеет в своем составе повторяющихся кортежей. Основные
примеры подобных отношений указаны ниже.
a) Хранимое отношение с объявленным первичным ключом.
b) Отношение, служащее итогом выполнения операции группирования у (при
группировании создается отношение, содержащее уникальные кортежи).
Вот несколько законов, связывающих оператор S с другими операторами:
• S(R х S) = S(R) x S(S);
• S(R \xS) = S(R) tx S(S)',
• S(R\xS) = S(R)\xS(S);
с с
• S(ac(R)) = cTc(S(R)).
Допустимо также применять оператор 8 к одному или обоим аргументам
"вложенного" оператора пересечения:
• S(R Пв S) = S(R) Пв S = R Пв S(S) = S(R) Пв S(S).
С другой стороны, аналогичные действия в отношении операторов \JB, -в и п в общем
случае запрещены.
Пример 16.13. Предположим, что отношение R содержит две копии кортежа /, a S — одну.
Тогда в S(R Utf S) окажется один экземпляр /, а в S(R) \JB S(S) — два. Аналогично, отношение
S(R -B S) получит одну копию /, в то время как в S(R) -B S(S) кортежей / не будет вовсе.
Теперь рассмотрим отношение Т(а, Ь), содержащее всего два кортежа— (1,2)
и (1,3). Отношение 8(^па(Т)) будет обладать одним экземпляром кортежа (1),
a /ra(S(T)) — двумя. □
Наконец, следует отметить, что конструирование сочетаний S с операторами Ц>, C\s,
и s вообще лишено какого-либо смысла. Поскольку применение "множественной"
версии оператора объединения, пересечения или разности само по себе служит гарантией
отсутствия кортежей-дубликатов, оператор S оказывается просто избыточным, например:
• S(Rl)sS) = Rl)sS.
Впрочем, нелишне напомнить, что при реализации Us и иных теоретико-
множественных операций в любом случае выполняется процесс удаления дубликатов,
по существу равнозначный применению оператора 8 (за подробностями обратитесь,
например, к разделу 15.2.3 на с. 697).
16.2.7. Законы группирования и агрегирования
При изучении оператора группирования и агрегирования у нетрудно убедиться, что
возможность применения тех или иных преобразований решающим образом зависит
от особенностей конструкций агрегирования, используемых в каждом конкретном
770
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
случае. Поэтому, в отличие от рассмотренных выше операторов, некие универсальные
законы с участием оператора у сформулировать нельзя. Одно из исключений — это
правило "поглощения" оператором /оператора S, упомянутое в разделе 16.2.6:
• S(yL(R)) = yL(R).
Другое достаточно общее правило заключается в возможности удаления ненужных
атрибутов посредством оператора проекции, применяемого к отношению перед
выполнением оператора группирования:
• Yl(R) = Yl(km(.R))i если М — список, содержащий, как минимум, все атрибуты
R, упомянутые в списке L.
Одна из причин, из-за которых другие операторы зависят от результатов
агрегирования посредством у, заключается в том, что на поведение некоторых операторов
агрегирования — в частности, MIN и мах — наличие или отсутствие кортежей-
дубликатов влияния не оказывает. Итог выполнения других операторов
агрегирования — sum, count и avg, — напротив, в общем случае определяется тем, выполнялось
ли предварительно удаление дубликатов или нет.
Будем называть оператор yL невосприимчивым к присутствию дубликатов (duplicate-
impervious), если в списке L нет других операторов агрегирования, кроме MIN и/или
мах. Если оператор yL является невосприимчивым к присутствию дубликатов, имеет
место соотношение:
Yl(R) = Yl(S(R)).
Пример 16.14. Обратимся к отношениям
MovieStar(name, address, gender, birthdate)
Starsln(movieTitle, movieYear, starName)
из "кинематофафической" базы данных с целью получения сведений о том, каковы
наименьшие значения возраста актеров, снимавшихся в кинофильмах, выпущенных
в каждом определенному году. Запрос можно представить следующим образом:
SELECT movieYear, MAX(birthdate)
FROM MovieStar, Starsln
WHERE name = starName
GROUP BY movieYear;
Начальный логический план, конструируемый непо- у movieYear, mx(birthdate)
средственно на основании запроса, показан на рис. 16.10.
Список предложения from представлен оператором
декартова произведения (х), условие предложения where —
оператором Выбора (&пате = starName), a ФУНКЦИИ фуППИрОВаНИЯ
и агрегирования — оператором YmovieYear, т^ымшсу При
необходимости план, изображенный на рис. 16.10, можно под- j^^
вергнуть следующим преобразованиям:
1) свести функции выбора и декартова произведе- MovieStar starsln
ния к операции соединения посредством равен- Рис 16ш Исходный логи_
ства (equijoin); цеский тан запроса к
2) вставить в дерево вершину S, дочернюю по отно- примеру 16.14
шению к корневой вершине у (поскольку
рассматриваемый оператор /невосприимчив к присутствию дубликатов);
3) разместить между вершинами у и 8 вершину п с целью получения проекции
данных на атрибуты movieYear и birthdate, так как только эти атрибуты
присутствуют в схеме итогового отношения у.
16.2. АЛГЕБРАИЧЕСКИЕ ЗАКОНЫ И ПЛАНЫ ЗАПРОСОВ
777
В результате выполнения перечисленных действий получим план,
приведенный на рис. 16.11.
Теперь после вершины, соответствующей оператору соединения посредством
равенства, можно включить пары вершин 8 и я. Дополненный логический план
изображен на рис. 16.12. Если name является первичным ключом MovieStar, в ветви,
ведущей к MovieStar, оператор S, строго говоря, уместно было бы исключить.
У movieYear, ШХ. (birthdate)
movieYear, birthdate
У movieYear, MAX.(birthdate)
' movieYear, birthdate
X!
name — starName
name = starName
MovieStar
Starsln
Рис. 16.11. Второй логический
план запроса к примеру 16.14
□
birthdate, name
MovieStar
' movieYear, starName
Starsln
Рис. 16.12. Третий логический
план запроса к примеру 16.14
16.2.8. Упражнения к разделу 16.2
* Упражнение 16.2.1. Если оказывается возможным применить оператор выбора (а)
к обоим аргументам "вложенного" бинарного оператора, следует принять решение
о том, стоит поступать подобным образом или нет. Насколько существенное
влияние на принятие такого решения оказывает наличие индексов для одного из
отношений-аргументов бинарного оператора? Рассмотрите для примера выражение
а с (R П S) при условии, что существует индекс для отношения S.
Упражнение 16.2.2. Предоставьте примеры, демонстрирующие, что
* а) оператор проекции (я) нельзя продвинуть ниже оператора объединения
множеств (Us);
b) оператор проекции нельзя продвинуть ниже операторов разности множеств
(-s) или мультимножеств (-#);
c) оператор удаления кортежей-дубликатов (S) нельзя продвинуть ниже
оператора проекции (я);
d) оператор удаления кортежей-дубликатов нельзя продвинуть ниже операторов
объединения мультимножеств (\Jb) или разности мультимножеств (-в).
! Упражнение 16.2.3. Докажите, что оператор проекции (я) всегда можно применить
к обоим аргументам оператора объединения мультимножеств (Ue).
! Упражнение 16.2.4. В одних случаях законы, справедливые для множеств, остаются
в силе и для мультимножеств, в других случаях — нет. Рассмотрите каждый из пе-
772
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
речисленных ниже законов, которые определенно выполняются для множеств,
и укажите, остаются ли они верными для мультимножеств, приведя либо
доказательство, либо соответствующий контрпример:
*а) R{JR = R — идемпотентный закон (idempotent law) объединения;
b) Rr\R = R — идемпотентный закон пересечения;
c) R-R = 0;
d) R U (S П T) = (R U S) П (R U T) — дистрибутивный закон объединения.
! Упражнение 16.2.5. Условие принадлежности (с) для мультимножеств определяется
следующим образом: RqS, если и только если каждый элемент х присутствует в R
не в большем количестве экземпляров, нежели в S. Ответьте, выполняются ли
указанные ниже соотношения в применении к мультимножествам (все они
справедливы для множеств), предоставив либо доказательство, либо
соответствующий контрпример:
e) если R с S, то R U S = S;
О если R с S, то R Л S = R;
g) если R с S и S с R, то R = S.
Упражнение 16.2.6. Начав с выражения nL(R(a,byc)xS(bycyd,e)), осуществите
продвижение оператора проекции вниз по дереву выражений до максимально
"глубокого" уровня, если список L выглядит как
*а) b + c->x, c + d->y;
b) a, b, a + d-> z.
! Упражнение 16.2.7. В примере 16.14 на с. 771 мы так и не сделали вывод о том,
какой из трех полученных планов является наилучшим. Каково ваше мнение?
! Упражнение 16.2.8. Изучите каждое из приведенных ниже соотношений
и докажите его справедливость либо предоставьте соответствующий контрпример:
С) XmIN (*) - У, X (Гa, SUM (/>) - X (Ю) = Г у , SUM ф) -> X \ /MIN (Я) -*у,Ь №));
, МАХ ф) -*Х\ /MIN (Я) -*у,Ь
!! Упражнение 16.2.9. Одни варианты оператора соединения, упомянутые в упражнении
15.2.4 на с. 701, поддерживают те или иные законы, о которых мы говорили ранее,
а другие — нет. Подтвердите справедливость каждого из приведенных ниже
выражений с помощью доказательства либо предоставьте опровержение,
подкрепленное соответствующим контрпримером:
*а) ctc(RxS) = ctc(R)xS;
*Ъ) ac(R><iS) = (7c(R)><iS;
c) ac(R ><L S) = Oc(R) ><LS, где условие С охватывает только атрибуты R;
d) ac(R ><L S) = R ><L <jc(S), где условие С охватывает только атрибуты S;
e) &L(R><S) = KL(R)><S;
16.2. АЛГЕБРАИЧЕСКИЕ ЗАКОНЫ И ПЛАНЫ ЗАПРОСОВ
773
0 (R&S) Аг=ДЙ(5>сГ);
g) R><S = S><iR;
h) R ><LS = S ><LR]
i) R\xS = S\xR.
16,3- От деревьев разбора к логическим планам запросов
Настало время возобновить прерванный разговор о проблемах компиляции
запросов. После создания дерева разбора (parse tree) (об этом мы рассказывали в разделе
16.1 на с. 754), представляющего запрос, надлежит преобразовать это дерево в
наиболее предпочтительный логический план запроса (logical query plan). Как указывалось на
рис. 16.1 (см. с. 754), процесс состоит из двух этапов. Вначале предстоит заменить
вершины и структуры дерева разбора соответствующими группами операторов
реляционной алгебры, пользуясь определенными правилами. Некоторые из подобных
правил мы рассмотрим ниже, а другие предложим в качестве упражнений. На втором
этапе полученное выражение реляционной алгебры подвергается преобразованию
в такое эквивалентное выражение, которое, как можно ожидать, позволит получить
наиболее эффективный физический план запроса (physical query plan).
16.3.1. От дерева разбора к дереву выражений реляционной алгебры
Здесь мы попытаемся неформально описать некоторые правила преобразования
деревьев разбора в алгебраические логические планы. Первое и, вероятно, наиболее
важное позволяет выполнять непосредственное преобразование всех "простых"
конструкций "select—from—where" в выражения реляционной алгебры.
• Если синтаксическая категория <Query> представляет собой конструкцию
<SFW> и подчиненная категория <Condition> этой конструкции не содержит
подзапросов, категорию < Query > целиком можно заменить выражением
реляционной алгебры, состоящим (в направлении "изнутри вовне") из
следующих компонентов:
a) декартова произведения всех отношений из списка <FromList>, которое
является аргументом;
b) оператора выбора <тс (С представляет условие <Condition>), в свою очередь
служащего аргументом;
c) оператора проекции 7tL (L соответствует списку атрибутов <SelList>).
Пример 16.15. Обратимся к дереву разбора, показанному на рис. 16.5 (см. с. 758).
Рассмотренный выше вариант преобразования применим ко всему дереву: достаточно
вычислить декартово произведение отношений Stars In и MovieStar, упомянутых в
списке <FromList>, осуществить выбор по условию, указанному в поддереве с корнем
<Condition>, и проецировать результат на атрибут movieTitle из списка <SelList>.
Итоговое дерево выражений реляционной алгебры представлено на рис. 16.13.
Дерево разбора, приведенное на рис. 16.3 (см. с. 757), трансформировать подобным
способом, однако, не удастся. Причина состоит в том, что в условии запроса задан
подзапрос. (О том, как "бороться" с подзапросами, мы расскажем в разделе 16.3.2.
Также рекомендуем познакомиться с текстом врезки "Ограничения на условия
выбора", где разъясняется, почему следует различать условия с подзапросами и без
таковых.) Впрочем, рассматриваемая схема вполне пригодна для преобразования
поддерева, соответствующего подзапросу (см. рис. 16.3). Вот как выглядит выражение
реляционной алгебры, описывающее этот подзапрос: ЯгштеуСьмыме like %i960' (MovieStar)). □
774
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Ограничения на условия выбора
Закономерно задаться вопросом, почему в условии С оператора выбора стс нельзя
описать подзапрос. В реляционной алгебре аргументы оператора — элементы, не
включаемые в подстрочный индекс, — принято трактовать как выражения,
возвращающие отношения. С другой стороны, параметры оператора — значения,
указываемые в индексе, — обладают типами, отличными от типов отношений.
Например, параметр С оператора ас — это условие булева типа, а параметр L оператора
nL — список имен атрибутов и выражений.
Если следовать такому соглашению, любой алгоритм вычислений,
определяемый параметрами оператора, может быть применен к каждому кортежу
отношений-аргументов оператора. Подобное ограничение, касающееся способов
использования параметров, позволяет упростить оптимизацию запросов. Допустим,
напротив, что разрешено применять оператор (скажем, ас(/?)), условие С которого
содержит подзапрос. Надо понимать, что подзапрос придется вычислять заново для
каждого кортежа /?? Подобные действия повлекут совершенно необоснованные
издержки — если только подзапрос не является коррелированным (correlated subquery),
т.е. таким, результаты которого определяются некими "внешними" условиями
(подзапрос на рис. 16.3 (см. с. 757), например, не относится к числу
коррелированных). Впрочем, даже коррелированные подзапросы можно выполнять, обходясь без
повторения вычислений для каждого кортежа.
movieTitle
СТ starName = name AND birthdate LIKE • % 19 6 0 '
X
Starsln MovieStar
Рис. 16.13. Дерево выражений
реляционной алгебры для дерева
разбора на рис. 16.5
16.3.2. Изъятие подзапросов из условий
Для деревьев разбора с вершинами <Condition>, обладающими дочерними
вершинами-подзапросами, введем в обращение некоторую промежуточную форму
оператора, которую можно воспринимать как компромисс между синтаксическими
категориями дерева разбора и операторами реляционной алгебры, применяемыми к
отношениям. Подобный оператор часто называют оператором выбора с двумя аргументами
(two-argument selection). В преобразованном дереве разбора оператор выбора с двумя
аргументами обозначают вершиной с меткой а без параметров. Левая дочерняя
вершина представляет отношение R, подвергаемое операции выбора, а правая —
выражение условия, применяемое к каждому кортежу R. Оба аргумента могут быть
элементами дерева разбора, дерева выражений либо "смешанного" варианта дерева.
Пример 16.16. На рис. 16.14 показан результат перезаписи дерева разбора,
приведенного на рис. 16.3 (см. с. 757), с применением оператора выбора с двумя аргументами.
При переходе от одной формы представления к другой в дерево были внесены
следующие изменения и дополнения.
16.3. ОТ ДЕРЕВЬЕВ РАЗБОРА К ЛОГИЧЕСКИМ ПЛАНАМ ЗАПРОСОВ
775
1. Подзапрос заменен выражением реляционной алгебры, упомянутым в конце
примера 16.15.
2. Основной запрос трансформирован в соответствии с рекомендациями,
указанными в разделе 16.3.1. Оператор выбора, однако, представлен в форме с двумя
аргументами, а не в виде традиционного оператора реляционной алгебры.
В итоге верхняя вершина <Condition> дерева разбора сохранилась и занимает
место аргумента выбора.
Stars In <Condition>
\
<Tuplc> IN я
<AttributO °birthdate LIKE '%1960'
starName MovieStar
Рис. 16.14. Промежуточный вариант дерева,
содержащий оператор выбора с двумя
аргументами
Это дерево требует дальнейших преобразований, о которых рассказано ниже. □
Необходимы правила, позволяющие заменить оператор выбора с двумя
аргументами оператором выбора с одним аргументом и какими-либо иными операторами
реляционной алгебры. Каждая из форм представления условия <Condition> может
потребовать применения специального правила. В обычных ситуациях оператор выбора
с двумя аргументами исключить удается — это позволяет прийти к "чистому"
выражению реляционной алгебры. В некоторых "экстремальных" случаях, однако,
оператор выбора с двумя аргументами можно оставить в неприкосновенности и трактовать
как часть логического плана запроса.
В качестве примера рассмотрим правило, которое дает возможность преобразовать
условие с оператором in, подобное представленному на рис. 16.14. Заметим, что
подзапрос в этом условии не является коррелированным; другими словами, итоговое
отношение, возвращаемое подзапросом, может быть вычислено однократно —
независимо от того, какой кортеж отношения из основного запроса тестируется в данный
момент. Правило изъятия синтаксической категории <Condition> подобного вида
выглядит следующим образом.
• Предположим, что первый аргумент оператора выбора с двумя аргументами
представляет собой некоторое отношение R, а второй — синтаксическую
категорию <Condition>, заданную в форме / IN S, где t — кортеж,
образованный из компонентов (определенных) атрибутов R, a S —
некоррелированный подзапрос. Для преобразования такого поддерева надлежит
выполнить следующие действия:
а) заменить <Condition> деревом выражений, соответствующим подзапросу S;
если подзапрос S способен возвращать кортежи-дубликаты, в качестве
корневой вершины дерева следует использовать оператор 8\
776
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
b) заменить оператор выбора с двумя аргументами оператором выбора <тс с
одним аргументом, где С представляет условие сравнения значения каждого
компонента кортежа t с соответствующим атрибутом отношения S;
c) в качестве аргумента оператора ас использовать декартово произведение R и S.
Процедура преобразования проиллюстрирована на рис. 16.15.
<Condition>
X
IN
' movieTitle
IX
starName = name
Starsln
Puc. 16.15. Преобразование оператора выбора с двумя
аргументами, один из которых представляет условие с оператором IN
Пример 16.17. Рассмотрим дерево, показанное на рис. 16.14 (см. с. 776), и применим
к нему указанное выше правило преобразования оператора выбора с двумя
аргументами, один из которых представляет условие с
оператором in. В данном случае роль R играет отношение
Starsln, отношение S является результатом
вычисления алгебраического выражения, которому
соответствует поддерево с корневой вершиной ятте, а
кортеж t состоит из единственного компонента,
отвечающего атрибуту starName.
Оператор выбора с двумя аргументами заменяется
оператором crstarName = name; условие С в этом случае
предполагает сравнение содержимого единственного
компонента starName кортежа t с атрибутом name
отношения S. Вершиной, дочерней для crstarName = mmt,
является х, а дочерними для х становятся вершина
с меткой starsln и корневая вершина поддерева,
описывающего подзапрос S. Обратите внимание, что
поскольку атрибут name служит первичным ключом
отношения Movies tar, поддерево S не нуждается
в вершине S, представляющей оператор удаления
кортежей-дубликатов. Новый вариант дерева изображен на рис. 16.16. Дерево состоит
только из выражений реляционной алгебры; несмотря на различия в структуре, оно
полностью равноценно дереву на рис. 16.13 (см. с. 775). □
Стратегия трансляции подзапроса в выражение реляционной алгебры существенно
усложняется, если запрос является коррелированным. Поскольку в процесс
выполнения коррелированного подзапроса вовлекаются заранее не известные значения,
определяемые за пределами тела подзапроса, последний нельзя рассматривать вне связи
с запросом верхнего уровня. При преобразовании такого подзапроса следует
предусмотреть в возвращаемом им отношении ряд дополнительных атрибутов, которые
позже должны быть сопоставлены со значениями "внешних" атрибутов. После осуще-
birthdate LIKE '%1960'
MovieStar
Рис. 16.16. Результат
применения правила удаления условия с
оператором IN
16.3. ОТ ДЕРЕВЬЕВ РАЗБОРА К ЛОГИЧЕСКИМ ПЛАНАМ ЗАПРОСОВ
777
ствления выбора с учетом условий, связывающих "внешние" атрибуты с
дополнительными атрибутами подзапроса, последние за ненадобностью могут быть удалены
посредством оператора проекции. Выполняя преобразование, надлежит особенно
внимательно следить за тем, чтобы вводимыми операторами не генерировались
кортежи-дубликаты (если в тексте запроса удаление дубликатов не предусмотрено явно).
Проиллюстрируем сказанное примером.
SELECT DISTINCT ml.movieTitle, ml.movieYear
FROM StarsIn ml
WHERE ml.movieYear - 40 <= (
SELECT AVG(birthdate)
FROM StarsIn m2 , MovieStar s
WHERE m2.starName = s . name AND
ml.movieTitle = m2.movieTitle AND
ml.movieYear = m2.movieYear
);
Рис. 16.17. Запрос к примеру 16.18
Пример 16.18. На рис. 16.17 приведена SQL-версия следующего запроса: "Найти
сведения о кинофильмах с участием только таких актеров, средний возраст которых
к моменту выхода фильма в свет не превышал 40 лет". Для простоты birthdate здесь
трактуется как год, а не как полная дата рождения, что дает возможность
непосредственно вычислять среднее арифметическое значений birthdate и сопоставлять
результат с содержимым компонента movieYear кортежа отношения Stars In. Каждая
из трех ссылок на отношения в тексте запроса снабжена собственной переменной
кортежа, дабы облегчить понимание того, что есть что.
На рис. 16.18 показан результат синтаксического анализа запроса и выполнения
частичной трансляции дерева разбора в дерево выражений реляционной алгебры.
В процессе начальной трансляции условие предложения where подзапроса
расщепляется на два, одно из которых используется для преобразования декартова
произведения отношений в соединение посредством равенства. Мы сохранили в дереве
псевдонимы ml, m2 и s, чтобы прояснить происхождение каждого из атрибутов. Разумеется,
можно было бы воспользоваться оператором расширенной проекции с целью
переименования атрибутов, но тогда результат оказался бы менее наглядным.
Для удаления синтаксической категории <Condition> и изъятия оператора выбора
сгс двумя аргументами необходимо создать выражение, описывающее отношение,
которое представляется правой ветвью вершины <Condition>. Однако поскольку
подзапрос относится к числу коррелированных, способов непосредственного получения
значений атрибутов ml.movieTitle или ml.movieYear из отношений, упомянутых
в тексте подзапроса (StarsIn с псевдонимом т2 и MovieStar), не существует.
Поэтому вычисление оператора выбора
&ml.movieTtile = ml.movieTitle and ml.movieYear = ml.movieYear
приходится отложить до момента, пока отношение, возвращаемое подзапросом, не
будет рассмотрено в сочетании с копией отношения stars in ml из основного
запроса. Для преобразования логического плана подобным образом следует
модифицировать оператор у с целью группирования данных по значениям атрибутов
m2 .movieTitle, m2 .movieYear, чтобы эти атрибуты оказались доступными при
необходимости выполнения выбора. Речь, таким образом, идет о вычислении
подзапроса как отношения, содержащего сведения о названиях и датах выпуска кинофильмов,
а также о средних арифметических значениях возраста актеров, участвовавших
в съемках этих кинофильмов.
778
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
5
ml.movieTitle, ml.movieYear
Starsln ml
- У AVG(s.birthdate)
I
ml.movieYear 40 a
m2.movieTitle = ml.movieTitle AND m2.movieYear = ml.movieYear
m2.starName = s.name
Starsln m2 MovieStar s
Рис. 16.18. Частично преобразованное дерево разбора для запроса на
рис. 16.17
Модифицированный оператор группирования представлен на рис. 16.19; помимо
введения двух группирующих атрибутов, нам пришлось переименовать в abd (от
"average birthdate") выражение среднего значения года рождения актеров, чтобы
обеспечить возможность обращения к нему в дальнейшем. На рис. 16.19 показан также
результат полной трансляции запроса в дерево выражений реляционной алгебры. Над
вершиной /расположена вершина, описывающая оператор соединения отношения Starsln
из основного запроса с отношением, возвращаемым подзапросом: условия оператора
выбора для подзапроса применяются к декартову произведению отношения starsln и
отношения-результата подзапроса, и оператор выбора принимает форму тета-
соединения, как и должно быть после применения алгебраических законов. Оператор
тета-соединения увенчан другим оператором выбора, который соответствует условию
предложения where основного запроса, предусматривающему сравнение значения года
выпуска кинофильма со средним значением года рождения актеров-участников съемок.
На верхних уровнях дерева, как и прежде, расположены операторы проекции схемы
итогового отношения на список требуемых атрибутов и удаления кортежей-дубликатов.
Как будет показано в разделе 16.3.3, для улучшения качества плана запроса
оптимизатор запросов способен сделать много больше. В рассматриваемом частном примере
удовлетворяются три условия, открывающие возможности дальнейшей оптимизации:
1) итоговое отношение освобождено от кортежей-дубликатов;
2) в результате проецирования из starsln ml удалены имена актеров;
3) при соединении Starsln ml с отношением, отвечающим остальной части
выражения, сравниваются значения атрибутов movieTitle и movieYear
отношений Starsln ml и Starsln m2.
Поскольку условия выполняются, можно заменить выражения ml.movieTitle
и ml.movieYear переменными m2 .movieTitle и т2.movieYear соответственно, что
позволяет избавиться от верхнего оператора соединения и ветви, указывающей на
аргумент starsln ml. В результате получим план запроса, показанный на рис. 16.20.
16.3. ОТ ДЕРЕВЬЕВ РАЗБОРА К ЛОГИЧЕСКИМ ПЛАНАМ ЗАПРОСОВ
779
5
ml.movieTitle, ml.movieYear
ml.movieYear-40 < abd
tx
ml.movieTitle = ml.movieTitle AND ml.movieYear - ml.movieYear
Starsln ml У ml.movieTitle, ml.movieYear, AVG(s.birthdate)
abd
IX
ml.starName = s.name
Starsln m2
MovieStar s
Рис. 16.19. Результат трансляции дерева на рис. 16.18 в
логический план запроса
' ml.movieTitle, ml.movieYear
ml.movieYear-40 < abd
Y ml.movieTitle, ml.movieYear, AVG (s.birthdate) —>• abd
IX
ml.starName = s.name
Starsln m2
MovieStar s
Рис. 16.20. Результат упрощения
логического плана на рис. 16.19
16.3.3. Улучшение логического плана запроса
Преобразуя запрос в выражение реляционной алгебры, мы получаем один из
возможных логических планов запроса. На следующей стадии план перезаписывается
с использованием алгебраических законов, о которых мы говорили в разделе 16.2 на
с. 760. Альтернативный способ действий предусматривает генерирование нескольких
логических планов, соответствующих различному порядку применения или сочетания
операторов. Однако мы будем полагать, что на этапе перезаписи запроса выбирается
единственный логический план, трактуемый как "наилучший" и способный с
большой долей вероятности привести к наименее дорогостоящему физическому плану.
780
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Пока, правда, остаются открытыми вопросы, касающиеся "порядка соединения", так
что логический план запроса с привлечением операций соединения (join) нескольких
отношений может восприниматься как семейство планов, соответствующих различным
способам упорядочения и группирования отношений в процессе их соединения.
Проблемам выбора порядка соединения посвящен раздел 16.6 на с. 809. Аналогично, план
запроса, в котором три или более отношения служат аргументами ассоциативно-
коммутативных операторов, подобных оператору объединения (union), надлежит
интерпретировать так, будто в ходе его преобразования в физический план допускается
возможность переупорядочения и перегруппирования операндов. Обсуждение вопросов
упорядочения и выбора физических планов мы начнем с раздела 16.4 на с. 783.
Улучшению качества логических планов способны послужить многие из
алгебраических законов, рассмотренных в разделе 16.2 на с. 760, но наиболее широкое
применение в оптимизаторах запросов находят следующие подходы.
• Продвижение операторов выбора "вниз" по дереву до максимально "глубокого"
уровня. Если условие выбора представляет собой конъюнкцию (and)
нескольких частных условий, его можно расщепить, чтобы продвигать каждый
оператор отдельно. Подобная стратегия является, вероятно, наиболее
эффективным приемом улучшения качества логических планов, но не следует
забывать (мы говорили об этом в разделе 16.2.3 на с. 765), что при
определенных обстоятельствах гораздо целесообразнее вначале продвинуть
оператор выбора "вверх" по дереву выражений, и только затем — "вниз".
• Продвижение существующих операторов проекции "вниз" по дереву или
добавление новых операторов, что, как и в случае с операторами выбора,
требует тщательного анализа (см. раздел 16.2.4 на с. 766).
• Изъятие операторов удаления кортежей-дубликатов или перемещение
в требуемые позиции дерева (см. раздел 16.2.6 на с. 769).
• Сочетание определенных операторов выбора с расположенными ниже по дереву
операторами декартова произведения с целью замены пары операций одной
операцией соединения посредством равенства (equijoin); реализация одной
операции, вообще говоря, сопряжена с меньшими затратами, нежели выполнение
нескольких операций, приводящих к тому же результату (см. раздел 16.2.5 на с. 769).
Пример 16.19. Вновь обратимся к дереву выражений, приведенному на рис. 16.13
(см. с. 775). Первым делом уместно расщепить
оператор выбора На Два— 0ГлГягЛ^ = лдт<г И (ТШШе LIKE .%1960.. П movieTitle
Последний может быть сразу перемещен вниз по I
дереву, поскольку в условии упоминается единст- ^
венНЫЙ атрибут, birthdate, ОТНОШеНИЯ starNnne = name
MovieStar. В условие первого оператора выбора, ^^^^^ *\^^
однако, вовлечены атрибуты отношений из обеих
частей выражения декартова произведения, причем stars n G birthdate like 'чаэбО'
значения атрибутов уравниваются, так что подоб- I
ное сочетание декартова произведения и выбора '
есть не что иное, как соединение посредством pa- MovieStar
венства. В результате проведения преобразований Рис. 16.21. Результат перезаписи
получим дерево, показанное на рис. 16.21. □ логического плана на рис. 16.13
16.3.4. Группирование ассоциативно-коммутативных операторов
Традиционными синтаксическими анализаторами не создаются деревья с
вершинами, обладающими неограниченно большим количеством дочерних вершин, —
обычно операторы пребывают только в унарной или бинарной форме. Однако опера-
16.3. ОТ ДЕРЕВЬЕВ РАЗБОРА К ЛОГИЧЕСКИМ ПЛАНАМ ЗАПРОСОВ
781
торы, для которых справедливы ассоциативный (associative law) и коммутативный
(commutative law) законы, способны обладать произвольным количеством операндов.
Более того, восприятие того же оператора соединения как п-арного оператора сулит
немаловажные преимущества: посредством переупорядочения операндов можно
добиться существенного снижения времени выполнения процедуры соединения как
последовательности частных бинарных операций соединения в сравнении с тем, когда
соединение обрабатывается в строгой последовательности, предусмотренной
исходным деревом разбора. Аспекты упорядочения операндов я-арных операторов
соединения исследуются в разделе 16.6 на с. 809.
Настало время обсудить последний шаг, отделяющий нас от получения
законченного логического плана запроса: речь пойдет о группировании соседних вершин
дерева, представляющих одноименные ассоциативно-коммутативные операторы, в единую
вершину со многими дочерними вершинами. Напомним, что к числу традиционных
ассоциативно-коммутативных операторов реляционной алгебры относятся
естественное соединение (natural join), объединение (union) и пересечение (intersection). Помимо
того, операторы естественного и тета-соединения допускают возможность взаимного
сочетания при выполнении следующих условий:
1) операторы естественного соединения заменены тета-соединениями с
условиями равенства одноименных атрибутов отношений-аргументов;
2) при переходе от естественного соединения к тета-соединению с помощью
оператора проекции удалены дубликаты атрибутов;
3) условия операторов тета-соединения ассоциативны (как упоминалось в
разделе 16.2.1 на с. 760, существуют образцы операторов тета-соединения, к
которым ассоциативный закон не применим).
Необходимо отметить, что оператор декартова произведения, интерпретируемый как
частный случай естественного соединения, может сочетаться с операторами
соединения, если они представлены смежными вершинами дерева выражений. На рис. 16.22
показан вариант преобразований в ситуации, когда в дереве логического плана
запроса присутствуют "грозди" из двух операторов объединения и трех операторов
естественного соединения. Обратите внимание, что буквами R—W обозначены произвольные
выражения, не обязательно служащие именами хранимых отношений.
М
/ \ / \
(J U V W
/ \
R U
/ \
S Т
Рис. 16.22. Заключительная фаза уточнения логического плана запроса:
группирование одноименных ассоциативно-коммутативных операторов
16.3.5. Упражнения к разделу 16.3
Упражнение 16.3.1. В приведенных ниже выражениях замените операторы
естественного соединения эквивалентными парами тета-соединений и проекций. Укажите,
образуют ли полученные тета-соединения ассоциативно-коммутативную группу.
782
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
* a) (R(a, b) tx S(b, c)) tx T(c, d).
S.c > T.c
b) (R(a, b) tx S(b, с)) х (т(с, d) tx U(d, e)).
c) (R(a, b) tx S(b, c)) tx (т(с, d) tx U(a, d)).
Упражнение 16.3.2. Преобразуйте в деревья выражений реляционной алгебры
деревья разбора, сконструированные вами при решении заданий (а) и (Ь) упражнения
16.1.3 на с. 760. Представьте две формы дерева, соответствующего запросу из
задания (Ь), — с оператором выбора с двумя аргументами и (после трансформации)
с "обычным" оператором выбора <тс.
! Упражнение 16.3.3. Разработайте правила преобразования каждого из
перечисленных ниже вариантов синтаксической категории <Condition> в дерево выражений
реляционной алгебры. Подразумевается, что все условия <Condition> могут
применяться (посредством оператора выбора с двумя аргументами) к некоторому
отношению R. Следует полагать, что подзапросы не коррелированны с R.
Позаботьтесь о сохранении статуса кортежей-дубликатов, заданного конструкцией SQL.
* a) EXISTS(<Query>).
b) a = ANY <Query>, где а — некоторый атрибут R.
c) а = ALL <Query>, где а — некоторый атрибут R.
!! Упражнение 16.3.4. Выполните задания упражнения 16.3.3, допуская возможность
корреляции подзапроса с R. Для простоты следует считать, что подзапрос
представлен в простой форме "select—from—where", рассматривавшейся в этом разделе,
и не содержит вложенных запросов.
!! Упражнение 16.3.5. Сколько различных деревьев выражений реляционной алгебры
могли бы являться "прародителями" дерева, изображенного в правой части рис. 16.22?
Учтите, что порядок следования дочерних вершин после их группирования не
обязательно совпадает с тем, который был принят в исходном дереве выражений.
16.4. Анализ стоимости операций
Предположим, что запрос подвергнут синтаксическому разбору и преобразован
в логический план. Далее с помощью определенных алгебраических правил план
трансформирован в некий "предпочтительный" логический план. Остается превратить
его в физический план. Обычно с этой целью рассматривается множество различных
физических планов, проистекающих из окончательного логического плана, и
вычисляется либо оценивается эффективность (или стоимость) каждого из них. По
завершении подобного процесса, часто называемого подсчетом стоимости (cost-based
enumeration), выбирается физический план, обладающий низшей оценкой стоимости;
именно этот план передается исполняющей машине (execution engine) — компоненту
процессора запросов, ответственному за практическое осуществление каждой из
операций, предусмотренных выбранным физическим планом запроса. При подсчете
стоимости всех возможных физических планов, которые удается сконструировать на
основе заданного логического плана, для каждого физического плана выбираются:
1) порядок следования и способ группирования одноименных ассоциативно-
коммутативных операторов, таких как соединение 0ОШ)> объединение (union)
и пересечение (intersection);
2) алгоритм реализации каждого оператора логического плана — скажем, метод
соединения посредством вложенных циклов против алгоритма соединения
на основе хеширования;
16.4. АНАЛИЗ СТОИМОСТИ ОПЕРАЦИЙ
783
Еще раз о системе обозначений
Напомним о соглашениях, принятых нами в разделе 15.1.4 на с. 687, для
представления размеров отношений, служащих аргументами операций:
• B(R) — количество блоков, требуемых для хранения всех кортежей отношения R;
• T(R) — количество кортежей отношения R;
• V(R, a) — счетчик значений атрибута а отношения R, т.е. количество различных
значений в пределах определенного столбца-атрибута а отношения R. В более
общем случае, если (ah аъ ..., ап) — некоторый список атрибутов отношения R,
тогда v(r, (дь а2,..., д„)) — количество различных наборов значений атрибутов
аи аъ ..., ап, или число кортежей в 8(па ч(1 а (/?)).
3) дополнительные операторы — сканирования, сортировки и т.д., —
необходимые для реализации физического плана, но отсутствующие в явном виде
в логическом плане;
4) способ передачи значений аргументов от одного оператора к другому —
например, посредством сохранения промежуточных результатов на диске либо
с помощью итераторов, позволяющих пересылать данные по одному
кортежу или одному буферу оперативной памяти в каждый момент времени.
Все эти вопросы мы обсудим ниже. Однако для получения правильных ответов на
них необходимо понимать, что представляют собой стоимости различных физических
планов. Мы не в состоянии определить значения этих стоимостей совершенно точно,
не выполнив план. Практически во всех случаях стоимость выполнения плана
существенно превосходит все затраты, связанные с выбором плана компилятором
запросов. Следовательно, нам определенно не хотелось бы выполнять более одного плана
для каждого запроса — напротив, мы вынуждены каким-то образом загодя оценивать
Каждый план, дабы избежать необходимости его предварительного выполнения.
Таким образом, прежде чем перейти к обсуждению тонкостей процесса подсчета
стоимости физических планов, целесообразно остановиться на том, каким образом
могут быть получены адекватные оценки стоимости планов. Подобные оценки
основываются на параметрах (см. врезку "Еще раз о системе обозначений" выше),
значения которых либо вычисляются точно, либо приобретаются в процессе сбора
статистических характеристик (statistics gathering) (о последнем мы расскажем в разделе
16.5.1 на с. 798). Имея такие значения, мы получаем возможность говорить о размерах
отношений, вовлеченных в те или иные операции, и осмысленно предсказывать
стоимость полного физического плана.
16.4.1. Оценка размеров промежуточных отношений
Физический план выбирается таким образом, чтобы свести к минимуму
примерную стоимость выполнения запроса. Независимо от метода выполнения плана и
способов подсчета его стоимости, на значение стоимости большое влияние оказывают
размеры промежуточных отношений, получаемых в процессе обработки операторов
плана. В идеале было бы неплохо иметь правила предсказания количества кортежей
в промежуточных отношениях,
1) дающие точные оценки;
2) простые в использовании;
3) логически непротиворечивые (в частности, оценка размера
промежуточного отношения не должна зависеть от способа его получения: например,
784
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
прогнозируемое значение объема отношения, получаемого в результате
соединения нескольких операндов, не должно определяться порядком
обработки этих операндов).
Универсального способа, который позволил бы удовлетворить все три условия, не
существует. Мы, тем не менее, предложим вашему вниманию несколько простых
правил, приемлемых в большинстве ситуаций. К счастью, целью прогнозирования
размеров отношений не является получение сколько-нибудь точных абсолютных оценок —
задача сводится к тому, чтобы просто облегчить выбор физического плана запроса.
Неточный метод предсказания может восприниматься как вполне терпимый, если он
ставит в соответствие наименьшее значение стоимости наилучшему физическому
плану, — даже в том случае, когда само это значение расходится с реальным, получаемым
в результате выполнения плана.
16.4.2. Оценка размера результата оператора проекции
Оператор проекции (projection) n в контексте обсуждаемой темы отличается от
других операторов тем, что объем результата его выполнения может быть вычислен
точно. Поскольку в итоговое отношение проекции включается каждый кортеж
отношения-аргумента, изменение объема данных обусловлено только трансформацией
структуры кортежа. Напомним, что оператор проекции относится, вообще говоря, к категории
"мультимножественных" операторов и сам по себе не обеспечивает удаление
повторяющихся кортежей; если после проецирования необходимо избавиться от дубликатов,
следует прибегнуть к услугам оператора S, предназначенного именно для такой цели.
Обычно оператор проекции предполагает сокращение длины кортежей за счет
изъятия компонентов отдельных атрибутов. Однако оператор расширенной проекции (extended
projection) (см. раздел 5.4.5 на с. 236), напротив, позволяет формировать новые
компоненты на основе существующих, так что в определенных ситуациях размер итогового
отношения не только не уменьшается в сравнении с исходным, но даже возрастает.
Пример 16.20. Обратимся к отношению R(a, Ъ, с), атрибуты а и Ъ которого относятся
к целочисленному четырехбайтовому типу, а компоненты атрибута с являются
строками длиной в 100 байт. Допустим, что под заголовок кортежа R отводится 12 байт.
Тогда для хранения каждого кортежа потребуются 120 байт. Предположим также, что
объем блока составляет 1024 байт, причем длина заголовка блока равна 24 байт.
Таким образом, в один блок способны уместиться 8 кортежей. Будем считать, что
T(R) = 10000, т.е. R содержит 10000 кортежей. Тогда B(R) = 1250.
Рассмотрим оператор S = яа + ь f (/?), предусматривающий замену компонентов а и Ъ
каждого кортежа R их суммой. Длина кортежа S составляет 116 байт: 12 для заголовка,
4 для суммы и 100 для строки. Хотя кортежи S несколько короче кортежей R, в один
блок можно уместить по-прежнему только 8 кортежей, так что T(S) = 10000 (это
очевидно) и B(S) = 1250.
Теперь воспользуемся оператором U=/rab(R), который предполагает изъятие
строкового компонента с. Длина кортежа U равна всего 20 байт, a T(U) = 10000. Сейчас
в один блок удается упаковать уже 50 кортежей, поэтому B(U) = 200, и в результате
проекции объем исходного отношения уменьшится в шесть с небольшим раз. □
16.4.3. Оценка размера результата оператора выбора
При выполнении оператора выбора (selection) а количество кортежей, как правило,
уменьшается, но размер отдельного кортежа сохраняется. В простейшем варианте
выбора, когда атрибут сравнивается с константой, оценить размер итогового отношения
несложно, если имеется возможность выяснить или приближенно оценить количество
различных значений сопоставляемого атрибута. Рассмотрим оператор 5= сгя = с (Я), где
16.4. АНАЛИЗ СТОИМОСТИ ОПЕРАЦИЙ
785
a — атрибут отношения R, а с — некоторая константа. В качестве оценки мы
рекомендуем использовать следующее соотношение:
• T(S) = T(R)/V(R,a).
Оценка становится точной, если все значения атрибута а распределены с равной
вероятностью. Впрочем, как указано в тексте врезки "Распределение Зипфа" ниже,
представленная формула все еще остается наилучшей оценкой в среднем — даже
в том случае, если распределение значений а не является однородным, но все
значения а одинаково часто упоминаются в запросах, в которых адресуется атрибут а.
Еще более близкие к точным оценки удается получить, если СУБД поддерживает
усовершенствованные функции сбора статистических характеристик и ведения
гистограмм (histograms) данных (подробности — в разделе 16.5.1 на с. 798).
Получение оценок размеров итоговых отношений становится более
проблематичным, если критерий выбора основан на неравенстве — скажем, S= cra<l0(R).
Навскидку можно было бы предположить, что в среднем одна половина значений
удовлетворяет подобному условию, а другая — нет, и потому использовать в качестве оценки
размера S значение T(R) 12. Однако интуиция подсказывает, что при обработке
запросов, в которых в качестве условий выбора привлекаются неравенства, вообще говоря,
достаточно обращаться к небольшой части всех кортежей. Поэтому мы предлагаем
правило, которое согласуется с подобными эмпирическими соображениями и
подразумевает, что типичный запрос с условием выбора, заданным в виде неравенства,
возвращает около трети, а не половину всех кортежей исходного отношения. Таким
образом, если S= cra<c(R), прогнозируемое значение T(S) выглядит как
• T(S) = T(R) 13.
Случай использования условия выбора "не равно" относительно редок. Впрочем,
если оператор вида S= cra*c(R) все-таки встретится, в качестве оценки T(S) мы
рекомендуем использовать соотношение T(S) = T(R), т.е. считать, будто практически все
кортежи исходного отношения удовлетворяют критерию а Ф с выбора. С другой
стороны, можно было бы применить и такую оценку, как T(S) = T(R)(V(R, a) - l) / V(R, а),
которая незначительно ниже величины T(R) и согласуется с эвристикой,
подразумевающей, что примерно (1 / V(R, а))-я часть всех кортежей R не удовлетворяет условию,
поскольку значения их компонентов а равны заданной константе с.
Если условие С выбора представляет собой конъюнкцию (and) нескольких
равенств и/или неравенств, оператор crc(R) следует трактовать как цепочку "вложенных"
операторов <т, каждым из которых проверяется один конъюнкт. Заметим, что порядок
перечисления частных операторов выбора несуществен. Прогнозируемый размер
итогового отношения в этом случае можно представить как количество кортежей
в исходном отношении, умноженное на коэффициенты "избирательности" всех
частных операторов — 1/3 для неравенств вида > и <, 1 для Ф и 1 / V(R, а) для условий
сравнения значений атрибута а с константой.
Пример 16.21. Рассмотрим отношение R(a,byc) и оператор S= cra = l0MJDb<20(R).
Допустим, что T(R) = 10000 и V(R, a) = 50. Тогда в качестве оценки T(S) можно принять
величину T(R) I (50 * 3) = 67, полагая, что примерно (1/50)-я часть кортежей R удовлетворяет
условию я=10, а(1/3)-я — условию Ъ < 20.
Забавный частный случай, опровергающий доводы в пользу применяемого нами
способа прогнозирования, связан с ситуацией, когда условие внутренне
противоречиво. Рассмотрим для примера оператор S= crazzl0mDa>20(R). В соответствии с указанным
правилом T(S) = T(R) I (3V(R, a)), т.е. отношение S должно было бы содержать примерно
67 кортежей. Однако совершенно очевидно, что кортежей, удовлетворяющих условиям
786
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Распределение Зипфа
Полагая, что условию, подобному а- 10, удовлетворяет (1 / V(R, а))-я часть всех
кортежей отношения R, мы принимаем как само собой разумеющееся то, что в
пределах любого кортежа R все значения атрибута а могут появляться с равной
вероятностью и что величина 10 является одним из таких значений, — впрочем,
последнее утверждение заведомо правомерно, поскольку в большинстве случаев в базе
данных ищутся такие элементы информации, которые действительно существуют.
Но предположение о равновероятном распределении значений на самом деле
далеко от истины, даже в сколько-нибудь приемлемом приближении.
Значения многих атрибутов отношений подчиняются функции распределения
Зипфа (G.K. Zipf), в соответствии с которой частота встречаемости /-го по степени
"популярности" значения пропорциональна величине 1 / V /. Например, если
наиболее употребительное значение встречается 1000 раз, тогда второе по количеству
экземпляров значение^ как можно ожидать, должно использоваться в пределах
столбца около 1000/V2 =707 раз, третье— 1000/V3 =577 раз и т.д. Изначально
сформулированному для описания относительных частот встречаемости слов
в предложениях на английском языке, распределению Зипфа, как было
установлено позже, подчиняются многие разновидности данных. Например, этому закону
приблизительно соответствуют значения плотности заселения отдельных штатов
США: так, скажем, количество жителей штата Нью-Йорк, второго по численности
населения, составляет около 70% от числа проживающих в наиболее
густонаселенном штате, Калифорния. Поэтому если вообразить отношение, содержащее,
например, сведения о подписчиках некоего журнала и включающее атрибут state,
который представляет информацию о количестве читателей в каждом из штатов,
можно ожидать, что значения компонентов state будут распределены не
однородно, а в соответствии с функцией Зипфа.
Если значения констант в условии запроса выбираются случайным образом,
конкретный вид распределения (скажем, согласно функции Зипфа) содержимого
атрибутов, вовлеченных в критерий выбора, роли не играет — средний размер
итогового отношения все еще оценивается величиной T(R) I V(R, а). Но если закону
Зипфа подчиняются и значения констант, тогда можно прогнозировать некоторое
увеличение размера итогового отношения относительно величины T(R) I V(R, a).
а=\0 и а>20 одновременно, не существует, так что в действительности T(S) = 0.
Выполняя перезапись логического плана, оптимизатор запросов руководствуется,
помимо всего прочего, множеством правил, отвечающих различным частным случаям. При
обработке рассматриваемого здесь условия выбора добротный оптимизатор способен
применить правило сведения условия к значению false и принять в качестве
результата операции пустое множество. □
Если критерий выбора образован на основе дизъюнкции (OR) отдельных условий
(скажем, S= ac 0Rc (Я)), тогда ожидаемый размер итогового отношения не столь
очевиден. Одно из подходящих на первый взгляд соображений состоит в том, что ни
один кортеж, якобы, не удовлетворяет одновременно обоим условиям, так что размер
итогового отношения можно представить как сумму количеств кортежей, отвечающих
каждому из условий. Подобная оценка, как правило, оказывается завышенной и
подчас способна привести к совершенно абсурдному заключению о том, будто в итоговом
отношении S больше кортежей, нежели в исходном R. Другой столь же простой и
несколько более корректный подход предполагает использование в качестве оценки
размера результата S минимального из двух значений — размера отношения-операнда
R и суммы количеств кортежей, удовлетворяющих отдельным условиям Сх и С2.
16.4. АНАЛИЗ СТОИМОСТИ ОПЕРАЦИЙ
787
Менее тривиальную и, вероятно, более точную оценку величины S = ас 0Rc (Я)
можно получить в том случае, если трактовать условия С{ и С2 как независимые.
Если R содержит п кортежей, тх из которых удовлетворяют условию Сь а т2 —
условию С2, количество кортежей в S можно представить как
л(1-(1-т1/л)(1-/и2/л)).
Внесем ясность: 1 -mi In — это доля кортежей, не удовлетворяющих условию Q,
а (1 -т2/ п) — часть кортежей, которые не отвечают условию С2; произведение этих
величин представляет часть кортежей R, которые не включаются в S, а разность
единицы и произведения — ту долю кортежей R, которые, напротив, в S "попадают".110
Пример 16.22. Рассмотрим отношение R(a, b) с Т(К) = 10000 кортежей и оператор
Ь = &а - ю OR b < 20 v ")*
Пусть V(#, a) = 50. Тогда количество кортежей, удовлетворяющих условию а = 10,
можно представить как T(R) I V(R, a) = 200, а число кортежей, соответствующих условию
Ь<20, — как Г(/?)/3«3333. Простейшая оценка размера S выглядит как сумма двух
значений, т.е. 3533. Применение более серьезного подхода, основанного на
допущении, что условия а = 10 и Ъ < 20 являются независимыми, дает
10000(1 - (1 - 200/10000)(1 - 3333/10000)) = 3466.
Впрочем, в этом случае оценки различаются весьма незначительно, и маловероятно,
что решение о предпочтении той или иной из них способно радикальным образом
повлиять на выбор наилучшего физического плана. □
Наконец, вкратце обсудим способ прогнозирования размера итогового отношения,
если в условии оператора выбора присутствует логический оператор not. Ожидаемое
количество кортежей отношения R, удовлетворяющих условию NOT С, равно T(R) за
вычетом приближенного числа кортежей, отвечающих условию С.
16.4.4. Оценка размера результата оператора соединения
Здесь мы собираемся сосредоточить внимание только на операторе естественного
соединения (natural join) ж — все иные варианты соединения могут трактоваться в
соответствии с указанными ниже правилами.
1. Количество кортежей в итоговом отношении, возвращаемом оператором
соединения посредством равенства (equijoin), после предполагаемого изменения имен
атрибутов вычисляется так же, как и в случае естественного соединения
(подробности — в примере 16.24 на с. 791).
2. Результаты выполнения тета-соединений других разновидностей оцениваются
(с учетом перечисленных ниже дополнительных соображений) так, как если бы
речь шла об операции декартова произведения, сопровождаемой операцией выбора:
a) количество кортежей в отношении, служащем итогом работы оператора
декартова произведения, равно произведению размеров отношений-операндов;
b) объем набора кортежей, удовлетворяющих условию равенства, можно
оценить, используя приемы, разработанные для прогнозирования результатов
естественного соединения;
c) условия, включающие неравенства с участием двух атрибутов (скажем,
R.a<S.b), следует трактовать как неравенства вида R.a<c, о которых мы го-
Эта же схема применима и для интерпретации неравенств вида <= и >=. — Прим. перев.
788
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
вор или в разделе 16.4.3 на с. 785; иными словами, имеются основания
считать, что такие условия обладают коэффициентом "избирательности",
равным 1/3, если, как можно полагать, условия относительно "экзотичны",
и 1/2 — в противном случае.
Начнем с предположения о том, что естественное соединение R(X, Y) х S(Y, Z) двух
отношений R и S выполняется на основе равенства двух атрибутов, т.е. Y представляет
единственный атрибут каждого из отношений, хотя X и Z могут быть произвольными
подмножествами атрибутов.
Основная проблема заключается в том, что заранее не известно, каким образом
связаны значения атрибутов Y отношений R и 5, поскольку
1) множества значений этих атрибутов могут не пересекаться, т.е. соединение
окажется пустым и T(R х S) = 0;
2) атрибут Y способен выполнять функцию первичного ключа S и внешнего
ключа R, так что каждый кортеж R соединяется с единственным кортежем
S kT(R\xS) = T(R);
3) большинство кортежей R и S может иметь одинаковые значения
компонентов Y, и в этом случае T(R х S) « T(R)T(S).
Имеет смысл направить усилия на анализ наиболее общих ситуаций, и для этого
придется принять два упрощающих положения.
• Принадлежность одного множества значений совпадающего атрибута другому.
Если Y является общим атрибутом отношений R и S, тогда значения Y в каждом
отношении выбираются в порядке их следования в списке (уь у2, уъ, •••)• Как
следствие, если V(R, Y) < V(S, Y), тогда каждое значение атрибута Y в R будет
присутствовать и в компонентах атрибута Y в S.
• Сохранность множеств значений несовпадающих атрибутов. При соединении
отношения R с другим отношением множество значений атрибута А, не
являющегося общим, не сокращается. Выражаясь более точно, если атрибут
А содержится в схеме R, но отсутствует в схеме S, имеет место соотношение
V(R tx S,A) = V(R, А). Заметим, что порядок соединения R и S в данном случае не
важен, поэтому ограничение можно представить и так: V(S х R, A) = V(R, A).
Первое допущение, касающееся принадлежности одного множества значений
атрибута соединения другому, вполне очевидно, на практике может быть с
легкостью нарушено — но удовлетворяется оно в том случае, если, скажем, Y служит
первичным ключом S и внешним ключом R. Мы вправе ожидать выполнения
этого условия и в других ситуациях: например, если S содержит "много" значений Y,
тогда заданное значение Y в R с большой долей вероятности будет наличествовать ив5.
Что касается предположения о сохранности множеств значений атрибутов, не
являющихся общими для нескольких отношений, то и его трудно назвать незыблемым,
хотя условие определенно удовлетворяется в тех случаях, когда атрибут соединения
RtxS является первичным ключом S и внешним ключом R. В действительности
единственная возможность нарушения обусловлена появлением "висящих" кортежей (dangling
tuples) R, не способных к соединению ни с одним кортежем S; впрочем, наличие
висящих кортежей R само по себе еще не означает, что условие утрачивает силу.
Принимая во внимание указанные допущения, попытаемся оценить размер
отношения R(X, Y) х S(Y, Z) следующим образом. Допустим, что V(R, Y) < V(S, Y). Тогда каж-
16.4. АНАЛИЗ СТОИМОСТИ ОПЕРАЦИЙ
789
дый кортеж t отношения R может быть соединен с определенным кортежем S с
вероятностью 1 / V(S, Y). Поскольку количество кортежей в S равно T(S), прогнозируемое
число кортежей, способных к соединению с t, оценивается величиной T(S) I V(S, Y), но
R содержит T(R) кортежей, поэтому примерный размер R tx S равен T(R)T(S) I V(Sy Y).
Если, напротив, V(R, Y) > V(S, У), "симметричные" доводы позволяют утверждать, что
T(R х S) = T(R)T(S) I V(Ry Y). Если трактовать оба случая в совокупности, в качестве
знаменателя дроби следует выбрать наибольшее из значений V(R, Y) и V(S, Y):
• T(R х S) = T(R)T(S) I max (V(R, У), V(S, Y)).
Пример 16.23. Рассмотрим три отношения со следующими статистическими
характеристиками:
R(a, Ъ)
T(R) = 1000
V(R, b) = 20
S(b, с)
T(S) = 2000
V(S, b) = 50
V(S, c) = 100
U(c,d)
T(U) = 5000
V(U, c) = 500
Предположим, что необходимо вычислить естественное соединение вида R x S x U.
Один из вариантов выполнения оператора состоит в фуппировании (R x S) x U. На
основании указанного выше правила T(R txS) = T(R)T(S) I max {V(R, b), V(S, Z?)) получим
1000 * 2000 / 50, или 40000.
Далее результат R x S подлежит соединению с U. Выражение оценки размера
итогового отношения можно записать как T(R x S)T(U) I max {V(R x S, с), V(U, с)). В
соответствии с предположением о сохранности множеств значений несовпадающих
атрибутов V(R х S, с) = V(S, с) = 100, т.е. при выполнении соединения ни одно из значений
атрибута с не "пропадает". В этом случае прогнозируемым значением количества
кортежей в R х S х U будет 40000 * 5000 / тах(100, 500) = 400000.
Выполнение операции RtxStxU можно начать и с соединения S с U. В этом случае
оценкой размера StxU окажется T(S)T(U) I max (y(St с), V(Uf с)), или 2000 * 5000 / 500 = 20000.
Ожидаемый размер итогового отношения равен T(R)T(S x U) I max (V(R, b), V(S x U, £)),
и с учетом допущения о сохранности множеств значений несовпадающих атрибутов,
V(S txU,b) = V(5,b) = 50, получим 1000*20000/50, или 400000. □
Совпадение оценок размера итогового отношения при выборе различного порядка
соединения, (R x S) x U и R x (S x U), наблюдаемое в примере 16.23, нельзя назвать
случайным. Одним из отправных положений, перечисленных в разделе 16.4.1 на
с. 784, напомним, является то, что прогнозируемый размер результата вычисления
составного выражения не должен зависеть от порядка выполнения частных операций.
Можно доказать, что два введенных нами допущения, касающиеся принадлежности
одного множества значений совпадающих атрибутов другому и сохранности множеств
значений несовпадающих атрибутов, гарантируют независимость оценки результата
оператора естественного соединения от способа группирования его операндов.
790
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
16.4.5. Естественное соединение отношений с несколькими общими атрибутами
Теперь исследуем случай, когда Y представляет не один, а несколько атрибутов,
общих для отношений R и S, подлежащих естественному соединению, R(X, Y) x S(Y, Z).
Для простоты рассмотрим оператор R(x, ух,у2) х S(yx,y2,z). Пусть г является одним из
кортежей R. Вероятность того, что г удастся соединить с определенным кортежем s
отношения S, может быть подсчитана следующим образом.
Прежде всего зададимся вопросом, какова вероятность совпадения г и 5 в атрибуте
ух. Предположим, что V(R,yx)>V(S,yx). Тогда с учетом допущения о принадлежности
одного множества значений совпадающих атрибутов другому можно утверждать, что
любое значение атрибута ух отношения S определенно присутствует в наборе значений
атрибута ух отношения R. Следовательно, вероятность того, что кортеж г обладает тем
же значением компонента ух, что и кортеж s, равна \/V(R,yx). Аналогично, если
V(R, yx) < V(S, yx), тогда значение ух кортежа г должно наличествовать в S, причем
вероятность совпадения содержимого компонентов ух кортежей г и s равна 1 / V(S, yx).
Вероятность того, что кортежи г и s согласуются в атрибуте ух, в общем случае
оценивается величиной 1 / max ( V(/?, yx), V(S, jo).
Те же доводы позволяют заключить, что вероятность совпадения кортежей г и 5 в
компонентах атрибута у2 равна 1 /max (v(R,y2), V(S,y2))- Поскольку значения атрибутов ух и у2
независимы, вероятность одновременного равенства обоих компонентов кортежей
г и 5 представляет собой произведение двух указанных дробей. Поэтому с учетом
общего количества различных пар кортежей R и S, равного T(R)T(S), прогнозируемое
число пар кортежей, совпадающих одновременно в компонентах ух и у2, равно
T(R)T(S) I (max (V{R, yi), V(S, yx)) * max (V{R, y2\ V(S, y2))).
Для получения оценки размера итогового отношения, возвращаемого оператором
естественного соединения в случае, когда отношения-операнды обладают
произвольным количеством общих атрибутов, используется следующее правило:
• прогнозируемый размер отношения R tx S равен произведению значений T(R)
и T(S), деленному на произведение максимумов из величин V(R, у) и V(S, у) для
каждого атрибута у, общего для отношений R и S.
Пример 16.24. Рассмотрим образец практического применения указанного выше
правила. Помимо того, покажем, что выводы, справедливые для естественного
соединения, остаются в силе и для любых разновидностей соединений посредством равенства.
Предположим, что отношения, служащие аргументами оператора
R(a, b, с) tx S(d, e,f),
обладают следующими статистическими характеристиками:
R(a, b, с)
T(R) = 1000
V(R, b) = 20
V(R, c) = 100
S(d, e,f)
T(S) = 2000
V(S, d) = 50
V(S, e) = 50
Подобный вариант соединения можно интерпретировать как естественное
соединение, если воспринимать атрибуты пары R.b, S.d и пары R.c, S.e как одноименные.
16.4. АНАЛИЗ СТОИМОСТИ ОПЕРАЦИЙ
791
Важен не только размер итогового отношения, но и...
Хотя до сих пор мы обращали внимание только на количество кортежей в
отношении, возвращаемом оператором, подчас надлежит учитывать и длину кортежей
этого отношения. Например, кортежи отношения, получаемого в результате
соединения, оказываются более длинными, нежели кортежи каждого из отношений-
операндов. Так, итогом соединения RtxS двух отношений R и S, каждое из которых
содержит по 1000 кортежей, может оказаться набор из 1000 кортежей, но для его
сохранения понадобится существенно большее количество блоков, чем для R или S.
Пример 16.24 иллюстрирует один тонкий нюанс. Хотя для прогнозирования
количества кортежей, получаемых в результате тета-соединения, мы с успехом
применили прием, разработанный для оценки естественного соединения, не следует
забывать о том, что кортежи тета-соединения содержат большее число
компонентов, нежели кортежи соответствующего варианта естественного соединения. В
частности, оператор R(a, b, с) х S(d, e,f) возвращает кортежи с шестью ком-
R.b = S.d M™ R.c = S.e
понентами, по одному для атрибутов от а до /, в то время как оператор R(a, b, с) >
< S(b, с, d) формирует то же количество кортежей, но только с четырьмя компонентами.
Тогда в соответствии с указанным выше правилом для получения оценки размера
итогового отношения следует перемножить значения 1000 и 2000 и поделить
произведение на большее из чисел 20 и 50, а затем — на большее из чисел 100 и 50, т.е.
1000 * 2000 / (50 * 100) = 400. □
Пример 16.25. Вновь обратимся к примеру 16.23 на с. 790, но рассмотрим третий из
возможных вариантов порядка соединения, в соответствии с которым вначале
выполняется операция R(a, b) х U(c, d). Такое соединение по существу представляет собой
декартово произведение, и количество кортежей в возвращаемом им отношении равно
T(R)T(U) = 1000 * 5000 = 5000000. Заметим, что количество различных значений в
компонентах атрибутов b и с этого отношения по-прежнему равно V(R, b) = 20 и V(U, с) = 500
соответственно. Для получения оценки размера отношения, получаемого при
дальнейшем соединении промежуточного результата с S(b, с), следует перемножить
количества кортежей в отношениях-операндах и поделить произведение как на
max (V(R, b), V(S, b)), так и на max (v(U, с), V(S, с)), т.е. 2000 * 5000000 / (50 * 500) = 400000.
Нетрудно убедиться, что и для третьего варианта соединения остается справедливой та
же оценка, которая получена в примере 16.23 для двух других. □
16.4.6. Соединение нескольких отношений
Рассмотрим, наконец, общий случай естественного соединения:
S = RltxR2tx — txRn.
Предположим, что атрибут А присутствует в схемах к отношений Я, и количества
различных значений компонентов А в этих к отношениях — т.е. величины V(Rh А), где
/=1,2,..., к, — равны vj < v2 < — < v* в порядке от меньшего к большему. Допустим, что
в каждом из к отношений выбрано по одному кортежу. Какова вероятность того, что
все эти кортежи совпадают в атрибуте Л?
Для получения ответа на вопрос рассмотрим кортеж tu выбранный из отношения
с наименьшим количеством vx различных значений атрибута А. В соответствии
с допущением о принадлежности одного множества значений совпадающего атрибута
792
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
другому (см. раздел 16.4.4 на с. 788), каждое из vx значений можно найти в компонентах А
кортежей всех других к- 1 отношений. Обратимся к отношению, содержащему v;
различных значений атрибута А. Выбранный из этого отношения кортеж /; совпадает с кортежем
t\ в атрибуте А с вероятностью 1 / v;. Поскольку подобное утверждение верно для всех
/ = 2,3,..., £, вероятность того, что все к кортежей совпадут в атрибуте Л, равна 1 / (v2 v3 - v*).
Теперь мы можем сформулировать правило прогнозирования размера итогового
отношения, возвращаемого оператором соединения с произвольным числом аргументов:
• перемножить количества кортежей во всех отношениях-операндах Я, и поделить
полученное произведение на все величины V(Rh А), кроме наименьшей, для
каждого атрибута А, присутствующего, как минимум, в двух отношениях.
Аналогичным образом можно оценить количество различных значений атрибута А
в отношении, полученном в результате соединения: согласно допущению о
принадлежности одного множества значений совпадающего атрибута другому, эта величина
равна минимальному из значений V(Rh A).
Пример 16.26. Рассмотрим операцию соединения R(a, Ъ, с) х S(b, c,d)\x U(b, ё) при
условии, что отношения-операнды обладают статистическими характеристиками,
приведенными на рис. 16.23. Для получения оценки количества кортежей в итоговом
отношении вначале перемножим размеры отношений R, S и U: 1000 * 2000 * 5000. Затем
отыщем атрибуты, присутствующие в схемах нескольких отношений: это Ь,
объявленный в схемах всех трех отношений, и с, содержащийся в двух. Разделим полученное
выше произведение на два самых крупных значения из числа V(R, b), V(S, b) и V(U, b),
т.е. на 50 и 200, и на более крупное из двух значений, V(R, с) и V(S, с), т.е. на 200.
Оценка, таким образом, примет вид
1000 * 2000 * 5000 / (50 * 200 * 200) = 5000.
R(a, b, с)
ЦК) = 1000
V(R, a) = 100
V(R, Ь) = 20
V(R, с) = 200
S(b, с, d)
T(S) = 2000
V(S, b) = 50
V(S, с) = 100
V(S, d) = 400
ЩЬ, е)
T(U) = 5000
V(U, b) = 200
V(U, e) = 500
Рис. 16.23. Статистические характеристики отношений к примеру 16.26
Наконец, в качестве оценок количеств различных значений каждого из атрибутов
итогового отношения можно использовать минимальные из величин таких количеств
по каждому отношению-операнду: для атрибутов а, Ь, с, d и е эти оценки равны 100,
20, 100, 400 и 500 соответственно. □
Принимая во внимание два допущения — о принадлежности одного множества
значений совпадающего атрибута другому и о сохранности множеств значений
несовпадающих атрибутов, — выдвинутые нами в разделе 16.4.4 на с. 788, можно
сформулировать любопытное и полезное свойство рассмотренного выше правила прогнозирования.
• Независимо от способа группирования и упорядочения аргументов выражения
естественного соединения п отношений, правило, применяемое к каждому
частному соединению отдельно, дает в сумме тот же результат, что и в случае
применения к соединению всех п отношений.
16.4. АНАЛИЗ СТОИМОСТИ ОПЕРАЦИЙ
793
Оценка размера результата соединения нескольких отношений не зависит
от порядка выполнения операций
Формальное доказательство такого утверждения следовало бы проводить по индукции
от количества отношений-аргументов, вовлеченных в операцию. Заниматься этим мы
не станем, но приведем некоторые эвристические соображения. Предположим, что
заключительный этап процедуры соединения нескольких отношений выглядит как
(/?! х — х Rn) х (S{ x ••• xi Sm)
Можно полагать, что, независимо от способа соединения отношений Rh
прогнозируемый объем результата этого соединения равен произведению размеров
операндов Rh деленному на содержимое всех счетчиков количеств различных значений,
кроме наименьшего, для всех атрибутов, общих, как минимум, для схем двух
отношений. Помимо того, оценка количества различных значений каждого атрибута
отношения-результата равно наименьшему из количеств значений этого атрибута среди
всех /?/, содержащих атрибут. Аналогичные выводы справедливы и для отношений 5).
Применяя правило оценки размера результата соединения двух отношений,
приведенное в разделе 16.4.4 на с. 788, к отношениям R' = Rlx--xRn
и S' = Si х • •• xi Sm, представляющим промежуточные итоги, получим величину,
равную произведению ожидаемых размеров отношений R' и 5", деленному на
максимальные количества различных значений атрибутов, общих для R' и 5". Эта
оценка определенно содержит множители, соответствующие размерам каждого из
отношений /?ь ..., Rh ..., Rn, Sb ..., Sj,..., Sm, а также (не меньшие) делители, равные
содержимому счетчиков количеств различных значений каждого общего атрибута.
Каждый подобный делитель либо присутствует в оценках размеров отношений R' и 5",
либо вводится при рассмотрении заключительного этапа соединения (если
соответствующий атрибут А принадлежит одновременно и R', и 5") и является наибольшим
из двух наименьших счетчиков среди V(Rh А) и V(SJt А) соответственно.
Примеры 16.23 (см. с. 790) и 16.25 (см. с. 792) содержат образцы практического
использования этого правила с привлечением трех вариантов группирования для
соединения трех отношений, включая случай, когда соединение по существу сводится к де-
картову произведению.
16.4.7. Оценка размеров результатов выполнения других операторов
Вы уже познакомились с двумя операциями, размеры результатов которых можно
описать с помощью точных формул:
1) оператор проекции (projection) не изменяет количество кортежей исходного
отношения;
2) оператор декартова произведения (Cartesian product) возвращает
отношение, размер которого равен произведению количеств кортежей
отношений-операндов.
Мы рассмотрели и две другие операции — выбор (selection) и соединение (join), —
допускающие возможность относительно точного прогнозирования характеристик
результатов. Размеры итоговых отношений, получаемых при выполнении других
операторов реляционной алгебры, предсказать сколько-нибудь верно, однако, не
столь просто. Впрочем, определенные соображения по этому поводу у нас,
разумеется, есть, и ими имеет смысл поделиться.
794
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Объединение
Размер результата объединения мультимножеств (bag union) определяется точной
суммой количеств кортежей отношений-аргументов. Величина объема итогового
отношения, возвращаемого оператором объединения множеств (set union), заключена
в интервале от значения максимума из размеров операндов до суммы этих размеров.
Мы предлагаем в качестве оценки использовать среднее арифметическое двух
граничных величин, т.е. сумму большего размера и половины меньшего размера.
Пересечение
Объем отношения, получаемого в результате выполнения оператора пересечения
(intersection), не зависит от выбора версии оператора ("множественной" или
"мультимножественной") и исчисляется значением из интервала от 0 до размера
меньшего из аргументов.
Другой подход связан с интерпретацией пересечения как некоего предельного случая
естественного соединения и допускает применение формулы из раздела 16.4.4 на с. 788.
Если подразумевается операция пересечения множеств, формула гарантирует, что
результат по числу кортежей окажется не большим, нежели меньшее из двух отношений-
операндов. В случае пересечения мультимножеств, однако, возможно возникновение
определенных аномалий, когда оценка результата превышает размер любого из
исходных отношений. Рассмотрим в качестве иллюстрации оператор R(a,b)C\BS(a,b), где
отношения R и S состоят из двух и трех копий кортежа (0,1) соответственно. Тогда
V(R, a) = V(S, a) = V(R, Ъ) = V(S, b)=l,
T(R) = 2 и T(S) = 3. Согласно правилу прогнозирования размера результата соединения,
получим 2*3/ (max (1,1)* max (1, 1)) = 6, хотя совершенно очевидно, что результат не
может содержать более min (г(Я), Г(5)) = 2 кортежей.
Разность
При вычислении оператора разности (difference) R-S размер результата
принадлежит интервалу от T(R) до T(R) - T(S). В качестве оценки мы рекомендуем использовать
среднее арифметическое граничных значений: T(R) - T(S) 12.
Удаление кортежей-дубликатов
Размер итогового отношения, возвращаемого оператором S(R), который
применяется к отношению R(aua2, ...,ап), составляет v(r, (au а2,..., дп)). Зачастую, однако,
подобная статистическая характеристика просто недоступна, что вынуждает пользоваться
приближенными оценками. В экстремальных случаях размер S(R) либо совпадает с
количеством кортежей в R (т.е. R не содержит дубликатов), либо равен 1 (все кортежи
R одинаковы).111 В качестве другого варианта значения верхней границы количества
кортежей в S(R) уместно использовать максимально допустимое число различных
кортежей, выраженное в форме произведения множителей V(R, at), где /= 1,2,..., п. Эта
величина может быть ниже в сравнении с другими оценками T^S(/?)). Существует ряд
правил прогнозирования значения T^S(/?)), но мы порекомендуем следующее:
вычислить минимум из T(R) /2 и произведения всех V(R, aj).
111 Строго говоря, если R пусто, пустым окажется и отношение S(R), т.е. нижняя
граница значений размера S(R) равна нулю. Этот тривиальный частный случай, однако,
интереса не представляет.
16.4. АНАЛИЗ СТОИМОСТИ ОПЕРАЦИЙ
795
Группирование и агрегирование
Предположим, что необходимо оценить размер отношения, возвращаемого при
вычислении оператора группирования (grouping) Yl(R)- Если статистическая
характеристика вида v(#, (#ь#2> —»g*)), где gh i= 1, 2,..., к, — фуппирующие атрибуты из списка
L, доступна, в качестве оценки следует использовать именно это значение. Однако
в реальной ситуации уповать на такую возможность довольно трудно, поэтому
необходимо изыскивать альтернативный способ прогнозирования. Количество кортежей
в yL(R) совпадает с числом фупп к. В одном "крайнем" случае итоговое отношение
способно содержать единственную фуппу, а в другом — по фуппе на каждый кортеж
R. Как и в случае с оператором удаления кортежей-дубликатов 8, в качестве верхней
фаницы количества фупп правомочно использовать произведение значений V(R, gj),
отвечающих фуппирующим атрибутам из списка L, а искомую оценку вычислять как
минимум из T(R) 12 и произведения всех V(R, g,).
16.4.8. Упражнения к разделу 16.4
Упражнение 16.4.1. Ниже приведены основные статистические характеристики
отношений W, X, Y и Z:
W(a, b)
T(W) = 100
V(W, a) = 20
V{W, b) = 60
X(b, c)
T(X) = 200
V(X, b) = 50
V(X, c) = 100
Y(c,d)
T(Y) = 300
V(Y, c) = 50
V(Y, d) = 50
Z(d, e)
T(R) = 1000
V(Z, d) = 40
V(Z,*)=100
Оцените размеры отношений, возвращаемых при вычислении следующих выражений:
*а) WxXxYxZ;
*Ь) crasl0(W);
c) crc = 20(Y);
d) crc = 20(Y)txZ;
e) WxY;
0 &d>i0(Z)',
*g) СГЛЯ1 AND* = 2(^)5
h) ^=1AND*>2(W)'
i) X tx Y.
X.c < Y.c
* Упражнение 16.4.2. Даны отношения E, F, G и Н, статистические характеристики
которых выглядят следующим образом:
Е(а, Ь, с)
ЦЕ) = 1000
V(E,a)= 1000
V(E, b) = 50
V(E, с) = 20
F(a, b, d)
T(F) = 2000
V(F, a) = 50
V(F,fc)=100
V(F, d) = 200
G(<z, c, d)
T(G) = 3000
V(G, a) = 50
V(G, c) = 300
V(G, d) = 500
Я(Ь, с, J)
Г(#) = 4000
V(H, b) = 40
V(//,c)=100
y(#, J) = 400
796
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Оцените размер результата соединения отношений, используя приемы,
рассмотренные в этом разделе.
! Упражнение 16.4.3. Предложите способ предсказания размера результата
полусоединения (semijoin) отношений (определение операции дано в упражнении
5.2.10 на с. 225).
!! Упражнение 16.4.4. Рассмотрим оператор соединения R(a, b) х S(a, с) отношений,
каждое из которых состоит из 1000 кортежей. Компоненты атрибутов а обоих
отношений содержат по 100 различных значений, и наборы этих значений для
отношений совпадают. Если полагать, что распределение значений а однородно, т.е.
каждое значение присутствует ровно в десяти кортежах каждого отношения, в
результате соединения будут получены 10000 кортежей. Допустим, однако, что
100 значений атрибутов а в обоих отношениях распределены в соответствии
с функцией Зипфа. Иными словами, если представить значения в виде
последовательности аь аъ ..., д100, каждое из отношений R и S содержит такое количество
кортежей со значением щ атрибута а, которое пропорционально 1 / V7 . Принимая во
внимание указанные условия, оцените размер отношения RtxS. (Тем
обстоятельством, что количество кортежей, содержащих заданное значение атрибута а, не
обязательно выражается целым числом, можно пренебречь.)
16.5. Выбор планов с учетом их стоимости
Выбирая логический план или конструируя на основе последнего физический план,
оптимизатор запросов нуждается в получении оценок стоимости вычисления
определенных выражений. Здесь мы обсудим общие вопросы, касающиеся выбора планов
с привлечением оценок стоимости операций (cost-based optimization), а раздел 16.6 на
с. 809 посвятим одной из наиболее важных и сложных частных проблем анализа
планов запросов, связанной с выбором порядка соединения (join) нескольких отношений.
Как и прежде, будем полагать, что определяющим компонентом стоимости
вычисления выражения является количество требуемых операций дискового ввода-вывода.
На значение этого параметра в свою очередь оказывают влияние следующие факторы:
1) типы и разновидности логических операторов, предназначенных для
практического воплощения запроса, которым отдано предпочтение в процессе
выбора логического плана;
2) размеры промежуточных наборов данных (о способах прогнозирования
подобных значений мы говорили в разделе 16.4 на с. 783);
3) типы физических операторов, призванных реализовать операторы логического
плана, скажем, за счет использования однопроходного или двухпроходного
алгоритма соединения либо принятия решения о необходимости сортировки
определенного отношения (эти вопросы обсуждаются в разделе 16.7 на с. 822);
4) порядок выполнения одноименных операций (особенно операций
соединения — см. раздел 16.6 на с. 809);
5) методы передачи данных от одного физического оператора к другому (об
этом мы также расскажем в разделе 16.7).
Осуществление эффективного выбора плана требует разрешения множества
проблем. Вначале мы остановим внимание на том, каким образом информация базы
данных помогает получать значения "размерных" статистических характеристик, столь
необходимых для прогнозирования (о чем говорилось в разделе 16.4 на с. 783)
объемов отношений, возвращаемых теми или иными операторами. Затем вновь вернемся
к алгебраическим законам, способствующим отысканию предпочтительного логиче-
16.5. ВЫБОР ПЛАНОВ С УЧЕТОМ ИХ СТОИМОСТИ
797
ского плана запроса. Анализ стоимости операций подтверждает жизнеспособность
и состоятельность многих эвристических правил (подобных тому, которое велит
продвигать операторы выбора вниз по дереву выражений — см. раздел 16.2.3 на с. 765),
применяемых для преобразования логических планов. Наконец, рассмотрим
различные подходы к проблеме сопоставительного анализа всех физических планов, которые
удается сконструировать на основе выбранного логического плана. Особенно важны
методы сокращения количества планов, сохраняющие потенциально наиболее
эффективный план среди тех, которые подлежат дальнейшему анализу.
16.5.1. Статистические характеристики данных
Формулы, представленные в разделе 16.4 на с. 783, основаны на предположении
о том, будто некоторые важные характеристики операндов — такие как T(R) (количество
кортежей в отношении R) или V(R, а) (количество различных значений в компонентах
атрибута а отношения R) —- известны заранее. Современные коммерческие СУБД, как
правило, позволяют пользователю или администратору явно активизировать процессы
сбора статистических характеристик (statistics gathering), или просто статистик,
подобных T(R) и V(R, а). Затем полученные статистики используются оптимизатором
запросов с целью прогнозирования стоимости тех или иных операций. Пересмотр
статистик, продиктованный серьезными изменениями, внесенными в содержимое базы
данных с момента последнего вычисления статистик, производится принудительно.
Простейший способ получения сведений о количествах кортежей, T(R), и
различных значений компонентов каждого атрибута a, V(R, а), отношения R связан с полным
сканированием R. Количество B(R) блоков, занимаемых отношением /?, можно
оценить либо путем непосредственного подсчета (если R компактно сгруппировано), либо
делением величины T(R) на число кортежей R в расчете на один блок (или на среднее
число кортежей, приходящихся на один блок, если кортежи имеют различную длину).
Заметим, что две эти оценки значения B(R), вообще говоря, не обязательно совпадают,
но обычно они в достаточной мере близки — главное, чтобы выбор одного из
подходов был осмыслен и последователен.
Помимо того, СУБД зачастую поддерживают функции вычисления гистограмм
(histograms) распределения значений атрибутов. Если значение V(R, а) для конкретного
атрибута а отношения R не слишком велико, гистограмма может представлять
количества (или доли количества) кортежей, содержащих каждое из значений а. Если же
различных значений атрибута а чрезмерно много, в гистограмме отдельно
фиксируются сведения только о часто встречающихся значениях, а количества всех других
значений подсчитываются по группам. К числу наиболее употребительных относятся
гистограммы перечисленных ниже типов.
1. С равной шириной (equal-width histogram). Выбираются значение ширины w
диапазона и константа v0 и сохраняются уровни количеств кортежей, содержащих
значения v, которые принадлежат диапазонам v0 < v < v0 + w, v0 + w < v < v0 + 2w
и т.д. В качестве v0 могут быть приняты минимально возможное значение либо
текущая нижняя граница значений атрибута. В последнем случае при
появлении нового значения нижней границы величина v0 уменьшается на w и в
гистограмму добавляется новый начальный диапазон.
2. С равной высотой (equal-height histogram). Подобные гистограммы реализуют
модель процентилей (percentiles), делящих область изменения значений на
интервалы с равной вероятностью попадания значений.
3. С наиболее часто встречающимися значениями (most-frequent-values histogram).
Фиксируются количества наиболее "популярных" значений. Подобная
информация нередко сопровождается обобщенными сведениями о группах значений либо
используется в совокупности с гистограммами с равной шириной или высотой.
798
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Одно из преимуществ, предоставляемых механизмом ведения гистограмм, состоит
в обеспечении большей точности прогнозирования размеров итоговых отношений,
возвращаемых операторами соединения, в сравнении с простыми методами
предсказания, рассмотренными в разделе 16.4 на с. 783. В частности, если некоторое
значение общего атрибута явно упоминается в гистограммах для обоих отношений,
подлежащих соединению, это дает возможность определить количество кортежей,
соединенных на основе такого значения, совершенно точно. Для получения оценки
количеств кортежей, соединяемых ввиду равенства тех значений общего атрибута,
которые не представлены в одной или обеих гистофаммах, следует применять методы из
раздела 16.4. Впрочем, при наличии гистофамм с равной шириной, содержащих
одинаковые наборы диапазонов изменения значений общих атрибутов обоих отношений,
вполне достаточно получить оценки результатов соединения подмножеств кортежей,
относящихся к соответствующим диапазонам, и суммировать эти оценки. Результат можно
считать вполне приемлемым, поскольку в подобном случае к соединению будут
способны только кортежи, обладающие равными значениями из совпадающих диапазонов.
Проиллюсфируем приемы практического использования гистофамм на примерах.
Пример 16.27. Предположим, что необходимо оценить размер результата вычисления
оператора R(a, b) tx S(b, с). Допустим, что для отношений R и S получены гистофаммы,
содержащие сведения о трех наиболее часто упоминаемых значениях общего атрибута
Ъ и о фуппах остальных значений в совокупности. Гистофамма, представляющая
статистику распределения значений R.b, имеет следующий вид:
1: 200; 0: 150; 5: 100; другие значения: 550.
Иными словами, из 1000 кортежей R 200 в компонентах Ъ содержат значение 1, 150 —
значение 0 и 100 — значение 5. Помимо того, 550 кортежей обладают значениями
атрибута, Ь, заведомо отличными от 1, 0 и 5, причем ни одно из таких значений не
присутствует в кортежах R 100 или более раз.
Допустим, что гистофамма, описывающая характеристики значений S.b, такова:
0: 100; 1: 80; 2: 70; другие значения: 250.
Предположим также, что V(R, b) = 14 и V(S, Ь) = 13, т.е. 550 кортежей R с неизвестными
значениями афибута b распределены по 11 фуппам по (в среднем) 50 кортежей в
каждой, а 250 кортежей S с неизвестными значениями того же общего афибута b
разделены на 10 фупп, и каждая фуппа содержит в среднем по 25 кортежей.
Значения 0 и 1 упоминаются в обеих гистофаммах — это позволяет утверждать, что 150
кортежей R, удовлетворяющие условию b = 0, подлежат соединению со 100 кортежами S,
обладающими тем же значением афибута Ь, с образованием 15000 соединенных кортежей.
Аналогичным образом должны быть соединены 200 кортежей R с b = 1 и 80
кортежей S с тем же значением Ь= 1, что даст в итоге еще 16000 кортежей.
Оценка степени влияния, оказываемого прочими кортежами, на общий результат
не столь фивиальна. Будем по-прежнему подразумевать, что каждое значение,
присутствующее в отношении с меньшим множеством различных значений (в данном
случае — S), должно наличествовать и во множестве значений другого отношения-
операнда (см. раздел 16.4.4 на с. 788). Одним из 11 оставшихся значений S является
заведомо известное значение 2, поэтому имеем основание считать, что 2 присутствует
ив/?, причем приблизительно в 50 экземплярах. Отношение S, вполне вероятно,
в свою очередь содержит 25 копий значения 5, поскольку относится к числу наиболее
упофебительных в R. Таким образом, в итоговое отношение, как можно ожидать, будут
включены дополнительно 70 * 50 = 3500 кортежей со значением 2 афибута b и 100 * 25 = 2500
кортежей с компонентами Ь, равными 5.
Наконец, следует учесть вероятность одновременного наличия в обоих
отношениях 9 других значений — допустим, что каждое из них присутствует
16.5. ВЫБОР ПЛАНОВ С УЧЕТОМ ИХ СТОИМОСТИ
799
в 50 кортежах R и 25 кортежах S и поэтому вносит в итоговое отношение
50 * 25 = 1250 кортежей. Общая оценка размера результата соединения составляет
15000 + 16000 + 3500 + 2500 + 9 * 1250 = 48250.
Заметим, что, применив более простой метод прогнозирования из раздела 16.4 на
с. 783, основанный на предположении о равенстве количеств экземпляров каждого
значения в каждом отношении, в качестве оценки того же параметра мы получили бы
величину 1000 * 500 /14 « 35714. □
Пример 16.28. Здесь мы собираемся продемонстрировать, каким образом наличие
гистограмм с равной шириной, свидетельствующих о том, что множества значений
общего атрибута двух отношений-операндов почти не пересекаются, способно
обусловливать результат прогнозирования размера итогового отношения, возвращаемого
оператором соединения. Даны отношения
Jan(day, temp)
July(day, temp)
к которым адресуется запрос
SELECT Jan.day, July.day
FROM Jan, July
WHERE Jan.temp = July.temp;
предусматривающий отыскание пар дней (day) в январе (Jan) и июле (July) с одной
и той же температурой (temp) воздуха.112 План запроса сводится к вычислению
соединения отношений Jan и July посредством равенства (equijoin) значений компонентов
temp с последующей проекцией результата на два атрибута day.
Предположим, что гистограммы значений атрибутов temp отношений Jan и July
выглядят так, как показано на рис. 16.24. Вообще говоря, если гистограммы с равной
шириной, полученные для одноименных атрибутов обоих отношений, содержат
одинаковые множества диапазонов (можно допустить, что некоторые диапазоны той или
иной гистограммы пусты), для вычисления оценки размера результата соединения,
как говорилось выше, достаточно определить значения объемов подмножеств
соединенных кортежей для каждого диапазона, а затем сложить их.
Диапазон
0-9
10-19
20-29
30-39
40-49
50-59
60-69
70-79
80-89
90-99
Jan
40
60
80
50
10
5
0
0
0
0
July
0
0
0
0
5
20
50
100
60
10
Рис. 16.24. Гистограммы значений температуры к примеру 16.28й2
112 На европейских просторах бывшего СССР подобная "проблема", к сожалению, не
возникает. — Прим. перев.
113 Читателям, волею судеб заброшенным по другую сторону экватора, придется поменять
местами содержимое столбцов Jan и July.
800
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
О различных критериях стоимости операций
До сих пор мы трактовали оценки количества операций дискового ввода-вывода
как наиболее адекватный инструмент прогнозирования подлинной стоимости
выполнения того или иного оператора. При определенных обстоятельствах процедуры
определения расходов, связанных с дисковыми операциями, оказываются
чрезмерно сложными либо потенциально уязвимыми, а подчас и просто невыполнимыми
(если объектом анализа являются логические, а не физические планы запросов).
В подобных случаях в качестве приемлемого критерия стоимости, как упоминалось
в разделе 16.4.4 на с. 788, могут рассматриваться оценки размеров промежуточных
результатов операций. Не следует забывать о том, что задачей оптимизатора
запросов является сопоставление планов, а не предвещание точных значений
продолжительности их выполнения. С другой стороны, оценки стоимости, учитывающие
только потребности в операциях дискового ввода-вывода, иногда могут выглядеть
слишком грубыми. Для их уточнения в процесс анализа могут быть вовлечены
затраты, связанные с перемещением головок дискового устройства; если и этого
недостаточно, следует принять во внимание расходы времени из-за манипуляций
данными в оперативной памяти.
Если два совпадающих диапазона "содержат" 7\ и Т2 кортежей соответственно
и количество различных значений, принадлежащих обоим диапазонам, равно V, следуя
методикам, изложенным в разделе 16.4.4 на с. 788, мы приходим к заключению, что оценка
количества соединенных кортежей, относящихся к этим диапазонам, имеет вид T{T2/V.
Для гистограмм, приведенных на рис. 16.24, многие из подобных частных оценок
обращаются в нуль из-за того, что Т{ либо Т2 равны 0. Нетрудно убедиться, что исключениями
являются только диапазоны 40—49 и 50—59. Поскольку ширина V каждого диапазона равна
10, вклад диапазонов 40—49 в итоговое отношение исчисляется 10 * 5 /10 = 5 кортежами,
а диапазоны 50—59 обеспечивают получение 5 * 20 /10 = 10 соединенных кортежей.
Итак, согласно нашей оценке, отношение, представляющее результат соединения,
должно включать 5 + 10= 15 кортежей. Не имея гистограмм и зная только о том, что
каждое отношение содержит по 245 кортежей со 100 значениями общего атрибута,
пробегающими интервал от 0 до 99, мы пришли бы к выводу, что отношение,
возвращаемое оператором соединения, должно состоять из 245 * 245 /100 = 600 кортежей. □
16.5.2. Вычисление статистик
Относительно редкое периодическое повторное вычисление статистик является
нормой в большинстве коммерческих СУБД, и тому есть несколько причин. Во-
первых, статистики, как правило, не подвержены радикальным изменениям в
продолжение коротких промежутков времени. Во-вторых, даже в чем-то не точные
статистики оказываются полезными, если они последовательно и единообразно
применяются для анализа всех планов. В-третьих, принятие решения об обеспечении
наивысшей степени актуальности статистических характеристик чревато избыточными
вычислительными затратами; активное использование статистик еще не означает, что
их следует обновлять столь же активно.
Процесс сбора статистических данных может активизироваться автоматически по
истечении определенного промежутка либо после выполнения заданного количества операций
обновления содержимого базы данных. Впрочем, если, как выясняется, оптимизатором
запросов выбираются не самые лучшие планы, администратор базы данных имеет право
послать запрос на принудительное вычисление статистик, чтобы исправить ситуацию.
Получение статистик для отношения R в целом может оказаться весьма
дорогостоящим, особенно в тех случаях, когда вычислению подлежат значения V(R, а) для
каждого атрибута а (или, что еще хуже, когда речь идет о конструировании гисто-
16.5. ВЫБОР ПЛАНОВ С УЧЕТОМ ИХ СТОИМОСТИ
801
грамм значений всех атрибутов а). Один общеупотребительный подход состоит в
приближенном вычислении статистик на основе выборок, охватывающих только
небольшие порции данных. Для примера предположим, что для получения оценки значения
V(R, а) требуется включить в выборку некоторую часть кортежей R. Алгоритм расчета,
следующий всем канонам математической статистики, обязан учитывать массу
различных факторов (в частности, тип распределения значений а). Однако анализ удастся
упростить, приняв во внимание следующие интуитивные соображения. Если после
просмотра малой выборки (скажем, охватывающей 1% всех кортежей R) выясняется,
что большинство значений а различны, довольно вероятно, что величина V(R, а)
близка к T(R). Если, напротив, выборка содержит небольшое количество кортежей с
различными значениями а, имеются определенные основания утверждать, что множество
этих значений незначительно отличается от полного набора различных значений а,
содержащихся в текущем экземпляре отношения R.
16.5.3. Эвристические правила сокращения стоимости логических планов
Одна из важных областей использования оценок стоимости выполнения операций
связана с эвристическими правилами преобразования запросов. Как было показано в разделе
16.3.3 на с. 780, некоторые эвристики, применяемые без учета результатов
прогнозирования стоимости, почти со 100-процентной вероятностью способны улучшить качество
логического плана запроса. Каноническим примером подобных преобразований служит
продвижение операторов выбора вниз по дереву выражений реляционной алгебры.
Однако в процессе оптимизации запроса возникают ситуации, когда анализ
стоимости плана, проводимый непосредственно до и после некоторого преобразования,
позволяет применять преобразование, если это выгодно, либо отказываться от него вовсе.
Поскольку здесь речь идет о предсказании стоимости логического плана запроса, когда
решения о выборе конкретных способов физической реализации операторов реляционной
алгебры еще не приняты, оценки стоимости не могут быть основаны на затратах,
связанных с операциями дискового ввода-вывода. Вместо этого мы предлагаем учитывать
размеры промежуточных результатов (с помощью приемов, рассмотренных в разделе
16.4 на с. 783) и трактовать сумму полученных величин как эвристическую оценку
стоимости логического плана в целом. Проиллюстрируем сказанное на примере.
Пример 16.29. Обратимся к исходному логическому плану запроса, изображенному на
рис. 16.25, полагая, что статистические характеристики отношений R и S выглядят так,
как показано ниже.
R(a, b)
ЦК) = 5000
V(R, a) = 50
V(R, b) = 100
S(b, с)
T(S) = 2000
V(S, b) = 200
V(S, c) = 100
В поисках способов преобразования исходного плана на рис. 16.25 в наилучший
окончательный план мы будем исходить из того, что оператор выбора (о) должен быть продвинут
вниз по дереву настолько, насколько это возможно. Однако полной уверенности в
необходимости перемещения оператора удаления кортежей-дубликатов (S) ниже оператора
соединения (х) у нас нет. Два альтернативных плана, различающихся взаимным
положением операторов Sw x, показаны на рис. 16.26. Заметьте, что в плане (а) оператор £
перемещен по обеим ветвям дерева. Если бы стало известно, что R и/или S не содержат
кортежей-дубликатов, операторы 8 из соответствующих ветвей можно было бы изъять.
802
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Оценки для алгебраически эквивалентных планов не всегда совпадают
Обратите внимание на то, что оценки размеров итоговых отношений,
представленные в виде меток корневых вершин алгебраически равноценных деревьев,
изображенных на рис. 16.26, различны: в одном случае мы предсказываем значение 250,
а в другом — 500. Дисциплина прогнозирования далека от "точных" наук, и
подтверждением тому является сама возможность возникновения подобных аномалий.
Более того, случаи, когда, как в разделе 16.4 на с. 783, удается гарантировать
регулярность получаемых оценок, являются скорее исключением, нежели правилом.
Интуиция подсказывает, что возрастание величины оценки для плана (Ь)
обусловлено следующей причиной. Если оба отношения, R и S, содержат кортежи-
дубликаты, при выполнении операции соединения количество дубликатов будет
увеличено: например, три экземпляра кортежа из R и два из S при соединении
образуют шесть кортежей итогового отношения R x S. В используемой нами простой
формуле оценки размера результата оператора S не принята во внимание
возможность приумножения дубликатов за счет применения какой-либо "вложенной"
операции, возвращающей аргумент для 8.
'а =10
М
R S
Рис. 16.25. Логический план запроса к примеру 16.29
50
100
'а =10
5000
R
250
м
1000
500
5
М
s
2000
100
а =10
1000
S
2000
5000
R
(а) (Ъ)
Рис. 16.26. Кандидаты на роль наилучшего логического плана запроса
Способ прогнозирования размера результата операции выбора нам известен
(см. раздел 16.4.3 на с. 785): T(R) I V(R, a) = 100. Ясно также, как оценить объем
отношения, возвращаемого оператором соединения (см. раздел 16.4.4 на с. 788): следует
перемножить размеры отношений-аргументов (T(R) и T(S)) и разделить полученное
произведение на max (v(R, b\ V(S, £)) = 200. А вот предсказать сколько-нибудь точный результат
применения операции удаления кортежей-дубликатов довольно затруднительно.
16.5. ВЫБОР ПЛАНОВ С УЧЕТОМ ИХ СТОИМОСТИ
803
Для начала рассмотрим оценку размера результата выполнения операции <?(<тя=10
. Поскольку кортежи отношения cra=w(R) содержат только одно значение а и до
100 значений Ъ и прогнозируемое количество кортежей равно 100, правило из раздела
16.4.7 на с. 794, касающееся оценки итога удаления дубликатов, подтверждает, что
произведение счетчиков количеств различных значений каждого атрибута не является
определяющим фактором. Поэтому мы оцениваем размер результата применения
оператора 8 как половину количества кортежей в cra=w(R); левая вершина 8 на
рис. 16.26 (а) снабжена соответствующей меткой 50.
Теперь попытаемся оценить результат, возвращаемый оператором 8 в плане,
изображенном на рис. 16.26 (Ь). Соединенные кортежи отношения cra=l0(R)txS содержат
одно значение а и прогнозируемые количества min (v(#, b), V(S, £)) = 100 значений Ь
и V(S, с) = 100 значений с. И вновь произведение счетчиков различных значений не
ограничивает размер результата применения оператора 8— мы оцениваем последний
как 500, т.е. как половину количества кортежей в сгд= l0(R) x S.
Для сравнения двух планов, представленных на рис. 16.26, следует сложить
оценки, полученные для всех вершин деревьев, за исключением корневых и вершин-
листьев, поскольку последние не зависят от того, какой из планов выбран. Сумма
оценок для промежуточных вершин плана (а) составляет 100 + 50+1000=1150, а для
аналогичных вершин плана (Ь) — 100+ 1000= 1100. Поэтому с небольшой
погрешностью можно утверждать, что в данном случае выполнение операции удаления
кортежей-дубликатов в последнюю очередь более выгодно. Случись так, что количество
различных значений общего атрибута b отношений R и S окажется меньшим и, как
следствие, число соединенных кортежей и стоимость плана (Ь), вероятно, возрастут,
мы могли бы прийти к противоположному заключению. □
16.5.4. Способы сопоставительного анализа физических планов
Рассмотрим приемы использования методов прогнозирования стоимости операций
в процессе преобразования логического плана запроса в физический план.
Основной — исчерпывающий — подход состоит в анализе всех комбинаций решений,
принимаемых для каждой из проблем, которые мы очертили в начале раздела 16.4 на
с. 783, — выбор способов реализации физических операторов, порядка соединений
и т.п. Каждому возможному физическому плану присваивается соответствующая
оценка стоимости, после чего выбирается план с наименьшей оценкой.
Впрочем, существует и целый ряд других подходов к задаче выбора физического
плана. Именно на них мы сосредоточим внимание в этом разделе, а раздел 16.6 на
с. 809 целиком посвятим особенно важной теме, связанной с выбором порядка
выполнения операций соединения (join). Прежде всего следует отметить, что практически
все методы анализа пространства возможных физических планов сводятся к одной из
двух указанных ниже стратегий.
• "Сверху вниз"— дерево, представляющее логический план запроса,
просматривается, начиная с корневой вершины: для каждого мыслимого варианта
реализации оператора, соответствующего корневой вершине, изучаются все
возможные сочетания способов вычисления его аргументов и определяются
оценки стоимости, а затем выбирается план с наилучшей оценкой.114
Напомним (см. раздел 16.3.4 на с. 781), что отдельная вершина дерева логического плана
запроса способна представлять группу из нескольких одноименных ассоциативно-коммутативных
операторов, подобных оператору соединения. Поэтому задача сопоставления всех вариантов
преобразования одной вершины сама по себе может оказаться достаточно сложной.
(Ю)
804
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
• "Снизу вверх"— для каждой ветви дерева логического плана запроса
подсчитываются (в направлении к корневой вершине) значения стоимости
вариантов реализации выражения, соответствующего этой ветви: затраты на
вычисление выражения, отвечающего некоторой ветви Е, определяются
с учетом стоимости каждого из сочетаний всех возможных способов реализации
частных подвыражений, образующих Е.
Если взглянуть на обе стратегии под максимально широким углом зрения,
различия между ними не покажутся столь принципиальными, поскольку, что ни говори,
в любом случае требуется проанализировать все возможные комбинации способов
реализации каждого оператора. Если толковать о том, какая из стратегий все-таки
более эффективна, то первая, предполагающая движение по дереву выражений сверху
вниз, например, позволяет избежать анализа таких опций, которые нельзя исключить
из рассмотрения при движении снизу вверх. Однако существуют и такие варианты
стратегии "снизу вверх", которые также открывают возможности сужения
пространства поиска, — на подобных методах мы и сосредоточим внимание в дальнейшем.
Одна из простых версий стратегии "снизу вверх" совершенно очевидна: при
вычислении плана текущего подвыражения в расчет принимаются только наилучшие планы
для каждого из подвыражений-аргументов. Такой подход, на который мы ссылаемся
ниже как на вариант метода динамического программирования (dynamic programming),
хотя и не гарантирует возможность получения наилучшего плана для целого выражения
в общем случае, зачастую, однако, позволяет достичь этой цели. Еще один
заслуживающий внимания подход, называемый оптимизацией по Селинджеру (Selinger-style
optimization), или оптимизацией в стиле System R (System-R-style optimization), санкционирует
анализ дополнительных свойств частных планов с целью выявления наилучших общих
планов в тех случаях, когда некоторые из частных планов не являются оптимальными.
Эвристический выбор
Одна из альтернатив заключается в использовании в процессе выбора физических
планов тех же эвристических подходов, которые применяются для поиска наилучшего
логического плана. В разделе 16.6.6 на с. 819, например, мы обсудим "жадный"
(greedy) эвристический алгоритм упорядочения аргументов п-арного оператора
соединения (j°in), предполагающий, что процесс соединения начинается с такой пары
отношений, которые в результате дают наименьшее ожидаемое количество соединенных
кортежей, и продолжается аналогичным образом до тех пор, пока не будут соединены
все операнды. Существует и множество других эвристических правил, наиболее
употребительными из которых являются следующие.
1. Если план предусматривает вычисление оператора выбора cra = c(R) и хранимое
отношение R снабжено индексом для атрибута а, для получения кортежей R,
удовлетворяющих условию а = с, использовать оператор индексного сканирования
(index-scan) (см. раздел 15.1.1 на с. 685).
2. Более общий случай: если помимо условия а = с критерий выбора содержит
и некоторое другое условие, использовать индексное сканирование с
последующими дополнительными действиями по выбору кортежей, называемыми
физической операцией фильтрации (filtering) (за подробностями обращайтесь
к разделу 16.7.1 на с. 822).
3. Если некоторый аргумент соединения обладает индексом для общих атрибутов,
использовать алгоритмы соединения на основе индексирования (index-based join)
(см. разделы 15.6.3 на с. 728 и 15.6.4 на с. 729).
4. Если один из аргументов соединения отсортирован по значениям общих
атрибутов, предпочесть алгоритм соединения с сортировкой (sort-join) (см. раздел
16.5. ВЫБОР ПЛАНОВ С УЧЕТОМ ИХ СТОИМОСТИ
805
15.4.7 на с. 714) алгоритму соединения с хешированием (hash-join) (см. раздел
15.5.5 на с. 720) либо, что не обязательно, алгоритму соединения, основанному
на индексировании, если применение такового также уместно.
5. При вычислении объединения (union) либо пересечения (intersection) трех или
более отношений вначале группировать самые малые отношения.
Метод ветвей и границ
Вариант метода ветвей и границ (branch- and-bound), находящий широкое
практическое применение, вначале предполагает использование определенных эвристических
правил для отыскания некоторого "хорошего" физического плана, реализующего
логический план запроса в целом. Пусть стоимость найденного плана равна С. Если по мере
рассмотрения планов подвыражений выясняется, что какой-либо частный план обладает
стоимостью, превышающей С, такой план исключается из числа потенциальных
кандидатов на участие в образовании полного плана. Если, напротив, удается сконструировать
полный план со стоимостью, меньшей С, в процессе дальнейшего анализа
пространства физических планов тот принимается в качестве текущего оптимального плана.
Важное преимущество метода состоит в возможности быстрого завершения поиска
и принятия наилучшего найденного плана. Например, если текущее значение С уже
достаточно мало, процедуру уместно завершить даже в том случае, если существуют и
лучшие планы, но вероятные выгоды от их использования нивелируются затратами,
сопряженными с дальнейшим продолжением поиска. Если, однако, величина С
сравнительно велика, гораздо разумнее затратить некоторое время в надежде на отыскание
более совершенного плана.
Метод поиска в локальной окрестности
В соответствии с версией метода поиска в локальной окрестности (hill climbing)
вначале с помощью какой-либо эвристики выбирается некоторый физический план.
Затем с целью отыскания "соседнего" плана, обладающего меньшей стоимостью,
в текущий план вносятся локальные изменения, связанные, скажем, с выбором
альтернативного алгоритма реализации того или иного оператора либо с переупорядочением
аргументов оператора соединения на основе ассоциативного и/или коммутативного
законов. Если найден такой физический план, который более не может быть улучшен за
счет каких бы то ни было локальных изменений, он принимается в качестве искомого.
Метод динамического программирования
Вариант метода динамического программирования (dynamic programming),
используемый оптимизатором запросов, предусматривает использование только оптимальных
планов каждого отдельного подвыражения. Подобный подход подробно исследуется
в разделе 16.6 на с. 809.
Оптимизация по Селинджеру
Алгоритм оптимизации по Селинджеру (Selinger-style optimization) (P. Griffiths-
Selinger), или оптимизации в стиле System R (System-R-style optimization), который
можно трактовать как усовершенствованную версию алгоритма динамического
программирования, способен учитывать для каждого подвыражения не только планы
с наименьшими значениями стоимости, но и некоторые другие, менее оптимальные,
планы, способные снизить стоимость планов подвыражений более высокого уровня за
счет изменения порядка сортировки промежуточных данных. Примерами могут
служить ситуации, когда результат вычисления подвыражения сортируется по значениям
1) атрибутов, указанных в операторе сортировки (г), размещенном в корневой
вершине дерева;
806
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
2) группирующих атрибутов "внешнего" оператора группирования (^);
3) общих атрибутов отношений-аргументов оператора соединения (х) более
высокого уровня.
Если стоимость плана оценивается в виде суммы размеров промежуточных отношений,
тогда сортировка аргументов операторов сама по себе не дает никаких преимуществ. Если,
однако, критерий стоимости основан на более точных условиях, связанных, скажем, с
количеством операций дискового ввода-вьшода, становятся очевидными и выгоды
использования процедур сортировки, позволяющих сократить объем вычислений на первом
проходе любого из алгоритмов, основанных на сортировке (см. раздел 15.4 на с. 706).
16.5.5. Упражнения к разделу 16.5
Упражнение 16.5.1. Оцените размер результата соединения R(a, b) x S(b, с) при
условии V(R, b) = V(S, b) = 20, используя приведенные ниже гистограммы, задающие
значения частоты повторяемости четырех наиболее употребительных значений
и групп остальных значений атрибутов R.b и S.b, общих для отношений R и S.
R.b
S.b
0
5
10
1
6
8
2
4
5
3
5
4
7
Другие значения
32
48
Как соотносится полученный вами прогноз с более простой оценкой, основанной
на предположении о равновероятном распределении всех 20 значений и условиях
ЦК) = 52, T(S) = 78?
* Упражнение 16.5.2. Оцените размер итогового отношения, возвращаемого
оператором соединения R(a, b) tx S(b, с), если данные отношений R и S соответствуют
следующей гистограмме.
R
S
Ь<0
500
300
Ь = 0
100
200
Ь>0
400
500
! Упражнение 16.5.3. В примере 16.29 на с. 802 упоминалось о том, что уменьшение
количества различных значений атрибутов R.b или S.b способно привести к тому,
что план (а) на рис. 16.26 (см. с. 803) окажется более удачным, нежели план (Ь).
При каких значениях
*а) V(R,b)9
b) V(S,b)
план (а) будет обладать меньшей стоимостью в сравнении с планом (Ь)?
! Упражнение 16.5.4. Рассмотрим четыре отношения, R, S, Т и V, содержащие
соответственно 200, 300, 400 и 500 кортежей, которые выбираются случайным и
независимым образом из единого набора, состоящего из 1000 кортежей (например,
вероятность того, что определенный кортеж принадлежит отношению R, равна 1/5,
отношению 5 — 3/10 и обоим отношениям одновременно — 3/50).
* а) Каков ожидаемый размер отношения R U S U T U V?
Ь) Какова оценка размера результата выполнения оператора R П S П Т П V?
16.5. ВЫБОР ПЛАНОВ С УЧЕТОМ ИХ СТОИМОСТИ
807
* с) При каком порядке объединения (U) отношений достигается минимум
стоимости (суммы размеров промежуточных отношений) операции?
d) При каком порядке пересечения (П) отношений достигается минимум
стоимости (суммы размеров промежуточных отношений) операции?
! Упражнение 16.5.5. Выполните задания упражнения 16.5.4 при условии, что все
четыре отношения содержат по 500 кортежей, наудачу выбранных из набора,
включающего 1000 кортежей.115
!! Упражнение 16.5.6. Рассмотрим выражение
ть (Д(д, Ь) х S(b, с) х Т(с, d)),
предусматривающее вычисление соединения отношений R, S и Т с последующей
сортировкой итогового отношения по значениям атрибута Ъ. Введем следующие
упрощающие условия:
i) отношения R и Т не соединяются первыми, поскольку по существу образуют
декартово произведение;
И) все другие операции соединения допускают реализацию только с помощью
двухпроходных алгоритмов, основанных на сортировке (sort-join) (см. раздел
15.4.7 на с. 714) или хешировании (hash-join) (см. раздел 15.5.5 на с. 720);
Ш) содержимое любого отношения или результата вычисления выражения
может быть упорядочено только посредством алгоритма сортировки двухфазным
многокомпонентным слиянием (two-phase, multiway merge sort) (см. раздел
11.4.4 на с. 513);
iv) результат первого соединения передается в качестве аргумента второму
оператору соединения по блокам и не сохраняется на диске;
v) каждое исходное отношение занимает 1000 блоков, а результат любой
операции соединения — 5000 блоков.
Дайте ответы на следующие вопросы.
* а) Как выглядит набор подвыражений (с учетом порядка их вычисления),
который следовало бы принять во внимание при использовании метода
оптимизации по Селинджеру?
Ь) Какой план запроса позволяет минимизировать количество операций
дискового ввода-вывода?116
!! Упражнение 16.5.7. Предложите пример логического плана запроса,
представленного в форме Ex F для некоторых выражений Е и F по вашему выбору, где
применение наилучших планов реализации Е и F не совместимо с алгоритмом
завершающей операции соединения, который обеспечивает минимальную стоимость
вычисления выражения Е tx F в целом. Допускаются любые предположения о
количестве свободных буферов оперативной памяти и размерах отношений,
вовлеченных в выражения Е и F.
115 Решения заданий этого упражнения не публикуются на Web-странице нашей книги.
116 Поскольку согласно условию упражнения круг допустимых способов реализации
операций весьма ограничен и специфичен, это дает возможность в качестве критерия стоимости
плана использовать количество дисковых операций, а не более простую, но менее точную
оценку размеров отношений.
808
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
16.6. Выбор порядка соединения
В этом разделе мы сосредоточим внимание на важнейшей проблеме оптимизации
стоимости планов запросов, связанной с выбором порядка (естественного) соединения
(join) трех или более отношений. Аналогичные подходы применимы и при анализе
других л-арных операций, подобных объединению (union) или пересечению (intersection),
хотя такие операции менее значимы с практической точки зрения, поскольку не столь
трудоемки, как операции соединения, и гораздо реже используются в вариантах п > 2.
16.6.1. Различия между левыми и правыми операндами соединения
При выполнении соединения следует помнить о том, что многие из алгоритмов
соединения, рассмотренных в главе 15 на с. 683, асимметричны, — имеется в виду,
что функции, выполняемые двумя отношениями-операндами, различны и стоимость
вычисления оператора зависит от порядка задания операндов. Что, вероятно, наиболее
важно, однопроходный алгоритм соединения, исследованный в разделе 15.2.3 на с. 697,
предусматривает считывание кортежей одного отношения — предпочтительно
меньшего—в буферы оперативной памяти, создание структуры (скажем, хеш-таблицы),
предназначенной для упрощения дальнейшего поиска и сопоставления данных, и только
затем — последовательную загрузку в память блоков другого отношения и соединение
кортежей этого отношения с ранее считанными кортежами первого отношения.
Предположим для примера, что при выборе физического плана принято решение
воспользоваться однопроходным алгоритмом соединения. Содержимое левого (как
следует считать, меньшего) аргумента, называемого опорным отношением (build relation),
загружается в структуры оперативной памяти. Кортежи правого — тестируемого (probe
relation) — отношения-аргумента считываются в память отдельными блоками и
сопоставляются с кортежами опорного отношения. К числу алгоритмов, предусматривающих
различную интерпретацию аргументов операции соединения, относятся также
1) алгоритмы соединения посредством вложенных циклов (nested-loop join)
(см. раздел 15.3 на с. 702) — содержимое левого отношения-операнда
обрабатывается во внешнем цикле;
2) алгоритм соединения на основе индексирования (index-based join) (см. раздел
15.6.3 на с. 728) — предполагается, что правое отношение-операнд снабжено
индексом для общих атрибутов.
16.6.2. Деревья соединения
При необходимости соединения двух отношений следует определить порядок их
перечисления в тексте оператора. В соответствии с принятым нами соглашением, в
качестве левого аргумента оператора соединения выбирается отношение с меньшим
прогнозируемым значением размера. Еще раз напомним, что упомянутые выше алгоритмы
соединения — однопроходный, циклический и алгоритм на основе индексирования —
демонстрируют более высокие показатели производительности, если меньшее из
отношений играет роль левого аргумента оператора. Если говорить более точно,
однопроходный алгоритм и алгоритм соединения посредством вложенных циклов трактуют
меньший из операндов как опорное отношение, просматриваемое во внешнем цикле,
а варианты алгоритма на основе индексирования имеет смысл выбирать только в том
случае, если одно из отношений достаточно мало, а другое снабжено индексом для общих
атрибутов. Существенные различия в размерах отношений довольно обычны, поскольку
в запросах, предполагающих необходимость соединения кортежей, часто используются
условия выбора по значениям хотя бы одного атрибута, и подобный выбор значительно
(и неравномерно) сокращает множества кортежей, подлежащие соединению.
