/










































































































































Автор: Акинин М.В. Никифоров М.Ф. Таганов А.И.
Теги: распознавание и преобразование образов искусственный интеллект цифровая обработка изображений искусственные нейронные сети
ISBN: 978-5-9912-0537-5
Год: 2017




Текст
М. В. Акинин, М. Б. Никифоров, А. И. Таганов
О О о о
Нейросетевые системы искусственного интеллекта в задачах обработки изображений
М. В. Акинин, М. Б. Никифоров, А. И. Таганов
Нейросетевые системы искусственного интеллекта в задачах обработки изображений
Москва Горячая линия - Телеком 2017
УДК 004.932.2
ББК 32.813
А39
Рецензенты: канд. техн, наук, профессор В. Л. Григорьев', доктор техн, наук, профессор Б. В. Костров
Акинин М. В., Никифоров М. Б., Таганов А. И.
А39 Нейросетевые системы искусственного интеллекта в задачах обработки изображений. - М.: Горячая линия - Телеком, 2017. -152 с.: ил.
ISBN 978-5-9912-0537-5.
Книга посвящена вопросам разработки систем компьютерного зрения, основной задачей которых является тематическая дешифрация аэрофотосъемки и спутниковых снимков, сделанных в видимом и инфракрасном диапазонах волн. В качестве основного инструмента дешифрации авторы предлагают использовать модели и алгоритмы теории искусственного интеллекта и теории машинного обучения. Большое внимание уделено вопросам построения и обучения нейросетевых классификаторов, основанных на нейронных сетях прямого распространения без обратных связей.
Для специалистов, может быть полезна аспирантам и студентам соответствующих специальностей.
ББК 32.813
Адрес издательства в Интернет WWW.TECHBOOK.RU
ISBN 978-5-9912-0537-5 © М. В. Акинин, М. Б. Никифоров,
А. И. Таганов, 2015,2017
© Издательство «Горячая линия - Телеком», 2017
Обозначения и сокращения
В - (англ.) blue, синий спектральный канал (длина волны около 450-515 нм).
DSP - (англ.) digital signal processor, цифровой сигнальный процессор.
ЕТМ+ - (англ.) enhanced thematic mapperplus, расширенный тематический картограф плюс (камера КА «LandSat-7»).
G - (англ.) green, зеленый спектральный канал (длина волны около 525...605нм).
GPGPU - (англ.) general-purpo segraphic sprocessing units, GPU общего назначения технология использования графического процессора видеокарты для выполнения общих вычислений (вычислений, не предназначенных для решения задач вывода компьютерной графики).
ICA - (англ.) independent component analysis, анализ независимых компонент.
ISRO - (англ.) Indian Space Research Organisation, Космическое агентство Индии.
JAXA - (англ.) Japan Aerospace Exploration Agency, Японское аэрокосмическое агентство.
KARI - (англ.) Korea Aerospace Research Institute, Корейский авиационно-космический научно-исследовательский институт.
MLP - (англ.) multilayer perceptron, многослойный перцептрон.
NASA-(англ.) National Aeronautic sand Space Administration, Национальное управление по аэронавтике иисследованию космического пространства (США).
NIR - (англ.) near-infrared, «ближний» инфракрасный спектральный канал (длина волны около750...1400 нм.).
NLCNN - (англ.) nonlinear cellular neural network, нелинейная ячеистая нейронная сеть.
NOAA - (англ.) National Oceanicand Atmospheric Administration, Национальное управление океанических и атмосферных исследований (США).
РСА - (англ.) principal component analysis, метод главных компонентов.
R - (англ.) red, красный спектральный канал (длина волны около 630...690 нм).
RBM - (англ.) restricted Boltzmann machine, ограниченная стохастическая машина Больцмана.
RMLP - (англ.) recurrent multilayer perceptron, многослойный перцептрон с обратными связями.
SMO - (англ.) sequential minima loptimization, последовательная минимальная оптимизация.
SVM — (англ.) support vector machine, машина опорных векторов.
SWIR - (англ.) short-waveleng thinfrared, коротковолновый инфракрасный спектральный канал (длина волны 1400...3000 нм.).
USGS - (англ.) United States Geological Survey, Геологическая служба США.
WGS-84 - (англ.) world geodetic system 1984, всемирная геодезическая система, мировой референц-эллипсоид.
WTA - (англ.) winner takesail, принцип «победитель получает все».
иТМ-(англ.) universal transverse Mercator, универсальная поперечная проекция Меркатора.
ГИС - геоинформационная система.
ГПСЧ - генератор псевдослучайных чисел.
ДЗЗ - дистанционное зондирование Земли.
ИНС - искусственная нейронная сеть.
КА - космический аппарат.
ЛА - летательный аппарат.
НЖМД - накопитель на жестких магнитных дисках.
ОС - операционная система.
ПО - программное обеспечение.
СКО - среднеквадратичное отклонение.
ТВ - телевизионное (изображение).
ТПВ - тепловизионное (изображение).
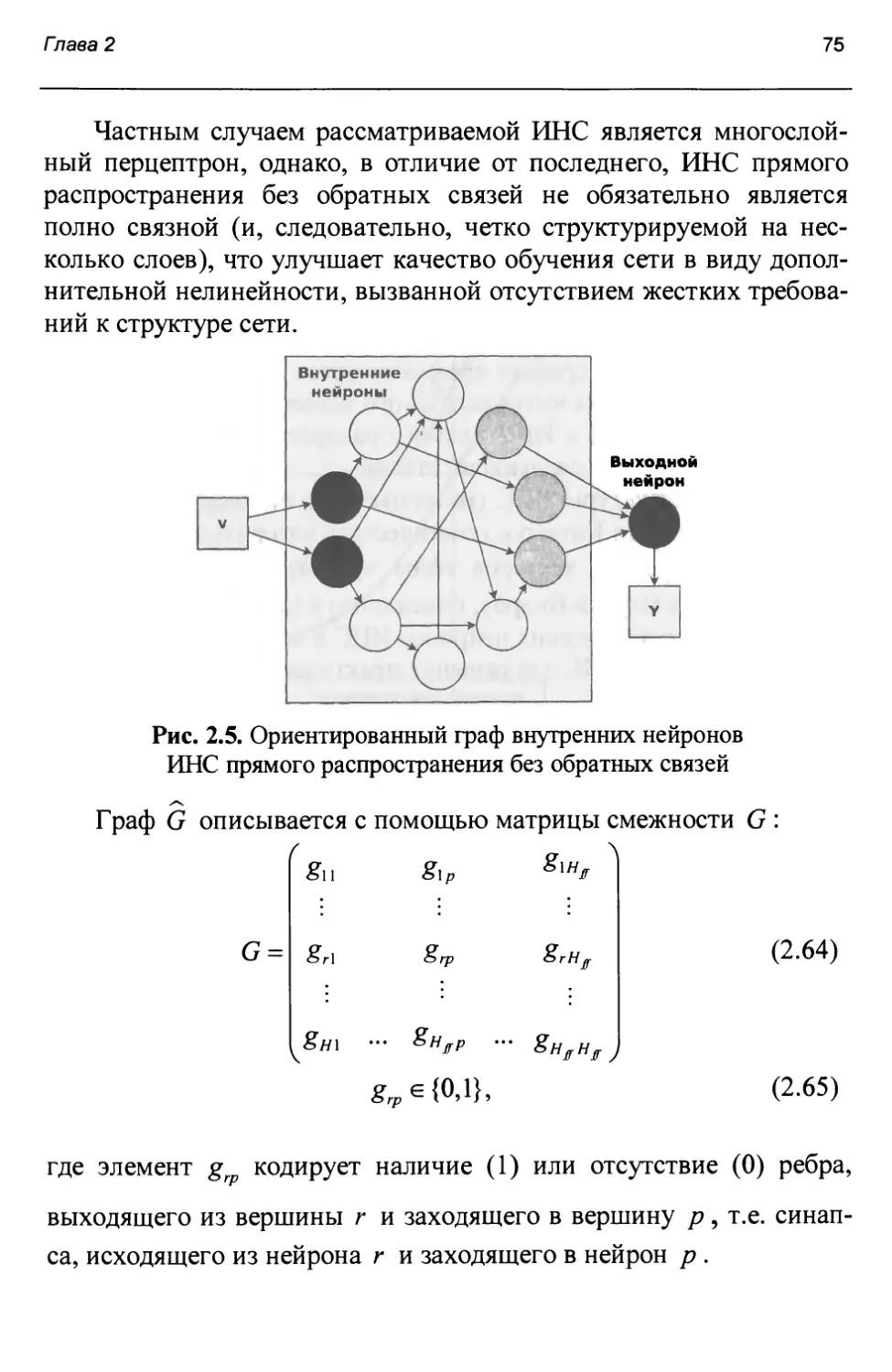
ФНЧ - фильтр низких частот.
ЦКМ - цифровая карта местности.
ЭВМ - электронная вычислительная машина.
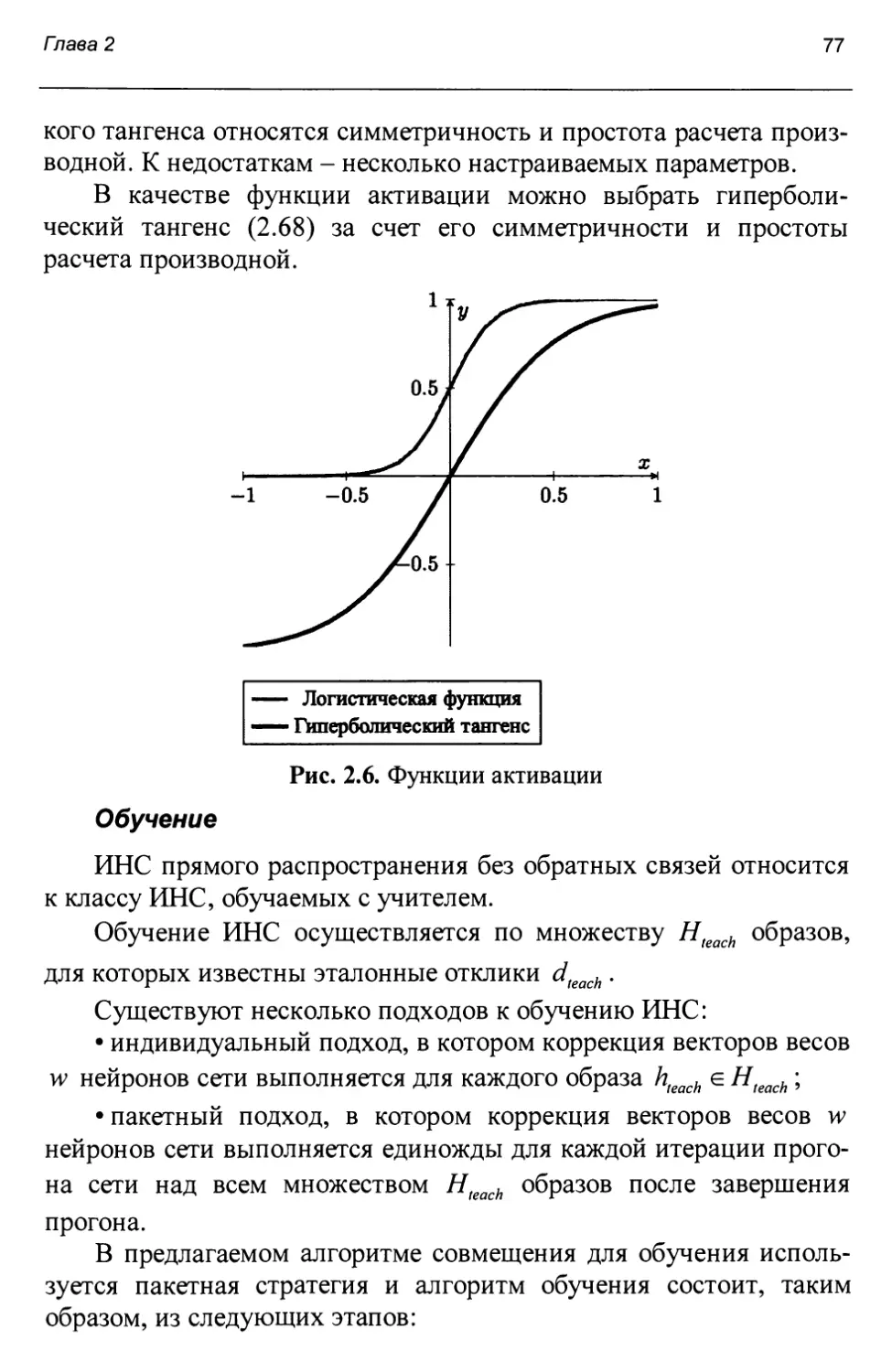
Введение
Совмещение данных дистанционного зондирования Земли (данных ДЗЗ) и цифровых карт местности (ЦКМ) в настоящее время является актуальной задачей, что подтверждается востребованностью совмещения при решении следующих задач обработки данных ДЗЗ:
- задачи автоматического и полуавтоматического уточнения топографических карт по актуальным спутниковым снимкам;
- задачи оцифровки картографического материала, имеющегося в бумажном виде, поскольку, как правило, привязка данного картографического материала к той или иной системе координат требует дополнительного уточнения;
- задачи первичной привязки спутниковых снимков по данным о положении и ориентации космического аппарата (КА), сделавшего снимок.
Разработка методов и алгоритмов автоматического совмещения данных ДЗЗ и ЦКМ позволит повысить оперативность и уровень автоматизации решения перечисленных задач.
Исследованию научных вопросов, связанных с обработкой изображений (в частности, с совмещением разнородных изображений), посвящены работы известных отечественных и зарубежных ученых. Большой вклад в развитие научных исследований в этой области внесли: Алпатов Б.А., Визильтер Ю.В., Джанджгава Г.И., Евтушенко Ю.Г., Еремеев В.В., Желтов С.Ю., Злобин В.К., Сергеев В.В., Сойфер В.А. и др. Значительное внимание этой проблеме уделяют и зарубежные ученые: Башков Е., Блейхут Р., Понс Ж., Прэтт У., Форсайт Д., Фукунага К.
Большой вклад в развитие научных исследований в области исследования научных вопросов, связанных с теорией искусственного интеллекта, теорией машинного обучения и теорией оптимизации, внесли: Вапник В.Н., Демидова Л.А., Каширин И.Ю., Кохонен Т., Корячко В.П., Ле Кун Я., Локтюхин В.Н., Осовский С., Платт Д., Розенблатт Ф., Ручкин В.Н., Скворцов С.В., Фукушима К., Хайкин С., Харалик Р.М., Червоненкис А.Я. и др.
Анализ публикаций в области теории и практики совмещения данных ДЗЗ и ЦКМ позволяет говорить о существовании ряда проблем в данной области, к которым относятся:
-отсутствие полностью автоматического подхода к решению задачи совмещения, основанного исключительно на анализе данных ДЗЗ и ЦКМ без использования дополнительной информации о положении КА, о существовании реперных точек, выделенных экспертом на спутниковом снимке и ЦКМ и других данных.
Таким образом, существующие методы являются либо полуавтоматическими с существенным и, в ряде случаев, ключевым участием эксперта, либо требуют дополнительную информацию, часто отсутствующую в наборах исходных данных к совмещению;
- существенные временные затраты на выполнение совмещения, обусловленные полуавтоматизмом существующих методов;
- отсутствие практических способов автоматического контроля за качеством совмещения, поскольку означенный контроль выполняется модифицированным алгоритмом совмещения, а значит перенимает от него все его недостатки, связанные с существенными временными затратами и низким уровнем автоматизации.
Сложность задачи совмещения существенно возрастает в ситуациях, требующих оперативного совмещения, поскольку в данном случае появляется четкое ограничение на время выполнения совмещения, выполнение которого не гарантируют существующие полуавтоматические методы и алгоритмы.
В книге описываются системы искусственного интеллекта и разрабатываются алгоритмы моделирования этих систем и численные методы оптимизации, решающие некоторые задачи обучения данных систем, реализующие в совокупности процесс совмещения данных ДЗЗ и ЦКМ и свободные от перечисленных недостатков.
Г л а в a 1
РАЗРАБОТКА И АНАЛИЗ
МАТЕМАТИЧЕСКОЙ МОДЕЛИ
ПРОЦЕССА СОВМЕЩЕНИЯ
РАЗНОРОДНЫХ ИЗОБРАЖЕНИЙ
1.1. Математическая модель процесса совмещения цифровых карт местности с данными дистанционного зондирования Земли
Данные ДЗЗ (спутниковые снимки), получаемые от сенсоров, установленных на КА, можно представить в виде изображения (спутникового снимка):
В = {Ьу}- (1.1)
bij ={Ьу,,...,Ьик,...,ЬуК}- biJk е[-1;1];
где: by - пиксель спутникового снимка В, находящийся в i -й строке пикселей, в j -м столбце; bijk - спектральная яркость пикселя by в к -м спектральном канале; I - количество строк пикселей в спутниковом снимке 5; J - количество столбцов пикселей в спутниковом снимке 5; К - количество спектральных каналов в спутниковом снимке В.
Спектральные яркости bijk должны быть масштабированы в диапазон [~1;1] для удобства дальнейшей работы с ними. Для масштабирования спектральных яркостей из первоначального диапазона уровней квантования может быть использовано линейное преобразование, которое для Q и уровней имеет вид:
bijk е[О;0; S^eZ, где Ьук - первоначальное (квантованное) значение спектральной яркости. При Q = 256 формула (1.2) приобретает вид (1.3):
Пусть coord - функция преобразования координат (х,у) пикселя bjjk в координаты (ху, yfj) системы координат спутникового снимка В. Функция coord определяется как:
(х//,Уу.) = соогб/((/,у)); (1-4)
ей-
ЦКМ М является множеством точечных, линейных и полигональных объектов, объединенных в векторные слои в соответствии с атрибутивной информацией. Одной из форм описания ЦКМ М является ее представление в виде множества точек (х,у) таких,
что:
У £ D'min, УтахЬ (1.5)
*,У,*тт>*та.х,Утт,УтахеК,
где: xmin, xmin - соответственно нижняя и верхняя границы диапазона координат ЦКМ по оси ОХ рамки карты; ymin, ymin - соответственно нижняя и верхняя границы диапазона координат ЦКМ по оси OY рамки карты.
Каждой точке (х,у)еЛ/ ставится в соответствие некоторая атрибутивная информация (наличие или отсутствие объекта в точке, тип объекта и т.п.).
Функция сотр , описывающая модель совмещения спутникового снимка В с ЦКМ М, задается как: сотр' = comp(B,M,coordy b = сотр'(В);
coord ’ = comp '(coord У, {(Л Г)} = сотр '((/, /));
(1-6)
comp' = <
/' = 1,Z'; j' = l,J';
где: В' - преобразованное изображение размером Г строк на J' столбцов; coord' - функция преобразования координат пикселей изображения В' в координаты системы координат спутникового снимка В.
Множество пикселей comp\(ibj))(z. В' имеет, в общем
случае, мощность \comp\(i,j))\—l (то есть отображение comp' {(/',/)} не является взаимно однозначным). Таким
образом, имеет место быть зависимость:
bij ~Ь'гг comp\i,j). (1.7)
Качество совмещения сотр оценивается с помощью количественной меры ошибки совмещения Е . К мере Е предъявляются следующие требования:
• Е —> О при увеличении качества совмещения;
• Е -> оо при уменьшении качества совмещения;
• Е должна быть определена для \/В,М,сотр\
• Е>0; ^В^М^сотр.
Одной из мер Е , удовлетворяющей перечисленным свойствам, является среднеквадратичное отклонение (CKO) Ermse:
(x'rr,y'Vj.) = coord\{i'J'y)-, Р = {р}’, P =
А(сотр\р)
х>2 + (у'гг~~уУ
| compel, у)) |
Yp.pA(P'>
EmJcomp\P)=^------
где Р - множество пар реперных точек р 9 выделенных на спут
никовом снимке В и ЦКМ М вручную. Ручное составление множества Р позволяет достичь высокой (практически идеальной)
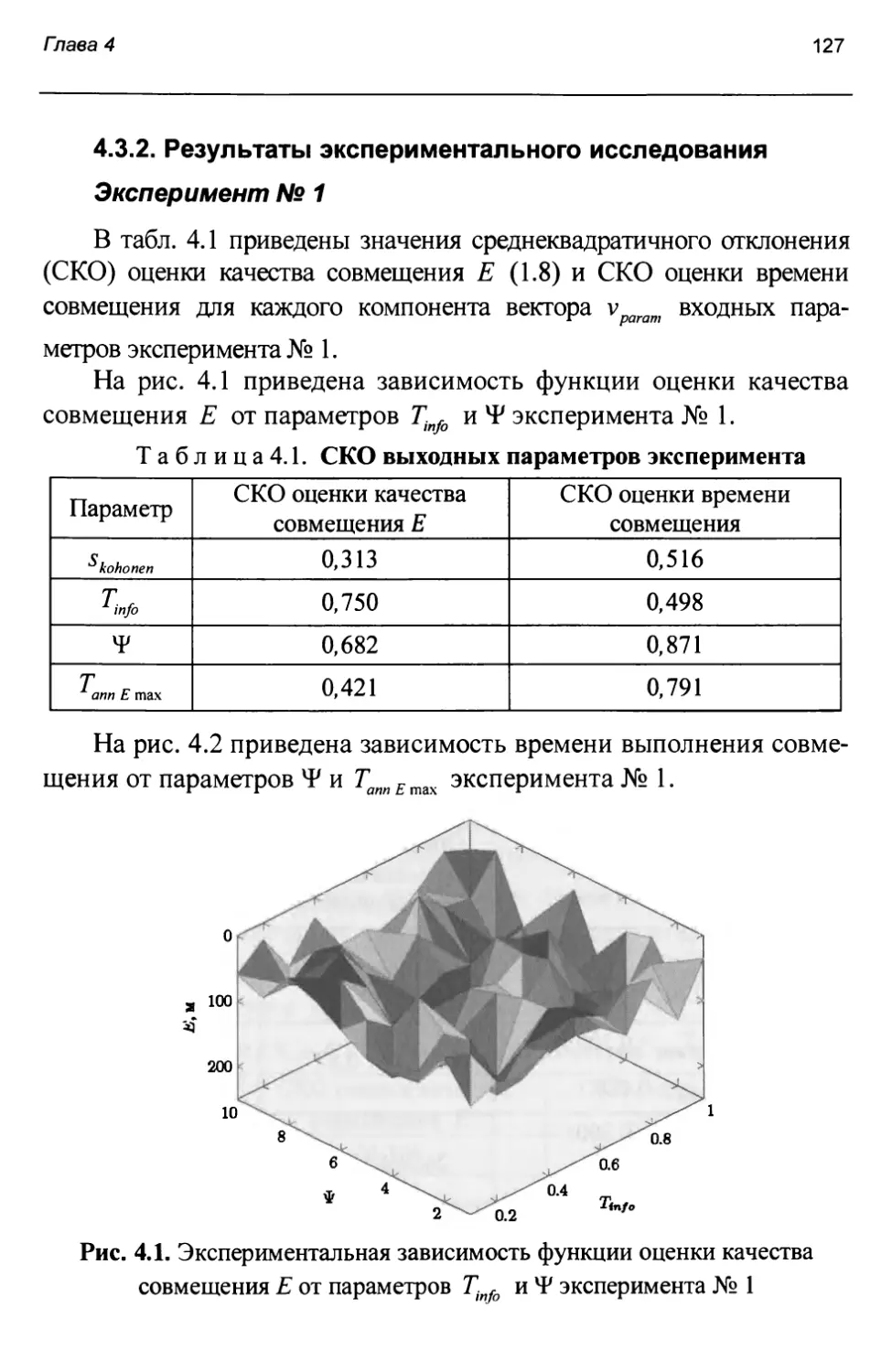
точности соответствия точек, выделенных на спутниковом снимке В, точкам, выделенным на ЦКМ М .
Размерность Ennse - размерность х и у, что обеспечивается, в том числе, отсутствием нормировки Е (требование Е —> оо при уменьшении качества совмещения). Таким образом, физический
смысл Ermse заключается в оценке вариации в конкретных величинах между идеальным смещением (математическое ожидание оцениваемой величины) и реальным результирующим смещением (оцениваемая величина) - ошибкой функции сотр .
Функция совмещения сотр предполагает выполнение следующих действий:
1) поиск findedu на спутниковом снимке В и карте М пар совпадающих точек pedu:
Prm. edu = findedu М,COOrd)-, (1.9)
Braw edu = {Pedu } ; Pedu = (fJedu ’ J edu X (Xedu > Уedu )X (1 •1 0)
2) расчет для каждой пары pedu точек вероятности совпадения validity^ edu\,
3) составление множества Pedu пар совпадающих точек:
Pedu 6 Pedu « VaHdity^Pedu )^Tedu’ (1 •1 1)
Pedu [0Л), где Tedu есть минимально допустимая для включения в множество Pedu вероятность (порог вероятности) того, что в рассматриваемой паре pedu точки совпадают друг с другом;
4) расчет eval по множеству /^„преобразования сотр'-.
сотр' = eval(Pedu). (1.12)
Этап поиска пар совпадающих точек pedu является самым сложным в ходе совмещения спутникового снимка В и ЦКМ М. Под «сложностью» в данном случае понимается как временная сложность, так и сложность по памяти.
Действительно, как показано в [1], один из самых эффективных по времени алгоритмов поиска совпадающих точек (контурное корреляционное совмещение) имеет сложность О (106У2). В работе [1] алгоритм контурного корреляционного совмещения применяется для поиска совпадающих точек на ракурсе трехмерной модели местности и данных от камер, установленных на борту летательного аппарата (самолета или вертолета), но принципиального упрощения данный факт не дает - нет принципиальной разницы в поиске совпадающих точек на фактически двухмерной сцене (спугни-
ковом снимке) и трехмерной сцене в случае, если нет необходимости в перегенерации трехмерного ракурса.
Оптимизация алгоритма контурного корреляционного совмещения приводит к существенным расходам памяти, необходимым для организации разнообразных кэшей, в том числе, кэшей потоков в случае, если используется параллельная версия алгоритма, описанного в [1].
Алгоритм контурного корреляционного совмещения дает низкую точность совмещения и нуждается в дополнительной настройке при изменении погодных условий, характера местности и ряда других факторов. Таким образом, актуальной является задача разработки алгоритмов совмещения, имеющих низкую временную сложность, дающих высокое качество совмещения и, по возможности, низкие затраты по памяти.
Функция validity оценки вероятности совпадения пары pedu имеет сложную природу, зависящую в общем случае от вида функции findedu и от значений параметров алгоритма, реализующего данную фукнцию. Наиболее простой реализацией validity является оценка вероятности validity5 по гистограмме отклонений 8Х и 8у\
(xedu, у edu) = coord ((iedu, jedu));
dx =1 xedu - Xedu I; 3y =1 yedu - yedu I;
validitys (pedu) = 1 - ----------------------------------,(1.13)
где <5xmax и <5vmax - максимальные значения Sx и Sv соответственно. Таким образом, validitys оценивает расстояние от pedu до моды гистограммы в случае, если гистограмма является унимодальной.
В качестве validity можно использовать validitys .
Как правило, процесс совмещения носит итерационный характер. Поиск оптимального преобразования сотр' происходит до тех пор, пока Е(сотр',Р)>ТЕ ,где Г£бК - максимально допустимая ошибка совмещения сотр', при которой процесс совмещения будет остановлен. На каждой итерации предполагается постепенное
уменьшение Tedu, что приводит к росту | Pedu |, и в свою очередь, приводит к тому, что для расчета преобразования сотр' используется больше точек из Ргаи.е<Л/. Таким образом, следствием постепенного уменьшения Tedu является постепенное уменьшение вклада в сотр' пар точек pedu, оценка вероятности совпадения которых validity(pedu) выполнена не точно.
Функция eval реализует алгоритм выбора конкретного вида функции сотр' и расчета ее параметров. Выбор происходит, в основном, в зависимости от | Pedu |, а также от ряда других факторов, таких как, например, распределение validity на Pedu . В качестве функции сотр' используются следующие преобразования В-^В' и coord coord':
• аффинное преобразование, линейный сдвиг и масштабирование (применяется чаще всего для задачи совмещения данных ДЗЗ и ЦКМ);
• преобразование Гельмерта [2];
• полиномиальные преобразования первого, второго, третьего и более высоких порядков;
• трансформация «резинового листа» ((англ.) rubbers heet) [3].
1.2. Анализ требований
к источникам исходных данных
1.2.1. Анализ требований
к данным дистанционного зондирования Земли, получаемым от сенсоров космических аппаратов
В качестве источников данных ДЗЗ можно рассматривать КА, соответствующие следующим критериям:
• достаточная информативность;
• доступность спутниковых снимков российскому потребителю (так, например, для некоторых КА действуют ограничения на точность данных, распространяемых среди потребителей-нерезидентов страны, владеющих данными КА);
• запуск КА в промежутке с 2012-го года по 2014-й год и не выработка КА расчетного срока службы.
Следующие факторы также являются существенными для выбора источника данных ДЗЗ:
• стоимость;
• частота обновления;
• возможность съемки на заказ интересующей области земной поверхности;
• способ распространения данных.
Под достаточной информативностью спутниковых снимков понимается соответствие снимков следующим критериям:
• разрешение должно быть достаточным для определения отдельных малых населенных пунктов (деревень и хуторов). Как правило, таким разрешением является 30...60 метров на пиксель;
• количество и тип спектральных каналов должны быть достаточными для выделения на снимке лесонасаждений, полей, пустырей, дорог, населенных пунктов и водных объектов. Как правило, для выделения на снимке перечисленных объектов достаточно наличие синего (В-(англ.) blue, длина волны около 450...515 нм), зеленого (О-(англ.) green, длина волны около 525...605 нм), красного (К-(англ.) red, длина волны около 630...690 нм) и нескольких ближних инфракрасных каналов (МК-(англ.) nearinfrared, длин волны около 750... 1400 нм).
Таким образом, спутниковый снимок должен состоять из телевизионного (ТВ; спектральные каналы В, G, R) и тепловизионного (ТПВ; спектральные каналы R и NIR) изображений подстилающей поверхности с разрешением не более 30...60 метров на пиксель.
Дистрибьютор данных ДЗЗ должен выполнять следующую предварительную обработку распространяемых спутниковых снимков:
• радиометрическая и геометрическая коррекция спутниковых снимков;
• привязка спутниковых снимков к системе координат WGS-84 и проецирование спутниковых снимков в проекцию UTM. Поскольку данные система координат и проекция являются общеупотребительными, их поддержка имеется в большинстве современных ГИС (ArcGIS, Erdas Imagine, Quantum GIS, GRASS и другие), большинство дистрибьюторов данных ДЗЗ распространяют спутниковые снимки.
В настоящее время российские дистрибьюторы данных ДЗЗ (компания «Совзонд», ИТЦ «СканЭкс», НЦОМЗ и другие) рас
пространяют продукцию ряда КА, из которых следующие могут рассматриваться как перспективные в плане получения данных ДЗЗ для решения поставленной задачи:
• WorldView-1;
• WorldView-2;
• Kompsat-2;
• GeoEye-1;
• ALOS (камера AVNIR-2);
• Cartosat-2;
• RapidEye (группировка KA);
• Ресурс-П;
• Landsat 7;
• Landsat 8.
