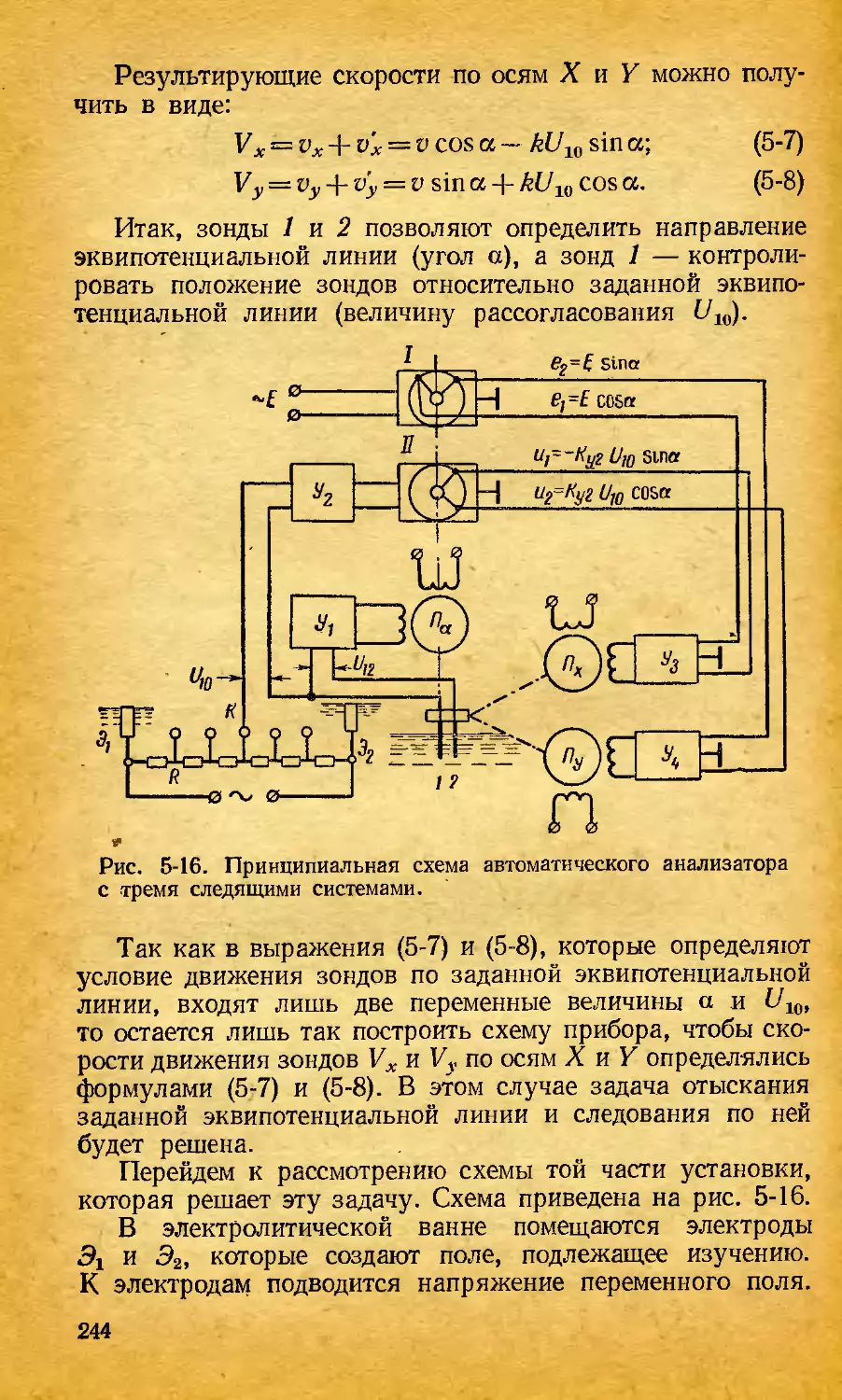
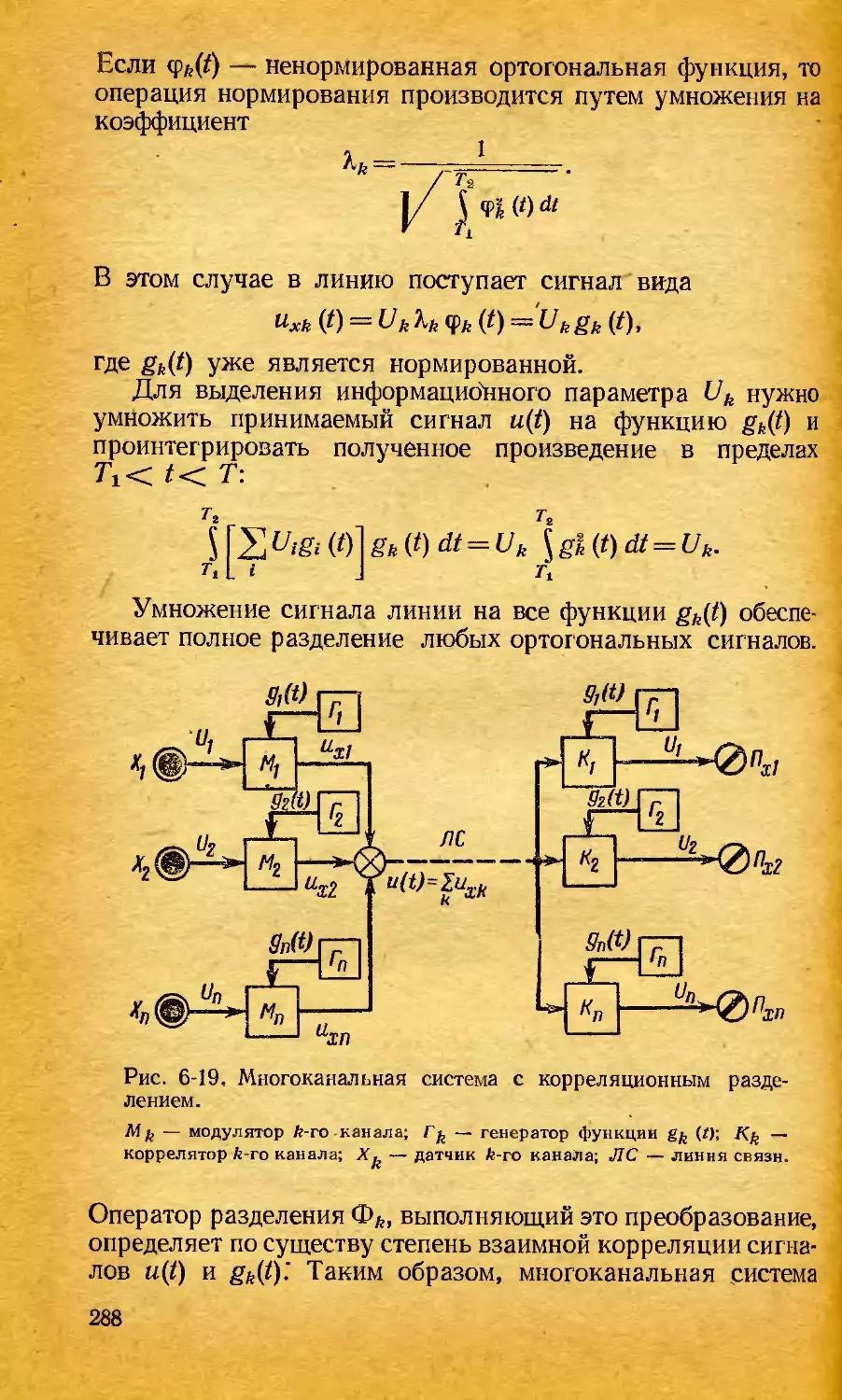
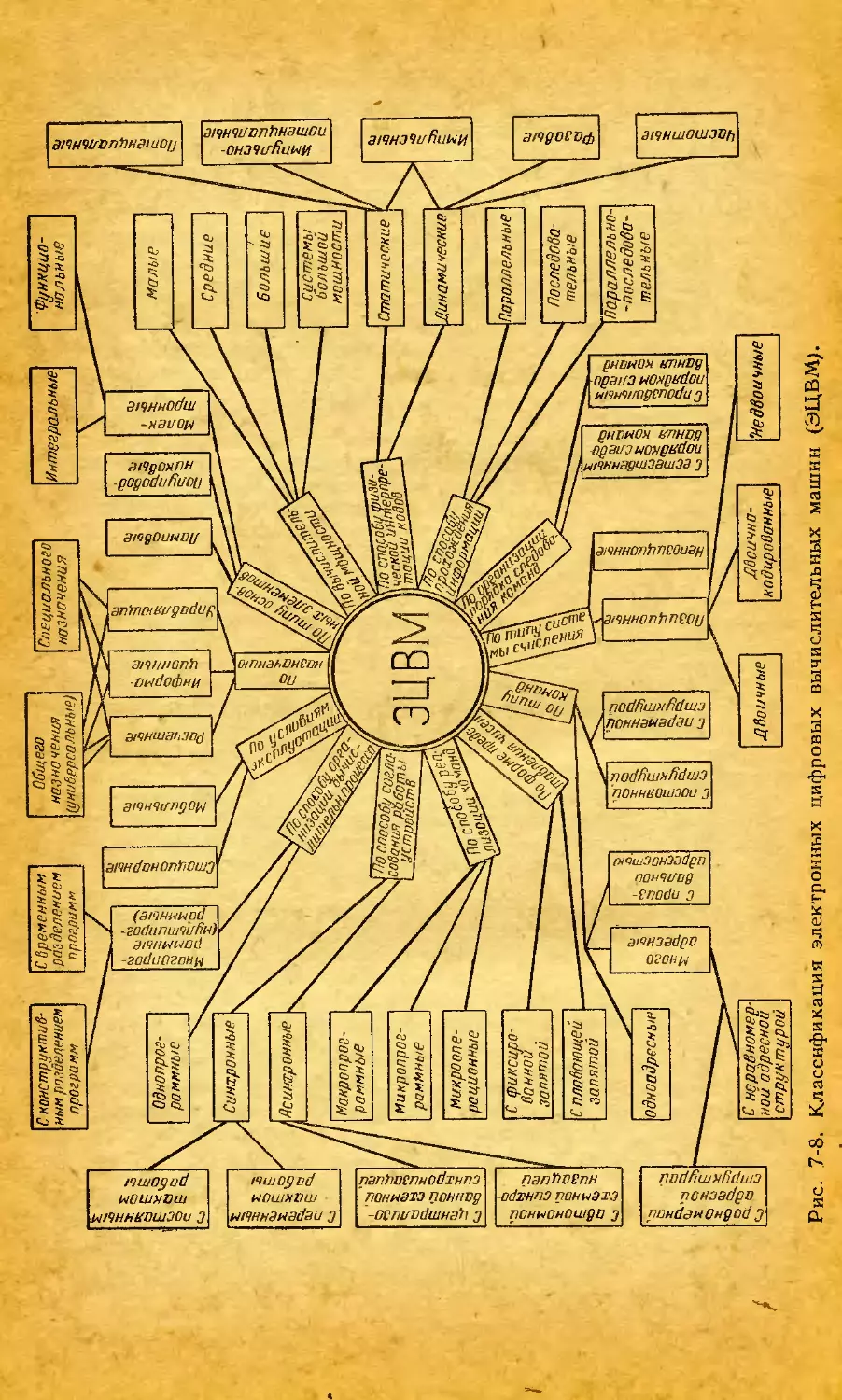
/






































































































































































































































































































































































































































Автор: Дмитриев В.И. Темников Ф.Е. Афонин В.А.
Теги: электротехника информатика кодирование информационные технологии
Год: 1971




Текст
Ф. Е. ТЕМНИКОВ,
В. А. АФОНИН,
В. И. ДМИТРИЕВ
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ
ИНФОРМАЦИОННОЙ
ТЕХНИКИ
Допущено Министерством высшего и
среднего специального образования
СССР в качестве учебного пособия для
студентов высших учебных заведений
«ЭНЕРГИЯ»
Москва 1971
6Ф6
Т 32
УДК 621.377.037.3 (075.8)
Темников Ф. Е. и др.
Т 32 Теоретические основы информацион-
ной техники, М., «Энергия», 1971.
424 с. с илл.
Перед загл. авт.: Ф. Е. Темников, В. А. Афонин,
В. И. Дмитриев
В книге рассмотрены основы теории информации,
вопросы кодирования и декодирования, модуляции и
демодуляции, восприятия, передачи, обработки и пред-
ставления • информации. Описаны современные информа-
ционные системы и их узлы.
Книга предназначается в качестве учебного пособия
для студентов вузов по специальностям «Автоматика и
телемеханика», «Информационно-измерительная техни-
ка», «Вычислительная техника» и «Автоматизированные
системы управления».
3-3-13
188-71
6Ф6
Федор Евгеньевич Темников,
Владимир Александрович Афонин,
Владимир Иванович Дмитриев
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ
ИНФОРМАЦИОННОЙ ТЕХНИКИ
Редактор И. М. Шенброт
Технический редектор Л. А. Пантелеева
Переплет художника Б. Дроздова
Сдано в набор 27/Х 1970 г. Подписано к печати 11/VI 1971 г.
Т09730 Формат 84Х108'/з2. Бумага типографская № 2.
Усл. печ. л. 22,26. Уч.-изд. л. 24,02. Тираж 35 000 экз.
Цена 1 р. 04 к. Заказ Ns 1478.
Издательство «Энергия». Москва, М-114,
Шлюзовая наб., 10.
Ордена Трудового Красного Знамени Ленинградская типография
№ 1 «Печатный Двор» им. А. М. Горького Главполнграфпрома
Комитета по печати при Совете Министров СССР, г. Ленин-
град, Гатчинская ул., 26.
Предисловие
Настоящая книга отвечает ряду разделов су-
ществующих учебных программ по курсу «Тео-
ретические основы информационной техники» и
близким ему курсам для специальностей инфор-
мационного и кибернетического направлений
высшей технической школы: «Автоматика и теле-
механика», «Вычислительная техника», «Инфор-
мационно-измерительная техника», «Автоматизи-
рованные системы управления».
В этой книге авторы стремились по возмож-
ности выдержать общий широкий подход к инфор-
мационной науке в целом. Более детально изло-
жен основной, в той или иной степени установив-
шийся материал, который уже в настоящее время
используется в научной и инженерной практике.
Наряду с авторами, указанными на титульном
листе, в создании книги приняли участие ряд
сотрудников МЭИ, написавших в основном сле-
дующие главы: В. Г. Долотов — гл. 2, Ю. Д. Хо-
ванский — гл. 7, Ю. А. Ивашкин — гл. 8.
Введение
Деятельность людей связана с обработкой материа-
лов, энергии и информации. Соответственно развивались
научные технические дисциплины, отражающие вопросы
технологии, энергетики и информатики. Теория инфор-
мации и информационная техника являются сравнительно
новыми отраслями, получающими наибольшее развитие
на этапе разработай и применения электронных вычис-
лительных машин (ЭВМ) и автоматизированных систем
управления (АСУ).
Вопросы технологии и энергетики продолжают интен-
сивно развиваться и играть важную роль в период авто-
матизированной информационной техники, но каждый
период характеризуется новым, более высоким уровнем
науки и техники. Иллюстрацией может служить эволю-
ция математики, метрологии и оружия, показанная в
табл. В-1. В ней условно выделены технические перио-
ды технологии, энергетики и информатики, влияющие на
методы и средства соответствующих областей.
Несмотря на то, что информатика является самой моло-
дой и неустановившейся наукой, она уже теперь находит
применение в самых разнообразных областях теории и прак-
тики (табл. В-2).
Наука эта еще не получила полного развития. Сущест-
вуют только отдельные ее ветви. Особое значение имеет
центральная ветвь — теория связи, созданная Шенноном
на основе „теории вероятностей.
По отношению к кибернетике информационные наука и
техника занимают подчиненное положение, так как, кроме
чисто информационных процессов (сбор, передача, перера-
4
Таблица В 1
Области науки и техники Период технологии Период энергетики Период информатики
Математика Математика предметов и Земли Математика дви- жения и энергети- ческих процессов Математика струк- туры, поведения и мышления
Измерения Измерение геометрических размеров, веса, твердости Измерение тепло- вых, электриче- ских, магнитных величин и энерге- тических характе- ристик Измерение сообще- ний, смысла, эмо- ций и степени организации
Промышлен- Машнны-ору- Машины-двигате- Машины-автоматы,
ность дия, приспо- собления, станки ли, теплотехника, электротехника системы наблюде- ния, вычисления, управления, интелектроннка
Военное дело Холодное и метательное оружие Пушки, ракеты, атомное и лазерное оружие Система оповеще- ния и противо- воздушной оборо- ны. Средства информационной и психологической борьбы
Таблица В-2
Области применения теории информации
Научно-технические области
1. Кибернетика
2. Системотехника
3. Исследование операций
4. Бионика
5. Автоматика
6. Телемеханика
7. Связь
8. Измерительная техника
9. Вычислительная техника
Другие области
1. Математика
2. Философия
3. Экономика
4. Социология
5. Управление
6. Физика
7. Химия
8. Биология
9. Психология
10. Медицина
11. Педагогика
12. Криминалистика
13. Разведка
14. Лингвистика
15. Библиография
16. Искусство
ботка, хранение и представление информации), в киберне-
тике рассматриваются объекты, цели, общие технологиче-
ские процессы, оптимизация управления, обратные связи
и т. д.
В ряду новых дисциплин (исследование операций, систе-
мотехника, административное управление) информацион-
5
Г ;-----------
ные наука и техника занимают одно из базовых положений,
т. е. во всех указанных дисциплинах теория и практика
информации используются или могут быть использованы
как одна из их существенных частей, относящихся к инфор-
мационным явлениям, наряду с рабочими операциями, веще-
ственными и энергетическими явлениями и системами,
вопросами надежности, организации, стратегии и т. п.
К информационной технике относятся средства, служа-
щие для восприятия, подготовки, передачи, переработки,
хранения и представления какой-либо информации, чер- .
паемой от человека, природы, машины, вообще от какого-
либо объекта наблюдения и управления.
Информационные системы отличаются от других есте-
ственных или искусственных (технических) систем тем, что
в них присутствуют органы и связи наблюдения или
управления, процессы обращения информации, сигналь-
ные формьТотображения вещественных или энергетических
явлении.
Строго говоря, информационные системы всегда бывают
наложены на рабсжш системы, но они могут быть представ-
лены либо чех никой, либо людьми.
Например, нпформационная система старинного корабля
состоит из людей (дозорные, сигнальщики, вестовые, боц-
маны, лоцманы), а современного корабля — из автомати-
ческих устройств передачи, обработки данных и управ-
ления.
Информация возникает тогда, когда устанавливаются
1г~пекоторыё общие свойства конкретных вещей и явлений,
поэтому под информацией можно понимать выделенную
cyj ность, характеристику этих вещей .и_явлений.
Слово «информация» (с латинского) обозначает сообще-
ние, осведомление о чем-либо. Однако такое переводческое
толкование иё может служить определением понятия «ин-
формация». .
Имеется множество определений понятия информации от
наиболее общего с] илософского (информация есть отражение
реального мира) до наиболее узкого практического (инфор-
мация есть все сведения, являющиеся объектом хранения.,
передачи и ’преобразования).
Понятие информации связано с некоторыми мод е -
л я м и реальных вещей, отражающими их сущность в~той
степени, в какой это необходимо для практических целей.
Это согласуется и с философской концепцией отражения
вещей друг в друге и в живых организмах.
6
Таким образом, под информацией нужно понимать не
сами предметы и процессы, а их' существенные и предста-
вительные_ характеристики, выделенную сущность явле-
нии_материального мира; имеются в виду не сами предметы
и процессы, а их отражения или отображения^ виде чисел,
фбрм^^’опйсаний, чертежей, символов, образов и т. п.
абстрактных характеристик.
Сама по себе" информация может быть отнесена к обла-
сти абстрактных -категорий, подобных, например, мате-
матическим формулам. Однако проявляется она всегда
в материально-энергетической форме в ви £ и г н а л о
Методологическая схема образования сигнала показана на
рис. В-1.
Физическии
оригинал
Мат ема т и * еские модели
Физическая
модель
Наблюдаемые
явления
начальная
информация
квантованная
информация
кодированная
информация
используемые
сигналы
Рис. В-1. Методологическая схема образования сигнала.
С передачей и обработкой информации связаны действия
любого автоматического устройства, поведение живого
существа, творческая деятельность человека, экономиче-
ские и социальные преобразования в обществе и сама жизнь.
Науку в целом можно рассматривать как сложную, разви-
вающуюся информационную систему, созданную человеком.
Как понятие энергии привело к единой и прогрессивной
точке зрения на физические явления природы и техники,
так и понятие информации выявляет качественные и коли-
чественные стороны сигнально-мыслительных и контрольно-
управляющих процессов.
Если материя (вещество) и энергия сравнительно полно
изучены, то законы получения и преобразования информа-
ции еще являются неизведанной областью, таящей в себе
много неожиданных проявлений.
В теоретических основах рассматриваются наиболее об-
щие вопросы информационной техники, которые как бы
7
«вынесены за скобки» многочисленных частных дисциплин
и стали их общей теоретической базой.
К таким общим вопросам относятся: понятие информа-
ции, измерение информации, принципы кодирования и моду-
ляции; теория восприятия, передачи и представления ин-
формации.
ФАЗЫ ОБРАЩЕНИЯ ИНФОРМАЦИИ
Рассмотрим восприятие, передачу и использование ин-
формации с целью управления некоторым объектом. Здесь
можно выделить несколько фаз в цикле обращения инфор-
мации (рис. В-2). Поскольку материальным носителем ин-
формации является сигнал, то этот цикл можно рассматри-
вать одновременно и как цикл обращения и преобразования
сигналов, несущих ин-
формацию.
Восприятие со-
стоит в том, что форми-
руется образ объекта,
производится его опо-
знание и оценка. При
восприятии нужно отде-
лить полезную инфор-
мацию от шумов, что в
некоторых случаях (тон-
кие биологические, фи-
зико-химические экспе-
рименты; сложные про-
изводственные условия;
радиосвязь, локация,
астрономия и др.) свя-
зано со значительными
трудностями. В резуль-
тате _вослрияхия подучается сигнал в форме, удобной для
передачи или обработки. В фазу_восприятиямогут. ..вклю-
чаться операции подготовки информации, ее нормализации,
квантования, кодирования, модуляции сигналов и построе-
ния моделей'
Передача информации состоит в переносе ее на рас-
стояние посредством сигналов различной физической при-
роды соответственно по механическим, гидравлическим,
пневматическим, акустическим, оптическим, электрическим
или электромагнитным каналам. Прием информации на
другой стороне канала имеет характер вторичного вое-
Передача
Обработка
Источник и потреби-
тель информации
Рис. В-2. Обращение информации
в автоматической системе.
Восприятие
Пре/дстабление
Воздействие
8
приятая с характерными для него операциями борьбы с
Рис. В-3. Обмен инфор-
мацией между машиной М
и человеком Ч.
X — информация наблюде-
ния; У — информация управ-
ления .
шумами.
Обработка информации заключается в машинном
решении задач, связанных с преобразованием информации,
независимо от их функционального назначения. Примене-
ние электронных цифровых управляющих машин обобщает
и централизует функции обработки, имеющие отношение
главным образом к моделям ситуаций и принятию решений
при управлении. Обработка произ-
водится при помощи устройств или
машин, осуществляющих аналого-
вые или цифровые преобразования
поступающих величин и функций.
Промежуточным этапом обработки
может быть хранение в запоми-
нающих устройствах. Последние
могут быть постоянными, долговре-
менными и оперативными и выпол-
няться на реле, магнитных бараба-
нах, дисках, лентах, картах и сер-
дечниках; электростатических, сег-
нетоэлектрических, электролюми-
несцентных и криотронных элемен-
тах, линиях задержки, материалах
перфораторной и поверхностной ре-
гистрации, диодных и штекерных
матрицах. Извлечение информации
из запоминающих устройств также
имеет характер восприятия и свя-
зано с борьбой с шумами.
п Р_ед СТ а В Л с-ние инфор-
мации требуется тогда, когда в
цикле обращения информации при-
нимает участие человек. Оно заключается в демонстрации
перед человеком условных изображении, содержащих ка-
чественные и количественные характеристики выходной ин-
формации. Для этого используются устройства, способные
воздействовать на органы чувств человека: оптические,
акустические и двигательные сигнализаторы (цифробуквен-
ные, стрелочные и изобразительные индикаторы); цифро-
вые и графические регистрирующие приборы с видимой за-
писью; электроннолучевые трубки с эк ранами; мнемониче-
ские плоские и объемные щиты, табло и макеты с встроен-
ными сигнальными и индикаторными элементами.
9
Из устройства обработки информация может выводиться
не только человеку, но и непосредственно воздействовать
на объект управления.
Воздействие состоит в том, что сигналы, несущие
информацию, производят регулирующие, управляющие или
защитные действия, вызывают изменения в самом объекте^
Не все информационные системы замкнуты. Наряду с
замкнутыми системами существуют и разомкнутые системы,
в которых информация передается от источника к прием-
нику или потребителю. Активное воздействие на отбирае-
мую от источника информацию может оказывать либо сам
источник, либо потребитель. Часть системы, оказывающую
активное воздействие на ее работу, называют субъектом,
а пассивную часть — объектом.
Как объектом, так и субъектом могут быть человек (Ч)
или машина (М). Возможные отношения между ними в ра-
зомкнутой информационной системе приведены на рис. В-3.
Объект как источник информации неисчерпаем. Но по-
давляющая часть потоков отображения его состояний рас-
сеивается и только небольшая часть, отвечающая...потреб-
ности и определяемая принятым в информационной системе
а языком,, ответвляется к приемнику в виде параметров
наблюдения X или управления У.
ВИДЫ ИНФОРМАЦИИ
Информацию можно различать по областям знаний (био-
логическая, техническая, экономическая и др.), по физиче-
ской природе восприятия (зрительная, слуховая, вкусовая
и др.), а также по метрическим свойствам.
Остановимся на последней классификации (табл. В-3),
наиболее пригодной для технических приложений.
Формы информации Таблица В-3
Параметрическая Тапологическая
Событие Ф° Точка Ф°
Величина Ф1 Линия Ф1
Функция Ф2 Поверхность Ф2
Комплекс Ф3 Объем Ф3 •
/7-пространство Ф" 7-пространство Ф”
К параметрической информации относятся наборы чис-
ленных оценок значений каких-либо параметров (измеряе-
мых величин), результаты количественных определений при
исследовании, анализе, контроле и учете.
Ю
К топологической — геометрические образы, карты ме-
стнбстй, различные изображения и объ'емныё объекты.
К абстрактной” — математические соотношения,, 06067
ценные образы и понятия,.
В табл. В-3 классы информации можно разделить по
мощности информационных множеств. Назовем информа-
цией мощности нулевого порядка (нульмерная информация)
такую, которая соответствует мощности точки, первого по-
рядка (одномерная информация) — линии, второго порядка
(двумерная информация) — поверхности, третьего порядка
(трехмерная информация) — объема, ..., «-го порядка («-мер-
ная информация) — «-мерного пространства.
Таким образом, строение информации можно изменять,
переходя от одного вида информации к другому. Все виды
информации можно интерпретировать геометрическими об-
разами, что бывает удобно на практике.
Параметрической информацией чаще всего пользуются
в науке и технике для выражения результатов изме-
рения.
Топологической информацией удобно выражать образы
и ситуации, подлежащие распознаванию.
Абстрактную информацию применяют в исследованиях
на высоком теоретическом уровне, когда нужны отвлечения,
обобщения и символизация.
В инженерной практике широкое распространение имеет
параметрическая информация, которую можно свести к сле-
дующим четырем основным формам: событию, величине,
функции и комплексу.
Событие А (рис. В-4, а)
Первичным и неделимым элементом информации является
элементарное двоичное событие — выбор из утверждения
или отрицания, истины или лжи, согласия или несогла.-.
.сия, наличия или отсутствия какого-либо явления. Приме-
ром могут служить сведения об импульсе или паузе в элект-
рической цепи, выпуске годного или негодного изделия,
достижении или недостижении измеряемой величиной од-
’його огщеделенного значения, черном или белом элементах
телевизионного изображения, попадании или непопадании
в цель, наличии или отсутствии команды и т. д.
Двоичность события позволяет7представлять его условно
в геометричегкой символике точкой и пробелом (• и О),
в арифметической символике — единицей и нулем (1 и 0),
в сигнальной символике — импульсом и паузой (л- и —).
11
Событие является категорией нулевоймсры, т. е. не
имеет геометрических измерений. Поэтому оно и предста-
вимо точкой.
Рис. В-4. Виды параметрической информации.
а — событие; б — величина; в — функция; г — комплекс.
Другие категории информации могут быть представлены
как'совокупности различных событий.
Величина X (рис. В-4, б)
Величина есть упорядоченное в одном измерении (по
шкале значений) множество событий, причем каждое из них
отвечает принятию величиной какого-либо одного значения.
Величина может быть или дискретной, или непрерывной;
в первом случае множество событий счетно, во втором —
несчетно. Геометрически величину можно представить ли-
нией (рис. В-4, б).
Функция X (Т) (рис. В-4, в)
Функция X (Т) (рис. В-4, в), X (N) или Х2 (Хг) есть соот-
ветствие между величиной и временем, пространством или
другой- величиной. В этом смысле функцию можно тракто-
вать как двумерное поле событий.
Комплекс X (Т, N) (рис. В-4, г)
Полный комплекс информации X (Т, N) есть соответствие
между величиной, с одной стороны, и временем и простран-
ством—с другой. Таким образом, полный комплекс инфор-
мации есть трехмерное поле событий.
Как указывалось, информация может быть представлена
моделями с различной размерностью. Отвлекаясь от кон-
12
кретного вида координат (параметр X, время Т, простран-
ство N) и введя обобщенную координату информации Ф
(согласно табл. В-4), получаем следующую классификацию:
Ф°, Ф1, Ф2, Ф3,Ф",
гдеФ° — нульмерная информация (событие); Ф1 — одномер-
ная информация (величина); Ф2 — двумерная информация
(функция); Ф3 — трехмерная информация (комплекс); Ф" —
/z-мерная информация (//-мерное пространство).
Таблица В-4
Структурные информационные формулы
События Пространство событий
Ф« (Д) Ф1 (Д1( А 2, Ад, ... , Дга) События во времени Ф1 (Д, Т) ФЧДь Л2, Д8, Д„, Т) Параметры Ф1 (X) Ф*(ХЬ Х2) ФЧХЬ Х2, Х8) Ф1 (X) Ф2(А\, n2) Ф® (Хь N2, 2V3) Пространство событий во времени ф2(М Г) Ф8 (Nlt N2, Т) Ф4 (Nlt N2, N3, Т) Параметрические пространства Ф2 (X, N)
Ф«(ХЬ Х2, Х8, ..., Х„) Параметры во времени Фа(Х, Т) Ф3(Х1, Х2> Т) Ф3(Х, N2) Ф4 (X, Х2, Х8) Параметрические пространства во времени Ф3(Х, N, Т) Ф4(Х, Nlt N2, Т)
Ф"(Х1> Х2> Х8> ..., Хп ь Т) Ф6 (X, ЛГЬ д/2, М8, Т)
Показатель степени указывает размерность или порядок
информации. Наиболее часто встречающиеся на практике
разновидности научной и технической информаций могут
быть выражены теперь структурными информационными
формулами (табл. В-4), которые отличаются тем, что в них
указываются только размерность и компоненты информации,
но не функциональные зависимости между компонентами.
Одно событие есть нульмерная категория, так что сово-
купность пронумерованных подряд событий занимает одно
измерение N.
Время Т само по себе не содержит информации. Вторая
группа формул в табл. В-4 описывает представление каких-
либо событий во времени Множество событий во времени
13
можно упорядочить относительно координат N и Т в виде
функции N (Т).
Чаще всего параметрическая информация сообщает
о различных физических величинах, оцениваемых по ин-
дивидуальным шкалам измерения или приведенных к одной
общей шкале. Эти физические величины будем называть
параметрами. Информация об одной скалярной величине
одномерна. Информация о функциональной зависимости
между двумя величинами, например Х2 = f (XJ, занимает
два измерения в координатах Хг и Х.2. Более сложные соот-
ношения между многими величинами представляются «-мер-
ными категориями или образами. Информация об измене-
нии параметров во времени занимает от двух до п измерений
в зависимости от количества отдельных параметров.
Геометрические пространства (линия, плоскость, объем)
представляют собой информационные категории только
в тех случаях, когда они определяют местоположение собы-
тий. Пространства, отнесенные к определенному времени,
также имеют информационный смысл только в связи с опи-
санием некоторых событий, например появления или пере-
мещения поездов на линии, кораблей в море, самолетов
в воздухе или обнаружения дефектов в проволоке, листо-
вом материале, слитке стали. Координата N представляет
событие на линии; Nx и N2 являются координатами плоско-
сти; Л\, Л/2, Ха характеризуют объем.
Параметрические пространства могут содержать инфор-
мацию о распределении некоторых параметров по линии,
плоскости или объему. К ним относятся, в частности, одно-
мерные, двумерные и трехмерные физические поля или
производственные комплексы, в которых точки контроля
описаны столбцом, плоской матрицей или объемным маке-
том.
Параметрические пространства, отнесенные к определен-
ному времени, могут содержать информацию об изменении
множества величин, упорядоченных относительно одной
(AZ), двух (ATj и N2) или трех (Л\, N2, N3) пространственных
координат и приведенных к одной общей унифицированной
шкале измерения. Примером может служить изменение фи-
зических полей во времени.
СТРУКТУРА ИНФОРМАЦИИ
Информация может претерпевать различные структур-
ные преобразования, показанные в табл. В-5. Последова-
тельность этих преобразований может быть различной в раз-
14
личных информационных системах. Получаемые в процессе
преобразований структуры имеют абстрактный характер и
не соответствуют строго тем или иным этапам обработки
информации в технических средствах информационных
систем.
Таблица В-5
Структура информации
Условное обозначение Структура Характеристика структуры
{X}, {Т}, {А} Натуральная Первоначальная структура информации
М, D, L {X}, {Т}, {А} Нормализованная Приведена к единому масштабу, диапазону и началу отсчета
{А, Т. N} Комплексированная Приведена к комплек- су с обобщенными координатами А, Т, N
XT V3? »xw Ж т TN Декомпонированная Преобразованы число измерений, структура и расположение
Gz {X, Т, А} Генерализованная Устранена избыточ- ность, выделена суще- ственная часть по условию А
A*, Т*, N* Дискретная (кван- тованная) Отсчеты в прерывной форме
9х- 9г> 9л Безразмерная Кодированная Дискретные отсчеты приведены к безраз- мерной форме Цифровая форма информации
Натуральная информация отражает реальное существо-
вание объектов. Она имеет аналоговую форму, засорена
шумами, неоптимальна по диапазонам и началам отсчетов
значений параметров. Все эти ограничения обусловлены
непосредственно физическими свойствами наблюдаемого
объекта. Натуральную информацию можно условно пред-
ставить как совокупности величин X, моментов времени Т
и точек пространства N в виде множеств {X}, {7} и {Л7}.
Нормализованная_гшформация отличается от натураль-
ноитем, что в ней каждое множество {X}, {7}, {X} уже при-
ведено к одному масштабу, диапазону, началу отсчета и
другим общим унифицированным характеристикам. Норма-
15
лизованную информацию можно трактовать как результат
воздействия на натуральную информацию операторов:
масштабного^М, диапазонного D и локализационного L.
Символическое описание нормализованной информа-
ции — см. в табл. В-5.
Комплексированная информация образуется в резуль-
тате приведения всей информации к полному комплексу,
т. е. к трехмерной системе XTN, где X — обобщенная ко-
ордината значений параметров или унифицированная шкала
каких-либо оценок; Т — обобщенная координата времени;
N — обобщенная координата пространства источников
информации. Комплексированная информация представ-
ляет собой связанное и координированное .множество {X,
Т, N}. Изменение количества измерений структуры и
расположения элементов в информационных комплексах
приводит к форме декомпонированной информации. Осо-
бенно часто применяют следующие два вида декомпозиции:
1) приведение физического пространства трех измере-
ний (объема) физических полей, объемных объектов, мно-
гомерных систем датчиков; векторных и комплексных вели-
чин к пространствам двух и одного измерений;
2) приведение полного комплекса информации XTN
к любой плоскости XT, XN, NT цли оси X, Т, N коорди-
нат изменений.
Декомпонированная информация декоррелирована, в
ней нарушены или удлинены связи между отдельными эле-
ментами информации.
. Структурная формула декомпозиции имеет вид:
В генерализованной информации исключены второсте-
пенные ее части, данные обобщены и укрупнены. Генера-
лизация может охватывать как номенклатуру параметров,
так и моменты времени, диапазоны измерения и степень
подробности их отображения.
Формула
Сд{Х, Т, N]
показывает, что производится генерализация С по алго-
ритму А комплекса {X, Т, N}.
Дискретная (квантованная) информация совпадает с ис-
ходной непрерывной информацией по физической размер-
16
ности, отличаясь от нее лишь прерывным характером.
Дискретизация может быть осуществлена по осям X, Т
и Л7 параметрического комплекса. Дискретная информация
удобна для расчетов и экономична в реализациях. Дискре-
тизация может быть равномерной или неравномерной, про-
изводиться по постоянному или изменяющемуся во времени
закону. Оптимальные интервалы дискретизации опреде-
ляются на основании теории дискретных отсчетов, элементы
которой излагаются в гл. 2.
Безразмерная информация отличается универсальной
безразмерной числовой формой. Число, отображающее
безразмерную информацию, соответствует количеству ин-
формационных элементов (квантов) и получается в резуль-
тате дискретизации информационного комплекса, т. е. равно
отношению любой коорди-
наты к ее интервалу дис-
кретности:
_ х _ т\
А/
N
Кодированная инфор-
мация имеет форму сово-
купности чисел, или циф-
ровую форму, основанную
на применении какой-либо
системы счисления или ко-
дирования. Методы коди-
рования излагаются в гл. 3.
УСТРАНЕНИЕ ИЗБЫТОЧНОСТИ
ИНФОРМАЦИИ
Рис. В-5. Этапы обогащения ин-
формации.
Из бесконечного множе- •
сгва физических процессов,
протекающих в объектах
наблюдения или управления, выделяются сигналы, форми-
рующие первичную информацию.
Первой фазой является структурное устранение избыточ-
ности (см. гл. 1).
Вторая фаза состоит в том, чтобы устранить статистиче-
скую избыточность путем учета вероятностных характери-
стик информации.
17
Третья фаза заключается в том, что выделяется смысло-
вое содержание, т. е. осуществляется семантическое обога-
щение информации.
Далее может последовать фаза формирования решений и
действий, после которой выдаются единичные командные
сигналы.
Перечисленные выше этапы устранения избыточности
показаны на рис. В-5 в виде пирамиды потоков информации
с последовательным уменьшением их плотности.
Часть первая
ИНФОРМАЦИОННАЯ МЕТРИКА
Глава первая
ИЗМЕРЕНИЕ ИНФОРМАЦИИ
t
Важнейшим вопросом теории информации является уста-
новление мерь? количества и качества информации.
Информационные меры отвечают трем основным напра-
влениям в теории информации: структурному, статистиче-
скому и семантическому.
Структурная теория рассматривает дискретное
строенйе~массйвбв-информации и их измерение простым
подсчетом информационных элементов (квантов) или комби-
наторным методом, предполагающим простейшее кодирова-
ние массивов информации.
~С~т 1Гт истине ска я теория оперирует понятием
э н тфГсГп и й как меры неопределенности, учитывающей
вероятность появления, а следовательно, и информатив-
ность тех или иных сообщений.
С е м_а нтическая теория учитывает целесообраз-
ность, "ценность^ полезность или существенность инфор-
маций.
Указанные три направления (структурное, семантиче-
ское и статистическое) имеют свои области применения,
каждое из них имеет право на существование и развитие.
Стр ктурная теория применяется для оценки возможностей
аппаратуры информационных систем (каналов связи, запо-
минающих и регистрирующих устройств) вне зависимости
от условий их_применения. Статистическая теория дает
оценки информационных систем в конкретных применениях,
например при передаче по системе связи информации с оп-
ределенными статистическими характеристиками. Наконец,
се [антическая теория прилагается к оценке эффективности
логического опыта.
19
Развиваются также более общие подходы к оценке ин-
формации с учетом разнообразных свойств источника, кана-
лов и приемников информации.
Прежде чем переходить к мерам информации, укажем,
что источники информации и создаваемые ими сообщения
разделяются на дискретные и непрерывные.
Дискретные сообщения слагаются из счетного множества
элементов, создаваемых источником последовательно во
времени. Набор элементов называется алфавитом
источника, а элементы — буквами. Понятие буквы в
данном случае шире, чем в письменности, оно включает
цифры и другие знаки. Число букв в алфавите называется
объемом алфавита.
Дискретный источник в конечное время создает конечное
множество сообщений. Типичными дискретными сообщения-
ми являются текст, записанный с помощью какого-либо ал-
фавита, последовательность чисел, представленных знаками.
Непрерывные сообщения отражаются какой-либо физи-
ческой величиной, изменяющейся в заданном интервале
времени. Получение конечного множества сообщений за
конечный промежуток времени в данном случае достига-
ется путем дискретизации (во времени) и квантования (по
уровню).
1-1. СТРУКТУРНЫЕ МЕРЫ ИНФОРМАЦИИ
При использовании структурных мер учитывается только
дискретное строение данного информационного комплекса,
в особенности количество содержащихся в нем информацион-
ный элементов, связей между ними пли комбинаций из них.
Под информационными элементами понимаются недели-
мые части — кванты — информации в дискретных мо-
делях реальных информационных комплексов, а также эле-
менты алфавитов в числовых системах.
В структурной теории различаются геометрическая,
комбинаторная и аддитивная меры информации.
Наибольшее распространение получила двоичная адди-
тивная мера, так называемая мера Хартли, измеряющая
количество информации в двоичных единицах — битах.
ч
Геометрическая мера
Определение количества информации геометрическим
методом сводится к измерению длины линии, площади или
объема геометрической модели данного информационного
20
комплекса в количестве дискретных единиц — определен-
ных выше квантов. Геометрическим методом определяется
потенциальное, т. е. максимально возможное коли-
чество информации в заданных структурных габаритах.
Это количество будем называть информационной
емкостью исследуемой части информационной системы.
Информационная емкость вычисляется как сумма дискрет-
ных значений по всем измерениям.
Информационная емкость может быть представлена чис-
лом, показывающим, какое количество квантов срдержится
в полном массиве информации.
Геометрическую меру можно применить не только для
оценки информационной емкости, но и для оценки количе-
ства информации, содержащегося в отдельном сообщении.
Если о величине, отображаемой сообщением, известно, что
она имеет максимальное значение из того ряда значений,
которые она уже принимала ранее, то можно считать, что
количество информации, содержащееся как в этом, так и
в любых более ранних сообщениях, определяется числом
квантов, содержащихся в максимальном значении.
Пусть информация отражается полным комплексом
XTN (см. рис. В-3).
Если дискретные отсчеты осуществляются по осям X,
Т и N соответственно через интервалы Дх, Д? и ДЛг, то не-
прерывные координаты распадаются на элементы (кванты),
количество которых составляет:
X Т N
гпх^тг--, tnT=x~-. mN=-K .
аХ aN
Тогда количество информации в полном комплексе XTN,
определенное геометрическим методом, равно в квантах
M = mxmTmN. (1-1)
Может иметь место неравномерная (по осям) и нестацио-
нарная (изменяющая свой характер во времени) дикретиза-
ция. Тогда количество информации определяется по более
сложным формулам, вытекающим из переменных характери-
стик. дискретизации.
Комбинаторная мера
К комбинаторной мере целесообразно прибегать тогда,
когда требуется оценить возможность передачи информа-
ции при помощи различных комбинаций информационных
элементов. Образование комбинаций есть одна из форм
кодирования информации.
21
Количество информации в комбинаторной мере вычис-
ляется как количество комбинаций элементов. Таким обра-
зом, оценке подвергается комбинаторное свойство потен-
циального структурного разнообразия информационных
комплексов.
Комбинирование возможно в комплексах с неодинако-
выми элементами, переменными связями или разнообраз-
ными позициями. Элементы неодинаковы, если они отли-
чаются один от другого любым признаком — размером,
формой, цветом и т. п.
Одинаковые по всем своим признакам элементы могут
стать неодинаковыми, если учесть их положение, позицию.
Тогда местоположение элементов оказывает влияние на
целое (позиционные системы счисления, формирование обра-
зов). Примером проявления влиятельности элементов мо-
жет служить перенос знаков в позиционной системе пред-
ставления двоичных чисел: 11110 и 01111 или 00001 и
10000. В первом случае меняет положение нуль, во вто-
ром случае — единица. В первом случае число меняется
с 30 на 15, во втором — единица превращается в 16.
Еще более выразителен пример переноса точки при обра-
зовании и преобразовании фигур и изображений, когда одна
безличная точка коренным образом меняет изображение и
его смысловое содержание.
В этом отношении показателен рисунок, в котором ста-
руха превращается в девушку добавлением двух штрихов.
Этот рисунок приведен в книгах: К. Штейнбух, Автомат и
человек, изд-во «Советское радио», 1967 и Системы с разде-
лением времени, изд-во «Мир»; случайно упавшая капля
стеарина решает образ в картине художника (Л. Толстой,
«Анна Каренина»). Точка на карте меняет военную ситуа-
цию и т. д.
В комбинаторике рассматриваются различные виды со-
единения элементов.
Сочетания из h элементов по / различаются соста-
вом элементов. Их возможное число равно:
м _й(й-1)--(й-г+1) п
\hj l\ (h— I) 1-2-3...Z ' {
Сочетания с повторениями также различаются составом
элементов, но элементы в них могут повторяться до I раз.
Число различных сочетаний с повторениями из h элементов
по I равно:
O-(l\ 1 \ (1.3ч
4 l\ (h—1)! + И 'Л
22
Перестановки h элементов различаются их по-
рядком. Число возможных перестановок h элементов
Q= 1-2-З...Л = Л! (1-4)
Перестановка с повторениями эле-
ментов, причем один из элементов повторяется а раз, дру-
гой — Р раз, наконец, последний — у раз, характери-
зуется возможным числом
Q _ (К + Р + --- + Т)1 /1
а! Р!...у! •
Размещения из й элементов по I элементов раз-
личаются и составом элементов и их порядком. Возможное
число размещений из h элементов по I
Q=^ = h(h-l)(h~2)...(h-l+l)=1^. (1-6)-
Возможное число размещений с по-
вторениями по I из h элементов
Q = O = hl. (1-7)
V4- / повт
При применении комбинаторной меры возможное коли-
чество информации Q совпадает с числом возможных соеди-
нений. Таким образом, определение количества информа-
ции Q в комбинаторной мере заключается не в простом
подсчете квантов, как это было при оценке в геометриче-
ской мере, а в определении количества возможных или дей-
ствительно осуществленных комбинаций, т. е. в оценке
структурного разнообразия.
Количество информации при том же количестве элементов
теперь многократно увеличивается. Так, например, в слу-
чае сочетаний из 10 элементов по 0, 1,2, 3, 4, 5, 6, 7, 8 и 9 эле-
ментов получается следующее число образований, являю-
щееся мерой количества информации:
„ 10! , 10! , , 10! , 10!
0! (10 — 0)! + 1! (10 — 1)! + ’" + 9!(10 —9)! + 10! (10— 10)! —
= 1 + 10 + 45 + 120 + 210 + 252 + 210 +
+ 120+ 45+10+1 = 1 024 образований.
Перестановки тех же 10 элементов дают:
Q = hl = 1 2-3-4-5-6-7-8-9 - 10 = 3 628 800 образований.
23
Размещения 10 различных элементов по 10 различным
позициям приводят к еще большему потенциальному коли-
честву информации:
Q — hl = 1010 =10 000 000 000 образований.
Конечно, не всегда все возможные комбинации состав
ляют действительные степени свободы данной системы.
Тогда расчет ведется по реализуемым комбинациям.
Аддитивная мера (Хартли)
В теории информации важную роль играет комбинато-
рика чисел и кодов.
Введем понятия глубины h и длины / числа (рис. 1-1).
Рис. 1-1. Схема информационного массива в виде
совокупности десятизначных десятичных чисел
(п = I = h = 10).
Глубиной h числа называется количество различ-
ных элементов (знаков), содержащееся в принятом алфа-
вите. Глубина числа соответствует основанию системы счис-
ления и кодирования. Один полный алфавит занимает одно
числовое гнездо, глубина которого также равна h.
24
В каждый данный момент реализуется только один какой-
либо знак из h возможных. На геометрической модели
рис. 1-1 реализация знака принимает форму выставления
наружу нужного знака из глубины гнезда, хранящего в оп-
ределенном порядке весь запас знаков. Технически это
может быть выполнено, например, путем смещения знаков
вперед или назад до появления нужного знака.
Длиной I числа называется количество числовых
гнезд, т. е. количество повторений алфавита, необходимых
и достаточных для представления чисел нужной величины.
Длина числа соответствует разрядности системы счисления
и кодирования. Один набор из Лгпезд-алфавптов составляет
одну числовую гряду, способную представлять и
хранить одно полное число длиной I.
- Некоторое количество чисел N представляется число-
вым полем.
При глубине h и длине I количество чисел, которое
можно представить с помощью числовой гряды, выразится
формулой
Q = hl, (1-8)
т. е. емкость гряды экспоненциально зависит о! длины
числа I.
На рис. 1-2, а—г в качестве примеров показаны геометри-
ческие модели числовых гряд для единичной (h = 1), дво-
ичной (й =2), десятичной (й = 10) и «бесконечной» (й ->оо)
систем счисления и кодирования.
Еще одна иллюстрация модели с числовыми гнездами и
показательного закона возрастания емкости числовой гряды
приведена на рис. 1-3. Здесь для конкретности использована
десятичная позиционная система счисления. Поэтому ка-
ждое числовое гнездо содержит десять знаков 0, 1,2, 3, 4,
5, 6, 7, 8 и 9.
Младшее (крайнее справа) гнездо единиц может отобра-
зить числа от 0 до 9. Следующее за ним гнездо десятков ото-
бражает числа от 00 до 90, а вместе с первым от 00 до 99.
Третье гнездо сотен расширяет диапазон до 999, четвертое —
до 9999, пятое — до 99999 и т. д.
Приведенная внизу кривая представляет собой сглажен-
ный график показательного возрастания емкости числовой
гряды.
Укажем на возможные конструкции подобных систем:
а) роликовый счетчик с / роликами и й цифрами на
ободке каждого ролика;
25
б) комбинированный коммутатор с I переключателями,
из которых каждый переключает h цепей;
в) запоминающее устройство с I ячейками, каждая ем-
костью h единиц;
г) изображение, состоящее из I дискретных элементов,
причем каждый элемент изображения характеризуется h
градациями цвета и тона;
Алфавит
Рис. 1-2. Системы счисления и соответ-
ствующая им глубина чисел.
рядов в одной си-
стеме счисления.
д) страница печатного литературного текста, в котором
содержится 1г строк и /2 букв в каждой строке (в среднем),
т. е. всего I = l± х /2 числовых или буквенных гнезд;
каждое гнездо имеет глубину h, т. е. способно выставить
одну из h букв.
Во всех указанных случаях общее количество возмож-
ных состояний определяется выражением (1-8).
Вследствие показательного закона зависимости Q от I
число Q не является удобной мерой для оценки информаци-
26
онной емкости. Поэтому Хартли ввел аддитивную двоич-
ную логарифмическую меру, позволяющую вычислять коли-
чество информации в двоичных единицах — битах, сокра-
щенно обозначаемых бит.
Для этого берется не само число Q, а его двоичный
логарифм:
I — log2 Q = Iog2 hl = I log2 h, бит. (1-9)
Здесь I обозначает количество информации по Хартли.
Если количество разрядов (длина I числа) равно единице,
принята двоичная система счисления (глубина h числа равна
двум) и используется двоичный логарифм, то потенциаль-
ное количество информации равно одному биту:
log2 2 = 1 бит.
Это и есть единица информации в принятой системе
оценки. Она соответствует одному элементарному событию,
которое может произойти или не произойти.
Аддитивная мера удобна тем, что она обеспечивает воз-
можность сложения и пропорциональность количества ин-
формации к длине числа I, т. е. количеству числовых гнезд.
Введенное количество информации эквивалентно количе-
ству двоичных знаков — нулей и единиц — при кодирова-
нии сообщений по двоичной системе счисления. Одному
биту соответствует одна двоичная единица.
Пусть, например, определяется потенциальное количе-
ство информации, содержащееся в системе, информацион-
ная емкость которой 'характеризуется десятичным числом:
Q — 1000^999 /1=10; / = 3;
I = log2 Q = log2 hl = log2103 = 31og210 10.
Закодируем это число по двоичной системе h = 2 и
найдем /:
Q = 2Z; log2Q = I-log2 2 = I.
Тогда
Z = log2 1 024= 10^/.
Это означает, что <по двоичной системе данное число за-
пишется (закодируется) десятью единицами:
Q=1024^ 1 023 = 28 + 28 + 27 + 2в4-25 + 24 +
-р 23 + 22 4-2х + 2° = 1111111111.
Точное значение Q= 1 024 = 210 нужно записать одной
единицей в позиции, соответствующей 210, и десятью нулями
27
10 000 000 000. Приближенные равенства показывают, что
количество знаков приходится брать равным либо I, если
I — целое число, либо дополнять его до ближайшего це-
лого числа, если I — дробное число.
При наличии нескольких источников информации общее
количество информации, которое можно получить от всех
источников, вместе взятых,
HQi, Q2,..., Qft) = Z(Q1) + Z(Q2) +••• + /(Qft). (1-10)
Примеры структурной оценки количества информации
Остановимся на структурной оценке измеряемых вели-
чин и функций с использованием аддитивной меры.
Можно считать, что любая измерительная информация
как-то кодирована.
Информация в аналоговой форме (рис. 1-4, а) закодиро-
вана по бесконечной системе счисления, которая характе-
Рис. 1-4. К понятию р бесконечной системе счисления и ко-
дирования (на примере измерения аналоговой величины).
ризуется тем, что каждый отсчет (каждое значение измеряе-
мой величины) берется одним тактом, т. е. одним числом
длиной I = 1, но зато глубина h числа весьма велика: она
равна самому числу X, выражающему значение измеряемой
величины, и стремится к бесконечности, если интервалы Дх
стремятся к нулю (рис. 1-4, а).
Информационная емкость аналоговой системы согласно
(1-9) бесконечно велика.
Информация в счетно-импульсной форме (рис. 1-4, б)
представляет собой второй предельный случай кодирования.
Здесь осуществляется кодирование по единичной (унитар-
ной) системе счисления, которая характеризуется тем, что
глубина h числа становится предельно малой (/i = 1), но
28
длина I числа предельно возрастает: она становится равной
самому числу X, выражающему значение измеряемой вели-
чины, и стремится к бесконечности, если шаг квантования
Дх стремится к нулю (рис. 1-4, б).
h = 1000, I = 1
0
п h — 32
т 1 = 2
1 I I
k k k
i i i
h h h
g g g
f f t
e e e
d d d
c c c
b b b
a a a
X X X
IX IX IX
VIII VII! VIII
VII VI1 VII
VI V! VI
V V V
VI IV IV
III HI III
I! II II /1 = 10
I I ] / = 3
0 0 0 000
9 9 9 999
8 8 8 888
7 7 7 777
6 6 6 666
5 5 5 555
4 4 4 444
3 3 3 333
2 2 2 222
1 1 1 I 1 !
i II III
Л = 4
/ = 5
00000
3 3 333 Д = 2;/=10
2 2222 0000000000 Л = 1; I — 1000
11111 1111111111 111111111111
IV ~v VI
б)
Рис. 1-5. К общей закономерности систем счисления и кодирования.
Промежуточные системы счисления и кодирования изме-
рительной информации показаны на рис. 1-5.
Для расчета информационной емкости измерительной си-
стемы с применением аддитивной меры необходимо опре-
делить количество возможных отсчетов (учитывая шаг
29
дискретности по оси времени и ДЛг по оси пространства)
и воспользоваться формулой
I = п т П]У 1 Og2 Пх,
где пт = Тмакс/Ду — максимальное количество отсчетов во
времени; nN — — максимальное количество от-
счетов в пространстве'; пх — XaaKJXx — максимальное чис-
ло квантов в одном отсчете.
Следующим важным примером является определение
информационной емкости документов автоматической реги-
страции. Последние обычно накапливают информацию в гра-
фической, топографической, цифровой и смешанной форме.
В современной технике автоматической регистрации
используются геометрические (у), физические (л) и цифро-
вые (о) символы. К геометрическим символам относятся
отрезки линий, расстояния между точками и углы; к физи-
ческим — интенсивность или цвет окраски, степень элект-
ризации или намагничивания и частота отметок; к цифро-
вым — цифры, буквы, знаки и их комбинации, соответст-
вующие определенным системам счисления и кодиро-
вания.
С применением указанных символов и отвечающих им
степеней свободы инструментов регистрации производится
фиксирование данных на точечных (L°), линейчатых (L1),
плоских (L2) или объемных (L3) носителях.
В носителях L° реализуется только глубинное измере-
ние (точка имеет глубину), заполняемое единичными зна-
чениями X посредством л- или о-символов.
В носителях L1 реализуются одно глубинное h и одно
геометрическое L измерения, заполняемые единичными
функциями X (Т) с применением ул-, ус- или сит-символов.
В носителях L2 реализуются одно глубинное h и два
геометрических измерения Llf L2, которые можно заполнить
символическими изображениями стационарных плоских
физических полей X (Nlt N2) или множеств N функций
X (Т) с применением уул-, ууст- или осто-символов.
В носителях L® реализуются одно глубинное h и три
геометрических измерения Llt L2, L3 для изображения
изменения плоских полей во времени, объемных стационар-
ных полей X (Nlt N2, Ns) и других четырехмерных прост-
ранств. При этом могут быть использованы ууул-, уууо-
или сктоо-символы.
Точечный носитель L° представляет собой накопитель-
ную ячейку с глубиной от h -» оо до h = 2. В последнем
3Q
h = 10 h^*-<x>
б) в) г)
Рис. 1-6. Информационные характеристики
регистрации на точечных носителях. '
Рис. 1-7. Информационные характеристики реги-
страции на линейчатых носителях.
' случае используются только два уровня л, обозначенные
на рис. 1-6, а белой и черной точками, а также знаками О
и 1. Емкость такой ячейки составляет одну двоичную еди-
ницу Информации
/ = log2 h = log2 2 = 1 бит.
Емкость носителя L0 с десятью уровнями л (рис. 1-6, б)
составляет:
/ — log2 10 3,32 бит.
31
При использовании непрерывной гаммы тональностей л
имеем h -> со (рис. 1-6, в) и исчисление количества инфор-
мации в двоичных единицах становится невозможным
(информационная емкость обращается в бесконечность).
Если заменить физические состояния знаками о
(рис. 1-6, г), то элементарная накопительная ячейка при-
обретает размеры X2, не связанные с геометрической симво-
ликой у. Минимальные размеры (0,005 мм) определяются
разрешающей способностью
сетчатки глаза.
Глубинное измерение ли-
нейчатого носителя L1 (рис.
1-7) также может изменяться
от h =2 (рис. 1-7, с) до
h —>-оо (рис. 1-7, в), размер
элемента — от X = 0 до X = о
и количество элементов — от
п = L/X -> оо до п = L/X =
= Ыа. На рис. 1-7, б пока-
зано применение десятичной
системы.
При использовании циф-
ровой символики о (рис. 1-7,г)
размер X соответствует про-
странственному периоду на-
несения знаков. Тогда плот-
ность знаков, или разрешаю-
щая способность носителя, от-
вечает пространственной час-
тоте f = 1/7. элементов на 1 см.
Если, например, значе-
ния X от'ООО до 127 реги-
стрируются (рис. 1-8, а) в цифровой символике а по двоич-
ной системе счисления (7i = 2, I = 7), то для одного зна-
чения используется длина носителя I = 7 М а на длине L
размещаются т — Ы (7 7. + X) значений.
Дополнительный элемент 7. соответствует разделитель-
ному промежутку."
Если значения X от 00 до 90 представляются по десятич-
ной системе счисления (рис. 1-8, б), то на длине L разме-
щаются т = L/(2 7. + 7.) значений.
Емкость носителя L для всех случаев кодирования
/ = ~ log2/z = /L log2/z, бит.
--L—------
// // /О/ О/"О/S //у
Q=12&
h=2
1=7*
а)
-----£ -- .--
Ж17
///в/ 7z7s7 /7/47 .
/Z/о/ 7< /7/, /7/6/
h=10
1=2Л
б)
Рис. 1-8. Цифровая регистра-
ция на ленточных носителях.
32
Рис. 1-9. Информационные характеристики регистра-
ции на плоских носителях.
На рис. 1-9 показана регистрация данных на плоских
носителях L2 точечными (7. ->0) и цифровыми (7. = а)
знаками. -
Емкость этих носителей
/ = Y г 1°ёг = f2 log2 h, бит.
Л1 Л2
Емкость объемных носителей
7 = Т Г Г lo& h = /3 £3log2 h, бит.
Л1 Л2 Л3
Рассмотрим теперь кодирование зрительных об-
разов и вычисление структурного количества содержа-
щейся в них информации.
К зрительным образам относятся картины, портреты,
плоские и объемные фигуры, натуральные объекты зритель-
2 Темников Ф. Е. и др.
33
кого восприятия. Остановимся на изображениях портрет-
ного типа.
Для того чтобы закодировать и рассчитать такое изобра-
жение, необходимо его дискретизировать, именно, сделать
мозаичным по поверхности и квантово-тональным или
квантово-красочным в глубину. Тогда элементы мозаики
будут играть роль числовых гнезд. Количество их I должно
быть не меньше такого, чтобы не терялось впечатление
целого, если не ставятся более строгие требования детали-
зации или эстетики. Глубина/г каждого гнезда определяется
количеством дискретных элементов гаммы красок и тонов.
Таким способом, например, была закодирована для веч-
ного хранения картина Леонардо да Винчи «Мона Лиза,
или Джиоконда».
Если размеры площади картины равны LXL2 и установ-
лены интервалы дискретности Aj и Д2, то общее количество
дискретных элементов-гнезд равно:
М Г2
Дг Д2’
откуда находится количество информации
/ = AiA"2log2/T’ бит-
1-2. СТАТИСТИЧЕСКИЕ МЕРЫ ИНФОРМАЦИИ
Вероятность и информация
При вероятностном подходе информация рассматри-
вается как сообщение об исходе случайных событий, реа-
лизации случайных величин и функций, а количество ин-
формации ставится в зависимость от априорных вероятно-
стей этих событий, величин, функций.
Когда получается сообщение о часто встречающихся
событиях, вероятность появления которых стремится к еди-
нице, т. е. к показателю полной достоверности, то такое
сообщение мало информативно. Столь же мало информа-
тивны сообщения о противоположных событиях (антисо-
бытиях'), вероятности которых стремятся к нулю и которые,
следовательно, почти невозможны. Например, событие
«часы идут» имеет вероятность р = 1, тогда как антисобы-
тие «часы не идут» имеет вероятность q = 1 — р = 0.
Событие и антисобытие составляют одно двоичное од-
нопредметное событие. Может быть также двоич-
34
ное двухпредметное событие, заключающееся
в выборе одного из двух возможных предметов, например,
черного или белого шара из урны, герба или решки на мо-
нете.
Большинство видов информации можно свести к двоич-
ным явлениям «да — нет» и к паре: «событие — антисобы-
тие». Именно эта пара явлений является простейшим и не-
делимым элементом (квантом) информации (табл. 1-1).
Другой вид сообщений составляют двух предметные
двоичные явления, которые распадаются на четыре элемен-
тарных акта. Например: 1) вынут белый шар; 2) не вынут
белый шар; 3) не вынут черный .шар; 4) вынут черный шар.
Могут быть также исключающие друг друга события.
Например, если выпал герб, то не может одновременно
выпасть решка. Если в цепи установилось напряжение
100 в, то не может в той же цепи одновременно существовать
напряжение 12 в.
Будем под событием далее понимать элементарное одно-
предметное явление, которое может быть с вероятностью
от р = 0 до р = 1 или не быть с вероятностью от
9 = 1— р = 1 до р = 1 — р = 0.
Когда р = 0,5 и q = 0,5, то будет иметь место наиболь-
шая неопределенность в ситуации.
Таблица 1-1
К. Двоичные од н (
Событие
Дождь идет
Снег идет
Машина работает.
Лампа горит
Уровень достигнут
Б. Двоичные дву:
Явление 1
Дождь
(то ли дождик)
/ \
идет не идет
(то ли будет) (то ли нет)
Белый шар
/ \
вынут не вынут
С б
События можно рассма:
некоторого опыта, причем
предметные события
Антисобытие
Дождь не идет
Снег не идет
Машина стоит
Лампа погашена
Уровень не достигнут
предметные события'
Явление 2
Снег
(то ли снег)
не идет идет
(то ли нет) (то ли будет)
Черный шар
не вынут вынут
швать как возможные исходы
все исходы составляют а н -
2*
35
с а м б л ь, или полную группу событий.
Последняя характеризуется тем, что сумма вероятностей
событий в ней равна единице:
Pi + Рг + • • • + Pt + • • • + Pk = 1 •
Опытом может быть и изменение случайной величины X,
принимающей различные значения. Тогда каждое опреде-
ляемое значение имеет смысл исхода, или элементарного
события.
Вообще событиями хь х2, .... xk могут быть k возмож-
ных дискретных состояний какой-либо физической си-
стемы, например k значений измеряемой величины, k поло-
жений регулирующего органа, состояние k элементов про-
изводственного оборудования и т. д.
Этому соответствует приведенная ниже табл. 1-2, назы-
ваемая схемой ансамбля.
В простейшем случае эти события несовместимы. Они
составляют полную группу, в которой обязательно реали-
зуется одно из событий и имеет место условие
к
У Р Ui) = Р (*г) + Р (х2) +... + Р (Xfe) = 1.
1 = 1
В общем случае вероятности не остаются постоянными.
Они могут изменяться во времени, в зависимости от условий
и обстоятельств. Тогда и статистические характеристики
(среднее значение и дисперсия) становятся переменными
величинами. Процессы, описываемые этими величинами,
называются нестационарными в статистическом смысле.
Пример 1-1. Прогнозируется температура на отдаленный день •
(для определенности в середине дня). Если на основании каких-либо
данных известно только то, что в заданный день температура не может
36
быть ниже 12° и выше 21°, то приходится пользоваться априорной (до-
опытной) равномерной плотностью распределения (рис. 1-10, графика):
х;...12 13 14 15 16 17 18 19 20 21
p(xi)...0,1 0,1 0,1 0,1 0,1 0,1 0,1 0,1 0,1 0,1
^p(Xi) = 1.
С приближением заданного дня появляется
вероятностей (рис. 1-10, гра-
можно описать
формация, уточняющая распределение
фикб). Тогда плотность распределения
следующим образом:
дополнительная ин-
х/...12 13
14 15 16 17 18
p(Xi)...O 0,05
0,1 0,15 0,2 0,2 0,15 0,1 0,05 0
= 1-
что с на
Естественно,
отуплением заданного дня и
часа прогнозируемое явление
становится реализованным,
>г°
19 20 21
2!°
Рис. 1-10. Деформация плотности рас-
пределения вероятности.
а — равномерное распределение; б — нор-
мальное распределение; в — дельта-рас-
пределенне.
устанавливается определен-
ная температура, например
х — 17° (рис. 1-10, график в).
Таким образом, неопределен-
ность снимается полностью и
апостериорное (послеопыт-
ное) конечное распределение
приобретает следующий вид:
Xi... 12 13 14 15 16 17 18 19 20 21
p(Xi)... 0000010000
2 Р (Xi) = 1.
Пример 1-2. Последовательное снятие неопределенности (пере-
дается число (слово) х— 3,’ выражаемое в двоичном коде как ОН).
Шаг 1. Передается 0; может быть 000, 001, 010, ОН.
Шаг 2. Передается 1; может быть 010, ОН.
Шаг 3. Передается 1; может быть ОН.
Примем теперь неравные начальные вероятности сообщений, как
показано в четвертом столбце табл. 1-3.
Оставшиеся вероятности умножаются на 4/3 — величину, обратную
сумме априорных вероятностей У р (х,) подмножества.Тогда имеем в пя-
г 141141 141 141
том столбце 4 • з — з ; 4'3 — 3: 8 ‘ 3 — 6 ’ 8 ’ 3 — 6 *
О * 1 3 1 1 3 1 D
В шестом столбце . = — • в седьмом столбце
6 1 2 6 1 2
1
2
37
Таблица 1 3
Вероятности сообщений
Ho- Кодо- Равные Априорные После по- После по-
мер вое лучения 0 лучения 1 лучения 1
i слово вероятно- сти вероятно- сти в первом разряде во втором разряде в третьем разряде
0 ООО 1/8 1/4 ' 1/3 0 0
1 001 1/8 1/4 1/3 0 0
2 010 1/8 1/8 1/6 1/2 0
3 Oil 1/8 1/8 1/6 1/2 1
4 100 1/8 1/16 0 0 0
5 101 1/8 1/16 0 0 0
6 110 1/8 1/16 0 0 0
7 111 1/3 cp)=i i 1/16 S р = 1 i 0 S р -1 i \ 0 2 Р (X.) = 1 i 0 S р <*i) = 1 i
Понятие энтропии
Неопределенность каждой ситуации характеризуется
величиной, называемой энтропией.
Понятие энтропии (от греческого эн-тропе — обраще-
ние) распространилось на ряд областей знания.
Энтропия в термодинамике означает вероятность тепло-
вого состояния вещества, в математике — степень неопре-
деленности ситуации или задачи, в информатике она харак-
теризует способность источника отдавать информацию.
Все эти понятия родственны между собой и в общем
отображают степени богатства и неожиданности состояний.
Согласно второму закону термодинамики (Больцмана)
энтропия замкнутого пространства выражается как
k
Г, 1 V ni
Н = —г. 7 n, In ~,
N 1 N ’
«=1
где — общее количество молекул в данном пространстве;
ni — количество молекул скорости vt + До.
Но есть частоты событий и, следовательно, вероят-
ности того, что молекулы имеют скорость о, + До:
tit/N = pt.
Тогда
k
Н = — 2 Piln Pi-
i=l
38
Можно заменить In на log2, учитывая, что log2 М
= 1,44 In М,
k
Н == — 1,44 У Pi log2 Pi.
i=l
Таким образом, энтропия, полученная разными спосо-
бами, может различаться постоянным коэффициентом перед
знаком суммы.
Все другие виды энтропии выражаются аналогичными
формулами.
Здесь следует только заметить, что с вероятностными
оценками нужно Поступать осмотрительно. Не всегда
можно полагаться на идеализированные характеристики,
начальные условия и неизменность (стационарность) пара-
метров.
На практике всегда что-либо меняется. Если не меняется
параметр состояния, то меняется время и место, и уже это
создает новую информацию. Кроме того, сам факт неиз-
менности является несокращаемой информацией, так как
в любой момент времени фактически может начаться или
произойти изменение. Может, наконец, меняться сам субъ-
ект — приемник информации при неизменном состоянии ис-
точника. Практически приходится учитывать всевозможные
обстоятельства: «что», «когда», «кто», «кому», «зачем», «как»,
т. е. конкретизировать вид информации, время, отправи-
теля и получателя, назначение и способ реализации, все
изменения, происходящие с ними.
Энтропия ансамбля
Ансамблем называется полная группа событий,
или, иначе, поле несовместных событий с известным распре-
делением вероятностей, составляющих в сумме единицу.
Здесь имеется в виду конечное множество событий и, сле-
довательно, дискретная система состояний, значений, по-
ложений и т. д.
Энтропия ансамбля есть количественная мера его не-
определенности, а следовательно, и информативности.
В статистической теории информации (теория связи),
предложенной Шенноном в 1948 г., энтропия количественно
выражается как средняя функция множества вероятностей
каждого из возможных исходов опыта.
Пусть имеется всего N возможных исходов опыта, из
них k—разных, и l-й исход (i =1,..., k) повторяется
п-, раз и вносит информацию, количество которой оцени-
39
Бается как /г. Тогда средняя информация, доставляемая
одним опытом,
I __ П1 Ц + П2 Д + ••• + nk Ik
/ср— ДГ
Но количество информации в каждом исходе связано
с его вероятностью р; и выражается в двоичных единицах
(битах) через логарифм
Л- = log2 ~ = —log2 Рь
Pi
Тогда
т __ni (~~ Pi) + n2 (— l°ga P2) + • • • + nk (— l°g2 Pk)
l4>~ N
Последнее выражение можно записать также в виде
ЛР = у (— 1об2 Pi) + у (— log2 Р2) + • • + (— 1о&: Pk)-
Но отношения riJN представляют собой частоты повто-
рения отдельных исходов, а следовательно, могут быть за-
менены их вероятностями
Its
Поэтому средняя информации в битах может быть выра-
жена следующим образом:
ЛР = Р1 (— log2 Pi) + Pi (—log2 р2) +... + Pk (— logs pk),
или в короткой записи
k
/ср = - 2 Pi log2 Pi-
i=l
Полученную величину Шеннон назвал энтропией и обоз-
начил буквой Н:
k
У, p;log2pf, бит. (1-11)
i= 1
Основание логарифма определяет единицу измерения
энтропии и количества информации. Двоичная единица,
соответствующая основанию, равному двум, называется би-
том. Основанию, равному е = 2,718, соответствует нату-
ральная единица — нит, 1 нит = 1,44269 бит. Основанию,
равному 10, соответствует десятичная единица — дит,
1 дит = 3,32193 бит. Десятичную единицу называют также
Хартли.
40
Чаще всего применяют двоичный логарифм, так как он
непосредственно дает количество информации в битах,
хорошо согласуется с двоичной логикой, двоичным кодиро-
ванием и двоичной (релейной) техникой.
Энтропия может быть определена так же, как среднее
количество информации на одно сообщение или математи-
ческое ожидание количества информации I для измеряемой
величины X:
k
Н (X) =Л1 [/ (X)] = - £ Pi (xt) log2 Pi (Xi).
i~ 1
Функция H (p), где p = {/?1( ..., pk} — вектор вероятно-
сти исходов, была выбрана Шенноном так, чтобы она удо-
влетворяла следующим требо-
ваниям:
1) Н (р) непрерывна на ин-
тервале 0 pi 1, т. е. при
малых изменениях р величина Н
изменяется мало;
2) Н (р) симметрична относи-
тельно р, т. е. не изменяется при
любой перемене мест аргумен-
Рис. 1-11. Энтропия развет-
вленной системы.
тов рр
3) Н (ръ р2, ..., pk^, qlt q2)=
= Н (pi, р2, pk) + pkH (q^/Pk,
q2lpk), T- e- если событие x;
состоит из двух событий x'i
и x'i с вероятностями и q2,
qr -j- q2 = pi, то общая энтро-
пия будет равна сумме энтропии — неразветвленной сис-
темы и разветвленной части с весом р при условных ве-
роятностях qjpk и q2/Pk (рис. 1-11). ч
Кроме того, энтропия Н характеризуется следующими
свойствами:
1. Энтропия всегда неотрицательна, так как значения
вероятностей выражаются дробными величинами, а их ло-
гарифмы — отрицательными величинами, так что члены
log2 pi — — (— а) неотрицательны.
2. Энтропия равна нулю в том крайнем случае, когда
одно событие равно единице, а все остальные — нулю.
Это тот случай, когда об опыте или величине все известно
заранее и результат не приносит никакой новой информа-
ции.
41
3. Энтропия имеет наибольшее значение в том случае^
когда все вероятности равны между собой:
Pi =ра=•••=А = •••== Рл=1/А.
В этом случае
Н = — log2y = log2 k.
(1-12)
Логарифмическая и статистическая мера информации
совпадает с аддитивной логарифмической мерой Хартли
(§ 1-1)
/' = log2h.
Для того чтобы связать (1-12) с результатами § 1-1,
необходимо положить в (1 -12) k —h, затем в формуле Хартли
(1-9) положить Z = 1, что соответствует приведению ин-
формации к одному гнезду
с алфавитом в h знаков, на-
конец, в формуле энтропии
(1-11) положить все вероят-
ности равными между собой:
Рис. 1-12. Изменение энтропии
в зависимости от вероятности
элементарного (двоичного) яв-
ления.
формации по Шеннону
системы. Так, энтропия
стояний одного элемента (й — 2) равна:
Н = — (A log2 + р2 log2 р2).
А = У = Р1=Р2 = --- = РЛ-
Тогда
H = log2/i, бит. (1-13)
Совпадение оценок коли-
чества информации по Шен-
нону и по Хартли свидетель-
ствует о полном использова-
нии информационной емкости
системы. В случае неравных
вероятностей количество ин-
меньше информационной емкости
для двух неравновероятных со-
Она меньше информационной емкости двоичной ячейки,
составляющей 1 бит, как это видно из приведенных ниже
примеров:
А. Равновероятные состояния:
Pi = As = 0,5; р1 + ра=1;
Я=— (0,5 log2 0,5 -}- 0,5 log20,5) =
= —[0,5 (—1) -[- 0,5 (—1)] = 1 бит.
42
Б. Неравновероятпые состояния:
Pi = 0,9; р2 = 0,1; р!-|-р2±=1;
Н = — (0,9 log2 0,9 4-0,1 log20,l) =
= - [0,9 (— 0,1520) + 0,1 (-3,3219)1 = 0,46 бит.
В. Детерминированные состояния:
л=1; р2=0; Pi+p2=i;
Н= — (1 log21 + 0 log20) — 0 бит.
Изменение энтропии Н в зависимости от вероятности р
однопредметного события показано на рис. 1-12. Максимум
Н = 1 достигается при р = 0,5, когда два состояния равно-
вероятны. При вероятностях р =0 или р = 1, что соот-
ветствует полной невозможности или подпой достоверности
события, энтропия равна нулю.
Энтропия объединения
Объединением называется совокупность двух и
более взаимозависимых ансамблей дискретных случайных
переменных.
Рассмотрим объединение, состоящее из двух ансамблей X
и Y, например из двух дискретных измеряемых величин,
связанных между собой вероятностными зависимостями.
Схема ансамбля X
хл х2 ... х, ... хп;
Р(м) р(х2)...р(х,)..р(х„).
Схема ансамбля Y:
У1 ' Рэ • • • Уг • • • Ут*
Р(У1) Р(.У2)---Р(У1)^-р(.Ут)-
Схема объединения X и У:
М х2 ... xh;
У1 Р(хи У1) P(xz, уг) ... р(хп, у^-,
Уч Р (м. Ра) Р (х2, у2) ... р (х„, у2),
Ут Р (М> Ут) P (Х2, ут) ... р (Хп, Упг).
Вероятность произведения (совпадения) совместных за-
висимых событий X и Y равна произведению безусловной
43
вероятности р (х) или р (у) на условные вероятности р (у | х)
или р (х | у).
Таким образом, имеем:
Р (X, у) = р (х) р (у\х) = р(у)р (х\у). (1-И)
Отсюда находятся условные вероятности (1-15) (1-16)
в зависимости от того, какое событие является причиной,
а какое — следствием.
В нашем случае дискретных переменных X и Y частные
условные вероятности могут быть записаны для х = xk как
п I V \ ___ Р (Xk, У1) п(,. I v \ _ Р (Х1:< У2)
P(yi\xk)—p(Xk) , РШ—р(Хк)
С объединением связаны понятия безусловной, услов-
ной, совместной и взаимной энтропии (табл. 1-4). Их иногда
называют также зависимой, коррелированной и взаимной
энтропией, или трансинформацией.
Введенные понятия можно проиллюстрировать примером
передачи информации по схеме рис. 1-13.
Рис. 1-13. Схема передачи дискретной информации
по каналу связи.
Последовательность символов xJt х2.....xt, ..., хп, соз-
даваемая источником, может претерпевать искажения по
пути к приемнику.
Символ xt может быть принят не только как .однозначно
ему соответствующий символ у;, но и как любой из возмож-
ных символовуъ у.2, уj, ...,утс соответствующими веро-
ятностями.
44
Таблица 1-4
Энтропия объединения
Наименование Обозначение Соотношения Диаграмма
Безусловная Я(Х) Н (X) ==: Н (Х|У) Н (Х) = Н (Х| У) +‘Я (X • У) X У
энтропия
Н (У) Н (У) =- Н (У|Х) Н (У) = Н (У1Х) + Н (X У) Л У
Я(Х|У) Я(Х|У) = Я(Х) — H(X-Y) X я
Условная энтропия
Н (ИХ) н (У|Х) = Н (У) - Н (X • У) X у
Совместная Н (X, У) = н (X, У) = Н(Х)+Н (У|Х) = X У
энтропия = Н (У, X) = И (У) + Н (Х'У) = Я(Х) + + Н (У) — И (X • У)
Взаимная Н (X У) = Н (X • У) = Н (X) - Н (Х| У) =
энтропия = н (У, X) = Н (У) — Н (У|Х) = = Н(Х, Y)-H (Х|У) — - Н (ИХ)
Различные виды энтропии в данной схеме имеют следую-
щий смысл:
Н (X) — безусловная энтропия источ-
ника, или среднее количество информации на символ,-
выдаваемое источником;
Н (У) — безусловная энтропия прием-
ника, или среднее количество информации на символ,
получаемое приемником;
Н (X, У) — взаимная энтропия системы пере-
дачи-приема в целом, или средняя информация на пару
(переданного и принятого) символов;
Н (У | X) — условная энтропия У относи-
тельно X, или мера количества информации в приемнике,
когда известно, что передается X;
Н (X |У) — условная энтропия X относитель-
но У, или мера количества информации об источнике, когда
известно, что принимается У.
45
Если в системе нет потерь и искажений, то условные
энтропии равны нулю
H(Y\X) = 0, Н (X\Y) = 0,
а количество взаимной информации равно энтропии либо
источника, либо приемника
ЦХ, Y) = H(X, Y) = H(X) = H(Y).
На основании статистических данных могут быть уста-
новлены вероятности событий ylt у2, ..., ух при условии,
что имели место события xit а именно р (th | хг), р (р2 | х;),
Р (Ут I xi)- Тогда частная энтропия будет равна:
т
H(Y\Xi) = — р(4//1xf)logsр(4/z|X/). (1-18)
/=1
Далее нужно подсчитать среднее значение Н (Y | Хг)
для всех переданных символов хг. Это будет условная энт-
ропия канала
Л
H(Y\X) = -% P(Xi)H(Y\Xi), (1-19)
i=l
или в развернутом виде
п т
Hiy\X) = — У р(хг, p7-)log2p(p7]x,). (1-20)
»=i }—i
Аналогично получается условная энтропия Н (X | Y),
учитывающая условные вероятности р (Xi | у/):
Н (X\Y) — — 2 р(У,)Н(Х\у,), (1-21)
/='
или
H(X\Y) = — 2 S p(Xi, P/)log2p(x,•!«/;). (1-22)
«=1 ;=i
Безусловная энтропия ансамбля X
Н (X) = — 2 р (xi) log3 р (xi). (Ь23)
i== 1
Безусловная энтропия ансамбля Y
= — £ Р (yj) log2 р (t/у). (1 -24)
46
Количество информации и избыточность
Количество информации только тогда равно энтропии,
когда неопределенность ситуации снимается полностью.
В общем случае нужно считать, что количество информа-
ции есть уменьшение энтропии вследствие опыта или какого-
либо другого акта познания.
Если неопределенность снимается полностью, то инфор-
мация равна энтропии
/ = Я.
В случае неполного разрешения имеет место частичная
информация, являющаяся разностью между начальной и
конечной энтропией:
1 = ^ — 1^. (1-25)
Наибольшее количество информации получается тогда,
когда полностью снимается неопределенность, причем эта
неопределенность была наибольшей — вероятности всех
событий были одинаковы. Это соответствует максимально
возможному количеству информации Г, оцениваемому
мерой Хартли,
r = log2Q = log2(l/p) = -log2p, (1-26)
где Q — число событий, ар — вероятность их реализации
в условиях равной вероятности всех событий. Таким обра-
зом,
Г = Нмакс, (1-27)
Абсолютная избыточность информации Da6c представ-
ляет собой разность между максимально возможным коли-
чеством информации и энтропией
Е\бс “ Е ~r~ Hi ИЛИ Е\бс “ 7/макс 7/. (1-28)
Пользуясь также понятием относительной избыточности,
D = 1 — _. (1-29)
^макс “макс
Иллюстрируя понятие избыточности, ограничимся рас-
смотрением упрощенной модели: допустим, что статистиче-
ские свойства информации косвенно учитываются через
постоянные и переменные составляющие какого-либо фи-
зического процесса. Тогда, выражая относительную избы-
точность, можно определять информацию в любых едини-
47
t
цах, например подсчитывать кванты в данном комплексе
информаций.
Пользуясь таким упрощенным подходом, определим из-
быточность для нескольких примеров информационных
систем.
Пример 1-3. Пусть полная шкала измерения содержит Нткс =
— 1 000 элементарных единиц (квантов), но допускается погрешность,
равная приблизительно ±1% от полной шкалы. Тогда Н = 50, так как
при погрешности ±10 квантов достаточно всю шкалу разделить на
50 квантов. В этом случае
Рис. 1-14. Изменение величины х во
времени.
О = /
50 __ л 95
1 000 °’ ’
Пример 1-4. Если для из-
мерения используется непре-
рывная шкала, то HM2KZ—-> со
при любых, но конечных
значениях допустимой по-
грешности.
Тогда
О= 1 — — = 1,
т. е. избыточность информации достигает максимума.
Пример 1-5. Имеется процесс, протекающий по-графику рис. 1-14,
причем достоверно известно, что значение величины X на отрезке вре-
---- i i -----..... ....------------пределах х2— хх; значение х2
мени /2 — 4 может изменяться только в
содержит 11 единиц, а значение х, —
4 единицы.
В этом случае относительная из-
быточность будет
£>=!—-1^0,64.
Эта избыточность объясняется
тем, что постоянная составляющая
Рис. 1-15. К усреднению из-
быточности информации в
графиках.
хг — х0 не пополняет информации.
На участке ts — t2 (рис. 1-14) ве-
личина х (I) вообще не изменяется, и
если известно ее начальное значение
х (0 — ха, то вся остальная информа-
ция избыточна.
Аналогично, если на участке 4 — ts
процесс описывается постоянной со-
ставляющей Хз и синусоидой с изве-
стными амплитудой (хГ) — х4)/2, фазой
и частотой, то информация об этом
процессе не нужна.
Пример 1-6. Процесс представляется графиком рис. 1-15, а.
С учетом изложенного в примере 1-5 вычитается постоянная составляю-
щая (рис. 1-15, б), синусоидальная составляющая (рис. 1-15, в) и необ-
ходимая безызбыточная информация сводится к показанной ца
48
рис. 1-15, 6. Относительную избыточность можно определить, задаваясь
квантованием по оси х и дискретизацией по оси t.
Из рассмотренных примеров видно, насколько неэкономично в ряде
случаев производятся передача и регистрация данных.
Необходимое усовершенствование можно провести двумя путями:
1. Если весь объем информации заранее задан или накоплен, то он
разделяется на стандартные, заранее зашифрованные элементы, а затем
передаются и регистрируются только знаки шифров. Так можно посту-
пить, например, в том случае, когда результаты испытания записаны
на диаграммной ленте, но их нужно передать и воспроизвести в прием-
ном пункте наиболее экономичным способом.
2. Если имеется текущая информация, поступающая от датчиков, то
используются анализирующие приборы, которые непрерывно опреде-
ляют частотный спектр функций, амплитудные переходы заданных уров-
ней квантования, взаимосвязь предыдущих показаний с текущими
и т. д., а затем воздействуют на устройства оптимального кодирования,
передачи и регистрации.
Примеры статистической оценки количества информации
Рассмотрим применение статистических методов оценки
информации для телевизионного изображения.
В телевидении принят точечный способ передачи изобра-
жения, при котором изображение переводится в электри-
ческий сигнал способом развертывания. При развертывании
изображения луч проходит с постоянной скоростью самую
верхнюю строку, затем быстро перебрасывается в начало
следующей строки и т. д. Число строк достаточно велико
(обычно I — 625), и при передаче всего кадра луч обойдет
все изображение, а затем вернется в начало первой строки.
Каждая точка изображения имеет собственную яркость.
Число различных дискретных значений яркости может
быть различным в зависимости от требуемого качества изоб-
ражения. В вещательном стандарте считается достаточ-
ным иметь h =128. В целях упрощения расчетов примем
/1=4.
Способ статистической оценки отличается тем, что он
позволяет дополнительно сократить количество информации
в сообщении, учитывая известные его вероятностные ха-
рактеристики.
Поясним понятие статистической избыточности на при-
мере свойств телевизионного изображения:
1. Уровни яркости в каждом элементе разложения не-
равновероятны и г^ппируются возле средней яркости,
зависящей от характера изображения (картины солнеч-
ного дня, ночные пейзажи и т. д.). Это приводит к тому,
что для известного характера сюжетов одни уровни яркости
49
ожидаются с большей вероятностью, чем другие, т. е.
имеется априорная информация о сообщении. Эту информа-
цию можно не передавать по каналу, а если она все же пере-
дается, то она избыточна.
2. Соседние по горизонтали и вертикали элементы раз-
ложения имеют зависимые значения яркости вследствие
того, что средние размеры элементарных геометрических
форм в изображении больше размеров одного элемента.
Поэтому соседние элементы разложения, как правило, при-
надлежат одной элементарной геометрической форме, и по
яркости одного из них можно с большой уверенностью
судить о яркости другого. Это значит, что каждый элемент
разложения содержит некоторую информацию о соседних,
так что в принципе нет необходимости при передаче сосед-
него элемента передавать полную информацию о нем. Пол-
ная информация будет избыточна в той своей части, которая
уже была передана на предыдущем элементе.
3. Элементы разложения с одинаковыми координатами,
но из соседних кадров, имеют зависимые значения яркости,
так как время между соседними кадрами выбирается с та-
ким расчетом, чтобы даже быстрые перемещения изображе-
ния не нарушали связного восприятия движения. Связность
обеспечивается тем, что в течение выбранного достаточно
малого времени между кадрами новые значения яркости
получает лишь незначительное число элементов соседнего
кадра. Но это и означает, что соответствующий эле-
мент в‘соседнем кадре с большой вероятностью сохранит
прежние значения яркости. Ясно, что и в этом случае
элемент данного кадра содержит информацию о соответ-
ствующем элементе соседнего кадра, так что независи-
мая передача элемента соседнего кадра связана с избы-
точностью.
Избыточность телевизионного сообщения существует
еще и в связи с тем, что зависимыми в нем являются не
только соседние элементы, но и другие близлежащие.
Обычно зависимость распространяется на расстояние около
пяти элементов.
В качестве вероятностной характеристики сигнала ис-
пользуем матрицу совместного распределения вероятностей
градаций яркости для двух соседних по горизонтали эле-
ментов (табл. 1-5).
Приведенное в таблице распределение соответствует
реальному сообщению, так что ее рассмотрение должно
подтвердить указанные выше свойства телевизионных
50
сообщений *. Действительно, последняя строка таблицы
говорит о том, что для любого наугад взятого элемента раз-
ложения вероятность первой градации яркости больше сум-
марной вероятности всех других градаций. Далее, тот факт,
что наибольшие значения вероятности расположены на
главной диагонали матрицы, указывает на тенденцию изоб-
ражения сохранить на следующем элементе прежнее зна-
чение яркости.
Таблица 1-6
1 I
i 2 3 4
1 0,574 0,071 0 0
2 0,050 0,192 0,020 0
3 0 0,005 0,063 0
4 0 0 0 0,025
р (/) = !>(«, 7) i 0,624 0,0268 0,083 0,025
В случае кодирования пар средняя энтропия Нср (0
одного символа определяется так:
нср (0=^-0.
Следует помнить, что Яср (i) отличается от Н (I) —
= — Sp (i) log2 р (i) тем, что f/cp‘(i) описывает неопре-
деленность одного символа в присутствии второго извест-
ного символа пары (i, /), тогда как И (г) не учитывает зави-
симости между символами этой пары.
Поэтому
Дср(О^Я(0.
Подставляя значения вероятностей из табл. 1-5 в фор-
мулу энтропии, получаем:
Н (I, /) == — 2 Р (Л /) log2 р (i, j) =
ч
= — (0,574 log20,574 + 0,1917 log2 0,1917 +
+ 0,06281og20,0628 + 0,0251og20,025 + 0,071 log2 0,071 +
+ 0,05 log2 0,05 + 0,0204 log2 0,0204 +
+ 0,0051 log2 0,0051)= 1,94 бит,
* Из-за погрешностей измерений таблица несколько отличается
от точной вероятностной схемы, но это не влияет существенно на даль-
нейшие результаты.
51
откуда
//ср (0 = —= 0,97 бит.
Можно сравнить полученную оценку 0,97 бит с оцен-
кой по Хартли.
На каждом элементе возможности четыре значения яр-
кости, так что
/ = loga4 = 2 бит.
Это означает, что учет статистических связей между
элементами сорбщения позволяет сократить количество
информации более чем в 2 раза.
Заметим, что при кодировании пар соседние элементы,
попавшие в разные пары, считаются независимыми. Точнее
говоря, для каждого элемента разложения из двух сосед-
них с ним слева и справа элементов только один, попавший
с ним в пару, создает учитываемую зависимость.
Такой способ кодирования возможен и состоит в том, что,
формируя элемент сообщения по каждому элементу изобра-
жения, учитывают только ту информацию о данном элементе
изображения, которую нельзя получить из уже известного
предыдущего элемента. Эта дополнительная информация
оценивается как
//(/10=тп -/(/ю,
где / (/ | 0 — количество информации, которое несет из-
вестный элемент i о соседнем элементе /; И (/) — энтропия
одного элемента, если считать его независимым.
Итак, если Н (j\i) окажется меньше Нср (0 и если най-
дется технический способ выделить Н (j |i) из полной энтро-
пии Н (j), то мы получим более эффективный способ кодиро-
вания по сравнению с кодированием пар элементов.
Проверим выполнение условия Н (j\i) < Нср (i). Для
вычисления Н (j [ i) используем соотношение (см. табл. 1-4)
Н(1, /) = Я(0+Я(/;О. (1-30)
Величина И (i, j) определена ранее, а И (I) подсчиты-
вается с использованием данных нижней строки табл. 1-5:
И (О =- 5 Р (i) log2 р (i) = - 0,624 log2 0,624 -
— 0,2678 log2 0,2678 — 0,0832 log2 0,0832 —
— 0,025 log2 0,025 = 1,365 бит.
52
Поэтому
Н (j\i) = H (i, j) — H (i) = 1,94 — 1,365 = 0,575 бит,
и
H(/|i) = 0,575 бит HQp (i) = 0,97 бит.
Теперь остается решить вопрос о том, какие преобразо-
вания сигнала должны быть выполнены, чтобы каждый
элемент изображения вместо случайной величины с энтро-
пией Н (i) = 1,365 бит отображался случайной величиной
с энтропией Н (/) = 0,575 бит.
Характер такого преобразования подсказывается сле-
дующими соображениями.
Пусть на основании информации I (j\i) по какому-то
правилу делается прогноз о случайной величине /, т. е.
предсказывается, что она имеет значение, например,
Если теперь взять отклонение истинного значения / от
предсказанного /', то полученная случайная величина
k = / — j' обладает тем свойством, что ее значения уже не
могут быть предсказаны и являются полностью неожидан-
ными. Ясно, что независимое кодирование такой случайной
величины уже не будет создавать избыточности.