16.6. ВЫБОР ПОРЯДКА СОЕДИНЕНИЯ
809
Пример 16.30. Вновь обратимся к запросу на рис. 16.4 (см. с. 758),
SELECT movieTitle
FROM Starsln, MovieStar
WHERE starName = name AND
birthdate LIKE ' %1960';
который предусматривает поиск названий кинофильмов с участием актеров,
родившихся в 1960 году, и приводит к предпочтительному логическому плану,
изображенному на рис. 16.21 (см. с. 781). План предполагает соединение отношения starsln
с отношением, которое возвращается оператором выбора, применяемым к отношению
MovieStar. Оценки размеров отношений Starsln и MovieStar нам неизвестны, но,
как можно полагать, выбор кортежей с информацией об актерах одного
определенного (1960-го) года рождения сократит объем MovieStar раз в пятьдесят. Поскольку
в кинофильме снимаются, как правило, несколько актеров, следует ожидать, что
отношение Starsln содержит больше кортежей, нежели MovieStar, даже до
выполнения выбора из MovieStar, так что второй аргумент соединения, сгШМшеъ1КЕ >%1960<
(MovieStar), окажется во много раз меньшим в сравнении с первым, Starsln.
Приходится заключить, что порядок задания аргументов оператора соединения в плане на
рис. 16.21 нуждается в изменении на противоположный. □
Если соединению подлежат два отношения, имеются всего две альтернативы,
связанные с тем, какой из операндов должен быть размещен слева, а какой — справа.
Если же операцией соединения охватывается сразу несколько отношений, количество
допустимых деревьев соединения (join trees) резко возрастает. Например, на рис. 16.27
показаны три из возможных пяти деревьев, которые отображают варианты
соединения четырех отношений R, S, Т и U, соответствующие различным способам
группирования аргументов с сохранением порядка их следования.117 Поскольку порядок
перечисления операндов также имеет немаловажное значение, каждому из пяти деревьев
соответствует семейство из 4! = 24 деревьев (количество перестановок из п элементов
равно л!), получаемых за счет всех возможных взаимных перемещений меток вершин.
м
/ \
М и
/ \
0 г
М
/ \
м м
/ \ / \
R S T U
М
/ \
R М
/ \
s M
/ \ / \
R S T U
(а) (Ъ) (с)
Рис. 16.27. Некоторые способы соединения четырех отношений
16.6.3. Левосторонние деревья соединения
На рис. 16.27 (а) изображено левостороннее (left-deep) дерево соединения.
Бинарное дерево называют левосторонним, если все его правые дочерние вершины
являются листьями. Дерево на рис. 16.27 (с), напротив, принадлежит к категории правосто-
117 Двум оставшимся вариантам соединения отвечают следующие способы группирования
аргументов: (R ex (S сх 7)) сх U и R сх ((S сх 7) сх U). — Прим. перев.
810
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
ронних (right-deep) — все его левые дочерние вершины не имеют дочерних вершин.
Деревья, подобные представленному на рис. 16.27 (Ь), которые не относятся ни к
левосторонним, ни к правосторонним, принято называть ветвящимися (bushy); если, как
на рис. 16.27 (Ь), все пути в ветвящемся дереве имеют одинаковую длину, дерево
является сбалансированным (balanced).
Ниже приведены два довода в пользу того, почему при соединении нескольких
отношений следует ограничивать внимание только такими вариантами группирования
операндов, которые описываются левосторонними деревьями.
1. Количество возможных левосторонних деревьев с заданным числом вершин-
листьев и свободным порядком их именования относительно велико, но,
разумеется, несоизмеримо мало в сравнении с количеством всех деревьев, что
позволяет существенным образом сузить пространство поиска. Этот аргумент,
конечно, не является решающим — в отличие от следующего.
2. Модель левосторонних деревьев адекватна требованиям общеупотребительных
алгоритмов соединения — в частности, однопроходного и алгоритма
соединения посредством вложенных циклов: эффективность алгоритмов возрастает,
если порядок группирования операндов описывается левосторонним деревом.
"Листья" в лево- или правостороннем дереве соединения на самом деле могут
быть промежуточными вершинами, представляющими операторы, отличные от
оператора соединения. Поэтому, например, дерево логического плана, показанное на
рис. 16.21 (см. с. 781), уместно трактовать как левостороннее дерево с одним
оператором соединения: тот факт, что к правая вершина-операнд представляет оператор
выбора, не исключает дерево из категории левосторонних.
Как указывалось в п. 1 выше, с увеличением числа аргументов п-арного оператора
соединения количество левосторонних деревьев возрастает гораздо медленнее, нежели
количество всех деревьев соединения. Для п отношений существует только одна
топологическая форма левостороннего дерева, представляющая семейство из п\ деревьев,
соответствующих различным способам связывания вершин с отношениями. Тот же
вывод справедлив и для правосторонних деревьев соединения. Количество Т(п)
топологических форм деревьев соединения п отношений в свою очередь подчиняется
рекуррентному правилу
Д1) = 1;
чп)=хпг=\тт(п-1).
Для пояснения второго выражения достаточно заметить, что количество
листьев/в левом поддереве относительно корневой вершины может быть представлено
числом из интервала от 1 до п - 1, и эти листья допускают размещение любым из Г(/)
способов, регламентирующих формы деревьев с / листьями. Оставшиеся п - i листьев
правого поддерева можно упорядочить одним из Т(п - /) способов.
Несколько первых значений Т(п) выглядят так: Г(1)=1, Г(2)=1, Г(3) = 2, Г(4) = 5,
Г(5) = 14 и Г(6) = 42. Чтобы получить общее количество деревьев с учетом
возможности взаимной замены меток их вершин (перемещения отношений-аргументов
внутри выражения соединения), достаточно перемножить величины Т(п) и я!. Так,
например, общее количество деревьев соединения с 6 листьями составляет
42 * 6! = 30240, 6! = 720 из которых являются левосторонними, другие 720 —
правосторонними, а все остальные — ветвящимися.
Теперь рассмотрим второй из упомянутых выше доводов в пользу применения
левосторонних деревьев соединения, декларирующий их способность к формированию
оптимальных планов запросов. Ниже мы приведем два примера, иллюстрирующих
следующие эффекты:
16.6. ВЫБОР ПОРЯДКА СОЕДИНЕНИЯ
811
Еще раз о роли менеджера буферов
Внимательный читатель мог обратить внимание на то, что мы как-то незаметно
отступили от предположения (использовавшегося в целой серии примеров — скажем, 15.4
на с. 704 и 15.7 на с. 713) о фиксированном количестве буферов оперативной памяти,
доступных для оператора соединения, и нынче используем более "выгодную" схему,
предусматривающую возможность использования любого "не слишком большого"
числа буферов. Напомним (см. раздел 15.7 на с. 732), что менеджер буферов (buffer manager)
наделен способностью чрезвычайно гибкого распределения ресурсов памяти. Если,
однако, единовременно выделяется слишком большое количество буферов, это
чревато опасностью вынужденного периодического "сбрасывания" данных части буферов
на диск с их последующей повторной загрузкой и, как следствие, снижением уровня
производительности алгоритма в сравнении с ожидаемым.
1) если однопроходный алгоритм соединения применяется к опорному
отношению, расположенному слева в дереве соединения, объем памяти,
требуемый в каждый момент времени, как правило, не столь велик в сравнении
с ситуациями, когда способ группирования отношений описывается
правосторонним или ветвящимся деревом;
2) при использовании алгоритма соединения посредством вложенных циклов
в условиях, когда во внешнем цикле обрабатываются данные левого
отношения-операнда, удается избежать необходимости неоднократного
конструирования каждого промежуточного отношения.
Пример 16.31. Обратимся к левостороннему дереву соединения, показанному на
рис. 16.27 (а) (см. с. 810), и предположим, что для вычисления каждого из операторов
х применяется однопроходный алгоритм соединения, рассмотренный в разделе 15.2.3
на с. 697. Как и прежде, будем считать, что опорным (т.е. целиком хранимым
в оперативной памяти) является левое отношение-аргумент. Для вычисления
оператора RxS кортежи R следует загрузить в буферы оперативной памяти и сохранять
там до завершения операции; итоговое отношение RxS также следует "держать"
в памяти; общее количество буферов памяти, требуемых для выполнения этой
части вычислений, таким образом, составит B(R) + B(R tx S). Если выбрать в
качестве R меньшее из отношений и понадеяться на то, что сопутствующий оператор
выбора еще более сократит количество кортежей R, проблемы с резервированием
указанного числа буферов, как можно ожидать, не возникнут.
Имея результат RxS, мы должны соединить его с отношением Т. К данному
моменту буферы, выделенные для кортежей R, более не нужны и могут быть повторно
использованы для хранения (части) результата вычисления оператора (R x S) х Т. При
дальнейшем выполнении соединения отношения (R ex S) сх Т с U, в свою очередь, отпадает
надобность в буферах, содержащих промежуточные данные RxS, и эти буферы могут
использоваться для временного сохранения блоков итогового отношения. Таким
образом, однопроходный алгоритм соединения, применяемый к выражению, которому
соответствует левостороннее дерево, требует пространства оперативной памяти, достаточного
для единовременного хранения не более двух (промежуточных) отношений.
Теперь рассмотрим схожую реализацию операции соединения, описываемой
правосторонним деревом (см. рис. 16.27 (с) на с. 810). Первое, что следует сделать, — это, как
и прежде, загрузить в буферы оперативной памяти содержимое отношения R, поскольку
812
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
в качестве опорного отношения всегда выбирается левый аргумент оператора. Затем
придется сконструировать отношение Stx(T\xU), чтобы воспользоваться им как
тестируемым в процессе выполнения соединения, представляемого корневой вершиной
дерева. Для вычисления S х (Г х U) надлежит загрузить в буферы памяти кортежи S, а затем
вычислить оператор TtxU, чтобы употребить его результат в качестве тестируемого
отношения, подлежащего соединению с S. Но для выполнения TtxU следует прежде считать
в память данные Т. Следовательно, в буферах памяти в один и тот же период времени
должны находиться кортежи отношений R, S и Т. Таким образом, процедура вьиисления
оператора соединения, которому соответствует правостороннее дерево с п листьями,
требует одновременного наличия в памяти блоков данных п - 1 отношений-операндов.
Разумеется, нельзя исключить ситуацию, когда значение B(R) + B(S) + В(Т)
окажется меньшим в сравнении с объемами пространства памяти, B(R) + B(R х S)
и B(R х S) + b((R x S) х г), необходимыми для хранения любого из промежуточных
отношений, получаемых в процессе соединения исходных операндов,
сгруппированных в виде левостороннего дерева.118 Однако, как упоминалось в примере 16.30 на
с. 810, в запросах, предусматривающих соединение нескольких отношений, часто
адресуется некоторое отношение сравнительно небольшого размера, которое можно
использовать в качестве "самого" левого операнда выражения, описываемого левосторонним
деревом. Если R как раз и является подобным отношением, можно ожидать, что
значение B(R х S) окажется существенно меньшим, нежели B(S), a b((R сх S) х Т) — гораздо
меньшим в сравнении с В(Т), что служит дополнительным оправданием преимуществ
модели левосторонних деревьев соединения. □
Пример 16.32. Теперь рассмотрим ситуацию, когда 4-арный оператор соединения,
представленный деревьями на рис. 16.27 (см. с. 810), требуется реализовать с
помощью алгоритма соединения посредством вложенных циклов. Предположим, что для
выполнения каждого из частных операторов соединения используется
соответствующий итератор (как в разделе 15.1.6 на с. 689). Помимо того, для простоты допустим,
что все четыре отношения — R, S, Т и U — являются хранимыми, а не виртуальными
таблицами или выражениями. Если используется вариант группирования операндов,
соответствующий левостороннему дереву (а), итератор для оператора корневой вершины
получает порции данных левого аргумента (R x S) сх Т объемом, равным размеру
свободной области оперативной памяти, и предпринимает попытки соединения кортежей
каждой порции со всеми кортежами U, но поскольку U является хранимым
отношением, достаточно выполнить его сканирование, а не конструирование. После загрузки
в память очередной порции данных левого аргумента содержимое и считывается снова,
но такова природа алгоритма с вложенными циклами — если размеры отношений-
операндов велики, избежать повторной загрузки кортежей правого операнда не удается.
Аналогично, для вычисления порции данных (R сх S) х Т следует получить порцию
отношения R х S и осуществить сканирование Т Для выполнения оператора (R x S) сх Т
в целом сканирование отношения Т также, вероятно, придется неоднократно
повторить. Наконец, чтобы получить кортежи RcxS, надлежит (возможно, несколько раз)
считывать порции R и сопоставлять их с содержимым S. Впрочем, при выполнении всех
этих действий многократно считываются только кортежи хранимых отношений.
118 Здесь, как и всегда, мы не учитываем стоимость хранения отношения, представляющего
результат вычисления "корневого" оператора.
16.6. ВЫБОР ПОРЯДКА СОЕДИНЕНИЯ
813
Теперь сопоставим поведение итераторов, применяемых для реализации вариантов
соединения, которые описываются левосторонним (а) и правосторонним (с)
деревьями на рис. 16.27. Итератор для оператора корневой вершины дерева (с) начинает
работу с загрузки порции данных R. Затем он обязан целиком сконструировать
отношение Stx(TtxU) и проанализировать возможность соединения кортежей этого отношения
с кортежами текущей порции R. При загрузке в память очередной порции R отношение
S х (Т ex U) должно быть сконструировано вновь. Разумеется, можно создать
отношение S сх (Г ex U) только один раз и сохранить его в памяти либо на диске. В последнем
случае для доступа к данным этого отношения придется выполнять дополнительные
операции дискового ввода-вывода, заведомо увеличивающие стоимость плана
в сравнении с планом, соответствующим левостороннему дереву. Если же
содержимое S х (Гсх U) сохраняется в памяти, это чревато теми же проблемами, связанными
со злоупотреблением ресурсом памяти, которые упоминаются в примере 16.31 и в тексте
врезки "Еще раз о роли менеджера буферов", приведенной выше. □
16.6.4. Динамическое программирование и выбор порядка соединения
При выборе порядка соединения многих отношений имеются три
альтернативы действий:
1) просматривать все множество вариантов;
2) ограничить область поиска подмножеством вариантов;
3) использовать эвристическое правило для выбора одного варианта.
Здесь мы сосредоточим внимание на одном "рациональном" подходе к задаче
перебора множества возможных решений, который является разновидностью метода
динамического программирования (dynamic programming). Вариант метода может быть
использован как для исследования полного множества способов группирования и взаимного
размещения аргументов оператора, так и для перебора отдельных подмножеств
решений (например, основанных на модели левосторонних деревьев). О применении
эвристик для выбора единственного варианта группирования и упорядочения отношений-
аргументов оператора соединения мы расскажем в разделе 16.6.6 на с. 819. Метод
динамического программирования является общей алгоритмической парадигмой.119
Центральная идея, лежащая в основе метода, состоит в заполнении таблицы оценок с
сохранением минимального объема данных, необходимых для принятия решения.
Обратимся к оператору соединения Rx ex R2 сх — х Rn. Рассматриваемый вариант
алгоритма динамического программирования предполагает создание таблицы с
элементами для каждого подмножества из одного или нескольких отношений /?,-. В
таблицу заносится следующая информация.
1. Прогнозируемый размер соединения соответствующего подмножества
операндов (для вычисления такого значения можно применить формулу, указанную
в разделе 16.4.6 на с. 792).
2. Наименьшая стоимость процедуры вычисления соединения отношений. В наших
примерах в этом качестве мы будем использовать сумму размеров промежуточных
отношений (без учета размеров отношений R{ и итогового отношения,
получаемого при соединении всех отношений, описываемых текущим элементом табли-
119 За описанием метода в его общей форме обращайтесь, например, к работе Aho A.V.,
Hopcroft J.E., Ullman J.D. Data Structures and Algorithms, Addison-Wesley, Reading, MA, 1984.
[Имеется перевод: Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы. — М.:
Издательский дом "Вильяме", 2000.]
814
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
цы). Напомним, что размеры промежуточных отношений — это простейший
критерий оценки подлинных затрат, обусловленных применением дисковых
операций, загрузкой процессора и иными факторами. Если ситуация допускает
возможность проведения дополнительных вычислений, ничто не запрещает
использовать и другие, более сложные и точные критерии, учитывающие, например,
общее количество операций дискового ввода-вывода. В подобных случаях
надлежит принимать во внимание и характеристики алгоритма, применяемого для
выполнения соединения, поскольку различным алгоритмам соответствуют и
различные значения стоимости. К этим аспектам мы обратимся несколько позже.
3. Описание выражения с участием отношений-операндов, подлежащих соединению,
которое задает определенный способ фуппирования и упорядочения операндов и
обладает наименьшей стоимостью. Можно ограничить внимание, например,
выражениями, которым соответствуют левосторонние деревья; в таком случае описание
выражения сводится к перечислению операндов в том или ином порядке.
Процесс конструирования таблицы можно описать индукцией по размеру
подмножества операндов. Существуют два варианта правил, разнящиеся тем, рассматриваются
ли все возможные формы деревьев либо только такие деревья, которые относятся к
категории левосторонних. Отличительные особенности этих вариантов описаны ниже.
Базис. Элемент таблицы, соответствующий отдельному отношению R, содержит
значение размера отношения R, величину стоимости, равную 0, и выражение,
представляющее собой идентификатор R как таковой. Элемент для пары отношений {/?,-, Rj]
вычисляется следующим образом. Значение стоимости равно 0, так как в процессе
получения соединения промежуточные отношения не используются, а оценка размера
итогового отношения вычисляется по правилу из раздела 16.4.6 на с. 792: произведение
объемов отношений /?, и Rj делится на величину размера большего из наборов различных
значений атрибутов, общих для Rt и Rj. В качестве выражения, строго говоря, может
задаваться либо RitxRj, либо RjtxRi. Но на основании правила, указанного в разделе
16.6.1 на с. 809, на роль левого операнда выбирается меньшее из отношений Я, и Rj.
Индукция. Вычисляются элементы таблицы для всех подмножеств, содержащих 3, 4
и т.д. операндов, вплоть до получения элемента для подмножества размера п. Этот
элемент содержит информацию о наилучшем способе соединения всех отношений и
указывает оценку стоимости процесса. Необходимо показать, как вычислять элемент
таблицы, отвечающий множеству Я из к отношений. Если ограничить внимание
только левосторонними деревьями, тогда для каждого R из к отношений в Я изучается
возможность соединения операндов, принадлежащих Я, путем вычисления
соединения членов Я- {R} с последующим соединением полученного результата с
отношением R. Стоимость процедуры соединения членов Я равна стоимости соединения для
Я- {R} плюс значение размера результата итогового соединения. Выбирается такое
отношение R, которое доставляет минимум функции стоимости. Выражение для Я
содержит наилучшее выражение соединения членов Я- {R} в качестве левого аргумента
итоговой операции соединения, a R — в качестве правого аргумента. Размер
результата соединения для Я определяется по формуле из раздела 16.4.6 на с. 792. Если же
необходимо рассмотреть все возможные деревья соединения, процесс вычисления элемента
таблицы, соответствующего некоторому подмножеству Я отношений, несколько
усложняется. Приходится исследовать все возможные способы разбиения Я на
непересекающиеся подмножества Ях и 7^. Для каждого варианта разбиения вычисляются суммы
16.6. ВЫБОР ПОРЯДКА СОЕДИНЕНИЯ
815
1) наилучших стоимостей для 7ZX и 7£2\
2) размеров 7ZX и ^.
Наилучшая суммарная стоимость принимается как стоимость для 7Z, а выражение
соединения членов 7Z образуется соединением наилучших выражений для 7ZX и 7^.
Пример 16.33. Рассмотрим оператор соединения четырех отношений R, S, Т и U. Для
простоты будем полагать, что все отношения содержат по 1000 кортежей. Схемы
и статистические характеристики отношений указаны на рис. 16.28.
Размеры, стоимости и наилучшие планы для единичных подмножеств-элементов
таблицы алгоритма динамического программирования представлены на рис. 16.29:
значение размера каждого отношения соответствует заданному (1000), величина
стоимости принята равной нулю, поскольку промежуточных отношений нет, а наилучший
(и единственный) план сводится к заданию идентификатора отношения как такового.
Теперь рассмотрим пары отношений. Величина стоимости соединения для каждой
пары равна нулю, так как необходимости в использовании промежуточных
отношений по-прежнему нет. Для каждой пары существуют два возможных плана
соединения, поскольку в роли левого (правого) аргумента может выступать любое из двух
отношений, но так как размеры отношений по условию одинаковы, осмысленный
критерий выбора одного из планов отсутствует: в каждом из случаев мы выбираем
алфавитный порядок следования аргументов операции. Размеры итоговых отношений
вычисляются по обычному правилу. Результаты сведены в таблицу на рис. 16.30.
Обратите внимание, что отношения R гх Т и StxU обладают максимальным размером,
равным 1000000, так как эти операции по существу сводятся к декартовым произведениям.
R(a, b)
V(R, a) = 100
V(R, b) = 200
S(b, с)
V(S, b)=\00
V(S, c) = 500
4c,d)
V(T, c) = 20
V(T, d) = 50
U(d, a)
V(U, a) = 50
V(U,d)=\000
Рис. 16.28. Статистические характеристики отношений-операндов соединения к примеру 16.33
Размер
Стоимость
Наилучший план
IR)
1000
0
R
{S}
1000
0
S
{Т}
1000
0
т
{U}
1000
0
и
Рис. 16.29. Таблица для единичных множеств
Размер
Стоимость
Наилучший план
[R.S]
5000
0
RtxS
{R,T}
1000000
0
R\xT
{R,U}
10000
0
RtxU
{S,T}
2000
0
StxT
{S,U}
1000000
0
StxU
{T,U}
1000
0
TxU
Рис. 16.30. Таблица для пар отношений
816 ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Теперь рассмотрим таблицу с описанием результатов соединения троек
отношений. Единственный способ вычисления соединения трех отношений в нашем случае
состоит в выборе двух отношений, подлежащих соединению первыми. Оценка
размера итогового отношения вычисляется обычным образом — детали мы опускаем;
напомним (см. раздел 16.4.6 на с. 792) только о том, что результат окажется одним и тем
же независимо от способа соединения операндов.
Оценкой стоимости вычисления соединения для каждой тройки аргументов является
размер промежуточного отношения, получаемого в результате соединения двух "левых"
отношений. Из трех вариантов группирования выбирается такой, которому
соответствует пара отношений, образующих при соединении отношение наименьшего размера.
Для определения вида выражения соединения вначале группируются два выбранных
выше отношения, и эта группа может быть как левым, так и правым аргументом
следующего оператора соединения. Предположим, что рассматриваются только такие
варианты соединения, которым соответствуют левосторонние деревья; поэтому результат
соединения двух первых отношений трактуется как левый аргумент оператора. Поскольку
во всех случаях ожидаемый размер результата соединения двух отношений равен, как
минимум, 1000 (величине объема каждого исходного отношения), в ситуации, когда
позволялось бы использование структур соединения в виде правосторонних деревьев, в
качестве левого операнда всегда следовало бы выбирать единственное оставшееся
отношение. Таблица с суммарной информацией о тройках отношений показана на рис. 16.31.
Размер
Стоимость
Наилучший план
{Я, S, Т]
10000
2000
(S ex T) ex R
{Я, S, Щ
50000
5000
(R ex S) ex U
{R, T, U}
10000
1000
(Гсх U)txR
{S, Т, Щ
2000
1000
(Гсх U) txS
Рис. 16.31. Таблица для троек отношений
Для примера рассмотрим, каким образом получены данные столбца таблицы для
тройки отношений {/?,£, Г}. Следует изучить свойства операций соединения
элементов каждой из трех возможных пар. Стоимость вычисления оператора RtxS равна
размеру получаемого итогового отношения (5000, как видно из рис. 16.30). Размер
промежуточного отношения, возвращаемого оператором RtxT, оценивается
величиной 1000000, а отношение SxT имеет размер 2000. Поскольку последнему варианту
соединения соответствует наименьшее значение стоимости, он и выбирается (в
столбце {/?, 5, Т} таблицы указаны значение стоимости 2000 и выражение соединения
(S х Т) х R, в котором группируются операнды S и Т).
Теперь настало время проанализировать возможности соединения всех четырех
отношений. По предварительной оценке итоговое отношение должно содержать около
100 кортежей, но подлинная стоимость операции определяется размерами
промежуточных отношений, поскольку при сопоставлении планов размер окончательного
результата не учитывается.
Существуют два120 основных способа вычисления 4-арного оператора соединения:
1) выбрать наилучший вариант соединения трех аргументов и соединить
полученный результат с оставшимся исходным отношением;
2) разделить четыре аргумента на пары и соединить результаты, возвращаемые
операторами соединения пар.
120 Остальные варианты соответствуют способам группирования, указанным в тексте сноски
на с. 810. — Прим. перев.
16.6. ВЫБОР ПОРЯДКА СОЕДИНЕНИЯ 817
Разумеется, если речь идет о выражениях, которым соответствуют левосторонние (или
правосторонние. — Прим. перев.) деревья, приемлем только первый способ, поскольку
другие приводят к получению выражений, описываемых ветвящимися деревьями. В
таблице на рис. 16.32 суммированы сведения о семи возможных вариантах группирования,
основанных на предпочтительных решениях, которые указаны на рис. 16.30 и 16.31.
Рассмотрим для примера первое выражение на рис. 16.32, предусматривающее
вычисление операторов StxT и (StxT)txR с последующим соединением результата
с отношением U. Данные таблицы на рис. 16.31 свидетельствуют о том, что
наилучший способ соединения аргументов R, S и Т состоит в первоначальном вычислении
оператора StxT. Выражение следует топологической форме левостороннего дерева,
и соединение его результата с отношением U эту форму не изменяет. Если
сосредоточить внимание только на выражениях, отвечающих модели левосторонних деревьев,
то рассматриваемая структура и порядок следования аргументов в ней определяют
единственное решение. Если же допустить возможность использования ветвящихся
деревьев, следовало бы присоединить отношение U слева, поскольку его размер
меньше в сравнении с результатом соединения трех других. Стоимость вычисления
выражения оценивается величиной 12000, которая складывается из значений
стоимости и размера (2000 и 10000 соответственно) операнда (5 ex T) cx R.
Выражение
((5 ex T) cx R) cx U
((/? cx S) сх и) cx T
((Г cx U) cx R) cx S
((Гсх U)txS)txR
(Гсх U)tx(RtxS)
(RtxT)tx(StxU)
(StxT)tx(RtxU)
Стоимость
12000
55000
11000
3000
6000
2000000
12000
Рис. 16.32. Варианты выражений и стоимости
соединения четырех отношений
В трех последних строках таблицы на рис. 16.32 представлены выражения, которым
соответствуют ветвящиеся деревья соединения, предполагающие разбиение множества
отношений-операндов на пары. Например, выражение в последней строке
предусматривает первоначальное выполнение операторов StxT и RtxU с последующим
соединением их результатов. Стоимость вычисления этого выражения представляет собой сумму
значений размеров и стоимостей отдельных пар: стоимости равны нулю, как и должно
быть при соединении хранимых отношений, а прогнозируемые размеры составляют
2000 и 10000 соответственно. Поскольку, как всегда, левый операнд соединения
должен быть меньше правого, выражение записывается именно как (StxT)tx(RtxU).
Итак, нетрудно убедиться, что наименьшей стоимостью вычисления (3000)
обладает выражение из четвертой строки таблицы — ((Г х U) cx s) cx R. Этот план и должен
быть выбран для реализации соединения, причем независимо от того,
рассматриваются ли только левосторонние деревья либо все множество деревьев соединения. □
818
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
16.6.5. Динамическое программирование и уточненные функции стоимости
Использование размеров отношений в качестве оценок стоимости существенно
упрощает вычисления, предусмафиваемые алгоритмом динамического профаммирования.
Однако недостаток подобного упрощения заключается в том, что подлинные значения
стоимости нередко во внимание не принимаются. Вот красноречивый пример.
Предположим, что оператор R(a, b) x S(b, с) предполагает соединение отношения R,
содержащего единственный кортеж, и отношения S. Если допустить, что S снабжено индексом
для общего афибута Ь, время выполнения операции окажется пренебрежимо малым.
Если, напротив, отношение S не имеет индекса, S придется сканировать, зафатив B(S)
операций дискового ввода-вывода — даже в том случае, когда, как мы условились, R
состоит всего из одного кортежа. Критерий стоимости, учитывающий только размеры
отношений R, S и R х S, не позволяет различить два рассмофенных случая, поэтому
оценка стоимости вычисления выражения R x S при его дальнейшем возможном фуппиро-
вании окажется либо заведомо завышенной, либо неоправданно заниженной.
Впрочем, изменение схемы динамического профаммирования, позволяющее
учесть особенности применяемого в конкретной ситуации алгоритма соединения, не
столь сложно. Прежде всего, в качестве критерия стоимости следует принять
количество дисковых операций либо время выполнения процедуры. При вычислении
стоимости вычисления выражения 7ZX x TZi суммируются значения стоимости для 7Z\, 7Zi
и наименьшей стоимости соединения этих отношений при использовании наилучшего
доступного алгоритма. Поскольку последнее слагаемое обычно зависит от размеров 7ZX
и 7^2, следует также получить оценки этих размеров (как мы и поступали в примере 16.33).
Еще более мощная версия алгоритма динамического профаммирования основана
на методе оптимизации по Селинджеру (Sdinger-style optimization), упоминавшемся в
разделе 16.5.4 на с. 804, и предусмафивает сохранение для каждого подмножества
отношений, допускающих соединение, не одного, а сразу нескольких значений
стоимости. Напомним, что в соответствии с алгоритмом оптимизации по Селинджеру рас-
смафиваются не только наименьшая стоимость получения результата соединения, но
и наименьшие стоимости консфуирования того же отношения, упорядоченного
согласно определенным "заслуживающим внимания" правилам. В число подобных
правил включаются такие, которые, как можно ожидать, обеспечат преимущества при
последующем использовании алгоритма соединения на основе сортировки либо
позволят получить итоговое отношение, упорядоченное именно в том виде, какой
необходим пользователю, активизировавшему запрос. Если результатом обработки
запроса должно быть отсортированное отношение, в качестве альтернативного варианта
реализации надлежит изучить возможность применения одно- или многопроходного
алгоритма на основе сортировки, но если фебование упорядочения итоговых данных
не выдвигается, алгоритмы соединения с хешированием следует считать, как
минимум, столь же, а вообще говоря, — более предпочтительными, нежели аналогичные по
назначению алгоритмы с сортировкой.
16.6.6. "Жадный" алгоритм выбора порядка соединения
Как было показано в примере 16.33 на с. 816, даже при тщательном Офаничении
просфанства поиска, обеспечиваемом алгоритмом динамического профаммирования,
с ростом количества отношений, подлежащих соединению, объем вычислений
увеличивается по экспоненциальному закону. Использование переборного алгоритма,
подобного методам ветвей и фаниц или динамического профаммирования, оправданно
только в тех ситуациях, когда число аргументов оператора соединения не превышает
пяти-шести. Если, однако, размерность задачи выходит за указанный предел либо
конкретные обстоятельства не позволяют расходовать большой ресурс времени на
16.6. ВЫБОР ПОРЯДКА СОЕДИНЕНИЯ
819
Коэффициент избирательности соединения
Удобный способ наблюдения за поведением эвристических правил (подобных
"жадному" алгоритму) выбора левостороннего дерева соединения нескольких
отношений связан с вычислением для каждого отношения R, рассматриваемого в
качестве потенциального кандидата на соединение с текущим деревом, коэффициента
избирательности (selectivity factor), который представляется отношением
размер результата соединения
размер результата вычисления текущего дерева
Поскольку точные размеры отношений обычно не известны, эти значения
надлежит прогнозировать так, как и прежде. На каждом этапе "жадного" алгоритма
выбора порядка соединения предполагается отыскание отношения с наименьшим
коэффициентом избирательности.
Если, например, атрибут соединения является первичным ключом отношения
R, коэффициент избирательности составит не более 1, что, как правило, далеко
неплохо. Аналогичную картину, напомним, мы наблюдали в примере 16.33 на с. 816,
где, как следует из рис. 16.28, атрибут d служит ключом отношения U, но ни один
из общих атрибутов других отношений не является ключевым — это еще одно
объяснение в пользу того, почему операция Т х U является наиболее удачным
начальным шагом соединения четырех отношений R, S, Т и U.
исчерпывающий поиск гарантированно наилучшего решения, оптимизатор запросов
должен предоставлять возможность применения каких-либо добротных эвристических
приближенных правил определения порядка соединения нескольких отношений.
Наиболее широкое признание завоевала эвристика, называемая "жадным" (greedy)
алгоритмом, в соответствии с которой частное решение относительно порядка
следования (некоторых) аргументов оператора соединения, принятое однажды, фиксируется
и позже не пересматривается. Ниже мы сосредоточим внимание на версии "жадного"
алгоритма, который конструирует выражение, отвечающее структуре левостороннего
дерева соединения. Свойство "жадности" алгоритма проистекает из требования возможного
снижения размера промежуточного отношения, соответствующего каждому уровню дерева.
Базис. Начать с пары отношений, прогнозируемый размер результата соединения
которых минимален. Соединение этих отношений трактовать как текущее дерево (current tree).
Индукция. Среди всех отношений, еще не включенных в текущее дерево, найти
отношение, которое при соединении с текущим деревом позволяет получить отношение
минимального ожидаемого размера. "Новое" текущее дерево в качестве левого операнда
включает "старое" текущее дерево, а выбранное отношение является правым операндом.
Пример 16.34. Рассмотрим способ применения "жадного" алгоритма к отношениям R,
S, Т и U из примера 16.33 на с. 816. Начальный этап заключается в отыскании пары
отношений, на основе которых можно получить множество соединенных кортежей
минимального размера. Информация из таблицы рис. 16.30 на с. 816 позволяет
заключить, что такой парой является {Г, U] — объем отношения TxU оценивается
величиной 1000. Поэтому TxU становится текущим деревом.
Теперь надлежит определить, какое из оставшихся отношений — R или S —
необходимо включить в дерево на следующем этапе. Для этого необходимо сопоставить
значения прогнозируемых размеров отношений (Ггх U) х R и {Тх U) x S. Таблица на
рис. 16.31 (см. с. 817) содержит требуемые сведения: второму— лучшему— варианту
820
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
соответствует значение стоимости 2000, а первому — 10000. Поэтому в качестве
нового текущего дерева принимается (Г х U) ex S.
Больше выбирать не из чего — на последнем этапе следует соединить выражение
текущего дерева с отношением R. Стоимость результата — ((Г ex U) ex s) tx R —
оценивается значением 3000, равным сумме размеров двух промежуточных отношений.
Заметьте, что результаты, полученные с помощью "жадного" алгоритма и метода
динамического профаммирования (см. пример 16.33 на с. 816), совпали. Обратные
ситуации, когда "жадный" алгоритм оказывается не в состоянии найти оптимальное
решение (в то время как метод динамического профаммирования всегда гарантирует
получение такового), в среднем встречаются, разумеется, чаще (за соответствующим
примером обратитесь к упражнению 16.6.4). □
16.6.7. Упражнения к разделу 16.6
Упражнение 16.6.1. Постройте таблицы метода динамического профаммирования
для отношений из упражнения 16.4.1 (см. с. 796), обеспечивающие получение всех
возможных вариантов фуппирования аргументов операции соединения для а) всех
деревьев соединения; Ь) левосторонних деревьев. Какой из планов является
лучшим в каждом из случаев?
Упражнение 16.6.2. Выполните задания упражнения 16.6.1 с учетом изменения
схемы отношения Z на i) Z(d, а) при условии ii) V(Z, a) = 100.
Упражнение 16.6.3. Выполните задания упражнения 16.6.1 в применении к
отношениям из упражнения 16.4.2 на с. 796.
* Упражнение 16.6.4. Рассмофим операцию соединения отношений R(a, b), S(b, с),
Т(с, d) и U(a, d), где R и U содержат по 1000 кортежей, а 5 и Г — по 100 кортежей.
Помимо того, компоненты каждого афибута каждого отношения содержат по
100 различных значений, за исключением афибутов с, для которых
V(S, с) = V(T, с) = 10.
a) Какой порядок соединения выбирается "жадным" алгоритмом? Какова
стоимость этой операции?
b) Каковы оптимальный порядок соединения и соответствующее значение
стоимости вычислений?
Упражнение 16.6.5. Сколько деревьев соответствуют различным вариантам
соединения *а) семи отношений; Ь) восьми отношений? Какая часть деревьев в одном
и другом случаях относится к категории ветвящихся?
! Упражнение 16.6.6. Предположим, что фебуется соединить отношения R, S, Т и U
одним из способов, указанных на рис. 16.27 (см. с. 810), обеспечивая сохранение
всех промежуточных отношений в оперативной памяти на протяжении всего
периода времени, пока они необходимы. Как и прежде, будем полагать, что порции
окончательного результата соединения всех четырех отношений передаются
некоторому внешнему процессу по мере их вычисления, так что содержать их в памяти
не нужно. Выразите в терминах количеств блоков исходных и промежуточных
отношений (скажем, B(R) или B(R ex S)) значения нижней фаницы М числа буферов
памяти, достаточных для хранения данных
* а) левостороннего дерева на рис. 16.27 (а);
b) ветвящегося дерева на рис. 16.27 (Ь);
c) правостороннего дерева на рис. 16.27 (с).
16.6. ВЫБОР ПОРЯДКА СОЕДИНЕНИЯ
821
Какие исходные предположения позволят утверждать, что для хранения одного
дерева потребуется заведомо меньший объем свободной памяти, нежели для других?
*! Упражнение 16.6.7. Сколько элементов таблицы метода динамического
программирования придется заполнить в процессе поиска оптимального варианта соединения
к отношений?
16.7. Завершение формирования физического плана запроса
К этому моменту мы уже обсудили процессы синтаксического анализа запроса,
преобразования дерева разбора в начальный логический план запроса и улучшения
плана с привлечением алгебраических законов и методов, рассмотренных в разделах
16.2 (см. с. 760) и 16.3 (см. с. 774). Составной частью процедуры выбора физического
плана является анализ стоимости всех возможных вариантов реализации операций,
о чем говорилось в разделе 16.5 на с. 797. В разделе 16.6 на с. 809 мы сосредоточили
внимание на проблемах выбора порядка соединения (join) нескольких отношений;
аналогичные подходы применимы и для группирования аргументов объединений (union),
пересечений (intersection) и любых других ассоциативно-коммутативных операторов.
Для завершения преобразования логического плана запроса в окончательный
физический план остается выполнить ряд действий. Нам предстоит осветить следующие
основные вопросы.
1. Выбор алгоритмов реализации операций, предусматриваемых планом, если
подобное не было сделано на более ранних стадиях формирования плана,
связанных, например, с определением оптимального порядка перечисления аргументов
операторов соединения с помощью метода динамического программирования.
2. Принятие решений о том, следует ли материализовать промежуточные
результаты, т.е. создать отношения и сохранить их на диске, либо организовать
каналы (сконструировать структуры данных в памяти для передачи порций
итогового отношения, возвращаемого одним оператором, другому оператору).
3. Выбор системы представления операторов физического плана, позволяющей
учесть особенности методов доступа к хранимым отношениям и алгоритмов
реализации операторов реляционной алгебры.
Тему, касающуюся выбора алгоритмов реализации операторов, обсуждать здесь заново
(см. главу 15 на с. 683) и во всей ее полноте мы не собираемся, но сосредоточим внимание
на двух наиболее важных операторах: об операторе выбора (selection) речь пойдет в разделе
16.7.1, а об операторе соединения (join) — в разделе 16.7.2 на с. 824. В разделах с 16.7.3
(см. с. 825) по 16.7.5 (см. с. 827) включительно затрагиваются аспекты материализации
(materialization) и организации каналов (pipelining) данных, а в разделе 16.7.6 на с. 830
рассматривается система представления операторов физических планов запросов.
16.7.1. Поиск метода выбора
Один из важнейших этапов формирования физического плана запроса связан
с поиском адекватных алгоритмов реализации каждого оператора выбора (selection).
В разделе 15.2.1 на с. 693 мы упоминали об одном из очевидных способов вычисления
оператора вида <тс(#), предусматривающем считывание всех кортежей отношения R и
выполнение проверки того, удовлетворяет ли каждый из них заданному условию С.
В разделе 15.6.2 на с. 726 исследовалась ситуация, когда С содержит условие равенства
атрибута некоторой константе и этот атрибут снабжен индексом, что позволяет
отыскать кортежи, удовлетворяющие С, не просматривая все содержимое R. Теперь
обратимся к более общему случаю: условие С представляет собой конъюнкцию (and)
нескольких условий, в каждом из которых определенный атрибут сопоставляется с
константой посредством оператора равенства (=) или неравенства (скажем, <).
822
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Если полагать, что многомерные индексы, охватывающие по несколько атрибутов
отношения, отсутствуют, физический план должен предусматривать использование
"традиционных" индексов, если таковые имеются, для всех атрибутов, упомянутых
в конъюнктах условия выбора. Индексы позволяют "быстро" идентифицировать
подмножества кортежей, удовлетворяющих каждому из частных условий. В разделах 13.2.3
(см. с. 601) и 14.1.5 (см. с. 643) мы уже рассказывали о технике пересечения множеств
указателей элементов индексов в оперативной памяти, позволяющей находить все
кортежи, удовлетворяющие одновременно нескольким критериям поиска, без
необходимости предварительного считывания отдельных подмножеств кортежей с диска.
Для простоты мы не будем рассматривать подобные способы использования
нескольких индексов и сосредоточим внимание на физических планах, которые предполагают
1) обращение к одному оператору сравнения вида А ©с, где А — атрибут,
снабженный индексом, с — некоторая константа, а © — оператор сравнения,
подобный = или <;
2) извлечение всех кортежей, удовлетворяющих условию п. 1, с помощью
физического оператора индексного сканирования (index-scan), упомянутого
в разделе 15.1.1 на с. 685;
3) проверку каждого кортежа из числа выбранных при выполнении п. 2 на
предмет совпадения с оставшейся частью условий выбора; физический
оператор, осуществляющий такую процедуру фильтрации (filtering), мы будем
называть Filter; оператор Filter — во многом подобно оператору а
реляционной алгебры — в качестве параметра принимает определенное условие,
используемое для выбора кортежей.
Помимо физических планов указанной формы мы обязаны принять во внимание и такой
план, который предусматривает считывание содержимого всего отношения — без
использования индекса, но с помощью физического оператора табличного сканирования (table-
scan) — и передачу каждого кортежа оператору Filter с целью проверки условия выбора.
Альтернативные физические планы, в которых реализуется заданный оператор
выбора, сопоставляются по критерию стоимости операции считывания данных.
Анализируя значения стоимости, мы более не можем полагаться на упрощенные оценки,
основанные на размерах промежуточных отношений, поскольку на данном этапе
рассматривается способ реализации отдельного оператора логического плана, и размеры
промежуточных отношений не зависят от выбора конкретного способа. Поэтому
теперь нам следует вернуться к модели подсчета дисковых операций, которая
использовалась в главе 15 на с. 683 для выбора алгоритмов и сопоставления значений
стоимости получаемых с их помощью решений. Как и прежде, для простоты будем
учитывать только стоимость доступа к блокам данных, но не к блокам индексов. Напомним,
что количество блоков индекса, подлежащих считыванию в процессе загрузки
содержимого отношения, намного меньше числа блоков самого отношения, поэтому
подобное упрощение вполне правомочно.
Рассмотрим вкратце методы прогнозирования стоимости различных планов
выполнения операции crc(R), где условие С представляет собой конъюнкцию (and)
нескольких условий сравнения атрибутов с константами. Примерами условий равенства
и неравенства могут служить выражения а = 10 и Ъ < 20 соответственно.
1. Стоимость алгоритма табличного сканирования в совокупности с
фильтрацией составляет:
a) B(R), если R компактно сгруппировано (clustered) (см. раздел 15.1.4 на с. 687);
b) T(R) — в противном случае.
2. Стоимость плана, предполагающего выбор частного условия вида а = 10 (для
атрибута а сконструирован индекс) и выполнение индексного сканирования для оты-
16.7. ЗАВЕРШЕНИЕ ФОРМИРОВАНИЯ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА
823
екания всех кортежей, удовлетворяющих выбранному конъюнкту, с последующей
фильтрацией по оставшейся части полного условия С, оценивается величиной:
a) B(R) I V(R, а), если индекс является группирующим (clustering) (см. раздел
15.6.1 нас. 725);
b) T(R) I V(R, a) — в противном случае.
3. Оценка стоимости плана, предполагающего выбор частного условия вида Ъ < 20
(для атрибута Ъ сконструирован индекс) и выполнение индексного
сканирования для извлечения всех кортежей, удовлетворяющих выбранному конъюнкту,
с последующей фильтрацией по оставшейся части полного условия С, равна:
a) B(R) 13, если индекс является группирующим',
b) T(R) / 3 — в противном случае.121
Пример 16.35. Рассмотрим оператор выбора crx=lANDy = 2mDZ<5(R), применяемый к
отношению R(x, у, z), которое обладает следующими статистическими характеристиками:
T(R) = 5000, B(R) = 200, V(R,x)=l00 и V(R, у) = 500. Допустим также, что R компактно
сгруппировано и снабжено индексами для всех атрибутов — х, у и г, — но
группирующим является только индекс для z. Имеются четыре варианта реализации
оператора, перечисленные ниже.
1. Табличное сканирование с последующей фильтрацией. Стоимость равна B(R),
или 200 дисковым операциям, поскольку R компактно.
2. Использование оператора индексного сканирования по значениям индекса х
с целью выбора кортежей, удовлетворяющих условию х = 1, с последующей
фильтрацией по условию у = 2 andz< 5. Так как компонентами х=\ обладают
примерно T(R) I V(R, x) = 50 кортежей и индекс для х не является группирующим,
для выполнения процедуры потребуются 50 операций дискового ввода-вывода.
3. Применение оператора индексного сканирования по значениям индекса у с
целью выбора кортежей, удовлетворяющих условию у = 2, с последующей
фильтрацией по условию х= 1 ANDz<5. Индекс для у также не является
группирующим, и стоимость операции оценивается величиной T(R) I V(R, у) = 10.
4. Использование оператора индексного сканирования по значениям
группирующего индекса z с целью выбора кортежей, удовлетворяющих условию г<5,
с последующей фильтрацией по условию х=\ мюу = 2. Количество дисковых
операций равно B(R) /3-67.
Нетрудно убедиться, что наиболее предпочтительным вариантом физической
реализации оператора является план 3 с прогнозируемой оценкой стоимости, равной 10,
в соответствии с которым вначале следует извлечь кортежи отношения R,
удовлетворяющие условию у = 2, а затем отфильтровать полученное подмножество данных по
УСЛОВИЮ X = 1 AND Z < 5. □
16.7.2. Поиск метода соединения
В главе 15 на с. 683 мы уже обсуждали различные алгоритмы реализации оператора
соединения (join) и приводили соответствующие оценки стоимости. Если полагать, что
количество доступных буферов оперативной памяти известно или может быть
предсказано, для оценки характеристик алгоритмов соединения с сортировкой (sort-join) следует
применять формулы из раздела 15.4.8 на с. 715, для алгоритмов соединения с хеширова-
121 Напомним (см. раздел 16.4.3 на с. 785), что процедура фильтрации данных с учетом
условия-неравенства возвращает в среднем 1/3 кортежей исходного отношения.
824
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
нием (hash-join) — из раздела 15.5.7 на с. 723, а для алгоритмов соединения на основе
индексирования (index-based join), — из разделов 15.6.3 (см. с. 728) и 15.6.4 (см. с. 729).
Если к моменту выполнения запроса количество свободных буферов памяти
доподлинно не известно (или не может быть определено вовсе) ввиду отсутствия
достоверной информации о том, чем еще "занимается" СУБД в то же самое время, либо
важные статистические характеристики вида V(R, а), определяющие свойства данных,
системой не собраны, определенные приемы выбора предпочтительного варианта
соединения, тем не менее, все еще существуют — они указаны ниже; аналогичные
выводы справедливы и в отношении других бинарных операторов, таких как объединение
(union), а также унарных операций над полными отношениями, 8 {удаление кортежей-
дубликатов — duplicate elimination) и у {группирование — grouping).
• Один из подходов заключается в обращении к однопроходному (one-pass)
алгоритму соединения (см. раздел 15.2.3 на с. 697) в надежде на то, что менеджеру
буферов удастся выделить достаточное количество буферов. Альтернативный
вариант (применимый только в случае оператора соединения) — выбрать
алгоритм соединения посредством вложенных циклов (nested-loop join) (см. раздел
15.3 на с. 702), уповая на то, что если для единовременной загрузки и хранения
данных левого аргумента оператора система и не сможет выделить достаточное
количество буферов памяти, содержимое аргумента все-таки не будет поделено
на чрезмерно большое количество порций и стоимость процесса соединения
в целом окажется приемлемой.
• Алгоритм соединения с сортировкой (sort-join) (см. раздел 15.4.7 на с. 714)
является удачным выбором, если выполняется одно из условий:
а) один или оба отношения-операнда предварительно отсортированы по
значениям общих атрибутов;
б) несколько отношений-аргументов оператора соединения обладают общим
атрибутом,
(Д(д, b) ex S(a, с)) х Ца, d),
где сортировка R и S по значениям атрибута а приводит к получению
отношения RtxS, упорядоченного по а и используемого в качестве аргумента
следующей процедуры соединения с сортировкой.
• Если существует возможность применения индекса — как, скажем, при
выполнении оператора R(a, b) x S(b, с), где отношение R, как предполагается,
невелико (возможно, является результатом выбора по значениям первичного ключа,
содержащим всего один или несколько кортежей), и имеется индекс для общего
атрибута S.b, — следует отдать предпочтение алгоритму соединения на основе
индексирования (index-based join) (см. разделы 15.6.3 на с. 728 и 15.6.4 на с. 729).
• Если же индексы или предварительно упорядоченные операнды отсутствуют
и требуется применение многопроходного алгоритма соединения, наилучшей
альтернативой, вероятно, окажется алгоритм соединения с хешированием (hash-join)
(см. раздел 15.5.5 на с. 720), поскольку количество предусматриваемых им проходов
зависит только от размера меньшего аргумента, а не от объемов обоих аргументов.
16.7.3. Организация каналов и материализация: за и против
Последним из важных вопросов, которые следует обсудить в связи с проблемой
выбора физического плана, является возможность передачи результатов одного
оператора другому. Прямолинейный подход к задаче выполнения плана запроса состоит
16.7. ЗАВЕРШЕНИЕ ФОРМИРОВАНИЯ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА
825
Материализация в памяти
Как может показаться на первый взгляд, помимо материализации и организации
каналов, существует и некий "промежуточный" подход, предполагающий, что
результат выполнения одной операции целиком накапливается в буферах
оперативной памяти (не на диске) и только затем передается операции-потребителю.
Мы трактуем подобный вариант действий как разновидность технологии
организации каналов: первое, что делает операция, принимающая результат другой
операции, — это формирует в памяти структуру данных с содержимым всего отношения-
операнда или его крупной порции. Примером может служить оператор выбора,
результат выполнения которого по каналу передается в качестве левого (опорного)
аргумента одному из алгоритмов соединения — однопроходному, многопроходному
с хешированием или алгоритму с сортировкой.
в соответствующем упорядочении операций во времени (таким образом, чтобы
операция не стартовала до тех пор, пока не будут целиком получены отношения-
аргументы) и сохранении результатов каждой операции на диске, откуда они могут
быть извлечены очередной операцией. Подобную стратегию принято называть
материализацией (materialization), поскольку каждое промежуточное отношение
формируется полностью (материализуется) и сохраняется на диске.
Более изящный и, как правило, более эффективный способ выполнения плана
запроса состоит в формировании потока вычислений, охватывающего сразу несколько
операций. Кортежи, возвращаемые одним оператором, сразу же передаются для
обработки оператору-потребителю и на диске не фиксируются. Речь в данном случае идет
о технологии организации каналов (pipelining), обычно реализуемой посредством сети
итераторов (iterators) (см. раздел 15.1.6 на с. 689), функции которых вызывают друг
друга в определенные моменты времени. Очевидные преимущества подобного подхода
связаны со значительным сокращением объема операций дискового ввода-вывода.
Стратегия организации каналов страдает, разумеется, и определенными недостатками.
Поскольку в каждый момент времени (ограниченный) ресурс оперативной памяти
делится между несколькими операторами, существует вероятность того, что оптимизатор
запросов отдаст приоритет алгоритму, выполнение которого сопряжено с большим
количеством обращений к диску, либо системе придется периодически "сбрасывать"
данные буферов памяти на диск, чтобы затем загружать их вновь, — все это способно
свести на нет ожидаемые преимущества и, более того, усугубить ситуацию.
16.7.4. Каналы и унарные операции
Унарные операции (unary operations) выбора (selection) и проекции (projection) —
прекрасные кандидаты на участие в обмене данными посредством каналов. Поскольку эти
операции предполагают обращение к отдельным кортежам (tuple-at-a-time),
необходимость в хранении более одного входного и одного выходного блоков данных не
возникает. Подобный режим работы схематически проиллюстрирован на рис. 15.5 (см. с. 694).
Унарные операции над отдельными кортежами допускают естественную
реализацию с помощью модели итераторов (iterators), рассмотренной в разделе 15.1.6 на
с. 689. Потребитель промежуточных данных, передаваемых по каналу, вызывает
функцию GetNext () по мере возникновения потребности в очередном кортеже.
В случае оператора проекции достаточно обратиться к источнику данных посредством
функции GetNext (), осуществить соответствующие действия по проекции очередного
кортежа и передать результат потребителю. Если же речь идет об операторе выбора <тс
(строго говоря, о физическом операторе Filter (О), для получения кортежа,
удовлетворяющего условию С, возможно, придется вызывать GetNext () неоднократно.
Процесс изображен на рис. 16.33.
826
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Потребитель
Кортеж,
удовлетворяющий условию С
Проверка
условия С
Повторение
GetNext
R
Рис. 16.33. Передача данных по каналу от оператора
выбора, выполняемого посредством итератора
16.7.5. Каналы и бинарные операции
Результаты выполнения бинарных операций также можно направлять по каналам.
Данные передаются потребителю по блокам при посредничестве одного буфера.
Количество дополнительных блоков, требуемых для вычислений, зависит от объемов
исходных и итогового отношений и может варьироваться. Рассмотрим пример, который,
надеемся, прояснит и преимущества, и недостатки подхода.
Пример 16.36. Проанализируем физические планы реализации оператора
(fl(w, x) tx S(x, у)) х U(y, z),
принимая во внимание следующие допущения.
1. Отношение R занимает 5000 блоков, a S и U — по 10000 блоков.
2. Объем промежуточного отношения RtxS исчисляется к блоками (для
некоторого к). Прогноз значения к можно получить на основе количества различных
значений компонентов х отношений R, S и размера кортежей (w, х, у) в
сопоставлении с размерами кортежей (w, х) отношения R и (х, у) — S. Более важно,
однако, выяснить, что произойдет при изменении к, поэтому вопрос,
касающийся конкретного значения к, мы оставляем открытым.
3. Обе операции соединения реализуются посредством алгоритма с хешированием —
либо одно-, либо двухпроходного, в зависимости от величины к.
4. Свободен 101 буфер оперативной памяти (это значение, как всегда, намеренно
занижено).
Эскиз выражения с учетом заданных значений параметров приведен на рис. 16.34.
Прежде всего, рассмотрим оператор соединения RcxS. Ни одно из отношений-
операндов не может быть загружено в буферы оперативной памяти целиком, что
вынуждает применить двухпроходный (two-pass) алгоритм соединения с хешированием
(hash-join) (см. раздел 15.5.5 на с. 720). На первом проходе алгоритма содержимое
отношения R может быть хешировано, самое большее, по 100 сегментам. Поэтому объем
одного сегмента должен исчисляться в среднем 50 блоками.122 На втором проходе для
1тт Для удобства будем полагать, что кортежи распределены по сегментам равномерно. Если
указанное условие не выполняется (а так, разумеется, чаще всего и происходит), понадобятся,
вероятно, и дополнительные буферы — остается надеяться, что менеджер буферов изыщет
возможность предоставления недостающих ресурсов памяти, хотя бы ценою временного
"сбрасывания" данных отдельных буферов на диск с их последующей повторной загрузкой.
Расходы, связанные с дополнительными дисковыми операциями, однако, учитывать не обязательно —
правомерно полагать, что они составляют только небольшую часть общей стоимости плана.
GetNext
ит
16.7. ЗАВЕРШЕНИЕ ФОРМИРОВАНИЯ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА
827
соединения кортежей сегмента R с кортежами сегмента S потребуется 51 буфер
памяти — 50 буферов остаются доступными для использования в процессе соединения
промежуточного итога R х S с отношением U.
X
Предположим, что к < 49, т.е. результат R х S зани- • ^
мает не больше 49 блоков. Эти данные можно передать ' \
по каналу в 49 буферов и организовать последние в ви- t^l U{y,z)
де хеш-таблицы, удобной для поиска, оставив один бу- у^ \. 10000
фер для последовательной зафузки блоков отношения U. в/ \ с г \ блоков
Таким образом, вторую операцию соединения удастся \w>x> \Х>У>
выполнить за один проход. Общее количество операций 5000 10000
дискового ввода-вывода в этом случае состоит из блоков блоков
1) 45000 - соединение операндов R и S посредст- Fuc- 16J4- Логический план
вом двухпроходного алгоритма с хешированием; запроса к примеру 16.36
2) 10000 — считывание кортежей U в процессе выполнения однопроходного
соединения (R x S) x U.
Стоимость процедуры равна 55000 дисковых операций.
Теперь предположим, что 49 < к < 5000. Результат операции RtxS все еще может
передаваться по каналу, но для выполнения соединения с и придется применять
двухпроходный алгоритм с хешированием.
1. До выполнения соединения RtxS содержимое U хешируется по 50 сегментам,
каждый из которых содержит по 200 блоков.
2. Как и прежде, выполняется двухпроходный алгоритм соединения R и S с
применением 51 сегмента, но после получения очередного кортежа RtxS тот
помещается в один из 50 оставшихся буферов, которые используются для
формирования 50 сегментов соединения R x S с U. По мере заполнения буферов их
содержимое сохраняется на диске — это обычное поведение двухпроходного
алгоритма соединения с хешированием.
3. Наконец, отношения RtxS и U соединяются сегмент за сегментом. Поскольку
£<5000, объем каждого сегмента R x S не превышает 100 блоков, так что
соединение оказывается вполне возможным. Тот факт, что размер сегмента и
составляет 200 блоков, не является проблемой — в процессе однопроходного
соединения сегментов содержимое сегментов RtxS выполняет функцию
опорного отношения (см. раздел 16.6.1 на с. 809), а сегменты U выступают в роли
тестируемого отношения.
Суммарное количество дисковых операций в этом случае состоит из следующих
компонентов:
1) 20000 — считывание кортежей U и распределение их по сегментам;
2) 45000 — соединение операндов R и S посредством двухпроходного алгоритма
с хешированием;
3) к — сохранение сегментов отношения RtxS;
4) к+ 10000 — считывание сегментов RtxS и U в процессе выполнения
заключительной операции соединения.
828
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Общая стоимость плана, таким образом, составляет 75000 + 2к. Заметьте, как резко
меняется значение стоимости при увеличении значения к с 49 до 50 — это обусловлено тем, что
при реализации завершающего оператора соединения вместо однопроходного выбирается
двухпроходный алгоритм. В реальности, однако, величина стоимости возрастает не столь
стремительно, поскольку однопроходный алгоритм, вообще говоря, все еще можно
применять и при нехватке свободных буферов оперативной памяти, если согласиться с тем, что
системе придется выполнять дополнительные действия по периодическому
"сбрасыванию" небольшой части данных на диск с их последующей повторной загрузкой.
Наконец, посмотрим, что произойдет в условиях, когда к > 50000. Теперь, если
содержимое отношения RcxS передается по каналу, система не сможет выполнить
двухпроходный алгоритм соединения при наличии 50 буферов памяти. Можно было
бы применить трехпроходный алгоритм, но тогда для каждого из аргументов
пришлось бы выполнить по две дополнительные операции дискового ввода-вывода в
расчете на каждый блок, или в общей сложности 20000 + 2к "лишних" операций.
Ситуацию удастся улучшить, отказавшись от механизма передачи данных RtxS по каналу.
Схема вычислений выглядит так.
1. Оператор RtxS вычисляется с помощью двухпроходного алгоритма соединения
с хешированием и результат сохраняется на диске.
2. Для соединения R х S с U также применяется двухпроходный алгоритм с
хешированием. Поскольку B(U)= 10000, эту операцию можно выполнить с
использованием 100 сегментов, независимо от того, насколько велико значение к. Если
использовать U в роли опорного отношения, последнее должно быть левым
аргументом оператора, показанного на рис. 16.34.
Количество дисковых операций, предусматриваемых таким планом, складывается из
следующих составляющих:
1) 45000 — соединение операндов R и S посредством двухпроходного алгоритма
с хешированием;
2) к — сохранение содержимого отношения /?и5на диске;
3) 30000 + Ък — соединение U и R\xS с помощью двухпроходного алгоритма
с хешированием.
Общая стоимость плана оценивается величиной 75000 + 4к, которая уменьшена за счет
отказа от применения трехпроходного алгоритма для выполнения заключительной
операции соединения. Суммарная информация о характеристиках всех трех планов
приведена в таблице на рис. 16.35.
Диапазон
изменения к
к<49
50<к< 5000
5000 < к
Организация канала/
материализация
Организация канала
Организация канала
Материализация
Алгоритм завершающей
операции соединения
Однопроходный
Двухпроходный,
50 сегментов
Двухпроходный,
100 сегментов
Общее количество
дисковых операций
55000
75000 + 2к
75000 + Ак
Рис. 16.35. Значения стоимости физических планов как функции размера промежуточного
отношения R х S
□
16.7. ЗАВЕРШЕНИЕ ФОРМИРОВАНИЯ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА 829
16.7.6. Система представления физических планов запросов
Вы уже познакомились с множеством примеров операторов, способных
участвовать в формировании логических планов запросов. Каждый оператор,
соответствующий промежуточной или корневой вершине дерева логического плана, преобразуется
в один или несколько операторов физического плана, а вершины-листья дерева
логического плана (хранимые отношения) в физическом плане становятся операторами
сканирования, применяемыми к отношениям. Процесс материализации обычно обозначается
оператором store с аргументом-отношением, подлежащим сохранению на диске, и
соответствующим оператором сканирования (как правило, табличного — TableScan, —
поскольку промежуточные отношения, если иное не оговорено особо, не имеют
индексов). Однако в приводимых ниже образцах деревьев физических планов каждый
"оператор" материализации для простоты обозначается двумя штрихами,
пересекающими дугу, которая соединяет вершину-источник данных с вершиной-получателем. Дуга
без штрихов, напротив, указывает на то, что данные передаются посредством канала.
Ниже вкратце рассмотрены различные операторы, находящие наиболее широкое
применение при конструировании физических планов запросов. (Следует заметить,
что, в отличие от жестко унифицированной системы обозначений, принятой для
описания операций реляционной алгебры, в каждой СУБД зачастую поддерживается
собственный набор изобразительных средств представления физических планов.)
Операторы для вершин-листьев
Каждое отношение R, выполняющее в логическом плане запроса функцию листа
(leaf), в физическом плане заменяется одним из операторов сканирования (scanning),
перечисленных ниже.
1. TableScan (R): все блоки с кортежами R считываются в произвольном порядке.
2. SortScan(R, L): кортежи R загружаются в порядке следования значений
атрибутов, заданных в списке L.
3. indexScan (R, с): С представляет собой условие вида А Ос, где А — один из
атрибутов R, &— оператор сравнения (скажем, = или <), а с — некоторая константа.
Доступ к кортежам R обеспечивается посредством индекса для атрибута А. Если
оператор & отличен от =, индекс должен быть таким (например, В-древовидным),
который обеспечивает поддержку запросов в диапазонах значений (range queries)
(см. раздел 13.3.4 на с. 614).
4. IndexScan (R, А): А — атрибут R\ содержимое отношения R считывается с
помощью индекса для R.A. Оператор действует подобно TableScan, но в
некоторых обстоятельствах демонстрирует более высокую эффективность (если,
скажем, отношение R не является компактно сгруппированным и/или
местоположение его блоков нельзя определить непосредственно).
Физические операторы выбора
Логический оператор выбора (selection) вида crc(R) нередко сочетается (возможно,
частично) с методом доступа к данным операнда R, если R является хранимым отношением.
В других случаях, когда R не относится к категории хранимых отношений или требуемый
индекс отсутствует, логический оператор выбора заменяется физическим оператором
фильтрации (filtering), называемым Filter. (Здесь уместно напомнить о том, что способы
реализации логического оператора выбора рассмотрены в разделе 16.7.1 на с. 822.)
Различные варианты описания физических операторов выбора перечислены ниже.
1. Алгебраический оператор <тс(#) имеет смысл непосредственно заменять
физическим оператором Filter (С), если отношение R не обладает индексами вовсе
830
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
либо существующие индексы не относятся к атрибутам, упоминаемым в
условии С. Если R является промежуточным отношением, передаваемым оператору
выбора по каналу, в применении иных средств реализации, помимо Filter,
необходимости нет. Если же R представляет собой хранимую таблицу или
материализованное промежуточное отношение, для доступа к данным R надлежит
воспользоваться оператором сканирования— TableScan(R) либо, возможно,
SortScan(R, L). Последнему целесообразно отдать предпочтение в том
случае, если результат выполнения crc(R) должен передаваться некоторому
оператору, который требует, чтобы данные аргумента были отсортированы.
2. Если условие С можно представить в виде А Ос and D, где D — некоторое
дополнительное частное условие, и существует индекс для R.A, для доступа к
содержимому R допустимо применить оператор сканирования
indexScan(R, А<9с), а затем подвергнуть полученные кортежи фильтрации
с помощью оператора Filter (D).
Физические операторы сортировки
Оператор сортировки (sorting) может располагаться в любом месте физического
плана запроса. Мы уже упоминали об операторе SortScan(R, L), который
осуществляет считывание кортежей отношения R и возвращает их в порядке следования
значений атрибутов, перечисленных в списке L. При реализации некоторых операций
(скажем, соединения или группирования) посредством алгоритмов, основанных на
сортировке, на начальной фазе вычислений предполагается упорядочение ранее
считанных данных отношения-аргумента в соответствии с заданным списком атрибутов.
С этой целью обычно используется оператор Sort(L). Этот же оператор может
располагаться и в корневой вершине дерева физического плана запроса, если ввиду
наличия в исходном запросе предложения order by итоговое отношение подлежит
принудительному упорядочению; в этом случае Sort(L) аналогичен по назначению
алгебраическому оператору rL (см. раздел 5.4.6 на с. 238).
Физические операторы для других операций реляционной алгебры
Все другие операторы реляционной алгебры при переходе от логического плана
к физическому также заменяются подходящими физическими операторами.
Последние могут быть снабжены дополнительными обозначениями, описывающими
1) природу выполняемой операции (скажем, "соединение" или
" группирование ");
2) требуемые параметры (например, условие тета-соединения либо список
элементов группирования);
3) принадлежность алгоритма определенному семейству — с сортировкой,
хешированием или индексированием;
4) количество проходов алгоритма (одно-, двух- или многопроходный);
решение о количестве проходов может приниматься и непосредственно в период
выполнения запроса;
5) предполагаемое число необходимых буферов оперативной памяти.
Пример 16.37. На рис. 16.36 представлено дерево физического плана, разработанного
в примере 16.36 для случая к > 5000. В соответствии с планом загрузка данных каждого
из отношений-аргументов тернарного оператора соединения (R х S) х U выполняется
посредством операторов табличного сканирования (table-scan). Вначале с помощью двух-
проходного алгоритма с хешированием вычисляется и материализуется (т.е. целиком со-
16.7. ЗАВЕРШЕНИЕ ФОРМИРОВАНИЯ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА 831
храняется на диске в виде промежуточного отношения) результат первого соединения,
RtxS, который затем используется в качестве аргумента второй ("верхней") операции,
также реализуемой посредством двухпроходного соединения с хешированием.
Поскольку левый аргумент завершающей операции материализован (с помощью оператора
Store) — этот факт отмечен на диаграмме дугой, перечеркнутой двумя штрихами, —
для считывания его содержимого применяется оператор табличного сканирования.
Двухпроходное
соединение
с хешированием,
101 буфер
Однопроходное
соединение
с хешированием,
50 буферов
Двухпроходное
соединение
с хешированием,
101 буфер
TableScan(C/)
Двухпроходное
соединение
с хешированием,
101 буфер
TableScan(IT)
TableScan(i?) TableScan(S')
TableScan(i?) TableScanCS)
Рис. 16.36. Дерево физического плана к при- Рис. 16.37. Альтернативный физический план,
меру 16.36 на с. 827 принимаемый в случае, когда прогнозируемый
размер R x S невелик
Вариант физического плана выполнения оператора соединения из примера 16.36,
соответствующий условию £<49, приведен на рис. 16.37. Обратите внимание на
различия планов: на сей раз алгоритмы соединения разнятся количеством проходов
и числом используемых буферов памяти, а содержимое левого аргумента "верхнего"
оператора не материализуется, а передается по каналу. □
Filter(x=l AND z<5)
IndexScan(R, y=2)
Рис. 16.38. Реализация
оператора выбора с
использованием наиболее
подходящего индекса
Пример 16.38. Рассмотрим оператор выбора из примера 16.35 на
с. 824. Напомним, мы выявили наилучший вариант реализации,
предполагающий использование индекса для атрибута у для
отыскания всех кортежей, удовлетворяющих условию у = 2, с
последующей фильтрацией их по условию х = 1 and z< 5. На рис. 16.38
представлен соответствующий физический план запроса.
Вершина-лист указывает на то, что доступ к данным отношения R
осуществляется посредством индекса для атрибута у к в результате
выполнения операции сканирования возвращаются только такие
кортежи, которые отвечают условию у = 2. Оператор фильтрации
завершает реализацию алгебраического оператора выбора,
извлекая из отношения-аргумента кортежи, содержащие х= 1 и z < 5. □
16.7.7. Упорядочение физических операторов
В завершение темы, связанной с физическими планами запросов, остановимся на
аспектах упорядочения операторов. Физический план запроса обычно представляется
в виде дерева, а структурам деревьев внутренне присущ некий порядок следования
элементов — в данном случае речь идет о "перемещении" порций данных от нижних
уровней дерева к верхним. Однако ветвящиеся деревья, например, способны
содержать такие промежуточные вершины, которые не являются ни предшественниками,
ни наследниками друг друга, так что порядок их обработки не всегда строго
определен. Более того, для обмена данными между операторами-вершинами дерева могут
832
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
использоваться каналы, созданные на основе итераторов, и вполне закономерна
ситуация, когда периоды выполнения различных операторов пересекаются во времени,
что еще более усложняет концепцию "упорядочения".
Если модель материализации используется очевидным образом ("сохранить, чтобы
извлечь позже"), а в основе структуры каналов лежат итераторы, это позволяет
установить строгую очередность событий, связанных с выполнением того или иного
оператора физического плана. В следующих правилах суммированы принципы
упорядочения событий, неявно подразумеваемые при рассмотрении любого дерева
физического плана запроса.
1. Расчленить дерево на поддеревья по дугам, представляющим операции
материализации. Поддеревья обрабатывать последовательно, по одному в каждый
период времени, в соответствии с порядком их следования в исходном дереве.
2. Задать порядок обработки операторов-вершин каждого поддерева снизу вверх
и слева направо.
3. Выполнять операторы каждого поддерева, используя сети итераторов,
единовременно (точный порядок протекания событий определяется режимом вызовов
соответствующих функций GetNext ()).
Следуя указанной стратегии, оптимизатор запросов способен превратить физический
план в исполняемый код, состоящий, вероятно, из последовательностей вызовов
библиотечных функций.
16.7.8. Упражнения к разделу 16.7
Упражнение 16.7.1. Рассмотрим отношение R(a,b,c,d), обладающее группирующим
(clustering) индексом (см. раздел 15.6.1 на с. 725) для атрибута а и индексами,
которые не являются группирующими, для остальных атрибутов. Статистические
характеристики отношения таковы: #(/?)= 1000, T(R) = 5000, V(R, a) = 20, V(R, b) = 1000,
V(R, с) = 5000 и V(R, d) = 500. Предложите наилучший план реализации каждого из
перечисленных ниже операторов выбора и оцените его стоимость:
*V &а= 1 AND£ = 2AND</=3 v^Vj
в) &а- 1 ANDfc=2ANDC>3 W'
С) &а= I AND/><2ANDr>3 v^V*
! Упражнение 16.7.2. Выразите в терминах B(R), T(R), V(R,x) и V(R, у) следующие
условия, касающиеся стоимости реализации оператора выбора в применении к
отношению R:
* а) оператор индексного сканирования более эффективен при использовании
индекса для х, не являющегося группирующим, и частного условия,
уравнивающего х с некоторой константой, нежели при использовании не-
группирующего индекса для у и конъюнкта, задающего условие
равенства у и некоторой константы;
b) оператор индексного сканирования более эффективен при использовании
негруппирующего индекса для х и условия равенства х и некоторой
константы, нежели при использовании группирующего индекса для у и конъюнкта,
задающего условие равенства у и некоторой константы;
c) оператор индексного сканирования более эффективен при использовании
негруппирующего индекса для х и частного условия, уравнивающего х с
некоторой константой, нежели при использовании группирующего индекса
для у и конъюнкта вида у > С для некоторой константы С.
16.7. ЗАВЕРШЕНИЕ ФОРМИРОВАНИЯ ФИЗИЧЕСКОГО ПЛАНА ЗАПРОСА
833
Упражнение 16.7.3. Каким образом изменятся выводы, касающиеся использования
механизма организации каналов для реализации оператора соединения из примера
16.36 на с. 827, если размер отношения R будет исчисляться не 5000 блоков, а
a) 2000 блоков;
! Ь) 10000 блоков;
! с) 100 блоками.
! Упражнение 16.7.4. Предположим, что необходимо вычислить оператор соединения
(#(д, Ь) х S(a, с)) х Т(а, d) в том порядке, который указан, при наличии М- 101
буфера оперативной памяти и при условии B(R) = B(S) = 2000. Атрибут соединения в обоих
случаях одинаков, и принимается решение о реализации первого оператора
соединения, R\xS, посредством двухпроходного алгоритма, основанного на сортировке,
чтобы затем применить необходимое количество проходов для выполнения второго
соединения, вначале поделив Т на некоторое количество подсписков, отсортированных
по значениям а, а затем осуществив их слияние с отсортированным и
организованным в виде канала потоком данных промежуточного отношения RtxS. При каких
значениях В(Т) для реализации соединения Тс RtxS следует употребить
* а) однопроходный алгоритм соединения (загрузить кортежи Т в оперативную
память и выполнять их сопоставление с кортежами R tx S по мере
получения последних);
b) двухпроходный алгоритм соединения (создать отсортированные подсписки
Г и в процессе выполнения RcxS "держать" в памяти по одному блоку из
каждого подсписка).
16.8. Резюме
♦ Компиляция запросов. В ходе компиляции исходный текст запроса
преобразуется в физический план запроса, представляющий собой
последовательность операций, которые могут быть реализованы
исполняющей машиной. К числу основных этапов процесса компиляции
относятся синтаксический анализ, семантический контроль, выбор
предпочтительного логического плана запроса (алгебраического выражения)
и генерация на основе последнего наилучшего физического плана.
♦ Синтаксический анализатор. На первом этапе обработки SQL-запроса — как
и в ситуации с кодом, написанным на традиционном языке программирования, —
осуществляется синтаксический анализ, результатом которого служит дерево
разбора с вершинами, отвечающими конструкциям SQL.
♦ Семантический контроль. Препроцессор анализирует дерево разбора, проверяет
семантическую достоверность наименований атрибутов, отношений, типов
и разрешает ссылки на атрибуты.
♦ Преобразование дерева разбора в логический план запроса. Компилятор обязан
превратить семантически действительное дерево разбора в алгебраическое
выражение. Большая часть преобразований вполне очевидна и прямолинейна —
определенной проблемой является трансформация подзапросов. Один из
подходов к ее решению связан с использованием оператора выбора с двумя
аргументами, размещением подзапроса в условии выбора и применением ряда
стандартных приемов реформирования.
834
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
♦ Алгебраические преобразования. Существует множество алгебраических законов,
на основе которых некоторый логический план запроса может быть
преобразован в более оптимальный план.
♦ Выбор предпочтительного логического плана запроса. Процессор запросов обязан
остановить выбор на таком логическом плане, который с большой долей
вероятности позволит получить эффективный физический план. Помимо
применения алгебраических законов, полезно осуществлять группирование
одноименных ассоциативно-коммутативных операторов (особенно операторов
соединения), чтобы оптимизировать порядок их выполнения в физическом плане.
♦ Прогнозирование размеров отношений. В процессе упорядочения соединений
и других ассоциативно-коммутативных операций, а также при выборе
наилучшего логического плана в целом в качестве критерия стоимости
вычислений используются оценки размеров промежуточных отношений.
Знание точных или приближенных статистических характеристик (в частности,
количества кортежей в отношениях и числа различных значений каждого
атрибута отношений) помогает достаточно верно предсказывать значения
размеров промежуточных отношений, возвращаемых в результате выполнения
той или иной операции.
♦ Гистограммы. Многие коммерческие СУБД накапливают и сохраняют
гистограммы значений заданного атрибута. Грамотное использование подобной
информации позволяет значительно повысить качество прогнозирования
размеров промежуточных отношений.
♦ Оптимизация планов по критерию стоимости. При выборе наилучшего
физического плана необходимо уметь оценивать и сопоставлять стоимости
каждого возможного плана. Существует ряд стратегий получения всех (или
некоторой части всех) физических планов, способных реализовать заданный
логический план.
♦ Стратегии выбора физических планов. К числу наиболее употребительных
средств поиска лучшего плана в пространстве всех физических планов
относятся метод динамического программирования (сохранение табличных
сведений о наилучшем варианте реализации каждого подвыражения заданного
логического плана), в том числе и усовершенствованный за счет применения
метода оптимизации по Селинджеру (сохранение информации о способах
реализации подвыражений с учетом возможности упорядочения их
результатов), "жадные" алгоритмы (принятие решений, оптимальных
в локальной окрестности) и метод ветвей и границ (анализ только таких планов,
которые заведомо не хуже лучшего из планов, найденных к текущему моменту).
♦ Левосторонние деревья соединения. При выборе способа группирования и порядка
следования аргументов я-арного оператора соединения зачастую принято
ограничивать пространство поиска левосторонними деревьями — бинарными
деревьями с вершинами, все правые дочерние вершины которых являются
листьями. Подобная форма выражения соединения позволяет с большой долей
вероятности получать самые эффективные планы с меньшими затратами на поиск.
♦ Физическая реализация операторов выбора. Процесс выполнения операции
выбора, если это возможно, должен быть разделен на два этапа: индексное
сканирование отношения-аргумента (обычно по частному условию, в котором
атрибут индекса сравнивается с некоторой константой) и последующая
фильтрация. Оператор фильтрации просматривает кортежи, найденные
оператором индексного сканирования, и возвращает те из них, которые
удовлетворяют оставшейся части общего условия выбора.
16.8. РЕЗЮМЕ
835
♦ Организация каналов и материализация. В идеальном случае результат
выполнения одного оператора, служащий аргументом другого оператора,
передается по "каналу" в оперативной памяти — возможно, посредством схемы
итераторов, функции которых управляют потоком вычислений и данных.
Подчас, однако, выгоднее сохранить ("материализовать") итоговое отношение,
возвращенное оператором, на диске, освободив часть пространства оперативной
памяти для других операций. В процессе получения физического плана запроса
должны рассматриваться обе альтернативы.
16.9. Литература
Обзоры, упомянутые в списке литературы к главе 15 (см. раздел 15.11 на с. 751),
содержат также ссылки на материал, относящийся к сфере компиляции запросов. Помимо
того, мы рекомендуем обратиться к специальному выпуску журнала [1], в котором
представлены сведения о подсистемах оптимизации запросов в составе коммерческих СУБД.
Наиболее ранние достижения в области оптимизации запросов отображены в работах
[3]—[5]. В столь же давнишней статье [6] впервые высказана идея о продвижении
операторов выбора вниз по дереву алгебраических выражений и продемонстрирован "жадный"
алгоритм выбора порядка соединения. Доклад [2] содержит сведения о методе
оптимизации по Селинджеру, а также описание оптимизатора запросов СУБД System R, который
воплотил в себе наиболее дерзкие подходы и заметные достижения своего времени.
1. Graefe G. (ed.) Data Engineering, 16:4 (1993), специальный выпуск, посвященный
проблемам обработки запросов в коммерческих системах управления базами данных.
2. Griffiths-Selinger P., Astrahan M.M., Chamberlin D.D., Lorie R.A., and Price T.G. Access
path selection in a relational database system, Proc. ACM SIGMOD Intl. Conf. on
Management of Data (1979), p. 23-34.
3. Hall P.A.V. Optimization of a single relational expression in a relational database system, IBM
J. Research and Development, 20:3 (1976), p. 244-257.
4. Palermo F.P. A database search problem, in Information Systems COINS IV (J.T. Tou, ed.),
Plenum Press, New York, 1974.
5. Smith J.M., Chang P.Y. Optimizing the performance of a relational algebra database interface,
Comm. ACM, 18:10 (1975), p. 568-579.
6. Wong E., Yossefi K. Decomposition — a strategy for query processing, ACM. Trans, on Database
Systems, 1:3 (1976), p. 223-241.
836
ГЛАВА 16. КОМПИЛЯЦИЯ И ОПТИМИЗАЦИЯ ЗАПРОСОВ
Глава 17
Профилактика системных
отказов и устранение
их последствий
В этой и двух следующих главах мы сосредоточим внимание на особенностях
функционирования тех компонентов СУБД, которые контролируют целостность данных.
Нам предстоит осветить две основные проблемы.
1. В случае возникновения отказа данные должны быть защищены от опасности
потери или разрушения. Ниже мы расскажем о способах обеспечения
живучести (resilience) системы, т.е. поддержки целостности данных в ситуациях,
когда система по той или иной причине выходит из строя.
2. Элементы данных не должны портиться только из-за того, что к ним
единовременно обращается несколько безошибочно действующих процессов, связанных
с выполнением запросов или команд модификации (за подробностями
обращайтесь к главам 18 на с. 879 и 19 на с. 949).
Центральный механизм обеспечения свойства живучести системы основан на
модели протокола (log), или журнала, в котором с абсолютной степенью
надежности фиксируется история изменения состояния базы данных. Мы обсудим три
различных режима ведения протокола, кратко называемых "undo" ("отмена"), "redo"
("повторение") и "undo/redo" ("отмена/повторение"), и расскажем о вариантах
процесса восстановления (recovery) информации после системного сбоя, использующих
данные протоколов всех трех разновидностей. Один из важных аспектов
протоколирования и восстановления состоит в сокращении объема актуальных данных
журнала за счет применения аппарата контрольных точек (checkpoints). В заключительном
разделе главы мы рассмотрим методики ведения архивов (archives), позволяющих
восстановить содержимое базы данных не только после кратковременных сбоев
системы, но и в случае полной утраты информации: при наличии наиболее свежего
архива и уцелевшей информации протокола удается реконструировать базу данных
в состоянии, в котором она пребывала в некоторый момент времени,
предшествовавший катастрофическим событиям.
17. 1. Модели живучести систем баз данных
Разговор о проблемах борьбы с системными отказами целесообразно начать с
обсуждения различных нештатных ситуаций и комплекса действий, которые может
и должна предпринять СУБД для предотвращения или преодоления всех пагубных
последствий. Вначале мы сосредоточим внимание на классификации технических
проблем, для профилактики и разрешения которых используются методы
протоколирования и восстановления, а в разделе 17.1.4 на с. 842 расскажем о модели управления
буферами памяти, которая лежит в основе механизма воссоздания нормального режима
работы системы; та же модель используется в следующей главе (см. с. 879) для описания
процессов параллельного доступа к данным со стороны нескольких транзакций.
17.1.1. Режимы отказов
В течение всего жизненного цикла базу данных подстерегают самые различные
опасности — от случайного ввода с клавиатуры неверного элемента данных до взрыва
в помещении, где расположен компьютер, выполняющий функции сервера. Ниже
рассмотрены наиболее общие нештатные ситуации и способы выхода из них.
Ошибочные элементы данных
Некоторые ошибки в данных выявить просто невозможно. Если, например, при
вводе телефонного номера человек-оператор случайно нажмет вместо одной цифровой
клавиши другую, система воспримет информацию как вполне приемлемую и никак на
подобную ситуацию не отреагирует. С другой стороны, если номер окажется на одну
цифру короче, ошибка станет очевидной.
Для своевременного выявления ошибок, которые по своей природе допускают
обнаружение, в современных СУБД применяются различные программные средства.
Стандарт SQL, как и все признанные реализации SQL, предоставляет дизайнеру
возможности включения в схему базы данных различных ограничений — скажем,
первичных (primary keys) (см. раздел 7.1.1 на с. 318) и внешних (foreign keys) (см. раздел 7.1.4
на с. 321) ключей, а также ограничений check уровня атрибута (см. раздел 7.2.2 на
с. 329) (учитывающих, например, что длина строки номера телефона не должна быть
короче заданного количества символов). Для проверки того, удовлетворяет ли
формируемый кортеж тому или иному критерию, определенному проектировщиком базы
данных, могут использоваться и триггеры (triggers) (см. раздел 7.4 на с. 336) — порции
кода, которые активизируются при наступлении событий, связанных с выполнением
определенных операций модификации содержимого конкретного отношения.
Разрушение носителя
Факт локального разрушения части носителя, затрагивающей один или несколько
битов, обычно выявляется механизмом проверки контрольных сумм (checksums),
которые ставятся в соответствие содержимому каждого сектора диска (см. раздел 11.6.2 на
с. 531). Последствия серьезных повреждений, обусловленных, большей частью,
поломкой головок дисковых устройств, из-за чего последние приходят в полную
негодность, обычно преодолеваются с помощью одного из следующих подходов:
1) применение схем массивов RAID (см. раздел 11.7 на с. 534), позволяющих
восстановить информацию, хранившуюся на утраченном диске, на основе
данных других дисков массива;
2) ведение архива — копии базы данных на носителях третичных устройств
хранения, таких как приводы магнитных лент или оптических дисков; архивы
создаются периодически, полностью или частично, в установленном порядке
и сохраняются в безопасном месте (подробнее — в разделе 17.5 на с. 870);
838
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
3) сохранение дополнительных копий базы данных, распределяемых по
нескольким точкам локальной или глобальной сети, в режиме on-line',
согласованность копий обеспечивается за счет использования инструментов
репликации (replication), рассмотренных в разделе 19.6 на с. 987.
Катастрофа
К этой категории относятся такие отказы системы, которые обусловлены полной
потерей носителя с базой данных из-за возникновения различных форс-мажорных
обстоятельств, связанных со взрывом, пожаром, наводнением, актами вандализма и т.п.
В подобных ситуациях модель массивов RAID демонстрирует полную
несостоятельность, поскольку единовременно выходят из строя все диски данных и резервные
диски со служебной информацией; однако технологии ведения архивов и
распределения данных посредством механизма репликации все еще способны оказать
действенную помощь в восстановлении утраченного.
Сбой системы
Процессы, реализующие запросы или команды модификации содержимого базы
данных, называют транзакциями (transactions). Транзакции, как и любые программы,
выполняются в виде последовательности определенных операций; зачастую некоторые
из подобных операций связаны с изменением данных. Каждая транзакция
характеризуется состоянием (state), представляющим текущую позицию внутри кода транзакции
и значения всех ее локальных переменных, которые могут быть востребованы позже.
Ситуации сбоя системы (system failure) способны приводить к утрате информации
о состоянии транзакции. Типичными причинами сбоев системы служат потеря
электропитания и ошибки в профаммном обеспечении. В качестве пояснения достаточно
заметить, что промежуточные результаты выполнения транзакции изначально
сохраняются, в оперативной памяти, а таковая, в отличие от диска, является
энергозависимым (volatile) устройством (см. раздел 11.2.6 на с. 499). Поэтому отключение питания
приводит к очистке памяти, в то время как данные, хранящиеся на носителях диска —
энергонезависимого (nonvolatile) устройства, — остаются в неприкосновенности.
Ошибка в программе, приводящая к перезаписи части данных оперативной памяти, также
способна оказать пагубное влияние на состояние транзакции.
При потере данных в оперативной памяти утрачивается и информация о
состоянии транзакции; другими словами, система более не в состоянии контролировать,
какая часть транзакции (включая операции по изменению содержимого базы данных)
была выполнена, а какая — нет. Повторное выполнение транзакции далеко не всегда
решает проблему. Предположим для примера, что в процессе протекания транзакции
к некоторому значению в базе данных должна быть прибавлена единица — каким
образом после сбоя системы, происшедшего в период выполнения транзакции, можно
достоверно узнать, осуществлена ли операция сложения или нет? Основная стратегия
преодоления последствий системных сбоев такова — вести протокол всех изменений
в базе данных, используя отдельный файл на энергонезависимом устройстве, который
при необходимости может быть использован для восстановления информации.
Однако механизмы безопасной и надежной поддержки процесса протоколирования — для
кого-то это окажется неприятным сюрпризом — достаточно сложны; к этой теме мы
приступим, начиная с раздела 17.2 на с. 846.
17.1.2. Подробнее о транзакциях
Вы уже знакомились с понятием транзакции, трактуемым с точки зрения
пользователя программы, написанной на языке SQL, в разделе 8.6 на с. 393. Перед тем как
продолжить разговор об обеспечении живучести систем баз данных и технологиях
восстановления информации после отказов, целесообразно более подробно обсудить
базовые свойства транзакций.
17.1. МОДЕЛИ ЖИВУЧЕСТИ СИСТЕМ БАЗ ДАННЫХ
839
Транзакция — это неделимая единица работы, связанной (в данном случае) с
выполнением операций над содержимым базы данных. Например, при обращении к системе
средствами базового интерфейса SQL (generic SQL interface) (см. раздел 8.1 на с. 350)
каждый запрос или команда модификации (вместе с сопутствующими действиями,
предусмотренными в тексте триггеров, если таковые созданы) принудительно оформляется
в виде отдельной транзакции. Используя интерфейс "внедренных" команд SQL (embedded
SQL) (см. тот же раздел 8.1), программист, напротив, самостоятельно контролирует
границы транзакции, которая наряду с операциями, описанными посредством базового
(host) языка, может включать целый ряд SQL-запросов и инструкций модификации
данных. В типичной системе, поддерживающей интерфейс внедренных команд SQL,
транзакция активизируется при выполнении любой операции с базой данных и
завершает работу, дойдя до команд фиксации (commit), или отката (rollback).
Как будет еще раз подчеркнуто в разделе 17.1.3, транзакция обязана действовать
атомарным образом (atomically), т.е. по принципу "все или ничего", и изолированно (in
isolation) — так, будто других транзакций, обрабатываемых системой в тот же самый
период времени, не существует. Ответственность за корректное поведение транзакций
возлагается на менеджер транзакций (transaction manager) — подсистему СУБД,
осуществляющую целый ряд функций и взаимодействующую, в частности,
1) с менеджером протоколирования (logging manager) (рассмотренным ниже),
в результате чего файл протокола (log) пополняется информацией в форме
записей протокола (log records);
2) с планировщиком заданий (scheduler), гарантирующим единовременное
безошибочное выполнение нескольких транзакций (подробнее — в разделе
18.1 нас. 880).
Структура взаимоотношений менеджера транзакций с другими составными частями
СУБД схематически отображена на рис. 17.1.
Менеджер
протоколирования
Менеджер
восстановления
Рис. 17.1. Взаимодействие менеджера транзакций с
другими подсистемами СУБД
Менеджер транзакций обращается к процессору запросов (query processor) с
требованиями о выполнении операций, составляющих транзакцию, отсылает менеджеру
протоколирования сообщения о результатах этих операций, а также запрашивает
дисковые данные и возвращает содержимое буферов оперативной памяти, подлежащее
сохранению на диске, при посредничестве менеджера буферов (buffer manager).
Менеджер протоколирования, неся ответственность за ведение протокола
операций с базой данных, обязан обращаться за содействием к менеджеру буферов, по-
840
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
скольку данные протокола изначально накапливаются в буферах оперативной памяти
и в определенные моменты времени должны "сбрасываться" на диск. Протокол, как
и основная информация базы данных, располагается на диске.
Следует вкратце упомянуть и роли менеджера восстановления (recovery manager),
который активизируется при возникновении нештатных ситуаций. В случае
необходимости внесения исправлений в содержимое базы данных менеджер восстановления
считывает файловую информацию протокола — разумеется, с помощью менеджера буферов.
17.1.3. Условия выполнения транзакций
Прежде чем окунуться в проблематику преодоления последствий системных отказов,
весьма желательно усвоить, что понимается под "корректными" условиями выполнения
транзакций. Для начала целесообразно предположить, что база данных состоит из неких
"элементов". Здесь мы не будем определять точный смысл понятия "элемент" —
достаточно допустить, что элемент обладает некоторым значением, которое может считывать-
ся и изменяться операциями транзакций. В различных системах концепция "элемента"
трактуется специальным образом, но в любом случае, говоря об "элементе" базы
данных, нам придется иметь дело с одной из следующих сущностей:
1) отношение или класс;
2) дисковый блок или страница;
3) отдельный кортеж отношения или объект класса.
В процессе последующего знакомства с рядом примеров можно воспринимать
"элементы" как кортежи — более того, во многих случаях просто как целочисленные
величины. Однако на практике нередко удобнее отдать предпочтение второму
варианту, т.е. интерпретировать элементы базы данных как дисковые блоки или страницы,
и тому есть несколько немаловажных причин. Если относиться к понятию "элемента"
именно так, содержимое буфера предстанет в виде отдельного элемента — это
позволит обойти целую полосу серьезных препятствий при обсуждении различных
технологий протоколирования, восстановления и управления транзакциями. Если, наконец,
воспринимать элементы как отношения или классы, объем которых превышает
размер одного блока, это также усложнит задачу — нам придется учитывать ситуации,
когда к моменту сбоя системы на носителе энергонезависимого устройства
оказывается сохраненной только некоторая часть "элемента".
База данных характеризуется собственным состоянием (state), которое определяется
совокупностью значений всех ее элементов.123 Одни состояния базы данных трактуются
как согласованные (consistent), а другие — нет. Информация базы данных, пребывающей
в согласованном состоянии, удовлетворяет и всем ограничениям, заданным в схеме
(таким как ключи или ограничения check), и условиям, поддерживаемым неявно за
счет применения триггеров, служащих частью схемы, введения регламентирующих
правил либо выдачи предупреждающих сообщений интерфейса пользователя, которые
генерируются прикладными программами, выполняющими операции модификации данных.
Одно из фундаментальных свойств транзакций можно описать следующим образом.
• Принцип согласованности (consistency principle): если транзакция начинает
выполнение в момент, когда база данных находится в согласованном состоянии,
и протекает в отсутствие других транзакций и системных сбоев, по завершении
транзакции состояние базы данных также должно оказаться согласованным.
123 Попросим не путать состояние базы данных с состоянием транзакции — последнее
обусловливается значениями локальных переменных транзакции, а не содержимым
элементов базы данных.
17.1. МОДЕЛИ ЖИВУЧЕСТИ СИСТЕМ БАЗ ДАННЫХ
841
Насколько согласован принцип согласованности?
Если предположить, что транзакция может заключать в себе единственную команду
модификации данных, введенную средствами базового интерфейса SQL неким
пользователем, который, возможно, не осведомлен обо всех неявных ограничениях,
предусмотренных склонным к фантазированию, но ленивым проектировщиком,
правомерно ли допускать, что все работоспособные транзакции обязаны неуклонно
переводить базу данных из одного согласованного состояния в другое, не менее
согласованное? Явно определенные ограничения поддерживаются на уровне
системы, так что любая транзакция, нарушающая какое-либо из них, будет
безоговорочно отвергнута и не окажет какого бы то ни было воздействия на состояние базы
данных. Что касается "мифических" ограничений, не оговоренных в схеме,
гарантировать их выполнение при всех обстоятельствах, не возьмется, разумеется, никто.
Наше мнение в пользу принципа согласованности транзакций таково: если некто
наделен правами модифицировать содержимое базы данных, он обладает столь же
полным и неотъемлемым правом интерпретировать неявные ограничения по
своему собственному разумению.
Существует очевидная опасность нарушения свойства согласованности, и это
служит основанием для применения как особых методик протоколирования, изложенных
в этой главе, так и механизмов управления параллельными процессами, обсуждаемых
в главе 18 на с. 879. Помимо принципа согласованности, транзакции должны
удовлетворять и другим условиям, которые в совокупности обозначают аббревиатурой ACID
(см. врезку "ACID: свойства транзакций" на с. 44):
• атомарность (atomicity) — транзакция осуществляется в соответствии с
принципом "все или ничего", т.е. должна быть выполнена либо вся целиком, либо
не выполнена вовсе; если допустить возможность осуществления только какой-
либо части транзакции, это с большой долей вероятности приведет к
рассогласованию элементов базы данных;
• изолированность (isolation) — процесс протекает таким образом, словно в тот же
период времени других транзакций не существует; если не принять особых мер по
контролю над взаимодействием параллельно выполняемых транзакций (см. главу
18 на с. 879), нарушение согласованности состояния базы данных неминуемо;
• устойчивость (durability) — результат выполнения завершенной транзакции не
должен быть утрачен ни при каких условиях.
17.1.4. Базовые операции транзакций
Теперь рассмотрим подробнее, каким образом транзакции взаимодействуют с
базой данных. В процессе выполнения транзакция имеет дело с тремя адресными
пространствами:
1) пространство дисковых блоков, содержащих элементы базы данных;
2) пространство адресов виртуальной или оперативной памяти, управляемое
менеджером буферов;
3) собственное локальное адресное пространство транзакции.
Чтобы транзакция смогла считать элемент базы данных, его содержимое
должно быть загружено (если это не было сделано прежде) в один или несколько
буферов оперативной памяти. Затем данные из буферов переносятся транзакцией
в собственное адресное пространство. Процедура присваивания (в рамках тран-
842
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
закции) элементу нового значения выполняется в обратном порядке: вначале
значение конструируется в адресном пространстве транзакции, после чего
копируется в соответствующие буферы.
Содержимое буферов не обязательно "сбрасывается" на диск сразу же; принятие
подобных решений, вообще говоря, относится к компетенции менеджера буферов.
Как будет рассказано ниже, один из основополагающих принципов протоколирования
как средства обеспечения живучести системы при угрозе ее потенциального отказа
состоит в том, чтобы запросы к менеджеру буферов со стороны менеджера
протоколирования, касающиеся "сброса" на диск информации, накопленной в буферах
оперативной памяти, выдавались в подходящие моменты времени. Однако с целью
уменьшения количества операций дискового ввода-вывода система может и должна
позволять сохранение измененных данных в уязвимом энергозависимом устройстве
памяти — по меньшей мере, в течение коротких периодов времени и при выполнении
определенного набора условий.
Чтобы облегчить изложение алгоритмов протоколирования и иных методов
управления транзакциями, следует ввести в обиход некую систему обозначений,
позволяющую описывать все операции внутри транзакции, предполагающие перемещение
данных между адресными пространствами. Мы будем пользоваться следующими базовыми
операциями (primitive operations) транзакций.
1. input (X) — копировать дисковый блок, содержащий элемент X базы данных,
в буфер оперативной памяти.
2. read(x, t) — копировать элемент X базы данных в локальную переменную /
транзакции; если блок с элементом X еще не загружен в буфер памяти, вначале
выполнить операцию input (X), а затем присвоить значение X переменной /.
3. write (X, t) — копировать значение локальной переменной t в буфер памяти,
соответствующий элементу X базы данных; если блок, содержащий элемент X,
еще не загружен в буфер памяти, вначале выполнить операцию input (X), а
затем присвоить значение переменной t элементу X.
4. output (X) — копировать блок с элементом X из буфера памяти на диск.
Указанные операции имеют очевидный смысл, если "часть" базы данных,
трактуемая как "элемент", умещается в пределах одного блока, т.е. в роли элементов
выступают блоки данных. Операции остаются в силе и в том случае, когда элементы
воспринимаются как кортежи и схема отношения не позволяет определять кортежи,
длина которых превышает размер свободной области блока. Если же элементы базы
данных занимают по несколько блоков, будем полагать, что каждая порция такого
элемента, имеющая размер блока, также является "элементом". Механизм
протоколирования обязан гарантировать выполнение следующего условия: транзакция
считается завершенной только в том случае, если значение X сохранено атомарным
образом, т.е. либо на диск записаны все блоки X, либо не записан ни один из них.
Поэтому в продолжение всего разговора о механизме протоколирования мы, не
теряя общности, будем полагать, что
• элемент базы данных обладает длиной, не превосходящей размер одного блока.
Важно понимать, что перечисленные команды активизируются различными
подсистемами СУБД: команды read и write вызываются из тела транзакции, a input
и output посылаются менеджером буферов, хотя команда output, как будет
показано ниже, при определенных обстоятельствах может инициироваться и
менеджером протоколирования.
17.1. МОДЕЛИ ЖИВУЧЕСТИ СИСТЕМ БАЗ ДАННЫХ
843
Роль буферов при обработке запросов и выполнении транзакций
Внимательно изучив способы применения буферов, рассмотренные в предыдущих
главах, вы, возможно, обратили внимание на то, что наша точка зрения на роль
буферов оперативной памяти в процессе вычислений сейчас претерпевает
некоторые изменения. В главах 15 на с. 683 и 16 на с. 753 внимание обращалось
преимущественно на то, каким образом в ходе обработки запросов буферы памяти
используются для получения промежуточных отношений. Да, это, несомненно,
важно, но необходимость в долговременном хранении промежуточных отношений
никогда не возникает, поэтому содержимое буферов, вообще говоря,
протоколированию не подлежит. С другой стороны, буферы со значениями, извлеченными из
базы данных, нуждаются в записи на диск — особенно в тех случаях, когда при
выполнении транзакции эти значения изменялись.
Пример 17.1. Чтобы продемонстрировать, каким образом указанные выше базовые
операции соотносятся в процессе выполнения транзакции, рассмотрим базу данных
с двумя элементами, А и В, которые в соответствии с заданным ограничением должны
быть равны во всех согласованных состояниях базы данных.124
Допустим, что транзакция Т, трактуемая с логической точки зрения, состоит из
двух следующих операций:
А := А * 2;
В := В * 2;
Обратите внимание, что если единственным условием согласованности состояния
базы данных является равенство А = в и транзакция начинает работу при
выполнении этого условия и протекает без каких бы то ни было осложнений, которые
могли бы возникнуть из-за влияния других транзакций и системных сбоев, по
завершении транзакции состояние должно остаться согласованным. Иными словами,
транзакция Т удваивает значения двух равных элементов с целью получения новых
равных значений тех же элементов.
В процессе работы транзакция Т должна осуществить чтение содержимого
элементов А и В с диска, выполнить арифметические вычисления в собственном локальном
адресном пространстве и сохранить новые значения А и В в соответствующих буферах.
Транзакцию Т, таким образом, можно представить в виде последовательности из
шести базовых операций:
READ(A, t); t := t * 2; WRITE(A, t);
READ(B, t); t := t * 2; WRITE(B, t);
Помимо того, менеджеру буферов вменяется в обязанность в определенный момент
времени выполнить базовые операции output, имеющие целью сохранение буферов,
содержащих значения элементов А и В, на диске. Допустим для определенности, что
изначально А = В = 8. Все действия транзакции Т с учетом команд output и с
отображением значений переменной / и элементов А и В в буферах памяти и на диске
приведены в таблице на рис. 17.2.
124 Резонно спросить, зачем возиться с двумя различными элементами, которые по условию
должны быть равны друг другу, а не создать и поддерживать только один элемент. Здесь мы
преследуем сугубо методические цели: подобное простое числовое ограничение вполне
адекватно отображает существо многих более правдоподобных ограничений, используемых в реальных
ситуациях, — например: "количество проданных билетов на авиарейс не должно превышать
число мест в самолете более чем на 5%" или "сумма остатков на лицевых банковских счетах
должна совпадать с сальдо определенного балансового счета".
844
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
Операция
READ(A, t)
t := t * 2
WRITE(A, t)
READ(B, t)
t := t * 2
WRITE(B, t)
OUTPUT(A)
OUTPUT(B)
t
8
16
16
8
16
16
16
16
А в памяти
8
8
16
16
16
16
16
16
В в памяти
8
8
16
16
16
А на диске
8
8
8
8
8
8
16
16
В на диске
8
8
8
8
8
8
8
16
Рис. 17.2. Операции транзакции и значения элементов данных в памяти и на диске
Первым делом транзакция Т предпринимает попытку считывания содержимого
элемента А: если блок, соответствующий А, в память еще не загружался, менеджером
буферов генерируется команда input (А). Командой read значение А копируется
в локальную переменную г, принадлежащую адресному пространству транзакции Т.
На втором шаге текущее содержимое t удваивается; эта операция, разумеется, не
оказывает влияния ни на буфер А, ни на значение А на диске. Далее значение /
копируется в буфер А, но по-прежнему не затрагивает дисковую копию элемента А. Три
следующих действия — это аналогичные операции, применяемые по отношению к
элементу В. В заключение новые значения А и В сохраняются на диске.
Обратите внимание на то, что в результате успешного выполнения транзакции
согласованное состояние базы данных не нарушается. Если какой-либо отказ
произойдет до обращения к команде output (А), это не окажет воздействия на
содержимое базы данных на диске — оно останется таким же (согласованным), как если бы
транзакция Т не выполнялась вовсе. Если же ошибка вдруг случится после
завершения команды output (А), но перед активизацией output (в), состояние базы данных
окажется несогласованным. Появление ошибки как таковой, конечно, предотвратить
нельзя, но система может и должна гарантировать возможность преодоления ее
последствий — либо путем обратного присваивания элементам А и В значений 8, либо за
счет единовременного повышения их до 16. □
17.1.5. Упражнения к разделу 17.1
Упражнение 17.1.1. Предположим, что содержимое элементов А и В базы данных
должно удовлетворять ограничению 0<А<В. Определите, сохраняет ли состояние
согласованности базы данных каждая из транзакций, перечисленных ниже.
*а)А:=А + В;В:=А + В;
b) В := А + В; А := А + В;
c) А := В + 1; В := А + 1;
Упражнение 17.1.2. Для каждой из транзакций, приведенных в условии
упражнения 17.1.1, укажите операции считывания и записи данных и выясните, какой
эффект оказывают эти действия на состояние буферов памяти и блоков на диске.
Примите, что изначально А = 5 и В= 10. Ответьте, возможно ли посредством
выбора подходящего порядка следования команд output (А) и output (в)
гарантировать сохранение согласованного состояния базы данных в случае возникновения
отказа системы в период выполнения транзакции.
17.1. МОДЕЛИ ЖИВУЧЕСТИ СИСТЕМ БАЗ ДАННЫХ
845
17.2. Протоколирование в режиме "undo"
Приступим к изучению технологий протоколирования (logging), обеспечивающих
гарантии атомарности (atomicity) транзакций — условия, в соответствии с которым
транзакция обязана выполняться либо целиком, во всей ее полноте, либо не
выполняться вовсе. Протокол, или журнал (log), — это последовательность так называемых
записей протокола (log records), каждая из которых несет в себе информацию об
определенном действии, выполненном транзакцией. В протоколе могут перемежаться
описания операций нескольких транзакций — скажем, фиксируется действие,
предпринятое одной транзакцией, за ним помещается запись об операции другой транзакции,
следом — сведения об очередном акте первой транзакции или об операции какой-
либо третьей транзакции и т.д. Подобное чередование затрудняет протоколирование,
но с этим приходится соглашаться — хронологию событий, происходящих внутри
отдельно взятой транзакции, фиксировать только после полного ее завершения нельзя.
В случае отказа системы протокол применяется для воссоздания картины действий
транзакции в период, предшествовавший аварии. Протокол может использоваться
и в сочетании с архивом — речь идет о реконструкции базы данных при порче носителя
в ситуации, когда диск, на котором располагается протокол, остается невредимым. Для
устранения губительных последствий сбоя системы одни транзакции будут выполнены
повторно, и изменения, произведенные ими и ранее сохраненные в базе данных,
зафиксируются вновь. Другим транзакциям придется отменить свои действия, и база данных
будет приведена в такое состояние, словно эти транзакции не активизировались вовсе.
Первый способ протоколирования, к которому мы обратимся, — называемый
режимом "undo", или режимом отмены (undo logging), — ориентирован на процедуры
восстановления, относящиеся к последнему из двух названных выше типов. Если
полной уверенности в том, что транзакция завершена целиком и ее результаты
сохранены на диске, нет, любые изменения, внесенные транзакцией в базу данных,
отменяются и последняя приводится в то состояние, в котором она пребывала в момент
времени, предварявший начало транзакции.
В этом разделе вы познакомитесь с моделью записей протокола, представляющих
информацию о различных операциях транзакции, включая и операцию фиксации
(commit), которая выполняется в результате успешного завершения транзакции. Мы
расскажем также о методике формирования записей протокола в оперативной памяти
и копирования их на диск посредством операции "сброса протокола " (flush log), а
затем остановимся на особенностях протокола "undo" и способах его использования для
восстановления данных, пострадавших в результате отказа системы. Далее вашему
вниманию будут предложены начальные сведения о модели контрольных точек
(checkpoints), которая позволяет избавляться от устаревших частей протокола и
существенно сокращать его размер. В завершение раздела мы рассмотрим метод введения
контрольных точек в режиме протоколирования "undo".
17.2.1. Записи протокола
Протокол, или журнал (log), можно представить как файл, открытый только для
пополнения. По мере осуществления операций транзакций менеджер
протоколирования (log manager) сохраняет в журнале информацию о каждом заслуживающем
внимания событии. Блоки протокола заполняются записями последовательно; каждая из
записей соответствует одному событию. Блок протокола изначально создается в
оперативной памяти и поддерживается менеджером буферов тем же образом, как и все другие
блоки, используемые в процессе функционирования СУБД. Сохранение блоков
протокола на носителе энергонезависимого устройства происходит в наиболее "подходящие"
моменты времени; эта тема подробно освещена в разделе 17.2.2 на с. 847.
Существует несколько форм записей журнала, общих для всех режимов
протоколирования, обсуждаемых в этой главе.
846
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
Каковы возможные причины аварийного завершения транзакций?
Уместно задаться вопросом, почему иногда выполнение транзакции может
аварийным образом прерываться до осуществления операции фиксации. Существует целый
ряд причин подобного развития событий. Простейший случай связан с ошибкой
в коде самой транзакции — скажем, с попыткой деления на нуль, — что
естественным образом вызывает необходимость досрочного прекращения транзакции. Нередко
СУБД принимает решение о преждевременном "снятии" одной или нескольких
транзакций и при отсутствии явных ошибок: например, транзакции могут быть
вовлечены в ситуацию взаимоблокировки (deadlock), когда каждая из них удерживает
право на модификацию определенного элемента базы данных и не в состоянии
уступить это право другой транзакции (за деталями обращайтесь к разделу 19.3 на с. 968).
1. <start T> -— выполнение транзакции Г начато.
2. <commit Т> — транзакция Т успешно завершена и дальнейшее изменение ею
содержимого элементов базы данных Fie предусмотрено. Результаты всех
операций модификации, выполненных транзакцией Т, должны быть зафиксированы
на диске. Поскольку принятие решений о копировании содержимого блоков
памяти на диск в общем случае является исключительной прерогативой
менеджера буферов, наличие записи <commit Т> в протоколе еще не служит полной
гарантией того, что изменения, произведенные транзакцией, действительно
зафиксированы на диске, — для полной уверенности в выполнении такого
требования последнее должно быть подкреплено менеджером протоколирования
(в режиме протоколирования "undo" именно так и происходит).
3. <abort T> — выполнение транзакции преждевременно остановлено. В
подобном случае никакие изменения, инициированные транзакцией Г, на диске не
отображаются; если в результате работы транзакции копия базы данных на
диске уже была модифицирована, эти результаты аннулируются -— подобные
обязанности возлагаются на менеджер транзакций. О том, каким образом
устраняются "следы", оставленные аварийно прерванными транзакциями, будет
рассказано в разделе 19.1.1 на с. 950.
Помимо записей перечисленных выше типов, протокол "undo" способен
содержать записи обновления (update records), представляющие собой тройки вида
<Т, X, v>. Смысл подобной записи таков: транзакция Т изменила прежнее
содержимое v элемента X базы данных. Изменение, представленное записью обновления,
обычно отображается в памяти, а не на диске; иными словами, такая запись журнала
является ответом на операцию write, а не output (за сведениями о различиях
названных операций обратитесь к разделу 17.1.4 на с. 842). Обратите внимание, что
в протоколе "undo" сохраняется только "старое" значение элемента. Как будет
показано ниже, в случае необходимости реставрации данных с помощью протокола "undo"
менеджеру восстановления придется осуществить единственную функцию —
аннулировать результаты работы транзакции, затронувшие содержимое копии базы данных
на диске, путем воссоздания прежних значений элементов.
17.2.2. Правила протоколирования в режиме "undo"
Существуют два правила (undo-logging rules), которым должны следовать
транзакции с целью обеспечения возможности восстановления данных с помощью протокола
"undo" в случае отказа системы. Правила регламентируют деятельность менеджера
буферов и предусматривают выполнение определенных действий при фиксации
(commit) результатов работы транзакции.
17.2. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO"
847
Насколько большой может быть запись обновления?
Если элементы базы данных трактовать как дисковые блоки и полагать, что запись
обновления содержит "старое" значение элемента (либо, более того, "старое"
и "новое" значения одновременно, как в режиме протоколирования "undo/redo",
о котором мы расскажем в разделе 17.4 на с. 865), придется согласиться с тем, что
длина записи журнала превышает размер блока. Впрочем, особого беспокойства
это вызывать не должно, поскольку файл протокола, как и любой другой файл,
можно воспринимать как последовательность дисковых блоков, в которой байты
данных располагаются без учета каких-либо явных границ блоков. Помимо того,
существуют и способы сжатия протокола. При определенных обстоятельствах,
например, достаточно отображать в журнале только изменение как таковое, т.е.
название атрибута для компонента кортежа, подвергшегося модификации, и прежнее
значение этого компонента; за информацией о технике подобного логического
протоколирования (logical logging) обращайтесь к разделу 19.1.7 на с. 957.
Ux: Если транзакция Т модифицирует элемент X базы данных, запись обновления
вида <Т, X, v> должна быть занесена в протокол до сохранения нового
значения элемента X на диске.
U2: При фиксации результатов транзакции Т запись <commit Т> следует
помещать в протокол только после "сбрасывания" всех измененных значений
элементов базы данных на диск, причем интервал между дисковыми операциями
сохранения данных и записи <commit 7> должен быть настолько коротким,
насколько это возможно.
Подытоживая правила U{ и и2, можно сказать, что информация, имеющая отношение
к действиям, выполняемым в рамках одной транзакции Т, должна сохраняться на
диске в следующем порядке:
1) записи протокола, свидетельствующие об изменениях, внесенных в
содержимое элементов базы данных;
2) новые значения элементов базы данных как таковых;
3) запись <commit T> протокола.
Порядок следования операций 1, 2, однако, касается каждого отдельного элемента
базы данных, а не группы элементов, подвергшихся изменению в процессе выполнения
транзакции в целом.
Чтобы форсировать сохранение записей протокола на диске, менеджер
протоколирования использует команду "сброса протокола" (flush log), вменяющую менеджеру
буферов в обязанность копировать на диск содержимое всех блоков журнала, которые
прежде еще не сохранялись либо с момента времени последнего копирования
претерпели какие-либо изменения. Для обозначения этой команды в последовательности
операций транзакции мы будем пользоваться строкой flush log. Менеджер
транзакций, в свою очередь, должен иметь возможность "принуждения" менеджера буферов
к выполнению операции сохранения значения элемента X на диске — для этой цели,
как и прежде, применяется команда output (X).
Пример 17.2. Рассмотрим транзакцию из примера 17.1 (см. с. 844) с точки зрения
необходимости протоколирования ее операций в режиме "undo". Рис. 17.3 содержит
версию таблицы из рис. 17.2 на с. 845, пополненную информацией о записях протокола
и командами flush log. Для удобства представления заголовки столбцов со сведениями
о состоянии копий элементов А и В в оперативной памяти и на диске сокращены: так,
например, заголовок "А—П" следует читать как "А в памяти", а "В—Д" — "В на диске".
