/



























































































































































































































































































































































































Автор: Іванченко Г.Ф.
Теги: навчальний посібник штучний інтелект інформаційни системи
ISBN: 978-966-483-544-9
Год: 2011




Текст
МІНІСТЕРСТВО ОСВІТИ І НАУКИ, МОЛОДІ ТА СПОРТУ УКРАЇНИ Державний вищий навчальний заклад «КИЇВСЬКИЙ НАЦІОНАЛЬНИЙ ЕКОНОМІЧНИЙ УНІВЕРСИТЕТ імені ВАДИМА ГЕТЬМАНА»
Г. Ф. Іванченко
СИСТЕМИ
ШТУЧНОГО ІНТЕЛЕКТУ
Навчальний посібник
Рекомендовано Міністерством освіти і науки України
Д,1І1 КНЕУ КИЇВ 2011
УДК 004.853 ББК 32.813 1-23
Рецензенти В. Я. Рубан, д-р екон. наук, проф.
(Київський національний університет технологій та дизайну)
О. О. Денісова, канд. екон. наук, доц.
(ДВНЗ «Київський національний економічний університет імені Вадима Гетьмана)
4 В. В. Гавриленко, д-р фіз.-мат. наук, проф.
(Національний транспортний університет)
Редакційна колегія факультету інформаційних систем і технологій
Голова редакційної колегії О. Д. Шарапов, канд. техн. наук, проф.
Відп. секретар редакційної колегії С. С. Ващаєв, канд. екон. наук, доц.
Члени редакційної колегії: 3. П. Бараник, д-р екон. наук, доц.; Г. І. Великоіваненко, канд. фіз.-мат. наук, доц.; В. В. Вітпінський, д-р екон. наук, проф.; В. К. Галіцин, д-р екон. наук, проф.; І. А. Джалладова, д-р фіз.-мат. наук, доц.; Ю. М. Красюк, канд. пед. наук; С. Ф. Лазарева, канд. екон. наук, доц.; О. П. Степаненко, канд. екон. наук, доц.; С. В. Устенко, д-р екон. наук, доц.
Рекомендовано до друку Вченою радою КНЕУ Протокол від 23.11.11 No З
Іванченко Г. Ф.
1-23 Система штучного інтелекту: навч. посіб. / Г. Ф. Іванченко. — К.: КНЕУ, 2011. — 382, [2] с.
ISBN 978-966-483-544-9
Посібник присвячений фундаментальним проблемам створення систем штучного інтелекту і наявним підходам до їх розв’язання. Розглядаються моделі подання знань, характеристики дедуктивного та індуктивного висновку, розпізнавання образів, сприйняття машиною навколишнього фізичного світу, конекціо- ністський підхід моделювання людського мозку і, нарешті, розуміння машиною природної мови.
Мета видання навчального посібника — забезпечити систематичний розгляд всього спектру тем, рекомендованих програмою для підготовки фахівців у галузі інформаційних систем та економічної кібернетики, включаючи як опис загальних підходів і принципів СШІ, так і алгоритмічних основ.
Призначений для спеціалістів у галузі інформаційних систем і технологій, магістрантів і докторантів вищих навчальних закладів економічних і технічних спеціальностей, а також усіх тих, хто не уявляє свого майбутнього без розвитку систем штучного інтелекту.
УДК 004.853 ББК 32.813
о.
Розповсюджувати та тиражувати без офіційного дозволу КНЕУ заборонено
ISBN 978-966-483-544-9
© Г. Ф. Іванченко, 2011 ©КНЕУ, 2011
Зміст
Передмова 6
Вступ 7
Розділ 1. БАЗОВІ ПОНЯТТЯ ШТУЧНОГО ІНТЕЛЕКТУ 11
Тема 1. Історичний та філософський аспекти проблеми штучного інтелекту 11
1.1. Історія розвитку систем штучного інтелекту . . 12
1.2. Соціальні результати інтелектуалізації комп’ютерних
технологій 20
1.3. Тест Тюринга і фактичний діалог 30
1.4. Сучасні дослідження напряму штучного інтелекту 32
1.5. Інтелектуальні роботи 36
Розділ 2. ПОДАННЯ ЗНАНЬ У СИСТЕМАХ ШТУЧНОГО
ІНТЕЛЕКТУ 45
Тема 2. Загальна характеристика моделей подання знань 45
2.1. Формалізація знань у системах штучного інтелекту 46
2.2. Концептуальні властивості знань 58
2.3. Моделі подання знань 66
2.4. Логічна форма моделі знань та формальна система 68
2.5. Числення висловів ! . . 73
2.6. Числення предикатів .... 81
2.7. Моделі знань на основі продукцій .. <» 90
2.8. Асоціативна модель знань 110
2.9. Семантичні мережі . 112
2.10. Фрейми /&.. 126
2.11. Об’єктно-орієнтована модель знань 145
2.12. Мережеві та інші моделі знань 148;
РОЗДІЛ 3. ОСНОВНІ МОДЕЛІ ВИСНОВКУ 161
Тема 3. Загальна характеристика дедуктивного та індуктив-^ ^ ного висновку 161
3.1. Формулювання завдання дедуктивного висновку 162,
4
Г.Ф. Іванченко
3.2. Стандартизація предикатних формул. 1631
3.3. Метод Ербрана 166
3.4. Принцип резолюції. 167
3.5. Стратегії пошуку 170
3.6. Використання принципу резолюції. . 171J
3.7. Принцип резолюції і мова Prolog 177
3.8. Індуктивні схеми міркувань 182
Тема 4. Висновки в умовах ненадійних або неповних знань... 187'
4.1. Види невизначеності. . . 187
4.2. Баєсовський метод 189
4.3. Метод коефіцієнтів упевненості 194$
4.4. Теорія свідоцтв Демпстера—Шефера 198
4.5. Нечіткі множини й нечітка логіка. . . 200
4.6. Приклади використання нечіткої логіки. 206
4.7. Неповнота знань та немонотонний висновок 215
Розділ 4. ШТУЧНІ НЕЙРОННІ МЕРЕЖІ 224
Тема 5. Конекціоністський підхід як спроба моделювання людського мозку 224
5.1. Персептрони та зародження штучних нейронних мереж .. 225
5.2. Біологічна модель штучних нейронних мереж. 231
5.3. Штучний нейрон та функції активації 234і
5.4. Одношарова та багатошарова нейронні мережі 2403
5.5. Радіально-базисні нейронні мережі . . j. 250
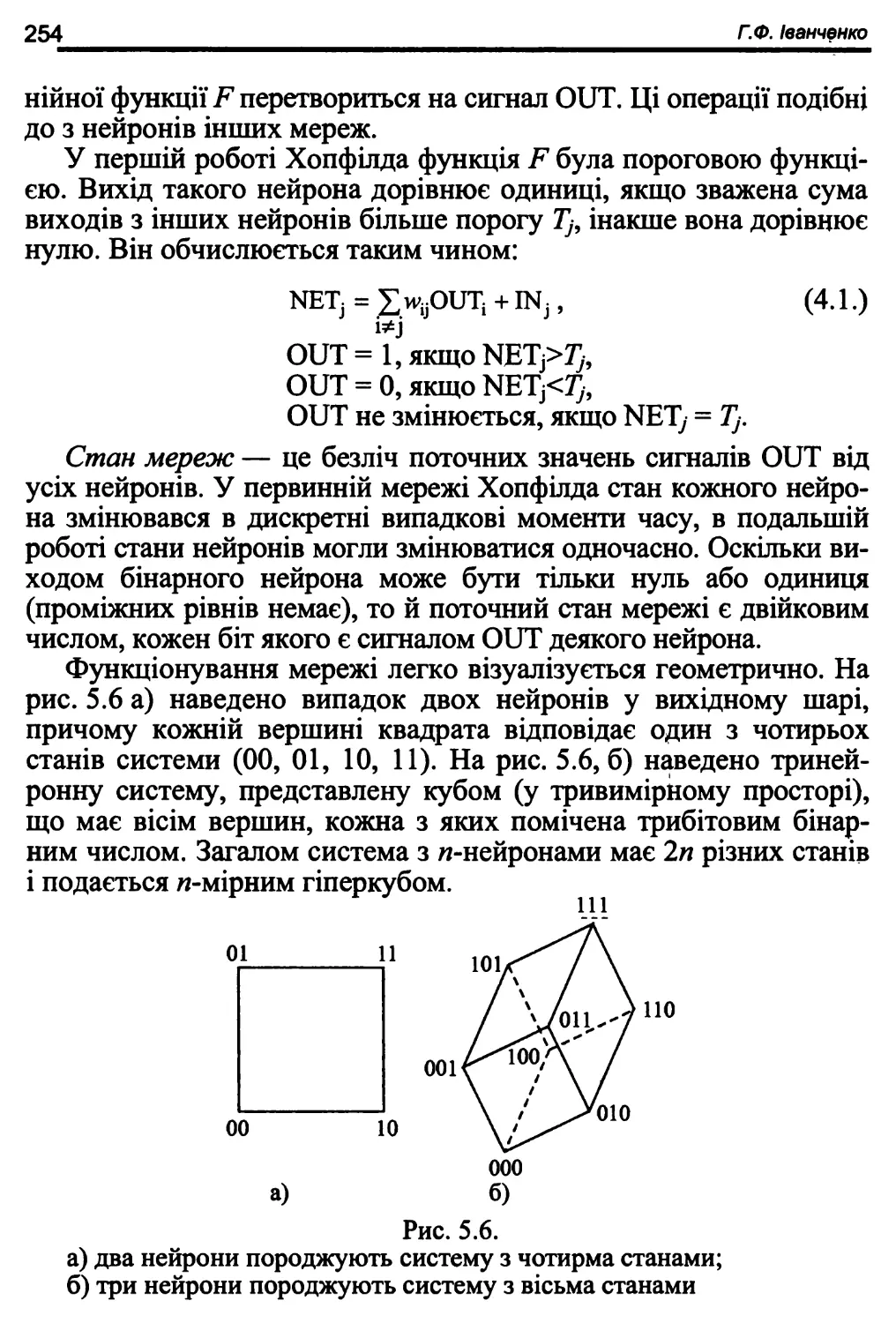
5.6. Мережі Хопфілда зі зворотними зв’язками 252
5.7. Статичні мережі Хопфілда і машина Больцмана 256
5.8. Нейронні мережі Хопфілда і Хеммінга 258
Тема 6. Навчання нейронної мережі v 266
6.1. Навчання нейронної мережі з учителем і без учителй^.. ?266
6.2. Особливості алгоритмів навчання персептрона 269
6.3. Метод сигнального навчання Хебба /г. .. . 3S. 273
6.4. Алгоритм навчання Кохонена. . 276
6.5. Алгоритм навчання Коші 278
6.6. Комбінування зворотного поширення з навчанням Коші.. . 279
6.7. Процедура зворотного поширення .... 281
Розділ 5. РОЗПІЗНАВАННЯ ОБРАЗІВ ТА АНАЛІЗ
ЗОБРАЖЕНЬ. 289
Тема 7. Основні поняття теорії розпізнавання образів .. і 7?. 289
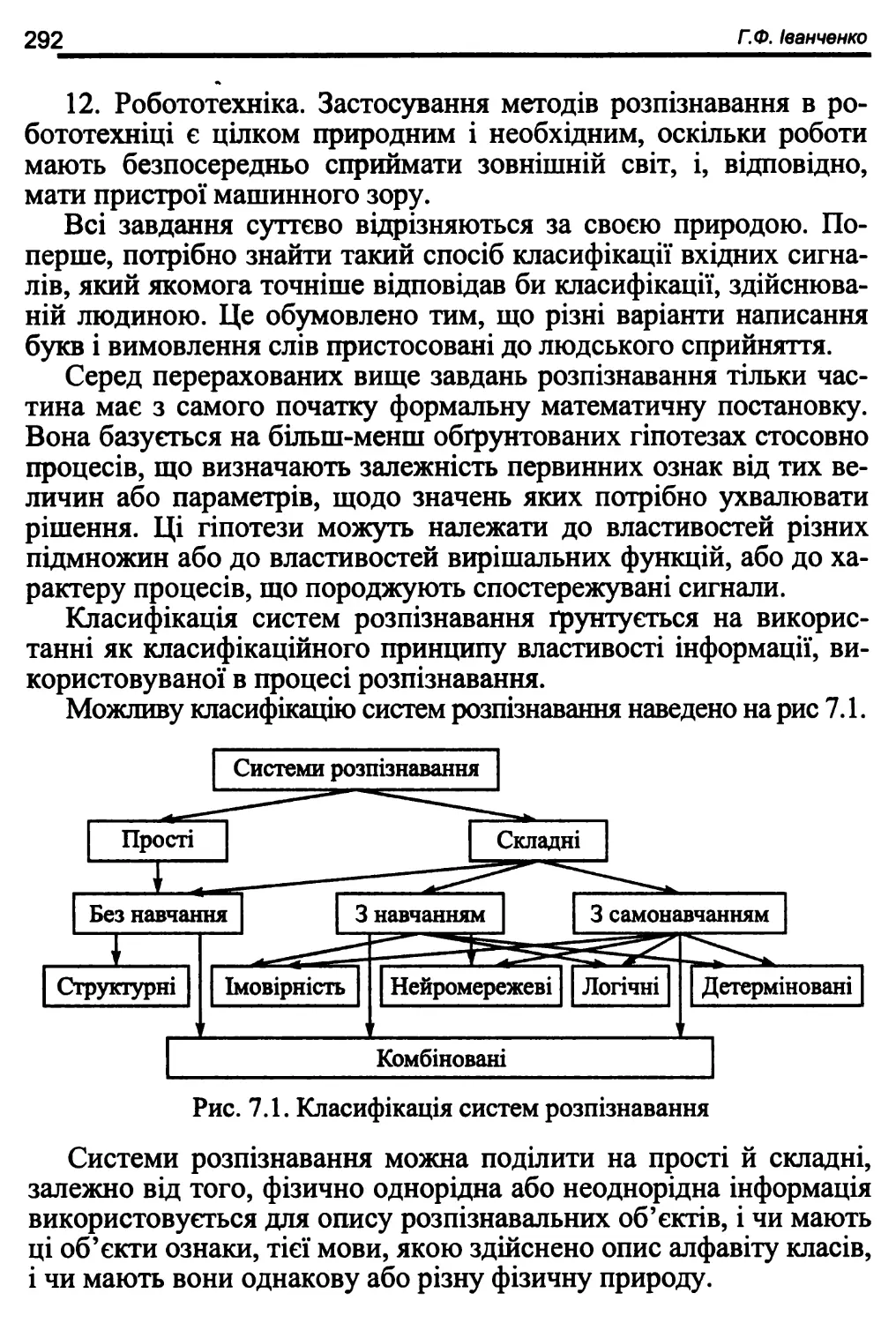
7.1. Класифікація систем розпізнавання 290
7.2. Класи та їх властивості. . 299
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
5
7.3. Класифікація основних методів розпізнавання 301
7.4. Розпізнавання в просторі ознак. . 302
7.5. Гіпотеза компактності. . . 307
7.6. Метод найближчого сусіда.... 313
7.7. Баєсівські методи розпізнавання. ... 314
7.8. Попередня обробка сигналів та зображень. . 315^
7.9. Алгоритм К середніх у СРО 322
7.10. Алгоритм косіаіа — ітеративний аналіз даних 324
7.11. Розпізнавання та обробка природної мови 328(
А
Бібліографія.. 336 /
Додатки 338
ПЕРЕДМОВА
Дисципліна «Системи штучного інтелекту» відіграє фундаментальну роль у підготовці фахівців у галузі інформатики й обчислювальної техніки. Різні навчальні курси з проблематики систем штучного інтелекту (СШІ) включено до навчальних планів багатьох університетів. Асоціаціями ACM, AIS і АІТР розроблено програму підготовки фахівців у галузі інформаційних систем, яку рекомендовано для міжнародного використання. Програмою передбачено в рамках дисципліни «Системи штучного інтелекту» розгляд таких тем: історія, основні поняття і напрями розвитку; подання завдань і простору пошуку рішень; основні стратегії управління висновком (пошук у глибину і в ширину, прямий і зворотний висновок); евристичний пошук; представлення знань; прикладні експертні системи й оболонки; нечітка логіка і нечіткий висновок; машинне навчання; розпізнавання образів; нейронні мережі; обробка природної мови; розпізнавання мови і машинний зір.
Мета видання навчального посібника — забезпечити систематичний розгляд всього спектра тем, рекомендованих для вивчення програмою підготовки фахівців у галузі інформаційних систем, включаючи й опис загальних підходів та принципів СШІ, і алгоритмічні основи.
Для опанування навчального посібника потрібні знання в галузі програмування і ЕОМ, вищої математики, теорії інформації та математичної статистики. Навчальний посібник заснований на матеріалах лекцій, прочитаних автором для студентів старших курсів ДВНЗ «Київський національний економічний університет імені Вадима Гетьмана» на кафедрі інформаційних систем в економіці.
Книга розрахована на студентів, що навчаються за напрямом підготовки 0403, 0804 «Комп’ютерні науки» спеціальності 6.080400, 7.080404, 8.080404, 7.04030302, 8.04030302 «Інтелектуальні системи прийняття рішень». Вона буде також корисна студентам, що навчаються за напрямами «Комп’ютерні науки», «Комп’ютерна інженерія», «Економічна кібернетика», «Системні науки та кібернетика», «Системи і методи прийняття рішень» і розробникам інтелектуальних систем.
ВСТУП
Людина є інтелектуальною від природи, і цей інтелект було вироблено упродовж мільйонів років еволюції. Вона в змозі вирішувати інтелектуальні завдання.. Багато хто вважає, що розуміє значення слова «інтелект», але якщо попросити дати його визначення, в переважній більшості чіткої відповіді не почуємо.
І справді, дати таке визначення, яке задовольняло б усіх, очевидно, неможливо. Втім це не заважає оцінювати інтелектуальність на інтуїтивному рівні.
Живий мозок, як інформаційна машина, постійно взаємодіє з об’єктним світом. Лише малу частку своїх здібностей він виділяє для усвідомлюваної творчості. А сам механізм свідомості — це безперервний процес, він працює, навіть коли ми спимо й нічого не усвідомлюємо. Усвідомлення себе — це лише один з численних процесів творчого (тобто неавтоматичного) сприйняття зовнішнього світу. Сприйняття світу не можна цілком автоматизувати, оскільки розумна істота повинна бути готова до непередба- чуваної зміни в навколишньому світі.
Діяльність мозку (що має інтелект), яка спрямована на вирішення інтелектуальних завдань, ми називатимемо мисленням, або інтелектуальною діяльністю. Інтелект і мислення органічно пов’язані з доведенням теорем, логічним аналізом, розпізнаванням ситуацій, плануванням поведінки, природною мовою і управлінням в умовах невизначеності. Характерними рисами інтелекту, що виявляються в процесі вирішення завдань, є здібність до навчання, узагальнення, накопичення досвіду (знань і навичок) й адаптація до умов, що змінюються, в процесі рішення задач. Завдяки цим якостям інтелекту мозок може легко перебудовуватися з одного завдання на друге. Таким чином, мозок, наділений інтелектом, є універсальним засобом вирішення широкого кола завдань (зокрема неформалізованих) для яких немає стандартних, зазадалегідь відомих методів розв’язання.
Слід враховувати, що існують інші, суто поведінкові (функціональні) визначення. Так, за А. Н. Колмогоровим, будь-яка мате¬
8
Г.Ф. Іванчвнко
ріальна система, з якою можна досить тривалий час обговорювати проблеми науки, літератури й мистецтва, має інтелект. Іншим прикладом поведінкового трактування інтелекту може служити відоме визначення А. Тюринга: в різних кімнатах знаходяться люди і ЕОМ. Вони не можуть бачити одне одного, та мають можливість обмінюватися інформацією (наприклад, за допомогою електронної мережі чи пошти). Якщо в процесі діалогу між учасниками тесту людям не вдається встановити, що один з учасників
— ЕОМ, то таку програмно-машинну систему можна вважати такою, що має інтелект.
До речі, А. Тюринг запропонував цікавий план імітації мислення:
«Чому нам замість того, щоб намагатися створити програму, що імітує інтелект дорослої людини, не спробувати створити програму, яка імітувала б інтелект дитини? Адже інтелект дитини коли отримує відповідне виховання, стає інтелектом дорослої людини. Наша думка полягає в тому, що пристрій, йому подібний, можна легко запрограмувати. Таким чином, ми розділимо нашу проблему на дві частини: на завдання побудови «програми- дитини» і завдання «навчання цій програми».
Забігаючи наперед, можна сказати, що саме цей шлях використовують майже всі системи штучного інтелекту (СШІ). Адже зрозуміло, що практично неможливо закластиі всі знання в досить складну систему. Крім того, тільки на цьому шляху виявляться перераховані вище ознаки інтелектуальної діяльності (накопичення досвіду, адаптація тощо).
Постійний динамічний контакт з об’єктним світом є обов’язковою умовою і життя, і розуму. А повноцінне розумне життя можливе лише в культурному середовищі серед людей. Для того щоб визнати істоту розумною, вона повинна пристосуватися до людської культури. Якщо папуга зможе пройти тест А.Тюринга, то ніхто не сумніватиметься, що він має свідомість, оскільки це тест на наявність людської свідомості.
Критерій розуміння — це працюючий самонавчальний алгоритм. Розробивши алгоритм (технологію) самонавчання, або універсальної адаптації, і забезпечивши цим алгоритмом штучну істоту, ми забезпечуємо його засобом для розвитку свідомості й усвідомлення себе. У математиці й кібернетиці клас завдань певного типу вважається вирішеним, коли для її вирішення встановлено алгоритм.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
9
Пошук алгоритму для завдань цього типу пов’язано з тонкими і складними міркуваннями, що вимагають неабиякої винахідливості й високої кваліфікації. Зазвичай вважають, що для подібної діяльності потрібно задіяти інтелект людини. Завдання певного типу, пов’язані з пошуком алгоритму вирішення, називатимемо інтелектуальними.
Щодо завдань, алгоритми вирішення яких вже встановлені, як відзначає відомий фахівець у галузі штучного інтелекту М. Мінський, «є перебільшенням приписувати їм такі містичні властивості, як «інтелектуальність». Насправді, після того, як такий алгоритм вже знайдено, процес вирішення відповідних завдань стає таким, що його в змозі точно виконати людина або обчислювальна машина (належним чином запрограмована) або робот, що не має анінайменшої уяви про сутність самого завдання. Потрібно тільки, щоб робот був спроможний виконувати ті елементарні операції, з яких складається процес, і, крім того, педантично й акуратно керувався запропонованим алгоритмом. Така штучна система, діючи, як кажуть в таких випадках, машинально, може успішно вирішувати будь-яке завдання цього типу.
Тому уявляється цілком природним виключити з класу інтелектуальних завдання, для яких існують стандартні методи вирішення. Як приклад можуть служити суто обчислювальні задачі розв’язання системи лінійних рівнянь алгебри, чисельна інтеграція диференціальних рівнянь тощо. Для вирішення подібних завдань є стандартні алгоритми, що є певною послідовністю елементарних операцій, яка може бути легко реалізована у вигляді програми для обчислювальної машини. На противагу цьому, для широкого класу інтелектуальних завдань, як-от розпізнавання образів, мови, гра в шахи, доведення теорем тощо, формальне розбиття процесу пошуку рішень на окремі елементарні кроки часто виявляється вельми складним, навіть якщо насправді їх вирішення складним не видається.
Таким чином, ми можемо перефразувати визначення інтелекту, як універсальний супералгоритм, який спроможний створювати алгоритми вирішення конкретних завдань. Навряд чи є сенс протиставляти поняття штучного інтелекту і інтелекту взагалі. Тому слід спробувати визначити поняття інтелекту незалежно від його походження.
Пропонований навчальний посібник є основним під час вивчення дисциплін бакалаврського та магістерського рівнів: «Сис¬
10
Г.Ф. Іванчвнко
теми штучного інтелекту», «Системи розпізнавання образів», «Нейромережеві системи», «Прикладні систем штучного інтелекту», які мають сформувати у студентів фундаментальні теоретичні знання та практичні навички з теорії проектування систем штучного інтелекту. Ще одне цікаве зауваження: професія програміста, виходячи з наших визначень, є однією з найінтелектуа- льніших, оскільки продуктом діяльності програміста є програми
— алгоритми в чистому вигляді.
Штучний інтелект (ШІ) можна визначити як галузь комп’ютерної науки, що займається автоматизацією розумної поведінки. Це визначення найточніше відповідає змісту навчального посібника, оскільки в ньому ШІ розглядається як частина комп’ютерної науки, яка спирається на її теоретичні й прикладні принципи. Ці принципи зводяться до структур даних, використовуваних для представлення знань, алгоритмів застосування цих знань, а також мов і методик програмування.
БАЗОВІ ПОНЯТТЯ ШТУЧНОГО ІНТЕЛЕКТУ
Тема 1
ІСТОРИЧНИЙ ТА ФІЛОСОФСЬКИЙ АСПЕКТИ ПРОБЛЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
Перелік знань та навичок
Після опанування теми студент має знати:
• історичні етапи систем штучного інтелекту;
• соціально-філософські наслідки створення та впровадження в життя систем штучного інтелекту;
• переваги та заперечення тесту Тьюринга і фактичний діалог;
• сучасні напрями дослідження у СШІ та їх класифікацію;
• узагальнену структуру інформаційної системи інтелектуального робота;
• три закони роботехніки Айзека Азімова.
Має вміти:
• пояснити визначення предмета теорії штучного інтелекту та системи штучного інтелекту (СШІ);
• навести приклади з розвитку цивілізації інформаційних революцій;
• пояснити спроможність моделювання мислення людини;
• пояснити місце інтелектуальної системи у СШІ;
• які є підходи в моделюванні інтелектуальної діяльності людини?
• описати та використати процедуру тесту Алана Тюринга;
• класифікувати напрямки досліджень у галузі штучного інтелекту за Хантом;
• визначати сфери застосування СШІ;
• скласти загальну характеристику символьного та конекціоні- стського підходів до створення систем штучного інтелекту.
12
Г.Ф. Іванченко
ЗМІСТ ПИТАНЬ ТЕМИ
1.1. Історія розвитку систем штучного інтелекту
Термін «штучний інтелект» — Artificial Intelligence (АІ) — був запропонований в 1956 р. на семінарі, присвяченому рішенню логічних задач, з аналогічною назвою в Дартсмудському коледжі (СІЛА).
Термін інтелект (intelligence) походить від латинського intellectus, що означає розум, глузд, розумові здібності людини. Відповідно штучний інтелект — ШІ (АІ) звичайно тлумачиться як властивість автоматичних систем брати на себе окремі функції інтелекту людини, наприклад, обирати й ухвалювати оптимальні рішення на основі раніше одержаного досвіду й раціонального аналізу зовнішніх дій.
В історії людства можна виділити кілька інформаційних революцій, які були переламними моментами в розвитку цивілізації.
Перша була пов’язана з появою мови. Мова дала можливість передавати знання від одного індивідуума до ідругого і, отже, зберігати його з покоління в покоління. І
Друга інформаційна революція була пов’язана з появою писемності. Писемність дозволила обмінюватися знаннями індивідуумам без безпосереднього контакту і, таким чином істотно збільшити доступність і надійність збереження знань.
Третя революція — поява книгодрукування ще збільшило доступ до знань і зробило можливим їх масове поширення і збереження. ^
Четверта революція була пов’язана з появою електрозв’язку електричним засобами запису знань (інформації).
П’ята революція, яку ми переживаємо зараз, пов’язана з появою масових ЕОМ, об’єднаних в мережі, і які мають потужні засоби для зберігання, накопичення й використання знань. В межах цієї інформаційної революції можна виділити також ряд етапів, останнім з яких є поява систем штучного інтелекту, або систем, заснованих на знаннях. Загалом п’ята революція дала змогу зберігати й мати швидкий доступ практично до необмеженого об’єму знань. Крім того, завдяки системі штучного інтелекту
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
13
з’явилася можливість вперше пов’язати безпосередньо знання з матеріальним виробництвом (або в більш загальному випадку — з навколишнім матеріальним світом), виключивши людину як проміжну ланку. Мало того, системи самі можуть виробляти нові знання. Для цього служать засоби видобування (або придбання) знань, наприклад з баз даних шляхом виявлення закономірностей і формулювання цих закономірностей у вигляді баз знань. У комп’ютерному світі набули поширення дослідження й розробки в галузі так званих технологій «data mining» — видобування корисних даних (знань) з великої їх кількості, зокрема з неструкту- рованих даних. %
Сучасна інформатика багато в чому зобов’язана дослідженням у галузі штучного інтелекту. Наприклад, багато розділів дослідження операцій з’явилося з розроблених методів обмеження перебирання варіантів при вирішенні завдань ШІ. На термінологію й методи розробки компіляторів вплинули дослідження в галузі машинного перекладу. Засоби розпізнавання й синтезу мови зараз вже є невід’ємною часткою деяких спеціалізованих інформаційних систем і претендують на широке використання в операційних системах. Системи розпізнавання тексту є звичайною часткою офісних програмних систем (друкарський текст) або кишенькових комп’ютерів перекладачів. Об’єктно-орієнтоване програмування виросло з представлення знань у вигляді фреймів, введених американським ученим Мінським. Нейромережеві технології і технології експертних систем успішно застосовують у системах економічного аналізу і прогнозування. Приклади можна було б продовжити.
Ці роботи поклали початок першому етапу досліджень у галузі ШІ, пов’язаному з розробкою програм з вирішення завдань на основі застосування різноманітних евристичних методів.
Евристичний метод вирішення завдання при цьому розглядався як властивий людському мисленню «взагалі», для якого характерно виникнення припущень про напрями вирішення завдання з подальшою їх перевіркою. Йому протиставлявся використовуваний в ЕОМ алгоритмічний метод, який інтерпретувався як механічне здійснення заданої послідовності кроків, що детерміновано приводить до правильної відповіді. Трактування евристичних методів вирішення завдань як суто людської діяльності й зумовила появу та подальше поширення терміну ШІ. Так, під час опису своїх програм Ньюелл і Саймон наводили результати порівняння записів
14
Г.Ф. Іванченко
доведень теорем у вигляді програм із записами міркування людини як доводи, що їхні програми моделюють людське мислення.
На початку 70-х років вони запропонували загальну методику складання програм, що моделюють мислення. Приблизно в той час, коли роботи Ньюелла і Саймона стали привертати до себе увагу, в Массачусетському технологічному інституті, Стенфорд- скому університеті і Стенфордскому дослідницькому інституті, де також сформувалися дослідницькі групи в галузі ШІ. На противагу раннім роботам Ньюелла і Саймона ці дослідження більше належали до формальних математичних уявлень. Способи розв’язання задач у цих дослідженнях розвивалися на основі розширення математичної й символічної логіки. А моделюванню людського мислення надавалося другорядне значення.
На подальші дослідження ШІ великий вплив справила поява методу резолюцій Робінсона, заснованого на доведенні теорем у логіці предикатів. При цьому визначення терміну ШІ зазнало змін.
Метою досліджень у ШІ стала розробка програм, здатних вирішувати «людські завдання». Так, один із знаних дослідників ШІ того часу Р. Бенерджі в 1969 році писав: «Галузь досліджень, яку зазвичай називають ШІ, мабуть, можна представити як сукупність методів і засобів аналізу та конструювання машин, здатних виконувати завдання, з якими до недавнього касу могла впоратися тільки людина. При цьому за швидкістю й ефективністю машини мали бути порівняні з людиною». Функціональний підхід до спрямування досліджень з ШІ зберігся в основному до теперішнього часу, хоча й нині ряд учених, особливо психологів, намагаються оцінювати результати робіт з ШІ з позицій їхньої відповідності людському мисленню. х
Дослідницьким полігоном для розвитку методів ШІ на першому етапі були різноманітні ігри, головоломки, математичні задачі. Деякі з цих задач стали класичними в літературі з ШІ (задачі про мавпу і банани, місіонерів і людоїдів, Ханойську башту, гра в 15 та інші). Вибір таких задач обумовлювався простотою і ясністю проблемного середовища, її відносною негроміздкістю, можливістю досить легкого підбору і навіть штучного конструювання «під метод». Розквіт подібних досліджень припадає на кінець 60-х років, згодом почалися перщі спроби застосування розроблених методів для завдань, що вирішуються не в штучних, а в реальних проблемних середовищах.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
15
Необхідність дослідження систем ШІ за їх функціонування в реальному світі привело до постановки завдання створення інтегральних роботів. Проведення таких робіт можна вважати другим етапом досліджень з ШІ. У Стенфордскому університеті і не тільки було розроблено експериментальні роботи, що функціонують в лабораторних умовах. Проведення цих експериментів довело необхідність розв’язання проблеми представлення знань про середовище функціонування, і одночасно недостатню дослідже- ність таких проблем, як зорове сприйняття, побудова складних планів поведінки в динамічних середовищах, спілкування з роботами на природній мові.
Ці проблеми були точніше сформульовано і поставлено перед дослідниками у середині 70-х рр., з початком третього етапу досліджень систем ШІ. Як його характерна межа — зміщення центру уваги дослідників із створення автономно функціонуючих систем, самостійно вирішуючих у реальному середовищі висунуті перед ними завдання, до створення людиномашинних систем, інтегруючих в єдине ціле інтелект людини і можливості ЕОМ для досягнення загальної мети — вирішення завдання, інтегральною людиномашинною системою.
Стало зрозуміло, що поєднання доповнювальних одне одного можливостей людини і ЕОМ дає змогу обійти гострі кути шляхом перекладання на людину тих функцій, які поки що не доступні для ЕОМ. На перший план висувалася не розробка окремих методів машинного вирішення завдань, а розробка методів, засобів, що забезпечують тісну взаємодію людини й обчислювальної системи упродовж всього процесу вирішення завдання з можливістю оперативного внесення людиною змін під час цього процесу.
Розвиток досліджень з ШІ в цьому напрямі обумовлювався також різким зростанням виробництва засобів обчислювальної техніки і також істотним їх здешевленням, що робить їх потенційно доступними для ширшого кла користувачів.
Із сказаного вище, випливає основна філософська проблема в галузі ШІ — спроможність або неспроможність моделювання мислення людини. У разі якщо колись буде отримана негативна відповідь на це питання, вся решта питань курсу не матиме й щонайменшого сенсу.
Отже, починаючи дослідження ШІ, ми заздалегідь припускаємо позитивну відповідь. Наведемо кілька міркувань, які підводять нас до відповіді.
16
Г.Ф. Іванченко
1. Перший доказ є схоластичним і доводить, що ШІ і Біблія не суперечать одне одному. Мабуть, навіть люди далекі від релігії, знають слова священного писання: «І створив Господь людину за образом і подобою свою...». Виходячи з цих слів, ми можемо припустити, що оскільки Господь, по-перше, створив нас, а по- друге, ми за своєю суттю подібні до нього, то ми цілком можемо створити когось за образом і подобою людини.
2. Створення нового розуму біологічним шляхом для людини справа цілком природна. Спостерігаючи за дітьми, ми бачимо, що більшу частину знань вони набувають шляхом навчання, а не як закладену в них заздалегідь базу знань на рівні хромосом. Таке твердження на сучасному рівні не доведене, але за зовнішніми ознаками все має саме такий вйгляд. Навколишнє середовище створює знання.
3. Те, що раніше здавалося вершиною людської творчості —
гра в шахи, шашки, розпізнавання зорових і звукових образів, синтез нових технічних рішень, на практиці виявилося не такою вже складною справою (тепер робота ведеться не на рівні можливості або неможливості реалізації перерахованого, а з метою знаходження найбільш оптимального алгоритму). Тепер часто ці проблеми навіть не відносять до проблем ШІ. Є сподівання, що й повне моделювання мислення людини виявиться не такою вже й складною справою. І
4. З проблемою відтворення свого мислення тісно межує проблема можливості самовідтворення.
Здатність до самовідтворення тривалий час вважали прерогативою живих організмів. Проте деякі явища, що відбуваються в неживій природі (наприклад, зростання кристалів, синтез складних молекул копіюванням), дуже схожі на самовідтворення. На початку 50-х років Дж. фон Нейман почав ґрунтовно висчати самовідтворення і заклав основи математичної теорії автоматів, що «самовідтворюються». Так само він довів теоретично можливість їх створення.
Існують також різні неформальні докази можливості самовідтворення, але для програмістів найяскравішим доказом, мабуть, буде існування комп’ютерних вірусів та програмних агентів.
5. Принципова можливість автоматизації розв’язання інтелектуальних задач за допомогою ЕОМ забезпечується її алгоритмічною універсальністю. Алгоритмічна- універсальність ЕОМ означає, що на них можна програмно реалізовувати (тобто представи¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
17
ти у вигляді машинної програми) будь-які алгоритми перетворення інформації — чи то обчислювальні алгоритми, алгоритми управління, пошуку доведення теорем або композиції мелодій. При цьому ми маємо на увазі, що процеси, що породжуються цими алгоритмами, є потенційно здійсненними, тобто що вони здійснені в результаті скінченного числа елементарних операцій. Практична здійсненність алгоритмів залежить від наявних у нашому розпорядженні засобів, які можуть мінятися з розвитком техніки. Так, з появою швидкодіючих ЕОМ стали практично здійсненними й такі алгоритми, які раніше були тільки потенційно здійсненними.
Властивість алгоритмічної універсальності не обмежується констатацією того, що для всіх відомих алгоритмів виявляється можливою їх програмна реалізація на ЕОМ.
Проте не слід вважати, що обчислювальні машини і роботи можуть вирішувати будь-які завдання. Аналіз різноманітних завдань спонукав математиків до чудового відкриття. Було суворо доведено існування таких типів завдань, для яких неможливий єдиний ефективний алгоритм, що розв’язував би всі завдання цього типу; неможливе вирішення завдань такого типу і за допомогою обчислювальних машин. Цей факт сприяє кращому розумінню того, що можуть робити машини і чого вони зробити не можуть. Насправді, твердження про неможливість алгоритмічного розв’язання певного класу задач є не зізнанням того, що такий алгоритм нам не відомий і ніким ще не знайдений. Таке твердження є водночас і прогнозом на майбутнє, що подібні алгоритми не існують.
Припустимо, що людина створила інтелект, що перевищує власний. Що тепер станеться з людством? Яку роль відіграватиме людина? І взагалі, чи потрібно у принципі створювати ШІ?
Оскільки припускається, що людина не завдаватиме шкоди самому собі, а ШІ тепер є частиною цього індивідуума (не обов’язково фізична спільність), то автоматично виконуються всі три закони роботехніки. При цьому питання безпеки зміщуються в галузь психології і правоохорони, оскільки система (навчена) не робитиме нічого такого, чого не хотів би її власник.
Історично склалися три основні підходи в моделюванні ШІ.
У рамках першого підходу об’єктом досліджень є структура і механізми роботи мозку людини, а кінцева мета полягає в розкритті таємниць мислення. Необхідними етапами досліджень у цьому які є побудова моделей на основі психофізіологічних да-
18
Г.Ф. Іванченко
них, проведення експериментів з ними, висунення нових гіпотез щодо механізмів інтелектуальної діяльності, вдосконалення моделей тощо.
Другий підхід як об’єкт дослідження розглядає ШІ. Тут ідеться про моделювання інтелектуальної діяльності за допомогою обчислювальних машин. Метою робіт у цьому напрямі є створення алгоритмічного й програмного забезпечення обчислювальних машин, що дозволяє вирішувати інтелектуальні завдання не гірше за людину.
Нарешті, третій підхід орієнтований ,ра створення змішаних людино-машинних, або, як ще кажуть, інтерактивних інтелектуальних систем, на симбіоз можливостей природного і штучного інтелекту. Найважливішими проблемами в цих дослідженнях є оптимальний розподіл функцій між природним та штучним інтелектом й організація діалогу між людиною і машиною.
Перші штучні «люди» були механічними роботами. Так, у Давньому Єгипті була створена «оживаюча» механічна статуя бога Амона. У Гомера в «Іліаді» бог Гефест кував людиноподібні істоти-автомати. З легенд середньовіччя відома лялька, що створив Хома Аквінський. Вона світилася і вміла ходити й говорити.
У літературі ідею штучного створення людини обігрували багато разів: Галатея в «Пігмаліоні», Буратіно тата Карла, Ксаверій у «Золотому ланцюзі» А. Гріна тощо. І це булй вже не механічні статуї, а істоти, здатні мислити, висловлювати свої думки й удосконалюватися.
Родоначальником власне штучного інтелекту як штучного мислення інколи вважають середньовічного філософа, математика і поета Раймонда Луллія, який у XIII ст. спробував створити логічну систему для вирішення різних завдань на основі класифікації понять і комбінування.
Першими теоретичними розробками в галузі штучного інтелекту можна вважати праці Г. Лейбніца і Р. Декарта, які незалежно один від одного продовжили ідею універсальної класифікації наук (XVIII ст.).
Проте формування ШІ як наукового напряму розпочинається після створення ЕОМ (у 40-ві рр. XX століття) і кібернетики Н. Вінера, а оформлення ШІ в самостійну галузь знань відбулося в 50—60-ті рр. XX ст.
Спочатку роботи в галузі ШІ починалися з моделювання елементарних ігор у кубики, хрестики-нулики тощо, створення інте¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
19
лектуальних роботів і планування їх поведінки. Ці завдання є класичними під час навчання теоретичним основам ШІ. На їх ідеях були розроблені основні моделі представлення знань: про- дукційні, семантичні мережі, фрейми.
Та, вважають, першими, які зробили істотний внесок у становлення ШІ як науки: Ф. Розенблатт і У. Мак-Каллок, що створили в 1956—1965 рр. перші нейронні мережі і пристрій, що одержав назву «персептрон» (perceptron) [1, 2]; А. Нюелл, Дж. Шоу, Р. Саймон створили машину «Логік-теоретик» й інші творці «ви- рішувачів завдань» [3]; М. Мінський (автор моделі фрейма і фреймового подання знань) [7].
Приблизно у ті ж 50—60 рр. XX ст. розпочалося становлення ШІ і в колишній Українській Радянській республіці. Але, на відміну від західних дослідників, вітчизняні йшли від моделювання ігор, створення пристроїв сприйняття типу «персептрон» й інтелектуальних роботів (тобто від практики, експериментів), і лише в 1990-ті рр. XX ст. з’явилися їх теоретичні праці (наприклад [6]).
На різних семінарах і в пресі тривалий період обговорювалися проблеми: чи може машина мислити, чи можна створити електронний мозок, подібний до мозку людини, чому неможливий штучний інтелект тощо. Подібні дискусії тривали до 80-х рр. XX ст. [5].
У 1957 р. американський фізіолог Ф. Розенблатт запропонував модель зорового сприйняття й розпізнавання — перцептрон. Поява програми, здатної навчатися поняттям і розпізнавати об’єкти, які пред’являються, становило надзвичайний інтерес не тільки для фізіологів, а й для представників інших галузей знань і породило великий потік теоретичних та експериментальних досліджень.
Перцептрон або будь-яка програма, що імітує процес розпізнавання, працює в двох режимах: у режимі навчання і режимі розпізнавання. В режимі навчання хтось (людина, машина, робот або природа), що відіграє роль учителя, пред’являє машині об’єкти і про кожен з них повідомляє, до якого поняття (класу) він належить. За цими даними будується вирішальне правило, що є, по суті, формальним описом понять. У режимі розпізнавання машині пред’являються нові об’єкти (взагалі-то відмінні від раніше пред’явлених), і вона повинна їх класифікувати, по можливості, правильно.
Проблема навчання розпізнаванню тісно пов’язана з іншим інтелектуальним завданням — перекладом з однієї мови на другу, а також навчання машини мові. За досить формальної обробки й
20
Г.Ф. Іванченко
класифікації основних граматичних правил та прийомів користування словником можна створити цілком задовільний алгоритм для перекладу, скажімо наукового або ділового тексту. Для деяких мов такі системи було створено ще наприкінці 60-х років XX ст. Працюють над такими програмами вже давно, але до цілковитого успіху ще далеко. Є також програми, що забезпечують діалог людини і машини урізаною природною мовою.
Починаючи з 1960 р. XX ,ст. було розроблено низку програм, здатних знаходити доведення теорем в обчисленні предикатів першого порядку. Ці програми мають, за словами американського фахівця в галузі ШІ Дж. Маккатті, «здоровий глузд», тобто здатність робити дедуктивні висновки.
Паралельно в 60—70-ті рр. XX ст. розроблялися окремі програми і проводився пошук розв’язання задач логіки, доведення теорем. Такі дослідження проводилися в Києві (в Інституті кібернетики АН УРСР під керівництвом В. М. Глушкова) і деяких інших наукових центрах.
Останнім часом для узагальненого найменування систем штучного інтелекту дедалі більшого поширення набуває термін інтелектуальні системи.
У програмі К. Гріна й ін., що реалізовує систему запитання- відповідь, знання записуються мовою логіки ііредикатів у вигляді набору аксіом, а запитання машині формулюються як такі, що вимагають доведення теореми. Великий інтерес становить «інтелектуальна» програма американського математика Хао Ванга. Ця програма за три хвилини роботи ЕОМ вивела 220 відносно простих лем і теорем з фундаментальної математичної монографії, а потім видала докази ще 130 складніших теорем, частина яких ще не була виведена математиками.
1.2. Соціальні результати інтелектуалізації комп’ютерних технологій
Позитивні соціальні результати інтелектуалізації інформаційних технологій зрозумілі та загальновідомі. З наслідків, не дуже сприятливих для людини, найочевидніший ;— це поступове витіснення людей машинами і в процесі виробництва, і в управлінні суспільством. Подібні тенденції почали проявлятися ще задовго до початку
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
21
комп’ютерної доби. Що стосується майбутнього, то тут письменни- ки-фантасти малюють похмурі картини цілковитого захоплення влади комп’ютерами і навіть фізичного винищення людства.
Було запропоновано ряд принципів, орієнтованих на зменшення ризиків, пов’язаних з комп’ютеризацією та інтелектуалізацією. Найбільш відомими є принципи, сформульовані американським фантастом Айзеком Азімовим. Ось ці наведемо їх:
— комп’ютер або робот не повинен заподіяти шкоди людині;
— він повинен виконувати накази людини, якщо це не суперечить першому принципу;
— він повинен прагнути до самозбереження, якщо це не суперечить першим двом принципам.
Інша проблема — як ці, або подібні до них принципи втілювати в життя. Серед інших негативних аспектів інтелектуалізації можна відмітити те, що сучасні комп’ютерні технології полегшують виконання не тільки корисних справ, а й різних зловживань та комп’ютерних злочинів тощо.
Переходячи до проблеми співвідношення можливостей людини і кібернетичної машини стосовно відтворення останньою функції мислення, слід насамперед указати на один важливий висновок, до якого привели кібернетика та математична логіка. Він полягає в тому, що будь-яка суворо окреслена й математично описана — формалізована й алгоритмізована — галузь інтелектуальної діяльності людини в принципі може бути передана машині (теза Тюринга). Іншими словами, будь-який детермінований процес, сутність якого можна пояснити людині, потенційно здійснюваний машиною, якій надано необмежений час і яка має необмежену пам’ять. Однак треба відрізняти потенційну здійснюваність від здійснюваності за допомогою наявних засобів. Збігатися обидва ці види можуть тільки для надприродного інтелекту.
Постає принципове запитання: чи можна моделювати інтелектуальну діяльність, а якщо можна, то як це зробити? Існує дві точки зору.
1. Багато вчених не мають сумніву, що обчислювальні машини і роботи можуть у принципі мати всі основні риси інтелекту. Таким чином, на запитання, чи можуть обчислювальні машини або роботи мислити, вони дають позитивну відповідь (А.Тимо- фєєв, А. Тюрінг, І. Шкловський).
2. Друга точка зору протилежна першій. Деякі схиляються на користь негативної відповіді на запитання, чи може машина
22
Г.Ф. Іванченко
уподібнитися людині. Серед них і творець кібернетики Джон фон Нейман. Розглядаючи завдання машинного моделювання ней- ронних структур мозку, він висунув гіпотезу, що якщо система досягає певного ступеня складності, її опис не може бути простішим, ніж вона сама. «Немає сумніву в тім, — писав Нейман, — що окрему фазу будь-якої уявної форми поведінки можна «цілком і однозначно» описати за допомогою слів. Цей опис може бути довгим, однак завжди можливим». З ідей фон Неймана випливає, що проблема створення машинної програми, здатної вирішувати всі ті різноманітні завдання, що успішно вирішує людський мозок, надзвичайно важка, якщо не безнадійна.
Раніше проблема штучного інтелекту розглядалася як технічна, позв’язана з реалізацією на ЕОМ програм, що здатні виконувати деякі класи інтелектуальних операцій. Згодом, однак, з одного боку, помітно зменшився оптимізм щодо інтелектуальних можливостей ЕОМ, а з другого — стало зрозуміло, що штучний інтелект — це не просто вдало написана програма, його створення — надзвичайно складна міждисциплінарна проблема, що вимагає для свого вирішення об’єднаних зусиль психологів, математиків, лінгвістів тощо. Так, психологія повинна дати чітке визначення знання для використання його в комп’ютерних системах. Лінгвістика мала б пояснити, як працює мова, що є не тільки носієм знань, а й бере активну участь |у їхньому формуванні. Оскільки ні та, ні інша наука не 1 дали необхідних відповідей, відомий представник дисципліни штучного інтелекту Р. Шенк змушений був констатувати, що конструктори комп’ютерних систем мусять створювати свої лінгвістичні й психологічні теорії, аби домогтися ефективного вирішення своїх завдань.
У нинішній час намітилося два шляхи дослідження штучного інтелекту:
1) машинні способи розв’язання інтелектуальних задач повинні будуватися без суворого огляду на людину, знання про те, як вона вирішує ті чи інші завдання;
2) «біонічно мислячі» вчені сподіваються на спеціально конструйовані мережі штучних нейронів та інші аналоги конструкцій, властиві людині.
Відзначимо один метод дослідження штучного інтелекту. Із самого початку зародження науки штучного інтелекту було поширено переконання щодо принципової здатності комп’ютера до самостійного дослідження моделі, що зберігається в ньому, тобто
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
23
до самостійного навчання стратегії досягнення поставленої мети. Лише до 80-го року була усвідомлена значущість проблеми використання в інтелектуальних системах людських знань про дійсність. Але ще раніше почалися дослідження, пов’язані зі спробою формального опису і комп’ютерної реалізації інтелектуальних систем, що не обмежуються моделюванням дійсності або знаннями про дійсність, але спираються на схеми усвідомлення і самої дійсності, і її образів. Схеми ці засновані на чіткому математичному описі структур рефлексії.
Філософська традиція називає рефлексією думки про думку, тобто коли предметом думки виявляється не річ, але факт мислення. Рефлексія — думка суб’єкта про наявний у нього образ дійсності, тобто критичний образ цього образу, що припускає оцінку створюваних в уяві моделей. Класична парадигма штучного інтелекту ігнорує цю обставину і тому не цікавиться рефлексією.
З усього вищесказаного випливає висновок, що до розходження між потенційно здійсненним і фактично реалізованим треба додати розходження між фактично реалізованим і нереалізованим у доступному майбутньому. А межі між потенційно здійсненним і нездійсненним за допомогою автоматів відповідає теза кібернетики. Для тих, хто визнає матеріалістичне положення про те, що будь-який процес природи пізнаваний за допомогою розуму, теза про принципову можливість моделювання на ЕОМ будь- якого реального процесу, якщо він зрозуміло й однозначно описаний якоюсь мовою, — є природним висновком з логіко-матема- тичної теорії обчислювання. На запитання, де пролягає межа між реально здійсненним для кібернетики і реально неможливим (хоча й можливо потенційним), відповіді ми не знаємо.
Так само немає вичерпних відповідей на такі запитання: на якій сировині (інформації чи знаннях) працюють системи штучного інтелекту, і чи означає це, що такого роду системи повинні імітувати розумові процеси людини? Нарешті, чи можна передати машині розумові здібності людини подібно до того, як нині в людському організмі природне серце заміняють на штучне?
Є багато заперечень із приводу можливості моделювання життєвих процесів психіки і розуму, які можна умовно розбити на три типи.
1. Еволюційне заперечення. Мозок сучасної людини — це результат процесу еволюції, що тривав мільярди років. Робота не
24
Г.Ф. Іванченко
можна навчати тривалий час. Тому ніколи не з’являться інтелектуальні роботи.
Помилка такого міркування полягає в постулюванні того, що автоматична система може імітувати відповідну біологічну функцію (мислення, політ тощо) тільки копіюванням механізму й еволюційного шляху свого біологічного прототипу. Роботи ж починають навчатися вирішенню інтелектуальних завдань, уже маючи дуже високу початкову організацію, закладену в них людиною. «Еволюційний стаж» людини споконвічно вкладається в стаж роботів. Крім того, можливий шлях природного накопичення інформації «кібернетичним зародком» через досвід спілкування [7].
2. Соціальне заперечення, згідно з яким людина — «істота
соціаде>на», а мислення — функція не людини, а людства, що виникло в результаті колективної діяльності (соціального життя) людей; а робот — індивідуальний за своєю природою, отже, він не може мати інтелект [8]. Це заперечення містить ту саму помилку — постулат про одиничність шляху до мислення. Сказане вище зовсім не виключає того, що інтелект може розвитися в процесі індивідуального вирішення дедалі складніших інтелектуальних завдань. Крім того, зовсім не виключено створення «колективу роботів» для спільного вирішення задач (ремонт самих себе, створення нових роботів, нового програмного забезпечення тощо). '
3. Третій тип пов’язаний із сумнівом щодо можливості імітації за допомогою неживих елементів явища життя взагалі. Тобто створення, відтворення її сутності на будь-якій якісно іншій основі. Однак якщо виходити з функціонального визначення поняття життя, за О. А. Ляпуновим, як «высокоустойчивого состояния вещества, использующего для выработки сохраняющих реакций информацию, кодируемую состояниями отдельных молекул» [9], то й у цьому плані не бачиться жодних принципових ускладнень. Способи кодування інформації можуть бути різні, і не обов’язково ґрунтуватися на білковій основі. Те саме стосується й вищого рівня організації життя, рівня цивілізації.
Усі ці заперечення поєднує одна загальна думка — штучний інтелект обов’язково має походити на інтелект людини.
Теза, що часто висувається: те, що робить людина, то і так само має робити це машина — дуже спірна. Невипадково введено слово «штучний» у назву «штучний інтелект», тому не зовсім
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
25
зрозуміла вимога деяких учених, щоб машинний інтелект обов’язково був подібний до людського. По суті, немає вагомих підстав казати, що машинні моделі розуміння і використання знань повинні наближатися за характером і структурою до схеми сприйняття й переробки інформації людиною [10].
Треба зазначити, що словосполучення найменування «штучний інтелект» фактично має метафоричний характер. Творці систем класу ШІ (штучний інтелект) не керуються психологічними структурами, що властиві процесу людського мислення. Природний інтелект співставляють зі штучним тільки за результатами їхнього функціонування. Необхідно додати, що штучний інтелект на сьогоднішній день не може претендувати на яке-небудь зіставлення з поліфункціональністю й безмежними здібностями людського інтелекту. Але за окремими параметрами комп’ютерні системи здатні значно перевершувати відповідні можливості людини. Спираючись на це, В. П. Зінченко називає комп’ютер не штучним інтелектом, а інструментом інтелектуальної дії, що може істотно полегшити, прискорити, підвищити точність прийняття рішення [11]. Великі надії нині покладаються на нейро- комп’ютери, що значно збільшать можливості «штучного інтелекту» і, на думку фахівців, зрештою перевершать інтелект свого творця.
Але припустимо, що людина спромоглася створити інтелект, що перевищує свій власний. Що буде з людством? Яку роль відіграватиме людина? І чи потрібно в принципі створення штучного інтелекту? Інтелектуальна система цілком може мати свої бажання і поводитися не так, як нам хотілося б. Таким чином, постає проблема безпеки. Чи не вийде так, що, тільки-но електронний мозок досягне людського рівня, людство виконає свою історичну місію (на кшталт динозаврів) і не буде потрібне більш ані природі, ані Богові, ні просто доцільності?
Як відзначалося, зовсім не виключено створення «колективу роботів». Уже існує глобальна мережа Internet, що поєднує ЕОМ в одне велике «комп’ютерне співтовариство», за допомогою якої відбувається «спілкування» комп’ютерів. Цілком можливе створення в майбутньому і цивілізації штучного розуму — машинної цивілізації. Н. С. Кардашев визначив цивілізацію як «высокоустойчивое состояние вещества, способного собирать, абстрактно анализировать и использовать информацию для получения качественно новой информации об окружающем и самом себе, для са¬
26
Г.Ф. Іванчвнко
мосовершенствования возможностей получения новой информации и для выработки сохраняющих реакций; цивилизация обособляется объемом накопленной информации, программой функционирования и пространством для реализации этих функций» [12]. З цього погляду немає протиріч у можливості існування цивілізації іншої природи, окрім білкової.
Машинна цивілізація — це не вигадка фантастів, а цілком обґрунтована реальність. Інша справа, чи хочемо ми її і чи так вона потрібна нам? Оскільки роботи в принципі можуть мати основні властивості біологічних систем, їх можна віднести і до «живих істот», якщо розуміти цей термін досить широко. Створюючи досконалих роботів, людина створює і нове життя — «життя роботів», високоорганізоване, але своєрідне і не схоже на наше життя. Зараз відбувається створення роботизованого «безлюдного» простору. Вважається, що роль людини в такому просторі зведеться тільки до складання програм, налагодження й ремонту устаткування. Ця тенденція вже спостерігається в розвинених країнах, де дедалі більше населення зайнято в цій сфері.
З розвитком техніки й створенням дедалі потужніших систем штучного інтелекту, коли вже і серце людини навчилися заміняти на природне, виникає питання про можливість «заміни» у майбутньому розуму людини на штучний. М. А. Берйяєв, наприклад, не бачив принципових труднощів у можливості впровадження техніки в органічне життя і навіть заміну його, але вважав це впровадження згубним для цивілізації [13]. У такому разі людина може перестати існувати як особистість, індивідуальність.
Під час створення штучного інтелекту вчені зіштовхнулися з низкою труднощів. Основні труднощі полягають у тому, що дотепер не існує однозначного і загальноприйнятого визначення й розуміння штучного інтелекту.
Так, А. В. Тимофеев пропонує називати інтелектом «здатність розуму вирішувати інтелектуальні задачі шляхом придбання, запам’ятовування і цілеспрямованого перетворення знань у процесі навчання на досвіді і адаптації до різноманітних обставин» [6]. Причому найважливішою відмінністю людського мислення є мова.
У філософії інтелект характеризує відносно стійку структуру розумових здібностей індивіда, що виявляються, наприклад, в умінні сприймати інформацію і використовувати її для розв’язання тих чи інших завдань.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
27
Існують суто поведінкові визначення. За О. Н. Колмогоровим, будь-яка матеріальна система, що з нею можна досить тривалий час обговорювати проблеми науки, літератури і мистецтва, має інтелект. Іншим прикладом інтелекту може слугувати відоме визначення А. Тюринга [14], засноване на спеціально організованій «грі в імітацію» між людьми і машиною, що знаходяться в різних кімнатах, але мають можливість обмінюватися інформацією. Якщо в процесі діалогу між учасниками гри людям не вдається встановити, що один з учасників — машина, то таку машину можна вважати наділеною інтелектом. Недоліком Тюрингівського визначення інтелекту є те, що, на його думку, в принципі можна побудувати автомат з повним набором рішень всіх можливих задач — і удаваний інтелект зведеться до простого вибору в пам’яті відповідного рішення.
У найзагальнішому значенні штучний інтелект — це сукупність автоматичних методів і засобів цілеспрямованої переробки інформації відповідно до досвіду, що набувається в процесі навчання, й адаптації при вирішенні різноманітних задач [6]. Особливості тієї чи іншої системи штучного інтелекту визначаються властивостями закладених у неї алгоритмів і програм та технічною реалізацією.
Штучний інтелект — галузь наукового знання, яка об’єднує велике число напрямів, принципів, які відповідають дослідженням і закономірностям розумової діяльності, моделювання завдань, які традиційно належать до інтелектуальних.
Отже, проблема визначення штучного інтелекту зводиться до визначення інтелекту взагалі: чи є він чимось єдиним, чи цей термін об’єднує набір розрізнених здібностей? Якою мірою інтелект можна створювати?
На цей час у число напрямів ШІ включають від дослідження принципів сприйняття (моделювання органів зору, дотику тощо) і моделювання функцій мозку до спеціальних методів доведення теорем, діагностики захворювань, розпізнавання образів то мови, гри в шахи, написання віршів і музичних творів, казок тощо.
Теорія штучного інтелекту має досить тривалу передісторію. Ідея створення штучної людини для вирішення складних завдань і моделювання людського розуму виникла ще в стародавні часи.
У сучасному уявленні ШІ — «Науковий напрям, метою якого є розробка апаратно-програмних засобів, що дозволяють не програмісту ставити і вирішувати свої, що традиційно вважаються
28
Г.Ф. Іванчвнко
інтелектуальними, завдання, спілкуючись з ЕОМ на обмеженій підмножині природної мови» [14].
Таке визначення охоплює практично всі напрями діяльності в широкій галузі знань, яку називають штучний інтелект. І в такому трактуванні результати досліджень у галузі ШІ найцікавіші для систем, що розвиваються, і вирішення завдань системного аналізу.
З давніх давен людині були потрібні помічники для полегшення виконання тих чи тих операцій. Було винайдено різноманітні механізми, машини тощо. Поява електронно-обчислювальних машин дала змогу автоматизувати виконання трудомістких розрахункових робіт. Згодом стало зрозуміло, що ці машини можна використовувати не тільки для обчислень, а й для керування різними пристроями, складними автоматизованими виробництвами тощо. Широкого поширення набули роботи — програмно керовані пристрої, здатні безпосередньо взаємодіяти з фізичним Літом та виконувати в ньому певні дії. Такі роботи широко використовуються у виробництві. Вони можуть працювати і в умовах, які людина не в змозі витримати — на дні океану, всередині ядерного реактора тощо. Але такі помічники вимагають автоматизованого керування, тобто їм постійно потрібно «підказувати», що і як вони мають робити в певній ситуації. |
Природна мова на сучасному етапі малопридатна для цього через свою складність та неоднозначність. Одним із шляхів вирішення цього завдання є формулювання інструкцій мовою, зрозумілою виконавцю, тобто написання програм.
Ми знаємо про складності сучасного програмування, пов’язані з необхідністю надмірної алгоритмізації, тобто детального ретельного розписування інструкцій з урахуванням усіх можливих ситуацій. Тут єдиний вихід — підвищення рівня «розумності», інтелектуальності сучасних комп’ютерів та роботів. Постає запитання, що розуміємо під такими поняттями, як «інтелектуалізація», «штучний інтелект»?
Можна стверджувати, що штучний інтелект у тому чи іншому розумінні повинен наближатися до інтелекту природного і в ряді випадків використовуватися замість нього; так само, як, наприклад, штучні нирки працюють замість природних. Що більше буде ситуацій, коли штучні інтелектуальні системи зможуть замінити людей, тим більш інтелектуальними будуть вважатися ці системи.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
29
Було зроблено чимало спроб дати формальне визначення поняття інтелекту, зокрема, штучного. Найвідомішим є визначення предмета теорії штучного інтелекту, яке було введене видатним дослідником у галузі штучного інтелекту Марвіном Мінським. Воно потрапило до багатьох словників та енциклопедій з невеликими змінами і відображає таку основну думку: «штучний інтелект є дисципліна, що вивчає можливість створення програм для вирішення завдань, які при вирішенні їх людиною потребують певних інтелектуальних зусиль». Але і це визначення має вади. Головна з них полягала в поганій формалізації поняття «певні інтелектуальні зусилля». «Певних інтелектуальних зусиль» вимагає, наприклад, виконання простих арифметичних операцій, але чи можна вважати інтелектуальною програму, яка здатна виконувати тільки такі операції? У ряді книг та енциклопедій до наведеного визначення додається поправка: «сюди не входять завдання, для яких відома процедура їх розв ’язання». Важко вважати таке формулювання задовільним. Розвиваючи цю думку далі, можна було б продовжити: отже, якщо я не знаю, як виконувати певне завдання, то вона є інтелектуальною, а якщо знаю — то ні. Наступний крок — це відомі слова Л.Теслера: «Штучний інтелект
— це те, чого ще не зроблено». Цей парадоксальний висновок лише підкреслює дискусійність проблеми.
Є деякі конструктивніші визначення інтелекту. Наприклад одне з них: «інтелект є здатність правильно реагувати на нову ситуацію». Там же наводиться й критика цього визначення: не завжди зрозуміло, що слід вважати новою ситуацією. Уявіть собі, наприклад, звичайний калькулятор. Цілком імовірно, що на ньому ніколи не обчислювали суму двох нулів. Тоді завдання «обчислити нуль плюс нуль» можна вважати ситуацією, новою для калькулятора. Безумовно, він з нею впорається («правильно від- реагує на нову ситуацію»), але чи можна на цій підставі вважати його інтелектуальною системою?
Ми в нашому підручнику інтелектом називатимемо здатність мозку вирішувати (інтелектуальні) завдання шляхом придбання, запам’ятовування і цілеспрямованого перетворення знань у процесі навчання на досвіді й адаптації до різноманітних обставин.
У цьому визначенні під терміном «знання» маємо на увазі не тільки у інформацію, яка надходить у мозок через органи чуття. Подібні знання надзвичайно важливі, але недостатні для інтелектуальної діяльності. Річ у тому, що об’єкти навколишнього сере¬
зо
Г.Ф. Іванчвнко
довища мають властивість не лише впливати на органи чуття, але й перебувати одне з одним у певних відносинах. Зрозуміло, що аби здійснювати в навколишньому середовищі інтелектуальну діяльність (або хоч би просто існувати), необхідно мати в системі знань модель цього світу. У цій інформаційній моделі навколишнього середовища реальні об’єкти, їх властивості і відносини між ними не тільки відображаються й запам’ятовуються, але й, як відмічено в цьому визначенні інтелекту, можуть у думках «цілеспрямовано перетворюватися». Суттєвим є те, що формування моделі зовнішнього середовища відбувається «в процесі навчання на досвіді й адаптації до різноманітних обставин».
1.3. Тест Тюринга та фактичний діалог
У 1950 році в статті «Обчислювальні машини і розум» (Computing machinery and intelligence) видатний англійський математик і філософ Алан Тюринг запропонував тест, щоб не виникало безглузде, на його думку, запитання чи «може машина мислити?».
Замість того, щоб відверто сперечатися про критерії, що дозволяють відрізнити живу мислячу істоту від машини, яка виглядає як жива і мисляча, він запропонував, як спосіб на практиці встановити це.
Суддя-людина обмежений час, наприклад 5 хвилин, переписується в чаті (у оригіналі — телеграфом) на природній мові з двома співбесідниками, один з них — людина, а другий — комп’ютер. Якщо суддя за наданий час не зможе надійно визначити, хто є хто, то комп’ютер пройшов тест.
Передбачається, що кожний із співрозмовників прагне, щоб людиною визнали його. З метою зробити тест простим і універсальним, листування зводиться до обміну текстовими повідомленнями.
Листування має проводитися через контрольовані проміжки часу, щоб суддя не міг зробити висновок виходячи із швидкості відповідей. (Тюринг ввів це правило тому, що в його часи комп’ютери реагували набагато повільніше за людину. Сьогодні навпаки, це правило необхідне, тому, що ЕОМ реагує набагато швидше, ніж людина).
Ідею Тюринга підтримав Джо Вайзенбаум, що написав у 1966 році першу програму, яка «розмовляє» — «Еліза». Програма
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
31
всього в 200 рядків лише повторювала фрази співбесідника у формі запитань і складала нові фрази з уже використаних у бесіді слів.
А. Тюринг вважав, що комп’ютери кінець кінцем пройдуть його тест, тобто на запитання, «чи може машина мислити?», він відповідав ствердно, але в майбутньому часі: «так, зможе!»
Алан Тюринг був не тільки видатним ученим, але й справжнім пророком комп’ютерної доби. Досить сказати, що в 1950 році він писав, що до 2000 року на столі у мільйонів людей стоятимуть комп’ютери, що мають оперативну пам’ять 1 мільярд біт (близько 119,2 Мб) і виявився в цьому абсолютно правий. На той час усі комп’ютери світу разом узяті навряд чи мали таку пам’ять. Він також передбачив, що навчання відіграватиме важливу роль у створенні потужних інтелектуальних систем, що сьогодні абсолютно очевидно для всіх фахівців з ШІ. Саме цей шлях і використовують практично всі системи ШІ. Крім того, на цьому шляху з’являються й інші ознаки інтелектуальної діяльності: накопичення досвіду, адаптація тощо.
Проти тесту Тюринга було висунуто кілька заперечень.
1. Машина, що пройшла тест, може не бути розумною, а просто дотримуватися певного хитромудрого набору правил.
На що Тюринг не без гумору відповідав: «А звідки ми знаємо, що людина, яка щиро вважає, що мислить, насправді не дотримується якогось хитромудрого набору правил?»
2. Машина може бути розумною і не уміючи розмовляти, як людина, адже не всі люди, яким не відмовити в розумі, вміють писати.
Можуть бути розроблені варіанти тесту Тюринга для неграмотних машин і суддів.
3. Якщо тест Тюринга й перевіряє наявність розуму, то він не перевіряє свідомість (consciousness) і вільний намір (intentionality), отже не вловлює вельми істотних відмінностей між розумними людьми і розумними машинами.
Сьогодні вже існують численні варіанти інтелектуальних систем, які не мають мети, але мають критерії поведінки: генетичні алгоритми й імітаційне моделювання еволюції. Поведінка цих систем має такий вигляд, неначе в них різна мета і домагаються її.
Щорічно проводяться змагання між програмами, що розмовляють і найбільш людиноподібним, на думку суддів, присуджується приз Лебнера (Loebner) у розмірі $ 100 000!
Існує також приз для програми, яка, на думку суддів, пройде тест Тюринга. Цей приз ще жодного разу не присуджувався.
32
Г.Ф. Іванченко
На останок відзначимо, що й сьогодні тест Тюринга не втратив своєї фундаментальності й актуальності, мало того — набув нового звучання у зв’язку з виникненням Internet, спілкуванням людей в чатах і на форумах під умовними ніками і появою поштових і інших програм-роботів агентів, які розсилають спам (некоректну нав’язливу рекламу й іншу незатребувану інформацію), зламують паролі систем і намагаються виступати від імені їх зареєстрованих користувачів, здійснюють інші неправомірні дії.
Таким чином сьогодні вже постає питання:
> розпізнавання, ідентифікації статі й інших параметрів співрозмовника;
> виявлення листів, написаних і відісланих не людьми, а також такого автоматичного написання листів, щоб відрізнити їх від написаних людьми було неможливо. Отже, антиспамовий фільтр на електронній пошті теж є щось на кшталт тесту Тюринга.
Подібні проблеми (ідентифікації: людина або програма) можуть виникнути і в чатах. Що заважає зробити мережевих роботів на зразок програми «Еліза», але значно більш розроблених, які самі реєструватимуться в чатах і форумах, братимуть участь у них з використанням слів і модифікованих пропозицій інших учасників? Простий варіант — дублювання з інших форумів і перенесення їх з форуму на форум без змін, що ми вже іноді спостерігаємо в Internet.
На практиці, щоб на вході системи визначити, хто в неї входить, людина або робот, досить при вході пред’явити простеньке для вирішення людиною, але таку що вимагає величезних обчислювальних ресурсів і системи, завдання розпізнавання випадкових наборів символів, представлених у нестандартних зображеннях, масштабах і поворотах на тлі шуму. Вирішив, отже стукається людина-корис- тувач, не вирішив — на вході робот-агент, що передається світовою мережею з невідомою, найчастіше непристойною метою.
1.4. Сучасні дослідження напряму штучного інтелекту
Однією з традиційних класифікацій напрямів досліджень у галузі штучного інтелекту є класифікація Ханта.
Перший напрАм має назву біологічний. У його основу покладено спроби вирішення інтелектуальних завдань шляхом безпосереднього моделювання психофізіологічних особливостей мозку
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
33
людини засобами електронно-обчислювальних машин. З часом стало зрозумілим, що розв’язати цю проблему в повному обсязі неможливо і недоцільно. Моделювання особливостей людського розуму в повному обсязі призведе до копіювання не тільки позитивних якостей, але й негативних. Стало зрозуміло, що таке моделювання хоч і має певне значення для створення штучного інтелекту, більше підходить для вивчення інтелекту природного. Таке вивчення оформилося у вигляді самостійної науки, яка отримала назву когнітивна психологія.
Інший підхід — прагматичний. Він майже не розглядає психофізіологічну діяльність людського мозку. Розвиваються підходи до вирішення інтелектуальних завдань незалежно від того, як співвідносяться ці підходи з тими процесами, що відбуваються в мозку людини.
Існує інша класифікація систем штучного інтелекту залежно від моделей та методів, що використовуються для вирішення практичних завдань. Ідеться про символьний та конекціоністсь- кий підходи. Ці підходи будуть детально розглянуті під час вивчення курсу; заразом можна відмітити, що символьний підхід орієнтований на моделювання процесів свідомого логічного мислення, а конещіоністський — підсвідомих рефлекторних процесів. Підходи можуть застосовуватися і окремо, і в комбінації. Найбільших успіхів можна досягти, лише комбінуючи ці підходи. Зрозуміло, що без використання рефлекторних методів жодну серйозну інтелектуальну проблему не можна розв’язати через «прокляття розмірності». Водночас, рефлекторні рішення не завжди правильні та оптимальні, і тому людина не може обійтися без логічного мислення, як не можуть без нього обійтись і системи штучного інтелекту.
Характерною особливістю сучасних досліджень є зближення та взаємопроникнення символьного та конекціоністського підходів. Галузі застосування ШІ:
• системи автоматизованого проектування кібернетичних та обчислювальних комплексів, інтелектуальних роботів;
• системи машинного перекладу, інформаційного пошуку, генерації документів, організації природного діалогу між користувачем і комп’ютером, оброблення та сприйняття природної мови та тексту;
• системи технічного зору, комп’ютерного бачення, розпізнавання зображень, мовних конструкцій, прийняття рішень, моде¬
34
Г.Ф. Іванчвнко
лювання інтелектуальних функцій поведінки, обробки нечисло- вих конструктивів;
• системи розпізнання та ідентифікації особи за біометричними показниками;
• системи ідентифікації комп’ютерного обладнання за унікальними показниками;
• системи захисту даних та контролю операцій з пластикови- ми банківськими картками;
• сучасні програмні системи моделей розуму, імітації інтелектуальної діяльності людини, бази знань;
• нейромережеві інтелектуальні системи для розв’язання нечітких і складних проблем, таких як розпізнавання геометричних фігур та кластеризація об’єктів;
• дорадчі економічні системи (ДЕС), системи автоматичного планування; системи передбачення прибутку та витрат; технологічного керування підприємства тощо;
• інтелектуальні системи управління житлом, які створені для контролю та автоматизації управління системами життєдіяльності будинку, такими як освітлення, водопостачання, вентиляція, кондиціювання, безпеки та пожежної сигналізації, що включають обладнання і програмне забезпечення для побудови цифрових систем відеоспостереження;
• інтелектуальні системи ГЕО, що надають клієнтам необхідні для бізнесу геоінформаційні продукти (наприклад комплект програм isgeoRegisterSS (isgeoRegister Software Suite) призначений для створення реєстраційних, кадастрових та інших інформаційних систем, у яких використовується зв’язок базової карти з тематичними даними);
• системи моделювання біологічних об’єктів засновані на ідеї генетичного підходу, що деякий алгоритм може стати ефективнішим, якщо відбере кращі характеристики у інших алгоритмів («батьків»);
• технологія інтелектуальних агентів в Інтернет. Відносно новий підхід, де ставиться задача створення автономної програми — агента, котрий співпрацює з навколишнім середовищем. А якщо належним чином примусити велику кількість «не дуже інтелектуальних» агентів співпрацювати разом, то можна отримати модель біологічного «мурашиного» інтелекту Swarm Intelligence (SI);
• цілий ряд прикладних систем впровадження в медичних та діагностичних комплексах, у проектуванні матеріалів з заданими
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
35
властивостями, програмуванні процесів хімічного синтезу, в технологіях збору і розповсюдження інформації, системи скринінг- діагностики здоров’я населення.
• ВСІ (Brain-Computer Interface). — системи, в яких викорис¬
товуються електричні, магнітні або гемодинамічні сигнали мозку для управління зовнішніми пристроями, такими як комп’ютери, перемикачі, управління транспортом, інвалідні коляски, побутові пристрої і нейропротези. >'
Уявно предметна область ШІ складається з реальних або абстрактних об’єктів — сутностей. Сутності предметної області знаходяться у визначених відношеннях (асоціаціях) одна до одної, які також можна розглядати як сутності і включати в предметну область. Між сутностями спостерігаються різні відношення подоби. Сукупність подібних сутностей складає клас сутностей, що є новою сутністю предметної області.
Для вирішення інтелектуальних задач необхідно використати знання з конкретної предметної області, подані в певній стандартній формі і створити програму їхньої обробки.
Класифікація проблемних середовищ ШІ може бути зроблена за такими вимірами:
• середовище, яке повністю або частково спостерігається;
• детерміноване або стохастичне середовище;
• епізодичне або послідовне середовище;
• статичне або динамічне середовище;
• дискретне або неперервне середовище;
• одноагентне середовище (коли в середовищі діє тільки один агент) або мультиагентне середовище (коли діють два агенти і більше).
Крім того, предметні області можна характеризувати такими аспектами: числом і складністю сутностей; їхніх атрибутів і значень атрибутів; зв’язністю сутностей та їхніх атрибутів; повнотою знань; точністю знань (знання точні або правдоподібні; правдоподібність знань подається певним числом або висловленням).
Задачі, що вирішуються інтелектуальними системами у проблемній області, класифікують:
• за ступенем зв’язності правил: зв’язні (задачі, що не вдається розбити на незалежні задачі) та малозв’язні (задачі, що вдається розбити на деяку кількість незалежних підзадач);
• з точки зору розробника: статичні (якщо процес вирішення задачі не змінює вихідні дані про поточний стан предметної об¬
36
Г.Ф. Іванчвнко
ласті) і динамічні (якщо процес вирішення задачі змінює вихідні дані про поточний стан предметної області);
• за класом вирішуваних задач:
1. Задачі розширення — задачі, у процесі вирішення яких здійснюється тільки збільшення інформації про предметну область, що не призводить ні до зміни раніше виведених даних, ані до вибору іншого стану області. Типовою задачею цього класу є задача класифікації.
2. Задачі довизначення — задачі з неповною або неточною інформацією про реальну предметну область, мета вирішення яких
— вибір з множини альтернативних поточних станів предметної області того, що є адекватний вихідним даним. У випадку неточних даних альтернативні поточні стани виникають як результат ненадійності даних і правил, що призводить до різноманіття різних доступних висновків з тих самих вихідних даних. У випадку неповних даних альтернативні стани є результатом довизначення області, тобто результатом припущень про можливі значення відсутніх даних. Дослідження учених в подальші роки напрямлено на ліквідацію розриву між згаданими вище напрямами. У 1994 p. Л. Заде ввів термін — «м’які обчислення» (soft computing). М’які обчислення це синтез методів (нечіткі системи + нейросистеми + генетичні алгоритми + імовірнісні обчислення (мережі довіри Байеса)).
3. Задачі перетворення — задачі, які здійснюють зміни вихідної або виведеної раніше інформації про предметну область, що є наслідком змін або реального світу, або його моделі.
Слід відмітити, що жодна з наявних систем штучного інтелекту, які працюють у перелічених галузях, не може реалізовувати зазначені вище функції інтелектуальної системи в достатньому обсязі. Тому про них краще казати як про інтелектуалізовані система, які мають деякі риси, що наближають їх до справді інтелектуальних систем.
1.5. Інтелектуальні роботи
Широким напрямом систем ШІ є роботехніка та штучне життя. У чому основна відмінність інтелекту робота від інтелекту універсальних обчислювальних машин?
Для відповіді на це запитання доречно пригадати вислів, що належить великому російському фізіологу І. М. Сеченову: «Вся нескінченна різноманітність зовнішніх проявів мозкової діяльно¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
37
сті зводиться остаточно лише до одного явища — м’язового руху». Іншими словами, вся інтелектуальна діяльність людини спрямована кінець кінцем на активну взаємодію із зовнішнім світом за допомогою рухів. Так само елементи інтелекту робота служать перш за все для організації його цілеспрямованих рухів. У той самий час основне призначення суто комп’ютерних систем ШІ полягає у вирішенні інтелектуальних завдань, що мають абстрактний або допоміжний характер, які зазвичай не пов’язані ані з сприйняттям навколишнього середовища за допомогою штучних органів чуття, ані з організацією рухів виконавчих механізмів.
Перші спроби моделювання таких сторін людської діяльності, що здаються людині дуже простими, зіткнулися із серйозними труднощами. (Наприклад, серйозною проблемою дотепер видається розпізнавання образів системами штучного інтелекту. Хоча, помітьмо, що проблеми розпізнавання текстів і перекладу, що вважалися раніше не менш серйозними, були частково розв’язані).
Треба відзначити, що останнім часом у сфері досліджень штучного інтелекту розвивається напрям, пов’язаний зі створенням нового класу пристроїв обчислювальної техніки — нейрокомп’ю- терів. Порівняно з традиційними універсальними ЕОМ, нейро- комп’ютери мають низку незвичайних властивостей, породжуваних їхньою архітектурою, що певною мірою відбиває динаміку інформаційних процесів головного мозку. Саме тому вони добре пристосовані до вирішення завдань розпізнавання образів [15].
Труднощі моделювання свідомості навіть на почуттєвому рівні пов’язані насамперед з цілісним, інтегративним характером її функціонування. Тому можна сказати, що діяльність свідомості має системний характер. Це має прояв, по-перше, у тім, що окремі форми почуттєвого пізнання виступають у взаємозв’язку і єдності; по-друге, їхня діяльність істотно залежить від мислення.
Проблема постала ще з часів Карела Чапека, який уперше використав термін «робот». Великий внесок в обговорення цієї проблематики зробили й інші письменники-фантасти. Як найві- доміші ми можемо згадати серії розповідей письменника- фантаста і вченого Айзека Азімова, а також досить свіжий твір Голівуда — «Термінатор». До речі, саме в Айзека Азімова ми можемо знайти ухвалене більшістю людей розв’язання проблеми безпеки. Йдеться про так звані три закони роботехніки.
1. Робот не може заподіяти шкоду людині або своєю бездіяльністю допустити, щоб людині було заподіяно шкоду.
38
Г.Ф. Іванчвнко
2. Робот має підкорятися командам, які йому дає людина, окрім тих випадків, коли ці команди суперечать першому закону.
3. Робот має піклуватися про свою безпеку тією мірою, якою це не суперечить першому і другому закону.
На перший погляд подібні закони, за їх цілковитого дотримання, мають забезпечити безпеку людства. Проте, якщо уважно розглянути, постають деякі питання. По-перше, закони сформульовано природною людською мовою, яка не припускає простого їх перекладу в алгоритмічну форму.
На відміну від деяких інших досягнень цивілізації, як-от автомобіль, літак, кухонна побутова техніка, штучний інтелект не має прототипів у народній творчості — міфах, легендах і казках. Міфи або мрії про нього виникають тільки з появою обчислювальної техніки й автоматики. Що стосується ранішньої міфології, найбільш близьким легендарним персонажем є штучна людина (андроїд або гомункулус). Проте він завжди присутній як бездумний слухняний господарю механізм. Можна пригадати залізну людину, яку виконував Гефесг на горі Олімп, дерев’яну людину, зроблену італійським майстром у Толедо і відому більше як Кам’яний гість О. С. Пушкіна, Голема—слугу середньовічного алхіміка з м. Праги.
Вони явилися прототипом сучасного робота. Проте, під час створення реальних сучасних роботів постава проблема спілкування з ними з метою формулювання їм завдань. Розв’язуючи цю проблему, ми почали розуміти, що якщо хочемо мати зручні й надійні засобі спілкування з роботом (або в загальному випадку з деякою складною системою), ми повинні забезпечити його засобами внутрішнього уявлення і вирішення завдань приблизно такими самими, як у людини. Інакше ми приречені абр вивчати штучну мову спілкування або програмування, або на «нерозуміння» роботом, що ми від нього хочемо.
Інтелектуальні роботи (іноді кажуть «інтелектні», або роботи зі штучним інтелектом) з’явилися з розвитком простих програмованих промислових роботів, у 60-ті роки. Тоді було закладено основи сучасних і майбутніх інтелектуальних роботів у дослідженнях, пов’язаних з координацією програмування роботів- маніпуляторів і технічного зору на основі телевізійної камери, планування поведінки мобільних роботів, спілкування з роботом на природній мові.
Експерименти з першими інтелектуальними роботами проводилися наприкінці 60-х — початку 70-х років у Стендфордському
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
39
університеті, Стендфордскому дослідницькому інституті (Каліфорнія), Массачусетському технологічному інституті (Массачусетс), Едінбурзькому університеті (Великобританія), в Електротехнічній лабораторії (Японія). Типовий інтелектуальний робот зовні схожий на людини, складається з однієї або двох механічних рук-захватів (маніпуляторів) і телевізійних камер, розміщених на рухомій частині системного блоку, сенсорів та мобільних літій-іонних батарей джерел живлення (рис. 1.1).
а) 6)
Рис. 1.1.Серія роботів-андроїдів: a) Asimo (Honda); б) Бойовий робот (Samsung)
Asimo (скорочення від Advanced Step in Innovative Mobility) — робот-андрощ. Створений корпорацією Центр фундаментальних технічних досліджень вако (Японія). Здатний пересуватися із швидкістю людини, що швидко йде — до 6 км/год, (див. таблицю).
Згідно з неофіційною версією, своє ім’я Asimo одержав на честь знаменитого автора трьох законів роботехніки (Айзека Азімова). У японській мові ім’я робота вимовляється як «Асімо».
40
Г.Ф. Іванчвнко
Маса
54 кг
Висота
130 см
Ширина
45 см
Глибина
37 см
Швидкість ходи
2,7 км/год 1,6 км/год (при перенесенні вантажу до 1 кг)
Швидкість бігу
6 км/год (по прямій) 5 км/год (з поворотами)
Відрив від землі
0,08 с
Батареї
Літій-іонні батареї 51,8 В / 6 кг цикл зарядки 3 години
Тривалість роботи
від 40 хвилин 1 год (у режимі ходи)
За інформацією 2007 року в світі існує 46 екземплярів Asimo. Вартість виробництва кожного з них не перевищує одного мільйона доларів, а деяких роботів можна навіть узяти в оренду за 166 000 доларів на рік.
З 2007 року Хонда додала Asimo масу функцій, які дозволили йому краще спілкуватися з людьми. Ці функції діляться на п’ять категорій:
• у Asimo в «голову» вбудовано відеокаме^у. За її допомогою Asimo може стежити за переміщеннями великого числа об’єктів, визначаючи дистанцію (лазерні дальноміри) Ідо них і напрям. Практичні застосування цієї функції такі: здатність стежити за переміщеннями людей (повертаючи камеру на інфрачервоне випромінювання), здатність переслідувати людину і здатність «вітати» людину, коли людина увійде в межі досяжності датчиків робота;
• Asimo вміє також правильно тлумачити рухи рук, розпізнає тим самим жести. В результаті можна віддавати Asimo Команди не тільки голосом, але й руками. Наприклад, Asimo навчено розуміти, коли співбесідник збирається потиснути йому руку, а коли махає рукою, кажучи «До побачення». Asimo може також розпізнавати вказівні жести на зразок «іди он туди»;
• Asimo вміє розпізнавати предмети й поверхні, завдяки чому може діяти безпечно для себе і для тих, хто поряд. Наприклад, Asimo «розуміє» поняття «сходинка» і не падатиме, якщо його не зіштовхнути зі сходів. Крім того, Asimo уміє рухатися, обходячи людей, що постають у нього на шляху;
• розрізнення звуків відбувається завдяки електронній системі HARK, у якій використовується вісім мікрофонів, розташованих
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
41
на голові і на корпусі андроїда. Asimo виявляє, звідки прийшов звук, і відокремлює кожен голос від зовнішнього шуму. При цьому Asimo не задають кількість джерел звуку і їх місцеположення. На цей час HARK здатна надійно (точність 70—80 %) розпізнавати три мовні потоки, Asimo здатний уловлювати і сприймати мову відразу трьох людей, на що звичайна людина не спроможна. Робот уміє відгукуватися на власне ім’я, повертати голову до людей, з якими говорить, а також обертатися на несподівані й тривожні звуки такі, як наприклад, звук меблів чи посуду, які падають;
• Asimo здатний розпізнавати знайомі обличчя, навіть під час руху. Тобто, коли рухається сам Asimo, рухається обличчя людини, або рухаються обидва об’єкти. Робот може відрізняти приблизно десять різних облич. Asimo вміє користуватися Інтернетом і локальними мережами. Після підключення до локальної мережі Asimo зможе розмовляти з відвідувачами через домофон, а потім доповідати господарю, хто прийшов. Після того, як господар погодиться прийняти гостей, робот зуміє відкрити двері і довести відвідувача до потрібного місця. Через Інтернет Asimo може, наприклад, повідомляти новини і розповідати про поточну погоду.
У планах Південної Кореї (фірма Samsung за ціною 200 тис. доларів за штуку) оснащення армії 1000 бойовими роботами (див. рис. 1.1 (б)).
Робот, оснащений звичайними камерами, інфрачервоними (може бачити в темряві і крізь чагарники), уміє бачити з великої відстані, відрізняти людину від інших об’єктів, розпізнавати голос і жести. Оснащений кулеметом. Мабуть, корейці не читали Азімова, бо цей робот не розуміє перше правило робототехніки те заподій шкоду людині»: він може відкривати вогонь не тільки по команді оператора, але й приймати рішення самостійно, за обставинами.
На рис. 1.2 показано узагальнену структуру інформаційної системи інтелектуального робота. Тут потрібно мати на увазі, що на підсистему сприйняття надходить великий обсяг різнотипної інформації від датчиків: візуальних, звукових, сенсорних, температурних, радіоізотопних, п’єзометичних, лазерних або ультразвукових далекомірів й інших більш спеціалізованих.
