/































































































































































































































































































































































































































































































































































































































































Автор: Филд А. Харрисон П.
Теги: вычислительная математика численный анализ математика программирование информатика информационные технологии
ISBN: 5-03-001870-0
Год: 1993




Текст
ФУНКЦИОНАЛЬНОЕ ПРОГРАММИРОВАНИЕ
A. Филд, П. Харрисон
ФУНКЦИОНАЛЬНОЕ
ПРОГРАМ М ИРОВАНИЕ
Перевод с английского
М. В. Горбатовой, А. А. Рябинина,
канд. техн, наук В. Л. Торхова,
М. В. Федорова
под редакцией
акад. АЕН РСФСР В. А. Горбатова
•Москва «Мир» 1993
Functional
Programming
Anthony J. Field
Peter G. Harrison
Imperial College of Science and Technology
University of London
Addison-Wesley
Publishing
Company
Wokingham, England • Reading, Massachusetts • Menlo Park, California
New York-Don Mills, Ontario - Amsterdam - Bonn
Sydney • Singapore • Tokyo • Madrid • San Juan
ББК 22.18
Ф 51
УДК 519.682
Филд А., Харрисон П.
Ф51 Функциональное программирование: Пер. с англ. — М.:
Мир, 1993. — 637 с., ил.
ISBN 5-03-001870-0
В книге английских специалистов рассмотрены проблемы аппликативного
программирования, существенно повышающего интеллектуальность разраба-
тываемых программ по сравнению с традиционным программированием. При
этом спецификация предметной области существенно упрощает труд програм-
миста. Особое внимание уделяется вопросам реализации функциональных
языков, основанной на Х-исчислении Черча. В качестве базового языка рас-
сматривается функциональный язык Норе, имеющий простой и ясный синтак-
сис. Изложение сопровождается многочисленными примерами конкретных
программ.
Для программистов как начинающих, так и профессионалов, а также спе-
циалистов в области информатики.
2404010000-060
041 (01)-93
125-91
ББК 22.18
Федеральная целевая программа книгоиздания России
Редакция литературы по информатике
ISBN 5-03-001870-0 (русск.)
ISBN 0-201-19249-7 (англ.)
© 1988 Addison-Wesley Publishing Com-
pany, Inc.
© перевод на русский язык, Горбатова
М. В., Рябинин А. А., Торхов В. Л.,
Федоров М. В., 1993.
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
Одно из значительных мест в исследованиях по теоретиче-
скому программированию занимает функциональное програм-
мирование. Ведущиеся в течение уже трех десятилетий разра-
ботки в этой области в последнее время имеют устойчивую тен-
денцию к расширению.
Выполнение программы на функциональном языке, говоря
неформально, заключается в вызове функции, аргументами кото-
рой являются значения других функций, которые в свою оче-
редь также могут быть суперпозициями в общем случае произ-
вольной глубины. С точки зрения программиста, основная часть
программы состоит из совокупности определений функций, как
правило, рекурсивных. Такая особенность функциональных язы-
ков обусловливает ряд достоинств, к основным из которых, на
наш взгляд, относятся следующие. Прежде всего это присущая
определению функций декларативность, позволяющая писать
программы в терминах того, что надо делать, а не как. это
делается. Далее, бесспорным преимуществом этих языков, су-
щественно повышающим надежность программирования, яв-
ляется свойство прозрачности по ссылкам (referential transpa-
rency)— то, что и понимается в рамках данной книги под функ-
циональностью языка. И наконец, имеющаяся возможность
формального преобразования функциональных программ с целью
их оптимизации. Все это делает функциональное программиро-
вание весьма привлекательным как в теоретическом, так и
в практическом аспектах.
Говоря о существующей практике применения функциональ-
ных языков, необходимо в первую очередь указать такую об-
ласть, как интеллектуальные автоматизированные системы.
Здесь функциональные языки прошли наиболее полную апро-
бацию и признаны вполне адекватным инструментом.
Предлагаемая монография представляется полезной для на-
учных работников и специалистов в области программирования,
создания интеллектуальных автоматизированных систем, а так-
же для аспирантов и студентов старших курсов соответствую-
щих специальностей.
Перевод книги выполнен М. В. Горбатовой (гл. 1—4),
А. А. Рябининым (гл. 5—14, приложения, предметный указа-
тель), канд. техн, наук В. Л. Торховым (предисловие, гл. 17,
18), М. В. Федоровым (гл. 15, 16, 19, 20, ответы к упражне-
ниям).
В. А. Горбатав
Посвящается Cape
ПРЕДИСЛОВИЕ
На протяжении последних десяти лет или что-то около того
наблюдался растущий интерес к функциональному программи-
рованию как в академических, так и в промышленных органи-
зациях. Возможно, привлекательность функциональных языков
вызвана тремя главными, присущими им особенностями. Во-
первых, функциональные программы неизменно оказываются
намного короче, с более высокой степенью абстракции и доступ-
ными для понимания по сравнению со своими аналогами, на-
писанными на императивных языках. Во-вторых, функциональ-
ные программы пригодны для формального анализа и манипу-
лирования. И в-третьих, они естественно поддаются реализации
на параллельных машинах. Каждое из этих* свойств обуслов-
лено неотъемлемо присущей функциональным языкам матема-
тической природой: конструкции функциональных программ
являются действительно функциями — математическими функ-
циями, описывающими преобразование входных значений в вы-
ходные и не касающимися контекста, в котором они применяют-
ся. С точки зрения программирования эта особенность притяга-
тельна тем, что функциональные программы являются своего
рода иерархическими спецификациями, так часто употребляе-
мыми в работах по технологии программирования. В то же
время вследствие того, что мы можем обратиться к обычному
математическому аппарату, формальное манипулирование функ-
циональными программами выполняется относительно просто
и при установлении их свойств, и при преобразовании программ
в более эффективные формы.
В книге рассматриваются три важных аспекта технологии
функционального программирования: функциональное про-
граммирование и функциональные языки в общем, реализация
функциональных языков и формальное манипулирование функ-
циональными программами с целью оптимизации, и в соответ-
ствии с этим она разбита на три части: «Программирование
с помощью функций», «Реализация» и «Оптимизация».
Монография ориентирована на студентов последних курсов
и аспирантов, специализирующихся в информатике и вычисли-
Предисловие 7
тельной технике, а также профессионалов, желающих познако-
миться с современным состоянием в области функционального
программирования и связанной технологии. При написании
книги мы старались сделать ее, насколько это возможно, замк-
нутой, хотя, очевидно, желательно применение и некоторого
опыта обычного программирования. Те читатели, кто уже зна-
ком с функциональными языками, но хотел бы почерпнуть
сведения по реализации и оптимизации, могут пропустить пер-
вую часть книги и перейти сразу к частям II и III.
Благодарности
Мы в значительной степени обязаны членам секции функ-
ционального программирования Империал-Колледжа за много-
численные предложения и замечания по материалу этой книги.
Мы бы хотели особо поблагодарить Хелен Пулл и Линдона
Уайла, посвятивших многие часы чтению черновиков и сделав-
ших множество конкретных и существенных замечаний, оказав-
шихся весьма ценными.
Империал-Колледж
Август 1987
Тони Филд
Пити Харрисон
Часть I
ПРОГРАММИРОВАНИЕ С ПОМОЩЬЮ
ФУНКЦИЙ
ВВЕДЕНИЕ
Операция традиционного вычисления основана на последо-
вательном выполнении инструкций, которые, возможно, яв-
ляются иерархически упорядоченными, с хранением промежу-
точных результатов. Такая «модель вычисления» разработана
давно, стала почти универсальной и до такой степени влияет
на характер языков программирования, что даже сегодня на
программы смотрят как на высокоуровневое кодирование по-
следовательностей инструкций. Причем разработанные в по-
следние годы языки программирования скрывают многие низко-
уровневые детали машинной архитектуры, что облегчает про-
граммисту задачу концентрировать внимание на проблемах
более высокого уровня абстракции. Однако остается в силе тот
факт, что традиционные языки по-прежнему предоставляют
технику программирования, которая основана на обеспечении
того, как данная проблема должна быть решена на компьютере.
Следовательно, программист всегда должен держать в голове,
как организовать вычисления, и только тогда он сможет напи-
сать правильную последовательность операций для решения
проблемы. Поэтому, основная идея процесса программирования
такова: «Я скажу — как»; иными словами, внимание в основ-
ном уделяется описанию решений проблем, а не описанию
проблем как таковых. Языки, реализующие эту концепцию, ча-
сто называются императивными, отражая то, что каждое утвер-
ждение в программе является указанием того, что необходимо
проделать на следующем шаге решения.
Однако, несмотря на сложившееся в программировании по-
ложение, продолжает существовать тенденция, направленная
на обеспечение все более и более абстрактных путей решения
проблем, жертвуя при этом скоростью вычисления программ
ради простоты программирования; каждый из шагов развития
языков все дальше отделяет программирование от модели по-
следовательного выполнения инструкций. Естественное и даже
Предисловие 9
неизбежное развитие языковой технологии отрывает процесс
программирования от выделения в целом модели вычисления.
Только тогда можно будет отойти от взгляда на программу как
на средство получения результата и вместо этого развивать
тенденцию, когда программа является ясным и выразительным
утверждением, которое и должно быть ответом, игнорируя при
этом весь длинный путь подсчета результатов. В этом случае
основная идея процесса программирования такова: «Я скажу —
что, а вы разработаете — как»; иными словами, она более осно-
вывается на абстрактной спецификации проблем, нежели на
описании методов их решений.
В последнее время появилось довольно большое число язы-
ков, преуспевших в отходе от формы традиционного импера-
тивного программирования; примером такого рода могут слу-
жить аппликативные, или функциональные, языки, описанию
которых и посвящена эта книга. Функциональные программы
строятся из «чистых» математических функций, которые по
сравнению с функциями многих императивных программ сво-
бодны от побочных эффектов, т. е. их вычисление не может
изменить среду вычислений. Иными словами, не существует
назначаемого состояния программы. Из-за этого нет возможно-
сти больше программировать «с помощью эффекта», так что
величина, которая должна быть вычислена программой, и сама
программа редуцируются к одному и тому же результату. Вы-
полнение программы тогда становится процессом изменения
формы требуемой итоговой величины так, что «8 -|- 1» можно
заменить на «9»; при этом обе они будут обозначать одну и ту
же величину.
Первая часть книги посвящена неформальному и интуитив- .
ному введению в функциональные языки и функциональные
концепции программирования. Первоначальная задача состоит
в том, чтобы показать, что программирование с помощью функ-
ций не только возможно, но также вполне естественно и приво-
дит к программам почти всегда более кратким, нежели анало-
гичные императивные программы, более простым в написании
и в объяснении. При изложении будем исходить из того, что
читатель не имеет априорных знаний о функциональных языках,
но достаточно хорошо знаком с основами традиционных спосо-
бов программирования; например, для иллюстрации важных
различий между императивным и функциональным стилем часто
будут даваться ссылки на программы на языке Паскаль. Для
логичности на протяжении всей книги будет использоваться
общий код, названный функциональным языком программиро-
вания Норе, так что большая часть материала в этой части
10 Часть I
направлена на описание языка Норе и общей техники про-
граммирования на нем. Однако не следует представлять Норе
как единственный или же как лучший функциональный язык,
поскольку, как говорится, «о вкусах не спорят». Для общего
представления будут рассмотрены подходы, принятые и в дру-
гих функциональных языках. Главная цель состоит в том, чтобы
описать характерный срез функциональных языков, а не ка-
кой-либо язык в отдельности.
Те читатели, которые уже знакомы с функциональным про-
граммированием, могут пропустить большую часть текста и
вместо этого обратиться к приложению А, где дано краткое
представление основных характеристик языка Норе.
Глава 1
ВВЕДЕНИЕ В ФУНКЦИИ
В этой главе предполагается объяснить, что такое матема-
тические функции и как они используются для построения про-
грамм с помощью метода композиции. Будет рассмотрено
также, как для решения тех или иных проблем функция пред-
ставляется в виде черного ящика; как эти ящики можно компо-
новать для построения более мощных функций, которые в свою
очередь можно также рассматривать в качестве черных ящиков
для построения еще более сложных функций. Затем мы иссле-
дуем свойство функциональности и обратимся к проблеме язы-
ков, не обладающих этим свойством. Используя обычный язык
типа Паскаля, мы увидим странные свойства поведения про-
граммы, возникающие потому, что язык допускает побочные
эффекты, позволяющие изменять состояние вычисления.
1.1. Чистые функции
В математике функция есть нечто, что обеспечивает отобра-
жение объектов из множества величин, названного областью
определения функции (доменом), в объекты из некоего целевого
множества, именуемого областью значений функции или диапа-
зоном значений функции.
Простой пример функции — отображение любого заданного
целого числа в одно из значений плюс, минус или нуль соответ-
ственно в зависимости от того, является ли данное число поло-
жительным, отрицательным или равным нулю. Назовем эту
функцию sign. Областью определения функции sign является
множество целых чисел, а диапазоном значений — множество
величин {плюс, минус, нуль}. Для более наглядного представ-
ления покажем элементы из области определения функции, об-
ласть значений функции, а также отображение каждого эле-
мента (рис. 1.1).
12 Часть I. Глава 1
sign( — 3 ) = minus
sign( — 2 ) = minus
S>gn( - 1 ) = minus
sign( 0 ) = zero
sign( 1 ) = plus
sign( 2 ) = plus
sign( 3 ) = plus
Рис. 1.1. Отображение функции sign.
Отметим, что функция sign отображает каждый элемент из
области определения функции в единственный элемент из ее
обдасти значений. Эта важная деталь означает, что не суще-
ствует неоднозначности в том, в какой элемент из области зна-
чений функции отображается заданный элемент из области
определения. По этой причине все функции называют правильно
определенными или детерминированными.
Отображение элементов из области определения в элементы
области значений можно представить в ином виде—используя
множество уравнений, по одному уравнению на каждый эле-
мент определения:
sign( —3) = минус
sign( —2) — минус
sign( — 1 ) = минус
sign(O) — нуль
sign( 1 ) = плюс
sign( 2) = плюс
sign( 3) = плюс
Такое представление довольно неудобно, поскольку для полной
характеристики функции (в данном случае sign) требуется
бесконечное число уравнений. Однако, как убедимся в
дальнейшем, без использования уравнений иногда трудно обой-
тись.
Введение в функции 13
Третий способ описания отображения, порождаемого функ-
цией, состоит в определении всего лишь одного правила:
' минус, если X <0
sign(x) = > нуль, если X = 0
. плюс, если X > 0
где х называется параметром функции sign и представляет
любой заданный элемент из области определения функции.
Основная часть правила (т. е. правая его часть) просто опре-
деляет, в какой элемент из диапазона значений функции ото-
бражается параметр х. В данном случае правило для функции
sign представляет собой бесконечное число отдельных уравне-
ний, по одному для каждой величины из области определения
функции. Поскольку эта функция справедлива для всех воз-
можных элементов домена, ее называют полной функцией. Если
же в правиле опущен один или несколько возможных элемен-
тов домена — это частичная функция. Примером частичной
функции может служить
{минус, если х < О,
плюс, если х > 0.
на области определения, состоящей из целых чисел; частичной
она является потому, что не существует правила, описывающего
случай, когда х = 0. При этом говорят, что функция sign2
не определена при х = 0.
Функцию, подобную sign, можно рассмотреть и как черный
ящик, где вход представляет собой параметр функции, а выход —
результат вычислений. Для sign выходом будет являться одно
из значений: минус, нуль или плюс, в зависимости от значения
числа, поданного на вход. Выходное значение определено пра-
вилом для функции sing, являющимся составной частью чер-
ного ящика. Например, если на вход поместить число 6, то на
выходе получим плюс:
6
плюс
где 6 является фактическим параметром функции, т. е. вели-
чиной, которая в данный момент поступает на вход функции.
14 Часть I. Глава 1
Процесс подачи на вход функции фактического параметра на-
зывается применением функции, и говорят, что функция sign
применена к 6, т. е. правило для sign использует 6 в качестве
фактического параметра. В зависимости от контекста нам часто
придется ссылаться на формальные и фактические параметры
функции как на ее аргументы. Описанное применение функции
можно записать в виде математического обозначения:
sign(6).
Говорят, что это выражение принимает значение плюс. Данный
факт можно записать в виде
sign( 6 )-> плюс.
Это означает, что черный ящик выдает величину плюс на вы-
ходе тогда, когда 6 подается на его вход. Знак -> можно чи-
тать как «равно», поскольку выражение sign (6) является про-
сто альтернативным обозначением для величины плюс. Вот еще
несколько примеров:
sign( —4) —> минус,
&\.£п(Ъ)->нуль.
Идея того, что функция является механически зафиксирован-
ным правилом преобразования входов в выходы,-—есть одно
из фундаментальных положений функционального программи-
рования. Черный ящик является конструктивным блоком для
функциональной программы, и с помощью объединения таких
ящиков можно порождать более сложные операции. Такой про-
цесс «объединения» ящиков называется функциональной ком-
позицией.
Для иллюстрации процесса функциональной композиции
возьмем функцию max, которая вычисляет максимум из двух
чисел тип:
тах(т, п) = т, если т > п,
= п в противном случае.
Областью определения функции max является множество пар
чисел, а областью ее значений — множество чисел. Можно рас-
сматривать max как черный ящик и использовать его для вы-
числения максимума двух чисел. Например: запишем
1 7
7
в виде тах(1,7)—>-7.
Введение в функции 15
Можно также использовать max как блок для более слож-
ной функции. Предположим, требуется построить функцию,
которая бы находила максимум не из двух чисел, а из трех. Эту
новую функцию (назовем ее тахЗ) определим следующим об-
разом:
тахЗ(а, Ъ, с) = а, если а^Ь и а>с или а'^с и а > Ь,
Ь, если Ь а и b > с или Ь с и Ь > а,
с, если с^а и с>Ь или с^&Ь и с > а,
а в противном случае.
(«В противном случае» —это если а = b = с.)
Это довольно неудобное определение^ Гораздо более эле-
гантный способ определения функции тахЗ состоит в исполь-
зовании уже определенной функции max:
max
Запишем это следующим образом:
тахЗ(а, Ь, с) = тах(а, тах(Ь, с)).
Поскольку тахЗ обеспечивает детерминированное отображение
тройки чисел в число, можно рассматривать ее как черный
ящик, работающий по своему собственному правилу:
а b с а b с
тахЗ
16 Часть I. Глава 1
Теперь можно забыть о том, какая работа совершается
внутри этого нового ящика и использовать его как единицу
вычисления или как конструктивный блок для других более
сложных функций. Например, при вычислении
max 3(1, 4, 2)
получим 4. Так же можно использовать ее для построения дру-
гих функций, например функции, вычисляющей знак максималь-
ного из четырех чисел а, Ь, с и d, применяя уже известные нам
функции sign и max:
SM4( а, b, с, d) = sign(тах( а, тахЗ(Б, с, d))).
В виде черного ящика это можно представить следующим об-
разом:
a bed abed
Таким образом, задав множество предварительно опреде-
ленных черных ящиков-функций, называемых встроенными
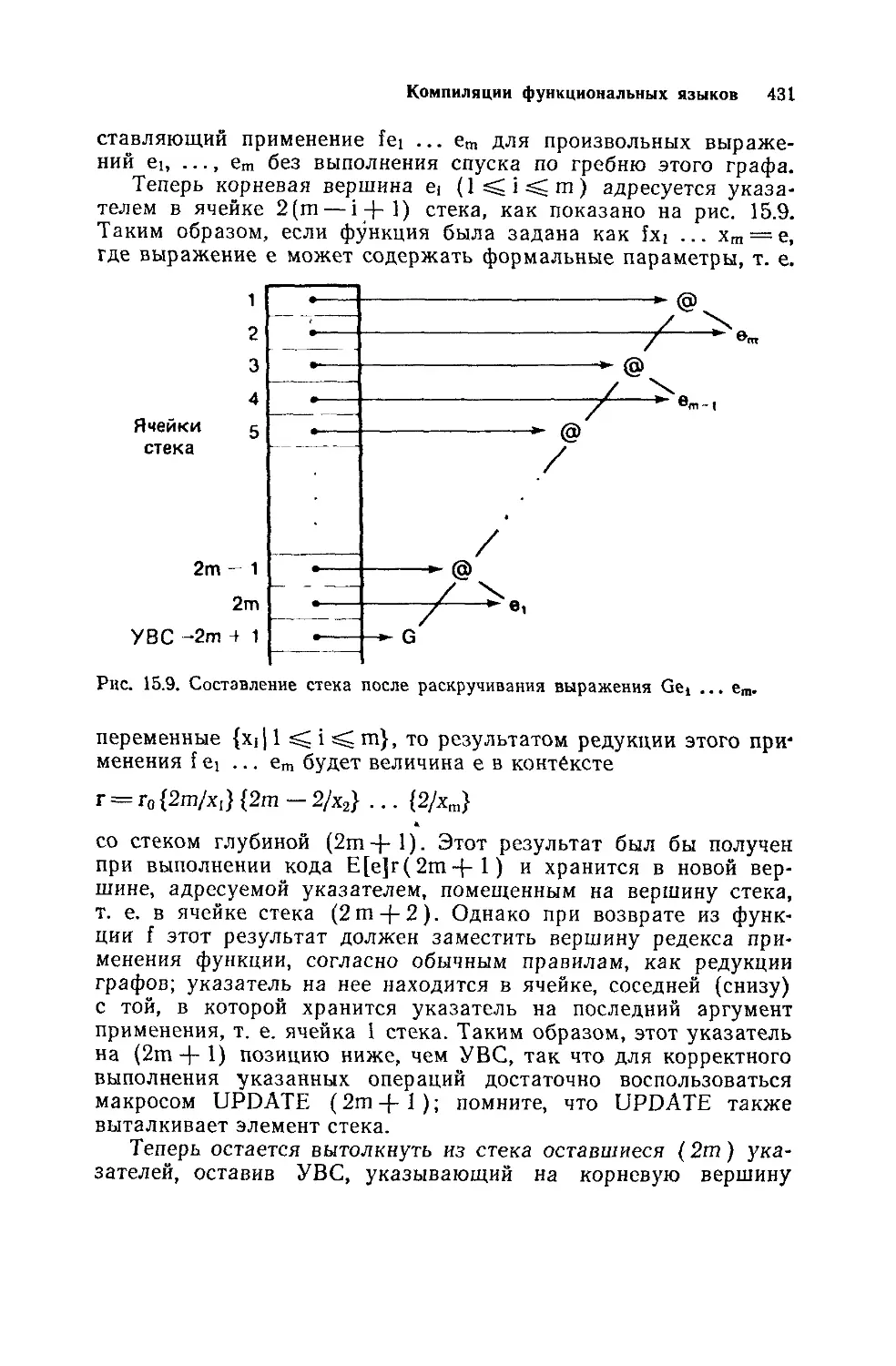
функциями или примитивами, для выполнения простых опера-
ций, подобных базовым арифметическим, можно строить новые
функции, т. е. новые черные ящики для выполнения более слож-
ных операций с помощью этих примитивов. Далее, эти новые
функции можно использовать как блоки для построения еще
более сложных функций и т. д.
Как и в традиционной практике программирования, мы мо-
жем определить новые функции, чтобы или разбить и, следо-
вательно, упростить определение более сложной функции, или
описать стандартную операцию и не переписывать одно и то же
выражение многократно.
Введение в функции 17
1.2. Функциональность
Фундаментальное свойство математических функций, кото-
рое дает нам возможность собрать воедино черные ящики,—
это функциональность (прозрачность по ссылкам). Существует
несколько интуитивных прочтений этого термина, но по суще-
ству он означает, что каждое выражение определяет един-
ственную величину, которую нельзя изменить ни путем ее вы-
числения, ни предоставлением различным частям программы
возможности совместно использовать это выражение. Вычисле-
ние выражения просто изменяет форму выражения, но не из-
меняет его величину. Все ссылки на некоторую величину экви-
валентны самой этой величине, и тот факт, что на выражение
можно ссылаться из другой части программы, никак не влияет
на величину этого выражения. Функциональность (прозрачность
по ссылкам) определяет различие между математическими
функциями и функциями, которые можно написать на импера-
тивных языках программирования, таких, как Паскаль, по-
скольку эти языки дают функциям возможность ссылаться на
глобальные данные и разрешают применять (разрушающее)
присваивание, что может привести к изменению значения функ-
ции при повторном ее .вызове. Такие динамические изменения
в величине данных часто именуются побочными эффектами.
Благодаря им значение функции может изменяться, даже если
ее аргументы и остаются без изменения всякий раз, когда к ней
обращаются. Это приводит к тому, что функцию трудно исполь-
зовать, поскольку для того, чтобы определить, какая величина
получится при выполнении функции, необходимо рассмотреть
текущую величину глобальных данных. Это же в свою очередь
требует рассмотрения истории вычисления для определения
того, что порождает величину глобальных данных в каждый
момент времени. Говорят, что императивные языки являются
нефункциональными. Для иллюстрации их нефукционально-
сти рассмотрим пример программы, написанной на языке Па-
скаль:
program example ( output);
var flag ! boolean ;
function f (n : integer ): integer ;
begin
if flag then f := n
else f :=2 *n;
flag not flag
end;
2 — 1473
18 Часть I. Глава 1
begin
flag := true;
writeln( f( 1 ) + f(2));
writeln(f(2)-|-f( 1))
end.
После выполнения этой программы на терминал будут выве-
дены два числа: 5 и 4. Однако это довольно странно, поскольку
с математической точки зрения коммутативность сложения поз-
воляет заменять х + у на у + х для любых х и у, а в этой
программе мы видим, что на языке Паскаль выражение f(l) +
+ f(2) дает результат, отличающийся от f (2) + f (1)!
Однако дело здесь не в изменении самой функции +• Проб-
лема состоит в том, что функция f, определенная выше, сильно
отличается от математических функций, которые мы до сих
пор рассматривали. Наше представление о математической
функции сводится к тому, что мы представляли ее в виде чер-
ного ящика, вычисляющего выходные величины исключительно
исходя из входных величин. Функция же, определенная в при-
веденной выше программе, является классическим примером
функции, которая в равной степени зависит от глобальных
данных, и от своих собственных параметров. Следует обратить
внимание на то, что величина глобальной переменной (т. е. flag)
в нашей программе на языке Паскаль имеет возможность из-
меняться, и именно это уничтожает свойство функциональности
языка. Значение же элементарной функции + не изменяется,
так как всегда обозначает функцию, суммирующую некоторые
величины. Источником таких проблем в программах на языке
Паскаль является операция присваивания
flag :=not flag,
изменяющая величину flag. Если перед выполнением данной
операции значение flag было «истина», то после выполнения оно
становится «ложь», и наоборот. Операции, подобные этой, в
математике не разрешены, поскольку математические рассуж-
дения базируются на идее равенства и возможности замены
одного выражения другим, означающим то же самое, т. е. опре-
деляющим ту же величину. Например, выражение 4 + 8 можно
заменить на 12, поскольку оба выражения являются обозначе-
нием одной и той же величины, т е. числа 12. Тот факт, что
в программе не содержится операции присваивания, является
характеристикой функциональных программ. Вместо представ-
ления о переменной как о величине, которая может периоди-
чески изменяться путем присваивания ей различных значений,
переменные в функциональной программе рассматриваются как
Введение в функции 19
переменные в математике: если они существуют, то, следова-
тельно, имеют какую-то величину, и эта величина не может
измениться. Вместо программы, являющейся последователь-
ностью императивов, описывающих, как компьютер должен ре-
шать задачу, основываясь на состоянии, изменяемом шаг за
шагом (т. е. на изменении переменных в результате присваи-
вания), функциональная программа описывает, что должно
быть вычислено, т. е. является просто выражением, определен-
ным в терминах заранее заданных функций и функций, опре-
деленных пользователем. Величина этого выражения является
результатом программы. Таким образом, тут отсутствует поня-
нятие состояния программы и предыстории ее вычислений.
Резюме
• Чистые (математические) функции могут быть использова-
ны для построения программ.
• Новые функции можно образовывать путем композиции уже
определенных функций.
• Языки, основанные на программировании с использованием
функций, обладают свойством функциональности (прозрачности
по ссылкам).
Глава 2
ВВЕДЕНИЕ В ФУНКЦИОНАЛЬНОЕ
ПРОГРАММИРОВАНИЕ. ЯЗЫК НОРЕ
В предыдущей главе мы познакомились с идеей программи-
рования с помощью функций. В последующих трех главах бу-
дет описана техника функционального программирования с ис-
пользованием языка Норе; единый язык используется для со-
гласованного изложения всего материала. Следует отметить, что
версия языка Норе, приведенная здесь, является расширением
оригинального языка Норе, описанного в работе [19].
В этой главе мы коснемся некоторых элементарных поня-
тий языка Норе, начиная с простых объявлений функций и
определений и кончая определенными пользователем типами
данных. Описание более сложных элементов Норе отложим до
глав 3 и 4. Мы не будем пытаться описать все возможности
языка, но того, что мы дадим, будет достаточно для полного
понимания методов функционального программирования и для
того, чтобы разобраться в примерах программ, приведенных
в частях II и III. Полное описание языка Норе можно найти
в книге [70], а краткие сведения о нем — в приложении А.
2.1. Введение понятия функции
В гл. 1 было показано, как можно определить математиче-
скую функцию с помощью правила, которое указывает, как
функция должна обрабатывать свой аргумент или аргументы,
чтобы получить требуемый результат. В языке Норе функция
описывается в два этапа. Первый этап включает в себя напи-
сание типа функции, точно задающего область определения
функции и диапазон ее значений. Второй—-описание того, ка-
кую операцию выполняет функция.
Рассмотрим простейшую функцию: возведение целых чисел
в квадрат. Сначала дадим функции имя square и объявим ее
тип:
dec square .'num—► num;
Введение в функциональное программирование. Язык Норе 21
dec — зарезервированное слово (все зарезервированные слова
будем выделять жирным шрифтом), задающее начало раздела
объявления типа. За ним следуют имя функции, тип которой
определяется, т. е. square, и выражение типа, определяющее
тип функции. Двоеточие (:) разделяет имя функции и выраже-
ния типа, и все определение заканчивается точкой с запятой
(;). Итак, написанная строка читается следующим образом:
’’square является функцией из num в num”; num есть базовый
тип (т. е. предопределенный или встроенный), предусмотренный
для представления целых чисел; в дальнейшем мы встретимся
с другими базовыми типами языка Норе.
Объявление типа любой функции имеет следующий формат:
dec name : А -> В ;
А определяет тип аргумента (или аргументов) функции (об-
ласть определения функции), а В — тип результата, получен-
ного после выполнения функций (диапазон значений функции).
Норе—это пример языка строгой типизации, в котором
функция определена для выполнения какой-то операции над
объектами определенного типа. Таким образом, применение
функции к объекту несоответствующего типа рассматривается
как ошибка. Однако, хотя тип каждой функции в языке Норе
должен быть объявлен явно, это не является общим требова-
нием для строгой типизации. В гл. 5 будет дан пример языка,
в котором тип каждой функции выводится автоматически, т. е.
без явного объявления в программе. Однако идеология языка
Норе такова, что объявление типа считается частью интеллек-
туального процесса программирования и потому является
обязательным; альтернативная идея заключается в минимиза-
ции числа определений, т. е. чем меньше их требуется, тем
лучше.
Принципиальное преимущество строгой типизации заклю-
чается в том, что многие программные ошибки могут быть
устранены прежде, чем программа будет запущена на выпол-
нение. Огромное количество программных ошибок происходит
из-за того, ч_то в функциях используются неправильные типы
аргументов. В случае же если язык строго типизирован, при
проверке типов программисту выдается сообщение об ошибках,
так как любое несоответствие типов в программе будет сразу
же обнаружено. Такая организация представляется более удоб-
ной, поскольку в противном случае ошибка проявляет себя уже
во время выполнения программы и ее анализ и локализация
требует значительных затрат времени. К вопросу о проверке ти-
пов мы вернемся в следующих главах, где увидим, что стро-
гая типизация исходной программы оказывает значительное
22 Часть 1. Глава 2
влияние на эффективность реализации. Сам же алгортим про-
верки типов описан в гл. 7.
Обратимся теперь к нашему примеру; в определении функ-
ции square описывается, что она делает со своим аргументом.
Определение имеет следующий формат:
-----square( х) <=х*х;
Это очень похоже на математическую запись, использованную
ранее. Все определения функций в тексте программы выделяют-
ся тем, что перед ними стоят три прочерка-----, а сами опре-
деления состоят из левой и правой частей, разделенных стрел-
кой <=. В левой части записаны имя определяемой функции
и список имен ее формальных параметров (или параметра);
правая же часть (обычно называемая телом функции) харак-
теризует то действие, которое необходимо проделать с этими
параметрами. Вся строка определения заканчивается точкой
с запятой. В нашем примере тело функции square (х) состоит
из выражения х*х. Знак (*) в этом выражении является при-
мером примитивной функции. То, что символ (*) появился
между ее аргументами, объясняется удобством записи; в этом
случае говорят, что (*) — инфиксная функция или инфиксный
оператор; (*) можно было бы определить и как префиксную
функцию, поскольку возможна другая равнозначная запись
*(х, х), однако мы выбрали инфиксную запись х*х, которая
хорошо знакома из элементарной математики. Полное множе-
ство примитивных функций (операторов), поддерживаемых в
языке Норе, приведено в приложении А.
Теперь, после того как функция square определена, ее можно
использовать для возведения в квадрат целых чисел, например
square(3)
Вычисление этого выражения происходит следующим об-
разом:
square(3)
-> 3 * 3 из определения функции,
->9 из предопределенной семантики примитивной функции *.
(Стрелка означает «равно», хотя, очевидно, и это является
упрощением: выражение, стоящее справа от стрелки, есть ре-
зультат упрощения выражения, стоящего слева от стрелки.) Как
все функции языка Hope, square является «чистой» функцией,
поэтому можно быть уверенным, что выражение square(3)
всегда равно 9.
Введение в функциональное программирование. Язык Норе 23
Теперь обратимся к более сложному примеру. В гл. 1 мы
определили функцию шах следующим образом:
max(m, n) = m, если m > n,
—п в противном случае.
Областью определения этой функции является множество
пар чисел, а диапазоном значений — множество чисел. Это от-
ражено в объявлении типа эквивалентной Норе-функции:
dec max : num # num - > num ;
В этом объявлении тип выражения слева от стрелки означает,
что max в качестве аргументов использует пару чисел в отличие
от функции square, где использовался лишь один аргумент.
Символ решетки (#=) обозначает декартово произведение ти-
пов, в данном случае-—пары чисел.
Правило для max выглядит следующим образом:
------max(m, n) <=if m>n then m else n;
Функция > (т. e. «больше») — еще один пример примитивной '
функции языка Hope. If ... then ... else ... — условная кон-
струкция Норе, не нуждающаяся в комментариях.
Теперь можно использовать max для определения других
функций, например функции max 3, приведенной в гл. 1:
dec тахЗ : num =#= num # num -» num;
------тахЗ(а, b, с)<=тах(а, max(b, с));
Заметим, что в объявлении типа функции тахЗ указано три
аргумента вместо двух.
Само понятие обозначения величины важно для отражения
свойства функциональности. Например, когда говорят, что
square(3) обозначает величину 9, это значит, что там, где
встречается square (3), его можно просто заменить на вели-
чину 9. Таким образом, хотя форма выражения может видоиз-
меняться, величина, которую оно представляет, остается
прежней.
2.2. Кортежи
Слово «кортеж» обозначает набор связанных величин или
объектов. Фактически мы уже встречались с несколькими при-
мерами кортежей, хотя и неявно. В выражении
тах( 1,2)
24 Часть I. Глава 2
функцию max мы рассматривали как функцию двух аргумен-
тов. Хотя, если быть более точным, в Норе надо рассматривать
аргументы как один кортеж величин, а не как совокупность
отдельных величин. Выражение типа функции max
dec max : num # num -> num;
следует читать так: «функция max берет двухэлементный- кор-
теж чисел (подчеркнуто) и возвращает одно число». Не суще-
ствует понятия кортежа, состоящего из одной величины. Дей-
ствительно, если функция берет единственный аргумент, не
являющийся кортежем, тогда круглые скобки, в которые заклю-
чен аргумент, при определении функции и ее применении мож-
но опустить. Это означает, что оба выражения
squarel2 и square(12),
относящиеся к ранее определенной функции square, равнознач-
ны и могут иметь место. Однако на протяжении всего изложе-
ния книги будем пользоваться вторым из приведенных форма-
тов. В случае же когда функция имеет один аргумент, скобки
следует рассматривать просто как ограничители, а не как син-
таксическое обозначение, имеющее место в кортеже.
Такое разграничение между списками аргументов' и корте-
жами не очень важно; действительно, обычно будем говорить,
что функция имеет «больше чем один аргумент», и это озна-
чает, что она имеет кортеж аргументов. Однако такая поста-
новка в дальнейшем нам очень пригодится.
До сих пор мы имели дело с функциями от одного или бо-
лее аргументов, имеющими единственный результат. Аналогич-
ным образом можно определить функцию, которая для любого
аргумента (или аргументов) выдает результат с бол.ее чем
одним компонентом, т. е. кортеж. Примером такой функции
может служить IntDiv, которая при целочисленном делении
для заданной пары аргументов вычисляет частное и остаток.
Например:
IntDiv(7, 3)
даст пару (т. е. двухэлементный кортеж)
(2, 1)
На языке Норе определение функции IntDiv будет выглядеть
следующим образом:
dec IntDiv : num#num-*num# num ;
-----IntDiv(m, n)<=(m div n, m mod n);
Введение в функциональное программирование. Язык Норе 25
где div и mod — инфиксные примитивы языка Норе. Следует
отметить, что тип аргумента функции IntDiv такой же, как и
результата выполнения этой функции, а именно num# num;
если мы применим IntDiv к двум аргументам (кортежу), то
получим два результата (сформированные в виде отдельного
кортежа).
Теперь, поскольку тип результата выполнения функции
IntDiv такой же, как и аргумента, необходимого, например, для
функции max, можно объединить эти две функции. Итак, в ре-
зультате
max( IntDiv( 11, 4))
получаем 3, поскольку IntDiv (11, 4) возвращает значение (2,3),
a max (2, 3) равна 3.
В дополнение к базовому типу num, обозначающему мно-
жество целых чисел, в языке Норе имеются и другие базовые
типы: truval, real и char. Тип truval (сокращение от trulh
value б) представляет тип булевых данных и в качестве своих
элементов принимает значение true (истина) или false (ложь);
real обозначает множество действительных чисел, a char—•
множество символов. Для того чтобы показать, как эти базо-
вые типы могут быть использованы на практике, введем функ-
цию, названную analyse, проводящую простой анализ действи-
тельных чисел. Заданное действительное число г функция
analyse преобразует в кортеж с тремя компонентами:
1) знак «—» или «+» в зависимости от того, меньше или боль-
ше число г числа 0, 0 соответственно;
2) значение истинности, показывающее, принадлежит ли дан-
ное число г диапазону (—1,0) — (+1,0) включительно;
3) «ближайшее» целое число к данному.
Описание поставленной задачи тут же подсказывает и тип тре-
буемой функции:
dec analyse : real -> char # truval # num ;
Тело функции analyse состоит из кортежа с тремя выражения-
ми, каждое из которых соответствует части результата:
------analyse( г) <= (if r<0 then '— ' else ' +
(r>=—1.0) and (r=< 1.0),
round( г));
Первый компонент является условным выражением, возвра-
щающим один из знаков «—» или «+» в зависимости от значе-
о Truth value — истинностное значение. — Прим. ред.
26 Часть I. Глава 2
ния г, второй является выражением булева типа, и третий —
простое применение примитивной функции round, округляющей
действительное число до ближайшего целого. Например, выра-
жение
analyse( —1,04)
будет иметь значение (’—’, false, —1), поскольку —1,04 являет-
ся отрицательным числом (следовательно, знак минус), не при-
надлежит диапазону (—1,0) — (+1,0) (поэтому false) и при
округлении дает —1.
Заметим, что в этом определении использована примитив-
ная функция >, аргументами которой являются два действи-
тельных числа, тогда как в определении функции шах, данном
ранее, функция была использована для операций над целыми
числами. Это может показаться довольно странным, поскольку
мы предположили, что все функции (включая примитивные)
строго типизированы, т. е. могут быть применены лишь к объ-
ектам определенного типа, как предписывается соответствую-
щим определением типа. Однако было бы довольно неудобно
при необходимости использовать различные символы для опи-
сания функции «больше» в зависимости от того, являются ее
аргументы действительными или целыми числами, или же в том
случае, когда один аргумент — действительный, а другой —
цедый. В Норе эта проблема решается использованием пере-
крытия, которое дает возможность одному символу функции
иметь то количество значений, которое требуется в зависимости
от той или иной ситуации. Можно представить четыре различ-
ные версии функции >:
dec > : num # num -> truval;
dec > : num # real -> truval;
dec > : real # num -»truval;
dec > : real # real -> truval ;
с соответствующими (предварительно заданными) определения-
ми. Хотя мы и используем один и тот же символ > в функциях
analyse и max, примитивная функция, к которой обращаемся
в каждом случае, фактически различна. Такое же правило при-
меняется и для других функций сравнения и арифметических
функций, подобных + и —, которые могут оперировать как це-
лыми, так и действительными числами.