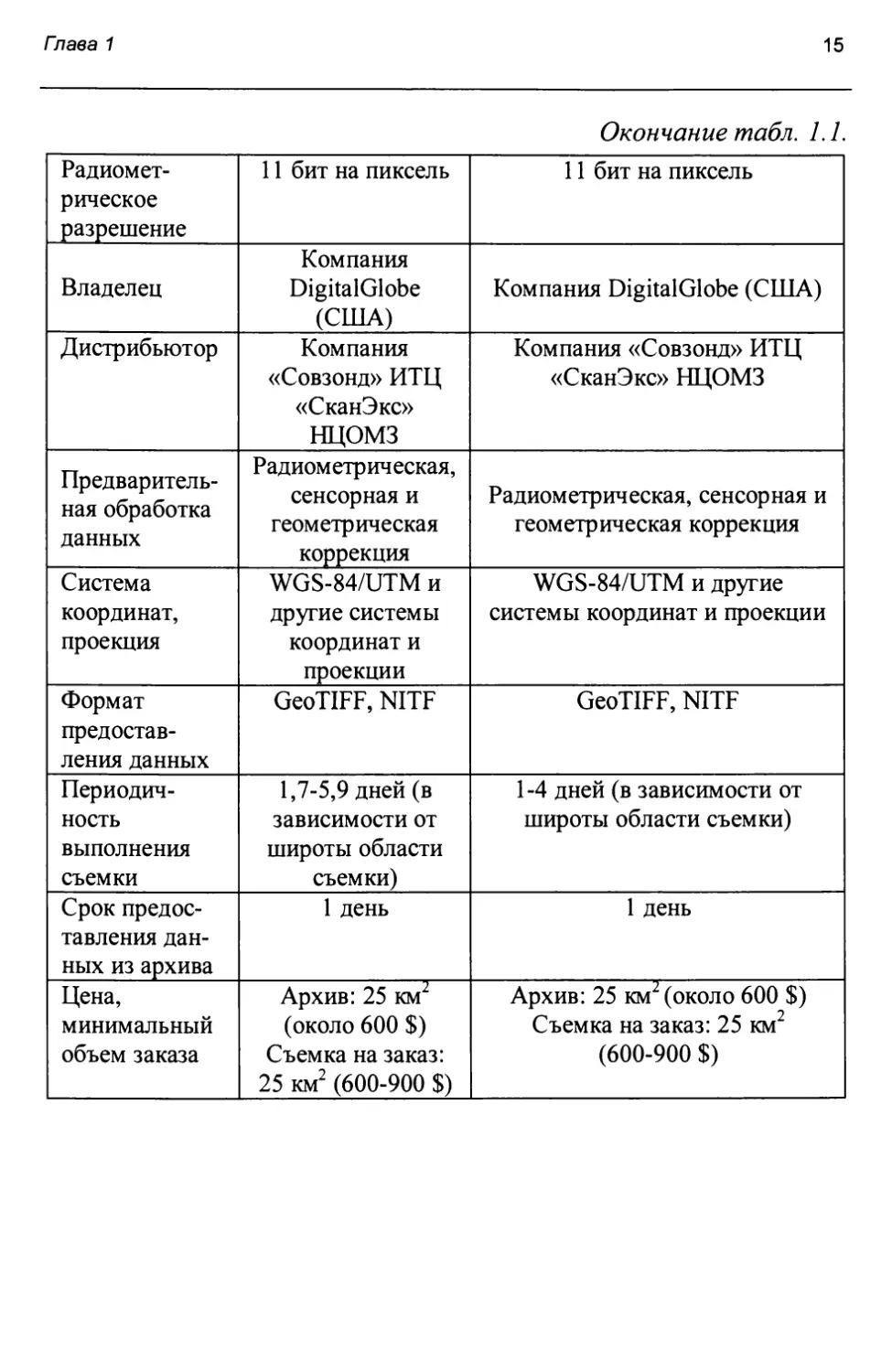
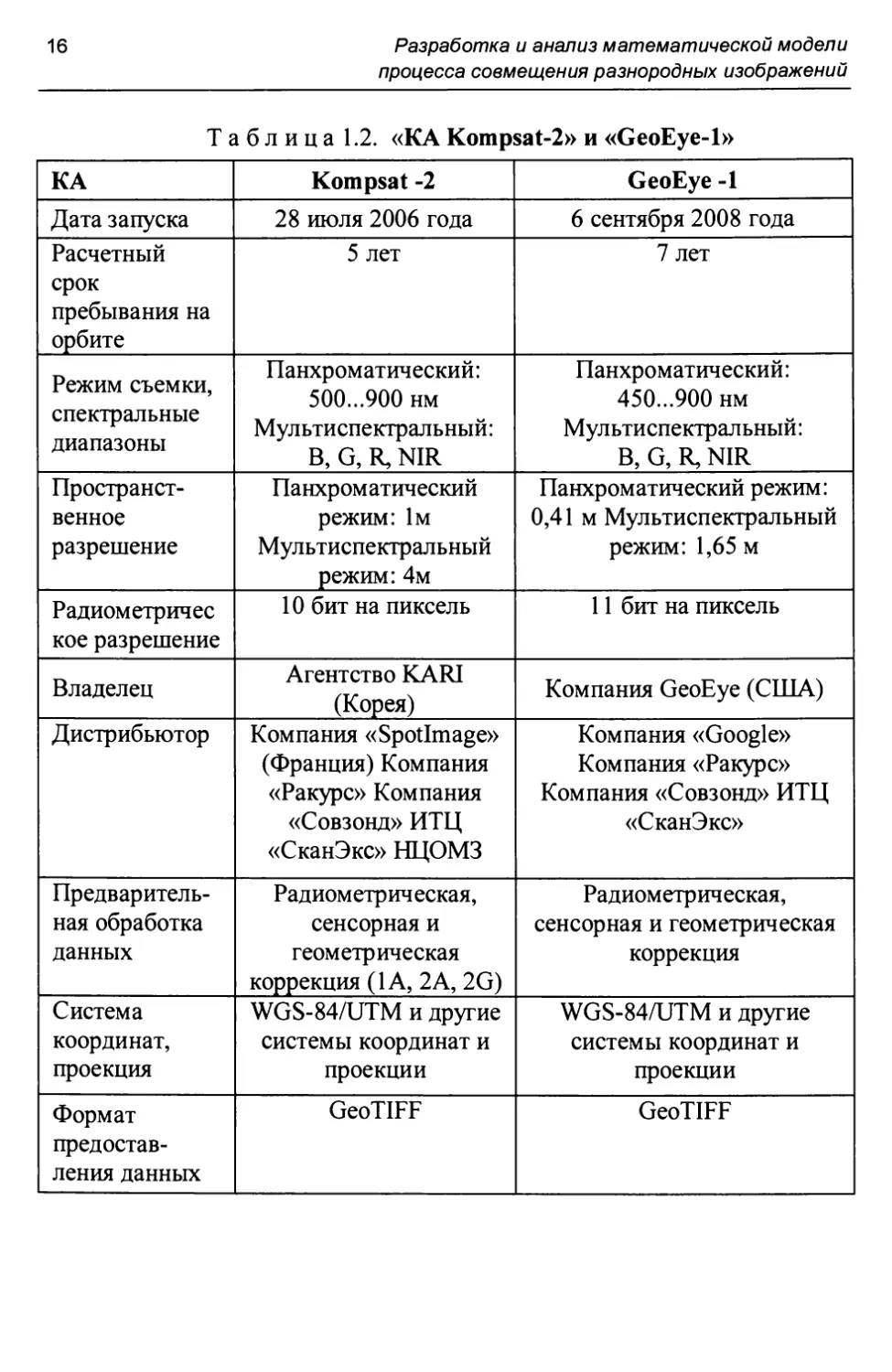
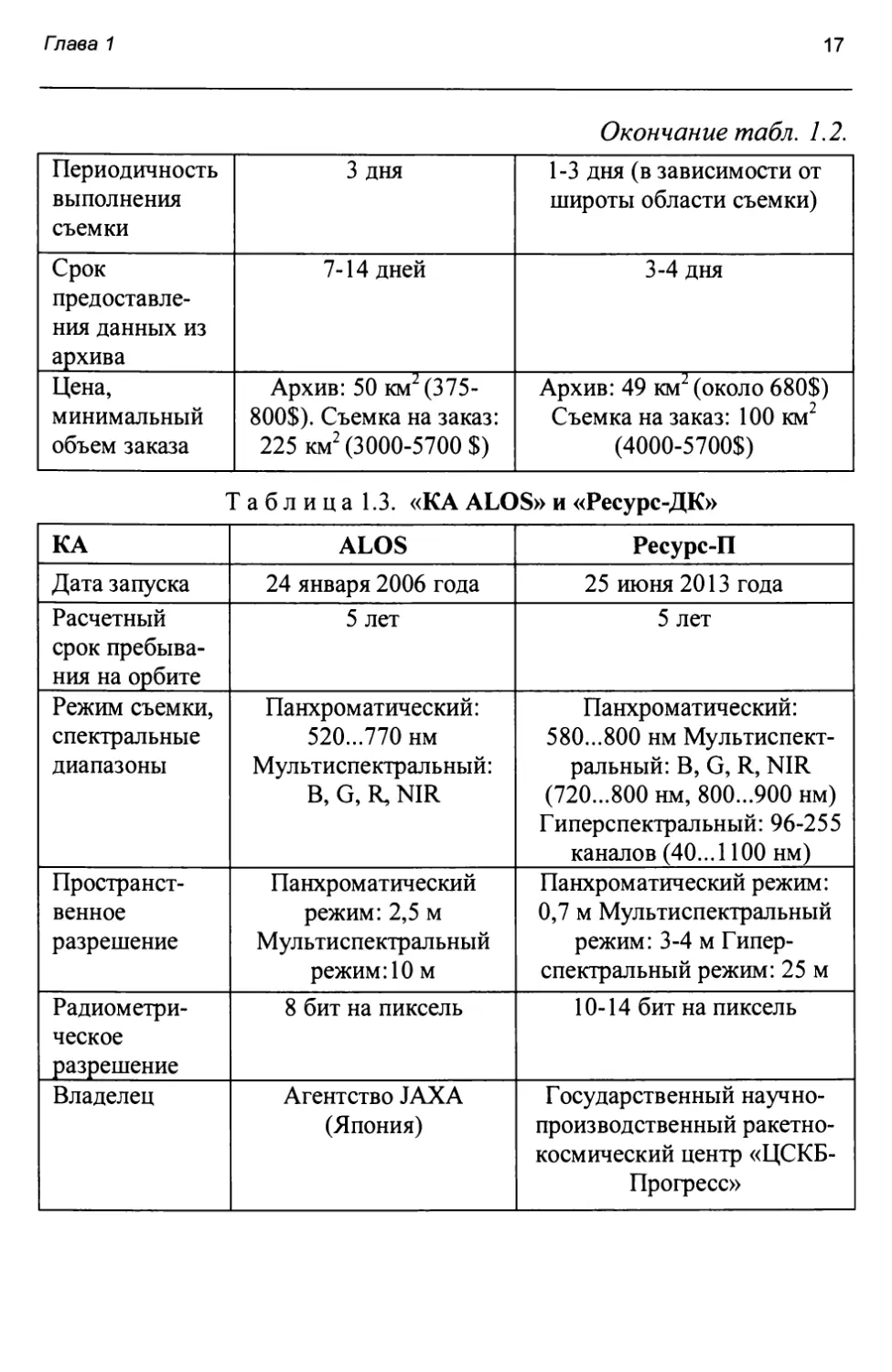
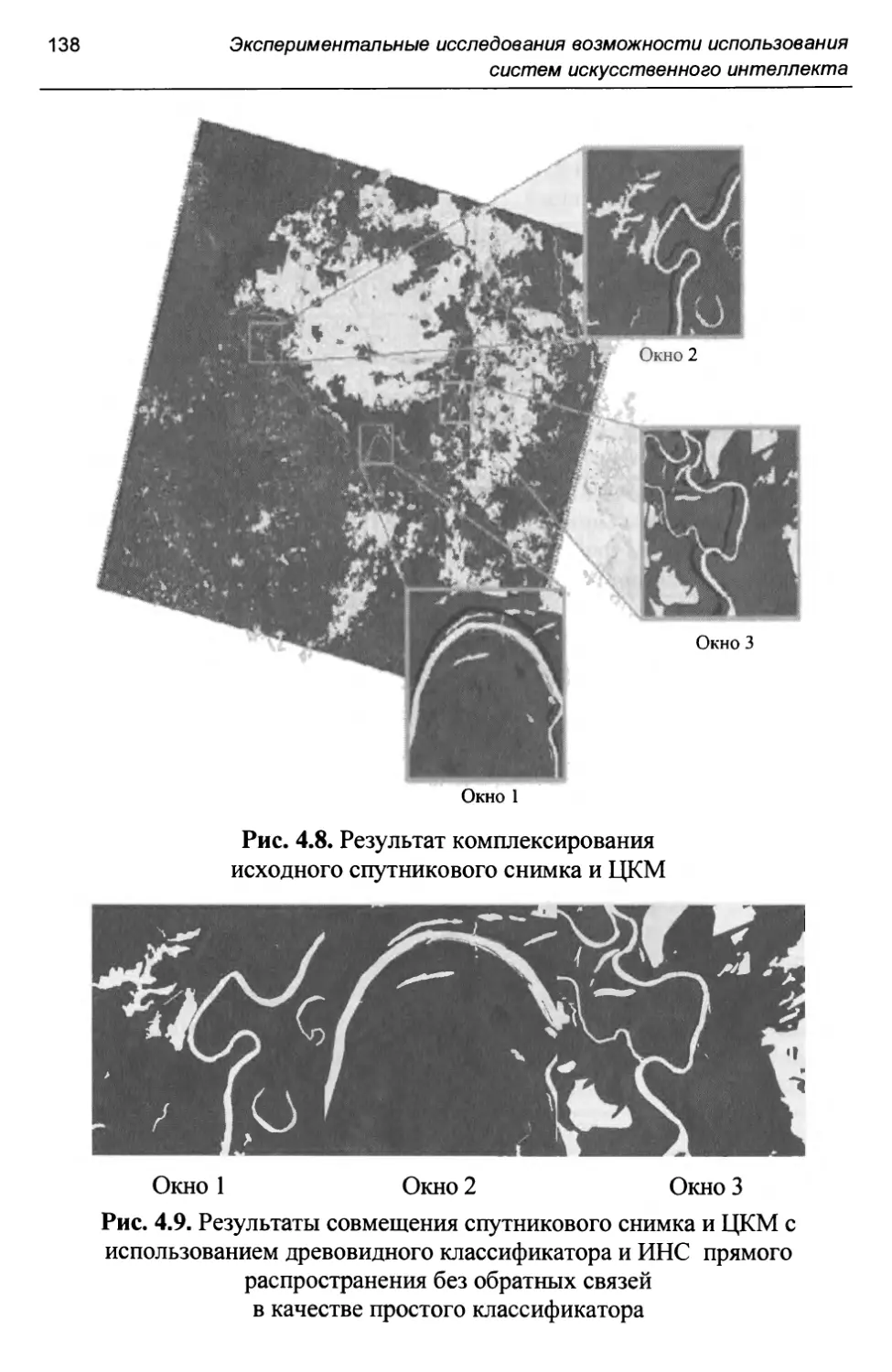
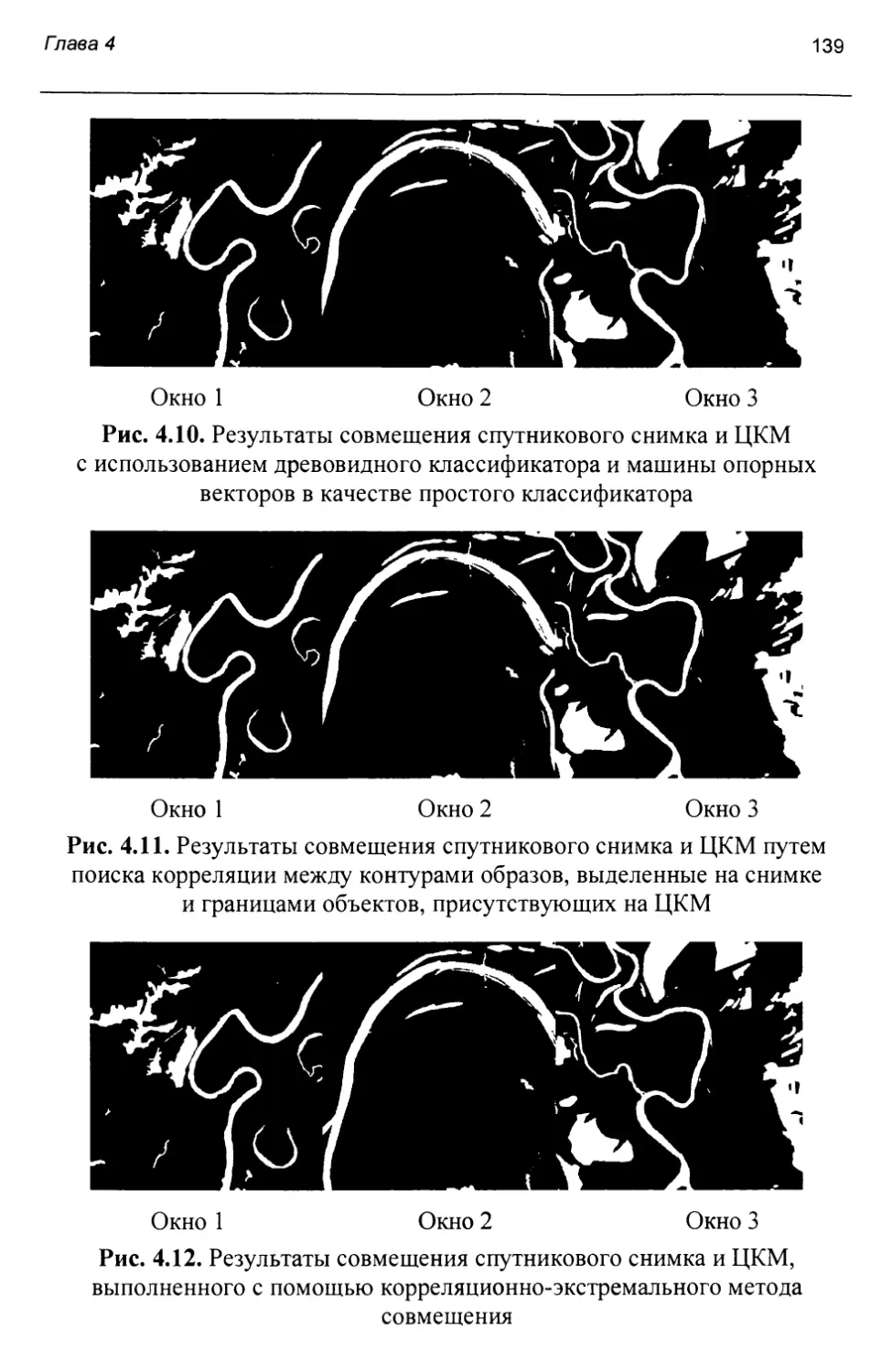
Информация о KA «WorldView-1» и «WorldView-2» сведена в табл. 1.1. Информация о КА «Kompsat-2» и «GeoEye-1» сведена в табл. 1.2. Информация о КА «ALOS» и «Ресурс-П» сведена в табл. 1.3. Информация о КА «Cartosat-2» и «RapidEye» сведена в табл. 1.4. Информация о КА «Landsat?» и «Landsat8» приведена в табл. 1.5.
Т а б л и ц а 1.1. «КА WorldView-1» и «WorldView-2»
КА WorldView -1 WorldView -2
Дата запуска 18 сентября 2007 года 8 октября 2009 года
Расчетный срок пребывания на орбите 7 лет 7 лет
Режим съемки, спектральные диапазоны Панхроматический: 500...900 нм Панхроматический: 500...900 нм Мультиспектральный: Coastal («прибрежный»), В, G, Yellow (желтый), R, RedEdge (красный граничный), NIR (NIR1 и NIR2)
Пространственное разрешение 0,5 м Панхроматический режим: 0,5 м Мультиспектральный режим: 1,8 м
Окончание табл. 1.1.
Радиометрическое разрешение 11 бит на пиксель 11 бит на пиксель
Владелец Компания DigitalGlobe (США) Компания DigitalGlobe (США)
Дистрибьютор Компания «Совзонд» ИТЦ «СканЭкс» НЦОМЗ Компания «Совзонд» ИТЦ «СканЭкс» НЦОМЗ
Предварительная обработка данных Радиометрическая, сенсорная и геометрическая коррекция Радиометрическая, сенсорная и геометрическая коррекция
Система координат, проекция WGS-84/UTM и другие системы координат и проекции WGS-84/UTM и другие системы координат и проекции
Формат предоставления данных GeoTIFF, NITF GeoTIFF, NITF
Периодичность выполнения съемки 1,7-5,9 дней (в зависимости от широты области съемки) 1-4 дней (в зависимости от широты области съемки)
Срок предоставления данных из архива 1 день 1 день
Цена, минимальный объем заказа Архив: 25 км2 (около 600 $) Съемка на заказ: 25 км2 (600-900 $) Архив: 25 км2 (около 600 $) Съемка на заказ: 25 км2 (600-900 $)
Таблица 1.2. «КА Kompsat-2» и «GeoEye-1»
КА Kompsat -2 GeoEye -1
Дата запуска 28 июля 2006 года 6 сентября 2008 года
Расчетный срок пребывания на орбите 5 лет 7 лет
Режим съемки, спектральные диапазоны Панхроматический: 500...900 нм Мультиспектральный: В, G, R, NIR Панхроматический: 450...900 нм Мультиспектральный: В, G, R, NIR
Пространственное разрешение Панхроматический режим: 1м Мультиспектральный режим: 4м Панхроматический режим: 0,41 м Мультиспектральный режим: 1,65 м
Радиометричес кое разрешение 10 бит на пиксель 11 бит на пиксель
Владелец Агентство KARI (Корея) Компания GeoEye (США)
Дистрибьютор Компания «Spotlmage» (Франция) Компания «Ракурс» Компания «Совзонд» ИТЦ «СканЭкс» НЦОМЗ Компания «Google» Компания «Ракурс» Компания «Совзонд» ИТЦ «СканЭкс»
Предварительная обработка данных Радиометрическая, сенсорная и геометрическая коррекция (1А, 2A, 2G) Радиометрическая, сенсорная и геометрическая коррекция
Система координат, проекция WGS-84/UTM и другие системы координат и проекции WGS-84/UTM и другие системы координат и проекции
Формат предоставления данных GeoTIFF GeoTIFF
Окончание табл. 1.2.
Периодичность выполнения съемки 3 дня 1-3 дня (в зависимости от широты области съемки)
Срок предоставления данных из архива 7-14 дней 3-4 дня
Цена, минимальный объем заказа Архив: 50 км2 (375-800$). Съемка на заказ: 225 км2 (3000-5700 $) Архив: 49 км2 (около 680$) Съемка на заказ: 100 км2 (4000-5700$)
Т а б л и ц а 1.3. «КА ALOS» и «Ресурс-ДК»
КА ALOS Ресурс-П
Дата запуска 24 января 2006 года 25 июня 2013 года
Расчетный срок пребывания на орбите 5 лет 5 лет
Режим съемки, спектральные диапазоны Панхроматический: 520...770 нм Мультиспектральный: В, G, R, NIR Панхроматический: 580...800 нм Мультиспектральный: В, G, R, NIR (720...800 нм, 800...900 нм) Гиперспектральный: 96-255 каналов (40... 1100 нм)
Пространственное разрешение Панхроматический режим: 2,5 м Мультиспектральный режим: 10 м Панхроматический режим: 0,7 м Мультиспектральный режим: 3-4 м Гиперспектральный режим: 25 м
Радиометрическое разрешение 8 бит на пиксель 10-14 бит на пиксель
Владелец Агентство JAXA (Япония) Государственный научно-производственный ракетно-космический центр «ЦСКБ-Прогресс»
Окончание табл. 1.3.
Дистрибьютор Компания «Совзонд» ИТЦ «СканЭкс» Компания «Совзонд» НЦОМЗ
Предварительная обработка данных Радиометрическая и геометрическая коррекция (1B2+RPC) В зависимости от дистрибьютора
Система координат, проекция WGS-84/UTM и другие системы координат и проекции WGS-84/UTM и другие системы координат и проекции
Формат предоставления данных GeoTIFF GeoTIFF
Периодичность выполнения съемки 46 суток 3 дня
Срок предоставления данных из архива 3 дня В зависимости от дистрибьютора
Цена, минимальный объем заказа Архив: 1225 км2 (около 1700 $). Съемка на заказ: невозможна
Т а б л и ц а 1.4. «КА Cartosat-»2 и «RapidEye»
КА Cartosat -2 RapidEye (группировка КА)
Дата запуска 10 января 2007 года 29 августа 2008 года
Расчетный срок пребывания на орбите 5 лет 7 лет
Режим съемки, спектральные диапазоны Панхроматический : 500...850 нм Мультиспектральный: В, G, R, Red Edge (красный граничный), NIR
Пространственное разрешение 1 м 5 м
Радиометрическое разрешение 10 бит на пиксель 12-16 бит на пиксель
Окончание табл. 1.4.
Владелец Агентство ISRO (Индия) Компания «RapidEyeAG»(r ермания)
Дистрибьютор Компания «Ракурс» Компания «Совзонд» ИТЦ «СканЭкс» Компания «Совзонд»
Предварительная обработка данных Радиометрическая и геометрическая коррекция. Приведение к картографической проекции Радиометрическая, сенсорная и геометрическая коррекция. Приведение к картографической проекции
Система координат, проекция WGS-84/UTM и другие системы координат и проекции WGS-84/UTM и другие системы координат и проекции
Формат предоставления данных GeoTIFF GeoTIFF, NITF
Периодичность выполнения съемки 4 дня 24 часа
Срок предоставления данных из архива 1 день 1 день
Цена, минимальный объем заказа Архив: 25 км2 (590 $). Съемка на заказ: 25 км2 (780 $) Архив: 2500 км2 (цена договорная). Съемка на заказ: 5000 км2 (цена договорная)
Таблица 1.5. «КА Landsat 7» и «Landsat 8»
КА Landsat 7 Landsat 8
Дата запуска 15 апреля 1999 года 11 февраля 2013 года
Расчетный срок пребывания на орбите 5 лет 5,25 лет
Окончание табл. 1.5.
Режим съемки, спектральные диапазоны Панхроматический: 520...900 нм Мультиспектральный: В, G, R, NIR, SWIR (760...900 нм и 2080...2350 нм) Панхроматический: 500...680нм Мультиспектральный: Coastal («прибрежный и аэрозоли»), В, G, R, NIR, SWIR(1360-1390 нм, 1560... 1660 нм, 2100...2300 нм)
Пространственное разрешение Панхроматический режим: 15 м Мультиспектральный режим: 30 м Панхроматический режим: 15 м Мультиспектральный режим: 30 м
Радиометрическое разрешение 8 бит на пиксель 8(12 изначально) бит на пиксель
Владелец NASA, USGS NASA, USGS
Дистрибьютор USGS USGS
Предварительная обработка данных Радиометрическая, сенсорная и геометрическая коррекция, приведение к картографической проекции Радиометрическая, сенсорная и геометрическая коррекция, приведение к картографической проекции
Система координат, проекция WGS-84/UTM и другие системы координат и проекции WGS-84/UTM и другие системы координат и проекции
Формат предоставления данных GeoTIFF GeoTIFF
Периодичность выполнения съемки 16 дней 16 дней
Срок предоставлени я данных из архива Моментально Моментально
Цена, минимальный объем заказа Архив: бесплатно Съемка на заказ: невозможна Архив: бесплатно Съемка на заказ: невозможна
Из рассмотренных выше КА данные следующих КА доступны бесплатно:
• данные, полученные от КА «GeoEye-1», доступны с помощью Интернет-портала «Google Maps» [4];
• данные, полученные от КА «Landsat 7» и «Landsat 8», доступны с помощью Интернет-портала «Earth Science Data Interface (ESDI) at the Global Land Cover Facility» [5].
Таким образом, для решения исследовательских задач, не требующих регулярной съемки интересующей области земной поверхности и съемок на заказ, наилучшим выбором представляется использование данных ДЗЗ, полученных от КА «Landsat 8», по следующим причинам:
• достаточное количество спектральных каналов приемлемого разрешения;
• бесплатность;
• наличие радиометрической и геометрической коррекции;
• распространение данных с привязкой к системе координат WGS-84 в проекции UTM;
• запуск КА в 2013-м году и невыработка им расчетного срока службы.
1.3. Методы и алгоритмы совмещения цифровых карт местности с данными дистанционного зондирования Земли
1.3.1. Краткая характеристика
существующих методов и алгоритмов совмещения
В настоящее время существует несколько подходов к решению задачи совмещения данных ДЗЗ и ЦКМ, среди которых можно выделить следующие.
Методы совмещения, основанные наручном выделении на спутниковом снимке и ЦКМ опорных точек
Одним из наиболее распространенных подходов к совмещению данных ДЗЗ и ЦКМ является подход, основанный на выделении на спутниковом снимке и ЦКМ множества пар опорных точек, по которым в дальнейшем выполняется расчет результирующего преобразования совмещения.
Парой опорных точек называются такие точки, для которых соответствующие позиции были идентифицированы как на спутниковом снимке, так и на ЦКМ. Поскольку опорные точки, проставленные вручную, должны точно отображаться пространственным преобразованием, они являются ограничением, которому данное пространственное преобразование должно удовлетворять.
В качестве пространственного преобразования, определяющего отображение спутникового снимка на ЦКМ (и соответственно опорных точек, выделенных на спутниковом снимке, в соответствующие точки, выделенные на ЦКМ), могут выступать преобразование из группы движения, преобразование подобия, проективное преобразование, аффинное преобразование, трансформация «резинового листа».
Одним из методов, реализующих данный подход, является метод, описанный в [6] и применяемый на первом этапе технологической схемы пространственной привязки спутниковых снимков по ЦКМ, описанной в [6], для выполнения первоначального (грубого) совмещения. Данный метод состоит в выделении пар опорных точек вручную оператором ГИС, после чего система выполняет расчет результирующего преобразования.
Недостатком данного метода является его неавтономность из-за необходимости присутствия оператора, выполняющего простанов опорных точек на спутниковом снимке и ЦКМ. В отличие от данного метода совмещения, нейросетевые методы являются полностью автоматическими.
Методы совмещения, основанные на полуавтоматическом и автоматическом поиске на спутниковом снимке и ЦКМ особых точек
Развитием методов, основанных на выделении множества опорных точек, являются методы, решающие задачу выделения опорных точек полуавтоматически или полностью автоматически.
Полуавтоматические методы совмещения выполняют выделение множества опорных точек, верификацию которого производит оператор вручную. Данные методы реализованы в большинстве современных ГИС (например, в Erdas Imagine) и являются достаточно популярными, однако не позволяют выполнять автоматическое совмещение данных ДЗЗ и ЦКМ.
Методом совмещения, предполагающим полуавтоматическое выделение на спутниковом снимке множества опорных точек, является метод, описанный в [7] и основанный на построении множества опорных точек по наземным ориентирам (в [7] в качестве такового ориентира выступает вагон-лаборатория). Данный метод предполагает поиск на спутниковом снимке объектов, точные координаты которых на ЦКМ известны заранее, формирование из точек, соответствующих данным объектам, множества опорных точек и расчет по сформированному множеству результирующего преобразования.
Для достижения полной автоматизации процесса совмещения данных ДЗЗ и ЦКМ применяется несколько подходов - в частности, часто реализуется подход, основанный на применении детекторов особых точек для выделения оных на спутниковых снимках и данных ДЗЗ.
В качестве детекторов особых точек применяются детекторы SIFT, SURF, Бедета, Фестнера, Харриса [8, 9]. Перечисленные детекторы реализуют эвристические алгоритмы выделения особых точек, основанные на поиске изгибов контурных линий, резких перепадов яркости и прочих особенностей изображений.
Недостатком методов совмещения, основанных на применении перечисленных детекторов, является их низкая точность при решении задач совмещения разнородных изображений, коими являются спутниковые снимки и данные ДЗЗ. Это объясняется, прежде всего, тем, что перечисленные детекторы ориентированы на использование при решении задач совмещения кадров видео-последовательностей или изображений, одно из которых является изображением части сцены, присутствующей на другом.
В отличие от рассмотренных методов совмещения, нейросетевые методы реализуют полностью автоматический подход к совмещению, позволяющий выполнять совмещение разнородных изображений, одно из которых (изображение карты) является искусственным и может быть выполнено в искусственных цветах.
Методы совмещения, основанные на автоматическом поиске одноименных объектов на снимке и векторной карте
Логическим развитием методов совмещения данных ДЗЗ и ЦКМ по множеству опорных точек является метод, основанный на автоматической или полуавтоматической идентификации объектов карты [10].
Данный метод предполагает поиск совпадений между образами объектов, выделенными на спутниковом снимке, и объектами, присутствующими на ЦКМ. Образ объекта и объект, совпадение между которыми идентифицировано с высокой вероятностью, позволяют включить в множество опорных точек соответствующие точки, лежащие в границах образа и объекта, например, точки изгибов их контурных линий.
В качестве искомых объектов могут выступать объекты различных классов. Так, в [10] рекомендуется искать совпадения между образами и объектами гидрографии (речная сеть, береговые линии морей и озер).
Данный подход к совмещению реализует нейросетевой метод совмещения, основанный на классификации образов. В отличие от метода, рассмотренного в [10], данный метод использует для поиска совпадений между образами объектов и объектами, присутствующими на ЦКМ, искусственные нейронные сети и другие концепции теории искусственного интеллекта.
Корреляционно-экстремальные методы совмещения
Корреляционно-экстремальные методы совмещения [11] основаны на решении задачи оптимизации целевой функции-меры сходства между спутниковым снимком и ЦКМ.
Для предотвращения ложных срабатываний методов, возникающих из-за изменения значений пикселей в поисковой области, мера сходства нормируется. Однако, как показано в [12], данные методы обладают слабой устойчивостью к геометрическим искажениям (за исключением сдвига). Для корректной работы методов часто необходимы дополнительные данные, так, например, для повышения точности совмещения данных ДЗЗ и ЦКМ предварительно необходимо выполнить высокоточное совмещение с ЦКМ
базового спутникового снимка, по совмещению с которыми будет выполняться дальнейшее совмещение других, перекрывающих его, спутниковых снимков.
Контурно-корреляционные методы совмещения
Частным случаем корреляционно-экстремального подхода к совмещению является подход, реализующий контурное корреляционное совмещение.