Під синтаксисом розуміється структура в просторі і часі цієї різнотипної інформації. Під семантикою — результат її сприйняття як безліч можливих типових ситуацій або образів, що вимагають будь- якої подальшої обробки. Під світом розуміється опис оточення робота як результат роботи його підсистеми сприйняття.
42
Г.Ф. Іванченко
Рис. 1.2. Структура інформаційної системи інтелектуального робота
Під дією розвіється досить складний рутовий акт, наприклад ( переміщення Деталі з вхідного бункера в шпиндель верстата і її закріплення там, на відміну від руху як результату спрацьовування якого-небудь одного ступеня свободи роб|ота, наприклад обертання робота навколо вертикальної осі на заданий кут.
с Резюме за змістом теми
• Штучний інтелект — галузь наукового знання, яка об’єднує велике число напрямів, принципів, займається дослідженням і закономірностей розумової діяльності, і моделюванням завдань, які традиційно відносять до інтелектуальних;
• область застосування ШІ це: доведення теорем, аналіз ситуацій; прийняття рішень, розпізнавання образів, логічне мислення, розуміння нової інформації, навчання й самонавчання, планування цілеспрямованих дій, адаптивне програмування, обробка даних на природній мові, нейромережі, програмні агенти, робототехніка;
• тест Тюринга не втратив своєї фундаментальності й актуальності, мало того набув нового звучання у зв’язку з виникненням глобальних мереж;
• майбутнє ШІ є створення роботехнікі та штучного життя.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
43
Терміни та поняття до теми
• Штучний інтелект (ШІ) — галузь комп’ютерної науки, що займається автоматизацією розумної поведінки.
• СШІ — система штучного інтелекту.
• Artificial Intelligence (АІ) — штучний інтелект був запропонований в 1956 р. на семінарі в Дортсмудськом коледжі (США).
• Перцептрон — нейрона модель зорового сприйняття й розпізнавання Ф. Розенблатта.
• Айзек Азімов сформулював три принципи створення робототехніки.
• Тест Алана Тюринга запропоновано 1950 року в статті «Обчислювальні машини і розум».
Питання для самоконтролю
1. Дайте пояснення терміну інтелект (intelligence).
2. Які були переломні моментами в розвитку цивілізації, які можна виділити інформаційні революції в історії людства?
3. Наведіть приклади евристичного методу завдань.
4. Поясніть спроможність або не спроможність моделювання мислення людини.
5. Які основні підходи історично склалися в моделюванні ШІ?
6. Дайте пояснення терміну «інтелектуальні системи» та їхнього місця у СШІ.
7. Які соціальні результати інтелектуалізації комп’ютерних технологій?
8. Які є підходи в моделюванні інтелектуальної діяльності людини?
9. Які є заперечення з приводу можливості моделювання життєвих процесів психіки і розуму?
10. Наведіть визначення предмета теорії штучного інтелекту, яке було введено видатним дослідником у галузі штучного інтелекту Марвіном Мінським.
11. Опишіть процедуру тесту Алана Тьюринга.
12. Які були заперечення проти тесту Алана Тьюрінга?
13. Який сенс в інтелектуалізації комп’ютерних технологій?
14. Назвіть декілька відомих вам інтелектуальних задач; опишіть, у чому вони подібні, і в чому відмінні.
15. Дайте пояснення за класифікацією Ханта напрямів досліджень у галузі штучного інтелекту.
16. У чому полягає основна проблема під час автоматизації логічних побудов?
17. Чи є логічне мислення людини бездоганним?
44
Г.Ф. Іванченко
18. Чи можна дати повне й загальноприйнятеє визначення інтелекту взагалі і штучного інтелекту зокрема?
19. Сфери застосування ШІ.
20. Охарактеризуйте біологічний та прагматичний напрями досліджень у галузі штучного інтелекту.
21. Дайте загальну, характеристику символьного та конекціоністсь- кого підходів до створення систем штучного інтелекту.
22. Три закони роботехніки Айзека Азімова.
23. Які функції спілкування з людьми має Авішо зразка 2007 року?
Завдання для індивідуальної роботи, обов’язкові та додаткові практичні завдання
1. Охарактеризуйте відомі методи оцінки інтелектуальних здібностей. Що між ними спільного та в чому полягає відмінність?
2. У чому полягають основні проблеми застосування інтелектуальних тестів для оцінки штучного інтелекту?
3. Чи зводиться процес отримання нових знань, зокрема процес виведення нових фактів з уже існуючих, до суто логічного виведення?
4. Охарактеризуйте роль інтуїції в розумовій діяльності людини.
5. Охарактеризуйте основні завдання, які повинна вміти виконувати інтелектуальна система.
6. Поясніть, яким чином сприйняття зовнішньої ситуації може впливати на внутрішній стан і знання інтелектуальної системи. Наведіть
_ декілька прикладів. 1
7. Охарактеризуйте позитивні та негативні соціальні наслідки інтелектуалізації комп’ютерних технологій.
8. Наведіть відомі вам приклади практичних досягнень у створенні систем штучного інтелекту.
9. У чому полягають основні проблеми застосування інтелектуальних тестів для оцінки штучного інтелекту?
10. Узагальнена структура інформаційної системи інтелектуального робота.
Література для поглибленого вивчення матеріалу
1. ЛюгерДж. Ф. Искусственный интеллект. — М.: Изд. дом «Вильямс», 2005. — 864 с.
2. Глибовець М М, Олецький О. В. Штучний інтелект. — К.: Видавничий дім «КМ Академія», 2002. — 366 с.
ПОДАННЯ ЗНАНЬ У СИСТЕМАХ ШТУЧНОГО ІНТЕЛЕКТУ
Тема 2
ЗАГАЛЬНА ХАРАКТЕРИСТИКА МОДЕЛЕЙ ПОДАННЯ ЗНАНЬ
Перелік знань та навичок
Після опанування теми студент має знати:
• визначення, класифікацію та властивості знань;
• сучасні моделей подання знань;
• логічну форму моделей знань та опис формальної системи;
• числення висловів;
• числення предикатів;
• побудову прямого та зворотного висновку в продукційних системах;
• асоціативну модель знань;
• структуру семантичної мережі та фреймову модель знань.
Має вміти:
• побудувати ППФ;
• написати двозначну логічну функцію — предикат;
• визначити безліч базових елементів (алфавіт) числення предикатів;
• видобувати знання за допомогою правил-продукцій;
• побудувати асоціативну, семантичну, фреймову моделі знань.
46
Г.Ф. Іванчвнко
ЗМІСТ ПИТАНЬ ТЕМИ
2.1. Формалізація знань у системах штучного інтелекту
Аспект представлення знань
Знання, як будь-яку інформацію, можна вважати даними [22]. Але знання є високоорганізованими даними, для яких характерна певна внутрішня структура та розвинені зв’язки між різними інформаційними одиницями. Іншим принциповим аспектом є те, що інформаційні системи (ІС), які ґрунтуються на знаннях, повинні мати можливість отримувати нові знання на основі існуючих. Сучасний етап розвитку інформатики характеризується розвитком моделей даних у напрямі переходу від традиційних моделей даних (реляційна ієрархічна, мережна) до моделей знань.
З розвитком досліджень у галузі ІС виникла концепція знань, які об’єднали в собі багато рис процедурної і декларативної інформації.
У БОМ знання так само, як і дані, відображаються в знаковій формі — у вигляді формул, тексту, файлів, інформаційних масивів і т.п. Тому можна сказати, що знання — і*е особливим чином організовані дані. Але це було б дуже вузьке розуміння. Тим часом, у системах ШІ знання є основним об’єктом формування, обробки і дослідження. База знань поряд з базою даних — необхідна складова програмного комплексу ШІ. Системи, що реалізовують алгоритми ШІ, називають системами, заснованими на знаннях, а розділ теорії ШІ, пов’язаний з побудовою інтелектуальних систем, — інженерією знань.
Не дивно, що перед тими, хто займається проблемою подання знань, постає питання, що таке знання, яка його природа й основні характеристики. У зв’язку з цим робляться спроби дати, наприклад, таке визначення знань, з якого можна було б виходити під час рішення завдань подання знань у комп’ютерних системах. Наголосимо, що для розробки засобів і методів подання знань необхідно використовувати результати когнітивної психології — науки, що виявляє структури, у вигляді яких людина зберігає інформацію про навколишній світ. Висловлюється думка, що мова і подання знань у системах штучного інтелекту повинні розглядатися в межах особливого наукового напряму — когнітології.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
47
Предметом когнітології повинно стати знання як самостійний аспект реальності.
Представленню даних притаманний пасивний аспект: книга, таблиця, заповнена інформацією пам’ять. У теорії штучного інтелекту особливо підкреслюється активний аспект уявлення: знання повинно стати активною операцією, що дозволяє не лише запам’ятовувати, а й витягувати сприйняті (набуті, засвоєні) знання для міркувань на їх основі. Отже, витоки представлення знань — у науці про пізнання {гносеологія), а його кінцева мета
— програмні засоби інформатики.
У багатьох випадках належні уявлення про знання належать до досить обмеженої галузі, для характеристики якої кажуть про «сфери міркувань» або «сфери експертизи». Чисельна формалізація таких описів загалом малоефективна. Навпаки, використання символьної мови, такої, як мова математичної логіки, дозволяє формулювати описи у формі, одночасно близькій і до звичайної, і до мови програмування. Втім, математична логіка дозволяє міркувати, базуючись на набутих знаннях: логічні висновки справді є активними операціями отримання нових знань з уже засвоєних.
Знання як основа СШІ
В особовому аспекті знання асоціюються з їх носіями, тобто тими, хто їх має: конкретною людиною, групою людей або штучним джерелом знань. Носієм знеособленого, або соціального, знання є соціум. Оскільки особові знання суб’єктивні, для їх адекватної інтерпретації потрібно враховувати точку зору (світогляд, погляди, звички) носія. У разі існування безлічі носіїв знань важливе значення мають особливості життєвого устрою людей, специфіка їх професійної діяльності тощо.
Для фахівців у галузі ШІ під час аналізу категорії знання характерне акцентування уваги на формально-логічних аспектах цих питань. Сказане ілюструє тлумачення знань як формалізованої інформації, на яку посилаються або використовують у процесі логічного висновку, й інформації, що зберігається (у ЕОМ), формалізованої відповідно до певних структурних правил, яку ЕОМ може автономно використовувати при розв’язанні проблем за такими алгоритмами, як логічні висновки. Відзначимо, що обидва визначення розкривають знання щодо їх практичного застосування.
Разом з тим, визначення, що таке знання, які його основні властивості і способи отримання, — це споконвічно філософське пи¬
48
Г.Ф. Іванченко
тання. Закономірним є прагнення дати філософське осмислення питань комп’ютерного представлення знань, виявляючи перш за все їх гносеологічні і філософсько-логічні аспекти.
Поняття «знання» можна вважати одним із ключових з погляду і теорії штучного інтелекту, і гносеології. Саме філософія намагається дати повну картину, повне пояснення природи того або того поняття. У цьому сенсі вона поза сумнівом має посідати перше місце, оскільки будь-яка наука повинна базуватися на суворих принципах. Філософському пізнанню належить ключова роль у розробці й дослідженні концепції знання, як об’єкта для моделювання. Таким чином, знання в гносеологічному сенсі є основою.
З введенням терміну «знання» з’являється властивість «усвідомлювати», тобто «розуміти» свої інтелектуальні можливості. У свою чергу це означає не що інше, як рефлексію.
У Філософському словнику знання визначаються як «відображення об’єктивних властивостей та зв’язків світу». Знання є інформаційною основою інтелектуальних систем, оскільки інтелектуальна система завжди співставляє зовнішню ситуацію зі своїми знаннями та керується ними під час прийняття рішень. Не менш важливим є те, що знання — це систематизована інформація, яка може певним чином поповнюватися, і на основі якої можна отримувати нову інформацію, тобто нові знарня.
Проблема представлення знань виникла як одна з проблем штучного інтелекту. Вона пов^язана з переходом досліджень у цій галузі в деяку нову фазу. Йдеться про створення практично корисних систем (перш за все так званих експертних систем), використовуваних у медицині, геології, хімії. Створення подібних систем вимагає інтенсивних зусиль з формалізації знання, накопиченого у відповідній науковій галузі.
З терміном «представлення знань» пов’язується певний етап у розвитку математичного забезпечення ЕОМ. Якщо на першому етапі домінували програми, а дані відігравали допоміжну роль своєрідної «їжі» для «голодних» програм, то на подальших етапах роль даних неухильно зростала. їх структура ускладнювалася: від машинного слова, розміщеного в одному елементі пам’яті ЕОМ, відбувався перехід до векторів, масивів, файлів, списків. Вінцем цього розвитку стали абстрактні типи даних, які забезпечують можливість створення такої структури даних, яка найбільш зручна під час вирішення завдань. Послідовний розвиток структур даних привів до їх якісної зміни і переходу від представ¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
49
лення даних до представлення знань. Рівень представлення знань відрізняється від рівня представлення даних не тільки складнішою структурою, але й істотними особливостями: інтерпретується наявність зв’язків (наприклад, зв’язок між знаннями, що належать до елемента множини, і знаннями про цю множину), що класифікуються, і які дають змогу зберігати інформацію, однакову для всіх елементів множини, записану одноактно при описі самої множини, і наявність ситуативних відносин (одночасності, перебування в одній точці простору тощо, ці відносини визначають ситуативну сумісність тих або тих знань, що зберігаються в пам’яті). Крім того, для рівня знань характерні такі ознаки, як наявність спеціальних процедур узагальнення, поповнення наявних у системі знань і низки інших процедур.
Для філософського аналізу цієї проблематики важливо з’ясувати, чи вважати термін «знання» у виразі «представлення знань» явищем професійного жаргону, або справді перехід від представлення даних до представлення знань має істотні гносеологічні характеристики, і які саме? Особливості ЕОМ як предмета-посе- редника в пізнанні багато в чому визначаються тим, що ЕОМ належать до такого типу предметів-посередників, як моделі.
Під час аналізу гносеологічні аспекти моделювання ЕОМ розглядалися у філософсько-методологічній літературі передусім як матеріальні моделі, що створюються на основі дії певних фізичних закономірностей і функціонують завдяки протіканню в них певних фізичних процесів. Моделювання на ЕОМ розумілося як технічна реалізація певної форми знакового моделювання. Проте, розглядаючи ЕОМ в гносеологічному сенсі як предмет-посеред- ник у пізнанні, доцільно не фіксувати увагу перш за все на «залізній. частині» (hardware) комп’ютера, а розглядати всю комп’ютерну систему як складну систему взаємозв’язаних і деякою мірою самостійних моделей — і матеріальних, і знакових, тобто ідеальних. Такий підхід не тільки відповідає розгляду комп’ютерних систем у сучасній інформатиці, але є гносеологічно виправданим. Багато важливих філософських аспектів проблем, що постають у зв’язку з комп’ютеризацією різних сфер людської діяльності, вимагають звернення передусім до знакових складових комп’ютерних систем. Це стосується і філософських аспектів проблем представлення знань.
В основі досліджень у галузі ШІ лежить підхід, пов’язаний із знаннями. Спиратися на знання — базова парадигма ШІ. Як і ба-
50
Г.Ф. Іванчвнко
ґато фундаментальних наукових категорій (наприклад, алгоритм, інтелект, діяльність тощо), поняття «знання» належить до інтуїтивно визначуваних.
Знання — перевірений практикою результат пізнання дійсності, вірне її відображення в свідомості людини. Знання бувають життєвими, художніми, науковими (теоретичними та емпіричними).
Знання є сукупністю відомостей про об’єкти, їх істотні властивості, відносини, що їх зв’язують, процеси, що відбуваються, методи аналізу і способи розв’язання асоційованих з ними проблем. Враховуючи таке широке тлумачення знань, коротко розглянемо інші тлумачення цієї базової категорії.
Знання визначається як «збагнення дійсності свідомістю» і «сукупність відомостей, пізнань у будь-якій сфері». Інтерпретація знань — «сукупність відомостей, що створюють цілісний опис, який відповідає певному рівню обізнаності про описуване питання, предмет, проблему тощо». Там же наведено тлумачення таких різновидів знань: декларативних, прагматичних, процедурних, евристичних, експертних, знань про предметну (або проблемну) галузь (ПРГ).
Вказані тлумачення знань дають змогу виділити такі характеристики: об’єктність і особистісність.
Об’єктні знання пов’язані з уявленням конкретного об’єкта або класу об’єктів (речей, процесів, явищ тсіщо). Метазнання, навпаки, описують систему найбільш загальних понять, принципів і закономірностей природи, суспільства і мислення.
Дещо інше розуміння знань притаманне психологам. Із їхньої точки зору знання є психічними образами — сприйняття, пам’яті, мислення, як такі виступають образи предметів і явищ зовнішнього світу, образи різних дій людини тощо. Часто знання розглядаються і як динамічні уявні моделі предметів, явищ, їх властивостей і відносин. У психологічному сенсі знання існують у формах чуттєвих моделей, моделей-зображень (зорових образів) і знакових моделей.
Згадані вище тлумачення знань можуть бути об’єднані в чотири групи (або рівні): психологічну, інтелектуальну, формально логічну та інформаційно-технологічну. Зрозуміло, що на першому рівні із знаннями оперують психологи. Другий і третій рівні відповідають інтерпретаціям цієї категорії фахівців у галузі ШІ і логікам. Нарешті, четвертий рівень близький до розуміння знань прагмати- ками-програмістами і розробниками інформаційних систем.
системи ШТУЧНОГО ІНТЕЛЕКТУ
51
Широко поширеним аспектом класифікації знань є їх поділ на декларативні (факти, відомості описового характеру), процедурні (інформація про способи розв’язання типових задач) і метазнан- ня. Метазнання найчастіше визначаються як «знання про знання» і містять загальні відомості про принципи використання знань. До рівня метазнань також належать стратегії управління вибором і застосування процедурних знань.
Декларативні знання складаються з безлічі описів станів і умов переходів між ними, які мають синтаксичний (символьний) характер, не містять у наочному вигляді опису виконавчих процедур.
Висновок і ухвалення рішень здійснюється процедурами пошуку в просторі станів, які враховують семантику (сенс) конкретної предметної галузі. Універсальність і спільність декларативних знань забезпечується поділом синтаксичних і семантичних знань.
Процедурні знання включають початкові стани і описи процедур, оброблюють початкові знання у разі потреби отримання повної множини похідних знань. Це дає змогу відмовитися від зберігання всіх станів бази знань (БЗ), потрібних під час виведення й ухвалення рішень. Тут семантика вводиться в описи процедур, що генерують синтаксичні знання. Так отримуємо економію пам’яті при зберіганні знань, але можливості виконання процедур погіршуються.
В основі поділу знань залежно від ступеня їх достовірності лежать так звані не-фактори, властиві знанням: неповнота інформації про цю галузь, неточність кількісних і розмитість якісних оцінок, неоднозначність науки правил виведення нових знань, неузгодженість деяких положень у БЗ й ін. Один із способів обліку подібних не-факторів при формалізації знань полягає у використанні апарату теорії нечітких множин. Прикладами декларативних і процедурних знань, що мають певний ступінь достовірності, можуть служити твердження: «Наступним днем календаря після 31 травня є 1 червня» і «Для кип’ячення води при нормальному тиску потрібен її нагрів до 100 °С». Знання з нечітким ступенем достовірності містяться в думках: «Завтра в Києві буде дощ» і «Під час гри в шахи не слід розташовувати коня на краю дошки».
До класу процедурних знань з нечітким ступенем достовірності належать евристики, що описують прийоми розв’язання задач, що базуються на досвіді експертів у даній ПРГ. Поняття евристичних правил, прийомів і методів є ключовими в теорії,
52
Г.Ф. Іванченко
творчій діяльності і креативній педагогіці. Типовим прикладом евристичного правила може служити приведена вище рекомендація про розташування коня на шахівниці.
Суб’єктивність евристик обумовлена віддзеркаленням в них особливостей уявлення предметної галузі (ПРГ) і аналізу проблемних ситуацій людиною. Звідси ж виходить правдоподібний характер більшості евристичних методів. На практиці евристики широко використовуються в СШІЕС, причому зазвичай їх застосування спрямоване на оптимізацію пошукових процедур і скорочення перебору релевантних варіантів розв’язання задач. Разом з тим, між виявленням евристичних закономірностей і створенням відповідних правил до БЗ ЕС значна «відстань». Для її подолання експерту з ПРГ й інженеру зі знань потрібно виконати такі чотири етапи. По-перше, експерт повинен сформулювати (описати) евристичний прийом. Якщо врахувати, що багато евристик фахівці використовують інтуїтивно, тобто на підсвідомому рівні, завдання не здаватиметься таким вже й тривіальним. По-друге, потрібно досліджувати сферу застосування виділеної евристики і вказати логічну умову її активації в БЗ. Ця умова визначає події, за яких пов’язане з евристикою правило почне виконуватися. По-третє, слід формалізувати саме евристичне правило, представивши його за допомогою обраної мови опису знань. І по-четверте, потрібно оцінити ступінь правдоподібності тієї евристики, щоізакладається в БЗ.
З погляду ступеня можливої формалізації розрізняють три групи евристичних методів: цілком формалізовані — алгоритми; неформалізовані на цю рівні розвитку науки — евризми; частково формалізовані, частково неформалізовані — евроритми. Зрозуміло, що основне значення під час розробки СШІ має третя група евристичних методів.
.Кажучи про евристики, не можна обійти психологічне тлумачення цього поняття. У цьому сенсі евристики інтерпретують як методи, операційні процедури, за допомогою яких людина одержує інформацію, необхідну для створення гіпотез і планів рішень, якщо останні не має наперед. Тлумачення евристик як механізмів, що регулюють процеси розумового пошуку, дає змогу співвіднести їх не тільки з рівнем процедурних знань, а й з мета- знаннями. Так, евристики можуть розглядатися як комплекс чинників, що впливають на вибір суб’єктом того або того правдоподібного міркування. Як бачимо, чотири зрізи розуміння знань взагалі мають місце і в разі евристичних знань.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
53
Останніми роками термін «знання» дедалі частіше використовують в інформатиці. Він зустрічається в таких словосполученнях, як «база знань», «банк знань», «мова подання знань», «системи подання знань», інших. Фахівці наголошують, що вдосконалення так званих інтелектуальних систем (інформаційно-пошуко- вих систем високого рівня, діалогових систем, людино-машинних систем, що базуються на природних мовах, інтерактивних, використовуваних в управлінні, проектуванні, наукових дослідженнях) багато в чому визначається тим, наскільки успішно вирішуватиметься завдання подання знань.
Визначення і класифікація знань наведено на рис. 2.1.
Джерела
знань
Види та характер знань
:'-...і.:
Стилі
Твердження
Евристики
Концепції
Стратегії
Повні І
Декларативні
Процедурні
Структурні
Параметричні
Вербальні
Математичні
Алгоритмічні
Реляційна
Предикативна
Продукційна
Лінгвістична
Проявії'Ч сутності ^
Факти
Відношення
Об’єкти
, Зв’язок
Формалізми
Функціональний
Логічний
Алгоритмічні
Об’єктні
Моделі та форми знань
Об’єктивна
Семантична
Фреймова
Універсальна
Асоціативна
Логічна
Багатошарова
Нейромережева
Рис. 2.1. Визначення і класифікація знань
Слід мати на увазі, що різкої межі між даними і знаннями немає, оскільки останні двадцять років розробники систем управління базами даних роблять їх дедалі більше схожими на знання. Прикладами можуть служити застосування семантичних мереж (формалізму для подання знань) для проектування баз даних, по-
54
Г.Ф. Іванчвнко
ява об’єктно-орієнтованих баз даних, процедур (це робить якоюсь мірою дані активними), що зберігаються, тощо. Таким чином, відмінності знань від даних, перераховані вище, з розвитком засобів інформатики згладжуються.
Джерелами знань є стислі і повні описи суті. Всі вони можуть використовуватися при формалізації знань, тобто подання їх з використанням певної формальної моделі знань, прийнятної для апаратно-програмних реалізацій. Залежно від джерела знань виділяються апріорні і накопичувальні знання. Перший вид знань визначається й закладається в БЗ до початку функціонування інтелектуальної системи.
Крім того, під час роботи з БЗ достовірність апріорних знань, що містяться в ній, не переоцінюється. На відміну від апріорних, безліч накопичувальних знань формується в процесі використання БЗ. Джерелами цих знань можуть бути експерти, зовнішні штучні пристрої-спостерігачі (різні датчики, механізми розпізнавання образів тощо), а також правила і процедури виведення і верифікації знань, що діють у межах інтелектуальної системи.
Існує багато підходів до визначення поняття «знання». На сучасному етапі домінуючою парадигмою, що лежить в основі най- відоміших моделей подання знань у системах!штучного інтелекту, можна вважати парадигму, характерну для символьного підходу. (Парадигмою називається певна сукупність ключових принципів.) Цю парадигму можна охарактеризувати як вербально-дедуктивну (або словесно-логічну), оскільки:
• будь-яка інформаційна одиниця задається вербально, тобто у формі, наближеній до словесної; у вигляді набору сформульованих тверджень або фактів;
• основним механізмом отримання нової інформації на базі існуючої є дедукція, тобто висновок «від загального до часткового». Такий дедуктивний висновок є бездоганним з логічної точки зору; в його основі лежать транзитивність імплікації (якщо з а випливає Ь, з Ь випливає с, то з а випливає с) і дія квантора узагальнення (якщо деяка властивість Р виконується для будь-якого елемента множини М, а хеМ, то Р виконується для х;
Але вербально-дедуктивне подання знань не є повним, оскільки:
• дедуктивний висновок не є єдино можливим. Мислення людини є багато в чому рефлекторним, інтуїтивним. Воно, зазвичай, спирається на підсвідомі процеси. Людина часто робить виснов¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
55
ки за аналогією, за асоціацією. Ці висновки не завжди є вірними, але вони істотно доповнюють процеси дедуктивного мислення, Провести дедуктивні логічні побудови з самого початку до самого кінця на практиці, зазвичай, неможливо. Без підсвідомого мислення стає неможливим будь-яке відкриття. Відкриття — це підсвідоме породження гіпотези, яка потім перевіряється або дедуктивним шляхом, або експериментально;
• не всі знання є вербальними. Так, жодне твердження не зберігається в пам’яті людини явно. Відомо, що в основі діяльності мозку людини лежить передача сигналів між нервовими клітинами. Часто людина не може сформулювати свої знання чітко. Наприклад, будь-хто знає, що таке гроші. Але якщо попросити людину дати визначення цього поняття, можуть виникнути проблеми. Таким чином, поняттями можна оперувати і, не знаючи чіткого визначення. Або типовими є слова: «Я не можу пояснити чому, але мені здається, що...»
Тому потрібно розвивати інші моделі знань, окрім вербально- дедуктивних.
Наприклад, у межах конекціоністського підходу можна розглядати моделі на основі однорідного поля знань. Однорідним полем знань називатимемо сукупність простих однорідних елементів, які обмінюються між собою інформацією; нові знання зароджуються на основі певних процедур, визначених над обсягом знань.
Знання про відповідні факти або поняття зберігаються полем знань вербально, якщо використання фіксованого набору процедур, визначених обсягом знань, дає змогу за реальний час отримати вербальне формулювання деякого факту або вербальний опис поняття.
Знання зберігаються полем невербально, якщо використання фіксованого набору процедур, визначені обсягом знань, дає змогу використовувати факт або поняття без отримання їх вербального опису.
Людина в своїй діяльності комбінує дедуктивні висновки з рефлекторними рішеннями. Таке комбінування має бути характерним і для розвинених інтелектуальних систем. Наприклад, можна організувати паралельне функціонування механізмів дедуктивного виведення і конекціоністських механізмів.
У межах вербально-дедуктивної парадигми можна дати таке визначення знань.
56
Г.Ф. Іванченко
Знаннями інтелектуальної системи (у вербально-дедуктивному розумінні) називаємо трійку <F, R, Р>, де F — сукупність очевидних фактів, які зберігаються в пам’яті системи, R — сукупність правил виведення, які дозволяють на основі відомих знань отримувати нові знання, Р — сукупність процедур, які визначають, яким чином слід застосовувати правила.
Базою знань (БЗ) інтелектуальної системи називатимемо сукупність усіх знань, що зберігаються в пам’яті системи.
У БЗ прийнято виділяти екстенсиональну та інтенсиональну частини. Екстенсиональна частина БЗ — сукупність усіх очевидних фактів.
Інтенсиональна частина БЗ — сукупність усіх правил виведення та процедур, за допомогою яких з наявних фактів можна виводити нові твердження.
У БЗ виділяють інтенсиональне і екстенсиональне знання. Якщо є кінцева безліч атрибутів А = {А1,А2,--,4,} і кінцева безліч відносин R = {RuR2,---,R„} , то схемою або інтенсионалом відносини Ri(l,2,...,OT) називається набір пар вигляду
INT(R,) = {...,[Aj,DOM(Aj)l...},
де DOM (Aj) — домен атрибута А, тобто безліч можливих значень атрибута. Екстенсионал відносини R, — це безліч фактів *
£ЩЯ,0Иад,..,^},
Fl,F1,...,Fp - факти eidHoctmRj, л
де Fl,F2,...,Fp — факти відносин, що зазвичай задаються у вигляді
сукупності пар «атрибут-значення». Факт конкретизує певне відношення. В графічній інтерпретації він є підграф, що має зіркоподібну структуру. Коренем підграфа є вершина предикативного типу з позначкою, відповідною імені відношення. На ребрах підграфа позначено імена атрибутів.
Інтенсиональна семантична мережа становить модельовану наочну галузь на узагальненому, концептуальному рівні, а екстенсиональна — наповнює її конкретними, фактичними даними. Таким чином, семантичну базу знань можна розглядати як сукупність об’єктів і відносин, частина з яких визначена інтенсиональ- но, а частина — екстенсионально.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
57
Приклад. Розглянемо фрагмент бази знань неформалізованого опису моделі Лотки—Вольтерра, добре відомої в екології.
Ф1. Заєць їсть траву.
Ф2. Вовк їсть м ’ясо.
ФЗ. Заєць є м’ясом.
ПІ. Якщо А є м ’ясом, а В їсть м ’ясо, то В їсть А.
П2. Якщо А їсть м ’ясо, то А є хижаком.
ПЗ. Якщо А їсть В, то В є жертвою.
П4. Якщо хижак вимирає, жертва швидко розмножується.
П5. Якщо жертва вимирає, хижак вимирає.
Літерами Ф позначені очевидні факти, які відображають елементарні знання; і їх безпосередній аналіз дає змогу експертній системі відповідати на найпростіші запитання, як-от «Вовк їсть м’ясо?». Для позитивної відповіді на це та подібні запитання досить просто знайти відповідний факт в екстенсиональній частині бази знань.
Принципово іншим є запитання «Вовк є хижаком?». Відповідь на нього простим пошуком знайти неможливо: такого очевидного факту в екстенсиональній частині бази знань немає. Тому для відповіді на це запитання необхідно застосовувати правила виведення, які дають змогу на основі очевидних фактів отримувати нові знання, тобто нові факти. Такі правила позначені у нашому прикладі літерою П. Так, для відповіді на поставлене запитання досить знання факту Ф2 і правила П2.
Безумовно, до бази знань можна було б одразу включити твердження «Вовк є хижаком». Але легко побачити, що якщо, крім вовків, розглядати інших хижаків (ведмедів, лисиць та ін.), то безпосередньо включати до бази знань очевидні факти, що вони є хижаками, недоцільно. Цікаве питання виникає стосовно статусу людини в цій базі знань. Все, що може бути виведене логічним шляхом, зазвичай, не варто оголошувати фактами.
Надалі ми називатимемо очевидні факти просто фактами, якщо це не викликатиме непорозумінь.
Нарешті, процедури визначають, яким саме чином слід застосовувати правила. Часто ці процедури є складовою частиною мови, якою програмується експертна система (це стосується, в першу чергу, спеціалізованих мов штучного інтелекту, таких як Лісп, Пролог тощо). Якщо таких процедур недостатньо, програміст має сам подбати про їх написання.
58
Г.Ф. Іванченко
За характером подавання знання можуть бути структурними або параметричними.
Структурне подавання знань характеризує відношення фактів або об’єктів.
Структура знань може змінюватися, за рахунок чого проводиться їх конкретизація під час опису заданої проблемної галузі. У динамічних БЗ структура знань може змінюватися еволюційно або адаптивно.
Параметричне Подання знань характеризується фіксованою структурою і змінними параметрами у фактах або об’єктах. Конкретизація знань під завдання здійснюється тільки налаштуванням параметрів. Частина параметрів звичайно використовується для налаштування сили зв’язків або відносин аж до їх відключення.
2.2. Концептуальні властивості знань
Внутрішня інтерпретація
Кожна інформаційна одиниця повинна мати унікальне ім’я, за яким ІС знаходить її, а також відповідає на запити, в яких це ім’я згадано. Коли дані, .що зберігаються в пам’яті! були позбавлені імен, то була відсутня можливість їх ідентифікації системою. Дані могла ідентифікувати лише програма, що витягує їх з пам’яті за вказівкою програміста, який написав програму. Що ховається за тим або тим двійковим кодом машинного слова, системі не було відомо.
Внутрішня інтерпретація знань ототожнюється з наявністю певної функції (способу) зв’язування змінних з тими або тими значеннями або інакше, способу породження пар <УІ} У/>. Така функція, або спосіб, називається також інтерпретаційною функцією (або просто інтерпретацією).
Оскільки дані — це пари виду <С„ С,>, де С — константа, суть конкретний об’єкт, то, очевидно, для них не потрібна інтер- претаційна функція (оскільки дані представляють самі себе).
Константа, очевидно, можна подати як пару <С„ С]>. Позначення <Уі, У)> із зв’язаною змінною V також є прикладом константи. Характеристики знань такі:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
59
Структурованість
Інформаційні одиниці повинні мати гнучку структуру. Для них має виконуватися «принцип стеріоскопічної антени», тобто рекурсивне вкладання одних інформаційних одиниць в другі. Кожна інформаційна одиниця може бути включена до складу будь-якої іншої, і з кожної інформаційної одиниці можна виділити деякі її складові. Іншими словами, має існувати можливість довільного встановлення між окремими інформаційними одиницями відносин на зразок частина — ціле, рід — вид або елемент — клас.
Таблиця 2.1
Прізвище
Рік народження
Спеціальність
Стаж, кількість років
Богдан
1985
Слюсар
5
Кривоніс
1986
Токар
4
Безхатько
1985
Муляр
7
Тягнибок
1987
Токар
5
Якщо, наприклад, у пам’ять ЕОМ потрібно було записати відомості про співробітників установи, наведені в табл. 2.1, то без внутрішньої інтерпретації в пам’ять ЕОМ було б занесено сукупність з чотирьох машинних слів, відповідних рядкам цієї таблиці. При цьому інформація про те, якими групами двійкових розрядів у цих машинних словах закодовані відомості про фахівців, у системи відсутні. Вони відомі лише програмісту, який використовує дані з табл. 2.1 для вирішення завдань, які постають. OLAP система не в змозі відповісти на запитання на зразок «Що системі відомо про кваліфікацію працівника Кривоніс?» або «Хто краще працює Богдан чи Тягнибок?».
Під час переходу до знань у пам’ять ЕОМ вводиться інформація про певну структуру інформаційних одиниць. У цьому прикладі вона є спеціальним машинним словом, у якому вказано, в яких розрядах зберігаються відомості про прізвище, рік народження, спеціальність і стаж. При цьому мають бути задані спеціальні словники, в яких перераховані наявні в пам’яті системи прізвища, роки народження, спеціальності і тривалості стажу. Всі ці атрибути можуть відігравати роль імен для тих машинних слів, які відповідають рядкам таблиці. За ними можна здійснювати пошук потрібної інформації. Кожен рядок таблиці буде екземпляром структури. На цей час система управління базами даних
60
Г.Ф. Іванчвнко
(СУБД) забезпечує інформаційні одиниці внутрішньою інтерпретацією, що зберігається в базі даних.
Друга характерна межа знань — рекурсивна структурованість і зв’язність. Рекурсивна структурованість визначається через поняття концепту — семантичне ціле поняття.
Поняття Р\ і Рг утворюють семантичне ціле, якщо має місце якась з перерахованих умов:
Р\ і Рг пов’язані одне з одним як відношенням і одним з його аргументів;
Р\ і Рг пов’язані одне з одним як дія і її носій, або суб’єкт;
Р\ і Рг пов’язані один з одне як функція і її аргумент (об’єкт і його властивість).
За індукцією витікає, що множина Р = {Р\, Рг,—, Р»} понять утворює семантичне ціле, якщо кожен Рі в Р{ } утворює семантичне ціле щонайменше з одним з Ру, де Р} є Р/{Рі}.
Концепт С є впорядкована множина С,-, де С,- — семантичне ціле, таке, що входить в С.
Розглянемо концепт С: «Персона Герман бере іпотечний кредит на квартиру сину». Тут можна виділити такі семантичні цілі: Сі= <Персона Герман> (об’єкт Герман; властивість — Персона)
Сг - <Герман бере іпотечний кредит> (об’єкт Герман; дія — бере) Сз= <кредит на квартиру сину> (об’єкт кредиті властивість — на квартиру сину). '
Таким чином, початковий концепт С утворений простим об’єднанням
С = Сі и С2 и Сг.
Відзначимо, що результат не залежить від порядку доданків, тобто С = Сі и С2 и Сз = Сг и Сі и Сз = Сз и Сг и Сі тощо.
Рекурсивність операції об’єднання и показується через тотожність
0иХ=Х;
{а}иХ= {а,Х};
{а, У} иІ= {а} и {Іи У}.
Зв’язність
В інформаційній базі між інформаційними одиницями має бути передбачена можливість встановлення зв’язків різного типу (не треба плутати 1-оо,оо-і,і-і,оо-оо). Передусім ці зв’язки можуть характеризувати відносини між інформаційними одиницями. Се-
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
61
мастика відносин може мати декларативний, або процедурний характер. Наприклад, дві або більше інформаційні одиниці можуть бути зв’язані відношенням «одночасно», дві інформаційні одиниці
— відношенням «причина — наслідок» або відношенням «бути поряд». Наведені відношення характеризують декларативні знання. Якщо між двома інформаційними одиницями встановлено відношення «аргумент — функція», то вони характеризують процедурне знання, пов’язане з обчисленням певних функцій.
Далі розрізнятимемо відношення структуризації, функціональні відносини, каузальні відношення і семантичні відношення. За допомогою перших задаються ієрархії інформаційних одиниць, другі несуть процедурну інформацію, що дає змогу знаходити (обчислювати) одні інформаційні одиниці через інші, треті задають причинно-наслідкові зв’язки, четверті відповідають усій решті відносин.
Між інформаційними одиницями можуть встановлюватися й інші зв’язки, наприклад, що визначають порядок вибору інформаційних одиниць з пам’яті або вказують на те, що дві інформаційні одиниці несумісні одна з одною в одному описі.
Перераховані особливості знань дають змогу запровадити загальну модель подання знань, яку можна назвати семантичною мережею, що є ієрархічною мережею, на вершинах якої знаходяться інформаційні одиниці. Ці одиниці забезпечені індивідуальними іменами. Дуги семантичної мережі відповідають різним зв’язкам між інформаційними одиницями. При цьому ієрархічні зв’язки визначаються відносинами структуризації, а неієрархічні
— відносинами інших типів.
Семантичний простір є метрикою. Ця властивість знань пов’язана з можливістю їх вимірювання в системі оцінок метрики (істинно, схибно — не істинно). У системі з нечіткою логікою використовується нескінченна множина оцінок істинності знання. Наприклад, висновок «завтра на біржі очікується курс валюти $
— 7,54 грн з ймовірністю 0,8» не є ні строго істинним, ані помилковим, тобто характеризується певним ступенем правдоподібності 0,8.
Семантична метрика. Безлічі інформаційних одиниць у деяких випадках корисно задавати відношенням, що характеризують ситуативну близькість інформаційних одиниць, тобто силу асоціативного зв’язку між інформаційними одиницями. їх можна було б назвати відношенням для інформаційних одиниць. Такі
62
Г.Ф. Іванчвнко
відношення дають можливість виділяти в інформаційній базі певні типові ситуації (наприклад, «збут російського газу на ринку України», «регулювання руху автотранспорту на перехресті вул. Хрещатик — вул. Прорізна»). Відношення релевантності під час роботи з інформаційними одиницями дає змогу знаходити знання, близькі до вже знайдених.
Активність знань
Це властивість знань адаптуватися під факти, що змінюються (тобто здібність до навчання і самокорекції). З моменту появи ЕОМ і розділення використовуваних у ній інформаційних одиниць на дані і команди створилася ситуація, за якої дані пасивні, а команди активні. Всі процеси, що протікають в ЕОМ, ініціюються командами, а дані використовуються цими командами лише в разі потреби. Для ІС ця ситуація неприйнятна. Як і в людини, в ІС актуалізації тих або тих дій сприяють знання, наявні в системі. Таким чином, виконання програм в ІС має ініціюватися поточним станом інформаційної бази. Поява в базі фактів або описів подій, встановлення зв’язків може стати джерелом активності системи.
Акцентування уваги на властивості активності знань обумовлене природним з прагматичної точки зору і штучним в психологічному сенсі поділом знань на декларативні та процедурні. За такого підходу активним, тобто що породжує нові знання, компонентом БЗ є процедурна складова, а пасивна декларативна частина використовується як сховище фактичних відомостей. Основний недолік подібної організації БЗ полягає в її невідповідності особливостям сприйняття, обробки й інтерпретації знань людським мисленням, для якого характерна активація декларативними знаннями процедурних. На практиці в процесі функціонування інтелектуальної системи вказана активація повинна мати місце в таких типових ситуаціях:
1. Під час вступу до системи нових знань має здійснюватися їх верифікація з метою узгодження нових знань і тих, що вже містяться в БЗ. Результатом цієї верифікації може бути модифікація нових знань і (або) відомостей з БЗ, генерація запиту на уточнення «сумнівних» положень чи ж повна фальсифікація інформації, що надійшла.
2. Під час пошуку відповіді на зовнішній запит у разі відсутності в БЗ релевантних «готових» знань використовуються меха¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
63
нізми виведення знань, у яких звернення до тих або тим компонентів БЗ може активувати асоційовані з ними процедури.
3. Під час автономного функціонування:
• при виявленні в БЗ застарілих відомостей виконується їх коректування (оновлення), що включає аналіз пов’язаних з ними компонентів БЗ;
• при виявленні в БЗ неповноти знань, що належать до певної ситуації, здійснюється генерація запиту на поповнення БЗ;
• при виявленні в БЗ «сумнівних» семантичних структур здійснюється їх перетворення з метою вирішення прихованих протиріч, що містяться в них;
• здійснюється формування оптимального предавання знань у БЗ з погляду частоти звернення до них, характеру зовнішніх запитів, що надходять, тощо.
На цей час практична реалізація властивості активності в БЗ переважно пов’язується з використанням структур, що об’єднують декларативні і процедурні компоненти БЗ. До подібних структур належать фрейми, слоти яких можуть асоціюватися з так званими приєднаними процедурами. У цьому сенсі перспективною є об’єктно-орієнтована парадигма.
Ще один аспект активності пов’язаний з переходом від знань, що інтерпретуються як фактичні відомості (знання-копії, знання- знайомства), до рівнів умінь і навиків. Поступове засвоєння і закріплення знань під час навчання має на меті перетворення цих знань у свого роду керівництво до дій: сукупність правил, безпосередньо використовуваних людиною в процесі ухвалення рішень. Таким чином, практичну цінність навчання правомірно пов’язати зі ступенем активності набутих знань або ступенем готовності їх застосування для здобуття нових знань.
Одна з ключових проблем, що постають під час побудови ІС, полягає в необхідності вибору і реалізації способу предання знань. Важливість цього завдання обумовлюється тим, що саме предання знань зрештою визначає характеристики системи. Використовуваний метод подання знань справляє вплив на вирішення таких питань інженерії знань, як-от отримання знань з різних джерел, від експертів, інтеграція й узгодження знань і т. ін.
Оскільки на практиці ІС створюються для вирішення не якогось одного, завдання, а безлічі завдань, формалізація знань, що лежить в їх основі, також має бути досить універсальною, тобто придатною для адекватного опису сукупності типових проблем¬
64
Г.Ф. Іванчвнко
них ситуацій. Співвідношення способу формалізації з класом типових проблем дає змогу казати про доцільність виділення знань про предметну (або проблемну) галузь, що відображають і загаль- ноздійсненні закони і правила, і специфіку об’єктів цієї ПРГ.
Функціональна цілісність
Під функціональною цілісністю знань розуміється їх несупе- речність, незалежність початкових посилань і вирішуваність. Оскільки поняття несуперечності і вирішуваності є фундаментальними поняттями логіки, то їх розгляд винесений у самостійні підрозділи. Обмежимося вказівкою на те, що несуперечність знань означає неможливість появи в базі знань двох взаємовиключних фактів ф і ф (на зразок «банк працює» чи «банк не працює — банк банкрут»). Хоча принципово можливі міркування на основі суперечливих посилань, оскільки на цей час не існує розвиненої теорії для цього випадку. Тому ми дотримуємося вимог класичної логіки.
Вимога вирішуваності полягає в тому, що будь-яке справжнє знання, що формалізується в базі знань системи, може бути виведено в ній за допомогою машинного висновку. Вимога вирішуваності, на жаль, не завжди здійснима.
СитуативнісПіь, незалежність, спільність
Наявність ситуативних зв’язків визначає сумісність тих або тих знань, що зберігаються в пам’яті. Як такі зв’язки можуть виступати відношення часу, місця, дії, причини й ін. Для нас важливі моделі подання знань в ЕОМ. Незалежність означає неможливість виведення єдиного знання з іншого у формальний спосіб.
Отже, одна з вимог подання знань — спільність, або відносна (в рамках вибраної) універсальність. Наступна подібна вимога полягає в застосуванні психологічного, інтуїтивно зрозумілого людям (експертам і користувачам системи) подання знань. Відмітимо, що більшість розглянутих вище концептуальних властивостей знань (структурний підхід, активність) були визначені на підставі аналізу психологічних аспектів природного мислення. Проте 100-відсоткове дотримання цієї вимоги неможливе, оскільки ЕОМ, оброблювані знання оперують з ними у внутрішньому, жорстко структурованому уявленні. Таким чином, потрібно забезпечити перетворення знань з внутрішнього в зовнішнє (призначене для користувача) уявлення і навпаки. В сучасних СІНІ ці
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
65
функції виконує інтерфейсний модуль, що реалізовує методи природно-мовного діалогу і візуалізації інформації, включаючи застосування мнемонічних схем, іконних образів (піктограм), ког- нітивної графіки і т. ін. Розвиток інтелектуальних інтерфейсів також пов’язаний з використанням мультимедіа-технології і системи віртуальної реальності.
Однорідність
Наступна важлива вимога до представлення знань — однорідність. Однорідне подання призводить до спрощення механізму управління логічним висновком і спрощення управління знаннями. Практично однорідність пов’язується з уніфікацією типів (одиниць) знань (понять, властивостей, відносин), введенням системи їх ієрархічних класифікацій, впорядкуванням зовнішніх запитів тощо.
В історичному плані можливість практичного застосування знань виникла разом з появою механізму логічних висновків, а механізм висновків, у свою чергу, був визначений з подання знань. Таким чином, для того, щоб система обробки знань забезпечувала реалізацію заданих функціональних потреб, потрібно створити відповідне подання знань. Сказане вкотре ілюструє щонайтісніший взаємозв’язок питань уявлення і обробки (використання) знань. Фактично до подання знань як напряму ІІІІ традиційно відносять завдання перевірки вмісту БЗ на несуперечність і повноту (верифікація знань), на поповнення БЗ за рахунок логічного висновку на основі наявних в базі знань, узагальнення і класифікації знань [10].
Диференціація ментальних уявлень людини і формально- логічного подання знань служить фундаментом для виділення поняття моделі знань, що визначає спосіб формального опису знань у БЗ. Модель — об’єкт, реальний, знаковий або уявний, відмінний від початкового, але здатний замінити його при вирішенні завдання. Вона визначає форму подання знань у БЗ.
Перераховані особливості інформаційних одиниць визначають ту межу, за якою дані перетворюються на знання, а бази даних переростають у бази знань. Сукупність засобів, що забезпечують роботу із знаннями, утворює систему управління базою знань (СУБЗ).
Нині не існує баз знань, у яких повною мірою були б реалізовані внутрішня інтерпретація, структуризація, зв’язність, введено семантичний ступінь і забезпечено активність знань.
66
Г.Ф. Іванченко
2.3. Моделі подання знань
Центральним питанням побудови систем, заснованих на знаннях, є вибір форми подання знань. Подання знань — це спосіб формального виразу знань про наочну галузь (ПРГ) у комп’ютерній формі, що інтерпретується. Відповідні формалізми, які забезпечують вказане уявлення, є моделями подання знань.
Подання знань і пошук рішень утворюють ядро штучного інтелекту. Поняття «знання» різними вченими тлумачиться по- різному і багато в чому має дискусійний характер. Ми розглянемо найпоширеніше тлумачення цього поняття.
Для формалізації задавання знань у системах штучного інтелекту необхідні певні формалізми, які називаються моделями задавання знань, або просто моделями знань.
Моделлю знань називаємо фіксовану систему формалізмів (понять і правил), відповідно до яких інтелектуальна система подає знання в своїй пам ’яті та здійснює операції над ними.
Модель знань є поданням системи знань за допомогою певного формалізму, універсального математичного апарату для коректного формального опису й побудови процедури розв’язування задачі. Можуть використовуватися такі формалізми, як функціональний, заснований на Х-обчисленнях, логічний — на численні предикатів першого порядку, алгоритмічний — на базі формальної машини Тюринга і об’єктний — на базі теорії факторів тощо.
Модель подання знань повинна відображати істотні характеристики розв’язуваної задачі і забезпечувати відповідною інформацією процедури, як виконують пошук рішень. При цьому вона повинна мати необхідну виразну здатність відображати всі деталі ПРГ задачі, що цікавлять, а також бути досить ефективним рішенням, який розглядають як висновок, що базується на знаннях. Виразна сила і обчислювальна ефективність — дві основні характеристики моделей подання знань. Багато моделей подання знань, що характеризуються чималими виразними можливостями, не піддаються ефективній реалізації. Тому пошук оптимального співвідношення між виразною моделлю подання знань, що використовується, і ефективністю її реалізації—основне завдання розробника СШІ.
Моделі задавання знань необхідні:
• для створення спеціальних мов описів знань і маніпулювання ними;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
67
• для формалізації процедур співставленим нових знань з уже існуючими;
• для формалізації механізмів логічного виведення. Як уже зазначалося раніше, найбільш розвиненими на сучасному етапі є моделі задавання знань, які ґрунтуються на вербально-дедуктив- ній парадигмі.
Вербально-дедуктивні моделі задавання знань мають багато спільного. Можна вважати, що всі вони мають єдину концептуальну основу.
При цьому основними вимогами до подання знань є однорідність, простота розуміння, несуперечність і повнота.
Підбиваючи підсумки аналізу проблеми подання знань, виділимо дев’ять ключових вимог до моделей знань:
1) спільність (універсальність);
2) «психологічна» наочність подання знань;
3) однорідність;
4) реалізація в моделі властивості активності знань;
5) відкритість та відвертість БЗ;
6) можливість відображення в БЗ структурних відносин об’єктів ПРГ;
7) наявність механізму проектування знань на систему семантичних шкал;
8) можливість оперування нечіткими знаннями;
9) використання багаторівневого подання (дані, моделі, мета- моделі, метаметамоделі тощо).
Жодна з моделей знань не задовольняє всім дев’яти вимогам. Сказане підтверджує актуальність розробки методики побудови комплексних багаторівневих моделей представлення ПРГ, які забезпечували б можливість реалізації властивостей, відповідних вказаним вимогам.
Моделі подання знань можна умовно розділити на декларативні і процедурні. В декларативних моделях знання представляють у вигляді описів об’єктів і відносин між об’єктами без явної вказівки, як ці знання обробляти. Такі моделі припускають відокремлення описів (декларацій) інформаційних структур від механізму висновку, що оперує цими структурами. В процедурних моделях знання подаються алгоритмами (процедурами), які містять потрібні описи інформаційних елементів і одночасно визначають способи їхньої обробки.
68
Г.Ф. Іванченко
2.4. Логічна форма моделі знань та формальна система
Система ШІ в певному значенні моделює інтелектуальну діяльність людини і, зокрема, логіку його міркувань. У спрощеній формі наші логічні побудови зводяться до такої схеми: з однієї або кількох посилань (які вважаються істинними) слід зробити «логічно істинний» висновок. Очевидно, для цього потрібно, щоб і посилання, і висновок були подані зрозумілою мовою, що адекватно відображає наочну галузь, у якій робиться висновок. У звичайному житті це наша природна мова спілкування, в математиці, наприклад, це мова певних формул тощо. Наявність мови припускає, по-перше, наявність алфавіту (словника), що відображає в символьній формі весь набір базових понять (елементів), з якими муситимо мати справу і, по-друге, набір синтаксичних правил, на основі яких, користуючись алфавітом, можна побудувати певні вирази.
Логічні вирази, побудовані в цій мові, можуть бути істинні або помилкові. Деякі з цих виразів, що є завжди істинними, оголошуються аксіомами (або постулатами). Вони становлять ту базову систему посилань, виходячи з якої і користуючись певними правилами висновку, можна одержати виснрвки у вигляді нових виразів, що також є істинними. і
Логічна форма асоціативної моделі знань заснована на використанні у вузлових елементах мережі логічних обчислювальних базисів: предикативного, продукційного, семантичного. Найчастіше процесування інформації в елементах мережі здійснюється в нечітко-логічному, імовірнісно-логічному базисах. При цьому у вузлах обчислюються оцінки у вигляді ступенів приналежності до нечітких множин або вірогідності фактів-подій з урахуванням сили коннекцій. Такі системи знаходять застосування при управлінні динамічними об’єктами, розпізнаванні образів і т. ін.
Логічні моделі реалізуються засобами логіки предикатів. У цьому разі знання про наочну галузь подаються у вигляді сукупності логічних формул. Тотожні перетворення формул дають змогу одержувати нові знання. Перевагою логічних моделей знань є наявність чіткого синтаксису і поширеної формальної семантики, а також теоретично обгрунтованих процедур автоматичного висновку. Основним недоліком цих моделей є неможливість отримання висновків у галузях, де потрібні правдоподібні висно¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
69
вки, коли результат виходить з певною оцінкою упевненості в його істинності. Окрім цього, такі моделі характеризуються монотонним характером висновку, тобто в базу знань додаються тільки істинні твердження, що унеможливлює суперечності. На практиці часто зустрічаються немонотонні міркування, які важко реалізувати в рамках логічної моделі.
Проте логічні моделі виступають я£ теоретична основа опису самої системи подання знань і поступово розширюють свої можливості. Тому цим моделям надається значна увага.
Якщо перераховані умови виконуються, то кажуть, що система задовольняє вимогам формальної теорії. Її так і називають — формальною системою (ФС). Система, побудована на основі формальної теорії, називається також аксіоматичною системою.
В основі логічних моделей подання знань лежить поняття формальної системи. Формальна система задається четвіркою:
М = {Т,Р,А,Щ, де Т — множина базових елементів; Р — множина синтаксичних правил; А — множина аксіом; і? — множина правил висновку. З’ясуємо суть елементів, які створюють ФС.
Множина Т складається з скінченного або нескінченного числа елементів різної природи. Елементи множини Т — алфавіт ФС, на основі якого будується вся решта складових частин ФС. На безліч Т жодних обмежень не накладається. Важливо тільки, щоб для Т існувала процедура перевірки приналежності деякого елемента множини Т.
Множина синтаксичних правил Р дозволяє будувати з базових елементів Т синтаксично правильні сукупності базових елементів. На множину синтаксичних правил також не накладається особливих обмежень. Потрібно тільки, щоб існувала конструктивна процедура, яка дозволяла б за певну кількість кроків дати однозначну відповідь на запитання, чи є ця сукупність елементів з Т є синтаксично правильною. Такі сукупності називають правильно побудованими формулами (ІШФ).
Обчислення висловів і обчислення предикатів (ОП) є класичними прикладами аксіоматичних систем. Ці ФС добре досліджені і мають чудово розроблені моделі логічного висновку — головної метапроцедури в інтелектуальних системах. Тому все, що може й гарантує кожна з цих систем, гарантується і для прикладних ФС як моделей конкретних наочних галузей ПРГ. Зокрема, це гарантії несуперечності висновку, алгоритмічної вирішуванос- ті (для обчислення висловів) і напіввирішуваності (для обчислення предикатів першого порядку).
70
Г.Ф. Іванчвнко
ФС мають і недоліки, які примушують шукати інші форми подання. Головний недолік — це закритість ФС, негнучкість. Модифікація і розширення тут завжди пов’язані з перебудовою всієї ФС, що для практичних систем складно і трудомістко. В них проблематично враховувати зміни, що відбуваються. Тому ФС як моделі подання знань використовуються в тих наочних галузях, які добре локалізуються і мало залежать від зовнішніх чинників.
Р є безліччю синтаксичних правил. За їх допомого за участю елементів Т утворюють синтаксично правильні сукупності. Наприклад, із слів обмеженого словника будуються синтаксично правильні фрази, з інтегральних схем за допомогою роботизованих САПР-технологій збираються нові ЕОМ. Декларується існування процедури П(Р), за допомогою якої за скінченне число кроків можна одержати відповідь на питання, чи є сукупність X синтаксично правильною.
У множині синтаксично правильних сукупностей виділяється певна підмножина А. Елементи А називають аксіомами. Як і для інших складових формальної системи, має існувати процедура П(А), за допомогою якої для будь-якої синтаксично правильної сукупності можна одержати відповідь на питання приналежності її до безлічі А.
Я є кінцевою множиною відношень між ІЦПФ. Застосовуючи їх до елементів А, можна одержувати нові синтаксично правильні сукупності, до яких знову можна застосовувати правила з Я. Так формується безліч тих, що виводяться в цій формальній системі сукупностей. Якщо є процедура П(Я), за допомогою якої можна визначити для будь-якої синтаксично правильної сукупності, чи є вона такою, що виводиться, то відповідна формальна система називається вирішуваною. Це показує, що саме правило висновку є найскладнішою складовою формальної системи.
Для знань, що входять у базу знань, можна вважати, що множину А утворюють всі інформаційні одиниці, які введено в базу знань ззовні, а за допомогою правил висновку з них виводяться (створюються) нові похідні знання. Іншими словами, формальна система є генератором породження нових знань, як створюють безліч знань, що виводяться в цій системі. Така властивість логічних моделей робить їх привабливими для використання в базах знань, дозволяє зберігати в базі лише ті знання, які утворюють безліч А, а всю решту знань одержувати з них за правилами висновку.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
71
Серед усіх ППФ виділяють деяку підмножину аксіом А. При цьому має існувати процедура, що дозволяє для будь-якої ППФ вирішити питання, чи є вона аксіомою цієї ФС.
Нарешті, множина К — це кінцева сукупність відносин між ППФ, які називають правилами висновку. Правило висновку — це відношення на множині формул. Якщо з формул без¬
посередньо виводиться формула її, то це часто записується у вигляді:
^ ’
де формули РІ,Р2,...,РП називаються посиланнями правша, а .Р — його наслідком (висновком).
Застосовуючи правила висновку до множини аксіом А, можна одержувати нові ППФ, до яких можна знову застосувати правила з множини і?. Це дозволяє здійснювати виведення нових ППФ. Множину Я називають також сукупністю семантичних правил. А множина ППФ, одержувана після використання правил до аксіом, називається множиною семантично правильних сокупностей.
Висновком формули В з формул Аі А2,...,А„ називається послідовність ППФ Р„Р2 Рт, така, що Рт=В, а для будь-кого і
(\<=і<=т) формула є або аксіома ФС, або одна з початкових формул АиА2,...,Ап, або безпосереднє слідство формул Р„Р2,...,РІ_1,
одержане за допомогою правил висновку. Деяка ППФ Р є виве- денною у ФС (є теоремою ФС), якщо існує висновок, у якому останньою формулою є К Скорочено висновок Р з Рх,Р2,...,Рп будемо запишемо у вигляді Р1,Р2,...,Р„ |— Р. Якщо є ефективна процедура, що дає можливість по цій ППФ і7 встановлювати, чи існує її висновок у ФС, то ця ФС називається вирішуваною, інакше — нерозв’язною.
Привабливим у ФС з погляду подання знань є те, що її можна розглядати як генератор нових знань. У цьому разі з безлічі аксіом А, що є знаннями, які спочатку зберігаються в базі знань ШІ, виводяться за допомогою правил висновку похідні знання [21]. Для цього машина висновку аналізує внутрішнє подання знань у пам’яті ЕОМ. Виділені в пам’яті ЕОМ ланцюжки символів, що подають конкретні знання про предметну галузь, називають об¬
72
Г.Ф. Іванченко
разами, а ланцюжки символів, відповідні посиланням правил, — зразками. Якщо образ і зразок зпівставити, то в базу знань додається новий елемент знань — висновок правила.
Розглянемо два класи ФС, що широко використовуються в системах штучного інтелекту: числення висловів і числення предикатів. Числення предикатів є розвитком числення висловів і включає його повністю як складову частину. Ці системи використовують модель дедуктивного висновку, тобто висновку, за якого із заданої системи посилань за допомогою фіксованого набору правил формуються власні висновки.
Щоб з’ясувати зміст цих формалізмів, розглянемо введену логічну модель як приклад аксіоматичної системи.
Як множина базових елементів Т тут використовуються елементи мови логіки предикатів: змінні, константи, функціональні і предикативні символи і допоміжні знаки.
Як множина правил Р побудови правильних (складних) об’єктів логіки предикатів виступають правила побудови формул логіки предикатів.
Відмінними рисами логічних моделей є єдиність теоретичного обґрунтування і можливість реалізації системи формально точних визначень і висновків. Основними завданнями, що вирішуються на логічних моделях, є такі: |
• встановити1' або спростувати можливість виведення деякої формули (у загальному випадку це завдання алгоритмічно неви- рішуване);
• доказ повноти/неповноти деякої формально логічної системи, представленої безліччю логічних формул;
• встановлення здійснимості системи логічних формул (знаходження інтерпретаційної функції) або відшукання контрприк- ладу, що спростовує їх;
• визначення наслідків із заданої системи формул;
• доказ еквівалентності двох формально-логічних систем;
• пошук вирішення завдання на основі доведення теореми існування рішення й ін.
Позитивними рисами логічних моделей знань загалом є:
• високий рівень формалізації, що забезпечує можливість реалізації системи формально точних визначень і висновків;
• узгодженість знань як єдиного цілого, що полегшує розв’язання проблем верифікації БЗ, оцінки незалежності і повноти системи аксіом тощо;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
73
• єдині засоби опису знань про ПРГ, а також способів рішення задач у цій галузі, що дозволяє будь-яке завдання звести до пошуку логічного виведення деякої формули в тій або тій ФС.
Відзначимо такі недоліки логічних моделей. По-перше, подання знань у таких моделях ненаочне: логічні формули важко читаються і сприймаються. По-друге, обмеження числення предикатів першого порядку не допускають квантифікації предикатів і використанні їх як змінних. По-третє, обґрунтованість позначення властивостей і відносин однотипними пропозиційними функціями викликає сумнів. Нарешті, по-четверте, опис знань у вигляді логічних формул не дає змоги виявитися перевагам, які є за автоматизованої обробки структур даних.
Шляхи підвищення ефективності логічних моделей знань пов’язані з використанням багаторівневих і спеціальних логік.
2.5. Числення висловів
Простою логічною моделлю є числення висловів. Аксіоматичний базис числення висловів становить сукупність правильно побудованих формул, що є тотожно ІСТИННИМИ). До системи аксіом висувають вимоги несуперечності, незалежності і повноти. Названим вимогам задовольняє система з чотирьох аксіом, запропонована Д. Гильбертом.
Числення висловів є одним з початкових розділів математичної логіки, основою для побудови складніших формалізмів. У практичному плані числення висловів застосовується в ряді ПРГ (зокрема, при проектуванні цифрових електронних схем). Проте як самостійна модель знань логіка висловів бідна на виразні засоби: її можливостей досить лише для опису зв’язків між висловами, що розглядаються як неподільне ціле. За допомогою подібного логічного числення не можна формалізувати висновки, в яких істотне значення має внутрішня логічна структура думок, що їх створюють.
Розвиток логіки висловів знайшов віддзеркалення в численні предикатів першого порядку. В основі числення предикатів лежить ототожнення властивостей і відносин з особливими функціями, які називають логічними, або пропозиційними. Аргумента¬
74
Г.Ф. Іванченко
ми препозиційних функцій (або предикатів) є терми, відповідні об’єктам-носіям властивостей і відносин, а значеннями цих функцій можуть бути істина або брехня. У разі вираження властивості істина інтерпретується як факт приналежності цієї властивості терму-аргументу, брехня позначає заперечення цього факту.
Висловом називається пропозиція, зміст якої можна оцінити як істинний або помилковий. У природних мовах вислови виражаються оповідними пропозиціями. Наприклад, «Сьогодні банк працює з 10-00», «П’ять менше за три» і т. ін. Вислови позначаються прописними пропозиційними (лат. ргоровШо — пропозиція, вислів) латинськими буквами А,В,С, ... Х,У,2. Пропозиційні букви можуть приймати два значення: істина (1) і неправда (0). Значення 1 і 0 називають істиноносними значеннями.
На основі заданих висловів за допомогою логічних зв’язків (союзів) утворюються складні вислови. Вказані зв’язки висловлюються в природній мові «і», «або», «якщо..., то...», «невірно, що А» і називаються: кон’юнкція, диз’юнкція, імплікація і заперечення. Для позначення цих зв’язок використовуються спеціальні символи, відповідно: л, V, -», А (або -А) Кожну логічну зв’язку можна розглядати як операцію, яка з простих висловів утворює складний. 1
Результати використання логічних операцій до простих висловів визначаються за допомогою таблиць істинності. Таблиця 2.2 визначає прості складові вислови, утворені за допомогою логічних операцій.
Таблиця 2.2
ТАБЛИЦЯ ІСТИННОСТІ ПРОСТИХ ВИСЛОВІВ
А
В
А
АлВ
Av В
л->в
А<г>В
0
0
1
0
0
1
1
0
1
1
0
1
1
0
1
0
0
0
1
0
0
1
1
0
1
1
1
1
Тут вислів А->В читається: «якщо А, то В» (інше позначення Л=>В. Наприклад, імплікацією буде вислів: «Якщо проект привабливий (А), то можно інвестувати (В)». В імплікації перший елемент А називається антецедентом (лат. antecedens — поперед¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
75
ній), а другий елемент В — консеквентом (сопвеяиепв — подальший). Вислів А <-» В називається подвійною імплікацією (еквіва- ленцією) і читається «якщо і тільки якщо А, то В». Це вислів істинний тоді і тільки тоді, коли А і В мають одне і те саме істинне значення. Еквіваленцією буде такий вислів: «Клієнт отримає страховий платіж (А), тоді і тільки тоді, коли настане страховий випадок (В)». Для позначення еквіваленції використовується також знак =.
Складні вислови, складені з початкових висловів (що позначаються пропозиційними буквами) і знаків логічних операцій, називають формулою. Так, вислів «Якщо ЗО ділиться на 2 і на З, то ЗО ділиться на 6» можна записати у вигляді формули АлВ-+С. Ця формула відповідатиме не тільки конкретному вислову, згаданому вище, але й безлічі інших висловів, що мають подібну структуру. Тому числення висловів не розглядає конкретний зміст, а займається аналізом і синтезом формул і вивченням відносин між формулами.
Множина базових елементів Т числення висловів складається з:
1) пропозиційних змінних—А, В, С,...;
2) логічних констант — «істина» (1) і« неправда» (0);
3) символів логічних операцій — л,у,-і;
4) дужок — 0-
ППФ числення висловів визначаються за допомогою таких правил:
1) будь-яка пропозиційна буква є ППФ;
2) логічні константи 1 і 0 — це ППФ;
3) якщо ^ та F2 ППФ, то л V ,Г, -> ,Р, ++Р2, —
також ППФ;
4) інших правил створення ППФ немає.
Правила 1) і 2) визначають елементарні формули (атоми), а правило 3) указує, як з елементарних формул будувати нові формули.
Нехай формула F складається з атомів А, А2 А„. Під інтер¬
претацією формули розумітимемо приписування атомам АІ А2,...,А„ істиних значень. Якщо у формулі є п різних атомів, то
можна задати 2” інтерпретацій формули.
Серед формул числення висловів виділяють формули, які істи- нинні в усіх інтерпретаціях. Ці формули називаються тавтологія- ми, або загальнозначущими формулами. Прикладами тавтологій є:
А V А, А а А. Щоб у цьому переконатися, необхідно скласти таб¬
76
Г.Ф. Іванчвнко
лиці істинності. Для вказівки того, що формула є тавтологією, використовується знак |=. Наприклад, |= (А -> В) л {В -» С) л А С.
Формула числення висловів називається суперечністю, якщо вона приймає значення «неправда» в усіх інтерпретаціях. Прикладом суперечності є Ал А.
Тавтології виконують особливу роль у численні висловів. Різні підстановлення в тавтологію, незалежно від їх конкретного змісту, завжди дають істинні вислови. Тому тавтології розглядають як логічно істинні схеми міркувань, які виконують роль законів числення висловів. Зрозуміло, що завжди можна встановити, чи є ця формула тавтологією, побудувавши її таблицю істинності. Водночас, формула не є тавтологією, якщо вона приймає значення «неправда» хоча б на одному наборі значень змінних. Ця обставина використовується для розпізнавання тавтологій методом зворотного міркування, який полягає в пошуку таких значень змінних, за яких формула виявляється помилковою.
Дотепер вводилися поняття, що стосуються тільки окремих формул. У численні висловів також розглядаються відносини між двома і більше формулами. Визначимо відношення рівносильно- сті і логічного проходження.
Дві формули називають рівносильними (еквівалентними), якщо вони приймают^ однакові значення на всіх наборах вхідних у них змінних (інтерпретаціях). Для позначення рївносильності застосовується знак <=> (або знак тотожності =, або знак рівності =), наприклад, ^ <=> ^. Дві формули рівносильні, якщо їх подвійна імплікація (еквіваленція) — тавтологія. Скорочено це
записується у вигляді: 1= ^ <->• Наприклад, подвійна імплікація (А-> В) <-> (А V В) має завжди істинне значення, тобто 1= (А -> В) (А V В). Отже, імплікація може бути виражена через диз’юнкцію і заперечення: (А->В)о(АуВ).
Відношення рівносильності дає можливість виражати одні логічні операції через інші. Наприклад, еквівалентні такі формули
(закони де Моргана): _ _
Av В о А лВ,
АлВо А VВ .
Відзначимо, що ці записи не є формулами числення висловів, оскільки знак <=> не входить до множини Т. Ці записи є вислова¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
77
ми про формули логіки, вираженими метамовою, на якій вивчається логіка.
Процес дедуктивного висновку базується на понятті логічного проходження. Формула В є логічним результатом формули А (пишуть А => В або А |= В), якщо В — істинна на всіх наборах значень змінних (інтерпретаціях), на яких істинна А. Можна показати, що А => В, якщо і тільки в цьому разі імплікація А->В є тавтологією, тобто І=А->В. Іншими словами, з істинності А завжди випливає істинність В, але якщо А помилкове, то стосовно В нічого не можна стверджувати. Поняття логічного результату можна узагальнити як сукупність висловів: А, л Аг л • • • л Ап => В, тобто В логічно виходить з істинних висловів А„А2---А„. іншими словами, і? виводиться з АІ,А2---Ап, тобто АІ,А2---Ап |-5.
Можна також показати, що формула В є логічним результатом послідовності формул АІ,А2---Ап тоді і тільки тоді, коли формула
А1лА2л---лА„лВ є суперечністю. Таким чином, доказ того, що формула В є логічним результатом кінцевої послідовності формул А,,А2---А„, зводиться до доказу загальнозначущої формули
А, лА2л---лА„ -» В або доказу суперечливості формули.
Для доказу загальнозначущої формули необхідно показати, що в будь-якій інтерпретації, в якій істинні Аі,А2-- А7і , В також істинне. Якщо у формулі є п змінних, то необхідно побудувати таблицю істинності на 2” входів, що приведе до експоненціального зростання часу обчислення залежно від п. Тому на практиці частіше застосовують другий спосіб, відповідний методу зворотного міркування.
Завданням висновку є утворення з деякої сукупності початкових тавтологій нових формул, які також є тавтологіями. Існує нескінченна множина тавтологій, а отже і законів логіки висловів. Тавтології формують систему аксіом числення висловів (множина А у визначенні ФС). Загалом, не всі загальнозначущі формули можуть бути виведені з довільної множини тавтологій. Водночас доведено, що можна обрати таку систему початкових тавтологій (аксіом числення висловів), з яких виводяться всі загальнозначущі формули. Множина аксіом — це формули, істинність яких постулюється без доказу. Постулати логіки предикатів мають вигляд схем аксіом. Схема аксіоми — це математичний вираз, який дає конкретну аксіому кожного разу під час підставлення замість якоїсь букви однієї і тієї ж формули.
78
Г.Ф. Іванченко
Найчастіше використовують систему аксіом логіки предикатів П. С. Новикова [20]:
1) А—►(В—t А)]
2) {а —у (в —^ с)) —► —> в) —> [а —► с)):
3) (АлВ)-їА ;
4) (АлВ)->В;
5) (А->(В->(АлВ)));
6) А —► (A v В) J
7) B->(AvB);
8) (Л->С)-»((Я->С)-»((^ £)-►<:));
10) .
Ця система аксіом має такі важливі властивості: повноту, не- суперечність і незалежність. Теорема про повноту числення висловів затверджує, що якщо ППФ А загальнозначуща, то вона є тією, що виводиться. Несуперечність означає, що в численні висловів не виводяться ніякі дві ППФ, одна з яких є запереченням другої. І нарешті, незалежність системи аксіом означає, що жодна аксіома не виводиться з решти аксіом.
Множина правил висковку R числення висловів задається двома правилами: правилом підставлення і правилом висновку.
Правило підставлення. Якщо Ф —формула, що виводиться (тавтологія), та містить букву А, то, замінивши в ній скрізь букву А на довільну ППФ В, одержимо формулу, що також виводиться (тавтологію). Правило можна записати у вигляді:
Ф(А)
Ф(В)
Як основні правила висновку в логіці предикатів використовуються правила modus ponens і generalization.
Правило висновку (modus ponens). Якщо А і А -> В — формули (тавтології), що виводяться, то В — також тавтологія. Це правило стверджує, що якщо істинні формули А і А В, то істинна формула В записується у вигляді:
А,А->В
В
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
79
Відзначимо, що це правило висновку є певною схемою, в якій символи А і В розглядаються як метазмінні, що допускають замінна інші ППФ.
Правило generalization: Є -» А(х) Справедливе і зворотне
С -> ЧхА(х)
С —*УхА(х) и
——— у ■ за умови, що С не містить змінної х. Це останнє правило важливе за реалізації найбільше вживаного резолютивного висновку, із змістом якого ми познайомимося пізніше.
Зокрема, якщо С — порожня формула, то має місце .
Приклад правила generalization:
(х + 5)2 =х2 +10х + 25 Vx((x + 5)2 =х2 +10х + 25)
Наприклад, така формула є правильно побудованою:
(Vx(3>'(3z(/>(x,у) —> (z))))), тоді як об’єкт (де -» Р(х,у)) v (3z((z))) не Є правильно побудованою формулою.
Відзначимо, що правила висновку в логіці предикатів не вичерпують безлічі відомих правил висновку. Проте правила висновку мають інший семантичний зміст.
У численні висловів часто застосовують додаткові правила висновку, які значно скорочують шлях доказу теорем. Наприклад, правило силогізму.
(А -» В),(В -» С)
А->С
Під час доказу широко використовується певний клас ППФ, які мають назву пропозиції Хорна. Пропозиції Хорна мають вигляд: Ах л А2 л ... л А„ В .
Є дві важливі власні форми пропозицій Хорна:
1) якщо В помилкове, то для загальнозначущої пропозиції Хорна вірне A, v А2 v • • • v Ап (ця пропозиція містить тільки негативні атоми);
2) коли п=1 та А і =true, одержуємо пропозицію true-»Я, яка еквівалентна атомарному істинному вислову В (ця пропозиція складається тільки з одного позитивного атома).
80
Г.Ф. Іванчвнко
Не кожну БЗ можна подати пропозиціями Хорна. Але в тих випадках, коли це можливо, використовуємо просту процедуру висновку, засновану на правилі modus ponens. Ця процедура має застосовувати modus ponens поки не припинять утворюватися нові пропозиції.
Використання правил висновку для отримання слідств спирається на властивість монотонності числення висловів. Припустимо, що в БЗ накопичено певну множину істинних висловів М, (формул), з якої виводиться вислів (формула) А. Монотонність означає, що додавання в БЗ нової множини висловів (формул) М2 , що виводяться, не вплине на той, що виводиться А,
тобто якщоМ{ 1-А, то {А/, uМ2) І-А.
Іншими словами, за такого логічного висновку всі істинні вислови залишаються істинними, а помилкові — помилковими. Висновок нового вислову не вимагає повернення до попередніх кроків висновку і зміни істинних значень раніше одержаних висловів.
Відзначимо такі основні властивості для відношення виведення.
1. Рефлективність: —.
Ф
2. Транзитивність:
І
і_ Ф_ і
<р ’ у
У
(якщо ф ВИВОДИТЬСЯ З Є І у 3 ф виводиться, то з є виводиться формула у).
3. Монотонність:
е_ ф Є. У ф
(якщо з є виводиться фррмула ф, то приєднання до є формули у не скасовує виведення ф). Відзначимо, що властивість монотонності в загальному випадку не має місця в деяких некласичних логіках.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
81
4. Теорема дедукції:
Якщо з є і у виводиться формула <р, то з є виводиться формула у —> Ф (—» — імплікація):
е»У
Ф
Е
У -> ф
Вірна також зворотна теорема:
е
У -» Ф є. У
Ф
Теорема дедукції має дуже важливе значення в логіці.
І нарешті зазначимо, що числення висловів — це розв’язна формальна система. Це витікає з теореми про повноту числення висловів, яка затверджує, що в численні висловів виводиться будь-яка за- гальнозначуща ГШФ. Отже, якщо ця формула загальнозначуща, то вона виводиться в числення висловів. Якщо це не так, то формула не належить до множини семантично правильних формул.
2.6. Числення предикатів
Логіка предикатів деякою мірою спеціальний математичний апарат формалізації людського мислення. Тому вважають, що мови програмування логічного типу є найбільш зручними для роботи з базами знань.
Алфавіт числення предикатів утворюється за рахунок додавання до алфавіту числення висловів символів предикатів, наочних змінних і констант, а також кванторів спільності й існування. Останні два символи відповідають операторам, що дають змогу уточнити обсяг класу об’єктів, на які поширюється дія того або того предиката. Квантор, розташований перед одномісним предикатом, що містить змінну як аргумент, перетворює цей предикат на вислів, що має певне істинне значення.
Безліч аксіом числення предикатів ґрунтується на сукупності аксіом логіки висловів, до яких додаються аксіоми, що характе¬
82
Г.Ф. Іванчвнко
ризують квантори. Аналогічно, безліч правил виведення числення предикатів базується на правилах виведення числення висловів.
Подання знань у рамках логіки предикатів служить основою напряму ШІ, що має назву логічне програмування [16—18]. Методи логічного програмування на цей час широко використовуються на практиці прй створенні ІС у ряді ПРГ.
Числення висловів характеризується обмеженими можливостями для подання знань. Пояснюється це тим, що в численні висловів розглядаються логічні зв’язки тільки між твердженнями, а сама структура тверджень не аналізується. Тому в численні висловів не можна встановити зв’язок між тим, про що йде мова (об’єкт), і тим, що повідомляється про цей об’єкт (предикат). Числення предикатів розглядає логічні зв’язки між різними елементами тверджень.
Предикатом називають неоднорідну двозначну логічну функцію від будь-якого числа аргументів. Її записують у вигляді Р{хх.х2 .---,х„) і називають и-розмірним предикатом. Тут аргументи (я,.х2у,хп) належать до однієї й тієї самої або до різних множин, що становлять об’єкти предметної галузі. Аргументи (хх.хг ---,х„) називають ^(предметними) наочними змінними, а їх конкретні значення — предметними константами. Функціональну букву Р називають предикативною буквою.
Предикат — логічна функція, яка приймає одне з двох можливих значень — «істина» або «хибність». Предикат можна розуміти як деяке твердження, істинність якого залежить від змінних — об’єктів, про які йдеться в цьому твердженні. Як приклад можна навести фразу: «X більше за 2». Цей предикат є функцією від аргументу X і приймає значення «істина», наприклад, при Х-3, та «хибність» — при Х=1.
Предметні змінні і предметні константи називають термами. При підставленні замість предметної змінної Х„ константи а, и-розмірний предикат Р{ххх2 •••,*„) від Х„ вже не залежить. Якщо всі змінні предиката замінити на відповідні предметні константан- ти, то виходить 0-розмірний предикат, або вислів. Наприклад, тримісний предикат Р{х1,х2,хг) =«хі є добуток хг на *з» переходить у вислів при постановці х\=6, *2=2, ху-2.
У загальному випадку и-розмірний предикат Р(ххх2 •••,*„) задає відношення між елементами Х1Х2, Х„, яке означає, що Х\Хг, Х„
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
83
знаходяться між собою у відношенні Р. При п= 1 предикат виражає властивість наочної змінної, наприклад «х — клієнт банку».
Концептуальна предметна змінна може бути-досить складною. Тому концептуальну одиницю, що є фактом, підчас зручно розглядати як кон’юнкцію більш елементарних тверджень, а саме — бінарних фактів, кожний з яких описується бінарним предикатом, тобто предикатом, який залежить від двох змінних. Якщо формалізувати правила об’єднання бінарних предикатів у складніші одиниці, на основі бінарних предикатів можуть бути сконструйовані які завгодно складні твердження та системи знань. Наприклад, маємо твердження: «Студент Шевчук отримав п’ятірку на іспиті зі штучного інтелекту».
Якщо переписати цю фразу у вигляді кон’юнкції бінарних фактів, запис може мати вигляд:
Є (Шевчук, Студент);
Є (Ісп_Шт_Інт, Іспит);
ІспШтІнт (Шевчук, 95).
Предикат Ісп Шт Інт був введений для задавання зв’язку між різними інформаційними одиницями.
Тріада «об’єкт-атрибут-значення» є просто іншою формою запису бінарного факту. Так, якщо переписати наш приклад у вигляді сукупності тріад «об’єкт-атрибут-значення», запис матиме вигляд:
Шевчук — Є — Студент;
ІспШтІнт — Є — Іспит;
Шевчук — Ісп_Шт_Інт_ — 95.
Остання тріада цього прикладу задає зв’язок між різними об’єктами.
У вигляді бінарного можна переписати й унарний предикат, тобто предикат, який залежить від однієї змінної.
Наприклад, предикат Птах(Х), який означає, що X є птахом, можна переписати в еквівалентному вигляді: Є (X, Птах). Якщо певний унарний предикат описує властивість об’єкта, наприклад: Літає(Л), її можна переписати у вигляді Літає(ЛГ, так) або у вигляді Є (X, Клас_Літ), де Клас_Літ — клас об’єктів, які літають.
Бінарним предикатам і бінарним фактам безпосередньо відповідає тріада «об’єкт-атрибут-значення». «Об’єкт» у цій тріаді
— це, зазвичай назва певної інформаційної одиниці. «Атрибут»
— це назва певної ознаки, а «значення» — конкретне значення ознаки для цього об’єкта.
84
Г.Ф. Іванчвнко
Замість предметних змінних в предикати можуть підставлятися «-розмірні функції f(xv,x2,x3), визначені на множині об’єктів предметної галузі.
Множина базових елементів (алфавіт) числення предикатів включає:
1) знаки логічних операцій д, v ;
2) знаки кванторів V , 3 ; (all 0; exists 0);
3) знаки пунктуації 0;
4) предметні змінні х, у, z...;
5) предметні константи а, Ь, с...;
6) функціональні символи/ g, h;
7) предикативні букви Р, Q, R, S, Т, V, N.
Множина синтаксичних правил, що визначають поняття ППФ числення предикатів, будується на основі понять терм і елементарних формул. Терм визначається таким чином:
1) кожна предметна змінна, або предметна константа є терм;
2) якщо ,/2, терми та/— и-розмірна функціональна буква, то Дг,,/2, ...,/„) є терм;
3) жодні інші вирази не є термами.
Елементарна формула (атом) вводиться таким чином: якщо Р
— предикативна буква, a tx,t2, ...,t„ — терми, то P(t{,t2,...,tn) — елементарна формула, або атом. Окремим випадком елементарної формули є вислів.
ППФ числення предикатів визначається таким чином:
1) будь-яка елементарна формула є ППФ;
2) якщо Р і О — формули, і х—предметна змінна, то кожний з виразів Р(Х), P(X)vQ(X), P(X)aQ(X), P(X)^>Q(X), VXP(X), ЗХР(Х)Є формула;
3) жодний інший вираз не є формулою.
Тут знаки 3 і V позначають відповідно квантори існування і узагальнення. Квантори — це знаки, які в поєднанні із змінними використовуються для всіх або деяких об’єктів. З кожним предикатом може бути пов’язаний квантор — елемент, який визначає, за яких умов предикат перетворюється на істинне висловлювання.
Елементарне твердження складається з предиката і пов’язаних з ним термів. Складні твердження будуються з елементарних за допомогою логічних зв’язок. Серед них можна виділити логічні зв’язки: «і» (and, д), «або « (от, v), «ні» (not,-і) і імплікацію (—»). Імплікація посідає особливе місце, оскільки вона вико¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
85
ристовується для побудови правил виведення і читається «якщо..., тоді...».
Наприклад, запис чоловік (X) —> людина (X) означає, що якщо дехто на ім’я X, є чоловіком, то він є і людиною.
Для імплікації та тотожності справедливі такі твердження:
А -*В дорівнює (-1/4) v В;
А<->В дорівнює (А л В) v (іА д -іВ);
А<-+В дорівнює (А-+В) л (В-*А).
Якщо и позначає змінну, а г — твердження, то запис V и г означає, що «г справджується для всіх и», а запис Зиг означає, що «існує и для якої г справджується». Перший квантор називають квантором узагальнення, оскільки кажуть про будь-що у всесвіті («для будь-якого и,...»). Для зручності запису його позначатимемо all. Другий називається квантором існування, тому що вказує на існування деяких об’єктів («існує и таке, що...»). Для зручності запису його позначатимемо exists.
Ось приклади використання цих кванторів: аЩХ,чоловік(Х) —> людина(Х)) означає, що для будь-якої змінної X, якщо ця змінна означає чоловіка, вона означатиме і людину також, або ж для будь-якого X, якщо X — чоловік, то АГ — людина; або ж: всі чоловіки—люди.
За тим самим принципом: exists(Z,6ambKo(ieaH,Z)A жінка(2)) означає, що існує певний об’єкт, що може бути означений змінною Z; при цьому Іван є батьком Z і Z — жінка. Ми можемо прочитати це таким чином: існує Z таке, що Іван є батьком ZiZ — жінка; або: Іван має доньку.
В логіці предикатів елементарним об’єктом, який має значення «істина», є атомарна формула (літерал). Атомарна формула включає в себе символьні позначення предиката і термів, які відіграють роль аргументів цього предиката. Загалом позначення предиката є ім’ям відношення, яке існує між аргументами.
Атомарна формула записується як позначення предиката і має такий вигляд: P(ti,t2, .-.Q, де Р — позначення предиката, а tut2, ...,t„ — терми. Число термів для кожного предиката фіксоване і називається його арністю. Правило побудована формула отримується в результаті комбінування атомарних формул за допомогою логічних зв’язок. Серед формул можна виділити спеціальний клас формул — тотожно істинні формули, які називають аксіомами. Приклад аксіоми: —>—А <->А.
86
Г.Ф. Іванченко
Літерал називають позитивніш, якщо він не стоїть під знаком заперечення. Літерал називають негативним, якщо він стоїть під знаком заперечення. Диз’юнктом (або фразою теорії) називають диз’юнкцію певної кількості атомарних формул.
У теорії і практиці автоматизованого доведення теорем найчастіше використовуваними є фрази спеціального типу, які називають фразами Хорна (або хорнівськими диз ’юнктами).
Фразою Хорна називають диз’юнкцію довільної кількості атомарних формул, з яких позитивною є не більше однієї (тобто у фразі Хорна лише одна атомарна формула може не стояти під знаком заперечення).
Фрази Хорна по суті є імплікаціями. Справді, розглянемо фразу —u4v—lSv-iCvZ) (кожний з літералів А, В, С, D може залежати від довільної кількості констант та змінних, тут це неістотно). Всі літерали, крім D, є негативними, отже фраза є фразою Хорна. Але відповідно до правил де Моргана вона еквівалентна фразі -і(ABC)vD. А це, в свою чергу є іншою формою запису імплікації (твердження D випливає з кон’юнкції тверджень А, В, Q.
Для конкретних застосувань іноді потрібно привести логічні формули до спеціального вигляду. Прикладом може послужити пренексна нормальна форма — це запис логічної формули у вигляді: К{х{,Кгхг, ...,К„х„,М, де Кі — один з квайторів (існування чи узагальнення), М— деяка кон’юнктивна нормальна форма, тобто кон’юнкція деякої кількості диз’юнктів.
Пренексну нормальну форму легко побудувати шляхом тотожних перетворень логічних формул. Після отримання пренексної нормальної форми потрібно усунути в цій формі квантори існування та узагальнення.
Квантори існування можна усунути зі збереженням несупереч- ливості формули. Вони усуваються шляхом введення так званих констант Сколема і функцій Сколема. Розглянемо два приклади, які прояснюють сутність методу.
Нехай маємо формулу Зх Р(х). По суті це означає, що можна вказати деяку предметну константу х — с, взагалі кажучи невизначену, для якої твердження Р(с) є істинним. Тоді квантор існування усувається явним введенням цієї предметної константи. Таким чином, здійснюється перехід від формули Зх Р(х) до формули Р(с), константу с називають константою Сколема.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
87
Нехай маємо формулу Vy Зх Р(х, у). Тут квантор існування перебуває у сфері дії квантора узагальнення, і процедура дещо ускладнюється. Знову таки ми можемо вказати деякий елемент с, для якого твердження Р(с, у) є істинним, але тепер с залежить від змінної у. Тому від формули Vy Зх Р(х, у) можна перейти до формули Vy P(h(y), у). Тут h(y) — деяка функція, взагалі кажучи, не- визначена; вона називається функцією Сколема.
Квантори узагальнення усуваються механічно за стандартною домовленістю: вважається, що якщо фраза залежить від деяких змінних, то всі вони зв’язані квантором узагальнення. Наприклад, якщо х, у, z — змінні, то від формули Vx Vy Vz Р(х, у, z) відбувається перехід до формули Р(X, у, Z).
Фразова форма запису логічних формул Як зазначалося раніше, логічна формула, записана за допомогою імплікацій та тотожностей, може бути переписана в термінах кон’юнкцій, диз’юнкцій та заперечень. Розглянемо, як твердження числення предикатів перетворюється на спеціальну уніфіковану фразову форму. Набори фраз, записаних у такій формі, нагадують програми логічних мов програмурання.