Кроме того, необходимо отметить, что элементы кортежа
могут быть смешанного типа; компоненты кортежа-результата
могут состоять из любой тройки значений таким образом, что
первое значение принадлежит множеству символов, второе —
Введение в функциональное программирование. Язык Норе 27
множеству булевых величин, а третье—множеству целых. Од-
нако кортежи
(true, 'а', 'Ъ') и ('a', true, 'Ь')
не являются кортежами одного тица, хотя оба они имеют два
символьных значения и одно булево.
2.3. Рекурсивные функции
Предположим, нам нужно написать функцию для подсчета
суммы п первых неотрицательных целых чисел. Можно присту-
пить к написанию очень большого определения функции:
dec sum : num num ;
------sum(n)<=if n = 0 then 0 else
if n = 1 then 1 else
if n = 2 then 3 else и т. д.
Трудность здесь, конечно, заключается в том, что функция
имеет бесконечно много случаев, которые нужно рассматривать
при ее вычислении (или, точнее, конечное число случаев, опре-
деляемое арифметическими ограничениями реализации). С по-
мощью традиционного языка программирования задача может
быть решена с использованием цикла какой-либо формы, на-
пример на языке Паскаль задача решается с помощью следую-
щей функции:
function sum( n : integer): integer;
var
loopcounter, acc : integer ;
begin
acc := 0;
for loopcounter := 1 to n do
acc := acc + loopcounter;
sum := acc
end;
Здесь для обновления значения аккумулятора асе, который
при выходе из цикла содержит требуемый результат, исполь-
зуется цикл for. В функциональном языке не существует цик-
лических конструкций и оператора присваивания, изменяющего
значение счетчика. В таких языках задача решается с исполь-
зованием рекурсивной функции. Рекурсивная функция — это
функция, вызывающая сама себя. Конечно, вызываемая функ-
ция должна решать более простую задачу, чем вызывающая,
иначе рекурсия никогда не закончится, поэтому одна из труд-
ностей при написании рекурсивной функции состоит в том,
28 Часть I. Глава 2
чтобы выделить из текущей задачи одну или несколько более
простых задач, аналогичных исходной. Функция, таким образом,
может вызывать сама себя для решения более простых задач,
а окончательное решение может быть получено из возвращае-
мых результатов. Чтобы решить нашу задачу нахождения сум-
мы с использованием рекурсии, рассмотрим структуру выраже-
ния для суммы первых п неотрицательных целых чисел:
sum( n) 1 + 2 + 3 + 4 + ... -]- (п — 1) -ф- п
Из этой формулы можно увидеть связь между суммой пер-
вых п целых и суммой первых п—1 целых: если удалить -|-п
в конце выражения, останется выражение, эквивалентное
sum(n—1). Такую связь часто называют рекуррентным отно-
шением, отсюда вытекает, что, имея целое число п, можно ис-
пользовать определенную нами функцию sum для суммирова-
ния первых п—1 целых и затем получить решение, добавив п
к результату, возвращенному функцией sum(n—1). Кроме
того, мы должны определить так называемый базовый случай,
специфицирующий, где рекурсивный процесс должен остано-
виться. Для нашей функции базовый случай имеет место, когда
аргумент равен 0, и мы ожидаем, что функция при этом воз-
вратит 0 (сумма нуля целых чисел равна нулю). Все это вме-
сте взятое дает следующее определение:
-----sum(n) < = if n = 0 then 0 else sum(n — 1) + n;
Хотя данное определение не требует, чтобы мы думали
о том, как работает рекурсия, можно видеть эффект рекурсии
из следующего примера:
sum( 4)
- > sum(3) + 4
- >(sum(2) + 3) + 4
- > ((sum( 1) + 2) + 3) + 4
- > (((sum( 0) + 1) + 2) + 3) + 4
_>((((0+l) + 2) + 3) + 4)
-> 10
Сравнивая определения sum на языке Hope и на языке
Паскаль, можно видеть наиболее важное различие между импе-
ративным и функциональным решениями задачи. Чтобы понять
решение на языке Паскаль, мы должны понять, что машина бу-
дет делать при выполнении каждого оператора программы. При
функциональном решении, с другой стороны, мы не должны
Введение в функциональное программирование. Язык Норе 29
думать о том, как программа будет выполняться на компьютере;
отсутствует всякое упоминание об изменяемом состоянии про-
граммы или о последовательном выполнении инструкций. Функ-
циональное решение является фактически формулировкой самой
задачи, а не рецептором ее решения, и именно в этом смысле
мы говорим о функциональной программе как о спецификации
того, что нужно сделать вместо последовательности инструкций,
описывающих, как это сделать.
Мы увидим еще много примеров рекурсивных функций
в следующих разделах этой главы и в остальных главах книги.
Несмотря на то что рекурсия ведет к очень абстрактным -и сжа-
тым решениям числовых задач, ее реальная мощность стано-
вится очевидной при рассмотрении функций, работающих с ти-
пами данных пользователя. Этот вопрос будет рассмотрен в
разд. 2.6.
2.4. Объявляемые инфиксные операторы
Функции, рассмотренные нами ранее, записаны в префикс-
ной нотации. В этом случае символ функции предшествует ее
аргументу или аргументам. Однако из элементарной математики
нам больше знакомы выражения вроде
1+3
Здесь функциональный символ расположен между операндами
и поэтому называется инфиксной функцией, или инфиксным
оператором.
При написании программ иногда удобно определить соб-
ственную инфиксную функцию, и это может быть сделано в
языке Норе с помощью зарезервированного слова infix. Оно
вводит имя нового оператора и его приоритет. Приоритет — это
целое число от 1 до 10, определяющее предпочтение оператора
относительно других операторов программы.
В качестве простого примера рассмотрим выражение
1+3*2
Здесь мы обычно предполагаем, что * имеет более высокий
приоритет по отношению к +, поэтому выражение читается как
1 +(3*2), а не (1+3)*2. В языке Норе приоритеты операто-
ров + и * соответственно равны 5 и 6 (приоритеты всех ин-
фиксных примитивов даны в приложении А). Более высокий
приоритет * означает такую расстановку скобок в рассмотрен-
ном выражении, какую мы ожидаем.
30 Часть I. Глава 2
Чтобы ввести новый оператор ОР с приоритетом Р, мы
пишем
infix OP : Р ;
Синтаксис объявления типа оператора точно такой же, как
у обычной функции, за исключением того, что объявление со-
держит всегда два аргумента:
dec OP : Typel #Туре2 н»Туре.З ;
где Typel, Туре 2, ТуреЗ — выражения типа. Аналогично, когда
мы определяем ОР, левая часть определения сама записывается
в инфиксном формате:
-----Р1 ОР Р2<= ;
где Pi и Р2 — формальные параметры ОР.
Для иллюстрации этого механизма приведем объявление
и определение инфиксного оператора f, означающего возведе-
ние в степень, т. е. дающего для двух целых аргументов х и у
значение ху. В математике возведение в степень имеет более
высокий приоритет по отношению к другим арифметическим
операциям, так что выражение а*Ьс читается а*(Ьс), а не
(а*Ь)с. Чтобы отразить этот факт, нам следует назначить
приоритет 7 оператору f, т. е. на единицу больше приоритета
оператора *
infix f : 7;
dec f : num # num -> num;
Определение f рекурсивно и основано на том, что
аь = а* аь-1
при базовом случае а°= 1. На языке Норе оно выглядит так:
-----х f у <= if у = 0 then 1 else х * х | (у — 1);
Например:
3 + 7 j 2 — 6 дает в результате 46
3 * 5 12 дает 75
2.5. Квалифицированные выражения
Рассмотрим следующую функцию:
dec f: num-► num ;
-----f(x) <— g( square( max (x, 4))) +
(if x—<1 then 1 else g(square(max(x, 4)))),'
Введение в функциональное программирование. Язык Норе 31
В этом определении подвыражение g (square (max (х, 4))) встре-
чается дважды. Более того, если аргумент f (т. е. х) больше 1,
то тело f эквивалентно
g(square(max(x, 4))) + g( square(max(x, 4)));
что приводит к необходимости дважды вычислять подвыраже-
ние g(square(max(x, 4))). Это довольно расточительно, так как
мы знаем, что результат обоих вызовов будет одним и тем же.
Можно избежать этих повторений двумя способами. Во-пер-
вых, мы можем определить вспомогательную функцию, скажем
fl, имеющую повторяющееся подвыражение в качестве пара-
метра:
-----f( х) <= f 1( g( square( max( x, 4))), x);
-----fl(a, b)<=a-|-(if b=< 1 then 1 else a);
Здесь мы основываемся на том факте, что аргументы функции
вычисляются не более 1 раза (это станет более ясным из гл. 6).
Второй способ заключается в использовании так называе-
мого квалифицированного выражения, оно позволяет нам при-
своить выражению имя и затем использовать это имя так же,
как мы используем формальный параметр. В некотором отно-
шении можно рассматривать этот механизм в качестве расши-
рения существующего набора формальных параметров. В языке
Норе существуют два эквивалентных вида квалифицированных
выражений: конструкция let:
let (имя) == (выражение^ in (выражение)2
и похожая на нее конструкция where:
(выражение)2 where (имя) == (выражение)!
(выражение)! иногда называют квалифицирующим выраже-
нием, или квалификатором, а (выражение)2 — результантом.
Обе эти конструкции имеют квалификатор, на который можно
ссылаться с помощью имени в результанте. Функция f теперь
может быть записана в виде
-----f( х) <== let a ==g( square( max( x, 4 )))
ina-|-(ifx=< 1 then 1 else a);
или в виде
-----f(x) <= a 4-(if x =< 1 then 1 else a)
where a == g(square( max(x, 4)));
Важно понять, что символ = = просто связывает имя с вы-
ражением. Его не следует путать с символом <= и с опера-
тором присваивания (: = ) императивных языков. Следующий
32 Часть I. Глава 2
пример иллюстрирует эту мысль:
let х —= El in
if( let x == E2 in E3)
then x
else 1 + x
Внешнее let-выражение связывает имя x и выражение El. После
этого величина, обозначаемая х, и.величина, обозначаемая Е1,
одинаковы. Внутреннее let-выражение в предикате условного
оператора не меняет значения внешнего х. Оно вводит новое
имя для выражения Е2, и это имя случайно оказалось таким
же, как во внешнем let-выражении. Следовательно, ссылки на х
в двух ветвях условного оператора относятся к Е1, а не Е2, но
внутреннее let-выражение подавляет внешнюю связку так, что
все ссылки на х в выражении ЕЗ в действительности относятся
к Е2, а не к Е1. Область действия нового имени поэтому огра-
ничена выражением, следующим за in в let-выражении и пред-
шествующим where в where-выражении.
Квалифицированные выражения обычно используют, когда
внутри какого-либо выражения на подвыражение ссылаются
более одного раза, но оно может также использоваться для
того, чтобы было легче читать определение функции. Третий
случай применения квалифицированного выражения относится
к декомпозиции кортежей. В качестве примера рассмотрим при-
веденную ранее функцию IntDivr Каждый ее вызов возвращает
пару чисел — частное и остаток от деления двух аргументов.
Один из способов выделить только одно из этих чисел состоит
в том, чтобы придумать вспомогательные функции, выполняю-
щие декомпозицию:
dec quot: num # num -> num ;
------quot(q, r)<=q;
dec rem : num # num num ;
------ rem( q, r) < = г ;
Например:
let pair == IntDiv( x, y) in quot( pair) * у + rem( pair)
Однако мы можем использовать квалифицированное выражение
для декомпозиции кортежа, полученного из IntDiv следующим
образом:
let (q, г) == IntDiv(x, у) in q*y + r
Это выражение именует первый элемент результирующего кор-
тежа символом q и одновременно второй элемент символом г.
Это простой пример того, что в языке Норе называется соло-
Введение в функциональное программирование. Язык Норе 33
ставлением с образцом; в приведенном выражении мы сопостав-
ляем пару (q, г) с результатом, полученным из функции IntDiv,
например (2,3). В результате сопоставления символу q припи-
сывается величина 2, а символу г величина 3. Мы иногда будем
использовать термин связка и говорить, что q привязано к 2, а г
к 3. Более глубоко эти вопросы рассмотрим в следующем
разделе.
2.6. Типы данных, определяемые пользователем
Итак, все функции, введенные в наших примерах, оперируют
с объектами таких основных типов, как num, real и char.
В большинстве приложений, однако, необходима возможность
использования расширенного набора типов данных за счет вво-
димых программистом новых гипов. Это так называемые типы
данным, определяемые пользователем.
В дополнение к основным типам данных многие языки про-
граммирования предлагают большой набор средств для по-
строения более сложных структур данных. Язык Паскаль, на-
пример, позволяет определить записи и указатели, благодаря
чему можно использовать записи для создания компонентов
структуры, а указатели — для ссылок на эти записи. При та-
ком подходе в языке Паскаль можно ввести списки, используя
записи для представления каждого элемента списка, указатели
для ссылок на них и специальную величину NIL для обозначе-
ния нулевого указателя. Определение списка как нового типа
данных будет в этом случае выглядеть следующим образом:
type
list = ''cell;
cell = record
head : integer;
tail :-eeH- List
end;
Графически такое представление списков будет выглядеть
как последовательность элементов-прямоугольников, соединен-
ных указателями-стрелками. Например, список, содержащий
элементы 1, 2 и 3, будет иметь следующий вид:
Указатель Р
2
Список достраивается путем образования новых записей и
заполнения их соответствующими значениями. Ниже в качестве
з -
34 Часть I. Глава 2
примера приводится часть программы, создающая список из
единственного элемента — числа 3:
NEW(L);
with L' do
begin
head := 3 ;
tail :=NIL
end;
Суть того, что мы делаем здесь, заключается в манипули-
ровании памятью на довольно высоком уровне: мы подробно
описываем элементы списка и заполняем их значениями, необ-
ходимыми для построения структуры.
Создание списков в Норе происходит путем определения
полностью нового типа данных и составных частей этого типа,
а не путем использования неких заранее зафиксированных
в самом языке примитивов, таких, как записи и указатели. Пре-
имущество такого подхода заключается в том, что нам следует
описать то, как выглядит вводимая структура данных, а не то,
как она может быть выражена через существующие типы
данных.
Теперь предположим, что нам необходимо так описать спи-
сок чисел, чтобы была возможна его передача от функции
к функции. Мы не будем задумываться над представлением
хранения списков в том виде, который используется в языке
Паскаль, а попробуем вместо этого создать рекурсивное описа-
ние структуры списка:
Список чисел есть такая структура данных, которая является либо пустой,
либо непустой, в случае чего она состоит из некоторого числа (голова спи-
ска) и другого списка чисел (хвост списка).
Синтаксис соответствующего определения в Норе в точности
отражает суть этого описания:
data Numlist =— nil -^-+ cons( num # Numlist);
здесь nil и cons называются конструкторами данных, поскольку
служат лишь для конструирования нового типа данных. Они
неявно определяются при появлении в выражениях data. Кон-
структоры часто называются конструирующими функциями,
а конструкторы без аргументов — константами данных.
Используя конструкторы, можно переписать определение
того же списка из одного элемента:
cons(3, nil)
Для наглядности в соответствии с термином «конструирую-
щая функция» мы применили конструктор так, как если бы он
Введение в функциональное программирование. Язык Норе 35
и в самом деле был обычной функцией. Однако для конструи-
рующих функций в отличие от других нет существующих пра-
вил, позволяющих манипулировать ими (упрощать, например).
Таким образом, выражение cons (3, nil) рассматривается как
некоторая величина в том смысле, что оно не может быть
упрощено путем применения к нему соответствующих правил.
В качестве более сложного примера приведем список, содержа-
щий числа 1, 2 и 3 и выраженный через конструкторы nil
и cons:
cons( 1, cons(2, cons(3, nil)))
Будем называть выражения, образованные при помощи кон-
структоров, термином составные данные.
Используя конструкторы nil и cons, можно построить про-
извольно большие списки чисел. Иногда, однако, бывает необ-
ходимо создать списки объектов иного рода, таких, как сим-
волы, вещественные числа или даже списки списков. Для опи-
сания списка символов, например, можно описать новый тип
данных CharList:
data CharList ===== NilCharList + +ConsChars( char # CharList);
Мы не можем использовать в описаниях различных типов одно
и то же имя конструктора, поэтому здесь мы не используем
nil и cons.
Можно заметить, что форматы определения CharList и опре-
деления NumList, введенного ранее, идентичны. Это является
следствием того, что общий вид списка символов аналогичен
виду списка чисел. Норе позволяет избежать необходимости
определять новый тип списка для каждого объекта нового типа
блаюдаря возможности определения родового или полиморф-
ного (многоформатного) типа данных. Это является отраже-
нием той мысли, что списки произвольных объектов идентичны
по структуре. Полиморфизм позволяет нам параметризовать
определение списка, т. е. вводить в него тип хранимых объек-
тов в качестве параметра. Ниже приводится полиморфное опре-
деление списка, которое может быть использовано для описания
списка объектов произвольного типа:
typevar any;
data list( any) ===== nil +4- cons( any # 1 ist( any));
где any называется переменной типа в том смысле, что она
является идентификатором, обозначающим некоторый тип.
Новые переменные типа объявляются командой typevar, как
указано выше.
з*
36 Часть I. Глава 2
С помощью этого единственного определения мы можем
использовать nil и cons для создания списков любого типа,
например:
cons( 1, cons( 2, nil) ) — список чисел,
cons( 'a', cons( 'Ь', cons( 'с', nil))) — список символов,
cons( nil, cons( cons( 1, nil ), nil ) ) — список списков,
nil — список объектов, тип которых не описан
Отметим, что все элементы данного списка должны быть одного
типа. Следовательно, список вида
cons(l, cons('a', nil))
некорректен, поскольку его компонентами являются и числа,
и символы. Для удобства программирования две переменные
типа alpha и beta определяются в самом Норе и могут быть
использованы в любом месте программы без предварительного
объявления.
Вследствие того что списки используются очень часто, они
также определяются заранее. Пустым конструктором, как и
выше, остается nil, а непустым становится конструктор : : (чи-
тается как cons) с приоритетом 7. Записанное в полном виде
данное определение списка выглядело бы так:
infix ::: 7 ;
data list( alpha ) == nil 4—P alpha :: 1 ist( alpha);
Ниже приводится другое описание указанных выше списков
уже при помощи определяемых в Норе конструкторов:
1 :: (2:: nil)
’я! :: ('Ъ':: ('с':: nil))
nilnil):: nil)
nil
Hope позволяет использовать различные сокращения в выраже-
ниях для списков. Так список
ej ::(е2::(е3::(... ::(en::nil) ...)))
может быть записан в виде
[еь е2, е3, ..., еп]
Далее, если все ei являются символами, то мы можем объеди-
нить их, заключив в двойные кавычки. Например, список
'H'::('o'::('p'::('e'::nil)))
Введение в функциональное программирование. Язык Норе 37
может быть записан с использованием этого сокращения как
['Н', 'о', 'р', 'е']
или в виде строки
"Норе"
Существует и другой способ описания данных, реализуемый
в Норе и заключающийся в произвольном наименовании типов
данных и их комбинаций (кортежей). Представим, например,
что нам необходимо создать набор функций, обрабатывающих
координатные пары (х, у). Вместо определения координатной
пары как
real ф real
можно ввести новый тип данных real# real при помощи опе-
ратора type:
type Coordinate == real # real;
и использовать идентификатор Coordinate вместо real#real
везде, где это необходимо, например:
Coordinate -> Coordinate
описывает точно то же, что и
real # real —> real # real
Заметим, что оператор type не создает нового типа данных,
как это делает оператор data, а просто приписывает некоторое
имя выражению типа данных.
2.6.1. Определение функций над типами данных
Задав набор необходимых типов данных, можно перейти
к описанию функций, работающих с ними. Для иллюстрации
того, как создаются такие функции, мы рассмотрим четыре не-
большие программы: первые три демонстрируют различные спо-
собы обработки списков, а четвертая работает с более сложным
типом данных — деревом.
Пример 1. Соединение двух списков
В этом примере мы создаем функцию Join с аргументами
в виде двух списков, которые необходимо соединить. Например:
Join("ET", "phone home")
38 Часть I. Глава 2
даст
"ЕТ phone home"
Как и в последующих примерах, мы начнем с описания типа
функции Join. Важной особенностью Join является ее способ-
ность соединять списки объектов произвольного типа. С этой
точки зрения Join является полиморфной функцией. Это озна-
чает, что она определяется параметрически — через переменные
типа данных. Мы будем использовать определяемую в самом
языке переменную alpha:
dec Join : list( alpha ) # list( alpha ) -> list( alpha );
Оба списка, играющие роль аргументов, должны содержать
объекты одного типа, поскольку иначе результирующий список
будет содержать объекты различных типов, что запрещено. Вы-
полнение этого ограничения обеспечивается использованием во
всем выражении одной и той же переменной типа alpha.
Определение функции, оперирующей с типом данных, пре-
следует достаточно очевидную цель: вместо использования
единственного правила для описания функции мы используем
набор правил (иногда называемых правилами переписывания
или уравнениями) по одному для каждой возможной «формы»
аргумента, т. е. по одному для каждого конструктора в описа-
нии типа данных. Так, в функции Join аргументами являются
списки, поэтому существуют два случая, которые надо рассмот-
реть: пустой список (конструктор nil) и непустой список (кон-
структор ::).
Во введенном определении Join мы предлагаем считать вто-
рой аргумент как нечто цельное, не разделяемое на компо-
ненты. С другой стороны, структура первого аргумента может
быть определена в более сложном виде. Если первый аргумент
является пустым списком, а второй — некоторым списком L,
то их соединение, очевидно, даст в результате L:
------- Join( nil, L)<=L;
Далее, если первый список имеет вид х::у, то соединение его
с L происходит путем присоединения у к L, а затем х к началу
образованного списка. Опишем это правило следующим об-
разом:
-----Join(x::y, L) <= х :: Join( у, L);
Это определение является полным, так как мы рассмотрели все
те формы, которые может принимать первый список.
nil и х::у в левых частях этих определений называются
образцами. Образец выполняет две задачи: во-первых, он опре-
Введение в функциональное программирование. Язык Норе 39
деляет вид, который должен иметь аргумент перед тем, как
будет применено соответствующее правило, а во-вторых, он как
бы разделяет аргумент на компоненты и дает им некоторые
названия (кроме того случая, когда образец представляет про-
сто константу). Например, образец х::у определяет непустой
список, голова которого имеет имя х, а хвост — у. При необ-
ходимости х и у могут использоваться при применении правила
переписывания для обращения к частям — голове и хвосту —
списка. Далее приводится пример использования введенной
выше функции Join:
Join("ET", "phone home")
== Join( 'E':: ('T' :: nil ), "phone home" ) — раскроем список "ET"
'E' .. ( 'T' :: nil )
- >'E':: Join('T':: ml, "phone home") —может быть подставлено во вто-
рое правило для Join с заменой:
х== 'Е' и у = 'Т':: nil
- > 'Е':: ( 'Т':: Join( nil, "phone home" )) — подставим 'T'::nil с заменой х =
= 'Т' и у = nil
- > 'Е':: ('Т':: "phone home" ) — применим первое правило для Join
- >'Е'::"Т phone home" —'применим оператор ::
- >"ЕТ phone home" —применим оператор ::
Благодаря полиморфизму функции Join она может быть
использована для объединения списков объектов и других ти-
пов, например
Join([true, true, false, true], [false false])
даст следующий список булевых величин:
[true, true; false, true, false, false]
Здесь необходимо отметить то, что подобное соединение спи-
сков не изменяет содержимого их аргументов. Join создает
полностью новый список, образованный из двух исходных, точно
таким же образом, как выражение x::L дает новый список
с головой х и хвостом L, причем сами х и L не изменяются.
В этом еще раз проявляется свойство функциональности, опи-
санной выше.
Очевидно, что для успешного сопоставления с образцом
необходимо отсутствие какой-либо двусмысленности в вопросе
выбора правила, применимого для данного аргумента или на-
бора аргументов.- Простейшим способом избежать подобной
двусмысленности является запрещение перекрывающихся левых
частей, таких, как
f( nil) <= ...
Цх)<=...
40 Часть I. Глава 2
(если аргументом f является nil, то оба правила эквивалентны).
Однако Норе допускает наличие перекрывающихся правил, если
они однозначны. Приведенное выше определение является до-
пустимым, поскольку величина nil (конструктор) является бо-
лее точной, нежели х (переменная). Все примеры в этой книге,
за исключением нескольких тривиальных функций в части III,
будут использовать неперекрывающиеся образцы, так что по-
добные определения не возникнут. Мы, однако, вернемся еще
раз к вопросу о перекрывающихся образцах в гл. 8, когда бу-
дем рассматривать сопоставление с образцом как важную часть
процесса трансляции исходных программ в промежуточную
форму.
Функция Join является очень полезной и широко исполь-
зуемой функцией, в связи с чем она определяется в самом
языке Норе. Она называется append и является инфиксным
оператором с проритетом 5л#Гаким образом, записи
"ЕТ"( )"phone home"
и
Join("ET", "phone home")
являются эквивалентными.------
Пример 2. Инвертирование списка
Рассмотрим простую функцию Rev, выраженную в терминах
append, инвертирующую список произвольно типизированных
объектов. Главная задача упражнения — как следует из назва-
ния — объяснить технику накапливания параметров, в которой
вспомогательные параметры добавляются к функции для на-
копления результата. Эта техника довольно проста, но сильно
влияет на время выполнения функциональной программы.
Требования к функции Rev заключаются в том, что выра-
жение
Rev([eb е2....еп_ь еп])
преобразуется в
[еп, еп_ 1,' ..., е2, ej
Отметим, что типы аргумента и результата функции, идентич-
ны, следовательно, справедливо определение
dec Rev : list( alpha) -> list( alpha);
Введение в функциональное программирование. Язык Норе 41
Поскольку аргументом функции является список, следует
рассмотреть два правила: первое — если список пуст, то ре-
зультатом будет nil, поскольку инвертирование пустого списка
порождает пустой список; второе — если' список имеет вид
х :: L, инвертировать его следует путем инвертирования L и до-
бавления списка [х] в конец результирующего списка.
Следовательно:
-----Rev(nil) '< = nil;
-----Rev(x::L)<=Rev(L)( > [х];
Следует отметить, что [х] формирует единичный список,
содержащий только х; это необходимо выполнить до примене-
ния операции < >.
Хотя определение и корректно, его можно сделать более
эффективным путем исключения вызовов < >. Проверка функ-
ции Rev покажет, что полное число вызовов :: (включая и те,
что получились от вызовов <>) пропорционально квадрату
длины инвертируемого списка. При использовании накапливаю-
щего параметра, можно уменьшить количество вызовов ’:: до
линейной зависимости. Этот дополнительный параметр (перво-
начально равный nil) накапливает требуемый инвертированный
список при каждом обращении к функции. Поскольку нам не-
обходима функция с дополнительным параметром, определим
вспомогательную функцию Rev2, которая вызывается из функ-
ции Rev, имея в качестве аргументов входной список и началь-
ную величину накапливающего параметра, равную nil:
dec Rev t list( alpha )->list( alpha );
dec Rev2 : list( alpha) # list( alpha) -> list( alpha);
------'Rev(L) <=Rev2(L, nil);
-----Rev2(nil, A) <=A;
-----Rev2( x :: 1, A) < — Rev2( 1, x :: A);
Например:
Rev([ 1, 2, 3])
->Rev2([ 1, 2, 3], nil)
->Rev2([2, 3], [1])
- ^Rev2([3], [2, 1 ])
- > Rev2( nil, [ 3, 2, 1 ])
- *I3, 2, 1]
Мы видим, что накапливающий список строится таким обра-
зом, что добавление нового элемента к результирующему списку
включает только операцию :: и совсем не использует вызов <>.
Благодаря этому количество вызовов :: теперь имеет .линейную
42 Часть I. Глава 2
зависимость от длины списка аргументов. В данном при-
мере функция Rev2 называется авторекурсивной функцией, по-
скольку результат функции в небазовом случае определяется
лишь результатом вызова самой функции (с более простым
«аргументом»). В следующем примере также показаны авто-
рекурсивные функции (авторекурсивные вызовы подчеркнуты):
------f(x) <= if х = 0 then 0 else f( х — 1);
------g( х) < = let а =— x — 2
in if P( a) then a else g( a);
В гл. 18 увидим, каким образом накапливающие параметры
могут быть использованы для «устранения рекурсии», т. е. пре-
образования, которое автоматически преобразует некоторую
функцию в авторекурсивную форму или же, что эквивалентно,
в циклы императивного языка, выполнение которых более эф-
фективно на обычных компьютерах.
Пример 3. Разделение предложения на лексемы
В этом примере мы рассмотрим функцию разделения пред-
ложения на составляющие его слова. Предположим, что слова
разделены одним или более пробелами (обозначенными симво-
лами "), хотя на практике могу г встречаться и другие разде-
лители, например символ «конец строки» (обозначаемый в
Hope crif) или знаки препинания, такие, как и т. д. На-
пример, для
SplitUp("The following words")
необходимо построить список слов
["The", "following", "words"]
Как всегда, вначале определим тип функции, которою будем
использовать. Для облегчения чтения программы будем также
использовать оператор type для определения слов и предложе-
ний. Все они являются списками символов, следовательно,
type word ===== list( char);
type sentence == list( char);
dec SplitUp i sentence-> list( word);
Разделение предложения можно проводить последовательным
извлечением из него первого слова и добавлением его к резуль-
тату разделения, проделывая эту операцию до тех пор, пока
Введение в функциональное программирование. Язык Норе 43
в предложении не останется больше слов. При этом предпола-
гается, что для удобства вводится дополнительная функция,
которая возвращает первое слово этого предложения и остав-
шуюся часть. Назовем эту функцию NextWord и объявим ее
следующим образом:
dec NextWord : sentence -> word # sentence ;
Для ее определения рассмотрим возможные формы входного
предложения. Базовым случаем является пустое предложение,
при этом и слово, и остаток предложения должны быть пусты:
NextWord(nil) <= (nil, nil);
Если же предложение непусто, оно будет иметь либо ограни-
читель в начале предложения (т. е. символ «пробел»), либо
какой-нибудь другой символ. В первом случае следует дойти
до конца следующего слова, и тогда результатом функции бу-
дет nil и остаток предложения:
------NextWord( Next:: Rest) <==
if Next = ’ ’
then(nil, Rest)
else ... ;
Если же началом предложения является какой-либо другой
символ, то для того, чтобы отделить остаток следующего слова
от оставшейся части предложения, можно использовать функ-
цию NextWord и затем добавить Next к началу следующего
возвращенного слова. Таким образом, полное определение при-
нимает вид
------NextWord( Next:: Rest) < =
if Next = ’ ’
then (nil, Rest)
else let (RestOfWord, RestOfSentence) ==
NextWord( Rest)
in (Next:: RestOfWord, RestOfSentence);
Например (в качестве аббревиатуры для RestOfWord будем
использовать R, а для RestOfSentence — S):
NextWord("The trouble with Tribbles")
—>let (R, S) =— NextWord("he trouble with Tribbles")
in ('T'::R, S)
—>('T':: "he", "trouble with Tribbles")
s("The", "trouble with Tribbles")
44 Часть I. Глава 2
Аналогично можно использовать функцию NextWord для опре-
деления функции SplitUp:
------SplitUp( nil) <= nil;
------SplitUp( Next:: Rest) < =
if Next —' '
then SplitUp(Rest)
else FirstWord :: SplitUp(RestOfSentence)
where (FirstWord, RestOfSentence) ==
NextWord( Next:: Rest);
Ради разнообразия для декомпозиции образованного кортежа
мы использовали where вместо let. Проверка на " относится
к конструкции первоначального предложения.
Заметим, что в определении SplitUp если следующий символ
в предложении не является пробелом, то аргумент функции
NexWord является тем же выражением, что и аргумент самой
SplitUp. Для получения результата (и написания программы)
это довольно неэкономно, поскольку сопоставление с образцом
декомпозирует входные данные, а тело программы опять соеди-
няет их. К счастью, язык Норе позволяет дать имя всему об-
разцу аргумента, так что подобной неприятности можно избе-
жать:
------SplitUp( Thelnput & Next:: Rest) <=
where (FirstWord, RestOfSentence) =—
NextWord( Thelnput);
Запись эта звучит так: ’’Thelnput является аргументом и дол-
жен быть непустым списком; начало его именуется Next, а ко-
нец— Rest”.
Однако иногда мы вовсе не заинтересованы в том, чтобы
присваивать имена образцам аргумента, например в случае,
когда интерес представляет только форма аргумента, а не его
компоненты. Хорошим примером тому является функция
IsEmpty, которая выдает true, если заданный аргумент является
nil, и false в противном случае:
dec IsEmpty : list( alpha) -> truval;
------IsEmpty( nil) <= true;
------IsEmpty(x:: 1) <=false ;
Во втором уравнении не требуется, чтобы х или I были ис-
пользованы в теле функции. Для того чтобы было проще при-
сваивать имена началу и концу списка, можно использовать
Введение в функциональное программирование. Язык Норе 45
оперативный символ подчеркивания, означающий ’’безразлично”
------IsEmpty( nil) <= true;
------IsEmpty( — :: — ) <= false ;
& и _ могут использоваться в качестве одного из символов об-
разца для присваивания (или неприсваивания) имен компонен-
там аргумента. Например, все нижеприведенные записи могут
иметь место:
х::(у& —)
а & (х :: 1):: —
— :: ((х & ( а :: Ь)):: — )
Помимо этого в образцах можно использовать любые константы
базовых величин, а в квалифицированных выражениях — про-
извольные образцы. Например, возможны такие записи:
'а'
'Pattern'
[true, false, х, у]
или выражение, использующее let или where:
let (Next:: Rest) =— SplitUp( "Big Ben") in Rest
3::P where [u, P&(y::z), [ v ] ] ===== f(x)
LabelName where ('L'LabelName) )== Label
Пример 4. Treesort —сортировка с использованием дерева
Treesort — это программа, сортирующая список чисел в по-
рядке возрастания путем преобразования начального списка
чисел в упорядоченное бинарное дерево и затем обратного
преобразования этого дерева в (отсортированный) список. При-
ведем несколько примеров бинарных деревьев:
(а) — пустое дерево;
46 Часть I. Глава 2
(б)-—дерево с единственным элементом, который называется
листом (на рисунке элемент подчеркивается) и имеет тип num;
(в) и (г)—примеры многоуровневых деревьев, построенных
из внутренних вершин, вершин-листьев и пустых деревьев.
Каждая внутренняя вершина содержит число и два поддерева.
Упорядоченное бинарное дерево — это такое дерево, в котором
для каждой внутренней вершины все элементы левого подде-
рева меньше или равны значению вершины, а все элементы
правого поддерева больше значения вершины. Приведенные
выше примеры являются упорядоченными бинарными деревья-
ми. «Разглаживание» дерева состоит в таком преобразовании,
при котором элементы дерева преобразуются в элементы линей-
ного списка. В качестве иллюстрации проделаем подобную опе-
рацию над деревом (г) и в результате получим список [1, 4,
8, 14, 15, 20].
Для того чтобы написать программу Treesort на языке Норе,
рассмотрим поставленную задачу в полном объеме. Treesort бе-
рет неупорядоченный список чисел и образует упорядоченный,
например:
15,2,1.9] -----------------► [1,2,5,9]
Т reesort
Однако при этом сначала строится промежуточное упорядо-
ченное бинарное дерево, а уж затем оно преобразуется в упо-
рядоченный список (разглаживается):
Подобное описание несет всю необходимую информацию о струк-
туре программы Treesort. Сначала, исходя из определения де-
рева, напишем определение данных на языке Норе
data tree == empty +4- Ieaf(num) ++ node( tree# num# tree);
Введение в функциональное программирование. Язык Норе 47
означающее, что дерево либо пусто, либо является листом, со-
держащий число, либо вершиной, содержащей число и два
поддерева'.
Диаграмма, приведенная выше, дает информацию не только
о типах главных функций, необходимых для сортировки, но
также и само определение Treesort:
dec Treesort : list( num) -> list( num);
dec MakeTree: list( num)--> tree ;
dec Flatten : tree-» list( num );
----- Treesort( UnsortedList) <=
Flatten( MakeTree( UnsortedList));
Все, что от нас теперь требуется, — это определить функции
MakeTree и Flatten. Начнем с MakeTree.
Аргументом функции MakeTree является список чисел; для
определения этой функции следует рассмотреть два случая:
один для пустого (nil) списка, другой для непустых списков.
«Базовый» случай прост:
------MakeTree( nil) <= empty ;
Если входной список не пуст и головой его является п, а хво-
стом rest, то требуемое дерево может быть построено путем
образования дерева из остатка входных данных и последующей
упорядоченной вставкой п в результирующее дерево. Для удоб-
ства определим вспомогательную функцию Insert, вставляющую
число в дерево таким образом, чтобы была сохранена упорядо-
ченность. Предлагается следующее объявление типа функции
Insert в соответствии с тем, выполнение какой операции от нее
требуется:
dec Insert: num # tree tree;
Теперь можно дополнить определение функции MakeTree:
------MakeTree( n :: rest) <= Insert( n, MakeTree( rest));
При определении Insert не следует забывать, что эта функ-
ция определена на дереве, следовательно, должно быть три пра-
вила, по одному на каждую из возможных конструкций дерева.
Вставка числа в пустое дерево означает построение новой вер-
шины-листа:
------Insert(n, empty )<= leaf(n);
Если дерево уже является листом, то формируем новую вер-
шину. Однако следует соблюдать правильную упорядоченность
48 Часть I. Глава 2
нового дерева:
------Insert(n, Oldleaf & leaf(m)) <==
if и = < m
then node(emply, n, Oldleaf)
else node(Oldleaf, n, empty);
Если же дерево уже является вершиной (т. е.1 используется
конструкция node), то новый элемент включается/либо в левое,
либо в правое поддерево в зависимости от значения величины
вершины:
------Insert(n, node(Ieft, value, right)) <=
if n—< value
then node( Insert(n, left), value, right)
else node( left, value, Insert(n, right));
Приведем пример работы функции Insert:
Insert(5, node( node( leaf( 1), 3, leaf(4)),
7,
leaf(9)))
->node( Insert(5, node( leaf( 1), 3, leaf(4)), 7, leaf(9)))
->node(node('leaf( 1), 3, Insert(5, leaf(4))), 7, Ieaf(9))
—» node( node( leaf( 1), 3, node(leaf( 4), 5, empty), 7, leaf(9)))
Теперь, выяснив, каким образом работает функция Insert,
можно рассмотреть и пример применения MakeTree:
МакеТгее([7, 5, 2])
-»Insert(7, МакеТгее([5, 2]))
—>Insert(7, Insert(5, MakeTree([2])))
->Insert(7, Insert(5, Insert(2, MakeTree(nil))))
— > Insert( 7, Insert(5, Insert(2, empty)))
~>Insert(7, Insert( 5, leaf(2)))
— >Insert(7, node(leaf(2), 5, empty))
- » node( leaf( 2), 5, Insert(7, empty))
- > node( leaf( 2), 5, leaf(7))
Для окончательного завершения программы осталось лишь
определить функцию Flatten (разглаживание). Поскольку функ-
ция Flatten имеет дело с деревьями, следует опять рассмотреть
три случая. Если дерево пусто, то результат принимает значение
nil:
Flatten( empty) < = nil;
В случае когда дерево состоит из листа, результатом будет яв-
ляться список из одного элемента:
Flatten( leaf(n)) <= [n];
Введение в функциональное программирование. Язык Норе 49
Если же' дерево является вершиной, то, поскольку оно упорядо-
чено, известно, что все элементы левого поддерева меньше значе-
ния величины вершины, а все элементы правого поддерева боль-
ше или ра^ны ей. Теперь представим это дерево в виде упоря-
доченного списка путем рекурсивного разглаживания левого и
правого поддеревьев и затем объединения результирующих спис-
ков с одновременной вставкой между ними значения вершины:
------Flatten^ node( left, value, right)) < =
Flatten( left) ( ) (value :: Flatter^ right));
Этим завершается определение функции Treesort,/но к ней мы
еще вернемся в следующей главе, где дадим ее обобщенный вид
для сортировки объектов произвольного типа.
Приведенные четыре примера должны продемонстрировать
особенности одного из стилей программирования на базе функ-
циональных языков, в данном случае—Норе, названного систе-
матической дефиницией функций, определенных на типах дан-
ных. Структура задачи моментально подсказывает структуру
решения, а структура типа данных — структуру каждой функ-
ции. Однако на базе функциональных языков существуют и дру-
гие стили программирования. Наиболае важные из них вклю-
чают в себя использования функций высшего порядка и «лени-
вого» вычисления. Эти особенности языка Норе будут рассмот-
рены в последних двух главах.
2.7 . Доказательства по индукции
Только что был приведен пример, показывающий, каким
образом пишутся рекурсивные программы для не очень сложной
задачи, причем программы обрабатывают смешанные типы дан-
ных простым написанием одного уравнения для каждой кон-
струкции аргумента типа данных. Завершим изложение этой
главы рассмотрением довольно мощной техники доказательств,
имеющей место в функциональных программах и основанной
на принципе математической индукции. Такая техника доказа-
тельств называется структурной индукцией, поскольку процесс
индукции проводится на синтаксической структуре функцио-
нального выражения.
Поясним эту концепцию в терминах простой индукции над
целыми числами, которая, вероятно, давно знакома большин-
ству читателей. Этот принцип утверждает, что можно устано-
вить некоторое именуемое предположением индукции свойство
Р(п) для всех неотрицательных чисел п, если мы сможем до-
казать справедливость Р(0) и, допустив существование P(k),
4 — 1473
50 Часть I. Глава 2
доказать Р(£-|-1) для всех целых чисел k 0. Это и назы-
вается принципом математической индукции. Простой иллю-
страцией этого примера может служить доказательство того,
что сумма S(n) от первых п чисел есть п(п-|-1)/2. В данном
случае для Р(п) мы имеем утверждение 'S(n) =1 п(п -)- 1)/2'.
Базовый случай имеет место тогда, когда п = 0,/ и не трудно
убедиться, что действительно S (0) = 0, следовательно, выраже-
ние Р(0) справедливо. Теперь, допустив существование P(k),
т. е. что 'S(fe) = k(k + 1)/2Z — истинны, имцем S(k-(- 1) =
= (Л+ 1) +S(fc) = (Л+ 1) + Л’(*Н-1)/2=(Лг+1) (Aj-}-2)/2, т. е.
Р (k + 1) истинно. Следовательно, использовав правило матема-
тической индукции, мы доказали, что Р(п) справедливо для
любых п.
Имеет место и аналогичный принцип индукции, утверждаю-
щий, что Р(п) истинно для всех неотрицательных целых п, если
Р(0) истинно и можно доказать Р(£) для любого k > 0, пред-
положив истинность Р(/), j < k. Это называется полной индук-
цией. Индукция работает на множестве неотрицательных чисел
Л3, поскольку Л3 можно определить следующими аксиомами:
(1) 0 содержится в Л3 («базовая» величина);
(2) если п е Л’, то succ (п) е Л3;
(3) в Л3 не существует никаких других элементов.
