/






















































































































































































































































































































































































































































































Автор: Губарев В.В.
Теги: информационные технологии вычислительная техника обработка данных информатика
ISBN: 978-5-7782-2778-1
Год: 2015




Текст
Министерство образования и науки Российской Федерации
НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
В.В. ГУБАРЕВ
ВВЕДЕНИЕ
В ТЕОРЕТИЧЕСКУЮ
ИНФОРМАТИКУ
Часть 2
Утверждено
Редакционно-издательским советом университета
в качестве учебного пособия
НОВОСИБИРСК
2015
УДК 004(075.8)
Г 93
Рецензенты:
Д.Е. Пальчунов, зав. кафедрой общей информатики,
зав. отделом ИДМИ НИЧ НГУ, д-р физ.-мат. наук, профессор
Б.Я. Рябко, зав. лабораторией информационных систем и защиты
информации ИВТ СО РАН, профессор НГУ, д-р техн. наук, профессор
Работа подготовлена на кафедре вычислительной техники
для студентов вузов, обучающихся по укрупненной группе
специальностей «Информатика и вычислительная техника»
(бакалавриат, магистратура, аспирантура)
Г 93
Губарев В.В.
Введение в теоретическую информатику: учеб. пособие /
В.В. Губарев. – Новосибирск: Изд-во НГТУ, 2015. – Ч. 2. – 472 с.
ISBN 978-5-7782-2778-1
В пособии с единых методических позиций рассматриваются системные
аспекты модельного представления объектов различной природы, излагаются
основные элементарные сведения теоретической информатики, ключевыми
словами которых являются: объект, модель, сигналы, данные, знания, алгоритмы, результат, информация, количество, качество. Описывается формальный
аппарат представления и исследования разнообразных видов процессов, структур, непрерывных и дискретных переходов состояний объектов.
Пособие ориентировано на подготовку бакалавров, магистров и аспирантов
по направлению 09.00.00 «Информатика и вычислительная техника». Оно может быть полезным для студентов, обучающихся по направлениям 02.00.00
«Компьютерные и информационные науки», 10.00.00 «Информационная безопасность», 11.00.00 «Электроника, радиотехника и системы связи», 27.00.00
«Управление в технических системах», а также специалистам в перечисленных
и смежных отраслях деятельности.
УДК 004(075.8)
ISBN 978-5-7782-2778-1
Губарев В.В, 2015
Новосибирский государственный
технический университет, 2015
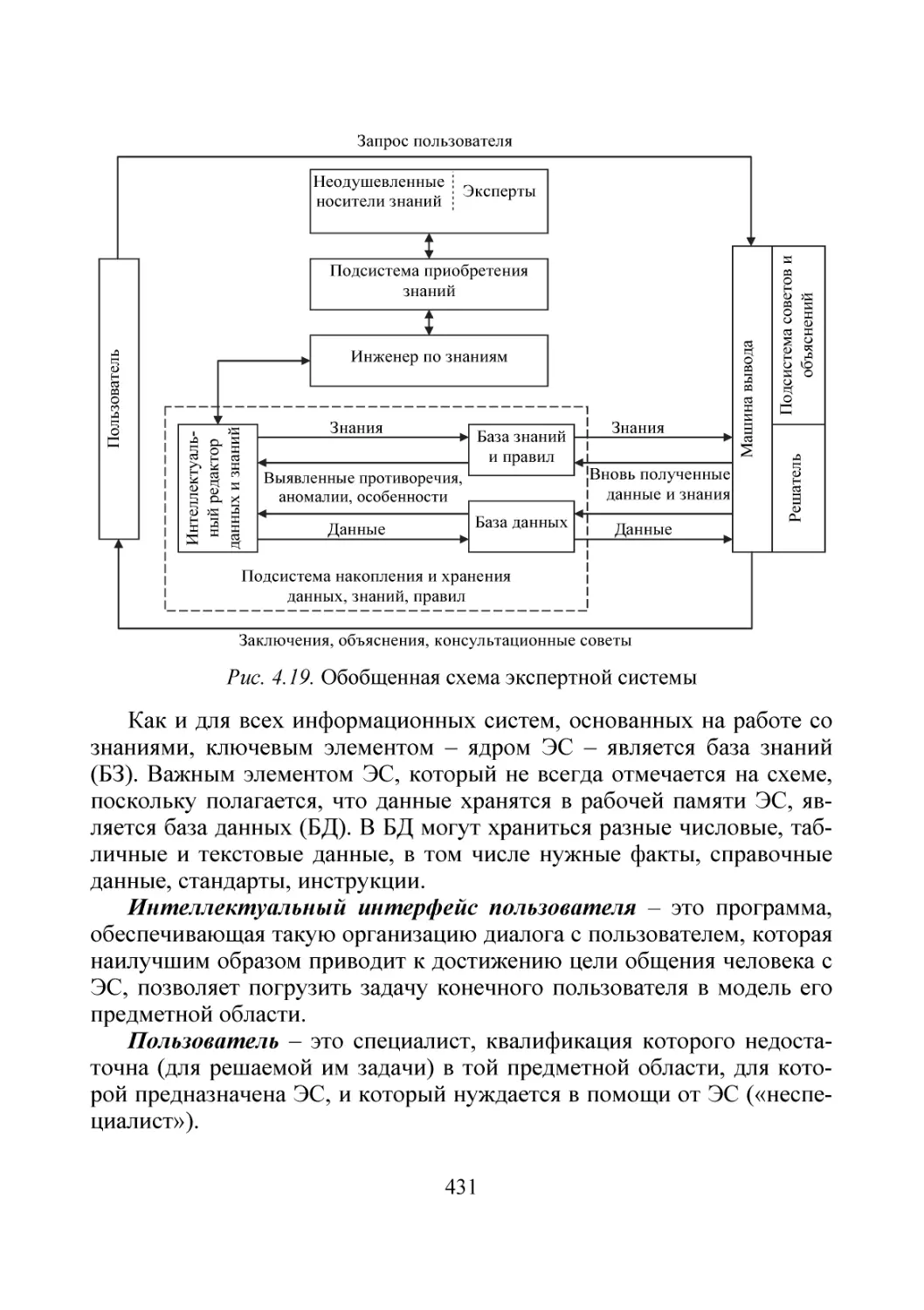
ПРЕДИСЛОВИЕ
В первой части пособия (опубликованной в издательстве НГТУ в
2014 г.) излагаются элементарные основы моделирования, системного
представления, измерения и экспериментирования как методов исследования объектов, а также следующий формальный аппарат описания
и исследования объектов: детерминированный, стохастический, нечеткий; интервальный; поиска оптимальных решений; динамического хаоса, фракталов; теории игр и массового обслуживания.
Во второй части рассматриваются: аппарат распознавания образов,
классификации, кластеризации, теории графов и сетей, автоматов; разные модели представления данных и результатов для их визуального
анализа; аппарат синтактической обработки сигналов и данных (дискретизации и квантования сигналов для разных приложений; получения, оформления, хранения и передачи данных и знаний). Отдельно
рассмотрены принципы построения технических средств, в частности
аналоговые, цифровые, когнитивные, нейронные и квантовые. Завершает пособие обширная глава, посвященная семантическим, событийным и прагматическим аспектам обработки современных данных, а
именно: видам задач и алгоритмов; понятию «проблема» и ее решениям; элементам информологии, понятию «информация» и мерам ее количества; структуре и методам искусственного интеллекта; различным
мягким методам и алгоритмам (нейросетевым, генетическим, роевым,
агентным, иммунным, деревьям целей и регрессий, когнитивным, визуального моделирования, неопределенных вычислений); различным
индуктивным методам обработки и анализа сигналов, данных и знаний, включая упорядочение и выбор моделей, методов и алгоритмов,
интеллектуальный и разведочный анализы данных; инженерии знаний
и управления ими, а также квалиметрии моделей и управлению качеством результатов моделирования объектов и анализа сигналов, данных и знаний.
3
ВВЕДЕНИЕ
Пособие посвящено фрагментарному изложению с единых системно-методических позиций основных элементарных сведений о моделировании и экспериментировании как методах исследований1 объектов разной природы; метрологии; теории информации; методах и
алгоритмах обработки, исследования, анализа сигналов, данных,
знаний.
Основное внимание в первой части пособия (Издательство НГТУ,
2014 г.) уделено методологическим аспектам моделирования объектов,
элементам системологии, экспериментированию как методу исследования и этапу моделирования объектов, а также следующим элементарным основам аппарата описания и исследования объектов различной
природы: детерминированного, стохастического, нечеткого, экспертного, динамического хаоса, фрактального, оптимизационного и теории
массового обслуживания.
Во второй части учебного пособия вначале завершается изложение формального аппарата, используемого для описания исследуемых
объектов, методов и средств обработки (в обобщенном смысле) сигналов, данных и знаний. Рассмотрены элементарные сведения аппарата распознавания образов, классификации и кластеризации; теории
графов и сетей; теории автоматов; синтактической обработки сигналов, данных и знаний, а именно дискретизации по аргументу и квантования по значению сигналов с учетом разных назначений этих
операций; получения, оформления, хранения и передачи сигналов,
данных и знаний.
1
Напомним (см. часть 1, § 1.1), что в пособии термин исследование понимается, как правило, в обобщенном виде, а именно как изучение, познание,
представление, управление, проектирование, анализ, синтез, передача и т. п.
4
Кратко описаны важные для моделирования и обработки сигналов,
данных и знаний принципы построения используемых для этого технических средств: аналоговых, цифровых, когнитивных, нейронных и
квантовых.
Большое внимание во второй части пособия уделяется вопросам
отличия современных данных, в частности Больших данных, подходов
к их представлению и алгоритмов обработки от тех, которые использовались еще совсем недавно. Они связаны, во-первых, с особенностью
исходных, «сырых» данных, прежде всего Больших, во-вторых, с появлением новых типов задач, включая туманные, проблемные,
в-третьих, с необходимостью перехода от дедуктивных к индуктивным
методам работы с Данными = сигналами данными знаниями, в которых единственным исходным «источником» в работе являются только сами Данные, в-четвертых, вынужденностью расширения классов
алгоритмов на класс мягких алгоритмов и их применения для индуктивной обработки современных Данных при решении задач различной
сложности, в-пятых, с необходимостью использования полимодельного представления объектов и решения задач, и, как следствие, упорядочения, выбора, совместного применения моделей, оценки качества
получаемых при этом результатов и управления качеством в интересах
итогового результата решения стоящей задачи. К мягким относят теоретически нестрогие алгоритмы, позволяющие получить за определенное время неточное, приближенное, но приемлемое решение таких задач, которые традиционными алгоритмами не решаются в тех же
исходных условиях. Их особенность – настроенность не столько на
строгую теоретическую обоснованность механизма получения результата, сколько на его достижимость и пригодность.
Рассмотрены также вопросы информологии, искусственного интеллекта, инженерии знаний и управления ими, а также элементарные
основы принципов построения технических средств информатики.
В заключение отметим, что пособие сознательно рассчитано на
разный круг читателей – от начинающих студентов до специалистов.
Студентам рекомендуется при первом чтении опускать частности, различные замечания, уточнения, детализации и сноски, которые могут
представить несомненный интерес для специалистов и преподавателей. Это, естетственно, привело к неравномерности ширины и глубины
изложения отдельных вопросов, за что автор приносит свои извинения.
5
В силу определенной новизны и неоднозначности изложения многих вопросов в учебной и научной литературе, дискуссионного характера некоторых затронутых в пособии тем автор с благодарностью
примет любые деловые конструктивные замечания и пожелания по
уточнению и улучшению содержания книги.
Автор благодарен рецензентам, коллегам, ученикам, аспирантам и
студентам, замечания которых, беседы и дискуссии с которыми способствовали написанию книги и улучшению ее содержания. Особую
благодарность заслуживает О.В. Малявко за большой вклад в подготовку рукописи первой и второй части пособия.
6
Глава первая
ФОРМАЛЬНЫЙ АППАРАТ ОПИСАНИЯ
И ИССЛЕДОВАНИЯ РАЗНООБРАЗИЯ
СТРУКТУР И ДИСКРЕТНЫХ ПЕРЕХОДОВ
СОСТОЯНИЙ ОБЪЕКТОВ: КУАЛИЗНЫЕ МОДЕЛИ
§ 1.1. ВВОДНЫЕ ЗАМЕЧАНИЯ
В первой части пособия был рассмотрен формальный аппарат, который используется для куомодного механизмового модельного представления исследуемых объектов, отвечающего на вопросы: «Как, каким образом устроен и функционирует объект?». Основное внимание
при этом уделялось описанию механизма строения и функционирования с точки зрения динамики их проявления и развития. В настоящей
главе основное внимание уделяется рассмотрению моделей статики
строения объекта, т. е. его типа, состава, структуры и частично дискретного перехода из одного статичного состояния в другое. Иными
словами, такие модели призваны помочь получить ответы на вопросы
вида: «Что за объект, какой это объект, как он называется, как его отличить от других, включая отличие по структуре (составу и связям), в
каком состоянии он находится, как его перевести в другое состояние,
каково их разнообразие и т. п.?». Напомним, что под объектом в настоящем пособии понимается то первичное, на что направлено исследование. В качестве объектов могут быть вещи, процессы, явления, события, факты, сигналы, ситуации и прочее, а также их модели, включая
знания. Для этих моделей важно, чтобы исследуемые объекты можно
было охарактеризовать конечным набором их некоторых свойств, особенностей, называемых признаками.
7
§ 1.2. МОДЕЛИ РАЗНООБРАЗИЯ ОБЪЕКТОВ
1.2.1. Необходимые пояснения
Прежде всего рассмотрим куализные модели, направленные на получение ответов на вопросы: «Что это за объект? Каково их разнообразие? К какому виду он принадлежит? Как его называть?». Сюда относятся модели, используемые в теориях разнообразия: распознавания
образов, классификации1, кластеризации.
В первую очередь обратим внимание на два важных обстоятельства.
Первое обстоятельство. Ответы на упомянутые в начале параграфа вопросы требуют модельного представления объекта на основе некоторого набора его свойств, представляемых в виде количественных
или качественных признаков, по значениям которых исследователь
ищет ответы на эти вопросы. В связи с этим надо иметь в виду, что, вопервых, модель есть целевое отражение объекта-оригинала, вовторых, наборы свойств (признаков), их суть и состав есть также модели объекта-оригинала. Поэтому, с одной стороны, в зависимости от
куализного модельного представления объекта ответы на поставленные вопросы являются неоднозначными. Они будут зависеть как от
постановки задачи исследователя, в частности, от цели поиска ответа
на поставленные куализные вопросы, так и от взаимосвязанного с целью, но самостоятельно определяемого набора показателей, свойств,
признаков объекта, по которым исследователь будет искать ответ. Замена цели, а следовательно, и набора признаков, которыми характеризуется объект, либо замена одного набора признаков при той же цели
на другой могут привести к совершенно разным ответам на те же вопросы. С другой стороны, используя одно- или многовариантное решение, исследователь стремится получить четкий ответ на поставленный в исследовании вопрос. Иначе решение стоящей перед ним
практической задачи потребует дополнительных исследований. Это
противоречие является трудно формализуемым, так как затрагивает
вопросы постановки цели, количества и состава признаков, их ранжирования и важности для решаемой задачи с учетом ценностных, нрав1
Чтобы избежать перечисления этих терминов до специального рассмотрения их сути и отличия и в дальнейшем, где это не будет входить в противоречие с контекстом, будем использовать наиболее часто употребляемое, интуитивно понимаемое большинством в более широком контексте слово
«классификация».
8
ственных, этических, эстетических и прочих особенностей исследователя. Для формализации выбора признаков можно лишь предложить
некоторые общие рекомендации. Это, например, следующие.
1. Вводимые и используемые признаки должны быть существенными, т. е. отражать те особенности объекта, которые наиболее значимы для достижения поставленной цели классификации.
2. Желательно, чтобы набор признаков был «ортогональным», т. е.
таким, когда проекция количественных или качественных значений
любого из них на другие будет точечной, а не интервальной. Это, в
частности, означает, что не должно быть комбинированных, состоящих из совмещенных наименований, признаков.
3. Желательно, чтобы альтернативы названий признаков были бинарными либо, при невозможности бинарности, тринарными. Это
означает, что наименование признака должно иметь два или три варианта проявления, реализации, наборов количественных или качественных значений.
Приведем примеры признаков, когда приходится рассматривать
три их значения. Первый пример. Пол особи: чаще всего – мужской
или женский; иногда: мужской, женский и гермафродитный, когда
особь содержит одновременно мужские и женские органы и, как следствие, имеет свойства, признаки и мужского, и женского пола. Второй
пример – мезатермы – животные с промежуточным метаболизмом, т. е.
одновременно тепло- и холодокровные (предположительно динозавры). Третий пример – форма представления информации в информационной системе или принцип построения ее аппаратных, технических
элементов: как правило аналоговый, цифровой либо аналоговый, цифровой и гибридный, совмещающий одновременно признаки аналогового и цифрового представления информации (см. гл. 3). Но деление на
аналоговый, цифровой и комбинированный, когда под комбинированным понимается поочередное выполнение законченных аналоговых и
цифровых операций, с точки зрения классификации нежелательно.
В подобных ситуациях следует не вводить комбинированные принципы как варианты реализации признака, а рассматривать средства, основанные на комбинации двух принципов. Доведение признаков такого уровня детальности, когда их проявление может быть только
двояким и в случае невозможности дуальности трояким, представляет
собой один из способов выполнения требования ортогональности.
4. Необходимо соблюдать методологический принцип бережливости – «принцип достаточного основания», называемый Бритвой Оккамы (см. [1], 1320 г.), который кратко можно описать в виде «не следует
9
множить сущее без необходимости». В приложении к рассматриваемому это означает, что набор признаков следует делать бережливо, не
включать в него те, без которых поставленная задача может быть
успешно решена. Иными словами, набор признаков должен быть как
можно меньшим, но таким, чтобы задачу удалось решить с требуемым
качеством с минимальными затратами. Это приводит к необходимости
минимизации признакового пространства. Обратим внимание, что использование малого числа признаков может привести к пересечению
классов, что существенно усложняет процедуры и уменьшает качество
классификации. Заметим, что наличие в наборе ортогональных признаков означает на языке теории вероятностей, что количественные
признаки должны быть некоррелированы, т. е. не должны содержать
значений, общих данных, сведений об объекте, выраженных, может
быть, в другой форме или в другой шкале, либо разных признаков, связанно отражающих одну и ту же особенность, свойство объекта.
5. Признаки могут быть измерены в разных количественных и качественных шкалах и иметь разное модельное представление. Это
означает, что количественные признаки могут быть точечными или
интервальными; детерминированными, стохастическими, нечеткими
и т. д. (см. часть 1, гл. 4). Категорийные признаки могут быть номинальными или порядковыми; логическими – в виде высказываний, допускающих бинарные выводы (истина, ложь); отражающими состояние, поведение объекта (наличие насморка, кашля, определенного вида
боли, растворимости в воде, …), или структурными (лингвистические,
синтаксические), отражающими структуру объекта, составляющие его
элементы, связи и правила взаимодействия между собой элементов.
В связи с использованием разных измерительных шкал уместно
напомнить следующие моменты из их теории (см. часть 1, раздел
3.1.3). В шкалах наименований числа, как и имена, названия, используются только для персональной идентификации и различения объектов. Примерами таких чисел являются ИНН, штрих-коды, номера телефонов, паспортов, страховых свидетельств и т. п. В порядковых
шкалах числа используются для упорядочения объектов: оценки на
экзаменах, номера домов и квартир, различные баллы.
В интервальных шкалах начала отсчета и единица измерения назначаются произвольно (например, температурные шкалы Цельсия,
Фаренгейта; положение точки относительно какого-то центра). В шкале же отношений единица измерения может быть произвольной, но
начало отсчета всегда считается заданным (масса, мощность, сила тока, температура по Кельвину, сопротивление, цена, электрическое или
10
магнитное напряжение, давление и т. п.). Наоборот, в шкале разностей
задается единица измерения, а начало отсчетов может быть произвольным (например, время, продолжительность жизни). И только в абсолютной шкале задаются как начало отсчета, так и единица измерения.
Второе обстоятельство. Оно связано с тем, что разные специалисты одни и те же термины используют по-разному.
Это обусловлено рядом причин, одни из которых изложены в части 1
в первой главе, другие будут обсуждаться в четвертой главе, часть 2.
Здесь только заметим следующее. Во-первых, любой термин лишь модель определяемого им понятия (см. часть 1, гл. 1) и поэтому неоднозначно отражает его. Во-вторых, междисциплинарные понятия, как
правило, являются по сути своей дефинициями с нечеткими границами. В-третьих, термины, особенно новые, междисциплинарные, часто
вводятся и используются на интуитивном уровне. В-четвертых,
общепринятые понятия окончательно появляются в тех научных дисциплинах, базовые основы которых становятся классическими и практически перестают развиваться. В-пятых, человеку свойственно образное мышление, поэтому зачастую ему, особенно ребенку, проще
показать объект, соответствующий какому-то понятию либо классу,
образу, чем дать определение этого объекта (класса, образа).
В-шестых, иногда термин обозначает как процесс, а порою и метод
действия, так и результат действия, определяемого этим или схожим
термином (например, оценка (см. 1-ю часть) и классификация (см.
настоящий параграф)). Наконец, в-седьмых, чрезмерно ограничительное определение (дефиниция) на стадии введения новых терминов,
особенно на этапе становления научной дисциплины, может оказаться
чрезмерно сковывающим, сравнимым, по меткому выражению
Л.И. Мандельштама1, с губительным пристрастием заворачивать младенца в колючую проволоку. Это вовсе не означает то, что термины
можно вводить произвольно, а лишь отражает сложность введения и
толкования разными специалистами одних и тех же терминов. Именно
поэтому в первой части пособия введено понятие «рабочее определение» термина.
1
Л.И. Мандельштам (см. о нем в [1]) обсуждал вопросы определения термина «колебания» и того, что составляет предмет теории колебаний. О подобных сложностях с определениями пишет Дж. Уизем, который отмечает, что,
по-видимому, не существует единого строгого определения волнам …, поскольку различным типам волн присущи различные характерные черты (Образование и общество. – 2010. – № 3. – С. 72–75).
11
Воспользуемся этим приемом. Далее нам придется подробно рассматривать термины «класс» и «классификация». Но до их детального
рассмотрения придется эти термины использовать.
В связи с этим приведем здесь их «рабочее» понимание. Чтобы избежать повтора, приведем разные трактовки терминов класс и классификация. Использование энциклопедического, специализированного
или конкретного понимания трактовки термина будет, надеемся, ясным из дальнейшего контекста.
Класс (от лат.– разряд, группа) это:
единица классификации в различных научных дисциплинах и
областях деятельности;
совокупность (разряд, группа, множество)1 объектов (предметов,
явлений) – экземпляров, элементов класса, обладающих общими признаками, выделенных и включенных в нее (совокупность) по этим признакам;
подмножество объектов, выделенное из бесконечного множества
объектов с определенной целью [5];
«генеральная совокупность, описываемая одномерным распределением вероятности» (в задачах статистической классификации) [9].
Под «классификацией» (от лат. classis и facere – делать) в обобщенном виде будем понимать, во-первых, систему классов; действия,
связанные с построением системы, а именно процедуры построения
классов, их изучения и использования (триаду «построение – изучение –
применение»), и саму построенную систему классов; во-вторых, метод
исследования объектов, основанный на выделении и изучении классов
и отнесение конкретного объекта к определенному классу. Заметим,
что этап классификации, связанный с отнесением объекта к тому или
иному классу с известным или создаваемым в ходе классификации
описанием, представляет собой идентификацию (параметрическую или
структурную) объекта куализной моделью. Именно в этом (куализном)
смысле логично понимать термин идентификация, иногда используемый в теории классификации рядом авторов (ср. с рис. 2.3, часть 1).
Все изложенное в полной мере относится к приводимым ниже терминам «распознавание» (образов), «классификация», «кластеризация»,
«таксономия» и т. п. Это затрудняет написание учебного пособия и
приводит к необходимости либо присоединиться к одной из групп
специалистов, либо к рассмотрению разных трактовок часто использу1
Желательно иметь и строить не просто множество, совокупность, а
именно систему классов, обладающую свойством эмерджентности.
12
емых определений, либо вводить уточнение, свое содержание терминов. Понятно, что в первом и третьем случаях это может не очень нравиться и воспринято специалистами, работающими в узкой сфере, а во
втором случае затруднит конкретное изложение сути моделей и методов, чтобы не ввести в заблуждение обучающихся. Приведем некоторые пояснения изложенному.
1.2.2. Абстрагирование как необходимый этап
моделирования объектов
Прежде всего введем необходимые понятия.
Одним из классических приемов при построении различных моделей реальности, в частности при установлении физических законов и
закономерностей, является абстрагирование, проявляющееся в использовании разных типов абстракции. Чаще всего выделяют следующие
четыре типа: изолирующая – вычленяющая исследуемый объект из некоторой целостности; обобщающая – дающая обобщающую картину
объекта; идеализирующая – замещающая реальный объект идеализированным в каком-то смысле объектом; мысленная – придуманная человеком без обязательной привязки к действительности (например, математические понятия, конструкции, аксиомы).
Методы, основанные на абстрагировании, на абстракции, – это
методы, базирующиеся на мысленном отвлечении от несущественных
свойств, связей, отношений объектов (предметов, явлений, процессов)
и на выделении тех из них, которые интересуют исследователя. Они
широко используются и содержат две явно различимые стадии: выявление, определение несущественных связей, свойств и замена исследуемого объекта моделью – другим объектом, сохраняющим главное в
сложном. Из изложенного ясно, что абстрагирование – это один из
важных этапов моделирования.
Как было отмечено, в моделировании абстракция бывает четырех
основных типов: изолирующей, обобщающей, идеализирующей и
мысленной. Что касается общенаучных видов абстрагирования, то выделяют обычно следующие: отождествление – образование понятий,
моделей путем объединения объектов по их свойствам в определенные
классы; изолирование – выделение свойств, неразрывно связанных с
объектом, и оперирование ими; конструктивизация – отвлечение от
неопределенности границ реальных объектов, их четкое очерчивание,
выделение; виртуализация – выявление допустимости потенциальной
13
осуществимости объекта, т. е. принципиально реализуемой, существующей в потенции, могущей быть реализованной в определенных
реальных условиях при наличии определенных средств, ресурсов, сил,
условий и других необходимых возможностей.
Например, в семантических моделях (структурах) Данных (см.
далее), учитывающих смысловое содержание Данных и смысловые
аспекты информации, для послойного рассмотрения проблемы, решения задачи на базе Данных, семантики знаний с отвлечением на каждом этапе решения от несущественных деталей и выделением принципиально важных фактов, используют наиболее часто следующие
абстракции: классификацию, агрегирование, обобщение и ассоциацию.
При классификации1, как методе исследования, осуществляется
распределение исследуемых объектов на взаимосвязанные классы по
наиболее существенным признакам, присущим объектам данного рода
и отличающим их от объектов других родов. При этом признаки, как
было указано, должны быть «ортогональными», относиться к разным
(«перпендикулярным») ортам системы координат признаков, а каждый
класс занимает в получившейся системе определенное постоянное место и, в свою очередь, может делиться на подклассы. Таким образом,
при классификации набор объектов рассматривается как новый объект
более высокого уровня – класс объектов, характеризующий свойства
каждого принадлежащего ему объекта. Это абстракция, в которой
связь между объектами и их свойствами, признаками представляется
по типу «экземпляр чего-либо». Например, распределение студентов
по полу, успеваемости и т. п.
Заметим, что в основе любой классификации лежат следующие два
принципа: 1) в один класс объединяются объекты, сходные между собой в принятом смысле; 2) степень сходства между собой объектов,
относимых к одному классу, должна быть больше, чем степень сходства между собой объектов, включаемых в разные классы [8]. При
этом, во-первых, число реально существующих классов всегда меньше
числа всевозможных сочетаний различных признаков, используемых
при классификации; во-вторых, элементы разных классов должны взаимно исключать друг друга; в-третьих, общее число расквалифицированных объектов должно равняться сумме объектов, включенных во
1
Термин классификация здесь понимается обобщенно и как система классов, и как построенная классификация, и как действия, связанные с процедурой выделения классов и отнесения объектов к ним.
14
все классы; в-четвертых, для одной и той же классификации должно
применяться одно и то же основание.
Обобщение – форма абстракции, посредством которой осуществляется переход от единичного к общему, от менее общего к более общему путем выделения одинаковых свойств объектов, принадлежащих
определенным группам, когда похожие объекты связываются с родовым объектом более высокого уровня и рассматриваются как его частные случаи (ср. с дедукцией), т. е. когда вводится, определяется новое
понятие, в котором находит отражение главное, основное, характеризующее объекты определенной группы, класса. Например, объекты
«университет», «академия» (учебная), «институт» есть частные случаи
объекта «вуз». Обобщение есть одно из основных средств для образования новых понятий, формулирования закономерностей, законов,
теорий. При обобщении связь между объектами представляется как
«это есть».
При агрегировании (от лат. aggregatus – присоединенный) рассматриваются не столько сами объекты, сколько связи между ними, свойства, однородные показатели, т. е. когда объекты рассматриваются через свои связи, свойства, показатели путем объединения их в объекты
(агрегаты) более высокого уровня, не отражающие (в определенном
смысле даже подавляющие) специфические детали исходных составляющих их объектов. С помощью данной абстракции обеспечивается
установление между объектами связи вида «часть чего-либо». Заметим, что объекты, входящие в агрегат, называются именно частями в
отличие от объектов, входящих во множество, в котором они называются элементами, или в классы, где их лучше в данном понимании
называть экземплярами.
Признаки агрегата, как совокупности однородных объектов, отображенные в понятии о нем, характеризуют лишь именно агрегат в целом, но не приложимы к каждому отдельному объекту этой совокупности. Например, в понятии «лес» отображены признаки совокупности
деревьев, входящих в этот агрегат, но существенные признаки этого
понятия нельзя приложить к каждому отдельному дереву: понятие
«строевой или хвойный лес» вовсе не означает, что все деревья этого
леса годны для строительства или являются хвойными. Именно это
отличает агрегат от класса, поскольку класс – это совокупность единичных объектов, когда каждому из них присущи одни и те же общие
свойства (например, животные, входящие в класс млекопитающих, все
имеют молочные железы, постоянную температуру тела, легочное дыхание и др.).
15
Таким образом, с помощью агрегирования, как формы абстракции,
обеспечивается установление между объектами связей вида «часть
чего-либо».
Наконец, ассоциация (от лат. associatio – соединение) – это форма
абстракции, устанавливающая связь между объектами, заключающаяся
в том, что появление при определенных условиях одного объекта влечет за собой появление другого или нескольких ассоциируемых с ним
объектов. Иными словами, это форма абстракции, оперирующая взаимосвязью между подобными объектами, которая рассматривается как
некоторый множественный объект более высокого уровня. Например,
множественный объект типа «персонал» определяется через составляющие объекты типа «сотрудник». При ассоциации между объектами
устанавливается связь вида «член чего-либо», причем сама связь заключается в том, что появление при определенных условиях одного
объекта влечет за собой появление другого или нескольких объектов.
Так, например, в ассоциативных запоминающих устройствах (ЗУ)
запись и/или выборка данных производится не по конкретному адресу
(как в адресных ЗУ), а путем ассоциативного поиска, т. е. по заданному сочетанию (ассоциации) признаков, свойственных искомой информации: часть, особенность или размер слова или его местоположение в
словосочетании. В ассоциативном программировании решение информационно-логических задач основано на программной реализации
ассоциативных связей между данными, хранящимися в ЗУ или в базе
данных. В средствах искусственного интеллекта помимо ассоциативного поиска применяются модели ассоциативных рассуждений, основанные на переносе приемов, использованных ранее, на текущую ситуацию. Ассоциативный поиск и ассоциативное рассуждение есть два
составных компонента исследуемых в психологии ассоциативных моделей мышления, основой которых является предположение о том, что
решение неизвестной задачи так или иначе базируется на уже решенных задачах, чем-то похожих на ту, которую надо решить, т. е. когда
новая задача рассматривается как уже известная, хотя и несколько отличная от нее, и поэтому может быть решена способом, близким к способу, позволяющему решить известную задачу. Структуры данных,
использующие семантические модели указанных четырех типов, представляются в виде соответствующих форм абстракции, каждая из которых может строиться в виде иерархической системы, подобной
«классическим» (см. далее).
16
1.2.3. О терминах «кластеризация», «группирование»,
«таксономия», «распознавание образов»
Прежде чем осуществлять классификацию, т. е. отнести какой-либо
объект к определенному классу, упорядочить объекты по их схожести,
необходимо выделить классы. Это можно сделать двумя путями: априори и апостериори. При априорном выделении классов сначала, исходя
из целей классификации, формализуются признаки классификации,
которые затем, оформляясь в достаточное множество, кладутся в основу описания классов, отделения одного класса от другого. Это, например, классификации в биологии, географии, геологии, библиотечном
деле, химических элементов, продукции и т. п. При этом можно использовать формальные процедуры для определения по экспериментальным данным ортогональности признаков и их информативность
[2, 3]. При апостериорном выделении классов исследователь располагает эмпирической выборкой (экспериментальными данными) и по
ним, используя формальные приемы, в частности различные меры расстояний между объектами, апостериори строит классы. Это разбиение
на группы отраслей промышленности или однородной продукции, задачи технической и медицинской диагностики, использующие приемы
распознавания образов, дискриминантного анализа, таксономии и
группирования, кластеризации.
Таксономия (от греч. táxis – расположение, строй, порядок и nómos –
закон) это: 1) теория классификации и систематизации сложно-организованных областей действительности (реальности), имеющих обычно
иерархическое строение; 2) выделение по эмпирическим данным типа
объект-свойства областей похожести объектов-таксонов и распределение объектов по ним; 3) автоматическая апостериорная классификация. При иерархической таксономии отношения между таксонами разных уровней можно представить себе в виде иерархической структуры
или дерева, состоящего из m объектов на нулевом уровне (уровень листьев) и Ki таксонов ( i 1,..., p) на каждом из p уровней [4]. Динамическая таксономия делается не на одновременно заданном множестве
объектов, а на объектах, возникающих по одному или небольшими
группами в ходе экспериментального исследования объектов [4].
Заметим, что как правило при решении задач таксономии на первое
место ставится максимизация связи внутри таксонов и минимизация их
между таксонами без учета назначения, цели, процедуры таксономизации. Если решения этих задач минимизации и максимизации достигаются в процессе таксономии автоматически, то иногда говорят об обу17
чении без учителя, или самообучении. Тогда под таксономией понимают только такие ее варианты, когда цели таксономии четко фиксируются до расчетов.
Заметим, что внешне кажущаяся объективной на самом деле таксономия является объективно-субъективной. Субъект всегда присутствует, в частности, на этапе выделения свойств объектов при формировании данных по типу объект-свойство, при выборе мер близости,
критериев качества, цели и т. п. [4].
Одним из вариантов такой таксономии является группирование или
кластеризация. Цель кластеризации и группирования – выявление и
выделение классов по эмпирическим данным. Под группированием
обычно понимают объединение в группы и расположение группой
(группами) независимо от того, естественны ли границы разбиения.
Под кластеризацией (от англ. cluster – кластер, гроздь, скопление
и от лат. facio – делаю) здесь понимается либо синоним понятия группирование, либо операции, связанные с процедурой, которая преобразует исходные данные в данные о кластерах, в частности, с процедурой
вычисления индексов сходства и различия. Обычно под кластером понимается группа наиболее близких друг к другу объектов [4].
Задача кластеризации (кластер-анализа) – обнаружение естественного разбиения на классы, свободного от субъективизма исследователя, выявление по эмпирическим данным, насколько элементы
«группируются» или распадаются на изолированные «скопления»,
«кластеры», а цель – выделение групп однородных объектов, сходных
между собой, при резком отличии этих групп друг от друга. При группировании и кластеризации основное – это выбор метрики, мер расстояния между объектами, мер близости, сходства и/или различия,
адекватных решаемой прикладной задаче. Заметим, что если решение
задачи кластеризации существует, то в отличие от группирования оно
может быть найдено с помощью любого (лучше наиболее простого)
алгоритма.
Обычно при классификации выделяют следующие начальные фазы
[3]: первая фаза – восприятие объектов и получение данных; вторая –
описание объекта с помощью признаков; третья – классификация либо
кластеризация, группирование, распознавание образов и т. д.
Промежуточное положение между априорной классификацией и
апостериорными группированием и кластеризацией занимает дискриминантный анализ. В нем математические классы предполагаются
априори заданными либо обучающей выборкой, либо плотностями
распределения вероятностей, а задача состоит в том, чтобы построить
18
разделяющую поверхность и вновь поступающий объект отнести в
один из этих классов. Синонимами термина «дискриминация» (от лат.
discrimination – различение, разделение) являются диагностика, иногда
«распознавание образов» с учителем, автоматическая классификация с
учителем, статистическая классификация и т. д. (см. далее). При этом
для построения системы диагностических классов применяют группирование или кластеризацию. Предметом дискриминантного анализа
является диагностика – процедура использовая классификации – отнесения вновь поступающего объекта к одному из выделенных классов, поскольку основная задача диагностики – отнесение той или иной
реальной ситуации с объектом к одному из имеющихся классов ситуаций [8]. Заметим, что иногда в медицинской диагностике предпочтение
отдается гипердиагностике, когда рациональнее часть легких больных
объявить тяжелыми, чем наоборот.
Наконец, распознавание образов (паттернов [7]) – определение
(выбор) имени образа (класса) из построенных в итоге таксономий,
которому принадлежит некоторый новый объект.
Применяя таксономию, исследователь создает начальную классификацию S ( S1 , S2 ,..., Sk ) множества m объектов. Если после предъявления нового объекта, не участвовавшего в таксономии, требуется
отнести к одному из этих классов, то, анализируя характеристики этого
объекта, необходимо распознать образ того класса Si , i 1, k , на который данный объект наиболее похож. Именно эта процедура и называется распознаванием образов. Процесс распознавания обычно состоит
из двух этапов: обучения и принятия решения. На этапе обучения происходит обнаружение закономерности связи между значениями характеристик, описывающих объект, и значением целевой функции – значения из шкалы наименований, который соответствует классу Si . На
этапе принятия решений и происходит собственно распознавание.
1.2.4. Другие определения терминов
Рассмотрим другие точки зрения. Для примера приведем цитаты и
некоторые идеи из [5].
Распознавание – это «задачи и методы, которые имеют дело с классификационной выборкой, для объектов которой известны значения
как описывающих, так и целевых признаков. Эта задача включает в
себя: 1) процесс “обучения”, т. е. обнаружения закономерностей связи
между значениями описывающих и целевых характеристик и форму19
лировки этих закономерностей (знаний) в виде “решающих правил” и
2) процесс использования этих правил для определения принадлежности контрольного объекта к тому или иному образцу. Контрольный
объект считается принадлежащим тому образу, на обучающие объекты
которого по описываемым характеристикам он похож больше, чем на
объекты других образов». Отметим, что в [5] образ считается синонимом класса, элементы (объекты) которого представлены своими индивидуальными «описывающими» характеристиками, по значению которых они похожи друг на друга и отличаются от объектов других
образов. Они также имеют еще одну «целевую» характеристику, измеряемую в номинальной шкале, – имя образа, по которому объекты одного образа неразличимы. Именно поэтому такие модельные представления объектов называются в настоящем пособии куализными.
В [5] приводятся свои понятия классифицирования, классификации, а также рассматривается задача анализа «полуклассификационной» выборки, занимающей промежуточное положение, когда для
одних объектов известны значения описывающих и целевых характеристик, а для других – значения только описывающих характеристик.
В этих случаях задача решается с применением таксономических решающих правил.
Под таксономией в [5] понимается формирование и продукт иерархических классификаций, а под «таксоном» или «кластером» понимаются элементы такой иерархической структуры. При этом отмечается,
что формирование классов одного уровня часто тоже называется
таксономией, а словом «кластер» обозначает таксон (класс, образ), который отделяется от любого другого таксона простой линейной границей. Все три случая являются частными случаями универсальной классификации.
В заключение обратим внимание на появление нового «междисциплинарного» термина «классификационные измерения» автометрия,
под которым понимается разновидность измерений, в процессе которых устанавливаются априори нечетко определенные состав и суть
обозначений (имен классов) категорийной измерительной шкалы, а
результатом является отнесение конкретного единичного объекта к
одному из выбранных классов.
В Википедии можно найти определение теории распознавания образов как «раздел информатики и смежных дисциплин1, развивающий основы и методы классификации, идентификации … объектов, которые
1
Не ясно, каких.
20
характеризуются конечным набором некоторых свойств и признаков», а
распознавание образов как «отнесение исходных данных к определенному классу с помощью выделения существенных признаков, характеризующих эти данные, из общей массы несущественных данных».
Здесь же под кластеризацией или автоматической классификацией,
ботриологией, понимается многомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов,
и затем упорядочивающая объекты в сравнительно однородные группы.
Не вдаваясь далее в рассмотрение разных определений, завершим
подраздел итоговым упрощенным изложением отличий в понимании
терминов как научной дисциплины и процесса, действия.
Распознавание образов (РО) (в обобщенном понятии) – раздел
информатики, занимающийся способностями субъектов, моделями,
средствами и технологиями исследования разнообразия объектов действительности разной природы.
Как фундаментальная научная дисциплина РО изучает и разрабатывает теоретические основы познания, обнаружения принципов, законов и закономерностей способности живых существ к выявлению
разнообразий действительности и их распознаванию (классификации,
кластеризации), создает теории для объяснения и моделирования таких
способностей.
Как прикладная научная дисциплина РО формирует теоретические
основы построения искусственных средств, предназначенных для решения задач распознавания объектов (предметов, состояний, процессов,
явлений, …), их классификации и кластеризации в прикладных целях.
Как область практической деятельности РО занимается реальным
созданием и применением этих средств.
Распознавание образов (в изначальном1, узком, понимании) – это:
а) определение «образцов», «шаблонов», к которым следует отнести конкретный (тестируемый, исследуемый) объект (например, определение почтового индекса по цифрам на конверте; кубика, трапеции
или шара, соответствующего подобной игрушке в руках; разрешенной
кодовой комбинации по принятой в канале связи с помехами комбинации и т. д.);
1
Термин «Распознавание образов» изначально появился от неудачного
перевода с английского «Pattern recognition», в котором «Pattern» означает
«образец», «образчик», «шаблон», «выкройка», а также «модель» (в дизайне,
проекте, плане, конструкции), «образ», «манера» (в аранжировке, теории
систем).
21
б) выбор «образа», понимаемого как совокупность (класс) образцов
(близких к цифре или букве ее написаний или произношений, «искаженных кубиков», кодовых комбинаций, полученных в канале связи с
помехами, которые могут получиться от разрешенной комбинации;
класс автомобилей ВАЗ и т. д.).
Формальное описание задачи РО
Дано:
1) совокупность «образцов», «шаблонов», классов объектов 1,
2, … , т, представленных совокупностью значений признаков х1,…,
хт, xl ( x1,l ,..., xn,l ) , l 1, m ;
2) тестируемый объект Oi , i 1, N , имеющий значение признаков
xi ( x1,i , x2,i ..., xn,i ) .
Необходимо: по значениям xi определить, какой «образец», «шабl 1, m соответствует тестируемому объекту Oi ,
i 1, N , или, наоборот, какому образцу l соответствует объект Oi .
Искусственный метод решения: вводится мера ( ,О) сходства
(близости, схожести) между образцом и объектом О, находятся ее
эмпирические значения для всех l 1, m и согласно принятому решающему правилу выбирается соответствующий «образец». Например,
эмпирические значения ( l, Оi) сравниваются между собой и для Оi
выбирается тот s-й «образец» s, для которого значение ( s, Оi) будет
наименьшим.
Реализация метода, т. е. выбор набора классов, их описания, решающего правила и варианта его использования, зависит от условий
метода: с обучением (с учителем), когда имеется и используется априорная прецедентная информация об «образцах» (образах, классах) и
правильном отнесении их к объектам (или объектов к ним) (распознавание с обучением, с учителем, классификация); без обучения (без
учителя), когда информации об образцах (образах, классах) и/или правильном отнесении объектов к ним (правильной классификации) априори нет и ее надо получить апостериори по имеющемуся эмпирическому материалу (распознавание, классификация без обучения, без
учителя, или кластеризация); смешанные, когда прецедентной априорной информации недостаточно для хорошего обучения, но она позволяет упростить распознавание и/или повысить его качество.
лон», класс
l,
22
Классифицирование:
отнесение объекта к определенному классу;
упорядочение объектов по их схожести;
разбиение неклассифицированной выборки на непересекающиеся подмножества, для объектов которой известны значения только
описывающих характеристик [5].
Классификация:
естественное или искусственное классифицирование объектов по
априори выделенным (исходя из целей классификации) классам (биология, география, геология; библиотека; химические элементы и т. п.);
конкретный результат классифицирования;
результат классифицирования по [5] в виде перечня классов с
указанием правил, по которым каждый класс можно отличить от
остальных [5];
«разделение рассматриваемой совокупности объектов или явлений на однородные (в определенном смысле) группы (как процесс или
его результат)» [9].
Формальное описание задачи
Дано:
формализованные признаки x (Oi ) xi ( x1,i ,..., xn,i ) классифи-
кации объектов O1 ,..., ON ;
заданный набор т классов K1 ,..., K m , отличающихся значениями
признаков x ( Kl ) l x ( l x1 ,..., l xn ) , l 1, m ;
один или несколько тестируемых объектов.
Необходимо: отнести эти объекты Oi , i 1, N (упорядочить их) по
разных классам Kl , l 1, m .
Метод: используется мера близости (сходства) объектов (Oi , O j )
внутри и вне классов и тестируемый объект Oi относится к соответствующему классу Kl согласно принятому решающему правилу.
Например, выбирается такой класс K s , для которого ( xi , s x ) меньше, чем для других l 1, m , l s .
Таксономия:
научная дисциплина и область деятельности, связанные с автоматической апостериорной классификацией объектов;
23
выделение по эмпирическим данным (типа таблиц «объект –
свойства» или кубов «объект – свойства – моменты времени») областей похожести объектов (таксонов) и распределение тестируемых
объектов по ним.
Формальное описание задачи
Дано:
множество структурированных, например сведенных в таблицу
или куб, эмпирических данных;
один или несколько тестируемых объектов.
Необходимо: определить области «сгущения» объектов в пространстве свойств (признаков), выделить набор таких таксонов и распределить объекты по этим таксонам.
Методы: максимизация (или минимизация) значений меры близости (связи) внутри таксонов и минимизация (максимизация) их между
таксонами без учета назначения, цели, процедуры таксономии.
Динамическая таксономия – делается не на всем множестве
объектов, а каждый раз по мере поступления новых тестируемых
объектов.
Чаще всего таксономию связывают с иерархической классификацией.
Кластеризация (группирование):
этап таксономии, связанный с выявлением и выделением свободных от субъективизма кластеров (групп) по эмпирическим данным;
прикладная разновидность таксономии – автоматическая апостериорная классификация.
Цель – выделение компактных групп однородных объектов, сходных между собой, при резком отличии этих групп друг от друга.
Основная проблема – выбор метрики, мер компактности кластеров,
расстояний между объектами, их близости, схожести и/или различия,
адекватных прикладной задаче. Именно конкретика, привязка к назначению отличает кластеризацию от «чистой» таксономии.
Формализованная постановка классификационных (кластеризационных) задач
Дано: Множество M (O1 ,..., ON ) N объектов Oi , i 1, N ,
имеющих одинаковые по составу для всех объектов, но разные по значениям описания I ( ) x1 (),..., xn () , где x j – значение показателя
x j ( ) – реализация классификационного признака x j объекта ,
j 1, n , п – размерность признакового пространства (число признаков).
24
Задан (выбран или разработан) исследователем критерий {I ()} ,
позволяющий отличать объекты друг от друга в определенных условиях, и, возможно, критерий L{i , j } , i, j 1, m , – позволяющий отличать классы i и j друг от друга.
Требуется: используя критерии () и L() , во-первых, разбить
наилучшим по выбранному критерию множество М на т непересекающихся (чаще наиболее желательно) или пересекающихся классов
j:
m
j , априори определенных при классификации или апо-
j0
стериори определяемых при кластеризации, во-вторых, построить решающее правило, позволяющее любой объект отнести к одному конкретному классу или (в случае пересекающихся его подклассов) к
определенному подмножеству классов, в-третьих, разработать меру качества результатов классификации (кластеризации), а в приложениях –
решения прикладной задачи с использованием классификации, кластеризации. При этом
l , j , l , j 1, m , l j I ( l ) I ( j ) ;
0, l j ,
L{l , j }
как можно большему значению при l j ,
а разбиение желательно сделать таким, чтобы классы были как можно
более компактными с точки зрения принятой меры компактности.
Дискриминантный анализ – апостериорное построение поверхностей, разделяющих классы (кластеры), и отнесение вновь поступающего
объекта к одному из разделенных классов. Это этап автоматической
классификации или кластеризации с учителем, т. е. с начальным обучением по «образцам».
Формальное описание задачи
Дано:
априори заданные классы или апостериори полученные по обучающей выборке кластеры (таксоны, группы) 1, … , т,;
вновь поступивший объект Oi , i 1, N .
25
Необходимо:
построить разделяющую поверхность в п-мерном признаковом
пространстве, описывающем классы (кластеры);
отнести поступивший объект к одному из классов, используя эту
разделяющую классы (кластеры) поверхность.
Примеры разделяющих поверхностей приведены на рис. 1.1.
х2
х2
Класс В –
х2
Класс В –
Класс А –
Класс А –
х1
Класс В –
Класс А –
х1
х1
а
б
в
Рис. 1.1. Примеры линейных и ломаных разделяющих поверхностей
классификации объектов на два класса А и В по значениям их двух
признаков х1 и х2:
а, б – непересекаюшиеся реализации классов; в – пересекающиеся
1.2.5. Практические аспекты распознавания образов
Рассмотрим практику решения задач распознавания образов (РО,
классификации, кластеризации). Первый важный прикладной аспект
решения задач РО связан с принципиальной неоднозначностью решения. Это обусловлено тем, что любое модельное представление объектов зависит от цели решения задачи, неоднозначности выбора наилучшего критерия качества результатов решения, числа классов, набора
признаков, выбора метрики и т. п.
Как уже отмечалось, узловым узким моментом, существенно определяющим результаты решения практических задач, является выбор
метрики (меры близости, схожести) между объектами, меры компактности классов1. В каждой конкретной задаче выбор производится по1
Класс называется компактным, если «внутреннее» сходство его объектов
(элементов) друг с другом велико, а «внешнее» сходство объектов других
классов с ними мало [5].
26
своему, исходя из постановки задачи исследования и сопутствующих
ей априорных и апостериорных данных. Различные меры для признаков, измеренных в разных шкалах, можно найти в [2–9].
В частности, для п признаков, измеренных в детерминированных количественных шкалах, принимающих значения x1 , x2 ,..., x N для объекта O и x1, x2 ,..., x N для объекта O , где xi ( x1,i ,..., xn,i ) , используются следующие меры близости (расстояний) (O, O) (сравним с
формулами (4.133), (4.134), приведенными в первой части пособия)1:
обобщенная Евклида (квадратичная)
E (O, O)
N n
k zk ,i zk,i
2
,
(1.1)
i 1 k 1
обобщенная Манхэттена (модулей)
N
M (O, O)
n
k
i 1 k 1
zk ,i zk ,i ,
(1.2)
обобщения Чебышева
Ч (O, O) max k zk ,i zk ,i ,
(1.3)
k
обобщенная Минковского
N n
(O, O) k zk ,i zk ,i
i 1 k 1
1
, 1,
(1.4)
,
(1.5)
Камберра
N n
xk ,i xk ,i
i 1 k 1
xk ,i xk ,i
К (O, O) k
1
В (1.1)–(1.5) предполагается, что значения xk ,i , k 1, n , i 1, N приведены к единому безразмерному стандартному виду. Например, преобразованиями zk ,i xk ,i xk S x , zk ,i ( xk ,i x 0,5 ) ( x0.9,k x0.1,k ) (см. обозначения
в 1-й части пособия). Другие нормировки смотри в начале разд. 4.5.5, часть 1.
27
где k (0,1] – весовые коэффициенты. При k 1 или k 1 N для
всех k 1, n , слово «обобщенная» необходимо опустить.
Особый интерес в последнее время проявляется к различным мерам
компактности классов, представленных признаками в разных измерительных шкалах, мерам близости между предикатами и знаниями,
сходства образов (расстояния между ними), иерархий и т. п. (см.,
например [4, 5]).
Что касается стохастических признаков [9], то для них чаще всего
используются методы типа среднего риска, в частности Байесовского
минимального риска, и апостериорных вероятностей (см. часть 1,
разд. 4.3.7, статистическая проверка гипотез, 4.4.2).
Второй важный аспект практики решения задач исследования
разнообразия объектов (распознавания образов и классификации) сводится к выбору метода и реализующего его алгоритма. Понятно, что
они существенно зависят от постановки задачи, используемых для
представления признаков моделей и измерительных шкал, априорной
информации о них и об объекте, других факторов. С их разновидностями желающие могут познакомиться по специальной литературе
(см., например [3–9]). В последнее время к ранее используемым детерминированным и статистическим методам и алгоритмам построения
моделей разнообразия, основанных на применении линейных,
ломаных (кусочно-линейных) и более сложных разделяющих поверхностей, добавились новые, самообучающиеся, основанные на идеях
интеллекта (генетические, нейронных сетей, роевые и т. п.) (см. главу
4), а также уже упоминавшиеся ранее логические, геометрические
(структурные, включая разделительные и объединительные, графовые,
иерархические) и другие. Они особенно интересны для разделения
объектов по пересекающимся классам, когда один и тот же объект может принадлежать к двум или большему числу классов. Как уже упоминалось, такая ситуация может иметь место априори, когда мал набор
признаков объекта, или апостериори, когда недостаточен объем данных, по которым производится поиск разнообразия либо когда принципиально эмпирические значения признаков попадают в общие зоны
значений признаков объектов из разных классов (как, например, с разными бесконечно протяженными распределениями одной и той же или
разных моделетек (см. далее)).
Для получения представления о методах автоматической (апостериорной статистической) классификации (кластеризации) рассмотрим
два метода кластеризации: k-ближайших соседей и k-средних.
28
Идея метода k-ближайших соседей заключается в том, что тестируемый объект относится к тому классу, который в признаковом пространстве является наиболее распространенным среди заданного числа
соседей этого объекта. Суть метода демонстрирует рис. 1.2.
x2
k=6
k=4
k=3
x1
Рис. 1.2. Пояснение к последовательной
автоматической апостериорной классификации (кластеризации) по методу k-соседей
На рисунке изображено расположение по значениям двух признаков x1 и x2 11 объектов двух классов: квадратов и ромбов, а также тестируемого объекта, изображенного черным кружком, а в качестве
меры расстояния (Oi , O j ) , i, j 1, N принято Евклидово (1.1). Необходимо отнести к классу квадратов или ромбов тестируемый объект O12 ,
изображенный на рисунке кружком. Тогда при k = 3, согласно рассматриваемому методу, тестируемый объект следует отнести к классу
ромбов, так как среди трех его ближайших соседей два ромба и лишь
один квадрат. При k = 6 объект O12 относится к классу квадратов, так
как в круг его ближайших соседей входят четыре квадрата и всего два
ромба. При k = 4 в ближайшие соседи к O12 попадают по два квадрата
и ромба. Правило отнесения объекта O12 к какому-то классу в ситуации равенства количества ближайших к нему соседей оговаривается
отдельно по договоренности, исходя из решаемой прикладной задачи.
Идея метода k-средних заключается в последовательном пошаговом итерационном уточнении так называемых эталонных точек
Э(r ) э1(r ) , э(2r ) ,..., э(kr )
каждого из k непересекающихся классов
29
(k задается априори) с соответствующим пересчетом приписываемых
им весов (r ) 1(r ) , (2r ) ,..., (kr ) на каждом r-м шаге (каждой r-й
итерации).
Рассмотрим эти шаги (итерации).
1. Строится нулевое приближение Э(0) с помощью случайно выбранных k несовпадающих (непересекающихся) точек эмпирического
признакового пространства исследуемой совокупности N объектов (совокупности одновременно полученных значений п признаков для N
объектов, п-размерных элементов N-мерной выборки), т. е. эl(0) xl ,
l(0) 1 , l 1, k .
2. На первой итерации извлекается произвольная точка xk 1 и рассчитывается, к какому из эталонов э(0)
s она оказалась ближе всего.
Этот эталон э(0)
s , самый близкий к xk 1 по принятой мере ,
и его вес заменяются на первой итерации на э(1)
s по правилу: на r-й
итерации э(sr ) l(r 1) эl(r 1) xk r
xk 1 , эl(r 1) min xk r , э(sr 1)
1 s k
l(r 1) 1 ,
и
l(r ) l(r 1) 1 , если
эl(r ) эl(r 1) , а
l(r ) l(r 1) ,
в противном случае, s 1, k .
Если в какой-то r-й итерации обнаружится несколько вдоль s 1, k
одинаковых минимальных значений xk r , э(sr 1) , то отнесение точки xk r к какому-то из таких эталонов определяется по условной договоренности, например, к эталону с минимальным порядковым номером [9].
Далее организуется итерационный процесс поиска кластеров возвращением ко второму шагу первой итерации и продолжением от него
до остановки итерации согласно применяемому критерию.
В качестве критерия остановки итераций обычно выступают следующие.
1. Разделение всего множества из N «тестируемых» (исследуемых)
объектов, т. е. когда кластеры выявлены по всему множеству объектов
и все объекты окажутся распределенными по непересекающимся кластерам.
30
2. Досрочное прекращение итерации на N1-й итерации, когда
N1 N или даже N1 N , если происходит настройка, обучение
«кластеризатора» по следующим обстоятельствам:
когда все возможные кластеры гарантированно удачно определены и это проявляются в том, что при следующих итерациях нет перехода объектов из кластера в кластер;
когда показатель качества кластеризации практически перестает
изменяться.
Поскольку итоги кластеризации зависят от выбора нулевого приближения, т. е. Э0, в ответственных ситуациях при решении особо
важных задач можно рандомизировать процедуру набора Э0 или организовать перебор разных стартовых вариантов Э0.
Третий аспект. Ранее рассматривался подход к исследованию разнообразия объектов, в частности данных, основанный на их модельном
сравнении и разделении исходя из описывающих (представляющих)
объекты (данные) признаков. Иногда такой подход называется
Q-анализом. Возможен и другой подход, когда модели разнообразия
строятся и используются для сравнения и разделения признаков на основе объектов данных (R-анализ объектов, данных), а также смешанный. Желающие могут ознакомиться с такими подходами и сферами
их приложения самостоятельно.
В тех случаях, когда число классов k не задано, а их надо найти по
имеющимся эмпирическим данным, значение k определяется перебором или автоматически. В первом случае выбираем k = 2, затем k = 3 и
так далее, вычисляем для них значение используемого показателя качества кластеризации или решения прикладной задачи и останавливаемся на таком значении k, которому соответствует наилучшее значение
этого показателя. Одна из процедур автоматического выбора k описана
в [9, с. 510, 511].
На рис. 1.3 приведены примеры практического применения метода
k-средних и переборного варианта нахождения наилучшего k для ежесуточных данных по инфекционным заболеваниям, передающимся
преимущественно водным путем, и показателям состояния окружающей среды (водопроводной питьевой воды и воздуха) [10]. Здесь
xk xk xk Sk , xk – эмпирическое среднее арифметическое, Sk –
эмпирическое среднеквадратическое отклонение, сокращение «мутность реки» имеет смысл «мутность воды в реке», а под средним понимается среднее по кластеру значение.
31
32
Процент от квартильного размаха значений
32
Рис. 1.3. Пример результатов кластерного анализа ежедневных данных по состоянию системы «Окружающая среда – Инфекции» в г. Барнауле за 2007–2008 годы
Процент от полного диапазона значений
1.2.5. Заключительные замечания
Первое заключительное замечание связано со следующим.
Ранее по тексту неоднократно упоминалось, что итоги решения задач по разнообразию объектов необходимо оценивать, а меры близости, методы и алгоритмы выбирать с учетом показателей качества результатов. Эти показатели следует разбить на две группы: частные
(локальные) и итоговые (глобальные). Первые ориентированы на определение качества результатов распознавания, классификации или кластеризации как итогов решения именно этих задач, т. е. достижения
локальной цели при исследовании объекта.
Например, как локальные (частные, собственные) показатели
(функционалы) качества разбиения объектов Oi , i 1, N на т кластеров S ( S1 , S2 ,..., Sm ) наиболее часто используются следующие1:
сумма внутриклассных «дисперсий» – средних квадратов расстояний от среднего
вк1 D1 ( S )
m
1
N
j xr S j
j 1
2 xr , x j ,
(1.6)
где N j – число объектов, попавших в кластер S j , N1 N 2 ...
N m N ; x j – среднее арифметическое значение признака х,
найденное по объектам, попавшим в j-й кластер;
сумма попарных внутриклассных расстояний между элементами
вк2 D2 ( S )
m
N
j 1
1
2 ( xr , x p ) ;
(
1)
N
j
j
xr x pS j
(1.7)
мера, основанная на статистике Фишеровского типа
вк3 D3 ( S )
m
2
2 x j , xk D1 ( S ) ,
m(m 1) j k
(1.8)
а также разные меры, основанные на гипотезах компактности [3–9].
1
Как и для мер вк (1.1)–(1.5) при k = 1, деление в (1.6)–(1.8) на число
суммируемых слагаемых N j , N j ( N j 1) , m(m 1) / 2 зачастую не производят.
33
Помимо мер расстояний между разделяемыми по значениям
признаков xi ( x1,i , x2,i , ..., xn,i ) объектов Oi , i 1, N вида (1.1)–(1.8)
вводятся также меры расстояния (близости) между группами (образами, классами, кластерами) ( S j , Sk ) , j , k 1, m объектов. Это особенно
важно в задачах кластеризации. Если xi , как и в мерах (1.1)–(1.8), измеряются в соответствующих шкалах, допускающих приводимые ниже
операции, например в абсолютных количественных, то среди таких
мер наиболее часто употребляются следующие:
расстояние между «ближайшими соседями» рассматриваемых
групп S j , Sk
мк1 min ( S j , Sk ) min ( xr , x p ) ;
xr S j ,
x pSk
(1.9)
расстояние между «дальними соседями»
мк2 max ( S j , S k ) max ( xr , x p ) ;
xr S j ,
x pSk
(1.10)
расстояние между «центрами тяжести» (внутригрупповыми
средними арифметическими x j и xk xk ,1 , xk ,2 , ..., xk ,n групп S j
и Sk )
мк3 ц ( S j , Sk ) ( x j , xk ) .
(1.11)
Наилучшим разбиением S* множества объектов Oi , i 1, N на т*
кластеров считается такое, при котором достигается экстремум (минимум или максимум) соответствующего выбранного функционала
качества.
Именно критерий Фишера – максимум значения статистики Фишера – отношения среднего квадрата межклассовых отклонений (между
центрами (средним арифметическим) кластеров) к среднему квадрату
внутриклассовых отклонений от их центров, характеризующего вариабельность признаков между и внутри кластеров соответственно
(см. (1.8) при E ), был использован в исследованиях, результаты
34
которых представлены на рис. 1.3. Именно по нему было найдено
наилучшее число кластеров, равное четырем. В качестве меры близости при этом использовалось Евклидово расстояние (1.2) между
стандартизованными по правилу xk xk xk S x эмпирическими
значениями признаков xk ,i , k 1, 4 , i 1,365 , где xk – годовое среднее
арифметическое признака xk , S x – годовое эмпирическое среднеквадратическое отклонение. Заметим попутно, что на рис. 1.3 внизу для
сравнения представлены два варианта визуального представления итогов кластеризации: нормированной к размаху выборки (x max x min )
( x( N ) x(1) ) , и к интерквартильной широте | x 0,75 x 0,25 | по каждому признаку.
Еще один показатель качества результатов классификации, кластеризации или распознавания конкретным алгоритмом – вероятность или
частость (частота) правильных ответов на тестовых примерах.
В качестве примера глобального содержательного критерия качества классификации и построения для этого разделяющих поверхностей приведем используемые в медицинской диагностике. Обозначим
через А – количество пациентов с правильно распознанной диагностируемой болезнью (больные распознаны как больные), В – количество
здоровых пациентов, которым ошибочно поставлена болезнь (здоровые не распознаны как здоровые), С – количество пациентов с нераспознанной болезнью (больные, не распознанные как больные) и D –
количество здоровых пациентов, признанных таковыми по отношению
к диагностируемой болезни (здоровые распознаны как здоровые).
Обычно при исследованиях средств и методик диагностик качество оценивается следующими показателями: диагностическая чувствительность
d ч A ( A C ) , диагностическая специфичность dc D / ( B D) и диагностическая точность d т ( A D) / ( A B C D) . Иными словами,
содержательно точность характеризует долю верных диагнозов среди
всех диагнозов, специфичность – среди здоровых пациентов, чувствительность – среди больных пациентов. Понятно, что идеальный случай, когда d т dс d ч 1 . Однако, из-за того что эмпирические данные могут иметь значения, выходящие за пределы нормы допустимых
значений, диагностических признаков и у здоровых, и у больных пациентов как из-за влияния внешних условий, так и из-за чувствительности, информативности используемых диагностических процедур по
35
отношению к диагностируемой болезни, а также из-за погрешности
измерения их значений или по другим причинам, происходит межклассовое пересечение данных, характерных для больных и здоровых
пациентов. Это приводит к тому, что реально эмпирические значения
d т , dс , d ч , как правило, меньше единицы. Поэтому исследователь исходя из стоящей перед ним задачи оценки качества средств диагностики, основанной на решении промежуточной задачи классификации,
дискриминантного анализа, выбирает важный для него критерий:
максимума (равенство или близость к единице) d т , d ч или dс либо
совокупность критериев. Например, руководствуется правилом гипердиагностики: рациональнее часть легкобольных объявить тяжелобольными, нежели сделать противоположную ошибку. Исходя из этого
разделяющая поверхность будет строиться так, чтобы максимизировать какой-то один или два коэффициента за счет двух других или третьего. Локальный показатель качества классификации или построения
разделяющей поверхности, например критерий Фишера, тогда должен
подчиняться этой глобальной оптимизации.
Второе важное замечание касается формального аппарата, используемого для решения задач моделирования разнообразия. Как уже было отмечено, признаки объектов могут измеряться в разных шкалах,
описываться детерминированными, стохастическими, нечеткими,
экспертными моделями, причем точечными или интервальными. Аналогичное можно сказать и о представлении совокупностей групп объектов (образов, классов, кластеров). Оно может быть детерминированным, стохастическим, нечетким, экспертным. В детерминированном
случае принадлежность любого объекта к соответствующей группе
определяется четко через индикаторную функцию, т. е. когда о каждом
объекте группы мы однозначно и четко утверждаем: да, он член
(экземпляр) группы, или нет, т. е. относится к другой группе. В стохастическом делении по группам мы говорим о принадлежности объекта
некоторой группе с определенной вероятностью. При этом вероятность
попадания в некоторое подмножество групп определяется суммой вероятностей попадания в каждую группу, если они не пересекаются,
или как вероятность объединения событий – объединения групп в рассматриваемое подмножество. Ясно, что в том и другом случае вероятность попадания в их полную группу или в любую из групп равна единице. В нечетком описании, во-первых, вместо вероятности попадания
в группу вводится мера принадлежности каждого объекта к соответ36
ствующей группе, во-вторых, состав группы, ее границы могут быть
неопределенными, в-третьих, группы могут не только попарно, но и в
большом количестве пересекаться. Что касается экспертного описания,
то как набор признаков, так и их пороговые значения, разграничивающие группы объектов, определяются экспертным решением и могут
варьироваться в зависимости от состава экспертов, решаемой прикладной задачи и других обстоятельств.
Это же касается и правил принятия решений при отнесении тестируемого объекта к соответствующей группе по эмпирическим значениям его признаков. Здесь ситуация сходна с правилом принятия решений при статистической проверке гипотез (см. часть 1, гл. 4,
разд. 4.3.7). Они могут быть детерминированными, вероятностными,
нечеткими, экспертными, с одной стороны, жесткими или рандомизированными – с другой.
Третье замечание касается того, что задачи моделирования разнообразия объектов могут ставиться как оптимизационные (см. часть 1,
гл. 4). Например, при кластерном анализе можно поставить задачу
нахождения оптимума числа кластеров с точки зрения локального или
глобального критерия качества решения задачи исследователя, оптимизации числа итераций по выделению кластеров и т. д. Желающие
могут познакомиться с такими постановками самостоятельно или
предложить свои.
Наконец, четвертое замечание. Одним из важнейших критериев
качества кластеризации может служить качественный или количественный показатель ее естественности, т. е. способности выявить при
кластеризации действительные, существующие на самом деле, классы
паттернов, четко отделяемые друг от друга любым методом, исследователем. Тогда, с одной стороны, критерием естественности классификации можно выбрать степень устойчивости, достоверности результатов кластеризации к замене используемых методов (алгоритмов),
с другой – считать лучшим, более близким к качественным, тот метод,
который дает лучшие показатели устойчивости на различных тестовых
задачах, с разными сопутствующими кластеризации условиями получения и качества данных. Более естественным может оказаться метод,
основанный на одновременном применении комбинации нескольких
разных методов (см. часть 2, гл. 4, вариативное моделирование).
Обобщенная схема технологического процесса решения задач
моделирования разнообразия объектов представлена на рис. 1.4 (ср.
с рис. 2.3, 3.10–3.13, 4.9, 4.19, 4.21, см. часть 1).
37
1. Глобальная постановка задачи прикладного исследования
(формулировка цели, перечня задач, назначение
глобального скалярного или векторного критерия качества
желаемого результата)
2. Совместный анализ постановки задачи прикладным
исследователем и специалистом по моделированию разнообразия
(по куализному моделированию) объектов
3. Совместная вербальная постановка локальной задачи
распознавания образов, классификации или кластеризации,
признаковое описание объектов исследования
(вид задач уточняется совместно)
4. Формализация постановки локальной задачи
(включая выбор или разработку частных критериев качества
результатов, метрик, измерительных шкал, метода и алгоритма
и т. п. (по необходимости))
5. Получение, корректировка, приведение к принятому стандарту
эмпирических значений разных признаков, разведочный анализ,
предварительный анализ признаков, минимизация признакового
пространства и т. п. (по мере необходимости)
6. Ручная, автоматизированная или автоматическая реализация
алгоритма распознавания, классификации или кластеризации
(в соответствии с результатами выполнения этапов 1–5).
Внутренняя проверка качества результатов.
Возврат к соответствующему этапу 1–5 по мере надобности
Апробация полученных результатов на прикладных задачах,
возврат на соответствующий этап по мере необходимости
Документальное оформление результатов, формирование
постановок новых задач для исследователей и специалистов
по моделированию
Рис. 1.4. Укрупненная схема технологического
процесса моделирования разнообразия объектов
38
§ 1.3. МОДЕЛИ СТРУКТУР ОБЪЕКТОВ
И СВЯЗНОСТИ ИХ ЭЛЕМЕНТОВ.
ЭЛЕМЕНТЫ ТЕОРИИ ГРАФОВ И СЕТЕЙ
1.3.1. Основные понятия
Помимо моделей разнообразия объектов к куализным можно отнести модели, предназначенные для описания структур объектов, их
топологий, состава и связей элементов в объекте.
Среди этих моделей такие, которые представляются в виде блок-,
структурных, функциональных, различных эквивалентных схем. С подобными моделями, в частности с блок-схемами алгоритмов и программ, читатель наверняка уже неоднократно сталкивался.
Особый интерес в различных разделах информатики имеют представления структур объектов (особенно разнообразных систем) в виде
графов [11–16]. Идея такого описания очень проста: представлять важные для исследования объекта составляющие его элементы в виде
вершин графа, а связи между ними – в виде ребер графа. Либо, наоборот, элементам объекта можно поставить в соответствие ребра, а связям – вершины. Такие графы называются реберными. И в том и в другом случае работа с такими моделями осуществляется согласно теории
графов. Рассмотрим основные ее понятия.
Граф G (V , ) – это множество V объектов x, y, z , v V , называемых вершинами, и любая совокупность неупорядоченных, называемых ребрами, и упорядоченных, называемых дугами, пар
( x, y ) этих объектов (вершин) x и y1.
Говорят, ребро ( x, y ) или (v, z ) соединяет вершины x и y либо v и z, а дуга ( x, y ) либо (v, z ) начинается в вершине x (либо v)
и заканчивается в вершине y (либо z)2. Графически вершины отображаются точками (кружками, шарами), ребра (v, z ) отображаются линиями (отрезками), соединяющими точки v и z, а дуги (v, z ) –
1
Для удобства вершины, т. е. элементы множества V, будем обозначать
латинскими буквами x, y, u , v, z , а ребра (дуги), т. е. элементы множества ,
греческими , , , , ,... .
2
Поскольку дуги есть направленные ребра, всюду, где это не может вызвать недоразумения, будем вместо сочетания «ребра (дуги)» писать просто
ребра.
39
стрелкой, направленной от точки v к точке z. Граф, содержащий только
ребра, называется неориентированным, а только однонаправленные
дуги – ориентированным, или орграфом. Граф, имеющий как ориентированные, так и неориентированные ребра, называется смешанным.
Для каждого орграфа G (V , ) может быть построен (существует)
обратный орграф G 1 (V , ) , полученный изменением ориентации
каждой дуги графа на противоположную.
Граф, имеющий конечное число ребер, называется конечным, в
противном случае – бесконечным.
Если пара вершин (v, z ) соединяется двумя или более ребрами (или
дугами одного направления), то такие ребра (дуги) называются кратными. Граф, в котором одна и та же пара вершин соединяется несколькими различными ребрами или дугами (в том же или разных
направлениях), называется мультиграфом. Если ребро замыкается на
одну вершину или дуга начинается и заканчивается в одной и той же
вершине, то такие ребра (дуги) называются петлями. Согласно определениям, каждому ребру (дуге) сопоставляется не более двух вершин,
которые называются концевыми. Иными словами, петля – это ребро, у
которого начальная и конечная вершины совпадают. Граф, имеющий
петли, иногда называют псевдографом. Таким образом, обычный
(обыкновенный) граф – это граф с неориентированными ребрами, без
кратных ребер и петель. Мультиграф – граф, содержащий кратные
ребра, а псевдограф – граф, содержащий петли.
Примеры элементов объектов, отражаемых в виде вершин, ребер и
дуг графов:
вершины – города страны или региона, остановки; ребра – линии, соединяющие эти города (остановки);
вершины – элементы (экземпляры) некоторого класса объектов,
элементы подклассов этих классов в иерархической схеме классификации, ребра (или дуги) – линии (направленные линии), соединяющие
классы с подклассами;
вершины – состояния некоторого объекта, дуги – направленные
линии переходов из одного состояния в другое или другие;
вершины – прародители, родители, дети, внуки, правнуки, …;
ребра (или направленные ребра при необходимости) – линии, отражающие связь дитя с его родителями и родителей между собой (наличие
брака, распад брака, гражданские отношения, случайная связь отражаются типом, цветом или другим показателем линии).
40
Другие примеры смотри далее в § 1.4.
Концевые вершины v и z ребер (v, z ) называются смежными, а само ребро называется инцидентным вершинам v и z. Две вершины v и z
являются смежными тогда и только тогда, когда существует ребро
графа, инцидентное им обеим. Смежными ребрами называют ребра,
имеющие общую вершину. Для обозначения смежности используется
знак . Например, v z, v, z V , или , , . Вершина, не инцидентная никакому ребру графа, называется изолированной, а граф, состоящий только из изолированных вершин, называют ноль-графом.
Множество U [ x] V всех вершин y U [ x] графа G (V , ) ,
смежных его вершине x V , называется окрестностью этой вершины х.
Для орграфа необходимо рассматривать две окрестности вершины х,
которые обозначим через U [ x] и U [ x] . Будем считать, что
y U [ x] , если ( y, x) , и y U [ x] , если ( x, y ) . Пусть,
например, V состоит из фигур на шахматной доске, а – множество
допустимых ходов фигур. Тогда понятие смежности х y может означать, например, что x, y V смежные, если х «бьет» y. Ясно, что речь
при этом идет о ходе – дуге ( x, y ) и такой граф G (V , ) является
орграфом. Окружность U ( x) представляет собой множество фигур y,
которые могут побить х, а U ( x) – множество фигур y, которые может
побить х.
Два графа G (V , ) и H (U , ) , для которых существует взаимно однозначное соответствие между множествами вершин V, U, с одной стороны, и множеством ребер (дуг) , , соединяющих эти вершины, – с другой, сохраняющее отношение инцидентности между
вершинами и ребрами (дугами), называются изоморфными.
Граф G (V , ) , образованный из графа G (V , ) удалением
некоторых вершин и ребер, называется частью графа G.
Подграф G (V , ) – это часть графа G (V , ) , образованная
некоторым подмножеством и всеми инцидентными им
вершинами1 V V V . Или, по-другому, подграфом G (V , )
графа G (V , ) называется граф с множеством ребер (дуг) и
1
Приведите вариант подграфа и суграфа для ранее рассмотренного шахматного примера.
41
множеством инцидентных им вершин V V . Таким образом, подграф
получается из графа удалением из него части вершин вместе с ребрами
(дугами), соединяющими эти вершины.
Суграф H V , 1 , 1 , – это часть графа G (V , ) , образованная удалением из исходного графа G некоторых ребер (дуг). При
этом количество n | V | вершин графа G и суграфа Н одинаково1.
Граф G (V , ) , в котором любая пара из п вершин инцидентная
единственному ребру, называется полным и зачастую обозначается
как U (V , ) или K n . Иными словами, полный – это граф, ребрами которого являются всевозможные пары всех его п вершин. Нетрудно
убедиться, что если n | V | – количество вершин графа G (V , ) , то
количество ребер | | в полном графе равно | | n(n 1) 2 . Граф
G (V , ) , ребра которого совместно с графом G (V , ) образуют полный граф U (V , ) , называется дополнением графа G (V , ) .
Граф G (V , ) пустой, если 0 пустое множество, т. е. | | 0 .
Иными словами, пустой – это граф, который не содержит ребер.
Пустой граф, состоящий из одного элемента, т. е. когда | V | 1 ,
называется тривиальным.
Граф G (V1 ,V2 , ) называется двудольным, если часть или все пары его вершин x V1 и y V2 смежны. Согласно определению, двудольный граф – это такой, множество вершин V которого можно разбить на две непересекающиеся части (доли) V1 и V2 таким образом,
чтобы концы любого ребра этого графа находились в разных из этих
частей. Понятно, что в полном двудольном графе каждая вершина из
первой доли V1 соединена ребром с каждой вершиной из второй доли
V2 . Обычно полный двудольный граф, имеющий p V1 вершин в
первой доле V1 и m V2 вершин во второй доле V2 , где p m n ,
обозначается K p ,m .
Наиболее часто используемым представлением графов является их
изображение на плоскости или в трехмерном евклидовом пространстве. Представление графа в двух- или трехмерном евклидовом пространстве в виде множества точек, соответствующих его вершинам,
соединенным линиями, отображающими соединяющие ребра (дуги),
называют его укладкой. В трехмерном пространстве любой граф с
42
конечным числом вершин можно представить таким образом, что линии, соответствующие ребрам, во внутренних точках графа пересекаться не будут. Другое дело, когда граф укладывается на плоскости.
Нетрудно убедиться, что при больших п не все графы можно изобразить на плоскости так, чтобы их ребра (дуги) не пересекались не только во внутренних точках изображения графа, но и в наружных. Граф,
который можно расположить на плоскости так, чтобы его ребра пересекались только по вершинам (и, следовательно, не пересекались вне
вершин), называется планарным или плоским.
Было показано [11], что отношение числа планарных графов на п
вершинах к числу всех графов, имеющих п вершин, стремится к нулю
с ростом п. Это означает, что множество всех планарных графов при
больших п имеет мощность, меньшую мощности всех графов с п вершинами. Простейшими примерами непланарных графов являются
полный пятивершинный граф K5 и полный двудольный граф K3,3
(рис. 1.5). Согласно теореме Понтрягина (1927 г.) – Куратовского
(1930 г.) граф является планарным тогда и только тогда, когда он не
содержит подграфов, гомеоморфных графам K5 и K3,3 .
Максимальный участок плоскости связного планарного графа,
включая внутренние и внешние его части, любые точки которого могут быть соединены линией, не пересекающей ребра графа, называется
его гранью. Ясно, что границей каждой грани является соответствующий цикл. Согласно формуле Эйлера, если G-связный планарный граф,
содержащий п вершин, т ребер и g граней, то всегда n m g 2 . Если это условие не выполняется, связный граф не может быть планарным. Кроме того, для произвольного связного планарного графа при
n 3 имеет место неравенство 3n m 6 [16]. Графы G1 и G2 называются гомеоморфными, если их можно получить из одного графа G с
помощью последовательности подразбиений ребер. Напомним, что под
разбиением геометрической фигуры понимается ее представление в
виде такого объединения своих частей, каждая из которых сама является фигурой, а общие точки фигур разбиения могут лежать лишь
только на их общих границах.
Обозначим через xi , xk Vi , i, k 1, n вершины, а через i ,k
ребро, соединяющее эти вершины. Последовательность смежных
ребер 1,2 , 2,3 ,..., l 1,l называется маршрутом, соединяющим вершины x1 и xl .
43
6
7
11
16
3
2
1
13
x3
x5
x4
x6
x7
x3
x6
10
14
17
x2
5
9
8
12
x1
4
18
x1
x4
x5
x7
15
x1
x2
x4
x3
x6
19
x5
x7
Рис. 1.5. Примеры графов:
1 – тривиальный граф; 2 – ноль-граф; 3 – полный (обыкновенный) планарный
граф; 4 – орграф; 5 – орграф, обратный по отношению к графу 4; 6 – смешанный
граф; 7 – (обыкновенный) непланарный граф K5; 8 – подграф графа 7; 9 – суграф
графа 7; 10 – дополнение графа 9 до графа 7; 11, 12 – мультиграфы; 13 – псевдограф; 14 – непланарный двудольный граф K3,3; 15 – планарный двудольный граф;
16 – полный граф K7 и полученное из него дерево 17 и фундаментальное дерево
18; 19 – двудольный граф; маршруты на графе 16: маршруты, соединяющие x1
с x7 : (1,4 , 4,5 , 5,7 ); (7,4 , 4,5 , 5,1 ) ; цепь, соединяющая x1 с x4 : (1,2 , 2,5 ,
5,7 , 7,4 ) ; цикл: (5,7 , 7,6 , 6,5 )
Маршрут замкнут, если x1 xl . Маршрут, в котором все ребра i,k ,
i, k 1, n , различны, называется цепью, а маршрут, в котором все вер44
шины различны, – простой цепью. Цепь, в которой первая вершина x1
и последняя xl совпадают, называется циклом. Иными словами, цикл
есть замкнутая цепь.
Количество ребер маршрута (цепи, простой цепи) в порядке их
прохождения называется длиной маршрута (цепи, простой цепи).
Длина кратчайшей простой цепи, соединяющей вершины x и y в
графе G (V , ) , x, y V , называется расстоянием d ( x, y ) между вершинами x и y графа. Заметим, что в связном неориентированном графе
расстояние d ( x, y ) удовлетворяет аксиомам евклидовой метрики.
Маршрут орграфа называется путем. Путь, в котором ни одна дуга
не присутствует более одного раза, называется простым, иначе – составным. Путь, в котором никакая вершина не встречается дважды,
называется элементарным. Конечный путь, начало первой дуги которого совпадает с концом последней, называется контуром. Контур,
состоящий из одной дуги, называется петлей. Таким образом, для орграфа понятия «ребро», «цепь», «цикл», используемые для неориентированного (обыкновенного) графа, заменяются на «дуга», «путь»,
«контур».
Граф называется связным, если любая пара его вершин соединена
маршрутами, или, иными словами, если в нем можно указать (найти)
маршрут, охватывающий все вершины.
Максимальный связный подграф G графа G называется компонентой связности. Дерево же представляет собой ациклический связный граф с наименьшим числом ребер. Граф G называется k-связным
(или k-реберно-связным), если удаление не менее k вершин (или ребер) приводит к потере связности.
Наименьшее число (G ) независимых циклов в неориентированном графе G, имеющем п вершин, т ребер и k компонент связности,
определяется выражением (G ) m n k и называется цикломатическим числом.
Обыкновенный граф без циклов называется лесом, а связный граф
без циклов называется деревом, или древовидным графом. Орграф
называется деревом (древовидным), если соответствующий ему неориентированный граф является древовидным и в орграфе отсутствуют
контуры. Следовательно, лес – это ациклический граф, каждая компонента связности которого является деревом, а дерево – связный ациклический граф, состоящий, по крайней мере, из двух вершин.
45
Фундаментальное дерево (остов) – это связный ациклический суграф, охватывающий все вершины графа и не образующий ни одного
цикла. Ребра графа G, вошедшие в дерево, называют ветвями дерева,
а ребра, не вошедшие в дерево, – хордами. Следовательно, хорды входят в граф G , являющийся дополнением к графу G. Если в неориентированном графе есть циклы, а в соответствующем ему орграфе нет
контуров, то такой орграф называется сплетением.
Приведенные понятия иллюстрируются рис. 1.5.
1.3.2. Формальное задание графов
Графическое представление графа является одним из способов
(вариантов) его задания. Рассмотрим другие способы формализованного задания (представления) графов.
Матричное представление. Существуют разные варианты такого
задания. Пусть x1 , x2 ,..., xn V – вершины графа G (V , ) , а
1 , 2 ,..., m , где k ik , jk , ik , jk 1, n , k 1, m , – его ребра.
Первый вариант – задание графа с помощью матрицы смежности.
Матрицей смежности графа G называется квадратная матрица
A ai , j , i, j 1, n , у которой элемент ai, j равен числу ребер (дуг
для орграфа) i , j , соединяющих вершины xi и x j (идущих из xi в x j
для орграфа), и ai, j 0 , если соответствующие вершины не смежны.
Ясно, что матрица смежности неориентированного графа является
симметричной.
Второй вариант – задание графа через его матрицу инцидентности.
Матрица инцидентности графа G – это прямоугольная матрица
B bi , j , i, j 1, n , в которой элемент bik 1 , если вершина xi инцидентна ребру k , и bik 0 , если вершина xi и ребро k не инцидент-
ны для всех k 1, m .
Списковое представление. Идея такого представления – наличие
списка пар вершин, соединенных ребрами (дугами), либо списка, в котором для каждой вершины задается множество смежных с ней
вершин.
46
1.3.3. Сети, гиперграфы, гиперсети
Введем вначале некоторые важные понятия.
Степень вершины ( xi ) неориентированного графа G есть число
его ребер, инцидентных вершине xi [13].
Число дуг ориентированного графа, начинающихся в вершине xi ,
называют полустепенью исхода вершины xi и обозначают
число ( xi ) дуг, которые имеют своей конечной вершиной
( xi ) , а
xi ,
назы-
вается полустепенью захода вершины xi . Ясно, что ( x1 ) ...
( xn ) ( x1 ) ... ( xn ) m .
Для ориентированного графа вводятся также следующие понятия.
Исток – вершина, которой инцидентны только исходящие из нее
дуги.
Сток – вершина графа, которой инцидентны только заходящие
дуги.
Вес ( xi ) вершины xi – действительное число, поставленное в
соответствие вершине xi и имеющее прикладную интерпретацию
(стоимость, пропускная способность, количество операций, доля чего-то и т. п.).
Вес ребра или дуги – число или набор чисел, интерпретируемых
как длина, пропускная способность, скорость и т. д.
Граф, вершины и/или ребра (дуги) которого взвешены, называется
сетью1.
Многополюсник (многополюсная сеть) – это сеть с выделенными
в ней вершинами – полюсами. Двухполюсник – сеть с двумя выделенными вершинами.
Примерами сетей являются транспортная сеть, сетевая модель и сети Петри.
1
Заметим, что иногда сетью называют произвольный неориентированный
граф или мультиграф (см., например, Криницкий Н.А. Автоматизированные
информационные системы / Н.А. Криницкий, Г.А. Миронов, Г.Д. Фролов //
под ред. А.А. Дородницына. – М.: Наука, 1982. – 384 с). Смотри также § 6.5,
часть 1.
47
Транспортная сеть – это ориентированный мультиграф G (V , )
без петель, для которого выполняются следующие условия:
существует одна и только одна вершина xi V , называемая вхо-
дом сети, для которой обратного графа G 1 ( x1 ) не существует, т. е.,
иначе, в которую не входит ни одна дуга;
существует одна и только одна такая вершина xn , называемая
выходом сети, для которой графа G ( xn ) не существует, т. е. из которой не выходит ни одной дуги;
каждой дуге отнесено (поставлено в соответствие) целое
число C () 0 , называемое ее пропускной способностью.
Сетевая модель – модель реализации некоторого комплекса взаимосвязанных работ, оформленная в виде ориентированного графа, не
содержащего контуров, и отражающая естественный порядок выполнения этих работ во времени [12]. В качестве весов разных элементов
такого графа могут быть время (выполнения работы или простоя), стоимость, ресурсы. Графическое представление сетевой модели на плоскости называется сетевым графиком.
Сеть Петри1 – это двудольный орграф или мультиорграф G (V , ) ,
в котором множество вершин V разделено на две доли Р и Т, т. е.
V , 0 . Элементы (вершины графа G) множества Р называются позициями (иногда местами), а элементы второй доли Т – переходами. Множество представляет собой множество дуг между Р и Т.
Сеть Петри отличается от обычного двудольного графа G (, ; )
следующими особенностями.
1. Позиции pi , i 1, n изображаются кружками , а переходы
t j , j 1, m – утолщенными вертикальными или наклонными черточками |.
2. Аналогом матриц смежности и инцидентности являются множества I входных и О выходных функций инцидентности – отображение
множества позиций в множестве переходов (I) и переходов в позиции
(О). Ясно, что входным функциям множества I соответствуют дуги
1
Название определяется тем, что впервые они были описаны Карлом Петри в 1962 г. Они используются как математический аппарат моделирования
динамических дискретных систем, из них – преимущественно параллельных
асинхронных.
48
(стрелки), направленные от позиций к переходам, такие позиции называются входными, а выходным функциям – дуги, направленные от переходов к позициям (такие позиции называют выходными). Заметим,
что, во-первых, неориентированных ребер в сети быть не может. Вовторых, дуги могут связывать только вершины разных долей (классов),
т. е. только позиции с переходами или наоборот, но не позиции друг с
другом либо переходы друг с другом. Иными словами, начало дуги
должно совпадать с позицией, а конец с переходом или наоборот.
В сети не может быть таких ситуаций как
,
,
,
,
.
Каждая функция f ( p) из I и О ставит в соответствие натуральное
число каждой позиции р из Р и называется разметкой или маркировкой позиции графа G. Именно граф, обладающий такими свойствами,
называется сетью Петри.
Разметка (маркировка) каждой позиции p сети показывается
большими черными точками внутри кружка (табл. 1.1), называемыми
метками (маркерами, фишками). Отсутствие метки в кружке позиции
р означает , что он пуст и, следовательно, f ( p) 0 . Совокупность количества меток (их чисел) для всех позиций сети называется разметкой сети. Отсутствие меток в какой-то позиции означает, что эта позиция имеет нулевую разметку. Заметим, что если число меток
велико, вместо точек в кружке позиции можно приводить это число.
Удаление по одной метке (маркеру, фишке) из каждой позиции pi ,
i 1, n , при котором для каждой позиции pi находятся дуги ,
направленные из Р в Т, т. е. к переходам t j , j 1, m , и добавление
метки в каждую позицию pk так, что для нее находится дуга ,
направленная из Т в Р, называется срабатыванием перехода t j . Каждое изменение разметки называется событием. Следовательно, каждое
событие сопряжено с соответствующим срабатыванием, заключающимся в перемещении меток из входных позиций перехода в выходные позиции. Заметим, что иногда говорят и пишут вместо слова срабатывание слова возбуждение или запуск. Примеры разметки позиций
до и после соответствующих им событий приведены в табл. 1.1.
49
Т а б л и ц а 1.1
Номер
сети
1
Примеры сетей Петри и их состояний (разметок)
Текущее состояние
Начальное
после (срабатывания)
Комментарии
состояние (а)
переходов ti (б, в, г, д)
р2
р1
р1
р2
t1
t1
после перехода t1
2
р2
р1
р2
р1
t1
t1
перехода t1 не было
3
р1
р2
р3
Срабатывание t1
перемещает метки
из р1 и р2 в р3
р2
Метка из р1 перемещена в р2 и р3
р1
р3
р2
t1
Переход t1 запрещен, так как р1
не имеет меток
t1
после перехода t1
4
р2
р1
р1
р3
t1
р3
t1
после перехода t1
5
t1
t1
6
после перехода t1
а)
б)
t1
р1
р2
р1
р2
р1
р2
t2
t1
р1
t3
р2
t2
t3
р3
р3
в)
t1
р1
р2
t2
t3
р3
50
t1 перемещает метку из р1 в р2 и возвращает в р1 по обратной дуге
а) Разрешены переходы t1, t2, запрещен переход t3
б) После перехода t1
в) После переходов
t1, t2 в сети
г) После переходов
t1, t2, t3 или t1, t3, t2
сети а
д) После перехода
t1 в сети г; другие
переходы в сети г)
и все переходы в
сети д) запрещены
О к о н ч а н и е т а б л. 1.1
Номер
сети
Текущее состояние
после (срабатывания)
переходов ti (б, в, г, д)
г)
Начальное
состояние (а)
t1
р1
Комментарии
р2
t2
t3
р3
д)
t1
р1
р2
t2
t3
р3
2
7
р1
р2
2
5
р3
2
а)
р3
t1
t1
8
после перехода t1
б)
р2
р2
t2
р1
3 2
р3
р5
р1
t3
t1
р4
В динамической
сети числа кратности могут быть изменены
р2
2
р1
3 2
2
р3
р4
t4
t2
t3
р5
а) Разрешен только
переход t1
б) Разрешены переходы t1, t3, t4, запрещен переход t2
t4
t1
в)
р3
р4
t1
51
р2
в) Проанализируйте сами
2
t2
t3
t4
р5
Еще раз подчеркнем, что срабатывание перехода t j , j 1, m означает появление события, связанного с удалением меток из каждой
входной для него позиции и добавление меток в каждую выходную
позицию перехода.
Срабатывание переходов осуществляется согласно следующему
правилу: переход t j разрешен, если для каждой из его входных позиций pi выполняется условие si i , где si – число меток в i-й позиции pi , а i – число дуг ij , идущих от i-й позиции к переходу t j .
При срабатывании перехода число si меток в позиции pi уменьшается
на i , а в k-й выходной позиции pk число sk увеличивается на k ,
равное числу дуг jk , связывающей j-й переход t j с выходной пози(k )
цией pk или выходными позициями pk(1) , pk(2) ,..., pk
. Если срабаты-
вание перехода t j возможно, говорят, что переход t j разрешен.
В противном случае срабатывание перехода запрещено. В таких случаях говорят, что переход запрещен.
Иногда из входной позиции pi необходимо удалить не одну, а li
меток, причем так, что по каждой дуге ij( q ) перемещается li( q ) меток,
( i )
li(1) li(2) ... li
li , 0 li( q ) n . Тогда над дугой ij( q ) , выходящей
из позиции pi , изображается число li( q ) удаляемых меток. Понятно,
что перемещение меток при этом будет возможно, если срабатывание
перехода будет разрешено, т. е. если будет выполняться условие
li i si . Аналогично, если из t j в выходную позицию pk надо пе-
( )
реместить по дуге ij( r ) h(jr ) меток hk(1) hk(2) ... hk k h , т. е. всего h меток из перехода t j в позицию pk , то каждая такая дуга помеча-
ется – над ней или под ней изображается число hk( r ) . В тех случаях,
когда число l ( q ) или h( r ) перемещаемых меток равно единице, дуги по
умолчанию не помечаются.
52
С точки зрения передачи меток числа li( q ) и hk( r ) эквивалентны
кратности дуг ij( q ) и (jkr ) , т. е. изображение
ражение
..
.
q
, содержащее q дуг, а изображение
.
заменяется на изобh
– на изображе-
ние ..
, содержащее h дуг. Сеть, в которой все дуги имеют кратность, равную единице, называется ординарной.
Примеры позиций и переходов.
Позиции – одни компоненты компьютера (например, ядра процессора – основные исполнители функций вычислительных операций)
и переходы – другие компоненты – ресурсы для функционирования
ядер в процессе решения задачи (единая база данных, память, принтеры, …). Срабатывание перехода – использование этих ресурсов.
Позиции – события вида отказ (прекращение работоспособности) блоков (элементов) типа 1, 2, …, п в некотором устройстве, механизме. Число блоков i-го типа есть число меток в позиции pi , соответствующей этому блоку. Переходы – события, связанные с
обоснованием неисправности в блоке (или его отказе, j 1) , обнаружением неисправного блока ( j 2) , его заменой ( j 3) , запуском
устройства (механизма) после ремонта ( j 4 ) и т. д.
Разметку сети до срабатывания любого первого перехода называют
начальной, исходной или стартовой. После срабатывания любого
перехода разметка сети меняется. При этом некоторые переходы могут
потерять возможность срабатывать или, наоборот, приобрести ее (см.
сети в табл. 1.1). Последовательное срабатывание переходов и соответствующее им изменение разметки сети называется процессом функционирования сети. Процесс функционирования завершается разметкой,
называемой конечной.
Конкретную разметку сети перед или после срабатывания очередного перехода, т. е. количество меток в каждой позиции сети, иногда в
их приложениях (например, в теории автоматов, см. § 1.4) называют ее
состоянием.
Наличие процессов функционирования сети позволяет имитировать на ней процессы в разных объектах, этапы которых связаны между собой причинно-следственной связью. Исследование процесса
функционирования разных сетей Петри является одной из важнейших
задач их теории. Предметами исследования являются выявление суще53
ствования и обязательности наличия определенных разметок (состояний) сети, возможные последовательности срабатывания переходов и
свойства получаемых при этом разметок сети, существования конечности функционирования сети, достижения ею конечной разметки, появления разметок типа тупиковой, смертельных объятий и т. п.
Тупиковой называется такая разметка, при которой ни один переход не сможет сработать. Примером тупикового состояния является
разметка, получаемая из начального состояния сети 6 в табл. 1.1 после
трех последовательно выполняемых срабатываний переходов t1 , t2 , t3 .
Теоретический анализ исходной сети 6 в табл. 1.1 показывает, что она
всегда приводит к тупиковой разметке. Для этой сети утверждение, что
она всегда останавливается, когда все метки собраны в позиции p3 ,
истинно. А вот утверждение, что эта сеть всегда останавливается и при
этом все метки собраны в позиции p3 , не является верным. Хотя эта
сеть действительно всегда обязательно останавливается, тупиковые
состояния могут быть разными. Попробуйте доказать это самостоятельно.
Пример тупиковой ситуации. Два пользователя должны на какомто этапе выполнения своих заданий одновременно использовать обычный (цифровой) процессор и графический. Если один из них займет к
этому этапу обычный процессор, а другой – графический, то оба они
не смогут завершить выполнение своего задания (по крайней мере, пока не договорятся сменить сетевой график их взаимодействия, сеть
Петри или процесс ее функционирования).
Если для любой сети в некоторый момент времени не существует
разрешенного перехода, то это означает, что функция разметки (состояния) более не определяется, и процесс, описывающий сеть Петри, завершается. Сеть перестает быть живой, становится неживой до следующей «живучей» разметки и запуска согласно принятому процессу
функционирования. Начальная сеть 5 в табл. 1.1 является «вечно живой», поскольку переход t1 всегда разрешен.
Сеть Петри называется безопасной, если каждая ее позиция содержит не более одной метки, т. е. либо содержит одну метку, либо не содержит ни одной. Заметим, что отсутствие меток в некоторых позициях сети может означать остановку процесса ее функционирования, в то
время как наличие меток в некоторых позициях свидетельствует о ее
безопасности и означает возможность протекания в ней процессов.
Сеть Петри называется ограниченной, если количество меток в
каждой позиции не может превысить некоторое целое число (рис. 1.6).
54
Пример ограниченной по определению сети – это безопасная сеть.
Второй пример ограниченной сети – консервативная сеть. Сеть Петри
называется консервативной, если общее число меток во всех позициях всегда постоянно, т. е. количество меток на входе каждого перехода
равно количеству меток на выходе перехода.
t1
р1
р2
р2
р1
t2
а
t1
t1
р3
р2
р1
t2
t2
б
t3
в
Рис. 1.6. Пример ограниченной (а), неограниченной (б) сетей и сети,
которая может остановиться или может продолжать функционировать (в)
В последнее время сети Петри получили широкое теоретическое
развитие и применение. Появились их разновидности. Они связаны с
введением дополнительных правил и условий, позволяющих предложить разные алгоритмы моделирования сетей. Это, например, иерархические, вложенные, ингибиторные, временные, стохастические, нечеткие, функциональные, в частности, цветные, Е-сети и др.
Так, во временных сетях вводится модельное время, позволяющее
моделировать не только последовательность событий, т. е. смену состояний сети, но и ввести их привязку ко времени. Это осуществляется, в частности, для придания переходам определенных весов – продолжительности (задержки) и срабатывания по определенному
правилу и алгоритму. Если эти задержки являются случайными величинами, то сеть будет стохастической. Другая разновидность стохастических сетей – введение вероятности срабатывания переходов, соединенных с одной и той же позицией.
Если задержки определяются как функции некоторых аргументов,
то сеть называется функциональной. Например, аргументами могут
быть количество меток в каких-то позициях.
Если описываемые сетью объекты относятся к разным видам и это
надо учитывать, то маркеры снабжаются параметрами – пометками,
называемыми цветами, а сети называются цветными. С их помощью
можно выделить «родственные» комплекты помеченных соответствующим цветом позиций. Цвет, кстати, может использоваться как аргумент в функциональных сетях.
55
Ингибиторные сети – это сети, отличающиеся тем, что в них допускается наличие запрещающих (ингибиторных) дуг. Наличие метки во входной позиции, связанной с переходом запрещающей дугой,
означает запрещение срабатывания перехода.
Наконец, в Е-сетях вводятся правила, условия, показатели взаимодействия между элементами сети. Это сети, ориентированные на модельное описание механизмов взаимодействия, в частности иерархического, элементов динамических объектов с жесткими и гибкими
структурами.
В заключение рассмотрим еще два понятия: гиперграф и гиперсеть.
Гиперграф H (V , ; R) есть совокупность графа G (V , ) и
двуместного предиката R ( x, ) , определенного для всех x V и
. Как и в графе G, элементы x V гиперграфа Н называются его
вершинами, ребра (дуги) – ребрами, а предикат R – инцидентором. Напомним (см., например, [12]), что п-местным на множестве M
предикатом называется функция, сопоставляющая каждому набору
m1 , m2 ,..., mn элементов т множества М одно из двух значений,
обозначаемых 1 (да) и 0 (нет) либо И (истина) или Л (ложь).
По аналогии с графами для гиперграфов вводятся понятия гиперлеса, гипердерева, каркаса и т. п. (см., например, [13]).
Пусть заданы гиперграфы
H (V , ; R ) H 0 (V0 , 0 ; R0 ),..., H i
(Vi , i ; Ri ),..., H k (Vk , k ; Rk )
.
Говорят, что последовательность вкладываемых друг в друга гиперграфов H i , получаемых последовательностью {Fi } , i 1, k , отображений
F
F
F
k
k 1 ...H
1 H H ,
{Fi }: H k
H k 1
1
0
определяет иерархическую абстрактную k-гиперсеть A ( H ,
H1 ,..., H k ; F1 ,..., Fk ) , если Vk Vk 1 ... V0 V и для любого
i 1, k , иначе i 1, k , и i i существуют () i 1 i 1 ,
Ri Ri 1{i 1} , а {i1} образует связную часть в гиперграфе H i 1 .
Абстрактная сеть называется гиперсетью, если первичная сеть –
гиперграф G (V , ; R) H 0 (V , 0 ; R0 ) и вторичные H1 ,..., H k являют56
ся гиперграфами, а F отображает ребра графов (Vi , i ) в маршруты
графа (V , ) .
Примеры транспортной сети, сетевых моделей и сетей Петри приведены на рис. 1.7.
а
х4
2
х2
2
2
Вход
сети
х6
1
х1
2
3
2
2
х5
х3
б
4
2
х7
4
6
7
3
3
10
2
1
5
8
Выход
сети
6
5
5
х10
3
х9
6
2
4
2
1
3
2
1
5
1
5
2
2
х8
3
9
R
10
в
8
2
2
Дни
6
4
4
3
2
5
5
2
6
2
2
1
4
7
2
–2
6
6
8
8
дни
р2
5
г
р6
р3
р1
t1
t2
10
Плановое время выполнения работ (Т, дн.) – резерв
времени (R, дн.): числа в кружочках отражают номера
работ, а числа над дугами – плановую продолжительность работ в днях
р5
р7
t3
t4
t5
5
12
14
9
Т
10
18
Сеть Петри для процесса возникновения и устранения неисправности в ЭВМ, имеюшей пять работающих однотипных плат (р2)
и одну резервную (р4) и свободную бригаду (р6): t1 – отказ одной
из плат; t2 – поиск неисправной платы (поскольку метка в р6
означает наличие бригады); t3 – выяснение характера неисправности и принятие решения о замене платы; t4 – замена платы (поскольку есть резервная плата, метка в р4); t5 – окончание ремонта
и приобретение новой резервной платы или восстановление неисправной
р4
Рис. 1.7. Разновидности сетей:
а – транспортная сеть; б – сетевой график выполнения работ по проекту
в традиционной форме; в – сетевой график в осях координат; г – сеть Петри
57
1.3.4. Задачи, решаемые в теории графов
Существует много прикладных задач, в которых используются
графы. Но и сама теория графов связана с решением многих своих собственных, внутренних, задач. Перечислим некоторые из них [11–15].
Алгебра графов
Прежде всего отметим, что под термином алгебра в обширном его
понимании подразумевается способ получения и передачи математических результатов посредством формул [12]. В более узком (конкретном) смысле под алгеброй некоторой совокупности (множества) рассматриваемых элементов (элементов логики или множества, графов и
т. п.) понимается само множество с определенными на его элементах и
подмножествах операциями с ними, обладающими соответствующими
свойствами.
Для графов такими операциями являются удаление или добавление
ребра или вершины, стягивание ребра; сумма и пересечение графов, их
композиция, транзитивные замыкания, декартовы произведения, преобразования графов и т. п.
Класс перечислительных (комбинаторных) задач, в которых определяется количество графов того или иного вида.
Класс задач раскраски графов. Эти задачи касаются как раскраски
ребер, так и его вершин. Примером такой задачи является поиск минимального числа q цветов (хроматического индекса графа), в которые
можно так покрасить ребра графа, чтобы ребра, имеющие общую вершину, были разноцветными. Минимальное число r цветов, в которые
можно раскрасить множество его вершин так, чтобы вершины, соединенные ребром, были разноцветными, называется хроматическим
числом графа G и обозначается (G ) . Граф G называется рхроматическим, если его вершины можно раскрасить р различными
красками так, чтобы никакие две смежные вершины не были раскрашены одинаково. Следовательно, r есть минимальное значение р.
Класс задач о маршрутах графа. Это задачи типа отыскания различных циклов, выделения разных деревьев, минимального по сумме
весов ребер маршрута (вида задачи коммивояжера) и т. п.
Следующие классы – это задачи, связанные с изоморфизмом графов; покрытиями графов (например, задача отыскания минимального
(по мощности) подмножества Vmin вершин графа G (V , ) , которое
содержит хотя бы по одной вершине из каждого ребра графа); геометрического представления графов, случайных графов и т. д.
58
Случайный – это граф, элементам которого ставится в соответствие
распределение вероятностей. Например, случайный – это граф случайной структуры, имеющий случайное число вершин и/или ребер, и/или
их весов. Второй пример: случайный – это граф, выбранный из некоторого множества графов в соответствии с заданным распределением
вероятностей, например, с равной вероятностью из генеральной совокупности графов.
Наконец, еще один, очень важный в приложениях, класс составляют задачи связности графов, сетей, гиперграфов и гиперсетей и построения моделей связности [15].
§ 1.4. МОДЕЛИ ДИСКРЕТНЫХ ОБЪЕКТОВ.
ЭЛЕМЕНТЫ ТЕОРИИ АВТОМАТОВ
1.4.1. Основные понятия
Из исследуемых кибернетических объектов особый класс составляют дискретные, а именно такие, у которых дискретными являются
множества значений входных и выходных сигналов, состояний объекта (предмета, процесса, явления, …) и моментов времени, в которые
поступают входные сигналы, выдаются выходные и меняются состояния. Напомним, что под дискретным множеством понимается такое,
все элементы которого изолированы друг от друга. Или, иначе, множество без предельных точек [12]. Модельным описанием таких объектов
занимается теория автоматов.
Рассмотрению простейших основ этой теории и посвящается
настоящий параграф.
Рассмотрение начнем с исходных, базовых для теории автоматов,
понятий.
Автомат1: 1) дискретный преобразователь дискретного множества его входных сигналов А в непустое дискретное множество М его
внутренних состояний и множество выходных сигналов В по функциям переходов из одних состояний в другие и функциям выходов ;
2) автоматическая модель преобразователя 1); 3) устройство или
управляющая система , реализующая преобразователь 1), т. е. преобразующая дискретное множество А его входных воздействий в непустое дискретное множество М внутренних состояний и дискретное
1
От греч. automatos – самодействующий.
59
множество ответов (реакций) В по известным правилам переходов и
образования выходов.
Функция переходов (a, m) – это правило, определяющее, в какое состояние m M перейдет преобразователь1 (автомат, модель,
устройство, управляемая система, объект), если он находился в состоянии т, а на его вход поступил сигнал а. Формально это записывается
в виде m (a, m) , a A , m, m M .
Функция выходов автомата – это правило, согласно которому образуется выходной сигнал b B (формируется ответ) автомата, если он
находился в состоянии т, а на его вход поступил сигнал а, т. е.
b ( a, m) , a A , m M , b B .
Примеры объектов, состояние и процессы перехода в которых часто описывают автоматными моделями, а конкретнее, только множествами их входных и выходных сигналов, и сути правил перехода из
одних состояний в другие.
Кодер или декодер данных. Здесь А – входной алфавит кодера
или декодера, В – их выходной алфавит; a A и b B – их символы
(буквы, цифры или их комбинации); (a, m) и (a, m) – функции (правила) кодирования или декодирования соответственно, М – множество
состояний – кодовых комбинаций.
Система (живой субъект, автоматическое и автоматизированное
средство) принятия решений. Здесь А – конечное множество существующих и/или ожидаемых формализованных условий функционирования объекта а, для которого надо выбрать по правилам (a, m) ,
(a, m) наилучший (по какому-то критерию) вариант b из конечного
множества возможных вариантов В для последовательного изменения
структуры, процесса, правил его «жизни», чтобы через какой-то момент времени он имел желаемые значения количественных или категорийных показателей качества этой «жизни», М – множество состояний объекта по ходу его «жизни» в процессе или по итогам принятия
решения.
Алгоритм решения некоторой (например, вычислительной) задачи. Здесь А – множество (совокупность) начальных состояний операндов алгоритма (исходных данных), В – совокупность возможных (ожидаемых) результатов, М – множество промежуточных состояний
1
Далее всюду будем писать упрощенно автомат.
60
операндов (промежуточных результатов); (a, m) , (a, m) – правила
запуска алгоритма, преобразования состояний операндов (промежуточных результатов), окончания (остановки) алгоритма, т. е. выполнения им операций извлечения (получения) итогового результата.
В теории абстрактных автоматов принято А называть входным
алфавитом, В – выходным алфавитом, М – множеством внутренних
состояний.
1.4.2. Разновидности автоматов
Как уже упоминалось, в теории автоматов полагается, что автомат
работает в дискретном времени. Это означает, что смена его состояний
происходит (или может происходить) в последовательные моменты
времени t0 , t1 , t2 ,..., tn , интервал между которыми может быть разным.
Для удобства эти моменты заменяются их индексами, т. е. полагают
t 0,1, 2,..., n . Конкретное состояние автомата m(t ) в момент t ti
обозначают как m(i ) m(ti ) , а m есть m(i 1) m(ti 1 ) . Состояние
m0 m(t0 ) в начальный момент времени t t0 , т. е. до того момента
времени t0 , когда на его вход поступает первый входной сигнал а
(первая буква из алфавита А), называется начальным состоянием автомата. Если начальное состояние автомата остается неизменным при
любых условиях его «жизни» и «экспериментирования» с ним, то такой автомат называется инициальным. Если состояния в автомате не
играют роли (например, как в кодовом замке), а его выходной сигнал
зависит только от текущего входного сигнала , например, одной правильной или нет «тайной» цифры (кодового замка), то такой автомат
называется комбинационным. Если же нужный выход зависит не
только от текущего, но и от предыдущих входных сигналов (для открытия кодового замка требуется «правильная» последовательность
«правильных» цифр, т. е. правильное число, набираемое не однократно, как в комбинационном автомате, а последовательно), то такой автомат называется последовательным. Автомат называется (дискретным) конечным1, если конечны все три его множества А, В и М,
1
Заметим, что любой конечный автомат можно, во-первых, представить
логической схемой, содержащей элементы типа «И», «ИЛИ», «НЕ», а также
элементы памяти: задержка, триггер, во-вторых, рассматривать как частный
случай алгоритма с конечной памятью [17].
61
иначе – бесконечным. Если речь идет только о конечных автоматах, то
слово конечный обычно опускается, а слово автомат заменяется аббревиатурой ДКА – дискретный конечный автомат. Если функции
(a, m) и (a, m) заданы на всех парах a, m , то автомат называется
вполне определенным, и частичным – иначе.
В зависимости от модельного представления функций и автоматы разделяются на детерминированные, случайные (вероятностные), нечеткие и т. п.