Запишемо неформальний опис такого перетворення. Це переведення має шість основних дій.
1. Вилучення імплікацій «-»> і тотожностей «<-»» можна здій¬
снити на основі формул, наведених у попередньому розділі. Наприклад, формула г
аІІ(Х,птах(Х)—>тварина(Х)) перетвориться на: all(X, —> nmax(X) vmeapunaQC)).
2. Перенесення заперечення всередину. Ця дія використовується для випадків, коли «-і» застосована у формулі, що не є частковою. Тоді робиться така заміна:
—і (тварина (пінгвін) л окивий(пінгвін)) переводиться в —і (тварина(пінгвін) v—i живий(пінгвін) та -і all (ї,тварини(ї)) перетворюється на exists (Y, —> тварини(Y)). Можливість цієї дії зумовлена такими рівностями:
-і (алЬ) означає те саме, що й (-і a) v(^,b);
-7 exists (и,г) означає те саме, що й all (и, г);
-? all (и,г) означає те саме, що й exists (и, ^ г).
Після другої дії у наших формулах залишаться лише заперечення, прив’язані до конкретних формул. Часткові твердження з
88
Г.Ф. Іванчвнко
або без «-і» попереду ми називаємо точними. В наступних кількох діях ми поводимемося з точними твердженнями як з простими одиницями.
3. Заміна змінних. Наступна дія включає видалення існуючих кванторів. Це робиться вставлянням нових константних символів на місце, де були змінні, що представляють існуючі квантори. Тобто замість того, щоб казати, що існує об’єкт з певним набором характеристик, можна створити ім’я для такого об’єкта і просто сказати, що в нього є характеристики. В цьому полягає основна суть введення сколемівських констант, названих так на честь відомого логіка. Ця дія є не повністю еківалентною, але вона має одну важливу властивість. Існує інтерпретація символів формули, яка справджує формулу тільки якщо існує інтерпретація для сколемівської версії формули. Для наших потреб цієї форми відповідності досить.
Тому, наприклад: exists (X, чоловік(Х) л бстгько(Х,Іван)) перетворюється за допомогою сколемізації на чоловік (gl) а батько (gljean), де «gl» — деяка нова константа, що ніде раніш не використовувалася. Константа «gl» представляє деякого чоловіка (чоловік), чиїм батьком (батько) був (Іван). Тут важливим є використання символу, який раніше ніде не вживався, тому що твердження «exists» не каже, що пебна людина є сином Ів|ана, а лише стверджує, що є така людина. Може виявитися, що «gl» пов’язана з якимось іншим константним символом, але ця інформація не надається цим твердженням.
Коли у формулі використовуються квантори узагальнення, то сколемізація стає не такою простою. Наприклад, якщо ми перетворимо:
all (X, людина(Х)-> exists (Y, мати(Х,У))) («кожна людина має матір») на all (Х,людина(Х) -*Mamu(X,g2)), то це означало б, що всі люди мають одну матір-«#2». Коли змінні зв’язані квантором узагальнення, їх перетворюють на функціональні символи, щоб показати наскільки «exists» залежить від того, з чим пов’язана змінна. Тому останній приклад потрібно перетворити таким чином: all(X,людина (X) ->Mamu(X,g2(X))).
У цьому разі «g2» позначає функціональний символ, який, отримавши ім’я людини, видасть вам ім’я її матері.
4. Переміщення квантора узагальнення назовні. Ця дія дуже проста. Квантор узагальнення переміщується назовні, при цьому формула зберігає свій попередній зміст. Наприклад:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
89
all (X, чоловік(Х) аІІ(ї,жінка(ї) —> подобається(Х, Y))) перетворюється на all (X, all(Y, чоловік(Х) —> (жінка(У)
-> подобається(Х, Y)))).
Оскільки кожна змінна тепер зв’язана квантором узагальнення ззовні формули, квантори узагальнення більше не несуть додаткової інформації. Отже, можна скоротити формули, опустивши ці квантори. Ми мусимо пам’ятати, що кожна змінна пов’язана кванторами узагальнення, які ми опустили.
5. Перенесення «д» через «V». Логічна формула має бути зведена до особливої форми — нормальної кон’юнктивної формули, в якій кон’юнкції не з’являються посеред диз’юнкцій. Для цього існує два правила:
(АдВ) v С дорівнює (AvB) д (BvC),
Av (ВаС) дорівнює (AvB) a (AvC).
Наприклад, фразу: криза_рік(Х) v (існує(банк,Х) л
(не_стабільний(банк) v не_девідентний(банк))) можна трактувати так «для будь-якого X, X може бути криза_рік, або банк може існувати в X і бути нестабільний або не_девідентний», можна перетворити на фразу: (криза_рік (X) v (існує (банк,Х) л (криза_рік(Х) v (не_стабільний(банк) v не_девідентний(банк)))).
Для всіх X, по-перше X або криза_рік, або банк працює в X, по-друге, або X криза_рік, або банк не_стабільний та не_девідентний).
6. Перехід до фраз. Тепер наша формула є набором атомарних формул розділених «и< або пов’язаних «а». Якщо не брати до уваги «V», в нас може бути таке: (А а В) a (Ca(D аЕ)), де змінні можуть заміщати складні твердження, але без «а» всередині. Тепер дужки не потрібні. Оскільки для «а» вони не мають значення, і наш вираз еквівалентний: А аВ аС aD аЕ.
По-друге, порядок теж не має значення. По-третє, нам не потрібні і «а», оскільки ми знаємо, що наша формула — це послідовність тверджень, з’єднана «а», і останні можна опустити, сказавши, що це є множина {А, В, С, D, Е). Стверджуючи, що це множина, ми наголошуємо на тому, що порядок не істотний. Елементи цієї множини називаються фразами. Отже, будь-яка формула предикатного числення еквівалентна (в деякому розумінні) множині фраз.
Повернемося до самої фрази. Оскільки елементами фрази є або точні або точні розділені «V» твердження, то їх загальний вигляд може бути зображений так: ((V v W) v X) v (Y v Z), де змінні
90
Г.Ф. Іванченко
є точними. Тому можна знову перейти до множини точних розподілених фраз {V, ЇУ, X, У, І).
Тепер формула остаточно досягла фразової форми. Зробимо кілька підсумків. Отже, фразова форма логіки предикатів задає такий спосіб запису формул, який використовує тільки з’єднувачі типу Л, V, -і.
Негативна або ж позитивна атомарна формула називається літе- ралом. Кожна формула — множина літералів, які з’єднані символом V. Негативні і Позитивні літерали відповідно групуються. Схематично фраза має такий вигляд: Рх V Р2 V ...Рп V ЛГ, V V ..Ля, де Р„ — позитивні літерали, а N1 ...Ит — негативні. Водночас, фразу можна розглядати як узагальнення поняття імплікації. Справді, якщо А і В атомарні формули, тоді формулу А —»5 можна переписати і в такому еквівалентному вигляді: -і А V В. Звідси отримаємо фразову формулу В V -і А.
Фраза має таку семантику. Всі позитивні атомарні формули виступають у ролі альтернативних висновків, а негативні — є необхідними умовами. Наприклад, Л V В V -іС V —Ю зазначає, що А і В будуть істинними тоді і тільки тоді, коли є Щетинними С і £>.
Елементарна фраза має тільки один літераЛ. Теорія записується у вигляді множини фраз, які неявно з’єднані між собою символом д. В літературі зустрічається і друга форма запису фрази за допомогою зворотної стрілки (читається «імплікується»). Так, остання фраза може мати вигляд А, В <- ~,С, —І).
Для скорочення об’ємів обчислень на практиці використовують спеціальний клас фраз, який отримав назву фраз Хорна. Фраза Хорна — це фраза, яка має тільки один позитивний літерал. Одну фразу Хорна можна записати у кілька способів. Наприклад, А V —і5 V —іС V -ій еквівалентне А <- В, С, О і в мовах логічного програмування отримує вигляд А: - В, С, И.
2.7. Моделі знань на основі продукцій
Продукційна модель подання знань є однією з найпоширеніших. Подання знань за допомогою правил-продукцій у деяких відносинах подібна до правил висновку логічних моделей, що дає змогу за допомогою продукцій виконувати ефективний висновок і, крім того, завдяки природній аналогії процесу міркувань людини ці моделі наочніше відображають знання.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
91
У системах продукцій знання подаються за допомогою наборів правил вигляду: «якщо А, то В». Тут А до В можуть розумітися як «ситуація — дія», «причина — слідство», «умова висновок» тощо. Часто правило-продукцію записують з використанням знаку логічного проходження: А=>В
У моделях цього типу використовуються деякі елементи логічних і мережевих моделей. З логічних моделей запозичено ідею правил висновку, які тут називаються продущіями, а з мережевих
— опис знань у вигляді семантичної мережі. В результаті застосування правил висновку до фрагментів мережевого опису відбувається трансформація семантичної мережі за рахунок зміни її фрагментів, нарощування мережі і вилучення з неї непотрібних фрагментів. Таким чином, у продукційних моделях процедурна інформація явно виділена і описується іншими, аніж декларативна інформація засобами. Замість логічного висновку, характерного для логічних моделей, у продукційних моделях з’являється висновок на знаннях.
Продукції разом з фреймами є найбільш популярними засобами подання знань у ШІ. Продукції, з одного боку, близькі до логічних моделей, що дає можливість організовувати на них ефективні процедури висновку, а з другого боку, наочніше відображають знання, порівняно з класичними логічними моделями. У них відсутні жорсткі обмеження, характерні для логічних обчислень, що дає можливість змінювати інтерпретацію елементів продукції.
Проте не слід ототожнювати правило-продукцію та відношення логічного проходження. Річ у тому, що інтерпретація продукції залежить від того, що стоїть ліворуч і праворуч від знаку логічного проходження. Часто під А розуміються деяку інформаційну структуру (наприклад, фрейм), а під В — деяку дію, що полягає в її трансформації (перетворенні). Логічна інтерпретація цього виразу накладає жорсткі обмеження на значення символів А і В, які мають розглядатися як ППФ. Тому поняття продукції ширше за логічне проходження.
Продукційні системи запропонував американський математик Еміль Пост (1943) і розглядав як модель організації обчислювального процесу. Як і логічні моделі, продукційні моделі в першу чергу концентруються на дедуктивному висновку, але є менш формалізованими і тому більше наочними, гнучкими і зручними. На сучасному етапі найбільш вживаним формалізмом для задания знань в експертних системах є саме продукційні моделі.
92
Г.Ф. Іванченко
При цьому правило-продукція тлумачили як оператор заміни одного ланцюжка літер у певному слові на інший. Систему про- дукций можна розглядати як формальну систему з алфавітом A = {al,a2,...,a„\, кінцевою безліччю аксіом і кінцевою множиною правил висновку, що мають вигляд Р, :а,s =>^,i = l,2,...,k, де а,, р,-,5 — слова алфавіту А.
Цікаві результати одержали А. Ньюелло і Г. Саймон при розробці системи GPS. Вони встановили, що правила-продукції відповідають елементам знань, накопичуваним у довгочасній пам’яті людини. Такі елементи знань активізуються, якщо виникає відповідна ситуація (за зразком). Нові елементи знань можуть накопичуватися в пам’яті без потреби перезапису наявних елементів. Робоча пам’ять продукційних систем аналогічна короткочасній пам’яті людини, яка утримує в центрі уваги поточну ситуацію. Вміст робочої пам’яті, зазвичай, не зберігається після вирішення завдання. Завдяки вказаній аналогії, продукційні моделі подання знань набули широкого поширення в експертних системах, що моделюють вирішення завдання людиною-експертом у тій або тій галузі.
Продукційною моделлю називається подання знань у вигляді сукупності продукцій. Продукція.визначається як вираз такого вигляду: І
(ijQ;P;A=>B;N. |
Тут (і) — ім’я продукції, за допомогою якого вона виділяється серед усієї множини продукцій. Як ім’я може виступати деяка лексема, що відображає суть цієї продукції (наприклад «придбання книги»), або порядковий номер продукцій у їх множині, що зберігається в пам’яті системи;
Q — сфера застосування продукції; предметна галузь, до якої вона належить. Такі сфери легко виділяються в когнітивних структурах людини. Наші знання неначе розкладені на поличках. На одній поличці зберігаються знання про те, як треба готувати їжу, на другій — як дістатися до роботи тощо. Розподіл знань на окремі сфери дає змогу економити час на пошук потрібних знань. Таке саме розділення на сфери в базі знань ШІ доцільне і під час використання для подання знань продукційних моделей;
Р — умова застосування продукції. Завичай Р є логічним виразом (як правило предикат). Коли Р приймає значення «істина», ядро продукції активізується. Якщо Р «помилкове», то ядро продукції не може бути використано;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
93
А => В — ядро продукції; інтерпретація залежить від конкретної ситуації. Інтерпретація ядра продукції може бути різною і залежить від того, що стоїть ліворуч і праворуч від знака секвенції (). Звичайне прочитання ядра продукції має такий вигляд: якщо
A, то В, складніші конструкції ядра допускають у правій частині альтернативний вибір, наприклад, якщо А, то В1, інакше — В2. Секвенція може тлумачитися в звичайному логічному сенсі як знак логічного проходження В з істинного А (якщо А не є істинним виразом, то про В нічого сказати не можна). Можливі й інші інтерпретації ядра продукції, наприклад А описує деяку умову, необхідну для того, щоб можна було зробити дію;
N — постумова продукції, постулює процедури, які потрібно виконати після реалізації ядра. Вони актуалізуються тільки в тому разі, якщо ядро продукції реалізувалося. Постумови продукції описують дії і процедури, які необхідно виконати після реалізації
B. Виконання N може відбуватися відразу після реалізації ядра продукції.
У продукційних моделях знання становлять набір правил, що мають такий вигляд: «Якщо А, то В», де умова правила А є твердженням про вміст бази фактів, а слідство В каже про те, що треба робити, коли це продукційне правило активізовано.
Продукційні моделі подання знань завдяки природній модульній правил, наочності й простоті їх створення широко застосовують в інтелектуальних системах.
Зазвичай, завдання, що формулюється для продукційної системи, має одну з таких структур:
завдання <5о, 5/-— ?> пов’язане з визначенням ситуації (стану) £/-, що задовольняє деякому критерію, яку можна отримати із заданої початкової ситуації.
Завдання <5о — ?, є зворотним стосовно до попереднього.
Завдання <5о, 5/, А — ?> полягає у відшуканні алгоритму перетворення початкової ситуації в кінцеву.
Завдання <5о, 5/— ?, А — ?> становить узагальнення першого та другого завдань, де: 5о — початкова ситуація, £/— кінцева (бажана, необхідна ситуація), А — алгоритм (послідовність виконуваних продукцій), що переводить систему із стану 5о у стан Я/.
Наведемо кілька типових прикладів продукцій. Нехай ідеться про систему керування авто. Продукції можуть мати такий вигляд: якщо температура двигуна перевищує 100 градусів, ввімк¬
94
Г.Ф. Іванченко
нути систему охолодження. Такі продукції задають умовні операції (якщо справедлива умовам, виконати дію В).
Наприклад, клієнт має рахунок у банку. Якщо клієнт бажає зняти певну сумму грошей, то він повинен написати видатковий ордер, внести зміни до бази даних.
Типовими продукціями є правила підстановки (замінити А на В), Прикладом можуть послугувати правила підставлення формальних граматик.
База знань, організована як сукупність продукцій, разом з механізмом керування продукціями утворює продущійну систему.
Якщо в пам’яті системи зберігається деякий набір продукції, ТО вони утворюють систему продукції. У системі продукції мають бути задані спеціальні процедури управління продукціями, за допомогою яких відбувається актуалізація продукцій і вибір для виконання тієї або тієї продукції з числа актуалізованих. У ряді систем ШІ використовують комбінації мережевих і продук- ційних моделей подання знань. У таких моделях декларативні знання описуються в мережевому компоненті моделі, а процедурні знання — в продукційному. В цьому разі кажуть про роботу продукційної системи над семантичною мережею.
Дуже перспективним видається поєднання продукційних моделей з фреймовими і мережевими. Наприклад, самі знання можна описувати на основі Семантичних мереж, аі операції над ними задавати як продукції, що зумовлюють замінУ одного фрагмента мережі на другий. Водночас, самі продукції можна включати до семантичних мереж і фреймів. Методи класу можна розглядати як продукції — особливо в разі, якщо вони є демонами, що запускаються під час виконання певних умов. Як типові продукції можна розглядати зв’язки функціональної мережі, які задають алгоритми обчислення одних величин через інші.
Популярність продукційних моделей зумовлена такими їх позитивними рисами:
• більшість людських знань можна записати у вигляді продукцій;
• модальність; продукції за невеликим винятком є незалежними, і внесення або вилучення окремих продукцій, зазвичай, не приводить до змін в інших продукціях;
• у разі потреби продукційні системи можуть реалізувати будь-які алгоритми;
• продукції можна порівняно легко розподілити за сферами застосування;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
95
• дуже перспективним є об’єднання продукційних систем і мережевих подавань;
• продукції можуть працювати паралельно та асинхронно, і тому їх зручно реалізувати на основі багатопроцесорних комплексів;
• універсальністю; практично будь-яку галузь знань можна представити в продукційній формі;
• декларативністю; продукції визначають ситуації наочної га- луз, а не механізм управління;
• природністю процесу ведення висновків, який багато в чому аналогічний процесу міркувань експерта;
• асинхронністю і природним паралелізмом, який робить їх вельми перспективними для реалізації на паралельних ЕОМ.
До основних проблем, пов’язаних з використанням продукційних систем, можна віднести складність перевірки несупереч- ливості та коректності функціонування.
Системи продукцій часто зручно відображати у вигляді графів, які отримали назву мереж виведення.
Мережі виведення будуються так: вершини графу відповідають умовам та діям, що входять до лівих і правих частин продукцій. Якщо в продукційній системі є продукція А-+В, то від вершини А до вершини В іде орієнтована дуга. А якщо є продукція А, В-їС, то дуги (АС) та (ВС) пов’язані відношенням І (кон’юнкції).
Так, для продукційної системи
А—>С; В—>С; В, ^ґ—ïQ', Ї),С— мережа виведення має такий вигляд (рис. 2.2):
Рис. 2.2. Приклад мережі виведення
На основі аналізу мереж виведення, стає більш наочним і очевидним те, що відповідь на запит користувача можна отримати шляхом зведення задачі до підзадач. Так, наприклад, щоб розв’язати задачу Є, потрібно розв’язати і задачу £>, і задачу С; розв’я-
96
Г.Ф. Іванчвнко
зання задачі С, у свою чергу, вимагає вирішення або А, або В. Таким чином, мережа виведення для кожної задачі є структурою, близькою до традиційних І-АБО-графів.
Множина продукційних правил утворює базу правил, кожне з яких становить відособлений фрагмент знань про розв’язувану проблему. Психологи називають такі фрагменти чанками (від англ. chunk). Вважається, що чанк — це об’єктивно існуюча одиниця знань, що виділяється людиною в процесі пізнавання навколишнього світу.
Системи, засновані на продукційній моделі, складаються з трьох типових компонентів (рис. 2.3): бази правил (продукцій), бази фактів, що містить декларативні знання ІІРГ, які використовують як аргументи в умовах застосовності продукцій, й інтерпретатора продукцій, який реалізовує функції аналізу умов застосовності продукцій, виконання продукцій і управління вибором продукцій (управління висновком у продукційній системі).
Інтерпретатор реалізує логічний висновок. Процес висновку є циклічним і називається пошуком за зразком. Розглянемо його у спрощеній формі. Поточний стан модельованої наочної галузі відображається в робочій пам’яті у. вигляді сукупності образів, кожний з яких подається за допомогою фактів. Робоча пам’ять ініціалізується фактами, що'оцисують задачу. По|гім вибираються правила, для яких зразки, що подаються передумовами правил, співставні з образами в робочій пам’яті. Ці правила утворюють конфліктну множину. Всі правила, що належать до конфліктної множини, можуть бути активізовані. Відповідно до вибраного механізму вирішення конфлікту активізується одне з правил. Виконання дії, що полягає у зв’язуванні правила, приводить до зміни стану робочої пам’яті. Надалі цикл управління висновком повторюється. Вказаний процес завершується, коли не виявиться правил, передумови яких співставні з образами робочої пам’яті.
Передумова правила часто розглядається як зразок. Зразок — це деяка інформаційна структура, що визначає узагальнену ситуацію (умову, стан і т. п.) зовнішнього середовища, за якої активізується правило. Робоча пам’ять (глобальна база даних) відображає конкретні ситуації (стани, умови), що виникають у зовнішньому середовищі. Інформаційна структура, що відображає конкретну ситуацію зовнішнього середовища в робочій пам’яті, називається образом.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
97
Таким чином, процес висновку, заснований на пошуку за зразком, складається з чотирьох кроків:
• вибір образу;
• зіставлення образу із зразком і формування конфліктного набору правил;
• дозвіл конфліктів;
• виконання правила.
Рис. 2.3. Продукційна система
Пояснимо процес функціонування продукційної системи на простому прикладі сортування рядка, що складається з букв А, В, С [20]. Правила сортування наведено на рис. 2.4. Якщо зразок, заданий передумовою правила, зіставимо з частиною сортованого рядка, то правило активізується. В результаті підрядок, який співпав з умовою правила, заміщується підрядком із завершальної частини правила.
1. Ьа=>аЬ\ 2. са=>ас; 3. сЬ=>Ьс.
Рис. 2.4. Сортування рядка за допомогою правил-продукцій
98
Г.Ф. Іванчвнко
Розглядаючи початковий і відсортований рядки як початковий і кінцевий стан задачі, а цродукційні правила — як оператори, що перетворюють один стан на інший, доходимо до висновку, що пошук рішення в продукційних системах відповідає пошуку в просторі станів. На рис. 2.4 зображено дерево станів задачі. Тут вершини дерева відповідають проміжним станам сортованого рядка, а ребра — правилам-продукціям.
На рис. 2.5 показано узагальнену схему типової інтелектуальної системи, побудованої на основі продукційних правил.
Рис. 2.5. Типова схема роботи продукційі|ої системи
До робочої пам’яті заносять факти, що задаються користувачем, а також його запити. Логічний блок співставляє цю інформацію з правилами, що зберігаються в базі знань, і застосовує ті правила, які можуть бути співставлені із вмістом робочої пам’яті. Так, наприклад, якщо в базі знань є продукції А=>В та В=>С, то вони можуть бути виконані, якщо користувач ввів дані про істинність факіу А.
Якщо в процесі активізації правила перші факти виявляться істинними, то в базу знань буде поміщений новий факт, що представляється триплетом об’єкт-атрибут-значення. Однією з переваг зберігання фактів у вигляді триплетів є підвищення ефективності процедур пошуку в базі знань, оскільки з’являється можливість впорядкування фактів за об’єктами й атрибутами.
Класифікація ядер продукції'
Ядра продукції можна класифікувати за різними підставами. Перш за все всі ядра поділяються на два великі типи: детерміновані і недетерміновані. У детермінованих ядрах за актуалізації
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
99
ядра і за здійснимості А права частина ядра виконується обов’язково; у недетермінованих ядрах В може виконуватися і не виконуватися. Таким чином, секвенція Р в детермінованих ядрах реалізується за потреби, а в недетермінованих — за можливості. Інтерпретація ядра в цьому разі може мати, наприклад, такий вигляд: якщо А, то можливо В.
Можливість може визначатися певними оцінками реалізації ядра. Наприклад, якщо задана імовірність виконання В за актуалізації А, то продукція може бути така: якщо А, то імовірністю р реалізувати В. Оцінка реалізації ядра може бути лінгвістичною, пов’язаною з поняттям множини терма лінгвістичною змінною, наприклад: якщо А, то з більшою часткою впевненості В. Можливі інші способи реалізації ядра.
Детерміновані продукції можуть бути однозначні й альтернативні. У другому випадку в правій частині ядра вказуються альтернативні можливості вибору, які оцінюються спеціальними вагами вибору. Як такі ваги можуть використовувати імовірнісні оцінки, лінгвістичні оцінки, експертні оцінки і т. п.
Особливим типом, що прогнозують продукції, в яких описуються очікувані результати за актуалізації А, є наприклад: якщо А, то з вірогідністю р можна очікувати В.
Існують різні режими керування виконаням готових продук- цій, тобто продукцій, ліві частини яких справедливі, і, відповідно, ці продукції можуть бути виконані негайно.
Можна виділити такі режими:
—режим негайного виконання;
—режим формування конфліктного набору.
У режимі негайного виконання, якщо знайдено першу-ліпшу продукцію, вона негайно і виконується.
У режимі формування конфліктного набору знайдені готові продукції не виконуються одразу, а включаються до конфліктного набору — списку продукцій, готових до виконання. Лише після завершення формування конфліктного набору відбувається вирішення конфлікту, тобто вибір зі списку готових продукцій якоїсь однієї.
Інша назва конфліктного набору — фронт готових продукцій.
Розглянемо деякі проблеми, пов’язані з конфліктними наборами.
Нехай маємо продукції:
1)А=>В,
2) А=>С,
і А істинне.
100
Г.Ф. Іванчвнко
Тоді обидві продукції: і 1), і 2) готові до виконання й утворюють конфліктний набір.
Якщо ядра продукцій інтерпретуються як імплікації, проблема є менш гострою. Продукційна система є суто декларативною. Після застосування, тобто виведення В, А залишається істинним, і ми завжди можемо використати продукцію. Таким чином, порядок застосування продукційних правил може впливати лише на час роботи системи, але не на істинність висновків.
Зовсім інша ситуація, коли ядра продукцій інтерпретуються як «виконати таку-от дію». Тоді після виконання 1) ситуація може змінитися; А може перестати бути істинним, і продукція
2) може стати недосяжною. Тому якщо насправді треба було вибирати С, вибір В стає помилкою, яку не завжди можна виправити.
Існують різні стратегії вирішення конфліктів, а також обмеження при включенні готових продукцій до конфліктного набору.
Виділяють також централізоване та децентралізоване керування продукціями.
За централізованого керування продукційна система має центр керування, який вирішує, коли має спрацювати та чи інша продукція.
За децентралізованого керування кожна продукція може самостійно прийняти рішення про свій запуск. Один з типових механізмів, який використовується при цьому, є механізм класної дошки.
«Класною дошкою» називаємо спеціальну рбласть пам’яті, доступну для різних продукцій. На ній продукції, що працюють паралельно, знаходять інформацію, що може ініціювати їх запуск, туди ж вони пишуть інформацію, що може виявитися корисною для інших продукцій. Зрозуміло, що «класних дошок» може бути кілька; можуть бути введені певні ієрархії класних дошок і т. п.
Існує два типи механізмів висновку в продукційних системах: прямий і зворотний. У першому разі відправною точкою міркувань служать початкові факти, до яких далі застосовують продукції. В процесі висновку нові факти і правила поповнюють БЗ. Часто подібні механізми називають висхідними висновками, або висновками, керованими даними.
Відправною точкою зворотних висновків є мета міркування, тобто знання, істинність яких потрібно довести (підтвердити) або спростувати. Якщо мета узгоджується з висновком якогось правила (з В), то посилання цього правила (А) береться за підмету, і процес повторюється доти, поки чергова підмета не узгоджува¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
101
тиметься з початковими фактами. Перевага зворотних (низхідних, або орієнтованих на мету) висновків полягає в тому, що при їх використанні аналізуються частини дерева рішень, що мають відношення до мети, тоді як для прямих висновків характерна наявність великого числа оцінок, що не мають безпосереднього до неї відношення.
У процесі висновку в продукційній системі може виникнути ситуація, коли на якомусь кроці задовольняються умови застосовності кількох продукцій. Для вибору виконуваного правила притягується інформація про пріоритетність, достовірність, значущість, взаємозв’язок й інші властивості продукцій. Ці знання містяться в передумовах правил і можуть бути евристичними.
У системах, що використовують правдоподібний висновок, кожній продукції приписується коефіцієнт достовірності (чинник упевненості), що відображає оцінку вірогідності отримання вірного висновку за допомогою цього правила. Таким чином, у разі конкуренції між собою кількох продукцій СШІ може видавати користувачу ряд альтернативних відповідей, забезпечених оцінками їх правдоподібності.
Реалізація логічних і продукційних моделей знань базується на мовах типу Прологу.
Отже, позитивні сторони продукційної моделі знань полягають у зрозумілості і наочності інтерпретації окремих правил, а також простоті механізмів висновку (виконання продукцій) і модифікації БЗ.
Недоліками продукційної моделі є:
• складність управління висновком, неоднозначність вибору конкуруючих правил;
• низька ефективність висновку загалом, негнучкість механізмів висновку;
• неоднозначність обліку взаємозв’язку окремих продукцій;
• невідповідність психологічним аспектам уявлення й обробки знань людиною;
• складність оцінки цілісного уявлення ПРГ;
• процес висновку має низьку ефективність, оскільки за великого числа продукций значна частина часу витрачається на непродуктивну перевірку умов виористання правил;
• перевірка несуперечності системи продукций стає вельми складною через недетермінованість вибору виконуваної продукції з конфліктної множини.
102
Г.Ф. Іванчвнко
Управління висновком у продукційних системах
Під час розв’язання проблеми машина висновку (інтерпретатор) виконує два завдання — власне логічний висновок і управління висновком. Логічний висновок у продукційних системах не відрізняється особливою складністю і реалізується на основі процедури пошуку за зразком, описаним вище.
Управління висновком у продукційних системах передбачає відповідь на два питання [21]:
1) з чого слід починати процес висновку;
2) як вчинити, якщо на деякому кроці висновку можливий вибір різних варіантів його продовження.
Відповідь на перше питання приводить до прямого і зворотного ланцюжка міркувань, а на друге питання — до механізмів вирішення конфліктів у продукційних системах.
Прямий висновок на основі наявних правил передбачає аналіз всіх наслідків з фактів, далі — наслідків з наслідків; процес триває, поки не буде встановлено істинність або хибність запиту користувача.
Наприклад, нехай є продукції Л=>В та В=>С; користувач оголосив про істинність факту А і спитав про істинність С. Ланцюжок прямого висновку буде мати вигляд: з А виходить В, з В виходить С, отже, С істинне, |
Прямий висновок не вважається ефективним через те, що може перебиратися дуже багато безперспективних продукцій, і відповідно, породжується дуже багато зайвих проміжних результатів. Експертні системи на основі прямого виведення використовуються, зазвичай, при плануванні і прогнозуванні.
За зворотного висновку логічний блок починає роботу з запиту користувача, тобто з твердження, яке перевіряється. Розглядається одне з правил, на основі якого можна вивести це твердження, після чого перевіряється істинність лівої частини цього правила. Процес повторюється, поки не дійде до фактів, які вважаються істинними.
У нашому прикладі ланцюжок зворотного висновок матиме вигляд: «С виходить з В, В виходить з А, А істинне, отже, і С істинне».
Як і в разі прямого висновку, зворотний висновок може вимагати повторень у разі невдалої спроби, і тому є стратегією перебирання.
Зворотний висновок тісно пов’язаний з резолюцією, зокрема з лінійною, і прологівським механізмом виконання програм.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
103
Як було відзначено вище, використання процедури пошуку за зразком у продукційних системах відповідає пошуку розв’язання задач у просторі станів, або просторі редукції задачі. Тому для управління висновком у продукційних системах можуть застосовуватися стратегії сліпого і впорядкованого пошуку, стратегії прямого і зворотного висновку (відповідно пошуку, керованого даними і метою).
Прямий висновок починається із завдання початкових даних розв’язуваної задачі, які фіксуються у вигляді фактів у робочій пам’яті системи. Правила, використані до початкових даних, забезпечують генерацію нових фактів, що додаються в робочу пам’ять. Процес триває, поки не буде отримано цільове збагачення робочої пам’яті.
У табл. 2.2 наведено приклад пошуку, керованого даними, на безлічі продукций, записаних у вигляді формул пропозіційної логіки. Тут на кожному кроці роботи машини висновку застосовується проста стратегія розв’язання конфліктів: активізується останнє з успішно зіставлених правил. Порядок зіставлення правил відповідає їхнім номерам.
Якщо активізувати на кожному кроці роботи машини висновку перше правило конфліктної множини, то граф рішення будуватиметься методом пошуку в ширину (рис. 2.6, б). У цьому разі всі альтернативні ланцюжки міркувань, що є на графі рішень, продовжуються паралельно, і жодна не обгонить іншу.
Таблиця 2.2
ПРЯМИЙ ВИСНОВОК У ПРОДУКЦІЙНИХ СИСТЕМАХ МНОЖИНА ПРАВИЛ ПРОДУКЦІЇ
1) влН->С 2) ІлК^й 3)ЬлМ-+Е 4
5) О-їР 6)С->А 7)В->Л 8 )Е->В
9)Р->В \0)А-+воа1 11 )В-*воаІ
Початок 5/агг={і, М, Щ
Крок
Робоча пам’ять
Конфліктна
множина
Активізоване
правило
0
І, А/, N
—
—
1
L, А/, N
3,4
4
2
L,MyN,F
3,9
9
3
L, М9 N, F, В
3,11
11
4
L, М9 N, F, В, Goal
3
Stop
104
Г.Ф. Іванченко
На рис. 2.6 а зображено граф рішення. Вершини графа відповідають висловам, а ребра — відповідним правилам висновку. Процес висновку починається з розміщення безлічі початкових фактів L, М і N у робочій пам’яті і закінчується, коли в робочу пам’ять буде поміщена цільова вершина Goal. Напрям висновку позначений поряд з графом і відповідає руху від стартової до цільової вершини, тобто від початкових даних (вислови L, М і N). Тому такий висновок називають висновком, керованим даними.
Відзначимо, що обрана стратегія активізації останнього правила, доданого до конфліктної множини, відповідає пошуку в глибину. Саме ця стратегія найчастіше застосовується в експертних системах продукційного типу, оскільки вона відповідає процесу міркувань експерта при вирішенні певного завдання. Поведінка системи для користувача має досить логічний вигляд: він бачить, що система прагне звести кожну мету до підмети.
Goal Goal
а) б)
Рис. 2.6. Прямий висновок: пошук в глибину (а) і пошук в ширину (б).
Безумовно, можливі і змішані стратегії висновку, коли об’єднуються обидва види пошуку — пошук у ширину і пошук у глибину, а також різні евристичні стратегії. Оскільки ці стратегії в продукційних системах пов’язані з правилами розв’язання конфліктів, то нижче ми розглянемо їх докладніше.
Окрім прямого висновку, в продукційних системах широко застосовується і зворотний висновок, тобто висновок, керований цільовими умовами. Такий висновок починається з цільового твер¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
105
дження, яке фіксується в робочій пам’яті. Потім відшукується пра- вило-продукція, висновок якого зіставний з метою. Умови цього правила розміщуються в робочу пам’ять і стають новою підмету. Процес повторюється доти, поки в робочій пам’яті не будуть знайдені факти, що підтверджують цільове твердження. Проілюструємо зворотний висновок на множині продукцій попереднього прикладу.
Процес висновку починається з того, що в робочу пам’ять по- міщують цільове твердження Goal, істинність якого потрібно підтвердити або спростувати, а також множина початкових фактів {L, М, N}, які вважаються істинними твердженнями.
Зручно розглядати змінні правил як багатозначні об’єкти, що характеризуються трьома можливими значеннями: «не визначено», «брехня», «істина». В цьому разі початкове значення змінної Goal
— «не визначено», а факти L, М, і N мають значення «істина».
Зворотний ланцюжок міркувань для цього прикладу зображено на рис. 2.7. Тут факти, що мають значення «істина», виділено курсивом. Висновок починається з твердження Goal, яке розглядається як поточна підмета. Всі продукційні правила, висновок яких зіставний з поточною подметою, додаються до конфліктної множини правил. На кожному кроці активізується перше правило конфліктної множини. Посилання цього правила додаються в робочу пам’ять і як наступний крок виступають як нова підмети системи. Така стратегія розв’язання конфліктів відповідає пошуку в ширину.
Таблиця 2.4
ЗВОРОТНИЙ ВИСНОВОК В ПРОДУКЦІЙНИХ СИСТЕМАХ
№
кроку
Рабоча пам’ять
Конфліктна
множина
Активізоване
правило
0
Goal, L, М9 N
10, 11
10
1
Goal, A, L, Му N
11,6,7
И
2
GoalyAyByLyMyN
6, 7, 8,9
6
3
GoalyAyByCyLyMyN
7, 8, 9,1
7
4
Goaly Ay By Су Dy L9 M9 N
8, 9, 1,2
8
5
Goaly Ay By Су D, E, L, M9 N
9, 1,2,3
9
6
Goal, Ay By Су Dy Ey F, L, My N
1,2, 3,4,5
1
7
Goaly Ay В, С, Dy F, F, G, tf, L, Af, N
2, 3, 4,5
2
8
Goaly Ay By Су Dy E, F, Gy Я, /, АГ, I, My N
3,4,5
3
9
Goal, A, By Су Dy Ey F, G, Я, /, K, L, My N
4,5
Stop
106
Г.Ф. Іванченко
Goal
Рис. 2.7. Зворотний ланцюжок міркувань
Указаний процес повторюється доти, доки всі умови (посилання) деякого правила не стануть істинними, тобто співпадуть з фактами, що є в робочій пам’яті. В цьому разі висновок правила теж набуває значення «істина». Це істинне значення поширюється вгору ланцюгом активізованих правил. Якщо цільова вершина набуває значення «істина», то процес пошуку на цьому закінчується. Якщо цього не відбувається, то знову вибирається перше правило конфліктної множини тощо.
За активізації правила 3 ^встановлюється, ща його посилання L і М є фактами. Отже, фактом є і висновок Е. Далі, якщо вірне Е, то вірно і В (правило 8). І нарешті, якщо вірно В, то справедливе і цільове твердження Goal (правило 11).
Розглянуті приклади показують, що висновок в продукційних системах загалом відповідає пошуку рішень в І-АБО графах. В окремому випадку, коли правила-продукції не містять в умовній частині кон’юнкцій, висновок у продукційних системах відповідатиме пошуку рішень у просторі станів. Тому розглянуті раніше методи пошуку рішень у просторі станів і в І-АБО графах успішно застосовують у продукційних системах. Часто в продукційних системах застосовують комбіновані методи пошуку рішень. Наприклад, застосовують двоспрямований пошук. У цьому разі спочатку пошук ведуть у прямому напрямі до тих пір, поки число станів не стане великим. Потім виконується зворотний пошук вже досягнутих станів. За такої організації пошуку є одна небезпека. Якщо застосовуються методи евристичного пошуку, то можливо, що підграфи, обстежувані в прямому і зворотному напрямі,
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
107
виявляться різними і не «зустрінуться». Це призведе до збільшення часу пошуку, порівняно з односпрямованим пошуком. Цієї небезпеки немає, якщо застосовуються методи «сліпого» пошуку. Тоді комбінований метод значно скорочує час пошуку.
Відзначимо, що ситуація, коли в робочу пам’ять наперед вносяться всі відомі факти, зустрічається рідко. Зазвичай у робочій пам’яті спочатку міститься тільки частина фактів, необхідних для висновку. Решта відомостей продукційна система з’ясовує сама, запитуючи користувача, опитуючи вимірювальні або інші підсистеми, пов’язані з нею.
Наприклад, прямуючи ланцюжком зворотних міркувань, зображеним на рис. 2.7, система спрямовує пошук від мети до фактів. Коли буде активізовано правило 1, то система намагається встановити, чи є вислови Є і Я фактами, тобто чи приписано їм значення «істина». Оскільки значення висловів Є і Я невідомі, то система може поставити користувачу запитання щодо істинності висловів Сг і Я. Отримана відповідь вноситься в робочу пам’ять. Якщо вислови Є і Я набудуть значення «істина», то це змінить хід міркувань системи і відпаде потреба в аналізі інших ланцюжків правил.
Порівнюючи прямий і зворотний висновки, слід зазначити, що прямий висновок має ширшу сферу використання. Пояснюється це тим, що зворотний висновок буде ефективний у тому разі, якщо вирішувана проблема характеризується небагатьма, чітко визначеними цільовими станами. Коли кількість цільових станів велика, або їх визначення є частиною самої проблеми, то зворотний висновок мало придатний. Подібні ситуації зустрічаються, наприклад, при вирішенні завдань планування, де план є одночасно і цільовим станом, і шуканим рішенням, у медичних експертних системах при призначенні методики лікування тощо.
Як наголошувалося вище, розв’язання конфліктів — важлива проблема, пов’язана з управлінням порядком використання правил, які створюють конфліктну множину.
Порядок активізації правил конфліктної множини визначається обраною стратегією розв’язування конфліктів. Раніше в прикладах конфліктна множина правил подавалася у вигляді впорядкованого списку. При цьому конфліктні правила дописувалися в кінець цього списку. Прості стратегії розв’язання конфліктів засновані на тому, що обирається або перше, або останнє правило, що входить до списку. Вибір першого правила відповідає пошуку в ширину, а вибір останнього правила (тобто щойно доданого) —
108
Г.Ф. Іванчвнко
пошуку в глибину. В багатьох продукційних системах найчастіше застосовують другий спосіб. Очевидно, найбільш загальним способом керування системою продукцій є комплексне планування її роботи, тобто прийняття рішень на основі аналізу усіх можливих дій та їх результатів з точки зору мети, що стоїть перед системою. Але зрозуміло, що вказаний принцип нечасто може бути застосований у повному обсязі, в першу чергу через екс- поненційне зростання можливих варіантів розвитку подій.
Існують стратегії керування розв’язанням конфліктів, мета яких — намагатися уникнути експоненційного зростання. Подібні стратегії можуть бути охарактеризовані переважно як евристичні.
Іншими принципами, що використовуються при розв’язанні конфліктів, є:
• принцип «стосу книг»;
• принцип найдовшої умови;
• принцип метапродукцій;
• принцип «класної дошки»;
• принцип пріоритетного вибору.
Принцип «стосу книг» полягає в тому, що список конфліктуючих правил упорядковується відповідно до частоти використання продукцій у минулому. В першу чергу вибирається продукція, яку використовували найчастіше. Ґрунтується на ідеї, що найбільш корисною є та продукція, яка використовується найчастіше (так само, як у стосі книг ті книги, які найчастіше використовуються, зазвичай, опиняються зверху). Відповідно, з фронту готових продукцій вибирається продукція з максимальною частотою використання. Відмічено, що керування за принципом «стосу книг» доцільно застосовувати, якщо продукції відносно незалежні одна від одної, наприклад, коли кожна з них являє собою правило «ситуація А => дія В».
Принцип найдовшої умови віддає пріоритет тій продукції, ядро якої має найдовшу умову. Такі продукції відповідають специфічним (вузьким) ситуаціям. Цей принцип спирається на той факт, що продукції з довгими умовами враховують більше інформації про поточну ситуацію, і це має приводити до прискорення пошуку рішення. Принцип найдовшої умови. З фронту готових продукцій вибирається та, для якої стала справедливою найдовша умова виконання. Ідеологічною основою цього принципу є міркування, Що часткові правила, застосовані до вузького класу ситуацій, є важливіші, ніж загальні правила для широкого класу ситуацій. Наприклад, нехай є дві продукції:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
109
(1) якщо А-банк, то А видає кредит.
(2) якщо А-банк і А -НАДРА, то А не видає кредит.
Якщо відомо, що А — НАДРА, то за принципом найдовшої умови слід вибирати (2).
Принцип найдовшої умови доцільно застосувати, якщо продукції прив’язані до типових ситуації, зв’язаних відношенням «часткове — загальне». До цього можна додати, що цей принцип заслуговує на особливу увагу під час аналізу винятків. Так, у нашому прикладі правило (2) є винятком з правила (1); якби ми були впевнені, що (1) не має винятків, ми могли б застосувати це загальне правило у будь-якій ситуації. Легко бачити очевидні аналогії принципу найдовшої умови з принципом блокування наслідування.
Принцип метапродукцій заснований на введенні в базу знань спеціальних метаправил, що впорядковують процес розв’язання конфліктів. На підставі метаправил здійснюється аналіз безлічі конфліктних правил і, в певних ситуаціях, активізуються ті або ті правила з цієї множини. Принцип метапродукцій ґрунтується на введенні до системи знань метапродукцій, тобто правил використання продукцій. Типовими метапродукціями можуть бути правила, які визначають, що слід робити, якщо до фронту готових продукцій ввійшли або не ввійшли ті чи ті конкретні продукції. Конфлікти розв’язуються на основі обміну інформацією з використанням «класної дошки». Застосування «класної дошки» часто комбінується із застосуванням метапродукцій.
У разі пріоритетного вибору з кожною продукцією зв’язується статичний або динамічний пріоритет, що визначає порядок її активізації. Кожній продукції надається пріоритет, що відображає її важливість. Ці пріоритети можуть бути різними для кожного типу ситуацій. Пріоритети можуть бути також статичними і динамічними. Динамічні пріоритети змінюються з часом і можуть відображати, наприклад, ефективність використання продукцій у минулому або час знаходження продукції у фронті готових продукцій. Аналіз часу знаходження продукції у фронті готових продукцій цікавий тим, що на його основі можна прийти до діаметрально протилежних висновків. З одного боку, система керування продукціями може з часом підвищувати динамічний пріоритет, щоб будь-яка продукція колись була обов’язково виконана. З іншого боку, система керування може дійти до висновку, що якщо продукція досі не виконувалася, то вона
110
Г.Ф. Іванченко
взагалі не потрібна і, відповідно, не підвищити її пріоритет, а, навпаки, знизити.
Іноді в постумовах продукції може вказуватися ім’я наступної продукції, яку необхідно виконати. Це перетворює систему про- дукцій на звичний алгоритм.
2.8. Асоціативна модель знань
Асоціативна модель знань. Ця модель використовує поняття формальної системи, що задається як А — <1/, С, Ь, />, де А — асоціативна мережа подання знань; V — множина вузлових елементів асоціативної мережі; С — множина конекцій (контактних зв’язків) елементів; Ь — множина правил побудови мережі й визначення параметрів конекцій; І— правила асоціативного висновку (процедури процесування знань).
В основі асоціативної моделі знань лежать асоціативна логіка, ней- родинамика і когнітологія. Історично ця модель має коріння в психології і нейродинаміці. Розвиток у рамках психології уявлень про пам’ять, навчання і мислення і формалізацію деякий з них у нейродинаміці привів до розробки асоціативного підходу в іфучному інтелекті.
Загальним для асоціативного підходу є поїдання знань у вигляді асоціативної мережі вузлових елементів, що мають конекції між собою відповідно до поставленого завдання. Тут під конекці- єю розуміється регульований контактний зв’язок між елементами. Саме керовані конекції забезпечують поданим знанням асоціативність, тобто здібність системи давати вірогідні рішення на виході навіть частиною вхідного вектора за рахунок паралельного процесування інформації, поширюваної мережею вузлових елементів, з урахуванням сили конекцій.
Інший бік асоціативного підходу — можливість забезпечення когнітивності (когнітивні системи) як здібності формування знань шляхом навчання й обробки їх у реальному часі подібно до того, як це робить нервова система людини.
Навчання тут розглядається як процес установлення конекцій вузлових елементів шляхом мінімізації відповідного критерію (функція ціни, енергетична функція) при запам’ятовуванні ряду правильних прикладів поведінки системи. Реальний час виконання завдання забезпечується за рахунок неасоціативного висновку
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
111
шляхом паралельного процесування знань. Когнітівність за ефективністю зближує такі системи з біологічним прототипом — нервовою системою людини.
Різні прояви асоціативної моделі вилилися в асоціативну логічну, нейронну форми, наприклад:
якщо Коефіцієнт загальної ліквідності > 2—2,5, то Клієнт кредитоспроможний;
якщо Коефіцієнт абсолютної ліквідності > 0,2—0,25, то Клієнт кредитоспроможний;
якщо Коефіцієнт автономності < 1, то Клієнт кредитоспроможний; якщо Коефіцієнт маневреності власних коштів > 0,5, то Клієнт кредитоспроможний;
якщо Коефіцієнт грошового потоку = 1, то Клієнт кредитоспроможний;
якщо Коефіцієнт процентних витрат > 1, то Клієнт кредитоспроможний;
якщо Клієнт не кредитоспроможний, то Відхилити прохання про кредит;
якщо Клієнт кредитоспроможний, то Вибрати форму кредиту; якщо Кредит під заставу цінних паперів, то Розмір кредиту в розмірі 90 % від заставної вартості;
якщо Кредит під банківські акції, зареєстровані на фондовій біржі, то Розмір кредиту в розмірі на рівні 70—80 % вартості акцій; якщо Кредит під котирувані цінні папери підприємницьких структур, то Розмір кредиту на рівні 60—70 % заставної ціни; якщо Сума кредиту розрахована, то Вибрати строк кредиту; якщо Строк кредиту вибраний, то Розрахунок %; якщо % розрахований, то Порядок видачі і погашення кредиту, ціна кредиту;
якщо Кредит контокорентний, то Ввести розмір кредиту; якщо Розмір кредиту внесений, то Ввести заставу, під яку надається кредит;
якщо Застава введена, то Вибрати строк кредиту;
якщо Строк кредиту вибраний, то Розрахунок %;
якщо % розрахований, то Порядок видачі і погашення кредиту,
ціна кредиту;
якщо Кредит іпотечний, то Ввести розмір кредиту; якщо Розмір кредиту внесений, то Ввести заставу, під яку надається кредит;
якщо Застава введена, то Вибрати строк кредиту;
112
Г.Ф. Іванченко
якщо Строк кредиту вибраний, то Розрахунок %;
якщо % розрахований, то Порядок видачі і погашення кредиту,
ціна кредиту;
якщо Кредит споживчий, то Споживчий кредит в іноземній валюті не надається.
2.9. Семантичні мережі
Семантичні мережі не є однорідним класом моделей подання знань. Часто загальною основою класифікація схеми подання знань як семантичної мережі є те, що вона подається у вигляді спрямованого графа, вершини якого відповідають об’єктам (поняттям, єствам) предметної галузі, а дуги — відношенням (зв’язкам) між ними. І вузли, і дуги, зазвичай, мають мітки (імена). Імена вершин і дуг зазвичай співпадають з іменами відповідних об’єктів і відношень наочної галузі.
Семантична мережа часто застосовується для відображення системи понять у проблемній галузі й висновку в цій системі. Вона підтримується спеціалізованими мовами семантичних мереж, як-от №ЇТЬ, АТІЧЬ. ,, і
Об’єкти предметної галузі, що відображаються в семантичній мережі, можна умовно поділити на три групи: узагальнені, індивідуальні (конкретні) і агрегатні об’єкти.
Семантична мережа — це граф, вершини якого відповідають об’єктам, або поняттям, а дуги, що зв’язують вершини, визначають відношення між ними. Введено також спеціальний тип вершин: вершини зв’язку. Вершина зв’язку не відповідає ані об’єктам, ані відношенням і використовується для вказівки зв’язку. Основними відношеннями в семантичній мережі є відношення приналежності до класу, властивості, специфічні для цього поняття і приклади цього поняття.
Найчастіше з цією метою використовують концептуальні графи Дж. Соува і блокові структури Г. Хендрікса. Вершинами концептуального графа є або об’єкти (поняття, єства) наочної галузі, або концептуальні відношення. Ребра концептуального графа зв’язують між собою вершини-поняття і вершини-відношення. При цьому ребра можуть виходити з вершини-поняття і закінчуватися у вершині-відношення, і навпаки.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
113
Концептуальні графи можуть містити вершини, які є пропозиціями. Такі вершини зображаються у вигляді прямокутного блоку, що містить підграф, відповідний пропозиції. Концептуальний граф дає змогу природним чином виражати кон’юнкцію.
Для подання заперечення на концептуальних графах застосовується унарний логічний оператор «ні». Оператора застосовують до пропозиції. Твердження, що фіксується пропозицією, вважається в цьому разі помилковим.
Використовуючи заперечення та кон’юнкцію, можна подати на концептуальних графах диз’юнкцію. Проте для спрощення концептуальних схем диз’юнкцію представляють у вигляді спеціального бінарного відношення «або», аргументами якого є вершини-пропозиції.
За своїми виразними можливостями концептуальні графи еквівалентні логіці числення предикатів. Існує можливість взаємного переходу від описів наочної галузі мовою числення предикатів до концептуального графу, і навпаки. Вибір тих або тих засобів визначається характером поставлених завдань і навичками розробників ІШ.
Семантичні мережі є окремим випадком мережевих моделей подання знань. Формально мережеві моделі задаються у вигляді:
Н =< /, С|, Cj, ... Сп, Q >,
де / — множина інформаційних елементів, що бережуться у вузлах мережі; С,, С2, ...С„ — типи зв’язків між інформаційними елементами; Q— відображення, яке встановлює відповідність між безліччю типів зв’язків і безліччю інформаційних елементів мережі.
Мережеві моделі подання знань розрізняються між собою типами зв’язків, що використовуються (відносин). Якщо мережа класифікує, то вона використовує ієрархічні зв’язки (клас—підклас, рід—вигляд і т. п.). Якщо зв’язки між інформаційними елементами подаються як функціональні відносини, що дають можливість обчислювати значення одних інформаційних елементів за значеннями інших, мережі називають функціональними (обчислювальними). Якщо в мережі допускаються зв’язки різного типу, то її називають семантичною мережею.
Семантична мережа є спрямований граф, у якому вершинам відповідають об’єкти (суть) наочної галузі, а дугам — відносини, в яких перебувають ці об’єкти. Висновок в семантичних мережах може виконуватися на основі алгоритмів зіставлення, шляхом виділення підграфів з певними властивостями.
114
Г.Ф. Іванчвнко
До Переваг семантичних мереж відносять: велику виразну здатність, Наочність графічного уявлення, близкість структури мережі до семантичної структури фраз природної мови. Недоліком подання знань у вигляді семантичних мереж є відсутність єдиної термінології. Ця модель представлення знань знаходить різне втілення у різних дослідників.
На відміну від неформального визначення, останнє визначення вимагає жорсткої фіксації схеми бази знань, тобто набору можливих інформаційних одиниць та типів можливих зв’язків. Існує значна кількість моделей знань на основі семантичних мереж; історично першою була модель Куїлліана.
Таке подання, зрозуміло, не є єдино можливим. Обговорюється, які переваги та недоліки можуїь бути пов’язані з різними формами задання баз знань у вигляді семантичних мереж.
Вперше семантичні мережі з’явилися в галузі машинної лінгвістики як засіб аналізу значення (семантики) природної мови. В 1967 році М. Р. Куілліаном була розроблена програма, що фіксує значення англійських слів, побудована за принципом тлумачного словника. В цій програмі певне слово англійської мови визначається в термінах, висловлюваних іншими словами. Кожне слово визначається безліччю покажчиків на інші слова. Сукупність покажчиків утворює мережу, «подорожуючи» в якій можна з’ясувати значення того або того слова. В семантичній мережі Куїшііана вершини відповідають визначуваному поняттю і забезпечуються покажчиками на ініиі слова, що розкривають це поняття. База знань організована у вигляді сторінок (площин), на кожній з яких подається граф, що визначає одне слово.
Нижче приведено текст програми, що реалізує семантичну мережу із використанням функцій бібліотеки пакету МаЙаЬ задачі оцінки кредитоспроможності позичальника юридичної особи на основі обраних фінансових коефіцієнтів.
% створюємо структуру для семантичної мережі 8К=8>Іпе\у;
% додаємо вузли іпсіисіеу «АБО» — значення атрибутів 8К=8Нас1<ЮКпо(1е(8М, ‘Більше >=0,25’, ‘Менше <0,25’, ‘Більше >=1’, ‘Менше <1’, ‘Більше >=1,2’, ‘Менше <1,2’,’Рішення’);
% додаємо вузли іпсіисіеу «ТА» — об’єкти і назви атрибутів 8К=8Кадс1А>ГОпо(іе(8М, ‘Клієнт’, ‘Індикатори’, ‘Рішення’, ‘Абсолютна ліквідність’, ‘Швидка ліквідність’, ‘Покриття забов.’, ‘Позитивно’, ‘Негативно’);
% додаємо відносини між вузлами
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
115
SN=SNaddrelation(SN, ‘Клієнт’, ‘include’, ‘Індикатори’); SN=SNaddrelation(SN, ‘Клієнт’, ‘include’, ‘Рішення’); SN=SNaddrelation(SN, ‘Рішення’, ‘include’, ‘Позитивно’); % позитивне рішення, надати кредит
SN=SNaddrelation(SN, ‘Рішення’, ‘include’, ‘Негативно’); % негативне рішення, не надавати кредит
SN=SNaddrelation(SN, ‘Індикатори’, ‘include’, ‘Абсолютна ліквідність’); SN=SNaddrelation(SN, ‘Індикатори’, ‘include’, ‘Швидка ліквідність’); SN=SNaddrelation(SN, ‘Індикатори’, ‘include’, ‘Покриття забов.’); SN=SNaddrelation(SN, ‘Абсолютна ліквідність’, ‘include’, ‘Більше >=0,25’);
SN=SNaddrelation(SN, ‘Абсолютна ліквідність’, ‘include’, ‘Менше <0,25’);
SN=SNaddrelation(SN, ‘Швидка ліквідність’, ‘include’, ‘Більше >=1’); SN=SNaddrelation(SN, ‘Швидка ліквідність’, ‘include’, ‘Менше <1’); SN=SNaddrelation(SN, ‘Покриття забов.’, ‘include’, ‘Більше >=1,2’); SN=SNaddrelation(SN, ‘Покриття забов.’, ‘include’, ‘Менше <1Д’); SN=SNaddrelation(SN, ‘Більше >=0,25’, ‘include’, ‘Позитивно’); SN=SNaddrelation(SN, ‘Менше <0,25’, ‘include’, ‘Негативно’); SN=SNaddrelation(SN, ‘Більше >=1’, ‘include’, ‘Позитивно’); SN=SNaddrelation(SN, ‘Менше <1’, ‘include’, ‘Негативно’); SN=SNaddrelation(SN, ‘Більше >=1,2’, ‘include’, ‘Позитивно’); SN=SNaddrelation(SN, ‘Менше <1,2’, ‘include’, ‘Негативно’);
% будуємо графічні зображення схеми семантичної мережі SNplot(SN, ‘hierarchy’); % ієрархічне розташування вузлів figure; % створюємо нове вікно для іншої схеми SNplot(SN, ‘circle’); % кругове розташування вузлів SN1=SN;
% видаляємо з мережі-запиту зайві вузли
SNl=SNdelnode(SNl, ‘Менше <0,25’, ‘Менше <1’, ‘Менше <1,2’, ‘Позитивно’, ‘Негативно’);
% додаємо до мережі-запиту цільовий вузол SNl=SNaddANDnode(SNl, ‘?’);
% додаємо до мережі-запиту відношення для цільового вузла SNl=SNaddrelation(SNl, ‘Рішення’, ‘include’, ‘?’); figure; % створюємо нове вікно для схеми % будуємо графічне зображення схеми мережі-запиту SNplot(SNl, ‘random’); % випадкове розташування вузлів % результати якого видаємо на екран Res=SNfind(SN, SN1)
116 Г.Ф. Іванчвнко
Результати роботи програми та повідомлення зображено на рис. 2.8.
а) ієрархічне розташуванням вузлів
б) кругове розташуванням вузлів
Рис 2.8. Програмно побудована схема семантичної мережі задачі оцінки кредитоспроможності позичальника юридичної особи на основі обраних фінансових коефіцієнтів.
Семантичні мережі є найбільш широким класом мережевих моделей, у яких поєднані різні типи зв’язків. Часткові випадки семантичних мереж відповідають спеціальним типам зв’язків.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
117
Виділяють, зокрема, класифікаційні мережі, функціональні мережі та сценарії.
Класифікаційні мережі дають змогу задавати відношення ієрархії між інформаційними одиницями.
Функціональні мережі характеризуються наявністю функціональних відношень, які дають змогу описувати процедури обчислень одних інформаційних одиниць через інші. їх часто називають обчислювальними моделями, оскільки за їх допомогою можна описувати процедури обчислення одних інформаційних одиниць через інші.
Введена класифікація об’єктів є відносною. Залежно від поставленого завдання один і той же об’єкт може розглядатися як узагальнений або індивідний, як агрегатний або неагрегатний.
Узагальнений об’єкт відповідає деякій збірній абстракції реально існуючого об’єкту, процесу або явища наочної області. Наприклад, «виріб», «підприємство», «співробітник» тощо. Узагальнені об’єкти фактично представляють певні класи наочної області.
Індівідний об’єкт — це якимсь чином виділений одиничний представник (екземпляр) класу.
Агрегатним називається складовий об’єкт, утворений з інших об’єктів, які розглядаються як його складові частини. Наприклад, виріб складається з сукупності деталей, підприємство складається з сукупності відділів, служб, цехів.
Семантичні мережі в пам’яті людини
Є ряд свідчень на користь того, що знання в людській пам’яті зберігаються у вигляді структур, які нагадують семантичні мережі. Про це свідчать, зокрема, результати дослідів, що проводилися школою Жана Піаже.
Дитині трьох з половиною років показали квадрат і попросили намалювати його. Спочатку вона намалювала фігуру, показану на рис. 2.9, а), що не дивно, але потім вона намалювала зовсім іншу фігуру.
Рис. 2.9. Перше та друге зображення квадрату
118
Г.Ф. Іванченко
Коли попросили пояснити свій малюнок, вона вказала на три елементи: «жорсткі речі», «речі, що йдуть вгору — вниз» і «боковинки». Коли вона показала на початковому квадраті, що мала на увазі, з’ясувалося, що «жорскі речі» відповідають кутам квадрата, «боковинки» — горизонтальним сторонам, а «речі, що йдуть вгору — вниз» — вертикальним.
Жан Піаже та його учні дають цьому таке пояснення. Людина зберігає зображення в своїй пам’яті не так, як воно сприймається органами почуттів, а у вигляді його структурного опису. Так, семантична мережа, що задає структурний опис квадрата, могла б мати вигляд:
Легко побачити подібність цієї структури (особливо фрагмента, обведеного рамкою) з малюнком, що був зроблений дівчинкою. Очевидно, коли дівчинка робила другий малюнок, вона пропустила стадію реконструкції зображення і намалювала квадрат у вигляді структури, яка зберігалася в її пам’яті.
Трирівнева архітектура семантичних мереж
Семантичні мережі можна розглядати на трьох рівнях ієрархії, які показані на рис. 2.11.
Повній базі знань відповідає вся семантична мережа; окремій концептуальній одиниці (окремому твердженню або описові окремого поняття) — концептуальний граф, який є підмножиною семантичної мережі. Семантичну мережу прийнято розглядати як структуру, що утворюється в результаті композиції окремих концептуальних графів. Запропонована певні правила, які дають можливість формалізувати таку композицію.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
119
Рис. 2.11. Трирівнева архітектура семантичних мереж
Зображена семантична мережа відповідає окремому реченню. Тому вона фактично є концептуальним графом, який може бути занурений у більш складну семантичну мережу.
Найнижчому рівневі (тріаді «об’єкт-атрибут-значення») відповідають два зв’язані вузли семантичної мережі разом із зв’язком між ними. Найчастіше «атрибутові» з цієї тріади відповідає зв’язок семантичної мережі.
Асиміляція нових знань на основі семантичних мереж
Формалізми, які можна застосовувати для під’єднання нового концептуального графу, що відповідає новому твердженню, до вже існуючої семантичної мережі, можна використовувати для вирішення на основі мережних моделей дуже важливого задания
— розуміння інтелектуальною системою нової інформації,
Розуміння нової інформації можна уявляти як переклад цієї інформації на внутрішню мову системи шляхом співставлення зі знаннями системи та формування вторинного опису у термінах знань системи. Цей процес зазвичай називають асиміляцією нової інформації.
Асиміляція може бути поєною і модальною. За повної асиміляції система сприймає нову інформацію як істинну й інтегрує її до бази знань у вигляді сукупності нових фактів. За модальної асиміляції система включає нові факти до своєї бази знань, але з певними помітками, які відображають джерело знань, ступінь згоди і т. п. Ідеться про те, що система розуміє інформацію, але може погоджуватися з нею чи ні.
Приклад. Менеджер вводить до інтелектуальної системи факт «’’Тріада” не повертає вчасно кредит достовірність 0,5».
За повної асиміляції система просто перекладає цей факт на свою внутрішню мову та заносить його до своєї бази знань. Надалі він може бути використаний у процесі логічного висновку поряд з іншими фактами.
120
Г.Ф. Іванчвнко
При модальній асиміляції система може сформувати такі знання, як: «менеджер вважає, що «Тріада» не повертає вчасно кредит», або «менеджер вважає, що «Тріада» не повертає вчасно кредит, але це не так», або «Є свідчення на користь того, що менеджер вважає, що «Триада» не повертає вчасно кредит; ступінь достовірності цього факту дорівнює 0.5» тощо. Подібні знання можна враховувати за логічного висновку, але лише при використанні спеціальних методик.
Для кожної моделі задания знань характерні свої процедури асиміляції. Асиміляцію на основі семантичних мереж можна описати так:
• сприйняття нової інформації та формування її вторинного опису у вигляді одного або кількох концептуальних графів або нового фрагмента семантичної мережі;
• підключення сформованих фрагментів до існуючої семантичної мережі на основі тих чи інших формальних процедур.
Процедурні та розділені семантичні мережі
Чимало досліджень присвячено уніфікації формальних описів семантичних мереж на основі введення єдиної семантики. Зокрема, запропоновано процедурні семантичні мережі.
Процедурна семантична йережа конструюється на основі класу (поняття), а вершини та дуги задано як об’єкти. Процедури визначають такі основні операції над дугами:
• встановлення зв’язку;
• анулювання зв’язку;
• підрахунок кількості вершин, з’єднаних цією дугою;
• перевірка наявності дуги між заданими вершинами.
Ряд процедур визначає основні дії над вершинами, наприклад:
• визначення екземпляра класу;
• анулювання екземпляра;
• підрахунок кількості екземплярів класу;
• перевірка належності екземпляра класу.
Апарат розділених семантичних мереж призначений для задания кванторів існування та таких кванторів загальності, для яких немає задовільного опису на основі зв’язків «є». Кожний квантор пов’язується з певною підмережею; вводиться ієрархія підмереж.
Типи зв’язків між об’єктами семантичних мереж можуть бути будь-ким. Але найчастіше застосовуються такі основні зв’язки (відносини): «рід—вид», «є представником», «є частиною». Наявність
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
121
зв’язку типу «рід-вид» між узагальненими об’єктами А і В означає, що поняття А загальніше, ніж поняття В. Будь-який об’єкт, що відображається поняттям В, відображається і поняттям А, але не навпаки. Наприклад, поняття банк — це родове поняття для об’єкта «кредит». Всі властивості родового об’єкта А, зазвичай, властиві й видовому об ’єкту В, тобто, об’єкт В успадковує властивості об’єкта А.
Зв’язок «є представником» існує зазвичай між узагальненим і ін- дивідним об’єктом, коли індивідний об’єкт виступає в ролі представника деякого класу. Екземпляр може бути представником кількох узагальнених об’єктів. У цьому разі він має властивості кількох узагальнених об’єктів, що відповідає множинному спадкоємству.
У ряді випадків між зв’язками «рід—вид» і «є представником» не роблять відмінностей, відзначаючи, що ці зв’язки задають відношення «загальне—приватне» (рис. 2.12). Іноді це призводить до непорозумінь. Тому для формалізації таких зв’язків використовуватимемо відносини ако (від англ. a kind of — різновид) і is а (від англ. is a member class — бути представником класу).
1) Клієнт
страхувальник
фізична особа юридична особа особа, яка прийшла на консультацію
2) Об’єкта страхування (тип об’єкта страхування: об’єкт страхування) майнове страхування
страхування майна громадян будівлі тварини домашнє майно страхування майна юридичних осіб основні фонди оборотні фонди страхування майна сільськогосподарських підприємств сільськогосподарські тварини будівлі та інше майно транспортні засоби
врожай сільськогосподарських культур
страхування транспортних засобів
3) Договір страхування
форма страхування обов’язкове добровільне вид страхування
Рис. 2.12. Концептуальна схема семантичної мережі «страховий бізнес»
122
Г.Ф. Іванчвнко
Не менш важливо відношення «є частиною» (англ. part). Це відношення пов’язує агрегатний об’єкт з його складовими частинами. Воно дає змогу відображати в базі знань структуру ПРГ.
Властивості передаються через зв’язки «is» і «has» («є» і «має»), наприклад, вислів «Об’єкти страхування є майнове страхування» інтерпретується фрагментом мережі як фраза «Договір страхування страхування транспортних засобів».
Як приклад на малюнку зображено семантичну мережу, що подає частину знань про страховий бізнес (рис. 2.12).
Якщо позначити фрагменти, показані на рис. 2.12, через Ф„ то в загальному випадку семантична мережа утворюється як з’єднання (а) цих фрагментів, тобто як ФідФ2Л...лФ„, причому порядок індексації фрагментів не має значення (операція з’єднання комутативна).
Важливий момент в організації моделі бази знань на основі семантичної мережі полягає в подаванні подій і дій. Концептуалі- зація дій будується з таких елементів:
Діяч — поняття виконавця Акту
Акт — дія, що відбувається стосовно об’єкта
Об’єкт — річ, над якою проводиться дія
Реципієнт — одержувач об’єкта в результаті Акту
Напрям — місцерозташування, до якого направлено Акт
Стан А — стан, у якому перебуває який-ребудь об’єкт
Для опису семантики дій використовують такі основні групи позначень і концептуальних схем:
Позначення:
РР — клас фізичних об’єктів;
ПРГ — фізичні об’єкти;
ACT — дії;
РА — властивості об’єктів;
LOC — місцерозташування;
Т — час;
АА — атрибути (характеристики) дій;
РА — атрибути (характеристики) об’єктів;
R — реципієнти;
І — інструменти, за допомогою яких виконується дія;
D — напрям дії.
Для завдання подій використовують тимчасові відносини, як-от «раніше», «пізніше», «на цей момент», «одночасно», «не пізніше» тощо.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
123
Окрім розглянутих понять, на семантичній мерейсі можуть бути визначені також мережеві продукції, які дають можливість:
— додавати або видаляти фрагменти мереж;
— додавати або видаляти зв’язки і вершини;
— перевірити, що деякий фрагмент міститься в мережі;
— будувати приклади відносин;
— знаходити фрагменти, загальні для двох і більше мереж й ін.
Особливістю і водночас недоліком семантичної Мережі є її
уявлення у вигляді такої цілісної структури, яка не дає змогу розділити базу знань і механізм висновків. Це означає, Що процес висновку, як правило, пов’язаний із зміною структури мережі шляхом застосування мережевих продукцій.
Методи висновку на семантичних мережах використовують асоціативні і зіставні алгоритми, які зводяться до знаходження шляхів на графі, та пошуку по перетину. Він дає змогу встановлювати відносини між двома словами. Пошук виконується методом у ширину по зовнішніх покажчиках з двох початкових сторінок доти, поки не буде знайдено загальне поняття, відповідне вершині перетину двох напрямів пошуку. Знайдені в результаті пошуку шляхи від початкових вершин до вершини перетину і становитимуть відношення між початковими словами-поняттями. Наприклад, слова-понятгя «автомобіль», «новий», «гроші» приводять до перетину шляхів пошуку у вершині «кредит — банк». В результаті аналізу шляхів пошуку модель дає змогу зробити такий висновок: «Кредит — це один із способів створення нового автомобіля».
Таким чином, завдяки моделі можна формувати відносини, які представлені в ній неявно і, отже, на її основі можна одержувати нові знання. Це дає можливість будувати системи розуміння природної мови, що мають такі можливості:
1) визначати основне значення тексту шляхом пошуку безлічі вершин перетину;
2) здійснювати вибір необхідного значення багатозначного слова на основі найкоротшого шляху від цього слова до інших слів цієї пропозиції (свого роду семантична метрика);
3) формувати відповіді на різні запити шляхом встановлення взаємозв’язків між словами-поняттями запиту і словами-гіонят- тями, що зберігаються в пам’яті системи.
Розглянутий підхід одержав розвиток у системі TLC (Teachable Language Comprehender: система розуміння мови), розробленій
124
Г.Ф. Іванченко
Квілліаном. Проте практичний успіх ТЬС був обмежений. Це пояснювалося тим, що набір типів зв’язок (відносин), що використовуються між поняттями, був недостатній. Використовувалися тільки такі зв’язки, як: «клас — екземпляр класу», «атрибут — значення». Крім того, сам пошук не враховував значення зв’язок. Подання знань вимагає введення в розгляд ширшого набору відносин між поняттями (об’єктами, єствами) ПРГ. В подальшому мережеві моделі подання знань розвивалися саме в цьому напрямі.
У своїх працях Р. Симмонс і К. Філмор вказали на важливу роль дієслів під час аналізу значення речення природної мови. Речення можна представити вершиною-дієсловом і різними відмінковими зв’язками (відношеннями). Таку структуру називають відмінковою рамкою. Серед відмінкових відношень виділяють такі: агент — відношення між дією і тим хто (що) виконує; об’єкт
— відношення між подією і тим, над чим виконується дія; інструмент — об’єкт, за допомогою якого виконується дія; місце
— місце виконання дії; час — час виконання дії. Під час аналізу
пропозиції програма знаходить дієслово і встановлює відповідні відмінкові відношення між частинами речення. Відмінкова рамка фіксує знання відмінкової (лінгвістичної) структури природних мов у вигляді мережевогр формалізму. і
Відповідно до введеного раніше визначення семантичної мережі, відсутні будь-які обмеження і на типи відношень, і на типи об’єктів, що відображаються в мережі. В більшості випадків різноманіття об’єктів мережі можна поділити на три групи:
1) об’єкти-поняття — відомості про фізичні й абстрактні об’єкти, наочну галузь;
2) об’єкти-події — абстрактні або конкретні дії, які можуть привести до зміни стану наочної галузі;
3) об’єкти-властивості — уточнюють поняття і події, наприклад, указують характеристики понять (колір, форму, розміри тощо), фіксують параметри подій (місце, час, тривалість).
Іншим ефективним засобом висновку є зіставлення із зразком. У цьому разі відбувається зіставлення окремих фрагментів семантичної мережі. При цьому запит до бази знань подається у вигляді автономного підграфа, який будується за тими самими правилами, що й семантична мережа. Пошук відповіді на запит реалізується зіставленням підграфа запиту з фрагментами семантичної мережі. Для цього здійснюють накладення підграфа запи¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
125
ту на відповідний фрагмент мережі. Успішним буде те накладання, в результаті якого фрагмент мережі виявляється ідентичним підграфу запиту.
У загальному випадку в підграфі запиту можуть бути задані об’єкти, атрибути, імена відносин, не подані в базі знань явно. Це вимагає виконання попередніх перетворень фрагментів семантичних мереж, що зіставляються. В результаті таких перетворень можуть бути одержані нові зв’язки. Вказані перетворення виконуються на основі простих базових операцій, розглянутих раніше.
Методи висновку на семантичних мережах, що використовують ідею перетину шляхів, або зіставляння фрагментів мереж, мають істотний недолік. Він пов’язаний з комбінаторним зростанням числа зіставлянь, або перетинів, у мережах досить великої розмірності.
У ряді систем, заснованих на семантичних мережах, використовуються спеціалізовані правила висновку. Методи дедуктивного висновку на семантичних мережах засновані на поняттях розфарбовування графів і операторах перетворення мереж, транзитивних замикань, виділення підграфів з певними властивостями. У багатьох випадках вони базуються на простих операціях над графами, як-от: видалення і додавання нових вершин і ребер, спеціалізація, пошук вершини або ребра за ім’ям, перехід від однієї вершини до другої по зв’язках, об’єднання підграфів й ін.
Різноманіття відносин, що використовуються в семантичних мережах, поділяється на такі групи:
1) лінгвістичні відносини, які, у свою чергу, поділяються на відмінкові (агент, об’єкт, інструмент, час, місце), дієслівні (нахил, час, вигляд, число, застава) і атрибутивні (колір, розмір, форма тощо);
2) логічні відносини (кон’юнкція, диз’юнкція, заперечення, імплікація);
3) теоретико-множинні відносини включають відносини типу «множина—підмножина («рід—вид», «клас—підклас»), «ціле— частина», «елемент множини» й ін.
4) кваліфіковані відносини, які поділяються на логічні квантори спільності й існування, нечіткі квантори (багато, дещо, часто тощо).
Таким чином, розглянуті раніше відносини, («рід—вид», «бути представником», «бути частиною», відмінкові відносини) але ніяк не вичерпують всього набору відносин, вживаних у семан¬
126
Г.Ф. Іванченко
тичних мережах. Але вони утворюють хорошу основу для побудови прикладних баз знань. Особливе місце при цьому посідають теоретико-мцожинні відносини, що мають транзитивні властивості. Відношення Д називають транзитивним, якщо для будь-яких об’єктів а,р,у тащх, що азР(аДР) та рзуфДу) у відношенні Я відповідає справедливість твердження « а знаходиться у відносинах Я з у, тобто (аЛРлрЛу)=>аЛ у .
Наприклад, транзитивність родовідного відношення забезпечує можливість спадкоємства властивостей від родового об’єкта до виду і підвиду. Механізм спадкоємства властивостей забезпечує проведення простих дедуктивних висновків на зразок: «Всі люди смертні. Сократ — людина. Отже, Сократ смертний».
2.10. Фрейми
Структура фрейме
Фрейм (від англ. frame — рамка, каркас, корпус) можна розглядати як фрагмент семантичної мережі, призначений для опису деякого об’єкта (події, ситуації) наочної галузі зі всією сукупністю властивостей. У цьому значенні фрейми —де підграфи семантичних мереж. Вони становлять блоки знань, рожним з яких можна маніпулювати як єдиним цілим, що дає можливість краще структурувати базу згіань [7].
Згідно з визначенням фрейми — це структури даних, призначені для уявлення стереотипних ситуацій. Коли людина опиняється в новій ситуації, вона витягує з пам’яті раніше накопичені блоки знань, що мають відношення до поточної ситуації, і намагається застосувати їх. Ці блоки знань і є фреймами. Ймовірно, знання людини організовані у вигляді мережі фреймів, що відображають його минулий досвід. Наприклад, ми легко можемо уявити типовий одномісний номер у готелі. Зазвичай він має ліжко, ванну кімнату, шафу для одягу, телефон, план евакуації у разі пожежі і т. ц. Деталі кожного конкретного номера можуть відрізнятися від наведеного опису. Але вони легко уточнюються, коли людина опиняється в конкретному номері: колір шпалер і завіс, положення вимикачів світла й ін.
Фрейм — це мінімальний опис деякої сутності, такий, що подальше скорочення цього опису призводить до втрати цієї сутно¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
127
сті. Фрейм будь-якого поняття може бути утворений шляхом об’єднання всіх бінарних фактів, пов’язаних з цим поняттям.
Фреймові моделі подання знань використовують запропоновану М. Мінським теорію організації пам’яті, розуміння й навчання. Фрейм складається із слотів (slot — кубло, щілка, паз). Значенням слота можуть бути числа, вирази, тексти, програми, посилання на інші фрейми. Фрейм може містити спеціальний слот, за допомогою якого задається відношення цього фрейму з інши? ми фреймам мережі Найчастіше в мережі фреймів використовують теоретико-множинні відносини, які дають змогу будувати ієрархічні структури. Спеціальний слот, що має назву is а слотом, фіксує відношення «екземпляр класу». Слот ако вказує, що цей фрейм є прямим підкласом вищого за ієрархією фрейму. Вищий фрейм називають батьківським фреймом, або суперкласом.
Сукупності фреймів утворюють ієрархічні структури, побудовані за родовидним ознаками, що дає можливість успадковувати значення слотів. Така властивість фреймів забезпечує економне розміщення бази знань у пам’яті. Окрім цього, значення слотів можуть обчислюватися за допомогою різних процедур, тобто фрейми комбінують у собі декларативні й процедурні подання знань.
Фрейм можна інтуїтивно уявляти собі як каркас, на якому тримаються знання, або як рамку, на основі якої описуються різноманітні об’єкти та ситуації.
Фреймові моделі базуються на теорії фреймів. М. Мінський запропонував гіпотезу, згідно з якою знання людини групуються в модулі, і назвав ці модулі фреймами. Мінський писав, що Коли людина потрапляє в нову ситуацію, вона співставляє цю ситуацію з тими фреймами, які зберігаються у неї в пам’яті.
М. Мінський давав більш вузьке визначення. Він наголошував на тому, що фрейм повинен задавати мінімально можливий опис цього поняття.
У простому випадку під фреймом розуміють таку структуру:
{п, (nsl, vs,, ps}), (ns2, vs2,ps2),..., (nsk, vsk ,psk)},
де л — ім’я фрейму, ns — ім’я слота, vs — значення слота, ps: — ім’я приєднаної процедури.
Фрейм будь-якого поняття може бути утворений шляхом об’єднання всіх бінарних фактів, пов’язаних з цим поняттям. Можна вважати, що у типовому фреймі зберігається така інформація:
• ім’я та загальний опис фрейму;
128
Г.Ф. Іванченко
• інформація про батьківський фрейм;
• інформація про окремі слоти: імена та значення слотів, а також їх властивості (наприклад, тип слоту; умови коректності інформації, яка зберігається в слоті тощо). Формально об’єкт в рамках фреймової моделі описується у вигляді: їм ’я фрейму, ((Атрибут\_1, значення_1), (Атрибут_2, значення_2), (Атрибут_п, значення_п)).
У цьому записі наголошується, що фрейм — це сукупний опис усіх основних характеристик об’єкта. У фреймових системах частина фреймів становить індивідні об’єкти ПРГ. Такі фрейми називають екземплярами фреймів, або фреймами-прикладами. Інші фрейми, що становлять узагальнені об’єкти, називають класами, або фреймами-прототипами. Фрейм-прототип відповідає інтен- сиональному опису множини фреймів-прикладів.
Ми бачимо, що слоти відповідають атрибутам (характеристикам, властивостям) об’єкта. Якщо значення слотів не визначені, то фрейм має назву фрейм-прототип. Замінюючи невідоме значення зірочкою («*») отримуємо такий фрейм-прототип:
{<Книга> <Автор><*> <Назвах*> <Жанр><*>}
Навпаки, фрейм, у якому всі слоти заповнені, має назву конкретний фрейм. Відзначимо, що імена слотів часто називають ролями. Основною процедурою над фреймами є пошук за зразком. Зразок, або прототип, — це фрейм, у якому заповнені не всі структурні одиниці, а тільки ті, за якими серед фреймів, що зберігаються в пам’яті ЕОМ, відшукуються потрібні фрейми. Іншими процедурами, характерними для фреймових мов, є наповнення слотів даними, введення в систему нових фреймів-прототипів, протофрейми а також зміни деякої множини фреймів, зчеплених по слотах (тобто що мають однакові значення для загальних слотів).
Фрейм складається із слотів. Слоти — це деякі незаповнені підструктури фрейма. Після заповнення слотів конкретними даними фрейм становитиме ту або іншу ситуацію, явище або об’єкт наочної галузі. Процедура є необов’язковим елементом слота. Як значення слотів можуть виступати імена інших фреймів, що забезпечує побудову мережі фреймів.
У свою чергу, кожному слоту відповідає певна структура даних. У слотах описується інформація про фрейм: його властивості, характеристики, факти, що належать до нього, тощо. Крім то¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
129
го, слоти можуть містити посилання на інші фрейми або вказівки на асоційовані з ними приєднані процедури. Уявлення ПРГ у вигляді ієрархічної системи фреймів наочно відображає внутрішню і зовнішню структури об’єктів цієї ПРГ.
Значенням слота може бути практично що завгодно (числа або математичні співвідношення, тексти на природній мові або програми, правила висновку або посилання на інші слоти цього фрейма або інших фреймів). Як значення слота може виступати набір слотів нижчого рівня, що дає змогу у фреймових уявленнях реалізувати «принцип матрьошки».
При конкретизації фрейма йому і слотам привласнюються конкретні імена і відбувається заповнення слотів. Таким чином, з протофреймів виходять фрейми-екземпляри. Перехід від початкового протофрейму до фрейму-екземпляру може бути багато- кроковим, за рахунок поступового уточнення значень слотів.
Наприклад, структура записана у вигляді протофрейму, має вигляд
(Список працівників:
Прізвище (значення слота 1);
Рік народження (значення слота 2);
Спеціальність (значення слота 3);
Стаж (значення слота 4)).
Якщо як значення слотів використовувати дані, то вийде фрейм-екземпляр
(Список працівників:
Прізвище (Петренко—Сидоров—Іванов—Степанко);
Рік народження (1985—1996—1955—1977);
Спеціальність (слюсар—токар—токар—сантехнік);
Стаж (10—5—30—25)).
Фреймова структура описує узагальнене, родове поняття, тобто групу (клас) однотипних об’єктів з однотипними характеристиками. Конкретні ж об’єкти зазвичай називають екземплярами фреймів.
Опис екземплярів фрейму утворюється в результаті конкретизації фреймів. Конкретизація полягає в заповненні слотів конкретними значеннями (іншими словами — у визначенні значень атрибутів). Якщо під час опису загального фрейму деякі слоти уже заповнені конкретними значеннями, ці значення передаються всім екземплярам цього фрейму.
Так, будь-якого студента можна описати на основі фрейму «Студент», якщо підставити в слоти конкретні дані.
130
Г.Ф. Іванченко
Для фреймових моделей характерна ієрархія понять. У нашому прикладі фрейм «Студент» є похідним від більш загального фрейму «Людина». Тоді він спадкує його слоти. У нашому прикладі фрейм «Людина» може мати слоти «Прізвище», «Ім’я та по- батькові». Тому відповідні слоти в описі фрейму «Студент» можна не задавати, а обмежитися лише слотами, специфічними для нього: «Факультет», «Курс». Якщо якісь слоти уже заповнені конкретними значеннями, то ці значення можуть успадковуватися фреймами-нащадками.
Фреймові моделі можна розуміти як мережеві моделі подання знань, коли фрагмент мережі представлено фреймом з відповідними одотами і значеннями. З фреймовими моделями пов’язані моделі подання знань на основі сценаріїв і об’єктів. Важливою характеристикою фреймів є можливість включення в слоти приєднаних процедур. Подальшим розвитком концепції фреймових моделей є сценарії.
Іншими словами, фрейм — це форма опису знань, що обкреслює межі цього (у поточній ситуації під час розв’язання цієї задачі) фрагмента ПРГ. В процесі адаптації узагальненого фрейму до конкретних умов виконується уточнення значень слотів, спочатку визначених за умовчанням. У разі пошуку в пам’яті фрейму, релевантного деякому образу, на першому £гапі перевіряється збіг всіх істотних слотів фрейму-кандидаті з відповідними складовими образу. На другому етапі значення слотів, задані за умовчанням, узгоджуються з іншими аспектами образу. Механізм подібного узгодження передбачає виявлення якісного зіставлення компонентів фрейму і образу (наприклад, приналежність атрибутів образу до інтервалів, визначених у слотах за умовчанням), після чого значення за умовчанням конкретизуються.
Зв’язки між фреймами задаються значеннями спеціального слота з ім’ям «Зв’язок». Частина фахівців з ІС вважає, що немає потреби спеціально виділяти фреймові моделі в поданні знань, оскільки в них об’єднані всі основні особливості моделей решти типів.
Фрейм може бути декларативного, процедурного і процедурно-декларативного типу. У фреймах процедурного типу процедури прив’язуються до слота шляхом вказівки послідовності виконуваних операцій. Такі процедури зазвичай називають приєднаними процедурами. Приєднані процедури можна розглядати як окремі слоти. На інтуїтивному рівні наявність приєднаних проце¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
131
дур дає підстави казати про те, що фрейм має здатність виконувати ті чи інші операції.
Частіше використовують тип приєднаної процедури, яка активізується шляхом зовнішнього виклику (за повідомленням, яке надходить від іншого фрейму).
Розрізняють два види процедур: процедури-«демони» і проце- дури-«слуги». Важливою характеристикою фреймів є можливість включення в слоти приєднаних процедур.
Процедура-«демон» запускається автоматично, коли фрейм задовольняє деякому зразку, за яким здійснюється пошук у базі знань. Процедури-«демони» активізуються автоматично за кожної спроби додавання або видалення даних із слота. Найчастіше використовуються три типи процедур-«демонів»: «яюцо-додано», «як- що-видалено» і «якщо-потрібно». Процедура «якщо-додано» виконується, коли нові дані поміщуюгься в слот. Процедура «якщо видалено» виконується, коли дані видаляються із слота. Процедура «якщо-потрібно» автоматично запускається, коли запитується інформація із слота, а з ним не пов’язані жодні значення. За допомогою вказаних процедур зазвичай виконуються всі рутинні операції, що забезпечують підтримку бази знань в актуальному стані.
Велике значення мають слотові «демони». На відміну від звичайних приєднаних процедур, що описують поведінку фрейму загалом, слотові «демони» пов’язані з конкретними слотами. Типовим є використання стандартних слотових «демонів», які визначають, що слід робити, якщо деякий слот змінився або якщо відбулося звернення до незаповненого слота.
Процедура-слуга запускається за зовнішнім запитом, а також використовується для завдання за умовчанням значень слотам, якщо вони не визначені. Процедури-слуги активізуються тільки за запитом при зверненні до слота.
Внутрішня процедура використовується для зміни вмісту цього фрейму, тоді як зовнішня — для зміни вмісту інших фреймів. Процедура виконує зміни в тій частині фрейму, яку називають термінальною (утворена безліччю терміналів — осередків для зберігання і запису інформації).
Структура даних фрейма на мові Prolog, який описує людину має назву і предикат з двома аргументами. Перший — ім’я рамки і другий — список слотів, відокремлених оператором дефіса від їх відповідних списків. Список аспектів складений з імен аспектів префіксної операції.
132
Г.Ф. Іванчвнко
val — the simple value of the slot;
def — the default if no value is given;
calc — the predicate to call to calculate a value for the slot;
add — the predicate to call when a value is added for the slot;
del — the predicate to call when the slot’s value is deleted.
Наводимо формат структури даних рамки:
Frame (name, [ slotnamel — [facetl valll, facet2 vall2, ...], slotname2 — [facetl val21, facet2 val 22,,..],...]).
Наприклад:
Frame (man, [ako-[val [person]], hair-[def short, del bald], weight- [calc male_weight] ]).
frame(woman,[ako-[val [person]], hair-[def long], weight-[calc female_weight] ]).
У цьому випадку і чоловік, і жінка мають ако слоти із значенням людини. Слот волосся має значення за умовчанням довгого і короткого волосся для жінок і чоловіків, але це було б знехтувано за значеннями в індивідуальних рамках. Обидва мають аспекти, які вказують на предикати, які мають використовуватися, щоб обчислити вагу, якщо ніхто не надасть її. Слот волосся чоловіка має аспект, який указує на програму-«демона», del bald, щоб буде викликаний, якщо значення для волосся не буде надано.
Подальшим розвитком концепції фреймових моделей є сценарії. Поняття сценарію введене Р. Шенком і Р. Абельсоном. Сценарій — це фреймоподібна структура, в якій визначені такі спеціальні слоти, як мета, сцена, роль, яка визначає послідовність подій, характерних для певного процесу чи для певної ситуацій, або причинно-наслідкові зв’язки між подіями.