Имеются различные способы предсказания, но мы выбе-
рем наиболее простой и в то же время весьма эффективный
по отношению к нашему сигналу. Будем считать, что на
следующем элементе будет та же градация яркости, что и
на данном, т. е.
f=i и k — j — i.
Естественно, что оправданием такого способа пред-
сказывания может быть только достаточная близость эн-
тропии Н (k) случайной величины k к значению Н (j |i) =
= 0,575 бит.
Проверим выполнение этого условия, для чего необхо-
димо найти распределение вероятностей случайной вели-
чины k.
Из рассмотрения табл. 1-5 видно, что случайная величина
Сможет иметь только 3 значения: 0, +1,’—1- Этим значениям
соответствуют следующие исходы предсказания: действи-
тельное значение случайной величины оказалось равным
предсказанному (/ = i); действительное. значение на еди-
ницу больше предсказанного (/ = i + 1); действительное
значение на единицу меньше предсказанного (/ = i — 1).
53
Соответствующие вероятности подсчитываются так:
p(/ = i) = p(t- = l, 7=l) + p(i = 2, / = 2) +
+ p(i = 3, 7 = 3) + p(i = 4, / = 4) = 0,574 + 0,1917 +
+ 0,0628 + 0,025 = 0,8535,
p(7 = i + l) = p(f = l, / = 2)+p(i = 2, / = 3) =
= 0,07J +0,0204 = 0,0914,
p(7 = i—l) = p(i = 2, 7=l) + p(i = 3, 7 = 2) =
= 0,05 + 0,0051 =0,0551.
Теперь можно подсчитать энтропию случайной вели-
чины k:
Н (k) = -% р (Л) log2 р (k) = — 0,8535 log2 0,8535—
k
— 0,0914 log2 0,0914 — 0,0551 log2 0,0551 = 0,741 бит.
Из полученного результата видно, что принятый нами
способ предсказания, хотя и не позволяет реализовать пол-
ностью величину Н (j |0 = 0,575 бит, но все же оправды-
вает применение метода статистического кодирования с
предсказанием, поскольку
//(Л) = 0,741 бит Нср (i) = 0,96 бит.
Подсчитаем теперь, пользуясь оценкой Хартли, количе-
ство информации, содержащееся в телевизионном сообще-
нии, которое длится 1 сек. Примем близкие к реальным
условиям: х
/х = 600 — число элементов разложения в одной строке;
/2 = 600 — число строк;
h = 128 — число градаций яркости;
т — 25 — число кадров в секунду.
Тогда искомое количество информации
/ = m/j l2 log2 h = 25 600 600 • log2 128 = 63 • 10е бит/сек.
Однако пропускная способность канала зрительного
анализатора человека составляет только 50—100 бит/сек.
Это несоответствие отчасти можно объяснить тем, что мозг
при восприятии интуитивно реагирует на поступающую
информацию с учетом ее новизны и неожиданности, так что
оценка Шеннона ближе к действительности, чем оценка
Хартли. Таким образом, можно объяснить снижение вели-
чины не более чем на два порядка.
54
Следует предполагать, что живые существа ипользуют
неизвестный пока механизм цельного восприятия образов,
который обрабатывает не всю поступающую информацию,
а только наиболее ценную ее часть. Все остальное отбрасы-
вается как ненужное и не загружает мозг. Мозг, обладаю-
щий памятью и способностью сопоставления, интерполя-
ции, прогнозирования, получает от рецепторов только такое
количество информации, которое ему не хватает для устра-
нения неопределенности в собственной модели наблюдае-
мого, а для этого ему вполне достаточно 50—100 бит!сек.
Для расчета энтропии и количества информации в при-
ложении приводятся таблицы двоичных логарифмов, двоич-
ных разрядов и энтропии двоичных событий.
Оценка качества измерения и контроля
Измерением называется совокупность экспери-
ментальных и в некоторых случаях вычислительных опера-
ций, имеющих целью определение значения измеряемой
величины (физической величины, параметра), выраженного
в принятых единицах.
Физическая величина, измеряемая
величина (параметр) есть существующее объек-
тивно свойство физического объекта (физического тела,
состояния или процесса), общее в качественном отношении
множеству различных объектов, но индивидуальное в коли-
чественном отношении.
Значение физической вел и~ч ины есть
информация о физической величине, свойственной объекту,
выраженная в принятых единицах.
Единицей физической величины на-
зывается физическая величина, принятая по соглашению за
основание для количественной оценки величин, однородных
с ней в качественном отношении.
Различают прямые, косвенные и совокупные измерения.
Прямые измерения есть измерения, при ко-
торых экспериментальная операция производится над вели-
чиной, подлежащей измерению.
Косвенные измерения есть измерения, при
которых прямым измерениям подвергают величины, свя-
занные с величиной, подлежащей измерению, известной
зависимостью.
Частным случаем косвенных измерений являются с о -
вокупные измерения, когда величина, подле-
55
жащая измерению, связана известной зависимостью с не-
сколькими величинами, получающимися в результате пря-
мых измерений.
Контроль есть вынесение суждения о том, что ве-
личина относится к одной из нескольких непересекающихся
областей, на которые разбита вся область определения конт-
ролируемой величины. Качество операции измерения или
контроля часто целесообразно оценивать не только по ко-
личеству информации, которая при этом получается, но
также по ошибке, с которой операция выполняется.
Ошибка измерения е определяется как разность между
результатом измерения у и действительным значением изме-
ряемой величины х:
Е = у—х.
Факторы, приводящие к ошибке измерения, имеют слу-
чайный характер, изменяя ошибку со временем или от од-
ного измерения к другому. Поэтому ошибку измерения
следует рассматривать как случайную величину, а если
представляет интерес поведение ошибки во времени — то
как случайный процесс е (Г).
В качестве численных характеристик ошибки исполь-
зуют моменты случайной величины е или случайного про-
цесса е (I), т. е. математическое ожидание (систематическую
ошибку) и средний квадрат ошибки, комплексно отображаю-
щий свойства систематической и случайной составляющих.
Может представлять интерес корреляционная функция
процесса ошибки и ее корреляция с измёряемой величиной
(процессом).
При контроле ошибка есть событие, заключающееся
в ошибочном отнесении контролируемой величины не к той
области, какой эта величина в действительности принадле-
жит. Это событие в общем случае случайно и его также можно
изучать статистическими методами.
1-3. СЕМАНТИЧЕСКИЕ МЕРЫ ИНФОРМАЦИИ
Под семантикой понимается смысл, содержание информации. Место
семантики в системе понятий семиотики (науки о знаках, словах и язы-
ках) указано в табл. 1-6 и на рис. 1-16.
Знаком называется условное изображение элемента сообщения,
словом — совокупность знаков, имеющая смысловое (предметное)
значение, языком — словарь и правила пользования им.
Соответственно приведенной выше структуре в семиотике разли-
чаются синтактический, семантический, сигматический и прагматиче-
ский аспекты теории информации.
56
Семиотика
Се^еион (греч.)— знак, признак
Наука о знаках, словах и языках
Таблица 1-6
Синтактика
Синтаксис-— греч.:
составление
Семантика
Семанти кос—греч.:
обозн ачающий
Сигматика
Сигматика—греч.:
учение о знаках
Отношение между
знаками и словами
Структурная
сторона языка
Z Z'
Значение знаков
и слов
Смысловая сто-
рона языка
Z — С
Отношение между
знаками (словами)
и объектами
отражения
Словарная сто-
рона языка
Z- О
П рагматика
Прагма — греч.:
действие, прак-
тика
Практическая по-
лезность знаков
и слов
Потребительская
сторона языка
z-> ч
Обозначения: Z—знак, Z'—соотно-
сящийся знак, С—смысл, О—объект,
Ч—человек.
Рис. 1-16. К основным поня-
тиям семиотики.
Рассмотренные в предыдущих параграфах структурная и ста-
тистическая оценки информации относятся к синтактическому ас-
пекту.
Сигматический аспект отображается теорией сигналов и кодов, рас-
сматривающей условные обозначения элементов информации. Сигналы
являются физическими носителями обозначенных элементов, а коды —
обозначениями этих элементов. Сигматические оценки не имеют пря-
мого отношения к мерам информа-
ции. Поэтому остается рассмотреть
семантические и прагматические
оценки информации.
В этом параграфе рассматри-
ваются оценки, отвечающие как
семантическому, так и прагматиче-
скому аспектам теории информа-
ции: в инженерных применениях
прагматические оценки сливаются
С_смаДйч^юимиЩпрслольку _ не
имеющие смысла сведения беспо-
лезны, а бесполезные сведения бес-
смысленны.
\^, Оценка эффективности логиче-
ского~~вь1иода, ^Степени приближе-
ния к истине требует некоторой
формализации, в данном случае —1
формализации смысла.
Один из” путей такой формали-
зации предлагается семантической
теорией информации.
Карнап и Бар-Хиллел [Л. 1-9] предложили использовать для целей
измерения смысла функции истинности и ложности логических высказы1
ваний (предложений).
За основу дискретного описания объекта берется атомарное (неде-
лимое) предложение, подобное элементарному событию теории вероят-
ностей и соответствующее неделимому кванту сообщения.
Полученная таким образом оценка получила название содержатель-
ности информации.
57
Содержательность информации
Мера содержательности обозначается cont (от английского content —
содержание).
Содержательность события i выражается через функцию меры
т (г) — содержательности его отрицания — как
cont (i) = т (~ г) = 1 — 'т (г),
где i — рассматриваемое событие; т — функция меры; ~ — знак от-
рицания.
Оценка содержательности основана на математической логике,
в которой логические функции истинности т (г) и ложности т(~г)
имеют формальное сходство с функциями вероятностей события р (г)
и антисобытия q (<) в теории вероятностей.
В обоих случаях имеют место сходные условия
от(0 + т(~г)=1; Р (0 + <7 (О = 1-
Как и вероятность, содержательность изменяется в пределах
(г) < 1.
Соответственно сходны статистическое и логическое количество ин-
формации.
Статистическая оценка количества информации (энтропия) согласно
1 = log2 ~ = — Iog2 р (О-
Логическая оценка количества информации, получившая обоз-
начение Inf, имеет сходное выражение:
lnf =Iog2 = ,og2 Й = ” 1062 т (~ °'
Отличие статистической оценки от логической состоит в том, что
в первом случае учитываются вероятности реализации тех или иных
событий, а во втором — меры истинности или ложности событий, что
приближает к оценке смысла информации.
Целесообразность информации
Если информация используется в системах управления, то ее полез-
ность разумно оценивать по тому эффекту, который она оказывает на
результат управления. В связи с этим А. А. Харкевичем была предло-
жена мера целесообразности информации, которая определяется как
изменение вероятности достижения цели при получении дополнительной
информации [Л. 1-26].
Полученная информация может быть пустой, т. е. не изменять
вероятности достижения цели, и в этом случае ее мера равна нулю.
В других случаях полученная информация может изменять положение
дела в худшую сторону, т. е. уменьшать вероятность достижения цели,
и тогда она будет дезинформацией, которая измеряется отрицательным
значением количества информации.
58
Наконец, в третьем, благоприятном случае, получается добротная
информация, которая увеличивает вероятность достижения цели и из-
меряется положительной величиной ко-
личества информации.
На рис. 1-17, а показано исходное со-
стояние (точка 1, из которого возможны
два пути: путь 1—2 и путь 1—3. Пусть
точка 3 представляет собой цель, а точка
2 — некоторый промежуточный пункт в
стороне от цели. Если неизвестны пути
к цели, то вероятности достижения цели
по путям 1—2 и 1—3 будут одинаковы,
а так как схема опыта содержит два ис-
хода, то можно записать условие
р (/— 2) = р (/— 3) = 1/2.
Предположим, что достигнута точка 2
(рис. 1-17, б) и в этой точке 2 получается
информация, однако эта информация
оказалась нейтральной, так как она оста-
вила неизменной вероятность достиже-
ния цели.
Тогда
, , р(2 — 3) , 3/6 _
z = lo&^^ = log2376 = 0-
Второй (неблагоприятный) случай по-
казан на рис. 1-17, в. Здесь в пункте 2
получена ложная информация, которая
уменьшила вероятность достижения цели
в виду преобладания ложных направле-
ний 4. Количество информации
Рис. 1-17. К применению
меры Харкевича
оценки информации,
лучаемой на пути дви-
жения к цели.
для
по-
Остановимся также на третьем (бла-
гоприятном) случае (рис. 1-17, г), когда
вероятность достижения цели 3 увеличивается. В этом случае также
в пункте 2 поступает информация, которая только два исхода из
шести оставляет ложными (направление 4), но четыре исхода из
шести являются благоприятными и ведут к цели 3. Количество ин-
формации
Мера целесообразности в общем виде может быть аналитически
выражена в виде соотношения
/цел = 10g2 Pl — 10g2 рй = Iog2 ,
Ро
где р0 и р, — начальная (до получения информации) и конечная (после
получения информации) вероятности достижения цели.
59
Динамическая энтропия
В том случае, когда целью извлечения информации является обра-
щение в нуль неопределенности ситуации, удобно пользоваться поня-
тием динамической энтропии [Л. 1-24].
В ходе распознавания образов, диагноза болезней или расследова-
ния преступлений энтропия (неопределенность) ситуации изменяется во
времени
Н = И (/).
Изменение обусловливается поступлением в определенные моменты
времени дополнительной информации: положительная информация
уменьшает неопределенность,- отрицательная (дезинформация) — уве-
личивает неопределенность ситуации.
Наименование сообщений и событий
Рис. 1-18. Последовательное уменьшение энтропии при расследовании
преступления.
Большинство ситуаций можно представить как множество отноше-
ний между следствиями {а,-} и причинами {fy}. Следствия наблюдаются,
а причины раскрываются по ним. Так, например, следствиями и причи-
нами могут быть: при распознавании — образы {cj и признаки {Ь,-};
при диагнозе болезней — заболевания {cj и симптомы {iy}; при рассле-
довании — преступления {с,-} и подозреваемые лица {<>/}.
Отношения между следствиями {аг} и причинами {b/} оцениваются
вероятностями ру (/).
Если нет связи между какими-либо следствиями и причинами, то
вероятность рц (t) = 0. Если же между ними имеется наибольшая (од-
нозначная и полная) связь, то рц (/) = 1.
Общее количество следствий в момент времени t обозначим N (/),
а общее количество причин М (/). Тогда отдельные следствия а, получают
нумерацию i = 1,2,3,..., N (/), а причины — / = 1,2,3,..., М (0-
Согласно статистической теории информации (§ 1-2) энтропия (не-
определенность) для данного множества отношений .
Л'(П W)
Ж0 = - £ £ log
60
По истечении единичного интервала времени поступает дополни-
тельная информация, могущая изменить: количество следствий {а,-} от
X (t) до X (<+ 1), количество причин {6,-} от М (t) до М (t + 1) и веро-
ятности отношений между ними от Ру (t) до ру (Z-j- 1).
В результате этого энтропия (неопределенность) ситуации в момент
(f+ 1) получает новое выражение:
W-H) ЛЦ/4-1)
= - S S Ру (t + 1) 10g Ру (t + 1).
i=i ’ /=1
В качестве меры информации, повлиявшей на энтропию в указанном
выше смысле, целесообразно принять разность
I =ЛН = Н (t) — H(t+ 1),
i
которая может быть как положительной, так и отрицательной величиной,
в зависимости оттого уменьшается или увеличивается неопределенность
ситуации.
Приложение этой оценки к практическим случаям рассмотрено на
примере раскрытия преступления (рис. 1-18).
Существенность информации
Параметрическая информация, как было показано во введении,
может быть представлена трехмерной моделью, в которой осями коорди-
нат являются параметр X, пространство N и время Т, причем под про-
странством понимается упорядоченное множество источников инфор-
мации, в частности измеряемых величин.
Значения величин,точки пространства и моменты времени не равно-
существенны как сами по себе, так и во взаимный отношениях.
Например, наиболее существенны высокие значения давления и
температуры в. точке выхода газа, в момент отрыва ракеты от земли.
В других точках и' в другие моменты времени эти параметры могут
быть несущественными.
Таким образом, можно различать: -ч.
1) существенность самого события;
2) существенность времени совершения события или его наблюде-
ния (рано — поздно — момент);
3) существенность места, адреса, номера, локализации, точки про-
странства, координаты совершения события.
Измерение величины X можно характеризовать несколькими функ-
циями величины X: вероятности р (х), погрешности измерения е (х)
и существенности с (х). Каждой из этих функций можно поставить в со-
ответствие определенную меру информации. Мерой Хартли оценивается
функция погрейшоств е при фиксированных значениях функций веро-
ятности (р = const) и существенности (с = const). Мерой Шеннона оце-
нивается функция вероятности (р = var) при фиксированных значениях
функций погрешности (е = const) и существенности (с = const). Мера
существенности относится к ситуации с фиксированными функциями
погрешности (е = const) и вероятности (р = const). Можно ввести
функции существенности сх, зависящие от величины Х,ст, зависящие от
величины времени Т, cN, зависящие от пространства (канала) N.
Функция существенности отражает степень важности информации
о том или ином значении параметра X с учетом времени Т и простран-
ства N и должна удовлетворять условию нормированное™.
61
1-4. ДРУГИЕ МЕРЫ ПОЛЕЗНОСТИ ИНФОРМАЦИИ
Энтропия, шум и тезаурус
До сих пор при оценке полезности информации мы не рассматривали
возможности ее восприятия и обработки приемником. Можно рассмотреть
полезность информации в зависимости
^формация
ЛктупииР
/запрос)
(ответ)
Система&л
Объект
Источник J
информациях
Ombem !>•
Язык X J
Структурах
Энтропия ?
Семантика)
(CucmeMaSy
-Л Субъект
{приемник
(вкгпуация
—I Запрос
{Язык У
( Композиция
-4 Тезаурус
{Прагматика
Рис. 1-19. Обобщенное представление
процесса обмена информацией между
двумя системами.
как от степени новизны, так и
от способности приемника к
ее восприятию и обработке.
. Следствием потребитель-
ского аспекта является до-
полнение информации поня-
тием актуации в смысле
активного запроса информа-
ции со стороны заинтересо-
ванного приемника. При этом
имеется в виду тесная связь
между этими понятиями, так
как в каждой актуации (за-
просе) может содержаться не-
которая информация.
Существуют три типа во-
просов: в одном отсутствует
предвосхищение ответа, в дру-
гом имеется некоторая доля
ответа, в третьем полностью
содержится ответ и требуется
только его подтверждение.
Таким образом, замы-
кается связь между двумя си-
стенами (рис. 1-19): системой Sx, являющейся поставщиком информа-
ции, и системой Sy — потребителем информации.
В последнее время появилось также понятие тезауруса (от
греческого «сокровищница»), под которым понимается запас знаний, или
словарь, используемый приемником информации.
Энтропия Шум Тезаурус
Н N 6 '
Рис. 1-20. Схема извлечения, передачи
и приема информации с учетом Н, N и 6.
С учетом сказанного можно систему извлечения, передачи и приема
информации представить в виде схемы рис. 1-20.
На этой схеме источник (объект) обладает определенной энтропией
Н, которая характеризует способность источника отдавать информацию.
Отдача может быть неполной.
62
Рис. 1 -21. Изменение энтропии
в зависимости от величины / (0).
достигается максимум восприятия.
Информация I = Нг — Я2 поступает в канал, где часть информа-
ции теряется или искажается шумом N.
Оставшаяся информация / достигает приемника и воспринимается
им в той степени, в какой это позволяет тезаурус.
Может оказаться, что несмотря на высокое богатство структуры и
статистики информации на передающей стороне, приемная сторона не
будет нуждаться в этой информации, так как она уже ею обладает, не
имеет в ней потребности или не умеет с ней обращаться.
Существует и другое положение. Если тезаурус не адекватен пере-
даваемой информации, очень мал или вообще отсутствует, то самая но-
вая и богатая информация не воспримется вследствие того, что она не
будет принята приемником.
С приемом новой информации тезаурус может обогащаться.
Пусть богатство тезауруса количественно оценивается некоторой
величиной 6 . Изменение тезауруса 6 под действием сообщения И можно
оцепить количеством информа-
ции I (Н, 6), которое представ-
ляется графиком на рис. 1-21.
Имеется некоторое мини-
мальное количество /мин (6)
априорной информации / (6)
тезауруса 0 в системе Sy, при
которой система Sy начинает
понимать сообщения, поступаю-
щие от системы Sx. После этого
воспринимаемая информация I
(Н, 0) возрастает при увеличе-
нии I (6) до точки с координа-
тами /макс(Н, 0) и /опт (0), где
Далее следует спад, обусловленный тем, что априорные знания (теза-
урус приемника) становятся настолько богатыми, что источник не при-
носит новой полезной информации.
В точке /мякс (6) восприятие информации прекращается, так как
система Sj, оказывается насыщенной знаниями в пределах возможностей
системы Хд- — потенциального источника информации.
Если языки X и Y однозначно определены, то могут быть предусмот-
рены трансляторы — переводчики Y —> X и X — У, располагаемые
в Sx, Sy или в Sx и S^, (совместно).
В других случаяхвозникает проблема взаимопонимания, которая
решается методами распознавания и самообучения.
При единстве языков может иметь место непонимание из-за действия
помех и искажений.
В ранее приведенной общей схеме рис. 1-20 указаны структурные,
статистические и семантические характеристики информации: струк-
тура, энтропия и семантика на стороне источника Sx; композиция сооб-
щения, в целом тезаурус и прагматика на стороне приемника Sy. 4
Композиция отражает те же стороны информационной системы,
что структура информации, тезаурус — те же, что энтропия, прагма-
тика — те же, что семантика, хотя связь между этими парами понятий
не является установившейся.
Наиболее близкими между собой являются понятия структуры и
композиции. Структура как основа исчисления количества информации
предполагает дискретное строение и декомпозицию информации, осу-
ществляемые на передающей стороне. Поэтому естественной функцией
приемной стороны является композиция, заключающаяся в том, что
63
по возможности восстанавливаются нарушенные связи между элемен-
тами информации или воссоздается непрерывность информационного
комплекса. В ряде случаев это может повлечь за собой переоценку ин-
формации.
Глава вторая
ДИСКРЕТИЗАЦИЯ ИНФОРМАЦИИ
В этой главе рассматриваются основные методы дискре-
тизации информационных комплексов по уровню (по обоб-
щенной шкале измерения X) и во времени (по обобщенной
шкале времени Т).
2-1. КВАНТОВАНИЕ ПО УРОВНЮ
Непрерывные сигналы в системе обобщенных коорди-
нат X, Т описываются непрерывными функциями х (t).
Переход от аналогового представления сигнала к цифро-
вому, который дает в ряде случаев значительные преиму-
щества при передаче, хранении и обработке информации,
связан с его дискретизацией по уровню X и по времени Т.
Кроме того, дискретизация по времени позволяет использо-
вать одни и те же устройства (каналы связи, устройства
обработки информации) для большого числа различных
сигналов.
Преобразование непрерывного информационного мно-
жества аналоговых сигналов в дискретное называется д и -
скретизацией, или квантованием по
уровню.
Квантование по уровню широко используется в систе-
мах связи, телеметрии, при автоматическом управлении,
контроле, обработке данных с помощью ЦВМ и т. д. При
квантовании по уровню диапазон возможных изменений
функции — интервал (а, Ь) — разбивается на п интервалов
квантования:
=xi — Xi—i, 1 = 1, 2,..., П, страницами
х0 = а, xlt..., xn-i, хп = Ь.
В результате квантования любое из значений х, при-
надлежащее интервалу (хг_х, xi), округляется до некоторой
величины Xi = t’Ax, xt £ (хг_х, Xi).
Величины Xi, i = 1, 2, ..., n носят название уровней
квантования. При квантовании по уровню произ-
водится отображение всевозможных значений величины X
64
на дискретную область, состоящую из величин х,- — уров-
ней квантования.
Замена истинных значений функций х соответствующими
дискретными значениями — уровнями квантования Xt, вно-
сит ошибку, или шум, кванто-
вания
I (х) = xt — х.
Частный случай квантования
по уровню — равномерное, при
котором интервалы (шаги) кван-
тования одинаковы:
л л Ь — а
&Х — &Х1 — Xi Xj-j — - ,
i = 1, 2,., п.
Оценим ошибку квантования,
начав с критерия наибольшего
отклонения:
sup g (х) = sup | X — хг |.
X X
При заданном п наибольшая
ошибка квантования sup || (х) |
минимальна, если ДХг- = Дх =
= const и уровень квантования х;
выбираются в середине интер-
вала:
Xi — g (Xi -f- Xi—p.
Рис. 2-1. Квантование по
уровню.
а — функциональная зависи-
мость квантованной величины
от непрерывной; б — зависи-
мость шума квантования от
квантуемой величины.
В этом случае наибольшая ошибка квантования равна:
sup | |(х) | = 0,5 Дх.
На рис. 2-1,а показана функциональная связь непрерыв-
ной величины с дискретной, полученной на выходе устрой-
ства квантования, а на рис. 2-1,6 — зависимость ошибки
квантования от непрерывной величины х.
Рассмотрим статистические характеристики шума кван-
тования. Ошибка равномерного квантования равна-:
| (х) = г Дх — X,
причем
Ах G’ ~ +4).
3 Темников Ф. Е. и др.
65
где Ах — удвоенное наибольшее значение ошибки квантова-
ния.
При неограниченной шкале квантования (а — — со,
b == оо) представленная на рис. 2-1 зависимость ошибки
квантования от квантуемой величины оказывается перио-
дической функцией и может быть разложена в гармониче-
ский ряд:
1(х) =
ДХ V (—l)ft - 2nfe
Л AJ k Д V
X.
Поскольку шум квантования, обозначаемый, когда он
рассматривается как случайная величина, через Е (х), функ-
ционально связан с непрерывной случайной величиной х,
то его статистические характеристики будут зависеть от ста-
тистических характеристик этой величины. Определим
математическое ожидание шума квантования:
М fE (х)] = § w (х) Е (х) dx =
— со
л СЛ
дх у (—l)ft
п k
*=|
, . sin 2л/г ,
W (х) —т----xdx,
ах
где w (х) —плотность распределения величины X.
Из формулы следует, что М [Е (х)1 = 0, если матема-
тическое ожидание непрерывной величины х — М [х] совпа-
дает с серединой или границами интервала квантования,
а плотность ее распределения w (х) является четной функ-
цией относительно математического ожидания. Если же
такого совпадения нет, то математическое ожидание М [х]
близко к нулю, когда среднеквадратичное отклонение про-
цесса велико по сравнению с шагом квантования Ах:
<т = )/ТГ[х] > Ах.
Например, при нормальном распределении непрерывной
величины с плотностью распределения
1 (ЛГ-МИ)8
w (х) = е 208
66
математическое ожидание ошибки равно:
*=1
i _е
k ' )/2л о
1 — (х—Л1[х])а . 2л/е .
- —-------sin . - хах =
дх
,8
2а2
ДХ V (—1)* • 2я/г
= — 7 sm -jr- ае
л k b.v
k = \ х
где а — погрешность дискретности при квантовании вели-
чины, равной математическому ожиданию:
— 2
Оценим М [Е (х)]. Так как значение экспоненты в фор-
муле убывает с увеличением k, то
— 2
/И [В (х)]<е
— 2
__IjA+Z р
(—1)* • 2л/е
— 7 1—г- Sin-*-a
k^l x
Очевидно, что при Ax о, что имеет место при доста-
точно большом числе уровней квантования (малом интервале
квантования Ах), математическое ожидание ошибки Л1[Е (х)]
можно практически считать равным нулю.
Определим дисперсию шума квантования:
СО д 2 СО СО
D[E(x)]= jj го(х)В2(х)г?х = ^ 2
— со й=1 Z=1
. 2л/г . 2л/ .
X sm д— х sin г— х ах.
ах
Заменяя интеграл суммы в предыдущей формуле суммой
интегралов, можем записать:
£>[S (*)J = J
(— l)'i+Z
kl
. 2л/г . 2л/ ,
sin - х sin х ах.
Za у Za у
ММ
В силу нечетности функции sin (2л/гх/Ах) выражение
для дисперсии шума примет вид:
. 2 С° Л3 °°
& —1 / = —cq k~ 1
3*
67
поскольку
У, w(x = ikx) ^х — 1.
is=—со
Сумма ряда 1//г2 равна л2/6. Таким образом, в оконча-
тельном виде дисперсия ошибки шума квантования при боль-
шом числе уровней квантования практически не зависит от
распределения непрерывной величины х и равна:
£>[Е(х)] = А^/12.
Поскольку, как правило, величина шага квантования
достаточно мала (Ах о = JDfxj), плотность вероят-
ности непрерывной величины х в интервале Ах можно счи-
тать равномерной.
Полученная выше дисперсия Ах/12 действительно соот-
ветствует равномерному закону распределения в интервале
от — Ах/2 до ф-Ах/2.
Среднеквадратичная ошибка квантования, равная
ое = Ах/(2ГЗ),
в ]ЛЗ раз меньше максимальной ошибки.
Полученные выводы справедливы лишь для равномер-
ного квантования. С точки зрения уменьшения среднеквад-
ратичной ошибки выгоднее неравномерное квантование,
причем выигрыш тем значительнее, чем более плотность
распределения непрерывной величины отличается от рав-
номерной. Тогда для более вероятных значений сигнала шаг
квантования выбирается меньшим, а для менее вероятных —
большим.
2-2. ДИСКРЕТИЗАЦИЯ ПО ВРЕМЕНИ И ВОССТАНОВЛЕНИЕ НЕПРЕРЫВНЫХ ФУНКЦИЙ
При дискретизации по времени непрерывная по аргу-
менту функция х (I) преобразуется в функцию х (/*) дис-
кретного аргумента t* или отображается конечным числом
некоторых величин (например, коэффициентов разложения).
В простейшем случае переход от функции непрерывного
аргумента к функции дискретного аргумента может быть
выполнен путем взятия отсчетов функции в определенные
дискретные моменты времени tk, k = 1, 2, ... В результате
функция х (/) заменяется совокупностью мгновенных зна-
чений х (tk). По этим мгновенным значениям х (tk) можно
восстановить исходную функцию с заданной точностью.
68
Функцию, полученную в результате восстановления по
отсчетам х (tk), будем называть воспроизводящей и обозна-
чать через у (t).
Воспроизводящая функция у (I) строится как взвешен-
ная сумма некоторого ряда функций Д (t — tk):
со
У (0 = У, at [х (/*), х (tk-i)...] ft (t — tk),
i=0
причем коэффициенты разложения су зависят от отсчетов
х (^k), % • • *
При обработке параметрической информации дискрети-
зация по времени должна производиться так, чтобы по от-
счетным значениям функции х (tk) (или коэффициентам
разложения) можно было получить воспроизводящую
функцию у (t), которая с заданной точностью отображает
исходную функцию х (t).
При дискретизации приходится решать вопрос о том,
как часто необходимо производить отсчеты функции, т. е.
каков должен быть шаг дискретизации Ar = tk —
При малых величинах Д7- количество отсчетов функции
на отрезке обработки [О, Т] будет большим и точность вос-
произведения — высокой. При больших А7 количество от-
счетов уменьшится, но при этом точность воспроизведения
снижается. Обычно задается допустимая погрешность вос-
произведения исходной функции. Оптимальной является
такая дискретизация, которая обеспечивает представление
исходной функции с заданной точностью минимальным коли-
чеством отсчетов х (tk). В этом случае все отсчеты сущест-
венны для восстановления исходной функции. В случае
неоптимальной дискретизации, кроме существенных, про-
изводятся и избыточные отсчеты.
Эти отсчеты не нужны для восстановления исходной
функции с заданной точностью. Наличие избыточной инфор-
мации нежелательно при передаче информации, так как
канал связи занимается на более длительное время, чем
необходимо, или требуются каналы с большей пропускной
способностью. При хранении избыточной информации уве-
личивается необходимый объем памяти, увеличивается
время поиска и считывания записанных данных. Ввод избы-
точной информации в ЦВМ при обработке данных отрица-
тельно сказывается на скорости обработки. В связи с этим
возникла проблема сокращения избыточной параметриче-
ской информации.
69
Устранение этой избыточной для потребителя информа-
ции может производиться в процессе дискретизации по вре-
мени сообщений, так что дискретизацию по времени можно
рассматривать не только как операцию преобразования
непрерывного сообщения в дискретное, но и как один из ме-
тодов устранения избыточной для потребителя информации.
Рис. 2-2. Классификация методов дискретизации.
Методы дискретизации и восстановления непрерывных
функций различаются по следующим основным признакам:
1) регулярность отсчетов;
2) критерий выбора отсчетов и оценка точности воспро-
изведения;
3) способ воспроизведения;
4) вид воспроизводящих функций.
На рис. 2-2 приведена классификация в соответствии
с перечисленными признаками.
Регулярность отсчетов
Регулярность размещения отсчетов по оси Т во многом
предопределяет степень устранения избыточности и слож-
ность устройств дискретизации и восстановления.
70
*
В соответствии с этим признаком можно выделить две
основные группы методов: равномерную и неравномерную
дискретизацию.
При равномерной дискретизации функции х (t) на всем
рассматриваемом диапазоне DT изменения аргумента интер-
вал между отсчетами неизменен (Ду =const). Величина этого
интервала (шаг равномерной дискретизации) Ду выбирается
на основе априорных сведений о характеристиках сигнала.
При неравномерной дискретизации интервал между от-
счетами изменяется по случайному закону или с учетом
изменения характеристик сообщения (адаптивная дискре-
тизация).
В зависимости от возможности изменения интервала
между отсчетами т,- при адаптивной дискретизации выделим
две группы методов:
1) интервал т,- = 1Д7-, i = 1, 2, 3, ...,
/ =0, 1, 2... —дискретная величина;
2) интервал т,-, тн11н т,- тмакс — непрерывная ве-
личина.
Назовем в первом случае метод адаптивной дискретиза-
ции методом с кратными интервалами, во втором случае —
с некратными интервалами.
Методы равномерной дискретизации характеризуются
простым алгоритмом, при этом нет необходимости регист-
рировать время отсчетов, но из-за несоответствия интервала
между отсчетами характеристикам дискретизируемого сооб-
щения при отклонении последних от априорных возможна
значительная избыточность отсчетов.
Методы адаптивной дискретизации характеризуются
более сложными алгоритмами и устройствами дискретизации
и восстановления, но позволяют значительно сокращать
число избыточных отсчетов, что существенно для больших
потоков информации.
Критерии отбора отсчзтов
и оценка точности воспроизведения
Качество способа дискретизации, согласно которому от-
бираются отсчеты или коэффициенты разложения функции,
оценивают по той ошибке, с которой удается воспроизвести
исходную функцию.
Группа критериев отбора отсчетов относится к таким
моделям сигнала и таким способам его воспроизведения, что
71
ошибку воспроизведения удается обратить в нуль или близ-
кое к нулю значение. К таким критериям относятся:
1) частотный критерий В. А. Котельникова [Л. 2-1], при
котором интервалы между отсчетами выбираются с учетом
частотного спектра дискретизируемого сигнала;
2) корреляционный критерий отсчетов, предложенный
Н. А. Железновым [Л. 2-17] и устанавливающий связь
интервалов между отсчетами с интервалом корреляции
сигнала. Этот критерий предполагает применение специаль-
ного фильтра, при помощи которого удается выполнить
безошибочное восстановление дискретизированной функции
за бесконечно большой интервал времени. В тех случаях,
когда не предусмотрено применение фильтра, обращающего
в нуль ошибку воспроизведения, требования к интервалу
между отсчетами формулируются исходя из той или иной
характеристики ошибки;
3) Ф. Е. Темников [Л. 2-4] предложил для детермини-
рованной модели сигнала квантовый критерий отсчетов,
указывающий зависимость интервалов между отсчетами от
величины ступени квантования по уровню и крутизны (пер-
вой производной) сигнала. Подробнее эти критерии рас-
сматриваются ниже.
В последнее время разрабатывают устройства, в которых
интервал между отсчетами выбирается автоматически в за-
висимости от значений той или иной характеристики ошибки
воспроизведения, которая в этом случае играет роль кри-
терия.
По такому критерию оценивается отклонение воспроиз-
водимой функции у (t) от исходного сигнала х (/) на каждом
из интервалов дискретизации Ту.
Чаще других для этих целей применяют следующие кри-
терии: 1) критерий наибольшего отклонения
еу (0 == sup | (/) —
2) среднеквадратичный
'о/
е2/ (0 = ) к/ (0 — У/ (ОГ dt, t £ р0/оу];
3) интегральный
V
72
4) вероятностно-зональный
где р к,- (/) £ SJ — вероятность выхода значения х (/) из
зоны S, на интервале т,-.
Заметим, что только критерий наибольшего отклонения
обеспечивает возможность регистрации и индикации любых
изменений функции, включая кратковременные выбросы.
Если величину интервала дискретизации т,- подбирать
с учетом заданной ошибки, то эта величина зависит от того,
насколько удачно выбрана приближающая функция.
Для равномерного приближения согласно теореме Чебы-
шева [Л. 2-9, 2-10] обобщенный многочлен Pf (/) является
многочленом наилучшего приближения функции х (/) на
интервале т,- = |/07, £(n+iyl, если существуют такие п + 2
точки
toj Ч/ <С • • • ^(пц). г
в которых разность х (ty) — Р равна
(—1)“тах | Xi (0 — Pj (01,
причем показатель степени а равен +1 или —1, i =0, 1, ...,
п -|- 1, / =0, 1, 2, ...
В случае ненаилучших приближений число таких точек,
где разность xf (/) — Р}- (t) принимает максимальное значе-
ние и соблюдается условие чередования знака этой разности,
естественно, меньше, чем п + 2.
Обозначим через Л максимальное число точек на интер-
вале дискретизациит7, выбираемых из условия, что разность
Xj (t) — Pj (/) принимает максимально допустимое зна-
чение при чередовании ее знака, и будем называть К показа-
телем качества приближения.
При использовании в качестве приближающих алгебраи-
ческих многочленов Рп (t) степени п в случае наилучшего
приближения на интервале т7- имеем ZM!IKC — п + 2.
Аналогично можно оценить качество интегрального и
среднеквадратичного приближения. Эффективность устране-
ния избыточности при дискретизации повышается с увели-
чением показателя К, закладываемого при проектировании
в алгоритм дискретизации.
Способ воспроизведения
Выделим два способа воспроизведения исходного сиг-
нала: 1) воспроизведение с экстраполяцией; 2) воспроизве-
дение с интерполяцией.
73
В соответствии с этим признаком методы дискретизации
разделены на два класса: экстраполяционные и интерпо-
ляционные.
Методы дискретизации с экстраполяцией воспроизводя-
щих функций не требуют задержки сигналов в пределах
интервала дискретности. Следовательно, они могут исполь-
зоваться в системах, работающих в реальном масштабе вре-
мени (например — в управляющих системах). Дискретиза-
ция с интерполяцией требует задержки сигналов на интер-
вал интерполяции.
Воспроизводящие функции
Подбор воспроизводящих функций у (t), которые при
минимальном числе членов ряда разложения обеспечивали
бы необходимую точность воспроизведения, в общем слу-
чае связан с определенными трудностями.
Априорные сведения о сигналах, подлежащих дискрети-
зации, как правило, весьма ограничены. Поэтому выбор
типа воспроизводящих функций в основном определяется
требованиями ограничения сложности устройств дискрети-
зации и восстановления сигналов. В классификационной
таблице (рис. 2-2) перечислены основные типы функций,
применяемых в качестве воспроизводящих.
Требованию простоты нахождения коэффициентов раз-
ложения прежде всего отвечают степенные алгебраические
полиномы [Л. 2-9, 2-10]. Наиболее полно из этого класса
функций исследовано применение полиномов нулевой и
первой степени [Л. 2-3 — 2-6].
В последнее время появился ряд работ, где для восста-
новления применяются ортогональные системы функций
Чебышева и Лежандра [Л. 2-7]. Использование в качестве
воспроизводящих ортогональных систем функций, т. е.
таких, для которых $ хг (/) xk (t) dt = O при i #= k, в ряде
случаев оказывается целесообразным, так как для такой
системы относительно просто вычисляются коэффициенты
разложения и вычисление их включает операцию интегри-
рования сигнала, что положительно сказывается на поме-
хоустойчивости алгоритма дискретизации. Заметим, что
лишь при наличии значительной априорной информации
о сигналах может решаться задача оптимального выбора
конкретного узкого класса воспроизводящих функций. Так,
например, если известно, что сигналы являются периодиче-
скими, то поиск следует направить в класс гармонических
функций.
14
2-3. ТЕОРЕМА КОТЕЛЬНИКОВА
Если непрерывная функция х (t) удовлетворяет усло-
виям Дирихле (ограничена, кусочно-непрерывна и имеет
конечное число экстремумов) и ее спектр ограничен неко-
торой частотой сос, то существует такой максимальный
интервал Дг между отсчетами, при котором имеется возмож-
ность безошибочно восстановить дискретизируемую функ-
цию х (0 по дискретным отсчетам. Этот максимальный интер-
вал равен:
Д “ =_L
т «т 2/ст-
Для доказательства рассмотрим выражения прямого и
обратного преобразования Фурье непрерывной функции
x(t):
CQ
S(/a) = 5 x(t)e4u“dt, (2-1)
X ~ (/®)
(2-2)
Полагаем, что спектр функции ограничен частотой а>т:
5(/й)#0 при — о)т о <
S (/со) = 0 при | св О ат.
Следовательно, в выражении (2-2) можно ограничить
пределы интегрирования значениями и — сот:
*(0 = 2л S (/“) d(,>-
(2-3)
т
Рассмотрим комплексный спектр функции х (t). По-
скольку он задан лишь на интервале (— а>т, ат), его можно
разложить в комплексный ряд Фурье:
где
S(/co) = У]
k= — со
т
J
(2-4)
(2-5)
75
Сравнивая выражения (2-3) и (2-5), замечаем, что
они совпадают с точностью до постоянного множителя
Az-=n/com, если принять t = — k&r.
Следовательно,
Cft= " X(—kbr).
wm
Подставляя это соотношение в формулу (2-4), будем
иметь:
СО
5(/и) = У х (_ ЛД7) (2-6)
k =—со
Подставим выражение (2-6) в формулу (2-3), изменив
знак при k на том основании, что суммирование произ-
водится по всем положительным и отрицательным зна-
чениям k. Кроме того, учитывая сходимость ряда и интег-
рала Фурье, производим перестановку операций сумми-
рования и интегрирования:
— <0 k=—со
т
со ш
т
У x(kbT) (2-7)
Й =— СО —(О
т
После вычисления интеграла
(t-k&T)da;:=
1
/ (/ /еЛ у-)
(7— /г А у)
2 sin com (/—/гАу)
t — kt\T
и подстановки в (2-7) в окончательном виде получаем
выражение, называемое рядом Котельникова:
х(о= 2
,, . , sin[com(/ — /г Л )]
х (/г Л г) —L~т?—h
" ыт (t—йДу)
(2-8)
76
Как видно из этого выражения, непрерывная функция
представляется суммой произведений, один из двух сомно-
жителей которых есть значение непрерывной функции в
точке отсчета, а другой является некоторой функцией вре-
мени и называется функцией отсчетов (рис. 2-3):
,, _ sin [и„гК —nfe/tom)]
J К — л/г/сост)
Свойства функции отсчетов:
1) в момент времени t = kA т она достигает своего наи-
большего значения, равного единице (рис. 2-3);
2) в моменты времени, кратные Д7- (I = (/г ± Z) Дг,
где I — любое целое число), функция отсчетов обращается
в нуль;
3) функции отсчетов ортогональны на бесконечно боль-
шом интервале времени.
Функция отсчетов представляет собой реакцию идеаль-
ного фильтра нижних частот на единичную импульсную
функцию.
Таким образом, непрерывная функция х (t) может быть
представлена своими отсчетами х (kAT). Для восстановле-
ния функции х (t) необходимо подать на вход фильтра с верх-
ней границей пропускания сос последовательность идеально
узких импульсов с амплитудой, соответствующей значе-
ниям непрерывной функции в точках отсчета и следующих
друг за другом с периодом Дг.
Время реакции фильтра возрастает с увеличением кру-
тизны среза на граничной частоте. Для идеального фильтра
крутизна среза бесконечно велика, поэтому такой фильтр
должен обладать бесконечно большим запаздыванием ре-
акции.
77
На рис. 2-4 показана некоторая функция х (f) с ограни-
ченным спектром и отдельные слагаемые ряда (2-8) с макси-
мальными ординатами х (feAy), причем в точке t = /гАу
/г-я составляющая равна х а все остальные равны
нулю. Сложение всех составляющих дает исходную функ-
цию х (t).
Теорема Котельникова сыграла большую роль в технике
передачи и приема информации.
Наряду с частотным представлением сигналов (разложе-
ние в ряд Фурье, использование спектральных функций)
стали применять временное представление (разложение во
Дт 2Д, ЗЛТ 5Л7
к=/
т am(t- Лт)
К=2
к=3
№4
Рис. 2-4. Представление непрерывной функции
с помощью функций отсчетов.
временной ряд), которое явилось основой для развития гео-
метрических методов исследования сигналов. В основе этих
методов лежит представление непрерывного сигнала в виде
вектора в /г-мерном пространстве с координатами, соответ-
ствующими отсчетным значениям непрерывной функции.
Новое представление непрерывного сигнала позволило зна-
чительно упростить решение задач, касающихся преобра-
зований сигналов в линейных электрических цепях, так как
при этом основные аналитические операции сводятся к ал-
гебраическим. Это же представление легло в основу теории
потенциальной помехоустойчивости сигналов [Л. 2-16].
Особое значение теоремы Котельникова состоит в том,
что она позволила заменить исследование передачи непре-
рывных сообщений более простыми задачами исследования
передачи дискретных сообщений.
В последние годы при изучении свойств сигналов на пер-
вый план стали выдвигать их способность быть носителем
сообщения. Сообщения по своей природе относятся к слу-
78
чайным явлениям, и, таким образом, сигнал может служить
переносчиком сообщения лишь в том случае, если представ-
ляющая его непрерывная функция недетермирована, слу-
чайна. Между тем теорема Котельникова является точной
лишь для функций с ограниченным спектром.
Случайные функции с ограниченным спектром относятся
к классу вырожденных, или сингулярных. Для таких функ-
ций по прошлым их значениям с помощью системы линей-
ного прогнозирования могут быть предсказаны ее будущие
значения в любые последующие моменты времени со сред-
неквадратичной ошиб-
кой, как угодно мало
отличающейся от нуля.
В свете сказанного
становится очевидным,
что теорема Котельни-
кова, строго говоря, не-
справедлива для сигна-
лов, являющихся носи-
телями сообщений.
Кроме того, реаль-
ные сигналы, являющие-
ся носителями информа-
ции, имеют начало и ко-
Рис. 2-5. Изменение восстановленной
нец, Т. е. непрерывные функции при дополнительных отсче-
функции, описывающие тах.
такие сигналы, имеют
конечную длительность. Но такие функции не могут
иметь ограниченный спектр. Таким образом, для сигна-
лов конечной длительности теорема Котельникова непри-
менима.
На практике использование теоремы Котельникова так-
же наталкивается на ряд трудностей.
В первую очередь следует отметить, что представление
непрерывной функции в виде дискретных отсчетов через про-
межуток времени А? = „4- не позволяет воспроизводить
4 т
процесс, развивающийся во времени.
Пусть, например, на интервале Т непрерывная функция
времени восстанавливается по своим N — 2 fT отсчетам
(рис. 2-5). Если теперь вне интервала получен хотя бы один
дополнительный отсчет, то при восстановлении изменяется
вся непрерывная функция на всем предшествующем интер-
вале Т (за исключением отсчетных значений). Таким обра-
79
зом, получение новых данных изменяет непрерывную функ-
цию в «прошлом».
Получение функции отсчетов сопряжено с использова-
нием фильтра нижних частот, причем функция воспроизво-
дится тем точнее, чем ближе используемый фильтр к идеаль-
ному.
Однако, как указывалось, увеличение крутизны среза
такого фильтра ведет к увеличению задержки в получении
сигналов на выходе, т. е. приводит к значительному запаз-
дыванию при восстановлении сигнала.
Наконец, для реальных сигналов граничная частота
среза frtl является неопределенным параметром, для выбора
которого не существует достаточно обоснованных критериев.
Приведенные замечания свидетельствуют, что примене-
ние теоремы Котельникова вызывает определенные труд-
ности в том случае, когда она рассматривается как точное
утверждение. Практически, однако, идеально точное вос-
произведение функции никогда не требуется, необходимо
лишь воспроизведение с определенной, фиксированной
точностью.
Поэтому теорему Котельникова можно рассматривать
как приближенную для функций с неограниченным спект-
ром.
В работе [Л. 2-2] приводятся оценки погрешности пред-
ставления функции с неограниченным спектром рядом Ко-
тельникова (2-8). Показано, что непрерывную функцию вре-
мени, удовлетворяющую условиям Дирихле и имеющую
неограниченный спектр, можно представить в виде трех
слагаемых
х (0 = Xi (0 + ^2 (0 + *з (0,
где
2., . sin[2jifm(Z —йд )]
k——ca ' ‘
Значение граничной частоты fm выбирается при этом
произвольно, а период дискретности равен 1/2 fm. Сла-
гаемое х, (/) не содержит частот выше fm, спектр функции
х2 (/) не ограничен, а спектр функции х3 (/) содержит со-
ставляющие с частотами выше fm. Если значение fm выбрано
так, что при частотах выше fm спектральная плотность
функции х (t) мала, то слагаемые х2 (t) и х3 (/) малы по срав-
нению с ху (/) и можно записать:
X (/) х, (/).
80
При этом отклонение (t) от функции х (I) оценивается
выражением
СО
—со
где Ет — энергия, заключенная в высокочастотной части
спектра, т. е. в полосе частот выше fm', q — число, опреде-
ляющее характер убывания модуля спектральной функции
в высокочастотной части спектра. Если убывание происхо-
дит достаточно быстро, то q — малая величина. При этом
энергия ошибки заключена между Ет и ЗЕт.
Погрешность восстановления функции с неограниченным
спектрсм рядом Котельникова (2-8), оцениваемая относи-
тельной величиной среднеквадратической ошибки, опре-
деляется неравенством
где Е — полная энергия спектра.
Дальнейшее развитие теории дискретизации непрерыв-
ных сигналов связано с работами Н. А. Железнова [Л. 2-17].
2-4. ПРИНЦИП ДИСКРЕТИЗАЦИИ ЖЕЛЕЗНОВА
Та же задача определения максимального интервала Дг
между отсчетами решена Н. А. Железновым для случайного
сигнала.
Отличительные свойства непрерывного сигнала в этой
модели следующие:
1) спектр сигнала сплошной и отличен от нуля на всей
оси частот — оо< + оо;
2) сигнал имеет конечную длительность;
3) рассматриваются сигналы, которые могут быть пред-
ставлены как стационарными, так и нестационарными слу-
чайными функциями;
4) функция корреляции сигналов равна нулю вне ин-
тервала т0.
Длительность сигнала Т должна быть много больше
интервала корреляции т0 : Т т0.
Неограниченность спектра сигнала и его конечная дли-
тельность являются большими преимуществами этой мо-
S1
дели: она в большей степени отвечает свойствам реальных
сигналов, чем модель В. А. Котельникова.
Единственным ограничением в этой модели является
ограничение функции корреляции, которая имеет вид,
показанный на рис. 2-6:
Вхх (т) =
Вхх (т),
О,
Это означает, что соседние значения непрерывной функ-
ции х (/]) и х (t2) (рис. 2-7), отсчитанные через промежуток
времени больший, чем т0, могут считаться независимыми.
Рис. 2-6. Корреляционная
функция и интервал корре-
ляции сигнала.
Рис. 2-7. Некоррелированные
отсчеты непрерывной функции.
Для стационарных случайных сигналов, обладающих
перечисленными выше свойствами, Н. А. Железновым было
показано, что они могут быть предсказаны системой линей-
ного прогнозирования со среднеквадратичной ошибкой е2,
как угодно мало отличающейся от нуля, лишь в промежутке
времени, равном интервалу корреляции т0.
Таким образом, для непрерывного сигнала конечной
длительности Т (при условии, что Т т0) число некоррели-
рованных отсчетов не превышает величины N:
N = T/t0.
Следовательно, дискретизация непрерывной функции
с интервалом т0 обеспечивает возможность безошибочного
восстановления значений непрерывной функции внутри
интервалов т0 с помощью системы линейного прогнозиро-
вания.
Покажем, как определяется интервал корреляции для
реальных сигналов.
82
Для определения интервала корреляции вводится поня-
тие эффективной полосы частот сигнала, определяемой по
его спектральной плотности Sxx (®):
СО
^хл'Д^эфф == “о ' \ Sxx (ffi)
°л'л'макс J
О
где ^л-л- макс — наибольшее значение спектральной плотности
сигнала; Д<оэфф = 2лД/’эфф — эффективная полоса частот
сигнала.
Графически эффективная полоса частот представляет
собой основание прямоугольника с высотой Sxx ыакс и пло-
щадью, равной площади, ограниченной кривой спектраль-
ной плотности сигнала и ося-
ми координат (рис. 2-8).
Выше рассматривалось
применение принципа дискре-
тизации Железнова для ста-
ционарных случайных сигна-
лов. Однако он может быть
распространен и на неста-
ционарные сигналы. Для
произвольных нестационар-
ных случайных сигналов
функция корреляции зависит
Рис. 2-8. к определению эффек-
тивной полосы частот по спек-
тральной плотности сигнала.
от времени. Для этих сигналов вводится понятие теку-
щего интервала корреляции т0 (/), причем справедливо
также соотношение
1
Т,'“2А^фф(/)>
где Д/эфф (0 — эффективная полоса частот мгновенной спек-
тральной плотности с точностью до постоянного множи-
теля.
Естественно, что некоррелированные отсчеты для неста-
ционарной случайной функции располагаются неравно-
мерно по оси времени.
Вводя понятие о средних характеристиках нестационар-
ного сигнала, Н. А. Железнов доказывает, что произволь-
ным нестационарным сигналам могут быть поставлены в со-
ответствие квазистационарные сигналы, у которых среднее
значение, взятое по множеству реализаций, спектральная
плотность и корреляционная функция совпадают с соответ-
ствующими характеристиками нестационарных сигналов.
83
У квазистационарных сигналов интервал корреляции тсср
не зависит от времени. Для таких сигналов утверждается,
что непрерывные квазистационарные сигналы с неограни-
ченным спектром могут быть представлены своими отсче-
тами через интервалы Аг с точностью, сколь угодно близкой
к предельной точности, если Аг т0 ср и Т т0 ср.
Предельная точность воспроизведения зависит от струк-
туры корреляционной функции и отношения т0 ср/Аг.
2-5. ВЫБОР ПЕРИОДА ДИСКРЕТИЗАЦИИ ПО КРИТЕРИЮ НАИБОЛЬШЕГО ОТКЛОНЕНИЯ
Найдем максимально допустимую величину интервала
между отсчетами (шаг, или период, дискретизации), прини-
мая в качестве воспроизводящих функций степенные много-
члены Лагранжа.
Многочлен Лагранжа для равноотстоящих узлов t-t на
отрезке Uo, tn] может быть записан в следующем виде [Л. 2-9,
2-101:
Ln (0 = ро + 7. А Тп\ =
чХ(Х-1)-(Х-«) у ]Vc>(0)
п! 4 X —i ’
М
где
il — — . . .= ti tl_! = A/„,
x=(t — t0)/bTn, n—0, 1, 2 ..., i = 0, 1, 2, .... n.
Погрешность воспроизведения исходной непрерывной
функции х (t) с ограниченными производными многочленом
Лагранжа Ln (t) определяется остаточным членом
(2-9)
где Мп+1 — модуль максимального значения (п + 1)-й про-
изводной функции х (t).
Шаг равномерной дискретизации нужно выбрать таким,
чтобы по отсчетам функции х (/,) можно было бы восстано-
вить исходную функцию х (t) многочленом Лагранжа Ln (t)
с погрешностью
Я„(0^ео, (2-10)
где е0 — допустимая погрешность дискретизации по вре-
мени.
84
Рассмотрим наиболее часто встречающиеся способы дис-
кретизации с восстановлением при помощи многочленов
нулевой и первой степени.
Нулевая степень воспроизводящего многочлена
(ступенчатая аппроксимация)
В этом случае остаточный член (2-9) имеет вид:
(2-11)
Очевидно, что максимальное значение (t) принимает
при % = 1. С учетом (2-10) и (2-11) шаг равномерной дискре-
тизации [Л. 2-4]
Дт-о^ео/Мр (2-12)
Воспроизводящая функция у (f) = Lo (t) для /-го интер-
вала дискретизации коу, t0 (у+п] (/ =0, 1,2...) при восста-
новлении с экстраполяцией имеет вид (рис. 2-9, а):
(2-13)
а при восстановлении с интерполяцией
yj(f)=x(tou+u). (2-14)
Показатель качества приближения на каждом из интер-
валов дискретизации Д7о, выбранных в соответствии с
(2-12), может достигать величины А.макс = 1.
Рис. 2-9. Ступенчатая аппроксимация сигнала при различных
значениях показателя качества приближения.
а—А = 1; б — А =2.
макс макс
85
При воспроизводящих функциях вида
к(<оу) + *Oo(/+ll)l
У] V ’ — 2
(2-15)
(см. рис. 2-9, б) шаг равномерной дискретизации может быть
увеличен в 2 раза без увеличения погрешности
(2-16)
Очевидно, что этот случай в пределе соответствует
наилучшему приближению (Х.ыакс = 2) функции х (t) на
интервале ДУ0 полиномом нулевой степени (2-15).
Первая степень воспроизводящего многочлена
(линейная аппроксимация)
Анализ формулы (2-9) показывает, что остаточный член
7?i (/) принимает максимальное значение при % =1/2.
С учетом этого положения и формул (2-9) и (2-10), най-
дем допустимый шаг [Л. 2-3] равномерной дискретизации
А 71 И8е0//И2-
(2-17)
После некоторого преобразования воспроизводящая
функция может быть представлена на /-м интервале
дискретизации, величина которого соответствует (2-17)
в виде
У] (?)—Х (А/) “Ь [* (А (7+1) Л (А/)] (^ А1)/^7’1> (2-18)
Рис. 2-10. Линейная аппроксима-
ция сигнала.
ГДС А/ ( ^== А (у+1) •
Рисунок 2-10 иллюстрирует рассматриваемый случай
равномерной дискретизации.
Показатель качества приближения на каждом из интер-
валов [/оу, t0 (у+1)] (j =0, 1, 2...) может достигать макси-
мально возможной величи-
ны А,акс — 1 •
При повышении качест-
ва приближения шаг рав-
номерной дискретизации
увеличивается (табл. 2-1).
Шаг равномерной дис-
кретизации для многочле-
нов Ln (t) степени тг > 2
находится по формулам
86
Таблица 2-1
Степень п многочлена Показатель качества при- ближения по Чебышеву Z Максимальное значение шага равномерной дискретизации &тп Интервал интер- поляции
1 fo!mi дто
0 2 2е0/Л11 Дуо
1 8&о1М 2 Д у
1 2 3,4Ке0/Л42 Д у
3 4 J/e0/Af2 Ду
2 1 V 15,6е0/Л43 2Дт2
3 1 ]/ 24 80 Л44 ЗДг3
4 1 ]/ 33 Sg/Mg 4Дт4
(2-9) и (2-10). Результаты вычислений для Ayra и т„м^4
приведены в табл. 2-1. Шаги дискретизации ^Тп, А’Тп и
Д'г„ в табл. 2-1 соответствуют показателям качества при-
ближении ^wai<c 1 э ^макс = 2 И ^макс == 3.
В заключение данного параграфа оценим выигрыш
в увеличении шага равномерной дискретизации Ду/г (умень-
шение частоты опроса) при увеличении степени воспроиз-
водящего многочлена Ln (t), использовав неравенство
[Л. 2-31:
Мп+1^(ОП+1 |х (Омаке! (2-19)
Введем коэффициент
= Д/л/Д/о,
характеризующий изменение величины шага Д7„ по срав-
нению с шагом Ду0 при п = 0.
Коэффициенты р„ найдем для шагов Д7п, выбранных
в соответствии с данными табл. 2-1 при ZMaKC= 1 и с учетом
(2-19):
рт^2,83/Кт0; (2-20)
р2«с2,5/У%; (2-21)
р3^2,22/К?1; (2-22)
р4^ 2,02/7^; (2-23)
где То — допустимая относительная погрешность дискре-
тизации.
87
На основе формул (2-20) — (2-23) можно найти зависи-
мость
Рп = Ф(То)-
Некоторые значения р„ = ф (у0) приведены в табл. 2-2.
Таблица 2-2
р« Vo
0,2 0,1 0,05 0,02 0,01 0,005 0,001
Р1 6,35 8,95 12,7 20 28,3 40 89,5
Ра 7,32 11,6 18,4 34 53,9 85,2 250
Рз 6,54 12,5 20 36,7 67 118 395
Р4 7,35 12,75 22,2 46,3 80,5 140 504
Анализ зависимости р„ = ф('Уо) показывает, что сущест-
венное снижение избыточности отсчетов для дискретизации
с шагом А7„, ц > 2 получается при малых значениях
допустимой относительной погрешности уо~сО,О1.
В зоне больших значений у0 эффективность равномерной
дискретизации с шагом ДГ1 (линейная аппроксимация)
близка к эффективности дискретизации с шагом &Гп при
и > 2.
Следует заметить, что лишь при дискретизации с шагом
Дуо по (2-12) воспроизведение функции Ln(t) возможно
без задержки, в остальных случаях вводится задержка,
равная интервалу интерполяции т„ (см. табл. 2-2).
2-6. ВЫБОР ПЕРИОДА ДИСКРЕТИЗАЦИИ
ПО КРИТЕРИЮ СРЕДНЕКВАДРАТИЧНОГО ОТКЛОНЕНИЯ
Предположим, что принята равномерная дискретизация,
а точность воспроизведения оценивается среднеквадратич-
ным отклонением в узловых точках. Выберем в качестве
узловых точек такие, для которых среднеквадратичное
отклонение будет наибольшим, гарантируя таким образом,
что при оценке точности в любых других узловых точках
среднеквадратичное отклонение будет меньше.
Предполагая, как и ранее, что дискретизации подлежит
стационарная случайная функция времени, а продолжи-
тельность непрерывной функции значительно превосходит
88
интервал дискретизации, определим среднеквадратичную
ошибку воспроизведения как
e2 = 7W{[t/(6) — х(6)]2}.
При ступенчатой аппроксимации воспроизводящая функ-
ция может быть записана в следующем виде:
4/(/,) = х(/г-Лу-),
где Д?-—интервал дискретизации. Таким образом,
е~2 = Л1{[х&-Ду)--х(/0]2}.
Раскрывая скобки и учитывая, что М [х2 (^)] =
= М [х2 (ti — Дг)1 = Вхх (0), а М [х (6) х (Л — Дг)] =
= Вхх (Ду), где Вхх (т) — корреляционная функция ди-
скретизируемого сигнала х (t). Вследствие четности Вхх (т)
получим:
е2 = 2 [ВЛ.Л. (0) — ВЛЛ. (Ау)]
или _
Вхх(Ду) = ВА.Л.(0)—
Таким образом, если известна корреляционная функция
и задано максимально возможное значение среднеквадра-
тического отклонения е2, интервал
дискретизации можно определить по
соотношению
Дг=В^[вАД0)-|],
где символом Вхх обозначена функ-
ция, обратная корреляционной.
Определение интервала дискрети-
зации в том случае, когда корреля-
ционная функция задана графически,
показано на рис. 2-11. Если предва-
рительные данные о непрерывном
процессе отсутствуют (корреляцион-
ная функция неизвестна), то для опре-
Рис. 2-11. Определе-
ние интервала дискре-
тизации по корреля-
ционной функции сиг-
нала.
деления интервала дискретизации может быть использован
прием, описанный в [Л. 2-18]. По некоторой реализации
задается интервал дискретизации Ду- и находится средне-
квадратичное отклонение
п
ёр = 12 + (1’+ ~ХУ~ ZW-
1=1
89
Рис. 2-12. Определение ин-
тервала дискретизации по
среднеквадратичной ошибке.
Далее определяется среднеквадратичное отклонение на
том же отрезке при вдвое большем интервале дискретиза-
ции
п
=4 2v+(г'+2) -х у ~
i—i
Точно таким же образом определяются е^2, e.f2,
Em — среднеквадратичные отклонения при интервалах ди-
скретизации ЗДу, 4Ду, тДу.
Строится график зависимости е^2 от величины интер-
вала дискретизации kA?-
Построенная зависимость стремится к пределу eg ,
соответствующему дисперсии непрерывной функции. Таково
будет среднеквадратичное откло-
нение при выборе интервала
дискретизации, превосходящего
интервал корреляции (значения
двух соседних отсчетов при этом
статистически независимы). По
допустимой величине средне-
квадратичного отклонения 8^ на-
ходим по графику допустимый
интервал дискретизации (рис.
2-12).
При линейной аппроксима-
ции воспроизводящая функция
внутри интервала дискретизации выражается как
у (Г) = х (tt) + [х (ti+1)—х (6)]
*1+1 —
где ti 6,1
Обозначим:
f — h f — h
-------------------— —------ — v
6+1 ------------------------ 6 Ду
Тогда
У (?) = X (ti) + [х (6-+1) - X (/,-)] х = X (ti) [1 — х] + хх (ti+l).
Среднеквадратичная ошибка воспроизведения равна:
&=М[х (?) - у (О] = М {[х(Г) - x(ti) (1 - х) + XX(6+1)]2} =
= М {[х (Г)]2 + [х2 (tt) (1 - х)2] + X2 [х2 (6+1)] -
— 2х (?) х (ti) (1 - х) — 2хх (Г) х (ti+l) + 2х (1 - X) *(6+i) х(6)}-
90
Учитывая, что М {к (£)]2} — В (0), а М {х (t')x (t;)} —
— В (I' — ti) — В (т), получаем:
ёг = В (0) + (1 - х)2 В (0) + х2В (0) - 2 (1 — х) В (т) ~
-2хВ (Ат-т) + 2х (1 - X) В (Аг) = В (0) [ 1 + (1 -х)2 +
+ Х2-2(1 -х)/'('г)-2Х/'(Ат--т) + 2х(1 -х)''(А7)],
где г — В (Дт)/В (0) — нормированная корреляцион-
ная функция.
Можно показать, что среднеквадратичная погрешность
максимальна, если узловые точки выбрать в середине интер-
вала, т. е.
— ti 1
X = Z-Z^:= 9 •
4+1 — Li z
В этом случае среднеквадратичное отклонение е„акс
равно:
Г 1 1 /ДЛ /дг\ 1
емакс = В (0) 1 + — Г р -~-j — Г ^2 / + ЗУ Г (А т) =
= В (0) [ 1,5 - 2г + 0,5г (А г)].
Таким образом, для заданного значения среднеквадра-
тичного отклонения eg выбранная величина интервала
дискретизации А, должна подчиняться соотношению
eg 1,5В (0) - 2В ( + 0,5В (Дг).
2-7. АДАПТИВНАЯ ДИСКРЕТИЗАЦИЯ
Общие принципы адаптивной дискретизации рассмотрены в
[J1. 2-4—2-6]. На каждом интервале дискретизации Ту (/ = 0,1,2,...)
находится некоторая функция z/y (f) выбранного типа и порядка (сте-
пени) в предположении, что она лучшим образом (для группы с показа-
телем качества Хмакс) будет приближать функцию х (f) на интервале Ту.
Указавное условие проверяется и, если необходимо и возможно, нахо-
дится новая функция, наилучшим способом воспроизводящая функцию
х (0. На интервале дискретизации Ту непрерывно проверяется близость
исходной и воспроизводящей функции в соответствии с принятым кри-
терием оценки погрешности воспроизведения. Погрешность воспроиз-
ведения е (0 сравнивается с максимально допустимым значением е0
и в момент равенства е (0 = е0 фиксируется конец интервала дискрети-
зации Ту.
На интервале Ту регистрируются отсчеты значений функции Ху (0
или некоторые характеристики функции z/y (0 (например, коэффициен-
ты разложения), по которым можно восстановить исходную функцию
91
с погрешностью, не превышающей допустимую. Кроме того, регистри-
руется величина интервала дискретизации.
Как отмечалось, при классификации методов дискретизации можно
выделить две группы методов адаптивной дискретизации: дискретиза-
цию с некратными интервалами и дискретизацию с кратными интерва-
лами. Ниже рассматриваются эти группы методов.
Рассмотрим принцип адаптивной дискретизации с некратными
интервалами и воспроизводящими степенными многочленами при оценке
верности воспроизведения по наибольшему отклонению.
Нулевая степень воспроизводящего многочлена
Рассмотрим три способа дискретизации с различным качеством при-
ближения.
1. Ф. Е. Темниковым [Л. 2-4] введен квантовый критерий отсчетов.
Аналитическое выражение квантового критерия может быть получено
при аппроксимации функции х (t)
отрезками полиномов нулевой сте-
пени (прямых), проходящими через
точки пересечения функции х (f)
с семейством линий квантования,
построенных с соблюдением соотно-
шения
Рис. 2-13. Адаптивная дискре-
тизация на основе квантового
критерия отсчетов.
(2-24)
где х' (0 | Ar — первая производная
сообщения на интервале А?-; Дх —
шаг квантования.
На рис. 2-13 приведен пример
адаптивной дискретизации сообще-
ния на основе квантового критерия
отсчетов.
Как видно из рис. 2-13, конец интервала (точнее отрезка) дискре-
тизации 1Уо/, 4h/+1)J (длительностью Ту) фиксируется при равенстве
| Дху (Z)| = | Xj (0 - х (tof) I = {»о. (2-25)
В этот момент производится отсчет сообщения х (4) <у+и) и Далее
вновь проверяется соотношение (2-25).
В процессе дискретизации осуществляется отсчет значений х (tbj)
и tOj (или Ту). По этим отсчетам восстанавливается исходная функция.
Воспроизводящая функция
tjj (t) = х
(2-26)
Качество приближения данного способа характеризуется значением
показателя ^макс ’ 1 *
2. Пусть воспроизводящая функция z/y(Q на интервале дискретиза-
ции [4>у, 4, (7+1)1 совпадает со значением исходной функции в началь-
ной точке 4)/ интервала:
У] (0 = х
92
В устройстве дискретизации на каждом из интервалов Т/ вычис-
ляется разность ts.Xj (Z) = Xj (t) — х модуль которой сравнивается
с допустимой погрешностью е(|. Конец интервала дискретизации Ту
фиксируется при равенстве
I Л*/ (О I = efi.
На рис. 2-14, а приведен пример дискретизации сообщения х (/)
в соответствии с этим алгоритмом.
Максимально возможное значение показателя качества приближе*
ния для данного алгоритма
^макс 1-
3. Пусть воспроизводящая
функция z/y(/) на интервале дис-
кретизации [/оу, 4ну+1)1 имеет
вид;
{/у(/) = х(/оу) + б,
В устройстве дискретизации
на каждом из интервалов опре-
деляется разность Алу (/) =
= Xj (t) — х (Zoy), проверяется
постоянство знака этой разно-
сти, записывается в ячейку па-
мяти знак разности sign Алут (Г)
при равенстве в первый раз ве-
личин Алу (/) и е0, проводится
сравнение | Алу (Q | с величи-
нами 0, е0, 2е0,
Рис. 2-14. Адаптивная дискретиза-
ция сигнала с воспроизводящими
функциями нулевой степени:
Восстановление
исходного
а — при
К
макс
сигнала производится (рис.
2-14, б) по значениям функции х (tQj) и
Воспроизводящая функция имеет вид:
== 1; б — при X = 2.
* макс
знаку приращения.
yj(t) = x(‘Oj) + e, (2-27)
где
g [ ± е0 при sign Axyi (/) = +!,
(. 0 при sign Алу (/) = var в зоне х(/0/)±е0.
Качество приближения для данного способа дискретизации харак-
теризуется значением показателя Хмакс 2.
Первая степень воспроизводящего многочлена
Рассмотрим несколько способов адаптивной дискретизации, разли-
чающихся качеством приближения, а следовательно, сложностью
алгоритмов и устройств дискретизации и восстановления:
93
1. Как и в случае многочлена нулевой степени, уравнения вос-
производящих функций найдем, разлагая сообщение в начальных точках
/„у интервалов Ту (/ = 0,1,2,...) в ряд Тейлора первого порядка:
г/7-(г) = х(^/) + х'(^7Н- (2-29)
В устройстве дискретизации иа каждом из интервалов генерируется
приближающая прямая (2-29) и непрерывно вычисляется разность
Дху (0 = Xj(f) — i/j (f). Конец интервала дискретизации определяется
равенством
|ДЛ7 (0| = е0.
Восстановление сообщения на интервале Ту производится с учетом
значений сообщения и его первых производных в начальных точках
Рис. 2-15. Адаптивная дискретизация
с воспроизводящими функциями пер-
вой степени.
интервалов в соответствии
с формулой (2-29).
Качество приближения
характеризуется значением
показателя Лмакс = 1.
На рис. 2-15 приведен
пример, иллюстрирующий
этот способ дискретизации.
Следует заметить, что на-
хождение воспроизводящей
ф) нкции связано с дифферен-
цированием сообщения. При
наличии высокочастотных по-
мех, наложенных на сообще-
ние, эффективность алгорит-
мов дискретизации, включаю-
щих операции дифференцирования, снижается. В таких случаях мо-
жет оказаться выгодным способ дискретизации, при котором исключена
операция дифференцирования.
2. Интерполяционно-экстраполяционная адаптивная дискретиза-
ция.
В тех случаях, когда известен модуль максимального значения
(п 4- 1)-й производной Л1„+1 сообщения х (f), воспроизводящую функ-
цию у (f) можно определить как интерполирующую по п + 1 отсчетным
точкам на начальной части интервала Ту.
На остальной части интервала воспроизводящая функция находится
путем экстраполяции найденной. На этом участке определяется разность
|Аху (0 | = | Xj- (0—yj(.t)l, которая сравнивается с допустимой
погрешностью е0.
Для многочлена степени п = 1 допустимая величина отрезка, на
котором погрешность не превысит е0, в соответствии с (2-17)
А V 8е0/Л12.
В устройстве дискретизации в начальной точке tBj интервала Ту
и точке /,,у + &Т1 осуществляется отсчет значений сообщения. По этим
данным находятся коэффициенты
«У = х
x(tBJ-+ Д^) — x(tBj)
bj— ~к ’
уравнения i/y (/) = ry + bjt.
94
Функция У] (t) эстраполируется на остальную часть интервала Ту.
Описанный способ дискретизации иллюстрируется рис. 2-16.
Качество приближения характеризуется значением показателя
^макс 1•
Повышение качества приближения сопряжено со значительным
усложнением алгоритма дискретизации. В [Л. 2-6] рассматриваются
алгоритмы с лучшим качеством приближения по сравнению с рассмот-
ренным выше алгоритмом.
При равномерной дискретизации интервал между отсчетами яв-
ляется постоянной величиной, что существенно упрощает дискретиза-
цию и восстановление сообщения. Адаптивная дискретизация эффектив-
нее равномерной, но неравномер-
ность отсчетов приводит к необхо-
димости их датирования. Адаптив-
ная дискретизация с кратными ин-
тервалами является в некоторой
степени компромиссным решением.
Алгоритмы кратно-адаптивной
дискретизации отличаются от алго-
б)
Рис. 2-17. Кратно-адаптивная
дискретизация.
а - при \акс = 1: 6 - при
Рис. 2-16. Интерполяционно-экс-
траполяционная адаптивная дис-
кретизация.
ритмов адаптивной дискретизации с некратными интервалами тем, что
конец интервала дискретизации длительностью Ту фиксируется лишь
в моменты 4/ + i^Tn, i — О, 1> 2...
Очевидно, что выполнение логических условий, указывающих на
окончание интервала Ту, может происходить в момент
li—1, j
В качестве последней точки интервала Ту в этом случае могут быть
приняты точки fjj, или Ту. Выбор в качестве последней точки t: ,,у
интервала Ту влечет за собой введение задержки сообщений в устрой-
стве дискретизации на интервал Ту и ограничивает длину следующего
интервала дискретизации Ту+1 величиной Д т .
С целью упрощения алгоритма, а следовательно, и устройств ди-
скретизации будем принимать за конечную точку интервала Ту точку
kj ~ 4>7+и и восстановление проводить с учетом этого обстоятельства.
Рассмотрим принцип кратно-адаптивной дискретизации при вос-
производящих многочленах нулевой степени. В качестве исходного
интервала возможен выбор интервала (2-12) или интервала (2-16).
95
В зависимости от качества приближения выделим два способа ди-
скретизации с исходным интервалом (2-12):
1. Алгоритм дискретизации совпадает с применяемым во втором
способе для п = 0, но отсчеты значений сообщения осуществляются
лишь в моменты tOj + i^To- Воспроизводящая функция у}- (f) на интер-
вале Ту:
при i = 1
'// (П = х Voj), (2-3°)
а при i ;=- 2 (рис. 2-17, а)
V/ (0 =
| tOj^t sS^oy+i
( (^оАх/+1) to (/+!>•
(2-31)
Наилучшее приближение при данном способе дискретизации дости-
гается при Лмакс = 1.
2. Дискретизация проводится как в третьем способе при п = 0,
но отсчеты и выдача данных производятся лишь в моменты ty
(рис. 2-17, б). Воспроизводящая функция при i =1 (Ту = Ду0) совпа-
дает с (2-30), а при i > 2 имеет вид:
J х (ioj) + 8> =£ t0 (у+1) — Ду0,
( Х (^0 < /+1) > ^0 < /+1> Дур ^0 1/+1П
Г -I- gg
где е = < в соответствии с (2-28).
Лучшему приближению для рассмотренного способа соответствует
значение показателя Хмакс = 2.
При выборе в качестве исходного интервала величины А^() алгорит-
мы дискретизации вторым и третьим способами при п — 0 совпадают,
но несколько меняются алгоритмы восстановления.
В заключение отметим, что первый из приведенных алгоритмов
кратно-адаптивной дискретизации сходен с разностно-дискретным пре-
образованием, названным в [Л. 2-12] ЛД-преобразованием.
Глава третья
КОДИРОВАНИЕ ИНФОРМАЦИИ
3-1. ОБЩИЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ. ЦЕЛИ ИОДИРОВАНИЯ
Рассматриваемые ниже общие принципы кодирования
информации справедливы как для систем, основная функ-
ция которых — передача информации в пространстве (си-
стемы связи), так и для систем, основная функция которых —
передача информации во времени (системы хранения инфор-
мации). В последних линией связи считается среда, в кото-
рой хранится информация.
Под кодированием в широком смысле слова
подразумевается представление сообщений в форме, удобной
96
для передачи по данному каналу. Обратная операция назы-
вается декодированием.
Рассмотрим общую схему системы передачи информации,
представленную на рис. 3-1.
Сообщению z на выходе источника информации ИИ нам
необходимо поставить в соответствие определенный сигнал.
Поскольку число возможных сообщений при неограничен-
ном увеличении времени стремится к бесконечности, а за
достаточно большой промежуток времени весьма велико, то
ясно, что создать для каждого сообщения свой сигнал прак-
тически невозможно.
Однако учитывая, что дискретные сообщения склады-
ваются из букв, а непрерывные также можно представить
последовательностью цифр в каждый момент отсчета, име-
ется возможность обойтись конечным числом образцовых
сигналов, соответствующих
отдельным буквам алфавита
источника.
При большом объеме ал-
фавита часто прибегают к
представлению букв в другом
алфавите с меньшим числом
букв, которые мы будем на-
зывать символами. Для обо-
значения этой операции ис-
пользуется тот же термин
кодирования, понимаемый те-
Рис. 3-1. Общая схема системы
передачи информации.
перь в узком смысле.
Поскольку алфавит символов меньше алфавита букв, то
каждой букве соответствует некоторая последовательность
символов, которую назовем кодовой комбина-
цией. Число символов в кодовой комбинации называется
ее з и а ч н о с т ь ю.
В процессе преобразования букв сообщения в сигналы
может преследоваться несколько целей. Первая из них
заключается в том, чтобы преобразовать информацию в та-
кую систему символов (код), чтобы она обеспечивала про-
стоту и надежность аппаратурной реализации информа-
ционных устройств и их эффективность. Это требование
означает простоту аппаратуры различения отдельных сим-
волов, минимальное время при передаче или минимальный
объем запоминающего устройства при хранении, простоту
выполнения в этой системе арифметических и логических
действий. Статистические свойства источника сообщения
4 Темников Ф. Е. и др.
97
и помех в канале связи при этом не принимаются во внима-
ние. Техническая реализация процесса кодирования в таком
простейшем виде при непрерывном входном сигнале осуще-
ствляется аналого-кодовыми преобразователями.
В своих основных теоремах Шеннон обосновал эффек-
тивность введения в тракт кодирующих, а следовательно,
и декодирующих устройств, цель которых состоит в согла-
совании свойств источника сообщений со свойствами канала
связи.
Одно из них (кодер источника КИ) имеет целью обеспе-
чить такое кодирование, при котором путем устранения
избыточности существенно снижается среднее число сим-
волов, требующихся на букву сообщения. При отсутствии
помех это непосредственно дает выигрыш во времени
передачи или в объеме запоминающего устройства, т. е.
повышает эффективность системы. Поэтому такое кодиро-
вание получило название эффективного, или опти-
мального.
При наличии помех в канале оно позволяет преобразо-
вать входную информацию в последовательность символов,
наилучшим образом (в смысле максимального сжатия)
подготовленную для дальнейшего преобразования.
Второе кодирующее устройство (кодер канала КК)
преследует цель обеспечить заданную достоверность при
передаче или хранении информации путем дополнительного
внесения избыточности, но уже по простым алгоритмам и
с учетом интенсивности и статистических закономерностей
помехи в канале связи. Такое кодирование получило назва-
ние помехоустойчивого.
Целесообразность устранения избыточности сообщения
методами эффективного кодирования с последующим пере-
кодированием помехоустойчивым кодом обусловлена тем,
что избыточность источника сообщения в большинстве слу-
чаев не согласована со статистическими закономерностями
помехи в канале связи и поэтому не может быть полностью
использована для повышения достоверности принимаемого
сообщения, тогда как обычно можно подобрать подходящий
помехоустойчивый код. Кроме того, избыточность источника
сообщений часто является следствием весьма сложных
вероятностных зависимостей и позволяет обнаруживать и
исправлять ошибки только после декодирования всего сооб-
щения, пользуясь сложнейшими алгоритмами и интуицией.
Итак, выбор кодирующих и декодирующих устройств
зависит от статистических свойств источника сообщений,
98
а также уровня и характера помех в канале связи. Если
избыточность источника сообщения и помехи в канале связи
практически отсутствуют, то введение как кодера источника,
так и кодера канала нецелесообразно.
Когда избыточность источника сообщения высока, а по-
мехи весьма малы, целесообразно введение кодера источ-
ника. Когда избыточность источника мала, а помехи велики,
целесообразно введение кодера канала.
При большой избыточности и высоком уровне помех
целесообразно введение обоих дополнительных кодирующих
(и декодирующих) устройств.
После кодера канала Л'К кодированный сигнал посту-
пает в устройство кодирования символов сигналами —
модулятор М. Получаемый на выходе модулятора сигнал х
подготовлен к передаче по конкретной линии связи ЛС
(либо к хранению в некотором запоминающем устрой-
стве).
В линии связи на сигнал накладываются помехи (посту-
пающие из условно показанного на схеме рис. 3-1 источника
помех ИП), так что в устройство декодирования сигналов
в символы — демодулятор ДМ — из канала связи при-
ходит сигнал, искаженный шумом, который обозначен на
схеме у. Устройство декодирования помехоустойчивого
кода — декодер канала ДК — и устройство декодирования
сообщений — декодер источника ДИ — выдают декодиро-
ванное сообщение и получателю П (человеку или машине).
3-2. КОДИРОВАНИЕ КАК ПРОЦЕСС ВЫРАЖЕНИЯ ИНФОРМАЦИИ В ЦИФРОВОМ ВИДЕ
Большинство кодов, используемых при кодировании
информации без учета статистических свойств источника и
помехи в канале связи, основано на системах счисления.
Любому дискретному сообщению или букве сообщения
можно приписать какой-то порядковый номер. Измерение
аналоговой величины, выражающееся в сравнении ее с образ-
цовыми мерами, также приводит к числовому представлению
информации. Передача или хранение сообщений при этом
сводится к передаче или хранению чисел. Числа можно
выразить в какой-либо системе счисления. Таким образом,
будет получен один из кодов, основанных на данной системе
счисления (см. также § 1-1).
Сравним системы счисления и построенные на их основе
коды с позиций применения в системах передачи, хранения
и преобразования информации.
4*
99
Общепризнанным в настоящее время является пози-
ционный принцип образования системы счисления. Значение
каждого символа (цифры) зависит от его положения —
позиции в ряду символов, представляющих число.
Единица каждого следующего разряда больше единицы
предыдущего разряда в т раз, где т — основание системы
счисления. Полное число получаем, суммируя значения по
разрядам,
i
Q = aiml 1 — alml1 + «7-1 + • • • +
где i — номер разряда данного числа; I — количество
разрядов; о,- — множитель, принимающий любые цело-
численные значения в пределах от 0 до т — 1 и показы-
вающий, сколько единиц г-го разряда содержится в числе.
Рис. 3-2. Зависимость количе-
ства разрядов в числе от осно-
вания системы счисления.
Чем больше основание сис-
темы счисления, тем меньшее
число разрядов требуется для
представления данного числа,
а следовательно, и меньшее
время для его передачи.
Однако с ростом основа-
ния существенно повышается
требование к линии связи и
аппаратуре создания и рас-
познавания сигналов, соответ-
ствующих различным симво-
лам. Логические элементы вы-
числительных устройств в этом
случае должны иметь большее
число устойчивых состояний.
Учитывая оба обстоятельства, целесообразно выбрать
систему, обеспечивающую минимум произведения коли-
чества различных символов т на количество разрядов I
для выражения любого числа. Найдем этот минимум по
графику на рис. 3-2, где показана связь между величинами
т и I при воспроизведении определенного достаточно боль-
шого числа Q (Q 60 000).
Из графика следует, что наиболее эффективной системой
является троичная. Незначительно уступают ей двоичная и
четверичная. Системы с основанием 10 и более существенно
менее эффективны. Сравнивая эти системы с точки зрения
удобства физической реализации соответствующих им логи-
ческих элементов и простоты выполнения в них арифмети-
100
ческих и логических действий, предпочтение необходимо
отдать двоичной системе. Действительно, логические эле-
менты, соответствующие этой системе, должны иметь всего
два устойчивых состояния. Задача различения сигналов
сводится в этом случае к задаче обнаружения (есть импульс
или нет импульса), что значительно проще.
Арифметические и логические действия также наиболее
просто осуществляются в двоичной системе. В таблицы
сложения, вычитания и умножения входит всего по четыре
равенства:
Правила Правила Правила
сложения: вычитания: умножения:
0 + 0 = 0 0-0 = 0 0-0 = 0
0+1 = 1 1-0=1 0-1=0
1 + 0=1 1-1=0 1-0 = 0
1 + 1 = 10 10-1 = 1 1-1 = 1
Наиболее распространенная при кодировании и декоди-
ровании логическая операция — это сложение по модулю.
В двоичной системе она также наиболее проста и опреде-
ляется равенствами:
0ф0 = 0 1ф1=0
0ф1 = 1 1ф0 = 1.
Алгоритм перевода числа из двоичной системы в привыч-
ную для человека десятичную систему несложен. Пересчет
начинается со старшего разряда. Если в следующем разряде
стоит 0, то цифра предыдущего (высшего) разряда удваи-
вается. Если же в следующем разряде единица, то после
удвоения предыдущего разряда результат увеличивается
на единицу.
Найдем, например, десятичный эквивалент двоичного
числа 1001. После первой единицы слева стоит 0. Удваиваем
эту единицу. Получаем число 2. Цифрой следующего млад-
шего разряда также является 0. Удваивая число 2, полу-
чаем 4. В самом младшем разряде стоит единица. Удваивая
число 4 и прибавляя 1, окончательно получаем 9.
Итак, для передачи и проведения логических и арифме-
тических операций наиболее целесообразен двоичный код.
Однако он не удобен при вводе и выводе информации, так
как трудно оперировать с непривычными двоичными чис-
лами. Кроме того, запись таких чисел на бумаге оказы-
вается слишком громоздкой. Поэтому, помимо двоичной,
101
получили распространение системы, которые с одной сто-
роны легко сводятся как к двоичной, так и к десятичной сис-
темам, а с другой стороны—дают более компактную запись.
К таким системам относятся восьмеричная, шестнадца-
тиричная и двоично-десятичная.
В восьмеричной системе для записи всех возможных
чисел используется восемь цифр, от 0 до 7 включительно.
Перевод чисел из восьмеричной системы в двоичную крайне
прост и сводится к замене каждой восьмеричной цифры
равным ей трехразрядным числом. Например, для восьме-
ричного числа 745 получаем:
7 4 5
111 100 101
Поскольку в восьмеричной системе числа выражаются
короче, чем в двоичной, она широко используется как
вспомогательная система при программировании.
Чтобы сохранить преимущества двоичной системы и
удобство десятичной системы, используют двоично-
десятичные коды. В таком коде каждая цифра деся-
тичного числа записывается в виде четырехразрядного
двоичного числа (тетрады). С помощью четырех разрядов
можно образовать 16 различных комбинаций, из которых
любые 10 могут составить двоично-десятичный код. Наиболее
целесообразным является код 8-4-2-1 (табл. 3-1). Этот код
относится к числу взвешенных кодов. Цифры в названии
кода означают вес единиц в соответствующих двоичных
разрядах.
Таблица 3-1
Число в деся- тичном коде Двон чн о-дес яти ч н ы й код с весами 8-4-24 Двоично-десятичный код с весами 5-1-2-1 Двои чио* десятич- ный код с весами 2-4-24
0 0000 0000 0000 0000 0000 0000
1 0000 0001 0000 0001 0000 0001
2 0000 0010 0000 0010 0000 0010
3 0000 ООН 0000 ООН 0000 ООН
4 0000 0100 0000 0111 0000 0100
5 0000 0101 0000 1000 0000 1011
6 0000 оно 0000 1001 0000 1100
7 0000 0111 0000 1010 0000 1101
8 0000 1000 0000 1011 0000 1110
9 0000 1001 0000 1111 0000 1111
10 0001 0000 0001 0000 0001 0000
102
Таблица 3-2
Число в деся- тичном коде Код Грея Число в деся- тичном коде Код Грея Число в деся- тичном коде Код Грея
0 0000 6 0101 и 1110
1 0001 7 0100 12 1010
2 ООП 8 1100 13 1011
3 0010 9 1101 14 1001
4 оно 10 1111 15 1000
5 0111
Этот двоично-десятичный код обычно используется как
промежуточный при введении в вычислительную машину
данных, представленных в десятичном коде.
Перевод чисел из десятичного кода в двоично-десятичный
осуществляется перфоратором в процессе переноса информа-
ции на перфоленту или перфокарты. Последующее преобра-
зование в двоичный код осуществляется по специальной
программе в самой машине. В той же табл. 3-1 представлены
два других двоично-десятичных кода с весами 5-1-2-1 и
2-4-2-1, которые широко используются при поразрядном
уравновешивании в цифровых измерительных приборах.
Среди кодов, отходящих от систем счисления, большое
практическое значение имеют также коды, у которых при
переходе от одного числа к другому изменение происходит
только в одном разряде. Наибольшее распространение
получил код Грея, часто называемый циклическим или
рефлексно-двоичным. Код Грея используется в технике
аналого-кодового преобразования, где он позволяет свести
к единице младшего разряда ошибку неоднозначности при
считывании. Комбинации кода Грея, соответствующие
десятичным числам от 0 до 15, приведены в табл. 3-2.
Правила перевода числа из кода Грея в обычный двоич-
ный сводится к следующему: первая единица со стороны
старших разрядов остается без изменения, последующие
цифры (0 и 1) остаются без изменения, если число единиц,
им предшествовавших, четно, и инвертируются, если число
единиц нечетно.
Выразим одно из чисел кода Грея, например 1010, в
обычном двоичном коде. Первая единица слева переписы-
вается. Следующая цифра будет единицей, так как в этом
разряде кода Грея стоит 0 и впереди только одна единица.
103
Далее необходимо записать нуль, так как в следующем
разряде исходного числа стоит 1 и впереди снова имеется
только одна единица. Поскольку перед последней цифрой
числа в коде Грея стоят две единицы, то она должна остаться
неизменной, т. е. нулем. Таким образом, числу 1010 в коде
Грея соответствует обычное двоичное число 1100.
3-3. ТЕХНИЧЕСКИЕ СРЕДСТВА ПРЕДСТАВЛЕНИЯ ИНФОРМАЦИИ В ЦИФРОВОЙ ФОРМЕ
Разновидности преобразователей
Устройства, позволяющие заменять непрерывную последователь-
ность значений аналоговой величины конечным числом дискретных зна-
чений и представлять их в заданном коде, получили название аналого-
кодовых преобразователей. Кодовые эквиваленты аналоговой величины
могут быть представлены комбинациями состояний оптических, электро-
механических, электронных и других элементов, а также параллельными
или последовательными во времени комбинациями электрических им-
пульсов.
Рис. 3-3. Классификация основных типов аналого-кодовых преобразо-
вателей.
В случае необходимости обработки информации посредством цифро-
вых вычислительных машин, как правило, используются представления
в двоичном коде.
Аналого-кодовые преобразователи являются основными блоками
в комбинированных вычислительных машинах, в которых информация
выражается в двух различных видах: аналоговом и цифровом. Посколь-
ку цифровые вычислительные машины выполняют элементарную опера-
цию за время в несколько десятков микросекунд, то предназначенные
для них аналого-кодовые преобразователи должны работать с такой же
скоростью.
В аналого-кодовых преобразователях, которые должны выдавать
кодовые эквиваленты на систему цифровой индикации или на регистри-
104
рующее устройство, непосредственно используемые человеком, целесо-
образно применять представления в десятичном коде.
Аналого-кодовые преобразователи можно классифицировать по
многим существенным признакам. Важнейшими из них являются прин-
цип работы измерительной части преобразователя и принцип получения
цифрового эквивалента.
По принципу получения цифрового эквивалента все разнообра-
зие существующих преобразователей может быть разбито на три
основные группы: преобразователей считывания, преобразователей
последовательного счета и преобразователей поразрядного уравнове-
шивания.
Принцип работы измерительной части преобразователя во многом
определяет его точность, быстродействие и простоту схемы. В связи
с этим преобразователи первых двух групп разобьем на подгруппы в со-
ответствии с тремя методами измерительных преобразований: прямым,
развертывающим и следящим (рис. 3-3, см. также гл. 5).
Аналоговой величиной, поступающей на вход преобразователя, мо-
жет быть напряжение, угол поворота вала, время и т. д. Рассмотрим
согласно нашей классификации примеры наиболее распространенных
преобразователей «напряжение — код».
В некоторых из них напряжение предварительно преобразуется во
временной интервал или в угол поворота вала. Это позволит нам од-
новременно получить представление и о преобразователях «время — код»
и «угол — код».
Аналого-кодовые преобразователи считывания
Этот метод определения цифрового эквивалента известен также под
названием метода масок. В процессе преобразования определяется,
какому месту на заранее заданном геометрическом пространственном
рисунке (кодирующей маске) соответствует данный входной сигнал.
Получение цифрового эквивалента
произвольного аналогового сигнала
связано с преобразованием его в гео-
метрическую координату.
Кодирующая маска выполняется
в виде прямоугольной пластины или
диска. В последнем случае знаки раз-
рядов наносятся на концентрические
дорожки, каждая из которых соответ-
ствует определенному разряду двоич-
ного числа. Внешняя дорожка дис-
ка соответствует низшему разряду
(рис. 3-4).
Таким образом, каждому дискрет-
Рис. 3-4. Кодирующий диск
С ДВОИЧНЫМ кодом.
ному значению угла сопоставляется
вполне определенная неповторяющая-
ся комбинация сегментов двух типов,
соответствующих символам 1 и 0.
Разрешающая способность диска определяется числом всех сегмен-
тов дорожки младшего разряда. Она может быть повышена применением
системы нескольких дисков, соединенных с помощью понижающего
редуктора.