Заметим, что в отсутствие третьей аксиомы индукция не может
иметь места, поскольку, возможно, существуют еще какие-то
элементы п множества Л3, для которых Р(п) не будет рас-
смотрено.
Однако индукция отнюдь не ограничивается целыми чис-
лами: подобная техника, которая в общем случае называется
правильно обоснованной индукцией, применима к любому ин-
дуктивно заданному множеству с хорошо определенной упоря-
доченностью элементов. Так, определяя рекурсивный тип дан-
ных, например список в языке Норе, мы определяем именно
такое множество. Это множество, которое мы назовем D, удов-
летворяет трем приведенным выше аксиомам в обобщенной
форме — фиксированные конечные целые числа, 1
sC I п):
(1) нерекурсивные «базовые» выражения blt ..., bm имеют
тип D, каждое из них является применением конструктора;
(2) если синтаксические выражения d, имеют тип D, тогда
с,(., di, ..., dj(I), ...) имеют тип D, где сг является кон-
структором D, т. е. функцией от каждого
(3) в D не существует никаких других элементов.
Введение в функциональное программирование. Язык Норе 51
Правильно обоснованная индукция в применении к утверж-
дениям на множестве D означает, что 'P(d) справедливо для
всех d типа D, если Р(Ьк) истинно для 1 k т, и что для
1 i п, предположив истинность P(d)) для l^j^J(i),
можно доказать Р(с>(.di, d;(t>, Этот принцип на-
зывается структурной индукцией. Базовые типы Ь\, ..., bm
часто могут являться конструкторами с отсутствующими аргу-
ментами, например nil в случае со списками, но в общем слу-
чае они могут быть и конструкторами, применимыми к другим
типам, отличным от D, если так, то этап базового случая в лю-
бом индуктивном доказательстве будет более сложным.
Структурную индукцию можно применять для доказатель-
ства многих свойств рекурсивно-определенных функций, и, хотя
способы доказательств не являются центральной темой книги,
структурной индукцией мы будем пользоваться и в некоторых
последующих главах. На самом же деле доказательства по
индукции идут бок о бок с рекурсивными функциями: когда
для написания программы используется рекурсия, то для обо-
снования ее свойств следует применять индукцию.
Для того чтобы дать читателю возможность увидеть осо-
бенность типа доказательства при конструктивном использо-
вании подобной техники, покажем, что функция Join:
------Join(nil, L)<=L;
------Join(x::y, L ) <= x :: Join( у, L);
с которой мы уже раньше имели дело, является ассоциативной
функцией, т. е.
Join(Join(x, у), z) = Join(x, Join(y, z))
для любых списков х, у, z.
Приведем доказательство, используя структурную индукцию
для х. Рассмотрение начнем с базового случая. Когда х — nil,
то Join(Jom(nil, у), z) =Join(y, z) ==Join(x, Join(y, z)) спра-
ведливо для любых списков у, z.
Предположим, что Join (Join (и, у), z) = Join (и, Join (у, z))
для всех списков и, у, z. Теперь для произвольного элемента
списка а имеем
Join( Join( а :: и, у), z) = Join(а :: Join(u, у), z) — по определению
Join;
— а :: Join( Join( u, у), z ) — аналогично;
= a :: Join( u, Join( y, z)) — по предположе-
нию индукции;
— Join( a :: u, Join( y, z)) — по определению
Join.
4*
52 Часть I. Глава 2
Итак, с помощью структурной индукции доказано, что функ-
ция Join является ассоциативной.
Резюме
• Норе является примером чисто функционального языка.
• Норе — строго типизированный язык.
• Существует несколько предварительно определенных базо-
вых типов и примитивных функций, из которых можно состав-
лять другие типы и функции.
• Вычисления, основанные на повторении, выражаются функ-
ционально с использованием рекурсии.
• Рекурсия является мощным и абстрактным средством реше-
ния задач.
• Для обеспечения удобства чтения программы, чтобы избе-
жать повторов при вычислении, выражениям могут быть при-
своены различные имена.
• Можно'вводить новые типы данных, определенные в терми-
нах функций-конструкторов.
• Типы данных и функции обладают свойством полиморфизма.
• Определение рекурсивных функций на типах данных являет-
ся простым, систематическим и мощным.
• Сопоставление с образцом упрощает определение функции
и дает возможность декомпозировать структуры данных на со-
ставные части.
• Структурная индукция может быть использована для дока-
зательства свойств функций на рекурсивных типах данных.
Упражнения
2.1. а. Определить функцию convert типа num num, переводя-
щую число из десятичной системы счисления в двоичную. На-
пример, применяя convert к числу 27, получим 11011.
б. Записать функцию sum типа num #= num -+ num, которая
к двоичному числу, полученному в предыдущем задании, при-
бавляет точно такое же двоичное число.
2.2. Дана функция, суммирующая элементы заданного списка
чисел:
dec sum : list( num) —> num;
------sum(nil-) < = 0;
------sum( x :: 1) <= x + sum( 1);
Определить эквивалентную функцию, использующую накапли-
вающий параметр для подсчета суммы. Уменьшилась ли при
этом алгоритмическая сложность функции?
Введение в функциональное программирование. Язык Норе 53
2.3. Рассмотрим некий «мешок» *>, который по сути своей подо-
бен множеству, за исключением лишь того, что данный элемент
может встречаться в нем более одного раза. Представим мешок
в виде списка пар, где каждая пара состоит из элемента и
числа, определяющего, сколько раз данный элемент встречается
в мешке. Следует написать полиморфное определение типа для
подобного мешка совместно с функциями: add — для добавле-
ния элемента в данный мешок, remove — й качестве результата,
выдающего произвольный элемент мешка совместно с самим
мешком, из которого данный элемент уже удален; Isempty —
возвращающая значение true, если данный мешок пуст. В тер-
минах add определить функцию union для мешков.
2.4. Написать объявление и определение функции search, про-
сматривающей часть текста в поисках заданной строки (когда
строка встречается впервые) и возвращающей значение либо О,
если строка в тексте отсутствует, либо п, если строка встре-
чается в тексте, начиная с позиции n-го символа. Предпола-
гается, что текст является списком символов. Например, для
заданного текста ’’Hence home you idle creatures” и искомой
строки ”eat” функция выдает значение 23.
2.5. Сортировка вставкой является алгоритмом сортировки, ко-
торый из входного списка порождает отсортированный путем
повторной вставки элементов исходного списка на правильные
позиции в частично отсортированный список. Для того чтобы
показать пример работы алгоритма, возьмем исходный список
вида [4, 1, 5, 3]:
Исходный список Отсортированный (частично)
4, 1, 5, 3 ] [ ]
1, 5, 3] [4]
5, 3] [ 1, 4]
3] 1, 4, 5]
1 [ 1, 3, 4, 5]
Результат = [ 1, 3, 4, 5 ].
Реализовать сортировку вставкой как функцию языка Норе.
2.6. Направленный граф есть сеть, состоящая из вершин, со-
единенных однонаправленными дугами. Каким образом можно
задать направлений граф в языке Норе?
Определить функцию pathlength, исходными даными которой
являются граф и две его вершины, а выходными либо мини-
мальное число дуг, которые необходимо пройти для того, чтобы
попасть из одной вершины в другую, либо 0, если между этими
вершинами не существует пути.
*> Далее термин «мешок» (bag) даем без кавычек. — Прим. ред.
54 Часть I. Глава 2
2.7. Предположим, что в Норе не существует встроенного типа
truval. Каким образом данные этого типа можно представить
в виде типов данных, определяемых пользователем? Для вы-
бранного представления написать объявления и определения
инфиксных логических функций: and, or и not.
2.8. а. Требуется создать базу данных штата сотрудников уни-
верситета, где для административных и организационных целей
на каждого сотрудника были бы заведены определенные дан-
ные. Есть два типа сотрудников: преподаватели и обслужи-
вающий персонал. Для обоих типов необходимо хранить сле-
дующие записи: фамилия, пол, дата рождения, дата зачисления
в университет и домашний адрес. Каждый сотрудник из штата
преподавателей принимает участие в одной 'из трех кафедраль-
ных секций: системы, математическое обеспечение, теория. Их
записи в базе данных помимо уже приведенной информации
включают также секцию преподавателя и список курсов, кото-
рые он ведет в настоящее время (каждый курс имеет свой соб-
ственный номер). Каждый сотрудник из обслуживающего
персонала принадлежит либо секретарскому штату, либо обслу-
живает компьютеры, либо занимается каким-то материально-
техническим обеспечением. Их записи в базе данных кроме уже
заданной информации включают и эту классификацию. Пред-
ложить возможный вариант этой базы данных на языке Норе,
написать требуемые определения type и data.
б. Определить Hope-функцию для каждого следующего
случая:
1) подсчитать общее количество преподавателей и обслуживаю-
щего персонала в базе данных;
2) получить фамилию сотрудника, преподающего заданный
курс;
3) вычислить отношение количества тех, кто обслуживает ком-
пьютеры, к числу тех, кто занимается материально-техническим
обеспечением.
2.9. С помощью структурной индукции докажите, что сложение,
определенное на множестве натуральных чисел следующими
соотношениями:
data nat == zero -|—Н succ( nat);
dec add : nat#nat-+nat;
-----add(n, zero)<=n;
-----—add(n, succ( m)) <— succ(add(n, m));
ассоциативно и коммутативно. (Подсказка: для выполнения
коммутативности надо показать, что add (n, succ( m )) =
== add ( succ (n ), m ) для любых n, m типа nat.)
Глава 3
ФУНКЦИИ ВЫСШЕГО ПОРЯДКА
Описанные ранее свойства языка Норе дают возможность
определять произвольные .структуры данных и произвольные
функции для обработки этих структур. Мы уже увидели, каким
образом Норе обеспечивает простое и абстрактное описание
данных, а также механический способ структурирования функ-
ций, оперирующих с этими данными. Такие характерные осо-
бенности приводят к стилю программирования, основанному на
определении функции с помощью указания каждого возмож-
ного образца аргумента данных.
В этой главе будет рассмотрено еще одно важное средство
функциональных языков, а именно функции высшего порядка.
В ранее приведенных примерах каждая функция рассматрива-
лась как статическая часть кода для преобразования входных
величин в выходные, т. е. по существу мы описывали подмноже-
ство первого порядка языка Норе. Концепция функций высшего
порядка возникает из идеи о том, что функции должны иметь
тот же статус, что и любой объект данных, так чтобы они сами
могли быть входными и выходными данными других функций.
В этой главе будет показано, Каким образом эта способность
может быть использована для представления общих образцов
рекурсии и, следовательно, для выражения рекурсивных функ-
ций через нерекурсивное применение функций высшего порядка.
Подобная техника приводит к очень сжатым и абстрактным
программам, которые часто просто удивительно коротки по
сравнению со сложностью выполняемых ими вычислений. Мы
рассмотрим также определенный стиль программирования, осно-
ванный на использовании функций высшего порядка, и не-
сколько. примеров, иллюстрирующих его применение на прак-
тике.
56 Часть I. Глава 3
3.1. Примеры рекурсии
Рассмотрим следующие функции языка Норе:
dec IncList: 1 ist( num) -> 1 ist( num);
------IncList( nil) <= nil;
----— IncList( x :: 1) <= (x -j- 1):: IncList( 1);
dec MakeStrings list( char) —> list( list( char));
------MakeStrings( nil) <= nil;
------MakeStrings( c :: 1) <= [ c] :: MakeStrings( 1);
Хотя эти функции и неодинаковы, поскольку выполняют раз-
личные операции над списками разных типов, они, однако,
сходны в том, что над каждым элементом списка выполняется
только одна операция. Первая функция увеличивает на единицу
каждый элемент в списке чисел, а вторая отображает каждый
элемент списка символов в список из одного элемента. Говорят,
что «тип рекурсии» в обоих случаях одинаков.
В функциональном языке этот тип рекурсии можно выра-
зить, используя функции высшего порядка. Функция высшего
порядка — это функция, которая может использовать в качестве
аргумента другую функцию либо результатом ее выполнения
является некая функция. Если быть более точным, то функция
первого порядка имеет тип А^В, где в выражениях А и В нет
стрелок. Таким образом, можно сказать, что функция высшего
порядка — это любая функция, не являющаяся функцией пер-
вого порядка.
В обоих вышеприведенных примерах функция применяется
к каждому элементу заданного списка.
В IncList она имеет следующее определяющее уравнение:
------1пс(п) <= п + 1 ;
в то время как для MakeStrings уравнение функции имеет вид
------Listifу( с) < = [с];
(с соответствующими объявлениями типа). Можно выявить об-
щую структуру таких функций, как MakeStrings и IncList,
определив функцию высшего порядка, которая, используя функ-
ции типа Listify или Inc в качестве аргумента, применяет их
к каждому элементу заданного списка, выступающему в роли
второго аргумента. Подобная функция высшего порядка ши-
роко используется и часто называется тар для отражения того
факта, что она отображает каждый элемент списка. Поскольку
мы не знаем наперед тип применяемой функции или тип обра-
батываемых элементов списка, то тар должна быть объявлена
Функции высшего порядка 57
полиморфной функцией. Полное ее определение выглядит так:
dec map : ( alpha —> beta ) ф list( alpha ) —> list( beta);
------map(f, nil) <=nil;
------map(f, x :: 1) <= f( x):: map(f, 1);
Теперь, используя map и вспомогательные функции Inc и Li-
stify, введенные ранее, можно выразить IncList и MakeString:
IncList( L ) map( Inc, L)
MakeString ( L) = map( Listify, L)
Удобство того, что для отображения списка предварительно
были определены функции Inc и Listify, очевидно. Однако яв-
ное определение подобных функций может быть довольно не-
удобно, в особенности если отображающая функция проста,
как, например, обе функции в нашем случае, и больше,нигде
в программе не используется — ведь нам придется и объявлять
эти функции, и определять их правила работы. К счастью, язык
Норе дает возможность записывать выражение (именуемое
лямбда-выражением), значением которого является функция,
позволяющая непосредственно выражать Inc и Listify. Напри-
мер, Inc будет описана так:
lambda х => х + 1
(Значение заранее определенного слова lambda будет конкре-
тизировано в гл. 6.) Запись станет понятна, если читать lambda
как «функция от...», а =$--как «..., которая выдает резуль-
тат...». Таким образом, в общем виде функция f, определяемая
уравнением:
------f(x)<=E;
где f не встречается в Е, эквивалентно' может быть представ-
лена как лямбда-выражение:
lambda х => Е
Покажем теперь применение функции IncList, используя тар
и лямбда-выражение:
IncList( L) тар( lambda х => х + 1, L)
и, аналогично, для MakeStr'ngs:
MakeStrings(L) тар(lambda с=> [с], L)
Тело лямбда-выражения может быть произвольным выраже-
нием, однако не следует забывать, что выражение подобного
типа, не может быть рекурсивным, поскольку не существует
58 Часть I. Глава 3
такого связанного с функцией имени, на которое можно было бы
ссылаться. Этого неудобства можно избежать, используя вне
lambda-утверждения операторы let или where. Let и where вво-
дят имя, которое, если это необходимо, может быть использо-
вано внутри выражения, определяющего это имя. Так, функ-
ция f, заданная в виде
fA <==... f ... ;
где А — произвольный образец, может быть представлена с ис-
пользованием let или where:
let f == lambda A => ... f ... in Ef
или
Ef where f == lambda A ==> ... f ...
Здесь Ef — некоторое выражение, содержащее f. Например:
let f == lambda x => if x = 0 then 0 else x + f( x — 1)
in f(3)
подсчитывает сумму первых трех целых чисел; т. е. 3 + 2 + 1 +
+ 0 = 6. Выражения let или where, задающие рекурсивную
функцию, часто называются рекурсивными let- или рекурсив-
ными where-выражениями. В некоторых языках рекурсивные
1е1;Выражения отличаются от нерекурсивных использованием
отдельного ключевого слова, такого, как letrec или whererec.
Пример такого языка будет дан в гл. 5.
В языке Норе лямбда-выражение может также содержать
включенные правила (т. е. включенные образцы), разделенные
символом |. Например, функция IsEmpty, определенная как
-----IsEmpty(nil) <= true;
-----IsEmpty( — ) <= false ;
мол^ет быть записана через лямбда-выражение:
lambda nil — > true | — => false
Другой пример — выражение
map( lambda nil =>"?" | h :: — => "Head is"( )[h],
["Monsters", nil, nil, "from", nil, "the", "Id"])
порождает список строк
["Head is M", "?", "?", "Head is f", "?", "Head is t", "Head is 1"]
Функции высшего порядка 59
а выражение
map( lambda с:: — => с, SplitUpf
"Time and relative dimension in space"))
(где функция SplitUp определена в предыдущей главе) выдает
строку "Tardis".
Функция тар имеет также свойство восстанавливать оригиналь-
ный список, в котором каждый элемент трансформируется в со-
ответствии с отображающей функцией. Однако иногда требует-
ся «уменьшить» список до какой-то иной величины, например
числа, являющегося либо длиной списка, либо максимальной,
величиной из списка. Подобный тип рекурсивной функции также
можно описать в терминах функций высшего порядка:
dec reduce : ( alpha =#= beta —> beta ) # beta # list( alpha ) —> beta ;
-------reduce(f, b, nil)< = b;
-------reduce( f, b, x ::!)<== f(x, reduceff, b, 1));
Для того чтобы посмотреть, как работает эта функция, отметим,
что выражение
reduce(f, b, [еь е2, ...,еп])
эквивалентно выражению
f(eb f(e2, ... f(en, b) ...))
где b — «базовая», т. е. полученная при редуцировании пустого
списка величина. Большое число сложных операций обработки
списков можно выразить с помощью функции reduce при соот-
ветствующей функции f и базовой величине Ь. Для наглядности
обратимся к простому выражению, подсчитывающему сумму
элементов списка чисел, обозначаемого буквой L:
reduce(+, О, L)
(Следует отметить, что, хотя reduce допускает только префикс-
ные функции, + является инфиксной функцией. Однако если
инфиксная функция встречается в виде параметра, она автома-
тически преобразуется в эквивалентную префиксную форму.)
Рассмотрим пример работы reduce на последовательности
вычислений для L = [l,3, 5] (префиксная функция + записы-
60 Часть I. Глава 3
вается как <+>):
reduce(+, 0, [1, 3, 5])
= reduce(+, 0, 1 :: (3 :: (5 :: nil)))
- >( + )(!, reduce(+, 0, 3 :: (5 :: nil)))
— ( + )(3, reduce(+, 0, 5::nil)))
- *< + >( 1, < + >(3, < + >(5, reduce(+, 0, nil))))
- >< + >( 1, < + >(3, ( + >(5, 0)))
->9
Аналогично работает и выражение
reduce( *, 1, L)
вычисляющее результат для списка чисел L (здесь базовым слу-
чаем является 1 — тождественный элемент для *). Вот еще не-
сколько примеров, демонстрирующих возможности и гибкость
функции reduce:
(1) Используя функцию шах из предыдущей главы, вычис-
лить максимум списка L неотрицательных чисел:
reduce(max, 0, L)
(2) Найти, какое количество людей имеет имя "Spock"
в списке L имен:
reduce(lambda (name, sum)=>
sum + (if name = "Spock" then 1 else 0), 0, L)
(3) Поиск в списке: результат есть true, если el принадле-
жит списку, false — в противном случае:
reduce(lambda (next, isthere)=>
if isthere then true else( next — el), false, L)’
(4) Функция MakeTree из примера Treesort, показанная в
предыдущей главе. Из списка чисел L порождается дерево:
reduce( Insert, empty, L)
(5) Функция индентичности списков:
reduce(::, nil, L)
Отметим, что в последнем примере конструктор :: выступает
в роли аргумента reduce. Это довольно удобно, поскольку кон-
структор ведет себя точно так же, как любая другая функция,
за исключением того, что он не имеет никаких правил.
Функции высшего порядка 61
3.2. Связывание
Важно не забывать, что величины переменных в лямбда-вы-
ражении устанавливаются тогда, когда выражение определяет-
ся, а не тогда, когда оно используется. Например, если пишется,
что
let х==1 in (let f ===== lambda y = >
x + у in (let x===2 in f(x)))
то в записи x + у переменная х имеет значение, равное 1, т. е.
значение переменной х в точке определения функции f. Это на-
зывается статическим связыванием. Есть языки (например, не-
которые диалекты языка Лисп), пользующиеся динамическим
связыванием, при котором определение переменных в лямбда-
выражении происходит в процессе его использования. Если бы
в Норе применялось динамическое связывание, то значение х
при вычислении х + у в нашем примере было бы равно 2 (т. к.
х равно 2 при использовании f). Первоначальное значение х
в данном случае теряется.
В общем случае динамическое связывание считается непри-
емлемым, поскольку значение функции может меняться в зави-
симости от контекста, в котором она используется. Это озна-
чает, что при вызове одной и той же функции можно получать
различные ответы, что противоречит идее функциональности.
Для устранения этой проблемы все современные функциональ-
ные языки используют статическое связывание. В гл. 9 мы еще
вернемся к свойствам, вытекающим из связывания, 'и увидим,
каким образом осуществляется статическое связывание в ин-
терпретаторе функционального языка.
3.3. Другие примеры рекурсии
Как уже было показано, функции высшего порядка направ-
лены на создание рекурсивной структуры, общей для многих
функций, имеющих дело со списками. Тем не менее можно опре-
делить такие типы данных произвольной сложности, для кото-
рых функции типа тар и reduce не являются функциями «аб-
страктной рекурсии». Однако нет никаких причин, запрещаю-
щих связывать различные функции высшего порядка с этими
типами данных для образования структур многих рекурсивных
функций, определенных на них. В качестве простого примера
рассмотрим, каким образом можно описать уже известную нам
функцию обработки дерева, используя эквиваленты тар и re-
duce, определенные для списков. Подобный подход может быть
62 Часть I. Глава 3
с успехом использован и для других типов, определенных поль-
зователем.
Для общности предположим наличие полиморфного опреде-
ления деревьев, в котором объекты, включенные в дерево, мо-
гут быть произвольного типа alpha. Также для простоты усло-
вимся рассматривать лишь деревья, построенные из пустых
деревьев и внутренних вершин (иначе говоря, опустим конструк-
тор leaf, представленный в программе Treesort предыдущей гла-
вы). Итак, определение данных будет выглядеть следующим
образом
data tree( alpha) —— empty ++ node( tree( alpha ) # alpha #
# tree( alpha ));
Можно создать обобщенную функцию, которая бы применяла
данную функцию к каждому элементу (типа alpha) в дереве,
т е. функцию высшего порядка МарТгее, являющуюся очевид-
ным расширением тар, определенным для списков:
dec МарТгее ( alpha -> beta ) # tree( alpha ) -> tree( beta );
------MapTree(f, empty) < = empty ;
------MapTree(f, node(left, value, right)) < =
node( MapTree( f, left), f( value), MapTree(f, right));
Теперь, например, мы можем увеличить на единицу каждый
элемент в дереве чисел Т:
МарТгее (lambda х=>х + 1, Т)
Эквивалент функции reduce для списков более интересен, по-
скольку теперь уже известно несколько способов рассечения де-
рева. Например, имеется возможность независимо друг от друга
редуцировать оба поддерева и затем применить функцию к ре-
зультатам:
dec TreeReduce : ( alpha # beta # beta + beta ) =#= beta #
# tree( alpha ) —> beta ;
------TreeReduce( f, b, empty )<=b;
------TreeReduce( f, b, node( left, value, right ))< =
Rvalue, TreeReduce(f, b, left), TreeReduce(f, b, right));
Так что, например:
TreeReduce( lambda (v, rl, r2 ) => rl ( ) (v :: r2 ), nil, T)
приводит к разглаживанию. дерева Т способом, описанным в
гл. 2, и
TreeReduce(lambda (v, rl, r2)—>max(v, max(rl, r2)), О, T);
Функции высшего порядка 63
вычисляет наибольшее число в дереве неотрицательных целых
чисел. Мы можем, однако, определить и такую форму reduce,
которая, используя результат редуцирования правого поддерева
в качестве «базового» случая, редуцирует левое поддерево:
dec TreeReduce3 : (-alpha # beta -> beta ) # beta # tree( alpha ) -►
—» beta ;
------TreeReduce3( f, b, empty )<=b;
------TreeReduce3( f, b, node(left, value, right ))< =
TreeReduce3( f, f( value, TreeReduce3( f, b, right)), left);
Отметим, что теперь требуется, чтобы параметр функции f был
функцией от двух аргументов Используя такую форму reduce,
можно переписать представленное ранее выражение для вычис-
ления максимального числа в дереве Т:
TreeReduce2( max, О, Т)
Дадим еще один вариант, в котором вызов f помещен в другое
место программы:
dec TreeReduce2 : ( alpha # beta beta) # beta # tree( alpha )->
-* beta ;
------TreeReduce2( f, b, empty) <=b;
------TreeReduce2( f, b, node( left, value, right)) < =
Rvalue, TreeReduce2(f, TreeReduce2(f, b, right), left));
Используя такое определение, мы можем осуществить разгла-
живание дерева без использования append:
TreeReduce3(::, nil, Т)
Проницательный читатель может заметить, что это выражение
эффективно разглаживает дерево при использовании «базовой»
величины в качестве накапливающего параметра. Аналогично
тому, как использование накапливающего параметра уменьшает
сложность функции Reverse, приведенной в гл. 2, от квадратич-
ной до линейной, также уменьшается и число вызовов : : от
О(п2) до О(п), где п — число элементов в дереве. Есть и другие
варианты функции reduce, отражающие различные способы
разбиения бинарного дерева.
Итак, путем определения небольшого набора функций выс-
шего порядка для обработки каждого типа данных можно избе-
жать написания многих явных рекурсивных функций для этого
типа, используемых вместо функций высшего порядка с соот-
ветствующими параметрами. В этом смысле данный способ срав-
ним с техникой полиморфизма: полиморфный тип данных дает
возможность описывать структуры с подобной общей формой
64 Часть I. Глава 3
в виде единственного определения; функции высшего порядка
позволяют описывать рекурсивные функции с подобной общей
структурой в виде единственной функции.
3.4. Пример применения
Для иллюстрации использования функций высшего порядка
на практике рассмотрим простую задачу текстовой обработки
и покажем, каким образом подобные функции могут быть ис-
пользованы для представления решения задач в очень кратком
и абстрактном виде. Проблема, которую предстоит рассмотреть,
связана с образованием списка счетчиков слов из текстового
файла. Предполагается, что текст состоит из некоторого количе-
ства слов и каждому слову в тексте сопоставлено целое число,
соответствующее тому, сколько раз данное слово встречается
в тексте. Результатом будет являться список пар вида
(word, count)
где count — это число встречающихся слов word в тексте. После
завершения написания этой программы мы увидим, каким об-
разом Treesort, представленная в предыдущей главе, может
быть расширена для сортировки подобных пар различным об-
разом путем трансформации ее в функцию высшего порядка.
Итак, пусть исходный текст составляют предложения, раз-
деленные точками, а каждое предложение есть совокупность
слов, разделенных одним или несколькими пробелами. Для про-
стоты определим слово как любую последовательность симво-
лов, исключая пробелы и точки. Например, преобразуем задан-
ный текст
"Hi said Bill. Hi said Ben."
в вид
[("Hi", 2), ("said", 2), ("Bill", 1), ("Ben", 1)]
Прибегнем к помощи функции, введенной в разд. 2.6.1, и
к тем определениям функций тар и reduce, которые были даны
ранее.
3.4.1. Подсчет слов
Вначале необходимо разбить предложения на составляющие
его слова. Однако нельзя сразу же применять функцию SplitUp,
поскольку текст содержит точки, которые разделяют предложе-
ния и не могут быть обработаны с помощью SplitUp. Прежде
чем применить к тексту функцию тар, следует заменить все
Функции высшего порядка 65
точки на пробелы (т. е. везде, где встречается символ «точка»,
надо поставить символ «пробел», а не удалять и то и другое,
чтобы не возникла ситуация, когда последнее слово одного
предложения слилось бы с первым словом следующего предло-
жения) :
map(lambda с => if с = '-' then ' ' else с, Text)
где Text — это обрабатываемый текст. Для разделения текста
после удаления точек можно применить функцию SplitUp:
SplitUp(map(lambda c=> if c = '-' then ' ' else c, Text))
Теперь можно приступать к построению требуемого списка
пар (слово, число его употреблений в тексте). Итак, начнем со
списка nil, в дальнейшем преобразуя список всякий раз, когда
в тексте встречается новое слово. Например, если список содер-
жит пары
[("the", 1), ("day", 1), ("of", 1)]
а следующее слово во входном тексте — "the", то новый список
принимает вид
[("the", 2), ("day", 1), ("of", 1)]
Если очередное слово в списке еще не содержится, то появ-
ляется новая пара с начальным значением 1. Например, если
в указанном тексте после "the" идет слово "jackal", то список
будет выглядеть так:
[("the", 2), ("day", 1), ("of", 1), ("jackal", 1)]
Определим отдельную функцию Update, выполняющую такую
операцию преобразования списка, которая сделает окончатель-
ный вариант программы более удобным для чтения:
type word == list( char);
dec Update : word # list (word # num) -> list (word # num);
------Update(w, nil)<=[(w, 1)];
------Update(w, ( Entry &( Word, Count)):: Rest) <=
if w = Word
then (Word, Count + 1):: Rest
else Entry :: Update(w, Rest);
Однако при таком варианте необходимо вызывать функцию
Update для каждого слова, встречаемого в тексте. Очевидно, что
этого неудобства можно избежать «уменьшением» списка слов
во входном тексте, используя функцию Update:
reduce(Update, nil, Wordlist)
5 — 1473
66 Часть 1. Глава 3
Таким образом, строится выражение
Update(wb Update(w2, Update(w3, ..., Update( wn, nil)...)))
где w, (1 i n) — слова-компоненты в Wordlist.
Теперь, после того как все объединено, можно определить
и окончательную функцию WCount, порождающую счетчик слов
из текстового файла. Обратим внимание на использование пред-
варительно определенной функции fromfile, которая, получив
имя файла в виде списка символов, возвращает содержимое
этого файла также в виде списка символов:
type filename ===== list( char );
dec WCount: filename -> 1 ist( word =#• num);
------WCount( name )<= reduce( Update, nil, Wordlist)
where Wordlist ===== SplitUp( map( RemoveStop,
fromfile(name)))
where RemoveStop ===== lambda c => if c =
' ' then ' ' else c;
Для демонстрации работы программы предположим, что
файл sample содержит текст
the dog and the cat
Выражение input (sample) выдает содержимое файла sample
в виде списка символов; результатом применения функции
RemoveStop к каждому элементу этого списка является анало-
гичный список с удаленными символами точек, находящихся
в конце предложения; вызов функции SplitUp порождает спи-
сок слов:
["the", "dog", "and", "the", "cat"]
В итоге, применение Update при базовом случае nil обраба-
тывает это выражение так:
Update( "the", Update( "dog", Update( "and",
Update("the", Update("cat", nil)))))
= [("cat", 1), ("the", 2), ("and", 1), ("dog", 1)]
что и требовалось.
3.4.2. Классификация выходных данных
Было бы замечательно, если, подсчитав сколько раз каждое
слово встречается в исходном тексте, можно было бы провести
сортировку, основанную либо на частоте встреч (наиболее ча-
сто встречающееся слово на первом месте), либо на текстовом
Функции высшего порядка 67
порядке слов. Для решения этой задачи можно использовать
программу Treesort, представленную в гл. 2, но, к сожалению,
она определена таким образом, что может быть применима лишь
для целых чисел; в данном случае желательно сортировать
списки пар. Для того чтобы использовать Treesort, необходимо
модифицировать эту программу для работы с более общими ти-
пами объектов.
Если обратиться к первоначальному варианту Treesort, то
видно, что упорядочивание элементов в промежуточном дереве
проводилось с помощью примитивного оператора =<. С его
помощью функция Insert обеспечивает то, что все элементы в
левом поддереве данной вершины меньше или равны элементам
правого поддерева. Однако Treesort можно сделать более силь-
ной, если параметризировать ее этой упорядочивающей функ-
цией. Тогда Treesort станет не только функцией высшего по-
рядка, но также и полиморфной, поскольку с ее помощью можно
будет сортировать объекты любого типа, если им присуще свой-
ство упорядоченности. Изменения, которые необходимо для
этого провести, очевидны. Сначала следует сделать тип данных
tree и соответствующие функции полиморфными, затем в виде
параметра добавить упорядочивающую функцию к Treesort,
MakeTree и Insert и, наконец, заменить ссылки на примитив
= < в Insert на этот новый параметр-функцию.
dec Treesort: list( alpha) # Ordering —> list( alpha);
dec MakeTree : list( alpha ) #• Ordering —> tree( alpha );
dec Insert: alpha # tree( alpha) # Ordering —> tree( alpha);
------Treesort( UnsortedList, TestFun) < =
Flatten( MakeTree( UnsortedList, TestFun));
—-----MakeTree(-List, f)< =
reduce) lambda (n, t) => Insert(n, t, f), empty, List);
—-----Insert(n, empty, —)<=leaf(n);
------Insert) n, OldLeaf & leaf) m), f)<=>
if f( n, m)
then node(empty, n, OldLeaf)
else node(OldLeaf, n, empty);
------Insert(n, node(left, value, right), f)<=
if f(n, value)
then node) Insert) p, left, f), value, right)
else node(left, value, Insert(n, right, f));
(Новая упорядочивающая функция не повлияла на определение
Flatten.)
Функцию Treesort можно заставить вести себя так же, как
и раньше, если употребить в ней первоначальную функцию
68 Часть I. Глава 3
упорядочивания, т. е. =<. Например, выражение вида
Treesort([5, 3, 4, 7, 2, 3], =<)
как и прежде, выдает отсортированный список [2, 3, 3, 4, 5, 7].
Однако эту функцию можно теперь использовать и для сорти-
ровки пар «слово — счетчик». Если потребуется отсортировать
пары по частоте появления слов, то упорядочивающая функция
будет основываться на сравнении счетчиков частоты. Вид этой
функции таков:
lambda((—, cl), (—, с2))=> (cl >=с2)
Если необходимо отсортировать пары в алфавитном порядке,
то надо сравнивать строки слов, и в данном случае упорядочи-
вающая функция будет выглядеть так:
lambda((wl, —), (w2, —))=> StringLessEq(wl, w2)
где StringLessEq — функция «меньше-или-равно», (оперирую-
щая со строками), которая определяется достаточно просто как
рекурсивная функция, работающая со списками.
Итак, например, если надо упорядочить по частоте уже из-
вестный список слов из текстового файла "sample", то
Treesort( WCount( "sample"), OrderingFunction)
where OrderingFunction ==lambda((—, cl), ( —, c2))=>
(cl >=c2)
в результате чего будет получен требуемый упорядоченный
список вида
= [("the", 2), ("dog", 1), ("and", 1), ("cat", 1)]
Надо отметить, что существует еще один подход к процессу
сортировки результирующего списка, заключающийся в такой
модификации функции Update, при которой промежуточные спи-
ски счетчиков слов располагались бы в необходимом порядке.
Такую операцию можно осуществить хотя бы путем помещения
пар (слово, число) в отсортированное дерево, которое затем
разглаживается и принимает вид упорядоченного списка; при
этом уменьшается сложность алгоритма. Здесь же, однако,
была поставлена цель найти простое и четкое решение задачи
путем разделения операций генерации и сортировки соответ-
ствующего списка слов. И уже затем, найдя такое решение, если
это требуется, можно заняться оптимизацией программы —
в идеальном случае это было бы сделано компилятором, что бу-
дет продемонстрировано в части III этой книги. Альтернативное
Функции высшего порядка 69
решение данной задачи, о котором тут было упомянуто, остав-
лено в качестве упражнения для читателя.
Итак, закончено обсуждение, функций высшего порядка и
приемов программирования этих функций. Следует отметить, что
в Норе, как и в большинстве функциональных языков, не суще-
ствует ограничений на количество и сложность подобных функ-
ций. Однако в гл. 5 будет рассмотрен функциональный язык FP,
в котором нет средств для определения пользователем функций
высшего порядка. Вместо этого язык обеспечен небольшим на-
бором встроенных функций высшего порядка, которые рассмат-
риваются как программно-встроенные блоки типа let, where,
условные выражения и др., которые в языке Норе обеспечивают
построение программных блоков.
Мы увидим также, каким образом многие рекурсивные про-
граммы могут быть переписаны в нерекурсивном виде, исполь-
зуя предварительно определенные функции высшего порядка.
В гл. 5 будет описан язык Miranda, где осуществлен совер-
шенно иной подход к функциям высшего порядка. В Норе объ-
ект, значением которого является функция, явно порождается
при помощи лямбда-выражения; в Miranda же нет механизма
для явного определения лямбда-выражения, функциональные
объекты в нем генерируются частичным применением суще-
ствующих функций. Для иллюстрации подобного подхода в
гл. 5 будет приведено несколько примеров.
Резюме
• Функции могут рассматриваться как объекты первого класса.
• Функции, которые в качестве параметров используют другие
функции или же возвращают их как результат своей работы,
называются функциями высшего порядка.
• Функции высшего порядка используются для описания общих
видов рекурсии.
• Применение функций высшего порядка часто приводит
к очень кратким и абстрактным программам.
• Отдельные функции высшего порядка могут соответствовать
всем типам данных.
• Многие функциональные языки статически связывают пере-
менные в телах функций.
• Многие функции, например обеспечивающие сортировку,
можно обобщить, используя функции высшего порядка.
Упражнения
3.1. Определите тар и <> в терминах функции reduce.
3.2. Предположим, что было выполнено несколько булевых
тестов, результаты которых хранятся в виде списка булевых
70 Часть I. Глава 3
величин. Используя функцию reduce, напишите отдельное выра-
жение, которое:
а) возвращает true, если по крайней мере один из тестов
выполняется (т. е. результатом его является true), и
false — если не выполняется ни один из них;
б) возвращает true, если выполняются все тесты, false —
если один из них не выполняется.
3.3. На языке Норе определите функцию одного параметра п,
генерирующую список длины п, где i-й элемент в списке есть
функция одного аргумента, которая при применении добав-
ляет i к заданному числу.
3.4. а. Определите compose-функцию высшего порядка, кото-
рая возвращает композицию двух заданных функций, являю-
щихся ее аргументами.
б. Напишите выражение, которое определяет функцию Tree-
sort в терминах compose, Fllatten и Maketree.
в. Пусть задан список функций F = [fi,f2, ..., fn], каждая
типа (alpha —> alpha); используя функции compose и reduce,
напишите на языке Норе выражение С такое, что
C(F)(x) = fi(f2( ... (fn(x)) ... ))
3.5. Рассмотрим на языке Норе следующую инфиксную
функцию:
infix / : 6;
dec/ : alpha -» (beta -> beta) # list( alpha) ( beta ) -> ( beta);
------f/nil <= lambda y = >y;
------f/x:: 1 <= lambda у => f(x) ((f /1)(у));
а) сравните эту функцию с функцией reduce для списков:
б) определите функцию sum в терминах /, которая бы сум-
мировала элементы заданного списка чисел;
в) определите функцию add имеющую тип
dec add : num —> (list( num) 1 ist( num));
где add(n) возвращает функцию, ставящую n на поло-
женное ему место в любом списке чисел, упорядоченном
по возрастанию;
г) напишите Норе-выражение, используя / и add, сортирую-
щие список [4, 2, 7, 3] в порядке возрастания.
3.6. Укажите для следующих функций:
------g(h, n)<=let х==5 in h(n-f-x);
------f( x) <= g( lambda у => x + у — 2, 6);
что будет являться величиной выражения /( 1) пр^
а) статическом связывании,
б) динамическом связывании.
Глава 4
ВИДЫ ВЫЧИСЛЕНИЙ
В языке, подобном Паскалю, при применении функции к ар-
гументу последний сначала вычисляется, а затем уже передает-
ся функции. В этом случае мы говорим, что аргумент передается
по значению, подразумевая при этом, что только его значение
передается в тело функции. Такое правило вычислений или ме-
ханизм вызова называется вызовом по значению. Преимуще-
ство вызова по значению заключается в том, что эффективная
реализация проста: сначала вычисляется аргумент, а затем вы-
зывается функция. Недостатком является избыточное вычисле-
ние, когда значение аргумента не требуется вызываемой функ-
ции. Альтернативой вызову по значению является вызов по не-
обходимости, в котором все аргументы передаются функции
в невычисленном виде и вычисляются только тогда, когда в них
возникает необходимость внутри тела функции. Преимущество
этого вызова состоит в том, что никакие затраты не пропадут
попусту в случае, если значение аргумента в конце концов не
понадобится. А недостаток — в том, что по сравнению с вызовом
по значению вызов по необходимости является более дорогим,
поскольку функциям передаются не значения тех или иных па-
раметров, а невычисленные выражения.
В контексте функциональных языков можно говорить о двух
видах вычисления, энергичном и ленивом, хотя существуют и
другие варианты. Принцип энергичного вычисления — «делай
все, что можешь». Другими словами —не надо заботиться о том,
пригодится ли в конечном случае полученный результат. Прин-
цип ленивого вычисления—«не делай ничего, пока этого не по-
требуется». В терминах традиционного программирования энер-
гичное вычисление можно приблизительно соотнести с механиз-
мом вызова по значению, а ленивое — с механизмом вызова по
необходимости. Однако между ними не существует тождествен-
ного равенства; точное соотношение между этими терминами
будет пояснено в гл. 6.
72 Часть I. Глава 4
Хотя можно сделать предположение о связи метода вычис-
ления лишь с эффективностью программы и ее компиляцией,
различные эффекты в зависимости от способа вычислений в
функциональном программировании простираются гораздо даль-
ше, чем это может показаться на первый взгляд. В этой главе
будет показано влияние различных видов вычислений на пове-
дение функциональной программы и то, каким образом опреде-
ленные классы задач полностью полагаются на тот факт, что
аргументы функции не вычисляются в точке вызова.
4.1. Понятие строгости
Говорят, что функция, которая всегда требует значение од-
ного из своих аргументов, является строгой по отношению
к этому аргументу. Например, к примитивной функции +
нельзя обращаться, пока оба ее аргумента не будут вычислены
до конкретного числа, т. е. она является строгой по отношению
к обоим аргументам. Однако некоторые функции могут выда-
вать результат и не знать при этом величину одного или не-
скольких своих аргументов. Например, определенная пользова-
телем функция
------- f( х, у) <= if х < 10 then х else у;
не всегда требует, чтобы была известна величина у. Хотя вели-
чину х знать необходимо, поскольку надо определить истин-
ность неравенства ’х < 10’. Говорят, что функция f является
строгой по отношению к х и нестрогой по отношению к у; а это
означает, что величина х требуется обязательно, а величи-
на у— нет.