У сценаріях використовують відношення типу «причина—наслідок», «дія», «засіб дії» та ін. Поняття сценарію можна визначити і на основі семантичних мереж (типовий сценарій можна розглядати як семантичну мережу, всі зв’язки якої мають тип «причина — наслідок» або «бути раніше — бути пізніше»). Це вкотре наголошує на тісному зв’язку між семантичними мережами та фреймами.
Наведемо приклад дуже простого сценарію, який визначає послідовність дій. Для цього сценарію визначено слоти Мета, Ролі (основні дійові особи), Змінні (риси, різні для різних конкретних реалізацій сценарію), Кількість сцен та слоти, що відповідають сценам (подіям — транзактам), що послідовно змінюють одна одну:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
133
< сценарій: банк
ролі: відвідувач, менеджер, касир мета: отримання споживчого кредиту сцена 1: вхід до банку
увійти до банку вибрати вільне місце пройти до вільного менеджера сісти
сцена 2: співбесіда
надати документи вирішити, умови підготувати договір замовити друк договору менеджеру сцена 3: договір
підготовка та підпіс договору отримання договору
сцена 4: видхід
отримання платіжного документа отримання грошей від касира вихід з банку >
Цей сценарій можна розглядати як базовий, на основі якого можна будувати подібні сценарії, що можуть виникати за іншого розвитку подій.
Сценарії відображають каузальні (причинно-наслідкові) ланцюжки наочної галузі, тобто мають розвиненішу семантику порівняно з класичними фреймами. Таким чином, сценарії розглядаються як засіб подання проблемно-залежних каузальних знань.
Як і інші типи фреймів, сценарії можна використовувати для поповнення опису ситуацій. Так, якщо інтелектуальна система сприймає текст «Петренко відвідав банк», вона співставляє його з відомими їй сценаріями і на основі цього може відповідати на запитання, пов’язані з тим, що саме робив Петренко у банку.
Під час спілкування з інтелектуальною системою людина запитає інтелектуального робота, який має фреймові моделі знань: —Де це?
— Що саме? — запитує робот.
— Сам знаєш, — відповідає людина.
— А... — каже робот, і приносить те, що потрібно.
134
Г.Ф. Іванчвнко
Тепер ми можемо пояснити, що може лежати в основі прийняття рішення інтелектуальним роботом. Механізм висновку може бути, наприклад, такий.
Робот спостерігає ситуацію, яка полягає в тому, що є запит: «Де це?». Система співставляє цю ситуацію зі своїми знаннями і знаходить кілька сценаріїв можливого розвитку подій. Робот не знає, який з них вибрати, і тому ставить уточнювальне запитання. Відповідь «Сам знаєш» інтерпретується так, що треба використати замовчування, тобто обрати той сценарій, який реалізується найчастіше.
Під час пошуку фреймів, які найбільше підходять для опису цього поняття, велике значення мають мережі подібностей або відмінностей. Кожний вузол такої мережі є фреймом опису певного поняття, а зв’язки відповідають подібностям чи відмінностям між фреймами.
За допомогою мереж подібностей можна визначати семантичну близькість між поняттями. Ця обставина може бути використана, наприклад, при співставлянні. Якщо при співставлянні з фреймом, що описує певне поняття, виникають розбіжності, мережа подібностей дає змогу переходити до сусідніх, подібних до них фреймів з метою пошуку більш точнішої відповідності.
Мережа відмінностей концентрується на опирі відмінностей між поняттями. Можна, наприклад, зафіксувати деякий фрейм як базовий, а для інших зберігати лише відмінності від базового або від сусіднього фрейму. Один предмет може описуватися різними фреймами, які відповідають різним умовам спостерігання цього предмета. Риси, спільні для цих різних фреймів, описуються базовим фреймом.
Позитивними рисами фреймової моделі загалом є її предметність, гнучкість, однорідність, високий ступінь структури- зації знань, відповідність принципам подання знань людиною в довготривалій пам’яті, а також інтеграція декларативних і процедурних знань. Разом з тим, для фреймової моделі характерні складність управління висновком і низька ефективність його процедур. Відзначимо, що фреймові моделі знань ефективні для структурного опису складних баз знань, проте для них немає специфічного формалізованого апарату, у зв’язку з чим фрейми часто використовують як базу даних системи продукцій.
Фреймова форма є ефективним засобом побудови великих ієрархічних систем знань під час обробки зображень, мовних образів, процесів управління, діагностування і т. ін. Для підтримки
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
135
розробки фреймових систем використовуються засновані на LISP мовні засоби типу FRL, FMS, KRL, GUS, OWL, HPRL, ПРЕФ, ДИЛОС, RLL. й ін.
Фреймові системи є ієрархічно організованими структурами, що реалізовують принцип спадкоємства інформації. Спадкоємство значень відбувається в напрямі «суперклас — клас», «клас — екземпляр класу». Тому емпляр класу успадковує всі властивості свого суперкласу. Зокрема, значення слота «елементи» може бути успадковано від суперкласу.
У ряді фреймових систем до складу слотів включають різні покажчики спадкоємства. Покажчик спадкоємства фіксує ту інформацію, яка передається від слотів фрейму верхнього рівня до відповідних слотів фрейму нижнього рівня. Розглянемо, як приклад, структуру фрейму системи FMS. Тут виділяють такі типи покажчиків спадкоємства: unique, same, range, override і ін.
Unique (унікальний) означає, що слоти з одними і тими самими іменами у фреймах, що знаходяться на різних рівнях ієрархії, можуть мати різні значення. Same (такий самими) показує, що слоти повинні мати однакові значення. Range (діапазон) встановлює деякі межі, в яких може знаходиться значення слота фрейму нижнього рівня. Override комбінує властивості покажчиків unique і same. Під час опису слотів фрейму в системі FMS указується також тип даних слота. Типи даних слотів відповідають типам даних, вживаних у мовах програмування високого рівня. Наприклад, INTEGER (цілий), REAL (дійсний), BOOL (логічний), STRING (строковий). Проте застосовуються також й інші типи даних, що підвищують ефективність роботи з системою. Наприклад, TEXT (текстовий), TABLE (табличний), LIST (обліковий), LISP (приєднана процедура), FRAME (покажчик на інший фрейм) й ін.
Узагальнюючи сказане, фреймову структуру даних системи FMS можна спрощено описати у вигляді формул:
< фрейм >::=< ім’я фрейму > < посилання на суперклас > < слот > {< слот >::=< ім’я > < покажчик спадкоємства > < тип даних >
< значення >
[< процедури-«демони» >]
< покажчик спадкоємства >.- unique| same| range| override
< тип даних >::= INTEGER] REAL| BOOL| STRINGI TEXT] TABLE| LISP) LIST] FRAME
< процедури-«демони» >::=< якщо — додано >| < якщо — видалено^ < якщо — потрібне >|
136
Г.Ф. Іванчвнко
Іншим прикладом фреймової системи є мова FRL (Frame Representation Language), що становить розширення мови Лісп. Об’єкти наочної галузі в мові FRL називають фреймами, а їх властивості — слотами. Слот містить дещо «фацет» (англ. facet — аспект, межа, бік), що характеризуються значенням. До складу слота входить шість фацетів:
$value — поточне значення слота;
Srequire — допустимі значення фацета value;
$default — значення за умовчанням для фацета value;
$if-added — процедура-«демон» «якщо-додано»;
$if-removed — процедура-«демон» «якщо-видалено»; $if-needed — процедура-«демон» «яюцо-потрібно».
Так, пропозицію «Авто сірого кольору» можна подати мовою FRL у вигляді: frame Авто, slot колір, facet $value, value сірий.
Кожний фрейм, створюваний мовою FRL, містить заздалегідь визначений слот ако, що дає змогу успадковувати значення слотів відповідно до ієрархії фреймів.
У моделях подання знань фреймами об’єднуються переваги декларативного й процедурного підходів. Фреймовий підхід широко використовується на практиці, про що свідчить наявність розвинених фреймових мов, наприклад, GUS* KRL, CONSUL і ін. Проте у фреймових системах відсутній спеціальний механізм управління висновком. Тому висновок зазвичай реалізується за допомогою процедур, вбудованих у фрейми.
Поповнення первинних описів на основі фреймових моделей Фрейми виявилися зручним інструментом для опису ситуацій, які сприймаються системою, та для співставлення цих ситуацій з тими знаннями, що зберігалися в пам’яті (власне, М. Мінський вважав, що саме в цьому і полягає одне з основних призначень фреймових моделей).
Нагадаємо, що первинним описом ситуації, або об’єкта, називається їх опис у тому вигляді, в якому вони безпосередньо сприймаються органами почуттів. Ми знаємо, що цей первинний опис, зазвичай, поповнюється на основі наявних знань.
Коли інтелектуальна система сприймає деякий об’єкт, вона формує первинний опис та співставляє цей опис з фреймами, що зберігаються в її пам’яті (формування первинного опису та співставлення можуть відбуватися і паралельно). Якщо співставлення з деяким фреймом пройшло досить успішно, система відносить новий об’єкт
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
137
до поняття, що описується цим фреймом. На основі цього очевидним чином здійснюється поповнення первинного опису, а саме:
• формується загальна структура опису нового об’єкта (фактично тепер він розглядається як екземпляр певного фрейму);
• заповнюються всі слоти нового екземпляру, значення яких визначаються в описі родового фрейму або задаються в первинному описі;
• якщо опис недосить повний (не вистачає значень деяких важливих слотів) або суперечливий (наприклад, якщо об’єкт співстав- ляється з декількома фреймами, або інформація, що вводиться, суперечить визначеній за успадкуванням), можуть бути активізовані процедури уточнення.
Нехай в пам’яті інтелектуальної системи зберігається фрейм опису одного дня навчання:
Заняття_в_університеті ((Вид_роботи, Навчання),
(Початок, 8.30),
(Кількість_пар, _),
(Закінчення, Початок+Кількістьпар* 1.5+
0.10*(Кількість_пар -1)),
(Коли, _),
(Хто, _),
(Де, <Вул. , 999>)).
Зверніть увагу, що атрибут Закінчення є обчислюваним, оскільки його значення залежить від кількості пар.
Нехай на вхід системи подається речення «Вчора Петренко був в університеті Вул. І. Франка». Система має на основі відомих їй алгоритмів виявити, що це речення співставляється з фреймом «Занятгя_в_університеті», і сформувати опис на основі цього фрейму (фактично новий екземпляр фрейму). Вона дає цьому описові назву, наприклад, «Занятгя_Петренко», і відображає в заголовку, що це екземпляр фрейму «Заняття_в_універ- ситеті». Далі заповнюються слоти, і опис набуває вигляду:
Заняття Петренко(Заняття в університеті)((Вид роботи, Навчання),
(Початок, 8.30),
(Кількість_пар, _),
(Закінчення, Початок+Кількістьпар* 1.5+
0.10*(Кількість_пар- 1)),
(Коли, Вчора),
(Хто, Петренко),
(Де, <Вул. І. Франка, 999>)).
138
Г.Ф. Іванченко
Слоти Вид_роботи та Початок були заповнені на основі базового фрейму, а слоти Де, Коли та Хто — з введеного тексту. Слоти Кількість_пар та Закінчення залишилися незаповненими — для їх заповнення не вистачає інформації.
Тепер система в змозі відповідати на ряд запитань, наприклад, «Що вчора робив Петренко?» або «Де вчора був Петренко?». Точнішу відповідь на запитання «Коли Петренко був у університеті?» система може дати, якщо вона має інформацію про поточний час.
Якщо ж у системи запитати: «Коли Петренко закінчив навчання у університеті», система повинна активізувати процедуру уточнення, у цьому разі спитати користувача, скільки було уроків. Після відповіді користувача система може здійснити потрібні обчислення та відповісти на поставлене запитання.
Описаний підхід має широке застосування в системах обробки природної мови.
І семантичні мережі, і фрейми в першу чергу є формалізмами для структуризації знань, на відміну від логічних та продукцій- них моделей, центральне місце в яких посідають процедури дедуктивного виведення. Семантичні мережі роблять більший акцент на описі різноманітних зв’язків між інформаційними одиницями, а фреймові — на відношеннях узагальнення та агрегації. і
Семантичні мережі та фрейми мають значно більше спільних рис, ніж відмінностей, і тому на сучасному етапі фреймові моделі та семантичні мережі розглядають, зазвичай, у спільному контексті. З одного боку, ніщо не заважає розглядати вузли семантичної мережі як фрейми з власною внутрішньою структурою. З другого, можна вводити різноманітні зв’язки між слотами фреймів. Тоді фрейм набуває рис семантичної мережі.
Фрейми і об’єктно-оріентоване програмування
Поняття фрейму, яке розглядається в теорії штучного інтелекту, та поняття об’єкта (в іншій термінології — класу) тісно пов’язані між собою. Парадигма об’єктно-орієнтованого програмування випливає з об’єктно-орієнтованого сприйняття світу, що складається з великої кількості об’єктів. Вони є порівняно незалежними, але постійно взаємодіють між собою. Кожний об’єкт має певні властивості та вміє виконувати деякі функції. Можна вважати, що об’єктна модель є конкретизацією більш абстрактної фреймової моделі.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
139
Об’єктом називають абстракцію, що характеризується станом, поведінкою та ідентифікованістю; сукупності схожих об’єктів утворюють клас; терміни «екземпляр класу» та «об’єкт» рівноправні.
Стан об’єкта характеризується переліком (зазвичай статичним) усіх властивостей об’єкта і поточними (зазвичай динамічними) значеннями кожної з цих властивостей.
До цього можна додати, що «статичний перелік властивостей» є характеристикою всього класу, а «поточні динамічні значення»
— характеристикою окремого об’єкта — екземпляру класу. Опис окремого екземпляру на основі загального опису класу можна отримати, якщо визначити конкретні значення властивостей.
Поведінка визначається тим, як об’єкт функціонує та реагує на зовнішні події; поведінку зазвичай характеризують у термінах зміни станів об’єкта та передаванні повідомлень між об’єктами; поточний стан об’єкта є сумарним результатом його поведінки.
Ідентифікованість — це така властивість об’єкта, яка відрізняє його від усіх інших об’єктів.
Важливим є те, що об’єкти слід розглядати як абстракції певних сутностей, тобто об’єкт описує властивості цієї сутності, що є найважливішими з певної точки зору.
При цьому для екземплярів класу спільними є всі характеристики, а не деякі. Точніше, спільним є перелік характеристик, а не конкретні значення; екземпляри одного класу можна розрізняти між собою саме за рахунок того, що характеристики різних екземплярів класу мають різні значення.
Об’єкти та класи мають такі найважливіші властивості:
1. Абстрагування — виділення в описі класу найважливіших характеристик деякої сутності, що відрізняють її від усіх інших сутностей.
2. Інкапсуляція — елементи об’єкта, що визначають його властивості та поведінку, мають бути відділені один від одного. Іншими словами, клас повідомляє про свої функціональні можливості, але ховає від зовнішнього світу особливості реалізації цих можливостей і свою внутрішню побудову.
Слід відмітити, що в програмуванні термін «інкапсуляція» часто вживається в більш вузькому значенні, а саме: в класі можуть бути описані процедури (методи), що визначають його поведінку.
3. Модульність — об’єкт складається з окремих відносно самостійних модулів.
140
Г.Ф. Іванчвнко
4. Ієрархія — об’єкти та класи є ієрархічно впорядкованими. Зокрема, вони утворюють ієрархію класів та ієрархію об’єктів.
5. Успадкування пов’язане саме з цими ієрархіями, в першу чергу — з ієрархією класів.
6. Поліморфізм — з грецької мови багатоликість.
Існує багато об’єктно-орієнтованих мов програмування, тобто мов, які безпосередньо підтримують об’єктну модель та об’єктно-орієнтовану парадигму програмування. Історично першою була мова Smalltalk. Нині популярними є багато мов (наприклад Visual Prolog, Java, Лісп), проте стандарт де-факто в галузі об’єктно-орієнтованого програмування — це C++.
Мова UML, розроблена Г. Бучем, Дж. Рамбо та А. Джекоб- соном, є мовою семантичного моделювання предметних галузей та подальшого проектування відповідних програмних засобів. В основі цієї мови лежить об’єктно-орієнтований аналіз, тобто виділення класів та опис їх характеристик і взаємозв’язків між ними. У 1997 р. цю мову консорціумом OMG (Object Management Group) прийняв як стандарт.
Основним елементом опису предметної галузі на основі UML є діаграма класів. Діаграма класів є описом класів та відношень між ними. В мові UML визначені формалізовані правила такого опису. Діаграма класів може бути легко реалізована в об’єктно- орієнтованих мовах програмування. і
Згідно з авторським описом у мові UML визначено такі основні типи відношень між класами: залежність, узагальнення, асоціація.
Асоціація описує структурні взаємозв’язки між класами. Важливим частковим випадком асоціації є агрегація. Узагальнення реалізується відношенням «Є» (клас-підклас). Залежність є відношенням, яке описує вплив однієї сутності на другу. Діаграми об’єктів дають змогу моделювати екземпляри сутностей, що описуються діаграмами класів.
Для побудови фреймової моделі моделі представлення знань процесу вибору постачальників обладнання на підприємстві і використано редактор онтологій Protege (рис. 2.13).
Це вільно розповсюджувана Java-nporpaMa для побудови (створення, редакції та перегляду) онтологій ПРГ. Вона включає редактор онтологій, який дозволяє проектувати онтології, розгортаючи ієрархічну структуру абстрактних та конкретних фреймів, класів та слотів.
питЬег І БІгі
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
141
Рис. 2.13. Фреймова модель представлення знань для вибору постачальників обладнання на підприємстві
142
Г.Ф. Іванчвнко
Управління висновком
Організація висновку у фреймовій системі базується на обміні повідомленнями між фреймами, активації й виконанні приєднаних процедур. Віддзеркалення в ієрархії фреймів родовидних відносин забезпечує можливість реалізації в рамках фреймової моделі операції спадкоємства, що дає можливість приписувати фреймам нижніх рівнів ієрархії властивості фреймів вищерозмі- щених рівнів. Аналогічні механізми спадкоємства використовують нині в об’єктно-орієнтованому проектуванні.
У фреймових системах використовується три способи управління висновком: за допомогою механізму спадкоємства; за допомогою процедур-«демонів»; за допомогою приєднаних процедур.
Механізм спадкоємства є основним вбудованим засобом висновку, яким оснащуються фреймові системи. Він забезпечує значну економію пам’яті й автоматичне визначення значень для слотів фреймів нижніх рівнів.
Фреймові системи також оснащуються набором спеціальних процедур, до яких належать процедури: конструювання класу, конструювання екземпляра класу, записи значення в слот, читання слота. Процедура конструювання класу формує фрейм-прототип з потрібним набором слотів і відповідними посиланнями на супер- класи. Фрейм може бути пов’язаний з декількома суперкласами. Процедура конструювання екземпляра класу дає змогу формувати фрейми-приклади. Вона автоматично встановлює зв’язок всіх таких фреймів з відповідним класом за допомогою й_а слота. Процедури запису й читання значень слотів забезпечують доступ до слотів відповідних фреймів і дають можливість користувачу ввести або визначити значення відповідного слота. Для цього, під час їх виклику їм передається ім’я фрейму й ім’я відповідного слота. У разі, якщо значення будь-якого слота під час виклику відповідної процедури конструювання не задається, то автоматично викликається процедура, завдяки якій встановлюється значення слота за умовчанням. Це часто виконується за допомогою механізму успадкування (спадкоємство). Розглянемо деякі особливості функціонування механізму успадкування.
Кожний підклас, або екземпляр класу, успадковує слоти свого суперкласу. Якщо підклас (екземпляр класу) і суперклас мають слоти, із іменами, що співпадають, то визначення значень слотів, зроблені усередині підкласу (екземпляра класу), перекривають визначення суперкласу.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
143
У загальному випадку порядок спадкування визначається за допомогою списку передувань. У разі лінійної ієрархічної схеми цей список формується відповідно до напряму й_а і ако зв’язків. У цьому разі його можна записати у вигляді: екземпляр класу —» універсальний клас.
Складніша ситуація виникає, якщо фрейм має декілька іу_а або ако зв’язків. У цьому разі кажуть про множинне спадкоємство. Правила формування списку передувань будуть складніші. Якщо користувача не задовольняє результат спадкоємства, то можна ввести додатковий клас, явно вказавши значення відповідного слота. Проте це виключає можливість передачі значення слота за умовчанням і вимагає додаткової памяті.
У цьому разі разом з пошуком у глибину і зліва направо застосовується принцип виключення із списку передувань елементів, що повторюються. В списку завжди залишається тільки та вершина, яка зустрілася останньою. Наприклад, для рис. 2.14 список передувань можна представити у вигляді: (екземпляр, суперклас 2, суперклас 4, суперклас 3, суперклас 5, суперклас 1, універсальний клас).
Рис. 2.14. Ієрархія фреймів з кількома к_а відносинами
Цей принцип дає можливість реалізувати вимогу, яка полягає в тому, що будь-який клас має з’являтися в списку передувань раніше, ніж його безпосередній суперклас. Реалізація цієї вимоги
144
Г.Ф. Іванченко
забезпечує передачу за умовчанням самих специфічних даних, що відповідає нашому інтуїтивному уявленню про спадкоємство властивостей.
У цьому списку порушена вимога, що полягає в тому, що будь-який безпосередній суперклас деякого класу повинен з’явитися в списку передувань раніше, ніж інший безпосередній суперклас цього ж класу, розташований праворуч (суперклас 2 слідує після суперкласу 3). Щоб задовольнити вказану вимогу, потрібно використовувати процедуру топологічного сортування.
Ідея такого сортування полягає в такому. На першому кроці складається список екземплярів і суперкласів, які (для цього фрейму) досяжні за допомогою й а і ако зв’язків.
На другому кроці для кожного елемента одержаного списку формується список пар суперкласів і екземплярів.
На третьому кроці переглядають елементи і виділяють той, який зустрічається тільки з лівого боку пари і ніколи не зустрічається з праворуч.
Якщо на деякому кроці описаної процедури на роль поточного елемента претендують відразу декілька суперкласів, то конфлікт розв’язуються на користь того суперкласу, який є безпосереднім суперкласом для найправішого суперкласу, що вже знаходиться в списку передувань.
Інша можливість висновку у фреймових системах заснована на використанні процедур-«демонів»: «яюцо-потрібно», «яюцо- додано», «якщо-видалено».
Процедура «якщо-потрібно» викликається, коли надходить запит, що вимагає встановлення значень відповідного слота. Процедуру, як і значення слота, успадковують підкласи й екземпляри класів. Тому скріплення її з одним із суперкласів може справити вплив на значення відповідних слотів фреймів, розташованих нижче за ієрархією. При цьому процедура безпосередньо не змінює значень слота, а кожного разу обчислює його наново, враховуючи певні умови.
Процедури «якщо-додано» і «якщо-видалено» активізуються під час запису й видалення значень із слота. Наприклад, процедура «якщо-додано» може активізуватися, коли слот «вигляд» активізовано. Можна сказати, що процедури «якщо-додано» і «якщо-видалено» встановлюють залежність значень одного слота від другого і зберігають відносини у фреймових системах.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
145
Третя можливість висновку у фреймових системах заснована на використанні приєднаних (службових) процедур. Ім’я приєднаної процедури виступає як значення слота. Приєднана процедура запускається за повідомленням, переданим з іншого фрейма. Для цього може використовуватися спеціальна функція MSG.
Ця функція забезпечує запуск приєднаної процедури, що знаходиться у відповідному слоті відповідного фрейму. При цьому приєднана процедура одержує необхідні параметри. У свою чергу, викликана приєднана процедура може також передати повідомлення в інший фрейм і викликати іншу приєднану процедуру тощо. Виникає ланцюжок передач повідомлень від одного фрейму до другого і; повернення відповідей. У результаті відповідь повертається в точку первинного виклику функції MSG і повідомляється користувачу. Таким чином, у фреймових системах на кожний з фреймів за допомогою приєднаних процедур покладаються певні обов’язки і забезпечується їх злагоджене виконання.
На закінчення відзначимо, що якщо у фреймових системах не використовувати процедури-«демони» і приєднані процедури, то фреймова модель подання знань відповідатиме семантичній мережі. Використання процедурних знань у фреймових системах підвищує їхню гнучкість, але ускладнює управління. Свій подальший розвиток фреймові системи одержали в системах об’єктно- орієнтованого програмування.
2.11. Об’єктно-орієнтована модель знань
Об’єктна модель знань. Ця модель використовує поняття формальної системи, що задається як: N = <С, О, Б, ї>, де N — мережа об’єктів, зв’язаних різними відносинами; С — множина класів об’єктів, зв’язаних відносинами класів; О — множина об’єктів, зв’язаних відносинами об’єктів; Я — структура класів і об’єктів, що визначає конкретні зв’язки між ними; І — правила перетворення об’єктів і висновку на мережі об’єктів.
В основі об’єктної моделі лежить теорія семантичних і фреймових мереж, а також теорія об’єктно-орієнтованого програмування. Дослідження в галузі семантичної пам’яті, а також методів запам’ятовування й обробки складних образів у мозку людини привели до розробки семантичних і фреймових моделей знань.
146
Г.Ф. Іванчвнко
Водночас, розвиток методів моделювання реального світу вилився у формування об’єкіного підходу при проектуванні і програмуванні систем моделювання. Загальним для цих підходів є поняття об’єкта знань як основного діючого елемента мережевої системи знань. У простому випадку об’єкт знання — це поняття у вузлі семантичної мережі, пов’язане з іншими подібними об’єктами різними відносинами. У складнішому випадку об’єкт знань
— фрейм, що містить декларативні знання і процедури, що дають змогу виконувати деякі дії над ними. Універсальним варіантом об’єкта знань є об’єкт, що містить дані або знання будь-якого вигляду і що має процедури, що виконують будь-йкі дії над ними. Система таких об’єктів знань будується як ієрархічна, така, що підтримує будь-яку структуру класів і об’єктів. Висновок у такій системі здійснюється відповідно до правил, що визначають обмін інформацією між об’єктами з урахуванням відносин класів і об’єктів типу спадкоємства, морфізму тощо, а також правил перетворень в об’єктах при настанні подій. '
Об’єктно-орієнтована модель знань одержала широке застосування в сучасних технологіях проектування різноманітних програмних і інформаційних систем. На цей час існує два основні підходи до моделювання знань, що базуються на об’єктній парадигмі. Це — модель MDA( (Model Driven Architecture) консорціуму Object Management i Group (OMG) і модель ODP (Model of Open Distributed Processing), зафіксована в стандарті ISO.
Модель MDA включає чотири концептуальні рівні: 4L-M0, 4L-M1, 4L-M2 і 4L-M3 (рис. 2.14). На рівні 4L-M0 подаються дані про об’єкти модельованої, парадигми створюючи універсум. На рівні 4L-M1 розташовуються моделі, яким відповідають описи об’єктів ПРГ на попередньому рівні. Кожна модель на рівні 4L-M1 відповідає певній точці зору на ПРГ (сфери інтересів). Рівень 4L-M2 посідають метамоделі, що визначають способи опису моделей рівня 4L-M1. Нарешті, на рівні 4L-M3 знаходиться єдина модель, незалежна від точки зору (галузі інтересів) і така, що визначає способи побудови метамоделей рівня 4L-M2.
Модель ODP включає три рівні: 3L-M0, 3L-M1 і 3L-M2 (рис. 2.15). Рівень 3L-M0 містить дані про об’єкти модельованої. На наступному рівні розташовуються моделі, що визначають спосіб опису об’єктів ПРГ на рівні 3L-M0 (по одній моделі для кожної). Всі моделі рівня 3L-M1 побудовані за допомогою одних і тих самих
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
147
засобів моделювання, поданих метамоделлю рівня 3L-M2. Таким чином, структура всіх моделей рівня 3L-M1 уніфікована.
Крім моделей, рівень 3L-M1 містить уявлення (viewpoints), відповідні різним точкам зору на ПРГ. їхня структура також уніфікована (як і в моделей). Стандарт ODP визначає п’ять можливих видів уявлень: корпоративне (enterprise), інформаційне (information), обчислювальне (computational), розробників (engineering) і технологічне (technology).
4L-M2 Метамодель 1 Метамодель 1
* \
^^ і
Модель 1.1 Модель 1.2 Модель l.m
Модель k.l Модель к.п
4L-Ml\4
4L-M0 Дані про об’єкти ПРГ 1
Дані про об’єкти ПРГ k
Рис. 2.15. Чотирирівнева модель MDA
Рис. 2.16. Трирівнева модель ODP
148
Г.Ф. Іванченко
На рівні ЗЬ-М2 розташовується єдина метамодель, що визначає спосіб побудови моделей рівня ЗЬ-М1. Вона відображає відносини між концептуальними категоріями в них, а також семантику засобів моделювання.
Порівняння розглянутих підходів показує, що вони дають змогу моделювати одну і ту саму з різних точок зору: у МБА
— моделями, розташованими на рівні 4Ь-М1, в СЮР — рівня ЗЬ-М1. Але якщо в МБА 4Ь-М1-моделі описують ПРГ безпосередньо, то в СЮР ЗЬ-М1-подання описують ПРГ через ЗЬ- М1-моделі. Це має і плюси (можливість встановлення формальної взаємної відповідності З Ь-М1-подань, побудованих для однієї і тієї самої), і мінуси (можлива втрата інформації під час переходу від ПРГ через ЗЬ-М1-модель до ЗЬ-М1-подання). Крім того, набір видів ЗЬ-М1 -подань зумовлений ЗЬ-М2- метамоделью.
Клас спеціальних моделей знань об’єднує моделі, що відображають особливості подання знань і розв’язання задач в окремих, відносно вузьких. Як приклад подібного способу формалізації знань можна навести модель уявлення ПРГ «об’єкт-ознаку», використовувану в автоматизованих системах пошуку аналогів і побудови класифікацій.
Застосування на практиці того або того способу формалізації обумовлюється специфікою завдання, для вирішення якого планується використовувати БЗ. На думку фахівців, найбільш перспективні змішані або комплексні моделі, які інтегруюють переваги розглянутих вище базових моделей уявлення ПРГ.
2.12. Мережеві та інші моделі знань
Залежно від типів зв’язків, використовуваних в моделі, розрізняють класифікуючі мережі, функціональні мережі і сценарії. У класифікуючих мережах використовуються відношення структу- ризації. Такі мережі дають можливість у базах знань вводити різні ієрархічні відносини між інформаційними одиницями. Функціональні мережі характеризуються наявністю функціональних відносин. їх часто називають обчислювальними моделями, оскіль¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
149
ки завдяки їм можна описувати процедури «обчислень» одних інформаційних одиниць через інші. У сценаріях використовуються каузальні відносини, а також відносини типів «засіб — результат», «знаряддя — дія» тощо. Якщо в мережевій моделі допускаються зв’язки різного типу, то її зазвичай називають семантичною мережею.
Найбільш загальний спосіб подання знань — це спосіб, за якого розглядається як сукупність об’єктів і відносин, що їх зв’язують, реалізований у мережевій моделі знань. Як носій знань у цій моделі може виступати семантична мережа, вершини якої відповідають об’єктам (поняттям), а дуги — відносинам між поняттями. Крім того, і вершинам, і дугам привласнюються імена (ідентифікатори) і описи, що характеризують семантику об’єктів і відносин ПРГ.
Типізація семантичних мереж обумовлюється змістом їх відносин. Наприклад, якщо дуги мережі виражають родовидові відносини, то така мережа визначає класифікацію об’єктів ПРГ. Аналогічно, наявність у мережі причинно-наслідкових (каузальних) відносин дає змогу інтерпретувати її як сценарій. Побудова мережі на асоціативних відносинах формує асоціативну структуру понять цього фрагмента ПРГ. Взагалі за практичного використання семантичних мереж для подання знань вирішальне значення мають уніфікація типів об’єктів і виділення базових видів відношень між ними. Облік особливостей об’єктів і відношень, заданих їх типами, забезпечує можливість застосування тих або інших класів висновків на мережі.
Оскільки фактично мережева модель об’єднує множину методів уявлення ПРГ за допомогою мереж, складно зіставити цю модель з іншими способами подання знань. Очевидні переваги мережевої моделі полягають в її високій сумісності, наочності відображення системи знань ПРГ, а також легкості розуміння подібного уявлення. В той самий час у семантичній мережі має місце об’єднання груп знань, що належать до абсолютно різних ситуацій при призначенні дуг між вершинами, що ускладнює інтерпретацію знань. Інша проблема мережевої моделі — складність уніфікації процедур висновку і механізмів управління висновками на мережі.
Перспективним напрямом підвищення ефективності мережевого уявлення, що розвивається є використання онтології і паралельних висновків на мережах.
150
Г.Ф. Іванченко
Особлива увага до мережевої моделі пояснюється її загальним характером і значними виразними можливостями, а також тим, що вона мало описана в літературі.
Різновидом мережевої моделі є онтологія. Швидкий розвиток онтологічного підходу останніми роками обумовлений поширенням Intemet-технологій, що використовують онтологічні моделі.
Порівняно з традиційними методами, головною примітною особливістю онтологічного підходу, є можливість подання визначеної (а не та, що мається на увазі), формальної й підтримуваної комп’ютером семантики понять моделі знань фахівця.
Онтологія — це точна специфікація концептуалізації предметної галузі, що дає можливість формувати модель знань фахівця за допомогою множини понять і відносин, що описують цю наочну галузь, а також правил й аксіом, що визначають їх інтерпретацію.
Онтологія — це загальноприйнята й загальнодоступна концеп- туалізація певної галузі знань (світу, середовища), яка містить базис для моделювання цієї галузі знань і визначає протоколи для взаємодії між агентами, що використовують знання з цієї галузі,
і, нарешті, включає домовленості про представлення теоретичних основ цієї галузі знань. і
Використання в ШІ онтологічного підходу розширює можливості фахівця з розвитку й знань.
Дослідження у області онтологічного представлення знань пов’язані з іменами таких вітчизняних і зарубіжних учених, як Д. А. Поспелов, А. С. Клещов, В. Ф. Хорошевській, Т. JI. Гаври- лова, Т. Грубер, Н. Гуаріно, Д. Сова, Д. Фензель, Е. Мотга і інших.
У найбільш загальному вигляді онтологія має такий вигляд: Поняття => Відношення => Правила => Аксіоми.
Так, для проектування схеми одноступінчастої механічної циліндрової передачі (рис. 2.17) потрібні дві «статичні» онтології: онтологія завдання параметричного проектування і онтологія предметної галузі проектування циліндрових передач, а також «процедурні» онтології методів вирішення для класу завдань параметричного проектування.
Схему одноступінчастої механічної циліндрової передачі наведено на рис. 2.17, де: 1 — ведучий вал, 2 — ведений вал Z\ — число зубців шестерні Z2 — число зубців колеса).
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
151
\ зіе "з
X
X
-А
3
2
Б 3
Е
Рис. 2.17. Одноступінчаста механічна передача
Процедурна онтологія методу описує розв’язання задачі як пошук у просторі станів, де спочатку в термінах понять з «статичних» онтологій завдання і предметної галузі визначається простір станів, а потім задаються оператори, застосування яких дають змогу здійснювати перехід з одного стану в другий, і структури знань, які керують вибором і використанням операторів.
Спрощений варіант онтології предметної галузі проектування циліндрових передач має вигляд:
— Предметна категорія: Циліндрова передача.
— Відносини;
— Складається з: шестерня, колесо, ведений вал, ведучий вал.
— Має атрибути: передавальне число (м), міжосьова відстань (а), модуль (пі), сумарне число зубців (z), контактна напруга (и).
— Мас значення: передавальне число [1.0, 1.25, 1.6, 2.0, 2.5, ,11-2]
— Мас значення: модуль [1.25,1.5,2.0,2.5,2.0,..., 14.0]
— Правила:
— Правило визначення діючої і максимальної контактної напруги.
'— Правило визначення міжосьової відстані.
— Аксіоми:
— Передавальне число дорівнює діленню числа зубців колеса на число зубців шестерні;
— діюча контактна напруга завжди має бути менша або дорівнювати максимально припустимій.
Можна використати систему Protégé, яка є середовищем, заснованим на знаннях з метою опису онтологій.
Protege являє собою гнучке, добре підтримуване й надійне середовище розробки онтологій. Використовуючи Protégé, розробники й експерти у цій галузі можуть легко створювати ефективні системи, засновані на знаннях, а дослідники можуть вивчати ідеї в різних наукомістких галузях.
152
Г.Ф. Іванчвнко
User ^ Interface
Persistent, Storage
Slot Plug-ins I _ Tab Plug-ins I J Protege Default User Interface External KB Applications
Default Protege Files ^
Flat file storage Relational database storage
Рис. 2.18. Архітектура системи Protégé
Рис. 2.19. Вікно візуалізації редактора онтології Protégé
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
153
Теперішня версія Protégé може працювати на різних платформах, підгримує розширене налаштування інтерфейсу користувача, включає в себе відкриту базу знань взаємодії зі стандартними форматами зберігання даних, такими як реляційні бази даних, XML.
За допомогою редакторів онтології Protégé на основі класів об’єктів і структури знань будується онтологія процесу (ієрархія понять та атрибутний склад). Після створення онтології будуються правила (обмеження) для проблемної галузі мовою KIF. Формуються запити до системи, що дають можливість отримувати потрібні знання з бази знань.
Універсальна форма
Універсальна форма асоціативної моделі знань використовує базис вузлових елементів мережі, що налаштовується з умов якнайкращого відображення системи знань. Зазвичай така форма застосовується для подання складних систем знань, тому вона має засоби структуризації. Компонентом структури може бути об’єкт, що містить локальну систему знань, засоби наповнення або корекції її шляхом навчання й інтерфейсні засоби введення- виведення й обміну з іншими об’єктами. Такий об’єкт може бути названий когнітивним, а самі системи — когнітивними системами. На цей час когнітивні системи на асоціативній моделі знань інтенсивно вивчаються.
Програмна підтримка асоціативних інтелектуальних систем здійснюється тільки спеціалізованими інструментальними засобами, такими як пакет для розробки асоціативної пам’яті STARAN, нейромережевий пакет BRAIN MAKER, пакет для розробки нечітких систем FUZZY TECH й ін.
У моделях знань ухвалення рішень здійснюється шляхом виведення висновків з використанням певним чином формалізованих знань про проблемну галузь. Методи ухвалення рішень, засновані на висновку в системі знань, різноманітні й безпосередньо пов’язані з моделями знань, тому їх класифікація повинна відповідати моделі знань.
Універсальна об’ємна форма в нині розвивається й часто використовується в практичних розробках потужних розподілених мережевих систем знань для моделювання, управління, проектування й ін. Програмна підтримка цієї форми знань широка: засновані на LISP мови типу CLOS, LOOPS і т. ін., об’єктно- орієнтовані мови типу Smallltalk, C++ тощо.
154
Г.Ф. Іввнчвнко
Нейронна фбрма
Нейронна форма припускає використання у вузлових елементах (формальних нейронах) мережі мульТиплікативно-адитивного базису з пороговим або линійно обмеженим виходом. Сила конек- цій трактується тут як сила синаптичних зв’язків нейронів і визначається тільки шляхом навчання. Нейронна форма асоціативного відображення знань порівняно з простою нейромережою завжди структурована, тобто складається із зв’язаних локальних нейромереж, об’єднаних ієрархічно. Така складна структура може мати когнітивні властивості, що відображається в назвах ней- ромоделей: ССЮМТІЮЧ КЕОССЮМТЖЖ і ін.
Такі моделі розвиваються в межах конйктивістського напряму в штучному інтелекті. Нейронні системи ефективні при вирішенні завдання класифікації й апроксимації. Детальніше про нейро- мережі див. Розділ 4.
Реляційна модель знань
Ця модель використовує поняття формальної системи, що задається як
Я = <Т, Р, А,
де і? — система відносин, Т — безліч базових елементів, Р — множина синтаксичних правил, що дають мозкливість будувати з безлічі елементів Т синтаксично правильні вирази; А — множина апріорно справжніх виразів (аксіом); Р — семантичні правила введення, що дають змогу розширити множину А за рахунок інших виразів.
В основі реляційної моделі лежить теорія відносин і логіка. Історично ця модель має коріння в численні висловів, від якого пізніше перейшли до числення предикатів (відношень). Завдяки розвитку автоматичних процедур доказу, заснованих на уніфікації, резолюції й евристичному пошуку з’явилася можливість використовувати логічні програми з предикатів для формалізації знань і висновку.
На цей час разом з предикативною логікою для побудови реляційної моделі знань застосовується дедуктивна логіка як основа системи продукцій з висновком, виходячи із заданої системи посилань. Розвивається і використовується також індуктивна логіка з висновком на основі узагальнення прикладів, логіка аналогій, псевдофізична логіка й ін.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
155
Резюме за змістом теми
Знання є сукупністю відомостей про об’єкти, їх суттєві властивості і відносини, що їх зв’язують, процеси, що протікають, а також методи аналізу ситуацій, які виникають і способи розв’язання асоційованих з ними проблем. Враховуючи широчінь подібного тлумачення знань, коротко розглянемо інші тлумачення цієї базової категорії.
Поняття «знання» можна вважати одним із ключових з погляду і теорії штучного інтелекту, і гносеології. Саме філософія намагається дати повну картину, повне пояснення природи того або іншого поняття.
Проблема подання знань виникла як одна з проблем штучного інтелекту. Вона пов’язана з переходом досліджень у цій галузі в деяку нову фазу. Йдеться про створення практично корисних систем (перш за все так званих експертних систем), використовуваних у медицині, геології, хімії. Створення подібних систем вимагає інтенсивних зусиль з формалізації знання, накопиченого у відповідній науці.
Поширеним аспектом класифікації знань є їх поділ на декларативні (факти, відомості описового характеру), процедурні (інформація про способи вирішення типових завдань) і метазнання.
Джерелами знань є стислі й повні описи суті. Всіх їх можуть використовувати при формалізації знань, тобто подання їх з використанням певної формальної моделі знань, прийнятної для апаратно- програмних реалізацій.
Будемо казати, що знання про відповідні факти або поняття поле знань зберігає вербально, якщо використання фіксованого набору процедур, що задані над полем знань, дає змогу за оптимальний час отримати вербальне формулювання деякого факту або вербальний опис поняття.
Людина в своїй діяльності комбінує дедуктивні висновки з рефлекторними рішеннями. Таке комбінування повинно бути характерним і для розвинених інтелектуальних систем. Наприклад, можна організувати паралельне функціонування механізмів дедуктивного виведення і конекціоністських механізмів.
У БЗ прийнято виділяти екстенсиональну та інтенсиональну частини. Екстенсиональною частиною бази знань називаємо сукупність усіх явних фактів. Інтенсиональною частиною бази знань називаємо сукупність усіх правил виведення та процедур, за допомогою яких з наявних фактів можна виводити нові твердження.
Структурне подання знань характеризує відносини фактів, або об’єктів. Структура знань може змінюватися, за рахунок чого вони конкретизуються при описі заданої проблемної галузі. У динамічних БЗ структура знань може змінюватися еволюційно або адаптивно.
156
Г.Ф. Іванченко
Концептуальні властивості знань: внутрішня інтерпретація; структурованість; зв’язність; активність знань; функціональна цілісність; ситуативність, незалежність, спільність; однорідність.
Подання знань — це спосіб формального подання знань про наочну галузь у комп’ютерні формі, що інтерпретується.
Моделлю знань називають фіксовану систему формалізмів (понять і правил), відповідно до яких інтелектуальна система подає знання в своїй пам’яті та здійснює операції над ними.
Ключові вимоги до моделей знань:
1) спільність (універсальність);
2) «психологічна» наочність подання знань;
3) однорідність;
4) реалізація в моделі властивості активності знань;
5) відвертість БЗ.
Логічні моделі реалізуються засобами логіки предикатів. У цьому випадку знання про наочну галузь подаються у вигляді сукупності логічних формул.
Алфавіт числення предикатів утворюється за рахунок додавання до алфавіту числення висловів символів предикатів, предметних змінних і констант, а також кванторів спільності й існування.
Елементарне твердження складається з предиката і поєднаних з ним термів. Складні твердження будуються з елементарних за допомогою логічних зв’язок.
Прямий висновок починається з приведенні початкових даних розв’язуваної задачі, які фіксуються у вигляді фактів у робочій пам’яті системи. Правила, використані до початкових даних, забезпечують генерацію нових фактів, що додаються в робочу пам’ять. Процес триває, поки не буде отримано цільове збагачення робочої пам’яті.
Окрім прямого висновку, в продукційних системах широко застосовується і зворотний висновок, тобто висновок, керований цільовими умовами. Такий висновок починається з цільового твердження, яке фіксується в робочій пам’яті.
Безумовно, можливі й змішані стратегії висновку, коли об’єднуються обидва види пошуку — пошук у ширину і пошук у глибину, а також різні евристичні стратегії, оскільки ці стратегії в продукційних системах пов’язані з правилами вирішення конфліктів,
Існують стратегії керування розв’язанням конфліктів, мета яких —уникнути експоненційного зростання.
В основі асоціативної моделі знань лежить асоціативна логіка, нейродинамика і когнітологія. Загальним для асоціативного підходу є подання знань у вигляді асоціативної мережі вузлових елементів, що мають конекції між собою відповідно до розв’язуваної задачі.
Семантичні мережі є найбільш широким класом мережевих моделей, у яких поєднані різні типи зв’язків. Часткові випадки семан¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
157
тичних мереж відповідають спеціальним типам зв’язків. Виділяють, зокрема, класифікаційні мережі, функціональні мережі та сценарії.
Фрейм — це мінімальний опис деякої сутності, такий, що подальше скорочення опису призводить до втрати цієї сутності. Фрейм будь- якого поняття може бути утворений шляхом об’єднання всіх бінарних фактів, пов’язаних з цим поняттям.
Терміни та поняття до теми
• ПРГ — предметна або проблемна галузь формалізації класу типових проблем, яка дає змогу казати про доцільність виділення знань у базу знань інформації (БЗ);
• EC — експертна система;
• СУБД — система управління (керування) базами данних;
• СУБЗ — система управління базою знань;
• ІС — інформаційна система;
• ФС — формальна система — це спосіб формального подачі знань ПРГ в комп’ютерний формі;
• ППФ — правильно побудована формула;
• предикат — неоднорідна двозначна логічна функція від будь- якого числа аргументів;
• ОП — обчислення предикатів;
• дедуктивний висновок, тобто висновок за якого із заданої системи посилань за допомогою фіксованого набору правил формуються власні висновки;
• атоми — елементарні формули;
• modus ponens і generalization — основні правила висновку в логіці предикатів;
• предикат — логічна функція, яка приймає одне з двох можливих значень — «істина» або «хибність»;
• фраза Хорна — диз’юнкція довільної кількості атомарних формул; з яких позитивною є не більш ніж одна;
• продукція — правила висновку з логічних моделей.
Питання для самоконтролю
1. Охарактеризуйте поняття «знання».
2. Які види знань зазвичай виділяють?
3. У чому полягає відмінність між декларативними і процедурними знаннями?
158
Г.Ф. Іванчвнко
4. Що таке евристики? Для чого вони використовуються?
5. Що належить до концептуальних властивостей знань? Поясніть кожну властивість.
6. Що таке розмиті квантифікатори?
7. Що становлять опозиційні шкали?
8. У яких типових ситуаціях має виявлятися активність знань?
9. Що розуміють під моделлю знань? Яка її роль?
10. Які існують класи моделей знань?
11. Дайте характеристику логічних моделей знань.
12. Що служить центральною ланкою продукцфної моделі знань?
13. Чим відрізняються прямий і зворотний висновки в продукційній моделі знань?
14. Охарактеризуйте фреймову модель знань.
15. Охарактеризуйте мережеві моделі знань.
16. Порівняйте об’єктно-орієнтовані моделі знань МОА і ОБР.
17. Сформулюйте основні вимоги до моделей зрань.
18. Охарактеризуйте вербально-дедуктивний підхід до опису поняття «знання». Чи є він єдино можливим?
19. Що означають поняття екстенсиональної та інтенсиональної частин бази знань?
20. Наведіть визначення експертної системи.
21. Що таке псевдофізичні логіки?
22. Охарактеризуйте поняття агрегації. ,
23. Опишіть поняття «клас» та «екземпляр кла(су».
24. Охарактеризуйте принцип логічного виведеїфя за успадкуванням.
25. Чим відрізняються відношення «екземпляр—клас» та «підклас—клас».
26. Охарактеризуйте «підклас—клас» як відношення часткового порядку.
27. Охарактеризуйте проблему винятків. вона пов’язана з монотонністю логічного виведення?
28. Перелічіть галузі знань, що застосовують для діалогових експертних систем.
29. Яким чином можна розкласти деящщ складний предикат на бінарні предикати? Наведіть приклади.
30. Яким чином можна перетворити удорщій предикат на бінарний? Наведіть приклади.
31. Охарактеризуйте поняття «об’єкт-атрц(5ут-значення».
32. Охарактеризуйте визначення фрейму як структури даних для опису певного поняття.
33. Що означає «мінімальність» опису у визначенні фрейму, що було дано Мінським?
34. Яким чином можна описати об’єкт на основі фреймової моделі?
35. Яким чином описи конкретних об’єктів утворюються з описів відповідних фреймів?
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
159
36» Опишіть схему поповнення первинних описів на основі фреймових моделей.
37. Що таке приєднала процедура? Що таке процедура «демон»?
38. Що таке мережі подібностей та відмінностей? Опишіть їх можливі застосування?
39. У чому полягає зв’язок між семантичними мережами і фреймами?
40. Що таке сценарій?
41. Опишіть деяку послідовність подій з деякої предметної галузі у вигляді сценарію, що залежить від ролей та змінйих.
42. Поясніть зв’язок між фреймовими моделями та об’ектно- орієнтованим моделюванням і програмуванням.
43. Перелічіть та охарактеризуйте основні властивості об’єктів та класів.
44. Дайте загальну характеристику мови ЦМЬ.
45. Що таке онтологія процесу (ієрархія понять та атрибутний склад)?
Завдання для індивідуальної роботи, обов’язкові та додаткові практичні завдання
1. Охарактеризуйте основні проблеми, які потрібно розв’язувати при розробці експертних систем і баз знань. Наведіть приклади.
2. Чому знання експерта важко формалізувати, тобто подати ці знання у вигляді, Придатному для занесення до бази знань?
3. Наведіть приклад бази знань з довільної предметної галузі, що включає до свого складу факти та правила.
4. Наведіть власний приклад бази даних, яку можна розкласти на ін- тенсиональну та екстенсиональйу частини.
5. Чому фреймові структури відіграють важливу роль у розумінні, зокрема, текстів?
6. Яким чином відношенню узагальнення, асоціації та залежності можуть бути реалізовані в ісонкретних мовах програмування?
Література для поглибленого вивчення матеріалу
1. ЛюгерДж. Ф. Искусственный интеллект. — М.: Изд. дом «Виздт ямс», 2005. — 864 с.
2. Бондарев В. Н., Аде Ф. Г. Штучний інтелект. Навчальний посібник для вузів. — Севастополь: Вид-во СевНТУ, 2002. — 615 с.
160
Г.Ф. Іванчвнко
3. Адаменко А., Кучуков А. Логическое программирование и Visual Prolog. — СПб.: БХВ. — Петербург, 2003. — 992 с.
4. Марселлус Д. Программирование экспертных систем на Турбо- Прологе. — М.: Финансы и статистика, 1994. — 256 с.
5. Братко И. Программирование на языке Пролог для систем искусственного интеллекта. — М.: Мир, 1990. — 560 с.
6. Тейз А., Грибомон П., Луи Ж. Логический подход к искусственному интеллекту: от классической логики к логическому программированию. — М.: Мир, 1990. —432 с.
ОСНОВНІ МОДЕЛІ
висновку
Тема З
ЗАГАЛЬНА ХАРАКТЕРИСТИКА ДЕДУКТИВНОГО ТА ІНДУКТИВНОГО ВИСНОВКУ
Перелік знань та навичок
Після опанування теми студент має знати:
• використання дедуктивних та індуктивних схем висновку в системах штучного інтелекту;
• дедуктивний висновок методом Ербрана;
• використання законів де Моргана;
• правила побудови пропозицій-диз’юнктів Хорна; .
• методи написання програми семантичної мережі та створення реляційної бази знань мовою Prolog;
• методи планування переміщень робота та алгоритм переміщення мурахи у просторі.
Має вміти:
• побудувати універсум Ербрана з константних термів;
• написати мовою Prolog конкретний список, що складається з елементів списку;
• написати мовою Prolog спеціальні засоби для організації баз фактів;
• написати програму семантичної мережі на прикладі сімейних відносин мовою Prolog;
• написати діалогову програму для реляційної бази знань, яка здійснює автоматичну вибірку та демонструє інтерфейс розмовної мови;
• використовувати дистрибутивний закон для приведення виразу до кон’юнктивної нормальної форми.
162
Г.Ф. Іванченко
ЗМІСТ ПИТАНЬ ТЕМИ
3.1. Формулювання завдання дедуктивного висновку
Під висновком розуміють процес отримання висновків з передумов. Існують різні моделі висновку. У другому розділі в логіку числення предикатів було введено поняття дедуктивного висновку, який базується на використанні певних правил висновку до множини початкових істинних тверджень, і лише позначено можливий напрям автоматизації цього процесу. В цьому розділі розглянемо загальні процедури, що дають змогу автоматизувати дедуктивний висновок з числень предикатів, і перш за все процедуру резолюції. З цією метою введемо поняття пропозиції для формул числення предикатів, потім розглянемо поняття універ- суму Ербрана і, нарешті, опишемо процедуру резолюції і її використання при вирішенні різних завдань.
Хоча числення предикатів є потужним інструментом для опису найрізноманітних сфер, проте воно не позбавлено недоліків. Зокрема, завдяки теорії числення предикатів можна отримати правильні висновки, спираючись на загальнозначущі твердження й обґрунтовані правила висновку. Разом з тим, іноді потрібно здійснювати висновок в умовах, коли початкові дані не є абсолютно достовірними і вичерпними, а правила висновку мають евристичний характер і ненадійні. В цьому разі застосовують процедури, що забезпечують висновок висновків з певною упевненістю (процедури висновку на ненадійних знаннях), а також процедури немонотонного висновку, що припускають отримання під час висновку висновків, які можуть логічно суперечити твердженням, що є в базі знань.
Окрім дедуктивного висновку, в системах штучного інтелекту широко використовують індуктивні схеми висновку. Такі схеми дають змогу породжувати узагальнення наявних власних тверджень. Здібність до узагальнення є важливою функцією природного інтелекту і використовується їм для отримання нових знань. Тому індуктивні схеми висновку є елементом підсистем штучного інтелекту, що навчаються. Оскільки при навчанні з сукупності фактів формуються шляхом узагальнення нові поняття й правила, то індуктивні схеми висновку знаходять широке використання при автоматизації процесу придбання знань.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
163
Були розроблені ефективні методи автоматизації дедуктивного висновку. Історія їх створення бере свій початок від праць Ж. Ербрана, який запропонував механічну процедуру дедуктивного висновку (1930). В 1965 р. Дж. Робінсон розробив принцип резолюції, що дає змогу автоматизувати процес спростування, і він є теоретичною базою для побудови багатьох систем автоматичного доказу теорек. Саме ці два підходи буде розглянуто під час опису дедуктивного висновку.
Нехай задача описується мовою числення предикатів. Якщо позначити через Ф0 множина початкових тверджень і через — цільове твердження, то задача у вигляді доведення теореми формально може бути записана у вигляді Ф0 => ^.
Іншими словами, необхідно довести, що формула і7* логічно ВИХОДИТЬ З безлічі формул Фо-
Формула ^ логічно виходить з Ф0, якщо кожна інтерпретація, що задовольняє Ф0, задовольняє і /у Коли множина Ф0 представлена формулами ^^2,-^1, то задачею дедуктивного висновку числення предикатів є з’ясування загальнозначущої формули л — л ~* •
Під час висновку часто використовують метод доказу від зворотного, тобто встановлюють, що загальнозначуща формула нездійснена:
ґ1а/,2л...лґл->ґ!;
^ л...лР„ лЕе.
Іншими словами, доводять, що об’єднання Ф0 нездійсненне. Такий доказ може бути істотно простіше за прямий висновок. Процес встановлення нездійсненності деякої безлічі формул називають спростуванням.
3.2. Стандартизація предикатних формул
Для здійснення дедуктивного висновку методом Ербрана або на основі принципу резолюції, всі формули множини Ф0
мають бути подані у вигляді диз’юнкцій літералів.
Літерапом називають елементарну формулу або її заперечення. Диз’юнкція літералів називається пропозицією або клозом (від
164
Г.Ф. Іванчвнко
англ. clause). Наприклад, формула P(x)v Q(x,y)v R(x,y) є пропозицією. Таким чином, формули множини Ф0 uFg мають бути записані у формі пропозицій. Оскільки пропозиція містить тільки знаки операцій диз’юнкції й заперечення, причому заперечення повинне поширюватися не більше ніж на одну предикатну букву, то для приведення формули до виду пропозиції потрібно виключити з неї всю решту операцій і скоротити сферу дії операції заперечення.
Приведення формул множини Ф0 uFg до виду пропозицій виконують в процесі вказаних нижче тотожних перетворень.
Виключення знаків імплікації і еквіваленції. Для цього використовують рівність:
(P^Q) = PvQ,
(P^Q) = (PvQ)a(QvP).
Зменшення сфери дії операції заперечення. При цьому використовують закони де Моргана:
(FVQ) = (Р a Q),(FWq) = (Pv 0,
VxP(x) = 3xP(x),3xP(x) = VxP(x).
Наприклад, Vx(P(x) а (Q(x) v ä(x))) = 1c(P(jc) v (Q(x) a R(x))).
Стандартизація змінних. У цьому разі перейменовують змінні, зв’язані кванторами спільності або існування, причому так, щоб кожний квантор зв’язував окрему змінну, що не зустрічається в інших кванторах. Наприклад, VxP(x) v 3xQ(x) = VxP(x) v Bzß(r).
Виключення кванторів існування. В простому випадку це відповідає правилу екзистенціальної конкретизації, яке дає змогу перейти від ЗхР(х) до Р(а), де а — константа.
Якщо квантор існування знаходиться в сфері дії квантора спільності, задача складнішає. Розглянемо, наприклад, формулу Vx3y(Q(y) л R(x,y)), яка може означати, що для каждого х існує такий конкретний у, що вірне Q(y) і R(x,y). В цій інтерпретації значення змінної у залежить від значення змінної х. Така залежність описується функцією y=f(x), яку називають функцією Ско- лема. Функція Сколема дає можливість виключити квантор існування і переписати формулу у вигляді Vx(Q(f(x)) а R(x,f(x))).
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
165
Якщо квантор існування знаходиться у сфері дії двох і більша кванторів спільності, то функція Сколема залежатиме від двох і більше аргументів. Для позначення функції Сколема не мають застосовуватися функціональні букви, які вже є у формулах.
Переміщення кванторів спільності. Всі квантори спільності записані на початку формули. Наприклад, формула Ух(Р(х) V VyQ(y)) перетворюється ДО ВИГЛЯДУ УхУу(Р(х) V 600)-
Приведення до кон’юнктивної нормальної форми. Для цього використовується дистрибутивний закон:
(АаВ)уС=(Ау С)л(Ву С). Наприклад, вираз (АлБ)\/ (Ву С) приводиться до кон’юнктивної нормальної форми таким чином:
д В) V (5 а С) = [у4 V (В л С)] а [5 V (5 л С)] =
= (АуВ)а(АуС)аВа(ВуС).
Виключення кванторів спільності. Оскільки всі змінні у формулах зв’язані кванторами спільності, а порядок проходження кванторів спільності не має значення, то їх можна не вказувати в явному вигляді, тобто виключити.
Виключення кон’юнкцій. Будь-яка інтерпретація задовольняє
формулі К1аК2а...аКп у тому разі, коли вона задовольняє формулам К1,К2,...,К„. Тому кожна формула, приведена до кон’юнктивної нормальної форми, може бути замінена множиною формул {Кі,К2,...,Кп}.
Розглянемо приклад перетворення формули до множини пропозицій. Нехай ця формула Ух{Р(х) {Уу[£?(*, .у) ->• ЛО)]} Виклю¬
чимо знаки імплікації: Ух{Р(х) V {Vу[(2(х,у) V Л(^)]}
Зменшимо сферу дії операції заперечення:
У*{Р(Д^{ЗЯЄ(*,^ЛОО]}.
Виключимо квантор існування: Ух{Р(х) V {[£>(>,/(*)) V Я(/0))]}.
Приведемо формулу до кон’юнктивної нормальної форми:
Ух{{Р(дс) V £(*,/(*)) V (Р(х) V Я(/(*)))}.
Виключивши квантор спільності і кон^юнкцію, одержимо множину пропозицій: {/’(де) V ()(х,/(х)),Р(х) V Я(/(х))}.
166
Г.Ф. Іванченко
3.3. Метод Ербрана
Як наголошувалося вище, доведення теореми Ф0 => ^ полягає в тому, щоб показати, що розширення множини формул, утвореної шляхом об’єднання множини аксіом Ф0 і заперечення цільового твердження іу, нездійсненне. Позначимо розширену множину формул, приведених попередньо до вигляду пропозицій (диз’юнктів), через 5. Множина диз’юнктів 5 нездійсненно тоді, коли не існує інтерпретації, яка йому задовольняє. Щоб це з’ясувати, потрібно перерахувати всі інтерпретації в усіх можливих сферах. Очевидно, розглянути всі інтерпретації в усіх сферах неможливо. Проте рішення задачі може бути знайдено. Воно ґрунтується на понятті універсуму Ербрана. Універсум Ербрана становить таку галузь інтерпретації Н, що якщо не існує інтерпретації множини пропозицій 5 у цій галузі, то її не існує взагалі. Універсум Ербрана будується з константних термів і визначається таким:
а) множина всіх наочних констант, що зустрічаються в 5, належить Я якщо в Б немає констант, то в Я включається довільна константа а;
б) множина всіх функцій, що зустрічаються в 5 і деяких на множині термів Я.
Проілюструємо побудову універсуму Ербрана на прикладі. Нехай
5 = {Р(дг, /(хуа))ч<2(х,а)чЯ(х,Ь)}-
У множину 5 входять предметні константи атаЬ, функціональна буква / В цьому випадку галузь Я становить нескінченну рахункову множину:
Н =, {а,Ь^(а,а),/(а,Ь),/(Ь,а),ПЬ,Ь),Па,Па,а)),/(а,Яа,Ь)1...}, яке формують послідовно у вигляді рівнів:
Н0={а,Ь},
Ні = {а, Ь, Да, а), /(а, Ь), /{Ь, а), ДЬ, Ь)},
н2 = {а,Ь,/(а,а),/(Ь,Ь),/(а,/(а,а)),/(а,/(а,Ь)),...},...
Тут Н0,НиН2 тощо — рівні універсуму Ербрана. Диз’юнкт, який не містить змінних, називається фундаментальним. Він отри-
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
167
мується заміною предметних змінних константними термами. Якщо терми є елементами універсуму Ербрана, то фундаментальний диз’юнкт називають фундаментальним прикладом диз’юнкта. Множина всіх фундаментальних атомів вигляду Р((1,і2,...,іп), де Р— предикатні букви, що зустрічаються в 5, а — елемен¬
ти універсуму Ербрана, називають ербранівською базою для 5. Наприклад, ербранівською базою для розглянутого вище прикладу є
множина: А = { р(а,/(а,а)),£>{а,а),Я(а,Ь),Р(Ь,/(Ь,а)),... }.
Інтерпретація множини 5 в галузі Н закінчують, коли з кожною атомарною формулою ербранівської бази пов’язане відповідне значення істинності.
Введені визначення дають змогу сформулювати теорему Ербрана: множина диз’юнктів 5 нездійсненна тоді і тільки тоді, коли існує кінцева нездійсненна підмножина фундаментальних прикладів диз’юнктів в 5. Ця теорема дає можливість формально побудувати процедуру спростування. Для встановлення нездійсненності множини диз’юнктів 5 потрібно:
1) створити множини зд, ...,5, фундаментальних прикладів диз’юнктів для кожного рівня і множини Я;
2) послідовно перевіряти їх на помилковість. Згідно з теоремою Ербрана, якщо 5, нездійсненно, то процедура знайде такий рівень і, що 5, буде помилковим.
На вказаному принципі працювали перші програми доказу теорем. Основним недоліком процедури Ербрана є експоненціальне зростання множини фундаментальних прикладів Б за збільшення рівня і. Тому на практиці вдається за допомогою процедури Ербрана доводити тільки прості теореми.
3.4. Принцип резолюції
Принцип резолюції є процедурою висновку, за допомогою якої народжуються нові диз’юнкти з S. Якщо під час використання цієї процедури виводиться пуста пропозиція, то S нездійсненно.
Правило висновку, що лежить в основі принципу резолюції, по суті, є розширенням правила modus ponens і правила силогізму. Правила висновку можна записати у формі:
168
Г.Ф. Іванченко
A,AvB * а. \ AwB.BwC , ч
— (modus ponens), — (силогізм).
У кожному з цих правил є диз’юнкти — посилання^що містять додаткові (контрарні) пари літер (А та А, В та В). Можна помітити, що висновок правил формально виходить викреслюванням у диз’юнктах-посиланнях контрарних пар літер й об’єднанням частин диз’юнктів, що залишилися, Розглянуті диз’юнкти-посилання містили одну або дві літери. Дж. Робін- сон поширив зазначений прийом на випадок довільних диз’юнктів з будь-яким числом літер і сформулював правила- резолюції: якщо будь-які два диз’юнкти D/ і D2 містять додаткову пару літер, наприклад L і L, то, викреслюючи їх, формуємо новий диз’юнкт з частин диз’юнктів Dі і А?, що залишилися. Знову сформований диз’юнкт називаються резольвентою (висновком) початкових диз’юнктів. Резольвента, одержана з двох диз’юнктів, є логічним висновком цих диз’юнктів. Правило резолюції дає змогу отримувати резольвенти множини диз’юнктів S. Якщо в процесі висновку резольвент виходять два однолітеральних диз’юнкти, які створюють контрарну пару, то резольвентою цих двох диз’юнктів буде порожній диз’юнкт, символом NIL.
Об’єднання початкової множини диз’юнктів з множиною всіх резольвентів, які можуть бути утворені з диз’юнктів, що входять в S, позначатимемо R(S). Застосовуючи принцип резолюції до R(S), отримуємо R(R(S)) = R2(S). В загальному випадку Rn+i(S) = R(R„(S)). При цьому R0(S>)=S. Легко помітити, що якщо множина S нездійсненна, то R,(S) за якого і> 1 також нездійсненно, і навпаки, якщо нездійсненно Л,(5), то нездійсненно і 5... Цю властивість називають повнотою принципу резолюцій. Її доводять такою теоремою Робінсона: якщо S — довільна кінцева множина диз’юнктів, то S нездійсненно тоді і тільки тоді, коли R,{S) містить порожній диз’юнкт. Теорема дає можливість побудувати процедуру спростування, яка для початкової множини S послідовно будує множини R\(S), R2(S), ...Ri(S) і перевіряє, чи містить множину Ri(S) порожній диз’юнкт.
Висновок за допомогою резолюції наочно можна проілюструвати за допомогою графа спростування. Вершинами графа є
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
169
початкові диз’юнкти і резольвенти, отримувані в процесі висновку. Диз’юнкти початкової множини Б становлять вершини графа, що розташовуються в його верхній частині. Якщо два диз’юнкти, що знаходяться в будь-яких вершинах графа, утворюють резольвенту, то вершина, відповідна резольвенті, зображується нижче за дані диз’юнктів і з’єднується з ними ребрами.
У логіці висловів знаходження контрарних пар не викликає труднощів. Складніше справа в логіці предикатів. Підставленням називають кінцеву множину (* = {*,/*,, г2/х2, ..., гя/,*„}. де хі — змінна; —терм, відмінний від х 1<і<п. Використання підставлення а до деякої формули і7 означає заміну всіх входжень змінної х{ на терм а. Формулу, отриману в результаті підставлення, позначають Ра і називають прикладом і7. Узагальнюючи сказане, відзначимо, що в логіці предикатів знаходження резольвенти двох пропозицій (диз’юнктів) зводиться до таких дій:
• змінні в пропозиціях перейменовуються так, щоб вони не співпадали;
• знаходиться підставлення, за якої літерал однієї пропозиції стає додатковим до будь-якого літерала іншої пропозиції;
• додаткові літерали викреслюються;
• якщо отримано однакові літерали, то всі вони, за винятком одного в будь-якій пропозиції, викреслюються;
• диз’юнкція літералів кожної з пропозицій, що залишилися, і є резольвента.
У процесі уніфікації можуть виходити чинники диз’юнктів. Якщо декілька літералів диз’юнкта Ь мають НЗУ (найбільш загальний уніфікатор) _а, то Д, називають фактором. Нехай £> = 6(х)уЄ(/(^))уР(х). Тоді НЗУ а = {/(>-)/*}, фактор А» = Q(J(y))vP(f(y)). Фактори є підстановлювальні окремі випадки, які дають можливість зменшити диз’юнкти по довжині. Принцип резолюції припускає використання не тільки резольвент, а й факторів.
Існує велике число модифікацій принципу резолюцій, спрямованих на знаходження ефективних стратегій пошуку найважливіших диз’юнктів для бінарної резолюції. Нижче розглянемо стисло тільки деякі стратегії пошуку, що знайшли найширше застосування.
170
Г.Ф. Іванченко
3.5. Стратегії пошуку
Для розв’язання проблеми «комбінаторного вибуху», виникає у разі безпосереднього використання принципу резолюцій, потрібно здійснювати цілеспрямований підбір пропозицій, що беруть участь у процесі уніфікації. Вибір має виконуватися так, щоб порожня пропозиція досягалася якнайшвидше. Зазвичай, на кожному етапі спростування вибір залежить від поточної ситуації. Проте є загальні стратегії пошуку, які, незалежно від контексту завдання, дають змогу скоротити число резолюцій. Нижче розглянемо такі чотири стратегії: стратегію унітарності, стратегію опорної множини, стратегію початкових даних, лінійну стратегію.
Стратегія унітарності Згідно з цією стратегією перевага віддається тим бінарним резолюціям, де одна з пропозицій містить єдиний літерал. Така стратегія гарантує зменшення довжини результаційних пропозицій. Наприклад, висновком однелітераль- ної пропозиції Р і пропозиції Р V 2 V Л буде б V Л, яка коротше за попередню пропозицію. Стратегія унітарності впорядковує вибір пар пропозицій, спрощуючи подальші етапи доказу нездійсненності початкової множини диз’юнктів.
Стратегія опорної множини. Ефективнішою може виявитися спроба виключити з розгляду відразу кілька пропозицій на основі поняття опорної множини. Нездійсненну множину пропозицій 5 можна розбити на дві підмножини 5і і Підмножина 5і складається з аксіом, а 5г — із заперечень тих пропозицій, які потрібно довести. Очевидно, що підмножина 5і не містить суперечностей. Тому знаходження резольвент пропозицій з не допускається. Опорною називають множину пропозицій, що складається з диз’юнктів, які входять в 5г, і резольвент тих пар пропозицій, з яких хоча б одна належить опорній множині. Стратегія опорної множини припускає виконання тих резолюцій, в яких, принаймні, одна з пропозицій входить в опорну множину. Якщо опорна множина відносно невелика, то це значно скорочує простір пошуку. Перевага стратегії опорної множини також полягає в тому, що формоване дерево спростування легко інтерпретується людиною, оскільки воно керується метою.
Якщо множина початкових пропозицій нездійсненно, то розглянута стратегія призводить до порожньої пропозиції, тобто во¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
171
на є повною. Стратегія опорної множини є спеціальним випадком загальнішої семантичної резолюції [21].
Лінійна резолюція. Спочатку знаходиться слідство двох пропозицій початкової множини 5. На наступних етапах у резолюції бере участь резольвента С, одержана на попередньому кроці (має назву центральний диз’юнкт), і диз’юнкт В (називають боковим), що є або одним з диз’юнктів початкової множини 5, або центральним диз’юнктом С], який передує у висновку диз’юнкту С, ,
тобто у < і. Лінійна стратегія є повною й однією з найефективніших у реалізації.
Стратегія вхідних даних. Така стратегія відповідає лінійній резолюції з одним обмеженням: як бокові диз’юнкти вибираються тільки диз’юнкти початкової множини Я. Вхідна резолюція є повною, тільки якщо пропозиції множини £ є диз’юнктами Хорна.
Розглянуті стратегії пошуку можна комбінувати. Наприклад, стратегії унітарності й опорної множини. Окрім цього, можна спрощувати множину початкових пропозицій 5. Для цього виключаються тавтології, пропозиції, що містять унікальні літера- ли, підвипадки. Наприклад, якщо множина 5 містить диз’юнкт Р(х), то немає сенсу включати до складу 5 диз’юнкти вигляду Р(а) або Р{а)\І<2(Ь), оскільки вони є підвипадки Р(х).
Розроблено велике число стратегій пошуку резольвент при доказі теорем. Основний спосіб розв’язання проблеми «комбінаторного вибуху» полягає у використанні семантики і вбудовуванні в правила висновку специфіки конкретної наочної галузі [21].
3.6. Використання принципу резолюції
Використання принципу резолюції припускає переклад початкової постановки завдання на мову числення предикатів. При цьому розглядаються два випадки. В першому випадку належить з’ясувати, чи виходить логічно деяка формула ^ з множини формул Ф0, у другому випадку, який зустрічається набагато частіше, ставиться завдання знаходження значення аргументу х, за якому ця формула Рв, що містить х, виходить з множини Фо. Іншими словами, в другому випадку належить спочатку встано-
172
Г.Ф. Іванчвнко
вити справедливість твердження Ф0 => (*), а потім знайти
значення змінної х, за якого вказане твердження виконується. З’ясуємо, як отримати з доведеної теореми відповідь на поставлене запитання. Процес формування відповіді розглянемо на прикладах завдань інформаційного пошуку, та планування переміщення робота.
Інформаційний пошук
Нехай є база даних, що містить відомості про хімічні сполуки [20]. Наприклад, факти, що вказують які з’єднання вважаються оксидами, і який колір має те або інше з’єднання. Припустимо, що серед багатьох фактів, що зберігаються в базі даних, є твердження про те, що з’єднання MgO— оксид, і колір оксиду — білий. Ці факти можна навести на мові числення предикатів у вигляді двох одномісних предикатів: oxide(MgO) і white(MgO). Тут як імена предикатів вибрано слова англійської мови oxide (оксид) і white (білий). Нехай потрібно встановити, чи існує оксид білого кольору. Запитання на мові числення предикатів запишеться у вигляді Fg (х) = 3x(oxide(x) д white(x)).
Формулу Fg(x), яку необхідно довести, називають припущенням. Знайдемо заперечення припущення Fg (x) = Vx(oxide (х) v white (*)) і доведемо, що множина
S = { oxide(MgO),white(MgO),oxide (х) v white (х) }
нездійсненна. Для цього побудуємо дерево спростування (рис. 3.1).
Потім потрібно отримати те власне значення змінної, що належить до квантора існування, яке і є відповіддю на поставлене запитання. Для цього будують модифіковане дерево доказу. Процес його побудови полягає в таукому:
1) до заперечення припущення дописують через диз’юнкцію саме припущення, тобто замість заперечення припущення записують тавтологію;
2) знаходять резольвенти тих же пропозицій, які брали участь в побудові дерева спростування,
У корені модифікованого дерева доказу виходить пропозиція, яка і використовується як розгорнута відповідь на поставлене запитання. Модифіковане дерево доказу зображено на рис. 3.2.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
173
Охі<ЩА^О) ЯЬіІе(І^О) ОхШе(х) V УПііІе (х)
Рис. 3.1. Дерево спростування
ОхісІвіМзО) White(MgO) Охі<іе(х) V МЬіІе (х) V Охіс1е(х) V МЬііе(х)
Рис. 3.2. Модифіковане дерево доказу
Інтерпретуючи пропозицію, що знаходиться в корені модифікованого дерева доказу, встановлюємо, що існує оксид MgO, який має білий колір.
Розглянутий приклад демонструє відповідь на запитання на зразок «так» чи «ні». Запитання, на зразок «скільки», також можна сформулювати у вигляді доказу теорем. Нехай є правило: «якщо в хет елементів типу у, авуєп елементів типу г, то вх є т*п елементів типу х». Це правило можна записати у вигляді формули,
174
Г.Ф. Іванченко
використовуючи предикат HP(a,b,c), який інтерпретується таким чином: «а» містить «с» елементів типу «b». Тоді правило отримуємо у вигляді Vx\/y{HP(x,y,m) a HP(y,z,n) ЯР(х,z,times(m,n)) }, де
функція times (т,п) позначає добуток т на п. Припустимо, що під об’єктом х розуміється людина. Системі відомо, що людина має дві руки, і на кожній руці — п’ять пальців. Треба з’ясувати, скільки пальців на руках у людини? Безумовно, з погляду природного інтелекту, це не питання. Проте відзначимо, що система має формально вивести відповідь на поставлене запитання на основі відомих їй фактів і загального правила.
Факти, відомі системі, і запитання можна записати в такому вигляді:
HP(man, hand, 2);
HP(hand, fingers, 5);
3k(HP(man, fingers, к)),
де man — людина, hand — рука, fingers — пальці. Запитання інтерпретується так: чи існує таке к, що справедливе
Зк(НР(тап, fingers, к)).
Побудуємо множину S. Для цього приведемо правило до виду пропозиції НР(х,у,т) v HP(y,z,ri) v HP{x,z,times(m,n)) І знайдемо заперечення припущення F(k) = VkHP(man, fingers, к), тоді
S= [НР{тап, hand,2),
HPihand, fingers,5),
HP(x, y,m) v HP(y, z,ri)v HP(x, z, times(m,«)),
HP(man, fingers, Л)}.
Модифіковане дерево доказу, побудоване за принципом вхідної резолюції, зображено на рис. 3.3. На першому кроці знаходиться слідство пропозиції, що становить правило, і заперечення цільового твердження. На другому і третьому кроках використовуються факти HP(man,hand,2), HP (hand, fingers, 5). В корені дерева формується відповідь на поставлене запитання НР(тап, fingers, times(2,5)), тобто кількість пальців на руках у людини можна обчислити за допомогою виклику функції times(2,5).
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
175
НР{х,у,т) v HP(y,z,ri) v НР(х, z, times(m, п))
НР(тап, fingers,к) v НР(тап,fingers, к)
al = {man / х, fingers / z, times(m, п)/к }
НР(тагі),у,т) v НР(у, fingers,п) v НР(тап, fingers,times(m,n)) HP(man,hand,2)
a2 = {hand /y,2/m } HP(hand, fingers, ri) v HP(man, fingers, times (2, n))
HP(hand, fingers,5)
a3 = {5/n }
HP(man, fingers, times(2,5))
Рис. 3.3. Модифіковане дерево доказу
У розглянутих вище прикладах припущення містило квантор існування. Якщо припущення містить квантор спільності, виникають додаткові труднощі. Річ у тому, що при запереченні квантора спільності він переходить у квантор існування, який у процесі стандартизації предикатних формул виключається шляхом введення функцій Сколема. Труднощі полягають в інтерпретації цих функцій, якщо вони з’являються у відповідь у твердженні. Рекомендується такі функції замінювати на нові змінні. Під час доказу в ці змінні не роблять ніяких підставлянь.
Планування переміщень робота
Дана задача формулюється як пошук шляху на графі станів (рис. 3.4.). У початковому стані задачі робот знаходиться в позиції «а». Потрібно знайти послідовність операторів, що забезпечують переміщення робота в позицію «с», яка відповідає стану розв’язаної задачі. Для розв’язання задачі маємо встановити відповідність між описом задачі в просторі станів і описом її мовою числення предикатів.
Операторам простору станів ставляться у відповідність функції мови числення предикатів. При цьому перетворення стану si у
176
Г.Ф. Іванчвнко
стан 52 задається’функцією 52~/(^1)- Для ділянки графа станів можна записати аксіому:
Р(*,)->Є(*2) або Р(^)-»Є(/(^)),
де РО,) — предикат, що описує властивість початкового стану ділянки графа;
£?(5г) — предикат, який задає властивість кінцевого стану ділянки графа. Іншими словами, якщо стан $і має властивість Р, то стан 5,2=Л‘Уі) має властивість ().
Рис. 3.4. Граф станів задачі переміщення робота
Введемо функцію то\е(х,у,$), яка відповідає переміщенню робота з точки х у точку у в стані 5. Для опису стану задачі використовуватимемо предикат АТ(х, б), що означає, що для стану задачі 5 робот знаходиться в точці х. У цьому разі мояща записати такі аксіоми:
ЛГ(а,$0),
У5,(^4Г(а, ^,) —> А Т (Ь, тоуе(а, Ь, і, ))),
У52(АТ(а,52) —> АТ(сі, тоУе(а, сі, £2 ))),
У.у3 (А Т(Ь, 53) -> А Т(с, гпоує(Ь, с, 53))),
\/з4(ЛГ(і/,з4) -> АТ(Ь,тоуе((і,Ь,))).
Цільове твердження формулюється таким чином: чи існує стан задачі х, за якого робот знаходитиметься в точці «с»? Мовою числення предикатів це можна записати у вигляді: ВхАТ(с,з).
Дерево спростування для цієї задачі зображено на рис. 3.5. Функція результату, що забезпечує перехід робота з точки «а» в точку «с», виходить у результаті серії підставлянь у змінну 5/ 5 = тоуе(Ь, с, тоуе(а, Ь, ,у0 )).
Виконання дій відповідно до цієї функції полягає в тому, що робот спочатку має переміститися з точки «а» в точку «6», а по¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
177
тім з точки «Ь» в точку «с». Розглянутий підхід використовував Грін у системі «питання—відповідь» С^АЗ.
Рис. 3.5. Дерево спростування для задачі пошуку шляху на графі У додатку А наведено алгоритми переміщення мурахи
Prolog [16—18] є компиляторно-орієнтованою мовою програмування високого рівня і призначений для програмування завдань з галузі штучного інтелекту. Як мова програмування він особливо придатний для створення експертних систем, динамічних баз даних, програм із застосуванням природно-мовних конструкцій; він також може бути використаний для інших завдань загального характеру. Prolog має вікна, кольорову графіку й інтерактивні засоби ведення-висновку, що свідчить про його максимальну зручність для користувача прикладних програм.
Prolog — це декларативна мова, програми на якій містять оголошення логічних взаємозв’язків, потрібних для вирішення завдання.
Prolog має внутрішні підпрограми для виконання зіставлення і пов’язаних з ним процесів.
Факти і правила є твердженнями, які утворюють ці програми на Prolog. Правила мають ліву і праву частину. Ліва частина
ATXb.sJv АТ(с, move(b,c,Si))
AT(c,s)
{move{b,c,s{)ls}
AT(a,Si)v AT(b, move(a,b,Si))
AW,s3)
A1\a,s0)
AT\b,Si)
NIL
3.7. Принцип резолюції і мова Prolog
178
Г.Ф. Іванчвнко
правила істинна, якщо істинна права його частина. Правила генерують нові факти, коли всі твердження опиняються обчисленими.
Prolog використовує повернення для визначення альтернативних шляхів обчислення мети або підмети. Якщо підмета виявилася неуспішною, а вказівники повернення були встановлені, то для попередньої підмети буде зроблено спробу домогтися успіху, починаючи з точки повернення.
Розглянуті раніше принципи доказу теорем знайшли своє втілення в системі (мові) логічного програмування Prolog. Власне кажучи, назва мови Prolog складається з двох слів: програмування логічне. В Prolog процес доказу теорем розглядається як процес обчислення, або виконання програми. Відповідність вказаних процесів була встановлена Р. Ковальським.
Prolog дає змогу виконувати цілий ряд операцій із списками, їх перелік включає: доступ до об’єктів списку, перевірка на приналежність до списку, поділ списку на два, злиття двох списків, сортування елементів списку у порядку зростання або убування. Це забезпечує можливості для зручної й ефективної обробки файлів. Сюди можна включити вбудовані предикати для обробки й закриття файлів, читання з файлу і запису у файл, зміни даних у файлі, а також дозапис у вже існуючий файлЛ Дані з файлу можуть оброблятися або як безперервний потік: символів, або як структуровані об’єкти типу записів бази даних.
Імена предикатів і констант у Prolog записують рядковими буквами. Імена змінних починаються з великої букви або знаку підкреслення. Конкретний список, що складається з елементів a, b, с, d записується мовою Prolog у такому вигляді [a,b,c,d\. Список в Prolog можна задавати за допомогою змінних, наприклад [Н\ 7], де Н— голова списку, Г-хвіст списку.
Доказ теорем у Prolog заснований на подаванні пропозицій у формі диз’юнктів Хорна. Диз ’юнкт Хорна — це пропозиція, що містить^ не більше одного позитивного літерала. Наприклад РvQvRvS.
У Prolog використовують три типи диз’юнктів Хорна;
1) диз’юнкт, що складається лише з одного позитивного літерала, наприклад Q;
2) диз’юнкт, один позитивний, що містить і довільне число негативнихлітералів,наприклад QvPlwP2v---vPn;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
179
3) диз’юнкт, що складається тільки з негативних літералів, наприклад i|vP2v-v?n.
Диз’юнкти першого типу відповідають фактам Prolog- програми, які становлять правдиві твердження, наприклад пар- не_число(2).
Диз’юнктам другого типу відповідають правила Prolog- програми. Правила описують твердження, які можуть бути істинні, якщо виконуються певні умови. Негативні літерали диз’юнктів Хорна другого типу формують умову, а позитивний літерал — висновок. Наприклад, наведений вище диз’юнкт Хорна другий тип відповідає імплікації (Р, aP2a...aP„)->Q, яка мовою Prolog виражається правилом: q\-q\,q2, • ••,qn-
У цьому правилі імплікації відповідає знак а
кон’юнкції відповідає кома. Позитивний диз’юнкт правила в Prolog називають головою правила, а негативні диз’юнкти — тілом правила.
Диз’юнкт, що містить лише негативні літерали, тобто диз’юнкт Хорна третього типу, відповідає запереченню цільового твердження. Використання диз’юнктів Хорна в системі Prolog дає змогу застосувати лінійну вхідну стратегію вибору диз’юнктів, що беруть участь у розв’язанні задачі.
Розглянемо використання принципу резолюції в системі Prolog на прикладі. Для цього звернемося до Prolog-програми, яка перевіряє входження елемента Н у список: member(H,[H|T]). member(H,[X|T]):-member(H,T).
Тут member(X,Y) є предикатом, що має значення «істина», якщо елемент X входить у список Y. Програма складається з факту member(H,[H|T]) і правила member(H,[X|T]):-member(H,T). За допомогою факту задається істинне твердження про те, що елемент Я і список [Н|Т], головний елемент якого є Я, знаходяться стосовно member. Правило member(H,[X|T]):-member(H,T) означає, що елемент Я і список [Х|Т] знаходитимуться у відношенні member, якщо вказане відношення має місце між елементом Я і хвостом списку Т. Інакше, елемент Я міститься в списку [Х|Т], якщо він входить у хвіст Т цього списку.
Розглянемо процес виконання програми на прикладі цільового твердження member(c,[a,6,c]), яке на Prolog записується у вигляді: ?-member(c,[a,fe,c]).
180
Г.Ф. Іванчвнко
У цьому випадку Prolog-система доводитиме нездійсненність множини:
S = {member (Н,[Н\Т]),
member (Н,[Х \ T~\v member (Н,Т]), member (с,Га,6,с1)}.
Відповідне дерево спростування, що реалізовує лінійну вхідну резолюцію, зображено на рис. 3.13.
Рис. 3.13. Дерево спростування для відношення member
Аналіз розроблено і для роботи з формулами у фразовій формі. Маючи дві фрази, що пов’язані відповідним чином, він створить нову фразу, що буде наслідком перших двох. Основна ідея полягає в тому, що якщо одна й та сама часткова формула зустрічається у правій частині однієї структури і в лівій частині другої, то фраза отримується з’єднанням двох фраз з вилученням дубльованих формул, які з них випливають.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
181
Наприклад семантична мережа сім’ї сЬіИ(“Микита Кирпа”) мовою Prolog може бути організована так: ґета1е(“Нелія Касаєва”). female(“4y6 Євдокія”). ґета1е(“Олена 1”). та1е(“Геннадій ібфпа”). та1е(“Микита Кирпа”). та1е(“Арсентій Кирпа”). та1е(“В’ячеслав 1”).
сЬі1сі(“Микита Кирпа”,“Геннадій Кирпа”,“Олена 1”). с1іі1(і(“Геннадій Кирпа”,“Арсентій Кирпа”,“Чуб Євдокія”). сШ<і(“Олена 1”,“В’ячеслав 1”,“Нелія Касаєва”). тапіе(1(“Олена 1”,“Геннадій Кирпа”).
grand_fath_m():- child(Name, Namel, Name2), X=Name2,child(X, Namel l,Namel2),Y=Namel l,male(Y),
write (“Grandfather_by_mother_line=“,Name 11, Per=”, Name, “\n”), fail.
grand_moth_f():-child(Name, Namel, Name2), X=Namel,child(X, Namel 1, Namel2),Y=Namel2,female(Y),
write (“Grandmother_by_father_line=“,Namel2,”, Per=“, Name, “\n”), fail.
Це виведення можна пояснити так. Із тверджень фактів female, male, child та married можна вивести твердження grand_fath_m() та grand_moth_f(), тобто хто є бабусею та дідусем сЬіШ(“Микита Кирпа”).
Завершеність аналізу означає, що якщо факти випливають з наших гіпотез, ми можемо довести їх істинність через використання аналізу. Коли ми кажемо, що аналіз зможе отримати порожню фразу, маємо на увазі, що існує послідовність дій (кожна з яких включає аксіоми чи фрази, виведені в попередніх діях), які закінчуються виведенням специфічної фрази. Хоча аналіз і дає змогу отримувати результати з двох фраз, але він не вказує на те, де шукати наступні відповідності. Звичайно, якщо ми маємо багато гіпотез, то буде і багато варіантів. І кожна з виведених фраз збільшуватиме цю кількість. Більшість з варіантів будуть помилковими, і якщо ми не будемо уважними, то витратимо безліч часу на обробку помилкових варіантів. Можемо просто не знайти правильний варіант.
Prolog має спеціальні засоби для організації баз даних — фактів. Ці засоби розраховані на написання діалогових систем саме
182
Г.Ф. Іванченко
для баз даних — фактів. Внутрішні процедури уніфікацій мови Prolog здійснюють автоматичну вибірку фактів з потрібними значеннями відомих параметрів. До того ж механізм повернення дає змогу знаходити всі наявні відповіді на поставлене запитання.
Як приклад у додатку Б наведена діалогова система саме для реляційної бази знань Geobase.dba, де здійснюється автоматична вибірка приведеної програми, яка демонструє інтерфейс розмовної мови з базою знань з географії СІЛА. База зданих — фактів містить інформацію про штати, площу, населення, столиці, міста, річки тощо. Не важко для потреби в Geobase.dba ввести свою власну інформацію.