Данные методы совмещения основаны на выделении контуров образов объектов на спутниковом снимке В, контуров объектов на ЦКМ М и дальнейшем сопоставлении (корреляции) контуров друг с другом.
Метод совмещения, описанный в [1], предполагает выделение на изображении, совмещаемом с ЦКМ, контуров с применением оператора Собеля, после чего коррелятор, основанный на поиске характерных точек изгибов контуров, выполняет сопоставление отдельных участков контуров образов объектов, выделенных на изображении, контурами объектов на ЦКМ.
Как было отмечено в [1], данный метод совмещения может быть использован при решении достаточно узкого круга задач, таких, как совмещение данных, поступающих от камер, установленных на летательном аппарате (ЛА), при заходе ЛА на посадку. Применение данного метода при решении задач совмещения данных ДЗЗ и ЦКМ ограничено и требует существенной ручной настройки параметров.
В [13] предложен алгоритм совмещения, основанный на поиске на изображении В окон, содержащих достаточно точное (в смысле некоторой меры расстояния) контурное представление окна, выделенного на ЦКМ. Для означенного поиска в [13] предлагается использовать генетический алгоритм, применение которого повышает автоматизм процесса совмещения, однако существенно увеличивает временные затраты на решения данной задачи.
В [6] описывается метод совмещения, основанный на поэтапном сканировании спутникового снимка В с некоторым окном, выделении контуров с помощью простейшего дифференциального оператора и сопоставлении очередного окне окном, выделенным на ЦКМ М. В качестве меры сходства в [6] предлагается использовать меру, учитывающую протяженность контура, его толщину и
направление. Данный подход хорошо поддается распараллеливанию, поэтому его реальные временные характеристики позволяют использовать его для оперативного решения задач совмещения, однако точность данного подхода непосредственно зависит от качества выделения контуров и алгоритма фильтрации помех, вызванных облаками, дымкой и другими факторами.
В [14] рассмотрен подход к совмещению спутниковых снимков В, полученных от геостационарных КА, основанный на координатной привязке снимков В по ЦКМ М и контурным точкам диска Земли. Подход основан на поиске соответствий между контурными линиями водных объектов на ЦКМ и контурами образов объектов на спутниковом снимке в некоторой зоне (области) поиска, задаваемой автоматически в ходе выполнения совмещения, конфигурация которой зависит от направления контура, его прогнозируемой толщины, его конфигурации. Для минимизации влияния облачности на качество совмещения в [14] предлагается использовать подходы, основанные на идентификации облаков на снимке, оценке степени перекрытия ими контуров водных объектов и принятии решения об использовании или исключении из рассмотрения отдельных участков контуров, перекрытых облаками.
Данный подход обеспечивает высокую точность координатной привязки и, следовательно, высокую точность совмещения данных ДЗЗ и ЦКМ, однако он не может быть использован при обработке данных ДЗЗ, полученных от КА, расположенных на негеостационарных орбитах, что существенно ограничивает применимость подхода.
Перечисленные методы совмещения данных ДЗЗ и ЦКМ имеют следующие отличия от нейросетевых подходов:
• от нейросетевого подхода, основанного на поиске образов объектов, присутствующих на ЦКМ, на спутниковом снимке, рассмотренные методы отличаются принципом работы - нейросетевой подход выполняет поиск соответствий между образами объектов на спутниковом снимке В и объектами, присутствующими на ЦКМ М, не рассматривая структуру образов и объектов, тогда как анализ структуры границ образов и объектов является основной особенностью перечисленных методов;
• от нейросетевого подхода, основанного на поиске корреляции между контурами образов, выделенных на спутниковом снимке, и границами объектов, присутствующих на ЦКМ, рассмотрен
ные методы отличаются тем, что для выполнения контурной корреляции нейросетевой подход использует нейросетевой коррелятор, который позволяет достичь различных эффектов, не достижимых рассмотренными методами, в частности, нейросетевой коррелятор способен автоматически восстанавливать мелкие разрывы контуров, что положительно сказывается на качестве совмещения.
В целом, применение методов совмещения, основанных на использовании систем искусственного интеллекта, позволяет осуществлять более точное совмещение из-за возможности учета различного рода помех, таких как зашумленность спутникового снимка, влияние облаков и дымок и т.д., в автоматическом режиме, тогда как рассмотренные методы контурно-корреляционного совмещения требуют для достижения похожих результатов использовать дополнительные эвристические алгоритмы. Кроме того, контурно-корреляционные методы совмещения имеют больше настроек, чем предлагаемые нейросетевые подходы, что понижает уровень автоматизма процесса решения задачи совмещения.
Однако необходимо отметить, что временные характеристики (без учета времени поиска параметров запуска алгоритмов) рассмотренных контурно-корреляционных подходов к совмещению чуть лучше, чем временные характеристики нейросетевых подходов.
Метод стабилизации изображений, основанный на преобразовании Фурье и вейвлет-преобразованиях
Методы стабилизации изображений выполняют поиск параметров и вида совмещения путем сравнения результатов различных интегральных преобразований между совмещаемыми спутниковым снимком и ЦКМ [15].
Основным недостатком данных методов является их низкие корректирующие способности - данные методы позволяют, как правило, компенсировать только сдвиг спутникового снимка относительно ЦКМ, при чем компенсация сдвига выполняется в достаточно узком диапазоне. Кроме того, данные методы, как правило, содержат в себе алгоритмы повышения разрешения, что обусловливает высокие требования по отношению сигнал/шум на спутниковом снимке.
В отличие от методов стабилизации, нейросетевые методы позволяют компенсировать не только сдвиг спутникового снимка
относительно ЦКМ, но и другие, более сложные, преобразования -такие как, например, поворот и масштабирование.
1.3.2. Методы и алгоритмы совмещения, основанные на использовании искусственных нейронных сетей и нейроподобных концепций
Рассмотренные подходы к решению задачи совмещения спутниковых снимков и ЦКМ имеют ряд недостатков. В настоящей работе рассматриваются системы искусственного интеллекта, алгоритмы моделирования систем и численные методы обучения систем, реализующие методы совмещения данных ДЗЗ и ЦКМ, свободные от перечисленных недостатков.
Оптимальным методом совмещения разнородных изображений с точки зрения минимизации средней ошибки на большой выборке тестовых данных является метод, реализуемый зрительными системами высокоорганизованных животных и человека [16]. На основании данного утверждения оказывается, что наилучшими подходами к автоматическому совмещению данных ДЗЗ и ЦКМ с точки зрения качества совмещения являются методы, максимально правдоподобно имитирующие деятельность зрительных систем высокоорганизованных животных и человека. К таким методам относятся подходы, основанные на моделировании систем искусственного интеллекта, включающих в себя искусственные нейронные сети (ИНС) различного типа и другие нейроподобные концепции теории искусственного интеллекта.
ИНС и нейроподобные конструкции обладают следующими достоинствами:
• способность к обобщению информации.
ИНС, выполняющая классификацию образов и обученная на репрезентативной выборке тестовых образов, вследствие своей нелинейной природы оказывается способна [17-19] к обобщению информации, что выражается в выделении общего набора характерных скрытых признаков для каждого класса образов. Данная способность ИНС и нейроподобных конструкций оказывается полезна при выполнении совмещения путем поиска соответствий между образами на спутниковом снимке и объектами на ЦКМ;
• способность к запоминанию и восстановлению информации.
ИНС и нейроподобные конструкции, реализующие ассоциативную память, способны [17-19] к восстановлению образов, ранее запомненных ими в процессе обучения.
• возможность распараллеливания вычислений, выполняемых в процессе обучения и использования ИНС и нейроподобных конструкций. Модульная структура ИНС и нейроподобных конструкций позволяет реализовывать [20] параллельные алгоритмы их обучения и использования для практически любых типов параллельных систем, к которым относятся параллельные системы, взаимодействующие через разделяемую память (многопроцессорные параллельные системы, системы, основанные на использовании технологии общих вычислений на видеокартах ((англ.) general-purpose graphics processing units, GPGPU, технология выполнения вычислений на графическом процессоре, не предназначенном для решения задач вывода компьютерной графики)), параллельные системы, взаимодействующие путем передачи сообщений (вычислительные кластеры, в том числе, вычислительные кластеры, организованные по технологии облачных вычислений).
Таким образом, интеллектуальные системы, построенные с использованием ИНС и нейроподобных структур, оказываются способны к горизонтальному масштабированию, ограниченному только контекстом вычислений (решаемой задачей).
Необходимо отметить возможность распараллеливания подходов к выбору структур ИНС и нейроподобных структур. Одним из таковых подходов является подход, основанный на использовании генетического алгоритма, который сам по себе достаточно хорошо поддается распараллеливанию [19-22].
К таковому аппаратному обеспечению относятся специализированные нейропроцессоры (подклассцифровых сигнальных процессоров (англ.) digital signal processor, DSP), к которым относится семейство процессоров NeuroMatrix [23]. Использование нейропроцессоров позволяет реализовывать ИНС и нейроподобные конструкции на аппаратном уровне, что приводит к существенному увеличению производительности системы искусственного интеллекта.
Существуют следующие подходы к решению задачи совмещения данных ДЗЗ с ЦКМ, основанные на использовании ИНС и нейроподобных концепций теории машинного обучения.
Подход, основанный на поиске образов объектов, присутствующих на ЦКМ, на спутниковом снимке
Данный подход предполагает выполнение следующих действий:
1) выделение на спутниковом снимке характерных образов (1-14);
2) классификация характерных образов (1.15);
3) поиск соответствий между образами, выделенными на спутниковом снимке, и объектами, присутствующими на ЦКМ:
Prm edu = f"ldedu <Л М,COOrd) =
conform(B,M,coord ,classification{separation{By).descy,
H = separation(By (1-14)
С = classification(H .descy (1.15)
Praw edu = conform(B, M, coord, C); (1.16)
H = {Л}; ftcft C = {c}- ccH;
\/cm, c„<=C; cmr^cn=0;
v = desc(hy v = {vpv2,...,v0}; VvogR; 0gN; (1.17) hc g c; hc g H.
Функция separation выполняет выделение образов объектов на спутниковом снимке В . Образы h формируют множество выделенных образов Н .
Множество образов Н является аргументом функции классификации classification . Другим аргументом функции classification является функция desc (1.17), выполняющая расчет векторов признаков v образов Л, выделенных на спутниковом снимке. Результатом функции classification является множество классов С = {с}. Классы не пересекаются друг с другом, то есть каждый образ h должен быть отнесен только к одному классу.
Множество классифицированных образов (множество классов) С является аргументом функции conform . Функция conform выполняет поиск соответствий между образами из классов С и объектам и на ЦКМ М с использованием информации о классах образов и их положении на спутниковом снимке. Результатом
функции conform является множество пар совпадающих точек Prawedu, по которым в дальнейшем выполняется расчет множества пар точек Pedu (1.11) и функции сотр' (1.12).
Функция separation может быть основана на использовании следующих методов:
• сегментация на основе выделения границ [10];
• алгоритм порогового преобразования [9, 10];
• алгоритмы наращивания областей (алгоритм центроидного связывания, алгоритм слияния-расщепления) [10];
• алгоритм морфологического водораздела [9];
• метод релаксационной разметки [10];
• кластеризация изображения с использованием многомерной нейронной карты Кохонена [20, 24, 25];
• кластеризация изображения с использованием алгоритма k-means [26];
• некоторые другие методы.
Сегментация на основе выделения границ, алгоритм порогового преобразования, алгоритмы наращивания областей, алгоритм морфологического водораздела и метод релаксационной разметки существенным образом зависят от освещения сцены. Например, некорректно выбранные параметры алгоритма выделения границ для сегментации на основе выделения границ, зависящие от освещенности сцены, ведут к выделению отдельных элементов образов объектов сцены, либо к объединению отдельных образов объектов сцены вследствие нечеткости их границы. Для учета условий освещенности сцены данные алгоритмы используют дополнительные эвристические подходы к расчету своих параметров, что приводит к усложнению процесса совмещения и увеличению вычислительной (а следовательно, и временной) сложности выделения образов.
Кластеризация изображений с использованием многомерной нейронной карты Кохонена и алгоритма k-means в меньшей степени зависят от освещенности сцены. Алгоритм k-means, по сравнению с многомерной нейронной картой Кохонена, предоставляет меньше возможностей по своей настройке (алгоритм k-means использует только Евклидово расстояние, тогда как многомерная нейронная карта Кохонена может работать с любой вещественной метрикой).
Таким образом, наилучшим выбором для выделения образов на сцене оказывается многомерная нейронная карта Кохонена.
В качестве функции classification могут быть использованы ИНС, нейроподобные конструкции и прочие концепции теории машинного обучения, обучаемые с учителем и решающие задачу построения регрессии:
d = f(h,desc); (1.18)
б/GN,
где d - номер класса, к которому относится образ h.
Классификация выполняется по вектору признаков v = desc(h) образа h, что позволяет говорить о процессе классификации как о процессе разбиения на непересекающиеся подмножества (классы) векторного пространства V = {v}, содержащего векторы признаков образов h.
Различные классификаторы, обучаемые с учителем, выполняют разбиение векторного пространства V на классы различными способами. Параметры разбиения рассчитываются по обучающему множеству образов Hteach - множеству заранее классифицированных образов h. Расчет параметров называется обучением классификатора. Качество выполненного обучения проверяется на тестовом множестве образов Htest - множестве заранее классифицированных образов h. Множества Hteach и Htest являются репрезентативными подмножествам и множества Hteach test заранее классифицированных образов h, при чем выполняются условие:
Множества H,each и Hust формируются путем случайной выборки из H,each ,esl.
Для классификации могут быть использованы следующие простые (не составные) классификаторы:
• дерево принятия решений [9].
Дерево принятия решений, используемое для решения сложных с точки зрения количества классов и размерности пространства признаков классификационных задач, состоит из достаточно большого количества узлов, требующих тонкой первоначальной настройки и дальнейшей подстройки в зависимости от особенное-
тей задачи, что ведет к необходимости эвристической настройки классификатора практически для каждой сцены;
• наивный Байесовский классификатор [8, 9].
Наивный Байесовский классификатор позволяет получить результат, оптимальный со статистической точки зрения. Данный классификатор позволяет выполнять линейное разделение классов, чего в ряде задач недостаточно из-за многомерности пространства признаков и сложности линейного разделения искомых классов;
• скрытая Марковская модель [26].
Основными проблемами при использовании скрытых Марковских моделей являются их колеблющаяся производительность, неприемлемая для решения поставленной задачи совмещения, и сильные структурные ограничения модели - используемые допущения обусловной независимости могут затруднить введение некоторых относительно простых условий;
• нейронная сеть прямого распространения без обратных связей [21, 22] (частный случай - многослойный перцептрон [17, 18, 26]).
Существенным недостатком нейронной сети прямого распространения и ее частного случая - многослойного перцептрона -является отсутствие алгоритма обучения, позволяющего достичь глобального минимума функции ошибки выполняемой классификации. Действительно, алгоритмы обучения нейронной сети прямого распространения - алгоритм градиентного спуска, квазиньютоновс-кие методы обучения (например, алгоритм Левенберга-Марквард-та), алгоритм сопряженных градиентов и прочие алгоритмы обучения позволяют достичь лишь локального минимума и требуют дополнительных эвристик для повышения вероятности схождения в глобальный минимум функции ошибки [27]. Таким образом, нейронные сети прямого распространения плохо подходят для решения сложных задач классификации - задач, линейное разделение классов в которых является достаточно сложным либо невозможным вовсе.
Влияние данного недостатка на точность классификации минимизируется с помощью специальных эвристических алгоритмов инициализации весов синапсов ИНС (алгоритм Нгуэна-Видроу, алгоритм Ле Куна), а также путем выбора структуры ИНС с помощью генетического алгоритма [21, 22].
Достоинством нейронной сети прямого распространения является низкая временная сложность алгоритмов ее обучения и работы, а также возможность распараллеливания их выполнения;
• сверточные ИНС-когнитрон, неокогнитрон, сверточная нейронная сеть Ле Куна, обученная с использованием методики «глубокого» обучения ((англ.) deep learning; (англ.) deep belief network) [28-32].
Обучение сверточных сетей является достаточно ресурсоемкой задачей и не гарантирует схождение функции ошибки к глобальному минимуму [29]:
• машина опорных векторов ((англ.) support vector machine, SVM) [17, 26];
• прочие классификаторы.
Таким образом, наилучшим выбором для решения задачи классификации образов оказываются нейронные сети прямого распространения без обратных связей, машины опорных векторов и сверточная нейронная сеть Ле Куна.
Нейронные сети прямого распространения, обладая низкой временной сложностью алгоритмов обучения и работы, могут быть эффективно использованы в составе классификатора, решающего задачу классификации образов в контексте поставленной задачи. Увеличение вероятности схождения сети к глобальному минимуму функции ошибки возможно с помощью эвристических алгоритмов инициализации весов синапсов нейронов и путем подбора структуры нейронной сети с использованием, например, генетического алгоритма.
Машина опорных векторов позволяет выполнять оптимальное с точки зрения достижения глобального минимума функции ошибки нелинейное разбиение классифицируемого векторного пространства на два класса.
Простые классификаторы могут быть объединены в составные классификаторы, содержащие функциональные блоки комбинирования выходов отдельных классификаторов (например, несколько классификаторов, значения на выходах которых есть вероятности принадлежности образа к каждому из соответствующих классов, могут быть объединены в составной классификатор, выходом которого будет номер класса, вероятность принадлежности образа к которому максимальна). Как правило, алгоритм классификации
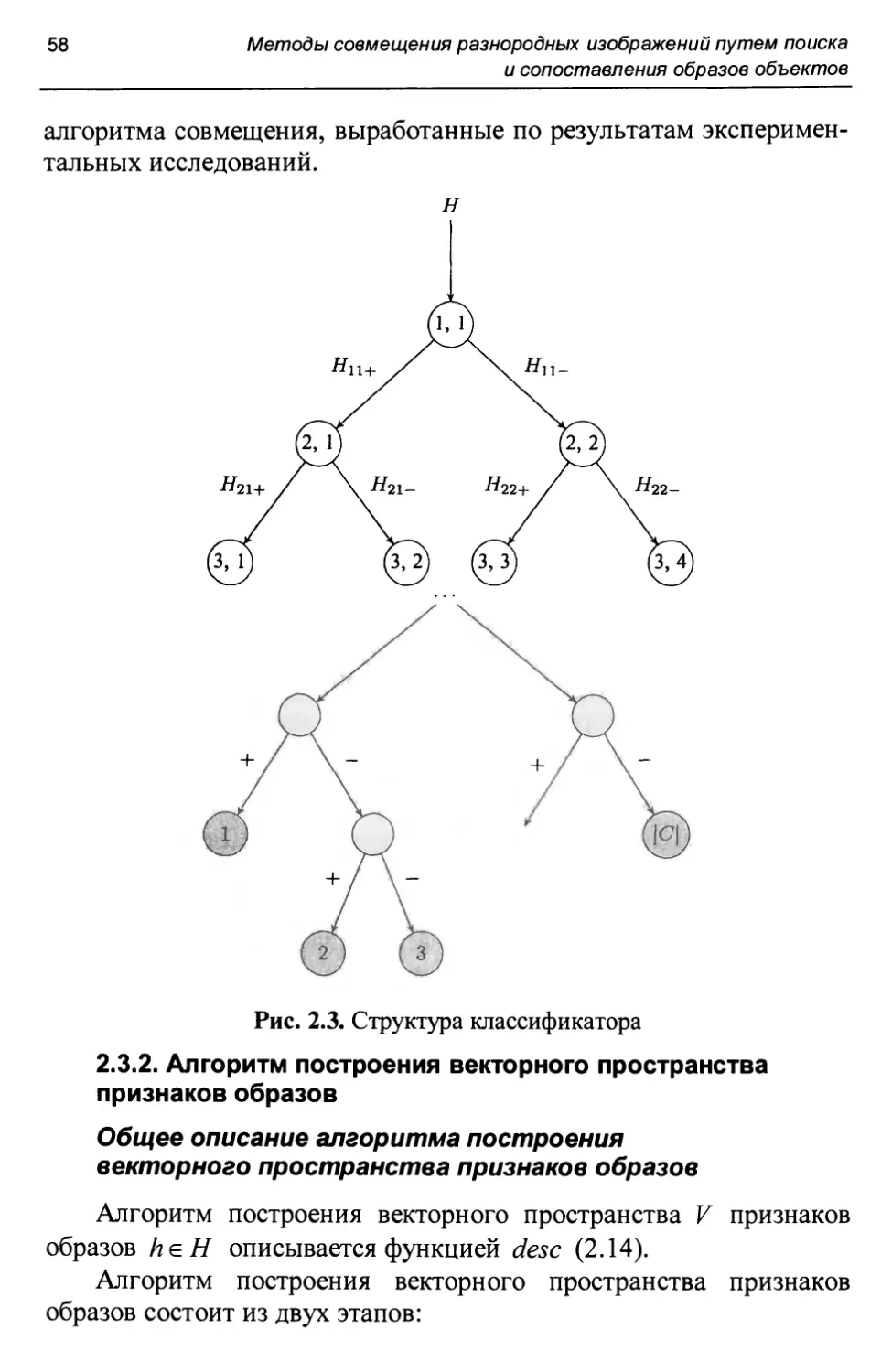
предполагает использование нескольких простых классификаторов, объединяемых в составной (сложный) классификатор [17]. Данное объединение может быть осуществлено следующими способами:
• объединение классификаторов в двоичное дерево [33, 34]. Объединение простых классификаторов в двоичное дерево позволяет минимизировать сложность задачи классификации, решаемой классификатором, помещенным в узел дерева. Действительно, каждый узел классификатора должен решить простейшую из возможных задач - задачу бинарной классификации;
• объединение классификаторов с использованием Boost-алго-ритмов [17]. В случае объединения классификаторов в составной с использованием Boost-алгоритмов результаты работы классификаторов уравновешивают друг друга, предоставляя на выходе Во-ost-алгоритма наиболее вероятный результат классификации, что также существенным образом повышает качество классификации.
Недостатком Boost-алгоритмов является необходимость дополнительных временных затрат на поиск оптимальной модели объединения классификаторов;
• организация экспертной системы (например, использование системы голосования) [17].
Экспертная система является наиболее эффективным средством объединения классификаторов с точки зрения качества работы составного классификатора, однако в процессе ее использования требуются существенные временные затраты на ее создание и обучение, что в контексте задачи оперативного совмещения данных ДЗЗ и ЦКМ делает экспертную систему очевидно неприменимой;
• другие способы комплексирования классификаторов.
Наилучшим средством объединения простых классификаторов в составной с точки зрения качества классификации и времени обучения классификатора оказывается объединение простых классификаторов в дерево - таким образом, каждый узловой классификатор будет решать простую задачу разделения векторного подпространства с выхода предыдущего узла дерева на два класса.
Расчет векторов признаков классифицируемых образов (функция desc ) может основываться на следующих алгоритмах:
• расчет минимального (усредненного) максимального вектора спектральных яркостей пикселей образа [35].
Недостатком данного подхода является невозможность описания им пространственной структуры текстур образов. Данный подход, будучи примитивным, но в то же время вычислительно эффективным, может быть использован для классификации образов в простейших случаях - например, в случае от деления класса образов, соответствующих водным объектам, до класса образов, соответствующих лесу, то есть в случаях, когда основная информация для работы классификатора содержится в спектральных яркостях пикселей образов и, следовательно, структура текстур образов может быть проигнорирована;
• расчет текстурных признаков пикселей:
- описание текстур с помощью расчета статистических характеристик выходов блоков пространственных фильтров [26].
К недостаткам данного подхода к описанию текстур относятся интуитивность составления блока пространственных фильтров, сложность формализации подходов по автоматическому составлению блоков и, вообще говоря, отсутствие каких бы то ни было критериев оптимальности составления блоков, кроме тестирования блоков на реальной или модельной задаче.
Отдельно необходимо упомянуть проблемы, возникающие в случае, если блок фильтров слишком мал или, наоборот, слишком велик. В первом случае возможно возникновение ситуации, при которой блок не даст достаточно информации для качественного решения поставленной задачи классификации образов, выделенных на изображении. Во второй ситуации, наоборот, возможен избыток информации, при котором происходит переобучение классификатора, выраженное в том, что количество векторов описаний, находящихся на границе разделения различных классов, становится пренебрежимо малым по сравнению с векторами описаний образов, типичных для каждого из классов, итак, граница разделения классов в существенной степени размывается, что негативно влияет на качество работы классификатора. Кроме того, в случае большого блока фильтров существенно увеличиваются временные затраты на получение описания текстур, что обусловливается необходимостью свертки исходного изображения В с каждым из фильтров;
- использование энергетических характеристик Лавса [8,36,37]. Энергетические характеристики Лавса обладают следующими достоинствами:
возможность компактного описания большинства возможных характерных паттернов структуры текстуры таких, как периодическое повторение элементов текстуры, множество не связных мелких элементов, отдельные относительно большие пятна и прочие;
возможность компактного описания уровня яркости текстуры, масштабированного к одинаковому уровню освещения по всему спутниковому снимку;
Недостатком данного подхода является необходимость свертки исходного изображения с набором пространственных фильтров, ведущая к существенным времен
ным затратам на расчет описания текстуры;
- использование текстурных признаков Харалика [37, 38].
Достоинством текстурных признаков Харалика является их большая информативность и большая гибкость характера описания по сравнению с рассмотренными подходами.
Недостатком текстурных признаков Харалика является их меньшая компактность, по сравнению с энергетическими характеристиками Лавса, что объясняется необходимостью расчета одних и тех же характеристик для нескольких матриц вхождений;
- прочие способы описания образов, выделенных на изображении.
Таким образом, в контексте поставленной задачи наилучшим выбором является использование следующих подходов к описанию образов, выделенных на изображении: - использование энергетических характеристик Лавса.
Данный подход к описанию образов используется на верхних уровнях дерева классификаторов, то есть на тех уровнях, на которых происходит разделение существенно отличных друг от друга классов, например, класса водных объектов от класса лесных насаждений;
- использование текстурных признаков Харалика.
Данный подход к описанию образов используется на нижних уровнях дерева классификаторов, поскольку он хорошо зарекомендовал себя для описания текстур в задачах разделения классов, если граница между классами является
существенно нелинейной (например в случае разделения класса хвойного леса и класса лиственного леса).
Необходимо также отметить тот факт, что, как правило, 0 (размерность вектора признаков) является достаточно большой, что ведет к увеличению временной сложности процесса классификации, поэтому целесообразно использование того или иного метода понижения размерности пространства признаков. К таковым методам относятся:
• попарное одношаговое или многошаговое усреднение векторов признаков. Попарное одношаговое или многошаговое усреднение векторов признаков может быть использовано в контексте решения достаточно простых задач-задач, в которых возможно линейное разделение классов, поскольку усреднение не позволяет учитывать и регулировать потери информации, происходящие при понижении размерности пространства признаков;
• применение преобразования Карунена-Лоева, матрица которого может быть рассчитана с использованием нейронной сети, реализующей анализ главных компонентов ((англ.) principal component analysis, РСА) [17, 18, 39, 40].
Для понижения размерности пространства признаков можно использовать преобразование Карунена-Лоева, поскольку оно позволяет оценивать и регулировать потери информации при понижении размерности пространства признаков.
Функция conform описывает многоэтапный алгоритм, состоящий из поискового алгоритма и алгоритма вероятностной оценки соответствия образа h, выделенного на спутниковом снимке В , объектам ЦКМ М , расположенным вблизи точек {coord((i, /))}; X/b^h [41].
Рассмотренный подход к совмещению обладает следующими достоинствами:
• низкие временные затраты на выполнение совмещения, что связано с широкими возможностями по распараллеливанию отдельных шагов алгоритма вследствие их нейросетевой природы, а также с тем, что для совмещения достаточно, как правило, нахождения не более нескольких десятков пар образов и объектов;
• высокая точность совмещения, обусловленная гибкой структурой классификатора, реализующего статистически оптимальную классификацию образов, выделенных на спутниковом снимке.
Подход, основанный на поиске корреляции между контурами образов, выделенных на спутниковом снимке, и границами объектов, присутствующих на ЦКМ
Данный подход предполагает выполнение следующих действий:
1) предварительная обработка спутникового снимка с целью устранения несущественных (слабых или прерывистых) контуров (1-19);
2) выделение контуров на спутниковом снимке (1.20);
3) описание контуров (1.21);
4) поиск совпадений контуров образов на спутниковом снимке с границами объектов на ЦКМ (1.22).
Prm edu = finked,. (В,М,СООГС1) =
= correlation(M,cdesc(contour(prepare(B))));
вр,р = prepare(B); (1.19)
Bcut = contour (Вргр)\ (1-20)
G = cdesc(Bml); (1-21)
prau edu = correlation^, G); (1.22)
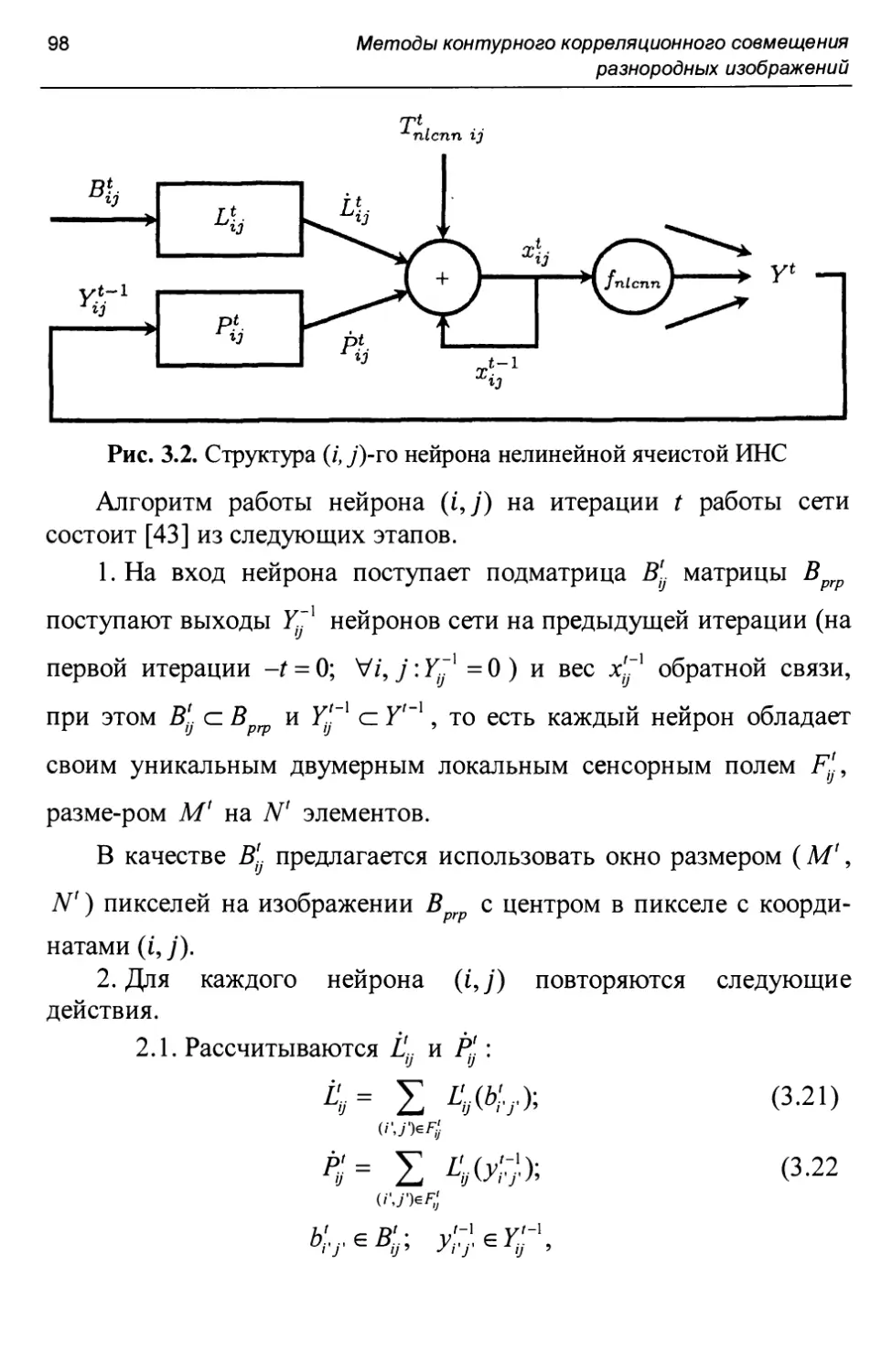
Bc„, = {bCMiJ}; i = U-, j = *OT/,e[0;l]; G = {g}.
Исходный спутниковый снимок В является аргументом функции предварительной обработки prepare , результатом которой является изображение В , на котором, в отличие от спутникового снимка В , отсутствуют несущественные (слабые или прерывистые) контуры.
Изображение Вргр является аргументом функции contour , которая выполняет выделение контуров на изображении. Результатом функции contour является контурная матрица Bcnt , каждый пиксель Bcnt у которой содержит меру силы контура, проходящего через пиксель Вргр у исходного изображения Вргр . Под мерой силы
контура в (1.20) понимается численная мера, принимающая значения из диапазона [0; 1], где 0 соответствует отсутствию контура, а 1 - максимально сильному контуру. В простейшем случае Bcnt является бинарной матрицей.