848
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
Кратко о других режимах протоколирования
При восстановлении данных с помощью протокола, созданного в режиме
повторения ("redo") (см. раздел 17.3 на с. 858), предусматривается повторное выполнение
всех транзакций, отмеченных в протоколе соответствующими записями
<commit...>; все другие транзакции игнорируются. Правила протоколирования
в режиме "redo" гарантируют возможность пренебрежения транзакциями, записи
<commit. . .> которых так и не были занесены в журнал. В процессе
восстановления данных на основе информации протокола, отвечающего режиму
отмены/повторения ("undo/redo") (см. раздел 17.4 на с. 865), предполагается отмена
результатов всех незафиксированных транзакций и повторение операций таких
транзакций, которые обозначены в журнале записями <commit...>. И вновь, как
и в других случаях, правомочность подобных действий подкреплена
соответствующими правилами ведения протокола и буферизации.
Шаг
1
2
3
4
5
6
7
8
9
10
11
12
Операция
READ(A, t)
t := t * 2
WRITE(A/ t)
READ(B, t)
t := t * 2
WRITE(B, t)
FLUSH LOG
OUTPUT(A)
OUTPUT(B)
FLUSH LOG
t
8
16
16
8
16
16
16
16
Л-П
8
8
16
16
16
16
16
16
B-Yl
8
8
16
16
16
A-JX
8
8
8
8
8
8
16
16
b-JX
8
8
8
8
8
8
8
16
Протокол
<START 7>
<T, A, 8>
<T, B, 8>
<COMMIT T>
Рис. 17.3. Операции транзакции, значения элементов данных в памяти и на диске и записи
протокола "undo"
Строка 1 таблицы на рис. 17.3 описывает начало транзакции: первое действие
связано с занесением в протокол записи < start T>. Строка 2 представляет операцию
считывания транзакцией Т значения элемента А и присваивание его локальной
переменной t. Строка 3 отображает инструкцию изменения содержимого переменной г, не
затрагивающую ни базу данных на диске, ни ее элементы, загруженные в
оперативную память. Поскольку операции, определяемые строками 2 и 3, на базу данных
воздействия не оказывают, они не нуждаются и в записях протокола.
Операция, указанная в строке 4, предусматривает сохранение нового значения
элемента А в буфере памяти. Изменение состояния элемента фиксируется записью
протокола <Т, А, 8>, которая гласит, что значение А изменено транзакцией Т
с прежнего, 8, на новое. Заметьте, что последнее (16) в журнале не отображается.
Строки 5—7 содержат описания аналогичных операций и записей протокола для
элемента В. К этому моменту транзакция уже выполнила все предписания, поэтому ее
результаты подлежат фиксации на диске. Следует обеспечить перемещение изменен
17.2. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO
849
Протокол, буферизация и параллельные транзакции
Если взглянуть на последовательность действий и записей протокола, подобную
показанной на рис. 17.3, можно подумать, будто транзакция протекает в полной
изоляции. Однако СУБД способны выполнять множество параллельных
транзакций одновременно. Поэтому записи протокола, относящиеся к некоторой
транзакции Т, могут перемежаться записями с информацией о других транзакциях. Более
того, если одна из "сторонних" транзакций инициирует команду сброса протокола
(flush log), не исключен вариант, когда записи протокола операций транзакции Т
окажутся на диске ранее запланированного момента времени. Впрочем, досрочное
появление в дисковой копии протокола записей со сведениями об операциях
модификации базы данных особого вреда не принесет. Главное условие, которого
следует придерживаться при использовании режима протоколирования "undo", состоит
в том, что запись <commit Т> не должна включаться в журнал до тех пор, пока не
будут завершены все операции output (...), предусмотренные транзакцией Т.
Более хитра, например, такая ситуация, когда несколько элементов (скажем, те
же А и В) базы данных делят один блок. Тогда сохранение на диске значения
одного элемента невольно приведет и к сохранению другого. В худшем случае
система нарушит правило Uu преждевременно "сбросив" на диск измененную копию
элемента. Для обеспечения работоспособности схемы протоколирования в режиме
"undo" в таких условиях, возможно, потребуются дополнительные ограничения,
касающиеся косвенного взаимодействия транзакций. Если элементы базы данных
трактуются как дисковые блоки, уместно воспользоваться, скажем, механизмом
блокирования (подробнее — в разделе 18.3 на с. 894), чтобы воспрепятствовать
возможности единовременного обращения нескольких транзакций к одному и тому
же блоку. Наличие этой и подобных проблем, возникающих в тех случаях, когда
в роли элементов базы данных выступают отдельные части блоков, служит лишним
доводом в пользу интерпретации элементов как целых блоков.
ных значений А и В в базу данных, но в таком порядке, который отвечает правилам
протоколирования в режиме "undo". Прежде всего, А и В не должны копироваться на
диск до тех пор, пока в дисковую копию журнала не будут занесены записи,
представляющие эти изменения. Поэтому в строке 8 содержимое протокола "сбрасывается" на
диск командой flush log и только затем, после выполнения операций output,
указанных в строках 9 и 10, в базу данных попадают новые значения элементов А и В.
Последние действия выполняются менеджером буферов по запросу менеджера
транзакций, подготавливающего операцию фиксации (commit) результатов транзакции Т.
Теперь допустимо выполнить фиксацию изменений, и на шаге 11 в протокол
заносится запись <commit T>. Наконец, надлежит еще раз инициировать команду
flush log, дабы гарантировать, что запись <commit T> сохранена в дисковом файле
журнала. В отсутствие такой команды не исключена ситуация, когда результаты
транзакции якобы зафиксированы, но при дальнейшем просмотре протокола обнаружить
этот факт не удается, что вызывает странное поведение системы в процессе
восстановления данных после возможного сбоя: результаты транзакции, которая с точки
зрения пользователя выглядит как завершенная и вполне "благополучная", вдруг
аннулируются (за подробностями обращайтесь к разделу 17.2.3). □
17.2.3. Восстановление с применением протокола "undo"
Предположим, что во время работы системы, поддерживающей режим
протоколирования "undo", произошел сбой. Возможна ситуация, когда некоторые изменения,
внесенные в содержимое базы данных определенной транзакцией, оказались
зафиксированными на диске, в то время как другие результаты той же транзакции попасть
850
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
на диск не успели. В подобном случае нарушается принцип атомарности транзакции,
что чревато опасностью перевода базы данных в несогласованное состояние.
Ответственность за воссоздание согласованного состояния базы данных с использованием
информации протокола возлагается на менеджер восстановления (recovery manager).
В этом разделе рассматривается только простейший вариант восстановления,
предусматривающий просмотр всего файла протокола независимо от его длины и
внесение соответствующих изменений в базу данных. В разделе 17.2.4 на с. 852 мы
сосредоточим внимание на более развитом и рациональном подходе к протоколированию
и восстановлению, предполагающем возможность периодического введения
контрольных точек (checkpoints) с целью уменьшения размера журнала и сокращения того
промежутка истории выполнения операций, который приходится преодолевать вспять
менеджеру восстановления.
Первая задача, стоящая перед менеджером восстановления, заключается в
распределении всех транзакций, упомянутых в протоколе, по двум категориям —
зафиксированные (committed) и незафиксированные (uncommitted). Если в журнале
существует запись <commit 7>, на основании правила и2 можно утверждать, что все
изменения, внесенные транзакцией Т, сохранены на диске и к моменту возникновения отказа
транзакция Т сама по себе не могла оставить базу данных в несогласованном состоянии.
Допустим, однако, что в протоколе содержится запись <start T>, но отсутствует
соответствующая запись <commit Т>. Тогда вполне возможна ситуация, когда часть
изменений, внесенных транзакцией Г, зафиксирована на диске до момента отказа,
в то время как другие операции либо не были выполнены вовсе, либо их результаты
остались только в буферах оперативной памяти, но не на диске. В этом случае
транзакция Т расценивается как незавершенная (incomplete) и подлежит отмене (undo);
другими словами, все элементы базы данных, подвергшиеся изменению, должны быть
возвращены в прежнее состояние. К счастью, на помощь приходит правило 1)и
которое гарантирует, что если транзакция Т успела изменить элемент X в базе данных на
диске до момента сбоя системы, в журнале наличествует запись вида <Т, X, v>,
которая была перенесена в дисковую копию журнала до сбоя. Поэтому восстановление
состояния элемента X сводится к присваиванию последнему значения v, сохраненного
в записи протокола. Заметим, что правило их исключает необходимость проверки
того, обладал ли элемент X ранее каким-либо определенным значением.
Поскольку протокол может содержать информацию о нескольких
незафиксированных транзакциях — или даже о таких незавершенных транзакциях, которые
изменяли значение одного и того же элемента X, — воссоздание состояний элементов
данных следует проводить в строгом порядке. Менеджер восстановления должен
осуществлять сканирование журнала, начиная с конца (т.е. с наиболее свежих записей)
и перемещаясь к началу. По мере просмотра данных протокола менеджер
"запоминает", какие транзакции были отмечены записями <commit Т> или
<abort 7>. Встречая запись вида <Т, X, v>, он выполняет следующее:
1) если Г является транзакцией, которой соответствует запись <commit 7>,
никакие действия не предпринимаются, поскольку транзакция зафиксирована
(committed) и ее результаты отмене не подлежат;
2) в противном случае транзакция Т трактуется как незавершенная (incomplete) или
прерванная (aborted); это значит, что содержимое X было изменено
непосредственно перед отказом системы и элементу X должно быть присвоено значение v.
Завершив указанные процедуры, менеджер восстановления обязан сохранить в
протоколе записи вида <abort T> для всех незавершенных транзакций, которые не были
отмечены подобными записями прежде, а затем инициировать команду flush log,
чтобы гарантировать "сброс" протокола на диск. Теперь система готова к
возобновлению нормального функционирования базы данных и к выполнению новых транзакций.
17.2. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO"
851
Пример 17.3. Рассмотрим последовательность действий, представленную в таблице на
рис. 17.3 (см. с. 849). Ситуация отказа может произойти в любой момент времени
выполнения транзакции Т, но мы исследуем только принципиально различные варианты.
1. Отказ произошел после шага 12. Запись <commit Т> уже занесена в дисковую
копию протокола, поэтому при восстановлении результаты транзакции Т
отменять не следует — всеми записями журнала, касающимися транзакции Т,
можно пренебречь.
2. Сбой случился в момент времени после завершения операции 11 и перед
началом операции 12. Возможна ситуация, когда запись <commit Т> все-таки
попадет на диск — например, менеджеру буферов для обслуживания другой
транзакции потребуется буфер, содержащий заключительный блок протокола, либо
некоторая транзакция спровоцирует выполнение инструкции flush log.
В этом случае процесс восстановления проследует по сценарию, указанному
в п. 1. Если же запись <commit Т> диска не достигнет, менеджер восстановления
будет трактовать транзакцию Т как незавершенную. По мере сканирования
протокола от конца к началу менеджер встретит запись <Т, В, 8> и присвоит
элементу В в базе данных на диске прежнее значение 8; затем менеджеру попадется
запись <Т, А, 8>, которая заставит его аналогичным образом восстановить
состояние элемента А. Наконец, менеджер восстановления занесет в журнал запись
<abort T> и посредством команды flush log осуществит "сброс" протокола.
3. Ошибка проявилась в момент времени между операциями 10 и 11. В такой
ситуации можно с уверенностью утверждать, что запись <commit Т> на диске не
сохранена, поэтому транзакция Т не завершена и ее результаты, как и в
случае 2, подлежат отмене.
4. Авария стряслась после завершения команды 8. Вновь, как и в случае 3,
транзакция Т не является завершенной. Единственное отличие состоит в том, что
изменения, затрагивающие элементы А и/или В, возможно, на диске не
зафиксированы. В любом случае прежние значения элементов, равные 8, в журнале
сохранены и подлежат восстановлению.
5. Неприятность приключилась до окончания выполнения операции 8. Сейчас
совершенно не очевидно, сохранились ли в дисковой копии протокола какие-
либо записи, касающиеся транзакции Т. Впрочем, это и неважно, поскольку
правило Ux дает основание утверждать следующее: если изменения, касающиеся
элементов А и/или В, зафиксированы в базе данных на диске, соответствующие
записи протокола также должны присутствовать на диске; если такие записи
действительно существуют, в процессе сканирования журнала менеджер
восстановления непременно их обнаружит и выполнит надлежащие операции отмены.
17.2.4. Введение контрольных точек
Как упоминалось выше, в процессе восстановления сканированию и анализу
подлежит, вообще говоря, вся дисковая копия протокола. Если протоколирование ведется
в режиме "undo", информацией о транзакции Г, которая отмечена записью
<commit Г>, сохраненной на диске, в процессе восстановления можно пренебречь.
Уместно спросить, допустимо ли очищать содержимое такого протокола. В общем
случае ответ отрицателен, поскольку часто в один и тот же период времени в активном
состоянии пребывает множество транзакций. Если выполнить усечение протокола после
успешного завершения некоторой транзакции, записи, касающиеся другой действующей
транзакции, будут безвозвратно утеряны — ими не удастся воспользоваться при
необходимости восстановления состояния базы данных после возможного отказа системы.
852
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
Отказы во время восстановления
Предположим, что в период восстановления данных после сбоя система вновь
выходит из строя. Способ ведения протокола "undo" предполагает сохранение
сведений о предыдущих, а не о новых значениях элементов базы данных; поэтому
процедура восстановления идемпотентна (idempotent) — ее повторение приводит к
тому же результату, что и однократное выполнение. Как упоминалось выше, отыскав
в протоколе запись <Т, X, v>, менеджер восстановления вправе присвоить
элементу X значение v, не принимая во внимание тот факт, что X, возможно, уже
содержит это значение. Поэтому при необходимости повторения прерванного
процесса восстановления можно не задумываться о том, что значения некоторых
элементов базы данных подвергались реставрации прежде — не случится ничего
плохого, если менеджер "восстановит" их вновь. Между прочим, эти же выводы
остаются в силе и при использовании других режимов протоколирования, о
которых речь пойдет ниже. Все процедуры восстановления идемпотентны — их можно
без какого бы то ни было ущерба повторять произвольное количество раз, не
заботясь о результатах предыдущих сеансов восстановления.
Удобный способ распутывания клубка потенциальных проблем состоит в
периодическом введении в протокол так называемых контрольных точек (checkpointing). В
самом простом случае для ввода контрольной точки системе надлежит выполнить
следующие действия:
1) приостановить прием запросов на активизацию новых транзакций;
2) дождаться, пока все действующие транзакции не выполнят операции
фиксации или прерывания и не сохранят в протоколе записи <commit . . . > или
<ABORT...>;
3) осуществить "сброс" протокола на диск командой flush log;
4) внести в протокол запись вида <скрт> и выполнить его повторный "сброс";
5) возобновить прием транзакций.
Любая транзакция, приступившая к работе до введения контрольной точки, будет
гарантированно завершена — правило U2 дает основание поручиться, что все внесенные
ею изменения зафиксированы на диске. Поэтому в процессе восстановления
необходимость в отмене операций такой транзакции не возникает: менеджер восстановления, как
и прежде (см. раздел 17.2.3 на с. 850), осуществляет сканирование журнала с целью
обнаружения незавершенных транзакций, но, встречая запись <скрт>, он "понимает", что
дальнейший анализ лишен смысла, поскольку других незавершенных транзакций быть
не может. Поскольку на время введения контрольной точки процесс активизации
транзакций приостанавливается, протокол после записи <скрт> будет содержать только
записи, относящиеся к "новым" транзакциям. Таким образом, часть протокола до записи
<скрт> может быть безболезненно удалена или повторно использована.
Пример 17.4. Допустим, что начало протокола выглядит так, как показано ниже
<START 7>
<Ти А, 5>
<START Т2>
<Т2, В, 10>
и в текущий момент времени система принимает решение ввести контрольную точку.
Поскольку транзакции Т{ и Т2 являются активными и их выполнение еще не
завершено, прежде, чем занести в журнал запись <скрт>, менеджер протоколирования обязан
дождаться окончания работы этих транзакций.
17.2. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO
853
Отыскание последней записи протокола
Протокол, или журнал, по существу представляет собой дисковый файл, блоки
которого содержат записи протокола. Пространство некоторого блока, которое ранее
не использовалось, может быть помечено как "пустое". Если записи журнала
прежде не переопределялись, менеджер восстановления способен найти последнюю
запись, осуществляя поиск первой "пустой" записи и трактуя запись, предыдущую
по отношению к "пустой", как последнюю.
Если же повторное использование части пространства протокола, содержащей
устаревшие записи, разрешено, система обязана поддерживать схему сквозной
нумерации записей, допускающую только увеличение номеров:
9
10
и
4
5
6
7
8
Тогда для обнаружения последней записи протокола следует отыскать запись с
номером, превышающим номер следующей записи; для воссоздания полной истории
событий достаточно отсортировать записи по их порядковым номерам.
В реальной практике крупномасштабный протокол может формироваться из
нескольких физических файлов, где файл "верхнего уровня" содержит наименования
файлов, составляющих протокол. В подобной ситуации менеджер восстановления
должен найти последнюю запись "файла файлов", проследовать к определенному
файлу данных и отыскать в нем последнюю запись протокола.
Возможный вариант развития событий приведен на рис. 17.4. Предположим, что
после вставки последней записи протокола, изображенного на рис. 17.4, произошел
отказ системы. Сканируя журнал от конца к началу, менеджер восстановления
обнаружит, что Тъ является единственной незафиксированной транзакцией, присвоит
элементам Е и F базы данных их прежние значения, 25 и 30 соответственно, а затем,
добравшись до записи <скрт>, примет решение о нецелесообразности дальнейшего анализа.
<START T{>
<Ти А, 5>
<START Т2>
<т2, в, ю>
<Т2, С, 15>
<ТХ, D, 20>
<СОММ1Т Тх>
<СОММ1Т Т2>
<СКРТ>
<START T3>
<ТЪ, Е, 25>
<ТЪ, F, 30>
Рис. 17.4. Пример протокола "undo "
□
17.2.5. Динамическое введение контрольных точек
Схеме введения контрольных точек, описанной в разделе 17.2А, свойствен один
недостаток — по существу она предполагает приостановку функционирования
системы на некоторый период, необходимый для завершения работы всех активных
транзакций. Поскольку действующим транзакциям для фиксации результатов их работы
854
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
или прерывания может потребоваться немалое время, система с точки зрения
пользователей будет выглядеть как "зависшая". Поэтому на практике обычно применяется
более развитая и сложная техника динамического введения контрольных точек
(nonquiescent checkpointing), допускающая возможность активизации новых
транзакций в период выполнения сеанса введения контрольных точек. В этом случае для
ввода контрольной точки система должна выполнить перечисленные ниже действия:
1) внести в протокол запись <start скрт (Гь ..., Тк)> и посредством команды
flush log осуществить "сброс" протокола на диск; здесь Ть ..., Тк —
наименования (идентификаторы) всех активных транзакций, которые еще не
зафиксировали на диске результаты своей работы;
2) дождаться момента фиксации (commit) или прерывания (abort) всех
транзакций Тх,..., Ть не запрещая возможности старта новых транзакций;
3) по завершении работы всех транзакций Ти ...,Тк сохранить в протоколе
запись <end ckpt> и инициировать команду flush log.
Процесс восстановления информации на основе протокола указанного типа
протекает следующим образом. Как обычно, менеджер восстановления сканирует журнал от
конца к началу, отыскивая все незавершенные транзакции и воссоздавая прежние
значения элементов базы данных, измененных этими транзакциями. Заслуживают
внимания две ситуации, когда по мере просмотра протокола первой встречается либо
запись <end ckpt>, либо запись <start скрт (Гь ..., Тк)>.
• Если вначале менеджеру восстановления попадается запись вида <end ckpt>,
это свидетельствует о том, что все незавершенные транзакции начали
выполняться после внесения в протокол последней записи <start скрт (Ти ..., Тк)>.
Поэтому достаточно осуществлять сканирование до достижения записи
<start скрт (7*1,..., Тк)>, после чего закончить процедуру восстановления,
поскольку все более ранние записи относятся к заведомо завершенным
транзакциям и интереса не представляют.
• Если же в ходе сканирования первой встречена запись <start скрт (Гь ..., Тк)>,
значит, отказ произошел в период выполнения процедуры введения контрольных
точек. Незавершенными окажутся только такие транзакции из числа транзакций
Th ...,ТЬ которые упоминались в записях журнала, следующих после записи
<start скрт (Гь..., Тк)>, и не успели осуществить фиксацию своих результатов
до возникновения ситуации отказа. Поэтому выполнять сканирование записей,
более ранних, нежели запись, обозначающая начало самой первой из таких
незавершенных транзакций, нецелесообразно. Предыдущая запись <start скрт. . .>,
если таковая существует, располагается заведомо раньше записи начала первой из
незафиксированных транзакций, причем дистанция, разделяющая эти записи,
зачастую довольно велика.125 Для повышения эффективности сканирования
протокола записи, относящиеся к одной и той же транзакции, могут связываться в
список посредством указателей; в подобном случае для отыскания записей,
содержащих описание действий определенной транзакции, просматривать весь
журнал не нужно — достаточно проследовать по цепочке указателей.
В качестве обобщения уместно отметить следующее: как только в протоколе
сохранена запись <end ckpt>, часть протокола, предшествующую предыдущей записи
<start скрт. . .>, можно безбоязненно удалить.
125 Следует напомнить, что поскольку речь идет о динамическом введении контрольных
точек, некоторые из незавершенных транзакций могли быть инициированы в промежутке между
началом и концом предыдущего сеанса задания контрольной точки.
17.2. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO
855
Пример 17.5. Пусть, как и в примере 17.4 на с. 853, протокол начинается с группы
записей, указанных ниже:
<START T{>
<ТХ, А, 5>
<START Т2>
<Т2, В, 10>
Предположим, что в этот момент инициируется процедура динамического ввода
контрольной точки. Поскольку транзакции 7\ и Т2 являются активными
(незавершенными), в журнал включается запись
<START СКРТ (Гь Т2)>
Допустим, однако, что в период ожидания завершения транзакций Т{ и Т2 стартует еще
одна транзакция, Г3. Возможный вариант продолжения процесса показан на рис. 17.5.
<START Ti>
<Т{1 А, 5>
<START T2>
<Т2, В, 10>
<START СКРТ (Ть Т2)>
<Т2, С, 15>
<START T3>
<Т{, D, 20>
<СОММ1Т 7>
<ТЪ, Е, 25>
<СОММ1Т Т2>
<END CKPT>
<ТЪ, F, 30>
Рис. 17.5. Пример протокола "undo" с инструкциями динамического
введения контрольной точки
Положим, что после внесения в протокол последней из записей, представленных
на рис. 17.5, произошел отказ системы. Сканируя журнал в направлении от конца
к началу, менеджер восстановления обнаружит, что транзакция Тъ не завершена и
потому подлежит отмене. Последняя запись свидетельствует, что элементу F базы
данных должно быть присвоено предыдущее значение 30. Следующей будет найдена
запись <end ckpt>, уведомляющая о том, что все другие незафиксированные
транзакции стартовали после предшествующей записи <start ckpt...>. В ходе
дальнейшего просмотра менеджер отыщет запись <Г3, Е, 2 5>, которая гласит, что
для элемента Е следует восстановить прежнее значение 25. В промежутке журнала
после этой записи и вплоть до записи <start скрт. . . > "следов" других транзакций,
которые могли быть начаты, но оказались незавершенными, нет, поэтому никакие
иные изменения в базу данных более не вносятся.
Теперь рассмотрим ситуацию, когда событие отказа системы происходит в
процессе ввода контрольной точки (протокол в том виде, как он выглядел непосредственно
перед сбоем, представлен на рис. 17.6). Сканирование журнала в обратном
направлении позволяет определить факт незавершенности транзакций Г3 и Т2 и выявить
изменения, внесенные этими транзакциями и подлежащие отмене. Дойдя до записи
<start скрт (Ти Т2)>, менеджер восстановления обнаружит, что единственной
транзакцией, которая могла остаться незафиксированной, является 7V Однако поскольку
ранее уже была встречена запись <commit Т{>, ясно, что транзакция Г, выполнена
целиком. Помимо того, прежде обрабатывалась и запись < start Г3>, поэтому даль-
856
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
нейшее сканирование протокола имеет смысл продолжать только до достижения
записи <start Т2>; при этом будет найдена последняя запись — <Т2, В, 10> — с
описанием изменений, которые надлежит отменить.
<START T{>
<Ти А, 5>
<START Т2>
<Т2, В, 10>
<START СКРТ (Гь Т2)>
<Т2, С, 15>
<START T3>
<TU D, 20>
<СОММ1Т Тх>
<ТЪ, Е, 25>
Рис. 17.6. Пример протокола "undo" в ситуации отказа системы
в период введения контрольной точки
П.2.6. Упражнения к разделу 17.2
Упражнение 17.2.1. Представьте записи протокола "undo" для транзакций
(обозначьте каждую из них как Г), упомянутых в упражнении 17.1.1 на с. 845,
полагая, что изначально А = 5 и В =10.
Упражнение 17.2.2. Для каждой из приведенных ниже последовательностей записей
протокола, представляющих действия, предпринимаемые транзакцией Г, опишите
все цепочки событий, допустимых с точки зрения правил протоколирования в
режиме "undo", обращая внимание на события сохранения на диске блоков с
содержимым элементов базы данных и блоков протокола с записями обновления и
фиксации. Примите к сведению, что записи журнала сохраняются на диске в
указанном порядке, т.е. невозможно "сбросить" на диск очередную запись, пока не
сохранена предыдущая.
* a) <start Т>;<Т, А, 10>; <т, В, 2 0>; <commit Г>;
b) <start 7>; <Т, А, Ю>; <Т, В, 20>; <Т, С, 30>; <commit Т>.
! Упражнение 17.2.3. Образцы протоколов, указанные в упражнении 17.2.2, можно
расширить на случай, когда транзакция сохраняет новые значения для п элементов базы
данных. Каково количество последовательностей событий, инициируемых такой
транзакцией, которые удовлетворяют правилам протоколирования в режиме "undo"?
Упражнение 17.2.4. Допустим, что последовательность записей протокола "undo",
сохраненных транзакциями Т и U, выглядит так: <start Г>; <Т, А, 10>; <start U>;
<U, В, 20>; <т, С, 30>; <и, D, 40>; <commit и>; <Т, Е, 50>; <commit т>.
Опишите действия менеджера восстановления, включая операции по изменению
содержимого базы данных и протокола, в случае возникновения сбоя системы в тот
момент, когда последней записью протокола, сохраненной на диске, является
а) <start U>;
* Ъ) <commit U>;
c) <Т, Е, 50>;
d) <commit Т>.
17.2. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO!
857
Упражнение 17.2.5. Изучив каждую из ситуаций, рассмотренных в упражнении
17.2.4, ответьте, какие из значений, измененных транзакциями Т и U, обязаны или
могут появиться в дисковой копии базы данных.
*! Упражнение 17.2.6. Предположим, что код транзакции U из упражнения 17.2.4
изменен таким образом, что вместо <U, D, 40 > в протокол заносится запись
<U, А, 40>. Каким образом изменится содержимое элемента А на диске в каждой
из ситуаций возникновения отказа, перечисленных в том же упражнении? Что
в этом случае можно сказать о способности механизма протоколирования к
сохранению свойства атомарности транзакций?
Упражнение 17.2.7. Рассмотрим последовательность записей протокола: <start S>;
<S, A, 60>; <commit S>; <start Г>; <Т, А, ю>; <start U>\ <U, В, 20>;
<Т, С, 30>; <start V>; <U, D, 40>; <v, F, 70>; <commit U>\ <т, Е, 50>;
<commit 7>; <V, В, 80>; <commit V>. Предположим, что процедура динамического
введения контрольной точки инициируется непосредственно после того, как запись
a) <S, At 60>;
*Ь) <Т, А, 10>;
c) <и, В, 20>;
d) <u, D, 40>;
e) <Т, Е, 50>
окажется в части журнала, расположенной в буферах оперативной памяти. Для
каждого из случаев
i) укажите, когда в журнал будет включена запись <end ckpt>;
ii) рассмотрите все возможные моменты возникновения ситуации отказа и
определите, насколько "глубоко" следует сканировать журнал, чтобы выявить
все незавершенные транзакции.
17.3. Протоколирование в режиме "redo"
Хотя режим отмены ("undo") (см. раздел 17.2 на с. 846) и представляет собой
простую и естественную стратегию ведения протокола и обеспечения средств
восстановления данных после отказа системы, он не является единственным доступным
подходом. Протоколирование в режиме "undo" сопряжено с потенциальной проблемой,
которая заключается в невозможности выполнения фиксации транзакции без
предварительного сохранения всех измененных ею данных на диске. Подчас удается
сократить потребность в дорогостоящих операциях дискового ввода-вывода, если
позволить порциям модифицированной информации относительно долго оставаться
в буферах оперативной памяти, — подобное решение вполне безопасно, поскольку
в случае отказа системы под рукой всегда окажется протокол, который поможет
восстановить согласованное состояние базы данных.
Требование незамедлительной фиксации изменений на диске удается обойти при
использовании механизма протоколирования в режиме "redo ", или в режиме
повторения (redo logging). Основные различия между режимами протоколирования "redo"
и "undo" перечислены ниже.
1. В процессе восстановления данных с использованием протокола "undo"
устраняются изменения, внесенные незавершенными транзакциями, и игнорируются
результаты зафиксированных транзакций; если же применяется протокол
"redo", игнорируются, напротив, незавершенные транзакции, а итоги
выполнения зафиксированных транзакций воспроизводятся вновь.
858
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
2. При использовании протокола "undo" измененные элементы базы данных
должны быть сохранены на диске до момента "сброса" в дисковую копию
протокола записи <commit...>; в режиме протоколирования "redo" запись
<commit. . .> должна появиться на диске прежде, чем будут сохранены любые
измененные значения.
3. В соответствии с правилами Ux и U2 протоколирования в режиме "undo" для
восстановления состояний измененных элементов базы данных требуется
заносить в протокол прежние значения элементов; если же протокол ведется в
режиме "redo", он, наоборот, должен содержать новые значения. Хотя формы
представления записей протоколов "undo" и "redo" совпадают, их
интерпретация, как будет показано ниже, принципиально различается.
17.3.1. Правило протоколирования в режиме "redo"
Запись <Т, X, v> протокола, сформированного в режиме "redo", имеет
следующий смысл: транзакция Т сохранила новое значение v элемента X базы данных. Легко
убедиться, что запись не содержит какой-либо информации о прежнем значении
элемента X. Каждый раз, когда некоторая транзакция Т присваивает элементу X
измененное значение v, в журнал должна быть включена запись вида <Т, X, v>.
Порядок попадания на диск измененных блоков данных и записей протокола
"redo" регламентируется единственным правилом (redo-logging rule), называемым
правилом опережающего протоколирования (write-ahead logging rule).
Rx\ Прежде чем транзакция Т сможет модифицировать элемент X базы данных на
диске, необходимо внести в копию протокола на диске все записи, имеющие
отношение к операции модификации X, включая запись обновления вида
<Т, X, v> и запись фиксации <С0ММ1Т Т>.
Поскольку запись <commit Т> может попасть в протокол только по завершении
транзакции Т в целом, т.е. эта запись должна заключать все записи обновления,
имеющие отношение к транзакции Г, уместно подытожить выводы,
проистекающие из правила R{ протоколирования в режиме "redo", отметив, что данные,
затрагиваемые транзакцией Т, и соответствующие записи протокола достигают
диска в следующем порядке:
1) записи обновления, отображающие изменения, которым должны
подвергнуться элементы базы данных;
2) запись <commit. . .>;
3) модифицированные значения элементов базы данных как таковые.
Пример 17.6. Давайте вновь обратимся к транзакции Г, рассмотренной в примере 17.2
на с. 848. На рис. 17.7 показана возможная последовательность событий,
инициируемых действиями транзакции при использовании режима протоколирования "redo".
Основные различия между содержимым таблиц на рис. 17.3 и 17.7 таковы. Во-
первых, в записях журнала, указанных в строках 4 и 7 рис. 17.7, отображены
новые, а не "старые" значения элементов А и В соответственно. Во-вторых, запись
<С0ММ1Т Т> включается в протокол раньше, на шаге 8. Только затем, когда
содержимое протокола оказывается "сброшенным" на диск командой flush log,
на диске сохраняются измененные значения элементов А и В (в данном случае это
происходит сразу после выполнения flush log —- в строках 10 и 11, — хотя в
реальных ситуациях копирование блоков данных из буферов памяти на диск может
быть надолго отсрочено). □
17.3. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "REDO"
859
Шаг
1
2
3
4
5
6
7
8
9
10
11
Операция
READ(A, t)
t := t * 2
WRITE(A, t)
READ(B, t)
t := t * 2
WRITE(B, t)
FLUSH LOG
OUTPUT(A)
OUTPUT(B)
t
8
16
16
8
16
16
16
16
А-П
8
8
16
16
16
16
16
16
B-Yl
8
8
16
16
16
A~JX
8
8
8
8
8
8
16
16
b-JX
8
8
8
8
8
8
8
16
Протокол
<START T>
<T, A, 16>
<T, B, 16>
<COMMIT T>
Рис. 17.7. Операции транзакции, значения элементов данных в памяти и на диске и записи
протокола "redo"
17.3.2. Восстановление с применением протокола "redo"
Одно важное следствие правила Rx протоколирования в режиме "redo" состоит в
следующем: до тех пор, пока в журнал не включена запись <commit T>, можно с
уверенностью утверждать, что никакие изменения, внесенные транзакцией Т, не отображены
в дисковой копии содержимого базы данных. Поэтому в ходе восстановления базы
данных с использованием протокола "redo" незавершенные транзакции могут трактоваться
так, будто их не было вовсе. Воссоздание состояния элементов, затронутых
зафиксированными транзакциями, однако, сопряжено с определенной проблемой: менеджер
восстановления доподлинно не "знает", какие из изменений, выполненных этими
транзакциями, действительно зафиксированы на диске, а какие — нет. К счастью, протокол
"redo" содержит всю необходимую информацию -~ новые значения элементов,
подвергшихся модификации; эти значения допустимо воссоздавать в дисковой копии базы
данных, не заботясь о том, делалось ли то же самое прежде. Для восстановления данных
с помощью протокола "redo" следует выполнить перечисленные ниже действия.
1. Идентифицировать все зафиксированные транзакции.
2. Сканировать протокол в направлении от начала к концу. Встречая очередную
запись обновления вида <Т, X, v>,
a) игнорировать ее, если Т является незавершенной транзакцией;
b) сохранять на диске значение v элемента X, если транзакция Т завершена;
3. Для каждой незафиксированной транзакции Т сохранить в журнале запись
<abort T> и выполнить команду flush log.
Пример 17.7. Рассмотрим образец протокола, приведенный на рис. 17.7, и покажем,
каким образом процедура восстановления выполняется в ситуациях, когда событие
отказа системы возникает в те или иные моменты времени.
1. Если сбой системы произошел после выполнения шага 9, к этому времени запись
<commit Т> успеет достичь диска. Менеджер восстановления идентифицирует Г как
зафиксированную транзакцию. В процессе сканирования протокола в прямом
направлении менеджер встретит записи <Т, А, 1б> и <Т, В, 1б>, что заставит его
860
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
О важности порядка повторения операций
Поскольку возможна ситуация, когда один и тот же элемент X базы данных
изменялся несколькими завершенными транзакциями, в процессе восстановления
информации после отказа системы протокол "redo" требуется сканировать в
направлении от начала к концу. В этом случае элементу X в базе данных в итоге будет
присвоено последнее упомянутое в протоколе значение, как, собственно, и должно
быть. Напомним (см. раздел 17.2.3 на с. 850), что в ходе восстановления состояния
базы данных на основе протокола "undo" последний, напротив, просматривается
от конца к началу — в результате элемент X приобретет значение, которым он
обладал до момента изменения командами любой из незавершенных транзакций.
Так как СУБД обязаны поддерживать свойство атомарности транзакций, при
использовании протокола "undo" должна быть исключена ситуация, когда две
транзакции (которые с определенной долей вероятности впоследствии могут оказаться
незафиксированными) модифицируют один и тот же элемент базы данных (см.
упражнение 17.2.6 на с. 858). Если же применяется режим протоколирования "redo",
внимание сосредоточивается на зафиксированных транзакциях, поскольку именно их
результаты подлежат повторному воспроизведению. Ситуация, когда несколько
завершенных транзакций в разные моменты времени вносят изменения в содержимое одного
и того же элемента базы данных, совершенно нормальна. Таким образом, порядок
повторения операций, упомянутых в журнале "redo", чрезвычайно важен, чего нельзя
сказать о порядке отмены действий, указанных в протоколе "undo" (разумеется, если
система придерживается верной стратегии управления параллельными заданиями).
сохранить на диске значения 16 элементов А и В. Говоря более точно, если отказ
возник в промежутке времени после выполнения команды 10 и до активизации
команды 11, операция сохранения значения А становится избыточной, но
поскольку результат изменения значения В на диске еще не отображен, операция
восстановления В возымеет существенное значение для воссоздания
согласованного состояния базы данных. Если предположить, что сбой произошел после
шага 11, избыточными окажутся обе операции восстановления, но их повторение,
разумеется, вреда не принесет.
2. Сбой случился в момент времени после завершения операции 8 и перед
началом операции 9. Хотя запись <commit Т> уже сохранена в журнале, она,
возможно, на диск не попадет — все зависит от того, было ли спровоцировано
выполнение инструкции flush log какими-либо внешними обстоятельствами.
Если "сброс" протокола произошел, процесс восстановления проследует по
сценарию, указанному в п. 1; в противном случае ситуация совпадает с той,
которая рассмотрена в п. 3 ниже.
3. Ошибка проявилась в момент времени до начала операции 8. В такой ситуации
можно с уверенностью утверждать, что запись <commit Т> на диске не
сохранена, поэтому транзакция Т трактуется как незавершенная: новые значения
элементов А и В в дисковой копии базы данных не отражены, и менеджер
восстановления сохранит в протоколе запись <abort T>, свидетельствующую
о том, что результаты выполнения транзакции игнорируются.
□
17.3.3. Введение контрольных точек в режиме "redo"
Протокол "redo", так же как и журнал "undo" (см. разделы 17.2.4 на с. 852 и 17.2.5
на с. 854), допускает введение контрольных точек (checkpoints). При задании
последних в режиме "redo", однако, возникает особая проблема. Поскольку процесс копиро-
17.3. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "REDO"
861
вания изменений, внесенных в содержимое базы данных зафиксированной
транзакцией, на диск может быть надолго отсрочен, множество заслуживающих внимания
транзакций не может быть ограничено только теми, которые пребывали в активном
состоянии в момент активизации процедуры введения контрольной точки.
Независимо от того, является процедура статической (quiescent) (прием новых транзакций
временно приостанавливается) или динамической (nonquiescent), основное действие,
подлежащее выполнению в период времени между началом и окончанием процедуры,
состоит в сохранении на диске всех элементов базы данных, которые были
модифицированы, но не зафиксированы завершенными транзакциями. Для достижения
подобной цели требуется, чтобы менеджер буферов отслеживал, какие буферы содержат
"мусор " (dirty buffers), т.е. измененные данные, не "сброшенные" на диск, и какие из
буферов модифицировались теми или иными транзакциями.
С другой стороны, процедуру введения контрольной точки можно завершить, не
дожидаясь фиксации или прерывания активных транзакций, поскольку в этот период
тем в любом случае запрещено сохранять на диске блоки своих данных. Процедура
динамического введения контрольной точки в режиме протоколирования "redo"
предполагает выполнение следующих действий:
1) внести в протокол запись вида <start скрт (Гь ..., Тк)>, где Ть..., Тк — все
активные (незафиксированные) транзакции, и выполнить "сброс" протокола
на диск командой flush log;
2) сохранить на диске значения всех элементов базы данных, измененные в
буферах памяти, но не скопированные на диск теми транзакциями, которые
к моменту включения в протокол записи <start скрт. . .> оказались
завершенными;
3) сохранить в протоколе запись <end ckpt> и инициировать команду
FLUSH LOG.
Пример 17.8. На рис. 17.8 представлен текст протокола, содержащий команду
динамического введения контрольной точки. В момент начала процедуры в активном
состоянии пребывала только транзакция Т2, но неизвестно, достигло ли диска значение А,
модифицированное завершенной транзакцией Т{. Если нет, до окончания процедуры
задания контрольной точки содержимое А должно быть зафиксировано на диске.
В нашем примере в период действия процедуры выполняются и другие операции:
транзакция Т2 изменяет значение элемента С, а транзакция Г3 стартует и сохраняет
новое значение элемента D. После инструкции <end ckpt> следуют только команды
фиксации транзакций Т2 и Г3.
<START T{>
<Ти А, 5>
<START T2>
<COMMIT 7>
<Т2, В, 10>
<START СКРТ (Г2)>
<Т2, С, 15>
<START Г3>
<ТЪ, D, 20>
<END CKPT>
<СОММ1Т Т2>
<СОММ1Т Тъ>
Рис. 17.8. Пример протокола "redo"
□
862
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
17.3.4. Восстановление на основе протокола "redo" с контрольными точками
Как и в случае протокола "undo" (см. раздел 17.2.5 на с. 854), включение в журнал
"redo" записей, отмечающих начало и конец процедуры динамического введения
контрольной точки, помогает сократить объем вычислений в процессе восстановления
данных после отказа системы. И вновь, как при использовании протокола "undo",
следует рассмотреть две ситуации, различающиеся тем, какая из записей —
<end ckpt> либо <start скрт. . .> — оказывается последней.
• Для начала предположим, что к моменту возникновения отказа в протокол уже
занесена запись <end ckpt>. В этой ситуации можно быть уверенным в том,
что любое значение, измененное транзакцией, которая была зафиксирована
еще до включения в протокол соответствующей записи
<start скрт (Ть..., Тк)>, сохранено на диске, поэтому заботиться о
восстановлении элементов данных, затронутых подобными транзакциями, более
нецелесообразно. Однако любая транзакция Г„ упомянутая в перечне (Ть ..., Тк) записи
<start скрт. . .> либо стартовавшая после начала процедуры введения
контрольной точки, все еще, возможно, не успела переместить измененные блоки
данных на диск — даже в том случае, если в журнале содержится
соответствующая запись фиксации <commit. . .>. Поэтому для восстановления следует
предпринять действия, указанные в разделе 17.3.2 на с. 860, но ограничить
внимание только теми транзакциями Г„ которые названы в последней записи
<start скрт (Гь..., Тк)> либо стартовали после внесения этой записи в
протокол. В процессе сканирования журнала необходимости в обращении к записям,
более ранним, нежели первая из записей <start 7>, нет. Однако следует
иметь в виду, что подобные записи <start. . .> могут располагаться гораздо
раньше многих предыдущих записей контрольных точек. Если записи,
относящиеся к одной и той же транзакции, связаны в список посредством указателей,
это помогает ускорить сканирование протокола, избегая необходимости
обращения к "ненужным" записям (как упоминалось в разделе 17.2.5 на с. 854,
аналогичная технология может применяться и в режиме протоколирования "undo").
• Теперь допустим, что сбой произошел в период выполнения процедуры
введения контрольной точки, т.е. в журнале содержится только запись
<start скрт (Гь..., Тк)>, a <end ckpt> отсутствует. В подобном случае нельзя
гарантировать, что все транзакции, завершенные к моменту внесения записи
<start скрт. . .> в протокол, смогли сохранить результаты своей деятельности
на диске. Поэтому надлежит переместиться к предыдущей записи <end ckpt>,
найти соответствующую ей запись <start скрт (Sb..., Sm)>126, а затем
повторить сохранение результатов всех зафиксированных транзакций Sj, которые
либо упомянуты в списке (Sh ..., Sm), либо стартовали после внесения в протокол
записи <start скрт (Sh ..., Sm)>.
Пример 17.9. Вновь обратимся к протоколу, приведенному на рис. 17.8. Если
допустить, что сбой произошел после внесения в протокол всех названных записей,
просмотр журнала в обратном направлении позволит найти запись <end ckpt>. В
качестве кандидатов, претендующих на повторение операций, в этом случае будет
достаточно рассмотреть только те транзакции, которые либо стартовали после включения
в протокол записи < start скрт (Г2)> (такая транзакция одна — Г3), либо упомянуты
126 Здесь необходимо отметить один нюанс: в журнале может оказаться такая запись
<START СКРТ. . .>, которая не имеет соответствующей записи <END CKPT> из-за предыдущего
сбоя системы; оттого искать ближайшую более раннюю запись <START СКРТ. . .> недостаточно:
вначале следует обнаружить запись <END CKPT> и только затем — <START СКРТ. . .>.
17.3. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "REDO
863
в перечне транзакций, указанном в этой записи (т.е. Т2). Поэтому множество
транзакций, на которые стоит обратить внимание, выглядит как {Т2, Тъ]. При сканировании
протокола найдены записи <commit Т2> и <commit Г3>, поэтому ясно, что результаты
каждой из транзакций Т2 и Т3 подлежат повторному воспроизведению. Достаточно
просмотреть протокол только до достижения записи <start Г2>; при этом будут
найдены записи обновления <Т2, В, 10>, <Т2, С, 15> и <ТЪ, D, 20>. Поскольку
гарантировать, что измененные значения 10, 15 и 20 элементов В, С и D соответственно
достигли дисковой копии базы данных, нельзя, следует повторить их присваивание.
Теперь предположим, что ситуация отказа возникла в момент времени между
включением в протокол записей <commit Т2> и <commit Г3>. Восстановление будет
протекать по аналогичному сценарию, но за тем исключением, что транзакция Г3
в данном случае не относится к категории зафиксированных. Поэтому изменение,
определяемое записью <T3l D, 2 0>, воспроизводить повторно не следует— элемент D
вообще не будет затронут в ходе восстановления, — хотя эта запись и находится в
интересующем нас диапазоне. По окончании процедуры восстановления надлежит
внести в протокол запись <abort Г3>.
Наконец, допустим, что система вышла из строя в момент, предшествующий
сохранению в протоколе записи <end ckpt>. Вообще говоря, в подобных ситуациях
следует сканировать журнал в обратном направлении до достижения предыдущей
записи <end скрт> и соответствующей ей записи <start скрт. . .>, но в данном
случае журнал не содержит иных контрольных точек, поэтому придется просмотреть его
до самого начала. В ходе поиска нетрудно обнаружить единственную
зафиксированную транзакцию, Т{; наличие записи <Ти А, 5> дает основание заново присвоить
элементу А значение 5. В завершение процесса восстановления в журнале
сохраняются записи <abort Т2> и <abort Тъ>. □
Поскольку транзакция может оставаться активной на протяжении нескольких
сеансов введения контрольных точек, уместно включать в записи
<start скрт (Ть ..., Тк)> не только наименования (идентификаторы) действующих
транзакций, но и указатели на позиции записей < start 7>, обозначающих моменты
начала выполнения этих транзакций. Это ускорит доступ к данным и облегчит
обнаружение ранних порций журнала, которые могут быть изъяты. Включение в протокол
записи <end ckpt> гарантирует, что в ходе дальнейшего сканирования будет
достаточно "добраться" до самой ранней из записей <start 7>, отвечающих активным
транзакциям Тъ ..., Тк, которые указаны в перечне записи <start скрт. . .>.
Предшествующую часть протокола обычно допустимо удалять.
17.3.5. Упражнения к разделу 17.3
Упражнение 17.3.1. Представьте записи протокола "redo" для транзакций
(обозначьте каждую из них как Г), упомянутых в упражнении 17.1.1 на с. 845,
полагая, что изначально А = 5и#=10.
Упражнение 17.3.2. Выполните задания упражнения 17.2.2 на с. 857 при условии
использования режима протоколирования "redo".
Упражнение 17.3.3. Выполните задания упражнения 17.2.4 на с. 857 при условии
использования режима протоколирования "redo".
Упражнение 17.3.4. Выполните задания упражнения 17.2.5 на с. 858 при условии
использования режима протоколирования "redo".
Упражнение 17.3.5. Используя данные из упражнения 17.2.7 на с. 858, для каждого
из случаев (а)—(е)
864
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
i) укажите, когда в журнал будет включена запись <end ckpt>;
ii) рассмотрите все возможные моменты возникновения отказа и определите,
насколько "глубоко" следует сканировать журнал, чтобы выявить все
незавершенные транзакции; изучите обе ситуации, когда запись <end ckpt>
была и не была занесена в журнал перед событием сбоя.
17.4. Протоколирование в режиме "undo/redo"
К этому моменту мы уже изучили (см. разделы 17.2 на с. 846 и 17.3 на с. 858) два
подхода к проблеме протоколирования изменений состояния базы данных,
принципиально различающиеся тем, какие значения модифицированных элементов базы
данных — "старые" или "новые" — подлежат сохранению в журнале. Каждой из
стратегий присущи определенные недостатки.
• Режим "undo" ("отмена") требует, чтобы измененные данные сохранялись на
диске непосредственно по завершении транзакции, что, вероятно, чревато
увеличением количества требуемых операций дискового ввода-вывода.
• Режим "redo " ("повторение"), в свою очередь, предполагает необходимость
хранения модифицированных блоков данных в буферах оперативной памяти до
момента, пока транзакция не будет зафиксирована (commit) и записи протокола не
окажутся "сброшенными" на диск, — это, вполне возможно, потребует увеличения
среднего количества буферов, используемых транзакциями в процессе работы.
• Использование обоих режимов иногда сопряжено с необходимостью
удовлетворения противоречивых требований, касающихся проблемы управления
буферами памяти в ходе сеанса введения контрольной точки, — если только элементы
базы данных не являются полными блоками или множествами блоков.
Например, если некоторый буфер содержит одновременно элемент А,
модифицированный зафиксированной транзакцией, и элемент Я, измененный транзакцией,
которая еще не сохранила на диске соответствующую запись <commit. . . >
протокола, этот буфер, с точки зрения транзакции, обращавшейся к элементу А,
подлежит сохранению на диске, но вместе с тем подобное действие запрещено
правилом /?ь применяемым в отношении элемента В.
В этом разделе мы познакомим вас с режимом протоколирования "undo/redo", или
режимом отмены/повторения, позволяющим более гибко упорядочивать выполняемые
транзакциями действия — правда, ценою некоторого увеличения объема журнала.
17.4.1. Правила протоколирования в режиме "undo/redo"
Протокол "undo/redo" содержит записи тех же разновидностей, что и протоколы
других типов, но с одним исключением. Запись обновления <Т, X, v, и»,
сохраняемая в журнале в случае изменения содержимого элемента базы данных, теперь
состоит не из трех, а из четырех компонентов, и означает, что транзакция Т изменила
прежнее значение v элемента X базы данных на новое, w. Ограничения, которым
должен следовать менеджер протоколирования, поддерживающий режим "undo/redo",
суммируются следующим правилом (undo/redo rule):
UR{: Прежде чем транзакция Т сможет модифицировать элемент X базы данных
на диске, необходимо внести в копию протокола на диске соответствующую
запись обновления <Т, X, v, w>.
Правило UR{ протоколирования в режиме "undo/redo", таким образом, поддерживает
ограничения, действующие одновременно в режимах "undo" и "redo". В частности, за-
17.4. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO/REDO"
865
пись <commit T> допускается включать в протокол до или после записей,
подтверждающих изменения, внесенные в содержимое элементов базы данных.
Пример 17.10. На рис. 17.9 изображен один из вариантов упорядочения действий,
выполняемых транзакцией Г, к которой мы обращались в последний раз в
примере 17.6 на с. 859. Обратите внимание, что теперь записи обновления содержат
и "старые", и "новые" значения элементов А и В. В данном случае мы предпочли
внести запись <commit T> в протокол в промежутке между командами вывода
значений А и В на диск, хотя с тем же правом запись могла бы занять место перед
строкой 8 или 9 либо после строки 11.
Шаг
1
2
3
4
5
6
7
8
9
10
11
Операция
READ(A, t)
t := t * 2
WRITE(A, t)
READ(B, t)
t := t * 2
WRITE(B, t)
FLUSH LOG
OUTPUT(A)
OUTPUT(B)
t
8
16
16
8
16
16
16
16
A-Yl
8
8
16
16
16
16
16
16
Я-П
8
8
16
16
16
A-JX
8
8
8
8
8
8
16
16
b-JX
8
8
8
8
8
8
8
16
Протокол
<START T>
<T, A, 8, 16>
<T, B, 8, 16>
<COMMIT T>
Рис. 17.9. Вариант упорядочения операций транзакции с отображением значений элементов
данных в памяти и на диске и записей протокола "undo/redo "
□
17.4.2. Восстановление с применением протокола "undo/redo"
Протокол "undo/redo", используемый для восстановления данных после сбоя
системы, содержит записи обновления, достаточные как для отмены результатов
транзакции путем воссоздания прежних значений измененных ею элементов, так и для
повторения операций модификации. Стратегия восстановления в режиме "undo/redo"
состоит в следующем:
1) повторить операции всех зафиксированных транзакций в порядке от более
ранних к более поздним;
2) отменить результаты всех незавершенных транзакций в обратном
хронологическом порядке.
Обе группы действий одинаково важны. Режим протоколирования "undo/redo"
разрешает гибкое изменение порядка взаимной очередности поступления на диск
записей <commit . . . > и блоков с модифицированными данными, поэтому вполне
допустимо существование и зафиксированных транзакций, все результаты которых не
отображены на диске, и незавершенных транзакций, успевших, напротив, сохранить на
диске все изменения.
866
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
Проблема отложенной фиксации
Как и в случае режима "undo", при использовании технологии протоколирования
"undo/redo" могут возникать ситуации, когда транзакция Т с точки зрения
пользователя (который, скажем, средствами Web-сайта заказал билет на самолет и закрыл
соединение с Internet) выглядит как вполне завершенная, хотя из-за задержки
операции "сброса" протокола, содержащего запись <commit Г>, последующий отказ
системы провоцирует отмену, а не повторение результатов транзакции Т. Если
подобная опасность действительно существует, рекомендуется следовать
дополнительному правилу протоколирования в режиме "undo/redo":
UR2: Запись <commit . . . > после внесения ее в протокол должна "сбрасываться"
на диск незамедлительно.
(Команду flush log, реализующую правило UR2, следовало бы, например,
включить в таблицу на рис. 17.9 непосредственно после строки 10.)
Пример 17.11. Обратимся к таблице на рис. 17.9 и рассмотрим различные варианты
восстановления состояния базы данных после отказа системы, происходящего в те
или иные моменты времени.
1. Допустим, что ситуация сбоя возникла после "сброса" на диск записи
<commit Т>. Транзакция Т трактуется как зафиксированная. Менеджер
восстановления должен повторишь присваивание элементам А и В значения 16 и
сохранить результаты на диске. В данном случае элемент А уже обладает этим
значением, чего нельзя сказать об элементе В — все зависит от того, произошел
ли отказ до либо после выполнения команды в строке 11.
2. Если система вышла из строя до момента сохранения на диске записи <commit Т>,
транзакция Т должна восприниматься как незавершенная. Итоги ее выполнения
отменяются — на диске восстанавливаются предыдущие значения (8) элементов А и В.
Если сбой произошел в промежутке между операциями 9 и 10, новое значение А,
16, уже окажется на диске, поэтому без воссоздания предыдущего, 8, обойтись не
удастся. В рассматриваемом примере отменять присваивание измененного значения
элемента В необязательно, а если отказ проявил себя еще до выполнения команды,
указанной в строке 9, тот же вывод будет справедлив и в отношении элемента А.
В общем случае, однако, что-либо подобное с полной уверенностью
гарантировать нельзя, поэтому операции отмены следует выполнять всегда.
□
17.4.3. Введение контрольных точек в режиме "undo/redo"
Процедура динамического введения контрольной точки в режиме "undo/redo"
более проста в сравнении с другими вариантами протоколирования и предполагает
выполнение следующих действий:
1) внести в протокол запись вида <start скрт (Гь ..., Тк)>, где Гь ..., Тк — все
активные транзакции, и выполнить "сброс" протокола на диск командой
flush log;
2) сохранить на диске информацию всех буферов, содержащих "мусор" (dirty
buffers), т.е. измененные значения элементов базы данных, не
"сброшенные" на диск; в отличие от режима "redo", сохранению на диске
подлежат блоки всех буферов, а не только те, которые модифицировались
зафиксированными транзакциями;
17.4. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO/REDO
867
Восстановление данных и аномалии поведения транзакций
Проницательный читатель мог обратить внимание на то, что мы не оговариваем,
какие именно действия — сопряженные с отменой или предполагающие
повторение — должны выполняться первыми в ходе восстановления с применением
протокола "undo/redo". Собственно говоря, независимо от того, чему именно
будет отдано предпочтение, возможна следующая ситуация. Пусть некоторая
транзакция Т оказалась зафиксированной и потому подлежит повторению.
Транзакция Г, однако, считывает и изменяет значение элемента X, сохраненное другой
транзакцией, U, которая — так случилось — не завершена и должна быть
отменена. Проблема не в том, осуществить ли вначале повторение операций
транзакции Т и воспользоваться значением элемента X, которым тот обладал до
выполнения транзакции U, либо первым делом произвести отмену результатов
транзакции U и оставить X со значением, присваиваемым транзакцией Т. Ситуация
бессмысленна в любом случае, поскольку итоговое состояние базы данных не
будет соответствовать результату, получаемому в результате выполнения любой
последовательности атомарных транзакций.
В действительности СУБД обязаны предлагать много большее, нежели ведение
простого протокола событий. Ситуации, подобные рассмотренной выше, должны
быть напрочь исключены некими специальными механизмами. В главе 18 на
с. 879, например, обсуждаются средства изолирования транзакций (скажем, тех же
Т и U), запрещающие последним взаимодействовать через посредничество
элементов базы данных (в нашем случае — X), а в разделе 19.1 на с. 949 рассматриваются
механизмы, препятствующие возможности считывания одной транзакцией (Г)
"мусора" (значения X), оставленного в буферах памяти другой —
незафиксированной (U) — транзакцией.
3) сохранить в протоколе запись <end ckpt> и инициировать команду
FLUSH LOG.
В дополнение к п. 2 уместно заметить, что ввиду гибкости режима "undo/redo",
касающейся порядка сохранения данных на диске, к ситуации сохранения
незавершенными транзакциями данных на диске следует относиться терпимо — допускается
даже возможность существования "мелких" элементов базы данных, делящих между
собой пространство одного блока. Единственное требование, которого надлежит
придерживаться, звучит так:
• транзакция не должна сохранять измененные значения (даже в буферах
памяти), если позже она способна принять решение о прерывании своей работы.
Как будет показано в разделе 19.1 на с. 949, подобное ограничение уместно
практически всегда — оно позволяет избежать несогласованного взаимодействия между
несколькими транзакциями. Нелишне напомнить, что при использовании режима
протоколирования "redo" выполнения указанного условия недостаточно — даже если
транзакция, изменяющая значение некоторого элемента В, и готова к фиксации,
правило Ri требует, чтобы запись <commit...> этой транзакции была "сброшена" на
диск прежде, чем будет сохранено значение В.
Пример 17.12. На рис. 17.10 приведен текст протокола "redo/undo", отличающийся от
варианта протокола "redo", представленного на рис. 17.8 (см. с. 862), только тем, что
в записи обновления помимо измененных значений элементов базы данных
включены и исходные. Для простоты будем полагать, что в каждом случае "старое" значение
на единицу меньше "нового".
868
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
<START 7>
<Tlt A, 4, 5>
<START T2>
<COMMIT 7>
<T2, B, 9, 10>
<START CKPT (T2)>
<T2f С 14, 15>
<START Г3>
<T3t D, 19, 20>
<END CKPT>
<COMMIT T2>
<COMMIT T3>
Рис. 17.10. Пример протокола "undo/redo"
Как и в примере 17.8 на с. 862, обнаруживается, что в момент начала процедуры
введения контрольной точки Т2 является единственной активной транзакцией.
Поскольку теперь речь идет о режиме "undo/redo", новое значение (10) элемента В,
присвоенное транзакцией Т2, может быть незамедлительно сохранено на диске (что не
разрешено в случае использования протокола "redo"). Впрочем, когда именно
произойдет эта дисковая операция, совершенно не важно. В период выполнения сеанса
введения контрольной точки значение В попадет на диск (если это не было сделано
ранее) в любом случае, поскольку менеджер протоколирования обязан "сбросить" на
диск все буферы, содержащие "мусор". Аналогичным образом будет сохранено на
диске (опять-таки, если то же не было предпринято прежде) и значение элемента Л,
измененное зафиксированной транзакцией Т{.
Предположим, что ситуация сбоя произошла после выполнения всех операций,
указанных на рис. 17.10. В этом случае транзакции Т2и Тъ идентифицируются как
зафиксированные. Транзакция Т{ завершилась до начала сеанса введения контрольной точки.
Поскольку протокол содержит запись <end ckpt>, правомерно полагать, что
изменения, внесенные транзакцией Тъ уже зафиксированы на диске. Поэтому, как и в примере
17.8, транзакция Т{ в расчет не принимается, а результаты транзакций Т2 и Т3
воспроизводятся вновь. Однако при повторении действий транзакций, подобных Тъ "заглядывать"
в записи, предшествующие записи вида <start ckpt (Г2)>, нецелесообразно, так как
заведомо ясно, что все изменения, внесенные транзакциями до начала сеанса введения
контрольной точки, в ходе сеанса гарантированно "сбрасываются" на диск.
Теперь допустим, что система вышла из строя непосредственно перед моментом
сохранения записи <commit Г3> на диске. Транзакция Г2, как и прежде, трактуется
как зафиксированная, но Г3 приобретает статус незавершенной. Повторение
результатов транзакции Т2 сводится к присваиванию дисковой копии элемента С значения 15;
сохранять же значение 10 элемента В смысла нет, поскольку это изменение было
зафиксировано до появления в протоколе записи <end ckpt>. Однако, в отличие от
ситуации с применением протокола "redo", сейчас надлежит выполнить и отмену
транзакции Т3, т.е., в частности, восстановить на диске прежнее (19) значение элемента D.
Если бы транзакция Г3 была активной уже к моменту старта процедуры введения
контрольной точки, менеджеру восстановления пришлось бы сканировать и записи,
предшествующие записи <start ckpt...>, в поисках "следов" других операций
транзакции, которые оказались зафиксированными на диске в период выполнения
сеанса введения контрольной точки и потому нуждались бы в отмене. □
17.4.4. Упражнения к разделу 17.4
Упражнение 17.4.1. Представьте записи протокола "undo/redo" для транзакций
(обозначьте каждую из них как Г), упомянутых в упражнении 17.1.1 на с. 845,
полагая, что изначально А = 5 и В = 10.
17.4. ПРОТОКОЛИРОВАНИЕ В РЕЖИМЕ "UNDO/REDO"
869
Упражнение 17.4.2. Для каждой из приведенных ниже последовательностей записей
протокола, представляющих действия, предпринимаемые транзакцией Г, опишите все
цепочки событий, допустимых с точки зрения правил протоколирования в режиме
"undo/redo", обращая внимание на события сохранения на диске блоков с содержимым
элементов базы данных и блоков протокола с записями обновления и фиксации.
Примите к сведению, что записи журнала сохраняются на диске в указанном порядке, т.е.
невозможно "сбросить" на диск очередную запись, пока не сохранена предыдущая.
* a) <start Т>;<Т, А, 10, и>; <Т, В, 20, 2i>; <commit Т>;
b) <START Т>\<Т, А, 10, 21>; <Т, В, 20, 21>; <Т, С, 30, 31>; <СОММ1Т Т>.
Упражнение 17.4.3. Допустим, что последовательность записей протокола
"undo/redo", сохраненных транзакциями Т и U, выглядит так: <start T>;
<Т, А, 10, 11>; <START U>\ <U, В, 20, 21>; <Т, С, 30, 31>;
<U, D, 40, 4l>; <commit U>;<T, Е, 50, 5l>; <commit Т>. Опишите действия
менеджера восстановления, включая операции по изменению содержимого базы
данных и протокола, в случае возникновения сбоя системы в тот момент, когда
последней записью протокола, сохраненной на диске, является
a) <start U>;
* b) <commit U>;
С) <Т, Е, 50, 51>;
d) <commit Т>.
Упражнение 17.4.4. Изучив каждую из ситуаций, рассмотренных в упражнении
17.4.3, ответьте, какие из значений, измененных транзакциями Т и U, обязаны или
могут появиться в дисковой копии базы данных.
Упражнение 17.4.5. Рассмотрим последовательность записей протокола: <start 5>;
<S, А, 60, 6l>; <commit S>; <start Т>\ <Т, А, 61, 62>; <start U>\
<U, В, 20, 21>; <Т, С, 30, 31>; <START V>\ <U, D, 40, 41>;
<V, F, 70, 71>; <COMMIT U>\ <Т, Е, 50, 51>; <COMMIT T>\ <V, В, 21, 22>;
<commit V>. Предположим, что процедура динамического введения контрольной
точки инициируется непосредственно после того, как запись
a) <S, A, 60, 61>;
*Ь) <Т, А, 61, 62>;
c) <U, В, 20, 21>;
d) <U, D, 40, 41>;
e) <Т, Е, 50, 51>
окажется в части журнала, расположенной в буферах оперативной памяти. Для
каждого из случаев
i) укажите, когда в журнал будет включена запись <end ckpt>;
ii) рассмотрите все возможные моменты возникновения отказа и определите,
насколько "глубоко" следует сканировать журнал, чтобы выявить все
незавершенные транзакции; изучите обе ситуации, когда запись <end ckpt>
была и не была занесена в журнал перед событием сбоя.
17.5. Защита от отказа дискового устройства
Протокол способен предохранить базу данных от порчи в тех случаях, когда
теряется временная информация в оперативной памяти, но копия на диске остается в
неприкосновенности. Однако, как упоминалось в разделе 17.1.1 на с. 838, в более серь-
870
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
езных случаях отказ системы бывает связан с выходом из строя одного или
нескольких дисков с данными. Вообще говоря, реконструировать базу данных удается и на
основе информации протокола, но только при выполнении следующих условий:
1) протокол располагается на носителе отдельного работоспособного дискового
устройства;
2) усечение протокола после введения контрольных точек никогда не проводится;
3) протокол относится к типу "redo" или "undo/redo", т.е., в частности,
содержит измененные значения элементов базы данных.
Журнал, однако, увеличивается в размерах, как правило, намного быстрее, нежели
база данных (несколько подробнее мы расскажем об этом ниже), так что поддерживать
его в "полном" виде в течение неограниченно долгого времени непрактично и иногда
просто невозможно.
17.5.1. Архив
Устранить опасность потери информации в случае отказа диска позволяет
решение, основанное на концепции архивирования (archiving) — ведения резервной копии
(backup copy) базы данных, физически отделенной от оригинала, которая создается на
носителе третичного устройства хранения (магнитной ленте или оптическом диске)
и содержится в безопасном месте, удаленном от точки расположения сервера с базой
данных. Резервная копия представляет базу данных в состоянии, которым та обладала
в момент архивирования; в ситуации отказа системы копия позволяет восстановить
базу данных именно в этом состоянии.
Чтобы воссоздать более "свежее" состояние базы данных, после ее восстановления
из копии можно воспользоваться протоколом — разумеется, если протокол,
охватывающий период работы системы с момента архивирования, после сбоя остался
невредим. Чтобы защититься от потери протокола, в подходящие моменты времени его
копию следует переправлять в то же место, где хранится архив: если в результате выхода
системы из строя страдают как база данных, так и протокол, для реконструкции
состояния данных используются архив в совокупности с протоколом.
Если база данных велика, сохранение ее архива оказывается длительным
процессом, поэтому обычно целесообразно избегать полного копирования в каждом сеансе
архивирования. С этой целью процедура часто разбивается на две стадии:
1) получение полного дампа (full dump), т.е. исчерпывающей копии базы данных;
2) сохранение инкрементного дампа (incremental dump) — копии тех элементов
базы данных, которые претерпели изменение с момента выполнения
предыдущего сеанса создания полного или инкрементного дампа.
Существует возможность использования дампов нескольких уровней в соответствии
со следующей схемой: на "нулевом" уровне располагается полный дамп, а в дамп
уровня / включаются значения элементов, модифицированных после момента
создания предыдущего дампа того же или "старшего" уровня.
Процесс восстановления базы данных с использованием информации полного
и инкрементных дампов во многом напоминает воссоздание состояния базы данных,
нарушенного отказом системы, посредством протокола, сконструированного в
режимах "redo" (см. раздел 17.3.2 на с. 860) или "undo/redo" (см. раздел 17.4.2 на с. 866).
Вначале в базу данных копируется содержимое полного дампа, а затем в
хронологическом порядке вносятся изменения, зафиксированные последовательными инкремент-
ными дампами. Поскольку в инкрементных дампах сохраняются только относительно
небольшие порции данных, они занимают меньшее пространство и обрабатываются
быстрее, нежели информация полного дампа.
17.5. ЗАЩИТА ОТ ОТКАЗА ДИСКОВОГО УСТРОЙСТВА
871
Почему бы просто не хранить полную копию протокола?
Естественно полюбопытствовать, зачем нужен "основной" архив, если копия
протокола и так сохраняется в надежном месте — ведь для восстановления наиболее
актуального состояния базы данных одного архива явно недостаточно. Возможно,
на первый взгляд это и не вполне очевидно, но для получения ответа на вопрос
следует принять во внимание, насколько быстро увеличивается в размерах
типичная база данных. С одной стороны, ежедневно, как правило, изменяется только
весьма небольшая часть содержимого базы данных; с другой стороны,
протоколированию подлежат все изменения, поэтому спустя некоторое время (скажем, через
год) протокол превзойдет по объему базу данных как таковую. Если не создавать
архивы, протокол нельзя будет "чистить", удаляя устаревшую информацию,
и стоимость его хранения вскоре превысит затраты на копирование базы данных.
17.5.2. Динамическое архивирование
Простой схеме архивирования, представленной в разделе 17.5.1, присущ один
серьезный недостаток, обусловленный тем, что большинство реальных баз данных не
допускает возможности остановки на длительный период времени (часто
исчисляемый часами), который требуется для создания резервной копии. Поэтому широкое
применение находят технологии динамического архивирования (nonquiescent archiving),
в чем-то напоминающие методы динамического введения контрольных точек
(nonquiescent checkpointing). Напомним, что в режиме динамического задания
контрольной точки (см. раздел 17.2.5 на с. 854) система предпринимает попытку
зафиксировать в дисковой копии протокола то состояние, в котором база данных пребывала
до начала сеанса введения контрольной точки. В случае отказа системы менеджер
восстановления, используя информацию небольшого участка протокола
в "окрестностях" контрольной точки и учитывая возможность старта новых
транзакций в продолжение периода времени, охватываемого этим участком, способен
реконструировать все отклонения от исходного состояния.
В процессе динамического архивирования аналогичным образом предпринимается
попытка сохранения состояния базы данных в момент начала процесса с учетом
возможности изменения многих элементов базы данных в течение минут или часов,
которые требуются для получения дампа. При необходимости восстановления базы
данных в совокупности с информацией архива используются и записи протокола,
внесенные в период создания дампа. Аналогия прослеживается на рис. 17.11.
В ходе динамического архивирования содержимое элементов базы данных копируется
в дамп в некотором фиксированном порядке — возможно, сразу же после изменения этих
элементов активными транзакциями. Поэтому не исключается ситуация, когда значение
элемента, помещенное в архив, не совпадает с тем, которым элемент обладал в момент
старта процедуры архивирования. Поскольку на протяжении периода архивирования
протокол ведется обычным образом, он позволяет легко устранить все несоответствия.
Пример 17.13. Рассмотрим весьма упрощенный образец базы данных, которая
содержит четыре элемента — А, В, С и D, — в момент старта процесса архивирования
обладающие значениями 1, 2, 3 и 4 соответственно. Во время процесса элемент А
получает значение 5, С — 6, а В — 7. Однако копирование значений в дамп
выполняется в определенном порядке; хронология событий приведена на рис. 17.12.
Хотя состояние базы данных перед началом архивирования описывается
последовательностью (1,2,3,4), а по завершении процесса— четверкой (5,7,6,4), в дамп
будут занесены значения (1, 2, 6, 4) — нельзя назвать ни один из моментов на
протяжении всего сеанса архивирования, когда элементы базы данных обладали бы
такими значениями одновременно.
872
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
Оперативная
память
Диск
При введении контрольной точки
информация копируется
из оперативной памяти на диск;
протокол способствует восстановлению
базы данных после отказа системы
При динамическом архивировании
дамп данных копируется
с диска на третичное устройство хранения;
архив и протокол позволяют восстановить
базу данных после разрушения носителя
Третичное устройство хранения
Рис. 17.11. Сходство процессов динамического
архивирования и динамического введения контрольных точек
Диск
А := 5
С := 6
В := 7
Архив
Копирование А
Копирование В
Копирование С
Копирование D
Рис. 17.12. Хронология событий в период динамического
архивирования
Если говорить более подробно, процесс динамического создания архива базы
данных можно представить в виде указанной ниже последовательности действий
(предполагается, что протокол ведется в режиме "redo" или "undo/redo" — для
совместного применения с процедурами архивирования протокол "undo" не пригоден):
1) внести в протокол запись <start dump>;
2) выполнить процедуру динамического введения контрольной точки по
правилам, соответствующим выбранному режиму протоколирования;
3) получить полный или инкрементный дамп содержимого базы данных и
убедиться, что информация сохранена на носителе третичного устройства хранения;
4) удостовериться, что порция протокола, включающая, по меньшей мере, его
начальную часть вплоть до инструкции завершения процедуры введения
контрольной точки (см. п. 2), т.е. достаточная для восстановления базы
данных в случае отказа диска, также сохранена в надежном месте;
5) внести в протокол запись <end dump>.
По завершении архивирования та часть протокола, которая предшествует началу
сеанса введения контрольной точки, предыдущего по отношению к выполненному в п. 2,
обычно может быть удалена.
17.5. ЗАЩИТА ОТ ОТКАЗА ДИСКОВОГО УСТРОЙСТВА
873
Пример 17.14. Предположим, что изменения, внесенные в содержимое базы данных,
рассмотренной в примере 17.13 на с. 872, вызваны действиями двух транзакций,
пребывавших в активном состоянии в момент начала процедуры динамического
архивирования: Тх модифицирует значения элементов А и Я, а Т2 воздействует на элемент С.
На рис. 17.13 показан вариант протокола "undo/redo", представляющий
последовательность событий в период архивирования.
<START DUMP>
<START СКРТ (Ть Т2)>
<Ти А, 1, 5>
<Т2, С, 3, 6>
<СОММ1Т Т2>
<Ти В, 2, 7>
<END CKPT>
<END DUMP>
Рис. 17.13. Фрагмент протокола "undo/redo"
с описанием действий в период архивирования
Обратите внимание, что факт фиксации транзакции Тх в журнале не отображен.
Собственно говоря, ситуация, когда транзакция остается в активном состоянии на
протяжении всего сеанса создания полного дампа (или, более того, нескольких
подобных сеансов) довольно необычна, но даже в этом случае корректность метода
восстановления, о котором мы собираемся рассказать в следующем разделе, не страдает. □
17.5.3. Восстановление с применением архива и протокола
Рассмотрим ситуацию отказа диска, вынуждающую прибегнуть к процедуре
реставрации базы данных с использованием наиболее свежего архива и достаточного
фрагмента протокола, сохраненных в безопасном месте. Процедура подразумевает
выполнение следующих действий.
1. Восстановить содержимое базы данных из архива:
a) найти наиболее поздний полный дамп и скопировать его в базу данных;
b) если существуют инкрементные дампы, осуществить их копирование в
хронологическом порядке создания.
2. Внести изменения, зафиксированные в протоколе, используя метод
восстановления, отвечающий режиму протоколирования.
Пример 17.15. Обратимся к данным из примеров 17.13 (см. с. 872) и 17.14 (см. с. 874)
и предположим, что дисковое устройство вышло из строя после того, как процедура
получения полного дампа завершилась и протокол, показанный на рис. 17.13, был
скопирован в безопасное место. Допустим также (чтобы придать ситуации
дополнительную остроту), что в уцелевшей порции протокола отсутствует запись <commit Tx>,
хотя запись <commit Т2>, включенная в рис. 17.13, наличествует. Вначале, в
результате копирования содержимого архива, элементам А, В, С и D базы данных
присваиваются значения 1, 2, 6 и 4 соответственно.
Теперь необходимо обратиться к информации протокола. Поскольку транзакцию
Т2 совершенно справедливо трактовать как зафиксированную, операцию
присваивания элементу С значения 6 следует, вообще говоря, повторить. В нашем случае С уже
обладает требуемым значением, 6, но возможны ситуации, когда
a) архив создан до момента изменения элемента С транзакцией Т2\
b) архив содержит значение С, которое позже не было сохранено транзакцией Т2.
874
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
Поскольку записи <commit Т{> в протоколе нет, результаты работы транзакции Т{
подлежат отмене. Записи протокола, относящиеся к Ти дают основание присвоить
элементу А значение 1, а элементу В — 2. Так случилось, что те же значения
сохранены и в архиве, но в другой ситуации содержимое архивных копий элементов А и/или
В могло бы оказаться иным. □
17.5.4. Упражнения к разделу 17.5
Упражнение 17.5.1. Ответьте на следующие вопросы, допуская, что в примерах
17.14 (см. с. 874) и 17.15 вместо режима протоколирования "undo/redo"
применяется режим "redo".
а) Как должен выглядеть такой протокол?
*! Ь) Каким образом в процессе восстановления данных с применением архива
и протокола скажется факт отсутствия в протоколе записи <commit Tx>1
с) Каким окажется состояние базы данных после ее восстановления?
17.6. Резюме
♦ Управление транзакциями. Две основные задачи, решаемые менеджером
транзакций при посредничестве других компонентов системы управления базами
данных, — это обеспечение возможности восстановления состояния базы данных на
основе информации протокола и управление параллельно действующими
транзакциями (последняя функция подробно рассматривается в главе 18 на с. 879).
♦ Элементы базы данных. Содержимое базы данных принято представлять в виде
совокупности элементов, в роли которых обычно выступают блоки дисковых
данных, но иногда под элементами понимаются кортежи, экземпляры классов
и иные единицы информации. Система оперирует элементами базы данных
в процессе протоколирования и управления транзакциями.
♦ Протоколирование. Сведения обо всех важных действиях, предпринимаемых
транзакцией, — таких как старт, изменение значения элемента базы данных,
фиксация результатов или прерывание работы —- в виде записей специального
формата заносятся в протокол. Информация протокола и изменения, вносимые
в содержимое элементов, должны сохраняться на диске синхронно, но
конкретный способ синхронизации зависит от выбранного режима протоколирования.
♦ Восстановление. В случае отказа системы протокол используется для
воссоздания согласованного состояния базы данных.
♦ Режимы протоколирования. Существуют три основных режима
протоколирования — "undo" ("отмена"), "redo" ("повторение") и "undo/redo"
("отмена/повторение"); их наименования соответствуют тем действиям,
которые предпринимаются системой в процессе восстановления состояния базы
данных, нарушенного в результате сбоя.
♦ Протоколирование в режиме "undo". В протоколе сохраняются только прежние
значения изменяемых элементов базы данных. Модифицированное значение
элемента достигает диска только после сохранения в дисковой копии протокола
соответствующей записи с описанием действия модификации, но до момента
"сброса" на диск записи фиксации результатов текущей транзакции. При
восстановлении воссоздаются прежние значения элементов, измененных всеми
незавершенными транзакциями.
♦ Протоколирование в режиме "redo". В протокол заносятся только новые
значения изменяемых элементов базы данных. Результат модификации отображается
17.6. РЕЗЮМЕ
875
на диске после сохранения соответствующих записей обновления и фиксации.
В процессе восстановления выполняется повторное сохранение новых значений
элементов, затронутых всеми зафиксированными транзакциями.
♦ Протоколирование в режиме "undo/redo". В протоколе фиксируются
одновременно "старые" и "новые" значения элементов базы данных. Режим более
гибок в сравнении с остальными, поскольку единственное предъявляемое им
требование сводится к тому, что запись протокола, подтверждающая изменение,
должна сохраняться на диске прежде, чем порция измененных данных как
таковая. Очередность сохранения записей фиксации не регламентируется.
Процесс восстановления сводится к повторению зафиксированных транзакций
и отмене результатов незавершенных транзакций.
♦ Введение контрольных точек. Все методы восстановления, вообще говоря, требуют
просмотра и анализа полного содержимого протокола. Для сужения области
поиска записей в процессе восстановления система позволяет вводить в протокол
контрольные точки. Устаревшие записи протокола, предшествующие записи
начала сеанса введения контрольной точки, при необходимости могут быть удалены,
что позволяет повторно использовать занимаемое ими дисковое пространство.
♦ Динамическое введение контрольных точек. Чтобы избежать необходимости
остановки системы на время введения контрольной точки, для каждого режима
протоколирования разработана соответствующая методика введения
контрольных точек непосредственно в продолжение периода штатного
функционирования системы. Единственный недостаток процедуры связан с тем, что при
восстановлении данных могут потребоваться записи протокола, предшествующие
записи начала сеанса выполнения этой процедуры.
♦ Архивирование. В то время как способы протоколирования позволяют
защитить систему от последствий потери данных в оперативной памяти, методы
архивирования предназначены для восстановления содержимого базы данных
в случае отказа дискового устройства. Архив (дамп) представляет собой
полную или частичную (инкрементную) копию базы данных, которая должна
сохраняться в безопасном месте.
♦ Инкрементные дампы. Вместо периодического копирования содержимого базы
данных в целом зачастую создается единственная полная копия, а затем время
от времени осуществляется копирование только таких элементов базы данных,
которые претерпели изменения с момента предыдущего сеанса полного или
частичного архивирования.
♦ Динамическое архивирование. Позволяется создавать копию содержимого базы
данных во время работы системы. С этой целью в протокол наряду с записями
введения контрольной точки включаются записи, отмечающие начало и конец
процедуры архивирования.
♦ Восстановление данных после отказа диска. Если дисковое устройство с
содержимым базы данных выходит из строя, согласованное состояние последней
восстанавливается на основании полной копии, последовательности инкре-
ментных дампов и архивной копии протокола.
17.7. Литература
Основным техническим руководством, освещающим все аспекты обработки
транзакций, включая методы протоколирования и восстановления, является книга [5].
Дополнительные замечания, касающиеся проблематики управления транзакциями, можно
найти в работе [3]; последнюю наряду с обзорами [4] и [8] можно считать наиболее
ценными источниками информации о технологиях протоколирования и восстановления.
876
ГЛАВА 17. ПРОФИЛАКТИКА СИСТЕМНЫХ ОТКАЗОВ...
В [2] в сжатой форме приведены более ранние результаты в области обработки
транзакций, а в [7] представлена свежая интерпретация модели восстановления.
Обзоры [1] и [6] содержат ссылки на большинство фундаментальных работ,
касающихся проблем восстановления данных после системных отказов, и трактуют
предмет с точки зрения трихотомической модели "undo—redo—undo/redo", которая
и использовалась нами при изложении материала этой главы.
1. Bernstein P.A., Goodman N., and Hadzilacos V. Recovery algorithms for database systems,
Proc. 1983 IFIP Congress, North Holland, Amsterdam, p. 799-807.
2. Bernstein P.A., Hadzilacos V., and Goodman N. Concurrency Control and Recovery in
Database Systems, Addison-Wesley, Reading, MA, 1987.
3. Gray J.N. Notes on database operating systems, in Operating Systems: an Advanced Course,
Springer-Verlag, Berlin, 1978, p. 393-481.
4. Gray J.N., McJones P.R., and Blasgen M.W. The recovery manager of the System R database
manager, Computing Surveys, 13:2 (1981), p. 223-242.
5. Gray J.N., Reuter A. Transaction Processing: Concepts and Techniques, Morgan-Kaufmann,
San Francisco, 1993.
6. Haerder Т., Reuter A. Principles of transaction-oriented database recovery — a taxonomy,
Computing Surveys, 15:4 (1983), p. 287-317.
7. Kumar V., Hsu M. Recovery Mechanisms in Database Systems, Prentice Hall,
Englewood Cliffs, NJ, 1998.
8. Mohan C, Haderle D.J., Lindsay B.G., Pirahesh H., and Schwarz P. ARIES: a transaction
recovery method supporting fine-granularity locking and partial rollbacks using write-ahead
logging, ACM Trans, on Database Systems, 17:1 (1992), p. 94-162.
17.7. ЛИТЕРАТУРА
877
Глава 18
Управление параллельными
заданиями
Менеджер
транзакций
Взаимодействие транзакций способно привести базу данных в несогласованное
состояние — даже в тех случаях, когда каждая транзакция, рассматриваемая в изоляции
от других, выполняется корректно и система функционирует безотказно. Поэтому
очередность осуществления отдельных операций различных транзакций должна тем
или иным образом регулироваться. Функции упорядочения операций транзакций
возлагаются на специальный компонент СУБД, называемый планировщиком заданий
(scheduler), а процесс, позволяющий сохранить свойство согласованности состояния
базы данных при одновременном выполнении многих транзакций, принято
обозначать общим термином управление параллельными заданиями (concurrency control). Роль
планировщика заданий в структуре СУБД схематически отображена на рис. 18.1.
Инициируемые транзакциями запросы на
чтение/запись содержимого элементов базы
данных передаются планировщику заданий.
В большинстве ситуаций планировщик
способен обрабатывать запросы непосредственно по
мере их поступления, обращаясь за помощью
к менеджеру буферов, если значение
требуемого элемента данных прежде еще не считы-
валось либо к текущему моменту уже удалено
из памяти. В некоторых случаях, однако,
незамедлительное выполнение подобных
запросов оказывается небезопасным —
планировщику приходится приостанавливать обработку
запроса или даже прерывать выполнение
транзакции, которая его активизировала.
Изучение проблематики управления
параллельными заданиями мы начнем с рассмотрения методов, гарантирующих
сохранение согласованного состояния базы данных в условиях единовременного
функционирования множества транзакций и реализующих абстрактное требование, которое
касается возможности последовательного упорядочения (serializability) операций
транзакций; более строгий вариант требования, предполагающий способность транзакций
к последовательному упорядочению с учетом конфликтов (conflict-serializability), поддер-
Планировщик
заданий
1
1
Запросы
на чтение/запись
Операции
чтения/записи
Буферы
Рис. 18.1. Планировщик заданий служит
посредником между менеджером
транзакций и буферами памяти
живается планировщиками заданий большинства коммерческих систем баз данных.
Особое внимание будет уделено наиболее значимым вариантам реализации
планировщиков заданий — ниже мы расскажем о методах блокирования (locking),
хронометража (timestamping) и проверки достоверности (validation).
При изложении сведений о способах упорядочения, основанных на механизме
блокирования, будет рассмотрена весьма важная концепция двухфазного блокирования
(two-phase locking), широко применяемая для подтверждения возможности
преобразования расписаний в последовательную форму. Мы также продемонстрируем варианты
использования разнообразных наборов режимов блокирования — предполагающих,
в частности, создание вложенньа (nested) и древовидных (tree-structured) коллекций
блокируемых элементов — с особыми сферами применения.
18.1. Последовательные и условно-последовательные расписания
Прежде чем приступить к изучению механизмов управления параллельными
заданиями, надлежит сформулировать условия, при удовлетворении которых множество
единовременно функционирующих транзакций сохраняет свойство согласованности
состояния базы данных. Одно из фундаментальных положений, на которое в разделе
17.1.3 на с. 841 мы ссылались как на принцип согласованности (consistency principle),
состоит в следующем: каждая транзакция, начинающая выполнение в момент, когда
база данных находится в согласованном состоянии, и протекающая в отсутствие
других транзакций и системных сбоев, по завершении обязана привести базу данных
в согласованное состояние. В реальности, однако, транзакция весьма часто
выполняется параллельно с другими транзакциями, поэтому непосредственное соблюдение
принципа согласованности затруднено. Это вынуждает говорить о расписаниях
(schedules), описывающих очередность действий транзакций и гарантирующих
получение точно таких же результатов, как если бы каждая транзакция функционировала
изолированно от других. Через всю главу красной нитью проходит тема, касающаяся
параллельного выполнения транзакций только такими способами, которые имитируют
поведение полностью обособленных транзакций.
18.1.1. Расписания
Расписание (schedule) — это упорядоченная во времени последовательность
значимых действий, предпринимаемых в процессе выполнения одной или нескольких
транзакций. Изучая аспекты управления параллельными заданиями, мы будем полагать,
что операции чтения и записи применяются по отношению к данным в буферах
оперативной памяти, а не на диске. Другими словами, значение элемента А базы данных,
помещенное в буфер некоторой транзакцией Г, может считываться или записываться
не только транзакцией Г, но и другими транзакциями, нуждающимися в обращении
к элементу А. Напомним (см. раздел 17.1.4 на с. 842), что при выполнении операций
read и write вызывается функция input с целью считывания содержимого элемента
с диска в буфер памяти, если это не было сделано прежде, но в остальных случаях
read и write адресуют значение элемента в буфере непосредственно. Таким образом,
при изучении способов упорядочения операций параллельных транзакций
к "значимым" мы будем относить только операции read и write, игнорируя
действия, связанные с вызовом функций input и output.
Пример 18.1. Рассмотрим две транзакции и влияние, оказываемое на состояние базы
данных при выполнении их действий в определенном порядке. Значимые действия
транзакций Тх и Т2 перечислены в таблице на рис. 18.2. Величины t и s являются
локальными переменными транзакций Т{ и Т2 соответственно и не имеют прямого
отношения к элементам базы данных.
880
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Ti
т2
READ(A, t)
t := t + 100
WRITE(A, t)
READ(B, t)
t := t + 100
WRITE(B, t)
READ(A, s)
s := s * 2
WRITE(A, s)
READ(B, s)
s := s * 2
WRITE(B, s)
Рис. 18.2. Операции двух транзакций
Предположим, что единственным ограничением, касающимся свойства
согласованности состояния базы данных, является условие А = В. Поскольку транзакция Тх
прибавляет константу 100 к содержимому обоих элементов, А и В, а транзакция Т2
одновременно удваивает эти значения, ясно, что каждая из транзакций,
рассматриваемая отдельно, сохраняет согласованное состояние базы данных. □
18.1.2. Последовательные расписания
Говорят, что расписание последовательно (serial), если оно предусматривает
выполнение всех действий одной транзакции, затем — всех операций другой транзакции и т.д.,
не допуская возможности их попеременного чередования. Выражаясь более точно,
расписание S является последовательным в том случае, если при условии предшествования
некоторого действия, предпринимаемого одной произвольной транзакцией Г, какому-
либо действию другой транзакции Т все действия Т предшествуют всем действиям Т.
т}
READ(A, t)
t := t + 100
WRITE(A, t)
READ(B, t)
t := t + 100
WRITE(B, t)
T2
READ(A,
s : = s *
WRITE(A,
READ(B,
s := s *
WRITE(B,
s)
2
s)
s)
2
s)
A
25
125
250
В
25~~
125
250
Рис. 18.3. Последовательное расписание, в соответствии с которым
предшествуют операциям транзакции Т2
действия транзакции Ti
Пример 18.2. Для пары транзакций, операции которых описаны в таблице на
рис. 18.2, существуют два последовательных расписания, в одном из которых
транзакция Т{ предшествует транзакции Т2, а в другом, наоборот, Т2 предшествует
Г]. На рис. 18.3 представлена последовательность событий, отвечающая ситуации,
18.1. ПОСЛЕДОВАТЕЛЬНЫЕ И УСЛОВНО-ПОСЛЕДОВАТЕЛЬНЫЕ РАСПИСАНИЯ 881
когда исходное состояние базы данных определяется условием А- В = 25 и вначале
выполняются все операции транзакции Гь а затем — все действия транзакции Г2.
(Здесь и далее мы придерживаемся договоренности, согласно которой ось
времени в расписаниях, представляемых в виде таблиц, направлена вниз. Помимо того,
задавая значения элементов базы данных, таких как А и В, мы имеем в виду их
содержимое в буферах оперативной памяти, которое не обязательно совпадает
с дисковой копией.)
Ъ
READ(A, t)
t := t + 100
WRITE(A, t)
READ(B, t)
t := t + 100
WRITE(B, t)
Tj.
READ(A, S)
S := S * 2
WRITE(A, s)
READ(B, S)
S := S * 2
WRITE(B, S)
A
25
50
150
В
25
50
150
Рис. 18.4. Последовательное расписание, в котором транзакция Т2 предшествует транзакции Т\
На рис. 18.4 показан другой вариант расписания, предполагающий, что первой
выполняется транзакция Г2, а затем — транзакция Тх. Начальное состояние базы
данных вновь описывается условием А = В = 25. Обратите внимание, что итоговые
значения элементов А и В, получаемые в двух случаях, различаются: если первой стартует
транзакция Ти оба значения оказываются равными 250; если же вначале выполняются
операции транзакции Г2, это приводит к А = В= 150. Абсолютные величины
результатов А и В, однако, не столь важны — главное, что они равны, т.е. условие
согласованности состояния базы данных не нарушается. Если говорить в более общем смысле,
рассчитывать на независимость итогового состояния базы данных от порядка
выполнения транзакций, как правило, нельзя. □
Последовательные расписания можно представлять так, как это сделано на
рис. 18.3 и 18.4, где перечисляются все действия, выполняемые транзакциями. Однако
поскольку очередность операций в последовательном расписании зависит только от
порядка активизации самих транзакций, зачастую удобнее опускать детали и задавать
только список транзакций, охватываемых расписанием. Так, например, расписание на
рис. 18.3 допустимо определить в виде пары (Гь Г2), а расписанию на рис. 18.4 должна
соответствовать пара (Т2, Т{).
18.1.3. Условно-последовательные расписания
Принцип согласованности транзакций свидетельствует, что любое
последовательное расписание сохраняет свойство согласованности состояния базы данных. Но
существуют ли какие-либо иные разновидности расписаний, которые также способны
гарантировать сохранение свойства согласованности состояния? Ответ положителен,
882
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
и в приводимых ниже примерах он будет обоснован. Вообще говоря, расписание
является условно-последовательным (serializable), если результат его реализации
оказывается таким же, как и при использовании некоторого последовательного расписания,
независимо от того, каково исходное состояние базы данных.
Тх
READ(A, t)
t := t + 100
WRITE(A, t)
READ(B, t)
t := t + 100
WRITE(B, t)
h.
READ(A, S)
S := S * 2
WRITE(A, S)
READ(B, s)
S := S * 2
WRITE(B, s)
A
25
125
250
В
25
125
250
Рис. 18.5. Пример условно-последовательного, но не последовательного, расписания
Пример 18.3. На рис. 18.5 приведено расписание функционирования транзакций из
примера 18.1 на с. 880, которое является условно-последовательным, но не
последовательным. Здесь транзакция Т2 адресуется к элементу А после того, как схожие
действия в отношении того же элемента предпринимаются транзакцией Ти но до момента
обращения Т{ к элементу В. Однако нетрудно убедиться, что результат подобного
упорядочения операций аналогичен итогам выполнения расписания (Гь Г2), показанным
на рис. 18.3. Чтобы доказать правомочность вывода в общем случае, следует
рассмотреть не только ситуацию, описываемую частным условием А = В = 25, но и некоторое
произвольное исходное согласованное состояние базы данных. Поскольку все
возможные согласованные состояния определяются выражением А = В = с для некоторой
константы с, легко обнаружить, что итоговые значения элементов А и В в расписании
на рис. 18.5 подчиняются правилу А = В = 2(с+ 100), т.е. свойство согласованности
сохраняется при любом значении с.
Теперь изучим расписание, изображенное на рис. 18.6. Очевидно, что оно не
последовательно, но, что более важно, его нельзя причислить и к категории условно-
последовательных. Основанием для такого заключения служит тот факт, что "приняв"
базу данных в согласованном состоянии А = В = 25, транзакции, следующие
расписанию, приводят ее в несогласованное состояние, где А = 250 и В= 150. Порядок
выполнения операций, в соответствии с которым транзакция Т{ первой обрабатывает
элемент А, но транзакция Т2 раньше Т{ обращается к В, фактически означает, что
значения А и В подвергаются совершенно различным преобразованиям — А := 2(А + 100)
против В := 2В +100. Расписание на рис. 18.6 служит одним из примеров ситуаций,
возможность возникновения которых должна исключаться корректно
функционирующими механизмами управления параллельными заданиями. □
18.1. ПОСЛЕДОВАТЕЛЬНЫЕ И УСЛОВНО-ПОСЛЕДОВАТЕЛЬНЫЕ РАСПИСАНИЯ 883
Ti
READ(A, t)
t := t + 100
WRITE(A, t)
READ(B, t)
t := t + 100
WRITE(B, t)
Тг
READ(A, S)
S := S * 2
WRITE(A, s)
READ(B, s)
S := S * 2
WRITE(B, s)
A
25
125
250
В
25
50
150
Рис. 18.6. Пример расписания, не являющегося условно-последовательным
18.1.4. О важности конкретной семантики транзакций
До сих пор, говоря о возможности последовательного упорядочения транзакций
и приводя их описания, мы подробно рассматривали все выполняемые ими значимые
действия, хотя могли бы, как кажется на первый взгляд, ограничиться списком вида
(Th Tj). В действительности конкретные детали поведения транзакций могут иметь
существенное значение, что мы и постараемся продемонстрировать в следующем примере.
Пример 18.4. Рассмотрим расписание на рис. 18.7, которое отличается от расписания,
показанного на рис. 18.6, только тем, какие именно вычисления выполняет
транзакция Т2: теперь вместо удвоения значение В умножается на I.127 По завершении работы
транзакций значения А и В сохраняют равенство — причем, как нетрудно проверить,
итоговое состояние базы данных оказывается согласованным независимо от того,
каким было исходное согласованное состояние, и совпадает с результатом выполнения
любого из двух возможных последовательных расписаний, (Гь Т2) и (Т2, Т{). □
К несчастью, требовать от планировщика заданий "умения" вникать во все детали
вычислений, подразумеваемых каждой из транзакций, мы не вправе. Поскольку
помимо фрагментов текста, написанных на языке SQL, в код транзакций нередко
включаются выражения на языках программирования общего назначения, ответить на
вопрос вида "выполняет ли транзакция операцию умножения значения элемента А на
константу, отличную от 1?" чаще всего не представляется возможным. Однако
планировщик заданий обязан отслеживать запросы на чтение/запись, инициируемые
транзакциями, и потому должен быть осведомлен о том, к каким элементам обращается
127 Мы предвидим возможное недоумение читателя и просим рассматривать подобное
решение только как иллюстрацию, имеющую методическое значение. Впрочем, вполне вероятны
реальные ситуации, когда в роли Т2 могли бы выступить транзакции, оставляющие содержимое
элементов А и В неизменным: например, транзакция Т2 просто считывает текущие значения А и В
и выводит их на консоль либо запрашивает у пользователя определенные данные и вычисляет
на их основе коэффициент F, на который позже умножает величины А и В (причем в каких-то
случаях получается, что F= 1).
884
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
каждая из транзакций и какие из них она может изменить. Для облегчения участи
планировщика заданий обычно принято считать, что
• любой элемент А базы данных, изменяемый некоторой транзакцией Г,
приобретает такое значение, что его зависимость от состояния базы данных не может
быть обусловлена случайным арифметическим совпадением.
Другими словами, если существует потенциальная возможность выполнения
транзакцией Т каких-либо действий, обращенных к элементу А и нарушающих согласованное
состояние базы данных, вероятность осуществления именно этих действий и следует
принимать в расчет. Мы вернемся к этому положению в разделе 18.2 на с. 887, где
обсудим достаточные условия принадлежности того или иного расписания к категории
условно-последовательных расписаний.
h
READ(A, t)
t := t + 100
WRITE(A, t)
READ(B, t)
t := t + 100
WRITE(B, t)
T2
READ(A, S)
S := S * 1
WRITE(A, S)
READ(B, S)
S := S * 1
WRITE(B, s)
A
25
125
125
В
25
25
125
Рис. 18.7. Пример расписания, которое является условно-последовательным только благодаря
конкретным особенностям охватываемых им транзакций
18.1.5. Система обозначений для представления транзакций и расписаний
Если принять, что характер вычислений, выполняемых транзакцией, может быть
произвольным, уместно отказаться от рассмотрения конкретных деталей, подобных
инструкциям вида t := t + 100, и сосредоточить внимание только на операциях
чтения/записи, что дает возможность использовать сокращенную систему обозначений, где
выражения гТ(Х) и wT(X) представляют действия, предпринимаемые транзакцией Т для
чтения и записи содержимого элемента X базы данных соответственно. Далее, поскольку
транзакциям обычно присваиваются имена Ти Т2 и т.д., удобно воспринимать г,(Х)
и w,(X) как синонимы более громоздких выражений гт(Х) и wT(X) соответственно.
Пример 18.5. Транзакции, приведенные на рис. 18.2 (см. с. 881), можно представить
следующим образом:
7V г,(Л); Wl(A); г,(Д); w^B);
Т2: г2(Л); w2(A); r2(B); w2(B);
Обратите внимание, что записи не содержат упоминаний локальных переменных t и s
и каких-либо ссылок на то, что происходит со значениями элементов А и В базы дан-
18.1. ПОСЛЕДОВАТЕЛЬНЫЕ И УСЛОВНО-ПОСЛЕДОВАТЕЛЬНЫЕ РАСПИСАНИЯ 885
ных после их считывания. На интуитивном уровне мы должны подразумевать
"худший" вариант изменения содержимого элементов.
В качестве другого образца применения указанного соглашения рассмотрим способ
определения условно-последовательного расписания выполнения транзакций Тх и Г2,
показанного на рис. 18.5 (см. с. 883):
г^Л); щ{А)\ г2(Л); w2(A); r{(B)\ Щ(В); г2(Я); w2(B);
□
Предлагаемая нами система обозначений, применяемая для описания транзакций
и расписаний, в более строгом изложении выглядит так:
1) действие (action) — выражение вида г,(Х) (или w,(X)), подразумевающее, что
транзакция Т, осуществляет считывание (запись) содержимого элемента X
базы данных;
2) транзакция (transaction) Г, — последовательность действий, определяемых
выражениями с подстрочным индексом /;
3) расписание (schedule) S для множества ^транзакций — последовательность
действий, в которой действия каждой транзакции Г, из ^перечисляются
в том же порядке, в котором они заданы в определении транзакции 7) как
таковой; говорят, что расписание S задает порядок чередования (interleaving)
действий транзакций, из которых оно образовано.
Расписание из примера 18.5, скажем, задает такой порядок перечисления действий-
выражений с индексами 1 и 2, который отвечает определениям транзакций Т{ и Т2.
18.1.6. Упражнения к разделу 18.1
* Упражнение 18.1.1. Допустим, что некоторая транзакция Ти инициируемая
системой бронирования авиабилетов, связана с выполнением следующих действий:
i) клиент посылает запрос, указывая дату вылета и наименования аэропортов
отправления и назначения; информация о рейсе сосредоточена в элементах
А и В (каждый из которых, возможно, занимает по одному дисковому блоку)
базы данных, извлекаемых системой;
и) клиенту передается информация о возможных альтернативах, на основе
которой тот выбирает нужный рейс (дата вылета и количество заявок на рейс
хранятся в В)] система регистрирует очередную заявку;
in) клиент выбирает желаемое место (соответствующие данные сохраняются
в элементе С);
iv) система считывает номер кредитной карты клиента и заносит счет на оплату
в список счетов, представляемый элементом D;
v) номер телефона клиента и информация о рейсе сохраняются в другом
списке (в элементе Е) с целью использования при отправке факсимильного
сообщения, подтверждающего заказ.
Оформите описание транзакции Т{ в виде последовательности действий г и w.
*! Упражнение 18.1.2. Если одна из двух транзакций состоит из четырех действий,
а другая — из шести, каково общее число различных вариантов чередования
операций этих транзакций?
886
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
18.2. Условно-последовательное упорядочение с учетом конфликтов
Здесь мы рассмотрим условие, достаточное для того, чтобы подтвердить
принадлежность некоторого расписания к категории условно-последовательных расписаний.
Планировщики заданий, используемые в коммерческих системах баз данных, как
правило, придерживаются именно этого, более строгого условия — мы будем называть
его способностью к последовательному упорядочению с учетом конфликтов (conflict-
serializability), — когда им приходится гарантировать, что некие транзакции действуют
в условно-последовательной манере. В основе условия лежит понятие конфликта
(conflict): пара последовательных действий в некотором расписании считается
конфликтной, если изменение взаимного порядка их выполнения оказывает влияние на
поведение по меньшей мере одной из транзакций, к которым относятся эти действия.
18.2.1. Конфликты
Для начала надлежит показать, что большинство вариантов пар действий
транзакций не являются конфликтными в том смысле, о котором говорилось выше. Будем
полагать, что 7} и 7} являются различными транзакциями, т.е. / Ф}.
1. Пара r,(X); rfY) не конфликтна даже в случае Х = У, поскольку ни одно из
действий не изменяет содержимое какого-либо элемента базы данных.
2. Пара r,(X); Wj(Y) не является конфликтной при условии Хф У, так как если 7}
сохраняет значение Y прежде, чем Tt считывает X, содержимое X не изменяется;
аналогично, операция чтения X транзакцией Г, не воздействует на поведение 7},
а поэтому и не затрагивает результат сохранения Y средствами 7}.
3. Пара w,(X); rj(Y) не относится к числу конфликтных по тем же причинам,
которые названы в п. 2.
4. Пара w,(X); wj(Y) становится неконфликтной в случае Хф Y.
С другой стороны, существуют три ситуации, в которых изменение порядка
следования действий транзакций, возможно, запрещено.
1. Два последовательных действия одной транзакции — скажем, г,(Х); и>,(У) —
конфликтны. Причина заключается в том, что очередность действий одной и той
же транзакции заведомо фиксирована и не может быть изменена системой.
2. Две операции записи значения одного и того же элемента базы данных,
выполняемые различными транзакциями (т.е. w,(X); w/X)), являются конфликтными.
Если действия осуществляются в указанном порядке, по их завершении в X
останется значение, лежащее "на совести" транзакции 7}. При изменении порядка
следования операций на w/X); w,(X) в X, напротив, будет занесено значение,
вычисленное транзакцией Г,. Предположение об отсутствии случайных
совпадений, выдвинутое нами выше, свидетельствует в пользу того, что значения,
сохраняемые различными транзакциями Г, и 7}, вообще говоря, должны
различаться — по меньшей мере, для некоторых исходных состояний базы данных.
3. Последовательные операции чтения и записи содержимого одного элемента
базы данных, осуществляемые разными транзакциями, также конфликтны.
Иными словами, конфликтными являются пары действий r,(X); w/X) и w,(X); r/Х).
Если вначале выполнить w/X), а затем а/Х), значением X, считываемым
транзакцией Г„ окажется то, которое сохранено транзакцией 7}, — оно, как можно
полагать, не обязательно совпадает с предыдущим содержимым X. Поэтому
изменение очередности действий г,(Х) и w/X) влияет на результат считывания X
транзакцией Г, и, как следствие, воздействует на ее поведение.
18.2. УСЛОВНО-ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ С УЧЕТОМ КОНФЛИКТОВ 887
Напрашивается следующее естественное заключение: два действия различных
транзакций можно переставлять местами, если только
1) они не затрагивают один и тот же элемент базы данных
или
2) ни одно из них не связано с операцией записи.
Рассмотренная модель конфликтных/неконфликтных пар действий транзакций дает
основание говорить о вероятной возможности преобразования произвольного расписания
в последовательное расписание путем осуществления ряда операций взаимной
перестановки неконфликтных действий. Если подобная цель оказывается достигнутой,
исходное расписание следует считать условно-последовательным, поскольку после каждой
перестановки действий неконфликтных пар состояние базы данных остается неизменным.
Будем говорить, что два расписания являются конфликтно-эквивалентными (conflict-
equivalent), если они допускают возможность взаимного преобразования посредством
выполнения ряда операций перестановки смежных неконфликтных действий.
Расписание называют условно-последовательным с учетом конфликтов (conflict-serializable), если
оно конфликтно-эквивалентно некоторому последовательному расписанию. Заметим,
что способность транзакций, охватываемых расписанием, к последовательному
упорядочению с учетом конфликтов является достаточным основанием для отнесения
расписания к категории условно-последовательных, т.е. расписание, условно-последовательное
с учетом конфликтов, является условно-последовательным. С другой стороны,
произвольное условно-последовательное расписание не обязано быть условно-последовательным
с учетом конфликтов, хотя именно это, последнее, требование чаще всего используется
планировщиками заданий коммерческих систем баз данных для того, чтобы гарантировать
принадлежность расписания к категории условно-последовательных расписаний.
Пример 18.6. Рассмотрим расписание
r{(A); Wl(A); г2(Л); w2(A); r№\ Щ{В)\ r2(B)\ w2(B)\
из примера 18.5 на с. 885. Мы утверждаем, что оно является условно-
последовательным с учетом конфликтов. На рис. 18.8 приведена группа операций
взаимной перестановки действий расписания, в результате выполнения которых
расписание преобразуется в последовательное, обозначаемое списком (Ть Г2): все действия
транзакции Т{ предшествуют всем действиям транзакции Т2. Смежные действия
транзакций, подлежащие перестановке, отмечены подчеркиванием.
г^Л); w{(Ay, r2(A); w2(A); rx(B)\ wx(B)\ r2(B)\ w2(£);
r{(A); Wl(A); r^; п(Я); w2(A); w{(B); r2(B); w2(B);
г^Л); Wl(A); r,{B)\ г2(Л); w2(A); wx(B)\ r2{B)\ w2(£);
г^Л); wx{A)\ rx{B)\ ЫЛ); ^(fl); w2(A); r2(B); w2(B);
r{(A); w{(A); г{(В); wx(B)\ r2(A); w2(A); r2(B)\ w2(B);
Рис. 18.8. Преобразование расписания, условно-
последовательного с учетом конфликтов, в
последовательное путем перестановки смежных действий
□
18.2.2. Графы предшествования и расписания, условно-последовательные с
учетом конфликтов
Проверить некоторое расписание S и решить, относится ли оно к категории
расписаний, условно-последовательных с учетом конфликтов, относительно просто. Тест
основан на следующем положении: если расписание S содержит какие-либо пары
888 ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Почему требование условного упорядочения с учетом конфликтов не является
необходимой предпосылкой возможности условного упорядочения
Один из примеров, отвечающий на вопрос, вынесенный в заголовок этой врезки,
вы уже видели на рис. 18.7 (см. с. 885): особенности поведения транзакции Т2
позволяют трактовать расписание как условно-последовательное — однако оно
не является условно-последовательным с учетом конфликтов, поскольку
значение элемента А вначале сохраняется транзакцией Ти а на элемент В первой
воздействует транзакция Т2. Поскольку изменить порядок записи значений ни Л, ни
В нельзя, какие бы то ни было способы размещения всех действий Т{ "впереди"
действий Т2 и наоборот отсутствуют.
Впрочем, существуют и такие примеры условно-последовательных расписаний,
не являющихся условно-последовательными с учетом конфликтов, которые не
зависят от конкретной семантики вычислений, подразумеваемой транзакциями.
Рассмотрим, скажем, три транзакции — Ти Т2 и Г3, — каждая из которых оказывает
влияние на содержимое элемента X базы данных. Помимо того, транзакции Т{ и Т2
прежде сохраняют значения элемента Y. Одно из возможных —
последовательных — расписаний выглядит так:
S{: w{(Y); w^X); w2(Y); w2(X); w3(X);
По завершении действий, предусматриваемых расписанием Sl9 элемент X остается
со значением, присвоенным транзакцией Г3, а в Y сохраняется результат работы
транзакции Т2. Однако тот же итог достигается и при реализации расписания
S2. wi(Y)\ w2(Y)\ w2(X); w{(X)\ w3(X);
Здравый смысл подсказывает, что значения X, сохраняемые транзакциями Т{ и Тъ
не важны, поскольку позже они все равно изменяются транзакцией Г3. Таким
образом, при выполнении расписаний S{ и S2 пары итоговых значений каждого из
элементов X и Y совпадают. Так как расписание S{ последовательно, a S2 оказывает
на состояние базы данных аналогичное влияние, понятно, что S2 относится к
категории условно-последовательных расписаний. Но поскольку действия w{(Y)
и w2(Y), а также wi(X) и w2(X) поменять местами нельзя, это значит, что S2 не удастся
преобразовать в какое-либо последовательное расписание с помощью операций
перестановки действий. Иными словами, расписание S2 является условно-
последовательным, но не условно-последовательным с учетом конфликтов.
конфликтных действий, транзакции, выполняющие эти действия, в любом конфликтно-
эквивалентном последовательном расписании должны следовать в том же порядке, в
каком они представлены в расписании S. Поэтому конфликтные пары действий
накладывают определенные ограничения на очередность следования транзакций в
гипотетическом конфликтно-эквивалентном последовательном расписании. Если подобные
ограничения не противоречивы, некоторое конфликтно-эквивалентное последовательное
расписание непременно существует. Наличие противоречий, напротив,
свидетельствует о том, что ни одно последовательное расписание сконструировать нельзя.
Говорят, что в заданном расписании S, охватывающем, в частности, транзакции Т{
и Тъ Тх предшествует (precedes) T2 (для отображения такого факта применяется запись
Т\ <s T2)i если существуют действия А{ транзакции Тх и А2 транзакции Т2, такие, что
1) Ах выполняется раньше А2\
2) как Аи так и А2 адресуют один и тот же элемент базы данных;
3) по меньшей мере одно из двух действий — А{ и А2 — связано с операцией
записи.
18.2. УСЛОВНО-ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ С УЧЕТОМ КОНФЛИКТОВ 889
Заметим, что это именно те условия, которые запрещают изменять очередность
следования действий А{ и А2. Поэтому А{ должно выполняться прежде А2 в любом
расписании, конфликтно-эквивалентном расписанию S. Как следствие, если одно из таких
расписаний последовательно, транзакция Т{ обязана выполняться раньше транзакции Т2.
Обобщения отношений предшествования находят естественное воплощение в
модели графов предшествования (precedence graphs). В роли вершин графа
предшествования в данном случае выступают транзакции расписания S. Поскольку, как говорилось
выше, транзакции обычно обозначают переменными Th вершину графа,
представляющую транзакцию Г„ для удобства уместно снабдить целочисленной меткой /. Граф
предшествования, соответствующий расписанию S, содержит направленную дугу,
соединяющую вершину / с вершиной у, если Г, ^5 ?}•
Пример 18.7. Рассмотрим расписание S, охватывающее три транзакции — Ти Т2 и Г3:
S: г2(Л); гх{В)\ "2(Л); г3(Л); и^Я); w3(A); г2(Я); w2(B);
Если обратить внимание на действия, касающиеся элемента А, становится понятным,
почему Т2 -<5 Тъ. Например, г2(А) опережает w3(A), a w2(A) выполняется раньше и г3(А),
и w3(A). Любой из трех указанных фактов является достаточным подтверждением того,
почему граф предшествования, показанный на рис. 18.9, содержит дугу, соединяющую
вершину 2 с вершиной 3.
^~. ^-^ —^ Последовательность действий над элементом В ана-
ч!у *ч£/ *ч1/ логичным образом проясняет вывод Тх <sТъ — доста-
Рис. 18.9. Граф предшествова- точно заметить, что действие гх{В) предваряет действие
ния для расписания S из приме- w2(B). Поэтому граф предшествования для расписания
ра 18.7 S должен содержать и дугу, направленную от
вершины 1 к вершине 2. Этим придется ограничиться —
последовательность действий расписания S не дает возможности обосновать наличие
каких-либо других дуг в графе предшествования, изображенном на рис. 18.9. □
Существует простое правило, позволяющее определить, является ли некоторое
расписание S условно-последовательным с учетом конфликтов:
• построить граф предшествования для S и ответить на вопрос, содержит ли граф
циклы; если да, S не относится к категории расписаний, условно-
последовательных с учетом конфликтов; если же, напротив, граф ацикличен,
S является условно-последовательным с учетом конфликтов и, более того,
любая топологическая очередность вершин графа128 определяет способ
конфликтно-эквивалентного последовательного упорядочения действий расписания.