3.8. Індуктивні схеми міркувань
Окрім дедуктивних міркувань, розглянутих у розділі 3.1, у системах штучного інтелекту широко використовують індуктивні схеми міркувань. Такі схеми дають змогу робити узагальнення наявних приватних тверджень. Здібність узагальнення є важливою функцією природного інтелекту. В результаті узагальнення формуються нові знання. Тому індуктивні схеми міркувань знаходять використання в підсистемах автоматичного отримання знань. При цьому процес отримання нових знань розглядається як навчання ІС. Під час навчання завдяки узагальненню сукупності наявних фактів формуються поняття і виводяться (відновлюються) загальні правила, що забезпечують віднесення об’єктів, подій, ситуацій до відповідних класів. Розглянемо основні поняття індуктивного висновку і процедури індуктивного формування понять на прикладах.
Індукцією називають висновок, який становить знання про клас предметів, одержане в результаті дослідження окремих представників цього класу. Якщо дедуктивний висновок будується за принципом руху думки від загального до приватного, то індуктивний висновок визначається як логічний перехід від приватного до загального, тобто як узагальнення.
Узагальнення тут розуміється як процес отримання знань, які пояснюють наявні факти. Метою узагальнення є формування понять.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
183
Поняття — узагальнена інформація про множина об’єктів (ситуацій, подій), представлених наборами значень ознак, яка:
а) відображає характерні для цієї множини логічні відносини між окремими значеннями озйак;
б) є достатньою, що розрізняти за допомогою певного правила розпізнавання (класифікації) об’єктів, що належать до множини, від об’єктів, що не належать їй.
Таким чином, поняття включає лише істотні ознаки об’єктів, ситуацій, подій, що об’єднують їх в один клас, і не включає ті ознаки, які індивідуалізують їх.
Завдання індуктивного формування понять можна визначити таким чином. Дано множина фактів (наглядів, даних) і7, що становлять специфічні знання про деякі об’єкти (ситуації, події тощо); множина обмежень, яким має задовольняти шукане поняття. Потрібно сформувати поняття Н (опис, гіпотезу), з якого виводяться всі факти, тобто #=>/% де відношення => розуміється ширше, ніж відношення логічного слідства в численні предикатів.
Нехай І) — множина значень /-тої, ознаки, і =1, 2,..., п; п — число ознак. Ознаковому опису понять відповідають точки п- вимірного простору ознак £> = /©, х.02 х£)3 х...х£>и}. Якщо кожному із значень ознак поставити у відповідність змінну, яка приймає значення 1 або 0, залежно від того, спостерігається або не спостерігається це значення ознаки, то можна описувати поняття виразами булевої алгебри. Кон’юнктивним називають поняття, описуване кон’юнкцією значень ознак. Запис поняття у вигляді логічного виразу є правилом класифікації. Якщо логічний вираз, що становить поняття, матиме значення 1, то спостережуваний об’єкт (ситуація, подія) узагальнюється цим поняттям.
Тому завдання індуктивного формування понять на основі аналізу конкретних фактів часто розглядають як завдання відновлення правил.
Спостережувані факти називають позитивними стосовно деякого поняття, якщо вони описуються цим поняттям, інакше їх називають негативними фактами цього поняття.
Завдання індуктивного формування понять можна розглядати як завдання навчання. Виділяють навчання з учителем (навчання на прикладах) і навчання без учителя (навчання на основі спостереження).
У першому випадку сукупність фактів ^ має вид повчальної вибірки, яка є безліччю прикладів об’єктів (ситуацій, подій) із за¬
184
Г.Ф. Іванчвнко
даною приналежністю до того або іншого класу (поняття) Кі,К2,...,Кп. В основі навчання лежить упорядкований відбір кон’юнкций значень ознак, що характеризують групи позитивних прикладів поняття і не визначають жодного з негативних прикладів (контрприкладів). Вимагається побудувати вирішальне правило, що дає можливість визначити приналежність довільного об’єкта, ситуації, події, до заданого класу Ки
У разі навчання без учителя апріорне розділення фактів за класами відсутнє. Вимагається за тими або іншими критеріями виділити сукупність класів {АГ,} і побудувати для них вирішальні правила. Таке завдання складніше за завдання навчання з учителем. Методи формування понять за фактами без їх апріорного розбиття на класи розглядаються в кластерному аналізі.
Центральна роль у процесі навчання належить індуктивному узагальненню. Розрізняють повну й неповну індукцію. Повною індукцією називають загальний висновок, який виводиться на підставі вивчення всіх наявних фактів. Це можливо лише у тому разі, якщо кількість можливих фактів кінцева й невелика. Якщо висновки виводяться на підставі вивчення лише частині фактів, то індукцію називають неповною. Висновки, зроблені за допомогою неповної індукції, є правдоподібними, оскільки з істинності приватного не обов’язково виходить істинність загального.
У основі індуктивних висновків лежить правило індуктивного р ^ р
узагальнення ——— , де? — множина відомих фактів; Я —
поняття (гіпотеза). Значення цього правила полягає в такому. Нехай є множина фактів Якщо ввести деяку гіпотезу Я і показати, що з Я виводимо будь-який факт Б, то гіпотеза Я вірна. Особливістю правила індуктивного узагальнення є те, що множина об’єктів, описуваних гіпотезою Я, ширше, ніж множина, відповідна фактам і7. Це може призводити до того, що з гіпотези Я ви- водитимуться й інші факти. Отже, є ризик зробити помилку. Тому під час вибору гіпотези Я потрібно прагнути до мінімального узагальнення.
На закінчення зазначимо, що завдання індуктивного формування понять близька до завдання навчання розпізнаванню образів. В обох випадках формується модель класу об’єктів, ситуацій, їіодій. Проте у разі формування понять, отримана модель має забезпечувати не лише розпізнавання, а й можливість генерації описів конкретних об’єктів, ситуацій тощо.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
185
Це пов’язано з розумінням процесу формування понять як процесу виділення закономірностей, придбання нових знань, які мають відображати однакові, структурні й логічні характеристики об’єктів, ситуацій, подій реального миру. Враховуючи вказану специфіку, нижче розглянемо процедури індуктивного узагальнення, які використовують у підсистемах придбання знань. Процедури навчання, орієнтовані на використання в завданнях розпізнавання образів, розглядаються в розділі 5.
Резюме за змістом теми
Розглянуто загальні процедури, що дають змогу автоматизувати дедуктивний висновок у численні предикатів, і передусім процедуру резолюції.
Індуктивні схеми висновку є елементом підсистем штучного інтелекту, що навчаються, оскільки під час навчання ьіз сукупності фактів формуються шляхом узагальнення нові поняття і правила.
Індукцією називають висновок, який становить знання про клас предметів, отриманий у результаті дослідження окремих представників цього класу.
Повною індукцією називають загальний висновок, який виводиться на підставі вивчення всіх наявних фактів.
Універсум Ербрана будується з константних термів.
Приведення формул множини Ф0 до виду пропозицій виконують у процесі вказаних тотожних перетворень: виключення знаків імплікації й еквіваленції; зменшення сфери дії операції заперечення; стандартизація змінних; виключення кванторів існування; переміщення кванторів спільності; приведення до кон’юнктивної нормальної форми; виключення кванторів спільності; виключення кон’юн- кцій.
Терміни та поняття до теми
• НЗУ — найбільш загальний уніфікатор;
• універсум Ербрана — становить таку сферу інтерпретації Н, що якщо не існує інтерпретації множини пропозицій S в цій сфері, то її не існує взагалі;
• літерал — елементарна формула або її заперечення;
• пропозиція, або клозом (від англ. clause) — диз’юнкція літералів;
• фундаментальний диз’юнкт, який не містить змінних.
186
Г.Ф. Іванченко
Питання длй вамбконтролю
1. Використання дедуктивних та індуктивних схем висновку в системах штучного інтелекту.
2. Наведіть приклади дедуктйвноґо висновку методом Ербрана.
3. Наведіть приклади елемейтгарких формул або їх заперечень, пропозицій, клозів.
4. Наведіть приклади використання законів де Моргана.
5. Які принципи стратегії йбшуку?
6. Як пояснити поняття диз’юнкт Хорна?
7. Поясніть принцип резолюції та процедуру висновку.
8. Який висновок називають індуктивним та дедуктивним, за яким принципом руху думки вбий будуються?
9. Яка мета узагальнення як процесу отримання знань?
Завдання для Індивідуальної роботи, обов’язкові та додаткові практичні завдання
1. Індуктивні схеми висновку.
2. Метод Ербрана.
3. Диз’юнкція літералів. ^
4. Закони де Моргана. І
5. Стратегії пошуку.
6. Процедура виключення кванторів існування.
7. Використання дистрибутивного закону для приведення до кон’юн- ктивної нормальної формі*
8. Універсум Ербрана та константні терми.
9. Диз’юнкт Хорна та пропозиції.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
187
Тема 4
ВИСНОВКИ В УМОВАХ НЕНАДІЙНИХ АБО НЕПОВНИХ ЗНАНЬ
Перелік знань та навичок
Після опонування теми студент має знати:
• види невизначеності;
• Баєсовський підхід до достовірності кожного з фактів бази знань;
• метод коефіцієнтів упевненості, застосований в експертній системі «Super Finance»;
• положення теорії Демпстера—Шефера (ТДШ);
• положення теорії нечітких, або розпливчастих, множин Лотфі Заде.
Має вміти:
• розраховувати коефіцієнти упевненості в експертних системах;
• застосовувати правила нечіткої логіки й функцій належності при моделюванні та створенні програмного забезпечення, яке використовує нечіткі або розпливчасті значення;
• визначити складність систем, які використовують нечітку логіку.
ЗМІСТ ПИТАНЬ ТЕМИ
4.1. Види невизначеності
У попередніх параграфах розглядався дедуктивний висновок, заснований на численні предикатів. Теорія числення, предикатів дає змогу отримувати правильні висновки, спираючись на загаль- нозначущі твердження й обґрунтовані правила висновку. Проте в багатьох випадках вимагається робити висновок в умовах, коли початкові дані не є абсолютно точними й достовірними, а правила висновку мають евристичний характер і ненадійні. Людина робить необхідні висновки в подібних умовах щодня: ставить медичні діагнози і призначає лікування, керуючись симптомами; з’ясовує причини поганої роботи двигуна за акустичним шумом;
188
Г.Ф. Іванченко
правильно розуміє уривки фраз природної мови; впізнає друзів за їх голосами тощо. Знанням, якими оперує людина у вказаних випадках, властива невизначеність. Ця невизначеність має різну природу. Вона може породжуватися неповнотою опису ситуації, характером імовірності спостережуваних подій, неточністю наданих даних, багатозначністю слів природної мови, використанням евристичних правил висновку і т. ін. Найважливіші види невизначеності можна начести у вигляді дерева, зображеного на рис. 4.1.
Невизначеність
Неповнота
Фізична невизначеність
Неоднозначність \
Лінгвістична невизначеність
Випадковість
Невизначеність Неточність значення слів
Рис. 4.1. Види невизначеності
Невизначеність змісту фраз
На першому рівні дерева зображено терміни, що становлять якісну оцінку характеру невизначеності. Невизначеність може бути пов’язана або з неповнотою знань, або з їх неоднозначністю. Неповнота знань виникає, коли зібрано не всю інформацію, потрібну для побудови висновків. Неоднозначність означає, що істинність тих або тих висловів не може бути встановлена з абсолютною достовірністю. Вона породжується або фізичними причинами (фізична невизначеність), або лінгвістичними (лінгвістична невизначеність). Фізична невизначеність може бути пов’язана з випадковістю подій, ситуацій, станів об’єкта або неточністю наданих даних. Лінгвістична невизначеність пов’язана з використанням природної мови для подання знань, що мають якісний характер, і виникає через множинність значень слів (полісемія) і значення фраз. Наприклад, «двигун часто перегрівається» або «Богдан вже великий». У цих прикладах неоднозначність обумовлена нечіткістю понять «часто» і «великий». Або, наприклад, «Він зустрів її на галявині з квітами» [31]. Як він її зустрів: з квітами або без квітів? Подібні невизначеності присутні в сис¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
189
темах, на поведінку яких значною мірою впливають думки людини. Під час аналізу невизначеності значення фраз виділяють синтаксичну, семантичну й прагматичну невизначеності.
Розглянута схема видів невизначеності певною мірою умовна. В реальних системах вказані види невизначеності можуть накладатися один на другий. Наприклад, фізична невизначеність може ускладнюватися лінгвістичною невизначеністю.
Часто вказані вище види невизначеності не виділяють в окремі групи, а розглядають у межах одного терміна «ненадійні знання». Основними поняттями, що використовуються під час побудови моделей висновку на таких знаннях, є поняття достовірності. Достовірність висновків на основі ненадійних знань може бути визначена за допомогою різних підходів. Найчастіше використовують: баєсовську логіку вірогідності, коефіцієнти упевненості, нечітку логіку, теорію Демпстера—Шефера.
Неповнота знань спонукає до немонотонних висновків. Для формальної обробки знань, що характеризуються неповнотою, використовують логіку умовчання Рейтера, немонотонну логіку Мак-Дермотта і Дойла, систему підтримки значень істинності.
4.2. Баєсовській метод
При баєсовському підході ступінь достовірності кожного з фактів бази знань оцінюється з імовірністю яка приймає значення в діапазоні від 0 до 1. Імовірність початкових фактів визначають або методом статистичних випробувань, або досвідом експертів. Імовірність висновків визначають на основі правила Баєса для обчислення апостеріорної умовної імовірності р(Н\Е) події (гіпотези) Я за умови, що відбулася подія (свідоцтво) Е:
р(н | Е )., (3.1.)
V ' р{Е) у
де Р(Е) — безумовна (апріорна) імовірність свідоцтва Е; Р(Е,Н)
— сумісна імовірність свідоцтва Е і гіпотези Я. Спільна імовірність Р(Е,Н) дорівнює добутку безумовної імовірності гіпотези Р(Н) на умовну імовірність того, що свідоцтво (факт) Е має місце, якщо спостерігається гіпотеза Я:
Р{Е,Н ) = Р(Н)*Р(Е\Н).
190
Г.Ф. Іванченко
Звідси витікає, що апостеріорну імовірність Р(Н\Е) можна обчислити за допомогою формули:
,3.2)
Уточнимо практичне використання формули (3.3) на простому прикладі. Нехай Я позначає деяке захворювання, а Е — симптом. Тоді апріона імовірність захворювання Я може бути визначена за формулою Р(Н )=ЛГЯ/ЛГ, де Йн— кількість мешканців певного регіону, що мають захворювання Я; N — кількість усіх мешканців регіону. Імовірність Р(Е) визначається аналогічно Р(Е )=МЕ/N, де Ие — кількість жителів, у яких спостерігається симптом Е. Як правило значення вірогідності р(Н) і р(Е) з’ясовують у експертів.
Імовірність р(Е\ Н) відповідає наявності симптому Е у хворого із захворюванням Я. Її значення також визначають методом досвіду експертів.
Формула (3.2) справедлива для випадку одного свідоцтва Е і однієї гіпотези Я. Вона дає змогу перераховувати значення імовірності гіпотези Я у тому разі, якщо знайдено свідчення Е на її користь, тобто отримаємо на основі апріорної імовірності р(Н) значення Р(Н\Е) апостеріорної імовірності. Якщо розглядається повна група несумісних гипотез Я/ Я^...., Н„ з апріорною імовірністю Р(Я!)ДЯ2), ...,Р(Я„), то апостеріорну імовірність кожної з гіпотез при реалізації свідоцтва Е обчислюють за допомогою формули
Р(НІЕ)~
і р(Е\нкур{нк) к=І
яку називають теоремою гіпотез Баєса.
Завдяки формулі можна спростити обчислення імовірності гіпотези Я при реалізації свідоцтва Е. Так, якщо розглядати дві несумісні гіпотези Я та -і Я («заперечення Я»), то
, Ч . Р(Е\Н ур(н) п
ПЩЕ)- р(е\нУр(н)+р(е\-лУ(і - р(н)) * (33)
де Р(Е |-ія) — імовірність свідоцтва Е за умови, що гіпотеза Я не спостерігається; 1 - Р(Н)=Р{—Л) — апріорна вірогідність невиконання гіпотези Я. У формулі (З.З.), на відміну від (З.2.), відсутня
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
191
апріорна імовірність Р(Е), яка незручна з погляду експертної оцінки. Введемо в розгляд відношення
р(Е\н) ї р(е\-,н) ’
яке називають відношенням правдоподібності. Воно характеризує відношення імовірності отримання свідоцтва Е за умови, що гіпотеза Я вірна, до вірогідності отримання цього ж свідоцтва за умови, що гіпотеза Я невірна. Поділивши чисельник і знаменник (3.3) на Р(Е І -іЯ), отримаємо
(3.4.)
\~р(н\е) е і-р(н) v '
Відносини, записані у виразі (3.4), називають шансами. Шанси
— це інша шкала для подання імовірності. Так, відношення
надає апріорні шанси на користь гіпотези Я, а відношення
0(н\е) = ^ P^Ąh\e)) — апостеріорні шанси. Наприклад, якщо
р(Н)=0,3, то 0(Я)=3/7, тобто три випадки «за» і 7 «проти». (3.4.)
витікає, що
Q(H\E)=De*0(h). (3.5.)
Таким чином, апостеріорні шанси вельми просто обчислюються через апріорні щанси. Для цього потрібно знати відношення правдоподібності свідоцтва Е. Вважається, що використання шансів відповідно до формули (3.5) для оцінки правдоподібності гіпотез простіше, ніж безпосереднє обчислення імовірності за формулою (3.4). Це пояснюється двома причинами:
1 — для багатьох користувачів використання шкали шансів має простіший вигляд; 2 -— шанси позначають цілими числами, а їх простіше вводити при відповідях на запитання системи.
Відзначимо, що можна отримати формулу, симетричну (3.5), що дозволяє обчислювати апостеріорні шанси на користь гіпотези Н, якщо задано, що Е вочевидь помилкове 0(н\-Е)= Ne * 0(н),
192
Г.Ф. Іванчвнко
де Ne—відношення правдоподібності Р(—Е \ Н) /Р(—£ | -Л). Отже, шанси на користь деякої гіпотези Я можна обчислювати, спираючись або на істинність свідоцтва Е, або на його помилковість. Такий підхід використовується в експертній системі «Prospector», в геології. При цьому відносини правдоподібності De і Ne називають відповідно чинником достатності і чинником необхідності. Чинники De і Ne пов’язані один з одним простим співвідношенням
„ 1-De*P{E\H)
= і р(е\-л) ЯКЄ ДаЄ змогУ встановити діапазон зміни їх
значень.
Можна показати, чта значення De належать діапазону [1, оо), а значення Ne — діапазону [0, 1]. З кожним правилом в системі «Prospector» зв’язують чинники De і Ne, значення яких можуть призначатися незалежно. Це іноді призводить до суперечностей. Щоб один раз вирішити такі суперечності, чинник De використовується, коли свідоцтво Е істинне, а чинник Ne—коли помилкове.
На практиці гіпотеза Я може підтверджуватися не одним свідоцтвом, а кількома. Формулу (3.5) легко узагальнити у разі кількох свідоцтв. Наприклад, якщо реалізувалися два свідоцтва Е1ЇЕ2 на користь гіпотези Я, то її апостеріорні шанси можна обчислити за формулою:
o{h\exe2)=dede*o{h) або o{h\e1e2)=dE2*o{h\e1).
Оскільки звичне De> 1, те отримання нових свідоцтв на користь гіпотези Я дає змогу збільшити її правдоподібність.
У розглянутих вище формулах передбачалося, що свідоцтва Е\^2,—уЕп повністю визначені, тобто підтверджуються з імовірністю 1. Проте на практиці факти, що використовують у системі, можуть підтверджуватися з меншою імовірністю. Це може відбуватися через невизначені відповіді користувача, а також у результаті логічного висновку, коли висновки одних правил виступають в ролі фактів (свідчень) інших правил. У цьому разі потрібно при обчисленні правдоподібності тієї або іншої гіпотези враховувати ненадійність фактів. Нехай відомо (наприклад з попередніх висновків), що свідоцтво Е підтверджується з імовірністю Р(Е\Е'), де через Е’ позначено певне свідоцтво, що підтверджує Е. Тоді апостеріорну імовірність гіпотези Я можна обчислити за формулою:
Р(Н]Е') = Р(Е\Е'Ур(Н\Е)+(і -
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
193
З формули виходить:
1 — якщо свідоцтво Е підтверджується з імовірністю Р(Е ІЕ 0=1, ТО Р(Н\Е У=Р(ЩЕ)\
2 — якщо Р(Е\Е г)=0 (тобто свідоцтво Е не підтверджується), то РІЩЕ^РІЩ-пЕ).
Крім того, якщо Р{Е\Ег)-Р(Е) (тобто свідоцтво підтверджується з апріорною імовірністю), то значення імовірності не повинно змінитися: /,(Я|£”)=Р(Я).
Таким чином, значення РІЩЕ”) перебуває в діапазоні від Р(Н\-Е) до Р(Н), якщо 0<=Р{Е\Е')<=Р(Е) і в діапазоні від Р(Н) до Р(Н\Е}}, якщо Р(Е)< =Р(Е\Е' )<= 1. Виконавши кусково-лінійну апроксимацію залежності Р(Н\Е’) від Р(Е\Е'), отримують формули:
P{H\E')=P(HhE)+ P^H^p^^*P(E\E'),
якщо 0<Р(£|£') </>(£);
Р(Н(Е') = Р(Н) + Р{-^~^^*(Р(Е\Е')-Р{Е)\
якщо Р{Е)< Р(Е\Е')й 1.
Формули дають змогу виконати корекцію значення Р(Н\Е) залежно від імовірності підтвердження свідоцтва Е. В експертній системі «Prospector» під час заповнення бази знань користувачам дозволяється замість імовірності Р{Е\ЕГ) задавати коефіцієнти (чинники) упевненості, що лежать в діапазоні від -5 до +4. Надалі значення цих коефіцієнтів перераховують у ймовірності Р(Е\Е *).
Значення апостеріорної імовірності Р(ЯІ Е 0, обчислене з урахуванням імовірності підтвердження свідоцтва Е, визначає ефективне відношення правдоподібності DE\
Р{Н\Е') 1-Р(Я)
е 1-Р{Н\Е') Р{Н)
Це відношення дає змогу виконувати корекцію апостеріорних шансів на користь гіпотези Я: 0(н\Е')=De*0{h\
Правила логічного висновку припускають об’єднання свідоцтв Еі.Ег, ...,Е„ за допомогою логічних зв’язок І, АБО, НІ. В такій ситуації обробка кожного правила виконується з урахуванням принципів нечіткої логіки. Для свідоцтв, пов’язаних логічною операцією І, вибирається мінімальна ймовірність. Для логічної
194
Г.Ф. Іванченко
операції АБО береться максимальна імовірність. Операція логічного заперечення не приводить до обчислення зворотної вірогідності.
При використанні баєсовського підходу для обробки неточних знань постають дві основні проблеми. По-перше, має бути відома вся апріорна умовна ймовірність свідоцтв, а також апріорна вірогідність гіпотез (або відповідні відносини правдоподібності та шанси). По-друге, з умов теореми Баєса виходить, що всі гіпотези, що розглядає система, мають бути несумісні, а ймовірності Р(Е|Н() та р(е) — незалежні. У ряді галузей (наприклад у медицині) остання вимога не виконується.
Окрім цього, при введенні нової гіпотези потрібно наново перераховувати таблиці ймовірності, що також обмежує застосування баєсовського підходу. Проте його досить широко застосовують в експертних системах, завдяки ґрунтовному теоретичному фундаменту. Важливо, що після багаторазового використання теореми Баєса вплив усіх початкових допущень на результат стає мінімальним. Тому хоча апріорна імовірність може визначатися приблизно, їх співвідношення обчислюється досить надійно. Свій подальший розвиток цей підхід одержав е баєсов- ських мережах довір’я.
4.3. Метод коефіцієнтів упевненості
Метод коефіцієнтів упевненості був уперше застосований в експертній системі «Мусіп», крім того його застосовують у системі «Super Finance». На відміну від баєсовського підходу, який використовує теорію імовірності для підтвердження гіпотез, метод системи «Super Finance» базується на евристичних міркуваннях, які були запозичені з практичного досвіду роботи експертів. Коли експерт оцінює ступінь достовірності певного висновку, він використовує такі поняття, як «точно», «мабуть», «можливо», «нічого не можна сказати» тощо. В системі «Super Finance» вирішили відобразити ці розмиті поняття на шкалу коефіцієнтів упевненості, що змінюються в діапазоні від -1 до +1. Для цього було введено дві оцінки — MB і MD. Оцінка MB відображає ступінь істинності деякого факту (свідчення) і приймає значення від
0 до +1. Оцінка MD відповідає ступеню помилковості деякого
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
195
факту і приймає значення в діапазоні від -1 до 0. Коефіцієнт упевненості факту С/7, що позначається, визначається як різниця оці- нок МВ і МО: СР = МВ - АЮ.
Тут 0<МВ<1 (при АЮ=0) і -1<ЛЮ<0 (при МВ=0). Якщо коефіцієнт упевненості приймає значення, що дорівнює +1, то факт вважається істинним. Якщо СР= -1, то факт помилковий. Шкалу зміни значень коефіцієнтів упевненості зображено на рис. 4.2.
Під час логічного висновку над фактами, що становлять передумови правил, виконуються логічні операції. В результаті цього утворюються складні вислови, коефіцієнти упевненості яких обчислюються за такими правилами:
1) при логічному зв’язку І між фактами Р\ і Рг лР2) = лЩО?(Рі), СР(Р2));
2) при логічному зв’язку АБО між фактами Р\ і Рг, СР(РхуР2)=МАХ(СР{Рх\СГ(Р2) ).
-1 -0,8 -0,6 -0,2 0 0,2 0,3 0,6 0,8 +1
У системах «Мусіп» та «Super Finance» коефіцієнти упевненості приписуються не тільки фактам, але й правилам. У такий спосіб забезпечується облік ненадійності правил, які часто формуються на основі евристичних міркувань. Позначимо коефіцієнт
упевненості правила через CFR. Коефіцієнт CFR відповідає ступеню істинності висновку правила за істинних передумов. Якщо передумови характеризуються коефіцієнтом упевненості CF„„переди * 1' то коефіцієнт упевненості висновку СРзатюн обчислюють за формулою CFm = CFnonepedH * CFK .
Розглянемо приклад правила a P2)vPj => С,(0,9), де Рх,Р2,Рг
— факти, що створюють передумови правила; С — висновок правила; 0,9 — коефіцієнт упевненості правила. Нехай факти характеризуються такими коефіцієнтами упевненості: CF(P1)=0,8;
І
Рис. 4.2. Шкала коефіцієнтів упевненості
196
Г.Ф. Іванчвнко
CF(P2)=0,6; CF(P3)=0,7-. Визначимо коефіцієнт упевненості висновку CF(C1):
CF{PX а Р2)= шіп(0,8;0,6) = 0,6;
CF((P, a?2)v?3)=max(0,6;0,7) = 0,7;
CFfcb 0,7 *0,9 = 0,62.
У процесі логічного висновку один і той самий висновок може підтверджуватися різними правилами, кожне з яких приписує висновку свій коефіцієнт упевненості. Очевидно, що коефіцієнт упевненості висновку, підтверджуваного кількома правилами, має збільшитися. Що більше буде підтверджень на користь певного висновку, то ближче до одиниці має бути його коефіцієнт упевненості. В загальному випадку комбінація свідоцтв на підтримку певного висновку виконується за такими формулами, що використовують у системі «Ешусіп»:
CF = CFX + CF2 - CF} • CF2, ЯКЩО CFX> 0, CF2> 0;
CF = CFX + CF2 + CF{ • CF2, ЯКЩО CFX <0, CF2< 0;
CF 4-CF
С'Г = 1-ш„^|.И|)'”Щ,° CF' CF‘£0' CF'*a' Cf’=*±1 якщо CF, = ±1 і CF2=± 1, to CF = \
Коефіцієнти упевненості висновків, сформованих трьома або більше правилами, можна вивести послідовно, застосовуючи вказані вище формули.
На закінчення зазначимо, що метод коефіцієнтів упевненості завдяки своїй простоті знаходить широке застосування в багатьох системах, що підтримують висновок на ненадійних знаннях. Недоліки методу пов’язані з відсутністю теоретичного фундаменту, а також складністю підбору значень коефіцієнтів упевненості.
Так, у системі «Super Finance» база знань яка використовує коефіцієнти упевненості висновків, тоді приклад має такий вигляд (рис. 4.3):
Титул
Секції
section start: ‘
advice
‘СТАН ПОГОДИ* ‘ДУЖЕ ХОЛОДНА ПОГОДА* ‘ЦЕ ПРАВДА
ФАКТОР ПІДРИМКИ* cold_weather_cf
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
197
Параметри
parameter cold_because_pfJce:“ type number range -1.0 1.0 rules
0.8ifice_on the river,
-1.0.
parameter cold_because_of_snow:" type number range -1.0 1.0 rules
0.7 if it is snowing,
-1.0. “ “
parameter cold_weather_cf:" type number range -1.0 1.0 rules
cf_add(cold_because_of_snow,cold_because__of_ice). parameter ice_on_the_river:" type boolean
question 'МОРОЗ ПОКРИВ РІЧКУ?' parameter it_is_snowing:“ type boolean
question 'СНІГ ІДЕ?'
a)
О)
В)
Рис. 4.3. Діалогові вікна системи «Super Finance», яка підтримує висновок на ненадійних знаннях
198
Г.Ф. Іванченко
4.4. Теорія свідоцтв Демпстера—Шефера
Підхід, прийнятий у теорії Демпстера—Шефера (ТДШ), відрізняється від баєсовського підходу і методу коефіцієнтів упевненості, по-перше, тим, що тут використовується не точкова оцінка упевненості (імовірність, коефіцієнт упевненості), а інтервальна оцінка. Така оцінка характеризується нижньою і верхньою межею, що надійніше. По-друге, ТДШ дає змогу виключити взаємозв’язок між невизначеністю (неповнотою знань) і недовір’ям, яка характерна для баєсовського підходу.
У рамках ТДШ множини висловів А приписується діапазон значень [ВІ (А),РІ(А)], в якому знаходиться ступінь довір’я кожного з висловів. Тут ВІ (А) — ступінь довір’я до множини висловів, що змінює свої значення від 0 (немає свідчень на користь А) до 1 (мноди- на висловів А істинна); РІ(А) — ступінь правдоподібності множини
висловів А, розрахована за допомогою формули РІ(А) = 1-5/ (А).
Значення ступеня правдоподібності також лежать у діапазоні від 0 до 1. Ступінь правдоподібності множини висловів А — це величина зворотна ступеня довір’я до множини протилежних висловів А. Якщо є чіткі свідоцтва на користь А, то ВІ (А) = 1, та ступінь правдоподібності А дорівнює нулю, тобто РІ(А) = 0. При РІ(А) = 0 ступінь довір’я ВІ (А) теж дорівнює нулю.
У разі відсутності інформації на підтримку тієї або тієї гіпотези вважається, що діапазон зміни значень ступенів ВІ і РІ дорівнює [0, 1]. З отриманням свідоцтв зазначений діапазон звужується. В теорії Демпстера—Шефера невизначеність знань подається за допомогою деякої множини X. Елементи цієї множини відповідають можливим фактам або висновкам. Невизначеність полягає в тому, що наперед невідомо, яке з можливих значень прийме факт або висновок хєХ Для характеристики ступеня визначеності в ТДШ вводиться деякий одиничний ступінь упевненості (вона має назву також одинична маса упевненості), який розподіляється між елементами X. При цьому якщо вся маса (ступінь) упевненості припадає на один елемент х є X, то жодної невизначеності немає. Невизначеність виникає, коли маса упевненості розподіляється між декількома елементами хєі На рис. 4.4 зображено розподіл мас упевненості між елементами множини X, наведеного у вигляді точок. Тут Х={хі, хг, хз).
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
199
Рис. 4.4. Розподіл мас упевненості
З кожним елементом множини X жорстко пов’язана відповідна маса упевненості. Так, X, відповідає /«і=0,3, хг- тг-0,1, хз — /из=0,2. Є також вільні маси упевненості /«4=0,2 і /«5=0,2, які належать відразу до декількох елементів. Маса т4 вільно переміщується між елементами х\ і хг, а маса т$ — між елементами хг і х$, тобто гп4 закріплена за підмножиною {х\, хг), а т$ — за підмно- жиною {хі, Х2}. Маси виражають ступінь упевненості в можливих значеннях фактів або висновків. Так, ступінь упевненості в значенні Хі може змінюватися від 0,3 до 0,4. Таким чином, ступінь незнання відповідає масі, місцерозташування якої не визначено.
У загальному випадку розподіл мас упевненості задається функцією т(А), що має такі властивості: т(0)=О, £т(Л) = 1.
А^Х
Тут А — множина, утворена з підмножин X, яким призначені відповідні маси (ступені) упевненості; т(А) — функція, яка задає відображення А на інтервал Г0,11. Для прикладу, зображеного на рис. 4.4, А={Оі,{хх},{хї},{х7і},{хихг},{х1,х7і\,{хх,х7і}}, а розподіл мас упевненості задається функцією т(А), що характеризується безліччю значень
т(А)= {0;0,3;0,2;0,1 ;0,2;0,2;0}.
Звернемо увагу, що А складається з підмножин. Позначимо кожну таку підмножину через Аі . Ступінь довір’я до висловів, відповідних підмножині А,, може бути обчислений за формулою ВІ(АІ)= 5X4). Тут підсумовування виконується по всіх під-
4/сЛ/
множинах Ау, що входить в А). Наприклад,
Щ{х\,х2}) = т(Ах) + т(А2) + т(АА) = т({х1}) + т({х2}) + т({хх,х2}) =
= 0,3+ 0,1+ 0,2 = 0,6.
Відповідні значення ступенів довір’я для всієї решти підмножин А і наведено в таблиці 4.1 {*,}.
200
Г.Ф. Іванчвнко
Таблиця 4.1
ЗНАЧЕННЯ ВІ(АІ) і РІ(Аі)
А і
0
{*|}
{*2}
{*»}
{*і,*2}
X
ВІ(Аі)
0
0,3
0,1
0,2
0,6
0,5
0,5
1
Рі(Аі)
0
0,5
0,5
0,4
0,8
0,7
0,9
1
Ступінь правдоподібності підмножини А визначається за формулою:
РІ{АІ) = \-ВІ(АІ) = \- £т(Л}).
Результати обчислень ступенів правдоподібності наведено в таблиці 3.1. Величини ВІ (Д). і Р/(Д). мають просту інтерпретацію: ВІ (4). становить загальну масу упевненості, яка залишається, якщо з X видалити всі елементи, не асоційовані з Д ;РІ (Д) становить максимальну масу упевненості, яку можна отримати, якщо зсунути вільні маси до елементів множини 4. Причому ВІ(АІ)< ВІ (4). Іншими словами, ВІ(АІ) становить нижню межу довір’я до Д, а ВІ 04) — верхню.
Найважливішим елементом ТДІІТ є правило комбінації свідоцтв:
ЕОТ1 (4і)*тг(Аи)
т(Ак) = .
1- £ті(Аи)* тг(Аи)
Л1,пЛ2]=0
Сума в чисельнику правила поширюється на множину
Ак = Аи гі А2,. Правило є евристичним і дає змогу здійснювати розподіл ступенів довір’я під час висновку.
4.5. Нечіткі множини й нечітка логіка
Для формалізації нечітких знань, що характеризуються лінгвістичною невизначеністю, застосовується теорія нечітких або розпливчастих множин.
Логічну систему, про яку піде мова в цій главі, в 1963 р. розробив Лотфі Заде (ЬоШ 7а<іеЬ), щоб подолати невідповідність
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
201
між системами справжнього світу і їх комп’ютерними втіленнями. Значення Буля істина-неправда втілюють в програмах унікальні елементи системи з двома значеннями. У реальності ми рідко маємо справу з такими системами, оскільки багато умов можуть бути частково істинними, а частково хибними (або тими й тими одночасно). Нечітку логіку (Fuzzy logic) вигадали для того, щоб дозволити програмам працювати в діапазоні різних ступенів істини. Замість подвійних систем, які відображають тільки істинне й помилкове значення, було введено ступені істини, що діють у діапазоні від 0,0 до 1,0 включно.
Нехай є множина X і його власна підмножина А, тобто АаХ. Тоді підмножина А можна навести у вигляді сукупності впорядкованих пар
А = {(х,Цл(х))},УхєЛГ, (3.5.)
де цА (де) — функція приналежності. Причому
[і, якщо хе А,
[О, якщо х&А,
Розглянемо як приклад множину, що становить можливі значення температури повітря. Тоді введення функцій приналежності, які на рис. 4.4 умовно зображеною суцільною лінією, дасть змогу виділити підмножину негативних температур, а зображеною пунктирною лінією, — підмножину позитивних температур. При цьому нульова температура належить до другої підмножини.
1
0,8 0,6 0,4 0,2 0
-50 -40 -30 -20 -10 0 10 20 30 40 50 /°С
Рис. 4.4. Функція приналежності до чіткої множини
Наведене визначення підмножини А і приклад функції приналежності, що приймає всього два можливі значення 0 і 1, від¬
МІНУС плюс
' 1 ■ 1 ' ■
Т І І І І І І І г
202
Г.Ф. Іванченко
повідає чіткій (звичній) підмножині. Визначення нечіткої під- множини виходить як узагальнення цього визначення. Нечіткою підмножиною А множини X називатимемо сукупність впорядкованих пар А= {(дс,цА(х))}, Ух є X, де функція приналежності цА(дс) кожному елементу х ставить у відповідність справжнє число з інтервалу [0,1], вказуючі ступінь приналежності елемента х підмножині А. Часто у виразі (3.5) замість коми, що розділяє х та цА(х), використовується вертикальна риса, тобто пишуть (х| |іаО)) . Це дає змогу виключити можливу плутанину, коли значення функції приналежності задають числами, в яких дробова частина і ціла розділені комою. Математична структура, визначена виразом А={(лг, |0,8),О210,3),(дг310),(лг410,5)}, де х\, х2, хз, Хц — елементи універсальної множини X, є прикладом нечіткої ПІДМНОЖИНИ. Тут ступені приналежності елементів Х\, *2, *3, *4 підмножині А задано числами після вертикальної риси. Найвищий ступінь приналежності має елемент х\. Елемент *з підмножині А не належить. Таким чином, використовуючи поняття нечіткої підмножини, можна подавати об’єкти (предметної) наочної галузі, що характеризуються розмитими межами описів. Нриіт«-я ттідмножнна А називається нормальною, якщо тахМ*) = 1
хєХ
Якщо ця властивість не виконується, то А називається субнор- мальною. Непорожню підмножину А завжди можна нормалізувати розподілом на максимальне значення функції приналежності. Носієм нечіткої підмножини А називають підмножину елементів X, для якихцА(х) > 0. Змінну х у виразі (3.5) називають базовою. При практичному використанні нечітких множин важливими є поняття нечіткої й лінгвістичної змінної. Нечітка змінна визначається набором <а,Х,Я>, де а— назва нечіткої змінної; Х={х} — галузь її визначення; 7? — нечітка підмножина множини X, що включає можливі значення х, обумовлені назвою а. Лінгвістичною називають змінну, значеннями якої є слова і фрази природної мови (терми). Формально лінгвістична змінна визначається набором <$,Т,Х,С,М >, де р — назва змінної; Г-терм—множина змінної р, тобто безліч її значень, причому кожне з таких значень (терм) є назвою нечіткої змінної а, галуззю визначення якої є множина X; Є— синтаксична процедура, що породжує на множині Т значення змінної р; М— семантична процедура, яка відо¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
203
бражає кожне нове значення нечіткої змінної а в нечітку підмно- жину М(а) множини X.
Розглянемо приклад. Нехай визначається температура навколишнього повітря за допомогою понять-значень: «дуже холодно», «холодно», «прохолодно», «не холодно», «тепло», «спекот- но». Кожному поняттю-значенню відповідає певна температура (рис. 4.6). При цьому мінімальна й максимальна температури відповідно дорівнюють - 40°С і + 40°С. Тоді формально лінгвістична змінна «температура» подається набором Температура, {дуже холодно, холодно, прохолодно, не холодно, тепло, спе- котно}[-40,+40], <7, М> де (т— процедура перебирання елементів терм-множини Т; М— процедура, яка ставить у відповідність нечітким змінним («спекотно», «тепло» тощо) температуру навколишнього повітря. Іншими словами, процедура М визначає взаємозв’язок нечітких змінних з відповідними функціями приналежності.
Рис. 4.6. Лінгвістична змінна «температура»
Залежно від характеру множини X лінгвістичні змінні розподіляються на числові й нечислові. Числовою називають таку лінгвістичну змінну, для якої базова змінна визначена на числовій множині. В розглянутому вище прикладі лінгвістична змінна «Температура» є числовою, а її значення (нечіткі змінні) — нечіткими числами. Кожній нечіткій змінній на рис. 4.6 умовно відповідає трикутна, або трапецеїдальна, функція приналежності, яка визначає ступінь приналежності температури навколишнього повітря до відповідного нечіткого поняття. Так, керуючись рисун¬
204 , Г.Ф. Іванчвнко
ком, нечітку змінну «не холодно» можна визначити за допомогою такої нечіткої множини:
те холодно» = {(510),(1511,0),(2510)}.
У загальному випадку функцію приналежності будують на основі експертних оцінок. Відповідні процедури побудови функцій приналежності описано нижче.
Нечіткі й лінгвістичні змінні дають змогу формулювати нечіткі твердження. Наприклад, «Сьогодні стабільне фінансування» або «Якщо банки стабільні, то девіденти виплачують, а відсотки ростуть швидко» тощо. Подібні твердження є об’єктом досліджень нечіткої логіки. Важливо відзначити, що, на відміну від формальної логіки, яка використовує таблиці істинності, нечітка логіка спирається на операції, виконувані над нечіткими множинами. Тому розглянемо основні операції нечітких множин.
Розглядатимемо нечіткі підмножини А і В множини X. Нечіткі множини А і В рівні (позначається А=В), якщо VxeX цА(х)=цв(х). Множина В міститься в множині А, якщо VxeX цв(х)^цА(х). Множини А і В доповнюють одна одну, якщо VxeX цв(х)=1- цА(х). Множина з функцією приналежності 1-цА(х)-є доповненням до множини А (позначається А).
Перетин двох нечітких множин А і В (позначається АпВ) — це нечітка множина, функція приналежності якої визначається виразом:
^апвМ= пш{ цА(*), цв(х)}, V, є X
Об’єднанням нечітких множин А і В (позначається АиВ) є нечітка множина з функцією приналежності:
Цдив = тах { ЦаМ, Цв W Ь v* є х ■
Операції перетину й об’єднання нечітких множин асоціативні
і дистрибутивні. В теорії нечітких множин часто використовують позначення цАпВ(*)= ца(х)Ацв(х) та цАоВ(*)=Иа(*) v М*)- Тут л та v відповідно тіп і тах.
Алгебраїчний добуток нечітких множин А і В (позначається АВ) є нечіткою множиною, для якої HabW^aOO^bW» УхєХ
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
205
Алгебраїчна сума нечітких множин А і В (позначається А + В) є нечіткою множиною з функцією приналежності
Ил+в (*)= Рл (*) + Ив (х) - Рл (*)' Це (*) •
Диз’юнктивна сума нечітких множин А і В визначається через операції об’єднання й перетини ЛДЯ=(апя)п(лІп 2?)= (А\В)и(В\А\ де вирази (А|В) = (аг\В) та (В|А)= (впа) становлять відповідні різниці множин А та В. В загальному випадку (А | В) * (51 А).
Важливим поняттям теорії нечітких множин є нечітке відношення. Нечітким бінарним відношенням Р: X, -> Х2 називають підмножину декартового добутку двох множин X, та Х2:
Р = {(х1,х2)\\ір(х1,х2)},Ух1єХ1,Ух2єХ2,
де ,х2) — функція приналежності пари елементів (хі, хг) доР.
У загальному випадку и-не нечітке відношення Р визначається на прямому добутку множини (ХиХ2,...,Хп) за допомогою формули Р = {(х1,х2 *„)|(ц/х„дс2,Де (хих2,...,х„) —елементи
множин X. Співставляючи визначення нечіткої множини й нечіткого відношення, можна помітити, що нечітке відношення — це нечітка множина, базова змінна якої є вектор.
У нечітких висновках беруть участь нечіткі твердження, над якими виконуються операції нечіткої логіки. В рамках нечіткої логіки існує два підходи до визначення ступеня істинності нечітких тверджень. У першому випадку ступінь істинності нечіткого твердження (нечіткого предиката) подається числом з діапазону [0, 1]. В другому випадку ступінь істинності характеризується лінгвістичними значеннями на зразок: «істинно», «помилково», «майже істинно», «майже помилково» тощо. Кожне таке значення, по суті, є нечіткою змінною, що становить нечітку підмножину одиничного інтервалу. Логіку з лінгвістичними значеннями істинності запропонував Заде, і вона має назву лінгвістичної. Зазначимо, що іноді логіку першого типу називають багатозначною, а лінгвістичну логіку — нечіткою.
Основним об’єктом багатозначної логіки є нечіткий логічний вираз, до складу якого входять нечіткі предикати. Нечіткий предикат Р(хих2 ...,хп) має відповідати конкретному набору нечітких змінних х1еХ1,х2еХ2,...,х„еХп, які перетворюють предикат у вираз зі ступенем істинності ц(Р) у діапазоні [0,1].
206
Г.Ф. Іванчвнко
4.6. Приклади використання нечіткої логіки
Приклад 1. Управління передачею даних каналом зв’язку.
Оператори нечіткої логіки подібні до звичайних бульових операторів. Функції приналежності й правила нечіткої логіки, піддані лінгвістичній модифікації, дають змогу значно розширити можливості системних операторів.
Розроблювачі можуть набагато спростити систему, використовуючи нечітку логіку, завдяки якій можна моделювати комплексні програми з більшою кількістю входів і виходів.
За допомогою нечіткої логіки можна домогтися зниження системних вимог, а отже, скоротити витрати на апаратні засоби. У багатьох випадках складне математичне моделювання краще замінити функціями приналежності й правилами нечіткої логіки, й за допомогою їх управляти системою. При скороченні обсягів інформації розміри коду зменшуються, тому система працює швидше. Крім того, це дає можливість використовувати менш досконалі апаратні засоби.
Нечітка логіка має велике значення під ча'с створення програмного забезпечення, яке використовують визначення при- ближень замість чітких. Оскільки людська логіка сама по собі є приблизною, під час проектування систем легше використовувати нечітку логіку, порівняно з детермінірованими алгоритмами.
Переваги нечіткої логіки проявляються, коли система аналізується за допомогою лінгвістики. Як приклад розглянемо алгоритм QoS (алгоритм якості обслуговування}, який управляє передачею даних визначеним каналом зв’язку. Його завдання полягає в тому, щоб забезпечити для програми постійну пропускну спроможність каналу. Якщо програма намагається відправити занадто багато даних, потрібно зменшити швидкість передачі. З точки зору управління можна виділити три елементи. Перший елемент — це швидкість надходження даних з програми, другий елемент — коефіцієнт вимірювання використання каналу, а третій — шлюз, який контролює потік даних між програмою і каналом зв’язку (рис. 4.7).
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
207
Програма
Швидкість Шлюз передачі
Канал
г
Коефіцієнт
використання
Рис. 4.7. Алгоритм QoS управління передачею даних
Задача шлюзу полягає в тому, щоб визначити, коли і скільки пакетів даних може бути пропущено через канал. Людина оцінює це завдання за допомогою простих правил:
«Якщо коефіцієнт використання каналу програмою занадто високий, для неї слід зменшити швидкість пропускання пакетів через шлюз». І навпаки: «Якщо коефіцієнт використання каналу програмою досить низький, для неї необхідно збільшити швидкість пропускання пакетів через шлюз». Ці правила показують, що існує «мертва зона» між високим і низьким використанням пропускної спроможності.
Питання у тому, як визначити поняття «високо» чи «низько» для програми? Нечітка логіка визначає ці поняття за допомогою функцій приналежності (рис. 4.8).
Й
J
Ом
О
Низький
Високий
І
EL
о
60 80 100 120 Використання каналу
140
Рис. 4.8. Функція приналежності для швидкості пропуску даних
Функції' обмеження
Важливим елементом систем нечіткої логіки є обмежувачі (Hedge) функцій приналежності. Вони надають системі нечіткої логіки додаткові лінгвістичні конструкціі при описі правил і дають змогу підтримувати математичну сталість. Розглянемо функції — обмежувачі VERY та NOT_VERY.
їх використовують разом с функціями приналежності та змінюють їх значення залежно від поставлених завдань. Функції обмеження показано на прикладах:
208
Г.Ф. Іванченко
VERY (m_x)=m_x2 (3.6)
NOT_VERY(m_x)=m_x0,5 (3.7)
Розглянемо використання цих функцій разом з функцією приналежності, показаною на рис. 4.8. За коефіцієнті швидкості 155 значення m_high дорівнюватиме 0,74. Якщо застосувати функцію обмеження VERY до функції приналежності (VERY(m_high(rate)), то отримане визначення становитиме 0,5625 (іншими словами,
недостатньо велике значення). Якщо коефіцієнт дорівнює 119,
mhigh становитиме 0,94. При застосувані функції VERY до цього значення отримуємо результат 0,903 (чи більше значення)
Аксіоми нечіткої логіки
Аналогічно бульовій логіці нечітка логіка має набір базових операторів. Вони співпадають з бульовими, але діють інакше. Аксіоми нечіткої логіки наведено в табл. 4.2.
Таблиця 4.2
АКСІОМИ НЕЧІТКОЇ ЛОГІКИ
ОПЕРАТОР
ФОРМУЛА ОБЧИСЛЕННЯ
Truth (A OR В)
MIN(truth(A), tmth(B))
Truth (A AND В)
MAX(truth(A), truth(B)
Truth (NOT А)
1,0 —truth (A)
Ці оператори забезпечують основу для операцій нечіткої логіки. Приклад умови: if (mwarm (boardtemperature) AND m high (fan_speed) ) then...
Ця форма не дуже зручна для читання, але допомагає точніше оцінювати стан системи.
Функції приналежності
Функція приналежності (Membership function) визначає рівень приналежності (рівень істини) заданої умови. Алгоритм QoS дає змогу отримати функцію приналежності для використання каналу (рис. 4.8).
На рис.4.8. наведено два сегменти, між якими знаходиться третій (мета). Низьке значення може бути задане, як показано у виразі:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
209
m_l°w(x) = {
0, якщо rate (х) >= 100 (3.8)
(100-rate (х)) / 20 якщо rate (х) > 80 і якщо rate (х) < 100
1, якщо rate (х) <= 80.
}
Високе значення може бути задано так, як зображено у виразі: m_high (х) = {
0, якщо rate (х) <= 100
(rate(x) - 100) / 20 якщо rate (х) > 100 і якщо rate (х) <120
1, якщо rate (х) <= 120. (3.9)
}
Табл. 4.3 ілюструє функції приналежності. В ній наведено значення швидкості проходження даних і також їх ступінь приналежності для двох функцій.
Таблиця 4.3
ПРИКЛАД СТУПЕНЯ ПРИНАЛЕЖНОСТІ
Швидкість передачі пакетів
mjow(x)
m_high (х)
10,00
1,00
0,00
85,00
0,75
0,00
90,00
0,50
0,00
95,00
0,25
0,00
100,00
0,00
0,00
105,00
0,00
0,25
110,00
0,00
0,50
115,00
0,00
0,75
180,00
0,00
1,00
За допомогою двох функцій приналежності можна задати ступінь приналежності для визначеної швидкості пропуску даних. Як же за допомогою цього ступеня управляти швидкістю пропуску пакетів даних і зберігати постійний рівень сервісу? Дуже простий механізм дає змогу включити ступінь приналежності в коефіцієнт, який використовує алгоритм шлюзу.
Функція визначає, скільки пакетів даних може пройти через шлюз у заданий проміжок часу (наприклад за одну секунду). Кожну секунду кількість пакетів даних, яким дозволяється пройти
210
Г.Ф. Іванченко
через шлюз, регулюється таким чином, щоб підтримувалася постійність. Якщо коефіцієнт користування занадто високий, кількість пакетів зменшується. Інакше кількість пакетів збільшується. Питання в тому, наскільки?
Механізм полягає в тому, щоб використовувати ступінь приналежності як коефіцієнт, який застосовується до дельти від кількості пакетів даних.
Розглянемо значення:
rate = rate + (m_low (rate) x pdelta) - (m_high (rate) x pdelta). (3.10)
Змінна rate — це справжня кількість пакетів, яким дозволяється проходити через шлюз у заданий час (одну секунду). Константа pdelta — змінний параметр, що визначає максимальну кількість пакетів, які можуть бути додані в коефіцієнт чи видалені з нього. Функції приналежності становлять ступінь приналежності, яка використовується як коефіцієнт для алгоритму зміни швидкості.
Розглянемо кілька прикладів, для яких використовується константа pdelta, прирівнювана до 10. Хоча коефіцієнт є нецілим числом, для налаштування алгоритму його буде змінено.
Якщо значення rate прирівнюється до 110, як при цьому алгоритм змінить коефіцієнт для механізму шлюзу? Використовуючи приклад (3.10), отримуємо:
rate = 110 + (0 х Ю) - (0,5 хЮ) = 105.
Якщо за наступної ітерації програма продовжує працювати з коефіцієнтом 110, буде отримано такий результат: rate = 105 + (0 х Ю) - (0,25 х Ю) = 102,5.
Процес триватиме до тих пір, поки не буде отримано значення, що дорівнює 100, яке вказує, що подальші зміни коефіцієнта не використовуватимуть.
Якщо коефіцієнт був невисокий (3.10), отримує такий вигляд:
rate = 80 + (1 х Ю) — (0 х Ю) = 90.
Таким чином, при використанні ступеня приналежності як коефіцієнта зміни швидкості отримуємо простий механізм керування.
Розглянемо використання нечіткої логіки на прикладі простої моделі зарядного приладу для акумуляторної автомобільної батареї, яка працює від сонячної енергії.
Приклад 2. Управління заряджанням батареї за допомогою нечіткої логіки
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
211
Зарядний пристрій працює в місці, де існує напруга заряду (наприклад, від сонячного світла), та навантаження. Напруга дає змогу заряджати батарею, тоді навантаження її розряджає. Зарядний пристій має два режими роботи: режим підзаряджання та режим швидкого заряджання. В режимі підзаряджання в батарею надходить тільки дуже невелика кількість струму, що приводить до неповного заряджання батареї. В режимі швидкого заряджання весь доступний струм спрямовується в зарядний пристій.
С точки зору систем управління слід визначити, коли потрібно переходити в режим швидкого заряджання, а коли — в режим підзаряджання. При заряджанні температура батареї підвищується. Якщо батарея заряджена повністю, додатковий струм, що проходить через неї, приводитиме до її нагрівання. Тому якщо батарея нагрівається, можна вважати, що вона повністью заряджена, а отже, слід перейти в режим підзаряджання. Окрім того, можна виміряти напругу батареї, щоб визначити, чи досягла вона межі, а потім переключитися в режим підзаряджання. Якщо батарея не нагрілась і не досягла межі в напрузі, слід перейти в режим повного заряджання. Це спрощені правила, оскільки крива температури батареї є оптимальним показником її заряджання.
Як вже казали, зарядний пристрій має два режими роботи: режим заряджання й режим швидкого заряджання. Стан батареї відстежують два датчики: датчик напруги і датчик температури. Для управління заряджанням використовуватимемо такі правила нечіткої логіки:
if m_voltage_high (voltage)
then mode = trickle_charge
if m_temperature_hot (temperature)
then mode = trickle_charge
if ((not(m_voltage_high (voltage))) AND
(not (m_temperature_hot (temperature))))
then mode = fast_charge
Ці правила не є оптимальними, оскільки останнє правило може виконуватися для всіх варіантів. Тут вони використовуються для опису більшої кількості операторів нечіткої логіки.
212
Г.Ф. Іванченко
Спочатку потрібно ідентифікувати правила нечіткої логіки. Ідентифікація здійснюється за допомогою аналізу проблеми, або ж для цієї мети викликається експерт. Наступне завдання полягає в тому, щоб визначити відповідність між словесним виразами правил і поняттями реального світу. Для цього потрібно створити функції приналежності.
При створенні функцій приналежності потрібно взяти лінгвістичні правила нечіткої логіки й визначити їх зв’язок з поняттями реального світу в заданому діапазоні. В цьому прикладі задано дві змінні: напруга й температура. Графік функції приналежності для напруги визначає в діапазоні напруги три функції приналежності: низьке, середнє і високе. Аналогічно задаються три функції приналежності для діапазону температури: холодно, тепло і гаряче. Ці значення використовують лише для демонстрації і не враховують технологію виробництва батарей.
Код, наведений у цьому розділі, пропонує ряд моделей для створення програмного забезпечення за допомогою нечіткої логіки. Крім того, тут наведено приклад використання цих моделей, що дає змогу продемонструвати їх можливості. Спочатку розглядаються загальні функціонально нечіткої логіки, а потім розповідається про приклад моделі.
Розробники програмного забезпечення зазвичай використовують два елементи нечіткої логіки: оператори нечіткої логіки і функції приналежності (додаток В).
Оператори нечіткої логіки — це звичайні функції AND, OR і NOT, модифікаційні для нечіткої логіки:
#defme МАХ (а, Ь) ((а>Ь)? а: Ь)
#define MIN (а, b) ((а<Ь)? а: Ь)
fiizzyType fuzzy And (fuzzy Type a, fuzzy Type b )
{ return MAX (a, b);}
fiizzyType fuzzyOr (fiizzyType a, fuzzyType b )
{ return MIN (a,b); } fuzzyType fuzzyNot (fuzzyType a)
{ Return (1.0 — a);}
Наступні програмні конструкції використовують при створенні функції приналежності. Вони дають змогу виробнику задати межі функції приналежності за допомогою групи значень, наведених її параметрами.
Програма викликає функцію, яка емулює процес безпосередньо зарядження-розрядження батареї, а потім дозволяє функції
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
213
управління зарядженням встановити потрібний режим для зарядного пристрою.
Перша функція, врікетРгоШе, задає звичайну функцію приналежності у вигляді трикутника, розробник вказує значення 1о і Ьі, які визначають базові вершини трикутника. Найвища точка задається як Ьі / 2.
Друга функція, рІаІеаиРгоШе, задає функцію приналежності у формі трапеції. Після чого за допомогою функції рІаІеаиРгоШе додатково створюють ті функції приналежності, які поширюються до межі нагріву. їх завдання полягає в тому, щоб визначити степінь приналежності для заданого значення і аргументів, і функцій.
Усі функції приналежності використовують функцію рІаІеаиРгоШе, щоб побудувати графік. Кожна з них приймає значення напруги і потім повертає значення, яке відповідає її ступеню приналежності. Кожна функція спочатку перевіряє передане значення на відповідність діапазону функції приналежності. Якщо значення не виходить за межі діапазону, воно передається у функцію рІаІеаиРгоШе. При цьому її сигнатура задається як вектор [1о, 1о_р1а^ Ьі_р1аІ, Ьі], а потім користувачу повертається результат.
Тепер можна звести задачу управління зарядним приладом до застосування правил нечіткої логіки, про які розповідалось раніше. Функція сЬа^еСоїіїгоІ дає змогу управляти процесом зарядження батареї.
Використовуючи правила нечіткої логіки й функції належності, вказана функція залежно від значень напруги і температури Змінює режим зарядження батареї.
На закінчення, головний цикл виконує функції управління процесом зарядження батареї, спираючись на задані параметри напруги й температури.
Приклад виконання коду наведено в додатку В. На рис. 4.9 графік демонструє напругу, температуру і режим зарядження.
Наявність вхідної напруги зарядного пристрою виявляється під час потрапляння 50 % сонячного світла на сонячні батареї. Вочевидь, що зарядне обладнання правильно вибирає режим зарядження для батареї з урахуванням наявного навантаження й наявності вхідного струму. Наведена модель відображає процес зарядження батареї та демонструє врахування обмежень стосовно напруги й температури.
214
Г.Ф. Іванчвнко
—■— voltage —■— temperature —*— chargeMode
424 847 1270 1693 2116 2539 2962
Рис. 4.9. Результати роботи програми зарядження-розрядження батареї
Інші сфери застосування
Нечітка логіка має широке застосування: передусім — це системи управління, яким нечітка логіка вже забезпечила комерційний успіх; в пристроях відеокамер і фотоапаратів з автофокусом, системах змішування цементу, автомобільний системах (наприклад системах АБС) (Anti-lock brakiny system) і навіть системах, заснованих на правилах.
Напевно, найкорисніші сфери застосування залишаються невідомими. Сама назва «нечітка логіка» не вселяє особливої довіри, хоча давно відомо, що це надійний метод ШІ. На цей час її дедалі частіше використовують у пристроях повсякденного вжитку, де вона більше не асоціюється зі штучним інтелектом.
У цій главі було введено поняття нечіткої логіки. Фундаментальні оператори нечіткої логіки розглядалися на прикладі дуже різних програм (потоку пакетів даних й управління заряджанням батареї). Також обговорювалися функції-обмежувачі, які використовуються як модифікатори для функцій приналежності. Потім було проаналізовано модель зарядного приладу для батарей, що демонструє створення функцій приналежності й елементів управління. Для ілюстрації цієї концепції використовувалася програма, яка включає набір механізмів нечіткої логіки. Нарешті, ми обговорили низку переваг нечіткої логіки, включаючи спрощення кода і зменшення витрат на апаратні засоби.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
215
4.7. Неповнота знань і немонотонний висновок
Стосовно розглянутих вище методів оцінки достовірності висновків висловлюються критичні зауваження. По-перше, всі розглянуті методи використовують кількісні методи невизначеності. При цьому мусимо задовольнятися суб’єктивними оцінками функцій приналежності, апріорної вірогідності, коефіцієнтів упевненості. Постає проблема визначення достовірності самих цих оцінок. По-друге, багато дослідників вважають, що кількісні оцінки невизначеності, не властиві міркуванням людини. Якщо запитати експерта, чому цей висновок характеризується невизначеністю, то, зазвичай, відповідь формулюється в термінах якісних взаємозв’язків, що існують у наочній галузі. По-третє, кількісні оцінки невизначеності не забезпечують виконання правдоподібних міркувань в умовах неповноти (відсутності) знань. Безумовно, з відсутніми елементами знань можна пов’язати низьку оцінку їхньої достовірності. Але що робити, якщо під час подальшого висновку елементи знань, на основі яких будувався висновок, будуть підкріплені досить надійними свідоцтвами, або, навпаки, визнані помилковими? Іншими словами, якщо знову отримані твердження суперечать початковим посиланням логічного висновку? Відповідь на це запитання дають методи немонотонної логіки, вживаної в умовах неповноти знань.
Системи логічного висновку, засновані на класичній логіці, обмежуються формалізацією загальнозначущих міркувань. При цьому мають виконуватися такі вимоги. По-перше, має бути задана безліч аксіом і правил висновку, завдяки яким можна робити висновки з передумов. По-друге, отримані результати не спростовуються подальшими висновками. По-третє, кількість загальнозначущих формул (теорем) монотонно зростає.
Об’єктом немонотонної логіки є твердження, які не є загаль- нозначухцими в класичному значенні, що модифікуються, тобто такі твердження підтверджуються не в усіх інтерпретаціях. Це означає, що твердження, сформовані правилами висновку немо- нотонних логік, здійсненні лише (підтверджуються хоча б в одній інтерпретації) за деяких припущень, обумовлених в посиланнях правил. Такі твердження називають правдоподібними. Під час вступу до системи нових відомостей правдоподібні твердження можуть стати нездійсненними і будуть знехтувані. В цьому разі
216
Г.Ф. Іванчвнко
кількість тверджень під час висновку може не тільки зростати, а й зменшуватися. Тому система, що формалізує таку схему висновку, стає немонотонною. Немонотонні системи логічного висновку дають змогу отримувати різну несумісну множину правдоподібних тверджень. При цьому таку множину тверджень, що виводяться, характеризують за допомогою «нерухомих точок». Нерухома точка — це безліч припущень, на основі яких не можна вивести жодного нового правдоподібного твердження.
Припущення, виконувані під час немонотонного висновку, дають можливість усунути неповноту знань. У базах знань, заснованих на класичній логіці, визначаються винятково істинні факти. Невизначені факти вважаються вочевидь помилковими. Таке припущення називають гіпотезою умовчання замкненого світу. Наприклад, подібний підхід використовують при визначенні предиката not мови Prolog. Людина часто використовує інший підхід до оцінки достовірності фактів, яких бракує. Вона зазвичай вважає деяке припущення істинним, поки не буде доведено зворотне. Іншими словами, людина виконує висновки, спираючись на узгодженість прийнятого припущення з уже виведеними твердженнями. Розглянемо, наприклад, правило «якщо х птах, то х літає». Тут за умовчанням прийнято припущення, що зазвичай птахи літають. Відзначимо, що висновок «х літає» буде лише здійсненний, а не загальнозначущий. Він істинний не за всік інтерпретацій х, а тільки за тих, коли є здійсненним прийняте припущення.
Для формалізації вказаних міркувань у немонотонній логіці вводяться спеціальні правила, доповнені умовами використання. Умови використання (або передумови) фіксують прийняті припущення і дають змогу перевірити здійсненність (узгодженість, непротиріччя) припущень (до використання правила) спільно з уже виведеними твердженнями. Ці правила називають правилами немонотонного висновку.
У немонотонних логіках передумови в правилах висновку записують за допомогою модальних операторів. Одним із таких операторів є оператор unless (англ. «поки не»). Розглянемо правило P(x)unlessQ{x) => R(x).
Правило дає змогу з посилання Р(х) вивести висновок R(x), поки не доведено припущення Q(x). Якщо будуть отримані відомості про здійсненність Q(x), то потрібно виключити R(x) з бази знань. З цією метою системи немонотонного висновку мають зберігати протокол висновку.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
217
Ідея введення в правила висновку припущень отримала подальший розвиток в логіці умовчань Рейтера. При цьому припущення, що використовують в процесі висновку, беруть такі, якими вони бувають у звичних ситуаціях, тобто їх значення приймають за умовчанням. Правила умовчань записуються у формі а: Аф
У
Тут М позначає модального оператора «узгоджується з» (здійсненно). Двокрапка відокремлює посилання правила від припущення. Значення правила таке: якщо вірно а і якщо р узгоджується зі всіма значеннями, отриманими до цього моменту, то здійсненно у. Правило «якщо х птах, то х літає» можна записати
птах(х): М літає(;с)
у вигляді такого правила умовчання — —
літає(дс)
Використання правил умовчання дає змогу отримувати різну несумісну множину значень. Наприклад, нехай вірно А і
А.МВ А\МС С ’ В
Тоді або В, або С виводиться з А, але не обидва відразу. Отже, В і С є множиною правдоподібних розширень початкових тверджень А. Кожне таке розширення розглядається як один із «можливих світів», який можна уявити, виходячи з прийнятих припущень.
У логіці умовчань сукупність правил умовчання і формул називають теорією з умовчаннями. Загалом правило умовчання (або просто умовчання) — це вираз вигляду:
а(х): Дфі(х),....,Аф„(х)
У(*)
де а(х),р,(дг), ,рт (дс),у(лг) — формули мови числення предикатів
першого порядку; х=(х<> • •••> х„) — предметні змінні; а(х) — вимога умовчання; р (де) — обґрунтування умовчання; у (х) — слідство умовчання. Вільні змінні формул в умовчанні вважаються зв’язаними квантором спільності. Якщо у формулах є вільні змінні, то умовчання називається відкритим. Теорія з умовчаннями задається парою Д = (ДР), де £> — множина умовчань; F — множина замкнених формул числення предикатів.
218
Г.Ф. Іванчвнко
Теорія з умовчаннями дає змогу отримати деяке число розширень. Розширення існують не для всіх теорій з умовчаннями. Розширення можливі тільки для замкнених теорій, які виходять шляхом конкретизації відкритих умовчань і формул. Окрім цього, існування розширень гарантується, якщо умовчання теорії є нормальними. Нормальними називають умовчання, в яких обґрунтування і висновок співпадають. Загальна формула нормального умовчання:
а(х): Л/р(де)
РОО ‘
Нормальне умовчання гарантує отримання щонайменше одного розширення. При цьому нормальні умовчання не застосовні, коли помилковість їх слідств вже доведено. Тому вони не можуть спростувати виконання слідств раніше застосованих нормальних умовчань. Через це нормальні теорії належать до напівмонотонних.
Рейтер побудував процедуру доказів для замкнених нормальних теорій. Процедура дає змогу для заданої замкненої формули з’ясувати, чи входить ця формула в одне з розширень замкненої нормальної теорії. В загальному випадку проблема перевірки існування розширення із заданою замкненою формулою не до кінця вирішуваною. і
У ряді випадків використання нормальних умовчань може приводити до небажаних висновків. Наприклад, опишемо нормальною теорією А = (/).^), де £) містить два нормальних умовчання: «якщо х птах, то х літає», або в символьному вигляді:
птах(х): М літас(х) . . _
— —, то «якщо х пінгвін, то х не літає», або в сим-
літає(х)
. птахіх): М літає(х)
вольному вигляді: — —.
літає(х)
Безліч формул Р запишеться у вигляді <а пінгвін». Очевидно, перший висновок не відповідає дійсності, щоб виключити можливість використання першого правила доцільно вдатися до його блокування, якщо виконується предикат пінгвін(х). Перепишемо
. птах(х): М літає(х) д пінгвін(х) перше правило у вигляді: — — —.
літає(х)
Тоді теорія Д = (£>.Р) дає лише одне слідство —літає все, але не пінгвін.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
219
Останнє правило називається напівнормальним. Воно запису-
Таке умовчання вочевидь управляється умовою, що задається формулою у(х). Теорії з напівнормальними умовчаннями не завжди мають розширення і, отже, їм не притаманна напівмонотон- ність. Проте напівнормальні умовчання дають змогу відображати в базах знань спадковість властивостей з винятками, що характерне для мережевого і фреймового подання знань.
Інший підхід запропонували Д. Мак-Дермотт і Дж. Дойл. Вони створили формальну систему немонотонного висновку, розширивши логіку числення предикатів. Для цього вони перевизначили поняття «формула», включивши в нього вираз Мр, де М— модальний оператор «здійсненно», р — формула мови числення предикатів. Додали до системи аксіом числення предикатів схеми модальних аксіом і, окрім цього, розширили множину правил висновку специфічним правилом немонотонного висновку, тобто правилом висновку лише здійсненних тверджень. Вибираючи різні підмно- жини із списку схем модальних аксіом, можна отримувати різні немонотонні логіки. Ці логіки дають змогу отримувати різну множину висновків (нерухомих точок) шляхом зміни порядку висновку. Наприклад, нехай дано множина формул:
де А, В — пропозиційні букви. Тоді можливі два рішення (дві нерухомі точки)._Одна нерухома точка містить, але не включає В. Другая містить В, але не включає А. Справді, якщо перша точка не містить В, то вона містить MB. Тоді з правила modus ponens МВ(МВ->■ А) виходить А. Аналогічно одержуємо для другої точки
В. Таким чином, рішення в цьому разі визначається неоднозначно.
Цінність немонотонних логік Мак-Дермотта і Дойла полягає в поширенні модальної логіки на формалізацію тверджень, що модифікуються. Проте залишаються серйозні проблеми, пов’язані з обґрунтуванням вибору системи модальних аксіом.
Одним із важливих завдань, що постають у системах немонотонного висновку, є управління висновком в умовах постійної зміни ступеня достовірності висновків. Наприклад, якщо на основі твердження R отримано висновок S, а надалі встановлено,
220
Г.Ф. Іванченко
що R більше не здійсненне, то потрібно не лише виключити з бази знань R, але також і S, якщо не є додаткових тверджень на підтримку S. Для підтримки несуперечності бази знань застосовуються спеціальні механізми, реалізовувані системами підтримки значень істинності (англ. Truth Maintenance System — TMS).
Системи підтримки значень істинності (СПЗІ) застосовуються для забезпечення логічної цілісності висновків, сформованих на основі неповних знань. Один з простих способів вирішення цього завдання полягає в запам’ятовуванні протоколу висновку. В протоколі висновку з кожним висновком пов’язано відповідне обґрунтування. Обґрунтування включає всі факти, правила і припущення, зроблені при висновку. Якщо обґрунтування припущення стає нездійсненним, то, використовуючи процедуру повернення до точок, в яких ухвалювалися альтернативні рішення, можна наново оцінити істинність тих або тих висновків. В простому випадку процедура здійснює сліпий хронологічний пошук точок повернення. Проте якщо простір пошуку великий, то хронологічний пошук стає неефективним. Для підвищення ефективності застосовують пошук, керований причиною суперечності. В цьому разі забезпечується негайне повернення до пропозиції, що є джерелом суперечності. Переміщуючись у прямому напрямі від нездійсненного припущення до подальших висновків, зроблених на його основі, видаляють ці висновки. При цьому є можливість для кожного висновку, що підлягає видаленню, виконати перевірку його здійсненності в новому оточенні. Якщо є припущення на підтримку висновку, то його не видаляють з бази знань.
Відомо два методи побудови систем пошуку, керованого причиною суперечності, які відповідно реалізуються в системах типу JTMS (justification based TMS — система підтримки значень істинності, що використовує обґрунтування) і ATMS (assumption based TMS — система підтримки значень істинності, що використовує припущення). Систему JTMS запропонував Дж. Дойл — перший дослідник, якому вдалося відокремити СПЗІ від механізму висновку. При цьому СПЗІ взаємодіє з механізмом висновку: отримує знову сформовані слідства і їх обґрунтування і повертає відомості про твердження, які достовірні на цьому кроці роботи механізму висновку.
Всі твердження в JTMS поділяються на достовірні й недостовірні. Достовірні твердження наголошуються міткою IN, а недостовірні — міткою OUT. При цьому твердження подаються у вигляді мережі обґрунтування достовірності. Така мережа містить вузли
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
221
двох типів. Вузли першого типу відповідають твердженням, а вузли другого типу — логічній зв’язці «І». Зв’язка «І» дає змогу відобразити в мережі взаємозв’язок передумови і припущення правила умовчання. Аналізуючи мережу, можна з’ясувати достовірність того або іншого твердження і встановити всі передумови і припущення, які підтверджують (підтримують) його достовірність. Якщо при додаванні нових знань виникає суперечність, то відбувається перегляд міток тверджень і модифікація мережі.
У системі ATMS не застосовують бінарні мітки IN (достовірно) і OUT (недостовірно). Тут мітка достовірності твердження подається у вигляді множини припущень (передумов), за яких це твердження вірне. Це робить системи типу ATMS гнучкішими порівняно з системами типу JTMS.
На закінчення зазначимо, що процес доказу в рамках некласич- них логік значно складніше піддається автоматизації. Це пов’язано головним чином з комбінаторним вибухом. Основний підхід до розв’язання цієї проблеми полягає в скороченні простору пошуку. Так, у багатьох модальних логіках обмежуються аналізом фрагментів, які формуються за допомогою модальних операторів.
Інший підхід до автоматизації доказу в некласичних логіках заснований на зведенні їх до класичних логік шляхом формалізації семантики некласичних логік термінами традиційної логіки. Наприклад, семантика модальних логік виражається за допомогою системи «можливих світів». Для їх формалізації кожен предикат класичної логіки забезпечується додатковим аргументом, який специфікує «можливий світ». Подальша квантифікація таких аргументів за допомогою кванторів спільності й існування дає змогу подати відповідних модальних операторів. Зв’язки між «можливими світами» виражаються за допомогою відносин між ними і враховуються в алгоритмах уніфікації. Це дає можливість автоматизувати процес доказу за допомогою процесора резолюцій.
Резюме за змістом теми
Теорія числення, предикатів дає змогу одержувати правильні висновки, спираючись на загальнозначущі твердження і обґрунтовані правила висновку
У багатьох випадках є потреба робити висновок в умовах, коли початкові дані не є абсолютно точними й достовірними, а правила висновку мають евристичний характер і ненадійні.
222
Г.Ф. Іванчвнко
Невизначеність може бути пов’язана або з неповнотою знань, або з їх неоднозначністю.
Часто всі види неоднозначності не виділяють в окремі групи, а розглядають у межах одного терміна «ненадійні знання». Основними поняттями, що використовують під час побудови моделей висновку на таких знаннях, є поняття достовірності.
Неповнота знань виникає, коли зібрано не всю інформацію, необхідну для побудови висновків
Коли істинність висловів не може бути встановлена з абсолютною достовірністю — це є неоднозначність.
Фізична невизначеність може бути пов’язана з випадковістю подій, ситуацій, станів об’єкта або неточністю подання даних.
Лінгвістична невизначеність пов’язана з використанням природної мови для подання знань.
Терміни та поняття до теми
• «Mycin», «Prospector», «Super Finance», «Emycin» — експертні системи;
• Fuzzy logic — нечітка логіка;
• JTMS (justification based TMS) — система підтримки значень істинності, що використовує обґрунтування;
• ATMS (assumption based TMS) — система підтримки значень істинності, що використовує припущення.
• СПЗІ — системи підтримки значень істинності.
Питання для самоконтролю
1. Охарактеризуйте поняття невизначеності.
2. Дайте визначення баєсовському підходу ступеня достовірності
3. Охарактеризуйте теорему гіпотез Баєса.
4. Яка теорія використовується для формалізації нечітких знань, що характеризуються невизначеністю?
5. Що таке лінгвістична змінна, значеннями якої є слова і фрази природної мови (терми)?
6. Поясніть формальну систему немонотонного висновку, розширивши логіку числення предикатів.
7. Дайте визначення нечіткої множини. Наведіть кілька власних прикладів.
8. Дайте визначення рівності та включення нечітких множин.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
223
9. Охарактеризуйте завдання, пов’язані з нечітким логічним виведенням.
10. Опишіть метод простого підставлення нечіткого значення, який може бути застосований у разі, якщо в умові вочевидь задається ступінь належності.
11. Що таке нечітке відношення?
Завдання для індивідуальної роботи, обов’язкові та додаткові практичні завдання
1. Метод коефіцієнтів упевненості.
2. Підхід, прийнятий в теорії Демпстера—Шефера.
3. Шанси — це інша шкала для представлення вірогідності.
4. Види невизначеності.
5. Баєсовський підхід як ступінь достовірності кожного з фактів бази знань.
6. Теорема гіпотез Баєса.
7. Відношення правдоподібності.
8. Метод коефіцієнтів упевненості, застосований в експертній системі «Super Finance».
9. Підхід, прийнятий у теорії Демпстера—Шефера, та відмінність від баєсовського підходу й методу коефіцієнтів упевненості.
10. Застосування теорії нечітких, або розпливчастих множин.
11. Опишіть функції пакету Matlab для створення нейро-нечітких мереж.
Література для поглиблення вивчення матеріалу
1. ЛюгерДж. Ф. Искусственный интеллект. — М.: Изд. дом «Вильямс», 2005. — 864 с.
2. Бондарев В. Аде Ф. Г. Штучний інтелект: Навчальний посібник для вузів. — Севастополь, Вид-во СевНТУ, 2002. — 615 с.
3. Представление и использование знаний / Под ред. X. Уэно, М. Исидзука. — М.: Мир, 1989. — 220 с.
ШТУЧНІ НЕЙРОННІ МЕРЕЖІ
Тема 5
КОНЕКЦЮНІСТСЬКИЙ ПІДХІД ЯК СПРОБА МОДЕЛЮВАННЯ ЛЮДСЬКОГО МОЗКУ
Перелік знань та навичок
Після опанування теми студент має знати:
• Визначення штучної нейронної мережі (ШНМ).
• Історичне систематичне вивчення ШНМ.
• Характерні риси штучних нейромереж як універсального інструменту для розв’язання задач
• Конекціоністський підхід у побудові систем штучного інтелекту.
• Стандарти класифікації нейромереж.
• Структура одношарової нейронної мережі.
• Структура багатошарового персептрона, або багатошарової нейронної мережі
• Структура двошарової мережі зворотного поширення.
• Нейронні мережі Хопфілда, Хеммінга, Больцмана
• Процедури навчання мережі.
Має вміти:
• Вибирати функції активації персептрона.
• Будувати схему нейрокомп’ютера — програмно-технічної системи, яка реалізує деяку формальну модель природної мережі нейронів.
• Вибирати кількость нейронів і шарів.
• Описати алгоритм навчання одношарового дискретного персептрона.
• Будувати БШП та вибрати його параметри.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
225
ЗМІСТ ПИТАНЬ ТЕМИ
5.1. Персептрони та зародження штучних нейронних мереж
Як науковий предмет штучні нейронні мережі вперше заявили про себе в 40-ві роки. Прагнучи відтворити функції людського мозку, дослідники створили прості апаратні (а пізніше програмні) моделі біологічного нейрона і системи його з’єднань. Коли нейрофізіологи досягли глибшого розуміння нервової системи людини, ці ранні спроби почали сприймати як вельми брутальні апроксимації. Проте на цьому шляху були досягнуті вражаючі результати, які стимулювали подальші дослідження, що привели до створення витонченіших мереж.
Першими почали систематично вивчати штучні нейронні мережі Маккалокк і Піттс в 1943 р. Вони досліджували мережеві парадигми для розпізнавання зображень, що піддаються зрушенням і поворотам. Просту нейронну модель, показану нижче на рис. 5.2 (див. с. 234), використовували в більшій частині роботи.
Елемент Е множить кожен вхід Хі на вагу і підсумовує зважені входи. Якщо ця сума більша за задане порогове значення, вихід дорівнює одиниці, інакше — нулю. Ці системи (та множина їм подібних) отримали назву персептронів. Вони складаються з одного шару штучних нейронів, сполучених за допомогою вагових коефіцієнтів з множиною входів, хоча описуються й складніші системи.
У 60-ті роки персептрони спричинили великий інтерес і оптимізм. Розенблатг [22] довів чудову теорему про навчання персептронів, яку наведемо нижче. Уїдроу [23, 24] переконливо продемонстрував системи персептронного типу, і дослідники в усьому світі прагнули вивчити можливості цих систем. Першу ейфорію змінило розчарування, коли виявилось, що персептрони не взмозі навчитися вирішувати ряд простих завдань. М. Мінський проаналізував цю проблему і показав, що є жорсткі обмеження на те, що можуть виконувати одношарові персептрони і, отже, на те, чому вони можуть навчатися.
Праця Марвина Мінського, можливо, й остудила запал ентузіастів персептрона, але забезпечила час для потрібної консолідації
226
Г.Ф. Іванчвнко
й розвитку теорії. Важливо відзначити, що аналіз М. Мінського не був спростований. Він залишається важливим дослідженням і має вивчатися, щоб помилки 60-х років не повторилися.
Незважаючи на обмеження, персептрони широко досліджують. Теорія персептронів є основою для багатьох інших типів штучних нейронних мереж, і персептрони ілюструють важливі принципи. Тому вони є логічною точкою відліку для вивчення штучних нейронних мереж.
Доведення теореми навчання персептрона [22] показало, що пер- септрон у змозі навчитися всьому, що він здатний представляти. Важливо вміти розрізняти подавання і навчання. Поняття подавання належить до здатності персептрона (або іншої мережі) моделювати певну функцію. Навчання ж вимагає наявності систематичної процедури налаштування ватів мережі для реалізації цієї функції.
Штучні нейронні мережі — сукупність моделей біологічних нейронних мереж. Вони є мережею елементів — штучних нейронів — зв’язаних між собою синоптичними з’єднаннями. Мережа обробляє вхідну інформацію і в процесі зміни свого стану в часі формує сукупність вихідних сигналів.
Робота мережі полягає в перетворенні вхідних сигналів у часі, в результаті змінюється внутрішній стан мережі і формуються вихідні дії. Зазвичай ШНМ оперує цифровими, а не символьними величинами.
Більшість моделей ШНМ вимагають навчання. У загальному випадку, навчання — такий вибір параметрів мережі, за якого мережа найкраще впорається з поставленим завданням, це завдання багатовимірної оптимізації, і для його вирішення існує безліч алгоритмів.
Штучні нейронні мережі — набір математичних й алгоритмічних методів для вирішення широкого кола завдань. Виділимо характерні риси штучних нейромереж як універсального інструменту для вирішення завдань:
1. ШНМ дають можливість краще зрозуміти організацію нервової системи людини і тварин на середніх рівнях: пам’ять, обробка сенсорної інформації, моторика.
2. ШНМ — засіб обробки інформації:
• гнучка модель для нелінійної апроксимації багатовимірних функцій;
• засіб прогнозування в часі для процесів, залежних від багатьох змінних;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
227
• класифікатор за багатьма ознаками, завдяки якому можна розбити вхідний простір на діапазони;
• засіб розпізнавання образів;
• інструмент для пошуку за асоціаціями;
• модель для пошуку закономірностей у масивах даних.
3. ШНМ вільні від обмежень звичайних комп’ютерів завдяки паралельній обробці і сильній зв’язаності нейронів.
4. У перспективі ШНМ мають допомогти зрозуміти принципи, на яких побудовані вищі функції нервової системи: свідомість, емоції, мислення.
Сучасні штучні ШНМ за складністю й «інтелектом» наближаються до нервової системи таргана, але вже демонструють цінні якості:
1. Навчання. Обравши одну з моделей ШНМ, створивши мережу і виконавши алгоритм навчання, ми можемо навчити мережу вирішувати завдання.
2. Здібність узагальнення. Після навчання мережа стає нечутливою до малих змін вхідних сигналів (шуму або варіацій вхідних образів) і дає правильний результат на виході.
3. Здібність абстрагування. Якщо пред’явити мережі кілька змінених варіантів вхідного образу, то мережа сама може створити на виході ідеальний відтворений образ, з яким вона ніколи не зустрічалася.
Існують й далі утворюють комп’ютерні системи, побудовані на основі штучних нейронних мереж. Такі системи отримали назву нейрокомп’ютерів. Нейрокомп’ютер — це програмно-технічна система (переважно спеціалізована), яка реалізує деяку формальну модель природної мережі нейронів. Більшого розвитку набули програмні пакети, які моделюють роботу нейронних мереж на універсальних комп’ютерах, як-от BrainMaker, OWL, «The АІ Trilogy», NeurallO, NeuroPro та ін. Серед основних сфер застосування таких систем розпізнавання образів, обробка сигналів та зображень, прогнозування природних та соціально-економічних явищ тощо.
Багато дослідників вважають, що майбутнє належить комп’ютерам, які базуються на аналізі зв’язків, а не на обробці символів, тобто конекціоністський підхід до створення систем штучного інтелекту стане домінуючим. Мінський казав, що якщо комп’ютер має діяти подібно до мозку, тоді й його конструкція має бути подібною до мозку.
228
Г.Ф. Іванченко
Головна відмінність нейрокомп’ютера від звичайних комп’ютерів обчислювального типу така: в традиційному обчислювальному пристрої для того, щоб при цьому вході дійти до бажаного виходу, потрібна точна програма, яка складається з конкретних інструкцій виконання. Нейрокомп’ютери мають можливості, що роблять їх істотно відмінними у досягненні бажаного результату,
— вони можуть навчатися на прикладах. Якщо існує навчальна вибірка, тобто певна множина пар даних, перша компонента яких є деяким вхідним кортежем, а друга — бажаним виходом на цьому кортежі, то ШНМ може навчитися змінювати власні ваги таким чином, щоб з кожним входом асоціювався вірний вихід. Така можливість є дуже важливою, оскільки є проблеми, коли відомий вірний результат, але важко визначити точну процедуру, або список правил, для пошуку результату. Якщо в таких випадках навчання на прикладах допомагає ШНМ побудувати власні приховані правила у термінах використання відповідних ваг, вона має безперечні переваги.
Конекціоністський підхід до побудови систем штучного інтелекту розвинувся на противагу символьному, що є характерним для сучасних моделей знань. В основі конекціоністського підходу лежить спроба безпосереднього моделювання розумової діяльності людського мозку. Відомо, що мозок людини складається з величезної кількості нервових клітин (нейронів), що взаємодіють між собою, тобто являє собою природну нейронну мережу [М. Амо- сов]. Ці «обчислювальні елементи» мозку функціонують набагато повільніше, ніж обчислювальні елементи комп’ютерних систем. Але незважаючи на це біологічні нейронні мережі вирішують багато завдань (особливо нечислових) у тисячі разів швидше, ніж електронний процесор.
Причини цього такі:
1. Нейрони людського мозку функціонують паралельно і постійно обмінюються інформацією.
2. У людському мозку пам’ять не локалізована в одному місці (як у традиційній обчислювальній машині), а є розподіленою. В біологічних системах пам’ять реалізується посиленням або послабленням зв’язків між нейронами, а не зберіганням двійкових символів.
3. Біологічні мережі реагують не на всі, а тільки на визначені зовнішні подразники. Кожний нейрон виступає як елемент прийняття рішення і як елемент зберігання інформації. Перевага такої структури — «життєздатність» (вихід з ладу декількох нейронів
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
229
не приводить до значної зміни даних, що зберігаються, або до руйнування всієї системи).
4. Можливість адресації за вмістом (асоціативної пам’яті) є ще однією важливою характеристикою систем з розподіленою пам’яттю (кожний елемент відшукується за його вмістом, а не зберігається в комірці пам’яті з визначеним номером).
Мислення людини є переважно асоціативним, і в основу роботи систем, які моделюють мислення людини, може бути покладений принцип асоціації. Під асоціацією розуміємо певний ступінь подібності або наявність певних спільних рис між тими чи іншими явищами й поняттями. Асоціативні зв’язки пронизують все мислення людини. При цьому процес породження асоціацій та висновків за асоціацією має підсвідомий та переважно випадковий і неконтро- льований характер. Існує думка, що процеси мислення мають хвильовий характер і є не що інше, як поширення певного збудження як деяка ланцюгова реакція. Недоліком такого типу мислення є те, що внаслідок нефіксованої організації такі системи можуть приходити до помилкових висновків, плутати різні об’єкти тощо. Людина більш-менш долає це шляхом навчання, звикання до конкретних ситуацій, контролю над своєю поведінкою. На підсвідомому рівні процес породження асоціацій, очевидно, також скеровується деяким механізмом, який спрямовує його в бажаному напрямі. Подібних рис мають набути й системи штучного інтелекту.
Важливою особливістю нейроноподібних систем є їх здатність до ефективного навчання, навіть в умовах, якщо не вдається на вербальному рівні, тобто в словесній формі, сформулювати мету системи та виробити правила її поведінки. Навчання відбувається переважно на підсвідомому рівні.
Всі ці особливості зумовили привабливість конекціоністсько- го підходу до побудови систем штучного інтелекту. Такі системи мають функціонувати за принципами, подібними до тих, за якими функціонує мозок людини, хоч самі ці принципи залишаються не до кінця зрозумілими. Безумовно, це не виключає використання в таких системах можливостей, характерних для символьного підходу, зокрема, — оперування поняттями, дедуктивне логічне виведення тощо.
Назва вказує, що штучна нейронна мережа — система, яка складається із деякої кількості пристроїв, так званих штучних нейронів, з’єднаних між собою. Ці пристрої називають штучними нейронами завдяки певній подібності до нейронів людського мозку. Однак во-
230
Г.Ф. Іванчвнко
ни не призначені для точного копіювання усіх електрохімічних процесів, які відбуваються у мозку людини. Мозок лише виступає як модель для побудови ШНМ. У деяких випадках ми називатимемо штучні нейрони просто нейронами, якщо при цьому не виникатиме загроза переплутати штучні та біологічні нейрони.