Контурная матрица Bcnt является аргументом функции описания контуров cdesc, результатом которой является множество G описаний g контуров, выделенных на изображении Вргр .
Множество G вместе с ЦКМ М являются аргументами функции correlation , выполняющей корреляционное совмещение ЦКМ и спутникового снимка. В ходе корреляционного совмещения контурам, описание которых присутствует в G, ищутся соответствия на ЦКМ (границы объектов), по результатам чего формируется множество пар совпадающих точек Pra}V edu, по которым в дальнейшем выполняется расчет множества пар точек Pedu (1.11) и функции сотр' (1.12).
Алгоритм выделения контуров, описываемый функцией contour, должен удовлетворять следующим требованиям:
• низкие временные затраты;
• точность, достаточная для дальнейшего автоматизированного совмещения спутникового снимка с ЦКМ.
Последнее требование предполагает выделение не всех, хорошо различимых для человеческого глаза, контуров, но выделение наиболее протяженных контуров и их дополнительное (в зависимости от характера контуров) сглаживание. Так, например, сглаживание может потребоваться при выделении контура водного объекта, имеющего растительность, произрастающую на его берегу и отсутствующую на карте. Для обеспечения такового выделения необходимо выполнение предобработки спутникового снимка, для чего используется функция prepare.
Существуют следующие алгоритмы выделения контуров на изображении:
• алгоритмы, основанные на дифференциальных операторах:
-алгоритм, основанный на использовании перекрестного градиентного оператора Робертса [9];
- алгоритм, основанный на использовании оператора Собеля (или частной версией оператора Собеля - оператора Щура) [9];
- алгоритм, основанный на использовании оператора Превитт [9];
- детектор краев Кэнни [8, 9].
Данные алгоритмы выделяют большое количество слабых контуров (в том числе, контуров, наличие которых на изображении обусловлено разного рода помехами), непригодных для решения задачи автоматизированного совмещения спутникового снимка с ЦКМ, что ведет к увеличению вычислительной и временной сложностей алгоритма совмещения и снижению качества совмещения;
• метод Хафа.
Данный метод предполагает существенные вычислительные затраты, связанные с большим количеством операций с плавающей точкой.
Рассмотренные алгоритмы выделения контуров не удовлетворяют в полной мере перечисленным выше условиям.
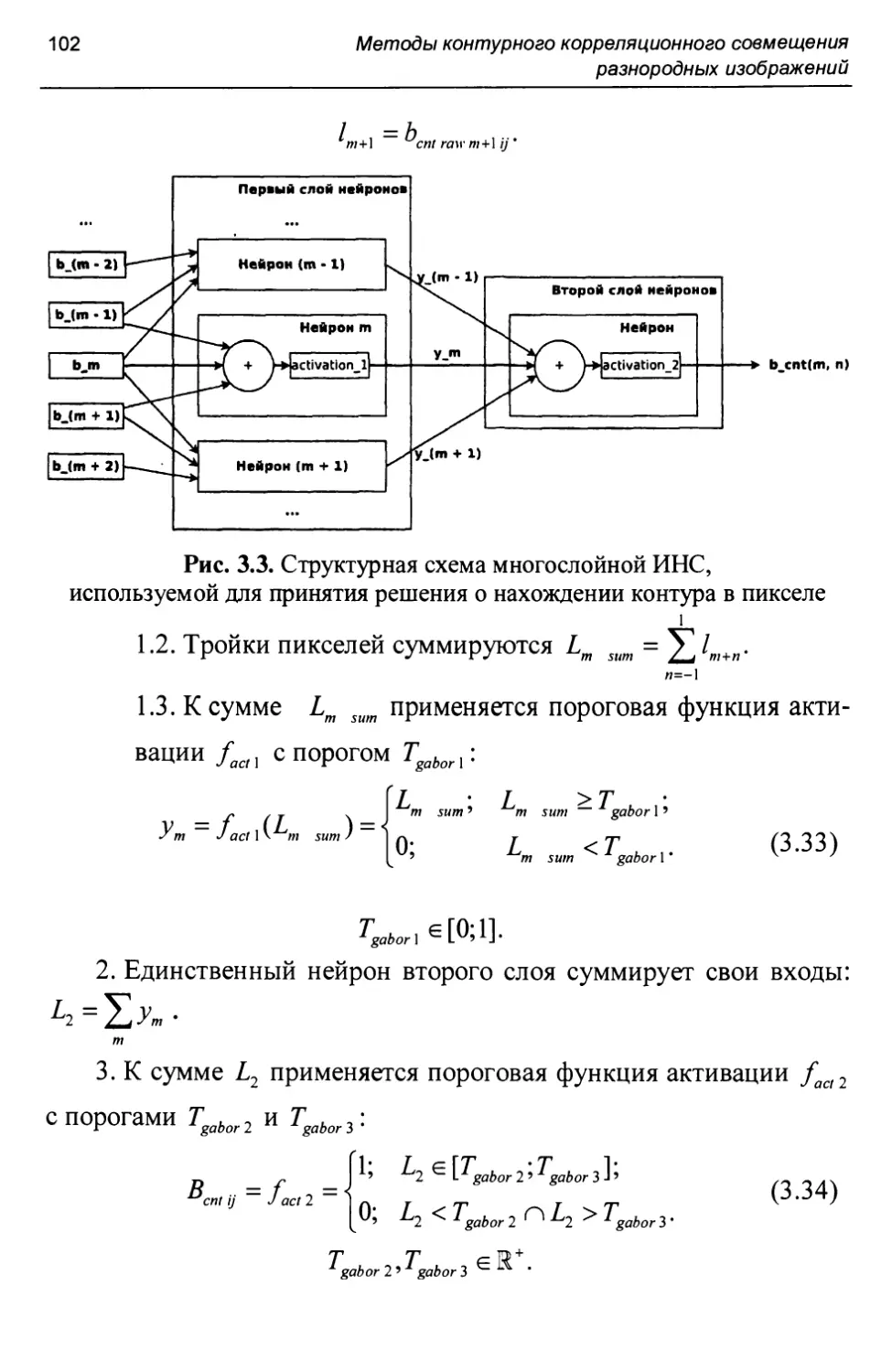
Методами выделения контуров, свободными от недостатков перечисленных алгоритмов, являются: нейросетевой подход к выделению контуров, основанный на использовании вейвлета Габора [42], и нейросетевой алгоритм выделения контуров, основанный на использовании нелинейных ячеистых искусственных нейронных сетей ((англ.) non linear cellular neural network, NLCNN) [43- 46].
Для описания cdesc контуров, выделенных на изображении, могут использоваться следующие подходы:
• формирование вектора пар координат пикселей спутникового снимка В, занятых контуром [9].
Недостатком подхода, описывающего контур путем формирования вектора пар координат пикселей, занятых им, является его чрезмерная информационная перегруженность, что особенно заметно на изгибах контуров, следствием которой является снижение временной эффективности работы алгоритма совмещения и высокая чувствительность к шумам различной природы;
• расчет цепочечного кода контура [8, 9]. К недостаткам цепочечного кода контура относится его существенная абстрагирован-ность от конкретной задачи - действительно, в контексте корреля
ционного совмещения с использованием ассоциативной памяти использование абстрактного кода приводит к необходимости его адекватного масштабирования в диапазон вещественных значений, с которыми работает ассоциативная память, что не всегда возможно;
• составление множества подматриц матрицы Всш фиксированного размера (множества окон), содержащих контур [46, 47].
Данный способ описания контуров не учитывает минимальные изменения на его протяжении, но оказывается достаточно информативным, простым (с временной точки зрения) для расчета и хорошо подходящим для совмещения с использованием ассоциативной памяти;
• прочие способы описания контуров.
Для описания контуров на изображении можно применять подход, основанный на составлении множества подматриц матрицы Всп( фиксированного размера (множества окон), содержащих контур.
Множество G описаний контуров, выделенных на спутниковом снимке В, является одним из аргументов функции correlation . Другим аргументом функции correlation является ЦКМ М. Функция correlation выполняет корреляционное совмещение спутникового снимка В с ЦКМ М , которое заключается в поиске соответствий между контурами, описания которых наличествуют в G, и границами объектов, присутствующих на ЦКМ М .
Существует ряд подходов к корреляционному совмещению:
• алгоритм предварительного совмещения изображений на основе выделения преобладающих углов характерных линий, описанный в [1].
Методы корреляционного совмещения, один из которых был писан в [1], обладают рядом недостатков, наиболее существенными из которых являются необходимость дополнительной настройки методов для каждого спутникового снимка вследствие существенного влияния погодных условий, условий освещенности, разнообразных прочих помех на результат совмещения и низкое качество результата совмещения, что позволяет использовать данные алгоритмы лишь при решении узкоспециализированных задач, которыми являются, например, задачи определения характеристик
(класс, атрибутивная информация) объекта на спутниковом снимке по ЦКМ;
• алгоритм совмещения, основанный на использовании поэтапного сканирования спутникового снимка [48].
Поэтапное сканирование предполагает фактически простой перебор возможных множеств Pran edu с расчетом качества совмещения для каждого. Простой перебор в данном случае предполагает существенные временные затраты на выполнение совмещения спутникового снимка и ЦКМ.
Существуют несколько эвристических подходов к оптимизации алгоритма поэтапного сканирования, однако ни один из них существенным образом не улучшает временные характеристики алгоритма;
• алгоритм совмещения, основанный на использовании генетического алгоритма [13].
Одним из подходов к улучшению временных характеристик алгоритма поэтапного сканирования является подход, основанный на использовании генетического алгоритма для совмещения данных ДЗЗ и ЦКМ. Генетический алгоритм, обладая временными характеристиками, лучшими по сравнению с простым перебором, все равно не применим в задачах, требующих оперативного совмещения. Кроме того, генетический алгоритм предъявляет существенные требования к объему оперативной памяти вычислительной системы и, таким образом, не применим во встраиваемых системах;
• подходы, основанные на использовании адаптивной памяти:
-подходы, основанные на использовании адаптивно-резонансной теории [29], подходы, основанные на использовании ИНС Хопфилда и ИНС Хемминга [17, 18].
Концепции адаптивно-резонансной теории, ИНС Хопфилда и ИНС Хемминга не могут рассматриваться в качестве серьезного инструмента для построения высокоточных систем совмещения данных ДЗЗ и ЦКМ, поскольку ИНС работают с двоичными образами (и, следовательно, требуют специальных преобразований между вещественным описанием контура и его двоичным описанием) и способны запоминать лишь относительно не большое количество восстанавливаемых образов. Оба недостатка обусловливают существенные
затруднения в процессе использования данных нейросетевых концепций и провоцируют горизонтальный рост системы искусственного интеллекта, реализующей совмещение; - подходы, основанные на использовании нейронной сети Коско (двунаправленная ассоциативная память) [29, 49].
Нейронная сеть Коско представляет интерес, в большей степени, как модель человеческого мозга;
- подходы, основанные на использовании многослойного перцептрона с обратными связями ((англ.) recurrent multilayer perceptron, RMLP) [18].
Основным применением многослойного перцептрона с обратными связями является удаление шумов из сигналов, хотя теоретически RMLP может быть использован для реализации адаптивной памяти;
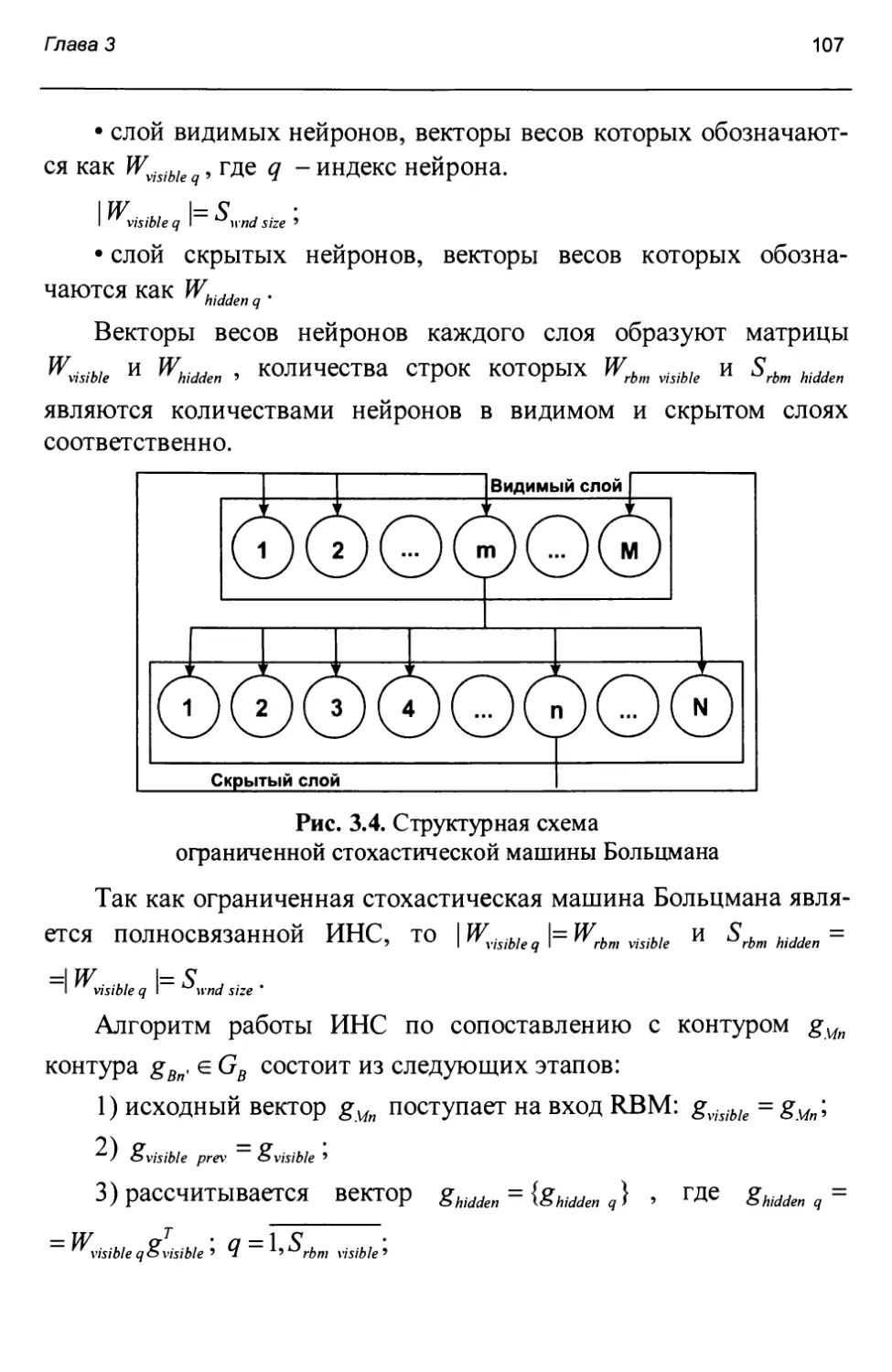
- подходы, основанные на использовании ограниченной стохастической машины Больцмана ((англ.) restricted Boltzmann machine, RBM) [17, 46, 47].
Данная концепция обеспечивает высокую точность восстановления, способна запоминать существенно больше образов по сравнению с концепциями адаптивно-резонансной теории, ИНС Хопфилда и ИНС Хемминга и может быть эффективно реализована в системе, поддерживающей параллельные вычисления.
Таким образом, единственной концепцией, которая может быть использована для решения задачи совмещения спутниковых снимков и ЦКМ, является ограниченная стохастическая машина Больцмана.
Рассмотренный подход, так же как и подход, основанный на поиске объектов, присутствующих на ЦКМ, на спутниковом снимке, обладает следующими достоинствами:
• низкие временные затраты на выполнение совмещения, что связано с хорошими возможностями по распараллеливанию отдельных этапов совмещения вследствие их нейросетевой природы;
• высокая точность совмещения, что обеспечивается нелинейностью процесса выполнения совмещения.
Г л а в a 2
МЕТОДЫ СОВМЕЩЕНИЯ РАЗНОРОДНЫХ ИЗОБРАЖЕНИЙ ПУТЕМ ПОИСКА
И СОПОСТАВЛЕНИЯ ОБРАЗОВ ОБЪЕКТОВ
2.1. Алгоритм моделирования системы искусственного интеллекта
На вход системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ, на спутниковом снимке, поступают следующие данные:
В - исходный спутниковый снимок;
М - исходная ЦКМ;
coord - функция преобразования координат (/, у) пикселя Ьи спутникового снимка В в координаты (х/у, у,..) точки на ЦКМ М в соответствии с системой координат и проекцией спутникового снимка В.
На выход системы искусственного интеллекта поступает множество пар совпадающих точек Praw edu (1.10), по которым в дальнейшем выполняется расчет множества пар точек Pedu (1.11) и функции сотр' (1.12), описывающей результирующее совмещение спутникового снимка В и ЦКМ М .
Система искусственного интеллекта состоит из следующих модулей:
1) модуль выделения на спутниковом снимке характерных образов (2.1);
2) модуль классификации характерных образов (2.2);
3) модуль поиска соответствий между образами, выделенными на спутниковом снимке, и объектами, присутствующими на ЦКМ (2.3).
Prm- edu findedu(B,M,coord) =
conform(B,M, coord ,classification(separation(B\desc)y,
Н = separation(B)', (2.1)
С = classification^ ,desc); (2.2)
Pmr edu = conform(B,M,coord,C); (2.3)
H = {h}, hcB;
C = {c}, ccH;
Уст- c„eC; cmnc„=0;
v = desc(h); v = {v1,v2,...,v0}; VvoeR; 0eN; (2.4) hc ec; hc e H.
Модуль separation выполняет выделение образов объектов на спутниковом снимке В. Образы h формируют множество выделенных образов Н.
Множество образов Н подается на вход модуля классификации classification . Другим входным параметром модуля классификации classification является модуль desc (2.4), выполняющий расчет векторов признаков v образов h, выделенных на спутниковом снимке. На выход модуля classification поступает множество классов С = {с}. Классы не пересекаются друг с другом, то есть каждый образ h должен быть отнесен только к одному классу.
Множество классифицированных образов (множество классов) С подается на вход модуля conform. Модуль conform выполняет поиск соответствий между образами из классов С и объектами на ЦКМ М с использованием информации о классах образов и их положении на спутниковом снимке. На выход модуля conform поступает множество пар совпадающих точек Prm edu, по которым в дальнейшем выполняется расчет множества пар точек Pedu (1.11) и функции сотр' (1.12).
В § 1.3.2. приведен детальный анализ возможных подходов к реализации каждого из модулей системы. Окончательно были выбраны следующие подходы:
• модуль separation - многомерная нейронная карта Кохонена;
• модуль desc - алгоритмы описания образов, основанные на использовании энергетических характеристик Лавса и текстурных
признаков Харалика, алгоритм понижения размерности пространства признаков, основанный на использовании РСА-сети;
• модуль classification - древовидный классификатор, ИНС прямого распространения без обратных связей и машина опорных векторов;
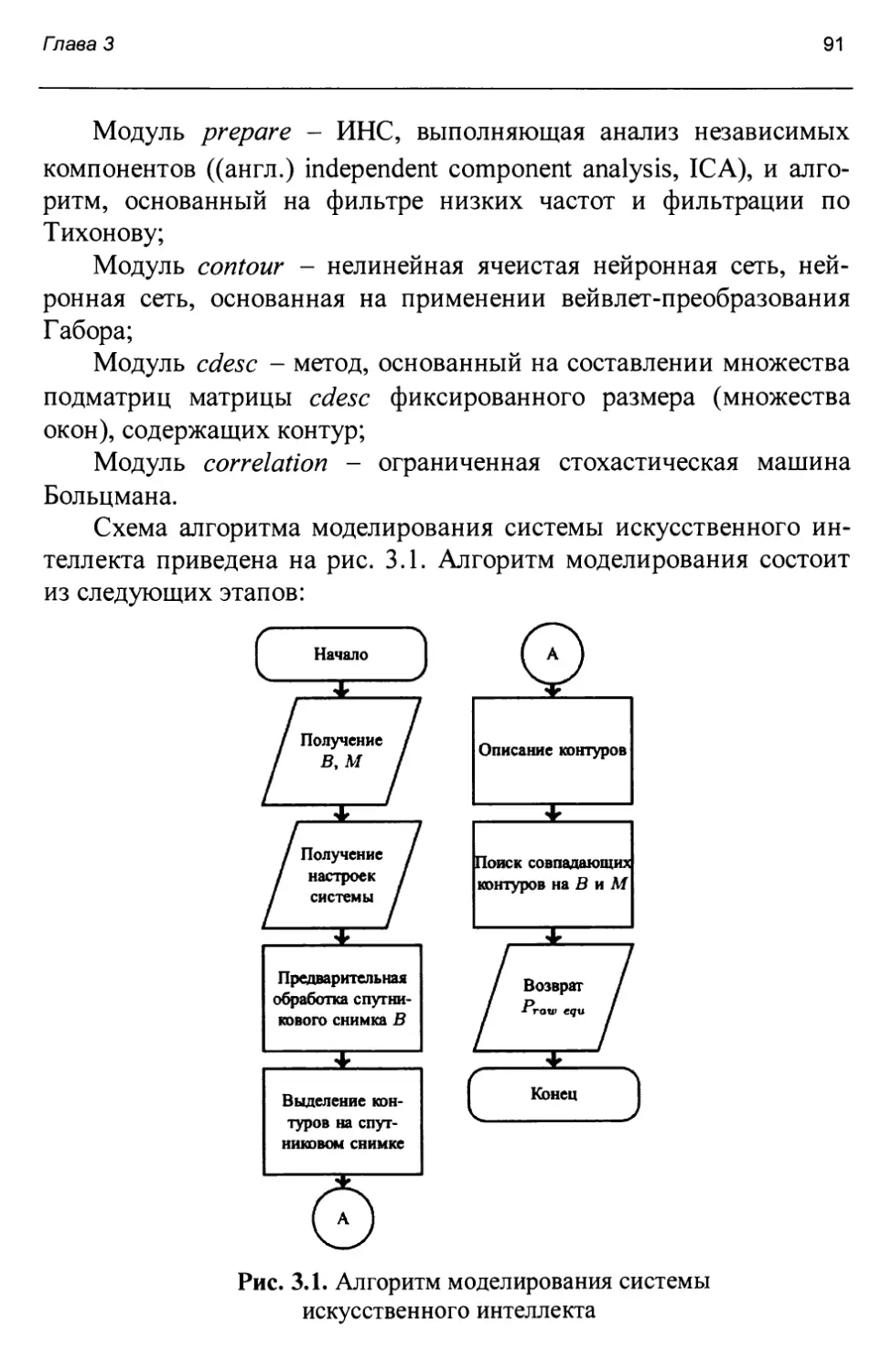
Рис. 2.1. Алгоритм моделирования системы искусственного интеллекта
• модуль conform - многоэтапный алгоритм, состоящий из поискового алгоритма и алгоритма вероятностной оценки соответствия образа h, выделенного на спутниковом снимке В, объектам ЦКМ М , расположенным вблизи точек {coord((i,jy)}; \/Ьу g h.
Схема алгоритма моделирования системы искусственного интеллекта приведена на рис. 2.1. Алгоритм моделирования состоит из следующих этапов:
1) выделение на спутниковом снимке характерных образов (2.1) с использованием многомерной нейронной карты Кохонена;
2) описание выделенных образов (2.4) с использованием энергетических характеристик Лавса и текстурных признаков Харалика;
3) понижение размерности пространства признаков с использованием РСА-сети;
4) классификация характерных образов (2.2) с помощью древовидного классификатора;
5) поиск соответствий между образами, выделенными на спутниковом снимке, и объектами, присутствующими на ЦКМ (2.3).
2.2. Выделение образов на спутниковом снимке
2.2.1. Структура, принципы обучения и функционирования
Существует несколько подходов к выделению образов на спутниковом снимке (функция separation в (2.1)). Как было показано в § 1.3.2, наиболее эффективным с точки зрения времени выполнения и требуемых вычислительных ресурсов и позволяющим получить при этом результат качества, достаточного для дальнейшего совмещения, является подход, основанный на использовании многомерной нейронной карты Кохонена [24].
Пусть V = {v} - векторное пространство, определенное над [-1;1] и содержащее векторы спектральных яркостей (| v |= К). Для спутникового снимка В справедливо, таким образом, В с: V .
Алгоритм выделения образов состоит из следующих этапов:
1) классификация векторов спектральных яркостей пикселей спутникового снимка В с помощью многомерной нейронной карты Кохонена;
2) кластеризация спутникового снимка В с получением множества Q = {q} кластеров.
Каждый кластер q является замкнутым множеством пикселей из В, отнесенных к одному и тому же классу.
Алгоритм кластеризации состоит из построчного сканирования В, классификации каждого пикселя и постепенного наращивания формируемых кластеров;
3) фильтрация выделенных кластеров с формированием на выходе множества Н выделенных образов. Для каждого кластера q рассчитывается количественная оценка quality полезности кластера для дальнейшего совмещения, с помощью которой формируется множество Н образов (2.5), выделенных на спутниковом снимке:
н = {q | quality(q) > TquaIity}; (2.6)
Я„ю„о.е[0;1],
где Tquality - пороговое значение, определяющее минимальную оценку полезности кластера q , при которой кластер будет включен в множество Н выделенных образов. Значение Tquality является одним из настраиваемых параметров алгоритма совмещения.
К quality предъявляются следующие требования:
• оценка должна быть определена всюду на V и непрерывна на всей области определения;
• областью значений оценки является диапазон [0; 1];
• значение оценки должно быть тем больше, чем выше полезность кластера q для дальнейшего совмещения.
В качестве quality могут быть использованы различные оценки. Экспериментальные исследования показали, что наилучшей с точки зрения временных затрат и качества результата является оценка, основанная на вычислении площади кластера q :
= (2.7)
a
a = IJ, где a - коэффициент нормировки, равный количеству пикселей на спутниковом снимке В (т.е. равный площади спутникового снимка В, выраженной в пикселях).
Ключевым элементом алгоритма выделения образов является многомерная нейронная карта Кохонена, выполняющая классификацию пикселей спутникового снимка В.
Многомерная нейронная карта Кохонена выполняет разбиение исходного векторного пространства V на набор классов { Va }; Va cz V, каждый из которых состоит из векторов, ближе всего расположенных к центральному вектору va данного класса в смысле используемой меры расстояния d .
Нейронная карта представляет собой многомерную сетку нейронов, каждый из которых рассчитывает меру расстояния между входным вектором и центральным вектором соответствующего класса.
Пусть 5 = {5j,...,5w,...,5v}; вектор размерностей карты.
Каждому нейрону, лежащему в узловой точке карты с координатами w = {Wj,...,ww,...,vvv} , можно поставить в соответствие вектор v'a , центральный для Va -го выделяемого класса, где .V
w = W] + -1) - номер класса. Важно отметить, что weN.
п=2
Вектор s является одним из параметров алгоритма совмещения и выбирается оператором.
Нейронная карта относится к классу ИНС, обучаемых без учителя. Обучение нейронной карты осуществляется с помощью алгоритма самоорганизации нейронной карты Кохонена.
Алгоритм классификации пикселей спутникового снимка В с помощью многомерной нейронной карты Кохонена состоит из следующих этапов:
1) инициализация нейронной карты - выбор параметров, инициализация векторов va весов нейронов;
2) самоорганизация карты на множестве В с И ;
3) прогон карты для каждого пикселя Ь<еВ , отнесение пикселя к одному из допустимых классов Va .
Принцип работы многомерной нейронной карты Кохонена проиллюстрирован рис. 2.2. На рис. 2.2 трехмерная карта описывает двухмерное векторное пространство в соответствии с его статистическими характеристиками. Несоответствие размерности (карта большей размерности описывает пространство меньшей размерности) позволяет достичь нелинейности описания, что поло-
жительно влияет на качество выполняемой классификации и соответственно на качество сегментации пространства.
Нелинейное описание картой двухмерного пространства
Самоорганизаци я нейронной карты
Рис. 2.2. Сегментация двухмерного пространства с помощью трехмерной карты Кохонена
В качестве меры расстояния d на векторном пространстве V могут быть использованы различные метрики. Экспериментально оказалось, что использование Евклидова расстояния (2.8) в качестве таковой метрики является лучшим выбором с точки зрения временных характеристики с точки зрения оценки качества совмещения.
v2) = . £(vu.-vlt)2. (2.8)
V
В случае использования Евклидова расстояния в качестве метрики d задача обучения нейронной карты сводится к построению разбиения Воронова множества В - т.е. к разбиению, минимизирующему дисперсию в результирующих классах относительно соответствующих центральных векторов.
2.2.2. Инициализация весов нейронов карты
с помощью датчика псевдослучайных чисел.
Выбор датчика псевдослучайных чисел
Существуют следующие подходы к инициализации весов нейронов нейронной карты Кохонена:
• инициализация весов нейронов нулевыми векторами;
• инициализация весов нейронов случайными значениями из диапазона [Tmin, TmaJ;
• инициализация весов нейронов случайными значениями из диапазона [Mv -Тт-т, Mv +Ттах].
По результатам экспериментальных исследований для инициализации весов нейронов нейронной карты Кохонена в контексте решения задачи совмещения данных ДЗЗ и ЦКМ была выбрана инициализация весов случайными значениями из диапазона [Tmin, Tmax]. Принимая во внимание ограничение v = {v„,}; vm е [-1; 1] обуславливаемое характером предметной области, в качестве ГтЬ1 и Гтах были выбраны следующие значения:
• Т’т-.п = -o,i;
• Т =0,1. max ’
В качестве датчика псевдослучайных чисел предлагается использовать генератор псевдослучайных чисел (ГПСЧ), получивший название «вихрь Мерсенна» ((англ.) Mersennetwister) [50].
Вихрь Мерсенна обладает следующими достоинствами:
• большой период, равный 219937 - 1;
• низкие временные затраты на генерацию псевдослучайных чисел и обновление внутреннего состояния ГПСЧ;
• хорошие статистические свойства ГПСЧ, о чем свидетельствует прохождение генератором тестов DIEHARD [51].
2.2.3. Обучение
Алгоритм самоорганизации нейронной карты по алгоритму Кохонена
Алгоритм самоорганизации нейронной карты был предложен финским ученым Тойво Кохоненом в 1982-м году [52]. Алгоритм обучения нейронной карты Кохонена состоит из следующих этапов:
1. Для каждого вектора Ь^В выполняется:
1) вектор b подается на вход нейронной карты;
2) нейронная карта определяет нейрон-победитель -нейрон, вектор весов которого находится ближе всего ко входному вектору;
3) значения элементов векторов v(i), соответствующих нейронам карты, корректируются (2.9) в сторону значений компонент входного вектора b :
v'at = + т1°(Ьк ~vak); (2.9)
k = ^K; 7?e(0;l];
ст = neighbour (w, wwinner); cr e [0; 1], (2.10)
где: г/ - коэффициент, определяющий скорость обучения. На первых итерациях процесса обучения г/ принимается достаточно малым и возрастает к последним итерациям обучения до 1; ст -коэффициент, определяющий степень соседства между нейроном-победителем и нейроном, вектор весов которого подвергается коррекции.
Коэффициенты т/ и ст позволяют уменьшить вероятность появления «пустых» нейронов в обучаемой нейронной карте, т.е. нейронов, слабо участвовавших в процессе обучения, в результате чего классы, соответствующие данным нейронам, оказываются разреженными. Для пространств, распределение векторов в которых имеет ярко выраженные «точки притяжения» (т.е. для статистически неоднородных пространств), появление таковых пустых векторов представляется существенной проблемой, вызывающей снижение эффективности применения к данным пространствам нейронных карт Кохонена.
К функции neighbour предъявляются следующие требования:
• функция должна быть непрерывна и определена всюду над N, так как Vw; w с N;
• чем ближе расположен нейрон-победитель к нейрону, вектор весов которого подвергается коррекции, тем ближе значение ст должно быть к 1 (и достигать 1 в случае, если выполняется коррекция значений весов нейрона-победителя, чего требует правило Уэбба);
2. К счетчику итераций цикла обучения прибавляется единица и, если счетчик не достиг максимального значения Tlura,i(m kohone„ leach, выполняется переход на шаг 1).
Рассмотренный алгоритм обладает следующими особенностями:
• необходимость выбора между нормализацией векторов или ее отсутствием. Проблема нормализации векторов состоит в выборе между выполнением и невыполнением нормализации векторов пространства V перед обучением и функционированием нейронной карты Кохонена. Нормализация векторов приводит к гарантированному схождению алгоритма (т.е. рано или поздно на очередной итерации цикла обучения ни один из векторов исходного пространства не сменит свой класс), но при этом коллинеарные векторы будут рассматриваться как эквивалентные без учета возможного существенного различия их модулей. В случае отсутствия нормализации векторов при вычислении расстояний между векторами будут учитываться также их модули, однако в данном случае сходимость алгоритма Кохонена не гарантирована.