Из изложенного следует, например, что вероятностные – это автоматы, в которых функции переходов и выходов являются случайными, т. е. в которых и , отображающие произведения множеств
A B в В и М задаются вероятностными мерами, определенными для
любых a A и b B на множествах А и В. В частности, вероятностным является автомат, у которого значение функции перехода есть
условная вероятность его перехода из состояния т при входном сигнале а в состояние m при выходном сигнале b.
Следующий признак классификации – вид элементов множества А
и В. Среди них различают абстрактные автоматы и структурные.
Абстрактные автоматы отличаются тем, что для них А и В – алфавиты. Кроме того, для абстрактного автомата характерны, во-первых,
один вход и один выход, во-вторых, сам автомат рассматривается без
учета его внутренней структуры, т. е. как «черный ящик» – преобразователь входных последовательностей букв (символов) в выходные. Автомат, структура которого важна и может изменяться в процессе
функционирования, называется автоматом с переменной структурой.
От абстрактных автоматов структурные (СА) отличаются тем, что
в них, во-первых, вместо одного входа и одного выхода имеется множество каналов и полюсов, во-вторых, структурный входной алфавит
есть множество сигналов, поступающих на каждый из входов СА, а
структурный выходной алфавит представляет собой множество сигналов, вырабатывающихся на каждом из выходов СА. В-третьих, элементами СА являются отдельные элементарные автоматы.
Автомат, в котором имеет место согласованность продолжительности входных сигналов с временем переходов сигналов, называется
синхронным, а когда согласованности нет – асинхронным. Примером
асинхронного автомата является последовательный кодовый замок.
Автоматы, реализующие одинаковые преобразования, т. е. получающие те же выходные сигналы b B при соответствующих им входных сигналах a A (иначе говоря, имеющие одинаковое неотличимое
62
снаружи поведение) называются эквивалентными. Заметим, что два
эквивалентных автомата 1 и 2 могут иметь разное число M1 и M 2
состояний.
Прежде чем переходить к рассмотрению способов описания (задания, представления) автоматов, выделим три их типа: автоматы Мили,
Мура1 и клеточные.
Автоматы Мили и Мура отличаются законами функционирования,
а именно способами формирования функций выходов, а клеточные
еще специфическим видом входных сигналов.
Для автомата Мили законы функционирования описываются соотношениями
m m(i 1) m(i ) , a(i ) , b(i ) m(i ) , a(i ) ,
(1.12)
где a(i ) , b(i ) , m(i ) – значения входных a(t ) A и выходных b(t ) B
сигналов (буквы входного А и выходного В алфавитов для абстрактного автомата), а m(i ) – состояние m(t ) M автомата в момент времени
t ti ; и – функции переходов () и выходов ().
Для автомата Мура эти соотношения имеют вид
m m(i 1) m(i ) , a(i ) , b(i ) m(i ) .
(1.13)
Из (1.12) и (1.13) видно, что функция выходов автомата Мили является двухаргументной, в то время как для автомата Мура – одноаргументной. Иными словами, символ алфавита в выходном сигнале автомата Мили появляется (обнаруживается) только при наличии
символа входного алфавита на входе автомата. В то же время в автомате Мура выходной символ появляется (определяется) только в зависимости от состояния автомата. Следовательно, в автомате Мура
символ b(i ) B на его выходе существует все время, пока автомат
находится в состоянии m(i ) . В связи с этим иногда выходную функцию автомата Мура называют функцией меток, так как она по каждому
состоянию автомата «ставит» метку на его выходе. С другой стороны,
автомат Мили ничем не отличается от абстрактного автомата, рассмотренного ранее.
1
По фамилии впервые рассмотревших их авторов: Mealy G.H. и Moore E.F.
63
Оказывается, что для любого автомата Мура существует автомат
Мили, реализующий ту же функцию, и наоборот. В связи с этим часто
рассматривается один из них – абстрактный автомат Мили.
Клеточные автоматы (КА)1 – это конечная совокупность К клеток k с заданными правилами перехода из клетки k в клетку k ,
определяющими состояние ki 1 конкретной клетки k в следующий
момент ti 1 по состоянию в момент ti тех клеток, которые находятся
от нее (от k ) на расстоянии не больше некоторого.
Наиболее часто рассматривают одномерные (линейные), двумерные (плоские) или трехмерные КА, в которых состояние определяется
самой клеткой k и ближайшими соседями, а совокупность клеток
(ячеек) образует квадратную или кубическую решетку. Множество,
как правило ближайших, клеток, влияющих на значение состояния
данной клетки k , за исключением ее самой, называется окрестностью клетки k . При этом каждая ячейка (клетка) КА считается занятой отдельным элементарным автоматом (ЭА). ЭА имеют конечный набор состояний, а их выходные сигналы есть номера их
состояний. В более общем виде состояние отдельной клетки в i-й момент времени характеризуется переменной, представляющей собой
целое, действительное или комплексное число либо набор из нескольких чисел. Из всех состояний КА выделяется одно специальное, называемое пассивным. В этом состоянии автомат считается включенным,
но он никак не взаимодействует с соседями. Клеточное пространство
считается пустым, если оно заполнено ЭА, находящимися в пассивных состояниях.
Для активации КА надо в момент времени t0 в пустое клеточное
пространство внести начальную активность в виде некоторого зародыша.
Зародыш – совокупность ЭА, которые внешним влиянием переведены из пассивных состояний в первичные активные. Тем самым с момента t t0 начинается функционирование КА.
КА отличают следующие особенности:
синхронность и дискретность: состояние клеток изменяется
синхронно через дискретные интервалы времени в соответствии с
1
Понятие введено Дж. фон Нейманом.
64
локальными детерминированными (детерминированные КА), вероятностными (вероятностные КА), нечеткими (нечеткие КА) правилами;
локальность и стабильность (стационарность) правил: на
новое состояние клетки могут влиять только элементы (клетки) ее
окрестности, а сами правила не могут меняться со временем;
ограниченность: множество возможных состояний клетки конечно. Это означает, что для получения нового состояния клеткам требуется конечное число операций;
однородность: ни одна область КА не может отличаться от другой по каким-либо особенностям, в частности правилам. Если эта особенность КА нарушается, то автомат называется неоднородным.
Синхронность означает, что значения во всех клетках меняются
единовременно, а именно в конце итерации, т. е. при смене ti на ti 1 , а
не по мере выполнения операции по правилам в каждой клетке.
Согласно изложенному в детерминированных КА состояние клетки k
в момент времени ti 1 однозначно определяется ее состоянием и состоянием клеток ее окрестности в предыдущий момент времени. Иными словами, состояние клетки k в ( i 1 )-й момент времени ti 1 является однозначной функцией от переменных состояния k и состояний
клеток ее окрестности в момент ti . Говорят, что такой КА не обладает
памятью и называется автоматом без памяти. КА, в которых состояние клетки k зависит не только от состояния ее и клеток ее окрестности в предшествующий момент ti , но и в предыдущие
(i 1),(i 2),...,(i l ) моменты, называется автоматом с памятью.
В вероятностных КА функция заменяется условными вероятностями изменения состояния клетки k в ( i 1 )-й момент времени ti 1 ,
т. е. состояния k(i 1) , если при t ti она (клетка k ) находилась в состоянии k(i ) , а клетки ее окрестности принимали свои четко определенные значения в этот момент времени ti .
КА, допускающие возможность изменения положения клетки k во
время эволюции системы, называются подвижными. В противном
случае, т. е. когда положения клеток в автомате во время эволюции
всегда остаются постоянными, они называются постоянными.
Аппарат клеточных автоматов нашел широкое применение, в частности, в теории однородных вычислительных систем, при имитационном моделировании различных объектов, для моделирования физико65
химических процессов в наноразмерных системах, в вычислительной
квантовой химии, в теоретической биологии и микромеханике, в программируемой материи и т. д.
1.4.3. Способы описания автоматов
Рассмотрев разнообразие автоматов, можем перейти к их формальному описанию (заданию, представлению), ограничившись лишь некоторыми способами.
Табличный способ
В этом способе конечные множества А, В, М задаются перечислениями, а значения функций и – при помощи таблицы переходов
(табл. 1.2) и таблицы выходов (табл. 1.3). Можно таблицы переходов и
выходов совместить, если на пересечении строки, соответствующей
a j , и столбца, соответствующего mi , расположить не одно значение
или , а пару ( (mi , a j ) , (mi , a j ) ) (см. табл. 1.4).
Рассмотрим в качестве примера задание автомата Мили, имеющего
два входных сигнала ( a1 и a2 , например, a1 0 , a2 1 ), два выходных
( b1 и b2 , например, b1 0 , b2 1 ), и три состояния ( m1 , m2 и m3 ), для
которых m (m, a) и b (m, a ) располагаются в соответствующих
ячейках таблицы (табл. 1.5 и 1.6).
Т а б л и ц а 1.2
а1
Таблица переходов
т
…
…
т1
тi
(m1 , a1 )
(mi , a1 )
тp
(m p , a1 )
.
.
.
аj
(m1 , a j )
(mi , a j )
( m p , a j )
.
.
.
аn
(m1 , an )
(mi , an )
(m p , an )
а
66
Т а б л и ц а 1.3
Таблица выходов
а
т1
т
тi
…
…
тp
а1
(m1 , a1 )
(mi , a1 )
(m p , a1 )
.
.
.
аj
(m1 , a j )
(mi , a j )
(m p , a j )
.
.
.
аn
(m1 , an )
(mi , an )
(m p , an )
Т а б л и ц а 1.4
Совместная таблица переходов и выходов
а
.
.
.
аj
.
.
.
т
тi
…
…
(mi , a j ) ; (mi , a j )
Рассмотрим в качестве примера задание автомата Мили, имеющего
два входных сигнала ( a1 и a2 , например, a1 0 , a2 1 ), два выходных
( b1 и b2 , например, b1 0 , b2 1 ), и три состояния ( m1 , m2 и m3 ), для
которых m (m, a) и b (m, a ) располагаются в соответствующих
ячейках таблицы (табл. 1.5 и 1.6).
Для автомата Мура табличное задание будет упрощено, поскольку
его выходной сигнал зависит только от состояния автомата и не зависит от входного сигнала. Пример табличного задания автомата Мура
представлен в табл. 1.7.
67
Т а б л и ц а 1.5
Т а б л и ц а 1.6
Пример таблицы переходов
для автомата Мили
Пример таблицы выходов
для автомата Мили
а1
а2
а1
а2
т1
т1
т2
т3
т1
т2
т2
т3
т1
т1
b2
b1
т2
b2
b1
т3
b1
b2
Т а б л и ц а 1.7
Пример таблицы переходов для автомата
Мили
а1
а2
b1
т1
т2
т3
b2
т2
т2
т3
b1
т3
т4
т1
b1
т4
т3
т2
Графический способ (диаграммы Мура)
Второй, графический (графовый, сетевой), способ задания ДКА –
это задание с помощью диаграмм Мура.
Диаграмма Мура есть множество р кругов (аналогов кружков в сетях Петри), внутри каждого из которых указывается один символ из
M (m1 , m2 ,..., m p ) , т. е. внутри различных кругов пишутся различные
символы m j , j 1, p . Затем для каждой пары (mi , a j ) , где mi M ,
a j A (a1 , a2 ,..., an ) от круга, в котором записан символ mi , проводится ориентированная стрелка (аналог дуги в сетях Петри) к кругу, в
котором записан символ mij (mi , a j ) , т. е. соответствующий
(mi , a j ) . Этой стрелке (дуге) приписывается значение (символы) пары
(a j , bij ) a j , (mi , a j ) . Следовательно, от каждого круга исходит
ровно п стрелок (см. ориентированный мультиграф в § 1.3.), где п –
число входных сигналов (символов входного алфавита) А.
Диаграммы Мура для автоматов Мили, заданных табл. 1.5 и 1.6, и
Мура, заданного табл. 1.7, представлены на рис. 1.8 и 1.9.
68
(a2 , b1 )
(a2 , b1 )
m1
m2
(a1 , b2 )
(a2 , b1 )
m3
( a1 , b2 )
(a1 , b2 )
Рис. 1.8. Диаграммы Мура для автомата Мили,
заданного табл. 1.5 и 1.6
(a1 , b1 )
m1
(a1 , b1 )
m2
( a1 , b1 )
(a2 , b2 )
m3
( a1 , b1 )
m4
( a1 , b2 )
( a2 , b1 )
( a2 , b1 )
Рис. 1.9. Диаграммы Мура для автомата Мура,
заданного табл. 1.7
1.4.4. Задачи теории автоматов
В заключение рассмотрим некоторые важные задачи теории автоматов [12].
Задачи анализа – по заданному автомату описать его поведение
или по неполным данным об автомате и его функционированию найти
(установить) его свойства.
Задачи абстрактного синтеза – построение автомата с наперед
заданными структурой, свойствами, поведением или функционированием.
Задачи структурного синтеза – выбор его структуры, типов элементарных автоматов и организации их функционирования, включая
кодирование состояния входных и выходных сигналов, обеспечивающих оптимальное значение показателей качества, например, по времени, ресурсам и точности.
69
Задачи полноты – выяснить, обладает ли подмножество автоматов свойством полноты – совпадает ли с множество всех автоматов, которые получаются путем конечного числа применений некоторых операций к автоматам из .
Задачи эквивалентных преобразований – найти полную систему
правил преобразований автоматов, удовлетворяющих определенным
условиям и позволяющих преобразовать произвольный автомат
в любой эквивалентный ему (имеющий одинаковое поведение)
автомат.
Задачи минимизации – найти оптимальное число состояний автомата, сохраняющих его поведение.
Практический пример использования КА при имитационном моделировании движения транспортного средства (ТС) по дороге с односторонним движением, когда необходимо учитывать расстояние (S,
измеряется числом пустых клеток) и скорости движения (V, измеряется
в клетках) между конкретным ТС a, b или с и с находящимся перед
ним или после него, представлен на рис. 1.101.
S
V
S
V
S
V
Vmax=5
S
V
а
б
S?3
V=4
S
V
S
V
S
V
в
Рис. 1.10. Моделирование состояния дорожного движения с использованием клеточных автоматов:
а – схематическое изображение дорог; б – моделируемый элемент
изображения; в – отображение смены состояний КА-моделью
1
Альшаер Д.Д. Математическое и программное обеспечение представления и обработки данных о мобильных объектах в реляционных СУБД: дис. …
канд. техн. наук // Д.Д. Альшаер; Новосиб. гос. техн. ун-т; науч. рук. В.В. Губарев. – Новосибирск, 2009.
70
§ 1.5. МОДЕЛИ ПРЕДСТАВЛЕНИЯ ДАННЫХ
И РЕЗУЛЬТАТОВ ДЛЯ ИХ ВИЗУАЛЬНОГО АНАЛИЗА
1.5.1. Вводные замечания
В последние годы все более явный интерес проявляется к конвергенции (схождению, приближению, единению) нейро-, нано-, био-,
инфо- и когнитологических (НБИК) знаний и технологий, построению
на их основе теорий и средств, направленных, в частности, на максимальное использование возможностей человека, его способностей к
познанию окружающего мира. Одной из задач такого единения является исследование того, как человек и животные познают мир, моделируют себя и свое окружение, взаимодействуют со своими элементами,
с другими существами и окружающим миром. Это необходимо не
только с познавательной целью, чтобы помочь человеку при решении
им разнообразных личных, рабочих, научных и прочих проблем, но и с
целью разработки новых средств и технологий, позволяющих заменить
или усилить те функции и способности человека, которые ему жизненно необходимы, но которые пока автоматизации не поддаются. К таким способностям и функциям относятся среди прочих те, что связаны
с восприятием действительности, преобразованием результатов восприятия и приспособлением их в своей жизни и деятельности. При
этом человек проявляет порою поразительные способности, во многом
недоступные искусственным средствам. Это связано в большой степени с отличительными особенностями человека. Отметим некоторые
важные из них.
Человек отличается от других материальных объектов, включая
любые искусственные технические и биологические, а также всех животных, тем, что для него наличие обратной связи для активности в процессе жизни и общения с окружением необходимо, но недостаточно.
Помимо обратных связей он использует существенно более сложные
способы активности и принятия решений: мышление, творчество, интуицию. При принятии решений для человека важны также самоосознание, ценностные предпочтения, совесть, этические и эстетические нормы. Это позволяет человеку лучше познавать действительность,
создавать и применять модели, находить направленные выходы из тупиков, принимать принципиально новые по сравнению с имеющимися нестандартные, неординарные технические, технологические, управленческие, диагностические и прочие решения.
71
Человек оперирует модельными образами действительности,
формируемыми на основе ассоциаций. При формировании образа мозг
извлекает значимое для человека всеми возможными путями, используя развитую многосенсорную сигнальную систему, смешивая сведения, поступающие от разных сенсоров – органов зрения, слуха, чувств.
Все это смешивается с учетом общей картины. Например, то, что мы
слышим, существенно зависит от того, что мы видим и чувствуем. В
ассоциациях большую роль играет то, что различные сенсорные области мозга сильно переплетены. Иными словами, человек имеет смешанное образное системное модельное восприятие действительности.
В мыслительных процессах в одно мгновение человек может переноситься к разным образам и ассоциациям в любые текущие, прошлые и будущие моменты времени и места пространства, в любую область знаний, которыми он обладает, быстро перебирать и строить
различные комбинации всего этого.
Мозг человека (в широком его понимании) по своей природе работает с моделями, включая виртуальные образы себя и своего тела, формируемые из разнообразных ощущений, приходящих от всех своих органов
чувств, проявляя при этом завидную пластичность, способность динамически перестраивать свою структуру, «перепрограммировать» себя.
У разных людей в различной степени развиты разнотипные виды
памяти: зрительная, ассоциативная, слуховая, моторная, универсальная
и другие (редкие) – обонятельная, осязательная. Зрительная память
позволяет осмысливать и сохранять в памяти то, что человек увидел сам.
Ассоциативная – разновидность зрительной, в которой запоминание
осуществляется по невидимым зацепкам, связям, аналогиям с тем, что
мы хорошо помним. При смысловой памяти осмысливается и сохраняется в памяти то, что слушается или читается вслух, в частности музыка.
При моторной (двигательной) памяти человек лучше всего усваивает и
запоминает то, что достигается опытом, деланием, мастерством, с использованием написания, рисования, движения, танцев и т. п. Наконец,
универсальная – это смешанный тип памяти: слухо-моторная, зрительнодвигательная, зрительно-слуховая – большинство людей.
Человек умеет совмещать две противоречивые группы процессов: познавательные, включая познание методом проб и ошибок, и оптимизационные, направленные на принятие наилучших решений. При
этом человек зачастую при решении сложных задач не прибегает
к перебору вариантов, ответов, не ищет именно оптимальное решение,
а ограничивается быстрым построением его аппроксимаций, зачастую
отличающихся от оптимальных лишь на несколько процентов.
72
Помимо мозга в узком смысле, как пластичного центрального
органа управления, и его памяти, участвующей в приеме, кодировании,
хранении, воспроизведении, обработке и генерации (источнике) информации, в информационных процессах человека, в его способности
модельного отображения действительности задействованы также сознание и подсознание, ум, проявляющийся в способности человека к
абстрактному мышлению, и разум, проявляющийся в способности человека понимать, рассуждать, принимать решения (мозг в широком
смысле). При этом скорость выполнения синтактических информационных операций в мозге, сознании и подсознании отличается на десятичные порядки: 107 бит/сутки для сознания (Адам Д. Восприятие,
сознание, память. – М.: Мир, 1983) и 10300 бит/сутки для мозга (Николас Дж. Динамика иерархических систем. – М.: Мир, 1989).
Человек способен учиться во сне, не только закрепляя и укладывая в соответствующие участки мозга (памяти) ранее полученные сведения, знания, но и получая новые через запах и звуки.
Для человека (его мозга в широком понимании) характерны:
высокопараллельная форма восприятия и обработки информации; способность управления многими делами при высокой энергетической эффективности; возможность передавать свое образное модельное представление другим; распределенность мозга по телу. Для человека
характерна способность совмещать моторные и сенсорные сигналы как
для управления конечностями, так и при восприятии окружающей среды.
Для человека характерна способность к целеполаганию и целеустремленности, оценивать прошлые, настоящие и будущие ситуации,
взаимодействовать с окружением, генерировать варианты и пути достижения цели и выявлять факты, мешающие и помогающие этому.
При решении интеллектуальных задач в мозге человека активируется множество его областей, отвечающих за разные функции.
Человек изначально целое, а не создаваемое по частям (см. понятие система), сложное, развиваемое, многогранное и противоречивое с
многоуровневым строением, с неоднозначной нелинейной системой
связи своих частей, допускающих эластичность и многофункциональную изменчивость, способное предлагать и создавать неочевидное, не
встречающееся, не имеющее аналогов в природе. Иными словами, человек от зачатия представляет собой холон – целое, являющееся
частью другого большего целого и представляющее собой структурный элемент сложной развивающейся системы, организационным
принципом строения которой является «часть сама является целым».
73
Наконец, важно отметить, что до 90 % сигналов, данных, знаний,
информации человек получает по зрительным каналам, существенно
превыщающим по пропускной и разрешающей способности аудио, кинестетические (чувственные: обонятельные, осязательные (тактильные),
вкусовые), а также мышечные и вестибулярные. При этом человеком
усваивается до 10 % аудио или вербально поступающей информации1,
до 20 % – визуальной, до 50 % – аудиовизуальной и до 90 % – смешанно
(аудио + визуально + моторно + кинестатически) поступающей информации. При восприятии и переработке Данных человек руководствуется «основным законом (селективного) восприятия информации» – выделять главное, рассматривая остальное как фон.
Изложенное позволяет сделать следующие выводы. Во-первых,
важность для человека многоканальности поступления информации.
Во-вторых, допустимость и необходимость модельного представления
способов и механизмов восприятия человеком Данных и выделения из
них требуемой ему информации как элементов сложной системы, обладающей ярко выраженным свойством синергии, эмерджентности. Втретьих, это подсказывает, что многие средства, включая интеллектуальные, добывания и передачи информации следует делать многоканальными, использующими разные источники Данных, что важно
иметь в виду при построении различных интеллектуальных, обучающих, автономных робототехнических средств и систем.
В связи с этим при исследовании различных объектов очень важным
является применение визуальных, зрительных модельных представлений данных, знаний и результатов их обработки. Рассмотрению простейших из таких представлений и посвящается настоящий параграф.
Прежде чем переходить к их описанию, заметим, что графические
образные модели, как и другие модельные представления, являются
целевыми отображениями исследуемых объектов. В связи с этим при
выборе того или иного зрительного модельного представления объекта
необходимо обязательно учитывать цель именно такого его образа.
1
Обратим внимание на разную информативность сигналов, воспринимаемых человеком. Число различаемых человеком цветовых оттенков 2,3…
7,5 млн, звуковых тонов – около 340 тыс., а человеческое обоняние способно
различать более одного триллиона запахов (Андреас Келлер, Рокфеллеровский
университет), хотя ранее считали – 10 тыс. различает человек и 200 тыс. – собака. Что касается животных, то у них на первом месте стоит нюх, после него
зрение и слух. Так, у собаки 225 млн обонятельных рецепторов (8–10 млн
у человека). В глазе человека 130 млн светочувствительных клеток.
74
1.5.2. Зрительные (визуальные) модели
Очень часто необходимо зрительно представить зависимость одних
величин – значений исследуемых показателей, параметров, характеристик от других, например, y от х или y от x1 , x2 , ..., xk , либо y1 от x1 ,
y2 от x1 или x2 , либо от x1 , x2 и т. д. Отражаемая зависимость может
быть детерминированной, статистической, нечеткой, описываемой моделями динамического хаоса; точечной или интервальной и т. п. Примеры таких представлений можно найти в 1-й части пособия (рис. 3.4,
3.9, 4.1, 4.3–4.8, 4.11–4.15 и др.). Кроме зависимостей иногда надо визуально представить соотношения между размерами объектов, частей в
целом. В настоящем разделе рассматриваются элементарные основы
построения таких зрительных представлений.
Зрительные (визуальные) модели могут быть статичными и динамичными. К первым относятся различные графические модели исследуемых объектов, ко вторым – фильмовые (покадровые), анимационные
(мультипликационные) и имитационные, моделирующие динамику развития объективно существующей действительности, реальности, виртуальную (возможную) реальность или мысленное (умственное) представление о каких-то процессах, явлениях, гипотезах. Все подобные
модели ориентированы на то, чтобы делать образ исследуемого объекта выразительным, лаконичным, универсальным, обозримым, доходчивым, запоминающимся, удобным для восприятия и побуждать
человека, оперирующего с ним, по возможности полнее проявить указанные выше свои отличительные способности. В частности, позволять
человеку осуществлять контроль достоверности данных и результатов
(за счет более яркого «выпячивания» имеющихся неточностей, выбросов, пропусков, пропорций, ошибок наблюдений и т. п.), выявлять закономерности связи и взаимосвязи, включая причинные, системные
свойства и особенности, тенденции развития и их проявления, структуры влияния, тем самым получать новые знания об объекте.
В настоящем разделе опишем статичные графические модели.
Вначале приведем необходимые понятия.
В рассматриваемом нами контексте, график1 – это, в узком смысле
слова, чертеж, применяемый для наглядного выражения количественной зависимости какой-либо величины от другой в виде линии, дающей наглядное представление о характере изменения этой зависимо1
От греческого ó – начертанный.
75
сти. В широком смысле график есть разновидность графической модели,
представляющая собой совокупность графических знаков (образов) –
геометрических фигур (точек, линий, плоских (прямоугольники, квадраты, круги, треугольники и т. д.) и объемных (шары, кубики, …) и
негеометрических фигур в виде силуэтов, лиц, рисунков и предметов, а
также вспомогательных элементов. По имени используемых геометрических фигур графики называют точечными, линейными, плоскостными и пространственными (объемными). Символические знаки штриховок, окрасок фигуры и рисунки, используемые при построении
графика, называются графическими знаками (образами), а место, на
котором выполняется изображение графика, – полем графика. Полями
графика являются листы бумаги, экран монитора, географические карты, план местности. К вспомогательным элементам графика относятся условные обозначения, оси координат, масштабные шкалы и
числовые сетки, а также экспликация графика.
Размеры и пропорции сторон поля графика образуют его формат.
Считается, что наилучшие для зрительного восприятия графика пропорции его сторон такие, которые подчиняются правилу «золотого сечения» или «золотой пропорции». Это правило деления отрезка АС
точкой В на две части таким образом, чтобы выполнялось равенство
отношений АВ : ВС = АС : АВ, где АВ – большая, а ВС – меньшая часть
отрезка АС. В первом приближении это отношение равно 5/3, точнее,
8/5, 13/8 и так далее, т. е. примерно 1,62. В литературе по статистическим графикам наилучшим на поле прямоугольной формы считается
пропорция сторон прямоугольника от 1 : 1,3 до 1 : 1,5.
Размещение графических образов на поле графика определяют
пространственные ориентиры. Они задаются системой координат,
координатной сеткой или контурными линиями и делят поле графика
на части, соответствующие значениям изображаемых на графике показателей. Если показатели являются физическими величинами, то по
осям координат или координатной сетки указываются их единицы измерения. Математические величины, в том числе представляющие безразмерные относительные физические показатели, единицами измерения не отмечаются.
Чаще всего для графиков используется прямоугольная (декартова)
система координат. Но могут быть и другие системы: полярные (круговые диаграммы) или картографические. В последних в качестве пространственных выступают неограниченные ориентиры (контуры суши,
линии рек, морей, океанов).
76
Помимо пространственных для построения графиков нужны еще и
масштабные ориентиры, которые придают графикам количественную значимость, передающуюся с помощью масштабных шкал, дополняющих измерительные.
Масштабная шкала представляет собой линию, отдельные точки
(элементы) которой воспринимаются (читаются) как определенные
(в соответствии с принятым масштабом) числа.
Масштаб графика – это мера перевода численной величины в
графическую, представляющая собой отношение размера графического
знака (определенной длины линии, площади или объема геометрической
фигуры, …) к ее действительной величине (длине, площади, …).
Например, 1 см на графике условно принимается за 1 км на местности
или соответствует 1 тыс. руб., 20 амперам и т. д. Масштаб обозначается
в виде дроби, числитель которой равен единице, а знаменатель – степень
уменьшения длины линий (площади, объема, рисунка, изображения, …)
изображаемого объекта. Например, 1 : 100 000 (1 см соответствует
100 000 см = 1 км) или 1 : 1000 (1 см соответствует 1000 руб. =
= 1 тыс. руб.).
Масштабные шкалы могут быть равномерными и неравномерными. Равномерной шкалой называется такая, в которой равным графическим образам шкалы (например, отрезкам линий) соответствуют
равные числовые величины.
Неравномерным шкалам соответствуют неравные числовые значения. Среди них чаще всего используются десятичная логарифмическая
шкала, натуральные числа п, точки отсчета (числа) которой равны показателям степени десятичных чисел, кратных десяти, т. е. n lg10n ,
n 1, 2,3,... , lg1 0 , а промежуточные между точками отсчета xл равны lg xд , где xд – значение показателя в десятичной натуральной
шкале. В [1, рис. П3.2, а] использована декадная шкала, в которой одно
декадное деление (один декадный отрезок) отличается от другого соседнего в 10 раз, а внутри деления используется равномерная разметка
не от нуля, а в виде 1, 2, …, 9 единиц нижней декадной физической
единицы (рис. 1.11).
Иногда на графике для повышения его информативности изображают кривые или диаграммы, относящиеся к показателям, измеренным
в разных шкалах или масштабах. Тогда по соответствующим осям
графика наносят разные измерительные и масштабные разметки (см.,
например, рис. 1.12 и далее рис. 1.13, а).
77
1018 в 2019 г.
4
Увеличение Rpeak в 10 раз
через каждые 15 лет
4
2
16
10
8
10
5
1
1015
1000
3
Коридор увеличения R peak в 10 раз
каждые 11 лет
500
2
100
14
10
Rpeak
50
10
1013
R peak
5
2
1012
8
1
1000
R max
6
500
100
2
1011
8
Увеличение в 10 3 раз
через каждые 11 лет
Rmax
50
2
1010
8
10
6
5
1
2012
2010
2011
200 8
2009
2007
2006
2004
2005
2002
2003
2001
200 0
1998
19 99
1996
1997
1994
1995
1993
109
Рис. 1.11. Графики роста производительности суперкомпьютеров списков
TOP500:
Rmax – наивысший результат производительности на тесте Linpac (Flops);
R реаk – теоретическая пиковая производительность (Flops); R – среднее по 500-м
суперкомпьютерам
78
Пользователи Интернет, млн чел.
0
Годы
Рис. 1.12. Рост числа пользователей Интернета с 1995 по 2009 год:
абсолютные значения;
проценты от населения планеты
Как уже упоминалось, вспомогательные элементы графика – это
оси координат, масштабные шкалы и числовые сетки, а также экспликация графика. Экспликация1 графика включает в себя заголовок графика и словесные пояснения содержания масштабных шкал, отдельных элементов графических знаков, различных по конфигурации,
штриховке или цвету, позволяющие мысленно перейти от геометрических образов к явлениям и процессам, отображаемым на графике.
1.5.3. Разновидности графиков и их назначений
Рассмотрим разновидности графиков.
По своему назначению они делятся на графики взаимосвязи показателей (зависимостей), сравнения, структуры, динамики, упорядочения и рассеяния значений показателей, системные.
1
От лат. explication – развертывание, разъяснение.
79
По способу построения графики делятся на диаграммы и карты,
включающие картограммы и картодиаграммы. Как уже было отмечено, по используемым графическим знакам графики делятся на точечные, линейные, фигурные (плоские или объемные) и пиктографики.
Возможны также детализации графиков и смешанные графики,
совмещающие разные назначения, способы построения и графические
знаки.
Не вдаваясь в описание подробностей, рассмотрим эти разновидности на конкретных примерах.
Диаграммы – графики количественных отношений – в свою очередь делятся на точечные, линейные, плоскостные (столбиковые, ленточные, полосовые), квадратные, круговые, радиальные (рис. 1.13) и
объемные (в частности, поверхности распределений, цилиндрические).
Ярким примером столбиковых диаграмм являются графические изображения гистограмм (см. часть 1, табл. 4.4, п.5.3, разд. 4.3.4), а также
рис. 1.13.
Круговые диаграммы делятся, в свою очередь, на два типа: собственно круговые, когда сравниваются площади кругов, как графических знаков, друг с другом, и секторные, в которых круг используется для сравнения площадей отдельных секторов друг с другом. Картограмма – это
схематическая (контурная) карта или план местности, на которой в зависимости от величины изображаемого показателя отдельные траектории
обозначаются с помощью штриховки или расцветки, точек.
Картодиаграмма – сочетание контурной карты (плана местности)
с диаграммой. Например, разных секторных диаграмм для каждого
района карты, чтобы отразить пространственную специфику изучаемого показателя.
Общим требованием графического представления изучаемых объектов является выполнение следующего правила: факторные признаки
(показатели) следует размещать по горизонтальной шкале (оси) графика и их изменения читать слева направо, а результативные признаки
(показатели) – по вертикальной шкале и читать снизу вверх.
Чаще всего функционная зависимость между значениями разных
величин изображается кривой на линейных графиках, а статистическая –
диаграммой рассеяния либо смешанным графиком – диаграмма рассеяния с нанесенной на нее теоретической или эмпирической кривой регрессии или кривой (прямой) среднеквадратической регрессии либо
скедастической кривой (см. часть 1, разд. 4.3.5), либо всеми способами
вместе (см. часть 1, рис. 4.7, 4.11, 4.13–4.15, 4.20), а также рис. 1.13).
80
количеств о слу чаев
температу ра в озду ха
3500
30
30
10
25
0
20
-10
15
-20
10
-30
5
-40
0
-50
3000
количество случаев
Количество
случаев
20
температура
Температура
воздуха,воздуха
С
35
количество случаев
инфекционных заболеваний
2936
2500
2061
2000
1721
1500
1675
1272
1000
500
341
233
01.01.2006
31.01.2006
02.03.2006
01.04.2006
01.05.2006
31.05.2006
30.06.2006
30.07.2006
29.08.2006
28.09.2006
28.10.2006
27.11.2006
27.12.2006
26.01.2007
25.02.2007
27.03.2007
26.04.2007
26.05.2007
25.06.2007
25.07.2007
24.08.2007
23.09.2007
23.10.2007
22.11.2007
22.12.2007
21.01.2008
20.02.2008
21.03.2008
20.04.2008
20.05.2008
19.06.2008
19.07.2008
18.08.2008
17.09.2008
17.10.2008
16.11.2008
16.12.2008
количество
случаев
Количество
случаев
40
119
0
70 63 43 40 33
27 27 26 26 25 23 23 21 15 14 12
7
3
2
1
225 227224 226201 211209 214218 207204 203216 208 222 219 223 210 212 220 215 206 221205 217213 228 202
источника
Код код
источника
дата заболев ания
Дата
заболевания
а
б
Variable: 21, Distribution: Gamma
Kolmogorov-Smirnov d = 0,04170, p < 0,05
Chi-Square test = 20,91088, df = 9 (adjusted) , p = 0,01305
количество наблюдений
Количество
наблюдений
250
200
150
100
50
0
0
2
4
6
8
10
12
14
16
18
20
22
24
26
28
30
32
число случаев
Число случаев
в деньв день
в
г
Рис. 1.131. Примеры различных вариантов графиков:
а – количество случаев «водных» инфекционных заболеваний (КС ВИЗ) в день
и среднесуточная температура воздуха за 2006–2008 гг. по г. Барнаул в С; б –
столбиковая диаграмма КС ВИЗ по водоисточникам; в – столбиковая диаграмма в
виде гистограммы КС ВИЗ с наложением модели гамма-распределения; г – линейный график, отражающий динамику распределения дней в 2007 и 2008 гг. по кластерам типа изображенных на рис. 1.4; д – диаграмма рассеяния пары «температура воздуха Х5 – щелочность Х4» в нормированных координатах с эмпирическим
значением парного коэффициента корреляции и наложенной кривой среднеквадратической регрессии; е, ж – столбцовая и секторная круговая диаграммы;
ж – ВИЗ в г. Барнаул; з – абстрактная z-образная ленточная диаграмма динамики;
и – абстрактная картограмма; к – объемная столбовая диаграмма (см. также с. 81)
1
Результаты НИР по проекту МНТЦ № 3796, выполненного под руководством В.В. Губарева, В.Б. Локтева коллективом исполнителей, в частности,
Альсовой О.К., Хиценко В.Е., Юн С.Г.
81
Количество заболеваний на 100 тыс. населения
3,5
x4
Заболеваемость на 100 тыс. населения
Щелочность воды, мгэкв/л
3
2,5
r45=‐0,77
2
1,5
1
x5
0,5
‐40
‐30
‐20
‐10
0
10
20
30
Среднесуточная температура воздуха, С
900
800
700
600
500
400
300
200
Другие
100
2008
год
Год
д
20
3% 3%
2009
2010
2011
A05.0
A02.8+ A02.9
A08.0
A04.9+ A04.8
е
40
60
80
100 %
11%
7%
2%
8%
11%
15%
64%
76%
Д ру гие
А05.0
А02.8+А02.9
А08.0
А04.8+А04.9
2008 год
2012
2009 год
8%
9%
1%
2011
2%
5%
9%
19%
17%
63%
66%
2010
1
2010 год
2011 год
ж
2
3
4
Заболевания
5
з
Вокзальный
Левобережный
Центральный
Речной
Октябрьский
Спальный
– от 5 до 15
– менее 2
– от 2 до 5
Распределение количества заболеваний по районам
А04.9 – бактериальная кишечная инфекция неуточненная; А05.9 –
бактериальное пищевое отравление неуточненное; А04.8 – другие уточненные бактериальные кишечные инфекции; А08.0 –
ротавирусный энтерит; А04.0 – энтеропатогенная инфекция,
вызванная Escherichia coli; А02.8 – другая уточненная сальмонеллезная инфекция; А02.9 – сальмонеллезная инфекция неуточненная; В99 – другие инфекционные болезни
и
к
– более 15
Рис. 1.13. Окончание
82
По оси абсцисс линейного графика откладываются, например, временные моменты, значения аргумента функции или другие объекты, а
на масштабной шкале по оси ординат – соответствующие им значения
показателя, функции.
Столбиковая диаграмма имеет тот же смысл, что и линейный график, только вместо соединяемых линий выстраивается вытянутый
вверх прямоугольник, соединенный (как в гистограммах) или отделенный от соседних. Чаще всего у столбиковых диаграмм, в которых ось
абсцисс размечается символами категорийных шкал, выравниваются
ширины прямоугольников и отдельно пробелы между ними. Следует
отметить, что при категорийных осях абсцисс это не является принципиальным. Столбики могут располагаться вплотную друг к другу либо
с произвольно определяемыми расстояниями между ними. Масштаб и
аналитический смысл имеет лишь высота прямоугольника. Другое дело, если ось абсцисс является количественной, как, например, в гистограмме.
В отличие от столбиковых в ленточных (или полосовых) диаграммах
оси координат меняются местами – масштабная шкала наносится на
горизонтальную ось. По своим возможностям зрительного анализа
данных и областям применимости оба варианта (столбиковые и ленточные) равноценны. Иногда те и другие диаграммы строятся как
направленные, которые отличаются двухсторонним расположением
столбиков или полос относительно начала отсчета в середине масштабной оси (шкалы). Как правило, области применения таких диаграмм связаны со сравнением показателей и с характеристикой состава
(структуры) совокупности объектов (данных, показателей).
Если столбиковые (ленточные) диаграммы используются в качестве сравнения, то они называются диаграммами сравнения. Назначение диаграмм сравнения – сопоставление нескольких показателей
между собой.
В отличие от диаграмм сравнения назначение структурных диаграмм – наглядная иллюстрация структуры какого-либо объекта (явления, данных и т. п.), выделение и характеристика его составных частей,
их удельных весов в целом, выявление, а также отображение структурных сдвигов, динамики изменения структуры, применение последовательного по времени набора диаграмм. В качестве структурных используются, как уже упоминалось, столбиковые или полосовые, а
также круговые секторные диаграммы. Следует, однако, заметить, что
секторные диаграммы имеют хорошую наглядность и выразительность
лишь при небольшом числе частей объекта (совокупности).
83
Для зрительного анализа динамики развития объекта во времени
строятся диаграммы динамики. Ими могут быть различные из перечисленных выше диаграмм: линейные, столбиковые, ленточные, круговые, радиальные и др. Их выбор определяется целью исследования и
особенностью деталей. Зачастую на линейных диаграммах динамики
используют следующие приемы: наносят на один график несколько
кривых, изображают несколько графиков вдоль еще одной или двух
координат, если результирующий показатель зависит от нескольких
аргументов или от аргумента (аргументов в многомерном изображении) и параметров показателя; используется возможность при нанесении на один график двух кривых одновременно изображать динамику
третьего показателя (например, изображается величина прироста или
убыли предлагаемой к продаже продукции между кривыми объема
выпуска и продажи ее); использование разных масштабных шкал (слева и справа, см. далее рис. 1.16), чтобы сравнить динамику двух показателей, имеющих разные единицы измерения. Примеры различных
видов графиков представлены на рис. 1.13.
Отметим два преимущества диаграмм перед другими типами графиков: первое – они позволяют быстрее произвести логический вывод
из большого количества исходных данных; второе – легко провести
проверку качества данных, выявить выбросы в них (см. далее разведочный анализ данных, гл. 4).
Одним из проблемных вопросов рассматриваемых графиков
(и диаграмм в частности) является ограниченность их восприятия и
раскрытия возможностей человека, если необходимо отражать большое число признаков.
Например, известно, что нетренированный человек может активно
воспринимать только небольшие фрагменты двух- или трехмерных
численных таблиц. Тем более, когда одновременно надо соотносить их
с указанными в таблице диапазонами возможных или граничных значений (это имеет место, например, в таблицах с итогами анализа крови
по многим показателям или в динамике (например, при помесячном
представлении итогов анализа в столбцах таблицы и диаграммах
(см. табл. 1.8). В этих ситуациях могут помочь радиальные (лепестковые) (рис. 1.14, а, б) или развернутые по показателям (рис. 1.14, в) диаграммы.
Используя вспомогательные элементы в виде штриховок, затемнений, расцветок, можно внутри и снаружи кольца «норма», изображенного на рис. 1.14, изобразить дополнительные кольца риска. Например,
84
кольцо «норма» раскрасить зеленым цветом, близкие к нему внутреннее и наружное кольца – желтым (предупредительное кольцо значений), а следующее кольцо – красным (опасно), либо изобразить зеленое кольцо «норма» и светло-желтые (внутреннее и внешнее кольца)
предупредительные, темно-желтые – слабо опасные, далее красные –
опасные; малиновые (сильно опасные) и лиловые (смертельно опасные). Либо передавать степень опасности плавным изменением цвета
без явного выделения границ колец.
Т а б л и ц а 1.8
Результаты общего анализа крови
Фамилия И.О. _____________ Дата рождения _______
№
п/п
1
2
3
4
5
6
7
8
9
10
11
12
Показатель
Эритроциты,
RBC
Гемоглобин,
HGB
Тромбоциты,
HTC
Лейкоциты,
WBC
Базофилы, BASO
Лимфоциты,
LYMPH
Моноциты,
MONO
СОЭ, ASR
Нейрофилы,
NEVT
Гематокриты
IG
МСНС (ср. концентрация гемоглобина)
Единица
измерения
Норма
1012 кл/л
4–5,5
4,5
ед. Сали г/л
120–165/
(132–173)
159
9
10 /л
180–400
109/л
4,0–9,0
Д1
Пол ______
Дата анализа
Д2
Д3
Д4
Д5
5,35
5,25
5,22
4,97
159
154
166
172
147
135
142
157
182
4,85
4,63
4,83
7,23
5,7
%
0,0–1,0
0,2
0,0
0,2
0,1
0,2
%
20–40
34,0
37,1
42,9
28,1
44,3
%
4,0–11,0
11,1
6,5
10,6
9,0
8,19
мм/ч
2,0–10,0
5
5
3
6
4
%
37–72
52,6
54,0
44,6
60,9
50,4
%
%
30–50
0,0–0,5
52,5
0,2
50,6
0,2
49,8
0,2
51,9
0,3
43,2
0,2
g/L (г/л)
330–370
(300–380)
314
306
310
313
330
Поскольку показатели, изображаемые на подобных графиках, являются связанными в одно или двухсторонних направлениях, степень
опасности отклонения от «нормы» может быть относительной. Она
может зависеть не только от значения рассматриваемого показателя,
но и от удаленности от нормы вверх и вниз других показателей.
Например, на концентрацию гемоглобина в крови влияет число эритроцитов (красных кровяных телец) как в среднем, так и для конкретно85
го индивида (пациента). Это можно отразить на графике конкретного
пациента изменением границ колец или соответствующей расцветкой.
В компьютерном варианте все это можно продемонстрировать врачу
или пациенту в динамике, чтобы активизировать использование регулирующей информационной обратной связи врачом или пациентом.
Тогда пациент, если для него это допустимо, может активнее участвовать в исправлении патологической ситуации, изменяя образ жизни,
структуру питания или принимаемых лекарств. Для отражения наличия и степени линейной и нелинейной парной и множественной связи
можно радиальную диаграмму сопроводить сетью, типа изображенной
на рис. 1.15, представлять ситуацию когнитивной моделью (см.
разд. 1.7.8).
12
МСНС
11
1
Эритроциты
IG
370
0,5
10
Гематокриты
52,5
330
52,6
СОЭ
2
Гемоглобин
159
165
4
120
0 314
30
37
147 180
4 4,85
2
0
6,0 4
20 0,2
10
8
4,5
0,2
50
72
9
Нейтрофилы
5,5
11,1
34
11,0
40
Лимфоциты
3
Тромбоциты
9,0
Лейкоциты
4
1,0
Моноциты
7
400
Базофилы
5
6
а
Рис. 1.14. Радиальные (сетчатые, паутинные, лепестковые)
(а, б) и развернутые по показателям диаграммы результатов общего анализа крови:
а – в обозначениях показателей согласно табл. 1.8; б – в единицах (в процентах), отнесенных к верхнему значению нормы;
в – в динамике (см. также с. 86)
86
12
11
100
100
10
89,2
105
Гематокриты
9
Нейтрофилы
60
73,1 51,4
100
72,7
40
36,8
44,4
45
100
3
Тромбоциты
50
100
85
100
7
100
96,4
53,9
100,9
СОЭ
2
Гемоглобин
81,8 100
84,9
72,7
36,4
50
100
8
1
Эритроциты
МСНС
IG
100
Лимфоциты
Моноциты
Лейкоциты
4
Базофилы
5
6
б
в
1
Рис. 1.14 . Окончание
1
Рис. 1.14 получен совместно с аспирантом Е.Ю. Городовым
87
–0,45/–0,53
–0,16/–0,16//–0,16
Влажность
воздуха Х6
–0,27/–0,34
0,12/0,07//0,29
Мутность
воды Х2
–0,07/–0,12//0
0,3/0,66
-0,05/-0,03//0,17
Число заболеваний Х1
–0,57/–0,73
–0,26/–0,20//0,46
–0,48/–0,5 0,45/0,7
Температура
воды Х3
–0,81/–0,77
Температура
воздуха Х5
0,41/0,42
Щелочность
воды Х4
Рис. 1.15. Смешанный граф-сеть показателей, указанных на рис. 1.14, отражающих состояние системы «Окружающая среда – водные инфекции»
На рис. 1.15 веса ребер (дуг) равны эмпирическим значениям ̂
парных коэффициентов корреляции Пирсона ij /парных коэффициентов корреляции Спирмена – оценок коэффициентов конкорреляции ij //
частных коэффициентов корреляции между числом заболеваний X1 и
показателями среды X i , i 2, n , 1,i(2,...,6) (см. часть 1, разд. 4.3.5).
Например, в 2007 г. ̂1,4 , ̂1,4 и 1,4(2,3,5,6) равны 0/0//0,21,
ˆ 2,6 0,38 , ˆ 2,4 0,91 . В качестве исходных использовались среднесуточные значения показателей. Единицы измерений показателей
X1 ,..., X 6 (рис. 1.15) можно опустить, так как веса ребер (дуг) представляют собой безразмерные величины.
На сети, рис. 1.15, ребра и их веса сознательно изображены поразному: как совокупность ребер, каждому из которых соответствует
свой вес в виде эмпирического значения традиционного коэффициента
корреляции ij между показателями X i , X j , коэффициента конкорреляции
ij
и частного коэффициента корреляции
88
i, j(1,...,6)
1960
1965
1970
1975
1980
1985
3,35
3,71
4,09
4,45
4,85
2010
1955
3,04
31.10.11
1950
2,78
7,0
1940
2,56
2009
1930
2,3
6,8
1920
2,02
2005
1910
1,81
6,76
1900
1,75
2000
1850
1,65
6,45
1800
1,1
1995
1750
0,9
6,07
1650
0,74
1990
1600
0,55
5,68
1500
0,48
7,5
7
6,5
6
5,5
5
4,5
4
3,5
3
2,5
2
7,0
6,5
6,0
5,5
5,0
4,5
4,0
3,5
3,0
2,5
2,0
1,5
1,0
0,5
5,28
1400
0,45
1200
0,38
0,35
7 млрд человек стало
30 октября 2011 г.
1955
1960
1965
1970
1975
1980
1985
1990
1995
2000
2005
2010
1940
1945
1950
1,5
1900
1905
1910
1915
1920
1925
1930
1935
0
1000
0,3
Год
0,1…0,28
Количество человек (млрд)
Человек (млрд)
(см. часть 1, разд. 4.3.5). Читатель сам может построить таблицу (или
таблицы), соответствующую рис. 5.15, и выяснить, какое представление – графическое или табличное – удобнее для анализа наличия, вида,
направления и степени связи рассматриваемых показателей (см.
разд. 4.3.5). Попутно заметим, что поскольку коэффициенты корреляции не содержат сведений о направлении связи (для них связь X i с
X j и X j с X i информационно равнозначна), на рис. 1.15 некоторые
ребра заменены дугами. Исходя из физики процесса читатель сам может некоторые ребра заменить дугами, отображающими причинноследственные связи, или двунаправленными дугами, характеризующими взаимосвязи.
В заключение приведем еще один прием, используемый на графиках, – выделение крупным планом («просмотр под лупой») отдельных
участков графика для более детального представления их (рис. 1.16 [1]).
годы
Р.х. 1
2
3
4
5
6
7
8
9 10 11 12 13 14 15 16 17 18 19 20 21
век н.э.
Рис. 1.16. График роста численности населения планеты Земля
(усредненные из разных источников данные)
89
Графическое представление данных и результатов позволяет не
только быстрее и системнее воспринимать информацию, но и с помощью аналитических или графических построений, используя идею
наложения на один график других графиков и/или вспомогательных
символов, наглядно визуально проверять справедливость некоторых
гипотез, утверждений. Эти приемы позволяют, например, выявить вид
зависимости (детерминированная, стохастическая; линейная, нелинейная) между двумя случайными величинами (см. часть 1, рис. 4.4–4.6;
часть 2, рис. 1.13) или справедливость закона Мура в разной формулировке ([1], рис. 1.17).
Разнообразие примеров графиков, правил их построения и форматирования можно найти самостоятельно через какой-либо поисковик,
например, с помощью Google по запросу «диаграммы в Excel».
Количество транзисторов на кристалле
109
41,42
10
10
19
1
7
Удвоение через 1 год
6
8
6
105
9
1 1
1
7
15
14
20
18
17 21
Удвоение через 2 года
5
104
103
22 23 26 28 29
Удвоение через 1,5 года
108
4
2
3
102
1
10
1965 1970
Годы
1975
1980
1985
1990
1995
2000
2005
2010
2015
Рис. 1.17. Иллюстрация закона Мура: точки отражают достигнутые
максимальные значения в соответствующем году конкретным
суперкомпьютером, указанным номером из таблицы в [1]
ЗАКЛЮЧЕНИЕ
В главе рассмотрены элементарные основы построения куализных
моделей на примере решения задач разнообразия объектов, их элементов и структур, а также модельной визуализации данных и результатов
90
их исследования. В частности, рассмотрены базовые элементы теории
и практики распознавания образов, классификации и кластеризации;
графов, сетей, автоматов; построения различных графических образов
промежуточных в технологическом процессе исследования результатов,
ориентированных на подключение в дальнейшем человека для улучшения их восприятия, осмысления, обсуждения, выявления закономерностей, принятия решений и выполнения других действий с ними согласно
цели исследования. В настоящей главе еще раз обращено внимание на
необходимость и продемонстрирована важность введения и понимания
терминов, используемых разными исследователями. Подчеркнута значимость абстрагирования как обязательного явно или неявно присутствующего этапа моделирования объектов и в силу этого отличия модельного представления объекта от его реального воплощения, а также
возможности и зачастую целесообразности применения разного модельного описания объекта для достижения одной и той же цели, при решении одной и той же теоретической или прикладной, исследовательской
или практической задачи.
ВОПРОСЫ ДЛЯ САМОПОДГОТОВКИ
1. Назовите и поясните причины неоднозначного соответсвия между
объектом и его моделью, между термином, его определением и пониманием, а также целесообразности во многих случаях использования при
исследовании объекта разных его моделей.
2. Перечислите и прокомментируйте с учетом материала первой части пособия и настоящей главы рекомендации по выбору признаков,
характеризующих объект. Как на этих рекомендациях отражаются постановка задачи исследования и другие факторы (какие)?
3. Что такое абстрагирование в теории моделирования? Каковы место и роль абстрагирования в моделировании исследуемого объекта?
Какие виды ее используются и к чему, к каким последствиям они приводят при решении теоретических и практических задач?
4. Что такое распознавание образов (РО)? Приведите основные понятия РО и формальное описание задачи РО.
5. Что такое классификация объектов? Приведите формальную постановку задачи классификации.
6. Что такое таксономия? Приведите формальное описание задачи
таксономии.
7. Что такое кластеризация? Приведите формальную постановку задачи кластеризации и примеры методов ее решения.
91
8. Что понимается под дискриминантным анализом данных (ДАД)?
Приведите формальную постановку задачи ДАД.
9. Что такое мера близости или расстояния между объектами и их
классами, мера компактности класса? Приведите примеры мер. Сможете
ли вы ответить на следующие вопросы: Какие меры – абсолютные и относительные (по отношению к чему?) следует выбирать в качестве мер
близости, расстояний, компактности? Какие меры предпочтительнее:
локальные или глобальные? Обоснуйте ваши ответы.
10. Что такое граф, орграф, мультиграф, двудольный граф, дерево,
лес? Для решения каких задач введены эти модели объектов?
11. Приведите основные понятия теории графов.
12. Перечислите и охарактеризуйте способы задания графов.
13. Что такое гиперграфы, сети, гиперсети?
14. В чем сходство и отличие транспортной сети, сетевой модели
(сетевого графика) и сетей Петри? Приведите их основные понятия и
поясняющие примеры.
15. Какие задачи решаются в теории графов и с их использованием?
16. Покажите, что граф 19 на рис. 1.5 является двудольным и его
можно представить в виде, подобном графу 14. Для удобства решения
задачи попробуйте все его вершины перенумеровать или обозначить в
виде, например, x1 , x2 ; y1 , y2 ; z1 , z2 ; v1 , v2 .
17. Можно ли пример карты дорог, изображенной на рис. 4.22 в
1-й части пособия, назвать транспортной сетью? Если нет, то что следует добавить или как изменить этот рисунок, чтобы новый рисунок отражал транспортную сеть?
18. Что такое дискретные автоматы? Приведите основные понятия
теории автоматов, разновидности автоматов.
19. Являются ли автоматы Мили и Мура эквивалентными? В чем
отличие их между собой и с клеточными автоматами? Приведите поясняющие примеры.
20. Приведите способы задания автоматов и охарактеризуйте их.
21. Какие задачи решаются в теории автоматов и с ее помощью?
22. Какой смысл вкладывается в слово сигнал в теории автоматов?
Сопоставьте его с пониманием термина сигнал в § 1.3 (1-я часть пособия).
23. Предложите представление алгоритма какой-нибудь задачи,
например, вычислительной в виде: блок-схемы, графа, сети Петри, автомата. Уместен ли здесь вопрос: «Какое представление является правильным»? Если нет, сформулируйте ваш вопрос так, чтобы он отражал
92
предпочтительность определенной формы представления алгоритма.
Имеет ли ваш вопрос однозначный ответ? Если нет, то почему? Попробуйте переформулировать его так, чтобы ответ получился однозначным.
Как все это связано с понятием модель?
24. Обоснуйте необходимость и/или целесообразность графического
представления результатов исследования объектов и Данных.
25. Что такое график? Какие разновидности графиков используются
в моделировании объектов? В чем их суть, назначение, отличие, сильные (достоинства, преимущества) и слабые (недостатки) стороны?
26. Приведите основные понятия, касающиеся графиков, и рекомендации по их построению.
27. Предложите разные варианты повышения информативности
графиков и их использования для выработки гипотез, отражения динамики, выявления или подтверждения законов и закономерностей, решения других (каких еще?) задач.
Используя рис. 1.12, изложите свой взгляд на справедливость закона
Гордона Мура в разных редакциях: удвоение количества транзисторов,
размещенных на компьютерном кристалле, через 1 год; через 1,5 года;
через 2 года?
93
Глава вторая
СИНТАКТИЧЕСКАЯ ОБРАБОТКА ДАННЫХ
§ 2.1. ВВОДНЫЕ ЗАМЕЧАНИЯ
В предыдущих главах пособия основное внимание было уделено
различным классам моделей объектов и моделированию как методу
исследования1 объектов разного типа, экспериментированию и измерениям. В настоящей главе рассматривается конкретный вид первичных
моделей объектов – данные. Именно они получаются в различных измерениях, наблюдениях и экспериментах в определенных условиях их
проведения и функционирования исследуемых объектов (см. часть 1,
рис. 1.3, 2.1, 2.3, 3.4, 3.10–3.12). Именно на основе их получения,
съема, сбора, хранения, передачи, обработки, кодирования, выполнения с ними других операций обработки, анализа, интерпретации, применения (см. часть 1, § 1.3) исследователь строит более сложные модели объекта, добывает необходимую для решения поставленной им
задачи информацию, обеспечивает получение искомого решения поисковых и прикладных научных и практических задач.
Перейдем к рассмотрению тех наиболее часто используемых операций с данными, причем, прежде всего, именно с данными, а не с
Данными (см. часть 1, § 1.3), которые относятся к классу синтактических, т. е. к их сбору и обработке в обобщенном понимании этого слова, приведенному в части 1, § 1.3. Напомним (см. часть 1, § 2.2), что
согласно термину синтактика синтактические –это такие операции с
Данными, в которых они рассматриваются как носители информации
безотносительно к их семантике, смысловому содержанию, в отличие
от семантических операций, направленных на работу с информацией,
1
Обобщенное понимание термина исследование изложено в § 1.1.
94
содержащейся в Данных (ее обнаружение, извлечение, корректировку,
преобразование и т. п.). Иными словами, в синтактических операциях
оперируют с формой, а не со смыслом, сутью Данных. При этом в процессе выполнения синтактических операций с Данными стараются не
изменять, не искажать, не терять, защитить, сохранить информацию,
содержащуюся в Данных. Зачастую именно по тому, как удалось сохранить информацию, судят о качестве самих операций и качестве их
исполнения. Показатель сохранности семантики Данных может вводиться как одно из важнейших требований, ограничений, накладываемых на синтактические операции с Данными.
Перейдем к рассмотрению некоторых из таких операций.
§ 2.2. ДИСКРЕТИЗАЦИЯ СИГНАЛОВ. ПОНЯТИЕ
О ТЕОРЕМАХ ОТСЧЕТОВ
Первой из синтактических операций с Данными рассмотрим дискретизацию сигнала по аргументу (см. часть 1, § 3.6). Например, преобразование непрерывного по аргументу сигнала (t ) в последовательность его отсчетов (ti ) , i 0, N 1 , получаемых в равностоящие
(эквидистантные) или неравностоящие моменты времени t , т. е. через
одинаковые или разные интервалы (шаги) дискретизации
ti 1 ti 1 ti (см. часть 1, рис. 3.5)1. Как и ранее вместо сигнала (t )
будем рассматривать его модель x(t ) , для которой дискретизация
означает преобразование непрерывной по t функции x(t ) в решетча-
тую x(ti ) или x(it ) , i 0, N 1 .
1
Заметим, что многое, излагаемое в настоящем параграфе, относится не
только к представлению сигналов их отсчетами, но и к дискретизации, т. е.
представлению отдельными отсчетами, различных результатов исследования
объекта и анализа данных, являющихся функциями некоторых аргументов
(законов распределения, корреляционных функций, спектральных плотностей
и т. п.). С другой стороны, сами данные могут быть непрерывными вдоль какого-то аргумента. Например, графическое, магнитное, электрическое зарегистрированное отображение сигнала, есть, согласно определениям (дефинициям) терминов, непрерывные данные об объекте – носителе сигнала.
Дискретизация позволяет преобразовывать такие непрерывные данные в дискретные. Именно о дискретных данных идет речь в данной главе. Слово дискретное при этом всюду опускается.
95
Дискретизация является необходимой операцией во всех случаях,
когда дальнейшие операции с отсчетами будут выполняться на средствах, использующих принцип дискретного действия, в частности
цифрой (см. § 3.4). Без выполнения дискретизации сигналов и квантования его (или его отсчетов) по уровню (см. часть 1, § 3.6, рис. 3.5,
также § 2.3, часть 2) невозможно осуществление многих современных
операций кодирования (см. далее), сжатия, хранения и других, разработанных под цифровые средства работы с Данными. Именно дискретизация и квантование сигналов позволяют преобразовать их в количественные данные об объекте, пригодные для их обработки на
большинстве современных средств. Изложенное поясняет, почему
именно дискретизацию и квантование по уровню мы рассматриваем в
начале настоящей главы. Заметим, что во многих бортовых и специализированных устройствах осуществляется обработка аналоговых сигналов аналоговыми средствами (см. далее § 3.3).
Первичным и наиболее важным при дискретизации сигнала (t )
является вопрос: «Как выбирать шаг дискретизации ti 1 ti 1 ti ?»,
который распадается, по крайней мере, на три вопроса: «Делать ли ti
постоянным по i, т. е. выбирать ли равномерную дискретизацию с
ti t const ?», «Если ti брать неравномерным, то как его назначать – по детерминированному или идентерминированному закону
(правилу), например, по случайному?», «Как назначать конкретные
значения ti во всех этих ситуациях?».
Ответы на эти вопросы зависят от цели (назначения) дискретизации, задаваемого критерия качества решения прикладной задачи и
ожидаемого допустимого изменения его значения от представления
(замены) сигнала (t ) последовательностью его дискретных отсчетов
(ti ) , i 0, N 1 , ti t0 t1 t2 ... ti ; модельного описания сигнала (t ) детерминированной, случайной, динамического хаоса функцией x(t ), X (t ) и ее свойств и т. д.
Рассмотрим кратко эти вопросы. В качестве первого назначения
дискретизации обсудим равноинформативную, равнозначную замену
сигнала (t ) (или функции x(t ) ) его отсчетами, т. е. такую дискретизацию, которая позволяет при необходимости восстановить исходный
аналоговый сигнал (функцию) по его (ее) отсчетам, а также без потерь
информации хранить, передавать, обрабатывать вместо сигнала его
отсчеты.
96
Понятно, что наилучшим решением было бы такое, при котором
последовательность отсчетов (ti ) , i 0, N 1 будет полностью представлять сигнал, т. е. будет равнозначна аналоговому сигналу (t ) на
том же временном интервале t t0 , t N 1 . Иными словами, такое, когда по отсчетам (ti ) можно теоретически идеально точно восстановить сигнал (t ) на нужном временном интервале, например
t0 , t N 1 , или меньшем.
Потенциальная возможность такой дискретизации следует из так
называемых теорем отсчетов. Под ними понимается совокупность теорем, устанавливающих необходимые и достаточные условия представления сигнала (математически – функций x(t ) , описывающих сигналы
(см. часть 1, § 3.6)) по его отсчетам без потери информации, содержащейся в нем, т. е. так, что сигнал может быть полностью восстановлен
по этим отсчетам для любого момента времени t.
Согласно изложенному в части 1, § 3.6, в дальнейшем вместо сигнала (t ) будем рассматривать его математическую модель x(t ) как
детерминированную функцию (по своей природе или как реализацию,
траекторию случайного процесса X (t ) ).
Первая математически точная формулировка1 теоремы отсчетов –
дискретизации и восстановления непрерывного аналогового сигнала
(t ) по его дискретным отсчетам – дана Владимиром Александровичем Котельниковым (1933 г., СССР). Это послужило мощным толчком
к развитию дискретной и цифровой обработки и передачи сигналов в
СССР.
Предположим, что аналоговый сигнал (t ) описывается функцией
x(t ) , имеющей конечно-заданный (финитный, см. часть 1, § 3.6) на
частотном интервале (m , m ) спектр X () (см. часть 1, формула
(3.9)), т. е. такой, что | X () | 0 при
(m , m ) , где m 2f m ,
f m – максимальная (верхняя f в ) линейная частота (в герцах) спектра.
1
В 1999 г. В.А. Котельников получил премию фонда Эдуарда Рейна (Германия) с формулировкой «За впервые математически точно сформулированную и опубликованную теорему отсчетов». Любопытно отметить, что
В.А. Котельников испытывал проблемы публикации этой теоремы в печати.
Его первая публикация теоремы была подписана к печати 19.11.1932 г.
97
Тогда (t ) / x(t ) / можно полностью представить его отсчетами (it )
/или x(t ) отсчетами x(it ) /, i 0, 1, 2,... , отстоящими через интервал (шаг) дискретизации t T 1 / (2 f m ) , и, следовательно, полностью (идеально) восстановить сигнал (t ) /или функцию x(t ) / по
таким его (ее) отсчетам. Это следует из теоремы отсчетов Котельникова, согласно которой при шаге дискретизации t T 1 / (2 f m )
/ m / в или при частоте дискретизации д 2 / t 2m
имеет место равенство
x(t )
x(k t )
sin m (t k T )
k
m (t k T )
.
(2.1)
Функции (рис. 2.1)
sinc k (t ) sin m (t k T ) m (t k T )
(2.2)
при k 0, 1, 2,... образуют семейство функций отсчетов
sinc t (sin t ) t , спектр которых Sinc() есть прямоугольная конечнозаданная функция
1 при | | (t ),
Sinc() Rect ()
0 при | | ( t ).
(2.3)
Как следует из (2.2), функция отсчета sinck (t ) имеет следующие
свойства:
при t k t она достигает максимального значения, равного единице;
при t (k l ) t , l 1, 2,3,... , т. е. при t кратных t , кроме
t k t , она обращается в нуль;
функции отсчетов sinc k (t ) и sinc n (t ) ортогональны на интервале времени (, ) ;
функция отсчетов представляет собой реакцию идеального
фильтра нижних частот H ( j) , частотная характеристика которого
совпадает с (2.3), на единичную импульсную входную функцию, где
c – частота среза фильтра.
98
x(t)
5
Отсчеты функции x(t)
4
3
2
1
0
t
–1
–1
0
1
2
3
4
5
6 i
Рис. 2.1. Иллюстрация восстановления функции x(t)
по ее отсчетам x(it)
Из последнего свойства функции отсчетов следует, что теоретически (идеально, потенциально) для восстановления (t ) / x(t ) / по их
отсчетам необходимо либо выполнить расчеты по (2.1) /для (t ) заменой x(t ) на (t ) /, либо подать на вход идеального фильтра нижних
частот (2.3) с верхней границей полосы пропускания (среза)
c д / 2 , где – частота дискретизации д 2m , последовательности идеально узких импульсов, равных (соответствующих в каком-то
масштабе) значениям в точках отсчета t k t и следующих друг за
другом с периодом t T . Напомним, что решетчатая функция
x(k t ) имеет спектр
X д ()
n
X ( nд )
2n
X
.
t
n
Графически изложенное изображено на рис. 2.2, 2.3.
99
(2.4)
sinct
1
Sinc()
1
–2t
–t
0
t
2t
t
–/t
а
б
Rect()
Xд()
Xд()
–д
/t
0
–д/2
д/2
0
д
в
Рис. 2.2. Иллюстрация |Xд()| и фильтра нижних частот Sinc()
при д > 2m
Rect()
|H()|
Xд()
–д
–д/2
0
д/2
д
Рис. 2.3. Иллюстрация частотного представления при д < 2m
и реальной частотной характеристике H() фильтра нижних частот
Сделаем несколько замечаний по изложенному.
1. В силу симметричной обратимости прямого и обратного преобразований Фурье (см. часть 1, формулы (3.9)–(3.11)) вместо x(t ) , заданного на интервале [0, T], теорему отсчетов можно применить для
100
X () . Для этого в (2.1) необходимо произвести следующие замены: t
на ; t на 2 T ; ширину спектра 2m на длительность Т сигнала x(t ) , а функцию отсчетов sinc n (t ) на Sinc k ()
T
2k
T
sin ( k ) sin
T
2
2
.
Sinc k ()
T
2k
T ( k ) 2
T
2
(2.5)
Такое представление делает функцию x(t ) периодически повторяющейся (аналогично (2.4)) с периодом T вдоль оси t или, иначе, к склеиванию графика сигнала (t ) , заданного на [0,T], в кольцо с возможностью прокрутки кольца сколь угодно раз. Эта периодичность, так же
как и периодичность спектра по (2.4), является следствием периодичности экспоненциально-косинусного тригонометрического базиса
преобразования Фурье. Действительно, поскольку exp{ jt}
cos(t ) j sin(t ) , заменим на nд , где [m , m ] ,
n 0, 1, 2, 3,... . Тогда при t k t и t 2 / д cos(k t ), приведенных в части 1 формулах (3.11), (3.10а) переходит в
cos nд k t cos(k t 2kn) cos(k t ) . Аналогично для
sin(t ) , а также при переходе к частотной области при 2 / T . Из
изложенного следует, что дискретный (решетчатый) сигнал имеет периодический спектр, а периодический сигнал имеет дискретный (решетчатый) спектр.
Возможность представлять x(t ) и X () их отсчетами и периодизация X д () и xд (t ) при переходе от непрерывных по аргументу
функций в решетчатые послужили основой дискретных преобразований Фурье (ДПФ), а также их разновидностей (финитных и конечных
дискретных преобразований) и конкретных реализаций – дискретных
быстрых преобразований Фурье (БПФ) (см., например, [18]).
2. Теорема, обратная по отношению к теореме отсчетов, несправедлива, поскольку из представления функции x(t ) рядом (2.1) вовсе
не следует, что она должна иметь преобразование Фурье, т. е. что для
нее будет существовать X () . Это значит, что конечная заданность
(финитность) X () является лишь достаточным условием справед101
ливости теоремы отсчетов. Необходимые условия сводятся к существованию для x(t ) преобразования Фурье, в частности, непрерывность функции x(t ) , удовлетворение ею условиям Дирихле (ограниченность, кусочная непрерывность и конечное число экстремумов),
конечность энергии и т. п.
3. Историю, связанную с появлением и развитием теоремы отсчетов, можно найти в [1] и более подробно в трудах института инженеров по электротехнике и радиоэлектронике (ТИИЭР), 1977, т. 65. –
№ 11. – С. 53–89, а также в журнале Радиотехника и электроника, 2008,
т. 53. – № 9. – С. 1158–1168. Она уходит своими истоками к работе
Э. Бореля (1897 г.), Э.Т. Уиттекера (1915 г.). Позже (1953–1976 и последующие годы) теорема была обобщена на случайные процессы, на
сигналы с полосовым и неограниченным спектром, комплексные и
другие функции и их производные, а также на неравноотстоящие отсчеты, в частности, случайную дискретизацию, и преобразования более общие, чем Фурье.
Для россиян это весьма важно, так как очень часто в зарубежной
литературе теорема отсчетов называется теоремой Шеннона либо Найквиста–Шеннона и реже Котельникова–Шеннона. Дело в том, что до
Г. Найквиста теоремы подобного рода рассматривались чистыми математиками при решении задач интерполяции функций. Найквист Г.
без каких-либо математических доказательств эвристически предложил в теории телеграфных систем частоту следования элементарных
посылок fп 1 (tп ) устанавливать из условия f п 2 f m , в то время
как В.А. Котельников именно в теории сигналов математически доказал необходимость выбирать частоту дискретизации f д (1 / t ) 2 f m
(см. рис. 2.2). Шеннон К.Э. несколько по-другому доказал (с приоритетом от 23.07.1940 г.) соотношение (2.1) в статье, которая была опубликована только в 1949 г. В этот же год независимо была опубликована
близкая по сути формулировка теоремы отсчетов И. Сомэя (Япония).
Шеннон К.Э. одним из первых распространил теорему отсчетов на стационарные случайные процессы. В связи с изложенным, следует согласиться со многими авторами называть ряд (2.1) рядом Э.Т. Уиттекера,
максимально возможный интервал дискретизации tmax 1 / 2 f m – интервалом Найквиста (по предложению, кстати, К.Э. Шеннона), а
теорему отсчетов – теоремой Котельникова или теоремой Котельникова (с приоритетом от 19.11.1932 г.) – Шеннона (с приоритетом от
23.07.1940 г.). Любопытно в связи с этим заметить, что, по-видимому,
102
первое реальное применение теоремы отсчетов принадлежит французу
А.Х. Ривзу, предложившему вместо передачи речи по проводам в непрерывной аналоговой форме осуществлять выборку речевых сигналов
в определенные интервалы времени, полученные отсчеты преобразовать в двоичную форму и уже последовательность нулей и единиц передавать по линиям связи (патент Франции № 852, 185 от 1938 г., патент США № 2, 272, 070 от 3.02.1942 г.) [1].
4. Как уже было отмечено, теорема отсчетов указывает на потенциальную возможность представить функцию x(t ) ее равноотстоящими
отсчетами с шагом t 1 / (2 f m ) без потери информации о ней, а также восстановить ее в любой точке t по отсчетам, если t 1 / (2 f m ) ,
т. е. f д 2 f m или д 2m . Это хорошо иллюстрируют рис. 2.2 и 2.3.
Чем больше значение f д значения 2 f m , тем дальше отстают друг от
друга лепестки спектра X д () , и, следовательно, с помощью идеального фильтра нижних частот Rect() можно из него выделить основной лепесток X () для (m , m ) . Другое дело, если f д 2 f m
(см. рис. 2.3). В этом случае происходит пересечение лепестков спектра и уже никакой фильтр не поможет идеально выделить нулевой лепесток.
5. На практике эту потенциальную возможность реализовать невозможно в силу следующих обстоятельств (рассмотрим отдельно
временное () представление сигнала и частотное ( ) ).
Любой реальный сигнал (t ) (а следовательно, и идеально описывающая его функция x(t ) ) ограничен во времени, так как существует только при t [t1 , t2 ] , где t1 , t2 . Например, при t [0, T ]
это автоматически, согласно свойствам преобразования Фурье и соотношению (3.6), приведенному в части 1, означает, что он должен иметь
неограниченный по частоте (нефинитный) спектр () / X () /. Поэтому для него лишь приближенно можно указать f m , соглашаясь на
приближенность представления сигнала (t ) / x(t ) / его отсчетами с
t 1 / 2 f m и восстановления его по таким отсчетам.
Реальное число слагаемых в (2.1) может быть только конечным,
какой бы ЭВМ мы для этого не воспользовались. Следовательно,
отбрасывание неучтенных слагаемых не позволит получить точное
воспроизведение (t ) / x(t ) / по его отсчетам.
103
Функции отсчетов sinc t бесконечно протяженные. В расчетах
мы должны отбрасывать ее концы и, следовательно, не учитывать соответствующие слагаемые в (2.1).
Чтобы точно найти (t ) /или x(t ) / в любой точке t, необходимо,
согласно (2.1), иметь как прошлые, так и будущие, еще реально не
наступившие значения (k t ) , k (, ) . А это невозможно в реальном времени либо потребует бесконечного запаздывания при восстановлении сигнала, что также невозможно.
В силу неограниченности по частоте X () для реальных сигналов может иметь место значительное перекрытие лепестков в спектре
X д () (см. рис. 2.2 и 2.3) даже при д 2m . Хвосты соседних с основным лепестком спектра периодических лепестков будут просачиваться в полосу (m , m ) основного лепестка, вызывая тем самым
высокочастотные флуктуации на медленно меняющихся траекториях
восстановленного сигнала xˆ(t ) по сравнению с x(t ) .
Идеальный фильтр Rect() реализовать невозможно. Дело в
том, что время реакции фильтра возрастает с увеличением крутизны
среза на граничной частоте. Крутизна же среза идеального фильтра
бесконечно велика и поэтому такой фильтр должен обладать бесконечно большим запаздыванием реакции. Это равносильно тому, что
для получения x(t ) по (2.1) надо иметь все отсчеты x(t ) для всех
k (, ) . Реальный же фильтр (см. рис. 2.3) будет иметь отличное
от единицы значение частотной характеристики в полосе своего пропускания и конечную крутизну спада за пределами полосы. Тем самым
при восстановлении сигнала (t ) по отсчетам (t ) будут снижаться
доли некоторых низких и высоких частотных составляющих (флюктуаций) (t ) и просачиваться быстрые от соседних лепестков: появятся
где-то сглаживания быстрых участков (t ) и «дребезжание» на поло
гих участках в (t ) .
В связи с этим в задачах представления сигнала (t ) его равноотстоящими отсчетами при необходимости в дальнейшем приближенного восстановления (t ) по отсчетам шаг дискретизации t выбирают,
задаваясь критерием качества соответствия восстановленного сигнала
104
(t ) исходному (t ) (см. далее). Например, по среднему квадрату от
личия (t ) от (t ) вдоль всех t.
Следует учитывать еще три важных обстоятельства. Первое связано с тем, что сигналы с ограниченным (финитным) спектром допускают линейное прогнозирование по прошлым их будущих значений с их
сколь угодно малым среднеквадратическим отклонениям. А это означает, что такие сигналы не пригодны в качестве носителей, передатчиков информации в смысле новых, свежих, неожиданных сведений.
Второе обстоятельство обусловлено тем, что реально отсчеты сигнала (t ) в дискретные моменты ti , i 0, N , идеально точно в реальности получить невозможно. Реальные значения будут иметь как погрешность их измерения, так и погрешность измерения (установки)
момента ti , например, при аддитивном представлении погрешностей в
(ti ) (ti ) (ti ) , где – погрешность измерения (задания,
установки) значения ti , а – погрешность измерения значения .
Третье обстоятельство заключается в том, что количество N 1 отсчетов, получаемых при равномерной дискретизации сигналов (t )
/или функций x(t ) /, рассматриваемых на участке to , t N , например,
[0, T ] , где T N t может быть избыточным при решении отдельных
прикладных задач (см. третье назначение дискретизации), например,
при измерении характеристик сигналов (t ) /оценивании характеристик x(t ) , X (t ) /.
Невзирая на то что теорема отсчетов для сигналов конечной длительности идеально неприемлема, ее практическая значимость бесспорна.
Изложенное выше является основанием для разработки таких вариантов дискретизации, когда значение t устанавливается по-другому,
является переменным для разных участков интервала [0, T ] , определяется детерминировано или случайно. Именно эти ситуации рассматриваются ниже.
Второе важное назначение дискретизации – сжатие данных, получаемых по сигналу (t ) . Здесь под сжатием данных об объекте понимается такое их преобразование к минимально возможному объему
105
(компактному виду), который обеспечивает требуемое качество приближения к полному («идеальному») представлению (описанию) объекта всеми данными. В таком понимании сжатие данных является многогранным и включает в себя как уже обсуждавшиеся вопросы
(уменьшение признакового и факторного пространств, планирование
эксперимента, селектирование коррелированных данных и/или их декорреляция и т. п.), так и те, что будут рассматриваться далее, в частности, при изучении кодирования, архивирования и т. д. Здесь мы этот
термин будем трактовать в узком смысле, а именно в приложении к
замене сигнала (t ) , заданного на [0, T ] , минимально возможным количеством его равноотстоящих или неравноотстоящих отсчетов, по
которым сигнал может быть представлен, сохранен, передан, восстановлен, предсказан , обработан, проанализирован с заданным качеством. Не вдаваясь в подробности, коснемся выбора шагов
ti ti 1 ti , i 0, N 1 при неравномерной дискретизации x(t ) , ориентированной на сжатие данных.
Ответ на вопрос об установлении значений ti для разных
i 0, N 1 зависит от назначения поставленной задачи минимизации
количества отсчетов (t0 ),..., (t N ) /или математически x(t0 ),..., x(t N ) /
для представления сигнала (t ) /или x(t ) /, полученного (наблюдаемого) на интервале [0, T ] . Это могут быть, например, следующие задачи:
приближения функцией xˆ (t ) , восстановленной по отсчетам x(ti ) на
интервале [0, T ] , функции x(t ) на том же интервале (задачи интерполяции и аппроксимации), предсказания назад (для t 0 ) или вперед
(для t T или t t1 , где t1 – граничный момент реального текущего
времени наблюдения (t ) на интервале t 0, t1 ) (задачи экстраполяции), адаптивной дискретизации, когда шаг ti ti ti 1 и момент ti
взятия очередного отсчета (t ) выбирается по мере поступления
(наблюдения) новых текущих значений (t ) так, чтобы гарантировать
требуемое качество приближения восстановленной по отсчетам кривой
(функцией) (t ) траектории (t ) при t ti , и т. д.
Напомним, что под интерполяцией (интерполированием) (от лат.
interpolare – подновлять, подделывать; interpolatio – изменение, переделка) функции x(t ) понимается восстановление функции x(t ) (точ106
ное или приближенное) в любой точке t по ее известным значениям
x(t0 ),..., x(t N ) , по значениям ее производной и/или других функций,
связанных с x(t ) . При интерполировании интерполирующая функция
xˆ (ti ) удовлетворяет равенствам xˆ (ti ) x(ti ) , i (0, N ) , т. е. интерполирующая функция обязательно проходит через значения функции
x(t ) в узлах (точках) интерполяции ti . В более общих задачах иногда
требуют совпадения в узлах интерполяции не только самой функции и
ее интерполяционного приближения, но и ее первых производных.
Аппроксимация, аппроксимирование функции x(t ) (от лат.
approximo – приближение) – приближенное выражение функции x(t )
другими, более простыми и близкими к исходным. Например, замена
кривых линий близкими к ним сплайнами, кусочно-линейными или
участками более простых в описании кривых.
Экстраполяция (экстраполирование) функций x(t ) (от лат. extra –
сверх, вне и polio – приглаживаю, выправляю, изменяю) – нахождение
по отсчетам (значениям функции) x(t0 ),..., x(t N ) , t0 ,..., ti ,..., t N [0, T ]
ее значений для t 0 или t T , т. е. продолжение функции x(t ) за
пределы ее области определения.
Из изложенного ранее ясно, что критерий качества приближения
(восстановления) x(t ) функцией xˆ(t ) должен определяться исходя из
той конечной задачи, ради решения которой получались отсчеты (ti )
/или x(ti ) /, i 0, N . Например, если по (ti ) , i 0, N , необходимо
спрогнозировать значение (t ) в точке t TN , критерий должен назначаться, ориентируясь на то, в какой прикладной задаче и как будет ис
пользоваться прогнозное значение (t ) . Если прикладная задача не
рассматривается, то критериями качества результата (t ) /или xˆ(t ) /
принимаются локальные. Это критерии минимума (максимума) меры –
расстояния (близости) xˆ(t ) и x(t ) на интервале [t0 , ..., t N ] , обычно
аналогичные тем, которые рассматривались в § 1.2. Чаще всего при
выборе t это следующие критерии(!)1.
1
Напомним, знак внимания (!) подчеркивает необходимость учитывать
некоторые ограничения на вид функции x (t ) и другие важные условия.
107
1. Критерий наибольшего m отклонения (t ) x(t ) x(t ) на интервале от ti до ti 1 (Чебышевская метрика)
m
max | (t ) |
tti , ti 1
max | x(t ) x(t ) | .
tti , ti 1
(2.6)
2. Критерий наибольшего квадрата отклонения (t ) на интервале
ti ,..., ti 1 (метрика (норма) в гильбертовом пространстве функций)
2 (t )
t
i 1
1
2 (t )dt .
ti 1 ti t
i
(2.7)
3. Вероятностный критерий
Ρ E (t ) 0 p0 при t ti , ..., ti 1 ,
(2.8)
где 0 – допустимое значение погрешности; E (t ) – случайная функция (процесс), описывающая отклонение (t ) ; p0 – допустимая (решаемой прикладной задачей) вероятность того, что погрешность приближения не превысит 0 .
Тогда рассматриваемая задача сжатия данных, а именно дискретизации (t ) с использованием его описания функцией x(t ) , т. е. выбора
интервалов дискретизации ti , i 1, N , математически может быть
сведена к задаче приближения функции x(t ) по критериям (2.6)–(2.8)
функцией x(t ) : для функции x(t ) , принадлежащей классу функций А (!),
определенных на интервале t0 , ..., t N , например, [0, T ] , найти функ
цию x(t ) из некоторого выбранного класса В или набора классов С и
функцию x(t ) в нем, для которого (класса В или С функций) и которой
(функции x(t ) в В или С) число ( N 1) точек разбиения ti , i 0, N ,
будет минимальным при заданном локальном или глобальном критерии. В качестве глобальных можно выбрать критерии типа (2.6)–(2.8),
108
отличающиеся тем, что в них интервал рассмотрения [ti , ..., ti 1 ] заменяется на весь интервал [t0 , ..., t N ] .
В качестве классов В, С функций обычно рассматривают полиномы, функции, разложимые по различным ортогональным (Лагерра,
Лежандра, Чебышева, Эрмита, Хаара, Виленкина-Крестенсона, Уолша
и т. д. (см., например, [12, 18, 19])) и неортогональным базисам.
Пусть, например, функция x(t ) строится на базе ее представления
обобщенным полиномом, т. е. в виде
x(t ) n (t )
n
k k (t ) , t t , t ,
(2.9)
k 0
на интервале [t , t ] , ,t t , t0 t , t t N , где k – искомые числа,
k (t ) – некоторые заданные функции. Тогда задача нахождения полинома n (t ) , т. е. его класса В, С, его чисел k и функций k (t ) при
условии, что m (6.6) примет минимально возможное значение, имеет
единственное решение, называемое функцией наилучшего приближения. Если k (t ) заданы, то минимальный набор t0 ,..., tn (t , t ) и
обеспечивающих наилучшее приближение по нему значений k при
допустимом m 0 определяется так, чтобы на интервале (t , t ) мак
симальное отклонение (t ) x(t ) x(t ) n (t ) x(t ) достигалось не
менее (n 2) раз таким образом, что между двумя максимумами (t ) ,
равными 0 , всегда был хотя бы один минимум, равный 0 , а между двумя минимумами 0 всегда был хотя бы один максимум 0 .
Набор (n 2) точек 0 ,..., i ,..., n 1 , в которых (t ) 0 , поочередно
меняя знак, образует так называемый Чебышевский альтернанс.
В случае отсутствия наилучшего приближения число точек, в которых | (t ) | 0 с последовательным чередованием знаков будет меньше, чем (n 2) . Число называется показателем качества Чебышевского приближения. Ясно, что при ступенчатом приближении (т. е. при
109
n 0 ) может принимать только два значения 1 или 2, при кусочнолинейчатом ( n 1 ) – 1, 2 или 3, при квадратичном ( n 2 ) – 1, 2, 3
или 4 и т. д. Такая дискретизация при максимальном обеспечит максимальное сжатие данных на локальном участке [ti , ti 1 ] за счет максимальной длительности ширины интервала ti 1 ti 1 ti , на котором
(t ) достигало (n 2) экстремальных значений с поочередно меняющимися знаками. Однако минимальное количество неравноотстоящих
отсчетов x(t ) / и, следовательно, (t ) / при заданном качестве приближенного восстановления функции x(t ) заменой ее на построенную та
ким образом x(t ) может привести к тому, что функция x(t ) будет
иметь разрывы первого рода величиной до 20 в точках отсчета
ti , ti 1 . Чтобы минимизировать количество точек отсчета при неравно
мерной дискретизации и обеспечить неразрывность x(t ) , т. е. безразрывную стыковку ее локальных частей, можно использовать разные
степени приближения на каждом локальном участке функции x(t ) .
Особенно это удобно делать в графической форме (рис. 2.4).
Понятно, что при равномерной дискретизации, т. е. при ti t
const , следует t выбирать по наиболее динамично изменчивому
участку, т. е. задавать такое максимальное значение t из N одинаковых укладываемых на [t0 , ..., t N ] , при котором | (t ) | 0 . При известной величине максимального значения модуля 2-й производной x(t )
d 2 max | x (2) (t ) | на [0, T ] и линейной интерполяции можно t выt
бирать, ориентируясь на неравенство [19]
t 80 d 2 .
(2.10)
Рекомендации по выбору значений t в других ситуациях можно
найти в специальной литературе, в которой эти вопросы рассматриваются подробнее (см., например, [19]).
Третье назначение – дискретизация с целью дискретной, в частности
цифровой, обработки отсчетов сигнала (или данных, полученных по
нему), ориентированной на минимизацию количества обрабатываемых
110
x(t)
x(t)
а
x (t )
+
–
t0
t1
t2
x(t)
x(t)
t
t3
б
x (t )
+
–
t0
t1
t
t3
t2
в
x(t)
x (t )
x(t)
+
–
t0
t1
t2
t3
г
x(t)
x(t)
t
t4
x (t )
+
–
t0
t1
t2
t3
t4
t5
t6
t7
t8
t9
t10
t11
t
Рис. 2.4. Иллюстрация методов адаптивной дискретизации:
а – равномерная дискретизация x(t) при ее аппроксимации разрывной кусочнолинейной функцией x(t ) ; б – неравномерная дискретизация x(t) при ее аппрок-
симации ломаной линейной функцией x (t ) ; в – неравномерная дискретизация
x(t) при ее ломаной линейной интерполяции функцией x(t ) ; г – равномерная
дискретизация x(t) при ломаной линейной интерполяции функцией x(t )
111
отсчетов без потери или с приемлемым уровнем потери качества результатов обработки по сравнению с тем качеством, которое может
быть получено по непрерывному сигналу. Рассмотрим этот вариант
дискретизации на примере оценок характеристик стационарных случайных сигналов.
Предположим, что по сигналу (t ) , описываемому стационарным
эргодическим1 по отношению к исследуемой характеристике Q() (см.
разделы 4.3.6, 4.3.7 и таблицу приложения 3 в части 1) процессом
X (t ) , необходимо измерить /или по эквивалентной (t ) траектории
x(t ) этого процесса X (t ) оценить/ эту его характеристику, т. е. измерить Q () или оценить Q X () .
Предположим, что измерения отсчетов (t ) проводятся идеально и
их значения принимаются в качестве значений x(t ) траектории процесса X (t ) . Тогда операцию косвенного измерения Q () можно свести к выполнению только вычислительных операций оценивания
Q X () по траектории x(t ) [18]. Рассмотрим именно этот случай. Допустим, что оценивание выполняется на дискретных вычислительных
средствах по дискретным эквидистантным (равноотстоящим) отсчетам x(0), x(t ), ..., x ( N 1)t . Возникают вопросы: «Как выбирать
значение t , чтобы дискретная оценка Q̂ X () , полученная по дискретному набору отсчетов, была приемлемым заменителем аналогич
ной ей по виду непрерывной оценки Q X () , при нахождении которой
используется вся имеющаяся траектория x(t ) , и при этом количество
отсчетов было по возможности минимальным?»; «Как выбрать t ,
чтобы при фиксированном числе N отсчетов x(t ) оценка Q̂() за счет
коррелированности отсчетов при малом t отличалась от оценки
Q() , найденной по некоррелированной выборке отсчетов того же
1
Эргодическим по отношению к характеристике Q() называется такой
процесс, тракторные характеристики которого Q() (см. часть 1, формула
(4.120)) сходятся (в среднем квадратическом, по вероятности, почти наверное)
к ансамблевым Q() .
112
объема N, не более чем на заданное значение показателя качества
оценки, а длина траектории T N t была при этом минимальной»?
Ясно, что для этого надо задаться показателем отличия Q̂ от Q и
Q() при разных или вдоль всех и критерием приемлемости такого отличия при решении прикладной задачи.
Желающие могут познакомиться с ответами на эти вопросы по монографиям [18, 20]. Приведем в качестве примера только рис. 2.5, построенный по материалам [18].
На рис. 2.5 приняты следующие обозначения1: T – отношение
дисперсии дискретной траекторной оценки Q̂ N () к дисперсии непрерывной оценки Q̂T () (см. часть 1, формулы (4.119), (4.120)); N –
отношение дисперсии дискретной оценки Q̂ N () при конкретном шаге дискретизации t траектории по сравнению с оценкой Q̂ nk () ,
найденной
в
предположении,
что
отсчеты
gQ X(it );
и
gQ X(k t ); некоррелированы при k i (см. часть 1, формулы
(4.125), (4.126)); gQ X(t ); – преобразование, определяемое видом
Q() (см. часть 1, разд. 4.3.7 и приложение 3 в 1-й части пособия);
0G – радиус корреляции (см. часть 1, формула (3.5а)) нормированной
автокорреляционной функции G (; ) процесса G (; ) gQ X(t ); ;
i () ,
i 1,5 , конкретные разновидности
1 ( ) exp | | ,
2 ( ) exp 2 2 ,
G (; ) , а именно:
3 () exp | | cos() ,
4 () exp 2 2 cos() , 5 () sin() () , 0 . На рис. 2.5
рассмотрены два случая изменения t : когда фиксирована длина траектории T N t const , и, следовательно, N var меняется при изменении t (рис. 2.5, а) и, наоборот, когда N const фиксировано, а
при изменении t меняется T N t var .
1
Предполагается, что все используемые характеристики существуют и
конечны.
113
N
T const ,
N var
5
13
1,2
3
1 2
4
2
9
7
5
15
3
0
1
2
3
4 Δt ~0 G
1
0
1, 2
3, 4, 5
0,01
1,0
а
1,0
Δt
2~0G
1,3
0,7
1,4
1,1
2~0G
Δt
11
0,2
0,3
0,5
Δt
1 ~
2 0G
1,5
N = const,
T = var
15
0,03
0,05
0,07
1,7
1,6
0,02
T
Δt ~0G
б
Рис. 2.5. Зависимость значений коэффициентов T и N изменения
среднего квадратичного отклонения дискретных траекторных ЭХ-оценок
Q̂ N () (типа (4.120, часть 1)) характеристики Q() от шага дискретизации Δt
Как следует из рис. 2.5, при T const разумно шаг t выбирать,
ориентируясь на OG (или интервал корреляции G , 0 ). Тогда он
может быть существенно большим, чем по теореме отсчетов, при приемлемом увеличении T по сравнению с минимальным, равным единице, т. е. когда дискретная оценка Q̂ N () заменяется на непрерывную Q̂T () . Тем самым можно существенно сократить требования к
быстродействию средств оценивания и уменьшить объем вычислений.
В то же время, если N const , например, когда имеет место ограничение на объем памяти процессора, t следует уменьшать до определенного предела, поскольку при малых t на дисперсию дискретных оценок начинает сильно оказывать влияние корреляция между отсчетами
gQ x (it ); и gQ x (k t ); при k i . Рекомендации по разумному
выбору t смотри в [18, 20]. Любопытно отметить, что для знакопеременных корреляционных функций G (; ) можно найти такие
114
значения t (см. рис. 2.5, б), при которых дисперсия DQ̂ N () будет
меньше, чем DQ̂ HK () . Однако получаемый при этом выигрыш по
статистическим погрешностям незначителен и связан с поиском оптимальных t в условиях априорной неопределенности о виде G (; ) .
В связи с изложенным с учетом результатов работ [18, 20] и аналогичных им для разных характеристик Q() отметим следующее.
Первое. При измерении (оценивании) разных характеристик сигнала шаг дискретизации t при фиксированной длине Т сигнала (t )
можно назначать значительно большим по сравнению с тем, который
определяется согласно рекомендациям, приведенным ранее, а именно
по теореме отсчетов или при равномерной либо неравномерной дискретизации с последующим восстановлением сигнала с помощью базисных функций, отличных от базиса функций отсчетов. Это равносильно существенному уменьшению числа N отсчетов, по которым
можно измерить (оценить) характеристики сигнала без существенного
увеличения статистических погрешностей результатов измерения
(оценивания) по сравнению с количеством отсчетов, которое необходимо для репрезентативного представления сигнала его отсчетами и
подробного восстановления сигнала по ним.
Второе. Уменьшение t или увеличение частоты дискретизации,
желательное при представлении сигнала его отсчетами и восстановлении его по ним, рекомендуемое согласно теоремам отсчетов, может
оказаться практически бесполезным (мало эффективным) и даже вредным, когда N фиксировано, при измерении характеристик сигнала с
точки зрения метрологических показателей качества результатов измерения, и очень нежелательным по другим, например техническим
(объем памяти, быстродействие, производительность и др.), показателям используемых при этом средств измерения (оценивания).
Наконец, возвращаясь к исходным вопросам, приведенным в начале настоящего параграфа, отметим, что в ряде случаев, в частности для
устранения погрешности «синхронности», обусловленной периодичностью дискретизации периодических сигналов (см. [18]), желательно
значение t выбирать не детерминировано, а рандомизовано по случайному закону. В [18], например, показано, что применение соответствующей рандомизации шага дискретизации позволяет избавиться от
проблем, обусловленных периодичностью дискретизации квазипериодических сигналов, а также при спектральном анализе (см., например,
115
периодичность и наложения лепестков дискретных спектров (2.4)), которые имеют место как для обычных, так и для рекуррентных алгоритмов обработки данных; обеспечить примерно такую же точность
измерения характеристик, как при их непрерывной обработке.
Резюмируя изложенное, еще раз обратим внимание на необходимость аргументированного выбора вида и шага дискретизации с учетом решаемой прикладной задачи. Укажем также на необходимость
учета неидеальностей реализации операций дискретизации на практике: задержка в получении значений отсчета (t ) из-за конечности времени работы АЦП (см. часть 1, § 3.6), измерения и цифрового представления значения (ti ) ; неидеальность измерения (задания) ti и т. п.
Впрочем, эти неидеальности носят инструментальный характер и рассматриваются обычно в специальной литературе, посвященной таким
инструментальным средствам (дискретизации, квантования по уровню
(АЦП), измерения, вычисления, передачи, управления и т. д.) и их
применению в прикладных задачах. Поэтому в дальнейшем об этом
упоминать не будем.
§ 2.3. КВАНТОВАНИЕ СИГНАЛОВ ПО УРОВНЮ
Наряду с дискретизацией важной синтактической операцией с сигналами является их квантование по уровню (см. часть 1, § 3.6). Эта
операция также относится к первичной при преобразовании сигналов в
данные и является необходимой при работе с данными на средствах,
построенных по цифровому принципу (см. далее § 3.4). Поскольку
элементарные понятия о квантовании были приведены в части 1, § 3.6,
а в настоящее время в широко распространенных средствах работы с
данными число цифровых разрядов в количественных данных чаще
вполне достаточно для решения многих задач, подробно останавливаться на квантовании не будем. Ограничимся лишь некоторыми комментариями, которые необходимо учитывать при получении (измерении, сборе) исходных данных, определении качества и интерпретации
итоговых результатов, получаемых по этим данным.
1. Как уже было отмечено в части 1, § 3.6, при квантовании по
уровню происходит замена непрерывнозначного сигнала (t ) /или
описывающей его функции x(t ) / квантованным (квантованной)
(см. часть 1, рис. 3.5). Такая замена приводит к дополнительным погрешностям при решении прикладных задач. Они обычно определяются
116
с учетом свойств шумов квантования – разностей (t ) (t ) k (t ) или
(t ) x(t ) xk (t ) , где k (t ) , xk (t ) – значения, принятые за квантованные эквиваленты (t ) и x(t ) для соответствующих рассматриваемых
моментов t. В свою очередь, свойства (t ) и (t ) зависят от свойств
(t ) , x(t ) , вида и параметров квантизаторов, а необходимость их учета
определяется их значимостью для решаемой прикладной задачи.
Например, в монографии [20] рассмотрено влияние количества интервалов квантования x q квантизаторов двух типов, изображенных
на рис. 2.6, укладывающихся на вероятном (интерквантильном) диапазоне значений x(t ) , на смещение и дисперсии непараметрических оценок различных характеристик стационарных случайных процессов:
одномерных начальных и центральных моментов разных порядков,
законов распределения, авто- и взаимных корреляционных функций.
Исследовано влияние законов распределения X (t ) на смещение оценок моментных характеристик, на смещение и дисперсии оценок корреляционных функций RXY () при разных видах и разном шаге квантования (количестве уровней квантования на интерквантильной
широте X (t ) ). Показано, что для процессов с L, J и U-образными распределениями вероятностей поправки типа Шеппарда для устранения
смещения от замены x(t ) на xk (t ) применимы лишь при нескольких
десятках уровней квантования на интерквартильном интервале
[x1/4 x 3/4 ] , когда сами поправки становятся практически бесполезными. Если же для таких процессов принять поправки при больших x ,
то это может ухудшить, а не улучшить результат оценивания (!). В работе [20] рассматриваются разные способы уменьшения погрешностей
от квантования по уровню помимо уменьшения шага квантования: использование разноуровневых квантизаторов в разных каналах при оценивании смешанных моментов и корреляционных функций; рандомизации x ; добавление к x(t ) перед квантованием интерполирующих
случайных сигналов в пределах шага квантования. Эти рекомендации
могут быть полезны, если исходные данные представлены при грубом
квантовании, а также при построении бортовых средств при малом
числе уровней квантования.
2. Любое квантование сигналов по уровню, как правило, сопровождается дискретизацией сигналов (см. часть 1, рис. 3.5) и представ117
лением квантованных значений в двоичном, десятичном, двоичнодесятичном или подобном им кодовом виде.
СII(x)
5
q
2
3
q
2
q/2
СI(x)
2q
q
5
3
q q
2
2 –q/2
q/2
–q
3
5
q
q
2
2
x
–2q
–q
–q/2 q
3
q
2
5
q
2
–2q
2q
II(x)
I(x)
q/2
–q/2
q
2
3q
2
x
–2q –q
–q/2 q
x
x
2q
3q q
2
2
q/2
Рис. 2.6. Выходные характеристики квантизаторов I и II типов
3. Как уже неоднократно указывалось, требования к виду квантизаторов и выбору значений шага квантования определяются требованиями к качеству результатов той конкретной прикладной задачи, ради
которой это квантование проводится, и теми алгоритмами, которые
используются при работе с квантованными значениями. Поскольку
при работе на ЦВМ квантование по уровню всегда имеет место, исследователь-расчетчик не всегда задумывается над необходимостью учета
связи количества значимых разрядов числового эквивалента квантованного значения xk (t ) с используемыми алгоритмами оперирования с
этими числами.
Особенно это важно иметь в виду при применении рекуррентных
алгоритмов, которые имеют место при оценивании, фильтрации, имитации (см. часть1, формула (4.153)), БПФ и т. д. Например, скользящую дискретную траекторную ЭХ-оценку Q̂() характеристики Q()
(см. часть 1, формула (4.120)) можно представить как в обычной, так и
в рекуррентной форме, а именно [18]
118
Q̂ n ()
1 n 1
gQ [ x (it ); ]
N i n N
ˆ
=Q
n 1 ()
где
1
ˆ
z ( n 1)t Q
n 1 () ,
N
(2.11)
gQ x (it ); , 0 i N 1,
z (it )
(2.12)
gQ x (it ); gQ [ x (i N )t ; ], N i n 1.
Предупреждаем читателя о том, что при использовании различных
рекуррентных процедур необходимо учитывать требования к разрядности (и, следовательно, к шагу квантования) операндов. Такие требования излагаются в книгах и статьях по различным прикладным задачам, в которых подобные алгоритмы применяются (!).
§ 2.4. ПОЛУЧЕНИЕ, ОФОРМЛЕНИЕ
И ХРАНЕНИЕ ДАННЫХ
Согласно приведенным в части 1, § 1.3 определениям все синтактические операции с Данными можно назвать обобщенным термином
сбор Данных. Под сбором предложено понимать совокупность всех
таких операций с Данными, которые сами по себе в силу своего назначения направлены на «считывание» и сохранение всей имеющейся в
исходных Данных информации об объекте, который они характеризуют, и при их идеальной реализации не требуют и не должны приводить
к изменению имеющейся в них информации, их смыслового содержания, семантики. К таким операциям (при идеальном их исполнении)
можно отнести уже рассмотренные дискретизацию и квантование сигналов, а также съем, восприятие, регистрацию, получение (измерение,
покупку, собирание1), передачу, обновление, накопление, хранение и
другие подобные им действия с данными и анзниями.
Понятно, что такое выделение операций и отнесение их к синтактическим является относительным, условным. Ведь даже на этапе та1
Складывание, помещение, объединение в одном месте, приобретение
или получение по частям от одного или многих источников, соединение,
скрепление этих частей.
119
ких простейших операций, как съем, накопление, получение, как правило выполняется некоторая предварительная обработка данных и
анзний, например, их объединение, систематизация, компактное представление, очистка от «мусора» и т. д. (см. далее главу 4). В связи с
этим в дальнейшем, рассматривая синтактические операции с данными, будем абстрагироваться от их обработки и анализа в той мере, в
какой сами синтактические операции не будут включать в свой состав
обработку и анализ данных, например, для их организации, хранения,
передачи, помня, однако, что даже простые операции объединения и
систематизации данных сопровождаются некоторыми «информационными» действиями с ними, иногда хорошо формализованными, которые привносят дополнительные и/или выделяемые из имеющихся данных сведения о них. Тем самым эти действия изменяют семантическое
наполнение объединенных и систематизированных данных как носителей информации.
Поэтому рассмотрим лишь некоторые из синтактических операций,
обращая основное внимание в первую очередь на модельные и лишь
частично, по мере необходимости, на технологические аспекты работы
с данными.
Прежде всего обсудим вопросы, связанные с получением данных,
их оформлением, накоплением, обновлением и хранением.
Как уже упоминалось, получение связано как с рассмотренными
ранее операциями измерения, наблюдения и экспериментирования,
дискретизации и квантования сигналов, так и с пока еще не рассматриваемыми, а именно с их собиранием, включая бесплатное или платное
приобретение, целенаправленный поиск.
Предмет нашего внимания – те важные особенности технологий
получения данных с помощью разных действий, которые необходимо
фиксировать, организовывать, всегда иметь ввиду, для того чтобы
учесть исполнение (реализацию) их в дальнейшем, в частности в
оформлении, описании, представлении данных. Эти сведения нередко
нужны для правильной обработки и анализа данных, а также при интерпретации получаемых при этом результатов, чтобы как можно
более полно, с учетом возможного искажения их внешними обстоятельствами, без упущения чего-то важного, значимого модельно представить исследуемый объект максимально ближе к истинному его состоянию и поведению, системному отражению, т. е. представлению не
только объекта, но и его окружения для выявления именно правдивых
искомых знаний, закономерностей, паттернов и других составляющих
120
информации об исследуемом объекте из этих данных, учета для этого
условий, соответствующих получению данных, качества и объема данных, других важных, влияющих на результат факторов.
Эти аспекты мы уже обсуждали, когда рассматривали измерение,
наблюдение, экспериментирование. Поэтому остановимся только на
том, чем должны дополняться, сопровождаться данные в процессе их
получения в тех случаях, когда они собираются из разных источников,
ведомств, регионов, отрезков времени, от разных объектов их исследуемой совокупности, отличаются по своей природе важными индивидуальными особенностями и прочее. Именно на тех аспектах, учет которых необходимо закладывать, во-первых, при планировании (в
широком смысле слова) сбора (приобретения) данных, во-вторых, при
их оформлении, накоплении, хранении, в-третьих, использовать при
семантической обработке, анализе и интерпретации результатов. Приводить их абстрактно, без привязки к конкретной прикладной решаемой задаче, бессмысленно. Поэтому мы вынуждены поступить следующим образом. Во-первых, обратить особое внимание на учет этих
аспектов приобретателей, собирателей данных, специалистов по организации их хранения и накопления, чтобы информационная ценность
данных была надлежащей и не обесцененной при дальнейшей работе с
ними. Во-вторых, привести примеры тех атрибутов, которыми должны
сопровождаться получаемые и особенно приобретаемые данные согласно постановке задачи, для решения которой эти данные получаются, приобретаются, а также используемым методам и средствам для
ее решения.
Это следующие аспекты.
Сведения (факты, вспомогательные данные) о технологиях и
условиях получения исходных данных, важные для дальнейшего моделирования, исследования, анализа, обработки данных, а также о дате и
месте их происхождения, получения. Например, в медицине это дата и
место заболевания либо регистрации, постановки или подтверждения
диагноза; используемые средства, методики, стандарты и реализующие
их лица, состояние этих средств и лиц; их квалификация и аттестация;
даты замены; сведения об единицах измерения и квалиметрических
показателях значений данных; прочие факты, которые могут послужить причиной изменения значений данных, привести к неверным
выводам и интерпретациям; индивидуальные особенности объекта
(например, пациента: его пол, возраст, состояние здоровья, прием лекарств, изменение режима, перенесенные стрессы и т. д.).
121
Сведения об уровне достоверности данных.
Сведения о полноте данных, возможных выбросах, промахах,
пропусках в них и причинах, по которым эти пропуски, выбросы, промахи произошли или могли произойти.
Сведения о показателях тех составляющих окружающей среды,
которые могли повлиять на результаты, отраженные в данных.
Другие сведения (факты, категорийные и количественные вспомогательные данные), учет которых поможет выбрать соответствующий инструментарий обработки и анализа данных, а также при интерпретации результатов решения поставленной задачи.
В дальнейшем при описании итогов решения поставленной задачи
и обнародовании промежуточных результатов необходимо отражать все эти аспекты, чтобы подтвердить достоверность результатов, сопоставить их с аналогичными результатами других исследователей, позволить другим подтвердить их или найти причины, по
которым выводы по таким исходным данным оказались неточными
или ошибочными.
Учитывая изложенное, можно выделить, по крайней мере, два пути
работы с собранными (приобретенными) данными. Первый – фиксация, оформление, накопление и длительное хранение до нужного востребования всех основных и вспомогательных данных (сведений, фактов). Это перестраховочный путь, который может быть трудно
реализуем или может привести к большой избыточности. Второй – выполнение синтактических и семантических операций предобработки и
исследования основных и вспомогательных данных; разведочного анализа; определения их полноты, качества; очистки от «мусора»; возможное восстановление пропусков, устранение выбросов и дублирования; снижение размерностей и прочее до их оформления, накопления и
хранения с учетом тех постановок задач, которые потом будут возможны и допустимы с «предобработанными данными». Некоторые из
подобных операций (приемов) будут рассмотрены в следующих параграфах. Каждый путь выбирается конкретно. Его выбор зависит от
многих обстоятельств.
Следующие важные действия – регистрация и оформление исходных данных. Здесь и далее не будем подробно останавливаться на тех
аспектах, которые рассматривались при описании приобретения данных. Будем полагать, что в понятие «данные» входят как основные, так
и вспомогательные их части, отображенные должным образом. Не будем рассматривать их полноту, качество и другие аспекты, а остано122
вимся только на существе тех действий, о которых идет речь по тексту,
по ходу изложения дальнейшего материала параграфа.
Остановимся на этих действиях на уровне основных понятий.
Регистрация данных (от лат. registrum, англ. – registraton – внесенное, записанное) – выполнение действий, связанных с фиксацией,
учетом, записью на материальном носителе основных и вспомогательных данных (результатов измерения физических величин, фактов, дат,
сведений об условиях получения, …).
Оформление данных – приведение данных к завершенному виду,
готовому к дальнейшим действиям с ними.
Накопление данных – постепенное увеличение объема массива
данных путем прибавления новых, их дополнительного сбора, получения, приобретения.
Хранение данных – действия, связанные со сбережением и накоплением данных, передачей их во времени, обеспечением неизменности,
направленные на то, чтобы они не исчезли, не утратили своего содержания, качества и другие показатели, не были испорчены, украдены,
были упакованы, упорядочены, быстро доступны, дополнены.
Как уже указывалось в § 2.1, в настоящей главе рассматриваются
только дискретные данные. Поэтому перейдем к описанию тех структурных модельных представлений (дискретных) данных, в которых
они (данные) рассматриваются именно как финальные модельные носители информации, являющиеся объектами автоматизации их регистрации, оформления, накопления и хранения.
§ 2.5. СТРУКТУРНЫЕ СИНТАКТИЧЕСКИЕ
МОДЕЛИ ДАННЫХ
2.5.1. Вводные замечания
В автоматизации процедур хранения и накопления данных в последние десятилетия доминирует подход, отличающийся следующим.
1. Данные рассматриваются как абстрактные объекты, существующие самостоятельно.
2. Семантика, содержательный смысл, собственно информация, носимая данными, остаются за пределами модельного представления
данных.
3. Хранение и накопление данных должны допускать многократное
использование их разными пользователями для различных приложений.
123
4. Поскольку конкретному пользователю необходимы конкретные
данные, для решения различных задач необходимо иметь средства для
их выделения из общей массы, представления их и, по возможности,
содержащейся в них информации в нужном быстро доступном пользователю виде и месте.
Техническим решением такого подхода явились базы (data base –
DB), хранилища (data warehouse – DW), витрины данных (data mart,
show-windows of data) и системы управления ими (database management
system – DBMS).
Не останавливаясь на многообразии различных определений этих
терминов, введем те из них, которые соответствуют контексту настоящего пособия. Для сравнения дадим юридический вариант термина
база данных.
2.5.2. Банки данных
В самом общем виде под базой данных (БД) понимают упорядоченный набор связанных данных, удовлетворяющих заданным требованиям, с которыми можно проводить операции добавления, удаления,
поиска и им подобные. В качестве требований выступают: возможность использования данных несколькими пользователями; минимальная или регулируемая избыточность, достаточная для решения задач
разными пользователями; допустимость инвариантности (независимости) к средствам (программам) пользователей с точки зрения их изменения, модификации, управления ими с помощью специальной
надстройки – системы управления; возможность хранения и автоматической или автоматизированной (с участием субъекта) обработки на
ЭВМ; агрегируемость – возможность рассмотрения данных на различных уровнях ее обобщения; историчность – обеспеченность высокого
уровня статичности данных и их взаимосвязей с привязкой их ко времени; прогнозируемость – пригодность к выполнению прогнозов,
применимость к различным временным интервалам. Именно включение тех или иных требований в определение термина база данных отличает эти дефиниции друг от друга.
Второе, «юридическое», определение термина возьмем из действующего с 01.01.2008 г. федерального закона России об авторском
праве (Гражданский кодекс РФ, статья 1262): «Базой данных является
представленная в объективной форме совокупность самостоятельных
материалов (статей, расчетов, нормативных актов, судебных решений
124
и иных подобных материалов, систематизированных таким образом,
чтобы эти материалы могли быть найдены и обработаны с помощью
электронной вычислительной машины (ЭВМ)». Близким было определение из текста закона «Авторское право и смежные права» № 5351-1 от
09.07.1993 г.: «База данных – объективная форма представления и организации совокупности данных (статей, расчетов и так далее), систематизированных таким образом, чтобы эти данные могли быть найдены и обработаны с помощью электронной вычислительной машины
(ЭВМ)».
Рекомендуем сопоставить эти понятия как между собой, так и с теми, которые приведены в описаниях БД, зарегистрированных, например, в Роспатенте как объекты охраны авторским правом.