Існує багато способів з’єднання між собою ШН, отже, можна виділити різні типи ШНМ. Переважно вони розрізнятися за такими двома параметрами, як операційні характеристики нейронів та різні конфігурації утворення мережі.
Оскільки поведінка мережі істотно залежить від поведінки окремих нейронів, почнемо з того, що розглянемо основні ідеї побудови штучного нейрона.
На цьому етапі ми розглядатимемо ШН як деякий абстрактний пристрій, що працює за такою схемою. Він отримує вхідні сигнали з одного або кількох входів. Зокрема, можна вважати, що ШН отримує на своїх входах кілька чисел. Тому вхідний сигнал ШН можна також сприймати як деякий кортеж чисел. Традиційно ШН перетворює значення всіх вхідних сигналів на мережевий вхід. Існує багато способів перетворення кортежу чисел на єдине число, але зазвичай ШН формує мережевий вхід, підраховуючи зважену суму входів за деякими коефіцієнтами.
ШН відповідає на різні значення мережевого входу різними значеннями мережевого виходу. Зв’язок між мережевим входом та мережевим виходом називають активаційною функцією нейрона. Існує багато можливих функцій, або зв’язків, які визначають, яке значення мережевого виходу відповідатиме цьому значенню мережевого входу.
Під час розробки штучних нейронних мереж постає ряд очевидних проблем.
По-перше, пряме моделювання мозку вимагає величезної кількості нейронів. Так, модель мурахи — використання близько 20 000 нейронів, людини понад 100 млрд нейронів, і реалізація поки таких моделей є практично неможливою.
По-друге, здатність мозку як високоорганізованої інтелектуальної системи до підсвідомого мисленння і навчання була вироблена упродовж сотень мільйонів років еволюції. Механізми ж самонавчання і самоорганізації штучних нейронних мереж, зв’язки яких можуть мати випадковий характер, сьогодні дуже недосконалі, і їх можна застосовувати лише для вузького кола порівняно простих завдань. Тим не менше, ці методики інтенсивно розвиваються.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
231
5.2. Біологічна модель штучних нейронних мереж
Людський мозок містить понад 100 мільярдів обчислювальних елементів, які називають нейронами. Перевищуючи за кількістю число зірок у Чумацькому Шляху галактики, ці нейрони пов’язані сотнями трильйонів нервових ниток, що мають назву синапси. Ця мережа нейронів відповідає за всі явища, які ми називаємо думками, емоціями, пізнанням, а також і за здійснення сенсомоторних та автономних функцій. Кожен нейрон має багато якостей, загальних з іншими елементами тіла, але його унікальною здатністю є прийом, обробка і передача електрохімічних сигналів нервовими шляхами, які утворюють комунікаційну систему мозку.
Поки мало зрозуміло, яким чином все це відбувається, але вже досліджено багато питань фізіологічної структури і певні функціональні галузі дослідники поступово вивчають.
Мозок є основним споживачем енергії тіла. Включаючи лише
12 % маси тіла, в стані спокою він використовує приблизно 20 % кисню тіла, мозок з енергетичної точки зору неймовірно ефективний. Навіть коли ми спимо, витрачання енергії триває. Насправді існують докази спроможності збільшення витрачання енергії під час фази сну, що супроводжується рухом очей. Комп’ютери з однією крихітною часткою обчислювальних можливостей мозку споживають багато тисяч ватів і вимагають складних засобів для охолоджування, що запобігають їх температурному саморуйнуванню.
Нейрон є основним будівельним блоком нервової системи. Він є клітиною, подібною до всіх інших клітин тіла, проте певні істотні відмінності дають змогу йому виконувати всі обчислювальні функції і функції зв’язку усередині мозку.
На рис. 5.1 показано структуру пари типових біологічних нейронів. Дендріти йдуть від тіла нервової клітини до інших нейронів, де вони приймають сигнали в точках з’єднання — синапсах. Прийняті синапсом вхідні сигнали підводяться до тіла нейрона. Тут вони підсумовуються, причому одні входи прагнуть збудити нейрон, другі — перешкодити його збудженню. Коли сумарне збудження в тілі нейрона перевищує деякий поріг, нейрон збуджується, посилаючи аксоном сигнал іншим нейронам. У цієї основної функціональної схеми багато ускладнень і винятків, проте більшість штучних нейронних мереж моделюють лише ці прості властивості.
232
Г.Ф. Іванчвнко
Були ідентифіковані сотні типів нейронів, кожен зі своєю характерною формою тіла клітини, що має звичайно від 5 до 100 мкм у діаметрі. Сьогодні цей факт розглядається як прояв випадковості, проте можуть бути знайдені різні морфологічні конфігурації, що відображають важливу функціональну спеціалізацію. Визначення функцій різних типів клітин є нині предметом інтенсивних досліджень і основою розуміння механізмів мозку.
Дендрити. Більшість вхідних сигналів від інших нейронів потрапляють у клітину через дендрити, що є структурою, що щільно гілкується від тіла клітини. На дедритах розташовуються си- наптичні з’єднання, які отримують сигнали від інших аксонів. Окрім цього, існує величезна кількість синаптичних зв’язків від аксона до аксона, від аксона до тіла клітини і від дендрита до дендрита; їх функції не дуже зрозумілі, але вони дуже широко поширені, щоб не зважати на них.
На відміну від електричних схем, синаптичні контакти зазвичай не є фізичними або електричними з’єднаннями. Натомість є вузький простір — синоптична щілина, що відокремлює дендрит від передавального аксона. Спеціальні хімічні
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
233
речовини, що викидаються аксоном у синаптичну щілину, дифундують до дендрита. Ці хімічні речовини, нейротрансмітери вловлюють спеціальні рецептори на дендриті і впроваджують у тіло клітини.
Визначено більш як ЗО видів нейротрансмітерів. Деякі з них є збуджувальними і прагнуть викликати збудження клітини і виробити вихідний імпульс. Інші гальмують і прагнуть подавити такий імпульс. Тіло клітини підсумовує сигнали, одержані від дендритів, і якщо їх результаційний сигнал вищий за порогове значення; виробляється імпульс, що проходить аксоном до інших нейронів.
Аксон. Аксон може бути і коротким (0,1 мм), і перевищувати довжину 1 м, поширюючись в іншу частину тіла людини. На кінці аксон має множину гілок, кожна з яких завершується синап- сом, звідки сигнал передається в інші нейрони через дендрити, а в деяких випадках просто в тіло клітини. Таким чином, лише один нейрон може генерувати імпульс, який збуджує або загальмовує сотні або тисячі інших нейронів, кожен з яких, у свою чергу, через свої дендрити може впливати на сотні або тисячі інших нейронів. Таким чином, цей високий ступінь зв’язаності, а не функціональна складність самого нейрона, забезпечує нейрону його обчислювальну потужність.
Функціонально дендрити одержують сигнали від інших клітин через контакти — синапси. Звідси сигнали проходять у тіло клітини, де вони підсумовуються з іншими такими самими сигналами. Якщо сумарний сигнал упродовж короткого проміжку часу є досить великим, клітка збуджується, виробляючи в аксоні імпульс, який передається наступній клітині. Попри очевидне спрощення, ця схема функціонування пояснює більшість відомих процесів мозку.
Нейрони в мозку дорослої людини не відновлюються, вони відмирають. Це означає, що всі компоненти мають безперервно замінюватися, а матеріали оновлюватися у разі потреби. Більшість цих процесів відбувається в тілі клітини, де зміна хімічних чинників приводить до великих змін складних молекул. Окрім цього, тіло клітини управляє витратою енергії нейрона і регулює безліч інших процесів у клітині. Зовнішня мембрана тіла клітини нейрона має унікальну здатність генерувати нервові імпульси (потенціали дії), що є життєвими функціями нервової системи і центром її обчислювальних здібностей.
234
Г.Ф. Іванчвнко
5.3. Штучний нейрон та функції активації
Штучний нейрон імітує в першому наближенні властивості біологічного нейрона. На вхід штучного нейрона надходить деяка множина сигналів, кожен з яких є виходом іншого нейрона. Кожен вхід множиться на відповідну вагу, аналогічну синаптичній силі, і всі добутки підсумовуються, визначаючи рівень активації нейрона. На рис. 5.2 наведено модель, що реалізовує цю ідею. Хоча мережеві парадигми дуже різноманітні, в основі майже всіх їх лежить ця конфігурація. Тут множина вхідних сигналів, позначених *і, *2,., х„, надходить на штучний нейрон. Ці вхідні сигнали, що в сукупності позначаються вектором X, відповідають сигналам, що приходять у синапси біологічного нейрона. Кожен сигнал множиться на відповідну вагу w\, w>2,., w„, і надходить на
п
блок — суматор, що підсумовує ^W, *Xt, позначена вага Wt від-
1=1
повідає «силі» одного біологічного синаптичного зв’язку. Множина вагів у сукупності позначається вектором W. Суматор відповідає тілу біологічного елемента, складає зважені входи, створюючи вихід, який ми називатимемо NET. У векторних позначеннях це може бути компактно записано таким чином: NET = XW. Вихідний сигнал нейрона у визначається шляхом пропущення рівня збудження net через нелінійну функцію активації F:
у = F(NET - 0j), де 0 і — деякий постійний зсув (аналог порога нейрона).
Нейрон складається із зваженого суматора і нелінійного елемента. Функціонування нейрона визначається формулами:
NET = 5>,х, , OUT = F(NET - 0),
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
235
де Хі — вхідні сигнали, сукупність всіх вхідних сигналів нейрона утворює вектор X;
м>і — вагові коефіцієнти, сукупність вагових коефіцієнтів утворює вектор вагів W;
NET — зважена сума вхідних сигналів, значення NET передається на нелінійний елемент;
0—пороговий рівень цього нейрона;
F— нелінійна функція, названа функцією активації.
Нейрон має кілька вхідних сигналів Xt і один вихідний сигнал OUT Параметрами нейрона, що визначають його роботу, є: вектор вагів Wj, пороговий рівень 0 і вид функції активації F. Залежно від типу функції активації розрізняють дискретні персептрони, що використовують порогову функцію активації, і реальні — що використовують реальні функції активації, наприклад сигмоїда- льну функцію.
Кожен нейрон має невелику пам’ять, реалізовану ваговими коефіцієнтами вхідних синапсів (міжнейронних контактів) і порогом нейрона. Тому нейрони можна розглядати як запам’ятовувальні пристрої. У той самий час нейрони можуть розглядатися як примітивні процесори, що здійснюють обчислення значення функції активації на основі різниці зваженої суми вхідних сигналів і порога.
Активаційні функції
Сигнал NET далі зазвичай перетворюється активаційною функцією F і дає вихідний нейронний сигнал OUT.
Активаційна функція може бути звичайною лінійною функцією. Застосовується для тих моделей мереж, де не потрібне послідовне з’єднання шарів нейронів один за одним (табл. 5.1).
Таблиця 5.1
АКТИВАЦІЙНІ ФУНКЦІЇ
236
Г.Ф. Іванчвнко
Продовження табл. 5.1
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
237
Закінчення табл. 5.1
Жорстка сходинка використовується в класичному формальному нейроні (ФН). Розвинена повна теорія, що дає змогу синтезувати довільні логічні схеми на основі ФН з такою нелінійністю. Функція обчислюється двома-трьома машинними інструкціями, тому нейрони з такою нелінійністю вимагають малих обчислювальних витрат.
Ця функція надмірно спрощена і не дає змогу моделювати схеми з безперервними сигналами. Відсутність першої похідної ускладнює застосування градієнтних методів для навчання таких нейронів. Мережі на класичних ФН найчастіше формуються, синтезуються, тобто їх параметри розраховуються за формулами, на
238
Г.Ф. Іванчвнко
протилежність навчанню, коли параметри підлаштовуються ітеративно.
У більшості випадків передавальна функція порівнює значення мережевого входу з деяким порогом. При значенні мережевого входу, дорівнює або більше за поріг, нейрон виробляє вихід 1, а в іншому разі не виробляє жодного виходу. Завдяки різкій зміні значення при досягненні порога така активаційна функція зветься жорсткою.
Історично поняття ПІН із жорсткою пороговою активаційною функцією вперше запропонували два вчених — Уоррен МакКа- лок та Уотер Пітс (Warren McCulloch, Walter Pitts) на початку сорокових років XX століття. На їхню честь нейрони подібного типу називають нейронами МакКалока—Пітса, або МР-нейронами.
Як «стискальна» функція часто використовується логічна або «сигмоїдальна» (S-подібна) функція, показана на рисунку. В роботах розглядаються моделі з безперервною активаційною функцією F, що моделює біологічний нейрон.
F(x) = ,
l+exp(-XNET)
де X — коефіцієнт, що визначає крутизну сигмоїдальної функції. Якщо X велике, F наближається до описаної раніше порогової функції. Невеликі значення X дають пологіший нахил.
Як і для бінарних систем, стійкість гарантується, якщо ваги симетричні, то Wy= Wjj і w u = 0 за всіх і. Якщо X велике, безперервні системи функціонують подібно до дискретних бінарних систем, остаточно стабілізуючись зі всіма виходами, близькими до нуля або одиниці, тобто у вершині одиничного гіперкуба. Із зменшенням X стійкі точки віддаляються від вершин, послідовно зникаючи з наближенням X до нуля.
За аналогією з електронними системами активаційну функцію можна вважати нелінійною підсилювальною характеристикою штучного нейрона. Коефіцієнт підсилення обчислюється як відношення приросту величини OUT до невеликого приросту величини NET, що викликав його. Він виражається нахилом кривої за певного рівня збудження і змінюється від малих значень при великих негативних збудженнях (крива майже горизонтальна) до максимального значення при нульовому збудженні і знову зменшується, коли збудження стає великим позитивним. Гроссберг (1973) виявив, що подібна нелінійна характеристика вирішує поставлену їм дилему шумового насичення. Яким чином одна і та
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
239
сама мережа може обробляти і слабкі, і сильні сигнали? Слабкі сигнали вимагають великого мережевого посилення, щоб дати придатний до використання вихідний сигнал. Проте підсилювальні каскади з великими коефіцієнтами посилення можуть привести до насичення виходу шумами підсилювачів (випадковими флуктуаціями), які присутні в будь-якій фізично реалізованій мережі. Сильні вхідні сигнали в свою чергу також призводитимуть до насичення підсилювальних каскадів, спричинюючи можливість корисного використання виходу. Центральний діапазон логічної функції, що має великий коефіцієнт підсилення, розв’язує проблему обробки слабких сигналів, тоді як діапазони з підсиленням падає, яке на позитивному і негативному кінцях підходять для великих збуджень. Таким чином, нейрон функціонує з великим підсиленням в широкому діапазоні рівня вхідного сигналу.
Цю функцію застосовують дуже часто для багатошарових пер- цептронів і інших мереж з безперервними сигналами. Рівність, безперервність функції — важливі позитивні якості. Безперервність першої похідної дає змогу навчати мережу градієнтними методами (наприклад, методом зворотного поширення помилки).
Функція симетрична щодо точки (NET=0, OUT=l/2), це робить рівноправними значення OUT=0 і OUT=l, що суттєво для роботи мережі. Проте діапазон вихідних значень від 0 до 1 несиметричний, через це навчання значно уповільнюється.
Ця функція — стискальна, тобто для малих значень NET коефіцієнт передачі K=OUT/ NET великий, для великих значень він зменшується. Тому діапазон сигналів, з якими нейрон працює без насичення, виявляється широким.
Іншою широко використовуваною активаційною функцією є гіперболічний тангенс. За формою вона подібна до логічної функції і часто застосовується біологами як математична модель активації нервової клітини.
Значення похідної легко виражається через саму функцію. Швидкий розрахунок похідної прискорює навчання. Також застосовується для мереж з безперервними сигналами. Функція симетрична щодо точки (0,0), у цьому її перевага порівняно з сигмо'щом.
Як і логічна функція гіперболічний тангенс є S-подібною функцією, але він симетричний щодо початку координат, і в точці NET = 0 значення вихідного сигналу OUT дорівнює нулю. На відміну від логічної функції, гіперболічний тангенс приймає значення різних знаків, що виявляється вигідним для ряду мереж.
240
Г.Ф. Іванчвнко
Полога сходинка розраховується легко, але має розривну пер-' шу похідну в точках NET - F, NET = F + Д, що ускладнює алгоритм навчання. Експонента: OUT = e~NET застосовується в спеціальних випадках.
NET
SOFTMAX-фунщія: OUT = —
'
і
Для цієї функції підсумування проводиться по всіх нейронах цього шару мережі. Такий вибір функції забезпечує суму виходів шару, що дорівнює одиниці за будь-яких значень сигналів NET,- шару, що дає змогу трактувати OUT,- як вірогідність подій, сукупність яких (всі виходи шару) утворює повну групу. Завдяки цій властивості SOFTMAX-функцію можна застосовувати в завданні класифікації, перевірки гіпотез, розпізнавання образів і в усіх інших випадках, де потрібні виходи — вірогідності.
Вибір функції активації визначається:
1. Специфікою завдання.
2. Зручністю реалізації на ЕОМ у вигляді електричної схеми або в інший спосіб.
3. Алгоритмом навчання: деякі алгоритми накладають обмеження на вигляд функції активації, це потрібно враховувати. Найчастіше вид нелінійності не робить принципового впливу на вирішення завдання. Проте вдалий вибір може скоротити час навчання у кілька разів.
Розглянута проста модель штучного нейрона ігнорує багато властивостей свого біологічного двійника. Наприклад, вона не бере до уваги затримки в часі, які впливають на динаміку системи. Вхідні сигнали відразу ж передаються у вихідний сигнал. І, що важливіше, вона не враховує дії функції частотної модуляції, що синхронізує функції біологічного нейрона, які ряд дослідників вважають вирішальним.
5.4. Одношарова та багатошарова нейронні мережі
На цей час не існує єдиної стандартної класифікації НМ, оскільки нейроінформатика є новою галуззю науки. Тому розглянемо класифікацію НМ тільки за деякими базовим характеристикам. Залежно від:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
241
• кількості шарів нейронів НМ підрозділяють на одношарові і багатошарові. Іноді особливо виділяють двошарові і тришарові НМ;
• типу функції активації НМ підрозділяють на дискретні, реальні (безперервні) і дискретно-безперервні;
• напрямку поширення сигналів НМ підрозділяють на мережі прямого поширення, мережі зворотного поширення і двоспрямо- вані НМ;
• кількості і структури зв’язків НМ підрозділяють на повно- зв’язні (усі нейрони зв’язані з усіма) і неповнозв’язні.
Формальні нейрони можуть об’єднуватися в мережі різним чином. Більші і складніші нейронні мережі мають, зазвичай, і великі обчислювальні можливості. Хоча створено мережі всіх конфігурацій, які тільки можна собі уявити, пошарова організація нейронів копіює шаруваті структури певних відділів мозку.
Хоча один нейрон і здатний виконувати прості процедури розпізнавання, перевага нейронних обчислень виникає від з’єднань нейронів у мережах. Проста мережа складається з групи нейронів, що створюють шар, як бачимо на рис. 5.3.
Рис. 5.3. Одношарова нейронна мережа
Відзначимо, що входи ліворуч слугують лише для розподілу вхідних сигналів. Вони не виконують жодних обчислень, і тому не вважаються шаром. З цієї причини вони позначені кругами, щоб відрізняти їх від обчислювальних нейронів, позначених квадратами. Кожен елемент з множини входів X сполучений окремою вагою з кожним штучним нейроном. А кожен нейрон видає зважену суму входів у мережу. У штучних і біологічних мережах багато з’єднань можуть бути відсутні, всі з’єднання показано з метою спільності. Можуть мати місце також з’єднання між виходами і входами елементів у шарі.
242
Г.Ф. Іванченко
Зручно вважати ваги елементами матриці W. Матриця має т рядків і п стовпців, де ти — число входів, а п — число нейронів. Наприклад м>2,з — це вага, що пов’язує третій вхід з другим нейроном. Таким чином, обчислення вихідного вектора N, компонентами якого є виходи OUT нейронів, зводиться до матричного множення N = XW, де N і X — вектори-рядки.
Багатошарова нейронна мережа
або багатошаровий персептрон
Основним обчислювальнм елементом багатошарового персеп- трона або багатошарової нейронної мережі (БНМ) є формальний нейрон. Він виконує параметричне нелінійне перетворення вхідного вектора х у скалярну величину у.
Серед різних структур штучних нейронних мереж (ШНМ) однією з найвідоміших є багатошарова структура, в якій кожен нейрон довільного шару пов’язаний зі всіма нейронів попереднього шару або, у разі першого шару, зі всіма входами ШНМ. Такі ШНМ називають повнозв’язними.
Нейрони утворюють мережу, що характеризується такими параметрами і властивостями: М — число шарів мережі, — число нейронів ц-го шару, причому зв’язки між нейронами в шарі відсутні.
Виходи нейронів ц-го шару, ц = 1,2, 1 надходять на входи
нейронів тільки наступного ц+1-го шару. Зовнішній векторний сигнал х надходить на входи нейронів тільки першого шару, виходи нейронів останнього М-го шару утворюють вектор виходів мережі У .
Кожний /-й нейрон ц-го шару (ц,-й нейрон) перетворює вхідний вектор на вихідну скалярну величину У^. Це перетворення складається з двох етапів: спочатку обчислюється дискримінанта функція net^, що далі перетворюється на вихідну величину
Дискримінантна функція являє собою відтинок багатовимірного ряду Тейлора. Коефіцієнти розкладання цього відтинка утворюють вектор вагових коефіцієнтів або пам’ять нейрона. Дискримінантна функція нейрона має вигляд:
netM = wp) + Z ,
j=l
де Wi0^,..., W1,0) — вектор вагових коефіцієнтів нейро¬
на; х}^ —j- а компонента TV-вимірного вхідного векторах^.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
243
Нелінійне перетворення У*’*') = \|/(net(,M)) задається функцією активації, що є монотонною й обмеженою. Зокрема, у разі негативних виходів нейрона такою функцією може бути сигмоїдальна функція V|/(jf) = 1/(1+е"*).
Позначимо через У = (Уй,1),Уц,2),...,Уц’лад)гвектор виходу нейронів ц-го шару.
Коли в мережі тільки один шар, алгоритм її навчання з учителем цілком очевидний, оскільки правильні вихідні стану нейронів єдиного шару свідомо відомі, і підлаштовування синаптичних зв’язків відбувається в напрямі, що мінімізує помилку на виході мережі. За цим принципом будується, наприклад, алгоритм навчання одношарового перцептрона. А в багатошарових мережах оптимальні вихідні значення нейронів усіх шарів, окрім останнього, зазвичай, невідомі, і двох або більше шарових перцептроів вже неможливо навчити, керуючись тільки величинами помилок на виходах ШНМ. Один з варіантів розв’язання цієї проблеми — розробка наборів вихідних сигналів, відповідних вхідним, для кожного шару ШНМ, що є дуже трудомісткою операцією і не завжди здійсненно. Другий варіант — динамічне підлаштування вагових коефіцієнтів синапсів, під час якого вибираються, зазвичай, найслабкіші зв’язки, і змінюються на незначну величину в той або інший бік, а зберігаються тільки ті зміни, які сприяли зменшенню помилки на виході всієї мережі. Очевидно, що цей метод, незважаючи на свою начебто простоту, вимагає громіздких обчислень. І, нарешті, третій, припустимий варіант — поширення сигналів помилки від виходів ШНМ до її входів у напрямі, зворотному прямому поширенню сигналів у звичайному режимі роботи. Цей алгоритм навчання ШНМ отримав назву процедури зворотного поширення.
Як вказувалося вище, багатошарові нейронні мережі мають більшу якісну потужність, аніж одношарові, лише в разі присутності нелінійності. Стискальна функція забезпечує потрібну не- лінійність. Таким чином, вихідний сигнал ШНЕ дорівнює 1 або 0.
Перший шар нейронів (сполучений з входами) служить лише як розподільні точки, підсумовування входів тут не здійснюється. Вхідний сигнал просто проходить через них до вагів на їх виходах. А кожен нейрон подальших шарів видає сигнали NET і OUT, як описано вище.
У літературі немає одноманітності щодо того, як рахувати число шарів у таких мережах. Одні автори використовують число
244
Г.Ф. Іванчвнко
шарів нейронів (включаючи вхідний шар, що не підсумовує), інші — число шарів ватів.
Як видно з публікацій, немає загальноприйнятого способу підрахунку числа шарів у мережі. Багатошарова мережа складається з безлічі нейронів і вагів, що чередується. Нейрони вхідного шару служать лише як розгалуження для першої множини вагів і не впливають на обчислювальні можливості мережі. Нейрон об’єднаний множиною вагів, приєднаних до його входу. Таким чином, ваги першого шару закінчуються на нейронах першого шару. Вхід розподільного шару вважається нульовим шаром.
Далі, ваги шару вважаються пов’язаними з наступними за ними нейронами. Отже, шар складається з безлічі вагів з наступними за ними нейронами, що підсумовують зважені сигнали.
Щоб побудувати НМ, необхідно обрати її параметри. Найчастіше вибір значень вагів і порогів вимагає навчання, тобто покро- кових змін вагових коефіцієнтів і порогових рівнів.
Загальний алгоритм побудови НМ
1. Визначити, який сенс вкладається в компоненти вхідного вектора X. Вхідний вектор має містити формалізовану умову завдання, тобто всю інформацію, необхідну для отримання відповіді.
2. Вибрати вихідний вектор так, щоб його крмпоненти містили повну відповідь на поставлене завдання.
3. Вибрати вид нелінійності в нейронах (функцію активації). Бажано врахувати специфіку завдання, оскільки вдалий вибір скоротить час навчання.
4. Вибрати число шарів і нейронів у шарі.
5. Задати діапазон зміни входів, виходів, вагів і порогових рівнів, враховуючи безліч значень вибраної функції активації.
6. Присвоїти початкові значення ваговим коефіцієнтам і поро- говим рівням і додатковим параметрам (наприклад, крутизні функції активації, якщо її налаштовуватимуть під час навчання). Початкові значення не мають бути великими, щоб нейрони не потрапили у насичення (на горизонтальній ділянці функції активації), інакше навчання буде дуже повільним. Початкові значення не мають бути і занадто малими, щоб виходи більшої частини нейронів не дорівнювали нулю, інакше навчання також сповільниться.
7. Провести навчання, тобто підібрати параметри мережі так, щоб завдання розв’язувалося найкращим чином. Після закінчен¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
245
ня навчання мережа готова вирішити завдання того типу, якому вона навчена.
8. Подати на вхід мережі умови завдання у вигляді вектора X. Розрахувати вихідний вектор, який і дасть формалізоване розв’язання задачі.
Вибір кількості нейронів і шарів НМ
Немає суворо визначеної процедури для вибору кількості нейронів і кількості шарів у мережі. Що більша кількість нейронів і шарів, то ширше можливість мережі, тим повільніше вона навчається і працює і тим більше нелінійною може бути залежність вхід—вихід.
Кількість нейронів і шарів зв’язана з:
складністю завдання;
кількістю даних для навчання;
потрібного кількістю входів і виходів мережі;
наявними ресурсами: пам’яттю і швидкодією машини, на якій моделюється мережа.
Були спроби записати емпіричні формули для числа шарів і нейронів, але застосовність формул виявилася дуже обмеженою. Якщо в мережі занадто мало нейронів або шарів:
1) мережа не навчиться і помилка під час роботи мережі залишиться великою;
2) на виході мережі не передаватимуться різкі коливання функції, що апроксимується, >>(*)•
Перевищення потрібної кількості нейронів теж заважає роботі мережі.
Якщо нейронів або шарів дуже багато:
1) швидкодія буде низька, а пам’яті буде потрібно багато — на фонейманівских БОМ;
2) мережа перенавчатиметься: вихідний вектор передаватиме незначні і неістотні деталі, залежно що вивчається, у(х), наприклад, шум або помилкові дані;
3) залежність виходу від входу виявиться різко нелінійною: вихідний вектор буде істотний і непередбачуваний мінятися за малої зміни вхідного вектора х;
4) мережа буде не здатна до узагальнення: у галузі, де немає або мало відомих точок функції у(х), вихідний вектор буде випадковий і непередбачуваний, не адекватний завданню.
Усі моделі нейромереж становлять множину нейронів, зв’язаних у певний спосіб між собою. Основними відмінностями моде-
246
Г.Ф. Іванченко
лей НМ є способи зв’язку нейронів між собою, механізми і напрямки поширення сигналів мережею, а також обмеження на функції активації, що використовуються.
Одна з найважливіших властивостей НМ — здатність до самоорганізації і самоадаптації з метою поліпшення якості функціонування. Це досягається навчанням НМ, алгоритм якого задається набором навчальних правил. Навчальні правила визначають, яким чином змінюються зв’язки у відповідь на вхідний вплив. Навчання засноване на збільшенні сили зв’язку (ваги синапсу) між одночасно активними нейронами. Таким чином, зв’язки, що часто використовуються, підсилюються, що пояснює феномен навчання шляхом повторення і звикання.
Алгоритм навчання одношарового дискретного персептрона має вигляд:
Крок 1. Вагам w,{0) (і=1,...Д) і пороговим 0(0) привласнюються випадкові значення (через w,{t) позначений ваговий коефіцієнт z'-ro входу персептрона на момент часу t, через 0(f) позначена величина зсуву (порога) нейрона на момент часу t).
Крок 2. Подається черговий вхідний вектор х={хі, ...^n}T з навчальної множини і бажаний вихід y*(t) (y*(t) = 1, якщо jc(/) належить до класу A, y*(t) = 0, якщо x(t) належить до класу В).
Крок 3. Обчислюється реальне значення н^ виході персептрона за формулами: і
net = '£wl(t)xi(t),
1=1
у(()= v(net - Є(/)).
Крок 4. Корегуються ваги відповідно до рівностей:
W,{/+1) = w,(/) + r\(y*(t) -y(t))xj(t), і = 1,2, ...Д,
0(f+l) = 0(0 + г,0*(0 -ЯОХ
де Г| — позитивний коригувальний приріст.
Крок 5. Якщо досягнуто збігу, то процедура навчання закінчується; інакше — перехід до кроку 2.
Відповідно до цього алгоритму спочатку відбувається ініціалізація параметрів персептрона випадковими значеннями. Потім по черзі подаються образи з відомою класифікацією, обрані з навчальної множини, і корегуються ваги відповідно до формул кроків 3 і
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
247
4. Величина корекції визначається позитивним коригувальним прирістом г|, конкретне значення якого обирається досить велике, щоб швидше здійснювалася корекція ваг, і водночас досить мале
— щоб не допустити надмірного зростання значень ваг.
Процедура навчання триває доти, доки не буде досягнута збіжність, тобто поки не будуть отримані ваги, що забезпечують правильну класифікацію для всіх образів з навчальної множини.
У разі, якщо навчальні вибірки розділити гіперплощиною неможливо, для навчання персептрона можна використовувати алгоритм Уїдроу—Хоффа, що мінімізує середньоквадратичну помилку між бажаними і реальними виходами мережі для навчальних даних. Цей алгоритм також можна застосовувати для навчання одношарового реального персептрона. Алгоритм Уїдроу—Хоффа можна записати в тому самому вигляді, що й описаний вище алгоритм, припускаючи, що у вузлах персептрона нелінійні елементи відсутні, а коригувальне збільшення т) у процесі ітерацій поступово зменшується до нуля.
Якщо для розв’язання задачі розпізнавання образів використовується дискретний персептрон, вирішальне правило відносить вхідний образ до класу А, якщо вихід персептрона дорівнює 1, і до класу В — у протилежному разі.
У разі, якщо для розв’язання задач розпізнавання образів використовується реальний персептрон, вирішальне правило відносить вхідний образ до класу А, якщо вихід мережі більше 0,5, і до класу В — у протилежному разі.
Процес навчання мережі здійснюється в результаті мінімізації цільової функції — певного критерію якості і7^), що характеризує інтегральний ступінь близькості виходів мережі у^ік) і вказівки учителя у*(к):
*■(-)-тіеМ*.»)).
к т=\
де к — номер поточного циклу навчання НМ; т=1, 2,..., к — номери попередніх циклів навчання НМ; м> — складений вектор- стовпець вагових коефіцієнтів мережі, що складається з векторів- стовпців = (н'(ц'1 , И^-2)Т,..., н^> )Т, \1 = кожного
шару.
Для навчання БНМ на практиці зазвичай використовують градієнтні алгоритми.
248
Г.Ф. Іванчвнко
Виявляється, що такі багатошарові мережі мають більші можливості, ніж одношарові, і останніми роками були розроблені алгоритми для їх навчання.
Багатошарові мережі (БНМ) можуть утворюватися каскадами шарів. Вихід одного шару є входом для подальшого шару. Подібну мережу наведено на рис. 5.4 і зображено зі всіма з’єднаннями. Найпоширенішим видом такої мережі став багатошаровий пер- цептрон.
І
к"
І
І
V
2*
'Ух
_К3_
Вага К
Рис. 5.4. Приклад двошарової нейронної мережі без зворотних зв’язків
Мережа складається з довільної кількості шарів нейронів. Нейрони кожного шару з’єднуються з нейронами попереднього й наступного шарів за принципом «кожен з кожним». Перший шар називають сенсорним, або вхідним, внутрішні шари називають прихованими, або асоціативними, останній — вихідним, або результативним. Кількість нейронів у шарах може бути довільною. Зазвичай у всіх прихованих шарах однакова кількість нейронів. Позначимо кількість шарів і нейронів у шарі. Вхідний шар: N1 нейронів; М/ нейронів у кожному прихованому шарі; N0 вихідних нейронів; X — вектор вхідних сигналів мережі; У — вектор вихідних сигналів.
Трапляється плутанина з підрахунком кількості шарів у мережі. Вхідний шар не виконує жодних обчислень, а лише розподіляє вхідні сигнали, тому іноді його рахують, іноді — ні. Позначимо через Ж повну кількість шарів у мережі, враховуючи вхідний. Роботу багатошарового перцептрона (БШП) описують формулами:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
249
NETj, =
OUTji = F (NETц-Qjt)
= OUT„
де індексом і позначатимемо номер входу, j — номер нейрона в шарі, / — номер шару.
Xtji — вхідний сигнал у-го нейрона в шарі /;
Wyi — ваговий коефіцієнт і-го входу нейрона номер j в шарі /;
NETji — сигнал NET у-го нейрона в шарі /;
OUTji — вихідний сигнал нейрона;
0,7 — пороговий рівень нейрона у в шарі /;
Щі — вектор-стовпець вагів для всіх входів нейрона] в шарі /;
W/ — матриця вагів усіх нейронів у шарі /.
У стовпцях матриці розташовані вектори Щ/. Аналогічно Xji — вхідний вектор-стовпець шару /.
Кожен шар розраховує нелінійне перетворення від лінійної комбінації сигналів попереднього шару. Звідси видно, що лінійна функція активації може застосовувати тільки для тих моделей мереж, де не потрібне послідовне з’єднання шарів нейронів один за одним. Для багатошарових мереж функція активації має бути нелінійною, інакше можна побудувати еквівалентну одношарову мережу, і багатошаровість виявляється непотрібною. Якщо застосовано лінійну функцію активації, то кожен шар даватиме на виході лінійну комбінацію входів. Наступний шар дасть лінійну комбінацію виходів попереднього, а це еквівалентно одній лінійній комбінації з іншими коефіцієнтами, і може бути реалізовано у вигляді одного шару нейронів.
Багатошарові мережі не можуть привести до збільшення обчислювальної потужності порівняно з одношаровою мережею лише в тому разі, якщо активаційна функція між шарами буде нелінійною. Обчислення виходу шару полягає в добутку вхідного вектора на першу вагову матрицю з подальшим множенням (якщо відсутня нелінійна активаційна функція) результаційного вектора на другу вагову матрицю (XW{)W2. Оскільки множення матриць асоціативне, то X(W\ W2).
Це показує, що двошарова лінійна мережа еквівалентна одному шару з ваговою матрицею, що дорівнює добутку двох вагових матриць. Отже, будь-яка багатошарова лінійна мережа може бути замінена на еквівалентну одношарову мережу. Таким чином, для
250
Г.Ф. Іванчвнко
розширення можливостей мереж, порівняно з одношаровою ме- режею, потрібна нелінійна активаційна функція.
Багатошарова мережа може формувати на виході довільну багатовимірну функцію за відповідного вибору кількості шарів, діапазону зміни сигналів і параметрів нейронів. Як і ряди, багатошарові мережі виявляються універсальним інструментом апроксимації функцій. Наприклад, функцію можна апроксимува- ти розкладанням у ряд /(х) = '£с,/і(х) чи використати нейронну
мережу.
/(х) = Р
*’(2>/іЛЛ,лі -0у,.)
2>< *2
шарі
“вЛ2...
шар 2
-Є
шар N
За рахунок почергового розрахунку лінійних комбінацій і нелінійних перетворень досягається апроксимація довільної багатовимірної функції за відповідного вибору параметрів мереж.
У багатошаровому перцептроні немає зворотних зв’язків. Такі моделі називають мережами прямого поширення. Вони не мають внутрішнього стану і не дають змогу без додаткових прийомів моделювати.
5.5. Радіально-базисні нейронні мережі
Радіально-базисна НМ (РБНМ) складається з двох шарів. Сполучні вагові вектори шарів позначатимемо де ц — номер шару (ц=1,2),у — номер нейрона (вузла) у шарі. Базисні (чи ядерні) функції в першому шарі здійснюють локалізовану реакцію на вхідний стимул. Вихідні вузли мережі формують зважену лінійну комбінацію з базисних функцій, обчислених вузлами першого шару.
Вихідні вузли відповідають вихідним класам, тоді як вузли першого шару становлять кластери (кількість кластерів т задає
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
251
користувач), на які розбивається вхідний простір. Позначимо х = (Х\,..., X;,..., Хм) іу = (уі,...,уі,...,ук) — вхід і вихід мережі відповідно. Тут N— кількість ознак, а К—число класів.
Вихід j-гo вузла першого шару, використовуючи ядерну функцію Гауссіан як базисну, визначається за формулою:
иі = ехр
(де - *М)Г (де -
2а,2
,7=1,2
де х — вхідний образ (екземпляр), >у(ІЛ — його вхідний ваговий вектор (тобто центр Гауссіана для вузла /) і а2,- — параметр нормалізації 7-го вузла, такий, що 0 < і/у < 1 (що ближче вхід до центру Гауссіана, то сильніше реакція вузла).
Вихід^ 7-го вузла другого шару визначається з виразу:
уГ^)Ти,]=\,2,..,К,
де — ваговий вектор для 7-го вузла другого шару і и — вектор виходів першого шару.
Мережа виконує лінійну комбінацію нелінійних базисних функцій. Завдання навчання мережі полягає в мінімізації помилки
де У у і — бажане і розраховане значення виходу 7-го вузла вихідного шару для 5-го екземпляра, 5 — розмір набору даних (кількість екземплярів), і К — число вихідних вузлів (число класів). Далі для наочності верхній індекс в випущено.
Навчання РБНМ може виконуватися у два різні способи.
Перший спосіб полягає в тому, що алгоритмом кластеризації формується фіксована множина центрів кластерів. Потім шляхом мінімізації квадратичної помилки, тобто мінімізації Е, одержують асоціації центрів кластерів з виходом.
Другий спосіб полягає в тому, що центри кластерів можуть бути також навчені поряд з вагами від першого шару до вихідного шару методом градієнтного спуску. Однак навчання центрів поряд з вагами може призвести до влучення мережі в локальні мінімуми.
Нехай фіксована множина центрів кластерів сформована на основі першого способу, а центри кластерів позначені
252
Г.Ф. Іванчвнко
у = 1,..., т. Параметр нормалізації Oj є ступенем розподілу даних, що асоційовані з кожним вузлом.
Навчання у вихідному шарі виконується після того, як визначено параметри базисних функцій.
Ваги зазвичай навчають, використовуючи алгоритм середньо- квадратичних відхилень:
Аи'(ц’-') = -т|ЄуИ,
де в) = У]-у*] та ті — коефіцієнт швидкості навчання.
5.6. Мережі Хопфілда зі зворотними зв’язками
У мереж, розглянутих раніше, не було зворотних зв’язків, тобто з’єднань, що йдуть від виходів деякого шару до входів цього таки шару або попередніх шарів. Цей спеціальний клас мереж називають мережами без зворотних зв’язків, або мережами прямого поширення. Мережі, що мають з’єднання від виходів до входів, називаються мережами із зворотними зв’язками.
У мереж без зворотних зв’язків відсутня пам’ять, їх вихід цілком визначається поточними входами і значеннями вагів. У деяких конфігураціях мереж із зворотними зв’язками попередні значення виходів повертаються на входи. Отже, вихід визначається і поточним входом, і попередніми виходами. З цієї причини мережі із зворотними зв’язками можуть мати властивості, подібні до короткочасної людської пам’яті, — мережеві виходи частково залежать від попередніх входів.
Відсутність зворотного зв’язку гарантує безумовну стійкість мереж. Вони не можуть увійти до режиму, коли вихід безперервно блукає від стану до стану і не придатний до використання. Але ця вельми бажана властивість досягається не без втрат у мережі без зворотних зв’язків більше обмежені можливості порівняно з мережами із зворотними зв’язками. На рис. 5.5 наведено мережу
із зворотними зв’язками, що складається з двох шарів.
Оскільки мережі із зворотними зв’язками мають передавати сигнали від виходів до входів, то відгук таких мереж є динамічним, тобто після застосування нового входу обчислюється вихід, і після передавання мережею зворотного зв’язку модифікує вхід. Потім
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
253
вихід повторно обчислюється, і процес повторюється знову. Для стійкої мережі послідовні ітерації приводять до дедалі менших змін виходу, поки врешті-решт вихід не стає постійним. Для багатьох мереж процес ніколи не закінчується, такі мережі називають нестійкими. Нестійкі мережі мають цікаві властивості і вивчалися як приклад хаотичних систем. Натомість ми сконцентруємо увагу на стійких мережах, які врешті-решт дають постійний вихід.
Шар 0 Шар 1
Рис. 5.5. Мережа зі зворотними зв’язками.
Пунктирні лінії позначають нульові ваги
Проблема стійкості заганяла в глухий кут перших дослідників. Ніхто не в змозі був передбачити, які з мереж будуть стійкими, а які перебуватимуть у постійній зміні. Мало того, проблема через те уявлялася такою складною, що багато дослідників були налаштовані песимістично щодо можливості її розв’язання.
На щастя, було отримано теорему [25], що описала підмножину мереж із зворотними зв’язками, виходи яких врешті-решт досягають стійкого стану. Завдяки цьому чудовому досягненню сьогодні багато учених досліджують складну поведінку і можливості цих систем.
Дж. Хопфілд зробив важливий внесок і в теорію, і в застосування систем із зворотними зв’язками. Тому деякі з конфігурацій відомі як мережі Хопфілда.
Спосіб уявлення дещо відрізняється від того, який використовував Хопфілд, але еквівалентний йому з функціональної точки зору. Нульовий шар, як і на попередніх малюнках, не виконує обчислювальної функції, а лише розподіляє виходи мережі назад на входи. Кожен нейрон першого шару обчислює зважену суму своїх входів, даючи сигнал NET, який потім за допомогою нелі¬
254
Г.Ф. Іванченко
нійної функції F перетвориться на сигнал OUT. Ці операції подібні до з нейронів інших мереж.
У першій роботі Хопфілда функція F була пороговою функцією. Вихід такого нейрона дорівнює одиниці, якщо зважена сума виходів з інших нейронів більше порогу 7}, інакше вона дорівнює нулю. Він обчислюється таким чином:
Стан мереж — це безліч поточних значень сигналів OUT від усіх нейронів. У первинній мережі Хопфілда стан кожного нейрона змінювався в дискретні випадкові моменти часу, в подальшій роботі стани нейронів могли змінюватися одночасно. Оскільки виходом бінарного нейрона може бути тільки нуль або одиниця (проміжних рівнів немає), то й поточний стан мережі є двійковим числом, кожен біт якого є сигналом OUT деякого нейрона.
Функціонування мережі легко візуалізується геометрично. На рис. 5.6 а) наведено випадок двох нейронів у вихідному шарі, причому кожній вершині квадрата відповідає один з чотирьох станів системи (00, 01, 10, 11). На рис. 5.6,6) наведено триней- ронну систему, представлену кубом (у тривимірному просторі), що має вісім вершин, кожна з яких помічена трибітовим бінарним числом. Загалом система з w-нейронами має 2п різних станів і подається и-мірним гіперкубом.
NETj = X^ijOUTj + INj,
(4.1.)
OUT = 1, якщо NETj>7},
ПТТТ = П aimmWET^T.
in
00
01
10
11
001
110
000
а)
б)
Рис. 5.6.
а) два нейрони породжують систему з чотирма станами;
б) три нейрони породжують систему з вісьма станами
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
255
Коли подається новий вхідний вектор, мережа переходить з вершини у вершину, поки не стабілізується. Стійка вершина визначається мережевими вагами, поточними входами і величиною порога. Якщо вхідний вектор частково неправильний або неповний, то мережа стабілізується у вершині, найближчій до бажаної.
Як і в інших мережах, ваги між шарами в цій мережі можна розглядати у вигляді матриці W. Мережа із зворотними зв’язками є стійкою, якщо її матриця симетрична і має нулі на головній діагоналі, тобто якщо н'у = м>уі- і м>ц = 0 для всіх і.
Стійкість такої мережі може бути доведена. Припустимо, що знайдено таку функцію, яка завжди зменшується у разі зміни стану мережі. Врешті-решт ця функція має досягти мінімуму і припинити зміну, гарантуючи тим самим стійкість мережі. Така функція, що має назву функція Ляпунова, для мереж із зворотними зв’язками може бути введена таким чином:
£ = -{ЕЕ^°иТіОиТі -Е/риї; +1^01^ , (4.2)
2 і І ) І
деЕ — штучна енергія мережі, м>у — вага від виходу нейрона і до входу нейрона у, ОІЛ] — вихід нейрона у, 7,- — зовнішній вхід нейрона у, 7}— поріг нейрона у.
Зміна енергії Е, спричинена зміною стану у-нейрона, є
8Е =
KV>UTd+INj-Tj i*j
80UT, = -[NET, - Tj ]50UT,, (4.3)
де 80UT, — зміна виходу j-го нейрона.
Припустимо, що величина NET нейрона у більше за поріг. Тоді вираз в дужках буде позитивним, а з рівняння (4.1) виходить, що вихід нейрона у має змінитися в позитивний бік (або залишитися без змін). Це означає, що 80UT може бути тільки позитивним або нулем, і 6Е має бути негативним. Отже, енергія мережі має або зменшитися, або залишитися без змін.
Далі припустимо, що величина NET менше за поріг. Тоді величина 60UT, може бути тільки негативною або нулем. Отже, знову енергія має зменшитися або залишитися без змін. І, нарешті, якщо величина NET дорівнює порогу, 8у дорівнює нулю, і енергія залишається без зміни.
256
Г.Ф. Іванчвнко
Це показує, що будь-яка зміна стану нейрона або зменшить енергію, або залишить її без змін. Завдяки такому безперервному прагненню до зменшення енергія врешті-решт має досягти мінімуму й припинити зміни. За визначенням така мережа є стійкою.
Симетрія мережі є достатньою, але не необхідною умовою для стійкості системи. Є багато стійких систем, наприклад всі мережі прямої дії. Наближеної симетрії зазвичай досить для стійкості систем.
5.7. Статичні мережі Хопфілда і машина Больцмана
Недоліком мереж Хопфілда є їх тенденція стабілізуватися в локальному, а не глобальному мінімумі функції енергії. Ця складність долається переважно за допомогою класу мереж, відомих під назвою машин Больцмана, в яких зміни станів нейронів обумовлені статистичними, а не детермінованими закономірностями. Існує тісна аналогія між цими методами і відпалом металу, тому й самі методи часто називають імітацією відпалу.
Це дуже нагадує відпал металу, тому для її опису часто використовують термін «імітація відпалу». У металі, нагрітому до температури, що перевищує його точку плавлення, атоми перебувають у сильному безладному русі. Як і у всіх фізичних системах, атоми прагнуть до стану мінімуму енергії (єдиного кристалу в цьому випадку), але за високих температур енергія атомних рухів перешкоджає цьому. В процесі поступового охолоджування металу виникають дедалі нижченергетичні стани, доки врешті-решт не буде досягнутий найнижчий з можливих станів, глобальний мінімум. У процесі відпалу розподіл енергетичних рівнів описується таким співвідношенням:
Якщо правила зміни станів задані статистично, а не детерміновано, для реалізації бінарної мережі Хопфілда запроваджується імовірність Рк зміни ваги, як функція від величини, на яку вихід нейрона OUT перевищує його поріг. Нехай £* = NET* - 0*, де NET* — вихід NET нейрона к; 0*, — поріг нейрона к, то
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
257
(в знаменнику ймовірнісна функція Больцмана), де Т — штучна температура.
У стадії функціонування штучній температурі Т приписується велике значення, нейрони встановлюються в початковому стані, визначуваному вхідним вектором, і мережі надається можливість шукати мінімум енергії:
1. Приписати стану кожного нейрона з імовірністю Рк значення одиниця, а з імовірністю (1-і*) — нуль.
2. Поступово зменшувати штучну температуру і повторювати крок 1, поки не буде досягнуто рівноваги.
Принцип машини Больцмана може бути перенесений на мережі практично будь-якої конфігурації, хоча стійкість не гарантується. Для цього досить вибрати одну множину нейронів як входи, а іншу множину як виходи. Потім надати вхідній множині значення вхідного вектора і надати мережі можливість працювати відповідно до описаних вище правил 1 та 2.
Процедура навчання для такої мережі складається з таких кроків:
1. Обчислити закріплену ймовірність:
а) надати вхідним і вихідним нейронам значення навчального вектора;
б) надати мережі можливість шукати рівновагу;
в) записати вихідні значення для всіх нейронів;
г) повторити кроки від а) до в) для всіх навчальних векторів;
д) по всій множині навчальних векторів обчислити імовірність того, що значення обох нейронів дорівнює одиниці.
2. Обчислити незакріплену імовірність:
а) надати мережі можливість «вільного руху» без закріплення входів або виходів, почавши з випадкового стану;
б) повторити крок 2 а багато разів, реєструючи значення всіх нейронів;
в) обчислити імовірність того, що значення обох нейронів дорівнює одиниці.
3. Скорегувати ваги мережі таким чином:
6\\Гу =11 (Ру — Ру ) ,
де 5щ — зміна ваги н»у, г| — коефіцієнт швидкості навчання.
Штучні нейронні мережі можуть навчатися по суті таким же чином за допомогою випадкової корекції вагів. Спочатку роб¬
258
Г.Ф. Іванченко
ляться великі випадкові корекції із збереженням тільки тих змін ватів, які зменшують цільову функцію. Потім середній розмір кроку поступово зменшується, і глобальний мінімум врешті-решт досягається.
Якщо зміна ваги приводить до збільшення цільової функції, то ймовірність збереження цієї зміни обчислюється за допомогою розподілу Больцмана:
Р(с)= ехр(-с/кТ), (4.4)
де Р(с) — імовірність зміни в цільовій функції, к — константа, аналогічна константі Больцмана, яку обирають залежно від завдання; Т — штучна температура за шкалою Кельвіна.
За високих температур Р(с) наближається до одиниці для всіх енергетичних станів. Таким чином, високоенергетичний стан майже такий само вірогідний, як і низькоенергетичний. Зі зменшенням температури ймовірність високоенергетичних станів зменшується порівняно з низькоенергетичними. За наближення температури до нуля стає малоймовірним, щоб система перебувала у високоенергетичному стані.
5.8. Нейронні мережі Хопфілда і Хеммінга
Серед різних конфігурацій штучних нейронних мереж зустрічаються такі, за класифікації яких за принципом навчання, строго кажучи, не підходять ані навчання з учителем, ані навчання без учителя. У таких мережах вагові коефіцієнти синапсів розраховуються тільки одного разу перед початком функціонування мережі на основі інформації про оброблювані дані, і все навчання мережі зводиться саме до цього розрахунку. З одного боку, надання апріорної інформації можна розцінювати, як допомога вчителя, але з другою — мережа фактично просто запам’ятовує зразки того, як на її вхід надходять реальні дані, і не може змінювати свою поведінку, тому казати про ланку зворотного зв’язку з учителем не марно. Серед мереж з подібною логікою роботи найбільш відомі мережа Хопфілда та мережа Хеммінга, які зазвичай використовують для організації асоціативної пам’яті.
Структурну схему мережі Хопфілда приведено на рис. 5.7. Вона складається з єдиного шару нейронів, число яких є одно¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
259
часно числом входів і виходів мережі. Кожен нейрон зв’язаний синапсами зі всією рештою нейронів, а також має один вхідний синапс, через який здійснюється введення сигналу. Вихідні сигнали, як завжди, утворюються на аксонах.
Зворотний зв’язок
Шарі
Рис. 5.7. Структурна схема мережі Хопфілда
Завдання, що вирішує ця мережа як асоціативна пам’ять, зазвичай, формулюється так. Відомий певний набір двійкових сигналів (зображень, звукових оцифрувань, інших даних, що описують певні об’єкти або характеристики процесів), які вважаємо за зразок. Мережа повинна вміти з довільного неідеального сигналу, поданого на її вхід, виділити («пригадати» за частковою інформацією) відповідний зразок (якщо такий є) або «зробити висновок» про те, що вхідні дані не відповідають жодному із зразків. Загалом будь-який сигнал можна описати вектором X = {*/.• /-0.../1-1}, п — число нейронів у мережі і розмірність вхідних і вихідних векторів. Кожен елемент Хі дорівнює або +1, або -1. Позначимо вектор, що описує к-ші зразок, через Хк, а його компоненти, відповідно, —Хік &=0.../я-1, т — число зразків. Коли мережа розпізнає (або «пригадає») який-небудь зразок на основі наданих їй даних, її виходи міститимуть саме його, тобто У = Хм, де У — вектор вихідних значень мережі: У = (у,: /=0,...и-1}. Інакше, вихідний вектор не співпаде з жодним зразковим.
Якщо, наприклад, сигнали є якимись зображеннями, то, відобразивши в графічному вигляді дані з виходу мережі, можна буде побачити картинку, що цілком співпадає з однією із зразкових (у разі успіху), або ж «вільну імпровізацію» мережі (у разі невдачі).
260
Г.ф. Іввнчвнко
На стадії ініціалізації мережі вагові коефіцієнти синапсів встановлюються таким чином:
Тут і, у — індекси, відповідно, предсинаптичних і постсинап- тичних нейронів; дсД х/ — і-ий іу-ий елементи вектора к-го зразка.
Алгоритм функціонування мережі такий (р — номер ітерації):
1. На входи мережі подається невідомий сигнал. Фактично його введення здійснюється безпосередньо встановленням значень аксонів: д>,(0)= хи і = 0...Л-1, тому позначення на схемі мережі вхідних синапсів в явному вигляді має суто умовний характер. Нуль у дужці у і означає нульову ітерацію в циклі роботи мережі.
2. Розраховується новий стан нейронів:
де/— активаційна функція у вигляді сходинки.
3. Перевірка, чи змінилися вихідні значення аксонів за останню ітерацію. Якщо так, то — перехід до пункту 2, інакше (якщо виходи стабілізувалися ) — кінець. При цьому вихідний вектор є зразком, що найкращим чином поєднується з вхідними даними.
Іноді мережа не може здійснити розпізнавання і видає на виході неіснуючий образ. Це пов’язано з обмеженістю можливостей мережі. Для мережі Хопфілда число образів т, що запам’ятовуються, не повинно перевищувати величини, що дорівнює близько 0,15п. Крім того, якщо два образи А і Б дуже схожі, вони, можливо, викликатимуть у мережі перехресні асоціації, тобто подавання на входи мережі вектора А приведе до появи на її виходах вектора Б, і навпаки.
Коли немає потреби, щоб мережа в явному вигляді видавала зразок, тобто досить, скажімо, отримувати номер зразка, асоціативну пам’ять успішно реалізує мережа Хеммінга. Ця мережа характеризується, порівняно з мережею Хопфілда, меншими витра¬
(4.5.)
п-\
+1) = И^цУАр) У-0...Я-1.
(4.6.)
і нові значення аксонів
(4.7.)
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
261
тами на пригадування й об’ємом обчислень, що стає очевидним з її структури (рис. 5.8).
Зворотний зв’язок
Рис. 5.8. Структурна схема мережі Хеммінга
Мережа складається з двох шарів. Перший і другий шари мають по т нейронів, де т — число зразків. Нейрони першого шару мають по п синапсів, сполучених з входами мережі (які створюють фіктивний нульовий шар). Нейрони другого шару зв’язані між собою негативними зворотними синаптичними зв’язками. Єдиний синапс з позитивним зворотним зв’язком для кожного нейрона сполучений з його ж аксоном.
Ідея роботи мережі полягає в знаходженні відстані Хеммінга від тестованого образу до всіх зразків. Відстанню Хеммінга називаємо число бітів, що відрізняються, один від одного в двох бінарних векторах. Мережа має обрати зразок з мінімальною відстанню Хеммінга до невідомого вхідного сигналу, в результаті буде активізований лише один вихід мережі, відповідний цьому зразку.
На стадії ініціалізації ваговим коефіцієнтам першого шару і порогу активаційної функції присвоюються такі значення:
хк
и>Л = , /=0...п-1, к=0...т-\
(4.8)
262
Г.Ф. Іванченко
Tk = nl2,k=0...m-\. (4.9)
Тут*,*— і-й елемент к-ого зразка.
Беруть вагові коефіцієнти гальмуючих синапсів в другому шарі, які дорівнюють деякій величині 0 <є< l/w. Синапс нейрона, пов’язаний з його ж аксоном, має вагу +1.
Алгоритм функціонування мережі Хеммінга такий:
1. На входи мережі подається невідомий вектор Х={хі.і=0...п-1}, виходячи з якого розраховуються стани нейронів першого шару (верхній індекс в дужках указує номер шару):
у? =s?=tw9x, +Tj у-O...m-l. (4.10)
і=0
Після цього набутого значення ініціалізувалися значення аксонів другого шару:
yf = У? J = О.../w-l. (4.11)
2. Обчислити нові стани нейронів другого шару:
sf\p +1) = yj(p) - z£y?\p)Jc * jj = 0...Ш -1 (4.12)
к=0
і значення їх аксонів:
yf\p +1)= /[sj2)(P + 1)}у = 0..Л» -1. (4.13)
Активаційна функція / має вид сходинки, причому величина F має бути досить великою, щоб будь-які можливі значення аргументу не приводили до насичення.
3. Перевірити, чи змінилися виходи нейронів другого шару за останню ітерацію. Якщо так — перейти до кроку 2. Інакше — кінець.
З оцінки алгоритму видно, що роль першого шару досить умовна: скориставшись один раз на кроці 1 значенням його вагових коефіцієнтів, мережа більше не звертається до нього, тому перший шар може бути взагалі виключений з мережі (замінений на матрицю вагових коефіцієнтів), що і було зроблено в її конкретній реалізації, описаній нижче.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
263
Резюме за змістом теми
Першим систематично досліджували штучні нейронні мережі Маккалокк і Піттс 1943 р.
Штучна нейронна мережа — система, яка складається із певної кількості пристроїв, так званих штучних нейронів, з’єднаних між собою.
Нейрон є основним будівельним блоком нервової системи. Він є клітиною, подібною до всіх інших клітин тіла.
Конекціоністський підхід до побудови систем штучного інтелекту розвинувся на противагу символьному. В основі конекціоністсь- кого підходу лежить спроба безпосереднього моделювання розумової діяльності людського мозку.
Мислення людини є переважно асоціативним, і в основу роботи систем, які моделюють мислення людини, може бути покладений принцип асоціації. Під асоціацією розуміємо певний ступінь подібності або наявність певних спільних рис між тими чи іншими явищами й поняттями.
На цей час не існує єдиної стандартної класифікації НМ, тому використовується класифікація за деякими базовими характеристиками.
Немає суворо визначеної процедури для вибору кількості нейронів і кількості шарів у мережі. Що більша кількість нейронів і шарів, то ширше можливість мережі, тим повільніше вона навчається і працює і тим більше нелінійної може бути залежність вхід-вихід.
Одна з найважливіших властивостей НМ — здатність до самоорганізації й самоадаптації з метою поліпшення якості функціонування.
Обравши одну з моделей ШНМ, створивши мережу й виконавши алгоритм навчання, ми можемо навчити мережу розв’язувати задачу. Після навчання мережа стає нечутливою до малих змін вхідних сигналів і дає правильний результат на виході.
Якщо пред’явити мережі кілька змінених варіантів вхідного образу, то мережа сама може створити на виході ідеальний відтворений образ, з яким вона ніколи не зустрічалася.
Терміни та поняття до теми
• Штучний нейрон — ШН.
• Штучні нейронні мережі (ШНМ) — сукупність моделей біологічних нейронних мереж, набір математичних й алгоритмічних методів для розв’язання широкого кола задач.
264
Г.Ф. Іввнчвнко
• Дендріти є структурою, що рясно гілкується від тіла клітини. На дедритах розташовуються синаптичні з’єднання, які отримують сигнали від інших аксонів.
• Штучний нейрон імітує в першому наближенні властивості біологічного нейрона.
• Активаційна функція застосовується для тих моделей мереж, де не потрібно послідовне з’єднання шарів нейронів один за одним.
• БНМ — багатошарові нейромережі.
• Навчання — обравши одну з моделей ШНМ, створивши мережу і виконавши алгоритм навчання, ми можемо навчити мережу розв’язанню задачі.
• Здібність узагальнення — після навчання мережа стає нечутливою до малих змін вхідних сигналів і дає правильний результат на виході.
• Здібність абстрагування — якщо надати мережі кілька змінених варіантів вхідного образу, мережа сама може створити на виході ідеальний образ, з яким вона раніше не зустрічалася.
• BrainMaker, OWL, «The АІ Trilogy», Neural 10, NeuroPro — програмні пакети, які моделюють роботу нейронних мереж на універсальних комп’ютерах.
Питання для самоконтролю
1. Поясніть структуру штучної нейронної мережі як набір математичних і алгоритмічних методів для розв’язання широкого кола задач.
2. Покажіть характерні риси штучних нейромереж як універсального інструменту для розв’язання задач
3. Що таке конекціоністський підхід у побудові систем штучного інтелекту та чим відрізняється від символьного?
4. Які системи (та багато їм подібних) отримали назву персептронів?
5. Поясніть принцип асоціації в мисленні людини.
6. Вибір функції активації визначається:
7. Назвіть стандартну класифікацію НМ.
8. Яка схема одношарової нейронної мережі?
Завдання для Індивідуальної роботи, обов’язкові та додаткові практичні завдання
1. Що є характерним для сучасних моделей знань?
2. Моделювання розумової діяльності людського мозку.
3. Конекціоністський підхід як спроба безпосереднього моделювання розумової діяльності людського мозку.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
265
4. Асоціативне мислення людини.
5. Нейрокомп’ютер як програмно-технічна система.
6. Двошарова мережа зворотного поширення.
7. Багатошаровий персептрон або багатошарова нейронна мережа.
8. Приклади навчання одношарового дискретного персептрона.
9. Радіально-базисні нейронні мережі.
10. Алгоритм функціонування мережі Хеммінга.
11. Структурна схема мережі Хопфілда.
12. Больцмановське навчання — стохастичний метод, що безпосередньо застосовують для навчання штучних нейронних мереж.
266
Г.Ф. Іванчвнко
Тема 6
НАВЧАННЯ НЕЙРОННОЇ МЕРЕЖІ
Перелік знань та навичок
Після опанування теми студент має знати:
• активаційні функції порогового елемента;
• основний принцип навчання модельних нейронів;
• класифікцію навчальних алгоритмів;
• алгоритм навчання Кохонена, Коші, Хебба;
• особливості алгоритмів навчання персептрона.
Має вміти:
• побудувати алгоритм навчання нейронної мережі за допомогою процедури зворотного поширення
• моделювати нейронні мережі за допомогою пакета МаИаЬ.
ЗМІСТ ПИТАНЬ ТЕМИ
6.1. Навчання нейронної мережі з учителем і без учителя
Здатність штучних нейронних мереж навчатися є їх найбільш інтригуючою властивістю. Подібно до біологічних систем, які вони моделюють, ці нейронні мережі самі моделюють себе в результаті спроб досягти кращої моделі поведінки.
Штучна нейронна мережа навчається за допомогою певного процесу, який модифікує її ваги. Якщо навчання проходить успішно, то подання мережі множини вхідних сигналів приводить до появи бажаної безлічі вихідних сигналів.
Навчальні алгоритми можуть бути класифіковані як алгоритми навчання з учителем і без учителя. У першому випадку існує вчитель, який надає вхідні образи мережі, порівнює результа- ційні виходи з потрібними, а потім налаштовує ваги мережі так, щоб зменшити різницю. Важко уявити такий навчальний механізм в біологічних системах; отже, хоча цей підхід привів до ве¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
267
ликих успіхів у розв’язанні прикладних задач, дослідники, які вважають, що штучні нейронні мережі обов’язково мають використовувати ті самі механізми, що й людський мозок, його відкидають.
Для навчання з учителем потрібен «зовнішній» учитель, який оцінював би поведінку системи й керував її подальшими модифікаціями. Під час навчання без учителя, що розглядатиметься в наступних розділах, мережа шляхом самоорганізації робить необхідні зміни. Навчання персептрона є навчанням з учителем.
Алгоритм називають алгоритмом з учителем, якщо під час навчання відомі і вхідні (X), і вихідні (У) вектори мережі. Є пари вхід + вихід — відомі умови завдання і розв’язання. В процесі навчання мережа змінює свої параметри і вчиться давати потрібне відображення Х->У. Мережа вчиться давати результати, які нам вже відомі. За рахунок здібності узагальнення мережею можуть бути отримані нові результати, якщо подати на вхід вектор, який не зустрічався під час навчання.
Навчання з вчителем припускає, що для кожного вхідного вектора існує цільовий вектор, що є необхідним виходом. Разом їх називають навчальною парою. Зазвичай мережа навчається на деякому числі таких навчальних пар. Вектори навчальної множини подаються послідовно, обчислюються помилки і ваги підлаш- товуються для кожного вектора доти, доки помилка по всьому навчальному масиву не досягне прийнятно низького рівня. Подається вихідний вектор, обчислюється вихід мережі і порівнюється з відповідним цільовим вектором, різниця (помилка) за допомогою зворотного зв’язку подається в мережу і ваги змінюються відповідно до алгоритму, який прагне мінімізувати помилку.
Алгоритм належить до навчання без учителя, якщо відомі тільки вхідні вектора, і на їх основі мережа вчиться давати якнайкращі значення виходів. Що розуміється під «якнайкращими»
— визначається алгоритмом навчання. У цьому випадку навчання здійснюється без вчителя, за пред’явленні вхідних образів мережа самоорганізовуватиметься за допомогою налаштування своїх вагів згідно з певним алгоритмом. Внаслідок відсутності вказівки потрібного виходу в процесі навчання результати непе- редбачувані з погляду визначення збуджувальних образів для конкретних нейронів. При цьому мережа організовується у формі, що відображає суттєві характеристики навчального набору. Наприклад, вхідні образи можуть бути класифіковані відповідно
268
Г.Ф. Іванчвнко
до ступеня їх подібності так, що образи одного класу активізують один і той самий вихідний нейрон.
Незважаючи на численні прикладні досягнення, навчання з учителем критикували за свою біологічну неправдоподібність. Важко уявити навчальний механізм у мозку, який би порівнював бажані й справжні значення виходів, виконуючи корекцію за допомогою зворотного зв’язку. Якщо припустити подібний механізм у мозку, то звідки тоді виникають бажані виходи? Навчання без учителя є набагато правдоподібнішою моделлю в біологічній системі. Розвинена Кохоненом й іншими, вона не потребує цільового вектора для виходів і, отже, не вимагає порівняння із зумовленими ідеальними відповідями. Навчальна множина складається лише з вхідних векторів. Навчальний алгоритм підлаштовує ваги мережі так, щоб виходили узгоджені вихідні вектори, тобто щоб пред’явлення досить близьких вхідних векторів давало однакові виходи. Процес навчання, отже, виділяє статистичні властивості навчальної множини і групує подібні вектори в класи. Пред’явлення на вхід вектора з цього класу дасть певний вихідний вектор, але до навчання неможливо передбачити, який вихід проводитиметься цим класом вхідних векторів. Отже, виходи подібної мережі мають трансформуватися в певну зрозумілу форму, обумовлену процесом навчання. Це не є серйозною проблемою. Зазвичай не складно ідентифікувати зв’язок між входом і виходом, встановлений мережею. Є два класи навчальних методів: детерміністський і стохастичний.
Детерміністський метод навчання — коли крок за кроком здійснюється процедура корекції ватів мережі, заснована на використанні їхніх поточних значень, а також величин входів, фактичних виходів і бажаних виходів. Навчання персептрона є прикладом подібного детерміністського підходу.
Стохастичні методи навчання виконують псевдовипадкові зміни величин вагів, зберігаючи ті зміни, які ведуть до покращення. Для навчання мережі може бути використана така процедура:
1. Обрати вату рандомізовано і підкоригувати її на невелике випадкове значення. Надати множину входів і обчислити виходи.
2. Порівняти ці виходи з бажаними виходами й обчислити величину різниці між ними. Загальноприйнятий метод полягає в знаходженні різниці між фактичним і бажаним виходами для кожного елемента навчаної пари, зведення різниць у квадрат і знахо¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
269
дження суми цих квадратів. Метою навчання є мінімізація цієї різниці, яку часто називають цільовою функцією.
3. Вибрати вагу рандомізовано і підкоригувати її на невелике випадкове значення. Якщо корекція допомагає (зменшує цільову функцію), то зберегти її, в іншому разі повернутися до первинного значення ваги.
4. Повторювати кроки з 1 до 3 доти, доки мережа не буде навчена достатньо.
Мета цього процесу — мінімізувати цільову функцію.
6.2. Особливості алгоритмів навчання персептрона
Мережа навчається, щоб для деякої множини входів давати бажану (або, принаймні, подібну до нього) множину виходів. Кожна така вхідна (або вихідна) множина розглядається як вектор. Навчання здійснюється шляхом послідовного подавання вхідних векторів з одночасним підлалітуванням ватів відповідно до певної процедури. В процесі навчання ваги мережі поступово стають такими, щоб кожен вхідний вектор виробляв вихідний вектор.
На цей час використовується величезна різноманітність навчальних алгоритмів. Алгоритми навчання, як і взагалі штучні нейронні мережі, можуть бути подані і в диференційній, і в кінцево-різницевій формі. Під час використання диференціальних рівнянь припускають, що процеси безперервні і здійснюються подібно до великої аналогової мережі. У біологічній системі, що розглядається на мікроскопічному рівні, все відбувається інакше. Активаційний рівень біологічного нейрона визначається середньою швидкістю, з якою він надсилає дискретні потенційні імпульси своїм аксоном. Середню швидкість зазвичай розглядають як аналогову величину, але важливо не забувати про справжній стан речей.
Якщо моделювати штучну нейронну мережу на аналоговому комп’ютері, то бажано використовувати уявлення за допомогою диференційних рівнянь. Проте сьогодні більшість розрахунків виконують на цифрових комп’ютерах, що примушує віддавати перевагу кінцево-різницевій формі яка легше програмується. З цієї причини ми будемо використовуватимемо кінцево-різницеве уявлення ШНМ.
270
Г.Ф. Іванчвнко
Штучні нейронні мережі навчаються найрізноманітнішими методами. На щастя, більшість методів навчання виходять із загальних передумов і мають багато ідентичних характеристик. Метою цього додатку є огляд деяких фундаментальних алгоритмів, і з погляду їх поточної застосовуваності, і з погляду історичної важливості. Після ознайомлення з цими фундаментальними алгоритмами інші, засновані на них алгоритми будуть досить легкі для розуміння, і нові розробки також бути краще зрозуміти й розвинути.
Алгоритм навчання нейронної мережі за допомогою процедури зворотного поширення припускає наявність якоїсь зовнішньої ланки, що надає мережі, крім вхідних, також і цільові вихідні образи. Алгоритми, що користуються подібною концепцією, називають алгоритмами навчання з учителем. Для їх успішного функціонування потрібна наявність експертів, що створюють на попередньому етапі для кожного вхідного образу еталонний вихідний.
Головна мета, що робить навчання без учителя привабливим,
— це його самостійність. Процес навчання, як і в разі навчання з учителем, полягає в підлаштуванні вагів синапсів. Правда, деякі алгоритми змінюють і структуру мережі, тобто кількість нейронів, і їх взаємозв’язок, але до таких перетворень правильніше застосувати ширший термін — самоорганізація. Очевидно, що під- лаштування синапсів може здійснюватися тільки на основі інформації, доступної в нейроні, тобто його стану і вже наявних вагових коефіцієнтів. Виходячи з цього міркування і, що більш важливо, за аналогією з відомими принципами самоорганізації нервових клітин, побудовано алгоритми навчання Хебба.
Використовуючи критерій лінійного розділення, можна вирішити, чи здатна одношарова нейронна мережа реалізовувати потрібну функцію. Навіть у тому разі, коли відповідь позитивна, буде мало користі, якщо відсутній спосіб як знайти потрібні значення для вагів і порогів. Щоб мережа становила практичну цінність, потрібен систематичний метод (алгоритм) для обчислення цих значень. Розенблатт зробив це в своєму алгоритмі навчання персептрона, водночас довівши, що персептрон може бути навчений усьому, що він може реалізовувати.
Алгоритм навчання персептрона може бути реалізований на цифровому комп’ютері або іншому електронному пристрої, і мережа стає в певному сенсі такою, що самоналаштовується. З цієї
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
271
причини процедуру підлаштування ватів зазвичай називають «навчанням» і кажуть, що мережа «навчається». Доказ Розенб- латта став основною віхою і дав могутній імпульс дослідженням в цій галузі. Сьогодні в тій або тій формі елементи алгоритму навчання персептрона зустрічаються в багатьох мережевих парадигмах.
Може виявитися складно визначити, чи виконано умову розділення для конкретної навчальної множини. Крім того, в багатьох ситуаціях, що зустрічаються на практиці, входи часто змінюються в часі. У доказі алгоритму навчання персептрона це йдеться також про те, скільки кроків потрібно для навчання мережі. Крім того, не доведено, що персептронний алгоритм навчання швидший порівняно з простим перебиранням усіх можливих значень вагів, і в деяких випадках цей примітивний підхід може виявитися кращим.
Тимчасова нестійкість
Якщо мережа вчиться розпізнавати букви, то немає сенсу вивчати «Б», якщо при цьому забувається «А». Процес навчання має бути таким, щоб мережа навчалася на всій навчальній множині без пропусків того, що вже вивчено. У доказі збіжності ця умова виконана, але потрібно також, щоб мережі пред’являлися всі вектори навчальної множини, перш ніж виконується корекція вагів. Потрібні зміни вагів мають обчислюватися на всій множині, а це вимагає додаткової пам’яті; після низки таких навчальних циклів ваги зійдуться до мінімальної помилки. Цей метод може виявитися даремним, якщо мережа перебуває в постійно змінюваному зовнішньому середовищі, так як один і той самий вектор може вже не повторитися. В цьому разі процес навчання може ніколи не зійтися, безцільно блукаючи або надто осцилюючи. У цьому сенсі зворотне поширення не схоже на біологічні системи. Ця невідповідність (у числі інших) привела до системи ART, що належить Гроссбергу.
Метою навчання мережі є таке підлаштування її вагів, щоб додаток деякої безлічі входів приводив до потрібної безлічі виходів. Скорочено цю безліч входів і виходів називатимемо векторами. Під час навчання передбачається, що для кожного вхідного вектора існує парний йому цільовий вектор, що задає потрібний вихід. Разом їх називають навчальною парою. Зазвичай, мережа навчається на багатьох парах. Наприклад, вхідна частина навчаль¬
272
Г.Ф. Іванченко
ної пари може складатися з набору нулів і одиниць, що являють собою двійковий образ деякої букви алфавіту.
Якщо через квадрат проходить лінія, то відповідний нейрон- ний вхід дорівнює одиниці, інакше він дорівнює нулю. Вихід може бути числом, що представляє літеру, наприклад, «В», або іншим набором з нулів і одиниць, який може бути використаний для отримання вихідного образу. Щоб розпізнавати за допомогою мережі всі букви алфавіту, були б потрібні навчальні пари відповідно до літер алфавіту. Таку групу навчальних пар називають навчальною множиною.
Перед початком навчання всім вагам потрібно привласнити невеликі початкові значення, обрані довільно. Це гарантує, що в мережі не станеться насичення великими значеннями вагів, і запобігає низці інших складних випадків. Наприклад, якщо всім вагам надати однакові початкові значення, а для функціонування потрібні нерівні значення, то мережа не зможе навчитися.
Параліч мереж
За деяких умов мережа може під час навчання потрапити в такий стан, коли модифікація вагів не веде до справжніх змін мережі. Такий «параліч мережі» є серйозною проблемою: один раз виникнувши, він може збільшити час навчання на кілька порядків.
Параліч виникає, коли значна частина нейронів отримує ваги, досить великі, щоб дати великі значення NET. Це призводить до того, що величина OUT наближається до свого граничного значення, а похідна від стискальної функції наближається до нуля. Як ми бачили, алгоритм зворотного поширення при обчисленні величини зміни ваги використовує цю похідну у формулі як коефіцієнт. Для уражених паралічем нейронів близькість похідної до нуля призводить до того, що зміна ваги наближається до нуля.
Якщо подібні умови виникають у багатьох нейронах мережі, то навчання може сповільнитися до майже цілковитої зупинки.
Немає теорії, здатної передбачати, чи буде мережа паралізована під час навчання, чи ні. Експериментально встановлено, що малі розміри кроку рідше приводять до паралічу, але крок, малий для одного завдання, може виявитися великим для другої. Ціна ж паралічу може бути висока. При моделюванні багато машинного часу може бути витрачено на те, щоб вийти з паралічу.
Попри численні успішні застосування зворотного поширення, воно не є панацеєю. Найбільше неприємностей спричинює неви-
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
273
значено тривалий процес навчання. У складних завданнях для навчання мережі знадобляться дні або навіть тижні, вона може взагалі не навчитися. Тривалий час навчання може бути результатом неоптимального вибору довжини кроку. Невдачі в навчанні зазвичай виникають з двох причин: паралічу мережі й потрапляння в локальний мінімум.
У процесі навчання мережі значення ватів у результаті корекції можуть стати дуже великими величинами. Це може призвести до того, що всі або більшість нейронів функціонуватимуть за дуже великих значень. OUT, у діапазоні, де похідна активаційної функції є дуже малою. Оскільки посилана процесі навчання помилка пропорційна цій похідній, то процес навчання може практично завмерти. У теоретичному відношенні ця проблема погано вивчена. Зазвичай цього уникають зменшенням розміру кроку ц, але це збільшує час навчання. Різні евристики використовувалися для запобігання паралічу або для відновлення після нього, але поки що їх можна розглядатися лише як експериментальні.
6.3. Метод сигнального навчання Хебба
У попередніх працях у загальному вигляді визначалося, що навчання в біологічних системах відбувається за допомогою деяких фізичних змін у нейронах, проте були відсутні ідеї, яким чином це може відбуватися. Грунтуючись на фізіологічних і психологічних дослідженнях, Хебб висунув гіпотезу^про те, яким чином може навчатися набір біологічних нейронів. Його теорія припускає тільки локальну взаємодію між нейронами за відсутності глобального вчителя. Отже, навчання є некерованим. Незважаючи на те, що його робота не включає математичного аналізу, ідеї, викладені в ній, такі зрозумілі і невимушені, що отримали статус універсальних припущень. Його книга стала класичною і широко вивчається фахівцями, що мають серйозний інтерес у цій галузі.
Більшість сучасних алгоритмів навчання виросли з концепцій Хебба. їм запропоновано модель навчання без учителя, в якій си- наптична сила (вага) зростає, якщо активізовані обидва нейрони, джерело і приймач. Таким чином, часто використовувані шляхи в мережі посилюються, і феномен звички і навчання через повторення отримує пояснення.
274
Г.Ф. Іванченко
По суті, Хебб припустив, що синаптичне з’єднання двох нейронів посилюється, якщо обидва ці нейрони збуджені. Це можна уявити як посилення синапсу відповідно до кореляції рівнів збуджених нейронів, що з’єднані з цим синапсом. З цієї причини алгоритм навчання Хебба іноді називають кореляційним алгоритмом.
Ідея алгоритму виражається такою рівністю:
Wi/t+l)= щ//)+ NET,-NET;,
де wy(t) — сила синапса від нейрона і до нейрона j у момент часу t; NET/ — рівень збудження пресинаптичного нейрона; NET; — рівень збудження постсинаптичного нейрона.
Концепція Хебба відповідає на складне запитання, яким чином навчання може здійснюватися без учителя. У методі Хебба навчання є винятково локальним явищем, що охоплює тільки два нейрони і з’єднувальний їх синапс; не вимагається глобальної системи зворотного зв’язку для розвитку нейронних утворень.
Подальше використання методу Хебба для навчання нейронних мереж привело до великих успіхів, але разом з цим показало обмеженість методу. Деякі образи не можуть використовуватися для навчання цим методом. У результаті з’явилася велика кількість розширень і нововведень, більшість з яких значною мірою заснована на роботі Хебба.
Як ми бачили, вихід NET простого штучного нейрона є зваженою сумою його входів. Це може бути виражено таким чином:
NET, = £OUT,w,,
І
де NET; — вихід нейрона j; OUT,- — вихід нейрона і; wy — вага зв’язку нейрона і з нейроном j.
Можна показати, що в цьому випадку лінійна багатошарова мережа не є могутнішою за одношарову мережу. Ці можливості мережі можуть бути поліпшені тільки введенням нелінійності в передавальну функцію нейрона. Кажуть, що мережа, яка використовує сигмо'ідальну функцію активації і метод навчання Хебба, навчається за сигнальним методом Хебба. В цьому випадку рівняння Хебба модифікується таким чином:
OUT = 1
- F(NET)
l + exp(-NETf)
W,;{*+!)= WyO)+ OUT/ OUT;,
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
275
де щ/і)— сила синапса від нейрона і до нейрона j на момент часу t; OUT, — вихідний рівень пресинаптичного нейрона дорівнює F(NET,); OUT, — вихідний рівень постсинаптичного нейрона дорівнює /'’(NET,-).
Мережі, що використовують навчання за Хеббом, конструктивно розвивалися, проте за останні роки були розвинені ефективніші алгоритми навчання. Зокрема, алгоритми навчання з учителем, що приводять до мереж з ширшим діапазоном характеристик навчальних вхідних образів і великими швидкостями навчання, ніж ті що використовують просте навчання за Хеббом.
Сигнальний метод навчання Хебба полягає в зміні вагів за таким правилом:
wij (0 = (*-1) + а • у\*~Х)-yf\ (4.14)
де у/"'1’ — вихідне значення нейрона і шару (и-1), у}п) — вихідне значення нейрона j шару п; wy(t) і Wy{t-\) — ваговий коефіцієнт синапса, що сполучає ці нейрони, на ітераціях t і /-1 відповідно; а
— коефіцієнт швидкості навчання. Тут і далі, для спільності, під п маємо на увазі довільний шар мережі. Під час навчання за цим методом посилюються зв’язки між збудженими нейронами.
Існує також диференціальний метод навчання Хебба:
= w9(f -1) + а • [уГ'ЧО - -1)]- [у<л)(0 - yf(t-1)]. (4.15)
Тут Уіп'і)(^) і у/”‘^(^-1) — вихідне значення нейрона і шару п-1 відповідно на ітераціях t і ґ-1; y/n\t) і y/n\t-1) — те саме для нейрона j шару п. Як бачимо з формули (4.15), найбільше навчаються синапси, що сполучають ті нейрони, виходи яких найдинаміч- ніше змінилися у бік збільшення.
Повний алгоритм навчання із застосуванням вищенаведених формул матиме такий вигляд:
1. На стадії ініціалізації всім ваговим коефіцієнтам привласнюються невеликі випадкові значення.
2. На входи мережі подається вхідний образ, і сигнали збудження поширюються по всіх шарах згідно з принципами класичних прямопоточних (feedforward) мереж, тобто для кожного нейрона розраховується зважена сума його входів, до якої потім застосовується активаційна (передавальна) функція нейрона, в результаті отримуємо його вихідне значеннями) і=0...МгІ, де Mt — число нейронів в шарі /; /i=0..JV-l, а N— число шарів в мережі.
276
Г.Ф. Іввнченко
3. На підставі'одержаних вихідних значень нейронів по формулі (4.14) або (4.15) проводиться зміна вагових коефіцієнтів.
4. Перехід з кроку 2, поки вихідні значення мережі не стабілізуються із заданою точністю. Застосування цього нового способу визначення завершення навчання, відмінне від зворотного поширення, тому що використалося для мережі, де значення синапсів фактично не обмежені.
На другому кроці циклу поперемінно пред’являються всі образи із вхідного набору.
Слід зазначити, що вид відгуків на кожен клас вхідних образів не відомий наперед і буде довільним поєднанням станів нейронів вихідного шару, обумовленим випадковим розподілом ватів на стадії ініціалізації. Разом з тим, мережа здатна узагальнювати схожі образи, відносячи їх до одного класу. Тестування навченої мережі дозволяє визначити топологію класів у вихідному шарі.
6.4. Алгоритм навчання Кохонена
Інший алгоритм навчання без учителя — алгоритм Кохонена передбачає підлаштування синапсів на підставі їх значень від попередньої ітерації:
»»(')- »,(' -0+« • [у!"11 -»»(' -О] <41«)
З вищенаведеної формули бачимо, що навчання зводиться до мінімізації різниці між вхідними сигналами нейрона, що надходять з виходів нейронів попереднього шару і ваговими коефіцієнтами його синапсів.
Повний алгоритм навчання має приблизно таку саму структуру, що й у методах Хебба, але на кроці 3 із всього шару вибирається нейрон, значення синапсів якого максимально схожі на вхідний образ, і підлаштування вагів за формулою (4.16) здійснюється тільки для нього. Ця, так звана, акредитація може супроводжуватися гальмуванням усієї решти нейронів шару і введенням вибраного нейрона в насичення. Вибір такого нейрона може здійснюватися, наприклад, розрахунком скалярного добутку вектора вагових коефіцієнтів з вектором вхідних значень. Максимальний добуток дає нейрон, що виграв.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
277
Інший варіант — розрахунок відстані між цими векторами в р вимірному просторі, де р — розмір векторів.
де у — індекс нейрона в шарі п, і — індекс підсумовування по нейронах шару (и-1), н>у — вага синапса, що сполучає нейрони; виходи нейронів шару (и-1) є вхідними значеннями для шару п. Корінь у формулі (4.17) брати не обов’язково, оскільки важлива лише відносна оцінка різних
Цього разу «перемагає» нейрон з найменшою відстанню. Іноді дуже часто, отримуючи акредитацію, нейрони примусово виключаються з розгляду, щоб «зрівняти права» всіх нейронів шару. Простий варіант такого алгоритму полягає в гальмуванні нейрона, який щойно виграв.
При використанні навчання за алгоритмом Кохонена існує практика нормалізації вхідних образів, так само — на стадії ініціалізації — і нормалізації початкових значень вагових коефіцієнтів:
де Хі — /-а компоненту вектора вхідного образу або вектора вагових коефіцієнтів, а п — його розмірність. Це дає змогу скоротити тривалість процесу навчання.
Ініціалізація вагових коефіцієнтів випадковими значеннями може привести до того, що різні класи, яким відповідають щільно розподілені вхідні образи, зіллються або, навпаки, роздроблюватимуться на додаткові підкласи у разі близьких образів одного й того самого класу. Щоб унеможливити подібну ситуацію, використовується метод опуклої комбінації. Суть його зводиться до того, що вхідні нормалізовані образи піддаються перетворенню:
(4.17)
(4.18)
(4.19)
де хі — і-а компоненти вхідного образу, п — загальне число його компонент, ґ — коефіцієнт, що змінюється в процесі навчання від нуля до одиниці, в результаті чого спочатку на входи мережі по¬
278
Г.Ф. Іванченко
даються практично однакові образи, а з часом вони дедалі більше сходяться до початкових. На кроці ініціалізації встановлюються вагові коефіцієнти, що дорівнюють величині
де п—розмірність вектора ватів для нейронів ініціалізованого шару.
На основі розглянутого вище методу будуються нейронні мережі особливого типу — так звані структури, що самоорганізову- ються, — self-organizing feature maps. Для них після вибору з шару п нейрона j з мінімальною відстанню Dj (4.17) навчається за формулою (4.16) не тільки цей нейрон, а й його сусіди, розташовані в колі R. Величина R на перших ітераціях дуже велика, отже навчаються всі нейрони, але з часом вона зменшується до нуля. Таким чином, що ближчий кінець навчання, то точніше визначається група нейронів, образів, що відповідають кожному класу.
У цьому методі при обчисленні величини кроку розподіл Больцмана замінюється на розподіл Коші — метод швидкого навчання подібних систем. Розподіл Коші має, як показано на рис. 5.3, довші «хвости», збільшуючи тим самим імовірність великих кроків.
Насправді розподіл Коші має нескінченну, невизначену дисперсію. За допомогою такої простої зміни максимальна швидкість зменшення температури Т стає пропорційною лінійній величині, а не логарифму, як для алгоритму навчання Больцмана. Це істотно зменшує час навчання. Цей зв’язок може бути виражений таким чином:
(4.20)
6.5. Алгоритм навчання Коші
(4.20)
Розподіл Коші має вигляд:
(4.21)
де Р(х) є імовірність кроку величини де.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
279
Р(х)
Розподіл Коші
/ / / / г /
✓
У
*
/ 1 / 1 / / / і / / / /
/ / ж/ ' у /
/
-» х 0 Розподіл Больцмана
Рис. 5.9. Розподіл Коші і розподіл Больцмана
У рівнянні (4.21) Р(х) може бути проінтегровано стандартними методами. Вирішуючи щодо х, одержуємо
хс = рГ(/)1§(ОД), (4.21)
де р — коефіцієнт швидкості навчання; хс — зміна ваги.
Тепер застосування методу Монте Карло стає просто. Для знаходження х у цьому разі вибирається випадкове число з рівномірного розподілу на відкритому інтервалі (-я/2, я/2) (потрібно обмежити функцію тангенса). Воно підставляється у формулу
(4.21) як Р(х), і за допомогою поточного Т обчислюється величина кроку.
6.6. Комбінування зворотного поширення з навчанням Коші
Зворотне поширення має перевагу прямого пошуку, тобто ваги завжди коректуються в напрямі, що мінімізує функцію помилки. Хоча час навчання і великий, він істотно менший, ніж за випадкового пошуку, що виконується машиною Коші, коли знаходиться глобальний мінімум, але багато кроків виконуються в невірному напрямі, що потребує багато часу.
З’єднання цих двох методів дало добрі результати. Корекція вагів, що дорівнює сумі, обчисленій алгоритмом зворотного поширення, і випадковий крок, що задається алгоритмом Коші, приводять до системи, яка сходиться і знаходить глобальний мінімум швидше, ніж система, що навчається кожним методом окремо. Проста евристика використовується для уникнення паралічу мережі, який може мати місце як за зворотного поширення, і при навчанні за методом Коші.