Итак, если в точке вызова вычисляются оба аргумента (т. е.
они передаются по значению, что соответствует энергичному вы-
числению), то некоторые из проделанных вычислений могут
оказаться лишними. Еще большая неприятность может слу-
читься, если при вычислении нежелаемого выражения аргумента
произойдет зацикливание и вся программа будет не в состоянии
завершиться, в то время как она завершилась бы при передаче
данного аргумента по необходимости. Например, при энергич-
ном вычислении выражения
f(4, (зацикленное выражение))
мы не получим результат за конечное время. Если к тому же
самому выражению применить ленивое вычисление, то ответ
будет равен 4.
Конечно, это не означает, что при ленивом вычислении можно
всегда избежать зацикливания: примером тому является выра-
Виды вычислений 73
жение
f( (зацикленное выражение), Е)
не способное завершиться независимо от способа вычисления,
поскольку всегда требуется знание первого аргумента функ-
ции f. При рассмотрении аргументов предполагается, что пер-
вый аргумент может быть передан и по значению, и по необхо-
димости, поскольку оба этих варианта дают в результате одно
и то же поведение функции f. Как будет показано в дальней-
шем, это является важным моментом, поскольку дает основу
для некоторых оптимизаций при реализациях функционального
языка.
Предполагается, что передача параметра по необходимости
помогает избежать лишних вычислений и зацикливаний. Приме-
ром тому является применение функции reduce, введенной в пре-
дыдущей главе:
reduce( lambda (el, isthere))=>
if isthere then true else ((N = el), false, L)
Пусть список L состоит из чисел [1, 3, 5, 7], необходимо про-
верить наличие в нем 1. При энергичном вычислении, прежде
чем будет получен результат, 1 пройдет сравнение с каждым
элементом списка (лямбда-выражение, записанное выше, обо-
значим Ь):
reduce(b, false, [1, 3, 5, 7])
= b( 1, b(3, b(5, b(7, false)))) (по определению функции reduce)
- >b( 1, b(3, b(5, false)))
- >b( 1, b(3, false))
- >b(l, false) (поскольку b ищет значение, равное 1)
->true
С другой стороны, при ленивом вычислении величину true мы
получаем сразу же:
reduce(b, false, [1, 3, 5, 7])
- > b( 1, reduce(b, false, [3, 5, 7]))
- > true
Вычисление заканчивается так быстро, поскольку для b нико-
гда не требуется значения его второго аргумента, иначе говоря,
b не является строгой относительно второго аргумента. Если
значение первого аргумента оказывается тем числом, которое
проверяется на принадлежность к списку, то второй аргумент
74 Часть I. Глава 4
попросту отбрасывается; такой случай и показан в вышеприве-
денном примере, где выражение отброшенного аргумента выде-
лено подчеркиванием.
Из данного обсуждения можно было бы заключить, что во
избежание лишних вычислений и зацикливания все реализации
функциональных языков должны быть ленивыми. Однако суще-
ствуют значительные затраты, связанные с передачей параметров
по необходимости, что будет показано в гл. 9 и в других гла-
вах книги. В связи с этим некоторые функциональные языки
обладают «строгой семантикой» или «энергичной семантикой»,
означающей, что все функции являются строгими ко всем своим
аргументам и все параметры последовательно передаются по
значению. Однако имеются и другие языки, с противоположным
подходом, обладающие «ленивой семантикой»; программа на
таком языке ведет себя так, будто бы все параметры пере-
даются по необходимости. Это не подразумевает, что все пара-
метры должны на самом деле быть переданы по необходимости,
поскольку, как было показано, параметр, который требуется
функции всегда, может быть передан любым способом без влия-
ния на поведение программы в целом. Таким образом, «ленивая
реализация» подразумевает просто сохранение ленивой семан-
тики, а не повсеместное использование вызова по необходимости,
хотя, конечно, и такое возможно.
Однако основанием для выбора энергичной или ленивой се-
мантики не может служить только критерий эффективности,
поскольку существует еще целый круг задач, при решении кото-
рых предполагается, что реализация, лежащая в основе, являет-
ся ленивой или по крайней мере «частично» ленивой и, таким
образом, безопасна в смысле проблемы завершения, описанной
ранее. В последующих трех разделах будут представлены инте-
ресные классы таких задач.
4.2. Обработка «бесконечных»
структур данных
Функция, порождающая бесконечную структуру данных —
в данном случае бесконечный список целых чисел х, х + 1,х-+-
+ 2, ..., — для заданной величины х имеет вид
dec from : num -> list( num);
•-----from( x) <= x :: from( x + 1);
При использовании энергичного вычисления любое примене-
ние функции from никогда не приведет к завершению. На-
Виды вычислений 75
пример:
from( 0)
— >0 :: from( 1)
— > О :: ( 1 :: from( 2))
— >О ::(1 ::(2::from(3)))
И т. д.
В случае ленивого вычисления оно прекратится, как только на
верхнем уровне будет порожден первый конструктор:
fro^i(O)
— > 0 :: from( 1)
Аргументы для :: не вычисляются в точке вызова. Поскольку ::
не имеет правил (или правила) вычислений, его вычисление
прекращается, а подчеркнутое выражение обозначает невычис-
ленный вызов функции. Запись будет оставаться в таком виде,
пока какая-нибудь другая функция не «форсирует» вычисления
остатка результирующего списка. Примером может служить
функция, подсчитывающая сумму первых п элементов в списке
чисел:
dec sum : num # 1 ist( num) -> num ;
------sum( n, x :: 1) <= if n = 0 then 0 else x + sum( n — 1, 1);
Вычисление sum (2, from( 1) ) развивается следующим образом
(невычисленные вызовы функции опять подчеркнуты):
sum( 2, from( 1))
Сопоставление с образцом не может быть проведено до тех пор,,
пока не известна структура подчеркнутого выражения, поэтому
проводится его вычисление до получения конструктора верхнего
уровня:
— >sum(2, l::from(2))
— > 1 + sum( 1, from( 2))
Следует помнить, что функция + является строгой по отноше-
нию к обоим аргументам, поэтому она немедленно вычисляет
рекурсивный вызов sum, что в свою очередь позволяет выпол-
нять вызов from, давая возможность проводить сопоставление
с образцом:
- * 1 + sum( 1, 2 ::from(3))
- * 1 +'(2 + sum( 0, from( 3)))
При проверке условия п = 0 в sum имеем true, таким образом.
76 Часть I. Глава 4
получаем 0, не вычисляя from(3):
— 1 + (2 + 0)
->3
А сейчас, хотя это и может показаться совершенно не нужным,
обратимся к программам, которые либо полагаются на беско-
нечные структуры, либо заключаются в ограниченном исследо-
вании таких структур. Простым примером подобной программы
может служить вычисление квадратного корня с использованием
алгоритма Ньютона — Рафсона для последовательной аппрокси-
мации, который, должно быть, знаком читателю по школьному
курсу математики. Работа программы состоит в порождении
последовательности аппроксимаций квадратного корня числа N,
начиная с некоторого исходного приближения а0 и далее, уточ-
няя его до тех пор, пока разница между двумя последующими
аппроксимациями не окажется в пределах некоторого наперед
заданного числа е. Новая аппроксимация аи+i получается из
предыдущей аь по следующему правилу:
Як+1 = ( ак + N/ak)/2
Для того чтобы убедиться в корректности данного правила,
надо рассмотреть предельный случай, когда можно заменить
an+i и ап на предел а (предположив, что он существует); в
итоге получаем N = а2, что и требовалось.
Желательно, конечно, не порождать большего количества
аппроксимаций, чем требуется, и поэтому можно было бы ис-
пользовать рекурсивную функцию, которая вычисляет следую-
щую аппроксимацию только в случае, если разница между двумя
предыдущими аппроксимациями больше заранее заданного по-
рога. Однако можно получить довольно ясное решение, основан-
ное на бесконечной структуре данных; на деле это решение
фактически является новой формулировкой проблемы: «Найти
предел ат бесконечного списка аппроксимаций [а0, аь аг, ...1
такой, что выполняется соотношение | ага — am-i | < е”. На
языке Норе подобная постановка задачи будет выглядеть сле-
дующим образом:
dec Limit: 1 ist( real) # real real;
dec Approximations : real # real —> 1 ist( real);
dec SqRoot : real # real =#= real —> real;
------Limit( a 1 :: (rest & ( a2 :: — )), epsilon) <=
if mod(al — a2) < epsilon then a2 else Limit(rest, epsilon);
------Approximations( a, n)<=
a :: Approximations (( a + ( n/a) )/2, n);
------SgRoot (N, Guess, epsilon) < =
Limit( Approximations( Guess, N), epsilon);
Виды вычислений 77
В данном случае функция Approximations строит бесконечный
список аппроксимаций, начиная с начального Guess; Limit по-
следовательно просматривает соседние элементы результирую-
щего списка, проверяя соотношение их разности с величиной
epsilon. Очевидно, подобная программа требует ленивого вы-
полнения, иначе вычисление списка аппроксимаций никогда не
сможет завершиться. Пример применения SqRoot, прослежи-
вающий вычисление SqRoot (4.0, 3.0, 0.01), приведен ниже:
SqRoot(4.0, 3.0, 0.01)
—>Limit( Approximations^.0, 0.01), 0.01)
-> Limit( 3.0 :: Approximations^. 17, 0.01), 0.01)
-> Limit( 3.0 :: (2.17 :: Approximations( 2.01, 0.01)), 0.01)
—> Limit( 3.0 ::( 2.17 ::(2.01 :: Approximations( 2.00, 0.01))), 0.01)
-> Limit( 3.0 :: (2.17:: (2.01 ::(2.00::
Approximations(2.00, 0.01)))), 0.01)
->2.00
Другим известным примером ленивой программы, результа-
том работы которой будет список всех простых чисел, является
«решето Эратосфена». Исходные данные программы — это бес-
конечный список целых чисел 2, 3, 4, 5, ..., и работа ее проис-
ходит следующим образом: от начала бесконечного списка отде-
ляется одно число и «фильтруется» через оставшийся список,
при этом вычеркиваются все элементы, делящиеся на это число.
На каждом шаге рекурсии список полученных чисел (а также
«отфильтрованных») убирается из основного списка:
dec Sieve : list(num)-*list(num);
dee Filter : num # list( num)
------Filter(n, m ::!)<—if (n mod m) = 0
then Filter(n, 1)
else m :: Filter( n, I);
------Sieve( n :: I) <= n :: Sieve( Filter( n, 1));
Список простых чисел затем вычисляется выражением
Sieve( from(2))
Конечно, если заняться вычислением этого выражения, то можно
убедиться, что оно вскорости прекратит вычисляться из-за при-
менения ::, которое не замедлит появиться на верхнем уровне:
Sieve( from( 2))
-> Sieve( 2 :: from( 3))
—> 2 :: Sieve( Filter( 2, from(3)))
78 Часть I. Глава 4
Однако, несмотря на это, можно получить и другие простые
числа, пользуясь функцией, для работы которой требуется
больше чем одна величина из результирующего списка. Напри-
мер, следующее выражение подсчитывает сумму первых трех
простых чисел (функция, применяемая на каждом шаге, выде-
лена жирным шрифтом):
sum(3, Sieve(from(2)))
— >sum(3, Sieve(2:: from(3)))
- >sum(3, 2 :: Sieve( Filter( 2, from(3))))
- *2 + sum(2, Sieve(Filter(2, from(3))))
- >2-|-sum(2, Sieve( FHter(2, 3 :: from( 4))))
— >2 4-sum(2, Sieve( 3 :: Filter( 2, from(4))))
— > 2 + sum( 2, 3 :: Sieve( Filter( 3, Filter( 2, from (4)))))
— >2 + ( 3 + sum( 1, Sieve(Filter(3, Filter(2, from(4))))))
— > 2-]-(3-j-sum( 1, Sieve( Filter( 3, Filter(2, 4 :: from( 5))))))
- > 2 -j- (3 -j- sum( 1, Sieve( Filter(3, Filter(2, from( 5 ))))))
— ► 2 -j- (3 -j- sum( 1, Sieve( Filter( 3, Filter(2, 5 :: from( 6))))))
->2 + (3 + sum( 1, Sieve(Filter(3, 5::Filter(2, from(6))))))
— >2 -|-(3 -|- sum( 1, Sieve(5 :: Filter(3, Filter(2, from(6))))))
—> 2 -j- (3 -f- sum( 1, 5 :: Sieve (Filter( 5,
Filter( 3, Filter(2, from( 6)))))))
— > 2 + (3 4- (5 -j- sum(0, Sieve(Filter(5,
Filter(3, Filter( 2, from(6))))))))
_>2 + (3 + (5 + 0))
10
Из работы программы видно, что вызываемая функция каж-
дый раз выдает только одно значение и потом прекращает свою
работу. Затем вызывающая функция «поглощает» значение,
а возможно, и сама выдает значение, возвращаемое в преды-
дущую вызывающую функцию, и т. д. Непосредственный эффект
от ленивого вычисления в этом примере заключается в том, что
результирующий список простых чисел составляется сразу же.
Только в том случае, когда предыдущее простое число погло-
щается и требуется следующее простое число (функцией +),
повторно вызывается Sieve.
Примеры, которые были здесь рассмотрены, основаны на
том, что аргументы функций-конструкторов не вычисляются до
тех пор, пока этого не потребуется, и в этом плане их можно
рассматривать только в качестве частично использующих ле-
нивое вычисление. Одним из наиболее эффективных примене-
ний ленивого вычисления является создание циклических струк-
тур, и в этой проблемной области становятся полностью оче-
видны все его преимущества.
Виды вычислений 79
Для иллюстрации понятия циклических структур рассмот-
рим функцию порождения бесконечного списка [1, 2, 1, 2, 1,
2, ...]
dec cycle : list( num);
------cycle <=[1, 2] () cycle;
Без ленивого вычисления работа этой функции не завершится,
поскольку аргумент функции < > будет вычисляться прежде,
чем вызывается < >. При этом произойдет обращение к рекур-
сивному вызову cycle и процесс будет повторяться бесконечно.
При использовании ленивого вычисления получается
cycle
= [1, 2]( ) cycle
= 1 :: ([2] < ) cycle)
В данном случае вычисление остановится после того, как кон-
структор :: появится на верхнем уровне. Такой процесс можно
определить как циркулярный, или циклический, поскольку все
сказанное выше есть описание структуры, замыкающейся на
себя:
Подобную функцию можно реализовать таким образом, как
будет показано при дальнейшем изложении.
4.3. Сети процессов
Используя функцию from, определенную в предыдущем раз-
деле, можно вычислить (бесконечный) список неотрицательных
целых чисел, применив в данном случае выражение from(O).
Однако существует и другой путь получения аналогичного ре-
зультата— использование приведенной ниже функции Ints:
dec IncList: num-»-list(num);
------IncList( n :: 1) <= (n + 1):: IncList( 1);
dec Ints : list(num);
------Ints < = 0 :: IncList( Ints);
Таким образом,
Ints
— > 0:: IncList( Ints)
- > 0:: IncList( 0 :: IncList( Ints))
- * 0:: 1 :: IncList( IncList( Ints))
80 Часть I. Глава 4
— > 0 :: 1 :: IncList( IncList(0 :: IncList( Ints)))
-» 0:: 1 :: IncList( 1 :: IncListf IncList( Ints)))
—>0 :: 1 :: 2 :: IncList( IncList( IncList( Ints)))
и T. Д.
(Конечно же, при ленивой реализации вычисление сможет
быть продолжено после второй строки только в том случае,
если пользователю потребуется несколько элементов данного
списка.)
Пока Ints выступала в роли рекурсивной функции. Однако
программу можно рассматривать и как описание сети процесса:
О
Дугами в этой сети являются бесконечные списки целых чисел
(часто называемые потоками), а вершиной IncList — процесс,
увеличивающий отдельные компоненты входного списка. Цик-
лическое соединение в сети появляется из-за рекурсивной сущ-
ности функции Ints. Интересной особенностью сети является
то, что каждую вершину можно рассматривать как статический
процесс. Например, хотя последовательность вычислений, пред-
ставленная выше, показывает, что работа Ints заключается в
выполнении рекурсивных вызовов самой себя, ее можно рас-
сматривать как статическую часть программы с одним входным
«буфером» и одним выходным, где каждый выходной элемент на
единицу больше соответствующего входного элемента.
-5,4,3,2,1
IncList —•—... 6,5,4,3,2
В этом отношении IncList можно рассматривать как инте-
рактивную программу, т. е. если поместить какое-либо число п
во входной буфер (как часть входного списка), то число n+ 1
появится в выходном буфере независимо от того, существуют
ли на входе какие-то другие величины. Если из выходного
буфера удалить полученное число, а во входной поместить но-
вое, то вся процедура повторится заново. Можно сформировать
статическую сеть процессов, «соединяя» соответствующие входы
и выходы статических процессов с помощью дуг, представляю-
щих потоки данных. Иногда подобную процедуру определяют
Виды вычислений 81
довольно расплывчатым термином "завязывание узлов". Выше-
приведенная программа является простым примером завязыва-
ния узлов. Под «узлом» тут подразумевается циклическое со-
единение выходной дуги из Ints со входной дугой IncList-npo-
цесса; это следует из уравнения, определяющего Ints.
Существует другой путь представления задачи, заключаю-
щийся в том, что Ints сам выступает в роли процесса:
S1
Целые числа
S2
где Ints имеет теперь такое определение:
dec Ints : list( num )-> list( num );
-------- Ints( s ) <= 0::s;
Ints сам больше ”не вяжет узлов” (он нерекурсивен!); для того
чтобы выполнить задуманное, а именно для описания соедине-
ний двух процессов, т. е. потоков S1 и S2, необходимо исполь-
зовать рекурсивное let или where:
S2 where (SI, S2) == (IncList( S2), Ints(Sl))
Результат вычисления этого выражения S2 — (бесконечный)
список целых чисел. Здесь мы видим, что сами процессы опи-
сываются с помощью функций, а взаимосвязь этих процессов —
рекурсивным выражением where. Читатель сам может убе-
диться в том, что данная программа работает только при лени-
вой реализации языка, на котором она написана.
В качестве примера немного более сложной сети процессов
можно рассмотреть другую известную задачу — программу под-
счета списка чисел Фибоначчи. Числа Фибоначчи задаются
в виде:
f, = l.
f2= 1,
2.
Однако эту последовательность можно представить так:
n 1 2 3 4 5 6 7 ...
fn 1 1 2 3 5 8 13 ... (S1)
fn+I 1 2 3 5 8 13 21 ... (S2)
fn(_, 2 3 5 8 13 21 34 ... (S3)
6 — 1473
82 Часть I. Глава 4
Принимая элементы каждого ряда за потоки SI, S2 и S3,
нетрудно подсчитать величину п-го элемента в S3, суммируя
n-е элементы S1 и S2. Зная Е и f2, можно вычислить первый
элемент S3. Следует отметить, что второй элемент S1 в точ-
ности совпадает с первым элементом S2 (который известен),
а второй элемент S2 — с первым элементом S3 (который теперь
также известен). Зная вторые элементы S1 и S2, не составляет
труда вычислить второй элемент S3. Сам процесс порождения
полного списка чисел Фибоначчи в потоке S1 может продол-
жаться бесконечно. Предлагается следующая сеть процесса:
Функции F и А, изображенные на этой диаграмме, задаются
так:
dec F : 1 ist( num) —>1 ist( num);
dec A : 1 ist( num ) =#- 1 ist( num) —> list( num);
-----F(s)<= 1 ::s;
-----A(fl::sl, f2::s2) < = (fl 4-f2):: A(sl, s2);
Этим определяются процессы в вершинах; для определения
взаимосвязи этих процессов следует «завязать узел», что снова
может быть сделано с использованием рекурсивного where:
SI where (SI, S2, S3)==(F(S2), F(S3), A(S1, S2))
Еще раз можно убедиться, что процессы легко описать с по-
мощью функций, а взаимосвязь процессов — используя рекур-
сивное выражение where.
Хотя представленные примеры программ являются не чем
иным, как множеством определений рекурсивных функций, их
можно рассматривать как спецификации сетей взаимосвязанных
процессов. Итак, несмотря на то, что они достаточно удобны
для вычисления при любой ленивой реализации языка, логиче-
ские процессы в такой сети можно рассматривать как физиче-
ские процессы, которые даже могут определять отдельные ком-
поненты аппаратного обеспечения. Если придерживаться по-
добной трактовки, то процессы станут выполняться параллельно
и можно будет добиться некоторого успеха в спецификации па-
Виды вычислений 83
раллельных систем без обращения к любым дополнительным
характеристикам языка, таким, как каналы, буферы или явная
синхронизация. Это довольно интересный аспект технологии
функционального программирования, и для более детального
ознакомления читатель может обратиться к работам {41, 55].
4.4. Вычисление с «неизвестным»
Для завершения обсуждения методов ленивого программи-
рования обратимся к способу, в котором результат работы
функции зависит от величин, которые неизвестны до тех пор,
пока вычисление не закончено. Подобное может показаться аб-
сурдным, однако иногда имеет место, когда реализация языка
является ленивой. В качестве примера рассмотрим функцию,
заменяющую каждый элемент в списке положительных чисел
на максимальный элемент этого списка. Назовем функцию
ReplaceByMax.
Как обычно, задача разбивается на две части: сначала вы-
числяется максимальный элемент списка, затем каждый эле-
мент списка заменяется на этот максимальный элемент. Напри-
мер (используя функции max, map и reduce, определенные в
предыдущих главах):
dec ReplaceByMax : list( num) -> list(num);
------ReplaceByMax] I) <= map( lambda —=>
reduce(max, 0, 1), 1);
Тут все очень точно и достаточно ясно, но существует неболь-
шое неудобство, заключающееся в том, что список необходимо
просматривать дважды. Однако, используя рекурсивные where-
(или let-) выражения в сочетании с ленивым вычислением,
можно проделать ту же самую операцию за один просмотр.
Функция, осуществляющая это, выглядит следующим образом:
dec ReplaceByMax 1 ist( num) -> list( num);
------ReplaceByMax( 1) <= Result
where (Result, big )== reduce] f, (nil, 0), 1)
where f —= lambda (x, (r, m))— >
(big::r, if x > m then x else m);
Вторым компонентом пары, генерируемой с помощью функции
reduce, является максимальный элемент исходного списка. Ин-
тересная особенность программы состоит в том, что все эле-
менты списка, образующие первый компонент возвращенной
функцией f пары, являются big. Однако величина big неизвест-
на, пока выполняется функция reduce! Причина этого заклю-
б1
84 Часть I. Глава 4
чается в том, что нет необходимости знать значение big, пока
не будет завершено выполнение функции reduce. Посмотрим,
что произойдет, если попытаться обработать элементы резуль-
тирующего списка. Например:
m where (m ::_)== ReplaceByMax([5, 1, 4])
Применение функции ReplaceByMax выглядит следующим об-
разом:
ReplaceByMax([ 5, 1, 4])
—►Result where (Result, big) == reduce( f, (nil, 0), [5, 1, 4])
where f == lambda(x, (r, m))= >
(big::r, if x > m then x else m)
S Result where (Result, big) == f(5, f( 1, f(4, (nil, 0))))
Result where (Result, big)==f(5, f( 1, (big:: nil, 4)))
-> Result where (Result, big) ===== f( 5, ( big :: ( big :: nil), 4))
-* Result where (Result, big) ===== ( big :: ( big :: (big :: nil)), 5)
Только теперь можно продолжать сопоставление (m::_1.
К данному моменту величина big известна и равна 5. Получен-
ный результат есть голова итогового списка, состоящего из мак-
симальных элементов, равных 5.
Эта версия ReplaceByMax далеко не так очевидна, как
предыдущая, и, вероятно, читателю придется более детально
ознакомиться с программой, прежде чем он убедится, что она
реализует необходимое преобразование. Следует, однако, вспом-
нить, что единственная цель, которая преследовалась, — это
уменьшение количества просмотров списка от двух до одного,
т. е. оптимизация. Некоторая непонятность этой версии про-
граммы еще раз напомнила старую поговорку, что уж если
и проводить оптимизацию, то только после того, как программа
станет абсолютно ясна. Использование же подобного стиля
программирования при разработке программы будет только
запутывать.
Как уже было сказано и в чем можно будет убедиться по
ходу дальнейшего изложения, поддержка ленивого вычисления
является очень дорогой, и для того, чтобы избежать его при
реализациях функционального языка, затрачиваются большие
усилия всякий раз, когда это возможно. Например, при анализе
ленивой функциональной программы часто определяется, что
функция, заданная пользователем, является строгой в одном
или нескольких своих аргументах. Эти строгие аргументы затем
могут передаваться по значению, давая некоторое увеличение
эффективности без изменения поведения программы при лени-
вой реализации. Подобная форма оптимизации, известная как
анализ строгости, более детально обсуждается в гл. 20.
Виды -вычислений 85
С этой позиции следует разъяснить семантику вызовов в
самом Норе. Существуют две реализации языка Норе, на обе
будут даваться ссылки в оставшихся главах книги, поэтому не
мешает остановиться на них подробнее. В стандартной реали-
зации Норе все функции вызываются по значению, за исклю-
чением функций-конструкторов, вызываемых по необходимости.
Это попросту означает, что аргумент конструктора не вычис-
ляется, пока он не будет передан не являющейся конструктором
функции как результат ее выбора при сопоставлении с образ-
цом. В ленивой реализации Норе все функции вызываются по
необходимости. Это означает, что строгие примитивные функции
получают свои аргументы в невычисленной форме и, таким об-
разом, должны сами проводить их вычисление, прежде чем
примитив можно будет использовать. Для пояснения следует
обратить внимание на то, что пример в разд. 4.2 (не последний,
cycle) будет работать при использовании любой реализации
Норе, а примеры в разд. 43 и 4.4 — только при ленивой реа-
лизации. В гл. 9 будет показано, каким образом энергичное
и ленивое вычисления могут быть применены в интерпретаторе
для функциональных языков, написанном на языке Норе, и то,
как две реализации Норе порождают различное поведение этого
интерпретатора.
Резюме
• Функциональные языки могут выполняться либо энергично,
либо лениво (возможно также использование различных комби-
наций этих двух способов).
• Энергичное вычисление соответствует вызову по значению
и в общем случае более эффективно, хотя может порождать
лишние вычисления или «ненужное» зацикливание.
• Ленивое вычисление соответствует вызову по необходимости
и приводит к завершению программы всякий раз, когда оно
возможно.
• Задачам, использующим для своего решения бесконечные
структуры данных, необходимы ленивые конструкторы.
„• Некоторым программам, строящим циркулярные струк-
туры, для завершения требуется полностью ленивая семан-
тика.
• Сети процесса обеспечивают альтернативную модель вычис-
лений некоторых бесконечных выражений.
• Ленивое вычисление может быть использовано для миними-
зации числа просмотров структур данных, но это связано с не-
обходимостью написания сложных программ.
86 Часть I. Глава 4
• Существуют две реализации Норе: стандартная, при которой
функции-конструкторы вызываются по необходимости, а все
другие функции по значению, и ленивая, когда все функции вы-
зываются по необходимости.
Упражнения
4.1. Обычно генератор случайных чисел включает в себя функ-
цию R, которая при вызове со специальной величиной, назы-
ваемой источником, возвращает псевдослучайное число в диа-
пазоне от 0 до 1 и новый источник, который может быть
использован при последующем вызове R. Предложите, как бес-
конечный список, определенный с использованием R, можно
использовать вместо многократных вызовов R. Как получается
«следующее» случайное число?
4.2. Пусть выражение Е вычисляет список символов, который
при выдаче на терминал покрывает 20 экранов текста. Объяс-
ните, что может увидеть пользователь, когда значение Е вы-
числено и затем распечатано с использованием полностью
энергичной реализации, а потом снова — применяя ленивую
реализацию.
4.3. Рассмотрим пример cycle, данный в конце разд. 4.2. Аль-
тернативное определение этой функции выглядит следующим
образом:
------cycle <= 1 :: (2:: cycle);
Требуются ли тут все возможности ленивого вычисления? Ка-
ково важное отличие между двумя версиями с точки зрения
возможности завершения работы программы?
4.4. а. (Прежде чем заняться этой задачей, следует вернуться
к упражнению 3.4(b).) С помощью reduce, map и compose
определите Hope-функцию pipe, строящую линейный конвейер
из заданного списка функций [fb f2, ..., fn]. (Подсказка-, ли-
нейный конвейер функций fb f2, ..., fn описывает систему обра-
ботки типа «конвейерной полосы», где каждый элемент потока
аргументов по очереди обрабатывается функциями fn, fn-i, .
... и т. д. до fi. Функции fj можно рассматривать как отдель-
ные физические модули обработки, которые могут работать
одновременно. Например, в то время как Е применяется к Ему
элементу потока аргументов, f2 работает с (i-(-l).-M элементом
и т. д.) Опишите поведение конвейера при использовании обыч-
ного ленивого вычисления. Особое внимание обратите на то,
что произойдет, если поток аргументов бесконечен.
б. Напишите выражение, использующее pipe для проверки
на пересечение двух списков объектов S и Т. Конвейер, кото-
Виды вычислений 87
рый надо построить, выглядит следующим образом:
sn sn_,... s2 s, ~-*~rQ-*-ftn,_1|—- ... —»[t7|—»• пересечение
где ti есть элементы списка I, sj (1 j sC n) —
элементы S, а пересечение — поток величин, каждая из которых
содержится и в S, и в Т. Ящик, содержащий величину t, пред-
ставляет собой процесс, проверяющий элементы S на равен-
ство t. {Подсказка: Пусть величины, проходящие через кон-
вейер, представляют собой пары вида (величина, флаг), где
«флаг» показывает, принадлежит ли данная величина множе-
ству пересечения.)
4.5. Используя метод, подобный описанному в разд. 4.4, опре-
делите функцию mintips, входными данными которой является
дерево чисел, а выходными — изоморфное дерево, где каждый
элемент заменен на минимальный в исходном дереве; при этом
допускается лишь один обход дерева.
Глава 5
ДРУГИЕ СТИЛИ ФУНКЦИОНАЛЬНОГО
ПРОГРАММИРОВАНИЯ
В предыдущих трех главах мы познакомились со стилем
функционального программирования на языке Норе. Однако
Норе никоим образом не является ни единственным, ни оконча-
тельным (в любом смысле этого слова) функциональным язы-
ком. Как мы видели, важными особенностями функционального
языка, отличающими его от языка любого другого типа, яв-
ляются прозрачность ссылок и детерминизм. Последняя особен-
ность служит отличительным фактором между функциональ-
ными и реляционными языками, такими, как Пролог [23]. Это
оставляет значительный простор для вариаций в таких обла-
стях, как строгая типизация, определенные пользователем типы
данных, функции высшего порядка и правила вычисления, а
также для косметических различий, например в синтаксисе
языка. В этой главе мы введем некоторые из альтернативных
стилей функционального программирования, рассмотрев вкрат-
це языки Miranda, Лисп и FP. Эти языки вместе с самим язы-
ком Норе дают хорошее представление о различных подходах
к разработке функциональных языков.
Раздел 5 1 описывает язык Miranda, являющийся строго ти-
пизированным, очень похожим на Норе, но значительно отли-
чающимся от последнего подходом к рассмотрению функций.
Раздел 5.2 описывает Лисп, который является нетипизирован-
ным языком обработки списков и в котором программы и дан-
ные имеют одинаковое представление. Раздел 5.3 описывает
FP, который также допускает только один тип данных (сим-
метричные списки) и значительно отличается от других функ-
циональных языков тем, что при программировании на нем рас-
суждения идут на уровне функций, а не на уровне объектов.
Это свойство делает FP олень мощной нотацией для представ-
ления формальных преобразований функциональных программ
и дает основу для методов программных преобразований, опи-
санных в гл. 18.
Другие стили функционального программирования 89
5.1. Miranda *>
Общий подход, принятый в языке Miranda, во многом похож
на подход языка Hope. Miranda — это строго типизированный
язык высокого уровня, поддерживающий типы данных пользо-
вателя и полиморфизм. Он является преемником двух более
ранних языков, разработанных Тернером, а именно языка
SASL [79] и языка KRC [82]. Главное отличие между языками
Miranda и Норе в том, что Miranda — это «карринговый» язык,
т. е. в нем объекты, значением которых является функция,
строятся путем частичного применения существующих функций,
а не с помощью явных лямбда-выражений, как мы делали это
в гл. 4. Miranda имеет ленивую семантику, так что все функции
вызываются по необходимости, но можно специфицировать стро-
гие конструкторы, пометив нужным образом аргументы кон-
структора. Этот аспект, однако, не обсуждается здесь.
5.1.1. Структура программы языка Miranda
Подобно языку Норе, программа на языке Miranda состоит
из множества определений. Однако в отличие от Норе не тре-
буется, чтобы тип каждого определения был специфицирован
программистом. Это не означает, что Miranda является нетипи-
зированным языком, поскольку тип каждого выражения выво-
дится автоматически программой проверки типов. (Фактически
то же самое справедливо для языка Норе: тип каждой функ-
ции определяется автоматически программой проверки типов
независимо от уравнений типов, заданных программистом. Един-
ственное отличие состоит в том, что в Норе выведенные типы
последовательно проверяются на совместимость с типами, за-
данными программистом.)
В качестве простого примера программы на языке Miranda
здесь приведена версия программы reverse, данной в гл. 3 на
языке Норе. Эта программа обращает заданный список объек-
тов, используя накапливающий параметр:
rev L = rev2 L [ ]
rev2 [ ] a = a
rev2( x : 1) a = rev21(x : a)
Каждое определение имеет левую и правую части, разделенные
символом = (эквивалентным <== в языке Норе). Подобно
языку Норе, определения могут содержать образцы в левой
*> Miranda™ — это торговая марка фирмы Research Software Ltd.
90 Часть 1. Глава 5
части; приведенный пример показывает использование сопостав-
ления с образцом для списков: [ ] обозначает пустой список (эк-
вивалент nil в языке Норе), и : является инфиксным конструк-
тором списков (эквивалентным :: в Норе).
Подобно языку Норе, в языке Miranda можно использовать
упрощенную форму записи для выражений списков и для спи-
сков символов; выражение
Х|: (х2: (х3: ... :(хп :[])...))
может быть записано в виде
[Xj, х2, х3, .... хп]
а в случае если каждый Х| является символом, все они могут
быть записаны в одну строчку и заключены в двойные кавычки,
например:
"Miranda"
Однако в отличие от языка Норе в языке Miranda возможна
сокращенная форма записи для арифметических последователь-
ностей. Конечная последовательность целых может быть скон-
струирована с помощью указания первого и последнего элемен-
тов, разделенных двумя точками .. . Например, список
[1, 2, 3, 4, 5]
можно записать в виде
[1 . 5]
Используя ту же форму записи, мы можем специфицировать
бесконечные списки, просто опустив верхнюю границу. Напри-
мер, выражение
[1 ••]
обозначает (бесконечный) список положительных целых (вспом-
ним, что Miranda — это ленивый язык, так что бесконечные
структуры данных могут быть выражены в нем без проблем).
5.1.2. Карринг
В приведенном примере программы rev аргументы каждой
функции разделяются пробелами, а не заключаются все вместе
в скобки. Причина такой формы записи в том, что каждая
функция в языке Miranda является по существу функцией выс-
шего порядка. Когда на языке Miranda мы записываем опреде-
Другие стили функционального программирования 91
ление вида
f х у z=...
мы можем обычным образом интерпретировать f как функцию
трех аргументов х, у, z или, как в языке Норе, в качестве функ-
ции от одной тройки аргументов. Однако в языке Miranda в
действительности f является функцией высшего порядка только
от одного аргумента х. Результатом применения f к аргументу
Еь который мы записываем в виде
fE1
является другая функция, снова только от одного аргумента у.
Применение этой функции к следующему аргументу Е2 снова
дает функцию от одного аргумента z. Полное применение f
записывается в виде
fEiE2E3
но правильно читать эту запись нужно следующим образом:
(((fE[) Е2) Е3)
Однако существует соглашение, по которому функция приме-
няется всегда к левому аргументу, так что скобки можно опус-
тить без изменения смысла выражения.
Идея обработки функции от п аргументов как конкатена-
ции п функций от одного аргумента называется каррингом (по
имени математика Карри (Н. В. Curry)). В языке Норе объект,
имеющий своим значением функцию, создается с помощью клю-
чевого слова lambda; в языке Miranda аналогичный объект со-
здается путем применения определенной функции к меньшему
числу аргументов по сравнению с тем, что указано в левой ча-
сти ее определения; иногда это называют частичным примене-
нием. Например, функция следования на множестве целых чи-
сел, которая может быть записана на языке Норе с помощью
лямбда-выражения
lambda х=> х + I
может быть записана на языке Miranda в виде частичного при-
менения примитивной функции + к аргументу 1:
( + )1
(Скобки превращают инфиксную функцию + в префиксную
функцию.) Оба выражения представляют функцию, которая
«прибавляет единицу к некоторому целому». В качестве еще
одного примера рассмотрим функцию тар, определенную на
92 Часть I. Глава 5
языке Норе в разд. 3.1. Она имеет следующее определение на
языке Miranda:
map f[ ] = [ ]
map f(x : l) = (f x): (map fl)
Функции, которые мы применяем к списку, могут сами быть
выражены частичным применением. Например, выражение
тар(( + ) 1) L
увеличивает на единицу каждый элемент L, а выражение
map(max 0)L
возвращает список, в котором каждый элемент L заменен мак-
симумом из 0 и этого элемента. Эквивалентное определение на
языке Норе включает использование lambda:
map( lambda n=>max(n, 0), L)
Одним из следствий формы записи в языке Miranda яв-
ляется то, что все функции должны иметь имена. В языке Норе
мы вводим вложенные функции, используя lambda-выражения;
в языке Miranda это достигается с помощью обычного опреде-
ления функции внутри where-выражения. Например, функция
map(f 5)L where f x y = y + x*x
прибавляет 25 к каждому элементу L. Заметим, что введенная
функция может быть рекурсивной благодаря тому, что имеет
имя.
Заметим также, что нет необходимости в том, чтобы все
функции были карринговыми, поскольку Miranda предоставляет
также механизм для построения кортежей и для композиции
этих кортежей с помощью сопоставления с образцом. Синтаксис
кортежа в языке Miranda идентичен синтаксису кортежа в Норе,
поэтому мы могли бы определить приведенную выше функцию
rev следующим образом:
rev( L ) = rev2( L, [ ])
rev2( [ ], a) = a
rev2(xil, a) = rev2(l, x:a)
5.1.3. Условные выражения
Условные выражения в языке Miranda записываются с по-
мощью примитивных булевых функций, выражающих условия,
а не с помощью ключевых слов, таких, как if, tren и else.
Другие стили функционального программирования 93
В качестве примера здесь мы приводим функцию max, которая
возвращает максимальное из двух чисел тип:
max т п = т, т > п
п, т<=п
> и <= (соответственно «больше» и «меньше или равно»)
являются примерами примитивных булевых функций, работаю-
щих с объектами типа num; num — это базовый тип в языке
Miranda, так же как в Норе, но в отличие от языка Норе он
включает как целые, так и вещественные числа. В результате
существует единственное правило для функций, подобных >,
и то, какой из четырех вариантов применения имеет место, опре-
деляется при вызове функции, т. е. во время выполнения. В этом
проявляется отличие от языка Норе, где выбор применяемого
правила определяется перед вычислением программы (т. е. во
время компиляции). Другими базовыми типами языка Miranda
являются bool и char, эквивалентные базовым типам truval и
char языка Норе.
5.1.4. Абстракции списков
Абстракции списков, называемые также включениями спи-
сков, дают элегантный метод сжатого описания определенных
операций обработки списков. Например, следующее выражение
вычисляет (бесконечный) список четных положительных целых,
используя выражение [1..] в качестве генератора бесконечного
списка положительных целых, из которого затем удаляются
те элементы, которые не делятся на два:
[п ] п < — [1 ..]; n rem 2 = 0]
rem является эквивалентом mod в языке Норе, а символ <—
(являющийся аппроксимацией символа е) обозначает опера-
тор принадлежности к списку. Поэтому данное выражение
можно читать следующим образом:
[п] п<-.[1 ..]; nrem2 = 0]
список всех п, таких что п входит в [1, 2, 3, ...] и п делится на 2
В качестве примера использования этой формы записи здесь
приводится функция языка Miranda для вычисления (бесконеч-
ного) списка простых чисел с помощью решета Эратосфена,
описанная в гл. 4:
primes = sieve[ 2 .. ]
where sieve( n : 1) = n : sieve[m <— 11 m rem n ~ = 0]
94
Часть I. Глава 5
Абстракция списка [т <—1|тгетп~ = 0] удаляет из 1 все
элементы, которые делятся на п, и идентична поэтому функции
Filter языка Норе, данной в гл. 4.
5.1.5. Типы данных, определенные пользователем
В языке Miranda мы можем определять наши собственные
типы данных во многом аналогично тому, как мы это делаем
в Норе. Синтаксис определения типа похож на БНФ-нотацию
для описания синтаксиса языка. Например, тип данных tree
(дерево), который мы определили в гл. 3 на языке Норе, может
быть определен на языке Miranda следующим образом:
tree ::= Empty| Tip num (Node tree num tree
.Заметим, что конструкторы также могут быть карринговыми, и
это объясняет синтаксис данного определения. Символ :: =
аналогичен символу == в языке Норе, а | аналогичен ++•
Заметим, что имена конструкторов по правилам языка Miranda
начинаются с большой буквы. Функция для представления де-
ревьев в виде списков, которая была определена на языке Норе
в гл. 3, может теперь быть определена обычным образом с по-
мощью нескольких уравнений:
flatten Empty = [ ]
flatten( Tip n) = [n]
flatten(Node left value right) =
==(flatten left)++(value : (flatten right))
H—|----это примитивная функция присоединения списков, экви-<
валентная функции <> в языке Норе.
Мы можем сделать определение tree полиморфным с по-
мощью переменных типа. В языке Miranda допустимыми пере-
менными типа являются *, **, *« и т. д. Полиморфное опреде-
ление деревьев выглядит так:
tree * ::= Empty | Tip * | Node( tree * ) * (tree * )
В язык также включена возможность переименования типов.
Выражение
string == [char]
просто присваивает имя string типу [char]. Это эквивалентно
следующему объявлению типа в языке Норе:
type string ===== list( char);
В язык также включена возможность определения несвобод-
ных типов данных. Это просто типы данных, к которым могут
Другие стили функционального программирования 95
быть прикреплены «свойства», например свойство, что каждый
элемент упорядоченного списка должен быть больше или равен
предыдущему элементу. Эти свойства выражаются в виде ра-
венств между термами конструкторов и реализуются в конеч-
ном счете с помощью некоторой формы встроенной системы пе-
реписывания термов. Мы не будем в дальнейшем касаться не-
свободных типов данных. Скажем только, что необходимость
встроенной системы переписывания термов несколько услож-
няет реализацию и ставит вопросы полноты и ограниченности,
выходящие за рамки этой книги. Интересующегося читателя
мы отсылаем к работе [83].