Обычно для создания БД ранее использовались следующие их типы: числовые, символьные или алфавитно-цифровые, а также даты. В
последнее время к ним добавились: временные (часы, минуты, секунды) или дата-временные; символьные переменной длины (хранение
текстов разной длины); двоичные, применяемые для хранения графических объектов, аудио, видеоинформации, пространственной, хронологической и другой информации; гиперссылки, ориентированные на
хранение ссылок на ресурсы, где хранятся нужные данные, находящиеся вне БД.
Для того чтобы базы данных, реализованные в электронном виде
на ЭВМ, позволяли хранить их и обеспечивать компактность, высокую
скорость обращения с ними, низкие трудозатраты (по сравнению с
ручным режимом), доступность и применимость, а также другие
улучшенные показатели качества хранения по сравнению с механическим (в частности, ручным), они дополняются автоматическими системами управления, образуя банки данных.
Система управления базами данных (СУБД) – есть совокупность
программных и языковых средств, предназначенных для создания, сопровождения и использования различных, но одинаково логически,
структурно-модельно представленных баз данных. Совокупность БД и
СУБД представляет собой банк данных (БнД).
Иными словами, необходимо различать БД, как упорядоченные наборы данных, и СУБД-программы, управляющие
хранением и обработкой данных. Объединение базы данных
с СУБД образует банк данных (БнД):
БнД = БД + СУБД
125
Создание и сопровождение БД предполагает включение в них операций загрузки, хранения, дополнения, извлечения, модификации данных, преобразование форматов, поиска и анализа данных и печати результатов поиска и анализа и других операций. Для этого, а также для
автоматизации использования данных, хранящихся в БД, они должны
иметь определенный формат как для ЭВМ, так и для прикладной программы, которая их использует. Подобный формат определяется метаданными, понимаемыми здесь как данные о данных, включающие
описание их характеристик, местонахождения, технологий, истории,
способов, средств и источников получения и использования основных
исходных данных, а также вспомогательные данные.
Под прикладной программой при этом понимается любая программа, служащая для обработки и анализа данных, вычислений и других операций с данными, а также формирования выходных документов
по заданной форме с использованием СУБД.
Помимо прикладной программы в привязке к БД рассматривается
термин приложение. Приложение представляет собой программу или
комплекс программ, использующих данные из БД и обеспечивающих
их обработку в рамках некоторой предметной области. Приложения
могут создаваться как в среде СУБД, так и с помощью систем программирования, использующих средства доступа к БД (Delphi, C++,
Builder, Java и др.). Приложения вне СУБД разрабатывают в тех случаях, когда требуется обеспечить удобства работы с БД неквалифицированным пользователям или интерфейс СУБД не устраивает пользователя. Приложениями могут выступать также программы, предназначенные
для выполнения стандартных действий, работ, операций. Например,
текстовые редакторы (Word и др.), графические (CorelDraw), электронные таблицы (Excel) и им подобные.
В качестве языков средств СУБД используются формализованные
средства – языки описания данных, язык манипулирования данными и
языки запросов данных. Это автономные языки, которые не включаются в универсальные языки программирования.
Язык описания данных (ЯОД) – язык, предназначенный для описания данных на трех уровнях: концептуальном, логическом и физическом (см. далее).
Язык манипулирования данными (ЯМД) – командный язык, обеспечивающий доступ к содержимому БД и его синтактическую обработку (как правило, вставку, удаление, изменение данных).
126
Язык запросов данных (ЯЗД, ЯЗ) – высокоуровневый язык обращения с данными, ориентированный на их поиск, сортировку, выборку
и обеспечивающий взаимодействие с БД пользователей.
Все три операции с БД (описание, манипулирование и запрос) часто совмещены в директивном языке программирования – языке последовательных запросов SQL (Sequence Query Language). Операции
описания в виде команд по формированию структуры таблиц и связей
между ними обеспечиваются визуальным языком программирования
QBE (Query By Example). Заметим, что в некоторых СУБД язык QBE
позволяет выполнять функции ЯОД, ЯМД и ЯЗД. По выполняемым
функциям СУБД делятся на два класса: транзакционные и аналитические. Первые относятся к системам операционной обработки данных,
вторые – к системам, ориентированным на анализ данных и поддержку
принятия решений.
Транзакционные1 (операционные) – это статические БД, отличающиеся тем, что в них доступ к данным ориентирован на их операционную обработку, а именно на оперативную обработку транзакций или
выполнение транзакций в режиме реального времени (On-line Transaction Processing – OLTP).
Транзакция – это логическая единица функционирования БД,
представляющая собой некоторое законченное с точки зрения пользователя действие, выполняемое над базой данных в виде неделимой (по
воздействию на БД) последовательности операций с данными. Главное
отличие транзакций от других способов доступа к данным – обязательная завершенность операций по изменению данных для сохранения целостности всей БД. Если транзакция успешно выполнена целиком, то она считается завершенной и осуществляется ее фиксация,
иначе (не важно по какой причине) вся БД возвращается к исходному
состоянию, предшествующему началу данной транзакции, – осуществляется откат. Кроме того, OLTP-технологии позволяют обеспечить
индивидуальность и изолированность операций над данными при совместном доступе к БД нескольких пользователей. Поэтому такая организация СУБД рассчитана на быстрое обслуживание относительно
простых запросов большого числа пользователей и на работу с данными, которые требуют защиты от несанкционированного доступа, от
нарушений целостности, от аппаратных и программных сбоев.
1
От англ. transaction – сделка.
127
Другой класс систем – аналитические (поддержки принятия решений) – ориентированы на выполнение более сложных запросов. Сюда относятся запросы, связанные с обработкой данных; с различными
видами их статистического, нечеткого, экспертного и других видов
анализа; моделированием процессов, событий, явлений предметной
области; их идентификацией, прогнозированием, имитацией; использованием различных методов искусственного интеллекта и графического модельного представления данных; получением знаний по данным и пр. Среди них системы оперативной аналитической обработки
(On-Line Analysis Processing – OLAP).
Для организации электронных данных в БД и управления ими
необходимо их модельное представление. Оно зависит от того, как
описывается предметная область. По отношению к пользователям используют трехуровневое представление (описание) предметной области: концептуальное, логическое и физическое (внутреннее).
Концептуальный уровень связан с обобщенным представлением
данных, не зависящим от СУБД и ориентированным на группы пользователей, выделяемых по общности информации, которую они хотят
получить из данных. В архитектуре БнД он является промежуточным
между внешним уровнем пользователей и внутренним логическим.
Модели предметной области этого уровня в терминах конкретной
СУБД содержат параметрическое представление полного набора данных и связей между ними, а также процесса циркуляции данных.
На этом уровне используются модели вида «сущность – связь» или
«объект – отношение» (ER – Entity Relationship) Питера Чена (1976 г.),
инфологические, семантические сети и другие, подобные им (см. далее).
Сущность – примитивный реальный или воображаемый объект
данных, отображающий элемент предметной области (человек, вещь,
место, продукция, потребитель и т. п.), информация о котором представляет интерес.
Связь – ассоциация, бинарное отношение между отдельными сущностями (примитивными или агрегированными объектами) данных
(пример: студент – студенческая группа) или сущности самой с собой
(рекурсивная связь, пример: человек (отец) – сын (отца, отец своего
сына)).
Атрибут сущности – любая деталь сущности, служащая для
уточнения сущности, ее идентификации, классификации, количественного представления, выражения состояния.
128
Тип данных – абстрактное объединение, агрегирование (см.
разд. 1.2.2) всех объектов определенного вида, назначения, свойства.
Тип охватывает все существовавшие, существующие и мыслимые объекты, относимые к нему, и не имеет пространственно-временной локализации (мысленный агрегат). Как следует из разд. 1.2.2, между понятием «тип» и «реальный объект» существует отношение «абстрактное –
конкретное», а именно реальный объект есть конкретная «часть» абстрактного типа (как часть чего-то) по аналогии с отношениями биологических объектов «конкретное дерево – часть леса». Другое дело – с
понятием множества, в котором любой конкретный элемент есть
«часть» «целого» – самого множества, где имеют место отношения
«абстрактное – абстрактное» или «реальное – реальное». Примеры типов данных: студенты, аспиранты как категории обучающихся, а не
как множества конкретных лиц какого-либо вуза.
Объект данных – часть, элемент набора данных, хранимых в БД,
содержащий информацию о реальном элементе предметной области.
Объект – в настоящем контексте – это подлежащая исследованию
определенная часть окружающей нас действительности (предмет, процесс, явление), о которой могут быть собраны или уже собраны данные.
Элемент данных – 1) некоторая наименьшая единица, имеющая
смысл на рассматриваемом уровне представления данных; 2) единица
поименованных данных.
Инфологическая (информационно-логическая) модель – это модель предметной области, определяющая совокупность информационных объектов, их атрибутов и отношений между ними, динамику изменений предметной области, а также потребностей пользователей в
данных и информации.
Семантическая сеть – разновидность семантической модели в
виде сети, орграфа, в вершинах которого расположены понятия предметной области (в терминальных вершинах – исходные элементарные
понятия), а дуги представляют отношения между понятиями.
Третий, физический, уровень описания предметной области и данных в электронных БД связан с технической реализацией БД, со способом хранения данных в физической памяти ЭВМ. Поэтому он подробно в пособии не рассматривается. Для нас наиболее интересным с
точки зрения синтактической обработки является средний уровень –
логический.
Логический уровень представления предметной области данными в
БД связан с обобщенным оформлением данных в абстрактной, отвле129
ченной от содержащейся в них информации, форме, пригодной для
всех пользователей. Описание БД на логическом уровне, т. е. ее логической структуры, называют схемой базы данных, а используемые для
этого модели – логико-структурными или структурными.
В настоящее время применяются следующие логико-структурные
модели данных: иерархические, сетевые, реляционные, объектноориентированные и их комбинация объектно-реляционные.
Иерархическая модель данных (ИМД) представляет собой граф вида дерево (точнее, «перевернутое» на 180, растущее вниз дерево) или
лес, в котором данные образуют совокупность деревьев, вершинами их
служат единицы данных, относящихся к объектам разного уровня, дуги отражают связи между этими единицами и классами (типами, объектами) данных, а каждая единица данных (объект) верхнего уровня
данных (предок) может включать в себя несколько элементов – потомков более низкого уровня. Объекты, имеющие одного предка, называют близнецами.
Сетевая модель данных (СМД) представляет данные в виде «объекты – связи», допускающем только бинарные связи «многие к одному» либо «один к многим» и оформленные в виде сетей – ориентированных графов. Сетевая модель является обобщением иерархической,
поскольку в ней единицы данных, во-первых, могут иметь не одного
(как в иерархических), а много предков, во-вторых, они связаны друг с
другом системой отношений, образующей произвольную, а не только
древовидную графовую структуру, когда любой элемент сети вышестоящего уровня может быть связан одновременно с любыми элементами следующего уровня. На связи элементов в сетевой модели, вообще говоря, не накладывается никаких ограничений. На первый взгляд,
может показаться, что сетевая модель тех же данных богаче иерархической. Однако это не так – с помощью специальных приемов одни и
те же данные могут быть представлены и как лес, и как сети.
Реляционная модель данных (РМД) использует представление данных на основе понятий «отношение», «связь» в виде таблиц (реляций1), построенных с помощью реляционной алгебры и раздела теории отношений реляционного исчисления. Элементами реляционной
алгебры являются таблицы, над столбцами (полями) и строками (записями об объекте) которых выполняется девять операциий: объединения, разности, пересечения, декартового произведения, проецирования,
1
От лат. relatio – сообщение, донесение; англ. relation – отношение.
130
селекции, соединения, слияния и деления. Реляционные исчисления
представляют собой совокупность правил оперирования с таблицами и
их элементами. Следует заметить, декларативные языки SQL и QBE
построены на реляционном исчислении! Примеры табличного представления сведений приводились в пособии неоднократно. Важным
примером является уже упоминавшаяся ранее таблица «объект – свойство» или «объект – признаки», в которых по строкам откладываются
номера1 и наименования исследуемых объектов одного типа, т. е. имеющих одинаковый набор свойств, по столбцам (полям) п их пронумерованных свойств (характеристик, признаков), а на пересечении i-й
строки, i 1, k , и j-го столбца, j 1, n , указываются конкретные значения j-го свойства для i-го объекта i, j , измеренные в соответствующих этим свойствам шкалах (табл. 2.1).
Т а б л и ц а 2.1
Объекты
(номер, название)
O1
Таблица «объекты – свойства»
Свойства (номер, название)
xj
x1
x2
…
…
…
…
1,1
1,2
1, j
.
.
.
Oi
.
.
.
i ,1
.
.
.
…
i,2
…
.
.
.
Ok
.
.
.
.
.
.
…
k ,1
k ,2
…
i, j
k , j
xn
1,n
…
.
.
.
…
i ,n
…
.
.
.
…
k ,n
Помимо двумерных в реляционных и других БД, основанных на таблицах, в последнее время все чаще используются многомерные модели
данных (ММД). Здесь термин «многомерность» означает не размерность
визуализации цифровых данных, а многоаспектное полиразмерное логическое представление структуры информации (семантики, сути), содержащейся в представлении данных и в операциях манипулирования дан1
Нумерация необходима либо для удобства, либо когда могут встретиться
объекты или свойства с одинаковыми наименованиями.
131
ными. Визуальное графическое представление ММД носит при этом
лишь демонстрационное назначение. Имеется три разновидности ММД.
Первая реализует идеи п-мерного гиперкубического или поликубического графического представления функции п-мерной переменной
y f ( x1 , x2 , ..., xn ) . Каждая из координат x1 , ..., xn , т. е. множество
однотипных данных, образующих одну из граней киперкуба, называется измерением, а значение – результат y – помещается в ячейке, находящейся на пересечении соответствующих значений измерений, в элементе поля, значение которого однозначно определяется фиксированным
набором значений измерений. Чаще всего тип такого поля является
цифровым. Для увеличения скорости доступа к данным шкала измерения представляется в индексной форме. В гиперкубической схеме
предполагается, что все ячейки определяются одним и тем же набором
измерений, а в поликубической – в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером п-мерного гиперкуба данных при
п = 3, т. е. просто куба, является трехвходовая таблица «объект – свойство – время» (ТОСВ) [4, 5] (рис. 2.7).
tm
(j,l)-столбец
tl
(i,l)-ряд
t1
a1
(i,j)-строка
ai
ak
а
б
Рис. 2.7. Графическое изображение многомерных моделей данных MOLAP:
табличных осей координат трехмерного куба (а) и трехмерного куба
данных «ТОВС» (б)
132
Подобное представление позволяет, например, решать задачи двух
связанных между собой направлений:
1) обнаружение свойств и закономерностей элементов куба, а также
закономерных связей между элементами;
2) использование обнаруженных свойств, закономерностей и закономерных связей для восстановления пропущенных (интерполяция) и
предсказания (прогнозирования) отсутствующих (экстраполяция) значений одних элементов трехмерной таблицы куба по известным присутствующим значениям других ее элементов (см. об этом подробнее
в [4, 5]).
Подобные ММД называются многоразмерными моделями оперативной аналитической обработки (ОАО) или ОАО многих измерений
(Multidimensional OLAP) и обозначаются MOLAP.
Вторая разновидность ММД – это ROLAP – реляционной оперативной аналитической обработки или ОАО реляций. Обычно такие
модели реализуются в виде двух структур: «звезда» и «снежинка». Обе
структуры содержат одну таблицу фактов (фактографическую таблицу) , в которой собственно хранятся данные, и несколько справочных,
каждая из которых характеризует один из аспектов факта. Здесь под
фактом понимают фактические сведения, оформленные в виде специальным образом организованных формализованных записей данных.
В отличие от фактографических способов представления данных в документальных способах сведения содержатся в документах в текстовой форме на естественном языке (книги, статьи, законодательные акты, исторические материалы и т. п.). Отличие «снежинки» от «звезды»
в детализации (конкретизации) отдельных составляющих какой-либо
справочной таблицы, допускающей такую детализацию. Модели
ROLAP устраняют основной недостаток MOLAP-моделей – ограничение на объем данных. Однако существенно уступают им по быстродействию реализующих их алгоритмов. Пример многомерных таблиц
фактов «звезда» и «снежинка» (рис. 2.8): оценки студентов, включающие в себя следующие составляющие: 1) номер семестра; 2) студенты;
3) дисциплина; 4) оценка. Справочные таблицы: Спр. 2: Студент;
2.1. Код студента; 2.2. Фамилия; 2.3. Имя; 2.4. Отчество; 2.5. Адрес
проживания; 2.5.1. Постоянно; 2.5.2. Временно; 2.5.3. Адрес прописки.
Наконец, третья разновидность ММД – HOLAP – гибридной оперативной аналитической обработки (Hibrid OLAP) совмещает те принципы построения MOLAP и ROLAP, которые обеспечивают достоинства этих моделей. Их идея – учитывать тот факт, что все данные БД
133
никогда не требуются, а каждый раз пользователь применяет лишь
только их некоторую часть. Ради этого следует: а) разделить предметные области на подобласти, которые получили в хранилищах данных
название витрины (или киоски, магазины) (см. разд. 2.5.3), б) центральное хранилище реализовать на РМД, а подобластные данные хранить в многочисленных витринах (киосках), реализующих объектноориентированный подход.
Спр.1
1.1
1.2
Спр. 3
3.1
3.2
3.3
Факты
1
2
3
4
Спр. 4
4.1
4.2
4.3
4.4
Спр. 1
1.1
1.2
1.3
1.4
Спр. 2
2.1
2.2
2.3
Спр. 3
3.1
3.2
3.3
Факты
1
2
3
4
Спр. 2.1
2.1.1
2.1.2
2.1.3
Спр. 2
2.1
2.2
2.3
2.4
2.5
Спр. 2.5
2.5.1
2.5.2
Спр. 4.2
4.2.1
4.2.2
4.2.3
а
Спр. 4
4.1
4.2
4.3
Спр. 4.3
4.3.1
4.3.2
4.3.3
б
Рис. 2.8. Графическое изображение реляционных моделей ROLAP
типа «звезда» (а) и «снежинка» (б)
Основным достоинством ММД является удобство и эффективность
аналитической обработки больших массивов данных, особенно связанных со временем. Основной недостаток ММД – громоздкость при решении простых оперативных задач с использованием таких данных.
Помимо реляционных БнД многомерные модели данных широко и
успешно применяются в объектно-ориентированных БнД.
Объектно-ориентированная модель данных (ООМД) объединяет в
себе идеи иерархических реляционных и сетевых моделей и ориентирована на создание БД со сложными структурами данных. Прежде чем
134
переходить к ее описанию, отметим, что, в отличие от других моделей
данных, до сих пор не существует общепринятого понятия «объектноориентированная модель данных». Поэтому нам следует определиться
с куализной моделью объекта ООМД. Дело в том, что в основе наименования иерархических, сетевых и реляционных баз используется одно
слово, определяющее суть идеи, лежащей в основе понимания модели.
Если идти по этому пути, то объектно-ориентированную модель следовало бы назвать объектной моделью аналогично реляционной.
Но словосочетание объектно-ориентированная подчеркивает, что эта
модель и БД, построенная по ней, используют объектно-ориентированный подход, идеи и методы объектно-ориентированных анализа,
программирования и проектирования. В отличие от структурного
подхода к анализу и проектированию сложных объектов, основанного
на алгоритмической декомпозиции (выделении этапов общего процесса), объектный подход ориентирован на декомпозицию и выделение не
процессов, а объектов, когда каждый объект рассматривается как экземпляр определенного класса. Поэтому, не вдаваясь в подробности
построения классификации структурных моделей данных, выделим
только те признаки их, которые позволяют понять суть ООМД и отличие ее от других моделей.
Заметим, что любая МД должна учитывать три аспекта ее построения: структурный, целостный и манипуляционный.
Структурный аспект означает выделение состава ее элементарных
единиц – операндов, связей их между собой и правил организации
связей.
Целостный аспект относится к целостности данных, т. е. такому
их состоянию, когда они сохраняют свое информационное содержание
и однозначность интерпретации в условиях различных непредвиденных воздействий на БД. Целостность считается сохраненной, если
данные не искажены, не стерты, не разрушены.
Манипуляционный аспект связан с возможностью СУБД выполнять
такие необходимые операции над данными, хранящимися в БД, как
открытие и закрытие БД, поиск, чтение, обновление, добавление и
удаление данных (единиц данных – записей, объектов) в БД.
Поэтому в качестве признаков разумно выбрать: 1) алгебру модели;
2) характер (структуры) связей; 3) способы обеспечения целостности и
мобильности.
Рассмотрим первый признак. Напомним, что под алгеброй понимается некоторое множество элементов – объединяемых по каким-то
135
общностям единиц, и операции над элементами, заданные на этом
множестве.
Единицами данных как элементами алгебры ИМД, СМД и РМД являются записи, отражающие конкретные сущности моделируемой реальности. При этом в ИМД и СМД реальные сущности делятся на
уровни, когда элементы одного нижнего уровня конкретизируют записи элементов предшествующего ему верхнего уровня (см. рис. 2.9).
В ИМД имеют место только бинарные связи между элементами соседних уровней, когда один потомок имеет только одного предка (родителя) и никакой потомок не может существовать без своего предка.
В СМД же могут быть связи бинарные, «многие к одному» и «один к
многим», когда некоторый потомок может иметь не только несколько
своих потомков, как предок в ИМД, но и любое число предковродителей, а не строго одного. В принципе в СМД каждый элемент
может быть связан с любым другим элементом. Связи между единицами одного уровня часто не рассматриваются, хотя в более сложных
моделях они могут вводиться, например, учетом связи по профилю
деятельности отделов, уровню компетентности и другим качествам
сотрудников с точки зрения выполняемых проектов.
В реляционных МД элементами множества являются таблицы (реляции), а операции над ними выполняются с использованием реляционной алгебры (см. описания РМД ранее). В РМД также используется
естественное представление данных, но все отношения принадлежат
одному уровню. Это затрудняет преобразование иерархических связей
вида «сущность – связь».
Отличительные особенности ООМД.
1. Данные хранятся не в виде отдельных единиц – конкретно записей, а в виде объектов как составных единиц, экземпляров, каждый из
котрых характеризуется определенным набором свойств (атрибутов),
отличающих его от всех остальных.
2. Объект является не конкретной, а абстрактной моделью единицы
данных. Здесь абстракция означает представление общих свойств объекта (например, типов объектов: «фирма», «автомобиль», «студент») без
конкретной его реализации (наименования фирмы, марки автомобиля,
фамилии студента). Абстрактная структура данных определяется функционально через выполняемые на ней операции.
3. Объектно-ориентированная модель строится послойно, на разных уровнях абстрактного представления реальности.
4. Всегда имеется возможность определения новых типов данных и
операций с ними. Тем самым допускается, что алгебра ООМД в отли136
чие от реляционной, может быть открытой как по составу, так и по видам операций над элементами (объектами) состава множества.
Рассмотрим эти вопросы подробнее.
Под объектом1 здесь понимается (в обобщенном виде) абстрактная
совокупность составных единиц, характеризуемых определенным набором свойств. Именно объекты являются операндами, элементами множества алгебры ООМД, с которыми производятся различные операции.
Каждый объект имеет уникальный идентификатор (ID, от
IDentificator), который связан с объектом во все время его существования и не меняется при изменении состояния объекта. Объект характеризуется двумя аспектами: состоянием и поведением. Состояние объекта определяется множеством значений его атрибутов (свойств,
экземплярных переменных, полей), а поведение описывается методами (процедурами, операциями, алгоритмами). Объекты могут объединяться в группы (конструкции, типы), в которых объекты обладают
одними и теми же множествами атрибутов и методов. Такие группы
называются классами. Классы допускают иерархию через подклассы
(подтипы), которые наследуют атрибуты класса и имеют также некоторые новые атрибуты, специфичные для принадлежащих им объектов
(как в ИМД и СМД). Например, объект «Библиотека» является родительским для объектов, являющихся экземплярами классов «Абонент»,
«Каталог», «Выдача». Различные объекты типа «Книга» могут иметь
одного или разных родителей. Объекты «Книга», имеющие одного и
того же родителя, различаются чем-то, хотя бы инвентарным номером,
но могут иметь одинаковые значения других свойств: УДК, автор,
название, год издания и т. п.
Начало работы класса задается с помощью специальных внутренних и внешних сигналов, называемых событиями [21].
В простейшей аналогии ОМД графически напоминает дерево, узлами которого являются объекты. В другом варианте – матрешку. Свойства объектов описываются классом, конструируемым пользователем.
Значение свойства типа класс есть объект, являющийся экземпляром
соответствующего класса. Каждый объект-экземпляр класса считается
потомком объекта-родителя, в котором он определен как свойство.
Что касается второй составляющей алгебры – операций, то в настоящее время формализованной объектно-ориентированной алгебры, в
1
До сих пор нет полного согласия в строгом определении термина «объект» в объектно-ориентированном подходе, что является одной из причин
отсутствия определения ООМД и путаницы в описании ООП.
137
отличие от реляционной, нет. Поэтому рассмотрим только специфичные для ООМД операции: инкапсуляции, наследования и обеспечения
полиморфизма.
Инкапсуляция (от лат. in – в и capsula – ящичек) – это выделение
класса с доступом к нему через атрибуты (свойства, данные) и методов
в виде описания реализации его, скрытого от использующих его модулей (средств). Инкапсуляция ограничивает область «видимости» имени
свойства пределами того объекта, в котором оно определено (как будто
бы образует капсулу вокруг свойства).
Наследование класса – порождение нового класса на основе уже
существующего. Существующий класс называют суперклассом, а новый – подклассом, который наследует все атрибуты (свойства) и методы суперкласса и добавляет к атрибутам свои, отражающие собственную индивидуальность подкласса. Отсюда следует, что наследование
распространяет область «видимости» свойства объекта на всех его
потомков. Например, всем объектам типа «Книга» как потомкам объекта «Каталог» можно приписать свойства родителя: УДК, автора,
название.
Полиморфизм – способность по-разному реагировать на одинаковые внешние события в зависимости от того, как реализованы методы
обеспечения полиморфизма. В объектно-ориентированных языках
программирования полиморфизм означает способность одного и того
же программного кода работать с разнотипными данными. Иными
словами, это означает допустимость в объектах разных типов иметь
методы с одинаковыми именами.
Объектно-реляционная модель данных (ОРМД) имеет две разновидности – комбинированную (часто называемую гибридной)1 и расширенную. В комбинированных ОРМД объектно-ориентированный
подход используется для создания интерфейса пользователя и алгоритмов приложения, а таблицы создаются с помощью реляционного
подхода. В расширенных ОРМД объектно-ориентированный подход
используется, кроме того, для построения систем таблиц.
Сопоставление терминов из теории структурных моделей данных
приведено в табл. 2.2 (см. [21]), а графическое представление их особенностей – на рис. 2.9.
БнД, построенные на основе ООМД, могут хранить произвольное
количество простых и других объектов, легко описывают часто встречающиеся на практике иерархические структуры для доступа к дан1
См. по поводу терминов «комбинированный» и «гибридный» разд. 1.2.1.
138
ным, не требуют отдельного языка запросов, поскольку доступ происходит непосредственно к объектам.
Т а б л и ц а 2.2
Сопоставление терминов и особенностей структурных моделей данных
Название
модели данных
Реляционная
Иерархическая
Элемент структуры
Таблицы: столбцы –
поля, строки – записи
Сегменты: исходный
и порожденный – аналоги таблиц
Записи: владелец
и член – аналоги таблиц
По ключу
Виды связей
в структуре
Линейные
По указателю
Линейные
Способ связи
По указателю и по Линейные,
ключу (связь имену- налинейные
ется); совокупность
записей и связь образуют набор
ОбъектноОбъекты (таблицы, По ключу
Линейные,
налинейные
реляционная
абстрактные
типы
данных)
Объектно-ориен- Классы объектов (ти- По объектной ссыл- Линейные,
тированная
пов данных, данных): ке и объектному налинейные
объект – строка, стол- указателю
бцы – свойства (константы, встроенные
объекты, потоки данных, коллекции, многомерные
переменные, ссылки)
Сетевая
Однако в таких БнД: отсутствуют общие средства манипулирования данными; нетривиальны проблемы целостности и быстрого извлечения данных из базы; изменение в одном классе требует изменения в
других классах приложения, связанных с ним, а их применение ограничивается отсутствием общей модели данных.
Поэтому ООМД рекомендуются, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру. Ассоциативная модель данных (АМД) – возможная модель, основанная
на ассоциациях (семантике, смысловом содержании), используемых
для организации хранения данных (по типу ассоциативного хранения
данных и знаний в мозге человека).
139
б)
проекты
Сотрудники
патентный НИР библиотека
а) Отделы
Сетевая
Связь 2
Связь 3
Связь 1
Реляционная
Наследуемые
свойства:
название
адрес
ректор
НОПД
Технические:
названия показателей, специифичных для технических вузов
Наследуемые
свойства:
название
адрес
ректор
НОПД
Консерватории:
названия показателей, специифичных для
консерваторий
Вузы
Свойства название
(атрибуты) адрес
ректор
НОПД
Объект (класс объектов)
Методы Атрибуты, свойобъекта ства экземпляров
(и всего объекта (класса)
класса)
Объектно-ориентированная
Рис. 2.9. Графическое представление структурных моделей данных: НОПД – названия
общих показателей деятельности
Выполняемые проекты
Сотрудники
Отделы
Организация
Иерархическая
Разновидность баз и банков данных представлена в табл. 2.3.
Т а б л и ц а 2.3
Фрагмент морфологической таблицы банков данных
ОтличительГлавные
ный признак
определяюфактора
щие факторы
Исходное
Форма воспредставлеприятия
ние данных
Оформление
данных
Уровневая
модель
данных
Концептуальный уровень
(концептуальные модели
данных)
Логический
уровень
(структурная
модель)
Физический
уровень
СтабильВозможность
ность данных изменения
данных во
времени
Способ выАлгоритмы
полнения
выполнения
операций
действий
Способ расПространпределения
ственная
(сосредоточесосредотония) данных
ченность
данных
Технология
Используиспользования
емые средсредств
ства
Назначение
Решаемые
(характер
задачи
хранения)
Связь с поль- Количество
зователями
пользователей
Интерфейс
связи
Возможные реализации признака
(наименование модели или БнД)
Видео
графическая
символь(изображеная (текний)
стовая)
Структурированное
Сущностносвязные (ER)
Иерархическая
(ИМД)
Аудио
Мультимедиа
Частичноструктурированное
Инфологи- Семантических
ческие
сетей
Сетевая
(СМД)
Реляционная
(РМД)
Объектнореляционная
(ОРМД)
Неструктурированное
Другие
Объектноориентированная
(ООМД)
Ассоциативная
(семантическая)
(АМД)
Заполните самостоятельно
Статические (статичные)
Динамические (динамичные)
стационармобильные
ные
Последовательные
Параллельные
Централизованный
Распределенный
локальные
интегрированные
однородные неоднородные
Частная (традиционная)
Арендная (облачная)
Операционные (транзакционные) (OLTP)
Аналитические (OLAP)
Однопользовательские
Многопользовательские
Собственные
Предприятия
(центра)
141
Сетевые
2.5.3. Хранилища и витрины данных
Хранилище данных (ХД) (англ. Data Warehouse) – предметноориентированная, интегрированная, привязанная ко времени, неизменяемая совокупность данных, специально созданная для решения аналитических задач и задач поддержки принятия решений. Интегрированная – значит, объединяющая несколько баз данных, корпоративная
БД. Поясним оговоренные в определении особенности ХД.
1. Предметная ориентированность означает целевую направленность создания ХД путем единого логического представления данных,
содержащихся в разнотипных БД или в единой корпоративной БД,
объединяемых для решения конкретных предметных задач и учитывающих основные аспекты предметной области, в частности, специфику
постановки и решения задач, разновидностей и технологий получения
данных и метаданных.
2. Интегрированность означает: если одни и те же оперативные
данные находятся в разных локальных БД, оформлены в разных форматах и/или выражены в разных единицах измерения, то при загрузке в
хранилище они должны быть проверены, очищены и приведены к единому виду. Это упрощает их анализ.
3. Привязка по времени означает их хранение в хронологическом,
историческом виде. Данные, выбираемые из различных локальных
оперативных БД, как получаемые из других источников, должны
накапливаться и храниться в ХД с привязкой их по времени их получения от исследуемого объекта, т. е. относиться к конкретному периоду
или моменту времени. Это позволяет исследовать тенденции развития
исследуемых процессов, объектов.
4. Неизменяемость данных означает, что, попав в хранилище, они
уже никогда не меняются. Тем самым обеспечивается их стабильность,
возможность повторной работы с ними того же или других пользователей.
Резюмируя, отметим следующее.
Во-первых, БД предназначены для автоматизации действий с данными. Поэтому в них чаще используются OLTP-средства и технологии. ХД же предназначены для содержательного анализа данных и
принятия решений по итогам такого анализа. Поэтому для них характерно применение OLAP-средств и технологий, что не исключает
вспомогательного применения OLTP.
Во-вторых, БД могут постоянно изменяться в процессе работы
пользователей, в то время как ХД стабильны и, если меняются, то по
142
определенному графику, с определенной целью, причем, как правило,
за счет добавления новых данных, а не исключения или исправления
имеющихся.
В-третьих, по отношению к ХД базы данных выступают как источники новых данных.
В-четвертых, БД ориентированы на приложения, в то время как ХД
– на предметную область.
Витрины данных (ВД) – специализированная разновидность ХД,
ориентированная и оперативно создаваемая для решения конкретных
оперативных задач пользователя. Как правило, в качестве стандарта
структур данных в ХД и ВД применяется ММД «звезда», основанная
на единственной таблице фактов и множестве таблиц измерений.
§ 2.6. СТРУКТУРНЫЕ СИНТАКТИЧЕСКИЕ
МОДЕЛИ ЗНАНИЙ
2.6.1. Знания как операнды синтактических
и семантических операций
Прежде чем рассматривать модели знаний, вернемся к обсуждению
термина знания в привязке к контексту пособия, т. е. обсуждая не вообще все аспекты термина знания, а лишь только те, которые характеризуют их, с одной стороны, как носитель, с другой – как часть информации о каком-то конкретном объекте. Согласно определению,
приведенному в части 1, § 1.3, знания о каком-то объекте – это его модель, представляющая собой результат познания объекта или «родственных» ему (по адекватности описания информационного (семантического) содержания) объектов, оформленный в виде идей, гипотез,
теорий, выводов, понятий, конструкций, законов, закономерностей,
концепций, … его рождения, строения, «жизни» (функционирования,
поведения), «смерти». При этом предполагается, что такие модели становятся знаниями, если они проверены на истинность теорией и практикой, допускают обновление и дополнение, несут (хранят) известные
конкретному субъекту или другим субъектам информацию об объекте,
являются источником новых, свежих смысловых сведений об объекте
либо являются самими этими сведениями как частью информации, получаемой конкретным субъектом об объекте.
Прокомментируем важные для нас аспекты такого понимания термина «знание».
143
1. Как уже отмечалось в § 1.3 (см. часть 1 пособия), широко используемый в настоящее время термин «знание» трактуется разными, а
иногда одними и теми же его пользователями в зависимости от не всегда четко определяемого контекста, и как носитель информации и как
часть или вся информация, и как нечто вне, сверх информации (см.,
например, [22, с. 6], и [23, с. 39–40]). Во избежание этого автором
настоящего пособия более 15 лет назад предложено, во-первых, разделить понятия «данные», «знания» и «информация», во-вторых, раздвоить термин «знания» на «знания-1» и «знания-2». В термине «знания-1»
знания понимаются как носители информации, названные «анзниями»1
(см. часть 1, § 1.3), а термин «знания» оставить за понятием «знания-2»,
которое означает семантику, смысл, используемую, нужную, добываемую, передаваемую, … часть информации, которую несут (содержат)
знания-1 (анзния) об объекте. Понятно, что если по контексту ясно, о
чем идет речь, то можно просто оставить термин «знание», который
будет трактоваться как «знание-1» (анзния), если речь идет о синтактических операциях с «знаниями», или как «знания-2», если речь идет
о семантических операциях со «знаниями», т. е. об извлечении, выделении из них, передаче сути, смысла, новизны, нового понимания или
генерирования идей, гипотез, законов, …, касающихся исследуемого
объекта, а также об «укладывании» семантики в «знания» как носитель
информации (в анзния) об объекте.
2. Еще раз обсудим отличие между сигналами, данными и знаниями (анзниями) как носителями информации.
Сигнал, как физический носитель информации об объекте, характеризуют следующие особенности. Во-первых, он неразрывен с объектом (см. часть 1, § 1.3). Во-вторых, содержащаяся в нем информация
потенциально, т. е. при идеальном варианте проявления, взаимнооднозначно отражает объект: каждый объект имеет свое специфичное
проявление того же самого по названию и назначению сигнала в конкретный момент времени, находясь в конкретном месте и в конкретных условиях, и этот сигнал потенциально, в идеальной трактовке, однозначно во всех своих нюансах с учетом прошлого и настоящего
отражает объект в те же моменты времени, в тех же местах и условиях
его «жизни». Именно это служит основанием для потенциальной воз1
Во избежание путаницы со знаниями-2, когда вместо «знания-1» и «знания-2» просто пишется и произносится «знания», а по контексту не ясно, о
каких из них идет речь.
144
можности познания объекта через его сигналы и полученным по ним
данным и знаниям1. В макромире субъект, не вмешивающийся в моменты времени, места и условия, не влияет на сигналы, оторван от них.
Сигналы порождаются только объектами. Субъект может лишь выбирать, какой из сигналов, на его взгляд, несет нужную, достаточную и
полезную информацию об объекте с точки зрения решаемой им задачи.
В этом смысле мы можем говорить, что информация, содержащаяся в
сигнале об объекте, является не зависящей от субъекта, объективной.
Ясно, что сигналы принципиально не повторимы.
В отличие от сигналов, данные, получаемые по ним (см. часть 1,
рис. 1.3), хотя и представляют объект, но уже оторваны от него, получаются с участием субъекта (хотя бы на уровне назначения, требований к ним, выбора измерительной шкалы при автоматическом получении), с какой-то погрешностью отражают сигнал и, следовательно,
объект, могут иметь такие же значения для разных объектов, т. е. характеризовать некоторое множество (класс родственных) объектов.
Следовательно, объективность данных «смазывается» субъектом, явно
или нет привносящим свою долю в информацию, семантику, сведения
об объекте, которые несут данные о нем.
Еще более «оторваны» от объекта знания. Во-первых, чтобы быть
полученными, достоверными, полезными, они получаются путем многократного общения с тем же объектом или с подобными ему объектами. Во-вторых, обязательно содержат след от участия в их формировании и оформлении одного или нескольких субъектов. В-третьих,
являются внутренне интерпретируемыми, структурированными, многослойными, допускающими декомпозицию, иерархическое структурирование, вложенность друг в друга по принципу матрешки или листьев капусты. Кроме того, как носители информации знания уже
содержат элементы вложенности в них новой информации от субъекта,
интерпретируемости, лучшей доступности для восприятия пользователем, имеют гораздо больше видов связности (причинно-следственных
или статистических, неявных контекстных или явных модельных
и т. д.), могут быть явными (осмысленными, легко воспринимаемыми,
описываемыми и передаваемыми другим) или неявными (накопленный
личный или коллективный опыт, результаты обучения и самообучения
1
Здесь и далее речь идет только о данных и знаниях, получаемых в результате измерения значений отсчетов сигналов, чтобы сопоставление отличия понятий «сигналы», «данные» и «знания» было конкретным, а не абстрактным.
145
в естественных или искусственных
ции, через ощущения, ассоциации,
активными при получении новых
сравнению с пассивными данными,
стрирует рис. 2.10 [1].
системах, получаемые по интуижитейскую мудрость, …), быть
знаний, порождать действия по
и т. д. Часть изложенного иллю-
Прагманды – операнды прагматических операций
Среда
Вред
Нейтральность
Польза
Знания (2)
Данные
Сигналы
Информационный
мусор
Синанды – операнды
синтактических операций
Анзния
Протознания
Информация
Субъект
Семанды - операнды семантических операций
ДЕЙСТВИ
Объект
Объект
Среда
Рис. 2.10. Условное изображение связи операндов, Данных, информации и их реальных проявлений с объектами и субъектами (степень
насыщения цвета отражает степень участия объекта или субъекта)
Многоуровневость, многослойность знаний можно проиллюстрировать, например, так. Протознания, содержащиеся в данных, условно
принять за еще не выявленные знания об объекте, т. е. за знания нулевого уровня. Метаданные, как данные о данных, полученные с участием Субъекта (или субъектов) – это знания 1-го уровня. Выявленные по
данным закономерности, паттерны, свойства объекта, представленные
в виде графиков, диаграмм, таблиц – знания 2-го уровня, которые
146
могут выступать как анзния или данные для дальнейших исследований. Полученные по знаниям 2-го уровня гипотезы, теории, идеи, концепции – знания 3-го уровня, и выше, а знания о знаниях, т. е. метазнания, как знания наивысшего (на конкретном этапе исследования
объекта) уровня.
2.6.2. Модели знаний как носителей информации
Теперь перейдем к компактному описанию различных моделей
представления знаний как синандов – операндов синтактических операций, анзний. В настоящее время наиболее часто рассматриваются
следующие из них: семантических сетей, логические, продукционные,
фреймовые и онтологические для явных знаний и различные модели
неявных знаний, которые будут рассмотрены в 4-й главе настоящего
пособия.
Сетевая модель знаний1 – это сеть, описывающая отношения (связи) между сущностями (понятиями, концептами) и конкретными объектами представляемого моделью знания. Вершинами сети являются
(или ставятся в соответствие) сущности, рассматриваемые в знании
(объекты, предметы, свойства, события, процессы, явления), а дугами –
отношения (связи) между сущностями. Например, если знания выражены в текстовой форме, в виде предложения на естественном языке,
то вершинами будут существительные с относящимися к ним определениями или отдельно существительные и определения, а дуги – глаголы, связывающие между собой существительные, или отражающие
принадлежность определений к существительному. Например, знание
«Петров сдал экзамен по ТОИ профессору в аудитории 317», сокращенное от «Петров пришел в аудиторию 317 и сдал экзамен по ТОИ» в
обозначениях: x1 – Петров, x2 – аудитория 317, x3 – экзамен, x4 –
профессор, x5 – дисциплина ТОИ; 1 – пришел, 2 – сдал, 3 – экзамен принимал, 4 – экзамен был (проходил) по (дисциплине) – можно
изобразить семантической сетью, изображенной на рис. 2.11.
Такие модели обладают относительной гибкостью, экономичностью и удобны для восприятия, хорошо соответствуют современным
представлениям об организации долговременной памяти человека.
1
См. разд. 2.5.2, концептуальные модели данных. Термин семантическая
сеть ввел Р. Куиллиан в 1968 г.
147
Однако при их применении возникают проблемы при реализации процедур поиска и наследования. Основной недостаток моделей в виде
семантических сетей – сложность
х5
формализации поиска вывода в
силу неметричности (несоблюде4
х2
ния аксиом теории меры) прох1
странства предметной области.
х3
Логическая модель знаний ос1
2
3
нована на применении формального описания знаний в виде опредех4
ленной системы, например, принятой в логике предикатов первого
Рис. 2.11. Пример семантической
порядка, когда в качестве конкретсети
ного элемента знания рассматривается некоторое утверждение, являющееся атомарной формулой языка
этой логики. Прежде чем переходить к описанию таких моделей рассмотрим разновидности знаний.
Декларативные – это знания в виде куомодных моделей, характеризующих статику объекта, наличие у него некоторых свойств, а также
отношения между объектами и их элементами, т. е. констатирующие у
объектов наличие некоторых свойств и отношений между ними.
Процедурные – это знания, содержащие куарные1 модели, отвечающие на вопрос, как сделать, и отражающие упорядоченную последовательность действий, операций, процедур, алгоритмы, методы и их
реализации.
Другие виды знаний.
Понятийные – это знания, содержащие разновидности куализных
моделей в виде набора понятий, терминов, используемых при решении
конкретной задачи.
Концептуальные – содержащие куомодные модели в виде совокупности структур, их элементов, взаимосвязей и взаимодействий
между ними.
Конструктивные – содержащие каузальные модели, отвечающие
на вопрос, почему.
Наконец, метазнания – знания о знаниях, их структуре, правилах
получения, дополнения и применения.
1
От лат. qua – как, каким образом; quare – какими средствами, как
сделать.
148
Фактуальные (фактографические) – представляющие собой по
природе их происхождения сведения об объектах отражаемой реальности, а именно количественные и качественные показатели, характеристики реальных объектов.
Операционные – это знания, отражающие зависимости и отношения между ними.
Любое знание в логических моделях представляется в виде формул
исчисления логики предикатов первого порядка и правил вывода. Описание в виде формул дает возможность представлять декларативные
знания, а правила выводов – процедурные.
Формулы представляют собой атомарные элементы А, В, их отрицание А, В, конъюнкцию А & В, дизъюнкцию А В, импликацию
А В, эквивалентность А В (или А В), а также xA и xA , где
А – формула, х – переменная, – квантор всеобщности, – квантор
существования.
В качестве правил вывода используются следующие [22]:
Modus Ponens: если А выводима и А влечет В, то В – выводимая
формула;
цепное: если формулы А В и В С – выводимые, то выводима и формула А С;
подстановки: если формула A( x) выводима, то выводима и формула A( B) , в которой все вхождения х заменены на В;
резолюций: если выводимы формулы двух дизъюнктов, имеющих контрарную пару А С и В С, то выводима формула дизъюнкта А В, полученного из этих двух удалением так называемой
контрарной пары В, В.
Заметим, что первые два правила являются частным случаем правила резолюций.
Пример логической модели знания «каждый студент АВТФ III курса сдал ТОИ»
( x ) [Студент АВТФ(х) III курс(х)] ТОИ(х) экзамен (х, сдал)
Достоинством логических моделей является единственность теоретического обоснования. Однако их применение затруднено при представлении трудно формализуемых знаний, например, знаний экспертов, с которыми приходится сталкиваться при решении трудно- или
неформализуемых задач. Напомним, задача называется трудно фор149
мализуемой, если: а) алгоритма ее решение нет или он не может быть
реализован из-за существующих ограничений; б) задача не определяется в числовой форме; в) в постановке задачи цель не может быть
выражена в терминах точно и однозначно определенной целевой
функции.
Продукционная модель знаний – это модель, основанная на совокупности правил вида продукций «ЕСЛИ <условие>, ТО <действие>.
Под условием (антецедентом) правила понимаются некоторые предикаты, которые могут быть истинными, ложными или иметь некоторую
взвешенную оценку истинности в конкретный момент времени и представляют собой предложение – образец, по которому осуществляется
поиск элементов знания. Под действием (консеквентом) понимаются
операции, выполняемые при успешном исходе поиска (например, постановка диагноза, выдача управляющих воздействий, модификация
или дополнение знаний). Выводы в базах знаний, построенных на такой модели, бывают прямые и обратные. При прямом выводе (от данных, фактов к поиску цели) или выводе, управляемом фактами,
отправной точкой являются исходные факты, по которым активизируются соответствующие правила для получения искомого результата.
При обратном выводе (от цели для ее подтверждения к фактам, данным), управляемом целью, отправной точкой является цель решения
задачи, по которой последовательно устанавливается совпадение ее с
имеющимися фактами. В ряде случаев к ядру продукции «если А
(условие), то В (действие)» добавляют входящее в нее постусловие С
[25]. Условие представляет собой предложение-образец, по которому
выполняет поиск в базе знаний, действие – те операции, которые выполняются после успешного поиска, а постусловие описывает операции и процедуры, осуществляемые после реализации действий.
Продукционные модели обеспечивают простоту создания, наглядности и понимания правил, пополнения и модификации знаний, механизма логического вывода. Однако они не позволяют отражать
концептуальную структуру предметной области. Для процедурных моделей характерны два важных принципиальных недостатка: сложность
проверки непротиворечивости множества продукций при их большом
числе и неоднозначность выбора выполняемой продукции, затрудняющая проверку корректности работы средств на основе таких моделей.
Примеры работы с такими моделями будут приведены при расмотрении баз знаний и экспертных систем.
150
Фреймовая модель знаний1 представляет знания через фреймы –
обобщенные образцы, описывающие множество похожих объектов,
«структуры данных для представления стереотипных ситуаций», по
М. Минскому, минимально возможные описания сущности объектов
(вещей, процессов, явлений, событий, ситуаций). Иными словами,
фрейм – это абстрактный образ, ситуация или их формализованная модель для представления некоторого стереотипа восприятия (например,
понятия «комната»). Различают два вида (типа) фреймов: фреймыобразцы (или протипы) и фреймы-экземпляры. Первые хранятся в базах знаний, а вторые создаются для отображения реальных ситуаций
на основе поступающих знаний. Фрейм описывает один представляемый им объект, конкретные свойства которого и относящиеся к нему
факты описываются в слотах.
Слоты – структурные элементы фрейма. Значения слотов для каждого конкретного объекта могут различаться.
Имя фрейма является его уникальным идентификатором в рамках
фреймовой модели знания, используемым для обращения к нему. Имя
слота – уникальный идентификатор его в рамках фрейма. Например,
имя фрейма: комната. Имена слотов фрейма: стена, пол, потолок, окно,
дверь. Значения слота «дверь»: входная, межкомнатная, двухстворчатая. Фреймовые системы могут иметь иерархическую структуру, когда
отдельные слоты могут представляться отдельными фреймами.
Например, фрейм «южная стена» может иметь слоты: окна, кресло,
рабочий стол и прочее, каждый из которых имеет свои значения.
Фреймовые модели знаний о мире могут отображаться через фреймы-структуры, фреймы-роли, фреймы-сценарии, фреймы-ситуации
[25]. Они сейчас быстро развиваются и благодаря своим широким возможностям и гибкости находят все более широкое применение. Основное преимущество фреймов как моделей знаний – их способность
отражать концептуальную основу организации памяти человека, ее
гибкость и наглядность, а также задавать основы описания (конструкцию) класса объектов. Поэтому фреймовая модель удобна для представления однотипных объектов, в которой фрейм выступает концентратором знаний об объектах класса, представляя собой как бы квант
знаний об объектах класса.
1
Ее концепция была предложена Мервином Минским (M.L. Minsky,
МТИ, США) [1]. Фрейм от англ. frame – каркас, рамка. Поэтому подобные
модели можно назвать каркасными, рамочными.
151
Онтологичекие модели знаний – ориентированы на совмещение
всеобъемлющей и детальной формализации некоторой области знаний
о реальном мире на уровне, близком к концептуальному, содержащем
термины, релевантные1 классы объектов, их связи и правила, включая
ограничения, теории и пр., принятые именно в этой предметной и
научной области, а также интеграцию разнородных данных и знаний
различных областей знаний, используя опыт решения одних задач для
других.
Термин онтология (от греч. on (ontos) – сущее и греч. logos – учение, наука) имеет как минимум три различных трактовки, две из которых философские, а третья – информационная. Первая философская
трактовка (Р. Гоклениус, 1613 г.; И. Клауберг, 1656 г.): онтология есть
учение о фундаментальных принципах, основах строения, структурах
и закономерностях сущего, бытия, мироустройства2. Вторая философская трактовка, по У. Куайну (США): онтология – содержание некоторой теории через объекты, постулируемые в ней в качестве существующих. Наконец, информационное понимание: онтология – форма
представления знаний о реальном мире и его частях в виде точной
спецификации их предметных областей через определения понятий
терминов, т. е. через модели терминологического куализного типа, их
иерархическую организацию и отношения между ними, в частности,
типа класс – вид, часть – целое. Иными словами, ядром информационной онтологии является совокупность терминов, понятий предметной
области с их формальными определениями, отражающими общие знания об этой области. Обратим внимание на имеющееся часто несовпа1
Релевантный (от англ. relevant – уместный, существенный), полезный
для потребителя, пользователя, пригодный для различных условий, имеющий
смысловое соответствие.
2
Сравни с терминами гносеология и когнитология.
Гносеология (от греч. gnosis – знание) – учение о познании человеком
окружающего мира, включая познание самого себя, общие механизмы познания, движение от незнания к знанию, отличие между истинным (достоверным) и ложным (недостоверным) знанием, т. е. учение о научном знании, касающееся методологии познания.
Когнитология (от лат. cognito – знание, познание, изучение, осознание) –
учение о мышлении, разуме, приобретении и применении знаний об окружающем мире, способности к умственному восприятию и переработке высшей
информации, смыслах, заложенных в ней, способности человека расшифровывать их и использовать в жизнедеятельности, т. е. учение о самом познании,
его сути, структуре, процессах и т. п.
152
дение и даже несовместимость значений, пониманий сходных по написанию терминов в разных предметных областях. Например, сущностное значение термина «поле» в агрономии (участок земли), в физике
(вид материи) и математике (абстрактная конструкция) либо понимание термина «земля» почвоведом, моряком и астрономом. Поэтому так
важно иметь общие онтологии, содержащие термины, общие, одинаково понимаемые, для многих предметных областей.
Выделяют следующие типы онтологий: мета-, предметной области,
конкретной задачи и сетевые.
Мета-онтологии – это такие, которые описывают общие понятия,
термины, не зависящие от предметных областей либо используемые в
большом числе областей.
Онтологии предметной области связаны с формальным описанием предметной области, а именно уточнением понятий, введенных,
принятых в мета-онтологии, определениями общей терминологической
базы предметной области.
Одним из вариантов онтологической формализации знаний в определенной предметной области является осуществление ее в виде схемы, отражающей структуру данных и знаний, состоящих из конкретных типов объектов, поделенных на классы, связей между ними,
правил и ограничений, действующих в этой области. Сами же онтологии строятся, например, на основе трех типов объектов – сущность,
событие, документ, их свойств и связей между ними.
Сущность – то реальное, что именуется существительным. Событие – это действие в прошлый, текущий или будущий момент времени, привязанное к координатам точки пространства. Документ –
неструктурированные текстовые данные, представленные в определенном формате, например, XML, HTML, XMLP. При этом предполагается, что структура объектов и их свойств такова, что с объектом сохраняются только некоторые (1-2) его собственные свойства. Все же
остальные его свойства хранятся отдельно, оставаясь привязанными к
объекту.
Второй вариант, когда онтологии строятся из экземпляров, понятий, атрибутов и отношений.
Экземпляры – это основные нижнеуровневые компоненты онтологии: физические (разные реальные объекты) или абстрактные (числа,
слова, модели).
Классы (иногда их называют понятия) – это абстрактные агрегированные наборы, группы объектов, включающие в себя экземпляры,
другие классы и их сочетания. Например, класс (понятие) «животные»,
153
вложенный в него класс (понятие) «люди», вложенный в него класс
(понятие) «человек». В зависимости от конкретного построения онтологической модели «человек» может рассматриваться вложенным
классом (понятием) или экземпляром (индивидом).
Атрибуты – это вспомогательные элементы онтологии, имеющие
имя и значения, необходимые для отражения специфичных особенностей объекта и позволяющих определять отношения (зависимости,
связи) между объектами онтологии. Часто отношение представляется в
виде атрибута, значением которого является другой объект. Например,
в онтологиях, связанных с продуктом или товаром (автомобиль, трактор, микропроцессор, компьютер), в котором новая модель В продукта
является наследником предшествующего продукта А, отношение между моделями можно определить как атрибут объекта В со значением А.
Подобные предопределенные отношения наследования существуют в
разных языках описания онтологий – формализованных языках, предназначенных для кодирования онтологий. В настоящее время существует более десятка таких языков.
Онтологии конкретной задачи – это те, которые определяют общую терминологическую базу этой задачи, решаемой проблемы.
Наконец, сетевые онтологии используются для описания конечных результатов действий, выполняемых объектами предметной области или конкретной задачи.
Формализовано онтологию О можно представить в виде O ( K ,
R, F ) , где K – конечное множество концептов (понятий, терминов),
R – конечное множество отношений между концептами, а F – конечное
множество функций интерпретации, заданных на концептах и/или отношениях.
В заключение обратим внимание на двойственность природы
онтологии и на критерии, определяющие ее содержание (см., например, [22]).
Двойственность онтологии проявляется в следующем. С одной
стороны, на семантическом уровне она представляет собой отображение во всех возможных конкретных ситуациях множества объектов из
определяемой ею области в множество отношений, с другой – на синтактическом уровне она формализует это отображение с помощью онтологических теорий и соглашений, использующих формальные знания о связях значений отношений, классов, других определяемых
терминов, свободных от конкретной ситуации.
154
Что касается критериев содержательности онтологий, то выделяют пять из них [22].
Критерий ясности отражает эффективность онтологии передавать подразумеваемые значения терминов.
Критерий согласованности определяет согласованность аксиом
и описаний всех терминов, используемых в теории онтологии.
Критерий расширяемости устанавливает допустимые границы
возможного применения создаваемой онтологии.
Критерий минимизации проблем с кодированием связан с предпочтительным выбором средств кодирования данных и знаний на символьном уровне с учетом форматов их представления.
Критерий минимизации онтологических соглашений сводится к
желанию налагать минимальные ограничения на моделируемую предметную область при условии достаточности этих ограничений для решения всех предполагаемых задач.
Характерной особенностью онтологических моделей является их
объективность, универсальность и интегративность. Под объективностью здесь понимается независимость от субъективных мнений отдельных экспертов, обеспечиваемая путем поиска согласия среди специалистов соответствующей области знаний или предметной области.
Универсальность означает, что онтологические модели позволяют
учитывать как базовые отношения понятий, независимые от контекста
решаемой задачи (причинно-следственные, обобщения и агрегации),
так и отношения, возникающие в контексте решаемой задачи, описываемые не предикатной, а дискриптивной (описательной) логикой. Интегративность – пригодность онтологических моделей для объединения
разнородных данных и знаний специалистов в различных областях знаний и использования опыта решения одних задач для других.
Еще один класс моделей знаний, аналогичный моделям данных,
графический, визуальный, рассчитанный на непосредственное восприятие их человеком или информационной системой.
Помимо знаний, как указывалось в части 1, § 1.3, в состав информации входят протознания или «скрытые знания» (hidded knowledge),
т. е. то семантическое содержимое в Данных, которое можно преобразовать в знания с использованием хорошо формализуемых алгоритмических процедур традиционного анализа Данных (см. предыдущие
разделы пособия) или в которых можно обнаружить, выявить либо добыть новые, релевантные для пользователя знания с помощью интеллектуального анализа Данных (см. далее гл. 4). В связи с этим возника155
ет необходимость введения моделей представления протознаний и/или
моделей получения релевантных знаний из протознаний или анзний,
как их носителей. Понятно, что, с одной стороны, для «скрытых» протознаний, явно не выделяемых из данных, подходят все известные способы модельного представления данных, с другой – для знаний, выделенных из протознаний, подходят все рассмотренные в настоящем
параграфе куализные и куомодные модели представления знаний, как
носителей информации (т. е. анзний). Остаются открытыми вопросы
модельного представления: а) протознаний и б) семантики и прагматики, включая интерпретацию, выделяемых из анзний. Что касается вопросов сущностного представления, т. е. куомодных моделей протознаний и их куализных моделей как более скрытых, чем анзния,
носителей информации, то, насколько известно автору настоящего пособия, таких моделей пока нет. Однако существует несколько подходов, пригодных, во-первых, к получению и накоплению знаний из данных и протознаний, во-вторых, получению новой неожиданной
семантики из анзний. Аспекты сути первого применения таких подходов рассмотрим ниже, а второго – в следующей главе.
Дело в том, что рассмотренные ранее модели знаний относятся к
типу констатирующих, «законовых», отражающих, условно говоря,
детерминированный апостериорный характер знаний, как уже полученных носителей информации – анзний. С точки зрения их оформления, хранения и выполнения с ними других синтактических операций,
они относятся к «априори заданным» для модельного представления в
отличие от только что формируемых, добываемых. Однако к категории
знаний относятся и механизмовые, созидательные, конструктивные,
т. е. такие, которые непосредственно формируются из протознаний в
процессе оперирования с Данными, контентом, метаданными. Для таких знаний характерен индетерминизм, т. е. не состоявшийся факт, который мы констатируем, утверждаем, регистрируем, модельно представляем, а ожидаемое новое, неожиданное, полезное, которое мы
хотим получить и уже после получения представить как «конструктивное» знание в виде шаблонов (образов, паттернов, гипотез, теорий, …).
Тогда на стадии получения таких знаний присутствует неуверенность в
их правдивости (истинности), полезности, что желательно было бы
отражать в модельном представлении подобных создаваемых, выращиваемых, добываемых знаний.
Итак, рассмотрим куарные механизмовые модели получения знаний из части данных – протознаний, названия которых условно пере156
несем на названия куализных моделей получаемых, формируемых знаний, приобретаемых в результате таких процедур, операций.
Аксиоматические модели знаний
Они основаны на описании знаний конкретной предметной области
или решаемой исследовательской или прикладной задачи в виде набора аксиом, на базе которых с помощью формализованных логических
приемов затем осуществляются необходимые рассуждения, доказательства или формируются соответствующие выводы. Тем самым получаются новые аксиоматические знания, требующие, возможно, выполнения дополнительных операций по их валидации (подтверждения
правдивости), релевантности (теоретической или практической пригодности), новизны и т. п. В качестве конструктивных моделей получаемых таким образом знаний являются логические модели (см. в [34]
аксиоматические методы).
Ассоциативные модели знаний
Подобные модели можно условно отнести к индетерминированному обобщению продукционных моделей. Продукционные модели отражают в определенном смысле причинно-следственную связь, согласно которой, если выполяются какие-то условия, при них (из них)
наступают (следуют) какие-то действия и постусловия. В отличие от
них ассоциативные модели также отражают множество одновременного (совместного, не обязательно одномоментного, синхронного) наличия условий и связаны с обнаружением, построением ассоциативных
правил следования. В отличие от продукционных правил следования
ассоциативные ориентированы на индетерминированное (стохастическое, нечеткое, экспертное) суждение [34]. Например, при стохастическом построении правило следования формируется так: «Если удовлетворяются следующие повторяющиеся условия, то вероятнее всего,
произойдут следующие действия … и последствия». Или, иначе: «Если
раньше было …, то, скорее всего, будет …», – и указывается не точечное, а вероятностное, нечеткое, экспертное, интервальное решение,
действие, вывод, т. е. формируется соответствующее индетерминированное ассоциативное знание. Например: «Если 65 % покупателей
попкорна приобретают еще и напитки, то при установке скидок на
попкорн и/или на напитки этот процент, скорее всего, повысится». Или
«Если сдается в эксплуатацию жилой дом, то, скорее всего, в течение
первого месяца после заселения следует ожидать увеличения покупателей новых холодильников и отделочных материалов, в ближайшие
157
месяцы – кухонной мебели и утвари и т. д.». Если же при этом есть
предыдущая статистика, то можно указать, с какой вероятностью можно ожидать подобные ассоциативные следствия.
Эвристические1 модели знаний
Они основаны на предварительном априорном введении эвристик и
добывании, самополучении новых знаний исследователем, обучаемым,
экспертом или интеллектуальной, в частности экспертной, системой.
Под эвристиками здесь понимаются исходные посылки, наводящие
вопросы, подсказки, а также совокупность логических приемов и методических правил теоретического исследования и отыскания истины,
обучения, способствующих развитию находчивости, активности мышления, продуктивного творчества. Сюда в определенной степени относятся не только формирование семантики знаний, но и выявление их
прагматики, а также практических аспектов получения знаний через
эвристические функции. Под ними понимают функции (правила, зависимости), позволяющие вычислять определенную выгодность, полезность, затратность (стоимость, эффективность) каждого следующего
шага создания эвристических моделей знаний (см. [34]).
Наконец, эволюционные2 модели знаний – это модели, во-первых,
получаемые путем последовательного преобразования, улучшения по
каким-то критериям предшествующих, имеющихся, их плавного развития; во-вторых, отражающие динамику, эволюцию развития объектов, к которым относятся знания. Конкретные разновидности таких
моделей связаны с конкретным эволюционным описанием объекта
(естественного отбора Ч. Дарвина, наследственности Ж. Ламарка, катастроф Г. де Фриза, прерывистого равновесия Гулда-Элдриджа, гиперциклов Эйгена-Шустера, случайных проб и ошибок К. Полпера,
нейтральной эволюции М. Кимура, синтетической эволюции Д. Дубинина [54]) и соответствующим такому описанию представлениям знаний (см. гл. 4, в которой будут также рассмотрены вопросы модельного представления неявных знаний и управления знаниями).
Сопоставление разных моделей знаний дано в табл. 2.4.
1
Эврика – от греч. радостного восклицания Архимеда: heurēka – «Нашел!», «Открыл!».
2
Эволюция (от лат. evolutio – развертывание) – процесс постепенного, непрерывного, плавного развития, количественного изменения, перехода от одного состояния к другому, в отличие от революции – коренного, качественного изменения, развития, перехода.
158
159
Фреймовая
Продукционная
2
3
Наименование
модели
Логическая
(предикатная)
№
п/п
1
Сложные недерминированные процессы,
исходы которых зависят от взаимодействия большого числа разнообразных
компонент с их поведением, определяемым сложившейся ситуацией, особенно
когда такой процесс надо проигрывать
«параллельно» в реальном времени, а не
последовательно с перерывами между
операциями
Представление логических взаимосвязей
между фактами, фактуальными знаниями, когда требуется строгая формализация и имеется удобный и адекватный
инструментарий, например, язык логического программирования; а при моделировании – ход рассуждений экспертов
Промышленные экспертные системы,
ориентированные на модульность, простоту внесения дополнений и изменений,
наглядность, простоту механизма вывода, последовательную реализацию правил продукции
Используемый аппарат – логика предикатов первого порядка и правила
логических выводов, теории рассуждений
Основой моделей является множество правил – продукций: ядра
«условие – действие, заключение и
постусловие» вида «если А, то В, постусловие С» и прямых и обратных
выводов на множестве этих продукций
Формализованный аналог психологической модели памяти человека и
его сознания, учитывающей процессы восприятия, распознавания, мышления и воображения через описание
однотипных объектов с помощью
фреймов – квантов знаний, их концентраторов, специальных ячеек
(шаблонных понятий) фреймовой
сети
Рекомендуемые области применения
Отличительные особенности
Сопоставительная таблица структурных моделей знаний
Т а б л и ц а 2.4
160
5
№
п/п
4
Онтологические
Наименование
модели
Семантических
сетей
160
Предметные области с хорошо установленной таксономией (см. разд. 1.2.4), когда требуется упростить поиск решения
задач
Основа моделей – ориентированный
граф, вершины которого соответствуют объектам – понятиям (вещам,
процессам, ситуациям, событиям), а
дуги – отношениям между ними типа
«это есть», «часть – целое», «принадлежать», «быть причиной», «входить в», «состоять из», «быть как»,
«больше – меньше», «далеко – близко», «раньше – позже», «иметь» и т.
п. Охватывает только отдельные этапы психической деятельности человека
Формальное описание терминов и
предметных областей, спецификация
концептуализации (выделение признаков понятия, понимания, значения
термина) и отношений между ними,
структурирование предметной области. Онтологическим моделям характерна объективность, универсальность и интегративность
Предметные области и интеллектуальные
системы, выходящие за границы тех, которые основаны только на знаниях, в
частности систем, компоненты коих
должны быть универсальными, легко
расширяемыми, способными работать в
быстро развивающихся открытых системах, когда-либо нет стандартов, либо они
описывают не все требуемые характеристики, параметры. Инструмент конструирования моделей для новой области (знаний, предметной)
Рекомендуемые области применения
Отличительные особенности
О к о н ч а н и е т а б л. 2.4
§ 2.7. ПЕРЕДАЧА И КОДИРОВАНИЕ ДАННЫХ
2.7.1. Элементарные понятия
информационных систем связи
Одной из важнейших синтактических операций с Данными является их передача, осуществляемая средствами связи. На рис. 2.12 представлена обобщенная структурная схема информационной системы
связи (ИИС). На рисунке под линией связи понимается часть окружающей физической среды и совокупность технических средств, позволяющих передавать сигнал (физическое средство переноса информации в пространстве1) от передатчика до приемника. Например, в радио
и телевидении сигналом являются электромагнитные колебания, параметры которых управляются выходным блоком передатчика, а техническими элементами линии связи выступают ретронсляторы, спецблоки спутника связи, станции «Орбита», кабели, маршрутизаторы и
другие элементы.
Исходное
сообщение
Отправитель
Передаваемый
Помеха
сигнал
Передатчик
Линия
связи
Получаемый
сигнал
Приёмник
Получаемое
сообщение
Получатель
Канал связи
Обратная связь
Рис. 2.12. Обобщенная схема информационной системы связи (ИСС)
Одной из важнейших синтактических операций при передаче Данных является кодирование. В общем виде под кодированием понимают преобразование Данных из формы, естественной или удобной для
непосредственного их восприятия, получения, производства (генерирования) и использования (применения), в форму, удобную для сбора,
1
Передача информации во времени – это назначение сигнала в системах
хранения информации (см. определение понятия сигнал в теории связи и
управления, данное в части 1, § 1.3).
161
хранения, передачи и обработки (прежде всего автоматической). Операция, обратная кодированию, называется декодированием. В связи с
этим обобщенно структуры передатчика и приемника системы связи
(см. рис. 2.10) можно представить в виде, изображенном на рис. 2.13.
1
1
0 0
1
0
1
1
0
t
Модель выходного сигнала
цифрового передатчика
Цифровой передатчик
Выходной преобразователь
х(t)
Декодер
Согласователь
Модель выходного сигнала
аналогового передатчика
Согласователь
t
Кодер
Данные
Входной преобразователь
х(t)
Цифровой приемник
Рис. 2.13. Элементы канала цифровой системы связи
Операция кодирования имеет место как для аналоговых, так и для
цифровых сигналов при аналоговом (для сигналов), цифровом (для
данных) и когнитивном (для анзний) (см. следующую главу) принципах построения систем связи. Однако реализуется она при этом поразному.
Например, в аналоговых системах она реализуется в виде модуляции, в цифровых – модуляции, эффективного и помехоустойчивого кодирования (или их комбинаций), в когнитивных – семантической договоренности и т. д. Не вдаваясь в детали, рассмотрим некоторые из них.
2.7.2. Модуляция сигналов
Как уже отмечалось при рассмотрении теоремы отсчетов, детерминированные сигналы (t ; 1 , .., i , ..., n ) с конечным числом п неизменяемых параметров α (1 , .., n ) , в частности периодические
сигналы с финитным спектром, не могут быть переносчиками информации при известной функции, описывающей сигнал: достаточно однократно точно измерить их параметры, чтобы по ним рассчитать все
прошлые, текущие и будущие значения сигналов. Однако такие физи162
ческие детерминированные сигналы (t ) можно использовать как
опорные 0 (t ) (физические несущие), если их параметры (один, два
или все) изменять согласно значениям информативного сигнала (t ) ,
т. е. такого, который несет необходимую пользователю, релевантную
решаемой им задаче информацию, но по каким-то причинам неудобен
для передачи в системе связи. Например, непригоден без кодирования
для построения многоканальных систем (см. следующую главу).
Операция изменения одного или нескольких (разделимых при демодуляции) параметров 1 ,.., n физических сигналов (процессов)
(t ; 1 ,.., n ) согласно изменениям мгновенных значений информативного сигнала (t ) (или описывающей его функции z (t ) ) называется модуляцией. При этом сигнал (t ) (или описывающая его функция z (t ) )
называется моделирующим (моделирующей), а 0 t ; 1 ,.., i ,..., n
(или описывающая его функция x , (t ) x t ; 1 ,..., i ,..., n , в котором
(ой) i изменяется согласно (t ) / Z (t ) /, называется модулированным
(ой). Чаще всего i имеет вид i 0,i (t ) , где 0,i – начальное
(опорное) значение параметра, а – коэффициент пропорциональности,
учитывающий физические размерности и (t ) .
Обратная операция восстановления (t ) по модулированному сиг,
налу (t ) называется демодуляцией.
В качестве носителей (t ) чаще всего выступают: постоянная величина тока, напряжения (такая модуляция называется прямой и обозначается ПМ); колебание (например, синусоидальное, описываемое
функцией x(t ) a sin(2ft ) ), (КМ)), последовательность импульсов
(импульсная модуляция, ИМ).
Если в КМ модулируется амплитуда а, то такая модуляция называется амплитудной (АМ), если частота f (или период T 1 / f ) – частотной (ЧМ), если фаза – фазовой (ФМ). Иногда ЧМ и ФМ называют угловой модуляцией (УМ).
Для периодической последовательности импульсов изменение их
амплитуды согласно (t ) называется амплитудно-импульсной модуляцией (АИМ), изменение частоты f или периода T 1 / f следования
импульсов называют частотно-импульсной модуляцией (ЧИМ); изме163
нение фазы (интервала времени от начала системы отсчета времени до
переднего фронта первого импульса) – фазо-импульсной модуляцией
(ФИМ), а ширины (длительности импульса) – широтно-импульсной
модуляцией (ШИМ). Иногда ФИМ и ШИМ объединяют одним понятием – времяимпульсная модуляция (ВИМ). Ряд авторов вводят еще один
вид модуляции (строго говоря, это не есть отдельный вид модуляции) –
кодо-импульсную (КИМ). Это разновидность одного из предыдущих
видов модуляции, когда параметры импульсной последовательности
отображают кодовые величины (выступающие моделирующими сигналами в периодической импульсной последовательности), или если
используется «квазипериодическая» с периодом Т последовательность
пачек импульсов внутри периода, когда информация передается числом импульсов в пачке (счетно-импульсная модуляция, СИМ).
Внимание! Попробуйте изобразить различные виды модуляции
графически. При затруднении обратитесь к специальной литературе,
например [19].
В аналоговых системах связи, использующих только модуляцию,
кодер и декодер, изображенные на рис. 2.13, представляют собой модулятор и демодулятор. Значительно большие возможности, с точки
зрения кодирования, имеют цифровые системы связи, оперирующие с
цифровыми сигналами, данными или анзниями. Это связано, в частности, с использованием эффективного и помехоустойчивого кодирования
данных. Побудительными мотивами развития этих методов явились
теоремы Клода Элвуда Шéннона для каналов связи. Не останавливаясь
на них подробно, поясним их на понятийном уровне на примере двух
теорем, излагаемых в упрощенной редакции, условно названных «теоремой эффективности» и «теоремой помехоустойчивости».
Однако прежде введем два важных замечания. Первое связано с
понятием пропускная способность канала связи (ПСКС). Под ней
понимается максимальное значение (строго говоря, верхняя грань)
скорости передачи данных по каналу связи (для двоичного канала –
двоичных единиц (бит) в секунду, т. е. бод = бит/с) при заданных фиксированных ограничениях на параметры канала. Заметим, что ПСКС
есть характеристика именно канала связи. Она никак не зависит от источника данных, от реальной физической скорости передачи данных,
хотя и ограничивает ее. Если же физическая скорость передачи канала
меньше его пропускной способности или канал допускает возможность изменения тех или иных его параметров (длительности сигнала,
способа кодирования или декодирования и пр.), то они выбираются из
164
условия получения наибольшей скорости передачи данных, т. е.
ПСКС, и приближения реальной скорости к ПСКС. Второе замечание
связано с использованием в теоремах К.Э. Шеннона энтропии как меры стохастической неопределенности данных, передаваемых по каналу. Она будет рассмотрена в гл. 4, поэтому постараемся пока обойтись
без нее. Для конкретизации положим, что выходным кодом кодера является двоичный (см. рис. 2.13). Символы алфавита дискретного сообщения назовем буквами, оставив слово символ за алфавитом кода, а
совокупности символов кода, соответствующих некоторой букве, – ее
(буквы) кодовой комбинацией.
2.7.3. Эффективное кодирование
Теорема эффективности: в цифровых системах связи без помех
можно найти такой способ кодирования исходных сообщений, при котором среднее число n ncp двоичных символов в канале связи на
один символ (букву алфавита x1 ,..., xk ) исходного сообщения будет
минимальным.
Реальное значение nср определяется рядом факторов. В частности,
вероятностями появления букв xi , i 1, k исходного сообщения, статистической зависимостью букв xi в их последовательности, представляющей исходное сообщение (например, букв русского алфавита в
передаваемом на русском языке сообщении), используемым способом
кодирования (перевода xi , i 1, k , или l-грамм (сочетаний из l смежных букв xi в последовательности букв сообщения), вероятностями
появления l-грамм. Данная теорема1 не указывает, каков должен
быть способ кодирования, но дает направление его поиска. Способ
кодирования должен быть таким, чтобы каждый символ кодовой комбинации, соответствующей кодируемому символу xi или l-грамме сообщения, т. е. для двоичного кодера – символы 0 или 1 в каждой позиции кодовой комбинации, появлялись по возможности (идеально,
точно) с равными вероятностями, а каждый кодовый символ (в двоичном случае 0 или 1) был независим от значений предыдущих символов
комбинации.
1
Как и другие подобные теоремы К. Шеннона, в частности, теорема помехоустойчивости (см. далее).
165
В качестве простейшего примера рассмотрим ситуацию, когда
между буквами (символами) исходного сообщения нет взаимосвязи.
Для нее сходные эффективные методы кодирования предложили Шеннон и Фано (Фэно), а сам эффективный код получил название кода
Шеннона–Фано. Суть метода кодирования (кода) базируется на следующих идеях. Если буквы xi неравновероятны, то следует использовать
для их кодирования неравномерный код, т. е. код с разным числом
символов (двоичных позиций, разрядов) для разных букв. Буквы с
бóльшей вероятностью появления кодировать наименьшим числом
позиций. Проводить бинарное ступенчатое (попозиционное) кодирование букв. Для определения символа «0» или «1» для первой слева позиции кодовой комбинации, соответствующей всем буквам алфавита,
разделяем все буквы, предварительно упорядочив их по значениям вероятности появления, на две группы так, чтобы суммы вероятностей
букв в каждой группе были как можно ближе друг к другу (идеально –
равны). Для букв одной группы ставим в 1-й позиции (в 1-м разряде)
кода 0 (или 11). Затем каждую из групп делим по тем же правилам на
подгруппы и продолжаем такое деление до тех пор, пока не поставим в
соответствие каждой букве выстроенную для нее кодовую комбинацию. Если вероятности появления букв равны 2 k , k 1, 2, 3,..., p , то
среднее число символов кода на одну букву будет минимальным, т. е.
обеспечивается наибольший эффект сжатия передаваемой последовательности букв x1x2 x1 x3 x2 x4 ... сообщения с помощью такого кодирования. В других ситуациях эффект сжатия будет тем ближе к наилучшему, чем ближе будут друг к другу две суммарные вероятности
попадания в бинарно построенные группы и подгруппы, т. е. вероятности появления 0 или 1 в соответствующей позиции кода. Два примера
кодирования по Шеннону–Фано приведены в табл. 2.5. Для второго
примера отличные от первого примера вероятности появления букв с и
d, или x1 , x4 , приведены в скобках второго столбца таблицы.
Если бы буквы, приведенные в табл. 2.5, кодировались равномерным кодом, например, x1 00 , x2 01 , x3 10 , x4 11 , то среднее
число n символов кода на одну букву равнялось бы 2, а средняя дли1
Выбор символа «0» или «1» в конкретном случае реализации метода
определяется техническими, энергетическими и прочими соображениями,
связанными с предпочтением передать сигнал, соответствующий символу «0»
или «1».
166
тельность передачи буквы в сообщении равнялась 2 . При эффективном кодировании для обоих примеров n (0,5 1 0, 25 2
0,125 3 0,125 3) 1,75 , а 1,75 . Отсюда легко получить значение выигрыша в скорости передачи кодовых последовательностей по
каналу связи.
Т а б л и ц а 2.5
Буквы
(символы)
исходного
сообщения
(например,
о состоянии
S объекта)
Пример построения кода Шеннона–Фано
Номер позиции
Символы
кода при делекода
Вероятность нии на группы
по номерам
появления
по равенству
его позиций
буквы
вероятностей
1
a (х1, S1)
0,5
b (х2, S2)
0,25
c (х3, S3)
d (х4, S4)
2
I
I
II
1
2
3
0
0,125
(0,15)
3
I
Длительность
символов
кода в сигнале на входе
линии связи
2
1
0
1
1
0
3
1
1
1
3
II
0,125
(0,1)
II
Как видно из табл. 2.5, кодовые группы имеют две важные особенности. Первая – в них 0 и 1 встречаются в группе примерно одинаково
часто: в первом примере вероятности их передачи в соответствующей
позиции равны. Например, вероятность появления 0 и 1 в 3-й позиции
в первом примере равна 0,125. Однако во втором примере в 3-й позиции P (0) 0,15 , P (1) 0,1 . Вторая – код Шеннона–Фано является
префиксным, т. е. таким, который допускает однозначное декодирование последовательности их кодовых комбинаций, соответствующей
конкретной последовательности букв, без введения дополнительных
(разделительных, межкомбинационных, межбуквенных) символов,
например, последовательности кодовых комбинаций, соответствующих сообщению x1x2 x4 x3 x1x4 ... . Кодирование по этому методу имеет
167
ряд недостатков. Первый, неоднозначность построения кода, когда
букв много и их вероятности сильно отличаются от 2 k , k 1, 2,... . От
этого недостатка свободна методика Хаффмена. Она основана на последовательном от меньших вероятностей к большим группировании
букв и каждый раз после такой перегруппировки перенумеровке групп
построения эффективного кода (см., например, [19]). Второй недостаток кода Шеннона–Фано – он не учитывает наличие зависимости между буквами. Этот недостаток устраняется путем перехода от кодирования отдельных букв последовательности x1x2 x4 x3 x1 x4 к кодированию
диграмм x1 x2 , x2 x4 , x4 x3 , …, триграмм x1x2 x4 , x2 x4 x3 , x4 x3 x1 , …,
l-грамм. При этом также достигается дополнительное повышение эффективности для букв с плохо группируемыми вероятностями. Примеры подобного кодирования можно найти в [19], а также нетрудно привести самостоятельно. Значение l определяется с учетом зависимости
букв между собой, сложности кодера и декодера, согласователей (см.
рис. 2.13), выполняющих, в частности, функции буфера из-за разной
длины кодовых комбинаций букв или l-грамм.
2.7.4. Помехоустойчивое кодирование
Теорема помехоустойчивости – если Р – средняя мощность сигнала на выходе канала связи с частотной полосой пропускания, ограниченной W f в [Гц], а помеха (см. рис. 2.12 и 2.13) представляет собой
«белый» шум1 мощностью N с равномерным спектром в полосе с верхней частотой W fв , то можно найти такой способ кодирования, при
котором можно передавать все сообщения, вырабатываемые отправителем, со скоростью, сколь угодно близкой к пропускной способности
канала связи (предел Шеннона)
PN
C W log
,
N
1
(2.13)
Белый шум – это шум, моделью которого является некоррелированный
стационарный процесс с гауссовским (нормальным) законом распределения, с
нулевым средним и дисперсией DN = N, т. е. имеющий равномерную (константа) спектральную плотность мощности вдоль всей оси частот f.
168
со сколь угодно малой частостью (теоретически – вероятностью) ошибочного опознания любого передаваемого сообщения. Обратное
утверждение теоремы – никакой метод кодирования не допускает длительной передачи сообщений со скоростью, большей пропускной способности линии связи с малой вероятностью (частостью) ошибок. Отсюда следует, что с малой вероятностью ошибки можно длительно
передавать только сообщения, вырабатываемые со скоростью, не превышающей пропускную способность канала, определяемую по (2.13).
Для двоичных каналов логарифм в (2.13) берется по основанию 2, а
существо теоремы можно изложить так: если скорость поступления
сообщений в дискретной системе связи с шумом меньше пропускной
способности канала, то существует код, позволяющий вырабатывать
двоичные символы и передавать сообщение со сколь угодно малой вероятностью ошибочного декодирования символов. Если же скорость
передачи больше пропускной способности канала, то вероятность
ошибочного приема (воспроизведения) сообщения не может быть произвольно малой.
Оригинальная формулировка приведенной теоремы относится к
одной из замечательных заслуг К. Шеннона. Во-первых, до нее бытовало мнение, что в каналах с помехами с повышением требований к
вероятности правильного приема сообщений скорость их передачи
должна уменьшаться. Во-вторых, теорема позволяет оценивать эффективность используемых методов кодирования (включая модуляцию) в
конкретных системах связи. В-третьих, теорема хотя и не содержит
алгоритмов подобного одновременного помехоустойчивого и эффективного кодирования, нацеливает на их поиск. Разработка таких методов не заставила себя ждать. Недаром на бронзовом листе могильного
памятника К. Шеннона изображено соотношение (2.13) по аналогии с
E mc 2 на памятнике А. Эйнштейна.
Одним из вариантов достижения предела (2.13) является двухступенчатая процедура: вначале эффективное, затем соответствующее
помехоустойчивое кодирование.
Основная идея обеспечения помехоустойчивости передачи сообщений путем кодирования заключается во введении избыточности кода и
проявляется в трех аспектах. Прежде чем переходить к их рассмотрению, введем необходимые понятия.
Число символов d, в которых две кодовые комбинации (или последовательности) одинаковой длины отличаются друг от друга, называ169
ется кодовым расстоянием Хэмминга. Оно равно числу единиц в
сумме этих комбинаций по модулю 2 (обозначается ). Например, кодовое расстояние d между комбинациями 1000111001 и 1101001010
равно 6, поскольку 1000111001 1101001010 = 0101110011 (перепишите для наглядности сложение в столбик!).
Кратность ошибки при передаче кодовой комбинации, соответствующей букве х, есть количество искаженных в ходе передачи символов в комбинации, т. е. кодовое расстояние Хэмминга между переданной и принятой комбинациями, приписываемыми букве х.
Кодовая комбинация, имеющая единицы в позициях (разрядах),
подвергшихся искажению, и нули во всех остальных позициях, называется вектором ошибок переданной комбинации. Это значит, что
любая искаженная комбинация есть сумма по модулю 2 разрешенной
комбинации и вектора ее ошибки.
Возможная причина искажений в канале с помехами иллюстрируется рис. 2.14.
х(t)
z(t) – помеха
х(t) + z(t)
х(t)
кодовый сигнал х(t)
порог
z(t)
t
t1
t2
t3
t4
t5
t6
t7
t8
Т
Рис. 2.14. Модельное пояснение причины возможного появления ошибок
На рисунке изображено искажение помехой двоичного сигнала в
линии связи и преобразование его в согласователе приемника (см. рис.
2.12 и 2.13) в кодовую комбинацию путем измерения значений сигнала
в моменты времени t1 , t2 ,... и сравнения их с порогом, по итогам которого принимается решение о символе «0» или «1» в соответствующей
позиции принятой кодовой комбинации. Как видно из рис. 2.14, была
170
передана комбинация 10011010, а принята 11000010, т. е. в процессе
передачи сигнала до декодера произошла трехкратная ошибка (d = 3).
Первый аспект идеи кодовой избыточности заключается во введении дополнительных позиций в кодовые комбинации каждой буквы по
сравнению с минимально необходимым (информационным) их количеством. Для примера рассмотрим равномерное кодирование. Пусть число букв алфавита исходного состояния таково, что его можно закодировать k информационными двоичными разрядами, т. е. представить
все буквы кодовыми комбинациями, содержащими k позиций (разрядов, длины k). Идея избыточности – для повышения помехоустойчивости передачи кодовых комбинаций надо кодировать буквы двоичными
комбинациями из n k позиций (п разрядами, двоичными символами).
Ясно, что в этом случае k символов являются информативными, а
n k 0 – избыточными для обозначения всех букв алфавита сообщения.
Второй аспект. Поскольку п-позиционный двоичный код позволяет получать 2n 2k при n k комбинаций, то l, 2k 1 l 2k , из них
будем считать приписанными к l буквам алфавита, разрешенными
(верными, соответствующими буквам алфавита), а остальные запрещенными, неразрешенными, искаженными.
Третий аспект. Закодируем буквы так, чтобы кодовые расстояния
между разрешенными комбинациями были попарно максимальными из
возможных, а сам код допускал наличие q таких комбинаций при q l .
Тем самым минимизируется допустимая (предельная) кратность ошибок в разрешенной комбинации, при которых она не сможет перейти в
другую разрешенную комбинацию. Сделаем в связи с изложенным два
замечания.
1. Для обнаружения ошибок, проявляющихся в искажении переданных комбинаций кратностью p r , необходимо, чтобы минимальное кодовое расстояние между любыми разрешенными комбинациями
d min удовлетворяло условию d min r 1 . Для исправления ошибок
кратностью p s и одновременно обнаружения ошибок кратности q r ,
при r s должно выполняться условие d min r s 1 .
2. Как следует из изложенного, чтобы п-значный двоичный избыточный код обладал способностью исправлять взаимно независимые
ошибки кратности s и менее , надо, чтобы число разрешенных комбинаций в нем (т. е. таких, для которых попарное кодовое расстояние
171
d min между всеми разрешенными комбинациями было не менее
d min 2s 1 ) удовлетворяло пределу Хэмминга
2n
s
Cni ,
(2.14)
i 0
где Cni – число сочетаний из п по i. При d min 1 (непомехоустойчивое
кодирование) 2n ; при d min 2 (обнаружение однократных ошибок) 2n1 ; при d min 3 (намерение обнаружить одно- и двукратные ошибки и исправить однократные ошибки) 2n (n 1) , т. е. при
d min 3 и n 3 2 . Для n 4 и s 1 число разрешенных комбинаций 3, 2 , а для n 5 5,3 . Подчеркнем важное пояснение неравенства (2.14). Оно указывает теоретическую границу значения п, а
именно минимально возможное число n k избыточных проверочных
символов, ниже которого соответствующее кодирование невозможно.
Дело в том, что, во-первых, для каждой из 2k 1 ненулевых комбинаций k-разрядного безызбыточного кода необходимо поставить в соответствие различные, в том числе разрешенные, комбинации из п символов. Часто значения символов в n k проверочных разрядах такой
комбинации устанавливают путем суммирования по модулю 2 значений символов в определенных информационных разрядах. Если результатом суммирования является нуль, то это означает, что сумма
единиц в разных позициях (разрядах) кода четная, если единица, – нечетная. Однако определяемое неравенством (2.14) минимальное п
очень часто невозможно реализовать практически, поскольку реально
п должно быть бóльшим, чем следует из (2.14). Это связано с двумя
причинами.
Первая причина. При исправлении s-кратных ошибок необходимо
установить не только факт наличия таких ошибок, но и определить, в
каких из позиций кода произошли эти ошибки. Для этого используется
опознаватель ошибки, и на приемном конце производится сопоставление каждой подлежащей исправлению ошибки с ее опознавателем,
вводимым для каждой разрешенной комбинации. Опознаватель ошибок – это контрольная последовательность символов, каждый символ в
172
которой определяется так, чтобы в приемнике выполнялась справедливость того равенства, которое было поставлено для определения значений проверочных символов при кодировании. Тем самым обеспечивается возможность по принятой комбинации определить, в каких
s-разрядах какой-либо разрешенной комбинации могла произойти исправляемая s-кратная ошибка или ошибка меньшей кратности.
Например, для исправления всех одиночных независимых ошибок
п-позиционного кода необходимо исправить п ошибок (по одной в любой из п позиций). Следовательно, опознавателей должно быть не менее п, а число добавочных проверочных разрядов n k должно быть
таким, что n 2n k 1 , чтобы закодировать не только п искаженных
комбинаций, но и разрешенную, переданную без искажения. В частности, для k 2 и n 5 требуется 5 < 7 опознавателей.
Вторая причина. Не следует забывать, что при передаче кодовой
комбинации может появляться ошибка такой кратности, когда разрешенная переданная комбинация переходит в другую разрешенную или
в такую другую искаженную, которая может получиться из другой
разрешенной комбинации при ошибке меньшей кратности. Например,
при k 2 и n 4 , т. е. при использовании кода (4,2) для кодирования
четырех букв x1 , x2 , x3 , x4 или четырех исходных сообщений 00, 01, 10,
11, можно было бы ввести следующие разрешенные комбинации: для
x1 00 0000 ; для x2 01 0101 ; для x3 10 1011 ; для
x4 11 1110 . Для них d1,2 2 , d1,3 3 , d1,4 3 , d 2,3 3 , d 2,4 3 ,
d3,4 2 . Следовательно, для кодовых комбинаций, соответствующих
буквам x1 и x2 или x3 и x4 двукратная ошибка в 1-м и 3-м справа
разрядах может перевести одну разрешенную комбинацию в другую.
При k 2 и n 5 (см. далее рис. 2.15, в) ошибки могут однозначно
исправляться, если они действительно однократные, но при возможности двукратных ошибок они однозначно определяются, но исправление однократных ошибок выполняется не по однозначности, а по
убеждению, что соответствующая исправляемая комбинация получилась, скорее, при однократной ошибке, нежели при двукратной. Тем
самым может быть допущено ошибочное отнесение соответствующей
кодовой комбинации к разрешенной. Изображенные на рис. 2.15, в
комбинации, находящиеся в пересечении множеств, могут появиться
как от однократной ошибки в одной разрешенной комбинации, так и
173
при двукратной ошибке в другой или даже двух других разрешенных
комбинациях.
Если использовать такое кодирование, то максимальное число кодовых комбинаций на входе декодера, не совпадающих ни с одной
разрешенной, будет равно 2k 2n 2k , т. е. 1 2k / 2n от общего
числа возможных комбинаций. При этом 2k разрешенных комбинаций
могут быть переданы безошибочно, а 2k 2k 1 комбинаций могут
перейти в другие разрешенные комбинации. Последние случаи соответствуют необнаружению ошибок только путем сравнения разрешенных и принятых комбинаций. Если, вычисляя кодовое расстояние dij
между i-й принятой и всеми разрешенными комбинациями, можно
найти такую j-ю разрешенную, для которой кодовое расстояние dij r
будет строго меньше, чем dis при других s j , то это наводит на
мысль, что передавалась j-я (разрешенная) комбинация, но в канале
произошла r-кратная ошибка. Поэтому вместо принятой i-й неразрешенной комбинации выбирают j-ю разрешенную, тем самым не только
обнаруживая, но и исправляя r-кратную ошибку. Нетрудно убедиться,
что отношение числа исправляемых таким образом ошибочных кодовых комбинаций к общему числу обнаруживаемых равно 1 / 2k и не
зависит от п.
Идею такого кодирования поясняет рис. 2.15.
На рис. 2.15, в приняты следующие обозначения: направление
возможных однократных ошибок;
направление возможных исправлений однократных ошибок, направление возможных двукратных
ошибок. На рисунке жирным шрифтом изображены разрешенные кодовые комбинации, соответствующие буквам x1 ,..., x4 (помечены черным квадратом), y на рис. 2.15, б и 2.15, в и x на рис. 2.15, в соответствуют искаженным (неразрешенным) комбинациям. Причем x
соответствует комбинациям, в которых произошла однократная обнаруживаемая и исправляемая ошибка, а y на рис. 2.15, в – двукратно искаженным, обнаруживаемым, но не исправляемым комбинациям.
Например, комбинация 00011 может появиться при однократной
ошибке из комбинации 10011 (разрешенной для x2 ), а также при
двукратной от разрешенных комбинаций, соответствующих x1 и x4 .
174
00
001
d1,2=1
01
х2
х1
d2,3=1
y4
100
011
х2
х1
d4,2=2
d1,4=1
y1
000
y2
010
d1,3=2
10
х3
х4
101
11
d3,4=1
y3
х4
111
а
б
11011
10111
x1
00011
10001
10010
00000
00001
00010
y1,
y4
x1′
01111
10000
00100
01000
x 4′
x4
110
d x1 , y3 d x2 , y4 d x4 , y2 3 ;
обнаружение однократной ошибки;
d1,2 = 2, d1,3 = 2, d1,4 = 2, d2,3 = 2, d3,4 = 2
Передача в канале без искажений
00101
00110
01001
01010
х3
y4
x2 10011
y1
x2′
11000
10100
y2
01100
11110
11101
y3
01101
01110
11111
00111
01011
x3′
y1
10101
10110
11001
11010
y4
y2,
y3
11100
y3
x3
y2
Исправление однократных и обнаружение двукратных ошибок
в
Рис. 2.15. Пояснение идеи обнаружения и исправления ошибок в линиях
связи путем добавления «избыточных» разрядов кода по сравнению
с минимально необходимым их количеством
175
Ясно, что при кодировании по рис. 2.15, а любая ошибка кратности
r 1 переводит одну разрешенную комбинацию в другую. Поэтому-то
здесь и нельзя не обнаружить, ни тем более исправить ошибки. При
кодировании по рис. 2.15, б одна и та же искаженная комбинация может получиться из двух «соседних» разрешенных при однократной
ошибке и из удаленных «противоположных» разрешенных при трехкратных ошибках (см. примеры на рисунке), а двукратные ошибки переводят одну разрешенную комбинацию в другую. Поэтому-то мы и
можем только обнаружить наличие ошибки (одно- или трехкратной),
но не можем исправить ни одну из них. Охарактеризуйте по аналогии
сами рис. 2.15, в. Рассмотрите, например, переходы разрешенных комбинаций в другие при кратности ошибок, равной 1, 2, 3 и 4.
Мы лишь заметим, что для кодирования четырех букв двоичным кодом надо иметь четыре разрешенных комбинации, т. е. d min 2 1 3 .
Это значит, что согласно (2.14), избыточный код для кодирования x1 ,
x2 , x3 и x4 с обнаружением одно- или двукратных ошибок и исправлении однократной ошибки должен иметь n 5 разрядов. Именно это
и изображено на рис. 2.15, в. Сделаем два замечания. Во-первых, для
того чтобы при кодировании x1 , x2 , x3 , x4 так, чтобы можно было обнаружить и исправить переход разрешенной комбинации в разрешенную, надо иметь d min 9 . Во-вторых, разрешенные комбинации
рис. 2.15, в получены по методу Хэмминга построения кода, исправляющего одну ошибку, когда информационные разряды – это 3 и 5, а
контрольные – 1, 2 и 4. При этом для 3 , 5 перебираются комбинации 00, 01, 10, 11, а значения 1 3 5 , 2 3 , 4 5 .
Коды, позволяющие исправлять ошибки, называются корректирующими. Если искажения символов кодовой комбинации взаимно независимы, то лучшие корректирующие коды такие, у которых разрешенные комбинации находятся на одинаковых максимально возможных
расстояниях друг от друга (см. рис. 2.15). Для многих помех при независимых ошибках вероятность появления ошибки кратности r меньше,
чем кратности p r . В этих случаях, как следует из изложенного, рассмотренные коды позволяют обнаруживать и исправлять не все, а
только наиболее вероятные для такого канала связи малократные
ошибки.
176
Отношение R (n k ) / k называют избыточностью кода1. Коды,
обеспечивающие требуемую корректирующую способность при минимально возможной избыточности, называют оптимальными.
В настоящее время разработано множество кодов и методов кодирования, позволяющих не только обнаруживать факты наличия ошибок, но и устанавливать позиции, в которых они произошли.
Например, из простейших, ориентированных на обнаружение однократных ошибок, используются следующие методы кодирования: с
проверкой на четность (добавляется дополнительная контрольная позиция (разряд), в который записывается сумма по модулю 2 всех символов исходной и проверяется совпадение суммы принятой комбинации с контрольным символом); с удвоением элементов, когда «1»
представляется как 10, а «0» как 01; инверсное – повторение исходной
комбинации, если она содержит четное число единиц, или инверсной,
если нечетное; Хэмминга, построенного на (n – k)-кратной проверке
принятой комбинации на четность, что позволяет не только устанавливать наличие ошибки, но и ее положение в кодовой комбинации, линейные (групповые) блочные коды, циклические, сверточные, алфавитные, Вагнера, учитывающие вероятности искажения символов, и
другие.
В заключение отметим, что выбор кода (метода кодирования) является одной из двух важнейших задач теории кодирования. Вторая важнейшая задача теории – описание источника помех, при котором указывается ограничение на число ошибок или задаются вероятностные
характеристики источника.
ЗАКЛЮЧЕНИЕ
Основное внимание в настоящей главе уделено тем синтактическим операциям, которые по отдельности или в совокупности присутствуют во всех технологических процессах работы с Данными. Это
1
Со словом избыточность в приложении к сочетанию «избыточность
данных» или «избыточность отсчетов», «сжатие данных» мы уже сталкивались в § 2.2. Там оно понималось как избыточное количество отсчетов, необходимых для решения конкретной задачи. В § 2.2 и других мы встречались
также с «элементной избыточностью данных», связанной с наличием существенной корреляции между элементами выборки. Здесь же речь идет о «кодовой избыточности». Понятно, что в первых двух случаях можно ввести
свои показатели избыточности отсчетов, элементов, данных.
177
178
Динамики
и Каким образом и как Фазовых траекторий, катамеханизма раз- происходит развитие? строф; игровые; самооргавития
низации; вейвлетные, динамического спектрального
анализа; автоматов
5
178
Состав и правила обра- Графовые, включая сетезования связей
вые, графические диаграммные, автоматов
Структурные
4
Как часто появляются Распределения вероятноотдельные экземпляры, стей, спектральные функзначения?
ции и плотности, скедастические функции; функции
принадлежности; графовые
Наличие, вид, характер, Характеистики связи слунаправление,
значи- чайных векторов и функмость (уровень) связи ций, связности графов;
иерархические,
сетевые,
реляционные
Связи
Распределения
(встречаемости)
Прикладные
примеры
Таблица химических
элементов Менделеева, таблица растений К. Линнея; классификации животных
Визуальные
Распределение размеров частей тела,
доходов населения,
потоков заявок, числа заболевших
Графовые,
Транспортные сети;
сетевые
связь
количества
вида заболеваний с
параметрами окружающей среды; связь
отказов системы с
режимами ее работы
СемантичеСтруктура инфорских сетей,
мационной системы,
визуальные
базы данных, системы управления
Фреймовые,
Развитие эпидемии,
онтологичезаболевания
конские, визуаль- кретного органа, воные
енных учений, поведения объекта
Примеры потенциально пригодных
моделей
Наименование
Суть
сигналов и данных
знаний
Разнообразия
Наличия
различных Распознавания
образов, Логические
видов, типов, семей, классификации, кластериклассов
зации; графов
Закон. Закономерность
3
2
1
№
п/п
Виды законов и закономерностей и соответствующие им модели
Т а б л и ц а 2.6
179
Следования
9
179
Приспосабли- Способности объекта Различные модели адаптаваемости
изменять свою струк- ции и адаптивные модели
(адаптивности) туру, правила поведения и параметры при
изменении внешних и
внутренних факторов
Появления и проявления следствий, поведений, ситуаций и т. п.
при определенных причинах, факторах, условиях
Логические,
визуальные
Визуальные,
продукционные, ассоциативные
Адаптивные,
адаптационные; управления знаниями;
интеллектуального
анализа
данных (гл. 4)
Детерминированные, сто- Продукционхастические с последстви- ные; ассоциаем; игровые; оптимизаци- тивные; управонные
ления знаниями
(гл. 4); ситуационного управления (гл. 4)
Регрессионного анализа для
аддитивных и скедастического анализа для мультипликативных трендов нестационарных стохастических моделей процессов;
вейвлет, динамического и
сингулярного спектральных
анализов
Повторяемости Наличие, вид и характер Корреляционный, конкорпериодичности,
цик- реляционный, спектральличности
ный анализы; выявления
скрытых периодичностей
Тенденций раз- Проявляющиеся
на
вития
большом
диапазоне
значений независимых
переменных
8
7
6
Сезонные заболевания; годовые колебания температур;
экономические
и
социальные циклы;
биоритмы организма
Аккомадация глаза;
адаптация человека
и искусственных систем к изменению
условий; перестройка
фирмы в новых условиях
Последствия принятых или непринтых
решений; изменения
погоды; хода выздоровления; поведения
системы при новых
условиях
Курсы валют, изменения климата, старение организма и
технических систем
180
Наличия способности к
равновесию и условий
его сохранения
12 Креативности
Способности к творчеству, самообучению,
познанию, самосовершенствованию
13 Интерпретиру- Прозрачности, доступемости и реле- ности
предметному
вантности
пользователю, рентабельности, эффективности, …
14 Другие
Закон. Закономерность
11 Устойчивости
№
п/п
180
Эвристических функций,
полезности и эффективности
Фазовых траекторий; катастроф; теории устойчивости
Экспертные
Прикладные
примеры
Появление и проявление новых качеств
исследуемых объектов при изменении
структуры
Продукцион- Выявление причин,
ные; ассоциа- характера и условий
устойчивости
тивные
Логические;
Выявление фактов и
эвристические условий появления
новых
знаний/решений
Продукцион- Решение
любых
ные
прагматических
задач
Примеры потенциально пригодных
моделей
Наименование
Суть
сигналов и данных
знаний
10 Синергетично- Проявления сложно- Сложности,
диссипатив- Фреймовые;
сти
сти, эмерджентности, ных структур; бифуркаций; онтологичеэкспертные
ские; визуальнеопределенности
ные
О к о н ч а н и е т а б л. 2.6
операции дискретизации и квантования сигналов, хранения данных и
знаний, передачи и кодирования сигналов и данных.
Акцент при этом сделан на модельные представления как самих
операндов технологических процессов, так и преобразований операндов, а именно сущности модельного представления, их слабым и сильным свойствам, качествам, примерам, а также вопросам практического
применения. Еще раз внимание читателя обращается на наличие различных модельных представлений объектов и их привязки к конкретным решаемым задачам. В качестве примера приведена табл. 2.6.
ВОПРОСЫ ДЛЯ САМОПОДГОТОВКИ
1. Что понимается под синтактическими операциями с Данными?
Приведите и охарактеризуйте примеры таких операций.
2. Что такое дискретизация сигналов и функций непрерывного
аргумента? Что понимается под теоремами отсчетов? В чем их суть?
Приведите примеры.
3. Какие ученые внесли вклад в формулировки теорем отсчетов?
В чем их приоритет, вклад? Кто, на ваш взгляд, является автором классической формулировки теоремы отсчетов?
4. Что такое функция отсчетов? Почему теоретически верные теоремы отсчетов не могут быть идеально точно применены на практике?
5. Из каких соображений выбирается частота или шаг дискретизации сигналов? Каким образом? Что понимается под сжатием данных,
интерполяцией, аппроксимацией и экстраполяцией сигналов? Когда
применяется и как осуществляется неравномерная дискретизация и
рандомизация при дискретизации?
6. Что понимается под погрешностями, вызванными квантованием сигналов и данных по уровню? Как и когда они учитываются? Что
на них влияет?
7. Что такое метаданные, сведения, сопутствующие данным? Зачем их надо иметь?
8. Что такое регистрация, оформление, хранение и накопление
данных?
9. Что такое базы, банки, хранилища и витрины данных? В чем
сходство и отличие между ними?
10. Укажите основные синтактические структурные модели данных. Охарактеризуйте суть каждой из моделей. В чем их особенности,
каковы возможные области применения? Приведите примеры, поясняющие ваши ответы, и основные понятия из этой области.
181
11. Что такое многомерные модели данных? Охарактеризуйте их
разновидности. Приведите примеры.
12. Какие могут быть разновидности банков данных? Охарактеризуйте каждую из разновидностей.
13. Что такое знания и как они связаны с понятием «информация»?
14. Перечислите структурные модели знаний. В чем их суть и особенности? Каковы рекомендуемые области применения. Приведите
примеры, поясняющие ваши ответы, и основные понятия, связанные с
такими моделями.
15. Что понимается под информационной системой связи? В чем
отличие аналоговой и цифровой систем связи? Что такое канал и линия
связи, кодер и декодер, модулятор и демодулятор?
16. Что понимается под кодированием Данных, под модуляцией
сигналов?
17. Укажите основные виды модуляции сигналов, их суть и особенности.
18. Нарисуйте и охарактеризуйте обобщенные схемы аналоговых и
цифровых систем связи. Что такое канал и линия связи?
19. Что понимается под пропускной способностью канала связи и
скоростью передачи данных в канале связи? От чего зависят их значения? Поясните суть теорем эффективности и помехоустойчивости К.
Шеннона. В чем их значимость?
20. Что такое эффективное кодирование и как оно осуществляется?
21. Какие коды называются префиксными? За счет чего (как) обеспечивается префиксность кода?
22. Что такое кодовое расстояние, кратность ошибки при передаче
кодовой комбинации, избыточность и оптимальность кода?
23. Что такое помехоустойчивое кодирование и в чем суть основных идей по его реализации? Приведите основные понятия, касающиеся помехоустойчивого кодирования.
24. Можно ли в принципе дать стопроцентную гарантию найти такой способ помехоустойчивого кодирования, при котором будут обнаружены все ошибки? А если наложить определенные (какие?) ограничения на канал связи и условия передачи сообщений? Или, иначе,
существуют ли способы повышения уверенности правильного приема
и приближения ее к 100 %, например, дублированием передачи сообщения?
182
25. Согласны ли вы с табл. 2.6? Следует ли ее модифицировать,
уточнить, дополнить? Например, представить перечень закономерностей в виде иерархической структуры или по-другому расставить модели в столбцах 4, 5, изменить столбцы 3 или 6?
26. Перечислите разновидности избыточности данных. Что такое
сжатие данных и с каким видом избыточности данных оно связано? В
чем суть и особенность элементной избыточности данных? Что понимается под кодовой избыточностью данных? Применимо ли слово
«оптимальный» к различным видам избыточности данных? Если да, то
предложите его определения (дефиниции) для каждого вида избыточности.
183
Глава третья
ПРИНЦИПЫ ПОСТРОЕНИЯ
ТЕХНИЧЕСКИХ СРЕДСТВ ИНФОРМАТИКИ
§ 3.1. ВИДЫ ИНФОРМАЦИОННЫХ
ТЕХНИЧЕСКИХ СРЕДСТВ
Рассмотрим прежде всего возможные и существующие варианты
построения различных информационных систем и их подкласса – сетей (ИС). Их многообразие можно представить, используя морфологический анализ. Под термином морфология1 ранее понималось, вопервых, учение о форме и строении животных и растительных организмов и геологических структур либо раздел грамматики, изучающий
структуру слова и выражение грамматических значений в пределах
слов, т. е. учение об их внутренней структуре; во-вторых, сама внутренняя структура таких объектов. В связи с широким развитием системного подхода и его реализации в виде системного анализа (лучше
писать и говорить системного исследования)2 под морфологическим
1
От morphē – форма и logos – учение.
Еще раз обращаем внимание на неудачное сочетание «системный анализ» как метода исследования объектов, основанного на разделении их на
части и исследовании по частям. Как следует из § 2.3, часть 1, сложную систему, в которой сильно проявляется свойство эмерджентности, принципиально нельзя познать только анализовыми методами. Лучше писать «системные исследования», т. е. под системным анализом объекта понимать его
познание, исследование, исходя из представления объекта как системы, т. е.
понимать слово «анализ» в другом контексте, как метод, основанный на выделении всех трех аспектов объекта как системы, вычленяя объект как целое,
как часть надсистемы и только потом уже как состоящий из внутренних
частей.
2
184
анализом любых объектов, рассматриваемых как система, понимается
метод исследования, направленный на рассмотрение внутренней
структуры объектов в рамках морфологического подхода как одной из
реализаций системного подхода. Основная идея морфологического
подхода – поиск как можно большего числа вариантов реализации исследуемого объекта (системы) путем комбинирования основных, выделяемых исследователем принципов его возможного построения,
комбинированием структурных элементов и/или их характерных признаков. При этом допускаются, во-первых, различные разбиения на
части принципов, структурных элементов и признаков объекта, вовторых, разные способы разбиения, в-третьих, различные аспекты рассмотрения объекта, его частей и разбиений.
Из большого разнообразия вариантов реализации морфологического подхода применим метод морфологического ящика Ф. Цвики в его
табличном представлении. Для этого выделим главные факторы, определяющие структуру исследуемого объекта (у нас – это техническая
реализация информационных систем (и сетей, как их разновидностей)),
отличительный разделительный («класификационный») признак и его
возможные реализации. Сразу заметим, что морфологическая таблица может, но не обязана быть классификационной. Ее цель – отразить
как можно более полно все возможное многообразие объектов, не в
полной мере выдерживая все правила (например, бинарности, ортогональности и т. п.) построения классификаций (см. разд. 1.2.1). Но она
может послужить хорошей основой соответствующей классификационной таблицы, построенной для достижения других целей модельного
представления разнообразия исследуемых объектов.
Один из вариантов морфологической таблицы информационных
систем (ИС) с точки зрения их технической реализации, представлен в
табл. 3.1 [1, 24].
Можно применить аналогичный подход не только к исследованию разнообразия всех систем, но и к их технической (аппаратной)
элементной базе, рассматривая основополагающие (концептуальные)
идеи (принципы) их построения. Такое разнообразие представлено на
рис. 3.1.
Дальнейшую детализацию продемонстрируем на примере средств
вычислительной техники (рис. 3.2).
Прокомментируем некоторые из разновидностей систем и принципов их построения.
185
186
3
2
1
3
2
1
k
i k
Класс решаемых
задач
Количество решаемых
разнотипных задач (достигаемых целей)
Количество функций, выполняемых
в рамках одного
направления (цели)
Способ выработки
информации
Отличительный
признак
Организация
1
выработки
информации,
представляемой пользоОтношение к инвателю, и от- 2 формации
ношение
к ней
Наличие предваОрганизация 1 рительной региввода и настрации
копления исНаличие накоплеходных дан2 ния данных перед
ных
обработкой
Выполняемые функции
Главные
факторы,
определяющие
структуру
i
i
2Pi k
Вычислительные
3Pi k
Измерительные
Получающие
дающие)
186
Без накопления
С накоплением
–
–
4Pi k
Прочие
–
–
–
(пере- Хранящие (вос- «Генерируюпроизводящие)
щие» (преобразующие)
Экстравертные
–
Без
предвари- С предварительной регистрацией
тельной
регивсех данных
части данных
страции
Добывающие
Интровертные
Однофункциональные
(узко- Многофункциоспециализирональные
ванные)
Многоцелевые
Специализиро(предванные (одноце- проблемно
метно)
ориентиро- универсальные
левые)
ванные
1Pi k
Управленческие
Возможные реализации признака
Морфологическая таблица информационных систем и сетей
Т а б л и ц а 3.1
187
7
6
5
4
Архитектур- 1
но-структурное решение
вычислиПринцип растельных
параллеливания
преобразо2 вычислений и
ваний
выполняемых
функций
Способ управ1
ления
Организация
управления и
перестройки 2 Автоматизация
перестройки
Архитектур2
но-структурное решение
всей системы
3
1
1
Размерность
исходных
данных, операндов, результатов
2
–
Программное
Автоматизированная Автоматическая
Программный
Аппаратный
187
–
–
–
–
–
–
–
–
–
–
–
–
–
Многокомандные
МКМД
ОКМД (SIMD) (мат- МКОД
(MISD)
(MIMD)
ричные, ассоциатив- (конвейерные,
(многопроные)
магистральные)
цессорные)
С распараллеливанием
Неоднородные
Распределенные
Многоуровневые
Аппаратное
Ручная
(n-
Многомерные, векторные (k-мерные),
k>1
Многовходовые
входовые), n>1
Без распараллеливания
Количество одновременно вводиОдновходовые
мых
массивов
данных (сигналов)
Размерность обрабатываемых
массивов и полу- Одномерные
чаемых результатов
Иерархичность Одноуровневые
Расстояние
Сосредоточенные
между элемен(локальные)
тами ИС
Сходство элементов аналоОднородные
гичного назначения
Однокомандные
Организация
потоков команд ОКОД (SISD) (пои данных
следовательные)
188
8
Элементная
база
Организация
управления и
перестройки
Главные
факторы,
определяющие
структуру
i
i
3
2
1
4
Централизация
управления
3
Учет вариаций,
внешних воздействий и окружающей среды. Уровень
самоперестройки
Физический
принцип действия
Форма представления Данных
Принцип выполнения вычислительных преобразований
i k
k
Отличительный
признак
Стохастические
Детерминированные
188
Цифровые
Оптические
–
Гибридные
Механические
СамоперестраиваюСамообучающиеся, самонастраищиеся
вающиеся
3Pi k
–
–
Прочие
Самоорганизующиеся
4Pi k
Смешанные
Глобальная
Децентрализоавтономия, лованные: глобальная и Глобальная ценкальная ценлокальная автономия трализация,
лотрализация
(множество,
набор кальная автоно(ИС в виде
подсистем)
мия (сети)
коллектива
подсистем)
Адаптивные (самоприспосабливающиеся)
2Pi k
Аналоговые
Электронные
Неадаптивные
(неперестраивающиеся)
Централизованные: глобальная и
локальная централизация
(одиночные
простые
системы)
1Pi k
Возможные реализации признака
О к о н ч а н и е т а б л. 3.1
189
Исполнение
Стандартизация,
унификация,
2 совместимость
Несовместимые
со
смежными
средствами
Возможность
Неагрегатируемые
агрегатирования
Совместимые по функциональным параметрам
метрологичеинформационно
ски
Совместимые по элементной базе
аппаратно
программно
Совместимые по внешним параметрам
эксплуатациконструктивно
энергетически
онно
Агрегатируемые
189
Примечание:
ОКОД – один поток команд, один поток данных (одни команды, одни данные) /SISD – single instruction single data/ –
архитектура фон Неймана;
ОКМД – один поток команд, много потоков данных /SIMD – single instruction multiple data/;
МКОД – много (потоков) команд, один поток данных /MISD – multiple instruction single data/;
МКМД – много потоков команд, много потоков данных /MIMD –multiple instruction multiple data/.