Выбор между выполнением и невыполнением нормализации векторов исходного пространства перед обучением и функционированием нейронной карты Кохонена производится, исходя из существующих практических соображений. В описываемом алгоритме совмещения не выполняется нормализация входных векторов нейронной карты Кохонена, а алгоритм ее обучения останавливается при достижении максимально допустимого количества итераций;
• фактор появления на карте «пустых» нейронов.
Проблема «пустых» нейронов состоит в появлении на карте нейронов, не участвовавших в процессе обучения, из-за чего векторы, соответствующие данным нейронам, оказываются в разреженных областях исходного пространства векторов.
Для минимизации негативного влияния данного фактора по рекомендации [18] в (2.9) используется коэффициент ст.
Расчет коэффициентов соседства нейронов
Важным элементом алгоритма самоорганизации нейронной карты Кохонена является функция neighbour (2.10). От выбора данной функции зависят скорость сходимости алгоритма и его вычислительная сложность. Существуют несколько подходов к определению функции neighbour , среди них:
Дельта-функция. В статье [24] в качестве функции neighbour была использована дельта-функция (2.11) в соответствии с принципом «победитель получает все» ((англ.) winner takes all, WTA):
a = neighbourly, wKimer) = <
0; w Ф w . ’ winner
(2.И)
В данном случае корректируется только вектор весов нейрона-победителя, что соответствует принципу Уэбба обучения нейронных сетей.
Проблемой данного подхода является нерастяжимость карты. На очередной итерации обучения коррекции подвергается только центральный вектор класса, ассоциированный с нейроном-победителем, что нарушает связи данного нейрона с соседними нейронами и снижает четкость границ между классами. Логично было бы предположить, что для повышения качества обучения карты необходимо, чтобы карта была «растяжима», т.е. на очередной итерации алгоритма обучения коррекции подвергались бы все нейроны сети, а степень коррекции определялась мерой близости нейрона к нейрону-победителю.
Достоинством данного подхода является его малая временная сложность.
Радиальная функция. Альтернативой использованию дельтафункции в качестве функции neighbour является использование радиальной функции (2.12):
i — i w . n n winner
о = neighbour (w,wwlnner) = ё
(2.12)
В данном случае достигается плавное уменьшение коэффициента соседства по мере удаления от нейрона-победителя и, следовательно, карта оказывается «растяжимой».
Проблемой данного подхода является его существенная временная сложность по сравнению с использованием дельта-функции.
Выбор функции расчета коэффициентов соседства нейронов
В ходе проведенных экспериментов использование радиальной функции в качестве функции neighbour при обучении нейронной карты Кохонена позволило получить большую точность совмещения, чем использование дельта-функции. Существенная временная
сложность радиальной функции в значительной степени нивелировалась возможностью распараллеливания ее вычисления.
2.3. Классификатор
2.3.1. Структура, принципы обучения и функционирования классификатора
Классификатор - это набор методов, алгоритмов и заранее определенных параметров алгоритмов, решающий задачу разбиения некоторого множества образов на набор непересекающихся подмножеств-классов.
Классификатор описывается функцией classification
С - classification^,desc\, (2.13):
H = {h}; C = {cd}; cdaH\ d^T\ Vcm,c„eC; cmr>cn=0, где: H - множество образов h таких, что hcB', С - результирующее множество классов cd, где d - индекс класса; desc - функция, описывающая алгоритм построения векторного пространства признаков образов:
v = desc(h\ (2.14)
v = {v,,...,v9,...,ve}; v,eK, где v - вещественный вектор признаков образа h.
Фактически, задача классификации сводится к задаче построения регрессии С по Н на основе набора обучающих данных -обучающем множестве образов Hteach и тестовом множестве образов Htes(9 для которых результат классификации (множества d,each и dus,) У®6 известен.
Функция classification имеет вид:
d = classification(h, desc). (2.15)
Таким образом, задача классификации предполагает маркировку входных образов целочисленными маркерами-индексами классов, к которым относится каждый из образов.
В качестве алгоритма построения векторного пространства признаков образов можно использовать алгоритм, основанный на использовании энергетических текстурных характеристик Лавса,
текстурных признаков Харалика и ИНС, реализующей анализ главных компонентов. Данный алгоритм описан в § 2.3.2.
В качестве классификатора предлагается использовать сложный классификатор, состоящий из набора простых (бинарных) классификаторов. Структура классификатора приведена на рис. 2.3.
Принцип работы простого классификатора представляется как: Dbinary = Classifier (Нтп); (2.16)
Нтп^Н; Нтп=нтп + ^нтп_- т,п^-,
^binary № binary I ’ ^binary { 1Д} »
где: m - порядковый номер уровня дерева, на котором расположен классификатор; п - порядковый номер классификатора на уровне т ’ Нтп ~ подмножество образов классифицируемого множества образов Н , отнесенное классификатором на предыдущем уровне к одному из двух классов; Нтп + - подмножество образов, отнесенных классификатором к классу, условно маркируемому как 1 (т.е. h е Нтп _ <=> classifier(h) = 1); Нтп _ - подмножество образов, отнесенных классификатором к классу, условно маркируемому как -1 (т.е. h^Hmn + classifier= Dbjnary - набор бинарных маркеров, определяющих класс образов h^Hmn в смысле данного бинарного классификатора.
Множества Нтп + и Нтп _ передаются на следующий уровень классификатора по соответствующим ребрам дерева.
Если узел (т, п) дерева является стоком, множество образов Нтп формирует соответствующий класс cd.
Обучающее множество образов Hteach , тестовое множество образов Htest и соответствующие им множества эталонных откликов dteach и dtest являются параметрами алгоритма совмещения.
Существуют две различные версии алгоритма совмещения. Одна из версий использует в качестве простых классификаторов ИНС прямого распространения без обратных связей, другая версия использует машины опорных векторов. Глава 4 содержит рекомендации по использованию той или иной версии предлагаемого
алгоритма совмещения, выработанные по результатам экспериментальных исследований.
Рис. 2.3. Структура классификатора
2.3.2. Алгоритм построения векторного пространства признаков образов
Общее описание алгоритма построения векторного пространства признаков образов
Алгоритм построения векторного пространства V признаков образов heH описывается функцией desc (2.14).
Алгоритм построения векторного пространства признаков образов состоит из двух этапов:
1)расчет вектора признаков v'gK' для каждого образа h^H с помощью того или иного алгоритма описания образов, в качестве которых можно использовать:
-алгоритм, основанный на использовании энергетических характеристик Лавса (2.17);
- алгоритм, основанный на использовании текстурных признаков Харалика (2.18).
v' = laws(h) (2.17)
v' = haralick(h) (2.18)
Энергетические характеристики Лавса используются на верхних уровнях дерева классификаторов, то есть на тех уровнях, на которых происходит разделение существенно отличных друг от друга классов, например, класса водных объектов от класса лесных насаждений. Текстурные признаки Харалика используются на нижних уровнях дерева классификаторов, поскольку они хорошо зарекомендовали себя для описания текстур в задачах разделения классов, если граница между классами является существенно нелинейной (например, в случае разделения класса хвойного леса и класса лиственного леса);
2) понижение размерности векторного пространства V' признаков с использованием ИНС, реализующей анализ главных компонентов (РСА-сеть) (2.19).
v = psa(v') (2.19)
На данном этапе на базе векторного пространства И' признаков образов h с помощью преобразования Карунена-Лоева формируется векторное пространство V . Расчет матрицы преобразования Карунена-Лоева выполняет РСА-сеть. Понижение размерности векторного пространства V' необходимо для улучшения временных характеристик и повышения показателей качества работы классификатора за счет перераспределения информации в векторном пространстве V .
Алгоритмы описания образов
Алгоритм описания образов, основанный на использовании энергетических характеристик Лавса
К.И. Лаве в [36] предложил использовать для описания текстур специальные энергетические характеристики. Алгоритм описания
образа h с помощью энергетических характеристик Лавса состоит из следующих этапов:
Сформирование набора пространственных фильтров Fen ; 1^1 = 25:
Fen = {FmxyY, xe{L,E,S,W,R}- у e{L,E,S,W ,R}\ F = ff\ en x у J en x у J en у ’
Дл={1;4;6;4;1}; fen E = {-l;-2;0;2;l};
Д s - {-l;0;2;0;-l}; fen w = {-1;2; 0; -2; 1};
Л„я={1;-4;6;-4;1},
где векторы fm L, fenE, fmS, fm w , fen R предполагают выделение отдельных характеристик текстуры:
• уровень спектральной яркости (вектор fen L);
• границы элементов текстуры (вектор fen Е);
• отдельные пятна на текстуре (вектор fen s );
• периодически повторяющиеся перепады яркости («волны»; вектор w);
• текстурную «рябь» (вектор fen R; «рябь» - ситуация, когда на текстуре повторяются с некоторой периодичностью отдельные, составляющие ее, элементы).
Комбинирование векторов /е„ L, fenE, fenS, fe„ w , fen R позво-ляет получать отдельные характеристики текстуры, например, фильтр Fen LE позволяет получить информацию о насыщенности вертикальных краев отдельных элементов текстуры. Каждый фильтр Fen ху > кроме Fen LL, имеет нулевую сумму составляющих его весов;
2) применение к образу h набора фильтров Fen, по результатам чего составляется набор матриц fen:
hm={hmxy}', (2-20)
xe{L,E,S,W,R}-, у e{L,E,S,W,/?};;
3) составление по набору матриц hen набора энергетических карт Den и набор матриц Den, содержащих характеристики текстур, покрывающих образ h:
Л (i+u'.j+ir) z, (;
Denxy(i,j)= £ (2.21)
-eh hen
Ца,„=2щ + 1; Qta„>=5; (2.22)
De„={Denv.}^{Denz}-
Den П = Den -W + Den v.v j X Ф у
Den z ~ 2Den zz
/-1,7; 7 = 1, J; ze{E,S,W,R}, где Q - размер окна, в котором рассчитываются энергетические признаки (выбирается оператором). Фильтр Fen LL является нормирующим фильтром - с его помощью из описания текстур удаляется влияние не равномерности освещения на спутниковом снимке;
4) ассоциирование с каждым пикселем bij eh вектора энергетических характеристик dt: J:
di,J = {Dai^i,J)}^{De„Si,j)}-, (2.23)
5) расчет вектора энергетических характеристик v' образа h:
v'=Ar^- <2-24)
|/г|
Алгоритм описания образов, основанный на использовании текстурных признаков Харалика
Р.М. Харалик в [38] предложил описывать текстуру характеристиками специальных матриц вхождений Н , рассчитываемых по образу h . Каждая матрица вхождений описывает структуру текстуры в соответствующем направлении от одного края обрабатываемого образа к другому. По результатам расчета характеристик матриц Н составляется вектор текстурных признаков v' образа h , которые могут рассматриваться как характеристики
текстуры, покрывающей каждый пиксель образа. Алгоритм расчета текстурных признаков Харалика vk для к -го спектрального канала образа h состоит из следующих этапов.
1. Выбор нескольких направлений a = {ax}; х = 1, X; ax е [0,2я), где ах суть есть угол, описывающий направление соответствующей матрицы вхождения Нх. В [37, 38] выполняется расчет матриц я- яг Зя\ вхождении для четырех направлении: а = {0,—,у,—}.
2. Выбор размера области соседства каждого пикселя образа. В [38] было выбрано Q = 3.
3. Заполнение матриц вхождений Н = {Нх}; х = 1,Х размером А на А элементов нулями, где А есть количество уровней квантования диапазона спектральных яркостей. Так как первоначально спектральные каналы спутникового снимка В являются, чаще всего, 8-ми битными без знаковыми целыми, то А = 256.
4. выполнение для каждой пары «пиксель», «матрица вхождений»: (6,. у, Яу); b^eh следующих операций:
4.1. «Наложение» на пиксель . окна размером на пикселей.
4.2. Расчет координат (ih , jh) крайнего пикселя bif jh по направлению ах:
• для ах =0; Qa =3 : ihx = ih- j* = jh + \',
• Для ^a=3: ihx=ih-\‘, AV=A + 1;
• для ax = —; Qa = 3 : = ih — 1; jkx = jh;
• для «x=Y; Q«=3: k=Jh-l-
4.3. Если координаты (zto , ) крайнего пикселя по направ-
лению ах выходят за пределы изображения В, то выполняется переход к следующей паре «пиксель», «матрица вхождений».
4.4. Расчет:
H(biik,b: i) = ffAblil!,biJ + l. (2.25)
* V 'hJhk ’ IhxJhx* 7 * V lhJhk ’ lh.xJhxk 7 V 7
5. Масштабирование матриц вхождений Hx к сумме своих
элементов, равной единице, для чего выполняется преобразование:
Уд V Н(т,п)
(2.26)
x = l,X;
6. Расчет (2.27) для каждой матрицы Нх характеристик Нх(р), рх то>г и Vx со! ~ средние по строкам и столбцам соответственно, сгх ГОТ), и <тх со1 - дисперсии по строкам и столбцам соответственно:
А А
ЯДр) = £ £ Нх(т,п); ре№ (2.27)
т=\ I и=1 \
\т+п=р)
Д Д
Axrow=£w£Hx(w,»);
771=1 77 = 1
Рхсо!
п=1 т=\
°х row = £ (т - К гом )2 £ Нх (т^ т=\ п=\
Д Д
О’х со! = Z (« " <^х со! )2 £ ("*> «)»
И=1 /п = 1
где р - коэффициент, зависящий от гистограммы образа. Для
упрощения Д вычислений р = у = 127,5 .
7. Расчет для каждой матрицы Нх следующих характеристик:
Ах1=£/п£(ЯДт,л))2; (2.28)
т=\ и=1
L ^((w,«))2; (2-29)
Р=О т=\ / п=\ )
\\m-n\=pj
У* УЛ m,nH uY rnuY
’ х\ ’ S Гх rowF*x col . (2 30)
х3 О’ О’ /
х row х col
hx4 = X (™ ™. )2 Hx (m’ (2-3 1 )
ZZ7 = 1 W = 1
/jx5=L"jLt77^—-уНх(т,пУ, (2.32)
2Д
hx6 = ^mHx(my (2.33)
m=2 2Д Д
hxl ='Xm^(m-hx6)2Hx(my (2.34)
m=2 w=l
hxt = ^^НЛт^°^Нх(т,п)У (2.35)
m=\ w=l
2Д
A9 =£/7x(w)log(/A(w) + e); e<10’8, (2.36)
m=2
где: hx] - однородность; hx2 - контраст; hx3 - корреляция; hxA -дисперсия; hx5 - гомогенность; hx6 - среднее по суммам; hxl -дисперсия по суммам; hxt - энтропия; /гх9 - энтропия по суммам (коэффициент е устраняет неопределенность логарифма при Нх(т) = 0-
8. Составление для каждого пикселя bt j; bt j eh вектора приз
наков djJk {/?v}=; x=\,X; у =1,9.
9. Расчет вектора признаков v'k для к -го спектрального канала образа h:
(2.37)
S diJk |Л| Наконец, вектор признаков v' образа h рассчитывается как
v' = LK •
Ь=1
Алгоритм понижения размерности векторного пространства признаков, основанный на использовании ИНС, реализующей анализ главных компонент
Структура, принципы обучения и функционирования
Анализ главных компонент ((англ.) principal component analysis, РСА) - является способом понижения размерности векторного пространства с регулируемой потерей информации.
Пусть имеется векторное пространство K' = {v'}; \V'\=Q'. Необходимо рассчитать однозначное преобразование V' —>К, где V - векторное пространство такое, что V = {v}-9 \V\=Q<Q' • Преобразование psa (2.19) должно выполняться с учетом возможных потерь информации, поэтому необходимо наличие некоторого порогового значения Tinfo е [0,1), определяющего минимальный объем информации, который должен «содержаться» в V из V' . Величину Tinfo proc=MXyTinfo можно рассматривать как процентную долю информации из V', сохраняемой в V .
В качестве функции psa анализ главных компонент использует преобразование Карунена-Лоева [39, 40], матрицу которого можно рассчитать с помощью специальной ИНС-РСА-сети. Таким образом, функцию psa можно записать в виде:
v = psa(y') = Wfvr; (2.38)
^ = KJ; n = \& (2.39)
где W - матрица преобразования Карунена-Лоева, являющаяся также матрицей весов нейронов РСА-сети.
Функция psa описывает процесс работы РСА-сети матричное умножение W'vT соответствует расчету взвешенных сумм входов нейронов сети (векторы весов которых являются строками матрицы W ), а функцией активации в данном случае является прямая у = х .
Алгоритм обучения РСА-сети состоит из следующих этапов:
1. Центрирование векторного пространства V' (2.40) с получением на выходе векторного пространства Vcenter:
у =(v V v =fv , „V V (2.40)
center I center ‘ ’ center I center 1’ ’ center q ’ ’ center Q > ’ V 7 v = v — Mv ’.
v center
Таким образом, Mvcenter = 0;
2. Расчет вектора весов первого нейрона РСА-сети с помощью правила Ойя [53], являющегося модифицированной версией правила обучения Уэбба:
2.1. Установ компонентов вектора w, в нулевое значение.
2.2. Пересчет вектора (2.41) для каждого vcenter g Vcenter:
(2.41) где г/ - коэффициент скорости обучения, е 77(0,1].
2.3. Повторение пункта 2.2 алгоритма для различных значений г/.
По результатам экспериментальных исследований в качестве стратегии изменения г/ было выбрано постепенное увеличение г/ с шагом 0,05 от r/Q =0,05 до r/^jsh =1.
3. Расчет вектора весов wm т -го нейрона РСА-сети с помощью правила Сенгера [54]:
3.1. Установ компонентов вектора ют в нулевое значение.
3.2. Пересчет вектора wm (2.42) для каждого vcenter g Vcenter:
= wm + ПУт(vcen,er ~ ymw„,); (2.42)
у = w vT : (2.43)
Ут in center > \ '
m-\
^center m center in -^УШ,
h=\
где г/ - коэффициент скорости обучения такой, что Т] е (0,1].
3.3. Повторение пункта 3.2 алгоритма для различных значений q , способ выбора которых приведен в пункте 2.3 алгоритма.
4. Повторение пункта 3 для т = 2,Q’.
5. Удаление из нейронной сети нескольких нейронов (и соответственно, удаление из матрицы W нескольких строк). Векторы wm являются собственными векторами для матрицы автокорреляции векторного пространства VatMr, причем | wm |= 1. Для каждо
го вектора wm рассчитывается соответствующее собственное число eigen после чего вектор собственных чисел eigen = {eigen т} нормируется.
Строки wm в матрице W изначально упорядочены по убыванию их собственных чисел. Нормированные собственные числа eigen можно рассматривать как относительный объем информации из векторного пространства V\ «сохраняемый» собственными векторами win в процессе преобразования Карунена-Лоева. Таким образом, в W должны быть оставлены только первые М строк, где М такое, что выполняется условие: т
^eigenm>Tinfo (2.44)
,77 = 1
Алгоритм обучения РСА-сети сохраняет в пространстве V как минимум Tmfo р,.ос°/о информации, имеющейся в И' , в смысле собственных векторов и собственных чисел матрицы автокорреляции векторного пространства V'.
2.3.3. Машина опорных векторов
Структура, принципы обучения и функционирования
Машина опорных векторов ((англ.) support vector machine, SVM) выполняет линейное разделение пространства образов на два класса. Пусть дано пространство V (2.46), состоящее из векторов v:
V = {v}-, ___ (2-45)
v = {vl,...,vq,...,vQ}; q = l,Q;
vq =e R.
В контексте решаемой задачи пространство V образуется из векторов признаков классифицируемых образов.
Ключевая особенность машины опорных векторов состоит в ее способности выполнять нелинейное разбиение классифицируемого векторного пространства V путем отображения V в векторное пространство V' такое, что |И|<|И'|, и линейное разделение которого возможно или производится с меньшей ошибкой, чем линейное разделение исходного пространства.
Векторное пространство V' (2.46) формируется следующим образом:
Г' = {у'}; (2.46)
v',. ={v'„q' = \,Q'\
v’?.GR.
у’=Ф(у>-
Разделяющая поверхность L рассматривается в пространстве V'. Разделение, таким образом, является линейным в отношении V'. Требуемая нелинейность разделения пространства V обеспечивается отображением ф . Размерности пространств V и V' необязательно совпадают и в общем случае имеет место быть следующее соотношение: Q < Q'.
Принцип работы машины опорных векторов проиллюстрирован рис. 2.4.
Обучающая выборка
Нелинейное отображение I&2 В Яз
Обучение машины опорных векторов
Рис. 2.4. Принцип работы машины опорных векторов
Машина опорных векторов в процессе своей работы не использует отображение ф - SVM оперирует ядрами скалярных произведений векторов пространства V'. Уравнение разделяющей поверхности L. описываемой машиной опорных векторов, имеет вид:
Qs
L(S,v) = w.kernel (st., v) + Г; (2.47)
/=i
kernels/9 v) = ^(s)^(y);
5’ = {5/}; z = l,05; ScV;;
FT = {vy,.}; magR;
TgR, где: L - разделяющая поверхность; S - множество опорных векторов; W - вектор коэффициентов при опорных векторах; kernel -ядро скалярного произведения - скалярное произведение образов векторов 5 и v в пространстве И'; Г - пороговое значение.
В качестве ядра скалярного произведения могут быть использованы функции, удовлетворяющие теореме Мерсера.
Пусть kerneltv^Vj) - непрерывное симметричное ядро, определенное на интервале у.,уу е [а, Д].
Ядро kernel описывается рядом (2.48):
kernel^, v,.) - J (v, gA (v;X*(vy); (2.48)
A=1
A,. > 0.
Для обеспечения корректности этого разложения и его абсолютной и равномерной сходимости необходимо и достаточно выполнение условия (2.49):
£ £ kernel^, vJ)^(yi)^(vJ)dxidvi >0; (2.49)
^(v)rfv<oo.
Доказательство теоремы приведено в [55].
Бинарная кластеризация, выполняемая машиной опорных векторов, состоит в том, чтобы рассчитать значение £(5,у) для некоторого входного вектора у. Если L(S, у) > 0 , то вектор у относится к классу, условно маркируемому +1, в противном случае £(5,у)<0 -вектор у относится к классу, условно маркируемому -1. Ситуация Z(5,y) = 0 рассматривается как некорректная, вектор у маркируется как «неклассифицированный», а образ, соответствующий вектору, в дальнейшем не рассматривается.
Таким образом, цель обучения машины векторов состоит в определении следующих ее параметров:
• множества S опорных векторов;
• вектора W весов при опорных векторах;
• порогового значения Т .
Ядро скалярного произведения векторов
Существуют следующие ядра kernel скалярного произведения векторов:
• полиномы натуральной степени kernelро1у (2.50);
• радиальная базисная функция kernelradial (2.51);
• гиперболический тангенс kernelth (2.52).
kernelPoiy^vii=^vT\v2+1)₽; (2-5°)
( 1 Л
kernelradiai^v2)^^\^\v\ ~v21 Ь ст e R ; (2.51)
kernelth(V\,v2) = th(pv[v2 + k\, p,k e R, (2.52)
где p, <y, p,k - параметры соответствующих функций, выбираемые оператором.
Экспериментальные исследования показали, что выбор радиальной базисной функции kernelradjal в качестве ядра скалярного произведения приводит в конечном счете к более высокой точности совмещения по сравнению с полиномами kernelро,у и гиперболическим тангенсом kernel^.
Обучение
Цели и задачи обучения
Как было показано в [17], задача обучения машины опорных векторов есть задача условной квадратичной оптимизации. Необходимо максимизировать функцию Лагранжа Q при выполнении условий Каруша-Куна-Такера (2.54) и (2.55) [56].
Q' 1 Q' Q'
Q(a) = -^'XYlaiajd'djkemel(v^v*^ (2-53) /=1 2 ,=1 у=1
о'
Zaidi=b (2-54)
/=1
0^CJwn; (2.55)
v*gH Г* с: Г;
Csuni ^R+, где: И* - обучающее множество векторов; Q* - мощность обучающего множества; D = {б/J; / = 1,0* - эталонные отклики для векторов из обучающего множества; А = {#,}; / = 1,0* - множество множителей Лагранжа, по которым выполняется оптимизация функции 0; С5ит - некоторая положительная константа - параметр алгоритма.
Вектор коэффициентов W при опорных векторах рассчитывается по множителям Лагранжа А и эталонным откликам D:
wi^aidi. (2.56)
В процессе обучения большинство множителей Лагранжа принимает значение 0, и таким образом, во множество S' опорных векторов входит лишь часть векторов, составляющих обучающее множество: S с Y*. Множество S опорных векторов представляет собой, в конечном счете, набор векторов из обучающего множества, ближе всего лежащих к поверхности L, разделяющей пространство на два класса.
Пороговое значение Т рассчитывается (2.57) следующим способом:
V - V - wkernel(si, у*) -r = ----------------------- (257)
Для решения задачи условной оптимизации функции Лагранжа Q используются различные алгоритмы, сравнение которых было выполнено в [41]. В контексте задачи совмещения лучшими показателями по времении качеству результата обладает алгоритм последовательной минимальной оптимизации ((англ.) sequential minimal optimization, SMO) [57].
Алгоритм последовательной минимальной оптимизации
Алгоритм последовательной минимальной оптимизации основан на идее разбиения задачи оптимизации целевой функции Q по
набору переменных А на несколько задач оптимизации по поднаборам переменных. При этом имеет место сходимость алгоритма к глобальному максимуму целевой функции Qmax .
Алгоритм SMO состоит из следующих этапов:
^формирование обучающего множества Г* векторов и множества D соответствующих им эталонных откликов;
2) установ значений элементов множества множителей Лагранжа Л в 0;
3) инициализация дополнительных переменных, используемых, в том числе, для улучшения временных характеристик алгоритма за счет введения дополнительных кэшей в оперативной памяти вычислительного устройства;
4) выбор пары множителей Лагранжа;
5) максимизация функции Q по выбранным множителям Лагранжа;
6) расчет новых значений элементов кэшей;
7) проверка на выполнение критерия останова алгоритма:
- если критерий останова выполнен, выполняется формирование множества S опорных векторов (куда попадают только те векторы из обучающего множества v*, для которых выполняется условие ai Ф 0 ), множества коофициентов W при опорных векторах, а также вычисляется значение порога Г, после чего происходит останов алгоритма обучения;
- если критерий останова не выполнен, то выполняется переход к этапу 4 данного алгоритма.
Алгоритм SMO останавливается в следующих случаях:
• превышено максимально допустимое количество итераций алгоритма;
• выполнены условия останова, специфичные для используемого алгоритма выбора пар множителей Лагранжа.
Для выбора пар множителей Лагранжа для очередной итерации алгоритма последовательной минимальной оптимизации предлагается использовать алгоритм Фана-Чена-Линя [58], предложенный группой тайваньских ученых: Rong-En Fan, Pai-Hsuen Chen, Chih-Jen Lin.
Алгоритм Фана-Чена-Линя базируется на использовании информации о второй производной функции ошибки Esum:
Esum(v) = L(V\v)-d. (2.58)
Первый множитель Лагранжа ai в паре множителей, кандидатов на оптимизацию, выбирается последующему принципу:
тир =т <С5„„, Ud, =l)n(a, >0ud, = -1}; (2.59)
i e max - {-d, VE(v,) | ? е Г }.
>=1.е
Второй множитель Лагранжа аг в паре множителей - кандидатов на оптимизацию, выбирается по следующему принципу:
Т1т. = {г | (a, < Csum и d, = -1) п (а, > 0 и d, = 1}; (2.60)
— I'^J;
а
о - kernel(y*, v*) + kernel(v*, v*) - 2kernel(y*, v*)didt;
j g min
a = <
IO’12; cr<0;
Y = -dyEslim(v;) + dyEsum(vy,
Благодаря (3 достигается максимальный «разброс» между парой множителей по второй производной, что приводит к максимизации эффекта от шага оптимизации.
Алгоритм SMO, использующий для выбора пары множителей Лагранжа на очередной итерации алгоритм Фана-Чена-Линя, останавливается также в случае, если выполняется условие:
6/.VE(v*) + ^.VE(v*) < е; (2.61)
ее R+, где е - параметр алгоритма, выбираемый оператором.
2.3.4. Искусственная нейронная сеть прямого распространения без обратных связей
Структура, принципы обучения и функционирования
В качестве бинарного классификатора classifier (2.16) наравне с машиной опорных векторов была использована ИНС прямого распространения без обратных связей [22].
Функционирование ИНС прямого распространения без обратных связей можно представить как:
dbinary = j >_ Q, (2-62)
d = ff(y) = ff(desc(h)),
где функция ff описывает ИНС. Каждый нейрон сети описывается в виде функции neuro:
yr = neuror(yr) = (2.63)
.иг
Л = v и/ = V v w ; г г гт гт>
т=\
r = l,Hff; A/r=|wr|; W = {wr}-,
где: г - индекс (порядковый номер) нейрона; Hff - количество внутренних нейронов в сети (настраиваемый параметр алгоритма); vr - входной вектор нейрона; w. - вектор весов нейрона размером Мг элементов; W - множество векторов весов нейронов ИНС; уг -выходное значение нейрона (уровень возбуждения нейрона); fact -функция активации нейронов сети.
Структура связей внутренних нейронов ИНС прямого распространения без обратных связей представляется в виде ориентированного графа без циклов G . где ребро графа описывает синапс ИНС, вес ребра графа определяет вес синапса, узел графа описывает нейрон ИНС и предполагает применение к взвешенной сумме возуждений синапсов, входящих в узел, функции активации. Пример представления ИНС прямого распространения без обратных связей в виде ориентированного графа без циклов приведен на рис. 2.5.
Частным случаем рассматриваемой ИНС является многослойный перцептрон, однако, в отличие от последнего, ИНС прямого распространения без обратных связей не обязательно является полно связной (и, следовательно, четко структурируемой на несколько слоев), что улучшает качество обучения сети в виду дополнительной нелинейности, вызванной отсутствием жестких требований к структуре сети.
Рис. 2.5. Ориентированный граф внутренних нейронов ИНС прямого распространения без обратных связей
Граф G описывается с помощью матрицы смежности G:
' gn £,Р
G = £r\ grp grHff (2.64)
^gH\ - ... gHfHr>
(2.65)
где элемент grp кодирует наличие (1) или отсутствие (0) ребра, выходящего из вершины г и заходящего в вершину р , т.е. синапса, исходящего из нейрона г и заходящего в нейрон р .
Особым подвидом внутренних нейронов сети являются нейроны, соответствующие истокам графа G . На вход данных нейронов поступают не выходы других нейронов, а входной вектор v сети. Для данных нейронов Mr = Q =| v |.
Кроме внутренних нейронов ИНС располагает также единственным выходным нейроном. На вход данного нейрона поступают выходы нейронов, соответствующих стокам графа G . Выходной нейрон рассчитывает среднее арифметическое своих входов, которое и используется в качестве выходного значения сети.
Алгоритм работы с ИНС прямого распространения без обратных связей состоит из следующих этапов:
1) выбор структуры ИНС (матрицы G) с помощью грамматик графовой генерации Китано и генетического алгоритма (§ 2.3.4);
2) инициализация векторов весов нейронов ИНС с помощью алгоритма Нгуэна-Видроу, описанного в [59];
3) обучение внутренних нейронов ИНС в пакетном режиме;
4) применение ИНС для решения практической задачи.
Функция активации нейронов
В качестве функции активации fact могут быть использованы следующие функции [17]:
• логистическая функция:
/„(0=7^^; (2.66)
rlogeR+. (2.67)
Логистическая функция имеет вид, приведенный на рис. 2.6 (верхняя кривая; т log = 10). К недостаткам логистической функции относятся ее асимметричность (устраняется вводом дополнительного вычитания 0,5 в 2.66), сложность поиска подходящего значения rlog и большой диапазон возможных значений rlog;
• гиперболический тангенс:
xth{T,h 2£); (2.68)
Г,А 1Л/, 2е«+- (2-69)
Гиперболический тангенс имеет вид, приведенный на рис. 2.6 (нижняя кривая; т/А , = 1, т,А 2 = 2). К достоинствам гиперболичес
кого тангенса относятся симметричность и простота расчета производной. К недостаткам - несколько настраиваемых параметров.
В качестве функции активации можно выбрать гиперболический тангенс (2.68) за счет его симметричности и простоты расчета производной.
— Логистическая функция — Гиперболический тангенс
Рис. 2.6. Функции активации
Обучение
ИНС прямого распространения без обратных связей относится к классу ИНС, обучаемых с учителем.
Обучение ИНС осуществляется по множеству Hteach образов, для которых известны эталонные отклики dteach.
Существуют несколько подходов к обучению ИНС:
• индивидуальный подход, в котором коррекция векторов весов w нейронов сети выполняется для каждого образа hteach g Hteach;
• пакетный подход, в котором коррекция векторов весов w нейронов сети выполняется единожды для каждой итерации прогона сети над всем множеством Hteach образов после завершения прогона.
В предлагаемом алгоритме совмещения для обучения используется пакетная стратегия и алгоритм обучения состоит, таким образом, из следующих этапов:
1. Расчет v,each = desc(hleaclt) для каждого h,each е H,each.
2- Еteach ~ О-
3. gradE = 0 , где gradE - градиент E,each(W).
4. Повторение для каждого hleach е Hteach следующих действий:
4.1. Расчет d = ff(y№ach).