Пример 18.8. Граф на рис. 18.9 ацикличен, поэтому расписание S из примера 18.7
является условно-последовательным с учетом конфликтов. Существует единственный
порядок следования вершин, или транзакций, согласующийся с набором дуг графа:
(Гь Т2, Г3). Действительно, вполне возможно преобразовать S в расписание, в котором
все действия каждой из трех транзакций выполняются именно в такой очередности;
подобное последовательное расписание выглядит следующим образом:
S': г{(Ву, w^B); г2(Л); w2(A); r2(fl); w2(B)\ г3(Л); w3(A);
128 Топологическая очередность (topological order) ациклического графа — это любой порядок
следования вершин, такой, что для каждой дуги я—>6 вершина а предшествует вершине b с точки
зрения рассматриваемой топологической очередности. Чтобы найти некоторую топологическую
очередность произвольного ациклического графа, достаточно последовательно исключать из
числа оставшихся вершин такие вершины, которые не имеют предшественников.
890
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Чтобы понять, каким образом можно получить S' из S посредством перестановки
смежных действий, вначале надлежит заметить, что пара г2(А); гх(В) неконфликтна,
поэтому эти действия допустимо переставить местами. Затем с помощью трех операций
замены можно переместить wx(B) на позицию непосредственно после гх(В), поскольку
все три действия, смежные по отношению к wx(B), затрагивают только элемент А, но
не В. Затем остается передвинуть г2(В) и w2(B) на позицию, следующую за w2(A) —
в каждом случае соседствовать с г2(В) и w2(B) будут такие действия, которые связаны
только с элементом А. В результате получим расписание S'. □
Пример 18.9. Теперь рассмотрим расписание
Sx: r2{A); rx(B); w2(A); r2(B); г3(Л); wx(B); w3(A); w2(B);
которое отличается от расписания S из примера 18.8 только тем, что действие г2(В)
перемещено на три позиции в направлении начала. Проверка действий, касающихся
элемента А, убедительно подтверждает справедливость отношения предшествования
T2<s Т3, но в результате анализа действий, связанных
с элементом В, выясняется, что из факта
предшествования гх(В) и wi(B) действию w2(B) следует Тх <s T2\ в то
же время, поскольку г2(В) выполняется раньше wx(B), Рис. 18.10. Циклический граф
имеем T2<s Тх. Граф предшествования, соответствую- предшествования— соответ-
1 ствующее расписание не явля-
щий расписанию Sb приведен на рис. 18.10. ется условно-последовательным
Граф, совершенно очевидно, содержит цикл. По- с учетом конфликтов
этому мы заключаем, что расписание 5! не является
условно-последовательным с учетом конфликтов — в любом последовательном
расписании, конфликтно-эквивалентном расписанию Su транзакция Тх должна была бы
одновременно предшествовать транзакции Т2 и следовать за нею, что невозможно. □
18.2.3. Обоснование корректности процедуры проверки графа предшествования
Как было показано выше, наличие цикла в графе предшествования обусловливает
необходимость введения взаимно противоречивых ограничений, касающихся
очередности выполнения транзакций в гипотетическом конфликтно-эквивалентном
последовательном расписании. Если цикл охватывает п таких транзакций, что
Тх —> Т2 —>...—> Тп —> Гь тогда в любом мыслимом последовательном расписании
действия транзакции Тх должны предшествовать действиям Тъ а те в свою очередь обязаны
предварять действия Г3 и т.д. вплоть до Тп. Но действия Гл, следующие, таким образом,
позже действий Тх, из-за наличия дуги Тп-*ТХ в то же время должны выполняться
раньше действий Тх. Поэтому присутствие цикла в графе предшествования дает
основание заключить, что расписание, представляемое графом, не относится к категории
расписаний, условно-последовательных с учетом конфликтов.
Обратный вывод получить несколько труднее. Мы должны показать, что если граф
предшествования не имеет циклов, существует способ перестановки смежных
неконфликтных действий, приводящий к преобразованию исходного расписания в
последовательное. Это будет означать, что любое расписание, которому отвечает ациклический граф
предшествования, является условно-последовательным с учетом конфликтов.
Доказательство проводится по индукции от количества транзакций, вовлеченных в расписание.
Базис. Если л = 1, т.е. в расписании упоминается единственная транзакция, такое
расписание заведомо последовательно и непременно условно-последовательно с
учетом конфликтов.
Индукция. Допустим, что расписанию S, которое представляет набор действий п
транзакций Тх, Т2,..., Тп, соответствует ациклический граф предшествования. Если ко-
18.2. УСЛОВНО-ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ С УЧЕТОМ КОНФЛИКТОВ 891
-©
нечный граф не имеет циклов, он содержит по меньшей мере одну вершину без
входящих дуг; предположим, что таковой является вершина *', отвечающая транзакции 7}.
Поскольку по определению вершина / не имеет входящих дуг, в расписании S не
может быть ни одного действия А, которое одновременно
1) относится к какой-либо транзакции 7}, отличной от Г,;
2) предшествует некоторому действию транзакции Г,;
3) образует с последним конфликтную пару.
(Если, напротив, допустить, что такое действие существует, в граф предшествования
пришлось бы включить дугу, соединяющую вершину у с вершиной /.) Поэтому оказывается
возможным переместить все действия транзакции Г;, сохраняя очередность их
следования, в начало расписания S. В таком случае расписание принимает следующую форму:
(действия транзакции Г;)(действия остальных п - 1 транзакций).
Теперь рассмотрим завершающую часть расписания S, состоящую из действий п - 1
транзакций за исключением транзакции Г,. Поскольку относительный порядок их
следования сохранен, графом предшествования для этой части расписания останется
тот же граф за вычетом вершины / и всех исходящих из нее дуг. Так как исходный
граф был ациклическим и удаление вершины и дуг не могло привести к образованию
циклов, имеем право заключить, что граф, отвечающий части расписания для п - 1
транзакций, также является ациклическим. Применим гипотезу индукции к
расписанию из п - 1 транзакций. Выполнение аналогичных операций перестановки
неконфликтных действий, относящихся к определенной транзакции, в расписаниях из п- 1,
л-2 и т.д. транзакций приводит к получению последовательного расписания, т.е.
можно утверждать, что S допустимо преобразовать в последовательное расписание,
в начале которого размещены действия транзакции Th а затем — действия других
транзакций в определенном последовательном порядке. Индукция завершена, и мы
приходим к заключению о том, что любое расписание, которому соответствует ациклический
граф предшествования, является условно-последовательным с учетом конфликтов.
18.2.4. Упражнения к разделу 18.2
Упражнение 18.2.1. Ниже приведены описания действий двух транзакций,
адресующих элементы А и В базы данных, которые можно трактовать как
целочисленные величины.
7^: READ(A, t) ; t := t + 2; WRITE(A, t) ; READ(B, t) ; t := t * 3; WRITE(B, t) ;
T2: READ(B, s) ; s := s * 2; WRITE(B, s) ; READ (A, s) ; s := s + 3; WRITE (A, s) ;
Предполагается, что транзакции Т{ и Г2, выполняемые поодиночке, сохраняют все
ограничения, определяющие свойство согласованности состояния базы данных
(условие А-В не относится к числу таких ограничений).
a) Оказывается, что оба последовательных расписания, (Тъ Т2) и (Т2, Тх),
эквивалентны, т.е. предусматриваемые ими действия оказывают одинаковое
влияние на состояние базы данных. Докажите этот факт, продемонстрировав
результаты выполнения расписаний в применении к некоторому выбранному
наудачу исходному набору значений элементов А и В.
b) Приведите по одному примеру расписаний (включающих 12 перечисленных
выше действий), одно из которых является условно-последовательным,
а другое — нет.
c) Каково общее количество последовательных расписаний выполнения
12 названных действий?
892
ГЛАВА 18, УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
*!! d) Сколько расписаний, охватывающих те же 12 действий, относятся к
категории условно-последовательных?
Упражнение 18.2.2. Две транзакции из упражнения 18.2.1, представленные в
сокращенной форме, предусматривающей необходимость отображения только
операций чтения/записи, выглядят так:
7V п(Л); Wl(A); rx{B); wx(B)\
Тг- г2(Я); w2(B); г2(Л); w2(A);
Дайте ответы на следующие вопросы.
*! а) Каково количество расписаний (содержащих 8 перечисленных выше действий),
которые конфликтно-эквивалентны последовательному расписанию (Гь Г2)?
Ь) Сколько расписаний выполнения тех же 8 действий являются
эквивалентными последовательному расписанию (Г2, Тх) (т.е. приводят базу данных в то
же состояние)?
!! с) Сколько расписаний, предусматривающих осуществление 8 названных
действий, эквивалентны (причем не обязательно конфликтно-эквивалентны)
последовательному расписанию (Ть Т2) при условии, что транзакции
оказывают такое же воздействие на состояние элементов базы данных, какое
упоминается в упражнении 18.2.1?
! d) Почему ответы на вопросы (с) этого упражнения и (d) упражнения 18.2.1
различны?
Упражнение 18.2.3. Предположим, что транзакции Т{ и Т2 из упражнения 18.2.2
изменены следующим образом:
7у. п(Л); Wl(A); rx(B)\ *>№\
Т2: г2(Л); w2(A); г2(Я); w2(B);
т.е. их семантика, описанная в упражнении 18.2.1, сохранена, однако транзакция
Т2 теперь обрабатывает вначале элемент А, а затем — элемент В. Определите
a) количество возможных расписаний, условно-последовательных с учетом
конфликтов;
b) общее число условно-последовательных расписаний (в предположении, что
транзакции воздействуют на базу данных так же, как это предусмотрено
в упражнении 18.2.1).
Упражнение 18.2.4. Рассматривая каждое из приведенных ниже расписаний,
* а) п(Л); г2(Л); г3(Д); ^(Л); r2(Q; г2(Д); и/2(Д); Wl(C);
b) r{(A); w{(B); r2(B); w2(Q; r3(Q; w3(A);
C) w3(A); п(Л); Wl(B); r2(B); w2(Q; r3(Q;
d) п(Л); г2(Л); w{(B); w2(£); r^B); r2(B); w2(Q; w{(D);
e) п(Л); г2(Л); ЫЯ); г2(Я); г3(Л); г4(Я); Wi(A); w2(B);
ответьте на следующие вопросы.
i) Что представляет собой граф предшествования, соответствующий расписанию?
и) Является ли расписание условно-последовательным с учетом конфликтов?
Если да, каковы все эквивалентные последовательные расписания?
! Ш) Существуют ли какие-либо последовательные расписания, которые
эквивалентны рассматриваемому расписанию (причем независимо от семантики
действий транзакций), но не конфликтно-эквивалентны ему?
18.2. УСЛОВНО-ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ С УЧЕТОМ КОНФЛИКТОВ 893
!! Упражнение 18.2.5. Транзакция Т предшествует транзакции U в расписании S (T<SU),
если каждое действие Т выполняется раньше любого действия S (в дополнение
к достаточному условию, указанному в разделе 18.2.2 на с. 888, неконфликтные
действия Т и U допустимо переставлять местами. — Прим. перев.). Если
помимо Т и U другие транзакции в S не упоминаются, из условия T<SU
непосредственно вытекает, что S есть последовательное расписание (Г, U). Если же,
однако, S охватывает и другие транзакции, из-за их влияния S может не быть не только
условно-последовательным, но даже условно-последовательным с учетом
конфликтов. Приведите пример такого расписания S, что i) транзакция Т{ предшествует
в S транзакции Т2 и ii) S является условно-последовательным с учетом конфликтов,
но Ш) в каждом последовательном расписании, конфликтно-эквивалентном
расписанию S, транзакция Т2 предшествует транзакции Т{.
! Упражнение 18.2.6. Поясните, каким образом для любого п > 1 можно
сконструировать расписание, граф предшествования которого включает цикл длины п и не
содержит циклов меньшей длины.
18.3. Последовательные расписания и механизмы блокирования
Представьте себе набор транзакций, выполняющих предписанные им действия
в отсутствие каких бы то ни было ограничений. Очередность протекания этих
действий определяется неким расписанием, но почти невероятно, что оно окажется
последовательным. Задача предотвращения возможности осуществления действий в таком
порядке, который не отвечает условно-последовательному, возлагается на
планировщик заданий. В этом разделе мы сосредоточим внимание на одной из наиболее общих
архитектур управления параллельными заданиями, которая предполагает
использование механизма блокирования (locking) элементов базы данных с целью препятствова-
ния непоследовательному выполнению действий транзакций. Коротко говоря,
транзакция получает право "владения" элементом, исключающее такую возможность
единовременного доступа к элементу со стороны других транзакций, которая
и обусловливает опасность непоследовательного поведения.
Ниже мы познакомим вас с понятием блокировки (lock), используя заведомо
и чрезмерно простую схему блокирования. В этой схеме рассматривается только одна
разновидность блокировки; транзакции, которым необходимо выполнить какое-либо
действие над элементом базы данных, обязаны явно затребовать право на
блокирование этого элемента. В разделе 18.4 на с. 901 представлены более реалистичные схемы,
позволяющие устанавливать блокировки нескольких различных категорий, включая
общеупотребительные, разрешающие общее/монопольное (shared/exclusive) владение
элементом, что соответствует привилегиям на чтение/запись данных элемента.
18.3.1. Блокировки
На рис. 18.11 показано, как планировщик заданий, осуществляя возложенные на
него функции, использует таблицу блокировок (lock table). Напомним, что
планировщик, или менеджер параллельных заданий, несет ответственность за обработку запросов
на чтение/запись, поступающих от транзакций, и либо разрешает их незамедлительное
выполнение, либо откладывает таковое до того момента, когда, по его "мнению",
возникнут подходящие безопасные условия. О том, каким образом таблица блокировок
оказывает содействие в принятии подобных решений, будет рассказано ниже.
В идеальном случае планировщик мог бы давать запросу "зеленый свет", если
и только если выполнение последнего не было бы чревато нарушением
согласованного состояния базы данных по завершении или после прерывания всех активных
транзакций. Однако получить достоверное решение подобной проблемы в режиме ре-
894
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
ального времени весьма непросто. Поэтому все планировщики руководствуются более
простым критерием, гарантирующим возможность сведения расписания к
последовательному виду ценою вероятного запрещения отдельных действий, которые сами по
себе не обусловливают потерю согласованности состояния базы данных.
Планировщик, применяющий механизм блокирования, как и большинство планировщиков
других видов, выдвигает требование условно-последовательного упорядочения
действий транзакций с учетом конфликтов, которое (мы упоминали об этом выше)
является более строгим, нежели критерий условно-последовательного упорядочения.
Запросы
от транзакций
Планировщик
заданий
Таблица
блокировок
S
Условно-последовательное
расписание действий
Рис. 18.11. Планировщик заданий и таблица
блокировок
При использовании планировщиком заданий схемы блокирования транзакции, наряду
с операциями чтения/записи значений элементов данных, обязаны также направлять
запросы на захват и освобождение блокировок. Схема блокирования должна быть верной
как с точки зрения структуры транзакций, так и относительно структуры расписаний.
• Согласованность транзакций. Основные действия транзакций и выполняемые
ими операции, связанные с блокированием элементов данных, должны
соотноситься строго определенным образом:
a) транзакция имеет право осуществить чтение или запись содержимого
элемента, если прежде она запросила блокировку этого элемента и блокировка
еще не освобождена;
b) если транзакция выполняет блокирование элемента, позже блокировка
должна быть непременно снята.
• Корректность расписаний. Блокировки должны использоваться по прямому
назначению и в соответствии с присущей им исходной семантикой: никакие две
транзакции не имеют права блокировать один и тот же элемент без
предварительного освобождения блокировки, установленной одной из транзакций.
Пришло время расширить используемую нами систему обозначений действий
транзакций, чтобы предоставить возможность описания операций по захвату и
освобождению блокировок:
/,(Х) — транзакция Tt блокирует (lock) элемент X базы данных;
Uj(X) — транзакция Тх освобождает, или разблокирует (unlock), элемент X.
Свойство согласованности транзакций с учетом механизма блокирования теперь
можно сформулировать так: всякий раз, когда транзакция Г, намеревается выполнить
действие г,{Х) или w,(X), она обязана предварительно осуществить операцию /,(Х),
причем операция щ(Х) должна следовать только после г,(Х) или w,(X). Принцип
корректности расписаний с блокировками гласит следующее: если в некотором расписании
предусмотрено действие //(X), за которым следует операция //Х), в промежутке между
ними обязано присутствовать действие и,(Х).
18.3. ПОСЛЕДОВАТЕЛЬНЫЕ РАСПИСАНИЯ И МЕХАНИЗМЫ БЛОКИРОВАНИЯ 895
Пример 18.10. Рассмотрим две транзакции, Тх и Тъ из примера 18.1 на с. 880.
Напомним, что транзакция Т{ прибавляет к значениям элементов А и В базы данных число
100, а Т2 удваивает их. Ниже приведены описания транзакций с учетом операций
захвата и освобождения блокировок и арифметических действий (последние включены
только для ясности)129:
7V lx(A); гх(А); А := А + 100 ; wx(A); их(А); 1Х(В)\ гх(В)\ В := В + 100 ; wx(B); их(В);
Т2: 12(Л); г2(А); А : = А * 2; w2(A); и2(А); /2(Я); г2(В); В : = В * 2; w2(B); u2(B);
Каждая из транзакций, рассматриваемая отдельно, согласованна: операции
чтения/записи значений А и В выполняются только после захвата блокировки, после чего
блокировка освобождается.
На рис. 18.12 представлено одно из возможных корректных расписаний
выполнения транзакций Т{ и Т2. Для экономии места мы включили в каждую строку таблицы
по несколько действий. Расписание действительно корректно, поскольку транзакции
одновременно не блокируют ни элемент А, ни элемент В: в частности, Т2 не вызывает
12(А) до тех пор, пока Тх не выполнит их(А), а операция 1Х(В) осуществляется
транзакцией Тх только после завершения транзакцией Т2 действия и2(В). Проанализировав
значения элементов, получаемые в процессе работы транзакций, легко убедиться, что
расписание, будучи корректным, не является условно-последовательным (и, помимо
того, оставляет базу данных в несогласованном состоянии, А фВ). В разделе 18.3.3 на
с. 897 мы познакомим вас с дополнительным условием двухфазного блокирования (two-
phase locking), которое гарантирует принадлежность корректных расписаний к
категории условно-последовательных с учетом конфликтов.
25 25
1№\ гх(А);
А := А + 100;
wx(A); ux(A); 125
/2(Л); г2(Л);
А := А * 2;
w2(A); и2(А)\ 250
Ш; г2(В);
В := В * 2;
w2(B); u2(B); 50
h(B)\ rx(B)',
В := В + 100;
wx(B);ux(B); 150
Рис. 18.12. Корректное расписание выполнения согласованных транзакций, которое, однако,
не является условно-последовательным
□
129 Следует иметь в виду, что фактические вычислительные действия, предпринимаемые
транзакциями, в принятой нами системе обозначений обычно опускаются, поскольку они
игнорируются планировщиком заданий в процессе принятия решения о том, разрешить или
запретить дальнейшую обработку запроса, посланного транзакцией.
896
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
18.3.2. Архитектура простого планировщика с блокированием
Планировщик заданий, основанный на механизме блокирования, выполняет
запрос, поступающий от транзакции, в том и только в том случае, если тот не влияет на
корректность расписания. Для достижения цели планировщик поддерживает таблицу
блокировок (lock table), в которой сохраняются сведения о том, какая транзакция в
данный момент владеет правом на использование того или иного элемента базы
данных. Структура таблицы блокировок более подробно рассматривается в разделе 18.5.2
на с. 915. Однако если принимать во внимание блокировки только одной
разновидности (до сих пор мы так и поступали), таблицу блокировок можно представить в виде
отношения Locks (element, transaction), содержащего пары вида (X, 7),
свидетельствующие о том, что транзакция Т в данный момент удерживает блокировку
элемента X базы данных. В этом случае планировщику достаточно обращаться к таблице,
выполняя запросы и простые команды модификации вида insert и delete.
Пример 18.11. Расписание, представленное на рис. 18.12, как мы говорили, корректно,
поэтому при его выполнении планировщик, основанный на механизме блокирования,
должен был бы давать ход каждому запросу, поступающему от той или иной
транзакции в указанном порядке. Ниже приведены описания транзакций Т{ и Т2 из примера
18.10 с небольшими (но важными — об этом будет рассказано в разделе 18.3.3 на
с. 897) изменениями, предусматривающими, что обе транзакции захватывают
блокировку элемента В до освобождения блокировки элемента А.
Тг: 1{{А)\ гх(А)\ А := А + 100 ; w^A); lx(B)\ их{А)\ гх{В)\ В := В + 100 ; w{(B); u{{B)\
Т2\ 12(Л)', г2(А); А : = А * 2 ; w2(A)\ 12{В)\ и2(А)\ г2(В)\ В : = В * 2 ; w2(B); u2{B)\
Выполняя расписание, показанное на рис. 18.13, после получения запроса
транзакции Т2 на блокировку элемента В планировщик обязан запретить операцию,
поскольку блокировка В все еще удерживается транзакцией Тх. Поэтому поток вычислений
транзакции Т2 приостанавливается, и далее выполняются действия транзакции Тх. Со
временем Т{ вызовет и{(В), и элемент В будет разблокирован. Теперь его сможет
заблокировать транзакция Тъ чтобы осуществить оставшиеся действия. Заслуживает внимания
следующее обстоятельство: поскольку транзакция Т2 вынуждена приостановить работу,
операция удвоения значения В выполняется после того, как Тх прибавит к содержимому
В число 100, что приводит к сохранению согласованного состояния базы данных (А = В). □
18.3.3. Двухфазное блокирование
Существует одно любопытное и в определенной степени неожиданное условие,
при выполнении которого любое корректное расписание обслуживания
согласованных транзакций гарантированно становится условно-последовательным с учетом
конфликтов. Требование, называемое двухфазным блокированием (two-phase locking, или
2PL) и широко применяемое в подсистемах управления параллельными заданиями
коммерческих СУБД, гласит:
• все запросы на блокирование, инициируемые каждой транзакцией, должны
предшествовать всем запросам на разблокирование, посылаемым той же
транзакцией.
"Первая" фаза условия 2PL связана с захватом блокировок, а "вторая" — с их
освобождением. Двухфазное блокирование — это условие (такое же, как условие
согласованности транзакций с учетом механизма блокирования), которое регламентирует
очередность действий транзакции. Транзакцию, удовлетворяющую условию 2PL,
называют двухфазно-блокированной (two-phase-locked transaction, или 2PL-transaction).
18.3. ПОСЛЕДОВАТЕЛЬНЫЕ РАСПИСАНИЯ И МЕХАНИЗМЫ БЛОКИРОВАНИЯ 897
ri
T2
А
В
25 25
Ш); г,(Л);
А := А + 100;
wi(A)\ Ш)\ щ(А); 125
/2М); г2(Л);
А := А * 2;
w2(A); 250
12(В) —- запрет
п(£);
В := В + 100;
w{(B); их(В)\ 125
/2(Я); и2(А); г2(В);
В := В * 2;
и/2(Я); и2(Д); 250
Рис. 18.13. Планировщик заданий, основанный на механизме блокирования, приостанавливает
выполнение запроса, угрожающего свойству корректности расписания
Пример 18.12. Транзакции, рассмотренные в примере 18.10 на с. 896, не
удовлетворяют условию двухфазного блокирования: транзакция Г1? скажем, освобождает
блокировку элемента А прежде, чем блокирует элемент В. Однако измененные версии тех
же транзакций, обсуждавшиеся в примере 18.11, напротив, являются двухфазно-
блокированными: транзакция Тх блокирует элементы А и В в ходе выполнения первых
пяти действий, а разблокирует их, осуществляя оставшиеся пять действий; аналогично
ведет себя и транзакция Т2. Если сопоставить расписания, показанные на рис. 18.12
и 18.13, нетрудно убедиться, что двухфазно-блокированные транзакции, верным
образом взаимодействуя с планировщиком заданий, обеспечивают сохранение
согласованности состояния базы данных, в то время как транзакции, не удовлетворяющие
условию 2 PL, допускают рецидивы несогласованного (и непоследовательного) поведения. □
18.3.4. Обоснование корректности условия двухфазного блокирования
Преимущества практического использования условия 2 PL, продемонстрированные
нами на частных примерах, сохраняются в силе и в общем случае, хотя это далеко не
очевидно. На интуитивном уровне каждую двухфазно-блокированную транзакцию
можно воспринимать как выполняющуюся непрерывно, начиная с момента отправки
первого из запросов на разблокирование (подобное поведение схематически отображено на
рис. 18.14). Последовательное расписание, конфликтно-эквивалентное расписанию S
выполнения 2PL-транзакций, относится к числу тех, в которых транзакции упорядочены
в соответствии с очередностью следования первых инструкций по разблокированию.130
Нам предстоит показать, каким образом произвольное корректное расписание S,
предусматривающее выполнение действий согласованных двухфазно-блокированных
транзакций, может быть преобразовано в конфликтно-эквивалентное
последовательное расписание. Для описания преобразования удобнее воспользоваться индукцией по
числу п транзакций расписания 5. Важно помнить о том, что аспекты эквивалентно-
1 Для некоторых расписаний существуют и другие конфликтно-эквивалентные
последовательные расписания.
898
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
сти с учетом конфликтов имеют отношение только к действиям, связанным с
операциями чтения/записи. При изменении порядка следования операций чтения/записи
действия по блокированию/разблокированию игнорируются. После определения
последовательной очередности функций чтения/записи их следует "обрамить"
соответствующими инструкциями захвата и освобождения блокировок, как того требует
семантика транзакций. Поскольку каждая транзакция освобождает все блокировки до
своего завершения, последовательное расписание окажется корректным.
С этого момента транзакция
выполняется непрерывно
t
Захват
блокировок
Время —*•»
Рис. 18.14. В каждой двухфазно-блокированной транзакции
есть позиция, начиная с которой транзакцию можно
трактовать как выполняющуюся непрерывно
Базис. Если я = 1, S уже является последовательным расписанием.
Индукция. Предположим, что расписание S охватывает п транзакций Гь Г2,..., Тп и Г,
представляет собой транзакцию, которая содержит первую среди всех инструкций
разблокирования — обозначим ее как и,(Х), — используемых в S. Мы утверждаем, что
возможно переместить все действия транзакции Г„ связанные с операциями
чтения/записи, в начало расписания, не вызывая ни один конфликт. Рассмотрим
некоторое действие Г, — скажем, Wj(Y). Может ли предшествовать действию Wj(Y) в S какое-
либо конфликтное действие — например, Wj(Y)? Если это так, тогда действия wj(Y)
и Wj(Y) должны быть разделены по меньшей мере парой инструкций Uj(Y) и lj(Y):
»■; и/,(У); .«; и/У); •••; /,(У); -; и/,(У); -
Поскольку Г, по предположению содержит первую в порядке очередности операцию
разблокирования, инструкция щ(Х) должна предшествовать в расписании S
инструкции Uj{Y), т.е. S может выглядеть следующим образом:
.«; w/У);.»; ц,(Х); -; ufX)\ •••; «У); ••■; w,(«; -
(и£Х) может занимать позицию даже до w/У))- В любом случае мы вынуждены
констатировать факт предшествования щ(Х) операции /;(У), а это означает, что Г, не является
двухфазно-блокированной транзакцией, каковой ей надлежит быть по определению.
Хотя мы доказали только невозможность существования конфликтных пар операций
записи, аналогичные доводы применимы к любой паре потенциально конфликтных
действий, одно из которых относится к транзакции Th а другое — к какой-либо иной
транзакции 7}. Имеем основание заключить, что в самом деле возможно переместить все
действия транзакции 7} в начало расписания S, используя процедуры перестановки
неконфликтных действий, связанных с операциями чтения/записи, и восстанавливая
в нужных позициях все инструкции блокирования/разблокирования, предусмотренные
транзакцией 7J. Таким образом, расписание S удастся представить в следующей форме:
(действия транзакции 7})(действия остальных п - 1 транзакций)
Оставшаяся часть расписания из п -1 транзакций по-прежнему является корректным
расписанием, охватывающим согласованные 2PL-транзакции, поэтому мы вправе
применить к нему гипотезу индукции; рассматриваемое расписание допускает
преобразование в конфликтно-эквивалентное последовательное расписание — таковым
является и расписание S в целом.
18.3. ПОСЛЕДОВАТЕЛЬНЫЕ РАСПИСАНИЯ И МЕХАНИЗМЫ БЛОКИРОВАНИЯ 899
18.3.5. Упражнения к разделу 18.3
Упражнение 18.3.1. Ниже приведены описания двух транзакций из упражнения
18.2.1 на с. 892, которые обладают тем необычным свойством, что их действия
благодаря внутренней семантике могут быть упорядочены в виде условно-
последовательного расписания, не являющегося, однако, условно-
последовательным с учетом конфликтов.
Т{: liiA); Г1(А); А := А + 2 ; w{(A); и^А); 1{{В)\ гх{В)\ В := В * 3 ; wx(B)\ ux{B)\
Т2: 12{В)\ г2(В); В : = В * 2 ; w2(B); и2(В); 12{А)\ г2(А); А : = А + 3; w2{A)\ u2(A);
Выполняя следующие задания, принимайте во внимание расписания, которые
содержат только действия, связанные с операциями чтения/записи.
* а) Приведите пример некорректного расписания, обслуживание которого
запрещается инструкциями блокирования.
! Ь) Сколько различных вариантов упорядочения восьми операций чтения/записи
из общего количества вариантов, равного числу сочетаний из 8 по 4, ( 4 ) = 70,
приводят к получению корректных расписаний?
! с) Сколько расписаний из числа корректных расписаний являются условно-
последовательными (в соответствии с семантикой транзакций Тх и Г2)?
! d) Сколько расписаний из числа корректных условно-последовательных
расписаний являются условно-последовательными с учетом конфликтов?
!! е) Поскольку транзакции Т{ и Т2 не относятся к категории двухфазно-
блокированных, можно предвидеть возможность существования построения
непоследовательных расписаний. Существуют ли корректные
непоследовательные расписания? Если ответ положителен, подтвердите его
соответствующим примером; в противном случае приведите необходимые доводы.
*! Упражнение 18.3.2. Ниже представлены транзакции из упражнения 18.3.1, в
которых операции разблокирования перенесены в конец, так что транзакции отвечают
условию двухфазного блокирования:
Т{: 1{(А); Г1(А)\ А : = А + 2; w{(A); 1{(В); г{(В); В : = В * 3 ; w{(B); u{(A)\ и{(В)\
Т2: 12(В); г2(В); В : = В * 2 ; w2(B); l2(A); г2(А); А : = А + 3 ; w2(A); u2(B)\ и2(А)\
Каково количество корректных вариантов упорядочения всех операций
чтения/записи указанных транзакций?
Упражнение 18.3.3. Предположим, что в каждом из расписаний, упомянутых в
упражнении 18.2.4 на с. 893, транзакция захватывает блокировку каждого элемента
базы данных непосредственно перед выполнением соответствующей операции
чтения/записи, а освобождает ее сразу вслед за финальным обращением к этому
элементу. Поясните действия планировщика заданий в отношении каждого из
расписаний, обращая внимание на то, выполнение каких запросов должно быть
приостановлено и когда именно оно будет возобновлено.
! Упражнение 18.3.4. Предположим, что в код каждой из транзакций
*а) riiA)\w№\
b) г2(Л); w2(A)\ w2(B);
следует включить по одной инструкции блокирования и разблокирования в расчете на
каждый адресуемый элемент базы данных. Определите, сколько вариантов
упорядочения операций блокирования, разблокирования, чтения и записи относятся к категории
900
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Об опасности возникновения взаимоблокировки
Одна из проблем, неразрешимых в рамках модели двухфазного блокирования,
связана с потенциальной угрозой возникновения ситуаций взаимоблокировки
(deadlock), когда одна или несколько транзакций переводятся планировщиком
в состояние бесконечного ожидания момента освобождения блокировки,
захваченной другой транзакцией. Рассмотрим пару 2PL-транзакций Тх и Т2 из примера 18.11
на с. 897 и предположим, что код транзакции Т2 изменен таким образом, чтобы
элемент В обрабатывался первым:
Тх: 1Х(А)\ гх(А); А := А + 100 ; и^Л); 1Х(В); щ(А)\ гх(В)\ В := В + 100 ; xvx(B)\ их(В)\
Тг- h(P)\ r2(B); В : = В * 2 ; w2(B); /2(Л); и2(В); г2(Л); А : = А * 2 ; w2(A)\ и2(А)\
Возможный вариант чередования действий транзакций изображен ниже.
Ti
ШУ, ri(A);
А := А + 100;
w,(A);
1Х(В) — запрет
т2
иву г2(ву
В := В * 2;
w2(£);
/2(Л) — запрет
А
25
125
В
25
50
Ни одна из транзакций не в состоянии продолжить работу и каждая вынуждена
пребывать в состоянии ожидания неопределенно долгое время. Позволить обеим
транзакциям возобновить выполнение нельзя, поскольку это может привести к
нарушению условия согласованности (А = В) состояния базы данных. Методы
преодоления подобных проблем подробно рассмотрены в разделе 19.3 на с. 968.
i) согласованных двухфазно-блокированных;
ii) согласованных, не являющихся двухфазно-блокированными;
Ш) несогласованных двухфазно-блокированных;
iv) несогласованных, не являющихся двухфазно-блокированными.
18.4. Системы с несколькими режимами блокирования
Схема блокирования, представленная в разделе 18.3 на с. 894, хотя и
демонстрирует определенную познавательную ценность, слишком проста, чтобы ее можно было
серьезно рассматривать с практической точки зрения. Основная проблема, которая ей
присуща, заключается в том, что любая транзакция Т обязана захватывать блокировку
некоторого элемента X базы данных даже в том случае, когда требуется всего лишь
считать содержимое X, а не изменить его. Это требование обойти не удается,
поскольку в противном случае вероятна ситуация воздействия на значение X со стороны
другой транзакции в момент считывания X транзакцией Г, что явно не укладывается
в схему последовательного поведения. С другой стороны, нельзя назвать
вразумительные причины, по которым группе транзакций следовало бы отказать в праве
единовременного обращения к X с операциями чтения при условии, что ни одна из них
в этот период не выполняет модификацию X.
18.4. СИСТЕМЫ С НЕСКОЛЬКИМИ РЕЖИМАМИ БЛОКИРОВАНИЯ
901
Названные доводы вызывают потребность в изучении первой и (наиболее
употребительной) из "реальных" схем блокирования, предусматривающей необходимость
использования блокировок двух различных категорий: одни (их называют общими —
shared locks, или read locks) разрешают выполнение операций чтения, а другие,
монопольные (exclusive locks, или write locks), соответствуют привилегиям на модификацию
содержимого элементов. Затем мы сосредоточим внимание на усовершенствованной
схеме, где транзакции позволяется захватывать общую блокировку и позже повышать
(upgrade) ее уровень до монопольного. Далее мы рассмотрим схему инкрементных
блокировок (increment locks), в которой особым образом трактуются операции записи,
предполагающие приращение или сокращение величин элементов; инкрементные
операции записи отличаются тем, что их позиции в расписании взаимозаменяемы,
в то время как операции модификации общего вида таким свойством не обладают.
Подобные частные примеры развития простейшей схемы блокирования позволяют
плавно перейти к обобщенной схеме, основанной на матрице совместимости
(compatibility matrix), которая определяет, какие разновидности блокирования
элемента базы данных допускаются в период действия блокировок иных типов.
18.4.1. Общие и монопольные блокировки
Поскольку два действия, связанные со считыванием содержимого одного и того же
элемента базы данных, не являются конфликтными, острой необходимости в
использовании блокирования или иного механизма управления параллельными заданиями,
вынуждающего располагать подобные операции чтения в строго определенном
порядке, нет. Как говорилось во введении к этому разделу, собираясь обратиться к
элементу с инструкцией чтения, мы, однако, все еще должны заботиться о его
блокировании, чтобы запретить возможность единовременного выполнения другими
транзакциями операций модификации. Впрочем, блокировка, обеспечивающая условия для
операции записи, должна быть более "жесткой", нежели блокировка,
сопровождающая действие по чтению, так как она обязана препятствовать и попыткам чтения,
и покушениям на запись, предпринимаемым другими транзакциями.
Рассмотрим вариант планировщика заданий, основанного на механизме
блокирования, в котором используются блокировки двух разновидностей — общие (shared
locks) и монопольные (exclusive locks). Коротко говоря, любой элемент X базы данных
может быть снабжен либо одной монопольной блокировкой, либо несколькими общими
блокировками: если X подлежит модификации, нужна монопольная блокировка Х\ если
же предполагается только считывать содержимое X, можно воспользоваться либо общей,
либо монопольной блокировкой X. Если заведомо известно, что значение X должно
только считываться, но не изменяться, предпочтительно применять общую блокировку.
Система обозначений действий транзакций нуждается в пополнении. Мы
намереваемся применять выражение 4(Х) для представления того факта, что "транзакция Tt
запрашивает обшую блокировку элемента X базы данных", а выражению xlt{X) будем
отводить роль синонима оборота "транзакция Т{ захватывает монопольную блокировку
элемента X базы данных". Функция щ(Х) сохраняет свой прежний смысл: "транзакция 7;
разблокирует элемент X, т.е. освобождает каждую блокировку X, которой она владеет".
Каждому из трех требований — ограничениям согласованности и двухфазного
блокирования транзакций и условию корректности расписаний — отвечает определенная версия,
адаптированная с учетом особенностей системы с общими/монопольными блокировками.
1. Согласованность транзакций. Нельзя выполнять запись, не обладая
монопольной блокировкой, и осуществлять чтение, не удерживая какую-либо
(монопольную или общую) блокировку. Говоря формально, в любой транзакции 7",
a) действию г,(Х), связанному с чтением содержимого любого элемента X, должна
предшествовать операция $lj(X) или xl,(X) без промежуточной операции м/(Х);
b) действие w,(X), предусматривающее модификацию значения элемента X,
обязано предваряться операцией jc/,(X) без промежуточной операции н,(Х).
902
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Все операции блокирования определенного элемента должны сопровождаться
инструкцией разблокирования этого элемента.
2. Двухфазное блокирование транзакций. Операции блокирования должны
предшествовать операциям разблокирования. Строго говоря, в любой двухфазно-
блокированной транзакции Tf ни одна из операций 4(Х) или л7,(Х) не может
предваряться инструкцией Uj(Y) для любого Y.
3. Корректность расписаний. Элемент базы данных может быть блокирован только
одной транзакцией монопольно либо несколькими транзакциями в общем
режиме, но не в обоих режимах одновременно:
a) если расписание содержит действие xlj(X), оно не может сопровождаться
действиями xlj{X) или slj(X), где у*/, без предварительного выполнения щ{Х)\
b) если в расписании присутствует действие slj(X), последующая операция
xlj(X), где j ф i, не может быть выполнена до тех пор, пока не будет
вызвана инструкция и,(Х).
Обратите внимание, что одной транзакции позволяется запрашивать и
удерживать общую и монопольную блокировки одного и того же элемента
базы данных, если эти действия не вступают в конфликт с операциями
блокировки, инициируемыми другими транзакциями. Если транзакция наперед
"осведохмлена" о будущих потребностях в блокировании, уместно использовать
монопольную блокировку; если же поведение транзакции заранее предсказать
трудно, в разные моменты времени она вправе обращаться как к общим, так
и к монопольным блокировкам.
Пример 18.13. Проанализируем одно из возможных расписаний выполнения двух
транзакций, использующих механизм общего/монопольного блокирования. Действия
транзакций описаны ниже.
Г,: s/,(A); г{(А); ^(Я); п(Д); щ(В)\ и,(А); и,{В)\
Т2: 5/2(А); г2(АУ, sl2(B)\ г2(Д); и2(А); и2(В):
Обе транзакции считывают значения А и В, но только Т{ модифицирует В и ни одна
не изменяет А.
На рис. 18.15 приведен вариант чередования действий транзакций Т\ и Тъ
предусматривающий, что 7^ начинает работу первой, захватывая общую блокировку элемента А.
Затем вступает в действие транзакция Тъ получая общие права на использование
элементов А и В. Теперь у транзакции Тх возникает потребность в монопольной блокировке
В, поскольку ей необходимо обращаться к В как для чтения, так и для записи. Однако
приобрести такую привилегию сразу не удается, так как элемент В в данный момент
заблокирован транзакцией Т2. Поэтому планировщик переводит Тх в состояние
ожидания. Со временем Т2 освобождает блокировку В, и Т{ получает возможность
возобновить и завершить поток вычислений. □
5/,(А); п(А);
s/2(A); г2(А);
sh(B)\ г2(Д);
xli(B) —■ запрет
н2(А); иг{В)\
хШ); г,(Д); W6B);
Рис. 18.15. Пример расписания с использованием общих и
монопольных блокировок
18.4. СИСТЕМЫ С НЕСКОЛЬКИМИ РЕЖИМАМИ БЛОКИРОВАНИЯ
Обратите внимание, что расписание на рис. 18.15 является условно-последовательным
с учетом конфликтов. Конфликтно-эквивалентным последовательным порядком действий
является (Т2, Т{), хотя транзакция Тх и стартует первой. Мы не будем строго доказывать это
положение — аргументы, которые приводились в разделе 18.3.4 на с. 898 в пользу того, что
расписания обслуживания согласованных 2РЬ-транзакций относятся к категории условно-
последовательных с учетом конфликтов, остаются в силе и для систем с
общими/монопольными блокировками. В расписании на рис. 18.15 транзакция Т2
осуществляет разблокирование раньше Тъ поэтому мы вправе ожидать, что в последовательном
расписании Т2 должна предшествовать транзакции Тх. Нетрудно проанализировать
действия расписания на рис. 18.15, связанные с чтением и записью, и заметить, что вполне
возможно переместить гх(А) в направлении конца расписания и расположить после всех
действий транзакции Т2, в то время как включить xv\(B) перед г2(В) нельзя — а именно
это пришлось бы сделать, если бы в конфликтно-эквивалентном последовательном
расписании транзакция Т{ могла предшествовать транзакции Т2.
18.4.2. Матрицы совместимости
При использовании нескольких режимов блокирования планировщик заданий
нуждается в регламенте, разрешающем или запрещающем возможность захвата
блокировки определенной категории при наличии других активных блокировок,
относящихся к тому же элементу базы данных. Принцип работы системы с
общими/монопольными блокировками вполне очевиден (см. раздел 18.4.1 на с. 902), но
широкое практическое применение находят и другие, значительно более сложные
системы, допускающие множество режимов блокирования. Здесь мы собираемся
познакомить вас с моделью регламента управления блокировками на примере простой
системы с общим/монопольным режимами блокирования.
Матрица совместимости (compatibility matrix) содержит по одной строке и по одному
столбцу для каждого режима блокирования. Строки соответствуют блокировкам элемента
X, которые, как можно полагать, в данный момент уже захвачены какой-либо "сторонней"
транзакцией, а каждый столбец отвечает определенному режиму блокирования элемента
X, запрашиваемому "текущей" транзакцией. Правило использования матрицы
совместимости в качестве инструмента принятия решений о предоставлении или запрещении
возможности захвата блокировки той или иной разновидности состоит в следующем:
• привилегия захвата блокировки элемента X в некотором режиме С может быть
дарована транзакции в том и только в том случае, если на пересечении каждой
строки R, соответствующей режиму блокирования, который в данный момент
применяется в отношении элемента X какой-либо иной транзакцией, и столбца
С расположено значение "Да".
Удерживаемая блокировка
s
X
Запрашиваемая блокировка
S X
Да Нет
Нет Нет
Рис. 18.16. Матрица совместимости режимов общего и монопольного
блокирования
Пример 18.14. На рис. 18.16 приведена матрица совместимости режимов общего
(shared — s) и монопольного (exclusive — x) блокирования. Данные столбца s
свидетельствуют о том, что планировщик заданий вправе разрешить захват общей
блокировки элемента, если все блокировки этого элемента, удерживаемые в данный момент
другими транзакциями, относятся только к категории общих. Столбец х гарантирует
возможность захвата монопольной блокировки элемента только в том случае, если
904
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
элемент в настоящее время не блокирован ни одной транзакцией. Обратите внимание
на то, как приведенная матрица совместимости реализует требования корректности
расписаний в системе с общим/монопольным режимами блокирования. □
18.4.3. Повышение уровня блокирования
Транзакция Г, приобретающая право блокирования элемента X в общем режиме,
"дружественна" по отношению к остальным транзакциям, в тот же период времени
владеющим привилегиями считывания содержимого X. Уместно поинтересоваться,
сохранится ли подобная "дружественность" отношений в том случае, если
транзакция Г, испытывающая потребность в чтении и записи значения X, вначале затребует
общую блокировку X, и только затем, когда надобность в выполнении модификации
X станет насущной, повысит (upgrade) требования до уровня монопольного режима
блокирования (т.е. наряду с активной общей блокировкой запросит монопольную
блокировку X). Разумеется, нет ничего, что смогло бы воспрепятствовать
транзакции в отсылке запросов на блокирование одного и того же элемента в различных
режимах. Мы уже подчеркивали, что операция щ(Х) в принятой нами системе
обозначений освобождает все блокировки элемента X, удерживаемые транзакцией Th —
впрочем, при необходимости можно было бы ввести в обиход операции
разблокирования, отвечающие отдельным режимам блокирования.
Пример 18.15. В рассматриваемом ниже случае транзакция Т{ оказывается способной
выполнять вычисления параллельно с операциями транзакции Т2, что было бы
невозможным, если бы Т{ изначально запросила монопольную блокировку элемента В.
Описания транзакций Тх и 72 выглядят так:
7\: slx(A); гх(А); slx(B); rx(B)\ xlx(B); w{(B); их(А); их(В);
Т2: sl2(A)\ г2(Л); sl2(B)\ г2(Д); и2(А)\ и2(В)\
Допустим, что транзакция Т\ считывает значения А и В и использует их в (возможно,
продолжительных) вычислениях, со временем сохраняя результат в В. Обратите
внимание, что вначале Тх приобретает общую блокировку В, а позже, по завершении
вычислений с участием значений А и В, запрашивает монопольную блокировку В.
Транзакция Т2 только считывает содержимое элементов А и В, но не модифицирует его.
Ti 72
slx(A); гх(А):
5/2(А); г2(Л);
sl2{B)\ r2(B);
sW)\ гх(В);
xlx(B) — запрет
и2{А)\ и2(В);
xlx(B)\ >v'i(#);
и,(А); щ{В)\
Рис. 18.17. Постепенное повышение уровня
блокирования увеличивает степень параллелизма операций
На рис. 18.17 представлено возможное расписание выполнения действий
транзакций Тх и Т2. Т2 получает общую блокировку элемента В прежде Гь но в четвертой
строке и Тх способна блокировать В в общем режиме. Теперь Т{ обладает значениями
А и В и в состоянии выполнить все необходимые вычисления. Только затем Тх пред-
18.4. СИСТЕМЫ С НЕСКОЛЬКИМИ РЕЖИМАМИ БЛОКИРОВАНИЯ 905
принимает попытку повысить уровень блокирования элемента В до монопольного, так
что планировщик заданий вынужден приостановить работу Т{ до момента
освобождения блокировки В, удерживаемой транзакцией Тъ после чего Тх захватывает
монопольную блокировку В, сохраняет значение В и завершает работу.
Заметим, что если бы Т\ изначально, до считывания значения элемента В,
затребовала его монопольную блокировку, запрос был бы отвергнут, поскольку общей
блокировкой В в тот момент владела бы транзакция Т2\ не считав значение В, Тх не смогла
бы осуществить все предписанные ей вычисления и отложила бы их выполнение до
момента освобождения блокировки транзакцией Т2. Таким образом, техника
постепенного повышения уровня блокирования позволяет транзакции 7^ добиться
сокращения временного цикла работы. □
Пример 18.16. К сожалению, неразборчивое применение механизма повышения
уровня блокирования служит еще одним источником возникновения ситуаций
взаимоблокировки (deadlock) (один из вариантов проблемы вкратце обсуждался в тексте врезки
"Об опасности возникновения взаимоблокировки" на с. 901). Предположим, что
каждая из транзакций 7\ и Т2 считывает значение элемента А базы данных и
модифицирует его. Если обе транзакции стартуют примерно в одно и то же время и, используя
технику повышения уровня блокирования, вначале захватывают общую блокировку А,
а затем повышают ее уровень до монопольной, весьма вероятно такое развитие
событий, которое проиллюстрировано на рис. 18.18.
7\ Т2
5/,(Л);
sl2(A);
xlx(A) — запрет
xl2(A) — запрет
Рис. 18.18. Применение механизма повышения
уровня блокирования сразу несколькими
транзакциями чревато опасностью возникновения
взаимоблокировки
Транзакции вправе приобрести общую блокировку элемента А. Но позже, когда
обе попытаются повысить уровень блокирования, планировщик заданий
принудительно переведет каждую из них в состояние ожидания ввиду того, что другая в то же
время обладает общей блокировкой Д. Ни одна из транзакций не сможет продолжить
работу и будет вынуждена пребывать в бесконечном цикле бездеятельности до тех
пор, пока система, возможно, не обнаружит ситуацию взаимоблокировки и не прервет
выполнение одной из транзакций, чтобы открыть дорогу для другой. □
18.4.4. Обновляемые блокировки
Существует способ, позволяющий избежать угрозы возникновения
взаимоблокировки, описанной в примере 18.16, за счет использования третьего режима
блокирования, предполагающего применение так называемых обновляемых блокировок (update
locks). Обновляемая блокировка ult(X) предоставляет транзакции Г, привилегию
считывания значения элемента X, но не его модификации. В такой системе, однако, только
обновляемая блокировка позже может быть повышена до уровня монопольной,
разрешающей запись, — общая блокировка такого права не дает. Транзакция способна
приобрести обновляемую блокировку X, обладая в то же время общей блокировкой X,
но как только обновляемая блокировка X захвачена, планировщик заданий отвергает
запросы на получение любых блокировок — общих, монопольных или
обновляемых — того же элемента X. Причина очевидна — если не запретить возможность од-
906
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
новременного блокирования X при наличии обновляемой блокировки X, транзакция,
которая владеет такой блокировкой, вероятно, не сможет позже повысить ее уровень
до монопольного из-за присутствия других блокировок X.
S
X
и
S
Да
Нет
Нет
X
Нет
Нет
Нет
и
Да
Нет
Нет
Рис. 18.19. Матрица совместимости режимов общего,
монопольного и обновляемого блокирования
Указанное правило находит воплощение в асимметричной матрице совместимости,
показанной на рис. 18.19: обновляемая блокировка (и) ведет себя так же, как общая
(s), когда она запрашивается, и как монопольная (х) — когда удерживается. Поэтому
столбцы и и s матрицы одинаковы; одинаковы и строки и и х.131
Пример 18.17. Применение схемы с обновляемыми блокировками не изменяет
поведение расписания, рассмотренного в примере 18.15 на с. 905. Выполняя третье
действие, транзакция 1\ могла бы вместо общей затребовать обновляемую блокировку,
и таковую удалось бы предоставить, поскольку элемент В в данный момент
блокирован только в общем режиме, но последовательность действий, указанная на рис. 18.17,
по существу не изменилась бы.
Однако проблема, которую мы обсуждали в примере 18.16 на с. 906, в контексте
схемы с обновляемыми блокировками вполне разрешима. Здесь транзакции Тх и Т2
вначале запрашивают обновляемые блокировки элемента А и только затем —
монопольные. Описания транзакций могут выглядеть следующим образом:
Г,: ulx(A)\ г,(Л); х/,(Л); Wl(A); и,(Л);
Т2: ul2(A); г2(Л); xl2(A); w2(A); и2(А),
а вероятная последовательность чередования действий — так, как показано на
рис. 18.20. Теперь работа транзакции Тъ которая второй запрашивает обновляемую
блокировку А, приостанавливается — право завершения предоставляется вначале
транзакции Т\ и только затем — Г2. Система блокирования фактически препятствует
параллельному выполнению действий транзакций Тх и Т2, но в этом конкретном
примере иначе быть и не может, поскольку в противном случае итогом окажутся
взаимоблокировка либо несогласованное состояние базы данных.
Тх 72
и/,(Л); ЫА);
ul2{A) — запрет
xlx{A)\ Wl(A); и,(Л);
и/2(Л); г2(Л);
л72(А); w2(A); и2{А)\
Рис. 18.20. Пример корректного расписания
с операциями обновляемой блокировки
□
Следует помнить о том, что матрица совместимости в подобном случае не отражает
важное дополнительное условие, касающееся свойства корректности расписаний: транзакция,
удерживающая общую, но не обновляемую блокировку элемента X, не в состоянии получить
монопольную блокировку X, хотя каждой транзакции, вообще говоря, не запрещено владеть
несколькими блокировками одного и того же элемента.
18.4. СИСТЕМЫ С НЕСКОЛЬКИМИ РЕЖИМАМИ БЛОКИРОВАНИЯ
907
18.4.5. Инкрементные блокировки
К еще одной любопытной и практически полезной категории относятся
инкрементные блокировки. Во многих случаях транзакции, обращающиеся к базе данных,
выполняют только операции приращения или сокращения величин хранимых
элементов. Вот характерные и красноречивые примеры:
1) перевод денежных сумм с одного банковского счета на другой;
2) резервирование авиабилета с уменьшением количества свободных мест на рейс.
Весьма важное свойство инкрементных действий связано с взаимозаменяемостью их
позиций в расписании: если две транзакции предусматривают прибавление констант
к значению одного и того же элемента базы данных, очередность операций значения
не имеет (этот факт схематически проиллюстрирован на рис. 18.21). С другой
стороны, инструкции приращения/сокращения значений не коммутативны по отношению
к операциям чтения/записи: если осуществить считывание содержимого элемента А до
и после его приращения, мы получим совершенно разные значения, а если инкремент-
ная операция в одном случае предшествует действию по записи значения Л, а в другом
следует после него, это не может не сказаться на содержимом элемента А в базе данных.
Рис. 18.21. Позиции двух инкрементных операций
в расписании взаимозаменяемы, и итоговое
состояние базы данных не зависит от их очередности
Рассмотрим в качестве одной из возможных категорий действий, выполняемых
транзакциями, инкрементную (increment) операцию, которую будем обозначать как
шс(А, с). Операция предполагает прибавление к содержимому числового элемента
А базы данных некоторой константы с. Величина с может быть и отрицательной —
в этом случае речь фактически идет об инструкции вычитания. На практике операция
INC применяется к компоненту кортежа, но объектом блокирования становится не
сам компонент, а целый кортеж.
Если говорить более строго, выражение inc(a, с) служит сокращенным
обозначением атомарно выполняемой последовательности из трех действий: read (A, t) ;
t := t + с; write (A, t) ;. Здесь мы не будем обсуждать особенности аппаратного
и/или программного механизма поддержки атомарности подобного рода — достаточно
заметить, что таковая относится к более низкому уровню, нежели атомарность
транзакций, обеспечиваемая инструментами блокирования.
Инкрементной операции соответствует инкрементная блокировка (increment lock).
Действие транзакции Th связанное с захватом инкрементной блокировки элемента X
базы данных, представляется в виде выражения /7,(Х), а для описания самой операции
приращения/сокращения величины X на определенную константу используется
функция inCj(X); конкретное значение константы в данном случае не важно.
Принятие модели инкрементных действий и блокировок вызывает необходимость
пересмотра определений согласованных транзакций, корректных расписаний и конфликтов.
1. Согласованная транзакция способна к выполнению инкрементного действия
в отношении элемента X только в том случае, если в этот момент она
удерживает инкрементную блокировку X; инкрементная блокировка, однако, не
позволяет осуществлять операции считывания/записи данных.
908
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
2. В корректном расписании допускается возможность единовременного
владения инкрементной блокировкой элемента X несколькими транзакциями.
Если, однако, какая-либо транзакция удерживает инкрементную блокировку X,
другим транзакциям в тот же период времени не позволяется захватывать ни
общие, ни монопольные блокировки X. Названные требования находят
выражение в матрице совместимости, приведенной на рис. 18.22 (здесь i
представляет иикрементный режим блокирования).
3. Действие inct{X) является конфликтным по отношению к r/Х) и w/X) при j Ф i, но
не конфликтует с incj(X).
S
X
I
S
Да
Нет
Нет
X
Нет
Нет
Нет
I
Нет
Нет
Да
Рис. 18.22. Матрица совместимости режимов общего,
монопольного и инкрементного блокирования
Пример 18.18. Рассмотрим две транзакции, каждая из которых вначале считывает
содержимое элемента А базы данных, а затем осуществляет инкрементную операцию
над значением элемента В (можно полагать, что к В прибавляется величина Л либо
некоторая константа, зависящая от А):
7У. shiA); Г!(Л); ilx(B)\ тсх(В)\ и,(Л); щ{В)\
Т2. 5/2(Л); г2(Л); il2(B)\ inc2(B)- и2(Л); и2(В);
Заметьте, что транзакции удовлетворяют условию согласованности, поскольку они
осуществляют инкрементные операции, владея инкрементными блокировками, а
операции считывания выполняются только при наличии общих блокировок. На
рис. 18.23 показан один из возможных вариантов чередования действий транзакций Т{
и Т2\ Т{ считывает значение А первой, затем Т2 осуществляет чтение А и инкрементную
операцию над В и, наконец, Т{ получает возможность захвата инкрементной
блокировки и изменения В на свой лад.
Тх 72
slx(A)\ гКЛ);
5/2(Л); г2(Л);
il2(B)\ inc2(B);
//,(/?); inc№\
и2(А); и2(В);
Ul(Ay, их{В)\
Рис. 18.23. Расписание с операциями захвата
инкрементных блокировок и инкрементными
действиями
Обратите внимание, что планировщику заданий нет необходимости задерживать
обслуживание каких бы то ни было запросов, предусмотренных расписанием на
рис. 18.23. Допустим для примера, что транзакция Тх посредством инкрементной
операции увеличивает значение В на величину Л, а транзакция Т2 — на величину 2А.
Действия способны выполняться в любом порядке — значение А остается постоянным,
а очередность инкрементных операций по определению может быть произвольной.
18.4. СИСТЕМЫ С НЕСКОЛЬКИМИ РЕЖИМАМИ БЛОКИРОВАНИЯ
909
Другими словами, опуская инструкции блокирования, действия расписания на
рис. 18.23 допустимо описать такой последовательностью:
S: г{(А); г2(Л); inc2(B); inc^B);
Последнее действие, incx{B), можно переместить на вторую позицию, поскольку оно не
конфликтует с инкрементной операцией inc2(B), применяемой к тому же элементу и
заведомо не конфликтует с операцией чтения значения другого элемента, А. Наличие
возможности подобной трансформации позволяет говорить о том, что расписание S
является конфликтно-эквивалентным последовательному расписанию r^A); incx(B)\ r2(A)\ inc2(B).
Аналогичным образом мы могли бы перенести первое действие, г{(А), расписания S на
третью позицию, что позволило бы получить последовательное расписание (Г2, 7^). □
18.4.6. Упражнения к разделу 18.4
Упражнение 18.4.1. Для каждого из расписаний
a) п(Л); r2(B); r3(Q; wx(B)\ w2(Q; *>гФ)\
b) г,(Л); г2(Д); r3(Q; wx{B)\ w2(Q; w3(A);
С) г,(Л); r2(B)\ r3(C); rx(B); r2(Q; r3(D); Wl(Q; w2(D); w3(£);
* d) г,(Л); г2(Я); r3(Q; r,(B); r2(Q; r3(D); Wl(A); w2(£); w3(Q;
e) п(Л); г2(Д); r3(Q; п(Д); r2(Q; г3(Л); Wl(A); w2(£); w3(Q;
охватывающих действия трех транзакций — Ти Т2 и Г3, — выполните
перечисленные ниже задания.
i) Вставьте инструкции захвата общих и монопольных блокировок и
соответствующие функции их освобождения. Непосредственно перед каждой
операцией считывания, которая не сопровождается последующей операцией
записи содержимого того же элемента, выполняемой той же транзакцией,
поместите инструкцию получения общей блокировки. Все другие действия по
считыванию/записи значений элементов базы данных предварите
функциями запроса подходящей монопольной блокировки. По завершении каждой
транзакции включите необходимые операции разблокирования.
и) Поясните ход выполнения расписания, полученного в п. (i), при содействии
планировщика заданий, поддерживающего механизм общего/монопольного
блокирования.
iii) Примените инструкции общего/монопольного блокирования таким
способом, который позволяет дальнейшее повышение уровня блокирования.
Поместите перед каждой операцией считывания функцию захвата общей
блокировки, предварите каждое действие, связанное с записью, инструкцией
вызова монопольной блокировки и завершите код транзакций
необходимыми операциями освобождения блокировок.
iv) Поясните ход выполнения расписания, полученного в п. (iii), при
содействии планировщика заданий, поддерживающего общие/монопольные
блокировки с возможностью повышения уровня блокирования.
v) Вставьте инструкции захвата общих, монопольных и обновляемых
блокировок и соответствующие функции их освобождения. Перед каждой операцией
считывания, после которой не предполагается повышение уровня
блокирования, поместите инструкцию получения общей блокировки. Другие
действия по считыванию значений элементов базы данных предварите
функциями запроса подходящей обновляемой блокировки, а действия по записи —
инструкциями монопольного блокирования. По завершении каждой
транзакции, как обычно, включите необходимые операции разблокирования.
910
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
vi) Поясните ход выполнения расписания, полученного в п. (v), при содействии
планировщика заданий, поддерживающего механизм общего/монопольного/
обновляемого блокирования.
! Упражнение 18.4.2. Рассмотрите транзакции
Г,: ЫА); п(Я); inc^A); inc{(B);
Т2: г2(Л); r2(B)\ inc2(A)\ inc2(B)\
и ответьте на следующие вопросы.
* а) Сколько вариантов чередования операций транзакций являются условно-
последовательными?
Ь) Сколько условно-последовательных расписаний вы сможете назвать, если
очередность инкрементных операций транзакции Т2 изменена (т.е. inc2(B)
выполняется раньше, a inc2(A) — позже)?
Упражнение 18.4.3. В расписаниях
a) п(Л); г2(Я); шс,(Я); inc2(Q; щ(С); w2(D);
b) r{(A)\ r2{B)\ incx(B)\ inc2(A)\ wx{C)\ w2{D)\
c) incx(A)\ inc2(B)\ inci(B)\ inc2(Q; w^Q; w2(D);
предварите каждое действие функцией захвата подходящей блокировки (общей,
монопольной или инкрементной) и включите требуемые инструкции разблокирования.
Поясните ход выполнения расписаний под управлением планировщика заданий,
поддерживающего механизм общего/монопольного/инкрементного блокирования.
Упражнение 18.4.4. В упражнении 18.1.1 на с. 886 обсуждалась гипотетическая
транзакция, выполняемая в системе бронирования авиабилетов. Если
предположить, что планировщик заданий поддерживает функции общего, монопольного,
обновляемого и инкрементного блокирования, какие из них вы предпочли бы при
реализации каждого шага транзакции?
Упражнение 18.4.5. Действие, связанное с умножением числового значения
элемента X базы данных на константу с, можно обозначить как мс (X, с) и описать
в виде следующей атомарно выполняемой последовательности операций:
read(x, t) ; t := с * t; write(x, t) ;. Имеет смысл рассмотреть и
специальный режим блокирования, предназначенный для совместного использования
с операциями вида мс (х, с).
а) Как может выглядеть матрица совместимости режимов
общего/монопольного блокирования и режима блокирования "умножения на
константу"?
! Ь) Отобразите матрицу совместимости режимов общего/монопольного/инкре-
ментного блокирования и режима блокирования "умножения на константу".
! Упражнение 18.4.6. Предположим для примера, что элементы базы данных
представляют собою двумерные векторы. Будем считать, что существуют четыре
операции, применимые в отношении таких векторов, и каждой соответствует
определенный режим блокирования:
i) изменение координаты по оси х (х-блокировка);
и) изменение координаты по оси у (Y-блокировка);
ш) изменение угла наклона (angle) вектора (а-блокировка);
iv) изменение длины (magnitude) вектора (м-блокировка).
18.4. СИСТЕМЫ С НЕСКОЛЬКИМИ РЕЖИМАМИ БЛОКИРОВАНИЯ
911
Дайте ответы на следующие вопросы.
Какие операции допускают взаимную перестановку? Например, если
осуществить поворот вектора до достижения угла в 120°, а затем присвоить
координате х значение 10, будет ли получен идентичный результат, если первым
выполнить аналогичное изменение координаты х, а второй — операцию
поворота на тот же угол?
Принимая во внимание результаты, полученные вами при решении задания
из п. (а), отобразите матрицу совместимости четырех упомянутых выше
режимов блокирования.
Предположим, что семантика четырех операций над двумерными векторами
изменена следующим образом: вместо присваивания нового значения
(координаты, угла или длины) подразумевается приращение/сокращение
текущей величины (скажем, "прибавить к значению координаты х
константу 10" или "повернуть вектор на 10° по часовой стрелке"). Какой вид
примет матрица совместимости режимов блокирования в таком случае?
! Упражнение 18.4.7. Ниже приведено расписание, одно из действий которого опущено:
П(А); г2(Д); ???; и^С); w2(A);
Проблема заключается в отыскании действий определенных категорий, при
размещении которых на позиции отсутствующей операции расписание перестает быть
условно-последовательным. Укажите все возможные варианты замены для каждой
из следующих категорий действий и соответствующих им режимов блокирования:
*а) чтение; Ь) запись; с) обновление; d) инкрементная операция.
18.5. Архитектура планировщика с блокированием
Теперь, когда вы познакомились с различными схемами блокирования, уместно
рассмотреть, как действует планировщик заданий (scheduler) при использовании какой-
либо из этих схем. Мы намереваемся ограничить внимание только простой
архитектурой планировщика заданий, основанной на следующих принципах.
1. Транзакции как таковые не запрашивают блокировки — эта обязанность
возлагается на планировщик заданий, который вставляет инструкции
блокирования в соответствующие позиции потока операций чтения, записи и иных
действий над данными.
2. Транзакции не несут ответственность за освобождение блокировок — функции
разблокирования выполняются планировщиком заданий, получающим от
менеджера транзакций уведомления о фиксации (commit) или прерывании (abort)
работы транзакций.
18.5Л. Планировщик заданий и вставка инструкций блокирования
На рис. 18.24 представлена схема двухкомпонентного планировщика заданий,
который воспринимает от транзакций запросы на чтение, запись, фиксацию, прерывание
и т.п. Планировщик поддерживает таблицу блокировок (lock table), которая в данном
случае изображена в виде вторичного хранилища данных, хотя на практике может
частично или полностью располагаться в оперативной памяти. Обычно для таблицы
блокировок отводится часть памяти, не относящаяся к пулу буферов, используемых
для обработки запросов и протоколирования. Таблицу блокировок можно трактовать
просто как особый компонент СУБД, для которого, как и для фрагментов кода и
внутренних структур данных СУБД, требуемые ресурсы отводятся операционной системой.
Действия, запрашиваемые транзакциями, как правило, отсылаются планировщику
заданий, который управляет их выполнением. При некоторых обстоятельствах работа
912 ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
транзакции может быть приостановлена в ожидании получения блокировки.
Компоненты планировщика заданий выполняют следующие функции.
1. Компонент I принимает поток заявок на операции, сгенерированных
транзакциями, и вставляет перед каждой операцией, связанной, скажем, с чтением,
записью, инкрементом или обновлением значения элемента базы данных,
подходящую инструкцию блокирования, отвечающую одному из поддерживаемых
режимов, после чего направляет поток компоненту II.
2. Компонент II получает поток операций над данными и инструкций
блокирования, сформированный компонентом I, и соответствующим образом их выпол-
Операции транзакций
I READ(A); WRITE(В);
1 COMMIT(T); ...
Планировщик
заданий,
компонент I
LOCK(A); READ(A);
Таблица
блокировок
Планировщик
заданий,
компонент II
READ(A); WRITE(В);
Рис. 18.24. Планировщик заданий, осуществляющий
вставку инструкций блокирования в поток
операций, выполняемых транзакциями
няет. По мере получения инструкций блокирования или операций
компонент II определяет, пребывает ли транзакция-источник Т в состоянии
ожидания захвата блокировки. Если ответ положителен, действие транзакции Т
откладывается и добавляется в список действий, подлежащих дальнейшему
выполнению. Если работа транзакции Т не была приостановлена (т.е. все ранее
запрошенные блокировки ею успешно приобретены), осуществляется следующее:
a) если действие связано с операцией над данными, оно выполняется;
b) если действие представляет собой инструкцию блокирования, компонент II
обращается к таблице блокировок за информацией о том, можно ли
удовлетворить запрос на блокирование.
i) При положительном ответе в таблицу включаются сведения о вновь
разрешенной блокировке.
и) В противном случае в таблицу помещается запись, свидетельствующая
о том, что запрос пока не удовлетворен. Компонент II планировщика
заданий приостанавливает выполнение транзакции Т до тех пор, пока не
возникнут условия, подходящие для разрешения запроса.
Если транзакция Т выполняет фиксацию или прерывание, компонент I, получая
соответствующее уведомление от менеджера транзакций, освобождает все
блокировки, захваченные транзакцией Т. Если существуют транзакции, нуждающиеся
в вызволенных блокировках, компонент I сообщает об этом компоненту II.
Когда компонент II получает от компонента I информацию о том, что некая
блокировка элемента X базы данных теперь доступна, компонент II определяет
18.5. АРХИТЕКТУРА ПЛАНИРОВЩИКА С БЛОКИРОВАНИЕМ
913
подмножество транзакций, которые вправе получить эту блокировку X.
Транзакциям, завладевшим блокировкой, разрешается выполнить столько
приостановленных действий, сколько удастся — либо до их полного завершения, либо
до достижения очередного запроса на блокирование, который в данный момент
не может быть удовлетворен.
Пример 18.19. Если множество поддерживаемых режимов блокирования ограниченно
(скажем, как в разделе 18.3 на с. 894), проблема, которую предстоит решать
компоненту I планировщика заданий, значительно упрощается. Встречая в потоке действий
операцию, обращенную к элементу X базы данных, и обнаруживая, что запрос на
блокировку X в пользу этой транзакции в поток еще не помещался, компонент I
вставляет в поток требуемую инструкцию блокирования. Если транзакция осуществляет
фиксацию или прерывание, компонент I после освобождения всех захваченных
транзакцией блокировок вправе о ней "позабыть" и гарантировать возможность повторного
использования соответствующей части ресурса памяти.
Если же речь идет о нескольких альтернативных режимах блокирования,
планировщику заданий могут потребоваться дополнительные извещения о том, какие
действия в отношении того же элемента базы данных будут проводиться в дальнейшем.
Вновь обратимся к сочетанию режимов общего/монопольного/обновляемого
блокирования и воспользуемся транзакциями из примера 18.15 на с. 905, представляя их без
инструкций блокирования/разблокирования:
7V n(A); r№; Wl(B);
Т2: г2(Л); г2(Я);
Сообщения, отсылаемые компоненту I планировщика заданий, должны включать не
только запросы на чтение/запись, но и информацию о возможных будущих действиях
в отношении того же элемента базы данных. В частности, если направляемый запрос
касается действия г{(В), планировщику необходимо знать, содержит ли дальнейший
код транзакции Тх операцию wx(A) (либо, если код включает конструкции ветвления,
может ли вообще существовать подобная операция). Имеется ряд способов получения
такой информации. Например, если транзакция связана с обработкой запроса,
заведомо понятно, что операции записи выполняться не могут. Если, скажем, транзакция
обслуживает команду модификации базы данных, процессор запросов может и должен
заранее выявить те элементы, содержимое которых подлежит как чтению, так и
записи. Если же транзакция представляет собой программу с "внедренными"
инструкциями SQL, компилятор, обладающий доступом ко всем директивам SQL, способен
определить, какие элементы базы данных, вероятно, будут изменяться.
Вернемся к нашему примеру и предположим, что события происходят в той
последовательности, которая представлена на рис. 18.17 (см. с. 905).Транзакция Т{ первой
отсылает инструкцию ri(A). Поскольку необходимость в повышении уровня блокирования
в будущем не предвидится, компонент I планировщика предваряет действие гх(А)
функцией sl{(А). Далее к планировщику поступают запросы от транзакции Т2 — г2(А) и г2(В).
И вновь, поскольку повышение уровня блокирования в дальнейшем проводиться не
будет, планировщик формирует такую последовательность действий: sl2(A)\ r2(A); sl2(B); r2(B).
Затем планировщик получает информацию о действии гх(В) наряду с
предупреждением о том, что уровень блокирования может быть повышен. Поэтому компонент I
планировщика генерирует пару операций ulx(B)\ rx(B) и отсылает ее компоненту II.
Последний обращается к таблице блокировок и обнаруживает, что разрешение
обновляемой блокировки допустимо, так как элемент В блокирован только в общем режиме.
При поступлении действия w{(B) компонент I планировщика формирует пару
операций xlx(B)\ wi(B). Однако компонент II не в состоянии сразу обработать запрос xlx(B),
поскольку элемент В заблокирован транзакцией Т2 в общем режиме. Это и
последующие действия транзакции Т{ задерживаются, и информация о них сохраняется
компонентом II с целью дальнейшего использования. Со временем транзакция Т2 выполнит
914
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
фиксацию, и компонент I освободит блокировки элементов А и В, которыми владела
Т2, после чего обнаружит, что возможность блокирования В ожидается транзакцией Гь
и уведомит об этом компонент II. Последний выявит, что блокировка xl{(B) теперь
доступна, поместит информацию о ней в таблицу блокировок и даст "добро" на
выполнение оставшейся части действий транзакции Т{. □
18.5.2. Таблица блокировок
С абстрактной точки зрения таблицу блокировок (lock table) можно представить
в виде отношения, которое, как показано на рис. 18.25, ассоциирует элементы базы
данных с информацией о фактах их блокирования. Подобное отношение может быть
реализовано, например, в виде хеш-таблицы, ключами которой являются адреса
элементов базы данных. Неблокированные элементы в таблице не упоминаются, так что
ее размер пропорционален текущему количеству заблокированных элементов, а не
объему базы данных как таковой.
Элемент А
базы данных
Информация
о блокировке А
Рис. 18.25. Таблица блокировок связывает
элементы данных с информацией об их
блокировании
На рис. 18.26 представлен характерный фрагмент данных, соответствующий записи
таблицы блокировок. В этом примере подразумевается, что планировщиком заданий
используется схема блокирования в общем/монопольном/обновляемом режимах,
рассмотренная в разделе 18.1.4 на с. 884. Запись таблицы, соответствующая типичному элементу А
базы данных, представляет собой кортеж, содержащий перечисленные ниже компоненты.
1. Обобщенный признак блокирования — суммарные сведения об условиях работы
транзакции, которая инициировала запрос на блокировку элемента А базы
данных. Вместо сопоставления содержимого запроса с полной информацией обо
всех блокировках элемента А, удерживаемых другими транзакциями,
планировщик заданий принимает решение о разрешении/запрещении запроса на
основании результатов его сравнения с обобщенным признаком блокирования.132
Для схемы общих/монопольных/обновляемых блокировок правило
формирования обобщенного признака блокирования таково:
a) S означает наличие только общих блокировок;
b) U — существует одна обновляемая и, возможно, одна или несколько общих
блокировок;
c) X — элемент блокирован в монопольном режиме и других блокировок нет.
132 Планировщик заданий обязан принимать к сведению и возможность возникновения такой
ситуации, когда транзакция-инициатор запроса уже владеет блокировками того же элемента в других
режимах. Например, при использовании обсуждаемой здесь схемы с общими/монопольными/
обновляемыми блокировками планировщик вправе удовлетворить запрос на монопольную
блокировку, если транзакция удерживает обновляемую блокировку элемента. В системах, не
поддерживающих механизм множественного блокирования элемента одной транзакцией, обобщенный
признак блокирования всегда содержит всю информацию, достаточную для принятия решений.
18.5. АРХИТЕКТУРА ПЛАНИРОВЩИКА С БЛОКИРОВАНИЕМ
915
При использовании других схем блокирования применяются иные подходящие
системы обозначений и способы формирования обобщенного признака
блокирования; соответствующие примеры предлагаются в качестве упражнений.
2. Признак ожидания свидетельствует о том, что существует по меньшей мере одна
транзакция, ожидающая разрешение на захват блокировки элемента А базы данных.
3. Список содержит ссылки на описания всех транзакций, которые либо
удерживают блокировки элемента Л, либо пребывают в состоянии ожидания момента,
когда им будет предоставлена такая возможность. Элементы списка могут
содержать следующие фрагменты полезной информации:
об элементе
А
Обобщенный признак блокирования: U
Признак ожидания: да
—^
—■»■
U
Режим Ссылка 1
Транзакция Ожидание Ссылка 2
Т1
S
нет
/
S
Т2
и
нет
/
S
Т
i3
X
Да
/
Рис. 18.26. Пример структуры записи таблицы
блокировок
a) наименование либо идентификатор транзакции, удерживающей или
ожидающей блокировку;
b) обозначение режима блокирования;
c) бит, удостоверяющий, что транзакция владеет блокировкой или пребывает
в состоянии ожидания.
Как показано на рис. 18.26, каждый элемент списка включает две ссылки.
Ссылки 2-й категории соединяют элементы, содержащие описания блокировок
конкретного объекта базы данных, а ссылки 1-й категории указывают на
элементы списка, имеющие отношение к определенной транзакции и находят
применение в случае фиксации или прерывания транзакции с целью быстрого
отыскания всех блокировок, подлежащих освобождению.
Обработка запросов на блокирование
Предположим, что транзакция Т запрашивает блокировку элемента А базы данных.
Если записи, отвечающей элементу А, в таблице блокировок нет, можно достоверно
утверждать, что блокировок А не существует, поэтому планировщик заданий создает
запись и удовлетворяет запрос. Если же в таблице блокировок имеется запись,
касающаяся элемента А, она принимается во внимание при принятии решения о
возможности разрешения запроса. Планировщик считывает значение обобщенного
признака блокирования (на рис. 18.26 признак равен и, т.е. соответствует режиму обнов-
916
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
ляемого блокирования). Если элемент захвачен в режиме обновляемого блокирования,
запросы на разрешение других блокировок отвергаются (за исключением случая,
когда владеет блокировкой и транзакция Т и все другие блокировки элемента А
совместимы с той, которая запрашивается транзакцией Т). В результате запрета в список,
соответствующий записи таблицы блокировок, включается элемент, удостоверяющий
запрос со стороны транзакции Т на определенную блокировку элемента А базы
данных и содержащий в поле "Ожидание" значение "да".
Если предположить, что обобщенный признак блокирования равен х (т.е. элемент А
находится в монопольном ведении какой-либо транзакции), выполняются те же
действия, что и в предыдущем случае, но если значением признака служит s (общая
блокировка), планировщик вправе удовлетворить очередной запрос на общую или
обновляемую блокировку элемента А. В подобном случае элемент списка, соответствующий
транзакции Г, будет содержать в поле "Ожидание" значение "нет", а в ячейке "Режим" —
признак и или s, отвечающий запрашиваемому режиму блокирования элемента А —
обновляемому или общему. Независимо от того, удовлетворяется ли запрос сразу или
откладывается, новый элемент списка связывается с существующими элементами посредством
полей ссылок 1 и 2. В любом случае запись таблицы блокировок содержит информацию,
достаточную для принятия решения без необходимости просмотра всех элементов списка.
Разблокирование
Теперь предположим, что транзакция Т освобождает блокировку элемента А базы
данных. Элемент (отвечающий транзакции Т) списка, который поставлен в
соответствие записи таблицы блокировок, содержащей сведения о блокировках элемента А,
удаляется. Если режим блокировки, которая удерживалась транзакцией Г, не
совпадает с обобщенным признаком блокирования (скажем, Т владела блокировкой S, а
значением признака является и), причин для изменения обобщенного признака
блокирования нет. С другой стороны, если режим блокирования элемента А транзакцией Т
совпадает с обобщенным признаком блокирования А, планировщику заданий, возможно,
придется проверить весь список в поисках нового значения признака. Например, в
ситуации, отображенной на рис. 18.26, ясно, что элемент может быть блокирован в
режиме и только единожды, так что при освобождении блокировки и новым значением
обобщенного признака блокирования может быть только s (если в активном состоянии
пребывают какие-либо общие блокировки) или "ничего" (если никаких иных
блокировок в данный момент нет).133 Если обобщенный признак блокирования содержит х,
это говорит о том, что иных активных блокировок нет, а если значением признака
служит S, необходимо определить, существуют ли другие общие блокировки.
Если флаг признака ожидания равен значению "да", планировщику предстоит
удовлетворить один или несколько запросов на блокирование, находящихся в стадии
ожидания. Существует несколько стратегий решения такой задачи, и каждая обладает
определенными преимуществами.
1. "Первым пришел — первым обслужен"— удовлетворить запрос, поступивший
первым. Такая стратегия позволяет избежать ситуации "гибели" транзакции ввиду
неограниченно долгого пребывания в состоянии ожидания захвата блокировки.
2. "Отдашь приоритет общей блокировке" — первым делом удовлетворить все
заявки на общие блокировки, затем разрешить один запрос на блокирование
в режиме обновления (если подобные запросы существуют), а одну из
претензий на монопольное блокирование принять только в том случае, если запросов
на блокирование в иных режимах не существует. В таком случае ситуация
На практике, разумеется, значение "ничего" не применяется, поскольку раз нет
блокировок и запросов на блокировку элемента данных, соответствующая запись таблицы блокировок
просто удаляется.
18.5. АРХИТЕКТУРА ПЛАНИРОВЩИКА С БЛОКИРОВАНИЕМ
917
"бесконечного" ожидания выполнения запроса транзакции вполне вероятна,
если запрос связан с обновляемой или монопольной блокировкой.
3. "Отдать приоритет повышению уровня блокирования": если существует
транзакция, владеющая блокировкой и, которая должна быть преобразована в
блокировку х, предоставить подобную возможность в первую очередь; в противном
случае действовать в соответствии с любой из других стратегий.
18.5.3. Упражнения к разделу 18.5
Упражнение 18.5.1. Предложите правила вычисления значения обобщенного
признака блокирования, если система поддерживает следующие режимы блокирования:
а) общий и монопольный;
*! Ь) общий, монопольный и инкрементный;
!! с) режимы, перечисленные в упражнении 18.4.6 на с. 911.
Упражнение 18.5.2. Разъясните действия рассмотренного в этом разделе
планировщика заданий, основанного на блокировании, в процессе выполнения каждого из
расписаний, указанных в упражнении 18.2.4 на с. 893.
18.6. Управление иерархиями элементов базы данных
Давайте вернемся к обсуждению различных схем блокирования, начатому в разделе
18.4 на с. 901. В частности, имеет смысл сосредоточить внимание на двух проблемах,
возникающих в тех случаях, когда данные представляются в виде древовидных структур.
1. Первая ситуация обусловлена использованием иерархий объектов,
допускающих блокирование. В этом разделе мы покажем, каким образом блокировать
доступ и к крупным элементам, подобным целым отношениям, и к их
частям — скажем, к группам кортежей либо к отдельным кортежам.
2. Вторая категория проблем, особо важных в контексте систем управления
параллельными заданиями, связана с применением древовидных структур
хранения данных как таковых. Характерным примером являются В-древовидные
индексы (см. раздел 13.3 на с. 609). Вершины В-дерева допустимо трактовать как
элементы базы данных, но в таком случае, как будет показано в разделе 18.7 на
с. 924, схемы блокирования, которые рассматривались до сих пор, демонстрируют
весьма неэффективное поведение и потому нуждаются в пересмотре и замене.
18.6.1. Блокировки с множеством степеней детализации
Напомним, что термин "элемент базы данных" мы оставили неопределенным
совершенно осознанно, поскольку в различных системах под объектами, подлежащими
блокированию, понимаются разные структурные элементы, такие как кортежи,
страницы (или блоки) и отношения. Некоторые приложения выигрывают от
использования мелких элементов данных (скажем, кортежей), в то время как другие ведут себя
наилучшим образом в условиях, когда в качестве "элементов" принимаются более
крупные единицы информации.
Пример 18.20. Рассмотрим базу данных банковского учреждения. Если придать смысл
"элементов" отношениям и, как следствие, допустить возможность использования
только одной разновидности блокировки, затрагивающей целое отношение,
содержащее, например, сведения об остатках на лицевых счетах клиентов, системе удастся
обеспечить только весьма небольшой уровень параллелизма. Поскольку в большинст-
918
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
ве случаев транзакции в банковской системе так или иначе связаны с
увеличением/уменьшением остатков на счетах, каждой из транзакций придется ожидать
разрешения на захват монопольной блокировки отношения, представляющего
информацию о состоянии счетов. Поэтому в каждый момент времени система сможет
выполнить только одну приходную или расходную операцию со счетом — независимо от
того, каким числом процессоров, доступных для обслуживания транзакций, оснащен
сервер базы данных. Более удачный выбор связан с блокированием отдельных
страниц или блоков данных: если кортежи со сведениями о двух счетах принадлежат
разным страницам, система сможет обновлять их единовременно, предлагая практически
наивысший уровень распараллеливания заданий. Экстремальным был бы вариант
блокирования каждого отдельного кортежа, что позволило бы обновлять в один и тот
же момент времени любое подмножество счетов, но подобная степень различения
объектов блокирования во многих случаях, вероятно, нецелесообразна и не
заслуживает тех дополнительных усилий, которые требуются для ее достижения.
Теперь в качестве иного, до некоторой степени противоположного, примера
рассмотрим базу данных, содержащую информацию, которая представлена в виде
документов. Документы изредка редактируются, но большинство транзакций связано
с поиском и извлечением целых документов. В таких условиях было бы разумно
трактовать "элемент" базы данных как полный документ. Поскольку практически все
транзакции, как мы условились, относятся к категории "только для чтения" (read-only) (т.е. не
предусматривают выполнения каких-либо действий по модификации данных),
механизм блокирования находит применение только в тех случаях, когда требуется
предотвратить возможность считывания документа, пребывающего в состоянии
редактирования. Увеличение степени детализации объектов блокирования (различение
отдельных абзацев, предложений и слов) по существу не обеспечит никаких
преимуществ — более того, принесет избыточные накладные расходы. Единственная
достойная внимания (и, вероятно, довольно редкая) ситуация, в которой применение
мелких блокируемых фрагментов базы данных, содержащей документы, можно было
бы считать оправданным, связана с возможностью считывания какой-то части
документа, другая часть которого в тот же момент подвергается модификации. □
В некоторых случаях могут рассматриваться одновременно и крупные, и мелкие
объекты блокирования. Для приложений банковской базы данных, о которой говорилось
в примере 18.20, очевидна необходимость применения схем блокирования страниц
и кортежей, но в некоторых ситуациях (скажем, при пересчете баланса) возникает
потребность и в захвате блокировки всего отношения с данными о лицевых счетах. Однако
использование общей блокировки отношения с целью вычисления каких-либо
агрегирующих функций наряду с монопольным блокированием отдельных кортежей способно
привести к непоследовательному поведению расписания, поскольку содержимое
отношения определенно меняется в то время, когда якобы "замороженная" копия
Данных используется в процессе обработки запросов с агрегирующими функциями.
18.6.2. Предупреждающие блокировки
Один из подходов к решению проблемы управления единовременно
применяемыми блокировками, относящимися к различным уровням детализации объектов базы
данных, основан на концепции так называемого предупреждающего блокирования
(warning locking). Подобный механизм особенно полезен в тех случаях, когда
элементы базы данных, как показано на рис. 18.27, образуют вложенные (nested)
иерархические структуры. Здесь отображены три уровня элементов:
1) отношения — самые крупные блокируемые элементы;
2) блоки (страницы), из которых состоит отношение;
3) кортежи, образующие блок.
18.6. УПРАВЛЕНИЕ ИЕРАРХИЯМИ ЭЛЕМЕНТОВ БАЗЫ ДАННЫХ
919
Отношения
Блоки
Правила управления блокировками
элементов иерархических структур данных в
совокупности называют протоколом предупреждающего
блокирования (warning-locking protocol),
регламентирующим возможности использования и
"обычных" {ординарных — ordinary) блокировок,
и предупреждающих блокировок.
Мы сосредоточим внимание на схеме с двумя
режимами — общим (s) и монопольным (х) —
ординарного блокирования. Предупреждающая
блокировка обозначается буквой i (от
"intention" — намерение), предшествующей
аббревиатуре ординарной блокировки; так,
например, is представляет намерение транзакции
захватить общую блокировку вложенного элемента данных. Правила протокола пре
дупреждающего блокирования перечислены ниже.
Рис. 18.27.
струк-туры
данных
Кортежи
Пример иерархической
блокируемых элементов
1.
Чтобы затребовать ординарную блокировку S или х любого элемента, следует
обратиться к корневой вершине иерархии элементов.
Если элемент, подлежащий блокированию, достигнут, завершить просмотр
иерархии и послать запрос на блокирование в режиме s или х.
Если элемент, который необходимо заблокировать, расположен ниже по дереву
иерархии, текущую вершину надлежит пометить предупреждающей
блокировкой: если транзакция намеревается воспользоваться общей или монопольной
блокировкой вложенного элемента, текущий элемент следует обозначить
блокировкой is или IX соответственно. Как только право на блокирование
текущего элемента получено, следует, осуществляя предписания, указанные в пп. 2,
3, продолжить движение по соответствующим ветвям дерева вплоть до
достижения нужного вложенного элемента.
IS
IX
S
X
IS
Да"
Да
Да
Нет
IX
Да"
Да
Нет
Нет
s
Да"
Нет
Да
Нет
X
Нет
Нет
Нет
Нет
Рис. 18.28. Матрица совместимости режимов
общего, монопольного и предупреждающего блокирования
Принимая решение о том, принять или отвергнуть запрос на блокирование в
одном из рассматриваемых режимов, планировщик заданий обращается к матрице
совместимости, представленной на рис. 18.28. Чтобы разобраться в ее логике,
вначале изучим столбец is. Запрашивая is-блокировку вершины 7V, транзакция имеет
намерение осуществить чтение одного из элементов, вложенных в N. Единственная
проблемная ситуация возникает только в том случае, если некоторая другая
транзакция в тот же момент времени обладает правом внесения изменений в
содержимое элемента данных, представляемого вершиной N\ поэтому в ячейке на
пересечении столбца is и строки х матрицы задано значение "нет". Обратите внимание на
следующее обстоятельство: если сторонняя транзакция намеревается
модифицировать какой-либо элемент, вложенный в N, что находит отражение в захвате ею IX-
блокировки элемента N, планировщик заданий имеет все основания разрешить еди-
920
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
новременный запрос на is-блокировку N, перенося возможный конфликт запросов
(если таковые действительно касаются одного и того же вложенного элемента
данных) на один из нижних уровней дерева.
Рассмотрим столбец IX матрицы. Если транзакция предполагает модифицировать
какой-либо элемент, вложенный в элемент N, она обязана препятствовать
возможности как записи, так и считывания содержимого всего элемента N. Поэтому в ячейках
на пересечении столбца IX и строк S и х матрицы находятся значения "нет". Однако,
как и в случае, касающемся столбца is, другая транзакция, предусматривающая
считывание или запись значения какого-либо элемента, вложенного в N, на уровне N не
конфликтует с другими блокировками IX и is.
Теперь обратимся к столбцу S. Операция считывания содержимого элемента N
совместима с операциями других транзакций, связанными с чтением значений того же
элемента N или любых вложенных элементов, так что ячейки матрицы на
пересечении столбца s и строк s и is обязаны содержать флаги "да". Однако в строках х и IX
размещены признаки "нет" — это значит, что некая сторонняя транзакция владеет
правом изменения по меньшей мере части данных элемента N, и поэтому разрешение
на считывание всего содержимого N дать нельзя.
Наконец, столбец х содержит только признаки "нет" — планировщик заданий не
может позволить модификацию данных элемента N в тот период времени, когда иной
транзакции разрешено считывать или изменять информацию элемента N или какой-
либо его части.
Пример 18.21. Рассмотрим отношение
Movie(title, year, length, studioName)
из "кинематографической" базы данных и предположим, что система поддерживает
возможность блокирования всего отношения и его отдельных кортежей. Транзакция
Гь реализующая запрос
SELECT *
FROM Movie
WHERE title = 'King Kong';
начинает работу с получения is-блокировки данных всего отношения, затем
просматривает отдельные кортежи (допустим, что отношение содержит два кортежа с
описанием кинофильмов, названных "King Kong") и блокирует их в режиме s.
Во время обработки первого запроса стартует транзакция Тъ в намерения которой
входит обновление содержимого определенного компонента атрибута year:
UPDATE Movie
SET year = 1939
WHERE title = 'Gone With the Wind";
Транзакция T2 испытывает потребность в приобретении ix-блокировки отношения,
поскольку намеревается модифицировать один из его кортежей. Необходимая IX-
блокировка совместима с блокировкой is, удерживаемой транзакцией Гь поэтому
заявка транзакции Т2 удовлетворяется. Отыскав кортеж со сведениями о кинофильме
"Gone With the Wind", транзакция T2 обнаруживает, что тот не блокирован, поэтому
беспрепятственно получает х-блокировку кортежа и вносит предписанные изменения.
Если бы Т2 попыталась модифицировать один из кортежей, соответствующих
кинофильмам "King Kong", ей пришлось бы приостановить работу до момента
освобождения s-блокировки транзакцией Тх — блокировки в режимах s и х несовместимы.
Описания блокировок, разрешаемых планировщиком заданий при обслуживании
запросов транзакций Тх и Тъ схематически представлены на рис. 18.29. □
18.6. УПРАВЛЕНИЕ ИЕРАРХИЯМИ ЭЛЕМЕНТОВ БАЗЫ ДАННЫХ
921
Обобщенный признак блокирования и режимы предупреждающего
блокирования
Матрица совместимости, представленная на рис. 18.28, демонстрирует ситуацию,
в которой мощь механизма блокирования проявляется наиболее убедительно.
Всякий раз, когда при использовании любой из ранее рассмотренных схем
блокирования элемент базы данных допускает возможность захвата блокировки как в
некотором режиме м, так и в режиме N, один из режимов (для определенности пусть это
будет м) преобладает над другим (n) — в том смысле, что строка (столбец) м не
может содержать значения "да" в тех ячейках, где строка (столбец) N содержит
"нет". В матрице совместимости, приведенной на рис. 18.19 (см. с. 907), например,
режим и преобладает над s, a x — как над s, так и над и. При использовании схем
блокирования, в которых порядок преобладания одних режимов над другими
определен однозначно, удается получить дополнительное преимущество за счет
консолидации результатов множественных блокировок одного элемента данных в
обобщенном признаке блокирования (см. раздел 18.5.2 на с. 915).
Как видно из таблицы, приведенной на рис. 18.28, ни один из режимов s и IX
не преобладает над другим. Более того, вполне возможна ситуация
единовременного блокирования элемента данных в режимах s и IX при условии, что владеет
блокировками одна и та же транзакция (напомним, что значения "нет" в ячейках
матрицы совместимости применимы только по отношению к блокировкам,
инициированным сторонними транзакциями). Транзакция вправе затребовать обе
блокировки, если ей необходимо считать содержимое элемента в целом, а затем
изменить какое-либо подмножество вложенных элементов. Если транзакция владеет
блокировками некоторого элемента одновременно в режимах s и IX, ее влияние на
возможность доступа к элементу со стороны других транзакций простирается до
таких пределов, которые устанавливаются обоими режимами блокирования.
Иными словами, можно представить такой гипотетический режим блокирования
(назовем его six), что столбец и строка six матрицы совместимости содержат
значения "нет" во всех ячейках, за исключением тех, которые относятся к режиму is.
Режим six ведет себя как обобщенный признак блокирования, если существует
транзакция, которая владеет блокировками в режимах s и ix, но не в х.
Может показаться, что аналогичные рассуждения справедливы и для схемы
с общими/монопольными/инкрементными блокировками, которой соответствует
матрица совместимости, изображенная на рис. 18.22, когда одна и та же
транзакция способна обладать как S-, так и I-блокировкой. Ситуация, однако,
равносильна владению блокировкой в режиме х, которую в подобном случае можно
трактовать как обобщенный признак блокирования.
rris
Т2" IX Movies
"King Kong" "King Kong" "Gone With the Wind"
Tx-S 7J-S T2-X
Рис. 18.29. Запросы на блокирование, удовлетворяемые
при обработке транзакций из примера 18.21
922
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
18.6.3. Фантомные кортежи и корректная обработка операций вставки
Когда транзакция создает новый элемент, вложенный в элемент, допускающий
блокирование, возникает ряд ситуаций, чреватых неприятностями. Проблема
заключается в том, что блокировать можно только существующие единицы информации;
простых способов блокирования элементов базы данных, которых нет, но которые
могут появиться позже, не существует. Проиллюстрируем сказанное на примере.
Пример 18.22. Предположим, что мы имеем дело с тем же отношением Movie, что
и в примере 18.21 на с. 921, и стартующая первой транзакция Тъ выполняет запрос
SELECT SUM(length)
FROM Movie
WHERE studioName = 'Disney';
Транзакция T3 нуждается в считывании всех кортежей с информацией о киностудии
"Disney", поэтому она вправе начать с получения is-блокировки всего отношения и S-
блокировок тех кортежей, которые удовлетворяют условию studioName = ' Disney' .134
Предположим, что в тот же период времени вступает в действие транзакция Г4,
которая предусматривает вставку в отношение Movie кортежей с данными о новых
кинофильмах, выпущенных студией "Disney". На первый взгляд кажется, что
транзакции Т4 блокировки не нужны, но при подобном подходе результат, возвращаемый
транзакцией Т3, может быть неверен. Такой факт сам по себе не относится к
проблематике управления параллельными заданиями, поскольку тот же итог может быть получен
при выполнении последовательного расписания (Г3, Г4). Однако более сложные
ситуации, когда те же транзакции, скажем, изменяют содержимое какого-либо иного
элемента X, причем Т4 делает это первой, грозят опасностью непоследовательного поведения.
Выражаясь более точно, предположим, что в отношении Movie существуют два
кортежа D{ и D2 со сведениями о кинофильмах студии "Disney", а транзакция Т4 выполняет
вставку еще одного кортежа, D3. Обозначим как L сумму продолжительностей
воспроизведения (length) всех кинофильмов студии "Disney", вычисленную транзакцией Г3,
и допустим, что одним из ограничений целостности, определенных в базе данных,
является требование равенства значения L сумме всех компонентов length кортежей,
ссылающихся на студию "Disney", которые наличествовали в момент последнего
сохранения вычисленной величины L. Тогда при использовании протокола предупреждающего
блокирования одной из допустимых последовательностей событий может быть такая:
гъфх)\ r3(D2); w4(D3); w4(X); w3(L); w3(X);
Здесь функция w4(D3) обозначает операцию создания кортежа D3 транзакцией ТА.
Указанное выше расписание не является условно-последовательным. В частности, значение
L не равно сумме компонентов length кортежей Du D2 и D3, которые присутствовали
в отношении к моменту завершения вычислений. Более того, тот факт, что X в итоге
содержит значение, сохраненное транзакцией Г3, а не Г4, исключает возможность
первенства транзакции Т3 в гипотетическом эквивалентном последовательном расписании. □
Проблема, продемонстрированная в примере 18.22, связана с наличием нового
фантомного (phantom) кортежа, который должен был быть заблокирован, но этого не
произошло, поскольку в момент захвата блокировки он еще просто не существовал.
Впрочем, имеется простой способ воспрепятствования появлению фантомных записей —
достаточно трактовать вставку или удаление кортежа как операцию записи, касающуюся
отношения в целом. Следуя такой стратегии, транзакция ТА в примере 18.22 обязана
была бы затребовать х-блокировку отношения Movie. Поскольку к тому моменту
транзакция Т3 уже захватила бы блокировку отношения в режиме is, который,
напомним (см. рис. 18.28 на с. 920), несовместим с режимом х, транзакции Г4 пришлось
бы приостановить выполнение до момента завершения операций транзакции Т3.
134 Если таких кортежей достаточно много, более эффективной, однако, была бы стратегия
захвата s-блокировки отношения в целом.
18.6. УПРАВЛЕНИЕ ИЕРАРХИЯМИ ЭЛЕМЕНТОВ БАЗЫ ДАННЫХ
923
18.6.4. Упражнения к разделу 18.6
Упражнение 18.6.1. Обратимся для разнообразия к объектно-ориентированной базе
данных. Допустим, что объекты класса С хранятся в двух блоках, В{ и Въ причем В{
содержит объекты Ох и Оъ а В2 — 03, Оа и 05. Экземпляры классов, блоки и
объекты образуют иерархию элементов базы данных, допускающих блокирование.
Укажите последовательность поступления запросов на блокирование и ответных
действий со стороны планировщика заданий, поддерживающего протокол
предупреждающего блокирования, при выполнении перечисленных ниже расписаний.
(Можете полагать, что все запросы генерируются непосредственно в тот момент,
когда возникает потребность в их использовании, а все инструкции
разблокирования вынесены в конец расписаний.)
* a) rx{Oxy, w2(02); r2(6>3); wiiOJ;
b) г{(05); w2(05); r2(03); w^Ofr
c) nCOO; ЫОД; r2(0{); w2(04y w2(05);
d) niOi); r2(02); r3(Oi); w{(03); w2(04); w3(05); и^ОД;"
Упражнение 18.6.2. Измените расписание из примера 18.22 на с. 923 таким
образом, чтобы выполняемая транзакцией ТА инструкция w4(D3) трактовалась как
операция записи, касающаяся отношения Movie в целом, и поясните действия
планировщика заданий, реализующего протокол предупреждающего блокирования, при
обработке этого расписания.
!! Упражнение 18.6.3. Покажите, каким образом пополнить протокол
предупреждающего блокирования условиями, отвечающими режиму инкрементных блокировок.
18.7. Протокол блокирования древовидных структур
Здесь мы сосредоточим внимание на другой проблеме, связанной с блокированием
элементов древовидных структур данных. В разделе 18.6 на с. 918 обсуждалась модель
дерева, формируемого в процессе идентификации мелких элементов базы данных,
вложенных (nested) в более крупные элементы. Здесь же мы собираемся рассмотреть
древовидные (tree-structured) структуры, образуемые за счет связывания элементов
между собой. Элементы таких структур, вообще говоря, представляют разъединенные
порции информации, и единственный способ доступа к тому или иному элементу
предполагает обращение к корневой вершине дерева с последующим перемещением
по соответствующему поддереву; важным примером подобной организации данных
является модель В-дерева (см. раздел 13.3 на с. 609). Тот факт, что каждому элементу
данных отвечает строго определенный путь в дереве, открывает новые возможности
управления блокировками, отличные от предусмотренных в схеме двухфазного
блокирования, с которой мы имели дело до сих пор.
18.7.1. Модель блокирования древовидных структур
Рассмотрим структуру В-древовидного индекса в контексте системы, которая
трактует отдельные вершины (блоки данных) дерева как элементы базы данных,
допускающие блокирование. Вершина дерева представляет необходимую и достаточную
степень детализации объектов блокирования, поскольку принятие в качестве
элементов меньших фрагментов данных дополнительных преимуществ не обеспечит; если же
придать смысл блокируемого элемента В-дереву в целом, это существенно сузит
возможности обращения к индексу со стороны параллельно действующих транзакций.
Если придерживаться схемы двухфазного блокирования со стандартным набором
режимов, подобных общему (shared), монопольному (exclusive) и обновляемому (update),
параллельное использование данных В-древовидного индекса окажется практически не-
924
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
возможным, поскольку каждой транзакции, намеревающейся обратиться к индексу,
придется начинать с блокирования корневой вершины В-дерева. Если транзакция
удовлетворяет условиям модели двухфазного блокирования, она не может освободить
блокировку корневой вершины до тех пор, пока не воспользуется блокировками всех
необходимых частей дерева и иных элементов базы данных.135 Более того, поскольку любая
транзакция, выполняющая операции вставки/удаления кортежей, вообще говоря,
способна спровоцировать модификацию корневой вершины В-дерева, в такой ситуации
транзакции необходимо захватить, как минимум, обновляемую блокировку корневой
вершины — или даже монопольную блокировку, если режим обновляемого
блокирования планировщиком заданий не поддерживается. Поэтому в каждый момент времени к
корневому блоку индекса сможет обращаться только одна подобная транзакция —
разумеется, наряду с транзакциями, которые действуют в режиме "только для чтения" (read-only).
Впрочем, в большинстве случаев потребность в изменении корневой вершины
В-дерева не возникает — даже если транзакция осуществляет вставку/удаление
кортежей. Например, если транзакция вставляет кортеж, но блок соответствующей
вершины, дочерней по отношению к корневой, не заполнен, можно быть уверенным, что
процесс возможной реорганизации вершин не затронет корневую вершину.
Аналогично, если транзакция удаляет один кортеж и текущая дочерняя вершина содержит
такое количество ключей и указателей, которое превосходит минимально допустимое,
корневая вершина также останется в неприкосновенности. Поэтому как только
транзакция считывает данные дочерней вершины и обнаруживает обычную ситуацию,
когда необходимости в модификации корневой вершины нет, она вправе сразу же
освободить блокировку корневой вершины. Те же соображения касаются и любой
промежуточной вершины В-дерева, хотя возможность параллельного выполнения
транзакций большей частью зависит от того, насколько быстро освобождаются блокировки
корневой вершины. К сожалению, преждевременное разблокирование фрагмента
данных корневой вершины не согласуется с принципами двухфазного блокирования,
поэтому гарантировать условно-последовательный характер расписания работы
нескольких транзакций, использующих один и тот же В-древовидный индекс, в общем случае
нельзя. Решение состоит в применении специального протокола блокирования,
который, нарушая условия 2PL, тем не менее обеспечивает возможность
последовательного упорядочения операций за счет эксплуатации того очевидного факта, что все
обращения к элементам древовидной структуры предполагают просмотр дерева в
направлении от корневой вершины к вершинам-листьям.
18.7.2. Правила доступа к элементам древовидных структур
Перечисленные ниже ограничения, касающиеся возможностей блокирования,
в совокупности образуют протокол блокирования древовидных структур (tree-locking
protocol). Предположим, что существует только один режим блокирования, которому
соответствуют запросы вида 1{(Х) (впрочем, подход можно распространить на произвольное
множество режимов блокирования). Помимо того, будем считать, что транзакции
согласованны, а расписания корректны (планировщик заданий обязан поддерживать
ограничения, разрешая очередную блокировку только в том случае, когда она не вступает
в конфликт с ранее захваченными блокировками той же вершины дерева), но
требования, относящиеся к модели двухфазного блокирования, здесь не выдвигаются.
1. Первый запрос на блокирование, инициируемый транзакцией, может
относиться к любой вершине дерева.136
135 Можно привести ряд убедительных доводов в пользу того, чтобы транзакция не
освобождала захваченные ею блокировки до того момента, пока не будет готова к выполнению
операции фиксации (commit) (подробнее — в разделе 19.1 на с. 949).
136 При обращении к элементам данных В-дерева (см. раздел 18.7.1 на с. 924) транзакция,
однако, обязана прежде всего запросить блокировку корневой вершины.
18.7. ПРОТОКОЛ БЛОКИРОВАНИЯ ДРЕВОВИДНЫХ СТРУКТУР
925
2. Последующие запросы на блокирование должны удовлетворяться только в том
случае, если транзакция обладает блокировкой вершины, родительской по
отношению к текущей.
3. Операции разблокирования разрешено выполнять в любые моменты времени.
4. Транзакция не имеет возможности повторного захвата блокировки элемента
после ее освобождения — даже в том случае, если принадлежащая транзакции
блокировка родительской вершины все еще активна.
Пример 18.23. На рис. 18.30 представлена древовидная
иерархия элементов данных, а на рис. 18.31 перечислены
действия трех транзакций, манипулирующих этими
элементами. Транзакция Тх начинает работу с обращения к вершине
Л, а затем выполняет операции с дочерними вершинами Я,
С и D. Транзакция Т2 первым делом блокирует вершину В,
а затем предпринимает попытку обращения к элементу Е,
которая вначале отвергается из-за того, что вершиной Е в
этот момент владеет транзакция Г3. Наконец, транзакция Г3
стартует с вершины Е и "перемещается" к вершинам F и G.
Заметьте, что Тх не является 2РЬ-транзакцией, поскольку
она освобождает блокировку А прежде, чем захватывает Рис. 18.30. Дерево элемен-
блокировку D. По аналогичным причинам транзакция Тъ тов, допускающих блоки-
также не относится к числу двухфазно-блокированных, хо- рование
тя Т2 — так уж случилось — удовлетворяет условиям 2PL. □
Тх Тг 7з
Ш; г,(А);
/i(S); г,(Д);
/i(Q; r,(Q;
w,(A); ux(A)\
/!(D); rx(D)\
w{(B); ux(B)\
km r2m
/3(£); г3(£);
Wl(D); Ul(D);
Wl(Q; Wl(Q;
l2(E) — запрет
/з(/0; r3(F)\
w3(F); u3(F);
/3(G); r3(G);
w3(£); n3(£);
/2(£); r2(£);
w3(G); n3(G);
w2(£); ц2(Д);
w2(£); n2(£);
Pwc. /<£J/. Расписание выполнения трех транзакций в соответствии с требованиями
протокола блокирования древовидных структур
926
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
18.7.3. Обоснование корректности протокола блокирования древовидных структур
Протокол блокирования древовидных структур поддерживает последовательный
порядок выполнения операций транзакций. Отношение предшествования транзакций
в этом случае можно определить следующим образом. Говорят, что транзакция Г,-
предшествует транзакции 7} (Tf-<sTj), если в соответствии с расписанием S обе
транзакции захватывают блокировку некоторой вершины, причем транзакция Г, владеет
блокировкой этой вершины раньше.
Пример 18.24. В расписании S, показанном на рис. 18.31,
транзакции Тх и Т2 блокируют вершину В, но Т{ делает это прежде Тъ
поэтому Тх < 5 Т2. Также нетрудно убедиться, что транзакции Т2 и Г3
в разное время владеют блокировкой вершины £, причем Г3 в
данном случае опережает транзакцию Г2, т.е. ТЪ<8Т2. Однако между
транзакциями Тх и Тъ непосредственное отношение
предшествования отсутствует, поскольку они не выполняют блокирование одной
и той же вершины. Соответствующий граф предшествования \ lo.JJ. 1раф
(см. раздел 18.2.2 на с. 888) изображен на рис. 18.32. □ предшествования
для расписания на
Если граф предшествования, полученный на основе частных от- рис. 18.31
ношений предшествования транзакций, не имеет циклов, можно
утверждать, что любая топологическая очередность выполнения транзакций
эквивалентна последовательному расписанию. Например, любой из упорядоченных списков
(Гь Г3, Т2) и (Гь Т3, Т2) представляет собой последовательное расписание, эквивалентное
расписанию на рис. 18.31, поскольку предусматриваемый ими порядок обращения
к вершинам дерева равносилен тому, который принят в исходном расписании.
Чтобы уяснить, почему граф предшествования, подобный описанному выше, не
должен иметь циклов, вначале примем к сведению следующее обстоятельство:
• если две транзакции предполагают обращение к нескольким общим
блокируемым элементам, порядок предшествования транзакций в каждом случае должен
сохраняться.
Рассмотрим для примера две транзакции Т и U, которые предусматривают
блокирование двух или более общих элементов базы данных. Прежде всего, заметим, что каждая
транзакция блокирует подмножество элементов, образующих дерево, и пересечение
этих деревьев само по себе является деревом. Поэтому определенно существует
некоторый элемент X наивысшего уровня, блокируемый обеими транзакциями.
Предположим, что первой захватывает блокировку X транзакция Г, но при этом существует
какой-либо другой общий элемент Y, который первым блокируется транзакцией U.
Тогда в дереве существует путь от X к Y, и Т и U обязаны обладать блокировками
каждого элемента, принадлежащего этому пути, поскольку нельзя блокировать вершину
дерева, не владея блокировкой родительской вершины.
Рассмотрим первый из элементов, принадлежащих этому пути (скажем, Z), который
(элемент), как показано на рис. 18.33, первым блокируется транзакцией U. Тогда
транзакция Т блокирует родительскую вершину Р вершины Z прежде транзакции U.
Но в таком случае Т все еще удерживает блокировку Р в момент захвата блокировки Z,
поэтому получается, что U, блокируя Z, не имеет прав на Р. Элемент Z не может быть
первым, который транзакция U блокирует наряду с транзакцией Т, поскольку обе
транзакции обладают блокировкой родительской вершины X (в частном случае она
может совпасть с Р, но не с Z). Таким образом, U не может блокировать Z до тех пор,
пока она не овладеет блокировкой Р, а это случится после того, как Т заблокирует Z.
Мы приходим к заключению, что транзакция Т предшествует транзакции U при
захвате блокировки каждой общей вершины.
18.7. ПРОТОКОЛ БЛОКИРОВАНИЯ ДРЕВОВИДНЫХ СТРУКТУР
927
Первыми блокируются транзакцией Т
\ Р
\ Z Первым блокируется транзакцией U
\ Y Первым блокируется транзакцией U
Рис. 18.33. Путь в дереве, содержащий элементы,
блокируемые двумя транзакциями
Теперь рассмотрим произвольное множество транзакций Гь Г2, ..., Тп, которые,
удовлетворяя требованиям протокола блокирования древовидных структур, блокируют
определенные вершины дерева в соответствии с расписанием S. Те из них, которые
захватывают блокировку корневой вершины, делают это в определенном порядке
и далее действуют в соответствии со следующим правилом:
• если транзакция Г, блокирует корневую вершину прежде транзакции 7}, тогда Г,
опережает транзакцию 7} и при блокировании всех остальных общих вершин
дерева, т.е. 7} -<5 7}, но не 7} -<5 Гу.
Можно доказать по индукции от числа вершин дерева, что для произвольного
множества транзакций существует некоторое последовательное расписание, эквивалентное
расписанию S.
Базис. Если дерево содержит единственную — корневую — вершину, очередность
захвата этой вершины транзакциями определяет последовательность их выполнения.
Индукция. Если дерево состоит из нескольких вершин, для каждого поддерева,
исходящего из корневой вершины, рассмотрим подмножество транзакций, которые
блокируют по одной или несколько вершин, принадлежащих этому поддереву. Заметим, что
транзакции, захватывающие блокировку корневой вершины, могут "относиться" к
нескольким поддеревьям, но транзакция, которая не обращается к корневой вершине,
"связана" только с одним определенным поддеревом. Например, среди транзакций,
представленных в расписании на рис. 18.31 (см. с. 926), только Т{ блокирует корневую
вершину (А) дерева, изображенного на рис. 18.30 (см. с. 926), и обращается к элементам
данных, принадлежащим обоим поддеревьям; транзакции Т2 и Г3, однако, имеют дело
только с вершинами дерева, обладающего корневой вершиной В. Согласно гипотезе
индукции существует некий последовательный порядок протекания транзакций,
блокирующих вершины, принадлежащие одному из поддеревьев. Мы должны осуществить
"смешивание" последовательных порядков, отвечающих различным поддеревьям.
Поскольку единственными транзакциями, упоминаемыми во всех подобных
упорядоченных списках транзакций, являются те, которые блокируют корневую вершину, и мы
установили, что эти транзакции блокируют каждую общую вершину в порядке захвата ими
корневой вершины, существование двух транзакций, блокирующих корневую вершину
и перечисленных в двух списках в различной очередности, невозможно. В частности, если
транзакции 7]и7] присутствуют в списке для некоторого поддерева, исходящего из
вершины С, дочерней по отношению к корневой, они должны блокировать С и перечисляться
в списке в том же порядке, в котором блокируют корневую вершину. Поэтому
последовательный порядок перечисления полного множества транзакций можно сконструировать,
начав с транзакций, которые блокируют корневую вершину в соответствующей
очередности, и учитывая транзакции, не блокирующие корневую вершину, в любом порядке,
согласующемся с последовательным порядком "связанных" с ними поддеревьев.
о
928
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Пример 18.25. Пусть из 10 транзакций Гь Т2,..., Г10 транзакции Ти Т2 и Т3 блокируют
корневую вершину дерева в указанном порядке. Предположим также, что первая
дочерняя вершина блокируется транзакциями Т{—Т7, а вторая — транзакциями Т2, Т3, Г8,
Т9 и Г10. Допустим, что последовательный порядок выполнения транзакций для первого
поддерева выглядит как (Т4, Тъ Г5, Тъ Г6, Г3, Г7) (заметьте, что очередность транзакций Гь
Т2 и Т3 сохранена), а последовательный порядок для второго поддерева — как
(Г8, Т2, Г9, Г10, Тъ) (транзакции Т2 и Т3, блокирующие корневую вершину, указаны в такой
очередности, которая совпадает с порядком выполнения этой операции блокирования).