В зависимости от способа съема кода (контактный, фотоэлектриче-
ский, магнитный и т. д.) сегменты, составляющие рисунок кода, выпол-
105
няются проводящими и непроводящими, прозрачными и непрозрач-
ными, магиитопроницаемыми и магнитонепроницаемыми и т. д.
Для считывания с каждого из разрядов устанавливаются чувстви-
тельные элементы: щетки, фотоэлементы, катушки индуктивности и т. д.
При опросе чувствительных элементов получаем комбинацию
электрических сигналов, представляющую в выбранном коде число,
соответствующее данному углу поворота. К сожалению, при использо-
вании масок с обычным двоичным кодом в местах, где одновременно
изменяется состояние нескольких чувствительных элементов, при счи-
тывании могут возникать значительные погрешности. Например, если
чувствительные элементы располагаются на границе между числом
7 (0111) и 8(1000), то преобразователь может выдать на выходе любое
число от 0 до 15. Это, конечно, недопустимо.
Указанный недостаток можно устранить, удвоив число чувстви-
тельных элементов (метод сдвоенных щеток). В данном случае удачно
используется специфичное свойство двоичного кода — изменение в его
старших разрядах происходит всегда справа от единицы младшего раз-
ряда. Для каждого разряда, начиная со второго, устанавливается по два
Рис. 3-5. Устранение неоднозначности считывания по
методу сдвоенных щеток.
чувствительных элемента, симметрично сдвинутых относительно чув-
ствительных элементов младшего разряда на £/2, где L — длина сег-
мента младшего разряда. Считывание во втором и более высоких раз-
рядах производится чувствительными элементами, которые не касаются
краев сегмента (рис. 3-5). Если в младшем разряде зафиксирована еди-
ница (положение Л), считывание производится с левых чувствительных
элементов, а если нуль (положение Б), то с правых.
Чувствительные элементы можно расположить на одной прямой,
цо тогда необходимо каждую из дорожек второго и более высоких раз-
рядов разделить на две дорожки, а затем сдвинуть их относительно
дорожки младшего разряда, одну на L/2 влево, а другую — вправо. Это
делается при изготовлении маски
Метод сдвоенных щеток обеспечивает считывание числа в обычном
двоичном коде с погрешностью, не превышающей единипы младшего
разряда, но требует дополнительной логической схемы для выбора
чувствительных элементов и диктует жесткие допуски на расположение
сегментов в диске в случае упомянутых выше деления и сдвига дорожек.
Другим способом устранения ошибки неоднозначности считывания
является использование масок с кодами, у которых при последователь-
ном переходе от числа к числу изменяется только один разряд. Кодирую-
щая пластина с кодом Грея изображена на рис. 3-6.
Нетрудно убедиться, что каждое последующее число отличается от
предыдущего только в одном разряде. Поэтому погрешность при счи-
тывании не может превосходить единицы младшего разряда вне зависи-
мости от того, в каком разряде имела место неопределенность. Если,
например, отсчет производится на границе между числами 7 и 8, то
106
чувствительные элементы первых трех разрядов уверенно зафиксируют
соответственно 0,0 и 1. Чувствительный элемент четвертого разряда мо-
жет зафиксировать как 0, так и 1. В первом случае на выход поступит
число 7, а во втором — 8. Таким образом, погрешность остается в преде-
лах единицы младшего разряда.
Использование этого способа приводит к необходимости иметь
дополнительный преобразователь для представления полученных в
коде Грея чисел в обыкновенном двоичном коде.
Аналого-кодовые преобразователи считывания выполняются с пря-
мым, развертывающим и следящим измерительным преобразованием.
А. Преобразователи с прямым измерительным
преобразованием
Примером такого преобразователя может служить специально раз-
работанная для этой цели электроннолучевая трубка (рис. 3-7). Пре-
образуемое напряжение Ux подается на вертикальные отклоняющие
пластины трубки 1. На горизонтальные пластины 2 действует линейно
Рис. 3-7. Аналого-кодовый преобразователь считыва-
ния с прямым измерительным преобразованием.
изменяющееся напряжение генератора развертки 8. В результате элект-
ронный луч прочерчивает линию на высоте, пропорциональной прило-
женному напряжению. При пересечении электронным лучом щелей ко-
дирующей пластины 6 в цепи анода 7 возникает последовательность
электрических импульсов, соответствующая цифровому эквиваленту
Ux. Для обеспечения однозначности преобразования амплитуда напря-
107
жения Ux на период развертки должна стабилизироваться. Кроме того,
при использовании обычного двоичного кода должна быть устранена
возможность попадания луча на границу между строками кодирующей
пластины. Для этого перед пластиной помещены направляющая решетка
6 и коллектор 4. Проволочки решетки прикрывают границы между стро-
ками. Луч, отклоненный до уровня границы между строками, попадает
на проволочку решетки и выбивают из нее вторичные электроны. По-
следние улавливаются коллектором 4 и создают на его нагрузке напря-
жение, которое по цепи обратной связи с усилителем 3 воздействует на
отклоняющие пластины 1 так,что луч смещается на середину ближайшей
строки кодирующей пластины.
Точность рассмотренного преобразователя зависит главным обра-
зом от линейности преобразования входного напряжения в угол откло-
нения луча и составляет 1—2%. Разрешающая способность используе-
мых кодирующих пластин ограничивается возможностями острого фо-
кусирования луча и составляет порядка тысячи чисел. Скорость преобра-
зования задается частотой линейно-меняющегося напряжения и может
быть весьма высокой, вплоть до 106 преобразований в секунду.
Б. Преобразователи с развертывающим измерительным
преобразованием
Преобразование напряжения в код осуществляется по схеме на
рис. 3-8. Кодирующий диск КД с прозрачными и непрозрачными сег-
ментами укреплен на валу синхронного двигателя СД. От того же дви-
гателя приводится в действие электромеханический генератор ГКН
линейно изменяющегося компенсирующего напряжения. Последний
Рис. 3-8. Аналого-кодовый преобразователь считыва-
ния с развертывающим измерительным преобразо-
ванием.
представлен на рис. 3-8 прецизионным линейным потенциометром, пи-
таемым эталонным током; генератор может быть выполнен и бесконтакт-
ным. С одной стороны диска располагается импульсный линейный источ-
ник света ИС, а с противоположной—экран с узкой щелью (до 0,1 мм),
пропускающий свет на фотоэлементы ФЭ (фотодиоды, фототранзисто-
ры). Каждому разряду соответствует свой фотоэлемент, оптически изо-
лированный от остальных.
Положение щетки потенциометра согласовано с положением диска.
Когда щетка находится в положении А и UK = 0, диск располагается
таким образом, что против щели диафрагмы Д оказывается цифровой
108
эквивалент 00000. По мере поворота щетки и нарастания напряжения
UK соответствующие ему цифровые эквиваленты как раз проходят перед
щелью. В момент компенсации срабатывает орган сравнения О.С и
вспыхивает импульсный источник света ИС. Луч прорезает тот цифровой
эквивалент, который соответствует преобразуемому напряжению Ux.
Код снимается параллельно. Фотоэлементы, против которых в момент
вспышки оказались прозрачные сегменты диска, дают на выходе ток,
что соответствует «единице» в соответствующем разряде кода. У фото-
элементов, закрытых непрозрачными сегментами, тока на выходе не
появляется, что соответствует разряду «0» кода.
Для устранения неоднозначности при считывании в таких устрой-
ствах обычно используются маски с кодом Грея. Поэтому на выходе
предусматривается дополнительный преобразователь кода Грея ПК
в обычный двоичный код г.
Точность рассмотренного аналого-кодового преобразователя в основ-
ном определяется линейностью генератора компенсирующего напряже-
ния и чувствительностью органа сравнения. Как правило, ошибка со-
ставляет несколько десятых долей процента.
Быстродействие преобразователя зависит от числа разрядов диска
I и длительности одной вспышки Поскольку за время tR перед щелью
должен проходить только один кодовый эквивалент, то время цикла
преобразования не может быть меньше ntB, где п = 2т — число всех
кодовых эквивалентов на кодирующем диске. Продолжительность и
интенсивность вспышки должны обеспечить надежное срабатывание фо-
тоэлементов. Известны преобразователи с 13-разрядным диском и источ-
ником с продолжительностью вспышки
6 мксек, обеспечивающие до 20 циклов
преобразований в секунду.
В случае преобразования в код угла
поворота вала кодирующий диск укреп-
ляется на этом валу, и схема упрощает-
ся. Цифровой эквивалент угла поворота
в любом положении оси снимается подачей
импульса считывания непосредственно на
источник света. Точность преобразования
может быть повышена до сотых долей
процента.
В. Преобразователи со следящим
измерительным преобразованием
Схема преобразователя напряжения
в код приведена на рис. 3-9. Кодируемое
напряжение Ux уравновешивается ком-
пенсирующим напряжением UK, которое
снимается с потенциометра, питаемого
Рис. 3-9. Аналого-кодо-
вый преобразователь счи-
тывания со следящим из-
мерительным преобразо-
ванием.
эталонным током. Если
Uxz£UK, на вход электронного усилителя У поступает сигнал
ошибки А1/, который усиливается по напряжению и мощности и при-
кладывается к обмотке компенсирующего реверсивного двигателя
РД. Последний перемещает движок потенциометра до состояния равно-
весия, когда АГ' = 0. Таким образом, входное напряжение Ux линейно
преобразуется в угловое перемещение. На оси компенсирующего дви-
гателя укрепляется кодирующий диск КД (или чувствительные эле-
менты). Цифровой эквивалент полученного углового перемещения сни-
мается с диска одним из ранее рассмотренных способов.
109
Точность преобразователен такого типа около 0,5%. Их целесо-
образно использовать для преобразования медленно меняющихся на-
пряжений.
Имея весьма высокую чувствительность, такой преобразователь
без дополнительного управления следит за всеми изменениями величины
Ux. Недостаток преобразователя связан с относительно большим вре-
менем установления при резких изменениях кодируемого напряжения
(несколько десятых долей секунды).
Аналого-кодовые преобразователи последовательного счета
В преобразователях этого класса непрерывная величина электри-
ческого тока или напряжения предварительно преобразуется в импуль-
сы, общее число которых соответствует ее значению. Эти импульсы
передаются последовательно к двоичному или десятичному счетчику,
где происходит их суммирование.
При заданном отнесенном к шкале шаге квантования преобразова-
теля 6Т, %, число импульсов тх, представляющих одно значение коди-
руемой величины Ux, может меняться в пределах
Если предельная частота счетчика /сч. макс, то время, требующееся на
один цикл преобразования, равно:
Тмакс = ^10°- + А, (3-2)
vxi сч. макс
где А — время считывания цифрового эквивалента и сброса счетчика.
Отметим, что для преобразователя последовательного счета со сле-
дящим принципом измерения такое время потребуется только в случае
резкого изменения кодируемой величины на полный диапазон преобра-
зования.
Самые быстродействующие из применяемых на практике счетчиков
работают на частотах до 5 Мгц. Параллельное считывание и сброс счет-
чика можно выполнить за время порядка 1 мксек.. Следовательно, при
относительном шаге квантования 0,1% преобразователи последователь-
ного счета в состоянии обеспечить до 5 000 преобразований в секунду.
Точность преобразователя зависит от принципа работы его измери-
тельной части.
Аналого-кодовые преобразователи последовательного счета выпол-
няются на основе прямого, развертывающего или следящего измери-
тельного преобразования.
А. Преобразователи с прямым, измерительным
преобразованием
Функциональная схема такого преобразователя приведена на
рис. 3-10. Частота следования выходных импульсов управляемого
генератора Ux — fx линейно изменяется в зависимости от величины
преобразуемого напряжения Ux.
В каждом цикле преобразования сигнал с генератора эталонных
временных интервалов на определенное время Т открывает схему сов-
падения Ит, пропуская импульсы в счетчик Сч. Количество импульсов,
НО
зафиксированное счетчиком за время Т, пропорционально кодируемой
величине Ux. По окончании сигнала, воздействующего на схему Ит<
генератор эталонных временных интервалов ГЭВ И выдает импульсы
на считывание цифрового эквивалента ги установку всех разрядов счет-
чика в исходное состояние (сброс). Далее процесс повторяется.
Рис. 3-10. Аналого-кодовый преобразователь после-
довательного счета с прямым измерительным преоб-
разованием.
Основная трудность при реализации такого преобразователя зак-
лючается в создании генератора с достаточно линейной зависимостью
частоты следования выходных импульсов от преобразуемого напряже-
ния. Трудно добиться и его стабильности, особенно при изменении на-
пряжения питания и температуры. Наи-
лучшие преобразователи этого типа редко
имеют ошибку меньше 0,2%.
Рис. 3-11. Аналого-кодо-
вый преобразователь пос-
ледовательного счета с не-
прерывным линейным ком-
пенсирующим напряже-
нием.
Б. Преобразователи с развертывающим
измерительным преобразованием
Функциональная схема преобразова-
теля изображена на рис. 3-11.
В начале каждого цикла преобразо-
вания запускается генератор ГКН ли-
нейно изменяющегося компенсирующего
напряжения (/к. Одновременно сигнал
с органа сравнения ОС открывает схему
совпадения И и импульсы высокостабиль-
ного генератора Г И начинают поступать
в счетчик Сч. В момент компенсации, ког-
да преобразуемое напряжение Пх срав-
нивается с компенсирующим напряже-
нием 1/к, состояние органа сравнения из-
меняется и доступ импульсов в счетчик прекращается. С выхода счет-
чика снимается цифровой эквивалент г, соответствующий Ux.
Число импульсов, поступивших в счетчик, пропорционально пре-
образуемой величине напряжения Ux. Временная диаграмма работы
преобразователя приведена на рис. 3-12.
По окончании цикла развертки компенсирующего напряжения
с блока синхронизации БС поступают импульсы на считывание цифро-
вого эквивалента и сброс счетчика. Далее процесс повторяется.
Блок синхронизации позволяет «привязать» момент начала разверт-
ки компенсирующего напряжения к одному из импульсов ГИ,что повы-
Ill
jiuiiumiiiniiiiiiiiiiiiiiiii выходги^
UK‘UJ. I
- j [--------~j Выход DC j
IIIIHHII llllllllllll Вход Ci j
Рис. 3-12. Временная диаграмма
работы преобразователя последова-
тельного счета с непрерывным ли-
нейным компенсирующим напря-
жением.
шает точность преобразования.
Действительно (рис. 3-13, б),
при отсутствии синхронизации
погрешность дискретности мо-
жет оказаться вдвое больше:
Блок синхронизации может
представлять собой счетчик, ко-
торый фиксирует число импуль-
сов, соответствующее циклу пре-
образования, и запускает по
окончании следования этого
числа импульсов генератор ком-
пенсирующего напряжения.
Точность преобразования
определяется характеристикой
органа сравнения и линейностью
компенсирующего напряжения.
У лучших образцов она дости-
гает 0,1%.
Более точными (до 0,05%) являются аналогичные преобразователи
со ступенчато-линейным компенсирующим напряжением (рис. 3-14).
Рис. 3-13. Погрешность дискретности преобразования:
а — при наличии синхронизации, б — при отсутствии син-
хронизации.
Как правило, оно получается в результате суммирования комму-
тируемых по двоичному закону эталонных напряжении (или токов),
амплитуды которых относятся друг
к другу как целочисленные степени
двух (1 : 2 : 4 : 8 и т. д.). Одна из
возможных схем источника ступенчато-
линейного компенсирующего напряже-
ния приведена на рис. 3-15.
Когда все триггеры двоичного
счетчика ДСч схемы управления нахо-
дятся в нулевом состоянии, ключи Kj,
К2, К3, Kt заперты. Выходное напря-
жение равно нулю. Первый импульс
с генератора опорных импульсов Г И
переводит триггер в состояние 1,
ключ Ki отпирается и стабилизирован-
ный ток I, протекая по сопротивле-
Рис. 3-14. Ступенчато-линей-
ное компенсирующее напря-
жение.
112
г г 2г
ДС1
Рис. 3-15. Источник ступенчато-линейного компен-
сирующего напряжения.
нию г, создает выходное напряжение 1/к= Д1/= г/. При этом пред-
полагается, что внутреннее сопротивление стабилизаторов тока /ь /2,
/8> бесконечно велико, по сравнению с суммой эталонных сопротив-
лений г, г, 2г, 4г.
Рис. 3-16. Аналого-кодовый преобразователь последо-
вательного счета со ступенчато-линейным компенси-
рующим напряжением.
Аналогично поступление второго импульса приведет к отпиранию
ключа /(2. Такой же ток /, протекая по двум сопротивлениям г, дает на
выходе напряжение 2Д U. После трех импульсов в положении 1 окажутся
два триггера Тгг и Тг2. Суммарное падение напряжения от двух токов I
становится равным ЗА(7. Нетрудно убедиться в том, что каждый раз,
когда содержимое счетчика увеличивается на единицу, выходное напря-
жение возрастает на одну ступеньку (рис. 3-17).
Блок-схема преобразователя со ступенчато-линейным изменением
компенсирующего напряжения показана на рис. 3-16. Импульсы от
113
генератора ГИ поступают на счетчик Тгг — Tsit состояние которого
определяет напряжение 1/к на выходе источника ступенчатого компен-
сирующего напряжения ИСКИ. Кодируемое напряжение Ux срав-
нивается со ступенчато-линейным напряжением UK. В каждый момент
Рис. 3-17. Временная диаграмма
работы преобразователя после-
довательного счета со ступен-
чато-линейным компенсирующим
напряжением.
времени на счетчике в двоичном
коде фиксируется число ступеней
компенсирующего напряжения, т.е.
его цифровой эквивалент. В мо-
мент компенсации, когда Ux = UK,
двоичное число на счетчике будет
являться цифровым эквивалентом
и для Ux.
Равенство напряжений Ux и U,:
отмечается органом сравнения ОС,
который и посылает импульс на
считывание цифрового эквивалента г
со счетчика. Временные диаграммы
работы преобразователя представ-
лены на рис. 3-17, где показаны
напряжения в точках а — г схемы
рис. 3-16; интервал времени, пропор-
циональный Йх, обозначен как tx.
В. Преобразователи со следящим
измерительным преобразованием
Преобразователь является циф-
ровой следящей системой (рис.
3-18), в которой входное напряже-
ние Ux сравнивается органом
сравнения ОС с напряжением
поступающим с источника линейно-
ступенчатого компенсирующего на-
пряжения ИСКИ.
В зависимости от разности напряжений Ux — Uv происходит такое
изменение кода в схеме управления источником, которое приводит к ра-
венству этих напряжений (Ux — UK).
Рис. 3-18. Аналого-кодовый преобразователь после-
довательного счета со следящим измерительным пре-
образованием.
114
Рис. 3-19. Последовательность отра-
ботки цифровых эквивалентов преоб-
разователем последовательного счета
со следящим измерительным преобра-
зованием.
Орган сравнения воздействует на две схемы совпадения И, через
которые импульсы генератора Г И поступают на входы реверсивного
счетчика PC, состоящего из триггеров Тгл — Тг5; если Ux > UK, т0
импульсы идут по каналу «+», а если Ux < UK, то по каналу «—».
При равенстве напряжений обе схемы И закрыты и импульсы на счет-
чик не поступают.
Минимальное напряжение срабатывания органа сравнения Г/ср
должно лежать в пределах МЛУ. АГ/, где АП —величина
напряжения одной ступень-
ки. При большей чувстви-
тельности значение младшего
разряда цифрового эквива-
лента беспрерывно изменяет-
ся даже при постоянном
значении Ux.
Отработка цифровых эк-
вивалентов некоторой изме-
няющейся аналоговой вели-
чины Ux преобразователем
со следящим уравновешива-
нием с момента его включе-
ния показана на рис. 3-19.
Внизу записаны двоичные эк-
виваленты значений Ux на
каждом такте. В схеме они
представлены состоянием
триггеров двоичного ревер-
сивного счетчика PC.
Для Ux, изменяющихся
во времени плавно и с ограниченной
скоростью, такой преобразователь, очевидно, обеспечит наибольшую
скорость преобразования, так как время получения цифрового эквива-
лента уменьшается до одного такта.
Точность, как и в предыдущих схемах, зависит от стабильности
органа сравнения и числа разрядов реверсивного двоичного счетчика
(ошибка порядка 0,1—0,05%).
Аналого-кодовые преобразователи поразрядного уравновешивания
Преобразователи, описанные в предыдущем параграфе, основаны
на методе, при котором Последовательно изменяется на единицу млад-
шего разряда уровень компенсирующего напряжения и посредством
органа сравнения каждый раз определяется, находится ли преобразуе-
мая величина на данном уровне или нет.
Этот метод неэффективен с точки зрения числа операций сравнения
(а следовательно, и быстродействия), необходимых для определения
цифрового эквивалента резко меняющейся величины IJX. Количество
операций сравнения можно значительно сократить. Рассмотрим эту
возможность.
Максимальное количество информации, которое можно полу-
чить в результате одной операции сравнения, равно 1 бит. Для дости-
жения этой величины каждую операцию сравнения необходимо прово-
дить на таком уровне, чтобы вероятности обнаружения преобразуемой
величины ниже и выше этого уровня были равны. Если вероятности всех
значений преобразуемой величины одинаковы, то первую операцию
115
сравнения при двоичном кодировании нужно провести на уровне
Ux макс/2. Цифровые эквиваленты напряжения Ux ниже этого уровня
будут иметь в старшем разряде 0, а выше уровня 1.
Следовательно, в результате операции сравнения будет определено
значение старшего разряда цифрового эквивалента (0 или 1). Аналогично
выбираются уровни сравнения для определения значений остальных
разрядов. Каждый из них будет в 2 раза меньше предыдущего. Опреде-
ление цифрового эквивалента производится поразрядно. При заданном
относительном шаге квантования 6Л., %, число разрядов находится из
соотношения
Z=log2™. (3-3)
Значение i-го разряда определяется после проведения операции
сравнения при поступлении с распределителя (i + 1)-го импульса. На
Рис. 3-20. Аналого-кодовый преобразователь поразрядного
уравновешивания.
цикл преобразования, следовательно, требуется не менее (/ + 1) им-
пульсов. Поскольку используемые распределители, как правило, рабо-
тают по принципу пересчетных схем, то их предельную частоту снова
обозначим через /сч. макс. Тогда для аналого-кодовых преобразователей
поразрядного уравновешивания максимально возможное число преоб-
разований в секунду можно оценить по формуле
f (сч. макс /о
/макс — 100 ' w
logs -д- + 1
Од-
Если принять, как и ранее, = 0,1% и (сч. ыакс = 5-10®, макси-
мальная частота преобразователя получается равной 4,5-105 гц, что
почти на два порядка превышает максимальную частоту преобразова-
телей с линейно-ступенчатым компенсирующим напряжением.
116
Метод преобразования с поразрядным уравновешиванием может
использоваться для получения цифровых эквивалентов Ux в любой си-
стеме счисления. В частности, в цифровых измерительных приборах
широко применяется поразрядная отработка цифрового эквивалента
Ux в десятичном и двоично-десятичном коде. Точность лучших преобра-
зователей этого типа того же порядка, что и у преобразователей с ли-
нейно-ступенчатым уравновешиванием, т. е. 0,05%. Конструктивно
они несколько более сложны, но в ряде случаев незаменимы сточки зре-
ния совмещения требований высокого быстродействия и высокой точ-
ности.
Функциональная схема одного из преобразователей поразрядного
уравновешивания приведена на рис. 3-20. Уровни сравнения устанав-
ливаются последовательным переключением триггеров двоичных раз-
рядов, начиная со старшего Тгп.
Эталонное напряжение каждого
уровня создается путем суммиро-
вания токов, пропорциональных
весам разрядов, на сопротивлении
г (г <С R). Схема питается напряже-
нием от источника Е.
Первый импульс с кольцевого
распределителя КР переводит триг-
гер Тгп в состояние «1», а осталь-
ные через схемы ИЛИ устанавли-
вает в «0». В замкнутом состоянии
оказывается только ключ Кп. При
этом компенсирующее напряжение
С7К1 пропорционально весу стар-
шего разряда (С/к1 — Un). Если
Ux UKi, то в цифровом эквива-
ленте Ux на месте старшего раз-
ряда должен стоять 0. В этом слу-
чае сигнал с органа сравнения ОС
Рис. 3-21. Последовательность
отработки цифрового эквива-
лента преобразователем пораз-
рядного уравновешивания.
открывает схемы совпадения И и при поступлении второго импульса
с распределителя триггер Тгп сбрасывается в 0. Тем же импуль-
сом в состояние «1» переводится триггер Тгп_х. Уровень компенси-
рующего напряжения снижается вдвое (Йк2 = Если
теперь Ux > (7К2, то на месте этого разряда в цифровом эквиваленте
Ux должна стоять 1. Знак выходного напряжения органа сравнения
изменяется на противоположный и схемы совпадения И запираются.
Поэтому третий импульс, переключающий триггер Тгп2, на триггер
не воздействует и последний остается в состоянии «1». Компен-
сирующее напряжение возрастает на величину t/„_2 = t/n-2~2 и
становится равным
UK3 = Un.2-^ + Un.2^.
Если Ux < 1/кз, то Тгн 2 очередным импульсом сбрасывается
в состояние «0», если Ux > 1/к3, то Тгп_ 2 остается в состоянии «1». Ана-
логично отрабатываются значения всех остальных разрядов, причем
значение младшего разряда определяется при поступлении с распреде-
лителя (п ф- 1)-го импульса.
Цифровой эквивалент Ux снимается в конце цикла преобразования.
На рис. 3-21 показана последовательность определения двоичного циф-
рового эквивалента при поразрядном уравновешивании напряжения
Ux = 26 в
117
Компенсирующие напряжения разрядов, вошедших в состав Ux,
изображены сплошными линиями и отмечены внизу знаком 1. Компен-
сирующие напряжения разрядов, не вошедших в состав Ux, изображены
пунктиром и отмечены внизу знаком 0. В результате уравновешивания
получен двоичный эквивалент числа 26—011610.
3-4. ЭФФЕКТИВНОЕ КОДИРОВАНИЕ
В предыдущих параграфах мы отмечали, что в боль-
шинстве случаев буквы сообщений преобразуются в после-
довательности двоичных символов. В рассмотренных устрой-
ствах это преобразование выполнялось без учета статисти-
ческих характеристик поступающих сообщений.
Учитывая статистические свойства источника сообще-
ния, можно минимизировать среднее число двоичных сим-
волов, требующихся для выражения одной буквы сообще-
ния, что при отсутствии шума позволяет уменьшить время
передачи или объем запоминающего устройства.
Такое эффективное кодирование базируется на основной
теореме Шеннона для каналов без шума.
Шеннон доказал, что сообщения, составленные из букв
некоторого алфавита, можно закодировать так, что среднее
число двоичных символов на букву будет сколь угодно
близко к энтропии источника этих сообщений, но не меньше
этой величины. Подробнее эта теорема рассматривается
в гл. 6.
Теорема не указывает конкретного способа кодирования,
но из нее следует, что при выборе каждого символа кодовой
комбинации необходимо стараться, чтобы он нес максималь-
ную информацию. Следовательно, каждый символ должен
принимать значения 0 и 1 по возможности с равными вероят-
ностями и каждый выбор должен быть независим от значе-
ний предыдущих символов.
Для случая отсутствия статистической взаимосвязи
между буквами конструктивные методы построения эффек-
тивных кодов были даны впервые Шенноном и Фэно. Их
методики существенно не отличаются и поэтому соответст-*
вующий код получил название кода Шеннона — Фэно.
Код строится следующим образом: буквы алфавита сооб-
щений выписываются в таблицу в порядке убывания вероят-
ностей. Затем они разделяются на две группы так, чтобы
суммы вероятностей в каждой из групп были бы по воз-
можности одинаковы. Всем буквам верхней половины в ка-
честве первого символа приписывается 0, а всем нижним 1.
Каждая из полученных групп в свою очередь разбивается
118
на две подгруппы с одинаковыми суммарными вероятно-
стями и т. д. Процесс повторяется до тех пор, пока в каждой
подгруппе останется по одной букве.
Рассмотрим алфавит из восьми букв. Ясно, что при
обычном (не учитывающем статистических характеристик)
кодировании для представления каждой буквы требуется
три символа.
Наибольший эффект сжатия получается в случае, когда
вероятности букв представляют собой целочисленные отри-
цательные степени двойки. Среднее число символов на
букву в этом случае точно равно энтропии. Убедимся в этом,
вычислив энтропию
8
н (Z)= — 2 p(?i) logp = 1 Ц
ё = 1
и среднее число символов на букву
8
Zcp = 2 P^i) П (zf)=lg,
i = l
где п (Zi) — число символов в кодовой комбинации *, соот-
ветствующей букве Zi-
Характеристики такого ансамбля и коды букв пред-
ставлены в табл. 3-3.
В более общем случае для алфавита из восьми букв
среднее число символов на букву будет меньше трех, но
больше энтропии алфавита И (Z).
Для ансамбля, приведенного в табл. 3-4, энтропия равна
2,76, а среднее число символов на букву 2,84.
Следовательно, некоторая избыточность в последова-
тельностях символов осталась. Из теоремы Шеннона сле-
дует, что эту избыточность также можно устранить, если
перейти к кодированию достаточно большими блоками.
Рассмотрим сообщения, образованные с помощью алфа-
вита, состоящего всего из двух букв 2| и г2 с вероятностями
появления соответственно р (zt) =0,9 и р (г2) =0,1.
Поскольку вероятности не равны, то последовательность
из таких букв будет обладать избыточностью. Однако при
побуквенном кодировании мы никакого эффекта не полу-
чим.
* Число разрядов в кодовой комбинации здесь и в дальнейшем
обозначено через п для того, чтобы избежать расхождения с общепри-
нятой терминологией в области эффективного и помехоустойчивого
кодирования.
119
Таблица 3-3
Буквы Вероят- ность Кодовые комбинации Ступень разбиения
Z1 1 2 1
1_ 4 01 I
г3 1 Т 001 II
1 16 0001 III
г5 1 00001 IV
г6 32 1 000001 V
г? 64 1 128 1 128 0000001 VI
Z* 0000000 VII
Таблица 3-4
Буквы Вероят- ности Кодовые комбинации Ступень разбиения
0,22 11
II
0,20 101 III
г3 0,16 100 I
Zi 0,16 01 IV
0,10 001
z6 0.10 0001
VI
z7 0,04 00001 VII
ZS 0,02 00000
Действительно, на передачу каждой буквы требуется
символ либо 1, либо 0, в то время как энтропия равна 0,47.
При кодировании блоков, содержащих по две буквы,
получим коды, показанные в табл, 3-5.
120
Так как буквы статистически не связаны, вероятности
блоков определяются как произведение вероятностей состав-
ляющих букв.
Среднее число символов на блок получается равным 1,29,
а на букву 0,645.
Кодирование блоков, содержащих по три буквы, дает
еще больший эффект. Соответствующий ансамбль и коды
приведены в табл. 3-6.
Среднее число символов на блок равно 1,59, а на букву
0,53, что всего на 12% больше энтропии. Теоретический
минимум Н (Z) = 0,47 может быть достигнут при кодиро-
вании блоков, включающих бесконечное число букв:
limZcp = tf(Z). (3-5)
Я-* СО
Следует подчеркнуть, что увеличение эффективности
кодирования при укрупнении блоков не связано с учетом
все более далеких статистических связей, так как нами
Таблица 3-5
Блоки Вероятности Кодовые комбинации Ступень разбиения
0,81 1
г1 г2 0,09 01 1
11
г2 0,09 001
III
Z2 г2 0,01 000
Таблица 3-6
Б ЛОКИ Вероятности Кодовые комбинации Ступень разбиения
Z1 г, г. 0,729 1
г2 Zi г. 0,081 011 J III
Z1 г2 г1 0,081 010 11
г1 zi г2 0,081 001 ГЛ/
г2 г2 Zi 0,009 00011 1 V Л71
гг Zj г2 0,009 00010 VI
Z1 гг гг 0,009 00001 V VII
Z2 г2 г2 0,001 00000
121
рассматривались алфавиты с некоррелированными бук-
вами. Повышение эффективности определяется лишь тем,
что набор вероятностей, получающийся при укрупнении
блоков, можно делить на более близкие по суммарным
вероятностям подгруппы.
Рассмотренная нами методика Шеннона—Фэно не всегда
приводит к однозначному построению кода. Ведь при раз-
биении на подгруппы можно сделать большей по вероят-
ности как верхнюю, так и нижнюю подгруппы.
Табл. 3-4 можно было бы разбить иначе, например, так,
как это показано в табл. 3-7.
При этом среднее число символов на букву оказывается
равным 2,80. Таким образом, построенный код может ока-
заться не самым лучшим. При построении эффективных
кодов с основанием т >2 неопределенность становится
еще больше.
От указанного недостатка свободна методика Хаффмена.
Она гарантирует однозначное построение кода с наимень-
шим для данного распределения вероятностей средним чис-
лом’символов на букву.
Для двоичного кода методика сводится к следующему.
Буквы алфавита сообщений выписываются в основной
столбец в порядке убывания вероятностей. Две последние
буквы объединяются в одну вспомогательную букву, кото-
рой приписывается суммарная вероятность. Вероятности
букв, не участвовавших в объединении, и полученная сум-
марная вероятность снова располагаются в порядке убыва-
ния вероятностей в дополнительном столбце, а две послед-
ние объединяются. Процесс продолжается до тех пор,
Таблица 3-7
Буквы Вероятности Кодовые комбинации Ступень разбиения
г1 0,22 11
II
г2 0,20 10 г
гз 0,16 011 IV
г4 0,16 010 HI
z5 0,10 001 V
0,10 0001 VI
г? 0,04 00001 V 1 V1T
г8 0,02 00000 VII
122
Таблица 3-8
Бук- Вероят- Вспомогательные столбцы
БЫ ности 1 1 2 1 3 1 4 5 1 6 7
г. 0,22 0,22 0,22 -0,26 —0,32 —0,42 1—0.58]- -1
Z2 0,20 0,20 0,20 0,22 0,26 0,32] 1 0,42]
г3 0,16 0,16 0,16 0,20 0,22] 0,26
га 0,16 0,16 0.16 0,16] 0,20] -
0,10 0,10 Г-0,161 0,16]-
ze 0,10 0.10] o.ioj -
Z, 0,041— _0,0б]
zs 0,02]
пока не получим единственную вспомогательную букву
с вероятностью, равной единице.
Методика поясняется примером, содержащимся в
в табл. 3-8. Значения вероятностей приняты те же, что и
в ансамбле табл. 3-4.
Для составления кодовой комбинации, соответствующей
данному сообщению, необходимо проследить путь перехода
сообщения по стро-
кам и столбцам таб-
лицы.
Для наглядности
строится кодовое де-
рево. Из точки, соот-
ветствующей вероят-
ности 1, направляют-
ся две ветви, причем
ветви с большей ве-
роятностью присваи-
вается символ 1, а с
меньшей 0. Такое
последовательное вет-
вление продолжаем
до тех пор, пока не
дойдем до вероятно-
Рис. 3-22. Кодовое дерево, построенное
по табл. 3-8, в соответствии с методом
Хаффмена.
сти каждой буквы. Кодовое дерево для алфавита букв, рас-
сматриваемого в примере табл. 3-8, приведено на рис. 3-22.
Теперь, двигаясь по кодовому дереву сверху вниз,
можно записать для каждой буквы соответствующую ей
кодовую комбинацию:
^3 М ^5 ^6 ^7 ^8
01 00 111 НО 100 1011 10101 10100
123
Рассмотрев методики построения эффективных кодов,
нетрудно убедиться в том, что эффект достигается благодаря
присвоению более коротких кодовых комбинаций более
вероятным буквам и более длинных менее вероятным бук-
вам. Таким образом, эффект связан с различием в числе
символов кодовых комбинаций. А это приводит к трудно-
стям при декодировании. Конечно, для различения кодовых
комбинаций можно ставить специальный разделительный
символ, но при этом значительно снижается эффект, кото-
рого мы добивались, так как средняя длина кодовой ком-
бинации по существу увеличивается на символ.
Более целесообразно обеспечить однозначное декодиро-
вание без введения дополнительных символов. Для этого
эффективный код необходимо строить так, чтобы ни одна
комбинация кода не совпадала с началом более длинной
комбинации. Коды, удовлетворяющие этому условию, назы-
ваются префиксными кодами. Последовательность комби-
наций префиксного кода, например, кода
Д Д <3 Д
00 01 101 100
декодируется однозначно:
100 00 01 101 101 101 00
Д Д Д Д Д Д Д'
Последовательность комбинаций непрефиксного кода,
например кода
Д z2 z3 z4
00 01 101 010
(комбинация 01 является началом комбинации 010), может
быть декодирована по-разному:
00 01 01 01 010 101
Д Z2 Z2 Z2 Z4 z3,
00 010 101 010 101
Д z4 z3 z4 z3
или
Нетрудно убедиться, что коды, получаемые в результате
применения методики Шеннона — Фэно или Хаффмена, яв-
ляются префиксными.
124
Рассмотрим кратко некоторые методы эффективного
кодирования в случае коррелированной последовательности
букв.
Декорреляция исходной последовательности может быть
осуществлена путем укрупнения алфавита букв. Подлежа-
щие передаче сообщения разбиваются на двух-, трех- или
/-буквенные сочетания, вероятности которых известны,
... z1zi Z4Z2 . . . Z2Z2Z1ZSZS
n n
Каждому сочетанию ставится в соответствие кодовая
комбинация по методике Шеннона — Фэно или Хаффмена.
Недостаток такого метода заключается в том, что не
учитываются корреляционные связи между буквами, входя-
щими в состав следующих друг за другом сочетаний. Есте-
ственно, он проявляется тем меньше, чем больше букв
входит в каждое сочетание.
Указанный недостаток устраняется при кодировании
по методу диграмм, триграмм или /-грамм. Условимся
называть /-г р а м м о й сочетание из / смежных букв сооб-
щения. Сочетание из двух смежных букв называют диг-
раммой, из трех — триграммой и т. д.
Теперь в процессе кодирования /-грамма непрерывно
перемещается по тексту сообщения
2-я /-грамма
1---------------1
ДД2423 Z1ZiZiZ2.
I__-___________I
1-я /-грамма
Кодовое обозначение каждой очередной буквы зависит
от/—1 предшествовавших ей букв и определяется по веро-
ятностям различных /-грамм на основании методики Шен-
нона— Фэно или Хаффмена.
Конкретное значение / выбирается в зависимости от
степени корреляционной связи между буквами или слож-
ности технической реализации кодирующих и декодирую-
щих устройств.
Подчеркнем в заключение особенности систем эффектив-
ного кодирования. Одна из них обусловлена различием
в длине кодовых комбинаций. Если моменты снятия инфор-
мации с источника не управляемы (например, при непре-
рывном съеме информации с запоминающего устройства
на магнитной ленте), кодирующее устройство через равные
промежутки времени выдает комбинации различной длины.
125
Поскольку линия связи используется эффективно только
в том случае, когда символы поступают в нее с постоянной
скоростью, то на выходе кодирующего устройства должно
быть предусмотрено буферное устройство («упругая» за-
держка). Оно запасает символы по мере поступления и
выдает их в линию связи с постоянной скоростью. Анало-
гичное устройство необходимо и на приемной стороне.
Вторая особенность связана с возникновением задержки
в передаче информации.
Наибольший эффект достигается при кодировании длин-
ными блоками, а это приводит к необходимости накапливать
буквы, прежде чем поставить им в соответствие определен-
ную последовательность символов. При декодировании
задержка возникает снова. Общее время задержки может
быть велико, особенно при появлении блока, вероятность
которого мала. Это следует учитывать при выборе длины
кодируемого блока.
Еще одна особенность заключается в специфическом
влиянии помех на достоверность приема. Одиночная ошибка
может перевести передаваемую кодовую комбинацию в дру-
гую, не равную ей по длительности. Это повлечет за собой
неправильное декодирование целого ряда последующих
комбинаций, который называют треком ошибки.
Специальными методами построения эффективного кода
трек ошибки стараются свести к минимуму [Л. 3-1].
3-5. ТЕХНИЧЕСКИЕ СРЕДСТВА КОДИРОВАНИЯ В ДЕКОДИРОВАНИЯ
ЭФФЕКТИВНЫХ КОДОВ
Материал предыдущего параграфа позволяет заключить, что
в общем случае кодер источника должен содержать следующие блоки:
устройство декорреляции, ставящее в соответствие исходной после-
довательности букв другую декоррелированную последовательность
букв;
собственно кодирующее устройство, ставящее в соответствие
декоррелированной последовательности букв последовательность кодо-
вых комбинаций;
буферное устройство, выравнивающее плотность символов перед
их поступлением в линию связи.
Декодер источника соответственно должен содержать:
устройство декодирования последовательности кодовых комбина-
ций в последовательность букв;
буферное устройство, выравнивающее интервалы между буквами;
устройство рекорреляции, осуществляющее операцию, обратную
декорреляции.
В частном случае, когда корреляционные связи между буквами
отсутствуют и имеется возможность управлять моментами считывания
126
информации с источника, схемы кодера и декодера источника суще-
ственно упрощаются.
Ограничимся рассмотрением этого случая применительно к коду,
приведенному в табл. 3-8.
Схема кодера источника приведена на рис. 3-23. В ней можно
выделить основной матричный шифратор 1 с регистром 3 и вспомога-
тельную схему управления считыванием информации, содержащую
матричный шифратор 2 с регистром сдвига 4. Число горизонтальных
шин шифраторов равно числу кодируемых букв, а число вертикальных
шин в каждом из них равно числу символов в самой длинной комби-
нации используемого эффективного кода.
Рис. 3-23. Устройство, осуществляющее кодирование эффективным
кодом, приведенным в табл. 3-8.
Включение диодов в узлах i-й горизонтальной шины основного
шифратора 1 обеспечивает запись в регистр сдвига 3 кодовой комбина-
ции, соответствующей букве Z;.
Во вспомогательном шифраторе 2 к каждой i-й горизонтальной
шине подключен только один диод, обеспечивающий запись единицы
в такую ячейку регистра 4, номер которой совпадает с числом символов
в кодовой комбинации, соответствующей букве г,-.
Кодирование очередной буквы г,-, выдаваемой источником инфор-
мации 7, осуществляется посредством подачи через схему совпаде-
ния импульса на i-ю горизонтальную шину шифраторов от импульс-
ного источника питания 6. При этом в регистр сдвига 3 записывается
кодовая комбинация, соответствующая букве z;, а в регистр 1 единица,
несущая информацию о конце этой кодовой комбинации. Продвигаю-
щими импульсами генератора 5 записанная в регистре 3 кодовая ком-
127
бинация символ за символом выталкивается в канал связи. Посред-
ством того же генератора сдвигается и единица в регистре 4. Соответ-
ствующий ей импульс появится на выходе регистра в тот момент,
когда из регистра 3 будет вытолкнут последний символ Кодовой ком-
бинации. Этот импульс используется как управляющий для перехода
к кодированию следующей буквы.
На рис. 3-24 приведена схема декодирующего устройства, разра-
ботанного Гильбертом и Муром [Л. 3-1].
Символы декодируемой кодовой комбинации, поступающие на вход
регистра 2, продвигаются по нему импульсами тактового генератора 5.
Поскольку некоторые из поступающих кодовых комбинаций начи-
наются с одного или нескольких нулей, то непосредственно по содер-
жанию регистра невозможно определить начало этих комбинаций,
а следовательно, и правильно их декодировать.
Рис. 3-24. Декодирующее устройство Гильберта и Мура для
эффективного кода, приведенного в табл. 3-8.
Для однозначного определения начала каждой кодовой комбина-
ции число ячеек регистра берется на единицу больше числа символов
в самой длинной комбинации используемого эффективного кода.
В дополнительной первой ячейке регистра перед поступлением в него
очередной декодируемой комбинации всегда записывается единица.
Продвигаясь по регистру, она сигнализирует о начале кодовой ком-
бинации, а следовательно, и о ее длине.
За каждым тактовым импульсом следует импульс с источника 6,
питающего матричный дешифратор 1. Последний построен в соответ-
ствии с комбинациями используемого кода, к которым со стороны стар-
шего разряда приписана лишняя единица. При поступлении в регистр
последнего символа декодируемой первой кодовой комбинации очеред-
ной импульс от источника 6 приводит к появлению импульса напряже-
ния на выходе г-й шины дешифратор а, что соответствует приему буквы zp
128
Через схему ИЛИ этот импульс записывается в промежуточную ячейку
памяти 4 и при считывании очередным импульсом с генератора сброса 3
используется для установления всех ячеек регистра в исходное состоя-
ние (в первой ячейке 1, в остальных 0). Далее поступает следующая
кодовая комбинация и процесс декодирования повторяется.
3-6. ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
Математическая модель дискретного канала связи с шу-
мом рассмотрена в § 6-3.
Теория помехоустойчивого кодирования базируется на
результатах исследований, проведенных Шенноном и сфор-
мулированных им в виде основной теоремы для дискретного
канала с шумом: при любой скорости передачи двоичных
символов, меньшей, чем пропускная способность канала,
существует такой код, при котором вероятность ошибочного
декодирования будет сколь угодно мала; вероятность
ошибки не может быть сделана произвольно малой, если
скорость передачи больше пропускной способности канала.
Как видно, в теореме не затрагивается вопрос о путах
построения кода, обеспечивающего указанную идеальную
передачу. Тем не менее значение ее огромно, поскольку,
обосновав принципиальную возможность такого кодирова-
ния, она мобилизовала усилия ученых на разработку кон-
кретных кодов.
Кодирование должно осуществляться так, чтобы сигнал,
соответствующий принятой последовательности символов,
после воздействия на него предполагаемой в канале помехи,
оставался ближе к сигналу, соответствующему данной пере-
данной последовательности символов, чем к сигналам,
соответствующим другим возможным последовательностям.
Это достигается ценой введения при кодировании избыточ-
ности, которая позволяет наложить на передаваемые после-
довательности символов дополнительные условия, проверка
которых на приемной стороне дает возможность обнару-
жить и исправить ошибки.
Коды, обладающие таким свойством, получили название
помехоустойчивых, или корректирующих. У
подавляющего большинства существующих в настоящее
время корректирующих кодов указанные выше условия яв-
ляются следствием их алгебраических свойств. В связи
с этим их называют алгебраическими кодами,
(в отличие, например, от кодов Вагнера, корректирующее
действие которых базируется на оценке вероятности иска-
жения каждого символа).
5 Темников Ф, Е. и др.
129
Алгебраические коды можно подразделить на два боль-
ших класса: непрерывные (рекуррентные) и бло-
ке в ы е.
В случае блоковых кодов процедура кодирования заклю-
чается в сопоставлении каждой букве сообщения (или
последовательности k символов, соответствующей этой
букве) блока из п символов. Блоковый код называется
равномерным, если п остается постоянным для всех букв
сообщения.
Если число символов в последовательностях, соответ-
ствующих отдельным буквам сообщения, различно, блоко-
вый код называется неравномерным. Такие коды полу-
чаются, например, при эффективном кодировании; в качестве
корректирующих они распространения .не получили, что
объясняется сложностью создания устройств для их реали-
зации.
Различают разделимые и неразделимые
блоковые коды. При кодировании разделимыми кодами
выходные последовательности состоят из символов, роль
которых может быть отчетливо разграничена. Это информа-
ционные символы, совпадающие с символами последова-
тельности, поступающей на вход кодера канала, и избыточ-
ные (проверочные) символы, вводимые в исходную после-
довательность кодером канала и служащие для обнаружения
и исправления ошибок.
При кодировании неразделимыми кодами разделить сим-
волы выходной последовательности на информационные и
проверочные невозможно.
Непрерывными (рекуррентными) называются такие коды,
в которых введение избыточных символов в кодируемую
последовательность информационных символов осуществ-
ляется непрерывно, без разделения ее на блоки. Непрерыв-
ные коды также могут быть разделимыми и неразделимыми.
3-7. БЛОКОВЫЕ КОДЫ
Общив принципы использования избыточности
Способность кода обнаруживать и исправлять ошибки
обусловлена наличием избыточных символов. На вход коди-
рующего устройства поступает последовательность из k
информационных двоичных символов. На выходе ей соот-
ветствует последовательность из п двоичных символов,
причем п >k.
130
Ри£. 3-25. Возможные
трансформации разрешен-
ных кодовых комбинаций
при прохождении по ка
налу с помехами.
Всего может быть 2* различных входных последователь-
ностей и 2" различных выходных последовательностей.
Из общего числа 2" выходных последовательностей только 2ft
последовательностей соответствует входным. Будем назы-
вать их разрешенными кодовыми комбинациями
Остальные 2" — 2fc возможных выходных последователь-
ностей для передачи не используются. Будем называть их
запрещенными кодовыми комбинациями.
Искажение информации в процессе передачи сводится
к тому, что некоторые из переданных символов заменяются
другими — неверными. Посколь-
ку каждая из 2к разрешенных
комбинаций в результате дей-
ствия помех может трансформиро-
ваться в любую другую, то всего
имеется 2й -2" возможных случаев
передачи (рис. 3-25). В это число
входит:
2к случаев безошибочной пере-
дачи (на рис. 3-25 обозначены
жирными линиями);
2к (2fc — 1) случаев перехода в
другие разрешенные комбинации,
что соответствует пеобнаруживае-
мым ошибкам (на рис. 3-25 обо-
значены пунктирными линиями);
2/г (2" — 2к) случаев перехода в
нации, которые могут быть обнаружены (на рис. 3-25 обо-
значены тонкими сплошными линиями) [Л. 3-21. -
Следовательно, часть опознанных ошибок от общего
числа возможных случаев передачи составляет:
комби-
2й (2я -- 2й) j _2Й
2й • 2я ~ 2я
(3-6)
Рассмотрим, например, обнаруживающую способность
кода, каждая комбинация которого содержит всего один
избыточный символ (и = k + 1). Общее число выходных
последовательностей составляет 2Л+1, т. е. вдвое больше
общего числа кодируемых входных последовательностей.
За подмножество разрешенных кодовых комбинаций можно
принять, например, подмножество 2k комбинаций, содер-
жащих четное число единиц (или нулей).
При кодировании к каждой последовательности из k
информационных символов добавляется один символ
б*
131
(3-7)
(О или 1) такой, чтобы число единиц в кодовой комбинации
было четным. Искажение любого нечетного числа символов
переводит разрешенную кодовую комбинацию в подмно-
жество запрещенных комбинаций, что обнаруживается на
приемной стороне по нечетности числа единиц. Часть опоз-
нанных ошибок составляет:
i_2L=l
2й+1 2 '
Рассмотрим случай исправления ошибок.
Любой метод декодирования может рассматриваться
как правило разбиения всего множества запрещенных
кодовых комбинаций на 2й непересекающихся подмножеств
М, каждое из которых ставится в соответствие одной из
разрешенных комбинаций. При получении запрещенной
комбинации, принадлежащей подмножеству Mh принимается
решение, что передавалась разрешенная комбинация Л,.
Ошибка будет исправлена в тех случаях, когда полученная
комбинация действительно образовалась из А,, т. е. в
2я — 2й случаях.
Всего случаев перехода в неразрешенные комбинации
2й (2я— 2й). Таким образом, любой корректирующий код
способен исправлять ошибки. Отношение числа исправляе-
мых кодом ошибочных кодовых комбинаций к числу обна-
руживаемых ошибочных комбинаций равно:
2" — 2К 1
2ft (2" — 2ft) 2ft ‘ (3 8)
Способ разбиения на подмножества зависит от того, какие
ошибки должны исправляться данным конкретным кодом.
Большинство разработанных до настоящего времени
кодов предназначено для корректирования взаимно неза-
висимых ошибок определенной кратности и пачек (пакетов)
ошибок.
Взаимно независимыми ошибками будем называть такие
искажения в передаваемой последовательности символов,
при которых вероятность появления любой комбинации
искаженных символов зависит только от числа искаженных
символов г и вероятности искажения одного символа р.
Количество искаженных символов в кодовой комбинации
называется кратностью ошибки.
При взаимно независимых ошибках вероятность искаже-
ния любых г символов в «-разрядной кодовой комбинации
равна:
Рг = Сгпрг{1 -р)п г.
(3-9)
132
Если учесть, что р I, то в этом случае наиболее
вероятны ошибки низшей кратности. Их и следует обнару-
живать и исправлять в первую очередь.
Связь корректирующей способности кода с кодовым расстоянием
Из предыдущего следует, что при взаимно независимых
ошибках наиболее вероятен переход в кодовую комбинацию,
отличающуюся от данной в наименьшем числе символов.
Степень отличия любых двух кодовых комбинаций
характеризуется расстоянием между ними в смысле Хэм-
минга, или просто кодовым расстоянием. Оно выражается
числом символов, в которых комбинации отличаются одна
от другой, и обозначается через d.
Чтобы получить кодовое расстояние между двумя ком-
бинациями двоичного кода, достаточно подсчитать число
единиц в сумме этих комбинаций по модулю 2. Например:
m 1001111101
1100001010
0101110111, d = 7.
Декодирование после приема может производиться таким
образом, что принятая кодовая комбинация отождествляется
с той разрешенной, которая находится от нее на наимень-
шем кодовом расстоянии. При этом исправляется наиболее
вероятная ошибка. Очевидно, что при d = 1 все кодовые
комбинации являются разрешенными.
Например, при п = 3 разрешенные комбинации обра-
зуют следующее множество:
000, 001, 010, ОН, 100, 101, ПО, 111.
Любая одиночная ошибка трансформирует данную ком-
бинацию в другую разрешенную комбинацию. Это случай
равнодоступного кода, не обладающего корректирующей
способностью.
Если d = 2, то ни одна из разрешенных кодовых комби-
наций при одиночной ошибке не переходит в другую разре-
шенную комбинацию. Например, подмножество разрешен-
ных кодовых комбинаций может быть образовано по прин-
ципу четности в них числа единиц, как это приведено ниже
для п =3: ООО, 0Ц, 101> цо
разрешенные комбинации
001, 010, 100, 111
запрещенные комбинации
133
Код обнаруживает все одиночные ошибки. В общем слу-
чае при необходимости обнаруживать ошибки кратности г
минимальное хэммингово расстояние между разрешенными
кодовыми комбинациями должно быть по крайней мере на
единицу больше г, т. е.
^мин t" + 1 •
(3-10)
Для исправления одиночной ошибки каждой разрешен-
ной кодовой комбинации необходимо сопоставить свое под-
множество запрещенных кодовых комбинаций. Чтобы эти
подмножества не пересекались, хэммингово расстояние
между разрешенными кодовыми комбинациями должно
быть не менее трех. При п = 3 за разрешенные комбинации
можно, например, принять ООО и 111. Тогда разрешенной
комбинации ООО необходимо поставить в соответствие под-
множество запрещенных кодовых комбинаций
001, 010, 100,
образующихся в результате возникновения единичной
ошибки в комбинации 000.
Подобным же образом, разрешенной комбинации 111
необходимо поставить в соответствие подмножество запре-
щенных кодовых комбинаций:
ПО, 011, 101,
образующихся в результате возникновения единичной
ошибки в комбинации 111:
001
010
000х 100
Разрешенные
комбинации
111. ОН
^101
но
Запрещенные
I комбинации
В общем случае для исправления ошибок кратности s
минимальное хэммингово расстояние между разрешенными
комбинациями должно удовлетворять соотношению
^мии^28-|- 1.
(З-Н)
Нетрудно убедиться в том, что для исправления всех
ошибок кратности s и одновременного обнаружения всех
ошибок кратности г минимальное хэммингово расстояние
нужно выбирать из условия
(3-12)
134
Вышеприведенные формулы, выведенные для случая
взаимно независимых ошибок, дают завышенные значения
минимального кодового расстояния при помехе, коррели-
рованной с сигналом.
В реальных каналах связи длительность импульсов
помехи часто превышает длительность символа. При этом
одновременно искажаются несколько расположенных рядом
символов комбинации. Ошибки такого рода получили назва-
ние пачек ошибок или пакетов ошибок. Длиной пачки оши-
бок называется число следующих друг за другом символов,
левее и правее которых в кодовой комбинации искаженных
символов не содержится. Если, например, кодовая комби-
нация 101011001111011 в результате действия помех транс-
формировалась в комбинацию 101010101011011, то длина
пачки ошибок составляет пять символов.
Описанный выше способ декодирования для этого
случая не будет являться наиболее эффективным.
Для пачек ошибок и асимметричного канала при той
же корректирующей способности минимальное хэммингово
расстояние между разрешенными комбинациями может
быть меньше.
Подчеркнем еще раз, что каждый конкретный коррек-
тирующий код не гарантирует исправления любой комби-
нации ошибок. Коды предназначены для исправления ком-
бинаций ошибок, наиболее вероятных для заданного канала.
Если характер и уровень помехи будет отличаться от
предполагаемых, эффективность применения кода резко
снизится. Применение корректирующего кода не может
гарантировать безошибочность приема, но дает возмож-
ность повысить вероятность получения на выходе правиль-
ного результата.
Показатели качества корректирующего кода
Одной из основных характеристик корректирующего
кода является избыточность кода, указывающая степень
удлинения кодовой комбинации для достижения определен-
ной "корректирующей способности. Если на каждые п
символов выходной последовательности кодера канала
приходится k информационных и п — k проверочных, то
относительная избыточность кода может быть выражена
одним из соотношений
(3-13)
135
или
п — k
k
k
(3-14)
Величина Rk предпочтительнее, так как лучше отвечает
смыслу понятия избыточности. Коды, обеспечивающие
заданную корректирующую способность при минимально
возможной избыточности, называются оптимальны-
м и (иногда — плотноупа кованным и).
В связи с нахождением оптимальных кодов оценим,
например, наибольшее возможное число Q разрешенных
комбинаций n-значного двоичного кода, обладающего спо-
собностью исправлять взаимно независимые ошибки крат-
ности s. Это равносильно отысканию числа комбинаций,
кодовое расстояние между которыми не менее d = 2s + 1.
Общее число различных исправляемых ошибок для
S
каждой разрешенной комбинации составляет X С1п.
i — 1
Каждая из таких ошибок должна приводить к запре-
щенной комбинации, относящейся к подмножеству данной
разрешенной комбинации. Совместно с этой комбинацией
S
подмножество включает 1 + V С1п комбинаций. Одно-
t=\
значное декодирование возможно только в случае, когда
названные подмножества не пересекаются. Поскольку общее
число различных комбинаций n-значного двоичного кода
составляет 2", число разрешенных комбинаций не может
превышать числа
•---s--- (3-15)
i+2 cin
i = 1
ИЛИ
on
Q^-Л-. (3-16)
Эта граница найдена Хэммингом. Для некоторых кон-
кретных значений кодового расстояния d соответствующие
N указаны в табл. 3-9 [Л. 3-21.
Однако не всегда целесообразно стремиться к использо-
ванию кодов, близких к оптимальным. Необходимо учиты-
вать другой, не менее важный показатель качества коррек-
136
Таблица 3-9
тирующего кода — сложность технической реализации про-
цессов кодирования и декодирования.
Если информация должна передаваться по медленно
действующей, ненадежной и дорогостоящей линии связи,
а кодирующее и декодирующее устройства предполагается
выполнить на высоконадежных и быстродействующих эле-
ментах, то сложность этих устройств не играет существен-
ной роли. Решающим фактором в таком случае является
повышение эффективности использования линии связи и
поэтому желательно применение корректирующих кодов
с минимальной избыточностью.
Если же корректирующий код должен быть применен
в системе, выполненной на элементах, надежность и быстро-
действие которых равны или близки надежности и быстро-
действию элементов кодирующей и декодирующей аппара-
туры (например, для повышения Достоверности воспроизве-
дения информации с запоминающего устройства цифровой
вычислительной машины), то критерием качества коррек-
тирующего кода является надежность системы в целом,
т. е. с учетом возможных искажений и отказов в устрой-
ствах кодирования и декодирования. В этом случае более
целесообразными часто оказываются коды с большей избы-
точностью, но обладающие преимуществом простоты техни-
ческой реализации.
Геометрическая интерпретация блоковых корректирующих кодов
Любая «-разрядная двоичная кодовая комбинация мо-
жет быть интерпретирована как вершина «-мерного еди-
ничного куба, т. е. куба с длиной ребра, равной 1.
При п = 2 кодовые комбинации располагаются в вер-
шинах квадрата (рис. 3-26); при п = 3 в вершинах единич-
137
ного куба (рис. 3-27); при п — 4 в вершинах четырехмер-
ного куба (рис. 3-28).
В общем случае п-мерный единичный куб имеет 2" вер-
шин, что равно наибольшему возможному числу кодовых
Рис. 3-26. Гео-
метрическая ин-
те р п р ета ни я
двухразрядного
двоичного кода.
Рис. 3-27. Геометриче-
ская интерпретация
трехразрядного двоич-
ного кода.
комбинаций. Такая модель дает простую геометрическую
интерпретацию и кодовому расстоянию между отдельными
кодовыми комбинациями. Оно соответствует наименьшему
числу ребер единичного куба, ко-
Рис. 3-28. Геометрическая
интерпретация четырех-
разрядного двоичного
кода
торые необходимо пройти, чтобы
попасть от одной комбинации к
Другой.
Теперь метод декодирования
при исправлении одиночных неза-
висимых ошибок можно пояснить
следующим образом. В подмноже-
ство каждой разрешенной комби-
нации относят все вершины, ле-
жащие в сфере радиусом (d — 1)/2,
и центром в вершине, соответст-
вующей данной разрешенной ко-
довой комбинации. Если в резуль-
тате действия шума комбинация
переходит в точку, находящуюся внутри сферы (d — 1)/2,
то такая ошибка может быть исправлена.
Если помеха смещает точку разрешенной комбинации на
границу двух сфер (расстояние d/2) или дальше (но не
в точку, соответствующую другой разрешенной комбина-
ции), то такое искажение может быть обнаружено. Для
кодов с независимым искажением символов лучшие коррек-
138
тирующие коды — это такие, у которых точки, соответст-
вующие разрешенным кодовым комбинациям, расположены
в пространстве равномерно.
Систематические коды
Самый большой класс разделимых кодов составляют
систематические коды, у которых значения про-
верочных символов определяются в результате проведения
линейных операций над определенными информационными
символами. Для случая двоичных кодов каждый провероч-
ный символ выбирается таким, чтобы его сумма с определен-
ными информационными символами стала равной нулю.
Символ проверочной позиции имеет значение 1, если число
единиц информационных разрядов, входящих в данное
проверочное равенство, нечетно, и нулю, если оно четно.
Число проверочных равенств (а следовательно, и число
проверочных символов) и номера конкретных информа-
ционных разрядов, входящих в каждое из равенств, опре-
деляются тем, какие и сколько ошибок должен исправлять
или обнаруживать данный код. Проверочные символы могут
располагаться иа любом месте кодовой комбинации.
При декодировании определяется справедливость про-
верочных равенств. В случае двоичных кодов такое опреде-
ление сводится к проверкам на четность числа единиц
среди символов, входящих в каждое из равенств (включая
проверочный). Совокупность проверок дает информацию
о том, имеется ли ошибка, а в случае необходимости и
о том, на каких позициях символы искажены.
Любой двоичный систематический код является группо-
вым кодом, так как совокупность входящих в него кодовых
комбинаций образует группу. С понятием «группа» необхо-
димо познакомиться более подробно.
Математическое введение к групповым кодам
Основой математического описания систематических ко-
дов является линейная алгебра (теория векторных про-
странств, теория матриц, теория групп). Кодовые комбина-
ции рассматриваются как элементы множества, например,
кодовые комбинации двоичного кода принадлежат мно-
жеству положительных двоичных чисел.
Множества, для которых определены некоторые алге-
браические операции, получили название алгебраических
систем. Под алгебраической операцией понимается одно-
139
значное сопоставление двум элементам некоторого третьего
элемента по определенным правилам. Обычно основную
операцию называют сложением (обозначается а -|- Ь = с)
или умножением (обозначается ab = с), а обратную ей —
вычитанием или делением, даже если эти операции прово-
дятся не над числами и не идентичны соответствующим
арифметическим операциям.
Рассмотрим кратко основные алгебраические системы,
широко используемые в теории корректирующих кодов.
Группой называется множество элементов, в котором
определена одна основная операция, причем она должна
быть ассоциативной [(о + Ь) + с = а + (b -ф с)-, а (Ьс) =
= (ah) с] (хотя не обязательно коммутативной, для которой
справедливо [а -ф- b = b -j- a; ab — ba]) и должна обладать
обратной операцией.
Из определения группы вытекают следующие следствия:
1. Любые три элемента группы а, b и с должны удовле-
творять равенству (а + Ь) + с = а ф- (Ь + с) (если основ-
ная операция — сложение) и равенству a (be) = (ab) с (если
основная операция — умножение).
2. В каждой группе Gn существует однозначно опреде-
ленный элемент, удовлетворяющий для всех а из Gn усло-
вию а + 0= 0 + а= а (если основная операция — сло-
жение) или условию
а 1 = 1 • а = а
(если основная операция умножение).
В первом случае этот элемент называется нулем и
обозначается символом 0, а во втором — единицей
и обозначается символом 1.
3. Всякий элемент а группы обладает элементом, одно-
значно определенным уравнением а + (— а) = — а ф- а =
= 0 (если основная операция сложение) или уравнением
а а 1 = о'1 а — 1 (если основная операция — умножение).
В первом случае этот элемент называется противо-
положным и обозначается через —а, а во втором —
обратным и обозначается через а-1.
Если операция, определенная в группе, коммутативна,
т. е. справедливо равенство а ф- b = Ь + а (для группы
по сложению) или равенство ab = Ьа (для группы по умно-
жению), то группа называется коммутативной,
или абелевой.
Группа, состоящая из конечного числа элементов, назы-
вается конечной. В конечной группе в результате
140
операции, применяемой к любым элементам группы, должны
снова образовываться элементы этой же группы (требова-
ние замкнутости).
Чтобы рассматриваемое нами множество «-разрядных
кодовых комбинаций было конечной группой, основная
операция должна быть выбрана так, чтобы указанное тре-
бование замкнутости соблюдалось.
Отсюда следует, что при выполнении операции число
разрядов в результирующей кодовой комбинации не должно
увеличиваться. Этому условию удовлетворяет операция
символического поразрядного сложения по заданному мо-
дулю Р, при которой цифры одинаковых разрядов элемен-
тов группы складываются обычным порядком, а результатом
сложения считается остаток от деления полученного числа
на модуль Р.
При рассмотрении двоичных кодов используется опе-
рация сложения по модулю 2. Результатом сло-
жения цифр данного разряда является нуль, если сумма
единиц в нем четна, и единица, если сумма единиц в нем
нечетна, например:
10 1110 1
ео 1 1 1 1 о 1
0 0 0 1 1 1 0
110 1110
Выбранная нами операция коммутативна, поэтому рас-
сматриваемые группы будут абелевыми.
Нулевым элементом является комбинация, состоящая
из одних нулей. Противоположным элементом при сложе-
нии по модулю два будет сам заданный элемент. Следова-
тельно, операция вычитания по модулю 2 тождественна
операции сложения.
Рассмотрим в качестве примера несколько множеств
кодовых комбинаций.
Множество
0001, ОНО, 0111, ООП
не является группой, так как не содержит нулевого эле-
мента.
Множество
0000, 1101, 1110, 0111
не является группой, так как не выполняется условие
замкнутости, например, сумма по модулю два комбинаций
141
1101 и 1110 дает комбинацию ООП, не принадлежащую
исходному множеству.
Множество
ООО, 001, 010, 011, 100, 101, НО, 111
удовлетворяет всем вышеперечисленным условиям и яв-
ляется группой.
Подмножества группы, являющиеся сами по себе груп-
пами относительно операции, определенной в группе,
называются подгруппами. Например, подмножество двух-
разрядных кодовых комбинаций
000, 001, 010, 011
образуют подгруппу указанной выше группы трехразряд-
ных кодовых комбинаций.
Пусть в абелевой группе G„ задана определенная под-
группа А. Если В — любой не входящий в А элемент из
G„, то суммы (по модулю 2) элемента В с каждым из эле-
ментов подгруппы А образуют смежный класс группы G„
по подгруппе А, порождаемый элементом В.
Элемент В, естественно, содержится в этом смежном
классе, так как любая подгруппа содержит нулевой эле-
мент. Беря последовательно некоторые элементы В; группы,
не вошедшие в уже образованные смежные классы, можно
разложить всю группу на смежные классы по подгруппе А.
Элементы называются образующими (главными)
элементами смежных классов подгруппы.
В таблице разложения, иногда называемой групповой
таблицей, образующие элементы обычно располагаются
в крайнем левом столбце.
Разложение для группы трех- и четырехразрядных
кодовых комбинаций по подгруппе двухразрядных кодовых
комбинаций приведено в табл. 3-10 и 3-11 соответственно.
Нетрудно убедиться в том, что два любых смежных
класса группы Gn по подгруппе А не могут иметь ни одного
общего элемента. В одном смежном классе также не может
Таблица 3-10
Ai = 0 000 Л2 001 ^8 010 он
Bl Л2 ф Ai Ф Bi At Ф Вх
100 101 ИО 111
142
Таблица 3-11
д1==о 0000 Аг 0001 А3 0010 Д4 ООП
В1 ^3 © As ф Bi Ai ф В]
0100 0101 ОНО 0111
в2 А3 ф В2 ^3 © <44 © В2
1010 1011 ХЮ 1001
в3 Дз ф В3 А3 Ф В3 Af ф В3
1100 1101 1110 1111
быть двух одинаковых элементов, так как все элементы
смежного класса являются суммами различных элементов Лг
с одним и тем же элементом Bj.
3-8, ПОСТРОЕНИЕ ГРУППОВОГО КОДА
Определение числа избыточных символов
Построение конкретного корректирующего кода произ-
водится исходя из требуемого объема кода О, т. е. необхо-
димого числа передаваемых команд или дискретных зна-
чений измеряемой величины и статистических данных
о наиболее вероятных векторах ошибок в используемом
канале связи. Вектором ошибки будем называть кодовую
комбинацию, имеющую единицы в разрядах, подвергшихся
искажению, и нули во всех остальных разрядах. Любую
искаженную кодовую комбинацию можно рассматривать
теперь как сумму (или разность) по модулю 2 разрешенной
кодовой комбинации и вектора ошибки.
Исходя из неравенства 2fc — 1 Ss О, определяем число
информационных разрядов k, необходимое для передачи
заданного числа команд обычным двоичным кодом.
Каждой из 2й — 1 ненулевых комбинаций ^-разрядного
безызбыточного кода нам необходимо поставить в соответ-
ствие комбинацию из п символов. Значения символов
в п — k проверочных разрядах такой комбинации устанав-
ливаются в результате суммирования по модулю 2 значений
символов в определенных информационных разрядах.
Поскольку множество 2* комбинаций информационных
символов (включая нулевую) образует подгруппу группы
всех «-разрядных комбинаций, то и множество 2й «-разряд-
ных комбинаций, полученных по вышеуказанному правилу,
143
тоже будет являться подгруппой группы «-разрядных
кодовых комбинаций. Это множество разрешенных кодовых
комбинаций и будет групповым кодом.
Нам надлежит определить число проверочных разрядов
и номера информационных разрядов, входящих в каждое
из равенств для определения символов в проверочных
разрядах.
Разложим группу 2" всех «-разрядных комбинаций на
смежные классы по подгруппе 2* разрешенных «-разрядных
кодовых комбинаций, проверочные разряды в которых еще
не заполнены. Помимо самой подгруппы кода, в разложе-
нии будет насчитываться 2"'* — 1 смежных классов. Эле-
менты каждого класса представляют собой суммы по
модулю 2 комбинаций кода и образующих элементов дан-
ного класса. Если за образующие элементы каждого класса
принять те наиболее вероятные для заданного канала
связи вектора ошибок, которые должны исправляться, то
в каждом смежном классе сгруппируются кодовые комби-
нации, получающиеся в результате воздействия на все
разрешенные комбинации определенного вектора ошибки.
Для исправления любой полученной на выходе канала
связи кодовой комбинации теперь достаточно определить,
к какому классу смежности она относится. Складывая ее
затем (по модулю 2) с образующим элементом этого смеж-
ного класса, мы получаем истинную комбинацию кода.
Ясно, что из общего числа 2" — 1 возможных ошибок
групповой код может исправить всего 2” k — 1 разновид-
ностей ошибок по числу смежных классов.
Чтобы иметь возможность получить информацию о том,
к какому смежному классу относится полученная комби-
нация, каждому смежному классу должна быть поставлена
в соответствие некоторая контрольная последовательность
символов, называемая о п о з н а в а т е л е м.
Каждый символ опознавателя будет определяться в ре-
зультате проверки на приемной стороне справедливости
одного из равенств, которые мы составим для определения
значений проверочных символов при кодировании.
Ранее указывалось, что в систематическом коде значе-
ния проверочных символов подбираются так, чтобы сумма
по модулю 2 всех символов (включая проверочный), входя-
щих в каждое из равенств, равнялась нулю. В таком
случае число единиц среди этих символов четное. Поэтому
операции определения символов опознавателя называют
проверками на четность. При отсутствии ошибок в резуль-
144
тате всех проверок на четность образуется опознаватель,
состоящий из одних нулей. Если проверочное равенство
не удовлетворяется, то в соответствующем разряде опозна-
вателя появляется единица. Исправление ошибок возможно
лишь при наличии взаимно однозначного соответствия
между множеством опознавателей и множеством смежных
классов, а следовательно, и множеством подлежащих испра-
влению векторов ошибок.
Таким образом, количество подлежащих исправлению
ошибок является определяющим для выбора числа избыточ-
ных символов п — k. Их должно быть достаточно для того,
чтобы обеспечить необходимое число опознавателей.
Если, например, мы желаем исправлять все одиночные
независимые ошибки, то исправлению подлежит п ошибок
ООО ... 01, 000 ... 10, 001 ... 00, 010 ... 00, 100 ... 00
п
Различных ненулевых опознавателей должно быть не
менее п. Необходимое число проверочных разрядов, следо-
вательно, должно определяться из соотношения
2n-k-l^n, (3-17)
или
2"*-1^С*.' £3-18)
Если необходимо исправлять не только все единичные,
но и все двойные независимые ошибки, соответствующее
неравенство принимает вид:
2^"-1^-Ch + C, (3-19)
В общем случае для исправления всех независимых оши-
бок кратности до s включительно получаем:
2"~ft-l^Cj( + C^+ ... +С*. (3-20)
Стоит подчеркнуть, что в приведенных соотношениях
указывается теоретический предел минимально возможного
числа проверочных символов, который далеко не во всех
случаях можно реализовать практически. Часто провероч-
ных символов требуется больше, чем следует из соответ-
ствующего равенства.
Одна из причин этого выяснится при рассмотрении про-
цесса сопоставления каждой подлежащей исправлению
ошибки с ее опознавателей.
145
Составление таблицы опознавателен
Начнем для простоты с установления опознавателен для
случая исправления одиночных ошибок. Допустим, что
необходимо закодировать 15 команд. Требуемое число
информационных разрядов тогда равно четырем. Пользуясь
соотношением 2" * — 1 — п, определяем общее число раз-
рядов кода, а следовательно, и число ошибок, подлежащих
исправлению (п = 7). Три избыточных разряда позволяют
использовать в качестве опознавателен трехразрядные
двоичные последовательности.
В данном случае ненулевые последовательности в прин-
ципе могут быть сопоставлены с подлежащими исправлению
ошибками в любом порядке. Однако более целесообразно
сопоставлять их с ошибками в разрядах, начиная с млад-
шего, в порядке возрастания двоичных чисел (табл. 3-12).
Таблица 3-12
Векторы ошибок Опознава- тели Векторы ошибок Опознава- тели
0000001 001 0010000 101
0000010 0000100 010 он 0100000 по
0001000 100 1000000 111
При таком сопоставлении каждый опознаватель пред-
ставляет собой двоичное число, указывающее номер разряда,
в котором произошла ошибка.
Коды, в которых опознаватели устанавливаются по ука-
занному принципу, известны как коды Хэмминга.
Возьмем теперь более сложный случай исправления
всех одиночных и двойных независимых ошибок. В качестве
опознавателей одиночных ошибок в первом и втором разря-
дах можно принять, как и ранее, комбинации 0 ... 001 и
0 ... 010.
Однако в качестве опознавателя одиночной ошибки
в третьем разряде комбинацию 0...011 взять нельзя. Такая
комбинация соответствует ошибке одновременно в первом
и во втором разрядах, а она также подлежит исправлению
и, следовательно, ей должен соответствовать свой опозна-
ватель 0...011,
В качестве опознавателя одиночной ошибки в третьем
разряде можно взять только трехразрядную комбинацию
146
О...О1ОО, так как множество двухразрядных комбинаций
уже исчерпано. Подлежащий исправлению вектор ошибки
0...0101 также может рассматриваться как результат сум-
марного воздействия двух векторов ошибок 0...0100 и 0...001
и, следовательно, ему должен быть поставлен в соответствие
опознаватель, представляющий собой сумму по модулю 2
опознавателей этих ошибок, т. е. 0...0101.
Аналогично находим, что опознавателем вектора ошибки
0...0110 является комбинация 0...0110.
Определяя опознаватель для одиночной ошибки в чет-
вертом разряде, мы замечаем, что еще не использована
одна из трехразрядных комбинаций, а именно 0...0111.
Однако, выбирая в качестве опознавателя единичной
ошибки в i-м разряде комбинацию с числом разрядов, мень-
шим i, необходимо убедиться в том, что для всех остальных
подлежащих исправлению векторов ошибок, имеющих
единицы в i-м и более младших разрядах, получатся опо-
знаватели, отличные от уже использованных. В нашем
случае подлежащими исправлению векторами ошибок
с единицами в четвертом и более младших разрядах явля-
ются:
0 ... 01001, 0 ... 01010, 0 ... 01100.
Если одиночной ошибке в четвертом разряде поставить
в соответствие опознаватель 0...0111, то для указанных
выше векторов опознавателями должны были бы быть соот-
ветственно
„0 ... 0111 ~0 ... 0111 д.0 ... 0111
^0 ... 0001 ®*0...0010 ^0 ... 0100
0 ... ОНО, 0 ... 0101, 0 ... ООН.
Однако эти комбинации уже использованы в качестве
опознавателей других векторов ошибок, а именно:
0 ... ОНО, 0 ... 0101, 0 ... ООП.
Следовательно, во избежание неоднозначности при деко-
дировании в качестве опознавателя одиночной ошибки
в четвертом разряде следует взять четырехразрядную ком-
бинацию 1000. Тогда для векторов ошибок
0 ... 01001, 0 ... 01010, 0 ... 01100
опознавателями соответственно будут:
0 ... 01001, 0 ... 01010, 0 ... 01100.
Аналогично можно установить, что в качестве опознава-
теля одиночной ошибки в пятом разряде может быть выбрана
147
не использованная ранее четырехразрядная комбинация
01111.
Действительно, для всех остальных подлежащих исправ-
лению векторов ошибок с единицей в пятом и более младших
разрядах получаем опознаватели, отличающиеся от ранее
установленных:
Векторы ошибок
0 ... 010001
0 ... 010010
0 ... 010100
О ... 011000
Опознаватели
О ... OHIO
О ... 01101
О ... 01011
О ... 00111
Продолжая сопоставление, мы можем получить таблицу
опознавателей для векторов ошибок данного типа с любым
числом разрядов. Поскольку опознаватели векторов ошибок
с единицами в нескольких разрядах устанавливаются как
суммы по модулю 2 опознавателей одиночных ошибок в этих
разрядах, то для определения правил построения кода и
составления проверочных равенств достаточно знать только
опознаватели одиночных ошибок в каждом из разрядов.
Для построения кодов, исправляющих двойные независимые
ошибки, таблица таких опознавателей определена [Л. 3-31
с помощью вычислительной машины вплоть до 29-го разряда.
Опознаватели одиночных ошибок в первых пятнадцати
разрядах приведены в табл. 3-13.
Таблица 3-13
№ разряда Опознаватель № разряда Опознаватель № разряда Опознаватель
1 00000001 6 00010000 и 01101010
2 00000010 7 00100000 12 10000000
3 00000100 8 00110011 13 10010110
4 00001000 9 01000000 14 10110101
5 00001111 10 01010101 15 попои
По тому же принципу аналогичные таблицы определены
и для ошибок других типов, например для тройных неза-
висимых ошибок, пачек ошибок в два и три символа
[Л. 3-3].
Определение проверочных равенств
Итак, для любого кода, имеющего целью исправлять
наиболее вероятные векторы ошибок заданного канала
связи (взаимно независимые ошибки или пачки ошибок),
148
можно составить таблицу опознавателен одиночных ошибок
в каждом нз разрядов. Пользуясь этой таблицей, нетрудно
определить, символы каких разрядов должны входить
в каждую из проверок на четность.
Рассмотрим в качестве примера опознаватели для кодов,
предназначенных исправлять единичные ошибки (табл. 3-14).
Таблица 3-14
№ № №
разрядов Опознаватели разрядов Опознаватели разрядов Опознаватели
1 0001 7 0111 12 1100
2 0010 8 1000 13 1101
3 4 ООН 0100 9 1001 14 1110
5 0101 10 1010 15 1111
6 оно 11 1011 16 10000
В принципе можно построить код, усекая эту таблицу
на любом уровне. Однако из таблицы видно, что оптималь-
ными будут коды (7, 4), (15, 11), где первое число равно п,
а второе k, и другие, которые среди кодов, имеющих одно
и то же число проверочных символов, допускают наиболь-
шее число информационных символов.
Усечем эту таблицу на седьмом разряде и найдем номера
разрядов, символы которых должны войти в каждое из
проверочных равенств.
Предположим, что в результате первой проверки на
четность для младшего разряда опознавателя будет полу-
чена единица. Очевидно, это может быть следствием ошибки
в одном из разрядов, опознаватели которых в младшем
разряде имеют единицу. Следовательно, первое провероч-
ное равенство должно включать символы 1-го, 3-го, 5-го
и 7-го разрядов:
ai Ф сз Ф аъ © — О-
Единица во втором разряде опознавателя может быть
следствием ошибки в разрядах, опознаватели которых имеют
единицу во втором разряде. Отсюда второе проверочное
равенство должно иметь вид:
«2 Ф «з ф аъ Ф ае = 0.
Аналогично находим и третье равенство
ai Ф аа Ф Ф а7 — О-
149
Чтобы эти равенства при отсутствии ошибок удовле-
творялись для любых значений информационных символов
в кодовой комбинации, в нашем распоряжении имеется три
проверочных разряда. Мы должны так выбрать номера
этих разрядов, чтобы каждый из них входил только в одно
из равенств. Это обеспечит однозначное определение зна-
чений символов в проверочных разрядах при кодировании.
Указанному условию удовлетворяют разряды, опознава-
тели которых имеют по одной единице. В нашем случае
это будут первый, второй и четвертый разряды.
Таким образом, для кода (7, 4), исправляющего одиноч-
ные ошибки, искомые правила построения кода, т. е. соот-
ношения, реализуемые в процессе кодирования, принимают
вид:
01 = о8 ф аъ ф а„
О2 = о8@а5фав,
О4 = о5фав@й7.
Используя табл. 3-13 и рассуждая аналогичным образом,
можно составить проверочные равенства для любого кода,
исправляющего все одиночные и двойные ошибки. Напри-
мер, для кода (8, 2), получающегося усечением этой таблицы
на восьмом разряде, найдем следующие проверочные ра-
венства: С1 Ф «6 Ф «8 = 0, й2 © а& Ф aS = 0» «в Ф аъ = 0, с4®е6 = 0, яв®о8 = 0, ^7 w —0.
Соответственно соотношениями правила построения кода выразятся С1=«6Ф«8, «2 = «5 © «8. «з == аъ, ^ = аъ, ав ~ а8г — Gg.
150
Матричная запись группового кода
Зная закон построения кода, можно определить все
множество разрешенных кодовых комбинаций. Расположив
их друг под другом, получим матрицу, насчитывающую п
столбцов и 2й — 1 строк. Например, для рассмотренного
нами кода (8, 2), исправляющего все одиночные и двойные
ошибки, матрицу можно представить в таком виде
ая а± а2 а3 ав а7
0 1110 0 11
10 11110 0
110 0 1111
Однако при больших п и k матрица оказывается слишком
громоздкой. Поэтому код записывают в сокращенном виде.
Строки получающейся матрицы линейно зависимы.
В приведенной матрице, например, третья строка может
быть получена суммированием по модулю 2 первых двух
строк.
Для полного определения кода достаточно записать
только линейно независимые строки. Среди 2* — 1 нену-
левых комбинаций кода их только k. Действительно, если
рассматривать k информационных разрядов корректирую-
щего (n, k) кода, как ^-разрядный неизбыточный код, то
все 2й — 1 ненулевых комбинаций этого кода можно запи-
сать компактно, приняв за линейно независимые строки
единичной матрицы.
Суммируя строки единичной матрицы в различных
сочетаниях, можно получить любую из 2й — 1 ненулевых
комбинаций ^-разрядного неизбыточного кода. Поэтому эту
матрицу называют образующей (порождающей, произ-
водящей) по отношению к данному коду. Если в этой мат-
рице единицы расположены по побочной диагонали, то такая
матрица называется образующей транспонированной мат-
рицей в канонической форме и обозначается . Для при-
дания коду корректирующей способности к k информа-
ционным разрядам добавляют п — k проверочных, т. е.
удлиняют каждую комбинацию, не меняя числа информа-
ционных разрядов. Образующую матрицу такого кода
(обозначим ее МП,А) можно составить из двух матриц:
1) единичной транспонированной в канонической форме
Д’, которая соответствует k информационным разрядам;
151
2) дописываемой справа дополнительной матрицы ft,
которая соответствует и — k проверочным разрядам.
Эта матрица содержит информацию о способе построе-
ния кода.
Каждую строку дополнительной матрицы получим,
записав на основании найденных уравнений значения про-
верочных символов для соответствующей строки единичной
транспонированной матрицы. Например, дополнительные
матрицы упоминавшихся выше кодов (8, 2) и (7, 4) имеют
вид:
G2 Gg
а1 g2 at йц ае а7
1 0 1
110 0 11
0 1 1
11110 0
1 1 1
1 1 0
По заданной дополнительной матрице легко определить
равенства, задающие правила построения кода. Единица
в последней строке каждого столбца указывает на то, что
при образовании соответствующего столбцу проверочного
разряда участвовал первый информационный разряд. Еди-
ница в предыдущей строке любого столбца говорит об уча-
стии в образовании проверочного разряда второго информа-
ционного разряда и т. д.
В коде (8, 2) первым информационным разрядом является
пятый разряд, а вторым — восьмой. Следовательно, в состав
равенства для определения значения символа, например,
во втором проверочном разряде должны быть включены
символы восьмого и пятого разрядов:
«2 = «8 Ф «5
Аналогично определяются и все остальные равенства.
Нетрудно убедиться в том, что все они полностью совпа-
дают с равенствами, использованными нами для построения
дополнительной матрицы кода (8, 2).
Запишем теперь полные образующие матрицы кодов
(8, 2) и (7, 4):
ав а8 aL а2 ал «4 ае а7
Й о 1 а «> 4 о ।
0 1110 0 11
10 11110 0
152
^6 ^6 ^7 ^2 ^"4
Полное множество разрешенных комбинаций каждого
из кодов можно получить, суммируя по модулю 2 строки
соответствующей матрицы во всех возможных сочетаниях.
3-9. ТЕХНИЧЕСКИЕ СРЕДСТВА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ
ДЛЯ ГРУППОВЫХ КОДОВ
Кодирующее устройство строится на основании совокупности
равенств, отражающих правила построения кода. Определение значе-
ний символов в каждом из п — k проверочных разрядов в кодирующем
устройстве осуществляется посредством сумматоров по модулю 2.
Схема сумматора на три входа представлена на рис. 3-29. Триггеры
Тг1, Тг2, Тг3 устанавливаются в положение 0 или 1 в соответствии
со входной информацией. Если сумма триггеров, находящихся в поло-
жении 1, четна, то поступающий на вход схемы импульс опроса пройдет
на выход О В противном случае он проходит на выход 1.
На рис. 3-29 триггеры Тгх и Тгя находятся в положении 1, а триг-
гер Тг2 — в положении 0. Импульс опроса проходит на выход 0 через
логические схемы ИЛИ-i, Hi, Иь, ИЛИ2, И? и ИЛИ^.
На каждый разряд сумматора (кроме первого) используется четыре
схемы И (вентиля) и две схемы ИЛИ.
Рассмотрим работу кодирующего устройства, используя код (7, 4),
имеющий целью исправлять одиночные ошибки.
Правила построения кода определяются равенствами
«1 = а3 © а& ®
о2 = а3 ® «6 © «7>
&1 = «5 © «в © «7-
153
Схема кодирующего устройства приведена на рис. 3-30.
При поступлении импульса синхронизации со схемы управления
подлежащая кодированию fe-разрядная комбинация неизбыточного
кода переписывается, например с аналого-кодового преобразователя,
Рис. 3-30. Кодирующее устройство группового
кода.
в информационные разряды /г-разрядного регистра. Предположим, что
в результате этой операции в регистре записалось число 1010, как то
показано в табл. 3-15.
Таблица 3-15
' Гг, Гг2 Tss Тг, Тг. Гг,
— — 1 — 0 1 0
С некоторой задержкой формируются выходные импульсы сумма-
торов Съ С2, С3, которые устанавливают триггеры проверочных раз-
рядов в положение 0 или 1 в соответствие с вышеприведенными равен-
ствами. Например, в нашем случае ко входам сумматора Ct подводится
информация, записанная в 3-м, 5-м и 7-м разрядах и, следовательно,
триггер Tzi первого проверочного разряда будет установлен в положе-
ние 1. Аналогично триггер Тг2 будет установлен в положение 0, а триг-
гер Тг\ — в положение 1.
Сформированная в регистре разрешенная комбинация (табл. 3-16)
импульсом, поступающим с блока управления, считывается в линию
связи. Далее начинается кодирование следующей комбинации.
Таблица 3-16
7^ Гг£ Тг., Гг. Тг. 71
1 0 1 1 0 1 0
154
Рассмотрим теперь схему декодирования и коррекции ошибок
(рис. 3-31). Она строится на основе совокупности проверочных равенств.
Для кода (7, 4) они имеют вид:
ai Ф аз © а5 © а7 = О"
а2 ф °3 © ав © = О'
а4 © °S © °6 © ~ О-
Кодовая комбинация, возможно содержащая ошибку, поступает на
n-разрядный приемный регистр (на рис. 3-31 триггеры Тгх — Гг7).
По окончании переходного процесса в триггерах с блока управления
Рис. 3-31. Декодирующее устройство группового кода.
на каждый из сумматоров (С, — С3) поступает импульс опроса. Выход-
ные импульсы сумматоров устанавливают в положение 0 или 1 триггеры
регистра опознавателей. Если проверочные равенства выполняются,
все триггеры регистра опознавателей устанавливаются в положение О,
что соответствует отсутствию ошибки. При наличии ошибки в регистр
опознавателей запишется опознаватель этого вектора ошибки. Дешифра-
тор ошибки ДО ставит в. соответствие множеству опознавателей множе-
ство векторов ошибок. При опросе выходных вентилей дешифратора
сигналы коррекции поступают только на те разряды, в которых вектор
ошибки, соответствующий записанному на входе опознавателю, имеет
единицы. Сигналы коррекции воздействуют на счетные входы тригге-
ров. Последние изменяют свое состояние, и таким образом ошибка
исправляется. На триггеры поверочных разрядов регистра импульсы
коррекции не посылаются, так как после коррекции информация спи-
сывается только с информационных разрядов. Для кода Хэмминга (7, 4)
любой опознаватель представляет собой двоичное трехразрядное число,
равное номеру разряда приемного регистра, в котором записан оши-
бочный символ.
155
Предположим, что сформированная ранее в кодирующем устрой-
стве комбинация при передаче исказилась и на приемном регистре
была зафиксирована в виде, записанном в табл. 3-17.
Таблица 3-17
Тг1 Тг2 Ге8 Гг4 Тг. Гге Tz?
1 0 1 1 1 1 0
По результатам опроса сумматоров получим:
на выходе Сг ах ф а3 ф а5 ф я7 = 1 © 1 ф 1 © 0 = 1;
на выходе С2 ^фПзфПефс^ — 0©1ф1ф0 — 0;
на выходе С3 ф а5 © ае © о, = 1 © 1 © 1 ф 0 = 1.
Следовательно, номер разряда, в котором произошло искажение,
101, или 5. Импульс коррекции поступит на счетный вход триггера Тгъ,
и ошибка будет исправлена.
3-10. ПОСТРОЕНИЕ ЦИКЛИЧЕСКИХ КОДОВ
Общие понятия и определения
Любой групповой код может быть записан в виде мат-
рицы, включающей k линейно независимых строк по п
символов и, наоборот, любая совокупность k линейно неза-
висимых «-разрядных кодовых комбинаций может рассмат-
риваться как образующая матрица некоторого группового
кода. Среди всего многообразия таких кодов можно выде-
лить коды, у которых строки образующих матриц связаны
дополнительным условием цикличности.
Все строки образующей матрицы такого кода могут быть
получены циклическим сдвигом одной комбинации, назы-
ваемой образующей для данного кода. Коды, удо-
влетворяющие этому условию, получили название цик-
лических кодов.
Сдвиг осуществляется справа налево, причем крайний
левый символ каждый раз переносится в конец комбинации.
Запишем совокупность кодовых комбинаций, получающихся
циклическим сдвигом одной «-разрядной комбинации, на-
пример шестиразрядной 010001:
010001, 100010, 000101, 001010, 010100, 101000.
Любые k « комбинаций этого множества могут соста-
вить образующую матрицу циклического кода.
156
Число возможных циклических (п, k) кодов значительно
меньше числа различных групповых (n, k) кодов.
При Описании циклических кодов более удобной оказы-
вается запись любого /t-разрядного двоичного числа в виде
многочлена (п — 1)-й степени, содержащего фиктивную
переменную х. Показатели степени у х соответствуют номе-
рам разрядов, а коэффициентами при х являются цифры
О и 1 (так как мы рассматриваем двоичные коды). При этом
наименьшему разряду числа соответствует фиктивная пере-
менная х° — 1. Запишем, например, в виде многочлена
пятиразрядную двоичную кодовую комбинацию 10101:
G(x) = l-x4 + 0-x3+l-x2 + 0-x+l-х°. (3-21)
Поскольку члены с нулевыми коэффициентами при
записи многочлена опускаются, окончательно получим:
С(я) = я4 + я2 + 1. (3-22)
Многочлен называется нормированным, если коэффи-
циент при старшей степени равен единице.
Теперь действия над кодовыми комбинациями сводятся
к действиям над многочленами.
Вышеупомянутый циклический сдвиг некоторого обра-
зующего многочлена степени /г — k соответствует простому
умножению на х. Умножив, например, многочлен я3 + я2 +
+ 1, соответствующий комбинации 0001101, на х, получим
многочлен я4 + я3 + я, соответствующий комбинации
0011010.
Нетрудно убедиться, что кодовая комбинация, получаю-
щаяся сложением этих двух комбинаций, также будет соот-
ветствовать результату умножения многочлена я3 + я2 + 1
на многочлен я + 1, если приведение подобных членов
осуществлять по модулю 2. Действительно,
0001101
0011010
0010111,
я3 + я2 + 0 + 1
я+ 1
я3 + я2 + 0Д1
я4Дя3+ 0 + я
У + 0 +я2 + я+ 1,
Отсюда ясно, что при соответствующем выборе образую-
щего многочлена любая разрешенная кодовая комбинация
циклического кода может быть получена в результате
умножения образующего многочлена на некоторый другой
многочлен. Иными словами, любой многочлен циклического
157
кода делится на образующий многочлен без остатка. Ни
один многочлен, соответствующий запрещенной кодовой
комбинации, на образующий многочлен без остатка не
делится. Это свойство позволяет обнаружить ошибку. По
виду остатка можно определить и вектор ошибки.
Умножение и деление многочленов весьма просто осу-
ществляется на регистрах сдвига с обратными связями,
что и явилось причиной широкого применения циклических
кодов.
Математическое введение к циклическим кодам
Поскольку каждая разрешенная комбинация «-разряд-
ного циклического кода является произведением двух
многочленов, один из которых является образующим, то
эти комбинации можно рассматривать как подмножество
множества всех произведений многочленов степени не выше
п — 1. Это наталкивает на мысль использовать для их
построения еще одну ветвь теории алгебраических систем,
а именно — теорию колец.