4-2. Eleach — Eteach +(dleach —d) .
4.3. gradE -gradE +gradcumM E, где gradcumnt E - градиент
Eteach
Eleach(W) на текущем прогоне ИНС.
Приращения gradcumn, Е и Нситп, Е рассчитываются с помощью алгоритма обратного распространения ошибки.
E^ch о А / I rr I '
V I Н (each I
gradE
6‘
I П teach I
7. Коррекция весов нейронов ИНС с использованием grad Е с помощью того или иного алгоритма коррекции весов.
По завершении обучения сети выполнятся тестирование качества обучения, для чего рассчитывается Etes{ по тестовому множеству Etest образов, для которых известны идеальные отклики dtest ИНС. Как правило, \Eteach |»| Etest |. Тестирование качества обучения применяется в процессе выбора структуры ИНС и выбора параметров обучения ИНС.
Основным требованием к Eteach и Etest является необходимость репрезентативности данных множеств.
Алгоритм обратного распространения ошибки
Рассмотрим нейрон г , которому соответствует вектор весов wr.
Для данного нейрона необходимо рассчитать те компоненты вектора gradcurrent Е и матрицы Hcurrent Е . которые соответствуют компонентам вектора w. в W .
Пусть вектор Rm - {rin} содержит индексы нейронов ИНС, выходы которых поступают на вход нейрона (| Rin \=МГ). Пусть вектор Roul = {гош} содержит индексы нейронов ИНС, на вход которых поступает выход рассматриваемого нейрона (| Roul |= Мои1) . При этом предполагается, что компоненты вектора gradcumM Е и матри-
цы Нситм Е, соответствующие нейронам из Rout, уже рассчитаны
(обратное распространение ошибки расчет градиента и гессиана от стоков графа G к его истокам).
Для нейрона г необходимо рассчитать:
• Sradcurren, Е т, m =
ЗЕ _ ЗЕ 8уг 8£г
Swrm 8 у,. 8£r 8w,.„,’
gradcumM Е
т
(2.70)
gradv ; m -1, M
ЗЕ ЗЕ 8уг 8^г
<5^, Swm
В (2.70) и (2.71):
Syr
grad
mi
(2.71)
Для нейронов, соответствующих стокам графа
3:«
Syr
_ leach-У/each , где fl _ КОЛИЧесТВО НвЙрОНОВ, СООТВСТСТВуЮЩИХ
Нои/
стокам графа G , то есть фактически частной производной функции ошибки по выходу стока графа G, является отклонение выхода сети от идеального выхода, нормированное по количеству стоков графа G.
У gradv
8Е г Tr
Для прочих нейронов: ---= oul oul-----;
8уг ^Ои/
$У г S^r
=Ш
е гт
8wrm
-^ = WW 3vrm
Алгоритмы коррекции весов ИНС
Для коррекции весов ИНС могут быть использованы следующие алгоритмы:
• алгоритм градиентного спуска.
Использует для коррекции весов только gradE.
Пусть PF0 — оптимальное множество весов сети (т.е. множество, дающее глобальный минимум ^feach(W)). Тогда имеет место быть следующее разложение в ряд Тейлора (2.72) в предположении, что ^teach(^) имеет сколь угодно много производных (среднеквадратичное отклонение, используемое в качестве Eteach(W)9 удовлетворяет этому условию):
Elead,^-W0) - Eleach{W) + gradE3W + R2, (2.72)
где R2 - остаточный член ряда Тейлора. Процесс обучения представляет собой итерационный процесс постепенного приближения к , поэтому (2.72) сводится к:
Е1еаЖе.) = E,eac/l(W) + gradE3W + R2. (2.73)
Для сходимости алгоритма к №0 необходимо, чтобы на каждой итерации процесса обучения выполнялось условие Eleach (W) > >Eleach(Wnal) , для чего достаточно выбрать 3W = -gradE , тогда -grad2E <0 всегда, и Eteach{W) будет гарантировано убывать. Таким образом, алгоритм градиентного спуска на каждой итерации своей работы выполняет коррекцию Wnext - W-r]lgradE, где г]1 е(0,1] -коэффициент скорости обучения, зависящий от номера итерации t;
• метод Гаусса-Ньютона, квазиньютоновские методы.
Данное семейство алгоритмов использует для коррекции весов нейронов не только градиент gradE, но также и гессиан НЕ (т.е. информацию о второй производной функции ошибки). Очевидно,
что для среднеквадратичного отклонения, используемого в качест-ве teach 1 Не будет всегда положительной квадратной формой.
Тогда:
R ,=-3WtHeSW + R.;
2 2 Е 3’
Elmch(W -Wo) = Eleach(W) + gradESW +±SWTHESW + R3. (2.74)
Очевидно, что при W - WQ: gradE = и HE =0, тогда 8W можно
1 T
1 рассчитать, исходя из утверждения gradE8W + —8W HE3W = 0, что 2 можно привести к виду:
gradE +^SWTHE = 0, (2.75)
предполагая, что на очередной итерации алгоритма 3W * 0. Тогда 8W = -Н~Е gradE .
Таким образом, метод Гаусса-Ньютона на каждой итерации выполняет коррекцию Wnext = W -rjtH~E gradЕ .
Расчет гессиана НЕ представляется вычислительно сложной задачей, поэтому существует ряд методов [27], апроксимирующих гессиан НЕ некоторой формой и получивших название квазиньютон овских методов.
Одним из таких методов является метод Левенберга-Марк-вардта, который использует для расчета приближения гессиана НЕ якобиан JE и вектор коэффициентов, рассчитываемых по собственным числам JE;
• эвристические методы.
Существует ряд эвристических подходов к коррекции весов ИНС прямого распространения без обратных связей. К таким методам относятся:
• метод сопряженных градиентов;
• алгоритм RPROP;
• алгоритм QuickPROP;
• другие алгоритмы.
В контексте поставленной задачи совмещения данных ДЗЗ и ЦКМ Для обучения ИНС прямого распространения без обратных связей был использован алгоритм градиентного спуска, поскольку данный алгоритм обеспечивает высокую производительность и приемлемое качество [особенно в сочетании с эвристическими алгоритмами инициализации весов нейронов ИНС, что существенно снижает вероятность схождения процесса обучения к локальному минимуму, позволяя достичь при этом глобального минимума функции ошибки Efeach(W)].
Кроме того, градиентный спуск, в отличие от методов, основанных на использовании информации о второй производной функции ошибки Eteach(W) (метод Гаусса-Ньютона, квазиньютоновские методы), менее требователен к точности представления чисел, тогда как означенные методы при расчете гессиана или приближения к нему требуют высокоточного представления вещественных чисел (лучше, чем двойная точность, то есть, чем максимальная точность, реализуемая аппаратно на современных вычислительных устройствах), что приводит к дополнительным временным задержкам и расходам оперативной памяти.
Алгоритм выбора структуры ИНС с помощью генетического алгоритма и грамматик графовой генерации Китано
В общем случае подбор структуры ИНС прямого распространения представляется сложной задачей. Существует ряд подходов к ее решению, из которых наиболее развитым является подход с использованием генетического алгоритма [19, 21] для поиска наилучшей структуры нейронной сети с точки зрения среднеквадратичной функции ошибки Eann:
test
Ъ.ат^ „)2
Еа„п^ПП,У1е51) = \
(2-76)
^„,=1^,1,
где: К,ет, - репрезентативное множество тестовых векторов; dlesl -множество эталонных откликов для векторов из Vlesl.
Кодирование и декодирование структуры ИНС
Важной проблемой, решаемой в процессе выбора структуры ИНС с помощью генетического алгоритма, является проблема кодирования структуры ИНС в виде непрерывной последовательности символов - последовательности хромосом, составляющих единственный ген генома каждой особи.
Н. Kitano в [60] предложил способ кодирования структуры ИНС, называемый грамматиками графовой генерации Китано. Имеет смысл использовать одно из развитий грамматик графовой генерации Китано [21], которое заключается во введении дополнительного параметра Т, определяющего глубину разбора начального правила грамматики и позволяющего задавать с помощью грамматик, содержащих одно и тоже количество правил, сети произвольного размера.
Структура ИНС прямого распространения описывается ориентированным графом без циклов. Каждая дуга в данном графе соответствует синапсу и имеет собственный вес, устанавливаемый в процессе обучения сети. Каждая вершина графа соответствует одному нейрону; с каждой вершиной связано пороговое значение соответствующего нейрона, настраиваемое в процессе обучения сети.
Имеющиеся в графе дуги могут быть заданы с помощью матрицы смежности G (2.64) ИНС, в которой единица кодирует наличие ребра, направленного от вершины с номером, равным номеру строки, к вершине с номером, равным номеру столбца, а ноль - соответственно, отсутствие такового ребра. Матрицу G можно закодировать с помощью набора правил порождающей грамматики А:
A = {S.SP.S^FT.FP.F^R}' (2.77)
5 = {0,l,w}; Sp={Spl}\ / = Ц6;
s.v = {s.vJ; ™ =
Fp=- FP9 0 0 0 [° [1 [° 01 0 0 Jo jo Jl jo 01 [0 [1 fo fl Jl fl 01 1 0 1 fo fl Jl [1
о/ 11 о] 01 oj F1^\ ?рб Fpv> ~* 1J 11 1J 01 1J Ррз Fpi Fp\\ oj 11 oj 01 oj 1 P4 грз F rP\2
Рр\з J1 |о 11 of Fpu ~* Jl jo 11 if Fp\5 Jl jl 11 of F 1 Pi6 Jl jl
~ {^Хт } ’ * $.\т *
р\.
5]’
a,p,y,8e(FxuFP),
О
1
1
1 О
1
1'
1
где: S - набор терминальных символов; Sp - набор предтерми-нальных символов; Sv - набор нетерминальных символов; FT -набор правил вывода для терминальных символов; Fp - набор правил вывода для предтерминальных символов; Fx - набор правил вывода для нетерминальных символов; R - стартовый нетерминальный символ.
Грамматика А называется грамматикой графовой генерации Китано. Одна грамматика А соответствует одной особи популяции генетического алгоритма.
Элементы S, Sp, Sv, FT, Fp фиксированы для любой А, и, следовательно, ген особи кодирует только набор правил Fx. Набор правил Fx кодируется по схеме, приведенной на рис. 2.7. Каждое правило FXm отображается в четыре хромосомы ат, Рт, ут, 8т, следующих друг за другом и за хромосомой 8т -1 в единственном гене особи.
Рис. 2.7. Схема кодировки набора правил
Алгоритм восстановления матрицы G из грамматики А состоит из следующих этапов:
1) создается начальная матрица G} = R ;
2) выполняется у/ = 1 шаг применения правил FT, Fp и Fv:
g1=s^g2 = <Xr Pr-
V R ^R
3) шаг 2 повторяется для каждого из правил aR, /3R, yR, 3R: G2 —>G3; размерность G3 оказывается, таким образом, равной 2<3~1) на 2<3-1) = 4 на 4 правила;
4) шаг 3 повторяется (Т - 2) раз - до получения матрицы Gv ;
5) в матрице G любой символ g е Sp и Sv рассматривается как символ w и преобразуется по соответствующему правилу в 0;
6) матрица Gv преобразуется в матрицу G по формуле (2.78)-таким образом, в матрице G гарантированно будут отсутствовать циклы:
0, г> р,
G = te,); G,=(g,„); g„= (2.78)
схр гр’ г*
Параметр Т алгоритма восстановления матрицы смежности G определяет максимально возможное количество нейронов, могущих быть в результирующей ИНС-2 т-1. нейронов. Учитывая тот факт, что число входов и выходов ИНС фиксировано, ток ИНС, описываемой соответствующим графом, присоединяются несколько нейронов:
• входные нейроны в достаточном количестве связываются синапсами с истоками графа; данные синапсы направлены от входных нейронов к истокам графа;
• выходные нейроны в достаточном количестве связываются синапсами со стоками графа; данные синапсы направлены от стоков графа к выходным нейронам.
Мощность Нх множества 5\. оказывает, равно как и параметр Т, существенное влияние на качество работы генетического алгоритма, поскольку именно Нх определяет длину гена (как 4 Нх хромосом) и, соответственно, степень «разнообразия» правил, кодируемых геном. Выбор Нх осуществляется эвристическим спо
собом - небольшое значение Нх приведет к вырождению популяции, и, следовательно, схождению алгоритма к локальному оптимуму, тогда как большее значение Нх, наоборот, увеличит разнообразие особей, но также увеличит время схождения генетического алгоритма возможно, к глобальному оптимуму.
По сравнению с традиционной версией грамматик графовой генерации Китано, предложенная версия позволяет одинаково компактно описывать нейронные сети с любым максимальным количеством нейронов, что достигается за счет параметра Т.
Генетический алгоритм
Генетический алгоритм, используемый для выбора структуры ИНС и использующий для кодирования структуры ИНС грамматики графовой генерации Китано, состоит из следующих шагов:
1) случайным образом создается начальная популяция особей Q={gz}', z =
2) из множества Vann случайным образом выделяются подмно-жества Vleach и Vlal; для множеств Vleach и V,al из множества dam выделяются соответствующие им подмножества dteach и dtest;
3) для каждой особи gz восстанавливается соответствующая грамматика Az, производящая нейронную сеть annz;
4) для каждой особи gz рассчитывается функция приспособленности suit(gz):
suit(gz)^-—-----Ц——; ееГ; е-Ю’8; (2.79)
Евя„(аииг,К,ет,) + е
5) особи gz сортируются в порядке убывания функции приспособленности suit(gz);
6) особи с индексами z ^[\\HQbest] образуют множество особей HQbes, > особи с индексами ze(Hebesl,Hebesl+HQcross] образуют множество особей HQcross; особи с индексами (HQbest + HQcr0SS,HQ] образуют множество особей HOcross, при этом должно выполняться условие HQbes, >2;
7) особи qeQcr0SS заменяются на особи qcros = cross(qx,qv) ; qx,qy eQbesl, то есть на особи - результаты скрещиваний случайных особей из множества Qbesl лучших особей популяции;
8) особи qeQmulaluo„ заменяются на особи Qmillalmnx = = mutatuon(qx); qx^Qbest. то есть на особи - результаты мутаций случайных особей из множества Qbes{ лучших особей популяции;
9) если лучшая особь q} популяции была лучшей и соответст-вовала условию останова Eannq >TannE^ на менее чем TamgeniMer предыдущих итераций алгоритма подряд, то выполняется переход на шаг 2, иначе алгоритм останавливается. Параметр TannE^ есть уровень, определяющий достаточное качество обучения ИНС.
По останову выполнения генетического алгоритма в качестве лучшей ИНС принимается ИНС, генерируемая грамматикой Ах (особь q} окончательной популяции). Генетический алгоритм обладает следующими параметрами:
* I Keach I’ I Kest I ” определяют размеры обучающей и тестовой выборок векторов; значения данных параметров зависят от предметной области и сложности задачи классификации, решаемой искомой ИНС;
• Но, Hobest, HOcross - определяют количество особей, сохраняемых при переходе к следующей итерации генетического алгоритма, заменяемых на результаты скрещивания и мутации;
• cross, mutatuon - функции скрещивания и мутации соответственно;
* ^annE а “ определяет верхний уровень качества обучения лучшей ИНС, достаточный для останова алгоритма;
* Та™ gen inter ~~ определяет достаточное для останова алгоритма количество итераций, на которых подряд должны повторяться условия останова для лучшей особи; очевидно, что чем больше Г ел/л/ег ’ тем больше вероятность схождения алгоритма к устойчивому оптимуму - к ИНС, дающей одинаковый по качеству обучения результат на произвольных Vteach и Vtest.
2.4. Поиск соответствий между образами, выделенными на разнородных изображениях
Алгоритм формирования множества Prawedu пар совпадающих точек по множеству классифицированных образов С , выделенных на спутниковом снимке В, состоит из следующих этапов:
1.Для каждого образа Гее; с g С выполняются следующие действия.
1.1. С помощью функции coord рассчитывается множество еМ точек, таких что р^Рч <-> р = coord ; Ьу g t.
1.2. Из множества Рч точек выделяется подмножество Р\4 lergest ТаКОе ЧТ0 lergest ОТНОСЯТСЯ К ОДНОМУ И
тому же объекту на карте и выполняется условие:
Р\4 subset Р\4
РМ lergest Р\4 subset I РМ lergest 1>1 РМ subset I ’ (2.80)
1.3. Если объект ЦКМ, описываемый множеством P^iergest. и образ t относятся к одному и тому же классу, то геометрический центр (х, у) объекта, содержащего P^tergesti и центроид (/, у) образа t включаются в множество Prawedu = ={((/,»,(х, т)}-
2. Для множества Ргтел, рассчитывается совместная гистограмма отклонений 8х, и 8у :
(x\y') = coord({i, у));
8х = \х'- х|; (2.81)
= (2.82)
3. Так как искомое геометрическое преобразование единственно, то гистограмма будет иметь одну ярко выраженную моду (а совместное распределение 8х, и Зу будет нормальным) - пары точек ((г, j),(x, у), формирующие моду, включаются в множество Pmredu паР совпадающих точек с использованием правила 3-х сигм.
Г л а в a 3
МЕТОДЫ КОНТУРНОГО КОРРЕЛЯЦИОННОГО СОВМЕЩЕНИЯ РАЗНОРОДНЫХ ИЗОБРАЖЕНИЙ
3.1. Алгоритм моделирования системы искусственного интеллекта
На вход системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ с помощью контурного корреляционного совмещения, основанного на использовании нейросетевой ассоциативной памяти, поступают следующие данные:
В - исходный спутниковый снимок;
М - исходная ЦКМ;
coord - функция преобразования координат (х, у ) пикселя Ьу спутникового снимка В в координаты (х;..,у;>) точки на ЦКМ М в соответствии с системой координат и проекцией спутникового снимка В.
На выход системы искусственного интеллекта поступает множество пар совпадающих точек Praw edu (1.10), по которым в дальнейшем выполняется расчет множества пар точек Pedu (1.11) и функции сотр" (1.12), описывающей результирующее совмещение спутникового снимка В и ЦКМ М .
Система искусственного интеллекта состоит из следующих модулей:
1) модуль предварительной обработки спутникового снимка с целью устранения несущественных (слабых или прерывистых) контуров (3.1);
2) модуль выделения контуров на спутниковом снимке (3.2);
3) модуль описания контуров (3.3);
4) модуль поиска совпадений контуров образов на спутниковом снимке с границами объектов на ЦКМ (3.4).
Pmr edu = findedu (В’ М,COOrd) = correlation{M.cdesc{contour{prepare{By)y)\
Bprp= prepare(B); (3.1)
Всм= contour (ВргрУ, (3.2)
G = cdesc{Bcnty, (3.3)
Prmt edu = correlation^, G); (3.4)
pen, = {bcnlij}-, i = U-, j=U; bCM tJ e[0;l]; G = {g}.
Исходный спутниковый снимок В представляет собой входной параметр модуля предварительной обработки prepare, результатом работы которого является изображение Вргр, на котором, в отличие от спутникового снимка В, отсутствуют несущественные (слабые или прерывистые) контуры.
Изображение Вргр подается на вход модуля contour , который выполняет выделение контуров на изображении. На выход модуля contour поступает контурная матрица Bcnt, каждый пиксель bcnt которой содержит меру силы контура, проходящего через пиксель Ьсп{ .. исходного изображения Вргр . Под мерой силы контура в (3.2) понимается численная мера, принимающая значения из диапазона [0;1], где 0 соответствует отсутствию контура, а 1 - максимально сильному контуру. В простейшем случае Bcnt является бинарной матрицей.
Контурная матрица Bcnt представляет собой входной параметр модуля описания контуров cdesc, результатом работы которого является множество G описаний g контуров, выделенных на изобра-жении Вргр.
Множество G вместе с ЦКМ М поступает на вход модуля correlation , выполняющего корреляционное совмещение ЦКМ и спутникового снимка - контурам, описание которых присутствует в G , ищутся соответствия на ЦКМ (границы объектов), по результатам чего формируется множество пар совпадающих точек Praw edu -> П0 которым в дальнейшем выполняется расчет множества пар точек Pedu (1.11) и функции сотр' (1.12).
В § 1.3.2 приведен детальный анализ возможных подходов к реализации каждого из модулей системы. Окончательно были выбраны следующие подходы:
Модуль prepare - ИНС, выполняющая анализ независимых компонентов ((англ.) independent component analysis, ICA), и алгоритм, основанный на фильтре низких частот и фильтрации по Тихонову;
Модуль contour - нелинейная ячеистая нейронная сеть, нейронная сеть, основанная на применении вейвлет-преобразования Габора;
Модуль cdesc - метод, основанный на составлении множества подматриц матрицы cdesc фиксированного размера (множества окон), содержащих контур;
Модуль correlation - ограниченная стохастическая машина Больцмана.
Схема алгоритма моделирования системы искусственного интеллекта приведена на рис. 3.1. Алгоритм моделирования состоит из следующих этапов:
Рис. 3.1. Алгоритм моделирования системы искусственного интеллекта
1) предварительная обработка спутникового снимка с целью устранения несущественных (слабых или прерывистых) контуров (3.1);
2) выделение контуров на спутниковом снимке (3.2);
3) описание контуров (3.3);
4) поиск совпадений контуров образов на спутниковом снимке с границами объектов на ЦКМ (3.4).
3.2. Предварительная обработка спутникового снимка
3.2.1. Описание алгоритма
Исходный спутниковый снимок В вследствие различных причин, к которым относятся разнообразные шумы, недостаточное разрешение аппаратуры и прочие, может содержать большое количество мелких и прерывистых контуров, непригодных для использования в процессе дальнейшего совмещения.
Наличие таковых контуров требует выполнения дополнительной предобработки спутникового снимка и постобработки (фильтрации) выделенных контуров с целью устранения контуров, непригодных для дальнейшего совмещения.
Модуль предварительной обработки спутникового снимка prepare минимизирует влияние на результат совмещения несущественных (слабых или прерывистых) контуров путем выполнения следующих действий:
1) фильтрация ica аддитивных помех, имеющихся на спутниковом снимке В (3.5), для чего используется ИНС, выполняющая анализ независимых компонентов ((англ.) independent component analysis, ICA);
2) фильтрация filter несущественных (слабых или прерывистых) контуров (3.6), для чего используется алгоритм, основанный на применении фильтра низких частот и фильтрации по Тихонову.
Bprp = prepare^) = filter (ica(B));
Bica=ica(B); (3.5)
Bprp=filter(Bica). (3.6)
3.2.2. Алгоритм устранения слабых и прерывистых контуров
Описание алгоритма
Алгоритм фильтрации на спутниковом снимке слабых и прерывистых контуров [61] имеет вид:
вргр = grey(filter(deblurring{low(Bjca))); (3.7)
B,m=lo^Bicay, (3.8)
Вм = deblurring{Blmv); (3.9)
Bp^grey^ (3.10)
и состоит, таким образом, из следующих этапов:
1) low (3.8) - поканальное применение к изображению Bica фильтра низких частот low , следствием чего является сильное размытие Bica - изображение Blow .
После применения к изображению фильтра низких частот (ФНЧ) все линии сглаживаются, но основная информация об объектах на изображении не теряется. Вся информация перераспределяется по некоторому закону и может быть восстановлена, за исключением мелких объектов и тонких линий, которые несущественны для дальнейшего совмещения;
2) deblurring (3.9) - поканальное восстановление четких границ размытых объектов ((англ.) deblurring).
После того, как с помощью ФНЧ тонкие линии и мелкие объекты были практически устранены из изображения Blow . выполняется восстановление четких границ крупных объектов с получением на выходе изображения Bdbl;
3) grey (3.10) - преобразование изображения Bdbl в одноканальное изображение В для упрощения дальнейшего выделения контуров, значимых для решения задачи совмещения изображений.
Фильтр низких частот
В [61] было выполнено сравнение ФНЧ, которые могут быть использованы в составе описываемого алгоритма, по результатам
которого наилучшим выбором для реализации функции low был признан медианный фильтр.
Медианный фильтр является пространственным фильтром, не описываемым ядром свертки. Значения отсчетов внутри окна фильтра сортируются в порядке возрастания (убывания), и значение, находящееся в середине упорядоченного списка, поступает на выход фильтра. В случае четного числа отсчетов в окне выходное значение фильтра равно среднему значению двух отсчетов в середине упорядоченного списка. Окно перемещается вдоль фильтруемого сигнала, и вычисления повторяются.
Центральный элемент заменяется медианой всех элементов изображения в окне. Медианой дискретной последовательности ( . .г N + 1
{ } для нечетного N является элемент —-— , для
А-1
которого существуют —-— элементов и меньших или равных ему
А-1 г по значению, и —-— больших или равных ему по значению.
Восстановление четких границ размытых объектов
По результатам выполненных в [61] экспериментов в качестве алгоритма восстановления границ был выбран алгоритм, основанный на сглаживающей фильтрации методом наименьших квадратов со связью (фильтрация по Тихонову) [9].
Алгоритм восстановления границ выполняет поканальное восстановление искаженного изображения Blow с помощью модели процесса искажения deform.
В качестве модели процесса искажения deform в [61] был выбран ФНЧ Гаусса:
fд2+^2 ^1
deform(a,b) - —ехр 2ст , (3.11)
2лсг где параметр ст влияет на остроту пика производящей функции Гаусса.
По модели процесса искажения deform создается искажающий пространственный фильтр Kde/orm . Сам процесс искажения
имеет вид (3.12) в пространственной области или как (3.13) в частотной:
(3.12)
(3.13)
de form = dft(Kde form ) ’
#k=dft(Bk\
где dft - прямое дискретное преобразование Фурье.
Для восстановления изображения необходимо решить задачу нахождения экстремума (минимума) некоторого сглаживающего функционала. В методе, основанном на фильтрации по Тихонову, в качестве такого функционала Р можно использовать квадрат нормы лапласиана:
p=z;Z(v2Btal.t)2 (з.14)
///=0 л=0
с дополнительным ограничением (связью) вида:
d = В,т к ~ Kde j-orm • Bdbl к,
ATA=rf. (3.15)
т] eR+.
Так как алгоритм фильтрации контуров предполагает применение ФНЧ к исходному спутниковому снимку (т.е. известна точная модель процесса искажения), коэффициент г/ в (3.15) принимает значение т] - 0 и выражение (3.15) сводится к:
АТА = О. (3.16)
Решение оптимизационной задачи (3.14) при условии (3.16) в частотной области имеет вид:
Г к* д* ___ ^de form
dWA'U</0™,r +Y\L'\2}
у eR;
i‘=W);
(о -1 (И
L= -1 4 -1
<0 -1 °,
(3.18)
где: коэффициент у должен быть выбран таким образом, чтобы выполнялось условие (3.16); матрица L - оператор Лапласа (3.18).
После того, как найдено решение Bdbl k оптимизационной
задачи (3.17), рассчитывается Bdbl k:
Bdbl^idft(B'dblk), (3.19)
где функция idf есть обратное преобразование Фурье.
Преобразование многоканального изображения к одноканальному
Изображение Bdbl необходимо преобразовать к одноканальному изображению Вргр с целью улучшения временных характеристик процесса выделения контуров и повышения качества его работы.
Преобразование многоканального изображения Bdbl к одноканальному Вргр имеет вид:
Bprp=gray(Bdb,y, (3.20)
К
^i^dblijk
Bprp ij = gf^y(Bdbl у) = —.
А
3.3. Выделение контуров на спутниковом снимке
3.3.1. Описание алгоритма
На вход модуля выделения контуров contour поступает изображение Вргр , полученное с выхода модуля предобработки спутникового снимка В. Результатом работы модуля выделения контуров является бинарная одноканальная контурная матрица Bcnt, маркирующая наличие или отсутствие в каждом пикселе спутникового снимка контура, пригодного для использования в ходе дальнейшего совмещения В и ЦКМ М.
Под «пригодностью» в данном случае понимаются следующие требования к выделенным контурам:
• достаточная протяженность контура - чем длиннее контур, тем больше информации он предоставляет для дальнейшего совмещения спутникового снимка и ЦКМ;
• толщина контура должна быть равномерной на всем его протяжении.
Для выделения контуров на спутниковом снимке В, удовлетворяющих перечисленным требованиям, применяются следующие методы:
1) выделение контуров с помощью нейронной сети, использующей вейвлет-преобразование Габора;
2) выделение контуров с использованием нелинейной ячеистой ИНС.
3.3.2. Алгоритмы выделения контуров
на спутниковом снимке
Алгоритм выделения контуров
на спутниковом снимке
с использованием нелинейной
ячеистой искусственной нейронной сети
Нелинейная ячеистая ИНС [(англ.) non linear cellular neural network, NLCNN] [43^46] является двухмерной искусственной нейронной сетью размером I на J нейронов (т.е. размер NLCNN совпадает с размером изображения Вргр ).
Каждый (£, у)-й нейрон сети рассчитывает свой выход у'. в момент времени t по набору входных данных с учетом обратной связи, имеющейся внутри нейрона. Существуют различные подходы к организации обратной связи для выделения контуров. В настоящей работе используется сеть NLCNN, работа которой дискретизирована по времени - обратная связь оказывает влияние на работу нейрона с задержкой в одну итерацию работы сети.
Выходы у'у нейронов сети образуют матрицу Y' выходов размером I строк на J столбцов.
На рис. 3.2 приведена схема структуры нейронной сети NLCNN.
Т1
nlcnn ij
Рис. 3.2. Структура (z, у)-го нейрона нелинейной ячеистой ИНС
Алгоритм работы нейрона (i,y) на итерации t работы сети состоит [43] из следующих этапов.
1. На вход нейрона поступает подматрица В^ матрицы Вргр поступают выходы У?1 нейронов сети на предыдущей итерации (на первой итерации -Г = 0; Vz, у:??1 = 0) и вес х'у~' обратной связи, при этом В},, о Вргр и cz К'"1, то есть каждый нейрон обладает своим уникальным двумерным локальным сенсорным полем разме-ром М' на N' элементов.
В качестве В\. предлагается использовать окно размером (М', N1) пикселей на изображении Вргр с центром в пикселе с координатами (i,y).
2. Для каждого нейрона (i,y) повторяются следующие действия.
2.1. Рассчитываются и Р^. :
4= S 4<-); <3-21)
р‘= Z (3.22
(/•.УЭеЛ;
где функции Д, и Т’' - нелинейные (в общем случае) функции расчета характера связи нейрона с элементами матриц В' и К'4.
2.2. Рассчитывается х'.:
^=-4’+4+^+7Х,^’ (3-23)
где Kknn ij ~ пороговое значение.
2.3. Рассчитывается Д:
<=Л/СПП(Ч)’ (З-24)
где fnicm - функция активации нейрона.
3. Шаг 2 повторяется до тех пор, пока не выполнится одно из следующих условий:
Сеть выполнила достаточно большое количество итераций.
Выполняется условие:
г(3.25) где пороговое значение Tnlcnn > 0 и выбирается в зависимости от характера задачи.
4. Формируется матрица Bcnt:
(3.26)
[0, у'=0, cn,ij и х *°-Важно отметить, что NLCNN является самообучающейся ИНС, сходящейся к оптимальному с точки зрения поставленной задачи результату.
Кроме того, необходимо отметить также тот факт, что процесс работы NLCNN хорошо поддается распараллеливанию, что обусловлено ее модульной структурой.
В [43, 45, 46] обосновывается использование для выделения контуров на спутниковом снимке следующих значения параметров работы сети:
. Мт =NT =3-
• Т1 = —V nlcnn ij ’
В [45, 46] приведены результаты сравнения различных функций fnlcnn активации нейронов сети для решения задач выделения контуров, исходя из которых в качестве функции fnlcnn следует выбрать гиперболический тангенс (3.27):
fmcnn(x) = th(x).
(3.27)
Нейросетевой алгоритм выделения контуров на спутниковом снимке, основанный на использовании вейвлета Габора
Анализ информации, поступающей в мозг человека от первичных зрительных органов, происходит с использованием крайне сложной системы нейронов. В частности, как показано в [26], для получения информации о контурах на изображении мозг человека использует сложные преобразования, схожие с вейвлет-преобразо-ванием Габора. Поэтому вейвлет Габора используется для достаточно точного моделирования действий зрительной системы человека по выделению и анализу контуров объектов на изображении.
Двухмерное вейвлет-преобразование Габора имеет вид:
gabor(x\y') = exp
cos(Ax’+ со у У
(3.28)
I J
х ’ = х cos 0 + у sin 0; у ’ = -x sin 0 + у cos 0.
На основе вейвлета Габора строится пространственный фильтр Sgabor{p,^,co,&), размер которого SgaborJllter адаптивно настраивается в зависимости от масштаба изображения.
Материнская функция вейвлета Габора (3.28) обладает следующими параметрами:
• /л - стандартное отклонение распределения Гаусса, входящего в состав вейвлета Габора;
• А, со - коэффициенты при координатах х и у;
• 0 - угол относительно оси ОХ, относительно которого оценивается сила контуров.