Рис. 18.34. Слияние последовательных порядков,
отвечающих поддеревьям, в последовательный порядок
выполнения всех транзакций
Ограничения, обусловленные последовательным порядком выполнения транзакций
Гь Т2,..., Г10, схематически показаны на рис. 18.34. Сплошные и пунктирные дуги
отображают последовательности выполнения транзакций для первого и второго
поддеревьев соответственно. Один из многих альтернативных вариантов очередности
следования вершин графа, изображенного на рис. 18.34, можно представить так:
(Г4, 7g, Ть Т5, Т2, Т9, Т* Г10, Г3, Г7). □
18.7.4. Упражнения к разделу 18.7
Упражнение 18.7.1. Предположим, что над В-деревом, приведенным на рис. 13.23
(см. с. 611), выполняются следующие операции:
* а) вставка ключа 10;
b) вставка ключа 20;
c) удаление ключа 5;
d) удаление ключа 23.
В какие моменты планировщик заданий, использующий протокол блокирования
древовидных структур, вправе освободить монопольные блокировки каждой из
просматриваемых вершин?
! Упражнение 18.7.2. Рассмотрим перечисленные ниже транзакции,
манипулирующие данными дерева, представленного на рис. 18.30 (см. с. 926):
7V г,(А); г,(Д); rrffi);
Т2: г2(А); г2(С); г2(Д);
Тъ: гъ(В)\ г3(£); г3(/0;
Если планировщик заданий следует протоколу блокирования древовидных
структур, сколько способов чередования операций транзакций — *а) Тх и Т2\ Ь) Тх и Г3;
!!с) Тъ Т2 и Т3 — он может использовать?
! Упражнение 18.7.3. Примем следующие допущения: из восьми транзакций Ть Т2, ...,
Г8 транзакции с нечетными номерами, т.е. Ти Г3, Т5 и Г7, блокируют корневую
вершину в указанном порядке; корневая вершина связана с тремя дочерними,
18.7. ПРОТОКОЛ БЛОКИРОВАНИЯ ДРЕВОВИДНЫХ СТРУКТУР
929
и первая из них блокируется транзакциями Ти Т2, Г3 и Г4 в заданной очередности,
вторая — транзакциями Г3, Г6 и Г5, а третья — транзакциями Г8 и Г7. Каково
количество последовательных вариантов упорядочения операций транзакций?
!! Упражнение 18.7.4. Предположим, что используется вариант протокола
блокирования древовидных структур с общим и монопольным режимами
блокирования, предназначенными для обеспечения возможности считывания и записи
элементов данных соответственно. Правило (2) протокола (см. раздел 18.7.2 на
с. 925), требующее для получения блокировки некоторой вершины осуществлять
захват блокировки вершины, родительской по отношению к текущей, в данном
случае должно быть изменено с целью предотвращения вероятности
непоследовательного поведения расписания. Как может выглядеть редакция правила (2),
учитывающая необходимость применения общего и монопольного режимов
блокирования? (Попробуйте ответить на вопрос, обязательно ли типы блокировок
родительской и дочерней вершин должны совпадать.)
18.8. Хронометраж действий транзакций
Ниже мы собираемся рассмотреть еще два метода обеспечения возможности
последовательного выполнения операций транзакций, отличные от технологий
блокирования и находящие применение в некоторых коммерческих реализациях СУБД.
1. Хронометраж (timestamping): планировщик заданий ведет учет моментов
времени, когда определенная транзакция последней обращалась к тому или иному
элементу базы данных с операциями чтения или записи, и сопоставляет
полученные временнб/е значения с целью подтверждения или опровержения того,
что последовательное расписание, упорядоченное по результатам хронометража,
эквивалентно фактическому расписанию выполнения транзакций.
2. Проверка достоверности (validation): планировщик сохраняет информацию
о действиях активных транзакций и проверяет ее непосредственно перед
выполнением операций фиксации каждой транзакции; последовательное
расписание, упорядоченное по значениям времени проверки, должно быть
эквивалентно фактическому расписанию выполнения транзакций (стратегия управления
параллельными заданиями, основанная на модели проверки достоверности,
обсуждается в разделе 18.9 на с. 939).
Оба подхода являются оптимистичными (optimistic) — в том смысле, что
основываются на принимаемом по умолчанию предположении, будто транзакциям удастся
избежать рецидивов непоследовательного поведения, и предполагают прерывание работы
транзакции, если опасность нарушения ею последовательного характера действий
становится очевидной. Все методы блокирования, напротив, подразумевают, что если не
предпринять упреждающих мер, расписание операций транзакций обязательно
окажется непоследовательным. Оптимистичные подходы отличаются от схемы
блокирования тем, что предусматривают единственный инструмент предотвращения
нарушений последовательности действий — прерывание и повторный старт транзакции,
виновной в происшедшем. Планировщики заданий, основанные на механизме
блокирования, в свою очередь, приостанавливают работу "опасных" транзакций, но
не прерывают их.137 Вообще говоря, планировщики, в основе деятельности которых
лежит одна из оптимистичных стратегий, являются более предпочтительными в срав-
Собственно говоря, это не значит, что в системе с планировщиком заданий, который
следует стратегии блокирования, транзакции никогда принудительным образом не прерываются;
в разделе 19.3 на с. 968, скажем, обсуждаются примеры, когда для выхода из ситуации
взаимоблокировки одна или несколько транзакций подлежат прерыванию. Однако планировщик
с блокированием никогда не применяет механизм прерывания просто в ответ на запрос
блокировки, который в данный момент не может быть удовлетворен.
930
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
нении со схемами блокирования, если многие из числа единовременно выполняемых
транзакций функционируют в режиме "только для чтения" (read-only), т.е. сами по
себе не способны привести к срыву последовательного порядка действий.
18.8.1. Хронологические признаки
Для реализации механизма хронометража (timestamping) как инструмента управления
параллельными заданиями планировщик заданий обязан снабдить каждую транзакцию Т
уникальным идентификатором -- хронологическим признаком (timestamp), TS(7).
Хронологические признаки генерируются в возрастающем порядке в моменты времени, когда
каждая транзакция впервые уведомляет планировщик заданий о начале своей работы.
Для получения значений хронологических признаков используются следующие методы.
1. Один из возможных способов вычисления хронологического признака связан
с использованием системных часов; предполагается, что планировщик
действует не настолько быстро, чтобы успеть назначить признаки двум транзакциям
в промежутке между соседними тиками (ticks) системных часов.
2. Другой подход предусматривает необходимость ведения планировщиком
внутреннего счетчика транзакций. Всякий раз в момент старта новой транзакции
значение счетчика увеличивается на единицу и присваивается транзакции в
качестве хронологического признака. В этом случае хронологические признаки по
существу утрачивают связь с абсолютными значениями параметра времени, но
сохраняют основное требуемое свойство: транзакция, стартующая позже других,
снабжается большим по величине признаком.
Независимо от применяемого метода генерирования значений хронологических
признаков планировщик заданий обязан поддерживать таблицу активных транзакций
и соответствующих им величин признаков.
Для использования стратегии хронометража действий транзакций каждому
элементу X базы данных надлежит поставить в соответствие два хронологических признака
и дополнительный битовый флаг:
1) RT(X) — время считывания (read time) X, т.е. значение хронологического
признака транзакции, которая считывала X последней;
2) WTPQ — время записи (write time) X — значение хронологического признака
транзакции, которая записывала X последней;
3) С(Х) — флаг фиксации (commit flag) X, содержащий значение "истина"
("true") в том и только в том случае, если транзакция, обращавшаяся к X
с операцией записи позже других транзакций, уже осуществила фиксацию;
флаг используется для того, чтобы избежать ситуации, когда одна
транзакция, Т, считывает данные, сохраненные другой транзакцией, (/, a U позже
прерывает выполнение; проблема, связанная с возможностью чтения
нефиксированных данных (read-uncommitted), (или "чтения мусора'' — dirty reads),
оставленных сторонней транзакцией, чревата опасностью перевода базы
данных в несогласованное состояние, и потому планировщик любой
архитектуры обязан принимать соответствующие меры для ее разрешения.138
18.8.2. Физически неосуществимые расписания
Чтобы разобраться в архитектуре и правилах использования планировщика
заданий, основанного на механизме хронометража, надлежит помнить о том, что
планировщик трактует порядок назначения хронологических признаков транзакций как по-
Впрочем, в коммерческих системах баз данных возможность "чтения мусора", вообще
говоря, изначально предоставляется как опция и не запрещается.
18.8. ХРОНОМЕТРАЖ ДЕЙСТВИЙ ТРАНЗАКЦИЙ
931
следовательную очередность, в которой они (транзакции) должны выполняться.
Поэтому помимо присваивания транзакциям значений хронологических признаков
и обновления величин RT, WT и С для элементов базы данных в обязанности
планировщика входит также слежение за тем, чтобы при выполнении любой операции чтения
или записи ее результат совпадал с тем, который мог бы быть получен, если бы каждая
транзакция с момента назначения ей хронологического признака выполнялась
непрерывно. Если подобное требование не удовлетворяется, говорят, что последовательность
операций физически неосуществима (physically unrealizable). Можно назвать две
разновидности проблем, обусловливающих физическую неосуществимость расписаний.
1. Слишком поздняя операция чтения. Транзакция Т предпринимает попытку
считывания содержимого элемента X базы данных, но время записи X
свидетельствует о том, что текущее значение X было сохранено после того, как Т должна
была бы им воспользоваться, придерживаясь последовательного расписания,
т.е. TS(T)<WT(X). Проблема проиллюстрирована на рис. 18.35. На
горизонтальной оси зафиксированы реальные моменты времени возникновения событий.
Пунктирные линии связывают фактические события со значениями
хронологических признаков транзакций, которые спровоцировали эти события. Очевидно,
что транзакция U, стартовавшая позже Г, записывает значение X прежде, чем Т
его считывает. Транзакция Т не должна была бы иметь возможность считать
значение, сохраненное U, поскольку в идеале обязана выполняться раньше U. У
транзакции Т, однако, нет иного выхода, как обратиться к текущему значению
X, сохраненному транзакцией U. Решение состоит в прерывании работы Т.
2. Слишком поздняя операция записи. Транзакция Т предпринимает попытку записи
содержимого элемента X базы данных, но время чтения X свидетельствует
о том, что некоторая другая транзакция должна была бы считать значение,
сохраненное транзакцией Г, но осуществила чтение какого-то иного значения,
т.е. WT(X) <TS(T) <КТ(Х). Ситуация схематически отображена на рис. 18.36.
Нетрудно убедиться, что транзакция U стартует после Т, но считывает значение X
прежде, чем Т получает возможность записать X. Когда Т пробует выполнить
операцию записи X, обнаруживается, что RT(X) > TS(7) — значение X уже считы-
валось транзакцией U, которая, однако, обязана была бы выполняться позже Т.
Легко удостовериться, что и WT(X) < TS(7) — никакая другая транзакция не
сохраняла значение X, которое перекрыло бы содержимое, записанное
транзакцией Т, и поэтому не принимала на себя обязанность транзакции Т по
предоставлению транзакции U требуемого значения.
U записывает X
г~т
Т считывает X
Т стартует U стартует
Рис. 18.35. Транзакция Т пытается
выполнить запоздавшую операцию чтения
U считывает X
\ t
Т записывает X
Т стартует U стартует
Рис. 18.36. Транзакция Т пытается
выполнить запоздавшую операцию записи
18.8.3. Операции "чтения мусора"
Существует ряд проблем, помощь в разрешении которых оказывает флаг фиксации
(commit flag) (см. раздел 18.8.1 на с. 931). Одна из них, связанная с "чтением мусора " (dirty
reads), представлена на рис. 18.37. Здесь транзакция Т считывает значение элемента X базы
данных, которое прежде было записано транзакцией U. Значение хронологического при-
932
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
знака U меньше величины признака Т, и операция чтения, инициируемая транзакцией Г, в
реальности осуществляется позже операции записи, выполняемой транзакцией U, так что
последовательность событий выглядит как физически осуществимая. Однако возможна
ситуация, когда после считывания транзакцией Г значения X, сохраненного транзакцией U,
выполнение последней прерывается по той или иной причине — возможно, ввиду
ошибки в локальных данных, повлекшей событие деления на нуль, либо из-за того, что
планировщик заданий обнаружил попытку выполнения транзакцией физически
неосуществимых действий (см. раздел 18.8.4 на с. 934). Поэтому несмотря на то, что в самой
операции чтения транзакцией Т значения X ничего крамольного нет, лучше тем не
менее отсрочить операцию до момента, когда транзакция U выполнит либо фиксацию,
либо прерывание. На то, что транзакция U не осуществила фиксацию, должен указывать
флаг фиксации X — С(Х) в этом случае будет содержать значение "ложь" ("false").
Uзаписывает X
Т считывает X
} г
U стартует Т стартует U прерывает работу
Рис. 18.37. Если транзакция U прерывает
работу, данные X, считываемые транзакцией
Т, оказываются "мусором"
Вторая потенциальная проблема иллюстрируется на рис. 18.38. Транзакция U,
обладающая, большим значением хронологического признака, нежели транзакция Т, однако,
первой осуществляет запись элемента X базы данных. Если транзакция Т попытается
выполнить запись, ей лучше этого не делать. Очевидно, что никакая транзакция V,
которая должна была бы считать значение X, записанное транзакцией Г, не получит
результат сохранения X транзакцией U, поскольку попытка чтения X транзакцией V в этом
случае отвергается как запоздавшая. Следующие операции чтения X будут нацелены на
получение значений, сохраненных транзакцией U или иными транзакциями, но никак
не Т. Регламент, согласно которому операция записи может быть пропущена, если к
текущему моменту элемент данных снабжен более поздним хронологическим признаком
записи, называют правилом записи Томаса139 (Thomas write rule) (R.H. Thomas).
U записывает X
Т записывает X
\ \
Т стартует U стартует
U прерывает работу
Т выполняет фиксацию
Рис. 16.38. Операция записи, инициируемая транзакцией
Т, отменяется, поскольку аналогичная операция
выполнена транзакцией U с более поздним хронологическим
признаком; транзакция U прерывает работу
139 Разумеется, речь идет о правиле записи,
шивания телефонных разговоров тов. Томаса. -
изобретенном Томасом, а не о способе подслу-
Прим. перев.
18.8. ХРОНОМЕТРАЖ ДЕЙСТВИЙ ТРАНЗАКЦИЙ
933
Правило записи Томаса, однако, небезгрешно. Если, как показано на рис. 18.38,
работа транзакции U позже прерывается, сохраненное ею значение X подлежит удалению,
а предыдущие состояние X и величина хронологического признака X — восстановлению.
Поскольку транзакция Т осуществляет фиксацию, может показаться, что значение X,
которое она якобы записала, — это именно то значение, которое должно быть
востребовано последующими операциями чтения X. Но в соответствии с правилом Томаса операция
записи X транзакцией Т была пропущена, и исправлять ошибку уже слишком поздно.
Существует множество различных способов преодоления указанных проблем, но мы
предложим вашему вниманию простую стратегию, основанную на следующем
предполагаемом свойстве планировщика заданий, использующего механизм хронометража:
• когда транзакция Т сохраняет значение элемента X базы данных, результат
операции записи расценивается как временный и в случае прерывания работы Т
может быть отменен; планировщик присваивает флагу фиксации С(Х) значение
"ложь" и создает копии прежних значений X и WT(X).
18.8.4. Правила упорядочения действий с помощью механизма хронометража
Здесь суммированы правила, которыми обязан руководствоваться планировщик
заданий, использующий схему хронометража, чтобы гарантировать невозможность
получения физически неосуществимых расписаний. Планировщик в ответ на запрос от
транзакции Т, касающийся операции чтения или записи, волен предпринять одно из
следующих действий:
1) удовлетворить запрос;
2) прервать работу транзакции Т (если операции Т вступают в противоречие
с требованиями физической осуществимости расписания) и заново
активизировать ее с новым значением хронологического признака;
прерывание транзакции с ее последующим повторным выполнением часто
называют откатом (rollback);
3) приостановить функционирование транзакции Г, чтобы решение о ее
прерывании или удовлетворении запроса на операцию принять позже, если
операция связана с чтением и существует угроза "чтения мусора"
(см. раздел 18.8.3 на с. 932).
Теперь непосредственно о правилах упорядочения действий транзакций с помощью
механизма хронометража.
1. Пусть планировщик заданий получает запрос гТ(Х) на чтение элемента X
транзакцией Т.
a) Если 1S(T) > WT(X), операция физически осуществима.
i) Если С(Х) есть "истина", удовлетворить запрос. Если TS(7) > RT(X),
установить RT(X) := TS(7); в противном случае значение RT(X) не изменять.
ii) Если С(Х) есть "ложь", приостановить выполнение Т до момента, когда
С(Х) приобретет значение "истина" либо транзакция, последней
выполнявшая операцию записи X, будет прервана.
b) Если TS{T) <WT(X), операция физически неосуществима. Выполнить откат Г,
т.е. прервать ее выполнение и активизировать повторно с новым значением
хронологического признака.
2. Планировщик получает запрос wT(X) на запись элемента X.
а) Если TS{T) > RT(X) и TS(T) > WT(X), операция физически осуществима и
подлежит выполнению.
934
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
i) Сохранить новое значение X.
ii) Установить WT(X) := TS(7).
iii) Установить С(Х) := false.
b) Если TS(T)>RT(X) и TS(D < WT(X), операция физически осуществима, но
в X присутствует значение, сохраненное позже. Если С(Х) есть "истина",
значит, транзакция, изменившая значение X, осуществила фиксацию
и операцией записи X, инициированной транзакцией Г, можно
пренебречь, позволяя Т продолжить работу. Если, однако, С(Х) есть "ложь",
работу транзакции Т надлежит приостановить, как в п. l-(a)-(ii).
c) Если же Т8(Г) < RT(X), операция физически неосуществима и транзакция Т
подлежит откату.
3. Планировщик получает запрос на фиксацию транзакции Т. Он обязан
отыскать (используя собственный внутренний список) все элементы X базы
данных, измененные транзакцией Г, и для каждого из них установить
С(Х) := true. Если существуют другие транзакции, ожидающие момента
фиксации элементов X (их можно обнаружить с помощью другого списка),
необходимо позволить им возобновить работу.
4. Планировщик получает запрос на прерывание транзакции Т или, как в пп. 1-(Ь)
или 2-(с), принимает решение об откате Т. Любая транзакция, ожидавшая
возможности обращения к элементу X, сохраненному транзакцией Г, должна повторить
попытку выполнения требуемой операции и убедиться, допустима ли таковая после
отмены результатов операций записи, осуществленных прерванной транзакцией Т.
Пример 18.26. На рис. 18.39 представлено расписание выполнения трех транзакций,
Ти Т2 и Г3, которые обращаются к трем элементам — А, В и С — базы данных.
Воображаемая ось времени, отображающая ход событий, направлена, как обычно, сверху
вниз. Теперь, однако, таблица пополнена столбцами, содержащими значения
хронологических признаков транзакций и времени чтения и записи элементов базы данных.
Будем считать, что изначально величины времени чтения и записи каждого элемента
равны 0, а хронологические признаки транзакций генерируются по мере получения
планировщиком уведомлений о начале функционирования транзакций. Обратите
внимание, что хотя транзакция Тх и обращается к данным первой, ее хронологический
признак не является наименьшим — прежде других о своем старте заявляет
транзакция Т2, следом вступает в действие Тъ и только потом — Т{.
Г, Т2 Т3 А В С
TS = 200 TS=150 TS=I75 RT = 0 RT = 0 RT==0
WT = 0 WT = 0 WT = 0
RT = 200
RT=150
r3(Q; RT=175
WT = 200
WT = 200
w3(A);
Рис. 18.39. Расписание выполнения трех транзакций под управлением планировщика заданий,
реализующего технологию хронометража
w2(Q;
Abort;
18.8. ХРОНОМЕТРАЖ ДЕЙСТВИЙ ТРАНЗАКЦИЙ
935
Первым делом транзакция Тх считывает значение В. Поскольку время записи
(WT = 0) В меньше величины хронологического признака (TS = 200) ГЬ операция
физически осуществима и поэтому допустима. Значением времени чтения В становится
200 — величина хронологического признака Тх. Вторая и третья операции чтения, так
же как и первая, корректны и приводят к присваиванию параметрам времени чтения
элементов Л и С значений хронологических признаков соответствующих транзакций
(Т2 и Г3), которые обращались к этим элементам.
На четвертом шаге расписания транзакция Тх сохраняет значение В. Так как время
чтения (RT = 200) В не превышает величину хронологического признака (TS = 200) T{,
операция записи трактуется как физически осуществимая, а поскольку в свою очередь
время записи (WT = 0) В также не больше хронологического признака Г,, операция
подлежит выполнению. При этом время записи В возрастает до 200 — это значение
хронологического признака транзакции Тх.
Далее транзакция Т2 предпринимает попытку записи значения элемента С. Однако
содержимое С уже считывалось транзакцией Т3 в гипотетический момент времени 175,
в то время как Т2 могла бы сохранить значение С раньше, у временной отметки 150.
Таким образом, операция транзакции Т2 должна восприниматься как физически
неосуществимая, и поэтому Т2 подлежит откату.
В заключение транзакция Г3 собирается выполнить сохранение данных элемента А.
Поскольку время чтения (RT= 150) А меньше хронологического признака (TS = 175) Г3,
операция формально корректна. Но после считывания содержимое элемента А уже
изменялось — к этому причастна транзакция Ти обладающая хронологическим
признаком 200. Выполнение транзакции Т3 не прерывается, хотя инициируемая ею
операция записи игнорируется. □
18.8.5. Множественные версии элементов и хронологических признаков
Один из важных вариантов механизма хронометража предполагает сохранение не
только текущих значений элементов базы данных наряду с хронологическими
признаками, но и ряда их прежних версий. Цель состоит в том, чтобы позволить транзакции
Т, выполняющей операцию чтения гт(Х) при условии, что текущая версия X
соответствует "будущему времени" транзакции Г, продолжить работу, считывая одну из
прежних версий X, соответствующую хронологическому признаку Т. Подход особенно
полезен, если элементы базы данных представляют собою дисковые блоки или
страницы, поскольку в этом случае ответственность перекладывается на менеджер буферов,
который обязан загружать в оперативную память определенные блоки, которые могут
оказаться востребованными той или иной активной транзакцией.
Пример 18.27. Рассмотрим набор из четырех транзакций, обращающихся к
некоторому элементу А базы данных согласно расписанию, показанному на рис. 18.40.
Транзакции управляются "традиционным" планировщиком заданий,
реализующим механизм хронометража. Когда транзакция Т3 пытается считать содержимое
А, обнаруживается, что величина WT(A) = 200 превосходит значение TS(T3) = 175,
так что функционирование Т3 в обычных условиях следовало бы прервать. Однако
если бы наличествовало прежнее значение А, сохраненное транзакцией Тх и
измененное Тъ оно оказалось бы вполне пригодным для считывания транзакцией Г3
(эта версия А обладает временем записи, равным 150, которое заведомо меньше
величины хронологического признака Г3). Если система сохраняет достаточно
полную историю изменения значений элементов базы данных и их
хронологических признаков, транзакция всегда сможет воспользоваться тем вариантом
элемента, который отвечает ее "возрасту".
936
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
тх
TS = 150
т2
TS = 200
Гз
TS = 175
тА
TS = 225
Л
RT = 0
WT = 0
rx(A)\ RT=150
wx(A)\ WT=150
г2(Л); RT = 200
w2(A)\ WT = 200
Ъ(А);
Abort;
r4(A); RT = 225
Рис. 18.40. Транзакция Т.? обязана прервать выполнение, если прежняя версия элемента А
недоступна
□
Планировщик заданий, поддерживающий множественные версии значений
элементов базы данных и их хронологических признаков, отличается от обычного
планировщика на основе механизма хронометража, описанного в разделе 18.8.4 на с. 934,
в следующих аспектах.
1. Если очередная операция записи wT(X) физически осуществима, создается
новая версия элемента X с временем записи TS(7); далее система ссылается на нее
как на Х„ где t = TS(7).
2. При обработке операции чтения гТ(Х) планировщик отыскивает такую версию
Хг элемента X, чтобы /<TS(7) при условии, что других версий Xr, /</'<TS(7), не
существует. Другими словами, используется версия X с временем записи,
непосредственно предшествующим величине хронологического признака
транзакции, выполняющей операцию чтения.
3. Значения времени записи ассоциируются RT = 80
с версиями элемента и позже никогда не I
изменяются. т
4. Величины времени чтения также связы- Т ■ Т
ваются с конкретными версиями элемента i
и используются планировщиком при не- 50 т ' к 10°
обходимости запрещения операций запи- с хронологическим признаком 60
си, время выполнения которых меньше пытается выполнить
времени чтения последней версии. Про- операцию записи элемента X
блема иллюстрируется на рис. 18.41. Сие- Рис 1841 Попытка транзакции со-
тема хранит информацию о двух версиях хранить новую версию элемента X
элемента X — Х50 и Х100, — последняя счи- приводит к физической неосуществи-
тывается в момент времени 80, а затем мости расписания
транзакция Т с хронологическим
признаком 60 предпринимает попытку записи X с созданием новой версии элемента.
Притязания транзакции Т должны быть отвергнуты — то значение X, которое
она пробует сохранить, должно было бы считываться транзакцией,
выполнявшей операцию чтения в момент времени 80.
5. Если версия Хг обладает таким временем записи г, что среди активных
транзакций нет ни одной, хронологический признак которой был бы меньше t,
планировщик заданий имеет право удалить все версии X, предшествующие Xt.
18.8. ХРОНОМЕТРАЖ ДЕЙСТВИЙ ТРАНЗАКЦИЙ
937
Пример 18.28. Вновь обратимся к расписанию, показанному на рис. 18.40 (см. с. 937),
с условием, что планировщик заданий поддерживает множественные версии элементов
данных и их хронологических признаков. В данном случае существуют три версии
элемента А: исходная А0, представляющая состояние базы данных до старта транзакций,
а также Л150 и А2оо, сохраненные транзакциями Тх и Т2 соответственно. На рис. 18.42
приведена последовательность событий создания и считывания версий элемента А.
Обратите внимание, что теперь планировщик не вынуждает транзакцию Т3 прерывать
выполнение, поскольку та имеет возможность воспользоваться более ранней версией А.
тх
TS = 150
т2
TS = 200
Т3
TS = 175
ТА
TS = 225
Л0
Л150
Л 200
П(А); Чтение
wi(A); Создание
г2(А)\ Чтение
w2(A); Создание
г3(А); Чтение
г4(А); Чтение
Рис. 18.42. Последовательность выполнения операций под управлением планировщика заданий,
поддерживающего множественные версии элементов данных и их хронологических признаков
□
18.8.6. Хронометраж и блокирование: за и против
Вообще говоря, схема хронометража предпочтительна в тех случаях, когда либо
большинство транзакций функционирует в режиме "только для чтения" (read-only),
либо ситуации единовременного обращения параллельно действующих транзакций к
одним и тем же элементам с операциями чтения и записи возникают редко. В среде,
насыщенной конфликтными событиями, однако, схема блокирования (locking)
(см. разделы 18.3—18.7 на с. 894-924) демонстрирует более высокую эффективность.
Доводы в пользу подобного эвристического правила таковы.
• В случае применения механизма блокирования работа транзакций,
нуждающихся в захвате блокировок элементов, нередко приостанавливается, что может
привести и к ситуациям взаимоблокировки (deadlock), когда несколько
транзакций длительное время пребывают в состоянии ожидания и для выхода из
тупика по меньшей мере одна из них подлежит откату.
• Если же параллельные транзакции часто считывают и записывают одни и те же
элементы, частыми окажутся и операции отката, а это чревато, возможно, даже
более длительными задержками, нежели при использовании схемы блокирования.
В некоторых коммерческих системах баз данных находит применение одно
любопытное компромиссное решение. Планировщик заданий распределяет транзакции по
двум категориям — "только для чтения" (read-only) и прочие. "Прочие" транзакции,
способные выполнять как чтение элементов данных, так и их модификацию,
действуют по правилам двухфазного блокирования, препятствуя возможности
единовременного обращения к заблокированным элементам со стороны любых сторонних
транзакций. Транзакции "только для чтения" функционируют в соответствии с
условиями протокола хронометража с множественными версиями элементов и
хронологических признаков. По мере создания транзакциями новых версий элементов те
поступают в распоряжение планировщика, который управляет ими таким образом, как
938
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
упоминалось в разделе 18.8.5 на с. 936. Транзакциям "только для чтения" разрешается
считывать те версии элементов, которые отвечают хронологическим признакам этих
транзакций. Поэтому последние никогда не прерывают выполнение и только изредка
вынуждены приостанавливаться.
18.8.7. Упражнения к разделу 18.8
Упражнение 18.8.1. Ниже приведены последовательности событий, в число которых
входит событие stj старта транзакции 7}. Последовательности соответствуют ситуациям
реального времени выполнения транзакций; планировщик заданий, основанный на
механизме хронометража, присваивает транзакциям хронологические признаки в
порядке старта. Опишите, что происходит во время выполнения каждого из расписаний.
* a) sty sty rx(A)\ r2(B); w2(A)\ w,(fl);
b) sty r{(A)\ sty w2(B)\ r2(A)\ wx{JB)\
c) sty sty sty п(Л); r2(B); wx(Q\ r3(B)\ r3(Q; w2(B); w3(A);
d) sty sty sty n(A)\ r2(B): Wl(Q: г3(Я); r3(Q; w2(B); w3(A);
Упражнение 18.8.2. Поясните ход событий, происходящих при реализации
указанных ниже расписаний планировщиком заданий, поддерживающим множественные
версии элементов базы данных и их хронологических признаков. Что случится
в каждой из ситуаций, если использовать планировщик, который не сохраняет
историю изменений содержимого элементов?
* a) sty sty sty sty wx(A)\ w2(A)\ w3(A); r2(A)\ rA(A)\
b) sty sty sty sty wx(A)\ w3(A); r4(A); r2(A);
c) sty sty sty sty Wj(A); w4(A); r3(A)\ w2(A)\
!! Упражнение 18.8.3. Говоря о планировщиках, основанных на схеме блокирования,
мы называли несколько причин возникновения ситуаций взаимоблокировки
транзакций. Угрожают ли аналогичные проблемы планировщику заданий,
применяющему механизм хронометража и ведущему учет значений флагов фиксации С(Х)
элементов X базы данных?
18.9. Проверка достоверности действий транзакций
Проверка достоверности (validation) действий транзакций — это еще одна
оптимистичная (optimistic) стратегия управления параллельными заданиями,
подразумевающая возможность доступа к элементам данных без их блокирования и периодический
контроль последовательного поведения транзакций в соответствующие моменты
времени. Проверка достоверности принципиально отличается от механизма
хронометража (timestamping) (см. раздел 18.8 на с. 930) тем, что планировщик ведет журнал
действий активных транзакций вместо фиксации моментов времени чтения и записи
элементов базы данных. Непосредственно перед выполнением транзакцией набора
операций записи элемента те проходят фазу проверки, в ходе которой множества
считанных элементов и элементов, подлежащих модификации, сопоставляются с
множествами элементов, измененных другими активными транзакциями. Если возникает
опасность физически неосуществимого поведения, транзакция откатывается.
18.9.1. Архитектура планировщика с функциями проверки достоверности
действий транзакций
При использовании стратегии проверки достоверности действий параллельных
транзакций как инструмента управления ими планировщик заданий должен
позаботиться о получении информации о подмножествах элементов, которые считывает
18.9. ПРОВЕРКА ДОСТОВЕРНОСТИ ДЕЙСТВИЙ ТРАНЗАКЦИЙ
939
и записывает каждая активная транзакция. Эти множества принято называть
множеством чтения (read set) и множеством записи (write set) и обозначать как RS(r) и \VS(T)
соответственно. Выполнение каждой транзакции протекает в продолжение трех фаз.
1. Чтение — транзакция считывает из базы данных значения элементов,
принадлежащих ее собственному множеству чтения, и вычисляет в локальном адресном
пространстве все результаты, которые предполагает сохранить в базе данных.
2. Проверка — планировщик ревизует достоверность действий транзакции,
сопоставляя ее множества чтения и записи с аналогичными структурами других
транзакций. О процессе проверки подробно рассказано в разделе 18.9.2 на с. 940.
Если итог проверки оказывается отрицательным, транзакция подлежит откату;
в противном случае транзакции разрешается перейти к третьей фазе.
3. Запись — транзакция сохраняет в базе данных значения элементов,
принадлежащих ее собственному множеству записи.
Каждую транзакцию, успешно прошедшую фазу проверки, можно воспринимать так,
будто она выполняется в момент осуществления проверки. Поэтому планировщик,
функционирующий в режиме проверки достоверности действий транзакций,
придерживается некоторого подразумеваемого последовательного порядка протекания транзакций
и основывает решения о целесообразности выполнения проверки с учетом того,
согласуется ли реальное поведение транзакшш с этим последовательным порядком.
Для обеспечения возможности принятия решений о необходимости осуществления
проверки планировщик должен поддерживать три множества данных.
1. START — множество транзакций, которые приступили к работе, но еще не
завершили фазу проверки. Для каждой транзакции Т, упомянутой в множестве
START, планировщик сохраняет значение START(r) времени ее старта.
2. VAL — множество транзакций, прошедших фазу проверки, но не выполнивших
фазу записи. Для каждой транзакции Т из множества VAL планировщик
фиксирует как величину START(r), так и значение VAL(7) момента времени, когда Т
подвергалась процедуре проверки; УАЦГ) расценивается как момент
воображаемого выполнения транзакции Т в гипотетическом последовательном расписании.
3. FIN — множество транзакций, завершивших фазу записи. Для каждой
транзакции Т, принадлежащей множеству FIN, наряду с величинами START(r) и WAL(T)
планировщик регистрирует значение FIN(r) момента времени окончания
выполнения Т. Множеству FIN присуща тенденция к постоянному возрастанию,
но, очевидно, планировщику нет необходимости сохранять информацию о
таких транзакциях Т, которые отвечают условию F1N(7) < START(/7) для любой
активной (т.е. упомянутой в множествах START или VAL) транзакции U. Поэтому
планировщик может периодически очищать журнал от устаревшей
информации, препятствуя неограниченному увеличению его объема.
18.9.2. Правила проверки достоверности действий транзакций
Информации, указанной в разделе 18.9.1 на с. 939, планировщику заданий
достаточно для обнаружения любого факта нарушения подразумеваемого последовательного
порядка выполнения транзакций — порядка, в котором действия транзакций подвергаются
проверке. Для разъяснения правил вначале целесообразно рассмотреть, что именно
может привести к нарушению порядка при попытке проверки некоторой транзакции Т.
1. Предположим, что существует транзакция U, такая, что:
a) U упоминается в VAL или FIN, т.е. U успешно проверена;
940
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Т считывает X
U записывает X
Ь±1
It!!
U стартует Т стартует I Т проверяется
U проверена
Рис. 18.43. Действия транзакции Т нельзя
проверять, если какая-либо более ранняя
транзакция U сохраняет данные, которые
должны быть считаны транзакцией Т
b) FIN(f/) > START(T); иными словами, к моменту старта Т выполнение U еще не
завершено;140
c) множество RS(7) П WS(L0 не пусто; предположим, что оно содержит, в
частности, элемент X.
Тогда возможно, что U сохраняет значение X после того, как Т считывает X.
В действительности U прежде могла не записывать X вовсе. Ситуация, когда U
сохраняет X, но "не вовремя", представлена на рис. 18.43. Для прояснения
картины достаточно сказать, что пунктирные линии связывают фактические события
с отметками на оси времени, когда эти события могли бы произойти,
выполняйся транзакции в моменты их проверки. Поскольку не известно, успела ли
транзакция Т осуществить чтение результата операции записи £/, Т подлежит
откату во избежание опасности, что очередность действий Г и £/ окажется
несовместимой с подразумеваемым последовательным порядком.
2. Теперь допустим существование такой транзакции U, что:
a) U присутствует в VAL, т.е. U успешно проверена;
b) FIN(L0> VAL(7); другими словами, к моменту вхождения Т в фазу проверки
выполнение U еще не завершено;
c) WS(7)n WS(£/)* 0; предположим, в частности, что элемент X принадлежит
обоим множествам записи.
Потенциальная проблема проиллюстрирована на рис. 18.44. Обе транзакции, Т и U,
должны осуществить запись значений элемента X, но если позволить транзакции
Т пройти фазу проверки, Г, возможно, сохранит X прежде, чем это сделает U.
Поскольку полной уверенности в том, что подобное не произойдет, нет,
планировщик должен произвести откат Г, чтобы гарантировать незыблемость
последовательного порядка действий, согласно которому U предшествует транзакции Г.
Проблемы, описанные выше, связаны с двумя единственно возможными ситуациями,
когда операция считывания или записи, выполняемая транзакцией Г, может оказаться
физически неосуществимой. В случае, представленном на рис. 18.43, если U завершает работу
прежде, чем Т стартует, Т определенно имеет основание считать значение X, сохраненное
транзакцией U. В ситуации, отображенной на рис. 18.44, если U финиширует раньше, чем
140 Заметьте, что если U присутствует в VAL, значит, к началу проверки Т транзакция U не
завершена и значение FIN((/), строго говоря, не определено. Однако в рассматриваемом случае
считается, что FIN(60 должно быть больше START(T).
18.9. ПРОВЕРКА ДОСТОВЕРНОСТИ ДЕЙСТВИЙ ТРАНЗАКЦИЙ
941
Т записывает X
U записывает X
\ I
U проверена Т проверяется U завершает работу
Рис. 18.44. Транзакция Т не должна подвергаться
проверке, если существует опасность, что Т
способна выполнить операцию записи раньше, нежели
аналогичное действие осуществит более ранняя
транзакция U
Т подвергается проверке, U правомочна осуществить запись X перед тем, как это сделает Т.
Указанные соображения естественным образом подводят нас к обобщенным правилам
проверки достоверности действий произвольной транзакции Т.
• убедиться, что RS(7) П WS(£/) = 0 для любой ранее проверенной транзакции U,
которая к моменту старта Т еще не завершила работу, т.е. удовлетворяет
условию FIN(U) > START(7);t
• удостовериться, что WS(7) П WS(L0 = 0 для любой ранее проверенной
транзакции U, которая к моменту начала процедуры проверки Т еще не завершила
работу, т.е. удовлетворяет условию ¥1Щ1Г) > VAL(7).
Пример 18.29. На рис. 18.45 изображен временной промежуток, внутри которого
четыре транзакции — Т, U, V и W — стартуют, выполняют определенные операции,
подвергаются проверке достоверности действий и завершают работу. На диаграмме
представлены множества чтения и записи для каждой из транзакций. Транзакция Т,
например, стартует первой, хотя U прежде других проходит фазу проверки.
RS-{5}
WS={Z)}
RS={A,D}
WS = {А, С }
= Старт
X = Проверка
О = Завершение
RS={A,B }
WS = {А, С }
RS-{5}
WS = { А Е}
Рис. 18.45. Последовательность событий старта,
проверки и завершения четырех транзакций
Проверка U. К моменту проверки U другие транзакции еще не проверялись, так что
условий, подлежащих контролю, нет. Поэтому U беспрепятственно проходит
стадию проверки и сохраняет предусмотренное ею измененное значение элемента D.
942
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
2. Проверка Г. К началу проверки Г транзакция U уже миновала стадию проверки,
но еще не завершила работу. Планировщик обязан убедиться, что ни
множество чтения, ни множество записи Г не имеют общих элементов с множеством
WS(L0 ={D]. Поскольку RS(7) = {Л, В] и WS(7) = {А, С}, т.е. общих элементов
действительно нет, оба правила удовлетворяются, и проверка Т успешно завершается.
3. Проверка V, К моменту проверки V транзакция U проверена и завершена, а Т
проверялась, но еще не финишировала. Помимо того, V стартовала до
окончания работы U. Поэтому с WS(T) должны сравниваться как RS(V), так
и WS(V), а с WS(£/) — только RS(V):
a) RS(V)nwS(D = {£}n{A,C} = 0;
b) WS(V) П WS(D = {D, E) П [A, C] = 0;
c) RS(V)nWS(^={5}n{D} = 0.
Все три условия выполняются, так что V благополучно проходит фазу проверки.
4. Проверка W. К началу проверки W выполнение транзакции U уже полностью
завершено, поэтому сопоставлять множества операций W и U необходимости
нет. Транзакция Т завершила работу до начала фазы проверки W, но в момент
старта W она еще пребывала в активном состоянии, так что необходимо
и достаточно сравнить содержимое множеств RS(W) и WS(7). К моменту
проверки W транзакция V уже прошла процедуру проверки, но, однако, не
финишировала; поэтому с WS(V) следует сопоставить как RS(W0, так и WS(W).
Вот как выглядят результаты сравнения:
a) RS(W0nwS(7) = M,D}n{A,C} = M};
b) RS(WOnwS(V)=M,D} ГИД Я} = {/>};
c) WS(W) П WS(V) = {Л, С} П {А Е) = 0.
Поскольку не все пересечения множеств пусты, транзакция W условиям
проверки не удовлетворяет и подлежит откату (без сохранения в базе данных
значений элементов Л и С).
□
18.9.3. Упражнения к разделу 18.9
Упражнение 18.9.1. В приведенных ниже последовательностях действий выражение
вида Rj(X) означает "старт транзакции Г, с множеством чтения, описываемым
списком X элементов базы данных", выражение V,- — "попытка проверки транзакции
Г,", а выражение Wt(X) — "финиш транзакции 7} с множеством записи,
представляемым списком X элементов базы данных". Поясните, что произойдет при
обработке каждого расписания планировщиком событий, реализующим схему проверки
достоверности действий транзакций.
* a) R{(A, В); R2(B, Q; Vy, tf3(C D); V3\ W{(A)\ V2\ W2(A); W3(B);
b) R{(A, B)\ R2(B, С); Vx\ R3(C, D)\ V3\ WX(A)\ V2\ W2(A); W3(D)\
c) R{(A, B)\ R2(B, Q; Vx\ R3(C, D); V3; W^C); V2; W2(A); W3(D);
d) R{(A, B)\ R2(B, С); R3(Q; V,; V2\ V3; W,(A); W2(B); W3(Q\
e) R{(A, B); R2(B, Q; R3(Q; Vx\ V2; V3; W,(0; W2(B); W3(A);
f) R{(A, B); R2(B, O; R3(Q; Vx\ V2; V3; W,(A); W2(Q; W3(B);
18.9. ПРОВЕРКА ДОСТОВЕРНОСТИ ДЕЙСТВИЙ ТРАНЗАКЦИЙ
943
Минутку...
Вас, возможно, смутило неявно подразумеваемое условие, касающееся того, что
процесс проверки должен протекать "мгновенно" (или в течение малого
неделимого промежутка времени). Приходится, например, задаваться вопросами такого
рода: завершился ли процесс проверки некоторой транзакции U до начала
проверки транзакции Т либо может ли транзакция U завершить фазу проверки в период
выполнения проверки транзакции Т.
Если в распоряжение системы баз данных предоставлены только один
аппаратный процессор и единственный процесс планировщика заданий, процедуры
проверки и выполнения иных действий под руководством планировщика можно в
самом деле воспринимать как неделимые и осуществляемые непрерывно: коль скоро
планировщик занялся проверкой транзакции Г, он не в состоянии одновременно
проводить проверку транзакции (/, поэтому в продолжение фазы проверки Т статус
"достоверности действий" U измениться не может.
Если же СУБД функционирует в среде многопроцессорной вычислительной
системы и поддерживает несколько процессов управления параллельными
заданиями, ситуация, когда в один и тот же момент времени фазу проверки проходят
две или более транзакций, вполне правдоподобна. В таком случае СУБД обязана
гарантировать атомарность процедур проверки, полагаясь на механизм
синхронизации межпроцессорного взаимодействия, предлагаемый аппаратной системой.
18.10. Сравнение схем управления параллельными заданиями
Каждый из трех рассмотренных нами подходов к проблеме обеспечения
последовательного характера действий параллельных транзакций — блокирование (locking)
(см. разделы 18.3-18.7 на с. 894—924), хронометраж (timestamping) (см. раздел 18.8 на
с. 930) и проверка достоверности (validation) (см. раздел 18.9 на с. 939) — обладает
определенными преимуществами и недостатками. Во-первых, подходы можно
сравнивать по степени эффективности использования ресурсов памяти и диска.
• Блокирование. Размер пространства, занимаемого таблицей блокировок,
пропорционален количеству заблокированных элементов базы данных.
• Хронометраж. В простейшем варианте предусматривается хранение значений
времени чтения и времени записи для всех без исключения элементов базы
данных, независимо от того, используются они в данный момент времени или нет.
При более тщательной реализации величины хронологических признаков
элементов, которые меньше значения момента времени старта наиболее ранней
транзакции, трактуются как "минус бесконечность" и не сохраняются. В подобном
случае в таблице, подобной таблице блокировок, могут сохраняться значения времени
чтения и записи только таких элементов, которые обрабатывались "недавно".
• Проверка достоверности. Память расходуется для хранения хронологических
признаков и множеств чтения/записи для каждой активной транзакции и,
возможно, еще некоторого числа транзакций, которые завершили выполнение
после старта каких-либо активных транзакций.
Таким образом, размер пространства памяти, используемого при реализации любого
из трех подходов, приблизительно пропорционален суммарному количеству элементов
данных, затрагиваемых всеми активными транзакциями. Схемы хронометража и
проверки достоверности действий транзакций вправе потребовать несколько больший
ресурс памяти, поскольку предусматривают необходимость дальнейшего хранения данных,
имеющих отношение к некоторым "недавно" завершенным транзакциям (из таблицы
944
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
блокировок подобные данные могут безболезненно исключаться). Механизму проверки
достоверности присуща одна потенциальная проблема, связанная с необходимостью
получения данных множества записи транзакции еще до выполнения ею операций записи
как таковых (но после завершения вычислений в локальном адресном пространстве).
Во-вторых, методы управления параллельными заданиями можно сопоставлять
и по их способности к обеспечению непрерывного прохождения операций транзакций.
Производительность каждой из схем зависит от того, насколько велика степень
взаимодействия транзакций между собой (т.е. вероятность единовременного обращения
нескольких параллельных транзакций к одному и тому же элементу базы данных).
♦ При использовании схем блокирования транзакции часто приостанавливаются, но
редко откатываются — даже если степень взаимного влияния транзакций высока.
Планировщики заданий, основанные на механизмах хронометража и проверки
достоверности, напротив, не приостанавливают работу транзакций, но способны
провоцировать их откат, а это следует воспринимать как более серьезную форму
приостановки, связанную к тому же с излишним расходом системных ресурсов.
♦ Если уровень взаимодействия транзакций невысок, ни схема хронометража, ни
механизм проверки достоверности действий транзакций не приводят к частым
откатам транзакций и могут рассматриваться как более предпочтительные
решения, поскольку в общем случае обусловливают меньшие накладные расходы,
нежели алгоритмы блокирования.
♦ Схема хронометража позволяет выявить некоторые возможные проблемы на
более ранней стадии, нежели механизм проверки достоверности, что позволяет
транзакции выполнить все внутренние действия до момента принятия
планировщиком окончательного решения о необходимости ее отката.
18.11. Резюме
♦ Согласованные состояния базы данных. Состояния базы данных,
удовлетворяющие ограничениям, подразумеваемым или явно определенным
проектировщиком в ее схеме, называют согласованными. Принципиально важно, чтобы
любые операции модификации сохраняли свойство согласованности состояния
базы данных, т.е. переводили ее из одного согласованного состояния в другое.
♦ Согласованность параллельных транзакций. Ситуация, когда несколько
параллельно функционирующих транзакций единовременно обращаются к одному
и тому же элементу данных, является вполне нормальной. Подразумевается, что
каждая из транзакций, выполняемая в изоляции от других транзакций,
поддерживает свойство согласованности базы данных. Ответственность за сохранение
того же условия при параллельной работе тех же транзакций возлагается на
планировщик заданий, или менеджер параллельных заданий.
♦ Расписания. Транзакции представляются в виде упорядоченных наборов
действий, преимущественно связанных с операциями чтения и записи элементов
базы данных. Последовательность действий одной или нескольких транзакций
называют расписанием.
♦ Последовательные расписания. Если транзакции выполняются по одной в
каждый период времени, такое расписание является последовательным.
♦ Условно-последовательные расписания. Расписание, эффект воздействия которого
на состояние базы данных равноценен результату выполнения
последовательного расписания, называют условно-последовательным. Соответствующим
образом перемежая действия нескольких транзакций, можно добиться условно-
последовательного, хотя и не последовательного, порядка их прохождения;
18.11. РЕЗЮМЕ
945
планировщик заданий, однако, обязан выбирать такую очередность обработки
действий, которая сохраняла бы согласованное состояние базы данных.
♦ Способность транзакций к последовательному упорядочению с учетом
конфликтов. Один из достаточных и легко проверяемых критериев
допустимости преобразования расписания в условно-последовательный вид состоит
в возможности взаимного перемещения соседних неконфликтных действий
транзакций. Такое расписание называют условно-последовательным с учетом
конфликтов. Конфликты возникают в тех случаях, когда местами меняются
действия одной транзакции или действия (по меньшей мере одно из которых
связано с записью) с участием одного и того же элемента базы данных.
♦ Графы предшествования. Простой способ проверки способности транзакций к
последовательному упорядочению с учетом конфликтов связан с построением графа
предшествования, отвечающего конкретному расписанию. Вершины графа
представляют транзакции; граф содержит дугу Г-> U, если некоторое действие
транзакции Т в расписании конфликтует с каким-либо более поздним действием
транзакции U. Расписание является условно-последовательным с учетом конфликтов, если
и только если соответствующий граф предшествования не содержит циклов.
♦ Блокирование. Наиболее общий подход к решению проблемы получения
условно-последовательных расписаний выполнения транзакций связан с
блокированием элементов базы данных перед обращением к ним с операциями чтения
или записи и освобождением блокировок после завершения операций.
Блокировка элемента, удерживаемая одной транзакцией, препятствует возможности
единовременного обращения к нему со стороны других транзакций.
♦ Двухфазное блокирование. Применение механизма блокирования как такового еще
не обеспечивает возможность условно-последовательного упорядочения действий
транзакций. Подобные гарантии дает, например, схема двухфазного
блокирования, в соответствии с которой транзакции обязаны вначале захватить все
требуемые блокировки, осуществить операции и только затем освободить блокировки.
♦ Режимы блокирования. Во избежание случаев чрезмерно жесткого блокирования
элементов данных СУБД обычно поддерживают несколько режимов
блокирования, подчиняющихся различным правилам и соответствующих определенным
ситуациям. Самое широкое применение находят режимы общего (для совместного
использования с операциями чтения) и монопольного (предназначенного для
ограничения возможности доступа к элементам во время их записи) блокирования.
♦ Матрицы совместимости. Матрица совместимости представляет собой
концентрированное выражение правил захвата блокировки в том или ином режиме
в случае, когда элемент данных уже блокирован в определенном режиме.
♦ Обновляемые блокировки. Планировщик заданий может позволить транзакции,
намеревающейся осуществить считывание, а затем сохранение содержимого
элемента, вначале захватить обновляемую блокировку, разрешающую чтение,
а затем повысить уровень блокирования до монопольного, необходимого для
записи. Обновляемая блокировка может быть предоставлена транзакции
и в том случае, когда элемент уже блокирован в общем режиме, но как только
обновляемая блокировка становится активной, она препятствует возможности
захвата иных блокировок того же элемента.
♦ Инкрементные блокировки. В тех довольно распространенных случаях, когда
действия транзакции сводятся к увеличению или уменьшению значения элемента на
некоторую константу, удобно использовать инкрементный режим блокирования.
Инкрементные блокировки одного элемента взаимно не конфликтны, но
вступают в противоречие с общими и монопольными блокировками.
946
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
♦ Блокировки с множеством степеней детализации. В случаях, когда разрешается
единовременное блокирование элементов различной структурной сложности —
скажем, отношений, дисковых блоков и отдельных кортежей, — для
обеспечения условно-последовательного характера расписания планировщик заданий
может применить механизм предупреждающего блокирования: транзакция
обозначает предупреждающей блокировкой крупного элемента данных намерение
обратиться к одному или нескольким вложенным элементам.
♦ Протокол блокирования древовидных структур. Если доступ к элементам данных
осуществляется только в направлении "вниз" по дереву иерархии (скажем, как
при использовании В-древовидных индексов), двухфазная стратегия
блокирования демонстрирует свою несостоятельность и подлежит пересмотру и замене.
Правила, составляющие протокол блокирования древовидных структур,
подразумевают необходимость получения блокировки родительской вершины дерева
с целью захвата блокировки дочерней вершины, хотя позже блокировка
родительской вершины может быть освобождена.
♦ Оптимистичные стратегии управления параллельными заданиями. Планировщик
заданий может трактовать расписание как условно-последовательное и вместо
блокирования осуществлять прерывание работы транзакций, если их поведение
угрожает последовательному ходу событий. К числу подобных оптимистичных
подходов относятся стратегии управления, основанные на механизмах
хронометража и проверки достоверности действий транзакций.
♦ Хронометраж действий транзакций. Планировщик, поддерживающий механизм
хронометража, присваивает каждой транзакции хронологический признак,
содержащий значение времени начала ее работы, и ассоциирует с элементами
базы данных моменты времени их считывания и записи, равные хронологическим
признакам транзакций, которые обращались к этим элементам последними.
Если планировщик обнаруживает одну из физически неосуществимых
операций (например, транзакция считывает значение, которое, строго говоря,
должно быть сохранено другой транзакцией позже), транзакция, виновная в
происшедшем, подвергается откату, т.е. прерыванию и повторному выполнению.
♦ Проверка достоверности действий транзакций. Планировщик, основанный на
схеме проверки достоверности действий транзакций, контролирует поведение
транзакций после выполнения ими операций считывания, но до осуществления
процедур записи. Транзакции, которые считывают или намереваются
записывать значения элементов, подлежащих сохранению другими транзакциями,
критериям проверки не удовлетворяют и откатываются.
♦ Множественные версии элементов и хронологических признаков. В коммерческих
системах баз данных для управления транзакциями, функционирующими в
режиме "только для чтения", зачастую применяется усовершенствованный
механизм хронометража, предусматривающий учет множественных версий значений
элементов и их хронологических признаков, когда после операции записи нового
значения сохраняется и информация о прежнем состоянии элемента; история
изменений поддерживается до тех пор, пока все текущие транзакции, которым,
возможно, понадобятся "старые" версии элементов, не завершат работу. Транзакции,
выполняющие операции записи, управляются с помощью схемы блокирования.
18.12. Литература
Одним из основных источников информации по общим вопросам упорядочения
операций параллельных транзакций и схемам блокирования является книга [6]. Еще
одна столь же важная работа — это монография [3]. Обзоры недавних результатов
в области управления параллельными заданиями содержатся в [11] и [12].
18.12. ЛИТЕРАТУРА
947
Вероятно, наиболее значимую роль сыграла в свое время статья [4], представившая
концепцию двухфазного блокирования. Сведения о протоколе предупреждающего
блокирования с множеством степеней детализации заимствованы из работы [5], а о модели
блокирования древовидных структур — из [10]. Аппарат матриц совместимости как
инструмента изучения взаимного влияния различных режимов блокирования предложен в [7].
Механизм хронометража впервые описан в [1] и [2], а стратегия проверки
достоверности действий транзакций — в [8]. Способы использования множественных
версий элементов и их хронологических признаков разработаны в [9].
1. Bernstein P.A., Goodman N. Timestamp-based algorithms for concurrency control in distributed
database systems, Proc. Intl. Conf. on Very Large Databases (1980), p. 285-300.
2. Bernstein P.A., Goodman N., Rothnie J.B. (Jr.), and Papadimitriou C.H. Analysis for
serializability in SDD-1: a system of distributed databases (the fully redundant case), IEEE Trans,
on Software Engineering, SE-4:3 (1978), p. 154-168.
3. Bernstein P.A., Hadzilacos V., and Goodman N. Concurrency Control and Recovery in
Database Systems, Addison-Wesley, Reading, MA, 1987.
4. Eswaran K.P., Gray J.N., Lorie R.A., and Traiger I.L. The notions of consistency and predicate
locks in a database system, Comm. ACM, 19:11 (1976), p. 624—633.
5. Gray J.N., Putzolo F., and Traiger I.L. Granularity of locks and degrees of consistency in
a shared data base, in Modeling in Data Base Management Systems (G.M. Nijssen, ed.),
North Holland, Amsterdam, 1976.
6. Gray J.N., Reuter A. Transaction Processing: Concepts and Techniques, Morgan-Kaufmann,
San Francisco, 1993.
7. Korth H.F. Locking primitives in a database system, J. ACM, 30:1 (1983), p. 55-79.
8. Kung H.-T., Robinson J.T. Optimistic concurrency control, ACM Trans, on Database Systems,
6:2 (1981), p. 312-326.
9. Papadimitriou C.H., Kanellakis P. On concurrency control by multiple versions, ACM Trans, on
Database Systems, 9:1 (1984), p. 89-99.
10. Silberschatz A., Kedem Z. Consistency in hierarchical database systems, J. ACM, 27:1
(1980), p. 72-80.
11. Thomasian A. Concurrency control: methods, performance, and analysis, Computing Surveys,
30:1 (1998), p. 70-119.
12. Thuraisingham В., Ко Н.-Р. Concurrency control in trusted database management systems:
a survey, SIGMOD Record, 22:4 (1993), p. 52-60.
948
ГЛАВА 18. УПРАВЛЕНИЕ ПАРАЛЛЕЛЬНЫМИ ЗАДАНИЯМИ
Глава 19
Дополнительные аспекты
управления транзакциями
В этой главе мы сосредоточим внимание на некоторых проблемах управления
транзакциями, не нашедших отражения в главах 17 (см. с. 837) и 18 (см. с. 879), и вначале
попытаемся согласовать подходы, которые использовались выше при изложении
вопросов восстановления состояния базы данных после системных сбоев, прерывания
транзакций и поддержки последовательного характера расписаний. Затем будут
освещены проблемы преодоления ситуаций взаимоблокировки (deadlock), которые обычно
возникают, когда нескольким транзакциям приходится пребывать в состоянии
бесконечного ожидания момента освобождения ресурса, захваченного другой параллельно
функционирующей транзакцией.
Глава включает также введение в технологии распределенных баз данных (distributed
databases). Мы расскажем, каким образом блокируются элементы частей базы данных,
разнесенных по нескольким рабочим площадкам (сайтам) (возможно, с
использованием реплицированных копий), и как принимаются решения о фиксации (commit)
или прерывании (abort) транзакции, затрагивающей данные на различных сайтах.
В завершение рассмотрим проблемы обработки длинных ("long") транзакций.
Существуют приложения — например, системы автоматизированного проектирования
(САПР) или разнообразные системы управления производством, — в которых
процессы взаимодействия человека и машины охватывают продолжительные периоды
времени, исчисляемые часами или даже сутками. Подобные системы, как и приложения
с "короткими" транзакциями (скажем, банковские системы или системы бронирования
авиабилетов), также нуждаются в сохранении согласованного состояния баз данных.
Однако методы управления параллельными заданиями, рассмотренные в главе 18, не
применимы в случаях, когда блокировки элементов удерживаются на протяжении
чрезмерно долгих промежутков времени либо решения о проверке достоверности действий
транзакций принимаются с учетом событий, имевших место в отдаленном прошлом.
19.1. Последовательное упорядочение операций
и восстановление данных
В главе 17 на с. 837 обсуждались технологии ведения протокола операций и его
использования с целью восстановления состояния базы данных после возможного
отказа системы. Мы познакомили вас с моделью вычислений, предполагающей обмен
данными между энергонезависимым (nonvolatile) дисковым устройством,
энергозависимой (volatile) оперативной памятью и локальным адресным пространством
транзакции. В случае системного сбоя различные методы протоколирования (logging)
обеспечивают гарантии восстановления (recovery) результатов действий {зафиксированных —
committed) транзакций в дисковой копии базы данных. Система протоколирования
сама по себе не несет ответственность за поддержку последовательного характера
расписания выполнения операций — она "слепо" реставрирует состояние базы данных,
явившееся итогом порядка действий, который, возможно, даже не был
последовательным. Более того, в коммерческих системах баз данных требование, касающееся
возможности последовательного упорядочения (serializability) операций транзакций,
выдвигается далеко не всегда, а в некоторых случаях оно реализуется только по
принудительному запросу со стороны пользователя.
В главе 18 на с. 879, напротив, внимание ограничивалось только проблемой
обеспечения последовательного прохождения операций. Планировщик заданий,
сконструированный в соответствии с изложенными нами принципами, вправе принимать
такие решения, которые идут вразрез с политикой, лежащей в основе деятельности
менеджера протоколирования. Например, стратегия последовательного упорядочения
как таковая не препятствует выполнению транзакцией, обладающей блокировкой
элемента А базы данных, инструкции сохранения нового значения Л в базе данных до
операции фиксации, что приводит к нарушению правила протоколирования в режиме
"redo". Еще хуже, транзакция может записать измененное значение, а затем оказаться
прерванной без отмены результатов операции, что повергнет базу данных в
несогласованное состояние — даже в отсутствие системных сбоев.
19.1.1. Проблема "чтения мусора"
Напомним (см. раздел 8.6.5 на с. 400), что данные считаются "мусором" (dirty data),
если они сохранены транзакцией, еще не выполнившей операцию фиксации (commit).
"Мусор" может появиться в буферах оперативной памяти, на диске или в обеих копиях
фрагментов базы данных одновременно — любая из ситуаций чревата опасностью.
Тх Т2 А В
25 25
/i(A); Г!(Л);
А := А + 100;
WxiA); h(B); u{(A); 125
«A); r2(A);
A := A * 2;
w2(A); 250
l2(B) — запрет
Abort; u{(B)\
/2(Я); ц2(Л); r2(B);
В := В * 2;
w2(B); u2(B)\ 50
Рис. 19.1. Транзакция Ti сохраняет "мусор " и прерывает работу
950 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Пример 19.1. Вновь обратимся к условно-последовательному расписанию, изображенному
на рис. 18.13 (см. с. 898), и предположим, что после считывания содержимого элемента В
транзакция 7^ по какой-либо причине прерывает функционирование. Последовательность
событий может выглядеть так, как показано на рис. 19.1. После прерывания транзакции 7^
планировщик заданий освобождает занятую ею блокировку элемента В; это действие
существенно, поскольку в противном случае элемент окажется "навсегда" закрытым для
доступа со стороны любых других транзакций.
Теперь транзакция Т2 пользуется информацией, которая не отражает согласованное
состояние базы данных: Т2 считывает значение Л, измененное транзакцией Ти и
содержимое элемента В, которое хранилось в базе данных до выполнения 7V В данном
случае не важно, сохранено транзакцией 7^ значение 125 элемента Л на диске или
нет — Т2 в любом случае получает его из буфера памяти. Обращаясь к
несогласованным исходным данным, транзакция Тъ естественно, оставляет дисковую копию базы
данных в несогласованном состоянии, где АфВ.
Проблема, проиллюстрированная на рис. 19.1, заключается в том, что значение А,
сохраненное транзакцией Тх и считываемое транзакцией Г2, является "мусором" —
независимо от того, находится оно в буфере оперативной памяти или на диске. Тот
факт, что транзакция Т2 использует в собственных вычислениях данные
сомнительного происхождения, ставит под вопрос правомочность ее действий. Как будет
показано в разделе 19.1.2 на с. 952, если подобные ситуации не запрещены, в случае их
возникновения прерыванию и повторному выполнению подлежат как транзакция,
являющаяся источником "мусора" (в данном случае — 7^), так и транзакции (Г2),
которые обращаются к таким данным. □
Т\ Тг 7з А В С
TS = 200 TS=150 TS = 175 RT = 0 RT = 0 RT = 0
WT = 0 WT = 0 WT = 0
WT= 150
RT=150
r3(C); RT=175
WT = 0
w3(A); WT=175
Рис. 19.2. Транзакция Ту, прочитавшая "мусор", оставленный транзакцией Т2, так же, как
и 1г, подлежит откату
Пример 19.2. Рассмотрим расписание, показанное на рис. 19.2 и представляющее
последовательность действий, выполняемых тремя транзакциями под управлением
планировщика заданий, который реализует технологию хронометража (timestamping)
(см. раздел 18.8 на с. 930). Предположим, однако, что планировщик не пользуется
информацией флага фиксации (commit flag). (Напомним — см. раздел 18.8.1 на с. 931, —
что назначение флага фиксации состоит в предотвращении ситуации, когда одна
транзакция считывает данные, сохраненные другой — незафиксированной —
транзакцией.) Таким образом, когда транзакция Т{ на втором шаге считывает значение Z?,
планировщик не проверяет флаг фиксации В — результат проверки должен был бы
привести к приостановке выполнения операций Т{. Транзакция Т{ продолжает работу,
и ей не воспрещается даже сохранить значения на диске и зафиксировать их
(подробности дальнейших действий Тх здесь опущены).
w2(B);
г2(А);
и>2(0;
Abort;
19.1. ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ ОПЕРАЦИЙ...
951
Позже транзакция Т2 предпринимает попытку изменить значение элемента С
физически неосуществимым образом, что приводит к необходимости ее прерывания.
Результат предыдущего изменения В9 произведенного транзакцией Г2, аннулируется;
значение В и время записи В восстанавливаются в том виде, в каком они пребывали
до операции, выполненной Т2. Транзакции Гь тем не менее, все еще позволяется
использовать это "недействительное" значение В в любых расчетах, связанных,
например, с получением новых величин Л, В и/или С и сохранением их на диске.
Транзакция Гь считавшая "мусор", таким образом, угрожает свойству согласованности
состояния базы данных. Если бы планировщик поддерживал и верным образом
использовал механизм флагов фиксации элементов, операция г{(В) была бы отсрочена
до момента прерывания транзакции Т2 и восстановления предыдущего (вероятно,
фиксированного и удовлетворяющего требованию согласованности) значения В. □
19.1.2. Каскадный откат
Как было показано в примерах 19.1 и 19.2, если транзакции имеют доступ к "мусору",
оставленному другими транзакциями, системе подчас необходимо выполнять процедуру
каскадного отката (cascading rollback). Если некоторая транзакция Г прерывается,
надлежит определить, какие транзакции осуществили чтение информации, измененной Г,
и прервать их, а затем рекурсивным образом осуществить прерывание всех иных
транзакций, обращавшихся к результатам транзакций, прерванных на предыдущем шаге: другими
словами, следует отыскать каждую транзакцию и9 считывавшую "мусор" транзакции Г,
прервать и9 найти все транзакции V, пользовавшиеся "мусором" U9 также прервать их
и т.д. Для аннулирования результатов прерванных транзакций используются данные
протокола, если тот ведется в таком режиме ("undo" или "undo/redo"), который
предусматривает сохранение прежних значений модифицируемых элементов. Для
восстановления можно было бы воспользоваться и дисковой копией базы данных, если "мусор"
не успел переместиться на диск. Оба подхода рассматриваются в следующем разделе.
Как упоминалось выше, планировщик заданий, основанный на механизме
хронометража с поддержкой флагов фиксации, не позволяет транзакции, намеревающейся
считать "мусор", продолжить работу, поэтому при использовании планировщика
подобного типа необходимость в применении схемы каскадного отката не возникает.
Планировщики заданий, реализующие алгоритмы проверки достоверности (validation)
действий транзакций, также исключают потребность в обращении к процедуре
каскадного отката, поскольку операции записи (даже в буферы памяти) осуществляются
только после того, как факт фиксации транзакции становится очевидным.
19.1.3. Восстановимые расписания
Чтобы любой из методов протоколирования, обсуждавшихся в главе 17 на с. 837,
смог оказать содействие в восстановлении данных после системного сбоя, множество
транзакций, трактуемых как зафиксированные после восстановления, должно быть
согласованным. Иными словами, если транзакция Ти рассматриваемая после
восстановления как зафиксированная, использует значение, сохраненное транзакцией Т2, та
после восстановления также обязана быть зафиксированной. Введем определение:
• расписание является восстановимым (recoverable schedule), если каждая
транзакция Т осуществляет фиксацию только после того, как зафиксирована любая
другая транзакция U, результатами которой пользуется Т.
Пример 19.3. В этом и нескольких следующих примерах расписаний, содержащих
действия, связанные со считыванием и записью элементов данных, инструкцией с, мы
будем обозначать операцию фиксации транзакции Тг Вот как может выглядеть
образец восстановимого расписания:
Si- n>i(A); Wi(B); w2(A); r2(B)\ c}; c2\
952 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Заметьте, что транзакция Т2 считывает значение элемента В, сохраненное транзакцией Гь
поэтому в восстановимом расписании Т2 должна осуществлять фиксацию только после Тх.
Расписание Su что совершенно очевидно, последовательно (разумеется, и условно-
последовательно), а также восстановимо, но указанные свойства, вообще говоря,
никак взаимно не обусловлены. Следующий вариант расписания S{ по-прежнему
восстановим, но не условно-последователен:
S2: w2(A); wx(B)\ W\(A)\ r2(B)\ c{\ c2\
В расписании S2, будь оно последовательным, транзакция Т2 должна была бы
предшествовать транзакции 7^ или наоборот, но при выполнении операций записи
содержимого элемента А транзакция Т2 опережает Ти а при сохранении измененных значений
элемента В транзакция Ти напротив, упреждает действие транзакции Т2.
Можно привести и такую версию расписания Sl9 которая является условно-
последовательной, но не восстановимой:
S3: wi(A); w{(B)\ w2(A); r2(B)\ c2; cf,
В расписании 53 транзакция Т{ предшествует транзакции Тъ но выполняемые ими
инструкции фиксации следуют в обратном порядке. Если к моменту возможного отказа
системы запись фиксации Т2 достигнет диска, а аналогичная запись транзакции Т{ — нет,
тогда независимо от режима ведения протокола — "undo", "redo" или "undo/redo" —
только транзакция Т2 будет считаться зафиксированной после восстановления. □
Для того чтобы восстановимые расписания допускали фактическую возможность
восстановления при использовании любого из трех режимов протоколирования,
в системе должно быть реализовано дополнительное правило:
• записи фиксации, заносимые в протокол, обязаны сохраняться на диске в
порядке их поступления.
Как показывает расписание 53 в примере 19.3, если допустимо нарушение порядка
сохранения на диске записей фиксации, согласованное восстановление данных после сбоя
системы может оказаться невозможным. Мы вернемся к этой теме в разделе 19.1.6 на с. 956.
19.1.4. Расписания без каскадного отката
Восстановимые расписания подчас предусматривают необходимость применения
механизма каскадного отката. Если бы, скажем, после выполнения первых четырех действий
расписания S{ в примере 19.3 транзакция Т{ нуждалась в откате, пришлось бы выполнить
и откат транзакции Т2. Чтобы гарантировать невозможность возникновения ситуации,
связанной с потребностью в использовании каскадного отката, следует принять условие,
более строгое в сравнении с требованием способности расписания к восстановлению:
• расписание позволяет избежать каскадного отката (avoids cascading rollback —
ACR), если транзакциям разрешено считывать значения, сохраненные только
такими сторонними транзакциями, которые осуществили фиксацию.
Иными словами, в ACR-расписании чтение "мусора" запрещено. Как и в случае
восстановимых расписаний, термин "зафиксированный" означает, что соответствующая
запись фиксации транзакции достигла дисковой копии протокола.
Пример 19.4. Расписания, рассмотренные в примере 19.3, не являются ACR-расписаниями:
в каждом из случаев транзакция Т2 считывает значение элемента В, сохраненное
незафиксированной транзакцией Тх. Приведем, однако, еще один вариант расписания:
S4: wx(A)\ wx{B)\ w2(A)\ c\\ r2(B)\ c2\
Теперь Т2 считывает В уже после операции фиксации транзакции Т{ — транзакция,
последней сохранившая измененное значение В, уже завершена, и ее запись
фиксации зарегистрирована в дисковой копии протокола. Поэтому расписание S4, оставаясь
восстановимым, приобретает свойство ACR. □
19.1. ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ ОПЕРАЦИЙ...
953
Обратите внимание, что если транзакция, подобная Т2 в расписании 54 из примера
19.4, считывает значение, сохраненное другой транзакцией (7^), после фиксации
последней, Т2 вправе завершить работу либо операцией фиксации, либо инструкцией
прерывания. Поэтому
• каждое ACR-расписание является восстановимым.
19.1.5. Управление процедурами отката с помощью схем блокирования
Выводы, полученные нами выше, применимы к расписаниям, которые генерируются
планировщиком любой архитектуры. В том весьма распространенном случае, когда
планировщик заданий реализует технологию блокирования (locking) (см. разделы 18.3—18.6 на
с. 894—918), существует простой и часто применяемый метод, позволяющий уклониться от
необходимости использования механизма каскадного отката (см. раздел 19.1.2 на с. 952).
• Строгое блокирование (strict locking): транзакция не должна освобождать
монопольные (или иные — скажем, инкрементные) блокировки, позволяющие
модифицировать значения элементов базы данных, до момента фиксации или
отката с регистрацией соответствующей записи в дисковой копии протокола.
Расписание обслуживания транзакций, следующих правилу строгого блокирования,
называют строгим (strict schedule). Ниже указаны два важных свойства строгих расписаний.
1. Каждое строгое расписание является ЛCR-расписанием (см. раздел 19.1.4 на
с. 953) — некоторая транзакция Т2 не в состоянии считать значение элемента X,
измененное другой транзакцией Гь до тех пор, пока Тх не освободит любую
(монопольную или иную) блокировку, позволяющую модифицировать X. При
использовании схемы строгого блокирования инструкция освобождения
блокировки может следовать только после операции фиксации.
2. Каждое строгое расписание относится к категории условно-последовательных
расписаний (см. раздел 18.1.3 на с. 882) — строгое расписание эквивалентно
последовательному расписанию, в котором каждая транзакция выполняется
непрерывно и безотлагательно с момента ее фиксации.
На рис. 19.3 изображены взаимоотношения между различными категориями
расписаний, с которыми мы успели вас познакомить.
Рис. 19.3. Взаимоотношения классов расписаний
Ясно, что в строгом расписании транзакция не может считать "мусор", поскольку
данные, занесенные в буфер незафиксированной транзакцией, остаются
заблокированными до тех пор, пока транзакция не осуществит фиксацию. Проблема
исправления значений элементов данных в буферах после прерывания транзакции, однако, все
954 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
еще имеет место, так как результаты работы такой транзакции должны быть
аннулированы. Насколько трудоемко решение подобной задачи — это зависит от того, что
именно представляют собой блокируемые элементы данных. Ниже рассмотрены два
наиболее важных варианта.
Откат изменений в содержимом блоков
Если блокируемыми элементами являются страницы (блоки) данных, достаточно
воспользоваться простым методом отката, который не требует обращения к
протоколу. Допустим, что транзакция Т приобрела монопольную блокировку страницы Л,
занесла в буфер измененное значение А, а затем была вынуждена прервать выполнение.
Поскольку в момент модификации элемент А был блокирован транзакцией Г, никакая
другая транзакция не имела возможности считывать его содержимое. Прежнее значение
А легко восстановить, если система придерживается следующего правила:
• блоки, модифицированные незафиксированной транзакцией, остаются
"закрепленными " (pinned) (см. раздел 12.3.5 на с. 566) в оперативной памяти (т.е.
не сбрасываются на диск) до момента выполнения операции фиксации.
В подобном случае откат результатов прерванной транзакции Т сводится к тому,
чтобы заставить менеджер буферов пренебречь значением элемента А, т.е. трактовать
буфер, занятый блоком Л, как свободный и включить его в пул буферов, доступных для
дальнейшего использования, что позволяет с уверенностью воспринимать дисковую
копию А как наиболее "свежее" значение, сохраненное некоторой зафиксированной
транзакцией, а это, разумеется, именно тот вариант Л, который необходим.
Существует еще один простой метод отката, совместимый с механизмом
поддержки множественных версий элементов и их хронологических признаков,
рассмотренным в разделе 18.8.5 на с. 936. В этом случае также подразумевается, что блоки,
измененные незафиксированными транзакциями, "закрепляются" в оперативной памяти.
В случае прерывания транзакции Т достаточно просто удалить из списка значений А то,
которое было ею сохранено. Следует заметить, что при совместном использовании
схем хронометража и блокирования (см. раздел 18.8.6 на с. 938) значение А до
момента прерывания транзакции Т будет блокировано.
Откат результатов модификации "мелких" элементов данных
Если система позволяет блокировать отдельные части страниц данных (скажем,
кортежи или объекты), рассмотренная выше простая схема отката изменений,
спровоцированных прерванными транзакциями, оказывается неработоспособной.
Проблема заключается в том, что в подобной ситуации произвольный буфер может содержать
фрагменты данных, модифицированные двумя или несколькими транзакциями; если одна
из транзакций прервана, изменения, внесенные остальными, все еще остаются в силе.
Можно указать несколько альтернативных решений задачи восстановления прежнего
значения "малого" элемента Л, измененного некоторой прерванной транзакцией:
1) считать исходное значение Л из копии базы данных на диске и
соответствующим образом реорганизовать содержимое буфера оперативной памяти;
2) если протокол ведется в режиме "undo" или "undo/redo", получить прежнее
значение А из протокола (программный код, используемый при
восстановлении данных после отказа системы, может быть использован и для реализации
принудительного отката изменений, внесенных прерванной транзакцией);
3) поддерживать в оперативной памяти отдельный "журнал" операций
модификации, выполняемых каждой транзакцией, до тех пор, пока та остается
активной, и использовать его для поиска и восстановления прежнего
значения элемента Л.
19.1. ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ ОПЕРАЦИЙ...
955
Когда именно транзакция фактически выполняет фиксацию?
Говоря о нюансах групповой фиксации, нельзя не напомнить о том, что с момента
окончания операций и до выполнения инструкции фиксации "завершенная"
транзакция способна пребывать в нескольких различных состояниях, и ни при каких
обстоятельствах, включая системный отказ, ее результаты не должны быть утрачены. Как
упоминалось в главе 17 на с. 837, в ситуации сбоя вполне возможна потеря итогов
работы транзакции даже в том случае, когда та зарегистрировала запись фиксации в
буфере оперативной памяти, но на диск запись попасть не успела. Более того, в разделе
17.5 на с. 870 мы приводили примеры, когда в процессе восстановления системы
после порчи носителя могут быть отменены результаты и таких транзакций, записи
фиксации которых были сохранены на диске, но не в резервной копии базы данных.
В отсутствие аномальных ситуаций названные состояния транзакций
равнозначны. Однако когда возможность возникновения сбоев исключать нельзя,
следует иметь в виду существенные различия между состояниями, хотя с неформальной
точки зрения все они сводятся к единому понятию "завершенная транзакция".
Ни один из названных подходов нельзя назвать идеальным. Первому сопутствует
необходимость выполнения дополнительных операций дискового ввода-вывода.
Второй, не обязательно предполагающий обращение к диску (если подходящая порция
протокола все еще находится в оперативной памяти), однако, может быть сопряжен
с излишними затратами, связанными с поиском записи обновления, содержащей
требуемое значение элемента. При реализации последнего подхода, вероятно,
потребуется чрезмерно большой объем ресурса оперативной памяти.
19.1.6. Групповая фиксация
При некоторых обстоятельствах необходимости чтения "мусора" удается избежать
даже тогда, когда каждая запись фиксации не "сбрасывается" на диск
незамедлительно. По мере регистрации записей в дисковой копии протокола в порядке их
поступления можно освобождать блокировки сразу после того, как соответствующие записи
фиксации заносятся в копию протокола в буферах оперативной памяти.
Пример 19.5. Предположим, что транзакция Тх сохраняет значение элемента X базы
данных, заносит в протокол запись фиксации, но та остается в буфере оперативной
памяти. Даже если Тх не будет зафиксирована таким образом, чтобы запись фиксации
оказалась в наличии после возможного отказа системы, допустим, что блокировки,
которыми владеет Гь освобождаются. Затем транзакция Т2 считывает содержимое X
и осуществляет фиксацию, но соответствующая запись протокола, следующая за
аналогичной записью транзакции Гь также остается в буфере. Поскольку записи
протокола "сбрасываются" на диск в очередности их поступления, транзакция Т2 не может
восприниматься как зафиксированная, если подобный статус не получит транзакция
Т\. Менеджеру восстановления придется иметь дело с тремя возможными случаями.
1. Ни Т{, ни Т2 не "сбросили" записи фиксации на диск. Обе транзакции
трактуются как прерванные, и то обстоятельство, что Т2 считывала значение X,
измененное незафиксированной транзакцией Гь не является существенным.
2. Транзакция 7^ зафиксирована, а Т2 — нет. Ситуация вполне нормальна, и тому
есть две причины: Т2 не пользовалась данными незафиксированной транзакции;
более того, Т2 подлежит прерыванию и не может оказать какое бы то ни было
влияние на состояние базы данных.
3. Обе транзакции зафиксированы. Значение X, считываемое транзакцией Тъ не
является "мусором".
956
ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Допустим, однако, что данные буфера, содержавшего запись фиксации транзакции
Т2, благополучно достигли диска (по той причине, что, скажем, менеджер буферов
принял решение о повторном использовании ресурса для каких-либо иных целей), но
запись фиксации Т{ к моменту сбоя системы оставалась в оперативной памяти. В
подобном случае менеджер восстановления воспримет транзакцию Т2 как
зафиксированную, а Тх — как прерванную: результат работы Тъ основанный на "мусоре",
оставленном транзакцией Ти будет закреплен в базе данных. □
Пример 19.5 позволяет сделать следующий вывод: блокировки элементов базы
данных могут быть освобождены прежде, чем запись фиксации транзакции, которая
ими владеет, достигнет дисковой копии протокола. Политика, часто называемая
групповой фиксацией (group commit), состоит в следующем:
• не освобождать блокировки до момента, пока запись фиксации транзакции не
окажется, по меньшей мере, в буфере оперативной памяти;
• осуществлять "сбрасывание" содержимого блоков протокола на диск в
хронологическом порядке их создания.
Политика групповой фиксации, так же как и стратегия поддержки восстановимых
расписаний (см. раздел 19.1.3 на с. 952), гарантирует невозможность использования
операций чтения "мусора".
19.1.7. Логическое протоколирование
Как говорилось в разделе 19.1.5 на с. 954, воспрепятствовать операциям чтения
"мусора" проще в том случае, когда объектом блокирования служит страница данных.
Впрочем, если элементами базы данных являются блоки, это порождает, как
минимум, две проблемы.
1. При использовании любых методов протоколирования требуется, чтобы в
протоколе регистрировалось прежнее или новое значение элемента (либо оба
одновременно). Если изменение затрагивает только небольшую часть блока — речь идет,
скажем, о модификации компонента или вставке/удалении одного кортежа
отношения, — в протокол будут заноситься изрядные порции избыточной информации.
2. При использовании восстановимых расписаний, где блокировки, захваченные
транзакцией, освобождаются только после ее фиксации, серьезным образом
снижается степень параллелизма операций. В разделе 18.7.1 на с. 924,
напомним, мы говорили о выгодах раннего освобождения блокировок при доступе
к данным при посредничестве В-древовидного индекса. Если в подобной
ситуации потребовать, чтобы транзакции удерживали блокировки вплоть до
момента фиксации, все преимущества будут утрачены — обращаться к В-дереву
в каждый момент времени сможет фактически только одна из множества
транзакций, выполняющих модификацию данных.
Оба вывода обусловливают потребность в применении техники логического
протоколирования (logical logging), предполагающей необходимость отображения в протоколе
только измененных фрагментов блоков. В зависимости от природы вносимых
изменений различают несколько уровней сложности процедуры протоколирования.
1. Изменяется несколько байтов элемента базы данных (скажем, обновляется поле
постоянной длины). Ситуация разрешается очевидным образом — достаточно
сохранить в протоколе только модифицированные байты и номера их позиций
(подробнее — в примере 19.6).
2. Изменение легко описать и просто воспроизвести и отменить, но оно касается
большинства байтов или значения элемента базы данных целиком. Как показа-
19.1. ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ ОПЕРАЦИЙ... 957
но в примере 19.7, операция модификации поля переменной длины способна
воздействовать на содержимое записи и даже повлечь необходимость сдвига
других записей внутри блока данных. Прежняя и новая версии блока могут
выглядеть как совершенно неодинаковые, если не принять во внимание
тривиальную причину наблюдаемых различий.
3. Операция модификации затрагивает большую часть блока, и дальнейшие
провоцируемые ею изменения способны воспрепятствовать возможности отмены
результатов операции. Подобная ситуация иллюстрирует подлинную суть
"логического" протоколирования: традиционными средствами описать процесс
отмены/повторения операций над элементами базы данных как таковыми уже
не удается —• следует обратиться к более высокому уровню "логической"
структуры элементов данных. Проблема демонстрируется в примере 19.8, где
изучается структура В-дерева, сформированная из дисковых блоков.
Пример 19.6. Рассмотрим элементы базы данных, представляющие собой блоки,
каждый из которых содержит подмножество кортежей отношения. Операцию обновления
компонента кортежа можно выразить в виде записи протокола, которая гласит, что
"значение компонента а кортежа / изменено с v} на v2". Чтобы зарегистрировать факт
вставки нового кортежа в пустое пространство блока, достаточно сохранить
следующую информацию: "кортеж / = (ah a2,..., ак) вставлен на позицию внутри блока,
отстоящую от начала на величину смещения /?". Если только измененное значение
компонента и новый кортеж не сопоставимы по размерам с объемом блока, для
сохранения подобных записей протокола потребуется небольшая часть пространства блока.
Более того, такие записи пригодны для использования в любом режиме
протоколирования — "undo", "redo" или "undo/redo".
Обратите внимание, что рассматриваемые операции идемпотентны (idempotent) —
их многократное применение дает тот же результат, что и разовое. "Обратные"
операции — восстановление значения компонента t[a] с v2 в v{ и удаление кортежа / —
также идемпотентны. Поэтому соответствующие записи протокола могут использоваться
совершенно так же, как и "обычные" записи обновления, к которым мы обращались
на протяжении всей главы 17. □
Пример 19.7. Вновь предположим, что элементы базы данных представляют собой
блоки с кортежами отношения, но пусть теперь каждый кортеж содержит некоторые
поля переменной длины. Если подобное поле претерпевает изменение, схожее с тем,
о котором говорилось в примере 19.6, может потребоваться сдвиг больших порций
содержимого блока в ту или иную сторону, чтобы освободить место для более длинного
значения либо, наоборот, утилизировать пространство, очистившееся за счет
уменьшения длины значения. В предельных случаях, возможно, придется создать блок
переполнения (overflow block) (см. раздел 12.5 на с. 576) для сохранения части
содержимого исходного блока или, напротив, изъять существующий блок переполнения, если
новое укороченное значение поля позволяет объединить данные двух блоков в один.
Если блок и соответствующие блоки переполнения трактуются как часть одного
элемента базы данных, для обеспечения возможности отмены или повторения операций
естественно сохранять "старое" и/или "новое" значения измененного поля. Однако в этом
случае структуру "блок плюс блоки переполнения" на некотором "логическом" уровне
следует воспринимать как хранилище определенных кортежей. Не исключена ситуация,
когда после отмены или повторения операций восстановить последовательности байтов
таких блоков в исходном состоянии не удастся ввиду реорганизации структуры блоков
в процессе выполнения операций модификации, повлекших изменение длины других
полей. Если же интерпретировать элементы базы данных как наборы блоков, в
совокупности представляющие определенные кортежи, операции отмены/повторения
в самом деле позволят восстановить "логическое состояние" элемента. □
958 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Впрочем, возможность расширения блоков за счет блоков переполнения,
рассмотренная в примере 19.7, не всегда доступна. В таком случае операции отмены/
повторения удастся осуществлять только на уровне, более высоком, нежели уровень
блоков. В следующем примере обсуждается весьма важный вариант структуры В-
древовидных индексов, где использование механизма блоков переполнения
запрещено, что вынуждает осуществлять операции отмены/повторения на "логическом"
уровне В-дерева как такового, не рассматривая отдельные блоки, из которых оно
сконструировано на "физическом" уровне.
Пример 19.8. Обратимся к проблеме логического протоколирования изменений,
затрагивающих вершины В-дерева. Вместо сохранения прежнего и/или нового
содержимого всего блока-вершины имеет смысл ограничиться внесением в протокол
коротких записей с описанием существа изменения:
1) вставки или удаления пары "ключ—указатель";
2) модификации значения ключа, связанного с указателем;
3) расщепления или слияния вершин.
Для того чтобы охарактеризовать каждую из названных операций, достаточно
относительно короткой записи протокола: для описания операции расщепления,
например, потребуется указать всего лишь адреса расщепленной и новых вершин,
а операция слияния однозначно определяется ссылками на вершины-операнды
и конкретным алгоритмом поддержки В-деревьев.
Схема протоколирования с применением подобных "логических" записей
обновления позволяет осуществлять освобождение блокировок "раньше", нежели это требуется
механизмом, реализующим модель восстановимых расписаний. Причина заключается
в том, что возможные операции чтения "мусора" в блоках В-дерева не составляют
проблемы — единственная цель использования таких блоков связана с необходимостью
обнаружения местонахождения данных, к которым транзакции надлежит обратиться.
Предположим для примера, что транзакция Т считывает данные вершины-листа N,
но транзакция U, последней изменившая содержимое блока N, прерывает
выполнение, так что результат изменения (обусловленный, скажем, операцией вставки в N
новой пары "ключ—указатель" в ответ на вставку транзакцией U нового кортежа)
подлежит отмене. Если и транзакция Т в свою очередь вставляла в N пару "ключ-
указатель", восстановить блок N в том состоянии, в котором он пребывал до момента
воздействия со стороны транзакции U, не удастся. Впрочем, устранить результат
изменения N транзакцией U довольно просто — в нашем случае достаточно удалить из N
пару "ключ—указатель", вставленную средствами U. Итоговая редакция блока N,
однако, не будет совпадать с исходной — в блоке содержатся данные, внесенные
транзакцией Т. Но это не говорит о несогласованности состояния базы данных, поскольку В-
дерево в целом по-прежнему отображает только те изменения, которые
спровоцированы зафиксированными транзакциями. Таким образом, состояние В-дерева
восстанавливается на логическом, а не на физическом уровне. □
19.1.8. Восстановление данных с помощью логического протокола
Если логические действия идемпотентны (idempotent) — т.е. допускают
многократное повторение без какого бы то ни было ущерба, — процедура восстановления
данных с помощью логического протокола не представляет трудностей. В примере 19.6 на
с. 958 показано, как операция вставки кортежа описывается в логическом протоколе
данными кортежа и позицией внутри блока, на которую этот кортеж помещен. Если
занести кортеж в ту же позицию дважды или несколько раз, итог будет выглядеть так,
будто операция выполнялась однократно. Поэтому в процессе восстановления
результатов операций транзакции, подлежащих повторению (redo), система вправе осущест-
19.1. ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ ОПЕРАЦИЙ...
959
вить вставку кортежа в соответствующее место определенного блока, не заботясь
о том, выполнялась ли операция прежде.
Теперь рассмотрим ситуацию, когда кортежи могут перемещаться внутри
отдельного блока или между блоками, как предполагалось в примерах 19.7 (см. с. 958) и 19.8
(см. с. 959). Теперь с кортежем нельзя связать определенное значение позиции
вставки: лучшее, что удастся сделать, — это включить в протокол описание вида "кортеж /
вставлен в некоторое место блока В". Если в ходе восстановления придется повторить
операцию вставки, не исключена возможность ошибочного включения в В нескольких
копий /. Что еще хуже, нельзя гарантировать, сохранена ли версия блока В, содержащая
одну копию t, на диске (вполне вероятно, что, скажем, другая транзакция, изменяющая
значение какого-либо элемента в том же блоке В, спровоцирует запись В на диск).
Для предотвращения опасности возникновения подобных ситуаций разработана
специальная технология ведения последовательных номеров записей протокола (log
sequence numbers).
• Очередная запись протокола снабжается номером, на единицу превосходящим
номер предыдущей записи,141 и принимает форму <L, Г, А, В>, где
L — целочисленный последовательный номер записи;
Т — идентификатор транзакции;
Л — описание действия, выполняемого транзакцией Т (например,
"вставить кортеж /");
В — адрес блока данных, который затрагивается действием транзакции.
• Каждому действию ставится в соответствие уравновешивающее действие
(compensating action), предназначенное для логической отмены исходного
действия. Как показано в примере 19.8 на с. 959, уравновешивающее действие не
обязательно приводит базу данных в то состояние S, в котором она пребывала
до выполнения начального действия, — речь идет о восстановлении состояния,
логически эквивалентного состоянию 5. Например, действию "вставить кортеж г"
отвечает уравновешивающий аналог "удалить кортеж /".
• Если транзакция Т прерывает работу* для каждого выполненного ею действия
над базой данных инициируется соответствующее уравновешивающее действие,
и факт его осуществления также фиксируется в протоколе.
• В заголовке каждого блока данных регистрируется номер записи протокола,
соответствующей последней операции по изменению содержимого блока.
Теперь рассмотрим примерную последовательность действий с использованием
логического протокола с целью восстановления данных после отказа системы.
1. Реконструировать состояние базы данных на момент сбоя с учетом
содержимого блоков, которое было загружено в буферы оперативной памяти и
оказалось утраченным:
a) найти в протоколе наиболее "свежую" контрольную точку и на ее основе
определить подмножество транзакций, которые во время отказа пребывали
в активном состоянии;
b) сопоставить номер L каждой записи <L, Г, А, В> с номером N в заголовке
блока данных В\ если N<L, повторить действие А (к блоку В оно еще не
применялось); если же N>L, никаких действий не предпринимать —
результат операции А уже зафиксирован в В\
141 По достижении верхней границы числовых значений последовательность номеров вновь
придется начинать с нуля, но период времени между подобными операциями инициализации
настолько велик, что вероятность возникновения двусмысленных ситуаций сводится к нулю.
960 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
с) для каждой записи протокола с информацией о старте, фиксации или
прерывании некоторой транзакции Т соответствующим образом
модифицировать подмножество активных транзакций.
2. Прервать выполнение транзакций, остающихся в активном состоянии по
достижении последней записи протокола:
a) осуществить повторное сканирование протокола в обратном направлении до
достижения записи предыдущей контрольной точки; для каждой записи
<L, Г, А, В>, соответствующей транзакции Т, подлежащей прерыванию,
осуществить действие, уравновешивающее операцию А над блоком В, и
сохранить сведения о факте выполнения такого действия в протоколе;
b) если прерываемая транзакция начала работу до момента внесения в
протокол последней контрольной точки (т.е. была упомянута в списке активных
транзакций записи контрольной точки), продолжить просмотр журнала до
достижения записи с информацией о старте транзакции;
c) сохранить в протоколе записи о прерывании транзакций.
19.1.9. Упражнения к разделу 19.1
* Упражнение 19.1.1. Изучите все возможные варианты вставки инструкций
блокирования (одного типа, как в разделе 18.3 на с. 894) в последовательность операций
гх(А)\ п(Д); wi(A); wx(B)\
транзакции Т{, которая является
a) двухфазно-блокированной (см. раздел 18.3.3 на с. 897) и строго блокированной;
b) двухфазно-блокированной, но не строго блокированной.
Упражнение 19.1.2. Предположим, что каждое из расписаний
* а) п(Л); r2(B)\ wx(B)\ w2(Q; г3(Я); r3(Q; w3(D);
b) г,(Л); wx(B); r2(B); w2(Q; r3(Q; w3(D);
c) r2(A); r3(A); rx(A); wx(B); r2(B); r3(B); w2(Q; r3(Q;
d) r2(A); r3(A); rx(A); wx(B)\ r3(B); w2(Q; r3(Q;
завершается инструкцией прерывания транзакции Т{. Укажите, какие транзакции
подлежат откату.
Упражнение 19.1.3. Рассмотрим расписания, приведенные в упражнении 19.1.2, но
допустим, что каждая из трех упомянутых транзакций осуществляет фиксацию
и сохраняет в протоколе запись фиксации непосредственно после выполнения
финального действия. Предположим, что в результате отказа системы завершающая
часть протокола, находившаяся в буферах оперативной памяти, оказалась
утраченной. Изучите различные варианты потери данных протокола и в каждом случае
ответьте на следующие вопросы.
i) Какие транзакции следует считать незафиксированными?
ii) Возникает ли опасность считывания "мусора" в процессе восстановления
данных? Если да, то какие транзакции подлежат откату?
Hi) Что можно сказать насчет вероятности считывания "мусора", если
утраченным окажется не завершающий, а какой-либо "средний" фрагмент протокола?
! Упражнение 19.1.4. Рассмотрим две транзакции,
7V Wl(A); wx(B)-9 ri(Q; cx\
Т2: w2(A); г2(Я); w2(Q; c2;
19.1. ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ ОПЕРАЦИЙ...
961
* а) Каково количество восстановимых расписаний выполнения действий
транзакций Тх и Г2?
b) Какие из них являются ACR-pacписаниями?
c) Сколько расписаний одновременно восстановимы и условно-
последовательны?
d) Каково число условно-последовательных ACR-расписаний?
Упражнение 19.1.5. Приведите пример ACR-расписания с использованием общих
и монопольных блокировок, которое не является строгим.
19.2. Условно-последовательное упорядочение с учетом
источников данных
Напомним, что основная цель, которая преследуется при проектировании
подсистем планирования заданий СУБД, состоит в обеспечении условно-последовательного
характера расписаний выполнения транзакций. Мы показали (см. раздел 18.1.4 на
с. 884), каким образом ответ на вопрос о принадлежности расписания к классу
условно-последовательных может зависеть от существа операций, инициируемых
транзакциями. В разделе 18.2 на с. 887 говорилось о том, что планировщики заданий обычно
реализуют строгое требование, предполагающее способность транзакций к
последовательному упорядочению с учетом конфликтов (conflict-serializability), которое гарантирует
возможность последовательного упорядочения операций независимо от их природы.
Существуют, однако, и более слабые критерии, также обеспечивающие
последовательный характер прохождения операций. В этом разделе мы сосредоточим внимание
на одном из них, называемом условно-последовательным упорядочением с учетом
источников данных (view-serializability) и предполагающем рассмотрение всех вариантов
"связи" транзакций Г и U, таких, что Т сохраняет значение элемента базы данных, a U
его считывает. Основное различие между требованиями условно-последовательного
упорядочения с учетом источников данных и такового с учетом конфликтов
проявляется в той ситуации, когда транзакция Т изменяет значение элемента Л, которое
позже ни одной транзакцией не используется (из-за того, что оно, скажем,
модифицируется какой-либо иной транзакцией). В подобной ситуации действие wj(A) может быть
размещено и на других позициях в расписании (где А по-прежнему никак не
используется), что не позволяется критерием условно-последовательного упорядочения
с учетом конфликтов. Ниже дано строгое определение возможности условно-
последовательного упорядочения операций с учетом источников данных и описана
процедура проверки выполнения критерия.
19.2.1. Эквивалентность расписаний с учетом источников данных
Пусть даны два расписания, S{ и 52, охватывающие операции одного и того же
множества транзакций. Представим, что существуют гипотетические транзакции Т0
(присваивает исходные значения всем элементам базы данных, используемым другими
транзакциями) и 7} (считывает содержимое каждого элемента, сохраненное одной или
несколькими транзакциями, по завершении каждого из расписаний). Тогда каждой
операции чтения г,(Д) в расписаниях соответствует некоторая предшествующая операция
записи wj(A), наиболее близкая по времени выполнения.142 В подобном случае говорят,
что транзакция 7} является источником (source) данных для операции чтения г,(А).
Заметим, что в роли 7} может выступать Т0, а функцию Г/ способна выполнять транзакция 7).
142 Хотя до сих пор мы не говорили о том, что транзакции запрещено модифицировать один
и тот же элемент дважды, это, вообще говоря, вряд ли целесообразно, поэтому в дальнейшем
полезно предполагать, что транзакция сохраняет значение определенного элемента только один раз.
962 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Если источники данных для каждой операции чтения в расписаниях Sx и S2
совпадают, расписания являются эквивалентными с учетом источников данных (view-
equivalent). Расписания, эквивалентные с учетом источников данных, эквивалентны
и в общем смысле: они приводят к одному и тому же результату для любого
исходного состояния базы данных. Если расписание S эквивалентно с учетом источников
данных некоторому последовательному расписанию, говорят, что S условно-
последовательно с учетом источников данных (view-serializable).
Пример 19.9. Рассмотрим расписание 5, определенное в виде следующей таблицы.
Г,: г№; wx(B);
Т2: r2m w2(A); w2(B);
Т3: г3(Л); w3(B);
Мы разнесли действия каждой транзакции по вертикали, чтобы упростить их
восприятие; расписание, как обычно, надлежит "читать" слева направо.
В расписании S транзакции Тх и Т2 сохраняют значения элемента Z?, которые далее
оказываются невостребованными и утрачиваются; "выживает" только вариант В,
получаемый в результате модификации транзакцией Г3, — по завершении обслуживания
расписания он "потребляется" гипотетической транзакцией 7}. Расписание S не
является условно-последовательным с учетом конфликтов. Чтобы разобраться в причинах,
прежде всего следует заметить, что Т2 сохраняет А до того, как Тх считывает А, поэтому
в предполагаемом конфликтно-эквивалентном последовательном расписании
транзакция Т2 должна предшествовать транзакции Тх. Тот факт, что действие wx(B)
предвосхищает w2(B), в свою очередь вынуждает Тх предшествовать Т2 в любом
конфликтно-эквивалентном последовательном расписании. Тем не менее ни wx(B), ни w2(B) не
оказывают существенного воздействия на состояние базы данных — это как раз тот
вариант операций записи, которыми в расписании, условно-последовательном с
учетом источников данных, при определении подлинных ограничений эквивалентности
последовательных расписаний можно пренебречь.
Чтобы придать выводам большую строгость, рассмотрим источники для всех
операций чтения, упомянутых в 5.
1. Источником г2(В) служит Г0, поскольку предшествующих операций записи В в S нет.
2. Источник гх(А) — это Тъ так как именно Т2 последней (перед выполнением гх(А))
сохраняет значение А.
3. Транзакция Т2 по той же причине является и источником г3(А).
4. Источником гипотетической операции чтения содержимого элемента А,
выполняемой транзакцией 7), служит транзакция Т2.
5. Источник для операции считывания В, инициируемой предполагаемой
транзакцией 7), — это транзакция Г3, которая модифицировала В последней.
Разумеется, Г0 предшествует всем реальным транзакциям в любом расписании;
аналогично, всякое расписание завершается операциями считывания,
инициируемыми транзакцией 7}. Если упорядочить транзакции как (Т2, Тх, Т3), источники всех
операций чтения совпадут с теми, которые характерны для операций расписания 5.
Другими словами, Т2 считывает В, и Г0 определенно является последней транзакцией,
изменяющей В до начала операции г2(В). Транзакция Тх считывает А, но Т2 уже
сохраняла А, поэтому источником гх(А) служит Тъ как и в 5. Транзакция Т3 также
считывает А; однако поскольку прежде значение Л сохранялось транзакцией Тъ
последняя, как и в расписании 5, является и источником г3(А). Наконец, гипотетическая
транзакция 7} считывает значения А и В — в расписании (Т2, Тх, Т3) источниками этих
19.2. УСЛОВНО-ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ С УЧЕТОМ ИСТОЧНИКОВ ... 963
операций служат транзакции Т2 и Т3 соответственно (вновь как в S). Имеем право
заключить, что расписание S является условно-последовательным с учетом источников
данных, а (Г2, Гь Г3), в свою очередь, эквивалентно S с учетом источников данных. □
19.2.2. Теоретико-графовая модель расписаний, условно-последовательных с
учетом источников данных
Существует обобщение модели графов предшествования, используемой для
проверки способности транзакций к последовательному упорядочению с учетом
конфликтов (см. раздел 18.2.2 на с. 888), на случай ограничений предшествования,
подразумеваемых в определении критерия условно-последовательного упорядочения с
учетом источников данных. Граф, отвечающий подобному расписанию, состоит из
следующих компонентов.
1. Каждая реальная транзакция и гипотетические транзакции Т0 и 7}
представляются отдельными вершинами.
2. В граф включается направленная дуга, соединяющая вершину 7} с вершиной Г„
если источником данных для операции г,-(Х) служит транзакция 7}.
3. Предположим, что 7} является источником r,(X), aft- еще одна транзакция,
изменяющая значение X. Транзакции Тк не позволяется "вклиниваться" между
7} и Г, — она должна либо предшествовать 7}, либо следовать за Г,. Это условие
представляется парой (штриховых) "компенсирующих" дуг, соединяющих Тк с 7}
и 7} с Тк. Одна или другая дуга пары является "реальной", но не важно, какая
именно: в процессе приведения графа к ациклическому виду может быть
оставлена (или удалена) любая из дуг. Существуют два важных частных случая, где
пара дуг вырождается в единственную дугу:
a) если 7} s Г0, то Тк не может предшествовать 7}, поэтому вместо пары дуг
в граф включается дуга Г,- —> Тк\
b) если Tj = 7}, тогда Тк не в состоянии следовать за Th так что пара дуг
заменяется дугой Тк -> Tj.
Рис. 19.4. Начальный вариант графа предшествования к
примеру 19.10
Пример 19.10. Обратимся к расписанию S из примера 19.9 на с. 963. На рис. 19.4
показана исходная версия графа предшествования для 5, содержащая вершины и дуги,
включенные на основании правила 2. Дуги обозначены метками, представляющими
наименования элементов базы данных, операции над которыми послужили причиной
появления дуг в графе. Так, например, значением Л, сохраненным транзакцией Тъ пользуются
транзакции Ти Т3 и 7}, а содержимое элемента В "передается" от Т0 к Т2 и от Г3 к 7}.
Теперь необходимо рассмотреть, какие транзакции способны служить
препятствием для взаимных связей других транзакций. Подобные потенциальные факты
"вмешательства" описываются на основании правила 3 парами дуг; как будет
показано ниже, в данном случае каждая пара вырождается в единственную дугу.
Рассмотрим дугу Т2—>Т{, включение которой обусловлено наличием операции над
элементом Л. "Авторами" значений Л являются транзакции Г0 и Тъ ни одна из которых
964 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
не может "расщепить" дугу, поскольку позиция Г0 неизменна, а Т2 уже располагается
в начале дуги. Таким образом, потребность в использовании дополнительных дуг не
возникает. Аналогичные доводы убеждают и в отсутствии необходимости применения
дополнительных дуг для исключения возможности расщепления связей Г2 —> Г3 и Т2 —» 7}.
Теперь обратимся к дугам, отображающим операции над элементом В. Значение В
изменяется транзакциями Г0, Ти Т2 и Т3. Прежде всего рассмотрим дугу Г0—> Т2.
Значение В сохраняется и транзакциями Тх и Г3 (то же делают транзакции Т0 и Тъ
представляющие начальную и конечную вершины дуги, — ими в данном случае можно
пренебречь). Чтобы не допустить размещения Т{ между Т0 и Тъ требуется, вообще говоря,
пара дуг (Тх —> Т0, Т2 —> Т{), однако поскольку никакая транзакция не может
предшествовать транзакции Г0, наличие дуги Тх —» Г0 невозможно. В данном частном случае
достаточно включить в граф дугу Т2-*ТХ. Но такая дуга (с меткой Л) уже есть, поэтому
граф в дальнейших изменениях не нуждается.
Далее рассмотрим дугу Г3 —> 7}. Так как транзакции Г0, Т{ и Т2 также модифицируют
значение В, влияние каждой из них на связь Т3 -» 7} должно быть исключено.
Транзакция Т0 не вправе занять место между Г3 и 7} по очевидной причине, но Тх или Тъ
как кажется, вполне могли бы. Однако поскольку ни Гь ни Т2 нельзя расположить
после Г/, следует ограничиться возможностью их размещения перед Г3. Дуга Т2 —» Г3,
впрочем, уже существует, поэтому достаточно пополнить граф дугой Тх —»Г3. Это
единственное изменение, которое надлежит внести в граф, приведенный на рис. 19.4.
Результат показан на рис. 19.5.
Рис. 19.5. Полный граф предшествования к примеру 19.10
□
Пример 19.11. В примере 19.10 каждая из пар "компенсирующих" дуг сводилась
к единственной дуге. На рис. 19.6 приведен образец расписания, охватывающего
действия четырех транзакций, в граф которого приходится включать полные пары
"компенсирующих" дуг.
J\ Т2 7з 74
Г!(Л); Wl(C);
г3(0;
г4(«;
w3(A);
r4(Q;
w2(D); r2(B)\
w4(A); w4(B);
Рис. 19.6. Пример расписания, граф предшествования которого должен включать пары
"компенсирующих " дуг
19.2. УСЛОВНО-ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ С УЧЕТОМ ИСТОЧНИКОВ ... 965
На рис. 19.7 изображен граф предшествования, содержащий только такие дуги,
наличие которых обусловлено связями между транзакциями, являющимися
"источниками" и "потребителями" данных. Как и на рис. 19.4 (см. с. 964), дуги
обозначены метками, представляющими наименования элементов базы данных, операции
над которыми послужили причиной включения этих дуг в граф. Необходимо изучить
возможные варианты пополнения графа парами "компенсирующих" дуг. Как было
показано в примере 19.10, существует ряд упрощений, возможность использования
которых следует принять к сведению. В роли Тк (транзакции, вероятность появления
которой в промежутке между транзакциями 7} и 7} надлежит исключить) может выступать:
• транзакция, выполнявшая операцию записи элемента, которая послужила
причиной существования в графе дуги 7} —> Г,;
• ни Г0 и ни 7}, которые не способны к перемещению в пределах расписания;
• ни 7} и ни Th представляющие оконечные вершины дуги.
Учитывая указанные правила, рассмотрим дуги, связанные с операциями записи
элемента А, осуществляемыми транзакциями Г0, Т3 и Т4. Транзакцию Т0 можно отбросить
сразу. Транзакция Т3 не должна влиять на связь Т4 —» 7}, поэтому граф пополняется
дугой Т3 —>Т4 (вторая дуга пары, 7}—» Г3, по понятным причинам исключается).
Аналогично, Т3 не может "вклиниваться" в Г0 —»Тх и Г0 —> Г2, так что в граф должны быть
добавлены "компенсирующие" дуги Т{ -» Т3 и Т2 -» Т3.
Рис. 19.7. Начальный вариант графа предшествования к примеру 19.11
Теперь обратим внимание на тот факт, что транзакция Т4 также не должна
оказывать воздействия на дуги с метками Л. Вершина Т4 находится в начале дуги Т4 —»7} -~
эта связь не важна. Следует исключить возможность размещения Т4 в середине дуг
Г0 —» Тх и Г0 —» Тъ поэтому в граф вносятся "компенсирующие" дуги Тх —> Т4 и Т2 —> Т4.
Далее изучим дуги, присутствие которых в графе связано с операциями записи
значений элемента Z?, выполняемыми транзакциями То, Тх и Т4. Вновь транзакцию Г0
можно опустить. Заслуживают внимания только дуги 7^ —> Г2, Т{-+Т4 и Т4 -* 7}; 7\ не
в состоянии расщепить две первые дуги, но третья требует включения в граф
"компенсирующей" дуги Т{ -> Т4.
Транзакция Т4 способна влиять только на дугу Тх -» Г2, которая, однако, никак не
связана с Г0 или 7}, поэтому в данном случае граф требуется пополнить парой дуг —
(Г4->ГЬ72-*Г4).
Наконец, сосредоточим внимание на транзакциях, модифицирующих содержимое
элемента С: Г0 и Тх. Как всегда, Т0 проблемы не составляет. Вершина Тх уже служит
частью каждой дуги, имеющей отношение к элементу С, так что повлиять на них Т{
не может. Операции над элементом D выполняются транзакциями Г0 и Тъ и по
аналогичным причинам дополнительные "компенсирующие" дуги в граф включать не
следует. Итоговая версия графа показана на рис. 19.8.
966 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Рис. 19.8. Полный граф предшествования к примеру 19.11
□
19.2.3. Обоснование корректности процедуры проверки графа предшествования
Поскольку приходится выбирать только одну из пары "компенсирующих" дуг,
последовательное расписание, эквивалентное расписанию 5, можно сконструировать
в том и только в том случае, если существует некоторое множество вариантов выбора
по одной дуге из каждой пары, обращающее граф S в ациклический граф. Чтобы
понять, почему, следует заметить, что если подобный ациклический граф
действительно существует, тогда в соответствии с любой топологической очередностью
графа ни одна из транзакций-вершин, модифицирующих элементы, не может
присутствовать между вершинами, которые представляют "источник" и "приемник" данных,
и каждая транзакция-вершина, сохраняющая данные, предшествует транзакциям-
вершинам, служащим "потребителями". Таким образом, набор связей между
"источниками" и "приемниками" в последовательном расписании точно такой же,
как и в 5: расписания эквивалентны с учетом источников данных, а потому S является
условно-последовательным с учетом источников данных.
Напротив, если расписание S условно-последовательно с учетом источников
данных, тогда существует некоторое последовательное расписание 5', эквивалентное
с учетом источников данных. Каждая пара дуг (Тк —> 7}, 7} —> Тк) в графе расписания S
должна быть такой, что в S' транзакция Тк либо предшествует 7}, либо следует за 7}; в противном
случае операция записи, выполняемая Тк, "разрывает" связь 7} и Г„ а это означает, что
расписания S и S' не эквивалентны с учетом источников данных. Каждая дуга графа
предшествования должна быть учтена в очередности следования транзакций,
представляемой расписанием 5'. Мы приходим к заключению, что существует определенное
множество вариантов выбора по одной дуге из каждой пары, приводящее граф к виду,
согласованному с последовательным расписанием 5'. Такой граф является ациклическим.
Пример 19.12. Рассмотрим граф предшествования, изображенный на рис. 19.5
(см. с. 965). Граф является ациклическим. Единственная топологическая
очередность — это тройка (Г2, Гь Г3), представляющая последовательное расписание,
эквивалентное с учетом источников данных расписанию из примера 19.10.
Теперь обратимся к графу, показанному на рис. 19.8. Надлежит рассмотреть
варианты выбора по одной дуге из каждой пары "компенсирующих" дуг. Если выбрать
дугу Т4->Т{, в графе останется цикл. Если же предпочесть дугу Т2 -» Г4, граф станет
ациклическим. Единственная топологическая очередность такого графа задается в
виде списка (Гь Тъ Г3, ТА) — это последовательное расписание, эквивалентное с учетом
источников данных исходному расписанию, которое, таким образом, является
условно-последовательным с учетом источников данных. □
19.2. УСЛОВНО-ПОСЛЕДОВАТЕЛЬНОЕ УПОРЯДОЧЕНИЕ С УЧЕТОМ ИСТОЧНИКОВ ... 967
19.2.4. Упражнения к разделу 19.2
Упражнение 19.2.1. Приведите графы предшествования для следующих
расписаний и перечислите все последовательные расписания, эквивалентные с учетом
источников данных.
* а) ЫА); г2(Л); г3(Л); w{(B)- w2(B)- w3(Z?);
b) о(Л); r2(A)\ г3(Л); г4(Л); w,(5); w2(£); w3(£); w4(B)\
c) n(A); r3(D); ^(Я); r2(B)\ w3(B); г4(Я); w2(Q; r5(Q; w4(£); r5(E); w5(£);
d) Wl(A); r2(A); w3(A); r4(A); w5(A); r6(A);
! Упражнение 19.2.2. Ниже указаны последовательные расписания. Определите
количество соответствующих им (i) конфликтно-эквивалентных расписаний и (И)
расписаний, эквивалентных с учетом источников данных.
* а) п(А); w{(B)\ r2(A)\ w2(B)\ r3(A); w3(Z?); (каждая из трех транзакций вначале
считывает содержимое А, а затем сохраняет значение В);
Ъ) r{(Ay, wx(B)\ wx(Q\ r2(A)\ w2(B)\ w2(Q\ (каждая из двух транзакций вначале
считывает содержимое А, а затем сохраняет значения В и С).
19.3. Разрешение взаимоблокировок
Мы уже не раз упоминали о возможности возникновения ситуации, когда
параллельно выполняемые транзакции, состязаясь за право владения ресурсом, попадают
в состояние взаимоблокировки (deadlock): каждая из группы транзакций ожидает
момента освобождения ресурса, занятого другой транзакцией, и ни одна из них не в
состоянии продолжить работу.