9
1
190
Вид
структуры
Элементарные
операции с
операндами
Базовые информационные операции
Показатели качества результатов
Вид
преобразований
Качественные
Вычислительные,
логические
Адекватность
Количественные
Измерительные
Точность
190
Измерительновычислительные
Количественные
Жесткая, внешне перестраиваемая при обучении
Дискретные,
операторные
Неявные, неформализованные «знания», приобретенные в процессе
самообучения, опыта
Структурно-логический
по алгоритму (правилам)
«учителя»
Нейронные
(интеллектуальные
2-го типа)
Достоверность, уверенность, истинность
Исчислительные
выводы
Качественные
Перестраиваемая
Квантовые
Логический, исчислительноселективный по правилам
Явные знания,
протознания
Рис. 3.1. Разновидности технических средств информатики
Программноперестраиваемая
Дискретные во времени,
цифровые
Жесткая
Непрерывные
во времени, непрерывнозначные
Алгоритмический
Структурный
(аппаратный, аналитический, аналоговый)
Когнитивные
(интеллектуальные
1-го типа)
К О М Б И Н И Р О В А Н Н Ы Е
Принцип
действия
,
Физические
сигналы
И Б Р И Д Н Ы Е
Данные, анзния, математические модели, контент
Г
Тип носителя
(форма представления)
информации
Цифровые
Аналоговые
Вид
носителей
информации
191
УВ
УУ
Среда,
сетка
ВУ
УВ
УУ
Решающие
блоки
ВУ
Р
Р
в
б
УВ
УУ
ОЗУ,
ВЗУ
АУ
ВУ
Лента n
Р
Р
Измеритель Р
состояний
кубитов
в
б
а
ИД Р
Пользователь
КОГНИТИВНЫЕ
(КВМ)
Рис. 3.2. Типовые структуры вычислительных машин:
Управляющий цифровой компьютер
Генератор импульсов
Квантовый вычислитель (преобразователь кубитов)
КОМПЬЮТЕР
Г И Б Р И Д Н Ы Е ЭВМ (ГВМ)
ЗУ
К В АН Т О В Ы Й
Программы
ИД
УУ
Дж. фон Неймана
ИДП
УВ
ЦИФРОВЫЕ (ЦВМ)
Тьюринга – Поста
головка
ИД Лента 1
а) структура НВМ
УУ
ИНС
4)
2)
ВУ
A
xn
x1
ВС
НП
ТВ
Вн. С
Вых. С
Q
V
г) условное изображение
Вх. С
n
в) нейронный элемент
1
б) архитектура искусственных
нейронных сетей (ИНС)
3)
1)
УВ
НЕЙРОННЫЕ (НВМ)
Процессор-учитель
191
КП–коммутационное поле; УВ–устройство ввода; ВУ–выходное устройство (устройство вывода, отображений);
УУ–устройство управления; ЗУ–запоминающее устройство (ОЗУ–оперативное ЗУ, ВЗУ–внешнее ЗУ); АУ–
арифметическое устройство; ИД–исходные данные; ИДП–исходные данные и программы; Р–результаты; ВС–
входной сумматор; НП–нелинейный преобразователь; ТВ–точка ветвления; Вх.С, Вых.С – входные и выходные
сигналы; Вн.С–внутренние состояния
УУ
На специальных физических
элементах (СФЭ)
ИД
СФЭ
ВУ
УВ
ИД
Р
а
На операционных усилителях
постоянного тока
КП
ИД
КП
АНАЛОГОВЫЕ (АВМ)
Сеточные
§ 3.2. ПОЯСНЕНИЯ К МОРФОЛОГИЧЕСКОЙ ТАБЛИЦЕ ИС
Прежде всего отметим, что обобщенные и некоторые детализированные структуры ИС по классу решаемых задач рассмотрены в [24].
Это следующие информационные системы: измерительные (ИИС), вычислительные (ИВС), различные управленческие (УИС), связи (ИСС),
справочные (СИС), обучающие (ОИС), автоматизированные системы
научных исследований (АСНИ) и комплексных испытаний (АСКИ).
Мощные классы составляют системы автоматизированного проектирования (САПР), автоматизированные системы подготовки принятия
решений (АСППР) и принятия решений (АСПР), технологической
подготовки производства (АСТПП), управления предприятиями
(АСУП), разные корпоративные комплексные и интегрированные системы. Попробуйте самостоятельно указать, какие из обеспечивающих
подсистем (см. часть 1, рис. 1.6, а) наиболее необходимы в каждой из
таких систем.
В табл. 3.1 понятие информационной сети выделено из информационных систем иерархического типа только по организации управления (см. п. 7.3 в таблице): в сетях имеет место глобальная (общая для
всех подсистем, аналогичных по функциональному назначению) централизация управления (единые технические, программные и прочие
средства, правила, стандарты, технологии) и локальная (внутри подсистем) автономия (свои для подсистем средства, правила, стандарты,
технологии, согласованные с централизованным на вышестоящем
уровне). Очень часто к понятию сеть «пристегивают» понятие распределенные (см. п. 5.2 таблицы). Однако это не тождественные, а дополняющие и уточняющие друг друга понятия (сравни, например, телефонная сеть, транспортная сеть, Интернет (сеть сетей), компьютерная
сеть и распределенная база данных, распределенный интеллект и т. д.).
Различные варианты топологических1 структур сетей, т. е. расположений узлов сети и их соединений линиями без учета длин линий и
мощности узлов, представлены на рис. 3.3.
Теперь обратим внимание на п. 8.3 табл. 3.1. Элементная база,
построенная по детерминированному принципу, работает либо с аналоговыми сигналами (аналоговые системы связи, аналоговые вычислительные машины (см. рис. 3.2 и далее § 3.3), либо с цифровыми
данными (цифровые системы связи, управления, цифровые ВМ, см.
1
Топология от греч. topos – место, местность и logos – учение.
192
8
8
1
1
8
1
7
2
7
2
7
2
6
3
6
3
6
3
4
5
а
5
4
5
4
б
в
г
д
е
ж
з
и
к
л
м
Рис. 3.3. Топологические структуры информационных сетей:
а – радиальная; б – кольцевая (петлевая); в – полносвязная; г – радиальнокольцевая; д – древовидная; е – звездообразная; ж – последовательная; з – магистральная; и – кустовая с тремя деревьями; к-м – сетевая;
– узел возможного
переключения направления информационного потока;
– узел без переключения
направления информационного потока
193
рис. 3.2 и далее § 3.4). Его отличает наличие детерминированного алгоритма работы элемента: выполнения преобразования, описываемого
аналитическими соотношениями; численных расчетов по аналитическим соотношениям; машинных, вычислительных или имитационных
экспериментов с помощью вычислительных преобразований. Например, численного нахождения интегралов (4.163), (4.163а) (формулы см.
в части 1 пособия), поразрядного сложения или умножения при
нахождении сумм и интегралов, нахождения площади листка дерева
(например, дуба) по числу клеток и их долей, закрываемых листком на
клетчатой странице бумаги, и т. д.
В отличие от детерминированных стохастическая элементная база
основана на применении идеи (принципа) рандомизации. Например,
замена нахождения значения интегралов (4.163), (4.163а), см. часть 1,
нахождением их по методу Монте-Карло (см. часть 1, разд. 4.3.8). Второй пример – стохастическое определение площади S л.д лепестка дуба. Укладываем физически (или модельно при машинной реализации
метода Монте-Карло) лепесток дуба (или обводим его контур) на противень – тонкий лист с загнутыми краями – и равномерно располагаем
на нем маковые зернышки (имитируем равномерно распределенные
точки в прямоугольнике, охватывающем (мажорирующем) наружный
контур лепестка в машинной реализации) и подсчитываем отношение
количества зернышек (точек), попавших в контуры лепестка, к количеству их, попавших на весь противень (в прямоугольник). Зная площадь Sп противеня, находим S л.д Sп . Третий пример. Вместо
нахождения суммы чисел а и b, т. е. c a b , ставим в соответствие
значению а вероятность P( A) события А, а b – вероятность P ( B) , где
А и В – несовместные (несовместимые) события. Имитируя события А
и В (см. разд. 4.3.8, часть 1), находим вероятность P (C ) , где событие С
есть сумма событий А и В, т. е. C A B (см. часть 1, табл. 4.6). Аналогично можно находить значение произведения a b переходом к
нахождению значения вероятности произведения событий P ( A B)
P( AB ) P ( A) P ( B ) P ( A) P( B) (см. часть 1, табл. 4.6). Такие методы бурно развивались в 60–70-х годах прошлого столетия. Однако
прогресс в цифровой технике вытеснил их, возможно, временно.
Теперь перейдем к другим пунктам табл. 3.1 и рис. 3.1 и 3.2.
194
§ 3.3. АНАЛОГОВЫЕ, ЦИФРОВЫЕ, КОГНИТИВНЫЕ,
НЕЙРОННЫЕ И КВАНТОВЫЕ ПРИНЦИПЫ
3.3.1. Описание принципов
Для сокращения материала поясним принцип на примере построения элементной базы электронных вычислительных машин (ЭВМ) [1].
Чтобы лучше уяснить различие между ними, рассмотрим вначале
рис. 3.1. Прежде всего обратим внимание на то, что аналоговые и цифровые средства относятся к синтактическим, т. е. работающим с синандами – Данными, а именно: аналоговые – с сигналами, а цифровые – с
данными, анзниями (знаниями как носителями информации, а не с их
семантикой), контентом. В то же время когнитивные и нейронные
условно отнесены к семантическим, как оперирующие с семандами,
т. е. со смысловым содержанием, имеющимся в носителях информации. Это приводит к тем отличиям, которые отражены на рис. 3.1.
Например, для всех аналоговых средств характерна работа с физическими носителями информации – сигналами, представляющими собой
токи, напряжения, давления, непрерывнозначные линейные перемещения, угловые повороты и т. п. Для них характерен структурный принцип включения в более сложные устройства, блоки, системы. Это
означает, что отдельный элемент аналоговых средств выполняет жестко предписанный для него набор функций, каждая функция из которого физически воплощается каждый раз при работе с элементом изменением его структуры, а для выражения нескольких операций
(функций) строится (изменяется) структура всего устройства, блока,
системы (см. приложение 4.1 в [1]). Самое важное с точки зрения информационных свойств таких элементов – это то, что в таких элементах основная используемая операция – количественная измерительная,
а показателем качества результатов является точность (точнее, погрешность, неопределенность, см. часть 1, § 3.5). Именно последние
особенности приводят к тому, что информационные средства, построенные на аналоговом принципе (вычислительные, связи, управления и
пр.), сильно чувствительны к помехам, шумам, технологическим разбросам параметров их схем и их нестабильностям при изменении
условий окружающей среды. В отличие от них цифровые принципы,
основанные на качественном (категорийном), например, двоичном
представлении данных (0 или 1), не столь чувствительны к помехам,
допускают помехоустойчивое кодирование, легко автоматически программно перестраиваются, работают по заданному алгоритму, допус195
кают иерархическую структуру алгоритмов, разбиение сложных задач
на простые. Однако для их применения требуется дискретизация и
квантование, а показателем качества, например в вычислениях, выступает не столько погрешность нахождения значения функции в отдельных точках, сколько адекватность представления функции на заданном
интервале [a, b] с учетом дискретизации, квантования по уровню, восстановления или нахождения значений характеристик функции по ее
отсчетам, включая, конечно, и точность нахождения этих отсчетов по
аргументу и по уровню.
Несколько слов о средствах, условно названных на рис. 3.1 интеллектуальными. Они оперируют с семандами, в качестве которых выступают явные, представленные, как правило, в формализованном виде
знания (когнитивные средства), или неявные, приобретенные в ходе
обучения или накопленного опыта (нейронные). Они требуют отличного от синтактических средств инструментария и реализуются в виде
структур, показанных на рис. 3.2. Примеры когнитивных и нейросетевых принципов вычислений будут рассмотрены ниже. Пример когнитивного принципа построения системы связи: договоренность между
отправителем и получателем, известная только им, о семантически
определенных типах сигналов: вид комнатного растения на окне или
цвет букета, означающий возможность принять гостя или запрет на
прием; количество и вид костров в партизанском отряде, ожидающем
прилет самолета; наличие и отсутствие определенного знака в сообщении, передаваемом разведчиком и сигнализирующим, что он свободен
или работает под наблюдением противника.
Сеточные АВМ на рис. 3.2 – это, как и все АВМ, моделирующие
устройства непрерывного действия. В них функции основного блока
физического вычислителя-измерителя играет сетка из пассивных или
активных элементов, модельно замещающих подобные им моделируемые ими элементы реальности: теплового, электрического или электромагнитного поля, поля влажности, давлений и пр. Пусть, например,
надо с помощью сеточной АВМ определить значение температуры в
разных точках комнаты1. Предположим, что теплопроводность среды,
мебели и других вещей в комнате известна и ее можно заменить (с соответствующими коэффициентами подобия) активными сопротивлениями – резисторами соответствующей проводимости. Спаяем сетку
1
Значения давления воды в разных точках плотины или дамбы, температуры в статоре, уровня радиации внутри какой-то камеры и т. п.
196
таких сопротивлений, имитирующих теплопроводность разных элементов, находящихся в поперечных, продольных и высотных сечениях
комнаты, и подадим в соответствующие точки спайки напряжения постоянного тока, пропорциональные источникам тепла (+), холода – поглощения тепла (–) и включим схему. Измеряя значение напряжения в
каждой точке такой схемы, получим аналог температуры в соответствующей пространственной точке комнаты.
Наиболее широкое распространение получили аналоговые элементы, построенные на базе операционных усилителей постоянного тока
(УПТ). Принцип их построения описан в [1, приложение П4.1] и поэтому здесь не рассматривается. Схемы некоторых типов решающих
усилителей представлены на рис. 3.4.
Uвх1
R1
i1
Uвх2
R2
i2
Uвхn
Rn
in
R0
R1
i1
Uвх2
R2
i2
U вых (t )
C
i0
t<0
UA
Uвых
в
б
i0
Uвх(t)
i0
C
t>0
Uвых(t)
1 t
U вх ()d U вых (0)
R1C 0
U вых (t ) RC
UA
C
t=0
U вых (t )
R
Uвх(t)
R0
Uну
R1
1 t
U вых (t )
U вх i ( )d
R
i 1 i C 0
i1
Uвых(t)
1 t
U вх ()d
RC 0
R2
in
n
UA
Uвых
a
Rn
I1
Uвх(t)
iA
Uвх1
C
i0
R
UA A
R0
U вхi
i 1 Ri
n
U вых
Uвхn
i0
Uвых(t)
г
dU вх (t )
dt
д
Рис. 3.4. Схемы различных вариантов решающих усилителей и математические модели, описывающие переходные процессы в них:
а – суммирующий; б – интегрирующий; в – интегрирующий сумму входных
напряжений; г – интегрирующий с заданием начальных условий; д – дифференцирующий; R – резисторы (сопротивлением R), С – конденсаторы (емкостью С)
197
Что касается третьего типа АВМ (рис. 3.2), то под СФЭ понимаются элементы, выходная характеристика (физическая зависисмость значения выходного сигнала от значения входного) описывается тем же
аналитическим соотношением, которое необходимо смоделировать на
АВМ (с учетом, конечно, коэффициентов подобия).
Заметим, что, невзирая на широкое распространение цифровой
элементной базы, аналоговые принципы и схемы находят большое
применение в бортовых системах, при допустимости относительно
слабых требований к качеству результатов, когда главными выступают
требования дешевизны, простоты, а иногда и общие затраты времени
на получение результата. Аналоговые принципы начинают возрождаться в оптической элементной базе.
На рис. 3.2 представлена типовая схема ЦВМ по фон Нейману, которая до недавнего времени была базовой при построении ЦВМ (см.
историю и другие схемы в [1]). С 2005 г. появились ЦВМ шестого поколения, отличающиеся применением многопотоковых и многоядерных микропроцессоров и многоядерных вычислений как одно из
решений по преодолению предела роста производительности одноядерных процессоров, построенных по схеме фон Неймана, определенного возможностями увеличения их сложности и тактовой частоты.
Параллелизм и многоядерность становятся наиболее эффективным
способом повышения вычислительной мощности процессоров без увеличения энергопотребления: несколько ядер на одном кристалле (или
нескольких ЦВМ в кластерных суперкомпьютерах) – это выполнение
большого числа операций за то же время при меньшем тепловыделении, а многопоточность (см. табл. 3.1) каждого ядра дает возможность
одновременно обрабатывать несколько команд. С 2008 г. начинают
быстро развиваться ЦВМ 7-го поколения (на базе архитектуры фон
Неймановского типа), когда изменяются фундаментальные принципы
статичной архитектуры ЦВМ на динамическую и вводится управление
ею под решаемую задачу (подобно структурной перестройке АВМ), а
также создаются структуры, ориентированные на массивнопараллельные процессоры (МРР), и гибридные, использующие наряду
с центральными обрабатывающими элементами (устройствами CPU1)
графические (GPU2). Графические процессоры ориентированы на решение задач типа графовых, обработки данных в социальных сетях,
1
2
Central Processing Unit.
Graphics Processing Unit.
198
ситуационного анализа и им подобных, для которых характертны: работа с данными, объем которых значительно превышает память вычислительного узла; повышенная интенсивность выполнения логических пересыльных и других операций с данными по сравнению с
вычислительными; большая непредсказуемость разбросанных по памяти адресов данных; допустимость распараллеливания с использованием взаимодействующих друг с другом процессов. Если для суперкомпьютеров, реализующих идеи CPU, существуют различные
ежегодные рейтинговые списки TOP500 (международный, с 1993 г.),
ТОР50 (страны СНГ, с 2004 г.), ТОР100 (Китай) и другие, место в котором определяется по тесту Linpack (решение системы из десятков и
сотен тысяч линейных уравнений), а производительность определяется
флопсами (Flops) – числом операций с плавающей запятой (точкой) в
секунду на этом тесте, то для графических процессоров и систем в
2010 г. был предложен свой рейтинг Graph500, в котором машины
ранжируются по способности решать сложные задачи, связанные с
теорией графов, а единицами производительности приняты GE/s и
ME/s – миллиард и миллион ребер графов, обходимых за секунду, а
также объем входных данных в баллах от 16 до 42.
Наконец, обратим внимание на идею пока все еще гипотетического
гибридного квантового компьютера (рис. 3.2, средняя колонка). В его
принципе действия совмещается количественный аналоговый принцип
измерения состояния кубитов с качественным (категорийным) цифровых вычислений, используемым при преобразовании кубитов. Такой
компьютер должен реализовать новый принцип построения технических средств информатики – квантовый, основанный не на классической, а на квантовой механике и описании состояний квантового компьютера волновой функцией. Логические операции в квантовом
компьютере производятся в системе кубитов, а кодирование данных
(информации) осуществляется последовательностью состояний отдельных кубитов. В отличие от цифровых двухуровневых элементов,
которые могут находиться только в двух состояниях «0» или «1»,
квантовый двухуровневый элемент может находиться не только в двух
чистых базисных состояниях a | 0 или b |1 , но и одновременно в
двух состояниях | a | 0 b |1 , | a |2 | b |2 1 . Здесь | x1 ,..., xn
есть обозначение П. Дирака для поляризованных состояний фотона,
означающее базисное состояние элемента, каждому состоянию xi ко-
торого соответствует комплексная амплитуда ai , i 1, n , а | – про199
извольное с комплексной амплитудой а. Иными словами, вектор состояния подобного элемента может представлять собой произвольную
когерентную суперпозицию базисных состояний a 0 | и
b 1| . Такой двухуровневый элемент был назван Б. Шумахером
(1995 г.) кубитом (quantum bit qubit).
Из изложенного следует, что если классический цифровой процессор, имеющий п двоичных разрядов, может находиться в одном из
N 2n состояний | 0 ,|1 ,...,| N N 1 , то квантовый процессор может
находиться одновременно во всех этих базисных состояниях. При этом
в каждом j-м из них | j со своей комплексной амплитудой (обозначим ее j ). Именно такое квантовое состояние называется квантовой
суперпозицией классических (свойственных цифровому процессору)
состояний и обозначается
N 1
j | j .
(3.1)
j 0
Допускаются и более сложные базисные состояния.
Любое квантовое состояние | может изменяться во времени с
помощью двух принципиально отличных операций: унитарная квантовая вентильная операция и измерение (наблюдение).
Квантовые вычисления представляют собой унитарные операции
(преобразования, выполняющие те или иные логические действия) над
одним, двумя или тремя кубитами. Итог вычислений – новое состояние
квантового процессора, а искомый результат «вычисления», т. е. новое
состояние, измеряется.
Результат измерения конкретного состояния | j рассматривается
как значение (реализация) дискретной случайной величины, которое
она принимает с недоступной для измерения вероятностью | j |2 . Сама операция измерения необратима. Как видно из рис. 3.2, квантовые
вычисления управляются (контролируются) цифровым компьютером.
При этом достигается естественный параллелизм, так как при измерении конечного состояния квантового регистра (процессора) квантовые
носители информации преобразуются в классическое – двоичное состояние регистра. Выигрыш из-за физического параллелизма обусловлен тем, что одна квантовая операция выполняется сразу над всеми
200
коэффициентами j суперпозиции квантовых состояний (3.1). Для
кубита | a | 0 b |1 вероятность получить при измерении «0»
равна | a |2 , а 1 – равна | b |2 . После измерения кубит переходит в новое
классическое квантовое состяние | 0 , и, следовательно, при следующем измерении состояния этого кубита мы получим его с вероятностью единица (!)1. В этом и состоит основная суть идеи квантового
принципа построения средств информатики: квантовая система из п
двухуровневых кубитов имеет 2n линейно независимых состояний,
что с учетом квантовой суперпозиции означает – пространство состояний такого квантового процессора (точнее, регистра) является 2n мерным гильбертовым2. Квантовая вычислительная операция приводит
к повороту вектора состояния квантового регистра в этом пространстве.
Тем самым одновременно задействуются фактически 2n классических
состояний – комбинаций из п двоичных цифр, т. е. достигается изменение всех 2n базовых состояний одновременно. А это приводит к существенному (степенному, экспоненциальному) росту быстродействия за
счет беспрецедентного одновременного параллелизма вычислений по
сравнению с классическим процессором фон Неймана (рис. 3.2, б).
Физическая реализация кубита – любые материальные объекты,
имеющие два устойчивых состояния: спиновые для ядер атомов, поляризационные для фотонов, электронные – изолированных атомов и
ионов.
Однако надо иметь в виду, что любой квантовый компьютер может
выдавать результат, являющийся верным только с определенной вероятностью, которую можно повысить за счет увеличения количества
операций (сравни с приемами повышения качества аналоговых и цифровых результатов, приводимых далее в разд. 3.3.2).
Круг задач, для которых квантовый принцип работы средств будет
пригоден, сейчас бурно исследуется.
1
Напомним, что, как и в первой части, знак (!) означает «при определенных условиях». Здесь таким условием является тождественность унитарной
операции. Унитарная операция – линейная операция в компактном евклидовом пространстве, сохраняющая скалярное произведение векторов.
2
Напомним, гильбертовым называется обобщение евклидова пространства на бесконечномерный случай.
201
3.3.2. Вычислительные примеры реализации принципов
Пример первый [1]
Необходимо найти значение определенного интеграла
I
b
1
f ( x) dx .
b a a
(3.2)
Рассмотрим, как найти его значение на ВМ различных типов.
Аналоговый принцип операционного типа (см. рис. 3.1 и 3.2).
Согласно рис. 3.4 для этого необходимо f ( x) заменить на U вх (t ) , т. е.
выбрать масштабные коэффициенты M x и M f преобразования х в t и
f в U вх , установить RC пропорциональным b-a и определить ta M x a
и tb M x b , учитывая масштабы M x и M f . Затем собрать и запустить
схему (см. табл. П4.1, часть 1), подав на ее вход U вх (t ) M f f M x t ,
начиная с ta , и измерить значение U вых (t ) в момент tb .
Цифровой принцип (см. рис. 3.1 и 3.2). При цифровом принципе
вычислений значения интеграла (3.2) находятся путем численного интегрирования (рис. 3.5). Диапазон [a, b) аргумента х разбивается на п
состыкованных участков шириной х так, чтобы заштрихованные
площадки участков могли быть легко вычислены с требуемой точностью как площади, заменяющие эти участки прямоугольниками, трапециями или другими приемами численного интегрирования.
f(х)
*
*
f ( x1 )
a
S1 f ( x1 ) x
b
x x
Рис. 3.5. Пояснение к численному интегрированию
202
х
Когнитивные принципы. Идея работы ВМ, основанных на когнитивных принципах: использование явных знаний, хранимых в памяти
или выдаваемых экспертами (см. рис. 3.1 и 3.2). В данном случае в качестве явных знаний выступают таблицы определенных или неопределенных интегралов, хранимых в памяти. Интеграл (3.2) сводится к табличному, из которого находится первообразная F ( x) . Далее,
подставляя в F ( x) конкретные числа а и b, определяем искомое значение I интеграла (П4.4, часть 1) методами цифровых вычислений.
Нейросетевой (нейрокомпьютерный) принцип. Нейросетевые
принципы базируются на двух идеях: 1) построение сети (см.
рис. 3.2, а, б) из k слоев, в каждом из которых по m1 ,..., mk нейронных
элементов (рис. 3.2, в), образующих сеть типа одной из изображенных
на рис. 3.2, б; 2) использование неявных, приобретенных в ходе самообучения сети, знаний в виде коэффициентов 1 ,..., n (рис. 3.2, в)
каждого из элементов. В рассматриваемом примере обучение сводится
к установлению значений 1 ,..., n по большому числу разнообразных
функций f ( x) , т. е. по значениям x1 ,..., xl [ a, b) и f x1 ,..., f xl ,
для которых значение интеграла I (3.2) (площади кривых на [a, b) ) заранее известны. Тогда, подавая на входы сети значения х и f ( x) для
интеграла (3.2), получаем искомый результат, как следствие приобретенного ранее опыта, неявных знаний.
Стохастический принцип. Все предыдущие принципы относятся
к детерминированным. Идея стохастического принципа – использование метода статистических испытаний Монте-Карло или оценивание
математического ожидания через среднее арифметическое большого
числа выборочных значений (реализаций) xi случайных величин, векторов или функций. В рассматриваемом примере I есть математическое ожидание М{Х} абсолютно непрерывной случайной величины Х
с равномерным на [a, b] законом распределения, т. е.
I M f ( X )
1 N
f ( xi ) .
N i 1
(3.3)
Правая часть (3.3) есть оценка I, которая тем точнее, чем больше N –
объем выборки. Это означает, что с помощью датчика равномерно
распределенных на [a, b] случайных величин, имеющихся в современ203
ных ПЭВМ, или из таблицы случайных (псевдослучайных) равномерно
распределенных и приведенных к [ a, b) чисел выбираются x1 ,..., xN , и
по формуле f ( x1 ) f ( x2 ) ... f ( xN ) N находится приближенное
значение интеграла I. Метод особенно хорош, если, во-первых, функция f () имеет сложный вид, трудно аналитически или численно интегрируемая, и, во-вторых, интеграл I многомерный. В этом случае приближение зависит прежде всего не от кратности интеграла (в отличие
от численного интегрирования), а от объема выборки N, т. е. от временных затрат на вычисления.
Пример второй
Необходимо найти значение
y sin x .
(3.4)
Аналоговый принцип. Значение y находим с помощью нелинейного электронного блока АВМ, преобразующего входное напряжение U вх
в выходное U вых sin (U вх ) . Иными словами, как и в первом примере,
устанавливаем U вх M x x , затем подаем его на вход нелинейного синусоидального блока и спустя время измеряем U вых , которое с соответствующим масштабным коэффициентом дает нам y.
Понятно, что, как и в первом примере, точность нахождения y имеет принципиальные ограничения, поскольку определяется тем, что
аналоговый принцип связан с выполнением количественных операций
(см. рис. 3.1): измерением напряжений, точностью выполнения преобразований f ( x) и sin x в блоках, колебаниями источников питания,
шумами и помехами в блоках АВМ, «уходом» значений параметров
схем от номинальных и т. д. Зато быстродействие определяется только
переходными процессами в блоках АВМ и просто осуществляется визуализация результатов.
Цифровой принцип. Функция, описывающая зависимость
y sin x , разлагается в ряд простейших функций, например, в ряд Маклорена
y
(1)k
k 0
204
x 2k 1
.
(2k 1)!
(3.5)
Затем для требуемого х по правой части (3.5) находится значение y.
Понятно, что точность нахождения y будет зависеть от разрядности
представления х в (3.5), а также количества используемых слагаемых в
сумме () правой части (3.5). Иными словами, здесь в силу качественного принципа выполнения операций нет принципиальных ограничений по точности: надо только брать больше разрядов х и больше слагаемых, что, конечно, приводит к потере производительности, требует
алгоритмизации и программирования, зато цифровые элементы существенно меньше подвержены колебаниям напряжений, шумам и помехам, допускают использование помехоустойчивых операций и т. д.
Когнитивный принцип. В этом случае для требуемого x x0 значение y находится по таблице синусов, выбираемой из памяти (блока
знаний рис. 3.1, КВМ). Если же в таблице нет значений sin x0 , а есть
только значения sin x1 и sin x2 для x1 x0 x2 , то значение y0 sin x0
находится приближенно через y1 sin x1 и y2 sin x2 , считываемые из
базы знаний, с помощью ЦВМ (см. рис. 3.2, КВМ) одним из численных
методов, например, с применением линейной интерполяции
y0 y1 ( x0 x1 )( y2 y1 ) ( x2 x1 ) .
(3.6)
Нейросетевой принцип. Аналогично предыдущему примеру, вначале происходит обучение сети получению y sin x для разных
x1 , ..., xl , а затем определяется y0 sin x0 , подачей на вход сети x0 и
вида функции – sin() .
В заключение обратим внимание, что аналоговые принципы вычислений являются как бы обратными по отношению к гносеологическому (познавательному) моделированию. При познавательном моделировании первично модель подбирается под физический процесс, а
при аналоговом моделировании – процесс (и обеспечивающие его протекание средства) подбирается под модель, под заданную вычислительную задачу. В аналоговых средствах осуществляется не вычисление, а его замена, эмуляция вычисления с использованием аналогии,
подобия1 и измерения.
1
Веников В.А., Веников Г.В. Теория подобия и моделирования. – М.:
Высшая школа, 1984. – 439 с.
205
Пример третий
Рассмотрим разное математическое представление работы аналоговых средств.
Ранее (см. часть 1, разд. 4.4.4) было обещано рассмотреть применимость разного математического описания одних и тех же объектов.
Сделаем это на примере аналоговых средств, изображенных на рис. 3.3.
Традиционно описание переходных процессов и, как следствие,
итоговых результатов работы схем рис. 3.3 осуществляется в предположении, что конкретные значения сопротивления резисторов R
(в омах) и конденсаторов (в фарадах) заданы и не изменяются в процессе эксплуатации. Это означает допустимость детерминированного
описания подобных схем. Например, коэффициент передачи
k1 U вых U вх решающего усилителя (рис. 3.3, а) по 1-му каналу будет определяться в виде k1д R0 R1 , т. е. при конкретных значениях
R0 r0 и R1 r1 будет представлять собой число k r0 r1 , т. е. иметь
точечное значение.
Однако при серийном производстве усилителей в силу особенностей производства и отбора резисторов и конденсаторов реальные значения R и С могут отличаться от приписываемых им, причем тем сильнее, чем менее «классными» являются резисторы и конденсаторы.
Кроме того, значения R, С могут существенно отличаться от приписываемых им номинальных в связи с «уходом» их из-за условий эксплуатации (перепады температур, влажности, пыльности, …). Поэтому в
тех случаях, когда есть априорные1 или апостериорные сведения о распределениях вероятностей R, С в процессе производства и эксплуатации, можно представить величины R и С не детерминированными, а
случайными.
Тогда величина k1 будет случайной, равной K1с R0 R1 , где R0
и R1 – независимые случайные величины с плотностями W0 ( x)
и W1 ( x) . Плотность распределения вероятностей WK ( x) будет равна
WK ( x)
W0 ( xy )W1 ( y ) | y | dy .
(3.7)
1
Например, гауссовское распределение при хорошо отлаженном технологическом процессе либо равномерное или близкое к нему при измерении значений каждого R, С и индивидуальной раскладке их по номиналам перед использованием в схеме усилителя.
206
По ней или другими приемами можно найти математическое ожидание, СКО и другие характеристики величины K1с .
Аналогично особенно при индивидуальной раскладке R и С по номиналам, их значения можно представить интервальными или нечеткими величина. В первом случае K1и будет определяться как интервальная величина, равная отношению двух интервальных величин
R0 r0 , r0 и R1 r1, r1 , принимающая значение (см. часть 1,
разд. 4.4.4)
K1и r0 r1 , r0 r1 .
(3.8)
Внимание!
Какой из двух приводимых ниже вопросов вы предпочтете: «Какая
из рассмотренных моделей более правдива, истинна?», «Какая из рассмотренных моделей более полезна, эффективна с точки зрения построения и эксплуатации таких усилителей?» Обоснуйте ваш ответ.
§ 3.4. ПРИМЕРЫ АППАРАТНОЙ И ПРОГРАММНОЙ
РЕАЛИЗАЦИИ ПРИНЦИПОВ
Рассмотрим несколько примеров реализации когнитивного и
нейросетевого принципа при построении средств связи и вычислительной техники (ВТ).
Когнитивные средства
Исторически первым (1620, 1622, 1652, 1672 гг., [1]) когнитивным1
средством ВТ является логарифмическая линейка. В традиционном
исполнении она предназначена для упрощения и ускорения работы с
логарифмическими таблицами, упрощению операций умножения, деления, возведения в степень, извлечения корня, а также расчета тригонометрических и логарифмических функций с использованием соответствующих специально организованных и нанесенных на линейке
таблиц переходом от исходных чисел и значений к их десятичным логарифмам. Стандартная линейка состоит из трех частей: корпуса,
движка и бегунка. Корпус и движок линейки выполняют роль физического носителя своеобразно организованной базы явных знаний о зна1
Заметим, что во многих книгах, справочниках и энциклопедиях логарифмическая линейка относится к аналоговым средствам, что нельзя признать
верным согласно рис. 3.1 и описываемому далее ее устройству.
207
чениях разных перечисленных выше функций, представленных в виде
шести шкал на лицевой стороне корпуса линейки и шести равномерных шкал на движке по три с его лицевой и обратной сторон. Бегунок
представляет собой прозрачную рамку, на середине которой нанесена
тонкая черта – указатель. На оборотной стороне линейки обычно приводятся различные справочные данные (когнитивный принцип!): математические и физические константы, коэффициенты расширений,
качений, трений, удельные веса тел и другие. Считывание искомого
результата, т. е. извлечение его из такой базы, осуществляется перемещением движка и бегунка по определенным правилам. Такая линейка стандартного размера 25 см позволяет получить результаты с точностью до четырех значащих десятичных цифр с погрешностью
(ошибкой), не превосходящей единицы последнего знака.
Второй пример – нереализованный японский проект (начат в 1979 г.,
финансирование прекращено в 1991 г., [1]) разработки ЭВМ 5-го
(по контексту – ЦВМ архитектуры фон Неймана!) поколения. На самом деле это была попытка построить ЭВМ нового типа – первого поколения когнитивных ЭВМ [1], структура которых представлена на
рис. 3.2.
Третий пример – действующий суперкомпьютер с искусственным
интеллектом «Watson» (фирма IBM; анонсирован в 2008 г, первая
апробация в 2011 г., [1]). Его основная функция – понимать и анализировать сложные вопросы, заданные на естественном языке и находить
ответы на них в базе данных (знаний). Названа в честь основателя
фирмы IBM Томаса Уотсона-старшего (Thomas John Watson) [1]. Суперкомпьютер состоит из 90 серверов Power7750, каждый из которых
содержит по четыре восьмиядерных процессоров Power7 и оперативную память объемом более 15 Терабайт. Имеет доступ к 200 млн страниц структурированных и неструктурированных данных и знаний
в 4 терабайта, включая полный текст Википедии! В настоящее время
IBM совместно с Nuace Communications разрабатывает на базе Watson
специализированную систему, направленную на помощь в диагностировании и лечении пациентов, а также в сферах страхования и эффективного энергопотребления.
Очевидным достоинством когнитивного принципа построения
средств ИС является быстрое получение ответа, возможность обеспечения общения на естетсвенном языке. Недостаток – ограничение возможностей используемых баз данных и знаний, жесткая зависимость
результатов от качества и детализации исходных сведений.
208
Нейросетевые средства
Хотя сама природа нейросетевой обработки информации аналоговая, нейросетевой принцип на уровне элементной базы может быть
реализован как аналоговыми, так и цифровыми или гибридными средствами со всеми свойственными им сильными и слабыми качествами
(достоинствами и недостатками). Это означает, что нейронные элементы (см. рис. 3.2, в) могут быть аналоговыми, в частности на мремристорах [1], цифровыми или гибридными. Специализированную аналоговую элементную базу имеют, например, Cellular Neural Networks
(CNN), Silicon Cortex-проект (SCX-1), Silicon Retina (Synaptics),
ETANN (Intel); цифровую – N64000 (Inova), MA-16 (Siemens). В последнее время проявился интерес к гибридным схемам, в которых интерфейс для связи с остальной аппаратной частью является цифровым,
а наиболее массовые операции выполняются аналоговым способом.
Это, например, нейросхемы RN-200 (Ricoh), NeuroClassifier (Mesa Research Institute). ИС, построенным по нейросетевому принципу, характерны следующие сильные стороны (достоинства, преимущества при
большом числе слоев и уровней по сравнению с ЦВМ): высокое быстродействие за счет естественной высокой параллельности работы; помехоустойчивость (устойчивость к помехам) и отказоустойчивость
(способность ИС сохранять работоспособность после отказа, появления неисправностей одного или нескольких элементов); живучесть
(способность выполнять основные свои функции, несмотря на значительные повреждения, во время атак и аварийных ситуаций и быстро
восстанавливать все функции после их устранения); устойчивость и
надежность (способность работать без сбоев, отказов в течение определенного времени в конкретных условиях) даже при низконадежных
элементах, имеющих значительный разброс значений параметров;
возможность применения для решения трудноформализуемых задач;
наличие единого стандартного способа решения многих нестандартных задач, при котором вместо программирования используется обучение; гибкость структуры; непосредственные операции с образами;
возможность обходиться без аналитического модельного представления
в тех случаях, когда задачи трудно формулируются, а данные имеют
сложный характер (см. далее гл. 4, мягкие алгоритмы § 4.7).
Основные слабые стороны (недостатки) нейросетевых ИС: неоднозначность выходного результата, получаемого по тем же исходным
данным, непонятность его получения из-за «логической непрозрачности» нейронной сети, так как формирование алгоритма происходит
209
путем обучения на примерах; отсутствие аналитического описания получаемых решений, что зачастую затрудняет их интерпретацию; необходимость специализации обучения под решаемые задачи, связанные с
самоорганизацией и нелинейностями; относительная дороговизна по
сравнению с цифровыми чипами, в частности, за счет меньшей тиражируемости и специализации.
В настоящее время в России и за рубежом выпускается целая серия
нейрочипов, нейропроцессоров, нейрокомпьютеров, нейросетей.
Например, отечественные NM6403, NM6404, платы ADP160PCI на базе элементной базы типа DSP фирмы Analog Devices (семейства Sharc)
и Texas Instruments (семества TMS320C), ADP44PCI, зарубежные Synapse 1, 2, 3, SNAPS/PC, ISA, PCI; нейрокомпьютеры Эмбрион 1, 2, 3, 4,
5; зарубежные SYNAPSE1-N110 (Siemens), CNAPS и CNAPS/PC
(Adaptive Solutions): 1,2 млрд межнейронных соединений в секунду
(мнс/с); нейрочипы фирм Hitachi (576 нейронов), серии FMR фирмы
Fujitsu; NETSIM (Texas Instruments) – 450 мнс/с. Наконец, укажем, что
в 2014 г. компания IBM создала крупномасштабный нейроморфный
чип TrueNorth, имеющий 5,4 млрд транзисторов – аналогов нейронов и
256 млн «синапсов», т. е. соединений между ними. В последнее время
в нейрокомпьютинге появилось новое гибридное направление, связанное с соединением электронных элементов (полевых транзисторов) с
помощью сверхминиатюрных нановолокон, нанотрубок (аналоговая
или цифровая часть) с биологическими элементами – нейронами
(нейронная часть). По аналогии с терминами Software («мягкий продукт» – программное обеспечение) и Hardware («твердый продукт» –
электронное аппаратное обеспечение) введен новый термин Wetware
(«влажный продукт» – гибрид биологического и электронного). Пример такого гибридного нейрочипа со встроенными клетками мозга –
NACNIP (2006 г., университет Падуа, Италия [1]).
Очень часто нейросетевой принцип реализуется программно на
ЦВМ. В 2003 г. на рынке нейрокомпьютеров было представлено более
200 нейропакетов. Это, например, программные системы Brain Maker,
Neuro Shell, Neural Works, Neuro Solutions и др. [55].
В действующей в настоящее время трансконтинентальной гетерогенной вычислительной сети, объединяющей суперкомпьютерные центры Германии (Штудгарт), США (Питсбург), Японии (Тшукуба) и Великобритании (Манчестер), часть пользовательских компьютеров
выполнена по нейросетевому принципу. Заметим, что эта сеть – один
210
из реальных итогов объявленной в 1991 г. Министерством торговли
Японии компьютеров 6-го поколения1 на нейросетях.
§ 3.5. ПРИНЦИПЫ РАЗДЕЛЕНИЯ КАНАЛОВ
В МНОГОКАНАЛЬНЫХ ИС
В современных ИС используются четыре вида связи между отправителями и получателями в канале информационных систем связи, а
также с элементами других средств информационных систем и сетей
(см. рис. 3.3): один с одним, один со многими, многие с одним и многие со многими. Это обеспечивается построением многоканальных
средств и систем связи. Рассмотрим наиболее часто используемые
принципы (способы, методы) построения таких систем. По своей сути
все они направлены на то, чтобы разделить тракты прохождения сигналов по линиям связи в пространстве, по времени или по частоте либо
другим каким-то образом. Такое разделение сигналов при их передаче
в многоканальных средствах связи называется разделением каналов.
В компактной форме наиболее часто используемые способы представлены в табл. 3.2, на которой O1 ,...,On – отправители, а П1 ,..., П m – получатели сообщений, где для простоты m n , хотя может быть m n
или m n .
Примером пространственного разделения каналов является телефонная связь по отдельно выделенным персональным телефонным
проводам для каждого отправителя и получателя.
Для способа временнóго разделения каналов в табл. 3.2 изображены, во-первых, одинаковые интервалы времени t , во-вторых, регулярное периодическое выделение этих интервалов для передачи сообщений. Ясно, что каждый отправитель Oi , i 1, n , и получатель Пi ,
i 1, n жестко увязаны с этими временными интервалами. Однако часто длины интервалов могут быть не одинаковыми, а соединение отправителя и получателя может осуществляться нерегулярно по более
сложной программе. Примером такого разделения может быть повременный опрос датчиков или измерителей состояния объекта с пред1
На самом деле это не проект создания 6-го поколения ЦВМ на базе архитектуры фон Неймана, а проект создания 1-го поколения ЭВМ нового
нейросетевого принципа (см. рис. 3.1, а также поколения ЭВМ в [1]).
211
ставлением результатов измерения одному или разным (по показателям) потребителям (получателям).
Т а б л и ц а 3.2
…
№
п/п
1
Методы разделения каналов в многоканальных системах связи
Наименование
Описание
Пояснение (графическое
метода
метода
представление) метода
ПространКаждому каналу
О1
П1
ственный
отводится своя
Оп
Пп
линия связи
Временнóй
Каждому каналу
отводится свой
отрезок времени:
Оп О1 О2
Оп О1
О1 О2
отправитель посылает, а полуt t
t t t
t t
чатель принимает сведения в
П1 П2
Пп П1 П2
Пп П1
строго опреде = nt
ленные, отведенные для них, отрезки времени
О1
О2
Частотный
Каждому каналу
Оп
отводится своя
полоса частот
…
2
3
f1′
f1
П1
4 Линейные
(ортогональные)
5 Адресный
(кодовый)
f1″
f2′
f2
П2
f2″
f n′
fn
t
f
f n″
Пп
См. примеры ортогональных функций
Передаваемый
сигнал есть линейная смесь модулированных
линейно независимых (в частности ортогональных) сигналов
При отправке по Каналы в цифровых ЭВМ, сотовая
закодированным связь, интернет
адресам передаваемый сигнал
снабжается адресами отправителя и получателя
212
О к о н ч а н и е т а б л. 3.2
Описание
метода
(например,
кодом, кодированным сигналом)
6 Когнитивные
Разделение
по
(семантические, смыслу, согласдоговорные)
но договоренности между отправителем и получателем
7 Другие
По уровню, по
форме и пр.
8 КомбинироКомбинации двух
ванные
и более разных
методов
Пояснение (графическое
представление) метода
П1
О1
…
№ Наименование
п/п
метода
Оп
Пп
При частотном разделении каналов каждому из них отводится
своя полоса частот шириной fi с граничными значениями fi – нижняя и fi – верхняя частоты i-й полосы, i 1, n . Примеры частотного
разделения каналов – системы радио и телевидения. При этом систему
связи стремятся построить так, чтобы полосы для каждого отправителя
и получателя как можно меньше перекрывались. Разделение сигналов
по полосам осуществляется, например, с помощью гармонической модуляции (как в системах радио и телевидения), а выделение полос в
приемнике осуществляется настройкой средней частоты полосы пропускания полосового фильтра частот на среднюю частоту полосы отправителя. Для пользователя это реализуется переключением каналов,
в которых подобная настройка уже «зашита», или поворотом настроечной ручки радиоприемника.
Суть линейных методов сводится к представлению сигнала (t ) ,
передаваемого в линию связи, функцией x(t ) вида
x(t )
n
xk (t )k (t ) ,
(3.9)
k 1
где k (t ) – детерминированный носитель k-го канала, причем k (t )
образуют систему линейно независимых функций; xk (t ) – функция,
213
описывающая амплитудно модулирующий сигнал, соответствующий
передаваемому в k-м канале сигналу k (t ) . Линейные методы фактически обобщают ранее рассмотренные временной и частотный методы,
а также включают в себя ортогональные методы, когда k (t ) , k 1, n
являются ортогональными на интервале передачи сигнала функциями.
Напомним, что система функций k (t ) , k 1, 2,... называется ортогональной с весом (t ) 0 на отрезке [t1 , t2 ] , если
t2
A при k i,
t1
0 при k i,
k (t )i (t )(t )dt
(3.10)
где А – некоторое число. При A 1 система k (t ) называется ортонормированной. Примером системы ортогональных функций является
система гармонических функций cos kt , sin kt , k 0, 1, 2, 3... , ортогональная с (t ) 1 на отрезке , .
Примером адресного разделения каналов является система почтовой связи и другие, указанные в табл. 3.2.
Как уже упоминалось ранее, когнитивные – это методы, основанные на знаниях, смысловом содержании сообщения, сведениях, договоренностях, известных заранее отправителю и получателю, конкретное значение которых сигнализирует получателю о его конкретных
действиях.
ЗАКЛЮЧЕНИЕ
Итак, в настоящей главе рассмотрены базовые принципы построения технического (аппаратного) обеспечения средств информационных систем и их элементной базы.
Вначале рассмотрены возможные и существующие разнообразные
варианты построения информационных систем и их разновидностей –
сетей.
Затем описаны основные принципы построения ИС и их элементной базы: аналоговые, цифровые, когнитивные, нейронные и квантовые. Приводятся примеры их реализации, сильные и слабые качества,
свойства. Завершается глава рассмотрением разных принципов разделения каналов в многоканальных ИС.
214
ВОПРОСЫ ДЛЯ САМОПОДГОТОВКИ
1. Что такое морфологический анализ? Как он реализуется практически и чем отличается от классификации?
2. Перечислите наиболее типичные отличительные структурные
признаки информационных систем, возможные реализации признаков
и названия соответствующих им ИС.
3. В чем отличие многофункциональных ИС от однофункциональных, многоканальных от одноканальных, многовходовых от одновходовых, многомерных от одномерных, многоуровневых от одноуровневых?
4. Укажите отличия между локальными и распределенными ИС,
однородными и неоднородными.
5. Что понимается под информационной сетью? Связано ли понятие сети с распределенностью ИС?
6. Что такое адаптивные ИС? Какие виды адаптации чаще всего
рассматриваются?
7. В чем отличие детерминированных ИС от стохастических?
Приведите поясняющие примеры.
8. Что понимается под агрегатированием в ИС? Можете ли пояснить, чем агрегатирование отличается от комплексирования, интегрирования?
9. Поясните расшифровки аббревиатур ОКОД (SISD), ОКМД
(SIMD), МКОД (MISD) и МКМД (MIMD)? Можете ли привести примеры структур ЦВМ, соответствующих каждой из подобных архитектурно-структурных решений (см. [1])?
10. Поясните суть, отличительные особенности, слабые и сильные
стороны аналогового принципа построения информационных средств.
Приведите примеры подобных средств.
11. Поясните суть, отличительные особенности, слабые и сильные
стороны цифрового принципа построения информационных средств.
Приведите примеры подобных средств.
12. Поясните суть, отличительные особенности, слабые и сильные
стороны когнитивного принципа построения информационных
средств. Приведите примеры подобных средств.
13. Поясните суть, отличительные особенности, слабые и сильные
стороны нейронного принципа построения информационных средств.
Приведите примеры подобных средств.
215
14. Поясните суть, отличительные особенности, слабые и сильные
стороны квантового принципа построения информационных средств.
Приведите примеры подобных средств.
15. Что понимается под гибридными и комбинированными средствами технического обеспечения ИС? Приведите примеры.
16. Приведите примеры и охарактеризуйте разные топологические
струкуры ИС.
17. Приведите и поясните пример применения различного математического представления одного и того же объекта (например, элемента АВМ).
18. Перечислите и охарактеризуйте различные принципы (методы)
разделения каналов в многоканальных системах.
216
Глава четвертая
ИНДУКТИВНОЕ МОДЕЛЬНОЕ
ПРЕДСТАВЛЕНИЕ ОБЪЕКТОВ. СЕМАНТИЧЕСКАЯ,
СОБЫТИЙНАЯ И ПРАГМАТИЧЕСКАЯ
ОБРАБОТКА ДАННЫХ
§ 4.1. НЕОБХОДИМЫЕ ПОНЯТИЯ
Для лучшего восприятия излагаемого в настоящей главе материала
рекомендуем вернуться к ранее использованным понятиям.
Прежде всего укажем на наличие в литературе разного понимания
терминов сигнал, данные и знания (причем знаний как носителей информации (анзния), с одной стороны, и составной части (семантики,
смысла) информации – с другой). Обратим внимание на их трактовку
в настоящем пособии, а также на трактовку терминов «Данные»,
«информация», «протознания», «информационный мусор», на важность, во-первых, понимания места и роли моделирования и модели в
науке, человеческой деятельности и жизни, в исследовании объектов,
во-вторых, на двоякость модели по отношению к информации (см.
дальше).
Введем также новые необходимые понятия. Важным аспектом описания объектов является не только формализация собственно модельного представления объектов, но и формализация задач, подлежащих
решению согласно цели исследования объекта, а также их классификация. Рассмотрим этот вопрос подробнее частично в настоящем параграфе, частично в § 4.4. Дело в том, что так же как при модельном
представлении объекта, формализованное описание задачи позволяет
лучше использовать возможности автоматизации ее решения, в част217
ности, с использованием компьютеров, и, следовательно, свести к минимуму степень участия человека в решении задачи1.
С точки зрения допустимости формализации задачи делятся на два
класса2: структурированные и неструктурированные. Очень часто в
отдельный класс выделяют частично-структурированные задачи.
Структурированные (формализуемые, хорошо структурированные) – это задачи, в которых известны все ее элементы и взаимосвязи
между ними. Структурированность допускает количественное описание, позволяет выразить содержание задачи в формализованном виде,
например, в виде математической модельной постановки, имеющей
точный алгоритм решения, осуществить полную автоматизацию решения, делает выполнение операций результативными, автоматическими,
механическими, сводит к нулю роль человека. К таким относятся,
например, многие расчетные задачи, решаемые по заданным алгоритмам: расчет зарплаты, параметров типовых конструкций; статистическая обработка данных; структурированные задачи управления, когда:
а) сложная задача разделена на подзадачи, для каждой из которых
можно сформулировать целевую функцию, критерии, ограничения;
б) частные цели согласованы с глобальной; в) не ожидаются риски и
конфликты интересов. Решение таких задач выполняется автоматическими средствами.
Неструктурированные (неформализуемые) – это задачи, для которых характерно отсутствие количественных показателей, а также
когда нельзя выделить отдельные элементы задачи и установить связь
между ними. Для таких задач характерно их качественное описание.
Это затрудняет автоматизацию и требует участия человека на разных
этапах формулировки и описания постановки задачи, который при
этом часто ориентируется на собственные знания и опыт, эвристические соображения, косвенные сведения, постепенно выявляя элементы
и этапы решения задачи, поддающиеся автоматизации. Пример такой
задачи – формализация отношений в коллективе, группе, классе.
Крайним проявлением неструктурированных задач является проблема (см. сноску на стр. 65 1-й части пособия) – сложный теоретиче1
Напомним о необходимости учитывать последствия излишней формализации (см. об этом заключения по 2 и 4 главам пособия и § 3.9, часть 1, а также разд. 1.2.5 и § 1.5), кроме этого присутствие или отсутствие специалистовпредметников при исследовании объектов.
2
Смотри правила классификации в разд. 1.2.1.
218
ский или практический вопрос, требующий изучения, решения, когда,
в отличие от задачи, не ясно, как это сделать; противоречивая
ситуация, которую мы не знаем, как разрешить, чтобы уменьшить степень недовольства исследователя (субъекта, решателя проблемы) сложившейся ситуацией.
Второй крайний случай неструктурированных задач – слабоструктурированные задачи. Сюда относятся те из них, которые имеют неполную, незаконченную структуру, неполные и нечеткие представления о том, как их решать. В определенной мере к ним примыкают
частично-структурированные задачи.
На решение неструктурированных задач и проблем ориентированы
средства естественного (человеческого) и искусственного интеллекта.
В частично-структурированных задачах известна часть элементов задачи и связей между ними. Для решения таких задач создаются
автоматизированные системы, в которых человек (естественный интеллект) или средства искусственного интеллекта решают те трудно
формализуемые элементы задачи, определяющие искомый результат,
которые нельзя выполнить формализованно, автоматически. Например, автоматизированные системы управления, проектирования, диагностики, принятия других решений.
По допустимости формализации постановки и виду получаемых
результатов решения задачи можно разделить на три вида: четкие, туманные1 и проблемные.
Четкие («видимые», «ясные», «светлые», «полнолунные») – это
задачи, в которых четко, однозначно определены исходные данные и
четко, однозначно известно наличие решения, т. е. существование одного или вполне определенно описываемого множества возможных
результатов решений. Примером таких задач является большинство
структурированных математических задач: нахождение экстремумов
гладких одно- или многоэкстремальных функций; нахождение корней
1
Термин «туманные» можно было бы заменить на «нечеткие» или «размытые». Однако эти термины уже заняты (см. часть 1, разд. 4.4.3). Согласно
излагаемому ниже контексту, «нечеткие», «размытые» множества решений
могут быть лишь подмножеством туманных. Пользуясь случаем, заметим, что
за основу рис. 4.12, часть 1, взят рисунок из публикации Штовба С.Д. «Введение в теорию нечетких множеств и нечеткую логику» [Электронный ресурс] –
Режим доступа: http://www.matlab.ru/fuzzy logic/book1/index.asp, сноска на что
была пропущена в 1-й части пособия.
219
алгебраических уравнений; решение непараметрических или параметрических статистических задач строго непараметрическими или соответственно параметрическими алгоритмами (см. разд. 4.3.7, часть 1).
Это задачи вида: ЧП-ЧР – четкая (однозначная) постановка – четкий
одно- или многозначный результат.
Туманные («расплывчатые», «плохо видимые», «потемковые»,
«плохопросматриваемые»). Сюда следует отнести два типа задач: ЧПТР и ТП-ЧР. Для первых (ЧП-ТР) характерно наличие четкой постановки задачи (ЧП), но допускается приемлемость туманных (расплывчатых) результатов (ТР), описываемых априори в виде интервальных,
нечетких моделей, либо апостериори оформляемых в виде априори
открытого (с неограниченными границами) множества с априорным
указанием вида функции (и апостериори ее значений) предпочтительности результатов из этого множества.
Примером такого типа являются задачи, решаемые с помощью
средств искусственного интеллекта, в частности, эволюционных алгоритмов – генетических, роевых, иммунных и им подобных (см. далее
§ 4.7).
Для вторых (ТП-ЧР) задач априорная их постановка затруднительна или без дополнительных исследований не может быть четко
(например, математически) поставлена (туманность постановки, ТП),
но будучи поставленной может быть четко решена (ЧР).
Примером являются математические и измерительные задачи, решаемые в два этапа, когда на первом этапе в условиях туманности,
априорной затруднительности выбирается вид модели объекта, а на
втором решается задача идентификации, измерения, оценивания по
уже выбранной на первом этапе модели. Это задачи прикладной статистики, решаемые смешанными (см. часть 1, разд. 4.3.7) методами, задачи структурно-параметрической идентификации объектов, когда
вначале определяется структура модели, а уже затем находятся значения ее параметров. Туманность в таких задачах «зашита» в неоднозначности итогов первого этапа и, как следствие, во множественности
возможных итоговых результатов решения, каждый из которых четко
«вырисовывается» из частных итогов первого этапа.
Наконец, третий вид задач – проблемные («ночные», «безлунные»,
«непросматриваемые», «невидимые»). Сюда относятся задачи, которые
мы, с одной стороны, не можем «сходу» сформулировать, с другой –
даже после понимания сути и оформления формулировки постановки
задачи не знаем, как ее решить, как сформулировать решение задачи.
220
Сюда можно отнести задачи, постановка и решение которых осуществляются экспертными методами, с помощью итерационных диалоговых процедур, некоторыми средствами искусственного интеллекта, например, коллектива интеллектуальных агентов в многоагентных
системах (см. далее § 4.4 и 4.6). Это задачи типа ОП-ОР – отсутствие
постановки (ОП), отсутствие вариантов решения и, следовательно,
возможных результатов решения (ОР). Не будем их детализировать.
Желающие могут сделать это самостоятельно.
По аналогии с задачами вводится классификация Данных на
структурированные (имеющие четкую, заданную структуру), полуструктурированные, слабоструктурированные и неструктурированные.
Приведем другие необходимые понятия.
Однородные данные:
1) данные, сгруппированные по одинаковым категориям (см. часть 1,
табл. 3.4);
2) полученные из одной и той же генеральной совокупности
(часть 1, разд. 4.3.7);
3) полученные для одного и того же объекта (объектов) в тех же
или допустимо сходных условиях, в одинаковых шкалах измерения.
В противном случае они называются неоднородными, разнородными. При этом часто в понятие разнородные включаются данные,
характеризуемые не только тем, что они получены от разных источников и/или в разных условиях, но и разноформатные, разного качества,
с другими свойствами, отличающими их от однородных.
Разнотипные данные:
1) измеренные в разных измерительных шкалах;
2) представленные разными структурными модельными типами.
Следующие разновидности данных – это необходимые, вспомогательные и избыточные.
Необходимые данные – это данные, без которых: а) поставленная
задача не может быть решена специалистом по обработке и анализу
данных; б) результаты решения задачи не могут быть правильно интерпретированы и применены прикладным специалистом. Первые –
это исходные, стартовые содержательные данные, необходимые для
решения задачи, вторые – необходимые для интерпретации и применения результатов решения. Пример первых: исходные, эмпирические,
экспериментальные данные (набор количественных и качественных
значений); ограничения, накладываемые при решении оптимизаион221
ных задач, и т. п. Пример вторых: метаданные – сведения о первичных,
исходных данных, о моментах и технологиях получения исходных
данных, о классе точности используемых средств измерения и т. п.
Вспомогательные данные – сведения в виде набора (множества,
базы) количественных или категорийных значений, графиков, схем,
правил, …, позволяющих ускорить решение задачи, уточнить результаты, упростить их интерпретацию и применение. Например, дополнительное правило остановки итерационного процесса; данные о показателях, отличных от исследуемого, которые могут улучшить качество
искомого результата.
Избыточные данные – другие, которые не относятся к необходимым или вспомогательным, но потребляют ресурсы без надобности
для этого.
Полные данные – это такие, которых достаточно для всесторонней
постановки и решения задачи, интерпретации и применения ее результатов1.
Неполные данные. Они рассмотрены в части первой, § 3.4, и связаны с неточностью, неопределенностью, нечеткостью (расплывчатостью), незнанием, нерепрезентативностью и неучтенностью.
Готовые (подготовленные, преобразованные) – это данные, готовые к обработке, анализу.
Сырые – требующие: предварительного исследования, очистки,
правки, восстановления пропусков и устранения выбросов; масштабного преобразования; выявления их полноты или неполноты; проверки
на степень достоверности и качественности, наличия внутренних противоречий; оценки степени их значимости, субъективности, уточнения
технологии и условий получения и прочих действий, которые следует
выполнить до их хранения, передачи, обработки и анализа, чтобы эти
операции в конкретных условиях могли быть верно выполнены согласно особенностям и свойствам используемых при этом алгоритмов,
а результаты – интерпретированы и применены.
1
Не следует путать понимаемую так полноту Данных, в том числе знаний
как носителей информации (анзний), моделей, методов, алгоритмов с полнотой знаний, трактуемой как фундаментальное свойство системы знаний не
изменяться при появлении новых знаний.
222
§ 4.2. ОСОБЕННОСТИ СОВРЕМЕННЫХ ДАННЫХ
ОБ ОБЪЕКТАХ И ЗАДАЧ ИССЛЕДОВАНИЯ ОБЪЕКТОВ
И ДАННЫХ
До средины ХХ столетия под анализом данных, как правило, понимался структурный и синтактический стохастический (статистический (САД): анализ распределений, регрессионный, дисперсионный,
факторный, корреляционный, спектральный и т. п., см. часть 1, § 4.3).
Его методологической основой являлись и являются дедуктивный и
синтактический подходы, априорная модельная заданность, определенность либо явное или неявное признание свойств данных и технологий их получения, формализация всех операций технологических
процессов оперирования с данными. Заметим, что по самой сути анализа при его применении исследуемое разделяется на части и исследуется по частям.
Дедуктивный подход (от лат. deductio – выведение) означает, что
искомый результат выводится из некоторых заданных мысленных посылок путем умозаключений от общего к частному, когда вывод о некотором элементе множества делается на основании знания общих
свойств всего множества. Он предполагает превалирующую активную
роль субъекта как в четырехместном отношении «объект – модель –
субъект – среда», так и в технологическом процессе исследования
(в широком смысле) конкретного объекта. Именно субъект формирует
постановку задачи, предлагает модель объекта, организует и участвует
во всех этапах технологических процессов, подобных изображенным
на рис. 2.1–2.4 (часть 1), включая процесс сбора, накопления и выполнения других синтактических операций с Данными с учетом поставленной им (субъектом) задачи. Именно субъект выбирает подлежащие
измерению характеристики, показатели, параметры, нацеливает исследование на обнаружение и описание ожидаемых им законов, закономерностей. Все излагаемое до настоящей главы было ориентировано
именно на такое активное участие субъекта. При дедуктивном подходе
решается частная задача, когда зачастую не рассматривается ее место и
роль в исследовании объекта и его свойств в целом, т. е. когда во главу
угла не ставится системный подход к исследованию объекта.
Синтактический подход связан с рассмотрением участвующих в
технологических операциях данных как синандов – операндов синтактических операций, т. е. операций, не требующих выявления сути,
сущности, смысла, содержащихся в данных. Формализованность
223
операций и их выполнение означает возможность алгоритмизации всего технологического процесса, из чего, согласно определению и свойствам алгоритма, следует результативность решения – единственность результата выполнения такого процесса, когда он (результат)
однозначно определяется для каждых конкретных исходных данных.
Примером реализации синтактического подхода является статистический анализ данных (САД). САД, во-первых, позволял и позволяет решать именно задачи, а не проблемы. Во-вторых, вся идеология САД
основана на усреднении результатов по выборке, т. е. сводится к получению и оперированию в дальнейшем «фиктивными», косвенными
(типа среднего значения, их распределения, корреляционной функции
и т. п.), а не конкретными значениями данных. Методы САД полезны
для проверки априорных гипотез и OLAP-образов данных, отражающих сложно организованные объекты.
Однако в связи с бурным развитием средств цифровой вычислительной техники, увеличением хранимых данных и ускорением их обработки, широкой автоматизацией и информатизацией разных сфер
человеческой деятельности наступило время лавинного накопления
данных и желание автоматизировать действия, ранее относимые исключительно к естественному (человеческому) интеллекту, требующие
выявления смысла, сути, закономерностей, установления не только
причинно-следственных и статистических связей, но и ассоциативных,
неявных, неизвестных ранее. С одной стороны, появилось понимание,
что данные лишь носители информации, а не сама информация, составной частью которой являются различные новые, релевантные
(практически полезные) знания, в частности законы, закономерности, а
также протознания и информационный мусор. Иными словами, возникла необходимость рассматривать данные, выступающие операндами технологических процессов при работе с ними, не только как синанды, но и как семанды, прагманды. При семантических операциях
данные рассматриваются как сырье, руда, из которых необходимо извлекать новые знания как о самих данных, так и о характеризуемых
ими объектах. С другой стороны, появились новые качества данных
(разнородность, разнотипность и т. п.) и, как следствие, новые проблемные вопросы по их обработке. Наконец, с третьей стороны, появилась необходимость оперировать не только и даже не столько усредненными показателями, ожидаемыми закономерностями, а выявлять
индивидуальные, неочевидные, неожиданные регулярности и паттерны, скрытые в «сырых» данных.
224
Многие современные данные, особенно в сфере бизнеса, стали относиться к категории Больших данных (Бд), для которых характерны:
атранзакционность (незавершенность операционной обработки данных
в режиме реального времени, обусловливающая их уязвимость) (V1),
неполнота (V2), ограниченная репрезентативность (V3), слабая исследованность (V4), разнородность, разнотипность (V5), многомерность,
практическая неограниченность объемов (V6), превышение темпов поступления новых данных над темпами их обработки (V7), непостоянство, большая изменчивость по составу и по отражению объекта (V8),
большая доля малосодержательных данных (V9). В англоязычной литературе эти особенности Бд очень часто лаконично характеризуют
набором из 3, 4 или более V: V1 – Vulnerability (уязвимость), V2 –
Vacancity (незаполненность), V3 – Veracity (правдивость, достоверность), V4 – Vagueness (неопределенность, смутность, неясность), V5 –
Variety (разнообразие), V6 – Volume (объем), V7 – Velocity (быстродействие, скорость (поступления и обработки)), V8 – Variability (изменчивость), V9 – Vacuity (пустота, бессодержательность, бессмысленность).
Среди Бд могут быть следующие: неточные, неполные (например, содержащие пропуски), с неясной технологией их получения, противоречивые, разнородные и разнотипные, представленные в разных измерительных шкалах как прямого, так и косвенного измерения. Сами Бд
могут иметь гигантские объемы. Все ярче и жестче стала проявляться
новая ситуация. Во-первых, модификация закона Парето: только не
более (а со временем всё менее) 20 % данных несут не менее 80 % полезных для потребителя сведений. Во-вторых, необходимость дополнения или замены дедуктивного подхода к обработке данных индуктивным (от частного к общему), когда, с одной стороны, данные
надлежит использовать не только для решения частных задач при исследовании объекта, а познавать объект в целом, во всем его многообразии, системном представлении, с другой – апостериори выявлять в
«сырых» данных априори неизвестные субъекту, частные и общие различные закономерности, связи, характерные состояния, отражающие
объект целиком и его связи с окружающей средой. В-третьих, необходимость апостериорного построения разных моделей данных и объектов в условиях различных априорных неопределенностей.
В-четвертых, при обработке данных стали допустимыми их слабая
структурированность и плохая формализуемость решаемых задач, появление вместо задач проблем; нестабильность, неустойчивость, нелинейность, необратимость и другие непривычные при традиционном
225
дедуктивном анализе свойства объекта и отражающих его данных;
необходимость иметь инструменты для обработки данных простые в
использовании, но позволяющие выдавать конкретные и понятные результаты. В-пятых, необходимость введения в технологический процесс обработки данных элементов интеллекта; изменения понятия
алгоритма, в частности введения в него неоднозначности, многовариантности результатов; решения плохо алгоритмизуемых задач; иметь
способность обучаться, например, по прецедентам, и делать общие выводы на основе частных данных, т. е. быть пригодным к индуктивному подходу, к работе в условиях отсутствия априорных моделей, а
также к системному синтетическому подходу в исследованиях, при
котором исследуемое всегда рассматривается, прежде всего, как часть
одной или нескольких надсистем, а не только и не столько к аналитическому дедуктивному подходу, который при этом может выступать
как вспомогательный. Плюс к этому – допустимость, необходимость и
полезность перебора или упорядоченного выбора моделей, их совместного сочетáнного1 (дизъюнктивного и/или конъюнктивного) полимодельного представления объекта и данных и сочета́нного многовариантного решения искомой задачи, в том числе с использованием
разных средств автоматизации тех технологических операций и соответствующих им действий, которые ранее даже не рассматривались
как объекты автоматизации и поэтому либо опускались, либо перекладывались на аналитиков, экспертов из-за их трудной формализуемости. Всё это означает замену дедуктивного решения задач, как в САД,
на индуктивное решение проблем. Отметим еще раз, что в отличие от
проблемы, которую не ясно, как решать, задача формулируется как
вопрос, требующий нахождения решения по известным исходным
данным известными или разрабатываемыми методами с соблюдением
известных условий.
1
Сочетáнное (от сочетáние – соединение, образующее единство, целое) –
это представление, полученное путем объединения и совместного использования нескольких модельных представлений, ориентированное на построение
системной картины объекта как целого и как части более сложной системы.
Дизъюнктивное (от лат. disjunctio – разобщение) – сложное представление, основанное на объединении двух или более разобщенных представлений
с использованием логических свойств союза «или».
Конъюнктивное (конъюнкционное) (от лат. conjunctio – союз, связь, совпадение) – представление, основанное на выявлении того общего, что есть в
совместно используемых моделях с помощью логических свойств союза «и».
226
В отличие от дедуктивного индуктивный подход (от. лат. inductio –
наведение) означает использование в качестве приема мышления индукции, посредством которой выводится общее правило (положение,
структура, свойство), присущее всем единичным объектам одного
класса, умозаключение от имеющихся фактов, Данных к некоторой
гипотезе, общему утверждению. Индуктивный метод исследования заключается в том, что для получения общего знания о каком-либо классе объектов необходимо исследовать отдельные его элементы – объекты, найти в них общие существенные свойства (признаки, отношения,
закономерности), которые и послужат основой для знания об общем,
присущем данному классу объектов. При этом необходимо учитывать
следующие обстоятельства. Первое. Индуктивное умозаключение может выступать в двух видах: полной и неполной индукции. При полной
индукции общий вывод о классе объектов делается на основе знаний
обо всех без исключения объектах этого класса. При неполной (расширяющей) индукции вывод делается на основании знаний о лишь некоторых объектах класса. Второе. В приложении к моделированию одного объекта или класса объектов метод неполной индукции означает, с
одной стороны, получение общих знаний об объекте (о классе объектов) при этом происходит не по всей совокупности требуемых для этого и полученных согласно дедуктивному подходу сведений, Данных, а
по имеющимся в распоряжении субъекта Данным, принимая их такими, какие они есть, в качестве простейших первичных моделей объекта
(объектов); с другой – неполная индукция может трактоваться как неполный перебор всех возможных вариантов, например, объектов, показателей, комбинаций переменных функции, средств решения для получения общего вывода по частным решениям [58]. Иными словами,
индуктивный подход ориентирован на построение по данным об объекте-оригинале как его простейшим моделям – носителям информации
об объекте, более общих моделей – знаний (см. часть 1, § 1.3; часть 2,
разд. 6.6.1, рис. 2.10), оформляемых аналитически, визуально, вербально, воплощением в действия. Третье. В силу ряда объективных
причин или из условий экономической целесообразности допускается
ослабление роли субъекта в технологическом процессе исследования,
включая постановку задачи. Повышается роль моделей и среды, точнее, тех средств и субъектов среды, которые участвуют в реализации
технологического процесса и потреблении результатов моделирования,
исследования. В индуктивном подходе считается допустимым, необходимым и полезным полимодельное представление объекта и Данных,
227
апостериорного перебора, упорядоченного выбора, самоприспособления, подгонки моделей под задачу. Интересно отметить точку зрения
[25, c. 81], согласно которой «основное отличие индукции от дедукции
состоит в том, что дедукция – это логический переход от одной истины
к другой, а индукция – переход от достоверного знания к вероятностному».
В-шестых, всё очевиднее стала формулироваться не просто задача
накопления данных, а задача (проблема) такого взаимодействия с ними, при котором конкретный пользователь может получить из данных
неизвестное ранее нечто – новое, неочевидное, неожиданное, практически полезное для него, необходимое или дополнительное для его деятельности и принятия им соответствующих решений.
Наконец, появилось чёткое понимание необходимости наличия при
получении, сопровождении, а также использования при анализе данных метаданных – сведений о данных, в частности, о технологиях их
получения, достоверности, качестве и других аспектах, важных для
извлечения знаний из данных, их интерпретации и применения.
Все это привело к появлению новых средств индуктивного модельного представления объектов, работе не только с числовыми, но и символьными графическими и другими Данными, переосмысливанию понятий «информация» и «интеллект», разработке идей и методов
работы в новых условиях, в частности, к появлению различных средств
интеллектуального и разведочного анализа Данных, в том числе Больших, и искусственного интеллекта. Рассмотрению некоторых из них
посвящена настоящая глава. Прежде чем переходить к их рассмотрению, в § 4.3–4.5 опишем важные для этого понятия.
§ 4.3. ПОНЯТИЕ О ТЕОРИИ АЛГОРИТМОВ
4.3.1. Уточнение понятия и куализные модели алгоритмов
Одним из важнейших в информатике является термин «алгоритм».
Как и с другими понятиями существуют десятки его определений.
В § 1.3 (часть 1) приведено обобщенное понимание алгоритма, которое
используется в различных научных дисциплинах и практической деятельности человека. Современный формальный стандартизованный
подход к пониманию алгоритма появился в 30-х годах XX века в математике и стал одним из базовых в зародившейся информатике. Первые
стандартизованные варианты понятия алгоритма появились через
228
формализованные модели вычислений (в обобщенном понимании
вычислений как операций с произвольными символами) в виде абстрактных идеализированных вычислительных машин А.М. Тьюринга
(1936 г.), Э.Л. Поста (1936–1947 гг.) и лямбда-исчисления (вычислимых
функций) А. Чёрча (1936 г.), а также через понятие рекурсивной функции С.К. Клини. Как было показано позже, варианты этих понятий
формально оказались эквивалентными друг другу. Удачное уточнение
было дано А.А. Марковым (1947 г.) введением понятия нормального
алгоритма.
Дело в том, что интуитивное обобщенное понятие алгоритма типа
приведенного в § 1.3 (часть 1 настоящего пособия) относится к первоначальным в математике и информатике, не допускающим их определения в терминах более простых понятий. Для него, как правило,
выделяют семь характеризующих его параметров (признаков, показателей): 1) совокупность возможных исходных данных1; 2) совокупность возможных результатов; 3) совокупность возможных промежуточных результатов; 4) правило начала; 5) правило непосредственной
переработки; 6) правило окончания; 7) правило извлечения результата
[12]. Строгость термина «алгоритм» связана с «уточнением» его понятия за счет сужения, состоящего в том, что для каждого из семи параметров точно описывается некоторый класс, в пределах которого этот
параметр может меняться. Выбор таких классов и отличает одно уточнение от другого. Сама по себе необходимость стандартизации понятия алгоритма и разработки теории алгоритмов возникла в связи с
предположением о невозможности алгоритмического разрешения многих математических проблем, толчком к которому явилось доказательство в 1931 г. Куртом Гёделем теоремы о неполноте формальных систем, включая арифметику.
Постепенно в виде специальных разделов математики [12] и информатики [11] и появилась теория алгоритмов.
Теория алгоритмов – научная дисциплина, изучающая общие
свойства, закономерности и проблемы алгоритмов, а также разнообразные формальные модели их представления. К задачам теории алгоритмов относятся: формальные определения алгоритма и доказательства алгоритмической разрешимости или неразрешимости задач,
существование единого алгоритма решения бесконечной серии одно1
В общем виде исходными данными и результатами алгоритма могут
быть разнообразные конструктивные объекты (см. разд. § 4.3.2).
229
типных единичных задач (массовая алгоритмическая проблема);
асимптотический анализ сложности алгоритмов; классификация алгоритмов по сложности; разработка критериев сравнительной оценки
алгоритмов, их качества, трудоемкости, методики выбора рациональных алгоритмов; алгоритмическая сводимость – возможность получения решения одной проблемы по любому решению другой и т. п.
По типу решаемых задач теорию алгоритмов обычно делят на дескриптивную (качественную) и метрическую (количественную). Дескриптивный раздел рассматривает алгоритмы с точки зрения устанавливаемого ими соответствия между исходными данными и
результатами, в частности, алгоритмические проблемы построения алгоритмов, обладающих теми или иными свойствами, и массовые проблемы поиска единственных алгоритмов. Метрический раздел теории
исследует алгоритмы с точки зрения сложности как самих алгоритмов,
так и задаваемых ими вычислений, т. е. процессов последовательного
преобразования конструктивных объектов [12].
Как уже указывалось, основой подхода к строгому формализованному пониманию (уточнению) алгоритма является их куализное
модельное представление в виде абстрактных идеализированных вычислительных машин (А. Тьюринг, Э. Пост), исчислений (А. Чёрч), вычислимых рекурсивных функций (С. Клини), точной формализацией его
типа (А.А. Марков) и представление конструктивных объектов как топологических комплексов определенного типа (А.Н. Колмогоров).
Рассмотрим чуть подробнее некоторые из таких моделей.
Модели А. Тьюринга и Э. Поста представляют собой абстрактный
исполнитель в виде вычислительной машины, являющейся расширением конечного автомата и способной (согласно тезису Чёрча–
Тьюринга)1 имитировать путем задания правил перехода все другие
исполнители, каким-либо образом реализующие процесс пошаговой
реализации элементарных вычислений (см. рис. 3.2).
Уточнение понятия алгоритм по Тьюрингу-Посту сводится к основной гипотезе алгоритмов (тезису Тьюринга): «Некоторый алгоритм
для нахождения значения функции, заданной в некотором алфавите,
существует тогда и только тогда, когда его (значение) можно вычислить на абстрактной ленточной машине» (названной затем машиной
Тьюринга), т. е. когда функция исчислима по Тьюрингу.
1
Любой алгоритм в интуитивном смысле этого слова может быть представлен эквивалентной машиной Тьюринга.
230
В модели А. Чёрча, основанной на лямбда ()-исчислении, рассматривается пара: -выражение и его аргумент, а вычислением считаются конечная цепочка в виде последовательности -выражений,
начиная с исходного, каждое из которых получается из предыдущих
применением соответствующих правил подстановки. Он предложил
уточнить понятие вычислимой функции отождествлением понятий
всюду определенной вычислимой функции, имеющей натуральные
аргументы и значения, и общерекурсивной функции. Напомним, что
под рекурсией1 понимается: 1) метод определения функции через ее
предыдущие и ранее определенные значения (см., например, часть 1,
формулы (4.76), (4.152), (4.153), (4.162), (4.185)); 2) способ организации вычислений (в программировании), при котором функция вызывает сама себя с другим аргументом. Обычно принято считать, что если
итерация означает решение задачи от простого к сложному, то рекурсия, наоборот, от сложного к простому.
Согласно тезису Чёрча, «числовая функция тогда и только тогда
алгоритмически исчислима, когда она частично рекурсивна».
Что касается нормального алгоритма Маркова, то он представляется в виде схемы последовательных применений подстановок, которые
реализуют определенные процедуры получения новых слов из базовых, построенных из символов некоторого алфавита. Функцию, которую можно исчислить нормальным алгоритмом, называют нормально
вычислимой.
Аналогично тезисам Тьюринга и Черча гипотеза Маркова, получившая название принципа нормализации Маркова, выглядит так: для
нахождения значений функции, заданной в некотором алфавите, некоторый алгоритм существует тогда и только тогда, когда функция нормально исчисляема.
Заметим, что, как и в машине Тьюринга, нормальные алгоритмы,
хотя и относятся к вычислительным, на самом деле не выполняют самих вычислений, а выполняют преобразование букв, слов (или элементов множества чисел) путем замены букв (элементов множества) по
заданным правилам.
Рассмотренные уточнения лишний раз подчеркивают, что алгоритм
можно представить в виде четкой (жесткой, механически выполняемой) системы инструкций, определяющих дискретный детерминированный процесс преобразования входных данных к искомому выход1
От лат. recursio – возвращение.
231
ному результату (если он существует!) за конечное число шагов. При
этом подразумевается, что если искомого результата не существует,
алгоритм либо никогда не завершает работу, либо заходит в тупик.
Именно поэтому такие алгоритмы называют жесткими.
4.3.2. Базовые понятия теории алгоритмов
Согласно [12] областью применимости Х алгоритма A называют
совокупность тех объектов, к которым он применим, т. е. в применении к которым дает результат. Говорят, алгоритм A вычисляет функцию f, если его область применимости Х совпадает с областью определения f, т. е. он перерабатывает всякий x X в f ( x) ; разрешает
множества А относительно множества Х, если он применим ко всякому x X , и перерабатывает всякий х из X A в слово «да», а всякий x X / A – в слово «нет»; перечисляет множество B, если его область применимости есть натуральный ряд, а совокупность
результатов есть В. Функция f называется вычислимой, если существует вычисляющий ее алгоритм. Множество называется разрешимым
относительно Х, если существует алгоритм A, разрешающий его относительно Х, и перечислимым, если оно либо пусто, либо существует
перечисляющий его алгоритм. Заметим, что область возможных исходных данных и область применимости любого алгоритма – перечислимые множества.
Как уже указывалось, алгоритмы оперируют с конструктивными
объектами – первоначальными объектами конструктивной математики. Под ними подразумеваются некоторые обобщенные абстрактные
объекты, которые в каждом конкретном случае представляются в
определенном виде. В нашем случае – это конкретный вид исходных
данных и результатов применения алгоритмов (например, слова в фиксированном алфавите, натуральные числа, рациональные числа).
Если рассматриваемые объекты изначально не относятся к конструктивным, для применения к ним алгоритмов неконструктивные
объекты обозначают, поименовывают. Этим занимается раздел теории
алгоритмов – теория нумерации. Изучением же вопросов взаимосвязи
между формализованными логико-математическими языками и математическими структурами, описываемыми с помощью этих языков,
занимается раздел математической логики, называемый теорией моделей. Под моделями в ней понимаются интерпретации формализованного языка, а под интерпретацией – сопоставление всем исходным поня232
тиям и отношениям данной аксиоматической теории некоторых математических объектов и отношений между ними [12].
Современная теория алгоритмов (ее дескриптивная и метрическая
ветви) развивается в основном по следующим трем направлениям:
классическая, практического и асимптотического анализов.
Классическая теория изучает вопросы формулировки задач в терминах формальных языков, их разрешимости и сложности, классификации по сложности.
Теория практического анализа вычислительных алгоритмов занимается задачами получения явных функций трудоемкости алгоритмов, точечных и интервальных значений таких функций, а также поиском практических критериев качества алгоритмов и разработкой
методик выбора рациональных алгоритмов.
Близким к рассмотренным направлениям является анализ алгоритмов как раздел математической теории программирования. Он
изучает характеристики исполнения алгоритмов, а именно время и
объем памяти, используемые алгоритмом [12]. Здесь под временем
работы t A ( x) алгоритма A понимается количество элементарных тактов, выполняемых на некоторой модели вычислительной машины на
входных данных x X . Под объемом памяти s A ( x ) понимается количество ячеек памяти, используемое алгоритмом A при обработке
входных данных х размером | x | .
Функции, описывающие зависимости t A (n) и s A (n) от размера
данных n | x | , а именно:
TA (n) sup t A ( x) : x X , | x | n ,
(4.1)
S A (n) sup s A ( x) : x X , | x | n ,
(4.2)
t,x
s, x
где sup – верхняя грань, характеризуют временную и емкостную
сложности алгоритма A.
4.3.3. Понятие о сложности алгоритмов и задач
Целью введения понятия трудоемкость и ее анализа является поиск
оптимальных алгоритмов решения для каждой массовой или индиви233
дуальной конкретной задачи1. В качестве критериального показателя
оптимальности при этом выбирается трудоемкость A алгоритма A –
количество элементарных операций, которые необходимо выполнить
для решения рассматриваемой задачи с помощью этого алгоритма.
Критериальная функция – это функция трудоемкости – соотношение,
описывающее зависимость входных данных алгоритмов с количеством
элементарных операций, необходимых для его реализации. Эта функция по-разному определяется в зависимости от конкретной ситуации
(алгоритмов решаемых задач): как функция только от объема исходных данных либо от значений данных или порядка их поступления,
либо от их совокупности.
Определение трудоемкости алгоритмов для каждого конкретного
случая зачастую становится нетривиальной задачей. Поэтому на практике одним из упрощенных вариантов анализа трудоемкости и других
характеристик исполнения алгоритмов является их асимптотический
анализ. Цель асимптотического анализа алгоритмов – сравнение трудоемкости, затрат времени и других ресурсов, характерных для различных алгоритмов, используемых для решения одной и той же задачи, при больших объемах входных данных. Используемый при этом
показатель оценки в виде значений функции трудоемкости, позволяющей определить скорость роста трудоемкости алгоритма с увеличением объема данных, называется сложностью алгоритма. В обобщенном виде под ней понимается величина, характеризующая длину
описания алгоритма или громоздкость процесса его реализации в применении к исходным данным.
Согласно определению сложность алгоритма может быть описательной или вычислительной (сложность реализации).
Сложность описания алгоритма характеризует длину его описания. Она зависит от выбора способа задания алгоритма (длина записи,
количество встречающихся в ней символов или выражений определенного типа, число внутренних состояний и внешних символов или число команд в программе машины Тьюринга и т. п.).
Вычислительная сложность, или сложность вычисления алгоритма, представляет собой функцию, определяющую зависимость объема
1
Если задача формально определяется общим списком всех своих параметров (свободных параметров, значения которых не заданы) и формулировкой свойств, которым должно удовлетворять решение (ответ) задачи, то она
называется массовой. Если всем параметрам задачи присвоить конкретные
значения, то она называется индивидуальной.
234
работы, выполняемой алгоритмом, от размера входных данных. Понятно, что данная характеристика, отражающая процесс решения конкретной задачи для конкретного исходного объекта, зависит от этих
факторов. Поэтому зачастую вычислительная сложность алгоритма
дополняется, во-первых, сложностью решаемой задачи, во-вторых,
сигнализирующей функцией алгоритма.
Сигнализирующая функция алгоритма A есть функция, сопоставляющая каждому объекту x A из области X A применимости алгоритма A число, характеризующее сложность применимости данного алгоритма к конкретному объекту х.
Сложность задачи – это сложность самого лучшего («быстрого»)
алгоритма решения задачи в худшем случае, т. е. нижний предел вычислительной трудоемкости решения задачи.
Воспользуемся приемом, принятым в математическом асимптотическом анализе для асимптотических выражений функций на основе
их асимптотического равенства или неравенства. Обозначим через
f (n) оценку функции сложности алгоритма, где п – величина
объема данных, длины входа. Будем считать, что оценка сложности
алгоритма A асимптотически задается интервально и запишем
f A ( n) g ( n) ,
(4.3)
если при g 0 и n 0 существуют такие положительные c1 , c2 и n0 ,
что
c1 g (n) f (n) c2 g (n)
(4.4)
при n n0 .
Оценка задает нижнюю асимптотическую оценку роста функции
f (n) , что записывается как
f ( n) g ( n) ,
(4.5)
0 cg (n) f ( n), n n0
(4.6)
если
для любых c 0 и n0 0 .
Понятно, что (4.3)–(4.6) определяют не отдельную функцию, а
классы функций, обладающих соответствующим свойством с точностью до постоянных множителей.
235
Оценка задает верхнюю асимптотическую оценку роста функции f (n) , что записывается как
f ( n) g ( n) ,
(4.7)
0 f (n) cg ( n), n n0
(4.8)
если
для любых c 0 и n0 0 .
Например, запись f (n) (n log n) означает, что g (n) n log n , т. е.
класс функций f (n) с увеличением п растет пропорционально n log n ;
f (n) ( n log n) – класс функций f (n) растет не медленнее, чем
g (n) n log n , а f ( n) (n log n) – что f (n) принадлежит классу
функций, которые растут не быстрее, чем g (n) n log n .
Заметим, что f (n) g ( n) тогда и только тогда, когда
f ( n) g ( n) и f ( n) g ( n) .
Примером алгоритмов, имеющих сложность (n log n) , являются
алгоритмы сортировки элементов некоторого множества путем попарного сравнения их элементов.
В заключение обратим внимание на простую трактовку соотношений
(4.3)–(4.8). Они означают, что для алгоритмов с оценкой f (n) g ( n)
имеют место асимптотические неравенства 0 c1 f (n) g ( n) c2 ; при
f (n) g (n) асимптотически имеем f ( n) g ( n) c 0 ; а при
f ( n) g ( n) 0 f ( n) g ( n) c .
4.3.4. Классы алгоритмов и задач по сложности
Как уже отмечалось, вычислительная сложность конкретного алгоритма зависит как от решаемой задачи, так и от объема входных данных. Поэтому, будучи важной сама по себе, в общем виде практический интерес она представляет прежде всего с точки зрения именно тех
задач и объектов, для которых алгоритмы предназначены.
Первое деление на классы алгоритмов проводят по виду функции
трудоемкости. Чаще всего выделяют следующие классы.
Количественно-зависимые по трудоемкости алгоритмы. К этому классу относят алгоритмы, для которых A (n) зависит только
от размерности и входного сигнала и не зависит от конкретных значе236
ний данных. Примеры: алгоритмы умножения матрицы на вектор,
умножения матриц.
Параметрически-зависимые по трудоемкости алгоритмы – это
алгоритмы, трудоемкость которых определяется не столько размерностью входных данных, сколько прежде всего конкретными значениями
обрабатываемых данных. Пример – алгоритмы вычисления элементарных функций с заданной точностью путем разложения функций в ряд
(степенной, тригонометрический и т. п.).
Подклассами этих алгоритмов являются порядко-зависимые по
трудоемкости алгоритмы. Их примеры – алгоритмы сортировки, поиска максимального или минимального элемента массива.
Количественно-параметрические по трудоемкости алгоритмы –
совокупность алгоритмов, для которых трудоемкость есть функция
не только п – количества входных данных, но и значений входных
данных. Пример: алгоритмы численных методов, в которых внешний
цикл вычислений, параметрически-зависимый по точности, включает в
себя количественно-зависимый по размерности фрагмент.
Что касается сложности, то по ней алгоритмы классифицируют в
привязке к их пригодности для решения соответствующих по сложности задач. Здесь под классом сложности понимается множество алгоритмов или задач, для которых существуют вычисления со сложностью, не превышающей границы из множества границ, задающих
класс. Обычно алгоритмы делятся на следующие четыре вычислительно сложностных класса.
1. Алгоритмы, сложность которых не превосходит линейную, т. е.
имеет порядок не больше (n) . Например, время поиска в кэштаблице (п = 1), сложение или вычитание чисел из п цифр, линейный
поиск в массиве из п элементов. Приведем также примеры алгоритмов решения задач, сложности которых находятся между (1)
и (n) . Это: время работы интерполирующего поиска п элементов
( (log log n) ); вычисление x n , двоичный поиск в массиве из п элементов ( (log n) ).
2. Алгоритмы полиномиальной сложности, для которых сложность
оценивается как ( n ) , 1 . Понятно, что алгоритмы класса 1 можно рассматривать как подкласс полиномиальных, положив 1 . Примеры: элементарные алгоритмы сортировки ( 2) ; обычное умножение матриц ( 3) . Пример алгоритмов решения задач, сложность
которых находится между (n) и (n 2 ) и равна ( n log n) . Это сор237
тировка слиянием п элементов, нижняя граница сортировки сопоставлением п элементов.
3. Алгоритмы экспоненциальной сложности, которая мажорируется оценкой 2( n ) или (C n ) или C ( n) , где C 1 , но не мажорируется никакой степенью с оценкой (n ) . Например, некоторые задачи
коммивояжера, алгоритмы поиска полным перебором.
4. Алгоритмы сложности большей, чем экспоненциальная.
Алгоритмы 4-го класса на практике могут использоваться только
при малых п (см. часть 1, приложение 1).
Класс P-сложных задач (от англ. polynomial). К данному классу
относятся задачи, время решения которых (т. е. количество операций,
в которых с помощью детерминированной вычислительной машины
(например, Тьюринга)) полиномиально зависит от объема исходных
данных п. Иными словами, это задачи, для алгоритмов решения которых при n характерна оценка (n) (n k ) или (n) a0 a1n
a2 n 2 ... ak n k , где k – некоторое натуральное число 1, 2, 3,…;
a0 , a1 ,..., ak – неотрицательные числа. Иными словами, для которых
существует константа k и решающий алгоритм с (n) (n k ) .
Для задач класса P характерно следующее. Во-первых, для большинства из них на практике k 6 (см. часть 1, табл. П1.1). Во-вторых,
класс P инвариантен к моделям вычислений (алгоритмов). В-третьих,
класс обладает свойством естественной замкнутости, так как сумма или
произведение полиномов есть полином. Примеры Р-сложных задач приведены выше1. К ним можно добавить задачу нахождения кратчайших
1
Напомним, что сложность задачи определяется сложностью самого
«быстрого» алгоритма ее решения. Так, например, для нахождения N равноотстоящих точек спектральной плотности мощности по N равноотстоящим отсчетам сигнала простым периодограммным алгоритмом требуется число опе2
раций сложения и комплексного умножения, пропорциональное N , а по
алгоритму быстрого преобразования Фурье – пропорционально N log 2 N [18].
Следовательно, сложность этой задачи O( N log 2 N ) . Для проверки планарности графа с п вершинами при разработке печатных плат, т. е для проверки непересекаемости проводников платы, реализующих их электрическую схему, первые алгоритмы имели сложность t (n) O(n6 ) , затем O(n 2 ) , потом O(n log n)
и, наконец, O(n) [81]. Следовательно, сложность такой задачи O(n) .
238
расстояний между всеми парами п вершин графа (сложность (n3 ) )
или максимизации потока между истоком (входом) и стоком (выходом)
сети, содержащей n внутренних вершин (сложность (n3 ) ).
Класс экспоненциально (степенно) сложных задач. Этот класс
составляют задачи, для которых время решения ограничено экспонентой (степенью) от размерности задачи, т. е. при линейном возрастании
размерности задачи время ее решения возрастает экспоненциально
(с соответствующей степенью). Сюда относятся подклассы, для кото-
рых (n) (2n ), (e n ), ( m n ), 2( n) , …, где т – некоторое число, большее 1, е – основание натурального логарифма.
Заметим, что так же как класс множеств неограничен по их мощности, класс задач неограничен по их вычислительной сложности. Распространено мнение, что задача решаема или алгоритм практически
полезен, если (n) (n), (n3 ), (n6 ) (что характерно для многих
задач), и мало приемлем или неприемлем при экспоненциальной сложности для п большой размерности1.
Класс NP-сложных задач (полиномиально проверяемых задач).
Существуют два эквивалентных определения данного класса задач.
Первое – это задачи, которые могут быть решены за полиномиальное
время с помощью недетерминированной вычислительной машины,
следующее состояние которой не всегда однозначно определяется
предыдущим, т. е. процесс решения задачи на которой можно представить в виде разветвляющегося на каждой неоднозначности процесса,
когда задача считается решенной, если хотя бы одно ветвление процесса приводит к искомому ответу. Второе – к классу NP относятся
1
Известен пример поиска представления большого числа, состоящего из
232 десятичных разрядов, в виде двух простых сомножителей со 116 и 116
разрядами [43]. Алгоритмический поиск потребовал 1020 вычислительных
операций и выполнялся на сотнях машин в Лозанне, Амстердаме, Токио, Париже, Бонне и Редмонде (США), которые сообща работали над задачей почти
два года. Подобная задача является трудноразрешимой для цифровых компьютеров, но может быть не очень сложной для квантовых, использующих
квантовый алгоритм нахождения простых множителей Питера Шора (1994 г.).
Аналогичное характерно для квантового алгоритма Лова Гровера поиска данных по большим неупорядоченным базам данных (1996 г.). Заметим, что понятия «простые» и «сложные» задачи в квантовых компьютерах переместились от вычислительных задач к задачам работы с такими компьютерами.
239
задачи, правильность решения которых можно проверить за полиномиальное время с помощью используемой извне дополнительной информации (данного извне, свыше сообщения) полиномиальной длины.
NP-задачи – это такие, сложность решения которых мажорируется экспонентой, для которых не известен алгоритм решения полиномиальной
сложности и не доказано, что такого алгоритма нет.
Пример NP-сложной задачи.
При заданных A1 , A2 ,..., AN и a1 , a2 ,..., an найти такой массив значений
x1 , x2 ,..., xn ,
где
xi 0
или
1,
для
которого
a1x1 a2 x2 ... an xn A j , j 1, N . Нетрудно убедиться, что для проверки правильности решения такой задачи при фиксированном небольшом N (или п) и переменном большом п (либо N) потребуется линейная (по п или N) функция от числа операций, а именно не более
n N операций.
NP-полные задачи (класс NPC, от англ. NP-complect) – это подкласс задач, из класса NP, полиномиальная разрешимость которых эквивалентна равенству Р или NP. Иными словами, NP-полная задача –
это такая, к которой можно свести любую другую задачу из класса NP
за полиномиальное время. Доказана теорема, согласно которой, если
существует полиномиальный алгоритм, то класс Р совпадает с классом
NP, т. е. P NP . Иными словами, NPС-полные задачи относятся к самым сложным из класса NP [27], поскольку если удается найти полиномиальный алгоритм решения какой-нибудь из них, то это означает,
что P NP , т. е. весь класс NP допускает полиномиальное решение.
Известно уже более трех тысяч примеров таких задач – это задачи о
рюкзаке, о вершинном покрытии и о раскраске графа, о коммивояжере.
Однако ни для одной из них пока не удалось найти полиномиального
алгоритма решения.
Вопрос о равенстве или эквивалентности классов Р, NP и NPC, т. е.
вопрос о возможности нахождения Р-решения для любой NP-задачи, а
следовательно, и для NPC, считается одной из самых сложных открытых проблем теоретической информатики, которую математический
институт Клэя включил в список проблем тысячелетия, предложив
награду размером в один миллион долларов США за ее решение. Словесная формулировка проблемы: можно ли все задачи, решение которых
проверяется с полиномиальной сложностью, решить за полиномиальное
время? Предполагаемое соотношение Р-, NP- и NPC-классов задач в
настоящее время представляется в виде, изображенном на рис. 4.1.
240
Не окажется ли решение данной проблемы подобным решению
континуум-проблемы: наличия множеств, мощности которых находятся между счетным и континуумом или континуумом и гиперконтинуумом. Суть решения – доказать или опровергнуть наличие
подобных множеств формальными приемами невозможно. Множественная проблема оказалась неразрешимой формальными методами.
Второй вопрос: «Может ли помочь в решении этой проблемы квантовый компьютер, найдя хотя бы на простом примере все возможные
решения для этого примера?».
Ko-NPC
Ko-NP
NP
P
NPC
P
Рис. 4.1. Соотношение между классами P, NP и NPC
В теории принятия решений помимо NP-задач рассматриваются
дополнительные к ним Ko-NP-задачи [56]. Дополнительность при этом
«означает, что для каждой задачи принятия решений из класса NP существует соответствующая задача в классе Ko-NP, на которую может
быть дан положительный и отрицательный ответ, противоположный
ответу на задачу из класса NP». Показано, что Р-задачи являются подмножеством и NP, и Ko-NP задач, а в Ko-NP входят Ko-NP-полные задачи, в которые не входят Р-задачи и которые являются самыми трудными задачами в классе Ko-NP. Иными словами, графически Ko-NP
задачи можно изобразить в виде зеркального отражения NP-задач (см.
рис. 4.1).
4.3.5. Расширение понятия и множества
куализных моделей алгоритмов
Рассматривая термин «алгоритм», в разд. 4.3.1 было отмечено, что
каждый алгоритм и их классы характеризуются семью параметрами
(признаками, показателями): видами данных и результатов, а также
правилами начала, переработки, окончания и извлечения результатов.
Там же было указано, что базовые основы теории алгоритмов связаны
241
с сужением его понятия путем уточнения, а именно повышения формальной математической строгости описания классов, к которым относятся эти параметры. При этом, как правило, считалось, что, вопервых, алгоритмы являются вычислительными, и, во-вторых, для них
по умолчанию выполненны следующие особенности, связанные с понятием «алгоритм» (см. часть 1, 3.1).
1. Значения входных и выходных (результаты) данных являются
количественными.
2. Задана точная, определенная инструкциями последовательность
процедур, выполняемых алгоритмом операций, в итоге чего результат
алгоритмического решения задачи однозначно определяется исходными (входными) данными, т. е. связь входные данные выходные данные (результат) является однозначной или, иначе, выполняется свойство однозначности алгоритма.
3. Явно проявляется детерминированность действий (см. часть 1, 3.1).
4. Множество результатов на выходе алгоритмического процесса
является канторовской, т. е. его характеристическая функция является
бинарной или, иначе, функция принадлежности конкретного результата этому множеству принимает только два значения 0 или 1.
5. Значения входных данных образуют канторовские множества.
Как уже упоминалось, подобные алгоритмы, жестко определяющие
детерминированный механически выполняемый порядок (процесс)
выполнения операции с начальными (входными) данными и их увязку
с итоговыми результатами на выходе, называются жесткими, или механическими, детерминированными.
Однако в последние десятилетия появилось много прикладных
задач, для которых рассмотренные формализации, вкладываемые в понятие «алгоритм», стали затруднять их решение, сдерживать осуществление соответствующих исследований и приложений. Возникла
необходимость не ужесточать строгость, а, наоборот, смягчить требования к формальному определению термина алгоритм, расширить его
понимание и, как следствие, ввести новые куализные модельные его
представления. Эти расширения коснулись «снятия запретов» на перечисленные особенности «строгих» алгоритмов. Алгоритмы, в которых
механический, детерминированный процесс выполнения операций заменяется на изменяемый по ходу процесс, называются гибкими. Рассмотрим их и другие расширения алгоритмов, упорядочивая изложение не по истории появления, а по порядку упоминания особенностей.
Первое расширение касается замены количественных входных данных алгоритмов на любые другие (символьные, графические, …).
242
Кстати, уже в алгоритмах Маркова это имело место. Да и сами определения, приводимые в § 1.1, часть 1 и в § 4.1, часть 2, свободны от этого
ограничения.
Второе расширение касается алгоритмических процессов. В жестких алгоритмах выполнение алгоритмических операций, т. е. работа с
алгоритмическими операндами, осуществляется согласно набору команд (указаний), выполняемых пошагово, последовательно (линейно)
во времени, друг за другом. Поэтому такие алгоритмы получили
название последовательных, линейных.
Алгоритмы, содержащие хотя бы одно условие, в результате проверки и выполнения которого может осуществляться разделение процесса решения на несколько ветвей, называются разветвляющимися.
Если решение по этим ветвям может происходить одновременно, то
такой подкласс разветвляющихся алгоритмов называется параллельными алгоритмами, а вычисления с помощью таких алгоритмов –
параллельными вычислениями.
Еще одной разновидностью гибких алгоритмов являются циклические.
Циклический алгоритм – это алгоритм, предусматривающий многократное повторение одного и того же действия (в виде выполнения
одних и тех же операций) над новыми (в том числе меняющимися в
ходе выполнения операций) данными.
Еще одно расширение связано с многоуровневостью («иерархичностью», «матрешковастью») алгоритмического процесса, когда некоторые алгоритмы, называемые подчиненными алгоритмами (иначе,
вложенными или вкладываемыми, подалгоритмами), составляют
часть более сложного алгоритма (см. часть 1, рис. 1.4). Если такие
алгоритмы заранее разработаны и целиком используются при алгоритмизации конкретной задачи, то они называются вспомогательными
алгоритмами, а соответствующие процедуры – подчиненными,
вспомогательными.
Третье направление в расширении многообразия алгоритмов связано с ходом алгоритмического процесса, с заменой детерминированных правил, процедур, порядков выполнения операций (см. третью
особенность жестких алгоритмов) индетерминированными: нечеткими,
вероятностными, экспертными, эвристическими и т. д. Предостережение! Не всегда верно отождествлять использование таких интедерминированных «находок» с названием алгоритма, аналогичным
наименованию «находок».
243
Например, понятие стохастические алгоритмы употребляют обобщенно в том случае, когда работа алгоритма и результат его работы
определяются не только исходными данными, но и значениями случайных элементов (величин, векторов, функций). Однако одно дело,
когда эти значения используются в ходе выполнения отдельных операций процесса (ситуация «а»), другое – для получения каждого результата на идеях вероятностного подхода («б»). В ситуации «а» случайность может использоваться, например, при вероятностном выборе
ветви в разветвляющихся процессах, добавлением равномерно распределенного в пределах шага квантования x шума в алгоритмах аналогоцифрового преобразования (см. § 2.3), случайного шага t дискретизации (см. § 2.2), для «ослучаивания» траекторий поиска в алгоритмах
оптимизации и т. д. Подобные алгоритмы лучше называть рандомизированными, квазидетерминированными, или алгоритмами с рандомизацией (с ослучаиванием).
В ситуации «б» стохастичность (вероятность, статистичность) заложена в саму идею алгоритма (см. разд. 4.3.8, часть 1, а также § 3.2,
часть 2 и далее). Подобные стохастические алгоритмы назовем статистическими или вероятностными (см. часть 1, табл. 2.2 и
рис. 3.3). Примеры статистических и вероятностных алгоритмов приведены в § 3.4 (расчет коэффициента передачи решающего усилителя),
в § 3.3 – алгоритмы метода Монте-Карло при нахождении значений
площадей определенных интегралов, а также алгоритмы Монте-Карло
для имитации позиционных игр (шахматы, го, нарды, карточные и т. п.).
Сделаем в связи с изложенным следующие замечания.
Во-первых, при реализации различных стохастических алгоритмов
на ЭВМ имитация значений случайных элементов производится, как
правило, программно детерминированными алгоритмами (см. часть 1,
разд. 4.3.8). Тогда любой из стохастических алгоритмов, по сути, переходит в детерминированный. Чтобы подчеркнуть этот факт, лучше
именно такие алгоритмы называть квазидетерминированными.
Во-вторых, еще раз предупредим о том, что желательно правильно
использовать слова «стохастический» или «статистический» в сочетании с другими, чтобы не исказить смысл, понимание всего сочетания.
Например, словосочетание «статистические алгоритмы измерений» не
тождественно сочетанию «алгоритмы статистических измерений» [20],
а словосочетание «статистическая проверка гипотез» не тождественна
словосочетанию «проверка статистических гипотез» (см. часть 1,
разд. 4.3.7, с. 251, 374).
244
В-третьих, стохастические алгоритмы часто оказываются эффективнее детерминированных, а иногда – единственным выходом для
решения задачи вида ЧП-ТР, а также ЧП-ЧР.
В последнее время бурно разрабатываются и применяются алгоритмы, идеи работы которых базируются на подражании принципам и
механизмам жизни, развития, эволюции естественных и искусственных отдельных объектов и их множеств. Процесс реализации таких
подражательных алгоритмов связан с имитацией процессов, происходящих в объектах-оригиналах. Поэтому такие алгоритмы получили
название имитационных. С ними мы уже сталкивались ранее (см.,
например, часть 1, разд. 4.3.8). Имитационные алгоритмы, в которых
реализуется подражание процессам, происходящим в природе, называют бионическими, подражающие процессам в социальных сообществах – социальными или коллективными, подражающие эволюционным процессам – эволюционными (им посвящен § 4.7).
Четвертое расширение понятия «алгоритм» связано с допустимостью нарушения свойства однозначности (см. вторую особенность
жестких алгоритмов) в части, касающейся выходных данных – результатов работы алгоритма, в условиях сохранения четвертой и пятой
особенностей – канторовости множества входных и выходных данных
алгоритма. Иными словами, это расширение вводит такой класс алгоритмов, для которого одним и тем же четко (точно) определенным
входным данным может соответствовать либо несколько выходных,
которые мы принимаем за приемлемые результаты решения конкретной задачи, либо многозначно интерпретируемые результаты, в частности, из-за неясности, скрытости процесса их получения. К этому
классу можно отнести многие квазидетерминированные алгоритмы.
Ведь применение в них «истинной» рандомизации по своей идее
должно привести к статистическому множеству приемлемых правдоподобных результатов, в среднем дающих точное решение. Сюда же
можно отнести многие эволюционные алгоритмы, описываемые в
§ 4.7, а также «алгоритмы» работы ИНС. Образно говоря, если жесткие
алгоритмы назвать «удочковыми», то четвертое расширение приводит
к их замене «сачковыми», «бреденевыми», «неводовыми» алгоритмами. Примерами таких алгоритмов являются различные рассматриваемые в § 4.7 популяционные алгоритмы. Один из таких алгоритмов реализован в многообъектной многопопуляционной искусственной
иммунной сети (ИИмС) МОМ-aiNet [53]. В этой ИИмС несколько
наборов равносильных решений противопоставляются одному набору
245
равносильных решений, т. е. явно проявляется многовариантность решений.
Пятое расширение классов алгоритмов касается отказа от канторовости (бинарности функции принадлежности) множеств входных или
выходных либо тех и других данных алгоритма (см. 4-ю и 5-ю особенности математических алгоритмов). Сюда относятся алгоритмы, в которых точечные канторовские множества заменяются на нечеткие,
вероятностные, интервальные, либо, когда выходные данные (результаты) образуют непустое множество с заданными мерами принадлежности в виде функции предпочтения, пригодности результата в качестве искомого. К последним относятся, например, генетические,
роевые, иммунные и подобные им алгоритмы, рассматриваемые в
§ 4.7. Для многих мягких алгоритмов характерно отсутствие строгих
теоретических доказательств сходимости к искомому (особенно к глобальному в оптимизационных задачах) решению, но экспериментально
установлено, что в большом числе случаев они дают хорошее решение.
Алгоритмы этого класса иногда называют мягкими, взяв за основу
зонтичный термин (umbrella term) «мягкие вычисления» (soft computing), введенный в 1994 г. Лотфи Заде. Под ними предлагалось понимать вычисления (в обобщенном смысле этого слова), связанные с
решением задач, которые характеризуются разными видами неполноты
данных (см. часть 1, § 3.4), априорной неопределенностью связей,
субъективностью исходных данных, приближенно количественно и
качественно представляющих исследуемый объект.
Вначале этот термин интерпретировался формулой: мягкие вычисления = нечеткие системы (методы) + искусственные нейронные сети
(ИНС) + генетические алгоритмы. Затем к ним были добавлены вероятностные, новейшие эволюционные методы (роевые, иммунные) и
другие рассматриваемые в искусственном интеллекте, точнее, в мягких
интеллектуальных системах (МИС). Коротко МИС описываются формулой МИС = управление неопределенностью + обучаемость + самоадаптация.
Под мягкими будем понимать алгоритмы, обеспечивающие получение за приемлемое полиномиальное время таких решений четких
экспоненциально- или NP-сложных задач типа ЧП-ЧР, а также туманных задач типа ТП-ЧР и ЧП-ТР, которые могут быть неточными, приближенными, но пригодными для применения. Важным побудительным мотивом развития мягких алгоритмов и вычислений является
также то, что зачастую точность получения при жестких компьютер246
ных вычислениях (hard computing) может быть избыточной при решении задач в условиях реальных исходных данных и степени их (а также разных моделей) соответствия реальному миру (см. особенности
работы мозга человека, разд. 1.5.1).
Наконец, шестое направление расширения понятия «алгоритм»
связано с попыткой решения алгоритмическими средствами проблем,
проблемных задач типа ОП-ОР. Это расширение связано с приближением алгоритмов к методам за счет отбрасывания детализации выполнения отдельных трудно формализуемых действий или, наоборот,
приближением методов к алгоритмам путем включения в «расширенный» метод как можно большего числа алгоритмически формализуемых операций, «курируемых» другими методами (см. часть 1, рис. 1.4).
Подобные квази- или полуалгоритмы оформляются в виде подробных
инструкций, предписаний, правил последовательности действий, направленных на использование для решения стоящей задачи универсальных или специальных логических процедур, способов принятия решений и других приемов, основанных на аналогиях, ассоциациях,
предпочтениях и прошлом опыте решения подобных или других сложных задач типа ОП-ОР.
К этому классу можно отнести эвристические алгоритмы, основанные на составлении и применении программы действий на базе
различных разумных соображений без строгих обоснований, в которых
достижение конечного результата выполнения этой программы однозначно не предопределено либо не полностью обозначена вся последовательность действий или не указаны все реализующие эти действия
средства (исполнители).