280
Г.Ф. Іванчвнко
Корекція ватів у комбінованому алгоритмі, що використовує зворотне поширення і навчання Коші, складається з двох компонент: (1) спрямованої компоненти, обчислюваної з використанням алгоритму зворотного поширення, і (2) випадкової компоненти, яку визначають розподілом Коші.
Ці компоненти обчислюються для кожної ваги, і їхня сума є величиною, на яку змінюється вага. Як і в алгоритмі Коші, після обчислення зміни ваги обчислюється цільова функція, якщо має місце покращення, визначене розподілом Больцмана.
Корекція ваги обчислюється з використанням наведених раніше рівнянь для кожного з алгоритмів:
^тпА.П+1) — Н'д)п>і(и) + Т| [(хДи’|ПЛ>*(и)+ (1 — (X) 8П>£ ОиТту] + (1 — Т|) хс,
де П — коефіцієнт, що керує відносними величинами Коші і зворотного поширення в компонентах вагового кроку. Якщо г| прирівнюється до нуля, система стає повністю машиною Коші. Якщо т| прирівнюється до одиниці, система стає машиною зворотного поширення.
Зміна лише одного вагового коефіцієнта між обчисленнями вагової функції неефективна. Виявилося, що краще відразу змінювати всі ваги цілого шару, хоча для деяких завдань може вигідніша інша стратегія. Цей алгоритм приводить до подолання мережевого паралічу комбінованим методом навчання. Як і в машині Коші, якщо зміна ваги погіршує цільову функцію, за допомогою розподілу Больцмана вирішується, чи зберегти нове значення ваги, чи відновити попереднє значення. Таким чином, є кінцева вірогідність того, що погіршуючу множину приростів ватів буде збережено. Оскільки розподіл Коші має нескінченну дисперсію (діапазон зміни тангенса тягнеться від -оо до +оо на області визначення), то ймовірне виникнення великих приростів вагів, що часто приводять до мережевого паралічу.
Проте рішення полягає в обмеженні діапазону зміни вагових кроків. Доведена збіжність системи до глобального мінімуму лише для початкового алгоритму. Подібного доказу за штучного обмеження розміру кроку не існує.
Інше рішення полягає в рандомізації вагів тих нейронів, які опинилися в стані насичення. Недоліком його є те, що воно може серйозно порушити навчальний процес, іноді затягуючи його до безкінечності.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
281
Для розв’язання проблеми паралічу було знайдено метод, що не порушує досягнутого навчання. Насичені нейрони виявляються за допомогою вимірювання їхніх сигналів OUT. Коли величина OUT наближається до свого граничного значення, позитивного або негативного, на ваги, що живлять цей нейрон, діє стискаюча функція. В діапазоні її зміни є інтервал (+5, -5) або інша відповідна множина. Тоді модифіковані вагові значення дорівнюють
. -5 + 10
Wm" ~ 1 + exp(-wmn/5) •
Ця функція істотно зменшує величину дуже великих вагів, дія на малі ваги значно слабкіша. Далі вона підтримує симетрію, зберігаючи невеликі відмінності між великими вагами. Експериментально було показано, що ця функція виводить нейрони із стану насичення без порушення досягнутого в мережі навчання. Не було витрачено серйозних зусиль для оптимізації використовуваної функції, інші значення констант можуть виявитися кращими. Комбінований алгоритм, що використовує зворотне поширення і навчання Коші, застосовувався для навчання кількох великих мереж. Наприклад, цим методом була успішно навчена система, що розпізнає рукописні китайські ієрогліфи. Але таке навчання може виявитися тривалим. Експерименти із чистою машиною Коші привели до значно тривалішого часу навчання.
6.7. Процедура зворотного поширення
Зворотне поширення (Backpropagation algorithm) — це найпо- пулярніший алгоритм для навчання за допомогою змінення коефіцієнтів ваги зв’язків. Як відомо з назви, помилка поширення від вихідного шару до вхідного, тобто в напрямку, протилежному напрямку проходження сигналу за нормального функціонування мереж. Хоча алгоритм досить простий, його розрахунок може затратити багато часу залежно від величини помилки.
Виконання алгоритму починається із створення вагів, що довільно згенерували для багатошарової мережі. Потім процес, повторюється доти, доки середня помилка на вході не буде визнана досить малою.
282
Г.Ф. Іванченко
Тривалий час не було теоретично обґрунтованого алгоритму дня навчання багатошарових штучних нейронних мереж. А оскільки можливості уявлення за допомогою одношарових нейронних мереж виявилися вельми обмеженими, то і вся галузь загалом прийшла в занепад.
Розробка алгоритму зворотного поширення зіграла важливу роль у відродженні інтересу до штучних нейронних мереж. Зворотне поширення — це систематичний метод для навчання багатошарових штучних нейронних мереж. Він має солідне математичне обґрунтування. Незважаючи на деякі обмеження, процедура зворотного поширення надто розширила сферу, в яких можуть бути використані штучні нейронні мережі, і переконливо продемонструвала свою потужність.
Зворотне поширення було використано в широкій сфері прикладних досліджень. Деякі з них описуються тут, щоб продемонструвати потужність цього методу.
Фірма NEC в Японії оголосила нещодавно, що зворотне поширення було використано для візуального розпізнавання літер, причому точність перевищила 99 %. Цього поліпшення було досягнуто за допомогою комбінації звичайних алгоритмів з мережею зворотного поширення, що забезпечує додаткову перевірку.
У системі Net-Talk зворотне поширення використовувалося в машинному розпізнаванні рукописних англійських слів. Букви, нормалізовані за розміром, наносилися на сітку, і бралися проекції ліній, що перетинають квадрати сітки. Ці проекції служили потім входами для мережі зворотного поширення..
Зворотне поширення використовується для стиснення зображень, коли зображення подавалися одним бітом на піксель, що дає восьмиразове поліпшення порівняно із вхідними даними. На рис. 5.2 показано нейрон, використовуваний як основний будівельний блок у мережах зворотного поширення.
На нейрон подається безліч входів, що йдуть або ззовні, або від попереднього шару. Кожний з них множиться на вагу, і добутки підсумовуються. Ця сума, що позначається NET, має бути обчислена для кожного нейрона мережі. Після того, як величина NET обчислена, вона модифікується за допомогою активаційної функції і виходить сигнал OUT.
Як показує рівняння (4.22), ця функція є дуже зручна, оскільки має просту похідну, що використовується при реалізації алгоритму зворотного поширення:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
283
^1 = 0UT(1 - OUT). (4.22)
5NET
Насправді є безліч функцій, які могли б бути використані. Для алгоритму зворотного поширення потрібно лише, щоб функція була гладкою. Сигмоїд задовольняє цій вимозі. Його додаткова перевага полягає в автоматичному контролі посилення. Для слабких сигналів (величина NET наближається до нуля) крива вхід— вихід має сильний нахил, що дає велике посилення. Коли величина сигналу стає більшою, посилення падає. Таким чином, великі сигнали сприймаються мережею без насичення, а слабкі сигнали проходять мережею без надмірного послаблення.
Процедура зворотного поширення застосовна до мереж з будь-яким числом шарів. Навчання мережі зворотного поширення вимагає виконання таких операцій:
1. Вибрати чергову навчальну пару з навчальної множини; подати вхідний вектор на вхід мережі.
2. Обчислити вихід мережі.
3. Обчислити різницю між виходом мережі і потрібним виходом (цільовим вектором навчальної пари).
4. Підкоригувати ваги мережі так, щоб мінімізувати помилку.
5. Повторювати кроки з 1 по 4 для кожного вектора навчальної множини доти, доки помилка на всій множині не досягне прийнятного рівня.
Операції, що виконуються кроками 1 і 2, подібні до тих, які виконуються при функціонуванні вже навченої мережі, тобто подається вхідний вектор і обчислюється вихід. Обчислення виконуються пошарово. Спочатку обчислюються виходи нейронів шару j, потім вони використовуються як входи шару к, обчислюються виходи нейронів шару к, які й утворюють вихідний вектор мережі.
На кроці 3 кожний з виходів мережі, які на рис. 5.10 позначені OUT, віднімається з відповідної компоненти цільового вектора, щоб отримати помилку. Ця помилка використовується на кроці 4 для корекції ватів мережі, причому знак і величина змін вагів визначаються алгоритмом навчання.
Після достатнього числа повторень цих чотирьох кроків різниця між справжніми виходами і цільовими виходами має зменшитися до припустимої величини, при цьому кажуть, що мережа навчилася. Тепер мережа використовується для розпізнавання, і ваги не змінюються.
284
Г.Ф. Іванченко
Вхідний шар і
Прихований шар j
Вихідний шар k
Target
Сигнал
1
Сигнал
Сигнал
Похибка,
Рис. 5.10. Схема мережі реалізації зворотного поширення
На кроки 1 і 2 можна дивитися як на «проходження вперед», оскільки сигнал поширюється мережею від входу до виходу. Кроки 3,4 становлять «зворотний прохід», тут обчислюваний сигнал помилки поширюється назад мережею і використовується для підлаштування ватів.
Прохід уперед. Кроки 1 і 2 можуть бути виражені у векторній формі таким чином: подається вхідний вектор X і на виході отримуємо вектор Y. Векторна пара вхід-мета X і Y береться з навчальної множини. Обчислення проводяться над вектором X, щоб отримати вихідний вектор Y.
Як ми бачили, обчислення в багатошарових мережах виконуються шар за шаром, починаючи з найближчого до входу шару. Величина NET кожного нейрона першого шару обчислюється як зважена сума входів нейрона. Потім активаційна функція F стискає NET і дає величину OUT для кожного нейрона в цьому шарі. Коли множина виходів шару отримана, вона є вхідною множиною для наступного шару. Процес повторюється шар за шаром, доки не буде отримана завершальна множина виходів мережі.
Ваги між нейронами можуть розглядатися як матриця W. Наприклад, вага від нейрона 8 у шарі 2 до нейрона S шару 3 позначається w82j . Тоді NET-вектор шару N може бути виражений як добуток X і W. У векторному позначенні N = XW. Покомпонент- ним застосуванням функції F до NET-вектора N виходить вихідний вектор OUT = F(XW).
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
285
Вихідний вектор одного шару є вхідним вектором для наступного, тому обчислення виходів останнього шару потребує застосування рівняння до кожного шару від входу мережі до її виходу.
Зворотний прохід. Підлаштування вагів вихідного шару. Оскільки для кожного нейрона вихідного шару задано цільове значення, то підлаштування вагів легко здійснюється з використанням модифікованого правила дельти. Внутрішні шари називають «прихованими шарами», для їх виходів немає цільових значень для порівняння. Тому навчання ускладнюється.
Процес навчання для однієї ваги від нейрона р у прихованому шарі j до нейрона q у вихідному шарі к. Вихід нейрона шару к, віднімається від цільового значення (Target), дає сигнал помилки. Він помножується на похідну, що стискає функції [OUT(l — OUT)], обчислену для цього нейрона шару к, отримуємо, таким чином, величину Ьду.
5д,к = OUT(l - OUT)(Target - OUT). (4.23)
Потім 5 помножується на величину OUT нейрона j, з якого виходить ця вага. Цей добуток в свою чергу помножується на коефіцієнт швидкості навчання г| (зазвичай від 0,01 до 1,0), і результат додається до ваги. Така сама процедура виконується для кожної ваги від нейрона прихованого шару до нейрона у вихідному шарі.
Ці рівняння ілюструють обчислення:
Av*W = n VOUT, (4.24)
= wMm+Awpqt, (4.25)
де WpqMn) — величина ваги від нейрона р в прихованому шарі к нейрона q у вихідному шарі на кроці п (до корекції); відзначимо, що індекс к належить до шару, в якому закінчується ця вага, тобто, згідно з прийнятою угодою, з якою він об’єднаний; wpq^\) — величина ваги на кроці п + 1 (після корекції); 5?>* — величина 5 для нейрона q, у вихідному шарі к; OUTPi/ — величина OUT для нейрона р у прихованому шарі j.
286
Г.Ф. Іванченко
Алгоритм зворотного поширення застосовується при створенні нейтроконтролерів для робототехніки. Нейтроконтролерами (Кеигосоїигоііег) зазвичай називають нейронні мережі, які використовують при управлінні.
Причина використання нейронних мереж як нейроконтролерів полягає в тому, що неможливо задати для робота поводження, які б осягали все можливе в навколишньому середовищі. Тому потрібно навчити нейронну мережу на обмеженній кількості прикладів (тобто зразків поведінки залежно від ситуації), згодом дозволити ШНМ самостійно генерувати поведінку в усіх інших ситуаціях. Здатність генерувати правильну реакцію на всі можливі ситуації, що не стосуються тих, хто навчає, є ключовим чинником під час створення нейроконтролера.
Інша перевага нейроконтролера полягає в тому, що він не є суворо заданою функцією, яка забезпечує взаємодію між навколишнім середовищем та роботом.
Програмна реалізація штучної нейронної мережі дає можливість підібрати оптимальний вид транспорту для перевезення вантажу, базуючись на його характеристиках та умовах доставки. Приклад реалізації алгоритму зворотного поширення для ШНМ наведено в додатку Д.
В цьому прикладі ми задіємо нейронну мережу, щоб обрати дію з доступного списку вибору автотранспорту для перевезення вантажу, зважаючи на те, в якому навколишньому середовищі знаходиться персонаж.
Резюме за змістом теми
• Штучна нейронна мережа навчається за допомогою певного процесу, що модифікує її ваги.
• Алгоритм називають алгоритмом з учителем, якщо під час навчання відомі і вхідні, і вихідні вектора мережі. Разом їх називають навчальною парою.
• Алгоритм належить до навчання без учителя, якщо відомі тільки вхідні вектора, і на їх основі мережа вчиться давати якнайкращі значення виходів.
• Зворотне поширення — це метод для навчання багатошарових штучних нейронних мереж.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
287
Терміни та поняття до теми
• Параліч мережі — в певних умовах мережа може під час навчання потрапити в такий стан, коли модифікація вагів не веде до справжніх змін мережі.
• Backpropagation algorithm — алгоритм зворотного поширення.
• Neurocontroller — нейтроконтролер, зазвичай називають комп’ютерні системи, побудовані на основі LLIHM.
Запитання для самоконтролю
1. Опишіть модель нейрона як пороговий елемент.
2. Що таке активаційна функція порогового елемента?
3. У чому полягає основний принцип навчання модельних нейронів?
4. Опишіть процедуру Уїдроу для навчання модельних нейронів.
5. Які функції, крім порогових, можуть використовуватися як активаційні?
6. Що таке сигмоїдальна функція? Наведіть приклад.
7. Опишіть узагальнену дельта-процедуру для сигмо'ідальної активаційної функції.
8. У чому полягають основні принципи використання методу зворотного поширення помилки для навчання нейромереж?
9. Як визначити апріорну інформацію про навчальну вибірку?
10. Як впливає задана кількість циклів навчання на точність навчання?
11. Як впливає задана точність навчання на тривалість навчання?
12. Які вимоги потрібно висувати до навчальної вибірки, та як це вплине на процес навчання?
Завдання для індивідуальної роботи, обов'язкові та додаткові практичні завдання
1. Параліч мереж.
2. Метод сигнального навчання Хебба.
3. Метод диференціального навчання Хебба.
4. Алгоритм навчання Кохонена.
5. Алгоритм навчання Коші Хебба.
6. Комбінування зворотного поширення з навчанням Коші.
7. Процедура зворотного поширення.
8. Пастки локальних мінімумів.
9. Моделювання нейронних мереж за допомогою пакета МаЙаЬ.
288
Г.Ф. Іванченко
Література для поглибленого вивчення матеріалу
1. ЛюгерДж. Ф. Искусственный интеллект. — М.: Изд. дом «Вильямс», 2005. — 864 с.
2. Головко В. А. Нейронные сети: обучение, организация и применение. — М.: ИПРЖР, 2001. — 256 с.
3. Барский А. Б. Нейронные сети: распознавание, управление, принятие решений. — М.: Финансы и статистика, 2004. — 176 с. — (Прикладные информационные технологии).
РОЗПІЗНАВАННЯ ОБРАЗІВ ТА АНАЛІЗ ЗОБРАЖЕНЬ
Тема 7
ОСНОВНІ ПОНЯТТЯ ТЕОРІЇ РОЗПІЗНАВАННЯ ОБРАЗІВ
Перелік знань та навичок
Після опанування теми студент має знати:
• класифікацію систем розпізнавання;
• деякі практичні галузі застосування систем розпізнавання;
• класи та їх властивості;
• метричні методи, засновані на кількісній оцінці цієї близькості;
• гіпотезу компактності;
• лінійну роздільність класів;
• типову схему розпізнавання в просторі ознак.
Має вміти
розраховувати відстань між об’єктами різними методами:
• відстань Хеммінга (відстань за Манхеттеном, метрика міських кварталів);
• Евклідову відстань;
• відстань Мінковського (узагальнену відстань);
• діагностичну міру відстані;
• відстань у неізотропному просторі ознак;
• узагальнену відстань у просторі ознак;
• відстань у нелінійному просторі;
• узагальнену (зважену) відстань Махалонобіса;
• відстань Камберра;
• відстань Чебишева;
• кореляційний метод знаходження відстані;
• кутову відстань.
290
Г.Ф. Іванчвнко
ЗМІСТ ПИТАНЬ ТЕМИ
7.1. Класифікація систем розпізнавання
Розпізнавання образів є однією з найбільш фундаментальних проблем теорії інтелектуальних систем. Водночас, завдання розпізнавання образів має величезне практичне значення [19].
Замість терміну «розпізнавання» часто використовують термін «класифікація». Ці два терміни у багатьох випадках розглядають як синоніми, але вони не є цілком взаємозамінними. Кожний з них має свої сфери застосування, й інтерпретація обох термінів часто залежить від специфіки конкретного завдання. Ми вважатимемо їх синонімами, якщо не буде вочевидь обумовлено щось інше.
Розпізнавання образів — процес, за якого на підставі численних характеристик (ознак) деякого об’єкта визначається одна або кілька найсуттєвіших, але недоступних для безпосереднього визначення характеристик. Зокрема, його приналежність до певного класу об’єктів. Вирішити завдання розпізнавання — означає знайти на підставі непрямих даних правила, за якими кожному набору значень ознак деякого об’єкта відповідає одне із заданої множини можливих рішень, що визначають суттєві характеристики цього об’єкта.
Методи розпізнавання образів та технічні системи (СРО), що реалізують ці методи, широко застосовують на практиці. Наведемо деякі з них.
1. Розпізнавання літер. Окрім усього іншого, розв’язання цієї проблеми має велике значення для власне комп’ютерних технологій. Системи розпізнавання літер працюють разом зі сканерами
— пристроями, які використовують для введення до комп’ютера друкованих зображень і текстів. При введенні друкованого тексту сканер формує лише графічне зображення. Щоб створити текстовий документ, з яким може працювати текстовий редактор, потрібно впізнати на цьому зображенні окремі літери. Аналогічно розпізнавання літер є необхідним для підтримки пристроїв рукописного введення. Цими пристроями, зовні схожими на звичайну авторучку, часто комплектуються надпортативні комп’ютери (персональні помічники).
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
291
2. Розпізнавання мови. Сьогодні інтенсивно розвиваються технології, пов’язані, по-перше, з голосовим керуванням комп’ютером, а по-друге — з введенням текстів з голосу з метою введення даних в ЕОМ або управління системою розпізнавання фраз або слів у тексті, написаному на формальній або природній мові.
3. Медична діагностика. Системи розпізнавання часто використовують і в медичній практиці. Найтиповіша ситуація, коли ті чи інші захворювання діагностують на основі аналізу кардіограм, рентгенівських знімків тощо, де безперервна множина рішень є безліччю способів лікування.
4. Технічна діагностика — діагностика несправностей машин і окремих їх деталей. На виробництві часто виникає потреба автоматизувати контроль якості деталей. Завдання полягає в тому, щоб виявити, чи є деталь дефектною, чи ні. Якщо з’ясовується, що деталь має дефект, часто потрібно визначити тип цього дефекту.
5. Обробка даних геологічної розвідки, за якої рішення ухвалюються щодо наявності певних копалин.
6. У військовій справі — обробка сигналів, радіолокацій, прийняття рішень щодо наявності певних об’єктів, яких виявляють, а також щодо значень параметрів, які характеризують ці об’єкти (свій—чужий).
7. Автоматична класифікація живих клітин, наприклад кров’яних тілець, спостережуваних під мікроскопом.
8. Обробка знімків слідів частинок у фізичних експериментах з метою визначення параметрів частинок і відбору знімків, що містять події, які цікавлять фізика.
9. Розпізнавання алгебри, виразів певних типів під час виконання формальних перетворень над формулами за допомогою ЕОМ.
10. Дактилоскопія — встановлення особи людини за відбитками пальця, а точніше, за так званим папілярним візерунком. Дактилоскопія ґрунтується на тому, що, по-перше, відбиток пальця унікальний (за всю історію дактилоскопії не було виявлено двох відбитків пальців, що належать різним особам, які співпадали), а по-друге, папілярний візерунок не змінюється впродовж всього життя людини.
11. Охоронні системи. Застосування методів розпізнавання в охоронних системах пов’язано, в першу чергу, ідентифікацією людини. Наприклад, потрібно ідентифікувати деяку особу, щоб визначити, чи має вона право входити на територію, що охороняється.
292
Г.Ф. Іванчвнко
12. Робототехніка. Застосування методів розпізнавання в робототехніці є цілком природним і необхідним, оскільки роботи мають безпосередньо сприймати зовнішній світ, і, відповідно, мати пристрої машинного зору.
Всі завдання суттєво відрізняються за своєю природою. По- перше, потрібно знайти такий спосіб класифікації вхідних сигналів, який якомога точніше відповідав би класифікації, здійснюваній людиною. Це обумовлено тим, що різні варіанти написання букв і вимовлення слів пристосовані до людського сприйняття.
Серед перерахованих вище завдань розпізнавання тільки частина має з самого початку формальну математичну постановку. Вона базується на більш-менш обґрунтованих гіпотезах стосовно процесів, що визначають залежність первинних ознак від тих величин або параметрів, щодо значень яких потрібно ухвалювати рішення. Ці гіпотези можуть належати до властивостей різних підмножин або до властивостей вирішальних функцій, або до характеру процесів, що породжують спостережувані сигнали.
Класифікація систем розпізнавання грунтується на використанні як класифікаційного принципу властивості інформації, використовуваної в процесі розпізнавання.
Можливу класифікацію систем розпізнавання наведено на рис 7.1.
Рис. 7.1. Класифікація систем розпізнавання
Системи розпізнавання можна поділити на прості й складні, залежно від того, фізично однорідна або неоднорідна інформація використовується для опису розпізнавальних об’єктів, і чи мають ці об’єкти ознаки, тієї мови, якою здійснено опис алфавіту класів, і чи мають вони однакову або різну фізичну природу.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
293
1) Прості системи розпізнавання. До них належать, наприклад, автоматичні, що розпізнають, читають, пристрої, в яких ознаки робочого словника є лише тими або іншими лінійними розмірами розпізнавальних об’єктів; розмінювальні автомати в метрополітені, де як ознаку, яку використовують для при розпізнавання монет, беруть їхню масу; автоматичні пристрої, призначені для вибракування деталей, в яких як ознаки для опису класів бракованих і небракованих деталей використовують або деякі лінійні розміри, або масу тощо.
2) Складні системи розпізнавання. До них належать, наприклад, системи медичної діагностики, в яких як ознаки (симптоми) можуть використовувати дані аналізу крові і кардіограми, температуру і динаміку кров’яного тиску тощо. Системи, призначені для розпізнавання зразків геологічної розвідки, в яких як ознаки беруть різні фізичні й хімічні властивості або зразки військової техніки ймовірного супротивника тощо.
Якщо як принцип класифікації використовувати спосіб отримання апостеріорної інформації, то складні системи можна поділити на однорівневі і багаторівневі.
3) Однорівневі складні системи. У цих системах апостеріорна інформація про ознаки розпізнавальних об’єктів визначається прямими вимірюваннями безпосередньо на основі обробки результатів експериментів.
4) Багаторівневі складні системи. У цих системах апостеріорна інформація про ознаки розпізнавальних об’єктів визначається на основі непрямих вимірювань.
Якщо як принцип класифікації обрати кількість первинної апріорної інформації про розпізнавальні об’єкти, то системи розпізнавання можна поділити на системи без навчання системи, що навчаються і самонавчальні.
5) Системи без навчання. У цих системах первинної апріорної інформації досить для того, щоб визначити апріорний алфавіт класів, побудувати апріорний словник ознак і на основі безпосередньої обробки початкових даних провести опис кожного класу мовою цих ознак, тобто в першому наближенні досить визначити вирішальні межі, вирішальні правила. Вважатимемо, що для побудови цього класу систем потрібдно мати в своєму розпорядженні вичерпну первинну апріорну інформацію.
6) Системи, що навчаються. У цих системах первинної апріорної інформації досить для того, щоб визначити апріорний ал¬
294
Г.Ф. Іванчвнко
фавіт класів і побудувати апріорний словник ознак, але не досить (або її з тих або інших міркувань недоцільно використовувати) для опису класів мовою ознак. Початкова інформація, необхідна для побудови систем розпізнавання, що навчаються, дає змогу виділити конкретні об’єкти, які належать до різних класів. Ці об’єкти є навчальними (навчальна послідовність, навчальна вибірка). Мета процедури навчання — визначення розділових функцій шляхом багаторазового пред’явлення системі розпізнавання різних об’єктів з указанням класів, до яких ці об’єкти належать. Системи розпізнавання, що навчаються на стадії формування, працюють з учителем. Ця робота полягає в тому, що вчитель багато разів пред’являє системі навчальні об’єкти всіх виділених класів і вказує, до яких класів вони належать. Потім учитель починає випробовувати систем розпізнавання, коректуючи її відповіді доти, доки кількість помилок у середньому не досягне бажаного рівня.
7) Самонавчальні системи. У цих системах первинної апріорної інформації досить лише для визначення словника ознак, але не досить для проведення класифікації об’єктів. На стадії формування системи їй пред’являють початкову сукупність об’єктів, заданих значеннями своїх ознак, проте через обмежений об’єм первинної інформації система не отримує вказівок про те, до якого класу об’єкти початкової сукупності належать. Ці вказівки замінюють на набір правил, відповідно до яких на стадії самонавчання система розпізнавання сама виробляє класифікацію, яка може відрізнятися від природної.
Якщо принцип класифікації використовує характер інформації про ознаки розпізнавальних об’єктів, які поділяються на детерміновані, ймовірнісні, логічні і структурні, то залежно від того, мовою яких ознак здійснюється опис цих об’єктів, іншими словами
— залежно від того, який алгоритм розпізнавання реалізований, системи розпізнавання можуть бути поділені на детерміновані, ймовірнісні, логічні, структурні й комбіновані.
8) Детерміновані системи. У цих системах для побудови алгоритмів розпізнавання використовують геометричні заходи близькості, які полягають у вимірюванні відстаней між розпізнавальним об’єктом й еталонами класів. Загалом застосування детермінованих методів розпізнавання передбачає наявність координат еталонів класів в ознаковому просторі або координат об’єктів, що належать до відповідних класів.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
295
9) Імовірнісні системи. У цих системах для побудови алгоритмів розпізнавання використовують імовірнісний метод розпізнавання, заснований на теорії статистичних рішень. Застосування ймовірнісних методів розпізнавання передбачає наявність ймовірнісних залежностей між ознаками розпізнавальних об’єктів і класами, до яких ці об’єкти належать.
10) Логічні системи. У цих системах для побудови алгоритмів розпізнавання використовують логічні методи розпізнавання, засновані на дискретному аналізі й численні висловів, що базується на ньому. Використання логічних методів розпізнавання передбачає наявність логічних зв’язків, виражених через систему булевих рівнянь, в яких змінні — логічні ознаки розпізнавальних об’єктів, а невідомі величини — класи, до яких ці об’єкти належать.
11) Нейромережеві системи. Ці системи засновані на використанні моделей і методів обчислювальних структур, подібних у певному розумінні до біологічних нейронних мереж. Перевагою цих систем є високі адаптивні і апроксимаційні здібності.
12) Структурні (лінгвістичні) системи. У цих системах для побудови алгоритмів розпізнавання використовують спеціальні граматики, що породжують мови, які складаються з пропозицій, кожна з яких описує об’єкти, що належать до конкретного класу.
Застосування структурних методів розпізнавання вимагає наявність множини пропозицій, що описують всю множину об’єктів, які належать до всіх класів алфавіту, класів системи розпізнавання.
При цьому безліч пропозицій має бути поділена на підмножи- ни за числом класів системи. Елементами підмножин і є пропозиції, що описують об’єкти, які належать до цієї підмножини (класу).
Таким чином, апріорними описами класів є сукупності пропозицій, кожна з яких відповідає конкретному об’єкту, що належить до цього класу.
13) Комбіновані системи. У цих системах для побудови алгоритмів розпізнавання використовують спеціально розроблений метод обчислення оцінок. Такі алгоритми розпізнавання називають алгоритмами обчислення оцінок (АОО). їх застосування вимагає наявність таблиць, де містяться об’єкти, що належать до відповідних класів, а також значення ознак, якими характеризуються ці об’єкти. Ознаки можуть бути детермінованими, логічними, ймовірнісними і структурними.
296
Г.Ф. Іванчвнко
У кожному завданні розпізнавання початковими даними є результати деяких спостережень або безпосередніх вимірювань. їх називають первинними ознаками, а сукупність всіх первинних ознак — вхідним сигналом.
Результатом одиничного акту розпізнавання є рішення, а результатом вирішення завдання розпізнавання — вирішальне правило (або алгоритм ухвалення рішення, або вирішальна функція), яке визначає відображення множини сигналів на множину рішень, тобто вказує на певне рішення для кожного сигналу. Якщо множина рішень дискретна і число різних рішень невелике, то розпізнавання можна розглядати як класифікацію. Вирішальна функція в цьому разі поділяє множину сигналів на підмножини, які називають класами, отже кожному класу відповідає одне певне рішення. У тому разі, якщо множина сигналів є топологічним простором, тобто коли доцільно казати про близькість двох сигналів, межі класів називають розділовими поверхнями (зокрема, це можуть бути гіперплощини).
В більшості випадків існує певна об’єктивна класифікація сигналів, яка може бути відома, якщо доступні деякі додаткові (стосовно вхідного сигналу) відомості. Проте можливі випадки, коли така об’єктивна класифікація не існує. Об’єктивну класифікацію можна описати за допомогою деякого шуканого дискретного параметра. Тоді сигнал слід вважати залежним від шуканого параметра Загалом може бути кілька шуканих параметрів, і вони можуть бути безперервними.
Розрізнюють чотири типи завдань, що полягають у розпізнаванні образів і відрізняються постановками. Нижче наводимо дещо спрощені постановки цих завдань.
1) Завдання опису. Задано множину деяких елементарних сигналів і правила складання складного сигналу з елементарних (правила синтезу). Потрібно знайти правила аналізу, тобто правила, за якими, маючи реалізації складного сигналу, можна знайти ті елементарні сигнали, з яких він складений, а також вказати використані під час його складання правила синтезу. Наприклад, зображення букви можна розглядати як складне зображення, складене з таких елементарних частин, як відтинки прямих ліній і дуг кіл. Правила синтезу визначають вибір потрібних відтинків і порядок їх з’єднання між собою. Опис цього зображення букви полягає в переліку відтинків, що входять до її складу і у вказівці їх взаємного розташування. Завдання опису ускладню¬
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
297
ється, якщо певні правила синтезу можна вказати лише для деяких сигналів; що ідеалізуються, які називаються еталонами, а спостережувані сигнали відрізняються від еталонів наявністю випадкових перешкод. У цьому разі або мають бути відомі статистичні властивості перешкод, або прийняті певні допущення про ці властивості. Вирішити завдання опису в цьому разі означає вказати правила знаходження такого еталона, який складений за заданими правилами синтезу й одночасно за цього сигналу є найбільш правдоподібним, тобто в певному значенні найбільш близьким до цього сигналу.
2) Завдання навчання постає в тих випадках, коли в умові одного із завдань на зразок а) при б) присутній, крім шуканого параметра, деякий інший невідомий параметр, тобто постійний параметр, про який відомо тільки, що він зберігає постійне значення, тобто розподіл ймовірності або умови, які задають під- множини сигналів або множину припустимих еталонів, визначені не повністю. Дано також навчальну вибірку, що є послідовністю сигналів, які спостерігалися в цих умовах, для кожного з них вказано правильне рішення. Потрібно побудувати вирішальну функцію. У разі навчання умови завдання визначають не єдину вирішальну функцію, а ціле сімейство таких функцій.
За допомогою навчальної вибірки і заданого критерію якості розпізнавання (ризику) можна обрати найкращу в сенсі цього критерію вирішальну функцію з сімейства.
3) Завдання самонавчання. Це завдання подібне до попереднього і відрізняється тільки тим, що навчальна вибірка містить лише послідовність сигналів без вказівки правильних рішень.
У процесі розпізнавання образів одним з основних є завдання класифікації, тобто розділення множини початкових даних на однорідні в певному розумінні підмножини. Критерії такого розділення не завжди можуть бути точно й безпосередньо формалізовані.
4) Завдання класифікації. Є розподіл імовірності сигналу, залежний від деякого шуканого дискретного параметра, або деякі умови, також залежні від параметрів, яким має задовольняти сигнал. Вказано деякий критерій — ризик розпізнавання, що характеризує якість вирішальної функції для різних значень параметра (в середньому або для «якнайгіршого» значення параметра). Можна сказати, що критерій характеризує ступінь відповідності одержуваних рішень справжнім значенням параметра, тобто
298
Г.Ф. Іванченко
«правильність^ рішень. Потрібно знайти якнайкращу (у сенсі цього критерію) вирішальну функцію. У разі, коли задано розподіл імовірності, розпізнавання зводиться до одного із завдань теорії статистичних рішень. Випадок, коли задано умови, що визначають непересічні підмножини значень сигналу для кожного значення шуканого параметра, на перший погляд уявляється тривіальним, оскільки рішення міститься в умовах завдання.
Проте це не завжди так, оскільки умови, що точно визначають підмножини, іноді дуже важко безпосередньо перевірити. У таких випадках потрібно знайти ефективний спосіб перевірки умов.
Замість терміну «розпізнавання» часто використовуються інший термін — «класифікація». Ці два терміни у багатьох випадках розглядають як синоніми, але вони не є повністю взаємозамі- нювані. Кожний з них має свої сфери застосування, й інтерпретація обох термінів часто залежить від специфіки конкретного завдання. Ми вважатимемо обидва терміни синонімами, якщо не буде вочевидь обумовлено щось інше.
Наведемо деякі типові постановки завдання класифікації.
• Завдання ідентифікації полягає в тому, щоб вирізнити певний конкретний об’єкт серед йому подібних (наприклад, впізнати серед інших людей свою дружину).
• Належність об’єкта певного класу. Це може бути, наприклад, завдання розпізнавання літер або прийняття рішення про наявність дефекту у якійсь технічній деталі. Віднесення об’єкта до певного класу відображає найтиповішу проблему класифікації, і коли кажуть про розпізнавання образів, найчастіше мають на увазі саме цю проблему. Саме її ми і розглядатимемо в першу чергу.
• Кластерний аналіз, який полягає в поділі заданого набору об’єктів на класи — групи об’єктів, схожих між собою за якимись критеріями. Це завдання часто називають класифікацією без учителя, оскільки, на відміну від попереднього, класи апріорно не задані.
Як уже зазначалося раніше, проблеми розпізнавання легко розв’язують люди, причому робиться це, зазвичай, підсвідомо. Спроби побудувати штучні системи розпізнавання не настільки переконливі. Основна проблема полягає в тому, що часто неможливо адекватно визначити ознаки, на основі яких слід здійснювати розпізнавання. Якщо в завданнях такі ознаки вдається виділити, штучні системи розпізнавання набули значного поширення і широко використовуються.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
299
7.2. Класи та їх властивості
Одне з найбільш вдалих формулювань ключової парадигми теорії розпізнавання: будь-який об’єкт у природі є унікальним, всі об’єкти є типізованими.
Зміст цієї парадигми такий. Кожен об’єкт має певні властивості. Наявність чи відсутність таких властивостей, а також якісні та кількісні характеристики цих властивостей розглядаються як ознаки об’єкта. Унікальність будь-якого об’єкта полягає в тому, що в природі не існує двох об’єктів, в яких співпадають абсолютно всі ознаки, і це дає змогу, принаймні теоретично, відрізнити один об’єкт від другого. Але деякі ознаки різних об’єктів можуть співпадати, і це дає підстави казати, що ці об’єкти належать до одного типу або класу.
Фундаментальні поняття «класу» та «об’єкту» неможливо повністю формалізувати. Спробуємо дати неформальні визначення цих понять.
Об’єктом у теорії розпізнавання зазвичай називають будь-яку сутність, що існує або могла б існувати в реальному світі, а також будь-яке явище або процес. Це дуже широке визначення, подальші уточнення можуть бути пов’язані з певним звуженням нашого розуміння того, що саме слід вважати об’єктом.
Класом у теорії розпізнавання образів зазвичай називають сукупність об’єктів, які мають якісь спільні ознаки. Клас може об’єднувати фізично існуючі сутності (наприклад, «людина», «яблуко») або бути абстрактним поняттям («криза», «економічне зростання» тощо).
Ознаки, що дають можливість відрізнити представників одного класу від другого, зазвичай називають інформативними ознаками.
Ознаки, спільні для всіх представників класу, називатимемо інваріантами класу. Клас є сукупністю об’єктів, пов’язаних між собою деяким відношенням еквівалентності, або, в крайньому разі, толерантності. Нагадаємо, що відношенням еквівалентності називають відношення, яке є симетричним, рефлексивним і транзитивним (наприклад відношення «дорівнювати»). Для відношення толерантності властивість транзитивності у загальному випадку не виконується (наприклад відношення «бути схожим»).
300
Г.Ф. Іванченко
Набори інформативних та інваріантних ознак можуть співпадати, але це зовсім необов’язково (наведіть відповідні приклади).
Інколи, щоб уникнути непорозумінь, ми називатимемо об’єкти і класи реального світу відповідно Р-об’єктами і Р-класами. Зрозуміло, що Р-об’єкт може належати до будь-якої кількості Р- класів.
Р-об’єкти часто називають реалізаціями, або зразками Р-класів.
Можна виділити такі основні властивості класів:
1. Усі представники класу мають певний набір спільних ознак (випливає з визначення).
2. Змінюваність реалізацій класів. По-перше, різні об’єкти, що належать до одного класу, можуть бути не схожі між собою. Вони повинні мати спільні інваріантні ознаки, але усі інші ознаки можуть як завгодно варіювати. По-друге, один і той самий об’єкт може змінюватися з часом і навіть поступово переходити від одного класу до іншого (наприклад, перетворення головастика на жабу). Усе це свідчить про те, що виділити чіткі межі класу часто неможливо.
3. Ознайомлення з деякою скінченною кількістю представників цього класу дає можливість впізнавати інших представників цього класу. Взагалі ця властивість може не виконуватися. Але якщо виконується (принаймні теоретично), це є дуже важливим твердженням. Воно по суті означає можливість навчатися на прикладах, тобто на основі спостереження певної кількості прикладів (можливо, разом з контрприкладами), сформулювати правило розпізнавання, яке дає змогу відрізняти представників цього класу від представників іншого (можливо, з певною достовірністю, тобто з певним відсотком помилок). У деяких випадках правилом розпізнавання може бути предикат, який залежить від інформативних або інваріантних ознак, інколи правило розпізнавання реалізується у вигляді деякої складної процедури.
Якщо навчання на прикладах неможливе або неефективне, правило розпізнавання інколи можна задати явно. Якщо не вдається, єдиною можливістю для надійного розпізнавання залишається запам’ятовування усіх можливих представників цього класу. Цей випадок не становить інтересу з теоретичної точки зору, і його можна реалізувати лише якщо кількість можливих представників не є надто великою.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
301
7.3. Класифікація основних методів розпізнавання
Передусім, слід згадати прості спеціалізовані методи розпізнавання на основі фіксованих наборів еталонних ознак. Самі об’єкти вважаються відносно незмінними. Кожний з цих методів розрахований на окреме специфічне завдання.
Існує декілька груп таких методів. Для прикладу згадаємо один із них — метод співставленим з еталоном. Основний принцип полягає в порівнянні зображення з набором попередньо сформованих еталонів. Порівняння здійснюється з використанням спеціальних технічних пристроїв, зокрема, фотомасок, матриць електричних елементів і т.п.
Наприклад, при використанні фотомасок зображення безпосередньо накладається на еталонні маски, набір яких охоплює всю множину еталонів. Ступінь співпадіння визначається за допомогою фотоелемента, розташованого за маскою.
Змінюваність реалізацій класів вимагає універсальніших методів. Основна відмінність між різними групами методів розпізнавання полягає в тому, яким чином формуються модельні описи об’єктів.
Найчастіше застосовують класифікацію, згідно з якою методи розпізнавання образів поділяють на дискримінантні (часто їх називають розпізнаванням у просторі ознак) і структурні.
При використанні дискримінантних методів розпізнавання кожен об’єкт описується точкою у просторі ознак, тобто координатами цієї точки виступають значення ознак об’єкта. Відповідно до цього основною метою навчання є поділ всього простору на зони, кожна з яких відповідає певному класові.
Дискримінантні методи розпізнавання в свою чергу поділяються на ймовірнісні та детерміністські.
При використанні ймовірнісних методів кожний об’єкт описується вектором, який розглядається як реалізація деякого випадкового вектора. Якщо відомі ймовірнісні характеристики розподілу випадкових векторів, то можна визначити ймовірності, за якими об’єкт може належати до того чи іншого класу, і на основі цього прийняти рішення про класифікацію. В основі ймовірнісних методів розпізнавання лежить прийняття рішень на основі баєсівського підходу.
302
Г.Ф. Іванченко
При використанні детерміністських методів не робиться жодних ймовірносних припущень, а рішення приймається на основі аналізу метричних ступенів близькості між різними точками.
Структурні методи застосовують під час розгляду структури об’єктів, які розпізнаються. Вони поділяються на синтаксичні (інша назва—лінгвістичні) та логічні.
При використанні синтаксичних методів кожен клас описується формальною мовою, на основі певної формальної граматики. Об’єкт, що розпізнається, описується певною фразою, і головний принцип розпізнавання полягає в тому, щоб визначити мову отриманої фрази.
Нарешті, логічні методи розпізнавання ґрунтуються на аналізі комбінацій характерних ознак. Кожен клас описується деяким предикатом, і об’єкт належить до класу, якщо відповідний предикат приймає значення «істина». Використання логічних методів розпізнавання — це по суті реалізація певної експертної системи.
Можна розглядати й іншу класифікацію методів розпізнавання, яка вираховує, чи є помилки на навчальній вибірці. Деякі методи гарантують, що в робочому режимі всі об’єкти навчальної вибірки розпізнаватимуться безпомилково. Для інших методів це не так.
7.4. Розпізнавання в просторі ознак
Як уже зазначалося, для дискримінантного розпізнавання, або для розпізнавання в просторі ознак, характерним є те, що кожен об’єкт зображується окремою точкою в деякому просторі. Координатними осями цього простору виступають ознаки, за якими здійснюється розпізнавання. Таким чином, як координати об’єктів виступають значення відповідних ознак. Далі, розпізнавання здійснюється на основі аналізу ступінь близькості між об’єктами.
Схема розпізнавання в просторі ознак цілком відповідає наведеній загальній схемі. Тут «модельним описом» об’єкта є його вектор ознак, і тому «формування модельного опису об’єкта» є не що інше, як виділення ознак, отримання числових значень ознак.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
303
Типова схема розпізнавання в просторі ознак наведена на рис 7.2.
Рис 7.2. Розпізнавання в просторі ознак
Виділення ознак не слід змішувати з іншим завданням — вибору інформативних ознак, за якими слід здійснювати класифікацію. Такий вибір має відбутися на етапі навчання; на етапі розпізнавання визначаються конкретні значення ознак для всіх об’єктів, що розпізнаються.
Легко зрозуміти, що всі ці етапи тісно пов’язані між собою. Уже з цього прикладу видно, що ідеальний класифікатор не вимагає виділення ознак, і навпаки, за ідеального виділення ознак робота класифікатора максимально спрощується. Основну проблему можна сформулювати таким чином: реальні методи отримання первинної інформації та доступні алгоритми виділення ознак часто не дають змогу отримати саме ті ознаки, які насправді відрізняють представників одного класу від іншого.
Існує величезна кількість дискримінантних методів розпізнавання. Тут ми обмежимося розглядом лише найпростіших детерміністських методів.
Виділяють різні типи ознак: дихотомічні (ознака може бути присутня або відсутня; наприклад — є крила або немає крил); номінальні (наприклад, колір: червоний, синій, зелений тощо); порядкові (наприклад, великий — середній — маленький); кількісні. Для кожного типу ознак можна вводити свої ступені відстані між об’єктами.
Існують спеціальні методики, які дають можливість здійснювати перехід від некількісних типів ознак до кількісних.
У більшості методів розпізнавання робиться природне припущення, що зображення об’єктів одного класу (образу) ближчі одне одному, аніж зображення різних класів. Метричні методи засновані на кількісній оцінці цієї близькості. Як зображення об’єкта приймається точка в просторі ознак, ступенем близькості вважається відстань між точками.
Метричним простором називюєть безліч об’єктів, над якими визначена метрика.
304
Г.Ф. Іванчвнко
Метрика — правило, за допомогою якого вводиться відстань сі(а,Ь) між елементами простору, і що задовольняє умовам:
1) сІ(а,Ь) ^ 0, причому <і{а,Ь)=0 тоді і тільки тоді, коли а=Ь;
2)сі(а,Ь)=сі(Ь,а);
3)Л(а,6)^ <1(а, с) + с!(Ь,с).
Розглянемо найчастіше використовувані метрики.
1. Відстань Хеммінга (відстань за Манхеттеном, метрика міських кварталів) між об’єктами хч і хё, що характеризуються доознаками хді та х8!, 5=1, 2,..., к:
2. Евклідова відстань між об’єктами х<, і х8, що характеризуються доознаками хч% та х&, 5=1,2,..., к:.
Якщо різні ознаки мають враховуватися різною мірою євклі- дова відстань в и-вимірному метричному просторі між векторами а = (а\, ..., а„) та Ь = (Ь\, ..., Ь„), кожній ознаці приписується вага м>і, і використовується зважена евклідова відстань:
^(а,Ь) = ^щ(аі-Ьі)г
3. Відстань Мінковського (узагальнена відстань) між
об’єктами хч і хй, що характеризуються к ознаками хді та %, 5=1,2,..., к:
і
де V — ціле число.
4. Діагностичний ступінь відстані між об’єктами хч і хг, що характеризуються к ознаками хЦ5 та хг! 5=1,2,..., к:
де V, ц — деякі числа.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
305
5. Відстань у неізотропному просторі ознак між об’єктами хч і х%, що характеризуються к ознаками хд5 та 5=1,2,...,к у багатьох випадках дає підвищену точність класифікації:
де а, — коефіцієнт значущості 5-ї ознаки.
Оскільки для розпізнавання важлива відносна вага, то можна використовувати умову нормування у вигляді:
Введення вагових коефіцієнтів деформує простір ознак. Якщо поставити умову, щоб за подібних деформацій зберігся об’єм діапазонів діагнозів, то умову нормування можна прийняти таку:
б. Узагальнена відстань в просторі ознак. Вирази для відстані в неізотропному просторі встановлює «нерівноправ’я» окремих координат у просторі ознак, але воно не враховує взаємозв’язок координати х$ і класу АГ,-. Значення ознак різне для різних класів і відстань точки (екземпляра) хч до точки що належить до класу К(.
де ои — середньоквадратичне відхилення ознаки (параметра) х3 для екземплярів, що належать до класу К» — безрозмірний коефіцієнт, що характеризує цінність ознаки.
Для дискретної ознаки хІ9 що має ш дискретних значень лг^і, де,2, можна прийняти:
к
к
Па» = і •
де V, (і — деякі числа.
Часто доцільно прийняти: ай = —,
= т±Р{х5рІк)\оШг{р{х;рІо)р(хзр)).
р=1
306
Г.Ф. Іванченко
Для безперервно розподілених ознак xs імовірність дискретних значень замінюється щільністю ймовірності, підсумовування — інтеграцією за діапазоном значень xs. У разі, якщо відсутні статистичні відомості, величини Cis можуть бути призначені на підставі експертної оцінки тощо.
Умови нормування:
k k
= 1 ^ Ь 2..., w., ^ ^ 2..., w.
5=1 5=1
7. Відстань у нелінійному просторі між об’єктами xq і xg, що
характеризуються доознаками xqs і xgs s=l,2,...,k у багатьох випадках дає підвищену точність класифікації:
s=1
де р — ступінь нелінійності, покликаний зменшити помилку кла- сифікації (зазвичай р = 2, 3), as — коефіцієнт значущості 5-ї ознаки.
8. Узагальнена (зважена) відстань Махалонобіса між
об’єктами хд і xg, векторами ознак хч, що характеризуються, і xg:
d = yj{xq-xJat 2Г'л(^-xg),
де 2 — коваріаційна матриця генеральної сукупності ознак, Л
— деяка симетрична ненегативна матриця вагових коефіцієнтів, яка найчастіше вибирається діагональною.
9. Відстань Камберра між об’єктами xq і xg, що характеризуються доознаками xqs та xgs, 5=1,2,..., k:
X ,
— Г
*qs
gs
х„„
+ JC__
qs
Ss
10. Відстань Чебишева між об’єктами хч і хг, що характеризуються доознаками хчз та х&, 8=1,2,..., к:
d = Max\xqs-xgs\.
11. Відстань « х2» між об’єктами хч і хе, що характеризуються доознаками хЧ5 та х#, 5=1,2,..., к:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
307
*
де Хр.=£хр,. і=і
12. Скалярні добутки за різних способів нормування між
об’єктами Хд та що характеризуються доознаками хді та хг5,
13. Кореляційний метод знаходження відстані між об’єктами хд та хг, що характеризуються доознаками хд! та хй1, 5=1,2,..., к:
14. Кутова відстань. Близькість вектора хч до еталонного вектора хе можна охарактеризувати за допомогою кута між векторами. Зручніше ввести косинус кута між векторами, визначаючи його за допомогою скалярного добутку:
Як уже зазначалося, будь-який об’єкт при застосуванні дис- кримінантних методів розпізнавання зображається вектором ознак у певному «-вимірному просторі, де « —• кількість ознак. Таким чином, будь-якому об’єктові відповідає X — вектор X- (х/,]= 1,...,«); де хі — значенняу-ї ознаки.
7.5. Гіпотеза компактності
308
Г.Ф. Іванченко
Навчальну вибірку зазвичай позначають у вигляді спеціальної матриці, яку часто називають матрицею даних:
У=(уф і =1 »•••>?;/ = 1 л+1), де ^ — загальна кількість предста¬
вників усіх класів, п — кількість ознак; у у (/ = 1,...,«) — значення 7-ї ознаки для і'-го об’єкта; уь п+1 — клас, до якого належить і- й об’єкт.
Усі дискримінанті методи так чи інакше спираються на гіпотезу компактності. Відповідно до цієї гіпотези класові відповідає компактна множина точок у певному просторі ознак.
Слово «компактний» тут використовують у дещо незвичному значенні. Компактною у цьому розумінні називають множину точок, для якої:
— число граничних точок мале порівняно з загальним числом точок;
— будь-які дві внутрішні точки можуть бути з’єднані плавною лінією так, щоб ця лінія пролягала лише через точки цієї ж множини;
— майже будь-яка внутрішня точка має в досить великому околі лише точки цієї ж множини.
Для простоти розглядатимемо випадок двох класів; методологія, яку буде описано, легко поширюється на більш загальний випадок.
Отже, нехай ми маємо два класи: К\ і Кг. Нехай довільний вектор х описується своїми координатами: х = (*і,..., х„). Кажуть, що функція g(x) розділяє ці класи, або є розділовою функцією, якщо для всіх векторів класу К\ g(x) > 0, а для всіх векторів класу Кг 8(х)<0.
Побудова й використання розділових функцій є основою багатьох методів розпізнавання. Насправді в робочому режимі ми, зазвичай, не можемо знати заздалегідь, до якого класу належить цей об’єкт (саме це й потрібно визначити). Натомість, якщо у нас є деяка розділова функція, що є наближенням до справжньої розділової функції, ми можемо на основі її аналізу прийняти певне рішення, а саме: рішення про належність вектора х до класу К\, якщо g(x) > 0, і до класу Кг, якщо ^х) < 0. Це рішення може бути помилковим. Таким чином, метою навчання має бути отримання справжньої роздільної функції, якщо вона існує, або побудова деякої наближеної розділяючої функції в іншому випадку. Саме такий зміст ми надалі вкладатимемо в поняття «роздільна функція».
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
309
Як уже зазначалося, особливо важливим є випадок, коли роздільна функція є лінійною, тобто є рівнянням гіперплощини, і має вигляд: #(х) = и>іХі+ + м>^с„ + коефіцієнти м>і мають бути визначені в процесі навчання.
Одним із найпростіших методів підбору параметрів є алгоритм персептрона. Алгоритм має таку назву через свій тісний зв’язок з навчанням персептронів (див. тема 6).
Алгоритм полягає в такому. Задається початковий вектор параметрів м>(0), який уточнюється з розпізнаванням елементів навчальної вибірки. Правила уточнення такі:
— якщо черговий елемент навчальної вибірки х(і) належить Кі, а g(x) <0, то: м'(Н-І) := м>(і) + с х(і); с >0;
— якщо черговий елемент навчальної вибірки х(і) належить до К2, а %(х) > 0, то: м>(і+1) := м>(і) - с х(і); с >0;
У випадку лінійної роздільності алгоритм збігається.
Кусково-лінійні розділяючі функції є складнішими, ніж лінійні, і побудова їх є складніша. Водночас, кусоково-лінійна роздільна функція може з достатньою точністю апроксимувати практично будь-яку роздільну функцію.
Одна з процедур побудови кусково-лінійних роздільних функцій була запропонована Аркадьєвим і Браверманом.
Добре відомим методом побудови роздільних функцій є також метод потенціальних функцій, запропонований Айзерманом, Браверманом і Розоноером.
Важливість належного вибору простору ознак, у якому класам відповідають компактні множини точок, ілюструють такі приклади. На всіх малюнках представники одного класу позначені кружальцями, а другого — зірочками.
У цьому випадку ознаки обрані дуже вдало. Класи добре відокремлені один від одного. Мало того, можна провести пряму лінію так, що всі представники першого класу лежатимуть по один бік цієї лінії, а всі представники другого класу — по інший бік. У такому разі кажуть, що класи є лінійно роздільними (рис. 7.3, а).
Лінійна розділовість дуже спрощує завдання розпізнавання. Правило розпізнавання на основі лінійних роздільних функцій є дуже простим і не вимагає великих витрат часу і пам’яті. Роздільну пряму лінію дуже легко побудувати.
У прикладі рис. 7.3, б лінійного поділу немає. Але все-таки можна побудувати лінію, хоч і не пряму, яка відокремлює один
310
Г.Ф. Іванчвнко
клас від другого. Процедури навчання і розпізнавання в цьому разі істотно ускладнюються.
о° о •О ° о
} о ° 0 о
' о О® °
; оо0 о
\° о0°
\
N О \
а) б)
Рис 7.3. Лінійний поділ класів.
У прикладі наведеному на рис. 7.4, а надійно відокремити класи один від другого не вдається, через це значно збільшується кількість помилок під час розпізнавання.
а) б)
Рис. 7.4. Класи частково або цілком перекриваються
У випадку наведеному на рис 7.4, б про жодне розпізнавання в такому просторі ознак казати, очевидно, марно.
Метричні методи відносять екземпляр до того класу, відстань до центру якого менша. Такий поділ буде безпомилковим, якщо
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ 311
класи добре поділяються і мають сферичне угруповання навколо центрів класів.
У ситуації, зображеній на рис. 7.5, екземпляри класів А і В згруповані навколо центрів класів, але діапазони цих угруповань витягнуті.
Рис. 7.5. Окремий випадок помилкової класифікації на основі метричних методів
В цьому випадку екземпляр, що належить до класу В (позначений «*»), метрична класифікація помилково відноситиме до класу А, оскільки за відстанню він ближче до А.
Проте легко бачити, що цей екземпляр знаходиться всередині діапазону, межа якої може бути апроксимована за навчальними даними, і цей екземпляр можна було б цілком упевнено віднести до класу В, якби класифікація здійснювалася за приналежністю екземпляра до діапазону класу (фігури, обмеженої деякою поверхнею, що апроксимує межу діапазону класу за точковими даними навчального експерименту).
Нехай у ^-вимірному ознаковому просторі є однозав’язний діапазон з центром в точці С, обмежена поверхнею Ь(х), тоді точка хч знаходитиметься на поверхні Ь(х), якщо Ь(хя)= 0; знаходитиметься усередині діапазону з центром в точці С, якщо Цх)<0; і поза діапазону з центром у точці С, якщо Ь(х)>0.
Припустимо, що Хд належить діапазону С, якщо Ь(хд) ^0. Тоді якщо відомі рівняння гіперплошин ЬА(х) і Ьв(х), які апроксиму- ють межі діапазонів класів С4 і Сг, то
Хд Є С4, ЯКЩО ЬА(Хд) ^ 0, Ьв(хд)>0;
Хд Є СВ, ЯКЩО Ь (Хд) ^ 0, Ь (хд)>0;
ХдєС4, ХдіС8, якщо (ЬА(хд) >0 і Ьв(хд)>0) або (ЬА(хд) <0 і
Ьв(Хд)<0), або (ЬА(Хд) = 0 і Ьв(Хд) = 0).
312
Г.Ф. Іванченко
Такі правила називатимемо упевненою класифікацією, оскільки вони однозначно визначають приналежність екземпляра.
Вирази гіперповерхонь меж областей класів, зазвичай, невідомі. Тому їх потрібно апроксимувати на основі точкових значень ознак екземплярів навчальної вибірки, що належать до відповідних класів.
Крім того, на практиці відомі не всі можливі екземпляри, що належать до С4 і С8, а лише деяка невелика їх підмножина (навчальна вибірка). Тому ЬА і Ьв, побудовані на основі навчальної вибірки, обмежуватимуть не діапазони класів для генеральної сукупності екземплярів, а діапазони класів для екземплярів навчальної вибірки і забезпечуватимуть упевнену класифікацію лише в цих діапазонах. Поза цими діапазонами класифікація на основі вищенаведених правил буде неможлива (відмова від класифікації).
Якщо ввести пріоритети для класів, визначивши, що екземпляр хд належить до класу А, якщо ЬА(хд) ^ 0, і до класу В — інакше, то це правило дасть змогу здійснювати класифікацію в усьому ознаковому просторі, втім певна частина екземплярів, які належать до класу А, але не потрапляють в діапазон С4 (тобто не входять до навчальної вибірки) можуть бути помилково віднесені до класу В.
Вибір виразу для Ьр(х), де р={А, В} позначення класу здійснюється з урахуванням попередньої інформації про характер зосередження екземплярів.
Наприклад, для Ьр(х) можна використовувати рівняння гіпер- еліпсоща (окремим випадком якого є гіперсфера):
де а? — деякі константи, що визначають напіврадіуси еліпсоїда. Константи а? слід знаходити за даними навчальної вибірки, наприклад за таким правилом:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
313
Оскільки центри еліпсоїдів, що апроксимуюють межі діапазонів класів, знаходяться не на початку координат, а зміщені в центри зосередження класів, то в Ьр(х) потрібно врахувати цей зсув, який за і-ою координатою дорівнюватиме і'-ій координаті центру р-то діапазону (7,:
На практиці використовується багато методів розпізнавання образів, ми розглянемо алгоритмічну реалізацію деяких з них. Метод найближчого сусіда є одним з найвідоміших і класичних дискримінантних методів розпізнавання. Його можна сформулювати таким чином: об’єкт класифікується системою розпізнавання до того класу, до якого належить його найближчий сусід з навчальної вибірки.
Метод не дає помилок на об’єктах навчальної вибірки. Його застосування фактично еквівалентне застосуванню деякої кусково- лінійної роздільної функції, хоч ця функція насправді не отримується. Тому метод не вимагає попереднього формування вирішального правила. Але його недоліком є те, що в пам’яті доводиться зберігати всю навчальну вибірку і знаходити відстані до кожного її елемента. Це призводить до великих витрат і пам’яті, і часу.
При застосуванні правила найближчого сусіда можливість провести попереднє навчання, в процесі якого скоротити повну навчальну вибірку. Для цього можна використовувати так зване стиснуте правило найближчого сусіда, запропоноване Хартом. Далі наводиться алгоритм цього правила, описаний на основі [Фукунага].
Для роботи алгоритму потрібні дві робочі множини — пам’ять та архів. Алгоритм виконує такі дії:
1. У пам’ять заноситься по одному представнику кожного кла-
2. Кожен наступний об’єкт навчальної вибірки класифікується за допомогою правила найближчого сусіда, але при цьому вико¬
7.6. Метод найближчого сусіда
су.
314
Г.Ф. Іванчвнко
ристовуються лише ті об’єкти, які знаходяться в множині пам’ять. Якщо цей об’єкт класифікується правильно, він викидається до архіву, інакше він заноситься в пам’ять.
3. Після перегляду всіх об’єктів описана процедура повторюється знову, але лише для елементів множини архів. Процедура завершується або за повного вичерпання архіву, або якщо під час чергового проходження жодний об’єкт з архіву не перейшов до пам’яті.
4. Після завершення роботи алгоритму як скорочена навчальна вибірка використовується множина пам’ять.
Модифікацією методу найближчого сусіда є правило к найближчих сусідів. Об’єкт система розпізнавання відноситься до того класу, до якого належить більшість з к його найближчих сусідів з навчальної вибірки.
7.7. Баєсівські методи розпізнавання
Баєсівські методи належать до ймовірнісних методів розпізнавання. Вони залучають до розгляду ймовірнісні характеристики класів, і врахування такої інформації дає змогу істотно підвищити якість розпізнавання.
Основну ідею баєсівьких методів можна неформально охарактеризувати таким чином. Нехай відомі ймовірнісні характеристики того, що об’єкт, який належить до певного класу, описується деяким вектором ознак. Якщо ми отримали вектор ознак, який потрібно розпізнати, ми можемо на основі правил Баєса розрахувати апостеріорні ймовірності належності цього вектора до кожного класу. Далі об’єкт система розпізнавання відносить до того класу, для якого ця апостеріорна ймовірність найбільша (іншими словами — до найбільш імовірного класу).
Дамо більш формалізований опис баєсівських методів.
Нехай ми маємо т класів К\, ..., Кт. З кожним класом пов’язана апріорна ймовірність Р(К,) — ймовірність появи об’єкта /-го класу. Нагадаємо, що ймовірності тісно пов’язані з частотою, і тому ймовірності Р(Кі) по суті характеризують, як часто зустрічаються об’єкти відповідних класів.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
315
Основною ймовірнісною характеристикою розподілу векторів певного класу в просторі ознак, є умовна гущина розподілу. Дамо необхідні визначення.
Функцією розподілу одновимірної неперервної випадкової величини 11 називають функцію ^(х) = Дт) < х).
Аналогічно вводиться поняття функції розподілу від векторної випадкової величини.
Гущиною розподілу називають похідну від функції розподілу.
Умовною гущиною розподілу Р(Хі / К/) називають гущина розподілу вектора X, за умови, що він належить до класу Кр
Для грунтовнішого ознайомлення з відповідним математичним апаратом читачеві рекомендується звернутися до будь-якого підручника з теорії ймовірностей.
Тепер можна описати баєсівське вирішальне правило.
Нехай ми маємо вектор У. Для класифікації цього вектора слід для кожного класу розрахувати величини
Р(К АР(У / К А
Р(К,ІТ) = іі,
і р,(Г)
які являють собою апостеріорні ймовірності належності цього вектора ознак для кожного класу. Слід обрати той клас, для якого ця ймовірність максимальна.
Далі, у знаменнику фігурує величина р(ї), яка є спільною для всіх класів, і яку можна скоротити. В результаті маємо таке вирішальне правило: вектор У слід віднести до того класу, для якого величина Р(К;)Р(ї/К^ є максимальною.
Баєсівські методи можна застосовувати і в разі, якщо необхідно враховувати ризики, пов’язані з неправильною класифікацією.
7.8. Попередня обробка сигналів та зображень
Як уже зазначалося, обробка експериментальних сигналів та зображень має велике значення для теорії і практики розпізнавання. Нагадаємо, що експериментальні сигнали описує функція однієї змінної (найчастіше — функція, яка задає зміну деякої фізичної величини з часом). Зображення описує функція двох змінних, яка задає значення яскравості в різних точках зображення.
316
Г.Ф. Іванчвнко
На етапі попередньої обробки вирішується ряд важливих завдань, у першу чергу такі:
• отримання первинних ознак;
• зменшення шумів та підвищення якості зображення (наприклад, підвищення чіткості обрисів фігур);
• сегментація (поділ зображення на зони, які оброблятимуться).
Існує величезна кількість завдань, пов’язаних з обробкою сигналів і зображень. Деякі з них, а також основні методи їх вирішення описані, наприклад, у [Верхаген, Брав, Павлидис ].
Найтиповішим і найбільш часто вживаним способом отримання первинних описів об’єктів, які задаються неперервними величинами, є дискретизація цих величин (інші назви — оциф- рування, цифрування). Дискретизація є аналого-цифровим перетворенням і полягає в тому, що аналогова величина реєструється у вигляді набору своїх значень у дискретних точках.
Нехай неперервна функція /(І) спостерігається на проміжку [а, Ь]. Зафіксуємо п дискретних точок, у яких вимірюватимуться значення функції: (\=а <Ь<... < /л-і < и-Ь. Ці точки часто називають вузлами. Тоді дискретизація функції /0) полягає у подаванні її вектором у = (уі, ..., у«), де Уj=J(tj) (тобто кожна координата вектора являє собою значення функції в черговому вузлі).
Дискретні значення у/=/і0 часто називають первинними ознаками сигналу. Найчастіше використовується рівномірна дискретизація, за якої відстань між будь-якими сусідніми вузлами є однаковою. У такому разі величину А = однакова для всіх j,
називають кроком дискретизації. Легко переконатися в тому, що крок рівномірної дискретизації може бути обчислений за формулою:
Величину q=\/h називають частотою дискретизації. Частота дискретизації характеризує кількість дискретних вузлів на одиничному інтервалі.
Частоту дискретизації не можна обирати довільно. Надто висока частота дискретизації (і, відповідно, надто малий крок дискретизації) призводить до надто великого обсягу інформації. Це, в свою чергу, спричинює надмірні витрати на зберігання й обробку такої інформації. У зв’язку з цим виникає проблема стискування інформації, яка у цьому контексті означає зберігання оциф- рованої інформації у більш економному вигляді.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
317
Водночас, зменшення частоти дискретизації призводить, як правило, до зменшення точності. Фундаментальна теорема Котельникова (аналогічний результат пізніше отримав Шеннон) встановлює, якою має бути мінімальна частота дискретизації, за якої інформація не втрачається (тобто при якій неперервна функція ще може бути точно відновлена за дискретними даними). Обговорення цієї теореми виходить за межі нашого курсу.
Аналогічно здійснюється дискретизація зображень. На зображення накладається двовимірна сітка, і тоді зображення можна закодувати матрицею, елементи якої дорівнюють сумарній яскравості зображення в окремому квадратику сітки. Часто застосовується й простіший спосіб кодування, за якого елемент матриці дорівнює 1, якщо у відповідному квадратику є фрагмент зображення, і 0 — якщо немає. Нехай сканується зображення, яке являє собою літеру В. Закодуємо це зображення за допомогою сітки розміром 8 х 6 та отримаємо матрицю:
0,
1
і!
і 1
1
1
0
1
о!
ІО
0
0
1
1
0!
10
0
0
1
1
І!
[•уі
1
1
V
1
0!
10
0
0
1
1
0!
10
0
0
1
1
0
Го
0
0
Г
г
"і!
І 1
г
~1
0
Рис.7.6. Приклад дискретизації зображення навчання розпізнавати зображення літери «В»
Слід звернути увагу на обставини, які ускладнюють обробку таких зображень:
1. Форма відсканованої літери дещо спотворюється; це стає особливо помітним за великого розміру клітинок сітки (за малого кроку дискретизації).
2. Сканер працює не бездоганно, і на відсканованому зображенні можуть з’являтися зайві лінії, яких не було на оригіналі, і навпаки — зникати ті, що були. В результаті, наприклад, літера О може бути сприйнята як літера С.
3. Результат кодування є дуже чутливим до позиціонування тексту стосовно сканера. Якщо літеру на рисунку трошки зсунути
318
Г.Ф. Іванчвнко
вбік, зображення літери потрапить в інші квадрати, і матриця істотно зміниться.
4. Одна й та сама літера може бути написана зовсім по-різ- ному.
Всі ці обставини зумовлюють добре відомі факти: якість розпізнавання друкованого тексту істотно перевищує якість розпізнавання тексту рукописного; якість розпізнавання знижується за недостатньої якості друку, а також за низької роздільної спроможності сканера; багато реальних систем розпізнавання орієнтовані на певний стиль написання літер, і користувач має попередньо засвоїти цей стиль (зокрема, це стосується сучасних персональних помічників).
Крім того, методи розпізнавання в просторі ознак є дуже чутливими до перелічених вище чинників, і тому для розпізнавання літер у першу чергу використовуються структурні, передусім синтаксичні, методи.
Розглянемо простір ознак, які обрані адекватно поставленому завданню. Перший етап вирішення полягає в тому, щоб відобразити в цьому просторі «хмару» точок (або, можливо, єдину точку), пов’язаних з одним і тим самим класом, а потім визначити один або кілька прототипів, що становлять майбутні класи. Ці представники класів зовсім не обов’язково мають співпадати з якимись конкретними реалізаціями, за якими отримані результати експериментальних вимірювань або спостережень. Швидше навпаки, за наявності деяких первинних відомостей про прототипи, можна управляти процесом вимірювань або іншим методом отримання початкових даних. Зазвичай прототипи називають іменами класів. На подальших етапах їх використовують для розпізнавання невідомого образу, початкові дані про який отримані таким самим методом, що й дані про вже відомі образи. Основу способу класифікації, що розглядаємо тут, становить процес навчання, завдання якого — поступове вдосконалення алгоритму поділу об’єктів на класи. Цей процес зазвичай прагнуть, автоматизувати. З цією метою відбирають частину об’єктів і використовують їх у процесі навчання для «тренування» системи. Масив початкових даних у системі складається з двох частин: навчальної вибірки і тестової вибірки, яку використовують у процесі випробувань (або іспиту). Природно виникає запитання про показність вибраної множини.
Якщо сукупність класів відома наперед, то навчання називають контрольованим (навчання з учителем). Роль розробника
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
319
полягає у виробленні якнайкращих критеріїв класифікації, що враховують відмінності між ознаками, характерними для окремих класів. Головним завданням стає в цьому випадку пошук оптимальних методів поділу.
На рис. 7.7 показано таку персептронна конфігурацію. Припустимо, що вектор X є розпізнавальним образом літери. Кожна компоненту (квадрат) X — (*і, хг,-, х„) помножується на відповідну компоненту вектора вагів \¥ — (м>і, м>2,..., м>„). Ці добутки підсумовуються. Якщо сума перевищує поріг, то вихід нейрона У дорівнює одиниці (індикатор світиться), інакше він — нуль. Ця операція компактно записується у векторній формі як У = ХЖ, а наступною є порогова операція.
Рис. 7.7. Персептронна система розпізнавання зображень
Персептрон навчають, подаючи множину образів поодинці на його вхід і підлаштовуючи ваги до тих пір, поки для всіх образів не буде досягнуто необхідний вихід. Припустимо, що вхідні образи нанесені на демонстраційні карти. Кожна карта розбита на квадрати, й від кожного квадрата на персептрон подається вхід. Якщо в квадраті є лінія, то від нього подається одиниця, інакше
— нуль. Множина квадратів на карті задає, таким чином, множину нулів і одиниць, яка й подається на входи персептрона. Мета полягає в тому, щоб навчити персептрон включати індикатор під
320
Г.Ф. Іванчвнко
час подачі на нього безлічі входів, що задають непарне число, і не включати у разі парного.
Для навчання мережі образ X подається на вхід і обчислюється вихід У. Якщо У правильний, то нічого не змінюється. Проте якщо вихід неправильний, то ваги, приєднані до входів, що підсилюють помилковий результат, модифікуються, щоб зменшити помилку.
а) Навчання з учителем. Головна особливість контрольованого методу класифікації полягає в обов’язковій наявності апріорних відомостей про приналежність до певного класу кожного вектора вимірювань, що входить до навчальної вибірки. Наприклад, якщо з великої відстані потрібно відрізнити поле, що засівають зерновими, від лісу або пустелі, то наперед проводять вимірювання відомих ділянок землі, на яких є поля, ліси, пустелі тощо. Таким чином, отримують множину векторів вимірювань від джерел, приналежність яких до певного класу наперед відома.
Роль навчальної вибірки в тому, щоб створити таку систему, яка дала б змогу кожен вектор вимірювань, джерело якого невідоме, віднести до одного з уже відомих класів.
Завдання полягає в уточненні й оптимізації процедури ухвалення рішень, яка часто будується інтерактивним методом за допомогою навчальної вибірки. В основу процедури покладено поняття відстані від цієї точки до межі, що відокремлює простір, який характеризується певними ознаками. Залежно від розмірності простору, від його форми межа може описуватися по-різному: лінія, гіперплощина, потенційний рельєф тощо. Одним з основних шляхів оптимізації слугує метод градієнтного спуску в просторі параметрів. Подібні системи мають усі переваги автоматичних систем: високу швидкість виконання операцій, точність, надійність, постійність характеристик тощо.
Якщо класи, що становлять навчальну вибірку, не відомі наперед, до початку процедури класифікації, то навчання називають не- контрольованим, або навчанням без учителя. Вирішення завдання за таких умов значно складніше, ніж у попередньому випадку.
б) Навчання без учителя. В процесі неконтрольованого навчання (без учителя) автоматичний пристрій самостійно встановлює класи, на які поділяється початкова множина, і одночасно визначає їхні ознаки.
Роль розробника полягає лише в тому, щоб повідомити машині критерії, відповідно до яких має виконуватися поділ на класи.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
321
Неконтрольоване навчання представляє собою значно складніша операція, ніж контрольоване. Справді, тут у більшості випадків невідомі ані число класів, ані характеристики кожного з них. Тому процес організують так, щоб серед усіх можливих варіантів групування знайти такий, за якого групи мали б найбільшу компактність. Структурна схема алгоритму, зображена на рис. 7.8, ілюструє метод послідовних наближень до шуканого рішення.
Рис.7.8. Схема процесу навчання без вчителя
Якщо отримана на якомусь етапі класифікація з будь-яких причин незадовільна, то слід повернутися до одного з попередніх етапів з урахуванням не використаної раніше інформації. Кожне повернення на черговий виток циклу характеризується певною ціною, за якою можна прийняти відстань, що відокремлює кінцевий етап від того, з якого починається новий цикл. Але потрібно врахувати, що така процедура не обов’язково буде такою, що сходиться.
322
Г.Ф. Іванченко
7.9. Алгоритм К середніх у СРО
Алгоритм К середніх відрізняється від алгоритму максиміну початковими умовами і числом центрів. Зазвичай використовують К перших елементів із списку даних або К0 перших сигналів від спостережуваних об’єктів. Процедура складається з таких операцій.
Фіксують число ядер К. Вибирають перші елементи з кожного ядра: Мі;...; И5\. Кожному з цих векторів приводять у відповідність свій діапазон простору. Формують ці діапазони, пов’язуючи вектори вимірювань з К ядрами згідно з правилом мінімальної відстані. На г-ому етапі вектор хр пов’язують з ядром 1^, якщо задовольняється така нерівність: || хр - Иіг || < || хр - Щг ||, V/ * і, тоді хр належить до діапазону ЬҐТаким чином, на г-ому етапі N*(1 подає діапазон, пов’язаний з ядром Визначають нові елементи, що характеризують нові ядра Л^і). За їх значення приймають х, що забезпечує мінімум середньоквадратичного відхилення:
Справді, У, приймає мінімальне значення лише за одного х, що дорівнює середньому арифметичному векторів, що належать до одного діапазону ІУ*,. Тоді нове ядро буде:
Бачимо, що для нового визначення потрібно обчислити К середніх значень (звідси і походить назва цього алгоритму).
Процедура закінчується, якщо положення центрів 1> стосовно положення попередніх центрів Міг не змінюється. Інакше її повторюють знову, починаючи з третього кроку, шляхом формування нових діапазонів навколо нових центрів. Програма алгоритму К середніх та результати її роботи наведено у Додатку Е.
Дактилоскопія (за деякими даними цей термін запровадив Жуан Вуцетіч) — це встановлення особи людини за відбитками пальця, а точніше, за так званим папілярним візерунком. Дактилоскопія ґрунтується на тому, що, по-перше, відбиток пальця унікальний (за всю історію дактилоскопії не було виявлено двох співпадаючих відбитків пальців, що належать різним особам, а по-друге, папілярний узор не міняється впродовж всього життя людини.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ 323
В якості масива данних було використано оцифрований відбиток пальця людини (рис. 7.9).
* *
а)
280
270
260
250
240
230
220
210
200
190
180
170
160
150
140
130
120
110
100
90
80
70
60
50
40
30
20
10
0
20 40 60 80 100 120 140 160 180 200 220 240 260
б)
Рис. 7.9. Відбиток пальця людини
а) оригінал — неоцифрований відбиток пальця
б) Ni(r+\) центрів відбитка пальця людини (алгоритм К середніх)
324
Г.Ф. Іввнченко
7.10. Алгоритм Isodata — ітеративний аналіз даних
Для побудови системи розпізнавання образів можна використати алгоритм Isodata (Iterative Self-Organizing Data Analysis, Ітеративний аналіз даних, що самоорганізовується), який є цілком визначеною, гнучкою послідовністю операцій. За їх ітеративного виконання основні елементи класифікації виробляються безпосередньо в процесі роботи. Зокрема, це стосується і ядер, кількість яких апріорі не була визначена. Алгоритм складається з таких етапів. Початкове розташування центрів обирають довільно. Досвід показує, що остаточний результат майже не залежить від первинного вибору. Визначають діапазони, в які входять точки, близькі (в евклідовому геометричному сенсі) до початкових центрів.
Поділяють на дві кожну групу, усередині якої середня відстань між точками перевищує поріг 0,.
Визначають нові «середні» точки кожного діапазону з урахуванням діапазонів, що знову з’явилися. Обчислюють відстані між кожною парою середніх точок. Об’єднують діапазони, пов’язані з середніми точками, відстань між якими менше за деякий поріг
02. Повторюють процедуру.
Суттєва відмінність алгоритму Isodata полягає в тому, що тут немає потоеби обчислювати всі відстані між кожною парою точок на другому етапі (визначення областей). Оператор може довільно обирати значення порогів 0, і 02. Сфера застосування цього алгоритму не обмежується лише розпізнаванням образів. Оскільки за його допомогою можна легко обробляти великі масиви початкових даних, його використовують також у метеорології, соціології й інших галузях.
Це метод автономної класифікації (unsupervised classification) півтонових багатоканальних зображень, котрий виконує класте- ризацію простору спектральних ознак шляхом покрокової класифікації, що чергуються, за заданою кількістю еталонів і корекцією еталонів за результатами класифікації. Алгоритм складається з кроків (додаток Ж):
Крок 1. Задаються параметри, що визначають процес класте- ризації:
К—потрібна кількість кластерів;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
325
Од, — параметр, з яким порівнюється кількість вибіркових образів, що ввійшли в кластер;
©5 — параметр, що характеризує середньоквадратичне відхилення;
0С — параметр, що характеризує компактність;
Ь — максимальна кількість пар центрів кластерів, які можна об’єднати;
І — допустима кількість циклів й ітерацій.
Крок 2. Задані N образів розподіляються за кластерами, що відповідають обраним початковим цетрам за правилами:
ХєБ,, якщо \\х - г\ < \х - г\, і=1, 2,..., ЛГС, і * j
Крок 3. Ліквідуються підмножини образів, до складу яких входять менше ©„ елементів, тобто якщо для деякої ] виконується умова лгус©„, то підмножини Sj виключаються із перегляду, і значення зменшується на 1.
Крок 4. Кожен центр кластера г}. У = 1,2ЬІС, локалізується і коректується
2, =77І^У-Ь2, ...,ЛГс N дгєі,
де N — число об’єктів, що ввійшли в підмножину 5;.
Крок 5. Обчислюється середня відстань Д між об’єктами, що входять у підмножину , і відповідним центром кластера за формулою:
А“Е|*-*і|,/=1.2,..., М,.
Крок 6. Обчислюється узагальнена середня відстань між об’єктами, що знаходяться в окремих кластерах, і відповідними центрами кластерів за формулою:
- 1 & —
N і
Крок 7:
а) якщо поточний цикл ітерації — останній, то задається ©с = 0; перехід до 10;
£
б) якщо умова Ис й — виконується, то перехід до кроку 8;
326
Г.Ф. Іванчвнко
в) якщо поточний цикл ітерацій має перший порядковий номер, або виконується умова > 2 К, то перехід на крок 11, інакше крок 8.
Крок 8. Для кожної підмножини вибіркових образів за допомогою співвідношення:
= лі~хГ~ 2(% ~2ІіУ » ..., И.У-1, 2, ...Д;
І /
вираховується вектор середньоквадратичного відхилення
де п є розмірність образу,
А# є г-ою компонентою £-го об’єктів підмножини,
5/, 2у є / -ою компонентою вектора, що становить центр кластера
Zj і Ц — кількість вибіркових образів, включених до підмножини 5/.
Кожна компонента вектора середнього квадратичного відхилення а, характеризує середньоквадратичне відхилення образу, що входить е півмножину Sj по одній із головних осей координат.
Крок 9. В кожному векторі середньоквадратичного відхилення Сту, У=1,2,...Де, виконуються умови сту мах >©5 і: а) Д >£» і
Ы, > 2(©л +1) або б) Ыс < К / 2, то кластер з центром 2І розщеплюється на два повних кластери з центрами 2* і 2~ відповідно, кластер із центром 2, ліквідується, а значення Ые збільшується на
1. Для визначення центра кластера 2* до компоненти вектора 2р що відповідає максимальній компоненті вектора сг, , додається задана величина у,; центр кластера 2~} визначається відніманням цієї ж величини у, від цієї компоненти вектора 2\
У і =^ітах,ДЄ 0<Л<1.
Крок 10. Якщо розщеплення відбувається на цьому кроці, то перейти на крок 2, інакше крок 10.
Крок 11. Вираховуються відстані Д, між усіма парами центрів кластерів.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
327
Иу =\\г, -г\, і = 1,2,...мс-і; у=1+1,...,*,.
Крок 12. Відстані £>,у порівнюються з параметрами ©с. Ті відстані, які виявилися менші за0с, ранжуються в порядку зростання:
ІАі(2 < А2/2 < • • • < А/// \ ■
Причому Ді,2 < А2і2 <•••< А/у/> а Ь — максимальна кількість пар центрів кластерів, які можна об’єднати.
Крок 13. Кожну відстань Деуе вирахувано для певної пари кластерів із центрами 2ц 2#. До цих пар послідовності, що відповідає збільшенню відстані між центрами, застосовується процедура злиття:
кластери з центрами 2ц і 2ц, /= 1,2,...,£, об’єднуються (за умови, що в поточному циклі ітерації процедура злиття не застосовувалася ні до того, ні до іншого кластера), причому новий центр кластера визначається за формулою:
Центри кластерів 2ц і 2# ліквідуються, і значення Ис зменшується на 1.
Припускається лише попарне злиття кластерів і центр отриманого в результаті кластера розраховується, виходячи з позицій, які посідають центри об’єднаних кластерів і взяті із вагами, визначеними кількістю вибіркових образів у відповідному кластері.
Крок 14. Якщо поточний цикл ітерації — останній, то виконання алгоритму припиняється. Інакше повертаємося на крок 1. Завершенням циклу ітерації вважається кожен перехід до кроку 1.
Результати роботи програми у системі МагіаЬ наведено на рис. 7.10 з експериментальних оцифрованих даних відбитку пальця людини система визначила п’ять кластерних образів.
Використання алгоритму дає можливість стійко розпізнавати об’єкти, які зберегли свою форму. Ще однією можливістю алгоритму Івосіаіа є об’єднання кластерів. Цього разу таке об’єднання здійснювалося на основі близькості центрів тяжіння кластерів. Після попередньої обробки зображення деякі об’єкти розпалися на п’ять частин.
328
Г.Ф. Іванчонко
200-
180-
160-
140
120
100
80
60
40
20
0-
50
—І 1 1—
100 150 200
Рис. 7.10. Приклад розпізнавання відбитка пальця алгоритмом ЬосЫа за п’ятьма кластерними образами
Наведені приклади показують можливість правильного розпізнавання (класифікації) об’єктів, навіть за не зовсім досконалих методів попередньої обробки або не зовсім якісних вхідних зображень (обробка в реальному масштабі часу без вивчення якості зображення).
Отримані результати дають можливість рекомендувати використання цього алгоритму в інших робототехнічних системах і системах розпізнавання образів на пластикових банківських платіжних картках.
7.11. Розпізнавання та обробка природної мови
Розуміння природної мови є однією з найважливіших та найскладніших проблем теорії та практики штучного інтелекту. Це завдання найчастіше пов’язується з проблемою створення систем штучного інтелекту, які здатні вести осмислений діалог з людиною. Відомо, що за останнє десятиліття в організації людино- машинного інтерфейсу було досягнено величезного прогресу, але переважно обхідним шляхом — на основі систем підказок, меню тощо. Успіхи щодо власне розуміння природної мови залишаються скромними: природна мова є надто складною й неоднозначною. І справа не лише в розумінні. В процесі діалогу машина має
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
329
реагувати на фрази людини і відповідати максимально адекватно, вона повинна враховувати мету діалогу, індивідуальні особливості співрозмовника тощо. На сучасному етапі марно сподіватися, що проблему буде цілком розв’язано. Водночас можна й потрібно казати про створення обмежених природних мов, які, з одного боку, припускатимуть ефективні методи аналізу, а з другого — вони мають бути досить природними для людини і не становити для неї особливих труднощів.
Але завдання обробки природної мови постає не тільки в процесі діалогу з людиною. Можна згадати, наприклад, системи автоматизованого перекладу, які дають змогу перекладати з однієї мови на іншу (відомі, зокрема, програми Stylus, Промпт та ін). Якість такого перекладу ще дуже недосконала, і такий переклад вимагає серйозного доопрацювання. Серед професійних перекладачів немає єдності з приводу доцільності застосування таких систем. Дехто переконаний, що вони істотно полегшують роботу перекладача, інші вважають, що якісний переклад простіше одразу набирати в ручний спосіб.
У цьому розділі ми розглядаємо обробку речень, отриманих у вигляді готових текстів.
Типова схема обробки природної мови
За всього розмаїття завдань, пов’язаних з обробкою природної мови, і підходів до & вирішення, роботу систем штучного інтелекту з природною мовою можна уявляти собі у вигляді такої загальної схеми:
1. Сприйняття тексту, написаного природною мовою (на практиці — зазвичай, обмеженою, речення якої прості за своєю структурою і належать до обмеженої предметної галузі.
2. Співставлення тексту зі своїми знаннями і переклад його на внутрішню мову системи — саме цей етап, власне кажучи, і становить основу розуміння.
3. Планування відповіді на основі певних алгоритмів, специфічних для цієї предметної галузі або загальноінтелектуальних метапроцедур.
4. Генерація відповіді — у вигляді зв’язного тексту або, можливо, в деякій іншій формі.
Для вирішення деяких практичних завдань не обов’язково глибоко занурюватися у зміст. Так, в основу роботи ряду інфор- маційно-пошукових систем, зокрема інтелектуальних агентів (ав-
330
Г.Ф. Іванченко
тономних мобільних програмних засобів, призначених у першу чергу, для роботи в Інтернеті) покладено прості продукційні правила, які нагадують ідею фактичного діалогу.
Слід розрізняти такі види аналізу речень природної мови:
• морфологічний, який виділяє окремі слова та форми слів;
• синтаксичний, метою якого є визначення структури речення;
• семантичний, у процесі якого з’ясовується значення фрази та як воно співставляється зі знаннями системи;
• прагматичний — з’ясування, з якою метою було сказано речення.
Для сучасних методик характерне значне взаємопроникнення усіх видів аналізу. Крім цього, необхідним є розуміння не тільки окремих речень, але й усього тексту. Можна вважати, що система розуміє текст, якщо вона дає правильні відповіді на будь-які запитання, що мають відношення до тексту. Інтуїтивно зрозуміло, що «розуміти» тексти можна різною мірою та з різною глибиною. Наведемо таку класифікацію рівнів розуміння.
Нехай на вході системи маємо текст В = <Т, Е, Р>, де Т — власне текст; Е — розширений текст, що включає умови його створення; Р — розширений текст, який враховує інформацію про суб’єкта, який створює текст.
Крім цього, введемо такі позначення: ТИ. — формальні правила поповнення тексту, що базуються на його внутрішній структурі та на псевдофізичних логіках; ЕЯ — правила поповнення тексту, що базуються на знаннях системи про світ; РЯ — правила поповнення тексту, що базуються на комунікативних та психологічних знаннях, а також на знаннях про особистість того, хто говорить: А — відповідь, що генерується системою.
Перший рівень характеризується схемою Т -> А, відповіді генеруються лише на основі прямого та безпосереднього сприйняття інформації. Нехай, наприклад, система сприймає текст: «Після доповіді та обговорення інвестиційого проекту було зроблено аналіз фінансового стану підриємства та отримано кредит».
На першому рівні розуміння система в змозі відповісти на запитання «Коли зроблено аналіз фінансового стану?» або «Коли отримано кредит?».
Другий рівень характеризується схемою <Т, ТЯ> —> А. Система в змозі відповісти на запитання на зразок «Що було раніше: обговорення інвестиційого проекту чи отримано кредит?»
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
331
Третій рівень характеризується схемою <Т, ТЯ, ЕЯ> —► А. Система може відповісти на запитання на зразок «Після чого піпри- ємство отримало кредит?». Легко зрозуміти, що відповідь може залежати великою мірою від наявних знань.
Четвертий рівень характеризується схемою <Е, Тії, ЕЯ> -> А. Крім власне тексту, беруться до уваги інші джерела інформації. Наявність таких джерел дає можливість правильно сприймати висловлювання на зразок «Який банк може фінансувати кредит підприємству?».
П’ятий рівень розуміння, який характеризується схемою <Р,ТЯ,РК> —> А, бере до уваги інформацію про конкретну особистість, яка є джерелом тексту, а також загальну інфорацію про психологію спілкування, про мету учасників спілкування тощо.
Крім цього, розглядаються метарівні розуміння, які визначають можливі зміни у базах знань та сприйняття і породження метафор та асоціацій.
Розглянемо один з найвідоміших класичних підходів до розуміння речень, написаних природною мовою. Він полягає в аналізі структури речення на основі глибинних відмінків. Під глибинним відмінком слід розуміти роль, яку відіграє це слово в реченні; ця роль визначає відношення слова до основної ситуації, яка описується в реченні.