• В разделе 18.3.4 на с. 898 было показано, что при использовании традиционной
схемы функционирования двухфазно-блокированных транзакций (t-^o-phase-
locked transactions) опасность появления взаимоблокировки сохраняется, если
одна транзакция удерживает ресурс, в котором нуждаются другие.
• В разделе 18.4.3 на с. 905 мы говорили о том, как при повышении (upgrading)
уровня блокирования возникновение взаимоблокировки также вполне
вероятно — когда каждая транзакция владеет общей блокировкой одного и того же
элемента и имеет намерения захватить монопольную блокировку.
Существуют два общих подхода, позволяющих справиться с проблемой: один
предполагает выявление и принудительное разрешение ситуаций взаимоблокировки,
а другой предусматривает применение таких методов управления транзакциями,
которые устраняют причины появления подобных ситуаций.
19.3.1. Обнаружение взаимоблокировок по истечении лимита времени
Если взаимоблокировка уже возникла, исправить положение таким образом,
чтобы позволить продолжить работу всем транзакциям, практически невозможно —
как правило, приходится выполнять откат (прерывание и повторное выполнение)
по меньшей мере одной из них.
Простейший метод выявления и разрешения взаимоблокировки связан с заданием
лимита времени (timeout) активности транзакций: если какая-либо транзакция
превышает лимит, система осуществляет ее откат. Если время функционирования типичной
транзакции исчисляется, скажем, миллисекундами, лимит, равный одной минуте,
затронет в действительности только те транзакции, которые оказались вовлеченными
в ситуацию взаимоблокировки. Если природа транзакций более сложна, лимит
времени их активности следует соответствующим образом увеличить.
968 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Если лимит одной из блокированных транзакций превышен, та освобождает
захваченные ею блокировки и системные ресурсы, предоставляя другим транзакциям
возможность финишировать до момента истечения их лимитов. Впрочем, поскольку
транзакции, попадающие в ситуацию взаимоблокировки, часто стартуют
приблизительно в одно и то же время (иначе одна успела бы завершиться до момента начала
другой), вполне возможно и такое развитие событий, когда лимиты времени
активности транзакций истощаются уже после разрешения взаимоблокировки.
19.3.2. Графы ожидания
Взаимоблокировки, появление которых спровоцировано тем, что одни транзакции
ждут освобождения блокировок, удерживаемых другими транзакциями, можно
описать средствами модели графов ожидания (waits-for graphs). Графы ожидания
используются как для выявления ситуаций взаимоблокировки, так и для их предотвращения.
Ниже мы сосредоточим внимание на второй функции: система управления
транзакциями должна сохранять и обновлять данные графа в течение всего времени ее
функционирования, отвергая те действия, которые чреваты образованием циклов в графе.
Напомним (см. раздел 18.5.2 на с. 915), что в таблице блокировок (lock table) для
каждого элемента X базы данных наряду с перечнем транзакций, владеющих блокировками
X, сохраняется и список транзакций, дожидающихся возможности блокирования X.
Каждая вершина графа соответствует транзакции, которая либо уже владеет блокировкой,
либо пребывает в состоянии ожидания. Граф содержит дугу, направленную от вершины
(транзакции) Т к вершине U, если существует элемент А базы данных, такой, что
1) U владеет блокировкой А;
2) Т ожидает возможности блокирования Л;
3) Г не в состоянии захватить блокировку Л в нужном режиме до тех пор, пока
U не освободит собственную блокировку.143
Если граф ожидания не содержит циклов, это значит, что каждая транзакция
имеет шанс со временем завершить работу: по меньшей мере одна из них не находится
в состоянии ожидания, и эта транзакция определенно сможет финишировать; позже
найдется, как минимум, еще одна транзакция, которая не ждет освобождения
блокировок и также будет успешно завершена, и т.д.
Если, однако, в графе наличествует цикл, ни одна из транзакций, которые его
образуют, не в состоянии продолжить работу, т.е. имеет место взаимоблокировка. Стратегия,
позволяющая избежать такой ситуации, состоит в принудительном откате каждой
транзакции, которая обращается с запросом, чреватым появлением цикла в графе ожидания.
Пример 19.13. Рассмотрим множество из четырех транзакций, каждая из которых
считывает содержимое одного элемента данных и модифицирует другой:
7V /rfA); Г!(Л); lx{B)\ *>i(B)\ **i(A); ux{B)\
Т2: /2(0; r2(Q; /2(A); w2(A); и2(С); и2(Л);
Т3: /3(Д); r3(B); /3(Q; w3(Q; u3(B); u3(Q;
Г4: /4(D); r4(D); /4(A); w4(A); иАф)\ и4(А);
Здесь мы используем простую схему с единственным режимом блокирования, хотя
те же выводы остаются справедливыми и для случая с общим/монопольным режима-
В системах с использованием традиционных режимов блокирования (скажем, общего
и монопольного) транзакции приходится пребывать в состоянии ожидания до тех пор, пока не
будут освобождены все блокировки элемента, удерживаемые другими транзакциями. Однако
существуют и такие множества режимов, где транзакции предоставляется право захвата
блокировки сразу после освобождения некоторых блокировок, инициированных сторонними
транзакциями (см. упражнение 19.3.6 на с. 977).
19.3. РАЗРЕШЕНИЕ ВЗАИМОБЛОКИРОВОК
969
ми блокирования, когда общие блокирозки применяются совместно с операциями
чтения, а монопольные обеспечивают возможность изменения данных.
На рис. 19.9 приведен образец расписания, охватывающего некоторые действия
рассматриваемых транзакций. При выполнении шагов 1—4 каждая транзакция
приобретает блокировку элемента, подлежащего считыванию. На шаге 5 транзакция Т2
пытается захватить блокировку Л, но запрос отвергается, поскольку искомая блокировка
в данный момент удерживается транзакцией Т{. Поэтому Т2 ожидает освобождения
ресурса, занятого Гь — об этом факте свидетельствует дуга, соединяющая вершины Т2
и Тх графа, который изображен на рис. 19.10.
Т{ 72 7з 7д
1) 1{(А)\ П(А);
2) /2(Q; г2(С);
3) /з(Я); г3(В);
4) /4Ф); г4ф);
5) /2(Д) — запрет
6) l3(Q — запрет
7) /4(А) — запрет
8) 1{(В) — запрет
Рис. 19.9. Начальный фрагмент расписания, приводящего к ситуации взаимоблокировки
По аналогичным причинам на шаге 6 запрещается захват блокировки элемента
С, инициированный транзакцией Т3 (блокировкой уже владеет транзакция Г2), а на
шаге 7 отвергается запрос на блокирование элемента Л со стороны Т4, поскольку
элемент находится в ведении транзакции Т{. Граф ожидания, отражающий
ситуацию, сложившуюся к этому моменту, показан на рис. 19.10. Как нетрудно
убедиться, граф не содержит циклов.
На шаге 8 транзакции Тх приходится ожидать освобождения блокировки элемента
Я, удерживаемой транзакцией Т3. Это значит, что в графе, как показано на рис. 19.11,
образуется цикл, охватывающий вершины Ти Т2 и Т3. Поскольку каждая из
транзакций, представляемых этими вершинами, находится в состоянии взаимного ожидания,
имеет место взаимоблокировка. Транзакция Г4, хотя
и не вовлеченная в цикл, также, между прочим, не
в состоянии продолжить работу, так как напрямую
зависит от дальнейшей деятельности транзакции Тх.
Поскольку подвергнуться откату может любая
транзакция, провоцирующая появление цикла в
графе ожидания, в данном случае на роль "жертвы"
выбирается Т{, а граф приобретает такую форму,
которая изображена на рис. 19.12. Транзакция Т{
освобождает занятую ею блокировку элемента Л, которая
затем может быть предоставлена в распоряжение
либо Тъ либо Г4. Предположим, что блокировка
отдается на откуп транзакции Т2 — последняя получает возможность завершения работы
и со временем освобождает блокировки элементов Л и С. Теперь способны к
дальнейшему функционированию и транзакции Т3 (ожидающая блокировку С) и Т4
(нуждающаяся в блокировке Л). В некоторый момент времени транзакция Т{
активизируется повторно, но она не сможет получить блокировки элементов А и В до
тех пор, пока не завершатся транзакции Тъ Т3 и Т4. □
©
® -® 4D
Рис. 19.10. Граф ожидания
после выполнения шага 7
расписания, приведенного на рис. 19.9
970 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Рис. 19.11. Граф ожидания с
циклом после выполнения шага 8
расписания, приведенного на рис. 19.9
®
©—-©
Рис. 19.12. Граф ожидания
после отката транзакции 1\
19.3.3. Предотвращение взаимоблокировок за счет упорядочения элементов данных
Рассмотрим альтернативные методы предупреждения ситуаций взаимоблокировки
транзакций. Первый, на котором мы сосредоточим внимание в этом разделе,
предполагает необходимость упорядочения элементов базы данных в некоторой
произвольной фиксированной очередности. Если, скажем, элементами являются дисковые
блоки, их можно упорядочить в лексикографической очередности следования физических
адресов. Напомним (см. раздел 12.3.1 на с. 559), что физический адрес блока
представляется последовательностью байтов, описывающей местоположение блока на
носителе системы хранения данных.
Если каждая транзакция получает блокировки элементов в определенном порядке
(это условие в большинстве случаев, разумеется, далеко от реальности), тогда
возникновение ситуации взаимоблокировки из-за ожидания транзакциями момента захвата
блокировок невозможно. Пусть для примера транзакция Т2 ожидает блокировку
элемента Аь удерживаемую Ти Т3 нуждается в блокировке А2, которой владеет Тъ и т.д.,
транзакции Тп необходима блокировка элемента Ал_р принадлежащая транзакции Тп_х
, а Тх требует блокировку элемента Ап, находящуюся в ведении транзакции Тп.
Поскольку Т2 владеет блокировкой А2, но при этом ожидает блокировку Аь элементы
должны подчиняться правилу упорядочения А2<А{. Аналогично, следует обеспечить
выполнение условий А/<А/_,,где / = 3, 4,..., л. Но так как Т{ обладает блокировкой Al5
ожидая момент захвата блокировки Ап, отсюда следует, что Ах<Ап. Теперь имеем
Ai <Л„<ЛЯ_!< — <л2<ль что невозможно, поскольку иначе должно быть А! <А{.
Пример 19.14. Предположим, что элементы базы данных отсортированы в алфавитном
порядке следования их идентификаторов. Если четырем транзакциям, рассмотренным
в примере 19.13 на с. 969, пришлось бы блокировать элементы в указанной
очередности, код транзакций Т2 и Г4 надлежало бы переписать, поменяв инструкции
блокирования/разблокирования местами:
7V /,(А); г,(Л); 1Х(В)\ и>,(Д); и,(А); щ{В)\
Т2: /2(А); /2(С); r2(Q; w2(A); u2(A); u2(Q;
T3: /3(Z?); r3(B); /3(Q; w3(Q; u3(B); n3(Q;
T4: /4(A); /4(D); r4(D); w4(A); «4(A); w4(D);
На рис. 19.13 отображена последовательность событий в том случае, если
транзакции выполняются в соответствии с тем же расписанием, которое показано на
рис. 19.9 (см. с. 970). Первой приступает к работе транзакция Гь получающая
блокировку элемента А. Следующей пытается стартовать Тъ которая также нуждается в
блокировке А, но ей приходится ждать, пока ресурс не будет освобожден транзакцией Т{.
Затем начинает выполняться Г3, захватывая блокировку Z?; транзакция Г4, однако,
также вынуждена ожидать освобождения блокировки А.
19.3. РАЗРЕШЕНИЕ ВЗАИМОБЛОКИРОВОК
971
тх т2 т3 тА
1)
2)
3)
4)
5)
6)
7)
8)
9)
10)
И)
12)
13)
14)
li(A); г,(А);
/,(В); w,(B);
н,(Д); и,(В);
12(А) — зап]
/2(А); /2(0;
r2(Q; w2(A);
и2(Л); и2(С);
/з(0; w3(C);
и3(Д); и3(0;
/4(Д) — запрет
/4(А); /4(D);
r4(D); w4(A);
w4(A); w4(D);
/Y/c. 79. /J. Принятие порядка блокирования элементов предотвращает возможность
возникновения взаимоблокировок
Поскольку выполнение транзакции Т2 приостановлено, в соответствии с
регламентом расписания на рис. 19.9 следующей стартует транзакция Т3 — она способна
захватить блокировку элемента С, что дает ей возможность на шаге 6 завершить работу.
Теперь, когда блокировки В и С, которые удерживались транзакцией Г3, освобождены,
шанс благополучного выполнения функций получает и транзакция Т{, что она и
реализует в строках 7 и 8. В этот момент становится доступной блокировка Л, которая,
если придерживаться стратегии "первым пришел — первым обслужен", должна быть
отдана транзакции Т2. Последняя получает в распоряжение все, необходимое для
завершения работы. Наконец, правом блокирования нужных элементов и
возобновления приостановленной деятельности наделяется и транзакция Г4. □
19.3.4. Выявление взаимоблокировок с помощью механизма хронометража
Как было показано в разделе 19.3.2 на с. 969, обнаружить ситуации
взаимоблокировки позволяет модель графов ожидания. Однако в конкретном случае подобный
граф может оказаться чрезмерно большим, а задача его анализа с целью выявления
циклов — слишком трудоемкой. Еще один способ обнаружения взаимоблокировок
связан с использованием механизма хронометража (timestamping). Планировщик
заданий ведет учет хронологических признаков каждой транзакции.
• Эта информация используется только для предотвращения потенциальной
опасности возникновения ситуаций взаимоблокировки и не имеет отношения
к схеме управления параллельными заданиями на основе хронометража
действий транзакций (см. раздел 18.8 на с. 930), хотя совместное применение двух
механизмов вполне допустимо.
• Если транзакция подвергается откату, она получает новое значение
хронологического признака, используемого для управления параллельными заданиями, но
признак, применяемый для выявления взаимоблокировок, никогда не изменяется.
972 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Механизм ведения хронологических признаков, рассматриваемый в этом разделе,
используется в том случае, когда транзакция Т вынуждена ожидать освобождения
блокировки, удерживаемой другой транзакцией U. Возможно возникновение двух
ситуаций, различающихся тем, какая из транзакций — Т или U — "старше", т.е. обладает
меньшим значением хронологического признака. Ситуациям соответствуют две
стратегии управления транзакциями и выявления взаимоблокировок.
1. Схема "ожидание—гибель " (wait-die scheme):
a) если Т "старше" V (т.е. значение хронологического признака Т меньше
величины признака U), транзакции Т позволяется пребывать в состоянии
ожидания возможности захвата блокировки, удерживаемой транзакцией U\
b) если, напротив, U "старше" Г, транзакция Т "гибнет", т.е. подвергается откату.
2. Схема "ранение—ожидайие"(wound-wait scheme):
a) если Т "старше" U, Т "ранит" U; "ранение" обычно носит "смертельный"
характер — транзакция U подлежит откату с освобождением всех блокировок
(в том числе и тех, которые ожидаются транзакцией Т); исключение
составляет ситуация, когда к моменту получения "ранения" транзакция V
оказывается завершенной — в этом случае U "выживает" и не нуждается в откате;
b) если же U "старше" Г, транзакция Т остается в состоянии ожидания
освобождения блокировки, которой владеет транзакция U.
Пример 19.15. Рассмотрим способ применения схемы "ожидание—гибель"
применительно к набору транзакций из примера 19.14 на с. 971. Будем полагать, что список
(Ть Т2, Т3, Т4) определяет порядок следования значений хронологических признаков
транзакций, т.е. Тх является наиболее "старшей", а Т4 — самой "младшей". Допустим
также, что если транзакция подвергается откату, она не может заново стартовать до
момента завершения других транзакций.
Г, Т2 Г3 ТА
1)
2)
3)
4)
5)
6)
7)
8)
9)
104
И)
12)
13)
14)
15)
/i(A); гМУ,
/,(В); w,(B);
и,(Л); «,(В);
/2(Л) — "гибель"
/3(Я); г3(Я);
/3(С); w3(C);
и3(В); u3(Q;
ЦЛ) — "гибель"
12(Л) — ожидание
/4(Л); l4(D);
r4(D); w4(A);
и4(А)\ w4(D);
h(A)\ /2(Q;
r2(Q\ w2(A);
u2(A)\ u2(Q\
Рис. 19.14. Пример предотвращения взаимоблокировки с помощью схемы "ожидание—гибель"
19.3. РАЗРЕШЕНИЕ ВЗАИМОБЛОКИРОВОК
973
Обоснование корректности процедуры обнаружения взаимоблокировок,
основанной на механизме хронометража
Можно утверждать, что при использовании любой из схем — "ожидание—гибель"
или "ранение—ожидание" — граф ожидания окажется ациклическим и,
следовательно, ситуация взаимоблокировки не возникнет. Допустим противное — граф
содержит цикл (например, Тх -» Т2 —> Т3 —> Т{). (Одна из транзакций — скажем,
Т2 — является "старшей".)
Схема "ожидание—гибель" предполагает необходимость ожидания только таких
блокировок, которые удерживаются "младшими" транзакциями. Поэтому
невозможно, чтобы Тх ожидала ресурс, захваченный Тъ так как Т2 по определению
"старше", нежели Тх. Схема "ранение—ожидание", напротив, предусматривает
необходимость ожидания только тех блокировок, которые находятся во владении
"старших" транзакций. В этом случае Т2 не может ожидать освобождения
блокировки "младшей" транзакцией Т3. Таким образом, цикл в действительности не
существует и взаимоблокировки нет.
На рис. 19.14 отображена допустимая последовательность событий при
использовании схемы "ожидание—гибель". Вначале транзакция Тх получает блокировку
элемента А. Когда ту же блокировку запрашивает транзакция Тъ она вынуждена
"погибнуть", поскольку владеющая блокировкой транзакция Тх "старше" Т2.
На шаге 3 Т3 приобретает блокировку элемента В, а на шаге 4 Т4 запрашивает
блокировку Л и также "гибнет", поскольку блокировка по-прежнему удерживается более
"старшей" транзакцией Т{. Далее Т3 блокирует элемент С, выполняет надлежащие
действия и завершает работу. Затем транзакция Тх обнаруживает, что блокировка В
свободна, захватывает ее, осуществляет определенные операции и также финиширует.
Теперь две транзакции — Т2 и Т4, — которые были подвергнуты откату, стартуют
повторно. Значения их хронологических признаков (рассматриваемые в контексте
задачи предотвращения взаимоблокировок) сохраняются неизменными: Т2, как
и прежде, "старше", нежели Т4. Однако мы полагаем, что Т4 активизируется раньше,
на шаге 9, и когда более "старая" транзакция Т2 на шаге 10 запрашивает занятую
блокировку А, она вынуждена ждать, но не прерывать выполнение. После того, как
на шаге 12 Т4 завершает функционирование, транзакции Т2 позволяется возобновить
приостановленную деятельность. □
Пример 19.16. Теперь обратимся к тем же транзакциям, расписание работы которых
(см. рис. 19.15) на сей раз подчиняется схеме "ранение—ожидание".
Как и в расписании на рис. 19.14, транзакция Т{ начинает работу с блокирования
элемента А. Когда на шаге 2 транзакция Т2 генерирует запрос на блокировку Л, ей
приходится переходить в состояние ожидания — Т{ "старше" Т2. Далее транзакция Т3
приобретает блокировку элемента В\ затем транзакция Т4, как и Тъ вынуждена ждать
освобождения блокировки Л.
Предположим, что на шаге 5 транзакция Тх продолжает работу, запрашивая
блокировку элемента В. Этой блокировкой уже владеет Г3, но транзакция Тх "старше",
и поэтому она "ранит" Т3. Поскольку функции Т3 еще не завершены, "ранение"
оказывается "смертельным" — Т3 освобождает блокировку и подвергается откату,
а Тх получает "зеленый свет".
Допустим, что после снятия транзакцией Тх блокировки Л последнюю получает
транзакция Т2. По окончании работы Т2 блокировка А "вручается" транзакции Т4,
которая продолжает действовать вплоть до завершения. Наконец, Т3 активизируется
повторно и выполняется без помех. □
974 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Ti
1)
2)
3)
4)
5)
6)
7)
8)
9)
10)
И)
12)
13)
14)
15)
h(A); r,CA);
/,(B); w,(B);
и,(Л); i/,(fl);
'г(^) — ожидание
/2(Л); /2(Q;
r2(Q; w2(A);
и2(А); и2(С);
/3(B); rj(B);
"Ранение"
/3(B); r3(B);
/3(Q; w3(Q;
н3(В); из(0;
/4(A) — ожидание
/4(A); /4(D);
r4(D); w4(A);
«4(A); w4(D);
Pwc. J9.15. Пример предотвращения взаимоблокировки с помощью схемы "ранение—ожидание"
19.3.5. Сравнение методов обнаружения и предотвращения взаимоблокировок
В обеих схемах — "ожидание—гибель" и "ранение—ожидание" — "младшие"
транзакции "умерщвляются" более "старшими". Поскольку транзакции, подвергшиеся
откату, активизируются повторно с сохранением исходных значений хронологических
признаков, каждая из них со временем приобретает статус самой "старшей" и потому
определенно сможет завершиться —- ей, таким образом, не грозит гибель от
естественного старения (starvation). Заметим, что другие механизмы, которые упоминались
в этом разделе, вовсе не обязательно препятствуют возможности "бесконечно"
долгого "барахтанья" транзакции в системе; если не принять дополнительных мер,
процесс старта, вовлечения во взаимоблокировку и отката транзакции способен
повторяться вновь и вновь (обратитесь к упражнению 19.3.7 на с. 977).
В особенностях поведения схем "ожидание—гибель" и "ранение—ожидание"
наблюдается, однако, небольшое различие. При использовании стратегии "ранение-
ожидание" транзакция, которая была активизирована позже и захватила блокировку,
"убивается" более "ранней" транзакцией, если та запрашивает ту же блокировку.
Если полагать, что транзакции блокируют элементы базы данных ближе к моменту
старта, ситуации, когда "старшая" транзакция "обижает" "младшую", должны возникать
относительно редко. Поэтому нечастой окажется и необходимость отката транзакций.
С другой стороны, при использовании схемы "ожидание—гибель" откату
подвергаются транзакции, которые, вообще говоря, все еше пребывают в стадии получения
блокировок, т.е. в самом начале своей деятельности. Хотя в этом случае частота
откатов и выше, нежели в системе, реализующей стратегию "ранение—ожидание",
транзакции к моменту отката, как правило, успевают выполнить только небольшую часть
функций. Напротив, когда транзакция откатывается в системе, придерживающейся
политики "ранение—ожидание", на выполнение операций транзакции, вполне
вероятно, уже затрачена немалая доля процессорного времени. Таким образом, любая из
схем может приводить к немалым накладным расходам — их величина зависит от
природы и частотных характеристик транзакций.
19.3. РАЗРЕШЕНИЕ ВЗАИМОБЛОКИРОВОК
975
Целесообразно рассмотреть преимущества и недостатки схем "ожидание—гибель"
и "ранение—ожидание" в сопоставлении с прямолинейным подходом,
предполагающим создание и анализ графа ожидания (см. раздел 19.3.2 на с. 969). Приведем
наиболее важные соображения.
• Практическая реализация схем "ожидание—гибель" и "ранение—ожидание"
более проста, нежели использование системы, обеспечивающей поддержку и
периодическое повторное конструирование графа ожидания. Недостатки
последней становятся еще более очевидными и угрожающими, если база данных
является распределенной и граф ожидания должен строиться на основе
информации целой коллекции таблиц блокировок, размещенных на различных
сайтах (подробнее — в разделе 19.6 на с. 987).
• Применение графов ожидания, однако, позволяет минимизировать частоту
прерывания транзакций из-за взаимоблокировок. Транзакция никогда не
прерывается до тех пор, пока ее участие во взаимоблокировке не становится
явным. С другой стороны, схемы "ожидание—гибель"* и "ранение—ожидание"
подчас приводят к необходимости отката транзакции даже в отсутствие
реальной опасности взаимоблокировки, когда таковая не могла бы возникнуть, если
бы транзакции было позволено продолжить работу.
19.3.6. Упражнения к разделу 19.3
Упражнение 19.3.1. Рассмотрим приведенные ниже последовательности действий,
полагая, что каждая операция чтения непосредственно предваряется инструкцией
захвата общей блокировки, а каждая операция записи — запросом на получение
монопольной блокировки. Допустим также, что команды разблокирования выполняются
сразу после выполнения последнего действия каждой транзакции. Поясните, какие
операция будут отвергнуты и возникнут ли ситуации взаимоблокировки.
Проанализируйте, каким образом изменяется граф ожидания по мере прохождения операций. При
возникновении взаимоблокировки обеспечьте выбор транзакции, подлежащей откату,
и продемонстрируйте, каким образом расписание должно выполняться в дальнейшем.
* а) п(Л); г2(Д); wx(Q; r3(D)\ r4(£); w3(B)\ w2(Q; w4(A); wx(D);
b) n(A); r2{B)\ r3(Q; wx{B)\ w2(Q; w3(D);
c) n(A); r2(B)\ r3(0; wx(B); w2(Q; w3(A);
d) п(Л); r2(B); w,(Q; w2(D); r3(Q; wx(B); w4(D); w2(A);
Упражнение 19.3.2. Изучите особенности выполнения каждого из расписаний,
определенных в упражнении 19.3.1, в системе, реализующей механизм
предотвращения взаимоблокировок, основанный на схеме "ранение—ожидание". (Очередность
назначения хронологических признаков определяется последовательностью
индексов в идентификаторах транзакций, т.е. (Тх, Тъ Г3, Г4). Транзакции активизируются
повторно в соответствии с порядком следования моментов их отката.)
Упражнение 19.3.3. Изучите особенности выполнения каждого из расписаний,
определенных в упражнении 19.3.1, в системе, реализующей механизм
предотвращения взаимоблокировок, основанный на схеме "ожидание—гибель". Примите к
сведению те же допущения, которые перечислены в упражнении 19.3.2.
! Упражнение 19.3.4. Может ли существовать граф ожидания, содержащий цикл
длины п, но не меньшей, для любого наперед заданного целочисленного значения п?
Что можно сказать насчет условия п - 1, т.е. цикла, охватывающего одну вершину?
!! Упражнение 19.3.5. Один из возможных подходов, позволяющих избежать
взаимоблокировок, состоит в том, чтобы каждая транзакция анонсировала потребности
976 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
в получении блокировок в самом начале своего рабочего цикла; система должна
либо предоставить транзакции все нужные блокировки, либо запретить их захват
и перевести транзакцию в состояние ожидания. Действительно ли такая схема
решает проблему? Если да, объясните, почему, либо приведите контрпример.
! Упражнение 19.3.6. Обратимся к системе, основанной на концепции
предупреждающего блокирования (warning locking) (см. раздел 18.6.2 на с. 919).
Продемонстрируйте способ конструирования графа ожидания, отвечающего реалиям такой
системы. В частности, изучите возможность блокирования элемента А базы данных
различными транзакциями в режимах is и либо S, либо IX. Если запрос на
получение блокировки А вынужденно откладывается, какие дуги следует ввести в граф?
*! Упражнение 19.3.7. В разделе 19.3.5 на с. 975 упоминалось о том, что методы
выявления взаимоблокировок, отличные от схем "ожидание—гибель" и "ранение—ожидание",
не обязательно препятствуют возможности естественного старения транзакций, когда
те периодически подвергаются откату и не в состоянии успешно финишировать.
Приведите пример ситуации, где политика отката любой транзакции, чреватой
образованием циклов в графе ожидания, способна послужить причиной
естественного старения транзакций. Помогает ли преодолеть проблему естественного
старения транзакций схема блокирования элементов в строгой очередности? Решает ли
задачу технология задания лимита времени (timeout) активности транзакций?
19.4. Распределенные базы данных
В этом разделе мы вкратце рассмотрим элементы систем распределенных баз данных
(distributed databases). Участие в обработке данных, хранимых под управлением
распределенной системы, принимают одновременно несколько относительно
автономных процессоров. Распределенные базы данных предлагают следующие возможности.
1. Поскольку на решение проблемы могут быть направлены ресурсы многих
компьютеров, степень параллелизма операций и скорость получения отклика
системы на запрос существенно возрастают.
2. Так как копии данных реплицируются по нескольким рабочим площадкам
(сайтам), обработка запроса вовсе не обязательно должна приостанавливаться
из-за выхода из строя какого-либо компонента или целого сайта.
С другой стороны, технологии распределенной обработки информации
увеличивают уровень сложности всех компонентов системы баз данных и вынуждают
пересматривать ее структуру вплоть до основополагающих элементов. Во многих
распределенных вычислительных средах затраты на поддержку коммуникаций могут
превалировать над стоимостью процессов вычислений как таковых, поэтому важнейшее
значение приобретает скорость обмена сообщениями, или пропускная способность
канала связи. Здесь мы остановим внимание на основных аспектах систем
распределенных баз данных, а два следующих раздела посвятим изучению двух важных
частных проблем, связанных с распределенной фиксацией (distributed commit) и
распределенным блокированием (distributed locking).
19.4.1. Концепция распределенных данных
Одна из важных причин, побуждающих к применению технологий распределения
данных, состоит в том, что многие компании и организации представляют собой
широко разветвленную сеть филиалов (сайтов), и в каждом из них используются
собственные массивы данных. Вот несколько примеров.
1. Банковское учреждение содержит сеть отделений. Каждое отделение или группа
отделений внутри крупного города должны поддерживать базу данных с ин-
19.4. РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННЫХ
977
формацией о счетах клиентов. Клиент, которому необходимо выполнить
финансовую операцию, может обратиться либо в "собственное" ближайшее
отделение, где открыты его счета, либо в любое другое отделение. Некоторые
порции информации служебного характера (скажем, данные о сотрудниках,
корпоративной политике, процентных ставках и т.п.) зачастую сосредоточены
в центральном офисе. Архивные копии данных каждого отделения или
центрального аппарата могут сохраняться как на месте, так и в других филиалах банка.
2. Крупная торговая компания владеет сетью универмагов и магазинов. Каждый
магазин или группа торговых заведений в пределах одного населенного пункта
поддерживают базы данных с локальной информацией об уровнях продаж и
остатках товаров на складах. Вполне вероятно и наличие центрального офиса,
в базе данных которого сохраняются сведения о служащих компании,
обобщенная учетная информация, номера кредитных карт клиентов, данные о
поставщиках товаров, взаимных задолженностях и т.д. Помимо того, в
центральном "хранилище данных" нередко сосредоточены копии сведений обо всех
фактах продаж; подобная информация используется аналитиками для
составления бизнес-планов и прогнозов будущих достижений компании (за
подробностями обращайтесь к разделу 20.4 на с. 1023).
3. Сообщества университетов поддерживают совместные цифровые библиотеки. В базе
данных каждого университета хранятся электронные копии книг и других печатных
документов. При выполнении запроса, посланного с любого сайта, осуществляется
поиск данных в каталогах всех сайтов; если результат поиска успешен, найденная
информация возвращается пользователю, активизировавшему запрос.
В некоторых случаях информация, которая с логической точки зрения
воспринимается в виде единого отношения, на самом деле физически рассредоточена по
множеству сайтов. Примером могут служить вышеупомянутые совокупные данные о
сделках продажи, осуществленных во всех магазинах одной торговой компании.
Информацию такого рода естественно трактовать в форме отношения вида
Sales(item, date, price, purchaser)
хотя последнее и не существует в физическом смысле. (Семантика атрибутов
отношения такова: item — "идентификатор товара", date — "дата продажи", price —
"цена", purchaser — "сведения о покупателе".) В действительности подобная
структура данных может представлять собой объединение большого числа отношений
с одинаковой схемой, по одному на каждую торговую точку. Локальные отношения
называют фрагментами (fragments), а разбиение логического отношения (в данном
случае — Sales) на физические фрагменты — горизонтальной декомпозицией
(horizontal decomposition). Мы называем разбиение "горизонтальным", поскольку
отношение можно представить в виде групп кортежей, относящихся к локальным
сайтам и разделенных горизонтальными линиями.
В других случаях удобнее использовать схему вертикальной декомпозиции (vertical
decomposition), когда логическое отношение формируется из нескольких
физических (размещенных на различных сайтах), каждое из которых содержит
определенное подмножество атрибутов. Например, если необходимо определить, какие
торговые сделки в Бостонском универмаге были совершены с покупателями, чья
задолженность по платежам составила 90 или более дней, уместно обратиться
к (виртуальной) таблице, которая включает данные компонентов item, date
и purchaser отношения Sales наряду с датами последнего платежа, совершенного
каждым из покупателей. В этом случае речь идет именно о вертикальной
декомпозиции: соединению (join) подлежат отношение с информацией о владельцах
кредитных карт, хранимое, вероятно, в центральном офисе компании, и фрагмент
отношения Sales с данными, касающимися Бостонского отделения.
978 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
К вопросу о затратах на коммуникации
Как известно, пропускная способность каналов связи неуклонно возрастает и
сервис, предоставляемый провайдерами телекоммуникаций, удешевляется.144 Так
почему при проектировании систем распределенных баз данных необходимо
учитывать расходы на обмен информацией между сайтами? Сегодня массивы
распределенных данных столь велики, что даже при использовании дешевых каналов связи
не учитывать стоимость приема/передачи, скажем, терабайтовой порции
информации попросту невозможно. При этом стоимость определяется не только
количеством переносимых битов реальных данных, но и затратами на поддержку
многоуровневого сетевого протокола, который управляет подготовкой информационных
пакетов к передаче и сбором полученных пакетов на сайте-приемнике. Реализация
каждого уровня протокола требует немалых вычислительных расходов. Последние
остаются весомыми, хотя затраты на обработку запросов как таковых по мере
развития технологий снижаются.
19.4.2. Распределенные транзакции
Следствием принятия концепции распределенных данных служит схема
транзакции, затрагивающей процессы, которые протекают на различных сайтах.
Традиционная модель транзакции — фрагмента кода, выполняемого конкретным процессором
и взаимодействующего с единственным планировщиком заданий и локальным
менеджером протоколирования в пределах определенного сайта, — подлежит
решительному пересмотру. Теперь транзакция представляется в виде взаимодействующих
компонентов (transaction components) — каждый из них действует на некотором сайте под
управлением локальных планировщика заданий и менеджера протоколирования.
В этом контексте заслуживают внимания две группы важных вопросов.
1. Каким образом должны приниматься решения о фиксации/прерывании
распределенной транзакции? Как быть, если отдельный компонент, как кажется,
обязан провоцировать прерывание целой транзакции, хотя все другие
компоненты действуют вполне успешно и готовы к фиксации достигнутых
результатов? В разделе 19.5 на с. 981 обсуждается технология двухфазной фиксации (two-
phase commit), которая позволяет принимать адекватные решения.
2. Каким образом гарантируется последовательное протекание операций
транзакций, если их компоненты выполняются на различных сайтах? К этой проблеме
мы обратимся в разделе 19.6 на с. 987, где покажем, как информация
локальных таблиц блокировок может использоваться для поддержки глобальных
блокировок элементов базы данных, обеспечивая условно-последовательный
характер расписаний выполнения транзакций в распределенной вычислительной среде.
19.4.3. Репликация данных
Одно из важных преимуществ распределенных систем состоит в их способности
к репликации данных (data replication) — поддержке копий данных на различных сайтах.
Один из неоспоримых доводов в пользу применения механизма репликации
заключается в том, что при выходе из строя одного сайта утраченная информация может быть
восстановлена из копий, размещенных на остальных сайтах. Другой аргумент связан
с увеличением скорости обработки запроса за счет перемещения требуемой порции
данных на сайт, где запрос был инициирован. Приведем несколько примеров.
Этот тезис справедлив, разумеется, только для стран с развитой рыночной
экономикой. — Прим. перев.
19.4. РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННЫХ
979
1. В банковской системе уместно распространять копии данных, касающихся
текущих значений процентных ставок, по базам данных всех отделений банка,
чтобы запросы, затрагивающие подобную информацию, не адресовались
центральному офису.
2. Компании, занимающиеся розничной торговлей, часто передают информацию
о поставщиках товаров во все отделения, чтобы региональные менеджеры,
отслеживающие процессы поступления товаров, могли быстро принимать
соответствующие решения, не обращаясь "по пустякам" к базе данных верхнего уровня.
3. При реализации цифровых библиотек целесообразно предусматривать
возможность локального кэширования популярных документов, дабы обеспечить
быстрый доступ к ним со стороны местных пользователей.
Впрочем, не все так гладко — вот некоторые проблемы, с которыми приходится
сталкиваться при использовании механизмов репликации.
1. Как обеспечить идентичность копий данных? Операция обновления элемента
реплицированных данных должна быть реализована в виде распределенной
транзакции, которая вносит одни и те же изменения во все копии.
2. Как принимать решения о том, где сохранять копии и сколько их должно быть?
Чем больше копий, тем сложнее процедура их обновления, но проще обработка
запросов. Например, отношение, которое обновляется редко, уместно
реплицировать повсеместно, чтобы максимизировать эффективность его использования;
если же, напротив, данные подвержены частым модификациям, их
целесообразно хранить в виде нескольких копий или даже в единственном экземпляре
(помимо, разумеется, архивного).
3. Что происходит при временном отказе сетевых коммуникаций, когда возникает
опасность свободной и неконтролируемой эволюции различных копий одних и
тех же данных? Как осуществлять согласование копий после восстановления
функций сети?
19.4.4. Распределенная оптимизация запросов
Необходимость обработки распределенных данных повышает уровень сложности
и изменяет состав инструментов проектирования физического плана запроса (physical
query plan) (см. раздел 16.7 на с. 822). Заслуживают внимания следующие проблемы,
которые подлежат разрешению при выборе наилучшего физического плана.
1. Если отношение /?, затрагиваемое запросом, наличествует в нескольких копиях,
какой из них лучше воспользоваться?
2. При выполнении какого-либо оператора (скажем, соединения — join),
применяемого к двум отношениям R и 5, имеется несколько альтернатив действий;
вот некоторые из них:
a) скопировать содержимое отношения S на сайт, где размещено отношение R,
и осуществить вычисления на сайте с /?;
b) наоборот, скопировать R на сайт с 5, где и произвести операцию;
c) создать копии R и S на. третьем сайте и воспользоваться его
вычислительными мощностями.
Какое решение окажется оптимальным — ответ на этот вопрос зависит от
нескольких факторов: например, какой из сайтов обладает требуемыми
ресурсами, должен ли результат операции сочетаться с данными, расположенными
на каком-либо конкретном сайте, и т.п. Скажем, при вычислении оператора
980
ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
(R xS)txT более уместно, возможно, доставить данные отношений R и S на
сайт, содержащий отношение Г, где и выполнить обе процедуры соединения.
Если отношение R состоит из фрагментов Rb R2,..., Rn, распределенных по
различным сайтам, при выборе логического плана отношение следует трактовать как
результат выполнения оператора
RiURiU-VRn.
Семантика запроса может быть такой, что выражение удастся существенно упростить.
Если, например, Я, представляет /-Й фрагмент отношения Sales (см. раздел 19.4.1 на
с. 977), а каждый фрагмент ассоциирован с определенным магазином, тогда при
обработке запроса, касающегося объемов продаж в Бостонском универмаге, всеми
фрагментами, кроме одного, можно пренебречь, удалив их из выражения объединения.
19.4.5. Упражнения к разделу 19.4
*!! Упражнение 19.4.1. Предположим, что существует отношение R, к которому
обращаются с п сайтов, причем с /-го сайта каждую секунду поступают qt запросов и щ
команд обновления, где /= 1, 2,..., п. Стоимость обработки запроса в том случае,
когда копия R наличествует на сайте, который инициировал запрос, оценивается
величиной с; если же копии R на "местном" сайте нет и запрос подлежит отправке
на удаленный сайт, стоимость возрастает до Юс. Аналогичная зависимость
характерна и для значений стоимости операций обновления — d и \0d соответственно.
Как определить оптимальное множество сайтов, на которые целесообразно
реплицировать копии отношения R при больших значениях п, в виде функции
вышеназванных параметров?
19.5. Распределенная фиксация
В этом разделе мы затронем проблему обеспечения атомарности выполнения
компонентов распределенной транзакции на различных сайтах, а следующий (см. с. 987)
посвятим другой важнейшей задаче, связанной с поддержкой условно-
последовательного характера расписаний протекания действий распределенных
транзакций. Для начала рассмотрим один красноречивый пример.
Пример 19.17. Вновь обратимся к информационной модели торговой компании, о
которой мы говорили в разделе 19.4 на с. 977. Предположим, что менеджеру, служащему
в центральном аппарате, необходимо запросить информацию об остатках зубной пасты на
складах всех магазинов сети и выдать рекомендации по поводу перемещения партий
товара с одних складов на другие, чтобы сбалансировать спрос и предложение. Операция
осуществляется в виде единой глобальной транзакции Г, представляющей собой набор
компонентов Г, (для /-го магазина) и Т0 (для центрального офиса). Последовательность
действий, предпринимаемых транзакцией Т, может выглядеть так, как показано ниже.
1. На сайте центрального офиса создается компонент Т0.
2. Компонент Т0 рассылает всем региональным сайтам сообщения с инструкциями
о том, как создать компоненты Г,.
3. Каждый компонент 7) выполняет запрос на сайте i, имеющий целью
определение величины остатков товара (зубной пасты) на складе /, и направляет
полученный результат компоненту Г0.
4. Компонент Т0 получает значения, собранные со всех сайтов, в соответствии
с некоторым алгоритмом (его детали мы обсуждать не будем) определяет, каким
образом следует перемещать партии товара с одних складов на другие, и рассы-
19.5. РАСПРЕДЕЛЕННАЯ ФИКСАЦИЯ
981
лает инструкции вида "магазин 10 должен передать магазину 7 500 упаковок
зубной пасты" соответствующим сайтам (в данном случае — 7-му и 10-му).
5. Магазины, получив инструкции, обновляют значения в локальных базах
данных и выполняют требуемые перевозки.
□
19.5.1. Поддержка распределенной атомарности
Глобальной транзакции Т, рассмотренной в примере 19.17, угрожают самые разные
опасности, и во многих случаях они находят выражение в утрате свойства
атомарности (atomicity), когда одни действия транзакции завершаются успешно, а другие —
нет. Механизмы протоколирования и восстановления, которые, как можно полагать,
функционируют на каждом отдельном сайте, обеспечивают атомарность протекания
операций, выполняемых компонентами Th но не транзакцией Т в целом.
Пример 19.18. Предположим, что из-за ошибки алгоритма перераспределения товаров
(зубной пасты) между магазинами торговой компании сайт 10 получил инструкцию
передать 7-му магазину больше пасты, чем есть в наличии. Выполнение кода компонента
7\о должно быть прервано — состояние фрагмента базы данных на сайте 10 не
изменится и товар отгружен не будет. Компонент Г7, однако, никакой ошибки не выявляет — он
обновляет фрагмент данных на сайте 7, отражая предполагаемую поставку товара.
Свойство атомарности транзакции Т нарушено, поскольку выполнение кода компонента Г10
не завершено. Более того, распределенная база данных остается в несогласованном
состоянии — информация не соответствует реальному положению вещей. □
Другой источник потенциальных проблем связан с опасностью выхода того или
иного сайта из строя или нарушения сетевых коммуникаций в период обработки
распределенной транзакции.
Пример 19.19. Предположим, что компонент Г10 реагирует на первое сообщение от Т0
и направляет на сайт центрального офиса информацию об остатках зубной пасты на
местном складе, но затем компьютер с базой данных на сайте 10 выходит из строя
и инструкции от Г0 до компонента Г10 не доходят. Способна ли распределенная
транзакция Т осуществить фиксацию в подобных обстоятельствах? Что должен
предпринять компонент Т10 после восстановления работоспособности сайта? □
19.5.2. Двухфазная фиксация
Для преодоления проблем, упомянутых в разделе 19.5.1 на с. 982, в системах
распределенных баз данных применяется сложный протокол, позволяющий принимать
адекватные решения по поводу возможности фиксации распределенных транзакций.
В этом разделе мы сосредоточим внимание на базовой концепции, лежащей в основе
этого протокола, — речь пойдет о механизме двухфазной фиксации (two-phase
commit).145 Глобальное решение о фиксации распределенной транзакции предполагает
либо фиксацию всех компонентов транзакции, либо их прерывание. Как обычно, мы
подразумеваем, что механизмы обеспечения атомарности, действующие на каждом
сайте, гарантируют либо успешную фиксацию локальных компонентов, либо
сохранение состояния фрагмента базы данных в неизменном виде, т.е. поддержку
атомарности операций каждого компонента. Поэтому правило, предусматривающее либо
фиксацию всех компонентов распределенной транзакции, либо их прерывание,
позволяет поручиться, что и транзакция в целом сохранит свойство атомарности.
145 Просьба не путать двухфазную фиксацию с двухфазным блокированием (см. раздел 18.3.3 на
с. 897). Это совершенно независимые технологии, разработанные для решения различных задач.
982 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Укажем несколько характерных особенностей, присущих механизму двухфазной
фиксации.
• На каждом локальном сайте ведется собственный протокол операций,
выполняемых компонентом распределенной транзакции, но глобальное
протоколирование не осуществляется.
• Один из сайтов, называемый координатором (coordinator), выполняет
специальные функции, касающиеся принятия решений о возможности фиксации
распределенной транзакции. Роль координатора способен играть, скажем, сайт,
с которого транзакция была инициирована (такой, как Г10, упоминавшийся
в примерах из раздела 19.5.1 на с. 982).
• Схема двухфазной фиксации предусматривает рассылку определенных
сообщений между координатором и остальными сайтами сети. По мере отправки
сообщения оно протоколируется на передающем сайте на случай восстановления
данных при возможном отказе подсистемы сайта.
Принимая во внимание названные особенности, приведем описание двух фаз
процедуры фиксации в терминах сообщений, которыми обмениваются сайты сети.
Фаза I
В продолжение фазы I процедуры двухфазной фиксации координатор,
управляющий некоторой распределенной транзакцией Т, решает, можно ли осуществить
фиксацию Т. Попытка фиксации предпринимается преимущественно после того, как
компонент транзакции Т, функционирующий на сайте-координаторе, сообщает о
готовности к фиксации, хотя, вообще говоря, перечисленные ниже действия должны
выполняться (с некоторыми упрощениями) даже в том случае, когда работа
компонента сайта-координатора подлежит прерыванию. Координатор опрашивает все сайты
с компонентами распределенной транзакции Т, чтобы выяснить намерения
компонентов относительно фиксации/прерывания.
1. Координатор включает в локальный протокол запись вида <Prepare T>.
2. Координатор отсылает всем сайтам с компонентами транзакции Т (в том числе
и себе) сообщение prepare Т.
3. Каждый сайт, получая сообщение prepare Г, принимает решение о том,
выполнять ли фиксацию/прерывание соответствующего компонента Т. Сайт
вправе задержать ответ, если код компонента еще не выполнен полностью, но рано
или поздно обязан отправить ответное сообщение.
4. Если сайт готов осуществить фиксацию компонента, он должен перейти в
состояние предварительной фиксации (precommit). Пребывая в состоянии
предварительной фиксации, сайт уже не в состоянии прервать работу соответствующего
компонента Т, не получив необходимой директивы от координатора. Для получения
сайтом статуса предварительной фиксации выполняются следующие действия:
а) удостовериться, что локальный компонент Т не подлежит прерыванию (даже
в ситуации, когда сайт претерпел системный отказ с последующим
восстановлением данных); таким образом, должны быть выполнены не только все
инструкции, предусмотренные логикой кода компонента, но и
соответствующие операции по протоколированию, чтобы в процессе восстановления
действия компонента Т могли быть повторены, а не отменены (разумеется,
существо процесса зависит от применяемого метода протоколирования, но
в любом случае записи протокола, отвечающие операциям компонента Г,
обязаны быть "сброшены" на диск);
19.5. РАСПРЕДЕЛЕННАЯ ФИКСАЦИЯ
983
b) поместить запись <Ready T> в локальный протокол и осуществить "сброс"
буферов протокола на диск;
c) отправить координатору сообщение ready Т.
В этот момент сайт не фиксирует локальный компонент Т — это делается во
время выполнения фазы II.
5. Если, напротив, работа компонента Т должна быть прервана, сайт обязан
внести в локальный протокол запись <Don't commit T> и отправить
координатору сообщение don't commit Т. Прерывание компонента вполне безопасно —
распределенная транзакция Т должна быть прервана даже в том случае, если
прерыванию подлежит хотя бы один из ее компонентов.
Взаимообмен сайтов сообщениями в течение фазы I схематически представлен на
рис. 19.16.
Фаза II
Фаза II начинается с приема координатором ответных сообщений ready или
don't commit, поступающих от каждого сайта. Некоторые из сайтов, возможно, не
пришлют сообщения из-за выхода из строя или отключения от сети. В подобном
случае по истечении определенного лимита времени (timeout) координатор вправе
трактовать ситуацию так, будто сайты направили сообщения don't commit.
1. Если координатор получил сообщения ready T от всех сайтов с компонентами
распределенной транзакции Г, он принимает решение о фиксации Т:
a) включает в локальный протокол запись <Commit T>\
b) направляет всем сайтам, принимавшим участие в выполнении транзакции Г,
сообщения commit Т.
2. Если от одного или нескольких сайтов поступили сообщения don't commit Г,
координатор
a) вносит в локальный протокол запись <Abort Г>;
b) рассылает всем сайтам с компонентами транзакции Т сообщения abort Т.
3. Если сайт получает от координатора сообщение commit Г, он осуществляет
фиксацию результатов работы соответствующего компонента Т и сохраняет
в собственном протоколе запись <Commit Т>.
4. Если же от координатора поступает сообщение abort Г, сайт прерывает
выполнение кода компонента Т и включает в протокол запись <Abort Т>.
Схема обмена сайтов сообщениями в продолжение фазы II представлена на рис. 19.17.
commit или
abort
ready или
don't commit
Координатор ^\^~n Координатор
Рис. 19.16. Обмен сообщениями при вы- Рис. 19.17. Обмен сообщениями при
полнении фазы I процедуры двухфазной выполнении фазы II процедуры
фиксации двухфазной фиксации
984 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
19.5.3. Восстановление распределенных транзакций
В любой момент периода времени выполнения процедуры двухфазной фиксации
возможен выход сайта из строя. Необходимо гарантировать, что действия, которые будут
предприняты после восстановления данных сайта, окажутся согласованными с
глобальным решением о фиксации/прерывании распределенной транзакции Т. Рассмотрим
несколько возможных ситуаций, особенности которых обусловлены тем, какая именно
запись, касающаяся операций транзакции Г, была внесена в локальный протокол последней.
1. Если завершающей записью протокола, имеющей отношение к транзакции Г,
оказалась <Commit T>, T, вполне очевидно, подлежит фиксации. В процессе
восстановления, возможно, придется повторить действия компонента Г,
функционировавшего на сайте.
2. Если последней в протокол была включена запись <Abort T>, ясно, что
координатором было принято решение о прерывании транзакции Т. Следует
отменить действия компонента Т на восстановленном сайте, если того требует
применяемый режим протоколирования.
3. Если к моменту отказа протокол содержал запись <Don' t commit Г>, это значит,
что на сайте было принято решение о прерывании работы компонента Т и, как
следствие, транзакции в целом. Результаты воздействия (если таковые существуют)
компонента на состояние локального фрагмента базы данных подлежат отмене.
4. Более труден случай, когда протокол содержит только запись <Ready Т>. После
восстановления сайта не известно, каким было глобальное решение координатора,
касающееся "судьбы" транзакции Т. Сайт обязан "проконсультироваться" по
меньшей мере с одним "коллегой". Если координатор пребывает в активном состоянии,
уместно обратиться именно к нему. Если же в данный момент координатор не
работает, "на выручку" способен прийти какой-либо другой сайт — ему достаточно
считать порцию данных собственного протокола, дабы определить, что произошло
с транзакцией Т. В худшем случае, когда ни один из сайтов сети не доступен,
локальный компонент Т на восстановленном сайте обязан оставаться активным
вплоть до момента, когда он сможет получить недостающую информацию.
5. Возможна и такая ситуация, когда локальный протокол вообще не содержит
записей, имеющих отношение к транзакции Т. В подобном случае сайт способен
принять одностороннее решение о прерывании работы "собственного"
компонента Г, согласованное с методом протоколирования. Возможно, что координатор
уже обнаружил факт исчерпания лимита времени, отведенного на обмен данными
с сайтом, и в свою очередь решил прервать транзакцию Т. Если отказ был
кратковременным, не исключено, что компоненты Т на других сайтах все еще находятся
в активном состоянии, но решение о прерывании, принятое сайтом, никогда не
вступит в противоречие с политикой, которой придерживается координатор, если
восстановленный сайт, будучи опрошенным в оставшийся период времени
протекания фазы I, отправит координатору ответ в форме don' t commit T.
Проводя анализ, мы подразумевали, что отказавший сайт не является
координатором. Если же во время выполнения процедуры двухфазной фиксации выходит из
строя именно сайт-координатор, возникают новые проблемы. Действующие сайты
сети обязаны либо дождаться момента восстановления координатора, либо выбрать на
роль координатора другой сайт. Поскольку величина периода времени, в течение
которого координатор может пребывать в отключенном состоянии, непредсказуема,
применение стратегии избрания лидера (leader election) — по меньшей мере, по
истечении определенного разумного лимита времени, достаточного для восстановления
системы-координатора во многих ситуациях, — совершенно обоснованно.
Техника избрания сайта-лидера в распределенной системе является
самостоятельной сложной проблемой, сколько-нибудь подробное изучение которой выходит за
19.5. РАСПРЕДЕЛЕННАЯ ФИКСАЦИЯ
985
рамки нашей книги. Впрочем, можно предложить простой метод, пригодный в
большинстве случаев. Уместно считать, что все сайты сети снабжены уникальными
идентифицирующими признаками (вполне подойдет схема IP-адресов). Каждый сайт-
участник отсылает сообщение, уведомляющее остальных о готовности принять роль
лидера и содержащее собственный идентификатор сайта. По истечении определенного
промежутка времени каждый участник определяет на роль координатора тот сайт,
который обладает наименьшим номером из всех полученных, и рассылает по сети
информацию о принятом решении. Если все сайты получили согласованные сообщения, это
значит, что новый координатор избран "единогласно" и информация доведена до всех.
Если же "мнения" разделились, процесс "выборов" повторяется вновь.
Новый координатор опрашивает сайты о состоянии компонентов каждой
распределенной транзакции Т. Каждый сайт возвращает координатору данные о последней
записи (если таковая существует) локального протокола, имеющей отношение к
транзакции Т. Возможны следующие ситуации.
1. Некоторый сайт содержит в локальном протоколе запись <Commit T>. Это
значит, что прежний координатор уже принимал решение о фиксации транзакции Т
и рассылал всем участникам сообщения commit Г, поэтому новый координатор
вправе согласиться с "мнением" предшественника и зафиксировать транзакцию.
2. Существует сайт, в протоколе которого имеется запись <Abort Г>, что
свидетельствует о факте прерывания транзакции Т прежним координатором. И
в этом случае вновь назначенному координатору лучше принять то же решение.
3. Ни в одном локальном протоколе нет записей вида <Commit T> или
<Abort T>, но по меньшей мере один сайт не внес в свой протокол запись
<Ready T>. Поскольку отправка сообщения предваряется соответствующей
операцией протоколирования, ясно, что "старый" координатор не получал от
сайта сообщение ready T, т.е. не мог принять решения о фиксации
транзакции. Новому лидеру целесообразно осуществить прерывание Т.
4. Более сложен случай, когда, как и прежде, записи <Commit T> и <Abort T> не
обнаружены, но в протоколе каждого действующего сайта имеется запись
<Ready T>. Сейчас уже нельзя быть уверенным в том, нашел прежний
координатор какие-либо основания для прерывания транзакции Т или нет; он мог,
например, прервать Т из-за собственных неполадок либо по причине получения
сообщения don' t commit T от сайта, который в данный момент неисправен, — либо,
наоборот, решил зафиксировать Т и уже изменил содержимое собственного
локального фрагмента базы данных. Поэтому новый координатор не в силах
принять осмысленный вариант действий и вынужден ждать момента восстановления
прежнего координатора. В реальных системах правом "вмешательства" наделен
администратор СУБД, который обладает возможностью "вручную" добиться
завершения работы компонентов транзакции. Результатом может оказаться утрата
свойства атомарности, но человек, освобождающий "блокированную"
транзакцию, как правило, способен предпринять определенные компенсирующие меры.
19.5.4. Упражнения к разделу 19.5
! Упражнение 19.5.1. Рассмотрим транзакцию Г, инициированную с домашнего
компьютера, которая обращается к базе данных банка В с требованием перевода
определенной суммы денег со счета в банке В на счет в банке С.
* а) Каковы компоненты распределенной транзакции 7? Какие действия должны
выполнить компоненты, функционирующие на сайтах В и С?
Ь) Чем обернется нехватка денег на счете в банке В?
986 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
c) Что произойдет при отказе компьютеров в одном или обоих банках или
разрыве сетевого соединения?
d) Каким образом транзакция обязана возобновить работу, если
работоспособность компьютеров и сети после возникновения нештатных ситуаций,
упомянутых в п. (с), восстановлена?
Упражнение 19.5.2. Здесь нам необходимо принять систему обозначений для
описания последовательностей сообщений, рассылаемых при выполнении процедуры
двухфазной фиксации. Пусть запись (i,j, M) свидетельствует о том, что сайт i
направляет сайту j сообщение М, причем М может принимать одно из следующих значений:
Р (prepare), R (ready), D (don11 commit), С (commit) и Л (abort). Остановим
внимание на простой схеме, где сайт 0 выполняет функции координатора, но в
обработке транзакции не участвует, а сайты 1 и 2 поддерживают компоненты транзакции.
Ниже приведен образец последовательности сообщений, которыми могли бы
обменяться сайты в процессе успешной фиксации некоторой распределенной транзакции:
(О, 1, Р), (О, 2, РХ (2, 0, /?), (1, О, Я), (0, 2, О, (0, 1, Q
* а) Предложите пример последовательности сообщений для случая, когда сайт 1
принимает частное решение о фиксации компонента транзакции, а сайт 2 —
о прерывании работы "собственного" компонента.
*! Ь) Каково общее количество последовательностей сообщений, подобных
указанной выше, которые отвечают ситуации успешной фиксации транзакции?
! с) Если сайт 1 предполагает выполнить фиксацию компонента транзакции,
а сайт 2 предусматривает прерывание работы компонента, сколько
вариантов последовательностей сообщений вы можете назвать при условии, что
сайты функционируют в штатном режиме?
! d) Если компонент на сайте 1 подлежит фиксации, а сайт 2 вышел из строя
и не отвечает на запросы координатора, каково общее количество
возможных последовательностей сообщений?
!! Упражнение 19.5.3. Предположим, что распределенная система охватывает сайт-
координатор и п сайтов, обслуживающих компоненты транзакции. Каково общее
количество последовательностей сообщений формата, предложенного в
упражнении 19.5.2, которые отвечают ситуации успешной фиксации транзакции?
19.6. Распределенное блокирование
В этом разделе мы рассмотрим варианты расширения модели планирования
заданий, основанной на механизме блокирования, на случай, когда транзакции действуют
в распределенной вычислительной среде и состоят из множеств компонентов,
функционирующих на различных сайтах. Будем полагать, что таблицы блокировок
поддерживаются на уровне отдельных сайтов и каждый компонент транзакции, относящийся
к определенному сайту, способен запрашивать блокировки элементов,
принадлежащих фрагменту базы данных, который находится в ведении этого сайта.
Если информация реплицируется, множественные копии каждого элемента X базы
данных должны модифицироваться единообразно каждой транзакцией. Это
требование обусловливает различие между процедурами блокирования логического элемента X
и одной или нескольких копий X. Ниже будет предложена модель трудоемкости
алгоритмов распределенного блокирования (distributed locking), применимая как в контексте
схемы репликации данных, так и вне ее. Однако прежде уместно остановить
внимание на очевидном (и зачастую вполне адекватном) решении проблемы поддержки
механизма блокирования в распределенной базе данных — речь пойдет о так
называемом централизованном блокировании (centralized locking).
19.6. РАСПРЕДЕЛЕННОЕ БЛОКИРОВАНИЕ
987
19.6.1. Централизованное блокирование
Вероятно, самый простой подход к проблеме блокирования элементов
распределенной базы данных связан с использованием единого сайта блокировок (lock site),
позволяющего поддерживать таблицу блокировок логических элементов базы данных
независимо от того, существуют на сайте (реплицированные) копии этих элементов
или нет. Если транзакции необходимо блокировать некоторый логический элемент X,
она отсылает запрос сайту блокировок, который вправе принять или отклонить
запрос. Поскольку получение глобальной блокировки элемента X по существу сводится
к приобретению локальной блокировки X на сайте блокировок, можно быть
уверенным в том, что механизм глобального блокирования действует верно, коль скоро сайт
блокировок корректно управляет локальными блокировками. Уровень трудоемкости
процедуры блокирования обычно определяется стоимостью пересылки трех
сообщений в расчете на одну блокировку (запрос, разрешение и освобождение), если только
транзакция не обрабатывается непосредственно на сайте блокировок.
Использование "центрального" сайта блокировок в некоторых ситуациях вполне
оправданно, хотя если количество сайтов и единовременно обрабатываемых
транзакций слишком велико, сайт блокировок становится "узким местом" системы. Помимо
того, если сайт блокировок выходит из строя, ни одна из транзакций на всех других
сайтах не сможет получить требуемые блокировки. Названные изъяны концепции
централизованного блокирования обусловливают необходимость разработки и
практической реализации альтернативных подходов к проблеме распределенного
блокирования, которые мы и обсудим ниже, после знакомства с общими приемами оценки
трудоемкости алгоритмов блокирования.
19.6.2. Модель трудоемкости алгоритмов распределенного блокирования
Предположим, что каждый элемент данных хранится только на одном из сайтов
(т.е. механизм репликации данных не действует) и планировщик заданий,
функционирующий на каждом сайте, управляет процессами блокирования соответствующих
элементов. В системе могут выполняться распределенные транзакции, и каждая
подобная транзакция состоит из ряда компонентов, обслуживаемых несколькими сайтами.
Существует несколько количественных факторов, определяющих затраты,
сопряженные с обслуживанием механизма блокирования, но многие из них представляются
постоянными величинами, не зависящими от способов получения блокировок.
Единственный заслуживающий внимания критерий — это количество сообщений,
рассылаемых между сайтами в процессе запрашивания и освобождения блокировок.
Поэтому при рассмотрении различных схем блокирования мы будем оценивать именно
количество сообщений, полагая, что каждая блокировка разрешается тотчас после
обслуживания запроса на ее получение. Разумеется, запрос на блокирование может
быть и отклонен; в этом случае потребуются, вероятно, два дополнительных
сообщения: одно с уведомлением о факте запрещения, а второе, более позднее, — с
разрешением блокировки. Однако поскольку частоту отказов в предоставлении блокировок
предсказать нельзя (и воздействовать на этот фактор в общем случае невозможно),
потребность в дополнительных сообщениях мы будем игнорировать.
Пример 19.20. Как упоминалось в разделе 19.6.1, обслуживание запроса на получение
блокировки в системе, реализующей механизм централизованного блокирования,
связано с рассылкой трех сообщений: одно представляет запрос как таковой, другое,
передаваемое сайтом блокировок, содержит разрешение, а третье уведомляет об
освобождении блокировки. Исключение составляют следующие ситуации:
1) сообщения не передаются, если сайт-инициатор запроса является по
совместительству "центральным" сайтом блокировок;
2) требуются дополнительные сообщения, если исходный запрос не может
быть удовлетворен немедленно.
988 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Можно полагать, однако, что подобные обстоятельства возникают относительно
редко, т.е. большинство запросов поступает от "рядовых" сайтов и тотчас
удовлетворяется. Поэтому тройка сообщений в расчете на одну блокировку — вполне адекватная
оценка трудоемкости алгоритма централизованного блокирования. □
Теперь рассмотрим модель, более гибкую в сравнении со схемой
централизованного блокирования: блокировки каждого элемента X поддерживаются на том сайте,
где располагается фрагмент базы данных, к которому относится X. Как может
показаться на первый взгляд, поскольку транзакция, которой необходимо захватить
блокировку X, обладает компонентом, функционирующим на сайте с X, необходимость в
обмене сообщениями между сайтами не возникает — локальному компоненту
транзакции достаточно "обсудить" проблему с планировщиком заданий, действующим на
том же сайте. Если, однако, распределенной транзакции требуется блокировать сразу
несколько элементов (скажем, X, Y и Z), она не сможет продолжить работу, не вступив
во владение всеми тремя блокировками. А если к тому же элементы X, Y и Z
размещены на различных сайтах, компоненты транзакции, присутствующие на этих сайтах,
должны, по меньшей мере, обменяться синхронизирующими сообщениями, чтобы
обеспечить требование единовременного блокирования трех элементов.
Вместо того чтобы погружаться в анализ всех мыслимых ситуаций, можно
остановить внимание на простой модели, определяющей способ "сбора" транзакциями
нужных блокировок. Достаточно предположить, что один из компонентов каждой
транзакции, называемый координатором блокировок (lock coordinator), несет
ответственность за получение блокировок, которые требуются всеми компонентами транзакции.
Для получения блокировки на сайте, где функционирует координатор блокировок,
рассылка сообщений не нужна, но во всех других случаях блокирование элемента X
сопряжено с приемом/передачей трех сообщений:
1) запроса к сайту с X на получение блокировки;
2) ответного сообщения, разрешающего блокировку (мы полагаем, как и
прежде, что все запросы удовлетворяются немедленно; в противном случае
вначале отсылается сообщение с уведомлением о факте запрещения, а позже —
с разрешением блокировки);
3) сообщения, адресованного сайту с X, об освобождении блокировки.
Поскольку в нашу задачу входит сопоставление параметров трудоемкости различных
схем распределенного блокирования, а не получение абсолютных оценок средней
частоты рассылки тех или иных сообщений, подобное упрощение вполне приемлемо.
Если на роль координатора блокировок выбрать сайт, фрагмент базы данных
которого содержит большее число элементов, блокируемых транзакцией, это позволит
минимизировать общее количество сообщений.
19.6.3. Блокирование реплицированных элементов
Если элемент X базы данных представлен несколькими реплицированными
копиями, размещенными на различных сайтах, модель блокирования требует уточнения.
Пример 19.21. Предположим, что в распределенной базе данных существуют две
копии, X! и Х2, элемента X. Допустим также, что транзакция Т получает общую
блокировку копии Х{ на одном сайте, а транзакция U — монопольную блокировку Х2 на
другом. Теперь U в состоянии изменить Х2, но не Хь а это чревато тем, что две копии
X в общем случае могут стать различными. Более того, поскольку транзакции Т и U
способны блокировать и другие элементы, а порядок выполнения операций чтения
и записи содержимого X очередностью захвата блокировок копий X не
регламентируется, вполне вероятно, что поведение Т и U окажется непоследовательным. □
19.6. РАСПРЕДЕЛЕННОЕ БЛОКИРОВАНИЕ
989
Проблема, продемонстрированная в примере 19.21, состоит в том, что если данные
подвержены репликации, ситуации захвата общей или монопольной блокировки
логического элемента X и получения локальной блокировки копии X, принадлежащей
фрагменту базы данных на сайте, следует трактовать как совершенно различные. Другими
словами, чтобы придать расписаниям условно-последовательный характер, надлежит
обеспечить возможность захвата транзакциями глобальных блокировок логических элементов.
Но логические элементы не существуют физически — в базе данных наличествуют
только их копии — и отсутствует глобальная таблица блокировок. Поэтому единственный
способ получения транзакцией глобальной блокировки X состоит в захвате локальных
блокировок одной или нескольких копий X на сайтах с фрагментами базы данных,
содержащими эти копии. Ниже рассмотрены методы "превращения" локальных
блокировок в глобальные, обладающие следующими требуемыми свойствами:
• никакие две транзакции не способны единовременно обладать глобальными
монопольными блокировками логического элемента X;
• если некоторая транзакция владеет глобальной монопольной блокировкой
логического элемента X, другая транзакция не вправе захватить глобальную
общую блокировку X;
• если не существует транзакции, которая приобрела глобальную монопольную
блокировку X, распоряжаться глобальными общими блокировками X могут
единовременно несколько транзакций.
19.6.4. Режим блокирования "главной копии"
Один из усовершенствованных вариантов схемы централизованного блокирования
(см. раздел 19.6.1 на с. 988) предполагает распределение функций сайта блокировок,
но сохранение требования о том, что с каждым логическим элементом связан
единственный сайт, ответственный за поддержку возможности глобального блокирования
этого элемента. Подобный метод распределенного блокирования называют режимом
блокирования главной копии (primary copy locking). Он устраняет опасность
превращения "центрального" сайта блокировок в "узкое место" системы и в то же время
отмечен простотой, присущей методу централизованного блокирования.
Режим предусматривает, что одному из экземпляров каждого логического элемента
X поручена роль "главной копии". Для захвата блокировки логического элемента X
транзакция направляет соответствующий запрос на сайт, где хранится главная копия
X. Сайт включает соответствующий элемент в собственную локальную таблицу
блокировок и разрешает либо запрещает блокировку. Если каждый сайт верно
администрирует процессы блокирования главных копий вверенных ему элементов, значит, можно
говорить и о корректной поддержке функций глобального ("логического") блокирования.
Как и при использовании "выделенного" сайта блокировок, при обработке
большинства запросов на блокирование главных копий элементов необходима пересылка
трех сообщений, за исключением случаев, когда инициатором запроса на
блокирование служит сайт, где хранится главная копия. Разумный выбор определенных
экземпляров элементов в качестве главных копий способен существенно сократить
потребности в обмене сообщениями.
Пример 19.22. Вернемся к схеме распределенной базы данных торговой компании
(см. раздел 19.4.1 на с. 977). Информация о продажах, хранимая во фрагменте базы
данных, поддерживаемом каждым из магазинов сети, должна трактоваться как главная
копия. Другие экземпляры тех же данных, которые, возможно, переносятся в
центральное "хранилище" для использования аналитиками компании, не являются
главными копиями. Типичная транзакция, вероятно, инициируется и протекает на
конкретном сайте и обновляет только локальные данные. В подобном случае в рассылке
сообщений необходимости нет — однако к сообщениям придется прибегнуть, если
транзакция считывает или изменяет данные на других сайтах. □
990 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Распределенные взаимоблокировки
Попытки получения глобальных блокировок элементов реплицированных данных
чреваты вовлечением транзакций в ситуацию взаимоблокировки. Существуют
адекватные способы конструирования глобальных графов ожидания, позволяющих
выявлять подобные тенденции. Впрочем, в распределенной вычислительной среде
зачастую гораздо проще и эффективнее использовать механизмы задания и анализа
лимитов времени (timeout) активности транзакций: транзакция, которая не
завершила работу по истечении определенного промежутка времени, воспринимается
как "заблокированная" и подлежит откату.
19.6.5. Глобальные блокировки на основе локальных блокировок
Другой подход состоит в "синтезе" глобальных блокировок на основе коллекций
локальных блокировок. В подобных схемах ни одна из копий элемента X базы данных не
считается "главной" — все они симметричны и в равной степени допускают локальное
блокирование в общем или монопольном режиме. Ключевое условие корректности схем
заключается в том, что прежде, чем транзакция сможет получить "глобальную"
блокировку X, она обязана захватить определенное количество локальных блокировок копий X.
Предположим, что элемент А существует в п копиях. Введем в обращение два
числовых параметра:
1) s — количество копий А, которые подлежат блокированию в общем режиме,
чтобы транзакция смогла захватить глобальную общую блокировку А;
2) аналогично, х — количество копий А, которые должны быть заблокированы
в монопольном режиме, чтобы служить залогом получения транзакцией
глобальной монопольной блокировки А.
Если Zx>n и s + x>n, требуемые свойства достигаются: в каждый момент может
существовать только одна глобальная монопольная блокировка А и не допускается
одновременное наличие глобальных общей и монопольной блокировок А. Поясним
сказанное. Если две транзакции обладали бы глобальными монопольными блокировками А,
то, поскольку 2х>п, существовала бы по меньшей мере одна копия А, локальные
монопольные блокировки которой оказались бы "дарованными" обеим транзакциям (так как
число разрешенных локальных монопольных блокировок превышает количество копий
А). Тогда, однако, схема локального блокирования утратит корректность. Аналогичным
образом, если бы одна транзакция обладала глобальной общей блокировкой А, а
другая — глобальной монопольной блокировкой А, то, ввиду s + x>n, некоторая копия
оказалась бы объектом единовременного блокирования в общем и монопольном режимах.
Количество сообщений, требуемых для получения глобальной общей блокировки,
составляет, вообще говоря, 35, а число сообщений, имеющих отношение к захвату
глобальной монопольной блокировки, равно 3*. Эти значения кажутся чрезмерно
большими, если сравнивать метод со схемой централизованного блокирования,
которая требует 3 или менее сообщений в расчете на одну блокировку. Однако существуют
"возмещающие" факторы — об этом свидетельствуют указанные ниже частные
варианты выбора пар значений (s, x).
• "Одна блокировка по чтению, все блокировки по записи" — 5=1 и * = /г. Получение
глобальной монопольной блокировки довольно трудоемко, но для захвата
глобальной общей блокировки требуются, самое большее, три сообщения. Хотя режим
блокирования главной копии (см. раздел 19.6.4 на с. 990) позволяет избежать
рассылки сообщений при считывании содержимого главной копии элемента данных,
схема "одна блокировка по чтению" обладает тем преимуществом, что избавляет от
необходимости взаимообмена сообщениями, если транзакция выполняется на
19.6. РАСПРЕДЕЛЕННОЕ БЛОКИРОВАНИЕ
991
сайте с любой копией элемента, подлежащего чтению. Поэтому схема заметно
более предпочтительна в ситуациях, когда многие транзакции действуют в режиме
"только для чтения" (read-only) и инициируются на различных сайтах. Примером
может служить распределенная цифровая библиотека, в которой кэшированные
копии документов хранятся на тех сайтах, где они чаще всего считываются.
• "Блокирование большинства"' — s = x = [(n+ 1)/2]. На первый взгляд, при таком
условии количество сообщений остается большим независимо от места выполнения
транзакции. Существуют, однако, дополнительные факторы, которые придают
схеме привлекательность и делают ее вполне приемлемой. Во многих сетевых
системах поддерживается механизм широковещательной рассылки (broadcasting)
сообщений, позволяющий транзакции отправить единственный общий запрос на
получение локальных блокировок, который будет замечен всеми сайтами. Для
освобождения блокировок также может потребоваться только одно сообщение.
Подобный вариант выбора значений s w x обладает и уникальным преимуществом:
он иногда позволяет транзакции действовать даже в ситуации разрыва сетевого
соединения. Коль скоро существует сегмент сети, охватывающий большинство
сайтов с копиями элемента X, транзакции все еще удастся захватить глобальную
блокировку X. Если другие — отсоединенные — сайты продолжают пребывать
в активном состоянии, они, очевидно, не смогут получить даже общую
блокировку X, и поэтому опасность непоследовательного поведения распределенных
транзакций, работающих в различных сегментах сети, исключается.
19.6.6. Упражнения к разделу 19.6
! Упражнение 19.6.1. Мы показали, как создавать глобальные общие и монопольные
блокировки на основе одноименных локальных блокировок. Продемонстрируйте
аналогичные приемы конструирования систем
* а) глобальных общих, монопольных и инкрементных (см. раздел 18.4.5 на
с. 908) блокировок;
Ь) глобальных общих, монопольных и обновляемых (см, раздел 18.4.4 на с. 906)
блокировок;
!! с) глобальных общих, монопольных и предупреждающих (см. раздел 18.6.2 на
с. 919) блокировок.
Упражнение 19.6.2. Рассмотрим систему из пяти сайтов, каждый из которых содержит в
"подведомственном" ему фрагменте базы данных копию элемента X. Один из сайтов
(назовем его Р) владеет главной копией X. Статистика обращений к элементу X такова:
i) 50% всех запросов предполагают чтение X и инициируются с Р\
и) каждый из четырех остальных сайтов является "зачинателем" 10% запросов
на чтение X;
ш) оставшиеся 10% запросов предполагают получение монопольной
блокировки и с равной вероятностью инициируются с любого из пяти сайтов (т.е. на
каждый из сайтов приходится 2% запросов).
Для каждого из перечисленных ниже методов блокирования —
* а) "одна блокировка по чтению, все блокировки по записи";
b) "блокирование большинства";
c) блокирование главной копии (копия размещается на сайте Р) —
укажите среднее количество сообщений, требуемых для получения блокировки,
полагая, что все запросы удовлетворяются незамедлительно и безотказно.
992 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
19.7. Длинные транзакции
Существует целое семейство приложений баз данных, для которых традиционная
модель обслуживания параллельно действующих "кратковременных" транзакций
становится неприемлемой. В этом разделе мы рассмотрим некоторые образцы подобных
приложений, укажем проблемы, связанные с их практическим использованием, а
затем обсудим особенности решения, основанного на схеме уравновешивающих
транзакций (compensating transactions), призванных отменять зафиксированные результаты.
19.7.1. Проблемы использования длинных транзакций
Длинной (long transaction) считается транзакция, грубо говоря, слишком
продолжительная, чтобы ей было позволено удерживать блокировки, в которых нуждаются другие
транзакции. В зависимости от конкретных условий понятие "слишком продолжительная
транзакция" может означать функционирование в течение секунд, минут, часов или
даже суток. Мы будем трактовать как "длинные" такие транзакции, которые действуют
в продолжение, как минимум, нескольких минут или часов. Можно назвать следующие
обширные классы приложений, предполагающих использование длинных транзакций.
1. Обычные приложения СУБД. Хотя в традиционных приложениях систем баз
данных в большинстве случаев применяются "короткие" транзакции, иногда
возникает потребность и в активизации "длинных" транзакций. Примером
может служить транзакция, осуществляющая пересчет баланса банковского
учреждения. Другой пример — функция, выполняющая повторное конструирование
индекса с целью оптимизации времени доступа к отношению.
2. Системы автоматизированного проектирования (САПР). Для многих систем
проектирования (в отраслях автомобилестроения, схемотехники, программного
обеспечения и т.д.) характерна необходимость расчленения проекта на
составляющие (скажем, файлы программного приложения), что позволяет участникам
коллектива работать над отдельными компонентами проекта параллельно.
Разумеется, нельзя допустить, чтобы, скажем, два программиста могли обратиться
к одному и тому же файлу, модифицировать его по собственному разумению
и сохранить новые версии файла, поскольку наборы изменений окажутся,
вообще говоря, взаимно противоречивыми. В таких ситуациях применяются
системы контроля версий, позволяющие проектировщику проверить версию
исходного файла и зафиксировать внесенные изменения — возможно, несколькими
часами или сутками позже. Файл, "занятый" одним из программистов, может
потребоваться другому — например, для взаимной сверки различных
компонентов проекта. Если бы модификация файла была сопряжена с обязательным
захватом монопольной блокировки, никто другой не смог бы получить доступ
к данным на протяжении чрезмерно долгого периода времени.
3. Системы управления технологическими процессами. В подобных системах одни
функции выполняются полностью автоматически, другие предполагают
взаимодействие с человеком-оператором, а третьи относятся к сугубой компетенции
последнего. Ниже приведен пример, относящийся к проблематике систем
управления документооборотом. Рабочий цикл подобных приложений часто
исчисляется несколькими сутками, и в течение всего этого времени некоторые
элементы базы данных могут служить предметом модификации. Если система
позволит блокировать данные, охватываемые одной транзакцией, в
монопольном режиме, параллельные транзакции окажутся попросту "не у дел".
Пример 19.23. Рассмотрим задачу возмещения командировочных расходов,
понесенных служащим некоторой компании. Целью сотрудника является получение денежной
суммы (скажем, $1000) с некоторого счета (для определенности назовем его А123).
Схема протекания процесса приведена на рис. 19.18. Процесс начинается с действия
19.7. ДЛИННЫЕ ТРАНЗАКЦИИ
993
Ль подразумевающего, что служащий или его секретарь в режиме on-line заполняет
электронную отчетную форму, содержащую описание цели командировки, номер
счета (А123) и величину денежной суммы ($1000).
Оправдательные первичные документы (квитанции, чеки, билеты и т.п.) в физическом
виде передаются в бухгалтерию компании, а электронная форма пересылается по сети
и поступает в распоряжение автоматизированной функции Л2. Последняя проверяет,
достаточен ли текущий остаток на указанном счете; если ответ положителен, требуемая сумма
резервируется, т.е. временно вычитается из остатка, но чек не выписывается. Если же средств
на счете недостаточно, выполнение транзакции прерывается. Она может быть
активизирована повторно после пополнения остатка на счете либо изменения номера счета.146
Действие Аъ выполняется бухгалтером, который проверяет первичные документы
и электронную форму. Операция Л3 вполне может быть отложена на день-другой
(часто именно так и происходит). Если все в надлежащем порядке, форма наряду
с бумажными документами утверждается и передается руководителю финансовой
службы; в противном случае транзакция прерывается; "истцу" рекомендуется внести
необходимые поправки и переслать форму заново.
Осуществляя действие Л4 (к этому моменту может пройти еще несколько дней),
руководитель либо утверждает отчет, либо отвергает его, либо передает на
рассмотрение своему заместителю, и решение, которое принимается последним, связано с
выполнением действия Л5. Если отчетная форма отвергается, транзакция прерывается —
"соискателю" придется повторить круг "мытарств" заново. Если же заветное
"утверждаю" получено, выписывается чек (действие Лб) и результат вычитания $1000
с остатка на счете А123 фиксируется окончательно.
Start
*i
Оформление
отчета
н
Среда
эдостат
А
2
Резервирование
суммы
гв
ОЧНО i
'
Средств
достаточно
А3
Бухгалтерия
1
За
Abort
Abort
Утверждение
Abort
Запрет
Руководитель
Abort
Запрет
Заместитель
Утверждение
Оформление
чека
Complete
Рис. 19.18. Диаграмма процесса возмещения командировочных
расходов
146 Разумеется, командированный (речь в любом случае не идет о сотруднике Станфорда) никогда
не сможет получить деньги с "левого" счета — источник финансирования командировочных расходов
должен быть задан совершенно однозначно. Это замечание мы вынуждены адресовать чиновникам
федеральной контрольно-ревизионной службы, которые заполонили весь Станфорд и упорно не
вылезают из его кабинетов, не в силах разобраться в тонкостях университетской бухгалтерии.
994 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Предположим на время, что единственный способ реализации рассматриваемой
технологии связан с использованием традиционной модели блокирования. В
частности, поскольку остаток на счете А123 может быть изменен только завершенной
транзакцией, данные, представляющие счет, должны быть заблокированы в монопольном
режиме при выполнении действия Л2 и не подлежат разблокированию вплоть до момента
прерывания транзакции или окончания процедуры оформления счета (действие Л6).
Блокировка может удерживаться на протяжении нескольких дней — за это время
многие другие, кто имел несчастье вернуться из командировки, потратившись до
копейки, успеют умереть с голоду. Если, напротив, лишить процесс какого бы то ни
было контроля, вполне вероятна ситуация, когда некоторые транзакции
зарезервируют суммы, которых просто нет на счете. Поэтому следует искать компромисс между
политикой жесткого блокирования с одной стороны и полной анархией — с другой. Q
19.7.2. Хроники
Хроника (saga) — это набор действий, подобных упомянутым в примере 19.23,
которые в совокупности формируют долговременную "транзакцию". Если говорить
более точно, хроника включает:
1) набор действий;
2) граф, вершины которого представляют "обычные" и специальные — Start
("начало"), Abort ("прерывание") и Complete ("завершение") — действия;
пары вершин соединяются направленными дугами; вершины Abort и Complete
(их называют оконечными — terminal) исходящих дуг не имеют.
Пути в графе, соединяющие вершину Start с любой из оконечных вершин,
представляют возможные последовательности действий. Пути, которые приводят к вершинам
Abort, вызьтают прерывание транзакции с ее последующим откатом, и охватываемые
ими действия не способны изменить состояние базы данных. Пути, завершающиеся
вершиной Complete, задают успешные последовательности действий, результат
выполнения которых фиксируется в базе данных.
Пример 19.24. Граф, изображенный на рис. 19.18, содержит следующие пути,
приводящие к вершинам Abort. А\АЪ А\А2АЪ, А{А2АЪАА и А\А2А^А4А5. К числу путей,
завершающихся вершиной Complete, относятся такие: А{А2АЪАААЬ и АХА2АЪААА5А6.
Заметьте, что в данном случае граф не имеет циклов, поэтому в нем существует
конечное количество путей, "упирающихся" в оконечные вершины. В общем случае,
однако, граф способен содержать циклы, и тогда количество путей, возможно,
окажется бесконечным. О
При реализации систем управления параллельными заданиями, из которых состоят
хроники, надлежит принять к сведению следующие соображения.
1. Каждое действие, входящее в состав хроники, может интерпретироваться как
("короткая") транзакция, при выполнении которой используется традиционный
механизм управления, такой как схема блокирования. Например, действие Л2
в примере 19.23 на с. 993 уместно реализовать так (вдаваться в детали мы не
станем): захватить блокировку счета А123, уменьшить остаток на счете на
величину, указанную в отчетной форме, и освободить блокировку. Блокировка
воспрепятствует попыткам единовременного сохранения новых значений остатка
несколькими транзакциями и возникновению денег "из ничего".
2. Транзакция, рассматриваемая в целом, которая может быть описана любым из
путей в графе хроники, приводящим к оконечным вершинам, управляется
посредством механизма уравновешивающих транзакций (compensating transactions),
представляющих действия, "обратные" по отношению к операциям-вершинам
19.7. ДЛИННЫЕ ТРАНЗАКЦИИ
995
графа. Задача уравновешивающей транзакции заключается в откате результатов
выполнения зафиксированного действия таким способом, который не зависит
от цепочки событий, происшедших в интервале времени между выполнением
действия и активизацией уравновешивающей транзакции. За подробностями
обращайтесь к следующему разделу.
19.7.3. Уравновешивающие транзакции
Каждому действию А, охватываемому хроникой, ставится в соответствие
уравновешивающая транзакция (compensating transaction), обозначаемая как А"1. Если выполнить
А, а затем А"1, состояние базы данных должно остаться таким, словно ни А, ни А"1 не
активизировались вовсе. Дадим формальное определение.
• Если D — некоторое состояние базы данных, а Вх В2 - Вп — последовательность
действий и уравновешивающих транзакций (относящихся к рассматриваемой
хронике либо к любой другой хронике или транзакции, обрабатываемой
системой), тогда выполнение последовательностей Вх В2 ••• Вп и А Вх В2 — Вп А"1
применительно к базе данных, пребывающей в состоянии D, приведет к получению
одного и того же состояния базы данных.
Если при выполнении хроники достигается вершина Abort, хроника подлежит
откату путем активизации уравновешивающих транзакций для каждого действия-
вершины в порядке, обратном по отношению к исходному. Благодаря указанному
выше свойству уравновешивающих транзакций результат выполнения хроники
нивелируется, и база данных приводится в такое состояние, будто ничего и не
происходило. За разъяснениями по поводу обоснования корректности схемы
уравновешивающих транзакций обращайтесь к разделу 19.7.4 на с. 997.
Пример 19.25. Рассмотрим действия АХ~А6 хроники, граф которой изображен на
рис. 19.18 (см. с. 994), и покажем, какими могут быть соответствующие
уравновешивающие транзакции. Операция А{ предусматривает создание электронного документа.
Если документ сохраняется в базе данных, транзакция 4-1 обязана обеспечить его
удаление. Заметьте, что результат такой компенсации удовлетворяет основному свойству
уравновешивающих транзакций: если мы создаем документ и осуществляем любую
последовательность а манипуляций (включая удаление документа, коль скоро это
необходимо), итоги выполнения наборов действий Ах а/\~1и а окажутся одинаковыми.
Реализация операции А2 требует особой тщательности. Предусматривается
"резервирование" денежного значения путем вычитания его из остатка на счете.
Значение остается "вычтенным" до тех пор, пока оно не будет восстановлено в сумме
остатка средствами уравновешивающей транзакции А~21. Операция А~21 является
корректной, если она удовлетворяет традиционным правилам обращения с банковскими
счетами. Для контраста полезно рассмотреть схожую транзакцию, где подобная очевидная
компенсация уже не приемлема; такой случай изучается ниже, в примере 19.26.
Каждое из действий А3—А5 предусматривает включение в отчетную форму той или
иной утверждающей резолюции. Ясно, что уравновешивающие транзакции обязаны
обеспечить удаление соответствующих резолюций.147
Наконец, для действия А6 разумную уравновешивающую транзакцию предложить
трудно. Потребности в выполнении каких-либо "противодействий" по существу
нет — раз операция А6 завершена, значит, хроника откату не подлежит. Впрочем,
действие А6 как таковое, строго говоря, не затрагивает состояние базы данных, поскольку
В рассматриваемой хронике компенсировать действия Л3—А5 практически целесообразно
только тогда, когда отчетная форма подлежит безусловному удалению, но уравновешивающие
транзакции по определению должны действовать изолированно и независимо от того,
выполняются ли другие уравновешивающие транзакции.
996 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Когда состояния базы данных следует считать "одинаковыми"
При использовании механизма уравновешивающих транзакций надлежит
тщательно оговаривать, что именно имеется в виду под выражением "возвратить базу
данных в прежнее состояние". Мы уже сталкивались с проблемой в примере 19.8 на
с. 959 при обсуждении схемы логического протоколирования изменений,
затрагивающих вершины В-древовидного индекса, и упоминали о том, что если
"отменить" операцию, состояние В-дерева вовсе не обязательно окажется
идентичным тому, в котором структура пребывала до выполнения операции, но может быть
логически эквивалентным. Если говорить в более общем смысле, выполнение
уравновешивающей транзакции, соответствующей действию хроники, не всегда
гарантирует восстановление состояния базы данных, буквально идентичного прежнему,
но различия между состояниями не должны обнаруживаться на уровне прикладных
программ, поддерживаемых СУБД.
денежное "наполнение" чека обеспечено операцией Л2. Если бы понятие "база
данных" пришлось расширить до границ реального мира, где, в частности, операция
выдачи наличности по чеку воздействовала бы на состояние неких данных,
транзакцию А~в можно было бы спроектировать так, чтобы первым делом
предпринималась попытка аннулирования чека, затем отсылалось письмо получателю денег
с требованием их возврата и, если предыдущие меры успеха не возымели, — долг
погашался бы из определенных резервных источников финансирования или за счет
лица, виновного в недостаче. □
Рассмотрим пример ситуации, когда изменение состояния банковского счета
нельзя компенсировать "обратной" операцией. Проблема связана с тем, что в обычных
условиях остаток на счете не может быть отрицательным.
Пример 19.26. Предположим, что транзакция В прибавляет $1000 к остатку на
счете, изначально равному $2000, а уравновешивающая транзакция В~1 вычитает
из суммы остатка то же значение. Допустим также, что транзакция, пытающаяся
выполнить расходную операцию, чреватую получением отрицательного остатка,
трактуется как недопустимая. Обозначим как С транзакцию, вычитающую из
остатка на счете значение $2500. Ясно, что В С В~{ щ С: если операция С выполняется
сама по себе, она завершается безуспешно и оставляет сальдо прежним ($2000);
если же С предваряется функцией В, значение остатка снизится до $500, но при этом
неудачу потерпит транзакция В"1.
Хроники с произвольными банковскими операциями, не допускающими
получения отрицательных значений сальдо, схемой уравновешивающих транзакций
напрямую не поддерживаются — условие "неотрицательности" остатков должно
быть ослаблено. □
19.7.4. Обоснование корректности модели уравновешивающих транзакций
Будем называть две последовательности действий эквивалентными (equivalent) (=),
если, будучи примененными к базе данных, пребывающей в некотором состоянии D,
они переводят ее в одинаковое состояние. Основное условие, определяющее
поведение уравновешивающих транзакций, можно сформулировать так:
• если А — произвольное действие и яг—- любая последовательность допустимых
действий и уравновешивающих транзакций, тогда А аА~{ = а.
Необходимо показать, что если последовательность действий А\А2 — Ап хроники
сопровождается выполнением уравновешивающих транзакций, следующих в обратном
19.7. ДЛИННЫЕ ТРАНЗАКЦИИ
997
порядке, A"1 A~i — A"i , и, возможно, перемежаемых любыми другими операциями,
результат окажется таким, словно ни действия, ни уравновешивающие транзакции не
активизировались вовсе. Проведем доказательство по индукции от п.
Базис. Если /2=1, последовательность действий, включающую А{ и
соответствующую уравновешивающую транзакцию А"!1, можно представить как А{ аАГ\. Согласно
основному свойству уравновешивающих транзакций имеем Ах аА~х s a, т.е. хроника,
подвергнутая "откату", воздействия на состояние базы данных не оказывает.
Индукция. Допустим, что утверждение справедливо для последовательностей,
содержащих до п - 1 действий включительно, и рассмотрим последовательность из п
действий, которая сопровождается уравновешивающими транзакциями,
перечисленными в обратном порядке, и, возможно, перемежается операциями любых
других транзакций:
Ах ахА2а2-Ап_{ а,г„ 1 Ап /3А;1 уп_у A'nl_{ - у2 А~21 ухА\\ (19.1)
где буквами греческого алфавита обозначены последовательности, содержащие нуль
или больше действий. По определению уравновешивающих транзакций АпРА~„ =р.
Поэтому выражение (19.1) эквивалентно следующему:
Ах ахА2а1-Ап„х Оп-хРУп^А^ _х-~ г2А~2х ухА~х1. (19.2)
Согласно гипотезе индукции конструкция (19.2) равносильна такой:
ах а2-ап_{Руп„х-у2ух.
Другими словами, при выполнении хроники с уравновешивающими транзакциями
состояние базы данных сохраняется прежним.
19.7.5. Упражнения к разделу 19.7
*! Упражнение 19.7.1. Процесс удаления (uninstall) программного приложения
можно воспринимать как транзакцию, уравновешивающую действия по его
установке (install). Рассмотрим простейшую модель установки/удаления, полагая, что
установка заключается в загрузке (loading) одного или нескольких файлов из
источника (скажем, компакт-диска) на жесткий диск компьютера. Загрузка файла/
состоит в его копировании (с возможным замещением, если файл / в
соответствующем каталоге диска уже существует). Для различения одноименных файлов
используются хронологические признаки, определяющие моменты
создания/обновления файлов.
a) Как может выглядеть транзакция, уравновешивающая действие по загрузке
файла/? Изучите оба случая, когда к моменту установки приложения файл/
на диске компьютера отсутствует и когда таковой существует.
b) Объясните причины, которые позволяют трактовать транзакцию,
предложенную вами при выполнении п. (а), как уравновешивающую. (Обратите
внимание на ситуацию, когда после замещения прежней версии файла
новой осуществляется еще одна операция замещения.)
! Упражнение 19.7.2. Опишите процесс бронирования авиабилета в виде хроники.
Рассмотрите случай, когда клиент посылает запрос, но билет не заказывает
(человек может забронировать место, но затем отказаться от него, не оплатить счет
в течение требуемого лимита времени и т.п.). Для каждого действия хроники
предложите соответствующую уравновешивающую транзакцию.
998 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
19.8. Резюме
♦ "Мусор". Информацию, сохраненную в буферах оперативной памяти или в
дисковой копии базы данных транзакцией, которая не была зафиксирована,
принято называть "мусором".
♦ Каскадный откат. Транзакции, которые обращаются к "мусору", оставленному
другими — незафиксированными — транзакциями, подлежат прерыванию с
последующей повторной активизацией.
♦ Строгое блокирование. Политика строгого блокирования предполагает, что
транзакция обязана удерживать блокировки (кроме общих) до того момента, пока
запись фиксации не будет "сброшена" в дисковую копию протокола, и
гарантирует невозможность считывания "мусора" — даже после потенциального
отказа системы с последующим восстановлением данных.
♦ Групповая фиксация. Условие строгого блокирования, предусматривающее
обязательное "сбрасывание" записи фиксации на диск, можно ослабить, если
поручиться, что записи протокола достигают диска в том же порядке, в котором
они инициируются. При этом гарантии невозможности использования
"мусора" все еще остаются в силе.
♦ Восстановление состояния базы данных после прерывания транзакции. Если
прерванная транзакция оставляет измененные значения элементов базы данных
в буферах оперативной памяти, прежние значения можно восстановить из
протокола или дисковой копии данных. Если изменения уже перенесены на диск,
для восстановления используется информация протокола.
♦ Логическое протоколирование. При использовании крупных элементов базы
данных, таких как дисковые блоки, объем протокола удастся уменьшить,
если отображать в нем только внесенные изменения. В некоторых случаях
приемы логического протоколирования, учитывающие особенности
структуры блоков данных, позволяют восстанавливать состояние базы данных на
"логическом" уровне — даже тогда, когда реконструировать исходное
физическое состояние нельзя.
♦ Условно-последовательное упорядочение с учетом источников данных. Если
транзакции сохраняют значения, которые позже оказываются не востребованными,
строгий критерий условно-последовательного упорядочения с учетом
конфликтов может быть ослаблен: достаточно полагать, что в эквивалентном
последовательном расписании каждая транзакция считывает значения из тех же
источников, что и в исходном расписании.
♦ Графы предшествования. Процедура проверки возможности условно-
последовательного упорядочения с учетом источников данных предполагает
конструирование графа, дуги которого соединяют вершины,
представляющие транзакцию-источник и транзакцию-приемник данных; в граф
включаются и пары дуг, компенсирующие возможность "вмешательства"
сторонних транзакций в связь между источником и приемником. Расписание
является условно-последовательным с учетом источников данных, если
и только если выбор одной дуги из каждой пары компенсирующих дуг
приводит граф к ациклическому виду.
♦ Взаимоблокировки. Встречаются ситуации, когда группа транзакций вынуждена
находиться в состоянии "бесконечно" долгого ожидания освобождения ресурса
(скажем, блокировки), которым владеет другая транзакция. Ни одна из
транзакций, вовлеченных в цикл взаимоблокировки, не в состоянии продолжить работу.
19.8. РЕЗЮМЕ
999
♦ Графы ожидания. Граф ожидания содержит вершины, соответствующие
параллельно действующим транзакциям; каждая дуга графа направлена в
сторону вершины-транзакции, которая должна освободить ресурс, ожидаемый
транзакцией в начале дуги. Наличие взаимоблокировки равносильно
присутствию в графе ожидания одного или нескольких циклов. Если
сконструировать граф и обеспечить удаление определенных вершин (прерывание
транзакций, ресурсы которых требуются другим транзакциям), ситуации
взаимоблокировки удастся избежать.
♦ Предотвращение взаимоблокировок за счет упорядочения элементов данных.
Реализация требования захвата ресурсов в заданном лексикографическом порядке
позволяет предотвратить возникновение взаимоблокировок.
♦ Выявление взаимоблокировок с помощью механизма хронометража. В схемах
обнаружения взаимоблокировок с помощью механизма хронометража принятие
решения о прерывании транзакции основывается на том, обладает ли ожидающая
транзакция таким значением хронологического признака, который меньше (или
больше) величины аналогичного признака транзакции, удерживающей ресурс.
♦ Распределенные данные. В распределенной базе данных порции информации
могут "расщепляться" горизонтально (группы кортежей отношения разносятся
по фрагментам базы данных, поддерживаемых различными сайтами) или
вертикально (схема отношения подвергается декомпозиции в несколько частных
схем, и "мелкие" отношения сохраняются на разных сайтах). Широкое
применение находит механизм репликации данных, когда идентичные копии
элементов данных размещаются в нескольких узлах распределенной сети.
♦ Распределенные транзакции. Транзакция, выполняемая в распределенной
вычислительной среде, может состоять из ряда компонентов, функционирующих на
тех или иных сайтах. Для обеспечения согласованного поведения транзакции,
рассматриваемой в целом, ее компоненты обязаны координировать свои
решения относительно фиксации или прерывания.
♦ Двухфазная фиксация — один из подходов к проблеме согласования решений
относительно фиксации/прерывания, принимаемых компонентами
распределенной транзакции, который пригоден даже при условии отказа системы с
последующим восстановлением данных. На первой фазе компонент-координатор
опрашивает другие компоненты об их намерениях, касающихся фиксации или
прерывания. На второй фазе координатор уведомляет компоненты о
необходимости фиксации (если и только если все они "согласны" с таким решением)
или прерывания (в противном случае).
♦ Распределенное блокирование. Если транзакция нуждается в получении
блокировок элементов, размещенных на различных сайтах сети, необходима технология
управления процессом: метод централизованного блокирования, например,
предусматривает использование "выделенного" сайта, контролирующего
блокирование всех элементов данных.
♦ Блокирование реплицированных элементов данных. Если элемент данных
существует в нескольких копиях, расположенных на различных сайтах, для получения
глобальной блокировки требуется заблокировать одну или несколько локальных
копий. Метод "блокирования большинства" предусматривает, например,
получение общих или монопольных блокировок большей части локальных копий.
В других случаях глобальная общая блокировка сводится к общей блокировке
любой локальной копии, а для захвата глобальной монопольной блокировки
требуется заблокировать в монопольном режиме все локальные копии.
1000 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
♦ Хроники. Если транзакция охватывает такие операции, которые
выполняются в течение "слишком" длительных периодов времени, традиционные
механизмы блокирования уменьшают степень параллелизма до
непозволительно низкого уровня. Хроника представляет собой граф с вершинами,
соответствующими "обычным" и "специальным" ("начало", "прерывание"
и "завершение") действиям.
♦ Уравновешивающие транзакции. Каждому действию хроники должна
соответствовать определенная "уравновешивающая" транзакция, отменяющая результат
влияния действия на состояние базы данных. Последовательности операций
хроники и уравновешивающих транзакций могут перемежаться действиями
других хроник и транзакций. Если выполнение хроники прерывается,
активизируется набор соответствующих уравновешивающих транзакций.
19.9. Литература
К числу наиболее полезных информационных источников общего характера,
охватывающих проблематику главы, можно отнести работы [1], [2] и [10]. Материал,
касающийся вопросов логического протоколирования, основан на результатах,
представленных в [9]. Концепция условно-последовательного упорядочения с учетом
источников данных освещена в [11].
Обзор методов предотвращения и выявления взаимоблокировок содержится в [7];
оттуда же заимствована модель графов ожидания. Схемы "ожидание—гибель"
и "ранение—ожидание" рассмотрены в [12].
Описание протокола двухфазной фиксации впервые предложено в отчете [8]. Более
мощная схема трехфазной фиксации (three-phase commit) (мы на ней не
останавливались) разработана в [13]. Проблемы избрания сайта-л ид ера распределенной системы
исследовались в [4].
Методы распределенного блокирования рассмотрены в работах [3]
(централизованное блокирование), [14] (блокирование главной копии) и [15] (синтез
глобальных блокировок на основе коллекций локальных блокировок).
Концепция длинных транзакций введена в докладе [6]; модель хроник
представлена в [5].
1. Barghouti N.S., Kaiser G.E. Concurrency control in advanced database applications, Computing
Surveys, 23:3 (1991), p. 269-318.
2. Ceri S., Pelagatti G. Distributed Databases: Principles and Systems, McGraw-Hill, New York, 1984.
3. Garcia-Molina H. Performance comparison of update algorithms for distributed databases,
Technical Reports No 143 and No 146, Computer Systems Laboratory, Stanford Univ., 1979.
4. Garcia-Molina H. Elections in distributed computer system, IEEE Trans, on Computers, C-31:l
(1982), p. 48-59.
5. Garcia-Molina H., Salem K. Sagas, Proc. ACM SIGMOD Intl. Conf. on Management of
Data (1987), p. 249-259.
6. Gray J.N. The transaction concept: virtues and limitations, Proc. Intl. Conf. on Very Large
Databases (1981), p. 144-154.
7. Holt R.C. Some deadlock properties of computer systems, Computing Surveys, 4:3 (1972),
p. 179-196.
8. Lampson В., Sturgis H. Crash recovery in a distributed data storage system, Technical Report,
Xerox Palo Alto Research Center, 1976.
9. Mohan C, Haderie D.J., Lindsay B.G., Pirahesh H., and Schwarz P. ARIES: a transaction
recovery method supporting fine-granularity locking and partial rollbacks using write-ahead
logging, ACM Trans, on Database Systems, 17:1 (1992), p. 94-162.
19.9. ЛИТЕРАТУРА
1001
10. Ozsu M.T., Valduriez P. Principles of Distributed Database Systems, Prentice Hall,
Englewood Cliffs, NJ, 1999.
11. Papadimitriou C.H. The serializability of concurrent updates, J. ACM, 26:4 (1979), p. 631-653.
12. Rosenkrantz D.J., Stearns R.E., and Lewis P.M. (II) System-level concurrency control for
distributed database systems, ACM Trans, on Database Systems, 3:2 (1978), p. 178—198.
13. Skeen D. Nonblocking commit protocols, Proc. ACM SIGMOD Intl. Conf. on Management of
Data (1981), p. 133-142.
14. Stonebraker M. Retrospection on a database system, ACM Trans, on Database Systems, 5:2
(1980), p. 225-240.
15. Thomas R.H. A majority consensus approach to concurrency control, ACM Trans, on Database
Systems, 4:2 (1979), p. 180-219.
1002 ГЛАВА 19. ДОПОЛНИТЕЛЬНЫЕ АСПЕКТЫ УПРАВЛЕНИЯ ТРАНЗАКЦИЯМИ
Глава 20
Интеграция информации
Существует множество направлений развития современных систем баз данных, и
обширное семейство новейших приложений СУБД попадает в категорию, которую
принято называть общим термином интеграция информации (information integration). В
подобных приложениях предусматривается использование содержимого двух или более
баз данных (источников информации — information sources) с последующим
конструированием одной крупной базы данных (возможно, виртуальной — virtual database), так
что пользователи могут обращаться к ней с запросами как к единому
информационному пространству. Роль источников способны выполнять как традиционные базы
данных, так и другие собрания данных (например, коллекции Web-страниц).
В этой главе вы познакомитесь с основными аспектами технологий интеграции
информации. Вначале мы осветим базовые подходы к проблеме интеграции,
связанные с использованием федеративных баз данных (federated databases), хранилищ данных
(data warehouses) и медиаторов (mediators). Затем обсудим концепцию оболочек
(wrappers) — программных компонентов, с помощью которых информационные
источники способны следовать единообразной общей схеме организации данных. В
системах интеграции информации приходится применять специальные приемы
оптимизации запросов; ниже вкратце упомянута схема оптимизации с учетом возможно-
стей источников (capability-based optimization) — весьма важный механизм, который
в традиционных СУБД реализуется, однако, все еще редко.
В завершение мы расскажем о конкретных сферах применения технологий интеграции
информации. Самого пристального внимания заслуживают запросы ОЬЛР (от on-line
analytic processing — "оперативная аналигическая обработка данных") и разработки, или
добычи, данных (data mining), относящиеся к числу наиболее сложных приложений,
предусматривающих использование информации баз данных. Мы познакомим вас и со
специализированной архитектурой кубов данных (data cubes) — средством организации
интегрированной информации, обеспечивающим поддержку запросов О LAP и разработки данных.
20.1. Обзор технологий интеграции информации
Существует несколько способов сочетания баз данных и иных распределенных
информационных источников в единое "целое". В этом разделе мы сосредоточим
внимание на трех наиболее распространенных подходах.
1. Федеративные базы данных (federated databases) — источники независимы, но
каждый из них способен получать требуемую информацию из других.
2. Хранилища данных (data warehouses) — копии фрагментов информации из
нескольких источников сохраняются в единой базе данных, возможно, с
предварительной обработкой — фильтрацией (filtering), соединением (joining) или
агрегированием (aggregating). Содержимое хранилища данных обновляется на
периодической основе, часто в моменты снижения нагрузки (скажем, ночью).
В процессе копирования данные подвергаются определенным преобразованиям
с целью согласования их структур с общей схемой хранилища.
3. Медиаторы (mediators) — программные компоненты, обеспечивающие
поддержку виртуальных баз данных (virtual databases), которые "внешне" выглядят
так, словно они материализованы (т.е. сконструированы физически, подобно
хранилищам данных). Медиатор сам по себе не сохраняет информацию —
вместо этого он транслирует запрос пользователя в один или несколько запросов,
адресованных первичным источникам. Получая результаты обработки частных
запросов, медиатор синтезирует на их основе ответ на исходный запрос.
С каждым из названных подходов вы познакомитесь более подробно. Одна из
ключевых проблем, присущих всем схемам интеграции информации, связана с тем, каким
образом осуществляется преобразование данных после их извлечения (выгрузки) из
источников. В разделе 20.2 на с. 1012 мы обсудим архитектуру подобных
"преобразователей", называемых оболочками (wrappers), но прежде, в разделе 20.1.1,
осветим ряд проблем, для решения которых и предназначены компоненты-оболочки.
20.1.1. Проблемы интеграции информации
Какая бы технология интеграции информации ни была выбрана, обойти
препятствия, связанные с тонкими проблемами смысловой интерпретации данных, не
удается — источники, содержащие даже схожую информацию, в общем случае отличаются
гетерогенным (heterogeneous) характером. Помощь в демонстрации типичных проблем
окажет следующий пример.
Пример 20.1. Автомобильная компания Aardvark Automobile Co. обладает сетью из
1000 дилеров, каждый из которых поддерживает собственную базу данных со
сведениями об автомобилях, выставленных на продажу. Компания стремится создать
интегрированную базу данных, которая охватывала бы информацию из всех
1000 первичных источников.148 Подобная "общая" база данных призвана помочь
дилерам в поиске конкретных моделей, отсутствующих в их распоряжении, и
аналитикам, занятым изучением и прогнозированием потребительского спроса.
Частные базы данных, однако, не укладываются в универсальную схему. В одном
случае дилер может хранить всю информацию об автомобилях в едином отношении
следующего вида:
Cars(serialNo, model, color, autoTrans, cdPlayer, ...)
где каждой необязательной характеристике отвечает атрибут булева типа (например,
cdPlayer — "наличие проигрывателя компакт-дисков"). Другой дилер вправе
вынести подобную информацию в отдельное отношение:
Autos(serial, model, color)
Options(serial, option)
148 Речь, разумеется, идет о вымышленной фирме. Большинство "настоящих" компаний
обладает схожими характеристиками, хотя история формирования их инфраструктуры
нередко отличается: в каких-то случаях, скажем, вначале конструируется центральная база данных,
а дилерам предоставляется возможность загрузки соответствующих порций информации
в собственные частные базы данных. Впрочем, сценарий, рассматриваемый в нашем
примере, не менее правдоподобен и вполне отвечает реалиям современного развития компаний во
многих промышленных отраслях.
1004
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Обратите внимание, что различия проявляются не только на уровне схемы базы
данных в целом — разнятся также имена семантически близких отношений (Cars
и Autos) и даже отдельных однородных атрибутов (serialNo против serial).
Что еще хуже, единые по смыслу фрагменты информации в тех или иных базах
данных могут быть представлены совершенно по-разному.
1. Различия в типах данных. Например, серийные номера автомобилей в одних
источниках хранятся в виде символьных строк переменной длины, в других
задаются как строки постоянной (причем, возможно, разной) длины, а в третьих
существуют в форме целочисленных значений.
2. Различия в множествах допустимых значений. Один и тот же признак в тех или
иных источниках может определяться различными наборами констант: скажем,
значению черного (black) цвета в одном случае поставлено в соответствие целое
число, в другом — строка ' black ', в третьем — символьный код ' BL • (нельзя
исключить ситуацию, когда тот же код в каком-то ином источнике служит
обозначением голубого (blue) цвета).
3. Семантические различия. Одно и то же понятие, описываемое в каждом из
источников, может толковаться своеобразно: один дилер вправе включить в
отношение Cars информацию обо всех транспортных средствах, включая
грузовики, а другой — только сведения о малолитражных автомобилях; один
принимает во внимание различия в форме кузова, другой — нет, и т.д.
4. Отсутствующие значения. В любом из источников может просто не быть такой
информации, которая наличествует во всех или большинстве других: какой-нибудь
дилер, скажем, не фиксирует данные о цвете автомобилей. В подобных случаях
нередко используются величины, предлагаемые по умолчанию, либо значения null.
Одна из современных тенденций связана с использованием модели
полуструктурированных данных (semistructured data) (см. раздел 4.6 на с. 187), призванной, в
частности, "сглаживать" различия в способах представления схожей информации,
которая содержится в нескольких базах данных, обладающих различными схемами.
При наличии любой из рассмотренных ситуаций на начальной стадии процесса интеграции
следует предусмотреть и реализовать те или иные механизмы трансляции данных. □
20.1.2. Федеративные базы данных
Простейший подход к интеграции заключается, вероятно, в реализации взаимных
связей между каждой из баз данных и всеми другими. Подобная связь позволяет
одной СУБД Dx обращаться с запросами к другой, D2, причем в таких терминах, которые
D2 способна воспринять адекватно. Основная проблема в этом случае состоит в том,
что если каждой из п систем баз данных необходимо "общаться" с оставшимися п - 1
системами, придется написать п(п-\) фрагментов
кода, обеспечивающих трансляцию запросов.
Соответствующая схема представлена на рис. 20.1. Здесь
федеративная база данных (federated database) образована на
основе четырех частных систем-источников. Для
каждой необходимо создать по три программных
компонента, обеспечивающих доступ к данным,
управляемым остальными системами.
Рис. 20. /. Для создания полноценной "федерации ",
охватывающей четыре базы данных, требуется
сконструировать 12 компонентов, обеспечивающих
трансляцию запросов, которыми обмениваются системы
DB1
*
1
i
1
npi
иг
-—-
X
DB2
I
DB4
20.1. ОБЗОР ТЕХНОЛОГИЙ ИНТЕГРАЦИИ ИНФОРМАЦИИ
1005
Несмотря на названные сложности, создание федеративной системы при
некоторых обстоятельствах является простейшим вариантом интеграции, особенно в тех
случаях, когда возможность взаимной коммуникации частных систем по своей природе
ограниченна. Ниже приведен пример, иллюстрирующий способы функционирования
компонентов трансляции.
Пример 20.2. Предположим, что дилерам компании Aardvark Automobile Co.
(см. пример 20.1 на с. 1004) необходимо иметь доступ к общей складской
информации, но каждый из них намеревается обращаться с запросами о наличии тех или иных
марок автомобилей к базам данных нескольких ближайших дилеров. Допустим для
определенности, что база данных дилера 1 включает отношение
NeededCars(model, color, autoTrans)
которое содержит кортежи со сведениями об автомобилях, заказанных покупателями
с учетом марки модели (model), цвета (color) и признака наличия или отсутствия
автоматической трансмиссии (autoTrans). В базе данных дилера 2 аналогичная
информация представлена в форме двух отношений, упоминавшихся в примере 20.1:
Autos(serial, model, color)
Options(serial, option)
Дилер 1 обладает программным приложением, которое обращается к "удаленной" базе
данных дилера 2 за сведениями об автомобилях, удовлетворяющих условиям, заданным
в отношении NeededCars. На рис. 20.2 приведен эскиз подобной программы с
"внедренными" инструкциями SQL. "Внедренный" код SQL представляет запросы, адресуемые
к базе данных дилера 2; результаты их обработки возвращаются дилеру 1. В соответствии
с принятым соглашением идентификаторы переменных, предназначенных для
сохранения значений, извлеченных из базы данных, предваряются символом двоеточия (:).
for {[для] каждого кортежа (:т, :с, а:) в NeededCars) {
if (:a = TRUE) { /* Требуется автоматическая трансмиссия */
SELECT serial
FROM Autos, Options
WHERE Autos.serial = Options.serial AND
Options.option = 'autoTrans' AND
Autos.model = :m AND
Autos.color = :c;
}
else { /* Автоматическая трансмиссия не требуется */
SELECT serial
FROM Autos
WHERE Autos.model = :m AND
Autos.color = :c AND
NOT EXISTS (
SELECT *
FROM Options
WHERE serial = Autos.serial AND
option = 'autoTrans'
);
}
}
Рис. 20.2. Дилер 1 обращается к базе данных дилера 2 за информацией о наличии
заказанных моделей автомобилей
Запросы обращены к отношениям из схемы базы данных дилера 2. Если бы дилеру 1
пришлось направить аналогичный запрос какой-либо третьей базе данных,
содержащей отношение
1006
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Cars(serialNo, model, color, autoTrans, cdPlayer, ...)