Коммутативным кольцом называется мно-
жество, в котором определены две операции — сложения
и умножения, обе коммутативные [а + b = b + а и ab =
Ьа], ассоциативные \а + (Ь с) = (а + Ь) + с и а (Ьс) =
= (ab) с] и связанные законом дистрибутивности [(« + Ь) с =
— ас + Ьс], причем сложение обладает обратной опера-
цией — вычитанием.
Кольцо, следовательно, является абелевой группой по
сложению, удовлетворяющей дополнительным условиям.
Операция сложения в нашем множестве всех «-разряд-
ных кодовых комбинаций (многочленов степени не выше
п — 1) была выбрана ранее (сложение по модулю 2).
Определим теперь операцию умножения. Нетрудно
видеть, что операция умножения многочленов по обычным
правилам с приведением подобных членов по модулю 2
может привести к нарушению условия замкнутости. Дей-
ствительно, в результате умножения могут быть получены
многочлены более высокой степени, чем п — 1, вплоть до
2 (п — 1), а соответствующие им кодовые комбинации
будут иметь число разрядов, превышающее п и, следова-
тельно, не будут относиться к рассматриваемому нами
множеству. Поэтому операция символического умножения
задается так:
1. Многочлены перемножаются по обычным правилам,
но с приведением подобных членов по модулю 2.
158
2. Если старшая степень произведения не превышает
п — 1, то оно и является результатом символического умно-
жения.
3. Если старшая степень произведения больше или
равна п, то многочлен произведения делится на заранее
определенный многочлен степени п и результатом символи-
ческого умножения считается остаток от деления.
Степень остатка не будет превышать п — I и, следова-
тельно, этот многочлен будет принадлежать к рассматри-
ваемому нами множеству «-разрядных кодовых комбина-
ций.
Для того чтобы найти вид этого многочлена «-Й степени,
найдем результат умножения многочлена степени п — 1
на х.
В общем случае это будет:
G (х) = х (хя 1 + х"2 +... + х + 1) = х" + хп1 +... + х. (3-23)
Чтобы результат умножения и теперь соответствовал
кодовой комбинации, образующейся путем циклического
сдвига исходной кодовой комбинации, в нем необходимо
заменить х” на 1. Такая замена эквивалентна делению,
полученного при умножении многочлена на х" + 1 с за-
писью в качестве результата остатка от деления, что обычно
называется взятием остатка или приведением по модулю
Xя + 1 (сам остаток в этом случае называется в ы ч е -
т о м).
Искомым многочленом n-й степени является, следова-
тельно, многочлен х” + 1.
Итак, при заданных нами операциях сложения и умно-
жения все множество многочленов степени не выше п — 1,
соответствующее множеству «-разрядных кодовых комби-
наций, образует кольцо.
Выделим теперь в нашем кольце подмножество всех
многочленов, кратных некоторому многочлену наименьшей
степени g (х). Такое подмножество называется идеа-
лом, а многочлен g (х) — порождающим мно-
гочленом идеала.
Количество различных элементов в идеале определяется
видом его порождающего многочлена. Если за порождаю-
щий многочлен взять 0, то весь идеал будет составлять
только этот многочлен, так как умножение его на любой
другой многочлен дает 0.
Если за порождающий многочлен принять 1 [g (х) == 1],
то в идеал войдут все многочлены кольца. В общем случае
159
число элементов идеала, порожденного простым многочленом
степени п — k, составляет 2fe.
Теперь становится понятным, что циклический двоич-
ный код в построенном нами кольце «-разрядных двоич-
ных кодовых комбинаций является идеалом.
Остается выяснить, как выбрать многочлен g (х), способ-
ный породить циклический код с заданными свойствами.
Требования, предъявляемые к образующему многочлену
Согласно определению циклического кода все много-
члены, соответствующие его кодовым комбинациям, должны
делиться на g (х) без остатка. Для этого достаточно, чтобы
на g W делились без остатка многочлены, составляющие
образующую матрицу кода. Последние получаются цикли-
ческим сдвигом, что соответствует последовательному умно-
жению g (х) нахе приведением по модулю хп + 1.
Следовательно, в общем случае многочлен #,(х) является
остатком от деления произведения g (х) х‘ на многочлен
хп + 1 и может быть записан так:
где
gi W = g (х) х1 - С (хп + 1),
(3-24)
С = 1 при g (х) х‘ Эг х” + 1;
С = 0 при g(x)xI<^x"+1.
(3-25)
(3-26)
Отсюда ясно, что все многочлены матрицы, а поэтому
и все многочлены кода, будут делиться на g (х) без остатка
только в том случае, если на g (х) будет делиться без остатка
многочлен хп + 1.
Таким образом, чтобы g (х) мог породить идеал, а сле-
довательно, и циклический код, он должен быть делителем
многочлена х" + 1.
Поскольку для кольца справедливы все свойства группы,
а для идеала — все свойства подгруппы, то кольцо можно
разложить на смежные классы, называемые в этом случае
классами вычетов по идеалу.
Первую строку разложения образует идеал, причем
нулевой элемент располагается крайним слева. В качестве
образующего первого класса вычетов можно выбрать любой
многочлен, не принадлежащий идеалу. Остальные элементы
данного класса вычетов образуются путем суммирования
образующего многочлена с каждым многочленом идеала.
160
Если многочлен g (х) степени т = п — k является
делителем х" + 1, то любой элемент кольца либо делится
на g (х) без остатка (тогда он является элементов идеала),
либо в результате деления появляется остаток, представ-
ляющий собой многочлен степени не выше т — 1.
Элементы кольца, дающие в остатке один и тот же много-
член ri (х), относятся к одному классу вычетов. Приняв
многочлены г (х) за образующие элементы классов вычетов,
разложение кольца по идеалу с образующим многочленом
g (х) степени т можно представить табл. 3-18, где f (х) —
произвольный многочлен степени не выше п—т — 1.
Таблица 3-18
0 g (х> xg{x) (х 4- 1) g (X) f (X) g (X)
о W g (х) + Г1 (X) xg (х) + г, (X) (X + 1) g (х) +п (х) f (X) g (X) + r, (X)
Г 2 W g (х) + (х xg (х) + гг (х) (х + !)g (х) + Гг (х) f (X) g (x) + r2 (X)
g <х> + гг <х) Xg (X) + гг (X) <x + \)g(x) + rg(x) f(x)g(x)+r?(x)
Ранее отмечалось, что групповой код способен исправить
столько разновидностей ошибок, сколько различных клас-
сов насчитывается в приведенном разложении. Отсюда
ясно, что корректирующая способность кода будет тем выше,
чем больше остатков может быть образовано при делении
многочлена сообщения на образующий многочлен кода.
Наибольшее число остатков, равное 2т — 1 (исключая
нулевой), может обеспечить только неприводимый (простой)
многочлен степени т. Это такой многочлен, который делится
сам на себя и не делится ни на какой другой многочлен
(кроме 1).
3-11. ВЫБОР ОБРАЗУЮЩЕГО МНОГОЧЛЕНА ПО ЗАДАННОМУ ОБЪЕМУ КОДА
И ЗАДАННОЙ КОРРЕКТИРУЮЩЕЙ СПОСОБНОСТИ
По заданному объему кода однозначно определяется
число информационных разрядов k. Далее необходимо найти
наименьшее п, обеспечивающее обнаружение или исправле-
ние ошибок заданной кратности. В случае циклического
кода эта проблема сводится к нахождению нужного много-
члена g (х).
Начнем рассмотрение с простейшего циклического кода,
обнаруживающего все одиночные ошибки.
6 Темников Ф, Е. и др.
161
Обнаружение одиночных ошибок
•Любая принятая по каналу связи кодовая комбинация
h (х), возможно содержащая ошибку, может быть представ-
лена в виде суммы по модулю 2 неискаженной комбинации
кода f (х) и вектора (кода) ошибки Е, (х):
h(x) = f(x)®l-(x). (3-27)
При делении h (х) на образующий многочлен g (х) оста-
ток, указывающий на наличие ошибки, будет обнаружен
только в том случае, если многочлен, соответствующий
вектору ошибки, не делится на g (х): f (х) — неискаженная
комбинация кода и, следовательно, на g (х) делится без
остатка.
Вектор одиночной ошибки будет иметь единицу в иска-
женном разряде и нули во всех остальных разрядах. Ему
будет соответствовать многочлен Е, (х) = х1. Последний не
должен делиться nag (х). Среди неприводимых многочленов,
входящих в разложение х" + 1, многочленом наименьшей
степени, удовлетворяющим указанному условию, является
х + 1. Остаток от деления любого многочлена на х + 1
представляет собой многочлен нулевой степени и может
принимать только два значения: 0 или 1. Все кольцо в дан-
ном случае будет состоять из идеала, содержащего много-
члены с четным числом членов, и одного класса вычетов,
соответствующего единственному остатку, равному единице.
Таким образом, при любом числе информационных разрядов
необходим только один проверочный разряд. Значение
символа этого разряда как раз и обеспечивает четность
числа единиц в любой разрешенной кодовой комбинации,
а следовательно, и делимость ее на х + 1.
Полученный циклический код с проверкой на четность
способен обнаруживать не только одиночные ошибки в от-
дельных разрядах, но и ошибки в любом нечетном числе
разрядов.
Исправление одиночных ошибок или обнаружение
двойных ошибок
Прежде чем исправить одиночную ошибку в принятой
комбинации из п разрядов, естественно, необходимо опре-
делить, какой из разрядов был искажен. Это можно сделать
только в том случае, если каждой одиночной ошибке в опре-
162
деленном разряде соответствует свой класс вычетов и свой
опознаватель. Поскольку в циклическом коде опознавате-
лями ошибок являются остатки от деления многочленов
ошибок на образующий многочлен кода g (х), то g (х)
должно обеспечить требуемое число различных остатков
при делении векторов ошибок с единицей в искаженном
разряде. Как уже отмечалось, наибольшее число остатков
дает неприводимый многочлен. При степени многочлена
т = п — k он может дать 2"“* — 1 ненулевых остатков
(нулевой остаток является опознавателем безошибочной
передачи).
Следовательно, необходимым условием исправления лю-
бой одиночной ошибки является выполнение неравенства
2n~k-\^Cln = n, (3-28)
где С1 — общее число разновидностей одиночных ошибок
в кодовой комбинации из п символов; отсюда находится
степень образующего многочлена кода
т = п — k log2 (п + 1)
(3-29)
и общее число символов в кодовой комбинации. Наибольшие
значения kun для различных т можно найти, пользуясь
табл. 3-19.
Таблица 3-19
т 1 2 3 4 5 6 7 8 9 10
п 1 3 7 15 31 63 127 255 511 1023
k 0 1 4 11 26 57 120 247 502 1013
Как указывалось ранее, образующий многочлен g (х)
должен быть делителем двучлена х" + 1. Доказано [Л. 3-5],
что любой двучлен типа х" + 1 = х2'”-1 -|- 1 может быть
представлен произведением всех без исключения неприво-
димых многочленов, степени которых являются делителями
числа т (от 1 до т включительно). Следовательно, для
6*
163
любого т существует по крайней мере один неприводимый
многочлен степени т, входящий сомножителем в разло-
жение двучлена х" + 1.
Пользуясь этим свойством, а также имеющимися в ряде
книг [Л. 3-4] таблицами многочленов, неприводимых при
двоичных коэффициентах, выбрать образующий многочлен
при известных пит несложно. Определив образующий
многочлен, необходимо убедиться в том, что он обеспечивает
заданное число остатков.
Выберем, например, образующий многочлен для случая
п = 15 и т р= 4. Двучлен х15 + 1 можно записать в виде
произведения всех неприводимых многочленов, степени
которых являются делителями числа 4. Последнее делится
на 1, 2, 4.
В таблице неприводимых многочленов находим один
многочлен первой степени, а именно х + 1, один многочлен
второй степени х2 + х + 1 и три многочлена четвертой
степени: х4+ х 4-1, х4 + х®+1, х4 + х3 + х2 -р х + 1 - Пере-
множив все многочлены, убедимся в справедливости соот-
ношения (х + 1) (х2 + х + 1) (х4 + х + 1) (х4 + х3 + 1)Х
X (х4 + х3 + х2 + х + 1) = х15 -|- 1. Один из сомножителей чет-
вертой степени может быть принят за образующий многочлен
кода. Возьмем, например, многочлен х4 + х® + 1 или
в двоичном коде 11001.
Чтобы убедиться, что каждому вектору ошибки соответ-
ствует отличный от других остаток, необходимо поделить
каждый из этих векторов на 11001.
Векторы ошибок т младших разрядов имеют вид:
00 ... 0001, 00 ... 0010, 00 ... 0100, 00 ... 1000.
f
Степени соответствующих им многочленов меньше сте-
пени образующего многочлена g (х). Поэтому они сами
являются остатками при нулевой целой части. Остаток,
соответствующий вектору ошибки в следующем старшем
разряде, получаем при делении 00 ... 10000 на 11001, т. е.
~ 10000 Ц1001
11001 --------
1001
Аналогично могут быть найдены и остальные остатки.
Однако их можно получить проще, деля на g (х) комбина-
164
пию в виде единицы с рядом нулей и выписывая все проме-
жуточные остатки:
^10000000000... 111001 Остатки
11001 1001
~ 10010 ® 11001 1011 1111
m 10110 11001 0111
1110
„ 11110 0101
® 11001 1010
m011100 11001 1101 ООП ОНО 1100 0001
г 0010100 11001
ш ною 0010
Ф 11001 0100 /
~ 0011000 Ф 11001 1000
00001000
При последующем делении остатки повторяются.
Таким образом, мы убедились в том, что число различных
остатков при выбранном g (х) равно п—15 и, следовательно,
код, образованный таким g (х), способен исправить любую
одиночную ошибку. С тем же успехом за образующий
многочлен кода мог быть принят и многочлен х4 + х + 1.
При этом мы получили бы код, эквивалентный выбранному.
Однако использовать для тех же целей многочлен
х4 + х3 + х2 + х + 1, оказывается, нельзя. При проверке
числа различных остатков обнаруживается, что их у него
не 15, а только 5. Действительно,
10000000 ... 111111 ^11111 ® 11111 00010000 Остатки 1111 0001 0010 0100 1000
Это объясняется тем, что многочлен х4 + х3 х2 +
+ х + 1 входит в разложение не только двучлена х15 1,
но и двучлена х5 -j- 1. В качестве образующего, слёдова-
165
тельно, целесообразно выбирать такой неприводимый мно-
гочлен g (х) (или произведение таких многочленов), кото-
рый, являясь делителем двучлена хп + 1, не входит в раз-
ложение ни одного двучлена типа х* + 1, степень которого
к меньше п. В этом случае говорят, что многочлен g (х)
принадлежит показателю степени п.
В табл. 3-20 приведены основные характеристики неко-
торых кодов, способных исправлять одиночные ошибки или
обнаруживать все одиночные и двойные ошибки.
Таблица 3-20
Показатель неприводимого многочлена т = п — k Образующий многочлен «(*) Число остатков 2т - 1 - Длина кода п
2 X2- -Л - h 1 3 з
3 х3 - -X - -1 7 === 7
3 X3 -J -х2-> -1 7 : 7
4 X4-! - X3 - -1 15 =gl5
4 X4- -X h 1 15 =sS15
5 X5 - -X2- -1 31 г£31
5 х5 Н I-X3- -1 31 г£31
5 X5 - 1-Х2- -х-|- 1 31 =g3l
Это циклические коды Хэмминга для исправления одной
ошибки, в которых в отличие от групповых кодов Хэмминга
все проверочные разряды размещаются в конце кодовой
комбинации.
Эти коды могут использоваться для обнаружения любых
двойных ошибок. Многочлен, соответствующий вектору
Двойной ошибки, имеет вид | (х) — х1 + х!, илй % (х) =
= х'(x/ l-|- 1), считая, что j >1. Поскольку / — 1< п,
a g (х) не кратен х и принадлежит показателю степени п,
то | (х) не делится на g (х), что и позволяет обнаружить
двойные ошибки.
Обнаружение тройных ошибок
Образующие многочлены кодов, способных обнаружи-
вать одиночные, двойные и тройные ошибки, можно опре-
делить, базируясь на следующем указании Хэмминга.
Если известен образующий многочлен рт (х) кода длины п, по
зволяющего обнаруживать ошибки некоторой кратности z, то
образующий многочлену (х) кода, способного обнаруживать
166
ошибки следующей кратности (z + 1), может быть получен
умножением многочлена рт (х) на многочлен х + 1, что
соответствует введению дополнительной проверки на
четность. При этом число символов в комбинациях кода за
счет добавления еще одного проверочного символа увели-
чивается до п + 1.
В табл. 3-21 приведены основные характеристики неко-
торых кодов, способных обнаруживать ошибки кратности 3
и менее.
Таблица 3-21
Показатель неприводимого многочлена т = п — k Образующий многочлен g (X) = (x-j-1) рт (х) Число информа- ционных символов k Длина кода п 1
3 (х 4- 1) (Xs + X + 1) 4 8
4 (х+1)(х* + х+1) ===11 16
5 (х+1)(х*4-х*4-1) =<26 32
Обнаружение и исправление независимых ошибок
произвольной кратности
Циклический код, исправляющий более одной ошибки
в любом сочетание, в общем случае можно построить
следующим образом:
1. По заданному k определяется п — k, необходимое
для исправления одной ошибки, и строится (n, k) код.
2. Рассматривая (п, k) код как некорректирующий
n-разрядный код, определяется пг — п дополнительных
разрядов для обеспечения исправления одной ошибки в этом
коде и строится код (пь п).
3. Повторяя данную процедуру t раз, можно получить
код, исправляющий независимые ошибки кратности до t
включительно.
Такой код, однако, оказывается неоптимальным с точки
зрения числа проверочных символов при данном k. Мини-
мального числа проверочных символов при заданном k и
заданной корректирующей способности требуют цикличе-
ские коды Боуза — Чоудхури. Математическая структура
этих кодов несколько отлична от приведенной ранее и тре-
бует значительно более сложных устройств для обнаруже-
ния и исправления ошибок.
167
Обнаружение и исправление пачек ошибок
Для всех циклических кодов, исправляющих пачки
ошибок, образующий многочлен g (х) представляет собой
произведение неприводимого многочлена степени т на
другой многочлен, вид которого определяется типом кода,
а старшая степень с — длиной пачки ошибок, на исправле-
ние которой код рассчитан. Следовательно, показатель
степени g (х) равен с 4- т.
В общем случае степени иг и с не могут принимать про-
извольных значений и для различных типов кодов связаны
между собой различной функциональной зависимостью.
Длина кодовой комбинации п также является функцией т
и с. Таким образом, общей для всех типов кодов, исправляю-
щих пачки ошибок, методики определения g (х) по заданному
k и заданной корректирующей способности не существует.
Однако, зная закономерности построения отдельных клас-
сов кодов, можно составить таблицы для определения объема
и корректирующей способности реализуемых кодов для
различных значений тис.
В настоящее время из циклических кодов, предназна-
ченных для исправления пачек ошибок, широко известны
коды Файра, Абрамсона, Миласа—Абрамсона и Рида—Соло-
мона.
Первые три разновидности кодов рассчитаны на исправ-
ление одной пачки ошибок в кодируемом блоке. Коды
Рида — Соломона способны исправлять несколько пачек
ошибок.
Наиболее обширным является класс кодов Файра.
Образующий многочлен имеет вид:
g(x) = /?(xm)(xc+l), (3-30)
где R (хт) — неприводимый многочлен степени т, а с —
некоторое постоянное число. Общее число символов п
в комбинации кода равно общему наименьшему кратному
си 1т— 1. Число проверочных символов равно с + т.
В [Л. 3-5] показано, что, используя эти коды, можно
исправлять, любую одиночную пачку ошибок длины b (или
менее) и одновременно обнаружить любую пачку ошибок
длины d > b (или менее) при условии
b + d - 1 sS с,
Ь^т.
(3-31)
(3-32)
168
Если код Файра предназначается только для обнаруже-
ния одной пачки ошибок, то ее максимальная длина не
должна превосходить числа проверочных символов, т. е.
т + с.
Методы образования циклического кода
Существует несколько различных способов кодирования.
Принципиально наиболее просто комбинации цикличе-
ского кода можно получить, умножая многочлены at (х),
соответствующие комбинациям безызбыточного кода (ин-
формационным символам), на образующий многочлен кода
g (х). Такой способ легко реализуется. Однако он имеет
тот существенный недостаток, что получающиеся в резуль-
тате умножения комбинации кода не содержат информа-
ционные символы в явном виде. После исправления ошибок
такие комбинации для выделения информационных символов
приходится делить на образующий многочлен кода g (х).
Применительно к циклическим кодам принято (хотя это
и не обязательно) отводить под информационные k символов,
соответствующих старшим степеням многочлена кода, а под
проверочные п — k символов низших разрядов.
Чтобы получить такой систематический код, приме-
няется следующая процедура кодирования.
Многочлен а (х), соответствующий fe-разрядной комби-
нации безызбыточного кода, умножается на хт, где tn =
= п — k. Степень каждого одночлена, входящего в а (х),
увеличивается, что по отношению к комбинации кода озна-
чает необходимость приписать со стороны младших разря-
дов т нулей. Произведение а (х) хт делится на образующий
многочлен g (х). В общем случае при этом получаем неко-
торое частное q (х) той же степени, что и а (х), и остаток
г (х). Последний прибавляется к а (х) хт. В результате
получаем многочлен
f (х) = а (х) хт ф г (х). (3-33)
Поскольку степень g (х) выбирается равной т, степень
остатка г (х) не превышает т — 1. В комбинации, соответ-
ствующей многочлену а (х) хт, т младших разрядов нуле-
вые, и, следовательно, указанная операция сложения рав-
носильна приписыванию г (х) к а (х) со стороны младших
разрядов.
Покажем, что f (х) делится на g (х) без остатка, т. е.
является многочленом, соответствующим комбинации кода.
169
Действительно, многочлен а (х) хт можно записать в виде
а (%) xm—q (х) g (х) ф г (х). (3-34)
Так как операции сложения и вычитания по модулю 2
идентичны, г (х) можно перенести влево, тогда
о (х) хт ф г (х) = f (х) = q (х) g (х), (3-35)
что и требовалось доказать.
Таким образом, циклический код можно строить, при-
писывая к каждой комбинации безызбытоПного кода остаток
от деления соответствующего этой комбинации многочлена
на образующий многочлен кода. Для кодов, число информа-
ционных символов в которых больше числа проверочных,
рассмотренный способ реализуется наиболее просто.
Следует указать на еще один способ кодирования.
Поскольку циклический код является разновидностью груп-
пового кода, то его проверочные символы, естественно,
должны выражаться через суммы по модулю 2 определенных
информационных символов. Доказано [Л. 3-5], что равенства
для определения проверочных символов могут быть полу-
чены путем решения рекуррентных соотношений
fe-i
= j (3-36)
где hj двоичные коэффициенты так называемого генератор-
ного многочлена h (х), определяемого как
/1(X) = A|^ = VH1X+...+/Ifex*. (3-37)
Соотношения (3-36) позволяют по заданной последова-
тельности информационных символов а0, аъ ..., ак_л вычис-
лить п — k проверочных символов ak, ak+1, ..., ап_г. Про-
верочные символы, как и ранее, размещаются на местах
младших разрядов. При одних и тех же информационных
символах комбинации кода, получающиеся таким путем.,
полностью совпадают с комбинациями, получающимися
при использовании предыдущего способа кодирования.
Применение данного способа целесообразно для кодов
с числом проверочных символов, превышающим число
информационных, например для кодов Боуза—Чоудхури.
Матричная запись циклического кода
Полная образующая матрица циклического кода М,',. k
составляется из двух матриц: единичной транспонирован-
ной в канонической форме I* (соответствующей k информа-
170
цибнным разрядам) и дополнительной матрицы С*_бгд.
(соответствующей проверочным разрядам):
= (3-38)
Построение матрицы 1J трудностей не представляет.
Если образование циклического кода проводится на
основе решения рекуррентных соотношений, то его допол-
нительную матрицу можно определить, воспользовавшись
правилами, указанными ранее. Однако обычно строки
дополнительной матрицы циклического кода С„ _ k опре-
деляются путем вычисления многочленов г (х). Для каждой
строки матрицы I* соответствующий г (х) находится деле-
нием информационного многочлена а (х) хт этой строки на
образующий многочлен кода g (х).
Дополнительную матрицу можно определить и не строя
Ц. Для этого достаточно делить на g (х) комбинацию в виде
единицы с рядом нулей и получающиеся остатки выписы-
вать в качестве строк дополнительной матрицы. При этом,
если степень какого-либо г (х) оказывается меньше
п — k — 1, то следующие за этим остатком строки матрицы
получают путем циклического сдвига предыдущей строки
влево до тех пор, пока степень г (х) не станет равной
п — k—1. Деление производится до получения k строк
дополнительной матрицы.
Для кода (15, 11) с образующим многочленом g (х) =
= xi + х3 + 1 такое деление мы уже проводили. Запишем
для него
00000000001 1001
00000000010 00000000100 00000001000 00000010000 1011 1111 0111 1110
Мт = 00000100000 00001000000 00010000000 0101 1010 1101
00100000000 01000000000 10000000000 ООН оно 1100
171
Существует другой способ построения образующей мат-
рицы, базирующийся на основной особенности, цикличе-
ского (n, k) кода.,. Он проще описанного, но получающаяся
матрица менее удобна, так как не имеет ступенчатой кано-
нической формы.
Первая строка образующей матрицы формируется путем
приписывания к представленному двоичным числом обра-
зующему многочлену кода k — 1 нулей со стороны стар-
ших разрядов. Каждая следующая строка матрицы полу-
чается циклическим сдвигом этой строки на один разряд
влево. Обычно такая матрица обозначается Mg„. к (х).
Для указанного ранее кода (15, 11) матрица имеет вид:
Mgi5.ll (х) —
000000000011001
000000000110010
000000001100100
000000011001000
00000011001ОО0О
000001100100000
000011001000000
000110010000000
001100100000000
011001000000000
110010000000000
Матричная запись кодов получила достаточно широкое
распространение.
3-12. ТЕХНИЧЕСКИЕ СРЕДСТВА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ
ДЛЯ ЦИКЛИЧЕСКИХ КОДОВ
Линейные переключающие схемы
Основу кодирующих и декодирующих устройств циклических
кодов составляют регистры сдвига с обратными связями, позволяющие
осуществлять как умножение, так и деление многочленов с приведе-
нием коэффициентов по модулю 2. Такие регистры также называют
многотактными линейными переключательными схемами и линейными
кодовыми фильтрами Хаффмена. Они состоят из ячеек памяти, сум-
маторов по модулю 2 и устройств умножения на коэффициенты много-
членов множителя или делителя. В случае двоичных кодов для умно-
жения на коэффициент, равный 1, требуется только наличие связи
172
в схеме. Если коэффициент равен 0, то связь отсутствует. Сдвиг инфор-
мации в регистре осуществляется импульсами, поступающими с гене-
ратора продвигающих импульсов, который на схеме, как правилр, не
указывается. На вход устройств поступают только коэффициенты
многочленов, причем начиная с коэффициента при переменной в старшей
степени [Л. 3-5].
Рис. 3-32. Многотактная переключающая схема для
умножения двух многочленов.
На рис. 3-32 представлена схема, выполняющая умножение про-
извольного (например, информационного) многочлена а (х) = +
+ UiX + ... + ak_r xft-1 на некоторый фиксированный (например, обра-
зующий) многочлен g (х) = &+&* + ... + g.n- kx'l k- Произведе-
ние этих многочленов равно:
а (*) S (*) = aogo + (йой1 + aiSo) х + • •
••• + (йЙ-2§П-Л + ak-lSn Л-1) х" 2 + ak-18n-kxn l-
Предполагается, что первоначально ячейки памяти находятся в нуле-
вом состоянии и что за коэффициентами множимого следует п — k
нулей.
На первом такте на вход схемы поступает первый коэффициент
ak^i многочлена а (х) и на выходе появляется первый коэффициент
произведения, равный а^лёпк- На следующем такте на выход посту-
пит сумма ak_2gn_k + ak_rgn_k ь т. е. второй коэффициент произведе-
ния, и т. д. На n-м такте все ячейки, кроме последней, будут в нулевом
состоянии и на выходе получим последний коэффициент flogo.
Рис. 3-33. Многотактная переключающая схема для де-
ления произвольного многочлена на фиксированный
многочлен.
На рис. 3-33 представлена схема, выполняющая деление произволь-
ного многочлена [например, многочлена а (х) хт = а0 + агх + ... +
+ ап_1хп^1] на некоторый фиксированный (например, образующий)
многочлен g (х) = g0 + g±x + ... + gn_kXn~k. Обратные связи регистра
соответствуют виду многочлена g (х). Количество включаемых в него
сумматоров равно числу отличных от нуля коэффициентов g (х), умень-
шенному на единицу. Это объясняется тем, что сумматор сложения
коэффициентов старших разрядов многочленов делимого и делителя
в регистр не включается, так как результат сложения заранее изве-
стен (он равен нулю).
173
За первые п — k тактов коэффициенты многочлена-делимого запол-
няют регистр, причем коэффициент при х в старшей степени достигает
крайней правой ячейки. На следующем такте «единица» делимого,
выходящая из крайней ячейки регистра, по цепи обратной связи по-
дается к сумматорам по модулю 2, что равносильно вычитанию много-
члена-делителя из многочлена-делимого. Если в результате предыду-
щей операции коэффициент при старшей степени х у остатка оказался
равным нулю, то на следующем такте делитель не вычитается. Коэф-
фициенты делимого только сдвигаются вперед по регистру на один
разряд, что находится в полном соответствии с тем, как это делается
при делении многочленов столбиком.
Рис. 3-34. Схема деления информационного много-
члена (х3 1) Xs на образующий многочлен х3 +
+ х2+ 1.
Деление заканчивается с приходом последнего символа много-
члена-делимого. При этом разность будет иметь более низкую степень,
чем делитель. Эта разность и есть остаток.
Отметим, что если в качестве многочлена-делителя выбран простой
многочлен степени т = п — k, то, продолжая делить образовавшийся
остаток при отключенном входе, мы будем получать в регистре по
одному разу каждое из ненулевых m-разрядных двоичных чисел.
Затем эта последовательность чисел повторяется.
Рассмотрим процесс деления многочлена а (х) хт = (х3 + 1) х3 на
образующий многочлен g (х) = х3 + х2 + 1. Схема для этого случая
представлена на рис. 3-34, (У, 2, 3 — ячейки регистра). Работа схемы
поясняется табл. 3-22.
Таблица 3-22
№ такта Вход Состояние ячеек регистра № такта Вход Состояние ячеек регистра
1 2 3 1 2 3
1 1 1 0 0 8 0 1 1
2 0 0 1 0 9 — 1 0 0
3 0 0 - 0 1 10 — 0 1 0
4 1 0 0 1 11 — 0 0 1
5 0 1 0 1 12 — 1 0 1
6 0 1 1 1 13 — 1 1 1
7 0 1 1 0 14 — 1 1 0
Вычисление остатка начинается с. четвертого такта и заканчивается
после седьмого такта. Последующие сдвиги приводят к образованию
в регистре последовательности из семи различных ненулевых трехраз-
рядных чисел. В дальнейшем эта последовательность чисел повто-
ряется.
174
Рассмотренные выше схемы умножения и деления многочленов
непосредственно в том виде, в каком они представлены на рис. 3-32,
3-33, в качестве кодирующих устройств циклических кодов на прак-
тике не применяются: первая — из-за того, что образующаяся кодовая
комбинация в явном виде не содержит информационных символов,
а вторая — из-за того, что между информационными и проверочными
символами образуется разрыв в п — k разрядов.
Кодирующие устройства
Все известные кодирующие устройства для любых типов цикли-
ческих кодов, выполненные на регистрах сдвига, можно свести к
двум типам схем согласно методам кодирования, рассмотренным на
стр. 169—170.
Схемы первого типа вычисляют значения проверочных символов
путем непосредственного деления многочлена а (х) хт на образующий
Рис. 3-35. Кодирующее устройство для циклического кода
на основе п — /г-разрядного регистра сдвига.
многочлен g (х). Это делается с помощью регистра сдвига, содержа-
щего п — k разрядов (рис. 3-35). Схема отличается от ранее рассмотрен-
ной тем, что коэффициенты кодируемого многочлена участвуют в обрат-
ной связи не через п — k сдвигов, а сразу с первого такта. Это позво-
ляет устранить разрыв между информационными и проверочными сим-
волами.
Рис. 3-36. Кодирующее устройство для цикличе- '
ского кода с образующим многочленом g (х) =
= х3 + х2 + 1 на основе п — ^-разрядного ре-
гистра.
В исходном состоянии ключ Ki находится в положении 1, а ключ К2
замкнут. Информационные символы одновременно поступают как
в линию связи, так и в регистр сдвига, где за k тактов образуется оста-
ток. Затем ключ К2 размыкается, ключ Ki переходит в положение 2
и остаток поступает в линию связи. Для рассматривавшегося ранее
случая g (х) = Xs + х2 + 1 и а (х) = х3 + 1 схема кодирующего
устрой тва приведена на рис. 3-36. Процесс формирования кодовой
175
Таблица 3-23
№ такта Вход Состояние ячеек регистра Выход
1 2 3
1 1 1 0 1 1
2 0 1 1 1 01
3 0 1 1 0 001
4 1 1 1 0 1001
5 0 — 1 1 01001
6 0 — 1 101001
7 0 — — — 1101001
комбинации шаг за шагом представлен в табл. 3-23, где черточками
отмечены освобождающиеся ячейки, занимаемые новыми информацион-
ными символами.
Схемы второго типа вычисляют значения проверочных символов
как линейную комбинацию информационных символов, т. е. построены
на использовании основного свойства систематических кодов. Кодирую-
щее устройство строится на основе й-разрядного регистра сдвига
Рис. 3-37. Кодирующее устройство для циклического кода на
основе /г-разрядного регистра сдвига.
(рис. 3-37). Выходы ячеек памяти подключаются к сумматору в цепи
обратной связи в соответствии с видом генераторного многочлена
Л = gfa) ~ + ^1Х + • • • "Ьhkx>t- (3-39)
В исходном положении ключ Ki находится в положении 1. За пер-
вые k тактов поступающие на вход информационные символы запол-
Рис. 3-38. Кодирующее устройство для цикличе-
ского кода с образующим многочленом g (х) = х3 +
4- х2 + 1 на основе /г-разрядного регистра сдвига.
няют все ячейки регистра. После этого ключ переводится в положе-
ние 2. На каждом из последующих тактов один из информационных
символов выдается в канал связи и одновременно формируется прове-
рочный символ, который записывается в последнюю ячейку регистра.
176
Таблица 3-24
Такты
Выход
Состояние ячеек регистра
1 2 3 4
1 0 0 1
1 0 0 1 0
10 0 1 0 1
100 1 0 1 1
1001 0 1 1 —
10010 1 1 —
100101 1 — — —
1001011 — — — —
1
2
3
4
5
6
7
Через п — k тактов процесс формирования проверочных символов
заканчивается, и ключ Ki снова переводится в положение 1.
В течение последующих k тактов содержимое регистра выдается
в канал связи с одновременным заполнением ячеек новой последова-
тельностью информационных символов. Для случая g (х) = у? + х2 + 1
и а (х) = xs + 1 схема кодирующего устройства приведена на рис. 3-38.
Связи с сумматором соответствуют генераторному многочлену
h (х) = ч 1 = х4 4- х3 + х2 -f-1. \
' х3 + х2 + 1 1
Процесс формирования кодовой комбинации поясняется табл. 3-24.
Декодирующие устройства
Декодирование комбинаций циклического кода можно проводить
различными методами. Существуют методы, основанные на использо-
вании рекуррентных соотношений, на мажоритарном принципе, на
вычислении остатка от деления принятой комбинации на образующий
многочлен кода и др. Целесообразность применения каждого из них
зависит от конкретных характеристик используемого кода.
Рассмотрим подробно устройства декодирования, в которых для
обнаружения и исправления ошибок производится деление произволь-
ного многочлена, соответствующего принятой комбинации, на образую-
щий многочлен кода g(x). В этом случае при декодировании могут
использоваться те же регистры сдвига, что и при кодировании.
Декодирующие устройства для кодов, обнаруживающих ошибки,
по существу ничем не отличаются от схем кодирующих устройств.
В них добавляется лишь буферный регистр для хранения принятого
сообщения на время проведения операции деления. Если остатка не
обнаружено (случай отсутствия ошибки), то информация с буферного
регистра считывается в дешифратор сообщения. Если остаток обнару-
жен (случай наличия ошибки), то информация в буферном регистре
уничтожается и на передающую сторону посылается импульс запроса
повторной передачи.
В случае исправления ошибок схема несколько усложняется.
Информацию о разрядах, в которых произошла ошибка, несет, как
и ранее, остаток.
177
Схема декодирующего устройства представлена на рис. 3-39.
Символы подлежащей декодированию кодовой комбинацищ воз-
можно, содержащей ошибку, последовательно, начиная со старшего
разряда, вводятся в «-разрядный буферный регистр сдвига Б PC и
одновременно в (п — k)-разрядный декодирующий регистр.
Рис. 3-39. Декодирующее устройство для циклического кода.
Электронный ключ Ki пропускает в буферный регистр только k
информационных символов. В декодирующем регистре за п тактов
определяется остаток г (х), после чего вход регистра отключается
(ключом К2) и в нем производится еще п сдвигов. С каждым сдвигом
буферный регистр покидает один символ, а в декодирующем регистре
появляется новый остаток (синдром).
Детектор ошибки ДО представляет собой комбинаторно-логиче-
скую схему, построенную с таким расчетом, чтобы она отмечала все те
синдромы, которые появляются в декодирующем регистре, когда каж-
дый из ошибочных символов занимает крайнюю правую ячейку в бу-
ферном регистре. При следующем сдвиге детектор образует единицу,
которая, воздействуя на сумматор коррекции, исправляет искажен-
ный символ.
Одновременно по цепи обратной связи (показанной пунктиром)
единица с выхода детектора подается на входной сумматор декодирую-
щего регистра, изменяя синдром так, чтобы он снова соответствовал
более простому вектору ошибки, которую еще подлежит исправить.
Продолжая сдвиги, обнаружим и другие выделенные синдромы. После
исправления последней ошибки все ячейки декодирующего регистра
должны оказаться в нулевом состоянии. Если в результате п автоном-
ных сдвигов состояние регистра не окажется нулевым, это означает,
что произошла неисправимая ошибка. Декодирование длится 2п так-
тов. Новая кодовая комбинация не может быть принята до тех пор,
пока предыдущая исправляется.
\ Сложность детектора ошибок зависит от числа выделяемых син-
дромов, т. е. от выбранного кода.
Самый простой детектор получается в том случае, если исполь-
зуется код, рассчитанный на исправление одиночных ошибок. Если
исказился символ старшего разряда, занимающий крайнюю правую
ячейку буферного регистра, то вектор ошибки равен 00...01. Соответ-
ствующий синдром также содержит единицу в старшем разряде и нуль
во всех остальных. На него и должен быть настроен детектор ошибки
178
В зависимости от номера искаженного разряда после первых й
сдвигов будем получать различные остатки Вследствие этого выделен-
ный синдром будет появляться в декодирующем регистре через раз-
личное число Последующих сдвигов, обеспечивая исправление иска-
женного символа.
Рис, 3-40. Декодирующее устройство для циклического кода
(7,4) с образующим многочленом g (х) = х3 + >? + 1.
На рис. 3-40 приведена схема декодирующего устройства для
циклического кода (7, 4) с образующим многочленом g (х) = х8 +
+ х2 + 1. В табл. 3-25 шаг за шагом представлен процесс исправле-
ния ошибки для случая, когда сформированная в табл. 3-24 кодовая
комбинация поступила на вход декодирующего устройства с искажен-
ным символом в четвертом разряде.
Таблица 3-25
№ такта Вход Состояние ячеек кодирующего регистра Выход
3 2 /
1 1 1 0 1
2 0 1 1 1
3 0 0 1 1
4 0 1 1 0
5 0 0 0 1
6 1 1 1 1
7 1 1 1 0
8 0 0 0 1 1
9 0 0 1 0 01
10 0 1 0 0 001
11 0 0 0 0 1001
12 0 0 0 0 01001
13 0 0 0 0 101001
14 0 0 0 0 1101001
179
При увеличении числа исправляемых независимых ошибок слож-
ность дешифратора существенно возрастает. Поэтому рассмотренный
способ декодирования применяется в основном для кодов, исправляю-
щих одиночные ошибки и пачки ошибок.
Корректирующие коды как метод повышения достоверности исполь-
зуются в настоящее время не только при передаче и хранении, но и при
логических и арифметических преобразованиях информации.
Гпава четвертая
МОДУЛЯЦИЯ НОСИТЕЛЕЙ ИНФОРМАЦИИ
Нанесение информации на носители достигается опре-
деленным изменением параметров некоторых физических
процессов, состояний, соединений, комбинаций элементов.
Чаще всего материализация информации осуществляется
изменением параметров физических процессов — колеба-
ний или импульсных последовательностей. Подобные опе-
рации называются модуляцией. Обратные операции
восстановления величин, вызвавших изменение параметров
при модуляции, называются демодуляцией.
Теория модуляции и демодуляции развилась в последнее
время в общую теорию сигналов.
4-1. ВИДЫ НОСИТЕЛЕЙ И СИГНАЛОВ
Сигналами называются физические процессы, пара-
метры которых содержат информацию. В телефонной связи
при помощи электрических сигналов передаются звуки
разговора, в фототелеграфии — тексты и чертежи, в теле-
видении — изображения. Назначение сигналов заклю-
чается в том, чтобы в каком-либо физическом процессе
отобразить события, величины и функции.
Для образования сигналов используются постоянные
состояния (рис. 4-1, а), колебания (рис. 4-1,6) или импульсы
(рис. 4-1, в) любой физической природы, которые рассмат-
риваются как носители информации. В исходном
состоянии эти носители представляют собой как бы чистую
поверхность, подготовленную к нанесению необходимых
данных — модуляции. Последняя заключается в том, что
изменяется какой-либо один или несколько (сложная моду-
ляция) параметров носителя в соответствии с передаваемой
информацией. Эти параметры будем называть информа-
ционными.
180
Если обозначить параметры носителя через аъ ап,
то носитель как функция времени может быть представлен
в виде
чв = ё(а1, , а„, t).
Модулированный носитель (сигнал) имеет вид:
ux = g\av, .... а( + Ла((1), ..., ап, /],
Рис. 4-1. Виды носителей ин-
формации.
а — постоянное состояние; б —
колебание; в — последователь-
ность импульсов.
где Ащ (/) — переменная составляющая параметра носи-
теля, несущая информацию, или модулирующая
функция. Последняя обычно свя-
зана с информационной (управ-
ляющей) функцией х линейной
зависимостью:
Да,- = Кх,
где К — коэффициент пропор-
циональности.
Первый вид носителя иа (I) —
постоянноесостояние (рис. 4-1, а),
например постоянное напряже-
ние имеет только один информа-
ционный параметр: это величина
напряжения. Модуляция в дан-
ном случае сводится к такому
изменению напряжения, чтобы
оно в определенном масштабе
представляло передаваемые дан-
ные. При этом может изменяться
и полярность напряжения.
Второй вид носителя — колебание (рис. 4-1, б); напри-
мер переменное напряжение содержит три таких пара-
метра: амплитуду U, фазу <р, частоту и (или период Т =
— 2л/со).
Третий вид носителя — последовательность импульсов
(рис. 4-1, в) предоставляет еще большие возможности.
Здесь параметрами модуляции могут быть: амплитуда
импульсов U, фаза импульсов <р, частота импульсов /, дли-
тельность импульсов или пауз т, число импульсов п и комби-
нация импульсов и пауз, определяющая код k. В последнем
случае имеет место так называемая кодо-импульсная моду-
ляция.
Ниже приводится перечень основных видов модуляции
с их названиями и обозначениями.
181
Носитель первого типа (рис. 4-1, а}
ПМ — прямая модуляция.
Примечание. Изменение постоянного напряжения или
тока избегают называть модуляцией, хотя последняя (от
латинского modulatio — мерность) характеризует придание
размера вообще.
Носитель второго типа (рис. 4-1, б)
AM — амплитудная модуляция (AM — amplitude modu-
lation);
ЧМ — частотная модуляция (FM — frequency modula-
tion);
ФМ — фазовая модуляция (РМ — phase modulation).
Примечание. Частотную и фазовую модуляцию иногда
совместно называют угловой модуляцией.
Носитель третьего типа (рис. 4-1, е)
АИМ — амплитудно-импульсная модуляция (РАМ —
pulse-amplitude modulation);
ЧИМ — частотно-импульсная модуляция (PFM — pul-
se-frequency modulation);
ВИМ — время-импульсная модуляция (РТМ — pul-
se-time modulation);
ШИМ — широтно-импульсная модуляция (PDM — pul-
se-duration modulation);
ФИМ — фазо-импульсная модуляция (PPM — pulse-pha-
se modulation);
СИМ — счетно-импульсная модуляция (PNM — pulse-
number modulation);
КИМ — кодо-импульсная модуляция (РСМ — pulse-code
modulation).
Примечания: 1) ШИМ и ФИМ являются частными слу-
чаями ВИМ; 2) строго говоря, КИМ нельзя рассматривать
как отдельный вид модуляции, хотя этот термин и получил
широкое распространение; при КИМ используется любой
вид модуляции носителя, параметры которого отображают
кодовые величины; 3) счетно-импульсная модуляция (СИМ)
является частным случаем КИМ.
Типичные сигналы, различающиеся видами модуляции,
показаны на рис. 4-2 для случая равномерного возрастания
отображаемой величины х (t). Как видно, счетно-импульс-
182
1
J
Рис. 4-3. Разновидности ампли-
тудно-импульсной модуляции.
Рис. 4-2. Виды модуляции.
Рис. 4-4. Разновидности время-им
пульсной модуляции.
183
ная (СИМ) и кодо-импульсная модуляция (КИМ) связаны
с квантованием по уровню непрерывной величины х. АИМ,
ВИМ, ФИМ и КИМ неизбежно приводят к дискретности
отсчетов во времени. Другие виды модуляции принци-
пиально сохраняют непрерывную структуру информации.
Амплитудно-импульсная модуляция имеет две разно-
видности: АИМ-1, при которой верхние участки импульсов
(амплитуды) повторяют форму модулирующей функции
(огибающей); АИМ-2, при которой амплитуда в пределах
элементарного импульса остается неизменной, определяемой
значением модулирующей функции в начале импульса
(рис. 4-3).
Время-импульсная модуляция выполняется в нескольких
вариантах, дополнительно представленных на рис. 4-4.
Информационным параметром сигналов ШИМ служит ши-
рина импульсов или пауз, а сигналов ФИМ — расстояние
между первым (опорным) и вторым (информационным)
импульсами каждого периода. Следует обратить внимание
на отличительные особенности симметричной модуляции
ШИМ-С и ациклических — ШИМ-А и ФИМ-А. Последние
наиболее экономичны, так как в них практически отсут-
ствуют неиспользуемые промежутки времени. Значащие
интервалы вплотную прилегают один к другому, а короткие
импульсы или паузы размечают границы.
Все импульсные сигналы могут иметь высокочастотное
заполнение — сигнал несущей чйстоты. Для подчеркивания
этого обстоятельства применяют двойные обозначения видов
модуляции, например. АИМ-ЧМ, КИМ-ФМ и т. д., где
второй вид модуляции относится к сигналам несущей ча-
стоты.
4-2, МОДУЛЯЦИЯ И КОДИРОВАНИЕ
Место модуляции в системах передачи дискретной инфор-
мации было показано схемой рис. 3-1 (модулятор Л4). В том
случае, когда параметр модуляции является не аналоговой
величиной, а цифровой, т. е. кодом, модуляцию следует
рассматривать как образование из чистых процессов (но-
сителей) физических эквивалентов знаков, пригодных для
дальнейшей переработки информации и передачи ее на рас-
стояние.
Кодо-импульсная модуляция сочетает любой вид им-
пульсной модуляции с кодированием по какой-либо сис-
теме. Предельным является случай, при котором кодиро-
вание происходит по «бесконечной» системе, когда цифровой
184
Таблица 4-1
Соотношение между модуляцией и кодированием
Кодирование
«Б есконечн а я» система h -» со Десятичная Двоичная Единичная система система система Й--2 /г = 1
Амплитудная (AM) Прямая (ПМ) и амплитудно- импульсная (АИМ) 0l23bSfi789 U 1 / ...1111111 - 1 1
130 ЛД(/ / -* с»
оз UlLu‘lub'Ot’ U • и А Л А ШШШ. А А
Моду- ляция Фазовая (ФМ) Фазо-импульс- ная (ФИМ) Частотная (ЧМ) Частотно-им- пульсная (ЧИМ) Широтно- импульсная (ШИМ) УЖ шши со Ар rmnm f » -v OI?J(56 78 S 0 1 i WWW 01 0 t 1 01 331,5 6789 0 1 1 11ШШ1 1 1 > 01'337.66789 0 1 ШНИ 1 L L 1 012313H16.S 0 1 I
сигнал переходит в аналоговый. При этом любое значение
измеряемой величины без квантования передается сораз-
мерным значением амплитуды, частоты, фазы или длитель-
ности. Параметр модуляции изменяется плавно, принимая
бесконечное множество значений в заданных пределах.
При кодировании по единичной системе параметр модуля-
ции может иметь только одно значение, легко отличимое
от состояния отсутствия сигнала. В общем же случае ко-
185
личество используемых значений параметра модуляции
должно быть равно основанию h кода.
Связь между модуляцией и кодированием наглядно
иллюстрируется табл. 4-1, где для знаков кодирования по
«бесконечной», десятичной, двоичной и единичной системам
использованы прямая, амплитудная, фазовая, частотная,
амплитудно-импульсная, фазо-импульсная, частотно-им-
пульсная и широтно-импульсная модуляции. В табл. 4-1
даны только наборы сигнальных элементов, соответствую-
щие кодовым алфавитам, но не законченное строение сиг-
налов.
4-3. ДЕТЕРМИНИРОВАННЫЕ И СЛУЧАЙНЫЕ СИГНАЛЫ
Для того чтобы сигнал содержал информацию, он дол-
жен принципиально быть случайным. При описании сигнала
некоторым количеством параметров часть из них может быть
детерминированной, т. е. известной заранее, а часть слу-
чайной, т. е. несущей информацию. Часто представляет инте-
рес изучение детерминированных характеристик сигнала, и
тогда можно условно говорить о детерминированном сигнале.
Так, например, если сигналом служит импульс заранее из-
вестной формы и величины, то неизвестным заранее па-
раметром является время его прихода; при этом о самом
импульсе можно говорить как о детерминированном сигнале.
При длительном существовании сигнала определенной
формы последний также может рассматриваться на опре-
деленном интервале как детерминированный.
Случайный сигнал представляет собой модулированный
носитель, у которого параметры Да,(Г) являются случай-
ными функциями времени. Случайный сигнал, у которого
лишь небольшое, число переменных параметров а;, носит
случайный характер, иногда называют квазидетерминиро-
ванным. В данной главе, когда речь идет о случайных сиг-
налах, рассматриваются лишь сигналы, пропорциональ-
ные информационной случайной функции x(t).
4-4. ВРЕМЕННАЯ И СПЕКТРАЛЬНАЯ ФОРМЫ ОПИСАНИЯ СИГНАЛА
Временная форма представления сигнала, т. е. описание
его изменения или изменения параметров модуляции в функ-
ции времени, позволяет легко определить такие важные
характеристики, как энергия, мощность и длительность
сигнала. Однако существуют другие адекватные формы опи-
сания сигнала, лучше отображающие другие параметры.
186
Например, представление в виде ряда Котельникова дает
возможность выделить некоррелированные интервалы.
Важнейшей характеристикой сигнала являются его
частотные свойства. Для их исследования используется
частотное представление функции в виде спектра, представ-
ляющего собой преобразование Фурье временной формы.
В процессе переработки и передачи сигнала эта харак-
теристика играет особую роль, так как определяет пара-
метры используемой аппаратуры.1
При рассмотрении спектров основных видов сигналов
главное внимание уделяется определению их ширины, по-
скольку в основном этот фактор используется для согла-
сования сигнала с аппаратурой обработки информации (ка-
налом): для исключения потери информации ширина спект-
ра не должна превышать полосы пропускания канала.
Для периодического сигнала их (f) спектр определяется
соотношениями
7'/2 '
Л = 5 ux(t)e~Jkatdt, k = ± 1, ±2, ±3, ... ; (4-la)
—'772
772
Ао=^ j ux(t)dt, (4-16)
— 772
где Ak — комплексный коэффициент ряда Фурье; Ло —
постоянная составляющая (среднее значение сигнала);
Т — период сигнала; Q = 2л/Т — основная круговая ча-
стота, так что
оо
МО =4 А^. (4-2)
k~—со
Здесь Ак и А_к являются комплексно-сопряженными
величинами.
Функция Лй(/®) (® = kQ, k пробегает все целые зна-
чения числовой оси от —оо до оо) носит название ком-
плексного спектра, ее модуль |Лй(/®)| — амплитудного
спектра сигнала ux(t), а зависимость фазы от частоты <рй(®)—
спектра фаз. Эти функции имеют решетчатый характер, так
как они отличны от нуля только при целых значениях k.
Таким образом, спектр периодической функции является
дискретным. Его ширина А® определяется полосой положи-
тельных частот м, на которой | Лй(/м) | имеет значимую
187
величину. Вследствие сопряженности комплексных ам-
плитуд их модули равны между собой:
|ЛЛ|=|Д-Й1.
Поэтому для представления спектра достаточно изо-
бразить только положительную полосу частот (рис. 4-5, я).
Дискретный спектр не обязательно означает периодичность
функции ux(t). Последнее имеет место лишь в случае, ког-
да расстояния между спектральными линиями j Ak | крат-
ны основной частоте Q. При невыполнении этого условия
Да/------------
б)
Рис. 4-5. Спектры периодиче-
ских и непериодических сигна-
лов.
а — спектр периодического сигна-
ла; б — спектр непериодического
сигнала.
спектр описывает так назы-
ваемую почти периодическую
функцию. Примером такой
функции может служить
спектр амплитудно-модулиро-
ванного сигнала с гармони-
ческой модулирующей функ-
цией, частота которой несо-
измерима с частотой несущей
(см. § 4-6).
Для непериодического сиг-
нала, определяемого на бес-
конечном интервале времени,
преобразования Фурье имеют
вид:
4-СО
S (;и) = § их (/) е-лл dt;
— со
(4-3)
со
«х(0=-^ s (/со) ej'at da.
— со
(4-4)
Из сравнения (4-4) и (4-2) видно, что роль спектральной
комплексной составляющей сигнала на частоте со выполняет
бесконечно малая величина
dA = -^-S (/со) da.
В связи с этим в случае непериодических функций рас-
сматривается не спектр сигнала, а его производная по
со S(ja), носящая название спектральной плотное-
т и, или, как и в случае периодического сигнала, ком-
плексного спектра; ее модуль | S (/со) | также назы-
188
вают спектром. Спектр непериодического сигнала имеет не-
прерывный характер (рис. 4-5, б). Ширина его Ди опреде-
ляется так же, как и для дискретного сигнала.
4-5. СПЕКТРЫ СИГНАЛОВ С НОСИТЕЛЕМ В ВИДЕ ПОСТОЯННОГО СОСТОЯНИЯ
Невозмущенный носитель
Невозмущенный носитель (процесс) в виде постоянного
состояния (напряжения или тока) может быть представлен
временной (/), частотной (и) или векторной (W) диаграмма-
ми (рис. 4-6, а):
/-диаграмма описывает состояние процесса во времени;
и-диаграмма дает частотное представление процесса;
^/-диаграмма изображает вектор напряжения или тока на
комплексной плоскости W (s, jo), где s и о — соответствен-
но действительная и мнимая составляющие синусоидаль-
ного сигнала, записанного в комплексной форме. Вектор-
ная форма представления удобна тем, что позволяет легко
получить как временную, так и частотную форму процесса,
однако она неудобна в тех случаях, когда число постоянных
частот (несущих или информационных) больше, чем 2—3.
В данном случае все диаграммы имеют простейший вид,
так как формула процесса есть иа = Uo — вектор лежит
на оси проекций, а процесс содержит только нулевую час-
тоту и0 = 0.
Прямая модуляция
Тот же носитель возмущаемым чувствительным элемен-
том подвергается изменениям и становится сигналом, пере-
носящим информацию x(t). Если модулирующая функция
Дц(Г) представляет собой единственную гармонику частоты
Q, то информационный параметр (амплитуда) носителя со-
держит это колебание и постоянную составляющую Uo: v
их (/) = Uо + cos Q/;
/-, и- и ^/-диаграммы имеют вид, изображенный на
рис. 4-6, б. Подразумевается, что за время периода 2л/й век-
тор АГ7т на ^/-диаграмме вращается против часовой стрелки
с угловой скоростью Q и проекция его на ось s дает коси-
нусоидальную составляющую в разные моменты времени.
В процессе имеются две дискретные частоты: ® = 0 и и =
=Й. Ширина спектра такого сигнала составляет й (от Одо
189
?- диаграмма
а/-диаграмма
оИМ
uD
и/
w -диаграмма
.Jff
^0
| ш
0 fl
„им
л
______I_____и>
0 %
u(tJ=U0cos,(wDt+^n)
Рис. 4-6. Временная, частотная и векторная формы представления
сигналов.
а — невозмущенный носитель в виде постоянного состояния; б — сигнал
с прямой модуляцией; в — невозмущенный гармонический носитель; г — ам-
плитуды о-модулированный сигнал; д — сигнал с угловой модуляцией.
190
Й). В случае более сложной модулирующей функции Лп(/)
IF - и «-диаграммы содержат большее число составляющих.
Ширина спектра при этом определяется гармоникой мак-
симальной частоты функции Ди(/). При Йо = 0 спектр
сужается, совпадая в этом случае со спектром модулирующей
функции.
4-6. СПЕКТРЫ СИГНАЛОВ С ГАРМОНИЧЕСКИМ НОСИТЕЛЕМ
Невоэмущенный носитель
Невозмущенный гармонический носитель
их (/) = Uo cos (®0/ + <р0)
в виде t-, со- и IF-диаграмм изображен на рис. 4-6, в, где
(р0 — начальная фаза колебаний. Постоянная составляю-
щая отсутствует.
Амплитудная модуляция
АМ-сигнал в общем виде описывается выражением
их (0 = Ро + (0]cos W + Фо)-
Информацию переносит компонента Ди(/) = Kx(t).
Если Дп(/) представлена суммой гармонических коле-
баний, то
п
1 + У l Al* cos (Qkt + Ф*)
fe=i
cos ((оо/ + ф0),
где Mk — частичные, пли парциальные, ко-
эффициенты модуляции, представляющие от-
ношения амплитуд высших гармоник к основной; и Ф* —
частоты и фазы составляющих Ди(/).
Общий коэффициент модуляции М есть наибольшее
симметричное относительное отклонение _!_ДИт амплитуды
носителя от среднего значения Un:
м=\ит/и0.
Если Ди(0 представлено одним низкочастотным синусои-
дальным колебанием частоты Q, то
их (/) = Uo [1 + М cos (Q/ + Ф)] cos (ю0/ + ф0),
или
их (0 = Uо {[cos (ю0/ + ф0)] + А4 cos (QZ + Ф) cos (со,/ + ф0)}.
191
Разлагая произведение косинусов
cos (О/ + Ф) cos (соо/ + ф0) =
= cos (<£>(/ + ф(| + Q/ + Ф) ~2 cos + Фо — Qi — Ф),
получаем:
их (О — UQ |cos (w0Z + <р0) + -g- cos [(coo + Q) t + <p0 + Ф] +
+ уСО8[(®0-Й)^ + ф0-Ф]}. (4-5)
Этим выявляются частотные составляющие соо, <в0 +
+Q и соо — Q. Последняя формула позволяет построить
IF- и co-диаграммы (рис. 4-6, г). На ^-диаграмме вектор
ий изображен неподвижным, а система координат—вращаю-
щейся по часовой стрелке. Дополнительные составляющие
вращаются в разные стороны со скоростью Q относительно
вектора Uo.
Более сложные модулирующие функции Лп(/) раскла-
дываются в ряд и анализируются аналогично. При этом
на co-диаграмме появляются дополнительные линии, а на
^-диаграмме дополнительные векторы с иной частотой вра-
щения. Полная ширина полосы частот сигнала получается
равной двойной ширине спектра модулирующей функции
Дц(0-
Частотная и фазовая модуляции
Рассмотрим теперь частотную и фазовую модуляции.
При изменении частоты всегда меняется фаза колебаний, а
при изменении фазы меняется частота. Этим определяется
общий характер частотной (ЧМ) и фазовой (ФМ) модуляций.
Иногда их объединяют под общим названием угловой
модуляции. ЧМ осуществляется прямым воздействием
датчика на генератор для изменения частоты его колебаний,
хотя при переходах меняется и фаза. При ФМ датчик воз-
действует на выходную цепь генератора, изменяя фазу
несущего колебания, однако при переходах от одной фазы
к другой меняется и-частота колебаний. Особенно наглядно
это видно (рис. 4-7) при скачкообразных изменениях со =
= / (х) и <р = / (х).
192
Рис. 4-7. Модуляция при скачко-
образном изменении информацион-
ной функции.
от средней частоты <в0 в соот-
Здесь уместно напомнить некоторые соотношения для
угловой частоты колебания о, частоты f в периодах,
периода колебания Т и полной фазы колебания ср:
х t
& = 2nf==2n • 1/7; a(f) = d(p/dt; ф(/) = $®<1/.
о
Из двух последних соотношений видно, что частоту мож-
но оценивать по скорости изменения фазы, а полную фазу
(угол) — по интегральному
значению угловой час-
тоты.
Учитывая это обстоя-
тельство, выражение для
сигнала при произвольном
изменении полной фазы
можно записать в виде
их (0 = Uо cos Ф (О =
t
— Uo cos го (/) dt.
о
При частотной модуля-
ции частота носителя (про-
цесса) отклоняется на Ат(/)
ветствии с информационной функцией x(t).
Пусть модулирующая функция
VM У, % %
Д® (/) = Д«т cos (Q/ + Ф).
Тогда угловая частота ®(/) носителя должна изменяться
по закону
И (Z) = «о + cos (Q/ + Ф).
Если теперь использовать носитель в виде стабильного
по амплитуде переменного напряжения
t
их (t) = Uo cos ф (/) = Uo cos ® (/) dt,
о
то, подставляя ®(Z) из вышеприведенной формулы, получаем:
t
их (0 = cos 5 [соо + cos (й/ + Ф)] dt=
о
Г *
= Uo cos <оо/ + $ cos (Ш + Ф) dt =
! о
= и„ cos [®0/ + sin (й/ + Ф) + ф0].
7 Темников Ф. Е. н др.
193
Максимальное отклонение Am„( от соо называется д е-
в нацией частоты, а отношение Acom/Q = т —
индексом модуляции. Используя последнее, пе-
репишем:
их (f) = Uo cos [w0Z + m sin (QZ + Ф) 4- ф0]. (4-6)
В случае более сложной модулирующей функции, пред-
ставляемой, например,рядом из косинусоидальных функций,
частотно-модулированный сигнал будет описываться выра-
жением
«х (0 = cos + У rnk sin (CW + Ф*) + <Pol
L k= i J
Здесь mk = Awft/Qft — частичные, или парциальные,
индексы модуляции, которые зависят от амплитуд и частот
соответствующих гармоник.
При фазовой модуляции осуществляется сдвиг фазы но-
сителя (процесса) на А<р(£) от средней фазы <р0. Если инфор-
мация по-прежнему передается элементарной косинусои-
дальной функцией, то
Аф (() = Аф„, cos (й/ 4- Ф)
и фаза носителя изменяется по закону
ф (0 = Фо + ДФ« cos № + Ф).
Следовательно, сигнал описывается выражением
их (t) — U0 cos [ы0/ 4- ф0 + Афт cos (Qt 4- Ф)].
В случае-фазовой модуляции также можно воспользо-
ваться индексом модуляции, учитывая, что изменение час-
тоты в пределах ±Acom равносильно изменению фазы в
пределах угла ±Афт = ±Ают/П.
Таким образом, индекс модуляции при ФМ равен девиа-
ции фазы
т = Афт,
соответственно девиация частоты
Ao)m = tnQ = АфотП.
Текущее изменение фазы при ФМ
Аф (() = Дфт cos (й/ 4- Ф) = т cos (Й/ 4- Ф).
Полученное выше выражение для сигнала приобретает
теперь вид:
их (0 — cos [w0Z 4- т cos (й/ 4- Ф) 4- Фо]- (4-7)
194
Если информация передается суммой косинусоидальных
функций, то ФМ-сигнал соответственно усложняется:
их (/) = Uо cos
п
+ У mk cos (Qkt + Oft) + <p0
*=i
где mk = A<p;. — частичные, или парциальные, индексы
модуляции, зависящие только от амплитуд гармоник.
Как показывают уравнения (4-6) и (4-7), при элемен-
тарной информационной функции х(/) = xmcosfiZ или x(t) =
— хт sin П/ и постоянной частоте fi сигналы ЧМ и ФМ труд-
но различимы. Однако в случае ЧМ в Сигнал ux(t) входит
интеграл информационной функции (1/fi) sin £2/ или
(—1/fi) cosfi/, а в случае ФМ — сама функция cos Qi или
sin fit Множитель 1/fi учитывается при выборе модуля-
торов и демодуляторов.
Рис.. 4-8. Особенности частотно- и фазо-моду-
лированных сигналов.
а — случай частотной модуляции; б — случай фазо-
вой модуляции.
При сложной информационной функции в виде суммы
элементарных гармоник или при изменяющейся частоте П
элементарной функции различие между ЧМ и ФМ выявля-
ется в полной мере.
Рассмотрим графики А<вт (fi) и А<рт (fi) для случаев ЧМ
(рис. 4-8, а) и ФМ (рис. 4-8, б). Амплитуда информационной
функции предполагается неизменной (хт = const), поэтому
А<вт (fi) при ЧМ и A<pm (fi) при ФМ представлены горизон-
тальными линиями (они не зависят от частоты fi). При ЧМ
девиация фазы A<pm = A©m/fi убывает с увеличением час-
тоты fi информационной функции. При ФМ девиация час-
тоты носителя Acom = mfi = A<pmfi пропорциональна час-
тоте информационной функции.
'7* 195
Различие сигналов ЧМ и ФМ в случае сложной функции
показывается на следующем примере. Пусть частота F =
=й/2л изменяется в диапазоне 1—10 гц при постоянной ам-
плитуде. Тогда при ЧМ с девиацией частоты носителя А/т =
== Д<от/2л = 1 000 гц отклонения фазы носителя составят:
при F=l гц kq>m = hf/F =1000 рад,
при F— 10 гц Л(рт = ЮО рад.
Для ФМ с вариацией фазы носителя Дф„ = 1 рад откло-
нения (девиации) частоты носителя составляют:
при F — 1 гц kfm = &q>mF = 1 гц,
при F=10aq Д)„,= 10 гц.
Таким образом, медленной модулирующей функции при
ЧМ соответствует очень большое отклонение фазы носителя,
а при ФМ — малая девиация частоты носителя. Быстрой
функции при ЧМ соответствует относительно малое откло-
нение фазы, а при ФМ — относительно большая девиация.
Сказанное видно также на рис. 4-8.
Для построения <в- и IC-диаграмм необходимы допол-
нительные преобразования.
Перегруппируем слагаемые в функции
их (0 = Uо cos [т sin (Й/ + Ф) + (<о0/ + ф0)]
и разложим ее по правилу косинуса суммы:
их (0 = U 0 cos [т sin (Qt 4- Ф)] cos (a>ot + ф0) —
— U0 sin [т sin (Qt 4- Ф)] sin (<»</ ф- ф0). (4-8)
При индексе модуляции т — много меньше еди-
ницы
cos [т sin (й/ + Ф)] Аа 1;
sin [т sin (Й/ ф- Ф)] а« т sin (й/ ф- Ф),
и полученное выражение запишется в виде
их (0 — U0 cos (<л0/ + ф0) — Uom sin (й/ ф- Ф) sin (aot ф- ф0).
Но
— sin (йг 4- Ф) sin (&ot 4- ф0) = у cos [(соо 4- й) / 4- ф0 4- Ф] —
— |cos [(соо — Й) г ф0 — Ф].
196
Тогда
их (t) = U0 cos (®014- фо) 4"
+ ^cos[(®0-hQ)Z + T0 + O]-
— cos [(®0 — Q) 14- ф0 — Ф].
Здесь вновь (как и в AM) получаются три частоты — не-
сущая ®0> верхняя боковая ®0 + Й и нижняя боковая <оо—
— й; однако нижняя гармоника входит со знаком минус.
Для рассмотренного случая т 1 на рис. 4-6, д по-
строены t-, со- и IF-диаграммы.
co-диаграмма имеет одинаковый вид для ЧМ и ФМ и при
малом т не отличается от AM [см. формулу (4-5)]. ^-диаграм-
ма для ЧМ отличается лишь направлением вектора нижней
боковой частоты.
На W-диаграмме вектор несущей ^-зафиксирован, сис-
тема координат вращается со скоростью соо, а векторы Uo X
X т/2 составляющих боковых частот <оо 4- й и <оо — Q вра-
щаются в противоположные стороны со скоростями Q и вы-
зывают качания равнодействующей в пределах угла фмакс =
= т в обе стороны от среднего положения. Длина результи-
рующей в действительности не изменяется, так как колеба-
ния совершаются по дуге (построение выполнено по при-
ближенным соотношениям).
Однако при увеличении индекса модуляции т частотный
спектр ЧМ- или ФМ- сигнала сильно разрастается и по ши-
рине превосходит спектр AM-сигнала. В этом состоит недо-
статок ЧМ и ФМ.
При общем анализе (для произвольного т) (4-8) разла-
гается в бесконечный ряд с коэффициентами, выражающи-
мися через функции Бесселя [Л. 4-6]. В этом случае в ЧМ-
п ФМ- колебаниях даже при элементарной информационной
функции x(t) = хт cos (П/ + Ф) обнаруживается бесконеч-
ный частотный спектр. Формула сигнала, записанная ь
форме ряда, имеет следующий вид:
ux(t) = U0 2 Я„(т)со8[(со04-пЙ)/4-пФ4-ф0],
И —— со
где Jn(m) — значение функции Бесселя первого рода по-
рядка п для заданного т.
Таким образом, имеет место бесконечный линейчатый
спектр с амплитудами гармоник, пропорциональными
197
I
Зп(т) : Un = U0Jn(m). Однако значения J„(m) быстро убы-
вают при увеличении п, начиная от п —т + 1, и можно
считать, что число боковых частот (с каждой стороны от <о0)
равно т + 1. Ширина спектра равна при этом
2Й (/п 4-1) = 2Й 4- 1) -= 2 (Дю 4- О).
В случае амплитудной модуляции она составляла 20.
При сложном сигнале О представляет собой наивысшую
модулирующую частоту.
Рис. 4-9. Зависимость отно-
сительной ширины спектра
ЧМ- и ФМ-сигналов от ин-
декса модуляции.
♦14x1
Рис. 4-10. Спектры ЧМ- и ФМ-сиг-
налов при различных индексах
модуляции.
Если отбросить гармоники малой относительной вели-
чины (менее 0,01 от основной), то будет получена так назы-
ваемая действительная ширина спектра.
На рис. 4-9 в логарифмическом масштабе построен сглажен-
ный график зависимости действительной ширины от ин-
декса модуляции т, причем по оси ординат отложена не
действительная ширина, а отношение ее к полосе частот
информационной функции 6. В пределе б = т, т. е. ширина
спектра становится равной полосе качания.
Характер изменения частотного спектра при переходе
от т 1 к м^>1 показан'на рис. 4-10.
4-7. СПЕКТРЫ СИГНАЛОВ С ИМПУЛЬСНЫМ НОСИТЕЛЕМ
Спектры одиночных импульсов
Прежде чем перейти к спектрам сигналов с импульсной
модуляцией, предварительно рассмотрим спектры одиночных
импульсов различной формы. Их определение производится
подстановкой аналитического описания импульса в формулу
198
(4-3) интеграла Фурье. Так, для прямоугольного импульса
рис. 4-11, а имеем:
т/2
S(/oi) = \ Ume~iat — =
' J m /со l<‘>
—1/2
2Um . сот
= -- sin -s- .
co 2
Модуль этой функции
|S (/co) |
При изменении положения импульса на временной оси
выражение для | S (/со) | будет отличаться от полученного
лишь аргументом, сохраняя модуль неизменным.
Характер спектров для других часто встречающихся форм
импульсов — треугольного, косинусоидального, экспонен-
циального, колокольного и скачкообразного — изображен
на рис. 4-11, б—е. На рис. 4-11, ж, з изображены предель-
ные случаи спектров дельта-функции и постоянной величины.
Из диаграмм видно, что их спектры обладают бесконечной
протяженностью, имея тенденцию к затуханию (кроме дель-
та-функции, обладающей равномерным спектром) с уве-
личением частоты со. Форма спектра, степень и характер
его затухания существенно зависят от формы импульса и его
длительности. Следовательно, форма и ширина импульса
влияют на действительную ширину спектра. Амплитуда
же сигнала на ширину спектра, не влияет, она определяет
лишь масштаб | S(/co) | по оси ординат.
Рассмотрим в связи с этим связь ширины спектра с ши-
риной импульса произвольной формы. Увеличение длитель-
ности импульса т в а раз эквивалентно уменьшению во
столько раз же аргумента под знаком временной функции
их (t/a). Спектр полученного импульса
СО
Sa(/w)= ux[~t^e4at dt =
— СО
= а их d t^ — ci ux(t')e ,aL"'1' df,
— co —co
где t' — tla,
или
Sa(jw) — aS (jaw).
199
ж)
I'S'
а>
О 2Я БК 8я 10Я
1ISI
о in w юг аг юя
г
Рис. 4-11. Спектры импульсных сигналов различ-
ной формы.
а — прямоугольный импульс; б — треугольный импульс;
в — косинусоидальный импульс; г — экспоненциальный
импульс; о — колокольный импульс; е — скачок; ж —
дельта-функция; з — постоянная величина.
200
Отсюда следует, что спектр расширенного в а раз им-
пульса во столько же раз уже спектра исходного сигнала.
Масштабный множитель а перед Sa (jco) на характер и ши-
рину спектра влияния не оказывает. Он лишь увеличивает
все амплитулы гармонических составляющих в а раз. Его
наличие вызвано изменением в а раз площади первоначаль-
ного импульса при расширении.
Рассматриваемый одиночный импульс и его спектр в об-
щем случае затухают лишь при бесконечно больших вели-
чинах аргументов. Однако если в соответствии с каким-либо
критерием ширину импульса т и ширину спектра Асо огра-
ничить некоторыми значениями аргументов, то согласно по-
лученному выше соотношению имеет место закономерность
тАсо = Х или тА/ — р,, (4-9)
где X, и ft — постоянные, зависящие только от формы им-
пульса. В качестве такого критерия часто используется энер-
гетический критерий, согласно которому интервалы т и
Асо выбираются так, чтобы энергия отсеченных частей функ-
ций ux(t) и S(jco) была пренебрежимо малой по сравнению
с энергией функций внутри интервалов. Для определения
граничных значений т и Асо должны быть известны зави-
симости между значимой долей энергии импульса и аргу-
ментами t и со.
Удельная мгновенная мощность сигнала их (t), т. е.
мощность, выделяющаяся на единичном сопротивлении,
равна ux(t), а полная удельная энергия составляет:
СО
Е — § их (t) dt.
—со
(4-10)
Полагая значимую долю энергии равной Ео = КЕ (коэф-
фициент 1, но достаточно близкий к единице, зада-
ется произвольно), практическую ширину импульса т мож-
но определить из соотношения
Ео = их (0 dt — К § их (0 dt.
о о
Для нахождения по этому же критерию практической
ширины спектра воспользуемся равенством Парсеваля,
связывающим энергию сигнала с энергией спектра. Для его
201
вывода соотношение (4-10) преобразуем следующим образом:
Е= Г ux(t)
1 ( S(/W)^d(O dt = 1 ( S(/X
L J X-J L J
— CO J —co
co
X da \ ux (t) dat dt — S (/co) 5 (— /co) da =
— co —co
co
= V I S (/co) I2 da.
где S(—ja) — функция, сопряженная с функцией S(ja).
Таким образом,
СО со
и2х (0 dt = I S (/со) I2 da.
—со О
Величина — | S (/со) |2 есть энергия, приходящаяся на
полосу частот da. Поэтому функция (/а) = | S(/a) |2
выражает спектральную плотность энергии. Практическая
ширина спектра Дсо определяется из равенства
Дсо со
| I S (/со) |2 dco = А S (/со) |2 da.
о о
Используя данный критерий, можно подсчитать вели-
чину для любой формы импульсов. Для изображенных
на рис. 4-11 импульсов пропорциональная ей константа
р = 2./2л лежит в пределах от 0,22 (для колокольного им-
пульса) до 1,13 (для экспоненциального импульса) [Л. 4-61.
Для ориентировочных оценок при любой форме импульсов
обычно принимают р = 1. Величина X характеризует эко-
номичность сигнала. Наиболее экономичным с этой точки
зрения является колокольный импульс, который требует
наименьшей полосы частот Дсо при заданной длитель-
ности т.
Спектры импульсных носителей
Для периодической последовательности импульсов (им-
пульсного носителя) спектр является дискретным и опре-
деляется выражением (4-1). Из сопоставления (4-1) с (4-3)
202
следует, что
Ak=^S(JkQ), 6 = 1, 2.3...;
A=1S(O),
т. е. комплексные амплитуды дискретного спектра могут
быть получены из непрерывного спектра при дискретных
LSI
О
U- Z - J
быть получены из непрерывного
значениях аргумента со = 6Q.
Другими словами, для импуль-.
сов одинаковой формы решетча-
тая функция (772) - Ak (/со),
со = 6Q вписывается в непре-
рывную S f/co). Постоянная со-
ставляющая Ло при этом имеет
вдвое меньшее значение. Это об-
стоятельство отображено на рис.
4-12, где спектры одиночного им-
пульса и последовательности им-
пульсов той же формы, изобра-
женных на диаграммах а и б,
совмещены (диаграмма в). Рас-
стояние между составляющими
дискретного спектра равно основ-
ной частоте носителя Q = 2п/Т.
Отсюда следует, что изменение
периода следования импульсов Т
приводит к изменению плотно-
сти дискретных составляющих, а
изменение скважности Т/т при
неизменном периоде (т. е. изме-
нение т) вызывает сужение или
расширение огибающей с сохранением ее формы, остав-
с;
Рис. 4-12. Связь спектров
одиночного импульса и пе-
риодической последователь-
ности импульсов.
а — одиночный импульс; б —
периодическая последователь-
ность импульсов; в — спектры
одиночного импульса и перио-
дической последовательности
импульсов.
ляя неизменным расстояние между линиями дискретного
спектра. При достаточно большой плотности этих линий,
когда между узлами размещается по крайней мере несколько
гармонических составляющих, что имеет место при Т
т, ширину спектра Ди импульсного носителя можно счи-
тать практически такой же, как и для одиночного импульса.
С приближением т к Т эти спектры могут оказаться раз-
личными по ширине. На рис. 4-13 изображены деформации
спектра импульсного носителя при изменении Т (диаграммы
fi) и т (диаграммы б) для импульсов прямоугольной формы.
Цифрами 0, 1, 2... обозначены соответствующие гармоники
дискретного спектра. В предельном случае т — Т в спектре
203
204
Рис. 4-13. Изменение характера спектра при изменении параметров импульсных последовательностей.
а — изменение спектра при изменении периода следования импульсов; б — изменение спектра при изменении длительности
импульсов.
s
ст
• Рис. 4-14. Изменение спектра конечной последовательности импульсов при возрастании их числа,
о — изменение спектра видеоимпульсов; б — изменение спектра радиоимпульсов.
остается одна линия на частоте со = 0; остальные линии
оказываются в узлах и их амплитуды равны нулю.
При неизменной амплитуде импульсов согласно соот-
ношению (4-9) огибающая дискретного спектра увеличи-
вается пропорционально увеличению площади импульсов,
что видно на рис. 4-13, б.
Следует отметить, что периодической последователь-
ности импульсов в чистом виде в природе не существует,
поскольку любая последовательность имеет начало и ко-
нец. Степень приближения зависит от числа импульсов в
последовательности. Поэтому для строгого описания импуль-
сного носителя последний должен рассматриваться как
одиночный импульс, представляющий собой пакет элемен-
тарных импульсов определенной формы. Такой сигнал имеет
непрерывный спектр. Однако по мере накопления числа п
импульсов в последовательности ее спектр дробится и де-
формируется таким образом, что все более приближа-
ется к решетчатому. Эта деформация показана на примере
импульсов прямоугольной (видеоимпульс) и синусоидаль-
ной (радиоимпульс) формы (рис. 4-14, а, б). Составляющие
на частотах дискретного спектра сужаются и быстро рас-
тут. Остальные составляющие подавляются.
Такое представление спектра в виде функции времени
S(co, t) (или, как в данном случае, числа импульсов) в про-
цессе формирования сигнала носит название текущего
спектра. Из рис. 4-14 видно, что для импульсного но-
сителя ограниченной длительности при условии Т т ши-
рина спектра остается практически такой же, как в случае
одиночного импульса.
Спектры сигналов с импульсной модуляцией
Импульсный носитель согласно (4-2) описывается рядом
Фурье
СО
/г——оо
Информационные параметры носителя — амплитуда им-
пульсов Uo, частота соо (или период следования импуль-
сов То = 2л/со0) и ширина импульсов т0 входят в выра-
жение для гармоник А6 [см. формулу (4-1а)1. Характер
изменения параметров определяет вид импульсной моду-
ляции.
206
Покажем, как меняется спектр при амплитудно-импульс-
ной модуляции типа АИМ. Для любой формы импульсов
формулу носителя можно представить в виде
СО
«нЮ=4^о 2
где A'k = Ak/U0.
При АИМ изменение амплитуды происходит по закону
их (0 — U 0 -ф- Ли (t).
При этом разложение модулированного носителя полу-
чает вид:
СО
их(о=4 [с/«+д« (о] 2 A*efli,oet-
k = —СО
В простейшем случае, когда модулирующая функция
содержит одну гармоническую составляющую
Ли (t) = AUm cos (Й/ 4- Ф),
или, что то же самое,
Ли (t) — ~ Лит[еЛ®1+ф’1
получаем:
ОО
ux(t) = ~U0 2 А'ке^ +
k=--------------00
+ ~лит 2 Ле/1(*“о+я)Н-ф|_|_
k~— со
оо
+ ~Лит 2
k — — со
Отсюда видно, что кроме основных линий, содержащихся
в спектре носителя (первое слагаемое), имеются дополни-
тельные линии меньших размеров, расположенные на час-
тотах ka>0 ± й, т. е. по обе стороны от основных на рас-
стоянии ±Й (рис. 4-15).
При более сложной модулирующей функции Au(t) по
обе стороны от каждой основной линии располагается полоса
дополнительных составляющих, число которых определя-
ется полосой частот модулирующей функции.
При время-импульсной и частотно-импульсной модуля-
ции даже при элементарной модулирующей функции с одной
207
гармоникой вокруг каждой линии спектра носителя распо-
лагается бесконечно большое число дополнительных гар-
моник носителя, которые, однако, быстро убывают.
Рис. 4-15. Спектр АИМ-сигпала.
Из сказанного следует важный вывод: несмотря на то,
что характер спектра при модуляции носителя изменяется
и зависит от вида модуляции, его ширина практически
остается такой же, как и для отдельного импульса. Она
определяется главным образом шириной этого импульса
и может быть оценена величиной
Дсо ?./т — 2лр/т,
где [х — постоянная, зависящая от формы импульса и имею-
щая порядок единицы.
4-8. СПЕКТРЫ СЛУЧАЙНЫХ СИГНАЛОВ
Случайный сигнал в отличие от детерминированного
нельзя охарактеризовать спектральной плотностью его реа-
лизации, так как амплитуды и фазы всех его спектральных
составляющих имели бы случайный характер. Однако для
стационарных случайных сигналов неизменными во времени
остаются моменты распределений. Поэтому в качестве детер-
минированного частотного аналога используется функция
Sxx (и), являющаяся преобразованием Фурье от корреля-
ционной функции Влх(т) случайного сигнала ux(ty.
4-00
$ Вхх (т) е ,ип dt.
—со
Разложив е~/т по формуле Эйлера, получим:
4- со -f-co
5 Вхх (т) cos сот dt — j $ Вхх (т) sin m dt.
— 00 — Q0
208
Так как Вхх(т;) есть четная функция, то Вхх(т) cosarr так-
же является четной, a Bxx(t) sin сот — нечетной функцией т.
Поэтому второе слагаемое равно нулю, а в первом можно из-
менить пределы интегрирования:
СО
Sxx (®) — 2 \ Вхх (т) cos сот dx.
о
Отсюда видно, что £ЛЛ(со) есть действительная и четная
функция аргумента со. Физический смысл проявляется, если
рассмотреть обратное преобразование Фурье:
оо
Вхх(г) = ^ S^cojc/^dco,
— оо
или в силу четности 5ЛЛ(со)
СО
Вхх (т) = | j Sxx (СО) dco. (4-11 а)
Положив т — 0, получим:
Вхх (0) = Dx = -i- Sxx (“) da, (4-11 б)
о
где через Dx обозначена дисперсия.
Но
£»Л = Л4[Х2(/)] = РЛ (4-11 в)
есть средняя мощность случайного сигнала. Следовательно
элементарная составляющая
dPx = ~ Зл-х(со) dco
J V
9
представляет собой долю средней мощности, приходящуюся
на диапазон частот da. Другими словами, бесконечно
малая величина dPx характеризует среднюю мощность эле-
ментарного колебания
dA = dAm sin (со/ -j- ср)
со случайной амплитудой dAm и фазой ср. При фиксирован-
ной амплитуде dAm мощность колебания составляет:
Т/2
2 С 1
dPx =~f\ dAmsin(a>t-\-(p)dt=-^dAm,
о
209
средняя же мощность колебания со случайной амплитудой
dPx = dP'x,
где черта над символом означает усреднение по времени.
Величина dP'x является случайной, однако средняя элемен-
тарная мощность
dPx — ~dA2m—~Sxx(a)da (4-12)
не случайна.
Таким образом, функция Sxx (со) описывает распределе-
ние средней мощности по частотам, в связи с чем она носит
название энергети-
ческого спектра,
или спектральной
плотности мощ-
ности, случайного
сигнала.
На рис. 4-16 пока-
зан характер корреля-
ционной функции (рис.
4-16,6) и энергетического
спектра (рис. 4-16, в) для
случайных сигналов, реа-
лизации которых изо-
бражены на рис. 4-16, а.
Случайные функции их1
и иа при одинаковых
математических ожида-
ниях тх и дисперсиях
DX1 =DM=DX характе-
ризуются различной сте-
пенью статистической
Рис. 4-16. Характеристики случайных
сигналов.
а — реализации случайных сигналов;
б — функции корреляции случайных сиг-
налов; в — энергетические спектры слу-
чайных сигналов.
связи в соседних сече-
ниях. При сильной ста-
тистической связи (реа-
лизация ых1) корреля-
ционная функция Вхх(г)
затухает медленнее, а
соответствующая ей кривая энергетического спектра Sxx(a)
спадает быстрее.
Функции их:. и uxi представляют предельные случаи пол-
ностью коррелированного ux(t) —а = const, т. е. детермини-
рованного сигнала, и совершенно некоррелированного сигна-
ла, называемого «белым шумом». В первом случае Bxx{t) —
210
= а2, а 5л.л(со) вырождается в дельта-функцию на нулевой
частоте с площадью, равной па2. Во втором случае Вхх(х)
вырождается в дельта-функцию, а энергетический спектр
5ЛЛ(со) имеет равномерный характер и неограниченную по-
лосу. Это обусловило и название процесса «белый шум», что
имеет аналогию в оптике в виде белого света с равномерным
и неограниченным спектром интенсивности.
Однако следует отметить, что изображенные характерис-
тики описывают идеальный «белый шум»,который принципи-
ально не может существовать. Действительно, его мощность,
определяемая площадью под функцией Sxx(a), должна быть
бесконечно большой, что никогда не имеет места. Поэтому
обычно пользуются практическим приближением, при кото-
ром энергетический спектр равномерен в широком, но конеч-
ном диапазоне частот. Сигнал с такой спектральной плот-
ностью называется реальным «белым шумом». Его корреляци-
онная функция в точке т = О имеет конечное значение, но
быстро затухает с изменением т.
Аналогично изложенному для частотного описания сис-
темы двух случайных стационарных и стационарно связан-
ных сигналов ux(t) и uv(t) используется преобразование Фурье
от взаимно корреляционной функции Вху(т):
+ со
Sxy(a)= Вху(т)е ’т dr,
— со
которое носит название взаимной спектральной плотности.
4-9. ПОМЕХОУСТОЙЧИВОСТЬ МОДУЛИРОВАННЫХ СИГНАЛОВ
В процессе практического использования модулирован-
ных сигналов огромное значение имеет учет их помехозащи-
щенности, которая существенно зависит от выбранного вида
модуляции. Материал данного параграфа преследует цель
проиллюстрировать этот факт и указать причины.
Паразитная модуляция
Воздействие помехи на носитель приводит к паразитной
модуляции его параметров.- При этом модуляции подверга-
ются, как правило, все информационные параметры. В ре-
зультате получается сложный сигнал
+ а2. + бй2(0> •••» + (Ь
211
в котором модулирующие функции баг (/) обусловлены влия-
нием помехи н. (/).
Покажем это на примере действия простейшей аддитив-
ной гармонической помехи
= U^m cos at
на носитель в виде колебания
«н = Uo cos соо t
с параметрами Uo и со0 [Л. 4-7]. Выражение для носителя с
наложенной на него помехой имеет вид суммы:
«н -|- COS ®о t + COS
На рис. 4-17 изображена ^-диаграмма 1/£ + UH. По-
скольку вектор С/н вращается против часовой стрелки с уг-
Urocos{%-^t ловой частотой а, то при
£ ' его фиксации система коор-
динат (S, jo) станет вра-
щаться по часовой стрелке
со скоростью соо, а вектор
Щ — со скоростью со0 — со.
Проекция вектора на
вектор Uu порождает ампли-
тудную модуляцию. Эта
проекция равна:
Рис. 4-17. Векторная диаграмма
гармонического носителя с нале- 11 \т] / \t
женной помехой. с^о cos (®о СО) Г.
Изменение угла Д<р(0 приводит к частотной модуляции.
Угол
Дср tfi Д(Р = .{WMcoq-cbH
Uo + UbnCos((i)()_w)t-
При U^m < f/0
Дер {U.JU^ sin (cd0 — co) t.
Закон изменения фазы ср результирующего вектора UK +
-|-Ц: имеет вид:
ф (О = Qo t + sin (®0 — со) t,
ИЛИ
t
ф (0 — [соо 4- (со0 — со) cos (соо — со) f J dt.
212
Таким образом, результирующий сигнал можно предста-
вить в виде
иу — [Ц> + cos (®о — ®) d X
X COS j [соо + dt =
t
—Ш» + (0]cos $ [% 4- б«> (0]
о
где bU(t) =L'\m cos(co0—a)t —изменение амплитуды исходного
колебания, порождающее AM; дот (/) = —— cos (соо —
— со) t — изменение частоты исходного колебания, порож-
дающее ЧМ.
Последнее выражение можно переписать в форме
— U0 [1 4~ М cos (соо — со) t] х
t
X cos $ [соо Ц- 6<om cos (<оо — со) t] dt,
о
где М = UimlU0 — глубина AM; 6сога = (U^mlV0) (соо—со)—
девиация частоты при ЧМ.
Следовательно, помеха вызывает как амплитудную, так
и частотную модуляцию, т. е. воздействует на оба информа-
ционных параметра Uo и соо.
Очевидно, что более сложный аддитивный сигнал также
вызывает паразитную модуляцию обоих параметров. К таким
же последствиям приводят и другие виды помех.
Помехоустойчивость
В процессе паразитной модуляции помеха оказывает раз-
личное влияние на разные параметры носителя. Это позволя-
ет путем выбора для передачи полезной информации таких
параметров, которые наименее подвергаются воздействию по-
мехи, повысить помехоустойчивость сигнала. При демодуля-
ции независимо от природы выбранного параметра дг полез-
ная Ап,(/) и вредная дп;(/) модулирующие составляющие
могут быть приведены к сигналу единого типа, например в
виде интенсивности. Это позволяет сравнивать различные
виды модуляции по соотношению между Ай,- (/) и 6о;(/). Ин-
тенсивность помехи характеризуется мощностью Р^, кото-
рая при нулевом среднем численно равна дисперсии D£i:
213
Соответственно интенсивность полезного сигнала опре-
деляет его средняя мощность
р^дмог.
Помехоустойчивость модуляции по i-му параметру оце-
нивается отношением этих мощностей:
рг = Pxi/Pa-
Это отношение для различных параметров доказывается
различным. Из двух видов модуляции, связанных с парамет-
рами а; и йу, более помехоустойчивым можно считать тот,
для которого это отношение больше. Сигналы с большим
отношением р,- обладают большими информационными воз-
можностями (см. гл. 6).
Используя 'данный критерий, проведем сравнение по по-
мехоустойчивости, двух видов модуляции — амплитудной -и
частотной, с носителем в виде колебания
uK~U0 cos (соо t -ф0).
Носитель имеет три информационных параметра: пг =
= Ц„ п2 = со0, Пз = (р0. При AM и ЧМ начальная фаза ср0 ин-
формации не несет, поэтому в дальнейшем будем полагать
Фо =0.
Модулированный сигнал при AM и ЧМ описывается со-
ответственно функциями
их (0 = + Ды Ц )1 cos “о I
и
t
их (/) — Un cos [соо -ф- Дсо (/)] di.
о
Определим рг при модуляции , синусоидальным колеба-
нием
х (t) = xm sin Qt
в предположении наличия аддитивной помехи типа реаль-
ного «белого шума», имеющего равномерный энергетический
спектр S£ в полосе 2Й (от —Q до соо О), т. е. в пределах
ширины спектра, модулированного по амплитуде полезного
сигнала. Модулирующая составляющая при AM
Дп, (/) = Дц (I) = (/) = ДСф, sin И/,
где АПт =Кхт.
214
Ее Средняя мощность
Рха = [Л« (О]2 = sin Й/]2 —
Т/2
= у (Д(7т)2 sir2 Й/ л = 1^1,
‘о
где Т = 2л/й.
Отношение сигнала к помехе имеет наибольшее значение
в случае стопроцентной модуляции, при которой Д Um = Uo
и, следовательно,
Pxa=U‘/2.
Средняя мощность помехи согласно (4-116) равна:
СО
1 С 1 С 9
= = — \ SK(co)dco = — \ Sffidco = —5ЙЙ.
О о
Помехоустойчивость при амплитудной модуляции
„ ____________________ Рха__ п^о
Р“-рЕа- 4QStf
Для частотной модуляции имеем:
Д«2 (/) = Дю (/) = Кх (/) = Д<от sin Й/,
где Дсот =Кхт.
Средняя мощность частотного сигнала равна:
r/s
Рх.0 = [Дсо (/)Г = | § (Дсот)2 sin2 Й/ dt = .
о
Определим теперь среднюю мощность Реь> помехи при
частотной модуляции.
В предыдущем параграфе указывалось, что случайную
помеху (t) можно рассматривать как бесконечную сумму
бесконечно малых гармоник со случайной амплитудой dAm
и фазой, но с детерминированной величиной средней мощно-
сти, определяемой соотношением (4-12). Однако, как было по-
казано в начале параграфа, гармоническое колебание с час-
тотой со и амплитудой dA„, при наложении на носитель при-
водит к модуляции последнего с модулирующей функцией
бсо (/) = (dAmlV^ (соо — со) cos (соо — со) I.
Средняя мощность этой функции представляет собой эле-
ментарную составляющую dP^, приходящуюся на диапазон
частот da:
----- 1
dP^ = 6<o(02= 2 -yf (соо~ со)2.
215
Учитывая, что согласно (4-12)
dA* 1 „
~2~ = (®)
элемент мощности модулирующей функции можно предста-
вить в виде
По условию энергетический спектр помехи равномерен
в диапазоне от соо—й до о0 + Q и равен нулю вне этого
диапазона. Поэтому
©о-}- £2
= § (®0-®)2dfi).
го»— £2
Сделав замену переменных.