5.2. Лисп
Лисп (LISP) был первым чисто функциональным языком.
Он был разработан Джоном Маккарти в начале 1960-х годов
[63]. Хотя оригинальный Лисп был чисто функциональным в
смысле прозрачности ссылок, появившиеся в последующие годы
диалекты включили в себя многие императивные особенности,
в частности конструкции для выполнения разрушающего при-
сваивания, уничтожившие простоту и элегантность, присущие
оригинальному языку. Существует, однако, «чистое» подмноже-
ство языка Лисп, встроенное во все эти диалекты, которое само
по себе можно использовать для написания функциональных
программ в нашем понимании этого термина. Хотя различные
реализации Лиспа отличаются довольно значительно по выбору
ключевых слов, имен примитивных функций и структуре про-
граммы в целом, в их основе лежат одни и те же принципы.
Однако семантические различия между различными диалектами
и реализациями являются более существенными, как мы уви-
дим далее. Здесь мы (произвольно) будем строить наше обсуж-
дение на синтаксисе диалекта Лиспа, называемого Lispkit, пол-
ное описание которого можно найти в [42].
5.2.1. S-выражения
Слово ’LISP’ является аббревиатурой от ’LISt Processing’
(обработка списков), и одной из особенностей Лиспа, которая
отличает его от большинства других языков (включая импера-
тивные языки), является то, что в нем поддерживается только
один составной тип данных — список. Списки в Лиспе являются
нетипизированными, т. е. могут включать произвольные компо-
ненты, и текстуально представляются с помощью так называе-
мых S-выражений. S-выражение является либо атомом, либо по-
следовательностью других S-выражений, разделенных пробелами
96 Часть I. Глава 5
и заключенных в скобки. Последний тип выражения называется
неатомарным S-выражением.
Атом может быть либо символьным, либо числовым. Число-
вой атом — это последовательность цифр (возможно, начинаю-
щаяся знаком + или —), а символьный атом — это любая
последовательность символов, начинающаяся с буквы. Неато-
марные S-выражения можно рассматривать просто как списки.
Например, список в языке Норе
[еь е2, ..., еп]
где е! (l^i^n) являются выражениями, представляется в
Лиспе в виде S-выражения
(е! е2 ... еп)
Однако в отличие от языка Норе, где ~все е, должны быть од-
ного типа, в Лиспе они могут иметь произвольный тип. Приве-
дем несколько примеров S-выражений:
42
Richard3
(Two on a Tower)
(( 1)(2)( 12 3 4))
((—6 —20) and (2 men in a boat) are both( S expressions))
(Заметим, что отдельные атомы в неатомарных S-выражениях
разделяются одним или несколькими пробелами.)
По очевидным причинам мы часто будем ссылаться на не-
атомарное S-выражение такого вида, как список. Предполагает-
ся, что все атомы в Лиспе являются неделимыми, так что мы
не можем расщепить символьный атом на отдельные символы.
Мы можем, однако, декомпозировать список, применяя прими-
тивные функции. В языке Норе мы декомпозируем список с по-
мощью сопоставления с образцом. Например, следующая функ-
ция языка Норе возвращает первый элемент списка (голову),
используя образец в левой части уравнения:
dec head : list( alpha ) -> alpha ;
------head( x :: _ ) <= x ;
Подобным образом
dec tail : list( alpha ) -> Iist( alpha );
------tail( _ :: 1) <= 1;
В Лиспе нет возможности сопоставления с образцом, а функ-
ции, подобные приведенным выше функциям head и tail, яв-
ляются примитивами языка и используются для выделения тре-
Другие стили функционального программирования 97
буемого элемента (или элементов) заданного S-выражения. Су-
ществуют четыре примитива для сборки и разборки S-выра-
жений:
CAR эквивалент head
CDR эквивалент tail (произносится "кудер" ("could егг"))
CONS эквивалент :: в языке Норе
АТОМ проверяет, является ли его аргумент атомом
Примитив АТОМ должен возвращать некоторое представление
булевых величин true или false; они представляются специаль-
ными атомами Т и F соответственно (сравните с языком Норе,
в котором истинностные величины поддерживаются в качестве
базовых). Функции декомпозиции имеют довольно странные
имена, которые совершенно не соответствуют выполняемым ими
операциям. Эти имена происходят из самой ранней реализации
Лиспа, в которой первый элемент неатомарного S-выражения
(голова) был доступен через специальный машинный регистр,
называемый «адресным регистром», а хвост — через другой спе-
циальный регистр, называемый «декрементным регистром». Го-
лова и хвост S-выражения могли, таким образом, быть доступ-
ны при обращении к содержимому адресного регистра (Con-
tents of Address Register) и к содержимому декрементного ре-
гистра (Contents of Decrement Register) соответственно. Отсюда
имена CAR и CDR.
В Лиспе мы представляем применение функции f к набору
аргументов аь ..., ап одним S-выражением:
(f а, а2 ... ап)
Это означает, что и применение в целом, и аргументы приме-
няемой функции представляются в виде списков (S-выражений).
Следует заметить, что большинство диалектов Лиспа имеют
строгую семантику, т. е. выражения аргументов аь ..., ап вы-
числяются до вызова функции f. Однако существуют исключе-
ния: диалект Lispkit, например, имеет ленивую семантику.
Недостатком представления применений функций в Лиспе
является то, что, например, S-выражение
(1 2 3)
имеет такой же формат, как и применение функции. Вследствие
этого мы можем читать данное выражение как применение 1
к списку аргументов (2 3), что не соответствует действительно-
сти. Для решения этой проблемы все константы в Лиспе долж-
ны бы и, шключены в кавычки. В действительности это дости-
7 — 1473
98 Часть I. Глава 5
гается применением функции QUOTE В к (постоянному) S-вы
ражению. QUOTE возвращает свой аргумент без изменений,
т. е. не интерпретирует его как выражение, которое необходимо
вычислить. Так, например, постоянные S-выражения
62 (4—7) (Tom Browns Schooldays)
должны записываться в виде
(QUOTE 62)(QUOTE (4-7))(QUOTE (Tom Browns
Schooldays))
соответственно. Дадим несколько примеров применения прими-
тивов, приведенных выше:
Выражение Результат
(CDR QUOTE (2)) NIL
( CAR ( CDR ( QUOTE( —23 NIL NIL (1 4) )))) NIL
( CONS ( QUOTE 1 ) ( QUOTE NIL )) ( 1 )
( ATOM ( QUOTE NIL )) T
'Теперь можно спросить, что произойдет, если применить CDR
к списку, состоящему только из одного компонента. В резуль-
тате мы получим специальный атом NIL, который в Лиспе обо-
значает пустой список. NIL обозначает такой же список, как
и конструктор nil языка Норе. Если мы хотим записать NIL
как часть другого выражения, мы должны, конечно, заключить
его в кавычки. Например:
Выражение Результат
(CAR (QUOTE (123))) 1
(CDR ( QUOTE (12 3))) ( 2, 3 )
( CONS ( QUOTE A )
(QUOTE (Boys Life))) (A Boys Life)
(ATOM (QUOTE 1 )) T
(ATOM (QUOTE (12))) F
( CAR ( CDR ( QUOTE ( CAR CDR QUOTE )))) CDR
5.2.2. Условные выражения и примитивные функции
Условное выражение в Лиспе — это просто S-выражение из
четырех компонентов. Первым элементом является специальный
атом IF; второй элемент — это выражение предиката (которое
возвращает Т или F в допустимом условном выражении), а
оставшиеся два элемента являются истинной и ложной ветвями
условного выражения. Например, выражение языка Норе
if х = 0 then 0 else х—1
° Слово ’’QUOTE” означает ’’кавычки”. — Прим, перев.
Другие стили функционального программирования 99
представляется в Лиспе следующим образом:
(IF (EQX( QUOTE 0))( QUOTE 0)( MINX (QUOTE 1)))
EQ и MIN являются еще двумя примерами примитивных функ-
ций. Применения таких функций записываются в префиксной
форме, а не в инфиксной, как в языках Норе и Miranda. Это
делает синтаксис применения примитивной функции идентич-
ным синтаксису применения функции пользователя. Список при-
митивных функций, на которые мы будем ссылаться, приведен
Таблица 5.1. Примитивы Лиспа
ADD АТОМ CAR CDR CONS EQ GTR LESS MIN MUL Арифметическое сложение Проверяет, является ли его аргумент атомом Возвращает голову списка Возвращает хвост списка Строит новый список из головного и хвостового элементов Проверка на равенство Проверка на больше Проверка на меньше Арифметическое вычитание (минус) Арифметическое умножение
в табл. 5.1, хотя могут поддерживаться также многие другие
примитивы.
5.2.3. Определение функций
В языке Норе мы можем непосредственно записать обозна-
чающее функцию выражение с помощью лямбда-выражения.
Например, функция, увеличивающая на единицу значение лю-
бого заданного аргумента, может быть записана в виде
lambda х = > х + 1
В Лиспе существует идентичный механизм, только функция
вводится с помощью специального атома LAMBDA, а не с по-
мощью ключевого слова (lambda), как в Норе. Лямбда-выра-
жение языка Лисп является S-выражением из трех компонен-
тов: первый компонент — это атом LAMBDA, второй — это спи-
сок имен формальных параметров функции, и третий — это тело
функции. Например, функция, увеличивающая на единицу за-
данное значение х, записывается следующим образом:
(LAMBDA (x)(ADD х (QUOTE 1)))
Приведенная ранее функция максимума из двух чисел, т. е,
-----max( т, n) <= if т > n then т else п;
7*
100 Часть I. Глава 5
на языке Норе, записывается на языке Лисп в виде
(LAMBDA (m, n)(IF (GTR m n) m n))
Заметим, что ссылки на формальные параметры функции запи-
сываются с помощью переменных тип соответственно. Они
отличаются от атомов тип, которые должны заключаться
в кавычки. Например, функция, добавляющая атом А к началу
заданного списка, может быть записана в виде
(LAMBDA (A)(CONS (QUOTE А)А))
Здесь мы видим, что кавычки делают атомы отличными от пе-
ременных.
Как и в языке Норе, в языке Лисп нет возможности сделать
лямбда-выражение рекурсивным, поскольку отсутствует имя, на
которое функция могла бы ссылаться в своем теле для вызова
самой себя. Однако мы можем дать имя выражению, заключив
лямбда-выражение внутри так называемого LETREC-выраже-
ния (рекурсивного let-выражения). В языке Норе существуют
два способа записи рекурсивной функции или набора взаимно
рекурсивных функций: мы можем либо объявить новую функ-
цию с помощью dec и затем дать ее определение, либо исполь-
зовать рекурсивное let- или where-выражение. В языке Лисп
все рекурсивные функции вводятся с помощью LETREC. На-
пример, выражение языка Норе
let f ===== El In Е2
где El содержит ссылку на f, может быть записано в языке
Лисп следующим образом:
(LETREC Е2' (f El'))
где El' и Е2' — это эквиваленты языка Лисп для Е1 и Е2. При-
ведем в качестве примера функцию языка Лисп, вычисляющую
факториал:
(LETREC fac
(fac (LAMBDA (x)
(IF (EQ x (QUOTE 0))
(QUOTE 1)
(MUL x (fac (MIN x (QUOTE 1))))))
Другие стили функционального программирования 101
Фактически это запись на языке Лисп следующего выражения
языка Норе:
let fac == lambda х if х = 0 then 1 else х * fac( х — 1)
in fac
Мы можем использовать LETREC для определения взаимно ре-
курсивных наборов функций, заключая определения этих функ-
ций внутри одного и того же LETREC-выражения. Например,
выражение для вычисления 3! может быть записано в виде
(LETREC (f (QUOTE 3))
(f (LAMBDA (x)
(IF (EQ x (QUOTE 0))
(QUOTE 1)
(g x))))
(g(LAMBDA (x )
(MUL x (f (MIN x (QUOTE 1))))))
)
что аналогично следующему выражению языка Норе:
let (f, g)==( lambda x=>if x = 0 then 1 else g(x),
lambda x => x * f( x — 1))
in f(3)
Мы можем выразить набор нерекурсивных определений с по-
мощью LET-выражения, которое имеет такой же формат, как
и LETREC-выражение. Например, выражение языка Норе
let (a, b)=—(h(x), h(у))
in f( a, b) + g( b, a )
может быть записано в виде
(LET (ADD (f a b)(g ba))
(a (h x))
(b (h y))
)
5.2.4. Функции высшего порядка в языке Лисп
Используя QUOTE и LAMBDA совместно, мы можем пере-
давать функции (лямбда-выражения) как параметры другим
функциям. В качестве примера приведем определенную ранее
функцию тар, применяющую заданную функцию f к каждому
элементу списка L. Рассмотрим применение тар, где в качестве
функции f используется функция, увеличивающая свой аргумент
102 Часть I. Глава 5
на единицу. Для того чтобы эту функцию можно было пе-
редать в качестве параметра, определяющее ее лямбда-выраже-
ние заключается в кавычки:
(LETREC (map (QUOTE (LAMBDA (х)(ADD х (QUOTE 1)))
(QUOTE (1 2 3)))
(тар (LAMBDA (fL )
(IF (EQ L (QUOTE NIL))
(QUOTE NIL)
(CONS (f (CAR L))(MAP f (CDR L)))
))
)
)
Заметим, что мы должны заключать в кавычки лямбда-
выражение, поскольку иначе оно будет интерпретироваться
как применение функции LAMBDA к списку аргументов
( (х )( ADD х( QUOTE 1))). Однако основная проблема при
использовании QUOTE в этом контексте в том, что если внутри
заключенного в кавычки выражения существуют ссылки на пе-
ременные, не «связанные» формальными параметрами некото-
рого лямбда-выражения внутри кавычек, то может возникнуть
конфликт имен, когда данное лямбда-выражение в конце кон-
цов применяется. Например, когда мы пишем
(LET (LAMBDA (x)(ADD х n))
(n (QUOTE 1))
то совершенно ясно, что п в лямбда-выражении ссылается на
значение 1. Однако если мы заключим в кавычки это выраже-
ние и передадим его другой функции, то связь n с 1 может
быть потеряна. Например:
(LET (f (QUOTE (LAMBDA (x)(ADD x n))))
(n (QUOTE 1))
(f (LAMBDA (g)(LET (g n)
(n (QUOTE 4)))))
)
Теперь существуют две возможные интерпретаци результата:
либо он равен (ADD 4 1), т. е. 5, либо (ADD 4 4), т. е. 8,
в зависимости от того, как мы обрабатываем вхождение п
в теле заключенного в кавычки лямбда-выражения, т. е. в за-
висимости от того, является ли п связанным статически или
динамически соответственно. Различные реализации языка Лисп
отличаются наиболее значительно именно стратегией связыва-
ния. Первые реализации Лиспа использовали динамическое свя-
Другие стили функционального программирования ЮЗ
зывание, но теперь считается, что это было ошибкой, и поэтому
самые последние диалекты (такие, как Lispkit) поддерживают
статическое связывание. Общий механизм статического связы-
вания описан в гл. 9.
Вероятно, самой удивительной (и привлекательной) особен-
ностью языка Лисп является простота его синтаксиса. Как мы
видели, программа на Лиспе строится только из восьми типов
выражений: переменных, констант, примитивов, условных вы-
ражений, применений, лямбда-, let- и letrec-выражений. Все
«специальные» выражения, подобные true, false и nil, представ-
ляются как атомы. Более того, программа на Лиспе сама яв-
ляется S-выражением, т. е. не существует явных ключевых
слов. Это приводит к одинаковому представлению программ и
данных. Хотя мы придаем специальный смысл атомам LET,
LETREC, LAMBDA и т. д., они тем не менее являются простыми
атомами. Если эти атомы встречаются в нужной позиции (т. е.
в начале списка), мы можем интерпретировать их как ключе-
вые слова. Подобным образом, если атомы ADD, MIN, CAR
и т. д. появляются в голове списка, мы можем интерпретировать
их как применения примитивных функций. Таким образом,
язык Лисп почти не имеет синтаксических правил, отличных от
правил формирования S-выражений. В этом отношении он ра-
дикально отличается от языков, подобных языку Норе, БНФ
которых занимает несколько страниц текста.
5.3. FP
До сих пор мы рассматривали языки, в которых функции
пользователя выражаются в терминах преобразований объек-
тов, имеющих явным образом указанные имена. Например, ко-
гда мы пишем что-нибудь вроде
------f(x) <= 1+ х;
в языке Норе, мы указываем не только имя функции f, но также
и имя объекта, к которому f в конечном счете применяется, т. е.
х. Поэтому определение функции в языке, подобном Норе, дает
имена объектам, передаваемым функции, и описывает затем, что
делать с этими переданными аргументами. Поначалу при напи-
сании программы этот подход является самым простым для по-
нимания: определение функции принимает вид набора уравне-
ний, определенных для всех возможных «форм» объектов.
В предшествующих главах мы видели несколько примеров функ-
ций, определенных таким образом.
Однако одной из наиболее «сильных» сторон функциональ-
ных языков является то, что они поддаются формальным преоб-
104 Часть I. Глава 5
разованиям. Одной из их форм является преобразование про-
граммы, использующее свойство прозрачности ссылок функцио-
нальных программ, чтобы «заменить подобное подобным», улуч-
шив при этом характеристики программы во время выполнения.
Как мы увидим в части III этой книги, формальные преобразо-
вания часто легче выразить, если ссылки на объекты могут
быть удалены из исходной программы, в результате чего каж-
дая функция редуцируется к форме, свободной от объектов (или
свободной от переменных).
В этом разделе мы кратко рассмотрим функциональный
язык, называемый FP, где каждая функция выражается именно
таким образом. FP может быть использован как язык програм-
мирования, но в этой книге мы будем использовать его скорее
как промежуточную форму записи, в которой могут быть выра-
жены формальные преобразования. Это относится в основном
к части III, но в гл. 13 язык FP также используется для введе-
ния категорийной комбинаторной логики первого порядка.
5.3.1. Компоненты FP-системы
FP-система состоит из трех компонентов: объектов, примити-
вов и комбинирующих форм.-
Объекты
Хотя объекты являются частью каждой FP-системы, не суще-
ствует механизма, который позволял бы функции пользователя
ссылаться на объект непосредственно; объекты появляются
только на этапе выполнения в качестве аргументов и возвра-
щаемых результатов вызова функции. Тем не менее обсуждение
объектов в языке FP уместно, поскольку чтобы определить
смысл различных FP-функций, мы должны рассмотреть, что
происходит, когда мы применяем эти функции к заданным объ-
ектам-аргументам.
В FP-системе существуют три типа объектов, а именно JL
(читается «основание»), атомы и последовательности.
Объект _1_ является «неопределенным» объектом и представ-
ляет ошибочное состояние. Например, попытка вычислить вы-
ражение 1/0 даст ±, поскольку деление не определено, когда
знаменатель равен нулю. Когда мы говорим, что при вычисле-
нии выражения получается _1_, мы обычно имеем в виду, что на
практике попытка вычислить данное выражение приведет к ава-
рийному завершению программы с выдачей сообщения об ошиб-
ке или к зацикливанию программы.
Атомом в FP является любая константа базового типа. На-
бор базовых типов, поддерживаемых FP-системой, произволен,
Другие стили функционального программирования 105
но обычно он включает множество целых 0, 1, -—1, 2, —2 и т. д.,
символы, например 'а', zb', 'с', булевы константы Т (true) и
F (false), действительные числа, например 11.9, 3.56Е — 2,
строки символов, например "Fred", «АТОМ» и "so on".
Последовательность в FP—это симметричный список, не
имеющий типа. Он симметричен в том смысле, что для каждой
операции, работающей с началом (головой) последовательно-
сти, существует симметричная операция, работающая с концом
(хвостом) последовательности. В отличие от Hope FP является
нетипизированным языком, так что не существует ограничений
на типы объектов, которые могут передаваться заданной функ-
ции, или на типы объектов, формирующих последовательность.
Мы записываем последовательность как набор объектов, разде-
ленных запятыми, заключенный в угловые скобки, например:
( ) обозначает пустую последовательность, сравните с nil в языке
Норе
(1, 2) обозначает последовательность чисел
(( ), (1)) обозначает последовательность последовательностей
(1, 'а', ( )) обозначает последовательность объектов разных типов
Последовательности имеют очевидное сходство с S-выражения-
ми Лиспа, описанными в предыдущем разделе. Мы говорим, что
последовательности в FP являются сохраняющими основание,
имея в виду, что последовательность не определена, если любой
или все ее компоненты являются неопределенными, т. е.
<хь х2, ..., хп> = -1-, если для любого i справедливо xi = ±
( 1 С i С п)
Примитивы
Как и в языке Норе, «примитивами» являются предварительно
определенные функции, которые поддерживаются непосредствен-
но реализацией, а не определяются явно программистом. Набор
примитивов, поддерживаемых FP-системой, произволен. «Ти-
пичный» набор примитивов (которые мы предполагаем суще-
ствующими здесь и далее) может быть таким, как в табл. 5.2.
В FP мы обозначаем применение функции f к аргументу х
с помощью символа :, т. е.
f :х
Если функция имеет больше одного аргумента, эти аргумен-
ты передаются ей в форме последовательности. Так, если f —
это функция от к аргументов, то применение f к аргументам
х);х2, ..., хи записывается в виде
f: (хь х2, ..., хк)
106 Часть I. Глава 5
Таблица 5.2. Примитивы FP
+, —, * и т. д. addk, subk, mulk и т. д. Арифметические операторы Примитивы, которые соответственно прибавляют к, вы- читают к и умножают на к заданный числовой аргу- мент
= , =/=, >, <, - and, or, not, ... eqk, neqk, ... 1, 2, 3, ... Операторы сравнения Булевы операторы И, ИЛИ, НЕ, ... Операторы сравнения с константой Функции-селекторы для последовательностей. Примене- ние Т к последовательности (длиной по крайней мере i) дает i-й элемент последовательности, например: 3 : <хь х2, х3, х4> = хз Если последовательность имеет меньше i элементов, ре-
Ir, 2r, 3r, ... зультатом будет _1_. «Правые» функции-селекторы, определенные аналогично функциям 1, 2, 3, ..., но выбирающие элемент, начи- ная с правого конца последовательности, например: 2г : <хз, х2, ..., Xn-i, хп> = хп_4
hd, tl Стандартные функции головы и хвоста последователь- ностей hd : <Xi, х2, .... х„> = Xi tl : <xt, х2 хп> = <х2, ..., хп> hd : х, tl : х = _1_, если х не является последователь- ностью
hr, tr Правые функции головы и хвоста: hr : <xi, х2, .... хп> = х„ tr : <xt, х2 xn> = <xi х„_1> hr : х, tr : х = _1_, если х не является последователь- ностью
cons Конструктор списков (эквивалентный :: в языке Норе), определенный в виде cons : <Xj, <х2, хз, .... Хп» = <х1, х2, .... хп> cons : х = _L, если х не является последовательностью • из двух компонентов, второй из которых сам является последовательностью
consr Правый конструктор списков: consr : «х4, х2, . . . , Хп-1>, Хп> = <Х1, Х2, .... Хп-1, Хп> consr : х = _L, если х не является последовательностью из двух компонентов, первый из которых сам является
null последовательностью Функция, проверяющая, является ли последователь- ность пустой (< )), т. е. null : < > = Т null : <х(, х2, ..., х„> = F null : х = _L, если х не является последовательностью
Другие стили функционального программирования 107
Продолжение табл. 5.2
distl Формирует из заданных объекта и последовательности последовательность пар: distl : <х, <уь Уг, .... уп» = «X, yi>, <х, у2>, ... .... <х, Уп» distl : х = _L, если х не является последовательностью из двух компонентов, второй из которых является по- следовательностью
distr Правый аналог distl: distr : «уi, у2, .... уп>, х> = «уь х>, <у2, х>, ... .... <Уп, х» distr : х = _1_, если х не является последовательностью из двух компонентов, первый из которых является по- следовательностью Функция ’’йота”. Имея целый аргумент п 0, возвра- щает последовательность первых п положительных це- лых, например: i :4 = <1, 2, 3, 4> i:0 = < >
id Тождественная функция id : х = х, для всех х
В этом отношении все функции в FP имеют арность, равную
единице.
Приведем несколько примеров применений примитивных
функций вместе с результатами каждого применения.
Применение Результат
+ =<1, 7) 4
+ 1:3 8
2:(4, 8, 6) 8
2г : (4, 8, 6) 8
hr : <1, 2, 3, 4) 4
distl :(1, {'a', 'b', 'с', 'd')) «1, 'а'), (1, 'b'>, (1, 'с'), (1/ d'»
Все функции в FP являются строгими, т. е. они возвращают
±, если применяются к аргументу, являющемуся
Комбинирующие формы
Комбинирующая форма (называемая также функциональной
формой или операцией формирования программы (ОФП)) —
это просто программная конструкция, т. е. строительный блок,
с помощью которого конструируются новые функции; сравните,
например, с конструкцией if ... then ... else ..., используемой
во многих языках программирования.
108 Часть I. Глава 5
В FP существует шесть комбинирующих форм: константа,
условное выражение, композиция, конструкция, «применить-ко-
всем» и вставка. Описание каждой из них вместе с некоторыми
примерами дано ниже. Заметим, что функции пользователя вво-
дятся в FP с помощью зарезервированного слова def. Например:
def f = ...
определяет функцию f; тело f выражается с помощью комбини-
рующих форм.
1. Константа. Константа в FP — это просто функция, которая
при применении к любому определенному объекту всегда дает
один и тот же результат. Мы будем использовать подчеркива-
ние для обозначения константных функций, и в общем случае
для объекта к:
к : х — к, если х =/= J_ ;
= J. в противном случае
Заметим, что подчеркивание необходимо, чтобы отличать кон-
стантную функцию к от функции-селектора к для последова-
тельности. Приведем еще несколько примеров:
"FP" "FP": х = "FP" для определенного х
F F:х = F для определенного х
—123 —123: х = —123 для определенного х
Заметим, что возвращаемые величины всегда являются атомами.
2. Условные выражения. Конструкция условного выражения
в FP имеет следующий синтаксис:
p^q; г
Однако в отличие от языка Норе здесь р, q и г являются функ-
циями. Чтобы понять, что означает p-*q; г, Мы рассмотрим, что
происходит, когда мы применяем такое условное выражение
к объекту х:
(р —q ; r):x = q:x, если р:х = Т, т. е. true;
= г:х, если p:x = F, т. е. false;
= ± в противном случае
Так, например, (T-»-q;r):x эквивалентно q:x, поскольку если
х определен, то Т:х —Т, а если x = J_, то оба выражения да-
дут ±, так как Т и q являются строгими функциями. Другим
примером является выражение
(eq->l; 2): (5, 6)
Другие стили функционального программирования 109
которое при вычислении дает 6, поскольку eq: <5,6> дает F
и 2 : <5, 6> дает 6.
Функция max, используемая ранее, легко выражается в FP
с помощью условной конструкции:
def max —> 1; 2
Так, например:
max: (2, 3)
= (>->1; 2): <2, 3)
— 2: (2, 3), поскольку > : (2, 3) дает F
_ з
3. Композиция. В FP композиция двух функций f и g записы-
вается в виде
fog
что означает
(f °g): x = f: (g : х)
Например, если мы хотим применить примитив 4- к первому
элементу последовательности пар чисел (пара чисел является
последовательностью из двух чисел), то это можно сделать
с помощью композиции двух функций, первая из которых вы-
бирает элемент последовательности, а вторая складывает два
числа первого элемента, т. е.
4~ ° 1
Например:
( + ° 1): «3, 4), (1, 5), (7, 2))
= 4-:(1:«3, 4), (1, 5), <7, 2)))
= 4-: <3, 4)
= 7
4. Конструкция. С помощью конструкций в FP строятся после-
довательности. Конструкция из п функций записывается в виде
[fx, h, . . .. fnl
Результатом применения такой конструкции к объекту х яв-
ляется n-элементная последовательность, в которой i-й элемент
является результатом применения fi к х (l=Ci^n), т. е.
[fx. f2. • • •, М: х == <fj: x, f2: x, ..., fn: x)
110 Часть I. Глава 5
Например, если функцию
def f = [id, addl, add2]
применить к числовому объекту х, получится последователь-
ность из трех элементов, состоящая из чисел х, х+1, х + 2.
Заметим, что конструкция может использоваться для построе-
ния последовательности аргументов для применения функции.
Например:
+ ° [id, id]
удваивает объект, к которому применяется
( + ° [id, id]): х
==+ : ([id, id]: х)
= + : <x, x)
= X + X
5. Функции высшего порядка. Отличительной особенностью FP
является то, что в нем нельзя выражать функции высшего по-
рядка, определенные пользователем. Однако существуют встро-
енные функции высшего порядка — это ОФП «применить-ко-
всем», левая вставка и правая вставка. Каждая из них работает
с последовательностями, и считается, что для большинства
практических целей других функций высшего порядка не тре-
буется.
Вспомним из гл. 4, что наиболее важным применением функ-
ций высшего порядка является обобщение функций, работаю-
щих со структурами данных, например функций, определенных
для работы со списками. Конструкция языка FP «применить-ко-
всем», левая вставка и правая вставка. Каждая из них работает
том для последовательностей функции тар, работающей со
списками, т. е. af обозначает функцию, которая применяет f
к каждому элементу в заданной последовательности аргументов:
(a f): <хь х2‘...хп> = (f: xb f: х2....f: хп>
Например, atl применяет функцию tail выделения хвоста после-
довательности к заданной последовательности последователь-
ностей:
(a tl): «1 2 3)<4 5 6><7 8 9))
= <tl: <1 2 3), tl :(4 5 6), tl: <7 8 9))
= «2 3), <5 6), (8 9»
Кроме функции тар, определенной для списков в языке Норе
в гл. 4, мы также определили функцию высшего порядка
Другие стили функционального программирования 111
reduce. В FP существуют два аналога этой функции, называе-
мые правой вставкой (обозначается /) и левой вставкой (обо-
значается \) и определенные для обработки последовательно-
стей. Функционал правой вставки аналогичен функции reduce,
за исключением того, что он не допускает какого-либо специ-
ального «базового» случая в своей основной форме:
(Л):<х> =х
(Д):<х1; х2, ..., xn) = f: (х,, (/f):(x2, .. ,,хп»
Функционал левой вставки определяется подобным образом, за
исключением того, что самым внутренним применением яв-
ляется
(\f):<x> =х
(\f): <xi, х2, ..., xn) = f: ((\f): <хь х2, ..., xn_i>, хп>
Мы используем слово «вставка», поскольку если мы представим
функцию от двух аргументов в виде эквивалентного инфикс-
ного оператора, то функции / и \ как бы вставляют этот опе-
ратор между каждыми двумя элементами последовательности.
Например, результат применения
(/+)-’<Х1, Х2, .. ., хп>
равен значению выражения
X, + х2+ ... + Хп_1 + хп
Существуют также варианты вставок, имеющих связанные
с ними базовые случаи. Они указываются индексами у симво-
лов / или \,например:
/о + : <х,, х2, ..., хп) = + : (х,, (/0 +): (х2, ..., хп»
/о+:<> = О
На этом заканчивается описание основных компонентов
FP-системы. В следующем разделе мы коротко обсудим стиль
программирования на языке FP. Этот вопрос представляет
здесь скорее академический интерес, поскольку мы будем ис-
пользовать FP в основном как инструмент описания преобразо-
ваний, а не как инструмент разработки программного обеспече-
ния. Однако, как мы увидим далее, FP хорошо иллюстрирует
мощность функциональной нотации, и в особенности вырази-
тельную силу функций высшего порядка. Более того, характер-
ный для этого языка стиль программирования делает его осно-
вой жизнеспособных функциональных языков для практического
использования [9].
112 Часть I. Глава 5
5.3.2. Некоторые примеры стиля программирования
на языке FP
Поскольку мы можем именовать наши собственные функции
с помощью оператора def, то допустимо записать определение
рекурсивной функции, сославшись на определяемую функцию
внутри ее собственного тела. Например, функция fac, вычис-
ляющая факториал заданного числа п, может быть выражена
следующим образом:
def fac = eq 0-* 1 ; *°[id, fac ° ( — ° [id, 1])]
Заметим, что в этом определении нет ссылок на объекты, и по-
тому нет символов применения функции. Тело состоит целиком
из функций и функционалов (функций, которые манипулируют
функциями). Однако, когда мы применяем fac к аргументу п,
выражение, получающееся в результате, выглядит более при-
вычно (по крайней мере, для программистов на языке Норе):
fac : n = eq 0 : n-> 1 : п ; * : (n, fac : ( — : (n, 1)))
Как мы могли бы ожидать, исходя из определений функциона-
лов композиции (°) и конструкции ([..]), композиции заме-
няются применениями, а конструкции — последовательностями.
Каждое вхождение функции тождества (id) также заменяется
объектом п, к которому эта функция применяется. Важно по-
нять, что это выражение конструируется только во время вы-
полнения и невидимо для программиста. Программист видит
тело fac как выражение, заданное в терминах функций, а не
объектов. Если бы в приведенном выше применении аргумент п
был равен 3, мы бы получили
eq0:3—>Л:3; * : (3, fac : ( — : (3, 1)))
= *:<3, fac: (— : <3, 1)))
что в точности соответствует 3*fac(3—1), как и ожидалось.
Если бы аргумент был равен 0, то был бы применен базовый
случай:
eq0:0—>£:0; * : (0, fac : (—’.(0, 1)))
= £:0
= 1
Любая рекурсивная функция может быть выражена в FP
подобным образом с помощью комбинирующих форм и прими-
тивов языка. Однако многие такие функции имеют альтернатив-
ное нерекурсивное определение в FP, использующее функции
Другие стили функционального программирования 113
а, /, \ для удаления рекурсии. Например, определенная выше
функция fac имеет нерекурсивный эквивалент, выраженный с по-
мощью функции вставки (со значением в базовом случае, рав-
ным 1):
def fac = /t * ° i
Это решение непосредственно вытекает из природы факториала:
выражение fac: и требует вычисления выражения 1*2*3* ...
... *(п—1)*п. Но это не что иное, как последовательность
целых от 1 до и с символами *, вставленными между каждыми
двумя соседними числами этой последовательности. Таким об-
разом, наше альтернативное определение fac корректно, по-
скольку примитив i при применении к п дает последователь-
ность целых от 1 до и, а /* вставляет в эту последовательность
символы *1
Приведем два других примера рекурсивных FP-программ
и их нерекурсивных эквивалентов.
Пример 1. Нахождение длины последовательности
Рекурсивное определение функции, которая вычисляет длину
последовательности, выглядит вполне естественно:
def len = null -> 0; +°[1, len°tl]
Нерекурсивное решение, однако, является довольно дерзким:
def len = /о + ° а 1
Оно просто говорит: «Замените каждый элемент последова-
тельности единицей и затем сложите все эти единицы друг
с другом!». Конечно, этот пример является слегка надуманным,
поскольку вероятно, что на практике функция len была бы при-
митивом FP-системы.
Пример 2. Тестирование последовательности на наличие в ней
заданного объекта
Следующая функция mem проверяет, является ли заданный
объект членом заданной последовательности. Рекурсивное ре-
шение выглядит так:
def mem = null ° 2 ->F; eq ° [I, hd°2]->T; memofl, tl о 2]
Нерекурсивная версия mem очень выразительна:
def mem = Д, or ° aeq ° distl
8 — 1473
114 Часть I. Глава 5
При чтении этого выражения справа налево, distl формирует
последовательность пар из двух аргументов mem, причем пер-
вым элементом каждой пары является элемент, наличие кото-
рого в последовательности мы проверяем, а вторым — один из
членов тестируемой последовательности, a eq применяет прими-
тив eq к каждой паре, давая в результате последовательность
истинностных величин, а /ог вставляет оператор or между чле-
нами этой последовательности. Так, например:
mem’. (I, (3, 5, 1))
=/or :(<xeq :(distl :< 1, (3, 5, 1))))
= /or: (aeq : «1, 3>, <1, 5), <1, 1»)
=/or: <F, F, T)
= T
Хотя эти примеры просты, они дают представление о стиле
программирования на языке FP. Фактически элегантность не-
рекурсивных решений в равной степени говорит о выразитель-
ной силе как функций высшего порядка, так и языка FP в це-
лом. В языках, подобных Норе, основанных на объектах, мы
можем получить похожие решения этих задач, используя описан-
ные ранее функции тар и reduce. Хотя можно возразить, что
FP, не имея строгой типизации и имея только последовательно-
сти для построения структур данных, недостаточно хорошо осна-
щен для использования в серьезных программных разработках,
существует много преимуществ в предписываемой этим языком,
свободной от переменных манере программирования. В действи-
тельности нет причин, по которым нельзя было бы соответ-
ствующим образом дополнить FP, и эта работа была начата
в проекте языка FL [9], который сохраняет свободный от пере-
менных стиль программирования.
На этом завершается наше обсуждение различных альтер-
нативных стилей функционального программирования. Четыре
рассмотренных нами языка — это далеко не все функциональ-
ные языки: интересующегося читателя мы отсылаем к описа-
ниям языков KRC [82] и SASL [79] (которые были предше-
ственниками языка Miranda), Ponder [32] и Orwell [84], кото-
рые все являются примерами «чистых» (т. е. прозрачных по
ссылкам) функциональных языков. Другим примером является
ML [36], хотя он содержит некоторые черты императивных язы-
ков, делающие его непрозрачным по ссылкам. Однако, как и
для «загрязненных» диалектов Лиспа, эти нефункциональные
особенности можно легко игнорировать. Наконец, следует за-
метить, что возможно также писать чисто функциональные про-
граммы на императивном языке, подобном языку Паскаль, опре-
делив подходящий абстрактный тип данных и используя при
Другие стили функционального программирования 115
написании программ только функции доступа для этого типа
данных. Полученный в результате «язык» имеет примерно та-
кую же выразительную силу, как и подмножество языка Лисп
первого порядка, и, хотя является ограниченным, может на-
учить нас многим принципам функционального программирова-
ния. Заинтересованного читателя мы отсылаем к работе [11],
где этот метод описан более детально.
Резюме
• Miranda является строго типизированным, полиморфным
функциональным языком высокого уровня, во многом похожим
на язык Норе.
• Функции в языке Miranda являются карринговыми, т. е. они
могут быть применены частично, давая в результате новые
функции.
• Miranda имеет средства абстракции списков и множеств.
• Лисп является нетипизированным языком высокого уровня
для обработки списков.
• Программы и данные в языке Лисп представляются одина-
ковым образом с помощью S-выражений.
• Заключенные в кавычки выражения в языке Лисп могут по-
родить проблемы конфликта имен.
• FP является нетипизированным функциональным языком,
который предписывает программирование на функциональном,
а не на объектном уровне.
• FP-система состоит из объектов, примитивных функций и
комбинирующих форм.
• Все структуры данных в языке FP строятся с помощью по-
следовательностей, которые являются симметричными списками.
• Все функции высшего порядка в языке FP являются встро-
енными.
• Программы на языке FP строятся из комбинирующих форм,
по-другому известных как функциональные формы или опера-
ции формирования программы (ОФП).
• Многие рекурсивные функции могут быть выражены нере-
курсивно с помощью одной или нескольких комбинирующих
форм.
Упражнения
5.1. Запишите на языке Miranda версию полиморфной про-
граммы Treesort, приведенной в гл. 3.
5.2. Рассмотрим карринговую функцию f языка Miranda, опре-
деленную в виде fX], ..., xn = Е.
8*
116 Часть I. Глава 5
а. Запишите эквивалентную функцию языка Норе с помощью
вложенных lambda-выражений.
б. Как можно определить f без использования кортежей с по-
мощью п функций языка Miranda от одного аргумента, объеди-
ненных во вложенном where-выражении?
5.3, Фред сказал: «Карринг обладает такой же мощностью, как
и использование лямбда-выражений, поскольку частичное при-
менение функции можно легко записать явно как лямбда-выра-
жение». Прав ли Фред?
5.4. Что делают следующие функции языка FP?
а. , consr
б. а + °р, где р =conso[[l о 1, 1 <?2], ро [tlо 1, tlо2]]
в. af»i, где f = а1 «и
5.5. а. Запишите рекурсивное определение функции арр при-
соединения последовательностей на языке FP такой, что
арр : «хь х2, ..., хп>, <уь у2, ..., ут» =.
==<хь х2....хп, уь у2, ..., ут>
б. Теперь запишите нерекурсивное определение арр, исполь-
зуя ОФП / и ° и примитивы cons и consr.
Часть II
РЕАЛИЗАЦИЯ
Введение
Первая часть этой книги достаточно полно знакомит чита-
теля с основами функционального программирования, и мы мо-
жем сейчас описать различные методы, используемые для реа-
лизации функциональных языков. Для того чтобы сохранить
общность в наших рассуждениях, мы будем использовать спе-
циальную нотацию для функциональных выражений, которая
является достаточно мощной, чтобы выразить все черты функ-
ционального языка, и в то же время достаточно простой, чтобы
легко описать различные методы реализации без рассмотрения
специфики исходных языков. Промежуточная нотация, которую
мы будем использовать, называется лямбда-нотацией и проис-
ходит из области математической логики, называемой лямбда-
исчислением, на котором основаны многие теоретические
результаты в области функциональных языков. Часть II начи-
нается с введения в лямбда-исчисление, где описывается синтак-
сис лямбда-выражений, а также правила переписывания, спе-
цифицирующие индивидуальные шаги, требуемые для вычисле-
ния, или редукции, заданного лямбда-выражения. Самое важное
из этих правил, называемое 0-редукцией, выражает в лямбда-
исчислении применение функции. Неформально роль 0-редукции
состоит в том, чтобы заменить каждое вхождение формального
параметра функции соответствующим параметром. Фактически
в основе любой реализации лежит порядок, в котором выпол-
няются последовательные 0-редукции, и условия, при которых
последовательность редукций завершается. Вообще говоря, су-
ществуют два пути выполнения 0-редукции: мы можем либо
оставить ссылку на формальный параметр без изменений, но
«запомнить» обозначаемую ею величину в отдельной структуре
данных, либо выполнить подстановку, которая физически заме-
няет ссылку на параметр его фактическим значением. Эти два
подхода ведут к реализациям, основанным на контексте и ко-
пировании соответственно.
118 Часть II
Лямбда-исчисление дает необходимую основу для всего
остального материала части II, который начинается с описания
трансляции исходного языка в промежуточный код, основанный
на лямбда-нотации. Процесс трансляции начинается с лексиче-
ского и синтаксического анализа исходного кода, но, поскольку
методы такого анализа хорошо известны, мы воздерживаемся
от их детального обсуждения, выбирая вместо этого представ-
ление правил синтаксического анализа в абстрактном виде.