тот выглядел бы иначе. Впрочем, главное, чтобы запросы отвечали реалиям той базы
данных, которой они адресуются. □
20.1.3. Хранилища данных
Интегрирующая архитектура хранилища данных (data warehouse) предусматривает
извлечение (выгрузку) информации из нескольких источников и сочетание ее в
рамках глобальной (global) схемы хранилища, которое воспринимается пользователем как
традиционная база данных. Диаграмма,
иллюстрирующая вариант интеграции на основе двух
источников, изображена на рис. 20.3.
Как только информация загружена в хранилище
данных, ее можно считывать совершенно так же,
как и содержимое любых баз данных. Операции
обновления данных в хранилище, напротив, обычно
запрещены, поскольку они не отражаются в
содержимом первичных источников.
Можно назвать по меньшей мере три способа
решения проблемы сбора информации в
хранилище данных.
Запрос
Результат
Хранилище
данных
Компонент
трансляции/загрузки
данных
1.
Компонент
извлечения
данных
Компонент
извлечения
данных
Источник
1
Источник
2
2.
Рис. 20,3. Хранилище данных пред-
ставляет информацию в форме
традиционной базы данных
Содержимое хранилища периодически
(скажем, еженощно) реконструируется на основе
текущей информации источников — наиболее
общий подход, основной недостаток которого
зачастую связан с необходимостью
"отключения" системы от внешнего мира на время
выполнения процедуры трансляции/загрузки,
нередко весьма продолжительной. Другой
изъян заключается в том, что данные в
хранилище быстро теряют актуальность.
В хранилище периодически заносятся данные
из источников, претерпевшие изменения
с момента осуществления последней загрузки.
Количество переносимых данных в этом
случае, как правило, существенно ниже, что весьма важно, если время, отводимое на
обновление информации, ограниченно и/или объем хранилища велик (обычной
практикой является создание и поддержка хранилищ, размер которых
исчисляется многими гигабайтами или даже терабайтами). Недостаток подхода состоит
в сложности процедуры инкрементного обновления (incremental update) в сравнении
с прямолинейным алгоритмом полной загрузки данных.
Информация в хранилище обновляется непосредственно в ответ на операцию (или
группу операций) модификации содержимого одного или нескольких источников.
Использование подобной стратегии предполагает интенсивный обмен данными
и может оказаться оправданным, вероятно, только в тех ситуациях, когда размер
хранилища невелик и частота операций изменения источников низка. Впрочем,
простор для исследований остается весьма обширным — удачный вариант
реализации хранилища такого типа сулит множество разнообразных преимуществ.
Пример 20.3. Предположим для простоты, что множество дилеров компании Aardvark
Automobile Co. (см. пример 20.1 на с. 1004) сведено до двух; допустим, что в их базах
данных содержатся отношения со схемами
Cars(serialNo, model, color, autoTrans, cdPlayer, ...)
3.
20.1. ОБЗОР ТЕХНОЛОГИЙ ИНТЕГРАЦИИ ИНФОРМАЦИИ
1007
и
Autos(serial, model, color)
Options(serial, option)
соответственно. Необходимо создать хранилище данных со схемой отношения
AutosWhse(serialNo, model, color, autoTrans, dealer)
Другими словами, глобальная схема схожа со структурой данных дилера 1, но в ней
сохраняются сведения только о наличии или отсутствии в автомобиле автоматической
трансмиссии и предусмотрен атрибут, указывающий на принадлежность автомобиля
тому или иному дилеру.
Программные компоненты, осуществляющие извлечение информации из частных
баз данных обоих дилеров и загрузку ее в хранилище, можно свести к форме SQL-
запросов. Запрос, предназначенный для выгрузки данных первого дилера и занесения
их в хранилище, довольно прост:
INSERT INTO AutoWhse(serialNo, model, color,
autoTrans, dealer)
SELECT serialNo, model, color, autoTrans, 'dealerl1
FROM Cars;
Компонент извлечения информации из базы данных дилера 2 и загрузки в
хранилище, однако, более сложен, поскольку на него возлагается дополнительная обязанность
по определению признака наличия в автомобиле автоматической трансмиссии. В
качестве значений атрибута autoTrans мы будем использовать строки 'yes' и 'по' —
их смысл очевиден. SQL-код компонента показан на рис. 20.4.
INSERT INTO AutoWhse(serialNo, model, color,
autoTrans, dealer)
SELECT serial, model, color, 'yes1, 'dealer2'
FROM Autos, Options
WHERE Autos.serial = Options.serial AND
option = 'autoTrans';
INSERT INTO AutoWhse(serialNo, model, color,
autoTrans, dealer)
SELECT serial, model, color, 'no', 'dealer2'
FROM Autos
WHERE NOT EXISTS(
SELECT *
FROM Options
WHERE serial = Autos.serial AND
option = 'autoTrans'
);
Рис. 20.4. Компонент извлечения/загрузки данных дилера 2
В этой простой ситуации в использовании специального компонента трансляции
(см. рис. 20.3 на с. 1007) необходимости нет — поскольку содержимое хранилища
данных является объединением (union) кортежей из отношений частных баз данных
дилеров, извлекаемая информация может быть загружена в хранилище
непосредственно. Однако во многих других случаях данные подлежат предварительной
обработке: скажем, отношения из нескольких источников соединяются Qo'm), и в хранилище
помещается результат операции; другой пример — в хранилище загружаются итоги
агрегирования исходных данных. Способы трансляции и сочетания информации из
первичных источников в общем случае могут быть самыми разными. □
1008
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
20.1.4. Медиаторы
Медиатор (mediator) обеспечивает поддержку набора виртуальных таблиц (views),
отображающих интегрированные данные из различных источников, — во многом так
же, как хранилище данных (warehouse) (см. раздел 20.1.3) представляет
материализованные отношения с обобщенной информацией из аналогичных источников. Однако
медиатор сам по себе не сохраняет данные, поэтому механизм его действия
существенно отличается от принципов функционирования хранилищ данных. На рис. 20.5
изображена схема интеграции информации двух источников средствами медиатора
(как и в случае хранилищ данных, количество источников, разумеется, может быть
произвольным). В ответ на запрос пользователя медиатор, не "владеющий" данными
непосредственно, обязан получить информацию из подходящих источников,
сформировать адекватный результат и передать его пользователю.
Запрос
LA
Результат
Медиатор
Запрос/ S Запрос
'Результат
Оболочка
Запрос
Результат
Оболочка
Запрос
Результат
Источник
1
Результат
Источник
2
Рис. 20.5. Медиатор и компоненты-
оболочки транслируют запрос в форму,
отвечающую структуре и семантике
содержимого источников, и возвращают
полученный результат пользователю
Как видно из рис. 20.5, медиатор посылает запросы каждой из оболочек (wrappers),
а те в свою очередь адресуют их соответствующим источникам. (В определенных
случаях медиатор способен направлять какой-либо оболочке целую серию запросов,
а к некоторым другим оболочкам не обращаться вовсе.) Оболочка передает медиатору
полученный ею итог обработки запроса, а медиатор, осуществляя сочетание и
трансляцию данных, возвращенных оболочками, формирует окончательный результат и
отсылает его пользователю; на рис. 20.5 отдельный компонент трансляции, подобный тому,
который применяется в схеме организации хранилища данных (см. рис. 20.3 на с. 1007), не
приведен, поскольку такие функции являются прерогативой самого медиатора.
Пример 20.4. Обсудим сценарий, схожий с рассмотренным в примере 20.3 (см. с. 1007),
но на сей раз с использованием медиатора. Допустим, что медиатор интегрирует те же
два источника с информацией об автомобилях в единую виртуальную таблицу со
следующей схемой:
AutosMed(serialNo, model, color, autoTrans, dealer)
Предположим, что пользователь адресует медиатору запрос, предусматривающий
отыскание сведений об автомобилях красного цвета:
SELECT serialNo, model
FROM AutosMed
WHERE color = 'red';
20.1. ОБЗОР ТЕХНОЛОГИЙ ИНТЕГРАЦИИ ИНФОРМАЦИИ
1009
В данном случае медиатор вправе передать полученный запрос напрямую каждой из
двух оболочек. Способы проектирования и реализации оболочек, предназначенных
для обработки подобных запросов, служат предметом обсуждения в разделе 20.2 на
с. 1012; в более сложных ситуациях, однако, медиатору приходится осуществлять
трансляцию и распределение отдельных "частей" исходного запроса между несколькими
оболочками. Здесь же надлежащие функции трансляции возлагаются на оболочки.
Оболочка, обслуживающая базу данных дилера 1, транслирует запрос в
соответствии со схемой
Cars(serialNo, model, color, autoTrans, cdPlayer, ...)
и результатом трансляции оказывается запрос
SELECT serialNo, model
FROM Cars
WHERE color = 'red';
После его выполнения оболочка возвращает медиатору некоторое множество пар
значений (serialNo, model).
Оболочка для базы данных дилера 2 преобразует тот же запрос с учетом
структуры схемы
Autos(serial, model, color)
Options(serial, option)
Возможный итог трансляции выглядит почти аналогично,
SELECT serial, model
FROM Autos
WHERE color = 'red';
и отличается только именами отношения и одного из атрибутов. Эта оболочка
возвращает медиатору множество пар (serial, model); пары (serial, model)
и (serialNo, model) интерпретируются единообразно.
Далее медиатор вычисляет объединение (union) наборов данных и возвращает
результат операции пользователю, инициировавшему запрос. Поскольку разумно
полагать, что атрибут "серийный номер" играет роль "глобального" ключа (т.е. совпадение
компонентов этого атрибута в нескольких кортежах — даже из отношений различных
баз данных — не допускается), медиатору надлежит употребить "множественную"
версию оператора объединения (set union). □
В примере 20.4 не нашел отражения ряд возможностей, которые используются
медиаторами в процессе обработки запросов. Например, медиатор способен направить
некоторый запрос одному источнику, проанализировать результат и только затем
принять решение о целесообразности рассылки остальных запросов. Подобный
подход оказался бы кстати, поинтересуйся пользователь тем, имеется ли в наличии любая
модель автомобиля "Gobi" голубого цвета: первый запрос следовало бы обратить,
скажем, к базе данных дилера 1, и только затем, если возвращено пустое множество
кортежей, адресовать данным дилера 2.
20.1.5. Упражнения к разделу 20.1
! Упражнение 20.1.1. Допустим, что компания А сохраняет сведения о продаваемых ею
персональных компьютерах и мониторах в отношениях со следующими схемами:
Computers(number, proc, speed, memory, hd)
Monitors(number, screen, maxResX, maxResY)
Например, кортеж вида (123, ' PHI', 1000, 128, 40) в отношении Computers
представляет информацию о том, что модель (number) 123 компьютера оснащена
процессором (proc) Pentium-Ill с быстродействием (speed) 1000 МГц, оператив-
1010
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
ной памятью (memory) объемом 126 Мбайт и диском (hd) емкостью 40 Гбайт.
Кортеж (456, 19, 1600, 1200), присутствующий в отношении Monitors,
свидетельствует, что в наличии имеется модель (number) 456 монитора с 19-дюймовым
экраном (screen) и максимальным разрешением в 1600 пикселей по горизонтали
(maxResX) и 1200 — по вертикали (maxResY).
Компания В продает только полностью укомплектованные системы, включающие
собственно компьютер и монитор, и использует базу данных со схемой
Systems(id, processor, mem, disk, screenSize)
Атрибут processor представляет целочисленное значение быстродействия
процессора; тип процессора (такой как Pentium-Ill) не фиксируется. Не сохраняется и
информация о максимальном разрешении экрана монитора. Атрибуты id, mem и disk
аналогичны по смыслу и назначению атрибутам number, memory и hd из схемы базы
данных компании Л, но емкость диска измеряется не в гигабайтах, а в мегабайтах.
а) Если компании А потребуется включить в свои отношения информацию о
продуктах компании Я, как должны выглядеть SQL-команды вставки кортежей?
* Ь) Если компании В понадобится вставить в отношение Systems как можно
больше кортежей со сведениями о компьютерах и мониторах, производимых
компанией А, какие SQL-команды наилучшим образом справятся с
получением такой информации?
*! Упражнение 20.1.2. Предложите глобальную схему, которая позволила бы сохранить
максимум информации о продуктах компаний А и В, упомянутых в упражнении 20.1.1.
Упражнение 20.1.3. Создайте SQL-запросы, призванные осуществить извлечение
информации из баз данных компаний А и В (см. упражнение 20.1.1) и ее загрузку
в хранилище данных с "глобальной" схемой, предложенной вами при решении
задания из упражнения 20.1.2. При необходимости проанализируйте альтернативные
варианты глобальной схемы.
Упражнение 20.1.4. Допустим, что глобальная схема, разработанная вами при
решении задания из упражнения 20.1.2 (или исправленная в процессе анализа
вариантов в упражнении 20.1.3), применяется в системе с медиатором. Каким образом
медиатор должен обслуживать запрос, предусматривающий поиск значения
максимальной емкости диска в компьютерных системах, оснащенных процессором с
быстродействием, равным 1500 МГц?
! Упражнение 20.1.5. Рассмотрите несколько иных вариантов схем представления
информации о персональных компьютерах (см. упражнение 20.1.1). Как следовало
бы интегрировать эти схемы в глобальную схему, предложенную при решении
задания из упражнения 20.1.2?
! Упражнение 20.1.6. В примере 20.3 на с. 1007 мы говорили о том, что отношение
Cars в базе данных дилера 1 обладает атрибутом autoTrans, который способен
принимать только два значения — ' yes • и ' по'. Поскольку те же значения
предусмотрены и для одноименного атрибута в глобальной схеме, процедура загрузки
данных в отношение Autoswhse оказывается особенно простой. Допустим, однако, что
атрибуту Cars. autoTrans должны присваиваться целочисленные значения: 0 для
автомобилей без автоматической трансмиссии или / > 0 — в случае, если
автомобиль оснащен /-ступенчатой автоматической коробкой передач. Приведите образец
SQL-запроса, осуществляющего трансляцию данных из Cars в AutosWhse.
Упражнение 20.1.7. Каким образом медиатор из примера 20.4 на с. 1009 должен
был бы осуществить трансляцию следующих запросов?
20.1. ОБЗОР ТЕХНОЛОГИЙ ИНТЕГРАЦИИ ИНФОРМАЦИИ
1011
* а) Найти серийные номера автомобилей с автоматической трансмиссией.
Ь) Найти серийные номера автомобилей без автоматической трансмиссии.
! с) Найти серийные номера автомобилей голубого цвета, поставляемых дилером 1.
Упражнение 20.1.8. Обратитесь к Web-сайтам нескольких виртуальных книжных
магазинов и попробуйте отыскать сведения об этой книге. Каким образом
следовало бы представить найденную информацию в глобальной схеме хранилища
данных или системы с медиатором?
20.2. Компоненты-оболочки
В схеме хранилища данных, подобной представленной на рис. 20.3 (см. с. 1007),
компонент- оболочка (wrapper) извлечения (выгрузки) данных включает
1) один или несколько "встроенных" (built-in) запросов, которые обращаются
к источнику и поставляют исходную информацию для хранилища данных;
2) адекватный механизм коммуникации, позволяющий оболочке
a) адресовать запросы источнику;
b) получать итоги обработки запросов;
c) передавать информацию в хранилище данных.
Встроенные запросы могут оформляться средствами SQL, если база данных источника
поддерживает SQL (именно этот вариант мы рассматривали в примерах из раздела
20.1 на с. 1003). Функцию запросов способны выполнять и операции, описанные на
иных языках, если источник не является системой баз данных: компонент-оболочка
может, например, заполнять форму на Web-странице, инициировать запрос к
электронному библиографическому каталогу или использовать иные возможности.
В системах, основанных на медиаторах, применяются, однако, более сложные
оболочки, нежели в хранилищах данных. Оболочка обязана воспринимать самые разные
запросы, отсылаемые медиатором, транслировать их с учетом особенностей источника
и возвращать медиатору полученные результаты. В этом разделе мы остановим
внимание на способах конструирования гибких компонентов-оболочек, пригодных для
совместного использования с медиаторами.
20.2.1. Шаблоны запросов
Строгий подход к проектированию оболочки, соединяющей медиатор с
источником данных, предусматривает классификацию множества допустимых запросов,
которые способны обрабатываться медиатором, в набор шаблонов (templates) — запросов
с параметрами, представляющими константы. Медиатор задает определенные
константы, а оболочка выполняет конкретный запрос. Применение схемы шаблонов
иллюстрируется следующим примером (используемое нами выражение вида Т => S
означает, что шаблон Т преобразуется оболочкой в запрос S, адресуемый источнику).
Пример 20.5. Предположим, что необходимо сконструировать оболочку для базы
данных дилера 1, включающей схему отношения
Cars(serialNo, model, color, autoTrans, cdPlayer, ...)
с целью использования в системе с медиатором, содержащей схему
AutosMed(serialNo/ model, color, autoTrans, dealer)
Покажем, каким образом медиатор может обращаться к оболочке за информацией об
автомобилях заданного цвета. Если обозначить параметр цвета как $с, шаблон примет
такой вид, как показано на рис. 20.6.
1012
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
SELECT *
FROM AutosMed
WHERE color = * $c';
= >
SELECT serialNo, model, color, autoTrans, * dealer1*
FROM Cars
WHERE color = '$c•;
Рис. 20.6. Шаблон, описывающий запросы, касающиеся поиска
информации об автомобилях определенного цвета
Оболочка может включать аналогичный шаблон с параметром $т,
представляющим номер модели, еще один шаблон, позволяющий определять наличие
автоматической трансмиссии, и т.п. В рассматриваемом случае существуют восемь вариантов
шаблонов, если допустить, что в запросах позволяется задавать значения любого
подмножества атрибутов model, color и autoTrans, связывая их операторами AND.
(Вообще говоря, если имеется возможность определения конъюнкции равенств,
охватывающей произвольное подмножество из п атрибутов, количество шаблонов
достигает величины 2п.)149 Для представления запросов, предусматривающих вычисление
общего количества автомобилей определенного типа, содержащих в предложении where
дизъюнкции (or) условий и т.д, понадобятся все новые и новые шаблоны. При таком
подходе общее число шаблонов может оказаться непомерно большим; впрочем,
допустимы некоторые упрощения за счет придания оболочке дополнительных функций
(об этом мы рассказываем, начиная с раздела 20.2.3 на с. 1014). □
20.2.2. Генераторы оболочек
Шаблоны компонента-оболочки должны быть преобразованы в код оболочки как
таковой. Программное обеспечение, предназначенное для конструирования компонентов-
оболочек, называют генератором оболочек (wrapper generator); по своему назначению оно
напоминает генератор синтаксических анализаторов (например, YACC), который
создает компоненты компилятора на основе набора высокоуровневых спецификаций.
Процесс, схематически изображенный на рис. 20.7, начинается с передачи генератору
оболочек некоторой спецификации, представляющей в данном случае набор шаблонов.
Генератор оболочек конструирует таблицу (table), которая содержит различные
образцы запросов, описываемых шаблонами, и код запроса к источнику, связанный
с каждым из образцов. В каждом компоненте-оболочке применяется драйвер (driver);
зачастую один и тот же драйвер может использоваться для генерирования всех
оболочек. Функции, выполняемые драйвером, таковы:
1) прием запроса от медиатора (механизм коммуникаций может зависеть от
особенностей конкретного медиатора, т.е. представляться в драйвере в виде
"встраиваемого" компонента (plug-in), поэтому один и тот же драйвер
допустимо применять в системах, элементы которых взаимодействуют по-разному);
2) поиск шаблона, подходящего для описания конкретного запроса (если в
результате просмотра таблицы шаблон найден, параметризованные значения,
149 Если источником информации служит система баз данных, поддерживающая SQL (как
в нашем примере), можно считать, что для обслуживания запросов с произвольными
подмножествами атрибутов, сравниваемых с константами, будет достаточно одного шаблона — стоит
трактовать как параметр предложение where в целом. Этот вывод справедлив, однако, только
в отношении SQL-систем и запросов, в которых задаются условия равенства атрибутов и
констант; в иных ситуациях, когда речь идет об источниках данных произвольной природы, нет
никаких оснований полагать, что способ трансляции одного запроса удастся применить для
обработки всех других (даже схожих) запросов.
20.2. КОМПОНЕНТЫ-ОБОЛОЧКИ
1013
переданные медиатором, используются для конструирования запроса к
источнику; если же надлежащий шаблон отсутствует, оболочка сообщает
медиатору об отрицательном результате обработки исходного запроса);
3) передача запроса к источнику (вновь посредством "встраиваемого"
коммуникационного компонента);
4) (возможная) трансляция и пересылка медиатору результатов обработки
запроса, адресованного источнику (в следующих разделах мы более подробно
остановимся на том, каким образом оболочки способны поддерживать более
широкие классы запросов).
Запросы от медиатора
Шаблоны
Результаты
Генератор
оболочек"
Таблица
Драйвер
Запросы
Результаты
Источник
Рис. 20.7. Генератор оболочек создает
таблицу для определенного драйвера;
драйвер в совокупности с таблицей
формирует компонент-оболочку
20.2.3. Фильтры
Предположим, что оболочка для базы данных дилера автомобильной компании
содержит шаблон с описанием запросов, предусматривающих поиск автомобилей по
цвету (см. рис. 20.6 на с. 1013). Медиатор, однако, получает запрос, имеющий целью
получение информации об автомобилях определенных марки и цвета. Не исключено,
что оболочка пополнена и более сложным шаблоном (обратитесь к рис. 20.8),
позволяющим обслуживать именно такие запросы. Но, как упоминалось в примере 20.5 на
с. 1012, возможность создания шаблонов для всех мыслимых форм запросов имеется,
мягко говоря, далеко не всегда.
SELECT *
FROM AutosMed
WHERE model = '$m' AND color = •$c';
= >
SELECT serialNo, model, color, autoTrans, 'dealer1'
FROM Cars
WHERE model = ' $irT color = '$c';
Рис. 20.8. Шаблон запросов, предполагающих отыскание сведений об
автомобилях заданных марки и цвета
1014
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Где располагается компонент фильтрации
В рассматриваемых примерах мы полагаем, что операции фильтрации выполняются
на уровне оболочки. Впрочем, оболочка способна передавать "сырые" данные,
перекладывая ответственность за их фильтрацию на медиатор. Если, однако, изрядная
доля данных, возвращаемых в результате обработки "шаблонного" запроса, не
удовлетворяет требованиям запроса медиатора, разумнее осуществлять фильтрацию
средствами оболочки, чтобы избежать дополнительных накладных расходов, связанных
с пересылкой медиатору заведомо избыточной или просто ненужной информации.
Альтернативный подход к проблеме поддержки оболочкой большего круга запросов
состоит в том, чтобы обеспечить возможность фильтрации (filtering) результатов,
принятых от источника. Если в составе оболочки имеется шаблон, который (после
соответствующей подстановки значений параметров) возвращает больше данных, чем может быть
получено в результате обработки исходного запроса, уместно отфильтровать содержимое
кортежей средствами оболочки и передать медиатору только те данные, которые
требуются. Задача определения того, служит ли множество данных, запрашиваемых
медиатором, подмножеством данных, возвращаемых при обработке запроса, который
описывается одним из шаблонов, наличествующих в оболочке, в общем случае, разумеется,
сложна, хотя в простых ситуациях, подобных рассмотренным выше, теория претворяется
в жизнь достаточно успешно. (Заинтересованного читателя мы отсылаем к разделу 20.8
на с. 1047, где приведены ссылки на публикации, полезные для дальнейшего изучения.)
Пример 20.6. Допустим, что оболочка содержит только такой шаблон (см. рис. 20.6 на
с. 1013), который позволяет отыскивать информацию об автомобилях указанного
цвета. Однако медиатору посредством запроса
SELECT *
FROM AutosMed
WHERE color = 'blue* AND model = * Gobi' ;
предписывается найти сведения о модели "Gobi" голубого цвета. Возможный способ
получения данных таков:
1) использовать шаблон на рис. 20.6 с параметром $с = 'blue* для отыскания
информации обо всех голубых автомобилях;
2) сохранить результат во временном отношении
TempAutos(serialNo, model, color, autoTrans, dealer)
3) с помощью запроса
SELECT *
FROM TempAutos
WHERE model = 'Gobi•;
выбрать из отношения TempAutos кортежи, содержащие в компонентах
model строки • Gobi '.
Результатом окажется искомое множество данных. На практике, однако, кортежи
схемы TempAutos отыскиваются и фильтруются по одному, в соответствии со схемой
канала (pipeline), а не сохраняются в материализованном отношении TempAutos,
которое подвергается фильтрации только по завершении конструирования. □
20.2.4. Другие функции оболочек
Оболочка способна выполнять и иные преобразования данных, если запрос к
источнику возвращает оболочке всю необходимую информацию. Например, прежде чем
передать медиатору набор кортежей, оболочка вправе спроецировать их на заданное
множество атрибутов либо даже осуществить операции агрегирования или соединения.
20.2. КОМПОНЕНТЫ-ОБОЛОЧКИ
1015
Пример 20.7. Предположим, что медиатору необходимо получить из баз данных всех
дилеров сведения о наличии моделей "Gobi" голубого цвета, включающие серийный
номер автомобиля, признак наличия или отсутствия автоматической трансмиссии
и наименование дилера (значения компонентов model и color очевидны — в их
извлечении потребности нет). Оболочка может функционировать таким же образом, как
и в примере 20.6 на с. 1015, но на последнем шаге, когда множество кортежей
подлежит передаче медиатору, оболочка, наряду с фильтрацией по условию
model = 'Gobi* в предложении WHERE, осуществляет операцию проекции в
операторе select. Выполнить подобное преобразование способен запрос
SELECT serialNo, autoTrans, dealer
FROM TempAutos
WHERE model = •Gobi';
причем, как и в примере 20.6, содержимое отношения TempAutos будет, вероятно,
передано по каналу (pipeline) (на принимающей стороне канала в данном случае
окажется оператор проекции), а не материализовано физически на уровне оболочки. □
Пример 20.8. Усложним задачу: пусть медиатору надлежит ответить на запрос,
предполагающий отыскание пар названий дилеров и моделей автомобилей при условии,
что каждый дилер имеет в наличии два автомобиля красного цвета одной и той же
модели, причем один оснащен автоматической трансмиссией, а другой — нет.
Предположим также, что единственным сколько-нибудь полезным шаблоном в составе
оболочки является тот, который позволяет отобрать данные об автомобилях
указанного цвета, продаваемых дилером 1 (см. рис. 20.6 на с. 1013). Запрос, передаваемый
медиатором, может выглядеть так, как показано на рис. 20.9. Заметьте, что
наименование дилера не задается ни для отношения А1, ни для А2, поскольку оболочка
способна обращаться только к данным дилера 1 (оболочки для баз данных других дилеров
получат от медиатора аналогичные запросы).
SELECT Al.model, Al.dealer
FROM AutosMed Al, AutosMed A2
WHERE Al.model = A2.model AND
Al.color = 'red* AND
A2.color = 'red* AND
Al.autoTrans = 'no1 AND
A2.autoTrans = * yes *;
Рис. 20.9. Образец запроса, передаваемого от медиатора к оболочке
Тщательно спроектированная оболочка способна обнаружить, что для получения ответа
на запрос медиатора первым делом следует сформировать из данных дилера 1 отношение
RedAutos(serialNo, model, color, autoTrans, dealer)
со сведениями обо всех автомобилях красного цвета, имеющихся в наличии. Достичь
подобной цели поможет шаблон на рис. 20.6, представляющий запросы с указанием
параметра цвета. В этом случае оболочка действует так, словно при обработке запроса
SELECT *
FROM AutosMed
WHERE color = 'red';
Затем компонент оболочки вправе осуществить соединение Coin) отношения
RedAutos с самим собой и выполнить необходимую операцию выбора, чтобы
получить отношение, которое предусмотрено запросом на рис. 20.9. Действия,
предпринимаемые оболочкой150 на этой стадии, можно описать так, как показано на
рис. 20.10.
При использовании иных вариантов систем интеграции информации подобная задача
в действительности может выполняться медиатором, а не оболочкой.
1016
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
SELECT DISTINCT Al.model, Al.dealer
FROM RedAutos Al, RedAutos A2
WHERE Al.model = A2.model AND
Al.autoTrans = 'no1 AND
A2.autoTrans = 'yes';
Рис. 20.10. Запрос, выполняемый оболочкой (или медиатором) с целью
завершения процедуры обработки запроса, приведенного на рис. 20.9
□
20.2.5. Упражнения к разделу 20.2
* Упражнение 20.2.1. На рис. 20.6 (см. с. 1013) приведен текст простого шаблона,
который осуществляет трансляцию запросов медиатора, касающихся информации об
автомобилях определенного цвета, в запросы, адресуемые базе данных дилера 1
с отношением Cars. Допустим, что система кодирования цветов, принятая в схеме
медиатора, отличается от системы обозначений, используемой в базе данных
дилера, и имеется отношение GtoL(globalColor/ localColor), задающее таблицу
преобразования одного множества кодов в другое и наоборот. Перепишите текст
шаблона так, чтобы тот позволил генерировать семантически корректные запросы.
Упражнение 20.2.2. В упражнении 20.1.1 на с. 1010 упоминались две компьютерные
компании, А и В, использующие базы данных с различными схемами. Рассмотрим
медиатор со схемой отношения
PCMed(manf, speed, mem, disk, screen)
кортежи которого содержат сведения о компании-производителе (manf) (А или В)
компьютерной системы, быстродействии процессора (speed), объеме оперативной памяти
(mem), емкости диска (disk) и размере экрана монитора (screen). Создайте шаблоны,
позволяющие описать перечисленные ниже типы запросов (заметьте, что в каждом
случае следует привести два шаблона, по одному для баз данных компаний А и В).
* а) Найти компьютеры с заданным значением быстродействия процессора.
b) Найти компьютеры с заданным значением размера экрана монитора.
c) Найти компьютеры с заданными значениями объема оперативной памяти
и емкости диска.
Упражнение 20.2.3. Допустим, что каждая из баз данных компаний-производителей
компьютерной техники (Л и В) снабжена оболочкой, содержащей шаблоны,
описанные в упражнении 20.2.2. Каким образом медиатор может использовать эти
средства для обработки перечисленных ниже запросов?
* а) Найти информацию о производителе, объеме оперативной памяти и размере
экрана монитора для всех компьютеров, оснащенных процессором с
быстродействием 1000 МГц и диском емкостью 40 Гбайт.
! Ь) Найти максимальную емкость диска в компьютерах с процессором,
быстродействие которого равно 1500 МГц.
с) Найти сведения обо всех компьютерах с оперативной памятью объемом
128 Мбайт, в которых размер экрана монитора (в дюймах) превышает
емкость диска (в гигабайтах).
20.3. Медиаторы и оптимизация с учетом возможностей
источников данных
В разделе 16.5 на с. 797 мы рассматривали стратегию выбора планов запросов
с привлечением оценок стоимости операций (cost-based optimization). Типичная
20.3. МЕДИАТОРЫ И ОПТИМИЗАЦИЯ С УЧЕТОМ ВОЗМОЖНОСТЕЙ...
1017
СУБД вычисляет стоимость каждого плана запроса и выбирает тот, который считается
"лучшим". Медиатор, получая запрос, редко бывает "осведомлен" о том, насколько
продолжительным окажется процесс его обработки системой источника. Более того,
многие источники не являются базами данных, поддерживающими SQL, и зачастую
способны справиться только с небольшим подмножеством типов запросов, которые
могут быть присланы медиатором. Поэтому процедуру оптимизации планов запроса
медиатором нельзя основывать только на оценках стоимости.
Выбирая план запроса, медиатор придерживается более простой стратегии,
известной как оптимизация с учетом возможностей источников (capability-based optimization).
Главное значение приобретает не вопрос о том, какова стоимость плана, а то,
является ли план принципиально выполнимым. Только такие планы уместно подвергнуть
дальнейшему стоимостному анализу.
Вначале мы покажем, почему учет возможностей конкретных источников данных
столь важен при выборе плана запроса на уровне медиатора, затем приведем систему
обозначений, помогающую классифицировать характеристики источников, а в
завершение обсудим стратегии выявления выполнимых планов запросов.
20.3.1. Проблема ограниченных возможностей источника данных
На сегодняшний день многие полезные информационные источники оснащены
только Web-интерфейсами — даже в тех случаях, когда в действительности они
представляют собой традиционные базы данных. Источники информации в среде Web
обычно допускают обращение исключительно при посредничестве форм (forms)
(описываемых, например, средствами языка HTML) и не воспринимают
произвольные SQL-запросы: пользователю предлагается ввести значения определенных
атрибутов, и в результате обработки запроса Web-сервер возвращает наборы значений других
атрибутов, удовлетворяющих заданным критериям.
Пример 20.9. Интерфейс широко известного Web-портала Amazon.com позволяет
запрашивать библиографические данные самыми разными способами: допускается,
скажем, указать имя автора, чтобы справиться обо всех его книгах, задать название
книги, дабы узнать полную информацию об издании, или ввести ключевые слова
и получить сведения о книгах, удовлетворяющих определенным критериям. Впрочем,
существуют такие порции информации, с которыми можно познакомиться, но нельзя
указывать в запросах. Например, Amazon ведет статистику продаж книг, но не
позволяет ввести запрос типа "какова десятка бестселлеров". Более того, система не
предоставляет возможности определения запросов "слишком общего" характера. Так,
средствами интерфейса Amazon нельзя сформулировать запрос вида
SELECT * FROM Books;
("расскажи-ка мне все о своих книгах"), хотя наше праздное любопытство, вероятно,
удалось бы удовлетворить, имей мы "прямой" доступ к базе данных Amazon. □
Можно назвать самые разные причины, по которым системы, управляющие
источниками данных, ограничивают круг возможностей оформления запросов на
получение информации.
1. Наличие унаследованных систем (legacy systems) — собраний данных,
поддерживаемых с помощью устаревших технологий или уникальных методов и приемов.
Многие ранние базы данных не управляются СУБД — тем более реляционными
системами, поддерживающими аппарат SQL-запросов. Такие структуры
спроектированы в расчете на применение особых разновидностей запросов, зачастую
не позволяют осуществить перенос данных в среду более современной системы
и нередко "обрастают" гигантским количеством весьма специфических
приложений. Подобное множество изъянов и неудобств, с которыми приходится вы-
1018
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
нужденно мириться, принято обозначать общим термином проблема
унаследованных баз данных (legacy database problem); надеяться на сколько-нибудь скорое
разрешение этой проблемы, как все мы понимаем, нет никаких оснований.
2. Система управления данными вправе ограничивать множество допустимых
запросов из соображений безопасности. "Нежелание" портала Amazon отвечать
на запросы вида "расскажи-ка мне все о своих книгах" — это самый очевидный
пример: система просто защищается от чрезмерной эксплуатации и происков
конкурентов. Другой пример: система баз данных с информацией
медицинского профиля может давать ответы на запросы среднестатистического
характера, но правомочна отклонять попытки (несанкционированного) доступа к
карточкам с историями болезни отдельных пациентов.
3. Индексы в крупных базах данных способны существенно ускорить обработку
определенных запросов; в других случаях потребуются чрезмерно большие
накладные расходы. Обратимся для примера к реляционной базе данных с
библиографической информацией. Если один из атрибутов представляет имя автора книги
и индекс для этого атрибута не создан, тогда для обработки запросов, в которых
указано только имя автора, системе придется просматривать миллионы кортежей.151
20.3.2. Классификация возможностей источника данных
Если данные обладают реляционной природой или могут восприниматься как
реляционные, допустимые формы запросов удается охарактеризовать с помощью
последовательностей описательных кодов (adornments), которые представляют ограничения,
касающиеся возможности определения каждого из атрибутов отношения в тексте
запроса, и перечисляются в стандартном порядке следования атрибутов. Укажем
наиболее употребительные типы ограничений и их обозначения.
1. / (от free) — значение атрибута можно определять свободно, без каких-либо
ограничений.
2. b (от bound) — с атрибутом должно быть связано некоторое значение;
допускается задание любых значений.
3. и (от unspecified) — определять значения атрибута не разрешается.
4. c[S] (от choice from set S) — атрибут должен быть специфицирован, причем
позволяется выбирать один из элементов, принадлежащих конечному множеству
S (примером может служить набор значений в интерфейсном элементе
раскрывающегося списка, размещенном на HTML-форме).
5. о [S] (от optional from set S) — значение атрибута задавать не обязательно; если же
оно определяется, надлежит выбирать один из элементов, принадлежащих
конечному множеству S.
Помимо того, код снабжается символом апострофа (скажем,/'), если соответствующий
атрибут не входит в итоговое отношение, возвращаемое в результате обработки запроса.
Спецификация возможностей источника (capabilities specification) выражается в виде
множества последовательностей кодов ограничений. Чтобы медиатор смог
гарантировать возможность успешной обработки запроса, адресованного источнику, запрос
должен удовлетворять спецификации возможностей источника (если некоторые
последовательности кодов в спецификации содержат свободные (f) или необязательные
(о) компоненты, вероятность успеха возрастает).
151 Следует отметить, что информация о тех или иных категориях продуктов (скажем, о
книгах, как на Web-сайте Amazom.com) не обязательно оформляется в виде реляционной базы
данных. Зачастую она представляется как набор текстовых документов, снабженный обращенным
(inverted) индексом (см. раздел 13.2.4 на с. 603).
20.3. МЕДИАТОРЫ И ОПТИМИЗАЦИЯ С УЧЕТОМ ВОЗМОЖНОСТЕЙ...
1019
Пример 20.10. Вновь обратимся к базам данных дилеров автомобильной компании
(см. пример 20.4 на с. 1009) и предположим, что структура источника данных дилера 1
описывается следующей схемой:
Cars(serialNo, model, color, autoTrans, cdPlayer)
Напомним, что прежде схема предусматривала возможность задания дополнительных
необязательных признаков, но здесь для простоты мы ограничим внимание двумя —
autoTrans ("наличие автоматической трансмиссии") и cdPlayer ("наличие
проигрывателя компакт-дисков"). Рассмотрим две из множества стратегий предоставления доступа
к информации, которым вправе следовать система управления данными дилера 1.
1. Пользователь задает серийный номер, а система возвращает всю информацию
(т.е. значения четырех оставшихся атрибутов) об автомобиле с указанным
серийным номером. Последовательность кодов, отвечающая подобному запросу,
выглядит как Ь'ииии. Другими словами, значение первого атрибута должно
быть задано, но оно не включается в итоговое отношение. Значения остальных
атрибутов могут не определяться, но, однако, подлежат включению в результат.
2. Пользователь указывает значения атрибутов model, color и, возможно,
autoTrans и/или cdPlayer. Система обязана вывести значения всех
компонентов кортежей, удовлетворяющих заданному критерию поиска. Подходящая
последовательность кодов представляется следующим образом:
ubb(?[yes,no] о [yes,no]
Выражение гласит, что серийный номер автомобиля можно не задавать;
значения атрибутов model и color, напротив, должны быть определены, причем
в эти поля разрешено вводить любые подходящие величины; при
необходимости позволяется указать признаки autoTrans и/или cdPlayer, используя одно
из двух возможных значений — "yes" или "по".
Стратегия, рассмотренная в п. 2, может быть усложнена: допустим, что
пользователь обязан вводить в поля model и/или color только корректные значения, т.е.
задавать любое из названий существующих моделей автомобилей, производимых
компанией Aardvark Automobile Co., и выбирать цвет из списка доступных значений. В этом
случае последовательность кодов должна выглядеть так:
и c[Gobi,...] c[red, blue,...] <?[yes, no] <?[yes, no]
□
20.3.3. Выбор плана запроса с учетом возможностей источника данных
Получив запрос, медиатор средствами оптимизатора, учитывающего возможности
источников данных, определяет, какие запросы, обращенные к источникам, помогут
получить ответ на исходный запрос. Если вообразить, что эти запросы отосланы и ответы на
них приняты, медиатор, вероятно, получит набор связей "атрибут—значение" для
большего количества атрибутов, и наличие этих связей сделает возможным отправку
источникам дополнительных запросов. Процесс повторяется до того момента, когда окажется, что
1) множество сгенерированных запросов, обращенных к источникам,
достаточно для разрешения всех условий, заданных в исходном запросе, и поэтому
ответ на него может быть получен (такой план запроса называют
выполнимым —feasible),
либо
2) дополнительные запросы к источникам сконструировать нельзя, а ответ на
исходный запрос все еще не получен (медиатор демонстрирует свою
несостоятельность, трактуя запрос как невыполнимый).
1020
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Что именно гарантируют последовательности кодов,
описывающие источник данных
Было бы замечательно, если бы источник, поддерживающий запросы, которые
отвечают определенной последовательности кодов, возвращал все требуемые
результаты. Источники, однако, обычно способны возвращать только некоторые
подмножества ожидаемых множеств данных. Так, например, в анналах Amazon.com
присутствуют сведения далеко не обо всех опубликованных книгах, а в базах
данных дилеров автомобильной компании в общем случае содержатся порции
информации о различных наборах автомобилей. Поэтому более правдоподобной
трактовкой последовательности кодов, описывающей источник данных, должна быть
такая: "Система даст ответ на запрос, представляемый последовательностью кодов,
и каждый ответ будет верным, но система не гарантирует возможности получения
исчерпывающего множества верных ответов".
Теперь рассмотрим, что произойдет в ситуации, когда несколько источников
предоставляют данные одного и того же отношения R. Вместо того, чтобы выбрать
единственный план выполнения запроса с участием Я, медиатор должен
предпочесть по одному плану, предусматривающему обращение к каждому источнику,
содержащему R. Если последовательности кодов с описанием R для этих источников
различны, планы также, вообще говоря, окажутся разными. Более того, если
некоторые отношения, упомянутые в запросе, присутствуют в нескольких источниках,
с увеличением количества таких отношений число различных планов будет
возрастать по экспоненциальному закону.
Простейшим образцом запроса, для обработки которого медиатор вынужден
прибегнуть к рассмотренной выше стратегии, является операция соединения Оош) отношений,
каждое из которых, описанное посредством определенных последовательностей кодов,
наличествует в одном или нескольких источниках данных. В подобном случае подход к
решению проблемы состоит в попытке получения кортежей для каждого операнда
соединения путем обеспечения количества связей "атрибут—значение", достаточного для того,
чтобы некоторый источник позволил обратиться к нему с запросом на передачу
содержимого этого операнда-отношения. Проиллюстрируем сказанное на коротком примере.
Пример 20.11. Обратимся к схемам отношений дилера 2 автомобильной компании
(см. пример 20.4 на с. 1009),
Autos(serial, model, color)
Options(serial, option)
но предположим, что отношения Autos и Options относятся к двум различным
источникам.152 Пусть единственной последовательностью кодов для Autos является ubf,
а отношение Options снабжено двумя последовательностями, Ъи и wc[autoTrans,cdPlayer],
представляющими два допустимых класса запросов, которые разрешено адресовать
этому источнику.
Рассмотрим запрос "найти серийные номера и цвета моделей Gobi, обладающих
проигрывателем компакт-дисков". Ниже перечислены три плана запроса, которые
медиатор обязан принять к сведению.
1. Задать в качестве значения атрибута model строку 'Gobi ', обратиться с
запросом к Autos и найти серийные номера и цвета всех автомобилей модели
"Gobi". Затем, пользуясь последовательностью кодов Ьи для Options, для каж-
152 Аналогичным образом мы могли бы допустить, что оболочка базы данных дилера 2
поддерживает механизм уровня медиатора, позволяющий оптимизировать запросы с учетом
возможностей источника данных.
20.3. МЕДИАТОРЫ И ОПТИМИЗАЦИЯ С УЧЕТОМ ВОЗМОЖНОСТЕЙ...
1021
дого полученного серийного номера найти множество вариантов модели и
отфильтровать его по критерию наличия проигрывателя компакт-дисков.
2. Выбрать опцию cdPlayer и обратиться к Options с запросом в формате
wc[autoTrans,cdPlayer], чтобы найти множество серийных номеров всех
автомобилей, оснащенных проигрывателем компакт-дисков. Затем адресовать
отношению Autos тот же запрос, что и в п. 1, для получения серийных номеров и
цветов автомобилей модели "Gobi" и осуществить пересечение (intersection) двух
множеств серийных номеров.
3. Запросить options, как в п. 2, чтобы выявить серийные номера всех автомобилей
с проигрывателем компакт-дисков, а затем использовать эти номера в запросе
к Autos и проверить, какие из найденных автомобилей относятся к модели "Gobi".
Любой из двух планов, указанных в пп. 1, 2, вполне приемлем. Третий план,
однако, невыполним, поскольку запрос к Autos не отвечает единственной известной
последовательности кодов и bf. □
20.3.4. Дополнительная оптимизация планов с учетом их стоимости
Выявлением планов на основе возможностей источников данных функции
оптимизатора запросов, действующего в составе медиатора, на исчерпываются. Обнаружив
множество выполнимых планов, оптимизатор обязан осуществить выбор одного из
них. Для получения осмысленной стоимостной оценки каждого плана запроса
медиатор должен быть в значительной мере осведомлен о стоимости операций,
составляющих план. Поскольку источники обычно никак не связаны с медиатором, обретение
достоверных сведений затруднено. Например, для обработки запросов, направленных
источнику в периоды снижения нагрузки, может потребоваться меньшее время, но
когда именно возникают такие периоды? Медиатору придется затратить немало
усилий даже для решения существенно более простой задачи, связанной с получением
статистики, касающейся времени отклика источника.
В примере 20.11 медиатор мог бы просто подсчитывать количество необходимых
запросов к источникам. При реализации плана 2 требуется направить к источникам
всего два запроса, но выполнение плана 1 сопряжено с отсылкой одного запроса
к Autos и п запросов к Options, если в Autos будут найдены п кортежей с
информацией об автомобилях модели "Gobi". Поэтому, как кажется, план 2 должен обладать
меньшей стоимостью. С другой стороны, если запросы к Options, по одному на
каждый серийный номер, удастся объединить в рамках единого запроса, план 1 вполне
способен стать более предпочтительным.
20.3.5. Упражнения к разделу 20.3
Упражнение 20.3.1. Допустим, что каждое из отношений
Computers(number, proc, speed, memory, hd)
Monitors(number, screen, maxResX, maxResY)
из упражнения 20.1.1 на с. 1010 является самостоятельным источником
информации. Используя систему классификации возможностей источников данных,
предложенную в разделе 20.3.2 на с. 1019, сконструируйте одну или несколько
последовательностей кодов для описания следующих особенностей источников.
* а) К отношению computers разрешено обращаться с запросами, в которых
заданы тип процессора (ргос) (значение из множества {"P-IV", "G4", "Athlon"}),
(произвольная) величина быстродействия (speed) процессора и
(необязательно) объем оперативной памяти (memory).
1022
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
b) Сведения о компьютерах (Computers) можно получить, если задать
произвольные значения емкости диска (hd) и/или объема оперативной памяти (memory).
c) Для получения данных о мониторах (Monitors) необходимо задать либо
номер (number), либо значение размера экрана (screen), либо величины
максимального разрешения экрана в обоих измерениях (maxResX и maxResY).
d) Допускаются запросы к отношению Monitors, в которых указано одно из
следующих значений размера экрана (screen), выраженных в дюймах: 15, 17, 19
или 21. Возвращаются компоненты всех атрибутов, за исключением screen.
! е) Разрешено адресовать отношение Computers, задавая значения любой пары
атрибутов из множества {proc, speed, memory, hd}.
Упражнение 20.3.2. Рассмотрим те же источники данных, что и в упражнении
20.3.1, но предположим, что компоненты атрибутов number обоих отношений
содержат номера укомплектованных систем (компьютер плюс монитор). Допустим
также, что возможности доступа к отношению Computers регламентируются
последовательностями кодов buuuu, ubbff и uuubb, а запросы к отношению
Monitors должны удовлетворять последовательностям bfff и ubbb. Приведите
примеры выполнимых планов обработки следующих запросов (исключая любые
планы, которые очевидно более дороги в сравнении с альтернативными).
* а) Найти системы, оснащенные оперативной памятью объемом (memory)
128 Мбайт, диском емкостью (hd) 80 Гбайт и 19-дюймовым (screen)
монитором.
Ь) Найти системы с процессором (proc) Pentium-FV, обладающим
быстродействием (speed) 2000 МГц, и 21-дюймовым (screen) монитором,
поддерживающим максимальное разрешение в 1600 пикселей по горизонтали
(maxResX) и 1200 пикселей по вертикали (maxResY).
! с) Найти системы, включающие процессор (proc) G4 с быстродействием
(speed) 750 МГц, оперативную память объемом (memory) 256 Мбайт, диск
емкостью (hd) 40 Гбайт и 17-дюймовый (screen) монитор.
20.4. Оперативная аналитическая обработка данных
Пришел черед обратиться к одному важному классу приложений систем
интеграции информации (в частности, хранилищ данных). Компании и организации
переносят в хранилища данных крупные порции информации и пользуются услугами
аналитиков, которые, обращаясь к хранилищу с запросами, выявляют важные
характеристики объекта анализа и прогнозируют тенденции их изменения. Подобная
деятельность, обозначаемая общим термином О LAP (от on-line analytic processing —
"оперативная аналитическая обработка данных"), основана на применении весьма
сложных запросов с использованием нескольких или многих агрегирующих функций.
Такие приложения часто называют запросами OLAP (OLAP queries), или запросами
поддержки принятия решений (decision-support queries). Некоторые примеры представлены
в разделе 20.4.1; наиболее типичный образец подобного запроса предполагает поиск
информации о продуктах (товарах) с возрастающим или убывающим уровнем продаж.
Выполнение запросов поддержки принятия решений обычно сопряжено с
обработкой весьма обширных порций данных, даже если итоговое отношение оказывается
небольшим. Обычные операции с базами данных, такие как перевод денежных сумм
со счета на счет в банке или бронирование авиабилета, напротив, затрагивают только
весьма малые фрагменты данных; такие категории функций обозначают
аббревиатурой OLTP (от on-line transaction processing — "оперативная обработка транзакций").
20.4. ОПЕРАТИВНАЯ АНАЛИТИЧЕСКАЯ ОБРАБОТКА ДАННЫХ
1023
Хранилища данных и запросы О LAP
Важность использования технологий хранилищ данных в приложениях О LAP
обусловлена несколькими причинами. Прежде всего, хранилище данных является
необходимым средством организации и централизации корпоративной информации
с целью поддержки запросов OLAP (исходные данные нередко распределены по
многим гетерогенным источникам). Но чаще еще более значимым оказывается тот
факт, что запросы OLAP, весьма сложные по природе и затрагивающие крупные
массивы данных, требуют чрезмерно больших временных затрат на выполнение
в среде традиционной системы обработки транзакций. Поэтому такие процессы
принято относить к категории "длинных" транзакций (в том смысле, о котором мы
говорили в разделе 19.7 на с. 993).
Длинные транзакции, "блокирующие" базу данных на длительное время,
существенно снижают вероятность успешного выполнения ординарных операций OLTP
(например, в период подсчета средних значений уровней продаж, осуществляемого
средствами запроса OLAP, окажется практически невозможным параллельное
сохранение данных о текущих операциях). Одно из наиболее практичных решений
состоит в копировании первичной информации в хранилище данных и
выполнении запросов OLAP исключительно в среде хранилища, а запросов и операций
модификации, попадающих в категорию OLTP, — в системах, обслуживающих
источники данных. Обычной практикой является обновление содержимого
хранилища данных ночью — на следующий день аналитики получают возможность
пользоваться наиболее "свежей" статической копией первичной информации.
Таким образом, данные в хранилище "устаревают", как правило, не более чем на 24
часа, но степень их актуальности в контексте большинства приложений поддержки
принятия решений остается вполне приемлемой.
Одним из недавних достижений являются новые технологии обработки запросов,
демонстрирующие особую эффективность при оптимизации запросов OLAP. Более того,
широкое распространение получают специальные разновидности СУБД, отвечающие
особой природе определенных классов приложений OLAP. Подобные технологии все
чаще реализуются в составе коммерческих реляционных систем баз данных (за
подробностями о соответствующих архитектурных решениях обращайтесь к разделу 20.5 на с. 1031).
20.4.1. Приложения OLAP
Характерным примером приложений OLAP являются запросы к хранилищу данных
со сведениями о продажах товаров. Крупные торговые компании, владеющие
обширными сетями магазинов, аккумулируют терабайты информации, представляющей
каждый факт продажи того или иного товара в каждом из магазинов сети. Грамотное
использование результатов запросов, агрегирующих данные по группам и выявляющих
самые значимые группы, способно значительно облегчить анализ текущей хозяйственной
деятельности компании и прогнозирование будущих тенденций развития ее бизнеса.
Пример 20.12. Предположим, что компания Aardvark Automobile Co. задалась целью
сконструировать хранилище данных, чтобы иметь возможность анализировать уровни
продаж производимых ею автомобилей. Упрощенная схема хранилища может быть такой:
Sales(serialNo, date, dealer, price)
Autos(serialNo, model, color)
Dealers(name, city, state, phone)
Разберем типичный запрос поддержки принятия решений, предполагающий
считывание данных о продажах, осуществленных с 1 апреля 2002 года, и анализ тенденций
изменения средней цены (price) на автомобиль в зависимости от того, в каком штате
(state) работает дилер. Текст запроса приведен на рис. 20.11.
1024
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
SELECT state, AVG(price)
FROM Sales, Dealers
WHERE Sales.dealer = Dealers.name AND
date >= '2002-01-04'
GROUP BY state;
Рис. 20.11. Анализ средних значений цен на автомобили по штатам
Обратите внимание на то, что запрос, показанный на рис. 20.11, затрагивает
большую часть содержимого базы данных, поскольку принимает во внимание вес
недавние факты продажи, группируя их по штатам, в которых действуют дилеры компании.
Традиционные запросы OLTP вида "найти цену, по которой продавались автомобили
с серийным номером 123", напротив, обычно касаются только небольших групп или
отдельных кортежей отношений. □
В качестве другого примера рассмотрим задачу получения сведений о
кредитоспособности клиента, актуальную для компаний, эмитирующих кредитные карты.
Компания создает хранилище данных со сведениями о клиентах и их кредитной истории.
Запросы О LAP должны учитывать целый ряд факторов, таких как возраст клиента,
уровень его дохода, владение недвижимостью, место проживания и т.д., и оказывать
содействие в принятии решения о том, можно ли доверять клиенту в будущем. В
лечебных учреждениях нередко используются хранилища данных со сведениями о
пациентах, охватывающими диагнозы, результаты анализов, противопоказания,
информацию о назначении лекарственных средств и т.п.; все эти данные помогают снизить
риск развития заболевания и выбрать наилучшие варианты лечения.
Автомобили
20.4.2. Многомерная модель данных OLAP
В типичном приложении OLAP используется некоторое "основное" отношение
(или иная структура данных), которое принято называть таблицей фактических
значений (fact table). Таблица фактических значений представляет базовые события или
объекты (скажем, описания продаж, как в примере
20.12). Зачастую полезно воспринимать кортежи
таблицы так, будто они размещены в многомерном
пространстве, или "кубе". На рис. 20.12 изображены элементы
трехмерных данных, представляемые точками внутри
куба; измерения куба названы нами как "автомобили",
"дилеры" и "время" и соответствуют изучаемой в этой
главе информационной модели автомобильной
компании. Каждую точку в данном случае следует
воспринимать как факт продажи одного автомобиля, а измерения
куба соответствуют параметрам продажи.
На пространства данных, подобные показанному на
рис. 20.12, мы будем ссылаться неформально как на
кубы данных (data cubes), хотя, строго говоря, их
следовало бы называть кубами исходных данных (raw-data
cube), чтобы отличить от более сложных "подлинных"
кубов данных, о которых рассказывается в разделе 20.5 на с. 1031. Последние мы
будем обозначать термином формальные кубы данных, если того требует контекст.
Формальный куб данных отличается от куба исходных данных в следующих аспектах:
1) наряду с отправными данными он содержит информацию, агрегированную
по всем подмножествам измерений;
2) точки в формальном кубе могут представлять собой агрегированные
варианты точек куба исходных данных; так, например, размерность "автомобили"
1
Дилеры
о
<*/
о
° о
о J
оо
о
о
о
у/О О
/о
о
о
О s'
Время —*►
Рис. 20.12. Пример организации
данных в виде многомерного
пространства
20.4. ОПЕРАТИВНАЯ АНАЛИТИЧЕСКАЯ ОБРАБОТКА ДАННЫХ
1025
куба исходных данных, определяющая сведения о продаже каждого
отдельного автомобиля, может быть сведена к размерности "модели", и тогда
точки в таком формальном кубе будут изображать элементы информации об
общих параметрах продаж определенной модели, осуществленных каждым
из дилеров в тот или иной день.
Различия между кубами исходных данных и формальными кубами данных находят
выражение в наличии двух до некоторой степени противоположных направлений
развития специализированных систем, которые поддерживают модель "кубовидных"
данных, используемых в приложениях OLAP.
1. ROLAP (от relational on-line analytic processing— "оперативная аналитическая
обработка реляционных данных"). В этом случае данные могут храниться в отношениях
специальной структуры, называемой схемой "звезды" (star schema) (подробнее —
в разделе 20.4.3). Одно из отношений играет роль таблицы фактических значений,
содержащей исходные неагрегированные данные, и соответствует тому, что мы
называем кубом исходных данных. Другие отношения предоставляют
информацию о значениях по каждому измерению. Особенности структуры нередко
учитываются в языке запросов и других компонентах конкретной системы.
2. МО LAP, или MD-OLAP (от multidimensional on-line analytic processing —
"оперативная аналитическая обработка многомерных данных"). Для хранения
информации, включающей в том числе и результаты агрегирования,
применяется специализированная структура формального куба данных. В системе могут
быть реализованы особые нереляционные операторы, обеспечивающие
эффективную поддержку запросов OLAP.
20.4.3. Схема "звезды"
Схема "звезды " (star schema) охватывает таблицу фактических значений, которая
связана с несколькими отношениями, называемыми размерностными таблицами (dimension
tables). Таблица фактических значений размещается в "центре" звезды, а на концах
"лучей" находятся размерностные таблицы. Таблица фактических значений обычно
содержит несколько атрибутов, представляющих размерности (dimensions), и один или
больше зависимых (dependent) атрибутов, определяющих свойства точки (факта, события,
кортежа) в целом. В примере с информацией о продажах функции размерностей могут
выполнять сведения о дате продажи, наименовании магазина, типе товара, способе
платежа (наличными деньгами или по кредитной карте) и т.д., а в качестве зависимых уместно
трактовать, скажем, атрибуты цены товара, его дополнительных характеристик и т.п.
Пример 20.13. Отношение
Sales(serialNo, date, dealer, price)
из примера 20.12 на с. 1024 по своему существу является таблицей фактических
значений со следующими размерностями:
1) serialNo — координата в пространстве допустимых серийных номеров
автомобилей;
2) date — значение даты продажи;
3) dealer — имя одного из существующих дилеров компании.
Единственным зависимым атрибутом в данном случае является price ("цена"),
который в типичных запросах OLAP, вероятно, будет использоваться в качестве
агрегируемого. Однако могут иметь очевидный смысл и такие запросы, в которых вместо
суммирования или агрегирования цен предполагается вычисление количеств продаж: "Найти
общее количество продаж, осуществленных каждым из дилеров в мае 2002 года". □
1026
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Таблицу фактических значений дополняют размерностиые таблицы (dimension tables),
содержащие описания значений по каждому измерению. Обычно каждый атрибут-
размерность таблицы фактических значений является, как показано на рис. 20.13, внешним
ключом (foreign key), ссылающимся на соответствующее значение первичного ключа (primary
key) определенной размерностной таблицы. Атрибуты размерностных таблиц в свою
очередь описывают возможные способы группирования, пригодные и уместные для
использования в предложениях group by SQL-запросов. Поясним сказанное на примере.
Размерностная
таблица
Размерностная
таблица
Размерностная
таблица
Размерностная
таблица
Рис. 20.13. Атрибуты-размерности таблицы
фактических значений ссылаются на
первичные ключи размерностных таблиц
Пример 20.14. Обратимся к данным примера 20.12 на с. 1024. Очевидно, что отношения
Autos(serialNo, model, color)
Dealers(name, city, state, phone)
играют роль размерностных таблиц. Атрибут serialNo таблицы фактических значений
Sales(serialNo, date, dealer, price)
служит внешним ключом, указывающим на атрибут serialNo размерностной таблицы
Autos.153 Атрибуты Autos.model и Autos.color представляют свойства конкретного
автомобиля. (Отношение Autos могло бы содержать и другие атрибуты — скажем, тот же
признак наличия автоматической трансмиссии.) Если осуществить соединение (join)
таблицы фактических значений Sales с размерностной таблицей Autos, это позволит
использовать атрибуты model и color в различных любопытных вариантах группирования:
например, интерес могут представлять статистика продаж автомобилей в зависимости от
их цвета или данные о продажах моделей "Gobi" "в разрезе" месяцев года и дилеров.
Атрибут dealer отношения Sales является внешним ключом, ссылающимся на
первичный ключ размерностной таблицы Dealers. Соединение Sales с Dealers даст
дополнительные возможности группирования данных о продажах (по штатам или
городам, в которых работают дилеры).
Закономерно спросить, а где же размерностная таблица, представляющая фактор
времени, с которым следовало бы связать атрибут date таблицы фактических
значений Sales? Так как время относится к категории самодостаточных физических явле-
В данном случае serialNo является также первичным ключом отношения Sales, но это
простое совпадение — требование о том, чтобы некоторый атрибут таблицы фактических
значений одновременно выполнял функции первичного ключа и внешнего ключа, ссылающегося на
какую-либо размерностную таблицу, не выдвигается.
20.4. ОПЕРАТИВНАЯ АНАЛИТИЧЕСКАЯ ОБРАБОТКА ДАННЫХ
1027
ний, сохранять сведения о его свойствах в базе данных нецелесообразно — запросы
вида "в каком году было 5 июля 2000 года" смысла не имеют. Однако поскольку
в аналитических запросах часто задаются различные временнб/е интервалы (дни,
недели, месяцы, кварталы и годы), наличие в базе данных некоего представления фактора
времени — как если бы оно было оформлено в виде размерностной таблицы
Days(day, week, month, year)
все же вполне оправданно. Типичный кортеж подобного "отношения",
определяющий данные о 5 июля 2000 года, можно описать следующим образом:
(5, 27, 7, 2000)
Речь идет о 5-м дне 7-го месяца 2000 года; этот день попадает в 27-ю полную неделю
2000 года. Информация до некоторой степени избыточна, поскольку номер недели
можно вычислить на основании трех остальных значений. Однако недели не вполне
четко разделены по месяцам, так что группировку данных по месяцам нельзя
получить на основании группировки по неделям и наоборот. Поэтому имеет смысл "хранить"
в такой "размерностной таблице" как номера недель, так и номера месяцев. □
20.4.4. Рассечение и расслоение куба исходных данных
Точки в кубе исходных данных можно воспринимать так, словно они
распределены по подмножествам координат каждого измерения с учетом определенного шага
разбиения. В измерении "время" куба данных, представляющего информационную
модель автомобильной компании, например, можно группировать данные (посредством
предложения group by в SQL-запросе) по дням, неделям, месяцам, кварталам или
годам (либо, разумеется, не группировать вовсе). Измерение "автомобили" допускает
возможность группирования по моделям, цветам либо моделям и цветам одновременно,
а измерение "дилеры" — по именам дилеров, городам и штатам.
При выборе некоторого способа разбиения множеств координат куб, как показано на
рис. 20.14, подвергается рассечению (dicing). Результатом оказывается набор мелких
"кубов", представляющих группы точек, характеристики которых агрегируются в соответствии
с условиями предложения group by SQL-запроса. Определяя предложение where,
пользователь имеет возможность сосредоточить внимание на определенных подмножествах
координат по одному или нескольким измерениям, т.е. осуществить расслоение (slicing) куба.
Пример 20.15. На рис. 20.15 показан результат расслоения куба с данными об
автомобилях по координате "время" с одновременным рассечением по двум другим
координатам — "автомобили" и "дилеры". Даты делятся на четыре группы (возможно, по
годам, на протяжении которых данные аккумулировались в хранилище). Затемненный
"слой" отвечает определенному году, указанному в предложении where запроса.
Автомобили
Автомобили
Дилеры
Время —+~
Рис. 20.14. Рассечение куба
данных посредством группирования
координат каждого измерения
t
Дилеры
/1
А
/
А
Л
гГ
Р^
Л, А,'
Л > /1
г
А
А
/\
Л
У\
И
Y
JZ
Время
Рис. 20.15. Выбор "слоя" в
"рассеченном " кубе
1028
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Множество значений координаты "автомобили" расчленено (посредством
предложения group by) на три подмножества (скажем, в зависимости от типа кузова —
"седан", "пикап" и "кабриолет"), а значения координаты "дилеры" — на два
(соответствующие, например, группам дилеров, работающих в восточной и западной
частях страны). В результате обработки запроса должно быть возвращено отношение,
содержащее, возможно, величины общих уровней продаж для шести категорий
"автомобили—дилеры" и заданного значения года. □
Формат запроса с "расслоением и рассечением " данных (slicing-and-dicing query)
можно описать следующим образом:
SELECT [выбрать] группирующие атрибуты и итоги агрегирования
FROM [из] таблицы фактических значений в соединении (join)
с одной или несколькими размерностными таблицами
WHERE [при условии, что] определенные атрибуты равны
заданным константам
GROUP BY [группировать по] группирующим атрибутам;
Пример 20.16. Продолжим рассмотрение информационной модели автомобильной
компании и допустим существование размерностной таблицы Days (мы говорили
о ней в примере 20.14 на с. 1027). Если предположить, что модель "Gobi" пользуется
недостаточно большим спросом, уместно попытаться выяснить, какие цветовые
оттенки не находят одобрения у покупателей. Подобный запрос предусматривает
обращение только к размерностной таблице Autos и средствами SQL может быть описан так:
SELECT color, SUM(price)
FROM Sales NATURAL JOIN Autos
WHERE model = 'Gobi'
GROUP BY color;
Запрос подразумевает рассечение пространства данных по атрибуту color и
расслоение по атрибуту model (точнее, по единственному значению model — 'Gobi ').
Предположим, что цель не достигнута — анализ результатов выполнения запроса
показал, что уровни продаж моделей "Gobi" различных цветов примерно одинаковы.
Поскольку рассечение по координате "время" не производилось, мы могли видеть только суммы
продаж без учета временного фактора. Может быть, уровни продаж моделей тех или иных
цветов снизились только в последнее время? Удовлетворить любопытство поможет
исправленная версия запроса с дополнительным группирующим атрибутом month:
SELECT color, month, SUM(price)
FROM (Sales NATURAL JOIN Autos) JOIN Days ON date = day
WHERE model = 'Gobi*
GROUP BY color, month;
(Следует напомнить, что отношение Days не является хранимой таблицей, хотя его
можно трактовать именно так:
Days(day, week, month, year)
Способность к использованию подобных "гипотетических" отношений — один из
аспектов, в которых системы, адаптированные к потребностям OLAP, могут отличаться
от традиционных СУБД.)
Не исключено, что в последний период стали плохо продаваться, скажем, модели
"Gobi" красного (red) цвета. В этом случае уместно поинтересоваться, характерна ли
эта проблема для всех дилеров или только для некоторых из них. Теперь
целесообразно сосредоточить внимание на "слое", соответствующем красным "Gobi", и добавить
"сечения" по размерности "дилеры":
SELECT dealer, month, SUM(price)
FROM (Sales NATURAL JOIN Autos) JOIN Days ON date = day
WHERE model = 'Gobi' AND color = 'red'
GROUP BY dealer, month;
20.4. ОПЕРАТИВНАЯ АНАЛИТИЧЕСКАЯ ОБРАБОТКА ДАННЫХ
1029
"Уточнение" и "огрубление" запросов
Пример 20.16 на с. 1029 содержит характерные образцы двух общих стратегий
применения последовательности запросов с "расслоением и рассечением" куба данных.
1. "Уточнение" (drill-down) — процесс более тщательного разбиения множеств
координат и/или выделения отдельных значений в каких-либо измерениях
(иллюстрацией могут служить все шаги, за исключением последнего,
предпринятые нами в примере 20.16).
2. "Огрубление" (roll-up) — распределение данных по более широким интервалам
изменения значений атрибутов (на последнем шаге в примере 20.16 в качестве
группирующего мы выбрали атрибут "год" вместо "месяц", чтобы исключить
фактор случайности и повысить уровень репрезентативности выборки).
Допустим, что помесячные уровни продаж моделей "Gobi" красного цвета настолько
малы, что отследить какие-либо тенденции не представляется возможным. Значит,
допущена ошибка: лучше осуществить группирование и агрегирование по годам,
причем обратить внимание на два последних года (например, 2001 и 2002).
Окончательная версия запроса приведена на рис. 20.16.
SELECT dealer, year, SUM(price)
FROM (Sales NATURAL JOIN Autos) JOIN Days ON date = day
WHERE model = 'Gobi* AND color = 'red* AND
(year = 2001 OR year = 2002)
GROUP BY dealer, year;
Рис. 20.16. Заключительный вариант запроса с "расслоением и
рассечением " данных об автомобилях "Gobi" красного цвета
20.4.5. Упражнения к разделу 20.4
* Упражнение 20.4.1. Предположим, что виртуальный компьютерный магазин
нуждается в сохранении информации о заказах. Клиенту, оформляющему заказ на
персональный компьютер, предоставляется возможность выбора любого из ряда
процессоров, требуемого объема оперативной памяти, нужной модели диска
и какого-либо привода CD или DVD. Таблицу фактических значений в такой
ситуации уместно представить так:
Orders(cust, date, proc, memory, hd, rd, quant, price)
Атрибут cust следует воспринимать как идентификатор клиента, служащий
внешним ключом, указывающим на размерностную таблицу со сведениями
о клиентах. Назначение атрибутов ргос ("процессор"), hd ("диск") и rd
("привод CD/DVD") аналогично: конкретное значение атрибута hd, например,
указывает на кортеж в соответствующей размерностной таблице,
представляющей информацию о характеристиках дисковых устройств. Компонент атрибута
memory описывается целым числом, выражающим количество мегабайтов
оперативной памяти. Атрибут quant задает количество компьютеров указанного типа,
заказанных клиентом, a price — цену каждого компьютера.
a) Какие из атрибутов отношения Orders представляют размерности, а какие
являются зависимыми?
b) Для каждого из атрибутов-размерностей следует включить в структуру базы
данных соответствующую размерностную таблицу. Предложите подходящие
варианты всех подобных таблиц.
1030
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
! Упражнение 20.4.2. Предположим, что данные, рассмотренные в упражнении
20.4.1, используются для прогнозирования закономерностей спроса на
персональные компьютеры и корректировки политики компании в области закупки
комплектующих. Опишите серию "уточняющих" и "огрубляющих" запросов,
выявляющих тенденцию повышения спроса на приводы DVD.
20.5. Кубы данных
В этом разделе мы сосредоточим внимание на модели формального куба данных
(formal data cube) и специальных операциях над элементами информации, хранимыми
в виде подобной структуры. Напомним (см. раздел 20.4.2 на с. 1025), что формальный
куб данных (здесь для краткости чаще мы будем пользоваться термином куб данных)
наряду с исходной информацией содержит все возможные — предварительно и
систематическим образом вычисленные — агрегированные значения. Что приятно,
расходы, связанные с необходимостью хранения дополнительных данных, зачастую вполне
приемлемы, а если к тому же частота изменения содержимого хранилища низка,
затраты на пересчет агрегированных величин с целью обеспечения достаточного уровня
актуальности информации становятся минимальными.
Перед помещением информации в куб и дальнейшим "исчерпывающим"
агрегированием исходные данные (raw data) обычно подвергаются определенному
предварительному афегированию. Если обратиться к примеру базы данных автомобильной
компании, размерность серийных номеров в схеме "звезды" можно заменить
размерностью моделей. В этом случае каждая точка в кубе данных будет представлять
описания модели, дилера и даты продажи в совокупности с суммой продаж этой модели,
осуществленных конкретным дилером в продолжение определенного промежутка
времени. Мы намереваемся по-прежнему трактовать множество точек в (формальном)
кубе данных как определенного рода "таблицу фактических значений", хотя между
подобными таблицами, отвечающими формальному кубу, с одной стороны, и кубу
исходных данных, с другой, наблюдаются незначительные различия.
20.5.1. Оператор cube
Для заданной таблицы фактических значений F можно определить
расширенную таблицу CUBE(F), которая содержит по одному дополнительному значению,
обозначаемому как *, для каждого измерения. Значение * на интуитивном уровне
воспринимается как "любое" и представляет
агрегированную величину, соответствующую
рассматриваемому измерению. На рис. 20.17
показана диаграмма процесса пополнения
трехмерного куба "слоями", отвечающими значениям *
по каждому измерению. Участки со светлой
заливкой обозначают агрегированные значения
в каждом отдельном измерении, более темным
цветом отмечены области пересечения двух
"слоев", а самый темный фрагмент в углу куба
соответствует величинам, агрегированным
одновременно по всем трем измерениям. Если
количество значений по каждому измерению велико, Рис. 20.17. Оператор CUBE расши-
но не настолько, что большинство позиций то- ряет куб данных за счет добавле-
чек внутри куба оказываются "занятыми", до- ния "слоев", представляющих
добавление очередного "слоя" не намного увели- регированные значения для всех
сочетаний измерений
20.5. КУБЫ ДАННЫХ
1031
чит объем куба, т.е. количество кортежей в таблице фактических значений. В
таком случае объем данных структуры CUBE(F) //е будет чрезмерно превышать
размер таблицы F как таковой.
Кортеж таблицы CUBE(F), обладающий значением * в одном или нескольких
атрибутах-размерностях, для каждого зависимого атрибута содержит сумму (или
результат выполнения иной афегирующей функции) значений компонентов этого атрибута
во всех кортежах, которые можно получить, заменяя * реальными величинами. В
результате в куб заносятся итоги афегирования по любому множеству измерений.
Однако следует заметить, что оператор cube не предполагает возможности
афегирования на промежуточных уровнях разбиения множеств значений размерностных таблиц.
Например, можно либо оставить данные в состоянии, когда они распределены по
дням (т.е. с учетом самого точного уровня разбиения координаты времени), либо
агрегировать их по атрибуту времени в целом, но не по неделям, месяцам или годам.
Пример 20.17. Вновь обратимся к версии базы данных автомобильной компании Aard-
vark Automobile Co. из примера 20.12 на с. 1024 и обсудим возможные способы
применения оператора CUBE. Напомним, что функцию таблицы фактических значений
в данном случае выполняет отношение
Sales(serialNo, date, dealer, price)
Афибут serialNo, однако, не подходит на роль одного из измерений куба, поскольку
является первичным ключом отношения: суммирование стоимости автомобилей по
всем дилерам и/или датам с сохранением фиксированных значений серийных
номеров эффекта не возымеет — мы получим "суммы" для каждого отдельного
автомобиля, обладающего конкретным серийным номером. Уместно было бы заменить
серийный номер двумя афибутами — model и color, — с которыми кортеж Sales связан
посредством внешнего ключа, указывающего на размерностную таблицу Autos. Если
заменить serialNo на model и color, ни в одном измерении куба более не будет
ключевых значений, что даст возможность получать афегированные величины для
всех автомобилей определенных модели/цвета, проданных тем или иным дилером
в течение некоторого периода времени.
Говоря о реализации таблицы фактических значений Sales в виде куба данных,
можно предложить еще один полезный вариант усовершенствования сфуктуры.
Поскольку оператор CUBE обычно осуществляет суммирование значений зависимых
атрибутов, но нередко возникает и пофебность в вычислении средних величин,
целесообразно предусмофеть хранение как сумм стоимостей для каждой категории
автомобилей (представляемой возможным сочетанием значений афибутов model, color,
dealer и date), так и количеств продаж по категориям. Теперь схема отношения
Sales приобретет следующий вид:
Sales(model, color, date, dealer, val, cnt)
Атрибут val предназначен для хранения суммарных величин стоимости
автомобилей по категориям модели, цвета, дилера и/или даты продажи, a cnt — для
размещения информации о количестве автомобилей, относящихся к каждой категории.
Заметьте, что в такой версии куба данных сведения о конкретных автомобилях
идентифицировать нельзя — они "учтены" в "совокупных" величинах val и cnt,
отвечающих определенной категории.
Рассмофим отношение cube (Sales). Гипотетический кортеж, присутствующий
одновременно в Sales и CUBE (Sales), мог бы выглядеть так:
('Gobi', 'red', '2002-05-21', 'Вася Сидорчук', 45000, 2)
Данные свидетельствуют о том, что 21 мая 2002 года дилер Вася Сидорчук продал два
автомобиля модели "Gobi" красного цвета суммарной стоимостью $45000. Кортеж
('Gobi', *, '2002-05-21', 'Вася Сидорчук', 152000, 7)
1032
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
в свою очередь, гласит, что тот же Вася тогда же умудрился "сбагрить" целых семь
автомобилей "Gobi" разных цветов на общую сумму в $152000. Подобный кортеж мог
бы присутствовать в CUBE (Sales), но не в Sales.
Отношение CUBE (Sales) содержит также такие кортежи, которые представляют
результаты агрегирования более чем по одному атрибуту. Кортеж
('Gobi', *, '2002-05-21', *, 2348000, 100)
например, указывает, что 21 мая 2002 года всеми дилерами было продано 100
автомобилей "Gobi", и общая сумма сделок составила $2348000, а кортеж
('Gobi', *, *, *, 1339800000, 58000)
удостоверяет тот факт, что с момента появления модели "Gobi" на рынке всеми
дилерами было продано 58000 таких машин на общую сумму $1339800000. Наконец, кортеж
(*, *, *, *, 3521727000, 198000)
подтверждает, что владельцами автомобилей компании Aardvark Automobile Co.,
проданных повсеместно за все время ее существования, стали 198000 счастливчиков; всем
им в совокупности, правда, пришлось выложить кругленькую сумму — $3521727000. □
Теперь обсудим, каким образом может быть получен ответ на запрос, в котором
определенные атрибуты отношения Sales связаны некоторыми условиями и
предусмотрено группирование по каким-либо атрибутам с вычислением суммарных/средних
значений стоимости и/или количеств продаж. При обработке подобного запроса необходимо
найти в cube (Sales) такие кортежи t, которые обладают следующими свойствами:
1) если в предложении where запроса оговорено значение v атрибута я, кортеж
t обязан содержать v в компоненте а\
2) если запрос предполагает группирование (group by) по атрибуту я, в ком-
доненте а кортежа / должно быть любое значение, отличное от *;
3) если атрибут а не упоминается ни в where, ни в GROUP by, компонент а
кортежа t должен содержать значение *.
В каждом кортеже t присутствуют значения суммы стоимостей и количества продаж
для одной из категорий модели, цвета, дилера и/или даты продажи. Если требуется
получить среднюю величину стоимости, в каждом кортеже / достаточно поделить
содержимое компонента val на значение компонента cnt.
Пример 20.18. Для получения ответа на запрос
SELECT color, AVG(price)
FROM Sales
WHERE model = 'Gobi'
GROUP BY color;
достаточно отыскать в CUBE (Sales) все кортежи вида
('Gobi', с, *, *, v, n)
где с — наименование любого определенного цвета, v — суммарная стоимость
проданных автомобилей марки "Gobi" этого цвета, ал — количество таких автомобилей.
Значение средней стоимости не сохраняется в CUBE (Sales) — и тем более в Sales —
непосредственно, но его легко вычислить как v I п. Ответом на запрос окажется
множество пар вида (с, v/и), полученных из всех кортежей ( 'Gobi ', с, *, *, v, л). □
20.5.2. Реализация куба на основе материализованных представлений
Обсуждая диаграмму на рис. 20.17 (см. с. 1031), мы говорили о том, что
пополнение куба агрегированной информацией не приводит к существенному увеличению
объема данных, но позволяет сэкономить время обработки типичных запросов под-
20.5. КУБЫ ДАННЫХ
1033
держки принятия решений. Наши выводы, однако, основаны на предположении о
том, что в запросах можно либо агрегировать все значения атрибута, либо не
включать атрибут в число агрегируемых вовсе. Некоторые размерности куба, вероятно,
позволяют осуществлять агрегирование на промежуточных уровнях разбиения множеств
значений размерностных таблиц. Мы уже рассматривали подобный случай — атрибут
времени допускает естественную возможность агрегирования по неделям, месяцам,
кварталам и годам, а не только по дням. Еще один пример: агрегирование по атрибуту
"дилер", разумеется, можно выполнять с учетом всего диапазона значений либо не
выполнять вообще. Помимо того, в некоторых ситуациях удобнее группировать дилеров
по городам или штатам, в которых они работают. Таким образом, в нашем
распоряжении имеются по меньшей мере шесть вариантов группирования "автомобильных"
данных по атрибуту времени продаж и четыре — по атрибуту "дилер".
С ростом количества способов группирования по каждому измерению стоимость
хранения результатов агрегирования для всех возможных сочетаний групп становится
непомерно высокой. Информации оказывается не просто слишком много — ее уже не
удается структурировать так внятно, как это можно сделать в случае (см. рис. 20.17 на
с. 1031), когда в агрегировании участвуют либо все значения, либо не участвует ни
одно из них. Поэтому многие коммерческие системы, реализующие модель кубов
данных, помогают выбрать и поддерживать те или иные материализованные
представления (materialized views) содержимого куба. Материализованное представление — это
результат выполнения некоторого запроса, который сохраняется в базе данных, а не
вычисляется заново в ответ на те или иные запросы пользователя. Представлениями,
которые целесообразно материализовать в контексте куба данных, обычно являются
результаты агрегирования.
Чем крупнее шаг разбиения множества значений атрибута, применяемый в ходе
группирования, тем меньшее пространство потребуется для размещения
материализованного представления. Если представление предназначено для реализации запросов
определенной разновидности, тогда величина шага разбиения множеств значений по
каждому измерению, "заложенная" в представлении, не должна превосходить ту,
которая предусматривается в запросах. Поэтому для повышения степени практической
пригодности материализованных представлений обычно требуется выбрать
компромиссную величину шага разбиения — не слишком малую (в противном случае
стоимость хранения данных возрастет), но и не чересчур большую (следует учитывать
особенности конкретных категорий запросов, которые могут использоваться в будущем).
Проиллюстрируем это положение на примере.
Пример 20.19. Вернемся к схеме
Sales(model, color, date, dealer, val, cnt)
куба данных, разработанной нами в примере 20.17 на с. 1032. Допустим, что в одном
из материализованных представлений уместно осуществить группирование дат по
месяцам и распределить дилеров по городам. Подобное представление (назовем его
SalesVl) создается при выполнении запроса, приведенного на рис. 20.18. Запрос нельзя
отнести к ведению SQL в строгом смысле слова, поскольку, как мы полагаем, отдельные
даты и единицы их разбиения и группирования (скажем, месяцы) интерпретируются
системой управления кубом данных непосредственно, без необходимости соединения
таблицы Sales с воображаемым отношением Days (см. пример 20.14 на с. 1027).
INSERT INTO SalesVl
SELECT model, color, month, city,
SUM(val) AS val, SUM(cnt) AS cnt
FROM Sales JOIN Dealers ON dealer = name
GROUP BY model, color, month, city;
Рис. 20.18. Материализованное представление SalesVl
1034
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
INSERT INTO SalesV2
SELECT model, week, state,
SUM(val) AS val, SUM(cnt) AS cnt
FROM Sales JOIN Dealers ON dealer = name
GROUP BY model, week, state;
Рис. 20.19. Материализованное представление SalesV2
В другом материализованном представлении, возможно, целесообразно обеспечить
группирование дат по неделям и информации о дилерах — по штатам. Такое
представление, Salesv2, определяется посредством запроса на рис. 20.19. И Salesvl,
и SalesV2 можно использовать для реализации запросов, в которых шаг разбиения
множеств значений по любому измерению не является более мелким, нежели
зафиксированный в представлении. Поэтому для получения ответа на запрос
Q{: SELECT model, SUM (val)
FROM Sales
GROUP BY model;
можно применять как вариант
SELECT model, SUM(val)
FROM SalesVl
GROUP BY model;
так и вариант
SELECT model, SUM(val)
FROM SalesV2
GROUP BY model;
С другой стороны, при необходимости выполнения запроса
Q2: SELECT model, year, state, SUM (val)
FROM Sales JOIN Dealers ON dealer = name
GROUP BY model, year, state;
удастся воспользоваться только данными представления Salesvl:
SELECT model, year, state, SUM(val)
FROM SalesVl
GROUP BY model, year, state;
Целесообразно еще раз обратить внимание на то, что запрос, подобный приведенному
выше, не является конструкцией SQL в строгом смысле слова, поскольку state не
входит в число атрибутов Salesvl (таковым является, скажем, city). Мы полагаем,
что система управления кубом данных "осведомлена" о том, как осуществлять
агрегирование по штатам на основе результатов агрегирования по городам (возможно, с
использованием размерностной таблицы с информацией о дилерах).
Получить ответ на запрос Q2 с привлечением данных представления SalesV2,
однако, нельзя. Хотя мы вправе "огрубить" (см. врезку "Уточнение и огрубление
запросов" на с. 1030) интервал разбиения размерности "дилеры" до уровня штатов,
преобразовать итоги агрегирования данных по неделям в адекватные показатели,
сгруппированные по годам, не удастся — годовой интервал не делится на недельные нацело,
и данные, относящиеся к неделе, которая начинается, скажем, 31 декабря 2001 года,
учитываются в агрегированных значениях и 2001 года, и 2002 года.
Наконец, запрос, подобный такому, как
Q3: SELECT model, color, date, SUM(val)
FROM Sales
GROUP BY model, color, date;
20.5. КУБЫ ДАННЫХ
1035
нельзя реализовать ни на основе представления Salesvi, ни с использованием
информации SalesV2: шаг разбиения размерности времени, предусмотренный в Salesvi,
слишком "груб", чтобы ("помесячные") показатели удалось трансформировать
в "посуточные", а представление SalesV2 не предполагает группирования данных по
значениям атрибута color. Чтобы получить ответ на запрос Q3, придется обратиться
к содержимому куба данных (Sales) в целом. □
20.5.3. Сетки представлений
Чтобы формализовать выводы, к которым мы пришли, разбирая пример 20.19,
удобно воспринимать возможные варианты разбиения множеств значений
каждого измерения куба данных в виде сетки (lattice). Узлы сетки соответствуют
единицам деления измерения. Говорят, что единица деления Р{ не больше
единицы деления Р2 (Л < Р2), если и только если каждая группа значений, полученная
при использовании единицы Рь целиком принадлежит некоторой группе,
отвечающей единице Р2.
Пример 20.20. В качестве примера сетки разбиения интервалов времени можно
выбрать диаграмму, показанную на рис. 20.20. Наличие дуги, соединяющей некоторый
узел Р2 с узлом Рь расположенным "ниже", означает, что РХ<Р2. Узлы сетки и их
взаимосвязи представляют не только допустимые единицы деления как таковые, но
и формируют систему единиц, поддерживаемых конкретной СУБД. Заметим, что узел
"дни" расположен ниже узлов "недели" и "месяцы", но уровни "недель" и "месяцев"
не связаны — если некоторое подмножество событий имело место в определенный
день, оно определенно охватывается одной неделей и одним месяцем, но события,
которые произошли в течение какой-либо недели, вовсе не обязательно относятся к
одному месяцу. Аналогично, нельзя утверждать, что выбранная наудачу "недельная"
группа данных непременно содержится в группе, соответствующей отдельно взятому
кварталу или году. На верхнем уровне диаграммы расположен узел "все интервалы",
который означает, что все события попадают в единую группу.
Все интервалы
Все дилеры
Штаты
i
Города
i
Дилеры
Рис. 20.21. Сетка разбиения
множества дилеров
автомобильной компании
На рис. 20.21 изображена другая сетка, определяющая способы разбиения
множества дилеров автомобильной компании: результаты агрегирования данных о продажах
по отдельным дилерам более информативны, нежели итоги агрегирования по городам,
которые, в свою очередь, более "детальны" в сравнении с показателями уровня
штатов. Верхний уровень сетки, обозначенный как "все дилеры", отвечает объединению
всех дилеров компании в одну группу. □
Годы
Недели
Кварталы
Месяцы
Дни
Рис. 20.20. Сетка
интервалов времени
разбиения
1036
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Обладая сетками разбиения множеств значений по каждому измерению, можно
определить сетку, представляющую "взаимоотношения" всех возможных
материализованных представлений содержимого куба данных, который сформирован путем
группирования значений каждого измерения в соответствии с некоторым шагом
разбиения. Если V] и V2 — два представления, сформированные на основе определенного
разбиения (группирования) данных по каждому измерению, тогда выражение Vx < V2
означает, что в каждом измерении единица деления Ри выбранная в Vu не больше
единицы Ръ принятой в Уъ т.е. Рх < Р2.
Во многих случаях семейства запросов OLAP также могут быть описаны в виде
сетки представлений. Зачастую запросы О LAP принимают именно такую форму,
которую мы рассмотрели: в них определяются некоторые группы значений по каждой
размерности. В других случаях "рассеченный" куб подвергается дальнейшему
"расслоению" с целью выделения определенных подмножеств данных (см. рис. 20.15
на с. 1028). Общее правило таково:
• для реализации запроса Q можно использовать материализованное
представление V, если и только если V < Q.
'Л
Sales
Рис. 20.22. Сетка
представлений и запросов из примера 20.19
Пример 20.21. На рис. 20.22 изображена сетка,
иллюстрирующая "взаимоотношения" представлений и
запросов, рассмотренных в примере 20.19 на с. 1034.
Заметим, что куб данных Sales как таковой также уместно
трактовать как материализованное представление. Как
упоминалось в примере 20.19, запрос Qx допускает
обращение как к Salesvl, так и к SalesV2; разумеется,
данные можно получить и из "полного" куба Sales, но
такой вариант менее предпочтителен, коль скоро
существуют подходящие и не столь "объемные"
материализованные представления. Запрос Q2 удастся удовлетворить только на основании
данных SalesVI или Sales, а для успешного выполнения запроса Q3 надлежит
адресовать только Sales. □
Использование приемов конструирования сеток представлений помогает
проектировать "кубовидные" базы данных. В ряде недавно разработанных программных
инструментов описания структур кубов данных на начальной фазе процесса
предусматривается определение набора запросов, которые следует считать "типичными". Затем
множество представлений, подлежащих материализации, выбирается таким образом,
чтобы каждый из "стандартных" запросов располагался на более высоком уровне
сетки, нежели хотя бы одно из представлений, с максимально возможной степенью
"близости" критериев группирования в большинстве измерений.
20.5.4. Упражнения к разделу 20.5
Упражнение 20.5.1. Каково соотношение размеров структур данных cube(F) и F,
если таблица фактических значений F обладает следующими характеристиками:
* a) F имеет десять атрибутов-размерностей, каждый из которых содержит по
десять различных значений;
b) F имеет десять атрибутов-размерностей, каждый из которых содержит по два
различных значения.
Упражнение 20.5.2. Обратимся к кубу данных cube (Sales) из примера 20.17 на
с. 1032, построенному на основе отношения
Sales(model, color, date, dealer, val, cnt)
20.5. КУБЫ ДАННЫХ
1037
Поясните, данные каких кортежей куба пришлось бы использовать для получения
ответов на следующие запросы:
* а) найти суммарные стоимости автомобилей голубого цвета, проданных
каждым дилером;
b) найти общее количество зеленых "Gobi", проданных дилером по имени
Фимка Собак;
c) найти среднее количество автомобилей модели "Gobi", проданных в каждый
из дней марта 2002 года каждым дилером.
*! Упражнение 20.5.3. В упражнении 20.4.1 на с. 1030 мы рассматривали структуру куба
данных с информацией о заказах на персональные компьютеры. Если говорить о
вариантах применения оператора cube, может оказаться полезным распределить
данные некоторых измерений по нескольким измерениям: скажем, вместо единого
атрибута ргос ("процессор"), вероятно, целесообразно предусмотреть два,
представляющих соответственно тип процессора (например, AMD Duron или Intel Pentium-IV)
и уровень его быстродействия. Предложите усовершенствованный набор размерност-
ных и зависимых атрибутов, который обеспечил бы возможность реализации
разнообразных агрегирующих запросов. Какова, по вашему мнению, роль атрибута cust?
Упражнение 20.5.4. Данные каких кортежей куба из упражнения 20.5.3 придется
использовать для получения ответов на следующие запросы:
a) для каждого значения быстродействия процессора найти общее количество
компьютеров, заказанных в продолжение каждого месяца 2002 года;
b) для каждой пары значений типа диска (например, SCSI или IDE) и типа
процессора получить количество заказанных компьютеров;
c) найти среднюю цену компьютеров, оснащенных процессорами с
быстродействием 1500 МГц и проданных в течение каждого месяца, начиная
с января 2001 года.
! Упражнение 20.5.5. Компьютерные системы, сведения о которых содержатся в кубе
данных из упражнения 20.5.3, поставляются без мониторов. Какими измерениями
следовало бы пополнить куб, чтобы обеспечить представление информации о
мониторах? (Можно полагать, что цена монитора включена в цену системы.)
Упражнение 20.5.6. Предположим, что куб данных содержит 10 измерений и
множество значений каждого из них можно разбить на группы с учетом пяти уровней
"детализации", включая крайние, когда все значения попадают в одну группу либо
каждое значение образует отдельную группу. Какое количество вариантов одного
материализованного представления удастся сконструировать, выбирая различные
уровни разбиения по каждому измерению?
Упражнение 20.5.7. Покажите, каким образом можно включить в сетку разбиения
интервалов времени, изображенную на рис. 20.20 (см. с. 1036), следующие
единицы времени: часы, минуты, секунды, двухнедельные периоды, декады и столетия.
Упражнение 20.5.8. Как следовало бы изменить сетку разбиения множества
дилеров (см. рис. 20.21 на с. 1036), чтобы отобразить в ней понятие географического
"региона", отвечающее следующим альтернативным условиям:
а) регион представляет подмножество штатов;
* Ь) регионы не соразмерны подмножествам штатов, но каждый город относится
только к одному региону;
1038
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
c) каждый регион "содержится" в определенном штате, некоторые города
принадлежат двум и более регионам и отдельные регионы охватывают по
несколько городов.
! Упражнение 20.5.9. В упражнении 20.5.3 предлагалось спроектировать куб данных,
подходящий для применения оператора cube. Некоторые измерения все еще
допускают возможность дальнейшего "дробления". Так, например, информацию
о типе процессора можно было бы структурировать по производителям (скажем,
SUN, Intel, AMD либо Motorola), сериям (SUN UltraSparc, Intel Pentium или
Celeron, AMD Athlon либо Motorola G-series) и моделям (Pentium-IV либо G4).
d) Создайте сетку разбиения множеств данных о типах процессоров.
e) Определите представление, в котором процессоры группируются по сериям,
диски — по типам, приводы CD/DVD — по значениям скорости, а все
остальные данные агрегируются.
f) Определите представление, в котором процессоры группируются по
наименованиям производителей, диски — по значениям скорости, а все остальные
данные, кроме объемов оперативной памяти, агрегируются.
g) Приведите примеры запросов, которые можно удовлетворить: i) только с
использованием данных представления (b); ii) только с привлечением
содержимого представления (с); ш) на основе обоих представлений; iv) только за
счет данных куба в целом.
*!! Упражнение 20.5.10. Если таблица фактических значений F, к которой
применяется оператор cube, разреженна (т.е. количество кортежей в F намного меньше
произведения количеств различных значений по каждому измерению), тогда
отношение размеров структур CUBE (F) и F может быть очень большим. Насколько?
20.6. Разработка данных
Приложения баз данных, относящиеся к сфере разработки данных (data mining),
становятся предметом все более пристального интереса, поскольку позволяют
"добывать" из существующих баз данных любопытные сведения и обнаруживать
неожиданные тенденции. Запросы разработки данных (data mining queries) можно
трактовать как расширенную форму запросов поддержки принятия решений (decision-support
queries), и различия между ними носят скорее неформальный характер (обратитесь
к врезке "Запросы разработки данных и запросы поддержки принятия решений",
приведенной ниже). В технологиях разработки данных особое значение придается как
компоненту оптимизации запросов, так и подсистеме управления элементами информации,
а также расширению языков запросов за счет конструкций, обеспечивающих
возможность эффективного получения выборок данных. В этом разделе мы осветим основные
направления развития методов разработки данных, а затем сосредоточимся на
обсуждении так называемой проблемы часто встречающихся наборов объектов (frequent itemsets
problem), которая (в контексте систем баз данных) заслуживает особого внимания.
20.6.1. Приложения разработки данных
Если говорить в общем смысле, запрос разработки данных предполагает
необходимость отыскания полезной информационной сводки, зачастую без задания каких бы
то ни было значений параметров, которые помогли бы оптимизировать такого рода
сводку. Задача в подобной постановке требует переосмысления традиционных
способов использования СУБД. Ниже рассмотрены некоторые приложения и проблемы,
возникающие в ситуациях, когда речь идет об использовании чрезвычайно крупных
порций данных. Поскольку многие из таких проблем до настоящего времени остаются
20.6. РАЗРАБОТКА ДАННЫХ
1039
Запросы разработки данных и запросы поддержки принятия решений
Хотя запрос поддержки принятия решений обычно и связан с просмотром и
агрегированием крупных массивов информации, аналитик, инициирующий такой запрос,
как правило, в силах указать системе, что именно надлежит сделать, т.е. на какие
порции данных стоит обратить внимание. Запрос разработки данных — это своего
рода шаг вперед: системе предлагается принять самостоятельное решение о том,
какие данные имеет смысл исследовать. Например, запрос поддержки принятия
решений способен выглядеть как "агрегировать уровни продаж автомобилей компании
Aardvark Automobile Co. по цветам моделей и годам", но схожий запрос разработки
данных может быть гораздо менее определенным: "Какие факторы оказывают
решающее влияние на уровень продаж автомобилей Aardvark?" Прямолинейная
реализация запроса разработки данных сводится к выполнению целого ряда
соответствующих "мелких" запросов поддержки принятия решений и зачастую требует настолько
больших затрат вычислительных ресурсов, что оказывается просто неприемлемой.
открытыми, кратко обсуждать возможности их разрешения нецелесообразно — в
отдельных случаях мы ограничимся перечислением "отягчающих" причин. Раздел 20.6.2
на с. 1042 посвящен одной из проблем, ощутимый прогресс в исследовании которых,
однако, уже определенно достигнут.
Конструирование дерева решений
В примере 14.7 на с. 647 рассматривался запрос, который мог бы стать основой
любопытной задачи из сферы разработки данных: "Кому по карману приобретение
драгоценностей?" В упомянутом примере мы ограничили внимание двумя свойствами
потребителей — возрастом и уровнем дохода. На сегодняшний день в базах данных
аналогичного назначения сосредоточена гораздо более полная информация о покупателях (половая
принадлежность, семейное положение, владение недвижимостью, адрес проживания,
сведения о предпочтениях в выборе тех или иных товаров и т.п.), получаемая из вполне
легитимных источников, которая часто интегрируется в структурах хранилищ данных.
В отличие от данных из примера 14.7, которые охватывают только тех, кто
действительно "замечен" в пристрастиях к драгоценностям, при проектировании структуры
дерева решений (decision tree) предусматривается разделение данных на два множества,
описывающих потенциальных "сторонников" и "противников" того или иного
процесса или явления (в данном случае — приобретения драгоценностей). Если прогноз
относительно надежен, продавец получает неплохую выборку субъектов, к которым
можно обратиться с прямой почтовой рекламой товаров.
Дерево решений в какой-то степени может выглядеть так, как показано на
рис. 14.13 (см. с. 661). С каждой промежуточной вершиной связаны определенный
атрибут и некоторое пороговое (threshold) значение. Дочерними могут быть либо другие
промежуточные вершины, либо вершины-листья, представляющие конкретные
решения — "за" или "против". Кортеж с данными, подлежащими классификации,
"помещается" в дерево и на каждом шаге "сдвигается" по дереву (в соответствии с
тем, каким значением обладает компонент атрибута, связанного с вершиной) вплоть
до достижения вершины-"решения".
Дерево конструируется на основе подготовленного множества (training set)
кортежей с данными, характеристики которых известны. В случае с покупкой
драгоценностей следует обратиться к базе данных о клиентах, включающей информацию о том,
кто из них приобретал товары, а кто — нет. Задача разработки данных заключается
в проектировании такого дерева решений, которое при появлении информации о
новом клиенте позволит с высокой степенью надежности определить, будет ли тот
покупать драгоценности. Другими словами, вначале требуется выбрать "наилучшие" атри-
1040
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
бут А и пороговое значение v этого атрибута, пригодные для размещения в корневой
вершине дерева. Затем для левой дочерней вершины надлежит найти "лучшие"
атрибут и значение, подходящие для покупателей, "параметр" А которых удовлетворяет
условию А < v. То же необходимо сделать для правой дочерней вершины, имея в виду
кортежи с А > v. Аналогичная задача решается на каждом уровне дерева. Процесс
продолжается до тех пор, пока остается возможность пополнения дерева "полезными"
вершинами (т.е. такими, которые определяют решение для достаточно больших
подмножеств подготовленного множества данных). Рассматривая свойства вершины, мы
должны определить, какая пара "атрибут—порог" позволяет разделить данные таким
образом, чтобы большая часть "за" попала в одно поддерево, а большая доля
"против" — в другое.
Кластеризация данных
Другой класс задач разработки данных предусматривает применение техники
кластеризации (clustering) — разнесения элементов информации по небольшому
числу групп таким образом, чтобы элементы каждой группы обладали некоторым
"схожим" свойством. На рис. 20.23 изображен пример диаграммы кластеризации
конечного множества двумерных данных (на практике количество измерений,
разумеется, может быть произвольным), на которой указаны приближенные границы
трех кластеров, соответствующих "наиболее приемлемому" варианту разбиения
множества. Некоторые точки располагаются чрезмерно далеко от центра любого
кластера; каждую из них можно трактовать как отдельный кластер либо включить
в ближайший существующий кластер.
Одним из примеров приложений, использующих
аппарат кластеризации, служат поисковые системы Web,
которые в ответ на запрос способны обнаруживать сотни тысяч
документов, удовлетворяющих заданным критериям
поиска. Для организации структуры хранения ссылок на
документы в системе может быть предусмотрена кластеризация
документов в соответствии с наличием в них тех или иных
слов. Каждому измерению пространства документов в этом
случае, вероятно, должно отвечать определенное слово (из
рассмотрения исключаются наиболее употребительные
слова — союзы, предлоги, артикли и т.п., — не несущие
собственной смысловой нагрузки, встречающиеся практически
в любом документе и ничего не сообщающие о его содер- ?ис- 20.23. Три кластера в
жании). Позиция документа в пространстве обусловливает- двумерном пространстве
ся относительной частотой встречаемости в нем каждого из данных
слов-измерений. Если, например, документ содержит 1000
экземпляров слов и два из них — это "database", значением координаты документа,
соответствующей слову "database", окажется 0,002. Осуществляя кластеризацию
документов в подобном пространстве, мы получим возможность получения групп документов,
относящихся к одной тематике. Документы, посвященные базам данных, с большой
вероятностью могут содержать и такие слова, как "data", "query", "lock" и т.д., хотя те же
слова вряд ли встретятся в документах о бейсболе ("baseball").
Проблема разработки данных в этом случае состоит в выборе "средних" или
"центральных" точек кластеров. Часто количество кластеров известно заранее, хотя
нередко может изменяться в процессе решения задачи. В любом случае, однако,
реализация прямолинейного подхода, предусматривающего выбор координат центров
кластеров таким образом, чтобы минимизировать среднее расстояние от каждой точки
до соответствующего ближайшего центра, сопряжено с выполнением многих
запросов, связанных со сложным агрегированием.
20.6. РАЗРАБОТКА ДАННЫХ
1041
20.6.2. Отыскание часто встречающихся наборов объектов
Рассмотрим одну проблему разработки данных, для которой разработаны
алгоритмы эффективного использования ресурсов вторичных устройств хранения
информации. Проблему проще всего описать в терминах известного приложения, связанного
с анализом рыночной корзины (market-basket problem).154 Современные
информационные системы торговых компаний позволяют регистрировать в хранилище данных
информацию о том, какие товары приобретены покупателем единовременно.
Покупатель подбирается к кассе, волоча "рыночную корзину", с верхом заполненную теми
или иными товарами. Кассовый аппарат средствами одной транзакции сохраняет в
базе данных запись обо всех покупках. Пусть нам ничего не известно о личности
клиента, пусть тот мог вернуться в магазин и что-то докупить — важно другое: те или
иные товары были приобретены одним человеком за время одного визита к кассе.
Если определенные товары одновременно попадают в рыночную корзину чаще,
чем этого можно было ожидать, аналитики торговой компании получают удачный
шанс изучить вероятные маршруты следования покупателей по залу магазина. Товары
можно разместить на стеллажах в определенном порядке, направляя мысль клиента
в "нужное" русло — к обоюдной выгоде заинтересованных сторон.
Пример 20.22. Упомянем один любопытный факт, подтверждаемый многими: те, кто
приобретает детские подгузники, необычно часто одновременно покупает и пиво.
Разработаны целые теории, призванные доказать или опровергнуть истинность
подобной связи: некоторые досужие наблюдатели, например, выдвигают предположение,
что человек, у которого есть маленький ребенок, вряд ли имеет возможность вечером
выскочить в бар и поэтому вынужден попивать пивко дома. А профессиональные
аналитики, основываясь на информации о передвижениях многих покупателей от полок
с детскими товарами до ящиков с пивом, непременно порекомендуют продавцам
включить в маршрут стеллаж с картофельными чипсами, солеными орешками и
сушеной воблой — уровни продаж всех этих товаров наверняка возрастут. □
Информацию о рыночной корзине можно описать следующей таблицей
фактических значений:
Baskets(basket, item)
где атрибут basket представляет собой уникальный идентификатор конкретной
корзины, a item задает некоторый товар, присутствующий в этой корзине. Заметим, что
отношение вовсе не обязательно должно содержать информацию именно о
покупках — структура пригодна для описания любых взаимосвязанных объектов: например,
в роли "корзин" способны выступать документы, а функцию "товаров" могут
выполнять слова, и задача в этом случае сводится к поиску наборов слов, встречающихся во
многих документах одновременно.
Проблема анализа рыночной корзины в своей простейшей форме состоит в
обнаружении подмножеств товаров, которые часто приобретаются совместно. Опорным
числом (support) подмножества товаров называют количество корзин, в которых все
товары подмножества наличествуют одновременно. Проблема отыскания часто
встречающихся наборов объектов (frequent itemsets) в более формальной постановке
заключается в том, чтобы для заданного порога s величины опорного числа найти все
подмножества (объектов) с опорным числом, не меньшим s.
Если количество "объектов" в базе данных велико, вычислительные затраты,
необходимые для определения опорных чисел подмножеств, окажутся чрезмерными даже
154 Просьба не путать с понятием потребительской корзины, обозначающим набор товаров,
необходимых для нормальной жизнедеятельности человека или семьи на протяжении
определенного периода времени. — Прим. перев.
1042
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
в том случае, если в расчет принимаются только пары объектов. Поэтому
прямолинейный алгоритм вычисления опорных чисел для каждой пары объектов / и j,
представленный на рис. 20.24, приемлемым считать нельзя.
SELECT Litem, J. item, COUNT (I. basket)
FROM Baskets I, Baskets J
WHERE I.basket = J.basket AND
I.item < J.item
GROUP BY Litem, J. item
HAVING COUNT(I.basket) >= s;
Рис. 20.24. Простой алгоритм поиска всех пар объектов
с опорными числами не ниже заданного порога
Запрос предусматривает соединение Ooin) отношения Baskets с самим собой,
группирование кортежей итоговой таблицы по парам значений item и удаление таких
групп, опорное значение которых ниже пороговой величины s. Заметим, что условие
I. item < J. item в предложении WHERE позволяет исключить из рассмотрения пары,
содержащие одно и то же значение item дважды.
20.6.3. Априорный алгоритм анализа рыночной корзины
Если пороговое значение опорного числа настолько велико, что ему удовлетворяет
всего несколько подмножеств объектов, уместно использовать эвристику, значительно
уменьшающую время выполнения запросов, подобных показанному на рис. 20.24.
Устанавливать высокую величину порога вполне разумно, поскольку список из тысяч
или миллионов пар (или, тем паче, более крупных подмножеств) объектов вряд ли
можно считать удобным для восприятия — запрос разработки данных должен
сосредоточивать внимание аналитика на небольшом наборе наилучших подмножеств-
"кандидатов". Априорный (a-priori) алгоритм анализа рыночной корзины основан на
следующем соображении:
• если множество объектов X обладает опорным числом s, тогда каждому
подмножеству множества X соответствует опорное число, не меньшее s.
Если, в частности, пара объектов [i,j] присутствует, скажем, в 1000 корзинах, можно
быть уверенным в том, что каждый из объектов / и j также наличествует не менее чем
в 1000 корзинах.
Обратное утверждение гласит, что если нам предстоит найти все пары объектов
с опорным числом, не меньшим s, мы вправе прежде всего исключить из рассмртре-
ния все объекты, каждый из которых, взятый по отдельности, встречается в
количестве корзин, меньшем s. Упомянутый априорный алгоритм предусматривает
осуществление следующих действий:
1) найти множество объектов-кандидатов, каждый из которых присутствует
в достаточном количестве корзин;
2) выполнить запрос, показанный на рис. 20.24, в применении к полученному
множеству кандидатов.
Алгоритм можно описать последовательностью из двух запросов, приведенных на
рис. 20.25: первый конструирует отношение Candidates (подмножество данных
отношения Baskets), содержащее сведения об объектах-кандидатах, каждый из которых обладает
достаточно высоким опорным числом, а второй делает то же, что и запрос на рис. 20.24.
20.6. РАЗРАБОТКА ДАННЫХ
1043
Правила ассоциации
Более сложные типы запросов разработки данных о рыночной корзине связаны
с поиском элементов информации, удовлетворяющих правилам ассоциации
(association rules), выраженным в форме {/ь /2, ...,in}=>j. Ниже упомянуты два
условия, которым могут удовлетворять "полезные" правила подобного рода.
1. Доверие: вероятность обнаружения объекта у в корзине, содержащей все объекты
{/ь i2,..., /„}, выше определенного порога (скажем, 50%), т.е., например, "не
менее 50% покупателей подгузников одновременно приобретают пиво".
2. Интерес: вероятность обнаружения объекта j в корзине, содержащей все
объекты {/ь /2> •••> 'лЬ значительно выше или ниже вероятности присутствия у
в корзине, выбранной наудачу. В терминах математической статистики
условие выглядит так: степень корреляции объекта у с множеством {/ь i2,..., in]
положительна (отрицательна). "Открытие", сделанное нами в примере 20.22
на с. 1042, можно сформулировать следующим образом: правило
{подгузники} => пиво представляет "немалый" интерес.
Даже если правило ассоциации и вызывает доверие или представляет интерес, оно
может оказаться "бесполезным" в случае, когда соответствующее множество
объектов обладает низким опорным числом.
INSERT INTO Candidates
SELECT *
FROM Baskets
WHERE item IN (
SELECT item
FROM Baskets
GROUP BY item
HAVING COUNT(*) >= s
);
SELECT Litem, J. item, COUNT (I .basket)
FROM Candidates I, Candidates J
WHERE I.basket = J.basket AND
I.item < J.item
GROUP BY Litem, J. item
HAVING COUNT(I.basket) >= s;
Рис. 20.25. Априорный алгоритм вначале находит все часто
встречающиеся объекты, а затем — часто встречающиеся пары объектов
Пример 20.23. Чтобы продемонстрировать эффективность априорного алгоритма анализа
рыночной корзины, рассмотрим универмаг, в котором продаются 10000 различных
наименований товаров. Предположим, что рыночная корзина содержит в среднем
20 товаров. Допустим также, что в базе данных зафиксирована информация об одном
миллионе вариантов корзины (на практике эта величина может быть существенно
выше). Тогда отношение Baskets обязано содержать 20000000 кортежей, а результат
соединения в запросе на рис. 20.24 (см. с. 1043) — 190000000 пар значений (количество
вариантов корзины, помноженное на число сочетаний из 20 по 2, ( 2 ) = 190). Все
190000000 кортежей должны быть сгруппированы и подсчитаны.
Предположим, однако, что задано пороговое значение опорного числа 5=10000,
"охватывающее" 1% всех корзин. Невозможно, чтобы более чем 20000000/10000 = 2000
товаров присутствовали, по меньшей мере, в 10000 корзин, поскольку Baskets
содержит только 20000000 кортежей и любой товар, наличествующий в 10000 корзин,
1044
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
упоминается, самое меньшее, в 10000 этих кортежей. Поэтому при использовании
априорного алгоритма, описанного на рис. 20.25, запрос, выполняющий поиск
кандидатов, не способен возвратить более 2000 кортежей (а в реальности вернет, вероятно,
намного меньше кортежей).
Предсказать размер отношения Candidates не удастся, поскольку в худшем случае все
товары, упомянутые в Baskets, могут присутствовать, по меньшей мере, в 1% корзин. На
практике, однако, объем Candidates окажется много меньшим в сравнении с размером
Baskets, если величина s достаточно высока. Допустим, что корзины, упомянутые
в Candidates, содержат в среднем по 10 товаров, т.е. вдвое "легче" корзин Baskets. Тогда
операция соединения отношения Candidates с самим собой, выполняемая при обработке
второго запроса на рис. 20.25, даст в итоге 1000000 * ( ) = 45000000 кортежей, что вчетверо
меньше размера результата соединения Baskets с Baskets. Можно ожидать, что время
выполнения априорного алгоритма составит 1/4 от времени работы "простого"
алгоритма. В типичных ситуациях, когда размер отношения Candidates намного меньше
половины количества кортежей Baskets, выигрыш окажется еще более значительным, так
как время обработки подобного запроса пропорционально квадрату количества
кортежей, вовлекаемых в соединение. □
20.6.4. Упражнения к разделу 20.6
Упражнение 20.6.1. Допустим, что восемь "рыночных корзин" с напитками
выглядят так, как показано на рис. 20.26.
в,=
в2 =
Въ--
ВА--
я5 =
fi6=
Вт-
в8 =
= [milk, соке, beer)
-- [ milk, pepsi, juice]
- [milk, beer]
- [coke, juice}
- [milk, pepsi, beer)
■ [milk, beer, juice, pepsi]
■ [coke, beer, juice]
- [beer, pepsi]
Рис. 20.26. Образец данных о рыночных корзинах
* а) Каково опорное число для множества {beer, juice], выраженное в процентах
от количества корзин?
Ь) Чему равно опорное число для множества {coke, pepsi}?
* с) Каков уровень доверия к правилу ассоциации {beer} => milk?
d) Вызывает ли доверие правило {milk} => juice?
e) Каков уровень доверия к правилу {beer, juice] => coke?
* f) Если порог опорного числа составляет 35%, какие пары напитков можно
считать часто встречающимися?
g) Какие пары получат статус часто встречающихся, если в качестве порогового
значения опорного числа принять 50%?
! Упражнение 20.6.2. Априорный алгоритм анализа рыночной корзины можно
использовать и для отыскания часто встречающихся множеств, содержащих более
двух объектов. Напомним, что множество X из к объектов не может иметь опорное
число, равное, по меньшей мере, s, если каждое подмножество множества X не
обладает опорным числом, не меньшим s. (В частности, все подмножества X,
содержащие по к - 1 объектов, должны характеризоваться опорными числами, не
меньшими 5.) Поэтому, отыскав часто встречающиеся подмножества (т.е. множества
20.6. РАЗРАБОТКА ДАННЫХ
1045
с опорным числом, не меньшим s) мощности к -1, в качестве множеств
кандидатов мощности к мы можем определить такие множества из к объектов, все
подмножества размера к - 1 которых обладают опорными числами, не меньшими s.
Сконструируйте SQL-запросы, которые на основе заданных часто встречающихся
множеств из к - 1 объектов вначале вычисляют множества из к кандидатов, а
затем — часто встречающиеся множества мощности к.
Упражнение 20.6.3. Используя данные из упражнения 20.6.1, ответьте на
следующие вопросы.
a) Каково множество кортежей-кандидатов при условии, что порог опорного
числа равен 35%?
b) Какие множества кортежей относятся к категории часто встречающихся при
том же условии?