(01 = и0 — со,
получим:
О
Помехоустойчивость при частотной модуляции
Р хш_Зл(/5
рю==р^==да'^Г'
Сравнивая рш с ра, получаем:
Рсо = з Ра = Зт2р„,
где т = Асо/Й — индекс частотной модуляции.
Из полученного соотношения следует, что помехоустой-
чивость частотной модуляции намного превышает помехо-
устойчивость амплитудной модуляции (в 3m2 раз).
Выигрыш в помехоустойчивости получается благодаря
расширению спектра сигнала, который при частотной моду-
ляции занимает значительно большую полосу (ориентиро-
вочно в т раз).
Аналогично обстоит дело и с импульсными сигналами. Фа-
зо-импульсная модуляция, например, обладает большей по-
мехоустойчивостью, чем широтно-импульсная, а широтно-
импульсная имеет большую помехоустойчивость по срав-
нению с амплитудно-импульсной [Л. 4-8].
216
Часть вторая
ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ
Глава пятая
ВОСПРИЯТИЕ ИНФОРМАЦИИ
5-1. ОСНОВНЫЕ ФОРМЫ И МЕТОДЫ ВОСПРИЯТИЯ
Классификация
Восприятием называется процесс целенаправленного
извлечения и анализа информации о каком-либо объекте
или процессе.
Простейшим видом восприятия является различение
двух противоположных состояний «да» и «нет» (двухальтер-
нативные ситуации).
Более сложным видом восприятия является измерение,
т. е. определение значений некоторых наблюдаемых вели-
чин в статике или в их изменении во времени, или прост-
ранстве.
Далее следуют еще более сложные процессы поиска,
анализа, оценки обстановки, предсказание событий и со-
стояний, распознавание объектов, фактов, ситуаций, со-
стояний, образов и понятий.
Систематизируя наиболее важные виды восприятия ин-
формации, их можно расположить в таком порядке:
1) первичное восприятие информации и измерение ве-
личин;
2) анализ;
3) обнаружение и распознавание;
4) прогнозирование ситуаций.
Эти процессы можно разделить на их составляющие.
Так, например, в первичном восприятии можно выделить
задачи поиска, локализации, избирания информации; ана-
лиз, охватывая процессы, явления, поля, вещества, может
иметь характер дисперсионного, корреляционного, регрес-
сионного, спектрального, анализа распределений и т. п.;
к обнаружению и распознаванию относятся различение
217
элементарных событий (контроль), распознавание состоя-
ний объектов (диагностика), проверка объектов, распозна-
вание образов.
В различных способах восприятия есть много общих сто-
рон. В частности, следует отметить единство методов обна-
ружения, измерения и распознавания, когда процедура в
основном сводится к установлению некоторых эталонов,
получению внешней информации и к сравнению информа-
ции с эталоном, причем, результат сравнения оценивается
на основании какого-либо критерия. Вместе с тем в теории
и практике восприятия получают применение разнообраз-
ные практические и теоретические приемы: аналитические,
статистические, логические, эвристические и другие.
Операционная схема процедуры восприятия
Задача восприятия имеет две стороны. Первая состоит
в нахождении параметров, содержащих информацию, и
признаков состояния источника информации, т. е. в постро-
ении информационного портрета, характеризуемого в § 5-2.
Эта часть задачи решается на основании изучения свойств
источника информации и установления связей информаци-
онных параметров с его состояниями. Вторая сторона зада-
чи заключается в определении настоящего, прошлого и
будущего состояния источника информации. Она решается
рядом последовательных функциональных операций.
Первой операцией в большинстве случаев служит изме-
рительное преобразование, цель которого состоит в пред-
ставлении величин параметров в некоторой унифицирован-
ной форме, более удобной для дальнейшей обработки. Такой
удобной формой является угловое или линейное перемеще-
ние ах, время Тх между двумя импульсами, унифици-
рованный электрический или пневматический сигнал срав-
нительно высокого уровня. Особенно удобно представле-
ние параметров в угловой и временной формах, которые
позволяют отображать весьма большие величины с вы-
сокой точностью, что оказывается невозможным для сиг-
налов интенсивности, всегда имеющих ограниченную ам-
плитуду.
Вторая операция зависит от цели восприятия. Простей-
шее определение состояния производится логическим рас-
познающим устройством, более глубокие свойства источ-
ника, например, статистические, выявляются анализатором,
для предсказания поведения источника используется эк-
218
“о
Рис. 5-1. Операционная схема про-
цедуры восприятия.
й„
страполятор, учитывающим результаты временного, стати-
стического и других видов анализа.
Определение состояния не всегда можно или целесооб-
разно производить за один шаг. Часто более экономичным
и эффективным оказывается целенаправленное возбуждение
источника информации по частям путем подачи на него сти-
мулирующих (управляю-
щих) воздействий и прове-
дение последовательной се-
рии экспериментов.
Указанные операции
представлены на обобщен-
ной схеме процедур вос-
приятия (рис. 5-1), где че-
рез х обозначен вектор па-
раметров источника инфор-
мации (объекта восприятия
0), через х' — вектор пара-
метров, полученных в процессе измерительного преобразо-
вания, через у — вектор стимулирующих сигналов и через
Е — вектор помех, И — измерительный, Р — распознаю-
щий, А — анализирующий, П — прогнозирующий и У —
управляющий блоки. Выходным параметром устройства вос-
произведения может явиться: отображение вектора состояний
/р = (Ор...ап), обобщенная, характеристика Fa (t), полу-
ченная в процессе анализа, или обобщенная прогнози-
рующая характеристика Fn (t + т), где т >0 — время
прогноза.
5-2. ПЕРВИЧНОЕ ВОСПРИЯТИЕ И ИЗМЕРЕНИЕ ИНФОРМАЦИИ
Информационный портрет источника
Источник информации можно охарактеризовать неко-
торым множеством явлений, подлежащих восприятию.
Это множество интерпретируется как множество состояний
источника в пространстве состояний. Обмен ин-
формацией с внешней средой осуществляется посредством
определенного набора информационных параметров или
признаков. Множество возможных значений призна-
ков называют пространством признаков.
Предположим, что воспринимаемое явление описывается
некоторой областью Аи в пространстве состояний А источ-
ника информации. В пространстве признаков X эта об-
ласть отображается в область Х° (рис. 5-2), которую назо-
219
Рис. 5-2. Отображение пространства
состояний в пространстве признаков.
вем информационным портретом данного источника ин-
формации. Часть параметров пространства X может не
участвовать в формировании области Х°. В этом случае
они не несут информации о состояниях источника, вклю-
ченных в область Ло. Исключение их сокращает размер-
ность пространства признаков. Построение информацион-
ного портрета сводится к выбору параметров и опреде-
лению характера и степени связи их с состояниями ис-
точника.
Заключение об информативности может быть сделано на
основании теоремы о несущественности данных [Л.6x10],
согласно которой параметр не содержит информации о со-
стоянии источника и им
можно пренебречь в том
и только в том случае,
если
Р (xt | U xJt Ло) =
— p(Xi\ U Xj),
т. е. вероятность того,
что параметр xt примет
некоторое значение (или
находится в некоторой
области) при условии, что множество остальных парамет-
ров (J Xj пространства X зафиксировано, а источник нахо-
дится в одном из состояний, принадлежащих области Ао, не
отличается от той же вероятности без условия, относя-
щегося к состоянию источника.
Так, например, если целью восприятия является обна-
ружение неисправности двигателя подвижного объекта,
то /1() состоит из двух точек (Ло =1 — двигатель испра-
вен и Ло =0 — двигатель неисправен), а Х° есть набор
параметров, связанных как непосредственно с агрегатами
двигателя, так и с системами обеспечения нормальных
условий его функционирования. Так, параметром, опреде-
ляющим исправность системы подачи топлива, пренебречь
нельзя, ибо тогда записанное выше равенство не будет иметь
места. Действительно, рассмотрим двоичный параметр X/,
определяющий исправность системы подачи топлива. Ис-
правному состоянию этой системы соответствует xt = 1,
неисправному х{ = 0. Предположим, что работоспособность
двигателя контролируется по двоичному параметру xJt
фиксирующему тяговое усилие. Тогда р (х; = 0 | ху =
= 0, Ад — 0) есть вероятность неисправности топливной
220
системы при условии, что тяга двигателя меньше нормы и не-
исправен один из собственных агрегатов двигателя. Эта
вероятность меньше вероятности р (xt = 0 | Xj = 0), когда
о состоянии агрёгатов двигателей ничего не известно, сле-
довательно, параметр xt должен быть включен в область Х°.
Во многих случаях, однако, набор параметров, формиру-
ющих Х°, может оказаться избыточным. Это имеет место,
когда о состояниях Ло можно судить по некоторой меньшей
совокупности Х0С Х° признаков. Тогда возникает более
глубокая задача выбора оптимальной совокупности пара-
метров и составления такого информационного портрета
Хо, при котором удовлетворяются основная цель воспри-
ятия, принятый критерий качества и технические требо-
вания.
Различные цели приводят к различным информационным
портретам Хо.
Связь источника информации с устройством восприятия
осуществляется посредством сигналов, передаваемых с
помощью средств связи и телевидения, радиолокационных
и телеметрических систем, читающих и вычислительных
машин, датчиков и первичных преобразующих приборов.
В автоматических системах основное значение имеет полу-
чение информации с помощью датчиков.
Критерием качества (эффективности) восприятия может
служить стоимость процедуры восприятия или количество
полученной информации. Требования в зависимости от
цели восприятия состоят в обеспечении достаточно малой
вероятности ошибки (или высокой достоверности) воспри-
ятия, заданного времени восприятия и т. д.
Эти компоненты влияют на качество оценки состоя-
ния источника информации. Формирование информацион-
ной} портрета всегда связано с определенными ограниче-
ниями (возможностями) восприятия: техническая доступ-
ность параметров, стоимость необходимого оборудования,
быстродействие технических средств.
Первичное восприятие
Восприятие информации от объектов осуществляется с
помощью датчиков. Датчики называют также чув-
ствительными элементами, восприни-
мающими элементами, или рецепто-
рами. В большинстве случаев датчики выражают входную
221
информацию в виде эквивалентного электрического пара-
метра, поскольку методы и средства измерения, передачи и
обработки электрических сигналов обладают рядом до-
стоинств; однако в последние годы широкое распростра-
нение получили также пневматические сигналы, обеспечи-
вающие взрывобезопасность аппаратуры и некоторые
другие преимущества.
Наиболее предпочтительны чувствительные элементы
с электрическими выходными параметрами. В этом случае
датчик может состоять только из одного такого преобра-
зователя. В качестве примера в табл. 5-1 приведены из-
вестные чувствительные элементы типа электрических со-
противлений. Совокупность чувствительных элементов
обеспечивает восприятие массовой информации со сложных
объектов. При этом существенное значение имеют методы
поиска и считывания информации. На рис. 5-3 приведена
систематизированная сводка теоретически возможных ме-
тодов поиска и считывания информации в точечных, линей-
ных, плоских и объемных средах.
На рис. 5-3, а показано восприятие информации то-
чечным рецептором; ЛОК и СКАН соответственно обо-
значены неподвижный (локализованный) датчик
и датчик с развертыванием (сканированием)
по оси. В данном случае применены обозначения О-ЛОК
и 0-СКАН, что означает установку датчика в одной точке
и отсутствие развертывания.
На рис. 5-3, б показана система из множества (в данном
случае шести) сосредоточенных и неподвижных восприни-
мающих элементов, занимающих ось У. Такая система
условно обозначается У-ЛОК. В этой системе применяется
цепочка сосредоточенных чувствительных элементов — пе-
редатчиков информации, установленных неподвижно в
пространстве.
На рис. 5-3, в показана система У-СКАН, отличающаяся
тем, что имеется один точечный датчик, совершающий
развертку пространственной координаты У.
На рис. 5-3, гид показаны аналогичные варианты
Х-ЛОК и Х-СКАН для пространственной координаты X.
Аналогичные системы синтезируются для поверхностей
и объемов.
На рис. 5-3, е показана двумерная система неподвиж-
ных чувствительных элементов, покрывающая всю иссле-
дуемую поверхность с координатами X и У. Такая сис-
тема обозначается Х-ЛОК, У-ЛОК.
222
Чувствительные элементы типа электрических сопротивлений
Чувствительные элементы
Перемещение
(движение) I
Сопротивления проводниковые
Сопротивления полупроводниковые
Сопротивления индуктивные (магнитные)
Сопротивления емкостные (диэлектрические)
Сопротивления взаимоиндукции (электромаг-
нитные)
Сопротивления жидкостные (ионные)
Сопротивления газовые (ионные)
№
№
Сопротивления вакуумные
Таблица 5-1
Измеряемые параметры
х-лок
о-лок
о-СКАН
х-лок
х-лок
х-скан
оХе)
ох-скан
м)
у Х-СКАН
х-конт
п)
Z
х-конт
___________р)
ж)
у-СКАН
х-скан
уХ-СКАН
К)
_________у
ХИ-КОНТ
__________
Х-СКАН
х-конт
<р)
Рис. 5-3. Сводка основных методов регулярного поиска и считывания
информации.
На рис. 5-3, ж датчики занимают только ось X, но обсле-
дование поверхности осуществляется перемещением датчи-
ка вдоль оси У. Ввиду того что по оси X датчики сосре-
доточены и неподвижны, система приобретает условное
название У-СКАН и Х-ЛОК-
Рисунок 5-3, з отличается от предыдущего только заме-
ной координат.
224
На рис. 5-3, и и к используется только один датчик,
который осуществляет развертывание петлями по всей по-
верхности. Названия таких систем: УХ-СКАН и ХУ-СКАН.
На рис. 5-3, л применяются две ортогональные системы
сосредоточенных датчиков по осям X и У, совершающие
развертывание по сопряженным осям: система Х-ЛОК
движется в направлении оси У, а система У-ЛОК движется
в направлении оси X. Таким образом, система приобретает
название Х-ЛОК, У-СКАН, У-ЛОК, Х-СКАН.
На рис. 5-3, м приведена система УХ-СКАН, заключаю-
щаяся в том, что один-единственный датчик совершает
спиральную развертку двумерного поля.
На рис. 5-3, н — с показаны системы с распределенными
по линии (континуальными) чувствительными
устройствами, которые для обследовапия..поверхности со-
вершают движения по осям X и У. Указанные на этих ри-
сунках системы обозначены: У-КОНТ, Х-КОНТ, У-КОНТ
и Х-СКАН, Х-КОНТ и У-СКАН, Х-КОНТ, У-СКАН,
У-КОНТ и Х-СКАН. В последнем случае имеются две рас-
пределенных по линии воспринимающих системы, совершаю-
щих развертывающее движение вдоль сопряженных осей.
На рис. 5-3, т показан теоретический случай покрытия
обследуемого двумерного поля распределенной по по-
верхности системой чувствительных элементов, причем
распределенное множество чувствительных элементов не-
подвижно относительно наблюдаемого поля.
На рис. 5-3, у и ф показаны объемные системы, которые
могут иметь все те разновидности, которые были указаны
выше с развитием натри измерения. Все варианты заклю-
чаются между предельными случаями, когда один-един-
ственный чувствительный элемент осуществляет петлеобраз-
ную и послойную развертку объемного поля рис. 5-3, у
и распределенной по объему системой чувствительных эле-
ментов рис. 5-3, ф.
Кроме приведенных выше методов регулярного поиска,
существуют методы случайного поиска, в которых преднаме-
ренно вводится элемент случайности при просмотре объекта.
Экспериментально доказано, что человек и животные
пользуются именно этим методом. Однако в настоящее вре-
мя не найдено приемлемых по сложности аппаратурных ре-
шений для его реализации. Поэтому пока рациональной
процедурой следует считать регулярный поиск.
Следующим этапом восприятия информации является
ее измерение.
8 Темников Ф. Е. и др.
225
Измерение
Характеристика измерения была дана в гл. 1.
Поскольку непосредственное сравнение с существующи-
ми единицами измерения удобно проводить только для
очень небольшого числа физических величин, измеряемую
величину часто определяют по значению другой величины,
связанной с ней функциональной зависимостью.
Как уже указывалось, это осуществляется посредством
датчиков.-
Рис. 5-4. Структурная схема метода
прямого измерительного преобразо-
вания.
Принципиальная возможность осуществления измере-
ний ограничивается в первую очередь порогом чувствитель-
ности датчика и мощностью, необходимой для получения
соответствующей информации. Большое значение имеют
также их динамические
свойства.
При выполнении из-
мерения .пользуются’из-
мерительным преобра-
зованием по одному из
трех методов: прямого,
следящего или развер-
тывающего: Структур-
ная схема метода прямого измеритёльн6Тб”преобразования
образуется рядом последовательно соединенных звеньев
без обратных связей и цепей сравнения; она показана на
рис. 5-4, где обозначены: Д— датчик, 77 х и /72 — преобра-
зователи. При прямом преобразовании измерение связано
с отбором мощности от первичной измерительной цепи. Ре-
зультирующий коэффициент усиления преобразователя опре-
деляется произведением коэффициентов усиления всех
составляющих звеньев, а на результирующую погрешность
преобразователя в равной мере влияют погрешности всех
входящих в него звеньев.
Наличие нелинейного звена в цепи преобразователя
приводит к нелинейности функции преобразования хвых =
(за исключением случаев специальной компенсации
нелинейности).
Изменение характеристик отдельных звеньев (их коэф-
фициентов усиления) вызывает изменение значения выход-
ной величины.
Значительные погрешности могут быть вызваны изме-
нением сопротивления линии связи между звеньями. Ес-
тественно, добиться высокой точности измерения методом
226
прямого преобразования весьма сложно. Конструкция их
достаточно проста.
Два других метода измерительного преобразования
основаны на автоматической компенсации измеряемой ве-
личины и позволяют по-
лучить более высокую
точность.
Следящий метод из-
мерительного преобра-
зования сочетает в себе
высокую точность и чув-
ствительность и позво-
ляет обеспечить боль-
Д .Т —
Рис. 5-5. Структурная схема метода
следящего измерительного преобразо-
вания.
шую мощность на выходе, которая достаточна не только
для индикации и регистрации, но и для решения задач
автоматического регулирования различных процессов.
Отличительной чертой этого метода является наличие
звена обратного преобразования выходной величины во
входную величину,
Рис. 5-6. Погрешность
нелинейности при сле-
дящем измерительном
преобразовании.
однородную с преобразуемой входной
величиной, и их сравнение. Струк-
турная схема метода следящего изме-
рительного преобразования представ-
лена на рис. 5-5, где Д — датчик,
ОС — орган сравнения, КО — ком-
пенсирующий орган.
Преобразованная измеряемая вели-
чина хх сравнивается с компенсирую-
щей величиной х2. Разность Дх —
= х2 — хх воздействует на компенси-
рующий орган КО таким образом,
чтобы свести этот сигнал рассогласо-
вания к нулю. В момент идеальной
компенсации мощность от измери-
тельной цепи не отбирается. Однако, учитывая наличие у лю-
бого реального органа сравнения ОС зоны нечувствительно-
сти, незначительный отбор мощности может иметь место. По-
скольку не известно, в какой точке зоны нечувствительности
произойдет баланс схемы, то существует бесконечное число
функций преобразования (в пределах зоны нечувствитель-
ности). Нелинейность характеристики органа сравнения за
пределами зоны нечувствительности на вид функции пре-
образования влияния не оказывает. Анализ показывает,
что функции преобразования, соответствующие границам
симметричной зоны нечувствительности, нелинейны и имеют
227
Рис. 5-7. Структурная схема
метода развертывающего изме-
рительного преобразования.
вид, показанный на рис. 5-6.
Отклонение от идеальной
функции преобразования (ли-
нейной зависимости) возмож-
но как в одну, так и в дру-
гую сторону. Погрешность
при градуировке учесть не-
возможно, но ее можно умень-
шить путем увеличения коэф-
фициента усиления /( органа
сравнения.
Относительное изменение коэффициента усиления К
равно относительному изменению максимальной погреш-
ности нелинейности 6маКс, взятому с обратным знаком,
АЙмакс______
^макс К
(5-1)
Однако увеличение коэффициента усиления при следя-
щем методе преобразования принципиально ограничено,
так как при К >/<пред в преобразо-
вателе возникают автоколебания.
При развертывающем методе из-
мерительного преобразования изме-
ряемая величина циклически сравни-
вается с другой однородной величи-
ной, изменяющейся по определенному
(чаще всего линейному) закону. Изме-
ряемая и компенсирующая величины
могут быть представлены электричес-
кими напряжениями, силами, пото-
ками радиации и т. п.
Структурная схема метода развер-
тывающего измерительного преобра-
зования представлена на рис. 5-7,
Рис. 5-8. Погрешность
нелинейности при раз-
вертываюЩем измери-
тельном преобразова-
нии.
где обозначения соответствуют примененным на рис. 5-6.
В момент компенсации срабатывает орган сравнения.
Время от начала цикла компенсации до момента срабаты-
вания органа сравнения пропорционально измеряемой ве-
личине.
vФункция преобразования также нелинейна (рис. 5-8)
вследствие наличия зоны нечувствительности у органа срав-
нения. Анализ показывает, что при развертывающем пре-
образовании максимальная погрешность нелинейности по
228
абсолютной величине вдвое меньше, чем при следя
щем преобразовании, так как отклонение от идеальной
функции преобразования наблюдается только с одной
стороны.
Погрешность нелинейности может быть частично ком-
пенсирована смещением нулевого уровня выходного сиг-
нала (пунктирная линия на рис. 5-8). Другой путь снижения
погрешности нелинейности заключается в увеличении коэф-
фициента усиления, причем в данном случае отсутствуют
какие-либо принципиальные ограничения. Влияние изме-
нения коэффициента усиления на Максимальную погреш-
ность нелинейности, как и в случае следящего измеритель-
ного преобразования, определяется зависимостью (5-1).
Вместе с тем метод развертывающего измерительного пре-
образования уступает методу следящего измерительного
преобразования в том, что допускает только дискретное во
времени отображение входной величины.
5-3. АНАЛИЗ
Все автоматические анализаторы характеризуются тем,
что получают информацию по нескольким координатам.
При двух координатах первой является шкала анализа,
т. е. признак, по-которому производится разделение слож-
ного состава, сложного состояния или сложного процесса;
вторая координата используется для количественной оценки
каждой выделенной компоненты. Если, кроме того, необ-
ходимо выражение результатов анализа во времени и по
множеству объектов, то соответственно добавляются третья
и четвертая координаты.
В анализаторах веществ признаком разделения явля-
ется качество (сорт) вещества, а признаком измерения —
количество вещества каждого сорта.
В анализаторах колебаний и анализаторах спектра
случайных процессов признаком разделения является ча-
стота колебаний (длина волны), а признаком измерения —
амплитуда или средняя мощность каждой гармонической
составляющей сложного колебательного процесса.
В анализаторах полей признаком разделения является
местоположение элементарных участков (точек) данного
физического поля, а признаком измерения — значение па-
раметра поля в каждой точке.
Автоматические анализаторы веществ, колебаний и
одномерных полей содержат по крайней мере по два испол-
229
нительных преобразователя, из которых один служит для
выполнения операций разделения, а второй — для выпол-
нения операций измерения. Соответственно этому в реги-
стрирующих приборах существует по два движения: первое
в направлении шкалы признака разделения и второе в
направлении шкалы признака измерения.
В анализаторах двумерных и трехмерных физических
полей количество исполнительных преобразователей и
движений регистрации увеличивается. Количество испол-
нительных преобразователей увеличивается также в тех
случаях, когда операции разделения в анализаторе любого
типа выполняются посредством системы настроенных ана-
лизирующих ячеек, постоянно связанных с системой изме-
рительных преобразователей.
На выходе измерителя получаются явления, использу-
емые для регистрации. Таким образом, измерители пред-
ставляют собой датчики или чувствительные элементы,
от которых могут работать исполнительные преобразова-
тели регистрирующих узлов анализаторов.
Анализатор или измеритель, кроме того, должен совер-
шать движения по шкале второго, качественного признака.
В дискретных системах эти движения могут быть заменены
действием ряда заранее установленных и настроенных на
определенные качественные признаки анализирующих
ячеек и измерителей. Тогда операции разделения и из-
мерения могут производиться не поочередно, а одновре-
менно.
В дискретных системах можно обойтись также одним
измерителем при наличии ряда анализирующих ячеек,
если воспользоваться переключателем, или же одним ис-
полнительным преобразователем в регистрирующем ус-
тройстве с переключателем, обслуживающим ряд измери-
телей.
Особое место занимают анализаторы случайных про-
цессов, предназначенные для получения обобщенных ста-
тистических характеристик источника информации. Эти
характеристики помогают понять сущность наблюдаемых
явлений, выявить причинно-следственные связи, прогнози-
ровать поведение источника, облегчают восприятие ин-
формации человеком. Для случайных процессов такими
характеристиками являются функции распределения, мо-
менты различных порядков, функции корреляции, энер-
гетический спектр и некоторые другие. В качестве примера
использования обобщенных сведений для представления
230
информации оператору можно привести статистический
индикатор отклонений, рассмотренный в § 8-4.
Ниже приводится описание принципов построения
некоторых автоматических анализаторов.
Анализаторы веществ
В термических анализаторах веществ используются свой-
ства поглощения или выделения тепла составными частями
сложного вещества в характерных для них точках терми-
ческого превращения. Такой метод называется термичес-
ким или термографическим.
В масс-спектральных анализаторах используется раз-
личие в массах атомов или молекул составных частей слож-
ного вещества, причем разделение их производится при
помощи электрических и магнитных полей. Метод назы-
вается масс-спектральным.
В оптических анализаторах используются свойства
излучения, поглощения, преломления и отражения электро-
магнитных колебаний световой и сверхвысокочастотной об-
ласти отдельными составными частями сложного вещества.
Существует ряд оптических методов анализа: спектральный^
рентгеновский, инфракрасный, микроволновый и колори-
метрический.
В акустических ана'лизаторах используются различия
в скорости распространения ультразвуковых колебаний
в разных составных частях сложного вещества. Такой ме-
тод анализа называется ультраакустическим.
В электрических (электромеханических) анализаторах
используются свойства электропроводности, электризации
или электролитического восстановления, различающиеся в
разных составных частях сложного вещества. Соответству-
ющие указанным свойствам методы анализа называются
кондуктометрическим, электрометрическим и полярогра-
фическим.
Существуют и другие методы анализа.
Состав сложного вещества может быть представлен
графиками (рис. 5-9), в которых по горизонтальным осям
расположены шкалы качества (сорта) составных частей по
выбранному признаку разделения М, а по вертикальным
осям — шкалы количества каждой составной части Р.
При бесконечно большом числе составных частей и приз-
наков шкала качества непрерывна и анализатор может
представлять собой непрерывную систему (рис. 5-9, а).
231
При конечном числе составных частей и признаков
шкала качества дискретна и соответствующий анализатор
является дискретной системой (рис. 5-9, б).
В тех случаях, когда необходимо производить анализ
во времени, добавляется третья ось (времени Т) и изобра-
жение становится трехмерным (рис. 5-9, в).
Принципиальные схемы спектрального и рентгено-
спектрального анализаторов, предназначенных для иссле-
дования сложных веществ неизвестного состава, показаны
на рис. 5-10, а, б.
Рис. 5-9. Диаграмма непрерывного (а),
дискретного (б) и трехмерного (в) анализа.
В случае спектрального анализа (рис. 5-10, а) йсточни-
ком излучения является электрическая дуга 1, горящая в
атмосфере анализируемого вещества. Сложное излучение
после отражения от коллиматорного зеркала попадает на
дифракционную решетку 2, являющуюся анализатором.
Дифракционная решетка развертывает сложное излучение
в спектр света, занимающий сектор 3, причем длина дуги
сектора в известном масштабе представляет шкалу длин
волн к. Измерительным (чувствительным) элементом служит
фотоэлемент или фотоумножитель 4, от которого ток, харак-
теризующий интенсивность спектральных линий I, подается
на исполнительный преобразователь Пс (/). На выходе этого
преобразователя получаются движения, соответствующие
интенсивности и, следовательно, количеству каждой состав-
232
ной части анализируемого вещества. Эти движения можно
использовать для перемещения пера относительно бумаги.
Развертка по фокальной дуге производится двигателем
/7Р (К), который одновременно перемещает диаграмму в
функции шкалы длин волн Л. Образец записи показан внизу
рисунка.
Рис. 5-10. Схема автоматических анализаторов веществ:
а — спектральный анализатор; б рентгеноспектральный
анализатор; в — спектральный анализатор с призмой; г —
масс-спектральный анализатор; д — полярографический ана-
лизатор.
В случае рентгено-спектрального анализа (рис. 5-10, б)
источником света служит рентгеновская трубка Л Длины
волн рентгеновских лучей имеют тот же порядок, что и
межатомные расстояния кристаллических решеток. Поэтому
233
в отраженных лучах можно получить спектр состава слож-
ного кристаллического вещества.
Если лучи направить под некоторым углом на анали-
зируемое вещество, помещенное в порошкообразном виде
на пластинке 2, которая укреплена на поворотном столе,
то часть их отразится под разными углами и образует спект-
ральный конус или сектор 5 с концентрическими элемен-
тами различной интенсивности. Если конус лучей опоясать
фотопленкой, будет получена рентгенограмма Дебая, рас-
крывающая состав анализируемого вещества.
В автоматических рентгено-спектральных анализаторах
сектор отраженных лучей опрашивается чувствительным
элементом 4, представляющим собой ионизационную камеру
или счетчик частиц. На выходе ионизационной камеры и
электронной схемы получаются ток или напряжение, ха-
рактеризующие интенсивность участков спектра. Преоб-
разователь Пс(1) создает соответствующие перемещения
регистрирующего органа. Столик 3 вместе с образцом и
чувствительным элементом 4 перемещается двигателем /7р(6)
в пределах сектора 5 (26). Эти движения сообщаются также
бумаге в регистрирующем устройстве. Получается запись,
показанная внизу рисунка.
По другой схеме построены спектральные анализаторы
с поворачивающейся призмой (рис. 5-10, в), масс-спектраль-
ные анализаторы с изменяющимся магнитным полем (рис.
5-10, г) и полярографические анализаторы (рис. 5-10, д).
В этих автоматах чувствительный элемент Д остается не-
подвижным, а тот или иной спектр вещества перемещается.
Развертывание производится двигателем /7р, воздействую-
щим на призму А (рис. 5-10, в), на регулятор поля А (рис.
5-10, г) или на регулятор напряжения А (рис. 5-10, д).
Это же развертывающее движение передается носителю
регистрирующего устройства для перемещения его по от-
ношению к шкале качества по признакам: длины волны А,
массы атомов или молекул т и потенциалу электролити-
ческого восстановления е. С чувствительным элементом Д
может быть связан преобразователь 77с (/) для передвиже-
ния регистрирующего органа в отношении шкалы интен-
сивности (количества) /.
Анализаторы колебаний
Задача анализа сложного колебательного процесса сво-
дится к измерению амплитуд колебаний для каждой
частотной составляющей.
234
Обычно звуковые или механические колебания при по-
мощи датчиков преобразуются в электрические колебания,
которые затем анализируются с помощью электрических
приборов.
В одном из первых анализаторов звука (рис. 5-11)
гармонические составляющие отделяются посредством вспо-
могательного регулируемого по частоте электронного ге-
нератора звуковых частот А.
Сложные колебания сщ., преобра-
зованные при помощи микрофона R
в электрические (модулирующие) ко-
лебания, смешиваются в мостовой
схеме с эталонными (несущими) ко-
лебаниями ак, частота которых может
постепенно увеличиваться посредст-
вом привода 77р (со).
Колебания смешиваются путем до-
полнительной модуляции перемен-
ного тока i микрофоном R, сопро-
тивление которого изменяется в соот-
ветствии с приходящими звуковыми
колебаниями cos. В каждый данный
момент времени и при каждом дан-
ном положении привода 77р (со) ток i
от звукового генератора А имеет
определенную частоту со/;.
Рис. 5-11. Автоматиче-
ский анализатор спек-
тра звука с разверты-
вающим генератором
звуковых колебаний.
Падение напряжения е на микро-
фоне зависит от величины сопротив-
ления микрофона и от тока:
е = Ri.
Ток от звукового генератора А изменяется по синусо-
идальному закону:
г == 1 т sin
где Im — максимальное значение (амплитуда) тока; cofc —
частота тока при данной настройке; t — время.
Сопротивление R микрофона изменяется от какой-
либо гармонической составляющей сложного колебания
также по синусоидальному закону:
R = Ro + Rm sin со;п/,
где Ro — неизменяющаяся часть переменного сопротив-
ления; Rm — максимальное значение (амплитуда) изменя-
235
ющейся части переменного сопротивления; и>т — частота
выделяемого простого колебания; t — время.
При одновременном действии со* и сот будет происходить
амплитудная модуляция напряжения е на микрофоне:
е — (Ro + Rm sin a>mt) Im sin
e = ImR0 sin co*/ + Цр cos (com - co*) t -I-^ cos (co.„ + co*) t.
Отсюда следует, что колебания будут складываться из
синусоидальных колебаний несущей частоты со* и колеба-
ний верхней (со* + сот) и нижней (со* — com) боковых частот.
В диагонали моста имеется электрический фильтр с
индуктивностью L и емкостью С, который пропускает к
прибору П(1) только ток очень малой частоты, порядка
единиц герц.
Отсюда следует, что прибор П(1) не будет отзываться
ни на несущие колебания с частотой со*, ни на верхнюю
боковую частоту колебаний с частотой <n>k + сот. Но он
будет измерять составляющую напряжения, имеющую
частоту com — со*,
е' =cos (сот - со*) t,
причем со* должна быть очень близкой к сот, с тем чтобы
разность частот сот — со* составляла единицы герц.
Прибор П(1) показывает амплитуду выделенной части
сложного колебания, характеризующейся частотой сот.
Если плавно изменять частоту со*, то будут выявлены
все составные части сложного колебания сох, со*, ..., сот, ...
..., соп путем последовательного получения колебаний с ма-
лыми разностными частотами сот — со*.
Подходя с точки зрения математики, действия автома-
тического анализатора можно трактовать как отыскание
коэффициентов ряда Фурье, в который разлагается сложный
колебательный процесс. Значения коэффициентов соот-
ветствуют интенсивности звука в каждой точке шкалы
частоты.
По принципу, изложенному выше, построено большое
количество автоматических анализаторов, в частности ана-
лизаторы высокочастотных электрических колебаний с
применением электронных гетеродинных схем. В таких
схемах также производится смешивание двух колебаний
для получения низкочастотных биений.
236
Другая группа анализаторов основана на прямом изме-
рении интенсивности дискретного ряда отфильтрованных
частотных составляющих сложного колебания.
Для получения трехмерных изображений изменения
спектра звука во времени разработаны специальные анали-
заторы, так называемые трансляторы, в которых сущест-
вуют оси интенсивности /, частоты to и времени Т.
Трехмерные изображения соответствуют графику на
рис. 5-9, в. В связи с конкретными требованиями и техни-
ческими решениями может быть допущена дискретность
по шкале частот или по шкале времени.
Рис. 5-12. Дискретный анализатор спектра звука с настроен-
ными фильтрами и специальным осциллографом для получе-
ния трехмерного изображения.
В следующем примере допущена дискретность по шкале
частот, обусловленная применением систем настроенных
фильтров.
На рис. 5-12 приведена'упрощенная схема транслятора
звука, в котором используется специальная электронно-
лучевая трубка. На цилиндрическом экране М трубки
получается изображение динамического спектра, причем
по высоте цилиндра располагается ось частот w, а по окруж-
ности цилиндра — ось времени t. Уровень звука переда-
ется интенсивностью свечения экрана, что условно показано
осью интенсивности I, расположенной под углом 45°.
Анализируемый звук со спектром частот <os поступает
через усилитель У на вход фильтров А.
Развертка по оси частот производится при помощи откло-
няющей катушки В и генератора напряжения пилообразной
237
формы, показанного в виде делителя напряжения 7? с
вращающейся контактной щеткой (Е — источник питания
делителя). Синхронно с разверткой луча О переключаются
выходы фильтров А, для чего предусмотрен переключа-
тель К. В действительности переключатель выполнен в
виде электронной кольцевой пересчетной схемы. Напря-
жения с выходов фильтров подаются на управляющую
сетку электроннолучевой трубки, изменяя тем самым ин-
тенсивность электронного луча О.
Развертка по оси времени осуществляется вращением
трубки при помощи привода /7(7) с редуктором. Картина
изменения спектра наблюдается через окно, открывающее
часть цилиндрической поверхности трубки. Люминесци-
рующий слой, экрана обладает длительным послесвечением.
Анализаторы полей
Анализаторы электрического поля часто применяются
для электрического моделирования различных физических
полей, например аэродинамических, гидродинамических.
Анализатор электростатических полей с автоматичес-
кой регистрацией эквипотенциальных линий показан на
рис. 5-13.
Электрическое поле создается электродами 2 и 3, к
которым подводится переменное напряжение, в ванне 1,
наполненной электролитом. Параллельно этим электродам
включен задающий делитель напряжения R, который пита-
ется от источника переменного напряжения Е. Число от-
водов от делителя определяется числом эквипотенциальных
линий, которые желательно зарегистрировать. Эквипотен-
циальная линия определяется, таким образом, положением
контакта на делителе R.
В ванне помещается зонд Д, который закреплен на од-
ном из концов пантографа 4. Потенциал зонда равен потен-
циалу той точки, в которой он в данный момент находится.
Напряжение АЕ, получающееся между зондом и контак-
том задающего делителя, подается на орган сравнения ОС.
Он выполнен в виде, фазочувствительной схемы, которая
реагирует на изменение фазы входного напряжения на
180°. Это изменение происходит в тот момент, когда зонд
проходит через заданную эквипотенциальную линию, т. е.
когда АЕ = 0. В этот момент орган сравнения ОС дает
короткий импульс, который усиливается усилителем до
величины 3 000 в и подается на отметчик О. Отметчик пан-
238
тографом связан с зондом и перемещается по бумаге М,
лежащей на металлической подкладке. Импульс i поступает
на отметчик в тот момент, когда зонд проходит через задан-
ную эквипотенциальную линию, и пробивает бумагу, ре-
гистрируя таким образом точку заданной эквипотенциаль-
ной линии.
После этого зонд перемещают от руки* так, чтобы он
снова прошел через заданную эквипотенциальную линию,
регистрируя еще одну точку, и т. -д.
После снятия одной эквипотенциальной линии вручную
переводят контакт заданного делителя в новое положение и
снимают еще одну эквипотенциальную линию, продолжая
так до тех пор, пока не будет получена картина всего
поля.
Рис. 5-13. Анализатор плоского электростатического
поля.
На рис. 5-13 справа представлена картина поля, которая
получается при работе с таким анализатором. Точки, при-
надлежащие одной эквипотенциали, соединяются плавной
линией.
Описанный ниже анализатор (рис. 5-14) автоматически
регистрирует заданное число эквипотенциальных линий и
после этого автоматически отключается.
Установка предназначена для анализа отдельных участ-
ков поля, на которых градиент поля не изменяет своего
направления больше чем на 90°. Установка не дает возмож-
ности анализировать все поле целиком и вычерчивать замк-
нутые эквипотенциальные линии. Это значительно ограни-
чивает область применения установки и является ее су-
щественным недостатком.
239
Посредством двигателя Пх зонду задается движение в
направлении оси X с некоторой постоянной скоростью.
Но лишь только зонд начнет свое движение по оси X, он
сейчас же сойдет с эквипотенциальной линии и его потен-
циал становится отличным от потенциала Uo линии.
Для того чтобы вернуть зонд на эквипотенциальную линию,
имеется следящая система, которая состоит из усилителя
У и следящего двигателя Пу.
Рис. 5-14. Автоматический анализатор с одной следящей системой
для анализа плоских электростатических полей.
Следящая система работает так, что при появлении
разности потенциалов (ошибки положения зонда) — Uo
двигатель Пу начинает перемещать зонд 3 по оси Y так,
чтобы сделать эту разность потенциалов равной нулю,
т. е. возвращает зонд на эквипотенциальную линию.
Таким образом, задача отыскания заданной эквипотен-
циальной линии выполняется следящей системой.
Задача следования по заданной эквипотенциальной линии
выполняется двигателем Пх, перемещающим зонд по оси X.
Как только зонд пройдет по эквипотенциальной, линии
до правого конца участка, срабатывает концевой пере-
ключатель В, включающий блок-реле Р, который пере-
ключает зонд на новую эквипотенциальную линию и ревер-
сирует двигатель Пх. Зонд начинает движение по оси X
в обратном направлении, а следящая система Пу устанав-
ливает зонд на эквипотенциальную линию.
240
Пройдя всю вторую эквипотенциальную линию, зонд
перебрасывает левый концевой переключатель, который
подключает зонд на следующую эквипотенциальную линию
и реверсирует двигатель Пх. Начинается движение зонда
по следующей эквипотенциальной линии и т. д.
После прохождения зондом последней эквипотенциаль-
ной линии срабатывание концевого переключателя В вы-
зывает отключение всей установки.
Регистрация осуществляется на обыкновенной бумаге
карандашом или пером О, которые связаны с зондом панто-
графом С.
В действительности с двигателями непосредственно
связан не зонд, а регистрирующий орган. Это обстоятельство
принципиально ничего не изменяет, но позволяет сделать
конструкцию более удобной и облегчает установку электро-
дов в электролитической ванне.
Заданная эквипотенциальная линия определяется по-
тенциалом, снимаемым с одного из девятнадцати отводов
делителя напряжения R, подключенного параллельно элект-
родам и Э2.
Напряжение, обусловленное разностью потенциалов
зонда и контакта, подается на усилитель У, который усили-
вает этот сигнал и подает его на одну из обмоток двухфаз-
ного асинхронного двигателя Пу. Другая обмотка этого
двигателя питается от сети.
При изменении фазы напряжения, подаваемого на вход
усилителя, двигатель Пу реверсируется. Напряжение вра-
щения его всегда таково, что зонд перемещается по направ-
лению к заданной эквипотенциальной линии.
Двигатель Пх также является двухфазным асинхрон-
ным двигателем, работающим от сети. Направление вра-
щения его определяется соединением контактов II.
Присоединение к контактам I и II осуществляется иска-
телем, который делает шаг каждый раз, когда срабаты-
вает концевой выключатель В.
При переключении на новую эквипотенциальную линию
выполняются две операции: переключается контакт на
задающем делителе и реверсируется двигатель Пх.
Если эти операции производить одновременно, то дви-
гатели Пх и Пу начнут одновременно перемещать зонд и
часть эквипотенциальной линии не будет зарегистрирована.
Поэтому необходимо на некоторое время остановить дви-
гатель Пх, чтобы дать возможность следящей системе уста»
новить зонд на новую эквипотенциальную линию. Только
241
после этого можно будет включить двигатель Пх. Это осу-
ществляется также с помощью блока реле Р.
Вся установка смонтирована в одном корпусе таким
образом, что из него выступает лишь один конец пантографа,
на котором помещен зонд. Ванна с электродами устанав-
ливается вблизи корпуса. Движение от двигателя переда-
ется с помощью ходовых винтов, причем движение ходово-
му винту от двигателя Пх передается через редуктор, а
движение ходовому винту от двигателя Пу — с помощью
пары конических шестерен, одна из которых закреплена
на оси ходового винта, а другая скользит по валику, вра-
щающемуся от двигателя Пу. Для того чтобы следящая
Рис. 5-15. К принципу действия автоматического анализа-
тора с тремя следящими системами для анализа плоских
электростатических полей.
система обеспечивала точное перемещение зонда при зна-
чительных искривлениях эквипотенциальной линии, ско-
рость перемещения зонда по оси Y должна быть значительно
выше скорости перемещения зонда вдоль оси X, что до1
стигается соответствующим выбором редукторов для дви-
гателей Пу и Пх. Зонд выполнен в виде куска тонкой про-
волоки, закреплен на пантографе и изолирован от него.
Электроды делаются из полированных листов и устанавли-
ваются в ванне на изолирующих подставках.
Для иллюстрации дальнейшего развития автоматических
анализаторов полей со следящим преобразованием ниже
приводится описание второго, более совершенного прибора.
Поместим в электролитической ванне, где создается
поле, подлежащее анализу, два жестко связанных зонда
1 и 2 (рис. 5-15).
Обозначим Uw — разность потенциалов зонда 1 и за-
данной эквипотенциальной линии О; Uw — разность потен-
242
циалов зонда 2 и заданной эквипотенциальной линии О,;.
(/12 — разность потенциалов зонда / и зонда 2.
Пусть зонды находятся на заданной эквипотенциальной
линии, когда (/10 = 0, Е720 = 0 и U12 = 0.
На рис. 5-15 видно, что если задать зондам движение по
оси X со скоростью
vx = v cos а (5-2)
и по оси Y со скоростью
vy = v since,
(5-3)
то зонды будут перемещаться по хорде 1—2 со скоростью v.
При этом происходит следующее: 1) зонд 1 сходит с за-
данной эквипотенциали ((/1о=^0); 2) зонд 2 сходит с задан-
ной эквипотенцпали ((/20 =/= 0); 3) зонды / и 2 оказываются
на разных эквипотенциалях ((/12 0).
Поворотом зонда 2 вокруг зонда 1 можно заставить зон-
ды встать на одну эквипотенциаль, но эта эквипотенциаль-
ная линия будет отличаться от заданной. Если позволить
зондам перемещаться в дальнейшем со скоростями vx и
vy, определяемыми новым углом поворота, то движение их
будет неопределенным; они не будут перемещаться по за-
данной эквипотенциальной линии.
Для того чтобы движение приобрело определенность,
необходимо заставить зонд 1 перемещаться только по задан-
ной эквипотенциальной линии. Осуществить это можно
следующим образом.
Как только зонд 1 сойдет с заданной эквипотенциальной
линии, появляется ошибка Uw 0. Заставим зонды пере-
мещаться не только по хорде 1—2 со скоростью v, но и по
направлению, перпендикулярному к хорде /—2, со ско-
ростью v', пропорциональной рассогласованию О1о. Если
скорость v' разложить по осям X и Y, то получим скорости
= c'cos = — v’ sina (5-4)
по оси X и
v'y = o'sin у.+ а = v’ cos а (5-5)
по оси Y. ,
При этом надо учитывать, что величина скорости v
прямо пропорциональна величине рассогласования О1о, т. е.
v' = А(/10. (5-6)
243
Результирующие скорости по осям X и Y можно полу-
чить в виде:
Уд. = vx + v'x = v cos а — kU10 sin a; (5-7)
Vy = vy v'y = v sin a 4- kU10 cos a. (5-8)
Итак, зонды 1 и 2 позволяют определить направление
эквипотенциальной линии (угол а), а зонд 1 — контроли-
ровать положение зондов относительно заданной эквипо-
тенциальной линии (величину рассогласования t/10).
Рис. 5-16. Принципиальная схема автоматического анализатора
с тремя следящими системами.
Так как в выражения (5-7) и (5-8), которые определяют
условие движения зондов по заданной эквипотенциальной
линии, входят лишь две переменные величины а и Ulo,
то остается лишь так построить схему прибора, чтобы ско-
рости движения зондов Vx и Vv по осям X и Y определялись
формулами (5-7) и (5-8). В этом случае задача отыскания
заданной эквипотенциальной линии и следования по ней
будет решена.
Перейдем к рассмотрению схемы той части установки,
которая решает эту задачу. Схема приведена на рис. 5-16.
В электролитической ванне помещаются электроды
31 и 32, которые создают поле, подлежащее изучению.
К электродам подводится напряжение переменного поля.
244
Параллельно электродам включается задающий делитель
напряжения R. Делитель имеет отводы, число которых
определяется требуемым числом эквипотенциальных ли-
ний. Эквипотенциальная линия определяется положением
контакта К на делителе напряжения.
Если зонды 1 и 2, помещенные в ванне, не находятся на
одной эквипотенциальной линии, то между ними существует
некоторая разность потенциалов 1712. Эта разность потен-
циалов усиливается усилителем Ух и подается на управ-
ляющую обмотку двухфазного индукционного двигателя
П„. Вторая обмотка этого двигателя — обмотка возбуж-
дения — питается непосредственно от источника перемен-
ного тока.
Усиленное напряжение U12 заставляет вращаться дви-
гатель Пг„ который через редуктор поворачивает зонд 2
вокруг зонда 1 в таком направлении, чтобы разность потен-
циалов U12 уменьшилась до тех пор, пока U12 не станет рав-
ным нулю, т. е. пока зонды 1 и 2 не окажутся на одной эк-
випотенциальной линии. При этом зонд 2 повернется вокруг
зонда 1 на угол а.
Таким образом, зонды, усилитель и двигатель Па
представляют в совокупности следящую систему, задача
которой заключается в том, чтобы удерживать зонды 1 и 2
на одной эквипотенциали и отрабатывать таким образом
величину угла наклона ^эквипотенциальной линии.
Двигатель /7а поворачивает не только зонд 2, но и
две щетки, скользящие по синусному реостату I, и две
щетки, скользящие по синусному реостату II.
На синусный реостат I подается напряжение переменного
тока, по величине равное Е. Щетки, скользящие по реоста-
ту, сдвинуты на 90', и с их помощью с реостата I снимаются
два напряжения, амплитуды которых соответственно про-
порциональны синусу и косинусу угла поворота щеток а:
ег — Е cos а, (5-9)
e2 = £sina. (5-10)
Напряжения ег и е2 подаются соответственно на усили-
тели и У2, которые усиливают эти напряжения и пода-
ют их на управляющие обмотки двигателя Пх и Пу. Эти
двигатели начинают перемещать зонды по осям X и У со
скоростями, пропорциональными величинам ег и е2:
vx = kyaE cosa, (5-11)
vy = kyiE sina, (5-12)
245
где kys и kyi —'коэффициенты усиления усилителей У3 и
У4, которые должны быть равны, чтобы не нарушалось
соотношение скоростей.
Тогда можно записать:
Vx — k^cos а, (5-13)
t^^^sin а, (5-14)
где Aj — коэффициент, определяемый усилителем, двига-
телем и величиной Е.
Как только зонды 1 и 2 начинают перемещаться, зонд 1
сходит с занятой эквипотенциальной линии и между ним и
контактом, определяющим потенциал заданной эквипотен-
циальной линии, появляется разность потенциалов Uw.
Эта разность потенциалов подается на вход усилителя У2,
усиливается им и после этого подается на синусный рео-
стат II. Две щетки этого реостата сдвинуты одна относи-
тельно другой на 90°, и, кроме того, они обе сдвинуты на
90° по отношению к щеткам синусного реостата I. Вслед-
ствие этого с реостата щетки снимают следующие напря-
жения:
U1 = U10ky2 cos (л/2 Да) = — йу2(710 since, (5-15)
t/2 = 2 sin (п/2 Д а) = Ay2t/10 cos а. (5-16)
Эти два напряжения, как и ег и е2, подаются соответ-
ственно на усилители У4 и У2 и таким образом корректируют
скорости движения зондов по-осям X и Y.
Величины скоростей по этим осям от напряжений
и U2 можно представить в следующем виде:
v'x = — k2U10 sin а; (5-17)
v'y — k2U10 cos а, (5-18)
где k2 — коэффициент, зависящий от коэффициента уси-
ления усилителей и от двигателей.
Корректирующие скорости v'x и v'y так изменяют направ-
ление перемещения зондов, чтобы разность потенциалов
Uw стала равной нулю, т. е. чтобы зонды встали на задан-
ную эквипотенциальную линию. Таким образом, совокуп-
ность элементов зонд 1 — усилитель У2 — синусный рео-
стат II — усилитель У3‘— двигатель Пх и зонд 1 — уси-
литель У2 — синусный реостат II — усилитель У4 — дви-
гатель /7„ вместе с задающим делителем представляют собой
систему автоматического регулирования, задача которой
246
заключается в том, чтобы удержать зонд 1 на заданной
эквипотенциальной линии.
Результирующие скорости по осям X и Y можно опре-
делить, суммируя уравнения (5-13) с (5-17) и (5-14) с (5-18):
Vx = vx + v'x = kr cos a — k2Uw sin a; (5-19)
Vy = vy 4- v'y = k± sin.a + k2Uw cos a. (5-20)
Сравнивая значения Vx и Vy, полученные в двух послед-
них выражениях, с теми, которые были указаны в выраже-
ниях (5-7) и (5-8), можно убедиться в полной их идентич-
ности.
Следовательно, система, построенная по описанной схе-
ме, решает задачу автоматического отыскания заданных
эквипотенциальных линий и следования по ним.
В анализаторе использованы один обычный усилитель
для следящей системы Ла и два суммирующих усилителя
для следящих систем Пх и Пу.
Корреляторы
В настоящее время известно большое число различных
принципов получения корреляционных зависимостей и
связанных с ними способов построения автоматических
корреляторов [Л. 5-101. Прямой путь расчета автокорре-
ляционной функции Вхх(т) или взаимной корреляционной
функции Вху (т) состоит в приближенном интегрировании
за конечное время Т произведения двух случайных функ-
ций:
г
ВХу (т) >=« у х (/) у (t + т) dt (при у = х получаем Вхх (т)).
о
В случае использования дискретной техники интегри-
рование заменяется суммированием:
N
Вху(т)^^2х^’
где — значение i-ro дискретного отсчета функции х (Z);
у® — значение i-ro отсчета сдвинутой на т функции у (t т);
ДО — число отсчетов.
Определение корреляционных функций по этим форму-
лам осуществляется схемами, содержащими блок умноже-
ния. В последнее время нашли применение способы, поз-
247
воляющие свести вычисления только к операциям сумми-
рования и сравнения.
Рассмотрим один из таких способов, основанный на
использовании вспомогательных случайных функций, фор-
мируемых по определенному закону. Предположим, что
х (t) — стационарная случайная функция с плотностью
распределения w (х), определенной в пределах хмин х^.
*макС. Пусть и (t) — не зависящая от х (t) вспомогатель-
ная случайная функция с равномерным распределением в
пределах —Л н + Л, где |х|< А. Разность этих
функций образует новый случайный процесс г (t) =х (/) —
— и (t). Рассмотрим знаковую функцию, определяемую
следующим образом:
+1 при z^>0,
sgnz =
О при г —О,
при z<^0.
Эта функция зависит от двух переменных х и и. Ее
математическое ожидание
4-00 4-00
M[sgnz] = § sgn zw (х, u)dxdu.
—со —со
В силу независимости хин имеем
М [sgn z] = J w (x) jj sgn zw (h) du dx. (5-21)
Учитывая, что плотность распределения щ(н) = 1/2Л
в области от — А до ф А и вне этой области тожде-
ственно равна нулю, внутренний интеграл представим
в виде
4-w х
$ sgn zw (н) du — sgn (x — u) w (h) du +
— co —A
Подставляя (5-22) в (5-21), получаем:
4-00
Л4 [sgn z] = xw (x) dx — M [X].
—oo
248
Таким образом, математические ожидания исходной
функции х (t) и знаковой функции sgn z совпадают с точ-
ностью до постоянного множителя А. На этом свойстве
знаковых функций основан метод расчета- корреляцион-
ной функции случайного процесса. Для ее получения
образуются вспомогательные функции u(t) и v (t), не
коррелированные ни между собой, ни с анализируемыми
функциями х (0 и у (f).
Введем обозначения
Z1 = X— U, Z2~y—V.
Определим математическое ожидание произведения зна-
ковых функций >
4-со 4'‘с0 4“°° 4-со
Af[sgnz1sgnz2] = $ $ $ $ [sgn zr sgn z2] x
—co —co —06 —co
X w (x, y, u, v) dx dy du dv.
Учитывая условия независимости, получаем:
Л/[sgn Zj sgn z2] =
-[-CO 4-00
= 5 \ w(x, у)
—00 — co
sgn zx sgn z2 w (u) w (v) du dv dx dy
= ^Л4[ХУ].
Полагая x = x (/), у — у (t + т), находим зависимость
функции корреляции от математического ожидания зна-
ковой функции:
(т) = М [х (0 у (t + т)] = А2М [sgn Zi sgn z2J.
Но
M[sgnz1sgnz2] = p(«<x, v<y)+p(u>x, v>y)-
-p(u<_x, v>y)-p(u>x, v<y) =
= (p~~+/') - (p~+ +p+~)=p-q,
где через рг~ обозначена вероятность одновременного
появления двух отрицательных значений, р++ — вероят-
ность одновременного появления положительных значений,
р"+ и р1 ~ — вероятности появления отрицательного и поло-
жительного значения функций sgn zT и sgnz2; через р и q
обозначены соответственно вероятности совпадения и не-
249
Совпадения значений знаковых функций. Схема, реализую-
щая зависимость
Вху(т) = А2 (p~q),
изображена на рис. 5-17.
В качестве генераторов 1\ и Г2 вспомогательных функций
могут быть использованы генераторы линейной развертки,
периоды которых несоизмеримы друг с другом и с периодом
следования тактовых импульсов, определяющих моменты
отсчета знаковых функций.
Рис. 5-17. Схема знакового коррелятора.
Г, и F2 —- генераторы случайных сигналов с равномерным
распределением; ОС — органы сравнения; т — схема задержки
импульса; СС — схемы совпадения; СП — схемы несовпаде-
ния; РПС — реверсивная пересчетная схема; ПС — накапли-
вающая пересчетная схема.
Реверсивная пересчетная схема РПС определяет число
импульсов, равное разности числа совпавших Np и не-
совпавших Nq значений знаковых функций: Л\, = Np —
—Ng. Накапливающий счетчик ПС подсчитывает общее
число импульсов Лг = Np + Ng за период наблюдения.
Отношение
оценивает значение функции корреляции Вху (т) при задан-
ном сдвиге т. Вся функция Вху £г) строится по точкам при
различных т.
250
Анализаторы спектра случайных процессов
Для получения энергетического спектра случайных -
процессов применяются анализаторы с узкополосными
фильтрами и анализаторы с корреляторами [Л.5-11].
Действие первых основано на следующих соотношениях.
Рассмотрим линейный полосовой фильтр, имеющий пере-
даточную функцию Ф (/<о) и импульсную переходную функ-
цию ф (t). Определим зависимость характеристик выходного
сигнала у (t) от соответствующих характеристик входного
сигнала х (t).
Выходной сигнал связан со входным интегралом свертки:
+<»
У (О = х (У — v) ф (v) dv.
—СО
Автокорреляционная функция выходного сигнала
2^ § У (О У V + т) dt = Пт 2^ х
' Г+°°
Вуу(г) = Jim
+ ?Г+со
X 5 х (/ — р) ф (р) dp J х (^ + т — v) ф (v) dv dt.
— 7 —со JI—со
Меняя порядок интегрирования и учитывая, что в силу
стационарности случайного процесса
+ г
Пт ™ \ х (t — р)х (t -фт— v)dt —
T-*coZJ Д
i К
= Нт ™ \ х (/) х (t + т + р — v) dt = Вхх (т + р — v),
7’-* со Ду,
получаем:
-{-СО 4-СО
В>5,(т) = $ 5 ф (В) <Р М Вхх (т + р - v) dp dv.
—со —со
Энергетический спектр выходного сигнала связан с
автокорреляционной функцией соотношением
-{-СО -{-СО -|-СО -{-00
SJ5,(cd)= \ Ryy(r)e-iu,TdT= $ $ 4>(n)<P(v)X
—СО —оо —со —со
х/3хх(т + р-v)e/lOTdpdvdT= $ § ф(р)е^ф(v)х
—со —со —со
хе '“’Вхх (т + В — v) е’) dx.
251
Импульсная переходная функция фильтра и его пере-
даточная функция связаны преобразованием Фурье:
<D(jw) = +jj cp(Oe-/Wdt
—00
Учитывая это в последнем соотношении, получаем окон-
чательно:
Syy (со) = Ф (/со) Ф (— /со) Sxx (со) = | Ф (/©) |г Sxx (со).
Средняя мощность выходного сигнала
Pj = у2 (t) — Вуу (0) = 2^- Syy (со) da» —
—со
= i S I Ф (/“) Г (®) d®.
—со
В пределах полосы пропускания Дсо узкополосного
фильтра значение функции Sxx (®) можно считать по-
стоянным.
Тогда
I/2 (/) = Sxx (®0) J | Ф (/'(о) |2 da> = Сф8хх (®0),
ю0 — Дш/2
где ®0 — частота настройки фильтра; Сф — постоянная
для данного, фильтра величина. Отсюда
т
Т y2U)dt
<? (to )_У2 V) °____________
Этому соотношению соответствует схема, изображенная на
рис. 5-18.
' о
Рис. 5-18. Анализатор энергетического спектра с по-
лосовым фильтром
Ф — полосовой фильтр; К — устройство возведении в
квадрат; И — интегратор.
252
?sMfT/cos<er
/ ГТ Sxx(a>)=2fgL (г)cosu/rdT
-ч*- И о *LU'
Рис. 5-19. Анализатор энергетического спектра
с коррелятором/
В — коррелятор; Г — генератор гармонических колеба-
ний; У — умножитель; И — интегратор.
Для'построения полной спектральной функции Sxx (со)
применяются многоканальные анализаторы, содержащие
набор фильтров, настроенных на различные частоты или
осуществляющих последовательный сдвиг спектра Sxx (со)
относительно частоты настройки единственного фильтра.
Спектральные анализаторы с корреляторами опреде-
ляют энергетический спектр по предварительно вычис-
ленной корреляционной функции в соответствии с форму-
лой (рис. 5-19):
+°О
Sxx (<о) = 2 $ Вхх (т) cos ют dx.
—00
5-4. ОБНАРУЖЕНИЕ И РАСПОЗНАВАНИЕ
Задача распознавания возникает в процессе восприятия
информации. Требуется распознавать зрительные и аку-
стические образй при считывании графической и восприя-
тии звуковой информации, отыскивать неисправности в
сложных объектах, распознавать малые сигналы на фоне
помех и т. д.
Задачи обнаружения и распознавания
Процесс распознавания состоит в классификации явлений
по имеющейся информации и отнесении воспринимаемой
совокупности или вектора признаков х = {хъ ..., хт} к
области, характеризующей одно из состояний источника
информации. С этой целью пространство признаков X раз-
бивается по какому-либо критерию на п областей Xit ..., Хп
(рис. 5-20), соответствующих точкам пространства состоя-
ний А — {аъ ..., ап\. Если разбиение производится на две
области, распознавание становится двухальтернативным
253
и представляет собой обнаружение некоторого
явления. Векторы х в пространстве признаков носят
Рис. 5-20. Пространство при-
знаков и его разбиение.
название векторов-реа-
лизаций, а области раз-
биения образуют множество
классов. В сферу задач
теории обнаружения и распо-
знавания входит: 1) определение
границ областей и 2) нахо-
ждение оптимальных алгорит-
мов классификации. В общем
случае зависимость реализаций х
от состояний а, источника носит
вероятностный характер. На рис.
5-21 отражены три характерных случая этих зависимостей
(для простоты изображены одномерные
а) случай непересекаю-
щихся условных распреде-
лений w (х|аг),
б) случай тождествен-
ных распределений;
в) случай пересекаю-
щихся распределений.
В первом случае воз-
можно безошибочное рас-
познавание. Для этого об-
ласти Xi, ..., Хп в про-
странстве признаков долж-
ны быть выбраны так,'
чтобы каждая из них вклю-
чала все возможные зна-
чения только одного соот-
ветствующего ей парамет-
ра. При этом вероятность
р (а, |Х;) правильного рас-
познавания i-ro состояния
распределения);
Рис. 5-21. Характерные случаи
расположения условных распреде-
лений.
а — непересекающиеся распределения;
б — тождественные распределения; в —
пересекающиеся распределения.
при условии х Х{, которую
можно подсчитать по формуле Байеса, равна единице:
р(а;) \ w(x.\ai)dx P(at) J ш(х|щ)йх
______ь_________________xi______________________
У; Р (fl,) j w (х | a,) dx р (а,) w (x | аг) dx
J xi
254
так как все условные распределения w (х |а7) в области
Xi ОтЧ) тождественно равны нулю.
Во втором случае — тождественно равных условных
распределений — распознавание по вектору-реализации не-
возможно. Действительно, какое бы разбиение на области
Xt ни проводилось, вероятность
=Р(Д,).
У РЦ) Р(ЧI О/) >1 Р (aj) р(Х{\6Zj)
j j
так как все р (Х;|ау) можно заменить на р (ХДаД. Полу-
ченный результат свидетельствует о том, что отнесение
вектора х к какой-либо области Хг не увеличивает вероят-
ности распознавания, которая остается равной априорной
Р (ai)-
Третий случай является промежуточным между первым
и вторым. Распознавание состояний при этом возможно с
вероятностями, лежащими в пределах р (а()<;р (а,-|Хг)<;1.
Характеристики качества распознавания
Основными характеристиками качества .распознавания
являются ошибки распознавания и средние потери. Пред-
положим, при х £ Xi принимается гипотеза о наличии со-
стояния Oi. Вероятность правильного решения составляет
при этом р (fli\Xi), а вероятность ошибки р,-ош — 1 —
-p(ai\Xi).
Средняя вероятность ошибки распознавания для всех
возможных реализаций
рош- 2 Р (Xi) [1 - р (<ц | Х;)] = 1 - £ р (Xi) р (at | Xi) =
i i
= 1.— 2 P (a<) § w (x I ai) dx- (5-23)
i xt
Здесь p (Х{) означает p (x Xt).
Из этого выражения видно, что рОП1 зависит от выбора
областей X/, т. е. от разбиения пространства реализаций.
Если ошибки распознавания отдельных состояний не-
равноценны, и с ними можно связать определенные потери,
то для характеристики качества распознавания может быть
принята величина средних потерь.
Обозначим через ri}- положительное число, определяю-
щее условные потери («штрафы») от ошибки в результате
заключения о состоянии в то время как источник ин-
255
формации находится в некотором другом состоянии а/.
При попадании вектора х параметров в область X,- потери
составят
fi = XiP(aj\x^rij,
а средние потери
г = 2 Р Р (aJ । Xd ГЧ =
» /
= Z р («/) У< гч Sw (х Iй/)dx- (5-24)
J ' xi
Величинагг носит название условного, аг — среднего риска
распознавания. В дальнейшем потери г1}-, связанные с пра-
вильными решениями, предполагаются равными нулю.
Ниже рассматриваются некоторые критерии, опреде-
ляющие разбиение пространства реализаций на области
Xit и связанные с ними методы распознавания, основанные
на использовании информации об условных распределе-
ниях щ(х|аг).
Статистические критерии обнаружения
В теории обнаружения широкое примейение получили
методы, используемые в математической статистике для
проверки статистических гипотез [Л. 5-7]. Эти принципы
эффективно используются при решении задач обнаружения
сигналов в условиях неопределенности и при наличии
помех (фиксация малых сигналов биотоков, ультразвуковая
дефектоскопия в условиях сильных помех, контроль шу-
мящих агрегатов по акустическим сигналам), определения
работоспособности сложных систем в процессе испытаний
и т. д. Во многих случаях ошибка обнаружения может
быть уменьшена, если суждение о состоянии а* источника
информации производится не по одному отсчету информаци-
онного параметра х, а по серии отсчетов xlt ..., хт, ста-
тистически связанных с состоянием fy. При этом совокуп-
ность последовательно получаемых значений параметра
также можно рассматривать как вектор-реализацию х =
— {хх, ..., хт} в пространстве признаков X. Статистичес-
кая связь вектора х с состояниями аг определяется услов-
ными плотностями распределения w (х|аг).
Для обеспечения возможности обнаружения прост-
ранство признаков должно быть разбито на две области
Xj и Х2. Граница этих областей носит название решающей
256
поверхности. В процессе обнаружения решающее устрой-
ство определяет, какой области принадлежит вектор-
реализация, и делает заключение о состоянии at источника.
Таким образом, в памяти решающего устройства должны
храниться данные о решающей поверхности. Поскольку
эта поверхность многомерна, ее задание и хранение Могут
встретить значительные трудности. Оказывается, однако,
что многомерный сдучай может быть приведен к одномерно-
му путем перехода к новой переменной, функционально
связанной с вектором х.
Эта переменная носит название отношения (или коэф-
фициента) правдоподобия и задается соотношением
Х(х)=а,^|.<Ц, (5-25)
' ' w (х I '
где w (х | at) — многомерная плотность распределения ве-
роятностей:
&y(x|£zi) = t0(x1, х2, .... хт|я().
Вместо уравнения решающей поверхности в этом слу-
чае достаточно запомнить одно число Х„, с которым сравни-
вается текущее значение коэффициента правдоподобия к.
Неравенству К соответствует х £ Х2. При этом де-
лается заключение (принимается гипотеза) о наличии со-
стояния а2. Случай sg; соответствует х X х. Уравнение
границы F (х) =0 определяется соотношением
а>.(х|дг)_,
W (X I щ) °"
Переход к использованию коэффициента правдоподо-
бия вместо векторных сигналов удобен еще и тем, что ис-
ключается зависимость решающего правила от размерности
пространства признаков. Однако указанные упрощения
достигаются за счет некоторого усложнения процедуры
восприятия, связанного с необходимостью вычислений от-
ношений типа (5-25).
Для всех рассматриваемых ниже критериев форма при-
ведения к одномерному случаю имеет одинаковый вид.
Принятый критерий определяет разбиение пространства
X на две области Хх и Х2, или, что то же самое, разбиение
оси X на две полуоси X Хо и К > Хо.
9 Темников Ф. Е. и др.
257
Критерий минимального риска Байеса
Этот критерий экономически наиболее целесообразен,
но требует максимальной априорной информации. Для его
использования должны быть известны, кроме условных
распределений ^(xloj) и ш(х|п2), априорные вероятности
состояний источника р (nJ и р (nJ и условные потери
Г21 и r12 (ru = г22 = 0).
Разбиение пространства признаков производится та-
ким образом, чтобы минимизировался средний риск. Это
означает, что при достаточно большом числе актов распоз-
навания экономические потери от ошибок будут минималь-
ными.
Средний риск согласно (5-24) для случая обнаружения
имеет вид: \
г = S гиР («2) w (х | nJ dx J- J r21p (nJ w (х | nJ dx,
X, х2
или
г = $ Г12Р («а) w (х I nJ dx — j г12р (nJ w (х | n2) dx Д-
X Ха
+ $ r21p (nJ w (х I nJ dx = r12 р (а2) Д- $ [r21p (nJ w (х | nJ —
Л'2 Х2
— r12p(a2)w(x\a2)]dx.
Величина г представляет собой функционал, зависящий
от области Ха интегрирования. Риск будет минимальным,
если область Х2 охватывает все отрицательные и только
отрицательные значения подынтегральной функции, т. е.
все векторы х , для которых
r21 р (nJ w (х | nJ — r12 р (nJ w (х | nJ < 0. (5-26)
В этом случае интеграл будет представлять собой мак-
симальное по абсолютной величине отрицательное число,
которое вычитается из первого слагаемого в выражении
для риска. Соответственно область Хг охватит все значения
х, для которых
г21 р (аг) w (х | nJ — г12 р (nJ w (х | nJ 0.
Отсюда уравнение решающей поверхности
Р (х) = ^21Р («1) w (*/а1) — ri2 Р («2)w (х I °г) — 0.
В одномерном случае, когда вектор х есть один отсчет
параметра х, решающая поверхность представляет собой
258
точку х0 пересечения функций г21р (aj w (х |ях) и r12p (а2) X
w (х |а2) (рис. 5-22).
Последнее уравнение можно представить в виде отно-
шения правдоподобия
ц>(х|д2)__^ __rZiP(ai)
ш(х|щ) 0 г1гр(а2)-
Таким образом, в процессе обнаружения для получен-
ного вектора х подсчитывается ве-
личина
? w(x а2)
^(х|а1)’
которая сравнивается с постоян-
ной величиной
= (5‘27)
*12 Р \а2)
При X >Х0 решающее устрой-
ство дает ответ, соответствующий
состоянию а2.
Риск распознавания при этом
оказывается минимальным.
rvp(at)iu(xla,)
р(аг)ш(г1а2)
г
*/ хо хг
Рис. 5-22. Разбиение про-
странства признаков на
области по критерию ми-
нимального риска (одно-
мерный случай).
Критерий идеального наблюдателя Зигерта —
Котельникова
Если сравнительную оценку потерь сделать трудно,
то их целесообразно принять' равными г12 =г21. Тогда
(5-24) выражает среднюю вероятность ошибки обнаружения:
Рош=р(а1) $ w(x\a1)dx-\-p(a2) $ w (х|а2) dx ==
х2 xL
--Р (^1) Рюш -ф" р Р20ПГ
Это выражение является частным случаем (5-23) для i = 2.
Для условных вероятностей рюш = а; р^оШ = р при-
няты следующие названия:
а — вероятность ошибки 1-го рода; другие названия —
вероятность ложной тревоги (в теории сигналов), риск
заказчика (в теории автоматического контроля), уровень
значимости (в математической статике); величину 1—а
называют оперативной характеристикой критерия;
Р — вероятность ошибки 2-го рода; другие названия —
вероятность пропуска сигналов, риск изготовителя; ве-
личину 1 — р называют мощностью критерия.
9*
259
Критерий минимального риска превращается в рассмат-
риваемом случае в критерий минимума средней ошибки
обнаружения, или критерий идеального наблюдателя. Пра-
вило решения принимает вид
^>Р(а1)/р (а2)
или
ш (х I а2) р (с2) ]
W (х I щ) р (щ)
Левая часть неравенства совпадает с отношением апосте-
риорных вероятностей
р (д2 | х) _ р (о2) w (х | а2)
р (аг I х) р (щ) w (х I щ) ’
что легко подсчитать, используя формулу Байеса. Таким
образом, решающее устройство, работающее по критерию
идеального наблюдателя, выбирает такую гипотезу, кото-
рая соответствует максимальной апостериорной вероят-
ности. Граничное значение коэффициента правдоподобия,
определяющее уравнение решающей поверхности,
1 _р(щ)
° Р(«аГ
Критерий максимального правдоподобия Фишера
При неизвестных априорных вероятностях р (ах) и
р (а2) решение может быть принято по соотношению между
w (х|а2) и w (xlaj. При этом предполагается Zo = 1, что
соответствует случаю р (аА) — р (а2) в критерии идеального
наблюдателя. Этот критерий носит название критерия
(принципа) максимального правдоподобия.
Минимаксный критерий
Более «осторожным» при неизвестных вероятностях
р (aj и р (а2) является минимаксный критерий, при кото-
ром для каждого X ищется наихудшее распределение,
т. е. такое, при котором средний риск имеет наибольшее
значение max г, а затем среди множества значений X с таки-
ми распределениями выбирается Xfl, обеспечивающее ми-
нимум г. При этом риск оказывается равным
г0 — min max г — max г (Zo),
Хо plas) pfaa)
где Хо определяется формулой (5-27).
260
Такой критерий носит название минимаксного. Учиты-
вая, что w (х | at)dx = w (A^dA и области Х± и Х2 в про-
странстве X соответствуют областям [О, Ао| и [Ао, оо] значе-
ний X, выражение для среднего риска можно записать в
виде
Ло [Р («а)] со
г~г12р(аг) $ w I аг) ^А + r2i Р (°i) 5 ©(AJa^dA,
0 Mp(°s)1
где граничная точка А„ представлена в виде функции от
вероятности р (а2).
Приравнивая производную риска по этой вероятности
нулю, получаем трансцендентное уравнение для опреде-
ления вероятности р (а^, обеспечивающей максимум риска
при условии (5-27):
^0 [р («2)1 со
r12 \ w (К | а2) dA — r21 $ w (А | aj d А = 0,
0 Ло [р (а2)]
ИЛИ
Ga ₽ [Р («2)1 = г21 а [р (о2)]. (5-28)
При этом условные риски а и ₽ являются функциям»
координаты Ао, которая в свою очередь связана с рас-
пределением априорных вероятностей соотношением (5-27).
Равенства (5-27) и (5-28) определяют значения Ао и р (а2),
дающие минимаксное решение.
Критерий наблюдателя Неймана — Пирсона
Часто ошибки 1-го и 2-го рода могут привести к сущест-
венно различным последствиям, которые невозможно оце-
нить в виде потерь. Это имеет место, например, если одна
из этих ошибок приводит к непредсказуемым катастрофи-
ческим последствиям. Такую ошибку необходимо ограни-
чить некоторой очень малой величиной. Вторую из ошибок
всегда желательно сделать возможно меньшей. Критерий,
отражающий эти требования, формулируется так: обеспе-
чить min р при a sg а0.
Величина Ао находится в этом случае по выражению
СО *
5 w (А| а1) dA —«0,
так как большие значения приводят к большим условным
ошибкам р, а меньшие — к недопустимым ошибкам й (а >
>«о).
261
Критерий минимальной длительности эксперимента
• Вальда
Предположим, что требуется обеспечить достаточно
малые вероятности ошибок как 1-го, так и 2-го рода:
« а0, Р Ро.
При использовании любого критерия уменьшение ве-
роятностей ошибки обнаружения достигается увеличением
размерности вектора х. Но при фиксированной размерности
не всегда могут быть обеспечены требуемые малые вероят-
ности а и Р ошибок. Большие возможности в этом случае
имеет гибкая процедура, состоящая в определении решаю-
щего правила, оперирующего с вектором неопределенной
размерности. Число т необходимых отсчетов .... хт
в каждом конкретном эксперименте может принимать
свое значение. Вальд предложил [Л. 5-13J процедуру,
обеспечивающую минимальное среднее значение т для
достижения заданной вероятности правильного решения.
Если считать стоимость эксперимента пропорциональной
его длительности, то такая процедура обеспечивает мини-
мальную среднюю стоимость. Этот метод, получивший наз-
вание последовательного анализа, состоит в следующем.
Ось X делится на три области: Лх, включающую все X sg Хь
область Л2, включающую все X Х2, и область Ло (Xj <
<Х < XJ; Лх и Л2 являются областями принятия решений,
Ло — областью неопределенности. На каждом i-м шаге
вычисляется отношение правдоподобия
_ tt)(x|f)| aj
1 К/(х”’! щ) ’
которое сравнивается с двумя порогами Х2 и Х2. Здесь
х(,) = {хь х2, ..., xt} — вектор-реализация размерно-
сти г.
При X At или X Л2 принимаются соответственно ги-
потезы о состоянии а± или а2, при попадании в область
неопределенности Х; Лю решение не принимается, а дела-
ется следующий отсчет x(i+1) параметра и рассчитывается
отношение
_ ai (х1**111 Па)
i+1 —а>(х»+м|Д1) ’
Вальд показал, что эта процедура конечна и приводит к
минимальной средней длине эксперимента (среднему числу
262
шагов) т при условии выбора порогов в соответствии С
отношениями
1 _1~Р 1 Р
При этом математическое ожидание т
М [ml — а ln + (1 — Р) 72
1 Lmj _ м
Статистические критерии распознавания
Критерий минимального риска
Согласно критерию правило распознавания должно
минимизировать потери, определяемые выражением (5-24).
Это правило, являющееся обобщением (5-26), имеет вид
[Л. 5-71:
<'*«• (!?и>
1
Гипотеза о состоянии a-t (i 1) принимается, если вы-
полняется п — 1 неравенств данного типа (для / = 1,..., п).
В противном случае гипотеза отвергается. При отклонении
всех гипотез at принимается решение о наличии состояния
q. Данная система неравенств определяет области при-
нятия решений Х2, Х3,..., Хп
п
и область Хг — Х —
« = 2
Уравнения разделяющих
поверхностей получаются при
замене знаков неравенства на
знаки равенства.
Критерий идеального Рис. 5-23. Распределение апо-
наблюдателя стериорных вероятностей со-
стояний.
Как указывалось выше,
метод, использующий крите-
рий идеального наблюдателя, основан на принятии гипо-
тезы, соответствующей максимальной апостериорной веро-
ятности р (й/|х). Так, в случае, изображенном на рис. 5-23,
должна быть принята гипотеза о состоянии ak.
Области принятия решений и уравнение решающих
поверхностей определяются выражением (5-29) при ра-
венстве потерь от неправильных решений.
263
Критерий заданного превышения
Если апостериорные вероятности нескольких состоя-
ний близки к максимальной, метод идеального наблюда-
теля приводит к большому, проценту ошибочных решений.
В этом случае может быть использован критерий заданного
превышения [Л. 5-12], согласно которому гипотеза о со-
стоянии принимается только тогда, когда
Р (°i \*)>Ср | х),
где р (су |х) — максимальная апостериорная вероятность;
p(aj\x) — ближайшая к максимальной вероятность; С —за-
данный коэффициент превышения.
Критерий суммарного превышения
Согласно этому критерию [Л. 5-12] решение принимается
только в случае, если
Р (ai | х) >[1 — р(аг|х)].
Для двух последних критериев пространство реализа-
ций содержит область неопределенности, при попадании в
которую вектора х решение не принимается, а запраши-
вается дополнительная информация.
Глава шестая
ПЕРЕДАЧА ИНФОРМАЦИИ
Использование информации потребителем связано с ее
транспортировкой от источника. Транспортировка всегда
осуществляется в пространстве и во времени. Однако в за-
висимости от того, какой фактор является определяющим,
различают передачу информации на расстояние и передачу
во времени или хранение информации. Оба вида передачи
имеют много общего и часто используют в процессе реали-
зации сходные методы — помехоустойчивое кодирование,
модуляцию и др. В дальнейшем рассматриваются вопросы
передачи в пространстве.
С передачей информации связан ряд проблем, в том
числе: ' .
1) повышение эффективности передачи, в частности
повышение скорости передачи информации по каналу, для
чего требуется разработка методов эффективного кодиро-
вания;
264
2) повышение надежности передачи путем использо-
вания методов помехоустойчивого кодирования и помехо-
устойчивости различных видов модуляции, повышения по-
мехоустойчивости каналов, применения методов помехо-
устойчивого приема; 4 ,
3) эффективное использование многоканальных систем
передачи;
4) использование новых перспективных видов связи.
По назначению передаваемую информацию можно раз-
делить на осведомительную (телеизмерение, телесигнали-
зация, дистанционное или местное измерение, связь, пе-
редача данных, обнаружение) и управляющую (теле-
управление, дистанционное управление, телерегулиро-
вание).
Информация, получаемая в результате измерения, пе-
редается как аналоговыми, так и цифровыми (кодовыми)
сигналами. Большое внимание при этом уделяется вопросам
сохранения точности информации. Системы передачи дан-
ных пли телекодовой связи служат для ввода цифровой
информации в вычислительные машины; к ним предъяв-
ляется требование повышенной достоверности передачи.
При передаче управляющей информации применяются
только кодовые сигналы, используемые для дискретного
(обычно двухпозиционного) управления объектами. Здесь
ставится задача обеспечения высокой надежности пере-
дачи.
Системы передачи предполагают наличие источника и -
приемника информации, разделенных определенным рас-
стоянием. Однако передающее устройство и источник ин-
формации не обязательно территориально совпадают. На-
пример, в локаторе передатчик и приемник конструктивно
совмещены, а источником информации служит обнаружива-
емый объект, находящийся на расстоянии. Передатчик
вообще может отсутствовать, в частности, в системах
пассивного обнаружения — например обнаружения источ-
ника звуковых колебаний.
Связь в системе осуществляется по каналам передачи.
Будем различать категории канал и линия связи.
Канал — это тракт движения сигнала в многократной
системе передачи, т. е. в системе с множеством входных и
выходных устройств. Линия связи представляет собой фи-
зическую среду, по которой передаются сигналы. Много-
канальные системы могут иметь одно- или двухпроводную
линию связи. Так, например, в телефонии два провода
265.
используются для передачи сообщений большого числа
абонентов. Соответственно различают аппаратуру канала
и аппаратуру линии, общую для всех каналов.
6-1. ВИДЫ КАНАЛОВ ПЕРЕДАЧИ
В технике передачи информации находят применение
механические, акустические, оптические, электрические и
радиоканалы, различаемые по используемым линиям связи
и по физической природе сигналов [Л. 6-1—6-3, 6-6]. Ос-
новным, но не единственным признаком в пределах каждого
из перечисленных видов каналов обычно служит диапазон
рабочих частот. Классификация каналов дана в табл. 6-1.
Механические каналы
Механические каналы применяются для передачи на
короткие расстояния (до 500 лг) сигналов в виде механичес-
ких усилий или давлений. Применяются следующие виды
механических каналов:
А. Жесткие, или собствейно механические каналы.
Простейшим примером служит трос управления дроссель-
ной заслонкой карбюратора. Протяженность таких каналов
может доходить до нескольких десятков метров.
Б. Гидравлические каналы, в которых передающей сре-
дой служит жидкость. Недостатком их являются плохие
динамические свойства, в связи с чем протяженность этих
каналов ограничивается несколькими метрами.
В. Пневматические каналы. По пневматическим каналам
передается сигнал в виде давления. Средой для' передачи
обычно служит воздух. Протяженность пневматических
каналов достигает нескольких, сотен метров.
Среди механических каналов пневматические получили
наибольшее распространение в связи с широким примене-
нием унифицированных пневматических систем контроля
и регулирования на предприятиях со взрыве- и пожаро-
опасной средой. Такой канал состоит из пневматического
датчика или преобразователя, вырабатывающего аналого-
вый пневматический сигнал в виде давления сжатого
воздуха в унифицированной шкале (чаще всего 0,2— 1 кг!см2),
пропорциональный величине измеряемого технологического,
параметра; пневматической линии связи; регистрирующего,
регулирующего или преобразующего прибора на выходе
линии. Основным препятствием, ограничивающим приме-
266
Виды каналов передачи
Виды каналов Классификационный признак
Механические Среда передачи
Акустические Диапазон частот
Оптические Диапазон частот
Электрические Диапазон частот
Радио Диапазон частот
Разновидности каналов
Жесткие
Гидравлические
Пневматические,
Звуковые
Ультразвуковые
Видимого спектра
Инфракрасного излучения
Ультрафиолетового излучения
Подтональных частот
Тональных частот
Надтональных частот
Высокочастотные
Длинноволнового диапазона
Средневолнового диапазона
Промежуточного диапазона
Коротковолнового диапазона
Ультракоротковолнового диа-
пазона
Таблица 6-1
Частота сигналов f или длина волны X
f С 20 кгц;
f > 20 кгц;
X > 15 км
Л <15 км
/ = 400 4- 1000 Ггц; Л = 0,3 4-0,75 мк
/ = 0,3 4- 400 Ггц; X = 0,75 4- 1000 мк
/= 1000 4-3 000 Ггц, Л = 0,01 4-0,3 мк
/ < 200 гц;
/ = 300 4- 3400 гц;
/ = 4000 4- 8500 гц;
/> 10 кгц;
1500 км
X = 90 4- 1000 км
X = 32 4- 75 км
X < 30 км
f < 300 кгц; X >, 1000 м
/ = 300 4-1500 кгц; X = 200 4- 1000 т
f = 1,5 — 6 Мгц; X = 50 4- 200 м
/ = 6 4- 30 Мгц; X = 10 4- 50 м
/ = 30 4- 30 • 105 Мгц; X = 0,0001 4- Ю м
нение пневматических систем, являются длительные пере-
ходные процессы в пневматических линиях связи, особенно
в линиях большой длины.
Акустические каналы
Акустические каналы предназначаются для передачи
колебаний. Средой для передачи могут служить любые
звукопроводящие материалы и среды. По диапазону частот
передаваемых сигналов акустические каналы делятся на
две группы:
1) каналы звукового диапазона (до 20 кгц);
2) каналы ультразвукового диапазона (свыше 20 кгц).
Акустические сигналы и каналы нашли разнообразное
применение в технике автоматического контроля, обнару-
жения и связи: акустический контроль состояния работаю-
щих механических объектов, ультразвуковая дефектоско-
пия, акустическое обнаружение объектов (подводных лодок,
самолетов), гидролокация, акустическая связь и др. При
пассивной передаче сигналов в процессе контроля или об-
наружения источниками звука являются контролируемые
или обнаруживаемые объекты. При активной передаче
(ультразвуковая дефектоскопия, локация, связь) акусти-
ческие сигналы создаются специальными генераторами.
В качестве источников и приемников звуковых и ультра-
звуковых колебаний широко используются для частот до
20—30 кгц магнитострикционные материалы, а для более
высоких частот — до 10® гц — пьезоэлектрические кри-
сталлы.
На рис. 6-1, а показана упрощенная схема канала с
активной передачей. Магнитострикционный генератор Г
и приемник П звуковых колебаний содержат сердечник из
магнитострикционного материала, который обладает свой-
ством преобразовывать электромагнитные колебания в
механические или обратно. К материалам такого рода от-
носятся- железо, никель и никелевые сплавы — пермаллой,
пермендюр, ферриты, кобальт.
При работе сердечника с обмоткой в режиме генератора
электромагнитное поле обмотки вызывает колебания сер-
дечника, а в режиме приемника в обмотке индуцируется
ток, создаваемый полем, которое возникает в результате
механической деформации сердечника при приеме акусти-
ческих сигналов из среды, служащей линией связи ЛС.
В устройствах с пьезоэлектрическими генераторами и
приемниками (рис. 6-1; б) используется пьезоэлектрический
268
От источника а)
сигнала
К выходному
прибору
От источника
сигнала
Рис. 6-1. Акустический канал с активной
передачей.
к выходному
прибору
а — акустический канал с магнитострикционным
преобразователем; б — акустический канал с пье-
зоэлектрическим преобразователем; Г генера-
тор; П — приемник; JJC — линия связи; 1 — ме-
таллические электроды; 2 — пластинка из пьезо-
электрической керамики.
эффект — изменение линейных размеров некоторых керами-
ческих материалов (кварц, сульфат лития, титанат бария
и другие) в соответствии с изменением электрического поля и
обратный эффект, изменения электрического поля под дей-
ствием механического усилия.
( ( Ш
пп
Рис. 6-2. Схема гидролокатора.
ПП — пьезоэлектрический преобразователь; ПУ — пе-
реключающее устройство; ГИ — генератор импульсов;
У И — усилитель принятых импульсных сигналов;
ГР — генератор развертки; ЭИ — электроннолучевой
индикатор; tx — время-импульсный сигнал, фиксируемый
на экране трубки.
В качестве примера системы с акустическим каналом
рассмотрим устройство гидролокатора. Источником и при-
емником акустических колебаний служит один и тот же
пьезоэлектрический (или магнитострикционный) преобра-
269
зователь, который сначала работает в режиме генера-
тора, излучая кратковременные импульсные сигналы, а
затем переключается на работу в режиме приемника, вос-
принимая отраженные от цели акустические сигналы. При
поиске цели излучатель локатора приводится во вращение,
вручную или автоматически. Схема гидролокатора (рис. 6-2)
содержит переключающее устройство ПУ, которое под-
ключает пьезоэлектрический преобразователь ПП пооче-
Таблица 6-2 Скорость распространения звуковых волн в различных средах редно к генератору им- пульсов ГИ и к усили- телю УИ; Одновременно с посылкой звукового
Среда Скорость распро- странения звуковых волн-, ти/сек сигнала генератор им- пульсов запускает гене- ратор развертки ГР электроннолучевого ин- дикатора ЭИ. Принятый импульс подается на вертикальные пластины трубки и формирует фа- зоимпульсный сигнал tx, длительность которого
Воздух Вода пресная Вода морская Дерево Стекло _ Сталь 331,45 1430 1500 3350 5400 6100
равна интервалу времени от момента излучения до мо-
мента прихода отраженного сигнала. Это время в свою
очередь пропорционально расстоянию до цели L:
L — vtx,
где v — скорость распространения акустических волн в
среде (табл. 6-2).
В настоящее время исследуются возможности практи-
ческого использования акустических сигналов и каналов
гиперзвукового диапазона (109—1013 гц), получаемых с
помощью кварцевых генераторов.
Оптические каналы
По диапазону используемых частот (или длине волны)
оптические каналы подразделяются (см. табл. -6-1) на сле-
дующие группы:
1) каналы видимой части спектра оптических сигналов
(с длиной волны 0,3 < Z < 75 мк);
2) каналы инфракрасной части спектра (0,75 < X <
< 1 000 мк)-,
3) каналы ультрафиолетовой части спектра (Z< 0,3 мк).
Расположение оптических каналов на волновой оси
электромагнитных излучений показано на рис. 6-3.
270
Устройства, работающие с инфракрасным излучением,
нашли более широкое применение вследствие ряда суще-
ственных преимуществ его перед видимым и ультрафиолето-
вым. Среди достоинств инфракрасного излучения отметим:
1) меньшее ослабление инфракрасного излучения ат-
мосферой по сравнению с излучением видимой и ультра-
фиолетовой части спектра;
2) распространение инфракрасного излучения в темноте,
скрытность передачи.
Видимое излучение
Ультрафиолетовое / Инфракрасное
излучение \ / / излучение
Рентгеновское \ I / Микроволновый
излучение \\ I диапазон
у-лучи \ \ / / / Радиоволны
К-11-Ю-8-В-Т-6 -S-4-3-Z-1 о I г 3 4 5 6 7 8 3 ЮНк
Длины волн, 10кМК
Рис. 6-3. Диаграмма распределения излуче-
ний на волновой оси.
На рис. 6-4 приведены зависимости интенсивности Е
излучения тел от длины волны X при различных темпера-
турах. Эти кривые свидетельствуют о том, что макси-
мум интенсивности из-
лучения большинства
тел на Земле приходится
на область инфракрас-
ного диапазона, что от-
крывает широкие воз-
можности для техники
инфракрасного контроля
и обнаружения.
Наиболее распро-
страненный диапазон в
инфракрасной области
от 0,75 до 15 мк.
На рис. 6-5 изобра-
Рис. 6-4. Распределение интенсивно-
сти излучения тел по длинам волн.
жена схема оптического
телефона. Электрические
колебания звуковой ча-
стоты, создаваемые микрофоном М, усиливаются усилителем
У и модулируют поток излучения, создаваемого источни-
ком И. Излучение источника проходит через инфракрасный
фильтр Ф и распространяется в атмосфере. Приемником
271
служит фотоэлемент ФЭ. После усиления сигналы фото-
элемента поступают в телефон Т.
Большие перспективы в технике передачи информации
имеет применение квантовых генераторов света — лазеров
(слово лазер образовано первыми буквами английского
Рис. 6-5. Схема оптического телефонного канала.
М — микрофон; У — усилитель; И — источник инфра-
красного излучения; Ф — инфракрасный фильтр; ФЭ —
фотоэлектрический приемник; Т — телефон; Л С — ли-
ния связи.
названия light amplification by stimulated emission of
radiation — усиление света с помощью индуцированного
излучения). В настоящее время разработаны многочислен-
ные конструкции кристаллических и газовых лазеров,
работающих в различных частях оптического диапазона.
3
2
Подсветка
Рис. 6-6. Упрощен-
ная схема оптического
В качестве приемников используются
фотосопротивления, фотодиоды и фото-
умножители.
На рис. 6-6 изображена схема ру-
бинового лазера. Один из торцов 1
рубинового кристалла 2 представляет
собой полупрозрачное зеркало; дру-
гой, посеребренный торец 3 является
непрозрачным зеркалом. При облуче-
квантового генератора.
1 — полупрозрачное зер-
кало; 2 — кристалл ру-
бина; 3 — непрозрачное
зеркало.
иии кристалла посторонним источни-
ком света (импульсной лампой), кото-
рый называется источником «подкач-
ки», происходит изменение энергети-
ческого состояния атомов хрома, со-
держащихся в рубине. Поглощая энергию «подкачки» и
возбуждаясь, атомы хрома переходят с основного (первого)
энергетического уровня на более высокий (третий). Затем,
отдавая часть своей энергии кристаллической решетке,
эти атомы переходят на второй метастабильный уровень,
вследствие чего на втором уровне накапливается большое
число возбужденных атомов. При переходе одного цз ато-
мов со второго уровня на первый излучается фотон, кото-
рый, встречаясь с другими атомами, расположенными на
втором уровне, вызывает их переход на первый энерге-
272
тический уровень. В результате возникает лавинный пе-
реход атомов со второго на первый вровень и интенсивное
излучение в области красного спектра. Многократное отра-
жение от торцов приводит к возникновению внутри кристал-
ла стоячей волны света, интенсивность которой непрерыв-
но возрастает. Поток излучения, параллельный оси крис-
талла, выходит через полупрозрачную поверхность. Потоки
других направлений не усиливаются и не принимают учас-
тия в формировании пучка. В результате образуется поток
излучения с весьма высокой направленностью — для крис-
таллических лазеров она составляет 0,5° и менее. Спектр
излучаемых фотонов имеет очень узкую полосу, так что
получается монохроматическое излучение.