Обсуждение нашей главной темы начинается в гл. 7, которая
описывает систему вывода и проверки типов, проверяющую
правильность структуры типов в программе. После того как
для программы была выполнена проверка корректности типов
ее выражений, мы можем транслировать программу в проме-
жуточную нотацию, и эта трансляция описывается в гл. 8. Как
мы увидим, большинство элементов исходного языка трансли-
руется очень просто и единственным исключением, требующим
специального рассмотрения, является трансляция сопоставления
с образцом.
Описав промежуточный код, мы затем объясняем, как он
может быть механически вычислен на компьютере. Наш первый
метод реализации основан на интерпретаторе для промежуточ-
ного кода. Косвенно обеспечивая реализацию исходного языка,
этот интерпретатор дает нам также операционную семантику
промежуточного языка, которая описывает язык, специфицируя
как вычисляется каждая языковая конструкция. Мы увидим,
что существует множество довольно тонких вопросов, особенно
когда пытаемся реализовать различные порядки вычислений.
Альтернативой механизму интерпретации является определение
абстрактной машины для вычисления выражений промежуточ-
ного кода, основанной на некоторой правильно определенной
вычислительной модели, и в гл. 10 мы описываем одну такую
машину — SECD-машину, — которая вычисляет выражения, за-
писанные в лямбда-нотации.
И наш интерпретатор, и SECD-машина являются основан-
ными на контексте, так что фактические параметры функции
запоминаются в отдельном контексте, а не подставляются физи-
чески в тело функции. Кроме того, обе эти реализации рас-
сматривают лямбда-выражения «текстуально», т. е. как строки
напечатанных символов. Альтернативой этому является исполь-
зование двумерного графового представления выражений. Вы-
числитель, редуцирующий выражения в этой форме к их ко-
нечным значениям, называется редуктором графов; а общая
модель вычислений — редукцией графов. Эта модель является
основанной на копировании, поскольку применение функции
к аргументу ведет к копированию графа тела функции с выпол-
Введение 119
нением соответствующей подстановки аргумента. Данная модель
естественным образом является ленивой, так что вычисляются
только те подвыражения, значения которых необходимы. Дру-
гими словами, мы говорим, что данная модель вычисления яв-
ляется управляемой запросами, имея в виду, что вычисление
выражения начинается, только когда его значение явным обра-
зом затребовано. Основная модель редукции графов описывается
в гл. 11, а различные ее оптимизации — в гл. 12 и 13.
В качестве альтернативы для редукции графов, где вычис-
ление выражения инициируется, только когда требуется его
значение, можно придумать графовую модель, в которой выра-
жение вычисляется при первой возможности; другими словами,
применение функции в такой модели имеет место, как только
аргументы этой функции становятся доступными. При этом вы-
числение начинается при наличии аргументов, а не тогда, когда
имеется запрос, а результирующая модель вычислений назы-
вается потоковой. Потоковая модель естественным образом
является управляемой данными и может рассматриваться как
оптимизированная форма энергичной редукции графов. Пото-
ковые реализации описываются в гл. 14.
Описав различные преобразования функциональных выра-
жений и различные модели вычислений, которые могут исполь-
зоваться в качестве основы для вычисления этих выражений,
мы сможем собрать все это воедино и построить полностью
компилирующую систему. В гл. 15 мы познакомимся с основ-
ными схемами компиляции, рассмотрев два примера реализа-
ций: «контекстную» реализацию, основанную на модели опти-
мизированной SECD-машины, и реализацию редукции графов,
основанную на копировании. Здесь мы описываем используемые
в этих реализациях различные промежуточные коды, архитек-
туры абстрактных машин и функции генерации кода, требуемые
для построения кода абстрактной машины из заданной про-
граммы. Динамическое использование памяти в системах, ко-
торые реализуют функциональные (или другие) языки, приво-
дит к появлению значительных объемов неиспользуемой
памяти. Поэтому, чтобы закончить картину, мы должны рас-
смотреть механизмы утилизации этой памяти, называемые сбор-
кой мусора, и в гл. 16 мы заканчиваем часть II описанием рабо-
ты некоторых наиболее часто используемых сборщиков мусора.
Глава 6
МАТЕМАТИЧЕСКИЕ ОСНОВЫ: 1-ИСЧИСЛЕНИЕ
В оставшейся части этой книги мы будем широко исполь-
зовать общепринятую форму записи функциональных выраже-
ний, которая используется в так называемом 1-исчислении [21].
1-Исчисление было использовано как средство для описания
(чисто синтаксического) свойств математических функций и
эффективной обработки их в качестве правил. Как мы видели
в предыдущих главах этой книги, функциональные программы
построены из «чистых» функций, т. е. функций в математиче-
ском смысле, и поэтому нотация 1-исчисления особенно удобна
для формального описания манипулирования функциями и
даже в качестве промежуточного кода, в который можно транс-
лировать исходную программу. В действительности функцио-
нальные языки программирования часто представляют собой
«улучшенные» версии нотации 1-исчисления в том смысле, что
все функциональные программы можно преобразовать в экви-
валентные 1-выражения. Хотя нотация 1-исчисления проста,
она является достаточно мощной, чтобы описать все черты
исходного функционального языка. В гл. 8 мы определим про-
межуточный код для функциональных языков, основанный на
нотации 1-исчисления, и опишем, как исходную программу
можно транслировать в этот код.
Мы начинаем эту главу с описания синтаксиса 1-выражений
и покажем затем, как 1-выражение может быть вычислено, или
редуцировано. В разд. 6.2 описываются правила преобразова-
ния выражений (правила вывода) в 1-исчислении, которые яв-
ляются элементарными действиями, используемыми для вычис-
ления значения 1-выражения.
В разд. 6.3 мы дадим более точный смысл термину «значе-
ние 1-выражения» и введем понятие нормальной формы. Рас-
смотрение различных путей преобразования выражения к нор-
мальной форме приведет нас к дискуссии о порядке редукций,
который предписывает нам, что делать дальше на каждом шаге
Математические основы: Х-исчисление 121
вычисления Х-выражения. Как мы увидим в разд. 6.4—6.6, ком-
бинация порядка редукций и нормальной формы ведет к раз-
личным возможным схемам редукции. Мы опишем, как эти
схемы редукции соотносятся с механизмами вызова, на которые
часто ссылаются в контексте языков программирования высо-
кого уровня. В разд. 6.7 будет продемонстрировано, как сред-
ствами Х-исчисления можно описывать рекурсивные функции.
Сначала мы рассмотрим функции, которые могут вызывать
только сами себя, а затем перейдем к наборам взаимно рекур-
сивных функций, каждая из которых может вызывать любую
другую из данного набора.
В конце главы мы опишем чистое Х-исчисление и канониче-
ское Х-исчисление. Начальные разделы главы описывают рас-
ширенную версию Х-исчисления, где предполагается наличие
множества предварительно определенных констант (атомов и
примитивных функций), например целых чисел и связанных
с ними операций, таких, как +, — и т. д. В чистом Х-исчисле-
нии эти константы не являются предварительно определенными,
но они могут быть представлены с помощью небольшого числа
примитивов. Мы рассмотрим некоторые из наиболее часто ис-
пользуемых констант и покажем, как они представляются в
чистом Х-исчислении. В каноническом Х-исчислении все иден-
тификаторы (имена переменных) заменены целыми числами.
Мы объясним преимущества этого представления и покажем,
как транслируются в каноническое исчисление правила преоб-
разования обычного Х-исчисления. Введенную нотацию мы снова
будем использовать в гл. 13, где описывается схема реализа-
ции, называемая категориальной абстрактной машиной.
6.1. Введение и синтаксис
Попросту говоря, Х-исчисление — это исчисление анонимных
(безымянных) функций. Оно дает, во-первых, метод представ-
ления функций и, во-вторых, множество правил вывода для
синтаксического преобразования функций.
Начнем с рассмотрения следующей простой исходной функ-
ции, которая удваивает значение своего аргумента:
------double( х) <= 2 * х ;
Чтобы представить эту функцию в нотации Х-исчисления,
мы опускаем имя функции ’’double”, делая ее анонимной. Она
представляется в виде Х-выражения следующим образом:
Хх.*2х
122 Часть II. Глава 6
Заметим, что мы записываем применение встроенных функ-
ций, таких, как *, в префиксной форме. Хотя мы пишем ”*2х”
в теле абстракции, мы можем читать эту запись как «два, умно-
женное на х». Причина выбора такой нотации скоро будет ясна.
Приведенное выражение должно быть знакомо из предыдущих
глав, относящихся к языку Норе; в этом языке мы можем за-
писать подобное выражение, используя ключевое слово lambda
вместо А и символ = > вместо «.».
lambda х = > 2 * х
Мы читаем символ А как «функция от» и точку (.) как «ко-
торая возвращает». A-Выражения такой формы называются
А-абстракциями.
Символ х после А называется связанной переменной аб-
стракции и соответствует понятию формального параметра в
традиционной процедуре или функции. Выражение справа от
точки называется телом абстракции, и. подобно коду тради-
ционной процедуры или функции, оно описывает, что нужно
сделать с параметром, поступившим на вход функции.
Тело абстракции может быть любым допустимым A-выра-
жением, и поэтому оно также может содержать другую абстрак-
цию, например:
Ах.Ху.* ( + х у)2
Это выражение читается как «функция от х, которая воз-
вращает функцию от у, которая возвращает (х + у)*2» и яв-
ляется выражением A-исчисления для следующей функции
языка Норе:
lambda х = > lambda у=>(х + у)*2
а также функции языка Miranda:
fxy = (х + у) * 2
К функциям в A-нотации применим карринг, поэтому все они
имеют только один аргумент (вспомним описание языка Mi-
randa в гл. 5). Все абстракции включают поэтому только один
символ А и единственную связанную переменную. Строго го-
воря, это означает, что применения функций должны заклю-
чаться в скобки, например:
(...((( Ах1. Ах2. . . . Ахп.Е )х1 )х2) ... хп)
Однако существует соглашение, по которому функция приме-
няется всегда к самому левому аргументу, и поэтому скобки
вокруг каждого вложенного применения можно опустить без
изменения смысла выражения:
(Axi.Ax2. ... Ax„.F)x1x2 ... х„
Математические основы: 1-исчисление 123
(Вспомним, что в языке Miranda также действует это согла-
шение.)
Мы рассмотрели все синтаксические особенности 1-выраже-
ний. Для полноты опишем 1-нотацию более формально в виде
БНФ:
(ехр) ::= 1 (id). {exp) | (id) । (exp) (exp) | ((exp)) | (con)
(id) ::= любой идентификатор
(соп)::= константа
Заметим, что набор констант произволен. Чтобы избежать
любых недоразумений, которые могут возникнуть, приводим
Таблица 6.1. Предварительно определенные константы
Константы Значение
0, 1, —1, 2, —2, ... TRUE, FALSE +, -, *, ... = > J > I < > SUCC, PRED Множество целых чисел Булевы константы Арифметические операции Булевы ’> функции Функции "следующий за” и "предшествующий” на мно- жестве целых чисел
EQ0 Функция, возвращающая TRUE, если заданное целое
COND CONS NIL HD TL IE (или NULL) равно 0 Условная функция Конструктор списков (сравните с в языке Норе) Пустой список Функция, возвращающая голову заданного списка Функция, возвращающая хвост заданного списка Функция IsEmpty, возвращающая TRUE, если задан-
TUPLE-n INDEX ный список пуст Функция, строящая n-кортеж выражений Функция индексирования кортежа
1) Строго говоря, это предикаты, определенные на множестве целых чисел. — Прим,
перев.
в табл. 6.1 список констант, используемых в данной главе.
В заключение дадим еще несколько примеров 1-выражений:
42
(+6)
It/. * 2у
(Xf .Ха.Xb. fab) (lx .(Ху. х))
Xf.Xx.COND( =xl )х(*х(Д —xl)))
6.2. Вычисление 1-выражений
Мы рассмотрели, как 1-нотация может быть использована
для представления функциональных выражений и сейчас го-
товы к тому, чтобы определить правила вывода 1-исчисления,
124 Часть П. Глава 6
которые описывают, как вычислять выражение, т. е. как полу-
чить конечное значение выражения из его первоначального вида.
Простейший тип Х-выражения — это константа. Константы
являются самоопределенными, т. е. их невозможно преобразо-
вать в более простые выражения. Вычисление целой констан-
ты 5, например, дает ту же самую константу 5; то же самое
относится к остальным константам из табл. 6.1.
Применение константной функции, однако, может быть пре-
образовано при наличии достаточного количества аргументов
с использованием встроенных правил, которые часто называют
б-правилами. Применение любой функции записывается в виде
выражения для этой функции, за которым следуют выражения
для ее аргументов. Например, выражение
+ 1 3
означает применение константы (встроенной арифметической
функции -(-) к двум числам 1 и 3. Это выражение может быть
преобразовано в число- 4 с помощью соответствующего 6-пра-
вила для функции +, которое мы записываем следующим об-
разом:
+ 1 3->в4
Такой процесс упрощения выражений называется редукцией.
Приведенный пример редукции можно прочитать: «+1 3 пре-
вращается в 4». Символ 6, которым помечена стрелка (->), го-
ворит о том, что редукция выполнена в соответствии с одним
из 6-правил. В общем случае, однако, аргументы функции мо-
гут не быть в нужной форме, и поэтому немедленная редукция
невозможна, например:
* ( + 1 2)(—4 1)
Чтобы преобразовать это выражение, мы должны сначала
преобразовать выражения аргументов функции *. Вычисление
этого выражения может происходить следующим образом:
* (+1 2)(-4 1)
- *6*(+1 2)3
— >j * 3 3
Мы будем опускать символ б везде, где ясно, что используемое
правило редукции является б-правилом.
Наиболее интересное правило редукции описывает, как при-
менять Х-абстракции. Рассмотрим следующее применение:
(Ах.* х х)2
Математические основы: k-исчисление 125
Ситуация аналогична!» вызову процедуры или функции языка
высокого уровня с фактическим параметром, замещающим ее
формальный параметр. В Х-исчислении такая замена является
чисто текстовой, и мы, таким образом, физически заменяем все
вхождения связанной переменной х в теле применяемой Х-аб-
стракции на выражение аргумента, 2, получая в результате
измененную форму тела. Следовательно:
(Хх.*х х)2 >р* 2 2
что можно, конечно, преобразовать в 4, применив встроенное
6-правило для *.
Процесс копирования тела абстракции с заменой всех вхож-
дений связанной переменной на выражения аргумента назы-
вается p-редукцией, обозначаемой символом р, которым поме-
чена стрелка (->). Процесс называется редукцией в том смысле,
что мы упрощаем выражение, убирая из него символ X,
связанную переменную и выражение аргумента и получая
измененную форму тела Х-абстракции. (Терминология представ-
ляется несколько неудачной, так как если -выражение аргумента
очень сложное и имеется много вхождений связанной перемен-
ной в теле абстракции, то результирующее выражение может
быть намного длиннее первоначального, однако математически
оно будет проще!)
Редукция абстракции, примененной к некоторому аргументу,
может дать в результате другую абстракцию, и в этом случае
процесс может быть продолжен. Например, в следующем вы-
ражении:
((Хх;Ху.+х у)7)8
мы начинаем с подстановки числа 7 вместо х в тело самой
внешней абстракции (т. е. Ху + х у), получая
(Ху. +7 у)8
и заканчиваем применением полученной абстракции к выраже-
нию аргумента 8, получая таким ообразом
+ 78
Данное выражение превращается в 15 с помощью 6-правила
для функции +•
Редуцируемое выражение называется редексом и мы на
данном этапе можем заключить, что процесс редукции Х-выра-
жения состоит из множества редукций, применяемых к редексам
*> Слово редекс (redex)—аббревиатура от английского reducible expres-
sion (выражение, которое может быть редуцировано). — Прим, перев.
126 Часть II. Глава 6
данного выражения до тех пор, noifa выражение включает
в себя хотя бы один редекс. В дальнейшем мы поясним это
утверждение и рассмотрим вопрос о порядке применения пра-
вил редукции. Мы будем иногда квалифицировать слово «ре-
декс» в соответствии с типом" правила, которое можно приме-
нить для упрощения данного выражения.
Термин 6-редекс поэтому соответствует выражению, которое
может быть упрощено с помощью 6-правила, а p-редексом на-
зывается выражение, которое можно упростить с помощью
p-редукции. Так же как в случае 6-редукции, мы не будем по-
мечать стрелку (->), обозначающую редукцию, символов Р
в тех случаях, когда ясно, что упрощаемое (под) выражение
является р-редексом.
Теперь рассмотрим следующее А-выражение:
Хх. ( Ах. х ) ( 4* 1 х )
Ясно, что х в теле внутренней абстракции (Кх.х) и х в выра-
жении аргумента ( + 1х) — это разные переменные, имеющие
одинаковое имя. Если'мы применим это выражение к аргументу,
скажем 1, то следующее выполнение p-редукции будет ошибкой:
(Ах. ( Хх.х ) (+1 х)) 1
->(Ах.1)( + 1 1)
1
При выполнении p-редукции следует быть внимательными
и не выполнять подстановку в тело абстракции, если связанная
переменная этой абстракции имеет такое же имя, как и заме-
няемая переменная. В этом случае нужно оставить такую (внут-
реннюю) абстракцию без изменений. Возможно избежать кон-
фликта имен с помощью переименования переменных — в дан-
ном случае следует переименовать одну из переменных х, чтобы
каждая переменная имела уникальное имя. Такое переименова-
ние называется «-преобразованием, и выражения, подвергнутые
«-преобразованию, т. е. эквивалентные с точностью до имен
переменных, называются алфавитно-эквивалентными. Этот во-
прос будет рассмотрен в разд. 6.4.
Чтобы показать, как работает Р-редукция, приведем сле-
дующий пример редукции выражения:
(Af.Ax.f 4 x)(Ai/.Ax. -]-х у)3
Шаг 1. Преобразуем единственный редекс, подставляя аргумент
(Ai/.Ax. + ху ) вместо f в тело абстракции ( A/.Ax.f 4х):
-> ( Ах.( Ai/. Ах. 4-х у) 4 х)3
Математические основы: А-исчисление 127
Шаг 2. Произвольно выбрав редекс (один из двух возможных),
подставляем аргумент 3 в тело абстракции ( Ку. 7.x -f- ху )4х,
но при этом оставляем без изменений внутреннюю абстракцию
- > (Ay.Ах. -j-x у) 4 3
Шаг 3. Преобразуем единственный редекс, т. е. ( Ау.Ах. + х у )4:
- >(Ах. +х 4)3
Шаг 4. Преобразуем единственный редекс
- * +3 4
Шаг 5. Преобразуем полученный редекс с помощью 6-правила
для функции +•
->7
Заметим, что первая редукция заключается в подстановке
вместо f функции ( Ку.Кх. + ху). Это вполне приемлемо; аб-
стракция, содержащая /, соответствует тому, что было бы функ-
цией высшего порядка в эквивалентной исходной программе.
Важно заметить, что на шаге 2 у нас был выбор между
двумя редексами и мы для преобразования произвольно взяли
внешний редекс. Однако можно было бы применить р-редукцию
и к внутреннему редексу, что привело бы к следующей цепочке
преобразований:
(Ах.(Ку .Кх. + х у) 4 х)3
- >(Ах.(Ах. + х 4)х)3
— >(Ах. х 4)3 (снова делаем произвольный выбор)
- ++3 4
-*7
Этот путь дает такой же результат и поэтому кажется вполне
разумным, но в общем случае можно получить совершенно
разное поведение для двух различных порядков выполнения
редукций. Этот вопрос является предметом следующего раздела.
6.3. Порядок редукций
и нормальные формы
Говорят, что A-выражение находится в нормальной форме,
если к нему нельзя применить никакое правило редукции.
Другими словамии, А-выражение — в нормальной форме, если
оно не содержит редексов. Нормальная форма, таким образом,
соответствует понятию конца вычислений в традиционном
128 Часть II. Глава 6
программировании. Отсюда немедленно вытекает наивная схе-
ма вычислений:
while существует хотя бы один редекс
do преобразовать один из редексов
end
{выражение теперь в нормальной форме}
Проблема, связанная с такой схемой, заключается в том, что
в выражении может быть несколько редексов и непонятно, ка-
кой и них выбрать для преобразования. Чтобы увидеть, сколь
важным может быть выбор, рассмотрим следующее выражение:
(лх. %//. у) ((Кг. z z)(Kz.z z))
Здесь два редекса:
{Kz.z z)(Kz.z z) и (Кх.Ку,у)(( Kz.z z)(Kz.z z))
Выбрав первый из них, получим следующую цепочку редукций:
(3. z. z z)(Kz.z z)
- ^(Kz.z z)(Kz.z z)
— >(Kz.z z)(Kz.z z)
• • • >
которая никогда не закончится. Выбрав второй, получим ре-
дукцию, которая заканчивается за один шаг:
(•' г .Ку .у) ((Kz .z z)(Kz.z z))
-^Ку.у
Эти рассуждения приводят нас к рассмотрению порядка редук-
ций, определяющего в случае нескольких редексов, какой из
них выбрать для преобразования. Вначале введем несколько
определений:
• Самым левым редексом называется редекс, символ К кото-
рого (или идентификатор примитивной функции в случае б-ре-
декса) текстуально расположен в Х-выражении левее всех
остальных редексов. (Аналогично определяется самый правый
редекс.)
• Самым внешним редексом называется редекс, который не
содержится внутри никакого другого редекса.
• Самым внутренним редексом называется редекс, не содержа-
щий других редексов.
Математические основы: 1-исчисление 129
В контексте функциональных языков и Х-исчисления суще-
ствуют два важных порядка редукций, на которые мы будем
постоянно ссылаться в этой книге:
• Аппликативный порядок редукций1’ (АПР), который предпи-
сывает вначале преобразовывать самый левый из самых вну-
тренних редексов.
• Нормальный порядок редукций (НПР), который предписы-
вает вначале преобразовывать самый левый из самых внешних
редексов. Возвращаясь к предыдущему примеру:
(lx.ly.z/)((lz.z z)(Xz.z z))
видим, что самым левым из самых внутренних редексов яв-
ляется
(Xz.z z)(Xz.z z)
а самым левым из самых внешних является
(Xx.l^.y)((lz.z z)(Xz.z z))
При аппликативном порядке редукций первым будет вычис-
ляться редекс ( (Xz.zz) (Xz.zz) ) и вычисление никогда не за-
кончится, тогда как при нормальном порядке редукций вычис-
ление Х-выражения закончится за один шаг.
Функция Хх.Ху.у— это классический пример функции, кото-
рая отбрасывает свой аргумент. НПР в таких случаях эффек-
тивно откладывает вычисление любых редексов внутри выра-
жения аргумента до тех пор, пока это возможно, в расчете на
то, что такое вычисление может оказаться ненужным. Страте-
гия выбора самого левого из самых внешних редексов предпи-
сывает поэтому выполнять подстановку для х в ку.у до любого
преобразования выражения аргумента. В результате за один
шаг получается нормальная форма У.у.у. АПР, с другой сто-
роны, вычисляет выражение аргумента в первую очередь, что
в данном случае приводит к зацикливанию. Хотя отсюда сле-
дует, что мы должны всегда выбирать нормальный порядок ре-
дукций, чтобы гарантировать, что вычисление закончится вся-
кий раз, когда это возможно, АПР оказывается значительно
более эффективным при реализации на обычных компьютерах,
что мы и увидим далее в этой книге. Проницательный читатель
уже мог обнаружить, что НПР и АПР соответствуют ленивому
о Здесь под редукцией понимается 0- или б-редукция—элементарный
шаг преобразования 1-выражения к нормальной форме. Можно говорить
о редукции аппликативного (или нормального) порядка, понимая под редук-
цией процесс преобразования в целом. Мы будем использовать оба этих
выражения как эквивалентные. В последнем случае слово «редукция» мы
иногда будем заменять словом «вычисление». — Прим, перев.
9 — 1473
130 Часть II. Глава 6
и энергичному вычислению, которые описаны в предыдущих
главах, хотя в данном случае полной эквивалентности нет.
В разд. 6.5.2 мы более детально рассмотрим это соответствие.
6.3.1. Две мощные теоремы
В качестве небольшого отступления заметим, что мы гово-
рили о множестве различных порядков редукций выражения при
неявном допущении: если вычисление закончится, то мы полу-
чим идентичные результаты при любом порядке редукций. Это
весьма вольное допущение, но оно оказывается правильным.
Более того, возможно также доказать, что НПР всегда приво-
дит выражение к нормальной форме, если нормальная форма
существует. Эти два результата представлены в виде двух тео-
рем, называемых соответственно теоремой Черча — Россера и
теоремой стандартизации:
• Теорема Черча—Россера (следствие). Если выражение Е
может быть приведено двумя различными способами к двум
нормальным формам, то эти нормальные формы являются ал-
фавитно-эквивалентными.
• Теорема стандартизации. Если выражение Е имеет нормаль-
ную форму, то редукция самого левого из самых внешних ре-
дексов на каждом этапе вычисления Е гарантирует достижение
этой нормальной формы (с точностью до алфавитной эквива-
лентности). Доказательство этих теорем можно найти в [13].
Единственность нормальной формы выражения является
следствием теоремы Черча — Россера. Сама теорема рассматри-
вает последовательности редукций вообще и ни в коем случае
не ограничивается р- и 6-редукциями.
Ромбическое свойство отношения редукции-»-заключается
в том, что если выражение Е может быть редуцировано к двум
выражениям £1 и Е2, то существует выражение N, которое
можно получить (повторно применяя -э-) как из £1, так и из
£2. Это иллюстрируется следующей диаграммой:
Мы используем символ —* для обозначения произвольного
числа, п 0, редукций, т. е.->-* является рефлексивным тран-
зитивным замыканием отношения -»-. (Рефлексивность озна-
Математические основы: k-исчисление 131
чает, что Е можно преобразовать само в себя, не делая ничего,
т, е. за п = 0 шагов.) Формально ромбическое свойство можно
записать так:
Е->*Е1 и Е->*Е2=>3# :£!->* N и E2->*;V
Мы говорим, что отношение редукции -+ называется редук-
цией Черча — Россера, если отношение ->* обладает ромбиче-
ским свойством, и доказательство, упомянутое выше, действи-
тельно демонстрирует, что p-редукция является редукцией Чер-
ча— Россера. Теорема Черча — Россера обычно записывается
в следующем виде:
X cnv*Y^3N :X->*N и Y-+*N
где -> означает p-редукцию; a cnv— симметричное отношение
р-преобразования:
X cnv УоХ->У или YX
(Если в отношение -> наряду с p-редукцией мы включим 6-ре-
дукцию, наша система редукций может в некоторых паталоги-
ческих случаях не обладать ромбическим свойством. Тем не ме-
нее так называемое слабое ромбическое свойство имеет место.
Оно отличается от ромбического свойства тем, что редукции
Е-+Е1 и Е^~Е2 должны быть одношаговыми, т. е. звездочки
у верхних стрелок в диаграмме опускаются, и формально запи-
сывается средующим образом:
Е-+Е1 и ЕE2=>3N : El—> * N и E2^*N
Говорят, что отношение редукции является слабой редукцией
Черча — Россера, если оно обладает слабым ромбическим свой-
ством. Однако ни одна из константных функций, используемых
нами, не нарушает ромбическое свойство.)
Сама теорема Черча — Россера ничего не говорит нам о
единственности нормальной формы выражения. Однако допу-
стим, что М и N— две различные нормальные формы одного
и того же выражения Е, т. е. мы имеем
£—> * М и Е~>* N
Применим теорему Черча — Россера:
3Z:M->*Z и W->*Z
Но так как М и N — это нормальные формы, возможен един-
ственный вариант:
M^N^Z
9*
132 Часть II. Глава 6
т. е. нормальная форма Е действительно единственна. (Мы ис-
пользуем символ = вместо —, так как речь идет об алфавит-
ной эквивалентности выражений.)
6.4. 0-Редукция и проблема конфликта
имен
Рассмотрим следующее выражение:
Хх.Ху.х у у
Мы говорим, что переменная х является связанной в данном
выражении, так как оно содержит Хх. Эквивалентно мы говорим,
что имеет место связанное вхождение переменной х в данное
выражение. Теперь рассмотрим тело самой внешней абстракции:
Az/.х у у
Хотя х входит в данное выражение, это вхождение не является
связанным, так как выражение не содержит Хх. Поэтому мы
говорим, что х является свободной переменной в данном выра-
жении. Однако переменная у по-прежнему связана благодаря
Ху. Если мы рассмотрим теперь тело самой внутренней абстрак-
ции, т. е.
х У У
то здесь как х, так и у являются свободными. Мы будем иногда
обозначать множество свободных переменных выражения Ё че-
рез FV(E), например:
FViXx.Xy.x у у) = { }
F]/(Xx.x у у) = {у}
FV(x у у) = {х, у}
FV можно определить более формально следующим образом:
FV(k) =0 k — это константа
Л’Е(х) = {х} х — это переменная
FV(E\ E2) = FV(E\)UFV(E2)
FV(Xx.E) — FV(E) — x
где множество S—х получается из множества S удалением
всех вхождений элемента х. X-Выражение Е, не содержащее
свободных переменных (т. е. FV(E)— 0), называется замк-
нутым.
Используя представления о свободных и связанных пере-
менных, мы можем теперь формализовать определение p-редук-
ции: 0-редукция — это такое правило преобразования выраже-
ния (Хх.Е)А, которое дает модифицированную форму Ё, где
Математические основы: 1-исчисление 133
все вхождения свободной в Е переменной х заменены на А.
К сожалению, существует проблема, связанная с р-редукцией,
которую можно проиллюстрировать на следующем примере:
Хх.((Ху.Хх, 4~х у)х)
Это выражение содержит единственный p-редекс, выделенный
подчеркиванием. Если мы попытаемся вычислить этот редекс,
то получим
Хх.(Хх +х х)
что, очевидно, является ошибкой.
Проблема состоит в том, что в этом примере выражение
аргумента содержит свободную переменную, имеющую одина-
ковое имя с одной из связанных переменных в теле абстрак-
ции, т. е.
(Лу.Ах. + х у) х
Этот х связан Этот х свобод ей
Чтобы безопасно выполнять p-редукцию, необходимо сначала
модифицировать абстракцию так, чтобы сделать все имена свя-
занных переменных уникальными по отношению к свободным
переменным в выражении аргумента. В нашем примере поэтому
нужно переименовать связанную переменную х в теле абстрак-
ции, скажем в х':
(Хг/.Хх.-фх #)->(Хг/.Хх'.+х' у)
Теперь выполнение p-редукции безопасно:
Хх. ((Ку. Хх'. -ф х'у) х)
—>Кх ,(Кх'. -|-х'х)
что совершенно правильно.
Этот процесс переименования называется « преобразова-
нием, или a-подстановкой. Он основан на той идее, что два та-
ких выражения, как
Хх.х и Ку.у
обозначают одну и ту же функцию, так как отличаются только
именами связанных переменных, другими словами, являются
алфавитно-эквивалентными. Мы говорим, что выражение Кх.х
может быть a-преобразовано в Ку.у, или что Кх.х и Ку.у яв-
ляются «-преобразуемыми, и записываем
Хх.х—а Ку.у
134 Часть II. Глава 6
В общем случае выражение лх.Е может быть преобразовано
в выражение Хх'.Е', где Е' получается- из Е заменой всех вхож-
дений свободной переменной х на х', при условии, что х' сама
не является свободной переменной в Е. Например, следующее
«-преобразование корректно:
Kx.f х y->a).2.f z у
А вот пример неправильного «-преобразования:
%x.f х у у
Проблема конфликта имен накладывает ограничения на [3-ре-
дукцию: мы можем безопасно выполнить |3-редукцию выраже-
ния £1 £2, только если ни одно имя свободной в £2 переменной
не совпадает с именами связанных в £1 переменных [43]. Пе-
реименование переменных в £1 является потенциально трудо-
емкой операцией, и мы будем стараться избегать ее при реали-
зации процесса редукции на компьютере. Одно из решений
проблемы заключается в принятии соглашения об именах пере-
менных [13]. Второе решение заключается в том, чтобы не вы-
полнять Р-редукцию в случае присутствия свободных перемен-
ных. Это предпочтительный подход, так как он требует изменить
только наше представление о нормальной форме, а не о схеме
редукции или схеме наименования переменных. Этот подход
К решению проблемы конфликта имен будет рассмотрен
в разд. 6.5.
6.4.1. Правило ^-преобразования
В дополнение к а- и p-преобразованиям существует третье
правило, называемое правилом ^-преобразования. Это правило
основано на том, что выражения
1.x. Ех и £
обозначают одну и ту же функцию при условии, что х не яв-
ляется свободной переменной в £, так как
(Лх.£х) Л->£ А
для любого выражения А. Это называется функциональной
экстенсивностью. Мы ришем
Лх • £х -+ п£
имея в виду, что выражение Хх.£х т]-редуцируется в выражение
£. Мы говорим также, что %х.£х является туредексом и назы-
ваем это преобразование туредукцией, так как подразумеваем
упрощение выражения слева от стрелки. Однако можно запи-
Математические основы: Х-исчисление 135
сать преобразование по-другому, используя символ —п, как
в случае a-преобразования. В этом случае говорят, что два вы-
ражения являются ^-преобразуемыми.
Обычно мы будем использовать термины «p-редукция» и
«т]-редукция», но не будем классифицировать «-преобразование
как редукцию, так как оно не упрощает структуру выражения.
Однако мы также оставляем за собой право использовать тер-
мин p-преобразование, как, например, при рассмотрении тео-
ремы Черча — Россера в разд. 6.3.1. X и Y являются р-преоб-
разуемыми, если или Х->рУ, или У->рХ; в последнем случае
мы иногда будем говорить, что У получено из X с помощью
р-абстракции.
Хотя в этой книге мы ссылаемся на ^-редукцию, мы не бу-
дем касаться вопроса о встраивании механизма ц-редукции в
какой-либо процессор Х-выражений, так как такое преобразо-
вание при необходимости можно сделать при компиляции. Сле-
довательно, при использовании слова «редекс» в контексте вы-
числений мы будем обычно подразумевать p-редекс или 6-ре-
декс, если явно не оговорено противное.
6.5. Обход проблемы конфликта имен
В разд. 6.4 мы познакомились с проблемой конфликта имен,
которая может возникнуть при p-редукции, когда выражение
аргумента содержит свободные переменные, имеющие одинако-
вые имена со связанными переменными тела применяемой
абстракции. Эта проблема может возникнуть всякий раз,
когда мы пытаемся преобразовать выражение в его нор-
мальную форму (т. е. форму без редексов). Например, выра-
жение
Хх.((Хг/.Хх. + х у)х)
не находится в нормальной форме, и перед проведением р-ре-
дукции необходимо «-преобразование. •
Оказывается, однако, что проблему можно решить без по-
мощи «-преобразования, определив ограниченную нормальную
форму, называемую слабой заголовочной нормальной формой.
Выражение Е находится в слабой заголовочной нормальной
форме (СЗНФ), если:
(1) Е является константой,
(2) Е является выражением вида Хх.Е' для любого Е',
(3) Е имеет форму РЕУЕ2 ... Еп для любой константной функ-
ции Р арности k > п.
Третье правило утверждает, что любая частично применен-
ная константная функция также является СЗНФ. Это вполне
136 Часть II. Глава 6
разумно, так как можно переписать выражение вроде
* 3
используя правило ^-преобразования, в выражение
Хх. * 3 х
которое находится в СЗНФ.
Заметим также, что выражение, состоящее из единственной
переменной, является СЗНФ, но здесь мы рассматриваем
только замкнутые выражения.
Преимущество приведения выражений к СЗНФ вместо пол-
ной нормальной формы заключается в том, что мы избегаем
необходимости применять p-редукцию в присутствии свободных
переменных. Мы можем встретить свободные переменные толь-
ко в случае, если «пройдем через X», так как все ссылки на пе-
ременную, стоящую после X, будут свободными только справа
от «.». Останавливаясь перед X, мы не входим в тело функции
и, следовательно, не можем встретить свободные переменные
вообще. Используя предыдущий пример снова:
Хх.( (Ху.Хх + У х)х)
мы не пытаемся вычислить подчеркнутый редекс, так как выра-
жение в целом находится в СЗНФ. Только когда выражение
применяется к аргументу, вычисление имеет место, и это вы-
числение начнется с удаления самой левой связанной перемен-
ной х в соответствии с правилами редукции нормального по-
рядка. Таким образом, мы заменим порождающее проблему
вхождение свободной переменной х в (Ху.Хх + ух)х значением
аргумента (которое также не может содержать свободных пе-
ременных), и проблема конфликта имен никогда не возникнет.
Например:
(Хх.((Ху.Хх. + у х)х))4
~>(Ху.Хх. +у х)4
->Хх. +4 х
Заметим, что в промежутке между нормальной формой и СЗНФ
расположена так называемая заголовочная нормальная форма
(ЗНФ). Говорят, что выражение Е находится в ЗНФ, если:
(1) Е является константой,
(2) Е является выражением вида Xxi.Xx2 Ххп.Е', где Е' не
является редексом,
(3) Е имеет форму РЕ\Е2 ... Еп для любой константной функ-
ции Р арности k~> п. Это определение включено для полноты.
Приведение к ЗНФ обычно не практикуется, так как при этом
Математические основы: k-исчисление 137
не удается избежать проблемы конфликта имен,/ Используем
наш пример снова:
Хх .((Ху .Хх + У х)х)
Выражение не является ЗНФ, так как (Ху.Хх. + у х) х — это
редекс. Поэтому будет выполнена внутренняя p-редукция и воз-
никнет конфликт имен.
Заметим, что все ЗНФ являются одновременно СЗНФ, но
обратное неверно. Например, Хх. + 23 — это СЗНФ, но не ЗНФ,
так как +2 3 является редексом.
6.6. Эффект разделения
Рассмотрим следующее выражение:
(Хх. + х х)Е
Применив к нему правило p-редукции, получим
+ Е Е
Чтобы преобразовать это выражение, мы должны сначала пре-
образовать аргументы функции +, а это означает, что выра-
жение Е должно быть редуцировано дважды. Понятно, что та-
кое вычисление очень неэффективно.
Один способ, гарантирующий, что аргумент никогда не бу-
дет вычисляться более одного раза, заключается в вычислении
его перед выполнением p-редукции. Это соответствует аппли-
кативному порядку редукций. Вместо подстановки аргумента
в исходном виде выполняется подстановка значения аргумента,
поэтому повторные вхождения связанной переменной не при-
водят к повторной редукции аргумента. Если, однако, мы хо-
тим реализовать нормальный порядок редукций, то должны
каким-то образом сделать так, чтобы первое вычисленное (т. е.
приведенное к СЗНФ) выражение аргумента «разделилось»
между всеми остальными выражениями этого аргумента, т. е.
заменило бы каждое из них своим значением. В таком случае
будем говорить, что выражение аргумента является разделяемым.
Здесь мы отходим от модели редукции, предлагаемой
в ^-исчислении, где вычисление выражений записывается в чи-
сто текстовой форме. Это означает, что можно записывать про-
межуточные выражения, формирующие последовательность ре-
дукций, с помощью набора символов на обычном листе бумаги
(такой процесс иногда называют редукцией строк). Если мы
хотим изучить эффект разделения, то должны выразить факт,
что два вхождения одного и того же идентификатора относятся
к одному и тому же выражению как-то иначе, нежели в случае
138 Часть II. Глава 6
копирования этого выражения дважды. Один из способов сде-
лать это состоит в представлении выражений в виде графов.
Это приводит нас к идее редукции графов, которая будет де-
тально описана в гл. 11. Здесь, однако, будем придерживаться
следующего соглашения.
Имея выражение вида
(Хх. ... х ... х ... ) Е
результат p-редукции этого выражения будем записывать в
виде
... х ... х ..., где х есть Е,
чтобы обозначить, что оба вхождения х в результирующем
выражении относятся к Е. Связь между именами переменных
и их значениями обычно называется контекстом, и мы говорим,
что механизм редукции является основанным на контексте, а не
на копировании, как в Х-исчислении. Мы более подробно рас-
смотрим контексты в гл. 9.
Смысл такого подхода в том, что когда х (т. е. Е) вычис-
ляется первый раз, редуцированная форма Е заменяет не толь-
ко х в выражении, но и £ в контексте этого выражения.
И когда нам в следующий раз потребуется вычислить х, он
будет немедленно заменен редуцированной формой Е. На-
пример:
(Хх. + хх) ( + 1 2)
—> + х х где х есть (4-12)
-> + 3 х где х есть 3
->4-3 3
->6
и мы видим, что выражение аргумента (4-12) вычисляется
только один раз.
6.6.1. Схемы редукции и механизмы вызова
Теперь, когда введено понятие разделения, можно сопоста-
вить различные возможные стратегии при вычислении Х-выра-
жений с механизмами вызова. Этот термин часто используется,
когда речь идет о языках программирования высокого уровня.
Механизм вызова определяет, как передаются параметры при
вызове процедуры или функции. Он поэтому тесно связан с на-
шим предыдущим обсуждением порядка редукций и эффекта
разделения.
Математические основы: Х-исчисление 139
Имея выражение вида
(Кх.Е\)Е2
мы знаем, что один способ упростить его заключается в вычис-
лении выражения аргумента £2 в первую очередь и в выпол-
нении затем p-редукции, подставляющей значение £2 вместо х
в £1. Этот способ соответствует аппликативному порядку вы-
полнения редукций и эквивалентен вызову по значению в тра-
диционных языках программирования. В функциональных язы-
ках программирования вызов по значению известен как
энергичное вычисление, о котором мы уже говорили в гл. 4
и которое в Х-исчислении мы можем определить следующим об-
разом:
Энергичное вычисление = АПР, приводящий выражение
к СЗНФ
В качестве альтернативы АПР можем сначала подставить
£2 вместо х в £1, что соответствует нормальному порядку ре-
дукций. В Х-исчислении, где отсутствует понятие разделения,
такая подстановка является чисто текстовой. Она поэтому со-
ответствует понятию вызова по текстовой замене. Как мы уже
видели, при этом может возникнуть конфликт имен и необхо-
димость повторного вычисления выражений аргументов. Если
мы обходим проблему конфликта имен (например, выполнив
a-преобразование для каждого выражения аргумента или при-
водя выражение только к СЗНФ), тогда такой механизм со-
ответствует вызову по имени. При этом, однако, мы не можем
избежать повторного вычисления аргументов.
Если мы реализуем нормальный порядок редукций и под-
щрживаем разделение (гарантируя, что аргументы вычисляют-
ся не более одного раза), тогда механизм редукции соответ-
ствует вызову по необходимости. В традиционных языках вы-
зов по имени и вызов по необходимости отличаются, только
если выражение аргумента дает побочные эффекты. В функ-
циональном языке не существует побочных эффектов, и, следо-
вательно, два этих механизма вызова дают всегда одинаковый
результат. Вызов по необходимости поэтому можем охаракте-
ризовать как нормальный порядок редукций, приводящий выра-
жение к СЗНФ вместе с разделением выражений аргументов.