Для выделения контуров на изображении необходимо сгенерировать набор фильтров F:
F = {fgabori’'"’fgaborin(F’^'’ftb(m~[')B®')’t"i.fgaborM’ (3.29)
M-Sgabor/mim, М>0- 8® = ^. (3.30)
Применение набора фильтров F к изображению Вргр позволяет получить на выходе набор изображений Bcntraw (3.31), каждое из которых содержит оценку силы контуров, идущих под углом (т -1 )<5©, в пикселях исходного изображения Вргр :
Bcntraw ^Bcnlrm.\,...,Bcnlrm,m,...,Bcnlmv!vl}. (3.31)
Применение набора фильтров F к изображению Вргр описывается как обработка изображения В с помощью многослойной ИНС W{. Действительно, каждый из фильтров можно рассматривать как отдельный нейрон с линейной функцией активации.
Задача выделения контуров на изображении заключается в выборе контурных пикселей В у исходного изображения по результатам анализа набора изображений Bcnlrm..
Для принятия решений о нахождении в пикселе 6 у контура используется многослойная ИНС W2, структурная схема которой приведена на рис. 3.3.
Алгоритм работы ИНС W2 для пикселя b у имеет следующий вид. __
1. Для каждого т - го нейрона первого слоя для т - 2, М -1 выполняются следующие действия.
1.1. На вход нейрона подается тройка пикселей 1т:
(3.32)
1 — h
ucnt raw /и-l ij * 1 — h tn ucnt raw m ij 9
Рис. 3.3. Структурная схема многослойной ИНС, используемой для принятия решения о нахождении контура в пикселе i
1.2. Тройки пикселей суммируются Lm sum = n=-l
1.3. К сумме Lm smn применяется пороговая функция акти-
вации /ос(1 с порогом Tgabor}:
т sum
^т sum ’ 0;
L >Т т sum gabor1 ’
L <Т
т sum gabor1 *
(3.33)
e[0;1].
2. Единственный нейрон второго слоя суммирует свои входы: L2 =£л, • т
3. К сумме L2 применяется пороговая функция активации fact2
с порогами Tgabor2 и Tgabor3:
1; L2 g [ Tgabor 2; Tgabor 3 ];
D
1Jcnt ij
(3.34)
U, 1^2 1 gabor 2 ^2 1 gabor 3 *
Tgabor 2 ’ tgabor 3 e ® •
Первый слой ИНС W2 оценивает силу контуров на изображении Вргр в соответствующих диапазонах направлений. Второй слой ИНС W2 оценивает наличие контуров в каждом из пикселей изображения - небольшое значение суммы Ь2 предполагает наличие в пикселе слабого контура, относящегося, скорее всего, к шумовым контурам; слишком большое значение суммы Ь2 указывает на нахождение пикселя на пересечении нескольких контуров - пиксель может находится на пересечении двух или трех контуров, но, когда количество таковых контуров больше трех, данный пиксель можно удалить скорее всего, каждый из контуров, проходящих через пиксель, является достаточно широким и анализируемый пиксель попадает в центр линии контура.
Окончательно алгоритм выделения контуров на изображении состоит из следующих основных этапов:
1) прогон изображения Вргр через ИНС Wx с получением на выходе набора изображений Bcntmr: Bcn, = W^Bprp,^,(o,Sgaborfitum, Sfilter ) ’
2) прогон набора изображений Встгак через ИНС W2 с получением на выходе бинарного контурного изображения Всп1: Всп1 = __ Tiy / 7J 'Т1 'Т’ 'Т’ \
“ 2 \ Jcnt raw ’ gabor 1 ’ gabor 2 ’ gabor 3'
Предложенный алгоритм выделения контуров обладает следующими параметрами:
•ИНС W\:p>^^co9Sgaborfnum^Sfilter;
• ИНС W2: Tgabor j, Tgabor 2, Tgabor 3.
Параметры используемых ИНС подбираются экспериментально с целью ускорить процесс подбора.
Описанный алгоритм выделения контуров хорошо поддается распараллеливанию. Каждый нейрон ИНС W\ и W2 является обособленным модулем, работающим независимо от прочих нейронов. Параллельная работа нейронов используемых ИНС была орга-низована на базе видеокарты, поддерживающей технологию GPGPU, поскольку видеокарты данного класса располагают большим количеством независимых вычислительных ядер в отличие от много-ядерных процес
соров общего назначения, располагающих в лучшем случае 16-ю и 32-мя вычислительными ядрами.
Выбор алгоритма выделения контуров
Каждый из рассмотренных алгоритмов выделения контуров используется в составе описываемого алгоритма совмещения спутниковых снимков и ЦКМ.
Нейросетевой алгоритм выделения контуров на спутниковом снимке, основанный на использовании вейвлета Габора, за счет более низких временных показателей используется для выполнения оперативного совмещения спутниковых снимков и ЦКМ. В тех же случаях, когда временные характеристики процесса совмещения оказываются менее важны, чем качественные, для выделения контуров на спутниковом снимке должен использоваться алгоритм, основанный на применении нелинейной ячеистой искусственной нейронной сети для выделения контуров.
3.4. Описание контуров
По результатам анализа способов описания контуров, выполненного в § 1.3.2, в качестве средства описания контуров был выбран способ, основанный на составлении множества подматриц матрицы Всп( фиксированного размера (множества окон), содержащих контур.
Алгоритм формирования множества GB={gBn} описаний gBn контуров, присутствующих на спутниковом снимке В , состоит из следующих этапов (здесь и далее символом g обозначается контур, окно, в котором находится контур (контурное окно), и вектор описания контура, получаемый разверткой контурного окна построчно):
1) матрица Bcnt разделяется на множество GB={gBn} непере-секающихся квадратных окон размером Swndsize на Swndsjze элементов;
2)окно gflneGBoTGmin<^^gBn<TGmax, где TGmin и ТСтт -минимальное и максимальное количество элементов окна gBn ,
занятых контуром, достаточные для использования контурного окна в процессе дальнейшего совмещения.
Пороговое значение TGmin позволяет исключать из рассмотрения контурные окна, содержащие небольшие (несущественные с точки зрения дальнейшего совмещения) контуры и фрагменты контуров.
Пороговое значение 7^тах позволяет исключать из рассмотрения контурные окна, содержащие избыточную информацию о контурах, приводящую к усложнению (и зачастую к невозможности) сопоставления контуров, выделенных на спутниковом снимке, с контурами объектов на ЦКМ.
Протяженные контуры, выделенные на спутниковом снимке В, для которых сторона минимального прямоугольника, содержащего контур, превосходит значение Swndsize пикселей, оказываются искусственно разделенными на несколько контурных окон, что положительно сказывается на качестве выполняемого совмещения, так как позволяет получить больше достоверного контурного материала для выполнения совмещения, поскольку чем протяженней контур, тем больше вероятность того, что соответствующий ему объект (или группа объектов) присутствует на ЦКМ и формирует соответствующий контур на ЦКМ.
Множество G4={g4n} описаний контуров объектов, присутствующих на ЦКМ М. формируется аналогичным образом.
3.5. Поиск совпадений контуров образов
3.5.1. Структура коррелятора, принципы его обучения и функционирования
Существует несколько подходов к решению задачи контурного корреляционного совмещения (задачи поиска соответствий между контурами, выделенными на спутниковом снимке В, и контурами объектов, присутствующих на ЦКМ М ). Как было показано в § 1.3.2, наиболее эффективным с точки зрения времени выполнения и требуемых вычислительных ресурсов и позволяющим получить при этом результат качества, достаточного для дальнейшего совмещения, является подход, базирующийся на использовании нейросетевой ассоциативной памяти, основанной на ограниченной
стохастической машине Больцмана ((англ.) restricted Boltzmann machine, RBM) [46, 47].
Пусть GB = {gBn} - множество описаний контуров gBn, выделенных на спутниковом снимке B(\GB\= NB); GM = {gMn} - множество описаний контуров g4n объектов, присутствующих на ЦКМ (\G„ \=N„).
Размерности векторов gBn и g4„ очевидно совпадают и равны
I &Вп I I S \4п I ^wnd size *
Алгоритм работы коррелятора состоит из следующих этапов:
1) обучение коррелятора на множестве GB описаний контуров, выделенных на спутниковом снимке В , с использованием алгоритма CD-k ((англ.) contrastive divergence), описанного в [62];
2) прогон коррелятора для каждого g4n eG4 п формирование пар описаний контуров (gBnf,g4n)^ G^ таких, что для контура g^n контур gBn' является наилучшим соответствием с точки зрения коррелятора;
3) формирование множества пар совпадающих точек Prav.edu по множеству Gpajr.
Ключевым элементом представленного алгоритма является коррелятор, основанный на применении ограниченной стохастической машины Больцмана.
Ограниченная стохастическая машина Больцмана относится к классу ИНС, реализующих ассоциативную память. Обучение стохастической машины Больцмана сводится к запоминанию входного множества векторов, после чего на вход машины подается некоторый входной вектор и машина выполняет ряд итераций до тех пор, пока выходы нейронов ее входного слоя не достигнут стабильного состояния, которое и будет являться вектором из обучающего множества, восстановленного для данного входного вектора.
Структурная схема ограниченной стохастической машины Больцмана приведена на рис. 3.4.
RBM состоит из двух слоев нейронов:
• слой видимых нейронов, векторы весов которых обозначаются как Wvjsjble q, где q - индекс нейрона.
I W I- с
I rr visible q I ^wndsize ’
• слой скрытых нейронов, векторы весов которых обозна-чаются как Whiddenq.
Векторы весов нейронов каждого слоя образуют матрицы ^sibie и WhiMe„ , количества строк которых Wrbm visible и Srbm hidde„ являются количествами нейронов в видимом и скрытом слоях соответственно.
Рис. 3.4. Структурная схема ограниченной стохастической машины Больцмана
Так как ограниченная стохастическая машина Больцмана явля-ется полносвязанной ИНС, то | Wrisibleq |= Wrbm visible и Srbmhidden = =\W l= s
I rr visible q I size ’
Алгоритм работы ИНС по сопоставлению с контуром gMn контура gBn, е GB состоит из следующих этапов:
1) исходный вектор gMn поступает на вход RBM: gvjsibte = gM„;
2) Svisible prev Svisible ’
3) рассчитывается вектор gbidden = {ghidde„ q} , где ghiddenq = ^visible qS visible 9 visible’
4) рассчитывается вектор gvjslble = {gvisible q} , где gviMe q ^hidden qghidden > Я hidden ’
5) рассчитывается 8gvlsible:
S visible
c
arbm visible
j visible q Svisible prev q}
<7=1
(3.35)
$
^rbm visible
6) если 8gvjsjble < Trbm stop , то выполняется останов алгоритма, иначе выполняется переход на шаг 2.
По завершении выполнения алгоритма очередной вектор gvisible принимается в качестве приближения gBn' к вектору gBn'.
Пороговое значение Trbm stop g R+ является максимально допус
тимым отклонением очередного вектора gvisible от соответствующего вектора на предыдущей итерации, при котором выполнение алгоритма останавливается и ИНС считается достигшей стабильного состояния.
Поиск вектора gBn ’ по его примерному значению gBn' из множества GB выполняется по алгоритму, состоящему из следующих этапов:
1) для каждого gBn g Gb рассчитывается 8gBn:
Slndsize, _2. \2
g=| (gBnq gBn'q ' . (3 36)
^wnd size
2) выбирается вектор gBnf такой, что n' = argmin5gBn.
Таким образом, в качестве gBn ’ выбирается вектор gBn ’ eGb, максимально близкий к gBn' в смысле Евклидовой меры расстояния.
SgBn =
3.5.2. Формирование множества пар совпадающих точек
Алгоритм формирования множества Prawedu (1.Ю) пар совпадающих точек по множеству Gpair пар совпадающих контуров состоит из следующих этапов:
1.Для каждой пары контуров (gBn.g\4n)^Gpair выполняются следующие действия:
1.1. Для контурного окна (контура) gBn’, выделенного на контурной матрице Всп{ , соответствующей спутниковому снимку В, рассчитываются координаты (/„.» jn,) его центрального пикселя &. , bj .
1.2. Для контурного окна (контура) g„n, выделенного на ЦКМ М. рассчитываются координаты (хп, уп) его центра.
1.3. Рассчитываются отклонения Зх и 8 у :
(xn.,yn.) = coord(,(i„.,jn.));
<5х=К-х„1; (3.37)
ёу=\у„'-уп\- (3.38)
2. Рассчитывается совместная гистограмма отклонений Зх и 8у.
З.Так как искомое геометрическое преобразование единственно, то гистограмма будет иметь одну ярко выраженную моду (а совместное распределение Зх и 8у будет нормальным) - пары точек ((in,, д,), (хп , уп)), формирующие моду, включаются в множество Prawedu пар совпадающих точек с использованием правила 3-х сигм.
Г л а в a 4
ЭКСПЕРИМЕНТАЛЬНЫЕ ИССЛЕДОВАНИЯ МЕТОДОВ СОВМЕЩЕНИЯ РАЗНОРОДНЫХ ИЗОБРАЖЕНИЙ
4.1. Описание программного стенда
Алгоритмы моделирования систем искусственного интеллекта, численные методы настройки их параметров, численные методы обучения классификаторов, а также непосредственно системы искусственного интеллекта, выполняющие совмещение данных ДЗЗ и ЦКМ, были реализованы в составе следующих программных продуктов:
• программа совмещения данных ДЗЗ с ЦКМ с использованием искусственных нейронных сетей - программная библиотека и пользовательский интерфейс к ней;
• программный стенд тестирования алгоритмов предобработки и совмещения изображений;
• программа построения и уточнения карт гарей лесных массивов на основе данных ДЗЗ с использованием системы искусственного интеллекта.
Для каждого из перечисленных программных продуктов имеется свидетельство о его регистрации в ФГБУ «Федеральный институт промышленной собственности Федеральной службы по интеллектуальной собственности, патентам и товарным знакам» (ФГБУ «ФИПС»-РОСПАТЕНТ).
Разработка программных продуктов была выполнена с помощью следующих инструментов:
• языки программирования: C++ (стандарт С++11), Python 3, Lua, R;
• программные библиотеки: GLibC, OpenCV, Qt 4, Qt 5, SDL;
• спецификации: OpenGL, OpenMP, OpenCL;
• программные утилиты: Doxygen, CMake, Git, Vim.
4.2. Порядок проведения экспериментального исследования
4.2.1. Цели экспериментального исследования
Целями экспериментального исследования являются:
• экспериментальное определение наилучших параметров алгоритма моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ, на спутниковом снимке -данная цель достигнута в рамках экспериментов № 1,2;
• экспериментальное определение наилучших параметров алгоритма моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска корреляции между контурами образов, выделенных на спутниковом снимке, и границами объектов, присутствующих на ЦКМ - данная цель достигнута в рамках эксперимента № 3;
• сравнение временных показателей и показателей качества совмещения, выполненного с помощью систем искусственного интеллекта, и совмещения, выполненного рядом существующих распространенных алгоритмов, данная цель достигнута в рамках эксперимента № 4;
• оценка пригодности использования разработанных алгоритмов моделирования, численных методов обучения систем искусственного интеллекта и непосредственно разработанных систем искусственного интеллекта для выполнения высокоточного оперативного совмещения данных ДЗЗ и ЦКМ.
Результаты совмещения оцениваются с временной точки зрения и с точки зрения точности выполненного совмещения.
4.2.2. Условия проведения
экспериментального исследования
Инструменты проведения экспериментального исследования
Экспериментальное исследование было выполнено с помощью программного стенда тестирования алгоритмов предварительной обработки и совмещения изображений.
Для обработки и анализа результатов экспериментов был использован язык программирования R.
Экспериментальное исследование было проведено с использованием вычислительного кластера, организованного по технологии Message passing interface (MPI), реализованной в виде программного комплекса Open MPL Вычислительный кластер был составлен из следующих вычислительных систем:
• управляющая вычислительная система кластера:
-аппаратная часть: Intel Core i53337U (частота процессора 2,7 ГГц; 4 вычислительных ядра; объем кэша L3-3 мегабайта), AMD Radeon HD 8750 М (частота процессора 775 МГц; объем ОЗУ - 2 гигабайта (технология DDR3); количество вычислительных ядер - 192), 4 гигабайта DDR3 ОЗУ;
- программная часть: ОС GNU/Linux (дистрибутив Arch Linux; версия ядра Linux 3.14.4), программная библиотека GLibC версии 2.19;
• вычислительная система № 1:
-аппаратная часть: Intel Corei 7-4960Х (частота процессора 3,6 ГГц; 6 вычислительных ядер; объем кэша L3-15 мегабайт), NVidia GeForce GTX 780 (частота процессора - 1071 МГц; объем ОЗУ - 3 гигабайта (технология GDDR5); количество вычислительных ядер - 192), 16 гигабайт DDR3 ОЗУ;
- программная часть: ОС GNU/Linux (дистрибутив ArchLinux; версия ядра Linux 3.14.4), программная библиотека GLibC версии 2.19;
• вычислительная система № 2:
-аппаратная часть: Intel Core i7-4770K (частота процессора 3,5 ГГц; 4 вычислительных ядра; объем кэша L3-8 мегабайт), NVidia GeForce GTX780 (частота процессора - 1750 МГц; объем ОЗУ - 3 гигабайта (технология GDDR5); количество вычислительных ядер - 240), 16 гигабайт DDR3 ОЗУ;
- программная часть: ОС GNU/Linux (дистрибутив ArchLinux; версия ядра Linux 3.14.4), программная библиотека GLibC версии 2.19.
Каждое ядро процессоров вычислительных систем, включенных в кластер, использовалось в качестве вычислительного узла кластера и, таким образом, кластер состоял из 14-ти вычислительных узлов (хостов).
Для уменьшения временных затрат на проведение экспериментального исследования каждый хост использовал мощности видеопроцессора, имевшегося в составе соответствующей системы, для дополнительного распараллеливания части вычислений с помощью технологии общих вычислений на видеокарте ((англ.) general-purpose graphics processing units, GPGPU).
4.2.3. Входные и выходные параметры экспериментального исследования
Тестовые примеры
Для проведения экспериментальных исследований было сформировано множество Tglobal lesl=tglobal ,esl} тестовых примеров global test < ^test ’ test * ^test ’ off set >’ ^Д^.
• В test ~ СПУТНИКОВЫЙ СНИМОК, Btest G Blest ;
• M,esl -ЦКМ;
• Ple5l - множество пар реперных точек, одна из которых отмечена на Blal , а другая - на Mlesl;
’ Offset ~ вектор, описывающий смещение Btesl offsel = = off set{B,es,voffse,) изображения Blesloffsel.
На вход тестируемого метода совмещения поступает смещенный спутниковый снимок Blal offset и ЦКМ Mtest. Задача исследуемого метода состоит в совмещении входных данных друг с другом. Результат совмещения оценивается с помощью среднеквадратичной меры ошибки Е (1.8) по множеству реперных точек Plesl.
В качестве источника данных ДЗЗ был использован сенсор «Thematic mapper» (ТМ), установленный на КА «Landsat 5». Для экспериментального исследования были использованы спектральные каналы В 10 (синий), В 20 (зеленый), В 30 (красный), В 40 (ближний инфракрасный) и И 50 (ближний инфракрасный) разрешением 30 м на пиксель таким образом, К = 5. Размер спутникового снимка, полученного от КА «Landsat 5», составляет 8231 на 7511 пикселей. Для уменьшения временных затрат на проведение экспериментального исследования в качестве BKst были использо
ваны окна размером I = 7 = 1024 пикселей, выделенные на исходных спутниковых снимках.
Экспериментальным полигоном были выбраны Рязанская область, а также области и республики, граничащие с Рязанской областью. Множество тестовых данных ДЗЗ Вtest состоит из спут-никовых снимков перечисленных регионов России за период с 1991 по 2008 годы.
В качестве источника ЦКМ был использован проект Open Street Maps [63].
Вектор voffsel ^{vrmoval,vrolale,vscale} описывает геометрическое ис-кажение спутникового снимка Btest, которое необходимо скорректировать посредством совмещения. Вектор voffset состоит из следующих компонентов:
* Vremovai ~ смещение в метрах (направление смещения не имеет значения, так как не существует зависимости информационной наполненности анализируемой сцены от направления ее обхода);
* vrotate ~ Угол поворота вокруг центра спутникового снимка относительно оси ОХ в радианах;
* vscaie ~ масштабный коэффициент линейного преобразования координат, безразмерная величина.
Множество Tglobal test было составлено, исходя из следующих соображений.
Множество Tglobal test должно содержать репрезентативное представление всех возможных состояний окружающей среды, поскольку вариации спектральных яркостей и текстурных характеристик образов одной и той же сцены на спутниковых снимках зависят в наибольшей степени именно от этого. Большой размер IxJ спутниковых снимков, получаемых от КА «Landsat 5» (полоса захвата 185 км), и выполнение дистрибьютором нескольких этапов предобработки обуславливает нормальное распределение погодных условий на снимке с модой в точке: полуденная яркость солнечного света, отсутствие осадков, низкая облачность. Таким образом, главным параметром, определяющим специфику состояния окружающей среды, оказывается время года и зависящие от него состояние растительности и характер выпадающих осадков.
систе-
Voff set
(4.1)
(4.2)
(4.3)
Для обеспечения репрезентативности представления множеством global test генеральной совокупности всех возможных состояний окружающей среды, которые могут быть различимы на спутниковых снимках в мере, значимой для оценки качества совмещения, необходимо обеспечить равномерное распределение в множестве Tglobal test тестовых примеров tglobal tes( относительно месяца производства спутниковых снимков Btest.
Множество Tglobal tes( должно являться репрезентативным представлением генеральной совокупности векторов vo#se,, которые могут быть теоретически скорректированы предложенными мами искусственного интеллекта.
Мощность генеральной совокупности векторов определяется как (4.3):
> т _ Vremoval max removal min
v off set max — c*
u yremoval
V —v
* rotate max rotate mm 8v v rotate
* Vscale max scale min
гДе: Ч™01а/тах; vre„ora/min - диапазон возможных значений
Svremovat - шаг квантования vremovat; vTOto,emax; vr0,a,emin - диапазон возможных значений vrolale , 8vrolale - шаг квантования vrolale ; ^ca/emaxi Barnin " ДИЭПаЗОН ВОЗМОЖНЫХ ЗНаЧвНИЙ Vscale, 8vscale ~ ШЭГ квантования vscale.
На основании инвариантности процесса совмещения к направлениям смещения и поворота можно принять:
v , = 0;
removal min ’
v = 0;
rotate min ’
V = 71.
rotate max
На основании пространственного разрешения тестовых данных ДЗЗ можно принять:
8vremoval = 30.
Значение 8vrotate можно рассчитать, исходя из угла поворота, обеспечивающего (минимальное) смещение на один пиксель по диагонали по наиболее удаленной от центра спутникового снимка стороне:
. 2*302/2 ...
= arcsin----------« 0,06,
rotate (1024*30)/2
из чего следует, что:
V removal max removal min Л ~
Ж
Очевидно также, что v . . =8v,. * ? scale min scale
Таким образом, (4.3) сводится к:
V (V , А
ът _ removal max scale max < /л их
\ scale J
Исходя из теоретических ограничений на качество работы алгоритма моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, связанных с минимально допустимым количеством образов объектов, пригодных для совмещения, Toty.min =20, можно рас-
считать vreni0Val max , для чего необходимо оценить по В test максимально возможное смещение, при котором количество объектов на соответствующей ЦКМ Mtest, совпадающих более чем на 50 % площади с соответствующими образами на Btest , больше либо равно Tobj min. В ходе подготовки к проведению экспериментальных ис-следований значение vremov(l/max было оценено как vre„0Vfl/max =1000.
Параметры vjrakmax и 3vscale были оценены, исходя из типовых значений коэффициента масштабного искажения, полученных в процессе обработки данных ДЗЗ, как vscale max = 3 и 8vscate = 0,1.
Окончательно Noffsel тах было оценено как:
^max =1^*|j[-l)* 52*50267. (4.5)
Поскольку Noffselmax » Blesl, то:
I \Tgloballesl\=Noffselmax- 50267, (4.6)
при этом должно выполняться требование равномерного распределения в Tglobal test месяцев производства спутниковых снимков B(esl.
Общие входные параметры экспериментов № 1 и №2
Общим параметром экспериментальных исследований алгоритмов моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ на спутниковом снимке, является множество Hteachtest =Hteach uHtesl, содержащее в себе заранее классифицированные образы, выделенные на спутниковых снимках Btest.
Подмножества множества Hteach и подмножества множества Htest применяются соответственно для обучения и тестирования качества обучения простых классификаторов, входящих в состав древовидных классификаторов.
Для корректного обучения классификаторов требуется, чтобы Нteach и Htest были репрезентативными подмножествам генеральной совокупности образов объектов, пригодных для обучения классификаторов в процессе обучения (настройки) разработанных систем искусственного интеллекта.
Древовидные классификаторы, обучаемые в ходе проведения экспериментальных исследований, должны классифицировать образы, относящиеся к образам водных объектов, лесных массивов и сельскохозяйственных полей, с вероятностью не менее 0,85, что, как показано в [17-19], является в среднем максимальной точностью, которая может быть достигнута машиной опорных векторов и ИНС прямого распространения без обратных связей в процессе бинарной классификации.
Для достижения заданной точности для каждого класса была рассчитана гистограмма многомерного распределения текстурных признаков Харалика образов объектов данного класса, выделенных на спутниковых снимках Btest. Текстурные признаки Харалика бы
ли использованы по причине их более высокой информативности по сравнению с другими средствами описания текстур.
Гистограмма распределения текстурных признаков Харалика для каждого из анализируемых классов с е. С является унимодальной, следовательно, с помощью правила трех сигм возможно формирование множества Hteach test с с= Hteach test, содержащего образы, относимые к классу с .
При обучении каждого простого классификатора множества образов Hteach и Htest должны содержать одинаковое количество образов каждого из двух классов, причем подмножества, содержащие образы соответствующих классов, должны повторять параметры распределения образов данных классов в соответствующих множествах Ht. tezt r. teach test c
Исходя из рекомендаций, изложенных в [17, 18], \H(each | = 300, I Htest I = 700. Для формирования данных множеств на основе множества Hteach test в ходе проведения экспериментальных исследований был использован датчик псевдослучайных чисел, распределенных нормально.
Общие выходные параметры экспериментов
Общими выходными параметрами экспериментов являются:
• время выполнения совмещения (без учета времени обучения модели) с точностью до 1-й миллисекунды;
• качество выполненного совмещения Е, оцененное по (1.8) и усредненное по Tglobal test, с точностью до 1-го метра.
Значимость качественной эффективности совмещения превосходит значимость временной эффективности, так как теоретические предпосылки позволяют говорить о том, что дисперсия временной эффективности работы каждой из исследуемых систем искусственного интеллекта будет существенно меньше, чем дисперсия качественной эффективности.
Входные параметры, специфические для каждого эксперимента
Различные комбинации фактических значений входных параметров, специфических для каждого эксперимента, образуют множество векторов параметров = {vpora„,}.
Для каждого из рассматриваемых параметров максимально допустимое значение выбирается заведомо большим, чем соответствующие теоретические оценки.
Эксперимент № 1. Входными параметрами-компонентами вектора Vparam - экспериментального определения наилучших с качественной и временной точек зрения параметров алгоритма моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ на спутниковом снимке, с использованием древовидного классификатора и ИНС прямого распространения без обратных связей в качестве простого классификатора, являются:
* skohonen ~ РазмеР нейронной карты Кохонена по каждой из размерностей.
В ходе проведения эксперимента № 1 для простоты вычислений количество размерностей нейронной карты Кохонена будет принято равным 3, причем по каждой из размерностей нейронная карта будет иметь одинаковый размер (таким образом, в пространстве координат нейронов используемая нейронная карта Кохонена может быть представлена как куб со стороной, равной skohonen нейронов).
Диапазоном возможных значений параметра был выбран диапазон skohonen е [1;51) , шаг квантования параметра был принят равным 8skohonen=5-,
• минимальный объем информации Tinfo. сохраняемый в классифицируемом векторном пространстве в результате преобразования Карунена - Лоева.
Диапазоном возможных значений параметра был выбран диапазон Tjnfo 6 (0;1], шаг квантования параметра был принят равным 8Tinf0 =0,1;
• количество шагов развертки грамматики графовой генерации Китано ЧЛ
Диапазоном возможных значений параметра был выбран диапазон 4^1; 10], шаг квантования параметра был принят равным <5Т = 1;
Максимальный уровень ошибки Голл£тах на тестовом множестве векторов , при котором генетический алгоритм выбора структуры ИНС прямого распространения без обратных связей останавливается.
Диапазоном возможных значений параметра был выбран диапазон ТатЕтах е (0;0,3] , шаг квантования параметра был принят равным STF = 0,03 .
Количество векторов параметров равно:
|К |=—.1 Т—- + 1Y — = 10000. (4.7)
pa am 5 0,1 1 ) 0,03
Эксперимент № 2. Входными параметрами-компонентами вектора vparam - экспериментального определения наилучших с качественной и временной точек зрения параметров алгоритма моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ, на спутниковом снимке, с использованием древовидного классификатора и машины опорных векторов в качестве простого классификатора, являются:
• размер skohonen нейронной карты Кохонена по каждой из размерностей.
В ходе проведения эксперимента № 1 для простоты вычислений количество размерностей нейронной карты Кохонена будет принято равным 3, при чем по каждой из размерностей нейронная карта будет иметь одинаковый размер (таким образом, в пространстве координат нейронов используемая нейронная карта Кохонена может быть представлена как куб со стороной, равной skohonen нейронов).
Диапазоном возможных значений параметра был выбран диапазон skohonen е [1;51), шаг квантования параметра был принят равным Sskohonen=5;
• минимальный объем информации Tinfo. сохраняемый в классифицируемом векторном пространстве в результате преобразования Карунена - Лоева.
Диапазоном возможных значений параметра был выбран диапазон Tinfo е(0;1] , шаг квантования параметра был принят равным 8Tinfo =0,1;
• параметр Ssun} обучения машин опорных векторов, определяющий верхнюю границу поиска множителей Лагранжа в ходе оптимизации соответствующей функции.
Диапазоном возможных значений параметра был выбран диапазон Ssum е (0; 10], шаг квантования параметра был принят равным 5С = 0,1.
Количество векторов параметров равно:
— • — = 10000. (4.8)
р 5 0,1 0,1
Эксперимент № 3. Входными параметрами-компонентами вектора vparam - экспериментального определения наилучших с качественной и временной точек зрения параметров алгоритма моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска корреляции между контурами образов, выделенных на спутниковом снимке, и границами объектов, присутствующих на ЦКМ, являются:
•размер Sconloursi!e окна выделения контуров (SC0nl0Iirsize = М' =N' для нелинейной ячеистой нейронной сети и Sconloursize = Sgaborfiller для нейросетевого алгоритма выделения контуров, основанного на использовании вейвлета Габора).
Диапазоном возможных значений параметра был выбран диапазон Sconloursize е [3;30] , шаг квантования параметра был принят равным <5S_J/ze = 3;
• количество Srbmvizible нейронов видимого слоя ограниченной стохастической машины Больцмана.
Диапазоном возможных значений параметра был выбран диапазон Srbmvizible е [1; 30] , шаг квантования параметра был принят равным SSrbmvizible =1;
•количество Srbn]hjdden нейронов скрытого слоя ограниченной стохастической машины Больцмана.
Диапазоном возможных значений параметра был выбран диапазон Srbmhjdden е[1;30] , шаг квантования параметра был принят равным SSrbm hidden *
Количество векторов параметров равно:
(зо-з Л Лзо—1 Л Лзо—1
|К 1= - + 1 • + l ^ + 1 =90000. (4.9)
। param I \ 1 / \ 1 J
Эксперимент № 4. Экспериментальное сравнение качественных и временных показателей совмещения, выполненного с помощью разработанных систем искусственного интеллекта, и совмещения, выполненного рядом существующих распространенных алгоритмов, не имеет специфических входных параметров.
4.2.4. План проведения экспериментальных исследований
План проведения экспериментов № 1 и № 2
Эксперименты № 1 и № 2, предполагающие экспериментальную проверку качественной и временной эффективности алгоритмов моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ на спутниковом снимке, были выполнены независимо по одинаковому плану, реализующему полный факторный эксперимент по компонентам векторов vparam .
План проведения экспериментов № 1 и № 2 состоял из следующих этапов:
1) К =V :
/ param current param ’
2) обучение древовидного классификатора для каждого набора параметров из Vparam current с использованием множества образов Т teach test ’
3) обработка каждым алгоритмом моделирования 1 % тестовых примеров из Tglobal test , выбранных с помощью датчика псевдослучайных чисел, распределенных равномерно;
4) построение гистограммы распределения качества совмещения;
5) поиск мод гистограммы;
6) формирование множества Vparam best векторов параметров эксперимента, лежащих на модах гистограммы, такого, что дисперсия Е по Vparam best не должна превышать 0,1 (т.е. отбор лучших векторов параметров vparanj алгоритмов моделирования с точки зрения качества совмещения для случайного подмножества тестовых примеров Tglobal test, на основании предположения о равномерном распределении оценки качества совмещения по Tglobal test);
7) V =V
' param current param best ’
8) повторение пунктов 2-7 для V currenl последовательно с использованием 10%, 25 %, 50 %, 75 % тестовых примеров из ^global test на этапе 3, что обеспечит постепенное повышение оценки точности качества совмещения для лучших векторов параметров из V param
Для оценки временной эффективности совмещения для каждого вектора параметров vparam временные затраты на непосредственное совмещение (без учета этапа обучения классификатора) аккумулировались и по окончанию эксперимента нормировались по количеству выполненных совмещений.