Большие перспективы в области передачи информации
принадлежат газовым лазерам, рабочим телом которых
служит смесь гелия с неоном, смесь углекислого газа, азота
и гелия и другие среды. Они могут работать в непрерывном
режиме и имеют высокий к. п. д. (до 30%). Индуцировайное
излучение возникает при электрическом разряде в газовой
среде без оптической подкачки. Излучение газовых лазеров
сосредоточено в угле менее 1'. Ширина спектра составляет
10—80 кгц при собственной частоте порядка 1014 гц. Боль-
шая собственная частота и узкий спектр позволят в будущем
осуществлять связь по огромному количеству каналов.
Высокая направленность принципиально дает возмож-
ность вести передачу на чрезвычайно большие расстояния
(десятки и сотни миллионов километров). Это делает пер-
спективным использование оптических квантовых генера-
торов в космической связи.
Техника использования квантовых генераторов для
передачи сообщений находится в стадии развития. В на-
стоящее время уже реализована система связи на небольшие
расстояния для речевых и телевизионных сигналов, опти-
ческий дальномер, система поиска и слежения за искус-
ственными спутниками Земли, ведутся работы по орга-
низации связи между космическими кораблями и Землей.
Электрические каналы
Наиболее распространены электрические каналы-.с при-
менением проводных линий связи. Для передачи информа-
ции используются как специально выделенные линии, так и
линии, сооруженные для других целей. Для передачи те-
лемеханических сигналов, например, широко применяются
273
линии энергоснабжения, высоковольтные линии электро-
передачи, телефонные и телеграфные линии.
Шкала частот, занимаемая сигналами в электрическом
канале связи, условно делится на четыре диапазона:
1) 0—200 гц — подтональные частоты;
2) 300—3 400 гц — тональные частоты;
3) 4000—8 500 гц — надтональные частоты;'
4) свыше 10 кгц — высокие частоты.
В случае применения индивидуальных линий связи
для передачи могут использоваться любые диапазоны. При
одновременном использовании линии для целей связи и
передачи телемеханической информации указанные диа-
пазоны частот распределяются следующим образом: то-
нальные частоты используются для телефонии и тональной
телеграфии, высокие частоты — для высокочастотной те-
лефонии, подтональные и надтональные частоты — для
передачи телемеханической информации.
Рис. 6-7. Схема замещения электрической (проводной) линии
связи.
Электрическая линия связи представляет собой длинную
линию с распределенными параметрами, которую можно
представить в виде большого числа последовательно со-
единенных четырехполюсников (рис. 6-7). Величина Ro
характеризует активное сопротивление линии, приходя-
щееся на один километр длины. Это сопротивление зависит
от материала, сечения проводов, температуры окружающей
среды и частоты передаваемых сигналов (при увеличении
частоты сопротивление Ro растет из-за наличия поверхност-
ного эффекта). Индуктивность Lo на единицу длины зави-
сит от материала, радиуса проводов, расстояния между про-
водами, частоты сигналов и температуры среды.. Проводи-
мость изоляции обозначена через Go. Она зависит от вида
изоляции, влажности окружающей среды и частоты сиг-
нала. Емкость утечки Со зависит от материала, радиуса
274
проводов и расстояния между ними. Эти параметры линии
связи определяют волновое сопротивление
у __1 /~ + /Д> Lp
с V Go + zwCo’
где <о — частота сигнала. Для того чтобы вся проходящая
по линии энергия поступала в нагрузку, нужно, чтобы соп-
ротивление нагрузки было равно волновому сопротивлению
линии. В противном случае возникает эффект отражения,
при котором часть энергии, отражаясь от конца линии, воз-
вращается к источнику сигнала. Для исключения этого
между линией и приемником помещают согласующие цепи,
обеспечивающие равенство нагрузки значению волнового
сопротивления. Километрический коэффициент затухания
сигнала Р и километрический коэффициент сдвига фаз а
определяются по постоянной распространения у:
У = ₽ + /а = К (7?o4-/®Lo)(Go + /®Co).
Для выражения затухания пользуются обычно величиной
In р, измеряемой в неперах.
Проводные линии связи делятся на кабельные и воздуш-
ные. Кабельные линии обладают большей надежностью и
меньшей зависимостью от условий внешней среды. Прово-
димость изоляции их очень мала и составляет Go = Ю 9 —
— Ю-10 1/ом-км. Но активное сопротивление Ro и емкость
Со кабельной линии больше, чем соответствующие пара-
метры воздушной линии, что обусловлено малцм диаметром
жил кабеля и малым расстоянием между ними.
Проводимость изоляции воздушных линий сильно за-
висит от метеорологических условий. В сырую погоду
допустимая проводимость составляет Go =0,5 -10 6 1/ом-км.
Весьма широко для передачи информации используются
уже имеющиеся «готовые» линии связи. Это относится
прежде всего к высоковольтным линиям 35—500 кв. Ис-
пользование для телемеханики линий электропередачи
имеет ряд преимуществ перед применением специальных
телемеханических линий. К ним относятся: высокая проч-
ность и надежность, значительно меньшая вероятность
случайных повреждений вследствие тщательного надзора
за этими линиями, большая протяженность, малое затуха-
ние. Обычно телемеханические сообщения требуется пере-
давать между пунктами, соединенными линиями электро-
передачи. Однако в высоковольтных линиях имеет место
275
Значительный уровень помех из-за наличия высших гар-
моник тока промышленной частоты, коронного разряда в
проводах, атмосферных помех и т. и. Это приводит к необ-
ходимости осуществлять передачу информации в высоко-
частотном диапазоне и использовать для восстановления
сигнала промежуточные усилители и формирователи.
Схема телемеханического канала связи, организован-
ного на основе линки электропередачи, показана на рис.
6-8.
ЛЭП
Рис. 6-8. Использование высоковольтной линии
для передачи информации.
ЛЭП — высоковольтная линия электропередачи;
ПВ — подстанция высоковольтной линии электро-
передачи; Ф — фильтр; ПТ — пост телемеханики;
Р — разрядник; ЗН ~ заземляющий нож; К — ка-
бель.
Передача ведется в диапазоне высоких частот в преде-
лах 30—300 кгц (в отдельных случаях до 1 Мгц). Для пре-
дохранения поста телемеханики ПТ и персонала от высокого
напряжения линии применяется высоковольтный разде-
лительный конденсатор С и разрядник Р. При пробое кон-
денсатора высокое напряжение попадает на разрядник,
который, пробиваясь, спекается и шунтирует аппаратуру
на землю. Заземляющий нож ЗН используется для шунти-
рования аппаратуры при ремонте. Полосовой фильтр Ф
задерживает низкочастотную составляющую высоковольт-
ного сигнала, а также помехи, возникающие в линии, и
пропускает полезный телемеханический сигнал. Высоко-
частотный фильтр — индуктивность L — предотвращает
прохождение телемеханических сигналов на подстанцию
высоковольтной линии ПВ.
276
I
Радиоканалы
Весьма широкое распространение получили радиокана-
лы передачи информации.
По диапазону частот радиосигналов различаются ка-
налы:
1) длинноволнового диапазона (длина волны % > 1 000 ж);
2) средневолнового диапазона (200 < 1 000 м);
3) промежуточного диапазона (50 < 200 .и);
4) коротковолнового диапазона (10 < > < 50 л*);
5) ультракоротковолнового диапазона (Z< 10 м).
па распространение радиоволн
влияют отражающие и поглощающие
свойства земной поверхности и атмо-
сферы, особенно слоя, носящего на-
звание ионосферы и расположенного
выше стратосферы. Ионосфера состоит
из заряженных частиц газов — элек-
тронов и ионов, образующихся в ре-
зультате воздействия солнечных лу-
чей, космического излучения и метео-
ритных частиц. Концентрация п ионов
имеет два максимума (рис. 6-9). Пер-
вый, называемый слоем Е, располо-
жен на высоте h — 110-4-130 км. Вто-
рой слой с максимальной концентра-
цией F расположен на высоте около
300 км. Ионизация сильно зависит от
Рис. 6-9. Диаграмма '
концентрации ионизи- •
рованных частиц в
ионосфере.
времени суток. Ночью степень ионизации намного меньше,
чем днем. Днем слой F становится «двугорбым» и появ-
ляется дополнительный ионизационный слой, располо-
женный ниже слоя Е.
Изменение концентрации ионов с высотой обусловливает
непрерывное изменение угла преломления радиоволн, в
результате чего волны распространяются криволинейно.
Если направление распространения становится горизон-
тальным, не достигнув уровня максимальной ионизации,
происходит отражение радиоволны в сторону земли. Часть
волн отражается слоем Е, другая часть — слоем F ионо-
сферы, третья часть — «пробивает» оба слоя и выходит
за пределы земной атмосферы. Преломляющая способность
ионосферы неодинакова для различных типов волн. Она
уменьшается с уменьшением длины волны. Чем больше
длина волны, тем меньшая степень ионизации требуется
277
для ее отражения. Волны, распространяющиеся вследствие
отражения от ионосферы, носят название пространствен-
ных. Кроме пространственных, имеют место так называемые
поверхностные волны, распространяющиеся вдоль поверх-
ности земли благодаря дифракции. Чем меньше длина
волны, тем быстрее затухает поверхностная волна (вслед-
ствие потерь В земной поверхности) и тем медленнее зату-
хает пространственная волна. Сигналы длинноволнового
диапазона полностью отражаются слоем Е. Ультракоротко-
волновые сигналы не претерпевают отражения и выходят
за пределы земной атмосферы, вследствие чего они могут
эффективно использоваться для космической связи. Сиг-
налы остальных диапазонов отражаются ионизированными
слоями Е и F.
Рис. 6-10. Радиорелейный канал связи.
Для передачи сигналов промышленной телемеханики
широко применяются радиорелейные каналы, осуществля-
ющие связь на ультракоротких волнах. Приемно-передаю-
щие станции располагаются в пределах прямой видимости
(рис. 6-10). Для передачи информации на большие расстоя-
ния используются промежуточные ретрансляционные стан-
ции, служащие одновременно для восстановления сигнала,
искаженного и ослабленного в процессе передачи. Если
прямая видимость ограничена только кривизной поверх-
ности земли, то расстояние между станциями (в километ-
рах) рассчитывается по формуле
/ = 7,2]//Г,
где h — высота антенной системы (в метрах). Так, при
h = 60 м I = 54 км.
Кроме радио- и радиорелейных каналов применяются
волноводные каналы. Волновод представляет собой полую
металлическую трубу, используемую для передачи электро-
магнитной высокочастотной энергии. В процессе передачи в
волноводе возбуждаются круговые волны, наводящие в
его стенках кольцевые токи. Последние обеспечивают
278
экранизацию, препятствуя выходу электромагнитной энер-
гии за пределы волновода. Отличительной особенностью
волноводных каналов является уменьшение потерь с уве-
личением частоты. Это позволяет вести передачу на очень
высоких частотах и с меньшими по сравнению с другими
видами каналов потерями. Перспективная область рабочих
частот волноводных каналов составляет 35—75 Ггц.
6-2. РАЗДЕЛЕНИЕ КАНАЛОВ
В многоканальных системах тракты всех сигналов долж-
ны быть каким-либо способом разделены, чтобы сигнал каж-
дого источника информации мог попасть в свой приемник.
Такая процедура носит название разделения каналов, или
разделения сигналов.
Введем обозначения: Uk (t) — сигналы датчиков, отоб-
ражающие информационные функции xk (t) и порождающие
модуляцию параметров ak носителя; uxk (t) — сигналы на
выходах передающих устройств отдельных каналов; и (t) —
суммарный сигнал в линии связи.
Сигнал в одном канале, как указывалось в гл. 4, описы-
вается выражением
•••> (0> •••> •••>
где параметр ak (t) передает информацию, а параметр
пли несколько параметров могут быть использованы для
характеристики индивидуальных каналов. Такими пара-
метрами могут быть принадлежность к определенной элект-
рической цепи, частота или фаза носителя, положение на
временной оси, форма и т. д. Каждому каналу соответствует
определенное значение а]Ь или область значений Aa7-ft
параметра aj. При использовании этого обозначения выра-
жение для сигнала £-го канала принимает вид:
•••> «л (О...aik (О....ап],
или сокращенно
^xk (О — Sk (OL
В линию связи поступает составной сигнал, обычно пред-
ставляющий собой сумму сигналов отдельных каналов:
и (0 = .SMM0L
k
279
Процесс разделения можно рассматривать как фильт-
рацию, осуществляющую выделение uxk (или сигнала дат-
чика Uk):
фл {У" gk К (^]| = gk [а* (*)]-
В зависимости от вида оператора фильтрации ФЛ, опреде-
ляемого в свою очередь выбранным параметром а}-, разли-
чают следующие методы разделения каналов: пространст-
венное (схемное), дифференциальное, частотное, временное,
фазовое, кодовое, по уровню, по форме, корреляционное
1Л. 6-4, 6-5, 6-7, 6-8, 6-101.
Пространственное разделение
Это простейший вид разделения, при котором каждому
каналу отводится индивидуальная линия связи ЛС (рис.
6-11).
Рис. 6-11. Многоканальная си-
стема с пространственным раз-
делением.
датчик &-го канала; —
приемник информации Л-го канала;
ЛСд, — линия связи £-го канала.
Рис. 6-12. Многоканальная система
с дифференциальным разделением.
А — телефонный аппарат; ДТ — диф-
ференциальный трансформатор; X —
датчик телемеханической системы;
Пх — приемник телемеханической си-
стемы .
Другие формы разделения каналов предполагают пере-
дачу сообщений по одной линии связи. В связи с этим много-
канальную передачу называют также уплотнением каналов.
Дифференциальное разделение
На рис. 6-12 приведена широко распространенная схема
использования телефонного канала для передачи телемеха-
• нических сигналов (от датчика X к приемнику Пх). В линию
на передающей и приемной стороне включаются дифферен-
циальные трансформаторы ДТ. Средние точки их соеди-
няются с X и Пх. Таким образом, телемеханические сиг-
налы не создают помех в первичных цепях дифференциаль-
280
ных трансформаторов, связанных с телефонными аппара-
тами А. Благодаря дифференциальному включению теле-
фонные сигналы также не создают помех в телемеханичес-
ких цепях.
Частотное разделенно
При частотном разделении для различных каналов от-
водятся непересекающиеся участки А/у, Af2, Afn на
частотной шкале f (рис. 6-13, а). Спектры сигналов uxk
соответствующих каналов должны укладываться в пределы
Л/*. Полоса пропускания линии связи AF„ определяется
крайними частотами (минимальной частотой интервала
Рис. 6-13. Многоканальная система с частотным разделением.
а — распределение каналов по шкале частот; б — схема частотного
разделения; М — модуляторы; Ф — фильтры; ДМ — демодуляторы;
X/j — датчик &-го канала; Пх^ — приемник t-ro канала; Л С — ли-
ния связи.
Aft и максимальной частотой интервала А/л). На рис.
6-13, б приведена схема многоканальной системы с частот-
ным разделением. Низкочастотные сигналы Uk датчиков
Xk модулируют по амплитуде или частоте высокочастотные
сигналы с несущими flt f2, ..., fn, которые вырабатываются
специальными генераторами. Сигналы на выходе моду-
ляторов М имеют спектры Afk, положение которых на шкале
частот определяется несущими частотами fk, а ширина за-
висит от ширины спектра сигналов датчиков. Полосовые
281
фильтры Ф передающей части служат для ограничения по-
лосы частот своих каналов. На приемной стороне фильтры
Ф разделяют сигналы, которые, пройдя через демодуляторы
ДМ, могут быть восприняты приемными устройствами Пхк.
Большим преимуществом систем с частотным разделе-
нием является возможность одновременной передачи сиг-
налов, относящихся к разным каналам. Второе их досто-
инство состоит в возможности передачи сигналов от рас-
средоточенных объектов. Их недостаток — сравнительно
большое взаимное влияние каналов из-за перекрытия спект-
ров сигналов, неидеальности полосовых фильтров и появ-
ления паразитных частотных составляющих вследствие
нелинейности электрических цепей (так называемая пере-
крестная модуляция).
Временное разделение
При временном разделении сигналы ихЬ датчиков пере-
даются только в отведенные для них непересекающиеся
отрезки времени А/* (рис. 6-14,а).
Рис. 6-14. Многоканальная система с временным раз-
делением.
а— распределение каналов во времени; б — схема времен-
ного разделения; Р — распределитель; — датчик fe-ro
канала; Пх& — приемник информации k-ro канала; Л С —
линия связи.
Разделение осуществляется распределителями Р (рис.
6-14,6), которые должны быть строго синхронизированы
(т. е. работать с одинаковой скоростью) и синфазированы
282
(работать без сдвига). Взаимное влияние каналов при вре-
менном разделении обычно незначительно, что позволяет
строить системы с большим количеством каналов. Благодаря
этому обстоятельству, а также простоте технических средств
этот метод используется весьма широко. Однако он эффек-
тивен лишь при сосредоточении опрашиваемых параметров
в одном месте — вблизи коммутаторов.
Фазовое разделение
Фазовое разделение применяют в двухканальной системе
(рис. 6-15) с синусоидальными сигналами, фазы которых раз-
личаются на 90°. Сигналы датчиков Xk модулируют ампли-
туду синусоидальных носителей, различающихся по фазе.
Рис. 6-15. Многоканальная система с фазовым
разделением.
М — модуляторы; ФД — фазовые детекторы; — дат-?
чик Л-го канала; Пх& — приемник k-ro канала; ЛС —
ливня связи.
Таким образом, сигналы ttxk на выходе модуляторов М имеют
амплитуды, определяемые модулирующими функциями дат-
чиков, и фазы соответственно <рх и <р2 = <Pi + у:
их1 = <7i sin соо t,
их2 = U2 sin ^<оо t -j- yj == <72 cos (% t.
Фазовые детекторы ФД выделяют соответствующие моду-
лирующие функции <7Х и U2.
Кодовое разделение
При кодовом разделении адрес нужного канала указы-
вается кодированным сигналом, посылаемым в линию связи.
Разделение на приемной стороне осуществляется декодирую-
щим устройством, направляющим сообщения по выбранному
каналу. Код адреса может быть как последовательным, так
283
и параллельным. В последнем случае используется отдель-
ная линия связи или индивидуальный частотный канал на
каждый разряд кода. Кодовое разделение каналов позволяет
производить опрос каналов в произвольном порядке, что
делает удобным его использование в
иг/ системах опроса по вызову и в си-
стемах с пространственно-времен-
ц г~]— ными адаптациями, в которых часто-
Т 7 / та опроса каждого канала зависит от
0 а) внешних побудителей и статистиче-
u ских свойств процесса [Л. 1-23].
Рис. 6-16. Временные
диаграммы сигналов
многоканальной систе-
мы с разделением по
уровню.
Разделение по уровню
В системах с разделением по уров-
ню параметром разделения служит ам-
плитуда сигналов, принимающая ряд
дискретных значений, а полезная ин-
формация может содержаться в дли-
тельности сигналов. Сигналы первого
канала имеют уровень (амплитуду) U6,
сигналы второго канала Uo/2, третьего
Х/о/22, n-го канала t/0/2n Ч Рассмот-
рим в качестве примера двухканаль-
ную систему.
Оба сигнала могут быть сдвинуты
один относительно другого и иметь раз-
личную длительность (рис. 6-16, а, б).
В линию поступает сигнал (рис. 6-16, в)
U = —|—
а — сигнал в I-м канале;
б — сигнал во 2-м кана-
ле; в — сигнал в линии
связи; г — разностный
сигнал.-
На приемной стороне из линейного
сигнала и выделяется с помощью двух
диодных ограничителей разностный
сигнал Ан (рис. 6-16,г).
Сигнал второго капала их2 получается путем вычитания
из и удвоенного значения Ан:
ихй = и — 2/\и.
Сигнал первого канала получается как разность:
При nZ>2 для разделения применяются несколько ди-
одных ограничителей и схем вычитания.
284
Разделение по форме
Для разделения сигналов, различающихся формой,
используются операции, наиболее чувствительные к изме-
нению формы, — обычно дифференциро-
вание, интегрирование и вычитание. Рас-
смотрим процедуру разделения, когда
функции носителя образуются путем
последовательного дифференцирования.
Пусть, например (рис. 6-17,а, б)
(0 =
(0 =
В линию поступает сумма (рис.
6-17, в)
u(t) — Ut.
Процесс разделения имеет целью вы-
деление информационных параметров иг
и U2. Выделение U2 осуществляется пу-
тем дифференцирования функции u(t).
Интегрирование U2 восстанавливает пе-
реданный сигнал второго канала uX2(t).
Щ получается путем вычитания uX2(t)
из u(t).
Рис. 6-17. Времен-
ные диаграммы сиг-
налов многоканаль-
ной системы с раз-
делением по форме.
а — сигнал в 1-м ка-
нале; б — сигнал во
2-м канале; в — сиг-
нал в линии связи.
Корреляционное разделение
В последнее время получили распространение корреля-
ционные методы разделения каналов. В ряде случаев сигналы
отдельных каналов могут быть представлены в виде
uxk (0=gk {ak (0] = ak (0 gk (0 = Uk (t) gk (0,
где функция gk(t) описывает носитель с некоторой заданной
величиной разделяющего параметра ajk, а информационный
параметр ak(t), модулирующий функцию gk(t) по амплитуде,
равен сигналу Uk(t) соответствующего датчика.
Этот параметр представляет собой функцию времени,
медленно изменяющуюся по сравнению с gk(t), и его можно
считать постоянным. Сигнал в линии представляет собой
линейную комбинацию функций gk'.
uif}=.^Ukgk(f).
k
265
Если gk линейно независимы, они могут быть разделены
линейными фильтрами. Такие многоканальные системы
передачи носят название линейных. К линейным относятся,
в частности, системы с частотным, временным, фазовым
разделением и разделением по форме. Важной разновид-
ностью линейно независимых сигналов являются ортого-
нальные сигналы, для которых существует общий метод
разделения, основанный на применении оператора корреля-
ционной фильтрации к сигналу, поступающему из линии
связи.
Для геометрической интерпретации понятия ортогональ-
ности рассмотрим две функции g,(/) и gj(t), определенные на
интервале < t < Т2. Представим их в виде совокупности
дискретных отсчетов g* и gf:
gi = {£/ (<i)> gi (Q.gi (Mb
= gj(Q.....gjAtm)}-
Эти совокупности можно рассматривать как два вектора
в /n-мерном евклидовом пространстве с координатами gi(th)
и gj(t^, k =1,2, ..., т. Если векторы ортогональны, то их
скалярное произведение равно нулю:
(gr, gJ) = %gi(tk)gj(tk) = Q.
k
При бесконечном увеличении числа отсчетов т дискрет-
ные функции превращаются в непрерывные. По аналогии
с предыдущим их также можно рассматривать как векторы,
но уже в бесконечномерном пространстве. Условие ортого-
нальности в этом случае принимает интегральный вид:
у
(gi (0> gj (0) = $ gi (0 gj (t) dt = 0.
n
Ортогональную систему образуют, например, следующие
функции.
1. Бесконечное множество функций coskat, smkat, где
k — целое неотрицательное число (рис. 6-18,а), ортогонально
на интервале 0< t<_ 2п/а. Носитель с такими функциями
используется в устройствах с частотным и фазовым разделе-
нием.
2. Множество произвольных функций, определенных на
непересекающихся интервалах времени, а в остальное время
тождественно равных нулю (рис. 6-18,6), также представ-
ляет собой ортогональную систему, так как при i j
gi(t)gj(t)==O.
286
3. Множество, состоящее из дискретных знакопеременных
функций, которые можно получить с помощью «-разрядного
счетчика в режиме вычитания, находящегося первоначально
в заполненном состоянии (рис. 6-18,в), ортогонально на
заданном интервале Т = m (т — длительность импульса
младшего разряда). Коды, соответствующие этим последо-
вательностям, относятся к групповым и носят название
кодов Рида—Мюллера 1-го порядка.
6)
Рис. 6-18. Примеры ортого-
нальных сигналов.
а — ортогональные сигналы на
гармоническом носителе; б —
ортогональные сигналы на лю-
бом носителе с разделением по
времени; в — ортогональные
сигналы на импульсном носи-
теле.
4. Ортогональными на определенных интервалах явля-
ются многие специальные функции: полиномы и функций
Лежандра, Чебышева, Якоби, Эрмита, Лагерра, Хаара,
Уолша, Радемахера и др.
Ортогональную систему удобно использовать в норми-
рованном виде, при котором выполняется условие
Т'
Ti
287
Если q>k(t) — ненормированная ортогональная функция, то
операция нормирования производится путем умножения на
коэффициент
^k —
1
<р| (!) dt
В этом случае в линию поступает сигнал вида
^xk (О ~ U k^k фг (О — Ukgk (О»
где gk(t) уже является нормированной.
Для выделения информационного параметра Uk нужно
умножить принимаемый сигнал u(t) на функцию gk(t) и
проинтегрировать полученное произведение в пределах
Л< t< Т:
т т
\ Utgt (01 gk (0 dt=uk\ gi (t) dt = uk.
Л1 i J Л
Умножение сигнала линии на все функции gk(t) обеспе-
чивает полное разделение любых ортогональных сигналов.
Рис. 6-19. Многоканальная система с корреляционным разде-
лением.
Мk — модулятор /г-го-канала; Г— генератор функции g£ (О; —
коррелятор k-ro канала; Х& — датчик Л-го канала; ЛС — линия связи.
Оператор разделения Ф/г, выполняющий это преобразование,
определяет по существу степень взаимной корреляции сигна-
лов u(t) и gk(t)'. Таким образом, многоканальная система
288
(рис. 6-19) на передающей стороне содержит генераторы
Гь ортогональных функций и модуляторы Mk с нормализато-
рами, а на приемной — такие же генераторы I'k и корреля-
торы Kk-
Эффективность корреляционного метода разделения со-
стоит в том, что он позволяет значительно ослабить влияние
перекрестных помех, а это особенно существенно в случае пе-
рекрывающихся спектров сигналов. Поэтому он в ряде слу-
чаев более эффективен, чем другие методы, например частот-
ные методы с применением фильтров.
Рассмотрим в качестве примера систему, использующую
полиномы Лежандра 1-го рода [Л. 6-13]. Эти полиномы
ортогональны на интервале —1 < х< + 1 и описываются
соотношениями
<р0 (0 = 1;
<Pi
(О = (2^ - 1) 5 Фй-1 (о dt -ь <рй_2 (0 ,
Скалярное произведение двух функций
-t-i О
$ = \ 2
-1 12/4-1
при I Ф j,
при i = /.
Следовательно, нормирующий множитель
Ай = -|/(2Л+1)/2.
Сигналы образуются на основе носителя в виде постоян-
ного состояния, промодулированного по форме в соответ-
ствии с приведенными соотношениями. Таким образом,
форма служит параметром разделения, а для перенесения
информации используется амплитуда Uk.
Функциональная схема генератора ортогональных функ-
ций приведена на рис. 6-20. Источник Е создает
постоянный сигнал Е = 1, который играет роль функции
<Ро(О. После интегрирования интегратором и последую-
щего вычитания ср0(/) из результата формируется функция
<Pi(0- Формирование следующих функций осуществляется
в соответствии с вышеприведенными рекуррентными соот-
ношениями путем последовательного интегрирования, функ-
10 Темников Ф. Е. и др.
289
z ций ф*„1(0 с умножением результата на соответствующий
коэффициент (2/г — 1) и прибавлением функции
После нормирования и модуляции образуется сигнал
ч-xk (0 = иk^kfk (0 ~ и kg k (О-
Полный сигнал в линии связи
k
Разделение каналов производится по общей схеме
рис. 6-19. С этой целью на выходной стороне используется
Рис. 6-20. Схема генератора ортогональных функций.
Е — источник сигнала постоянного тока; И — интеграторы.
аналогичный генератор полиномов Лежандра, сихронизи-
рованный с первым, и коррелятор, выделяющий информа-
ционные параметры Uk.
Комбинированные методы разделения
Одновременное использование нескольких методов раз-
деления позволяет увеличить число каналов и уменьшить
их взаимное влияние. Так, разделение по форме в сочета-
нии с частотным разделением или временным удваивает
общее число каналов. Перекрестные искажения ограничи-
вают емкость систем с частотным разделением 10—20 кана-
лами. Кроме того, аппаратура систем с частотным разделе-
нием при большом числе каналов оказывается сложной и
громоздкой из-за наличия разделительных фильтров. Ком-
бинирование частотного метода с временным устраняет эти
недостатки. При этом временное разделение осуществля-
ется коммутацией одного или нескольких частотных каналов.
Применяются также комбинации кодового и частотного,
кодового и временного методов разделения и другие.
290
6-3. ПЕРЕДАЧА ИНФОРМАЦИИ ПО КАНАЛУ
Канал передачи информации состоит из линии связи,
модулятора и демодулятора (кроме случая, когда для пере-
дачи используется простая модуляция, при которой сигнал
в линии совпадает с сигналом датчика), кодирующего и
декодирующего, а также решающих устройств, позволяю-
щих с высокой степенью достоверности принять и передать
сообщение. Для увеличения надежности передачи приме-
няются также каналы обратной связи (см. § 6-4). Варианты
структур каналов приведены в табл. 6-3. Решающие
Таблица 6-3
Варианты структур каналов передачи информации
Вид структур Схема
Элементарная ЛС |>w| :. |—
С модуляцией 1—1 ЛС Г-n Г-Л |##|— ______- »|/?#]
С модуляцией и ко- дированием pwj —*1— ।—FT Т—*1ЯЙ1
С решателем на приеме , ЛС ______ c#i лтьдминч 1 "~i—
С решателями на приеме и передаче . ЛС _ „ _ ри нр Н Н г”*-1 j—
С информационной обратной связью ПК _______ — — 1“ лс у — ОК
С решающей обрат- ной связью f ,,лс т Ок
Обозначения:
ИИ — источник информации: ПИ — приемник; J1C — линия связи; ПК—
прямой канал; ОК — обратный канал; М — модулятор; М~ — демодулятор;
К — кодер; К~ — декодер; Р — решающее устройство передачи; Р~ — решающее
устройство приема.
10й
291
устройства Р и Р~ служат для классификации сомнительных
сигналов, отождествляя их с достаточно высокой степенью
достоверности с состоянием источника информации или с
определенным кодом.
Количество информации отдельного сигнала, имеющего
вероятность р, составляет log2(l/p) бит и может быть сколь
угодно велико. Однако в среднем в достаточно длинном
сообщении двоичный сигнал переносит не более одного
бита информации. В общем случае в сообщении, состоящем
из сигналов алфавита емкостью Л, среднее количество инфор-
мации не может превышать одной единицы информации
этого алфавита на символ. Однако не все сигналы несут
информацию. Случайно возникший в линии импульс помехи
информации не несет и мешает передаче. Иногда дополни-
тельные (избыточные) сигналы вводятся специально для
повышения помехоустойчивости. В этих случаях среднее
количество информации, переносимое одиночным сигналом,
уменьшается. Случай, когда сообщение состоит из символов,
несущих максимальное количество информации, встреча-
ется редко. Это имеет место при отсутствии помех в линии,
при равномерном распределении вероятностей между симво-
лами и при отсутствии статистической зависимости между
последовательно передаваемыми символами.
При невыполнении одного из этих условий количество
информации оказывается меньшим.
При заданном характере и уровне помех, задача повыше-
ния эффективности передачи решается прежде всего путем
определенного преобразования сигнала, приводящего к
увеличению среднего количества информации в сигнале.
Информационная модель канала
Для анализа информационных возможностей удобно
пользоваться обобщенной информационной моделью канала
связи, представленной на рис. 6-21. Источник информации
ИИ создает сигналы г, которые после кодирования и моду-
ляции в преобразователе Пх превращаются в сигнал х и
поступают в линию связи ЛС. Для удобства сигналы источ-
ника будем называть сообщениями, а сигналы х в линии
связи — просто сигналами. В результате действия помех
сигнал у на приемной стороне отличается отх. Помехи имеют
случайный характер и подчиняются статистическим зако-
нам. Удобно условно считать, что помехи создаются некото-
рым воображаемым источником помех ИП с определенными
292
статистическими свойствами и поступают в линию связи
в виде мешающего сигнала Приемная часть содержит
преобразователь П2, демодулирующий и декодирующий
принятые сигналы у, и приемник информации ПИ, перера-
батывающий принятые сообщения и. Если канал использу-
ется для передачи кодо-ймпульсных сигналов, он называ-
ется дискретным. Если же передаваемые сигналы имеют
непрерывный характер, канал называется непрерывным.
Рис. 6-21. Информационная модель канала связи.
ИИ — источник информации; ГН, — преобразователи
информации; ИП — источник помех; ЛС — линия связи;
ПИ — приемник информации.
Для организации эффективной передачи информации
по каналу требуется решение следующих проблем: опреде-
ление максимально возможной скорости передачи информа-
ции по каналу; разработка кодов, позволяющих увеличить
скорость передачи информации; согласование канала с ис-
точником с целью передачи информации с минимальными
потерями. Решение этих задач зависит от свойств источни-
ков, уровня и характера помех.
Если уровень помех мал, и искажениями сигнала можно
пренебречь, канал называется каналом без помех.
Отметим, что если источник информации вырабатывает
непрерывную функцию z(t), то путем ее дискретизации по оси
времени t и квантования по уровню методами,, описанными
в гл. 2, всегда можно перейти от непрерывного канала к дис-
кретному.
Дискретный источник информации характеризуется ал-
фавитом символов Z ={zlt гг....z„}, из которых строятся
сообщения, и вероятностями создания отдельных символов
(которые могут зависеть от того, какие символы были пере-
даны ранее).
Преобразователь ГД содержит кодирующее устройство,
преобразующее сообщения z в сигналы х, состоящие из
символов другого алфавита X = {х1г х2, ..., х„г} (в частном
случае алфавит X может совпадать с алфавитом Z, т. е.
т = п). Статистические свойства источника сигнала, кото-
293
рым является вся схема на входе линии связи (источник
информации плюс преобразователь), в общем случае отли-
чаются от статистических свойств источника сообщения.
Ниже будет показано, что выбором подходящего кода
можно повысить скорость передачи информации по каналу.
В случае непрерывного сигнала преобразователь П1
может содержать модулирующее и преобразующее устрой-
ства, изменяющие статистические характеристики непрерыв-
ного сигнала.
Важнейшей характеристикой канала является пропуск-
ная способность С, которая определяется как наибольшая
возможная скорость передачи информации по данному
каналу:
C = vxmax{I(Y, Л)}. (6-1)
Здесь через vx обозначена средняя скорость передачи
по каналу элементарных сигнала? (символов). Эту скорость
можно выразить через среднюю продолжительность симво-
лов тА- передаваемого сигнала:
№х-
При одинаковой продолжительности тЛ всех передавае-
мых символов =тА. Но в ряде случаев символы могут
иметь различную длительность, например при телеграфной
передаче. Тогда вычисляется тА.
Через шах {/(У, X)} обозначено максимально возможное
значение среднего количества информации, содержащееся
в одном символе принятого сигнала. Максимум функционала
7(У,Х) ищется на множестве функций распределения вероят-
ностей {/?(%)} между символами алфавита X (или других
возможных алфавитов) источника сигналов. Количество
информации I(Y, X), переносимое одним символом, равно
уменьшению степени неопределенности нашего знания о
передаваемом сигнале в результате приема. Неопределен-
ность не устраняется полностью, так как принятый сигнал
может оказаться искаженным помехой. Это количество
информации равно (см. табл. 1-4)
/(У, Х) = Н (Х)-Я(Х|У),
где Н(Х) — энтропия источника сигналов, характеризую-
щая среднюю неопределенность передаваемого сигнала до
приема; H(X\Y) — средняя.условная энтропия ансамбля сиг-
налов х при известных принятых сигналах у, характеризую-
294
щая остаточную среднюю неопределенность передаваемых
сигналов, если известны принимаемые.
Отсюда видно, что среднее количество информации,
содержащееся в символе, зависит от распределения вероят-
ностей между возможными символами, вырабатываемыми
источником сигналов, и от характера и уровня шумов, кото-
рые определяют условную энтропию Н(Х | У).
Скорость vx определяется только свойствами канала и не
зависит от источника сигналов. То же самое можно сказать
и о значении max {/(У, X)}, которое также не зависит от
применяемого источника, так как эта величина есть макси-
мум средней информации, которая может быть передана
по каналу одним символом при оптимальном источнике.
Таким образом, пропускная способность зависит исклю-
чительно от канала.
Рассмотрим вопросы передачи сообщений для трех видов
каналов* дискретного канала без помех, дискретного канала
с помехами и непрерывного канала с помехами. Определим
для этих каналов зависимость скорости передачи информа-
ции от вида и уровня помех и от вида источника сообщения
(от распределения вероятностей на множестве символов
сообщений источника). Эти вопросы, являющиеся основными
в теории передачи информации, были впервые глубоко
исследованы Шенноном [Л. 6-9].
Дискретный канал без помех
Пропускная способность канала
Дискретный источник информации создает сообщения,
состоящие из символов определенного алфавита Z — {гъ
z2, .... zn}. Символы сообщения могут быть независимыми
или зависеть от предыдущих символов, как, например,
в языковом тексте. Предположим, что каждый переданный
символ зависит от г предыдущих. Понимая под состояниями
различные комбинации из г предшествующих символов,
будем говорить о дискретном множестве состояний источ-
ника. Если г = 0 (все символы сообщения независимы),
имеется только одно состояние, которому соответствует
определенное распределение вероятностей р(гг) между симво-
лами гг:
Z2 ... Zn
P(Z1) р(га) ... P(z„).
295
При г — 1, т. е. когда каждый переданный символ зави-
сит от предыдущего, число состояний равно п, так как каж-
дому новому символу может предшествовать один из п
символов алфавита. Этому случаю соответствует п различ-
ных распределений указанного выше типа. При г —k
число состояний равно всем возможным комбинациям пред-
шествующих k символов. Число таких комбинаций равно
nk. Каждому состоянию sf дискретного источника соответ-
ствует распределение условных вероятностей между
символами алфавита, определяемое этим состоянием:
z2 ... zn
P^\Sj) p^sj) ... p(z„|sy).
Каждое такое распределение имеет энтропию Hj (см. гл. 1).
Энтропия источника Н(Z) определяется в единицах информа-
ции на символ сообщения как математическое ожидание
энтропий Hf.
k - k
H(Z)= у p (sy) Hj = — 2 p (sy) p {Zi I Sy) loga (Zi I Sy),
/=1 y=l i = l
где основание логарифма а определяет единицу измерения
информации.
Таким образом, энтропия источника представляет собой
среднюю условную энтропию выбора символа сообщения
из алфавита Z, если известны все возможные состояния
источника. В частном случае, когда символы независимы,
pfafy) =p{zt). При этом, учитывая, что 2 р (Sy) =1,по-
7=1
лучаем:
H{Z) = — 2 р (zi) log„ р (Zi).
i = 1
Чтобы не усложнять изложения, в дальнейшем будем
рассматривать только этот случай, но все теоремы и резуль-
таты справедливы для общего случая.
Аналогично определяется и энтропия источника сигнала
Н(Х).
Перейдем теперь к рассмотрению дискретного канала
без помех. В любом реальном канале всегда присутствуют
помехи. Однако если их уровень настолько мал, что
вероятность искажения практически равна нулю, можно
условно считать, что все сигналы передаются неискажен-
296
ными. В этом случае среднее количество информации,
переносимое одним символом,
7 (У, Х) = ЦХ, Х) = Н(Х)\
его максимальное значение
max {7 (У, Х)} = 77т(Х),
где Нт(Х) — максимальная энтропия источника сигналов,
получающаяся при равномерном распределении вероятно-
стей символов алфавита источника:
р(х1) = р(х2) = ... =
Но максимальная энтропия выражается в единицах
информации на символ сигнала как
Нт (X) ---- log„ т.
Следовательно, пропускная способность дискретного
канала без помех в единицах информации за единицу вре-
мени равна:
C = ujog0m.
Основная теория Шеннона о кодировании для дискретного
канала без помех
Основная теорема о кодировании, сформулированная
Шенноном, утверждает, что если источник информации
имеет энтропию Н(Z) единиц информации на символ сообще-
ния, а канал связи обладает пропускной способностью С
единиц информации в единицу времени, то 1) сообщения,
вырабатываемые источником, всегда можно закодировать
так, чтобы скорость аг их передачи была сколь угодно близ-
кой к
vem = C/H(Z),
гдещт измеряется в символах сообщения за единицу вре-
мени; 2) не существует способа кодирования, позволяющего
сделать эту скорость большей, чем vzm.
Величина
Z7'(Z) = ^/7 (Z)
называется потоком информации, создаваемой источником.
Согласно сформулированной теореме существует метод ко-
дирования, позволяющий при H'(Z) передавать всю
297
информацию, вырабатываемую источником. При >С
такого метода не существует.
Докажем следующее утверждение, из которого вытекает
справедливость теоремы: если источник информации имеет
энтропию H(Z), то сообщение всегда можно закодировать
так, чтобы средняя длина кода /ср (символов сигнала на
символ сообщения) была сколь угодно близкой к величине
F(Z)/logom.
Предположим, кодирующее устройство преобразует со-
общения в двоичные сигналы. В этом случае нужно доказать,
что можно получить
где е — сколь угодно малая величина. В частности, если
информация измеряется в битах (а =2), то
/ср = Н (Z) — е.
Доказательством может служить указание процедуры
кодирования, приводящей к желаемому результату. Такая
процедура, предложенная Шенноном, приводит к тем же
результатам (за исключением последней цифры), что и опти-
мальное кодирование Фэно (код Шеннона — Фэно, ск гл. 3).
Для иллюстрации метода рассмотрим пример кодирова-
ния по Шеннону сообщений, составленных из символов
алфавита Z, имеющих следующее распределение вероят-
ностей p(z/):
zt : z1zftz8z4z6zez1z8
,,11111111
4 4 8 8 8 16 32 32-
Предварительно символы располагаются в порядке
убывания вероятностей (как в рассматриваемом примере).
Затем каждому символу г,- ставится в соответствие число
Qi, определяемое следующим образом:
Qi = 0;
Сг = РЦ);
Сз=р(г1) + р(г2);
Qn — р (^i) р (^д-1)-
Так как все р(гг) отличны от нуля, все числа Qi оказы-
п
ваются различными, а поскольку^ р(2/) = 1, все Qt<, 1.
i = l
298
Представим эти числа в виде двоичной дроби. Как из-
вестно, представление любого числа Q в системе счисления
с основанием h определяется выражением
Z—1
Q = У qfl = + ... + %/i° + q^h'1 + ... + q-kh\
j=-k
где /г и / — соответственно число разрядов дробной и целой
части Q; е/,- принимают целые значения от 0 до h—1.
Поскольку все Qt<Z 1, имеем:
Qi = q-Jr1 + ?_2/г2 + ...
(в общем случае дробь имеет бесконечное число членов).
В случае двоичной дроби (h = 2)
„ 1 , | . 1 ,
Qi q~t 2i q~% 23 ~г" з 2з ' ’ *' *
где qj могут принимать значения от 0 или 1. Выражение,
составленное из qjt представляет собой двоичную правиль-
ную дробь х
Qi = 9-19-29-3 •••
(целая часть опущена).
Разложение каждого числа осуществляется до тех пор,
пока число членов разложения /,• не окажется в пределах
,0&^^7г<1+1°ё2^. (6-2)
Остальные члены разложения отбрасываются.
В этом случае имеем:
, . ’ 1
р(г;)а=-/7.
2 1
Так как все Qk при k отличаются от Qt по меньшей
мере на р(г{) (что следует из их определения), их двоичные
разложения будут по крайней мере на 1/2Z< больше, чем
разложение для Qt. Это означает, что между ними имеется
различие хотя бы в одном двоичном разряде q. Отсюда сле-
дует, что все разложения будут различными.
Таким образом, каждому символу zt сопоставляется
двоичное число (код) z*, содержащее /г членов:
Qi 9-19-29-3 ••• 9-*, = **»
где 4 определяется соотношением (6-2).
299
Процедуру кодирования поясним на предложенном выше
примере. Имеем:
zp- Zl z2 zs z4 Zt, ze г, z8
Р (Zi): 1/4 1/4 1/8 1/8 1/8 1/16 1/32 1/32
2 2 3 3 3 4 5 5
li- 2 2 3 3 3 4 5 5
Qt- 0 1/4 2/4 5/8 6/8 7/8 15/16 31/32
Представляем все Q, в виде двоичных дробей:
Q1==0000 ...,
Q2 = -|-°+t’ 1 + 4’° + или 010 -
Q3 = v- 1+4--О+4--О + и™ 100 ...
z 4 о
<?4 = у- 1 +4--° + |’1+ - или 101 ...
Об — g" • 1 + ’ 1 + -g-' 0 + pg ’ 0 + • ••» или 1100 ...
ов=4‘1 +т’1 +4’1 +i‘°+i’0+ ил-и 11100 -
о7=у-1 +4-1 +4’1+А’1 +i'°+i’°+ - ’
или 111100 ...
08 = 4" 1 + 4‘ 1 +4’ 1 1 +з2‘ 1 +бГ-°+48‘°+ -
» или 1111100 ...
Оставив в разложениях только lt первых членов, полу-
чим:
Код Длина кодовой комбинации li Код Длина кодовой комбинации
z* = 00 2 z* = 110 3
z* = 01 1 2 z*= 1110 4
z*= 100 3 z* = 11110 5 5
z* = 101 3 zf = 11111 5
Этим путем можно осуществить кодирование не
только символов Z;, но и целых сообщений, создаваемых
источником. Из букв алфавита, содержащего п символов,
можно составить nN сообщений длины N. Например, из
300
алфавита (гъ z2, ..., z8) можно составить 82 = 64 сообщения,
каждое из которых состоит из двух символов,
^2^1 > • • • » ^8^1>
z2z2, .... z8z2,
^1^8’ ^2^8» • • • » ^8^8’
83 = 512 сообщений, состоящих из трех символов, и так
далее.
Набор из k =nN возможных сообщений можно рассмат-
ривать как новый алфавит, содержащий k символов, Z' —
— {г[, z%, ..., z'k}. Кодирование символов этого алфавита
приводит к средней длине кодовой комбинаций /ср, в общем
случае меньшей, чем при кодировании символов исходного
алфавита. Покажем это, осуществляя кодирование сообще-
ний длины 7V рассмотренным выше способом. Имеем:
z’r. z’l z2 .... zk
p{.Zi)-. p(z\) p(z'J ... p{zk).
Здесь p(z/) — распределение вероятностей между сообще-
ниями zit имеющими N букв. Длина lN. кодовой комбинации
каждого сообщения zj согласно (6-2)
- log2 Р Ijv. < - log2 р (z;) + 1,
или, что то же самое,
10g«P(4)_; , ,pQ4
- log0 2 Ч <--------+ 1 • (6'3>
Средняя длина кодовой комбинации на одно сообщение
равна:
ь
Ц.р ~ 2 ЦР (20-
Подставляя значения lN. из (6-3), получаем:
k k
1] [loga р (гН] р (з) S [logs р (г'г)] р (*а
i— 1 1 i = 1
log0 2 logs2
или
я (л ,
logo 2 л'ср 10go 2 -г
(6-4)
где H(Z') — энтропия алфавита Z' = {z’lt z2, z2, ..., z'k}.
301
Средняя длина кодовой комбинации на символ исходного
алфавита Z
1.p = In/N- (6-5)
ср
Выразим H(Z') через H(Z). Пусть N =2, т. е. рассмат-
ривается множество двухбуквенных сообщений. В этом
случае H(Z') можно рассматривать как энтропию сложного
опыта, состоящего в выборе по одному символу из двух
одинаковых /алфавитов, совпадающих с алфавитом Z: Zx =
= гг> гп} и Z2 = {гь г2, .... гп}. Но энтропия сложного
опыта
H(Zlt Zi) = H(Z1) + H(Zz\Z1\
где через Н (Z2 | Zj) обозначена условная энтропия, харак-
теризующая среднюю неопределенность выбора символов
из алфавита Z2 при условии, что имел место выбор символа
из алфавита Zr. Если отдельные буквы передаваемого сооб-
щения независимы, то
и Н (Z') = Н (Z1; Z2) = Н (Zi) + Н (Z2) = 2Н (Z).
Для слов с N независимыми буквами методом индукции
можно получить:
H(Z') = NH(Z).
Подставляя в (6-4) и учитывая (6-5), получаем:
logo 2 +1’
или
H(Z) , 1
log02~~ cp loga 2 + N •
При N, стремящемся к бесконечности, получим искомый
результат:
/
*ср —k>ga2‘
Можно также показать, что это соотношение имеет место
и в случае наличия взаимосвязи между буквами сообщения.
Таким образом, имеем:
/
Ар =2= loga2*
302
Распространение данного вывода на общий случай
(т S& 2) приводит к результату
I >0^-
ср"" log0m‘
Предельно достижимая скорость образования и передачи
сообщений связана со средней длиной кода соотношением
Цг “ ^х/^ср-
Следовательно, максимальная скорость передачи сооб-
щений, вырабатываемых источником информации,
„ С
гт~ H(Z) ~ Н (Z) '
что доказывает первую часть теоремы.
Вторая часть, утверждающая, что нельзя осуществлять
без потерь передачу, если поток информации источника
сообщений больше пропускной способности канала, следует
из того факта, что пропускная способность канала равна
максимально возможной скорости передачи информации для
заданного класса источников. Если используется источник,
создающий большее количество информации в единицу вре-
мени, неизбежны потери.
Рассмотренная выше основная теорема указывает предел
игт, но не дает метода экономичного кодирования (кодирова-
ние методом Шеннона или Шеннона — Фэно совершенно не
обязательно, могут быть и другие методы, приближающие
к о?т).
Дискретный канал с помехами
Пропускная способность канала
Дискретный канал с помехами характеризуется услов-
ными вероятностями p(yj | xt) того, что будет принят сиг-
нал У], если передан xit т. е. матрицей
₽(й|*1) •••
Р(й1*2) рШ*2) ••• Р(Ут\х2)
Р (У11 Хт) Р (У2 I Хт) • • • Р (Ут | Хт)
(при отсутствии помех все p(yf | xt) при / =£ i равны 0 и при
j — i равны 1).
303
Среднее количество информации на символ сигнала,
получаемое при приеме одного элементарного сигнала,
равно:
/(У, X) = H(Y) —H(Y\X).
В случае независимости отдельных символов сигнала
энтропия на выходе линии
Н (у) = — S Р (Vi) 1оёа Р (Уд
к ( = >
(предполагается, что число букв алфавита Y = (ylt у2, •••
..., Ут} равно числу букв алфавита X — {хь х2, .... хт} и
равно, следовательно, т). Средняя условная энтропия
Н (У | X) = — р (xt) 2 р (уу | Xi) loga р (yj\ х{).
i— 1 7=1
Пропускная способность канала вычисляется по формуле
(6-1):
C = vxmax{I (Y, X)},
где максимум ищется по всем возможным распределениям
вероятностей, характеризующих источник сигнала.
Для иллюстрации вычислений пропускной способности
рассмотрим следующий пример.
Пусть требуется определить пропускную способность
капала связи, по которому передаются двоичные сигналы
со скоростью vx, если вероятность превращения в резуль-
тате действия помех каждого из этих сигналов в противопо-
ложный равна р (вероятность правильного приема, следо-
вательно, 1 — р). Передаваемые символы предполагаются
независимыми.
В этом случае алфавит X и алфавит У состоят из двух
символов: X =-- {лу, х2}, У = {уъ у2}. Диаграмма рис. 6-22
показывает возможные варианты передачи и соответствую-
щие им вероятности.
Канал такого типа носит название симметричного.
Средняя условная энтропия
я (у IX)=— 2 р (*<) Zi р (У/1 10§« р I *0=
« = 1 7=1
= — Р (*1) [(1 - Р) lOga (1 - Р) + Р 10ga Р] ~
-P(^)[plogop4 (l -P)log„(l -P)l =
= — [р (Xj) + р (ха)j [р loga р + (1 - р) loga (1 - Р)]-
Р(*1) + Р(*2)= 1-
304
Поэтому
Я(У |Х) = —plogflp-(l -р) log0 (1 — р).
Отсюда видно, что Н (У | X) не зависит от характеристик
источника, т. е. от р (хг) ‘и р (х2)-
Максимальное количество информации на один символ
получается, следовательно, при таком распределении веро-
P(y№i)=i-p
Неискаженная передача
Р(у’^р
Передаваемый Принимаемый
сигнал сигнал
^&Р&г1з:г)=р
неискаженная передача
Pfy№)='~P
Рис. 6-22. Диаграмма передачи двоичных
сигналов по симметричному каналу.
ятностей р (Xi), при котором оказывается максимальным
член Н (У). Но Н (У) не может превосходить величины
Ят(У) —log0m = loga 2
[что достигается при р (xj = р (х2) = 1/2]. Поэтому имеем:
max {/ (У, X)} = loga 2 + р log„ р + (1 - р) loga (1 - р)
и, следовательно, пропускная способность
С = vx max {/ (У, X)} =
= vx [10ga 2 + р loga р + (1 - р) loga (1 - р)].
Отсюда следует, в частности, что при р = 0, т. е. при
отсутствии шумов в канале, имеем максимальное значение С
Омакс = Vx loga 2.
При р = 1 также имеем детерминированный случай, ког-
да сигналы хг переводятся в сигналы х2 и наоборот с вероят-
ностью 1. При этом пропускная способность канала также
максимальна:
Смаке = UX loga 2.
Минимальное значение пропускная способность имеет
при р =1/2.
305
В этом случае независимо от полученных сигналов ничего
нельзя сказать о том, какой сигнал был послан: имеет место
такая же ситуация, как если бы в линию связи вообще не
посылались сигналы. Тогда, естественно, пропускная спо-
собность
СМИН = 0.
Основная теорема Шеннона о кодировании
для дискретного канала с помехами
Основная теорема о кодировании для канала с помехами,
приводимая здесь без доказательства, аналогична теореме
для канала без помех: если источник информации имеет
энтропию H(Z), а канал связи обладает пропускной способ-
ностью С, то:
1) сообщения, вырабатываемые источником, всегда мож-
но закодировать так, чтобы скорость ог передачи была сколь
угодно близкой к величине
Vgm = C/H(Z)
и чтобы вероятность ошибки в определении каждого пере-
данного символа была меньше любого заданного числа;
2) не существует метода кодирования, позволяющего
вести передачу со скоростью выше огт и с малой вероят-
ностью ошибки.
Другими словами, если поток информации
’ H'(Z) = vzH (Z)^C,
то может быть подобран специальный код, позволяющий пере-
давать всю информацию со сколь угодно малой вероятностью
ошибки. При Н' (X) > С такого кода не существует.
Этот результат оказывается особенно ценным, так как
интуиция его не подтверждает. Действительно, очевидно,
что при уменьшении скорости передачи информации можно
повысить достоверность. Этого можно добиться, например,
путем многократного повторения каждой буквы сообщения.
Однако для обеспечения нулевой ошибки интуитивно ка-
жется, что скорость передачи иг должна стремиться к нулю
(число повторений должно быть бесконечно большим). Тео-
рема же утверждает, что. всегда можно обеспечить скорость
передачи, равную vzm (путем выбора подходящего кода).
Теорема не дает ответа на вопрос, как выбирать этот код.
Но для приближения к пределу огт общим методом, как и
306
для канала без помех, является кодирование длинных сооб-
щений, а не отдельных символов.
Для иллюстрации рассмотрим пример.
Предположим, по каналу можно передавать двоичные
сигналы (т =2) со скоростью vx. Таким образом, алфавит
сигналов состоит из двух символов: X — {хъ ха}. Помехи
в канале таковы, что в каждой тройке передаваемых симво-
лов может исказиться (т. е. хг перейти в х2 или наоборот)
не более одного символа, причем вероятность искажения
каждой тройки и вероятность приема неискаженной тройки
равны между собой. • 1
Определим пропускную способность С такого канала.
По определению
С = vx max {/(У, X)}.
Скорость передачи vx по каналу элементарных сигналов
х предполагается заданной, и для определения С нужно
найти max {/ (У, X)}.
Среднее количество информации, переносимое сигналом
х, равно:
/(У, X) = H(Y)-H(Y\X).
Следовательно, задача сводится к нахождению выраже-
ний для Н (Y) и Н (У | X) и максимизации их разности.
Для вычисления этих величин рассмотрим новый алфа-
вит X', содержащий все возможные группы из трех симво-
лов. Общее количество таких групп равно т3 =8:
, X-^X^Xq>
XjXjXg > ^*2'^Т^'2»
*1*2*1, *2*2*1,
*2*1*1 , *2*2*2 •
Каждой из этих групп поставим в соответствие новый
символ х/. В результате получим алфавит X' = {xi, хЬ, ...
..., xg}.
Аналогично вместо алфавита У принятых символов будем
рассматривать алфавит У', символы которого сопоставляются
всем возможным тройкам принятых сигналов у. Этот алфа-
вит также содержит т3 — 8 символов: У'= {yi, yi ..., у'8].
Среднее количество информации /(У', X'), переносимое
одним символом сигнала х', в 3 раза больше среднего коли-
чества информации / (У, X), переносимого символом х,
так как каждый сигнал х' состоит из трех символов х. Но
307
скорость vx’ передачи по каналу символов х' в 3 раза меньше
скорости vx. Поэтому пропускная способность может быть
подсчитана как
С = ^тах{/(У,) X')},
где
/ (У', X') = Н (Yr) — H(Y'\ X').
По условию каждый переданный символ х’{ может пре-
вратиться в один из четырех возможных символов у], причем
вероятности этих превращений равны между собой и равны
P(y'i I хд =1/4. Например, x't может превратиться в ре-
зультате искажений помехой в у’2, у’а, у[ или остаться неис-
каженным (у{). Таким образом, таблица условных вероят-
ностей выглядит так:
р(у'1\х’1), РЙК), •••. Р(^К)
Р (y'i I х2), Р (Уъ I х'ч), р(У&\ 4)
p(lh\x's), p(yi\x's), .... p(y's\x's)
В каждой строке четыре члена равны 1/4, а остальные
равны 0. Следовательно,
Я (У' | X') = — 2 Р (x'i) 2 р (у} | x'i) log« Р (у) I x'i) =
r = l /=1
= - |p(^)-4--|’logoT + ^^-44Iog«T + ”♦
... + p(Xg)• 4•loga — I = logo4„
Отсюда видно, что условная энтропия Н (У' | X') не
зависит от энтропии источника. Поэтому
max {/ (У', X')} = Нт (Yr) -H(Y'\ X').
Но энтропия И (У') достигает максимального значения
при р (у\) = р (у2) = ... — р (y't) = 1/8. В этом случае
Hm(Y') = loga8.
Следовательно,
шах {/ (У', X')} = log0 8 - logH 4 = logs2.
Пропускная способность канала связи
C^vx- logo2 = ^loga2.
308
При отсутствии помех Н (У' | X') = 0 и
max {I (Yr, X')} = Нт (У') = log0 8 = 3 loga 2.
При этом
С = ^3 • loge 2 = рд. loga 2.
Отсюда следует, что наличие помех указанного типа
уменьшает пропускную способность канала в 3 раза.
Перейдем теперь к применению основной теоремы. Пред-
положим, что источник информации создает сообщения из
символов алфавита Z = {zb z2, гп}, и энтропия источника
равна Н (Z). Тогда согласно основной теореме символы
z можно передавать со скоростью, сколь угодно близкой к
п — с — log«2
гт H(Z) 3 H(Z)
и co сколь угодно малой вероятностью ошибки. Для этого
сообщения должны быть определенным образом закодиро-
ваны. Задача выбора подходящего кода для каждого кон-
кретного канала решается в каждом случае индивидуально.
Для данного примера можно указать следующий метод
кодирования. Предположим сначала, что помехи в канале
отсутствуют. Тогда, осуществляя кодирование достаточно
длинных сообщений методом Шеннона или Шеннона — Фэно,
можно достичь скорости, сколь угодно близкой к пределу
. _o.Jog02
Vzm~ Н(Х) ’
без какой-либо потери информации. Тем более можно достичь
скорости
_pxlog02
— з н •
При этом символы в канале будут следовать с частотой
их/3. Чтобы полностью использовать пропускную способ-
ность, можно после каждого кодового символа, который
назовем информационным, передавать два дополнительных,
избыточных символа, не несущих информации сообщения.
Эти символы служат для повышения помехоустойчивости
(коррекции ошибок).
Предположим, что в каждой тройке передаваемых симво-
лов qr q2 q3 символ qr является информационным, a q2 и
q3 — корректирующим#. Выберем q2 и q3 так, чтобы суммы
и <71 + <?3
309
оказались четными. При приеме сообщения эти суммы вы-
числяются. Нарушение четности свидетельствует о наличии
одиночной ошибки, которая после обнаружения может быть
исправлена. Поскольку по условию исказиться может не
более одного символа в каждой тройке, ошибки при пере-
даче не будет. Таким образом, передача с указанной ско-
ростью может вестись без ошибок так, как если бы она дейст-
вительно велась по каналу без помех.
Непрерывный канал с помехами
Большой интерес представляет случай, когда канал ис-
пользуется для передачи непрерывных сигналов. Такой
канал носит название непрерывного. Непрерывный сигнал
удобно рассматривать как предел дискретного при уменьше-
нии величины кванта параметра Дх и интервала дискретиза-
ции времени Дг. Уменьшение Дх равносильно переходу
к передаче кодовых сигналов с большим основанием, а
уменьшение Дг — увеличению скорости vx передачи сигна;
лов. Следовательно, непрерывный канал позволяет переда-
вать в принципе большее количество информации. Случай
непрерывного канала является весьма важным, во-первых,
из-за широкого распространения аналоговых сигналов,
а во-вторых, в связи с тем, что он является предельным и
поэтому может служить для различных оценок.
Ширина спектра помехи и полезного сигнала на выходе
канала ограничена его полосой пропускания. Наиболее
просто описывается помеха типа «белого шума», имеющая
равномерный спектр в пределах полосы пропускания
О f fm. Будем считать, что в линии действует помеха
такого типа, имеющая мощность и распределенная по
нормальному закону:
У 2л
Ограничение спектров сигнала и помехи позволяет при
определении количества информации вместо непрерывной
функции x(t) рассматривать дискретизированную х (ik),
tk = /гДг, где интервалы дискретизации определяются по
теореме Котельникова:
Промежуточные значения функции x(t) являются избы-
точными и при условии восстановления функции x(i) с
помощью фильтра Котельникова информации не несут.
310
Интервал Дг определяет необходимую скорость передачи
импульсов x(tk) по каналу:
^=1/Ar=2fm.
Теперь рассмотрим вопрос о максимальном количестве
информации, содержащейся в одном импульсе х Цк). В слу-
чае дискретного канала мы имеем
7 (У, X) = H(X)-H(X\Y).
При отсутствии помех принимаемое количество информа-
ции численно равно энтропии:
7 (У, Х) = Н(Х). .
Максимальное количество информации равно при этом
максимальной энтропии
max {I (У, X)} = Нт (X) = loga т = loga ,
где т — число квантов Дх, содержащихся в интервале
возможного изменения функции 0 х хт. Для не-
прерывной величины Дх-> 0 и Нт(Х) оо. Таким
образом, при отсутствии помех количество информации на
один импульс оказывается бесконечно большим.
Иначе обстоит дело в случае наличия помех. С одной
стороны, при уменьшении Дх увеличивается Н(Х). Но одно-
временно увеличивается вероятность ошибочного принятия
переданного сигнала и, следовательно, Н(Х | У). В резуль-
тате при стремлении Дх к нулю /(У, X) стремится к опреде-
ленному конечному пределу. Пропускная способность не-
прерывного канала с помехами определяется общим соотно-
шением (6-1):
C = vxmax{I (Y, X)},
где vx есть частота дискретных отсчетов.
Определим количество информации /(У, X) для непре-
рывных величин, исходя из количества информации для
дискретных величин, путем предельного перехода при
Дх -> 0. В случае дискретных величин
т
I(Y, X)^H(X)-H(X\Y) = -^lp(xt)]ogap(x1) +
i= 1
т tn
+ 2 р (уА 2 р 1 У/) 1о£« р I у А-
j = 1 i— 1
311
Учитывая, что
У P(yj\xt)=l,
перепишем первый член в виде
т
-У Р (Xi) loga р (Xi) =
i — 1
т г- т
= — У Р (Xi) loga Р (Xi) У р (у/ I Xi) =
i=ll_ /=1
т т
= — 2 У Р (Xi) Р (У/ | Xi) loga р (Xi) =
i=\j=\
т т
= — 2 у Р (Xi, У}) loga Р (Xi).
i=i;=i
Второй член перепишем как:
т т
2 Р (У]) У Р (Xi I yj) lpg« Р (Xi | yj) =
j=\ i=\
m tn
= У У P (У]) P (Xi I Pj) 10ga P (Xi I IJj) =
f =1 y=l
m m
= 22/’ (X“ V'A 10ga P (Xi | Pj).
i = l /=1
Тогда
mm . *
/(r, x)=2
i = 1 j = 1
Для непрерывных величин вместо дискретных вероят-
ностей используются плотности распределения w(x, у),
ш(х | у) и w(x). При стремлении величины квантов к нулю,
а их числа к бесконечности получим выражение для коли-
чества информации.
т т . .. . л
I УДу
7 (У, X) = lim 2 W (Xi’ ЛхЛу 10g« ) L =
Дх->и \ I* Л
Aj-»0I = 1 /==1
т -*оо
-j-co -j-oo
= 5 5 W(x, y)\oga^^ dxdy.
—co —co
12
Учитывая, что
w(x, y) = w(y)w(x\y),
I(Y, X) можно представить в виде
I(Y, X) = H(X)-H(X\Y),
где
4-со
Н (X) = — J w(x) log„ w (х) dx,
— со
4“ СО 4“СО
H(X\Y) = — w(y)w(x\y)logaw(x\y)dxdy.
—со —со
По аналогии с дискретным распределением X и Y вели-
чина Н(Х) называется энтропией, а Н(Х | Y) — условной
энтропией величин с непрерывным распределением. Нужно,
однако, иметь в виду, что эти характеристики не являются
результатом предельного перехода! из энтропии дискретных
величин Н(Х) и Н(Х | Y), поскольку такого предела
не существует и значение этих величин неограниченно воз-
растает.
Таким же образом можно получить соотношение
/(У, Х) = ЦХ, Y) = H(Y)-H(Y\X).
Предположим, влияние помехи подчиняется соотношению
У=х + %,
т. е. помеха добавляется к переданному сигналу и не зависит
отх. Такая помеха называется аддитивной. Этот класс помех
имеет значительное распространение и наиболее хорошо
изучен.
Так как элемент случайности вносит только помеха £,
то при любом фиксированном значений х вероятность того,
что случайная величина у примет значение между у и у +
+ dy, равна вероятности того, что помеха будет находиться
в пределах между g и g + т. е.
w(y\x)dy=w(l)dl, '
или
Но
dy _ dx dg _ 1
di “d&^dg-1’
313
так что
W (у I х) = W (£).
Учитывая это, можно записать:
+ СО -ф-СО
77(У|Х) = — $ J w(x)w(y\x)\ogaw(y\x)dxdy =
—оо —со
= — $ &у(х)Г Jj tw(g) loge^(g)dgldx.
—°° L—°0 J
Так как £ не зависит от х, то
4-СО Ч-ОЭ
H(Y\X) = — j w (£) loga w (E-) d% J w(x)dx=
— co —co
-I-co
= — $ w(l)\ogaw(l) d% = H(B),
—co
где 77(E) — энтропия источника помех. Следовательно,
7 (У, Х) = Я(У)—77(E).
Для помехи типа «белого шума»
w(g)= 1—е 2°1.
У 2зг
Логарифм этого выражения равен:
log„ w (|) = — -1 logo 2ло| - logo «
Подставляя в выражение для Н (Е), получаем:
I logo 2ло| © dg + (g) dg.
---<*' __r.i
Интеграл в первом слагаемом равен 1, а интеграл
второго слагаемого есть дисперсия of. Следовательно,
Н (s) = у loga 2ло| + logo е = у logo 2лео|.
Но о( есть средняя мощность шума, которую будем обо-
значать через Тогда
Н (S) = j loga (2леР?). (6-6)
314
Максимальное количество информации, которое может
содержаться в одном отсчете
max {/(У, Х)} = гпах{//(У) —/7(S)},
будет иметь место при таком распределении вероятностей
w(y), при котором H(Y) достигает максимума. Если задана
средняя мощность Ру сигнала У, равная его дисперсии
то задача сводится к отысканию условного максимума выра-
жения
СО
// (У) = — w (у) loga W (у) dy (6-7)
—оэ
при заданных ограничениях
со
Ру= $ ifw(y)dy = uy,
—со
со
5 w(y)dy=l.
—со
(6-8)
Это — задача вариационного исчисления. /7(У) представ-
ляет собой частный случай функционала типа
ъ
F(g) = \f[g(y)> S'(У). y}dy, (6-9)
а
ставящего в соответствие множеству функций g(y) множество
чисел F. В данном случае
g(y) = w(y)‘,
f [g («/)» g’ (У)> y] = ~w (у) logc w (у)
(в рассматриваемом случае f не зависит от производной
Ш)-
На некоторой функции g(y) =g0(y) или семействе
функций функционал (6-9) может иметь экстремум. Ограни-
чения (6-8) имеют одинаковый интегральный вид:
ь
$ fi [g (g). g' (у)> y]dy = Ci (1=1, 2),
a
где
1л=у^(у), f2 = w(y),
Cj — Uy, C2 — 1.
315
Для определения g0(y) ищется экстремум вспомогатель-
ного функционала
ь
a
2
ф(^) = $ f(g’ g', У) + £ Wi(g, ё'’ У> АУ~
II
ь
= $W g’, y)dy,
а
где — неопределенные множители Лагранжа, а через ф
обозначено подынтегральное выражение (аргументы при
g и g' опущены). Экстремум Ф совпадает с экстремумом
F. Необходимое условие эстремума определяется
нием Эйлера:
уравне-
chp _ d йф___р
dg~ dy'dg~~
(6-10)
Подставляя в
ние, получаем:
(6-10) вместо гр соответствующее
выраже-
2
« [+\ад -А Д
dg ' Li 1,1 dy dg
2
= 0.
:=i
i = l
Второй член уравнения равен нулю вследствие незави-
симости f и fi от g'. В результате имеем:
I— w (у) logo w (у) + lltfw (у) + %2w (г/)]=0,
или
— logo W (у) - + f.yf + Х2 = 0.
Отсюда
12) (//) г— У2а 4" ^2 а — 1,
Множители и Х2 определяются из ограничивающих
условий (6-8):
y2w(y)dy= § ^gZ.tj'lna + X.lna—1
—со —со
_еА«1уо-1|^/2
~ (- \ In а)3/а
И
+.“ +.го , ?csIne—
1= V w(y)dy= e?4j2Ine-l-X,Ina— I dy —-----------—--—-
Л Л (-МПа)!/®
316
Из трех последних выражений получаем:
У2
— плотность нормального закона распределения.
Это решение максимизирует функционал (6-7). Таким
образом, максимум //(У) имеет место, если распределение
ш(г/) является нормальным.
Этот результат, в частности, показывает, что нормальное
распределение соответствует «наиболее случайному» про-
цессу по сравнению с любыми другими случайными процес-
сами, дисперсия (или средняя мощность) которых имеет ту
же величину. Например, процесс с равномерным распреде-
лением «менее случаен», чем процесс с нормальным распре-
делением, имеющий ту же среднюю мощность.
Как известно, сумма двух независимых случайных вели-
чин у = х + £, распределенных по нормальному закону,
также имеет нормальный закон распределения с дисперсией
<j| = о® + <т|. Следовательно, шах {/(К, X)} имеет место
в случае, если сигнал х распределен по нормальному за-
кону. В этом случае в соответствии с результатом (6-6)
имеем:
Нт (У) = loga 2пеРу = у log„ 2ле (Рх + Pg).
При этом
max {I (У, Х)} = Нт (У) - И (Е) = * log„
'i
Если спектр помехи и сигнала на выходе линии ограни-
чен величиной fm, то частота отсчетов по Котельникову
Vx ~
и пропускная способность канала
С = ^шах{7(У, X)} = 2fm llogc =
= fmloga(l+^). (6-11)
Этот весьма важный результат указывает теоретический
предел скорости передачи информации по каналу связи при
ограниченной средней мощности передаваемых сигналов и
при наличии аддитивной помехи в виде «белого шума» с
ограниченным спектром. В табл. 6-4 указан порядок
317
Таблица 6-4
Пропускная способность канала
Вид канала связи С (десятичных единиц информации)
Телевизионные каналы Телефонные, фототелеграфные, радиотрансляционные каналы Телеграфные каналы Органы зрения Органы слуха Органы осязания Органы обоняния Органы вкуса Центральная нервная система Миллионы — десятки миллионов Тысячи — десятки тысяч Десятки — сотни Миллионы Тысячи Десятки тысяч Единицы — десятки Единицы Единицы
пропускной способности некоторых технических и биоло-
гических каналов.
Так как энергетический спектр помехи типа «белого
шума» равномерен в пределах от 0 до fm, мощность Р.
можно выразить через удельную мощность Ро на единицу
частоты. Тогда формула (6-11) примет вид:
С — fm loga ( 1 +
\ 'oZi
При расширении полосы пропускания канала fm про-
пускная способность увеличивается, но стремится к конеч-
ному пределу:
с --L?*
т In а Ро •
При измерении в битах
Ст= 1,443РХ/РО.
Это — ограничение, вносимое помехой с уровнем мощ-
ности Ро, которое не может быть превышено без увеличения
мощности сигнала.
Если распределение w(z) непрерывных сообщений, выра-
батываемых источником информации, отличается от нор-
мального, то скорость передачи информации будет меньше С.
Однако путем пропускания сообщений г через нелинейный
функциональный преобразователь, характеристика которого
318
х = <p(z) подобрана соответствующим образом, можно полу-
чить сигналы х с нормальным распределением w(x). Функ-
цию <р(г) легко получить графически, построив имеющееся
распределение w(z) и желаемое ш(х) (рис. 6-23). Путем такого
функционального преобразования, приводящего к измене-
нию закона распределения
вероятностей, можно уве-
личить скорость передачи
информации. Естественно,
что на приемной стороне
должно быть осуществлено
обратное преобразование
с целью расшифровки.
Использование кодо-
импульсной модуляции с
кодированием непрерыв-
ных сообщений z(t) в ка-
кой-либо конечной системе
Рис. 6-23. Графическое построение
функции х = <р (г).
счисления также приводит к уменьшению скорости пере-
дачи информации. Предположим, что осуществляется ко-
дирование в системе счисления с основанием т. Тогда
полный набор кодирующих импульсов (алфавит) содержит
т сигналов:
— —ту— . — 2Дг, — кг, 0, + кг, ф- 2Дг, ...,*+ 2 1; кг,
где кг — принятая величина кванта переменной г. При
достаточно большом кванте кг передача будет вестись со
сколь угодно малой вероятностью ошибки. Это эквивалентно
передаче по каналу без помех. Пропускная способность
канала, использующего символы из этого алфавита, равна
С = vx loga m = у loga m2 = vx loga m2,
где vx — скорость передачи кодирующих импульсов по
линии связи. Пропускная способность достигается при рав-
ной вероятности pt всех т уровней 1кг(1 =0, ±1, ±2
и т. д.). В этом случае средняя мощность сигнала х = ikz
равна:
т (т—0/2
(m—1)/2
2Д*2 V /2
i=l
319
Как известно, сумма ряда
2 п (п + I) (2п + 1)
f=i
Следовательно,
Отсюда
Рх = ~(т2-1).
т2~ 1 + Дг2/12‘
Подставляя это выражение в формулу для С, получаем:
С=й1ов„(1+^). (6-12)
Из этого выражения видно, что с уменьшением Аг про-
пускная способность увеличивается. Однако величина кванта
ограничена снизу допустимой вероятностью искажения
сигнала в результате действия помехи. В случае аддитивной
помехи с плотностью распределения w (£) вероятность иска-
жения совпадает с вероятностью выхода реализации помехи
за пределы интервала квантования ( — , так как
в этом случае переданный квантованный сигнал будет отож-
дествлен с сигналом, имеющим другое число квантов. Сле-
довательно, вероятность, ошибки
— Дг/2 +°э
рош= ™ (£)&,.
—со + Дг/2
Для нормально распределенной помехи
СО _
рош = 2 f —L—е 2ai^=l-of—
где Ф — табулированная функция ошибок [Л. 4-7]. Отсюда
видно, что рош есть функция отношения /г = —- =
С увеличением k рош уменьшается.
В современных системах передачи информации благо-
даря принимаемым мерам по повышению помехоустойчи-
вости вероятность искаженного приема не превышает 10 6 —
10-9. Полагая рош = 10“®, найдем, что это требование
удовлетворяется при k = 10.
320
Выражая Дг через и k, перепишем (6-12) в виде
C = ^logo(l+|22^).
(6-13)
Если частоту ’ отсчетов оставить 'такой же, как и для
непрерывного сигнала (vx = 2fm или vx = fm), то из сравне-
ния (6-13) и (6-11) видно, что пропускная способность канала
в случае передачи кодированного сигнала меньше. Если же
мы хотим сделать пропускные способности одинаковыми,
мощность сигнала Рх должна быть увеличена в &2/12 раз,
при k = 10 — примерно в'8 раз.
Пропускная способность, определяемая формулой (6-11),
есть предельная скорость передачи информации по каналу
со сколь угодно редкими ошибками, достигаемая путем
применения сложных методов преобразования и кодирова-
ния сообщений. Для обеспечения этой скорости передавае-
мый сигнал должен обладать свойствами «белого шума».
Это должен быть случайный нормально распределенный и
слабо коррелированный, имеющий широкий равномерный
энергетический спектр, сигнал.
Если помеха имеет неравномерный энергетический спектр,
то скорость передачи информации может быть увеличена
путем перераспределения мощности сигнала с увеличением
ее на участках спектра, где мощность помехи меньше. Канал
с неравномерным спектром помехи имеет большую пропуск-
ную способность. Следовательно, в этом смысле помеха
типа «белого шума» обладает наихудшей спектральной
характеристикой.
Шенноном получены также оценки пропускной способ-
ности каналов при ограничении пиковой мощности сигнала
[Л. 6-9], что всегда имеет место на практике, так как пере-
датчик обладает конечной мощностью. Верхняя граница
определяется следующими соотношениями: для больших
сигналов -=r > 1
\Рь /
для малых сигналов
11 Темников Ф. Е. и др.
C^fm logo(l+^).
«
321
Снизу .пропускная способность ограничена неравенством
где Рх — пиковая мощность сигнала; — средняя мощ-
ность помехи.'
При передаче со скоростью большей С никакие методы не
могут обеспечить малую вероятность ошибки.
Рассмотрим в качестве примера один из возможных
методов преобразования и кодирования, позволяющих
приблизиться к пропускной способности канала. Этот спо-
соб, указанный Шенноном, состоит в следующем.
Предположим, имеется дискретный источник сообщений,
и сообщения кодируются оптимальным образом, т. е. так,
что средняя длина кодированной комбинации (в двоичных
символах на букву алфавита источника) близка (с заданной
точностью) к величине H(Z). При этом средняя частота каж-
дого из двух кодовых символов и г2 будет одинаковой, а
последовательные символы независимыми. Если источник
непрерывный, то предварительно квантуются с заданной
точностью дискретные значения функции, отсчитываемые
в интервалы времени kA-/. _
Как было показано выше, для возможно более полного
использования пропускной способности канала нужно,
чтобы передаваемый сигнал обладал шумовыми свойствами.
Для этого передаваемые закодированные сообщения должны
быть преобразованы в сигналы, подобные «белому шуму».
Это можно сделать следующим образом. Предварительно
создаются с помощью генератора «белого шума» 2Z «образ-
цов» шума длительностью НС, которые запоминаются.
Такие «образцы» должны храниться на приемной и передаю-
щей стороне. Затем закодированное сообщение разбивается
на группы по I символов в каждой группе. Полный набор
различных групп типа qt, q2, ..., qt (q, = гу или z2) составляет
N = 2Z. Будем рассматривать этот набор как новый алфавит
X = {хъ ..., Xjy}. Каждой его букве х, ставится в соответ-
ствие один из «образцов» шума. Для передачи вместо двоич-
ных импульсов qi используются «образцы» шума из алфавита
X = {*i> •••» М- Таким образом, в линию связи посту-
пает сигнал в виде «белого шума», причем чем больше I,
т. е. чем больше применяется «образцов», тем более сигнал
в линии приближается к истинному «белому шуму». По-
скольку длительность каждого символа составляет НС,
длительность одного символа исходного сообщения равна
322
Ml 4/C = 1/C. Таким образом, передача информации ведется
со скоростью С. В процессе передачи сигнал искажается,
и на приемную сторону приходит шум, отличный от передан-
ного. Принятый сигнал на каждом интервале длины НС
сравнивается с «образцами» шума, и из них выбирается
наиболее близкий (по какой-либо метрике) образец, напри-
мер «образец» с наименьшим среднеквадратичным отклоне-
нием, которому соответствует определенная кодовая комби-
нация qrq2 ... qt. При расшифровке переданного сигнала
неизбежно возникают ошибки. Чтобы уменьшить их вероят-
ность, нужно кодировать более длинные сообщения. С увели-
чением длины I кодируемых групп qrq2 ...qiH, следовательно,
длительности «образцов» шума ошибка может быть сделана
сколь угодно малой.
В процессе практической реализации выбор шумовых
сигналов производится таким образом, чтобы взаимная кор-
реляционная функция образцов шума была близка к нулю
при любых сдвигах, а автокорреляционная функция об-
разцов имела единственный узкий всплеск при нулевом
сдвиге.
Однако использование для передачи информации естест-
венного шума ограничивается рядом технических труднос-
тей. К ним относится необходимость хранения точных копий
сложных сигналов на передающей и приемной сторонах,
необходимость и трудность осуществления синхронизации,
недостаточное использование мощности передатчика в связи
со значительными различиями в величине средней и пиковой
мощности шума. Поэтому большее применение нашли
детерминированные сигналы, обладающие указанными выше
свойствами шума, но лишенные этих недостатков. Такие
сигналы получили название шумоподобных или псевдо-
случайных.
В настоящее время разработан ряд оригинальных методов
и устройств получения шумоподобных сигналов [Л. 6-111.
Один из эффективных методов состоит в формировании по
определенному закону двоичных кодовых последователь-
ностей, обладающих шумовыми свойствами.
Такие сигналы могут быть образованы, в частности, на
основе циклических т-последовательностей Хаффмена, отли-
чительная черта которых состоит в том, что любая кодовая
комбинация при циклической перестановке разрядов при-
нимает исходное значение через т шагов. Этот период для
т-последовательностей является максимальным по отноше-
нию к периодам других циклических кодов. Таким образом,
11*
323
число разрешенных кодовых комбинаций N = m. Если
п — число информационных разрядов, то
т = 2п — 1.
Отсюда видно, что т всегда
ность является эквидистантным
Рис. 6-24. Реализация шумоподоб-
ного кодового сигнала.
a — временная функция; б — функция
автокорреляции.
где Тт — длительность одной
нечетно, т-последователь-
кодом с расстоянием между
любой парой комбинаций
Примером может слу-
жить следующий набор
(т = 7):
1110100, 0111010,
0011101, 1001110, 0100111,
1010011, 1101001.
Подобный код сущест-
вует ДЛЯ любого П Эг 2.
Если его изобразить в виде
последовательности поло-
жительных и отрицатель-
ных импульсов (рис.. 6-24,а)
длительности То — Тт/т,
комбинации, то функция,
корреляции такого сигнала, изображенная на рис. 6-24, б,
имеет треугольный вид. При нулевом сдвиге Вхх(0)
равна мощности импульса Р, а при сдвигах, больших
То, Bxx(t) = . Для достаточно больших т Вхх (т) при-
ближается к дельта-функции, поскольку Р/т неограниченно
убывает, а То стремится к нулю. При кодировании пакетов
из I символов алфавита Z с увеличением /.растет и необходи-
мая разрядность т, а сам код приближается к шумоподоб-
ному. При этом скорость передачи информации может быть
сделана сколь угодно близкой к пропускной способности
канала [Л. 6-121.
Согласование характеристик сигнала и каната
Сигнал может быть охарактеризован различными пара-
метрами. Таких параметров, вообще говоря, очень много,
но для задач, которые 'приходится решать на практике,
существенно лишь небольшое их число. Например, при
выборе прибора для контроля технологического процесса
может потребоваться знание дисперсии сигнала; если
324
сигнал используется для управления, существенным яв-
ляется его мощность, и т. д. Рассмотрим три основных
параметра сигнала, существенных для передачи по каналу
[Л. 4-7]. Первым важным параметром является время пере-
дачи сигнала. Второй характеристикой, которую прихо-
дится учитывать, является мощность Рх сигнала, передавае-
мого по каналу с определенным уровнем помех Р^. Чем боль-
ше величина Рх по сравнению с тем меньше вероятность
ошибочного приема. Таким образом, представляет интерес
отношение Рх / Р£. Удобно, как будет видно дальше, поль-
зоваться логарифмом этого отношения, называемым превы-
шением сигнала над помехой:
£x=10go(Px/P|).
Третьим важным параметром является спектр частот
Fx. Эти три параметра позволяют представить любой сигнал
в трехмерном пространстве с координатами L, Т, F в виде
параллелепипеда с объемом Тх Fx Lx. Данное, произведение
носит название объема сигнала и обозначается через Vx:
Vx — TXFXLX.
Соответственно канал связи может быть охарактеризован
временем использования канала Tk (т. е. временем, в течение
которого канал предоставлен для работы), полосой пропуска-
ния Fk и динамическим диапазоном Lk, равным разности
максимально допустимого уровня сигнала в канале и уровня
помех (в логарифмическом масштабе):
^ = logoPXMaKC- log0PE = loga^^.
Таким образом, канал также можно охарактеризовать
объемом 'ь
Vk — TkFkLk.
Для того чтобы сигнал мог быть передан по каналу,
необходимо выполнение условий:
Tx^Tk-, Fx^Fk- Lx^Lk, (6-14)
т. е. сигнал должен полностью уместиться в объеме Vk.
При этом, конечно, Vx <1 Vk, однако только этого условия
недостаточно. Тем не менее, если Vx Vк, но условия
(6-14) не выполняются, сигнал может быть определенным
325
образом преобразован, так что передача окажется возмож"
ной.
Рассмотрим связь между количеством информации и объ-
емом сигнала.
Максимальное количество информации, которое можно
передать по каналу связи в течение времени наблюдения
Tk =ТХ, равно:
/ = ^C = 7xfmlog0(l+^. (6-15)
кого импульса. Как видно из
Здесь 2fm есть скорость передачи отсчетов хг функции
x(t) по каналу, численно равная удвоенной максимальной
частоте спектра сигнала x(t). Импульсы, следующие с
частотой 2fm, могут занимать спектр, больший fm. Этот спектр
определяется формой и продолжительностью импульсов.
Можно, однако, показать, что в предельном случае ширина
спектра сигнала, состоя-
щего из последовательно-
сти импульсов, составляет
FX = fm-
Для этого рассмотрим
. последовательность им-
пульсов x'i, форма которых
описывается функцией
sin-^- (t—
Xt = xi . (6-16)
д- (t — iAT)
Такой сигнал, как ука-
зывалось в гл. 2, полу-
чается на выходе фильтра
нижних частот при подаче
на его вход очень корот-
рис. 6-25, сигнал симметри-
чен относительно точки /Ду и имеет амплитуду xt. Спектр
с 1
такого импульса не содержит частот выше fm = ,
так как согласно теореме Котельникова сумма подобных
импульсов формирует функцию с предельной частотой fm.
Нули функции, описывающей импульс, приходятся на мо-
менты времени k\T Поэтому если производить от-
счеты в моменты времени (Ду, будут измеряться только амп-
литуды тех импульсов, максимум которых приходится на
эти моменты времени.
326
Таким образом, полоса частот, требуемая для передачи
информации, составляет Fx —fm. Учитывая это, можно
записать для *> 1:
1 (,
I = TxFx\oga^=TxFxLx=Vx. (6-17)
При полном использовании характеристик канала
Vx = Vk. Следовательно, при увеличении отношения сиг-
нал/шум предельное количество информации, которое
можно получить при наблюдении за процессом, стремится
к объему канала.
Рис. 6-26. Преобразования переноса без изменения
объема сигнала.
а — перенос во времени; б — перенос по оси частот;
в — перенос по шкале превышений.
Посмотрим теперь, каким явлениям соответствуют раз-
личные преобразования объема сигнала, применяемые
с целью согласования с каналом, т. е. для обеспечения
выполнения условий (6-14).
На рис. 6-26 изображены преобразования переноса (без
изменения формы и объема сигнала). Перенос вдоль оси
времени вправо (рис. 6-26, а) означает задержку на время
То. Перенос влево соответствует опережению. Случай То — О
327
Рис. 6-27. Преобразования дефор-
мации без изменения объема сиг-
нала.
б)
означает, что передача началась в момент времени t = 0.
Перенос на оси частот F (рис. 6-26, б) соответствует одно-
полосной модуляции с не-
сущей частотой Fo.
сигнала Fx при этом остает-
ся неизменным. Перенос
вдоль оси L (рис. 6-26, е)
означает усиление или ос-
лабление сигнала, содер-
жащего помеху, так что
превышение остается преж-
ним.
Рассмотрим теперь пре-
образования деформации
без изменения объема сиг-
нала. На рис. 6-27 показана возможность деформации
объема путем увеличения измерения Fx и соответствую-
щего уменьшения измерения Тх и наоборот, путем увели-
чения Тх и уменьшения Fx по
сравнению с первоначальными
размерами. При этом объем сиг-
нала остается неизменным. При-
мером деформации этого вида
служит запись сообщения на
магнитную ленту, перемещаю-
щуюся с повышенной скоростью
v2, и последующее воспроизве-
дение с нормальной скоростью
г?!. При этом время передачи
(воспроизведения) возрастает в
v2/vi раз, но во столько же раз
уменьшается полоса частот вос-
производимого сигнала. Такое
преобразование позволяет согла-
совать сигнал с каналом, имею-
щим полосу пропускания мень-
шую, чем спектр первоначального
сообщения. Наоборот, если поло-
са пропускания канала не исполь-
зуется полностью, можно сокра-
тить время передачи, записывая
сигнал на ленту, движущуюся
замедленно, а затем воспроизводя
его с нормальной скоростью.
х=г*
h=i
гпппгпгп ГП »
Дт I*-
ф
Рис. 6-28. Преобразование
сигнала изменением системы
кодирования.
а — исходный непрерывный
сигнал; б — сигнал, закодиро-
ванный в системе счисления
с основанием т\ в — сигнал,
закодированный в двоичной си-
стеме счисления.
328
Другим примером деформации с изменением объема
служит изменение системы кодирования. Предположим,
максимальное значение функции z(t) сообщения есть гт
(рис. 6-28) и кодирование осуществляется в системе счис-
ления т = +1 (рис. 7-28, б), т. е. сигнал x(t) в линии
представляет собой закодированную последовательность z*
отсчетов функции z(t). Тогда переход от системы счисления
соснованием/г = т к двоичной h =2 (рис. 7-28, в) позволя-
ет уменьшить среднюю мощность закодированного сигнала,
и, следовательно, уменьшить превышение Lx = log,, (Рх/Р^.
Но если время передачи Тх остается неизменным, в ин-
тервале Дг должен будет уместиться не один импульс,
а I = logc т импульсов. При этом ширина каждого импуль-
са уменьшится, а спектр сигнала увеличится в I раз и бу-
дет равен Fx — IFX. Если же мы хотим оставить неизмен-
ным спектр Fx, должно быть увеличено время Т'х = 1ТХ.
6-4. ПОВЫШЕНИЕ ПОМЕХОУСТОЙЧИВОСТИ ПЕРЕДАЧИ И ПРИЕМА
Повышение помехоустойчивости является одной из наи-
более важных задач передачи информации. Увеличение
помехоустойчивости не дается даром. Оно связано с вве-
дением определенной избыточности, т. е. с увеличением
объема сигнала. Если емкость канала это допускает, мо-
гут быть приняты меры, повышающие надежность пере-
дачи. Отметим некоторые из них.
1. Простейшей мерой является увеличение мощности
сигнала. Это приводит к дополнительному превышению Lx
сигнала над помехой и соответствующему увеличению объема
сигнала.
2. Применение помехоустойчивого кодирования. По-
мехоустойчивое кодирование, как отмечалось в гл. 3, всег-
да связано с введением избыточных символов в код переда-
ваемого сообщения. Эти символы позволяют на приемной
стороне обнаружить и исправить ошибки. Введение до-
полнительных символов увеличивает либо время передачи
Тх, либо частоту fm передачи символов кода, что приводит
к расширению спектра Fx, либо то и другое одновременно.
3. Применение помехоустойчивых видов модуляции.
Большая помехоустойчивость отдельных видов модуляции
(см. гл. 4) достигается либо благодаря широкому спектру Fx
модулированного сигнала (частотная, фазовая, фазо-им-
пульсная и другие виды модуляции), либо путем увели-
329
чения времени Тх передачи (например, при использовании
для кодо-импульсной модуляции достаточно широких им-
пульсов, что уменьшает спектр, но увеличивает длитель-
ность передачи).
4. Применение помехоустойчивых методов приема. Как
будет показано ниже, применение различных методов
фильтрации принимаемого сигнала увеличивает поме-
хоустойчивость, но связано с увеличением времени при-
ема и, следовательно, требует увеличения времени пере-
дачи Тх.
5. Применение каналов с обратной связью. Если име-
ется возможность установить дополнительный канал связи
между передающим и приемным пунктами или такой ка-
нал уже существует, то его можно использовать как канал
обратной связи (см. табл. 6-3). В ряде случаев обратный
канал может иметь большую надежность, чем прямой,
либо в связи с малым объемом информации, передаваемой
по нему, что дает возможность использовать помехоустой-
чивые методы передачи, либо в связи с различием харак-
теристик этих каналов (приемно-передающих средств).
Это обстоятельство позволяет повысить надежность пря-
мой передачи. По каналу обратной связи может передавать-
ся либо весь объем принимаемой информации с целью
контроля работы прямого канала и принятия мер по по-
вышению достоверности передачи, либо только информация
о сомнительных сигналах, которые требуется повторить.
В последнем случае на приемной стороне включается решаю-
щее устройство, дающее заключение о том, какой сигнал
был передан. Если уверенность в переданном сигнале
достаточно велика, обратный сигнал не посылается, если
же уверенность недостаточна, делается запрос на повторную
передачу. Работа такой системы напоминает телефонный
разговор, когда абонент переспрашивает неясные слова
или фразы, в то время как работу системы первого типа
можно сравнить с разговором, когда слушающий повторяет
все без исключения фразы, а сообщающий делает заключе-
ние о качестве работы линии и степени восприятия. Сис-
темы передачи первого типа называются системами с ин-
формационной обратной связью, системы второго типа —
системами с решающей или управляющей обратной связью,
или системами с переспросом. В последних могут эффектив-
но применяться статистические методы приема, например
последовательный анализ (см. § 5-4), позволяющие значи-
тельно увеличить помехоустойчивость. Повышение помехо-
330
устойчивости связано в данном случае с увеличением обо-
рудования (два канала вместо одного)и с увеличением вре-
мени передачи’ Тх.
Вопросы помехоустойчивого кодирования и модуляции
излагались в главах 3 и 4. Ниже рассматриваются методы
помехоустойчивого приема информации.
Задача помехоустойчивого приема состоит' в использо-
вании избыточности, а также имеющихся сведений о свой-
ствах и характеристиках сигнала и канала для увеличения
вероятности правильного приема [Л. 4-7, 4-8].
Физические модулированные сигналы будем обозначать,
как в гл. 4: их — переданный сигнал, иЕ — помеха, иу —
принятый сигнал. Для определенности будем рассматривать
обычно встречающуюся при приеме кодовых сигналов
пс
Uy(t)=Ux(t)
₽£
Рис. 6-29. Схема приемника сигнала.
Ф — фильтр; Р — решающее устройство.
задачу. Предположим, имеем двоичный сигнал ux(t) в виде
импульса или отрезка синусоиды, амплитуда которого может
принимать два значения 0 и U хт, соответствующих кодам
О и 1. В процессе передачи на сигнал их (t) накладывается
помеха (/), в результате чего принимается искаженный
сигнал
uy(t) = ux (t)(f).
Задача состоит в том, чтобы определить, содержится ли
в принятом сигнале иу (t) полезный сигнал их (t) или иу (/)
представляет собой только шум. Такую задачу называют
задачей обнаружения сигналов. Задача обнару-
жения не имеет точного решения, так как всегда имеется
вероятность (пусть малая), что большой всплеск шума
будет отождествлен с полезным сигналом.