Если соединим вызов по необходимости с ленивыми конструк-
торами, то получим ленивое вычисление, с которым уже встре-
чались в гл. 4. Ленивым называется конструктор, аргументы
которого остаются невычисленными, т. е. не приведенными
К СЗНФ. Следовательно, описать ленивое вычисление значения
140 Часть II. Глава 6
Х-выражения можем следующим образом:
Ленивое вычисление = НПР, приводящий выражение к СЗНФ
+ разделение
+ленивые конструкторы
или эквивалентно:
Ленивое вычисление = вызов по необходимости + ленивые
конструкторы
Фактически конструкторы (за исключением, может быть,
предварительно определенных конструкторов, таких, как кон-
структор списков CONS) обычно реализованы как кортежи (см.
гл. 8). Поэтому применения функции-конструкторов трансли-
руются в вызовы предварительно определенной функций
TUPLE-n, приведенной в табл. 6.1. Это означает, что строгость
конструкторов определяется строгостью функции TUPLE-n.
Именно по этой причине ленивые конструкторы указаны от-
дельно в определении ленивого вычисления. Стандартная реа-
лизация языка Норе, в котором смешаны энергичное и ленивое
вычисление, может быть определена следующим образом:
АПР, приводящий выражение к СЗНФ + ленивые
конструкторы
Это соответствует вызовам функции TUPLE-n по необходи-
мости, а всех остальных функций по значению, хотя следует
быть осторожными при обработке условных выражений. Мы
рассмотрим эту тему более детально в гл. 9.
6.7. Рекурсивные выражения
До сих пор мы рассматривали представление только нере-
курсивных функций в Х-исчислении. В языках программирова-
ния высокого уровня, однако, необходимо иметь возможность
записывать определение рекурсивных функций. Мы можем вы-
разить рекурсию в языке высокого уровня, так как имеем воз-
можность дать имя каждой функции, используемой в программе.
На такие имена можно ссылаться где угодно в программе (при
определенных ограничениях, обусловленных языком), даже
в теле функции, названной тем именем, на которое ссылаемся.
Теперь рассмотрим проблему рекурсивных функций в Х-ис-
числении, где функции не имеют имени. Поэтому для представ-
ления рекурсии необходимо придумать метод, позволяющий
функциям вызывать себя не по имени, а каким-то другим обра-
зом. Другой (гораздо менее очевидный) взгляд на рекурсию
Математические основы: 1-исчисление 141
состоит в том, чтобы представить рекурсивную функцию как
функцию, имеющую самое себя в качестве аргумента. В этом
случае функция может оказаться связанной с одной из ее соб-
ственных переменных и будет, таким образом, содержать
в своем теле ссылки на самое себя.
Рассмотрим, напри-мер, рекурсивную функцию sum, опреде-
ляемую на языке Норе следующим образом:
-----sum( п) <== if п = О then 0 else n + sum( п — 1);
Это выражение может быть представлено в виде %-абстракции,
имеющей дополнительный параметр, который при применении
этой абстракции связывается с самой функцией. Мы запишем
эту промежуточную версию функции SUM:
SUM = ks.kn.COND( = n 0)0(+^(з( — п 1)))
Все, что нам осталось сделать теперь, — это связать перемен-
ную $ со значением функции sum, которую пытаемся опреде-
лить. Это можно сделать, использовав специальную функцию,
называемую У-комбинатором, которая удовлетворяет следую-
щему уравнению:
П = ДУ f)
Y также известен как комбинатор фиксированной точки. «Фик-
сированная точка» функции f — это выражение, которое не из-
меняется при применении к нему функции f. (Заметим, что
функция может иметь несколько фиксированных точек.
Например, функция тождества кх.х, имеет бесконечное их
число.)
Выражение Yf дает наименьшую фиксированную точку
функции f. Чтобы понять смысл этого термина, мы должны
«погрузиться глубже» в теорию функций. В этой книге не тре-
буется детальное понимание данного вопроса, но для заинтере-
сованного читателя мы включили приложение Б, в котором
дано краткое руководство по теории доменов. Знакомство
с приложением Б поможет понять смысл термина, а более де-
тальное обсуждение предмета можно найти в [75].
Посмотрим теперь, что получится при применении Y к функ-
ции SUM, приведенной выше:
Y SUM
= Y(/.sU.n.COND(=n 0)0(4-n(s(— п 1))))
-+(Xs.kn.COND(=n 0)0(+n(s(—n 1))))(У SUM)
(l.n.COND (—n 0)0(-М(У SUM)(—n 1))))
142 Часть П. Глава 6
Это оказалось тем, что нам нужно. Чтобы убедиться в этом,
распишем внутреннее выражение (YSUM) подобным образом:
->(kn.COND (=п 0)
0
(+п((Лп.СОУР(=пО)0(+п((У SUM)(-n 1))))
(-« 1))))
Мы видим, что данное выражение ведет себя точно так же, как
исходное рекурсивное определение sum. Внутреннее вхождение
У SUM конструирует копию исходной функции SUM, поме-
щая само себя (т. е. У SUM) вместо s в тело копии. Это то,
что нам нужно. Таким образом, функция sum выражается в
Л-исчислении в виде
У SUM, т. е. Y(ks.kn.COND ( =п 0)0( + n(s( — п 1))))
В общем случае рекурсивная функция f с телом, задаваемым
выражением £, записывается в Х-исчислении в виде
Y(Xf.E)
6.7.1. Взаимная рекурсия
В общем случае можно определить набор взаимно рекур-
сивных функций, таких, как
-----/„(...)<=£„;
где Ei может ссылаться на любую (или на все сразу) из функ-
ций fj( 1 i, j^.n). Чтобы реализовать такие определения,
мы используем так называемое кортежирование. Идея заклю-
чается в том, чтобы упаковать набор из п взаимно рекурсивных
функций в n-кортеж и затем транслировать ссылки на /,• в ин-
декс i-го элемента такого кортежа. Для реализации этой идеи
необходимо использовать константные функции TUPLE-n и
INDEX, приведенные в табл. 6.1 и определяемые следующим
образом:
TUPLE-/: Е[Е2 ... Еп строит кортеж, состоящий из выражений
Е1у Е2, ...,Еп, который мы будем запи-
сывать в виде: (Et, Е2, ...,Еп)
INDEX k {Еь .... En) = Ek
Математические основы: 1-исчисление 143
Сначала запишем функции ft, ..., fn в виде %-выражений
L\, ..., Ln, оставляя каждое вхождение любой из функций f/
в телах функций fi, ..., fn без изменений. Соединим затем эти
выражения в n-кортеж Т, используя функцию TUPLE-n:
Т = TUPLE-nLxL2 ... Ln
Модифицируем теперь элементы Т, заменяя все сслыки на
функцию ft в L/(l I, j п) на вызовы функций INDEX сле-
дующим образом:
fi->INDEXiT
Модифицированные выражения L/ будем обозначать L'j. Те-
перь Т имеет вид
Т = TUPLE-n L'.L' ... L'
12 П
Заметим, что данное определение рекурсивно, поскольку каж-
дое L' может само содержать ссылку на Т. Поэтому, чтобы
завершить определение, нужно к выражению Т применить
У-комбинатор точно так же, как мы это делаем при любом ре-
курсивном определении:
Т s* Y ( LT.TUPLE-n L\L'2 ... L'n)
Данное выражение является представлением нашего набора
функций fi, .... fn.
Чтобы увидеть, как все это работает, в качестве простого
примера рассмотрим две взаимно рекурсивные функции
-----f(n)<=if n = 0 then 0 else g(n);
-----g(n)<=n4-f(n— 1);
Они могут быть представлены следующим Х-выражением:
Y (LT.TUPLE-2 (Ln.COND (=п 0)0((INDEX 2 Т)п))
(Ln. +n((INDEX 1 Т)(—п 1))))
вычисление которого дано в качестве упражнения в конце этой
главы.
6.7.2. Определение Y
Чтобы завершить рассмотрение рекурсии, мы должны дать
определение Y. Очевидный путь сделать это состоит в том,
чтобы включить Y в множество констант, т. е. сделать эту функ-
цию встроенной подобно + или COND. Однако существуют два
других пути. В частности, первый из них предполагает, что все
Х-выражения представлены в графовой форме; У в этом случае
144 Часть II. Глава 6
реализуется просто установкой циклического указателя; мы
вернемся к этому вопросу в гл. 12.
Особое значение здесь, однако, имеет тот факт, что Y мо-
жет быть записан в виде Х-выражения, что очень важно для
чистого Х-исчисления, не имеющего встроенных функций. Рас-
смотрим следующее Х-выражение, которое имеет довольно не-
обычный вид:
ХЛ. (Хх. h (х х)) (Хх. Л (х х))
Именно это выражение и представляет собой функцию У. Чтобы
убедиться в этом, применим данное выражение к функции ft
Yf
= (X/i. (Хх. /г (х х))(Хх.Л(х х))) /
->(Xx.f(^ х))(Хх .f (х х))
->}(Хх./(х х))(Хх .f (х х))
~f(Yf)
Y редко реализуется таким путем из соображений эффективно-
сти. Существует много реализаций расширенного Х-исчисления,
где имеется возможность давать имена Х-выражениям. В гл. 8
мы построим «улучшенную» версию расширенного таким обра-
зом Х-исчисления.
6.8. Чистое Х-исчисление
В предыдущих разделах этой главы была описана версия
Х-исчисления, в которой предполагается наличие предваритель-
но определенного множества констант, например целых чисел,
булевых констант и списков, а также связанных с этими кон-
стантами функций.
Первоначальная версия Х-исчисления, однако, не предусмат-
ривала такого множества констант, поэтому выражение Е
в этом так называемом чистом Х-исчислении имеет следующий
синтаксис:
(exp) :: = X {id). {exp) \ (exp) (exp) |((ехр))
Хотя из отсутствия б-правил можно заключить, что базовые
арифметические операции, обработка списков и т. д. невоз-
можны, на самом деле это далеко не так. Фактически любое
из рассмотренных нами ранее выражений Х-исчисления может
быть выражено (хотя и в несколько необычной форме) сред-
ствами чистого Х-исчисления. В данном разделе мы попробуем
дать читателю ощущение выразительной силы чистого Х-исчис-
ления и продемонстрируем, как его средствами можно выра-
зить натуральные числа, арифметические функции, булевы кон-
Математические основы: Х-исчисление 145
станты, булевы операции, списки и функции обработки списков.
Этот раздел включен в целях полноты; мы не будем исполь-
зовать чистое ^-исчисление как основу для реализаций, опи-
санных в этой книге.
6.8.1. Булевы константы и булевы операции
Когда мы записываем выражение вида
if Р then Q else R (или COND PQR)
мы обычно представляем условный оператор (COND) как
встроенную функцию, которая выбирает Q или R в зависимости
от значения предиката Р. Другими словами, предикат услов-
ного оператора можно рассматривать как функцию, которая
сама выбирает одно из выражений Q или R. Выражение COND
PQR в этом случае транслируется в PQR с правилами преоб-
разования
TRUE х у-^-х
FALSE х у-+у
Этот альтернативный подход дает основу для представления
булевых констант и операций средствами чистого Х-исчисления.
Условный оператор COND выражается следующим образом:
COND — Lp.Lq.Lr.p q г
и, как теперь можно ожидать, TRUE и FALSE представляются
в виде
TRUE — Lx.Ly,х
FALSE = Lx .Ly .у
Так, например:
COND TRUE A В
= (Xp.Lq.Lr.p q r)(Lx.Ly.x) A В
- +(Lq.Lr.(Lx.Ly.x) q г) A В
- > (Lr.(Lx.Ly.x) A r)B
—>(Lx.Ly.x)A В
-+(Ly.A)B
— »A
как и ожидалось. Имея такое представление TRUE и FALSE,
можно теперь записать выражения для вычисления A OR В,
A AND В, NOT А и т. д. Например, функции AND и OR выра-
10 — 1473
146 Часть II. Глава 6
жаются следующим образом:
AND — Кх .Ку .х у FALSE
OR = kx.ky.(x TRUE)y
Правильность такого представления может быть доказана
получением соответствующих таблиц истинности. Например:
TRUE AND FALSE
~(Кх.Ky.x y(Kx.Ky.y))(Kx.Ky.x)(Kx.Ky.y)
->(Ky.(Kx.Ky.x)y(Kx.Ky.y))(Kx.Ky.y)
~->(Kx.Ky.x)(Kx.Ky.y)(Kx.Ky.y)
-+(Ky.(Kx.Ky.y))(Kx.Ky.y)
-*(Kx.Ky.y)
FALSE
6.8.2. Списки в чистом К-исчислении
Теперь, имея представления для булевых констант TRUE и
FALSE, можем использовать их для определения списков.
Обычно списки строятся с помощью двух функций-конструк-
торов, одна из которых обозначает пустой список (NIL), а дру-
гая строит новый список из элемента и старого списка (CONS).
Язык Норе, например, использует для этих целей nil и инфикс-
ный оператор ::. Чтобы представить CONS в чистом X-исчис-
лении-, следует рассматривать выражение
CONS h t
как функцию, берущую в качестве одного из ,своих аргументов
функцию-селектор и применяющую ее к выражениям для го-
ловы (h) и хвоста (t) списка. Следовательно,
CONS = Kh.Kt .Ks .s h t
где переменные h, t, s соответствуют голове списка, хвосту
списка и функции-селектору.
Селекторы — это такие функции, которые возвращают либо
первый, либо второй аргумент функции-конструктора. Поэтому
они могут быть представлены в виде следующих Х-выражений:
Kh.Kt.h и Kh.Kt.t
что в точности соответствует определениям TRUE и FALSE,
приведенным выше. Это означает, что функции для выделения
головного и хвостового элементов списка L (т. е. HD и TL со-
ответственно) могут быть определены следующим образом:
HD = KL.L TRUE
TL = KL.L FALSE
Математические основы: Х-исчисление 147
Применение функций HD или TL к выражению CONSab дает
в результате а или b соответственно. В этом легко убедиться:
HD(CONS а Ь)
= (кс.с TRUE)((Mi.M.Ms.s h t)a b)
— > ((X/i.M.Xs.s h t)a b)TRUE
— >(Xs.s a b)TRUE
- > TRUE a b
= (kh.M.h)a b
->(M.a)b
—>a
Последней функцией обработки списков, которую мы опре-
делим в терминах чистого Х-исчисления, будет функция IE,
которая при применении к пустому списку (т. е. NIL) возвра-
щает TRUE. Определение этой функции приводит нас к удоб-
ному представлению пустого списка. Начнем с рассмотрения
выражения
IE (CONS а b)
IE (CONS a b) .
= IE ((Lh.M.Xs.s h t)a b)
-+IE (Ls.s a b)
Так как мы ожидаем, что это выражение дает FALSE для лю-
бых значений а и Ь, ясно, что это выражение для функции IE
должно иметь вид
1Е — Кс.с( Mi.М.FALSE)
Отсюда естественным образом мы приходим к выражению для
пустого списка, определяемому таким образом, чтобы IE х да-
вало TRUE, если x — NIL, и FALSE в противном случае:
NIL = Lx.TRUE
В качестве примера приведем последовательность редукций
для выражения IE (TL ( CONS 1 NIL ) ):
IE (TL(CONS 1 NIL))
= (M.c(Mi.M.FALSE))(TL(CONS 1 NIL))
- *(TL(CONS 1 NIL))(Mi.M. FALSE)
= ((Xc.c FALSE)(CONS 1 NIL)) (Mi.M.FALSE)
- +((CONS 1 NIL) FALSE) (Mi.M.FALSE)
= (((Mi.M.Ms.s h t) I NIL) FALSE)(Mi.M.FALSE)
- >(((M.M;.s 1 t) NIL) FALSE)(Mi.M.FALSE)
- >((Ls.s 1 NIL) FALSE)(Mi.M.FALSE)
(FALSE 1 NIL)(Mi.M.FALSE)
= ((Mc.Ly.y) 1 N IL) (Mi.M. FALSE)
io*
148 Часть II. Глава 6
- > (( Ку. у) NIL) (Mi. W. F ALSE)
— NIL(Lh.Lt.FALSE)
- > (Lx. TRUE )(Lh.Lt. FALSE)
-+TRUE
6.8.3. Натуральные числа в чистом L-исчислении
Используя введенное выше представление списков и рас-
сматривая число п как n-элементный список объектов, имею-
щих произвольные значения, можно теперь определить нату-
ральные числа. Число 0 в этом случае соответствует пустому
списку (NIL), и, аналогично, функции EQ0 и PRED соответ-
ствуют функциям обработки списков IE и TL. Функция SUCC,
возвращающая следующий за п элемент натурального ряда,
т. е. прибавляющая единицу к данному числу п, должна только
расширить на один элемент представляющий п список. По-
этому она определяется следующим образом:
SUCC —Ln.CONS "any" п
где "any" — это любое Х-выражение.
Существует множество представлений для таких объектов,
как булевы константы, натуральные числа и списки; представ-
ления, приведенные выше, ни в коем случае не являются един-
ственными. Альтернативную модель для натуральных чисел
можно найти, например, в [13]. Важно отметить, что мы нашли
путь для представления натуральных чисел и операций SUCC,
PRED и EQ0. Так как мы имеем также У-комбинатор (описан-
ный в разд. 6.7), то можем реализовать любую рекурсивную
функцию, что вытекает из теории рекурсии [67]. Таким обра-
зом, хотя материал этого раздела представляет только акаде-
мический интерес, с учетом остального содержания данной
книги он дает пример выразительной силы Х-исчисления, даже
когда казавшиеся поначалу такими важными 6-правила отсут-
ствуют.
6.9. Z-исчисление де Брейна
В ^.-исчислении вполне возможно записать два выражения,
которые являются семантически идентичными, но синтаксически
отличаются друг от друга из-за различных имен переменных.
Основная идея канонического %-исчисления де Брейна (1972 г.)
заключается в том, чтобы удалить из Х-выражения все имена
переменных, заменив их на целые числа. %-Выражение в таком
случае состоит из целых чисел, представляющих порядковые
номера символов L, связывающих переменные, замененные
Математические основы: Х-исчисление 149
этими целыми числами, и из самих символов %. При этом се-
мантически эквивалентные Х-выражения являются также син-
таксически эквивалентными. Целое число, заменяющее пере-
менную, можно рассматривать как «смещение» или «глубину
вложенности» вводящего эту переменную символа X, после ко-
торого в этом случае нет никакой необходимости указывать
имя переменной.
В качестве примера приведем представление в Х-исчислении
де Брейна функции «следующий за» (SUCC)t
X. +Z.0 1
Более сложное Х-выражение
Xx.Xz/.Xf,f(XY.x)( + х у)
имеет следующее каноническое представление:
X.X.X.L0(X.L0)(+ L2 Z.1)
Поскольку в каноническом Х-исчислении нет имен перемен-
ных, там нет эквивалента правилу a-преобразования выраже-
ний, и это ставит вопрос о возможности выполнения 0-редукции
в присутствии свободных переменных. Оказывается, можно вы-
полнять преобразование, эквивалентное 0-редукции в Х-исчис-
лении (будем называть его 0*-редукцией), без каких-либо яв-
ных требований переименования. Но правило 0*-редукции яв-
ляется более сложным по сравнению с правилом 0-редукции,
так как оно перенумеровывает канонические переменные в теле
функции, даже если эти переменные не нужно замещать; это
во многом похоже на a-преобразование. Интересное свойство
0*-редукции в присутствии свободных переменных состоит
в том, что такое переименование (перенумерация) связанных
переменных с целью сделать их имена уникальными по отно-
шению к свободным переменным аргумента становится фор-
мальным алгоритмом (фактически частью самого правила 0*-
редукции) в Х-исчислении де Брейна. Детальное описание пра-
вила 0*-редукции можно найти в [89].
При рассмотрении редукции Х-выражений использование
представления де Брейна дает немногим больше, чем формаль-
ное определение правила переименования. Тем не менее нота-
ция де Брейна используется в схеме реализации, называемой
категориальной абстрактной машиной, которую мы рассмот-
рим в гл. 13.
Резюме
• Х-Исчисление — это исчисление безымянных функций. Оно
включает в себя нотацию для записи выражений и набор пра-
вил преобразования этих выражений.
150 Часть II. Глава 6
• Правилами преобразования ^-исчисления являются «-преоб-
разование, которое соответствует переименованию, р-преобра-
зование, соответствующее применению функции, и трпреобра-
зование, соответствующее функциональной экстенсивности.
• %-Исчисление может быть также дополнено произвольным
набором констант, таких, как целые числа, и связанных с ними
функций, называемых б-правилами.
• Подвыражение, которое может быть преобразовано с по-
мощью одного из правил преобразования или одного из б-пра-
вил, называется выражением, которое может быть редуциро-
вано, или редексом; выражение, не имеющее редексов, назы-
вается нормальной формой.
• Когда есть возможность выбрать редекс для преобразова-
ния, выбор определяется порядком редукций. Двумя альтерна-
тивными стратегиями выбора являются аппликативный порядок
редукций и нормальный порядок редукций, тесно связанные
с энергичным вычислением и ленивым вычислением соот-
ветственно.
• Нормальный порядок редукций гарантирует завершение пре-
образования, если это возможно. Так утверждает теорема стан-
дартизации.
• Если две различные последовательности редукций приводят
выражение к двум нормальным формам, то эти нормальные
формы эквивалентны с точностью до имен переменных. Таково
следствие теоремы Черча — Россера.
• Рекурсивные функции могут быть выражены в ^-исчислении
с помощью специальной функции, называемой У-комбинатором,
которая находит наименьшую фиксированную точку функции.
• Удалив б-правила, мы получим чистое Х-исчисление. В нем
можно выразить любые функции, несмотря на отсутствие
б-правил.
• В Х-исчислении де Брейна все имена переменных заменены
целыми числами, обозначающими глубину вложенности сим-
вола %, связывающего соответствующую переменную; 0-преоб-
разование в этом исчислении выполняется с помощью правил
Р*-редукции.
Упражнения
6.1. Укажите связанные и свободные переменные в каждом из
следующих ^.-выражений:
а) (Ах.х у)(Ку.у)
б) Кх.Ку.z(Kz.z(Kx.у))
в) (Кх.Ку.х z(y z))(Kx.y(Ky.y))
Математические основы: Х-исчисление 151
6.2. Для каждого из следующих выражений:
(i) Xx.Xy.(Xz.z)x(+ у 1)
(ii) (Xx.Xz/.x(Xz.z/ z))(((Xx .ky .y)8)(kx .(ky .y) x))
(iii) (XA.(Xx.h(x x))(Xx.h(x x)))((Xx.x)( + 1 5))
а) подчеркните все |3-, т]- и 6-редексы;
б) найдите самый левый из самых внешних и самый левый
из самых внутренних редексов;
в) найдите нормальную форму и слабую заголовочную нор-
мальную форму, используя нормальный порядок редукций.
6.3. а. Рассмотрим выражение F = ( кТ.Т Т ]|( Xf.Xx.f ( fx)). По-
кажите, как проявляется конфликт ^мен при приведении этого
выражения к нормальной форме с помощью нормального по-
рядка редукций.
б. Покажите, что FsuccO, где succ = Хх. + х 1, приводится
к 4 при нормальном порядке редукций и при приведении
к СЗНФ.
6.4. Рассмотрите следующее выражение:
Xx.(Xz/.z/)7
а. Покажите, что если при p-редукции оно замещает не-
сколько вхождений переменной, то редекс ('ку.у) 7 будет вы-
числяться каждый раз при применении данного выражения,
даже если механизм редукции основан на контексте (подразу-
мевается приведение к СЗНФ с использованием НПР). В этом
смысле НПР является неоптимальным.
б. Можете ли вы предложить модификацию НПР, гаранти-
рующую, что такие редексы будут вычисляться не более одного
раза.
6.5. а. Приведите пример функции, имеющей:
(t) много фиксированных точек;
(и) ровно одну фиксированную точку.
б. Что является наименьшей фиксированной точкой выраже-
ния Хх.*хх? Каковы его остальные фиксированные точки?
в. Объясните решение упражнения 6.2.в в случае выраже-
ния (iii).
6.6. Рассмотрим две взаимно рекурсивные функции языка Норе:
f(n) <=if n = 0 then 0 else g(n);
------g(n)<=n + f(n— 1);
которые имеют эквивалентное выражение Х-исчисления:
Y (kT.TUPLE-2 (kn.COND (= п 0)0((INDEX 2 Т)п))
(кп. +n((lNDEX 1 Т)( — п 1))))
152 Часть II. Глава 6
Покажите последовательность вычислений выражения f(l).
6.7. а. Для предложенного в разд. 6.8.1 представления булевых
величин TRUE и FALSE в чистом 1-исчислении
(i) покажите, что TRUE AND TRUE = TRUE,
(ii) определите NOT и EXCLUSIVE-OR (исключающее или).
б. Для предложенного в разд. 6.8.3 представления целых
чисел в чистом 1-исчислении определите функцию PLUS (плюс).
в. Целое число п 0 в чистом 1-исчислении можно опреде-
лить следующим образом:
tv= Lx .Ly .х (х ( ... х (z/) ... ))
Определите для этого представления функцию SUCC.
6.8. Покажите представления де Брейна для следующих 1-вы-
ражений:
a) Lx.Ly.y (Lz.z х)х
б) 1х.(1х.х x)(Ly.y(Lz.x))
в) (lx. + x((lt/.y)( — x(Lz.3)(ky.y у))))
Глава 7
СИСТЕМА ВЫВОДА ТИПОВ И ПРОВЕРКА ТИПОВ
В первой части этой книги говорилось о роли строго типи-
зированных функциональных языков в процессе разработки про-
грамм. В таких языках задачи решаются в терминах отображе-
ний на множестве сложных объектов данных, имеющих струк-
туру, соответствующую логике решения, а не компьютеру, на
котором выполняется программа. Кроме того, понятие полимор-
физма (введенное в гл. 2) позволяет определять родовые функ-
ции, которые могут выполнять одинаковые операции с данными
разного типа, причем конкретный тип данных получается в ре-
зультате приписывания значений переменным типа, входящим
в некоторый полиморфный тип. Альтернатива полиморфизму
в строго типизированных языках состоит в определении отдель-
ной версии функции для каждого типа данных, к которому она
применима. При этом тела в определениях таких функций бу-
дут одинаковыми. Более того, если реализация типизированного
языка обеспечивает проверку типов на этапе компиляции, нет
никакой необходимости хранить информацию о типах на этапе
выполнения программы, так как можно считать, что созданный
компилятором код не содержит ошибок, связанных с типами
данных. Это означает, например, что функции всегда приме-
няются к аргументам правильного типа.
Таким образом, проверка типов важна по двум причинам.
Во-первых, она позволяет выявить множество логических оши-
бок программы еще на этапе компиляции. Многие логические
ошибки являются результатом несоответствия типов выраже-
ниям, так что запускать программу для выявления этих ошибок
просто нет необходимости. Во-вторых, как мы только что заме-
тили, программа на этапе выполнения работает гораздо более
эффективно, так как всякое упоминание о типах данных может
полностью отсутствовать в коде, создаваемом компилятором.
В разд. 7.1 на двух примерах будут проиллюстрированы ос-
новные проблемы вывода типов функциональных выражений и
154 Часть II. Глава 7
определены типы выражений путем решения системы уравне-
ний. Каждое уравнение представляет собой ограничение, накла-
дываемое на тип некоторого подвыражения рассматриваемых
выражений. Процедура вывода наиболее общего типа выраже-
ния может рассматриваться как доказательство в достаточно
простой системе логического вывода, имеющей небольшое число
правил. В разд. 7.2 мы рассмотрим такую систему. Хотя фор-
мальное описание вывода типа является строгим и полным в том
смысле, что если выражение имеет тип, то его можно вывести,
остается неясным вопрос о выборе нужной последовательности
шагов доказательства и, следовательно, о том, как автоматизи-
ровать процедуру. Схемы проверки типов являются алгорит-
мами, выводящими наиболее общие типы выражений детерми-
нированно, и их можно рассматривать как руководства по по-
строению доказательств в системе вывода типов.
Другими словами, схемы проверки типов можно рассматри-
вать как доказатели теоремы. Они обычно включают в себя
отождествление пар выражений типа и реализуются с помощью
алгоритма отождествления Робинсона [73], который находит
наиболее общий унификатор (подстановку для переменных типа)
пары выражений. Поэтому мы можем быть уверены, что такая
схема находит действительно наиболее общий тип; это можно
доказать частично с помощью результатов Робинсона. В разд. 7.3
мы рассмотрим самый первый алгоритм проверки типов Ж [66],
который достаточно прост и обладает важными свойствами
обоснованности и полноты. В разд. 7.4 мы покажем, как можно
расширить Ж, чтобы он мог проверять тип функций, определен-
ных с помощью сопоставления с образцом. В последнем разделе
данной главы мы рассмотрим циклически определенные типы,
которые нельзя вывести с помощью W.
7.1. Неформальное введение
в проверку типов
Тип — это или переменная типа, которую мы будем обозна-
чать какой-либо греческой буквой, или применение оператора
типа к определенному числу аргументов типа. Базовые типы,
такие, как пит (целый тип) и truval (булев тип), являются
операторами типа без аргументов, a list — это оператор типа
с одним аргументом. Мы также используем бинарные инфикс-
ные операторы -> (оператор типа функции, эквивалентный->
в языке Норе) и X (оператор типа декартова произведения,
эквивалентный =#= в языке Норе). Типы, содержащие по крайней
мере одну переменную, являются полиморфными (политипами),
а типы, не содержащие переменных типа, являются мономорф-
Система вывода типов и , проверка типов 155
ными (монотипами). Таким образом, базовые типы являются
монотипами, так же как и типы многих примитивных функций,
например succ : пит-► пит и is-zero: num-*-truval. Однако не
все примитивные функции являются мономорфными, например
hd: list а->а является полиморфной, так как ее определение
типа содержит переменную типа а. Конечно, можно определить
произвольно сложные выражения типа, например выражение
типа для функции тар может быть записано следующим обра-
зом: (а-> Р)Х list a-*- list |J. Можно было бы ввести в рассмот-
рение произвольное число базовых типов, но нам вполне доста-
точно num, truval и list, чтобы объяснить рассматриваемые
принципы.
При проверке типа выражения мы хотим найти наиболее об-
щий тип, который оно может иметь, в том смысле, что все мо-
номорфные типы, которые это выражение может принимать, т. е.
типы, получаемые при присваивании переменным типа конкрет-
ных значений, являются частными случаями этого наиболее об-
щего типа. Другими словами, нам необходимо сконструировать
систему вывода типов, которая могла бы или определить наи-
более общий тип, или прийти к противоречию, которое означает,
что выражение не имеет наиболее общего типа. Если исходная
программа содержит пользовательские объявления типов, как
это может быть в языке Норе, тогда последующая проверка
типов необходима, чтобы гарантировать, что объявленный тип
совместим с выведенным типом. Для этого нужно, чтобы поль-
зовательский тип можно было получить из выведенного типа
с помощью подстановки определенных значений вместо пере-
менных типа. Это может потребовать больше работы, чем при
прямом выводе, но для языков сопоставления с образцом, где
функция может быть определена с помощью нескольких урав-
нений, выведенный тип каждого уравнения может быть прове-
рен на соответствие объявленному типу. Такая проверка, вы-
полненная независимо для каждого уравнения, может потенци-
ально быть более эффективной, чем соответствующий вывод
типа, который отождествляет типы, выводимые из каждого урав-
нения, чтобы получить наиболее общий тип.
7.1.1. Два неформальных вывода типа
Тип функционального выражения часто может быть выведен
эвристическими методами, и в этом разделе мы рассмотрим два
примера: применение тождественной функции к числу 3 и по-
лиморфную функцию тар. В частности, мы увидим, что поли-
типы, ассоциированные с let-связанными переменными (т. е.
с переменными, введенными в квалифицированных выражениях),
156 Часть II. Глава 7
которые называем родовыми, должны обрабатываться совер-
шенно не так, как политипы, ассоциированные с неродовыми
Х-связанными переменными, если мы не должны допускать при-
сваивания неправильного типа.
Основную идею можно понять, рассматривая применение
функции f к выражению е. Если мы знаем, что е имеет тип а,
то можем немедленно сделать вывод, что тип f — это о—>-р, где
р — тип, который должен быть выведен. Следовательно, мы мо-
жем рекурсивно выводить типы чисто аппликативных выраже-
ний; при этом самые внутренние выражения с известными
типами обеспечивают базовые случаи. Если включить в рассмот-
рение квалифицированные выражения, ситуация становится бо-
лее сложной, так как тип присваивается идентификатору дваж-
ды (в квалификаторе и в результанте), и поэтому мы должны
отождествить такие типы, чтобы получить наиболее общий тип.
Рассмотрим для начала выражение Е вида
let fx = х in f 3
которое записано в форме функционального «псевдокода». Что-
бы имело место согласование между типами его подвыражений,
требуется выполнение уравнений, приведенных ниже, в которых
мы обозначаем тип идентификатора ide символом o,de, а неиз-
вестный тип символом р, (i > 0):
аз = пит
Of = пит > pi
Ох = Ра
Of = Р2 * Рз
Рз = Р2
(базовый тип) (1)
(f 3 — это применение функции) (2)
(тип х неизвестен) (3)
(fx — это применение функции) (4)
(две части равенства = должны иметь одинаковый (5)
тип)
(Мы опустили уравнение для подвыражения х в fx. Оно имело
бы вид Ох = р4, и затем мы получили бы Of =р4->р3. Но из
двух уравнений для ох мы могли бы заключить, что рг = Р4-)
Из этих уравнений можно видеть, что р2 = пит, pi = р3 (из
уравнений (2) и (4)), р3 = р2 (уравнение (5)), что в резуль-
тате дает pi = р2 = рз = пит, и типом выражения f3 является
Pi = пит, как и ожидалось. Тот факт, что система уравнений
имеет решение, говорит о корректности выражения Е с точки
зрения его типа.
Аналогичные рассуждения справедливы для полиморфных
выражений. Рассмотрим следующую версию функции тар, вы-
раженной не через сопоставление с образцом, а с помощью при-
митивных функций-селекторов null, nil, cons, hd и tl:
map(f, m) = if null(m)
then nil
else cons( f (hd{ m)), map(f, ll(m)))
Система вывода типов и проверка типов 157
Поскольку примитивные функции обработки списков яв-
ляются полиморфными, мы присваиваем новые неизестные
типы ть Т2, ... переменным типа этих функций. Эти переменные
типа являются родовыми, и разным их вхождениям мы при-
сваиваем разные неизвестные типы, хотя в данном примере су-
ществует только одно вхождение каждой переменной. Начнем
со следующих присваиваний:
<т„ип = list tj —> truval
anit — list T2
Ghd — Ust T3—>T3
о и — list r4 —> list t4
Gcons = ( T5 X list x5)-+list T5
Продолжая, как в предыдущем примере, запишем теперь
уравнения, гарантирующие соответствие типов каждого подвы-
ражения в определении тар. Начиная слева направо, получим
следующи^уравнения:
° тар — Gf ~> Pi Для некоторой неизвестной переменной
типа pj (1)
Gnuii = Gm-> truval (2)
Ghd Gm * Pg (3)
«Tf = P2-*P4 (4)
Gtl = Gm-^pi (5)
Gmap — X Рз ""* P5 (6)
Gcons P4 X Pa * Рб (^)
Наконец нам нужно уравнение, гарантирующее, что обе
ветви условного выражения имеют одинаковый тип, который
является типом всего условного выражения, и уравнение, тре-
бующее, чтобы обе части равенства в определении тар имели
одинаковый тип. Вместе эти уравнения имеют вид
Pi — Gnli — р6. (8)
Эта система из восьми уравнений вместе с уравнениями для
типов примитивных функций в общем случае может быть решена
с помощью основанного на отождествлении алгоритма, который
мы рассмотрим в разд. 7.3. Здесь же мы решим эту систему
с помощью простых логических рассуждений. Из уравнения (2)
и уравнения для null имеем
csm = list iq
а из уравнения (3) и уравнения для hd имеем
Gm = list т3 и р2 = т3
158 Часть II. Глава 7
Подобным образом из уравнений (4) — (7) получим
Рз = ат —list т4
Рз = стт и p5 = Pi (сравнивая два уравнения для отар)
Р4 = Т5
р5 = list т5
р6 = list т5
Используя эти уравнения и уравнение' (8), получим решение:
Pi = р5 = р6 =/is/ х2 = list->r5 (поэтому Т2 = Т5)
р2==т1 = т3 = т4 (используя уравнения для ат)
p3 = am = list Т!
Р4 = т5 = т2
Наконец, получаем Of = Р2~*~Р4, поэтому отар = ( tj ->• Тг) X
X list tl list Т2- Так как типы Xi и тг являются произвольными,
заключаем, что полиморфный тип тар имеет, как и ожидалось,
вид
(а->- ₽)Х list a—* list р
7.1.2. Родовые переменные типа
Рассмотренные примеры не доставили нам особых трудно-
стей, и теперь рассмотрим функцию g, имеющую вид
g = Af.(f3, ftrue)
Тип этого выражения не может быть определен, так как мы не
знаем полиморфные характеристики А-связанной переменной f.
Первое вхождение f требует, чтобы ее тип был пит-*-а, тогда
как второе вхождение требует, чтобы тип f был truval^»-а. Пе-
ременные типа, относящиеся к Х-связанному идентификатору,
такому, как f, не являются родовыми, поскольку, как можем
видеть в этом примере, они относятся к каждому вхождению f
в теле функции, и некоторые значения этих переменных могут
вызвать конфликт. Если бы мы дали g тип ( а->р )->( Р X Р ).
выражение могло бы быть вычислено правильно в случае при-
менения к определенным аргументам, таким, как Ах.О, что дает
в результате (0,0). Однако функция succ («следующий за»)
имеет тип, который соответствует а->р и является поэтому до-
пустимым аргументом для g, но ее применение к аргументу true
приведет к ошибке. Поэтому данный тип выражения g в общем
случае неверен, и мы говорим, что выражение g не может иметь
Система вывода типов и проверка типов 159
тип. В действительности расширение Милнера (Milner) системы
типов, которое мы рассмотрим в данной главе, дает возможность
определить тип g, но этот вопрос выходит за рамки нашей
книги.
Внешне похожим примером является выражение
let f — kx.x in (f3, f true)
тип которого мы можем определить, используя полиморфизм.
Это действительно так, поскольку теперь f является let-связан-
ным идентификатором, локальным в выражении, так что мы
точно знаем, как он определен, и можем использовать эту ин-
формацию в каждом отдельном случае его вхождения. Здесь f
имеет тип а—>-а, который может принять вид пит пит, когда
f применяется к аргументу 3, и truval—>- truval, когда f приме-
няется к аргументу true. В первом примере данного раздела
тип f зависит от типа аргумента, к которому применяется вы-
ражение g, и поскольку мы заранее не знаем тип каждого та-
кого аргумента, то не можем заранее определить тип f. Пере-
менная типа, такая, как а, входящая в выражение типа let-свя-
занного идентификатора, называется родовой и может получать
различные значения для различных вхождений идентификатора
при условии, если она не входит одновременно в выражение
типа %-связанного идентификатора, область действия которого
в выражении включает область действия let-связанного иденти-
фикатора. Если мы попытаемся решить проблему, с которой
столкнулись при рассмотрении первого примера, с помощью вы-
ражения
let f — g in (f3, ftrue)
у нас ничего не получится. Снова применение данного выраже-
ния к функции succ даст ошибку, так как любая переменная
в типе f теперь не является родовой, поскольку входит в тип
Л-связанного идентификатора g.
В заключение можно сказать, что переменная типа, входя-
щая в тип выражения Е, является родовой, если и только если
она не входит в тип идентификатора связанной переменной лю-
бой Х-абстракции, для которой Е является подвыражением.
Перед тем как в следующем разделе формально определить
систему вывода типов, покажем, как обрабатываются рекурсив-
ные квалифицированные выражения. Мы будем делать это с по-
мощью оператора фиксированной точки fix (представляемого
в Х-исчислении в виде У-комбинатора), обрабатывая объявле-
ния вида
let f = ... f ... in ... f ...
160 Часть II. Глава 7
как если бы определение f было расширено для получения не-
рекурсивной формы следующим образом:
let f = fix f. ... f ... in .. . f ...
где fixx.e можно рассматривать как Yhx.e, хотя для целей вы-
вода типов fix не обязательно должен давать наименьшую фик-
сированную точку.
Таким образом, полный синтаксис выражений, для которых
мы будем выводить типы в следующих двух разделах, имеет вид
{exp} ::={id} | if {exp} then {exp} else {exp} | X {id).{exp} |
{exp} {exp) | let {id} = {exp} in {exp} |
fix {id.}.{exp}
{id} ::= идентификатор
7.2. Система вывода типов
В предыдущем обсуждении мы немного сократили нотацию
для записи выражений типа, опустив квантор «для любого»,
обозначаемый символом V. Например, когда мы записываем
сс—>-р, то на самом деле имеем в виду Va.V₽.a->-р. В системе
типов Милнера, на которой основана эта глава, все переменные
типа связаны кванторами общности на верхнем уровне; кван-
торы не могут быть введены внутрь выражений типа. Таким об-
разом, мы будем иметь дело исключительно с так называемыми
поверхностными типами, т. е. такими, которые имеют вид
Vocj ... Voc/гТ (п^О), и выражение типа т не содержит кван-
торов. Система вывода допускает типы, не являющиеся поверх-
ностными, однако алгоритма проверки типа, который мог бы
работать с ними, у нас нет. Теперь, поскольку все типы являют-
ся поверхностными, мы можем опустить кванторы, считая их
заданными неявно. Однако мы будем помнить о них, так как
они хорошо проясняют разницу между родовыми переменными
типа (которые соответствуют свободным переменным в выраже-
нии, содержащем кванторы) и неродовыми переменными типа
(которые соответствуют переменным, связанным кванторами).
Приведем здесь восемь правил вывода (см. [20]), первое из
которых является аксиомой, а остальные — это действительно
правила вывода. Запись А |— е: т означает, что из набора допу-
щений А мы можем сделать вывод о том, что выражение е
имеет тип т (символ Н называется крестовиной). Допущение —
это соединение типа т и переменной х, обозначаемое х: т. Запись
А.х:х обозначает набор допущений, полученный из набора А
присоединением к нему допущения х:х (сам набор А не содер-
жит такого допущения).
Система вывода типов и проверка типов 161
Запись
А
В
читается «из А мы можем вывести В». Наконец, запись [<т/а]т
означает подстановку or вместо всех свободных вхождений а
в выражение типа т (предполагается, что а не входит в зону
действия связанной квантором общности переменной с име-
нем о). Правила имеют следующий вид:
Переменные А.х:х |- х : т [УД/?]