Понятно, что путем объединения или сращивания разных алгоритмов из перечисленных типов можно получать большое множество
комбинированных или гибридных алгоритмов, ориентированных на
обеспечение синергетического эффекта от такого единения частей в
целое (см. примеры далее в разд. 4.6.3).
Адаптивные алгоритмы – способные перестраиваться, приспосабливаясь к условиям их применения (см. табл. 3.1, п. 7.4). Адаптация (от лат. adaptation – приспособление, прилаживание, приноровление) – это приспособление строения и функций организма к
изменившимся условиям его существования, обстановке, среде. Назначение адаптации в алгоритмах – получение лучших результатов путем
постоянной подстройки их под входные Данные и условия, сопутствующие работе с Данными. В искусственных средствах, системах и
247
алгоритмах адаптация (самоприспособление) может осуществляться
путем самоперестройки (самонастройки), самообучения или самоорганизации (см. часть 1, табл. 2.4 и часть 2, табл. 3.1). При самоперестройке приспособление обеспечивается автоматически текущим изменением параметров и функций настройки, например, поиском их
оптимальных по какому-то скалярному или векторному критерию значений, видов. Это, например, алгоритмы с оптимальными (по среднему
квадрату отклонения оценок при изменяющемся объеме выборки) значениями параметров при заданной весовой функции (ВФ) при ядерном
оценивании плотностей распределения вероятностей и спектральных
плотностей мощности или вида ВФ и значений ее параметров (см.,
например, [18] и часть 1, разд. 4.3.7), динамические алгоритмы [18],
системы с автоматическим согласованием амплитудного или частотного диапазона входных сигналов (данных) с диапазонами входных элементов средств их измерения и обработки.
При самообучении перестройка, приспособление осуществляются
автоматически изменением отдельных подалгоритмов и/или значений
параметров алгоритмов на основе ранее накопленного опыта решения
сходных задач для повышения качественных показателей (метрологических, технических, экономических и прочих) результатов их решения. Это, например, алгоритмы работы искусственных нейронных сетей, алгоритмы с запоминанием наилучших значений параметров,
процессов, схем решения в зависимости от условий их применения с
автоматическим выбором их при возвращении подобных условий,
двухэтапные алгоритмы, когда на первом этапе отыскивается начальное приближение по одним алгоритмам, а на втором – автоматический
выбор и реализация алгоритма для уточнения решения задачи.
Наконец, при самоорганизации в процессе функционирования алгоритма или информационной системы автоматически изменяется их
структура, т. е. состав элементов и связей между ними, приспосабливаемая к конкретным условиям. Например, в гибридных алгоритмах изменяются состав и функции подалгоритмов, реализующих разные методы для выполнения различных алгоритмических операций, а также
алгоритмы, меняющие состав операций, алгоритмический процесс решения задачи, в частности, путем распараллеливания, разветвления.
Эволюционные алгоритмы: 1) алгоритмы, в которых осуществляется подражание постепенному и непрерывному изменению строения
организмов, механизмов их жизни и поведения в ходе эволюционного
развития вида с учетом изменяющихся условий окружающей среды;
248
2) алгоритмы, в которых в ходе их многочисленных применений происходят постепенные накапливающиеся изменения, ориентированные
на сохранение или повышение качества получаемых результатов с учетом изменяющихся условий, приспособления к ним. Напомним
(см. разд. 2.6.2), что эволюция (от лат. evolution – развертывание) –
процесс развития кого- или чего-либо путем постепенного непрерывного, включая накапливающегося, изменения, перехода от одного
состояния к другому, в частности, постепенным накапливающимся
количественным или структурным изменением, приводящим к качественным сдвигам в развитии. В отличие от эволюции революция (от
лат. revolution – поворот, переворот) связана с быстрыми, коренными,
скачкообразными качественными изменениями состояний, форм, видов. Примеры эволюционных алгоритмов будут рассмотрены в § 4.7.
Завершая раздел, посвященный алгоритмам и их куализному модельному представлению, отметим, что наиболее часто структура и
реализуемая последовательность алгоритма представляются в виде
блок-схем, иногда называемых структурными или граф-схемами алгоритмов. Абстрактные примеры таких моделей представлены на
рис. 4.2. Заметим, что очевидные стрелки зачастую на графиках не
изображаются.
Начало
Начало
Начало
Ввод а, b
Ввод а, b
Ввод а1,…, ап
x=a+b
x = a2 – b2
i = 1, х = x0 = 0
y = x2
Да
х0
Нет
y
Конец
а
Нет
y 1 | x |
x
Да
i>n
Вывод у
Вывод x
x = xi = xi-1 + ai
Конец
Выход х
i=i+1
в
Конец
б
Рис. 4.2. Блок-схемы алгоритмов:
а – линейного; б – разветвляющегося; в – циклического
249
§ 4.4. ОБ ИССЛЕДОВАТЕЛЬСКИХ ПРОБЛЕМАХ
И ИХ РЕШЕНИИ
Как указано в § 4.2, одна из особенностей работы с современными
Данными – это необходимость не только решения при этом задач, но и
проблем. Они могут появляться на любом этапе процесса исследования объектов, начиная с постановки задачи исследования до интерпретации и применения его результатов. При этом проблема может быть
как стартовой, с осознания, формулировки и решения которой начинается исследование, так и появляться в ходе исследования, в том числе
по ходу решения отдельных задач, когда возникает некоторая неудовлетворенность ходом или результатами решения задачи, требуется
изменить их, но не ясно, как это сделать. Поэтому рассмотрим отдельные аспекты понимания, что такое проблема и как ее решить. При этом
основной акцент сделаем, во-первых, на системном подходе1 (см. часть 1,
§ 2.6), во-вторых, только на особенности проблем, которые необходимо иметь в виду при исследовании (в узком смысле: познание, моделирование, см. часть 1, § 1.1) объектов, в работе с Данными. Заметим, что
близкие нам вопросы, касающиеся проблем и методов их решения,
наиболее полно описаны в литературе, посвященной менеджменту,
управлению организациями, социальными и экономическими системами. Желающие могут подробнее ознакомиться с ними, например, по
[2, 45].
Прежде всего уточним, что будем понимать под термином «проблема» (от греч. problema – преграда, трудность, задача). Рабочее понимание ее уже приводилось (см., например, первую часть пособия,
§ 2.6, ссылка на стр. 65, а также § 4.1 и 4.2). Другие понимания и определения термина в той или иной степени связаны со словосочетанием
«проблемная ситуация». Поэтому рассмотрим вначале этот термин.
Проблемная ситуация – это:
«условия, порождающие проблему»; «разрыв» в деятельности,
«рассогласование между целями и возможностями субъекта» [45];
«некоторое реальное стечение обстоятельств, положение вещей,
которым кто-то недоволен, неудовлетворен и хотел бы изменить» [2];
1
Помимо него часто рассматриваются комплексный, информационный,
целевой, ценностный, процессный и другие подходы, которые могут применяться как отдельно, так и в рамках системного подхода.
250
«такая ситуация, когда неудовлетворительность существующего
положения осознана, но неясно, что следует сделать для его изменения» (Перегудов Ф.И., Тарасенко Ф.П.).
Проблемная ситуация возникает: когда результаты деятельности не
соответствуют целям; известные решения либо не дают ожидаемого
эффекта, либо не могут быть по какой-то объективной причине использованы; имеющиеся факты и результаты противоречат теоретическим представлениям и т. п. Теперь приведем некоторые определения
термина «проблема», контекстуально близкие к тематике главы.
Проблема – это:
субъективное отрицательное отношение субъекта к реальности [2];
неудовлетворительное состояние системы, некоторое противоречие, требующее разрешения [45];
в широком смысле – сложный теоретический или практический
вопрос, требующий изучения, разрешения; в науке – противоречивая
ситуация, возникающая в виде противоположных позиций в объяснении каких-либо явлений, объектов, процессов и требующая адекватной
теории для ее разрешения; осознание, формулирование концепции о
незнании; в бизнесе – препятствие на пути к достижению цели (энциклопедии, Википедия).
В дальнейшем будем понимать термин «проблема» в научном и широком смысле. Примеры других определений смотрите в работе [45].
В связи с приведенными определениями отметим следующее.
1. В дефинициях термина «проблема» учитываются два обстоятельства – обязательное наличие в ней объективного (реальная ситуация) и субъективного (неудовлетворенность ситуацией субъектом).
2. Проблемы могут встретиться в любой сфере деятельности человека.
3. Проблема – это не нечто непосредственно наблюдаемое, а модель ситуации, извлекаемая из опыта деятельности.
4. Решить проблему, значит, снять или хотя бы уменьшить неудовлетворенность субъекта ситуацией.
5. Научные, исследовательские проблемы отличаются от управленческих, бытовых, экономических, личностных и других. Некоторые их
отличия рассмотрим по ходу изложения дальнейшего материала.
6. Проблема становится актуальной, если: а) ее решение может
принести пользу; б) имеется обоснованная надежда на ее решение.
251
Чтобы хотя бы неглубоко вникнуть в эти отличия, рассмотрим вначале наиболее широко описанные, близкие к рассуждаемым нами
научные, управленческие проблемы.
В [2] по мотивам работ Р.Л. Акоффа рассматриваются два варианта
решения управленческих проблем: влияние на субъект, не изменяя саму реальную ситуацию, или вмешательство в ситуацию с целью ее изменения. Первый вариант реализуется тремя способами: путем дополнительного, обязательно положительного, информирования субъекта о
реальной ситуации; изменения восприятия им ситуации; прерыванием
взаимодействия субъекта с ситуацией.
Что касается вмешательства в реальность, то оно может решаться
четырьмя путями: невмешательством (проблема сама разрешится, пропадет, рассосется); частичным вмешательством (ослабление остроты
проблемы); нахождением наилучшего (оптимального) в каком-то
смысле в условиях конкретных ограничений вмешательства (оптимального решения проблемы); растворением проблемной ситуации.
Обычно для решения управленческих проблем рекомендуется
4–12-этапный процесс [2, 45]. Выберем и переформулируем содержание тех из них, которые близки к решению научных проблем.
Первый укрупненный этап – регистрация, осознание, диагностика
проблемы и формализация постановки задачи для ее решения.
В управленческих задачах этот этап связан с формулировкой проблемы, поставленной клиентом-заказчиком для ее решения. Эта постановка может быть неадекватной как по отношению к проблемной ситуации, так и по отношению к неясно представляемым желаниям
клиента.
Для проблем, связанных с анализом и исследованием Данных, этот
этап включает в себя следующие особенности. Выявление и формулировка проблемы и проблемной ситуации может иметь место как на
стадии постановки задачи исследования объекта клиентом-заказчиком,
так и на разных стадиях работы специалистов с Данными, начиная от
постановки задач наблюдения или экспериментирования до интерпретации и применения результатов анализа Данных их пользователями.
Типичные сложности и ошибки, возникающие на этом этапе: неадекватное, несистемное, неточное, неполное или даже неверное понимание, модельное представление проблемной ситуации, сути проблемы
или даже замена ее другой. Например, замена может быть, если ставится проблема получения малых для имеющейся техники шага дискретизации по времени или шага квантования по уровню при преобра252
зовании аналоговых сигналов в цифровые без учета цели, для которой
это преобразование делается (см. § 2.2 и 2.3), или когда рассматривается проблема значительного уменьшения погрешностей измерения
мгновенных значений сигналов без учета помех, алгоритмов их дальнейшей обработки, постановок решаемых задач и т. д. Здесь конечная
цель обеспечения требуемого качества итогового результата решения
задачи потребителя заменена «ложной» целью, например, целью
уменьшения шага дискретизации, вызывая тем самым рождение ложной проблемы. На самом деле проблемы может и не быть, если для
достижения изначальной цели можно иметь бóльшие, чем требует заказчик, интервалы дискретизации, использовать рандомизацию интервала дискретизации и другие приемы, позволяющие на той же технической базе достичь необходимого качества итогового результата.
Первый этап непосредственно связан с анализом и диагностикой1
проблемы. Анализ проблемы связан с поиском ответов на серию вопросов типа: «Что имеем сегодня?», «Что не нравится?», «Что хотим?», «Какая ситуация нас устроила бы или будет предпочтительнее?», «Что мешает этого достичь?», «Какие шаги надо предпринять
для управления ситуацией или ее устранения?». Диагностика проблемы означает отнесение ее к одному из двух типов и их подтипов: проблемы, требующие воздействия на субъекта (например, на заказчика
решения проблемы) или требующие изменения реальности, ситуации.
В определенной степени в этот этап можно включить, если это будет необходимо (например, когда результаты решения проблемы могут
представить интерес для разных пользователей или если решается
многокритериальная задача), составление списка заинтересованных
участников («защитников» критериев), выявление проблемного месива
и целевыявление [2]. В связи с целевыявлением отметим те опасности,
которые обычно при этом подстерегают: подмена целей, смешение целей со средствами для их достижения, неполное перечисление целей,
неспособность выразить цель и т. п.
Второй укрупненный этап – сбор априорных и апостериорных
данных для уточнения формулировки проблемы, отбора или выработки критериев для выбора вариантов решения проблемы, построения и
усовершенствования модельного аппарата для описания ситуации.
Например, при системном подходе к описанию ситуации, проблемы
1
В управленческих проблемах их диагностика иногда [2, 45] рассматривается как отдельный этап решения проблемы.
253
или исследуемого объекта необходимо определиться – будем ли мы их
рассматривать, используя кибернетическую методологию «черного
ящика» (см. часть 1, разд. 2.3.2 и § 3.7), либо, наоборот, синергетическую, самореферентную, автопоэтическую состава и структуры объекта (см. рис. 1.2). В методологии «черного ящика» особый упор делается: а) на рассмотрение исследуемого объекта как цельного целостного
целого; б) на внешние связи представляемого такой моделью объекта с
окружающей средой, отнесения их к входным, выходным, факторным,
помеховым. В других же системных методологиях упор делается
прежде всего на условное «вычленение», «различение» его составных
частей и их связей между собой. Это в итоге приводит к разным структурным моделям объекта и связи элементов с окружающей средой.
Обратим лишний раз внимание, во-первых, на целевой характер модельного представления любого объекта субъектом и в связи с этим на
возможность разных модельных представлений, во-вторых, на те
«проблемные» трудности, которые при этом могут встретиться (см.,
например, [2]). Это признание субъектом связи существенной, когда
она на самом деле таковой не является; наоборот, признание связи не
существенной, не включение ее в модель, когда без нее цель не может
быть достигнута; незнание о существовании связи; неверное отнесение
связи к входу, выходу, факторам, помехам; выделимость частей объекта как элементов, их границ, уровня дробления; отделение объекта от
окружающей среды и выделение ее важных подсистем и т. д.
Третий этап – генерация альтернативных вариантов решения проблемы. В приложении к рассматриваемым проблемам для них применимы как известные варианты генерации альтернатив (активизация
творчества, мозгового штурма, Делфи, синектики, коллективных ассоциаций, морфологического анализа, дерева целей, сценариев (см. часть
1, разд 4.4.7, [2, 16, 45]), так и характерные только для них. Например,
использование методов и средств искусственного интеллекта и когнитивного анализа данных (см. далее).
Четвертый этап – выбор конкретного решения (или решений) из
сгенерированного набора альтернатив. На этом этапе осуществляется
определение «идеального» решения; исключение неосуществимых решений, т. е. таких, которые не могут быть реализованы в заданных
условиях, не соответствуют ограничениям; оценка оставшихся решений с учетом поставленных целей, требуемых результатов; оценка
рисков, связанных с «наилучшим» решением; принятие решения [45].
Для оценки решения привлекаются соответствующие специалисты и
254
заинтересованные лица. С трудностями, возникающими на этом этапе,
в частности с известными парадоксами голосования, можно ознакомиться по книгам [2, 45] (см. также часть 1, разделы 4.4.7, 4.5.5, 4.5.6).
Пятый этап – реализация принятого решения. Специфика научных проблем, в отличие от управленческих, проявляется на этом этапе
в том, что реализация решения проблемы, связанной с изменением реальной ситуации, означает достижение той цели исследования, которую ранее не удалось достичь на стартовом тактическом этапе с помощью любого наиболее приемлемого (например, дешевого) варианта
решений. Реализация же решения управленческой задачи, связанного с
изменением состояния, требует поиска и реализации стратегического
улучшающего вмешательства в ситуацию, т. е. такого изменения проблемной ситуации, которое положительно оценивается хотя бы одним
из ее участников и неотрицательно – всеми остальными [2].
В приложении к проблемам, возникшим при работе с Данными, и
привязки результатов этой работы к исследуемым (в широком смысле)
объектам возможны разные варианты из перечисленных. Например,
отстранение субъекта, не являющегося «заказчиком», а представляющего собой исполнителя, решателя, от ситуации может осуществляться передачей решения проблемы другому человеку (специалисту,
коллективу специалистов, экспертов). Если и другим не удается
сформулировать и/или решить проблему, можно осуществить частичное вмешательство в ситуацию, обратившись к методам и средствам искусственного интеллекта, в которых детерминированные
однорезультатные алгоритмы решения задач заменяются многорезультатными правилами построения средств, в том числе алгоритмов,
позволяющих осуществлять поиск неявного неоднозначно определяемого решения (см. далее § 4.7), когда участие субъекта будет переориентировано на осознание, подготовку, проверку и выбор получаемых решений.
Приведем примеры проблемных вопросов, возникающих при исследовании объектов. Это формулировка постановки задачи; выбор
моделей, включая отнесение объекта к системам определенного вида
(см. часть 1, § 2.5), и типов моделей (см. часть 1, разд. 2.1.3); выбор
методов, алгоритмов и других средств; определение критериев
наилучших решений; учет указанных в § 4.2 особенностей Данных
и т. д.
255
§ 4.5. ЭЛЕМЕНТЫ ИНФОРМОЛОГИИ
4.5.1. Вводные замечания
Настоящий параграф посвящен самым дискуссионным, зачастую
по-разному трактуемым, понятиям и вопросам, по которым существуют как сходные, так и диаметрально противоположные взгляды и на
существо рассматриваемых вопросов, и на необходимость, актуальность, правомерность их введения, постановки. Ситуация усугубляется
тем, что зачастую некоторые термины получают такие трактовки и
«теоретические» обоснования, которые отторгают их использование.
Тем не менее актуальность их постановки и освещения требует изложения авторского взгляда по этим вопросам. Это касается, прежде всего, такого базового, важного для настоящей главы, широко используемого термина, как информация, а также вынесенного в заголовок
параграфа термина информология.
Рассмотрим эти понятия, стараясь не прибегать к дискуссии или
освещать ее лишь в минимально необходимой степени.
Прежде всего поясним термин информология, как сложное двухкоренное слово, образованное от слов информация и логос (от греч. logos –
учение), понимая под ним именно «учение об информации». Воздержимся трактовать его как «наука об информации» (см. часть 1, § 1.2) в
силу неоднозначности трактовки и отсутствия единства взглядов по
таким базовым основам ее, как существо и определение объекта исследования, методология и понятие истинности (см. далее), но оставляя за
этим термином право в дальнейшем называться наукой, если таковая
состоится.
Объектом исследования в такой научной дисциплине будет именно
информация. Предметами информологии как фундаментальной научной дисциплины логично рассматривать суть, сущность информации,
ее состав, виды, структуры, формы существования и проявления, а
также свойства, информационные процессы и превращения, различные
количественные и качественные характеристики (метрические, квалиметрические, физические, другие), информационные законы и закономерности, место и роль информации в природе и обществе и т. п.
Возможные предметы информологии как прикладной научной дисциплины – это теоретические основы создания, эффективного применения информации с заданными свойствами, качеством, характеристиками, оперирования ею и с ней, защиты информации от нее и т. п.
256
В области практической деятельности человечества предметами информологии, как составной части информатики (см. часть 1, рис. 1.6),
могут стать разработка и использование информации в требуемом
объеме заданного качества в требуемые сроки при минимальной себестоимости, а также ее сбор, хранение, передача, обработка, анализ, интерпретация, защита и другие действия, выполняемые методами и
средствами информатики именно с информацией, а не только и не
столько с ее носителями.
Подобное понимание информологии автор настоящего пособия
сформулировал в 1998 г.
Введение термина информология чаще всего приписывают Сифорову В.И.1 и Суханову А.П. (1977 г.) с пониманием его ими так: «Информология – это наука о процессах и законах передачи, распределения, обработки и преобразования информации» [29] или, с учетом
дополнений (см. [30]), – «наука о техногенных, антропогенных и биогенных информационных операциях». Позже термин «информология»
в разном его понимании, включая понимание под информологией общей теории информатики, а также такие близкие к нему понятиясателлиты (по образному выражению А.С. Бондаревского), как «информационные знания», «инфодинамика», «информациология» (см. об
этом подробнее в [30]), вводили и использовали многие авторы:
В.З. Коган (1985 г.), В.С. Мокий (1994 г.), А. Хори (A. Horri, 1993 г.),
Кизлов В.В. (2006 г.), Партыко З.В. (2009 г.). Так, например, Кизлов В.В.
под информологией понимает область на стыке физики, философии и
информатики, изучающую информационные аспекты процессов взаимодействия тел и понятия, использующиеся при описании информационных процессов (см. [30], а также интернет http://www.portalus.
ru/modules/science/rus_readme.php? и сайт Кизлова В.С. http://rawgor.
narod.ru/).
4.5.2. О теории информации
и мерах количества и качества информации
Согласно наиболее принятым точкам зрения под теорией информации понимают:
«раздел математики, исследующий процессы хранения, преобразования и передачи информации» [11, 12];
1
См. о нем в [1].
257
«самостоятельная научная дисциплина, связанная с восприятием, передачей и переработкой, хранением и использованием информации» [17];
«ветвь статистической теории связи (ее часто с нею отождествляют), основное содержание которой связано с исследованием методов
кодирования сообщений и надежной передачей их по каналам связи с
шумом»;
теория информации входит в состав теоретической кибернетики –
науки об управлении [35];
многие считают, что теория информации – это аппарат и фундамент теории связи.
По Википедии, «Теория информации (математическая теория связи) – раздел прикладной математики, радиотехники (теория обработки
сигналов), информатики, аксиоматически определяющий понятие информации1, ее свойства и устанавливающий предельные соотношения
для систем передачи данных». Здесь же добавляется, что она, как и
любая математическая теория, оперирует с математическими моделями, а не с реальными физическими объектами (источниками и каналами связи).
Первое, что следует из двух последних приведенных определений, –
основными задачами теории информации являются задачи измерения
количества информации, кодирования (см. § 2.7) и передачи сообщений. Именно они чаще всего и рассматриваются в ней.
Другое, что следует из определений, – это аксиоматичность определения понятия «информация». Дело в том, что началом развития
теории информации считаются введение в 1948 г. К. Шенноном фундаментального понятия количественной меры неопределенности – энтропии и построенных на его основе понятий, – количества информации и самой информации (см. далее), использующих аппарат теории
вероятностей. Как заметил Д.С. Чернавский [33], предложенное
К. Шенноном на примере текстовых сообщений определение количества информации предшествовало определению (дефиниции) самой
информации. Это оказалось полезным для решения ряда практических
задач (например, эффективное и помехоустойчивое кодирование,
§ 2.7), но привело к определенным недоразумениям в связи с другими
пониманиями термина «информация» и сочетанием слов «теория информации», которую сам К. Шеннон, называемый «отцом теории
1
Согласно К. Шеннону.
258
информации», трактовал вначале как математические основы теории
связи. Этому способствовало и то, что, как указано в [33], сам К. Шеннон не разделял понятия «информация» и «количество информации»,
определяя информацию через ее меру (см. далее), и понимал наличие
пределов теории информации [63, c. 667].
Одним из важных разделов обсуждаемой теории информации являются меры ее количества и ценности (полезности).
Рассмотрим некоторые из них, придерживаясь подходов, в рамках
которых они вводились [24, 34].
В комбинаторном подходе количество информации определяется
как функция числа элементов конечного множества с учетом их комбинаторных отношений. Примером комбинаторной меры количества
информации (неопределенности) является мера Р. Хартли (1928 г.),
определяемая через логарифм числа исходов некоторого события, а
именно как
I X H k log a M ,
(4.9)
где I X – количество информации, получаемое при наступлении события или которое может быть получено, когда наступает какой-либо
исход события; Н – количество неопределенности события; M – число
возможных исходов (вариантов, комбинаций, состояний) события;
а – основание логарифма; k – коэффициент пропорциональности (при
а = 2 и k = 1 единица количества информации называется битом, при
а = e и k = 1 – нитом (натом), при а = 10 и k = 1 – дитом и т. д.).
Выбор функции log = loga объясняется желанием, чтобы мера количества информации удовлетворяла требованию (условию) аддитивности. Согласно рассуждениям Хартли, если в заданном множестве,
содержащем М элементов, выделен какой-то элемент х, о котором заранее известна лишь его принадлежность этому множеству, то, чтобы
найти х, необходимо получить количество информации, равное log2 M
битов. Если же надо угадать элемент х из множества в М1 элементов и
одновременно y из множества в М2 элементов, то число комбинаций
будет М1М2. Следовательно, I X log a M1M 2 log a M1 log a M 2
I1 I 2 . Это и есть свойство аддитивности.
Использование меры Хартли позволяет решать многие задачи. Одна из них приведена в [33].
Существенным недостатком меры Р. Хартли является то, что она не
учитывает возможные неравные шансы появления разных элементов
259
множества. Например, ее нельзя использовать для определения и сравнения информативности буквы “а” латинского и/или русского алфавитов в смысловом тексте, так как разные буквы встречаются не одинаково часто в каждом тексте не только в силу того, что число букв
алфавита разное, но и из-за строения слов, фраз, предложений на латыни, в английском, немецком, французском и/или русском языках.
В определенной мере этот недостаток устраняет вероятностностатистический подход, основателем которого является Клод Элвуд
Шеннон, опубликовавший в 1948 году книгу «Математические основы теории связи» (обратите внимание на название: основы теории
связи, а не информации, хотя К. Шеннона после этой книги, как уже
упоминалось, стали считать «отцом» именно теории информации).
Его подход основан на следующих посылках. Во-первых, на фундаментальной роли количественной меры неопределенности – энтропии
(в ее математической трактовке!). Во-вторых, на случайности природы (и, следовательно, вероятностного описания) носителей информации – сигналов. В-третьих, на необходимости введения ее количественной меры в виде
Вероятность появления
данного события для приемника
Количество
после приема сообщения
полученной log
Вероятность появления
информации
данного
события для приемника
до
приема сообщения
,
(4.10)
что для случая отсутствия шумов в канале связи, дает минус (–) log
[вероятность появления данного события для приемника до приема
сообщения]. В-четвертых, в нахождении среднего количества информации, приходящегося на один символ (4.10).
Под информацией здесь понимается уменьшаемая, снимаемая неопределенность, а под количеством информации – разность количественных мер неопределенностей до и после получения информации
(рис. 4.3). Поясним ее введение на конкретном примере.
Пусть получатель сообщения Y имеет некоторые представления о
возможных наступлениях интересующих его n событий Х. Эти представления в общем случае недостоверны, а степень их возможного появления определяется вероятностями p1 , p2 ,..., pn , когда p1 p2 ...
pn 1 . Величина
260
n
H ( X ) = pi log pi
(4.11)
i=1
называется шенноновской энтропией (средней, математической, вероятностной), в отличие от сходной с ней физической S1 и характеризует неопределенность априорных (до получения сообщения) знаний
получателя об этих событиях. Например, если Х – дискретная случайная величина, принимающая значения х1 , ..., хn с вероятностями р1 , р2 ,..., рn , то H(Х) – мера неопределенности этой величины.
Для абсолютно непрерывных случайных величин вместо энтропии
(4.11) вводится дифференциальная энтропия (см. рис. 4.3).
Любопытно отметить, что из всех дискретных случайных величин,
принимающих п значений, максимальную энтропию имеет величина Х
с равномерным законом распределения. Для нее H ( X ) log 2 n, что
совпадает с мерой количества информации Хартли. Аналогично среди
всех абсолютно непрерывных случайных величин, заданных на (а, b),
т. е. плотность вероятностей которых равна нулю при x a и x b ,
наибольшую дифференциальную энтропию имеет величина с равномерным на (а, b) распределением. Другое дело, когда случайные величины могут принимать неограниченные значения. Для них экстремальные значения энтропии определяются разными условиями. Так,
среди всех законов распределения абсолютно непрерывной случайной
величины Х, для которой задана одна и та же дисперсия DX или
начальный момент второго порядка m2 X , максимальную дифференциальную энтропию имеет нормальный закон (см. для сравнения и
дополнения центральную предельную теорему теории вероятностей),
а среди неотрицательных случайных величин с заданным k-м начальным моментом mk – максимальную дифференциальную энтропию
имеют частные случаи -распределения. В частности, при k = 1, т. е. с
заданным математическим ожиданием mX M{ X } , максимальную
1
Согласно Л. Больцману (1877 г.), физическая энтропия S определяется
формулой S K ln P , где K – постоянная Больцмана, а Р – статистический вес
(вероятность) термодинамического состояния системы (которая тем больше,
чем более неупорядоченное это состояние). Эта формула высечена на памятнике ему.
261
КОЛИЧЕСТВО ИНФОРМАЦИИ ПО К.Э. ШЕННОНУ
pij
Μ log
, если X, Y дискретные величины,
pi , p, j
IШ ( X , Y )
Μ log W ( X , Y ) , если X , Y (абсолютно) непрерывные случайные величины;
W ( X )W (Y )
f ( xi , y j ) pij , если X,Y дискретные величины;
j
Μ f ( X , Y ) i
f ( x, y )W ( x, y )dxdy, если X,Y непрерывные величины;
- -
log pi , энтропия дискретной случайной величины X ;
H (X )
log W ( X ) дифференциальная энтропия непрерывной величины Х ;
H ( X , Y ) Μ log Pij
pij P
или H ( X , Y ) Μ log W ( X , Y ) ;
X x i Y y j ,
p, j P
pij ;
Y y j i
pi , P X x i
j
pij ;
P{ A} – вероятность события A;
W(x), W(y), W(x,y) – плотности распределения величин X или Y и вектора (X,Y).
I(X,Y) = 0, если X и Y – независимы, т. е. p ij = p i, p, j или W(x, y)=W(x)W(y);
I(X,Y) = H(X) = H(Y), если X = Y; I(X, Y) = I(Y, X).
H(X)
H(Y/X)
I(X,Y)
H(X/Y)
H(Y)
H(X,Y)
Рис. 4.3. Иллюстрация соотношений между мерой количества неопределенности энтропией и шенноновской мерой количества информации
262
энтропию имеет величина с экспоненциальным распределением (см.
системы массового обслуживания). Среди абсолютно непрерывных пмерных случайных векторов с заданной корреляционной матрицей
максимальную дифференциальную энтропию имеет вектор с п-мерным
нормальным законом распределения и т. д.
Если сообщения Y касаются состояний Х системы, которая может
находиться в состояниях х1 , х2 ,..., х n с вероятностями р1 , р2 ,..., рn , то
Н(Х)-энтропия – мера неопределенности – есть количество априорной
неопределенности о положении (состоянии) системы. Предположим,
что после приема сообщения Y о состояниях системы получатель приобрел некоторое дополнительное количество информации I{X,Y} о состояниях системы, уменьшивших его априорную неосведомленность
настолько, что апостериорная (послеопытная, после получения сообщения) неопределенность о состояниях X системы стала H(X/Y). Тогда
количество информации I{X,Y} о состояниях Х системы, полученной в
сообщении Y о состояниях системы, определяется разностью
I Ш { X , Y } H ( X ) H ( X / Y ) H (Y ) H (Y / X )
H ( X ) H ( X , Y ) I (Y , X ) 0,
(4.12)
где
n
H ( X )= - pi, log pi, ,
(4.13)
i=1
m
H (Y ) = p,j log p,j ,
(4.14)
j 1
n m
pij
i 1 j 1
pi , p,j
H (Y )=- pij log
pi,
m
pij Χ xi ,
j 1
pi , j Ρ
,
n
(4.15)
p,j pi ,j Υ y j ,
i 1
Χ xi Υ y j
263
,
H(X), H(Y), H(X,Y) – энтропия величин Х,Y или вектора (X,Y), { A} –
вероятностная мера, вероятность события А.
Что касается основания логарифма log, то оно, как уже указывалось, может быть любым. Обычно выбирают логарифм по основанию 2,
реже по основанию натурального логарифма е. Один бит есть количество информации, получаемое при раскрытии неопределенности, содержащейся в двух равновероятных исходах, состояниях. Величина
I{X, Y} и есть количество информации по К. Шеннону для дискретных
случайных величин X и Y (см. рис. 4.3). Нетрудно убедиться, что, если
X и Y независимы (сообщение Y не снимает неопределенность о состояниях системы X), т. е. если H(X/Y) = H(Х), то H(X, Y) = H(Х) + H(Y) и
I{X, Y} = 0. Если же Y = Х, т. е. сообщение раскрывает всю неопределенность о состояниях системы X, то Н(Х) = I{X,Y}. В этом смысле говорят, что энтропия есть максимальное количество информации о состояниях Х системы или мера недостающей информации. Обратим
внимание на то, что здесь мы говорим о неопределенности как наших
сведений (знаний) о системе (объекте), так и самой системы (объекта).
На основе предложенной меры количества информации К. Шенноном и его последователями были получены важные понятия и результаты. Например, такие, как скорость создания и передачи информации,
избыточность сигналов, пропускная способность канала связи. Доказана возможность обеспечить передачу информации без потерь при любых помехах и шумах в канале связи, что породило поиск методов такой передачи и привело к созданию теории кодирования (см. § 2.7).
Создан инструментарий для решения задач определения минимального
количества шагов и поиска стратегий при выборе вариантов в условиях
статистической (вероятностной) априорной неопределенности. Примером может служить определение минимального количества взвешиваний при поиске единственной фальшивой монеты из множества монет
путем взвешивания на рычажных весах без гирь. Допустим, что имеется 24 монеты, одна из которых фальшивая, отличающаяся от других
весом (массой). Какое минимальное количество взвешиваний надо
произвести, чтобы: а) просто узнать, легче она или тяжелее, б) найти
фальшивую монету? Попробуйте решить эту задачу, используя меры
Хартли и Шеннона.
Помимо шенноновской есть и другие вероятно-статистические меры количества информации. Так, например, в математической статистике вводится количество информации (по Фишеру, 1921 г.) о скалярном или векторном θ (1 ,..., k ) параметре, содержащемся в одном
264
наблюдении х i случайной величины Х. Для скалярного параметра это
количество определяется как
d log Q X ; 2
I
,
d
(4.16)
а для N независимых значений (выборки объема N) х1, х2,..., х N количество информации будет равно NI() (вот оно свойство аддитивности!),
где Q(х,) это P(х,) или W(х,). Для векторного параметра θ вводится
информационная матрица Фишера
I (θ) Iij (θ), i, j 1, k ,
(4.17)
log Q(X ; θ) log Q(X ; θ)
I ij (θ) Μ
.
i
j
(4.18)
где
Мера количества информации, по Кульбаку, представляет собой
меру неопределённости величины X, имеющей распределение вероятностей Q1(x), относительно величины Y с распределением вероятностей Q2(y). Она имеет вид:
I Q { X , Y } Μ1 log Q1 ( X ) Q 2 ( X ) ,
(4.19)
берётся по распределению Q1(x). Например, для
где оператор 1{}
дискретных X и Y
IQ{ X ,Y }
i
P1 ( X xi )log P1 ( X xi ) P2 ( X xi ) .
(4.20)
Одним из принципиальных недостатков вероятностно-статистических мер количества информации является привлечение именно вероятностно-статистического описания объектов, имеющих ограниченную область приложений, т. е. применимость такой меры, во-первых,
только к множеству объектов, ситуаций, а не к отдельным из них, вовторых, оперирование с описанием их «в среднем».
Что касается комбинаторной меры Хартли, то она, во-первых, также не применима к индивидуальным объектам (исходам), во-вторых,
265
неявно предполагает равную неопределенность обо всех комбинациях,
ситуациях, состояниях.
В этом перед ними имеют преимущество алгоритмические меры.
Алгоритмический подход к определению количества информации
связан с именем академика АН СССР А.Н. Колмогорова – «отца» аксиоматической теории вероятностей. Он предложил (1962–1965) определять меру количества информации через алгоритмическое понятие
сложности, отражающей меру упорядоченности объекта, а именно: в
качестве меры количества информации он предложил минимальную
длину записанной в виде последовательности 0 и 1 программы, которая позволяет построить x, имея в своём распоряжении y (где x и y –
некоторые числовые последовательности), или, иначе, преобразовать
один объект (одно множество) в другой (другое множество). Другими
словами, мера количества информации в сообщении может определяться, например, через минимальное число операций или минимальную длину программы, которые осуществляют преобразование сообщений в передаваемые физические сигналы. В формальном виде
алгоритмическая мера А.Н. Колмогорова имеет вид
IK (x, y) = h(x) – h(x/y) IK (y/x),
(4.21)
где h(x) и h(x/y) – алгоритмическая и условная алгоритмическая энтропии индивидуальных объектов x и y. В (4.21) h(x) интерпретируется
как количество информации, необходимое для воспроизведения x (речь
идет о последовательностях двоичных разрядов); h(x/y) – как количество информации, которое необходимо добавить к информации, содержащейся в y, чтобы восстановить x. Разность между ними и есть
количество информации, содержащейся в y об x. Основу этой меры
составляет измерение относительной сложности индивидуального конечного объекта «x» (слова, конечной последовательности натуральных чисел и т. д.) при заданном конечном объекте «у» через длину самой короткой последовательности (алгоритма, программы ее
формирования) «p», состоящей из 0 и 1, по которой, используя «y»,
можно восстановить «x». Например, есть две последовательности (два
сообщения): первая 0101010101010101 и вторая 0110001011100101.
Какое из этих сообщений сложнее? Второе, так как оно менее упорядоченное. Алгоритм (программа) генерации первой последовательности прост: (01)8 или «напиши 01 восемь раз». Второе сообщение имеет
алгоритм (программу) той же длины, что и сообщение. Второй пример.
266
Надо написать число = 3,141..., имеющее бесконечное число цифр.
Экономная программа: а) писать просто букву ; б) написать алгоритм
расчета отношения длины окружности к ее диаметру или отношения
периметра вписанного в круг (окружность) либо описанного вокруг
него (нее) правильного п-угольника к диаметру окружности при
n . Третий пример: а) выписать последовательность из N двоичных цифр, соответствующих основанию натурального логарифма
е = 2,711828…, имеющего бесконечное число цифр; б) написать просто е;
в) составить экономный алгоритм, позволяющий получать N цифр по
конечной формуле e lim (1 1 / n) n . Приведенные примеры позволяn
ют ввести простое определение алгоритмической меры сложности
произвольной последовательности символов из некоторого фиксированного алфавита – это длина (количество двоичных разрядов) самой
короткой программы, генерирующей эту последовательность [80]. Понятно, что здесь речь идет не о сложности алгоритмов (см. разд. 4.3.3),
а об алгоритмическом подходе к определению сложности последовательности символов. Любопытно отметить, что алгоритмическая
сложность любой последовательности длины N не превосходит N энтропий, по Шеннону, ее появления из последовательностей длины Т,
состоящих из символов того же алфавита [80].
Сигнальный (компьютерный) подход. Его идея сводится к фактической замене информации и меры ее количества на материальные
носители информации – статические и динамические сигналы (данные,
анзния, сообщения, …) и количественные меры измерения объемов
для них.
В качестве меры количества информации (данных, сигнала, знаний,
сообщения) при этом чаще всего используют меры объема: выборки,
памяти и т. п. Например, объем данных VД измеряется количеством
символов (разрядов) в байтах (8 битов), дитах (десятичных разрядах);
количеством V = N чисел определенной разрядности; количеством V =
N отчетов выборки (сигнала) или длиной Т его траектории (реализации) – длиной временного отрезка, в течение которого получена (представлена) траектория, и т. д. Производные от этой меры количества
информации – это такие понятия, как коэффициент сжатия (уплотнения) данных (информации), равный отношению объема V1 до применения процедуры уплотнения к объему V2 после применения процедуры
267
уплотнения к тому же массиву данных, т. е. V1 / V2 , коэффициент
(степень) информативности (лучше – лаконичности) сообщения, равный отношению количества информации (в каком-либо одном и том
же для сравниваемых сообщений измерении) к объему данных
k л I / VД , где I – синтактическое количество информации, например, по Шеннону, и им подобные.
Следует признать наибольшую распространенность во многих дисциплинах в области информатики и вычислительной техники именно
этого подхода и его мер количества информации, реже статистического Шеннона и еще реже алгоритмического Колмогорова.
Помимо рассмотренных вводятся и другие понятия, касающиеся
количества информации или объема ее носителей, такие, например,
как «информационная тара» В.И. Корогодина (1991 г.), «информационная емкость» [33], топологическая мера Н.П. Рашевского (1955 г.) [1,
34], минимально-символьная [24], а также такие, как информационные
ток, напряжение, сопротивление [13] и др.
Отличительная особенность, объединяющая рассмотренные меры
количества информации – все они являются абстрактными, не учитывающими сути сообщений, синтактическими, следствием синтактического подхода к пониманию информации. Фактически они определяют только количественные объемные возможности носителей
сообщений, а не смыслового содержания, информации в них. Этого и
следовало ожидать, поскольку сама суть синтактического подхода требует отвлечения от смысла, содержания информации. Например, фраза
«Я тебя люблю», сказанная на русском, английском, французском или
другом языке содержит одинаковый смысл, одинаковую ценность, но
количественно, по К. Шеннону, определяется разными значениями,
причем такими же, как если бы вместо букв этой фразы были любые
другие символы, но с теми же вероятностями. С другой стороны,
именно это позволяет в теории связи и передачи информации строить
единый математический аппарат для описания каналов связи, пригодный для разных областей, сфер бытия, где имеют место каналы передачи информации. Например, при передаче по системе связи (см.
рис. 2.12) текстовых сообщений каналу связи неважно, какое смысловое содержание, какую семантику, новизну несет сообщение, т. е. какую информацию в ее понимании отправителем и получателем несет
это сообщение, а также ее ценность, полезность для получателя.
268
Другой подход – семантический, ориентирован на оценку количества сути, семантического содержания1, смысла информации, например, на оценку количества информации в какой-либо базе данных с
точки зрения интересов того или иного ее пользователя, покупателя.
Под информацией здесь понимается то содержательное, смысловое,
семантически ценное, что несут в себе Данные как семантические операнды об объекте, т. е. сведения, смысл, знания (семантика символьных записей, изображений, значений сигналов), содержащиеся в Данных, как операндах-носителях. Иными словами, информация – это
совокупность содержательных сведений, новых знаний, которые могут
быть выработаны, собраны, переработаны, воспроизведены, проанализированы, интерпретированы, использованы. Например, Д. Обэр-Крис
под информацией понимает именно знания, полученные из анализа
данных. Под (семантическим) количеством информации здесь понимается величина I c CVД , где С – коэффициент содержательности.
Второй характеристикой, связанной с семантическим и прагматическим количеством информации, является тезаурус пользователя – совокупность Данных, сведений, терминов, которыми располагает пользователь или информационная система в какой-либо области о какомлибо объекте. В определенном смысле тезаурус один из элементов внутренней, а именно культурной, среды, о которой шла речь в части 1,
§ 1.1. Сторонники данного подхода убеждены, что между семантическим количеством информации I c , воспринимаемой и накапливаемой
ее получателем (пользователем), т. е. воспринимаемой и включаемой
им в дальнейшем в свой тезаурус, и объемом тезауруса S р существует
детерминированная зависимость типа изображенной на рис. 4.4 (вряд
ли все так просто, может быть это все-таки зависимость типа регресси1
Заметим, что К. Шеннон подчеркивал важность семантического содержания сообщений. В докладе «Некоторые задачи теории информации» на
Международном конгрессе математиков (1950 г., труды, часть II, стр. 262–
263) он подчеркивает, что «любое обратимое преобразование сообщений, создаваемых стохастическим процессом, скажем, посредством невыраженного
преобразователя с конечным числом состояний, следует рассматривать как
содержащее ту же информацию, что и первоначальное сообщение. С точки
зрения теории сообщений знание зашифрованного кодом Морзе текста телеграммы эквивалентно знанию самого текста» [63, c. 461]. Рекомендуем подсчитать количество информации по К. Шеннону некоторого сообщения до его
кодирования, а также после его простого и эффективного кодирования.
269
онной, т. е. отражающей поведение в среднем, тенденцию). Здесь под
объемом тезауруса можно понимать число релевантных терминов,
объем релевантных Данных, сведений. При малом S р 0 пользователь не в состоянии воспринимать информацию, не понимает ее (она
для него недоступна для понимания или не представляет интереса), а
при больших S р пользователь уже все знает об объекте и поступающая информация не добавляет ничего нового, не нужна ему. Подобный вид имеет также зависимость эффективности Eff решения конкретной задачи от имеющейся при этом или получаемой для этого
информации I (рис. 4.4). На рис. 4.4 S p opt и I opt – оптимальные (лучшие) в смысле максимума I c и E ff значения S р и I.
Помимо рассмотренных, приведем другие варианты (попытки) реализации семантического подхода.
Одна из попыток построения, выявления и оценки количества семантической информации принадлежит Р. Канапу и И. Бар-Хиллеру.
Суть ее сводится к применению аппарата символической логики и логической семантики и определению семантического количества информации с помощью логической вероятности, отражающей степень подтверждения разных гипотез. В такой мере семантичное количество
информации, содержащейся в сообщении, возрастает при уменьшении
степени подтверждения априорной гипотезы. Если гипотеза является
апостериорной, полностью построенной на эмпирических данных, и полученное сообщение его полностью подтверждает, то количество извлекаемой из сообщения семантики нулевое, т. е. такое сообщение не приносит ее получателю чего-то нового, а логическая вероятность гипотезы
равна единице. Следовательно, семантическое содержание сообщения в
таком варианте определяется не тем, что содержание подтверждает, а
тем, что исключает. Этот вариант получил развитие в трудах Дж. К. Кемени, Я. Хинтикка и других авторов. Однако подобный подход оказался
мало пригодным для многих приложений, в частности для оценки семантики содержания высказываний на естественном языке. Например,
согласно этому подходу фраза: «На Марсе есть жизнь» – содержит информацию, а «На Земле есть жизнь», – лишено смысла (семантики, информации), так как это знание достоверное. Мало продуктивным для
разных приложений оказывается синтез статистического и логикосемантического подходов, развиваемый Е.К. Войшвило, логической семантики Д. Харроха и др.
270
МЕРЫ КОЛИЧЕСТВА ИНФОРМАЦИИ
Физико-модельная (минимально-символьная)
n
I ln N ki , N ki – число элементов k-го алфавита в i-й подсистеме
i 1
Комбинаторная Хартли (максимально-разнообразностная)
I H k log a M , M – число возможных разнообразий (состояний, вариантов)
Вероятностно-статистическая Шеннона (максимально-неопределенностная)
I ( X , Y ) H ( X ) H ( X Y ) H (Y ) H (Y X )
n
n
H ( X ) H (Y ) H ( X , Y ) pij log
H() – вероятностная энтропия.
i 1 j 1
pij
pi p j
I (Y , X ),
Алгоритмическая Колмогорова (минимально-сложностная)
I ( x, y ) h( x) h( x y ) I ( y,x),
h() – алгоритмическая энтропия.
Сигнальная
Объем данных (сигнала) VД,
Коэффициент информативности (лаконичности) данных kc I VД .
Ic
Семантическая
Ic max
Семантическое количество Ic = CVД.
Объем тезаураса пользователя Sp.
Sp opt
Прагматические показатели качества
(свойства) информации
Ценность, защищенность, репрезентативность, содержательность, достаточность, доступность, актуальность, своевременность, точность, достоверность (истинность), устойчивость,
интенсивность, ...
Eff
Iopt
Рис. 4.4. Меры количества информации
271
Sp
I
Потребительский (прагматический, практический) подход. Основной упор в этом подходе делается не столько на количество или
семантическое качество, сколько на пользовательские характеристики
(показатели) информации, отвечающие на вопросы: какая (по содержанию и качеству), какому (какой категории потребителей), когда
(к какому сроку) и в какой форме (форма, вид представления) информация нужна потребителю согласно его запросам. При этом подходе
информация, как и любой другой потребительский продукт, товар1,
должна отвечать некоторым предъявляемым к ней требованиям. Возможность формулирования требований и определения их выполнимости осуществляется с помощью набора показателей и сопоставления их
качественных и количественных значений со свойствами и значениями
тех показателей, которыми обладает конкретная информация как продукт, товар. Рассмотрим некоторые из таких качественных и количественных показателей и свойств.
Ценность (полезность) – свойство информации, определяемое ее
пригодностью к практическому использованию в различных областях
целенаправленной человеческой деятельности для достижения определенной цели, т. е. свойство, определяющее ту максимальную пользу,
которую данное количество информации способно принести при
должном ее использовании. В литературе можно встретить как разные
меры (количественные показатели) ценности информации, так и отрицание ценностного подхода к информации, мотивируемое тем, что такой подход автоматически эквивалентен субъективному подходу к самому понятию информации. Если она – физическая величина, то она
должна иметь только одну однозначно определенную меру подобно
тому, как ее имеют энергия, длина, масса, количество вещества (ведь
здесь не ставится вопрос о ценности этих объектов!). Отрицание ценностного подхода к информации не означает отрицания ценностного
подхода вообще, а означает лишь перенос рассмотрения ценности с
информации к информационным системам (не путать ценность с ценой!). По-видимому, лучшим вариантом здесь могла бы быть замена
слова «ценность» на полезность, в частности, чтобы не путать цен1
Продукт какой-либо деятельности – это доступный другим интеллектуальный или материальный результат ее (предмет, вещь, модель, статья, изобретение, …), а товар – продукт труда, предназначенный для широкого применения, обмена или купли-продажи, имеющий потребительскую ценность и
стоимость; предмет торговли.
272
ность с ценой. Ведь в полезности не всегда цена играет определяющую
роль.
Чаще всего в качестве мер ценности (полезности) информации используют следующие [1, 32].
1. Вероятностная мера А.А. Харкевича (1960 г.), аналогичная мере
прироста информации Ф.М. Вудворта (публикация на русском языке
1955 г.) и синтактической для одного варианта мере К.Э. Шеннона (см.
(4.10)) с заменой вероятности появления события на вероятность достижения цели
VX log 2 q p log 2 q log 2 p log 2 p log 2 q ,
(4.22)
где р и q – вероятности достижения цели до (р) и после (q) получения
информации (сообщения).
Из (4.22) следует, что если q p , то ценность полученной информации нулевая, т. е. независимо от ее объема она не имеет отношения
к достижению цели. Чем q больше р, тем более ценной является полученная информация и, наоборот, если q p , то ценность полученной
информации отрицательная, а сама информация является «дезинформацией», ухудшающей достижение цели. Ясно, что мера VX применима лишь, когда, во-первых, допустим вероятностный подход к оценке
ценности информации, во-вторых, известны или могут быть объективно найдены вероятности (или их оценки) q и р, в-третьих, как правило,
когда p 1 и q 1 . Заметим также, что если из п возможных равновероятных до приема информации вариантов можно наверняка
принять один из них, то q 1 , а p 1 n и, следовательно,
VX Vmax log 2 n , т. е. совпадает с максимальным количеством информации, которое необходимо для достижения цели. В этом случае
ценностная мера VX Харкевича совпадает с синтактической мерой количества информации I X log 2 n Хартли, в которую в этих условия
переходит мера Шеннона.
2. Вероятностная мера полезности информации М.М. Бонгарда
(1967 г.) обобщает меру Харкевича (4.22). Бонгард М.М. ввел понятие
«полезная информация», связал сообщение с тем, какую задачу решает
его получатель, что он знает до прихода сообщения и как его истолковывает, понимая под пользой разность между неопределенностью выбора i-го варианта до и после приема сообщения (ср. (4.10), (4.22)):
273
VБ log 2 qi p ,
(4.23)
где qi – апостериорная вероятность достижения цели после выбора i-го
из п вариантов на основе поступившей информации, а р – априорная
вероятность достижения цели до выбора любого варианта. Близким
формальным аналогом (4.23) является мера ценности информации, рассматриваемая Д.С. Чернавским [33, c. 113].
3. Мера ценности В.И. Корогодина
VК
q p
,
1 p
(4.24)
где р и q – априорная и апостериорная вероятности достижения цели.
Несомненное достоинство меры Корогодина то, что VК [0,1] . Но, как
и меры Харкевича и Борнгарда, она оперирует с вероятностями.
4. Мера М.В. Волькенштейна (1970 г.)
VB
aIS p cS p I
,
e
bI
(4.25)
где I – количество поступающей информации; S p – объем тезауруса;
а, b, с – константы. Максимальная ценность информации достигается
при объеме тезауруса S p , равном I c , т. е. пропорциональном количеству получаемой информации; при S p 0 и S p VB 0 , а при
I VB aS p (см. рис. 4.4). Как следует из (4.25), данная мера не
требует знания вероятностей, если без нее можно обойтись при определении I.
5. Стоимостная (ценовая) мера полезности (ценности) Р.Л. Стратоновича (1965 г., [32]).
Ориентируясь на синтактические меры Шеннона и Колмогорова,
Р.Л. Стратонович предложил считать, что польза, приносимая информацией, состоит в уменьшении не неопределенности, а потерь путем
минимизации средних штрафов (см., например, байесовский риск в
1-й части пособия, § 4.3.7). Иными словами, полезность (ценность)
информации есть максимальная польза, которую определенное количество информации способно привнести в уменьшение средних
потерь.
274
В простом выражении полезность, по Стратоновичу, можно представить в виде «бытовой» стоимостной (ценовой, затратной) меры
VСт Z1 Z 2 Z3 ,
(4.26)
где Z – временные или материальные (стоимостные, ценовые) затраты
на решение стоящей перед получателем задачи: Z1 – до получения
информации, Z 2 – после получения ее, Z3 – затраты на получение
(приобретение) информации. Ясно, что при Z 2 Z3 Z1 положительного эффекта от полученной информации нет. С другой стороны, чем
больше VСт , тем более экономически полезной является получаемая
информация.
Помимо перечисленных существует множество других подходов к
определению полезности, ценности информации. Отметим одну из
них. Волькенштейн М.В. (с начала 1970-х гг.) предлагает трактовать
повышение ценности биологической информации как снижение избыточности, рост степени незаменимости информации в ходе эволюционного и индивидуального развития.
В связи с рассмотрением показателей ценности (полезности) информации сделаем несколько замечаний.
1. Говорить о ценности информации, значит, иметь в виду наличие,
во-первых, рецептора – получателя или приемника информации, вовторых, самой цели, для достижения которой рецептор намеревается
использовать эту информацию, и, в-третьих, среду (в частности, условия), в которой будет это использование. В связи с этим ясно, что ценность информации, рецептор, цель и среда, в которой происходит получение и использование информации, связаны четырехместным
отношением, типа изображенного в части 1 на рис. 1.1 (или рис. 1.1,
1.2 в [24]). Отсюда следует относительность ценности информации,
значимости ценности информации как по отношению к субъекту (рецептору), так и цели. То, что является ценным для одного субъекта или
одной цели, может не иметь ценности или быть малоценным (малополезным) или даже вредным для других, и наоборот. Субъективность
ценности и особенно полезности информации проявляется также в индивидуальных качествах субъекта, его способности правильно ставить
цель, выявлять нужное из информации, его возможности и способности использовать ее для достижения поставленной цели и других его
личностных особенностей. В тех случаях, когда рецептор не может
поставить цель (например, «не дорос», занят, не является интеллекту275
альным (неживая природа), принимаемая им информация не имеет для
рецептора ценности в понимаемом до сих пор смысле. Однако она может быть полезной или даже необходимой1 (как, например, генная информация2 или фоновая для живых существ), поскольку без нее или
без информационного общения с окружением, со средой рецептор
«жить» и хорошо, правильно функционировать не сможет. В таких ситуациях следует рассматривать не меру ценности (полезности) информации, а вводить меру ее необходимости, меру ее количества и качества, времени наличия или отсутствия, недостатка или избыточности,
минимальные и максимально допустимые граничные значения ее, временных интервалов ее наличия или отсутствия, по типу того, как это
имеет место для живых существ в отношении пищи, воды, воздуха и
другого соответствующего материального окружения.
2. Если речь идет о ценности, полезности семантики, смыслового
содержания информации, необходимо учитывать наличие ее контекстной связанности, зависимости. Например, переданное сообщение:
«Температура воздуха равна плюс десять градусов Цельсия», – мало
информативно без учета того, какой ситуации оно соответствует (время суток, дата, день года, регион (место) измерения, влажность и сила
ветра, сопутствующие температуре, и т. д.). Помимо этого ценность
сообщения зависит от того, кому оно адресовано или кто и для чего
интересуется температурой, является ли это сообщение новым для получателя или повторяющимся. Кстати, заметим, что вероятность появления такой температуры для каждой ситуации разная. Это никак не
учитывается синтактической мерой К. Шеннона количества информации, содержащейся в этом сообщении, оперирующей только вероятностями появления букв или их сочетаний. Тем самым подтверждается
утверждение: «Любые выводы, основанные на вероятностях, нельзя
считать информацией о событии. А количественную меру, построенную на вероятности, нельзя считать мерой информации» [42, с. 43].
Понятно, что неинтеллектуальному миру недоступна семантика и не
имеет смысла говорить о контекстной зависимости. В то же время для
субъектов интеллектуального мира может иметь место как контекстносвязанная (контекстно-зависимая), так и контекстно-независимая информация. Наличие контекстной зависимости желательно учитывать в
1
Но недостаточной.
Именно генная информация делает возможной жизнедеятельность, рост,
развитие и размножение всех биологических организмов Земли.
2
276
семантических и, может быть, в некоторых специальных ценностных
мерах информации.
3. В приложении к интеллектуальным объектам мира важными являются не только вопросы текущей ценности информации, но и вопросы возникновения, рождения, вопросы об источнике информации, эволюции ее и ее ценности.
4. Не следует отождествлять ценность (полезность) информации с
ее синтактическим и, порою, семантическим объемом. С одной стороны, как уже упоминалось, ее ценность, полезность, нужность, новизна,
эффективность использования могут зависеть или не зависеть от синтактических и семантических объемов, количества вновь поступающей
информации и тезауруса рецептора (см. рис. 4.4). С другой – при одном
и том же синтактическом или семантическом количестве информации ее
ценность для разных рецепторов, субъектов может быть разной.
5. Важным понятием, связанным с ценностью информации, являются ее понятность и осмысленность [33]. Они проявляются не только в способности информации быть понятой, семантически осмысленной рецептором (без чего для него она не будет иметь ценность
(полезность)), но и с точки зрения ее нужности, необходимости.
Например, как указывается в [33], в приложении к геному смысл словосочетания «генная информация» означает «поглощать какой-то субстракт, чтобы жить», когда цель организма – сохранить свою «смысловую» информацию, для того чтобы жить.
6. Семантика, ценность, полезность информации существенно зависят как от среды, в которой происходит ее «рождение», хранение,
передача, прием, применение, так и от самой информации, ее вида,
формы проявления (см. далее разд. 4.5.3) других ее качественных (категорийных и количественных) показателей (свойств), рассмотрению
некоторых из которых посвящен разд. 4.5.4.
Здесь же рассмотрим только потребительские показатели качества
(свойства) информации.
Секретность (защищенность) – это свойство (показатель), характеризующее уровень, степень возможного несанкционированного использования информации.
Репрезентативность информации связана с ее способностью
полно, адекватно отражать интересующие пользователя свойства исследуемого (изучаемого, проектируемого) им объекта, т. е. с правильностью постановки задачи по ее получению, ее получения (отбора,
формирования, добывания), обоснованностью, полнотой и т. д.
277
Содержательность (существенность) информации означает ее
семантическую емкость и определяется, в частности, через семантическое количество I c , коэффициент информативности kc .
Достаточность (полнота, избыточность) информации – свойство, характеризующее наличие в ней минимального, но достаточного
(полнота) или излишнего (избыточность) количества сведений, необходимых для принятия правильного решения (создания моделей, проекта, плана) или выполнения какой-либо функции. Заметим, что как
неполная, т. е. недостаточная для принятия правильного решения, так
и избыточная информация снижают эффективность ( E ff ) принимаемых пользователем решений (рис. 4.4).
Новизна (свежесть) информации отражает неизвестность ее содержания до получения, наличие в ней того, что является новым, только что полученным, не содержащим ранее известного, повторяемого.
Доступность информации для восприятия и применения пользователем – свойство, связанное как с формой ее представления и восприятия, так и с тезаурусом пользователя.
Актуальность – свойство, характеризующее: а) способность информации сохранять семантическую ценность для принятия решений в
момент ее использования в зависимости от динамики изменения ее
пригодности для решения задач пользователя; б) соответствие информации временным границам в отображении ситуации, для которой
необходимо принимать решения.
Объективность – независимость от субъектов, от чьего-либо мнения, суждения.
Своевременность информации – свойство, отражающее возможность и факт ее поступления точно в момент времени, согласованный с
временем решения задачи пользователем, незапаздывания ее к моменту принятия решения. Например, для выработки и принятия решения
существует промежуток времени, после которого эффективность его
воздействий падает, а затем может вообще не иметь смысла. В системах с обратной связью несвоевременность поступления сигнала обратной связи может привести к катастрофическим последствиям.
Адекватность информации – свойство, определяющее степень соответствия информации характеризуемому ею объекту (объектная
адекватность), цели ее получения (целевая адекватность), научной и
прикладной интерпретируемости (физическая, химическая, биологическая, математическая, практическая адекватность), условиям ее получения (ингерентная адекватность), используемым ресурсам (ресурсная
278
адекватность). С понятием адекватность тесно связаны ее достоверность, истинность (точность, справедливость), верность (идентичность).
Точность информации – свойство, определяющее степень метрической, метрологической близости получаемой информации (образа,
построенного с ее помощью) реальному объекту (его структуре, свойствам, процессам). К ней примыкают такие понятия, как «погрешность
измерений и ошибки вычислений», в частности, «формальная точность
вычислений», измеряемая значением единицы младшего разряда числа; «реальная точность», определяемая значением единицы последнего
разряда числа, верность которого гарантируется; «максимальная точность», которая достигается в конкретных условиях; «необходимая точность», определяемая назначением, и т. д. В теории ошибок рассматривается понятие мера точности ошибки, под которой понимается
h 1
2 2 ,
(4.27)
где – систематическая, а – среднеквадратическая составляющие
ошибки [12]. Для измерительной информации понятие «точность информации» (точнее, «точность измерения» (см. часть 1, табл. 3.4))
эквивалентно (но не тождественно!) понятию «истинность информации», поскольку точность измерения характеризует близость результата измерения к истинному значению измеряемой величины. В более
общей трактовке (см. часть 1, § 1.2) под истинностью информации понимается подтвержденность ее с помощью принятых критериев истинности (например, подтвержденностью экспериментами, корректностью
доказательств, решением прикладных задач и т. д.).
Достоверность информации – свойство, характеризующее ее способность отражать реально существующие объекты с необходимой
определенностью (высокой точностью, малой погрешностью, неопределенностью). В измерительных задачах количественной мерой достоверности являются обычно точностные характеристики ее – доверительный интервал погрешности результата или доверительная
вероятность, т. е. вероятность того, что отображаемое информацией
значение результата (например, измеренное значение физической величины) отличается от истинного значения в пределах определенной
(допустимой) погрешности. В задачах классификации, проверки
гипотез достоверность определяется через вероятность правильной
классификации, значение ошибок 1-го и 2-го рода, в диагностике диа279
гностической чувствительностью, специфичностью и точностью
(см. разд. 5.2.5.) и т. д.
В системах связи достоверность передачи трактуется как передача
информации без ее искажения, а достоверность передаваемых данных
(информации) измеряется отношением количества ошибочно переданных знаков к общему числу переданных знаков или вероятностью
ошибок. Помимо достоверности информации иногда рассматривается
понятие верность информации. Под ней понимается степень идентичности (например, подражания в имитационном моделировании)
сведений, содержащихся в информации (модели), характеризуемому
ею объекту.
Устойчивость – свойство, отражающее способность информации
реагировать на изменения исходных условий и Данных без нарушения
ее достоверности.
Из изложенного вытекает следующее. Первое. Каждое из перечисленных свойств информации становится лишь тогда практически полезным, когда имеется количественная мера для его измерения. Второе. Многие из перечисленных свойств – не только и не столько
свойства информации, сколько характеристики информационных систем и технологий разного назначения, видов и форм проявления информации в них (см. далее). Третье. Перечень свойств неполный – в
него не включены, например, экономические показатели, интенсивность (скважность) и другие (см. также разд. 4.5.4).
Рассмотренные подходы поясняются рис. 4.5.
4.5.3. Информация как объект исследования информологии
Как указано в разд. 4.5.1, важнейшей причиной того, что до сих пор
информология не состоялась как наука, является отсутствие единого
понимания ее объекта – информации. Отсутствие единого понимания
подчеркивают многие отечественные и зарубежные ученые и специалисты (см., например, работы [11, 12, 29–44] и приводимые в них источники). Многие ученые отмечают важность наличия общепринятого понимания термина информация для общения, образования, грамотного
управления в обществе. Так, например, главный редактор журнала «Философия» академик РАН В.А. Лекторский отмечает [38], что «отсутствие ясности в понятии информации мешает плодотворному развитию
междисциплинарных связей и сдерживает развитие ряда научных
направлений». Отсутствие общности ученых в решении этого вопроса,
280
ПОЛЬЗОВАТЕЛЬСКИЕ ПОКАЗАТЕЛИ
КАЧЕСТВА ИНФОРМАЦИИ
П О Л Е З Н О С Т Ь = ПРИГОДНОСТЬ К ПРАКТИЧЕСКОМУ ИСПОЛЬЗОВАНИЮ
Ц Е Н Н О С Т Ь = МАКСИМАЛЬНАЯ ПОЛЬЗА ПРИ ПРИМЕНЕНИИ
С Е К Р Е Т Н О С Т Ь , З А Щ И Щ Е Н Н О С Т Ь = УРОВЕНЬ
НЕСАНКЦИОНИРОВАННОГО ИСПОЛЬЗОВАНИЯ
Р Е П Р Е З Е Н Т А Т И В Н О С Т Ь = ПРЕДСТАВИТЕЛЬНОСТЬ, АДЕКВАТНОСТЬ
ИССЛЕДУЕМЫМ СВОЙСТВАМ ОБЪЕКТА
СОДЕРЖАТЕЛЬНОСТЬ =
СЕМАНТИЧЕСКАЯ ЁМКОСТЬ
ДОСТАТОЧНОСТЬ (ПОЛНОТА, ИЗБЫТОЧНОСТЬ) =
= МИНИМАЛЬНОЕ, НО ДОСТАТОЧНОЕ КОЛИЧЕСТВО СВЕДЕНИЙ
ДОСТУПНОСТЬ =
АКТУАЛЬНОСТЬ =
ВОЗМОЖНОСТЬ ВОСПРИЯТИЯ ПОЛЬЗОВАТЕЛЕМ
СПОСОБНОСТЬ СОХРАНЯТЬ СЕМАНТИЧЕСКУЮ ЦЕННОСТЬ
С В О Е В Р Е М Е Н Н О С Т Ь = ПОСТУПЛЕНИЕ, НАЛИЧИЕ В НУЖНЫЙ МОМЕНТ
Т О Ч Н О С Т Ь = СТЕПЕНЬ БЛИЗОСТИ ЗНАЧЕНИЯ (МОДЕЛИ, ОБРАЗА) РЕАЛЬНОСТИ (ОБЪЕКТУ)
ДОСТОВЕРНОСТЬ (ИСТИННОСТЬ, ВЕРНОСТЬ) =
= ОТРАЖЕНИЕ РЕАЛЬНЫХ ОБЪЕКТОВ С НЕОБХОДИМОЙ АДЕКВАТНОСТЬЮ (ДОСТОВЕРНОСТЬ),
ТОЧНОСТЬЮ (ИСТИННОСТЬ) ИЛИ ИДЕНТИЧНОСТЬЮ (ВЕРНОСТЬ)
У С Т О Й Ч И В О С Т Ь = СТЕПЕНЬ РЕАКЦИИ НА ИЗМЕНЕНИЕ УСЛОВИЙ
Рис. 4.5. Фрагмент прагматических показателей качества информации
(ее свойств и требований к ней)
в необходимости становления информологии приводит к превалированию прагматической концепции понимания информации, когда на первое место ставится извлечение пользы, текущей выгоды для себя, либо
нанесение вреда другим с помощью информации, когда не задумываются о близких, а тем более отдаленных последствиях такого подхода для
человечества.
281
Рассмотрим возможные варианты выхода из сложившейся ситуации.
1. Во многих случаях допустимо метонимическое употребление
рассматриваемого термина «информация», т. е. замена им других слов
на основе связи их значений по смежности. Это часто имеет место в
СМИ, в быту, в жаргонных выражениях. Например, мы говорим и пишем: получил информацию из такого-то источника; информация о погоде; загрузил информацию в компьютер или передал ее в сеть. Однако
если это допустимо в разговоре, в быту, во многих других ситуациях, то
это неуместно в параграфе, посвященном рассмотрению информации
как объекта информологии, вряд ли в большом числе случаев уместно в
учебном процессе, особенно связанном с изучением средств сбора,
накопления, хранения, передачи данных и особенно информации. Вот
что по этому поводу считает, например, специалист в этой области
Джозеф Регер – технический директор компании Fujitsu Technology
Solutions по региону СЕМЕА, занимающийся анализом современных
тенденций в ИТ-индустрии, прогнозированием основных технологических трендов и их реализаций в корпоративной сети (Открытые системы. – 2011. – № 10. – С. 39): «Когда мы научились собирать, сохранять
огромные массивы данных и оперировать ими, то стало ясно, что этого
недостаточно, и требуются алгоритмы и методы для извлечения информации, содержащихся в этих данных». Милан Желены в [77, c. 211]
отмечает, что «практика и теория информационных технологий и систем страдают от того, что термины, такие как данные, информация и
знания, часто используются один вместо другого. Эта двусмысленность может быть «убийственной», как, например, неопределенное понятие «интеллект» в термине искусственный интеллект (AI) или
«жизнь» в концепции искусственной жизни (AL)».
2. Признать, что слово «информация», используемое в разных
научных и учебных дисциплинах, является одним из омонимов – слов,
имеющих одинаковое звучание, но различное значение. Но тогда следует выписать четкие пояснения этих значений для каждой дисциплины. Не приведет ли это к междисциплинарной путанице, если не будет
ясного понимания сущности, определяемой термином «информация»,
а будут лишь описания его проявления? Разнообразие оттенков содержательного понимания слова «информация» специалистами разного
профиля можно найти в литературе из разных областей знания (см.
приложение 2).
3. Наконец, третий, исследовательский, обязательный для информологии, – попытаться разобраться в феномене, называемом «инфор282
мация», как объекте исследования, признать, согласиться, выявить или
доказать наличие разных видов, форм ее проявления, не столько альтернативность, сколько дополнительность большинства определений
этого термина как отражающих различные виды, формы проявления
информации, встречающиеся в разных ситуациях и на разных стадиях
информационных процессов. Вот как об этом пишет, например,
Д.С. Чернавский [33, с. 26]: «Все (или почти все определения, приведенные в «коллекции»1, имеют смысл и относятся к разным сторонам
информационного процесса».
Не останавливаясь подробно на разных определениях термина,
сделаем их краткий обзор. В [38] обсуждаются подходы, связанные:
а) с атрибутной концепцией (А.Д. Урсул, И.М. Гуревич, И.Б. Новик,
Л.Б. Баженов, Л.А. Петрушенко, А.И. Берг, Ю.И. Черняк и др.), полагающей, что информация присуща всем физическим процессам и системам (всей материи) и связана с отражением2 реальности в сознании
людей, с отражением разнообразия; б) с функциональной, считающей,
что информация есть свойство лишь самоорганизующихся систем
(биологических и социальных) (П.В. Копнин, Ф.М. Коршунов,
B.C. Тюрин, Б.С. Украинцев, Д.И Дубровский и др.); в) когда информация рассматривается в виде особой идеальной сущности (К. фон
Вейцзекер, Д. Чапмерс) или реальности (по К.К. Колину), которая
«объективно существует независимо от деятельности сознания и является таким же важным компонентом реальности, как и физическая»
[39]; г) информация есть «содержание сообщения» (Н. Винер,
О.С. Ахматова); «информация – это не материя и не энергия»
(Н. Винер), «а при взаимодействии материальных объектов между ними происходит обмен не только веществом и энергией, но и информацией» (А.Д. Урсул); это получаемые или добываемые (Ф. Махлуп)
знания, сведения, известия (в обыденном смысле); д) понимание информации как процесса (И.В. Мелик-Гайказян), когда в термодинамике
информация рассматривается аналогом не энтропии и энергии, т. е. не
1
Собранной в книге: Мелик–Гайказян И.В. Информационные процессы и
реальность. – М.: Наука. – Физматлит, 1997.
2
Под отражением при этом обобщенно понимается «определенный аспект
взаимодействия (воздействия) двух или нескольких объектов , когда из всего
содержания взаимодействия выделяется лишь то, что в одной системе появляется в результате воздействия другой системы и соответствует (тождественно,
изо- или гомоморфно) этой последней» [41, с. 64–65].
283
функций состояния, а теплу и работе – процессам; е) информация, по
Генри Кастлеру, как случайный и запомненный выбор одного варианта
«из нескольких возможных и равноправных» (подход, поддерживаемый Д.С. Чернавским [33]). Кроме того, следует обратить внимание на
такие определения информации, приводимые в [33], как Р. Эйгена и
Р. Винклера: «информация... есть план строения клетки и, следовательно, всего организма»; Э. Янча, трактующего информацию как «инструкцию к самоорганизации в процессе эволюции биологических
структур», В.И. Корогодина: «информация есть некий алгоритм» или
«совокупность приемов, правил или сведений, необходимых для построения оператора». Приведем также еще концепцию рассмотрения
информации как универсальной физической сущности (А.В. Шилейко,
Ю.И. Шемакин, А.А. Романов, Б.Б. Кадомцев и др.). Например,
Б.Б. Кадомцев пишет: «...я полагаю, что -функция представляет собой реальность, существующую независимо от всяких приборов и методов измерения... Она имеет чисто информационный характер».
«Можно сказать, что волновая функция представляет собой физический объект, гораздо более тонкий по сравнению с обычными физическими полями» [36]. «Информация – это физическая величина и в той
же степени, как энергия, присуща всем без исключения формам существования материи» [42, с. 90]. «Информация физична, нет смысла говорить о квантовых состояниях без рассмотрения информации этих
квантовых состояний» [43, с. 391]. «Информация – это еще одно измерение окружающего мира, воспринимаемого как многомерная структура: 3 измерения пространства + время (как изменение состояния
пространства) + энергия + информация» [11]. Информация есть «снятая» неопределенность (К. Шеннон), либо «снятые» разнообразие, неоднородность (У.Р. Эшби, В.М. Глушков1, А.Д. Урсул [41], А.Н. Колмогоров), мера упорядоченности или отраженное разнообразие;
«Информация есть текущие данные» (Ф. Махлуп); «Информация – это
философская категория, рассматриваемая наряду с такими, как про1
Глушков В.М. считал, что информация независима от нашего сознания, а
ее объективный характер обусловлен объективностью существования источника – разнообразия неоднородности. Эшби У.Р. под разнообразием множества различных элементов понимал: а) число различных элементов; б) логарифм этого числа по основанию 2. Тогда его закон необходимого
разнообразия (см. часть 1, разд. 2.3.2, стр. 58) математически можно представить выражением, сходным с (4.22) и (4.23).
284
странство, время, материя» (Г.Г. Воробьев); информация – это первичное, неделимое понятие типа понятий «точка», «прямая»; генетическая
информация – это код (Г. Кастлер).
И еще несколько толкований. «Вселенная есть квантовый компьютер. Информация считается в ней первичной, а вещество и энергия есть
порождение информации» (К.Ф. фон Вайцзеккер, А. Цейлингер,
С. Ллойд, К. Цузе, Х. Падж, С. Хокинг, Я. Бекенштейн, В.Д. Плыкин и
др.). «Любая информация является знанием, но не любое знание можно
назвать информацией» (Ф. Махлуп). «Информация – это организованные и переданные кому-либо данные» (М. Пора). «Информация есть
совокупность интерпретированных данных, а знания продукт ее использования» (Дж. Ходжсон) (Проблемы теории и практики управления. – 2012. – № 6. – С. 103–108).
Приведем еще понимание термина «информация» в Законе РФ
«О информации, информационных технологиях и о защите информации» от 06.04.2011 г. «Информация – сведения (сообщения, данные)
независимо от формы их представления».
В заключение обзора хотелось бы узнать, как понимает читатель
термины «информация» и «информационный» в формулировках заслуг
Нобелевских лауреатов и в цитатах из публикаций ученых, работающих
в разных областях, приведенных в приложении 2.
Разнообразие различных определений и подходов к пониманию
термина «информация» многих, в том числе очень известных, ученых
из разных областей знания наводит на мысль о том, что этот термин не
может отразить информацию в прямом виде, т. е. в виде первичного
элементарного, не разложимого на более простые понятия (дефиниции), в силу неоднозначности объекта, определяемого этим термином.
Логично предположить, что термин «информация» представляет собой
агрегированное соборное понятие (см. часть 1, рис. 1.2), допускающее
системное строение определяемого понятием объекта, подобно таким,
как «математика», «физика», «лес», «материя». Соборный термин заведомо предполагает наличие в определяемом им объекте структурных
составляющих, представляющих собой части, виды, формы существования объекта. Так, например, математика включает в себя арифметику, алгебру, дифференциальное и интегральное исчисление и другие
разделы (части), физика – механику, электричество и магнетизм, акустику и оптику, термодинамику и молекулярную физику, квантовую
физику, атомную и ядерную физику и т. д. Материя имеет следующие
виды: вещество, энергия (поле), вакуум (парен), кварк-глюонная плаз285
ма; антиматерия; темная материя (вещество, энергия). Сейчас рассматривается гипотеза о голографическом строении Вселенной. В свою
очередь, вещество имеет следующие состояния: твердое, жидкое, газообразное, плазменное, фермионное (одномерная квази-ферми-жидкость), коллапсирующее (черные дыры, в которых пространство и
время могут меняться местами).
В качестве исходных «рабочих» определений термина «материя»,
используемых при изучении феномена материи1, в разных научных
дисциплинах можно условно выделить три: 1) «Все объективно существующее», «Все, из чего состоит Вселенная» (условно назовем его
«общефилософским»); 2) объективная действительность (реальность),
существующая независимо от человеческого сознания и отображенная
им (философско-материалистическое); 3) субстракт, субстанция (вещественно-энергетическая или энергетическая), проявляющая свое существование через движение в пространстве и времени («физическое»).
Соборное понимание термина «информация» не эквивалентно метонимическому. Оно означает, что термин «информация» ориентирован на
агрегированное (см. разд. 1.2.2) представление ее частей, составляющих
ее и отличающих ее от других объектов, а также ее видов, форм существования, проявления. Рассмотрим этот вопрос чуть подробнее.
По характеру участия объектов и субъектов во взаимодействии их
и с ней в информационных процессах можно выделить пять видов (типов) информации: добываемая, передаваемая (получаемая, отражаемая),
хранимая (воспроизводимая), создаваемая (генерируемая, преобразованная) и используемая (потребляемая) (см. табл. 3.1). Понятно, что может быть и смешанная информация. Например, объединяющая активно
добытую (добываемую) и пассивно полученную (получаемую).
Добываемая – это целевая информация об объекте, явно или неявно собираемая, извлекаемая, формируемая разово или накоплением
неким субъектом (живым организмом, социумом, информационной
системой) путем измерений, познания, с помощью органов чувств, при
развитии, становлении личности, накоплении опыта, приобретении
рефлексов, при импринтинге2 и т. д.
1
От лат. materia – материя, вещество, первичное начало.
Импринтинг (от англ. imprinting – запечатление) – обучение высших живых особей в определенном возрасте «раз и навсегда», закрепляемое в памяти
в виде отличительных признаков действующих на них внешних объектов и
некоторых врожденных поведенческих актов, например, реакции следования
зрелозарождающихся птенцов и детенышей за родителями и друг за другом.
2
286
Коммуникативная информация – это отображаемая, передаваемая, распределяемая в пространстве и во времени или получаемая объектами, субъектами, проявляющаяся внутри них и при взаимодействии
между собой с помощью сообщений, образов, инстинктов, средств
языка, органов чувств, различных каналов и цепей ее передачи в процессе функционирования, жизни, образования объектов, субъектов.
Хранимая – разновидность информации, «законсервированная»,
закодированная, запомненная, … для ее сохранения (и применения при
необходимости) в пространстве и/или во времени. Например, итоги
обучения, импринтинга; информационная суть инстинктов; информация, хранимая на жестких носителях (бумаге, дисках, в оперативной
или внешней памяти ЭВМ); генетическая информация.
Создаваемая (генерируемая, порождаемая, …) – это вновь «рождаемая» информация. Например, информация, консервируемая в создаваемых объектах интеллектуального1, патентного или авторского права, а также воплощаемая в виде конструкций, идей, моделей, гипотез,
последовательности символов (букв, знаков препинания, пробелов,
нот, …), проявляющаяся в виде мыслей, снов, фантазий, мечтаний,
информационных составляющих генотипа2 и фенотипа3.
1
Из контекста законов, касающихся интеллектуального права, можно заключить, что в качестве объектов права выступает не информация, содержащаяся в объектах права, не материальные, а финальные модельные носители
информации (см. часть 1, § 1.3), представляющие собой последовательность
текстовых и графических, изобразительных (в литературных и научных произведениях) или музыкальных, нотных (в музыкальных произведениях), схемы, изображения – в патентном, промышленном праве. Эти законы лишь косвенно (контекстно, нюансно, чувственно, по смысловому содержанию)
касаются информации, вкладываемой в финальные модельные носители их
авторами. Тем самым проявляется свойство множественности разнообразия
информации, выделяемой (добываемой, получаемой, извлекаемой) из ее носителей и, возможно, дополняемой ее потребителем. Что касается именно «информации», часто по своему трактуемой каждым работающим с ней, то правовое регулирование оперирования с ней защищается законами,
относящимися к информационному праву.
2
Генотип – совокупность генов конкретного организма, характеризующая живую особь (В.А. Иогансен /Johannsen/, 1909 г.).
3
Фенотип – совокупность характеристик, присущих индивиду на определенной стадии развития, формирующаяся на основе генотипа под влиянием
факторов внешней среды.
287
В виде подкласса создаваемой или в виде отдельного класса следует рассматривать еще один тип информации – преобразуемая. Эта информация, получаемая с помощью определенных процедур из другой
информации. Например, к преобразуемой можно отнести информацию, полученную по результатам эксперимента и подвергаемую интерпретации; информацию, содержащуюся в литературном произведении при написании по нему сценария; информацию, переоформляемую
при перекодировании стволовых клеток для превращения их в плюрипотентные, т. е. способные превращаться в клетки различных органов.
Вторым подклассом создаваемой информации является управленческая, назначение которой – формирование поведения (в том числе
целесообразного) управляемой системы, получающей информацию.
Другими подклассами являются проектная, научная, творческая и другие виды создаваемой информации.
Используемая (потребляемая) информация – это та часть информации, ее вид, формы проявления, которую субъект использует для
достижения своих целей, в своей деятельности, при решении своих
теоретических и практических задач, проблем.
По форме проявления для получателя, субъекта и вида носителя
под информацией понимается семантика (смысл, предназначение) сведений, знаний, образов действительности и мысленных (мечты, сны,
фантазии); планы, конструкции, архитектуры; кодовые представления;
существо объектов интеллектуальной собственности.
По степени важности и характеру воздействия для объекта и
субъекта информация делится на жизненно-необходимую (например,
генную, генотипную, фенотипную); полезную (чрезвычайно важную,
ценную, релевантную1); нейтральную (фоновую, не представляющую
интереса, не требующую затрат); мусорную (не приносящую пользу, но
увеличивающую издержки получателя, добытчика, хранителя, генератора, пользователя); вредную, в том числе опасную дезинформацию,
избыточную, поглощающую нужные для жизни, функционирования
ресурсы; катастрофическую, в частности, сознательно ориентированную на причинение вреда, прекращение жизни, функционирования ее
получателя.
По степени востребованности различают информацию постоянного востребования (вся жизненно-необходимая, например, генетиче1
Здесь под релевантной информацией об объекте уточненно понимается
та часть полезной информации об исследуемом объекте, которая изменяет
степень неполноты знаний о нем у ее получателя, добытчика, потребителя.
288
ская) и востребованную, требуемую по мере необходимости (архивная,
знаниевая, контентная, новостная).
По характеру кодирования, представления, формализации, учета
контекстной связанности и среды (см. часть 1, рис. 1.1) семантическую информацию можно разделить на явную, понятную, легко выделяемую, воспринимаемую, кодируемую (знания в виде моделей, гипотез, теорем, законов, справочных таблиц) и неявную (информация,
«зашитая» в приобретенном опыте, навыках, умениях, компетенциях;
литературных и музыкальных произведениях; ЭКГ, ЭЭГ, рентгеновских и ультразуковых, компьютерных томографических и других
снимках, получаемых при диагностических технических и медицинских исследованиях).
Можно ожидать, что, если соборное понимание термина «информация» станет объектом исследования, со временем будут предложенны новые термины для разных частей, видов и форм проявления информации, аналогично тому, как много терминов введено в разные
части математики и физики. Прежде чем ввести «рабочий» термин
«информация» в соборном его понимании, рассмотрим еще специфические свойства и особенности информации, часто приписываемые ей,
несмотря на разную трактовку сути термина «информация», и приведем краткие комментарии к ним. Заметим при этом, что некоторые
приводимые далее свойства имеют место для отдельных частей, видов,
форм проявления информации или, наоборот, для агрегативно понимаемой информации, но не всегда для ее отдельных частей (см. обсуждение примеров признаков для леса и отдельных деревьев в разд. 1.2.2).
4.5.4. Сущностные свойства информации
Вначале сделаем следующие вступительные замечания.
1. Как для любого объекта исследования, для информации следует
выделять два типа свойств. Назовем их условно «внутренними» и
«внешними». Внутренние свойства – это «скрытые», «спрятанные»
внутри объекта фундаментальные (отражающие то, из чего состоит
объект (информация)), сущностные (что собой представляет объект в
целом, его части и их взаимодействия друг с другом) и атрибутные
(без которых объект существовать не может), отражающие объект при
рассмотрении его как целого, цельного, целостного (см. часть 1,
разд. 2.3.1). Внешние свойства – это свойства, выпячиваемые наружу,
проявляющиеся при взаимодействии объекта (информации) с другими
289
и характеризующие его поведение как целого во внешней среде (системе). Понятно, что при решении задач классификации объектов, при
построении куализных моделей, в зависимости от цели классификации
и моделирования разнообразия, можно использовать внутренние и
внешние свойства объектов как порознь, так и совместно. Поскольку
нас будут интересовать принципиальные вопросы отличия информации от материи, тщательнее рассмотрим именно внутренние свойства
и только кратко внешние, доверив читателю самому выявить, какие из
них специфичны для информации.
2. Как уже упоминалось в разделах 4.5.2 и 4.5.3, свойства и отражающие их количественные и категорийные показатели качества информации зависят от того, о каком типе, виде существования и каких
формах проявления и представления ее идет речь. Так, например, описанные в разд. 4.5.3 прагматические показатели и свойства относятся к
добываемой, создаваемой и используемой информации и могут быть
мало интересными для хранимой или коммуникативной информации.
3. Для лучшего понимания обсуждаемых далее свойств рассмотрим
разные типы, виды и формы существования и проявления (представления, хранения) информации. Как и в других главах книги, используем
приемы морфологического аппарата, не оформляя его результаты в
виде классификационных (см. разд. 1.2.1 и § 3.1).
По способу выработки информации и характеру взаимодействия с
ней, как уже упоминалось в разд. 4.5.3, она делится на следующие типы: добываемую, хранимую, коммуникативную, создаваемую, преобразуемую и используемую.
По характеру происхождения и взаимодействию с окружением:
эндогенная (внутреннего происхождения) или экзогенная (наружного
происхождения); экстравертная (обращенная во вне), интровертная
(обращенная на себя) или неориентированная; латентная (внешне не
проявляющаяся), толерантная (не реагирующая на внешнюю среду),
чувствительная (реагирующая на внешнюю среду).
По способу восприятия человеком и видам физических носителей
информация делится на следующие виды: невоспринимаемая (напрямую человеком) (генная, хромосомная, теломерная; электронная (квантовая, электромагнитная, тепловая, гравитационная и т. д.)), воспринимаемая: (визуальная, аудиальная, осязательная (тактильная),
обонятельная, вкусовая, мышечная, вестибулярная (см. разд. 1.5.1)).
По форме представления: образная (изобразительная: фото, кино,
архитектурная, скульптурная, музыкальная); символьная (знаковая):
290
буквенная (текстовая), численная; графическая, жестовая, звуковая,
моторная; письменная, устная, электронная, …; смешанная (комбинированная, мультимедийная).
По источнику происхождения: биологическая, химическая, синоптическая, экономическая, …; личностная (индивидуальная), популяционная; измерительная, статистическая и т. п.
По назначению (для используемой информации): личная (для себя),
персональная (характеризующая индивидуум), социальная; массовая
(общего назначения) и специальная (научная, техническая, управленческая, проектная, производственная, финансовая, образовательная и
т. п.). Например, специальная организмовая информация в биологии
связывается, с одной стороны, с рождением, жизнью, смертью, с целесообразным поведением живых организмов, с добыванием, получением и использованием ее организмом о себе (от себя) и об окружающей
среде (от среды); с другой – с исследованием механизмов наследования, мутаций, наличия, передачи, изменения генной информации во
всех клетках организма; с познанием сути содержащейся в ней «схемы» строения организма. Управленческая информация связывается с
тем, что вызывает или способно вызвать изменение поведения управляемого объекта или позволяет принять решение.
По объему отражения объекта: элементная, порционная (частная), организмовая (объект как изначально целое), комплексная, системная; микро, макро, мега.
По востребованности объектом: жизненно-необходимая, важная,
комфортная, фоновая (второстепенная, ненужная (бесполезная)), вредная, катастрофическая.
Теперь перейдем к рассмотрению важнейших внутренних свойств
информации, связанных с ее сутью, строением, со способностью к созданию, передаче-приему, хранению, обработке (преобразованию) и
применению.
Свойство материальной ингерентности (связанности с материей,
встроенности в нее): а) невозможность проявления информации вне
взаимодействия материальных объектов; б) физическая материальность ее стартовых и промежуточных носителей (см. часть 1, § 1.3).
Многие современные ученые считают, что существование пустого (без
материи) пространственно-временного континуума невозможно. Если
из пространства и времени, как считал еще Рене Декарт, удалить все
физические тела, то пространство и время перестанут существовать.
Есть полное основание считать, что это же относится и к информации
291
в разном ее понимании: без материи не может быть информации и без
информации не может быть материи, по крайней мере, отдельных ее
проявлений, например, «живой» материи.
Свойство сохранности (неисчезаемости, «подарочного», «беззатратного» размножения, неограниченной тиражируемости) при взаимодействии ее носителей (объектов, субъектов): наличие возможности передачи ее одним носителем (материальным объектом) другому
без потери для одного при приобретении другим.
Свойство множественного разнообразия: информацию можно
по-разному и многогранно выделить (добыть, получить) из одного и
того же «информационного» сырья, содержащегося в носителе, в отличие от ограниченных материальных ресурсов.
Прокомментируем два последних свойства. Эти свойства отличают
информацию от физической материи, для которой справедливы законы
сохранения материи (массы, энергии, зарядов, спинов, импульсов, количества движения и т. п.). Отличие первого свойства хорошо иллюстрирует такой пример. Если вы имеете какой-то предмет (часы, телефон, фрукт, яблоко у Б. Шоу) и ваш друг имеет такой или другой
предмет и вы поменялись одинаковым числом предметов, то вы остались собственником (носителем) того же числа предметов. Если же вы
имеете одну идею (анекдот) и ваш друг имеет другую идею (анекдот) и
вы поменялись ими, то каждый из вас стал носителем («собственником») двух идей (анекдотов). Третье свойство безграничного разнообразия хорошо иллюстрирует пример фотографии некоего человека, как
носителя информации о нем, по которой совершенно разную информацию могут получить родственники, любящий человек, врачи разных
специальностей, следователь, таможенник, другие субъекты и даже
искусственные средства. То же касается генной информации, содержательно представляющей собой «схему создания и работы» будущего
организма, передаваемой через ее носитель – генетический код1. Эта
1
Префиксный (см. разд. 2.7.3) генетический код (код ДНК) – это набор
сочетаний кодонов, кодирующих тринуклеотидов, состоящих из трех нуклеотидов («букв») – четырех видов азотистых оснований: аденина (А), гуанина
(Г), тимина (Т), цитозина (Ц), кодирующих определенные (из 20) аминокислот
белка. Он представляет собой носитель («язык») генетической (наследственной) информации в виде непрерывной последовательности кодонов (предложений), определяющих последовательность аминокислот в полипептидной
цепи белка, определяемой этим геном.
292
«схема» (информация) по ходу транскрипции кодируется и переносится от ДНК, хранящейся в клетке, в РНК, а от РНК в процессе трансляции в белки для синтеза, в ходе которого происходит сборка отдельных клеток и постепенное формирование организма. Для организма
генная информация – это «схема» сборки, структура РНК и белков, для
исследователя – добываемые сведения о принципе работы и наследственных особенностях организма, источник выявления возможных
заболеваний и патологий в организме.
Свойство относительной инвариантности к носителю (материальному, промежуточному либо к финальному, например, к ее кодовому представлению). Под относительной инвариантностью к носителю понимается следующее. Если информация об исследуемом
объекте относится к добываемой, получаемой через его сигналы, то ее
инвариантность к сигналам, как ее стартовым материальным физическим носителям – источникам информации, будет иметь место только
для таких сигналов, которые позволят считывать, воспринимать нужную информацию из них с одинаковым количеством и качеством.
Например, сигналом носителем – источником информации может быть
такое патологическое изменение тканей легкого, которое можно выявить с помощью рентгеновских лучей как носителей-считывателей
информации при флюорографии либо при помощи средств компьютерной томографии. Тогда запечатленный на пленке рентгеновский
снимок будет носителем-хранителем информации. В то же время оптические, ультразвуковые, инфракрасные и другие лучи как носителисчитыватели информации могут не позволить получить требуемую
адекватную информацию о состоянии легкого. С другой стороны, если
мы ведем речь о хранимой или коммуникативной информации, то
здесь действительно она может не зависеть от вида материального носителя ее (будет ли рентгеновский снимок на исходной пленке, на бумаге или в электронном виде). Мы рассмотрели одну сторону относительности инвариантности информации к ее носителям, а именно
потенциальную независимость. Но есть еще и вторая сторона относительности – физическая независимость. Она связана с ограниченными
возможностями носителя обеспечить качественную и количественную
сторону несомой ими информации, т. е. с ее возможными искажениями, потерями, помехоустойчивостью носителя, физическим старением.
Примеры возможности изменения носителя генетической информации.
293
Первый пример. Создание менее года назад (Scripps Research
Institute, Калифорния, США) бактерии, в которой к двум парам нуклеатидных оснований, кодирующих жизнь на Земле и располагаемых на
двойной (А-Т и Г-Ц) спирали ДНК друг против друга, была добавлена
третья – искусственная. Она почти не имеет химического сходства с
нуклеотидами А, Г, Т, Ц и содержит две новые «буквы» Z и Р генетического кода. Тем самым была показана возможность новых способов
хранения и передачи записанной генетической информации. Кстати,
она реплицировалась и передавалась новым поколениям бактерий на
протяжении недели (Денис Малышев).
Второй пример – создание ксенуклеиновой кислоты КсНК (Филипп Холлингер, Кембриджский ун-т) и на ее основе набора новых
двухспиральных молекул, наделенных всеми свойствами, присущими
ДНК и РНК (В мире науки. – 2013. – № 2. – С. 14).
Третий пример – создание в 2011 г. Крейгом Вентером (США) с
коллегами первого в мире искусственного организма «микроплазма
лабораториум», на отдельных «непринципиальных» отрезках синтетической ДНК которой было закодировано имя К. Вентера, имена 46 его
сотрудников, адрес вебсайта и три классические цитаты (Вопросы философии. – 2012. – № 12. – С. 3).
В связи с изложенным свойство относительной инвариантности к
носителю лучше сформулировать как свойство инвариантности к ее
финальному (кодовому) носителю. В приложении к семантической
трактовке термина «информация» это означает, что существо, содержание информации не зависят от формы и способов ее представления,
если, конечно, при замене формы и способов не происходит ее искажение и потеря качества.
Свойство неаддитивности: не для каждого типа информации
(например, в ее семантическом понимании) ее добавление к уже имеющейся увеличивает ее суммарное количество1 на величину прибавления (например, по семантической мере Ic количества информации (см.
разд. 4.5.3)). Одним из аспектов этого свойства является фундамен1
Очевидно, что это свойство, как и свойства некоммутативности и неассоциативности, зависят от используемой меры количества информации. Ясно,
что при этом мера количества рассматриваемого типа информации должна
быть сама аддитивной, коммутативной.
294
тальное алгебраическое свойство информации – идемпотентность1
ее автосложения, т. е. сложения самой с собой.
Свойство некоммутативности – суммарное количество1 информации (например, семантическая составляющая сообщений) может
зависеть от последовательности ее поступления (поступления сообщений) (см. тезаурус и пояснения к нему). Например, семантика сообщения С = А + В, как суммы последовательно поступивших сообщений А
и В, не всегда может совпадать с семантикой сообщения D B A
(например, по мере Ic).
Свойство неассоциативности. Количество информации (например, по мере Ic) может зависеть от сочетания поступающих ее частей:
( A B) C
A (B C) ,
где символ означает «не обязательно равняется».
Свойство активности: информация, в отличие от пассивных данных, может активно участвовать в материальных процессах. Например,
с помощью информации можно управлять поведением человека, множества людей (на чем основаны информационные войны); самовнушение может вызывать ожоги, а самовнушение + информация извне могут способствовать выздоровлению, останавливать начало заболевания
или, наоборот, вызывать его, способствовать его переходу в хроническое, приводить к самоорганизации социальной группы живых существ (людей, муравьев, пчел, волков, крыс).
Свойство самоорганизуемости: кумулятивности (накопления),
структурированности (например, для генной информации) и внешней
активности, способности управлять построением физических, включая
биологические, и социальных структур и процессов, по-разному влиять на материальные объекты и процессы. Например, управлять ходом
принятия и запоминания вариантов решений, бифуркаций, мутаций;
запускать новые «схемы» развития; управлять социумом, активно
участвовать в выборе траектории движения к цели, в формировании
1
От лат idem – тот же самый и potens – сильный, способный – сохраняющий объект (математический) при повторном действии над ним. Например,
идемпотентная операция сложения «да» + «да» = «да». Заметим, что свойство
идемпотентного сложения характерно не только для информации, но и для
некоторых интеллектуальных продуктов (см. разд. 4.9.4, интеллектуальный
капитал), затрудняющих выполнение бухгалтерских операций с ними.
295
целеполагания, ценности установок, личностных качеств человека, его
обучении, воспитании, развитии.
В связи со свойствами неаддитивности, некоммутативности и неассоциативности, активности и самоорганизации напомним два обстоятельства. Во-первых, наличие двух видов физических величин: экстенсивных (аддитивных) и интенсивных (неаддитивных) (см. часть 1,
§ 1.2). Это важно иметь в виду как при работе с измерительной информацией и информацией, полученной от нее, так и при проведении
сравнения и аналогии между информацией и материей. Во-вторых,
возможность проявления свойств пороговости и эмерджентности, когда информация приобретает качества сложной системы.
Свойство конечности и дискретности: квантовости по объему,
разрывности во времени.
Свойство пространственной и временной распределенности –
получение от разнесенных в пространстве и времени источников, распределенного хранения и передачи.
Свойство допустимости многократного преобразования: а) возможность получения различной релевантной информации не только от
источника, но и по ходу, на разных этапах ее переработки и в различных операциях информационного процесса; б) возможность изменения
сути (сущности, семантики), способа, вида и формы существования;
в) способность допускать различные варианты кодирования без искажения.
Свойство дуальности проявления статичности и динамичности: с одной стороны, информация способна к запоминанию и сохранению в течение длительных промежутков времени (пока не разрушится носитель), с другой – она способна изменяться во времени,
включая ее накопление, ухудшение, совершенствование, разрушение
под действием внешней информации, переходить из пассивной формы
(просто храниться, никак себя не проявлять, но постоянно быть готовой к использованию) в активную; сохраняться во времени без изменения и устаревать (перестать отражать истинное положение дел, терять
ценность, полезность и т. д.) при получении новой информации или,
наоборот, приобретать эмерджентность.
Динамические свойства информации – возможность изменения
информации во времени: ускоряющийся рост общего объема добываемой и генерируемой, хранимой и передаваемой человечеством информации; изменение ценности одной и той же информации во времени
296
для тех же и разных пользователей; изменение возможностей некоторых носителей информации и средств оперирования с ней; контролируемость и управляемость; отсутствие «материальных» причин потери надежности, отказоустойчивости, живучести и других свойств,
присущих искусственным материальным, в частности техническим,
объектам.
Для тех типов, видов информации, которые имеют практическую
значимость (полезность, ценность), можно отметить еще такие ее
особенности (свойства), как сложность, порою неоднозначное соответствие между ее количеством и качеством, ценностью, полезностью;
нечеткая, не всегда прогнозируемая зависимость ценности (полезности) информации от затрат на ее получение (см. меры ценности); устареваемость – способность прекращать отражать истинное положение
дел; эргономичность – удобство оперирования с ней потребителя
и т. п.
4.5.5. «Рабочее» определение термина «информация»
Интегрируя описанное в § 4.4, можно констатировать, что на сегодняшний день, по аналогии с темной материей, информация – нечто
непонятное, но бесспорно существующее, и предложить логично вытекающее из изложенного стартовое («рабочее») определение термина
«информация» для его дальнейшего уточнения и развития.
Информация – это аликвид1, специфичное гало, отражающее «модельно» прошлое, существующее или будущее действительности и содержащее семантику «модели», в том числе запомненные варианты
имевшихся, имеющихся или будущих «схем», конструкций, правил,
планов, программ, законов, закономерностей, процессов, …, сути строения, поведения, развития материальных объектов Вселенной, проявляющийся в процессе взаимодействия с этими объектами в различных
видах и формах, хранимых и реализуемых через их естественные и/или
искусственные материальные носители.
Прокомментируем такое понимание термина «информация».
1. Оно не противоречит соборному толкованию термина «информация». В качестве частей информации могут выступать разные сущ1
От лат. aliquid – нечто. В работе сознательно введен латинский термин,
чтобы он одинаково воспринимался в каждом современном языке.
297
ности (аналоги составляющих материи, ее видов и форм существования, например, типы и виды, рассмотренные в разд. 4.5.3), их особенности, обусловливающие участие ее в информационных процессах,
последовательностях преобразований, направленных на добывание,
получение, передачу, хранение, кодирование информации, изменение
ее сути, видов и форм. Из соборности информации, как следствие,
должны появиться различные составные части информологии, содержащие разные замкнутые по В. Гейзенбергу1 теории, по типу классической механики И. Ньютона или квантовой механики, термодинамики, электричества и магнетизма. Законы и положения замкнутой
теории признаются справедливыми везде и всегда, когда опытные данные могут быть описаны в понятиях этой теории. Так, например, для
ньютоновской механической картины мира, как замкнутой теории материи, точными исходными понятиями являются: масса, сила, ускорение. В теории о теплоте, т. е. в термодинамической картине мира, исходными являются понятия: объем, давление, температура, энергия и
энтропия [42]. Для каждых таких частей информологии будут справедливы свои законы, закономерности, правила, принципы, аналоги или
антиподы законов механики, термодинамики и других физических
теорий.
2. Как уже упоминалось, положение с информацией сейчас напоминает положение с темной материей (Фриц Цвики, 1937 г.), темным
гало: это нечто непонятное, ненаблюдаемое, но реально существующее. В настоящее время нет замкнутой теории о темной материи (веществе и энергии)2, о ее составе. Мы судим о ее существовании косвенно по ее проявлению в гравитационных взаимодействиях, в
частности, в виде скопления галактик, кривых вращения дисковых галактик, рентгеновском излучении из галактик и их скоплений, грави1
К критериям замкнутости научной теории В. Гейзенберг относит: а) ее
внутреннюю непротиворечивость, включая четкость (точность) понятий и
строгость отношений между ними; б) изобразительность и способность что-то
означать в мире явлений [42].
2
Считается, что в нашей Вселенной темное вещество составляет 23 %,
темная энергия 73 % от полной плотности материи (вещества, энергии), в то
время как привычная (барионная) материя 4 %.Точность значений этих оценок считается высокой, но (что весьма важно в контексте материала настоящего пособия) подвергается сомнению некоторыми учеными из-за возможности их модельной зависимости.
298
тационному микролинцентрированию, ускоренному расширению видимой Вселенной. Аналогично темному гало1, информационный аликвид пока можно понимать как информационное гало, которое проявляется косвенно через гены, геномы, генотипы и фенотипы организма,
мысли, интуицию, инстинкты; научные, литературные, художественные, музыкальные и прочие произведения, информационные войны и в
других явлениях. Заметим, что зачастую человеческий инстинкт и интеллект предвидят будущее лучше, чем аппарат, основанный на формальных, алгоритмических, механически выполняемых процедурах, в
частности статистических. Они способны помочь человеку предвидеть
трудно предсказуемое, но радикально влияющее на состояние дел (эффекты «черного лебедя», «белой вороны»). «Именно интуиция, а не
логика приводят людей к истинному знанию» (А. Эйнштейн), к озарению (А. Пуанкаре). Заметим, что животные в естественных условиях
используют три источника «знаний»: наследственно обусловленные
программы обучения, индивидуальный опыт и социальное обучение,
основанное на подражании (Наука в России. – 2011. – № 6. – С. 27).
3. Если человек, как материальный объект, взаимодействует со
средой напрямую, то он же, как субъект, взаимодействует со средой
только через модельное представление о ней. Это же справедливо и о
его взаимодействии с информацией, с информационным гало. Как было указано в § 1.5, взаимодействие человека, как живого организма, с
информацией происходит через модельное представление объективной
действительности в виде воспринимаемой им реальности. Реальность,
как конкретная для каждого человека абстрактная или виртуальная
(см. часть 1, § 1.1.) (фантомная, призрачная, воображаемая, мнимая)
модель действительности, является итогом взаимодействия человека с
внутренней и внешней по отношению к нему информацией, представляет собой «информационный фантом» действительности, который
можно до ее (модели или фантома) регистрации на материальном носителе считать частью воспринятой, переработанной и оформленной
информации, получаемой человеком о действительности и от нее.
1
Гало – в настоящем контексте это компонент Вселенной, состоящий из
напрямую ненаблюдаемой и непонимаемой сущности, проявляющийся косвенно. В первоначальном понимании (halo от др. греч. – аура, нимб,
ореол) – это феномен, атмосферное явление, проявляющееся в виде светящихся колец вокруг источника света. Заметим, что природа атмосферного гало
выяснена.
299
Именно в этом смысле мы до сих пор, специально не аргументируя
это, понимали и будем понимать модель как часть, а именно «фантомную» разновидность информации, понимая, что знания, воспринимаемая семантика, законы, закономерности, схемы, планы, конструкции,
алгоритмы, «запомненные варианты», как результаты познания, есть
фиксированные, зарегистрированные модельные представления действительности. Например, когда мы познаем, что такое генная информация, мы в процессе познания собираемся построить модель «схемы»
сборки клетки, организма, потенциальной динамики его становления,
развития и смерти через добываемые сведения (знания) об участвующих в строительстве организма элементах, процессах, условиях, влияющих факторах. Рассогласование признаков состояний организма с его
фантомной информационной моделью может быть одной из важных
причин старения организма. Собственно саму генную последовательность нуклеотидов можно рассматривать как материальную созидательную биолого-химическую модель будущего организма и процессов его
формирования, а получаемую при ее познании информационную модель ее как часть фантомной информации об элементах, механизмах,
процессах, участвующих в этом. В формировании организма, его протеома1, генотипа и фенотипа участвует не только генная последовательность нуклеотидов, в которой закодирована наследственная генная
информация, но и другие молекулярно-биологические элементы (ферменты, межклеточная жидкость и процессы, транскрипции, трансляции, мутации и пр.), имеющиеся и происходящие в организме и посвоему «раскодирующие» вклад всех внутренних и внешних активных
и пассивных участников формирования организма через бесконечное
многообразие их значений. Поэтому здесь мы фактически имеем дело
с «полем информации», участвующей в этом. Конкретное присутствие
поля в организме может проявиться в «ценном» наследуемом «запомненном варианте», обеспечивающем устойчивое развитие организма и
его потомков. Иными словами, мы приходим к идее информационного
поля (по крайней мере, таким образом понимаемого), в котором создается, формируется, живет организм. Для познания такого поля, т. е.
1
Протеом: а) совокупность (состав) всех белков (протеинов) и их модификаций в клетке, в ткани и организме, отражающая любые (все) молекулярно-биологические процессы, происходящие в живых организмах (Марк Уилкинс, 1994 г.); б) воплощение генетической информации в конкретных
функциональных внутриклеточных системах.
300
познания механизмов хранения, кодирования и раскодирования
«схем», «механизмов», процессов вклада каждого внутреннего и
внешнего участника организма в формирование всего организма, а
также «конструктивных» и «деструктивных» значений параметров
участников мы вынуждены создать фрагментарные фантомные модели
поля, как отдельные части всего «фантомного информационного поля», окружающего жизнь организма.
Резюмируя изложенное, можно заключить, что добываемую и создаваемую информацию человек воспринимает через ее составные
фантомные модели, которые затем используются как средства для
осуществления любой его деятельности. Они могут быть зафиксированы на материальных (стартовых, промежуточных, финальных) носителях, оформлены в форме семантических знаний, схем, законов, графиков, соотношений, сообщений, кодовых комбинаций и т. д. Таким
образом, для добываемой и создаваемой информации модель при
непосредственном общении с информационным гало выполняет на
первом этапе функции фантома как элемента реальности, т. е. воспринятой и переработанной человеком (живым организмом) части информации о действительности. Назовем такую модельную реальность первичной. Именно в этом смысле в пособии понимается, что информация
об объекте – это его (фантомная) модель (см. часть 1, § 1.3). А поскольку незарегистрированные знания, конструкции, схемы, сведения,
программы действий, семантика сообщений, выбранный вариант, в
частности «запомненный», представляют собой форму модельного
фантомного отображения объекта-оригинала, это же относится и к ним
(см. часть 1, § 1.3 и предшествующий текст пособия). На втором этапе
работы с добываемой и создаваемой информацией фантомная модель,
как фантомная часть информации, кодируется и регистрируется на материальном носителе, превращаясь в хранимую или передаваемую.
Тем самым в ходе этих двух этапов взаимодействия с информационным гало модель оказывается результатом взаимодействия и носителем «реальностной» информации о той части действительности, которая будет отражена в модели. Что касается получаемой и используемой информации, то она считывается либо напрямую самим
человеком из фантомной модели, либо из модели, хранимой в носителе
или передаваемой тем же или другим человеком либо средством. Заметим, что в системах, организмах, нормально функционирующих в относительно стабильных условиях, без нового внешнего вмешательства,
301
хранение, передача, кодирование, считывание и декодирование
информации в носителях, в том числе генной, может происходить
практически механически. Понятно, что в лучшем случае считанная
информация будет дубликатом фантомной информации о реальности,
как модели действительности. На самом деле с учетом всегда присутствующих искажений в процессе всех преобразований информации
она будет приближенно представлять не только действительность, но и
первичную модельную реальность (рис. 4.6). Изложенное во многом,
видимо, справедливо для других биологических организмов, если в
приложении к ним термин «модель» объекта, как целевое отражение
объекта-оригинала, заменить его аналогом, словосочетание «целевое
отображение» в дефиниции модели (см. часть 1, § 1.1) увязывать не с
сознательным созданием модели, а рассматривать как промежуточный
элемент – звено во взаимодействии любого организма с информационным гало. Это вовсе не означает, что реальное отражение действительности для различных организмов будет одинаковым. Оно-то как раз
разное. Например, реальность для человека, собаки, кошки имеет существенное отличие как модель действительности. Речь идет о сходстве механизма взаимодействия с действительностью, изображенного
на рис. 4.6 (ср. с рис. 1.1, часть 1). Итак, отношения между информацией и моделью проявляются двояко: добываемая и создаваемая информация являются источником построения модели; модель является
средством оформления, регистрации и представления добываемой и
создаваемой информации, носителем хранимой, коммуникативной информации и источником используемой информации. Заметим также,
что в приложении к объекту следует различать информацию об объекте, для объекта, в объекте и из объекта, а также понимать отличие в
словосочетаниях информация кодируется, кодирует, закодирована, отражающие активность и пассивность ее по отношению к кодированию.
4. Для познания, выявления структуры, процессов, законов, закономерностей, свойственных информации, информационному гало,
пригодны все современные методы: теоретическое исследование, физическое и машинное экспериментирование, имитационное моделирование, в том числе основанное на результатах реальных экспериментов. Понятно, что предпочтение, которое следует отдать тому или
другому методу, зависит от того, какое модельное представление,
стартово оформленное в виде дефиниции информации (см. § 4.5 и приложение 2), будет взято в начале исследования и к каким частям, видам и формам проявления эта информация будет отнесена.
302
Т
И
Е
Л
Ь
О
В
Н
Л
Т
В
Ь
С
О
Л
Е
О
Н
С
Е
А
С
Т
Й
Е
Ч
Кодирование и регистрация фантомной модели
(носитель информации)
Р
Д
Хранение и передача
модели (информации)
Ф
Б
А
М
Н
И
А
Т
О
О
Т
М
Л
Е
Н
А
О
Р
Я
Прием и использование
модели (фантомной
информации)
М
О
Г
И
Я
,
И
Ч
И
Е
Н
Ф
Й
Д Е
Д Е
Л Ь
С
О
К
Р
Т
В
А
Ь
Ь
Т
И
Е
И
Т
С
О
Н
Ь
Л
О
А
З
Г
И
Н
Г
О
Л
М
Е
А
О
Р
Й
И
М
С
К
Т
Носитель модели
(информации)
Е
Н
Н
О
Ц
И
Рис. 4.6. Условная схема отношений «действительность –
человек – реальность – модель – носители информации»
§ 4.6. МЕТОДЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
4.6.1. Понятие об интеллекте
Как уже неоднократно убеждался читатель, рассмотрение новой
области знаний начинается, зачастую, с констатации отсутствия единого общепринятого толкования базовых терминов, используемых в данной области. Это справедливо и для терминов «интеллект», «искусственный интеллект». Не вдаваясь в детали рассмотрения разных
определений этих терминов, дадим обобщенное представление их понимания.
303
Интеллектом1 человека (или живого существа) обобщенно называется его способность пользоваться мыслительными операциями,
осуществлять познание, обучение, понимать, обобщать, рассуждать,
решать проблемы и творческие задачи.
Различают несколько разновидностей интеллекта, его составляющих, проявлений. Обобщенно выделим четыре из них, важные для
дальнейшего изложения материала.