Для уменьшения вероятности ошибки может быть произ-
ведено такое преобразование сигнала иу (/), которое увели-
чит отношение полезной составляющей к помехе. Такого
’типа преобразование будем называть фильтрацией. Таким
образом, блок-схему приемного устройства (рис. 6-29)
можно представить в виде последовательного соединения
331
фильтра Ф и решающего устройства Р. На вход фильтра
поступает сигнал
Отношение мощности сигнала к мощности помехи
Ру = Р х/Р^-
На выходе фильтра имеем сигнал
Ug (0 = Ub (t) 4- «г; (О,
в котором слагаемое ub (t) характеризует полезную состав-
ляющую, связанную с их (t), а (t) — шум, связанный с
п. (t). Отношение рг = P jPy\ Для выходного сигнала' фильтр^
имеет большую величину, чем ру. Решающее устройство
определяет значение х* [х2 = 1 или = 0 — наличие или
отсутствие полезного сигнала их (/) ₽ принятом сигнале
Uj, (/)].
Рассмотрим некоторые методы фильтрации, позволяющие
увеличить отношение по сравнению с pv. Результаты,
полученные для двоичных сигналов, легко обобщаются на
коды с любым основанием.
Частотная фильтрация
Предположим, что переданный сигнал представляет
собой отрезок синусоиды
их (0 = Uxm sin ю0/,
определенный на интервале Тх, и в линии связи имеет место
помеха типа «белого шума».
Для выделения полезного сигнала такого вида широко
применяются частотные полосовые фильтры, настроенные
на частоту сигнала.
Реальный «белый шум» имеет равномерный спектр в ши-
роком, но конечном интервале частот, в связи с чем средняя
мощность помехи ограничена величиной Р£. Следователь-
но, отношение
' Ру=Рх/Р^
также конечно. Обозначим через Ро среднюю мощность по-
мехи, приходящуюся на единицу частоты, и через Асоо —
полосу пропускания фильтра. Тогда мощность шума на
выходе фильтра
Рч = Р0Аю0 = 2лА/0Р0.
332
Мощность же полезной составляющей остается прежней:
Рь = Рх.
Отношение мощностей сигнала и помехи
Отсюда видно, что чем меньше полоса пропускания фильт-
ра А<оо (или А/о), тем больше отношение рлг.
Покажем теперь, что увеличение помехоустойчивости
(отношение р(,) связано с увеличением времени наблюдения
Тх. Если бы сигнал их (t) длился бесконечно долго, спектр
его состоял бы из одной линии, т. е. был бы бесконечно
узким. В действительности же их (t) представляет собой от-
резок синусоиды, который можно рассматривать как импульс
синусоидальной формы длительностью Тх. Поэтому спектр
его занимает некоторую полосу частот, отличную от нуля.
При увеличении числа периодов в синусоиде (при возраста-
нии Тх) спектр сужается от бесконечности до нуля (см.
гл. 4, рис. 4-14,6). Ширина спектра А/ и длительность сиг-
нала Тх связаны соотношением (4-9), которое для приня-
тых обозначений имеет вид:
Д/т\=р,
где р — постоянная для данной формы сигнала величина,
имеющая порядок единицы.
Отсюда
А/ — р/Тх-
Длительность сигнала Тх должна быть выбрана такой,
чтобы его спектр стал меньше полосы пропускания фильтра:
Только в этом случае мощность полезного сигнала на
выходе фильтра можно считать равной Рх. Подставляя в
(7-18) вместо АД величину р/7'х, получаем:
= 2лр/\) ‘ (6-18а)
Из этого выражения видно, что чем большее значение
рё требуется получить, тем больше должна быть длитель-
ность сигнала Тх (время наблюдения). Формулы (7-18) и
(7-18а) позволяют рассчитать необходимые значения А/о
и Тх.
333
Метод накопления
Предположим, что их представляет собой постоянный
сигнал
ux=U0
и в течение времени передачи этого сигнала Тх (т. е. на ин-
тервале, равном длительности передаваемого импульса)
осуществляется многократное его измерение. Покажем,
что суммирование этих отсчетов позволяет увеличить от-
ношение р.
Рис. 6-30. Фильтрация методом накопления.
а — фильтрация постоянного сигнала; б — фильтрация периодиче-
ского сигнала.
Поскольку принимаемый сигнал есть сумма передан-
ного сигнала и помехи (рис. 6-30, а)
Нд, --- Uq —j-
он представляет собой случайную функцию времени. Обоз-
начим последовательность отсчетов через иу1:
= Ц) Н-
= Uq —j— W.2’
— Uq —j-
Рассмотрим случай, когда указанные отсчеты не кор-
релированы, т. е. берутся через интервалы времени А/>
(т0 — интервал корреляции). На выходе фильтра имеем:
~ — j” tl^f == Ilf) —j” 11ц.
i=l j=l
334
Отношение мощностей на выходе фильтра
ul n2 Us
о ==---— —_________° ,
£>[(/] Г» 1’
D
-‘ = 1 J
п
где через DlU^] = D{ E7£i] обозначена дисперсия помехи
i=l
и^. Вследствие принятого допущения о независимости от-
счетов U,;
' / - г'
Li —1 J г=1
В силу стационарной помехи (t):
D [£7е J = D [t/E J =... = D [t7e„] = D [UJ,
поэтому
«2 ui Ul
nD [l/J ~n D [t/e] ~ П P>”
т. e. pg растет пропорционально числу отсчетов п.
Если их представляет собой не постоянный сигнал,
а последовательность периодических импульсов произволь-
ной формы (рис. 6-32, б), то отсчеты нужно брать через
интервалы Л?, кратные периоду функции их. Результат
получается тот же самый. В этом случае метод носит наз-
вание синхронного накопления.
Корреляционный метод фильтрации (временная фильтрация)
Будем считать, что передаваемый сигнал есть синусоида:
их (/) == Uxm sin w01.
Принятый сигнал есть смесь переданного сигнала и по-
мехи:
иу (t) = их (t) ф- (t).
Пропускание этого сигнала через корреляционный
фильтр позволяет увеличить отношение pg.
Определим автокорреляционную функцию Вуу (т) для
принятого сигнала:
Вуу (т) = иу (/) иу (t 4- т) = [их (/) + м. (0] [их (t 4-т) +
+ (t 4-Т)1 = их (0 их (i 4-т) + (О и* + т) +
+ Ux (t) м£ (/ 4- т) + м. (t) Uk (t 4- т) = Вхх (т) 4 В^х (т) 4-
+ Вх^ (т) + В^ (т)
335
(черта означает усреднение), где Вхх(т)— автокорреля-
ционная функция сигнала их (t), Вее(т) — автокорреляцион-
ная функция помехи uk(t), Вх.(т) и В,х(т) — взаимнокор-
реляционные функции ux(t) и u.(f).
Поскольку передаваемый сигнал и помеха статистически
независимы, их взаимно корреляционные функции равны
нулю:
ВХ^ = ВСХ=‘О,
а автокорреляционная функция приходящего сигнала
вуу (т) = Вхх (т) + В* (т) = иь (т) (т) = ug (т),-
где иь (т) = Вхх (т) и uTj (т) = Bfi (т) соответствуют состав-
ляющим их(t) и(t) сигналаиу (t)~НоВхх(т) есть автокорре-
ляционная функция си-
мда нусоиды, которая пред-
б)
Рис. 6-31. Упрощенная схема авто-
корреляционного фильтра.
а — автокорреляционная функция сигнала,
искаженного шумом; б — схема корреля-
ционного фильтра; У — устройство ум-
ножения; 3 — элемент задержки; И —
интегрирующее устройство.
ставляет собой косинусо-
иду с амплитудой Uxm/2,
а В^ (т) неограниченно
убывает при т->оо (рис.
6-31, а).
Отсюда следует, что
отношение сигнала к
помехе неограниченно
ведена
тора, осуществляющего преобразование
возрастает с увеличе-
нием сдвига т. Теорети-
чески метод позволяет
выделить сколь угодно
малый сигнал при не-
ограниченном увеличе-
нии т и времени инте-
грирования в процессе
получения автокорреля-
ционной функции..
На рис. 6-31, б при-
схема
корреля-
т
Вуу (т) ~r Uy (f) иу (t т) dt.
о
Устройство умножения У образует произведение двух
функций, поступающих на его вход, — функции иу (t) и
функции иу (t + т), снимаемой с блока задержки 3. Интег-
ратор И усредняет полученное произведение за время Т.
336
Таким образом, за интервал времени Т 4 т рассчитывается
одна точка автокорреляционной функции, соответствующая
установленному блоком задержки значению т. Если через '
т0 обозначить интервал корреляции, на котором В^ (т)
практически затухает по сравнению с Вхх (г), то максималь-
ное время расчета одной точки функции Вуу (т)равно Т + т0.
Для ускорения построения всей автокорреляционной функ-
ции можно использовать параллельные каналы, содержащие
индивидуальные линии задержки т. Тогда общее время пост-
роения Вуу (т), т. е. построения всех точек, составит Т 4 т0.
Для ускорения построения в одноканальном корреляторе
Рис. 6-32. Упрощенная схема взаимно кор-
реляционного фильтра.
Г — генератор гармонических колебаний стабиль-
ной частоты; У — устройство умножения; 3 —
элемент задержки; И — интегрирующее устрой-
ство.
используют предварительную запись процесса иу (t) и
последующее ускоренное воспроизведение его при расчетах
точек функции Вуу (т).
Указанный метод фильтрации позволяет одновременно
определить частоту соо переданного сигнала. Если же час-
тота <оо заранее известна, эту дополнительную информацию
можно использовать для улучшения качества фильтрации.
Для этого с помощью генератора Г стабильной частоты (рис.
6-32) создается гармонический сигнал иг (t), отличающийся
от их (t) только амплитудой,
- иг (t) = kux (f) = kUxm sin coo t
и вместо автокорреляционной функции строится взаимно
корреляционная функция Вуг'
В>г'(т) = иу (0 иг (t 4 т) = [их (t) + (0] иг (t т) =
= их (0 иг (t + т) 4 (0 иг (I + т) = Вхг (т) + В^ (т).
337
Если шум (t) не коррелирован с сигналом их (I), то
он не коррелирован и с сигналом uz (t). Поэтому второй член
равен нулю. Поскольку иг (t) = kux (t), то Вхг = (т) =
= kBxx (т) и, следовательно,
I
By? (У) = kBxx (т).
Таким образом, знание частоты соо позволяет избавиться
от составляющей помехи В^ (т), которая была на выходе
автокорреляционного фильтра. Дополнительного интервала
т0, необходимого для затухания В^ (т), здесь также не тре-
буется. Если помехи содержат не только случайные, но
и периодические составляющие, отличные от со0, то эти
составляющие также будут отфильтрованы, так как функ-
ция взаимной корреляции содержит только частоты, общие
для их (t) и uz (t). Поэтому взаимно корреляционный фильтр,
содержащий генератор очень стабильной частоты, является
аналогом частотного фильтра с очень узкой полосой про-
пускания. Часто может оказаться более простым создание
генератора стабильной частоты, чем фильтра с узкой
полосой (особенно в случае приема функций низкой
частоты).
Время наблюдения Тх за процессом определяемся време-
нем интегрирования Т при определении Вуу (г), которое в
идеальном случае должно быть бесконечно большим. Прак-
тически ограничиваются значением Тх = Т 10 т0.
С увеличением Тх точность вычисления Вуу (г) увеличива-
ется, следовательно, увеличивается и рг.
Корреляционный фильтр позволяет выделять не только
гармонические сигналы, но и сигналы любой другой формы.
В этом случае он должен содержать генератор функции
иг (i) той же формы, линейно связанной с их (/).
Согласованная фильтрация
Рассмотрим импульсный сигнал их (t) произвольной
формы, определенный на интервале (0, Тх) и равный нулю
вне этого интервала. Предположим, принятый сигнал
иу (t) =их (t) + и, (t) пропускается через линейный фильтр,
импульсная переходная функция которого имеет вид
Ф (0 = их (Тх — t).
Функцию Ф (Г) можно изобразить, нанеся их (t) влево
от точки Тх (рис. 6-33). Фильтр с такой характеристикой
338
носит название согласованного. На выходе фильтра имеет
место реакция, определяемая интегралом свертки:
wg(/) = S иу<У)ф(*— v)dv= § их(у)их(Тх—t + v)dv +
+ $ (v) их (Тх -1 4- v) dv.
Полученные два интеграла представляют собой с точ-
ностью до постоянного множителя
корреляционные функции Вхх и ux(t)
В~х, т. е.
• Ug (t)=к [вхх (тх -1) + t
+ в,х (Тх - 0], о А
где К — ПОСТОЯННЫЙ коэффициент. Рис. 6-33. Форма переда-
Отсюда видно, что реакция ваемого сигнала их (t)
I и импульсной реакции
согласованного фильтра совпадает согласованного фильтра
с выходным сигналом корреля- Ф (1).
ционного фильтра.
Но при согласованной фильтрации нет необходимости ис-
пользования устройств перемножения и генераторов.
, Потенциальная помехоустойчивость приема по Котельникову
Помехоустойчивость к действию помехи типа «белого
шума» носит название потенциальной (по Котельникову)
[Л. 6-14], если она обеспечивает минимальную среднюю
ошибку различения сигналов. Это достигается при исполь-
зовании критерия идеального наблюдателя, делающего
заключение о передаче кода х2 путем сравнения отношения
правдоподобия с определенным порогом:
W (Чу (*1)
И) (йу | Х1) р (х2)'
(6-19)
Предположим, передаваемые сигналы их1 (t) и их2 (t),
соответствующие кодам х1 и х2, имеют произвольную форму,
а принятый сигнал иу (t) = их (f) + (0- Представим
сигнал иу (f) в виде совокупности отсчетов иу1,..., иуп,
разделенных интервалами А у = Д-. Как было показано
339
раньше (§ 6-3), при отсутствии корреляции между
значениями шума в моменты отсчетов распределению
w (иу |х;) в пространстве сигналов иу соответствует распреде-
ление w (н,) = w (иу — uxi) в пространстве сигналов и^, т. е.
w (иу | Xt) — w (lly
п
ГТ^Д-е
Li У2л ас
п
--------=/— 1
(/2л ае)”
где o,==/D[£7£| — среднеквадратичное отклонение по-
мехи.
Правило решения получаем в форме
2 (“х/~ W" S (иу<~ ихаГ
или
2о|
е 6
после логарифмирования
р (*г) ’
>1пр(а1) —1пр(а2).
(6-20)
Перейдем снова к непрерывным функциям, полагая
их (t) и wf (() на малых интервалах Дг постоянными Тогда
суммы можно заменить на интегралы в соответствии с
приближенными равенствами:
п Тх
У (uyJ — uxlj)2/\T-= luv (О ~ U^i (OF ^0
/=1 о
Тх
У, («У/ - “х2/)2 Л 7 = \ [“у (0 — (OF dt-
/=1 о
Так как &rz=0- t то (6-20) принимает вид:
Тх
[^(/)-^(/)]2Л-рр(х2)<
J 1m
О
т
с ai
< \ 1иу (0 — uxi (OF dt — г Р .(^1)-
340
Схема, реализующая это правило, изображена на рис.
6-34. Она получила название оптимального приемника.
Рассмотрим важный частный случай, когда вероятности
р (хА) и р (х2) равны между собой, и функции (f) и их2 (t)
Uy(t)
• 2
Sluy(thuxl(ttrdt
UylV-u^tt)
ci
из
из
.2
чп
1 9
KiiyW-Uj.jft)} dt-C,
Uy(t)-Ux2(t)
ОС
Рис. 6-34. Схема оптимального приемника.
Г. — генераторы функций к . (I); ИЗ — измеритель энергии;
С. — уставкн смещений с£ ОС — орган сравнения.
x,=0
'jlUydf-u^Hlfdi-Cg
аг
*rn
пронормированы таким образом, что их энергии на интер-
вале одинаковы. Раскрыв в последнем соотношении скобки,
получим:
(0 dt —
о
тх os
tiy (t) иЛ2 (t) dt ~ р (х2)<^
J /т
тх
<С § u*i (О dt —
о
т
рЛ' ст2
- \uy(t)uxl(f)dt — -^p(X1).
J Im
Рис. 6-35. Схема корреляцион-
ного приемника.
Г. — генераторы функций uxi (t);
К. — корреляционные фильтры;
ОС — орган сравнения.
Первые слагаемые каждой
части неравенства, представ-
ляющие собой энергии полезных сигналов, и последние сла-
гаемые взаимно уничтожаются. Правило решения в этом
341
случае превращается в сравнение выходных сигналов
взаимно корреляционных фильтров
т т
X X
иу (/) uX2 (/) dt \ иу (t) их1 (t) dt.
о о
Соответствующая схема (корреляционный приемник)
изображена на рис. 6-35.
Глава седьмая
ОБРАБОТКА ИНФОРМАЦИИ
7-1. ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ
В общем случае под обработкой информации
понимают такой процесс преобразования информации, вы-
раженной в знаке или сигнале, в результате которого
содержание ее станет максимально подготовленным для
реализации следующего этапа, которым может быть пред-
ставление информации получателю — человеку для при-
нятия решения или управляющее воздействие.
Часто используемый термин «переработка информации»
представляет собой более широкое понятие. Переработ-
к а информации — логическое, аналитико-синтетическое или
эвристическое преобразование информации человеком или
некоторыми видами сложных информационно-логичес-
ких систем, связанное с обобщением, выработкой суждений,
умозаключений, понятий, образов и другими формами выс-
шей нервной деятельности. Более узкое понятие обработки
информации можно рассматривать как формализованную
часть процесса познания, осуществляемого человеком, или
процесса управления.
Обработка и переработка информации — более высокие
ступени познания, чем простое восприятие и тем более ощу-
щение. Познание ограничено невозможностью иметь в нашем
распоряжении огромную, собственно говоря, бесконечную
массу . данных об изучаемом объекте и необходимостью
выбора из этого разнообразия каких-то существенных за-
висимостей. В отличие от других информационных про-
цессов при обработке и переработке мы воспринимаем, ис-
толковываем и познаем лишь кое-что из огромной сложности
разнообразия объективной реальности, с помощью выбора
подходящих вариантов, упрощений и абстракций совер-
шается определенное ограничение этого разнообразия,
342
выявляется общее и существенное, позволяющее нам или
управляющему устройству принимать решение в каждой
конкретной ситуации. Количество информации в процессе
обработки, как правило, уменьшается, зато ценность и со-
держательность её возрастает.
Большинство задач обработки может быть решено при
помощи устройств, принципиальная структура которых
показана в виде функциональной схемы на рис. 7-1.
Приведенная схема устройства обработки представляет
собой конечный автомат, осуществляющий последователь-
ное преобразование входных сигналов хг из некоторого
%
Рис. 7-1. Функциональная схема устройства
обработки информации.
множества X (входной алфавит) в выходные сигналы у,
из множества Y (выходной алфавит) с использованием не-
которого множества S внутренних состояний автомата
[Л. 7-2]. Устройства обработки реализуются схемно в виде
«жесткой структуры» или на вычислительных машинах с
помощью программ, которые являются записями алгорит-
мов решения задач в некоторой специальной форме.
На вход устройства обработки поступают последователь-
ности массивов входных данных
Xi = {at; рр, х!?',...} i = 0, 1, 2, ... (7-1)
Каждый массив хг содержит:
1) адресную часть ait указывающую' ячейку памяти,
содержимое которой S(af) необходимо для обработки х;;
2) номер программы р1г который дает возможность опре-
делить, по какой из хранящихся в памяти программ должен
обрабатываться входной массив хр,
343
3) множество основных элементов х<9, наиболее полно и
точно характеризующих входную информацию в массиве х;.
В результате обработки в самом общем случае полу-
чаются два новых массива:
массив выходных данных
yi^=VPi[Xi, ъ-! (gj)] (7-2)
и новый массив в памяти
Ss (й/)= Spi [xj, (^«)]> (7-3)
причем St (а{) — содержимое ячейки памяти после обра-
ботки, (аг) — то же перед обработкой i-ro входного
массива; S,- (а;) состоит в свою очередь из отдельных элемен-
тов:
s (яг) = {s«” (аг), s(1) (яг)..(7-4)
Массив выходных данных также содержит множество
отдельных элементов — результатов обработки:
г/г = {^0,> (7-5)
Приведенная схема может характеризовать функцио-
нальную структуру устройств обработки информации в
различных сферах применения. Элементами входных и вы-
ходных массивов могут быть результаты измерений всевоз-
можных параметров (или одного параметра, представлен-
ного в виде отсчетов, произведенных через определенные ин-
тервалы времени), отдельные реквизиты и показатели (в
экономической информации), семантические множители и
коды документов (в документалистике). Количество отдель-
ных элементов определяется конкретной задачей и возмож-
ностями применяемых технических средств.
В качестве функции выходов Yp и функции переходов
Sp. могут выступать различные математические и логи-
ческие функции и операторы: функциональные преобразо-
ватели, операторы идентификации, упорядочения, сорти-
ровки и др. В общем случае схема представляе’г собой ре-
куррентную структуру обработки данных: результат об-
работки i-ro массива зависит от результатов обработки
предшествующего (i—1)-го массива.
Если в системе содержимое" памяти не меняется в ре-
зультате обработки и входные массивы обрабатываются
независимо друг от друга — это соответствует отсутствию
операций, описываемых выражением (7-3). В других частных
случаях, если имеет место только накопление в памяти
344
входных информационных массивов или выдача накоплен-
ных выходных массивов соответственно, отсутствуют опе-
рации, описываемые выражениями (7-2) или (7-1). Приме-
рами могут служить системы, в которых используются ста-
тистические методы обработки результатов экспериментов,
информацион но-поисковые или информационно-логичес-
кие системы.
Количество отдельных программ (подпрограмм) рг мо-
жет быть различным в зависимости от конкретной области
применения и возможностей используемых устройств об-
работки.
7-2. АЛГОРИТМЫ И ПРОГРАММЫ ОБРАБОТКИ ИНФОРМАЦИИ
И ЯЗЫКИ ДЛЯ ИХ ОПИСАНИЯ
Процессы обработки информации, производимые че-
ловеком или вычислительной машиной в информационных
системах, предназначенных для решения любого класса
задач, осуществляются пО определенным законам, называе-
мым алгоритмами.
Под алгоритмом понимают систему формальных
правил или предписаний, определяющих процесс достиже-
ния конкретной цели — преобразования некоторых дан-
ных в искомый результат, — и набор условий, определяю-
щих порядок применения этих правил к обрабатываемым
данным.
Алгоритм должен обладать тремя свойствами:
а) определенностью, состоящей в четкости и недву-
мысленности образующих его указаний;
б) массовостью, заключающейся в применимости ал-
горитма к некоторому множеству исходных данных, т. е.
не к одной единственной задаче, а к целому классу задач;
в) результативностью, заключающейся в том, что для
всякого допустимого множества исходных данных число
операций, приводящих к определенному результату, ко-
нечно.
Обычно алгоритм распадается на ряд элементарных ак-
тов, каждый из которых выполняется по вполне опреде-
ленным и достаточно простым правилам, может быть, за-
висящим от значений некоторых параметров, и ряд прове-
рок некоторых элементарных условий, определяющих по-
рядок выполнения этих актов. После выполнения всех
актов, соответствующих данному значению параметра,
и проверки условий, ему соответствующих, происходит
изменение значения данного параметра. Порядок выполне-
345
ния отдельных актов и проверки необходимых условий,
а также порядок последовательных изменений значений
параметра заранее четко определены.
Следует, однако, отметить, что существует класс задач,
характерных для ряда проблем оптимального экономичес-
кого планирования и исследования операций, распозна-
вания образов, самообучения, доказательства теорем и выд-
винутых гипотез, принятия решений в новой сложной
ситуации, при решении которых не удается использовать
введенное выше понятие алгоритма. При решении подоб-
ных задач используются эвристические алгоритмы, или
эвристики, сводящиеся к расчленению процесса решения
задачи на ряд последовательных этапов и применения ме-
тода попыток с анализом ошибок на каждом этапе. При
этом широко используется метод информационного дина-
мического моделирования принципов переработки инфор-
мации головным мозгом человека [Л. 7-13].
Представление алгоритма решения задачи в форме, вос-
принимаемой вычислительной машиной, или на Машинном
языке называется программированием. Машин-
ный язык — это язык в системе команд, используемой ЦВМ.
Программа — полная последовательность пронуме-
рованных команд и вспомогательных кодов с отмеченной
начальной командой, обладающая тем свойством, что если
ее ввести в ячейки памяти ЦВМ с теми же номерами, пере-
слать начальную команду в управляющее устройство и пус-
тить машину в ход, то машина выдаст решение предложен-
ной задачи.
Программирование для ЦВМ состоит из двух основных
этапов: 1) разработка блок-схемы (логической схемы) прог-
раммы решения данной задачи по ее математическому опи-
санию: 2) написание самой программы по ее логической
схеме.
Различают непосредственное (ручное) прог-
раммирование иавтоматическое программирование.
При непосредственном программировании вся работа, на-
чиная от разработки схемы программы и кончая кодирова-
нием и вводом программы в машину, выполняется челове-
ком-программистом.
Для наглядности представления алгоритма решения за-
дач при непосредственном программировании обычно ис-
пользуются блок-схемы, которые представляют со-
бой графическое изображение структуры программы, т. е.
ее отдельных составных частей и взаимосвязей. Обычно
346
в блок-схемах используются три типа блоков, изобража-
ющих операции (этапы) алгоритмического процесса (рис. 7-2):
1) блок, осуществляющий вычислительную опе-
рацию, с содержанием операции, записанным (словами или
формулами) внутри блока;
2) блок, осуществляющий логическую операцию
и показывающий разветвление алгоритмического процесса
в зависимости от некоторого условия;
вы числительная
Логическая
операиия
операиия
Рис. 7-2. Символы блок-схемы алгоритма.
Соединитель
3) соединитель, показывающий, от кого прини-
мается или кому передается управление, и служащий для
разбиения алгоритмического процесса на отдельные участки
и устранения большого числа пересекающихся линий в
блок-схеме.
Пример 7-1. Рассмотрим систему п совместных уравнений с п
неизвестными хъ .... хп:
°ii xi + °12 х2 + • + ат хп = Уь
«21 Х1 -I- °22 х2 + • • 4- <hn Хп = !/2.
Лп1 “Ь Лп2 х2 4~ • * • + ®пп Хц — Уп-
Эта система допускает единственное решение X; = х; (ап, ..., апп,
.....у„), если по крайней мере одно из чисел tji не равно нулю и
если определитель det (с;у) 0. Система может быть решена сведением
ее по методу Гаусса [Л. 7-13, 7-32] к специальной системе, в которой
диагональные коэффициенты равны единицам, а коэффициенты ниже
диагонали — нулям (т. е. Syfc = 1 при j = k и s]k = 0 при j > /г);
из этой системы решение быстро получается простой подстановкой
последовательно вычисляемых значений неизвестных х, начиная со
старшего. Блок-схема алгоритма решения совместной системы линейных
уравнений по методу Гаусса приведена на рис. 7-3.
Любую блок-схему программы можно построить в виде
г р а ф-с х е м ы, представляющей собой ориентированный
линейный граф, каждый узел которого соответствует ло-
гической операции, начальной или конечной вычислитель-
347
ной операции или любой точке на блок-схеме, в которой
встречаются две вершины стрелок.
Положить xfa
Положить п равным числу уравнении
Полоакить\,
Сформировать уравнение
(^делением уравнения
(j)J~7 на коэффициент Xj
Положить
Умножить уравнение (j)i на
коэффициент при х, в урав-
нении (к)(1П и вычесть . .
результат из уравнения^)”''
чтобы сформировать
уравнение (к)?
вычислить
Останов
Рис. 7-3. Блок-схема алгоритма решения системы линейных
уравнений.
Пример 7-2. Граф-схема, соответствующая блок-схеме программы
рис. 7-3 из примера 7-1, показана на рис. 7-4. В этом примере каждое
логическое условие имеет два исхода, обозначенных на блок-схеме
значками > и . Соответственно этому граф содержит для каждой
логической операции две дуги, обозначаемые через а и а'.
Из граф-схемы программы может быть получена' матрица
соединений тц. Элемент т(-7- этой матрицы равен нулю
Рис. 7-4. Граф-схема алгоритма решения системы ли-
нейных уравнений.
348
всякий раз, когда узлы графа I и / не связаны какой-либо
дугой. Если узлы i и / связаны единственной дугой Alf то
mij = А- Если узлы i и / связаны дугами Дъ А2....., Ап, то
mij == Al + А2 • • • + Ап.
Диагональный элемент тг; равен нулю, если не сущест-
вует дуги, начало и конец которой встретились бы в узле i.
Пример 7-3. Матрица мера 7-2 имеет вид: соединений граф-схемы рис. 7-4 из при-
0 4,0 0 0 0 0 0 0
0 0 л8 0 0 0 0 0 0
ООО А 0 0 0 0 0
ООО 0 а'Д4 0 0 аД8 0
ООО 0 0 Д6 0 0 0
ООО о Мо ° о о
ООО 0 0 0 0 0 0
ООО оооо о а
0 0 т'Дц 0 0 0 0 0 -
Граф-схемы и матрицы соединений программ весьма по-
лезны для анализа блок-схем программ, синтеза эффек-
тивных составных программ и других целей.
В соответствии с намеченными блок- или граф-схемами на
втором этапе программирования составляются последо-
вательности машинных команд для отдельных участков
сначала в буквенных (условных) адресах. Затем отдельные
участки программы (подпрограммы) объединяются и уста-
навливаются действительные адреса ячеек памяти машины.
Распределение памяти машины является весьма трудоемким
процессом, который выполняется после составления общей
блок-схемы программы. Наибольшие трудности вызывает
распределение памяти в тех случаях, когда обрабатывается
большой объем данных, которые приходится размещать на
магнитных Лентах и барабанах, применяя при этом .спе-
циальные команды.
Написание программы в виде последовательности команд
машины является самой трудоемкой и наименее творчес-
кой частью подготовки задачи к решению на вычислитель-
ной машине. Поэтому с самого появления вычислительных
машин делались попытки частично или полностью передать
эту часть работы самой машине. Передача функций прог-
раммиста вычислительной машине на втором этапе програм-
349
мирования — написание самой программы по ее логи-
ческой схеме ’ в системе команд определенной ЦВМ — на-
зывается автоматизацией программиро-
вания.
Наиболее ранним методом автоматизации программиро-
вания является метод библиотеки стандарт-
ных подпрограмм. Можно легко заметить, что
существует большое число частных задач, которые встре-
чаются в значительном количестве программ (например,
перевод чисел из одной системы счисления в другую, вы-
числение элементарных и специальных функций и т. д.).
Для каждой такой задачи пишется раз и навсегда програм-
ма, обычно удовлетворяющая некоторым несложным пра-
вилам и ограничениям. Все эти программы, называемые
стандартными подпрограммами, располагаются во внешней
памяти машины — на магнитной ленте или магнитном
барабане. Стандартные подпрограммы объединяются в
библиотеку при помощи специальной обслуживающей
программы. В процессе программирования программист ука-
зывает обслуживающей программе, какие стандартные
подпрограммы из имеющихся в библиотеке ему нужны и
в каком месте памяти их надо расположить. По этим ука-
заниям обслуживающая программа выбирает нужные стан-
дартные подпрограммы, расставляет их на указанных
местах и организует обращение к ним из основной программы.
Обслуживающие программы бывают двух типов: ком-
пилирующие и интерпретирующие. К
компилирующей программе программист обращается толь-
ко один раз, обычно сразу после ввода основной программы.
После вызова и расстановки стандартных подпрограмм
компилирующая программа уже не нужна и на ее месте
в памяти могут быть расположены другие данные (например,
результаты вычислений). Интерпретирующая программа
хранится в памяти в течение всего времени работы основной
программы. Обращение из основной программы происходит
только к ней, а она уже обращается к соответствующей
стандартной подпрограмме. Оба эти метода автоматиза-
ции программирования позволили сократить объем прог-
рамм, составляемых вручную, однако они не обеспечивают
необходимой гибкости, стандартизации и универсальности
составляемых программ.
Интересный метод автоматизации программирования,
а именно метод операторных схем, был предло-
жен А. А. Ляпуновым [Л. 7-14, 7-15]. В этом методе алго-
350
ритм решения задачи разбивается на элементарные еди-
ницы действия, называемые операторами. Каждый
оператор выполняет последовательность арифметических
действий, проверку логических условий и т. п. подобно
отдельным блокам алгоритма. Все операторы обознача-
ются большими латинскими буквами с индексами. Опера-
торная схема алгоритма записывается последовательностью
букв, обозначающих отдельные операторы, с индексами,
обозначающими порядковые номера соответствующих опе-
раторов. После операторов, проверяющих логические ус-
ловия, ставятся стрелки, указывающие, куда надо пе-
рейти, если условие не выполнено. Если между двумя со-
седними операторами нет связи, между ними ставится точ-
ка с запятой.
Пример 7-4. Пусть заданы величины ант (а>0). Требуется
а
определить величину / = \хт dx.
1
Для решения достаточно будет, очевидно, разбить алгоритм иа
следующие операторы:
1) проверка условия т = —1;
2) вычисление / = In а;
лГП+1 __ I
3) вычисление I = ------
т+ 1 ‘
Обозначая арифметические операторы через Л,-, а логические —
через Р[, операторную схему можно записать так:
У.Л4 Ag
I___________t
где UB — оператор начала программы; а — оператор окончания
программы.
На основе метода операторных схем была создана одна
из первых в ССОР систем автоматизации программирова-
ния — программирующая программа (ПП) для ЦВМ «Стре-
ла». В дальнейшем, однако, были найдены более совершен-
ные методы построения систем автоматизации программи-
рования, и метод операторных схем дальнейшего развития
не получил. Тем не менее запись алгоритмов в оператор-
ной форме весьма распространена из-за своей компактности
и часто используется в литературе.
Дальнейшее развитие автоматизации программирования
шло в направлении приближения языка, на котором пишет-
ся программа, к языку математических формул. На этом
пути были созданы и создаются различные системы авто-
матизации программирования, носящие общее название
автокодов. Наиболее простые из них созданы по мето-
351
ду символического программирования,
когда строение машинной программы сохраняется, но
код операции заменяется символом или условным бук-
венным обозначением, а вместо адреса стоит буквенное обоз-
начение соответствующей переменной. В других автокодах
операция имеет структуру математической формулы, од-
нако для сложной формулы каждую операцию надо распи-
сывать отдельно.
Все автокоды независимо от степени сложности имеют
одну общую черту: они привязаны к конкретной машине и
в той или иной степени учитывают особенности этой машины
(длину ячейки, систему команд и т. п.).
Дальнейшим этапом явилось применение алгоритми-
ческих языков, ориентированных не на определенные типы
машин, а на определенные классы задач. Алгоритмичес-
кий язык представляет собой набор символов и терминов,
связанных синтаксической структурой, с помощью которых
по определенным правилам можно описать алгоритмы ре-
шения задач. Эти алгоритмы затем автоматически самой
ЦВМ с помощью специальной программы — трансля-
тора — могут быть переведены в программы, написанные
в системе команд конкретной ЦВМ.
Подходя несколько шире к проблеме обработки инфор-
мации и алгоритмизации этого процесса, можно сказать,
что любой алгоритм описывает ход решения задачи на опре-
деленном языке. Таким языком могут быть естественный
язык, язык общепринятых математических выражений,
язык таблиц, блок-схем, язык машинных команд и т. д.
С этой точки зрения автоматическое программирование
можно рассматривать как частный случай машинного
перевода с одного языка на другой, результатом которого
является готовая программа, составленная в системе команд
данной машины.
Вообще под языком понимают множество (конечное
или бесконечное) предложений, каждое из которых имеет
конечную длину и образовано из конечного множества
простейших символов или выражений посредством пов-
торного применения некоторой данной системы правил
[Л. 7-19].
Алгоритмические языки, или языки
программирования, — это набор формальных
правил, позволяющих описывать алгоритмы и процессы
решения любых задач данного класса на машинах без
детального знания устройств самих машин.
352
Автоматическое программирование можно рассматри-
вать как частный случай машинного перевода с одного язы-
ка на другой. В общем случае в процессе перевода могут
участвовать четыре языка:
1) исходный (входной) язык, с которого производится
перевод;
2) выходной машинный язык, на который производится
перевод;
3) рабочий промежуточный язык, с помощью которого
осуществляется перевод;
4) метаязык, используемый для описания трех указан-
ных выше языков.
В отдельных частных случаях некоторые из этих язы-
ков совпадают.
При автоматическом программировании алгоритм обрабо-
тки информации записывается на алгоритмическом языке,
который является исходным, в виде последовательности сим-
волов, воспринимаемых машиной. Выходным языком являет-
ся машинный язык — конкретная машинная программа. Пе-
ревод состоит в замене символов и синтаксиса исходного
языка символами и синтаксисом выходного языка с сохра-
нением содержания переводимых выражений. Процесс
перевода осуществляется машиной с помощью програм-
мирующей программы, или транслятора, двумя
принципиально различными способами:
1) путем широкого использования метаязыка для опре-
деления всех символов и возможных структурных единиц
исходного языка на выходном языке;
2) путем ограниченного использования метаязыка, с
помощью которого определяются лишь некоторые основные
правила синтаксиса исходного языка на выходном (или ра-
бочем) языке, с последующим расширением определений ис-
ходного языка на выходном языке на основе синтаксиса
исходного языка.
Трансляторы на основе первого способа представляют
собой наборы функциональных блоков, осуществляющих
обработку и перевод исходных выражений определенных
типов по способу «разговорников», т. е. путем применения
отдельных подпрограмм для перевода различных выражений
исходного языка на выходной язык.
Более универсальным является принцип работы тран-
слятора, основанный на использовании синтаксиса исход-
ного языка (синтаксический транслятор). Принципиальная
особенность синтаксического транслятора состоит в том,
1/212 Гемников Ф, Е. и др.
353
что перевод каждого очередного символа определяется не
только его собственным значением, но и той синтаксичес-
кой структурой, в которую он входит.
В весьма упрощенном виде процесс перевода программы
с исходного алгоритмического языка на выходной язык с
помощью синтаксического транслятора может быть представ-
лен следующим образом. Пусть S (е) и I (в) являются соот-
ветственно определениями (синтаксисом и семантикой)
исходного языка и выходного языка, данными на мета-
языке. Кроме того, необходимо иметь определение S (/),
т. е. определение исходного языка в терминах выходного
языка в виде системы металингвистических правил, пред-
Рис. 7 5. Схема использования синтаксического транс-
лятора.
ставляющих собой либо простую замену символа исход-
ного языка соответствующими символами выходного языка,
либо рекурсивные определения новых структур через пред-
шествующие. При таком подходе синтаксический трансля-
тор можно рассматривать как некоторое преобразование
Т, такое, что Т [S (/)] = I, и с тем свойством, что если
Р (S) является программой, записанной на исходном язы-
ке, то (рис. 7-5)
т {р [S (/)!}=р {т [s
где Р (/) — программа, переведенная в термины выходного
языка.
Таким образом, работа транслятора состоит в «просмотре»
последовательных символов программы, записанной на ис-
ходном языке, сравнении этих символов с символами опре-
деления исходного языка и преобразования их в символы
выходного языка согласно синтаксису и семантике описания.
При использовании синтаксического принципа работы
транслятора один и тот же транслятор может осуществлять
354
перевод с различных языков, причем последовательность
выполняемых им циклов работы сохранится неизменной.
Специфика перевода с разных языков будет определяться таб-
лицами определений, задаваемыми отдельно для каждой
пары переводимых языков.
В настоящее время существует большое количество
различных алгоритмических языков. Все они, как уже упо-
миналось выше, ориентированы не на определенные типы
Рис. 7-6. Классификация алгоритмических языков.
машин, а на определенные классы задач. Разбиение по клас-
сам задач, решаемых с помощью алгоритмических языков,
и положено в основу классификации, представленной на
рис. 7-6. В соответствии с этой классификацией все языки
программирования можно разбить на четыре основных типа:
1) языки для математических и научно-технических
вычислений;
2) языки для решения экономических задач;
3) языки описания алгоритмов контроля и управления;
4) языки для решения информационно-логических задач.
Основными представителями первой, наиболее широко
распространенной группы являются языки АЛГОЛ и ФОРТ-
‘/J2*
355
РАН. Эти языки удобны для записи алгоритмов решения
задач, сводящихся к численным методам алгебры и матема-
тического анализа. К таким алгоритмам относится широкий
класс алгоритмов оптимизации, моделирования производ-
ственных процессов и исследования объекта.
АЛГОЛ (AlGOrithmic Language) — первый алгорит-
мический язык, получивший строго формальное описание.
1 Его широкие возможности породили тенденцию рассмат-
ривать его как универсальный язык программирования в
международном масштабе (вариант АЛГОЛ-60). АЛГОЛ
служит также эталонным языком для построения конкрет-
ных алгоритмических языков (входных языков).
В основу АЛГОЛ положен общепринятый язык матема-
тических формул, дополненный средствами, необходимыми
для формального описания автоматического выполнения
алгоритмов. Отличие АЛГОЛ от обычного языка матема-
тических формул заключается в линейности записи (в одну
строку) всех символов (в том числе индексов, показателей
степени), а также в более полной формализации записи
действия (явное указание операций умножения, четкое
определение типов чисел при вычислениях и т. п.), в стро-
гом разграничении способов использования всех символов
(скобок, запятых, точек с запятой и т. д.).
В основу построения АЛГОЛ положен блочный прин-
цип. Любая программа на АЛГОЛ представляет собой блок
и сама может состоять из блоков, внутри которых могут
быть другие блоки и т. д.
Блок в АЛГОЛ — это автономный участок программы,
включающий в себя информацию двух видов: описания
объектов, участвующих в вычислениях, и операторы,
охватывающие законченную последовательность действий
программы.
Описания и операторы можно рассматривать как отдель-
ные предложения языка. После каждого такого предложения
ставится точка с запятой.•
Блоки АЛГОЛ-программы строятся по общему пла-
ну. В начале блока идут все описания, затем пишутся подряд
все операторы в порядке их выполнения. Описания имеют си-
лу только внутри данного блока. Блок начинается словесной
скобкой begin (НАЧАЛО) и заканчивается словесной скоб-
кой end (КОНЕЦ). Эти же скобки используются и для об-
разования так называемых составных операторов, представ-
ляющих собой группы операторов, разделяемых точками с
запятой. Отличие составного оператора от блока заклю-
356
чается в отсутствии в составном операторе описаний.
Внутри любого блока или составного оператора в качестве
операторов могут фигурировать снова составные операторы
и блоки, так как они являются разновидностями операто-
ров. Каждый блок получает некоторые входные данные (от
других блоков или в процессе ввода информации) и выдает
выходные данные другим блокам или на выходные устрой-
ства машин (печать, перфорацию). Помимо входных и вы-
ходных данных в блоке используются и свои местные (ло-
кальные) величины, которые не используются вне данного
блока. Эти величины должны сопровождаться в данном
блоке описаниями.
За символом end (КОНЕЦ) ставится, как правило,
точка с запятой либо другой символ end (КОНЕЦ), либо
символ else (ИНАЧЕ), используемый для построения услов-
ных переходов.
Блок обладает свойствами локализации переходов внутри
блока. Обращение возможно только к началу блока; все
операции, используемые внутри блока, доступны только
для операторов перехода, находящихся внутри блока.
Переходы извне могут совершаться только к началу
блока.
Основные типы и иерархическая структура операторов,
описаний, символов и выражений АЛГОЛ приведены на
рис. 7-7. Подробная организация данных и грамматика
АЛГОЛ изложены в [Л. 7-13, 7-16, 7-17].
Для решения экономических задач и вообще задач,
связанных с обработкой больших массивов информации,
имеющей сложную, но полностью детерминированную струк-
туру (обработка историй болезней в Клиниках, управление
материальными потоками, обработка результатов экспери-
мента и т. д.), используются алгоритмические языки типа
КОБОЛ (COmmon Business Oriented Language) и ТАБСОЛ.
Основное достоинство КОБОЛ [Л. 7-13] заключается
в том, что как сама программа, так и вся информация, под-
лежащая обработке, записывается на языке, близком к
естественному (английскому). Поэтому он особенно удобен
для записи алгоритмов, связанных с обработкой нечисловой
информации, характеризующей, например, качество сырья,
наименования поставщиков, адреса получателей, вид об-
работки изделия и т. п.
Алгоритмы, содержащие такую информацию, трудно
выразить обычной математической символикой, и для
их записи приходится прибегать к словесному описанию.
12 Темников Ф. Е. и др.
357
Описание, данное
в терминах
Структуры, входящие д программу на языке О Л ГО Л
Списков
символов
Граммати ческих
форм
Синт а ней чесних
определений,
семантических
пояснений
Синтаксических
определений,
семантических
пояснений
Рис. 7-7. Анатомия языка, показывающая иерархию структур АЛГОЛ (по Ледли).
Основное отличие КОБОЛ от АЛГОЛ заключается в при-
способленности к алгоритмам, предусматривающим много-
кратное повторение однотипных операций над последователь-
ными группами данных, а также в том, что сами исходные
данные отделены от программы, которая должна их обраба-
тывать.
Алгоритмический язык ТАБСОЛ [Л. 7-9] предназначен
для обработки информации табличного типа, широко приме-
няющейся в инженерной практике для описания различ-
ных процессов и объектов, а также при выполнении учетно-
статистических, экономических, финансовых и тому по-
добных работ. По сравнению со словесными описаниями
табличный способ представления информации обладает
рядом достоинств, заключающихся в наглядности, компакт-
ности, простоте подготовки таблиц и обращения с ними.
Табличным способом весьма удобно могут описываться так-
же различные структурные схемы управляющих систем и
алгоритмы управления и обработки информации.
Алгоритмические языки третьего тица основываются на
АЛГОЛ и представляют его дополнения и расширения для
описания алгоритмов контроля и управления. Примерами
таких языков являются АЛКОПОЛ — язык для записи
алгоритмов централизованного контроля и управления
производством [Л. 7-10], АЛГОС — язык алгоритмичес-
кого описания производственных процессов, ДЖОВИАЛ —
язык для программирования задач обработки информации
в реальном масштабе времени и управления в сложной
управляющей системе военного назначения, включаю-
щей в себя большое количество вычислительных машин,
каналов связи и командных пунктов [Л. 7-9] и др. В допол-
нение к задачам, решаемым с помощью АЛГОЛ, эти язы-
ки позволяют описывать сложные управляющие алгоритмы,
такие, как опрос датчиков, управление сблокированными
группами механизмов, представление и запись информации
и т. п.
Большую и быстро развивающуюся группу алгоритми-
ческих языков представляют языки для решения информа-
ционно-логических задач. Эти задачи связаны с хранением
и логической обработкой больших объемов информации.
Информация представляется не только в количественной
числовой, но и в качественной форме, при помощи слов и
предложений естественных языков (с определенной формали-
зацией), причем объем и состав информации заранее неиз-
вестны. Более того, в ходе обработки структура информа-
12*
359
ции меняется, что требует соответствующего перераспреде-
ления памяти машин.
К числу языков этой группы относятся информацион-
но-поисковые языки, служащие для накопления и поиска
научной и библиографической информации. Эти языки
являются дальнейшим развитием классификационных язы-
ков докибернетическцго периода. Примерами информаци-
онно-поисковых языков являются простейшие дискретные
языки без грамматики: классификационный язык Рангана-
тана [Л. 7-7), координатное индексирование Таубе ]Л. 7-7];
дескрипторные языки с грамматикой; РИКОЛ (REtrie-
val COmmand Language) — язык команд для автоматизиро-
ванного поиска данных в картотеках [Л. 7-9] и др.
К четвертой группе алгоритмических языков принадле-
жат языки для описания процессов обработки буквенно-
цифровых символов при решении лингвистических за-
дач (машинный перевод, исследования языков и др.). При-
мером этих языков является алгоритмический язык КОМИТ
]Л. 7-9], характерной особенностью которого является на-
личие списка правил —средства, позволяющего производить
быстрый поиск по словарю. Элементы этого списка, пред-
ставляющего собой отсылочный словарь, рассортированы по
специальной системе КОМИТ, которая позволяет выполнять
поиск значительно быстрее, чем при линейном поиске.
Сущность решения многих информационно-логических
задач сводится к так называемой категоризации объектов,
т. е. к разделению объектов на виды, типы, классы и т. д.
в зависимости от их свойств и признаков. При этом запись
новой информации об объектах в память машины или поиск
информации в машине осуществляются по значениям этих
признаков. Для эффективного решения подобных задач
необходима специальная организация работы запоминаю-
щих устройств, которая позволяла бы осуществить поиск
информации не только по ее адресам, но и по ее признакам.
Для этой цели используются языки ассоциативного програм-
мирования (списковые языки), позволяющие устанавливать
ассоциативные связи между различными данными, храня-
щимися в памяти машины. Группы специально упорядо-
ченных данных или данных, связанных адресами связи,
называются списками.
Языки списковой структуры, созданные для работ в об-
ласти искусственного интеллекта и моделирования процес-
сов познания, представляют собой весьма перспективное
направление в развитии алгоритмических языков.
360
Характерным представителем списковых языков яв-
ляется язык ЛИСП (List Information Symbol Processing)
[Л. 7-9], разработанный для решения неарифметических
задач. Для построения списков в ЛИСП используется цеп-
ная адресация, при которой каждый член списка кроме
информации о самом себе (в виде непосредственного значе-
ния или адреса, указывающего, где находится это значение)
содержит также и информацию о положении следующего
члена списка (в виде адреса связи). Достоинствами адреса
ЛИСП являются:
а) единообразный и компактный способ представления
различных функций и вычислительных процедур при по-
мощи рекурсивных выражений;
б) гибкость в использований памяти машины, обеспечи-
ваемая организацией в виде списков как самих данных,
участвующих в обработке, так и программ обработки;
в) отсутствие необходимости в предварительном распре- ,
делении памяти и оперировании при программировании
задач с фактическими адресами величин; размещение дан-
ных и результатов вычислений, а также промежуточных
величин в рабочих ячейках машины осуществляется авто-
матически.
Другой списковый язык ФЛПЛ (Fortran List Proces-
sing Language) [Л. 7-9], использовавшийся для моделиро-
вания процесса доказательства геометрических теорем,
является развитием алгоритмического языка ФОРТРАН,
сходного с АЛГОЛ и наиболее распространенного в США.
В ФЛПЛ. применяется ряд дополнительных операторов — ,
функций, осуществляющих типовые списковые операции.
Эти операторы обрабатыватся транслятором ФОРТРАН (до-
полнительными блоками), в результате чего получается
единая программа на машинном языке, обеспечивающая
реализацию как списковых, так и обычных операций.
Большой интерес с точки зрения изучения возможностей
создания специальных языков для решения сложных ин-
формационно-логических задач представляют принципы
построения спискового языка ИПЛ-V (Information Pro-
cessing Language, 5-й вариант) [Л. 7-9], созданный для мо-
делирования мыслительных процессов при выработке до-
казательств теорем математической логики, для модели-
рования на машине игры в шахматы и эвристической прог-
раммы балансировки сборочного конвейера. Так же, как
и в ЛИСП, распределение памяти машины при использова-
нии ИПЛ-V происходит автоматически в ходе обработки
361
данных, что позволяет решать задачи, в которых требования
к распределению памяти не могут быть определены заранее,
и достаточно сложные структуры данных создаются в про-
цессе обработки.
Язык ИПЛ-V позволяет строить процессы обработки
информации в виде нескольких уровней, подобно тому
как человек строит свои логические рассуждения, связан-
ные с поисками решения, когда каждый последующий уро-
вень рассмотрения задачи является детализацией предшест-
вующих уровней (например, при игре в шахматы может
вестись разговор об общем состоянии позиции на доске;
более детальный уровень языка фиксирует конкретные фи-
гуры и их позиции, еще более детальный уровень — же-
лаемые ситуации, например контроль центра и т. д.).
К списковым языкам примыкает адресный язык прог-
раммирования Института кибернетики АН УССР [Л. 7-23].
Этот язык связан с определенной машинной реализацией
и рассматривает принципы построения адресных формул и
операций по расположению данных в ячейках машинной
памяти.
В последнее время возникла тенденция к созданию
универсального алгоритмического языка, пригодного для
записи алгоритмов задач любого из перечисленных выше
классов. Работы по созданию такого языка развиваются
в двух направлениях.
Сторонники первого направления пытаются создать
так называемый «язык-ядро». Это язык, в котором имеется
строго формализованное ядро из основных понятий и грамма-
тических правил, дополненное возможностями расширения
этого ядра путем введения новых объектов в язык. Такой
язык создается на базе АЛГОЛ и носит условное название
АЛГОЛ-Х. Один из вариантов этого языка был опублико-
ван под названием АЛГОЛ-67.
Сторонники второго направления разрабатывают «язык-
оболочку». Под этим названием подразумевается язык, в
который с самого начала введено максимальное количество
основных понятий и правил обращения с ними, из которых
можно выбрать подмножество языка, пригодное для конк-
ретных классов задач. Примером такого языка является
разработанный на фирме IBM язык PL/1 [Л. 7-18].
Кроме этих языков, предназначенных для ЦВМ, в нас-
тоящее время разрабатываются языки, предназначенные для
внутренних нужд программирования. Таковы, например,
«языки-посредники». Дело в том, что создание транслятора
362
с алгоритмического языка на конкретную машину представ-
ляет собой очень трудоемкую задачу, которую с созданием
каждой новой машины приходится решать заново. "Поэ-
тому возникла идея создать промежуточный язык и перево-
дить сначала с алгоритмического языка на промежуточный,
а затем — с промежуточного в машинный код, причем тран-
слятор с алгоритмического языка на промежуточный запи-
сывается на этом промежуточном языке. Сам же промежу-
точный язык стремятся сделать таким, чтобы максимально
облегчить создание транслятора с этого языка на машинный,
пусть даже за счет некоторого усложнения записи алгорит-
мов на этом языке. В данном случае это затруднение не очень
существенно, так как с этим языком будут работать только
высококвалифицированные программисты.
7-3. МАТЕМАТИЧЕСКИЕ ОПЕРАЦИИ ОРИ ОБРАБОТКЕ ИНФОРМАЦИИ
Любая операция обработки данных представляет собой
некоторую математическую (вычислительную или логичес-
кую) операцию.
Математические преобразования, имеющие непосредст-
венное отношение к процессам обработки параметрической
информации, сводятся в большинстве случаев к следую-
щим операциям [Л. 7-221:
а) к получению некоторых функций от исходных данных
(функциональным преобразованиям) и
б) к нахождению корней уравнений или системы урав-
нений.
В подавляющем большинстве случаев нахождение кор-
ней уравнений или системы уравнений сводится к совокуп-
ности функциональных преобразований. Что касается функ-
циональных преобразований, то они в задачах обработки
могут быть самыми различными, а порой и довольно гро-
моздкими.
При обработке информации часто, прибегают к функцио-
нальному преобразованию исходных данных, при котором
результат обработки у связан с исходной величиной х
однозначной функциональной зависимостью у — f (х).
Вид этой зависимости может быть чрезвычайно разно-
образным, и на него не накладывается никаких ограни-
чений.
Примерами простейших функциональных преобразо-
ваний могут служить операции суммирования двух или нес-
кольких исходных величин с одинаковыми или различными
363
весовыми коэффициентами at (которые могут быть и отри-
цательными)
получения произведения двух или нескольких исходных
величин
У=хгх2 ... хп,
а также вычисления отношения величин
y=xl/xv
Среди функциональных преобразований можно выделить
широкий класс так называемых интегральных преобразо-
ваний:
ъ
y=K^q>(s)x(s) ds, (7-6)
а
где у — результат обработки, К — постоянная, <р (s) — ве-
совая функция, х (s) — исходная функция.
Выражение (7-6) представляет интегральные преобразо-
вания в наиболее общем виде. Из него могут быть получены
различного вида частные случаи.
Если аргументом является время t, а <р (/) == 1 и К = 1,
то результатом обработки является интеграл функции
х (t) в пределах до t2:
*2
y=\x(f)dt. (7-7)
ti
При К = 1 1 имеем среднее значение функции
за интервал времени Т:
т
у~~ x(t)dt.
о
(7-8)
Если <р (7) принять равной х (t), то в результате обработ-
ки получим величину, пропорциональную энергии
т
y = K\x2(t)dt. (7-9)
о
364
При К = 1 IT получим среднюю мощность процесса
х (t) за интервал времени Т
т
y = -T^x‘(t)dt. (7-10)
о
Если в качестве весовой функции берется х (t + т),
результат будет функцией параметра т:
1 т
г/ (т) = у х (t -|- т) х (t) dt, (7-11)
1 о
и при Т^> т может приближенно рассматриваться как авто-
корреляционная функция процесса х (/). Для двух различ-
ных функций хг (f) и х2 (0 и Т^> т получим взаимно корре-
ляционную функцию
т
у (т) = 1 (t + т) х2 (/) dt. (7-12)
О
При ф (s) = е ~’wt, К = 1 и достаточно больших Т ре-
зультатом обработки будет спектр процесса х (t):
т
A(fn) = \e1atx{t)dt. (7-13)
о
Следует также добавить, что определение всех статисти-
ческих характеристик величин так или иначе связано с опе-
рациями вида (7-6).
Интегральные операции могут производиться не только
над функциями времени. Часто необходимо получать сред-
ние значения нескольких исходных величин. Преобразование
в этом случае может быть записано как
y=K^aiXi, (7-14)
j=i
где Xt — исходная величина; су — весовой коэффициент,
характером которого определяется конкретный вид об-
работки, /С — коэффициент, который в данном случае
может предоставлять собой функцию от числа исходных
величин п.
Аналогичные (7-14) преобразования применяются тогда,
когда функция времени, подлежащая обработке, вводится
365
дискретно через определенные интервалы времени тг:
У = К У (kXiXi. (7-15)
i=l
Введение тг в качестве коэффициента при отсчетах
Xi соответствует ступенчатой аппроксимации непрерывной
функции х (t) в промежутках между отсчетами
При равенстве интервалов времени между отсчетами
Xi = т выражение (7-15) упрощается:
y=xK^aiXi. (7-16)
В процессе обработки данных при косвенном контроле
объектов интересующий потребителя параметр при-
сутствует в нескольких исходных величинах yt. Однако в
каждой из этих величин отражены и другие неизвестные
параметры: х2, xs,..., хп. Часто выходные сигналы г/г пред-
ставляют собой взвешенные суммы параметров хг:
У \ К и М -ф- К12 Х2 -ф- . . . -ф-
У 2 == 7Сг1 М 4“ ^22 х2 Ч- • • • 4“ К2п хп, , (7-17)
У 1 Kii Хг -ф- Х2 -ф" • • | Хп.
Весовые коэффициенты К -могут быть известны априори
из теоретического или экспериментального анализа. Тогда
определение х± сводится к решению системы уравне-
ний- (7-17).
Могут встретиться и другие случаи, в которых выходные
сигналы являются не взвешенными суммами, а более слож-
ными функциями параметров xt. Возможности обработки
зависят от того, разрешима ли система уравнений, связы-
вающих между собой неизвестные параметры. Следует
заметить, что если число выходных сигналов превышает
число параметров, подлежащих контролю, то имеется воз-
можность снизить влияние погрешностей, содержащихся
в выходных сигналах, путем использования метода наимень-
ших квадратов.
К математическим вопросам, связанным с обработкой
данных, относится также оценка погрешностей результатов
обработки.
Результаты обработки характеризуются определенной
погрешностью в первую очередь из-за погрешности исход-
366
ных данных, а также из-за неточности самого процесса об-
работки. На практике весьма существенной является проб-
лема оценки погрешности результата обработки по извест-
ным погрешностям исходных данных и определения требо-
ваний к процедурам обработки, чтобы погрешность окон-
чательного результата была не выше некоторого допусти-
мого значения.
Если результат обработки данных представить функци-
ей нескольких аргументов
х2, ..., хп), (7-18)
причем предполагается, что функция f дифференцируема
по каждому аргументу и каждый аргумент х, может быть
задан с абсолютной погрешностью |Дх; |, весьма малой по
сравнению с величиной самого аргумента, то абсолютную
систематическую погрешность результата обработки |Дг/|
можно оценить как
dxi
п
21 Д hА%г ।=।Аума,;с
i = 1
(7-19)
т. e. абсолютная систематическая погрешность резуль-
тата обработки приближенно равна сумме частных диффе-
ренциалов функции по каждому из аргументов, причем
в качестве конечного приращения аргумента записана
его погрешность.
Для относительной погрешности (отнесенной к текуще-
му значению исходной величины) имеем следующую верх-
нюю оценку:
п п
V Дх/| = V | AInfOq, х2, .... х„)||Дхг|.
i — \ i=l
(7-20)
Существенной для систем обработки информации яв-
ляется оценка случайных погрешностей, т. е. таких погреш-
ностей, которые остаются после вычитания из полной пог-
решности ее средней, систематической составляющей.
Величина случайной погрешности задается законом распре-
деления вероятностей ее значений. Возникновение случай-
ных погрешностей обычно связано с воздействием различ-
ного рода помех при измерении и передаче данных. Посту-
пая вместе с данными в обрабатывающее устройство,
погрешности, как правило, изменяют свои законы распреде-
ления. Значение случайной погрешности на выходе обраба-
367
тывающих устройств может быть найдено приближенно,
если принять следующие допущения:
1) случайная погрешность невелика по сравнению с об-
рабатываемым сигналом;
2) случайная погрешность на выходе может быть опре-
делена как сумма частных случайных погрешностей, вно-
симых с исходными данными;
3) случайные погрешности, сопровождающие различ-
ные исходные данные, статистически независимы.
В большинстве случаев эти допущения приблизительно
соответствуют реальным условиям работы рассматриваемых
технических систем и намного упрощают подход к оценке
случайной погрешности на выходе обрабатывающего уст-
ройства. Значение дисперсии случайной погрешности резуль-
тата обработки Оре3в этом случае может быть выражено сле-
дующей формулой:
п
<7-2»
i — 1
где a't — дисперсия случайных погрешностей, сопровождаю-
щих исходные данные хг.
Частная производная dy/dxt имеет тот же смысл, что и
в формуле (7-19). При коррелированных случайных погреш-
ностях дисперсия будет зависеть от вида корреляционных
связей между погрешностями и от характера математичес-
ких операций, производимых при обработке. В общем слу-
чае оценка случайных погрешностей результатов обработки
является достаточно сложной проблемой. Подробный ана-
лиз того, какие изменения претерпевают статистические
характеристики случайных погрешностей при различного
рода функциональных преобразованиях, рассматривается
в [Л. 7-20, 7-21].
7-4. ТЕХНИЧЕСКИЕ СРЕДСТВА ОБРАБОТКИ ИНФОРМАЦИИ
Любая задача обработки информации почти во всех существующих
информационных системах решается средствами вычислительной тех-
ники. если она может быть сведена к математической (вычислительной)
или логической задаче. Современная вычислительная техника распо-
лагает вычислительными средствами, в основу которых положены раз-
личные физические принципы. Существуют механические и электро-
механические счетно-клавишные, счетно-аналитические и счетно перфо
рационные устройства. В недалеком будущем получат распространение
пневматические, оптико-электронные и электрохимические вычисли-
тельные устройства. Однако в настоящее время наиболее распростра-
нены и удобны для целей обработки информации электронные вычис-
368
лительные устройства, делящиеся на две основные группы: аналоговые
и цифровые [Л. 7-1].
Каким бы сложным ни было аналоговое вычислительное
устройство, для каких бы громоздких вычислений оно ни предназна-
чалось, его можно рассматривать как совокупность сравнительно
простых устройств, производящих элементарные математические опе-
рации:
а) суммирование (алгебраическое) двух или нескольких величин;
б) умножение переменной величины на постоянный положительный
или отрицательный множитель;
в) получение произведения двух переменных величин;
г) получение частного двух переменных величин;
д) дифференцирование и интегрирование функций времени;
е) нелинейные преобразования переменных величин (ограничение,
возведение в степень, логарифмирование, коррекция нелинейности
датчиков).
Располагая этим ассортиментом решающих элементов, а также
рядом вспомогательных устройств, осуществляющих запоминание
изменяющихся во времени величин, определение знака переменных
величин и т. д., можно синтезировать схемы, производящие достаточно
сложные математические операции, непосредственно руководствуясь
видом математических соотношений, которые необходимо реализовать
в проектируемом вычислительном устройстве.
В цифровых вычислительных устройствах все математиче-
ские операции над числами, как известно, сводятся к четырем арифме-
тическим действиям, которые в свою очередь могут быть сведены
к одному — сложению. Разумеется, для автоматического решения задач
обработки данных недостаточно автоматизации одних лишь арифмети-
ческих действий. Необходимы устройства, осуществляющие логиче-
ские операции (обычно связанные с сопоставлением разлитых вели-
чин), необходимо наличие автоматического запоминающего устройства
для хранения исходных и промежуточных данных и программ обра-
ботки, устройств ввода и вывода информации. Наконец, должна быть
предусмотрена возможность автоматического осуществления порядка
действий над числами, к которым сводится решение задач, более
сложных, чем простое суммирование двух чисел. Современная цифро-
вая вычислительная техника представляет собой уже достаточно четко
сформулированное техническое направление. Она располагает ком-
плексом технологических принципов, практических рекомендаций,
остроумных технических и технологических решений, особых приемов
и даже традиций, основанных на обобщенном опыте создания и прак-
тического применения многочисленных конкретных разработок.
На рис. 7-8 приведена схема разветвленной классификации электрон-
ных цифровых вычислительных машин по различным техническим и
эксплуатационным признакам [Л. 7-5].
Решение практических задач обработки данных возможно сред-
ствами как аналоговой, так и цифровой техники. Каждый из этих видов
средств имеет свои достоинства и недостатки. Иногда наиболее удачные
технические решения можно получить, идя по пути сочетания аналого-
вых и цифровых устройств в одной системе (комбинированные системы).
Однако следует отметить, что аналоговые устройства, как правило,
применяются в тех системах обработки, где объем поступающих данных
очень велик, а сам процесс обработки производится по ограниченному
числу не очень сложных программ. В системах обработки, предназна-
ченных для решения широкого круга задач в самых различных произ-
369
Интегральные
$ 5 ?
ла 5: Р: S'
Специального
назначения
Однопрог-
раммные
микро опе-
рационные
Микропрог-
раммные
С конструктив-
ным разделением
программ
Общего
назначения
(универсальные)
С временным
разделением
программ
С IpUKCUpO-
ваннои
запятой
малые
рроре-
Статические
Динамические
Параллельные
'не двоичные
двоичные
Рис. 7-8. Классификация электронных
Двоична-
кодированмые
9J Г- -
X S
Oj 5
с неравномер-
ной адресной
структурой
I Функцио-
нальные
С равномерней с автономной С централизо- С переменным с постоянным
адресной схемной синхро- ванной схемной тактом тактом
структурой низацией синхронизацией роботы роботы
§ 2?
g’s
s *
Синхронные
Асинхронные
Микропрог-
раммные
С плавающей
запятой
одноадресные
ЭЦВМ
Cредкие |
Большие
Системы
большой
мощности
Последова-
тельные
Параллель но-
-последови-
тельные
Частотные Разовые Импульсные потенциальные Пате1,чиальные
цифровых вычислительных машин (ЭЦВМ)
водственных условиях и для обслуживания научных экспериментов,
применяются обычно цифровые вычислительные устройства.
Наиболее мощными и гибкими вычислительными устройствами,
пригодными для обработки больших объемов информации по любым
сложным алгоритмам, являются универсальные цифровые вычислитель-
ные машины. Можно считать, что по мере дальнейшего развития науки
и техники с созданием информационных и информационно-управляю-
щих систем универсальные ЦВМ будут являться основным устрой-
ством обработки информации.
Однако это не исключает использования при обработке информа-
ции специализированных цифровых вычислительных машин, обычно
более простых по конструкции, дешевых и удобных в эксплуатации,
чем универсальные ЦВМ. Наибольшее распространение в настоящее
время имеют быстродействующие специализированные ЦВМ следую-
щего назначения:
машины для решения систем обыкновенных дифференциальных
уравнений — дифференциальные анализаторы;
машины для вычисления коэффициентов и функций корреляции —
корреляторы;
машины для решения систем линейных алгебраических уравнений;
машины для решения дифференциальных уравнений в частных
производных методом статистических испытаний (метод Монте-Карло).
Особым видом специализированных ЦВМ являются управляющие
цифровые вычислительные машины, предназначенные для управления
какими-либо объектами или производственными процессами.
Основные технические, эксплуатационные и конструктивные пара-
метры отечественных ЦВМ приведены в табл. 7-1.
Параметры универсальных, да и многих специализированных ЦВМ
(система счисления, форма представления чисел, система команд,
адресность, разрядность чисел и команд, структура числовых и команд-
ных машинных слов, система основных элементов) выбираются исходя
из условий наиболее выгодного осуществления вычислительных опе-
раций. В измерительных же приборах и системах обработка данных
неразрывно связана с процессами измерений и представлением резуль-
татов измерений потребителю в форме, наиболее удобной для дальней-
шего использования (принятия решения при управлении или для науч-
ной интерпретации). При разработке и использовании вычислительных
устройств для измерительных систем кроме удобства проведения вычис-
лительных операций должны учитываться специфические особенности
связи устройств измерения и обработки с датчиками, первичными
преобразователями, устройствами кодирования и формирования сигна-
лов, а также особенности связи вычислительных средств различного
типа между собой и с устройствами представления информации потре-
бителю.
Органической составной частью измерительных систем являются
устройства, осуществляющие дискретизацию и квантование аналоговых
непрерывных сигналов: аналого-цифровые преобразователи, преобразо-
ватели кодов чисел из последовательной формы в параллельную и
обратно, из одной системы счисления'в другую и т. д.
Устройства обработки, которые включаются в систему до цифро-
вого преобразователя, обрабатывают непрерывные или решетчатые
(непрерывные по параметру и дискретные по времени) аналоговые
сигналы (частотно-импульсные, широтно-импульсные и амплитудно-
импульсные) и являются вычислительными устройствами аналогового
типа.
371
Параметры машины Мииск-22 Минск-23 Урал-11
Длина слова, двоичных 37 Переменная 12 и 14
разрядов
Представление чисел Двоичная фикси- Двоичная фикси- Двоичная и
(система счисления, поло- рованная и роваииая и десятичная
жение запятой) плавающая плавающая фиксированная
Адресность 2 2 1
Среднее быстродейст- 5-6 1.5-3.5 50
вие, тыс. опер/сек
Время сложения с фик- 12 (72) (72) 25
еироваиной запятой (с
плавающей), мксек
Время умножения с 200 200 25 и 100
фиксированной запятой (с плавающей), мксек
Емкость памяти на МС, 4-8 8-40 8—16
тыс. слов
Тип н емкость внешних накопителей, млн. слов МЛ 0,4—1.6 МЛ 6 МЛ 1—8 МБ 0,049-0,4
Количество прерываний — 256 30
Тип и количество вход- ных каналов связи с объектом Тип и количество вы- ходных каналов связи Система АЦС-1: непрерывных 512, релейных 1024 Система АЦС-1: непрерывных 32
с объектом
Тип и скорость ввода, сек ПК 4 карты ПЛ 800 строк ТЛ 7 знаков ПК 5 карт -ПК 1800 цифр ПЛ 1000 цифр
Тип и скорость вывода, ПЛ 20 строк ПЧ 7 строк ПЧ 800 знаков
сек ПЧ 5 строк ПК 2 карты ПЧ 7 знаков ПК 2 карты ПК 150 цифр ПЛ 20 цифр
Приблизительная цена, \ 190 210 200
тыс. руб.
Потребляемая мощ- 4 10 4—15
ность, кет
Занимаемая площадь, 100—120 120 40
м*
Вес, кг 5550 3100
Параметры машины Мир Он era-11 внииэм-з
Длина слова, двоичных разрядов Переменная 13, 26, 39 деся- тичных разрядов 24 (12 и 48)
Представление чисел (система счисления, поло- жение аапятой) Десятичная Десятичная фиксированная Двоичная фиксированная и плавающая
Адресность Многоадресная 1 1
Среднее быстродейст- 1—2 2 40
вие, тыс. опер/сек
Время сложения с фик- 4 454 25 (833)
сированной запятой (с
плавающей), мксек •
372
Таблица^/-1
Урал-И Урал-16 БЭСМ-4 БЭСМ-6 Наири
24 48 45 48 36
Двоичная и десятичная фиксированная Двоичная фиксированная и плавающая Двоичная' плавающая Двоичная плавающая Двоичная фик- сированная и плавающая
1 1 3 2
45 100 20 1000 1,5-2
25 10 (20» 47
300 50 95
16-65 131—512 8 4—32 1
МЛ 1—8 МБ 0,18—1,4 МД 5—40 МЛ 1—8 МБ 0,18—1,4 МД 5—40 МЛ 4—8 МБ 0,016-0,065 МЛ 3—48 МБ 0,017—0,13
64 64 — — —
Система АЦС-1 — - — —
Система АЦС-1 - - - -
ПК 12 карт ПЛ 100 строи ПК 12 карт ПЛ 100 строк ПК 12 карт ПК 48 карт ПЛ 800 строк ПЛ 7 знаков ТЛ 7 знаков
ПЧ 7 строк ПК 2 карты ПЛ 80 строк ПЧ 7 строк ПК 2 карты ПЛ 80 строк ПК 1 карта ПЛ 20 строк ПЧ 5 строк ПК 2 карты ПЛ 20 строк ПЛ 7 знаков ПЧ 7 знаков
500 600 200 - 40
7,5 20 8 20 1,6
- - 65 200 20
— - — — 620
Днепр-1 Дн.епр-2 KBM-I УМ-1 УМ1-НХП
26 32 (8—64) 26-52 21 15
Двоичная фиксированная Двоичная фиксир ов аин а я и плавающая Фиксирован- ная и пла- вающая Двоичная фиксирован- ная Двоичная фиксирован- ная
1—2 0-1 1
20 40 100 0,9 1
50 200
373
Параметры машины Мир Онега-11 ВНИИЭМ-3
Время умножения с фиксированной запятой (с плавающей), мксек 20000 62 (500)
Емкость памяти на МС, тыс. слов 4 0.4-1 4—28
Тип и емкость внешних накопителей, млн. слов — МЛ 0.2—2 МЛ 2—32
Количество прерываний — - 168
Тип и количество вход- ных каналов связи с объектом — — Непрерывные Релейные 1 Цифровые / 1x012
Тип и количество вы- ходных каналов связи с объектом — - Непрерывные 4X31 Релейные и цифровые J А
Тип и скорость ввода, сек 7 знаков ПЛ 200 строк ПЛ 1000 слогов
Тип и скорость вывода, сек Приблизительная цена, тыс. руб. ПЧ 7 знаков 70 ПЛ 20 строк ПЧ 5 строк ПЧ 7 знаков ПЧ 640 слогов ПЛ 20 слогов 300
Потребляемая мощ- ность, кет Занимаемая площадь, Л/2 Вес, кг 1 Основной блок 1,8X0,75 300 20 8 3000
Примечание. МД — магнитные диски; МЛ — магнитная лента;
нитные карты; ПЧ — печатающее устройство; ТЛ — телеграфаня лента: МБ —
Различного рода функциональные преобразования и математиче-
ские операции при измерениях, описанные в § 7-3, осуществляются как
с помощью специализированных аналоговых узлов и машин, так и
на ЦВМ.
Вычислительные устройства, осуществляющие обработку резуль-
татов измерений, являются, как правило, цифровыми вычислительными
устройствами.
7-5. ОРГАНИЗАЦИЯ СИСТЕМ ОБРАБОТКИ ИНФОРМАЦИИ
Возрастание объемов информации во всех областях науки и тех-
ники, многообразие форм ее представления, большое количество одно-
временно функционирующих и пространственно разнесенных источни-
ков информации, повышение требований к своевременности, точности
и удобству представления информации потребителю требуют автома-
тизации всех информационных процессов. Эта задача не может быть
374
Продолжение табл. 7-1
Днепр-1 Диепр-2 КВМ-1 УМ-1 УМ1-НХП
250 1000
4 4-65 4-126 1—4 0,256
МЛ 100—120 МЛ 30 МК 8,4 МЛ 20
28 80 16
Непрерывные 250 Релейные 1344 Цифровые 192 Непрерывные 4X512 Релейные. 4X1056 Цифровые 4X192 Непрерывные 96—656 Релейные 140—280 Цифровые 20—40 Непрерывные 384 Релейные 720 Цифровые 360 Непрерывные 2,8
Непрерывные 60 Релейные 480 Непрерывные 4x64 Релейные 4X512 Цифровые 96 Непрерывные 46—92 Релейные 128—256 Цифровые 64 Непрерывные 114 Релейные 1140 Непрерывные Цифровые 1
ПЛ 45 чисел ПЛ 1000 строк ТЛ 7 знаков ПК 5 карт ПЛ 80 строк ПК 5 карт ПЛ 200 строк
ПЧ 7 знаков ПЧ 20 строк ПЛ 20 строк ПЧ 150 строк ПЧ 7 знаков ТЛ 7 знаков ПК 2 карты ПЛ 80 строк ПЛ 100 строк ПК 2 карты ПЧ 600 знаков ПЛ 16 строк ПЧ 7 знаков
70 200
4 7,5 о.з
Основной блок 40
900 1700 300
МС — магнитные сердечники; ПК — перфокарты; ПЛ — перфолента; МК — маг-
магнитный барабан.
решена без разработки и использования сложных информационных
систем, в том числе и систем сбора и обработки информации, включаю-
щих в себя вычислительные устройства различных типов, устройства
передачи, хранения и документального представления информации.
Никакая обработка данных невозможна, если мы не располагаем
кроме них какими-либо априорными сведениями о характере исследуе-
мых объектов и источников информации или о характере задачи, кото-
рая должна решаться с использованием этих данных. Эти априорные
сведения должны быть заранее введены и храниться в памяти системы
сбора и обработки.
На рис. 7-9 в общем виде приведена функциональная схема системы
автоматической обработки информации.
На вход системы исходные данные от источника информации могут
поступать на носителях любой физической природы (сигналы всевоз-
можных датчиков, магнитные ленты, фотограммы, перфокарты, перфо-
ленты, микрофильмы, цифры, буквы и графики на различной бумаге
375
и т. д). Ввод исходных данных в основное устройство обработки (про-
цессор) может осуществляться преимущественно в двух формах:
1) в режиме непосредственной связи с исследуемым объектом (прямой
Рис. 7-9. Общая схема системы автоматической обработки ин-
формации.
ввод), когда ввод сигналов в процессор осуществляется в реальном
времени (информация о состоянии и поведении объекта поступает
с датчиков, воспринимающих сигналы о состоянии процессов) и 2)
в режиме предварительных преобразований информации (перегруп-
пировка, унификация, масштабирование, кодирование, дискретизация,
аналого-цифровые преобразования, преобразования последовательного
376
кода в параллельный и обратно, считывание данных с носителя и т. д).
к виду, удобному для последующей автоматической обработки в про-
цессоре. Второй режим очень важен для исследовательской практики,
так как он позволяет вести оперативную обработку результатов,
получаемых при многократных экспериментах.
В качестве основного устройства обработки могут использоваться
универсальные или специализированные вычислительные, информа-
ционно-поисковые или информационно-логические машины.
Выдача результатов обработки может осуществляться также в двух
основных формах: 1) в режиме прямой связи с потребителями инфор-
мации (прямой вывод), когда преобразованная информация, минуя
буферное накопление, сортировку и устройства представления резуль-
татов, непосредственно выводится на исполнительное устройство в виде
сигналов, и 2) в режиме буферного накопления с использованием
устройств представления результатов обработки потребителю.
Управление информационной системой, а также обеспечение
связей между отдельными ее элементами для перестройки и регулиро-
вания основного информационного потока в зависимости от изменив-
шихся внешних и внутренних условий осуществляется центральным
устройством управления. Оно содержит селектор ввода-вывода
данных в процессор, дешифратор и блоки выработки команд управле-
ния. В центральном устройстве управления имеются также не показан-
ные на схеме блоки памяти, в которых хранятся необходимые для нор-
мального функционирования системы априорные данные.
Для сравнения различных систем обработки информации и прове-
дения систематизации методов и способов обработки необходимо рас-
смотреть основные характеристики этих систем с точки зрения выпол-
нения технологических операций и требований ко входной и выходной
информации.
Такими характеристиками систем обработки являются:
1) пропускная способность, определяемая скоростью выполнения
вычислительных работа и работ по вводу и выводу информации (бит
в секунду, массивов в сутки и т. д.);
2) производительность, зависящая от трудоемкости работ по алго-
ритмизации и программированию задач и от пропускной способности
системы (количество задач в сутки, вычислительных операций в секунду
и т. п.);
3) точность, определяемая величиной и количеством ошибок,
возникающих при обработке информации;
4) надежность, возможность контроля и самопроверки;
5) уровень автоматизации операций в системе;
6) принцип организации информационных потоков и массивов,
определяемый объемом одновременно вводимых в систему данных,
формами и языками представления информации, удобством деления
входных массивов на подмассивы, сложностью выходной информации
для восприятия, параллельностью или последовательностью операций,
возможностью непосредственного управления потоками и т. д.;
7) экономичность, определяемая затратами на приобретение и
эксплуатацию машинного оборудования и их математического обеспе-
чения;
8) временной режим работы системы, регулярность, непрерывность
или периодичность выдачи информации;
9) гибкость, т. е. способность системы перестраиваться на решение
новых задач, ее приспособленность к перераспределению задач, к
распределению вычислительных работ;
377
10) принципы организации информационного обмена между вычис-
лительными средствами;
11) принципы закрепления функций за отдельными техническими
средствами;
12) степень однородности технических средств;
13) степень централизации вычислительных операций;
14) наличие устройств хранения промежуточных результатов и
результатов обработки.
Приведенные характеристики позволяют систематизировать системы
с различными методами и способами обработки (Л. 7-4, 7-12].
В зависимости от уровня автоматизации системы обработки инфор-
мации можно разделить на;
1) неавтоматизированные (ручные) системы — си-
стемы, в которых машинной (механизированной) обработке подвер-
гаются только простые, но наиболее трудоемкие с точки зревия чело-
веческого труда операции. Эти системы служат-для того, чтобы пре-
одолеть узкие места, с которыми нельзя справиться при ручной работе,
а также устранить определенные типы ошибок, связанных с ручным
трудом. При этом в основном используются простейшие устройства
для выполнения несложных вычислительных работ;
2) механизированные системы — системы, в которых
для машинной обработки используются целые подсистемы, однако
связь между этими подсистемами осуществляется через человека.
Системы обработки этого типа можно отнести к классу систем «человек —
машина», где человек является одним из звеньев системы. В системе
используются счетно-перфорационные, специализированные электронно-
вычислительные машины (корреляторы, дифференциальные анализа-
торы, настольные электронные ЦВМ и т. д.), различного рода устрой-
ства ввода-вывода и преобразования информации;
3) автоматизированные системы — системы обработки,
в которых деятельность человека ограничена сбором данных, оценкой
результатов и принятием решений на их основе. Все остальные опера-
ции выполняются автоматически с использованием сложных электрон-
ных устройств преобразования, передачи и представления информа-
ции, непосредственного ввода-вывода ее в ЦВМ и т. д.;
4) автоматические системы — системы собственно авто-
матической обработки, где техническим устройствам передаются функ-
ции сбора информации, распознавания ситуаций и выработки решений,
и человек почти полностью исключен из сферы обработки. Его функции
сводятся к подготовке системы для обработки данных и принятия
в процессе обработки решений в ситуациях, которые не были запро-
граммированы для системы заранее.
Автоматические системы обработки применяются в настоящее
время только для управления производственными и технологическими
процессами,, а в системах сбора и обработки информации при проведе-
нии научных экспериментальных исследований проблема принятия
решения всегда будет оставаться сферой деятельности человека.
В зависимости от разнообразия н сложности задач, решаемых
системой обработки, различают фрагментарный и комплексный спо-
собы обработки.
При комплексном способе ведется обработка данных, отно-
сящихся ко всей задаче в целом, для чего разрабатываются соответ-
ствующие алгоритмы и программы. Однако во многих случаях задача
в целом может быть настолько сложна, что комплексная обработка
будет превышать возможности людей и оборудования.
378
Тогда используется фрагментарный способ, при котором
общая задача в целях более эффективного ее решения разделяется на
отдельные подзадачи, которые могут решаться независимо одна от
другой, а потом объединяться вместе.
Комплексная обработка требует более производительных и слож-
ных вычислительных устройств, чем фрагментарная обработка. Про-
граммы обработки при комплексном способе гораздо сложнее, чем
отдельные программы, составленные при фрагментарном способе.
Однако время обработки существенно меньше, поскольку не произво-
дится многократного пропуска основного массива данных через систему
обработки.
На практике встречаются как фрагментарный, так и комплексный
способы обработки. Как правило, фрагментарный способ используется
в системах с низкой производительностью оборудования. Однако и
в системах с высокопроизводительным оборудованием введение ком-
плексной обработки из-за сложности составления мультипрограмм
вызывает много трудностей.
В зависимости от организации входных данных (объема, регуляр-
ности и скорости поступления, качества и формы представления) и
требований к выходным данным можно говорить о пошаговой и груп-
повой обработке. При пошаговой обработке во всех устройствах
системы одновременно обрабатывается ограниченное количество дан-
ных, поступающих непосредственно на вход системы или после неслож-
ных операций упорядочения и сортировки. Результаты обработки
выдаются почти непосредственно и в той же последовательности. Под
групповой обработкой понимают такой режим работы системы,
при котором в системе одновременно обрабатывается большое коли-
чество данных, образующих группу. Процесс обработки разделяется
на следующие друг за другом операции. Прежде чем перейти к следую-
щей операции, все информационные блоки, составляющие группу,
должны пройти предыдущую операцию. Достоинство групповой обра-
ботки состоит в том, что можно достигнуть высокой производитель-
ности оборудования, которое само по себе может быть менее сложным,
чем при пошаговой обработке. Однако существенным недостатком
является длительное общее время обработки. В реальных системах
обработки эти оба режима работы, как правило, комбинируются раз-
личным образом в зависимости от конкретной сферы применения для
достижения оптимального согласования требуемой скорости обработки,
сложности и производительности оборудования и других показателей.
Систематизация способов и методов обработки по организации
потока информации через систему с дополнительным учетом характери-
стик устройств ввода и вывода информации, устройств предваритель-
ной обработки, преобразования и представления результатов позво-
ляет выделить:
а) поточную обработку;
б) автоматическую обработку с некоторой задержкой;
в) непоточную обработку.
Поточная обработка представляёт собой быстрый способ
сбора, передачи и ввода данных в обработку и получения результатов.
Данные поступают в устройство обработки без каких-либо промежуточ-
ных стадий классификации или сортировки между получением данных
и их полной обработкой. Поточная система дает быстрый и непрерываю-
щийся поток данных от точки их получения до устройства обработки,
подобным же образом вывод данных и представление результатов
обработки потребителю осуществляется без задержки.
37&
Для реализации этого способа используются сложные автоматиче-
ские устройства сбора, передачи и преобразования, непосредственного
ввода и вывода информации, которые минимально зависят от человека.
Поточная обработка в широком смысле включает вычисление резуль-
татов и внесение изменений в целях улучшения процесса или операций
по мере того, как поступают исходные данные.
К системам с поточной обработкой относятся и системы обработки
в реальном масштабе времени, применяемые для работ, которые должны
давать немедленный ответ на каждую поступающую единицу инфор-
мации. В этих системах получение данных, обработка их и выработка
решений совпадают по времени с событиями на объекте? Как правило,
сюда относятся все системы оперативной обработки, применяемые для
управления сложными производственными и технологическими про-
цессами в промышленности, при проведении испытаний в недоступных
или труднодоступных для человека объектах, при отработке и запусках
космических летательных аппаратов и т. д.
Автоматическая обработка с задержкой представляет
собой обработку данных без предварительной проверки, сортировки или
других подобных операций, за исключением операций временного
хранения. В системах автоматической обработки с задержкой исполь-
зуются обычно устройства преобразования форм представления вход-
ных данных и буферные оперативные запоминающие устройства, в кото-
рых накапливаются данные в форме, удобной для дальнейшей обра-
ботки. По мере накопления в памяти входных данных они через соот-
ветствующие интервалы времени обрабатываются процессором в той же
последовательности, в какой поступают в систему. Автоматическую
обработку с задержкой можно рассматривать как поточную обработку,
выполненную с меньшим напряжением во времени. При этом может
использоваться то же оборудование и те же программы обработки.
Однако при этом процессор может обладать возможностями, необхо-
димыми в расчете на среднюю, а не на пиковую загрузку. Вводимые
данные периодов большой загрузки могут храниться в памяти до более
удобного момента времени, так что в среднем использование оборудова-
ния более высокое, чем при поточной обработке. Автоматическая обра-
ботка с задержкой применяется обычно для полной обработки данных
в системах автоматического контроля, телеметрических системах кон-
троля работы космических аппаратов и системах обработки экспери-
ментальных данных при проведении научных исследований, а также
в некоторых современных системах обработки экономической и управ-
ленческой информации.
Непоточная обработка наряду с преобразованием поступаю-
щих данных в стандартные форматы вычислительных устройств пред-
полагает предварительное накапливание, проверку и переупорядоче-
ние их, возможно, путем сортировки. При этом производится расчле-
нение поступающих данных по классам, видам ц зонам с тем, чтобы
в обработке могли быть использованы программы, относящиеся к опре-
деленным типам данных. Уровень автоматизации систем при непоточ-
ной обработке невысокий. Обычно применяются счетно-клавишные,
счетно-перфорационные машины и несложные ЦВМ с небольшим объемом
внутренней памяти. Подготовительные операции могут поглощать зна-
чительное время работы процессора. Весьма большой объем занимают
ручные операции. Непоточная обработка хотя и не имеет преимущества
перед другими системами обработки данных по производительности
и длительности обработки, часто оказывается единственно возможной,
когда оборудование имеет ограниченное быстродействие и емкость
380
памяти, поступающие данные сложны и разнородны по своему харак-
теру, а объем их очень велик, что особенно характерно для обработки
экономической информации и некоторых видов научно-исследователь-
ской информации.
Дальнейшее развитие систем обработки информации связано
с различными способами организации одновременной работы вычисли-
тельных средств: мультипрограммированием, мультипроцессированием
и автоматическим распределением машинного времени [Л. 7-3].
При использовании мультипрограммного принципа одна
и та же ЦВМ может одновременно выполнять разные команды одной
и той же или различных программ, которые хранятся в запоминающем
устройстве этой машины. Наиболее распространено совмещение опе-
раций ввода-вывода информации с вычислительными операциями.
Если какая-нибудь одна из программ окончена или прервана из-за
отсутствия необходимой информации, то сейчас же начинается выпол-
нение другой программы.
Для мультипроцессирования характерна одновремен-
ная работа нескольких ЦВМ по реализации нескольких зависимых
программ или различных частей одной большой программы. При этом
обеспечивается возможность обращения любой ЦВМ к оперативной
памяти любой другой ЦВМ.
Система автоматического распределения
машинного времени отличается тем, что она одновременно
решает ряд задач: в зависимости от принятой дисциплины обслужива-
ния система сама выбирает поочередно отдельные части каждой задачи
для обработки в данный момент. Система состоит из единого вычисли-
тельного центра, связанного линиями передачи данных с абонентами,
которые могут находиться на большом расстоянии от вычислительного
центра. С помощью пультов управления абоненты могут дистанционно
вводить необходимую программу в запоминающее устройство одной
из машин вычислительного центра и после реализации этой программы
получать результаты вычислений.
Наиболее перспективным для обработки больших массивов инфор-
мации в настоящее время считается использование многомашин-
ных вычислительных систем, объединенных общей системой йязи,
в которых в той или иной степени сочетаются все способы организации
работы вычислительных средств (Л. 7-3, 7-8]. В этих системах нет
жесткого закрепления запоминающих устройств и устройств ввода-
вывода за каждой ЦВМ. Благодаря большому объему общей памяти
система может решать гораздо более сложные задачи обработки. Много-
машинные вычислительные системы могут вести параллельную обра-
ботку информации от нескольких устройств сбора и передачи. Скорость
обработки информации близка к скорости наиболее быстродействую-
щего устройства ЦВМ — арифметического устройства, — в резуль-
тате чего резко повышается производительность отдельных узлов й
сводится к минимуму время простоя.
На рис. 7-10 приведена блок-схема многомашинной вычислитель-
ной си'стемы.
Все устройства системы делятся на следующие группы:
1. Группа внешних устройств ввода-вывода информации ВУ,
в состав которых входят различного рода читающие, печатающие,
фотосчитывающие устройства, всевозможные каналы связи и т. д.
2. Группа оперативных запоминающих устройств ОЗУ.
3. Группа внешних запоминающих устройств ВЗУ на магнитных
лентах, магнитных дисках и магнитных барабанах.
281
4. Группа непосредственной обработки информации, состоящая
из нескольких ЦВМ.
Центральная группа устройств системы объединена в управляю-
щую машину УМ, на которую возлагаются функции управления рабо-
той всех устройств вычислительной системы.
В состав управляющей машины входят следующие узлы:
1. Центральное обрабатывающее устройство ЦОУ, состоящее из
центрального устройства управления ЦУУ, арифметического устрой-
ства АУ, отдельной оперативной памяти, в которой размещена про-
грамма-диспетчер, ОЗУ ПД. При помощи программы-диспетчера ЦОУ
управляет режимами работы всех устройств вычислительной системы,
Рис. 7-10. Блок-схема вычислительной системы для мультиобработки
информации.
организует процесс обработки поступающей информации в соответ-
ствии с принятыми принципами, переводит программы, записанные
на входном языке, на язык комплексируемых ЦВМ, подготавливает и
распределяет эти программы между ЦВМ, выполняет функции, свя-
занные с проверкой работы устройств системы, а также осуществляет
связь между оператором и вычислительной системой.
2. Система прерывания СПр, которая состоит изг отдельных триг-
геров, фиксирующих заявки на обслуживание от различных узлов
системы, и системы опроса состояния этих триггеров. Таким образом,
связь всех устройств системы, в том числе комплексируемых ЦВМ,
пультов управления и т. д. с ЦОУ осуществляется через СПр.
3. Центральное устройство времени ЦУВ, к регистрам которого
имеет доступ ЦОУ. В ЦУВ фиксируется информация об абсолютном
и относительном времени, которая используется для организации
работ вычислительной системы.
382
4. Селектор оперативной памяти СОП, с помощью которого осу-
ществляется связь комплексируемых ЦВМ, ЦО У и селектора внешней
памяти СВП с группой оперативных запоминающих устройств ОЗУ. СОП
обеспечивает доступ любого из указанных устройств к любому ОЗУ.
5. Селектор внешней памяти СВП, который обеспечивает обмен
информацией между ВЗУ и оперативной памятью системы по несколь-
ким каналам одновременно и независимо от работы всех других
устройств системы.
6. Селектор внешних устройств СВУ, служащий для организации
обмена информацией между группой внешних устройств и внутренней
памятью системы.
7. Математический пульт управления МПУ, через который осу-
ществляется связь оператора с системой, задается приоритет в обслужи-
вании ряда вспомогательных математических пультов управления и т. д.
8. Инженерный пульт управления ИПУ, служащий для наладки
отдельных устройств системы, для контроля их работы и т. д.
Все поступающие данные и задачи обслуживаются в порядке посту-
пления их в систему, за исключением некоторых случаев:
1) наличие особо приоритетных данных и задач;
2) наличие отладочных задач, пропускаемых вне очереди;
3) устройства ввода не справляются с работой и заполняются все
магнитные ленты ввода;
4) встречаются последовательности задач, у которых объем про-
межуточных результатов больше, чем объем ВЗУ, отведенный под
промежуточные результаты.
Глава восьмая
ПРЕДСТАВЛЕНИЕ ИНФОРМАЦИИ
Под представлением информации в общем случае пони-
мается преобразование ее в форму, удобную для восприятия
и переработки человеком. Для этой цели информация
отображается в виде наглядных и легко воспринимаемых
сигналов и символов, формируемых с учетом психофизичес-
ких и психофизиологических возможностей человека.
Известно [Л. 8-1], что человек, воспринимающий сигналы
с помощью своих органов чувств, около 80% всей информа-
ции получает через зрительный канал. Поэтому в процессе
передачи информации человеку в системах контроля основ-
ную роль играет ее визуальное представление. Слуховой
и осязательный каналы используются только как вспомога-
тельные для предупредительной и аварийной сигнализа-
ции.