20.7. Резюме
♦ Интеграция информации. Зачастую содержимое различных баз данных и иных
информационных источников некоторым образом взаимосвязано. Существуют
способы сочетания данных из нескольких источников в пределах единой
структуры. Нередко, однако, схемы данных отличаются гетерогенным характером; их
несовместимость бывает обусловлена различием в типах данных, приемах
представления значений и способах семантической интерпретации последних.
♦ Технологии интеграции информации. Ранние подходы к проблеме интеграции
информации предусматривали образование "федераций", где каждая система
баз данных могла генерировать запросы, "понятные" другим системам. Более
современные решения связаны с применением хранилищ данных, где данные
транслируются в глобальную схему и копируются в центральное хранилище.
Альтернативная архитектура предполагает использование механизма
медиаторов — виртуальных хранилищ, допускающих возможность активизации
запросов, обращенных к глобальной схеме: данные не копируются, а запросы
транслируются с учетом особенностей конкретных источников информации.
♦ Компоненты-оболочки. Технологии хранилищ данных и медиаторов
предусматривают применение программных оболочек, выполняющих функции
извлечения и копирования информации из источников (для переноса в хранилище)
и взаимной трансляции запросов и результатов их выполнения между
глобальной и локальными схемами.
♦ Генераторы оболочек. Один из методов проектирования компонентов-оболочек
состоит в использовании шаблонов, в которых описываются способы преобразования
определенных классов запросов от медиатора к локальной схеме источника.
Шаблоны сохраняются и интерпретируются драйвером, который осуществляет
сопоставление реальных запросов и шаблонов. Иногда драйвер способен комбинировать
шаблоны и выполнять дополнительные функции (например, фильтрацию).
♦ Оптимизация с учетом возможностей источников данных. Источники
информации, с которыми имеет дело медиатор, зачастую способны обрабатывать
запросы только ограниченных классов. Медиатор обязан выбрать план запроса,
учитывая особенности источника, и только затем предпринять попытки
оптимизации стоимости плана.
♦ OLAP. Одним из важных свойств систем хранилищ данных является
способность к обработке сложных запросов, затрагивающих крупные массивы инфор-
1046
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
мации и предусматривающих ее агрегирование. Подобные запросы часто
относят к сфере оперативной аналитической обработки данных.
♦ ROLAP и МО LAP. При проектировании хранилища данных, ориентированного на
потребности приложений OLAP, часто полезно воспринимать информацию так,
будто она структурирована в многомерном пространстве с координатными осями,
соответствующими тем или иным атрибутам. Системы, поддерживающие
подобный подход, позволяют облечь данные в реляционную форму (ROLAP-системы)
либо реализуют специализированную модель кубов данных (MOLAP-системы).
♦ Схемы "звезды". В схеме "звезды" каждый "основополагающий" элемент
данных сохраняется в одном отношении, называемом таблицей фактических
значений, а информация вспомогательного характера, задающая дополнительные
свойства объекта по каждому измерению, размещается в соответствующей
размерностной таблице.
♦ Оператор cube. Специализированный оператор cube осуществляет
предварительное агрегирование содержимого таблицы фактических значений по всем
подмножествам измерений. Применение оператора способствует
существенному возрастанию скорости обработки запросов О LAP при незначительном
увеличении объема таблицы.
♦ Сетки разбиения и материализованные представления. В некоторых версиях
кубов данных используются более мощные, нежели оператор cube,
инструментальные средства, позволяющие устанавливать различные уровни детализации
агрегирования по каждому измерению (например, выбирать те или иные
интервалы времени). Хранилище данных проектируется с учетом возможности
материализации определенных представлений, содержащих информацию,
агрегированную различными способами по различным измерениям. Для реализации
конкретного запроса выбирается представление, наиболее "близкое" по степени
детализации агрегированных данных.
♦ Разработка данных. Содержимое хранилищ данных используется не только для
получения ответов на конкретизированные OLAP-запросы, но и для решения
менее формализованных задач путем кластеризации элементов данных по
критерию "близости" их свойств, проектирования деревьев решений, позволяющих
предсказывать значения одних свойств объекта на основании других, и
отыскания подмножеств часто встречающихся объектов.
20.8. Литература
Недавние обзоры, касающиеся проблематики хранилищ данных и близких
технологий, содержатся в работах [3], [7] и [9]. Обзор результатов, связанных с моделью
федеративных систем, предложен в [12]. Концепция медиаторов впервые введена в статье [14].
Способы реализации медиаторов, компонентов-оболочек и генераторов оболочек
освещены в [5]. Техника оптимизации запросов с учетом возможностей источников
информации разработана [11] и [15].
Оператор cube предложен в [6]. Аспекты реализации кубов данных на основе
материализованных представлений исследованы в [8].
Книга [4] содержит обзор технологий разработки данных. Той же тематике
посвящена и Web-страница [13]. Априорный алгоритм анализа рыночной корзины
заимствован из [1] и [2].
1. Agrawal R., Imielinski Т., and Swami A. Mining association rules between sets of items in large
databases, Proc. ACM SIGMOD Intl. Conf. on Management of Data (1993), p. 207-216.
2. Agrawal R., Srikant R. Fast algorithms for mining association rules, Proc. Intl. Conf. on Very
Large Databases (1994), p. 487-499.
20.8. ЛИТЕРАТУРА
1047
3. Chaudhuri S., Dayal U. An overview of data warehousing and OLAP technology, SIGMOD
Record, 26:1 (1997), p. 65-74.
4. Fayyad U.M., Piatetsky-Shapiro G., Smyth P., and Uthurusamy R. Advances in Knowledge
Discovery and Data Mining, AAAI Press, Menlo Park, С A, 1996.
5. Garcia-Molina H., Papakonstantinou Y., Quass D., Rajaraman A., Sagiv Y., Vassalos V., Ull-
man J.D., and Widom J. The TSIMMIS approach to mediation: data models and languages,
J. Intelligent Information Systems, 8:2 (1997), p. 117-132.
6. Gray J.N., Bosworth A., Layman A., and Pirahesh H. Data cube: a relational aggregation
operator generalizing group-by, cross-tab, and subtotals, Proc. Intl. Conf. on Data Engineering
(1996), p. 152-159.
7. Gupta A., Mumick I.S. Materialized Views: Techniques, Implementations, and Applications,
MIT Press, Cambridge, MA, 1999.
8. Harinarayan V., Rajaraman A., and Ullman J.D. Implementing data cubes efficiently, Proc.
ACM SIGMOD Intl. Conf. on Management of Data (1996), p. 205-216.
9. Lomet D., Widom J. (eds.) IEEE Data Engineering Bulletin, 18:2 (1995), специальный
выпуск, посвященный проблемам использования материализованных представлений
и хранилищ данных.
10. Papakonstantinou Y., Garcia-Molina H., and Widom J. Object exchange across heterogeneous
information sources, Proc. Intl. Conf. on Data Engineering (1995), p. 251—260.
11. Papakonstantinou Y., Gupta A., and Haas L. Capabilities-base query rewriting in mediator
systems, Conf. on Parallel and Distributed Information Systems
(http://dbpubs.Stanford.edu/pub/1995-2).
12. Sheth A.P., Larson J.A. Federated databases for managing distributed, heterogeneous, and
autonomous databases, Computing Surveys, 22:3 (1990), p. 183—236.
13. Ullman J.D. (http: //www-db. Stanford, edu. /-ullman/mining/mining.html).
14. Wiederhold G. Mediators in the architecture of future information systems, IEEE Computer,
C-25:l (1992), p. 38-49.
15. Yemeni R., Li C, Garcia-Molina H., and Ullman J.D. Computing capabilities of mediators,
Proc. ACM SIGMOD Intl. Conf. on Management of Data (1999), p. 443-454.
1048
ГЛАВА 20. ИНТЕГРАЦИЯ ИНФОРМАЦИИ
Послесловие редактора
перевода
Хочется выразить уверенность в том, что книге классика жанра Джеффри Ульмана
и его именитых коллег по Станфордскому университету Гектора Гарсиа-Молина
и Дженнифер Уидом уготована такая же долгая и счастливая судьба, как и прежним
их работам, знакомым русскому читателю.
В настоящем издании исправлены ошибки, неточности и опечатки, замеченные
в оригинальной версии книги в процессе ее перевода, равно как и изъяны,
обнаруженные ранее и перечисленные авторами в документах, которые обнародованы на
страницах университетского Web-сайта по адресу:
http://www-db.Stanford.edu/~ullman/dscb/errata.html.
(Стоит заметить, что здесь упомянуты далеко не все и отнюдь не самые серьезные
замечания, посланные редактором русского издания. Умению воспринимать
здоровую критику и публично признавать ее справедливость необходимо учиться, и
делать это никогда не поздно.)
Именной указатель
А
Abiteboul S., 50; 200
Afrati F., 200
Agrawal R., 1047
Aho A.V., 463; 515; 696; 755; 814
Apt K.R., 487
Armstrong W.W., 121; 123; 147
Astrahan M.M., 50; 316; 836
В
Baeza-Yates R., 636
Bancilhon F., 201; 487
Barghouti N.S., 1001
Batini Carlo, 86
Batini Carol, 86
Bayer R., 636
Beckmann N., 680
Beeri C, 147
Bentiey J.L., 680; 681
Berenson H., 417
Bernstein P.A., 50; 147;417; 877; 948
Blair H., 487
Blasgen M.W., 751; 877
Bool J., 297
BosworthA., 1048
Buneman P., 200
Burkhard W.A., 681
С
Cattell R.G.G., 201; 417; 452; 582
Celko J., 316
Ceri S., 86; 348; 681; 1001
Chamberlin D.D., 316; 836
Chandra A.K., 487
Chang P.Y., 836
Chaudhuri S., 751; 1048
Chen P.M., 548
Chen P.P., 86
Chou H.-T., 751
Cochrane R.J., 348
Codd E.F., 34; 123; 126; 146; 147; 205;
247; 487
Comer D., 636
D
Darwen H., 316
Date C.J., 316
Dayal U., 348; 1048
Delobel C, 147; 201
DeWitt D.J., 751
Diaz O., 348
E
Eswaran K.P., 751; 948
F
Fagin R., 147;417; 636
Faloutsos C, 636; 681
Faulstich L.C., 201
Fayyad U.M., 1048
Finkei R.A., 681
Finkeistein S.J., 487
Fisher ML, 417
Friedman J.H., 681
G
Gaede V., 681
Gallaire H., 487
Garcia-Molina HL, 201; 548; 1001; 1048
Gibson G.A., 548
Goodman N., 877; 948
Gotlieb L.R., 751
Graefe G., 751; 836
Gray J.N.,417; 548; 877; 948; 1001; 1048
Griffiths-Selinger P., 417; 805; 806; 808; 836
Gulutzan P., 316
Gunther O., 681
Gupta A., 247; 1048
Guttman A., 681
H
Haas L., 1048
Haderle D.J., 877; 1001
Hadzilacos V., 877; 948
Haerder Т., 877
Hall P.A.V., 836
Hamilton G., 417
ИМЕННОЙ УКАЗАТЕЛЬ
1051
Hapner M., 417
Hard D., 487
Harinarayan V., 247; 1048
Held G., 50
Hellerstein J.M., 50
Hinterberger H., 681
Holt R.C., 1001
Hopcroft J.E., 696; 814
Howard J.H., 147
Hsu M, 877
Hull R., 50
Imielinski Т., 1047
I
К
Kaiser G.E., 1001
Kanellakis P., 201; 948
Katz R.H., 548; 751
Kedem Z., 948
Kim W., 201
Kitsuregawa M., 751
Knuth D.E., 512; 582; 636
Ко H.-P., 948
Kolaitis P., 200
Korth H.F., 948
Kossman D., 751
Kreps P., 50
Kriegel H.-P., 680
Kumar V., 877
Kung H.-T., 948
Lampson В., 548; 1001
Larson J.A., 1048
Lewis P.M. (II), 1002
Li C, 1048
Lindsay B.G., 877; 1001
Litwin W., 636
Liu M., 487
Lomet D., 582; 1048
Lorie R.A., 836; 948
Lozano Т., 681
M
Mattos N., 348; 487
McCarthy D.R., 348
McCreight E.M., 636
McHugh J., 200
McJones P.R., 877
Melkanoff M.A., 147
Melton J., 316; 417
Minker J., 487
Mohan C, 877; 1001
Moore G., 496
Moto-oka Т., 751
Mumick I.S., 487; 1048
N
Naqvi S., 487
Navathe S.B., 86
Nicolas J.-M., 247
Nievergelt J., 636; 681
О
Olken F., 751
O'NeilE., 417
O'NeilR, 417; 681
Ozsu M.T., 1002
Palermo F.P., 836
Papadimitriou C.H., 948; 1002
Papakonstantinou Y., 201; 1048
Paton N.W., 348
Patterson D.A., 548
Pelagatti G., 1001
PelzerT., 316
Peterson W.W., 636
Piatetsky-Shapiro G., 1048
Pippenger N., 636
Pirahesh H., 348; 487; 877; 1001; 1048
Price T.G., 836
Putzolo F., 548; 948
Quass D., 200; 247; 681; 1048
R
Rajaraman A., 1048
Ramakrishnan R., 487
Reuter A., 877; 948
Rivest R.L., 681
Robinson J.T., 681; 948
Rosenkrantz D.J., 1002
Rothnie J.B. (Jr.), 681; 948
Roussopoulos N., 681
Rustin R., 147; 487
1052
ИМЕННОЙ УКАЗАТЕЛЬ
Sagiv Y., 1048
Salem K., 548; 1001
Salton G., 636
Schneider R., 680
Schwarz P., 877; 1001
Seeger В., 680
Sellis Т.К., 681
Sethi R., 755
SevcikK., 681
Shapiro L.D., 751
Shaw D.E., 751
Sheth A.P., 1048
Silberschatz A., 948
Simon R., 316
Skeen D., 1002
Smith J.M., 836
Smyth P., 1048
Snodgrass R.T., 681
Srikant R., 1047
Stearns R.E., 1002
Stonebraker M., 50; 751; 1002
Strong H.R., 636
Sturgis H., 548; 1001
Subrahmanian V.S., 681
Suciu D., 200; 201
Swami A., 1047
Tanaka H., 751
Thalheim В., 86
Thomas R.H., 933; 1002
Thomasian A., 948
Thuraisingham В., 948
Той J.T., 836
Traiger I.L., 948
Turing A, 203; 351
и
UUman J.D., 50; 147; 463; 487; 515; 696;
755; 814; 1048
Uthurusamy R., 1048
Valduriez P., 1002
VanGelderA., 487
Vassalos V., 1048
Vianu V., 50
VitterJ.S., 548
w
Wade B.W., 417
Walker A., 487
Weiner J.L., 200
White S.,417
WidomJ., 200; 201; 348; 1048
Wiederhold G., 582; 1048
Wong E., 50; 836
Wood D., 751
Yemeni R., 1048
Yossefi K., 836
Zaniolo C., 147; 681
Zicari R., 681
ZipfG.K., 608; 787
ИМЕННОЙ УКАЗАТЕЛЬ
1053
Предметный указатель
1~4
INF — см. Нормальная форма, первая, 134
2NF — см. Нормальная форма, вторая, 134
3NF — см. Нормальная форма, третья, 134
4NF — см. Нормальная форма,
четвертая, 134
А
Access control — см. Доступ,
управление, 349
ACID — см. Транзакция, свойства, 44
ACR schedule — см. Расписание, без
каскадного отката, 953
Action — см. Транзакция, действие, 886
Active element — см. База данных,
активный элемент, 317
Address space — см. Память, адресное
пространство, 559
Agent — см. База данных, агент, 382
Aggregated attribute — см. Атрибут,
агрегируемый, 235
Aggregation — см. Агрегирование, 206
Alias — см. SQL, псевдоним, 252
ANSI, 249
Antisemijoin — см. Обратное
полусоединение, 225
Archives — см. База данных, архив, 837
Arithmetic atom — см. Язык, Datalog,
атом, арифметический, 454
Array — см. Массив, 161
ASCII — см. Набор символов, ASCII, 379
Assertion — см. Ограничение, общего
вида, 317
Atom — см. Язык, Datalog, атом, 453
Atomic type — см. Тип, атомарный, 150
Atomicity — см. Транзакция,
атомарность, 32
Attribute — см. Атрибут, 34
Authorization ID — см. Доступ,
авторизация, идентификатор, 405
Authorization — см. Доступ,
авторизация, 46
Average seek time — см. Диск, время,
поиска, среднее, 505
В
Backup copy — см. База данных, резервная
копия, 871
Bag — см. Мультимножество, 161
Balanced binary tree — см. Дерево,
сбалансированное, бинарное, 46
Balanced tree — см. Дерево,
сбалансированное, 46
Basic type — см. Тип, базовый, 161
BCNF — см. Нормальная форма, Бойса-
Кодда, 123
Binary Large Object — BLOB —
см. Объект, крупный двоичный, 550
Binary relationship — см. Связь,
бинарная, 53
Binary search — см. Алгоритм, бинарного
поиска, 586
Bitmap index — см. Индекс, точечный, 637
BLOB — см. Объект, крупный
двоичный, 550
Block header — см. Диск, блок, данных,
заголовок, 557
Block — см. Диск, блок, данных, 549
Boyce-Codd normal form — BCNF —
см. Нормальная форма, Бойса-Кодда, 123
Branch-and-bound — см. Алгоритм, ветвей
и границ, 806
Broadcasting — см. Транзакция,
широковещательная рассылка
сообщений, 992
B-tree — см. В-дерево, 46
Bucket — см. Хеш-таблица, сегмент,
599; 601
Bucket array — см. Хеш-таблица, сегмент,
массив, 624
Buffer — см. Буфер, 41
Buffer manager — см. Менеджер,
буферов, 41
Buffer-replacement strategies — см. Буфер,
стратегии замещения, 734
Build relation — см. Отношение,
опорное, 809
Bushy tree — см. Дерево, ветвящееся, 811
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1055
В-дерево, 46; 47; 565; 584; 587; 588; 609;
635; 637; 642; 657; 666; 686; 730; 830;
918; 924; 929; 947; 957; 959; 997
С
Cache memory — см. Память, кэш-, 493
Call-level interface — CLI —
см. Интерфейс, уровня вызовов, 349
Cartesian product — см. Декартово
произведение, 205
Cascading rollback —- см. Транзакция,
откат, каскадный, 952
Catalog — см. База данных, каталог, 376
CD — см. Компакт-диск, 36
Centralized locking — см. Транзакция,
блокирование, централизованное, 987
Character set — см. Набор символов, 379
Checkpoint — см. Протоколирование,
контрольная точка, 837
Checksum — см. Диск, сектор,
контрольная сумма, 531
Circular constraint — см. Ограничение,
циклическое, 325
Class — см. Класс, 52
Class properties — см. Класс, свойства, 153
CLI — см. Интерфейс, уровня
вызовов, 349
Client — см. База данных, клиент, 37
Clock algorithm — см. Алгоритм,
часов, 734
Cluster — см. База данных, кластер, 376
Clustered file — см. Файл, компактно
сгруппированный, 601
Clustered relation — см. Отношение,
компактно сгруппированное, 688
Clustering index — см. Индекс,
группирующий, 725
CODASYL, 34
Collation — см. Метод сопоставления
строк, 379
Collection operator — см. Оператор
коллекции, 151
Collection type — см. Тип, коллекции, 151
Commit — см. Транзакция, фиксация, 325
Common Object Request Broker
Architecture — CORBA, 153
Compatibility matrix — см. Транзакция,
бло-кирование, матрица
совместимости, 902
Compensating action — см. Транзакция,
действие, уравновешивающее, 960
Compensating transaction — см. Транзакция,
уравновешивающая, 993
Component — см. Компонент, 88
Compressed bitmap index — см. Индекс,
точечный, сжатый, 673
Concurrency-control manager — см.
Менеджер, параллельных заданий, 41
Conflict — см. Расписание, конфликт, 887
Conflict-equivalent schedule —
см. Расписание, конфликтно-
эквивалентное, 888
Conflict-serializable schedule —
см. Расписание, условно-
последовательное, с учетом
конфликтов, 879
Connecting entity set — см. Множество,
сущностей, соединяющее, 60
Connection — см. Система,
"клиент/сервер", 380
Consistency — см. База данных,
согласованность состояния, 44
Constraint — см. Ограничение, 44
Constructor function — см. Конструктор-
функция, 438
Coordinator — см. База данных, сайт,
координатор, 983
Correlated subquery — см. SQL, подзапрос,
коррелированный, 275
Cross join — см. Перекрестное
соединение, 277
Cursor insensibility — см. Курсор,
нечувствительность, 359
Cursor — см. Курсор, 354
Cylinder — см. Диск, цилиндр, 502
D
Dangling tuple — см. Кортеж, висящий, 211
Data bus — см. Шина данных, 502
Data cube — см. Куб данных, 639
Data Definition Language — DDL —
см. Язык, определения, данных, 32
Data disk — см. RAID, диск, данных, 535
Data file — см. Файл, данных, 40
Data Manipulation Language — DML —
см. Язык, управления данными, 32
Data mining — см. Разработка данных, 39
Data prefetching —- см. Диск, считывание
данных, предварительное, 526
Data region — см. R-дерево, область,
данных, 666
Data replication — см. Репликация
данных, 39
1056
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Data source — см. Источник данных, 48
Data warehouse — см. Хранилище
данных, 39
Database — см. База данных, 31
Database address space — см. Память,
адрес-ное пространство, базы
данных, 559
Database administrator — DBA — см. База
данных, администратор, 40
Database instance — см. База данных,
экземпляр, 54
Database Management System —
см. СУБД, 31
Database schema — см. База данных,
схема, 32
Database system — см. СУБД, 31
Datalog — см. Язык, Datalog, 453
Date value — см. Значение, даты, 297
DBA — см. База данных,
администратор, 40
DBMS - см. СУБД, 31
DDL — см. Язык, определения,
данных, 32
DDL compiler — см. Компилятор,
DDL, 40
Deadlock -~ см. Транзакция,
взаимоблокировка, 43
Decision tree — см. Дерево, решений, 1041
Decision-support query — см. Запрос,
поддержки принятия решений, 639
Declare section — см. SQL, внедрение,
секция объявления, 352
Default value — см. Значение,
по умолчанию, 291
Deferred constraint checking —
см. Ограничение, проверка,
отложенная, 324
Dense index — см. Индекс, плотный, 584
Dependency — см. Зависимость, 45
Dependency graph — см. Граф,
зависимостей, 481
Dependent attribute — см. Атрибут,
зависимый, 1026
Derived class — см. Класс,
производный, 152
Dicing — см. Куб данных,
рассечение, 1028
Dictionary — см. Словарь, 161
Difference — см. Разность, 205
Digital versatile disk — DVD, 36
Dimension table — см. Таблица,
размерностиая, 641
Dirty reads — см. Чтение, мусора, 400
Disjunctive normal form — см. Нормальная
форма, дизъюнктивная, 463
Disk assembly — см. Диск, блок,
дисков, 500
Disk block — см. Диск, блок, данных, 41
Disk crash — см. Диск, отказ, полный, 531
Disk I/O — см. Диск, ввод-вывод, 496
Disk read — см. Диск, считывание
данных, 496
Disk striping — см. Диск, блок, данных,
попеременное распределение, 548
Disk write — см. Диск, запись данных, 496
Distributed atomicity — см. Транзакция,
атомарность, распределенная, 982
Distributed commit — см. Транзакция,
фиксация, распределенная, 977
Distributed database — см. База данных,
распределенная, 949
Distributed locking — см. Транзакция,
блокирование, распределенное, 977
Distributed transaction — см. Транзакция,
распределенная, 979
DML — см. Язык, управления данными, 32
Document type definition — DTD —
см. Язык, XML, определение типа
документа, 192
Domain — см. Домен, 74
Domain constraint — см. Ограничение,
домена, 74
DRAM — см. Память, динамическая с
произвольным доступом, 500
Drill-down — см. Запрос, уточнение, 1030
DTD — см. Язык, XML, определение типа
документа, 192
Duplicate-elimination — см. Кортеж, -
дубликат, удаление, 232
Durability — см. Транзакция,
устойчивость, 32
DVD, 498
Dynamic hash table — см. Хеш-таблица,
динамическая, 626
Dynamic programming — см. Алгоритм,
динамического программирования, 805
Dynamic random-access memory —
DRAM — см. Память, динамическая
с произвольным доступом, 500
Е
EBCDIC — см. Набор символов,
EBCDIC, 551
ЕСА rule — см. Правило "событие-
условие—действие", 339
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1057
EDB — см. База данных,
экстенсиональная, 458
Elevator algorithm — см. Алгоритм,
лифта, 523
Embedding — см. SQL, внедрение, 349
Encapsulation — см. Инкапсуляция, 152
Entity — см. Сущность, 52
Entity component — см. Сущность,
компонент, 62
Entity set — см. Множество,
сущностей, 52
Entity-relationship diagram —
см. Диаграмма, сущностей и связей, 52
Entity-relationship model —
см. Модель,"сущность—связь", 45
Enumerative type — см. Тип,
перечислимый, 155
Equal-height histogram — см. Гистограмма,
с равной, высотой, 798
Equal-width histogram — см. Гистограмма,
с равной, шириной, 798
Equijoin — см. Соединение, посредством,
равенства, 697
ER-diagram — см. Диаграмма, сущностей
и связей, 53
ER-model — см. Модель, "сущность-
связь", 45
Error-correcting code — см. Код,
с исправлением ошибок, 540
Event—condition—action rule —
см. Правило "событие—условие-
действие", 339
Exception — см. Класс, исключение, 159
Exception handler — см. SQL, исключение,
обработчик, 372
Exclusive locking — см. Транзакция,
блокирование, монопольное, 894
Execution engine — см. Исполняющая
машина, 40
Extended projection — см. Проекция,
расширенная, 236
Extensible hash table — см. Хеш-таблица,
расширяемая, 627
Extensible Markup Language — XML —
см. Язык, XML, 45
Extensional Database — EDB — см. База
данных, экстенсиональная, 458
Extensional predicate — см. Язык, Datalog,
предикат, экстенсиональный, 458
Extensional relation — см. Отношение,
экстенсиональное, 458
Extent — см. Класс, экземпляр, 168
F
Fact table — см. Таблица, фактических
значений, 641
FD — см. Зависимость,
функциональная, 87
Federated system — см. Система,
федеративная, 1003
Fetching — см. Курсор, кортеж,
извлечение, 356
Field — см. Поле, 150
Filtering — см. Отношение,
фильтрация, 805
First normal form — INF —
см. Нормальная форма, первая, 134
Fixed-length string — см. Строка,
постоянной длины, 296
Flash memory — см. Память, флэш-, 500
Floating-point value — см. Значение,
числовое с плавающей запятой, 297
Flush — см. Протоколирование, запись,
сброс, 846
Foreign key — см. Ключ, внешний, 317
Foreign-key constraint — см. Ограничение,
внешнего ключа, 318
Fourth normal form — 4NF —
см. Нормальная форма, четвертая, 134
Fragment — см. Отношение, фрагмент, 978
Full dump — см. База данных, дамп,
полный, 871
Full outerjoin — см. Полное внешнее
соединение, 279
Full theta-outerjoin — см. Полное внешнее
тета-соединение, 280
Functional dependency — FD —
см. Зависимость, функциональная, 87
G
Gap — см. Диск, зазор, 501
General constraint — см. Ограничение,
общего вида, 74
Generalized module — см. Модуль, общего
вида, 382
Generalized projection — см. Проекция,
обобщенная, 236
Generator method — см. Тип,
пользовательский, метод, -
генератор, 447
Generic SQL interface — см. SQL,
интерфейс, базовый, 249
Grammar — см. Грамматика, 754
1058
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Grant diagram — см. Диаграмма,
назначения привилегий, 411
Grant option — см. Доступ, привилегия,
право передачи, 409
Grant statement — см. Доступ,
привилегия, 380
Greedy algorithm — см. Алгоритм,
жадный, 805
Grid file — см. Файл, сеточный, 638
Group commit — см. Транзакция,
фиксация, групповая, 957
Grouping — см. Группирование, 233
Grouping attribute — см. Атрибут,
группирующий, 235
н
Hamming code — см. Код, Хемминга, 540
Hash function — см. Хеш-функция, 624
Hash key — см. Хеш-ключ, 624
Hash table — см. Хеш-таблица, 46
Hash-based algorithm — см. Алгоритм,
основанный на, хешировании, 692
Hash-join — см. Соединение, с
хешированием, 720
Head — см. Диск, головка, 501
Head assembly — см. Диск, блок,
головок, 500
Heap — см. Куча, 600
Histogram — см. Гистограмма, 786
Horizontal decomposition —
см. Отношение, декомпозиция,
горизонтальная, 978
Host language — см. Язык,
программирования, базовый, 349
HTML - см. Язык, HTML, 51
Hybrid hash-join — см. Соединение,
с хешированием, гибридное, 721
Hypertext Markup Language — HTML —
см. Язык, HTML, 51
I
I/O computation model — см. Модель,
вычислений, с функциями ввода-
вывода, 511
IDB — см. База данных,
интенсиональная, 458
IDL — см. Язык, описания
интерфейса, 153
Immediate constraint checking —
см. Ограничение, проверка,
непосредственная, 326
Immutable object — см. Объект,
неизменяемый, 151
Increment locking — см. Транзакция,
блокирование, инкрементных
операций, 902
Incremental dump — см. База данных,
дамп, инкрементный, 871
Index — см. Индекс, 36
Index file — см. Файл, индексный, 40
Index-based algorithm — см. Алгоритм,
основанный на, индексировании, 692
Index-based join — см. Соединение, на
основе, индексирования, 702
INGRES, 50
Inheritance — см. Наследование, 150
Instance variable — см. Переменная,
экземпляра, 150
Integer value — см. Значение,
целочисленное, 297
Intensional Database — IDB — см. База
данных, интенсиональная, 458
Intensional predicate — см. Язык, Datalog,
предикат, интенсиональный, 458
Intensional relation — см. Отношение,
интенсиональное, 458
Interface Description Language — IDL —
см. Язык, описания интерфейса, 153
Interior region — см. R-дерево, область,
внутренняя, 666
Intermediate collection — см. Коллекция,
промежуточная, 431
Intermittent failure — см. Диск, отказ,
перемежающийся, 530
Internet, 50
Intersection — см. Пересечение, 206
Inverted index — см. Индекс,
обращенный, 604
IP-адрес, 567; 986
Isolation — см. Транзакция, изоляция, 32
Isolation level — см. Транзакция, уровень
изоляции, 400
Iterator — см. Итератор, 685
J
Java Database Connectivity — JDBC —
см. Интерфейс, уровня вызовов,
JDBC, 349
Join tree — см. Дерево, соединения, 809
Join — см. Соединение, 132
Joined tuple — см. Кортеж,
соединенный, 211
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1059
к
k-dimensional search tree — kd-tree —
см. kd-дерево, 638
kd-tree — см. kd-дерево, 638
kd-дерево, 638; 657; 659; 679; 680
группирование промежуточных
вершин, 664
множественное ветвление, 663
Key — см. Ключ, 74
Key constraint — см. Ограничение,
ключа, 74
L
Large-scale buffering — см. Диск,
крупномасштабная буферизация
данных, 526
Latency time — см. Диск, время,
задержки, 504
Lattice — см. Куб данных, сетка, 1036
Leader election — см. Система,
распределенная, избрание лидера, 985
Left outerjoin — см. Левое внешнее
соединение, 239
Left theta-outerjoin — см. Левое внешнее
тета-соединение, 240
Left-deep tree — см. Дерево,
левостороннее, 810
Legacy database — см. База данных,
унаследованная, 39
Level-2 cache — см. Память, кэш-, 2-го
уровня, 493
Linear hash table — см. Хеш-таблица,
линейная, 630
List — см. Список, 161
Literal — см. Литерал, 155
Lock coordinator — см. Транзакция,
компо-нент, координатор
блокировок, 989
Lock site — см. База данных, сайт,
блокировок, 988
Lock table — см. Таблица, блокировок, 43
Locking — см. Транзакция,
блокирование, 43
Logging manager — см. Менеджер,
протоколирования, 41
Logging — см. Протоколирование, 43
Logical address — см. Память, адрес,
логический, 560
Logical logging — см. Протоколирование,
логическое, 848
Logical query language — см. Язык,
запросов, логический, 47
Logical query plan generator — см. План
запроса, логический, генератор, 754
Logical query plan — см. План запроса,
логический, 48
Logical value — см. Значение,
логическое, 297
Long transaction — см. Транзакция,
длинная, 48
м
Main memory — см. Память,
оперативная, 36
Main-memory DBMS — см. СУБД,
размещаемая в оперативной памяти, 495
Map table — см. Память, адрес, таблица,
соответствий, 560
Materialization — см. Материализация, 691
Materialized view — см. Представление,
материализованное, 1034
MD — см. Зависимость, многозначная, 106
Mean time to failure — см. Диск, время,
среднее наработки на отказ, 534
Media decay — см. Диск, разрушение
носителя, 530
Mediator — см. Медиатор, 49
Merge sort — см. Алгоритм, сортировки,
слиянием, 512
Metadata — см. Метаданные, 40
Method — см. Класс, метод, 151
Method declaration — см. Класс, метод,
объявление, 159
Method signature — см. Класс, метод,
сигнатура, 159
Mining — см. Разработка данных, 39
Mirror disk — см. Диск, зеркальный, 522
Module — см. Модуль, 381
MOLAP — см. Оперативная
аналитическая обработка, многомерных
данных, 1026
Monotonous relation — см. Отношение,
монотонное, 482
Most-frequent-values histogram —
см. Гистограмма, с наиболее часто
встречающимися значениями, 798
Multidimensional index — см. Индекс,
многомерный, 47
Multidimensional on-line analytic
processing — MOLAP —
см. Оперативная аналитическая
обработка, многомерных данных, 1026
1060
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Multimedia — см. Мультимедиа, 38
Multipass algorithm — см. Алгоритм,
многопроходный, 512
Multiple inheritance — см. Наследование,
множественное, 166
Multiple-key index — см. Индекс,
с несколькими ключами, 638
Multivalued dependency — MD —
см. Зависимость, многозначная, 106
Multiway relationship — см. Связь,
многосторонняя, 53
Mutable object — см. Объект,
изменяемый, 151
Mutator method — см. Тип,
пользовательский, метод, -
модификатор, 447
Mutually recursive relation —
см. Отношение, взаимно
рекурсивное, 481
N
Natural join — см. Естественное
соединение, 211
Nearest-neighbor search — см. Поиск,
ближайших соседних объектов, 639
Nested relation — см. Отношение,
вложенное, 181
Nested-loop join — см. Соединение,
посредством, вложенных циклов, 702
Nonuniform memory access — NUMA —
см. Система, с неоднородным доступом
к памяти, 742
Nonvolatile storage — см. Устройство
хранения, энергонезависимое, 499
Normalization — см. Нормализация, 45
Null, 70; 95; 101; 103; 145; 158; 233; 239;
242; 247; 258; 279; 323; 406; 552; 580; 610
NUMA — см. Система, с неоднородным
доступом к памяти, 742
О
Object — см. Объект, 52
Object Data Management Group — ODMG,
149; 200
Object Definition Language — ODL —
см. Язык, определения, объектов, 45
Object identity — OID — см. Объект,
идентификационный номер, 150
Object Query Language — OQL —
см. Язык, объектных запросов, 46
Object-relation — см. Объект, -
отношение, 181
Observer method — см. Тип,
пользовательский, метод, -
обозреватель, 446
ODBC — см. Интерфейс, уровня вызовов,
ODBC, 382
ODL — см. Язык, определения,
объектов, 45
Offset — см. Запись, смещение поля, 554
Offset table — см. Диск, блок, данных,
таблица смещений записей, 561
OLAP — см. Оперативная аналитическая
обработка, данных, 1003
OLTP — см. Оперативная обработка
транзакций, 1024
On-board cache — см. Память, кэш-,
встроенная, 493
One-dimensional index — см. Индекс,
одномерный, 47
One-pass algorithm — см. Алгоритм,
однопроходный, 692
On-line analytic processing — OLAP —
см. Оперативная аналитическая
обработка, данных, 1003
On-line transaction processing — OLTP —
см. Оперативная обработка
транзакций, 1024
Open Database Connectivity — ODBC —
см. Интерфейс, уровня вызовов,
ODBC, 382
Optical disk jukeboxe —
см. Автоматический привод оптических
дисков, 498
OQL — см. Язык, объектных запросов, 46
Outerjoin — см. Внешнее соединение, 233
Output collection — см. Коллекция,
итоговая, 431
Overflow block — см. Диск, блок, данных,
переполнения, 577
Overloaded method — см. Класс, метод,
перегруженный, 159
Р
Page — см. Память, страница, 41
Parity — см. Диск, сектор, четность, 531
Parse tree — см. Дерево, разбора, 684
Partial match query — см. Запрос,
к данным с совпадением отдельных
координат, 639
Partition attribute — см. Атрибут,
группирующий, 430
Partitioned hash function — см. Хеш-
функция, раздельная, 638
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1061
Password — см. Доступ, авторизация,
пароль, 408
Percentile — см. Гистограмма,
процентиль, 798
Persistent Stored Modules — PSM —
см. Стандарт, SQL/PSM, 364
Phantom tuple — см. Кортеж,
фантомный, 404
Physical address — см. Память, адрес,
физический, 559
Physical query plan — см. План запроса,
физический, 48
Physically unrealizable schedule —
см. Расписание, физически
неосуществимое, 932
Pinned block — см. Диск, блок, данных,
закрепленный в памяти, 566
Pinned record — см. Запись, закрепленная
в памяти, 566
Pipeline — см. Канал, 691
Platter — см. Диск, пластина, 500
Pointer swizzling — см. Память, адресное
пространство, подмена указателей, 563
Pool — см. Память, пул, 733
Precedence graph — см. Граф,
предшествования, 890
Precommit — см. Транзакция, компонент,
предварительная фиксация, 983
Predicate — см. Язык, Datalog,
предикат, 453
Primary copy locking — см. Транзакция,
блокирование, главной копии, 990
Primary index — см. Индекс,
первичный, 599
Primary key — см. Ключ, первичный, 75
Prime attribute — см. Атрибут,
первичный, 136
Priority queue — см. Очередь,
с приоритетами, 515
Privilege — см. Доступ, привилегия, 405
Probe relation — см. Отношение,
тестируемое, 809
Projection — см. Проекция, 124
PSM - см. Стандарт, SQL/PSM, 364
Q
Quad tree — см. Дерево, квадрантов, 638
Query compiler — см. Компилятор,
запросов, 40
Query execution — см. Запрос,
выполнение, 683
Query language — см. Язык, запросов, 32
Query optimizer — см. Оптимизатор
запросов, 44
Query parser — см. Синтаксический
анализатор запросов, 44
Query plan -— см. План запроса, 40
Query preprocessor — см. Препроцессор,
запросов, 44
Query processor — см. Процессор,
запросов, 43
Query rewrite — см. Запрос, перезапись, 684
Queue — см. Очередь, 511
Quick sort — см. Алгоритм, сортировки,
быстрой, 512
R
RAID, 534; 547; 838
level
1, 535; 547
4, 536; 544; 547
5, 539; 544; 547
6, 540; 543; 547
диск
данных, 535
резервный, 535
матрица резервирования, 540
RAM disk — см. Диск, виртуальный, 500
RAM — см. Память, оперативная, 36
Random access — см. Память,
оперативная, произвольный доступ, 494
Random-access computation model —
см. Модель, вычислений, с
произвольным доступом к данным, 510
Range query — см. Запрос, в диапазоне
значений, 639
Read locking — см. Транзакция,
блокирование, общее, 902
Read-committed — см. Чтение,
фиксированных данных, 403
Read-only cursor — см. Курсор, "только
для чтения", 360
Read-only transaction — см. Транзакция,
"только для чтения", 399
Read-uncommitted — см. Чтение,
нефиксированных данных, 403
Record — см. Запись, 549
Record header — см. Запись, заголовок, 556
Record structure — см. Тип, структуры
записи, 150
Recoverable schedule — см. Расписание,
восстановимое, 952
Recovery manager — см. Менеджер,
восстановления, 41
1062
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Recursive SQL — см. SQL, рекурсивный, 351
Redundant Array of Independent Disks —
см. RAID, 534
Redundant disk — см. RAID, диск,
резервный, 535
Reference column — см. Атрибут,
ссылочный, 442
Reference following — см. Обращение по
ссылке, 445
Reference type — см. Тип, ссылочный, 151
Referenceable relation — см. Отношение,
адресуемое, 443
Referential integrity constraint —
см. Ограничение, ссылочной
целостности, 74
Region tree — R-tree — см. R-дерево, 666
Relation — см. Отношение, 34
Relation current instance — см. Отношение,
экземпляр, текущий, 90
Relation instance — см. Отношение,
экземпляр, 90
Relation schema — см. Отношение,
схема, 88
Relational algebra — см. Реляционная
алгебра, 44
Relational atom — см. Язык, Datalog, атом,
реляционный, 454
Relational calculus — см. Модель,
реляционного исчисления, 487
Relational model — см. Модель,
реляционная, 45
Relational on-line analytic processing —
ROLAP — см. Оперативная
аналитическая обработка, реляционных
данных, 1026
Relationship — см. Связь, 53
Relationship set — см. Связь, множество
данных, 55
Renaming — см. Переименование, 206
Repeatable-read — см. Чтение,
повторяемое, 403
Replication — см. Репликация данных, 39
Resilience — см. СУБД, живучесть, 837
Resource manager — см. Менеджер,
ресурсов, 40
Right outerjoin — см. Правое внешнее
соединение, 239
Right theta-outerjoin — см. Правое
внешнее тета-соединение, 240
Right-deep tree — см. Дерево,
правостороннее, 811
ROLAP — см. Оперативная аналитическая
обработка, реляционных данных, 1026
Role — см. Роль, 57
Rollback — см. Транзакция, откат, 43
Roll-up — см. Запрос, огрубление, 1030
Rotational latency time — см. Диск, время,
оборота, 505
R-tree — см. R-дерево, 638
Run-length code — см. Код,
периодический, 674
Runtime error — см. Ошибка периода
выполнения, 273
R-дерево, 638; 657; 666; 680
S
Saga — см. Хроника, 995
Scalar — см. Скаляр, 272
Scanning — см. Отношение,
сканирование, 683
Schedule — см. Расписание, 396
avoids cascading rollback — ACR —-
см. Расписание, без каскадного
отката, 953
Scheduler — см. Планировщик заданий, 41
Scope — см. Контекст, 443
Search key — см. Ключ, поиска, 583
Second normal form — 2NF —
см. Нормальная форма, вторая, 134
Secondary index — см. Индекс,
вторичный, 599
Secondary storage device — см. Устройство
хранения, вторичное, 36
Sector — см. Диск, сектор, 501
Seek time — см. Диск, время, поиска, 505
Selection — см. Выбор, 205
Selinger-style optimization — см. Алгоритм,
оптимизации, по Селинджеру, 805
Semantic checking — см. Семантический
контроль, 759
Semijoin — см. Полусоединение, 225
Semistructured data —
см. Полуструктурированные данные, 45
Sequential file — см. Файл,
последовательный, 47
Serial schedule — см. Расписание,
последовательное, 396
Serializable schedule — см. Расписание,
условно-последовательное, 396
Server — см. База данных, сервер, 37
Session — см. База данных, сеанс, 381
Set — см. Множество, 161
SGML - см. Язык, SGML, 192
Shared locking — см. Транзакция,
блокирование, общее, 894
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1063
Shared variable — см. Переменная,
общая, 352
Single-row select — см. Выбор,
единственного кортежа, 354
Singleton collection — см. Коллекция,
единичная, 435
Single-value constraint — см. Ограничение,
уникальности, 74
Slicing — см. Куб данных, расслоение, 1028
Sort key — см. Ключ, сортировки, 511
Sort-based algorithm — см. Алгоритм,
основанный на, сортировке, 692
Sort-based join — см. Соединение, на
основе, сортировки, 712
Sorting — см. Сортировка, 233
Sort-join — см. Соединение, с
сортировкой, 714
Spanned record — см. Запись,
связанная, 573
Sparse index — см. Индекс,
разреженный, 579
SQL, 34; 46; 49; 87; 149; 175; 203; 232; 249;
314; 317; 349; 440; 749; 754
', 256
%, 255
*, 250
_, 255
||, 295
<, 253; 255; 273
<=, 253; 255; 273
О, 253; 273
=, 253; 273; 756
->, 445
>, 253; 255; 273
>=, 253; 255; 273
ADD, 298; 335
AFTER, 341; 343; 344
ALL, 273; 280; 284; 314; 315; 783
ALL PRIVILEGES, 410
ALTER TABLE, 298; 304; 305; 315;
334; 347
AND, 35; 250; 254; 259; 756
ANY, 273; 280; 314; 783
AS, 252; 265; 305; 342; 371; 380; 440; 479
ASC, 260
AUTHORIZATION, 380; 407
AVG, 285; 288; 315; 696; 771
B, 256
BEFORE, 341; 343
BEGIN, 341; 366; 372
BIT, 297; 553
BIT VARYING, 297
BOOLEAN, 297
CALL, 366; 374
CASCADE, 323; 412
CHAR, 296; 441; 551
CHECK, 328; 329; 330; 332; 333; 334;
337; 347; 406; 415; 838
CLOSE, 368; 371
COMMIT, 341; 398; 399; 400; 404; 840
CONDITION FOR, 369
CONNECT, 341; 380; 407
CONSTRAINT, 334
CONTINUE, 373
COUNT, 285; 288; 315; 641; 696; 771
COUNT(*), 285; 288
CREATE ASSERTION, 337; 347; 378
CREATE FUNCTION, 365; 441
CREATE INDEX, 300; 315; 320; 599
CREATE METHOD, 441
CREATE ORDERING, 448
CREATE PROCEDURE, 364
CREATE SCHEMA, 378
CREATE TABLE, 297; 304; 305; 315;
318; 319; 321; 327; 330; 378; 442; 443;
550; 556
CREATE TRIGGER, 340; 378
CREATE TYPE, 440
CREATE UNIQUE INDEX, 320
CREATE VIEW, 305; 312; 315; 378
CROSS JOIN, 277; 282
CURSOR FOR, 371
DATE, 256; 297; 553
DECIMAL, 297
DECLARE, 366; 369; 372
DEFAULT, 299; 380
DEFERABLE, 326
DEFERRED, 326
DELETE, 341
DELETE FROM, 293; 301; 305; 308; 315
DEREF, 445
DERIVED, 443
DESC, 260
DISCONNECT, 341; 381
DISTINCT, 283; 284; 285; 292; 293; 308;
315; 755; 758; 760
DO, 371
DOMAIN, 410
DOUBLE PRECISION, 297
DROP, 298; 334
DROP ASSERTION, 339
DROP INDEX, 301
DROP TABLE, 298; 305; 310; 315
DROP TRIGGER, 342
DROP VIEW, 310
ELSE, 367
1064
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
ELSEIF, 367
END, 341; 366; 372
END FOR, 371
END IF, 367
END LOOP, 369
END REPEAT, 371
END WHILE, 371
EQUALS ONLY BY STATE, 448
ESCAPE, 257
EXCEPT, 268; 272; 284; 314; 481
EXCEPT ALL, 284
EXISTS, 273; 280; 314; 337; 756; 760; 783
EXIT, 373; 374
FALSE, 254; 258; 297; 339; 755
FETCH, 368; 369; 371; 386
FLOAT, 297; 551
FOR, 370; 371; 373; 442
FOR EACH ROW, 341
FOR EACH STATEMENT, 341
FOREIGN KEY, 321; 347
FROM, 35; 250; 289; 314; 329; 412; 481;
755; 759
FULL OUTER JOIN, 280; 282
GRANT, 409; 410
GROUP BY, 283; 285; 286; 289; 315; 755;
760; Л027
HANDLER, 372
HAVING, 283; 287; 289; 291; 315; 755; 760
IF, 367
IMMEDIATE, 326
IN, 273; 280; 314; 329; 365; 756; 776
INFORMATION_SCHEMA, 377
INITIALLY DEFERRED, 326
INITIALLY IMMEDIATE, 326
INOUT, 365
INSERT, 341
INSERT INTO, 291; 295; 301; 305; 308;
315; 320; 329; 330; 353; 392
INSTEAD OF, 343
INT, 297
INTEGER, 297; 551
INTERSECT, 268; 272; 284; 314
INTERSECT ALL, 284
INTO, 368
IS NOT NULL, 258
IS NULL, 258; 288
ISOLATION LEVEL
READ COMMITTED, 403; 405
READ UNCOMMITTED, 402; 405
REPEATABLE READ, 403; 405
SERIALIZABLE, 403; 405
JDBC, 398
Connection, 390
Connection.createStatement, 390
Connection.prepareStatement, 390
DriverManager, 390
DriverManager.getConnection, 390
PreparedStatement, 390; 391; 393
PreparedStatement.executeQuery, 391
PreparedStatement. Execute Update, 391
PreparedStatement.setlnt, 393
PreparedStatement.setString, 393
ResultSet, 391; 392
ResultSet.getFloat, 392
ResultSet.getlnt, 392
ResultSet.getString, 392
ResultSet.next, 392
Statement, 390; 391
Statement.executeQuery, 391
Statement.executeUpdate, 391
драйвер, 390
соединение, 390
JOIN, 278; 282; 755; 756
LEAVE, 369; 370
LEFT OUTER JOIN, 280
LIKE, 255; 257; 756
LOOP, 369; 371
MAX, 285; 288; 315; 696; 771
METHOD, 441
MIN, 285; 288; 315; 696; 771
NATURAL FULL OUTER JOIN, 279; 282
NATURAL JOIN, 278; 282; 314
NATURAL LEFT OUTER JOIN, 280
NATURAL RIGHT OUTER JOIN, 280
NEW ROW, 341; 342
NEW TABLE, 341; 342
NOT, 254; 255; 259; 273; 282; 756; 760
NOT DEFERABLE, 326
NOT NULL, 328
NULL, 95; 103; 239; 258; 259; 279; 288;
291; 293; 299; 308; 314; 318; 319; 321;
322; 323; 327; 328; 346; 373; 571
NUMERIC, 297
OF, 341; 442
OLD ROW, 341; 342
OLD TABLE, 341; 342
ON, 278; 282; 300; 340; 410; 411
ON DELETE, 323
ON UPDATE, 323
OPEN, 368; 371
OR, 254; 259; 756; 760
ORDER BY, 260; 289; 686; 755; 760; 831
ORDERING FULL BY RELATIVE
WITH, 449
OUT, 365
OUTER JOIN, 314
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1065
PRIMARY KEY, 318; 319; 321; 347
PUBLIC, 405; 408; 418
REAL, 297
RECURSIVE, 479
REF, 443; 445
REF IS, 443
REFERENCES, 321; 347
REFERENCING, 340
REPEAT, 371
RESTRICT, 412
RETURN, 365; 366
RETURNS, 365; 374; 441
REVOKE, 411
REVOKE GRANT OPTION FOR, 413
RIGHT OUTER JOIN, 280
ROLLBACK, 341; 398; 399; 400; 401;
404; 840
SCOPE, 443
SELECT, 35; 250; 285; 289; 308; 314;
755; 760
SELF, 441
SET, 294; 341; 366
SET CATALOG, 379; 381
SET CONNECTION, 381
SET CONSTRAINT, 326; 334
SET NULL, 323
SET SCHEMA, 379; 381
SET TRANSACTION, 403
READ ONLY, 400; 403; 404
READ WRITE, 400; 403
SHORTINT, 297; 554
SQL/CLI, 398
SQL_CHAR, 383; 387
SQL_HANDLE_DBC, 383
SQL_HANDLEJENV, 383
SQL_HANDLE_STMT, 383
SQLJNTEGER, 383; 387
SQL_NO_DATA, 386; 387
SQLJSTTS, 385; 386
SQL_NULL_HANDLE, 384
SQLAllocHandle, 383; 390; 391
SQLBindCol, 386; 388
SQLBindParameter, 389
sqlcli.h, 383; 386
SQLExecDirect, 386
SQLExecute, 385; 386; 389
SQLFetch, 386; 387; 388
SQLGetData, 388
SQLHDBC, 383
SQLHDESC, 383
SQLHENV, 383
SQLHSTMT, 383
SQLPrepare, 385; 386; 388; 389; 391
SQLRETURN, 384; 386
выполнение, 385
заголовочный файл, 383; 386
запись, 383
команда, 383; 385
описание, 383
передача аргументов, 388
подготовка, 385
связывание, 386
соединение, 383
среда, 383
структура, 383
указатель, 383
SQLSTATE, 352; 353; 354; 369; 372; 398
START TRANSACTION, 398
SUM, 285; 288; 315; 696; 771
SYSTEM GENERATED, 443
THEN, 367
TIME, 257; 297; 553
TIMESTAMP, 257
TO, 410
TRUE, 254; 258; 297; 317; 336; 755
UNDO, 373
UNION, 268; 272; 284; 314; 480; 755
UNION ALL, 284
UNIQUE, 318; 319; 320; 321; 347
UNKNOWN, 254; 258; 259; 297; 314
UNTIL, 371
UPDATE, 294; 295; 305; 308; 315;*320;
329; 330; 341
VALUES, 291; 353
VARCHAR, 297; 552
WHEN, 340; 341
WHERE, 35; 250; 293; 294; 301; 308; 314;
329; 336; 367; 614; 755; 760
WHILE, 371
WITH, 479
WITH GRANT OPTION, 410
X, 256
внедрение, 349; 382; 384; 388; 394; 398;
416; 420; 840
BEGIN DECLARE SECTION, 352
CLOSE, 356
CURSOR FOR, 355
DECLARE, 355
DELETE, 358
END DECLARE SECTION, 352
EXEC SQL, 352; 355; 366; 382
EXECUTE, 362; 385
EXECUTE IMMEDIATE, 362
FETCH, 356; 359; 386
FETCH ABSOLUTE, 361
FETCH FIRST, 360
1066
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
FETCH LAST, 360
FETCH NEXT, 360
FETCH PRIOR, 360
FETCH RELATIVE, 360
INSENSITIVE, 359
INTO, 354; 356
OPEN, 356
PREPARE, 362; 385
READ ONLY, 360
SCROLL, 360; 364
SELECT, 354
UPDATE, 358
WHERE CURRENT OF, 358
динамическое, 361; 362; 385; 416
курсор — см. Курсор, 355
секция объявления, 352
грамматика, 755
запрос, 35; 250; 282; 289; 291; 314; 353;
368; 491; 755
правильный, 755
интерфейс
JDBC - см. SQL, JDBC, 390
SQL/CLI - см. SQL, SQL/CLI, 383
базовый, 249; 350; 374; 382; 398;
416; 840
внедрения — см. SQL, внедрение, 349
исключение, 372; 400
обработчик, 372
команды модификации, 291; 317; 320
стратегии, 322; 327; 328
кортеж
вставка, 291; 301; 315; 320; 329; 330;
353; 406; 923
обновление, 291; 294; 301; 315; 320;
329; 330; 406
удаление, 291; 293; 301; 315; 406
модуль — см. Модуль, 381
хранимый — см. Модуль,
хранимый, 349
отношение
изменение, 296; 298; 304; 305; 315
объявление, 296; 297; 304; 305; 315;
318; 451
удаление, 296; 298; 315
переменная кортежа, 265; 276
подзапрос, 271; 281; 289; 292; 301; 314;
329; 368; 407; 774; 834
коррелированный, 275
привилегия доступа — см. также
Доступ, привилегия, 406
DELETE, 406
EXECUTE, 406
INSERT, 406
REFERENCES, 406
SELECT, 406
TRIGGER, 406
UNDER, 406
UPDATE, 406
USAGE, 406
псевдоним, 252; 261; 265; 276
рекурсивный, 351; 476; 478; 486
семантика, 251; 255; 268
системные аспекты, 349
среда, 377; 417
агент — см. База данных, агент, 382
иерархия, 378
каталог — см. База данных,
каталог, 377
кластер — см. База данных,
кластер, 377
клиент — см. База данных, клиент, 380
сервер — см. База данных, сервер, 380
схема — см. База данных, схема, 377
транзакция — см. Транзакция, 393
хранимая
процедура — см. Процедура,
хранимая, 364
функция — см. Функция, хранимая, 364
цикл, 369; 370; 373
Query — см. Запрос, 32
Exception — см. Класс, исключение, 372
Stable storage — см. Диск, устойчивое
хранилище, 531
Standard Generalized Markup Language —
SGML - см. Язык, SGML, 192
Star schema — см. Отношение, схема,
"звезды", 1026
Starvation — см. Транзакция, естественное
старение, 975
Static hash table — см. Хеш-таблица,
статическая, 626
Static method — см. Класс, метод,
статический, 159
Statistics — см. Статистика, 42
Status bit — см. Диск, сектор, бит
индикации состояния, 531
Stemming — см. Выделение корневой
основы слов, 605
Stop word — см. Слово-разделитель, 605
Storage manager —
см. Менеджер, хранения данных, 41
Stored function — см. Функция,
хранимая, 364
Stored module — см. Модуль, хранимый, 349
Stored procedure — см. Процедура
хранимая, 364
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1067
Strict locking — см. Транзакция,
блокирование, строгое, 954
Strict schedule — см. Расписание,
строгое, 954
Structured address — см. Память, адрес,
структурированный, 560
Structured Query Language — см. SQL, 34
Subclass — см. Подкласс, 64
Subgoal — см. Язык, Datalog, правило,
подцель, 455
Subquery — см. SQL, подзапрос, 271
Superclass — см. Класс, базовый, 61
Superkey — см. Суперключ, 109
Supporting relationship — см. Связь,
поддерживающая, 82
Swapping — см. Подкачка данных, 495
System failure — см. СУБД, отказ, 837
System R, 50; 805; 806; 836
System-R-style optimization —
см. Алгоритм, оптимизации, в стиле
System R, 805
т
Tagged field — см. Поле, тэгов, 572
Таре silo — см. Ленточный бункер, 498
Таре storage — см. Магнитная лента, 497
Template — см. Оболочка, шаблон, 1012
Ternary relationship — см. Связь,
тернарная, 56
Tertiary storage device — см. Устройство
хранения, третичное, 36
Theta-join — см. Тета-соединение, 212
Theta-outerjoin — см. Внешнее тета-
соединение, 240
Third normal form — 3NF —
см. Нормальная форма, третья, 134
Three-phase commit — см. Транзакция,
фиксация, трехфазная, 1001
Three-phase multiway merge sort —
см. Алгоритм, сортировки, слиянием,
трехфазным многокомпонентным, 517
Time value — см. Значение, времени, 297
Timeout — см. Транзакция, лимит
времени активности, 968
Timestamping — см. Транзакция,
хронометраж, 880
Tombstone — см. Диск, блок, данных,
признак-"обелиск", 561
TPMMS — см. Алгоритм, сортировки,
слиянием, двухфазным
многокомпонентным, 489
Track — см. Диск, дорожка, 501
Training set — см. Множество,
подготовленное, 1041
Transaction — см. Транзакция, 31
Transaction commands — см. Транзакция,
команды, 43
Transaction component — см. Транзакция,
компонент, 979
Transaction manager — см. Менеджер,
транзакций, 43
Transaction processor — см. Процессор,
транзакций, 41
Transfer time — см. Диск, время,
передачи, 505
Translation table — см. Память, адрес,
таблица, трансляции, 562
Tree-like graph — см. Граф,
древовидный, 609
Trigger — см. Триггер, 46
Tuple — см. Кортеж, 35
Tuple variable — см. SQL, переменная
кортежа, 265
Two-argument selection — см. Выбор,
с двумя аргументами, 775
Two-pass algorithm — см. Алгоритм,
двухпроходный, 693
Two-phase commit — см. Транзакция,
фиксация, двухфазная, 979
Two-phase locking — см. Транзакция,
блокирование, двухфазное, 880
Two-phase multiway merge sort —
TPMMS — см. Алгоритм, сортировки,
слиянием, двухфазным
многокомпонентным, 489
Туре — см. Тип, 150
Type constructor — см. Тип,
конструктор, 161
и
UDT — см. Тип, пользовательский, 440
Unicode — см. Набор символов,
Unicode, 551
Union — см. Объединение, 205
Unique key — см. Ключ, уникальный, 318
Uniqueness constraint — см. Ограничение,
уникальности, 54
Updatable view — см. Представление,
обновляемое, 308
Update locking — см. Транзакция,
блокирование, обновляемое, 906
User-defined type — UDT — см. Тип,
пользовательский, 440
1068
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
V
Valid parse tree — см. Дерево, разбора,
действительное, 759
Valid XML document — см. Язык, XML,
действительный документ, 192
Validation — см. Транзакция, проверка
достоверности, 880
Varying-length string — см. Строка,
переменной длины, 297
Verifying — см. Диск, запись данных,
проверка, 508
Vertical decomposition — см. Отношение,
декомпозиция, вертикальная, 978
View — см. Представление, 296
View-equivalent schedule —
см. Расписание, эквивалентное, с
учетом источников данных, 963
View-serializable schedule —
см. Расписание, условно-
последовательное, с учетом,
источников данных, 962
Virtual address space — см. Память,
адресное пространство, виртуальное, 559
Virtual database — см. База данных,
виртуальная, 49
Virtual memory — см. Память,
виртуальная, 494
Virtual table — см. Таблица,
виртуальная, 296
Volatile storage — см. Устройство
хранения, энергозависимое, 499
W
Waits-for graph — см. Граф, ожидания, 969
Warehouse — см. Хранилище данных, 39
Warning locking — см. Транзакция,
блокирование, предупреждающее, 919
Weak entity set — см. Множество,
сущностей, слабое, 77
Web-броузер, 39
Web-сайт, 37
Web-сервер, 37; 1018
Well-formed SQL query — см. SQL, запрос,
правильный, 755
Well-formed XML document — см. Язык,
XML, правильный документ, 192
World Wide Web, 31; 50; 150; 187; 315; 603
Wrapper — см. Оболочка, 191
Wrapper generator — см. Оболочка,
генератор, 1013
Write failure — см. Диск, отказ, записи, 530
Write locking — см. Транзакция,
блокирование, монопольное, 902
Write-ahead logging — см.
Протоколирование, опережающее, 859
WWW Consortium, 200; 201
X
XML - см. Язык, XML, 45
z
Zig-zag join — см. Соединение,
зигзагообразное, 730
А
Автоматический привод оптических
дисков, 498; 546
Авторизация — см. Доступ,
авторизация, 46
Агрегирование, 206; 226; 233; 234; 247; 252;
283; 285; 315; 429; 430; 451; 483; 641;
644; 696; 709; 719; 746; 770; 796; 1004
Аксиомы Армстронга, 121; 123; 147
Алгоритм
4ОТ-декомпозиции, 141
BCNF-декомпозиции, 128; 141; 211; 215
first-in, first-out — FIFO, 511; 524; 526;
529; 734
бинарного поиска, 586; 588; 623
ветвей и границ, 806; 819; 835
вычисления замыкания множества
атрибутов, 116; 121; 146; 147
двухпроходный, 693; 706; 717; 750; 827
динамического программирования, 805;
806; 814; 819; 835
жадный, 805; 819; 835; 836
лифта, 523; 526; 528; 529; 547
многопроходный, 512; 693; 706; 738; 750
однопроходный, 692; 750; 825
оптимизации
в стиле System R, 805; 806
по Селинджеру, 805; 806; 808; 819;
835; 836
основанный на
индексировании, 692; 725; 750
сортировке, 692; 706; 738; 750; 751
хешировании, 692; 717; 739; 750
параллельный, 741; 751
сортировки
быстрой, 512; 737
слиянием, 512; 737
k-фазным многокомпонентным, 518
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1069
двухфазным многокомпонентным,
489; 513; 516; 519; 521; 526; 547; 686;
689; 691; 693; 706; 712; 714; 808
трехфазным многокомпонентным,
517; 518
часов, 734
Атрибут, 34; 47; 53; 59; 74; 85; 88; 90; 91;
145; 172; 250; 490; 549; 550; 755
агрегируемый, 235; 285; 696; 709
группирующий, 235; 286; 430; 641; 696;
709; 719; 796
зависимый, 1026
ключевой, 75; 80; 81; 83; 86; 93; 95; 96;
108; ПО; 145; 151; 168; 178; 204; 318;
327; 347
первичный, 136
размерностный, 641; 1026
ссылочный, 442
тип, 80; 145; 181; 182; 187; 200; 207; 250;
296; 315; 490; 561
Б
База данных, 31
агент, 382; 408; 562
администратор, 40
активный элемент, 317
архив, 837; 838; 871; 872; 876; 980
виртуальная, 49; 1003; 1004; 1047
восстановление, 837; 850; 860; 863;
866; 868; 874-876; 949-952; 959;
961; 982; 999
распределенное, 985
дамп
инкрементный, 871; 876
полный, 871
домен — см. Домен, 379
интегрированная, 1003
интенсиональная, 458
каталог, 376; 377; 379; 417
текущий, 379; 381
кластер, 376; 377; 417
клиент, 37; 46; 49; 341; 380; 383; 417;
559; 562
метод сопоставления строк — см. Метод
сопоставления строк, 379
моделирование, 51; 87; 149; 296
модификация, 291; 295; 301; 315; 341
инкрементная, 1007
набор символов — см. Набор
символов, 379
объектно-ориентированная, 149; 181;
200; 296; 419; 549; 559
объектно-реляционная, 45; 51; 149; 181;
200; 440; 550; 561
привилегия доступа — см. Доступ,
привилегия, 380
проектирование, 45; 51; 87; 149; 296;
301; 317; 332
основные принципы, 66; 86
распределенная, 949; 976; 977; 982; 1000
резервная копия — см. База данных,
архив, 871
реляционная, 34; 49; 176; 296; 314; 549
сайт, 976; 977; 1000
блокировок, 988; 990; 1000
координатор, 983; 1000
сеанс, 341; 381; 407; 417; 490
сервер, 37; 46; 49; 341; 380; 383; 417;
559; 562
согласованность состояния, 44; 394; 399;
400; 841; 844; 845; 875; 880; 882; 901;
945; 949; 950; 997
схема, 32; 40; 49; 51; 54; 76; 88; 145; 149;
189; 199; 204; 250; 317; 349; 376; 377;
378; 406; 407; 410; 417; 490; 841; 945
аномалии, 123; 124; 174
декомпозиция, 123; 124; 146; 183;
211; 215
избыточность, 124; 137; 146; 183
реляционная, 45; 52; 88; 90; 91
текущая, 379; 381
унаследованная, 39; 190; 1018
экземпляр, 54; 76; 92; 145
экстенсиональная, 458
Буфер, 41; 44; 48; 49; 496; 512; 515; 522;
526; 559; 586; 589; 687; 693; 695; 732; 749;
751; 812; 826; 840; 842; 879; 912; 955
стратегии замещения, 734
В
Виртуальная память — см. Память,
виртуальная, 494
Внешнее соединение, 233; 239; 247; 258;
277; 279; 282; 314; 701
левое — см. Левое внешнее
соединение, 239
полное — см. Полное внешнее
соединение, 279
правое — см. Правое внешнее
соединение, 239
Внешнее тета-соединение, 240
левое — см. Левое внешнее тета-
соединение, 240
1070
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
полное — см. Полное внешнее тета-
соединение, 280
правое — см. Правое внешнее тета-
соединение, 240
Выбор, 205; 206; 209; 213; 214; 217; 246;
250; 251; 253; 278; 314; 462; 465; 686;
691; 693; 725; 726; 744; 762; 785; 788;
822; 826; 830
единственного кортежа, 354
законы расщепления, 762
из мультимножеств, 229
с двумя аргументами, 775; 834
Выделение корневой основы слов, 605
Г
Генератор логического плана запроса,
754; 759
Гистограмма, 786; 798; 807; 835
процентиль, 798
с наиболее часто встречающимися
значениями, 798
с равной
высотой, 798
шириной, 798
Грамматика, 754
атом, 754
правило, 754
синтаксическая категория, 754
Граф
древовидный, 609
зависимостей, 481
назначения привилегий —
см. Диаграмма, назначения
привилегий, 411
ожидания, 969; 976; 1000; 1001
ациклический, 969; 977; 1000
глобальный, 991
циклический, 969; 977; 1000
полуструктурированных данных, 188;
192; 193; 196; 200
предшествования, 888; 891; 927; 946;
964; 967; 968; 999
ациклический, 890; 927; 946; 964;
967; 999
топологическая очередность вершин,
890; 927; 967
циклический, 891
рекурсии, 476; 481
сущностей и связей — см. Диаграмма,
сущностей и связей, 52
хроники, 995; 1001
Группирование, 233; 234; 235; 247; 252;
283; 285; 286; 315; 429; 430; 451; 693;
694; 701; 709; 716; 719; 738; 740; 746;
770; 796; 825
Д
Декартово произведение, 205; 206; 210; 212;
217; 263; 267; 277; 278; 283; 314; 464; 693;
697; 699; 700; 701; 763; 769; 794
мультимножеств, 230
Дерево
ветвящееся, 811; 821
выражений реляционной алгебры —
см. Реляционная алгебра, дерево
выражений, 214
квадрантов, 638; 657; 664; 679; 680
левостороннее, 810; 821; 835
областей — см. R-дерево, 666
правостороннее, 811
разбора, 684; 753; 754; 760; 774; 834
действительное, 759
решений, 1041; 1048
сбалансированное — см. В-дерево, 46
сбалансированное бинарное, 46
соединения, 809; 821; 835
Диаграмма
назначения привилегий, 411; 415; 418
сущностей и связей, 52; 53; 77; 79; 85;
91* 92* 165* 187
Диск, 36; 41; 47; 48; 49; 302; 489; 495; 500;
546; 549; 583; 742; 826; 839; 912; 950
RAID - см. RAID, 534
Zip, 498; 503
блок
головок, 500; 501; 505; 523; 546
данных, 41; 46; 302; 495; 501; 503; 504;
505; 516; 546; 549; 550; 560; 567; 574;
580; 585; 687; 841; 843; 846; 919; 955;
957; 999
адрес, 558
заголовок, 557; 577; 580; 590; 596; 690
закрепленный в памяти, 566; 581;
735; 955
идентификатор, 557
переполнения, 577; 579; 581; 592;
596; 624; 647; 958
попеременное распределение, 548;
574; 581
признак-"обелиск", 561; 568; 578;
581; 595; 622; 677
смещение записи, 555; 557
таблица смещений записей, 561;
568; 577; 578; 579; 581; 595
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1071
дисков, 500; 503
ввод-вывод, 496; 580; 585; 607; 686;
749; 843
виртуальный, 500
восстановление данных, 534
время
задержки, 504; 546; 623
оборота, 505; 520; 546; 623
передачи, 505; 520; 546; 623
поиска, 505; 520; 546; 623
среднее, 505
среднее наработки на отказ, 534
гибкий, 498; 503; 504
головка, 501; 505
дорожка, 501; 503; 504; 546; 559; 567; 581
живучесть, 535
зазор, 501; 504; 546
запись данных, 496; 504; 508
проверка, 508
зеркальный, 522; 528; 534; 535; 547
идентификатор, 559; 581
количество
байтов на дорожке, 503
дорожек на поверхности, 503
пластин, 503
контроллер, 41; 502; 505; 507; 511; 521;
523; 525; 546
крупномасштабная буферизация
данных, 526; 529; 547
магнитный — см. Диск, 495
магнито-оптический, 495
оптический, 495; 871
отказ, 530; 547; 870; 876
записи, 530; 533
перемежающийся, 530; 531; 547
полный, 531; 534; 547
параметры доступа, 504
пластина, 500; 503; 504; 505; 546
плотность записи, 504
разрушение носителя, 530; 533; 547
резервирование — см. RAID, 534
сектор, 501; 503; 505; 531; 546; 567; 581
бит индикации состояния, 531
контрольная сумма, 531; 547; 838
четность, 531; 532; 547
скорость вращения блока дисков, 503
считывание данных, 496; 504
предварительное, 526; 529; 547
упорядочение операций, 523; 528
устойчивое хранилище, 531; 532; 547
цилиндр, 502; 505; 523; 546; 559; 567;
574, 581; 583
группирование данных, 519; 526; 528;
547; 695
Дисперсия, 369; 376
Домен, 74; 80; 89; 145; 207; 250; 379; 410
Доступ
авторизация, 46; 381; 405
идентификатор, 405; 408
пароль, 408
безопасность, 405; 408
привилегия, 380; 405; 406; 417
аннулирование, 411; 418
назначение, 409; 418
право передачи, 409; 418
создание, 407
управление, 349; 376; 405
Е
Естественное соединение, 211; 217; 239;
246; 277; 278; 464; 467; 697; 700; 701;
716; 728; 740; 782; 788; 791; 792
закон
ассоциативный, 232; 467
коммутативный, 232; 467
мультимножеств, 231
3
Зависимость, 45
многозначная, 106; 137; 146; 244; 246
вычитание, 144
дополнение, 140; 142
нетривиальная, 141; 146
объединение, 144
пересечение, 142; 144
проецирование, 142
транзитивность, 139; 142
тривиальная, 144
функциональная, 87; 106; 137; 145; 146;
175; 182; 241; 243; 246; 247
верная, 116
заданная, 119
нетривиальная, 114; 126; 146
объединение, 113
полное расширение, 122
полностью нетривиальная, 114
проецирование, 120
производная, 119
псевдотранзитивность, 122
разделение, 113
расширение, 121
рефлективность, 121
сложение, 122
транзитивность, 113; 118; 121
1072
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
тривиальная, 114
эквивалентность, 113
Закон
Мура, 496; 500; 546
Пуассона, 634
Запись, 549; 550; 554; 580; 583; 690
адрес, 558; 567
вставка, 568; 576; 579; 581; 592; 596
заголовок, 556; 569; 573; 578; 580
закрепленная в памяти, 565; 566
обновление, 579; 581
переменной длины, 551; 569; 580; 581; 677
постоянной длины, 554
связанная, 573; 580
смещение поля, 554; 569
схема, 554; 556; 569; 580
удаление, 561; 568; 577; 579; 581; 592;
594; 595
указатель, 561
Запрос, 32; 203; 249; 314
OLAP, 1023
в диапазоне значений, 614; 626; 635;
639; 641; 651; 657; 659; 662; 679; 830
выполнение, 683; 749; 753
к данным с совпадением отдельных
координат, 639; 651; 659; 662; 672;
679; 680
компиляция, 683; 749; 753; 834; 836
обработка, 40; 189; 215; 238; 301; 583;
683; 749; 753
огрубление, 1030
оптимизация, 684; 728; 749; 751; 753;
836; 1003
распределенная, 751; 980
перезапись, 684; 760
поддержки принятия решений, 639;
1023; 1040
разработки данных, 1040
синтаксический анализ, 684; 753; 754;
834
уточнение, 1030
Значение
времени, 297; 553
даты, 297; 553
логическое, 297
по умолчанию, 291; 292; 299; 314; 315;
346; 406
строковое
битовое, 297; 553
переменной длины, 296; 552; 580
постоянной длины, 296; 551; 553; 580
целочисленное, 297; 551; 553; 580
числовое с плавающей запятой, 297; 551
И
Индекс, 36; 40; 42; 44; 47; 49; 189; 299; 315;
319; 320; 549; 562; 564; 565; 583; 683; 692;
750; 822; 830; 835; 957; 993; 1019
В-древовидный — см. В-дерево, 609
kd-древовидный — см. kd-дерево, 638
R-древовидный — см. R-дерево, 638
вторичный, 599; 607; 635; 636; 641
выбор, 301; 583
группирующий, 725; 727; 824; 833
многомерный, 47; 637; 823
многоуровневый, 588; 599; 601; 635
обращенный, 604; 608; 635
одномерный, 47; 637
первичный, 599; 677
плотный, 584; 585; 589; 599; 634
разреженный, 579; 584; 585; 586; 589;
599; 634
с несколькими ключами, 638; 657; 679
сегмент, 601; 604
точечный, 637; 638; 671; 680
сжатый, 673; 680
хешированный — см. Хеш-таблица, 624
Инкапсуляция, 152
Интеграция информации, 38; 48; 50; 187;
189; 572; 1003; 1046
Интерфейс
SQL базовый — см. SQL, интерфейс,
базовый, 249
уровня вызовов, 349; 350; 376; 382; 417
JDBC, 349; 383; 390; 417
ODBC, 382; 417
SQL/CLI, 349; 382; 383; 417
Исполняющая машина, 40; 41; 44; 783; 834
Источник данных, 48; 191; 1003; 1014; 1047
спецификация возможностей, 1019
Итератор, 685; 687; 689; 691; 749; 826; 836
К
Канал — см. также Итератор, 691; 754;
768; 822; 825; 826; 827; 831; 836; 1015
Класс, 52; 102; 149; 150; 151; 153; 187;
199; 841
атрибут, 153; 154; 172; 199; 420
ключевой, 168; 178; 199
тип, 150; 155; 161; 172; 181; 199
базовый, 61; 64; 152; 165; 425
-интерфейс, 167; 169; 184
исключение, 159; 426
метод, 151; 152; 153; 159; 181; 185; 199;
200; 420; 551
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1073
код, 159; 551
объявление, 159
перегруженный, 159
сигнатура, 159
статический, 159
объявление, 154; 187; 199
производный, 152; 165
свойства, 153; 420
связь, 153; 155; 177; 187; 199; 420; 551
бинарная, 164; 199
многосторонняя, 164
множественность, 158
обратная, 156; 199
схема, 164
экземпляр, 164; 167; 184; 187; 199; 420;
422; 442; 549; 583
Клиент — см. База данных, клиент, 37
Ключ, 74; 75; 80; 81; 83; 85; 86; 87; 91; 93;
95; 108; ПО; 141; 145; 151; 164; 168; 178;
199; 204; 318; 420; 584
внешний, 317; 321; 327; 838; 1027
дубликаты значений, 589; 599; 612; 633
минимальный, 108; 112
первичный, 75; 77; 109; 317; 318; 321;
327; 347; 442; 512; 576; 584; 838; 1027
поиска, 583; 584; 599; 612; 624; 637; 657
сортировки, 511; 579; 584; 709
уникальный, 318; 319; 321
Код
периодический, 674
с исправлением ошибок, 540; 544; 547
Хемминга, 540; 544
Коллекция, 151; 162; 437; 451
единичная, 435; 451
итоговая, 431
промежуточная, 431; 433
Компакт-диск, 36; 498; 871
Компилятор
DDL, 40
запросов, 40; 44; 48; 49; 254; 683; 753;
834; 836
Компонент, 88; 90; 145; 272; 490; 550
тип
атомарный, 89
базовый, 89
Конкатенация, 237; 253; 295; 392
Конструктор-функция, 438
Контекст, 443
Кортеж, 35; 47; 88; 90; 145; 184; 250; 272;
490; 549; 550; 554; 841
висящий, 211; 233; 238; 279; 314; 324; 789
вставка, 576
вставка — см. SQL, кортеж, вставка, 291
-дубликат, 206; 225; 226; 227; 237; 318; 691
удаление, 232; 233; 276; 283; 289; 315;
693; 694; 701; 706; 716; 718; 738; 740;
745; 769; 795; 825
идентификатор, 181
обновление — см. SQL, кортеж,
обновление, 291
соединенный, 211
ссылка, 181; 182; 183; 185; 200
удаление — см. SQL, кортеж,
удаление, 291
фантомный, 404; 923
Куб данных, 639; 1003; 1026; 1031; 1047
CUBE, 1031; 1047; 1048
рассечение, 1028
расслоение, 1028
сетка, 1036; 1048
Курсор, 354; 355; 369; 383; 385; 392; 416
закрытие, 356; 370; 371
кортеж
извлечение, 356; 369; 371; 385; 386
модификация, 358
порядок просмотра, 360; 370
нечувствительность, 359; 417
объявление, 355; 369
открытие, 356; 369; 371
"только для чтения", 360; 399; 417
Куча, 600
Кэширование, 37; 507
Кэш-память — см. Память, кэш-, 493
Л
Левое внешнее соединение, 239; 280
Левое внешнее тета-соединение, 240; 280
Лексический анализатор запросов, 49
Ленточный бункер, 498; 546
Литерал, 155
м
Магнитная лента, 497; 534; 546; 871
Массив, 161; 175; 199
Материализация, 691; 754; 822; 825; 836
в памяти, 826
Медиатор, 49; 1003; 1004; 1009; 1013; 1018;
1047; 1048
Менеджер
буферов, 41; 49; 690; 732; 750; 812; 840;
842; 843; 846; 879; 955
восстановления, 41; 43; 566; 841; 851; 956
1074
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
параллельных заданий, 41; 43; 690; 879;
894; 912; 950; 979
протоколирования, 41; 43; 45; 840; 843;
846; 950; 979
ресурсов, 40
транзакций, 43; 49; 840; 875; 879
хранения данных, 38; 41; 49
Метаданные, 40; 42; 49; 684
Метод сопоставления строк, 379
Множество, 161; 172; 173; 176; 181; 185;
199; 203; 205; 206; 225; 228; 232; 233;
276; 283; 284; 289; 315; 350; 420; 423;
433; 440; 459; 461; 550; 697; 761
атрибутов, 115; 119; 146
замыкание, 115; 122; 146; 147
кортежей, 89; 203; 225
подготовленное, 1041
сущностей, 52; 53; 59; 73; 85; 87; 91;
145; 151; 164; 187
дерево, 62
ключ, 75; 86
корневое, 62; 75; 100
подкласс, 61; 86; 91; 100
слабое, 77; 81; 85; 86; 91; 96; 145;
151; 170
соединяющее, 60; 70; 82
экземпляр, 55
Модель
XML, 192
блоковая дисковых данных, 47; 495; 549
вычислений
с произвольным доступом
к данным, 510
с функциями ввода-вывода, 510
объектно-ориентированная, 149; 180;
187; 199; 200; 296; 419
объектно-реляционная, 51; 149; 180;
181; 192; 200; 419
отказов дисковых устройств, 534
полуструктурированных данных, 45; 51;
149; 187; 192; 200; 1005
реляционная, 34; 45; 49; 51; 87; 145; 146;
149; 168; 171; 180; 181; 187; 192; 199;
203; 242; 350; 419; 486
реляционного исчисления, 487
рыночной корзины, 1042; 1048
"сущность-связь", 45; 51; 85; 87; 149;
157; 164; 168; 171; 187; 203
часто встречающихся наборов объектов,
1040; 1042; 1048
Модуль, 381; 407
общего вида, 382
хранимый, 349; 364; 382; 417
Мультимедиа, 38; 50
Мультимножество, 161; 172; 175; 176; 181;
185; 199; 203; 205; 206; 225; 226; 228;
232; 233; 246; 276; 283; 284; 289; 315;
391; 422; 433; 440; 459; 461; 683; 761
н
Набор символов, 379
16-битовый, 551
8-битовый, 551
ASCII, 379; 551
EBCDIC, 551
Unicode, 551
Наследование, 150; 152; 164; 166
множественное, 166
Нормализация, 45; 87; 123; 175; 182; 204
Нормальная форма
Бойса-Кодда, 123; 126; 146; 174; 178;
179; 183; 211; 215
декомпозиция, 128; 146
вторая, 134
дизъюнктивная, 463
первая, 134
третья, 134; 146
четвертая, 134; 141; 146; 175
декомпозиция, 141; 146
О
Оболочка, 191; 1003; 1004; 1009; 1012;
1047; 1048
генератор, 1013; 1047; 1048
драйвер, 1013; 1047
шаблон, 1012; 1014; 1047
Обратное полусоединение, 225; 701
Обращение по ссылке, 445
Объединение, 205; 206; 207; 217; 226; 246;
263; 268; 284; 314; 429; 433; 451; 458;
461; 469; 481; 685; 693; 697; 710; 740;
745; 763; 782; 806; 809; 825
закон
ассоциативный, 232
дистрибутивный к пересечению, 232
коммутативный, 232
множеств, 207; 698; 701; 709; 720; 795
мультимножеств, 227; 691; 697; 709;
720; 795
Объект, 52; 102; 149; 150; 151; 153; 184;
419; 549; 550; 841
брокер, 559
идентификационный номер, 150; 151;
153; 168; 179; 182; 185; 199; 442;
451; 551
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1075
изменяемый, 151
крупный двоичный, 550; 569; 574; 581
неизменяемый, 151; 437
-отношение, 181
ссылка, 181; 182; 183; 185; 200
сертификат, 179
текущий, 151
Ограничение, 44; 46; 74; 203; 241; 247;
249; 317; 406; 556; 838; 841; 945
внешнего ключа, 318; 327
домена, 74; 80; 89; 244
именование, 334; 336
классификация, 74
ключа, 74; 91; 317; 318; 327; 347
модификация, 334; 347
общего вида, 74; 241; 317; 331; 332; 333;
336; 345; 347; 406; 415
проверка, 324; 347
непосредственная, 326; 334
отложенная, 324; 334; 398
ссылочной целостности, 74; 78; 80; 83;
86; 91; 106; 241; 242; 247; 317; 318;
321; 327; 328; 347; 406
уникальности, 54; 74; 77; 81; 318; 319
уровня
атрибута, 296; 328; 329; 347; 406
кортежа, 328; 330; 333; 347; 406; 415
отношения, 296; 318; 328
схемы, 328; 336
циклическое, 325
Оперативная аналитическая обработка
данных, 1003; 1023
многомерных данных, 1026
реляционных данных, 1026
Оперативная обработка транзакций, 1024
Оперативная память — см. Память,
оперативная, 36
Оператор коллекции, 151
Оптимизатор запросов, 44; 48; 49; 215;
238; 684; 728; 753; 836; 980; 1003
Отношение, 34; 47; 87; 90; 91; 145; 146;
149; 184; 187; 203; 205; 225; 250; 296;
377; 410; 419; 440; 490; 549; 554; 583;
756; 841
адресуемое, 443
базис, 119
базовое, 306; 313; 314; 315
взаимно рекурсивное, 481
вложенное, 181; 182; 200
декомпозиция, 123; 124; 146
вертикальная, 978; 1000
горизонтальная, 978; 1000
интенсиональное, 458; 479; 486
ключ, 108; ПО; 146
компактно сгруппированное, 688; 698;
725; 726; 727; 738; 823; 830
логическое, 978; 1000
монотонное, 482
объединение, 95
опорное, 809; 826
сканирование, 683; 684; 685; 749; 830
индексное, 685; 689; 725; 749; 805;
823; 835
с сортировкой, 686; 689; 749
табличное, 685; 688; 690; 749; 823; 831
суперключ, 109; 119; 126; 146
схема, 88; 90; 92; 95; 145; 175; 182; 187;
199; 207; 556
"звезды", 1026; 1047
изменение — см. SQL, отношение,
изменение, 296
объявление — см. SQL, отношение,
объявление, 296
удаление — см. SQL, отношение,
удаление, 296
тестируемое, 809
фильтрация, 805; 823; 830; 835
фрагмент, 978; 981
экземпляр, 90; 92; 95; 107; 145; 164;
199; 458
текущий, 90
экстенсиональное, 458; 486
Очередь, 511
с приоритетами, 515
Ошибка периода выполнения, 273
п
Память
адрес
логический, 560; 561; 578; 581
структурированный, 560; 567; 577; 581
таблица
соответствий, 560; 561; 562; 568;
578; 581
трансляции, 562; 564; 565
физический, 559; 567; 578; 581
адресное пространство, 559; 562; 742; 842
базы данных, 559; 562; 842
виртуальное, 559; 562; 842
подмена указателей, 563; 566; 581
автоматическая, 564; 568
запрет, 565; 568
по требованию, 564; 568
программное управление, 565
транзакции, 842
1076
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
виртуальная, 494; 495; 559; 563
динамическая с произвольным
доступом, 499
иерархия, 47; 489; 492; 546
кэш-, 493; 504; 546; 741; 742
2-го уровня, 493
встроенная, 493
оперативная, 36; 41; 48; 49; 302; 489;
493; 494; 496; 504; 511; 521; 546; 555;
559; 581; 586; 589; 687; 693; 742; 749;
826; 839; 842; 912; 950
произвольный доступ, 494
подкачка данных, 495; 733
пул, 733; 912; 955
регенерация, 500
страница, 41; 495; 496; 841; 919; 955; 957
флэш-, 500
Параллельные вычисления, 36; 48; 49;
349; 359; 394; 400; 417; 492; 562; 741;
850; 875; 879; 947; 949
Переименование, 206; 207; 215; 217;
236; 244
Перекрестное соединение —
см. Декартово произведение, 277
Переменная, 151
локальная, 364
общая, 352; 353; 420
экземпляра, 150
Пересечение, 206; 208; 214; 216; 246; 263;
268; 281; 284; 314; 429; 433; 451; 460;
481; 693; 697; 710; 720; 738; 740; 746;
763; 782; 795; 806; 809
закон
ассоциативный, 232
дистрибутивный к объединению,
232; 762
коммутативный, 232
множеств, 207; 698; 701; 716
указателей, 602; 603; 642; 644; 823
мультимножеств, 227; 699; 701
План запроса, 40; 44; 49; 749
выполнимый, 1020
логический, 48; 684; 692; 728; 749; 753;
760; 774; 834; 981
генератор, 754; 759
подсчет стоимости, 783; 1018; 1047
учет возможностей источников данных,
1018; 1047; 1048
физический, 48; 684; 692; 749; 753; 760;
774; 822; 834; 980
Планировщик заданий, 41; 43; 44; 840;
879; 894; 897; 912; 939; 950; 979
двухкомпонентный, 912
Подзапрос — см. SQL, подзапрос, 271
Подкачка данных, 495; 733
Подкласс, 64; 152; 164; 165; 425
Поиск
бинарный — см. Алгоритм, бинарного
поиска, 586
ближайших соседних объектов, 639; 643;
652; 657; 659; 663; 679
в локальной окрестности, 806
Поле, 150; 549; 550; 551; 554; 569; 580; 583
переменной длины, 569; 580
повторяющееся, 570; 580
тэгов, 572
Полное внешнее соединение, 279
Полное внешнее тета-соединение, 280
Полусоединение, 225; 701; 797
обратное — см. Обратное
полусоединение, 225
Полуструктурированные данные, 45; 51;
149; 187; 192; 200; 1005
Правило "событие—условие—действие", 339
Правое внешнее соединение, 239; 280
Правое внешнее тета-соединение, 240; 280
Представление, 296; 305; 315; 344; 759
материализованное, 1034; 1048
модификация, 308
обновляемое, 308; 313
объявление, 305; 312
удаление, 310
Препроцессор, 350; 353; 361; 382; 416
запросов, 44; 754; 759
Программирование
объектно-ориентированное, 38; 46; 149;
159; 390; 419; 552
приложений баз данных, 45; 46; 204;
250; 317; 349
Проект
HiPAC, 348
INGRES, 50
LORE, 200
System R, 50; 316; 805; 806; 836
TSIMMIS, 200
Проекция, 124; 205; 206; 208; 214; 217;
226; 231; 241; 246; 251; 314; 462; 466;
693; 701; 766; 785; 794; 826
мультимножеств, 228
обобщенная, 236
расширенная, 233; 236; 241; 247; 267;
766; 785
Протоколирование, 43; 48; 49; 398; 837;
875; 912; 950; 952; 955; 982; 985
запись, 840; 846
сброс, 846; 848; 999
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1077
контрольная точка, 837; 846; 851; 852;
854; 861; 867; 872; 876
логическое, 848; 957; 959; 999; 1001
опережающее, 859
режим
"redo", 858
"undo", 846
"undo/redo", 865
Процедура хранимая, 364; 374; 375; 376;
377; 382; 406; 453
Процессор, 497; 502; 505; 516; 546; 741; 977
запросов, 43; 49; 251; 683; 735; 840
транзакций, 41; 43
Р
Разность, 205; 206; 208; 216; 217; 246; 263;
268; 281; 284; 314; 429; 433; 451; 461; 481;
693; 697; 710; 720; 740; 746; 763; 795
множеств, 207; 698; 701
мультимножеств, 227; 699; 701; 716
Разработка данных, 39; 1003; 1040; 1048
кластеризация, 1041; 1048
Расписание, 396; 880; 945
без каскадного отката, 953; 954; 962
восстановимое, 952; 954; 962
конфликт, 887; 946
конфликтно-эквивалентное, 888; 893;
963; 968
корректность, 895; 903; 909
последовательное, 396; 398; 880; 881;
892; 945; 949
строгое, 954
условно-последовательное, 396; 879;
880; 882; 885; 889; 895; 900; 945; 950;
954; 962
с учетом
источников данных, 962; 964;
999; 1001
конфликтов, 879; 887; 888; 895; 900;
946; 962; 999
физически неосуществимое, 931; 937
эквивалентное, 892
с учетом источников данных, 963; 968
Реляционная алгебра, 44; 45; 203; 246;
249; 251; 255; 263; 267; 268; 271; 281;
291; 453; 468; 486; 683; 741; 753; 760
выражение, 206; 214; 458; 460
линейное представление, 217
оптимизация, 215
эквивалентность, 215
дерево выражений, 214; 217; 311; 313;
466; 753; 760
закон
ассоциативный, 761
дистрибутивный, 762
коммутативный, 760
запрос, 207
оператор
AND, 209; 213; 214
AVG, 234
COUNT, 234
MAX, 234
MIN, 234
SUM, 234
агрегирования —
см. Агрегирование, 233
внешнего соединения — см. Внешнее
соединение, 233
внешнего тета-соединения —
см. Внешнее тета-соединение, 240
выбора — см. Выбор, 205
группирования —
см. Группирование, 233
декартова произведения —
см. Декартово произведение, 205
естественного соединения —
см. Естественное соединение, 211
зависимый, 216
идемпотентный, 241
левого внешнего соединения —
см. Левое внешнее соединение, 239
левого внешнего тета-соединения —
см. Левое внешнее тета-
соединение, 240
монотонный, 224
независимый, 216
обратного полусоединения —
см. Обратное полусоединение, 225
объединения — см. Объединение, 205
переименования —
см. Переименование, 206
пересечения — см. Пересечение, 206
полусоединения —
см. Полусоединение, 225
правого внешнего соединения —
см. Правое внешнее
соединение, 239
правого внешнего тета-соединения —
см. Правое внешнее тета-
соединение, 240
проекции — см. Проекция, 205
разности — см. Разность, 205
соединения — см. Соединение, 205
сортировки — см. Сортировка, 233
1078
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
тета-соединения — см. Тета-
соединение, 212
удаления кортежей-дубликатов —
см. Кортеж, -дубликат, удаление, 232
реализация операторов, 683; 684; 749
Репликация данных, 39; 839; 949; 979; 981;
987; 988; 1000
Роль, 57; 93
САПР, 638; 949; 993
Связь, 53; 85; 91; 93; 145; 187
isa, 61; 75; 81; 86; 91; 101; 103; 145; 166
древовидная, 62; 86
бинарная, 53; 55; 60; 70; 80; 83; 85
ключ, 80
многосторонняя, 53; 56; 73; 82; 94; 111
преобразование, 60; 70
множественность, 55; 85
множество данных, 55; 80; 157
параллельная, 63
поддерживающая, 82; 85; 96
тернарная, 56
четырехсторонняя, 58; 94
экземпляр, 55
Сеанс — см. База данных, сеанс, 341
Семантический контроль, 759; 834
Сервер — см. База данных, сервер, 37
Синтаксический анализатор запросов, 44;
361; 684; 753; 754; 834
Система
автоматизированного
проектирования — см. САПР, 638
баз данных — см. СУБД, 31
банковская, 33; 63; 71; 90; 152; 153; 163;
186; 191; 349; 394; 528; 534; 908; 918;
949; 977; 980; 986; 993; 997; 1024
бронирования авиабилетов, 33; 100; 394;
519; 528; 534; 886; 908; 949; 1024
географическая информационная,
638; 679
интегрированная, 1003
"клиент/сервер", 37; 349; 380; 381; 383;
407; 417; 559
контроля версий, 993
корпоративная, 33
многопроцессорная, 493; 741; 750; 751
операционная, 41; 495; 559; 733
UNIX, 257; 405; 490
параллельная, 741; 750
распределенная, 37; 48; 153; 559; 949;
977; 982; 1000
избрание лидера, 985; 1001
с неоднородным доступом к памяти, 742
с обособленными ресурсами, 741;
743; 751
с общей памятью, 742; 750
с общими дисками, 743; 750
управления базами данных —
см. СУБД, 31
управления документооборотом, 993
файловая, 31; 32; 41; 49; 149; 405; 490;
495; 552
федеративная, 1003; 1005; 1047; 1048
Скаляр, 272
Словарь, 161; 175; 179; 199
Слово-разделитель, 605; 608
Соединение, 132; 205; 206; 211; 217; 238;
246; 263; 277; 282; 314; 464; 468; 685;
691; 693; 697; 725; 728; 738; 746; 749;
750; 751; 754; 761; 763; 769; 788; 805;
822; 824; 1004; 1028
внешнее — см. Внешнее соединение, 233
выбор порядка, 797; 804; 809; 836
дерево, 809; 821; 835
естественное — см. Естественное
соединение, 211
зигзагообразное, 730
коэффициент избирательности, 820
мультимножеств, 230
на основе
индексирования, 702; 728; 805; 809; 825
сортировки, 712
перекрестное — см. Декартово
произведение, 277
посредством
вложенных циклов, 702; 736; 750;
809; 825
равенства, 697; 700; 732; 740; 758; 788
с сортировкой, 714; 805; 808; 824; 825
с хешированием, 720; 806; 808; 825; 827
гибридное, 721; 751
тета см. Тета-соединение, 212
Сортировка, 233; 238; 247; 260; 320; 489;
511; 512; 513; 518; 576; 683; 686; 692;
706; 738; 750; 831
Список, 161; 172; 175; 199; 238; 423; 436;
451; 512
Ссылочная целостность, 74; 78; 80; 83; 86;
91; 106; 241; 242; 247; 317; 318; 321; 327;
328; 347; 406
обеспечение, 322
Стандарт
ANSI SQL, 249
CODASYL, 34
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1079
CORBA, 153
HTML, 51; 192
IDL, 153
ODL, 45; 51; 60; 149; 152; 203; 296; 365;
419; 452; 551
OQL, 46; 168; 203; 419; 451; 552; 717
PSM-96 — см. Стандарт, SQL/PSM, 364
SGML, 192
SQL, 46
SQL/PSM, 351; 364; 382; 441; 453
SQL2, 249; 315; 348; 453
SQL3, 149; 249; 314
SQL-92, 249
SQL-99, 149; 172; 181; 186; 249; 314; 315;
342; 348; 419; 440; 453; 476; 478; 486; 487
XML, 45; 51; 150; 187; 192
Статистика, 42; 687; 784; 798; 801; 835
Строка
битовая, 297
переменной длины, 297
постоянной длины, 296
СУБД, 31; 49
администратор, 986
живучесть, 837; 838
объектно-ориентированная, 149; 171;
181; 200; 296; 419; 451; 549; 559; 733
объектно-реляционная, 38; 149; 181;
200; 440; 451; 550; 561
отказ, 837; 949; 950; 952; 987
режимы, 838
размещаемая в оперативной памяти,
495; 733
реализация, 45; 47; 187; 489
реляционная, 34; 49; 176; 314; 549
структура, 39; 49
экземпляр, 377
Суперключ, 109; 119; 126; 141; 146
Сущность, 52; 53; 85; 87
компонент, 62; 86
т
Таблица, 87; 145; 296
блокировок, 43; 894; 897; 912; 915; 969;
976; 987; 988
виртуальная, 296; 305; 315; 344; 377; 410;
759
модификация, 308
обновляемая, 308; 313
объявление, 305; 312
удаление, 310
размерностная, 641; 1026
фактических значений, 641; 1025; 1026
Тета-соединение, 212; 217; 244; 246; 277;
278; 465; 697; 700; 762; 788
внешнее — см. Внешнее тета-
соединение, 240
мультимножеств, 231
Тип, 150; 185; 199; 250; 296; 406; 551
атомарный, 150; 161; 175; 181; 199; 437
базовый, 161; 437
коллекции, 151; 162; 175; 185; 199; 437
конструктор, 161; 173; 181; 185; 199;
424; 437
массива, 151; 161; 175; 199
множества, 151; 161; 172; 173; 181;
185; 199
мультимножества, 161; 172; 175; 181;
185; 199
перечислимый, 80; 155; 156; 161; 437; 553
пользовательский, 440; 451
метод, 441
-генератор, 447
-модификатор, 447; 452
-обозреватель, 452
определение, 440
сопоставление объектов, 448
реляционной схемы, 182; 185
словаря, 161; 175; 179; 199
составной, 151; 161; 175; 181; 199; 437
списка, 151; 161; 172; 175; 199
ссылочный, 151; 442; 451; 562
структуры записи, 150; 155; 173; 185
Транзакция, 31; 325; 349; 393; 398; 417;
839; 879; 949
адресное пространство, 842; 950
аномалии поведения, 868; 956
атомарность, 32; 41; 48; 49; 349; 394;
396; 405; 417; 840; 842; 846
распределенная, 982
блокирование, 43; 48; 397; 399; 850; 880;
894; 938; 944; 946; 947; 954
главной копии, 990; 1001
глобальное, 979; 988; 990; 991;
1000; 1001
двухфазное, 880; 896; 897; 898; 900;
903; 946; 947; 948; 961; 968
иерархий элементов данных, 918; 924;
947; 948
инкрементных операций, 902; 908;
946; 954
логическое, 990
локальное, 979; 988; 990; 991; 1000; 1001
матрица совместимости, 902; 904; 907;
909; 920; 946; 948
1080
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
монопольное, 894; 902; 946; 954
обновляемое, 906; 946
общее, 894; 902; 946
повышение уровня, 902; 905; 968
предупреждающее, 919; 948; 977
распределенное, 949; 977; 987;
1000; 1001
с множеством степеней детализации,
918; 947; 948
строгое, 954; 961; 999
упорядочение, 971; 1000
централизованное, 987; 990; 1000;
1001
взаимоблокировка, 43; 48; 404; 847; 901;
906; 938; 949; 968; 976; 999; 1001
распределенная, 991
глобальная, 981; 982
действие, 886
уравновешивающее, 960
длинная, 48; 949; 993; 1001; 1024
естественное старение, 975; 977
изоляция, 31; 41; 48; 49; 840; 842; 945
уровень — см. также Транзакция,
уровень изоляции, 400
команды, 43
компонент, 979; 982; 986; 987; 1000
координатор блокировок, 989
предварительная фиксация, 983
лимит времени активности, 968; 977;
984; 991
незавершенная, 851
обработка, 41; 42
откат, 43; 341; 398; 400; 417; 840; 934;
961; 968; 976
каскадный, 952; 954; 999
распределенный, 949; 982; 991; 1000
правило записи Томаса, 933
прерывание, 398; 400; 847; 912; 949;
950; 999
распределенное, 949; 982; 1000
проверка достоверности, 880; 930; 939;
944; 947; 948; 952
распределенная, 979; 981; 982; 985;
986; 1000
свойства, 44; 842
семантика операций, 884; 889; 900
согласованность, 841; 880; 882; 892; 895;
902; 908; 945
состояние, 839
"только для чтения", 919; 931; 938
управление, 31; 41; 42; 341; 359; 393;
875; 879; 947; 949
уравновешивающая, 993; 995; 996; 1001
уровень изоляции, 400; 403; 417
повторяемое чтение, 404; 405; 417
последовательный, 403; 405; 417
чтение нефиксированных данных,
403; 405; 417
чтение фиксированных данных, 403;
405; 417
устойчивость, 32; 41; 43; 48; 842
фиксация, 325; 341; 398; 400; 417; 840;
846; 847; 851; 912; 930; 950
групповая, 956; 999
двухфазная, 979; 982; 985; 987;
1000; 1001
отложенная, 867
предварительная — см. Транзакция,
компонент, предварительная
фиксация, 983
распределенная, 949; 977; 981; 1000
трехфазная, 1001
хронометраж, 880; 930; 938; 939; 944;
947; 948; 951; 952; 972; 1000
широковещательная рассылка
сообщений, 992
Триггер, 46; 249; 317; 328; 332; 336; 339;
344; 347; 377; 398; 406; 838; 840; 841
действие, 339
событие, 339
уровня
команды, 342
кортежа, 342
условие, 339
У
Устройство хранения
вторичное — см. Диск, 36
дисковое — см. Диск, 36
иерархия, 47; 489; 492; 546
первичное — см. Память,
оперативная, 36
третичное, 36; 49; 489; 497; 546; 871
энергозависимое, 499; 839; 950
энергонезависимое, 499; 839; 950
Ф
Файл, 32
данных, 40; 41; 490; 549; 584
индексный, 40; 584
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1081
компактно сгруппированный, 601; 607;
726; 727
последовательный, 47; 584; 634; 637; 686
сегментов, 602; 605; 606
сеточный, 638; 645; 646; 647; 679; 680
упорядоченный, 583; 584; 599
формат
GIF, 569; 574
JPEG, 574
MPEG, 550; 569; 574
Флэш-память — см. Память, флэш-, 500
Функция
Зипфа, 608; 787; 797
-конструктор — см. Конструктор-
функция, 438
хранимая, 364; 374; 375, 376; 382; 406; 441
X
Хеш-ключ, 624
Хеш-таблица, 46; 47; 565; 584; 599; 624;
635; 636; 637; 657; 683; 692; 695; 739; 915
динамическая, 626; 635
линейная, 626; 629; 635; 636
многомерная, 638
расширяемая, 626; 627; 635; 636
сегмент, 599; 624; 647
массив, 624
статическая, 626
Хеш-функция, 624; 635; 637; 718; 740; 745
выбор, 625; 749
раздельная, 638; 645; 646; 652; 679;
680; 745
Хранилище данных, 39; 48; 978; 1003;
1004; 1007; 1024; 1047; 1048
Хроника, 995; 1001
ц
Цифровая библиотека, 978; 980
ч
Чтение
мусора, 400; 417; 862; 931; 932; 950; 952;
957; 959; 961; 999
нефиксированных данных —
см. Чтение, мусора, 403
повторяемое, 403; 404; 417
фиксированных данных, 403; 417
ш
Шина данных, 502; 505; 521; 742
Я
Язык
Datalog, 453; 486
анонимная переменная, 456
атом, 453; 486
арифметический, 454
реляционный, 454
запрос, 455; 460
нерекурсивный, 453
правило, 453; 454; 460; 486
заголовок, 454; 460; 486
лево-рекурсивное, 472
нелинейное рекурсивное, 472
подцель, 455; 460; 486
право-рекурсивное, 472
рекурсивное, 469; 486
тело, 455; 486
предикат, 453; 486
интенсиональный, 458; 460; 486
экстенсиональный, 458; 486
рекурсивный, 453; 468
условие безопасности, 456; 460; 486
HTML, 51; 192; 194; 605
SGML, 192
XML, 45; 51; 150; 187; 192; 200; 605
атрибут, 197
действительный документ, 192
идентификатор, 197; 200
компонент, 194
объявление, 193
определение типа документа, 192;
194; 195
правильный документ, 192; 193
ссылка, 197; 200
тэг, 192; 200
элемент, 192; 194; 200
запросов, 32; 34; 40; 49; 232; 246; 419
абстрактный, 47; 453
логический, 47; 453; 486
объектных запросов, 46; 168; 203; 419;
451; 552; 717
описания интерфейса, 153
определения
данных, 32; 40; 49; 249; 296; 315
объектов, 45; 51; 60; 149; 152; 199;
203; 242; 296; 365; 419; 452; 551
программирования
ADA, 350
С, 46; 53; 75; 150; 151; 159; 161; 253;
297; 349; 350; 383; 394; 417; 420; 436;
445; 550; 552; 556
1082
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
C++, 46; 149; 150; 151; 159; 203; 209;
420; 435; 436; 445; 550; 552
Cobol, 350
Fortran, 350
Java, 149; 150; 159; 209; 349; 383; 390;
417; 420; 435
M, 350
Mumps — см. Язык,
программирования, М, 350
Pascal, 350
PL/I, 350
Prolog, 487
Smalltalk, 150; 420; 552
базовый, 349; 350; 362; 382; 420;
435; 840
включающий — см. Язык,
программирования, базовый, 349
структурированных запросов —
см. SQL, 34
управления данными, 32; 40; 49; 87;
249; 296
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1083
Научно-популярное издание
Гектор Гарсиа-Молина, Джеффри Д. Ульман,
Дженнифер Уидом
Системы баз данных. Полный курс
Литературный редактор И.А. Попова
Верстка В.И. Бордюк
Художественный редактор В.Г. Павлютин
Корректоры Л.А. Гордиенко, Т.А. Корзун,
Л.В. Коровкина, О.В. Мишутина
Издательский дом "Вильяме".
101509, Москва, ул. Лесная, д. 43, сгр. 1.
Изд. лиц. ЛР № 090230 от 23.06.99
Госкомитета РФ по печати.
Подписано в печать 20.12.2002. Формат 70x100/16.
Гарнитура Times. Печать офсетная.
Усл. печ. л. 87,72. Уч.-изд. л. 79,3.
Тираж 3000 экз. Заказ № 2068.
Отпечатано с диапозитивов в ФГУП "Печатный двор"
Министерства РФ по делам печати,
телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловский пр., 15.
ПРОЕКТИРОВАНИЕ
БАЗ ДАННЫХ
С ПОМОЩЬЮ
UML
Роберт А. Максимчук,
ЭрикДж. Нейбург
Проектирование
ш данных
с помощью
UML
isiiii^iiiiiiiiei
ЩМ&ч^ОюШ &$>№*$<<$<***
1
.-_
•
www.williamspublishing.com
В книге подробно рассматривается
использование UML на всех этапах
процесса проектирования баз
данных: моделирование прецедентов
и объектов деятельности,
определение требований, анализ
и предварительное проектирование,
детальное проектирование,
развертывание. Выбранная авторами
нестандартная методика изложения
материала позволяет читателю стать
одним из участников реального
проекта, рассматриваемого на
протяжении всей книги, и, вместе
с командой разработчиков баз
данных, успешно решить проблемы,
возникающие в процессе работы над
этим проектом.
Книга рассчитана на читателей
с различным уровнем подготовки,
интересующихся вопросами
моделирования и проектирования
приложений с помощью UML.
в продаже
БАЗЫ ДАННЫХ:
ПРОЕКТИРОВАНИЕ,
РЕАЛИЗАЦИЯ И
СОПРОВОЖДЕНИЕ.
ТЕОРИЯ И
ПРАКТИКА.
3-Е ИЗДАНИЕ
Томас Коннолли,
Каролин Бегг
THOMAS bCINNOi tY»CAROLYN MQG
' A Practical Approach to
Design, Implementation,
and Management
Third Edition T.,;.: 4
www.williamspublishing.com
Плановая дата выхода
2 кв. 2003 г.
Авторы этой книги
сконденсировали на ее страницах весь свой опыт
разработки баз данных для нужд
промышленности, бизнеса и науки,
а также обучения студентов в
университете Пейсли, Шотландия.
Результатом их труда стало
беспрецедентно полное справочное
руководство по проектированию,
реализации и сопровождению баз
данных. Ясное изложение
теоретического и практического
материала, включающего детально
разработанную методологию
проектирования и реализации баз данных,
а также подробное рассмотрение
существующих языков и
стандартов, делает эту книгу доступной
и полезной как студентам, так
и опытным профессионалам.
Третье издание книги дополнено
несколькими новыми главами,
освещающими новейшие
технологии в этой области — объектные
базы данных,
объектно-реляционные базы данных, использование
СУБД в Web, использование
хранилищ данных и средств
комплексного анализа (OLAP), а также
большим количеством новых примеров
и переработанных упражнений.
Ясное и четкое изложение материала,
наличие двух полномасштабных
учебных примеров и множества
контрольных вопросов и
упражнений, позволяет использовать эту
книгу не только при
самостоятельном обучении, но и как основу для
разработки курсов обучения
любых уровней сложности — от
студентов младших курсов, до
аспирантов, а также как
исчерпывающее справочное руководство
для профессионалов.
СИСТЕМЫ
БАЗ ДАННЫХ.
ТЕОРИЯ И ПРАКТИКА
ИСПОЛЬЗОВАНИЯ
В INTERNET
И СРЕДЕ JAVA
Грег Риккарди
В книге рассматривается широкий
круг вопросов, связанных с
- - системами баз данных. Автору
• удалось соединить изложение
общих теоретических положений
^ ^ * *! (модели данных, реляционная
Jpm . * шика алгебра) с углубленным
'*' < \ спользова #я ^, рассмотрением практических
в Internet и среде avo аспектов (языки SQL и Java,
физические характеристики баз
.-■..-. .* •' данных, взаимодействие с Internet,
" - . " объектно-ориентированные
' |" системы).
Ф \ л ", л Изложение материала
t fv^^ сопровождается рядом примеров,
' * Г V начиная от простых иллюстраций
J3 отдельных понятий и заканчивая
Ш полномасштабной рабочей
±2 Грег Риккарди моделью СУБД для обслуживания
компании по прокату видеокассет.
Книга изначально задумывалась
www.williamspublishing.com в качестве У466™™ пособия тя
г э студентов старших курсов, но
благодаря удачному объединению
сведений о взаимодополняющих
областях информатики может
быть полезной самому широкому
в продаже кругу читателей.
ОСНОВНЫЕ
КОНЦЕПЦИИ
КОМПИЛЯТОРОВ
Робин Хантер
Основные концепции
кошшлято» ♦
РФшХжтх'р
www.williamspublishing.com
Эта небольшая, но емкая книга
является введением в теорию
создания компиляторов, а также
кратким описанием принципов
их работы. Материал изложен
в расчете на читателя, не
знакомого с данным предметом. В тексте
предлагаются рекомендации по
дополнительной литературе и
даны подсказки по средствам
инструментальной поддержки.
Для закрепления материала
приводятся упражнения (с
решениями). В завершение книги
приводится словарь терминов,
используемых в данной области. Книга
может быть полезна как
студентам, так и преподавателям,
читающим соответствующий курс
лекций.
Робин Хантер является старшим
преподавателем отдела
компьютерных наук Университета Стратклайда
(University of Strathclyde), а также
членом Британского
компьютерного общества и Компьютерного
общества IEEE. Опыт его работы
с языками программирования
и компиляторами насчитывает
около 30 лет, ранее им были
написаны две книги по компиляторам
и множество научных статей.
в продаже
» »
Гектор Гарсиа-Молина, Джеффри Д. Ульман и Дженнифер Уидом, профессора
Станфордского университета и широко известные специалисты в области компьютерных
наук, предлагают уникальное введение в системы баз данных. Первая половина книги
содержит всесторонний обзор технологий баз данных, ориентированный на потребности
проектировщиков, прикладных программистов и пользователей баз данных различного
назначения, охватывающий новейшие стандарты SQL-99, SQL/PSM, SQL/CLI, JDBC, ODL, XML
и раскрывающий проблематику SQL более широко и глубоко, нежели большинство других
публикаций. Вторая половина книги посвящена аспектам реализации систем управления
базами данных. Здесь авторы рассматривают задачи управления данными и основные
подходы к их решению, уделяя самое серьезное внимание вопросам оптимизации запросов
и приемам применения передовых технологий многомерных и точечных индексов,
распределенных транзакций и интеграции информации. Издание может служить как
прекрасным учебным пособием, так и исчерпывающим профессиональным руководством.
ЦЕННЫЕ ОСОБЕННОСТИ КНИГИ:
■ используется доступный и вместе с тем строгий стиль представления материала;
■ приводятся сотни наглядных примеров;
■ излагаются аспекты программирования на SQL, недостаточно подробно освещаемые во
многих других пособиях, — SQL/PSM, JDBC, SQL/CLI и ODBC;
■ охватываются как объектно-ориентированная (ODL), так и объектно-реляционная (SQL-99)
парадигмы проектирования;
■ всесторонне исследуются приемы обработки и оптимизации запросов, поддерживаемые
аппаратом расширенной реляционной алгебры;
■ раскрываются проблемы и методы интеграции информации, связанные с использованием
хранилищ данных, медиаторов, кубов данных, технологий OLAP и разработки данных;
■ изучаются важные специальные вопросы исправления ошибок в дисковых массивах RAID,
применения точечных индексов, статистик и способов подмены указателей;
■ поддерживается Web-сайт с разнообразными сведениями о книге, размещенный по
адресу: http://www-db.stanford.edu/~ullman/dscb.html.
Издательский дом Вильяме"
www.williamspublishing.com
Pearson
Education
PRENTICE HALL
Upper Saddle River, NJ 07458
www.prenhall.com
ISBN 5-8459-0384-X
02154
9 H785845H903846'