Академический интеллект (АИ) – способность человека к познавательной деятельности, обучению, творчеству, неординарному мышлению.
Практический интеллект (ПИ) – наличие у человека соответствующих профессиональных компетенций, способностей решать в
повседневной жизни практические задачи, включая профессиональные
с плохо определенными условиями, способность адаптироваться к изменяющимся ситуациям жизни либо видоизменять их.
Социальный интеллект (СИ) – способность к общению, правильному пониманию и прогнозированию поведения других людей.
Эмоциональный интеллект (ЭИ) – способность к пониманию
своих и чужих эмоций и управлению ими, умение настраиваться на
свои и чужие эмоции и предпринимать адекватные действия.
Прокомментируем приведенные пояснения.
Прежде всего обратим внимание на разные составляющие интеллекта, их сильную взаимосвязь между собой, а также на важность проявления их в разных действиях и на возможность их измерения.
Академический (а точнее, его часть – логический) интеллект часто
измеряют с помощью коэффициента интеллектуальности (IQ –
Intellectual /intelligence/ Quotient), отражающего умственное развитие
детей (А. Бине, 1903 г.), способность к логическому мышлению, уровень общих знаний и осведомленности (Вильям Штерн, 1912 г.; другие, 1962 г. [1]). Позже появился коэффициент EQ (Emotional Quotient)
эмоционального интеллекта2 (ЭИ) человека (Дэниел Гоулман /Daniеl
Goleman/, 1955, 1998 гг.; Рувен Бар-Он, 1997 г. и другие), который, как
считается в последнее время, сам по себе или в совокупности с IQ характеризует интеллект точнее, чем только способность логически
1
От лат. intellëctus – разумение, познание, понимание, постижение; понятие, рассудок.
2
С историей исследований в области ЭИ можно ознакомиться по книге
Гиту Бхарвани «Важнее, чем IQ: EQ:Эмоциональный интеллект». – СПб:
Прайм-ЕВРОЗНАК, 2009.
304
мыслить. Так, согласно исследованиям Д. Гоулмана, успех управленческой работы на 85 % определяется EQ и только на 15 % – IQ (см.,
например, [45]); 70 % неудачных карьер связано с низким эмоциональным интеллектом и лишь 30 % – с другими причинами (Г. Бхарвани,
стр. 160). Очень большая роль ЭИ в успехе обучения. Социальный интеллект измеряется в SQ, например, по шкале социальной зрелости Эдгара Долла (1935 г.).
Во всех составляющих интеллекта важной функцией и качеством
его является понимание. Кроме понимания в интеллекте важно творчество, умение создавать новое, неизвестное, находить неординарные
решения; а также способность мыслить, мечтать, осознавать себя и
свои действия. Это особенно важно при сравнении естественного интеллекта (интеллекта человека) с искусственным при ответе на вопросы типа: «Может ли машина мыслить?», «Может ли робот полностью
заменить человека?».
Искусственный интеллект (Аrtifical intelligence, ИИ, AI): 1) сделанный наподобие настоящего, природного; 2) сделанное человеком
средство (например, компьютерная, информационная система или
программа), воспроизводящее некоторые стороны умственной деятельности человека; 3) наука и технология создания интеллектуальных
машин (Джон МакКарти, автор термина, 1956 г.); 4.1) область компьютерной науки, занимающаяся автоматизацией разумного поведения
[46, с. 27]; 4.2) дисциплина, исследующая закономерности, лежащие в
основе разумного поведения, путем построения и изучения артефактов, предопределяющих эти закономерности [46, с. 781]; 5) раздел информатики, связанный с изучением, созданием и применением искусственных средств, способных к рассуждениям, разумным действиям,
решению задач и проблем в случаях, когда алгоритм решения заранее
неизвестен, могущих дополнить и усилить умственные способности
человека с помощью вычислительных или иных искусственных
устройств, систем, организмов. Сделаем два замечания по поводу приведенных определений.
1. В русском варианте используется термин «Искусственный
интеллект» (artifical intellect), в то время как в англоязычной литературе
(согласно авторскому термину Джона МакКарти (John МcCarthy),
1956 г.) «Artifical intelligence». «Intelligence» переводится как ум, интеллект, умение разумно рассуждать, несколько уже, чем «intellect» –
ум, интеллект, рассудок (см. описанные ранее составляющие интеллекта и материал, излагаемый ниже). В контексте излагаемого термин
«аrtifical intelligence» можно по-русски образно трактовать как «искусственный интеллектик» – молодой, только начинающий формироваться,
305
«детский» интеллект, а некоторые несовершенные варианты ИИ – «интеллектишком».
2. По отношению к термину «Искусственный интеллект» как научной дисциплины, применимо изложенное для информологии: объект
исследования – интеллект – до сих пор однозначно, общепринято не
определен. Тем не менее это учение и область деятельности очень бурно развиваются (см. далее и специальную литературу). Иногда (см.,
например, [56]) ИИ, способный действовать «интеллектуально», или
имитирующий интеллект называют слабым искусственным интеллектом, а ИИ, обладающий разумом (а не только имитирующий его
или разумную деятельность), называют сильным искусственным интеллектом.
Некоторые отечественные авторы (см., например, [25, c. 167]) считают, что до середины 70-х годов ХХ столетия в русском научном варианте в качестве термина «искусственный интеллект» выступал термин «ситуационное управление», под которым также понималось
«представление знаний» [25, 26].
Резюмируя изложенное, обратим внимание на два параллельно развиваемых в настоящее время подхода к созданию ИИ: имитационный
(подражательный) бионический и изобретательский прагматический.
Бионический1 или социально-бионический подход ориентирован на
создание искусственных методов, средств и систем, моделирующих интеллектуальную психофизическую деятельность человека, в частности,
человеческого мозга, а также биологические (и социальные для социально-бионического подхода) механизмы жизни различных живых организмов (их взаимодействующих коллективов), в частности, для создания искусственного индивидуального или «коллективного» разума.
Второй – изобретательско-прагматический – подход связан с
изобретением новых, не обязательно подражающих природным2 спо1
Бионика – научное направление, относимое к кибернетике и прикладной
информатике, изучающее принципы построения и функционирования живых
природных организмов и систем с целью использования полученных знаний
(«идей» природы, открытых «механизмов», закономерностей и обнаруженных
свойств) для решения инженерных задач и построения искусственных технических устройств и систем, приближающихся по своим характеристикам к
естественным, как правило выбранным из лучших организмов и систем.
2
Например, изобретенные для полета самолетов и вертолетов принципы и
конструкции, не идентичны их аналогам, которыми обладают птицы, хотя
частично «подсказанны» природой.
306
собов и искусственных процессов и средств, позволяющих (например,
на базе ЭВМ) воспроизводить не саму мыслительную деятельность, а
аналоги ее результатов, имеющие практическую ценность.
В дальнейшем речь будет идти как о методах и средствах, созданных в рамках второго подхода, так и о методах, реализующих бионический или социально-бионический подход, а также смешанных, когда
за основу взят бионический (или социально-бионический) подход, а
при его реализации используется изобретательско-прагматический вариант.
Оба подхода реализуются согласно трем точкам зрения на ИИ и их
переплетениям. Первая связана с рассмотрением ИИ как области фундаментальных исследований, ориентированной на создание (изобретение) новых методов и средств решения трудно формализуемых, не
поддающихся автоматизации задач, ранее относимых к таким, решение
которых доступно только человеку, живому существу, обладающему
соответствующим интеллектом. Вторая точка зрения на ИИ – рассмотрение его как теоретической основы разработки новых архитектур, аппаратных, математических, программных и других подсистем ЭВМ и
информационных систем (ИС), связанных с приближением возможностей ЭВМ и ИС к человеческим при решении интеллектуальных задач.
Третья же точка зрения – рассмотрение ИИ как экспериментальной
научной дисциплины, позволяющей познать, как устроен мозг человека, что такое ум, разум и другие элементы организма человека, обеспечивающие ему разные интеллектуальные способности, принципы и
механизмы индивидуального и коллективного поведения других живых организмов, характерные для «интеллектуальных» особей и их
сообществ, с целью применения полученных знаний для создания новых прикладных информационных систем, способных решать такие
задачи, которые непосильны существующим искусственным системам,
построенным по ранее разработанным принципам построения.
Приведем другие использованные ранее и используемые далее понятия в контекстной связанности их с излагаемым материалом.
Головной мозг – центральный орган управления, пластичный, способный перестраиваться, изменяться при повреждениях и обучении,
реорганизовывать поврежденную кору (серое вещество). Важнейшая
функция мозга – прогностическая, благодаря чему мозг способен к
упреждающему управлению на базе созданных им моделей. Одна из
гипотез пластичности мозга – наличие единого «алгоритма», однород307
ных правил работы с любой информацией как внутренней, в том числе
извлекаемой из памяти, так и внешней, поступающей от разных источников, органов чувств. Именно эта однородность правил и структурная
однородность строения придают невероятную гибкость коре головного
мозга, способность мозга работать даже при очень сильных повреждениях. Отличительная особенность головного мозга человека, а именно
его коры, – в формировании поведения человека, его способности к
творчеству и тем действиям, которые не свойственны другим высокоразвитым живым организмам, возобновляющим «старый» застывший
мозг (даже для дельфинов).
Разум – способность понимать, рассуждать, прогнозировать и принимать решение. В то время как Джордж Ф. Люггер определяет искусственный интеллект как область компьютерной науки, занимающуюся
автоматизацией разумного поведения [46, с. 27], Джефф Хоккинс считает, что «одна из наиболее вопиющих ошибок – вера в то, что разумное поведение предопределяет разум» [47, с. 13], а главная ошибка в
невозможности создать по настоящему искусственный интеллект (ИИ),
разумные машины в том, что разработчики ИИ, старающиеся реализовать человеческий разум, пытались воссоздать человеческое поведение
без понимания сущности разума, его роли в запоминающе-прогностических операциях.
Именно прогнозирование, а не поведение является свидетельством
наличия разума. Согласно этому разумная машина, по Д. Хокинсу, не
должна выглядеть, действовать и чувствовать, как человек [47, с. 203].
«Однако машина не сможет обладать разумом, подобным человеческому, если мы не насытим ее эмоциональными системами и человеческим опытом. Маловероятно, что столь сложная задача когда-либо
окажется выполнимой» [47, с. 202]. Заметим, что именно ошибочные
аналогии являются общим для псевдонауки, фанатизма, религиозности, нетерпимости и т. п.
Сознание – это способность человека модельно отображать действительность в виде реальности. Одними из результатов такого отражения, «работы» модели являются мысли, не все из которых зависят от
событий действительности (реального мира), а могут являться «чистыми, умственными» продуктами модельного отображения действительности.
Ум – способность к абстрактному мышлению.
Рассудок – разум сознание ум.
308
В связи с изложенным заметим следующее.
1. Если прав Брюс Крайер (2000 г.), утверждающий: «Очевидно,
что интеллект распределен по всему организму человека, а не локализован в мозге, и что сердце – интеллектуальный орган, оказывающий
сильнейшее воздействие на мозговые процессы», – то из проблемы создания ИИ, равного или превышающего человеческий, вытекает необходимость познания не только того, как функционирует мозг человека,
но и всего человека как системы либо использования изобретательского направления создания ИИ.
2. Исследования нейробиолога Дика Свааба показывают, что самые
серьезные решения принимаются людьми более правильно, когда это
делается интуитивно, нежели после долгого анализа.
3. В 2014 г. 80 ведущих университетов мира объединили усилия,
чтобы в течение ближайших 10 лет создать полную молекулярную модель головного мозга человека, намереваясь целиком воссоздать искусственным путем его структуру (видимо, по модельному описанию,
предложенному в 2012 г. Генри Маркрамом).
Аватар – 1) естественные или искусственные смертные существа с
привнесенной в них душой; 2) искусственная телесная оболочка,
управляемая человеческим мозгом; 3) искусственный «духовный»
двойник человека.
Гуманоид – человекообразное существо, человекоподобный робот.
Киборг – 1) кибернетический организм – живое существо, в котором часть органов, тканей или костей заменены на механические аналоги (Майнфрейд Клайнс, 1960 г.); 2) синтетический1 биологический
гуманоид – человекоподобное существо – робот; 3) искусственный гуманоид, изготовленный из небиологических материалов.
Робот2 – автомат, машина, устройство с человекоподобными действиями, частично или полностью заменяющий человека при выполнении определенных работ.
Андроид – 1) искусственное подобие человека в средние века;
2) автомат, воспроизводящий реакции человеческого организма.
Анимат – искусственные животные – автоматы, подобные
животным.
1
Синтетический – это созданный человеком на базе биологического материала.
2
От чешского робота – тяжелая работа, ввел Иозеф Чапек, 1917 г. (см. [1]).
309
4.6.2. Структура искусственного интеллекта
как раздела информатики
В § 1.5 (см. часть 1 настоящего поосбия) перечислены элементы
теоретических основ искусственного интеллекта (ИИ). Понятно, что
это сделано условно, в первом приближении, в начале книги с целью
простого перечисления наиболее часто относимых к теоретическим
основам разделов формального аппарата. Если же задаться вопросами
структуризации или классификации разделов, то следует выделить
цель и признаки классификации (см. § 1.2) или структуризации (см.
п. 1.2, а также п. 2.3 в [1]). Это лучше сделать в виде отдельной темы
на практических занятиях со студентами или в виде реферативной работы. Например, попробуйте ответить на вопрос: «Удачно ли отнесены
подразделы «компьютерные игры» или «теория обучения» к разделу
«Системология»»? Не лучше ли было отнести «компьютерные игры» к
разделу «Базовые математические дисциплины», а «теорию обучения»
включить в раздел «Теоретические основы искусственного интеллекта»? Попробуйте ответить на эти вопросы и обоснуйте ваш ответ. А к
какому разделу отнести «компьютерную вирусологию» или «искусственные иммунные системы» в части их теоретических основ? Попробуйте ответить на этот вопрос.
Не выделяя отдельно набор признаков классификации или структуризации, дополним и прокомментируем некоторые разделы, приведенные в части 1, § 1.5.
Помимо добавления к ИИ разделов, связанных с имитационным
моделированием систем как составной части теории моделей и моделирующих систем (см. часть 1, п. 3.9 в перечне § 1.5), следует добавить
интеллектуальные методы и средства такого моделирования. Теоретические основы и практические средства теории обучения, классификации и распознавания образов, включенные в раздел 2 перечня § 1.5,
часть 1, «Системология», так же как синергетики, самореферентики и
автопоэтики могут быть включены в теоретические основы ИИ.
В пункт 3.14 «Другие разделы ИИ» иногда включаются такие направления, как интеллектуальные и этические роботы, искусственные (машинные) разум и жизнь; имитация поведения и чувств; интеллектуальные технологии постановки и решения задач и проблем; ситуационное
управление; коллективное поведение автоматов, роботов; создание
информационного общества; имитация или искусственное усиление
310
естественного интеллекта, в частности, поддержки и усиления творческих процессов; интеллектуализация ЭВМ и интеллектуальные интерфейсы; машинное обучение, творчество; понимание искусственными
системами (ЭВМ, роботами, аватарами, гуманоидами и т. п.) естественного языка и общение с ними на естественном языке; разработка
отдельных компонентов сложных систем (интеллектуальных датчиков,
агентов, интеллектуальных подсистем управления, проектирования,
экспериментирования, исследования, комплексных испытаний и т. д.);
интеллектуальные средства анимации, визуального моделирования. Не
следует ли добавить в п. 3.6 перечня § 1.5 (часть 1) помимо искусственных (интеллектуальных) средств и методов синтеза еще «средств
и методов анализа, исследования»?
Внимание! В свете изложенного, подумайте, не следует ли переформулировать пункты раздела 3 перечня § 1.5 (часть 1)?
Прокомментируем подобные изменения в структуре ИИ на примере еще одного дополнения – когнитивная графика. Согласно [17] изначально под когнитивной графикой (не путать с машинной, компьютерной!) понималась совокупность приемов и методов образного
представления математической задачи, которое позволяет либо сразу
увидеть ее решение, либо получить подсказку для его нахождения. В
отличие от алгебраических или логико-аналитических методов решения математических задач графические позволяют получить ответ,
взглянув на графическое изображение постановки задачи с учетом
условий, ограничений. Как указывается в [17], «один из пионеров этого направления – математик А.А. Зенкин, используя методы когнитивной графики, сумел доказать ряд труднейших теорем теории чисел,
десятилетиями не поддававшихся решению».
Рассмотренный аспект когнитивной графики, положенный в основу
ее определения (куализной модели), можно дополнить, опираясь на
материал § 1.5. Например, расширить понимание термина «когнитивная графика» следующим образом.
Когнитивная графика – это совокупность методов и средств визуального (зрительного, образного) представления задачи или проблемы,
Данных и/или результатов их исследования, обработки, анализа, а
также сопутствующих условиий, позволяющих либо сразу увидеть искомое решение, либо получить подсказку для его нахождения или интерпретации, либо получить неожиданные результаты, используя разнообразные возможности человека или коллектива лиц по системному
311
восприятию многомерных визуальных носителей информации, порождающему эмерджентность при решении сложных задач, а также путем
явного многоуровнего отражения в образе накопленных знаний, доступных для восприятия неспециалистом в области обработки и анализа Данных.
Из определения следует, что когнитивная графика ориентирована
на визуальное отображение Данных, моделей и результата исследования таким образом, чтобы максимально активизировать образноинтуитивные и другие познавательные механизмы восприятия информации и мышления человека. Речь идет, в частности, о замене или дополнении рассмотренных в разд. 1.5.2 зрительных моделей, представленных в виде компьютерных графиков, диаграмм, картограмм,
кардиограмм, графов, сетей, когнитогафиками, когнитограммами, когнитографами и подобными им образами. Эти зрительные когнитообразы должны быть специально организованы под максимальную активизацию человеческих возможностей к познанию, творчеству,
абстрагированию, обобщению, специализации, детализации, озарению,
к способности человека думать, объяснять, обосновывать, искать и
находить новое, неожиданное, предлагать действия, идеи, гипотезы,
т. е. использовать, активно демонстрировать свой разум.
Примеры такого типа когнитивных графиков представлены на
рис. 1.13 и 1.14. Вариантом превращения графика в когнитивный является изображение на нем накопленных знаний. Например, дополнение
графиков рис. 1.14 легко воспринимаемым представлением знаний о
возможных причинах патологических отклонений показателей от нормы, последствиях таких отклонений и степени срочности обращения к
специальной врачебной помощи.
Второй пример – сопроводить цветом, колером, штриховкой или
другими графическими знаками и экспликациями, отражающими итоги диагноза, традиционный черно-белый рентгеновский снимок или
кардиограмму так, чтобы они напрямую (без специальной расшифровки узким специалистом или после него) были доступны непосредственному восприятию лечащим врачом (или больным, если это допустимо). При этом на когнитографиках также можно закодировать,
указать вид, степень патологий, их причины и последствия.
312
§ 4.7. МЯГКИЕ МЕТОДЫ И АЛГОРИТМЫ.
МЕТОДЫ НАХОЖДЕНИЯ РЕШЕНИЙ ДЛЯ ОБРАБОТКИ
ДАННЫХ, ОТНОСИМЫЕ К ИНДУКТИВНЫМ, К МЕТОДАМ
ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
4.7.1. Вводные замечания
Как уже было отмечено в § 4.1, индуктивный подход к решению
задач – это такой, при котором субъектом выводится, формируется
общая гипотеза из частных фактов: когда субъект является прежде всего заказчиком, пользователем, в меньшей степени участником исходных модельных построений; модели строятся апостериори по имеющимся данным, порою их перебором в силу отсутствия достаточных
априорных предпочтений; от Данных наблюдений и экспериментов, от
частных фактов и явлений субъект переходит к установлению общих
правил, законов, закономерностей, обнаружению общих паттернов; по
частным свойствам, характеристикам выстраивается общая картина знаний об объекте. Поэтому индуктивные методы плотно связаны с ИИ.
К методам искусственного интеллекта1 обычно относят такие, в которых либо расширяется понятие алгоритма, реализующего метод, либо метод реализуется в виде совокупности обобщенных правил, допускающих возможность появления множества результатов, не все из
которых априори предсказуемы и однозначно повторяемы; либо методы относятся к категории адаптивных, самоприспосабливающихся
(самоперестраиваемых, самообучаемых, самоорганизуемых), способных к целеполаганию, а реализующие их алгоритмы образуют иерархическую систему взаимоподчиненных алгоритмов разного уровня,
когда алгоритмы определенного уровня не детерминируют те или иные
действия, операции, а обеспечивают такие правила обработки Данных,
информации, на основании которой в новых условиях удается получить искомый результат, обеспечить необходимое целесообразное
поведение. Алгоритмы более высокого уровня могут обеспечивать выработку правил, алгоритмов адаптации, самообучения всей иерархической системы алгоритмов, т. е. обладающих некоторыми свойствами,
1
Ко всем ли из них применим термин «интеллектуальный метод»? Или
такой термин лучше не использовать, учитывая, в частности, отличие между
словами «интеллект», «искусственный интеллект», «intellect», «artifical intellect» и «artifical intelligence»?
313
характерными для человеческого, прежде всего умственного (академического), интеллекта.
Рассмотрим идейные основы, принципы построения наиболее часто используемых методов такого типа.
4.7.2. Нейросетевые методы
Эта группа методов, бионический (со слабой архитектурной аналогией) принцип работы которых изложен в § 3.2 и 3.3, реализуется в
виде параллельных распределенных адаптивных аппаратных или программных искусственных нейронных сетей (ИНС)1, развивающихся и
адаптирующихся в процессе обучения на конкретных примерах. Различают две технологии обучения ИНС: обучение с учителем и без учителя. В первом случае обучение происходит на множестве примеров,
для каждого из которых отклик или поведение ИНС заранее известны.
В обучении без учителя (самообучение, самоорганизация или самоперестройка) процесс обучения происходит автономно, без вмешательства извне, когда по мере поступления новых данных на входы ИНС
самостоятельно находит некоторые характеризующие их, присущие
поступившим данным свойства, закономерности, и сеть обучается выдавать (отражать) найденное на выходе. Само обучение представляет
собой автоматический поиск закономерности2 между совокупностью
обучающих данных и заранее известным результатом. Для конкретной
ИНС оно сводится к изменению весовых коэффициентов нейронных
элементов сети (см. рис. 3.2) всех ее уровней и подбору такого их
набора во всех элементах, которые обеспечивают требуемое качество
решения задачи. Существует множество методов обучения и самообучения ИНС, часть из которых, сводимая к задачам оптимизации, будет
рассмотрена далее (генетические, виртуальных частиц, имитации
1
Важно отметить, что в среднем мозг человека состоит из 8,6 1010
нейронов, из которых кора головного мозга (серое вещество) содержит
(1,9–2,3) 1010 нейронов, ассоциативная область мозга 3 105 нейронов у
женщин и 109 у мужчин, при этом у женщин мозг в среднем содержит в 6 раз
меньше серого вещества, ответственного за обработку информации, чем у
мужчин, но в 10 раз больше белого, ответственного за распределение задач
между отделами мозга. У мыши же мозг содержит 7 107 нейронов, из которых 4 106 нейронов в коре головного мозга.
2
Заметим, именно закономерности, а не закона (см. отличия между ними,
отраженные в § 2.3.2 и на рис. 3.3).
314
отжига и др.). Дело в том, что от того, насколько качественно обучена
сеть, зависит ее способность решать поставленные перед ней задачи в
дальнейшем, после этапа обучения.
Представим условно ИНС в виде системы, формирующей выходной сигнал Y, cоответствующий входному сигналу Х, путем реализации некоторой априори не заданной функции Y g ( X ) из некоторого
множества G. Предположим, что решение задачи описывается функцией Y f ( X ) и представлено (задано) парами ( x1 , y1 ), ( x2 , y2 ),...,
( xn , yn ) , где yk f ( xk ) , k 1, n . Тогда степень близости решения
ИНС к истинному можно оценить через функционал качества Е как
некоторую функцию ошибки, показывающую для каждой функции g
степень ее близости к f. Обучение состоит в поиске (выборе или синтезе) функции g, т. е. весовых коэффициентов , соответствующих ей,
оптимальной по Е. Обычно обучение требует длительных вычислений,
настроек, итерационных процедур, когда число итераций может лежать в пределах от 103 до 108. В обучении могут использоваться
разные методы локальной и глобальной оптимизации из классов детерминированных, стохастических или нечетких, точечных или интервальных.
Методы обучения определенным образом зависят от типа ИНС: являются ли они однослойными (см. рис. 3.2, б, схема 1) или многослойными (рис. 3.2, б, схема 2); полносвязными (схема 1) или слабо (локально) связными (рис. 3.2, б, схемы 3, 4); без обратных связей или с
обратными связями и т. д..
В однослойных сетях изначально алгоритмы обучения основывались на принципе распространения ошибок от входа к выходу, например, с использованиием процедуры сходимости как в перцентроне [49,
50]. Однако многослойные (три- и более слоев ИНС уже практически
невозможно обучить, руководствуясь только значениями ошибок на
выходах сети. Наибольшее применение для таких ИНС получил метод
обратного распространения ошибок, основанный на распространении
сигналов ошибки от выходов ИНС к ее входам, т. е. в направлении,
обратном прямому распространению сигналов в работе ИНС после
настройки.
Кроме рассмотренных ИНС известно много нейронных сетей, реализующих свойства биологических организмов, основанных на ассоциативной памяти.
315
4.7.3. Генетические методы и алгоритмы
Эта группа методов (Джон Холланд /John Holland/, 1975 г.) в своей
идейной основе относится к эволюционным1 бионическим, стохастическим, самообучающимся, поисковым, пригодным для приближенного решения разных задач, в том числе NP-сложных, подражающих
генетическим, селекционным механизмам. Алгоритмы методов (генетические алгоритмы (ГА)) основаны на таких эволюционных понятиях,
используемых в моделях размножения живых организмов, как наследственность, изменчивость и отбор.
В биологии наследственность – это способность живых организмов – живых существ передавать свои основные признаки, качества и
особенности развития потомству. Наследственность – один из трех
(наследственность, наследственная изменчивость и естественный отбор) важнейших факторов эволюции живых организмов. Материалом,
обеспечивающим наследственность организма, является ДНК, отвечающая за конкретный генотип организма, генофонд популяции, вида в
целом.
Основная часть признаков наследуется через ядра клетки, ее ядрышки – хромосомы. Однако некоторые признаки могут наследоваться
цитоплазматическим путем, т. е. через автономные кольцеобразные
ДНК клеточной структуры (митохондрии, пластиды), а также через
уникальную для каждого организма межклеточную жидкость сравнительно автономно от клетки. В растениях такие признаки передаются
дочерним поколениям, причем только по материнской линии или вегетативно. При этом в процессе эволюции наследуются не конкретные
признаки, а в целом генотипы, являющиеся носителями этих и других
признаков. Наследственность позволяет всем живым существам сохранять в своих потомках характерные черты вида.
Изменчивость – способность организмов приобретать наследственным путем или под влиянием внешней среды признаки, отсут1
Для эволюции живых существ, скорости течения, начала и скорости ее
изменений характерно использование преходящих, мимолетных условий. Заметим, что важнейшим эволюционным критерием «хорошести» анатомической конструкции особей популяции является минимизация расхода энергии.
Недаром одна из гипотез вытеснения кроманьонцами более физически мощных, так же как и они разговорчивых, неандертальцев, является энергетическая гипотеза.
316
ствующие у предшествующих родительских форм. Биологическая изменчивость1 может быть двух типов: генотипической (наследственной)
1
В связи с новой для информатиков или забытой ими биологической терминологией, напомним не упоминавшиеся ранее понятия из биологии (см.
также разделы 4.5.3–4.5.5).
Ген – единица передачи наследственной информации – участок ДНК,
влияющий на определенную характеристику организма (В.Л. Иогансен, Дания, 1909 г.). Иными словами, ген – это часть молекулы ДНК (дезоксирибонуклеиновой кислоты), последовательная цепочка нуклеотидов в которой определяет последовательность аминокислот в конкретном белке. Заметим, что
ранее принятое в качестве абсолютной истины положение «один ген – один
белок» не является верным. На процесс формирования белка влияют и другие
факторы, включая, как предполагается, и информационные. Количество генов
у различных видов биоорганизмов разное. Например, у человека их 26 тысяч,
у вируса гриппа – 8, у осьминога – 33 тысячи. Количество звеньев цепочки
(участка ДНК) природных биологических генов обычно лежит в пределах от
265 до 350, минимальное количество звеньев – 256.
Геном – 1) совокупность наследственного материала – специфически организованных последовательностей аминокислот, нуклеиновой кислоты, заключенного в клетке организма. У человека это 3 млрд пар нуклеотидов ДНК,
находящихся в 23 парах хромосом. У комара – 3 пары хромосом. Другими
словами, геном – это 2) совокупность всех генов подобных организмов
(Г. Винклер, 1920 г.), совокупность генов, заключенных в наборе хромосом
организмов одного биологического вида. По Г. Винклеру, в отличие от генотипа, геном представляет собой характеристику популяции как элементарной
единицы эволюции, или вида, а не особи.
Генофонд популяции (вида) – совокупность всех генотипов, присутствующих в популяции или в группе популяций, составляющих вид (А.С. Серебровский, 1928 г.), т. е. совокупность генов всех особей, входящих в состав
популяции (вида).
Популяция – совокупность индивидуумов одного вида, связанных общим
происхождением, способностью к скрещиваниям и общностью территории.
Хромосома – ядрышко ядра клетки, содержащее «делегированный» ей
ДНК набор генов и представляющее собой особую, видимую в клетке во время деления, структуру, образованную ДНК в ассоциации с белками. Топологически модельно укладка ДНК в хромосоме имеет вид складчатой (crumped)
фрактальной глобулы – иерархической системы складок – компонентной
структуры без углов, плотно заполняющей все пространство. Хромосомы отличаются у разных организмов как по размерам и форме, так и по численному
составу. Поскольку у большинства биоорганизмов количество генов во много
раз превышает число хромосом, в одной хромосоме располагается одновре-
317
и модификационной (возникающей только под влиянием внешней среды). Заметим, что модификационная (иначе фенотипическая) биологическая изменчивость не затрагивает наследственный аппарат. Она является следствием реакции генотипа1 на действие окружающей среды,
а проявляется в пределах нормы реакции всего спектра фенотипических признаков, которые возможны у данного генотипа или генофонда,
не передается по наследству и поэтому не влияет на ход и темпы эволюционных процессов.
В генетических алгоритмах рассматривается именно наследственная (генотипическая) изменчивость. Она обеспечивает генетическое
разнообразие популяции вида и имеет недетерминированный (чаще
всего он считается случайным, стохастическим, хотя источник мутации часто спонтанный, не массовый, см. часть 1, рис. 3.3) характер и
позволяет появляться особям с новыми признаками, способными выжить и оставить потомство в новых, изменившихся, условиях среды
обитания. Наследственные изменения возникают из-за мутаций (такая
изменчивость называется мутационной) или скрещивания.
Мутация – внезапно возникшее естественно или вызванное искусственно изменение наследственных свойств организма. Мутации бывают геномные, хромосомные, генные (точечные), трансформационные и трансдукционные, а также комбинативные. Геномные мутации
затрагивают сразу весь геном организма. Они связаны с изменением
числа хромосом, при котором структура гомологичных (развивающихся из общих зачатков) хромосом не меняется. Хромосомные мутации
вызывают перестройку разными способами самих хромосом, не изменяя при этом их количества. Наиболее часто встречаемые в природе
генные мутации вызывают изменение последовательности нуклеотидов в ДНК, т. е. структуры конкретного гена. При этом генотип и
структура хромосом не нарушаются. Поэтому-то они и называются
генными, точечными.
менно несколько генов. Гены, входящие в состав одной хромосомы, называются сцепленными. Они образуют группу сцепления и наследуются как единое целое. Взаимный обмен участками парных (гомологичных) хромосом,
определяющий их перераспределение и образование новых комбинаций (рекомбинацию) расположенных в них генов, называется кроссинговером (от
англ. crossingover – перекрест) или, сокращенно, кроссовером.
1
Для любопытных отметим, что «перекраивание» генетической информации у позвоночных осуществляется на уровне ДНК, а у насекомых – на
уровне РНК.
318
Трансформационные и трансдукционные мутации имеют место у
прокариот (бактерии, грибы) и низших, эукариот (простейших, одноклеточных)1.
Трансформация связана с переносом генетического материала от
одной клетки к другой клетке или с его поступлением из внешней среды в виде участков ДНК. Трансдукция – изменение генетического материала с помощью умеренных (не разрушающих клетку) вирусов, генетический материал которых встраивается в геном хозяина.
Комбинативная изменчивость связана с половым размножением.
Она является частью генотипической изменчивости, поскольку ее результатом является также частичная перестройка хромосом.
Рассмотренные наследственные изменения характеризуют первый
естетственный путь их происхождения, когда они происходят естественным путем (спонтанно) или индуцированы при искусственном
внешнем вмешательстве в клетку методами генной инженерии и эволюционно реализуются путем естественного отбора. Напомним, естественным отбором называется процесс, в ходе и результате которого
преимущественно выживают только особи, имеющие полезные для
текущих условий, адаптированные к ним наследственные признаки.
Второй путь – искусственных мутаций и отбора. Он реализуется
без серьезного вмешательства во внутрь клетки, хромосом, генов.
Наиболее часто используются два варианта осуществления такого пути: скрещивание и селекция.
Скрещивание – это метод получения нового вида растений или породы животных путем опыления растений или спаривания животных
одного или разных видов, сортов, пород. Организмы, получаемые в
итоге скрещивания генетически различающихся родительских форм,
называют гибридами, а скрещивание разнородных в наследственном
отношении организмов – гибридизацией (см. разд. 1.2.1).
Селекция (от лат. selectio – выбор, отбор) – метод создания и совершенствования пород животных, сортов растений и штаммов микроорганизмов, использующий массовый и индивидуальный виды целевого искусственного отбора особей по нескольким, наиболее важным для
данной цели, признакам и условиям среды с последующим одновременным естественным отбором. Основой наследственной изменчивости при этом являются мутация, гибридизация и полиплоитизация –
увеличение числа наборов хромосом в ядрах клетки.
1
Заметим, что помимо клеточной существует еще и внеклеточная форма
жизни – вирусы.
319
После изложенных пояснений перейдем к сути генетических алгоритмов (ГА, genetic algorithms, GA) на уровне его первичных основ
(Дж. Холланд, 1975 г. и Дэвид Голдберг /David E. Goldberg/, 1989 г.) в
общем виде и на примере нахождения глобального экстремума (максимума или минимума) функции п переменных, n 1, 2,3,... .
Любая задача, решаемая с помощью ГА, формализуется так, чтобы
ее решение могло быть представлено в виде вектора генов – хромосомы.
В качестве гена – элемента (позиции) вектора (хромосомы) – может
выступать бит, число, другой символ, разряд (позиция) цепочки (двоичной комбинации), соответствующие хромосоме – двоичному представлению значения. Гены располагаются в различных позициях хромосомы, называемых локусами, и принимают значения (числовые или
функциональные), называемые аллелями. Например, ген – двоичный
разряд (бит) двоичного представления переменной х (хромосомы) или
одной из переменных x1 , x2 ,..., xn (набора хромосом) п-мерной переменной x ( x1 , x2 ,..., xn ) функции f (x ) либо аргумент глобального
экстремума функции f (x ) , значение которого мы отыскиваем. Тогда
локус – позиция гена в строке кодового представления х, а аллель – его
значение (0 или 1). В этой позиции длина хромосомы, т. е. размерность
вектора или число генов в хромосоме, может варьироваться. В классических алгоритмах предполагается, что в процессе применения ГА
длина хромосомы фиксирована.
Каждый вариант решения задачи – это набор хромосом, который
называется особью (либо индивидуумом, или его генетическим кодом),
либо генотипом. В простейшем варианте каждая особь может состоять
из одной хромосомы. Иначе, генотип (genotype) – это совокупность
генов конкретной особи. На основе генотипа формируется фенотип
(phenotype) – совокупность характеристик, присущих этой особи на
определенной стадии ее развития.
Совокупность генотипов, индивидуумов, особей одной эпохи развития объединяются в популяцию. Она условно разделяется на две равные колонии – родительскую и потомков. В ГА принято, что новые потомки полностью замещают только особей в колонии потомков.
Родительская колония при этом остается неприкосновенной. Чтобы
избежать «эффекта бутылочного горла» – сокращения генофонда популяции в результате критического уменьшения численности (в нашем
примере приводящего к «застреванию» в одном из локальных экстремумов f (x ) ), в ГА практикуется, во-первых, уничтожение дубликатов
320
особей и, во-вторых, запрет на скрещивание особей самих с собой. Если при этом колония родителей окажется неполной, то новые потомки
заполняют свободные места в колонии родителей, а оставшиеся помещаются в колонию потомков. Тем самым размер популяции может меняться от эпохи к эпохе, аналогично тому, как это происходит в живой
природе.
С целью определения пригодности генотипа (варианта решения)
как итогового (или промежуточного для дальнейшего сравнения его с
другими) вводится «функция приспособленности» (ФП, fitness
function, FF). Конкретное значение ФП (ЗФП или VFF) для рассматриваемого варианта (особи) определяет, насколько этот генотип хорошо
решает поставленную задачу [49–51]. Обычно в качестве ФП выбирают такую функцию, для которой, с одной стороны, рельеф является как
можно более «гладким», чтобы разрывы, существующие на поверхности ее значений, незначительно влияли на полную эффективность решения стоящей задачи, с другой – он был разнообразным, т. е. не имел
больших плоских участков (иначе ГА будет не эффективен – не сможет выбирать лучшие решения).
В нашем примере, если отыскивается минимум многоэкстремальной функции f (x ) , в качестве ФП может быть использована сама
функция f (x ) , минимальное из минимальных значений которой будет
соответствовать искомому решению – глобальному минимуму f (x ) .
Тогда та особь (вариант решения) x (набор хромосом x1 , x2 ,..., xn )
будет хорошей, для которой значение f (x ) будет наименьшим, т. е.
значение ФП будет наилучшим. Вместо решения f (x ) можно выбрать
также среднее значение приспособленностей по популяции, т. е. среднее из f (x1 ), f (x2 ), ..., f (x N ) , где x1 ,..., x N – особи популяции.
Блок-схема ГА представлена на рис. 4.7.
Далее рассмотрим схему алгоритма подробнее.
Заранее исходя из опыта решения схожих задач подбирается представление вариантов решения задачи, задается адекватная задаче ФП,
размер и структура хромосом и популяции, затем выполняются следующие шаги (этапы).
1. Случайным образом генерируется исходная популяция (протопопуляция), т. е. гены хромосом каждой из N особей популяции.
2. Определяются ЗФП для каждой особи популяции.
3. Выполняется цикл следующих операций.
321
0. Постановка задачи, выбор вариантов решения, задание ФП, атрибутов алгоритма и их параметров1
1. Очищение от прошлых данных и инициация – генерация исходной популяции
2. Определение ЗФП для каждой особи популяции
3. Выполнение цикла операций
3.1. Селекция, отбор родителей и эталонных особей
3.2. Репродуцирование особей, формирование нового поколения
3.3. Генерационное формирование новой популяции и подготовка ее к следующей эпохе
Нет
3.4. Проверка критерия останова цикла
Да
Завершение работы алгоритма и оформление результата решения (работы
алгоритма)
4.
Рис. 4.7. Укрупненная схема генетических алгоритмов1
3.1. Подготовка популяции к размножению: удаление дубликатов;
селекция особей – выбор из текущей популяции и сохранение родительских особей (с лучшими ЗФП) из половины популяции, выделение
и сохранение эталонной особи (с лучшим ЗФП).
3.2. Осуществление процесса репродуцирования – размножения популяции, т. е. рождения новых особей, и формирование нового поколения. Главное требование к размножению – потомки должны унаследовать черты родителей, смешав их каким-либо образом. Репродукция –
это процесс копирования хромосом по принципу «выживает сильнейший», т. е. с учетом ЗФП, когда при копировании хромосомы с лучшими ЗФП имеют большую вероятность попадания в следующую популяцию. При этом используется правило Холланда: хромосомы с
1
В других алгоритмах, описываемых далее, этот элемент (эти операции)
алгоритма опускается, т. е. включается по умолчанию самим читателем в
нужной редакции.
322
ЗФП выше среднего живут и копируются, а с ЗФП ниже среднего –
умирают.
Вначале выполнения операции селекции отбираются брачные пары
родителей (или их тройка, четверка подобно суррогатным матерям),
допущенных к скрещиванию для получения нового потомка.
Затем выполняются три генетические операции: кроссовера (кроссоверинга, скрещивания), мутации и инверсии, порядок которых неважен. Наиболее значительной из них является кроссовер, поскольку
именно оператор кроссовер генерирует (рождает) новую хромосому
потомка, объединяя генетический материал родителей. Рассмотрим
простейший вариант кроссовера для нашего примера, когда хромосомами родителя являются x1 и x2 , а ребенка – y1 . Двоичное (генетическое) представление родителей «перерезается» в случайно выбранной
позиции (точке)1 и новая хромосома y1 потомка получается из начала
одной и конца другой родительской хромосомы
x1 00111001| 001011
00111001110100 = y1.
x2 11011100 | 110100
Перерезание хромосом родителей в кроссовере может выполняться
не в одной, а в двух (двойной кроссовер) или большем числе точек,
нахождением оптимального по заданному критерию их числа и расположений, скрещивание более чем двух родителей, а также с применением других различных вариантов мутации, рассмотренных ранее. Все
эти операции позволяют генетическому алгоритму на несколько порядков уменьшить скорость определения оптимума целевой функции
при решении оптимизационных задач, не зацикливаться и находить
глобальный экстремум. Мутация – это случайное изменение одной
или нескольких позиций (битов, разрядов) в хромосоме, а инверсия –
изменение порядка следования битов в хромосоме или в ее фрагменте.
Простейший вариант мутации – случайное изменение хромосомы,
например, с помощью разрядной инверсии, т. е. простым изменением
состояния одного из битов на противоположное:
0011001110100 0011100010100.
1
Отмечена вертикальной линией. Если родителей больше двух (3, 4, …),
то генетическое представление ребенка (потомка) той же длины состоит из
частей каждого из 3, 4, … родителей.
323
Второй вариант мутации – инверсия – изменение порядка бит в
хромосоме путем их циклической перестановки случайное число раз,
например, однократно 4 бит:
0011101110100 0100001110111.
Заметим, что для каждого скрещивания и мутации родители каждый раз отбираются вновь.
3.3. Осуществляется подготовка популяции к следующей эпохе.
Эта алгоритмическая операция связана с выявление лучшего (по ЗФП)
потомка путем сравнения его с эталонным, имеющим наибольшее
ЗФП. Если хромосомы лучшего потомка лучше эталонной, происходит
замена эталонной хромосомы, т. е. замена эталонной особи на новую,
имеющую лучшее ЗФП.
3.4. Если выполняются условия остановки, то конец цикла, иначе –
в начало цикла к п. 3.1. Он может выполняться частично, если многие
действия выполнены в п. 3.3.
В качестве критерия остановки цикла (алгоритма) выбирают:
нахождение глобального либо субоптимального (см. часть 1,
разд. 4.5.5) решения;
исчерпание заданного заранее числа поколений (эпох), отпущенных на эволюцию;
исчерпание времени, отпущенного на эволюцию.
4. Выбор после завершения цикла лучшей или заданного числа
лучших особей (решений) как результата работы алгоритма.
Таким образом, формально ГА можно представить в виде
GA N ; S (α), M (β), O, R; F ( γ ); ,
(4.28)
где N – начальный размер популяции; S – оператор скрещивания и значения его параметров , например, вероятность и количество точек
перерезания; M (β) – оператор мутации и его параметры (вероятность
мутации, параметры правил инверсии, …); О – оператор отбора (селекции) особей; R – оператор редукции; F ( γ ) – функция приспособленности – правило (оператор) расчета ЗПФ с векторным параметром
; – критерий останова цикла. Примеры различных операторов скрещивания, мутации, отбора можно найти в [51].
В заключение заметим следующее.
1. ГА стремятся для размножения выбирать особи из всей популяции, а не только из особей, выживших на первом шаге, а также вводить
324
разные варианты скрещивания, мутации, инверсии. Это связано с
главной причиной плохой работы ГА – возможностью появления малого разнообразия особей в конкретной эпохе, что может привести к
вырождению генотипа и попаданию в какой-нибудь локальный экстремум.
2. ГА, как и многие другие из рассматриваемых в данном параграфе, в частности ИНС, нечеткие, роевые, относятся к мягким алгоритмам с явным или неявным параллелизмом. Мягкие (см. разд. 4.3.5) –
это неточные, приближенные алгоритмы, которые не гарантируют
нахождение глобального решения задачи, зачастую не имеющей решения за полиномиальное время, но позволяют найти «приемлемо хорошее» ее решение «сравнительно», «допустимо» быстро. Явный параллелизм проявляется в том, что алгоритм допускает очевидное
одновременное выполнение одних и тех же операций для каждой особи популяции. Заметим, что при сложных расчетах ЗПФ может привести к большим вычислительным затратам. Это, кстати, характерно и
для других популяционных алгоритмов. Неявный параллелизм ГА
означает, что, как показал Дж. Холланд в 1992 г., если ГА явным образом обрабатывает п строк в каждом поколении, то он неявно обрабатывает около п3 коротких схем низкого порядка и с высокой приспособленностью.
3. В процессе поиска решения ГА параллельно использует несколько точек поискового пространства вместо последовательного перехода от точки к точке, как это делается в традиционных детерминированных и стохастических алгоритмах поиска решений. При решении
задач оптимизации это позволяет преодолеть опасность попадания в
локальный экстремум многомодальной целевой функции. Иными словами, ГА, как и другие популяционные алгоритмы (см. далее), относится не к «удочковым», а «бредневым», когда искомый результат получается не путем постепенного улучшения одного решения, а путем
проработки сразу нескольких близких или даже сильно отличных на
определенном этапе альтернативных решений, т. е. когда при решении
многоэкстремальных задач необходимо находить компромисс между
сужением сферы поиска (направления развития популяции) для ускорения нахождения локального экстремума и одновременно стараться
расширять зону поиска, чтобы найти другие экстремумы, в том числе
глобальный.
4. ГА оперирует не с параметрами, а с закодированным множеством параметров.
325
5. Для работы ГА не требуется никакой дополнительной информации, априорных или апостериорных данных, кроме области допустимых
значений параметров алгоритмов и ФП (ЦФ) в произвольной точке.
6. ГА используют совместно элементы детерминированных и стохастических алгоритмов, а именно вероятностные (стохастические)
правила для порождения новых особей и детерминированные правила
перехода от одной особи к другой, от поколения к поколению. Кстати,
их можно заменить рандомизованными, нечеткими, экспертными. Это
может дать дополнительные преимущества ГА по сравнению с алгоритмами, использующими раздельно только детерминированные, стохастические или другие правила.
4.7.4. Роевые методы и алгоритмы
Эту группу методов и алгоритмов (далее роевые алгоритмы, РА,
Swarm Algorithms, SA) часто относят к разделу искусственного интеллекта, названному Херардо Бени и Ван Цзином в 1989 г. роевым интеллектом (Swarm intelligence) и связанному c коллективным поведением децентрализованных самоорганизующихся систем [51].
Идейной основой создания роевого интеллекта и роевых алгоритмов служат модели случайного (коллективного) поведения множества
родственных особей (саранчи, сверчков, волков, птиц, рыб, толпы людей), детерминированные образования сообществ типа колоний (муравьев, термитов) и роев (пчел, ос) и, прежде всего, их стайного (колониевого, роевого) движения. Речь идет о сообществах тех живых
существ, стайное поведение которых заложено на генном уровне в виде простых правил. Эти правила поведения, движения позволяют сообществу таких существ (семейств) формировать нечто подобное суперорганизму с коллективным разумом1, заставляющее принимать
решение «за всех» и всему сообществу как единому организму (муравьям не скучиваться, а разбегаться в разные стороны и собираться на
1
Иногда понятия «коллективный разум», «коллективная самоорганизация» (управление) и «стайный разум», «стайная самоорганизация» (управление) различают. Когда используют слово «коллективный», имеют в виду, что
особи «коллектива» имеют возможность обмениваться друг с другом информацией о его целях, задачах, составе и т. п. Слово «стайное» предполагает, что
ее члены либо не имеют информационной связи между собой, либо она ограничена, локальна, не имеют сведений о составе коллектива, его ближайших
задачах и т. д.
326
коротких путях от муравейника к пище в условиях нехватки традиционной пищи, адаптироваться к изменению условий, находя новый
кратчайший путь; саранче сбиваться в тучи для перелета, а сверчкам –
в полосы при нехватке пищи, чтобы удобнее поедать себе подобных, и
т. д.), быстро ориентируясь и адаптируясь к изменению условий окружающей среды и текущей обстановки. Одним из механизмов такого
поведения в критических ситуациях является подражание (следуй как
большинство и за ним), а движущей силой – действия лидеров (делай
как они).
Для формирования у читателя системного мыщления и побуждения
его к творчеству, к разумному конструированию новых алгоритмов
хорошо бы изложить (хотя бы как для ГА) некоторые элементарные
основы эволюционных причин рождения, поддержания и развития подобных природных и социальных «семейных» секретов, их механизмов. Однако ограниченные рамки пособия не позволяют этого сделать.
Рекомендуем проделать это каждому, желающему специализироваться
в области разработки новых, совершенствования и применения существующих алгоритмов рассматриваемого класса (ГА, РА, агентных,
иммунных (см. далее) и им подобных. Здесь мы кратко укажем на некоторые аспекты и ограничимся лишь кратким описанием существующих алгоритмов. Попытаемся восполнить этот пробел вопросами для
самоподготовки и для саморазвития в конце настоящей главы. То же
самое проделаем для других описываемых далее алгоритмов.
Группа РА объединяет алгоритмы, находящиеся на стыке и совмещающие принципы эволюционных бионических, социальных и многоагентных систем и процессов. Это связано с тем, что в РА учитываются, во-первых, особенности отдельных особей, их способности
«планировать» и отрабатывать собственные траектории своего движения к цели в условиях изменяющейся среды, адаптируясь к ней, коллективного поведения особей в колониях муравьев, роях пчел, стаях
птиц, рыб, волков и других подобных сообществ (семейств) особей,
образующих обособленную, держащуюся вместе группу. В-третьих,
системы, исследуемые и разрабатываемые в рамках роевого интеллекта, рассматривают как состоящие из множества сравнительно
простых агентов, локально взаимодействующих между собой и с
окружающей средой. Подобные системы являются подклассом многоагентных (мультиагентных) систем, включая системы с интеллектуальными агентами, рассматриваемых в соответствующем разделе
ИИ (см. далее).
327
Как уже отмечалось, обобщенным термином «роевые алгоритмы»
(РА) объединена группа алгоритмов, в основы работы которых положены принципы функционирования различных социально связанных в
обособленные группы особей (агентов, боидов). Первая особенность
таких сообществ состоит в том, что в них отдельные особи локально
взаимодействуют между собой и с окружающей средой, следуя сравнительно простым правилам. Вторая особенность – они взаимодействуют в условиях отсутствия какой-то централизованной системы
управления их поведением, которая бы определяла каждой особи ее
поведение в конкретных условиях, ситуациях. Третья особенность –
взаимодействие особей (локальное, спонтанное) приводит к самоорганизации сообщества (группы), к возникновению «интеллектуального»
глобального поведения его, неконтролируемого каждой отдельной
особью и напоминающего разумное поведение. Иными словами, общественное поведение агентов (особей) в таких сообществах подчинено
не многоуровневым иерархическим, а одноуровневым гетерархическим1 правилам, которые, в отличие от иерархических, предполагают
не вертикальные связи между агентами (особями, элементами) системы (сообщества), а горизонтальное распределение системных функций
между агентами, при котором сами агенты равноправны между собой.
Основная идея популяционного РА, имитирующего социальное поведение сообщества, сходна с идеей построения рассмотренных эволюционных генетических алгоритмов (ГА). Начальная популяция сообщества (особей потенциальных решений) в РА генерируется
случайно. Затем РА в процессе выполнения операций ищет оптимальное или субоптимальное решение задачи путем перегруппировки и изменения направления (траектории) движения каждой особи (решения)
с учетом успехов своих соседей. Если одна особь (одно решение)
находит хороший перспективный путь достижения цели (решения задачи), то остальные быстро перестраиваются и следуют за ней, даже
если изначально находились далеко. При этом необходимо, чтобы в
сообществе остались «сумасшедшие», «не в ногу идущие», «непослушные» особи, либо предусмотрены случайности в изменении траектории движения. Это необходимо, чтобы пространство поиска решений оставалось всегда настолько большим, что могло бы захватить всю
допустимую, необходимую, но не избыточную, обычно используемую
его область. Это обеспечивает нахождение, во-первых, не только
1
От греч. heteros – другой, иной, различный и arche – власть, начальство.
328
субоптимальных решений, во-вторых, еще более лучших (быстрых,
экономных) возможных вариантов решений.
Разнообразие РА обусловлено разнообразием механизмов, порождающих и поддерживающих такую перестройку популяции, коллективное поведение особей в разных колониевых, роевых, стайных сообществах и отражается в названиях видов алгоритмов. Рассмотрим
некоторые из них.
Муравьиные алгоритмы (иначе алгоритмы оптимизации муравьиной колонии, Ant Colony Optimization, ACO, Марко Дориго /Marco
Dorigo/, Бельгия, 1992 г.) основаны на механизме маркировки муравьями удачных (например, наиболее коротких) дорог их перемещения
феромонами. Каждый муравей ориентируется в локальной обстановке,
но не имеет представления обо всей ситуации в колонии в целом. При
этом, проходя от муравейника до пищи и обратно, оставляет за собой
дорожку пахнущих веществ – феромонов. При этом феромоны испаряются, поэтому уровень запаха со временем уменьшается и пропадает. Другие муравьи устремляются к помеченным запахом дорожкам.
Поскольку каждый из них также оставляет дорожку феромонов, то чем
больше муравьев проходит по определенному, привлекательному для
них пути, тем сильнее он пахнет. Ясно, что чем короче этот путь от
муравейника до источника пищи, тем меньше времени требуется муравьям на него и, как следствие, тем более пахучим, заметным будет этот
путь для других муравьев. Именно эту особенность колонии муравьев
для достижения цели (поиска пищи) и используют муравьиные алгоритмы.
Каждая особь (агент, боид), называемая в муравьиных РА (МРА)
муравьем, хранит в памяти список пополняемых на каждом шаге
пройденных им узлов, которые считаются запретными для дальнейших
движений. Перед новой итерацией алгоритма, т. е. перед началом нового прохождения всего пути, память запретов опустошается. В некоторых модификациях МРА муравей запоминает также лучший его
путь, а также, «обмениваясь» с другими, – самый лучший предшествующий путь. При выборе узла помимо запретов муравей руководствуется
привлекательностью (приспособленностью) ребер, соединяющих узлы,
по которому он может дальше двигаться. «Привлекательность» (приспособленность) ребра зависит от постоянного значения – веса ребра,
учитывающего расстояние между узлами, и переменного уровня интенсивности запаха феромонов на этом участке, который меняется на
каждой итерации.
329
Тогда степень возможности и целесообразности перехода муравья,
находящегося в i-м узле, i D , в доступный для перехода j-й узел,
j D , можно описать, например, вероятностью перехода (функцией
приспособленности – ФП)
Pij ij 1 ij
ij 1 ij ,
iD
где ij – интенсивность феромона на пути от узла i до узла j; ij – вес
ребра, соединяющего узлы i и j; и – регулирующие параметры,
определяющие важность интенсивности запаха феромонов () и веса
ребра () при выборе пути. Чем больше значение Pij (ЗПФ), тем целесообразнее, привлекательнее, предпочтительнее это ребро, т. е. эта
траектория, путь движения муравья. Значение = 0 соответствует
жадному алгоритму1 (greedy algorithm), т. е. такому, в котором принимается локально оптимальное решение на каждом этапе, допуская,
что конечное решение также окажется оптимальным. При = 0 алгоритм может быстро сойтись к некоторому субоптимальному решению.
Поэтому выбор правильного соотношения между и – одна из проблем пользователя алгоритма.
Особенность, связанную с необходимостью пометки ребра, муравей-боид решает, оставляя после успешного прохождения всего маршрута на всех пройденных ребрах след – добавку ij L интенсивности феромона на каждом i,j-м участке, обратно пропорциональную (с
регулируемым коэффициентом пропорциональности ) длине L пройденного пути (маршрута). Специфика, связанная с испаряемостью
1 следов феромона за время прохождения пути, т. е. с необходимостью изменения интенсивности феромона ij на каждом шаге итерации, учитывается, например, умножением ij на (1 ) . Иными словами, по окончании успешного прохождения маршрута все
1
Для жадных алгоритмов характерны две особенности. Первая – для них
применим принцип жадного выбора, согласно которому там, где он применим, последовательность локально оптимальных выборов дает глобально оптимальное решение. Вторая – они обладают свойством оптимальности для
подзадач: оптимальное решение задачи, имеющей это свойство, содержит в
себе оптимальные решения для всех ее подзадач.
330
предшествующие интенсивности ijп пересчитываются в новые ijн согласно правилу
ijн (1 )ijп ij .
Различные модификации МРА связаны в основном с бóльшим использованием истории поиска, более тщательным исследованием областей вокруг уже найденных удачных решений, введением «элитных
муравьев», способных находить еще более короткие пути, обучением
алгоритмов и обновлением весов не только по окончании маршрута, но
и от узла к узлу, бóльшим обменом между муравьями.
Пчелиные алгоритмы (В-алгоритм, Bees Algorithms, Дэвис Карабога /Dervis Karaboga/, 2005 г.) поэтапно имитируют поведение кормовых медоносных пчел. Используются три разновидности боидов,
участвующих поэтапно: рабочие пчелы, пчелы-надзиратели и пчелыразведчики. Пчелы-разведчики осуществляют на первом этапе детерминированный отбор медоносных участков, затем пчелы-рабочие –
вероятностный на отобранных пчелами-разведчиками участках, а пчелы-надзиратели выполняют отказ от истощенных источников питания
в кормовом процессе. Тем самым популяция пчел определяет окрестности решений и каждая пчела использует локальный поиск в окрестности решения. Решения, не полезные больше для поиска, отбрасываются и добавляются новые. Происходит как бы встряска популяции.
При этом все пчелы на каждом шаге выбирают как элитные участки
для исследования, так и участки в окрестности элитных. Это позволяет
разнообразить популяцию решений в последующих итерациях и увеличить вероятность обнаружения решений, близких к оптимальным.
Как и в других РА, алгоритм «параллельно» оперирует с каждой
пчелой (боидом), передвигая ее на небольшую величину и циклично
двигая через весь рой, т. е. перемещая ее через все пространство решений, как если бы она была пчелой в рое, рассчитывая пригодность
решения и корректируя скорость движения пчелы по разным направлениям.
Алгоритмы роя частиц (АРЧ, Particle Swarm Algorithms (PSA)
или Particle Swarm Optimization (PSO), Джеймс Кеннеди (James
Kennedy) и Рассел Эберхарт (Russel Eberhart), 1995 г.) – это алгоритмы
численной оптимизации непрерывных нелинейных функций, для которых не нужно знать точного градиента оптимизации. Они имитируют
многоагентную систему, в которой агенты (боиды) – частицы двигают331
ся к оптимальным решениям, используя обмен информацией с соседями. При этом текущее состояние каждой частицы характеризуется координатами в пространстве решений и вектором скорости перемещений. Частица хранит координаты лучшего из найденных ее решений и
лучшее из найденных всеми частицами решений, т. е. лучший из пройденными ими путь. На начальном этапе оба эти параметра, как и в других РА, задаются случайным образом, а их суть и допустимые интервалы для поиска оптимальных значений задаются на первом шаге
реализации алгоритма, до начала цикла. Идейную основу АРЧ составляют модели поведения толпы, птиц в стае и рыб в косяке.
Помимо рассмотренных, к классу РА относятся также следующие
алгоритмы: «биологические» – косяков рыб, серых волков, летучих
мышей, светляков, сорняков, капель воды, кукушки, обезьян, лягушек,
оптимизации передвижения бактерий, альтруизма особей, а также
«технические» – гравитационного поиска, формирования реки, стохастического диффузного поиска и подобные им. Желающие могут ознакомиться с их особенностями самостоятельно. Некоторые из этих алгоритмов описаны в [51]. Там же рассмотрены различные подобные
алгоритмы многоцелевой оптимизации и параллельные популяционные алгоритмы поисковой оптимизации.
Обобщенная схема РА представлена на рис. 4.8.
Формально обобщенно-роевые алгоритмы можно представить в
виде
SA N ; F (α ), R (β); S ( γ ); C ; ,
(4.29)
где N N1 N 2 N3 – размер популяции и ее составных частей
(например, N1 – число пчел-разведчиков, N 2 – рабочих, N3 – надзирателей); F (α ) – оператор (правило, формула) расчета ЗПФ с задаваемыми параметрами и выбора лучшего решения; R(β) – оператор
расчета очередного шага боида с параметрами ; S ( γ ) – правила селекции (встряски) популяции с параметрами ; С – правило коммуникации между боидами; – критерий останова цикла.
Некоторые операторы (4.29) для конкретных разновидностей РА могут отсутствовать или детализироваться. Например, в п. 3.2 (рис. 4.8)
обновление («встряска») популяции выполняется для повышения
вероятности локализации глобального экстремума многоэкстремальной ЦФ. Обновление осуществляется по своим правилам, например, по
332
1. Очищение памяти боидов от прошлых данных. Инициация – генерация новой
популяции и расположения боидов
2. Вычисление ЗПФ для каждого боида и выбор ими (для них) привлекательной
траектории движения, распределение боидов по ролям
3.
Выполнение цикла операций
3.1. Расчет очередного шага движения для каждого боида (каждым боидом)
и перемещение его по выбранному маршруту на очередной шаг
3.2. Пересчет ЗПФ для новых состояний боидов и пройденных маршрутов.
Осуществление «встряски» популяции (итерационное формирование новой
популяции по своему циклу)
Нет
3.3. Проверка критерия останова цикла
Да
4. Завершение работы, отбор и оформление результата решения (работы
алгоритма)
Рис. 4.8. Обобщенная схема роевых алгоритмов1
типу обновления в ГА, разово или итерационно. В последнем случае
вначале удаляется n1 боидов с худшими ЗПФ, затем вместо них генерируется n1 новых. Завершается цикл итерации по своему критерию
останова, который включается в оператор (правило) S ( γ ) как составная часть векторного параметра .
4.7.5. Нечеткие и экспертные методы и алгоритмы
Идейная сущность этих методов изложена в части 1, разделы 4.4.3
и 4.4.7. Поэтому более детальное рассмотрение и описание реализующих их алгоритмов, в частности, связанных с рассуждениями в условиях неопределенности, опустим.
1
Напомним, что подготовительный этап (см. рис. 4.4) на рис. 4.5 и последующих подобных ему рисунках не указывается.
333
4.7.6. Агентные методы. Многоагентные системы
Прежде всего определим исходные понятия (см. также [26, 52]).
Агент1 (от лат. agens (agentis) – действующий): некоторый автономный объект (человек, предмет, техническое или программное средство), который уполномочен владельцем или пользователем действовать в интересах другой сущности и при этом самостоятельно
выполнять (решать) конкретные делегированные ему функции (задачи), взаимодействуя с другими агентами и процессами.
Согласно [56], агент – «все, что может рассматриваться как воспринимающее свою среду с помощью датчиков и воздействующее на
эту среду с помощью исполнительных механизмов». Например, датчики – это глаза, уши, органы чувств для человека, видеокамеры и инфракрасные дальномеры для роботов. Исполнительные механизмы –
это руки, ноги, рот для человека и различные двигатели для роботов.
Для программных агентов входными являются содержимое файлов и
сетевых пакетов, инициируемые нажатием клавиш, а аналогом выходных действий исполнительных механизмов являются вывод данных на
экран, запись файлов и передача сетевых пакетов.
Общим для всех агентов является допущение, что они могут воспринимать свои собственные действия, а некоторые также и результаты действий.
Интеллектуальный агент (ИА) – это агент, внешне проявляющий свойства, качества, черты разума, соответствующие «интеллекту»
при рациональном решении поставленных перед ним задач хотя бы на
примитивном уровне инстинктивных действий и поведений простейших живых организмов. В определениях, принятых в искусственном
интеллекте, часто добавляют: на базе получаемой, в том числе через
систему сенсоров, информации о состоянии процессов и влиянии на
них (агентов) окружения. В конкретных системах и приложениях это
понятие можно трактовать менее общо – без явной увязки его с биологическим «интеллектом», «разумом». Так, в программировании интеллектуальный агент – это программа, самостоятельно выполняющая в
течение длительных промежутков времени задание, указанное пользователем компьютера. В распределенной обработке данных ИА – это
1
Отмечая многообразие определений термина «агент», в [26] понятие
агента рекомендуется трактовать как мегаимя или класс, который включает
множество подклассов.
334
вспомогательная программа, помогающая пользователю в организации
распределенной обработки данных (см. далее виды ИА).
Вместо того чтобы вдаваться в рассмотрение и обсуждение разных
определений (дефиниций) термина «интеллектуальный агент», используемых в ИИ, приведем наиболее часто приписываемые ему в литературе свойства. Укажем некоторые из них:
активность – способность брать инициативу в свои руки;
реактивность – способность адекватно воспринимать ситуацию
и избирательно действовать, реагировать на ее изменение;
автономность – способность к целенаправленному, инициативному и самозапускающемуся поведению (см., например, активные системы принятия решений и управления в [16]) без вмешательства со
стороны владельца;
коммуникативность1 – способность взаимодействовать с другими агентами средствами некоторого «языка»;
рациональность – способность агента выбирать «правильные»
действия, т. е. такие, которые максимизируют показатели его производительности в пределах его возможностей в определенных условиях,
например, рациональный агент достигает наилучших результатов из
всех ожидаемых в конкретных условиях [56]. Согласно [56] «фундаментальная идея теории решений состоит в том, что любой агент является рациональным тогда и только тогда, когда он выбирает действие,
позволяющее достичь наибольшей ожидаемой полезности, усредненной по всем возможным результатам данного действия». Это так называемый принцип максимума ожидаемой полезности (Maximum Expected Utility – MEU);
общительность (коммуникабельность и кооперативность)* –
способность обмениваться информацией с окружающей средой и другими агентами, вступать с ними в сотрудничество;
рассудительность – способность иметь собственный уровень
знаний (тезаурус), собственную модель окружающей его среды («мира»), общаться с другими агентами на этом уровне;
обучаемость – способность к обучению, рассуждению, изменению моделей окружения, построению рассуждений, адаптивности и
мобильности поведения (когнитивные агенты);
1
Звездочка означает, что это свойство часто приписывают не только интеллектуальным агентам многоагентных систем.
335
целенаправленность – наличие собственных источников мотивации поведения, действий;
реактивность* – наличие адекватного восприятия состояния
среды и реакций на его изменения (реактивные агенты);
альтруизм – способность к приоритетному достижению общих
целей и выполнению общих задач по сравнению с личными;
мобильность* – способность к миграции, передвижению для достижения цели.
Многоагентная система (МАС, Multi-agent system (MAS)) – система, состоящая из множества взаимодействующих агентов, совместно выполняющих весь спектр ее задач, распределяемых между всеми
агентами по определенным правилам.
Обычно к МАС относят системы, обладающие набором важных для
них характеристик. Это, например, такие характеристики и свойства:
автономность – агенты системы полностью или частично независимы;
адаптивность – способность подстраиваться к изменениям
окружающей среды;
ограниченность – ни у одного из агентов нет полного представления о всей системе (ее строении, предназначении, поведении или
решаемой задаче, проблеме) или она настолько сложна, что знание о
ней агент не может применить в интересах всей системы;
децентрализация – в системе нет агентов, управляющих всей системой;
синергетичность – способность системы внутренне перестраиваться, отыскивая необходимое решение без внешнего вмешательства,
в том числе оптимальное, на которое тратится наименьшее количество
ресурсов (энергии, времени, памяти, …);
гибкость, масштабируемость – способность модификации и
дополнения без значительной переделки.
Как правило, архитектура МАС ориентирована на методы работы
со знаниями либо на поведенческие модели вида «схема – реакция»,
либо на их комбинации или гибриды.
Отличительная черта МАС – наличие активного взаимодействия
между агентами, установление динамических двух- или многосторонних отношений между ними. При этом главной особенностью взаимодействий является их непрерывность, избирательность, интенсивность,
динамичность, гетерархичность или иерархичность. Направленность
означает проявление при взаимодействии положительного или отрица336
тельного влияния на работу агента, наличие в работе кооперации или
конкуренции, сотрудничества или конфронтации, координации или
субординации. Избирательность – особенность взаимодействия, проявляющаяся в «подборе» агентов-коллег, соответствующих, подходящих, помогающих друг другу при решении своих конкретных задач, и
замене их другими при решении других задач. Интенсивность – определенная частота и сила взаимодействия. Динамичность определяется
наличием, силой и направленностью изменения взаимодействий с течением времени. Гетерархичность или иерархичность означают горизонтальное (одноуровневое) равноправие или уровневую подчиненность, строгую определенность прав, возможностей каждого агента.
Взаимодействие агентов проявляется в организации сотрудничества (кооперация агентов), в наличии конфронтации или конфликтных
ситуаций (конкуренция агентов), в учете интересов других агентов
(установлении компромисса), отказе от своих интересов в пользу других (конформизм или альтруизм), а также в уклонении от взаимодействия (намеренном – саботаж, отвиливание; воздержанном или непреднамеренном отстраненном, неподдержанном, «неоцененном»).
Формально МАС можно представить в виде
MAC MAS (U , M , F , R, S , A, E ) ,
(4.30)
где U – множество системных единиц, включая отдельных агентов и
их классов; М – характеристика среды, включая описание пространства, в которых существуют агенты и исследуемые объекты; F – множество получаемых агентом задач, функций, ролей; R – множество отношений (связей, подчиненности, взаимодействий и т. п.) между
агентами; S – множество конфигураций (организационных, топологических и прочих структур), формируемых агентами; А – множество
действий, выполняемых агентами, включая совместные; Е – эволюционные возможности.
В заключение обратим внимание на два аспекта. Первый – многообразие названий ИА, отражающее круг решаемых ими первоочередных задач. Например, коллаборативные (отвечающие за совместные
действия); интерфейсные (поддержка активных действий и связи с
пользователем); мобильные (самостоятельные, способные «бродить по
сетям»); реактивные (реагирующие по схеме «стимул – реакция»); автономные (в которых свойства автономности является важнейшим,
главным). Второй аспект – необходимость централизованного или распределенного планирования действий агентов в МАС. Очень часто
337
основу алгоритмов планирования составляют популяционные, в частности роевые и иммунные, алгоритмы. Вопросы планирования особенно актуальны при произвольных, оперативно меняющихся, не запланированных при проектировании МАС целях.
4.7.7. Иммунные методы и алгоритмы
Искусственные иммунные системы
Биологическая иммунная система способна распознавать огромное
количество молекулярных структур, итогом чего является обучение,
непрерывное формирование и изменение иммунной памяти к конкретному антигену. Это означает, что она способна создавать, совершенствовать и использовать знания об окружающем мире, не имея центральной структуры управления, а обладая лишь набором временных
коллективов клеток в лимфатических узлах, непрерывно перестраивающихся и обменивающихся сигналами и клетками. Иными словами,
она может рассматриваться как своеобразная сложная адаптивная децентрализованная распределенная многоуровневая высокопараллельная система обработки и анализа информации, в которой реализован
механизм обучения, запоминания и ассоциативного поиска для решения задач распознавания и классификации [53].
В связи с этим в искусственном интеллекте в последние годы появилось новое направление, названное «искусственные иммунные системы», принципы построения и алгоритмы функционирования которых основаны на принципах иммунологии и механизмах работы
иммунных систем высших животных.
Прежде чем переходить к рассмотрению иммунных алгоритмов,
введем необходимые понятия.
Иммунитет (от лат. immunitas (immunitatis) организма – освобождение, избавление, защитная реакция) – способность организма
противостоять воздействиям чужеродных агентов, вызывающих повреждения организма, а именно его способность защищаться от инфекционных агентов (бактерий, вирусов и т. д.), чужеродных веществ
(токсинов, ядов, паразитов и т. п.) и патогенных (болезнетворных) клеток (например, раковых), сохраняя свою целостность и биологическую
индивидуальность. Назначение или биологический смысл иммунитета –
обеспечение генетической целостности организма на протяжении его
индивидуальной жизни.
Иммунный: – 1) (от лат. immunis – свободный от чего-либо, нетронутый) невосприимчивый по отношению к инфекционным заболева338
ниям и другим возбудителям болезней – антигенам; 2) создающий такую невосприимчивость, вызывающий способность противостоять
воздействию антигенов; 3) производный от слова «иммунитет».
Иммунная система (ИмС) организма – система органов и тканей,
защищающих организм от заболеваний путем обнаружения, распознавания и уничтожения патогенов и опухолевых клеток. Назначение
ИмС – уничтожение чужеродных агентов, обеспечивая при этом биологическую индивидуальность организмов.
Иммунный ответ – процесс обнаружения и удаления (уничтожения) чужеродных агентов, а иммунная реакция – взаимодейтсвие антитела с соответствующим антигеном.
Существует два основных варианта иммунного ответа: гуморальный (жидкостный), в котором участвуют В-клетки и Т-хелперы, и клеточный, в котором участвуют Т-клетки.
Иммунная память – способность ИмС реагировать более быстро
и эффективно, формируя вторичный ответ, на антиген, с которым у
организма был предварительный контакт. Это достигается за счет создания долгоживущих клеток памяти на базе некоторых лимфоцитов,
активизированных в ходе первичного иммунного ответа, сохраняя
«знания» об антигене и его особенностях. Иммунная память – элемент
приобретенного иммунитета. Она относится к классу ассоциативных,
рассредоточенных.
Антигены (Аг, от англ. antigens, Ag) – чужеродные данному организму вещества и другие патогенные организмы, вызывающие иммунный ответ, т. е. воспринимаемые данным организмом как чужеродные и
вызывающие образование в крови, лимфе и других тканях его антител.
Антитела (Ат, англ. antibodes, Ab) – белки группы иммуноглобулинов, образующиеся в организме человека и теплокровных животных
при попадании в него антигенов и нейтрализующие их вредное действие.
Помимо антител к основным компонентам естественной иммунной
системы (ИмС), играющим важнейшую роль в формировании и поддержании иммунного ответа, относятся макрофаги и лимфоциты.
Макрофаги (И.И. Мечников, 1887 г.) – клетки соединительной ткани животных и человека, способные к активному захвату и перевариванию бактерий, остатков клеток и других чужеродных или токсичных
для организма частиц.
Лимфоциты – одна из пяти форм лейкоцитов – клеток крови,
имеющих ядра, способных опознавать антигены по их поверхности и
339
вырабатывать специфические белковые молекулы – антитела, связывающие эти чужеродные агенты. Лимфоциты подразделяются на две
основные группы: В- и Т- лимфоциты. В-лимфоциты – это клетки, происходящие из костного мозга (bone marrow), обладающие уникальной
структурой поверхностных рецепторов и способные продуцировать
Y-образные антитела, распознающие конкретные антигены. Т-лимфоциты – это клетки, созревающие в тимусе (thymus, отсюда их
название). Они делятся на ципоскопические (или Т-киллеры (от англ.
killer – убийца), убивающие клетки), которые предназначены для
уничтожения собственных зараженных клеток, и Т-хелперы (от англ.
helper – помощник), которые усиливают либо подавляют (при автоиммунных заболеваниях) иммунный ответ путем регуляции выработки
антител В-лимфоцитами, управляя иммунным ответом и направляя
другие клетки макрофаги на уничтожение зараженных клеток или
непосредственно возбудителей.
Иммунитет делится на два вида: естественный и искусственный,
каждый из которых делится на два подвида. Естественный врожденный иммунитет – это тот, что передается организму генетически от
предков, а естественный приобретенный возникает, когда организм
сам вырабатывает антитела к какому-то антигену (переболев корью,
оспой и т. п.), сохранив структуру этого антигена в своей иммунной
памяти. Искусственный активный иммунитет формируется путем введения в организм ослабленных бактерий или других возбудителей болезней (при вакцинации), а искусственный пассивный – при введении
сыворотки – множества готовых антител от переболевшего животного
или человека. Последний иммунитет самый нестойкий, непродолжительный (сохраняется только до нескольких недель).
Основная роль ИмС в организме – распознавание всех клеток (молекул) организма и их классификация на «своих» и «чужих». «Чужие»
клетки подвергаются дальнейшей классификации с целью стимуляции
защитного механизма соответствующего типа. Считается, что ИмС
состоит из центральной (ЦИС) и периферической (ПИС) систем. ЦИС
взаимодействует с собственными антигенами организма, а ПИС отвечает за реакции на внешние антигены.
Если функцией нервной системы человека управляет мозг, то
центрального органа управления функцией ИмС не существует. С точки зрения модельного системного представления (см. часть 1, § 2.5,
табл. 2.4, а также часть 2 § 3.2, табл. 3.1) ИмС представляет собой
сложную адаптивную, динамическую, децентрализованную, распреде340
ленную, активную, когерентную систему, эффективно использующую
различные механизмы защиты от внешних и внутренних антигенов,
имеющую высокопараллельную сетевую структуру, способную к обучению, работающую как система с использованием всей совокупности
локальных сетевых взаимодействий ее элементов как на уровне отдельных элементов, так и на системном уровне, всегда ориентируясь
на поддержание целостности организма.
Заметим, что клетки ИмС, как ее основные элементы, сами являются сложными высокоорганизованными живыми «машинами». Компонентами ИмС являются как «боевые» элементы и микроэлементы
(макрофаги, антитела различных специфичностей, В-лимфоциты и Ткиллеры), так и «управленческие» (Т-хелперы), способные выступать в
различных комбинациях, подстраивая их под огромное множество
«противников», каждый из которых специфичен, имеет свой «образ
жизни» и «способ заражения», повреждения организма, защищаемого
ИмС. ИмС представляет собой набор временных коллективов клеток,
находящихся в лимфатических узлах, непрерывно перестраивающихся
и обменивающихся клетками и сигналами. В этом смысле ее можно
рассматривать как естественную адаптивную децентрализованную
распределенную обучающуюся систему обработки, анализа и использования информации, обладающую, во-первых, мощными и гибкими
возможностями децентрализованной обработки информации и, вовторых, превосходными адаптивными элементовыми механизмами на
локальном уровне и эмерджентными системными механизмами поведения на глобальном уровне. Именно эта особенность ИмС и является
основой для разработки различных иммунных алгоритмов [53].
При этом учитывается, что, во-первых, при попадании в организм
антигена лишь малая часть клеток ИмС способна к его распознаванию,
во-вторых, распознавание стимулирует процессы размножения и дифференцировки лимфоцитов, приводящие к образованию антител –
клонов1 идентичных клеток. Этот процесс размножения клонов формирует многочисленную популяцию специфичных к антигену антителопродуцирующих клеток. При таком размножении часть иммуннокомпетентных клеток приводит, с одной стороны, к разрушению
1
Клон (от греч. klön – ветвь, отпрыск) – один из популяции потомков в
последовательности поколений наследственно однородных потомков одной
исходной особи (растения, животного, микроорганизма, клетки), образующихся в результате бесполового размножения (клонирования).
341
(нейтрализации антигена), с другой – к сохранению части образовавшихся клеток для иммунной памяти.
Любопытно отметить следующее. Первое. Клетки памяти оказывают избирательное предпочтение тому типу тканей, в котором они
впервые встретились с антителом. Предположительно – это одна из
причин быстроты вторичного ответа – клетка памяти возвращается в
тот участок тела, где она, скорее всего, снова встретится с антигеном.
Второе. Процесс циркуляции В- и Т-лимфоцитов тщательно контролируется. Именно это обеспечивает попадание соответствующих клеточных популяций как наивных («необученных»), так и эффекторных клеток, а также клеток памяти в разные места их назначения. Тем самым
происходит избирательная миграция лимфоцитов в различные органы
и ткани.
Разные иммунные алгоритмы учитывают разные свойства ИмС
[53]. Приведем некоторые из них.
Распознавание молекулярных структур (МС) и избирательное реагирование на них.
Выделение особенности МС и реакция на них в качестве «фильтра», подавляющего молекулярный шум, и «линзы», фокусирующей
внимание лимфоцитов – рецепторов.
Разнообразие – использование для «надежности», «гарантии» комбинированного механизма образования множества лимфоцитов – рецепторов, из которых хотя бы один сможет взаимодействовать с любым (из наперед заданных) известным или неизвестным антигеном.
Обучение – изменение концентрации лимфоцитов с учетом структуры конкретного антигена.
Память – сохранение только минимально необходимой, но достаточной памяти о предыдущих контактах с антигеном на основе использования краткосрочных и долгосрочных механизмов хранения,
при которых обеспечивается идеальный баланс между экономией ресурсов и исполнением функций.
Распределенный поиск антигенов за счет непрерывной рециркуляции ее клеток через кровь, лимфу, лимфотические органы и остальные
ткани и осуществления иммунного ответа при встрече с ними.
Саморегуляция – регуляция иммунного ответа на локальном (элементарном) и глобальном (системном) уровнях в отсутствие центрального контролирующего и управляющего центра ИмС.
Пороговый механизм – реакция, т. е. формирование иммунного ответа и размножение иммунокомпетентных клеток, только после преодоления некоторого порога «значения» силы химических связей.
342
Совместная стимуляция – активация В-лимфоцитов только после
дополнительного стимулирующего сигнала Т-хелпера, обеспечивающего толерантность и различение серьезной и «ложной» угрозы, т. е.
опасных и неопасных антигенов.
Динамическая защита – создание динамического баланса между
изучающей и защитной функциями адаптивного иммунитета путем
продуцирования высокоэффективных иммунокомпетентных клеток.
Стохастическое обнаружение – наличие стохастических процессов обнаружения антигена и формирования перекрестных реакций в
ходе иммунного ответа. Это приводит к тому, что лимфоцит может
взаимодействовать с несколькими структурно сходными антигенами.
Кроме того, в формировании иммунного агента проявляются такие
свойства ИмС, как ее адаптируемость, специфичность, самотолерантность, дифференцировка и другие. Особо следует отметить существенное проявление в ИмС сетевого взаимодействия, при котором все ее
сигнальные молекулы участвуют в реализации сразу нескольких распределенных задач и при этом каждая задача реализуется с участием
нескольких сигналов, а для выполнения определенной задачи организуется группа агентов путем распределения задач между агентами и
«вознаграждения» агентов за успешное достижение поставленных целей и подцелей или наказаний за неудачи. Разные варианты поведения
клеток ИмС – это секретирование, уничтожение патогенов, перемещение и активирование (размножение). Причем в ИмС эти варианты могут реализовываться параллельно во времени. Вместо использования
вознаграждения в виде подкрепления для выбора следующего варианта поведения, часто используемого для роботов, в ИмС интенсивность
всех вариантов поведения регулируется с помощью обобщенной
функции размножения. Наконец, при разработке иммунных алгоритмов могут оказаться важными следующие два приема защиты в организмах, где есть ИмС. Первый – принципиально разный уровень защищенности различных тканей и клеток (например, внешних,
напрямую контактирующих с окружающей средой, и внутренних).
Второй – повышение устойчивости к инфекциям за счет разделения
при этом функциональных клеток и стволовых клеток. Функциональные клетки защищены относительно слабо, периодически обновляются
и в случае инфекции удаляются. Поэтому их популяции формируются
более защищенными стволовыми клетками, доступ к которым тщательно контролируется ИмС. Именно поэтому даже успешная инфекция может привести лишь к временному повреждению, снижению
343
эффективности работы организма. Это важно иметь в виду, например,
при создании компьютерных ИмС. Кроме того, порою полезно учитывать, что иммунные реакция и ответ – лишь механизмы отторжения
человеческим и другими организмами антигенов. Причина же отторжения – генетическая. Она обусловлена наследственной информацией.
Иммунные алгоритмы базируются на разных, порою противоречащих друг другу, модельных представлениях, механизмах функционирования ИмС: иммунной сети, отрицательного (негативного) отбора,
клонального отбора (клональной селекции), опасности (дендридные
алгоритмы), обучения и т. д.
Рассмотрим основы некоторых иммунных алгоритмов без их детализации.
Алгоритмы клонового отбора (селекции). Алгоритмы данного
класса базируются на модельном представлении того, как ИмС справляется с чужеродными антигенами при врожденном и приобретенном
иммунитете путем отбора (селекции) клонов. Основой такого модельного представления является гипотеза о том, что те клетки, которые
способны распознать чужеродный антиген, размножаются пропорционально степени их способности к распознаванию: чем лучше клетка
распознает антиген, тем большее количество ее клонов (потомства)
рождается (генерируется) при этом. В ходе процесса репродукции
клетки отдельные клоны подвергаются такой мутации, которая позволяет им иметь более высокое соответствие (большую аффинность) к
распознаваемому антигену: чем выше аффинность родительской клетки, тем в меньшей степени она подвергается мутации в потомке (в
клоне), и наоборот. Тем самым обеспечивается обучение в ИмС: необходимо увеличивать относительный размер популяции и аффинности
тех лимфоцитов, которые уже доказали и доказывают свою ценность,
пригодность при распознавании конкретного антигена, т. е. лучше соответствуют ему. Иными словами, в процессе размножения (генерирования) множества антител из набора клеток памяти следует удалять
антитела с низкой аффинностью и способствовать созреванию аффинности других клеток, т. е. осуществлять повторный отбор клонов пропорционально их аффинности к антителам.
Именно единый принцип выполнения таких преобразований популяции антител, в результате которых индивидуумы увеличивают свою
аффинность, отличает алгоритмы клонового отбора АКО (или клоновой селекции, АКС) от других иммунных алгоритмов и сближает их с
генными и другими эволюционными алгоритмами (ЭА). В АКО под
344
аффинностью1 (англ. affinity) понимается степень соответствия антитела (Ат, Ab) антигену (Аг, Ag), т. е. сила связывания между ними.
Функция аффинности (ФА) является аналогом функции пригодности в
эволюционных алгоритмах, а именно функции приспособленности в
генетических алгоритмах или функции пригодности (привлекательности) в роевых алгоритмах. Так же как в ГА и РА, в тех случаях, когда
АКО используется для решения оптимизационных задач (а не задач
распознавания и других), в качестве функции аффинности применяется целевая функция (ЦФ), подлежащая оптимизации, аргументами которой являются антитела и антигены, точнее, их кодовые представления. Тогда при нахождении минимума ЦФ аффинность тем выше,
лучше, чем меньше значение ЦФ для данного антитела (это антитело
лучше соответствует антигену), а при нахождении максимума ЦФ,
наоборот, аффинность «хорошеет» с увеличением значения ЦФ.
В задачах распознавания, классификации и других подобных им в качестве мер аффинности типа Аb–Аg и Аb–Аb, когда индивидуумы Аb
и Аg характеризуются l координатами (атрибутами), например,
Ab ( Ab1 , Ab2 , ..., Abl ) или Ag ( Ag1 , Ag 2 , ..., Agl ) , могут использоваться меры сходства вида (1.2.1)–(1.2.5). При этом чем меньше расстояние , т. е. значение ФА (ЗФА) между соответствующими индивидуумами, тем выше их аффинность друг к другу.
При распознавании популяция антигенов может представлять собой набор данных, которые нужно распознать. Например, набор N векторов значений x1 ,..., x N , где xi ( i 1, N ) есть xi ( xi,1 , xi,2 , ..., xi , p ) –
т. е. вектор р показателей (характеристик, параметров) распознаваемого объекта. Набор антител – это набор значений таких показателей из
разных классов объектов.
При аппроксимации и прогнозировании взад или вперед популяция
генов, антигенов – это набор данных, популяция антител – это набор
конкретных значений параметров аппроксимирующей данные функции (АФ), т. е. в итоге – значений АФ, а критерий аффинности – это
1
От лат. affinis – родственный, сходный. По отношению к ИмС аффинность отражает качество ее элемента в отношении внешней среды, в которой
он находится. В теории ИмС рассматривают два типа аффинности: аффинность связи «антитело – антиген», т. е. Ат–Аг – аффинность (Аb–Аg affinity),
отражающую степень различия, и Ат–Ат – аффинность (Аb–Аb affinity), характеризующую степень подобия.
345
критерий качества ЦФ аппроксимации или прогнозирования с помощью АФ, построенной на всем множестве данных (генов и антигенов).
Тогда скалярная величина аффинности будет зависеть от близости к
оптимальным значениям параметров при заданном виде АФ и/или оптимальности точек аргумента для выбора оптимальной АФ.
Формально АКО можно представить в виде
AKO CLONALG Ab0 , Ag ; N , n, m, L; F ( γ ), ; ,
(4.31)
где Ab0 (antibodies) – исходная популяция антител (Ат); Ag (antigens) –
популяция антигенов (Аг); N – количество антител в популяции; п –
количество антител, отбираемых для клонирования, т. е. имеющих самую высокую аффинность; т – количество антител, имеющих самую
низкую аффинность и поэтому подлежащих замене новыми клонами;
L – длина рецептора антитела; F ( γ ) – функция (оператор) аффинности
с параметрами ; – коэффициент, регулирующий количество клонов
отобранных антител; – критерий останова алгоритма.
Обобщенная схема алгоритма клонового отбора представлена на
рис. 4.9.
1. Инициация – генерация исходной популяции (N антител)
2. Провоцирование иммунного ответа – взаимодействия с антигеном, расчет ЗФА
для каждого антитела
3. Формирование иммунного ответа
3.1. Отбор п клеток (антител), имеющих более высокую аффинность к антигену
3.2. Репродукция клонов антител и организация генетической изменчивости
3.3. Осуществление мутации антител
3.4. Создание новой популяции («встряска» популяции)
3.5. Проверка критерия останова алгоритма
Да
Нет
4. Отбор и оформление результата
Рис. 4.9. Обобщенная схема иммунного алгоритма клонового отбора
346
Прокомментируем алгоритм (сравни с ГА и РА).
1. Шаг (этап) первый. Инициация. Случайным образом генерируется исходная популяция Ab0 из N антител (т. е. N кодовых комбинаций,
каждая из которых соответствует своему антителу – решению задачи).
2. Шаг второй. Взаимодействие с антигеном – провоцирование
иммунного ответа. Получается образец неизвестного антигена и рассчитывается значение функции аффинности (иначе аффинность связи
его) со всеми антителами исходной популяции Ab0 .
3. Шаг третий. Формирование иммунного ответа. Выполняется
цикл следующих операций.
3.1. Отбор: отбираются п клеток, имеющих наиболее высокую аффинность к заданному антигену.
3.2. Репродукция и генетическая изменчивость: создаются клоны
антител (копии иммунных клеток) по правилу «чем лучше каждое антитело (чем больше его аффинность), тем больше , т. е. тем больше
клонов такого антитела (копий клеток) создается.
3.3. Осуществление мутации: в каждом классе антител произвести
мутации по инверсивно-пропорциональному правилу: чем выше аффинность, тем меньше уровень мутации.
3.4. Создание новой популяции, включив в нее новые клоны, убрав
т худших (с наименьшей аффинностью антител) и добавив до N случайно сгенерированные новые антитела.
3.5. Проверка критерия останова алгоритма. Если нет, то повторить цикл 3.1–3.4, пока не будет достигнут заданный критерий останова, т. е. не будет полностью сформирован иммунный ответ.
Шаг 4. Завершение работы, отбор и оформление результата решения (работы алгоритма).
Различные модификации АКО связаны с различными способами
представления антител (решений) и антигенов, функциями аффинности, размером популяции, операциями мутации и замещения («встряски»), количеством итераций и правилами остановки алгоритма.
Например, с заменой п «верхним» порогом аффинности в , когда в
операции 3.1 отбираются те, для которых B , либо заменой т на
нижний порог н , когда «худшими» считаются те клоны (антитела),
для которых н ; вариантами мутации; правилом назначения , в
том числе рандомизованным, либо правилом назначения общего числа
N клонов, сгенерированных из п отобранных, например, в порядке
347
убывания аффинности по правилу N E{N } E N / 2 ...
E N / n , где E x – целая часть числа х, а E N i , i 1, n , есть
количество клонов с i-й аффинностью. Ясно, что размер популяции в
каждом поколении может отличаться от объема N исходной популяции
и устанавливаться по своим правилам.
Таким образом, АКО представляет собой расширенный мягкий алгоритм, операндом и промежуточным результатом работы которого
является популяция, представляющая собой набор антител (решений),
когда каждое антитело представляет собой возможное решение искомой задачи и оценивается мерой пригодности – «хорошести» ее как
результата решения задачи. С помощью серии итеративных процедур
итоговое решение приближается к искомому результату. Иными словами, в этом смысле АКО подобны ГА и РА. Отличительная особенность АКО – совмещение кооперативного принципа поиска решения с
конкурентным. В нем антитела (клоны) конкурируют за распознавание
антигена (или решение оптимизационной задачи), как в ГА, но сотрудничают как ансамбль индивидуумов, как в РА, представляющий конечное решение. В АКО значение аффинности получаемого клона
(антитела, очередного «частного», «индивидуального» решения) используется для определения уровня мутации к каждому члену популяции, в то время как в ГА, например, принимаемый уровень мутации и
кроссовера обычно игнорирует пригодность индивидуальной хромосомы (индивидуального частного решения). Следствием этого является
лучшая адаптируемость АКО к конкретной ситуации.
Клонально-селективное модельное представление ИмС успешно
отражает многие важные аспекты иммунного ответа. Оно основано на
аксиоматическом утверждении, что все «чужие» клетки отличаются от
«своих» клеток организма по структуре, форме и содержанию. Однако,
во-первых, на некоторые ключевые вопросы функционирования ИмС
такое представление не позволяет ответить. Например, оно не дает ответа на то, что дает возможность лимфоцитам поддерживать иммунную память длительное время [53]. Согласно клонально-селективному
представлению предполагается, что любой иммунный ответ запускается антигеном. Но у некоторых живых существ, имеющих ИмС, стимуляция клонирования иммунных клеток может происходить также
благодаря внутренним механизмам. Описание такого механизма объясняет модельное представление ИмС в виде иммунной сети.
Во-вторых, нормальный иммунный ответ действительно происходит в случае, если количество «чужого» внешнего агента в организме
348
превышает некоторый порог, называемый порогом толерантности.
Но при некоторых условиях в результате «сбоя», а также когда ранее
скрытые антигены не распознались сразу, ИмС может ошибочно принять часть клеток и тканей хозяйского организма за «чужие». Тогда
возникает аутоиммунный ответ – аутоиммунная реакция, что может
привести к развитию аутоиммунного заболевания1 (коллагенезы,
нефрит, аутоиммунная офтальмия, системная красная волчанка, миастения и др.), направленного против собственных тканей и органов.
В этом случае аксиоматическое утверждение, лежащее в основе клонально-селективной модели ИмС, оказывается неверным. Ведь собственные клетки являются «своими» по структуре, форме, содержанию, но ИмС атакует их как «чужих». Представление о механизме
работы ИмС, связанного с врожденными и «сбойными» реакциями,
дают модели отрицательного (негативного) отбора, опасности. Рассмотрим два класса алгоритмов, основанных на этих двух модельных
представлениях механизма функционирования ИмС.
Алгоритмы идиотипических иммунных сетей (АИС). В 1974 г.
Н.К. Ерне (N.K. Jerne) предложил модель ИмС в виде регулируемой
сети молекул и клеток, распознающих друг друга даже при отсутствии
антигена [53]. Такая модель получила название модели в виде идиотипических2 сетей (idiotypic networks) лимфоцитов (молекул и клеток)
(сетевая модель первого поколения, СМПП). Гипотеза, лежащая в основе модели, базируется на двух ключевых постулатах: 1) единичная
клетка продуцирует лишь один тип антител; 2) различные клоны лимфоцитов друг от друга не изолированы, а поддерживают связь путем
взаимодействий между своими рецепторами и антителами. Иными
словами, антитела и лимфоциты разной специфичности функционально не изолированы и вступают во взаимодействия между собой. В силу
этого распознавание антигена осуществляется не единичным клоном
клеток, а, скорее, на системном уровне единой сетью, т. е. с участием
различных клонов, между которыми имеет место взаимодействие по
типу реакций антиген – антитело. При этом антиген в ходе формиро1
Одной из причин появления аутоиммунного заболевания у человека является продолжение активного функционирования тимуса – вилочковой железы, небольшого лимфатического органа, который хорошо развит только в детском возрасте, стимулируя рост и формирование ИмС. В период полового
созревания тимус практически исчезает.
2
От греч. idios – свой, своеобразный; особый.
349
вания иммунного ответа вызывает лишь реакцию ИмС, проявляющуюся в выработке первого набора антител Аb1. Эти «первичные» антитела, выступая своеобразными антигенами, вызывают выработку второго
набора «антиидиотипических» антител Аb2, распознающих идиотипы
на антителах Аb1. Аналогично антитела Аb2 вызывают выработку третьего набора (популяции) антител Аb3, распознающих идиотипы в антителах Аb2.
В сетевых моделях ИмС второго поколения (СМВП [53]) добавлены следующие предположения качественного характера.
1. Иммунная сеть состоит из клонов В-лимфоцитов, связанных
идиотипическими взаимодействиями. Участие Т-лимфоцитов игнорируется.
2. Игнорируется различие, рассмотренное Н.К. Ерне, во взаимодействии между идиотопами (idiotopes) – эпитопами1, характеризующими
поверхностные рецепторы и антитела некоторого клона лимфоцитов, и
паратопами2 – участками антитела, распознающими антигенную детерминанту.
3. Степень активации и динамика популяций лимфоцитов существенным образом контролируется уровнем лигирования3 рецепторов
растворимыми молекулами иммуноглобулинов.
4. Основными посредниками идиотипических взаимодействий служат растворимые молекулы иммуноглобулинов.
При этом в 1-м и 2-м поколениях модельного представления ИмС в
виде сетей рассматриваются два типа моделей иммунных сетей, ориентированных на выделение центральной (ЦИС) и периферической
(ПИС) ИмС (см. описание ИмС). Однако такое разделение ИмС не всегда является продуктивным. Поэтому были предложены модели 3-го
поколения иммунных сетей (СМТП) [53]. Их основой является обобщение ЦИС- и ПИС-подходов к представлению сети. Это позволяет
согласованно описать структурные и функциональные свойства ЦИС и
ПИС и выявить, как формируется различие между ними.
Было предложено несколько модификаций сетевых моделей ИмС
1–3-го поколений и построенных на их основе алгоритмов идиотипи1
Эпитоп (эпи от греч. epi – на, над, сверх, при, у, после) – это антигенная
детерминанта – участок антигена, непосредственно распознаваемый антителом.
2
От греч. para – возле, при.
3
Лигирование – от англ. ligation – сшивание концов макромолекул.
350
ческих сетей (АИС) (idiotypic networks algorithms, INA), или сетевых
иммунных алгоритмов (СИА). Рассмотрим обобщенно их принцип
действия. В его основе лежит идея представления ИмС в виде сети, в
узлах которой находятся связанные между собой В-лимфоциты, над
которыми проводятся определенные клонирования и мутации. При
графовом представлении сети антителами (клонируемыми, продуцируемыми клетками) являются узлы, а алгоритм обучения сети связан с
наращиванием или сокращением расстояний между ними (узлами) на
основе принятой меры их близости, сходства. Поэтому они чаще всего
используются в задачах кластеризации, визуализации данных, выявлении, контроле и оптимизации соответствующих областей значений показателей, а также при построении ИНС.
Для задач оптимизации сетевое модельное представление ИмС может использоваться в гибридных алгоритмах. Так, например, в работе
Т. Фукуда, К. Мори и М. Цукияма ([53], с. 240–249) описан алгоритм,
основанный на принципах соматической1 и сетевой гипотез о работе
ИмС, а также генетического алгоритма как инструмента для получения
разнообразия антител. Согласно соматической гипотезе увеличение
разнообразия антител происходит за счет соматической рекомбинации
и мутации генов, а согласно сетевой – контроль размножения клонов
осуществляется в результате взаимного распознавания антител, функционирующих как единая сеть. Фрагмент схемы подобного иммунного
алгоритма решения задачи оптимизации мультимодальной функции
представлен на рис. 4.10.
Прокомментируем его.
Шаг 1. На первом шаге (распознавание антигена) определяется вид
задачи оптимизации, т. е. определяется вид ЦФ (оптимизируемой
функции) и ограничений. Этот этап аналогичен этапу распознавания
ИмС антигенного вторжения и определению связанности его с чужеродной или собственной клеткой организма.
Шаг 2 (выработка N антител). Он связан с извлечением из памяти
алгоритмов успешного решения подобных задач в прошлом и отбором
вариантов решения, пригодных для данной задачи. Это соответствует
активированию клеток памяти, которые начинают вырабатывать антитела для уничтожения данного антигена.
Шаг 3. Производится вычисление ЗФА (значений ЦФ), т. е. аффинности Abi Ab j антител i и j и Abi Ag аффинности i-го антитела и
1
От греч. sōma – тело.
351
данного антигена. В [53] для этого предлагается использовать меру
неопределенности Шеннона. Этот шаг аналогичен распознаванию поверхностей структуры нового антигена, на основании чего производится отбор клеток, продуцирующих наиболее подходящие антитела.
1. Распознавание антигена (формулировка постановки задачи)
2. Выработка антител (выработка вариантов решения)
3. Вычисление аффинности (нахождение значений ФА, ЦФ)
4. Дифференцировка антител (выбор и сохранение
локально-оптимальных значений переменных)
5. Стимуляция и супрессия1 размножения антител в ИмС
(отбор значений переменных)
6. Доразмножение антител (выработка новых значений переменных с помощью ГА)
Рис. 4.10. Упрощенное представление фрагмента иммунного
сетевого алгоритма оптимизации1
Шаг 4 – выбор и сохранение тех решений, т. е. антител – значений
переменных функции, при которых достигается текущее наилучшее
(«локально-оптимальное») решение, подходящее для следующего шага
поиска. Эта операция аналогична тому, как некоторые В-лимфоциты
ИмС, антитела которых соответствуют антегену, становятся клетками
иммунной памяти либо уничтожаемыми клетками («забываемыми, отбрасываемыми решениями»), если концентрация антител превысит
некоторое пороговое значение.
Шаг 5 – размножение и подавление антител, направленное на регулировку концентрации и сохранение разнообразия антител в популяции
лимфоцитов («встряска» популяции). Это означает, что алгоритмом
1
Супрéссия (от лат. suppressio – давление) – полное или частичное восстановление у наследственно измененных форм организма (мутантов) нормального проявления признака вследствие новой мутации.
352
стимулируется размножение антител, приобретших высокую аффинность к антигену, но при этом размножение антител, концентрация которых слишком велика, подавляется. В дополнение к шагу 4, ориентированному на отслеживание локальных мод, т. е. на нахождение
значений переменных, соответствующих локальным экстремумам (в
нашем примере максимумам) оптимизируемой функции, это позволяет
поддерживать разнообразие направлений поиска, в том числе для
нахождения глобального экстремума.
Шаг 6. Доразмножение антител. Вместо антител, удаленных на
5-м шаге, образуются новые антитела для поиска новых мод, аналогично тому, как для иммунного ответа на ранее не встречавшиеся антигены в костном мозге происходит образование новых лимфоцитов
вместо уничтоженных антител. Использование ГА на этом шаге не
обязательно. Оно оправдано, если ГА более эффективен по сравнению
с генерацией антител методом Монте-Карло. В [53] приведены результаты численных экспериментов по оптимизации разных функций с помощью подобного алгоритма.
Понятно, что рис. 4.10 отражает лишь идейную сторону алгоритма.
На рисунке не отражены детали, в частности точки ветвления, связанные с пороговыми условиями, правилом останова, выводом результатов и т. д. Попробуйте добавить их самостоятельно. С другими алгоритмами можно ознакомиться в [51].
Формально алгоритм может быть представлен в виде
АИС INA Ab0 , Ag ; N , n; m; L; F (α ); ,
(4.32)
где Ab0 – исходная популяция антител, Ag – популяция антигенов; N –
количество антител в популяции, п – количество антител, имеющих
наивысшую аффинность; т – количество антител, подвергаемых подавлению (удалению, стимуляции или супрессии); F (α ) – функция
(оператор) аффинности; – критерий останова.
Формальное представление иммунной сети можно представить в
виде [51]
ИмС IN S b , S g , Rbb , Rbg , S m ; nb , nc , bs , bb , br , bn ,
где S b – популяция антител (детекторов), S g – популяция антигенов
(данных), R – совокупность расстояний b-b ( Rbb ) и b-g ( Rbg ); nb –
353
число лучших антител, отбираемых для клонирования и мутации из
Sb , а nc – число клонов, создаваемых каждым из отобранных антител;
bs – степень селекции, т. е. относительное число лучших антител, отбираемых из множества клонированных клеток; bb – пороговый коэффициент гибели или стимуляции антител в зависимости от значения их
b-g аффинности; br – пороговый коэффициент сжатия иммунной сети;
bn – коэффициент обновления сети.
Обобщенную схему алгоритма, соответствующего такому описанию иммунной сети, легко составить по описанию алгоритма, приведенному в [51, c. 199].
Алгоритмы негативного (отрицательного) отбора (АНО,
negative selection algorithms, NSA). Эти алгоритмы разрабатываются с
1994 г. [53] и ориентированы, прежде всего, на решение задач кластеризации, распознавания проблемных областей на базе имеющихся знаний, обнаружения аномалий и т. п.
В основе алгоритмов данного класса лежит модельное представление о том, что все созреваемые в тимусе лимфоциты (Т-клетки), способные, как уже упоминалось, с помощью своих рецепторов распознавать патогены, расположенные на поверхности других клеток, перед
тем как попасть в кровеносную систему для выполнения этой задачи,
подвергаются отрицательному (негативному) отбору. Он позволяет
отсеять те Т-клетки, которые способны реагировать на собственные
антигены организма. Это позволяет избежать «ложного срабатывания»
ИмС.
Компактно идею АНО можно представить в виде трехшаговой
(трехэтапной) последовательности операций.
Шаг 1. Определяем свое – совокупность того, что необходимо защищать, контролировать, распознать, в виде множества S из L строк
длины l, используя конечный алфавит (например, двоичный). Совокупность S может отражать нормальный паттерн устойчивого поведения исследуемого объекта (предмета, процесса, системы) или паттерн
его активности и представлять собой программу либо файл данных,
например, отсчетов участка временного ряда, либо данных, отражающих нормальную форму деятельности, активности и другие характеристики объекта, подразделяемые на подстроки равной длины аналогично тому, как белки расщепляются ИмС на отдельные субъединицы,
распознаваемые рецепторами Т-клеток.
354
Шаг 2. Создается набор детекторов1 R, ни один из которых не
совпадает с любой из L строк множества S. Поскольку точное совпадение может быть маловероятным, используется правило частичного соответствия, согласно которому две строки соответствуют друг другу
(«совпадают») тогда и только тогда, когда они идентичны (совпадают),
по крайней мере, не менее чем в r смежных (следующих друг за другом) позициях. Величина r – некоторый целочисленный параметр, выбираемый в зависимости от решаемой задачи.
В начале АНО, на первом исходном этапе, кандидаты в множество
детекторов R генерируются случайно. Затем они подвергаются цензуре
(цензурированию) на соответствие любой строке своего (т. е. множества S) и негативному отбору: если для рассматриваемого кандидата
соответствие имеет место, то он отвергается.
Процедура продолжается до тех пор, пока не будет создано заданное число п детекторов или не обеспечено требуемое качество решения
задачи. Однако случайное генерирование детекторов приводит к экспоненциальной по L вычислительной сложности. Поэтому были предложены другие алгоритмы генерации с разной вычислительной сложностью. Например, есть двухэтапные алгоритмы линейной сложности.
На первом этапе методом динамического программирования пересчитывается (формируется) множество допустимых детекторов. На втором этапе из допустимых детекторов случайным образом формируется
множество строк детектора R. Например, на первом этапе для конкретного набора L строк множества S и порога соответствия r определяются общее множество S строк, не совпадающих со строками S. Затем на
втором этапе часть строк из S используется для формирования детектора R.
Шаг 3. Вновь поступившие в S данные контролируются или изменения в S проверяются путем непрерывного сопоставления детекторов
из R с элементами из S. Обнаружение совпадения хотя бы с одним детектором рассматривается как изменение (отклонение в поведении)
контролируемого объекта, поскольку детекторы по определению отобраны так, чтобы не соответствовать любой из строк множества L.
Формально такой алгоритм можно представить в виде
AHO NSA ( S , L, l ; R, n, r ; F (α ); ) ,
(4.33)
1
Детектор (от лат. detector – открыватель, раскрывающий, обнаруживающий) – преобразователь, обнаружитель чего-то.
355
где п – число детекторов (строк) в R; F (α ) – функция (оператор) аффинности – правило определения ЗФА; – критерий останова алгоритма.
В зависимости от конкретизации и детализации АНО в (4.33) могут
добавляться другие его параметры. В частности, явно не задаваться L
или N; N может определяться алгоритмом по уровню достоверности
(надежности, качества) решения задачи (например, через один из критериев остановки ), оцениваемому статистическими методами.
Внимание! Нарисуйте блок-схему алгоритма самостоятельно. При
этом учтите, что АНО опирается на три важных принципа [53]: 1) каждый вариант алгоритма уникален; 2) процесс выявления изменений
имеет индетерминированный , например, стохастический, характер;
3) надежный алгоритм должен обнаруживать не только заданные известные варианты изменений в S, но и любые изменения, чужеродные
для S активности.
Кроме того, следует учитывать, что для многих вариантов своего и
сочетаний значений величин l и r случайная генерация может быть невозможной [53].
Другие иммунные алгоритмы. Множество иммунных алгоритмов
не ограничивается алгоритмами рассмотренных трех классов. В настоящее время разработано большое многообразие алгоритмов, учитывающих разные модели функционирования ИмС. Рассмотрим идею одного класса таких алгоритмов, а именно алгоритмов, основанных на
гипотезе опасности (2002 г.). Согласно этой гипотезе ИмС работает не
только на основании подхода «свой – чужой». Как уже было указано
при рассмотрении АНО, иногда ИмС атакует собственные клетки.
Кроме того, воздействие пищи и множества бактерий, попадающих в
организм человека через кишечный тракт, вообще не инициирует иммунный ответ, они не определяются как «свои» или «чужие». Поэтому
была предложена новая модель работы ИмС, по которой ее активация
происходит в зависимости от того, существует опасность для организма или нет. Такое модельное представление о работе ИмС не отрицает
механизма «свой – чужой», а указывает на то, что помимо него существуют и другие, приводящие к инициированию иммунного ответа.
Это позволяет разграничить различные эффекты воздействия в зависимости от текущих условий и окружающей среды. Одним из алгоритмов, основанных на модели опасности, является алгоритм дендридной
клетки (АДК). В естественных условиях дендридные клетки (ДК) зарождаются и вначале существуют в незрелой фазе, в которой они
356
выполняют функции сбора различных химических сигналов, связанных с переменными уровнями опасности для организма антигенов, и
«образцов» антигенов. По мере того как ДК испытывает высокий уровень сигнала опасности, она взрослеет и, став зрелой, перемещается в
лимфоузел. В нем она представляет свой антиген Т-клеткам, тем самым инициируя иммунную реакцию против этого антигена. Используемый при этом метод, которым ДК определяет, должен ли антиген
быть представлен Т-клеткам, базируется в основном на ассоциациях:
антиген, наблюдаемый перед поступлением сигнала опасности, является причиной этой опасности. Ошибки, допускаемые отдельными ДК,
компенсируются наличием многих ДК, представляющих тот же самый
антиген.
Из других алгоритмов отметим те, в которых используются модели, имитирующие: способности ИмС находить общие структуры в зашумленной среде; возможности эффективного обучения в разных
условиях; возможности обнаружения и поддержки охвата структур,
принадлежащих различным классам; иммунных автономных распределенных систем в виде мультиагентных сетей [53], а также алгоритмы
иммунных адаптивных критиков, адаптивного управления, децентрализованного выбора поведения автономных мобильных роботов [53].
О встроенной компьютерной иммунной системе. Последние годы характеризуются постоянным появлением новых компьютерных
вирусов, резким увеличением скорости их глобального распространения в различных средствах электронных услуг, автоматизацией
процесса их распространения, возрастанием трудностей по их обнаружению и обезвреживанию. Это приводит к идее перехода от использования отдельных антивирусных программ (или наряду с ними) к
применению «врожденных» искусственных иммунных систем,
встроенных их разработчиками в электронные средства, особенно в
сложные информационные, включая вычислительные (компьютерные),
инфокоммуникационные системы и сети.
Попытки создания таких компьютерных иммунных систем
(КИС), подобных естественным ИмС, уже имеют место (см., например,
[53]). Не останавливаясь на рассмотрении вариантов их построения,
ограничимся перечислением требований, предъявляемых к КИС [53],
исходя из того, что КИС должна содержать компоненты как врожденной, так и адаптивной, в том числе приобретенной, защиты. Для этого
КИС должна:
1) иметь врожденный иммунитет, т. е. быть способной автоматически обнаруживать присутствие большого количества незнакомых
357
искусственных вирусов, включая распознавание ранее не встречавшихся вирусов всех возможных типов: файловых, загрузочного сектора, макровирусов (требование врожденности);
2) уметь по одному экземпляру вируса автоматически вырабатывать предписание для его обнаружения и удаления по мере возможности всех его экземпляров (требование адаптивности);
3) осуществлять доставку и распространение антивирусного предписания зараженным элементам информационной системы или сети
как локально, так и глобально – по всему миру (требование осуществления доставки);
4) осуществлять доставку антивирусного предписания быстрее
скорости распространения вируса (требование быстродействия – скорости доставки);
5) допускать модульное наращивание и иметь высокую производительность, чтобы обеспечивать выполнение тысяч и более запросов на
анализ вирусных атак и быстро обновлять антивирусные базы данных
миллионов разных разнесенных компьютеров (требование масштабируемости и производительности);
6) иметь высокую надежность автоматического сохранения и распространения антивирусных предписаний (требование надежности);
7) иметь защиту от перехвата и чтения третьей стороной образцов
вирусов, а также сохранности предписаний, вырабатываемых элементами КИС конечного пользователя (требование информационной защищенности, безопасности);
8) учитывать возможности и интересы пользователей, в частности
по обмену ими образцами вирусов, предписаниями и т. п. (требование
потребительского контроля).
Пример КИС, удовлетворяющей данным требованиям, описан в
[53, c. 272–296].
4.7.8. Другие методы и алгоритмы, пригодные
к использованию в искусственном интеллекте
и мягких вычислениях
Рассмотренные генетические, роевые, иммунные и подобные им
«природные» «биологические» алгоритмы реализуют имитационный
бионический подход к созданию искусственного интеллекта (ИИ). Однако в настоящее время существует много методов, реализующих второй, изобретательский прагматический, подход к созданию ИИ, либо
358
не бионический, а «технократический» имитационный, либо гибрид из
имитационного и изобретательского подходов. Приведем примеры некоторых из подобных методов.