8-1. ОСНОВНЫЕ ФОРМЫ ЭЛЕМЕНТАРНОГО ПРЕДСТАВЛЕНИЯ ИНФОРМАЦИИ
В настоящее время используют три способа представле-
ния оперативной информации о состоянии объектов кон-
троля и управления, а именно сигнализация, индикация
и регистрация,
383
Под сигнализацией понимается сообщение
оператору о факте перехода величины из одной области
в другую, причем этот переход выясняется в результате
выполнения операций контроля. При сигнализации имеется
возможность использовать наряду со зрительным слуховой
и осязательный каналы, характеризующиеся меньшей по-
роговой чувствительностью к изменению сигнала. При
визуальной сигнализации основным средством представле-
ния является сйгнальная лампа, осуществляющая дискрет-
ное световое воздействие на зрительные анализаторы
человека. Значительно реже применяются электромехани-
ческие и механические элементы: бленкеры, флажки, сема-
форы, клапаны, затворы. Для звуковой (акустической)
сигнализации используют сирену, звонок или голос, пред-
варительно записанный и воспроизводимый в нужный
момент. Через осязательный (тактильный) канал сигналы
передаются с помощью механических и вибрационных
воздействий.
Однако наряду с результатом контроля оператору в боль-
шинстве случаев для управления объектом желательно рас-
полагать также результатом измерения текущих значений
контролируемых величин. Представление результатов изме-
рения называется индикацией. Эта форма представ-
ления воздействует главным образом на зрительный канал.
Индикация может быть осуществлена как в аналоговой,
так и в цифровой форме. Аналоговые индикаторы представ-
ляют информацию в виде изменения некоторых физических
величин, например угловых и линейных перемещений,
расстояния между двумя точками, интенсивности свечения,
звука, механических воздействий и т. д. К этому классу
относятся всякого рода указательные шкальные приборы,
а также индикаторы с яркостной, акустической и про-
чими шкалами. Наиболее характерные современные спо-
собы и средства аналоговой индикации иллюстрируются
табл. 8-1.
Цифровые индикаторы представляют значение величины
символами. Их можно классифицировать по способу вос-
произведения цифр, основанию системы счисления, а также
по функциональным и конструктивным признакам [Л. 8-2].
Основные способы воспроизведения цифр — мозаичный
(рис. 8-1, а, б) и фигурный (рис. 8-1, в, г).
По первому способу знак синтезируется из отдельных
точек или отрезков, различные сочетания которых опре-
деляют конфигурацию символа. Точечный способ воспроиз-
384
Технические средства аналоговой индикации
Таблица 8-1
Общий вид Отсчетный Метод индикации индикатора инструмент Назначение
У гловое перем6- о с щение механиче- | ского или светового * о указателя е с Шкала изме- Индикация вели- нения величины чины с ошибкой, сравнимой с од- ним делением
(квантом) шкалы
липсипис перс- 1 р- 1 1 IV /АС 1U Ж мещение механиче- (1 j
ского, жидкостно- -—* х го, светового или электроннолучево- । го указателя
Дифференциаль- ~ I Г ное перемещение J- I жидкостного столба L 1 » » Индикация раз- ности между изме- ряемой и известной величинами сошиб-
Изменение пло- z щади свечения Пространственное перемещение симво- лического указате- ля кой, сравнимой с _ делением шкалы X Поверхность Приближенная ууу .свечения индикация величи- ны Угол и рас- Индикация поло- стояние относи- жени я тельно коорди- натных плоско- стей i
кация на экране л электроннолучевой | трубки dllliiH шкалы изме- ириилиженная I нения величин индикация сово-
—-л/ _/ и ил раоме- куиносхи селичин щения на шкале N экрана
ведения (рис. 8-1, а) реализуется различными цифросинте-
зирующими устройствами с лампами накаливания, а также
электроннолучевыми индикаторами, создающими точечные
растры с модуляцией яркости точек. Фрагментный синтез
знаков (рис. 8-1, б) из отдельных отрезков (сегментов)
осуществляется главным образом электролюминесцентными
индикаторами с 7—8 сегментами при воспроизведении цифр
и 10—14 при воспроизведении букв и специальных знаков.
Фрагментный синтез реализуется и электроннолучевыми
индикаторами путем формирования по заданной программе
или с помощью кривых Лиссажу определенной траектории
385
луча, включающей контуры, всех представляемых знаков,
и высвечивания на экране отдельных ее участков.
Фигурный способ воспроизведения цифр предполагает
использование заранее подготовленных фигур (рис. 8-1, в)
либо вычерчивание символа в момент его отображения на
экране (рис. 8-1, г). Основные технические средства реали-
зации фигурного способа приведены в табл. 8-2.
Третья форма представления информации — реги-
страция — предназначается для записи в некоторой
символической форме отдельных факторов, величин и явле-
ний с целью их документирования и накопления на некото-
ром материальном носителе. Регистрация в большинстве
случаев сопровождает процесс индикации и по окончании
его позволяет в нужный момент представить накопленную
информацию в форме графиков, кодов, физических состояний.
Рис. 8-1. Способы воспроизведения цифр.
а — мозаичный точечный; б — мозаичный фрагментный;
в — фигурный с подготовленными символами; г — фигур-
ный с вычерчиваемыми символами.
Символы, применяемые при регистрации, разделяются на
две основные группы — аналоговые и цифровые; аналоговые
символы можно разделить на геометрические и физические.
Геометрические символы отображают значение какого-
либо фактора геометрическим положением точки или услов-
ного знака, расстоянием между точками, длиной отрезка
и т. д. Подобная форма регистрации широко используется
в различных самопишущих приборах (вольтметрах, ампер-
метрах, гальванометрах, автоматических мостах, потенцио-
метрах и др.), записывающих в процессе индикации непре-
рывный или дискретный график (рис. 8-2, а, б) изменения
параметра X во времени Т или пространстве N. В качестве
материала носителя в этих случаях, как правило, исполь-
зуется обычная бумага, а регистрирующими органами слу-
жат держатели с графитами, чернильные перья, печатающие
и копирующие стержни.
386
Таблица 8-2
Технические средства реализации фигурного воспроизведения цифр
Средство
воспроизве-
дения
Общая схема устройства
воспроизведения
Принцип действия
Механический
индикатор
с подвижными
элементами
Стробоскопи-
ческий инди-
катор
Оптический
проекционный
индикатор
Светопровод-
ный индика-
тор
Знаковая
электронно-
лучевая
трубка —
характрон
выбор
цифр
Коррек-
тирующие
катушки
возврат
луча
Электронный матрица выбор'
прожектор с трафаретами адреса
Представление цифры
осуществляется механи-
ческим поворотом оцифро-
ванных барабанов, сво-
бодно вращающихся иа
горизонтальной оси
Используется полый
вращающийся барабан
с отверстиями в виде
цифр, подсвечиваемых
при отображении нужной
«цифры. Неподвижное изо-
бражение достигается
благодаря инерции зре-
ния и большой скорости
вращения
Маленькая освещенная
цифра проектируется че-
рез увеличивающую оп-
тическую линзу на мато-
вое стекло
Пластины из органиче-
ского стекла с выгравиро-
ванными контурами фи-
гур используются как
светопроводы светового
потока, подводимого к
ним с торца подсвечиваю-
щими лампами. Выграви-
рованная фигура создает
контур рассеяния света
Электронный луч с по-
перечным сечением, соот-
ветствующим форме изо-
бражаемого знака, фор-
мируется в результате
прохождения пучка элек-
тронов через матрицу
с трафаретами знаков
387
Продолжение табл. 8-2
Средство
воспроизве-
дения
Общая схема устройства
воспроизведен ня
Принцип действия
Газоразряд-
ная индика-
торная лампа
Представление знаков
осуществляется катодным
свечением, имеющим место
при возникновении тлею-
щего разряда между ано-
дом и одним на катодов,
выполненных в виде цифр
Газоразряд-
ная счетная
лампа — де-
катрон
Электронно-
лучевой
индикатор
Светящееся пятно тлею-
щего разряда переходит
от одного катода к дру-
гому при поступлении
последовательных им-
пульсов. Результат под-
счета представляется све-
тящимся пятном, распо-
ложенным за изображе-
нием цифры
Т раектория перем еще-
ния луча по экрану элек-
троннолучевой трубки,
соответствующая контуру
символа, задается развер-
тывающими напряжения-
ми в сочетании с гаше-
нием луча на отдельных
участках
Наиболее многочисленную и интересную группу состав-
ляют методы регистрации изменением состояния вещества
носителя. В этих случаях регистрация может быть осу-
ществлена как геометрическими, так и физическими сим-
волами. Последние отображают значение параметров физи-
ческим состоянием носителя, в роли которого выступают
электротермическая, электрохимическая и светочувстви-
тельная бумага, а также ферромагнитные диэлектрические
и люминесцирующие слои, наносимые на некоторую
основу. При этом механические регистрирующие органы
уступают место электрическим, магнитным, электронным
и оптическим.
Регистрация физическими символами является одним из
основных средств для ввода и хранения информации в опе-
388
ративных и долговременных запоминающих устройствах
ЦВМ. Для этих целей наибольшее распространение получил
метод электромагнитной регистрации, связанный с измене-
нием величины магнитной индукции участков или элементов
ферромагнитного носителя. Регистрирующим органом в этом
д)
е>)
|10 1516151003030506
122224221s з юшю
13 25 26283018 10 10 ft
12 25 30 3842 50151312
«26 303545 40 201613
1427 30344350351614
1528 303242 60 50 2015
142730365063604016
122530385270805017
шз'лзохчгзоипе
14162236 5453536010
2012 8 27 42 70804015
22131019 3040402010
'7^. IS II 17 1918'1515
"£ Х\®>2 1013 2023
f / \ IB 15 18 2325
Iz и\22 15 16 2225
—*-»/ |5 22 202025
с)
Рис. 8-2. Возможные формы документов, получаемых в процессе реги-
страции.
случае является электромагпитная-записывающая головка
(рис. 8-3), создающая намагничивающий или размагничи-
вающий. поток, пропорциональный величине регистрируе-
мого сигнала. Метод характеризуется высокой скоростью,
точностью, стабильностью и относительной простотой,
однако он не дает возможности непосредственно представ-
лять результаты записи человеку.
Для визуального представления информации физиче-
скими символами используют эффекты, связанные либо
389
Рис. 8-3. Схема электромагнит-
ной головки.
1 — кольцевой магнитопровод;
2, 3 — рабочий и вспомогательный
зазоры; 4 — ферромагнитная плен-
ка; 5 — обмотки с регистрируемым
током I.
с интенсивностью окраски по-
верхности носителя (топогра-
фия), либо со степенью почер-
нения светочувствительного
материала (фотография), либо
с интенсивностью свечения
люминесцентного вещества
(люминография). При этом
наряду с ранее отмеченными
формами регистрации возмож-
но комплексное представле-
ние данных в виде некото-
рых наглядных образов (рис.
8-2, а, д).
Особые принципы лежат в
основе устройств цифровой
регистрации, записывающих
и представляющих информацию в виде цифр, букв, услов-
ных знаков и их комбинаций (рис. 8-2, в, е). Общеизвестным
технический средством такой регистрации являются элек-
тромеханические печатающие устройства с цифровыми штан-
гами, штифтами, барабанами и колесами [Л. 8-4, 8-5].
Последние (рис. 8-4) при-
меняются, например, при
автоматической регистра-
ции в многоточечных мо-
стах и потенциометрах.
Однако в целях повыше-
ния быстродействия при-
меняют и немеханические,
бесконтактные устройства
цифропечатания, исполь-
зующие профилированные
в форме регистрируемого
знака электрические и маг-
нитные поля, световые,
электронные и тепловые
потоки, создающие на со- п „ . „
Рис. 8-4. Печатающее цифровое
ответствующем носителе колесо для многоточечных автома-
символическое изображе- тических потенциометров.
ние, видимое или скрытое,
подлежащее последующему проявлению. Так, например,
феррографический способ [Л. 8-5] основан на воздействии
на носитель магнитного или электромагнитного поля задан-
390
ной конфигурации. В результате на носителе создается скры-
тое магнитное изображение знака, проявляемое порошковы-
ми составами из ферромагнитных материалов. В соответствии
с физической природой процесса различают электростати-
ческие, магнитографические, ксерографические, фотогра-
фические, электрохимические, электротермические, элек-
тронные и электроискровые методы цифропечатания. При-
мер реализации одного из них с использованием цифровой
электроннолучевой трубки — характрона, приведен на
рис. 8-5.
Рис. 8-5. Схема ксерографической регистрации с характроном.
Основу устройства составляет вращающийся ксерогра-
фический барабан 2 с тонким слоем полупроводникового
материала, заряжаемого через электрод 7 положительным
зарядом. Под действием светового изображения 3 знака,
проектируемого с экрана трубки 1 оптической системой
4—5—6, заряд снимается, и на освещенном участке бара-
бана остается скрытое электрическое изображение знака.
При проявлении в камере 8 барабан соприкасается с крася-
щим порошком, оседающим на разреженные участки его
поверхности. Далее запыленное изображение переносится
на отрицательно заряженную электродом 10 бумажную
ленту 11 и закрепляется оплавлением пыли в термостате 12.
При возвращении в исходное состояние поверхность бара-
391
бана очищается щетками 9. Регистрация протекает непре-
рывно со скоростью, достигающей 9 000 знаков в секунду.
Рассмотренные формы элементарного представления кон-
тролируемых величин в процессах сигнализации, индика-
ции и регистрации предназначены для отображения теку-
щих значений и состояний контролируемых величин. Однако
в условиях управления сложными технологическими про-
цессами и большими системами перед одним оператором
может концентрироваться огромное количество различных
приборов, представляющих в той или иной форме отдель-
ные величины и состояния, характеризующие объект. В ре-
зультате создается громоздкая и рассеянная картина
состояния объекта, трудно воспринимаемая и перерабаты-
ваемая человеком, особенно если для восприятия и пере-
работки отводится ограниченный интервал времени. Облег-
чение деятельности оператора при комплексном представ-
лении требует организации так называемых информацион-
ных моделей, под которыми понимается [Л. 8-6] организо-
ванная некоторым образом совокупность средств отобра-
жения текущих и априорных данных о состоянии объекта
и внешней среды. Наблюдая за информационной моделью,
оператор имеет возможность своевременно диагностировать и
оценивать текущую ситуацию, принимать решения об управ-
ляющих воздействиях, прогнозировать поведение объекта.
Эффективная информационная модель должна быть ком-
пактной, объединяющей отдельные средства сигнализации,
индикации и регистрации в единую информационную си-
стему, представляющую в удобной для оператора форме
конкретную обстановку с существенными ее деталями.
К последним относятся: многообразие существующих взаи-
мосвязей между контролируемыми величинами, отношение
сигналов к объекту и целевым функциям, значимостью
параметров и их связей в решении той или иной оператив-
ной задачи. Необходимая полнота представления данных
о состоянии объекта должна обязательно согласоваться
с психофизиологическими возможностями оператора [Л. 8-1]
по восприятию и переработке информации.
8-2. ПСИХОФИЗИОЛОГИЧЕСКИЙ АСПЕКТ ПРОБЛЕМЫ КОМПЛЕКСНОГО ПРЕДСТАВЛЕНИЯ
ИНФОРМАЦИИ ОПЕРАТОРУ
Психофизиологический аспект деятельности оператора
связан с оценкой того количества информации, которое он
может принять и переработать в заданный временной
392
Рис. 8-6. Зависимость времени ответ-
ного действия человека от количества
представляемой информации, получен-
ная в различных экспериментах (по
В. И. Николаеву) [Л. 8-1].
интервал при конкретных условиях. Важность этого вопроса
обусловлена тем, что человек в единицу времени способен
воспринять лишь ограниченное количество информации,
в то время как с увеличением сложности управляемых
объектов представляемое ее количество резко возрастает.
В связи с этим для надежного функционирования систем
«человек — машина» оказывается необходимым планомер-
ный учет как объективных, так и субъективных факторов,
влияющих на скорость переработки информации человеком.
Экспер иментально ус-
тановлено [Л. 8-1], что
для заданных условий
с увеличением количе-
ства представляемой ин-
формации, определен-
ного по Хартли, время
Тп ее переработки чело-
веком линейно возрас-
тает (рис. 8-6). При этом
величину Z= //Тп, об-
ратную крутизне зави-
симости Т„ = f (/), оп-
ределяют как пропуск-
ную способность «сен-
сорного входа» человека
по приему и переработке
информации. В общем
случае пропускная спо-
собность X зависит не
только от количества ин-
формации, но и от способов ее представления, целей и задач
оператора, субъективных и внешних факторов. Такое
многообразие и разнородность аргументов обусловливает
большие трудности в нахождении однозначных эксперимен-
тальных зависимостей и аналитической оценки пропуск-
ной способности оператора.
Несмотря на это, однако, очевиден тот факт, что в силу
ограниченных возможностей оператора по восприятию и
обработке информации скорость ее поступления у (бит
в единицу времени) не должна превышать пропускной
способности человека. Таким образом, неравенство v X
есть необходимое условие надежной информационной связи
человека-оператора с управляемой им системой. При соблю-
дении этого условия пропускная способность X обеспечи-
13 Темников Ф. Е. и др.
393
вает переработку текущего количества информации I в допу-
стимый интервал времени Тп_ доп, т. е.
1 = 7>С7\ДОП. (8-1)
Невыполнение условия (8-1) резко усложняет работу
человека как приемника информации и приводит к различ-
ным неблагоприятным эффектам перегрузки, а именно
к пропуску и ошибочному опознаванию сигналов и задержке
в их передаче. По мере роста поступающего количества
информации перегрузка отчасти компенсируется фильтра-
Рис. 8-7. Зависимость пропуск-
ной способности Л и времени Тп
переработки заданного объема
информации от времени обу-
чения.
циеи потока информации и
параллельным включением
дополнительных сенсорных
каналов, но в конце концов
перегрузка приводит к пре-
кращению восприятия. По-
следнее означает потерю связи
между человеком и управляе-
мой им системой вследствие
значительного превышения
скорости предъявления ин-
формации над скоростью ее
переработки.
Перечисленные эффекты
перегрузки наблюдаются при
управлении большими систе-
мами, когда человеку-опера-
тору приходится перерабатывать -огромное количество ин-
формации, представляемое ему различными методами и
средствами. В этих случаях для выполнения соотношения
(8-1) приходится либо сокращать теми или иными способами
количество информации, поступающее в заданный времен-
ной интервал, либо увеличивать скорость ее переработки
оператором. Последнее во многих случаях может быть до-
стигнуто благодаря таким субъективным факторам как
степень обученности и тренированности. Эксперименталь-
ные кривые, приведенные на рис. 8-7, показывают характер
изменения времени Т„ переработки заданного количества
информации и величины пропускной способности % от вре-
мени обучения т. Зависимости получены [Л. 8-1] на осно-
вании лабораторного эксперимента, в котором процесс
‘ переработки информации заключался в установлении соот-
ветствия между комбинациями включаемых тумблеров и
394
упорядоченным зажиганием ламп. При этом количество
информации, перерабатываемой оператором, было постоян-
ным и равным 117,5 бит.
Однако подобный характер кривых подтверждается
[Л. 8-71 и для случая диагностирования сложных ситуаций
в системах централизованного контроля и управления,
когда при выбранном методе и средствах представления
время диагностирования Тп экспоненциально убывает с
увеличением степени обученности и тренированности.
В результате зависимость Тп =[ (т) можно аппроксими-
ровать уравнением вида
Тп = (То — Тост) e~kx — Т^, (8-2)
где То — время переработки в начальный момент обучения;
Гост — время переработки при т -> оо; К — коэффициент,
характеризующий постоянную времени обучения.
Величина остаточного времени Тост при т -> оо обуслов-
лена физиологическими возможностями каждого конкрет-
ного оператора, а также способом представления инфор-
мации.
Таким образом, надежность функционирования систем
«человек — машина» во многих случаях может быть обес-
печена специальным отбором и подготовкой операторов.
Однако такой подход состоит по существу в приспособлении
человека к существующей системе контроля и управления
и не предполагает развития и совершенствования самой
системы.
В то же время правильная организация информацион-
ной модели, представляющая информацию с учетом различ-
ных взаимосвязей в форме, удобной для восприятия чело-
веком, рационально сокращает информационную нагрузку
оператора при решении конкретных задач, а также значи-
тельно способствует процессу его адаптации до требуемой
пропускной способности. Поэтому особую важность при-
обретает вопрос о рациональном отображении множества
контролируемых параметров, обеспечивающем максималь-
ную в заданных условиях скорость переработки информа-
ции.
8-3. КОМПЛЕКСНОЕ ОТОБРАЖЕНИЕ ИНФОРМАЦИИ НА ЩИТАХ И ЭКРАНАХ
Способы и средства построения информационной модели при ком-
плексном представлении информации существенно зависят от специ-
фики исследуемого объекта. Так, при управлении различными техно-
логическими и производственными процессами, когда основная масса
13*
395
информации с помощью сигнализирующих, индицирующих и -реги-
стрирующих приборов выводится на ч контрольные щиты и пульты
управления, основные методы организации модели связаны с ком-
бинаторными и схематическими представлениями.
Наиболее простыми являются комбинаторные модели, группирую-
щие индицируемые параметры по какому-либо признаку и представ-
ляющие исходные множества параметров {X} в разбиении на отдель-
ные классы. Группирование может произ-
водиться по следующим признакам:
1) по агрегатам;
2) по однотипности измеряемых пара-
метров;
3) по значимости параметров;
4) по взаимосвязанности параметров;
5) по порядку контроля параметров.
Подобные модели применяются при
относительно небольшом количестве кон-
тролируемых точек.
Более эффективное направление со-
ставляют схематические методы, представ-
ляющие не только отдельные классы мно-
жества {X}, но и существенные взаимо-
связи между элементами и классами этого
множества. Иными словами, эти методы
связаны с активным использованием
априорной информации в качестве фона,
вспомогательного изображения, для пред-
ставления новой оперативной информации.
Такая форма представления существенно
улучшает условия восприятия большой
совокупности данных, сокращая количе-
ство оперативной информации благодаря
активному использованию ее избыточности.
Наиболее распространенным и эффек-
тивным способом схематической органи-
зации являются мнемонические схемы, представляющие собой (рис.
8-8) комплекс символов, изображающих элементы контролируемого
объекта и их взаимные технологические связи. Такие схемы вместе
с нанесенными / на иих средствами индикации образуют опера-
тивную информационную модель объекта, отображающую технологи-
ческую структуру сообщения. Они облегчают оператору процесс вос-
произведения представлений о реальных управляемых объектах, их
взаимосвязях и предыстории развития процесса, помогая тем самым
осуществлять переход от информационной модели к оперативному
образу состояния.
Мнемонические схемы делятся на статические, информационные и
информационно-оперативные. Первые представляют собой графическую
схему или диаграмму, на которой показаны основные узлы и агрегаты
технологического оборудования. Они являются дополнением к другим
способам представления информации и не изменяют своего состояния
при изменениях, происходящих в контролируемом объекте. Информа-
ционная мнемосхема состоит из схем со встроенными в них средствами
сигнализации и индикации. При необходимости совмещения полей
стимулов (сигналов) и реакций (ответных действий) пользуются инфор-
мационно-оперативной мнемосхемой.
Рис. 8-8. Мнемоническая
схема участка сырьевого
цеха цементного произ-
водства.
i — приемный бункер; 2 —
транспортер; 3 — дробилка;
4 — пропускной клапан;
5 ~ смеситель; 6 — элек-
тродвигатель; 7 — сборник
шлама; 8 — сигнальная лам-
па; 9 — промежуточная ем-
кость.
396
Подобная организация оказывается недостаточной при необходи-
мости распознавания сложных ситуаций, определяющихся совокуп-
ностью большого числа взаимосвязанных признаков и параметров.
В этом случае наряду с представлением текущих значений контроли-
руемых параметров и технологической структуры объекта эффективно
отображение конкретных фуукционально-логических и корреляцион-
ных связей между параметрами в момент их проявления. Схематиче-
ское представление структур взаимодействия в виде графов, в узлах
которых располагаются средства индикации, позволяет вскрыть при-
чинно-следственные отношения между признаками сложных нарушений
и облегчает нахождение причин их возникновения. Однако при исполь-
зовании обычных индицирующих приборов не удается построить ком-
Рис. 8-9. Некоторые варианты комплексного пред-
ставления информации на экране электроннолучевой
трубки.
а. б, в — точечно-столбцовая индикация; г — сигнализа-
ция зон отклонения контролируемых параметров.
пактные, сосредоточенные* мнемонические и структурные модели и
получать быструю интегральную оценку состояния в сложных ситуа-
циях. В целях компактного представления оперативной информации
разработан и используется [Л. 8-8] ряд электроннолучевых средств
отображения, заменяющих множества отдельных индицирующих при-
боров одним экраном. В этом случае состояние отдельных параметров
представляется отображающими элементами в форме точек, столбиков,
знаковых отображений и т. д. (рис. 8-9), упорядоченных по линии раз-
вертки. При этом координатное расположение элементов на экране
соответствует номеру контролируемой точки, пространственному ее
расположению в объекте либо отсчету во времени.
На рис. 8-9, а — в представлены некоторые варианты комплекс-
ной индикации параметров, когда вдоль горизонтальной развертки
расположены их порядковые номера, а значение определяется либо
расстоянием точек от горизонтальной оси (рис. 8-9, а), либо размером
вертикальных отрезков (рис. 8-9, б). Вертикальные отрезки могут
располагаться и по обе стороны линии отсчета (рис. 8-9, в) в случае
397
индикации отклонения параметров от нормы. Для одновременного
представления текущего и заданного значений в изображение вводят
дополнительные отметки, например, в виде горизонтальных черточек
(рис. 8-9, б), характеризующих нормальное значение параметра.
Такое компактное упорядоченное представление в аналоговой
форме значительно способствует быстрому восприятию состояния
большой совокупности контролируемых точек (обычно до 128).
Для получения подобных точечно-столбцовых представлений на
экране электроннолучевой трубки (рис. 8-10) на ее пластины горизон-
тального и вертикального отклонения подаются сигналы Un и Uх,
пропорциональные соответственно кодам адреса п и значениям пара-
метров х. Высвечивание точек достигается временным сдвигом импуль-
сов отклоняющих напряжений UK и Ur относительно импульса под-
света Un, отпирающего луч по окончании адресных перемещений.
Для формирования столбца напряжение вертикального отклонения
должно иметь пологий спад.
Рис. 8-10. Упрощенная блок-схема электроннолучевого индикатора.
БПП — блок промежуточной памяти; ЦАП — цифро-аналоговый преобразо-
ватель; ФП — формирователь импульса подсвета; Уг, Ув, Уп — усилители
соответственно горизонтального и вертикального отклонений и подсвета.
Другая форма комплексного представления информации на экране,
показанная на рис. 8-9, е, связана с многоточечной сигнализацией.
Каждому параметру в плоскости экрана присваивается участок с коор-
динатами i, j (t = 1, ..., n; /= 1, ..., т), на котором высвечивается
символ, соответствующий зоне состояния параметра. Например, нахо-
ждение в нормальной зоне может отображаться точкой, отклонение
в предупредительную зону — знаками «+» и «—», отклонение в аварий-
ную зону — мигающими знаками «+» и «—». Сигнализация дюжел
быть осуществлена и физическими символами путем увеличения диа-
метра светящейся точки или интенсивности ее свечения. В результате
получается сосредоточенная матричная картина состояния контроли-
руемого объекта. Для удобства соотнесения представляемых сигналов
с объектом и облегчения считывания адреса перед экраном ставится
прозрачная мнемосхема или координатная сетка. При наличии комму-
тирующих устройств описываемый способ достаточно просто реали-
зуется на электролюминесцентных табло, позволяющих создать инфор-
мационные модели большой площади, предназначенные для одновре-
менной работы нескольких операторов.
398
Существенной особенностью рассмотренных в данном параграфе
методов комплексного представления информации является сохранение
принципа детального представления, при котором каждому параметру
соответствует свой индицирующий прибор или какой-либо отображаю-
щий элемент. Однако в больших информационных системах сохранение
такого принципа не всегда удобно, так как множество детальных коли-
чественных характеристик параметров и их взаимосвязей требует слож-
ного анализа при восприятии и общей оценке ситуации. В этих случаях
становится необходимым сочетание детализированных представлений
с качественными, формирующими обобщенную интегральную картину
исходного информационного комплекса, способствующую его быстрой
качественной оценке. Подобное сочетание позволяет осуществить про-
цесс передачи информации человеку по некоторой иерархии от общего
к частному, представляя на каждом иерархическом уровне оптимальное
в психофизиологическом смысле количество информации.
Качественное представление может быть реализовано с помощью
некоторых обобщенных характеристик, отражающих существенные
признаки состояния исходного множества.
8-4. ОБОБЩЕННОЕ ПРЕДСТАВЛЕНИЕ МАССОВОЙ ИНФОРМАЦИИ
. Методы обобщенного представления информации связаны с так
называемой генерализацией (см. введение), под которой понимается
процесс обобщения и выделения данных из первичного множества
параметров с целью формирования групповых обобщенных характе-
ристик, позволяющих судить о существенных признаках поведения
и состояния исходного множества данных.
В свете понятия генерализации комбинаторные и схематические
информационные модели, рассмотренные в предыдущем параграфе,
можно рассматривать как некоторый первичный этап генерализации,
подготавливающий переход от детальных характеристик и параметров
к групповым обобщенным.
В зависимости от свойств обобщенных характеристик и методов
их формирования можно выделить [Л. 8-9] три направления генерали-
зации, а именно: функционально-логическое, аналитическое и стати-
стическое.
Первое основано на использовании функциональных и логических
связей параметров между собой, а также их отношений к состоянию
объекта и целевой функции управления. Учет взаимосвязей позволяет
выделить так называемые представительные характеристики и пара-
метры, возглавляющие Иерархические системы генерализации взаимо-
связанных параметров и отражающие изменение каждого из ниже-
стоящих в данной иерархии. По характеру отражения различаются
дизъюнктивные и конъюнктивные представитель-
ные параметры, отражающие изменение нижестоящих в соответствии
с логическими функциями ИЛИ и И.
Примером дизъюнктивных характеристик могут служить пара-
метры, стоящие в вершинах причинно-следственных иерархических
схем .генерализации. Они удобны для отображения нормального состоя-
ния системы, когда все первичные контролируемые параметры нахо-
дятся в поле допуска. В случае отклонения хотя бы одного из них от
заданной нормы представительный параметр отражает факт нарушения.
Использование дизъюнктивных характеристик для контроля совокуп-
ности функционально связанных параметров было описано в [Л. 8-10].
399
Одиако дизъюнктивные параметры, отражая факт нарушения,
не позволяют непосредственно установить его первоначальную при-
чину. Для этого необходимо последовательное представление пара-
метров нижестоящих уровней иерархии вплоть до начального. В про-
тивоположность им конъюнктивные представительные характеристики
однозначно определяют ситуацию, исходя из необходимой совокуп-
ности признаков.
С этим направлением связан метод автоматического предъявления
названия событий в диагностирующих системах, заключающийся в том,
что оператору представляется не совокупность отдельных параметров
и признаков, по которым он должен прийти к определенному выводу,
Рис. 8-11. Структурная схема 24 событий в объекте кон-
троля.
а. — контролируемые параметры и признаки состояния.
а собственно вывод о состоянии объекта в символической или аналого-
вой форме. Для этого информация об отдельных параметрах и призна-
ках поступает в вычислительную машину, которая, -анализируя по
заданной программе различные их сочетания и комбинации, устанав-
ливает соответствие между конкретным состоянием точек контроля и
общим состоянием объекта. Решение может представляться либо в виде
надписи на табло событий, либо мнемоническими символами.
Развитием такого способа является метод структурных схем собы-
тий [Л. 8-7], согласно которому оператору представляется полная сово-
купность параметров и признаков, графически объединенных в ком-
400
пактные группы взаимосвязанных событий. Информационная модель
имеет вид направленного древовидного графа, каждая ветвь которого
представляет одно из сложных событий, определяемых совокупностью
признаков (параметров), стоящих в узлах данной ветви (рис. 8-11).
Таким образом, представление сложного события в объекте опреде-
ляется конъюнкцией признаков, входящих в вершины отдельной ветви
древовидного графа.
Недостатком подобных представлении является невозможность
алгоритмизации, а следовательно, и отображения редко встречаемых
и априорно незапрограммированных событий. В первую очередь это
относится к методу автоматического предъявления,
бесполезным при возникновении
новой ситуации.
Поэтому особую важность
приобретают обобщенные мо-
дели, дающие наглядное пред-
ставление о текущем состоянии
объекта в соответствии с целе-
вой функцией управления им.
Такие модели, используя функ-
циональные связи множества
контролируемых параметров с
изменением общего состояния
объекта, качественно отобра-
жают возникшую ситуацию, со-
здавая у оператора эффект не-
посредственного ее восприятия.
оказывающемуся
6)
Примером может служить си-
стема «Коналог» [Л. 8-11], раз-
работанная в США и предна-
значенная для представления
визуального аналога движения
в системах управления скоро-
стными самолетами и подвод-
ными лодками. Внешняя обста-
Рис. 8-12. Виды изображения на
экране индикатора системы «Кона-
лог».
а — правильный курс; б — глубина
меньше заданной; в — глубина больше
заданной; г — отклонение курса впра-
во с одновременным увеличением глу-
бины.
новка воспроизводится на теле-
визионном экране в трех параллельных плоскостях (рис. 8-12, а), соот-
ветствующих изображению верхнего и нижнего пределов перемещения,
например поверхности воды и дна океана, и зоне движения — «до-
роги», расположенной па заданном уровне (глубине). При увеличении
или уменьшении глубины .погружения полотно «дороги» соответственно
смещается вверх или вниз относительно первоначального уровня
(рис. 8-12, б, в), а в случае отклонения от заданного курса — искрив-
ляется (рис. 8-12, г). Аналогично при управлении самолетом летчику
представляется изображение линии горизонта, контрольной плоскости
земной поверхности, очертания неба и траектория полета, что в сово-
купности отображает информацию о высоте и положении самолета,
направлении его движения и угле атаки. В результате оператор имеет
целостное картинное изображение ситуации перемещения объекта
в пространстве, которое освобождает его от считывания информации
с отдельных приборов, дешифрации ее и мысленного перехода к при-
вычному представлению о реальном положении вещей. Однако подоб-
ная натурализация представления при всех ее преимуществах трудно
применима для отображения состояния технологических процессов, не
имеющих визуального аналога. Тогда для представления связи со-
401
Рис. 8-13. Геометриче-
ская модель комплекса
информации.
вокупности признаков с заданными критериями качества модель
должна быть достаточно абстрактной.
В ряде случаев это достигается аналитической генерализацией,
в результате которой представляются интегральные, инкрементные и
экстремальные характеристики множества данных. Такой подход
оказывается эффективным при контроле объектов с распределенными
параметрами. В этом случае используется
полный комплекс информации {X, N, 7} и
его геометрическая модель (рис. 8-13) в трех-
мерной системе координат X (параметр), Т
(время) и N (пространство). К координате X
приводятся унифицированные по шкале зна-
чения контролируемых параметров и при-
знаков, а координата N обозначает либо
геометрическую координату пространства,
либо номер точки измерения. Комплекс мо-
жет быть непрерывным или дискретным по
любой из координат.
Потенциальный рельеф поверхности ком-
плекса можно описать некоторой функцией
X (N, Т) для непрерывного и X (Л'; , Ту) —
для дискретного комплекса.
Обобщенные характеристики состояния комплекса, отображающие
существенные стороны его потенциального рельефа, формируются
методом проекций, согласно которому спроектированная на поверхность
точка имеет яркостную метку, соответствующую длине пути проекти-
рующей линии по телу комплекса (рис. 8-14). Подобные характеристики
Рис. 8-14. Представление пол-
ного комплекса {X, N, Т} мето-
дом проекций.
соответствуют распределению в про-
странстве двух измерений инте-
гральной характеристики (напри-
мер, числа квантов) третьего изме-
рения, представляя, таким образом,
информационный объем комплекса,
распределенный в двумерном про-
странстве. Наряду с этим они дают
возможность наглядно представить
поверхностный интеграл комплекса,
а вместе с тем и его инкрементные
и экстремальные характеристики.
П роцесс проектирования может
быть продолжен с поверхностей
на линии, а с линий в точку.
Проектирование плоскостных
проекции на координатные оси
соответствует интегрированию ком-
плекса по двум направлениям и рас-
пределению двумерной интегральной характеристики вдоль третьей
координаты. Особый интерес представляет распределение вдоль коор-
динаты параметра X, при котором каждая точка такой характеристики
отображает пространственно-временную область, охватываемую дан-
ным уровнем, что в частном случае соответствует статистическому
распределению параметров X или их отклонений от нормы.
Проектирование линейных проекций в точку соответствует инте-
грированию первичного комплекса по всем трем измерениям с по-
лучением «нуль-мерной» интегральной характеристики, отображаю-
402
щей комплекс в виде числового значе-
ния его информационного объема.
Плоскостные проекции комплекса
могут быть представлены на экране
электроннолучевого индикатора в ви-
де распределения дискретных точек,
яркость свечения которых пропор-
циональна значению третьей коорди-
наты комплекса. Однако ограниченное
число воспринимаемых яркостных гра-
даций (до 6—8) обусловливает лишь
приближенное представление третьей
координаты. На рис. 8-15, а, б приве-
дены осциллограммы проекций NT
конусообразного дискретного ком-
плекса, отображающие пространст-
венно-временные распределения зна-
чений параметров X. При этом по
вертикальной оси развертываются упо-
рядоченные номера датчиков Nt, а по
горизонтальной — временные отсчеты
Tj. Характер распределения ярко-
стных зон на экране дает обобщенное
картинное представление о состоянии
параметрического поля с его экстре-
мальными значениями, а также о ха-
рактере его изменения в пространстве
и времени.
Точное изображение рельефа ком-
плекса достигается использованием
инкрементных представлений в виде
совокупности линий равного уровня X '
либо совокупностей пространственных
и временных распределений X. По
форме и взаимному расположению кри-
вых в общем случае можно судить
о поверхности комплекса, его границах,
точках экстремума, производных по
направлению и частных производных.
Представление осуществляется ме-
тодом сечений, согласно которому на
координатные плоскости проектиру-
ются кривые, являющиеся линиями
пересечения поверхности комплекса
с заданным семейством поверхностей.
Примеры такого рода проекций
для непрерывного комплекса X =
= <р (N, Т) приведены на рис. 8-16.
Семейства секущих поверхностей в
данном случае составляют плоскости,
параллельные соответствующим коор-
динатным плоскостям и следующие
через равные интервалы.
В результате на плоскости ХТ представляется совокупность вре-
менных функций параметров X в дискретных точках пространства N,
Рис. 8-15. Осциллограммы
проекций и сечений конусо-
образного информационного
комплекса.
а, б — яркостная проекция в
плоскости NT; в — дискретная
эквипотенциаль параметра X;
г — совокупность пространст-
венных (временных) распреде-
лений параметра X.
403
8-16. Представление
на XN — совокупность кривых пространственного распределения
параметров X для каждого дискретного момента времени, а на NT —
совокупность линий равного уровня параметров X, форма и взаимное
расположение которых определяют рельеф поверхности <р (N, Г) с ее
характерными точками.
В реальных системах представления методы проекции и сечений
эффективно сочетаются и дополняют друг друга. Так, например, вос-
приятие всей совокупности дискретных эквипотенциалей в плоскости
NT затруднительно и нерационально. Более целесообразно вначале
весь комплекс представить несколькими яркостными зонами, а при
необходимости количественных уточнений высвечивать требуемую
эквипотенциаль (рис. 8-15, в). В свою очередь в плоскостях XN и ХТ
значительно большее самостоятельное значение имеют изображения
в виде комплекса функций N (рис.
8-15, г), с возможностью выделения
каждой отдельной функции.
Рассмотренные представления мно-
жества данных эффективны в случае
картинного отображения потенциаль-
ных параметрических полей, когда вся
организация информационной модели
ограничивается учетом геометриче-
ского подобия. В общем же случае
такое обобщение возможно в стадии
накопления человеком информации
о функциональной структуре взаимо-
действия между параметрами, а также
в целях установления соответствия
между абстрактными картинами их
распределения и качественными со-
стояниями объекта. В последнем слу-
чае степень абстрактности может быть
увеличена сверткой плоскостного изображения по одной из осей и
переходом к линейным представлениям (рис. 8-14).
Для целей анализа и прогнозирования случайных протестов боль-
шое значение имеют сведения о различных статистических характери-
стиках и параметрах. С их формированием и представлением связано
направление статистической генерализации, предполагающее переход
от множества отдельных значений параметров к их^статистическим
распределениям и <
обобщенного представления
в качестве обобщенной характеристики предлагалась характери-
стика текущего статистического распределения отклонений всей сово-
купности контролируемых параметров от установленных для них
нормальных значений. Одним из основных этапов формирования такой
характеристики является нормирование отклонений физически разно-
родных параметров, т. е. приведение их к единой метрике. Это дости-
гается переходом от абсолютных отклонений аг = — x;° к относи-
тельным вида
Рис.
комплекса {X, Л', 7} мето-
дом сечений.
спектральным характеристикам. Подобная форма
гавления была обоснована в работе [Л. 8-12], где
хг-4
г;==_д—
(8-3)
где А* — абсолютное значение кванта отклонения параметра х;,
используемое в качестве нормирующего коэффициента.
404
Относительная величина гг характеризует в квантах степень уда-
ленности значений переменной от границ допуска. Таким образом,
совокупность значений г,- становится однородной независимо от их
физической природы.
Нормированные значения отклонений параметров группируются
с учетом знака и индицируются на выходном устройстве в виде гисто-
граммы <р (г) распределения отклоне-
ний. Получаемая таким образом груп-
повая характеристика дает качественно
обобщенную картину по всему множе-
ству параметров, контролируемых в
ходе технологического процесса. Так,
в идеальном случае стабилизирован-
ного процесса, когда все отклонения
а,- = 0, имеет место дельта-распреде-
ление (рис. 8-17, а), в реальных же
условиях — нормальное распределение
с малой дисперсией (рис. 8-17, б). На-
личие неисправностей в каком-либо
блоке влечет за собой появление от-
дельных выбросов (рис. 8-17, в), а пол-
ному расстройству (дестабилизации)
всей системы может соответствовать
равномерное распределение (рис.
8-17, г).
Характеристика может быть пред-
ставлена [Л. 8-13] на экране электрон-
нолучевой трубки и с помощью свето-
вого индикатора, отображающего кри-
вую распределения интенсивностью
свечения. При использовании светового
индикатора (рис. 8-18) нормированные
значения отклонений параметров в
двоичном коде поступают на входы 1
дешифратора 2 двоичного кода в еди-
ничный. Для передачи знака откло-
нений используется дополнительный
двоичный разряд знака, обозначенный
sign.
С выхода дешифратора сигналы
подаются на знаковые распредели-
тели 3, 4 сигналов, коммутирующие их
в зависимости от знака отклонения.
С выходов знакового распределения
Рис. 8-17. Возможные формы
статистического распределе-
ния отклонений контроли-
руемых величин.
а — дельта-функция, характер-
ная для идеального течения про-
цесса; б — нормальное распре-
деление, соответствующее реаль-
ным условиям; в — нормальное
распределение с отдельными вы-
бросами, характеризующими
неисправность в каком-либо
блоке; г — равномерное распре-
деление, отражающее макси-
мальную дезорганизацию про-
цесса.
импульсы поступают в накапливающие
счетчики 5, которые управляют делителями 6 напряжения, изменяю-
щими в зависимости от числа, накопленного в счетчиках, доли напря-
жения U, подаваемого на входы ячеек светового индикатора 7.
Световой индикатор может быть выполнен в виде линейчатого
набора элементов 8, отображающих накопленную информацию интен-
сивностью свечения. В качестве элементов могут быть использованы
лампы, электролюминесцентные ячейки и т. д. Яркость свечения каждой
ячейки будет пропорциональна числу, хранящемуся в соответствующем
счетчике, что в совокупности отображает яркостную (глубинную) кри-
вую распределения информации.
405
Недостатком такой обобщенной характеристики является отсут-
ствие адресных представлений того или иного отклонения, что опреде-
ляет необходимость в дополнительных средствах представления.
Рассмотренные методы обобщенного представления ин-
формации, естественно, не исчерпывают всех возможностей
решения этого вопроса как в рамках отмеченных направ-
лений, так и в смысле определения самих направлений.
Рис. 8-18. Блок-схема индикатора текущего распре-
деления отклонений множества параметров.
1 — входы дешифратора; 2 — дешифратор; 3,4 — знаковые
распределители; 5 — накапливающие счетчики; 6 — дели-
тели напряжения; 7 — световой индикатор; 8 — ячейки све-
тового индикатора.
Разработка новых, более эффективных форм представления,
учитывающих свойства восприятия человека при конкрет-
ной его деятельности, требует больших инженерно-психо-
логических исследований вопросов приема и переработки
информации оператором, а также вопросов количественной
оценки эффективности той или иной системы отображения,
необходимых для научно обоснованного подхода к разра-
ботке информационных моделей в конкретных условиях.
8-5. ОЦЕНКА СИСТЕМ ПРЕДСТАВЛЕНИЯ ИНФОРМАЦИИ
Система представления информации, организованная
в виде информационной модели, осуществляет прямую
связь человека-оператора с объектом управления, вслед-
ствие чего ее оптимальность должна определяться, с одной
стороны, с учетом специфики объекта, а с другой, — с уче-
том психофизиологических особенностей воспринимающего
ее человека. В связи с этим появляется необходимость
как в объективной оценке модели независимо от конкрет-
ного оператора, так и в субъективной, учитывающей его
психофизиологические свойства.
408
Первый фактор можно охарактеризовать условием пол-
ного определения состояния объекта ¥ информационной
моделью X в пределах заданной точности. Это достигается
стремлением к нулю условной энтропии Н (У|Х) модели
относительно объекта, т. е.
Н (У | X) = — Р (Xi) 2 Р (Pj I */) log2 р (У; | xt) -> 0, (8-4)
i j
гдер (х{) — вероятность i-ro состояния модели X; р (yj\xi) —
условная вероятность /-го состояния объекта Y при i-м
состоянии модели.
Выражение условной энтропии (8-4), оценивая полноту
представляемой информации об объекте, позволяет выявить
исходное множество признаков параметров, необходимое
для снятия неопределенности о его состоянии. Последнее
определяет так называемую информационную емкость мо-
дели, т. е. максимальное количество оперативной информа-
ции, которое может быть передано оператору выбранными
средствами отображения и равно сумме энтропий отдель-
ных средств при равновероятности всех возможных сиг-
налов.
Однако, используя априорную информацию о статисти-
ческих свойствах сигналов, функционально-логических и
корреляционных связях между отдельными параметрами
и т. д., можно организовать модель, значительно сокра-
щающую фактическое количество информации, представ-
ляемое оператору. Тогда эффективность модели в смысле ин-
формационной разгрузки оператора можно оценить [Л. 8-14]
степенью избыточности представления
/? = 1 — (8-5)
/0
где /0 — информационная емкость модели; / — информа-
ционное содержание модели, т. е. среднее значение коли-
чества оперативной информации, представляемой оператору.
Избыточность /?, характеризующая степень использова-
ния априорной информации, определяет информационную
разгрузку оператора при контроле заданного объекта по
отношению к максимально возможной нагрузке, обуслов-
ленной информационной емкостью модели. В связи с этим
она может служить критерием для сравнения различных
моделей, отображающих состояние заданного объекта задан-
ными средствами. Более эффективна та модель, которая
обеспечивает максимально возможную информационную
разгрузку оператора.
407
Основная сложность количественного выражения такого
критерия заключается в отсутствии общей методики опре-
деления информационного содержания I, однако для ряда
комбинаторных и схематических' моделей оно может быть
определено в рамках классической теории информации
[Л. 8-14].
Другой подход к оценке информационной модели
[Л. 8-15] связан с экспериментальным определением пока-
зателей эффективности деятельности человека-оператора
в той или иной системе управления, а именно: частотой
ошибок, приводящих к отказам, временем выполнения
особо важных операций, числом операций в единицу вре-
мени, точностью выполнения операций и т. д. Под опера-
циями в данном случае понимаются не только двигательные,
но и мыслительные операции по приему и обработке инфор-
мации: речь идет о таких психофизиологических показа-
телях человека, как время и точность обработки информа-
ции и его пропускной способности, которые существенно
зависят от способа и средств представления информации
и — в конкретном случае — от качества организации ин-
формационной модели. Однако, как указывалось в § 8-2,
психофизиологические показатели деятельности оператора
сильно изменяются в процессе его обучения и тренировки,
так что значения этих показателей сами по себе без привязки
к процессу обучения не могут характеризовать качества
модели. Но в связи с тем что правильное построение модели
значительно способствует процессу адаптации оператора
до достижения требуемой пропускной способности, ее каче-
ство можно оценивать по значениям психофизиологических
показателей для определенного нормированного интервала
времени обучения и тренировки. С другой стороны, оценка
может быть дана -по нормированному времени подготовки
оператора до некоторого значения пропускной способности,
достаточной для нормального функционирования системы
«человек — машина».
Наряду с этим возможны и другие подходы к оценке
качества системы представления, основанные на исполь-
зовании некоторых частных критериев, оценивающих либо
поверхностную плотность представления информации, либо
возможность выполнения отдельных оперативных задач.
ПРИЛОЖЕНИЯ
Таблица П-1
Двоичные логарифмы чисел от 1 до 128
X logs X X 'og2 X X logs X X logs X
1 0,00000 33 5,04439 65 6,02237 97 6,59991
2 1,00000 34 5,08746 66 6,04439 98 6,61471
3 1,58496 35 5,12928 67 6,06609 99 6,62936
4 2,00000 36 5,16993 68 6,08746 100 6,64386
5 2,32193 37 5,20945 69 6,10852 101 6,65821
6 2,58496 38 5,24793 70 6,12928 102 6,67242
7 2,80735 39 5,28540 71 6,14975 103 6,68650
8 3,00000 40 5,32193 72 6,16992 104 6,70044
9 3,16993 41 5,35755 73 6,18982 105 6,71425
10 3,32193 42 5,39232 74 6,20945 106 6’72792
11 3,45943 43 5,42626 75 6,22882 107 6,74147
12 3,58496 44 5,45943 76 6,24793 108 6,75489
13 3,70044 45 5,49185 77 6,26679 109 6,76818
14 3,80735 46 5,52356 78 6,28540 ПО 6,78136
15 3,90689 47 5,55459 79 6,30378 111 6,79445
16 4,00000 48 5,58496 80 6,32193 112 6^80732
17 4,08746 49 5,61471 81 6,33985 113 6,82018
18 4,16993 50 5,64386 82 6,35755 114 6,83289
19 4,24793 51 5,67242 83 6,37504 115 6,84549
20 4,32193 52 5,70044 84 6,39232 116 6,85798
21 4,39232 53 5,72792 85 6,40939 117 6,87036
22 4,45943 54 5,75489 86 6,42626 118 6,88264
23 4,52356 55 5,78136 87 6,44294 119 6,89482
24 4,58496 56 5,80735 88 6,45943 120 6,90689
25 4,64386 57 5,83289 89 6,47573 121 6,91886
26 4,70044 58 5.85798 90 6,49185 122 6,93074
27 4,75489 59 5,88264 91 6,50779 123 6,94252
28 4,80735 60 5.90689 92 6,52356 124 6,95420
29 4,85798 61 5,93074 93 6,53916 125 6,96578
30 4,90689 62 5,95420 94 6,55459 126 6,97728
31 4,95420 63 5,97728 95 - 6,56986 127 6,98869
32 5,00000 64 6,00000 96 6,58496 128 7,00000
Таблица П-2
Двоичные логарифмы (разряды), составляющие целые числа
X logs X X logs X X logs*
1 0 128 7 16 384 14
2 1 256 8 32 768 15
4 2 512 9 65 536 16
8 3 1 024 10 . 71072 17
16 4 2 048 11 142 144 18
32 \ 6 4 096 12 284 288 19
64 8 192 13 568 576 20 4
409
Таблица П-3
Энтропия Н при вероятностях р и q двоичного события
р — logs Р —Р logs р н — Я logs Я — logs я Q
0,0005 10,965784 0,005483 0,006204 0,000721 0,000722 0,9995
0,0010 9,965784 0,009966 0,011408 0,001442 0,001443 0,9990
0,0015 9,380882 0,014071 0,016234 0,002162 0,002166 0,9985
0,0020 8,965784 0,017932 0,020814 0,002882 0,002888 0,9980
0,0025 8,643956 0,021610 0,025212 0,003602 0,003611 0,9975
0,0030 8,380882 0,025142 0,029464 0,004322 0,004335 0,9970
0,0035 8,158429 0,028555 0,033595 0,005041 0,005058 0,9965
0,0040 7,965784 0,031863 0,037622 0,005759 0,005782 0,9960
0,0045 7,795859 0,035081 0,041559 0,006477 0,006507 0,9955
0,0050 7,643856 0,038219 0,045415 0,007195 0,007232 0,9950
0,0055 7,506353 0,041285 0,049198 0,007913 0,007957 0,9945
0,0060 7,380822 0,044285 0,052915 0,008630 0,008682 0,9940
0,0065 7,265345 0,047225 0,056572 0,009347 0,009408 0,9935
0,0070 7,158429 0,050109 0,060172 0,010063 0,010134 0,9930
0,0075 7,058894 0,052942 0,063721 0,010780 0,010861 0,9925
0,0080 6,955784 0,055726 0,067222 0,011495 0,011588 0,9920
0,0085 6,878321 0,058466 0,070676 0,012211 0,012315 0,9915
0,0090 6,795859 0,061163 0,074088 0,012926 0,013043 0,9910
0,0095 6,717857 0,063820 0,077460 0,013640 0,013771 0,9905
0,0100 6,643856 0,066439 0,080793 0,014355 0,014500 0,9900
0,0110 6,506353 0,071570 0,087352 0,015782 0,015958 0,9890
0,0120 6,380822 0,076570 0,093778 0,017208 0,017417 0,9880
0,0130 6,265345 0,081449 0,100082 0,018633 0,018878 0,9870
0,0140 6,158429 0,086218 0,106274 0,020056 0,020340 0,9860
0,0150 6,0 18894 0,090883 0,112361 0,021477 0,021804 0,9850
0,0160 5,965784 0,095453 0,118350 0,022897 0,023270 0,9840
0,0170 5,878321 0,099931 0,12248 0,024316 0,024737 0,9830
0,0180 5,795859 0,104325 0,130059 0,025733 0,0 6205 0,9820
0,0190 5,717857 0,108639 0,135788 0,027149 0,027675 0,9810
0,0200 5,643856 0,112877 0,141441 0,028563 0,029146 0,9800
0,0210 5,573467 0,117043 0,147019 0,029976 0,030619 0,9790
0,0220 5,506353 0,121140 0,152527 0,031388 0,032094 0,9780
0,0230 5,442222 0,125171 0,157969 0,032797 0,033570 0,9770
0,0240 5,380822 0,129140 0,163346 0,034206 0,035047 0,9760
0,0250 5,321928 0,133048 0,168661 0,035513 0,036526 0,9750
0,0260 5,265345 0,136899 0,173917 0,037018 0,038006 0,9740
0,0270 5,210897 0,140694 0,179116 0,038422 0,039488 0,9730
0,0280 5,158428 0,144436 0,184216 0,039825 0,040972 0,9720
0,0290 5,107803 0,148126 0,189352 0,041226 0,042457 0,9710
0,0300 5,058894 0,151767 0,194392 0,042625 0,043943 0,9700
0,0310 5,011588 0,155359 0,199382 0,044023 0,045431 0,9690
0,0320 4,965784 0,158905 0,204325 0,045420 0,046921 0,9680
0,0330 4,921390 0,162406 0,209220 0,046815 0,048412 0,9670
0,0340 4,878321 0,165863 0,214071 0,048208 0,049904 0,9660
0,0350 4,836501 0,169278 0,218878 0,049600 0,051399 0,9650
0,0360 4,795859 0,172651 0,223642 0,050991 0,052895 0,9640
0,0370 4,756331 0,175984 0,228364 0,052380 0,054392 0,9630
410
Продолжение табл. П-3
р — logs Р — Р logs Р Н - <7 logs <7 — logs Q Q
0,0380 4,717857 0,179279 0,233046 0,053767 0,055891 0,9620
0,0390 4,680382 0,182535 0,237688 0,055153 0,057392 0,9610
0,0400 4,643856 0,185754 0,242292 0,056553 0,058894 0,9600
0,0410 4,608232 0,188938 0,246858 0,057921 0,060397 0,9590
0,0420 4,573467 0,192086 0,251388 0,059303 0,061902 0,9580
0,0430 4,539519 0,195199 0,255882 0,060683 0,063409 0,9570
0,0440 4,506353 0,198280 0,260341 0,062061 0,064917 0,9560
0,0450 4,473931 0,201327 0,264765 0,063438 0,066427 0,9550
0,0460 4,442222 0,204342 0,269156 0,064814 0,067939 0,9540
0,0470 4,411195 0,207326 0,273514 0,066188 0,069452 0,9530
0,0480 4,380822 0,210279 0,277840 0,067560 0,070967 0,9520
0,0490 4,351074 0,213203 0,282134 0,068931 0,072483 0,9610
0,0500 4,321928 0,216096 0,286397 0,070301 0,074001 0,9500
0,0520 4,265345 0,221798 0,294833 0,073035 0,077041 0,9480
0,0530 4,237864 0,224607 0,290007 0,074400 0,078564 0,9470
0,0540 4,210897 0,227388 0,303152 0,075763 0,070078 0,9460
0,0550 4,184425 0,230143 0,307268 0,077125 0,081614 0,9450
0,0560 4,158429 0,232872 0,311357 0,078485 0,083141 0,9440
0,0570 4,132894 0,235575 0,315419 0,079844 0,084670 0,9430
0,0580 4,107803 0,238253 0,319454 0,081201 0,086201 0,9420
0,0590 4,083141 0,240905 0,323462 0,082557 0,087733 0,9410
0,0600 4,058894 0,243534 0,327445 0,083911 0,089267 0,9400
0,0625 4,00000 0,250000 0,337290 0,087290 0,093109 0,9375
0,0650 3,943416 0,256322 0,346981 0,090659 0,090659 0,9350
0,0675 3,888969 0,262505 0,356524 0,094019 0,100824 0,9325
0,0700 3,936501 0,268555 0,365924 0,097369 0,104697 0,9300
0,0725 3,785875 0,274476 0,375185 0,100709 0,108518 0,9275
0,0750 3,736966 0,280272 0,384312 0,104039 0,112475 0,9250
0,0775 3,689660 0,285949 0,393308 0,107360 0,116379 0,9225
0,0800 3,643856 0,291508 0,402179 0,110671 0,120294 0,9200
0,0825 3,599462 0,296956 0,410227 0,113972 0,124220 0,9175
0,0850 3,556393 0,302293 0,419556 0,117263 0,128156 0,9150
0,0875 3,514573 0,307525 0,428070 0,120544 0,132104 0,9125
0,0900 3,473931 0,312654 0,436470 0,123816 0,136062 0,9100
0,0925 3,434402 0,317682 0,444760 0,127078 0,140030 0,9075
0,0950 3,395929 0,322613 0,452943 0,130329 0,144010 0,9050
0,0975 3,358454 0,327449 0,461020 0,133571 0,148001 0,9025
0,1000 3,321928 0,332193 0,468996 0,136803 0,152003 0,9000
0,1025 3,286304 0,336846 0,476871 0,140024 0,156016 0,8975
0,1050 3,251539 0,341412 0,484648 0,143236 0,160040 0,8950
0,1075 3,217591 0,345891 0,492329 0,146438 0,164076 0,8925
0,1100 3,184425 0,350287 0,499916 0,149629 0,168123 0,8900
0,1125 3,152003 0,354600 0,507411 0,152811 0,172181 0,8875
0,1150 3,120294 0,358834 0,514816 0,155982 0,176251 0,8850
0,1175 3,089267 0,362989 0,522132 0,159143 0,180332 0,8825
0,1200 3,058894 0,367067 0,529361 0,162294 0,184425 0,8800
0,1225 3,029146 0,371070 0,536505 0,16534 0,188529 0,8775
0,1250 3,000000 0,375000 0,543564 0,168564 0,192645 0,8750
0,1275 2,911431 0,378857 0,550542 0,171684 0,196773 0,8725
411
Продолжение табл. П-3
р - l°g2 Р — р logs р И - <7 log8 р - logs <7 Q
0,1300 2,943416 0,382644 0,557438 0,174794 0,200913 0,8700
0,1325 2,915936 0,386361 0,564255 0,177893 0,205064 0,8675
0,1350 2,888969 0,390011 0,570993 0,180982 0,209228 0,8650
0,1375 2,862496 0,393593 0,577654 0,184061 0,213404 0,8625
0,1400 2,836501 0,397110 0,584239 0,187129 0,217591 0,8600
0,1425 2,810966 0,400563 0,590749 0,190186 0,221791 0,8575
0,1450 2,785875 0,403952 0,597185 0,193233 0,226004 0,8550
0,1475 2,761213 0,407279 0,603549 0,196270 0,230228 0,8525
0,1500 2,736966 0,410545 0,609840 0,199295 0,234465 0,8500
0,1525 2,713119 0,413751 0,616061 0,203311 0,238715 0,8475
0,1550 2,689660 0,416897 0,622213 0,205315 0,142977 0,8450
0,1575 2,666576 0,419986 0,628295 0,208309 0,247251 0,8425
0,1600 2,643856 0,423017 0,634310 0,211293 0,251539 0,8400
0,1625 2,621488 0,425992 0,640257 0,214265 0,255839 0,8375
0,1650 2,599462 0,428911 0,646138 0,217227 0,260152 0,8350
0,1675 2,577767 0,431776 0.651954 0,220178 0,264678 0,8325
0,1700 2,556393 0,434587 0,657705 0,223118 0,268817 0,8300-
0,1725 2,535332 0,437345 0,663392 0,226047 0,273169 0,8275
0,1750 2,514573 0,440050 0,669016 0,228966 0,277534 0,8250
0,1775 2,494109 0,442704 0,674577 0,231873 0,281912 0,8225
0,1800 2,473931 0,445308 0,680077 0,234769 0,286304 0,8200
0,1825 2,454032 0,337861 0,685516 0,237655 0,290709 0,8175
0.1850 2,434403 0,450365 0,690894 0,240529 0,295128 0,8150
0,1875 2,415037 0,452820 0,696212 0,243393 0,299560 0,8125
0,1900 2,395929 0,455226 0,701471 0,246245 0,304006 0,8100
0,1925 2,377070 0,457586 0,706672 0,249086 0,308466 0,8075
0,1950 2,358454 0,459899 0,711815 0,251916 0,312939 0,8050
0,1975 2,340075 0,462165 0,716900 0,254735 0,317427 0,8025
0,2000 2,321928 0,464386 0,721928 0,257542 0,321928 0,8000
0,2050 2,286304 0,468692 0,731816 0,263124 0,330973 0,7950
0,2100 2,251539 0,472883 0,741483 0,268660 0,340075 0,7900
0,2150 2,217591 0,476782 0,750932 0,274151 0,349235 0,7850
0,2200 2,184425 0,480573 0,760167 0,279594 0,358454 0,7800
0,2250 2,152003 0,484201 0,769193 0,284992 0,367732 0,7750
0,2300 2,120294 0,487668 0,778011 0,290344 0,377070 0,7700
0,2350 2,089267 0,490978 0,786626 0,295648 0,386468 0,7650
0,2400 2,058894 0,494134 0,795040 0,300906 0,395929 0,7600
0,2450 2,029146 0,497141 0,803257 0,306116 0,405451 0,7550
0,2500 2,000000 0,500000 0,811278 0,311278 0,415037 0,7500
0,2550 1,971431 0,502715 0,819107 0,316392 0,424688 0,7450
0,2600 1,943416 0,505288 0,826746 0,321458 0,434403 0,7400
0,2650 1,915936 0,507723 0,834198 0,326475 0,444184 0,7350
0,2700 1,888969 0,510022 0,841465 0,331443 0,454032 0,7300
0,2750 1,862496 0,512187 0,848548 0,336362 0,463947 0,7250
0,2800 1,836501 0,514220 0,855451 0,341230 0,473931 0,7270
0,2850 1,810966 0,516125 0,862175 0,346049 0,483985 0,7150
0,2900 1,785875 0,517904 0,868721 0,350817 0,494109 0,7100
0,2950 1,761213 0,519558 0,875093 0,355535 0,504305 0,7050
0,3000 1,736966 0,521090 0,881291 0,360201 0,514573 0,7000
412
Продолжение табл. П-3
р - log2 Р - Р logs Р н - Я logs Я — logs я
0,3050 1,713119 0,522501 0,887317 0,364816 0,524915 0,6950
0,3100 1,689660 0,523795 0,893173 0,369379 0,535332 0,6900
0,3150 1,665576 0,524972 0,893861 0,373890 0,545824 0,6850
0,3200 1,643856 0,526034 0,904381 0,378347 0,556393 0,6800
0,3250 1,621488 0,526984 0,909736 0,382752 0,567041 0,6750
0,3300 1,599462 0,527822 0,914926 0,387104 0,577767 0,6700
0,3350 1,577767 0,528552 0,919953 0,391402 0,588574 0,6650
0,3400 1,556393 0,529174 0,924819 0,395645 0,599462 0,6000
0,3450 1,535332 0,529689 • 0,929523 0,399834 0,610043 0,6550
0,3500 1,514573 0,530101 0,934068 0,403967 0,621488 0,6500
0,3550 1,494109 0,530409 0,938454 0,408046 0,632629 0,6450
0,3600 1,473931 0,530615 0,942683 0,412068 0,643856 0,6400
0,3650 1,454032 0,530722 0,946755 0,946755 0.4J6034 0,6350
0,3700 1,434403 0,530729 0,950672 0,419943 0,666576 0,6300
0,3750 1,415037 0,530639 0,954434 0,423795 0,678072 0,6250
0,3800 1,395929 0,530453 0,958042 0,427589 0,689660 0,6200
0,3850 1,377070 0,530172 0,961497 0,431325 0,701342 0,6150
0,3900 1,358454 0,529797 0,964800 0,435002 0,713119 0,6100
0,3950 1,340075 0,529330 0,967951 0,438621 0,724993 0,6050
0,4000 1,321928 0,528771 0,970951 0,442179 0,736966 0,6000
0,4050 1,304006 0,528122 0,973800 0,445678 0,749038 0,5950
0,4100 1,286304 0,527385 0,976500 0,449116 0,761213 0,5900
0,4150 1,268817 0,526559 0,979051 0,452493 0,773491 0,5850
0,4200 1,251539 0,525645 0,981454 0,455808 0,785875 0,5800
0,4250 1,234464 0,524648 0,983708 0,459061 0,798366 0,5750
0,4300 1,217591 0,523564 0,985815 0,462251 0,810966 0,5700
0,4350 1,20091 0,522396 0,987770 0,465374 0,823670 0,5650
0,4400 1,184425 0,521147 0,989588 0,468441 0,836501 0,5600
0,4450 1,168123 0,519815 0,991254 0,471439 0,849440 0,5550
0,4500 1,152003 0,518401 0,992774 0,474373 0,862496 0,5500
0,4550 1,136062 0,516908 0,994149 0,477241 0,875672 0,5450
0,4600 1,120294 0,515335 0,995378 0,480043 0,888969 0,5400
0,4650 1,104697 0,513684 0,996462 0,482778 0,902389 0,5350
0,4700 1,089267 0,511956 0,997402 0,485446 0,915936 0,5300
0,4750 1,074001 0,510150 0,998196 0,488046 0,929611 0,5250
0,4800 1,058894 0,508269 0,998846 0,490577 0,943416 0,5200
0,4850 1,043943 0,506313 0,999351 0,493038 0,957356 0,5150
0,4900 1,029156 0,504282 0,999711 0,495430 0,971431 0,5100
0,4950 1,014500 0,502177 0,999928 0,497751 0,985645 0,5050
0,5000 1,000000 0,500000 1,000000 0,500000 1,000000 0,5000
Литература
Литература к введению
В-1. Бриллюэн Л., Наука и теория информации, Физматгиз,
1960.
В-2. Добров Г. М., Наука о науке, изд-во «Наукова думка»,
Киев, 1966.
В-3. Железнов Н. А., Принцип дискретизации стохасти-
ческих сигналов с неограниченным спектром и некоторые резуль-
таты теории импульсной передачи сообщений. — «Радиотехника и
электроника», вып. 1, 1958.
В-4. Кларк А., Черты будущего, изд-во «Мир», 1966.
В-5. Кур ба ков К. И., Кодирование и поиск информации
в автоматическом словаре, изд-во «Советское радио», 1968.
В-6. Моль А., Теория информации и эстетическое восприятие,
изд-во «Мир», 1965.
В-7. Новицкий П. В., Основы информационной теории изме-
рительных устройств, изд-во «Энергия», 1968.
В-8. Поваров Г. Н., Предисловие к книге Гуда и Макола
«Системотехника», изд-во «Советское радио», 1962.
В-9. Ратнер В. А., Генетические управляющие системы,
изд-во «Наука», Новосибирск, 1966.
В-10. С и м о и о в П. В. Что такое эмоция? Изд-во «Наука»,
1966.
В-11. Т е м н и к о в Ф. Е., Информатика, Известия вузов, «Элек-
тромеханика», 1963, № 11, см. также [Л. 1-23].
В-12. Тринчер К-С., Биология и информация, изд-во «Наука»,
1964.
В-13. Ч е р и ы ш В. И., Информационные процессы в обществе,
изд-во «Наука», 1968.
В-14, Шеннон К., Работы по теории информации и киберне-
тике, Изд-во иностр, лит., 1963.
В-15. Электротехнический справочник, т. 3, книга 2, изд-во «Энер-
гия», 1966.
Литература к гл. 1
1-1. Бонгард М. М., О понятии «Полезная информация».
Проблемы кибернетики, вып. 9, Физматгиз, 1963.
1-2. Б р и л л ю э н Л., Наука и теория информации, Физмат-
гиз, 1960.
1-3. Ветров А. А., Семиотика и ее основные проблемы, Полит-
издат, 1968.
414
1-4. Войшвилло Е. К., Попытка семантической интерпрета-
ции статистических понятий и энтропии, Кибернетику на службу ком-
мунизму, т. 3, изд-во «Энергия», 1966, см. также Войшвилло Е. К.,
«Понятие», Изд-во МГУ, 1967.
1-5. Г а в у р и н М. К., О ценности информации, Вестник Ленин-
градского университета, § 9, серия «Математика, механика и астроно-
мия», вып. 4, Ленинград, 1963.
1-6. Грекова И., К вопросу об информации, «Наука и жизнь»,
1967, № 3.
1-7. Г у б и и с к и й А. И., О некоторых проблемах теоретико-
информационного подхода к инженерной психологии, «Проблемы ин-
женерной психологии», вып. 2, Ленинград, 1965.
1-8. Земан И., Познание и информация, изд-во «Прогресс»,
1966.
1-9. Карнап Р., Значение и необходимость, Изд-во иностр,
лит., 1959. См. также комментарии в книге Джордж Ф., Мозг как вы-
числительная машина, Изд-во иностр, лит., 1963; Bar-Hillel, R. Carnap,
Semantic information, Brit. J. Phil. Sei., 4, 1953.
1-10. Клаус Г., Сила слова, изд-во «Прогресс», 1967.
1-11. Клюев И. И., Информационные основы передачи сообще-
ний, изд-во «Советское радио», 1966.
1-12. Колмогоров А. Н., Три подхода к определению поня-
тия «Количество информации», «Проблемы передачи информации»,
т. I, вып. 1, 1965.
1-13. Майлс, Измерение ценности научной информации, «Зару-
бежная радиоэлектроника», 1965, № 1.
1-14. Михайлов А. И., Черный А. И., Г и л я р е в -
с к и й Р. С., Основы информатики, изд-во «Наука», 1968.
1-15. Моль А., Теория информации и эстетическое восприятие,
изд-во «Мир», 1965.
1-16. Николаев В. И., Определение времени, затрачиваемого
оператором на решение задач по управлению судовой энергетической
установкой,-Известия АН СССР, «Энергетика и транспорт», 1965, № 4;
см. также Николаев В. И., Контроль работы судовых энергети-
ческих установок, ч. I, Элементы теории, изд-во «Судостроение», 1965.
1-17. Новицкий П. В., Основы информационной теории
измерительных устройств, изд-во «Энергия», 1968.
1-18. Рабинович В. И., Цапенко М. П., Информацион-
ные характеристики средств измерения и контроля, изд-во «Энергия»,
1968.
1-19. Симонов П. В., Что такое эмоция? Изд-во «Наука»,
1966.
1-20. Солодов А. В., Теория информации и ее применение
к задачам автоматического управления и контроля, изд-во «Наука»,
1967. (
1-21. Стратонович Р. Л. и Гришанин Б. А., серия
статей о ценности информации, Известия АН СССР, «Техническая
кибернетика», 1965, № 5; 1966, № 3; 1966, № 5; 1966, № 6; 1967, № 2;
1967, № 5.
1-22. Тарасенко Ф. П., Введение в курс теории информации,
Томский государственный университет, Томск, 1963.
1-23. Темников Ф. Е., Телемеханика и теория информации;
Электротехнический справочник, т. III, книга 2, изд-во «Энергия»,
1966; см. также Темников Ф. Е., Каноническая форма информа-
тики, Доклады МЭИ, «Автоматика и телемеханика», ч. II, Москва,
415
1967, Темников Ф. Е., Теория развертывающих систем, Госэнер-
гоиздат, 1963.
1-24. Уилмер, Измерение информации в криминалистике, Зару-
бежная радиоэлектроника, 1967, № 8.
1-25. Урсул А. Д., Прагматический аспект научной информации
(Методологические проблемы), Научно-техническая информация, се-
рия 2, 1968, № 8.
1-26. Харкевич А. А., О ценности информации, «Проблемы
кибернетики», вып. 4, Физматгиз, 1960.
1-27. Харрах Д., Серия статей: Phil, of Sci., 28 (1961), 30(1963),
33 (1966), См. также Harrah D., Communication — a logical model,
MIT Press, 1967.
1-28. Хартли P., Передача информации, сб. «Теория информа-
ции и ее приложения», Физматгиз, 1959.
1-29. Ш а ф ф А.; Введение в семантику, Изд-во иностр, лит.,
1963.
1-30. Шеннон К., Работы по теории информации и киберне-
тике, Изд-во иностр, лит., 1963.
1-31. Шрейдер Ю. А., О семантических аспектах теории
информации, Информация и кибернетика, сб. под ред. А. И. Берга,
изд-во «Советское радио», 1967.
Литература к гл. 2
2-1. Котельников В. А., О пропускной способности
эфира и проволоки в радиосвязи, изд. Всесоюзного энергетического
комитета, МГУ, 1933.
2-2. Т у р б о в и ч И. Т., Метод близких систем и его применение
для создания инженерных методов расчета линейных и-нелинейных
радиотехнических систем, Изд-во АН СССР, 1961.
2-3. Хлистунов В. Н., Основы цифровой электроизмеритель-
ной техники, изд-во «Энергия», 1966.
2-4. Темников Ф. Е., Автоматические регистрирующие при-
боры, Машгиз, 1960.
2-5. Темников Ф. Е., Теория развертывающих систем, Гос-
энергоиздат, 1963.
2-6. Фридрих 3., К теории дискретных отсчетов, Труды МЭИ,
вып. 52, 1963.
2-7. Виттих В. А.,Гинзбург А. И.,Об одном алгоритме
управления сбором информации, «Автометрия», 1965, Ns .4.
2-8. Витушкин А. Г., Оценка сложности задачи табулирова-
ния, Физматгиз, 1959.
2-9. Березин И. С., Ж и д к о в Н. П., Методы вычислений,
т. I, изд-во «Наука», 1966.
2-10. Ахиезер Н. И., Лекции по теории аппроксимации,
Гостехиздат, 1947.
2-11. Ляпунов А. А., О логических схемах программ, кн.
«Проблемы кибернетики», вып. I, Физматгиз, 1958.
2-12. Шастова Г. А., Кодирование и помехоустойчивость пере-
дачи телемеханической информации, изд-во «Энергия», 1966.
2-13. Математический практикум, под ред. Г. Н. Положего, Физ-
матгиз, 1960.
2-14. Электрические методы автоматического контроля, под ред.
К. Б. Карандеева, изд. «Энергия», 1965.
416
2-15. Ефимов В. М., Квантование по времени при измерении и
контроле, изд-во «Энергия», 1969.
2-16. Котельников В. А., Теория потенциальной помехо-
устойчивости, Госэнергоиздат, 1956.
2-17. Железнов Н. А., Принцип дискретизации стохасти-
ческих сигналов с неограниченным спектром и некоторые результа-
ты теории импульсной передачи сообщений. — «Радиотехника и эле-
ктроника», вып. I, 1958 г.
2-18. Ицкович Э. Л., Определение необходимой частоты изме-
рений при дискретном контроле, «Автоматика и телемеханика», 1961,
№ 2.
2-19. Мар кюс Ж-, Дискретизация и квантование, изд-во «Энер-
гия», 1969.
2-20. Шенброт И. М., Гинзбург М. Я., Расчет точности
систем централизованного контроля, изд-во «Энергия», 1970.
Литература к гл. 3
3-1. Новик А. А., Эффективное кодирование, изд-во «Энергия»,
1965.
3-2. ХаркевичА. А., Борьба с помехами, изд-во «Наука»,
1965.
3-3. Теория кодирования, сборник статей под ред. Э. Л. Блоха,
изд-во «Мир», 1964.
3-4. Удалов А. П., Супрун Б. А., Избыточное кодирова-
ние при передаче информации двоичными кодами, изд-во «Связь», 1964.
3-5. Питерсон У., Коды, исправляющие ошибки, изд-во
«Мир», 1964.
3-6. Самойленко С. И., Помехоустойчивое кодирование,
изд-во «Наука», 1966.
3-7. Бородин Л. Ф., Введение в теорию помехоустойчивого
кодирования, изд-во «Советское радио», 1968.
3-8. Колесник В. Д.,Мирончиков Е. Т., Декодирова-
ние циклических кодов, изд-во «Связь», 1968.
3-9. Методы введения избыточности для вычислительных систем
(Сборник статей), изд-во «Советское радио», 1966.
3-10. Дроздов Е. А., Пят и братов А. П., Автоматиче-
ское преобразование и кодирование информации, изд-во «Советское
радио», 1964.
Литература к гл. 4
4-1. Жуховицкий Б. Я., Системы телемеханики и их пре-
образование, изд. 2, изд-во «Энергия», 1968.
4-2. Зиновьев А. Л., Филиппов Л. И., Введение в тео-
рию сигналов и цепей, изд-во «Высшая школа», 1968.
4-3. Крамер Г., Лндбеттер М., Стационарные случайные
процессы, изд-во «Мир», 1969.
4-4. Левин Б. Р., Теоретические основы статистической радио-
техники, изд-во «Советское радио», т. I, 1969, т. II, 1968.
4-5. Ф е л ь д б а у м А. А. и др. (под ред. А. А. Фельдбаума),
Теоретические основы связи и управления, Физматгиз, 1963.
4-6. Харкевич А. А., Спектры и анализ, Физматгиз, 1962.
4-7. Харкевич А. А, Очерки общей теории связи, Гостех-
издат, 1955. ..
4-8. Харкевич А. А., Борьба с помехами, Физматгиз, 1963.
417
Литература к гл. 5
5-1. Агейкин Д. И., Костина Е. Н. и Кузнецо-
ва Н. Н., Датчики контроля и регулирования, изд. 2, изд-во «Маши-
ностроение», 1965.
5-2. Васильев В. И., Распознающие системы, изд-во «Наукова
думка», Киев, 1969.
5-3. К а тыс Г. П., Информационные сканирующие системы,
изд-во «Машиностроение», 1966.
5-4. Кузнецов П. И., Пчелинцев Л. А. и Гайден-
ко В. С., Контроль и поиск неисправностей в сложных системах,
изд-во «Советское радио», 1969.
5-5. Курочкин С С., Многомерные статистические анали-
заторы, Атомиздат, 1968.
5-6. Сысоев Л. П., Оценки параметров, обнаружение и разли-
чение сигналов, изд-во «Наука», 1969.
5-7. Левин Б. Р., Теоретические основы статистической радио-
техники, изд-во «Советское радио», 1968, т. II.
5-8. Темников Ф. Е., Теория развертывающих систем, Гос-
энергоиздат, 1963.
5-9. Т у р и ч и н А. М., Электрические измерения неэлектриче-
ских величин, изд. 4, изд-во «Энергия», 1966.
5-10. Синицын Б. С., Автоматические корреляторы и их при-
менение, Изд-во СО АН СССР, 1964.
5-11. Мирский Г. Я-, Аппаратурное определение характе-
ристик случайных процессов, изд-во «Энергия», 1967.
5 12. Барабаш Ю. Л. и др., Вопросы статистической теории
распознавания, изд-во «Советское радио», 1967.
5-13. Вальд А., Последовательный анализ, Физматгиз, 1960.
Литература к гл. 6
6-1. Гуткин Л. С., Современная радиоэлектроника и ее про-
блемы, изд-во «Советское радио», 1968.
6-2. Ильин В. А., Телеконтроль и телеуправление, изд-во
«Энергия», 1969.
6-3. Малов В. С., Телемеханика в энергетических системах,
Госэнергоиздат, 1955.
6-4. Малов В. С., Телемеханика, изд-во «Энергия», 1965.
6-5. Рай нес Р. Л., Горяйнов О. А., Телеуправление,
изд. 2-е, изд-во «Энергия», 1965.
6-6. Статистическая теория связи и ее приложение, под ред.
А. В. Балакришнана, пзд-во «Мир», 1967.
6-7. Борисов Ю. П., Пенин П. И., Основы многоканальной
передачи информации, изд-во «Связь», 1967.
6-8, Назаров М. В, Кувшинов Б. И., Попов О. В.,
Теория передачи сигналов, изд-во «Связь», 1970.
6-9. Шеннон К- Э., Работы по теории информации и киберне-
тике, перевод с английского, под ред. Р. Л. Добрушина и О. Б. Лупа-
пова, Изд-во иностр, лит., 1963.
6-10. Возенкрафт Дж., Джекобс И., Теоретические
основы техники связи, изд-во «Мир», 1969.
6-11. П е т р о в и ч И. Т., Размахин М. К-, Системы связи
с шумоподобными сигналами, изд-во «Советское радио», 1969.
418
6-12. Солодов А. В., Теория информации и ее применение
к задачам автоматического управления и контроля, изд-во «Наука»,
1967.
6-13. Бэллард А. Н., Новый метод уплотнения каналов связи
«Зарубежная радиоэлектроника», 1967, Ns 11.
6-14. Котельников В. А., Теория потенциальной помехо-
устойчивости, Госэнергоиздат, 1956.
Литература к гл. 7
7-1. Анисимов Б. В., Четвериков В. Н., Основы тео
рии и проектирования цифровых вычислительных машин, Машгиз,
1962.
7-2. Глушков В. М., Введение в кибернетику, Изд-во АН СССР,
Киев, 1964.
7-3. Голубев-Новожилов Ю. С., Многомашинные ком-
плексы вычислительных средств, изд-во «Советское радио», 1967.
z 7-4. Грегори Р.,Ван Горн Р., Системы автоматической
обработки данных, изд-во «Статистика», 1965.
7-5. Данильченко И. А.,К вопросу о систематизации элек-
тронных вычислительных машин, в сб. «Цифровая вычислительная
техника и программирование», под ред. А. И. Китова, вып. 1, изд-во
«Советское радио», 1966.
7-6. Демидович Б. П., Марон И. А., Основы вычисли-
тельной математики, Физматгиз, 1963.
7-7. Денисов П. Н., Принципы моделирования языка, Изд-во
МГУ, 1965.
7-8. Е в р е и и о в Э. В., К о с а р е в Ю. Г., Однородные вы-
числительные системы высокой производительности, Новосибирск,
изд-во «Наука», 1966.
7-9. Ефимова М. Н., Алгоритмические языки, изд-во «Совет-
ское радио», 1965.
7-10. Ицкович Э. Л., Трахтенгерц Э. А., Алгоритмы
централизованного контроля и управления производством, изд-во
«Советское радио», 1967.
7-11. Китов А. И., Программирование информационно-логиче-
ских задач, изд-во «Советское радио», 1967.
7-12. Королев М. А., Обработка экономической информации
на электронных машинах, изд-во «Экономика», 1965.
7-13. Л ед л и Р. С., Программирование и использование цифро-
вых вычислительных машин, пер. с англ., изд-во «Мир», 1966.
7-14. Ляпунов А. А., Об алгоритмах для переработки инфор-
мации, Известия вузов, «Радиофизика», 1958.
7-15. Л я п у н о в А. А., О логических схемах программ, «Про-
блемы кибернетики», вып. 1, 1958.
7-16. Мак-Кракен Д. Д., Программирование для цифровых
вычислительных машин, Изд-во иностр, лит., 1960.
7-17. Прохоров В. И., Погорелко В. А., Яков-
лев В. А., Основы программирования для электронных цифровых
вычислительных машин, изд-во «Высшая школа», 1967.
7-18. Универсальный язык программирования PL/1, пер. с англ.,
изд-во «Мир», 1968.
7-19. Хомский Н., Миллер Д ж., Введение в формальный
анализ естественных языков, «Кибернетический сборник», Ns 1, изд-во
«Мир», 1965.
419
7-20. Ше нбр от И. М., Гинзбург М. Я., Расчет точности
систем централизованного контроля, изд-во «Энергия», 1970.
7-21. Щиголев В. М., Математическая обработка результатов
измерений, Физматгиз, 1962.
7-22, Электрические методы автоматического контроля, сб. под
ред. К. Б. Карандеева, изд-во «Энергия», 1965.
7-23. Ю щ е н к о Е. Л., Адресное программирование, Гостех-
издат, УССР, 1963. .
Литература к гл. 8
8-1. Л о м о в Б. Ф., Человек и техника, Изд-во ЛГУ, 1966.
8-2. Бруфман С. С., Цифровые индикаторы, изд-во «Энергия»,
1964.
8-3. Темников Ф. Е.,Шенброт И. М., Машины и системы
централизованного контроля, ГОСИНТИ, 1964.
8-4. Темников Ф. Е., Автоматические регистрирующие при-
боры, изд-во «Машиностроение», 1968.
8-5. Каминский Ю. Д., Коменда Э. И., Индикаторные
и регистрирующие устройства для систем автоматического контроля,
изд-во «Энергия», 1967.
8-6. Попов Д. Ю., Зинченко В. П., Построение систем
управления и проблемы инженерной психологии, сб. «Инженерная
психология», изд-во «Прогресс», 1964.
8-7. Галактионов А. И., Представление информации опе-
ратору, изд-во «Энергия», 1969.
8-8. Эйгенброт В. М., Применение электронно-лучевых тру-
бок для многоточечного контроля, изд-во «Энергия», 1965.
8-9. Темников Ф. Е., И в а ш к и н Ю. А., О представлении
массовой информации перед оператором в системах наблюдения и управ-
ления, Сборник статей под ред. В. В. Солодовникова «Вычислительная
техника для управления производством», изд-во «Машиностроение»,
1970.
8-10. Карибский В. В., Пархоменко П. П., С о го-
м о пн Е. С., Техническая диагностика объектов контроля, изд-во
«Энергия», 1967.
8-11. Электронные системы отображения информации,
сб. статей под ред. Дж. Ховарда, пер. с англ., Воениздат, 1966.
8-12. Темников Ф. Е., Статистическая индикация (регистра-
ция) множеств величин при автоматическом централизованном конт-
роле производственных и испытательных процессов, Труды 4-й кон-
ференции «Автоматический контроль и методы электрических измере-
ний», т. 2, Новосибирск, 1964.
8-13. Проблемы центротехникп, труды МЭИ, вып. 52, изд-во «Энер-
гия», 1963.
8-14. Ивашкин Ю. А., Информационные характеристики
систем отображения и их взаимосвязь с психофизиологическими пока-
зателями деятельности оператора, «Приборы и системы управления»,
1969, № 4.
8-15. Панасенко И. М., Ф а т к и н А. В., К методике ана-
лиза и оценки щитов и пультов управления, «Приборы и системы
управления», 1967, № 12,
Содержание
Предисловие ............................................... 2
Введение.................................................. 4
Фазы обращения информации.............................. 8
Виды информации....................................... 10
Структура информации ................................. 14
Устранение избыточности информации ................... 17
Часть первая. ИНФОРМАЦИОННАЯ МЕТРИКА ..................... 19
Глава первая. Измерение информации.......................... 19
1-1. Структурные меры информации.......................... 20
Геометрическая мера................................... 20
Комбинаторная мера.................................... 21
Аддитивная мера (Хартли).............................. 24
Примеры структурной оценки количества информации ... 28
1-2. Статистические меры информации...............• . . . . 34
Вероятность и информация.............................. 34
Понятие энтропии . -.................................. 38
Энтропия ансамбля .................................... 39
Энтропия объединения...................'.............. 43
Количество информации и избыточность.................. 47
Примеры статистической оценки количества информации 49
Оценка качества измерения и контроля.................. 55
1-3. Семантические меры информации........................ 56
Содержательность информации........................... 58
Целесообразность информации........................... 58
Динамическая энтропия................................. 60
Существенность информации............................. 61
1-4. Другие меры полезности информации.................... 62
Энтропия, шум и тезаурус.............................. 62
Глава вторая. Дискретизация информации.................... 64
2-1. Квантование по уровню.......................-........ 64
2-2. Дискретизация по времени и восстановление непрерывных
функций................................................ 68
Регулярность отсчетов................................ -70
Критерии отбора отсчетов и оценка точности воспроизведения 71
Способ воспроизведения................................ 73
Воспроизводящие функции............................... 74
421
2-3. Теорема Котельникова.................................... 75
2-4. Принцип дискретизации Железнова........................ 81
2-5. Выбор периода дискретизации по критерию наибольшего
отклонения............................................. 84
Нулевая степень воспроизводящего многочлена (ступенчатая
аппроксимация) .......................................... 85
Первая степень воспроизводящего многочлена (линейная
аппроксимация) .......................................... 86
2-6. Выбор периода дискретизации по критерию среднеквадратич-
ного отклонения........................................ ... 88
2-7. Адаптивная дискретизация................................ 91
Нулевая степень воспроизводящего многочлена ............. 92
Первая степень воспроизводящего многочлена............... 93
Глава третья. Кодирование информации ........................ 96
3-1. Общие понятия и определения. Цели кодирования .... 96
3-2. Кодирование как процесс выражения информации в цифро-
вом виде.............................................. 99
3-3. Технические средства представления информации в цифро-
вой форме............................'............... 104
Разновидности преобразователей.................... 104
Аналого-кодовые преобразователи считывания........ 105
Аналого-кодовые преобразователи последовательного счета 110
Аналого-кодовые преобразователи поразрядного уравнове-
шивания ............................................... 115
3-4. Эффективное кодирование........................... 118
3-5. Технические средства кодирования и декодирования эффек-
тивных кодов 126
3-6. Помехоустойчивое кодирование........................... 129
3-7. Блоковые коды.......................................... 130
Общие принципы использования избыточности.............. 130
Связь корректирующей способности кода с кодовым расстоя-
нием .................................................. 133
Показатели качества корректирующего кода............... 135
Геометрическая интерпретация блоковых корректирующих
кодов................................................. 137
Систематические коды................................... 139
Математическое введение к групповым кодам.............. 139
3-8. Построение группового кода............................. 143
Определение числа избыточных символов.................. 143
Составление таблицы опознавателей ..................... 146
Определение проверочных равенств....................... 148
Матричная запись группового кода....................... 151
3-9. Технические средства кодирования и декодирования для
групповых кодов........................................ 153
3-10. Построение циклических кодов.......................... 156
ч Общие понятия и определения............................ 156
Математическое введение к циклическим кодам............ 158
Требования, предъявляемые к образующему многочлену 160
3-11. Выбор образующего многочлена по заданному объему кода
и заданной корректирующей способности ........ 161
- Обнаружение одиночных ошибок........................... 162
Исправление одиночных ошибок или обнаружение двойных
ошибок................................................. 162
422
Обнаружение тройных ошибок.......................... 166
Обнаружение и исправление независимых ошибок произ-
вольной кратности................................. 167
Обнаружение и исправление пачек ошибок............ 168
Методы образования циклического кода.............. 169
Матричная запись циклического кода.................. 170
3-12. Технические средства кодирования и декодирования для
циклических кодов.................................. 172
Линейные переключающие схемы...................... 172
Кодирующие устройства............................... 175
Декодирующие устройства..............................177
Глава четвертая. Модуляция носителей информации 180
4-1. Виды носителей и сигналов.......................... 180
4-2. Модуляция и кодирование............................ 184
4-3. Детерминированные и случайные сигналы.............. 186
4-4. Временная и спектральная формы описания сигнала ... 186
4-5. Спектры сигналов с носителем в виде постоянного состояния 189
Невозмущенный носитель.............................. 189
Прямая модуляция ................................... 189
4-6. Спектры сигналов с гармоническим носителем......... 191
Невозмущенный носитель ............................ 191
Амплитудная модуляция .............................. 191
Частотная и фазовая модуляции....................... 192
4-7. Спектры сигналов с импульсным носителем............ 198
Спектры одиночных импульсов......................... 198
Спектры импульсных носителей....................... 202
Спектры сигналов с импульсной модуляцией . ..... 206
4-8. Спектры случайных сигналов......................... 208
4-9. Помехоустойчивость модулированных сигналов......... 211
Паразитная модуляция................................ 211
Помехоустойчивость................................ 213
Часть вторая. ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ................... 217
Глава пятая. Восприятие информации...................... 217
5-1. Основные формы и методы восприятия................ 217
Классификация...................................... 217
Операционная схема процедуры восприятия............. 218
5-2. Первичное восприятие и измерение информации 219
Информационный портрет источника................ ... 219
Первичное восприятие ............................. 221
Измерение.......................................... 226
5-3. Анализ............................................ 229
Анализаторы веществ.............................. 231
Анализаторы колебаний............................... 234
Анализаторы полей................................... 238
Корреляторы..................................... ... 247
Анализаторы спектра случайных процессов............. 251
5-4. Обнаружение и распознавание........................ 253
Задачи обнаружения и распознавания.................. 253
Характеристики качества распознавания............... 255
Статистические критерии обнаружения ................ 256
Статистические критерии распознавания............... 263
423
Глава шестая. Передача информации........................264
6-1. Виды каналов передачи...............................266
Механические каналы..................................266
Акустические каналы................................ 268
Оптические каналы....................................270
Электрические каналы.................................273
Радиоканалы..........................................277
6-2. Разделение каналов..................................279
Пространственное разделение.................... . . . 280
Дифференциальное разделение..........................280
Частотное разделение.................................281
Временное разделение ............................... 282
Фазовое разделение...................................283
Кодовое разделение ................................. 283
Разделение по уровню.................................284
Разделение по форме..................................285
Корреляционное разделение............................285
Комбинированные методы разделения....................290
6-3. Передача информации по каналу.......................291
Информационная модель канала ....................... 292
Дискретный канал без помех...........................295
Дискретный канал с помехами..........................303
Непрерывный канал с помехами . . . '.................310
Согласование характеристик сигнала и канала ...... 324
6-4. Повышение помехоустойчивости передачи и приема .....329
Частотная фильтрация ................................332
Метод накопления.....................................334
Корреляционный метод фильтрации (временная фильтрация) 335
Согласованная фильтрация.............................338
Потенциальная помехоустойчивость приема по Котельникову 339
Глава седьмая. Обработка информации......................342
7-1. Основные понятия и определения......................342
7-2. Алгоритмы и программы обработки информации и языки для
их описания..........................................345
7-3. Математические операции при обработке информации . . . 363
7-4. Технические средства обработки информации...........368
7-5. Организация систем обработки информации.............374
Глава восьмая. Представление информации..................383
8-1. Основные формы элементарного представления информации 383
8-2. Психофизиологический аспект проблемы комплексного пред-
ставления информации оператору.......................392
8-3. Комплексное отображение информации на щитах и экранах 395
8-4. Обобщенное представление массовой информации........399
8-5. Оценка систем представления информации..............406
Приложения...............................................409
Литература ............................................. 414
ф.Е.ТЕМНИКОВ
ВЛ АФОНИН
В. И. ДМИТРИЕВ
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ
I
ТЕХНИКИ