План проведения эксперимента № 3
Эксперимент № 3, предполагающий экспериментальную проверку качественной и временной эффективности алгоритма моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска корреляции между
контурами образов, выделенных на спутниковом снимке, и границами объектов, присутствующих на ЦКМ, был выполнен по плану, реализующему полный факторный эксперимент по компонентам вектора .
План проведения эксперимента № 3 состоял из следующих этапов:
1) V =V :
/ param current param ’
2) обработка каждым алгоритмом моделирования 1 % тестовых примеров из Tglobal lesl, выбранных с помощью датчика псевдослучайных чисел, распределенных равномерно;
3) построение гистограммы распределения качества совмещения;
4) поиск мод гистограммы;
5) формирование множества V т best векторов параметров эксперимента, лежащих на модах гистограммы, такого, что дисперсия Е по Vparam besl не должна превышать 0,1 (т.е. отбор лучших векторов параметров v алгоритмов моделирования с точки зрения качества совмещения для случайного подмножества тестовых примеров Tglobal tal , исходя из предположения о равномерном распределении оценки качества совмещения по Tglobal ,esl);
6) V =V
' param current param best ’
7) повторение пунктов 2-6 для К ш curreM последовательно с использованием 10%, 25 %, 50 %, 75 % тестовых примеров из ^global test на этапе 3, что обеспечит постепенное повышение оценки точности качества совмещения для лучших векторов параметров из V param
Для оценки временной эффективности совмещения для каждого вектора параметров vparam временные затраты на непосредственное совмещение аккумулировались и по окончанию эксперимента нормировались по количеству выполненных совмещений.
План проведения эксперимента № 4
Эксперимент № 4 предполагал сравнение результатов экспериментов № 1 и № 3 с оценками времени и качества совмещения, выполненного следующими методами и алгоритмами:
• корреляционно-экстремальный метод совмещения, рассмотренный в [48];
• метод стабилизации изображений, основанный на преобразовании Фурье;
• метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SIFT;
• метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SURF;
• метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора Харриса.
План проведения эксперимента № 4 состоял в обработке множества тестовых примеров Tglobal test каждым из перечисленных алгоритмов, усреднении временных показателей и показателей эффективности с точки зрения качества совмещения и сравнении полученных результатов с результатами экспериментов № 1 и № 3.
4.3. Результаты экспериментального исследования
4.3.1. Методика анализа результатов экспериментального исследования
Методика анализа
результатов экспериментов № 1 и № 3
Целями анализа результатов экспериментальных исследований качественной и временной эффективности алгоритмов моделирования систем искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ, стали:
• поиск наилучших с качественной и временной точек зрения наборов параметров исследуемых алгоритмов моделирования систем искусственного интеллекта, выполняющих совмещение данных ДЗЗ и ЦКМ;
• визуализация зависимостей выходных параметров моделирования (временной оценки и оценки качества выполненного сов
мещения) на наборе тестовых примеров Tglobal test от параметров исследуемых алгоритмов моделирования.
Алгоритм визуализации означенных зависимостей состоит из следующих этапов:
1) расчет среднеквадратичного отклонения исследуемого выходного параметра эксперимента для значения входного параметра для каждого из входных параметров, специфических для анализируемого эксперимента;
2) выбор двух входных параметров эксперимента с наибольшим СКО;
3) построение трехмерного графика зависимости исследуемого выходного параметра эксперимента от двух входных параметров с наибольшим СКО.
Ме тодика анализа результатов эксперимента № 4
Целью анализа результатов экспериментального сравнения временных показателей и оценок качества совмещения, выполненного с помощью разработанных систем искусственного интеллекта, и совмещения, выполненного рядом существующих распространенных алгоритмов, стала визуализация результатов сравнения в виде сводной таблицы, содержащей следующие данные:
• для каждой из систем искусственного интеллекта:
- оценка качества совмещения и оценка временной эффективности совмещения для наилучшего с точки зрения качества совмещения набора параметров vparam данной системы искусственного интеллекта;
- оценка качества совмещения и оценка временной эффективности совмещения для наилучшего с временной точки зрения набора параметров vparam данной системы искусственного интеллекта;
• для каждого из существующих распространенных алгоритмов совмещения - оценка качества совмещения и оценка временной эффективности совмещения, усредненные по множеству тестовых примеров Tgloballesl.
4.3.2. Результаты экспериментального исследования Эксперимент № 1
В табл. 4.1 приведены значения среднеквадратичного отклонения (СКО) оценки качества совмещения Е (1.8) и СКО оценки времени совмещения для каждого компонента вектора vparam входных параметров эксперимента № 1.
На рис. 4.1 приведена зависимость функции оценки качества совмещения Е от параметров Tinfo и Т эксперимента № 1.
Таблица 4.1. СКО выходных параметров эксперимента
Параметр СКО оценки качества совмещения Е СКО оценки времени совмещения
Skohonen 0,313 0,516
Т * info 0,750 0,498
¥ 0,682 0,871
т ann Е max 0,421 0,791
На рис. 4.2 приведена зависимость времени выполнения совмещения от параметров Т и TannE тах эксперимента № 1.
Рис. 4.1. Экспериментальная зависимость функции оценки качества совмещения Е от параметров Tjnfo и Т эксперимента № 1
В табл. 4.2 приведены векторы параметров vparam эксперимента, наилучшие с точки зрения временной и качественной эффективности совмещения.
Рис. 4.2. Экспериментальная зависимость времени выполнения совмещения от параметров Т и Tann Е тах эксперимента № 1
Таблица 4.2. Результаты эксперимента № 1
Вектор параметров эксперимента vparam Оценка качества совмещения E (метры/пиксели) Оценка времени совмещения (секунды)
s.. = 11; Т:f = 0,300; Т=8; kohonen ’ info ^,^^^9 х ^9 ТтпЕтм = 0,120. 23,546 / 0,785 1,212
7^ = 0,100; Т = 8;Т =0,120. 24,813/0,827 1,390
s. . = 16; T. , =0,200; kohonen ’ info *=!0; ^„^ = 0,150. 26,204 / 0,873 1,010
^„=11; ^„ = 0,500; ^=l;^£max = 0,120. 26,322 / 0,877 2,800
Окончание табл. 4.2.
Skohonen ^mfo 0,200; * = 7; ^я£тах=ол5о. 27,189/0,906 3,100
^onen =Ь Tinf0- 0,300; У=10;^л£тах = 0,240. 31,341 / 1,045 0,755
= 6;^ = 0,400; ^ = 1;т;яя£тах = о,о9о. 28,123/0,937 0,786
^Аояея= И; Tinf0 = 0,300; * = 8; Та„„Етях = 0,090. 29,896 / 0,997 0,807
skohonen= 21; 7^, = 0,300; * = 6; ТатЕтхх = 0,240 51,392/ 1,713 0,945
^А0ЯеЯ=И; Tinf0 = 0,400; ^ = 5; т;яя£тах = 0,300 43,201 /1,440 1,030
Эксперимент № 2
В табл. 4.3 приведены значения СКО оценки качества совмещения Е (1.8) и СКО оценки времени совмещения для каждого компонента вектора vparam входных параметров эксперимента № 2.
На рис. 4.3 приведена зависимость функции оценки качества совмещения Е от параметров Tinfo и Csum эксперимента № 2.
На рис. 4.4 приведена зависимость времени выполнения совмещения от параметров skohonen и Csum эксперимента № 2.
Таблица 4.3. СКО выходных параметров эксперимента
Параметр СКО оценки качества совмещения Е СКО оценки времени совмещения
с kohonen 0,328 0,601
Т 1 info 0,680 0,422
sum 0,645 0,731
Рис. 4.3. Экспериментальная зависимость функции оценки качества совмещения Е от параметров Tinfo и Csum эксперимента № 2
Рис. 4.4. Экспериментальная зависимость времени выполнения совмещения Е от параметров skohonen и Csum эксперимента № 2 В табл. 4.4 приведены векторы параметров vparam эксперимента, наилучшие с точки зрения временной и качественной эффективности совмещения.
Таблица 4.4. Результаты эксперимента № 2
Вектор параметров эксперимента vparam Оценка качества совмещения E (метры/пиксели) Оценка времени совмещения (секунды)
^„=11; Tinf0 = 0,900; СЯ(И = 0,100 22,088 / 0,736 1,139
Tinf0= 1,000; C,„m=l,800 22,638 / 0,755 1,981
^0Пе„ = 6; Tmf0 = 0,100; стт= 1,900 23,118/0,771 1,913
^А0ПеЛ=И;^/0 = 0,400; с,ит = 9,900. 24,146/0,805 3,930
^„=11; ^/о = 0,400; Q„„, = 9,900 24,146/0,805 3,930
^тел = Н;^ = 0,100; С = 4,400. 24,472/0,816 2,561
S =46; Т., = 0,300; kohonen ’ info ’ ’ С = 9,700 34,512/1,150 0,755
^„=1; ^ = 0300; csum = 2,200 27,534/0,918 0,760
^««=46; Tlnf0 = 0,300; csum = 0,100 28,781/0,959 0,817
5.. = 1; T. f =0,200; kohonen 9 info ’ ’ C = 6,800 25,212/0,840 0,819
hohonen= Il ^ = 0,200; Csum = 9,300 25,452/0,848 0,849
Эксперимент № 3
В табл. 4.5 приведены значения СКО оценки качества совмещения Е (1.8) и СКО оценки времени совмещения для каждого компонента вектора v т входных параметров эксперимента № 3.
На рис. 4.5 приведена зависимость функции оценки качества совмещения Е от параметров Srbmvizible и Srbmbidden эксперимента № 3.
Таблица 4.5. СКО выходных параметров эксперимента
Параметр СКО оценки качества совмещения Е СКО оценки времени совмещения
с ° contour size 0,298 0,611
С ° г bm vizible 0,671 0,451
$ ° rbm hidden 0,689 0,482
Рис. 4.5. Экспериментальная зависимость функции оценки качества совмещения Е от параметров Srbmrizlble и Srbmhiddm эксперимента № 3
На рис. 4.6 приведена зависимость времени выполнения совмещения Е от параметров Sconlourzlze и Srbmhidden эксперимента № 3.
В табл. 4.6 приведены векторы параметров v т эксперимента, наилучшие с точки зрения временной и качественной эффективности совмещения.
Рис. 4.6. Экспериментальная зависимость времени выполнения совмещения Е от параметров Scorilour size и Srbnhidden эксперимента № 3
Таблица 4.6. Результаты эксперимента № 3
Вектор параметров эксперимента vparom Оценка качества совмещения E (метры/пиксели) Оценка времени совмещения (секунды)
S = 27‘ S =5* ° contour size ’ ^rbmvizible rbm hidden 20,678 / 0,689 1,340
S = 21; Sk ..k, =29; contour size 9 rbmvizible 9 rbm hidden 22,032/0,734 3,623
C = 21 ‘ S =3' ° contour size 9 u rbmvizible rbm hidden 23,882 / 0,794 4,341
S contour size ^rbmvizible ' rbm hidden 23,607 / 0,787 2,681
Scontour size ^4, ^rbmvizible ^7, S, hidden = ^2 rbm n laden 23,822 / 0,794 4,341
S =30' S’ =5* ° contour size 'JV'9 u rbmvizible 9 rbm hidden 27,821/0,927 0,781
Окончание табл. 4.6.
о _ zs. с = 7‘ ° contour size 9 ‘rbmvizible ’ rbm hidden 31,681/1,056 0,890
о = 27* C =6" contour size 9 'rhmvizihle v’ S. . .. =30 rbm hidden 45,622/1,521 0,897
S = 30* S =7* ‘contour size '}YJ'9 rbmvizible '9 Srbm hidden 0 63,126/2,104 0,972
c =24- S =7’ contour size 9 ‘rbm vizible 9 rbm hidden 55,452/1,848 0,975
Эксперимент № 4
В табл. 4.7 приведены результаты экспериментального сравнения временной эффективности и оценки качества совмещения, выполненного с помощью разработанных систем искусственного интеллекта, и совмещения, выполненного рядом существующих распространенных алгоритмов.
В табл. 4.7 используются следующие обозначения:
• FF-обозначает алгоритм моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ, на спутниковом снимке с использованием древовидного классификатора и ИНС прямого распространения без обратных связей в качестве простого классификатора;
• SVM-обозначает алгоритм моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска образов объектов, присутствующих на ЦКМ, на спутниковом снимке с использованием древовидного классификатора и машины опорных векторов в качестве простого классификатора;
• RBM-обозначает алгоритм моделирования системы искусственного интеллекта, выполняющей совмещение данных ДЗЗ и ЦКМ путем поиска корреляции между контурами образов, выделенных на спутниковом снимке, и границами объектов, присутствующих на ЦКМ.
Процесс совмещения проиллюстрирован рис. 4.7^1.16.
На рис. 4.7 приведен исходный спутниковый снимок Рязанской области, сделанный камерой ТМ, установленной на КА «Landsat 5». Спутниковый снимок сделан 29 июля 2011 года.
На рис. 4.8 приведен результат комплексирования исходного спутникового снимка и ЦКМ. Невязка между спутниковым снимком и ЦКМ обусловлена смещением по обеим координатным осям, а также поворотом спутникового снимка вокруг своего центра.
На рис. 4.9 и 4.10 приведены результаты совмещения исходного спутникового снимка и ЦКМ, выполненного путем поиска образов объектов, присутствующих на ЦКМ, на спутниковом снимке с использованием древовидного классификатора. На рис. 4.9 приведены результаты совмещения, полученные с применением ИНС прямого распространения без обратных связей в качестве простого классификатора. На рис. 4.10 приведены результаты сов-мещения, полученные с применением машины опорных векторов в качестве простого классификатора.
На рис. 4.11 приведены результаты совмещения исходного спутникового снимка и ЦКМ, выполненного путем поиска корреляции между контурами образов, выделенных на спутниковом снимке, и границами объектов, присутствующих на ЦКМ.
На рис. 4.12—4.16 приведены результаты совмещения исходного спутникового снимка и ЦКМ, выполненного с помощью корреляционно-экстремального метода совмещения (рис. 4.12), с помощью метода стабилизации изображений, основанного на преобразовании Фурье (рис. 4.13), с помощью метода, основанного на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SIFT (рис. 4.14), с помощью метода, основанного на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SURF (рис. 4.15), с помощью метода, основанного на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора Харриса (рис. 4.16).
Оценка качества выполненного совмещения и оценка времени, затраченного на совмещение, приведены для данного примера в табл. 4.8. В табл. 4.8 используются те же обозначения, что и в табл. 4.7.
Таблица 4.7. Результаты эксперимента № 4
Метод/алгоритм совмещения Оценка качества совмещения Е (метры/пиксели) Оценка времени совмещения (секунды)
FF 1,546/0,052 1,341/0,045 1,212 0,755
SVM 1,088/0,036 1,512/0,050 2,139 0,755
RBM 1,678/0,056 1,821/0,061 1,340 0,781
Корреляционно-экстремальный метод 60,817/2,027 2,091
Метод стабилизации изображений, основанный на преобразовании Фурье 121,361/4,045 1,981
Метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SIFT 91,421/3,047 15,438
Метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SURF 81,471/2,716 17,201
Метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора Харриса 75,941/2,531 14,261
Таблица 4.8. Оценка качества выполненного совмещения и оценка времени, затраченного на совмещение
Метод/алгоритм совмещения Оценка качества совмещения Е (метры/пиксели) Оценка времени совмещения (секунды)
FF 22,141/0,738 1,134
SVM 19,045/0,635 2,081
RBM 27,918/0,931 1,241
Корреляционно-экстремальный метод 45,321/1,511 1,971
Окончание табл. 4.7.
Метод стабилизации изображений, основанный на преобразовании Фурье 98,891/3,296 1,760
Метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SIFT 82,473/2,749 13,091
Метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SURF 67,537/2,251 16,547
Метод, основанный на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора Харриса 54,831/1,828 13,011
Рис. 4.7. Исходный спутниковый снимок (зеленый, красный и ближний инфракрасный спектральные каналы; Рязанская область; камера ТМ КА «Landsat 5»)
Окно 1
Рис. 4.8. Результат комплексирования исходного спутникового снимка и ЦКМ
Окно 1
Окно 2
Окно 3
Рис. 4.9. Результаты совмещения спутникового снимка и ЦКМ с использованием древовидного классификатора и ИНС прямого распространения без обратных связей в качестве простого классификатора
Окно 1 Окно 2 Окно 3
Рис. 4.10. Результаты совмещения спутникового снимка и ЦКМ с использованием древовидного классификатора и машины опорных векторов в качестве простого классификатора
Окно 1 Окно 2 Окно 3
Рис. 4.11. Результаты совмещения спутникового снимка и ЦКМ путем поиска корреляции между контурами образов, выделенные на снимке и границами объектов, присутствующих на ЦКМ
Окно 1 Окно 2 Окно 3
Рис. 4.12. Результаты совмещения спутникового снимка и ЦКМ, выполненного с помощью корреляционно-экстремального метода совмещения
Окно 1 Окно 2 Окно 3
Рис. 4.13. Результаты совмещения спутникового снимка и ЦКМ, выполненного с помощью метода стабилизации изображений, основанного на преобразовании Фурье
Окно 1 Окно 2 Окно 3
Рис. 4.14. Результаты совмещения спутникового снимка и ЦКМ, выполненного с помощью метода, основанного на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SIFT
Окно 1 Окно 2 Окно 3
Рис. 4.15. Результаты совмещения спутникового снимка и ЦКМ, выполненного с помощью метода, основанного на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора SURF
Окно 1
Окно 2
Окно 3
Рис. 4.16. Результаты совмещения спутникового снимка и ЦКМ, выполненного с помощью метода, основанного на поиске на спутниковом снимке и ЦКМ особых точек с помощью детектора Харриса
Заключение
Описанные алгоритмы моделирования систем искусственного интеллекта, численные методы обучения данных систем и комплекс программ, реализующий перечисленные алгоритмы моделирования и численные методы, позволяют выполнять высокоточное оперативное автоматическое совмещение данных ДЗЗ и ЦКМ, что подтверждено соответствующими экспериментальными исследованиями.
Библиографический список
1. Муратов Е.Р. Алгоритмы предварительной обработки изображений в системах комбинированного видения летательных аппаратов // Диссертация на соискание степени кандидата технических наук. Рязань: РГРТУ, - 2013.
2. Комаровский Ю.А. Использование различных референц-эллипсоидов в судовождении. Владивосток: Государственный морской университет имени адмирала Г.И. Невельского, - 2005.
3. Moore L., Harris W., Kochis T. Raster image warping for geometric correction of cartographic bases // US Geological Survey, Mid-Continent Mapping Center Rolla. - 2003.
4. Google Maps [Электронный ресурс]. URL:http://maps.google, ru/maps, Дата обращения: 01.05.2014.
5. Earth Science Data Interface (ESDI) at the Global Land Cover Facility [Электронный ресурс]. URL:http://glcfapp.glcf.umd.edu:8080/ esdi/index.jsp, Дата обращения: 01.05.2014.
6. Злобин B.K., Еремеев В.В. Обработка аэрокосмических изображений. М.:ФИЗМАТЛИТ, - 2006.
7. Пронченко Р.С. Система обработки и анализа изображений контактной сети железнодорожного транспорта по данным сканерной съемки // Диссертация на соискание степени кандидата технических наук. Рязань: РГРТУ, - 2009.
8. Шапиро Л., Стокман Д. Компьютерное зрение. М.:БИНОМ. Лаборатория знаний, - 2006.
9. Гонсалес Р., Вудс Р. Цифровая обработка изображений. М.:Техносфера, - 2005.
10. Злобин В.К., Еремеев В.В., Кузнецов А.Е. Обработка изображений в геоинформационных системах: Учебное пособие. Рязань: РГРТУ,- 2006.
11. Конкин Ю.В. Разработка системы определения координат летательного аппарата на основе совмещения радиолокационной и картографической информации // Диссертация на соискание степени кандидата технических наук. Рязань: РГРТУ, - 2007.
12. Елесина С.И., Зотов В.В., Никифоров М.Б. Повышение эффективности методов глобальной оптимизации на основе кластеризации области поиска//Вестник РГРТУ № 3 (выпуск 37). 2011,-С.38-42.
13. Elesina S., Lomteva О. Increase of Image Combination Performance in Combined Vision Systems Using Genetic Algorithm // 3rd Mediterranean Conference on Embedded Computing (MECO-2014). -2014.
14. Козлов Е.П. Алгоритмы и технология высокоточной координатной привязки снимков от геостационарных космических систем по электронным картам // Диссертация на соискание степени кандидата технических наук. Рязань: РГРТУ, - 2009.
15. Лагуткин В.Н., Радченко Ю.В. Применение вейвлет-преобразования в задаче оценки смещения объекта И Вопросы радиоэлектроники, сер. РЛТ, вып. 1. - 2004.
16. F.R. Principles of neurodynamics: perceptrons and the theory of brain mechanisms. USA, Michigan: Spartan Books, - 1962.
17. Хайкин С. Нейронные сети: полный курс, 2-е изд., испр.: Пер. с англ. М.:ООО«И.Д. Вильямс», - 2006.
18. Осовский С. Нейронные сети для обработки информации: Пер. с польского. М.: Финансы и статистика, - 2002.
19. Аксенов С.В., Новосельцев В.Б. Организация и использование нейронных сетей (методы и технологии). Томск: Издательство НТЛ,-2006.
20. Комарцова Л.Г., Максимов А.В. Нейрокомпьютеры. М.: Издательство МГТУ имени Н.Э. Баумана, - 2004.
21. Akinin M.V., Konkin Y.V., Nikiforov М.В. Using Kitano’s grammar encoding for finding optimal multilayer artificial neural network without feedback in image processing problems // Science and Education: Materials of the III International research and practice conference (vol. I). - 2013.
22. Червяков Л.М., Акинин М.В. Нейросетевой алгоритм уточнения векторных топографических карт по данным дистанционного зондирования Земли // Известия Юго-Западного государственного университета № 6 (51), часть 2, 2013, - С.32^10.
23. Модуль [Электронный ресурс]. URL:http://www.module.ru, Дата обращения: 01.05.2014.
24. Kohonen Т. Self-Organizing Maps. USA, NewYork: Springer-Verlag, - 2001.
25. Акинин М.В., Конкин Ю.В. Применение искусственных нейронных сетей для решения задач уточнения топографических карт // Проблемы информатики в образовании, управлении, экономике и технике: сборник статей XI Международной научно-технический конференции, - 2011.
26. Форсайт Д., Понс Ж. Компьютерное зрение. Современный подход. М.:Издательский дом «Вильямс», - 2004.
27. Акинин М.В., Конкин Ю.В. Исследование подходов к обучению многослойного перцептрона, - 2012.
28. Fukushima К. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position//Biological Cybernetics, 36. 1980,-C. 193-202.
29. Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика. М.:Мир, - 1992.
30. Gradient-based learning applied to document recognition I LeCunY., BottouL., BengioY. [и др.] // Proceedings of the IEEE, 86(11),- 1998.
31. Акинин M.B. Нейросетевой алгоритм совмещения спутниковых снимков и цифровых карт местности, основанный на использовании сверточной нейронной сети ЛеКуна // Вторая международная научно-техническая конференция «Актуальные проблемы создания космических систем дистанционного зондирования Земли», - 2014.
32. Ranzato М.А., Boureau Y.L., LeCun Y. Sparse feature learning for deep belief networks, - 2007.
33. Люгер Д.Ф. Искусственный интеллект: стратегии и методы решения сложных проблем. М.: Издательский дом «Вильямс», - 2003.
34. Акинин М.В., Конкин Ю.В. Нейросетевой способ составления карт гарей лесных массивов по данным дистанционного зондирования Земли // Информатика и прикладная математика: межвузовский сборник научных трудов. 2012, - С. 51-57.
35. Акинин М.В., Конкин Ю.В. Нейросетевой способ составления карт гарей лесных массивов по данным дистанционного зондирования Земли // Владимирский государственный университет имени А.Г. и Н.Г. Столетовых. 2012, - С. 37—45.
36. Laws K.I. Textured image segmentation. // Диссертация на соискание степени Ph.D. США, Лос-Анджелес: Университет Южной Калифорнии, - 1980.
37. Акинин М.В., Логинов А.А., Никифоров М.Б. Способы описания текстур в задачах построения топографических карт И Материалы XI Международной научно-технической конференции «АВИА-2013» (том 4) - 2013.
38. Haralick M.R., Shanmugam К., Dinstein I. Textural features for image classification // IEEE Transactions on systems, man and cybernetics. Vol. SMC 3. № 6. 1973, - C.610-621.
39. Акинина H.B., Акинин M.B., Никифоров М.Б. Применение нейросетевых методов анализа главных компонент при решении задач обработки данных дистанционного зондирования Земли // Mezinarodni vedecka a prakticka conference «World&Science», - 2014.
40. Клочко А.Я., Бычкова Н.А., Акинина Н.В. Нейросетевые методы анализа главных компонент в задачах обработки данных дистанционного зондирования Земли // Известия Юго-Западного государственного университета № 6 (51), часть 2. 2013, - С.69-76.
41. Акинин М.В., Конкин Ю.В. Особенности обучения машины опорных векторов в задачах формирования карт лесов // Методы и средства обработки и хранения информации. 2010, - С. 133-143.
42. Акинин М.В., Лапина Т.И., Никифоров. Нейросетевой алгоритм выделения контуров на изображениях, основанный на вейвлете Габора // Известия Тульского государственного университета (технические науки). Выпуск 9 (часть 1). 2013, - С.208-217.
43. Chua L.O., Roska Т. Cellular neural networks and visual computing. Foundations and applications. United Kingdom, Cambridge: Cambridge University Press, - 2004.
44. Cimagalli V., Balsi M. Cellular neural networks: a review // Proceedings of Sixth Italian Workshop on Parallel Architectures and Neural Networks, - 1993.
45. Akinin M.V., Nikiforov M.B. Edge detection algorithm based on non linear cellular neural networks //11 th International Conferenceon Pattern Recognition and Image Analysis: New Information Technologies (PRIA-11 2013; vol. I), - 2013.
46. Akinin M., Nikiforov M., Taganov A. Automated Combining Remote Sensing Data and Digital Maps, Based on Non-linear Cellular Neural Network and Boltzmann’s Restricted Stochastic Machine // 3rd Mediterranean Conference on Embedded Computing (MECO-2014). -2014.
47. Акинин M.B., Никифоров М.Б. Нейросетевой алгоритм совмещения векторных карт и спутниковых снимков // 6-я международная научно-техническая конференция «Космонавтика. Радиоэлектроника. Геоинформатика», - 2013.
48. Елесина С.И. Алгоритмы совмещения радиолокационных изображений в корреляционно-экстремальных системах реального времени // Диссертация на соискание степени кандидата технических наук. Рязань: РГРТУ, - 2011.
49. Kosko В., Guest С. Optical bi-directional associative memories // Sosiety for Photo-optical and Instrumentation Engineers Proceedings: Image Understanding. 1987, - C. 758:11-18.
50. Matsumoto M., Nishimura T. Mersenne twister: a 623-dimen-sionally equidistributed uniform pseudo-random number generator // ACM Transactionson Modelingand Computer Simulation (TOMACS; volume 8, issue 1). 1998, - C. 3-30.
51. The Marsaglia Random Number CDROM including Battery of Tests of Randomness [Электронный ресурс]. URL: http://www.stat. fsu.edu/pub/diehard/, Дата обращения: 12.05.2014.
52. Kohonen T. Self-organizing formation of topologically correct feature maps // Biol. Cyb. 1982, - C. 59-69.
53. Oja E., Ogawa H., Wangviwattana J. Learning in nonlinear constrained hebbian networks // Proc. ICANN-91, Espoo, Finland. 1991,-C. 385-390.
54. Sanger T.D. Optimal unsupervised learning in single layer linear feedformed neural network // Neural Networks, Vol. 2. 1989, -C. 459-473.
55. Mercer J. Functions of positive and negative type and their connection with the theory of integral equations // Transactions of the London Philosophical Society (A, vol. 209). 1909, C. 415—446.
56. Fletcher R. Practical Methods of Optimization. New York, -1987.
57. Platt J.C. Fast Training of Support Vector Machinesusing Sequential Minimal Optimization H Advances in Kernel Methods-Support Vector Learning. 1998, - С. 185-208.
58. Fan R.-E., Chen Р.-H., Lin C.-J. Working Set Selection Using Second Order Informationfor Training Support Vector Machines // Journal of Machine Learning Research (6). 2005, - C.1889-1918.
59. Nguyen D., Widrow B. Improving the learning speed of 2-layer neural networks by choosing initial values of the adaptive weights // Proceedings of the International Joint Conference on Neural Networks, vol3. 1990,-C. 21-26.
60. Kitano H. Designing neural network using genetic algorithm with graph generation system // Complex Systems. Vol. 4. 1990, -C.461—476.
61. Соколова A.B., Акинин M.B., Никифоров М.Б. Алгоритм антиалиасинга текстур виртуальной модели местности, основанный на методах деблюринга изображений // Mezinarodni vedecka а prakticka konference «World&Science», - 2014.
62. Hinton G. Practical A. Guide to Training Restricted Boltzmann Machines. Canada, Toronto: Department of Computer Science, University of Toronto, - 2010.
63. OpenStreetMap [Электронный ресурс]. URL:http://www.openstreetmap.org, Дата обращения: 01.05.2014.
Оглавление
Обозначения и сокращения..............................3
Введение..............................................5
Глава 1. Разработка и анализ математической модели процесса совмещения разнородных изображений...........7
1.1. Математическая модель процесса совмещения цифровых карт местности
с данными дистанционного зондирования Земли.......7
1.2. Анализ требований к источникам исходных данных......................12
1.2.1. Анализ требований к данным
дистанционного зондирования Земли, получаемых от сенсоров космических аппаратов..12
1.3. Методы и алгоритмы совмещения
цифровых карт местности с данными дистанционного зондирования Земли.......21
1.3.1. Краткая характеристика существующих методов и алгоритмов совмещения...............21
1.3.2. Методы и алгоритмы совмещения, основанные на использовании искусственных
нейронных сетей и нейроподобных концепций.....28
Глава 2. Методы совмещения разнородных изображений путем поиска и сопоставления образов объектов.....................45
2.1. Алгоритм моделирования системы искусственного интеллекта.................45
2.2. Выделение образов на спутниковом снимке......48
2.2.1. Структура, принципы обучения и функционирования............................48
2.2.2. Инициализация весов нейронов карты с помощью датчика псевдослучайных чисел.
Выбор датчика псевдослучайных чисел...........51
2.2.3. Обучение...............................52
2.3. Классификатор.................................56
2.3.1. Структура, принципы обучения и функционирования классификатора..............56
2.3.2. Алгоритм построения векторного пространства признаков образов.............................58
2.3.3. Машина опорных векторов................67
2.3.4. Искусственная нейронная сеть прямого распространения без обратных связей...74
2.4. Поиск соответствий между образами, выделенными на разнородных изображениях............88
Глава 3. Методы контурного корреляционного совмещения разнородных изображений...................89
3.1. Алгоритм моделирования системы искусственного интеллекта..................89
3.2. Предварительная обработка спутникового снимка....92
3.2.1. Описание алгоритма......................92
3.2.2. Алгоритм устранения слабых и прерывистых контуров........................93
3.3. Выделение контуров на спутниковом снимке.....96
3.3.1. Описание алгоритма.....................96
3.3.2. Алгоритмы выделения контуров на спутниковом снимке.........................97
3.4. Описание контуров...........................104
3.5. Поиск совпадений контуров образов...........105
3.5.1. Структура коррелятора, принципы его обучения и функционирования.......105
3.5.2. Формирование множества пар совпадающих точек..............................109
Глава 4. Экспериментальные исследования методов совмещения разнородных изображений...........ПО
4.1. Описание программного стенда................110
4.2. Порядок проведения экспериментального исследования..................111
4.2.1. Цели экспериментального исследования..111
4.2.2. Условия проведения экспериментального исследования................111
4.2.3. Входные и выходные параметры экспериментального исследования................113
4.2.4. План проведения экспериментальных исследований....................122
4.3. Результаты экспериментального исследования....125
4.3.1. Методика анализа результатов экспериментального исследования...................125
4.3.2. Результаты экспериментального исследования.127
Заключение...............................................142
Библиографический список.................................143
Адрес издательства в Интернет WWW.TECHBOOK.RU
Научное издание
Акинин Максим Викторович, Никифоров Михаил Борисович, Таганов Александр Иванович
Нейросетевые системы искусственного интеллекта в задачах обработки изображений
Монография
Редактор А. Е. Пескин Компьютерная верстка И. А. Благодаровой Обложка художника В. В. Казюлина
Подписано в печать 04.12.2015. Формат 60x88/16. Уч. изд. л. 9,5. Тираж 1000 экз. Изд. №150537 ОСЮ «Научно-техническое издательство «Горячая линия - Телеком»