Метод имитации отжига решения задач глобальной оптимизации. Он основан на имитации физического процесса управляемого
охлаждения кристаллизации вещества, например металла, при его
отвердевании (называемого отжигом). В процессе отжига с понижением температуры кристаллизация расплава сопровождается глобальным
уменьшением его энергии. При этом бывают ситуации, когда большинство атомов уже выстроились в кристаллическую решетку, но еще
возможны с какой-то вероятностью переходы отдельных атомов из
одной ячейки в другую. Причем вероятность перехода уменьшается с
понижением температуры. Устойчивость решетки соответствует минимуму энергии атомов. Поэтому «неустроенный» атом либо переходит в состояние с меньшей энергией, либо остается на месте. Возможны также ситуации, в том числе при использовании подогрева
расплава для избежания слишком быстрого его остывания, когда энергия может возрастать на каком-то отрезке времени. Это позволяет избежать нежелательных ловушек локальных минимумов энергии.
Реализующие метод алгоритмы, например нахождения точек локального и глобального минимума многоантимодальной ЦФ f ( x ) ,
x ( x1 , x2 , ..., xn ) , относятся к пороговым циклическим стохастическим локального поиска, в которых на первом шаге начинается старт
из начальной выбранной точки х (решение х), соответствующей температуре отжига T Tmax . В зависимости от решаемой задачи под Т,
условно называемой в методе температурой, понимается своя величина, контекстно аналогичная Т. Затем циклически на шаге 2 пока T 0
N раз выполняются операции: выбор нового решения x из окрестности x ; расчет изменения ЦФ f ( x ) f ( x ) ; если 0 , принять
x x , иначе x x с вероятностью, зависящей от и Т и уменьшающейся при T 0 и увеличении ; шаг 3 – уменьшить температуру Т
(на T ), полагая T T , где – случайное равномерно распределенное на (0,1) число, и повторить шаг 2. На 4-м шаге, когда Т станет равным нулю, может быть проведено обучение алгоритма или той системы (сети), в которую он встроен, например ИНС, обычными методами
локальной оптимизации. Заметим, что метод отжига часто оказывается
эффективным в комбинаторной оптимизации.
359
Метод виртуальных (случайных) частиц. Его идея – использовать случайные сдвиги аргумента оптимизируемой (например, минимизируемой) функции и усреднение значений функции в точках сдвига, чтобы сгладить влияние рельефа функции на процесс поиска
глобального экстремума. Суть метода состоит в том, что к оптимизируемой точке (частице) добавляется несколько других, траектории которых получаются из траектории данной частицы сдвигом на случайный вектор. Эти виртуальные частицы по соответствующим правилам
время от времени уничтожаются и вместо них рождаются новые так,
чтобы уменьшалось (при минимизации) или увеличивалось (при максимизации) среднее значение оптимизируемой функции в этих точках1.
Другие примеры «технических» изобретательских и гибридных методов и алгоритмов приведены в [51], а также будут упомянуты далее
(см., например, упругие карты данных).
Деревья целей и решений. Настоящий пункт раздела касается задач декомпозиции, классификации (в обобщенном понимании, см.
разд. 1.2.2), поиска, выбора вариантов и принятия решений, построения различных моделей разнообразия объектов, их состояний и поведений. Жестким алгоритмам решения таких задач посвящено множество работ, включая десятки учебников и монографий. Часть вопросов
освещена в разделе 4.3.7, § 4.5 (часть 1), а также § 1.2. (часть 2). Проблемные вопросы выбора вариантов, включая коллективный выбор и
семь парадоксов голосования, изложены в [2]. В данном пункте рассмотрим только простейшие наглядные мягкие методы, использующие
для своей реализации человеческий интеллект или алгоритмы, описываемые в данном разделе. Это методы деревьев2 поиска и/или представления результатов поиска вариантов, решений, подцелей, задач и
т. д. Первым рассмотрим методы типа «дерево целей». Как отмечает
Р.Л. Акофф [57], конечные цели организации бывают трех типов:
«идеалы (ideals), промежуточные цели (objectives) и задачи (goals)».
Идеал – цель, которая никогда не может быть достигнута, но к которой
можно бесконечно приближаться. Она может быть составной частью
1
Напомним, что, как указывалось в разд. 4.5.2 (см. часть 1), заменой f ( x )
на – f ( x ) задачу отыскания максимума функции f ( x ) можно заменить на
задачу отыскания минимума – f ( x ) и наоборот. Поэтому часто, описывая
метод или алгоритм, рассматривают не задачу отыскания экстремума, а отыскания только минимума или максимума.
2
См. понятие дерева в разд. 1.3.1, рис. 1.5.
360
миссии организации. Промежуточная – цель, достижимая в отдаленном будущем (например, победа в матче), а задача (как цель) – это то,
что можно достичь за короткое время (забить гол, выиграть текущую
встречу). Подобное деление вполне применимо в моделировании и
анализе данных: цель-идеал – решить задачу пользователя с требуемым качеством за приемлемое время при ограниченных ресурсах.
Цель-задача – получить исходные данные с нужным качеством, промежуточная цель – измерить или оценить корреляционную функцию,
функцию регрессии при соответствующем достаточном для этого модельном описании объекта или без достаточного, но допустимого модельного описания.
Подобное деление целей произведено по их конечному назначению. Второй признак деления – используемая шкала измерения. По
нему цели делятся на качественные и количественные. Третий признак
деления – иерархическая подчиненность. По этому признаку, как уже
неоднократно упоминалось, цели можно разделить на глобальные и
локальные, в том числе выступающие в качестве подцелей целей более
высокого уровня. Именно к этому признаку и относится дерево целей.
Дерево целей (ДЦ) (goals tree)1 – совокупность иерархически
структурированных целей, связей между ними и, по возможности,
средств их достижения, графически изображенная в виде дерева или
допускающая такое изображение.
Построение дерева целей начинается с «корня» – глобальной, генеральной, главной цели, имеющей самый высокий «нулевой» (или 1-й)
иерархический уровень. Обычно дерево целей графически представляется в виде перевернутого дерева. Видимо, именно поэтому иногда
вместо слова «корень дерева» используется неудачно (см. разд. 1.3.1)
сочетание «вершина дерева». 1-й (2-й), 2-й (3-й) и последующие более
низкие уровни включают в себя подцели вышестоящих целей в вершинах графа (узлах ветвления дерева) и могут отображаться в них порядковыми номерами, например, 1.2.1.3. – 3-я подцель цели 1.2.1 или подцель 3 подцели 1 (цели 1.2) подцели 2 цели 1. Ребра графа – ветви
дерева. Признаком завершения построения ДЦ является формулировка
таких целей, отображаемых на конце веток – листьях, которые дальше
не расчленяются и отображают конечные конкретные результаты, которые определяются главной целью (корнем дерева).
1
Термин введен У. Черчменом /C.W. Churchman/ и Р.А. Акоффом /Russel L.
Ackoff/ в 1957 г. [1].
361
При построении ДЦ используются их соподчиненность, развертываемость и соотносительная важность.
Соподчиненность целей обусловливается либо иерархичностью
построения систем управления, либо их важностью по времени, по
значимости для получения итогового (главного) результата или по последовательности в порядке действий, необходимых для этого.
Развертываемость целей – способность целей к декомпозиции, к
делению целей и подцелей каждого уровня на подцели более низкого
уровня.
Соотносительная важность целей заключается в том, что цели
(подцели) одного и того же уровня имеют различную значимость для
достижения цели (подцели) более высокого уровня. Это позволяет
ранжировать цели (подцели) с помощью количественных коэффициентов значимости, устанавливаемых экспертно, по предыдущему опыту,
путем имитационных исследований, экспериментов и другими приемами. При этом сумма неотрицательных коэффициентов значимости
целей каждого уровня должна равняться 1, или в процентах достижения – 100 %. Эти коэффициенты могут изображаться около ребер (ветвей) дерева, как веса этих ветвей. Тогда коэффициент значимости конкретной цели, например, 1.2.1.3 ( 1.2.1.3;1 ) по отношению к главной
цели 1 (или «родной» цели высшего уровня, например, 1.3.1.1;1.3) определяется как произведение коэффициентов (весов ) каждой ветви от
этой конкретной цели (1.2.1.3) до корня дерева (1) (рис. 4.11). Понятно,
что если главная (глобальная) цель сопровождается определяющим ее
векторным показателем качества, то коэффициенты значимости будут
векторными. Иногда для «критических» целей можно помимо коэффициента значимости указывать индикатор , равный 1, если главная
цель будет достигнута, когда цель соответствующего уровня будет достигнута, или 0 в противном случае.
Значение ДЦ и коэффициентов значимостей дает ориентиры для
распределения ресурсов, позволяет представить полную картину взаимосвязей событий по достижению глобальной цели, организовать
работу исполнителей, в частности, ввести распараллеливание (см.
рис. 1.7, в), выбирать стратегию достижения глобальной цели, распределить и согласовать качество результатов достижения каждой подцели с качеством итогового результата или, наоборот, декомпозировать
требуемое качество по уровням, доведя их до качества получения исходных данных, измерения, расчетов в косвенных измерениях, качества оценок и т. д.
362
1.1.2.2
1.2.1.1
1.2.1.2
1.3.1.1
1.3.2=0,4
1.3.1=0,6
1.2.3=0,3
1.2.1.3
1.3.2
1.3.1.2=0,5
1.1.2.1
1.3.1
1.2.3
1.3.1.1=0,5
1.2.1.2=0,4
1.2.2
1.3
1.2.1.3=0,3
1.2.2=0,2
1.1.3=0,3
1.2.1=0,5
1.2.1
1.2.1.1=0,3
1.1.3
1.1.2.2=0,5
1.1.2
1.2
1.1.2.1=0,5
1.1.1
1.1.2=0,3
1.1.1=0,4
1.1
1.3=0,2
1.2=0,5
1.1=0,3
1
1.3.1.2
Рис. 4.11. Фрагмент дерева целей с нанесенными на него коэффициентами
значимости (важности) целей: 1.2;1 = 1.1 = 0,5; 1.2.1.3;1 = 1.2.1.31.2.11.2 =
= 0,30,50,5 = 0,075; 1.3.1.1;1.3 = 1.3.1.11.3.1 = 0,50,6 = 0,3
На необходимость ориентироваться на главную, глобальную цель
при решении любых конкретных задач уже неоднократно указывалось
в пособии (см., например, часть 1, § 3.8 и часть 2, § 6.2, 6.4). Рассмотрим еще один пример.
При аналитической аппроксимации (идентификации) эмпирических распределений и/или проверке гипотез об их соответствии определенным моделям распределений, необходимо вначале выявить глобальную цель такой аппроксимации (идентификации распределения
или проверки гипотезы). Ею может быть компактное представление
имеющихся эмпирических данных для хранения в памяти или для
имитации в последующем выборочных значений, стохастически аналогичных имеющимся; определение долей попадания значений в определенные диапазоны; выявление «механизма» образования случайности по аналитическому описанию распределения и формирование
портфолио для подобных данных или моделей; расчет вероятностей
выхода за пределы допуска, например, при исследовании высокона363
дежных изделий с постепенными отказами; расчет мер неопределенностей ситуаций, например, по Шеннону, или информативности выборки, по Фишеру или Кульбаку-Лейблеру; описание закона распределения погрешностей измерения и т. д. При этом необходимо знать, какое
именно распределение представляет интерес для идентификации или
проверки гипотезы: исходное эмпирическое или очищенное от внешних факторов. Одно дело, когда надо проверить гипотезу об «очищенном» распределении, другое – когда аппроксимация (идентификация)
эмпирического распределения нужна для упрощения решения прикладной задачи, «расщепления» его на составляющие распределения и
поиска «источников» появления смеси либо для аналитического преобразования выборки с целью применения затем к преобразованной
выборке имеющихся пригодных для нее средств распознавания образов, имитации новых выборочных последовательностей из той же генеральной совокупности и т. д.
В зависимости от этого подцели типа «определение наилучшего
вида и значения показателя качества аппроксимации» или «определение наилучшего способа проверки гипотез», «нахождение оптимальных, целесообразных или рекомендуемых значений параметров алгоритмов оценивания распределений и/или проверки гипотез», «очистка
выборки», «определение однородности выборки», «расчет погрешности измерения элементов выборки», как и ДЦ в целом, будут существенно зависеть от главной цели.
Внимание! Попробуйте изобразить ДЦ для разных главных целей
аппроксимации распределений при разных априорных сведениях о выборке или о результатах предварительного исследования ее. Потребуется ли вам для этого знание об обоснованности применимости для
описания объекта, к которому относятся эмпирические данные, именно стохастического, а не нечеткого или интервального подхода? Иными словами, не окажется ли сформированная вами глобальная цель
подцелью более общей постановки задачи?
Подобное ДЦ рекомендуется изображать при решении задач идентификации и прогнозирования временных рядов, корреляционном, регрессионном, спектральном анализе как, впрочем, и во всех других задачах моделирования и исследования объектов.
В ряде случаев, например, когда цель определяется векторным показателем, возможен лес из деревьев целей, а также усложнение структуры дерева целей.
364
Помимо собственно методов построения дерева целей в класс методов типа «дерево целей» включаются другие, отражающие бесцикловое ветвящееся развитие событий, процессов, функций и т. п. Они
называются по-разному в зависимости от приложений. Например, в
задачах принятия решений применяется термин «дерево решений»;
при исследовании систем – «дерево функций» или «дерево целей и
функций»; при исследовании – «дерево проблем» или «дерево задач»;
при разработке сценариев, прогнозов – «дерево направлений развития»
или «прогнозный граф» и т. д. При этом имеются специфические особенности построения и изображения таких деревьев. В частности, они
отличаются приемами включения в них или отсечения отдельных узлов и ветвей, правилами разделения объектов, остановки, т. е. оценки
целесообразности дальнейшего разбиения, обучения и т. п. Для многих
из них характерны правила, описываемые логической конструкцией
вида «если …, то …», а каждому объекту, к которому применяется это
правило, соответствует единственный узел, дающий решение. Чаще
всего при этом используются следующие понятия. Объект – это рассматриваемая вещь, пример, шаблон, результат, субъект и т. п. Атрибут – признак, свойство, независимая переменная, характеризующие
объект. Метка класса (решения) – целевая переменная, зависимая переменная, признак, определяющий класс объекта. Узел – внутренняя
вершина (узел) дерева; точка (вершина) ветвления – точка (вершина,
узел) проверки. Единственный особый узел, являющийся основой дерева, называется корневым или корнем дерева (узел 1 на рис. 4.11).
Лист – конечный (наружный) узел дерева, узел конкретного решения.
Проверка (тест) – условие в узле проверки, т. е. узел, находящийся в
конце любой цепочки подряд идущих ребер (узлы 1.1.3, 1.2.2, 1.2.3,
1.3.2 и все нижние по уровню на рис. 4.11).
Для удобства визуального восприятия дерева его узлы разных типов представляются разными геометрическими фигурами (см., например, рис. 4.11). При дополнительной детализации может применяться
более двух геометрических фигур. Например, для деревьев решений
узлы детерминированных решений изображаются квадратом, вероятностных – кругом, нечетких – ромбом, замыкающие узлы (листья) –
треугольниками.
Иногда вместо дерева целей или решений может использоваться
лес целей и решений, как набор деревьев, используемых для решения
той же задачи. При этом с отдельными или со всеми деревьями леса
могут проводиться разные операции, связанные с итерационным
365
приближением к искомому решению, уточнению атрибутов, получению усредненных многоточечных или интервальных решений, их
ранжированию и т. д.
Одним из приложений ДЦ является его использование как модели
представления знаний [23]. В приложение к обработке данных обычно
рассматривают деревья решений (Decision Trees – DT) и деревья описания данных, а также деревья классификации и деревья регрессии.
Деревья описания данных – это иерархическая структура компактного представления о данных или точного описания их элементов.
Деревья классификаций – иерархическое решение задач модельного представления разнообразия исследуемых объектов путем их
классифицирования с использованием мягких алгоритмов. При этом
множество выходных решений (меток) является дискретным и касается конкретных категорийных или количественных элементов входных
данных.
Деревья регрессий отличаются от деревьев классификаций рядом
важных особенностей. Рассмотрим три из них. Первая – выходные
данные, метки измеряются в непрерывных количественных шкалах и
могут представляться в числовой, графической или аналитической
форме. Вторая – выходной результат представляется в виде среднего
значения метки – скалярной или векторной целевой переменной, зависящей от количественных или качественных атрибутов и отражающей
итоги «непреднамеренной» кластеризации атрибутов («объясняющих»
переменных) с помощью мягких алгоритмов поиска наилучших частных (кластерных) регрессий. Третья особенность вытекает из второй и
связана с тем, что «кластеризация» происходит не на уровне отдельных элементов выборки (значений атрибутов), а усреднено, через
среднее значение метки.
Пример построения подобного дерева с использованием модификации муравьиного алгоритма приведен на рис. 4.121.
Наиболее часто используемыми средствами построения деревьев
классификации и регрессий являются: CART (Classification And
Regression Тrees, 1983 г.), Random forest (случайный лес), Tree Net,
Stoxastic Gradient Boosting (Стохастическое Графическое Добавление,
1999 г.).
1
Мельников Г.А. Метод построения деревьев регрессии на основе муравьиных алгоритмов // Г.А. Мельников, В.В. Губарев. – Доклады ТУСУРа,
2014, № 4 (34). – С. 72–78.
366
Рис. 4.12. Пример разбиения данных на сегменты и соответствующего
ему дерева регрессии
Когнитивные методы1. Включение этого пункта в настоящий раздел объясняется четырьмя обстоятельствами. Первое – когнитивные
методы – это одно из направлений семантического, знаниевого и событийного подходов к исследованию объектов. Второе – они уже нашли
различные практические приложения. Третье – когнитивное моделирование – одна из важных областей применения рассмотренных ранее
мягких методов. Четвертое – когнитивные методы и результаты анализа отдельных личностей и сообществ могут оказаться полезными при
создании искусственного интеллекта. В частности, они могут помочь
имитировать влияние на личность и социум когнитивных факторов,
выявить наиболее доступные когнитивные способы влияния на них,
воссоздать или имитировать имеющиеся у человека знания, даже если
он их намеренно скрывает. Дело в том, что по своей сути когнитивный
подход к исследованию различных объектов, в том числе к анализу,
исследованию Данных, основан на акцентировании внимания на процессах представления, хранения, обработки, интерпретации и производства именно знаний, на системном рассмотрении процессов восприятия, мышления, познания, объяснения и понимания, свойственных
человеку. Подчеркнем, не только и даже не столько на интуиции человека, сколько на упорядочении и проверке истинности (верификации)
знаний о сложном объекте, системе, задаче, проблеме, ситуации.
1
Считается, что впервые термин «когнитивная карта» ввел в рассмотрение Э. Толмен в 1948 г., а методологию когнитивного моделирования предложил Р. Аксельрод (R. Axelrod, США, 1976 г.).
367
Считается, что когнитивные методы не изменяют имеющуюся информацию, но создают условия, при которых она превращается в иное
знание, получает иной смысл, т. е. они относятся к семантическим, событийным методам работы не столько с Данными, сколько с информацией. Так ли это – вы выясните, используя излагаемое ниже.
Чаще всего в классе когнитивных методов рассматривают методы
когнитивного анализа и когнитивного моделирования.
Побудительным мотивом введения когнитивного анализа и моделирования явился хорошо известный факт того, что, сталкиваясь с одними и теми же объектами, ситуациями, событиями, явлениями, фактами, люди могут очень по-разному их воспринимать и оценивать и,
как следствие, по-разному на них реагировать. Одной из важнейших
причин этого является то, что люди извлекают из жизни, событий,
фактов разные знания. Причем этот процесс извлечения определяется
когнитивными факторами, влияющими на процесс познания людей,
осмысления ими получаемой информации, выявления определенного
смысла в ней в каждой конкретной ситуации, при каждом конкретном
событии.
В основе когнитивного анализа Данных (КАД) лежит познавательная (когнитивная) структуризация знаний об исследуемом объекте и
окружающей его среде.
В настоящее время под термином «когнитивный анализ данных»
понимают чаще всего область работы с данными, ориентированную на
эмпирические предсказания, распознавание образов, машинное обучение, интеллектуальный анализ данных, направленные на реализацию
индуктивного подхода к исследованию объектов такими методами, с
помощью которых человек и животные приобретают и применяют
знания об окружающем мире [5]. Индуктивный подход здесь проявляется в том, что в КАД основной упор делается на эмпирические данные об исследуемом объекте с целью обнаружения скрытых в данных
эмпирических закономерностей и использования этих закономерностей для решения задач распознавания, прогнозирования, принятия
решений и им подобных. Получаемые в ходе КАД закономерности
имеют характер предположений, эмпирических гипотез, справедливость которых затем необходимо проверить на конкретных примерах.
Рабочим инструментом КАД являются методы, рассмотренные ранее в § 1.2, а также методы ИАД, рассматриваемые в настоящем параграфе (см. также § 4.9), а также методы построения решающих правил,
определения компактности образов, кластеризации и классификации,
368
выбора информативных признаков, обнаружения ошибок и заполнения
пробелов в данных, анализа знаний и структур. Часть этих методов
рассмотрена в настоящем пособии, часть описана в работе [5], в которой основное внимание уделено относительной (вместо ранее использованных абсолютных) мере «конкурентного» сходства между объектами и мере компактности образов, а также разным измерительным
шкалам. Рекомендуем ознакомиться с рассматриваемой в [4, 5] классификацией задач анализа данных, построенной по «кубу данных»
«Объект – Свойство – Время» и ориентированной на обнаружение закономерностей, скрытых в данных, и использование этих закономерностей для предсказания новых данных.
Под когнитивным анализом или когнитивной структуризацией
среды (задачи, проблемы, ситуации, предметной области и т. п.) понимается метод исследования нестабильной, сложной, слабоструктурированной внешней по отношению к исследуемому (в широком смысле)
объекту среды путем выявления основных факторов, влияющих на
развитие ситуации, отражающей состояние и поведение системы «объект – внешняя среда», причинно-следственной взаимосвязи состояния
и поведения этой системы между собой и взаимовлиянии факторов,
когда среда описывается как объективно через количественные зависимости, так и субъективно через экспертов. Здесь под нестабильной
понимается очень динамичная, подвижная, плохопредсказуемая среда,
под сложной – многоаспектная, под слабоструктурированной – плохоформализуемая, а под «причинно-следственной» понимается либо
законовая (детерминированная), причинная связь, либо статистическая
(закономерностная), нечеткая, экспертная связь, когда направление
связи имеет смысл, обоснованный «физикой», «механизмом» ее действия. Кстати, в зависимости от ситуации для некоторых факторов
направление может измениться на противоположное.
Одним из элементов когнитивного анализа является построение когнитивной модели ситуации, в которой находится система «объект –
среда»1. Когнитивная модель затем служит инструментом для дальнейшего анализа, когнитивного моделирования системы «объект –
среда».
Когнитивная карта (схема) ситуации (среды) – это ориентированный граф, вершины которого представляют собой выделенные
1
Обычно объект в модели подразумевается, присутствует косвенно, однако его всегда важно иметь в виду, поскольку без него модель не имеет смысла.
369
базовые факторы (наиболее значимые признаки, характеристики ситуаций, среды), а дуги – причинно-следственные связи между факторами
(см., например, [84]).
Когнитивная модель ситуации (среды) – это функциональный
граф, представляющий собой орграф (когнитивную карту) с нанесенными на нее значениями весов дуг графа (оценок влияния и взаимовлияния факторов).
Что касается весов графа, то они могут представлять собой аналитическое описание зависимости (например, регрессионной, скедастической) между факторами (или номер ссылки на нее), число, отражающее количественно степень связи (как в графе, изображенном на
рис. 1.15), или значение лингвистической переменной вида: «слабый»,
«умеренный», «большой», «ажиотажный» спрос на продукцию или
билеты. Кроме когнитивных карт (схем ситуаций) могут использоваться когнитивные решетки (шкалы, матрицы), ориентированные на
определение стратегии поведения системы. Решетки образуются с помощью такой системы факторных координат, когда каждая координата
соответствует своему фактору, количественному или категорийному,
четкому или нечеткому (лингвистическому) показателю или некоторому интервалу изменения фактора (показателя), а область решетки –
соответствующему поведению системы [84].
Обратим внимание на то, что влияние факторов друг на друга по
характеру может быть положительным или отрицательным. При положительном влиянии увеличение (или уменьшение) действия одного
фактора приводит к увеличению (уменьшению) действия другого, а
при отрицательном – увеличение (уменьшение) влияния (действия)
одного фактора приводит к уменьшению (увеличению) действия другого. На когнитивных картах тип связи указывается знаком «+» для
положительной связи, знаком «–» для отрицательной и «» для знакопеременной. Заметим еще раз, что при изменении условий влияние
может быть знакопеременным.
Факторы, представляющие наибольший интерес для субъекта (исследователя, пользователя), называют целевыми. Это выходные факторы когнитивной модели, поскольку назначением когнитивного моделирования в процессе подготовки решений является помощь в
обеспечении желательного изменения именно целевых факторов. Из
многообразия факторов выделяют базовые, существенно влияющие на
ситуацию, и «избыточные», малозначащие, слабо влияющие на ситуацию и на другие факторы. В задачах управления среди базисных выде370
ляют управляющие факторы, рассматриваемые как «входные» факторы
когнитивной модели. Кроме того, выделяют внутренние и внешние
(предсказуемые и непредсказуемые) факторы, краткосрочные или долгосрочные, факторы-причины и факторы-следствия, факторыиндикаторы изменения ситуации (типа флагов катастроф).
Наличие разнообразия факторов и разные направления и степени
связи между ними являются важнейшей трудностью при их ранжировании, отнесении к базовым или другим на этапе построения когнитивной модели.
В заключение приведем обобщенную схему технологического процесса когнитивного анализа и моделирования ситуаций, изображенную
на рис. 4.13 (см. часть 1, рис. 2.3, 3.4, а также [84]), и заметим, что когнитивный анализ в качестве составных может содержать элементы и
результаты технического анализа, направленного на формализованное выявление количественных показателей состояния среды при
практическом игнорировании качественных аспектов взаимовлияния
факторов. Обычно в бизнесе и финансовой сфере технический анализ
(ТА) направлен на прогнозирование движения цен (точнее, на оценку
картины происходящего) на рынке, основанное на гипотезе существования «памяти рынка», т. е. на закономерностях, существовавших в
прошедшем периоде, и построенное путем анализа истории изменения
котировок по графикам в определенный период вероятных направлений трендов. Иными словами, ТА ориентирован на прогнозирование
цен в будущем на основе графических закономерностей, имеющих
аналогичные изменения (паттерны) цен и сопутствующих им обстоятельств в прошлом в схожих ситуациях без выяснения причин происходящего.
Одно из достоинств когнитивного моделирования – предоставляемая им возможность действовать на опережение, использовать упреждающее управление, не доводить состояние ситуаций до критических. Согласно [84], когнитивный инструментарий позволяет снижать
сложность исследования, формализации, структурирования, моделирования системы. Помимо когнитивных карт позновательно-целевая (когнитивная) структуризация и когнитивный анализ выполняются с помощью других видов анализа, например, PEST- и SWOT-анализа.
В PEST-анализе выделяются следующие четыре группы аспектов
(факторов) состояния и поведения исследуемых объектов, ситуаций;
политика (Policy), экономика (Economy), общество (социум, социальная сфера) (Society) и технология (Technology). В SWOT-анализе – это
371
сильные (положительные) стороны (Strengths), недостатки (слабые
стороны) (Weaknesses), возможности (Opportunities), угрозы (Threats),
характерные для текущего состояния объекта, ситуации.
Постановка задачи
(формулировка цели и задач)
исследования
Изучение объекта исследования, сбор данных,
выявление требований, ограничений
Построение когнитивной карты или
иерархии карт ситуации (выявление
и ранжирование факторов, их видов,
направлений, характера связи, …)
Построение когнитивной модели или
иерархии моделей ситуации (определение
направлений и весов факторов, нанесение
их на карту, верификация модели, …)
Исследование ситуации по модели
(разработка сценария развития ситуации,
прогноз, синтез комплекса мероприятий,
определение граничных точек и т. д.)
Апробация, внедрение и проверка модели
на практике, оформление итогов анализа
и моделирования
Рис. 4.13. Обобщенная схема технологического процесса
когнитивного анализа и моделирования ситуации (задачи,
проблемы)
Визуальное моделирование. Как уже неоднократно отмечалось,
визуальные средства являются хорошим помощником при работе с
Данными и информацией, в частности, при восприятии информации,
ее семантической обработке человеком.
Визуальное моделирование – это моделирование естественных и
искусственных объектов действительности, окружающего мира, когда
372
модель представляет собой зрительный образ (см. разд. 1.5.2), т. е.
зримую абстракцию исследуемого (в широком смысле, см. § 1.1)
объекта.
В последнее время оно все чаще применяется в проектировании
программного обеспечения, баз данных, электронных схем и устройств, строительных конструкций, технических изделий, реконструкции геологических производств по имеющимся геофизическим данным, как эффективный метод исследования в космологии. Особенно
эффективно его применение там, где возможно создание визуальных
3D-моделей трехмерных пространственных объектов, характеризуемых большим количеством показателей и большим объемом сопутствующих им данных, а также динамических моделей их развития во
времени, в частности, в виде анимаций (от лат. animatus – живой, одушевленный). Трехмерное представление, особенно динамичное, характерно тем, что все его компоненты создаются с сохранением «физического смысла» происходящего, с локализацией их без использования
каких-либо условных представлений и искусственных преобразований
для представления на плоскости.
Визуальные модели, как любые другие модели, могут создаваться с
разной целью и выполнять разные функции (см. часть 1, рис. 1.1 и
табл. 2.2, а также [24, 34]). Например, визуальные модели могут быть
моделями-имитаторами, интерпретаторами, «передатчиками» и т. п.
Одним из важнейших свойств и качеств визуальных моделей, а
также требований к ним являются свойства и требования компактности, выразительности (наглядности), когнитивности, побудительности,
отражения динамики развития объекта, конкретизирующие и дополняющие общие свойства и требования, приведенные в разд. 2.1.2
(часть 1). Требование (свойство, качество) когнитивности означает,
что визуальная модель и визуальное моделирование должны содержать
и создавать по возможности все необходимые или хотя бы достаточные релевантные знания об исследуемом объекте с учетом цели исследования и при этом учитывать способности субъекта к обработке,
интерпретации и производству знаний с учетом его процессов восприятия зрительных образов, мышления, познания, объяснения и понимания. Требование (свойство) побудительности модели означает, что
она должна побуждать субъекта проявлять все свойственные ему способности, обеспечивать появление системного эффекта синергии,
эмерджентности, проявления озарения и т. д.
Визуальные модели могут выполнять функции моделей-имитаторов или моделей-интерпретаторов. Модели-имитаторы (подража373
тели) призваны взаимнооднозначно или однозначно передать все пространственные и другие соотношения и связи между элементами объекта, в то время как модели-интерпретаторы ориентированы на максимально наглядное представление ее пользователю в удобной для его
задач форме без необходимости взаимнооднозначного отображения
объекта.
Заметим, что, как уже указывалось, требования могут быть противоречивыми и по-разному ранжироваться. Так, например, для обеспечения требований когнитивности и побудительности на второй план
могут отступить требования ингерентной адекватности и точности
(см. часть 1, § 1.2). Образно говоря, визуальная реалистичность модели
может оказаться второстепенной по отношению к ее информативности.
Хорошим инструментом визуального моделирования являются
следующие средства.
1. Специальные, ориентированные на это программные языки.
Например, языки графического визуального моделирования типа
UML – унифицированного языка моделирования (Unified Modeling
Lanquage), который широко применяется при проектировании различных информационных систем. Он позволяет детально описать систему,
начиная с создания ее концептуальной модели, описывать особенности
реализации системы, в частности, классы ПО, модели данных и т. д.
2. Модели зрительного представления данных и результатов их
анализа, рассмотренные в § 1.5, а также методы и средства компьютерной (машинной) графики и когнитивной графики.
3. Совмещение аналитических математических приемов с графическими. Например, использование метода главных компонент (МГК)
(см. математическая статистика) и метода фазовых траекторий в
пространстве или на плоскости (см. часть 1, разд. 4.4.5) для качественного отслеживания динамики какого-то процесса. Так, в [82] МГК был
применен для выделения в стационарном временном ряде x(it ) ,
i 0, 1, 2, ..., N 1 , t – одни сутки (день), первых пяти значимых по
убывающей величине дисперсии некоррелированных составляющих
y1 (it ), y2 (it ), ..., yk (it ), ..., y N (it ) (рис. 4.14).
А в [83] использовано совмещение аналитического представления
регрессионной оценки логистической вероятности p(α ) – развития сердечно-сосудистых заболеваний (ССЗ) мужчин в возрасте 35–65 лет
от количественных и качественных данных с расцветкой или разметкой
374
Объем притока, км 3
Второй компонент, км 3
38
1914
1924
1934
1944
1954
–30
–90
–20
–10
0
10
20
30
–80
39
48
22
13
1431
15
305
25
–60
12
4
21 36
46
6
51
24
28
32
б
1994
- многоводные годы
1984
43
–40
19
53
9
–30
10
18
- маловодные годы
44
11
33 27
1974
20 45
34
26
42
52
17
35
–50
8
41
1964
Первый компонент, км3
–70
47
37
49
23 50
16
40
ТРАЕКТОРИЯ
ФАЗОВАЯ
а
Год
30
30
1904
40
40
20
50
50
20
1894
60
60
прогнозный объем притока
70
80
80
70
90
90
–20
3
–22
–66
–18
–14
–10
–6
–2
2
6
10
86
87
–60
85
94
95
–54
2001
97
84
2000
–48
82
92
89
в
Первый компонент, км
93
96
88
ФАЗОВАЯ
ТРАЕКТОРИЯ
3
99
83
98
–42
90
91
–22
–36
–18
–14
–10
–6
–2
2
6
10
прогнозная траектория
реальная траектория
375
а – временного ряда среднегодового объема притока воды
реки Обь к створу Новосибирской ГЭС за 1904–1977 годы;
б – фазовой траектории в пространстве первой и второй
главных компонент ряда за 1904–1952 годы; в – фазовая траектория первой и второй компонент ряда за 1954–1997 годы
с расчетом прогнозных значений
Рис. 4.14. Графическое отображение эмпирических
и расчетных гидрологических данных:
Второй компонент, км
1
на графике (рис. 4.15). Здесь pˆ (α ) – оценка вероятности p 1 e z ,
где z 0 1 x1 ... n xn – регрессионная зависимость z от xi ,
i 1, n , количественных значений xi i-го фактора риска заболевания
ССЗ; α (0 , 1 , ..., n ) – параметры, подлежащие оцениванию по
выборке из N значений ( x1 , ..., xn ) популяции индивидуумов объема N.
Некурящие мужчины
0,9
0,9
0,8
0,8
0,7
0,6
0,5
0,4
0,3
0,2
Курящие мужчины
1
Вероятность развития
Ве роятность развития
1
0,7
0,6
0,5
35 лет
40 лет
45 лет
50 лет
лет
55 лет
60 лет
65 лет
0,4
0,3
0,2
0,1
0,1
0
0
90
100 110
120 130 140 150 160 170 180
90
Систолическое давление, мм р. ст.
100 110 120 130 140 150 160 170 180
Систолическое давление, мм р. ст.
Рис. 4.15. Зависимость эмпирической вероятности развития ССЗ у курящих и некурящих мужчин в возрасте от 35 до 65 лет от среднесуточного систолического давления: жирная горизонтальная прямая отражает
значение среднепопуляционного риска от разных факторов и лет
4. Многомерные модели данных (см. § 1.2) и карты данных для визуального представления многомерных данных. Карты данных – это
метод и результат представления п-мерных данных n 3 на плоскости
путем преобразования (нелинейного сокращения) данных из п-мерного
пространства в двумерное. К ним относятся, например, самоорганизующиеся карты Т. Кохонена и упругие карты1 А.Н. Горбаня – А.Ю. Зиновьева – А.А. Питенко [59]. Согласно [49], цель нелинейных методов
отображения п-мерных данных, когда n 3 , в двух-, реже в трехмерное пространство – построение наглядного геометричесмкого представления, отражающего особенности структуры данных. По своей
1
Термин отражает взятый А.Н. Горбанем за аналог принцип минимизации
энергии упругой деформации мембраны или пластинки в механике.
376
сути они свободны от ограничений на вид преобразования – лишь бы,
во-первых, отражение структуры данных однозначно соответствовало
их фактическому составу, во-вторых, новое координатное пространство имело понятную интерпретацию. Для этого вводится некоторая
мера искажения данных при преобразовании и критерий качества,
направленный на минимизацию . Чаще всего такая мера основана на
взвешенном среднеквадратическом сравнении попарных расстояний
между элементами данных в исходном и новом пространствах. Карты
данных являются примерами моделей-интерпретаторов, ориентированных на отражение отдельных необходимых пользователю свойств,
составов и других особенностей данных с максимальной наглядностью
и повышенной степенью выразительности, не учитывая, пренебрегая
или даже искажая другие особенности, не интересующие пользователя,
но так, чтобы не исказить при этом необходимые особенности. Иными
словами, в таких моделях-интерпретаторах визуальная реалистичность
модели выступает второстепенным показателем (характеристикой) ее
качества по отношению к информативности модели.
5. Средства географических информационных (геоинформационных) систем (ГИС) – многофункциональных систем сбора, хранения,
анализа и графической визуализации географических пространственных данных и связанных с ними сведений о существующих объектах,
необходимых при решении разнообразных расчетных задач, подготовке и принятии решений.
Визуальное моделирование является одним из инструментариев визуального анализа данных в контексте их исследования (см. далее разведочный анализ данных, связанный с операцией построения апостериорных гипотез) путем вовлечения человека в процесс отыскания свойств и
особенностей данных, скрытых в них закономерностей. Идейной основой такого исследования (анализа) является переход от спискового, табличного и других форм представления данных, особенно их больших
объемов, к такой форме, при которой человек мог бы увидеть, распознать, обнаружить, понять то, что трудно формализовать, сделать алгоритмически. Это особенно полезно, когда объем данных велик, они
представляются многомерно по многим показателям, о них мало что
известно и, что особенно важно, когда не до конца понятна цель их исследования и ее может подсказать визуальная модель данных (ТП-ЧР).
Это следует из того, что согласно изложенному ранее, визуальное моделирование и анализ могут быть эффективными в тех ситуациях, когда:
отсутствуют формализация, четкие алгоритмы работы с данными, возникает необходимость прибегать к использованию способно377
стей человека, его интуиции и других отличительных особенностей
работы с информацией и ее носителями (задачи ТП-ЧР, ОП-ОР);
специалисты, привлекаемые к работе с данными или вынужденные работать с ними в силу своих профессиональных обязанностей, не
владеют необходимым математическим аппаратом, а визуальный анализ позволяет обойтись без сложной детерминированной и стохастической обработки данных;
необходимо бегло выделить интересные паттерны (шаблоны, образцы) и закономерности данных, с тем чтобы с ними можно было
непосредственно работать далее, подвергать очистке, фильтрации, рассматривать в большем масштабе или, наоборот, детализировать информацию, содержащуюся в данных.
При этом в качестве данных могут выступать одномерные и многомерные количественные и качественные массивы и временные ряды;
плоскостные и объемные данные как точки двумерного или трехмерного пространства; тексты и гипертексты; различные схемы, структуры; алгоритмы и программы и т. д.
Помимо указанных в разд. 1.5.2 зрительных моделей часто используются: теоретические и эмпирические диаграммы разброса данных
(типа изображенных на рис. 4.5–4.7, часть 1, и на рис. 1.1–1.3, часть 2),
пиксельные (рекурсивные шаблоны, циклические сегменты (см. часть 1,
рис. 4.17, 4.18), в том числе отображающие значения результата измерения в виде цветных пикселей); иерархические структуры; иконки,
отражающие не только значения элементов многомерных данных, но и
свойства образов (типа лиц Чернова, смайликов и т. д.).
Методы недоопределенных вычислений. Отдельный класс составляет подкласс задач (типов ЧП-ОР, ТП-ОР, ОП-ЧР), находящийся
на стыке «задач» и «проблем». Это задачи, для которых известна ее
модель, но нет алгоритма решения. При этом модель задается в виде
неупорядоченной совокупности отношений, связей, существующих
между параметрами задачи. Эти отношения принято называть «ограничениями». Они представляются в виде уравнений, неравенств, логических выражений и т. п. Сами параметры априори не разделяются на
входные или выходные, некоторые из них, как считает пользователь,
заданы точно, некоторые не известны совсем, а некоторые – представлены приблизительно – в виде ограничений на множество их возможных значений.
В самом общем виде постановки таких задач выглядят так. Имеются переменные x1 , x2 ,..., xn с областями их значений X1 , X 2 ,..., X n .
378
В конкретной задаче на возможные значения xi , i 1, n накладывается
система из k ограничений Cl ( x1 , ..., xn ) , l 1, k . Требуется найти наборы значений (a1..., an ) , ai X i , i 1, n , которые удовлетворяли бы
всем ограничениям одновременно. Такая постановка часто называется
проблемой удовлетворения ограничений, а методы автоматического
нахождения решения таких задач – программированием в ограничениях
(с ограничением), как отличное от императивного, алгоритмического,
логического, функционального и др. [85, 66]. Такие методы особенно
полезны там, где возможности обычных математических методов не
помогают.
Рассматриваемые в таких задачах переменные называют недоопределенными. Их отличие от классических состоит в следующем. Значение классической переменной, во-первых, отражает некоторую конкретную, заданную условиями решаемой задачи, сущность (денотат),
представляемую в задаче именем данной переменной, во-вторых, не
меняется в рамках одной задачи, в-третьих, оно либо точно известно,
либо неизвестно. Неопределенная же переменная, во-первых, принимает значения из непустого подмножества универсума Х, включающего в себя как точное значение (как классическая переменная), так и неопределенные значения (интервалы, набор альтернатив, полностью
неизвестное значение). Во-вторых, ее значение может изменяться, а
именно уточняться при поступлении новых данных большего объема
или более точных, когда неопределенные вначале значения становятся
в ходе решения задачи все более определенными (интервалы сужаются, количество альтернатив уменьшается и т. д.) и в пределе может
стать точной, т. е. равной денотату.
Рассмотрим идею недоопределенных вычислений на простейшем
примере решения системы из двух линейных уравнений [85]
( F1 ),
y x 1,
2 y 3(2 x), ( F2 ),
(4.34)
если известно, что x [1, 4] .
Рассмотрим каждое из уравнений системы (4.34) в виде неявных
функций F1 и F2 от двух переменных х и y. Лучше изобразить их графически. Теперь по текущей оценке х, y поочередно вычисляем проекции F1 и F2 на х и y (точки на прямых F1 и F2 проецируем на
379
оси х, y). Первая проекция F1 на y для x [ 1, 4] равна интервалу значений yˆ [2,3] . Теперь, вычисляя по y [2,3] проекцию F2 на х,
получаем уточненное значение xˆ [0,10 / 3] . Продолжая такое итерационное проецирование и изображая его графически (сделать это самостоятельно!), получим точное решение в виде точки пересечения F1
и F2 . Графически это будет представляться в виде закручивающихся
прямоугольных спиралей, отражающих приближение текущих оценок
( xˆ , yˆ ) к решению снизу и сверху.
Одним из наиболее часто используемых вариантов решения подобных задач является метод недоопределенных моделей (Н-моделей) Нариньяни [85], являющихся частным случаем обобщенной вычислительной модели (ОВМ) Нариньяни–Телермана [66]. Под ОВМ понимают
кортеж M V ,W , C , R , состоящий из следующих элементов [66]: V –
множество объектов из заданной предметной области; W – множество
функций присваивания; С – множество функций проверки корректности; R – множество ограничений на значения объектов из V.
Второй разновидностью ОВМ являются G-модели [66]:
M G X, RM , PM , M , где X xi , i 1, n – конечное множество
переменных, характеризующих объекты из заданной предметной области; RM – конечное множество отношений на множестве Х; PM – конечное множество предикатов, предметными переменными которых
являются элементы из Х; M – отображения RM в PM , ставящее в
соответствие каждому отношению из RM элемент из PM .
Одним из инструментов для решения недоопределенных задач является программная система UniCalc, которая выдает сообщение о несовместимости системы уравнений либо может выдать для каждой переменной интервал, но никогда для несовместимой системы не будет
выдано точное значение в качестве решения [85].
Помимо решения систем линейных алгебраических уравнений подобный подход используется при нахождении корней полиномов п-го
порядка, тригонометрических уравнений, задач оптимизации (например, нахождение минимума функции Розенброка или функций ппеременных) и т. д.
Завершим раздел сопоставительной таблицей рассмотренных методов (табл. 4.1).
380
381
2
№
п/п
1
Генетические
Принципы и механизмы наследственности
и естественного отбора в процессе биологической
эволюции;
совмещение детермини-
Класс методов
Идейная
и алгоритмов
основа
Нейросетевые Структура и механизм
работы биологических
нейрона и нейронных
сетей
381
1. Необходимость привязки алгоритмов к задаче
2. Должно быть не менее 50–
100 наблюдений для настройки
3. Большие затраты труда и
времени на настройку и переобучение сети
4. Возможное попадание в
«ловушки» в виде локальных
экстремумов
5. Необходимость тщательного выбора диапазона входных
переменных
6. «Непрозрачность» процесса
получения решения
7. Возможность
получения
больших ошибок, если поступающие данные отличаются
от тех, по которым обучалась
сеть
1. Независимость аппроксимирующих свойств сетей
(погрешностей аппроксимации) от размерности пространства
2. Необходимость только
переобучения сети при учете новых факторов вместо
изменения правил работы,
что может уменьшить затраты времени на решение
конкретной задачи
3. Параллельность решения задач
4. Возможность экстраполировать результаты
5. Пригодность для решения задач, когда есть много примеров, но нет алгоритмов решения, имеется
много входных данных;
имеет место зашумленность, частичная противоречивость, неполнота или
избыточность данных, явная или неявная зависимость в них
1. ГА не накладывают
никаких ограничений на
вид целевых функций
2. Пригодность для решения сложных задач, в том
числе крупномасштабных
1. Поиск оптимальных решений для сложных задач часто
является очень времяемким
2. Плохая масштабируемость
под
сложность
решаемой
задачи
Слабые стороны
Сильные стороны
1. Поиск экстремумов
и оптимизация функций
2. Задачи на графах
(в том числе NP-сложные)
Задачи распознавания
и классификации, регрессии, идентификации, управления, прогнозирования, диагностики, вычислений, оптимизации и т. п.
Области приложений
Краткая характеристика мягких методов и алгоритмов, используемых в ИИ
Т а б л и ц а 4.1
382
3
№
п/п
Роевые
Принципы и механизмы коллективного поведения
множества
социально связанных
в обособленные группы родственных особей
382
1. Простота реализации
2. Пригодность для задач
с большими размерами.
3. Совместимость процедур локального поиска
с вариацией размера задачи
4. Высокая скорость сходимости к субоптимальному решению
Класс методов
Идейная
Сильные стороны
и алгоритмов
основа
Генетические
рованных и стохасти- 3. Отсутствие необходических процедур
мости иметь дополнительную информацию или допущения
4. Широкий круг решаемых задач, в том числе
в условиях с изменяющейся средой
5. Простота реализации
1. Раскраска графа, задачи о назначении, коммивояжера, о маршрутизации, другие комбинаторные
2. Распознавание образов
3. Извлечение знаний
из данных, в частности
методами кластерного
Области приложений
3. Настройка и обучение
ИНС
4. Задачи компановки
5. Составление расписаний
6. Поиск итоговых стратегий
7. Аппроксимация функций
8. Задачи создания искусственной жизни
Слабые стороны
3. Зачастую нахождение только локального оптимума решения задачи вместо глобального
4. Проблемы с условием остановки
5. Трудность применения для
изолированных функций (задача типа «поиск иголки
в стоге сена»)
6. Малая пригодность, когда
надо найти все решения
7. Решение находится в виде
множества точек, а не отдельной точки
8. Используется только ЦФ,
а не ее производные и другие
дополнительные сведения
9. ГА «игнорируют» пригодность индивидуальных решений. Результат отыскивается
не путем улучшения одного
решения, а «разработкой»
популяции, использованием
кодирования параметров
1. Проблема
автоматизации
выбора настраиваемых параметров, адаптации их к решаемой задаче
2. Невысокая (без дополнительных усилий) вероятность
локализации глобального экстремума
3. Как и в других популяционных алгоритмах возможна
П р о д о л ж е н и е т а б л. 4.1
383
5.
4
Иммунные
Агентные
Принципы и механизмы работы иммунной
системы высокоразвитых живых существ по
обнаружению и подав-
Правила и механизмы
решения общей сложной задачи, допускающей
разложение
на совокупность более
простых
подзадач,
коллективом самостоятельных исполнителей,
когда общее решение
является
результатом
скоординированных
действий всех исполнителей
383
5. Пригодность, как и
других популяционных
алгоритмов, при решении
многоэкстремальных и
плохо формализованных
задач
1. Наличие возможности
централизованного администрирования
2. Высокие гибкость, живучесть, устойчивость к
сбоям и адаптируемость
МАС, возможность создания себе подобных агентов
(по крайней мере, программных)
3. Возможность экономного распределения агентов
в пространстве и их мобильность
4. Возможность самоорганизации и кооперации
агентов в МАС, накопление ими опыта, самостоятельного поиска ими и накопления информации
5. Способность агента адаптироваться к пользователю
(его предпочтениям, желаниям
6. Простота масштабируемости и легкость программирования за счет
модульности МАС
1. Простота и прозрачность технологий
2. Совмещение достоинств
ИНС и МАС
1. Невысокая скорость сходимости к решению
2. Возможное
проявление
сильной зависимости между
1. Необходимость четкого распределения общей задачи на
подзадачи, функций и действий отдельных агентов, их
координации
2. Возможность
проявления
нежелательных труднопредсказуемых действий отдельных агентов (особенно интеллектуальных) или их групп
3. Трудность формализации и
реализации соблюдения агентами моральных норм, этики и
эстетики действий, поведений
4. Жесткая
привязанность
агента к системе и, зачастую,
невозможность его самостоятельной работы вне системы
сильная зависимость их эффективности* от начального
приближения
1. Вычисления, поиск и
оптимизация,
распознавание образов
2. Обнаружение аномалий и неисправностей
анализа, деревьев регрессий и скедастических функций
4. Позиционирование
роботов в пространстве
5. Машинное обучение
Игры, транспорт, логистика, ГИС, сетевые
и мобильные технологии
384
Нечеткие
Деревьев решений
7
Сильные стороны
384
3. Получение разнообразного множества локальных
решений, включая глобальный оптимум
4. Многие алгоритмы используют аффинность каждого получаемого антитела
(решения) для определения
уровня мутации применительно к каждому члену
популяции, что обеспечивает лучшие адаптационные способности алгоритма
вероятность
5. Высокая
локализации глобального
оптимума (экстремума ЦФ)
6. Наличие памяти и способность к обучению,
хорошие адаптационные
способности
Возможность неби1. Менее жесткие требованарной принадлежно- ния к данным по сравнести одних и тех же
нию со стохастическим апэлементов данных
паратом
разным различным
2. Интуитивная простота апмножествам
парата.
3. Сокращение объема вычислений по сравнению со
стохастическим аппаратом
Правила
последова- 1. Простота и наглядность
тельного
построения структуры данных и позрительных иерархиче- нимания получения реских структур объектов зультатов
2. Допустим малый объем
данных и дополнительных
Класс методов
Идейная
и алгоритмов
основа
Иммунные
лению влияния чужеродных
организмов,
повреждающих существо воздействий
6
№
п/п
Области приложений
1. Громоздкость в оперативном обучении
2. Используемые для обучения
жадные алгоритмы приводят
к затруднениям в получении
1. Описание данных.
2. Классификация
данных
3. Наглядное представление целей и секционированных
целевой функцией и критери- 3. МАС, коллективный
ями оптимальности
интеллект, распределенные системы
4. Обучающиеся системы и машинное обучение
5. Прогнозирование
6. Компьютерная и Интернет-безопасность
7. Методы извлечения
информации
8. Обработка сигналов
и изображений
9. Обработка неструктурированных данных
10. Сжатие данных
11. Адаптивный контроль
12. Моделирование
искусственной жизни
1. Отсутствие
стандартных Различные задачи из
методик
конструирования разных сфер человеческой деятельности как
нечетких систем
2. Сложность математической альтернатива или дополнение стохастичеформализации
3. Меньшая точность, большая скому аппарату
неопределенность результатов
Слабые стороны
О к о н ч а н и е т а б л. 4.1
385
8
Принципы и механизмы познания, поведения, понимания и
взаимодействия человека при общении с
окружающим миром,
познавательно-целевая
структуризация знаний
об объекте и среде
385
статистических зависимостей
(деревья
регрессии и скедастические).
4. Банковское
дело,
промышленность, медицина, биология, сельское хозяйство и т. д.
1. Трудность и субъективность Управление в социальвыделения и ранжирования ных и организационных системах
факторов
2. Отсутствие формализованных процедур не способствует
«объективности» отображения
ситуации
3. Ориентированность когнитивных карт на статику ситуации, а не на динамику изменения факторов и ее влияния на
ситуацию и взаимодействие
факторов, которые моделируются с помощью динамических сценарных имитационных средств
оптимальных по качеству и
размерам деревьев
3. Возможность появления переобучения – чрезмерно тщательной подгонки и появления
слишком сложных структур,
которые недостаточно полно
представляют данные
4. Нахождение оптимальных
деревьев относится к NPсложным задачам
Примечание. Например, вероятности локализации глобального экстремума или скорость сходимости решения.
Когнитивные
анализ и моделирование
сведений и способность
работать с большим объемом данных
3. Гибкость, пригодность
для данных, измеренных в
разных шкалах
4. Нет
необходимости
хранить выборку данных,
применявшихся для обучения данных, осуществлять подготовку данных
5. Способность использовать модель «белого ящика»
6. Ориентированность на
фактическую конкретику
1. Применимость для исследования сложной нестабильной слабоструктурированной среды
2. Возможность отображения причинно-следственных связей и целевых
фактов
3. Возможность использования для упреждающего
управления,
разработки
сценариев развития событий
4. Возможность представления
многоаспектных
изменчивых
ситуаций,
учета системных и процедурных,
тактических,
оперативных и стратегических знаний об объекте,
среде, ситуации
§ 4.8. ИНДУКТИВНЫЕ МЕТОДЫ
И АЛГОРИТМЫ ОБРАБОТКИ И АНАЛИЗА ДАННЫХ
4.8.1. Вводные замечания. Эволюция взглядов
на анализ массовых эмпирических данных
Как уже указывалось в § 4.1, содержание предшествующих семи
глав было в основном неявно ориентировано на использование дедуктивного или аналóгового1 подхода к моделированию объектов. Все рисунки «технологических» процессов (см. часть 1, рис. 2.1–2.4, 3.8,
3.10–3.13, 4.9, 4.10; часть 2 рис. 1.4, а также рис. 4.8), реализующих
такие подходы, предполагают активное участие субъекта – специалиста по работе с данными («специалиста по данным», «data scientist»)
на начальном инициативном этапе технологического процесса. Да и
само словосочетание «анализ данных» до середины ХХ столетия, как
правило, связывалось с синтактическим статистическим анализом
сигналов и данных (САД): анализом распределений, регрессионным,
дисперсионным (дисперсным), факторным, корреляционным, спектральным и им подобными. Их теоретическую основу составляли математические результаты и положения, построенные на дедуктивных
методах рассуждений.
Действительно, в 1623–1706 гг. постепенно становится и развивается статистика, изначально понимаемая как «политическая арифметика» об описании политического состояния и достопримечательностей государств [1]. Для 1766–1907 гг. характерно постепенное
становление, а с 1907 г. бурное развитие математической, а затем в
ХХ веке и прикладной статистики, становление статистического анализа сигналов и данных, получаемых в ходе пассивных наблюдений и
активных экспериментов (САД).
Характерные особенности САД.
1. Идейная основа:
пользователь ориентируется на оперирование усредненными по
массиву значениями (различными средними);
при анализе Данных реализуется строго математический дедуктивный подход;
1
Аналóговый подход предполагает получение выводов, умозаключений
путем аналогий, т. е. поиском сходства объектов одинаковой общности, их
сравнением между собой, выявлением отличий в объектах, ассоциаций друг с
другом [24, 34].
386
используемая модель данных либо считается априори известной,
либо строится в условиях строгих априорных допущений;
ключевым является синтактический подход к работе с сигналами
и данными.
2. Жесткие требования к свойствам сигналов и данных, а также к
условиям, сопутствующим работе с ними.
3. Строго алгоритмическое решение задач, обязательность полной
формализации, допускающей автоматичность расчетов, т. е. всех алгоритмических операций, и однозначность результатов на выходе алгоритмического процесса.
С 1978 г. с подачи французских математиков [4, 5] начинается период развития направления работы с данными, получивший название
анализ данных (АД). Становление АД сопровождалось бурной дискуссией математиков, специалистов по САД и лиц, специализирующихся в АД, по вопросам правомочности применения и будущих возможностей и приложений АД.
Отличительные особенности «анализа данных»:
Кибернетическая идеология «черного ящика» при идентификации (см. часть 1, рис. 2.3) объектов и данных.
Исходными априорными сведениями являются сами данные и
желательно сведения об условиях их получения.
Работа с данными осуществляется алгоритмическими средствами.
Отсутствие априорной заданности того, какие модели, характеристики, закономерности следует искать, исследовать, использовать.
Все чаще с течением времени развития АД проявляется помимо
синтактического подхода к обработке данных прагматический, ориентированный на полезность, ценность результатов для их потребителей.
Допустимость ослабления условий и ограничений на исходные
данные, используемые средства и получаемые результаты.
Постепенное включение в анализ не только данных, но и знаний,
под которыми понимается «краткое обобщенное описание основного
содержания информации, представленной в данных» [4, c. 6, 7]1.
1
Кстати, сама книга посвящена описанию двух процедур анализа «данных», «знаний», «структур» и других форм представления информации: процедуры обнаружения закономерностей, содержащихся в представленной информации, и процедуры использования обнаруженных закономерностей для
предсказания одной части информации по известным значениям другой ее
части [4, c. 5].
387
Тем самым по мере становления АД осуществлялся переход от дедуктивного подхода работы с данными к индуктивному.
Наконец, с подачи Г. Пятецкого-Шапиро (1992 г.), начинается бурное развитие методов и средств нового вида анализа данных, получившего в русском языке (см. об этом разд. 4.8.6) название «Интеллектуальный анализ данных» (ИАД).
Приведем характерные особенности задач и методов ИАД:
появление новых видов данных из разных областей (большие
объемы и скорость поступления, разнородность, разнотипность, разнообразие, слабая структурированность, априорная или апостериорная
неопределенность);
появление и усиление необходимости и возможности работать
не только с данными, но и с сигналами, и со знаниями (анзниями) как
носителями информации;
появление необходимости решать не только задачи, но и проблемы;
отсутствие при работе с данными четкого алгоритма: есть только
цель, которую надо достичь, и правила, рекомендации, указания, касающиеся пути достижения этой цели;
необходимость дополнения синтактического и прагматического
подхода к работе с данными семантическим, а используемого дедуктивного подхода (от общего к частному, логический переход от одной
истины к другой) индуктивным (от частного к общему, от достоверного знания к вероятностному), дополнение обработки данных познанием объекта и подобных ему в целом, во всем его (их) многообразии,
выявлением в данных скрытых закономерностей, обобщением полученного знания на класс объектов;
направленность на получение в ходе ИАД нового, неожиданного, неочевидного, релевантного;
работа не только, а зачастую не столько с усредненными, сколько с индивидуальными значениями данных, с отдельными элементами
массивов данных;
необходимость использования интеллекта (человеческого (естественного) или искусственного), полимодельности, модельной, мéтодовой и алгоритмической многовариантности;
осознание необходимости и обязательности сопровождения данных метаданными или выявление метаданных в имеющихся данных.
388
В ИАД индуктивный подход к работе с данными становится превалирующим. Опираясь на его понимание, изложенное в § 4.2, рассмотрим важные отличия индуктивного подхода к анализу Данных на примере одного из вариантов его применения.
4.8.2. Важные особенности индуктивного подхода
к моделированию объектов и анализу данных
Один из вариантов применения индуктивного подхода к исследованию объектов представлен на рис. 4.16. Прежде всего обратим
внимание на два принципиальных отличия индуктивного подхода,
изображенного на рис. 4.16, от дедуктивного, отраженного на предыдущих рисунках.
Потребитель результатов
Метаданные
Постановка задачи
потребителем
результатов
Прагматический анализ результатов,
их интерпретация и применение
Объект
Данные
Интеллектуальный анализ данных
Банк или
хранилище данных
Исследование (разведочный анализ)
данных
Постановка задачи
специалистом
по данным
Индуктивная работа с данными
Рис. 4.16. Условное изображение укрупненной схемы варианта
индуктивного подхода к исследованию объектов
1. «Первичным материалом» является не сам (как в дедуктивном
подходе) объект (объекты), наблюдая за которым или экспериментируя
с которым по определенным правилам, требованиям, при фиксируемых, контролируемых или управляемых условиях и ограничениях,
389
субъект – специалист по данным получает исходные для дальнейших
операций данные, а кем-то полученные данные (зачастую в неизвестных условиях, ненадлежащего объема, качества и прочее). Это могут
быть, в частности, Большие данные со всеми свойственными им особенностями ( V1 V9 (см. § 4.2) и другие).
2. Заказчиком на работу с данными выступает потребитель результатов, не являющийся специалистом по данным. Он руководствуется
прагматическими соображениями типа: «Зачем мы собираем, храним,
накапливаем все новые и новые данные? Нельзя ли от них получить
какую-нибудь практическую пользу, перекрывающую расходы по их
сбору и поддержке?» (см. примеры в разд. 2.6.2, касающиеся ассоциативных моделей знаний), либо: «Мне необходимо постоянно решать
задачи по диагностике, мониторингу, прогнозу, управлению, принимать тактические, оперативные, стратегические решения, но мне не
всегда хватает необходимых для этого сведений, знаний. Можно ли их
«позаимствовать» из используемых или слабо используемых до сих
пор данных, имеющихся у меня, в нашей фирме, в вышестоящей инстанции или где-то еще»? Чаще всего потребитель даже не может поставить задачу перед специалистом по данным, который сам не всегда
способен это сделать самостоятельно, поскольку не владеет сведениями о нужности, полезности тех знаний, которые надо бы и можно извлечь из данных.
Теперь отметим другие важные отличия.
1. Индуктивный подход связан с решением задач и проблем типа
ТП-ТР (см. разд. 4.3.5), причем в такой их особенности, когда «туманным» может быть сам объект-оригинал исследования. Одним из результатов исследования может быть как раз создание наиболее подходящего для потребителя модельного понимания, т. е. куализной
модели исследуемого объекта (предмета, ситуации, явления, процесса)
или обобщенного класса объектов.
2. Для работы с данными может потребоваться, во-первых, их
предварительное исследование, их разведочный анализ, во-вторых,
использовать несколько моделей, мягкие методы и алгоритмы, втретьих, постоянно уточнять постановку задачи, применять не только
внутренние, но и внешние критерии качества моделей и результатов, а
также их разные комбинации.
Внутренние критерии – это такие, нахождение критериальных
показателей (функций) которых основано на тех же данных, что и для
получения самих моделей, искомых результатов.
390
Примером внутреннего критерия селекции или качества идентификации временного ряда является коэффициент детерминации R 2 .
Предположим, что мы располагаем эмпирическими парными значениями ( xi , yi ) , i 0, N 1 , отражающими связь значений некоторого исследуемого показателя y при конкретных значениях x1 ,..., xN влияющего фактора х. Например, развитие зависимости показателя y от
времени t. Здесь х есть t, а набор ( yi , ti ) или yi y (ti ) , в частности
yi y (it ) , i 0, N 1 , как указывалось ранее, образует временной
ряд (ВР). Для идентификации, т. е. модельного представления
этой зависимости, используется аналитическое выражение yˆ( x)
f ( x; ˆ 1 , ..., ˆ k ) , где f () – некоторая функция из заданного класса, а
1 ,..., k – параметры, отражающие как структуру (состав и связи элементов) функции f () , так и параметры отдельных элементов и их связей, подлежащие определению (оцениванию ̂ ) по имеющемуся набору эмпирических данных ( xi , yi ) , i 0, N 1 . Пусть далее yˆi есть
рассчитанные по f x; ˆ 1 ,..., ˆ k значения yˆi f ( xi ; ˆ 1 , ..., ˆ k ) для
каждого xi , i 0, N 1 . Найдем неисправленную1 эмпирическую (выN
1 N 1
( yi y )2 , где y (1 / N ) yi – вы
N i 0
i 0
борочное среднее показателя y вдоль всех рассматриваемых значений х.
Математически SY2 можно представить в виде суммы двух слагае-
борочную) дисперсию SY2
мых S ŷ2 и 2ŷ
SY2
1 N 1
1 N 1
2
2
ˆ
y
y
i
yˆi yi S y2ˆ 2yˆ ,
N i 0
N i 0
где 1-е слагаемое S ŷ2 есть выборочная дисперсия модельных значений относительно y , а 2-е слагаемое есть средний квадрат отклонений
1
См. табл. 4.4 в 1-й части пособия. Деление на N (неисправленная дисперсия) или на (N – 1).
391
(ошибок идентификации) модельных значений yˆi от «истинных» эмпирических значений yi вдоль всех yi , i 0, N 1 .
Коэффициент детерминации, как внутренний критерий качества
идентификации зависимости y от х, определяется как
R 2 S y2ˆ S y2 1 2yˆ S y2
или как исправленный (скорректированный)
N 1
1 N 1
2 1
2
ˆ
Rи2 1
y
y
yˆi yi ,
i
N 1 i 0
N k i 0
где k – число определяемых по эмпирическим данным (оцениваемых,
измеряемых) параметров 1 ,..., k модели f x; 1 ,..., k . Ясно, что
чем ближе к единице значение R 2 , т. е. чем меньше доля дисперсии
остатков (ошибок) идентификации дисперсии эмпирических значений yi , то либо тем адекватнее (ближе, точнее) функциональное (детерминированное) представление y f ( x; 1 , ..., k ) эмпирической
совокупности ( xi , yi ) и гипотетически (как надеется исследователь!)
реальной зависимости y от х, если она детерминирована, функциональна, а разброс yi обусловлен неточностью измерения y (ti ) , либо адекватнее представлению функции регрессии mY ( x) , т. е. среднего значения Y при конкретных х, если зависимость Y f ( X ) статистическая.
Внешние критерии – те, нахождение значений критериальных
показателей (функций) которых производится на данных, не использованных при получении модели, результата. Например, если все имеющиеся данные используются для построения модели (для идентификации), исходя из критерия значения какого-либо показателя качества
модели, то такой критерий будет внутренним. Если же данные разбиты
на две части и оптимальная по 1 модель находится, выбирается (либо
при настройке, обучении или самонастройке, самообучении модели
синтезируется) по рабочей (обучающей) части выборки, то значение
критерия 2 того же или другого типа по сравнению с 1 должно находиться либо по проверочной выборке, либо по критерию 2 той главной цели, ради которой создается модель (см. часть 1, § 2.6, 3.8, заклю392
чение по второй и четвертой главам, а также разд. 1.2.5 во второй части пособия).
Помимо поверочной функции внешний критерий 2 может выступать как внешнее дополнение (см. часть 1, разд. 2.3.2: принцип внешнего дополнения С.Т. Бира и А.Н. Тихонова и закон (принцип) необходимого разнообразия У.Р. Эшби) для выбора оптимальной по нему
структуры модели. Обычно структура модели считается оптимальной
сложности, если она соответствует минимуму внешнего критерия 2.
Иначе будет недоусложненной или переусложненной. Например, по
числу п структурных составляющих: модель будет недоусложненной
при n nопт и переусложненной при n nопт (см., например, составляющие нестационарной случайной функции в части 1, подразд.
4.3.6.1; составляющие функции, аппроксимирующей эмпирическую
функцию регрессии (завершающая часть разд. 4.3.5, часть 1), по количеству п слагаемых в моделях типа авторегрессии и скользящего
среднего (часть 1, разд. 3.2.3, 3.3; часть 2 разд. 4.2.1, 4.3.1 в [18] и т. п.).
Если же возникнет желание оптимизировать доли обучающей и поверочной частей имеющихся данных, то потребуется второе внешнее
дополнение, оформленное с помощью второго внешнего критерия 3.
Выборку при этом надо будет разделить на три части: обучающую,
проверочную и экзаменационную1. Подобная ситуация может иметь
место, например, при построении прогнозных моделей временного ряда, когда обучающая часть данных – это набор ретроспективных отсчетов ряда, по которым, во-первых, настраивается модель, во-вторых,
отыскивается длина интервала ретроспекции, обеспечивающая лучшее
прогнозирование новых значений ожидаемых отсчетов ряда. Тогда 1
относится к внутреннему критерию качества идентификации имеющихся отсчетов ряда моделью, 2 – к качеству прогноза на определенный лаг l, зависящему от значения длины интервала ретроспекции L,
а 3 – к 2 , оптимальному вдоль значений l, L.
Кроме структурной сложности моделей можно рассматривать их
параметрическую сложность, когда учитывается не количество со1
По поводу выбора размеров этих частей и их представительности в
условиях неопределенностей о свойствах данных, а также необходимости
привлечения для этого внешних дополнений и разбиения данных на три части, советуем руководствоваться рекомендациями, изложенными в § 5.10 книги [4].
393
ставляющих (структурных элементов) модели, а минимальное число
включаемых в нее, оцениваемых (измеряемых) параметров, обеспечивающих требуемое качество решения поставленной задачи. Например,
если полученная по исходным данным модель оказалась сложной, содержащей много параметров, ее для целей хранения, имитации данных
и других задач можно аппроксимировать «вторичной» моделью,
например, простой функцией, кусочно линейно- или сплайн-заданной,
которая для каждого своего «участка действия» или вдоль всего диапазона задания будет содержать меньшее число параметров, чем «первичная» модель (функция) (см., например, рис. 2.4).
Иногда возникает вопрос о построении компактных моделей, под
которыми понимаются такие, что содержат как можно меньше символов, в том числе цифр и букв, обозначающих параметры, для своего
задания (описания, представления). Например, аналитическая модель
простейших функций математики компактнее ее представления в виде
развернутого степенного ряда, а свернутый ряд, представленный через
символ суммирования или произведения , компактнее, чем развернутый; аналитическое описание периодической функции может
быть компактнее ее представления рядом Фурье; индивидуальное
представление частного члена семейства распределений, например
экспоненциального, компактнее, чем его представление с указанием
принадлежности к семейству (Эрланга, гамма, Вейбулла или распределения) [61].
В связи с изложенным, обратим внимание на следующее.
Согласно теории множественности моделей [58], по эмпирическим данным об объекте принципиально нельзя найти единственную
модель, пользуясь только внутренним критерием. В связи с этим
утверждения типа «разработанная теория, предложенная гипотеза позволили построить “правильную” или “истинную” теоретическую кривую, которая весьма близко по критерию соответствует эмпирическим данным (или подтверждается ими), нельзя признать серьезным,
тем более единственным обоснованием достоверности теоретического
результата. Более того, как указано в работе [5] со ссылкой на теоремы
К.Ф. Самохвалова, «создать индуктивный алгоритм обучения, который
гарантировал бы получение непротиворечивых предсказаний, нельзя.
Все методы научного познания эмпирического мира, какими бы формальными доспехами они не защищались, не гарантируют истинности1
1
См. § 1.2, а также рис. 1.5 (часть 1 пособия).
394
получаемых результатов. Доказать истинность эмпирических знаний
(гипотез, закономерностей, законов природы) нельзя. В них можно
только верить, и степень веры в гипотезу зависит от того, насколько
она экспериментально подтверждена и теоретически объяснена» (см.
далее разд. 4.8.4).
Ориентированность индуктивного подхода на применение множества моделей может реализовываться по разным вариантам. Первый –
определением модели той же оптимальной структурной сложности
путем изменения ее структуры, состава или значений параметров,
влияющих на структуру, включая самоприспособление с помощью алгоритма самообучения, самоорганизации, самонастройки. Второй вариант – перебор или формализованный упорядоченный выбор подходящей или оптимальной модели из некоторого набора моделей одного
и того же или разных классов. Вариант третий – совместное использование нескольких моделей одного или разных классов.
Следует быть аккуратным в поиске оптимальных по сложности
моделей. С одной стороны, понятие оптимальности модели требует
соответствующей априорной определенности о свойствах данных, которой может не быть и которая может не укладываться в идеологию
индуктивного подхода к анализу данных. Во-вторых, требуется постоянно помнить об особенностях оптимальных моделей, часть из которых указана в п. 7 заключения по второй главе (см. часть 1). В-третьих,
как уже неоднократно отмечалось, утверждения типа «чем сложнее
модель, тем она точнее» – чаще всего не соответствуют истине, могут
противоречить требованию помехоустойчивости модели, устойчивости
получаемых оптимальных решений при изменении условий, не согласовываться с целью анализа и т. д. Очень часто модель сознательно
недоусложняется. Недоусложненность, грубость модели может играть
роль регуляризатора, делать ее более простой, но устойчивой к помехам и погрешностям измерений, робастной к изменениям условий (см.
часть 1, разд. 2.1.2).
В условиях априорных неопределенностей и других особенностей, сопутствующих анализу данных в рамках индуктивного подхода,
особую роль приобретают те из мягких методов и алгоритмов, которые
допускают адаптацию, самоприспособление как их самих, так и получаемых или используемых при этом моделей.
Поэтому перейдем к рассмотрению в следующих разделах § 4.8
некоторых деталей реализации поливариантности решения задач,
а в § 4.9 – к вопросам разведочного (РАД) и интеллектуального (ИАД)
анализов данных.
395
Прежде чем переходить к их изложению, отметим, что в большинстве случаев целесообразно гибридное или комбинированное совместное использование индуктивного и дедуктивного подходов к моделированию и анализу данных. Это обусловлено тем, что дедуктивный
подход зачастую является заведомо лучшим в простых, априори понятных ситуациях, особенно при однокритериальных одноуровневых
показателях качества результатов моделирования и анализа.
4.8.3. Самоприспособление моделей
по критерию структурной сложности
Изначально заметим, что вопросам адаптации систем, моделей, алгоритмов посвящено много работ. Даже краткий обзор идей, принципов, приемов, критериев и прочих элементов, используемых при этом,
потребовал бы значительного места. Поэтому ограничимся только
описанием на идейном уровне предложенного А.Г. Ивахненко широко
используемого в ИАД метода самоорганизации моделей по их структурной сложности, получившего название МГУА – метод группового
учета аргументов (см., например, [49, 50, 58]). Положенный в основу
МГУА принцип самоорганизации моделей можно сформулировать так.
В условиях наличия шума, помех в исходных данных, погрешностей
измерения данных, погрешностей измерения (оценивания) параметров
модели и подобных им неидеальностей, по которым строится модель,
при постепенном увеличении сложности модели того же класса, той же
структуры (например, переходом от полиномиальной модели 1-й степени (линейной) к квадратичной, третьей степени и т. д.) значение
внутренних критериев монотонно падает, а при тех же условиях используемые внешние критерии проходят через свои экстремумы (как
правило, минимумы). Тогда это дает возможность определить модель
оптимальной сложности, причем единственную для каждого внешнего
критерия. В [58] рассмотрены различные внешние критерии, которые
можно использовать в качестве критериев селекции одной модели из
множества возможных. Это критерии: регулярности (минимума средневкадратического отклонения значений yˆ1 ,..., yˆ Nп , рассчитанных по
модели y f ( x ) , полученной на обучающей части данных объема N о ,
от «истинных» значений y1 ,..., y Nп , содержащихся в поверочной части
данных объема N п для тех же значений аргумента х функции f),
396
минимума смещения двух моделей, полученных на разных частях данных с разными среднеквадратическими (масштабными) отклонениями
значений элементов в них; баланса переменных при решении задач интерполяции и экстраполяции функций по ее известным отсчетам
(см. § 2.2); баланса прогнозов, найденных при разных шагах дискретизации переменных, и другие, а также комбинированные.
В настоящее время разработано множество простых комбинаторных (переборных) и более сложных алгоритмов МГУА, способных работать, когда число п входных переменных x1 , x2 , ..., xn модельной
функции f ( x ) , x x1 , x2 ,..., xn , используемых для полного описания
данных (объекта), удовлетворяет условиям n N и n N .
Для уяснения принципа работы МГУА рассмотрим два простейших
примера.
Первый пример. Пусть модель строится в виде полиномиальной
функции f ( x) одной переменной х, полное описание которой имеет вид
y f ( x) a0 a1x a2 x 2 ... ak x k .
(4.35)
Семь 2k 1 частных вариантов описаний получаются из полного
(4.35) приравниванием нулю разных коэффициентов a1 ,..., ak или их
комбинаций. Самоорганизация модели вида (4.35) осуществляется по
критерию ее сложности, т. е. по минимуму количества отличных от
нуля коэффициентов a1 , a2 ,..., ak , иначе по минимальному числу слагаемых в (4.35), при которых будет выполняться внешний критерий,
например, 2 будет минимальным. Тогда путем простой переборной
селекции мы перебираем все 2k 1 частных моделей (вариантов
(4.35)), по обучающей части данных оцениваем их «действующие» параметры a0 , a1 ,..., ak по внутреннему критерию, например, по минимальному 1, по проверочной части данных рассчитываем для каждой
i-й из них частное значение (2i ) и выбираем в качестве модели оптимальной сложности ту j-ю модель, для которой (2 j ) будет иметь ми-
нимальное значение из всех (2i ) .
Второй пример. Пусть полное описание модели имеет вид
y f ( x ) a0 a1 x1 a2 x2 a3 x12 a4 x22 a5 x1x2 .
397
(4.36)
Ему соответствует 25 1 31 частных полиномов. Процедура поиска модели оптимальной сложности здесь аналогична описанной для
первого примера.
4.8.4. Полимодельные дедуктивные, индуктивные
и анало́говые методы
Что такое полимодельное моделирование и в чем его необходимость?
Полимодельное моделирование – это такое, в котором используется не менее двух моделей одного и того же, сходного или совершенно
разных классов. Оно может применяться не только для самонастройки,
но и для увеличения объема (полноты) знаний об объекте и/или повышения качества моделирования. Понятие «модели разных классов»
означает, что они могут быть исследовательскими и созидательными;
микро-, макро- и мегамоделями; материальными и идеальными; априорными и апостериорными; регулярными и иррегулярными; одного
класса, но разных типов и уровней сложности; выполнять разные
функции или быть ориентированными на достижение разных целей и
т. д. Например, набор моделей, взятых из тех, что используются в
САД, ИНС, генетических, роевых, иммунных, когнитивных алгоритмах, либо получены с помощью периодограммного и сингулярного
[60] спектрального анализа, вейвлет-анализа и других подобных им.
Понятно, что для совокупности разных используемых моделей можно
применить как методы адаптации, самоприспособления самих моделей, так и набора моделей.
Необходимость полимодельного описания объектов и данных обусловлена рядом причин. Среди них [18]:
неопределенность или необходимость наличия нескольких целей
и изменения целей моделирования;
необходимость удовлетворять нескольким требованиям, показателям качества моделирования и/или системным принципам (см. часть
1, разд. 2.1.2, 2.3.2);
априорная неопределенность и неточность знаний о моделируемом объекте (о Данных), об условиях его функционирования и получения Данных о нем;
следствие необходимости использовать индуктивный подход к
исследованию объекта;
398
необходимость учитывать и использовать разнообразие «природы», «физики» и технологии получения данных, измерения, возможного модельного представления разнообразия классов объектов (см.
часть 1, рис. 3.1–3.4, табл. 2.4, 3.2), искать наиболее подходящие для
решаемой задачи модели (см., например, разд. 3.3.2 и вопросы после
выражения (3.8));
необходимость использовать разные модели для отдельных элементов, подсистем сложных объектов и объединять их для получения
общего модельного представления объекта;
необходимость учитывать или желание использовать способ
возникновения модели: эвристический (феноменологический, логический); аналитический, в частности оптимизационный, предельный;
априорный физический или апостериорный эмпирический.
Рассмотрим некоторые варианты полимодельного индуктивного
подхода к анализу данных и моделированию объектов.
Селективное полимодельное моделирование
Селективное моделирование – это простейшая разновидность полимодельного моделирования, осуществляемого в два этапа. На первом априори формируется полный набор моделей. Термин «полный
набор» здесь понимается исходя из постановки конкретной решаемой
задачи. Например, набор упрощенных моделей, получаемых из модели
наибольшей сложности, как в МГУА, либо набор, учитывающий разные аспекты физического механизма явления [см. далее формулу (4.37)].
На втором этапе из набора выбирается одна модель, являющаяся
лучшей по внешнему критерию селекции, методом простого или организованного по определенному правилу ускоренного перебора, селекции.
Изложенная в разд. 4.8.3 идея самоорганизации и селективного выбора моделей пригодна и тогда, когда модели относятся к разным
классам. Например, одна модель представлена в замкнутой аналитической форме; другие – ее разложением в какой-то ряд; полная модель
временного ряда Y (t ) содержит аддитивные составляющие: трендовую
m(t ) , сезонную s (t ) , циклическую c(t ) , инерционные стационарные
центрированные X (t ) и Z (t ) , а также случайную шумовую E (t ) , каждая i-я из которых входит в Y (t ) со своими коэффициентами ai ; иными словами,
399
Y (t ) a1m(t ) a2 s(t ) a3c(t )
a4 X (t )
l
j Z (t t j ) a5 E (t ) ,
(4.37)
j 1
где каждая составляющая сама по себе может быть представлена аддитивной смесью. При этом модели, рассматриваемые в качестве частных, могут быть из разного класса. Заметим, что часто не только
случайные компоненты в моделях вида (4.37) могут представляться
авторегрессионной суммой 1Z (t t1 ) ... l Z (t tl ) , но и разные деz (t ) a0 a1 (it )
терминированные
компоненты.
Например,
2 z (i 1)t z (i 2)t , для любого периодического сигнала
z (t ) z (t T ) , где Т – период, и т. д. Характерная особенность селективного моделирования (СМ) по Y (t ) проявляется в том, что вначале
априори на базе (4.37) формируется весь набор частных моделей,
составляющих Y (t ) , которые на втором этапе селектируются. В последние годы идеи селективного моделирования совмещаются с моделированием (в частности при прогнозировании) временных рядов коллективом методов (см., например, Радиотехника. – 2015. – № 6. –
С. 48–54).
Вариативное (поливариантное) моделирование
Вариативное1 (или вариантное, поливариантное) [О.К. Альсова,
В.В. Губарев, 2000 г.] моделирование (VM) – есть метод исследования,
основанный на замене исследуемого объекта-оригинала набором не
менее двух разнообразных моделей, на одновременной совместной
работе с ними и переносе полученных результатов моделирования на
объект-оригинал [18].
1
Вариативный – от русск. допускающий варианты; лат. variare – разнообразить, видоизменять; англ. variety – разнообразие, разновидность. Вариантное – от русск. вариант - разновидность, видоизменение чего-либо; лат. vario –
изменяю; variantis – меняющийся; фр. variante – видоизменение, разновидность, одна из возможных комбинаций. В связи с тем что термины вариативный, вариантный и поливариантный явно не выпячивают, а в некоторых их
трактовках могут затушевывать основную особенность такого моделирования –
одновременное применение моделей, возможно, следует заменить эти термины, например, на вариарное моделирование.
400
Согласно определению, отличительной особенностью рассматриваемой разновидности полимодельного моделирования являются: вопервых, разнообразие классов моделей набора, во-вторых, в нем обязательным является совместное применение моделей набора.
На целесообразность использования нескольких методов обработки
данных для выявления объективности нашего представления о реальности уже давно указывают многие специалисты (см., например, Саати
Т. Принятие решений. – М.: Радио и связь, 1993). Концептуальным
обоснованием такой точки зрения служит убеждение в том, что совпадающие или сходные результаты и выводы, полученные и подтверждаемые разными методами и средствами, скорее всего, отражают нечто действительно реальное, объективно существующее в объектах
или данных об объектах, в отличие от тех ситуаций, когда результаты
и выводы субъективны, меняются от метода к методу, зависят от исследователя.
Вектор-модель (характеристика), или векторная модель (характеристика), объекта (ВМ) – это система из минимального сочетания1
(набора не менее двух) родственных по назначению, как можно более
простых, эквивалентных по сложности моделей (характеристик), отражающих в совокупности все интересующее исследователя многообразие существа (сути), закономерностей, свойств и особенностей
состояния, строения и функционирования (поведения) объекта-оригинала на требуемом уровне и обеспечивающих появление системного
свойства эмергентности (эмерджентности, синергии) [18, 61].
Термин вектор-модель является простым обобщением2 (2000 г.)
термина вектор-характеристика, введенного в 1990 г. в учебном пособии [64]. Важные три отличительные особенности вектор-моделей
(вектор-характеристик) выделены в определении курсивом. Во-первых,
это не просто набор, а система, сочетание моделей. Во-вторых, система из моделей как можно более простых, близких по сложности.
В-третьих, это набор, удовлетворяющий требованиям полноты и минимальной избыточности числа моделей (характеристик) с точки зрения назначения вектор-модели (характеристики) и множества их
свойств, включая свойства, получаемые за счет эмерджентности
1
Такого соединения, включения в набор, при котором обеспечивается
взаимное дополнение, согласование, соответствие, образуется единство,
целое.
2
А конкретнее заменой слова «характеристика» на слово «модель».
401
системы. В [64] необходимость введения векторных характеристик
(ВХ) рассмотрена на примере характеристик случайных элементов (величин, векторов, функций). Она обусловлена следующим. Известно,
что каждая характеристика случайных элементов может быть использована, во-первых, для решения вполне определенных теоретических и
практических задач, во-вторых, при некоторых конкретных условиях.
Изменение условий или переформулировка задачи может потребовать
для ее успешного решения перехода к новым характеристикам, которые при той же сложности не всегда могут быть удобными, легко интерпретируемыми, отвечать на разные вопросы пользователя. Выходом
из этого положения является применение либо более сложных (требующих больше априорных сведений, более высокого уровня описания
случайного элемента, более сложных процедур оценивания, вычислений и т. п.) характеристик, либо векторных характеристик.
При формировании ВХ следует использовать паспорт (портфолио)
характеристик, включающий в себя разные разделы: теоретические
свойства характеристики; вопросы оценивания характеристики по выборке с произвольными и заданными свойствами выборки и алгоритмами оценивания; прикладные аспекты (целесообразная область применения, интерпретируемость, простота использования при имитации
выборок и т. п.). В теоретические свойства характеристик входят:
назначение; диапазон значений; условия, при которых характеристика
принимает граничные значениями т. п. В вопросы оценивания включаются потенциально и реально возможные и достижимые значения
точностных показателей оценок, получаемых по выборке с определенными свойствами по произвольным или по конкретным алгоритмам на определенном классе случайных элементов, попадающем в
область интересов пользователя; ресурсные затраты, необходимые
для реализации алгоритма оценивания, и т. п. В состав ВХ входит
минимально возможный набор таких элементарных характеристик,
которые согласно паспорту удовлетворяют требованию полноты, т. е.
полностью накрывают область интересов пользователя, возможные
практические ситуации, позволяют при их применении и интерпретации в совокупности, в сравнении, в сопоставлении получать новые
знания и ответить на все вопросы пользователя, и имеют минимальные пересечения паспортных данных, дополняя друг друга без существенных пересечений.
Оставляя вопросы формирования ВМ, ВХ до следующего раздела,
рассмотрим их примеры.
402
Простейший пример ВХ – это вектор-характеристика уровня (положения) случайной величины (см. часть 1, табл. 4.4) вида <математическое ожидание (среднее), мода (или антимода), квантиль порядка р
(например, медиана)>.
Более сложным примером вектор-модели является векторхарактеристика R , , Y | X , X |Y – система из четырех характери-
стик парной связи случайных величин Х и Y: коэффициента корреляции Пирсона XY , коэффициента конкорреляции Губарева
XY и двух корреляционных отношений Y | X и X |Y [18] (см.
часть 1, разд. 4.3.5, табл. П2.4, а также рис. 4.4–4.6). В таблице знак +
означает пригодность характеристики для решения задачи, указанной в
левом столбце. Только их совместное сочéтанное, а не раздельное
применение позволяет ответить на разные вопросы о связи величин Х и
Y (или функций X (t ) , Y (t ) ): выявить ее наличие или отсутствие; характер (детерминированная (функциональная) или статистическая);
вид детерминированной зависимости (и порою функции регрессии):
линейная или нелинейная, однозначная или неоднозначная, взаимно
однозначная или нет; определить степень тесноты связи. Появившееся
свойство эмерджентности системы – дополнительная, не обеспечиваемая каждой отдельной характеристикой связи, возможность через коэффициенты нелинейности регрессий (см. часть 1, (4.44), (4.45)) определить степень нелинейности регрессии, а также получить другие
сведения. Например, дополнительное подтверждение линейности регрессии через коэффициент конкорреляции, поскольку для случайных
величин Х, Y или функций X (t ) , Y (t ) ) с линейной парной регрессией
X , FY (Y ) XY и FX ( X ),Y XY , где FX ( x) – функция распределе-
ния Х, X (t ) , – символ пропорциональности.
Полисистемное моделирование
Полисистемное моделирование – есть метод исследования, основанный на представлении исследуемого объекта в виде полисистем и
расслоения сложных объектов (образований) на множество непересекающихся слоев – системных представлений объектов исследования.
Полисистема рассматривается как множество непересекающихся
(независимых) разнокачественных систем (слоев), связанных друг с
другом посредством различного рода отображений (морфизмов). Дифференциация объектов на слои разного рода называется расслоением,
403
а свойство объектов состоять из слоев различного вида – полисистемностью объектов [62].
В основе полисистемного моделирования лежит методология полисистемного анализа и синтеза знаний, получаемых с применением различных системных моделей. Полисистемный анализ объектов основан
на расслоении их на множество непересекающихся слоев – системных
представлений объектов исследования, когда каждый слой – это проекция объекта в ту или иную предметную область. Такое расслоение
объекта аналогично его представлению в многомерном пространстве
ортогональных (непересекающихся) независимых координат - моделей
(характеристик, показателей), в котором каждая модель (характеристика, показатель) есть точка координаты этого пространства.
Заметим, что в определение вектор-модели (вектор-характеристики) не входит требование ортогональности, но оно и не противоречит дополнению этого требования в дефиницию. Иными словами,
частные модели вектор-модели являются ее элементами, т. е. векторные модели уподобляются вектор-строке и вектор-столбцу матрицы в
теории матриц, аналогично случайному вектору (см. часть 1,
разд. 4.3.1, табл. 4.3), в то время как полисистемная модель уподобляется вектору в векторном исчислении (см. требование ортогональности
к признакам (характеристикам) классификации в разд. 1.2.1 настоящего пособия).
В полисистемном моделировании каждый слой расслоения – это
проекция объекта на конкретную предметную системную плоскость
исследования. Совокупность всех системных плоскостей есть пространство расслоений. Слой (срез) объекта в конкретной предметной
области называется моносистемой, а вся совокупность моносистем
объекта, выделенных по разным системным основаниям, – полисистемой [62].
Рассмотрим способы оперирования с результатами поливариантного и полисистемного моделирования.
Первый способ – сочета́нное использование. Набор (систему) моделей мы используем, сочетая все их возможности, усиливая положительные свойства (качества) и нивелируя негативные. Пример такого
использования приведен при описании вектор-модели (см. часть 1,
табл. П2.4). Добавим к нему, что если среди данных могут быть массовые качественные, то вектор-модель R можно дополнить соответствующими характеристиками связи величин, измеренных не в количественных, а в категорийных измерительных шкалах (см., например
404
[8], а также характеристики (4.54), (4.55), см. часть1, и окрестный, поясняющий эти характеристики, текст). При необходимости учесть влияние других факторов на рассматриваемые величины X и Y, вектормодель R можно дополнить частными и совокупными коэффициентами корреляции, конкорреляции, конкорреляционными отношениями.
Второй способ – визуальное представление. Результаты полимодельного моделирования представляются в виде многомерного зрительного визуального образа объекта, отражающего объект через значения его количественных или категорийных, точечных или
интервальных, четких или нечетких (размытых), включая лингвистические значения, показателей, полученных в итоге моделирования (см.
разд. 1.5.2 и визуальное моделирование).
Третий способ – сверточное использование. Разные модификации
этого способа отличает то, что полимодельное моделирование заранее
ориентируется не на разностороннее, многоаспектное, многопоказательное исследование объекта, а для обеспечения требуемого или
улучшения существующего качества одного результатного показателя,
характеризующего объект. Рассмотрим некоторые модификации третьего способа.
М1. Комбинирование и гибридизация моделей и коллектива методов
Рассмотрим два примера комбинирования моделей и коллектива
методов, порождающих эти модели.
Первый связан с комбинированными методами измерения (оценивания) вероятностных характеристик [18].
Комбинированная оценка Q() характеристики Q() (см. часть 1,
разд. 4.3.7) имеет вид
n
ˆ (),
Q() i Q
i
i 1
n
i 1 ,
(4.38)
i 1
где – пустой, скалярный или векторный аргумент; 0 i 1 ; а Q̂1 () –
непараметрическая оценка Q() , полученная по данным натурного
эксперимента (одна модель); Q̂ 2 () – параметрическая или смешанная
оценка (вторая модель); Q̂3 () – оценка, полученная машинным экспериментом; Q̂ 4 () – оценка, полученная по данным натурного эксперимента с использованием упрощенной физической модели объекта;
405
Q̂5 () – априорная оценка, полученная по аналогии; Q̂6 () – экспертная оценка и т. д. (см. [18], § 9.3.2). Коэффициенты подбираются
экспериментально, исходя из условий лучшего качества Q() в требуемом смысле.
В последние годы подобный подход бурно развивается в так называемом «прогнозировании коллективом методов», когда в качестве
Q() выступает прогнозируемый ряд, а Q̂i () – результаты прогноза
его i-м методом.
М2. Комбинирование неопределенностей [65]
Эта модификация ориентирована на совместное использование исходных статистических данных и экспертных знаний при оценивании
параметров моделей. Для него характерны следующие особенности.
Во-первых, экспертные суждения формируются в форме, привычной
для специалистов в предметной области. Во-вторых, все статистические и экспертные сведения объединяются в единую модель неопределенности, на основе анализа которой находятся оценки параметров искомой модели объекта. Такое объединение оказывается возможным за
счет того, что модель неопределенности, отвечающую экспертным
суждениям, можно задать на параметрическом множестве модели исследуемых процессов и на этом множестве определить модель неопределенности, отвечающую выборке. Это позволяет привести экспертные суждения и статистические данные к единой единице измерения
[65]. В-третьих, трактовка термина «оценка параметров» является отличной от ее трактовки в математической статистике (см. часть 1,
разд. 4.3.7). Здесь это возможное минимальное, максимальное или вероятное значение параметра.
М3. Последовательная и скользящая идентификация объектов
Суть этой модификации способа заключается в постепенном наращивании сложности искомой модели объекта, как правило, но не обязательно аддитивной, за счет включения в нее новых составляющих
(последовательная идентификация) или изменением состава при
поступлении новых текущих данных (скользящая идентификация). Последовательный способ идентификации является альтернативой «одновременной» идентификации, в которой модель строится путем одновременного совместного построения всех компонент модели. Примерами
реализации последовательной идентификации являются построения моделей вида (4.37) гидрологических и инфекционных временных рядов
по их эмпирическим значениям [67, 68].
406
В [67], например, в качестве модели эмпирического временного ряда y (it ) , i 0,1, 2,... ; t 0 использовалось представление
Y (t ) T (t ) S (t ) H (t ) F (t ) E (t ) ,
(4.39)
где T (t ) – трендовая; S (t ) – сезонная, H (t ) – инерционная случайная;
F (t ) – факторная и E (t ) – безынерционная случайная составляющие.
Последовательная идентификация сводится к пошаговой процедуре.
На каждом последовательно выполненном шаге выделяются и модельно описываются T (t ) , S (t ) , H (t ) и F (t ) . После каждого шага исследуются модельные остатки, полученные после вычитания из исходного
эмпирического ВР значений, рассчитанных по выделенным составляющим, проверяется адекватность очередной модели и качество идентификации. Проверка выполняется по значению коэффициента детерминации, закону распределения и автокорреляционной функции
остатков, а также по качеству прогнозов по модели на 1, 2, …, 10 суток
вперед. Трендовая и сезонная составляющие выделялись с помощью
комбинации сингулярного спектрального анализа и модификации «Гусеница» метода главных компонент. Расчеты выполнялись на зарегистрированной в Роспатенте программной системе VarForecasts.
Суть скользящего метода идентификации и прогнозирования (Альсова О.К., Губарев В.В., ИСТ, сб. науч. ст., 2001, Т. 4. – С. 5–25; Автометрия. – 2006. – № 6. – С. 45–52) легко уясняется из рис. 4.17, на котором приведена перестраиваемая по мере поступления свежих
данных регрессионная модель поквартального прогнозирования объема притока воды в реке Обь к створу Новосибирского водохранилища.
Четвертый способ – многокритериальное использование. Его суть
в формировании набора моделей, исходя из желания представить объект по разным его показателям. Для каждого показателя строится одна
или более моделей, каждой из которых соответствуют свои критерии
качества. Тогда решение задачи использования набора моделей аналогично тому, как это делается при многокритериальной оптимизации
(см. разд. 4.5.5, часть 1).
Пятый способ – предпочтительное использование. В этом способе
предполагается, что все модели имеют то же назначение, оцениваются
теми же критериями качества, но априори не ясно, какая из них предпочтительнее в смысле скалярных или векторных требований пользователя. В связи с этим осуществляется построение и апробация всех
моделей набора, и в итоге рекомендуется (выбирается) для решения
407
408
Январь–
сентябрь
9,412
Апрель
9,990
Май
5,456
Июнь
4,821
Июль
3,943
Август
3,201
Сентябрь
1,966
Октябрь
(1)
Год = 6,51 + 2,41июнь + 7,82февр. + (2)
+ 1,09апрель + 0,77май
Год = 9,09 + 1,35июнь + 1,58июль+
(3)
+ 1,25апрель + 0,93май
Год = 4,93 + 1,37июнь + 1,8август +
(4)
+ 1,2апрель + 0,9май + 0,96июль
Год = 3 + 1,07июнь + 1,03август +
(5)
+ 1,18апрель + 1,03май + 2,04сентябрь +
+ 0,96июль
Год = 18,93 + 2,13май + 1,36апрель
Прогнозное уравнение
49,65
43,64
49,65
49,65
43,64
43,64
49,65
49,65
Среднее
43,64
43,64
Наблюдаемые
значения
45,52
44,46
45,07
43,92
53,04
Прогнозные
значения
38,0
38,0
38,0
38,0
38,0
64,3
64,3
64,3
64,3
64,3
Доверительный
интервал
95%
Прогнозирования годового объема притока в км3 на 1997 год
0,932
Март
–1,88
–0,83
–1,43
–0,28
–9,4
Остаток
0,977
Ноябрь
4,3 %
1,9 %
3,28 %
0,64 %
21,5 %
% остатка
от наблюдаемых
значений
0,937
Декабрь
408
Рис. 4.17. Иллюстрация скользящего метода идентификации и прогнозирования
годового и квартальных объемов притока воды в створе Новосибирской ГЭС на 1997 год
Примечание: В таблицах среднее и доверительный интервал построены по данным объема притока за 1967–1997 гг.
Для прогнозирования годового объема притока на текущий год необходимо выбрать уравнение (1)–(5) (оно выбирается в зависимости от имеющихся данных по объему притока, например, если есть данные по объему притока за январь–май прогнозируемого года, то выбирается уравнение (1)),
и подставить в него соответствующие значения вновь поступающих месячных объемов притока.
Год
Январь–
май
Январь–
июнь
Январь–
июль
Январь–
август
Прошедшие
месяцы
0,813
1,187
Период
Февраль
Январь
Среднемесячный объем притока в км3 за 1997 год
конкретной задачи та из них, которая будет предпочтительнее по мнению пользователя. Например, по минимуму среднего значения смещения или показателя разброса количественного результата решаемой
пользователем задачи. Отличие данного способа от селективного – в
составе набора моделей. В селективном способе набор состоит из
частных моделей, получаемых из полной. В способе предпочтений –
модели набора могут быть из разных классов.
Шестой способ – привлечение дополнительных системно связанных моделей. Предположим, что исследователя интересует некоторый
показатель X (t ) объекта и он располагает сведениями о том, что его
значения статистически линейно или нелинейно связаны с некоторым
скалярным или векторным показателем Y(t ) Y1 (t ), Y2 (t ),..., Y p (t ) ,
характеризующим элементы надсистемы, в которую входит исследуемый объект. Например, показатель X (t ) – количество определенных
заболеваний, урожайность культуры, мутность воды и им подобных
статистически связан с солнечной активностью Y1 (t ) , температурой
окружающей среды Y2 (t ) , влажностью воздуха Y3 (t ) и т. п. Тогда, располагая данными об Y (t ) и строя их модельное влияние на X (t ) ,
например в виде аддитивной смеси или более сложной функции, можно по ней строить модель X (t ) и решать прикладные задачи, в том
числе прогнозные, даже когда ряд данных по X (t ) отсутствует или на
основе следующего – балансового – способа. Частным случаем такого
способа прогнозирования является предложенный К. Симпсом
(Economenrica, 1980, v. 48, p. 1–48) модель VAR (векторной авторегрессии) как альтернатива системы одновременных уравнений. В нем
X (t ) элемент X k (t ) вектора X1 (t ),..., X n (t ) , Y1 (t ),..., Yn (t ) авторегрессионные модели X i (t ) , i 1, n , i k , а прогнозная модель X k (t )
строится по аддитивной смеси предшествующих значений X i (t ) ,
i 1, n , i k .
Наконец, седьмой способ – балансовый. Он может реализовываться
как самостоятельно, так и в виде разновидности предыдущих. Его
идейная основа – использовать в качестве дополнительного критерия
(критериев) балансовое соотношение (соотношения), имеющее (ие)
важный смысл для задач пользователя.
409
Рассмотрим некоторые из них на примере прогнозирования временных рядов (ВР) x(it ) , i 1, 2,... 1.
1. Метод полимодельного балансового прогнозирования
Предположим, что для прогнозирования x ( N k )t , где k 1,
2, 3,... определяет лаг k t прогнозирования (интервал времени упреждения), а N – число ретроспективных отсчетов ВР, по которым строится идентификационная модель ВР x(t ) , используются т разных моделей (алгоритмов). С помощью каждого i-го метода в качестве
прогноза x ( N k )t используется значение xl ( N k ) t , l 1, m .
Тогда естественное условие баланса сводится к желательным
равенствам xl ( N k )t x j ( N k )t x ( N k ) t для всех i j ,
i, j 1, m . Поэтому в качестве единого прогнозного значения можно использовать xˆ ( N k )t 1x1 ( N k )t ... m xm ( N k )t ,
1 2 ... m 1 , когда 1 ,..., m выбираются из условия минимума меры () отклонения xˆ ( N k )t от x ( N k )t для конкретного значения k при построении xi (t ) по разным участкам ретроспекции
(обучающей выборки), либо для разных упреждающих значений
k 1, 2,3,... при построении каждой xi (t ) по одной и той же или по
нескольким их предшествующим выборкам.
2. Функциональное балансовое прогнозирование
Предположим, что ВР y (it ) однозначно функционально связан с
x1 (it ),..., xm (it ) , т. е. y (it ) f x1 (it ),..., xm (it ); α , i 1, 2,3,... , где
– векторный параметр, например, в виде сомножителей l перед
xl (it ) , l 1, m . Предположим далее, что мы по имеющимся данным
нашли отдельно прогнозные значения yˆ ( N k )t , xˆ1 ( N k )t ,...,
xˆm ( N k )t . Тогда можно сбалансировать прогнозные значения ŷ и
xˆl , l 1, m , поиском значений так, чтобы значение меры () отли1
Подобные методы рассматривались в диссертации Русина Г.Л. Идентификация и текущее прогнозирование показателей энергетических систем:
дис. … канд. техн. наук / Г.Л. Русин; научн. рук. В.В. Губарев; Новосиб. электротехн. ин-т, Новосибирск, 1983. – 213 с.
410
чия ŷ от f xˆ1 , ..., xˆm было минимальным при фиксированном k или
вдоль нескольких значений k 1, 2,3,... .
3. Закономерностное балансовое прогнозирование
Предположим, что необходимо спрогнозировать значения т ВР
x1 (t ),..., xm (t ) , для которых известно, что их текущие значения xl ,i
для каждого t it , т. е. xl xl [it ] , i 1, 2,..., N ,... , подчиняются некоторой статистической закономерности ( x; α ) . Часто это закономерность – убывание значений xl при l 1, 2,3,..., m по закону Парето
либо ему подобному. Тогда мы по ретроспективным данным можем
найти вид и оценку α̂ параметра такой закономерности, а затем подгонять прогнозные значения xˆ1 xˆ1 ( N k )t ,..., xˆm xˆm ( N k ) t
либо как лежащие на кривой или подчиняющиеся кривой ( x; α ) для
каждого xˆl , либо располагая их так, чтобы обеспечивался минимум
меры близости xˆl ; ( xl ; αˆ ) вдоль всех xl , а также вдоль разных k.
В заключение обратим еще раз внимание на три момента.
1. Необходимость постоянного согласования разных моделей при
использовании полимодельного моделирования, желательность, а иногда [18, 66] обязательность применения для этого диалогового взаимодействия исследователя и пользователя на разных этапах технологического процесса моделирования.
2. Желательно, чтобы модели были гибкими, способными к адаптации, т. е. содержали такие структурные составляющие и параметры,
которые можно менять в определенных диапазонах для достижения
целей моделирования [58, 66].
3. Полимодельное моделирование можно рассматривать как один
из вариантов реализации системных принципов (см. часть 1,
разд. 2.3.2), в частности, функционального подобия, ограниченности
ресурсов, внешнего дополнения, декомпозиции, дополнительности,
разнообразия.
4.8.5. Упорядочение и автоматизация выбора моделей,
методов и алгоритмов
Одной из важнейших задач индуктивного подхода и полимодельного моделирования является упорядочение и автоматизированный
или автоматический выбор моделей, методов и алгоритмов. Подзада411
чей этой задачи является формирование набора моделей [18, 58, 61, 64,
66]. По аналогии с хранением данных и знаний направлением решения
подобной задачи может быть создание банков и хранилищ моделей,
методов и алгоритмов. Рассмотрим вариант подобных хранилищ: моделе-, методо- и алгоритмотеки.
Моделетека (МТ) (от модель и греч. thёkё – вместилище, хранилище) – это упорядоченное множество моделей, удовлетворяющее требованиям полноты, минимальной избыточности, уровня описания и
исследованности в приложении к конкретной предметной области1.
Ключевые слова, отражающие отличительные особенности моделетеки
(МТ) как множества моделей, выделены в определении курсивом. Поскольку элементарные основы построения МТ подробно рассмотрены
в [18, 61, 64], остановимся здесь только на комментариях к ним.
Под упорядоченным множеством моделей понимается такое, в котором модели, как элементы множества, расположены в определенном
порядке. В [18, 61, 64] рассмотрены основы и варианты формализации
упорядочения моделей, позволяющие автоматизировать их помещение
в моделетеки и априорный или апостериорный выбор из нее. На примере моделей «маломодальных» одномерных распределений вероятностей в [18, 61, 64] рассмотрены и продемонстрированы разные формальные методы упорядочения и апостериорного выбора моделей (см.
далее).
Полнота моделетеки означает, что для любых эмпирических данных, для которых пригодны модели из моделетеки, найдется хотя бы
одна модель из нее. При этом полнота может трактоваться формально
и содержательно.
При формальной трактовке полнота МТ означает, что все включенные в нее модели полностью покрывают область значений идентификаторов МТ, допустимую для любых моделей, которые могут быть
включены в моделетеку. Здесь идентификатор – это скалярный или
векторный куализный показатель модели, измеренный в количественной или качественной шкале и предназначенный для отражения отличия моделей друг от друга.
При содержательной трактовке полнота МТ понимается по охвату
моделями моделетеки всех «физических» особенностей исследуемого
объекта, соответствующих его структурам, свойствам, правилам,
1
Термин моделетека введен В.В. Губаревым в 1986 г. взамен более раннего (с 1979 г.) «библиотека моделей».
412
режимам функционирования и поведения. Это соответствие может
быть отражено идентификаторами моделей, измеренными в категорийных шкалах, например номерами свойств модели и решаемых с ее
помощью задач (см., например, табл. П2.3 и П2.4 в 1-й части пособия).
Минимальная избыточность моделей МТ понимается двояко.
Во-первых, как минимально возможное количество моделей, все множество которых позволяет удовлетворить требованию полноты.
Во-вторых, что из эквивалентных по назначению решаемым задачам и
другим показателям, по которым модели отбираются для упорядочения
в МТ, в МТ включаются прежде всего наиболее простые модели.
Необходимость совместной реализации требований полноты и минимальной избыточности может привести к следующим двум ситуациям: отсутствие избыточности в МТ и наличие набора моделетек. Отсутствие избыточности означает, что каждой области (зоне)
значений идентификаторов МТ будет соответствовать только одна модель. Иными словами, при отсутствии избыточности пересечение областей, занимаемых любыми разными моделями в МТ, объединение
которых покрывает всю допустимую область, является пустым. Наличие набора моделетек является следствием того, что помимо моделей,
включенных в моделетеку, есть еще множество сходных моделей, области значения которых совпадают с областями моделей, включенных
в моделетеку. Поэтому с учетом требования минимума избыточности
их следует включить в другую моделетеку. Число моделетек может
быть неограниченным. В [18, 61] приведены наборы моделетек одномерных законов распределения вероятностей, упорядоченных как по
одним и тем же, так и по разным идентификаторам. Что касается выбора конкретной МТ из их набора, то он может осуществляться априори или выполняться в процессе разведочного анализа данных (см. далее). Заметим, что отбор моделей для включения в конкретную
моделетеку не является тривиальной задачей.
Наконец, требование «уровень описания и исследованности модели» означает следующее.
1. Все модели имеют необходимые (для решения с их помощью
конкретной задачи исследователя или потребителя) описание, представление (предпочтительнее, аналитическое).
2. Каждая модель МТ сопровождается:
соответствующими ей характеристиками (см., например, часть 1,
табл. 4.4) и соотношениями, связывающими параметры характеристик
с параметрами моделей (см. многочисленные примеры таких соотношений в [61]);
413
формулы связи моделей друг с другом (см. многочисленные
примеры в [61], а также далее функционное упорядочение моделей);
специализированные хорошо аттестованные и проверенные алгоритмы оценивания параметров моделей и их характеристик, а также
имитации выборочных значений, сопровождаемые показателями качества алгоритмов;
области возможных и целесообразных приложений, свойства и
особенность моделей, а также примеры удачных применений (в виде
портфолио).
В [18, 61] рассмотрены разные классы и внутриклассовые разновидности методов формирования МТ, упорядочения моделей в них и
апостериорного выбора модели из МТ. Это следующие классы.
Методы перебора. Для этого класса методов характерны три особенности [18]: экспертное формирование возможного набора (множества) моделей; последовательный выбор, оценка и апостериорная
апробация моделей из ; отбор наилучших или приемлемых моделей
из апробированных. Пример – методы, используемые в селективном
индуктивном моделировании.
Методы формализованного идентификаторного упорядочения.
В методах этого класса каждой параметрически заданной модели
i M i (1 , 2 , ..., k ) , где 1 , ..., k θ – вектор параметров, ставится
в
соответствие
количественный
векторный
идентификатор
α (1 , 2 , ..., n ) . Формирование МТ и упорядочение моделей в ней
происходит по областям (точка, линия, зона ненулевого объема) в пмерном пространстве значений идентификатора для каждой i-й модели i . Апостериорный выбор конкретной модели (или двух или трех
близких моделей) выполняется в два шага. На первом по исходным
данным находится значение α̂ оценки идентификатора . На втором
определяется, в какую зону п-мерного пространства идентификаторов
попала точка αˆ ˆ 1 , ˆ 2 , ..., ˆ n . Модель или соседние модели, в «зону притяжения» которых попала точка α̂ , и есть выбираемая(ые) модель(и). Если моделей будет выбрано больше одной, их необходимо
подвергнуть селекции с использованием дополнительного критерия
или критериев, например, из методов статистической проверки гипотез. Суть методов этого класса иллюстрируется рис. 4.18.
В [18, 61] приведены примеры упорядочения моделей «маломодальных» вероятностных распределений по разным идентификаторам,
414
а также примеры наборов различных моделей: плоскости моментов,
плоскости квантильных характеристик, плоскости распределений,
плоскости информационных характеристик, плоскости мер расстояний,
плоскости мер близости, канонических представлений, разложения в
ряд, затянутости хвостов распределения, иерархии распределений,
функциональных преобразований случайных элементов, комбинированные.
2
̂ 2
«Разрешенная» зона
6
Зона 5
9
Зона 4
8
Зона 7
2
3
Зона «притяжения»
оценки (ˆ 1 , ˆ 2 )
1
«Запрещенная» зона
1
̂1
Рис. 4.18. Иллюстрация упорядочения моделей на плоскости двумерного идентификатора α (1 , 2 )
Методы иерархического упорядочения. Этот класс методов относится к моделям, заданным параметрически, и реализуется как конкретизирующий модели, выбранные по идентификаторному методу. Суть
упорядочения – в построении иерархической классификации всех моделей, входящих в параметрическое семейство. Пусть семейство моделей описывается моделью M (, , ) , где , , – параметры формы
(типа) модели. Тогда частные модели i семейства получаются, когда один или несколько параметров , , принимают точечные значения i , i , i (см. примеры иерархического упорядочения разных
распределений вероятностей в [18, 61]). Апостериорный выбор частной
модели осуществляется по попаданию значения идентификаторов
в зону «притяжения» i-й модели i . Желательность перехода от обобщенной модели к частной i объясняется требованием простоты
(компактности) и положительными последствиями от выполнения этого требования (проще, компактнее аналитическая запись, лучшие специализированные алгоритмы оценивания параметров, имитации последовательностей выборочных значений и т. п.).
415
Методы функционального упорядочения. Эти методы используются тогда, когда модель MY показателя Y исследуемого объекта может
быть представлена одним или несколькими соотношениями вида
Y f ( X1 , X 2 , ..., X n ) , где f – некоторая функция, а X1 , X 2 , ..., X n –
другие показатели (величины, векторы, функции других аргументов),
описываемые моделями M X1 , ..., M X n . Упорядочение здесь выполня-
ется упорядочением видов функций f и моделей M X1 , ..., M X n . При-
меры таких упорядочений приведены в [61].
Методы матриц (таблиц) сопряженности. Суть методов – упорядочение моделей по их соответствию решаемым задачам. Она легко
усматривается из абстрактной табл. 4.2.
Т а б л и ц а 4.2
Пример матрицы сопряженности для упорядочения моделей
по их соответствию решаемым задачам
Задачи моделирования
или требования к моделям
Задача 1 (требование 1)
Задача 2 (требование 2)
Задача 3 (требование 3)
Задача 4 (требование 4)
Задача 5 (требование 5)
1
–
+
+
–
+
2
+
–
–
+
–
Свойства моделей
3
4
–
+
+
–
+
–
+
+
–
+
5
+
–
+
–
+
6
+
+
–
+
+
Согласно табл. 4.2, поставленные задачи 1, 2, 4, 5 могут быть решены (требования 1, 2, 4, 5 удовлетворены) с помощью множества ,
состоящего из одной модели 6; задачи 1–5 с помощью (1) = (1, 2),
либо (2) = (3, 4), либо (3) = (3, 5), … .