Виділяють різні системи глибинних відмінків. Однією з найвідоміших є система відмінків Філмора. Основними відмінками Філмора є такі: агент (суб’єкт, що є ініціатором події); контрагент (сила, проти якої спрямовано дію), пацієнт (суб’єкт, що відчуває на собі ефект дії), джерело (місце, з якого починається дія) тощо.
Зазвичай, виділення структури глобальних відмінків має сенс лише тоді, коли вдається розробити формальні правила, за допомогою яких можна отримувати конкретні значення цих відмінків. Ці правила можуть ґрунтуватися на формальній структурі речення (наприклад, деякий відмінок може йти лише після визначеного прийменника), на специфічних знаннях про предметну галузь тощо.
Однією з перших програм, побудованих на цій основі, була відома програма Т. Винограда.
Уїнстон описує, яким чином можна використовувати теорію глибинних відмінків під час аналізу речень, які написані простою мовою і належать до обмеженої предметної галузі.
332
Г.Ф. Іванчвнко
У більшості речень ідеться про певну дію або про перехід з одного стану в інший. Це описується дієсловом, яке в такому разі виступає ключовим елементом речення. Отже, аналіз речення має починатися з виділення основного дієслова.
Далі з’ясовуються значення глибинних відмінків, які показують, як саме іменники, які входять до речення, пов’язані з ключовим дієсловом:
1. Агент — те, що викликає дію або зміну стану. Наприклад, у реченні «Банк нарахував гроші фірмі» «агентом» виступає слово «банк».
2. Об’єкт — те, на що спрямована дія. У попередньому реченні «об’єкт» — це «гроші».
3. Інструмент — засіб, який використовує агент.
4. Співагент — той, хто допомагає агентові в здійсненні дії.
5. Пункт відправлення — початковий стан.
6. Пункт призначення — кінцевий стан. Наприклад: «фірмі».
7. Спосіб доставлення. Спосіб, у який здійснюється переміщення з пункту відправлення до пункту призначення.
8. Траєкторія. Траєкторія, якою здійснюється переміщення.
9. Місцезнаходження. Місце, де здійснюється дія.
10. Споживач. Той, для кого виконується дія.
11. Сировина. Відмінок «сировина» виникає, якщо деякий матеріал зникає, перетворюючись на продукт.
12. Час. Час виконання дії.
Отже, аналіз речення можна розглядати як заповнення деякої фреймоподібної структури. Слотами цієї структури виступає ключове дієслово та глибинні відмінки, які розкривають роль іменників по відношенню до дієслова. Можна також вводити слоти, які описують ознаки іменників, спосіб виконання дії («багато», «недостатньо» тощо).
Після того, як аналіз речення здійснено, система може відповідати на запитання, пов’язані з цим реченням. Для відповіді на запитання, очевидно, досить звернутися до слотів, асоційованих з цим типом запитань.
Наприклад, до системи вводиться текст «Аудитор зробив аналіз фінансового стану фірми», після чого її запитують «Хто зробив аналіз фінансового стану фірми?». Якщо з запитанням «Хто?» асоційований відмінок «Агент», система звертається до відповідного слота і відповідає: «Аудитор».
Під час аналізу природної мови широке застосування знаходить формалізм розширених мереж переходів, які збільшують
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
333
можливості базових мереж переходів. Базова мережа переходів являє собою граф переходів скінченного автомата і, відповідно, дає змогу аналізувати мови, що створюють автоматні граматики.
Рекурсивні мережі переходів дають можливість здійснювати рекурсивні виклики. Вони відповідають контекстно-вільним граматикам.
Нарешті, розширена мережа переходів становить рекурсивну мережу переходів, дуги якої можуть мати додаткові позначки. Ці додаткові позначки, по-перше, можуть задавати умови, за яких може бути здійснений перехід (наприклад, перехід неможливий, якщо значенням деякого слота є певне «заборонене» слово»), а по-друге — дії, які слід здійснити при реалізації переходу (наприклад, занести до певного слота останнє слово).
Резюме за змістом теми
• Розпізнавання образів — процес, за якого на підставі численних характеристик (ознак) деякого об’єкту визначаються одна або кілька найбільш суттєвих, але недоступних для безпосереднього визначення його характеристик, зокрема, його приналежність до певного класу об’єктів.
• Класифікація систем розпізнавання ґрунтується на застосуванні принципу властивості інформації, яку використовують у процесі розпізнавання.
• Системи розпізнавання можна поділити на прості й складні залежно від того, фізично однорідна або неоднорідна інформація використовується для опису об’єктів, які потрібно розпізнати чи мають вони ознаки, тієї мови, якою здійснено опис алфавіту класів, чи мають вони одну або різну фізичну природу.
• Об’єктом теорії розпізнавання зазвичай називають будь-яку сутність, що існує або могла б існувати в реальному світі, а також будь- яке явище або процес.
• Основна відмінність між різними групами методів розпізнавання полягає в тому, яким чином формуються модельні описи об’єктів.
• У більшості методів розпізнавання робиться природне припущення, що зображення об’єктів одного класу (образу) ближчі одне одному, аніж зображення різних класів.
• Метричні методи засновані на кількісній оцінці цієї близькості. Як зображення об’єкта приймається точка в просторі ознак, ступенем близькості вважається відстань між точками.
334
Г.Ф. Іванченко
Терміни та поняття до теми
• Завдання ідентифікації полягає в тому, щоб вирізнити певний конкретний об’єкт серед йому подібних.
• Віднесення об’єкта до певного класу, наприклад, завдання розпізнавання літер або прийняття рішення про наявність дефекту у деякій технічній деталі.
• Кластерний аналіз полягає в поділі заданого набору об’єктів на класи, які подібні між собою за тим чи іншим критерієм.
• Класом у теорії розпізнавання образів зазвичай називають сукупність об’єктів, які мають якісь спільні ознаки.
• Метрика — правило, за допомогою якого вводиться відстань між елементами простору.
• Гіпотеза компактності — відповідно до якої класові відповідає компактна множина точок у деякому просторі ознак.
Запитання для самоконтролю
1. Охарактеризуйте класифікацію систем розпізнавання
2. Які вам відомі приклади практичного застосування систем розпізнавання?
3. Метричні методи, засновані на кількісній оцінці цієї близькості.
4. Наведіть типову схему розпізнавання в просторі ознак.
5. Чи можна для будь-якої предметної галузі використовувати розпізнавання в просторі ознак? Наведіть прикладй.
6. Охарактеризуйте дискримінантні методи розпізнавання.
7. Що таке простір ознак?
8. Перерахуйте відомі вам типи ознак.
9. Які ви знаєте ступені близькості між об’єктами, якщо ознаки є кількісними?
10. Наведіть формулу євклідової відстані між векторами.
11. Що таке зважені євклідові відстані? В якому випадку їх доцільно використовувати?
12. Охарактеризуйте гіпотезу компактності.
13. Опишіть типову схему розпізнавання в просторі ознак.
14. Охарактеризуйте баєсівські методи розпізнавання образів.
15. Сформулюйте метод найближчого сусіда.
16. Чи вимагає метод найближчого сусіда попереднього вироблення вирішального правила?
17. Охарактеризуйте основні переваги й недоліки методу найближчого сусіда.
18. Опишіть стиснуте правило найближчого сусіда. З чим пов’язана доцільність його застосування?
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
335
Теми для рефератів та обговорення
1. У чому полягають основні проблеми під час створенні штучних систем розпізнавання?
2. Опишіть відомі вам постановки завдання класифікації.
3. Перерахуйте відомі вам практичні застосування методів класифікації.
4. Наведіть ключову парадигму теорії розпізнавання.
5. Що таке клас у теорії розпізнавання?
6. Що таке інваріанти класу?
7. Що таке інформативні ознаки?
8. Перерахуйте основні властивості класів.
9. Охарактеризуйте можливі напрями розвитку діалогових людин- но-машинних систем та систем автоматизованого перекладу.
10. Що змінюється при переході від нижчого рівня розуміння до вищого?
11. Наведіть приклади речень, які можна перекласти з однієї мови на іншу без розуміння змісту цих речень.
Література для поглибленого вивчення матеріалу
1. ЛюгерДж. Ф. Искусственный интеллект. — М.: Изд. дом «Вильямс», 2005. — 864 с.
БІБЛІОГРАФІЯ
1. МакКаллок У. С., Пите. 5. Логическое исчисление идей, имитирующих нервную активность // Нейрокомпьютер. — 1992. — № 3, 4. — С. 40—53.
2. Розенблат Ф. Принципы нейродинамики. Персептроны и теория механизмов мозга. — М.: Мир, 1965.
3. Вычислительные машины и мышление. — М.: Мир, 1967. — 552 с.
4. МакКаллок У. С., Пите. Я. Логическое исчисление идей, имитирующих нервную активность // Нейрокомпьютер. 1992. # 3, 4. — С. 40—53.
5. Искусственный интеллект: за и против // В кн.: Кибернетика: Перспективы развития. — М.: Наука, 1981. — С. 74—124.
6. Гаазе-Раппопорт М. Г., Поспелов Д. А., Семенова Е. JI. Порождение структур волшебных сказок: Препринт. — М.: АН СССР, 1980. — 20 с.
7. Минский М. Фреймы для представления знаний: Пер. с англ. — М.: Энергия, 1979. — 151 с.
8. Искусственный интеллект: за и против // В кн.: Кибернетика: Перспективы развития. — М.: Наука, 1981. — С. 74 — 124.
9. Половинкин А. И. Методы инженерного творчества. — Волгоград: Изд-во ВолгПИ, 1984. — 366 с.
10. Поспелова Г. С. Искусственный интеллект — основа новой информационной технологии. — М.: Наука, 1988. — 280 с.
11. Поспелов Д. А., Пушкин В. Н. Мышление и автоматы. — М.: Сов. радио, 1972.
12. Поспелов Д. А. Фантазия или наука: на пути к искусственному интеллекту. — М.: Наука, 1982. — 224 с.
13. Поспелов Д. А. Ситуационное управление: теория и практика.— М.: Наука, 1986.
14. Гаврилова Т. АХорошевский В. Ф. Базы знаний интеллектуальных систем. — СПб.: Питер, 2000. — 382 с.
15. Девятков В.В. Системы искусственного интеллекта: Учебное пособие. — М.: Изд-во МГТУ им. Н. Э. Баумана, 2001. — 352 с.
16. Адаменко А., Кучуков А. Логическое программирование и Visual Prolog. — СПб.: БХВ—Петербург, 2003. — 992 с.
17. Марселлу с Д. Программирование экспертных систем на Турбо- Прологе. — М.: Финансы и статистика, 1994. — 256 с.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
337
18. Братко И. Программирование на языке Пролог для систем искусственного интеллекта. — М.: Мир, 1990. — 560 с.
19. Люгер Дж. Ф. Искусственный интеллект. — М.: Изд. дом «Вильямс», 2005. — 864 с.
20. Бондарев В. Н., Аде Ф. ГШтучний інтелект: Навчальний посібник для вузів. — Севастополь: Вид-во СевНТУ, 2002. — 615 с.
21. К. Нейлор. Как построить свою экспертную систему. — М.: Энергоатомиздат, 1991. — 287 с.
22. Глибовець М. М., Олецъкий О. В. Штучний інтелект. — К.: Видавничий дім «КМ Академія», 2002. — 366 с.
23. Rosenblatt R. — 1959. — Principles of neurodynamics. — New York: Spartan Books.
24. Widrow B. — 1959. — Adaptive sampled-data systems, a statistical theory of adaptation. 1959. IRE WESCON Convention Record, part 4. — New York: Institute of Radio Engineers.
25. Widrow B., Hoff M. — Adaptive switching circuits. — 1960. — IRE WESCON Convention Record. — New York: Institute of Radio Engineers.
26. Hebb D. O. — 1949. — Organization of behavior. — New York: Science Editions.
ДОДАТКИ
Додаток А
Алгоритми переміщення мурахи
У цьому додатку розглядається цікавий алгоритм, що базується на використанні кількох агентів, за допомогою яких можна розв’язати найрізноманітніші задачі. Алгоритми мурахи (Ant algorithms), або оп- тимізація за принципом мурашиної колонії (ця назва була вигадана винахідником алгоритму Марко Доріго (Marco Dorigo)), мають специфічні властивості, притаманні мурахам, і використовують їх для орієнтації у фізичному просторі. Природа пропонує різні методики для оптиміза- ції деяких процесів. Алгоритми мурахи особливо цікаві тому, що їх можна використовувати для розв’язання не лише статичних, а й динамічних проблем, наприклад, проблем маршрутизації в сітках, що змінюються.
Мурахи хоча й сліпі, вони вміють переміщатися в складних місцевостях, знаходити харчі на великій відстані від мурашника та успішно повертатися додому. Виділяючи ферменти під час переміщення, мурахи змінюють навколишнє середовище, забезпечують комунікацію, а також шукають і знаходять зворотний шлях до мурашника:
Найдивовижніше в цьому процесі — це те, що мурахи вміють знаходити найоптимальніший шлях між мурашником та навколишніми пунктами. Що ближча зовнішня точка до мурашника, то більше разів до неї переміщалися мурахи. Що стосується віддаленішого пункту, то до нього мурахи дістаються рідше, тому дорогою до нього вони застосовують сильніші ферменти. Що вища концентрація ферментів на шляху, то більшу перевагу віддають йому мурахи порівняно з іншими доступними. Так мурашина «логіка» дає змогу обирати коротший шлях між кінцевими пунктами.
Алгоритми мурахи цікаві, оскільки мають ряд специфічних якостей, притаманних самим мурахам. Мурахи легко йдуть на компроміс і співпрацю один з одним заради досягнення спільної мети. Це має прояв у тому, що змодельовані мурахи розв’язують проблему та допомагають у подальшій її оптимізації.
Розглянемо приклад, який наведено на рис. 1. Дві мурахи з мурашника мають дістатися їжі, яка знаходиться за перепоною. Під час переміщення кожна мураха виділяє небагато ферменту, використовуючи його як маркер.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
339
т
„99
Рис.1. Початкова конфігурація (Т0 )
За інших рівних умов кожна мураха обирає свій шлях. Перша обирає верхній шлях, а друга — нижній. Оскільки нижній шлях у два рази коротший за верхній, друга мураха досягне цілі за час Тх. Перша мураха в цей момент подолає лише половину шляху (рис. 2).
Коли мураха дістається їжі, вона бере один з об’єктів і повертається до мурашника тим самим шляхом. За час Т2 друга мураха повернулася до мурашника з їжею, а перша тільки дістається їжі (рис. 2).
т
*
.9?
*
Рис. 2. Минув один період часу (ТО
340
Г.Ф. Іванченко
Згадайте, що під час переміщення кожної мурахи на дорозі залишається трохи ферменту. Для першої мурахи за час Т0 - Т2 шлях був вкритий ферментом тільки один раз. Водночас друга мураха вкрила шлях ферментом двічі. За час Т4 перша мураха повернулася до мурашника, а друга встигла ще раз сходити до їжі й повернутися. При цьому концентрація ферменту на нижній дорозі буде в два рази вища, ніж на верхній. Тому перша мураха наступного разу обере нижній шлях, оскільки там концентрація ферменту вища.
У цьому й полягає базова ідея алгоритму мурахи — оптимізація шляхом непрямого зв’язку між автономними агентами.
Припустимо, що навколишнє середовище для мурахи презентує закриту двовимірну мережу. Згадайте, мережа — це група вузлів, що з’єднуються за допомогою меж. Кожна межа має вагу, яку ми позначимо як відстань між двома вузлами, з’єднаними нею. Граф двоспрямова- ний, тому мураха може подорожувати ним в будь-якому напрямку (рис. 3).
Граф з вершинами V = {1,2,3,4}
МежіЕ= {{1,2}, {1,4}, {1,3}, {2,3}, {2,4}, {3,4}}
Рис. 3. Граф двоспрямований Мураха
Мураха — це програмний агент, котрий є членом великої колонії і використовується для розв’язання будь-якої проблеми. Мураха доповнюється набором простих правил, котрі дають змогу йому обирати шлях у графі. Він підтримує список табу (tabu list), тобто список вузлів, котрі він вже відвідав. Таким чином, мураха має проходити через кожен вузол лише один раз. Шлях між двома вузлами графа, за котрим мураха відвідав кожен вузол тільки один раз, називають шляхом Гамільтона (Hamiltonian path), за ім’ям математика сера Вільяма Гамільтона (Sir William Hamilton).
Вузли в списку «поточної подорожі» розташовуються в тому порядку, у котрому мураха відвідував їх. Пізніше список використовується для визначення довжини шляху між вузлами.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
341
Справжній мураха під час переміщення шляхом лишатиме за собою фермент. В алгоритмі мурахи агент лишає фермент на межах мережі після завершення подорожі. Про те, як це відбувається, розповідається у розділі «Подорожі мурахи»
Після створення популяція мурах нарівно розподіляється вузлами мережі. Потрібний рівний поділ мурах між вузлами, щоб усі вузли мали однакові шанси стати відправною точкою. Якщо всі мурахи почнуть рух з однієї точки, це буде означати, що дана точка є оптимальною для старту, а насправді, ми цього не знаємо.
Рух мурахи
Рух мурахи засновується на одному і дуже простому ймовірнісному рівнянні. Якщо мураха ще не закінчила шлях (path), тобто не відвідала всі вузли мережі, для визначення наступної межі шляху використовується рівняння:
р т(г,ц)ахг|(г,ц)р Хкт(г,и)° хті(г,и)р
Тут т(г,м) — інтенсивність фрагмента на межі між вузлами г та м, і(г,м) — функція котра представляє виміри зворотної відстані для межі, а — вага ферменту, ар — коефіцієнт евристики. Параметри а і р визначають відносну значущість двох параметрів, а також їх вплив на рівняння. Згадайте, що мураха подорожує тільки вузлами, котрі ще не були відвідані (як вказано списком табу). Тому ймовірність розраховується тільки для меж, котрі ведуть до ще не відвіданих вузлів. Змінна к є представником меж, котрі ще не були відвідані.
Подорож мурахи
Шлях, який пройшла мураха, відображається, коли мураха відвідає усі вузли діаграми. Зверніть увагу, що цикли заборонені, оскільки до алгоритму включено список табу. Після завершення довжина шляху може бути підрахована — вона дорівнює сумі всіх меж, якими мандрував мураха. Рівняння показує кількість ферменту, що був залишений на кожній межі шляху для мурахи к Змінна Q є константою:
Q
Дт*.(0 =
Lk{t)
Результат рівняння засобом вимірювання шляху — короткий шлях характеризується високою концентрацією ферменту, а довший шлях — нижчою. Потім отриманий результат використовується, щоб збільшити кількість ферменту вздовж кожної з меж пройденого мурахою шляху:
342
Г.Ф. Іванченко
Tj(/) = AT#(f) + (T$(Oxp).
Зверніть увагу, що це рівняння застосовується до всього шляху, при цьому кожна межа помічається ферментом пропорційно довжині шляху. Тому слід дочекатися, поки мураха закінчить подорож, і тільки після цього оновити рівні ферменту, в іншому разі справжня довжина шляху залишиться невідомою. Константа р має значення між Oil.
Випаровування ферменту
На початку шляху в кожної межі є шанс бути обраною. Щоб з часом від далити межі, що входять у найгірші шляхи в мережі, до всіх меж застосовується процедура випаровування ферменту (Pheromone evaporation). Використовуючи константу р, ми отримуємо рівняння:
^(0 = ^(0х(і-р).
Тому для випаровування ферменту використовується зворотний коефіцієнт оновлення шляху.
Після того, як шлях мурахи завершено, межі оновлено відповідно до довжини шляху і відбулося випаровування ферменту на всіх межах, алгоритм запускається вдруге. Список табу очищується, і довжина шляху обнулюється. Мурахам дозволяється переміщуватися мережею, здійснюючи вибір межі. Цей процес може виконуватися для постійної кількості шляхів або до того моменту, коли упродовж декількох запусків не було помічено повторних змін. Потім визначається кращий шлях, що і становить рішення.
Приклад ітерації
Давайте розберемо функціонування алгоритму на простому прикладі, щоб побачити, як працюють рівняння. Згадайте простий сценарій з двома мурахами, які обирають два різних шляхи для досягнення однієї цілі. На рис. 4 наведено цей приклад з двома межами між двома вузлами (V0 і Vx ). Кожна межа ініціалізується та має однакові шанси на те, щоб бути обраною.
Дві мурахи знаходяться у вузлі V0 і позначаються як А0 і А1. Оскільки ймовірність вибору будь-якого шляху однакова, в цьому циклі ми проігноруємо керування вибору шляху. На рис. 4 кожна мураха обирає свій шлях (мураха Ад йде верхнім шляхом, мураха Ах — нижнім).
Мураха А0 зробила 20 кроків, а мураха Ах — лише 10. Розраховуємо кількість ферменту, який має бути нанесений. Рівень ферменту б/подолана відстань для А0 —0,4, для Ах —0,7.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
343
Рис. 4. Навчальна конфігурація проблеми
Роботу алгоритму можна змінити, перерахувавши його параметри (наприклад р,ачи Р), наприклад придбавши більшу вагу ферменту чи відстані між вузлами. Далі за допомогою рівняння розраховується кількість ферменту, яка буде застосована. Для мурахи А0 результат такий:
Дт1 = 0,1+(0,5 х 0,6)=0,4, а для мурахи А1 — Дт2 = 0,1+(1 х 0,6)=0,7.
Для мурахи А1 результат становить: Дт2 =0,1+ (1,0x0,6) = 0,7. Далі визначається, яка частина ферменту випарується і, відповідно, скільки залишиться. Результати (для кожного шляху):
х° = 0,4 X (1,0-0,6) = 0,16; і1 = 0,7 х (1,0-0,6) = 0,28.
Ці значення становлять нову кількість ферменту для кожного шляху (верхнього і нижнього, відповідно). Тепер перемістимо мурах зворотно
344
Г.Ф. Іванчвнко
у вузол V0 і використаємо імовірне рівняння вибору шляху, щоб визначити, який шлях мають обрати мурахи. Імовірність того, що мураха обере верхній шлях, представлений кількістю фермента 0,16, становить:
(ОД б)3’0 X (0,5)''° /((0,1 б)3-0 X (0,5)1,0) + ((0,28)3'° х (1,0)10) =
= 0,002048/0,024 = Р(0,085).
Імовірність того, що мураха обере нижній шлях (який представлений кількістю ферменту 0,28), становить:
(0,28)3’° х (1,0)10 /((ОД б)3’0 х (0,5)‘-°) + ((0,28)3’° х (1,0)1>0) =
= 0,021952/,024 = Р(0,915).
При порівнянні двох імовірностей обидві мурахи оберуть нижній шлях, який є найбільш оптимальним.
Приклад задачі
Як приклад розглянемо задачу комівояжера (Traveling Salesman Problem — TSP). Вона полягає в тому, щоб знайти найкоротший шлях між містами, за якого кожне місто відвідуватиметься лише один раз. Тобто треба знайти найкоротший Гамільтонів шлях у графі, де вузлами виступають міста, а межами — шляхи, що їх з’єднують. Математики вперше вивчили задачу TSP у 1930-ті pp., зокрема, нею займався Карл Менгер (Karl Menger) у Відні. Слід зазначити, що ца Сході задачі досліджував ще у 19 ст. ірландський математик сер Уільям Ромен Гаміль- тон (Sir William Hamilton).
У наступному розділі розглядається початковий код програми, яка використовується для розв’язання задачі, і наведено варіанти розв’язання.
Початковий код
Лістинги ілюструють алгоритм мурахи, який використовується для пошуку оптимального розв’язання задачі комівояжера.
Спочатку вивчимо структуру даних і для міст, і для агентів (мурах), які ними мандруватимуть. Лістинг включає типи даних і символьні константи, як використовують для подання міст і мурах.
Програмний код мовою C++:
Файл Common.h:
#ifndef COMMOISNH
#define COMMON _Н
#include <math.h>
#include <stdlib.h>
системи ШТУЧНОГО ІНТЕЛЕКТУ
345
#define MAX_CITIES 53 #define MAX_ANTS 20 #define MAX_DISTANCE 100 #define MAXTOUR (MAX_CITIES * MAX_DISTANCE) typedef struct { int x; int y;
} cityType; typedef struct { int curCity; int nextCity;
unsigned char tabu[MAX_CITIES]; int pathlndex;
unsigned char path[MAX_CITIES]; double tourLength;
} antType;
#define getSRand() ((float)rand() / (float)RAND_MAX) #define getRand(x) (int)((x) * getSRand())
#define ALPHA 1.0
#define BETA 5.0
#define RHOO.5
#define QVAL 100
#define MAX_TOURS 500
#define MAX_TIME (MAX_TOURS * MAX_CITIES)
#define INIT_PHEROMONE (1.0 / MAX_CITIES)
#endif
Файл Antcpp:
#inciude <vci.h>
#pragma hdrstop ^include "Ant.h"
#include <stdio.h>
#include <conio.h>
#inciude <time.h>
#inciude <assert.h>
#include "Common.h"
#pragma package(smartjnit)
#pragma link "Chart”
#pragma link "Series"
#pragma link "TeEngine"
#pragma link "TeeProcs"
#pragma resource "*.dfm"
TMainForm *MainForm;
cityType cities[MAX_CITIES];
antType ants[MAX_ANTS];
double distance[MAX_CITIES][MAX_CITIES];
double pheromone[MAX_CITIES][MAX_CITIES];
double best=(double)MAX_TOUR;
int bestlndex;
346
F.0. leaHHOHKO
void init( void)
{int from, to, ant;
for (from = 0; from < MAX_CITIES; from++) { cities[from].x = getRand( MAX_DISTANCE ); cities[from].y = getRand( MAX_DISTANCE ); for (to = 0; to < MAX_CITIES; to++) { distance[from][to] = 0.0; pheromone[from][to] = INIT_PHEROMONE;}} for (from = 0; from < MAX_CITIES; from++) { for (to = 0; to < MAX_CITIES; to++) { if ((to != from) && (distance[from][to] == 0.0)) { int xd = abs(cities[from].x — cities[to].x); int yd = abs(cities[from].y — cities[to].y); distance[from][to] = sqrt((xd * xd) + (yd * yd)); distance[to][from] = distance[from][to];}}} to = 0;
for (ant = 0; ant < MAX_ANTS; ant++) { if (to == MAX_CITIES) to = 0; ants[ant].curCity = to++; for (from = 0; from < MAX_CITIES; from++) { ants[ant].tabu[from] = 0; ants[ant].path[from] = -1;} ants[ant].pathindex = 1; ants[ant].path[0] ants[ant].curCity; ants[ant].nextCity = -1; ants[ant].tourLength = 0.0; ants[antj.tabu[ants[ant].curCity] = 1;}} void restartAnts( void)
{int ant, i, to=0;
for (ant = 0; ant < MAX_ANTS; ant++) { if (ants[ant].tourLength < best) { best = ants[ant].tourLength; bestlndex = ant;} ants[ant].nextCity = -1; ants[ant].tourLength = 0.0; for (i = 0; i < MAX_CITIES; i++) { ants[ant].tabu[i] = 0; ants[antj.path[i] = -1;} if (to == MAX_CITIES) to = 0; ants[ant].curCity to++; ants[ant].pathlndex = 1; ants[antj.path[0] ants[ant].curCity; ants[ant].tabu[ants[ant].curCity] = 1;}} double antProduct( int from, int to)
{return ((pow(pheromone[from][to], ALPHA) * pow((1.0 / distance[from][to]), BETA)));} int selectNextCity( int ant)
{int from, to;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
347
double denom=0.0;
from = ants[ant].curCity;
for (to = 0; to < MAX_CITIES; to++) {
if (ants[ant].tabu[to] == 0) {
denom += antProduct(from, to);}}
assert(denom != 0.0);
do {double p;
to++;
if (to >= MAX_CITIES) to = 0; if (ants[ant].tabu[to] == 0) { p = antProduct(from, to)/denom; if (getSRand() < p) break;}} while (1); return to;}
int simulateAnts( void)
{int moving = 0, k;
for (k=0; k < MAX_ANTS; k++) {
if (ants[k].pathlndex < MAX_CITIES) {
ants[k].nextCity = selectNextCity(k);
ants[kj.tabu[ants[k].nextCity] = 1;
ants[k].path[ants[k].pathlndex++] = ants[k].nextCity;
ants[k].tourLength += distance[ants[k].curCity][ants[k].nextCity];
if (ants[k].pathlndex == MAX_CITIES) {
ants[k].tourLength += distance[ants[k].path[MAX_CITIES-1]][ants[k].path[0]];} ants[k].curCity = ants[k].nextCity; moving++;}} return moving;} void updateTrails( void)
{int from, to, i, ant;
for (from=0; from < MAX_CITIES; from++) { for (to = 0; to < MAX_CITIES; to++) { if (from != to) {
pheromone[from][to] *= (1.0 — RHO);
if (pheromone[from][to] < 0.0) pheromone[from][to] = INITPHEROMONE;
}}}
for (ant=0; ant < MAX_ANTS; ant++) { for (i=0; i < MAX_CITIES; i++) { if (i < MAX_CITIES-1) { from = ants[ant].path[i]; to = ants[ant].path[i+1];} else { from = ants[ant].path[ j; to = ants[ant].path[0]; }
pheromone[from][to] += (QVAL / ants[ant].tourLength); pheromone[to][fromj = pheromone[from][to];}} for (from=0; from < MAX_CITIES; from++) { for (to=0; to < MAX_CITIES; to++) { pheromone[from][to] *= RHO;}}} void emitDataFile( int ant)
{int city; FILE *fp;
348
Г.Ф. Іванчвнко
fp = fopenfcities.dat", "w");
for (city = 0 ; city < MAX_CITIES ; city++) {
fprintf(fp, "%d %d\n'\ cities[city].x, cities [city]. y);}
fclose(fp);
fp = fopenfsolution.dat", V); for (city = 0 ; city < MAX_CITIES ; city++) { fprintf(fp, "%d %d\n", cities citiss
fprintf(fp, "%d %d\n' cities cities
ants[ant].path[city] ].x, ants[antj.path[cityj j.y);}
fn "°/~H 0/_H\nn
ant].path[0] ].x, 'ant].path[0] j.y);
| ants[;
^ antsf. fclose(fp);' void emitTable(void)
{int from, to;
for (from = 0 ; from < MAX_CITIES ; from++) { for (to = 0 ; to < MAX_CITIES ; to++) { printf("%5.2g", pheromone[from][to]);} printfCVi");} printf("\n");}
void fastcall TMainForm::FormCreate(TObject ‘Sender)
{XYGraph->Series[0]->Clear();
PathMemo->Lines->Clear();
TimePathProgressbar->Position=0;}
void fastcall TMainForm::CalculatePathButtonClick(TObject ’Sender)
{int curTime = 0, city; char pathtime [50], maxcities [50]; srand(time(NULL)); init();
TimePathPragressbar->Position=0;
PathMemo->Lines->Clear(); while (curTime++ < MAX_TIME) { if (simulateAnts() == 0) { updateTrails();
if (curTime != MAX_TIME) restartAntsQ; sprintf(pathtime, "Час %d (%g)\n", curTime, best); PathMemo->Lines->Add(pathtime); TimePathProgressbar->Position++;}} sprintf(pathtime, "Найкращий шлях — %g", best); sprintf(maxcities, "Кількість міст — %d", MAX_CITIES); PathMemo->Lines->Add("\n\n");
PathMemo->Lines->Add(maxcities);
PathMemo->Lines->Add(’4n");
PathMemo->Lines->Add(pathtime);
XYGraph->Series[0]->Clear();
for (city = 0; city < MAX_CITIES; city++) {
XYGraph->Series[0]->Add(cities[ants[bestlndex].path[city]].x,
cities[ants[bestlndex].path[city]].y);}
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ 349
XYGraph->Series[0]->Add(cities[ants[bestlndex].path[0]].x, cities[ants[bestlndex].path[0]].y); emitDataFile(bestlndex);}
Рис. 6. Результата робота програми
Зміни параметрів алгоритму
Марко Дорито (винахідник оптимізації за принципом мурашиної колонії) у статті «Система мурах: оптимізація за допомогою колонії агентів, які співпрацюють» (The Ant System: Optimization by a Colony of Cooperating Agents) пропонує дуже цікаву дискусію за параметрами алгоритму. Параметр а асоціюється з кількістю ферменту, а параметр р — з видимістю (довжиною перешкоди). Що більше значення параметра, то важливіший він для вірогідного рівняння, котре застосовується при виборі межі. Зверніть увагу, що в одному випадку значущість параметрів однакова. В усіх інших випадках видимість важливіша при виборі шляху.
Параметр р становить коефіцієнт, який застосовується до ферменту, що розпилюється на шлях, а (1,0 — р) становить коефіцієнт випаровування для наявного ферменту. Були проведені тести при р > 0,5, та всі вони показали цікаві результати. При встановленні значення р < 0,5 результати були незадовільні.
В першу чергу цей параметр визначає концентрацію ферменту, який зберігається на межах.
Кількість мурах впливала на якість отриманих рішень. Хоча збільшення кількості мурах може здатися хорошою ідеєю, найкращий ре¬
350
Г.Ф. Іванченко
зультат досягаєтеся в тому разі, якщо кількість мурах дорівнює кількості міст.
Алгоритм мурахи застосовується для вирішення інших завдяки, наприклад, прокладання маршрутів для автомобілів, роботів, розрахунку кольорів для графіків і маршрутизації у мережах. Детальніше способи вживання алгоритму мурахи викладено у книзі Марко Доріго «Алгоритми мурахи для абстрактної оптимізації» (Ant Algorithms for Discrete Optimization).
Алгоритм мурахи моделює поведінку мурах в їхньому природному середовищі, щоб визначити оптимальний шлях у просторі (за графом або мережею). Ця технологія розглядалась як засіб розширення завдання комівояжера (TSP). Крім того, були описані можливості зміни параметрів алгоритму і надані комбінації параметрів, котрі демонструють хороші результати.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
351
Додаток Б
Діалогова система для реляційної бази знань Geobase.dba
domains
ENT = string % Names of entities ASSOC= string % Names of associations RELOP= string % gt, It, eq for comparisons UNIT = string % kilometers, citizens etc.
STRINGLIST = STRING* facts — language
schema(ENT,ASSOC,ENT) % Entity network: entity-assoc-entity
entitysize(ENT,STRING) % This attribute tells which words can be
% user to query the size of the entity
relop(STRINGLIST,string) % Example: relop([greater,than],gt]
assoc(ASSOC,STRINGLIST) % Alternative assoc names
synonym(string.ENT) % Synonyms for entities ignore(string) % Words to be ignored minn(string) % Words stating minimum maxx(string) % Words stating maximum size(string,string) % big, long, high....
unit(string,string) Units for population, area...
facts — data
state(STRING name,STRING abbreviation,STRING capital,REAL area,REAL admit, INTEGER population,STRING city,STRING city,STRING city,STRING city) city(STRING state,STRING abbreviation,STRING name,REAL population) river(STRING name,INTEGER length.STRINGLIST statelist) border(STRING state.STRING abbreviation,STRINGLIST statelist) highlow(STRING state,STRING abbreviation,STRING point,INTEGER height,STRING point,INTEGER height)
mountain(STRING state.STRING abbreviation.STRING name.REAL height) lake(STRING name.REAL area,STRINGLIST statelist) road(STRING number,STRINGLIST predicates
nondeterm member(STRING,STRINGLIST) clauses
member(X,[X|J).
member(X,L|L])>
member(X,L).
predicates
nondeterm db(ENT,ASSOC,ENT,STRING,STRING)
nondeterm ent(ENT.STRING)
clauses
% ent returns values for a given entity name. Ex. if called by % ent(city,X) X is instantiated to cities. ent(continent,usa).
ent(city,NAME)> city(__,_,NAME,_).
ent(state,NAME)>
state(NAME, _,_,_)•
ent(capital.NAME):- state(_,_,NAME, ent(river,NAME)> river(NAME,_,J.
352
Г.Ф. Іванчвнко
ent(pointpOINT):-
highlow(_, POINT, J.
ent(point,POINT):-
highlow(_,_,PÖINT, ent(mountain,M)>
mountain(_,_,M,_). ent(lake.LAKE):- lake(LAKE,_,J.
ent(road,NUMBER):-road(NUMBER,J.
ent(population,POPUL):-city( .POPUL1),
str_real(POPUL,POPUL1 ).
ent(population,S):-
state(_,_l_,POPULl_l__p-, str__real(S,POPUL). db(city,in,state,CITY,STATE):- city(STATE,_,CITY,J. db(state,with,city,STATE,CITY):- city(STATE,_,CITY,J. depopulation,of,city.POPUL,CITY):- city(_,_,CITY,POPUL1), str_real(POPUL,POPUL1 ). depopulation,of.capital,POPUL.CITY):-
city(_,_.CITY,POPUL1 ),str_real(POPUL,POPUL1 ). db(abbreviation,of,state, ABBREVIATION, STATE):- state(STATE, ABBREVIATION,
db(state,with,abbreviation,STATE,ABBREVIATION):- state(STATE, ABBREVIATION, db(area,of, state, AREA, STATE):- state(STATE,_,_,_,AREA1, str_real(AREA,AREA1 ). db(capital,of,state,CAPITAL,STATE):- state(STATE,_, CAPITAL, db(state,with,capital,STATE,CAPITAL):- state(STATE,_, CAPITAL, depopulation,of,state.POPULATION,STATE):- state(STATE,_,_,POPUL,
str_real(POPULATION,POPUL). db(state, border, state, STATE1, STATE2):- border(STATE2,_,LIST), member(STATE1 ,LIST). db(length,of,river,LENGTH,RIVER):- river(RIVER,LENGTH1, J, strJnt(LENGTH,LENGTH1 ). db(state,with,river,STATE,RIVER):- river(RIVER,_,LIST), member(STATE,LIST). db(river,in,state,RIVER,STATE):- river(RIVER,__,LIST), member(STATE.LIST). db(point,in,state,POINT,STATE):- highlow(STATE,_,POINT, db(point,in,state,POINT,STATE):- highlow(STATE,_,_,_,POINT,J. db(state,with,point,STATE,POINT)> highlow(STATE,_,POINT,
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
353
db(state,with.point,STATE,POINT):- highlow(STATE,POINT,J. db(height,of,point,HEIGHT,POINT):- highlow(_, POINT, H), strJnt(HEIGHT.H), !.
db(height,of,point,HEIGHT,POINT):- highlow(_,_, POI NT, H str_int(HEIGHT,H), !.
% Relationships about mountains db(mountain,in,state,MOUNT,STATE):- mountain(STATE,_,MOUNT,_). dbfstate.with.mountain.STATE.MOUNT):- mountain(STATE,MOUNT,_). db(height,of,mountain,HEIGHT,MOUNT):- mountain(_,_,MOUNT,H1), str_real(HEIGHT,H1).
% Relationships about lakes db(lake,in,state,LAKE,STATE):- lake(LAKE,_,LIST), member(STATE.LIST). db(state,with,lake,STATE,LAKE):- lake(LAKE,_,LIST), member(STATE,LIST). db(area,of,lake,AREA,LAKE):- lake(LAKE,A1,J, str_real(AREA,A1).
% Relationships about roads db(road,in,state,ROAD,STATE):- road(ROAD,LIST), member(STATE.LIST). db(state,with,road,STATE,ROAD):- road(ROAD,LIST), member(STATE.LIST). db(E,in,continent,VAL.usa):- ent(E,VAL). db(name,of,_,X,X):- bound(X). predicates
writeJist(INTEGER,STRINGLIST)
write_list2(STRINGLIST)
nondeterm append(STRINGLIST,STRINGLIST,STRINGLIST) unik(STRINGLIST.STRINGLIST) index(STRINGLIST,INTEGER,STRING) clauses
index([X|J,1,X):- !.
index(L|L],N,X):- N>1,
N1=N-1,
index(L,N1,X).
unik(D.D).
unik([H|T],L):-
member(H,T), !,
unik(T,L). unik([H|T],[H|L]):-
354
r.O. leaHveHKO
unik(T,L). append(0,L,L). append([Ah|At],B,[Ah|C]):- append(At,B,C). write_list(_,n). writeJist(_,[X]):- !,
write(X). writeJist(4,[H|T]):- !,
write(H), nl, writeJist(O.T). writeJist(3,[H|T]):- strJen(H.LEN),
LEN>13, !, write(H), nl,
write_llst(OfT). writeJist(N,[H|T]):- strJen(H.LEN),
LEN>13, !, N1=N+2,
writef("%-27 M,H), writeJist(N1 ,T). writeJist(N,[H|Tl):- N1=N+1, writef("%-13 ”,H), writeJlst(N1 ,T).
writejist2(0).
writeJist2([H|T]):- write(H,’ *), write_ ist2(T). domains
QUERY = q_e(ENT);
q_eaec(ENT,ASSOC,ENT,STRING); q_eaq(ENT,ASSOC,ENT,QUERY); CL.sel(ENT,RELOP,ENTfREAL);
CLmin(ENT, QUERY); q_max(ENT,QUERY); q_not(ENT,QUERY); q_or(QUERY,QUERY); q_and(QUERY,QUERY)
PREDICATES
write__unit(STRING) write_solutions(INTEGER) scan(STRING.STRINGLIST)
filter(STRINGLIST,STRINGLIST) pars(STRINGLIST,STRING,QUERY) nondeterm eval(QUERY,STRING) listlen(STRINGLIST, INTEGER) loop clauses loop:-
write("Query:"), readln(STR),
STR ><
scan(STR,LIST), filter(LIST,LIST1), pars(LIST1 ,E,Q),
findall(A,eval(Q,A),L),
unik(L,L1),
write_list(0,L1),
write_unit(E),
listlen(L1,N),
write_solutions(N),
•»
loop.
loop.
scan(STR,[TOK|LIST]):-
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
355
fronttoken(STR,SYMB,STR1),!, upperJower(SYMB,TOK), scan(STR1 .LIST).
scan(_,Q).
filter(["."|T],L):-!, filter(T.L). filter(r,-|T],L):-!, filter(T.L). filter(["?"|T].L):-!, filter(T.L). filter([H|T],L)> ignore(H), !,
filter(T.L). filter([H|T],[H|L]):- filter(T,L). filter(D.D).
write_unit(E):- unit(E,UNIT)f!, write(‘ ‘.UNIT). write_unit(_). write_solutions(0):- !,
write("No solutions\n"). write_solutions(1)> !, nl.
write_solutions(N):-!,
writef("°/o Solutions\n",N). listlen(Q.O). listlen(L|T],N):-
llstlen(T.X), N=X+1. predicates
nondeterm entn(STRING.STRING) nondeterm entity(STRING) nondeterm ent_synonym(STRING, STRING) nondeterm ent_name(STRING,STRING)
clauses
ent_synonym(E,ENT):- synonym(E,ENT). ent_synonym(E,E).
ent_name(ENT,NAVN):-entn(E,NAVN), ent_synonym(E,ENT), entity(ENT). entn(E.N):- concat(E,V,N). entn(E,N):-free(E),bound(N), concat(X,HiesM,N), concat(X,"y",E). entn(E,E). entity(name):-!. entity(continent):-!. entity(X):- schema(X,_,_).
predicates error(STRINGLIST) nondeterm known_word(STRING) clauses error(LIST):- write("»"), member(Y,LIST), not(known_word(Y))f !, writefUnknown word: ",Y),nl. error(_):-
write("Sorry, the sentence can’t be recognized”). known_word(X)> str_real(X,_), !. known_word(Hand")>!. known_word("or"):-!.
356
r.0. leatweHKO
known_word("not"):-!. known_word("alT):-!. known_word("thousand"):- known_word(Mmillion"):- known_word(X):-minn(X), known_word(X):-maxx(X),!. known_word(X):- known_word(X):- known_word(X):- known_word(X):- known_word(X):- known_word(X)>
known_word(X)> l(X):-
size(_,X),!. ignore(X),!. unit(_,X),!. assoc(_,AL), ent_name(_,X), entity(X),
known_word(>
relop(L,_),
entity(E),
member(X,AL),
i!
member(X,L),
not(unit(E,J),
!.
ent(E,X).
predicates
nondeterm get_ent(STRINGLIST,STRINGLIST,STRING) nondeterm get_cmpent(STRINGLIST,STRINGLIST,STRING,STRING) ent_end(STRINGLIST) clauses
get_ent([E|S],S,E):- ent_end(S), !. get_ent(S1 ,S2,ENT)> get_cmpent(S1 ,S2," ",E1), frontchar(E1, ,E), ENT=E.
get_cmpent([E|S],S,IND,ENT):- ent_end(S), concat(IND,E,ENT). get_cmpent([E|S1],S2IIND,ENT):- concat(IND,E,ll), concat(ll," Mil), get_cmpent(S1 ,S2,III,ENT). ent_end(D). ent_end(["and"|J). ent^end^for-U). predicates
nondeterm s_rel(STRINGLIST,STRINGLIST,STRING) sjjnit(STRINGLIST,STRINGLIST,STRING) s_val(STRINGLIST,STRINGLIST,REAL) clauses
sjrel(S1 ,S2,REL)> relop(RLIST,REL), append(RLIST,S2,S1). s_unit([UNIT|S],S,UNIT). s_val([X,thousand|S],S,VAL):- !, str_real(X,XX),
VAL=1000*XX. s_val([X,million|S],S,VAL):- !, str_real(X,XX),
VAL=1000000*XX. s_val([X|S],S,VAL):- strjreal(X,VAL). predicates
nondeterm s_attr(STRINGLIST,STRINGLIST,STRING,QUERY) nondeterm s_minmax(STRINGLIST,STRINGLIST,STRING,QUERY) nondeterm s_rest(STRINGLIST,STRINGLIST,STRING,QUERY)
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
357
nondeterm s_or(STRINGLIST,STRINGLIST,STRING,QUERY) nondeterm s__or1 (STRINGLIST.STRINGLIST.STRING.QUERY.QUERY) nondeterm s_and(STRINGLIST,STRINGLIST,STRING,QUERY) nondeterm s_and1 (STRINGLIST.STRINGLIST.STRING.QUERY,QUERY) nondeterm s_elem(STRINGLISTlSTRINGLIST,STRING,QUERY) nondeterm s^assocfSTRINGLIST.STRINGLIST.STRING.QUERY) nondeterm s_assoc1 (STRINGLIST.STRINGLIST.STRING.STRING.QUERY) nondeterm s_nest(STRINGLIST,STRINGLIST,STRING,QUERY) nondeterm get_assoc(STRINGLIST,STRINGLIST,STRING) clauses
pars(LIST,E,Q):-
s_attr(UST,OL,E,Q),
OL=D, !. pars(LIST,_,J:-
error(LIST), fail. s_attr([BIG,ENAME|S1]fS2,E1 ,q_eaec(E1 ЛЕ2.Х)):- ent__name(E2,ENAME), size(E2,BIG), entitysize(E2,E1), schema(E1AE2), get_ent(S1 ,S2,X), !. s_attr([BIG|S1],S2,E1 ,q_eaec(E1 ,A,E2,X)):- get_ent(S1,S2,X), size(E2,BIG), entitysize(E2,E1), schema(E1,A,E2), ent(E2,X), !.
s_attr([BIG|S1],S2,E1 ,q_eaq(E1 AE2.Q)):- size(_,BIG),
s_minmax(S1 ,S2,E2,Q), size(E2,BIG), entitysize(E2,E1), schema(E1 ЛЕ2),!. s_attr(S1fS2,E,Q):-
s_minmax(S1 ,S2,E,Q). s_minmax([MIN|S1],S2,E,q_nriin(E,Q)):- minn(MIN), !,
s_rest(S1,S2,E,Q). s_minmax([MAX|S1],S2fE,CLmax(E,Q)):- maxx(MAX), !,
s_rest(S1,S2,E,Q). s_minmax(S1 ,S2,E,Q):-s_rest(S1 ,S2PE,Q). s_rest([ENAME],D,E,q_e(E)):-!, ent_name(E,ENAME). s_rest([ENAME|S1],S2,E,Q):- ent_name(E,ENAME),s_or(S1,S2fE,Q). s_or(S1 ,S2lE,Q):-s__and(S1 .S3.E.Q1), s_or1 (S3,S2,E,Q1 ,Q).
_or1 (["or",ENT|S1],S2lElQ1 ,q_or(Q1 ,Q2)):- ent_name(E,ENT), !,
s_or(S1,S2fE,Q2). s_or1 (["or’,|S1],S2,E,Q1 ,q_or(Q1 ,Q2))> !,
s_or(S1,S2fE,Q2). s_or1(SfS,_,Q,Q).
358
r.0. leaHHBHKO
s_and(S1 ,S2,ElQ):-s_elem(S1 .S3.E.Q1), s_and1 (S3,S2,E,Q1 ,Q).
s_and1 ([',andH,ENT|S1]lS2,E,Q1 ,q_and(Q1 ,Q2))> ent__name(E,ENT), !,
s_elem(S1 ,S2,E,Q2). s_and1 ([nand"|S1]lS2,ElQ1 ,q_and(Q1 ,Q2))> !,
s_elem(S1 ,S2,E,Q2). s_and1(S,Sf_,Q,Q).
% not QUERY
s_elem(["not"|S1]lS2lE,q_not(E,Q)):- !, s_assoc(S1,S2,E,Q). s_elem(S1lS2,EtQ):- s_assoc(S1 ,S2,E,Q).
%... longer than 1 thousand miles - REL VAL UNIT s_assoc(S1,S4,E,q__sel(ElRELfATTR,VAL)):- s_rel(S1,S2,REL), s_val(S2,S3,VAL), s_unlt(S3lS4,UNIT), !, unit(ATTR.UNIT). s_assoc(S1,S3,Efq_sel(E,REL,ATTR,VAL)):- s_rel(S1,S2lREL), s_val(S2,S3,VAL),!, entityslze(E,ATTR). s_assoc(S1 ,S3,E,Q):- get_assoc(S1 ,S2,A), s_assoc1 (S2,S3,E,A,Q). s_assoc1 ([MIN|S1],S2,E1 ,Afq_eaq(E1 AE2,q_min(E2fQ))):- minn(MIN), !,
s_nest(S1 ,S2,E2,Q), schema(E1,A,E2). s_assoc1([MAX|S1]lS2lE1,Alq_eaq(E1 ,A,E2fq__max(E2,Q))):- maxx(MAX), !,
s_nest(S1,S2lE2lQ), schema(E1 ,A,E2). s_assoc1([ATTR|S1],S4,E,A,q_sel(E,REL,ATTRlVAL))> s_rel(S1,S2,REL), s_val(S2,S3,VAL), s_unlt(S3,S4,UNIT 1), !,
ent_name(E2,ATTR)l schema(E,A,E2)> unlt(E2,UNIT),
UNIT=UNIT1, !.
s_assoc1([ATTR|S1]lS3lE,Alq_sel(E,REL,ATTRfVAL)):- s_rel(S1 ,S2,REL), s__val(S2,S3,VAL),!, ent_name(E2,ATTR), schema(E,A,E2), unit(E2,_).
s_assoc1 (S1 ,S4,E,A,q__sel(ElRELlE2,VAL)):- s_rel(S1,S2,REL)f s_val(S2,S3,VAL), s_unit(S3,S4,UNIT 1), !,
schema(E,A,E2), unit(E2,UNIT),
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
359
иміт=имгп, !.
з.аББОСІ (Б1 ,83,Е,А,с|_8ЄІ(Е,РЕІ_,Е2Л/АІ)):- 8_геІ(81,82ДЕІ_), в^аІ^ЗЗЛ/АІ-),!,
8сИета(Е,А,Е2),
ипК(Е2,_).
8_а880с1([АТТР|81],83,Е|А,сь8е1(Е,ея(АТТР|УА1)):-
8_уаІ(81,82,УАІ-),
8_ипИ(82,83,иМІТ1), !,
еп1_пате(Е2,АТТК),
8сИета(Е,А,Е2), ипК(Е2,иМІТ2), иМ1Т1=иЫ1Т2, !.
8_а880СІ([АТТР|81],82,ЕЛсі_8ЄІ(Е,вд,АТТР,УАІ)):-
8_уаІ(81,82,УАЦ,
еп1_пате(Е2,АТТР),
8сЬета(Е,А,Е2), ипК(Е2,_), !.
8_а880с1 ([ЕМАМЕ|81],82,Е1 ,А,сі_еаес(Е1 ,А,Е2,Х)):- деЦ*т(81,82,Х), еп1_пате(Е2,ЕМАМЕ), по!(ипК(Е2,_)),
8сИета(Е1 ,А,Е2), еШ(Е2,Х), !.
8_а880с1 (81,82,Е1 ,А,о_еад(Е1 ,А,Е2,0)):- 8_пе8І(81,82,Е2,0),
8сИета(Е1,А,Е2),!.
8_а880с1 (81,82,Е1 ,А,с|_еаес(Е1 ,А,Е2,Х)):- де1_егії(81,82,Х),
8сЬета(Е1,А,Е2), еггї(Е2,Х), !.
8_пе8І([ЕМАМЕ|81],82,Е,0):-
еггї_пате(Е,ЕМАМЕ),
8_еіет(81,82,Е,0).
8_пе8І([ЕМАМЕ|8],8,Е,с|_е(Е)):-
еггї_пате(Е,ЕМАМЕ).
деІ_а880с(ІІ_,ОІ.,А):-
аррегкЦАвЦОиЦ,
а880с(А,А8І_).
ргесЛсаІег
8ЄІ_тіп(8ТРІМО>8ТРІМО,РЕАІ,8ТРІМО,8ТРІМ6,8ТКІМСІІ8Т)
8ЄІ_тах(8ТРІМС,8ТтМ6,РЕАЦ8ТРІМ6,8ТтМ6,8ТтМОи8Т)
сіаиБев
еуаІ(с|__тіп(ЕМТ,ТРЕЕ),АМ8)>
findall(X,eval(TREE,X),L),
епШу8І2е(ЕМТ,АТТР),
8ЄІ_тіп(ЕМТ,АТТК,99е99,И",АМ8,1) еуаІ(д_тах(ЕМТ,ТРЕЕ),АМ8)>
flndall(X,eval(TREElX),L),
епШу8І2е(ЕМТ,АТТК),
8ЄІ_тах(ЕМТ,АТТР,-1 еОО,"", А^,!.).
еуаІ(с|_8ЄІ(Е,дІ,АТТР,\/АІ-),АМ8):-
8сЬета(АТТР,А880С,Е),
db(ATTRlASSOC,E,SVAL2,ANS),
360
r.0. Iqqhhqhko
str_real(SVAL2,VAL2),
VAL2>VAL. eval(q_sel(E,lt,ATTR,VAL)fANS):- schema(ATTR,ASSOC,E), db(ATTR,ASSOC,E,SVAL2,ANS)I str_real(SVAL2,VAL2),
VAL2<VAL. eval(q_sel(E,eq,ATTR,VAL),ANS):- schema(ATTR,ASSOCfE)l db(ATTR,ASSOC,E.SVAL,ANS), str_real(SVAL,VAL). eval(q_not(E,TREE),ANS):- findall(X,eval(TREE,X)pL), ent(E,ANS), not(member(ANS,L)). eval(q_eaq(E1 ,A,E2,TREE),ANS):- eval(TREE,VAL), db(E1 ,A,E2,AN5,VAL). eval(q_eaec(E1 ,A,E2fC)lANS):- db(E1,A,E2,ANS,C). eval(q_e(E),ANS):- ent(E,ANS). eval(q_or(TREE,J,ANS):- eval(TREE.ANS). eval(q_or(_,TREE),ANS):- eval(TREE,ANS). eval(q_and(T1,T2),ANS)> eval(T1 ,ANS1), eval(T2,ANS),
ANS=ANS1. seLmin(__f_,_fRES,RES,D). sel_min(ENT,ATTR,MIN,_,RES,[H|T])> schema(ATTR, ASSOC, ENT), db(ATTR, ASSOC, ENT, VAL.H), str_real(VAL,HH),MIN>HH, !, sel_min(ENT,ATTR,HH,H,RES,T). seLmin(ENT,ATTR,MIN,NAME,RES,LIT]):- seLmin(ENT,ATTR,MIN,NAME,RES,T). sel_max(_._._.RES,RES,0). sel_max(ENT,ATTR,MAX,_,RES,[H|T])> schema(ATTR,ASSOC,ENT), db(ATTR,ASSOC,ENT.VAL.H), str_real(VAL,HH),MAX<HH,!f seLmax(ENT,ATTR,HH,H,RES,T). sel_max(ENT,ATTR,MAX.NAME,RES,L|T]):- seLmax(ENT,ATTR,MAX.NAME,RES,T).
goal
consult("GEOBASE.DBA",data), consult("GEOBASE.LAN",language), write("Examples are:"),nl, write(" Rivers that runs through texasM),nl, write(" give me the cities in california"),nl, write(" what is the biggest city in california"),nl,
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
361
writer which rivers are longer than 1 thousand kilometers"),nl, writef what is the name of the state with the lowest point"),nl, write(" which states border alabama"),nl, writef which rivers do not run through texas"),nl,
write(" which rivers run through states that border the state with the capital austin"),nl,nl, loop.
362
Г.Ф. Іванчвнко
Додаток В
Управління зарядженням батареї за допомогою нечіткої логіки
Г
* Fuzzy Logic Operators Types and Symbolics */
#ifndef _FUZZY_H
#define _FUZZY__H
typedef float fuzzyType;
fuzzyType fuzzyAnd( fuzzyType, fuzzyType );
fuzzyType fuzzyOr( fuzzyType, fuzzyType );
fuzzyType fuzzyNot( fuzzyType );
#endif /* _FUZZY_H */
#include <stdio.h>
#include<fstream.h> int main()
{int i;
extern float timer; extern int simulate(void); extern void chargeControl( float * ); extern float voltage; extern float temperature; extern int chargeMode; ofstream outfileftest.dat"); for (і = 0 ; і < 3000 ; i++) { simulate();
chargeControl( &timer ); timer += 1.0;
printf("%d, %f, %f, %d\n", i, voltage, temperature, chargeMode );
outfile«voltage«" "« temperature « " " « chargeMode «endl;} return 0;}
Г
* Fuzzy Logic Basic Operators */
#include <assert.h>
#define MAX(a,b) ((a>b) ? a: b)
#define MIN(a.b) ((a<b) ? a: b)
Г
* fuzzyAnd()
V
fuzzyType fuzzyAnd( fuzzyType a, fuzzyType b )
assert(a >= 0.0); assert(a <= 1.0); assert(b >= 0.0); assert(b <= 1.0); return MAX(a,b);}
Г
* fuzzyOr()
*/
fuzzyType fuzzyOr( fuzzyType a, fuzzyType b )
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
363
assert(a >= 0.0); assert(a <= 1.0); assert(b >= 0.0); assert(b <= 1.0); return MIN(a,b);
}
r
* fuzzyNot()
7
fuzzyType fuzzyNot( fuzzyType a )
{
assert(a >= 0.0); assert(a <= 1.0); retum( 1.0 — a );
}
r
* normalize()
7
int normalize( fuzzyType in )
{
if (in >= 0.5) return 1; else return 0;
}
r
* spikeProfile()
7
fuzzyType spikeProfile( float value, float lo, float high )
{float peak;
value += (-lo);
if ((lo < 0) && (high < 0)) {
high = -(high — lo);
} else if ((lo < 0) && (high > 0)) { high += -lo;
} else if ((lo > 0) && (high > 0)) { high -= lo;} peak = (high / 2.0); lo = 0.0;
if (value < peak) { retum( value / peak );
} else if (value > peak) { return( (high-value) / peak);
} return 1.0;}
r
* plateauProfile()
7
fuzzyType plateauProfile( float value, float lo, float lojDlat, float hi_plat, float hi)
{
value += (-lo); if (lo < 0.0) {
lo_plat += -lo; hi__plat += -lo; hi += -lo; lo = 0;
} else {
364
r.0. leameHKO
lo__plat -= lo; hi plat -= lo; hi -= lo; lo = 0;
rf (value < lo) return 0.0; else if (value > hi) return 0.0;
else if ((value >= lo_plat) && (value <= hi Dlat)) return 1.0; else if (value < lo_plat) return ((value-lo) *(1 .0 / (lo_plat — lo))); else if (value > hi_plat) return ((hi-value) * (1.0 / (hi — hi_plat))); return 0.0;}
r
* m__temp_hot()
fuzzyType m_temp_hot( float temp)
const float lo = 34.0; const float lo_plat = 44.0; const float hi_plat = 44.0; const float hi = 44.0; if (temp < lo) return 0.0; if (temp > hi) return 1.0;
return plateauProfile( temp, lo, lo_plat, hi_plat, hi);}
r
* m_temp_warm()
fuzzyType m_temp_warm( float temp )
const float lo = 14.0;
const float lo_plat = 24.0;
const float hi_plat = 34.0;
const float hi = 44.0;
if ((temp < lo) || (temp > hi)) return 0.0;
return plateauProfile( temp, lo, lo_plat, hi_plat, hi);
} » r
* m_temp_cold()
fuzzyType m__temp_cold( float temp)
const float lo = 14.0; const float lo_plat = 14.0; const float hi_plat = 14.0; const float hi = 24.0; if (temp < lo) return 1.0; if (temp > hi) return 0.0;
return plateauProfile( temp, lo, lo_plat, hi_plat, hi);
)*
* m_voltageJow()
fuzzyType m_voltageJow( float voltage)
const float lo = 4.0; const float loj3lat = 4.0; const float hi_plat = 4.0;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
365
const float hi = 10.0; if (voltage < lo) return 1.0; if (voltage > hi) return 0.0;
return plateauProfile( voltage, lo, lo_plat, hi_plat, hi);
)*
*m voltage_medium()
*/
fuzzyType m_voltage_medium( float voltage )
const float lo = 4.0; const float lojDlat = 10.0; const float hi_plat = 20.0; const float hi = 24.0; if (voltage < lo) return 0.0; if (voltage > hi) return 0.0;
return plateauProfile( voltage, lo, lo_plat, hi_plat, hi);
}
I* * m_voltage_high() 7
fuzzyType m_voltage_high( float voltage )
const float lo = 20.0; const float lo_plat = 24.0; const float hi_plat = 24.0; const float hi = 24.0; if (voltage < lo) return 0.0; if (voltage > hi) return 1.0;
return plateauProfile( voltage, lo, lo_plat, hi_plat, hi);
#define TRICKLE_CHARGE 0
#define FAST_CHARGE 1
int normalize( fuzzyType); fuzzyType m_temp_hot( float temp); fuzzyType m_temp_warm( float temp); fuzzyType m_temp_cold( float temp ); fuzzyType m_voltageJow( float temp); fuzzyType m_voltage_medium( float temp); fuzzyType m_voltage_high( float temp);
#include <math.h>
#include <stdlib.h>
#define getSRand() ((float)rand() / (float)RAND.MAX)
#define getRand(x) (int)((x) * getSRand())
float voltage = 20.0;
float temperature = 12.0;
float timer = 0.0;
#define MAXJ-OADS 5
const float load[MAX_LOADS]={0.02, 0.04, 0.06, 0.08, 0.1}; static int curLoad = 0; double charge( int t)
double result;
result = sin( (double)t/100.0 ); if (result < 0.0) result = 0.0; return result;
366
r.0. Ibqhvohko
}
int simulate( void)
{
extern int chargeMode; static int t=0;
I* First, update the loading if necessary 7
if (getSRand() < 0.02) {
curLoad = getRand( MAX_LOADS );
}
r Affect the current battery voltage given the load 7 voltage -= load[curLoad];
r Next, update the battery voltage given input charge 7 if (chargeMode == FAST_CHARGE) { voltage += (charge(t) * sqrt(timer));
} else {
voltage += ((charge(t) * sqrt(timer)) /10.0 );
if (voltage < 0.0) voltage = 0.0; else if (voltage > 34.0) voltage = 34.0; r Update the temperature 7 if (chargeMode == FAST_CHARGE) { if (voltage > 25) {
temperature += ((load[curLoad] * (sqrt(timer)/24.0)) * 10.0); }else if (voltage > 15) {
temperature += ((load[curLoad] * (sqrt(timer)/20.0)) * 10.0); } else {
temperature += ((load[curLoad] * (sqrt(timer)/14.0)) * 10.0); } else {
if (temperature > 20.0) {
temperature -= ((load[curLoad] * (sqrt(timer)/20.0)) * 10i0);
} else { i
temperature -= ((load[curLoad] * (sqrt(timer)/100.0)) * 10.0);
!
if (temperature < 0.0) temperature = 0.0; else if (temperature > 40.0) temperature = 40.0; t++; return 0;
)•
* Fuzzy Logic Simulated Battery Charge Controller 7
#include <stdio.h>
int chargeMode = TRICKLE CHARGE;
r
* chargeControl()
7
void chargeControl( float *timer)
static unsigned int i = 0; extern float voltage, temperature; if ((i++ % 10) == 0 ) {
if (normalize( m_voltage_high( voltage ))) { chargeMode = TRICKLE_CHARGE;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
367
*timer = 0.0;
} else if (normallze( mJemp_hot( temperature ))) { chargeMode = TRICKLE_CHARGE;
*timer = 0.0;
} else if (normalize(
fuzzyAnd( fuzzyNot( m_voltage_high( voltage )), fuzzyNot( m_temp_hot( temperature))))){ chargeMode = FAST_CHARGE;
*timer = 0.0;))
printf( "%d, %f, %f %d\n", i, voltage, temperature, chargeMode );)
368
Г.Ф. Іввнчвнко
Додаток Д
Алгоритм зворотного поширення для ШНМ лістинг-програми
Таблиця!
ВХІДНІ ДАНІ:
Відстань (кілометри)
Маса (тонни)
Час (дні)
Габаритність
0: х <= 500 км 1: 500км.< х < =1000 км 2: х> 1000 км
0: < 1 т
1: 1 т. < =х < =5 т 2: > 5 т
0: 1<Час <=7 1: 7<Час <=14 2: 14<Час <=25
0: — габаритний 1: — не габаритний
Приклади роботи програми:
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
369
#include <vcl.h>
#pragma hdrstop #include "Inflation.h"
#include <vcl.h>
#pragma hdrstop #include "Inflation.h"
#include "AN70.h"
#include "Kamaz.h"
#include "Maz.h"
#pragma package(smartjnit)
#pragma resource "*.dfm"
#pragma hdrstop #include <condefs.h>
#pragma argsused #pragma hdrstop #indude <condefs.h>
#include <math.h>
#include <conio.h>
#include <iostream.h>
#include <stdio.H>
#include <string.h>
#include<fstream.h>
#pragma argsused #define INPUT_NEURONS 4 #define HIDDEN JMEURONS 3 #define OUTPUT_NEURONS 3 #define LEARN_RATE 0.2 #define MAX_SAMPLES 15
#define RAND_WEIGHT (((float) rand() / (float)RAND MAX)-0.5) «define getSRandO ((float)rand() / (float)RAND_MAXf #define getRand(x)(int)((x)* getSRand())
#define sqr(x) ((x)*(x))
double wih[INPUT_NEURONS+1][HIDDENJMEURONS];
double who[HIDDEN_NEURONS+1][OUTPUT_NEURONS];
double inputs[INPUT_NEURONS];
double hidden[HIDDEN_NEURONS];
double target[OUTPUT_NEURONS);
double actual[OUTPUT_NEURONSJ;
double erro[OUTPUT_NEURONS];
double errh[HIDDEN_NEURONS];
typedef struct {
double podie_1;
double podie_2;
double podie_3;
double podie_4;
double out[OUTPUT_NEURONSJ;
} ELEMENT;
ELEMENT samples[MAX SAMPLES]»{
{0.0,0.0, 0.0,1.0, {1.0,1.0, 2.0, 0.0, {2.0, 2.0, 0.0, 0.0, {0.0,1.0,1.0,1.0, {1.0,1.0, 0.0,1.0, {2.0,1.0,1.0, 0.0,
0.0, 0.15,1.0] 0.0,1.0, 0.0 1.0, 0.0, 0.0 0.0,1.0, 0.0 1.0, 0.0,1.0 :o.o, 1.0, o.o'
370
r.0. leaH^eHKO
{1.0, 2.0, 2.0, 0.0;{0.0, 0.0, 1.0}}, {0.0, 1.0, 1.0, 1.0, {0.0, 1.0, 0.0} ‘
{1.0, 2.0, 0.0, 0.0, {1.0, 0.0, 0.0}}, {1.0, 1.0,1.0, 0.0, {0.0, 0.0,1.0}},
{2.0, 1.0, 2.0, 0.0, {0.0, 0.0, 1.0}}, {2.0,1.0, 2.0, 0.0, {0.0, 0.0, 1.0}},
{2.0, 0.0, 0.0, 1.0, {1.0, 0.0, 0.0}},
{1.0, 0.0, 2.0, 1.0, {0.0,1.0, 0.0}}, {0.0, 1.0,1.0,1.0, {0.0, 1.0, 0.0}}
char *strings[3]={”AN-70", "KAMAZ", "MAZ"};
TForml *Form1;
void assignRandomWeights(void)
{int hid, inp, out;
for (inp=0; inp < INPUT_NEURONS+1; inp++)
{for (hid=0; hid < HIDDEN_NEURONS; hid++)
{wih[inp][hid] = RAND_WEIGHT;}}
for (hid=0; hid < HIDDEN_NEURONS+1; hid++)
{for (out=0; out < OUTPUT_NEURONS; out++)
{who[hid][out] = RAND_WEIGHT;}}
double sigmoid(double val)
{return (1.0 / (1.0 + exp(-val)));} double sigmoidDerivative(double val)
{return (val * (1.0 — val));} void feedForward()
{int inp, hid, out; double sum;
for (hid=0; hid < HIDDEN_NEURONS; hid++)
{sum=0.0;
for (inp=0; inp < INPUT__NEURONS; inp++) I
{sum+= inputsfinp] * wih[inp][hid];} sum+= wih[INPUT_NEURONS][hid]; hidden[hid]= sigmoid(sum);
for (out=0; out < OUTPUT_NEURONS; out++)
{sum=0.0;
for (hid=0; hid < HIDDEN_NEURONS; hid++)
{sum+= hidden[hid] * who[hid][out];} sum+= who[HIDDEN_NEURONS][out]; actual[out]= sigmoid(sum);
}}
void backPropagate(void)
{int inp, hid, out;
for (out=0; out < OUTPUT_NEURONS; out++)
{erro[out]= (target[out]-actual[out]) * sigmoidDerivative(actual[out]);}
for (hid=0; hid < HIDDEN_NEURONS; hid++)
{errn[hid] = 0.0;
for (out=0; out < OUTPUT_NEURONS; out++)
{errh[hid]+= erro[out] * who[hid][out];} errh[hid] *= sigmoidDerivative(hidden[hid]);
for (out=0; out < OUTPUT_NEURONS; out++)
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
371
{for (hid=0; hid < HIDDEN_NEURONS; hid++)
{who[hid][out]+= (LEARNJRATE * erro[out] * hidden[hid]);
who[HIDDEN_NEURONS][out]+= (LEARN_RATE * erro[out]);} for (hid=0; hid < HIDDEN_NEURONS; hid++)
{for (inp=0; inp < INPUT_NEURONS; inp++)
{wih[inp][hid]+= (LEARN_RATE * errh[hid] * inputs[lnp]);} wih[INPUT_NEURONS][hid] += (LEARN_RATE * errh[hid]);}
Int action(double ^vector)
{int index, sei; double max; sel=0;
max=vector[sel];
for (index=1 ; index < OUTPUTJSIEURONS; index++)
{if (vectorflndex] > max)
{max= vectorflndex]; sel= index;}} retum(sel);
void fastcall TFörm1::Button1Click(TObject *Sender)
{double err, b;
int i, sample=0, iterations=0; int sum=0;
AnsiString error;
if(DistanceComboBox->ltemlndex==-1) ShowMessagefBBeAiTb інф. про відстань!"); else
if(WeightComboBox->ltemlndex==-1) ShowMessage("BßeAiTb інф. про вагуГ); else
if(TimeComboBox->ltemlndex==-1) ShowMessageCBeeAiTb інф. про час!"); else
if(SpecialComboBox->ltemlndex==-1) ShowMessage("BeeAiTb інф. про габаритність!"); else{
Chartl ->Series[0]->Clear();
ErrorProgressbar->Position=0; srand(tlme(NULL)); assignRandomWeights(); while (1){
if (++sample == MAX_SAMPLES) sample=0; inputs[0] = samples[sample].podie_1; inputs[l] = samples[samplej.podie_2; inputs[2] = samples[samplej.podie_3; inputs[3j = samples[samplej.podie_4; target[0] = samples[sample].out[0]; target[1] = samples[sample].out[1]; target[2] = samples[samplej.out[2]; target[3] = samples[sample].out[3]; feedForward(); err=0.0;
for (i=0; і < OUTPUTJMEURONS; i++)
{err+= sqr((samples[sample].out[ij — actual[i]));
} err=0.5*err;
372
Г.Ф. Іванченко
error="ERROR ?" + FloatToStr(err);
ErrorMemo->Lines->Add(error);
ErrorProgressbar->Position++;
if (iterations** > 18000Kgetch(); break;}
backPropagate();}
for (NO; і < MAXSAMPLES; i++)
{inputs[0] = samples[j].podie 1;
inputs[1
inputs[2
inputs[3
target[0
target[1
target[2
target[3
= samplesp].podieJ2;
= samples[i].podie_3;
= samples[ij.podie_4;
= samplesfi].out[0] ;
= samples[ij.out[lj;
= samples[i].out[2j;
= samples[ij.out[3j; feedFbnvard(); sum++;}
b=((float)sum / (float)MAX SAMPLES)# 100.0; error="Network is "+FloatTbStr(b)+"% cx>rrect";
ErrorMemo->Lines->Addr");
ErrorMemo->Lines->Add(error);
inputs[0] = StrToFloat(StringReplace(lntToStr(DistanceComboBox->ltemlndex), TRepiaceFiagsO « rfReplaceAJI)); inputs[1] = StrToFloat(StringReplace(lntT oStr(WeightComboBox->ltemlndex), V. TRepiaceFiagsO « rfReplaceAII)); inputs[2] = StrToFloat(StringReplace(lntToStr(TimeComboBox->ltemlndex), TRepiaceFiagsO « rfReplaceAII)); inputs[3] = StrToFloat(StringReplace(lntToStr(SpecialComboBox->ltemlndex), V, TRepiaceFiagsO « rfReplaceAII)); feedForwardO; switch (action(actual)) { case 0: AN70Form->ShowModal(); break; case 1: KamazForm->ShowModal(); break; case 2: MazForm->ShowModal(); break;} getch();
TStringList* List; int ListCount;
List = new TStringList;
List->LoadFromFile(”result.daf);
ListCount = List->Count;
Chart 1 ->Series[0]->Clear();
for (int і = 0; і < ListCount; і = і + 18)
{Chart1->Series[0]->Add(StrToFloat(StringReplace(List->Strings[i]f TReplaceFlags() « rfReplaceAII))li,clRed);
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
373
Додаток Е
Програма алгоритму К середн1х:
unit Unitl;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls, TeEngine, Series, ExtCtrls, TeeProcs, Chart;
type
TForml = class(TForm)
Chartl: TChart;
Seriesl: TPointSeries;
Buttonl: TButton;
Open Dialog 1: TOpenDialog;
procedure Buttonl Click(Sender: TObject);
private
{Private declarations} public
{Public declarations} end;
var
Forml: TForml; i: integer;
implementation
{$R *.dfm}
procedure TForml.Button 1Click(Sender: TObject);
type point = record
x,y: double;
index: integer,
cluster: integer;
end;
type dist = record d: double; i: integer; end;
var f: textfile;
x.y: double;
an: array of point;
z1,z2,z1old,z2old: point;
i,j,k1,k2,a:integer;
d1,d2: array of dist;
label next;
Procedure find(x,y:double;n: integer; var k: integer);
var i: integer;
begin
374
r.O. leaHveHKO
k:=9999; for i:=0 to n do
if ((Chartl .SeriesList[0].XVaiue[i]=x) and (Chartl .Serie$Ljst[0].yValue[i]=y)) then begin
k:=i; break; end;
end;
begin
OpenDialogl .execute; if OpenDialogl .FileNameo“ then begin // read file
assignfile(f,OpenDialog1.filename); reset(f);
Chartl .SeriesList[0].CIear; setlength(arr.O); i:=0;
while not(eof(f)) do begin readln(f,x,y);
Chartl .SeriesList[0].AddXY(x,y); setlength(anr,length(arr)+1); arrf arr arr arr inc
high(arr)].x:=x; high(arr)].y:=y; high(arr)].index:=i; high(arr)j.cluster:=0;
j); end;
closefile(f);
// calculate here
setlength(d1 ,Length(arr)); setlength(d2,Length(arr)); z1:=arr[0J z2:=arr[1
next:
z1old:=z1;
z2old:=z2;
//Chartl .SeriesList[0].ValueColor[0]:=clYellow; for i:=0 to high(arr) do
begin d1[i].d:=sqrt(sqr(z1.x-arr[i].x) + sqr(z1 .y-arr[i].y));
d1[i].i:=arr[i].index;
end;
for i:=0 to high(arr) do
begin d2[i].d:=sqrt(sqr(z2.x-arr[i].x) + sqr(z2.y-arr[i].y));
d2[i].i:=arr[i].index;
end;
k1:=0; k2:=0;
for i:=0 to high(arr) do
begin
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
375
if d1[i].d<d2[i].d then begin
arr[i].cluster:=1; k1:=k1+1;
end else
begin
arr[i].cluster:=2; k2:=k2+1;
end;
end;
z1 .x:=0;z1 .y:=0;z2.x:=0;z2.y:=0; for i:=0 to high(arr) do begin
if arr[i].cluster=1 then begin
z1.x:=z1.x+arr[i].x;
z1.y:=z1.y+arr[ij.y;
end
else begin
z2.x:=z2.x+arr[i].x;
z2.y:=z2.y+arr[ij.y;
end;
end;
z1 .x:=z1 .x/k1; z1.y:=z1.y/k1; z2.x:=z2.x/k2; z2.y:=z2.y/k2;
if ((z1 .x<>z1old.x) or (z2.x<>z2old.x)or (z1 .y<>z1old.y)or (z2.y<>z2old.y)) then
begin
z1old:=z1;
z2old:=z2;
goto next;
end;
for i:=0 to high(arr) do begin
find(arr[i].xlarr[i].y,length(arr),a);
if arr[i].cluster= 1 then Chartl .SeriesList[0].ValueColor[a]:=clYellow
else Chartl .SeriesList[0].ValueColor[a]:=dBlue;
end;
Chartl .SeriesList[0].AddXY(z1 .x,z1 .y); find(z1 .xfz1 .y,length(arr)+1 ,a);
Chartl .SeriesList[0].ValueColor[a]:=clGreen;
Chartl .SeriesList[0].AddXY(z2.x,z2.y); find(z2.x,z2.yflength(arr)+2,a);
Chartl .SeriesList[0].ValueColor[a]:=clGreen;
end;
end;
end.
376
Г.Ф. Іванчвнко
Додаток Ж
Програма алгоритму Isodata
function [Z, Xduster, Yduster, A, cluster] = isodata(X, Y, k, L, I, ON, ОС, OS, NO, min);
s=size(X);
s=s(2);
cluster=zeros(1,s);.
iter=0;
final=0;
vuelve3=0;
A=1;
primeravez=1; Z= I
_ : inicializa_centros(X, Y, A); while final==0, if primeravez==0,
if vuelve3==0,
[Ltemp, Hemp, ktemp, ONtemp, OCtemp, OStemp]=parametros(L, I, k, ON, OC, OS, iter);
end;
end;
prlmeravez=0; vuelve3=1; for i=1:s, cluster(i)=cercano(X(i), Y(i), Z, A); end;
[Z, A, cluster]=eliminar(A, duster, Z, X, Y, ON);
£=recalcula(cluster, X, Y, A, Z); if(iter==l), final=1; next=0; else
next=decide78(lter, k, A); end;
if next==1, next=2;
hubo_divislon=0;
A2=A;
divlde^O;
[Di, D, STM]= dispersion(X, Y, Z, duster, A); i=0;
while (hubo_division==0) & (i < A),
M+1;
index=find(duster==i); sindex=size(index); sindex=sindex(2); if (STM(i)>OS) & ( ((Di(i,1 )>D(1)) & (Di(i,2)>D(2)) & (slndex>(2*(ON+1)))) (A<=(k/2))), hubo_division=1; next=1;
[Z, cluster]=dividir(STM, A, cluster, Z, I, (A+1), X, Y); % Division. A=A+1; % Indicamos que hay un nuevo agrupamiento. iter=iter+1; end;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
377
end;
end;
if next==2,
[orden, Dy= distanda_centros(A, Z, OC, L); %Si orden=0 ->nohay nada para mezdar. if orden(1)>0,
[cluster, Z, A]=union(A, orden, cluster, Z, Dij);
Z=recalcula(cluster, X, Y, A, Z); end;
end;
if next==2
[iter,final,vuelve3]= termina_oJtera(iter, I, NO);
end;
end;
for j=1:s
temp=0;
P=[X0)Y(i)]; for i=1:A,
if distancia(P,Z(i,:)) > min,
temp=temp+1;
end;
end;
if temp==A, ciuster(j)=0; end; end;
Xcluster=0;
Ycluster=0; for m=1:k inedx=0;
index=find(cluster==m); s2=size(index); s2=s2(2); for n=1 :s2
Xcluster(1,n,m)= X(index(n));
Ycluster(1,n,m)= Y(index(n));
end;
end;
function [m] = cercano(x, y, Z, k) dtemp=0; d=0; for j=1:k P=[x y];
d=distancia(Z(j,:), P); if j<2, m=j;. dtemp=d; elseif d < dtemp, m=j;
dtemp=d;
end;
end;
function [Zoutl] = recalcula(cluster, X, Y, k, Z) s=size(X);
378
r.0. lBQH*40HK0
8=8(2);
valor=zeros(1 ,k);
Zout=zeros(k,2); for m=1:k index=find(cluster==m); if isempty(index)==0 sindex=size(index); sindex=sindex(2);
Zout1(m,1)=(sum(X(index))) / sindex;
Zout1(m,2)=(sum(Y(index))) / sindex; else
Zout1(m,:)=Z(m,:);
end;
end;
function [Ditemp, Dtemp, STMAX] = dispersion(X, Y, Z, cluster, A) Ditemp=zeros(A,2);
Dtemp=zeros(1,2);
ST=zeros(A,2);
STMAX=zeros(1 ,A); for i=1 :A, suma=[0 OJ; index=find(cluster==i); sindex=size(index); forj=index,
P=PC0).Yfl)]; d=distancia(Z(i,:), P); suma(1)=suma(1) + (d * X(j)); % sumax suma(2)=suma(2) + (d * Y(j)); % sumay end;
% Dispersion por agrupamiento Ditemp(i,:)=suma / sindex(2);
% Dispersion global temporal
Dtemp(1,:)=Dtemp(1,:) + (Ditemp(i,:) * sindex(2));% Sumatorio Ni*Di %Dispersion por variable ST (i, 1 )=std(X(index));
ST (i,2)=std(Y(index));
STMAX(i)=max(ST(i,:));
end;
Dtemp(1 ,:)=Dtemp(1,:) / A;
function [Ztemp, Atemp, clustertemp]=eliminar(A, cluster, Z, X, Y, ON)
desplazamiento=zeros(1 ,A); % Sus posibles valores son: -1, (=0) o (>0). for i=1 :A, % Si -1: este grupo se alimina. Si 0: no varia. cont=find(cluster==i); % Si >0: se le restan tantas posiciones como indique su valor. scont=size(cont);
if scont(2) < ON desplazamiento(i)=-1; if i < A, forj=(i+1):A
desplazamiento(j)=desplazamiento(j)+1;
end;
end;
end;
end;
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
379
%Actuacion.
[Ztemp, Atemp, clustertemp]=reduG6(desplazamiento, A, cluster, Z);
if isempty(Ztemp)==1,
Atemp=1;
Ztemp(1,1 )=median(X);
Ztemp(1,2)=median(Y); end;
vacio=find(clustertemp==0); if isempty(vacio)==0 for i=vacio,
clustertemp(i)=cercano(X(i), Y(i), 2temp, Atemp); end;
end;
function [clustertemp, Ztemp, Atemp]=union(A, orden, cluster, Z, Dij) clustertemp=cluster; sorden=size(orden); unidos=0; uindex=0;
sunidos=size(unidos);
marca=zeros(1,A);
imarca=0;
for i=1:sorden(2),
yaunido=0;
temp=[0 0];
[fcnum(1),fcnum(2)]=find(Dij==orden(i)); % fcnum(1) < fcnum(2) for j=1:2,
if isempty( find(unidos==fcnum(j)) )==0,
yaunido=1;
else
temp(j)=fcnum(j);
end;
end;
if yaunido==0
for h=1:2;
unindex=uindex+1;
unidos(unindex)=temp(h);
end
marca(fcnum(2))=-1;
selec=find(clustertemp==fcnum(2));
clustertemp(selec)=fcnum(1);.
end;
end;
adicion=0;.
for i=1:A
if marca(i) >= 0,
marca(i)=marca(i)+adicion;
else
adicion=adicion+1;
end;
end;
[Ztemp, Atemp]=reduce(marca, A, clustertemp, Z);
380
r.0. leahweHKO
function [Ztemp, Atemp, clustertemp]=reduce(desplazamiento, A, cluster, Z) Atemp=A;
clustertemp=cluster;
Ztemp=find(Atemp==999999);
for i=1:A
if (desplazamiento(i) < 0), selec=find(cluster==i); if isempty(selec)==0 clustertemp(selec)=0; end;
Atemp=Atemp-1;
else
Ztemp( (i-desplazamiento(i)),:)= Z(i,:); selec=find(clustertemp==i);
clustertemp(selec)=clustertemp(selec)-desplazamiento(i);
end;
end;
function [orden, Dij]= distancia_centros(A, Z, OC, L)
Dij=zeros((A-1),A); for i=1:(A-1), forj=(1+i):A,
Dij(i,j)=distancia(Z(i,:), Z(j,:));
end;
end;
index= find( (Dij>0) & (Dij<OC))’;
if (isempty(index))==0,
orden=sort(Dij(index));
sorden=size(orden);
if sorden(2)>L
orden=orden(1,1:L);
end;
else
orden=0;
end;
function [Ztemp, clustertemp]=dividir(ST, A, cluster, Z, ncentro, Atemp, X, Y) clustertemp=ciuster;
Ztemp=Z;
k2=0.5; % 0 < k2 < 1 Yi=ST(ncentro) * k2;
Ztemp(Atemp,:)=Ztemp(ncentro,:);
m=find( Ztemp(ncentro,:)==max(Ztemp(ncentro,:)));.
Ztemp(ncentro,m)=Ztemp(ncentro,m)+Yi; % Z+=Z(ncentro)
Ztemp(Atemp,m)=Ztemp(Atemp,m)-Yi; % Z-=Z(Atemp)
dividendo=find(clustertemp==ncentro);
for i=(dividendo),
P=[X(i), Y(i)];
if (distancia( P, Ztemp(ncentro,:))) >= (distanda(P, Ztemp(Atemp,:))), %d(Z+) >= d(Z-)
dustertemp(i)=Atemp;
end;
end;
function [dist]= distanda(Z1, Z2) dist=sqrt( ((Z1(1)-Z2(1))A2) + ((Z1 (2)-Z2(2))^2));.
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
381
function [Z]=inicializa_centros(X, Y, k)
% Distribuye los centres unifomnemente dx= (max(X)Hmin(X)); dy= (max(Y)Hmin(Y));
dzx= dx/(k+1); % distancia entre centres coordenada X. dzy= dy/(k+1); % distancia entre centres coordenada Y. for i=1:k,
Z(i,1)=min(X)+(dzx*i);
Z(i,2)=min(Y)+(dzy*i);
end;
function [Ltemp, ltemp, ktemp, ONtemp, OCtemp, OStemp]=parametros(L, I, k, ON, OC, OS, iter)
Ltemp=L; ltemp=l; ktemp=k; ONtempON; OCtemp=OC; OStemp=OS;
comienza=0;
while comienza==0,
preg=find(comienza==9);% Da resultado vacio. fprintf(‘\n\n\n\n\n\n\n\n\n\n\n\n\nn\n\n\n’); fprintf(‘lteracion actual: %d \n’,iter);
fprintf('L=%d, l=%d, k=%d, ON=%d, OC=%d, OS=%d Vn’.L.I.k.ON.OC.OS); fprintf('Que paramètre deseas modificar? \n(1: L / 2: I / 3: k / 4: ON / 5: OC / 6: OS / 7: Ninguno) \n’);
while isempty(preg)==1,
preg=input(‘Eleccion:’);
end;
if preg==7
comienza=1;
else
valor=find(comienza==9); while isempty(valor)==1, valor=input(‘Valor:’); end;
if preg==1,
Ltemp=valor; elseif preg==2, ltemp=valor; elseif preg==3,
Ktemp=valor; elseif preg==4,
ONtemp=valor; elseif preg==5,
OCtemp=valor; elseif preg==6,
OStemp=valor;
end;
end;
end;
function [itertemp,FINtemp,vuelve3temp]= termina_oJtera(iter, I, NO) itertemp=iter;
FINtemp=0; vuelve3temp=1 ; if itertemp==l,
FINtemp=1;
else
if NO==1
382
r.0. leaHveHKO
vuelve3temp=1s
else
preg2=find(lter==0); % Resp. vacia fprintf(An\n\n\n\n\n\n\n\n\n\n\n\n\n\n’); fprintf('lteraclon actual: %d \n\itertemp); while (isempty(preg2)==1) | ((preg2~=2) & (preg2--1)), fprintffDesea modificar algun parametro antes de volver iterar? (Sl=1 I N0=2) \n Respuesta:’);
preg2=input(");
end;
if preg2==1
vuelve3temp=0; % Ve a paso2 (modifiqa parametros). else
vuelve3temp=1; % Ve a paso3.
end;
end;
itertemp=itertemp+1; end;
function [nexttemp]=decide78(iter( k, A) nexttemp=0; if A <= (k/2)
nexttemp=1; % Va a paso 7. end
if ((A>=(2*k)) | ((iter>0) & (((iter+1)/2)>(eeil(iter/2))))) % Si a>=2k o la iteracion es par.
nexttemp=2; % Va a paso 8.
end
if nexttemp==0
nexttemp=1;
end;
Навчальне видання
Іванченко Г еннадій Федорович
СИСТЕМИ ШТУЧНОГО ІНТЕЛЕКТУ
Навчальний посібник
Редактор В. Шолудько Художник обкладинки Т. Зябліцева Коректор С. Фіялка Верстка В. Піхота
Підп. до друку 08.11.11. Формат 60x84/16. Папір офсет. № 1.
Гарнітура Тип Тайме. Друк офсет. Ум. друк. арк. 22,31.
Обл.-вид. арк. 25,40. Наклад 255 пр. Зам. № 10-3941
Друку ТОВ "Видавництво “Аспект-Поліграф", м. Ніжин, тел. факс: (04631) З-П-08, 3-ІН-03 Державний вищим навчальним заклад «Київський національний економічний університет імені Вадима Гетьмана» 03680, м. Київ, проспект Перемоги, 54/1
Свідоцтво про внесення до Державного реєстру суб'єктів видавничої справи (серія ДК, № 235 від 07.11.2000)
Тел./факс (044) 537-61-41; тел. (044) 537-61-44 E-mail: publish@kneu.kiev.ua