С конкретным примером подобной матрицы мы встречались, рассматривая формирование вектор-характеристик (см. табл. П2.4 в первой части пособия).
Еще одним вариантом индуктивного апостериорного упорядочения
моделей является метод деревьев решений (см. рис. 4.11).
Кстати, отметим, что некоторые методы упорядочения могут
успешно использоваться в классификационных измерениях, под которыми понимается разновидность измерений, в процессе которых устанавливаются априори нечетко определенные состав и суть обозначений (классов) категорийной измерительной шкалы, а результатом
416
является отнесение единичного объекта к одному из выбранных классов (Губарев В.В., Горшенков А.А., Кликушин Ю.Н., Кобенко В.Ю.
Автометрия. – 2013, т. 49. – № 2. – С. 76–84).
Наконец, отметим, что заменив в определении слово «модель» на
слово «метод» или «алгоритм», получим определение терминов методотека и алгоритмотека, для которых применимы методы упорядочения типа матриц соответствия, деревьев решений, сетей Петри [69].
Метод моделетеки в автоматизации совместного решения задач
идентификации, измерения характеристик и имитации (задач ИИИ).
В [18, 61, 64] описано применение принципов построения и особенностей моделетеки в индуктивном методе моделетеки совместного решения задач ИИИ. Стержнем метода являются следующие положения.
Метод ориентирован на такие задачи, когда по эмпирическим
данным необходимо решить не менее двух задач из трех: а) измерение
(оценивание) нескольких характеристик Q() , получаемых из базовой
Q0 () 1; б) идентификации имеющихся и в) имитации новых данных,
характеристики которых имеют требуемый вид, определяемый Q()
или через Q() ( Q0 () ).
Идентификация характеристики Q() осуществляется с использованием моделетеки моделей Q() или базовой характеристики
Q0 () , положенной в основу формирования моделетеки.
Измерения любых характеристик Q() , связанных с Q0 () , известными хранимыми в моделетеке аналитическими соотношениями,
осуществляется параметрическими методами (см. соотношение (4.127)
в 1-й части пособия) по наилучшим для выбранной модели в конкретных условиях алгоритмам, хранимым в моделетеке.
Имитация по методу моделетеки осуществляется в два этапа. На
первом этапе априори задается либо апостериори строится модель
имитируемого случайного элемента (величины, вектора, функции). На
втором – по специфичному для этой модели хорошо проверенному
аттестованному как лучший алгоритму осуществляется генерация последовательности выборочных значений случайного элемента, описы1
Примерами базовых характеристик являются плотность и функция распределения вероятностей, по которым, согласно дефиниции, определяются
все числовые характеристики случайных элементов, а также характеристические и кумулянтные функции, спектральные плотности мощности.
417
ваемого этой моделью. При этом, во-первых, очень могут пригодиться
иерархическое и функционное упорядочение моделей, во-вторых,
использование конкоров как характеристик связи (см. часть 1,
разд. 4.3.8).
Более подробные сведения о методе моделетеки, его слабых
и сильных сторонах при идентификации, измерении характеристик
и имитации случайных элементов можно получить по работам [18,
61, 64].
4.8.6. Интеллектуальный и разведочный анализы Данных
Как уже было отмечено в разд. 4.8.1, термин «интеллектуальный
анализ данных» (ИАД) является не совсем удачным переводом введенного в 1992 г. термина «Data Mining» (DM), под которым предлагалось понимать «процесс обнаружения в «сырых» данных ранее неизвестных, нетривиальных, практически полезных, доступных для
интерпретации знаний, необходимых для принятия решений в разных
сферах человеческой деятельности» [49].
Попытки адекватных переводов с английского термина DM типа
«добыча данных», «раскопка данных» и им подобных, не отражающих
сути термина, привели к тому, что в результате в русскоязычной литературе появилось приравниваемое к этому термину, но не адекватное
ему понятие «интеллектуальный анализ данных» (ИАД). Неудачность
отождествления понятий DM и ИАД связана, по крайней мере, с двумя
обстоятельствами. Первое, очевидное, термин DM не отражает суть
понятия, выражаемого дефиницией, определением. Ведь в определении речь идет о добыче не данных, а знаний из них. В этом смысле
ближе предложение Загоруйко Н.Г. [4]: адекватнее переводить DM как
«обогащение данных» по аналогии с обогащением руды при добыче
полезных ископаемых. Более радикальное решения заменить термин
DM на KDD – Knowledge Discovery in Data – обнаружение, открытие,
нахождение, раскрытие, узнавание знаний в данных, как это уже делают многие, или когнитивным анализом данных (КАД) [5].
Второе обстоятельство. В русском языке слово «интеллектуальный» предполагает, во-первых, более широкое и глубокое выполнение
неформализуемых или трудно формализуемых операций с данными и,
во-вторых, наличие других назначений у используемых для этого
средств, чем просто извлечение знаний из данных. Это, кстати, отражено в определении, но не проявляется в названии термина DM. Заме418
тим, что для человеческого интеллекта характерно высокопараллельное многомодельное восприятие, обработка и анализ поступающей с
помощью разных носителей информации, эластичность, многофункциональность и масштабируемость, способность выявлять, предлагать
и создавать новое, в том числе неочевидное, не встречающееся, не
имеющее аналогов в природе или ранее при решении схожих задач.
Подобные требования к искусственным средствам ИАД, а также к количеству привлекаемых аналитиков, очевидны. Особенно понятно требование масштабируемости – не более чем линейная или даже логарифмическая зависимость объёма работы от объёма данных.
Известные попытки расширенного понимания термина ИАД ориентированы на специфику современной концепции анализа данных. Однако
они учитывают только часть особенностей задач и данных, требующих
интеллектуальных усилий для понимания сути данных и решения задачи в конкретных условиях и приложениях, а также не в полной мере
необходимость наделения алгоритмов анализа данных «элементами
интеллекта». В силу этого подобные попытки не в полной мере отражает термин ИАД. Поэтому перейдем к его обобщенному понимаю.
Расширение (обобщение) понимания ИАД
Прежде всего расширение понимания ИАД связано с заменой
в нем слова данные на Данные, которые предлагается понимать как
Данные = сигналы данные анзния контент метаданные, где –
символ дизъюнкции. В этом и есть суть первого направления расширенного понимания ИАД, поскольку многие идеи, методы и средства
ИАД пригодны не только для оперирования с данными, но и с сигналами, анзниями, контентом и метаданными. Это расширение предлагается отразить заменой светлой буквы Д на полужирную, т. е. ИАД
на ИАД.
Второе расширение связано с увеличением количества задач, решаемых в ИАД, и методов их решения. Обосновывается оно описанной в
§ 4.2 современной концепцией понимания данных, их анализа, извлечения из них и применения знаний о представляемых ими объектах.
Ориентируясь на первые движения в этом направлении, изложенные в [1, 18], выделим четыре составляющих ИАД.
Первая составляющая ИАД-1 связана с теми же задачами, что и в
традиционных DM, KDD, КАД, а именно с задачами и технологиями
извлечения знаний об объекте из имеющихся Данных о нем. Сюда
относятся следующие задачи, а также приемы, методы и средства их
419
решения. 1. Задачи и методы, являющиеся основой DM, KDD, КАД,
ориентированные на поиск скрытых в Данных закономерностей, а через них закономерностей, связей, паттернов (шаблонов, образцов) в
объекте, нетривиальных, ранее неизвестных, практически полезных,
доступных интерпретации. 2. Исследования Данных с целью очистки
их от несовершенства и «мусора», т. е. направленные на отыскание,
устранение в них или корректировку тех их частей, которые не несут
полезную для решаемой задачи информацию, но содержат ошибки,
сбои, выбросы, противоречия (Data Cleaning (DC)), традиционный разведочный анализ данных РАД. 3. Исследования Данных с целью извлечения из них тех сведений, которые позволят улучшить структурирование, организацию, модельное представление Данных для
хранения, передачи, обработки, проведения DM, KDD, КАД, традиционного РАД. 4. Извлечения из баз данных и знаний тех вспомогательных сведений (метаданных и метазнаний), которые необходимы для
правильной обработки Данных, интерпретации и применения выявляемых знаний.
Вторая составляющая (ИАД-2) связана со следующими задачами и
методами. 1. Коллективное получение новых знаний об исследуемом
объекте с привлечением специальных методов и средств естественного
(человеческого) и искусственного интеллекта, в частности интеллектуальных инструментальных средств анализа типа Business Intelligence
Tools (BIT). Здесь под виртуальными понимаются Данные, имеющиеся
в базе или хранилище либо в свободном доступе, не относящиеся
напрямую к объекту, но позволяющие получить дополнительные знания об объекте, важные для решаемой задачи (например, данные о
солнечной активности или температуре окружающего воздуха при исследовании заболеваний или урожайности). 2. Получение новых знаний об объекте на основе извлеченных при ИАД-1, а также виртуальных и модельных Данных с помощью естественного (аналитиков) или
искусственного (интеллектуальных, в частности экспертных, систем)
интеллекта. 3. Применение выявленных знаний (в частности, путем
управления ими) для систематического приобретения, наполнения,
синтеза, обмена и использования дополнительных явных и неявных
(например, в виде опыта) знаний для поддержки принятия решений и
достижения других целей пользователем.
Третья составляющая (ИАД-3) связана с применением интеллекта в
тех трудно формализуемых задачах, которые направлены на поиск,
420
выбор, синтез и исследование пригодности для решаемой задачи методов, моделей, алгоритмов, аппаратных, программных и других средств
и технологий для постановки задачи, планирования и организации эксперимента, сбора, обработки, анализа, интерпретации и применения
Данных согласно поставленной задаче, т. е. с учетом цели исследования (познания, синтеза, управления, …) объекта и сопутствующих исследованию условий, ограничений. Сюда можно отнести следующие
задачи и методы. 1. Дополнение традиционного дедуктивного анализа
предшествующим ему или совмещенным с ним поиском, выбором,
синтезом моделей, методов, средств, технологий сбора, обработки,
анализа и интерпретации с учётом поставленной цели исследования
объекта и присутствующих ограничений. 2. Вариативное, в том числе
вектор, моделирование, полисистемное моделирование, самоорганизация моделей. 3. Интеллектуализация и автоматизация самих технологических операций поиска, выбора, синтеза моделей, методов, средств.
Четвертая составляющая (ИАД-4) ориентирована на использование
интеллекта для решения прагматических вопросов полезности и эффективности извлечения знаний, т. е. на исследование Данных как
прагмандов – операндов технологических операций по выявлению полезности, ненужности или даже вредности (с учетом затрат на их добывание) получения знаний из них. Иными словами, ИАД-4 направлен
на построение куанти́моделей (от лат. quanti – за какую цену, как дорого) Данных.
Разведочный анализ (разведочное исследование) данных и его
расширенное понимание
Термин «Разведочный анализ данных» (РАД, Exploratory Data
Analysis (EDA)) введен Дж. Тьюки [71]. Он рассматривал его как первый исследовательский (разведочный) этап технологического процесса
статистического анализа данных. До сих пор такая трактовка РАД не
изменилась (см, например, [60, 72–75]). Считается, что РАД ориентирован на выявление внутренних закономерностей, проявляющихся в
данных, завершается выдвижением апостериорных гипотез о модели и
свойствах данных, которые принимаются или отвергаются на втором
подтверждающем этапе.
Однако особенности современных данных, прежде всего Больших
данных, приводят к необходимости расширить такое понимание РАД
[70]. Ведь под РАД до сих пор принято понимать исследование данных
в условиях априорной неопределенности о них, направленное в
421
первую очередь на преобразование на первом этапе анализа данных
самих данных, а также на разработку способов их наглядного визуального представления с целью выявления таких внутренних особенностей данных, закономерностей, которые помогут выдвинуть апостериорные гипотезы о модельном описании данных, подтверждаемые на
втором этапе традиционными статистическими методами оценки параметров и проверки гипотез. Это, прежде всего, выявление в них основных структур данных, связей, паттернов-шаблонов; обнаружение
отклонений и аномалий; разработка гипотез о моделях распределений
значений. Иными словами, в условиях отсутствия нужных для анализа
априорных моделей данных (а через них о моделях объектов, представляемых данными) в РАД предлагаются апостериорные модели
данных, пригодные для дальнейшего подтверждения, корректировки и
применения при решении задач описания, предсказания, управления,
синтеза, диагностики, мониторинга состояния конкретного объекта и
других, подобных ему. Иначе, без РАД пришлось бы работать с данными «вслепую». Наличие проверенных результатов РАД позволяет
использовать их для получения и анализа новых данных. В то же время
«сырые», не подтвержденные результаты РАД являются лишь разведочными, промежуточными, а не окончательными. Отсюда следует,
что РАД, во-первых, прежде всего ориентирован на внутреннее исследование данных; во-вторых, на выдвижение апостериорных гипотез;
в-третьих, на обязательную последующую проверку справедливости
таких гипотез статистическими методами. Однако, как указано в
разд. 4.8.2, данные, с одной стороны, стали другими, с другой – превратились в Данные, несущие информацию о некотором реальном объекте, способные быть полезными при решении различных теоретических и практических задач; в-четвертых, требуют системного подхода
к их анализу, точнее, исследованию. Последнее, кстати, означает, что
РАД должны подвергаться не только сами данные, но и соответствующие им либо специально отыскиваемые, выявляемые метаданные.
Все это и побуждает расширить понимание РАД, во-первых, на РАД,
во-вторых, на именно исследовательскую сторону анализа, в-третьих,
по перечню решаемых РАД проблем и задач, распространив его на все
этапы технологического процесса моделирования и исследования объекта по модели с использованием Данных о нем, начиная с постановки
задачи исследования и сбора Данных до интерпретации и применения
полученных в итоге результатов [4, 12] с учётом особенностей реали422
зации каждого из этапов процесса и метаданных. Это следующие проблемы и задачи1.
1. В условиях индуктивного подхода обеспечение правильной
формулировки постановки задачи исследования, определения класса
моделей и Данных, адекватных рассматриваемому объекту, условиям
его состояния и функционирования, условиям получения Данных.
Например: выяснение корректности применения детерминированных,
стохастических, нечетких, экспертных и других моделей; допустимости считать объект стационарным, траекторию поведения объекта
эргодической, а выборку однородной; наличия точечного или интервального представления данных; применения количественных и категорийных измерительных шкал; особенностей плана эксперимента и
измерения; обоснованности выбора отражающих состояние и функционирование объекта характеристик, показателей, а также методов, алгоритмов, средств их измерения; правильности задания параметров
алгоритмов (шага дискретизации сигналов, объёма выборки, согласованности объёма и возможной корреляции выборки с задаваемыми
значениями метрологических показателей промежуточных результатов
и, главное, глобальному показателю качества итогового результата
решаемой задачи) и т. д. (РАД-1 – построение верификационных и верифицированных /от лат. verus – истинный и facio – делаю/ апостериорных моделей Данных).
2. Исследование корректности, согласованности получения исходных «сырых» данных с поставленной задачей и сопровождения процесса их получения сведениями, которые понадобятся в дальнейшем
при извлечении, интерпретации и применении знаний. Например, согласованности амплитудных и частотных диапазонов применяемых
средств, их классов точности, частот дискретизации, разрядности операндов между собой и с применяемыми далее алгоритмами и средствами (РАД-2 – построение апостериорных моделей согласованности
Данных с постановкой задачи, с используемыми средствами и технологиями).
1
Понятно, что в каждом конкретном случае перечень задач может быть
сужен, если какие-то этапы до применения РАД уже были выполнены. Тогда
назначение РАД выяснить, соответствуют ли данные объекту с учетом условий их получения и условий функционирования объекта. Иными словами,
РАД должен выявить метаданные, позволяющие реконструировать предшествующие этапы исследования объекта.
423
3. Выполнение традиционного РАД, направленного на выявление в
данных аномалий, асимметрии, пропусков; распределения их значений; линейных или нелинейных регрессий; стационарности или нестационарности сигналов, ряда; однородности, разнотипности; наличия и
вида зависимостей, связей и других важных для дальнейшего особенностей исходных данных с целью допустимости применения типовых
или выбора специальных моделей, характеристик для их представления, алгоритмов обработки, очистки, восстановления пропусков,
устранения выбросов, преобразования данных к виду, допускающему
применения имеющихся средств и осуществления специальных приёмов для обеспечения требуемого качества итогового результата по
имеющимся данным либо получения новых или дополнительных данных; их объединения, приведения к единому стандартному виду не
только с точки зрения обработки, но также хранения и последующей
интерпретации результатов (РАД-3 – построение апостериорных куомодных моделей Данных).
4. Исследование потенциальных возможностей Данных и используемых средств с точки зрения максимального достижения качества
итогового и промежуточных результатов как для получения таких результатов, сравнения полученного качества с потенциальным, так и
для оценки эффективности, рентабельности необходимых для этого
затрат (см. ИАД-4), подготовки соответствующих рекомендаций (РАД4 – построение куанту′мных /от лат. quantum – сколько, насколько/
апостериорных моделей, возможностей, потенций Данных).
5. Исследование возможностей и целесообразности использования
тех же Данных или дополнительных сведений для улучшения качества
первичных «сырых» результатов, организации адаптивных средств,
полимодельного, в частности вариативного или полисистемного моделирования, привлечения векторных моделей и характеристик. Подготовка рекомендаций по этому поводу (РАД-5 – построение квалитасных /от лат. qualitas – качество/ (квалиметрических) апостериорных
моделей Данных).
6. Исследование Данных для интерпретации результатов ИАД, выявление и дополнение метаданных и метазнаний (РАД-6).
7. Исследование опыта применения предыдущих результатов ИАД
для решения прикладных задач (ИАД-4) с целью накопления опыта,
формирования неявных знаний и использования их в ИАД-1–ИАД-3 в
дальнейшем (РАД-7 – построение обучающихся апостериорных моделей Данных и /после завершения ИАД/ знаний об объекте).
424
В заключение сделаем три замечания.
Первое связано с особенностью сигналов как носителей информации: их нельзя повторить. Зарегистрированный сигнал – это уже данные.
Второе замечание. Для ИАД и РАД пригодны и широко совместно
применяются мягкие методы и алгоритмы, описанные в § 4.6, 4.7 и
разделах 4.8.1–4.8.5.
Третье замечание. Если за РАД можно сохранить название, правда,
лучще заменив слово «анализ» на «исследование», т. е. РАД на РИД,
то ИАД по смыслу следовало бы переименовать в индуктивное апостериорное добывание знаний (ИАДЗ) или «апостериорный синтез
знаний» (АСЗ) по Данным.
§ 4.9. ПОНЯТИЕ ОБ ИНЖЕНЕРИИ ЗНАНИЙ
И УПРАВЛЕНИИ ЗНАНИЯМИ
4.9.1. Используемые понятия
Как указано в части 1, § 1.5 и части 2, разд. 4.6.2, к искусственному
интеллекту часто относят инженерию знаний и управление ими.
Анализируя разные определения (см., например, [22, 25, 26, 55])
термина «инженерия знаний» (англ. knowledge engineering)1, можно
условно объединить их в три группы.
Инженерия знаний – это:
1) раздел (дисциплина) инженерии, направленный на внедрение
знаний в компьютерные системы для решения сложных задач, «обычно требующих богатого человеческого опыта» (Э. Фейгенбаум,
МкКордак, 1983 г.);
2) область наук об искусственном интеллекте, связанная с разработкой экспертных систем и баз знаний, изучающая методы и средства
извлечения, представления, структурирования знаний (Википедия);
3) раздел информатики, искусственного интеллекта и информационных технологий, связанный с разработкой и применением искусственных систем (моделей, методов, средств и технологий) для решения задач и проблем с использованием знаний, а именно для
получения, анализа, представления, структурирования и обработки
знаний, а также создания и обслуживания подобных систем.
1
Термин введен Э. Фейгенбаумом в 1977 г.
425
Здесь эксперт – это 1) высококлассный специалист в своей предметной области; 2) квалифицированный специалист, вырабатывающий
и приобретающий определенные знания и суждения об исследуемых
объектах путем научного поиска и/или практического опыта и использующий их в практической деятельности (см. [76]).
Инженер по знаниям (knowledge engineer) – специалист, проектирующий и создающий экспертную систему (ЭС). Это, как правило,
специалист высокого уровня, имеющий системное мышление и владеющий соответствующими методами системного анализа и искусственного интеллекта, основные функции которого сводятся к заполнению
базы знаний сведениями, нужными для функционирования экспертной
системы (ЭС), работе со знаниями, извлечению их из источника знаний (эксперта, документации, …), их систематизации, взаимодействию
с пользователем ЭС. Его искусство состоит в умении по словесной
формулирвке задачи построить адекватную ей математическую задачу,
перевести задачу Пользователя в проблемную модель его предметной
области. Он имеет нужные сведения в предметной области пользователя и способен анализировать ее и вести диалог с пользователем.
Иногда инженера по знаниям называют аналитиком, когнитологом,
инженером-интерпретатором [26].
Предметная область1 (теории, информационной системы, моделирования, …) – это область действительности (класс объектов, их
свойств, отношений, закономерностей, …) и/или человеческой деятельности, на решение задач которой направлены или к решению задач
которой применяются теория, информационная система, моделирование, … . Модельное представление предметной области является одной из первостепенных задач соответствующей теории, сферы применения системы, модели, инженерии знаний. Из изложенного ранее
ясно, что толкование различных терминов является относительным
зачастую даже в узкой области знаний, теорий, области человеческой
деятельности, неоднозначным. Это характерно и для инженерии знаний и управления ими. Так, например, в [55, 76–79] приведены более
20 определений термина знания. Во многих публикациях в этой области под сущностями, определяемыми терминами «данные», «информация» и «знания», понимают следующее (см. разд. 2.6.1).
1
В ряде случаев количество предметных областей, к которым относятся
данные из базы или хранилищ данных или знания из баз (хранилищ) знаний,
используются как показатель семантической сложности (semantic complexity)
баз, хранилищ.
426
Данные – это: 1) отдельные факты, характеризующие объекты
предметной области, а также их свойства; 2) неструктурированные
факты и цифры вне контекста. Очень часто в литературе по ЕС слово
«данные» заменяется словом «факты».
Информация – результаты обработки данных.
Знания: 1) результаты обработки информации; 2) результат, полученный познанием; 3) закономерность предметной области; 4) хорошо
структурированные данные и метаданные, описывающие не только
факты, но и взаимосвязи между ними; 5) отношения между элементами данных, их взаимосвязи; 6) совокупность профессиональных навыков, умений, способностей, жизненного опыта и мудрости, которые
используются людьми для достижения поставленных целей [77].
Образно многие подобные понимания отражены в [25] в виде равенств:
«Данные + процедура обработки = информация».
«Информация + процедура обработки = знание».
Продолжить цепочку можно так
«Знания + глубокое понимание, основанное
на познании жизни, опыте = мудрость».
В [78, c. 201] подчеркивается, что факты – это свойства вещей, существующие независимо от мыслительных процессов человека, тогда
как знания – свойства воспринимающих их субъектов, причем информация является связующим звеном между ними. Но «факты» не есть
«истина». В отношении «фактов» можно делать неправильные заключения.
С точки зрения целенаправленной координации действий эти понятия можно представить как [78, c. 214]: данные (сведения, факты) –
ничего не знать; информация – знать, как; знание – знать, что; мудрость – знать, почему. Знания – накопленный потенциал для действия
[78, c. 209].
При этом иногда подчеркивают два момента: относительность понятий «информация» и «знания» [77]: для одних нечто есть информация, а для других – знания либо наоборот; знания получаются с использованием умственных усилий, связаны с применением
семантических процедур.
Внимание! О каком виде информации здесь идет речь (см. разд. 4.5.3)?
427
Управление знаниями – совокупность регулярно проводимых действий, процессов, направленных на повышение эффективности создания, хранения, распространения, обработку и применение знаний
внутри предприятий в их интересах.
4.9.2. Приобретение и представление знаний
Приобретение знаний означает реализацию двух функций – получение их извне и их систематизацию. Получение знаний связано с добыванием их из Данных, получением от эксперта, извлечением их из
него, считыванием из книг, Интернета, документов и т. д. В свою очередь, систематизация связана с модельным представлением приобретенных знаний.
Поскольку вопросы извлечения знаний из данных и модельного
представления знаний уже рассматривались в § 2.6, 4.7 и разд. 4.8.6;
остановимся кратко на методах приобретения знаний от экспертов, из
текстов, графиков, изобретений.
Прежде всего обратим внимание на сложность получения знаний
от эксперта, послужившую основанием называть эту процедуру извлечением знаний из эксперта. Трудности извлечения знаний встречаются
тогда, когда эксперт либо не желает, либо не может передать свои знания. Причины, по которым эксперт зачастую не может передать свои
знания инженеру по знаниям, следующие:
знания эксперта многослойны, а со временем звенья переходов в
памяти от слоя к слою знаний забываются и трудно восстанавливаются;
зачастую эксперт знает гораздо больше, чем он сам осознает
свои знания в текущий момент;
часть знаний и умений хранится в памяти рассредоточенно,
в связанном сложной логико-ассоциативной сетью виде;
эксперт не может сообщить, как он получил свои знания, умения,
навыки, компетенции и как оперирует ими;
большинству лиц, в том числе экспертов, не свойственна аналитичность и способность к ясному изложению, тем более, что по мере
накопления опыта специалист-эксперт зачастую утрачивает умение
словесно выражать свои знания (факт Джонсона [49]);
многие неявные знания эксперта, его опыт являются следствием
интуиции, озарения, трудно поддающихся описанию.
428
Вторая сложность извлечения знаний из экспертов – это проверка
их истинности. Это особенно важно, когда эксперт активно противится
процессу извлечения. Поэтому желательно, чтобы методы извлечения
«гарантировали» истинность знаний эксперта, их ориентированность
на успешное решение тех задач, где они будут применяться.
В связи с этим инженерия знаний предлагает много активных и
пассивных методов (приемов, способов) по «раскручиванию» самих
экспертов (при их нежелании) или зон, лабиринтов их памяти, в которых хранятся извлекаемые знания (при неспособности экспертов помочь), ориентированных на получение «истинных» знаний.
Перечислим некоторые из них. Более подробно с ними можно
ознакомиться по специальным учебникам и монографиям, например,
по [26, 49, 55].
Прежде всего рассмотрим коммутативные методы, ориентированные на непосредственный контакт с источником знаний – экспертом.
Пассивные коммутативные методы – это такие, в которых ведущая роль в процедуре извлечения принадлежит (передается) эксперту.
Роль инженера по знаниям при этом – протокольная, регистрировать
любым способом рассуждения эксперта во время его реальной работы
по решению практической задачи, например, по принятию решения с
использованием своих знаний. К этим методам относятся: наблюдения,
протоколирование и анализ «мыслей вслух» и хода рассуждений; запись лекций путем обсуждения, описания и анализа экспертом задач,
оценивания им ЭС и проверки ее работы и т. п.
В активных коммутативных методах инициатива полностью в
руках инженера по знаниям, который выбирает индивидуальную работу с отдельными экспертами или групповую, коллегиальную. В первом
случае инженер использует следующие методы: анкетирование, интервьюирование, диалоговое взаимодействие, экспертные игры. Из
групповых распространены следующие методы: «мозгового штурма»
(см. часть 1, разд. 4.4.7), круглого стола, ролевых игр и другие.
Помимо коммутативных методов извлечения знаний часто используются методы, условно называемые текстологическими, когда знания
экспертов извлекаются косвенно из опубликованных ими работ (учебных или научных публикаций, описаний объектов промышленного
права и т. п.), а также из разных документов, т. е. из неодушевленных
носителей знаний. Отметим также, что одним из важных методов при429
обретения знаний является обучение, в частности, обучение по примерам на основе аналогий, индукций, эвристик, в том числе обучение
инженера по знаниям1.
4.9.3. Экспертные системы
В настоящее время разработаны и широко применяются относящиеся к разным классам информационные системы, основанные на знаниях.
Это, например, системы таких классов: интеллектуальные информационно-поисковые системы (ИИПС), экспертные (ЭС), обучающие
(ОС) и самообучающиеся, системы с интеллектуальным интерфейсом.
Иногда к ним относят адаптивные [55].
В качестве примера рассмотрим класс экспертных систем как
наиболее известный.
Экспертные системы (ЭС) – это интеллектуальные узкоспециализированные программные средства, аккумулирующие знания специалистов в определенных предметных областях, способные делать логические выводы на основании этих знаний, консультировать менее
квалифицированных пользователей и обеспечивать решение конкретных специфических задач на профессиональном уровне, в том числе
быстро принимать стандартные решения.
Основная цель построения конкретной ЭС – это создание искусственной системы, способной работать на уровне консилиума высококлассных специалистов при решении узких практических задач.
Обобщенная схема ЭС представлена на рис. 4.192.
Основная цель построения конкретной ЭС – это создание искусственной системы, способной работать на уровне консилиума высококлассных специалистов при решении узких практических задач.
1
Бытует мнение, что «человек, впервые начинающий применять возможности современных информационных технологий в 40-летнем возрасте, абсолютно не обучаем» [55, c. 181]. Так ли?
2
Зачастую знания в ЭС делят на факты (фактические, фактуальные, фактографические знания (см. разд. 2.6.2)) и правила (знания для принятия решения, см. процедурные знания в разд. 2.6.2). Однако поскольку многие авторы
относят факты к данным, иногда будем специально выделять слова данные,
знания и правила, хотя чаще для сокращения оставлять только два слова данные и знания, полагая, что правила – это процедурная часть знаний.
430
Запрос пользователя
Неодушевленные
носители знаний
База знаний
и правил
Выявленные противоречия,
аномалии, особенности
Данные
База данных
Знания
Вновь полученные
данные и знания
Данные
Решатель
Знания
Машина вывода
Инженер по знаниям
Интеллектуальный редактор
данных и знаний
Пользователь
Подсистема приобретения
знаний
Подсистема советов и
объяснений
Эксперты
Подсистема накопления и хранения
данных, знаний, правил
Заключения, объяснения, консультационные советы
Рис. 4.19. Обобщенная схема экспертной системы
Как и для всех информационных систем, основанных на работе со
знаниями, ключевым элементом – ядром ЭС – является база знаний
(БЗ). Важным элементом ЭС, который не всегда отмечается на схеме,
поскольку полагается, что данные хранятся в рабочей памяти ЭС, является база данных (БД). В БД могут храниться разные числовые, табличные и текстовые данные, в том числе нужные факты, справочные
данные, стандарты, инструкции.
Интеллектуальный интерфейс пользователя – это программа,
обеспечивающая такую организацию диалога с пользователем, которая
наилучшим образом приводит к достижению цели общения человека с
ЭС, позволяет погрузить задачу конечного пользователя в модель его
предметной области.
Пользователь – это специалист, квалификация которого недостаточна (для решаемой им задачи) в той предметной области, для которой предназначена ЭС, и который нуждается в помощи от ЭС («неспециалист»).
431
Интеллектуальный редактор данных и знаний – это программная система, позволяющая инженеру по знаниям создавать и корректировать в диалоговом режиме содержимое БЗ и БД, т. е. добавлять,
удалять, модифицировать данные и знания, факты и правила. Слово
интеллектуальный здесь относится, прежде всего, к знаниям и понимается, как обеспечивающий целостность, корректность, многозначность,
непротиворечивость семантического наполнения знаний и другие важные для получения выводов свойства хранимых знаний, отличающих
их от данных, а также сохранения одинаковых свойств, качеств данных
и знаний. В зависимости от реализации редактор может выполнять
часть или все функции систем управления базами знаний и данных.
Если же традиционные «интеллектуальные» функции выполняются
отдельными СУБД и СУБЗ, то тогда на рис. 4.1 БЗ и БД следует заменить на банки данных (БнД) и знаний (БнЗ). Заметим, что схема, изображенная на рис. 4.19, является обобщенной, т. е. отражающей наличие
в ЭС обязательных элементов (блоков). Для конкретных ЭС структуры
ЭС и ее элементов могут отличаться деталями, в том числе отражающими особенности управления базами, участия блоков в их актуализации и диалоговом взаимодействии с каждым элементом.
Машина выводов – это программа, позволяющая осуществлять логические выводы, обеспечивающая способ и последовательность (порядок) актуализации алгоритмической части работы БЗ, БД, а с ними и
оперирования с их содержимым. Ее реализация зависит от моделей
знаний и данных, используемых в БЗ и БД.
Решатель (иногда его называют интерпретатор) – программа, моделирующая ход рассуждения эксперта на основании знаний, правил и
данных, имеющихся в БЗ и БД. Он формулирует план достижения цели, последовательность применения правил для обработки знаний и
данных и получения искомого решения.
Подсистема советов и объяснений – программа, позволяющая
отражать, как получены логические выводы, предоставлять различные
комментарии, советы, прилагаемые к заключению, выдаваемому машиной вывода, объяснять мотивы появления такого заключения. Это
один из важнейших элементов ЭС, определяющий эффективность ее
применения. Поскольку в любой интеллектуальной системе используются не только строго алгоритмические способы получения решений,
очень часто ценность имеет не только и даже не столько само решение,
полученное человеком (естественным интеллектом) и искусственной
интеллектуальной системой, а процесс получения решения, т. е. ход
432
решения1. В ЭС – это процесс получения решения человеком в диалоге
с ней. Поэтому данная подсистема должна помочь пользователю получить ответ на вопросы типа: «А почему так?», «А почему так, а не
так?», «Как была получена та или иная рекомендация, совет?», «Почему ЭС приняла именно такое решение?» и т. п. Это саязано с тем, что,
как уже упоминалось, в основе работы ЭС лежит последовательная
схема связи вида: данные и знания, основанные на фактах, вывод
промежуточная гипотеза вывод заключительная гипотеза пояснения к ней.
Наконец, подсистема приобретения (получения, извлечения) знаний – это человеко-машинный элемент ЭС, ориентированный на получение знаний от экспертов или из неодушевленных носителей знаний,
в том числе результатов ИАД, для наполнения, поддержки, обновления
БЗ, БД.
В заключение сделаем три замечания. Первое касается термина интерпретация (см. часть 1, § 1.3). В ЭС очень часто используется термин
«интерпретация данных» как «процесс определения смысла данных,
результаты которого должны быть согласованными и корректными»2
[26, c. 41]; интерпретация фактов, ситуаций, вновь поступающих данных [25]; построение описаний ситуаций по наблюдаемым данным [50]
(см. интерпретация результатов, часть 1, § 1.3).
Второе замечание об особенности процесса взаимодействия предметного специалиста с ЭВМ с использованием ЭС и без нее, т. е. при
традиционных «не экспертных» расчетах. Она сводится [25] к замене
этапов: «выявление целей консультирования» вместо «выявление параметров и методов расчета»; «построение плана достижения цели и
его корректировка пользователем», «осуществление плана (по модели)
и расчет основных параметров решения» вместо «проведенние расчетов»; выяснение у пользователя «удовлетворительности решения» и
«корректировка целей консультирования» вместо «оценка удовлетворительности и корректировка параметров»; «конец консультации»
вместо «конец расчета».
1
Не во всех интеллектуальных информационных системах (ИИС) это
приводит к наличию в них подсистемы советов и объяснений. Причина этого,
во-первых, в ее востребованности, во-вторых, в сложности ее реализации для
некоторых ИИС, в том числе для некоторых ЭС, в частности, из-за особенностей используемых в ИИС модельных представлений.
2
В [49] подобные задачи относятся к задачам Data Mining.
433
Третье замечание связано с рекомендациями и предупреждениями
для тех, кто занимается созданием ЭС. Они подробно рассмотрены в
специальной научной и учебной литературе, в частности, в [22, 25,
26, 50].
4.9.4. Управление знаниями
Стремительный переход человечества к обществу, основанному на
знаниях, привел к появлению нового раздела в менеджменте – управлении организациями – раздела «управление знаниями». Управление
знаниями (knowledge management) – это:
в широком смысле – вид деятельности, ориентированный на добычу (открытие, создание), исследование, обработку и распространение знаний в чьих-то интересах;
в узком смысле – «создание организационных, технологических
и коммуникационных условий, при которых знания и информация будут способствовать решению стратегических и тактических задач организации» [77];
это «управление процессами, связанными со знаниями, или управление процессами работы со знаниями» [76].
Впервые этот термин был введен в 1986 г. Карлом В. Виигом
(K.M. Wiig) на конференции ООН [76, 77]. В практику термин вошел с
1989 г. в связи с появлением консорциума «Управление активами компаний» американских компаний [77]. Необходимость управления знаниями обусловлена несколькими причинами. Перечислим лишь некоторые из них:
при разговорном общении с экспертом у инженера по знаниям
остается лишь около 24 % информации от эксперта [26];
в среднем до 50 % рабочего времени сотрудники организаций
расходуют на поиски необходимых им знаний [77];
по подсчетам компании Arthur Andersen, если сейчас знания удваиваются каждые пять лет, то к 2020 году – через каждые 72 дня [77];
около 80 % имеющихся в организации знаний находятся в
«скрытом» состоянии [76];
объекты действительности охвачены более чем 200 типами отношений (временные, пространственные, причинно-следственные,
«часть – целое» и др. (Д.А. Поспелов [26, c. 68]).
Согласно [77] управление знаниями – это выполнение принципа
«четырех Н» (по Биллу Гейтсу): создание условий, при которых нуж434
ные люди смогут получить нужную информацию и знания в нужное
время для выполнения нужных задач1.
Существует два типа исследователей и специалистов, занимающихся управлением знаниями (УЗ) [79]. Исследователи первого типа
аналогичны исследователям искусственного интеллекта. Их целью является познание природы знаний и управление ими. Сюда относятся
как те, кто видит в компьютере полезное средство для извлечения знаний из данных, обработки больших массивов знаний, так и те, которые
пытаются научить компьютер думать аналогично человеку. Исследователи второго типа ориентированы на то, чтобы соединить людей
непосредственно с носителями знаний – людьми [77]. Поэтому здесь
важны коммуникации, связи. Первую группу исследователей можно
отнести к тем, кто пытается описать проблему. Вторая группа включает в себя специалистов классического менеджмента знаний. Они ориентированы на получение корпоративных преимуществ отдельной
компании на базе управления знаниями. Именно об этом направлении
далее в основном и будет идти речь, поскольку элементы первого
направления мы уже рассматривали.
В последнее время выделяют следующие подходы к управлению
знаниями [26, 76-79].
Первый подход (первое поколение УЗ): формировать знания и искать то, что является общеизвестным, что хранится [77]. При этом
подходе исходят из того, что знания в организации уже существуют,
созданы и требуется только их должным образом зафиксировать, закодировать, распространить. Тогда целью УЗ является не совершенствование процесса создания знаний, а улучшение применения знаний в
практической деятельности организации [76]. Иными словами, основная направленность первого подхода – соединить сотрудников компании с информацией. Только около 20 % знаний организаций, компаний
находятся в формализованном виде, а около 80 % – это знания, оставшиеся у их сотрудников. Поэтому стал развиваться второй подход к УЗ
и к формированию интеллектуального капитала компаний.
Второй подход (второе поколение УЗ, с 2002 г.): знания не существуют в готовом виде. Их надо искать, соединять «источники» и
«потребители» знаний. Иными словами, в этом подходе считается, что
1
Сравни с областью практической деятельности в информатике, см. часть
1, § 1.4, а также [24, 34], заменив в словосочетании «в нужном объеме заданного качества в требуемые сроки при минимальной себестоимости» подчеркнутые слова на слова «нужного», «нужные», «нужной».
435
знания непрерывно производятся в процессе их обработки (knowledge
processing) , а их использование в бизнес-процессах проверяет знания,
выявляет новые проблемы, формирует новый спрос на них, требующий его удовлетворения.
Процессный акцент в управлении знаниями проявляется, в частности, в определении УЗ. Например, как в [26]: «Управление знаниями –
это совокупность процессов, которые управляют созданием, распространением, обработкой и использованием знаний внутри предприятия».
И в том и в другом подходе рассматривают явные и неявные знания людей, компаний.
Явные знания (explicit knowledge) – это описания теорий, методов,
методик, технологий, механизмов, машин, конструкций, систем и т. п.
Иными словами, явные знания компании – это все то, что остается в
ней, когда ее сотрудники уходят домой, увольняются, и без чего эффективная деятельность компании невозможна, т. е. это знания, которые люди осмыслили и задокументировали, выразили в отчетах, инструкциях, теориях и т. д.
Неявные (скрытые) знания (tacit knowledge) – это опыт, секреты
мастерства, культура мышления, интуиция, ощущения, впечателения,
ассоциации, ноу-хау, навыки, житейская мудрость и прочее, спрятанные глубоко в головах людей как результат генетической наследственности, образования, приобретенного жизненного опыта. Иными словами, – это знания, определяющие способность человека к решению его
профессиональных, интеллектуальных, житейских задач в условиях
неопределенности, к адаптации в меняющихся условиях.
Согласно Милану Желены [78, c. 213], знания – это целенаправленное координированное действие. Его можно продемонстрировать
только действием. А единственное доказательство или способ демонстрации заключается в достижении цели. Поэтому качество знания
может быть оценено по качеству результата достижения цели, т. е.
по качеству продукта деятельности, или по качеству координирования процесса достижения цели, особенно в условиях воздействия неконтролируемых факторов, влияющих на достижение цели.
Как отдельный современный подход или элемент первого или второго подходов УЗ рассматривает такое управление ими (знаниями),
которое ориентировано на формирование интеллектуального капитала
компании (ИКК). Это проявляется, например, в определении термина
«управление знаниями» из Википедии «Менеджмент знаний – это
систематические процессы, благодаря которым создаются, сохраняют436
ся, распределяются и применяются основные элементы интеллектуального капитала, необходимые для успеха организации; стратегия,
трансформирующая все виды интеллектуальных активов в более высокую производительность, эффективность, стоимость».
Это же следует и из работы [79], в которой управление знаниями
рассматривается как совокупность следующих мероприятий по управлению интеллектуальным капиталом (ИК): идентификация, разработка
политики в отношении ИК, аудит, документальное оформление ИК и
занесение его в базу знаний, защита ИК.
Что же такое интеллектуальный капитал? В связи с неустановившейся терминологией приведем несколько пониманий термина на
примере ИК организации, компании (ИКК).
ИКК – это «нематериальные активы, без которых компания теперь
не может существовать» [79, c. 30]. К таким активам Э. Брукинг относит рыночные, человеческие, интеллектуальные и инфраструктурные
[78, 79].
Рыночные активы – это потенциал, связываемый с рыночными
операциями, обеспечивающими компании конкурентное преимущество
во внешней среде (марки обслуживания, марки товаров, корпоративное
имя, деловое сотрудничество, лицензионные соглашения и т. д.).
Человеческие активы – совокупность коллективных знаний сотрудников предприятия, их творческих способностей, умений решать
проблемы, лидерских качеств, предпринимательских и управленческих
навыков.
Интеллектуальные активы – это объекты интеллектуальной собственности, защищенные промышленным правом (изобретения, полезные модели, промышленные образцы /охранный документ1 – патент/),
селекционные достижения (сорта растений, породы животных)
/патент, авторское свидетельство2/; топологии интегральных микросхем/ свидетельство о государственной регистрации/; товарные знаки и
знаки обслуживания /свидетельство/; наименования мест происхождения товара /свидетельство/; секреты производства (ноу-хау)/ конфиденциальность сведений без охранных документов/; единые технологии /охраняются составные компоненты/; объекты, защищаемые
1
Согласно законам по интеллектуальному праву РФ, действующим с
01.01.2008 г.
2
Патент удостоверяет приоритет, авторство и исключительное право, а
авторское свидетельство – только авторство.
437
авторским правом (например, программы для ЭВМ, базы данных /свидетельства о регистрации/), а также неохраняемая техническая документация, результаты НИОКР, торговые секреты и т. п.
Инфраструктурные активы – те технологии, методы и процессы,
которые делают работу компании возможной (концепции управления,
структурные активы, управленческие процессы, распределение полномочий, связи и отношения внутри и вне компании, правила и процедуры принятия решений, системы стимулирования и мотивации, брендактивы (корпоративная культура, известность, репутация, доброе имя
компании) и т. п.).
Другие трактовки ИКК сводятся к его пониманию как те нематериальные активы, которые не указываются в финансовых документах компании, управляются компанией (Голубкин В.Н. и соавторы); сумма
таких знаний всех работников компании, которая обеспечивает ее конкурентоспособность (Просвирина И.И.); человеческий, потребительский
и структурный капитал (Кит Брадли); коллективный мозг, аккумулирующий научные и обыденные знания работников, интеллектуальную собственность и накопленный опыт, общение и организационную структуру, информационные сети и имидж фирмы (В.Л. Иноземцев) и т. п.
Близким является еще одно важное понятие «Обучающаяся, или
самообучающаяся, организация» (Learning organization, Питер Сенге
/Peter Senge, 1990 г.), под которой понимается организация, создающая, приобретающая, передающая и сохраняющая знания, способная
успешно изменять формы поведения, отражающие новые знания или
проекты. «Обучающая организация – это организация, которая постоянно и непрерывно генерирует, приобретает и распространяет знания,
имеет и совершенствует свое поведение на основе изучения собственного опыта, создает новые продукты и услуги, постоянно используя
идеи сотрудников и анализируя знания клиентов и партнеров» [77,
c. 300]. Иными словами, – это организация, постоянно активно формирующая, накапливающая и применяющая интеллектуальный капитал
для повышения эффективности своей деятельности.
Как уже понятно из изложенного, системы управления знаниями
(СУЗ) могут быть построены как с использованием классических синтактических приемов и технологий работы со знаниями, так и семантических, основанных на применении взаимосвязанного набора методов и технологий работы со смыслом знаний, семантикой данных, а
также их комбинаций с учетом жизненного цикла знаний: выявление
потребности в знаниях, производство (создание) знаний и потребление
438
(утилизация) знаний [76]. При этом учитываются три источника и три
составные части управления знаниями [77]: люди, процессы, технологии, с учетом роли в УЗ трех «К» – координация взаимодействия, коммуникации и кооперации сотрудников организации (компании).
Завершая рассмотрение управления знаниями и интеллектуального
капитала, еще раз акцентируем внимание на следующих обстоятельствах.
1. Управлять знаниями в компании – значит создавать такие условия в работе компании (организации), при которых накопленные явные
и неявные знания будут эффективно использоваться для выполнения
важных для нее задач, повышения ее конкурентной способности и эффективности.
2. Управление делается не из-за моды или любви к процессу, а с
какой-то целью, которой может лучше соответствовать первый или
второй подход, либо их комбинация в целом по компании или по подразделениям.
3. В зависимости от цели необходимо оперировать не со всеми знаниями, а только с теми, которых достаточно для достижения цели.
4. Вместо принуждения людей делиться их знаниями более предпочтительным может быть использование различных материальных и
нематериальных средств мотивации и стимулирования сотрудников
для этого [77].
5. Управление должно быть постоянным, каждодневным, а сотрудники – носители элементов ИКК должны чувствовать, что им комфортнее оставаться в компании, чем уйти из нее, что их знания востребованы именно в этой компании.
6. Ответственный за организацию УЗ должен быть сам лидером в
этой области.
§ 4.10. ПОНЯТИЕ О КВАЛИМЕТРИИ МОДЕЛЕЙ.
ОБЕСПЕЧЕНИЕ КАЧЕСТВА РЕЗУЛЬТАТОВ
МОДЕЛИРОВАНИЯ (ИССЛЕДОВАНИЯ) ОБЪЕКТОВ
И АНАЛИЗА ДАННЫХ, УПРАВЛЕНИЕ КАЧЕСТВОМ
4.10.1. Постановка задачи
Как уже неоднократно указывалось, получение требуемого качества результатов моделирования объектов, обработки и анализа Данных, решения задач измерения характеристик, идентификации, имита439
ции, прогнозирования, принятия решений и прочих подобных им задач
(см. часть 1, рис. 2.1 и 2.4) является одной из целевых установок для
тех, кто ответствен за получение именно этих результатов [18]. Однако
для пользователя этих результатов оно выступает лишь как средство к
достижению своей цели – управления, изучения особенностей функционирования, анализа и синтеза, прогнозирования и имитации поведения конкретного материального объекта в заданных условиях, обучения обслуживающего персонала и т. п. Для достижения своей цели
пользователь зачастую вынужден варьировать требованиями к значениям показателей качества и даже самими (порою противоречивыми)
показателями качества промежуточных результатов измерения, идентификации, имитации, прогнозирования, распознавания, управлять
ими, отыскивая наилучшее или компромиссное для его итогового решения значение. Например, уменьшать с целью повышения разрешающей способности при спектральном анализе систематические погрешности (смещения оценок) за счет приемлемого увеличения
дисперсии и (или) среднего квадрата погрешности частных результатов; для повышения оперативности или для уменьшения влияния нестационарности сигнала пойти на уменьшение объема выборки, т. е. на
увеличение статистических погрешностей; менять характеристики
случайных сигналов, выбирая те из них, которые лучше всего подходят
для решения его задачи, и т. д. Это требует разработки методов и
средств управления качеством результатов моделирования и исследования объектов, чему посвящен настоящий параграф пособия.
Задача управления качеством результатов моделирования и исследования объектов в широком смысле может быть сформулирована
следующим образом: при известных априори целях пользователя (т. е.
назначениях результатов, решаемых с их помощью задач и требованиях к качеству результатов решения этих задач), управляемых и неуправляемых факторах плана наблюдения (измерения) обеспечить
управление выбором и выбрать такие показатели качества результатов
(включая точностные и ресурсные) и их граничные значения, модели,
измеряемые характеристики, алгоритмы измерения, идентификации,
имитации и выполнения других операций (включая различные модификации алгоритмов и значения их параметров), а также значения
управляемых факторов, которые позволят пользователю получить искомый результат, наилучшим образом соответствующий цели при минимально возможных или допустимых затратах. При этом пользователь должен иметь возможность изменять (перераспределять) значения
440
выбранных показателей качества с целью углубленного изучения явления (задачи пользователя), применять поливариантные приемы,
исключая абсолютизацию получаемых результатов и возможные
ошибки. Задача управления качеством результатов в узком смысле отличается переносом в ограничения дополнительных сведений (показателей качества, моделей, измеряемых характеристик, вида алгоритма и
т. п.) и управлением оставшимися варьируемыми факторами (значения
показателей качества, модификации и параметры алгоритма и т. д.).
С известной степенью условности можно выделить, по крайней мере, четыре группы методов управления качеством результатов моделирования и исследования объектов: модельные, алгоритмические (методические), технические (аппаратно-программные) и организационные.
Модельные методы связаны с созданием и выбором таких моделей, в
том числе вектор-моделей, объектов и сигналов, включая выбор характеристик, которые позволят решить поставленную пользователем задачу с требуемым уровнем качества. Алгоритмические методы основаны на совершенствовании существующих или конструировании
новых алгоритмов (методов) идентификации, измерения искомых
характеристик, имитации объектов и сигналов, выполнения других
операций, что в приложении к рассматриваемым средствам связано с
применением формальных процедур, лежащих в основе их функционирования. Технические же методы связаны с изменением аппаратной
или программной реализации математических соотношений, формальных процедур. Условность разделения методов на модельные, алгоритмические и технические связана с тем, что некоторые (структурные, в отличие от элементных) аппаратные приемы управления
качеством обязательно сопровождаются изменением алгоритма функционирования данного средства. При этом алгоритм функционирования включает в себя как часть алгоритм измерения, идентификации
или имитации в смысле формульного математического преобразования. Алгоритмическое управление качеством может осуществляться на
непараметрическом или параметрическом уровнях. В первом случае
выбирается вид (тип) алгоритма и (или) архитектурно-структурного
аппаратно-программного решения, во втором – параметры алгоритма и
(или) архитектурно-структурного решения, элементная база и т. п.
В связи с этим рассмотрим некоторые элементарные основы в этой
области.
441
4.10.2. Квалиметрия моделей,
результатов моделирования объектов и анализа Данных
Термин квалиметрия1 (qualimetry) предложен в 1968 г. группой
отечественных научных работников, руководимой Г.Г. Азгальдовым, и
образован от лат. qualis – какой, какого качества и греч. metron – мера,
metreō – измеряю.
Квалиметрия – это научная дисциплина, занимающаяся разработкой, исследованием и совершенствованием количественных показателей качества различных материальных или интеллектуальных продуктов человеческой деятельности, методов и средств их измерения
(оценки), а также область деятельности, реализующая измерение,
оценку качества.
Здесь под качеством продукта понимается совокупность его
свойств, обусловливающих возможность удовлетворения ими требований потребителя продукта с учетом назначения продукта [80]. Эта совокупность свойств может быть оформлена в виде дерева свойств –
графического представления декомпозиции (разложения) интегрированного (общего) сложного качества на более простые, единичные.
Свойство – первичное, неопределяемое понятие, выражаемое в
одном или нескольких показателях, измеренных в своих шкалах. Использование количественных шкал для показателей позволяет получить количественные оценки качества рассматриваемого материального или интеллектуального продукта человеческой деятельности.
Показатель качества продукта – это количественная характеристика одного или нескольких свойств продукта, входящих в его качество, рассматриваемая применительно к определенным условиям его
создания и потребления (ГОСТ 15467–79. Управление качеством продукции. Основные понятия, термины и определения).
Каждый продукт обладает своей номенклатурой показателей, зависящей от многих факторов: функциональных, технических, метрологических, технологических, экономических, эргономических, эстетических, патентно-правовых и т. д. Показатели бывают абсолютные
(базовые) и относительные; единичные (зависящие от одного параметра), комплексные (объединяющие ряд свойств, каждое из которых
1
Корень «квали» означает «качество» (например, квалификация в русском) и похоже произносится на разных языках: англ. guality (кволити), итал.
qualitas (квалита), исп. culidad (квалидад), нем. qualitat (квалитет), франц. qualite (калитé).
442
описывается своим единичным показателем: надежность, живучесть,
…) и интегральные (объединяющие ряд комплексных); формализованные (количественные) и неформализованные (категорийные: удобство, красота). Иногда качество продукта увязывается с его полезностью (utility) следующей формулой: полезность = качество +
удовлетворение потребностей.
Согласно изложенному под квалиметрией моделей1 (моделеметри1
ей ) и результатов моделирования и анализа Данных (МиАД) следует
понимать научные дисциплины и области практической деятельности,
занимающиеся созданием, изучением и реализацией методов и средств
оценки качества моделей и результатов МиАД. Развивая имеющуюся
базу в этой области (см., например, [18, 66] и ссылки в них), выделим
первоочередные проблемные задачи подобной квалиметрии.
1. Выбор, разработка, описание и классификация показателей качества моделей и результатов МиАД.
2. Разработка описания отдельных моделей, результатов и их классов, ориентированных на взаимосвязь их между собой, их упорядочение и сравнение с помощью различных показателей, метрик.
3. Разработка методов комбинирования и гибридизации количественных и категорийных показателей качества, измеренных в разных
шкалах, а также многокритериального анализа, выбора и упорядочения
моделей и результатов МиАД, обеспечения качества и управления им.
4. Разработка основ синтеза и применения технологий моделирования объектов и анализа Данных, обеспечивающих нужное потребителю качество их результатов в нужные (требуемые, допустимые) сроки
при необходимых и нужных (допустимых) затратах и потерях.
4.10.3. О методах обеспечения гарантированного
качества моделей и результатов МиАД
и управления качеством
Рамки пособия не позволяют хотя бы кратко остановиться на существующих методах обеспечения гарантированного качества моделей и
результатов МиАД. Отошлем читателя к работам [18, 66], в которых
приведены ссылки на другие первоисточники. Здесь лишь перечислим
некоторые алгоритмические методы обеспечения качества и управления качеством результатов измерения вероятностных характеристик
1
Термины из [66].
443
сигналов или оценивания характеристик и параметров случайных величин, векторов и процессов [18]. Это методы, ориентированные на
точностные показатели качества: моделе-, методо- и алгоритмотеки
для выбора моделей, методов и алгоритмов; смешанного и комбинированного оценивания; сегментации выборок и оценок; сшивки и накопления оценок; многократного усреднения, а также такие методы обеспечения качества и управления им по техническим показателям как
методы ускорения, упрощения и сокращения объема вычислений или
измерений, адаптации, самонастройки, самообучения.
В заключение заметим, что все изложенное можно применить не
только к моделям и результатам, но и методам, алгоритмам.
ЗАКЛЮЧЕНИЕ
Четвертая глава посвящена в основном индуктивному и семантическому подходам к модельному представлению объектов и анализу
Данных.
Вначале вводятся и поясняются понятия, рассматриваются особенности современных Данных об объектах и задачи исследования объектов и Данных. Описывается отличие дедуктивного и индуктивного
подходов к анализу данных. Затем коротко освещаются элементы теории алгоритмов, сложности алгоритмов и задач, их классы по сложности и априорных неопределенностей при постановке задачи, расширение понятия «алгоритм», включая рассмотрение мягких алгоритмов.
Обсуждаются вопросы исследовательских проблем и их решения.
Особое внимание уделяется рассмотрению информологии, как раздела и объекта исследования информатики, посвященного изучению
того, что такое информация, меры ее количества, показатели качества,
какие свойства она имеет и каким образом трактуется разными учеными и специалистами. Предлагается термином «информация» обозначать соборное агрегированное понятие, рассматривая информацию на
настоящий момент ее изученности как (информационное) гало – непонятное, ненаблюдаемое, но реально существующее (по типу темной
материи – темного гало).
Обсуждается понятие «интеллект» и «искусственный интеллект»,
структура искусственного интеллекта как раздела информатики, разнообразные мягкие методы и алгоритмы решения задач, связанных с
моделирование объектов. Относительно подробно рассматриваются
индуктивные методы и алгоритмы обработки и анализа Данных, поли444
модельное моделирование, вопросы упорядочения и автоматизации
выбора моделей под прикладную задачу, интеллектуальный и разведочный анализ Данных.
Завершается глава пояснением понятий «инженерия знаний»,
«управление знаниями», «квалиметрия моделей» и управление качеством результатов моделирования объектов и анализа Данных.
ВОПРОСЫ ДЛЯ САМОПОДГОТОВКИ
1. На какие классы делятся данные? Перечислите и охарактеризуйте их.
2. Что понимается под термином «Большие данные»? Какие особенности характерны для современных Данных и как они влияют на
средства обработки и анализа Данных?
3. В чем сходство и отличие дедуктивного и индуктивного подходов к анализу массовых данных?
4. Что такое алгоритм? Зачем нужно уточнение и расширение понятия алгоритм?
5. Что понимается под сложностью алгоритмов и задач? На какие
классы делятся алгоритмы и задачи по их сложности?
6. Перечислите и охарактеризуйте разновидности алгоритмов.
7. В чем отличие между задачей и проблемой? Что такое проблемная ситуация? Перечислите основные укрупненные этапы решения проблем.
8. Что такое «информология»? Изложите ваш взгляд на место и
роль информологии в информатике.
9. Что в настоящее время чаще всего понимается под теорией информации? Согласны ли вы с таким пониманием?
10. Перечислите и охарактеризуйте существующие меры количества информации? Что такое синтактическая, семантическая и прагматическая меры количества и качества информации? Сможете ли вы
привести и охарактеризовать примеры каждой из подобных мер?
11. Можно ли и следует ли ставить вопрос о том, что такое информация как объект исследования информологии? Аргументируйте ваш
ответ и ваше восприятие понимания термина «информация» в приведенных в пособии цитатах.
12. Перечислите разновидности и основные свойства информации.
13. Изложите ваше отношение к рабочему определению термина
«информация». Чем вы аргументируете ваш ответ?
445
14. Что такое «интеллект» и «искусственный интеллект»?
15. Если искусственный интеллект рассматривать как раздел информатики, то какие подразделы вы считаете следует туда включать?
16. Опишите наиболее часто применяемые мягкие методы и алгоритмы: нейросетевые, генетические, различные роевые, иммунные,
многоагентные, деревьев целей, решений, регрессий и классификаций,
когнитивные, а также визуального моделирования.
17. Перечислите и охарактеризуйте основные особенности индуктивного подхода к моделированию и анализу данных, интеллектуального и разведочного анализов Данных.
18. Что такое полимодельное моделирование объектов? Перечислите и охарактеризуйте его основные разновидности.
19. Как осуществляется автоматизация упорядочения и выбора моделей, методов, алгоритмов? Что такое моделетека, методотека, алгоритмотека?
20. Что понимается под инженерией знаний? Под экспертной системой?
21. В чем причина и суть управления знаниями?
22. Что означает квалиметрия моделей, качество результатов моделирования объектов и анализа Данных?
23. Зачем необходимо управлять качеством результатов моделирования объектов и анализа Данных? Каков механизм управления?
24. Составьте и изобразите графически алгоритм кластеризации по
методу k-ближайших соседей и по другим методам.
446
ЗАКЛЮЧЕНИЕ
Итак, во второй части учебного пособия основное внимание уделено системно-методологическим аспектам только части разделов, относимых к теоретической информатике. Это следующие разделы.
1. Основные определения и понятия, их разные трактовки. В частности, рассмотрено понимание термина «информатика», объекты,
предметы, методы и понятия истинности в информатике, ее структуры.
2. Моделирование как метод исследования объектов различной
природы: понятие и свойства модели, требования к модели, виды моделей, элементы технологий моделирования.
3. Элементарные сведения о системологии как науки о системах:
основные понятия, свойства и виды объектов как систем, системные
принципы, законы и закономерности, особенности системного подхода
к исследованию объектов.
4. Наблюдение и экспериментирование как методы исследования и
этапы моделирования объектов: основные понятия, виды физических
величин, элементы теории измерений, разновидности экспериментов и
эмпирических данных, понятие об их неполноте, а также о планировании и технологии наблюдения и экспериментирования.
5. Временное и частотное представление сигналов.
6. Различный формальный аппарат представления и исследования
объетов, сигналов и данных: детерминированный, стохастический, нечеткий, динамического хаоса, фрактальный, экспертный; оптимизационный; теории массового обслуживания; разнообразия объектов, в
частности распознавания образов, классификации, кластеризации; теории графов, сетей, автоматов. Внимание при этом обращается не только на существо аппарата, но и область его возможного и целесообразного применения с точки зрения пригодности и интерпретируемости
результатов.
7. Модели представления данных и результатов исследований для
их визуального анализа.
447
8. Методы и алгоритмы синтактической обработки сигналов и
данных, а именно дискретизации сигналов под разные задачи, квантования их по уровню, модели данных и знаний как объектов хранения и
передачи; теории передачи и кодирования сигналов и данных.
9. Те принципы построения технических средств сбора, хранения,
обработки и имитации сигналов, данных и знаний, которые непосредственно связаны с модельным описанием объектов.
10. Особенности современных данных как объектов их обработки.
11. Элементы теории алгоритмов: базовые определения, понятие
сложности и классы сложности алгоритмов, задач, проблем; различные
расширения классов алгоритмов, включая класс мягких алгоритмов, и
вопросы решения исследовательских проблем.
12. Элементы информологии как учения об информации: понятие о
теории информации, различных синтактических, семантических и
прагматических мерах ее количества и качества, свойствах; информация как объект исследования информологии в ее различных трактовках, включая авторскую.
13. Понятие об интеллекте, его структуре как раздела информатики.
14. Различные мягкие методы и алгоритмы обработки и анализа
данных, решения прикладных задач: «природные» нейросетевые,
генетические, разные роевые и иммунные, а также «технические» имитации отжига, виртуальных частиц, деревьев целей и решений; многоагентные, когнитивные, визуального моделирования, недоопределенных вычислений.
15. Индуктивные подход, методы и алгоритмы обработки и анализа сигналов, данных и знаний: основные понятия и особенности индуктивного подхода к моделированию (исследованию) объектов и анализу
данных; самоприспособление моделей; полимодельные методы и алгоритмы, автоматизация упорядочения и выбора моделей под решаемую
задачу; интеллектуальный и разведочный анализ (исследование)
Данных.
16. Элементы квалиметрии моделей, обеспечения качества результатов моделирования (исследования) объектов и анализа Данных,
управления качеством.
17. Приложения содержат дополнительный материал для желающих глубже разобраться в сути воспросов, освещаемых в настоящем
пособии.
448
ПОСЛЕСЛОВИЕ
Резюмируя изложенное, еще раз выделим основные акценты, на
которые постоянно обращалось внимание в пособии.
1. Любое дело, действие, в частности исследование, должно начинаться с обоснования его необходимости и формулировки постановки
задачи, четкого определения цели, желаемого итогового и подчиненных ему локальных результатов, на достижение которых направлено
это действие, исследование. Обычно цель декомпозируется на подцели
(задачи, проблемы), которые необходимо решить, чтобы ее достичь.
Необходимо четко осознавать и выполнять требование подчиненности
показателей качества промежуточного результата конечной (главной,
глобальной) цели, а также качеству итогового результата.
2. Прежде чем браться за реализацией достижения цели, необходимо четко спланировать свои действия, в частности, выбрать средства и
технологии решения задач, разобраться с используемой, особенно мало знакомой, терминологией, согласовать показатели качества промежуточных результатов и их значения с учетом качества итогового искомого результата. Следует помнить, что термин – это модель
определяемого понятия. Поэтому может быть много трактовок одного
и того же термина и, наоборот, одной и той же сущности может соответствовать несколько терминов.
3. В любом действии человек явно или неявно оперирует с моделями предметов, явлений, процессов, событий, действий и т. п. При этом
одни модели присутствуют в начале действий, другие – по ходу выполнения действий, третьи – как итог, результат действий. Необходимо четко это представлять себе, различать и понимать вид, суть, роль,
место и возможности каждой из таких моделей в ходе выполнения
действий.
4. Для решения одних и тех же задач можно использовать разные
средства и технологии, модели, методы, алгоритмы, разный формаль449
ный аппарат. Истинность, корректность используемых моделей и алгоритмов, аппарата исследуются и доказываются в их теории, а на практике подтверждается не истинность, а только пригодность и полезность их применения для решения данной конкретной задачи в
конкретных условиях. Выбор разного формального аппарата, средств и
технологий, в том числе моделей, алгоритмов, следует делать исходя
из максимизации их полезности в конкретных ситуациях. В ряде случаев целесообразно противопоставлять результаты, полученные разными способами, подходами, но зачастую следует гармонично использовать их совместно. Например, использовать сочетание концепций
погрешностей средств измерений и неопределенностей результатов измерений, минимизации сложности и компактности модели объекта или
алгоритма решения задачи с качеством получаемых результатов, включая их устойчивость (робастность), адекватность, достоверность и т. п.
5. Механическое объединение, сочетание возможностей и результатов различных подходов, методов, средств не всегда дает синергетический эффект эмерджентности. Необходим системный подход к такому объединению, единение усилий специалистов разных профилей,
понимание «физики», «механизмов» выполняемых действий.
6. Используя системный подход к исследованию объекта, следует
обязательно выявить, к какому классу относится этот объект: кибернетическому, синергетическому, самореферентному или автопоэтическому; однородному или неоднородному; стационарному или нестационарному и т. д. (см. часть 1, табл. 2.4).
7. Прежде чем использовать тот или иной формализм, формальный
математический аппарат, а также интерпретировать и понимать получаемые с его помощью результаты, сопоставьте условия его применимости с теми, в которых функционирует исследуемый объект, с классом, к какому он относится, с тем, какими эмпирическими данными
сопровождается, т. е. в каких шкалах они измерены, в каких условиях
получены, какова технология их получения и т. д. (см. часть 1, рис.
3.1–3.4, табл. 2.1–2.4, 3.4 и им подобные).
8. Постоянно имейте в виду, что относительная простота и возможность получения различных эмпирических зависимостей, закономерностей и других эмпирических результатов всегда сопровождается
ограничениями области их рационального применения, условиями, в
которых они были получены.
9. Следует четко различать такие понятия, как методология, метод
и алгоритм; сигналы, данные, знания, модели как носители информа450
ции, информация и «оформленная» информация, которая в результативной форме может быть семантически представлена в виде новостей,
знаний, моделей.
10. Помните, что многословный или лаконичный рассказчик могут
изложить один и тот же семантический объем информации (новостей)
с помощью сильно отличающегося количества данных (слов), т. е. при
разных значениях синтактических показателей (например, по Шеннону) количества этой информации. Научитесь распознавать, когда избыточность данных является бесполезной, практически неоправданной, а
когда принципиально необходимой при решении разных прикладных
задач.
11. Автор надеется, что материал пособия послужит формированию у читателя не только системного, но и организмового подхода.
Отличие организма как объекта исследования в том, что он изначально
возникает и формируется как целое, а не собираемое по частям, в силу
чего имеет ряд специфических особенностей (см. часть 2, разд. 1.5.1 и
гл. 4).
451
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Губарев В.В. Информатика: прошлое, настоящее, будущее / В.В. Губарев. – М.: Техносфера, 2011. – 432 с.
2. Тарасенко Ф.П. Прикладной системный анализ (Наука и искусство
решения проблем): учебник / Ф.П. Тарасенко. – Томск: Изд-во ТГУ, 2004. –
186 с.
3. Анисимов Б.В. Распознавание и цифровая обработка изображений /
Б.В. Анисимов, В.Д. Курганов, К.Д. Злобин. – М.: Высш. шк., 1983. – 295 с.
4. Загоруйко Н.Г. Прикладные методы анализа данных и знаний /
Н.Г. Загоруйко. – Новосибирск: Изд-во ИМ СО РАН, 1999. – 270 с.
5. Загоруйко Н.Г. Когнитивный анализ данных / Н.Г. Загоруйко. – Новосибирск: Акад. изд-во «Гео», 2013. – 186 с.
6. Кластеризация и кластер / редактор Дж. Вэн Райзин. – М.: Мир,
1980. – 389 с.
7. Гренандер У. Лекции по теории образов. В 3 т / У. Гренандер. – М.:
Мир. – Т. 1, 1979. – 383 с; Т. 2, 1981. – 446 с; Т. 3, 1984. – 420 с.
8. Елисеева И.И. Группировка, корреляция, распознавание образов /
И.И. Елисеева, В.О. Рукавишников. – М.: Статистика, 1977. – 144 с.
9. Айвазян С.А. Прикладная статистика и основы эконометрии: учеб. для
вузов / С.А. Айвазян, В.С. Мхитарян. – М.: ЮНИТИ, 1998. – 1022 с.
10. Губарев В.В. Статистический анализ параметров воды в городах Востока России и их влияния на инфекционные заболевания, передающиеся
водным путем / В.В. Губарев, В.Б. Локтев, О.К. Альсова, В.Е. Хиценко,
E. Naumova и др. // Материалы VI МНТК «Решение проблем экологической
безопасности в водохозяйственной отрасли». – Новосибирск: МУП «Горводоканал», 2010. – С. 17–21.
11. Математика. Информатика: Энциклопедия. – М.: ЗАО «РОСМЭНПРЕСС, 2007. – 544 с. (Современная иллюстрированная энциклопедия).
12. Математический энциклопедический словарь / гл. ред. Ю.В. Прохоров. – М.: Сов. энциклопедия, 1988. – 847 с.
13. Денисов А.А. Теория больших систем управления / А.А. Денисов,
Д.Н. Колесников. – Л.: Энергоиздат, Ленингр. отд-ние, 1982. – 288 с.
452
14. Основы кибернетики. Математические основы кибернетики / под ред.
К.А. Пупкова. – М.: Высш. шк., 1974. – 413 с.
15. Попков В.К. Математические модели связности / В.К. Попков. – Новосибирск: Изд-во ИВМиМГ. – Ч. 1. Графы и сети, 2000. – 175 с.; Ч. 2. Гиперграфы и гиперсети, 2001. – 288 с.
16. Ехлаков Ю.П. Теоретические основы компьютерных систем обработки информации и управления / Ю.П. Ехлаков, В.В. Яворский. – Караганда:
Изд-во КарГТУ, 2005. – 394 с.
17. Поспелов Д.А. Информатика: Энциклопедический словарь для начинающих / Д.А. Поспелов. – М.: Педагогика-Пресс, 1994. – 352 с.
18. Губарев В.В. Алгоритмы спектрального анализа случайных сигналов /
В.В. Губарев. – Новосибирск: Изд-во НГТУ, 2005. – 660 с.
19. Темников Ф.Е. Теоретические основы информационной техники /
Ф.Е. Темников, В.А. Афонин, В.И. Дмитриев. – М.: Энергия, 1979. – 512 с.
20. Губарев В.В. Алгоритмы статистических измерений / В.В. Губарев. –
М.: Энергоатомиздат, 1985. – 272 с.
21. Советов Б.Я. Базы данных: теория и практика: учеб. для вузов /
Б.Я. Советов, В.В. Цехановский, В.Д. Чертовский. – М.: Высш. шк., 2007. –
463 с.
22. Советов Б.Я. Представление знаний в информационных системах:
учебник / Б.Я. Советов, В.В. Цехановский, В.Д. Чертовский. – М.: Изд. центр
«Академия», 2011. – 144 с.
23. Советов Б.Я. Информационные технологии: учеб. для вузов /
Б.Я. Советов, В.В. Цехановский. – М.: Высш. шк., 2008. – 263 с.
24. Губарев В.В. Информатика в рисунках и таблицах. Фрагменты системного путеводителя по концептуальным основам: учеб. пособие / В.В. Губарев. – Новосибирск: Изд-во НГТУ, 2003. – 198 с.
25. Смолин Д.В. Введение в искусственный интеллект: конспект лекций /
Д.В. Смолин. – М.: Физматгиз, 2007. – 264 с.
26. Гаврилова Т.А. Базы знаний интеллектуальных систем / Т.А. Гаврилова, В.Ф. Хорошевский. – СПб.: Питер, 2000. – 384 с.
27. Макконнелл Дж. Основы современных алгоритмов / Дж. Макконнелл. –
М.: Техносфера, 2004. – 368 с.
28. Зюзьков В.М. Математическая логика и теория алгоритмов: учеб. пособие для вузов / В.М. Зюзьков, А.А. Шелупанов. – М.: Горячая линияТелеком, 2007. – 176 с.
29. Сифоров В.И. Информация, связь, человек / В.И. Сифоров, А.П. Суханов. – М.: Знание, 1977. – 36 с.
30. Бондаревский А.С. Сателлиты информатики: подвижки и имитации
(«информационные знания», «информология», «инфодинамика», «информациология») / А.С. Бондаревский // Международный журнал прикладных и
фундаментальных исследований. – 2012. – № 2. – С. 20–27.
453
31. Колесник В.Д. Курс теории информации / В.Д. Колесник, Г.Ш. Полтырев. – М.: Наука, 1982. – 416 с.
32. Стратонович Р.Л. Теория информации. – М.: Сов. радио, 1975. – 424 с.
33. Чернавский Д.С. Синергетика и информация: Динамическая теория
информации / Д.С. Чернавский. – М.: Наука, 2004. – 288 с.
34. Губарев В.В. Концептуальные основы информатики / В.В. Губарев. –
Новосибирск: Изд-во НГТУ, 2002. – Ч. 1. Сущностные основы информатики. –
149 с.
35. Эшби У.Р. Введение в кибернетику. – М.: ИЛ, 1959. – 432 с.
36. Кадомцев Б.Б. Динамика и информация / Б.Б. Кадомцев. – М.: Ред.
журнала «Успехи физических наук», 1999. – 400 с.
37. Зверев Г.Н. О термине «информация» и месте теоретической информатики в структуре современной науки / Г.Н. Зверев // Открытое образование. –
2010. – № 2. – С. 48–62.
38. Пирожков В.В. Информационный подход в междисциплинарной перспективе (материалы «круглого стола») / В.В. Пирожков // Вопросы философии. – 2010. – № 2. – С. 84–112.
39. Колин К.К. Философские проблемы информатики / К.К. Колин. – М.:
БИНОМ. Лаборатория знаний, 2010. – 264 с.
40. Гуревич И.М. Информация – всеобщее свойство материи: характеристики, оценки, ограничения, следствия / И.М. Гуревич, А.Д. Урсул. – М.:
Книжный дом «ЛИБРОКОМ», 2012. – 312 с.
41. Открытое образование. – 2011. – № 6. – С. 64–107.
42. Шилейко А.В. Беседы об информатике / А.В. Шилейко, Т.И. Шилейко. –
М.: Мол. гвардия, 1989. – 287 с. (Эврика).
43. Глик Д. Информация. История. Теория. Поток / Джеймс Глик. – М.:
АСТ, 2013. – 576 с.
44. Информатика как наука об информации: Информационный, документальный, технологический, экономический, социальный и организационный аспекты / Р.С. Гиляревский, И.И. Родионов, Г.З. Залаев и др. – М.: ФАИРПРЕСС, 2006. – 592 с.
45. Лапыгин Ю.Н. Системное решение проблем / Ю.Н. Лапыгин. – М.:
Эксмо, 2008. – 336 с.
46. Люггер Д.Ф. Искусственный интеллект: стратегии и методы решения
сложных проблем / Д.Ф. Люггер. – М.: Изд. дом «Вильямс», 2003. – 864 с.
47. Хокинс Д. Об интеллекте / Д. Хокинс, С. Блейксли. – М.: ООО «И.Д.
Вильямс», 2007. – 240 с.
48. Логвинов В.В. Все открытия и достижения науки и техники за последние 200 лет. Летопись / В.В. Логвинов. – М.: Книжный дом «ЛИБРОКОМ»,
2002. – 448 с.
49. Дюк В. Data mining: учебный курс / В. Дюк, А. Самойленко. – СПб.:
Питер, 2001. – 368 с.
454
50. Корнеев В.В. Базы данных. Интеллектуальная обработка информации /
В.В. Корнеев, А.Ф. Горев, С.В. Васютин, В.В. Райх. – М.: Нолидж, 2001. – 496 с.
51. Карпенко А.П. Современные алгоритмы поисковой оптимизации. Алгоритмы, вдохновленные природой / А.П. Карпенко. – М.: Изд-во МГТУ
им. Н.Э.Баумана, 2014. – 448 с.
52. Тарасов В.Б. От многоагентных систем к интеллектуальным организациям. – М.: УРСС, 2002. – 352 с.
53. Искусственные иммунные системы и их применение / под ред.
Д. Дасгупты. – М.: ФИЗМАТЛИТ, 2006. – 344 с.
54. Гладков Г.А. Генетические алгоритмы / Г.А. Гладков, В.В. Курейчик,
В.М. Курейчик / под ред. В.М. Курейчика. – М.: ФИЗМАТЛИТ, 2006. – 320 с.
55. Андрейчиков А.В. Интеллектуальные информационные системы:
учебник / А.В. Андрейчиков, О.Н. Андрейчикова. – М.: Финансы и статистика, 2004. – 424 с.
56. Рассел С. Искусственный интеллект: современный подход. – 2-е изд. /
Стюарт Рассел, Питер Норвиг. – М.: Изд. дом «Вильямс», 2007. – 1408 с.
57. Акофф Р.Л. Менеджмент в ХХI веке (преобразование корпорации) /
Р.Л. Акофф, пер. с англ. Ф.П. Тарасенко. – Томск: Изд-во Том. ун-та, 2006. –
418 с.
58. Ивахненко А.Г. Индуктивный метод самоорганизации моделей сложных систем / А.Г. Ивахненко. – Киев: Наук. думка, 1981. – 296 с.
59. Зиновьев А.Ю. Визуализация многомерных данных / А.Ю. Зиновьев. –
Красноярск: Изд. КГТУ, 2000. – 180 с. (http:pca.narod.ru/ZINANN.htm).
60. Большаков А.А. Методы обработки многомерных данных и временных рядов: учеб. пособие для вузов / А.А. Большаков, Р.Н. Каримов. – М.:
Горячая линия – Телеком, 2014. – 522 с.
61. Губарев В.В. Вероятностные модели: справочник. В 2 ч. / В.В. Губарев. – Новосибирск: Изд-во НЭТИ, 1992. – Ч. 1. – 196 с., Ч. 2. – С. 197–421.
62. Черкашин А.К. Полисистемное моделирование / А.К. Черкашин. –
Новосибирск: Наука, 2005. – 280 с.
63. Шеннон К. Работы по теории информации и кибернетике / К. Шеннон. – М.: Изд-во иностр. литературы, 1963. – 830 с.
64. Губарев В.В. Идентификация, измерение характеристик и имитация
случайных сигналов: метод моделетеки: учеб. пособие / В.В. Губарев. – Новосибирск: НЭТИ, 1990. – 72 с.
65. Головченко В.Б. Комбинирование моделей неопределенностей /
В.Б. Головченко. – Новосибирск: Наука, 2002. – 190 с.
66. Охтилев М.Ю. Интеллектуальные технологии мониторинга и управления структурной динамикой сложных технических объектов / М.Ю. Охтилев, Б.В. Соколов, Р.М. Юсупов. – М.: Наука, 2006. – 410 с.
67. Альсова О.К. Решение задачи управления Новосибирским водохранилищем на основе прогнозирования притока воды к створу ГЭС / О.К. Альсова,
455
В.В. Губарев // XII Всероссийское совещание по проблемам управления
ВСПУ-214. Москва, 16–19 июня 2014 г.: Труды (электронный ресурс). – М.:
ИПУ РАН, 2014. – С. 3148–3158 (номер гос. регистрации 0321401153).
68. Губарев В.В. Использование вариативного моделирования при идентификации временных рядов инфекционной заболеваемости / В.В. Губарев,
О.К. Альсова, В.Б. Локтев // Известия Волгоград. гос. тех. ун-та. Серия
«Актуальные проблемы управления, ВТ и информатики в технических системах. – 2011. – Т. 11. – № 12. – С. 42–47.
69. Губарев В.В. Автоматизация выбора методов анализа эмпирических
данных / В.В. Губарев, Е.И. Федоров, Н.В. Булгакова // Информационные и
телекоммуникационные технологии. – 2013. – № 19. – С. 29–34.
70. Губарев В.В. Обобщенное понимание терминов «интеллектуальный»
и «разведочный» анализы данных / В.В. Губарев, Р.В. Терехов, Е.И. Федоров //
Материалы XI МНТК «Инновации на основе информационных и коммуникационных технологий (ИНФО-2014), 1–10 октября 2014 г., Сочи. – М.: НИУ
ВШЭ, 2014. – С. 62–64.
71. Тьюки Дж. Анализ результатов наблюдений. Разведочный анализ /
Дж. Тьюки. – М.: Мир, 1981. – 693 с.
72. Myatt G. Making Sence of Data Analysis and Data Mining / G.J. Myatt. –
Hoboken: John Wiley & Sons, 2007. – 280 p.
73. Berman J.J. Principles of Big Data: Preparing, Sharing and Analyzing
Complex Information // J.J. Berman. – Waltham: Morgan Kaufmann, 2013. – 261 p.
74. Behrens J.T. Principles and Procedurex of exploratory Data Analysis /
J.T. Behrens // Pxychological Methods, 1997, № 2. – P. 131–160.
75. Waltenburg E. Exploratory Data Analysis. A Primer for Undegraduates /
E. Waltenburg, W.P. McLauchlan // Purdue University. Purdue e-Pubs, 2012. –
77 p. (http://docs.lib.purdue.edu).
76. Тузовский А.Ф. Системы управления знаниями (методы и технологии) /
А.Ф. Тузовский, С.В. Чириков, В.З. Ямпольский. – Томск: Изд-во ТГЛ, 2005. –
260 с.
77. Мариничева М.К. Управление знаниями на 100 %: Путеводитель для
практиков / М.К. Мариничева. – М.: Альпина Бизнес Букс, 2008. – 320 с.
78. Информационные технологии в бизнесе / под ред. М. Желены. – СПб.:
Питер, 2002. – 1120 с.
79. Брукинг Э. Интеллектуальный капитал / Энни Брукинг. – СПб.: Питер, 2001. – 288 с.
80. Квалиметрия в машиностроении: учебник / Р.М. Хвастунов, А.Н. Фефанов, В.М. Корнеева, Е.Г. Нахапетян. – М.: Изд-во «Экзамен», 2009. – 285 с.
81. Кайгородцев Г.И. Введение в курс метрической теории и метрологии
программ: учебник / Г.И. Кайгородцев. – Новосибирск: Изд-во НГТУ, 2011. –
192 с.
456
82. Губарев В.В. Исследование гидрологических временных рядов притока реки Обь в створе Новосибирской ГЭС методом главных компонент //
В.В. Губарев, О.К. Альсова // Научный вестник НГТУ. – 2000. – № 2 (9). –
С. 3–16.
83. Gubarev V.V. Construction Prognostic of Models in the Automated System
of Comples Medical Monitoring / V.V. Gubarev, N.V. Nasonova // The second
internet forum on strategic technology: proc. of IFOST 2007, Ulanbaatar, Mongolia, 3-5 oct. 2007. – Ulanbaatar, 2007. – P. 189–193.
84. Казиев В.М. Введение в анализ, синтез и моделирование систем: учеб.
пособие / В.М. Казиев. – М.: ИНТУИТ; БИНОМ, 2006. – 244 с.
85. Нориньяни А.С. Программирование в ограничениях и неопределенные
модели / А.С. Нориньяни // Информационные технологии. – 1998. – № 7. –
С. 13–22.
457
ПРИЛОЖЕНИЯ
ПРИЛОЖЕНИЕ 1
Примеры затрат времени на решение задач
различной сложности [81]
Т а б л и ц а П1.1
Зависимость времени решения задачи от ее сложности
(алгоритмическая операция (шаг) выполняется за одну микросекунду)
Размерность п
Сложность
20
50
100
200
500
1000
1000 п
0,02 c
0,05 с
0,1 с
0,2 с
0,5 с
1с
1000 п log n
0,09 с
0,3 с
0,6 с
1,5 с
4,5 с
10 с
1000 п2
0,04 с
0,25 с
1с
4с
25 с
2 мин
10 п3
0,02 с
1с
10 с
1 мин
21 мин 2,7 ч
n
23
2n
3n
0,0001 с
0,1 с
2,7 ч
1с
58 мин
35 лет
2109 век
3104 век
3104 век
Т а б л и ц а П1.2
Влияние роста производительности ЭВМ на время решения задачи
в зависимости от ее сложности
Производительность
Сложность
Современные
ЭВМ, в 100 раз
ЭВМ, в 1000 раз
ЭВМ
более быстрые
более быстрые
п
N1
100 N1
1000 N1
п2
N2
10 N2
31,6 N2
п3
N3
4,64 N3
10 N3
п5
N4
2,5 N4
4 N4
2п
N5
N5 + 6,64
N5 + 10
3n
N6
N6 + 4,19
N6 + 6,3
458
ПРИЛОЖЕНИЕ 2
П2.1. Относящиеся к информации результаты,
удостоенные Нобелевской премии [48]
1933 г., Физиология и медицина. Т.Х.Морган: «За доказательство
того, что хромосомы являются носителями наследственной информации и что гены расположены в них линейно».
1957 г., Физиология и медицина. Д. Балтимор, X.М. Темин: «За
открытия, касающиеся взаимодействия между вирусами опухолей и
генетическим материалом клетки», в частности, за открытие обратной
транскриптазы – фермента, способствующего переносу генетической
информации от РНК к ДНК» (совместно с Р. Дульбекко).
1962 г., физиология и медицина. Ф.X.К. Крик, Д.Д. Уотсон: «За
открытие молекулярной структуры молекулы ДНК и ее значения в передаче информации в живой материи», в частности, за создание пространственной модели этой молекулы – хранителя и передатчика
наследственной информации.
1965 г., Физиология и медицина. Франсуа Жакоб, Ш.Л. Moнo:
«за открытия, касающиеся генетической регуляции синтеза ферментов
и вирусов», в частности, за описание информационной РНК, механизмов экспрессии и транскрипции генов (совместно с А.М. Львовым).
1975г., Химия. К.Б. Анфинсен: «За работы по рибонуклеазе», в
частности, за исследование связи между последовательностью аминокислот и информацией биологически активной молекулы (совместно с
С. Муром, У.X. Стайном).
1981 г., Физиология и медицина. Т.Н. Визел, Д.X. Хьюбел: «За
открытия, касающиеся принципов переработки информации в зрительной системе».
2007 г., Физика. П. Грюнберг, А. Фер: «За открытие и исследование магнитосопротивления, что позволило значительно увеличить
плотность записи информации на компьютерные жесткие диски».
П.2.2. Цитаты из публикаций ученых,
работающих в разных областях
«Одна из особенностей квантового измерения состоит в том, что
квантовую систему невозможно измерить, т. е. получить какую-либо
информацию о ней, не возмутив при этом ее состояния, причем тем
459
сильнее, чем больше информации извлекается при измерении»
(В.Ф. Петренко (д-р психол. наук). Вернем психологии сознание! //
Вестник Московского университета, серия 14 «Психология». – 2010. –
№ 3. – С. 130).
«Масло в огонь дискуссий подливают последние работы по
квантовой информатике, заявления астрофизиков и других учёных о
том, что чёрные дыры поглощают и излучают информацию, что в каждой структурно-организованный физический объект вложена информация, что Вселенная есть гигантский компьютер, функционирующий
в соответствии с фундаментальными законами природы» (Г.Н. Зверев,
д-р техн. наук [37, с. 48]).
«Следовательно, в живых системах не обнаруживается никаких
свойств, которыми не обладали бы разные неживые объекты»
(Г.Р. Иваницкий (Институт теоретической и экспериментальной биофизики РАН) XXI век: что такое жизнь с точки зрения физики [Успехи физических наук. – 2010. Т. 180. – № 4. – С. 339]).
«Нелепо полагать, что информация, которую несет одна простейшая бактерия, путём репликации может развиться так, чтобы появился человек и все живые существа, населяющие нашу планету».
«Число перестановок, необходимых для появления жизни, на многие
порядки превышает число атомов во всей видимой Вселенной» (Г.Р.
Иваницкий цитирует астрофизика Н.Ч. Викрамасингха [Успехи физических наук. – 2010. Т. 180. – № 4. – С. 348]).
«По существу, информация – идеальная грань действительности,
природа которой все еще остается до настоящего времени не выясненной» (К.В. Судаков (академик РАМН, д-р мед. наук) / От И.М. Сеченова к современным представлениям о системной организации психической деятельности» // Психологический журнал. – 2010, Т. 31. – № 2. –
С. 77–79).
«Символично, что именно в последний год прошедшего тысячелетия была полностью расшифрована наследственная информация,
кодирующая все признаки и биологические процессы человеческого
организма» (П. Чумаков (д-р биол. наук) / Выход за пределы возможного: проект «геном человека» // Наука в России. – 2012. – № 4. –
С. 72–79).
«Каждая материальная частица обладает энергией, массой, волновой функцией и информацией» (Р.Б. Сейфуль-Мулюков, д-р г.-м.
наук, профессор, Ин-т проблем информатики РАН // Открытое образование. – 2011. – № 6. – С. 95).
460
В книге «Квантовая теория сознания» Стюарт Хамерофф и Роджер Пенгроуз пишут, что человеческий мозг есть квантовый компьютер, наше сознание – его программное обеспечение, а душа – информация, накопленная на квантовом уровне, которая не может быть
уничтожена, так как носитель квантовой информации «соткан» из
фундаментальной ткани, являющейся основой всей Вселенной.
«Необходимо запоминать удачные для выживания ситуации,
чтобы накапливать опыт выживания и размножения в будущем». «Обнаружен обмен генами между совершенно неродственными организмами, даже между бактериями и высшими животными и растениями»
(Г.Р. Иваницкий // Успехи физических наук. 2012. Т. 182. – № 11. –
С. 1238, 1243).
А. Марков (Рождение сложного. – М.: Астраль: CORPUS, 2012):
«Жизнь развивается как единое целое. «Блочная среда», информационный обмен, кооперация, симбиоз – вот на чем, как мы теперь видим,
основывалось развитие жизни с самых первых ее шагов на Земле»
(с. 507). «Один и тот же ген может кодировать несколько разных белков. То, какой именно белок будет производиться в каждой конкретной
ситуации, зависит от сложных регуляторных систем, о которых пока
еще очень мало известно» (с. 487). «Только у позвоночных это «перекраивание» генетической информации осуществляется на уровне ДНК,
а у насекомых – на уровне РНК» (с. 489). «Выбор брачного партнера –
это не что иное, как целенаправленное манипулирование наследственными свойствами потомства, т. е. управление эволюцией» (с. 506–507).
«Предрасположенность к обучению речи, к обмену информацией
с сородичами у человеческих детенышей уникальна, и она заложена на
генном уровне» (Е. Клещенко, член-корр. РАН и РАМН // Химия и
жизнь. – 2012. – № 12. – С. 10).
«Система есть целое, которое не может быть разделено на независимые части без потери ее существенных свойств или функций»
(Р.Л. Акофф, Менеджмент в XXI веке (Преобразование корпорации). –
Томск: Изд-во ТГУ, 2006. – с. 18). «Все живые системы являются организмами – они живут, но не все организмы являются живыми системами. Современное определение жизни – автопоэзис – означает сохранение отдельности и целостности при том, что компоненты непрерывно
или периодически заменяются и перестраиваются, создаются и уничтожаются» (Zeleny, 1985). «Живые системы являются самоорганизующимися и самосохраняющимися. Из этого определения следует, что социальные и экономические системы тоже живые» (с. 35).
461
«Биологи-синтетики создали целый набор новых (двухспиральных) молекул под общим названием КсНК, которые наделены всеми
свойствами, присущими ДНК и РНК, а также другими «талантами». …
«Стивен Беннер сумел расширить генетический алфавит, добавив в
него еще два нуклеотида, Z и Р» (Феррис Джабр // В мире науки. –
2013. – № 2. – С. 14). КсНК – это ксенуклеиновая кислота (от греч.
xenos – чужой).
«Вся информация о каждом человеке, его внешнем виде, склонностях, предрасположенностях к болезням, способностях записана в
его геноме» (Чумаков П., д-р биол. наук (РФ, США) // Наука в России. –
2012. – № 4. – С. 76).
«Звук есть следствие физиологического и биомеханического
процессов, но в то же время это сигнал, несущий некую информацию
другому существу» (Резник Н.Л., Биоакустика растений: попытка рождения // Химия и жизнь. – 2013. – № 9. – С. 16).
«Соседние растения перехватывают сигналы из происходящей
неподалеку «запаховой беседы», которые дают им необходимую
информацию, помогающую защищать себя… Они явно не имеют обонятельных нервов, соединяющихся с мозгом, который обрабатывает
сигналы… но дикорастущие растения по всему миру реагируют на феромоны точно так же, как мы» (Даниел Чамовец. В мире науки. –
2012. – № 12. – С. 63).
«Наш мозг мощнее, чем Google, и работает лучше всех роботов
вместе взятых… Нейробиологи еще не донца понимают, как мозг выбирает значимую информацию из всех проходящих через него сигналов» (Терри Сейновский, Тоби Дельбрюк // В мире науки. – 2012.–
№ 12. – С. 54).
Урсул А.Д. отмечает: «Информация обладает способностью стимулировать и даже порождать движение, а оно проявляется в разного
рода взаимодействиях». «Концепция информационной теории взаимосдействия Н.Е. Невского для элементарных частиц, электрического,
магнитного и гравитационного полей исходит из того, что любые,
включая физические, взаимодействия имеют информационную природу» (Открытое образование. – 2011. – № 6. – С. 68).
Колин К.К. [39]: «Информация порождает движение материи и
энергии в пространстве и времени…, а движение, в свою очередь, порождает время» (с. 94–95). «Информация в широком понимании этого
термина представляет собой объективное свойство реальности, которое проявляется в неоднородности (асимметрии) распределения мате462
рии и энергии в пространстве и времени, в неравномерности протекания всех процессов, происходящих в мире живой природы, а также в
человеческом обществе… Понятия «материя», «энергия» и «информация» являются равнозначными по уровню общенаучными философскими категориями… , многоплановым феноменом реальности. …
Можно предположить, что существуют некоторые фундаментальные
закономерности проявления информации, которые являются общими
для информационных процессов, реализующихся в объектах, процессах и явлениях любой природы» (с. 96–97).
«Информационный мир в потенциале содержит всю совокупность знаний о том, что было, есть и будет, но не обязательно свершится. Энергетический мир включает в себя всю информацию о том,
что свершилось и совершается в настоящее время. Наконец, материальный (плотский) мир содержит информацию только о том, что непосредственно происходит» (Черкашин А.К., д-р геогр. наук [62, c. 573]).
В [62] информационный мир связывается с духом, а энергетический –
с душой.
«С помощью науки удалось разрушить множество иллюзий, которые были у человечества, но предстоит открыть еще немало нового в
картине мира, особенно в области квантовых вычислений, чтобы разобраться в таких понятиях, как пространство, время, причинность и выяснить, какую роль играет информация» (Антон Цайлингер /Anton
Zeilinger, Австрия, автор пионерских работ в области квантовой информации; выступление перед молодыми новаторами, Берлин, 2014/
http://vcg.quantum.at/reserch/people/detaiils/14-antonzeilinger.html).
463
ПРИЛОЖЕНИЕ 3
Вопросы для саморазвития
1. Согласны ли вы, что разделение концепций понимания информации на атрибутную, функциональную, отражательную, процессную,
вариативную, алгоритмическую и тому подобное – то же самое, что
делить концепции познания и понимания материи на вещественную
(корпускулярную), волновую (полевую, энергетическую), квантовую,
… либо механическую, термодинамическую, оптическую, ядерную,
голографическую и т. п.? Или это просто разные модельные (следовательно, целевые!) формы отражения проявления одной и той же действительности (сущности), единую модель которой мы предложить
пока не можем? Какова ваша точка зрения по этому вопросу?
2. Можно ли и нужно ли, создавая искусственные организмы, системы, алгоритмы, перенимать у природы также принцип красоты: у
искусственных и синтетических организмов (субъектов, систем) должно быть все прекрасно: и «тело», и «душа», и «мысли», и «действия»?
3. Как использовать при создании мягких алгоритмов тот факт, что
одни живые организмы, включая высокоразвитых животных, предпочитают геопатологические зоны с отрицательной энергетикой, а другие с положительной?
4. Если мозг человека в каждый момент запоминает куда больше
образов, чем человек может ввести в поле своего сознания, разума и
пользоваться ими, то зачем он это делает? Стоит ли этому подражать
при создании искусственных систем?
5. Как наилучшим образом использовать при создании искусственных средств и систем особенности процессов коммуникаций живых
организмов одинаковых и разных видов, сочетания ими различных
сигналов (химических, в частности запаховых, оптических, звуковых и
других), в том числе отвечающих за синхронизацию (одномоментность, синфазность, кратность периодов) различных биологических
циклов?
6. Корректно ли говорить, что приобретение некоторыми алгоритмами свойства жадности – останавливаться на одном локальном оптимуме – сродни переходу болезни в хроническую? Нет ли здесь одинакового механизма?
7. Почему и зачем сильно развита интуиция у крыс, а у женщин
она более развита, чем у мужчин? Действительно ли, как считал
464
А. Эйнштейн, именно интуиция и ее разновидность – вдохновение, а
не логика, приводят людей к истинному знанию, озарению? Может ли
это объяснить гипотезу о том, что интуитивное мышление основывается на выборе кратчайших путей и эмпирических правил, а аналитическое требует больших затрат времени и усилий? Как это можно связать
с мягкими алгоритмами и использовать при создании интеллектуальных средств и систем?
8. В каждой клетке человеческого организма существует внутренняя иммунная система, центральным компонентом которой является белок Р53. Именно она вызывает самоуничтожение клетки в ответ
на внештатные ситуации, повреждения или сбои процессов. Используется ли этот механизм в существующих иммунных алгоритмах и искусственных системах? Как его можно использовать эффективнее?
9. Какие из объектов: «геном живого организма», «семейный суперорганизм», «иммунная система», «семейные сообщества» – можно
сравнить с оркестром, играющим без дирижера?
10. В последнее время проводятся работы по искусственному «непорочному» зачатию – получению зародыша без участия стороннего
генетического материала, в результате деления только женской яйцеклетки. Не является ли это аналогом естественного клонирования почкованием некоторых организмов? Важным направлением в биологии
является перепрограммирование клеток для получения из развитых
клеток эмбриональных путем переноса ядра из зрелой клетки в яйцеклетку, из которой предварительно был удален собственный генетический материал, а также возврат (перепрограммирование) взрослых клеток человеческого организма к плюрипотентным – прешественникам
половых клеток (незрелые, аналогичные эмбриональным, способны
развиваться в разные ткани организмов; Джон Гордон и Синья Яманака, премия Ласкера за 2009 г., Нобелевская премия за 2012 г.). Некоторые бактерии способны перепрограммировать клетки, превращая их в
подобие подвижных половых клеток, используемых для проникновения в мышечную и нервную систему организма. Как все это можно
использовать в мягких алгоритмах?
11. Для многих живых организмов свойственна «вынужденная»
жертвенность во имя сохранения вида, рода, доходящая до альтруизма,
причем «закономерностная» на длительном отрезке времени у одних
(муравьи в войнах и при заболеваниях, сайгаки при землятресениях,
волки при заболеваниях и т. д.) и «спонтанная», проявляющаяся на
коротком отрезке времени (птицы, животные в минуты опасности
465
другого и при защите детей), каннибализм (поедание себе подобных/
сверчки, бациллы – убийцы (до 50 %)/ и альтруисты /жертвующие собой/ бациллы – жертвы при голодании у микробов-бактерий Bacillus
subtilis), передача «сигналов тревоги» (растения, микроорганизмы,
многие птицы и животные), у высших животных есть свой «кодекс чести» (не нападать на водопое при засухе, не воспринимать ближайших
«соседей» как еду и т. п.). Какие из этих механизмов уже используются
и могут быть использованы в мягких алгоритмах?
12. Все живое обладает генетической памятью, хранящей различные «сведения о прошлом», включая сведения о его предшественниках. Что это за память, как она функционирует? В каких алгоритмах
это используется? Можно ли это свойство рекомендовать к более широкому использованию и в каких алгоритмах?
13. Можно ли и как эффективнее идеи механизма многовариантного функционирования мозга использовать при вариантивном и полимодельном моделировании объектов?
14. Во время сна мозг человека может не только выделять и закреплять ранее полученную внешнюю информацию, но и усваивать
новую, а также обрабатывать внутреннюю. Не потому ли «утро вечера
мудренее»? Где в искусственных системах и как это используется?
15. Существует обмен генами между совершенно неродственными
организмами, даже между бактериями и высшими животными и растениями. Как это можно использовать в генетических алгоритмах?
16. Как используются и как могут использоваться в муравьиных
алгоритмах отличие запахов ферамонов царицы и жертвенность
охранников при опасности, угрожающей царице?
17. Рассматривается задача регрессионного анализа зависимости
водных инфекционных заболеваний от влияющих факторов окружающей среды или одних факторов от других тремя методами. Первый –
предварительное выделение кластеров (см. часть 2, рис. 1.3) и построение внутрикластерных регрессий, т. е. регрессий, когда независимые
переменные принимают значения только внутри соответствующего
кластера. Второй – кусочной аппроксимацией полной функции регрессии (см. часть 2, рис. 1.3, 1.13, д, 4.9) по участкам: а) относящимся к разным кластерам, выявленным на этапе кластерного анализа; б) полученным при аппроксимации всей эмпирической функции регрессии как
экспериментальной кривой. Третий метод – использование деревьев регрессии. Будут ли эти результаты эквивалентными при синтактическом,
семантическом и прагматическом подходе к их интерпретации?
466
700
650
0,66
600
0,65
550
1
500
467 469
450
435 385
0,62
400
394
0,61
350
362
348
311
285
300
0,60
253
297
0,60
250 2
0,59
220
200
193
0,58
150
100
50
0,45
0
0,69
0,68
0,67
0,66
0,65
0,64
0,63
0,62
0,61
0,60
0,59
0,58
0,57
0,56
0,55
Абсолютное превышение нормы средней
температуры на Земле, С
Количество опасных явлений погоды в России
18. На рисунке представлены графики последствий изменения
климата в XXI веке (см. «Комсомольская правда», 2013, 7–14 февраля).
Можно ли восстановить пропущенные на температурном графике значения формальными приемами? Если да, попробуйте это сделать, а
также найдите эмпирическое значение в данных национального центра
климатической информации США.
2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012
Годы
Последствия изменения климата:
– количество опасных явлений погоды по данным Гидрометеоцентра России;
– абсолютное превышение нормы средней температуры на Земле за последние годы по данным национального
центра климатической информации США: климатическая норма это
средняя температура за тридцать лет, 1951–1981 гг.; 0,45 в 2012 г.
19. Охарактеризуйте справедливость, ложность или некорректность шуточного утверждения: «Информация – это то, что от нас
скрывают. Все остальное – реклама».
20. Зачем и какие функции выполнял президент России В.В. Путин, имитируя своим полетом на летательном аппарате в 2012 г. роль
лидера стаи выращенных в питомнике молодых стерхов – белых сибирских журавлей. С какими мягкими алгоритмами это связано?
21. Основным ресурсом первого технологического уклада (примерно 1770–1850 годы) являлась энергия воды; второго (1830–1990) –
энергия пара, угля; третьего (1880–1950) – электрическая энергия; чет467
вертого (1930–1980) – энергия углеводородов, начало ядерной энергетики; пятого (1970 – примерно 2030) – атомная энергетика. Что является ресурсом развиваемого с 2010 года шестого технологического
уклада? Какие главные отрасли, ключевые факторы и достижения
характерны для всех этих укладов? Какова роль в развитии шестого
уклада нано-, био-, информационных, когнитивных и социальных
(НБИКС) технологий?
22. Как можно сочетать в «биологических» алгоритмах «механизмы» инстинкта, импринтинга и обучения, а также мутализма – взаимовыгодного симбиоза животных, птиц и растений?
23. Можно ли для индуктивных методов, ИАД и РАД утверждать,
что мы ищем зависимости в данных, но заранее не знаем, что найдем?
Делать выводы по локальным данным об объекте с помощью индуктивных методов сомнительно, как при любом переходе от частного к
общему? Если да, то при каких условиях эта сомнительность может
быть рассеяна, хотя бы отчасти?
24. Можно ли полагать, что исследование объекта или решение задачи, в частности оптимизационной, по известной модели, и извлечение знаний об объекте при этом является прямой задачей моделирования объекта, а выбор конкретной модели из некоторого множества на
основе Данных и дополнительных сведений об объекте является обратной задачей моделирования объекта?
468
ОГЛАВЛЕНИЕ
ПРЕДИСЛОВИЕ ...................................................................................................... 3
ВВЕДЕНИЕ .............................................................................................................. 4
Глава первая. Формальный аппарат описания и исследования разнообразия структур и дискретных переходов состояний объектов: куализные модели ......................................... 7
§ 1.1. Вводные замечания .................................................................................. 7
§ 1.2. Модели разнообразия объектов .............................................................. 8
1.2.1. Необходимые пояснения ........................................................................... 8
1.2.2. Абстрагирование как необходимый этап моделирования
объектов................................................................................................... 13
1.2.3. О терминах «кластеризация», «группирование», «таксономия»,
«распознавание образов» ....................................................................... 17
1.2.4. Другие определения терминов ................................................................ 19
1.2.5. Практические аспекты распознавания образов ..................................... 26
1.2.5. Заключительные замечания .................................................................... 33
§ 1.3. Модели структур объектов и связности их элементов. Элементы теории графов и сетей ..................................................................... 39
1.3.1. Основные понятия ....................................................................................39
1.3.2. Формальное задание графов.................................................................... 46
1.3.3. Сети, гиперграфы, гиперсети .................................................................. 47
1.3.4. Задачи, решаемые в теории графов ........................................................ 58
§ 1.4. Модели дискретных объектов. Элементы теории автоматов ............. 59
1.4.1. Основные понятия ................................................................................... 59
1.4.2. Разновидности автоматов ........................................................................ 61
1.4.3. Способы описания автоматов ................................................................. 66
1.4.4. Задачи теории автоматов ......................................................................... 69
§ 1.5. Модели представления данных и результатов для их визуального анализа........................................................................................... 71
1.5.1. Вводные замечания .................................................................................. 71
1.5.2. Зрительные (визуальные) модели ........................................................... 75
1.5.3. Разновидности графиков и их назначений ............................................. 79
Заключение ............................................................................................................. 90
Вопросы для самоподготовки ............................................................................... 91
469
Глава вторая. Синтактическая обработка данных ....................................... 94
§ 2.1. Вводные замечания ................................................................................ 94
§ 2.2. Дискретизация сигналов. Понятие о теоремах отсчетов ................... 95
§ 2.3. Квантование сигналов по уровню....................................................... 116
§ 2.4. Получение, оформление и хранение данных ..................................... 119
§ 2.5. Структурные синтактические модели данных ................................. 123
2.5.1. Вводные замечания ................................................................................ 123
2.5.2. Банки данных ......................................................................................... 124
2.5.3. Хранилища и витрины данных ............................................................. 142
§ 2.6. Структурные синтактические модели знаний .................................. 143
2.6.1. Знания как операнды синтактических и семантических операций ...... 143
2.6.2. Модели знаний как носителей информации ........................................ 147
§ 2.7. Передача и кодирование Данных........................................................ 161
2.7.1. Элементарные понятия информационных систем связи ................... 161
2.7.2. Модуляция сигналов .............................................................................. 162
2.7.3. Эффективное кодирование .................................................................... 165
2.7.4. Помехоустойчивое кодирование .......................................................... 168
Заключение ........................................................................................................... 177
Вопросы для самоподготовки ............................................................................. 181
Глава третья. Принципы построения технических средств информатики ....................................................................................... 184
§ 3.1. Виды информационных технических средств .................................. 184
§ 3.2. Пояснения к морфологической таблице ИС ...................................... 192
§ 3.3. Аналоговые, цифровые, когнитивные, нейронные и квантовые
принципы ............................................................................................. 195
3.3.1. Описание принципов ............................................................................. 195
3.3.2. Вычислительные примеры реализации принципов ............................ 202
§ 3.4. Примеры аппаратной и программной реализации принципов......... 207
§ 3.5. Принципы разделения каналов в многоканальных ИС ................... 211
Заключение ........................................................................................................... 214
Вопросы для самоподготовки ............................................................................. 215
Глава четвертая. Индуктивное модельное представление объектов.
Семантическая, событийная и прагматическая
обработка данных ............................................................ 217
§ 4.1. Необходимые понятия ......................................................................... 217
§ 4.2. Особенности современных Данных об объектах и задач исследования объектов и Данных ........................................................ 223
§ 4.3. Понятие о теории алгоритмов ............................................................. 228
4.3.1. Уточнение понятия и куализные модели алгоритмов......................... 228
4.3.2. Базовые понятия теории алгоритмов.................................................... 232
470
4.3.3. Понятие о сложности алгоритмов и задач ........................................... 233
4.3.4. Классы алгоритмов и задач по сложности ........................................... 236
4.3.5. Расширение понятия и множества куализных моделей алгоритмов .................................................................................................... 241
§ 4.4. Об исследовательских проблемах и их решении ............................. 250
§ 4.5. Элементы информологии .................................................................... 256
4.5.1. Вводные замечания ................................................................................ 256
4.5.2. О теории информации и мерах количества и качества информации ..................................................................................................... 257
4.5.3. Информация как объект исследования информологии....................... 280
4.5.4. Сущностные свойства информации ..................................................... 289
4.5.5. «Рабочее» определение термина «информация» ................................. 297
§ 4.6. Методы искусственного интеллекта................................................... 303
4.6.1. Понятие об интеллекте .......................................................................... 303
4.6.2. Структура искусственного интеллекта как раздела информатики ...... 310
§ 4.7. Мягкие методы и алгоритмы. Методы нахождения решений
для обработки данных, относимые к индуктивным, к методам
искусственного интеллекта ................................................................ 313
4.7.1. Вводные замечания ................................................................................ 313
4.7.2. Нейросетевые методы ............................................................................ 314
4.7.3. Генетические методы и алгоритмы ...................................................... 316
4.7.4. Роевые методы и алгоритмы ................................................................. 326
4.7.5. Нечеткие и экспертные методы и алгоритмы ...................................... 333
4.7.6. Агентные методы. Многоагентные системы ....................................... 334
4.7.7. Иммунные методы и алгоритмы. Искусственные иммунные
системы.................................................................................................. 338
4.7.8. Другие методы и алгоритмы, пригодные к использованию
в искусственном интеллекте и мягких вычислениях ........................ 358
§ 4.8. Индуктивные методы и алгоритмы обработки и анализа Данных ....... 386
4.8.1. Вводные замечания. Эволюция взглядов на анализ массовых
эмпирических данных .......................................................................... 386
4.8.2. Важные особенности индуктивного подхода к моделированию
объектов и анализу данных .................................................................. 389
4.8.3. Самоприспособление моделей по критерию структурной сложности ...................................................................................................... 396
4.8.4. Полимодельные дедуктивные, индуктивные и анало́говые методы........................................................................................................ 398
4.8.5. Упорядочение и автоматизация выбора моделей, методов и алгоритмов ................................................................................................ 411
4.8.6. Интеллектуальный и разведочный анализ Данных ............................. 418
§ 4.9. Понятие об инженерии знаний и управлении знаниями .................. 425
4.9.1. Используемые понятия .......................................................................... 425
4.9.2. Приобретение и представление знаний................................................ 428
471
4.9.3. Экспертные системы.............................................................................. 430
4.9.4. Управление знаниями ............................................................................ 434
§ 4.10. Понятие о квалиметрии моделей. Обеспечение качества результатов моделирования (исследования) объектов и анализа.
Данных, управление качеством ........................................................ 439
4.10.1. Постановка задачи ............................................................................... 439
4.10.2. Квалиметрия моделей, результатов моделирования объектов
и анализа Данных ................................................................................ 442
4.10.3. О методах обеспечения гарантированного качества моделей и
результатов МиАД и управления качеством .................................... 443
Заключение ........................................................................................................... 444
Вопросы для самоподготовки ............................................................................. 445
ЗАКЛЮЧЕНИЕ .................................................................................................... 447
ПОСЛЕСЛОВИЕ.................................................................................................. 449
БИБЛИОГРАФИЧЕСКИЙ СПИСОК ................................................................ 452
ПРИЛОЖЕНИЯ ................................................................................................... 458
Приложение 1. Примеры затрат времени на решение задач различной
сложности [81] .......................................................................... 458
Приложение 2 ....................................................................................................... 459
П2.1. Относящиеся к информации результаты, удостоенные Нобелевской
премии [48] ..................................................................................................... 459
П.2.2. Цитаты из публикаций ученых, работающих в разных областях ............ 459
Приложение 3. Вопросы для саморазвития ....................................................... 464
Губарев Василий Васильевич
ВВЕДЕНИЕ В ТЕОРЕТИЧЕСКУЮ ИНФОРМАТИКУ
Часть 2
Учебное пособие
Редактор Л.Н. Ветчакова
Выпускающий редактор И.П. Брованова
Дизайн обложки А.В. Ладыжская
Компьютерная верстка Н.В. Гаврилова
Налоговая льгота – Общероссийский классификатор продукции
Издание соответствует коду 95 3000 ОК 005-93 (ОКП)
Подписано в печать 05.11.2015. Формат 60 × 84 1/16. Бумага офсетная
Тираж 100 экз. Уч.-изд. л. 27,43. Печ. л. 29,5. Изд. 149. Заказ № 1551
Цена договорная
Отпечатано в типографии
Новосибирского государственного технического университета
630073, г. Новосибирск, пр. К. Маркса, 20
472