Условные выражения
А к- е : truval А к- е': т А к- е" : т
-------------------------------- [СОЛФ]
А |- (it е then е' else е" ): т
Абстракции
Д|-е:<т->т Д > е': <т
Применения ----------------------- [ЛЛР]
А [- ( ее'): т
А\- е' -.в Л. х : ст |- е: т
Let-выражения ------------------------ [LET]
А |- (let х = е' in е ): т
А .х : т е: т
Фиксированная тонка -------------- [F/XJ
А |- ( fix х.е ): т
/1 Г~ с . L
Обобщение ----------- (а не является свободной в Д) [GEN]
А |- е: Уа.т
А е : Va.r
Специализация ----------- [SP.EC]
А [- е : [а/а] т
В качестве простой иллюстрации того, как эти правила
можно использовать для вывода типа выражения, рассмотрим
функцию тождества (Хх.х). Наиболее общий тип этого выраже-
ния может быть выведен следующим образом:
х : а |— х : а [УЛ/?]
I— (Хх.х): а -> а [ЛВ5]
Н (Xx.x):Va.a—>a [GEN]
И — 1473
162 Часть II. Глава 7
Специализированный тип функции тождества можно получить
с помощью [SPEC]:
|— (Хх .х)'. Va.a —» a
Н(Хх.х)1 пит -> num [SPEC]
Тот же самый результат можно получить более коротким
путем, если на первом шаге присвоить переменной а тип пит.
В этом случае получим
х : пит Н х : num [V АР]
Н (Хх.х): пит—>пит [ABS]
Можно вывести, что типом выражения (Хх.х) 3 является пит".
3 : пит, х : пит Н х : num [VАР]
3 : num |- (Хх.х): пит->пит [ЛЕЕ] 3 : num I— 3 : пит [7 АР]
3 : num I- ((Хх. х) 3): пит [ АРР]
В действительности эта система способна выводить типы для
выражений, с которыми наш алгоритм справиться не в силах.
Простейшим примером является выражение (Хх.хх), включаю-
щее в себя запрещенное самоприменение хх. Обозначив тип
Va.a-»-а через ф, получим
х : Ф Н х : Ф[У AR]
х : Ф I— х : ф->ф[8РЕС] х'ф\-х:ф [7АР]
х: Ф н х х : Ф [АРР]
I—(Хх.х х):ф->ф [ABS]
Не рассматривая первый «эвристический» шаг х:ф\- х:ф,
можно считать ключевым шагом данного доказательства ис-
пользование правила [SPEC], представляющего вместо а вы-
ражение Va.a-»-а, что дает тип, не являющийся поверхност-
ным. Давайте теперь вернемся к нашему предыдущему при-
меру let f = Хх.х in (f 3, f true). Будет удобно для целей нашей
дискуссии представить кортеж (/3,ftrue) как результат приме-
нения функции tuple-2 (имеющей тип a-»-0->-aX ₽ )> введен-
ной в гл. 6. Это объясняется тем, что мы пока не имеем правил
*> Этот алгоритм описан в следующем разделе. — Прим., перев.
Система вывода типов и проверка типов 163
вывода для кортежей. Перепишем поэтому наше выражение в
следующем виде:
let f = Xx.x in tuple-2 (f3)(ftrue)
Предположим, что набор допущений А = { 3 : num, true : truval,
tuple-2 : Va.Vp.a->-₽-> а X P } и Ф == Vа.а а, как и ранее.
Тип выражения выводится следующим образом:
A.f:j>{-f:j>
Л. f : <f> Н f : пит -> пит А. f : $ Н 3 : пит
A.f ф I— f 3 : пит
A.f:<f>t-f:f
Л.f : $ Н f : truval -> truval A.f : <f> i- true : truval
A.f : ф I— f true : truval
A H tuple-2 : Va. Vp.a->p —>a X P
A I— tuple-2 : V₽. num —> p —► num X P
A H tuple-2 : num—►truval num X truval A.f ’.ф H f 3 : num
A.f :<f> H tuple-2 (f 3): truval —> num X truval A.f :/l— f true : truval
A.f tuple-2 (f 3) (f true): num X truval
Наконец, используя результат для функции тождества, по-
лучим
Л F— Хх.х'. ф A.f : 1- tuple-2 (f 3) (f true): num X truval
ЛН(1е1 f = Kx.x in tuple-2 (f3)(f true)): num^, truval
Однако при определении типа эквивалентного выражения
(Kf.tuple-2 (f 3) (f true) ) (1.x.x) невозможно вывести поверх-
ностный тип для kf.tuple-2 (f 3) (ftrue). Тип этого выражения
не является поверхностным и имеет вид (Va.Vp.a->P)->
—>-(Vy.V6.y X 6). Его можно получить с помощью аналогичного
доказательства, начав с допущения f :a—>-р.
Теперь ясно видно отличие между родовыми и неродовыми
переменными типа. Если переменная входит в тип %-связанного
идентификатора, она должна входить в набор допущений для
того, чтобы можно было последовательно применять правило
[ЛВ5]. Следовательно, переменная является родовой, если она
и*
164 Часть II. Глава 7
не фигурирует в наборе допущений, вследствие чего мы можем
применить правило [G£W] и связать ее квантором V. Поэтому
существует прямая связь между родовыми переменными и кван-
торами общности.
Конечно, не все этапы приведенных выше доказательств яв-
ляются очевидными a priori, и для практической проверки ти-
пов необходимо автоматизировать процедуру доказательства в
рассматриваемой системе вывода. Фактически это означает, что
необходимо построить алгоритм проверки типа выражения,
определяющий порядок применения правил вывода. Такой ал-
горитм можно рассматривать как эвристику доказательства. Су-
ществует формальный способ установления соотношения между
описанной выше системой вывода и алгоритмами проверки типа,
в частности, можно доказать, что если с помощью алгоритма
найден тип какого-либо выражения, то этот тип можно выве-
сти в описанной системе вывода. В деталях этот вопрос рас-
смотрен Милнером в [66].
7.3. Алгоритм проверки типа Ж
При разработке функции для вывода типа, о которой чаще
говорят как об алгоритме для проверки типа, возникает не-
сколько синтаксических и семантических вопросов, требующих
рассмотрения. Во-первых, нужно определить синтаксическую
схему типов, которая присваивает уникальный (наиболее об-
щий) тип каждому синтаксически допустимому выражению. Та-
кие выражения называются правильно типизированными, а их
типы называются правильными типами. Во-вторых, необходимо
показать, что схема типов является семантически правильной,
т. е. все синтаксически правильные выражения не содержат се-
мантического несоответствия типов. Так, необходимо быть уве-
ренными, что при вычислении правильно типизированного вы-
ражения все его примитивные функции будут применяться к ар-
гументам соответствующих типов. В-третьих, алгоритм должен
быть синтаксически правильным. Это означает, что если с по-
мощью данного алгоритма найден тип выражения, то это вы-
ражение является правильно типизированным. Наконец, хоте-
лось бы также, чтобы алгоритм проверки типов был полным
в том смысле, что если выражение имеет правильный тип, то
алгоритм находил бы его по крайней мере в большинстве слу-
чаев. В данной книге мы не рассматриваем теоретические ас-
пекты перечисленных выше вопросов, отсылая читателя к ра-
боте [66]. Наша версия алгоритма Ж является упрощенным
вариантом алгоритма Милнера и тесно связана с системой вы-
Система вывода типов и проверка типов 165
вода, описанной в предыдущем разделе. Мы запишем алгоритм
проверки типов в виде функции.
'ff вычисляет наиболее общий тип выражения, если поверх-
ностный правильный тип существует. Он основан на алгоритме
отождествления Робинсона.
Теорема 7.1 (см. [73])
Существует алгоритм У, имеющий на входе любую пару вы-
ражений ст, т (над некоторым алфавитом переменных), такой,
что или У(ст, т) дает в результате подстановку U, удовлетво-
ряющую условиям:
(1) L/o = Ux, т. е. U отождествляет о и т;
(2) если R отождествляет и и т, то для некоторой подстановки S
имеет место R = SU;
(3) U затрагивает только переменные, входящие войт;
или
У (ст, т) заканчивается неудачей.
Когда У завершается успешно, именно свойство (2) подста-
новки U гарантирует, что U — это наиболее общий унификатор.
В нашем случае выражениями являются выражения типа, а ал-
фавит— это множество переменных типа. Поэтому, например,
У (а, а) дает в результате подстановку U = I (тождественную
подстановку), а У(а->-р, питпит) дает подстановку U =
= [пит/а, пит/$\, где подстановка выражения ст,- вместо пере-
менной а,- (1 t п) обозначается [сп/си, ..., стп/ап]. Однако
У (аtruval, питпит) заканчивается неудачей.
Для полноты определим сейчас функцию, реализующую У
и основанную на идее несогласованной пары выражений типа.
Говоря неформально, это означает, что для данных термов е, е'
(в нашем случае это выражение типа) несогласованная пара
D(e, е') содержит первые два подтерма в е и е' соответственно,
которые различаются между собой; если е = е', оба компонента
пары пусты, и мы обозначаем такую пару символом л = ( , ).
Например, D( пит-^пит, a^num) = (num,a,),D(a,a,-+$) —
= (а,а->-р), D(num—^пит, пит->-пит) = л, D(у-+ пит
(а->- пит)-^ пит) = (у, а->па/п). Заметим, что в послед-
нем случае выражения типа не могут быть отождествлены.
Проще всего дать точное определение несогласованной пары
в форме функции. Предположим, что каждое выражение типа
записано в виде ТДсть ..., стл(1)) (t^l), где Т,- обозначает
операцию типа арности n(i), а ст/ обозначает выражение типа
(j^l). Так, например, мы записываем а->(РХ?) в виде
->(а, X (₽,?)). а базовый тип, такой, как пит, арности О,
в виде пит.
166 Часть II. Глава 7
Наша функция несогласованной пары имеет вид
Р(Г{(аь .аг„(/)), Г/(ть ...,тп(/)))
= if T^Ti
then (ГДоь ГДть ...,тП(Л))
else if п(г) = 0
then я
else D' (1)
where D' (k) = if k = n (i)
then D(ok, rk)
else if D(ak, тк) = я
then D' (k 4- 1)
else D(ak, тк)
Функция отождествления
У3: терм X терм подстановка
может быть определена на основе вспомогательной функции
unify : подстановка X терм X терм -> подстановка
следующим образом:
У (е, е') = unify( I, е, е')
unify( S, е, е') = if Se = Se'
then S
else let («, v) — D(Se, Se') in
if и — это переменная, не входящая в и
then unify( [u/u] S, e, e')
else if v—это переменная, не входящая
в и
then unify( [u/u] S, e, e')
else НЕУДАЧА
Композиция двух подстановок S и Т обозначается ST-, на-
пример, ( [u/w]S)x является термом, получаемым заменой пе-
ременной и на терм v в терме St. Мы опускаем определения
функций, проверяющих, являются ли и или v переменными и
входят ли и или v соответственно в v или и. Если ни и, ни v
не являются переменными, тогда отождествление заканчивается
неудачей, но, согласно данному определению, оно закончится
неудачей также, если и — это переменная, входящая в и (и в
этом случае не может быть переменной) или и — это перемен-
ная, входящая в и. В каждой из этих ситуаций существует воз-
можность циклической подстановки, приводящей к зациклива-
нию алгоритма, поэтому отождествление прекращается. Эта
простая проверка возможного зацикливания называется про-
веркой вхождения. Проверка вхождения предотвращает зацик-
Система вывода типов и. проверка типов 167
ливание при отождествлении, но она может привести к тому,
что некоторые унификаторы не будут найдены, хотя на самом
деле они существуют (другими словами, циклическая подста-
новка не имеет места). Поэтому существует определенное коли-
чество допустимых циклических типов, которые не могут быть
выведены с помощью реализации Ж, использующей данный ал-
горитм. Позднее мы еще вернемся к этому вопросу.
Рассмотрим работу описанной выше функции на следующем
простом примере:
^(а->Р, р у) = unify( I, а—>Р, ₽-►?)
= ищ/г/([р/а], а^₽, Р->у)
так как Z)(a-*p, p~>y) = (a, р)
= иш7у([у/Р][Р/а], а—>р, Р->у)
так как D([p/a](a->P), [ P/a ] (р-> у)) = Г>( р — р, P~>Y)
= (Р, Y) = [ Y/P][₽/a]
так как [ y/P ] [ P/a] (a-*Р ) = [ у/Р ] [ P/a] (Р-> у)
= Y^Y = [Y/P. P/a]
Вернемся теперь к алгоритму Ж. Имея набор допущений А
(присваивающих типы переменным, как в предыдущем раз-
деле) и выражение е, мы в случае успешного завершения ал-
горитма Ж получим А, е ) = ( Т, т), где т — это наиболее об-
щий тип е, а Т — это подстановка, такая, что ТА определяет
соответствующие типы переменных из А. Фактически Т возвра-
щается только как часть результата, что дает возможность про-
должать рекурсивное применение if. Ниже показано, как вы-
глядит полный «алгоритм»
У\А, е) — (Т, т)
где
(а) Если е — это идентификатор х, то Т = 1, и если x:Vai ...
... ал.б е А, то
* = [ Р1/«1 ] • • • [ Рл/а„ ] <т
где {р,-11 <: i <: п} — это новые переменные типа.
(Ь) Если е = fg, пусть
(/?, р) = Г(Л, f)
(S, а) = Ж(/?Л, g)
U = r(Sp, а->Р)
168 Часть II. Глава 7
где р — это новая переменная типа. Тогда Т — USR и т — 1/р.
(с) Если е = if р then f else f', пусть
(/?, р) = Г(Д, р)
U = /’( р, truval)
(S, <т) = 5Г,({7/?Д, f)
(S', o') = ^(SC//M, f)
U' = r(S'a, a')
Тогда T = U'S'SUR и т = U'a'.
(d) Если e — Kx.f, пусть
(/?, р) = У(Л.х:₽, f)
где р — новая переменная типа, t/= У(р). Тогда Т =
= /?₽ + р.
(е) Если е ~ fix x.f, пусть
(Л р) = Г(Л.х:₽, f)
где р — новая переменная типа, U = y(R$, р). Тогда Т~
= UR и т = UR$.
(f) Если е = letх = fing, пусть
(/?, P) = ]T(A-f)
(S, а) = Л/гЛ-х:р', g)
где p' = Vai ... an.p и ои, ..., ал — это свободные переменные
в р, не входящие в RA. Тогда Т = SR и т = о.
Вспоминая рассмотренную в предыдущем разделе взаимо-
связь между родовыми переменными и кванторами общности,
мы можем видеть, что в случае (а) новые переменные типа р,
заменяют только родовые переменные в типе х, которые по-
этому могут быть заменены независимо от их вхождений в дру-
гие типы; это соответствует применению правила вывода
[SPEC], Напротив, в случае (f) все свободные переменные
в типе х, не встречающиеся в наборе допущений RA, связаны
квантором общности, поскольку являются родовыми; это соот-
ветствует немедленному применению правила вывода [ GEN ]
столько раз, сколько возможно.
Примеры, иллюстрирующие работу алгоритма Ж, очень уто-
мительны, и мы рассмотрим только главные шаги алгоритма
для двух случаев: во-первых, для функции, уже использовав-
шейся нами при демонстрации различия между родовыми и не-
родовыми переменными в разд. 7.2, и, во-вторых, для рекурсив-
ной функции, находящей длину списка. Данные примеры затра-
Система вывода типов и проверка типов 169
гивают все шесть случаев описанного выше алгоритма. Все
символы р с индексами или без будут обозначать новые пере-
менные типа. Мы будем использовать два различных результата
для типа единичной переменной, соответствующих неродовому
и родовому случаям:
)Г( А.х : а, х) = ( I, а)
2Р(А.х.:а, х) = (1, р)
Оба они следуют из (а), и из (d) мы немедленно получаем
Г(Л, kx.x) = (R, (/?р)->р)
где (7?, р) = 1^(Л.х:р, х) = (/, р)
= (/, р->р)
Теперь рассмотрим выражение
e = let f = Zx.x in tuple-2 (f 3)(f true)
и набор допущений
A = (3:num, true'.truval, tuple-2: e->-S->eXM
e) = (S^, aj
где ( 7?b Pi ) = Ж( A, kx.x) — (I, Pi~>Pi), как мы только что видели.
(Sb сг1) = Ж’(Л[1, tuple-2 (f 3)(f true))
где Aa — A.f 1 Va.a—>a согласно (f)
Таким образом, повторно применяя (b), мы получаем
(Sb a1) = (t/IS2/?2, t/,p2)
где (R2, р2) = Ж(Ла, tuple-2 ЦЗ))
(S2, а2) = Ж(/?2Ла, (ftrue))
U У1 {S2p2, ст2 —> p2)
( ^2> P2 ) — ( Uг^З^З, U203 )
где (R3, р3) = Г(Ла, tuple-2) — (I, e->6-(>X6))
(S3, а3) = Г(74 (P))
t72 — ^( 53p3, 03—>P3)
(S3, a3) — (U3P4)
где (Ri, р4) = Ж(Ла, П = (Л 05->05)
(S4, о4) = Г(/Ла, 3) = (/, пит)
t/3 = r(S4p4, а4->04) = Л05->₽5, n«m->04)
=?[n«m/p5, n«m/p5]
170 Часть II. Глава 7
так что
S3 = U3, а3 = пит
и
{/2 = >(е X 6), пит-> р3) = [num/z, Ь—^пит'Х.б)/^]
/?2 = U2^3 ( так как ^3 = I )> Р2 = ^ —> ( ««« X 6 )
Подобным образом
(S2, ст2) = (£74S5/?5, £/4₽6)
где (Я5, р5) = ^(/?2Ла, /) = (/, р7^р7)
(S5, о5)= (/, truval)
£/4 = У’(р7->Р7, /гиаа/->Рб) = [/гиоа//р7, truval^}
так что
S2 = Ui, ^2 = truval
Таким образом,
U{ = 7(б->(ш/тХ6), truval->^2) = [truvallb, (питХ. truval)/^]
и
St — U JJJJ2U3, <Tj = num X truval, R{~ I
так что
Ж^Л, e) = (Sb num'XJruval)
Заметим, что как и при рассмотрении системы вывода в преды-
дущем разделе, родовая переменная а в типе f заменяется раз-
личными типами Рб и р7, которые в процессе отождествления
превращаются в пит и truval соответственно.
Для нашего следующего примера запишем в нерекурсивной
форме, которая удобна для применения алгоритма Ж3, функцию
length, находящую длину списка:
length = fix f.hx.e, где e = it null x then 0 else succ(f(tl x))
Набор допущений, который мы используем, имеет вид
А = {null: list а, —> truval, tl: list а2 —> list щ,
0 : num, succ : num —> num}
Тогда на основании случая (е) алгоритма Ж3 имеем
Г(Л, length) = {U0Rb UoR^)
где {R\, Pi) = l^(A.f : pb 2.x.e)
U0 = y(R&, P1)
Система вывода типов и проверка типов 171
Тогда
(Л1, Р1) = (Л2, Л2₽2“*р2) на основании (d)
где (Р2) = ^’(^2> е)> где Л2 обозначает A.f
= (t72S2S|t/i/?3, t/2a2) на основании (с)
где (i) (Я3> Рз) = ЛЛ. null x) — (U3S3R4, П3Рз) из (Ь)
(Ль Р4) = ^э(А> null) — (I, list «[—>truval) из (а)
(S3?or3) = ^(M2, х) = (/, ₽2)
Тогда
Л3 — U3 = F( list aI truval, p2 -> p3)
= [list aj/Рг, truvalj^]
(ii) t/1 = y(p3> truval) = £73P3, truval) = I
(iii) (Sb ) — 7f\UxR3A2, 0) = (/, num)
(iv) (S2, ст2) = Ж’(51(/1/?3^2, succ(f(tl x)))
= ^(U3A2, succ{f{tl x)))
(v) [/2 = r(S2ab o2)
Теперь, повторно применяя (b), получаем
O2 = ^4?4 и S2 — U4U3Uq
где U4 = [num/a4, пит/ft 4]
U3 — [list aj—>Ps/Pi]
(^6=[al/a2> list “i/M
(Переменные a4, P4, P5, Ре введены при применении случая (b)
и не нужны нам больше.) Тогда
<т2 = пит
и2 = У’(о1, пит) = [пит/а1]
S^U^I
Rx = R2 = U2U4U3U&U3
р2 = С/2о2== пит
Pi — Л2Р2 -* Рг = at —> пит
Наконец,
^о = ^(Л1Р1, p() = F(/tsf cq-s-Ps, list ах -> num) = [num/p5]
так что
Ж( A, length) — (UaU2U4U3U3, list at -> num)
172 Часть II. Глава 7
Для практического использования алгоритм УГ недостаточно
эффективен, и Милнер предложил императивный алгоритм 3",
который использует глобальные данные для хранения значений
переменных типа, и процедуру unify, которая не возвращает
результат, а модифицирует эти глобальные данные в качестве
побочного эффекта. В действительности легко видеть, что ST
моделирует Ж, и это дает основу для доказательства того, что
У и F эквивалентны.
7.4. Расширения УГ
для практической проверки типов
Не говоря об эффективности, отметим, что Ж не вполне
подходит нам для практической проверки типов в таких тради-
ционных функциональных языках, как Норе и Miranda, так
как некоторые свойства этих языков не включены в синтаксис,
с которым работает УГ. В первую очередь это составные типы
данных пользователя и сопоставление с образцом, где образцы
могут включать кортежи. Включение составных типов данных
не является проблемой, так как определенные пользователем
типы можно рассматривать как новые примитивные операторы
типа (аналогичные, например, —пит и list), а функции-кон-
структоры, работающие с пользовательскими типами, как при-
митивные функции (аналогичные cons, nil и т. д.). В этом слу-
чае определенный пользователем тип каждого конструктора
просто добавляется к глобальному набору допущений. Напри-
мер, имея определение данных на языке Норе
data shape == rectangle( num # num) -|—|- circle( num);
мы бы добавили следующие допущения:
rectangle : num X num —» shape и circle : num —> shape
к глобальному набору допущений. Все типы теперь обрабаты-
ваются одинаковым образом, так что если Т\ и Т2 представляют
собой конструкторы, то 7’( Т\ (<Ti, о2), Т2( ц, Т2)) заканчивается
неудачей, если 7\ =^=Т2 (например, если 1\ —rectangle и Т2 =
— cons).
Как мы уже видели, кортежи могут обрабатываться подоб-
ным образом с помощью семейства примитивов кортежирования
tuple-n (и > I), тип которых в глобальном наборе допущений
выглядит следующим образом:
tuple-n-. сс| —> а2 ... -> а., —> (а! X «2 • • • X )
Однако удобно рассматривать кортежи как специальные объ-
екты из-за их особой роли в определении функций, имеющих
Система вывода типов и проверка типов 173
больше одного аргумента, к которым не применим карринг.
Напрашивается поэтому идея расширения алгоритма проверки
типов таким образом, чтобы он мог выводить типы кортежей
непосредственно, и если мы сделаем такое расширение, то смо-
жем обойтись без рассмотренных выше глобальных допущений.
Требуется только одно дополнительное правило для "W3, очевид-
ное в свете наших предыдущих обсуждений. Кортеж в этом
правиле мы записываем обычным образом — в круглых скобках:
(g) Если е = (ei, е2, ..., ел), пусть
(Яь Р1) = Г(Л, е,)
(Я2, Р2) = Г(4 е2), р„) = ЛЛ„, е„)
где 41 = 4 и Л(+1 = RtAt ( 1 X i sC п). Тогда Т = RnRn-i...
...Ri и т = Тф! X Т2р2>< ... ХТ„р„, где Tt = Rn ... Ri+X
Tn = I.
Однако эта модификация сама по себе ничего не значит, так
как в нашем правиле для определения типа %-абстракции Хх./
переменная х предполагается простой. Такое предположение
вполне подходит, когда имеешь дело с исходными функциями
вида gX\X2 ... хп — Е, к которым применим карринг, но оно не
годится для функций, определенных с помощью кортежей, на-
пример g(x\, х2, .... хп) = Е. Чтобы выйти из положения, не-
обходимо цвести новый тип выражения, называемый v-абстрак-
цией и записываемый в виде vp.e. Он аналогичен Х-абстракции,
за исключением того, что аргумент р может быть произвольным
образцом, (мы используем эту идею снова в приложении В).
bJoBoe правило алгоритма Ж, определяющее тип v-абстрак-
ции, вклЮчае’г в себя правило (d), так как переменная является
частным случаем образца, т. е. vx.e = kx.e,’если х— это пере-
менная. Новое правило подобно правилу (d), за исключением
того, что тип образца-аргумента должен быть выведен так же,
как и тип тела абстракции:
(d') Если е = vp.b, пусть
(R, p) = T(A.Xl-.^. ... х„:р„, р)
и
(/?', p') = ^RA.x{'.R^. ... хп: R$n, b)
где все 0,- (1 i п) являются новыми переменными
типа, a Xi — это переменные, входящие в об-
разец р. Тогда Т = R'R и -г = R’p -> р'.
Заметим, что если р является кортежем из k элементов, тип р
будет получен для р с помощью нашего нового правила (g).
174 Часть И. Глава 7
Теперь нам осталось только решить проблему, как вывести
тип функции, определенной с помощью т > 1 уравнений, каж-
дое из которых в общем случае имеет вид
fPn • - • Pin = ei,
где Pik (1 k ^п) является произвольным образцом (в язы-
ке Норе п=1). Как можем ожидать, при проверке типа i-e
уравнение рассматривается как v-абстракция
f = vpn- ... vpin.6i
Если нам нужно только проверить соответствие -типа f объяв-
ленному пользователем типу т, мы можем просто выполнить
отождествление У(сц, т) для каждого из т уравнений по от-
дельности, где Gt— это тип, выведенный для уравнения i ( 1
i т). Если ни одно из отождествлений не закончилось
неудачей, мы завершаем проверку типов, считая объявленный
тип т правильным.
С другой стороны, чтобы вывести наиболее общий тип функ-
ции f, согласующийся с типом каждого из т уравнений, необ-
ходимо отождествить типы, выведенные для этих т уравнений.
Это дает новое правило (h) для алгоритма УТ.
(h) Если f определена с помощью набора из т уравнений
{fpn ... pin(i) = е,| 1 С i С т}, тогда ^(A,/) = (Qm ...
... QiS 1 ... Sm, Qmom), где Qk = Т( Gk) (2 k
m ), Qi = I и' для 1 i m, (St, gi ) =Ж (A, fix f.vpn....
• • - vpintG-ei).
Теперь мы имеем всю необходимую информацию, чтобы реали-
зовать проверку типов для практических полиформных функ-
циональных языков, таких, как Норе, и отсылаем всех, интере-
сующихся дополнительными сведениями, к опубликованным
статьям по данному вопросу, например к более эффективному
алгоритму Милнера и к программе контроля типов Кар-
делли [20].
В заключение рассмотрим вопрос определения типов для
множества взаимно рекурсивных функций. Предположим, что
функции fug определены как взаимно рекурсивные. Тогда,
используя оператор fix, можем выразить f только через g (и g
только через f), возможно используя в каждом случае сопостав-
ление с образцом. Таким образом можно найти тип f исходя
из предположения о типе g и, с другой стороны, можно опре-
делить тип g исходя из предположения о типе f. Все, что нам
теперь осталось сделать, — это отождествить выведенный и
предполагаемый типы f. Эти рассуждения приводят-нас к сле-
дующему правилу:
Система вывода типов и проверка типов 175
(i) Если {ft = et\ 1 I п} является набором взаимно рекур-
сивных уравнений для идентификаторов функций fi, пусть
At — A.fi: ₽(....fi-t: ₽£_1-Л+1 • 0£+1...fn'- Рп
K{Rt, Pj) = F(Rt_1 ... R{Alt et)
Тогда для любого k, 1 k п, '%p{A,fk) = {US\,x), где
Si — Rn — Ri (1 , т = t/SiP* и U = V°(Sk+iPk,<Si0*).
7.5. Ограничения
В заключение этой главы вернемся к вопросу о цикличе-
ски определенных типах и рассмотрим проблемы вывода таких
типов с помощью 2Г.
Предположим, мы хотим вывести тип выражения е =
= 'Kx.consxx. Применяя W к е с набором допущений А, вклю-
чающим cons : аlist (а,)list (а), получим
Г(Д e) = (R, R0->p)
где (R, р) = А. х : 0, cons х х)
= (СМ?ь £Л0.)
где Ui = Sjpi, <Т[ —> 01 ) (после некоторого упрощения)
(Ri, р[) = >Г( А.х : 0, cons х)
= ([а/0, /zsZ(a)->/zs/(a)/02], Ust{ а) -> list{ а)) (после
некоторого упрощения)
И (8Ь о1) = Г(«1(Д.х:0), х)
= >9((/?1Л).х:а, х)
= (Л а)
Таким образом Ui = F( list(a )-*-list( a), a->0i) и отож-
дествление закончится неудачей, так как «проверка вхождения»
обнаружит, что переменная а входит в другой компонент не-
согласованной пары list (а,). Если мы допускаем бесконечные
типы, можем видеть, что тип выражения consxx имеет вид
list( list{ ... (list{ a))...)) = a)
и что типом "kx.consxx является поэтому listco{ a )-> list00 {a ).
He было бы серьезной проблемы, если бы наша проверка типов
заканчивалась неудачей только в случае бесконечных типов, но,
к сожалению, проверка вхождения накладывает более серьез-
ные ограничения. В частности, отождествление всегда завер-
шится неудачно, если мы попытаемся вывести тип выражения,
176 Часть II. Глава 7
содержащего самоприменение, например такого, как /-комбина-
тор, имеющий тип (а->а)-*а.
Чтобы убедиться в этом, рассмотрим выражение хх, кото-
рое имеет тип т, получаемый из
]Г(х: ₽, х x) = (USR, £/₽') на основании правила (Ь)
где (/?, p) = (S, ст) = (/, ₽)
Ht7 = r(Sp, <т->0') = Г(₽, ₽->0')
Таким образом, отождествление U даст ошибку, так как
переменная 0 входит в выражение типа 0->0'. Некоторые схе-
мы проверки типа несколько более сложны, чем рассмотренная
нами, и не выполняют немедленно проверку вхождения. На-
пример, в случае У-комбинатора, определенного в виде У =
= kf.(Xx.f(xx)) (kx.f(xx)), может быть выполнена следую-
щая цепочка выводов (опускаем несколько промежуточных
шагов):
х : о = о —> т
хх: т
f: т —> х'
f (хх): х'
Ax.f(xx): ст—>т'
Самоприменение (Xx.f(xx)) дает вывод (Xx.f (хх)): ст = стт',
и, таким образом, мы имеем равенства
а = ст —> т = ст —>х'
из которых можем заключить, что т = х' и, следовательно,
Теперь уже легко сделать вывод, что У: (т->т )->т.
Вывод о том, что х = х', был сделан не с помощью алгоритма.
Он является примером дополнительных возможностей, кото-
рыми должна обладать схема проверки типов, способная рабо-
тать с простейшими циклическими типами.
Резюме
• Проверка типов позволяет выявить много программных оши-
бок на этапе компиляции и избежать проверки типов на этапе
выполнения, что повышает эффективность программ.
• Тип выводится для каждого подвыражения в программе и
проверяется на непротиворечивость. Типы, объявленные поль-
зователем, также проверяются сравнением с выведенными
типами.
Система вывода типов и проверка типов 177
• Let-связанные переменные типа являются родовыми и могут
быть заменены разными типами в одном и том же выражении;
^-связанные переменные не являются родовыми и таким свой-
ством не обладают.
• Логическая система вывода может вывести тип выражения
формально, но не автоматически.
• Алгоритм Л? Милнера выводит поверхностные типы, эффек-
тивно автоматизируя процедуру доказательства для простой си-
стемы вывода типов.
• Ж может быть расширен, чтобы иметь возможность работать
с сопоставлением образцов, но проверка вхождения в алго-
ритме отождествления может приводить к неудаче при проверке
типов некоторых правильно типизированных выражений, таких,
как У.
Упражнения
7.1. Найдите неформальным способом наиболее общие типы сле-
дующих функций языка Норе:
а)------f( a, b, с) <=if a(b) then [с] else [b ::с];
Ь)------g(x, у) <= lambda z => if z(x) then у else z;
c)------h(a, b, c)<= [lambda x=>(b(x, 2), c(b(a, 1)) x)];
7.2. Имея допущение pair : a—>-p—>-( aX ₽ ), выведите с по-
мощью Ж’ типы следующих функций:
funpair = kf.kg.ka.kb.(f a, g b)
tagpair = ka.funpair( pair a, pair a)
7.3. а. Используйте расширенную версию Ж, чтобы вывести тип
функции apply, определенной на языке Норе следующим об-
разом
-----applu (f, х) <= f х ;
б. Теперь допустим, что кортежи не выражаются с помощью
синтаксиса исходного языка, а представляются с помощью яв-
ного применения функций кортежирования. Определите в этом
случае функцию apply.
в. Выведите тип функции apply, которую вы определили
в пункте б, предполагая, что типы функций кортежирования
включены в глобальный набор допущений. (Вам теперь не по-
надобится правило (g).)
7.4. Определите функцию языка Норе, которая применяет кар-
ринг к функции арности 3, и выведите ее тип, используя расши-
ренную версию Ж.
12 — 1473
178 Часть II. Глава 7
7.5. В новом правиле (d'), введенном для обработки сопостав-
ления с образцом, мы должны найти в аргументе р новые пере-
менные х, чтобы вывести тип р. Покажите, как можно обойти
этот поиск, определив v-правило рекурсивно с Х-правилом в ка-
честве базового случая; при этом нужные переменные будут
включены в набор допущений. Предположите, что ко всем
функциям-конструкторам и всем функциям кортежирования
применим карринг, а их типы включены в набор допущений.
{Подсказка-, для функции f = v(cpi'... рп).е, п>0, рассмот-
рите Ж (Л, vpi. ... -vpn.e) и определите базовые случаи, когда
р — это переменная, а арность с равна 0).
7.6. Покажите, как Ж делает вывод о том, что следующие
функции не имеют типов:
a) sum t /г = if zz = O then t else sum(t-f-n)
(Это классический пример функции, для которой нельзя выве-
сти тип и которая, к счастью, не может быть выражена сред-
ствами языка Норе. Ее тип — это объединение типов пит-+
-+пит^>~ пит, пит-^-пит-^пит-^-пит, ... и все это можно
записать в виде:
sumпит —► пит (FIX. т. (пит —|- пит -> т))
где FIX — это оператор наименьшей фиксированной точки для
выражений типа, a обозначает объединение типов.)
б) taut 0 f = f
taut{ n-j- 1 )f — taut n( f true) и taut n( f false)
(Эта функция потенциально «полезна»!) Имея предикат (к ко-
торому применим карринг), следующий за ее арностью в каче-
стве аргумента, она возвращает true, если предикат является
тавтологией, и false в противном случае. Ее тип имеет вид
пит-+ bool-*• FIX x.(bool-\—[-bool-^x.)
7.7. Опишите в общих чертах модификацию необходимую,
для поддержки совмещения идентификаторов.
Глава 8
ПРОМЕЖУТОЧНЫЕ ФОРМЫ
В этой главе мы предложим промежуточный код для функ-
циональных языков, основанный на нотации Х-исчисления,
описанного в гл. 6. Мы несколько расширим эту нотацию, что-
бы иметь возможность именовать выражения; это позволит
создать простой механизм для описания рекурсивных функций,
что в свою очередь упростит трансляцию исходной программы
в промежуточный код. Результирующий код можно рассматри-
вать как модифицированную версию Х-нотации, вследствие чего
она будет использоваться во многих методах реализации, опи-
санных в следующих главах.
После того как промежуточный код будет описан, мы пока-
жем, как транслировать в этот код язык высокого уровня. Мы
делаем предположение, что перед трансляцией программа
прошла фазу синтаксического разбора и проверки типов, т. е.
является правильно типизированной, и представлена в виде
абстрактного синтаксического дерева. Таким образом, фаза
трансляции заключается в отображении абстрактного синтакси-
ческого дерева исходной программы в абстрактное синтакси-
ческое дерево эквивалентной программы на промежуточном
коде, хотя в рамках данного обсуждения будем считать, что
трансляция происходит из исходного текста в исходный текст.
Это дает* сжатый и абстрактный способ выразить правила
трансляции. Конкретный промежуточный код можно получить
из результирующего абстрактного синтаксического дерева, хотя
вполне вероятно, что именно последнее в дальнейшем будет
обрабатываться в соответствии с методами, описанными в сле-
дующих главах.
В данной главе мы сосредоточимся на правилах трансляции
для языка Норе, так как в этой книге он является нашим основ-
ным исходным языком. Однако, и это очевидно, трансляция
других исходных языков может быть описана подобным об-
разом.
12*
180 Часть Н. Глава 8
8.1. Промежуточный код
для функциональных языков
Промежуточный код, который мы здесь описываем, — это
%-нотация, рассмотренная в гл. 6, но расширенная дополни-
тельными средствами наименования выражений. Синтаксис
выражения ехр промежуточного кода можно записывать в виде
БНФ следующим образом:
(exp)::= (id) | Z (id). (exp) |(exp) (exp) | ((exp)) | con |
let (def) in (exp) | letrec (defs) in (exp)
(defs) ::= (def) |(def), (defs)
(def) ::= (id) = (exp)
(id) ::= идентификатор
(con) константа
Из двух расширений Х-нотации letrec является более важ-
ным, так как let-выражения можно эквивалентно определить
с помощью вспомогательных функций:
let x = Ej in Е2 = (Хх.Е2)Е1
Мы включаем в промежуточный код let-выражения главным
образом ради удобства, хотя это дает также некоторые преиму-
щества в смысле эффективности, что станет ясным, когда мы
рассмотрим в гл. 15 компиляторы функциональных языков.
Набор констант, как и раньше, произволен. Реализация функ-
ционального языка, основанная на этом типе промежуточного
кода, будет использовать, по всей вероятности, большое число
примитивных функций и несколько базовых типов. Все прими-
тивные функции, которыми мы будем пользоваться в этой главе,
приведены в табл. 6.1. Кроме этого нам понадобится семейство
примитивов выбора: CASE-1, CASE-2 и т. д., определяемое
следующим образом:
CASE-n SEEoEtEz ... En_i = Es, если 0 S n — 1,
= E, если S<0 или S^n.
Эти примитивы будут использованы при трансляции сопостав-
ления с образцом, описанной в разд. 8.4. Ниже дано несколько
примеров выражений промежуточного кода:
13
(+3 9)
(Ax.Ay.f( + ) 1 (— х у))
CASE-2 (g х)0(+х 1 )(INDEX 5 Т)
let х = 1 in Лу. — х у
letrec f = (Лх. + х 1), g = (Лх. f( * х х)) in (g 5)
Промежуточные формы 181
8.2. Абстрактные синтаксические деревья
Первой фазой трансляции языка высокого уровня в проме-
жуточный код является фаза синтаксического разбора, когда
исходная программа (часть конкретного синтаксиса) преобра-
зуется в абстрактное синтаксическое дерево (структуру дан-
ных). Как мы уже отмечали, тип выражений обычно прове-
ряется перед выполнением их трансляции или интерпретации.
type string == list( char );
data hope-object == DEF( hope_object # hope_object) + +
APPLY(hope_object # hope_object) -]—F
FUN( string ) -j—F
PRIM( string) ++
CON( string) ++
VAR( string) ++
INT( num ) -|—F
REAL( real )++
CHAR(char)++
TUPLE( list( hope-object)) + +
COND( hope-object # hope_object # hope_object) -|—F
QIJAL( hope_object # hope_object hope_object) + +
RECQUAL( hope-object # hope_object #
hope_object) ~F+
LAM( 1 ist( hope_object)) -|—F
LAMRULE( hope_obj # hope_obj) -j—F
EQU1V( hope_object # hope_object);
(Подчеркивания (_) в образцах обрабатываются как переменные в абстракт-
ном синтаксическом дереве.)
Рис. 8.1. Определение данных абстрактного синтаксического дерева языка
Норе.
Поэтому здесь мы будем предполагать, что программа, с кото-
рой мы работаем, корректна с точки зрения типов ее выражений.
Чтобы дать читателю представление о том, как выглядит
абстрактное синтаксическое дерево программы на языке Норе,
приводим на рис. 8.1 определение данных абстрактного син-
таксического дерева Норе-программы (называемых hope_object).
Для записи данных используется синтаксис языка Норе. Это
определение включает по одному конструктору для каждого
типа Норе-выражений точно так же, как определение данных
для деревьев, например, включает по одному конструктору для
каждого различного типа дерева. На рис. 8.2 кратко опи-
саны различные конструкторы вместе с правилом трансля-
ции Н, которое показывает абстрактное синтаксическое дерево,
182 Часть II. Глава 8
DEF Уравнение определения функции; LHS и RHS обозначают левую и правую части уравнения соответственно Н[ LHS <= RHS ;] = DEF( Н [ LHS ], Н [ RHS ])
APPLY Применение функции H[FA] = APPLY(H[F1 Hl А])
FUN Имя функции пользователя H[f] = FUN(f), f—это имя функции пользователя
PRIM Имя примитивной функции; отличие от функций пользователя делается, чтобы упростить трансляцию в промежуточный код (см. ниже) Н [ Р ] = PRIM( Р ), Р — это имя примитивной функции
CON Имя функции-конструктора; отличие от других функций поль- зователя делается, чтобы упростить трансляцию в промежуточ- ный код (см. ниже) Н 1 С ] — CON( С ), С — это имя конструктора.
VAR Ссылка на переменную Н [ v ] = VAR( v), v — это переменная.
INT Целый литерал Н [ i } = INT( i ), i — это целый литерал.
REAL Литерал действительного числа Н [ г ]| = REAL( г ), г — это литерал действительного числа.
CHAR Символьный литерал Н [ с ] = CHAR( с ), с — это символьный литерал
TUPLE Кортеж. Компоненты кортежа запоминаются в виде списка hope-объектов в TUPLE-вершине Н[(ЕЬЕ2 En)}( = TUPLE([H[EI],H[E2} H[EhJ])
COND Условное выражение Н [ if El then Е2 else Е3 ] = COND( Н [ Е, ], Н [ Е2 ], Н [ Е3 ])
QUAL Нерекурсивное квалифицированное выражение, т. е. let-выра- жение или where-выражение Н [let P==Et in E2] = QUAL(H[PJ, H [ E, ], H [ E2 ] ) H [ E2 where P == E, ] = QUAL( H [ P ], H [ E, ], H [ E2 J )
RECQUAL Рекурсивное квалифицированное выражение. Оно имеет те же самые правила трансляции, что и нерекурсивные квалифици- рованные выражения, только имя конструктора в данном слу- чае RECQUAL, а не QUAL
LAM Л-выражение Hflambda Ri | R2 | ... [ Rn ] = LAM( [ Н[ Ri ], H[R2],... • • -,Н [ Rn] ]).
LAMRULE Правило Л-выражения, определяющее Rj. Н[Р=> E]=LAMRULE(H[P], Н[Е])
EQUIV Эквивалентность в образцах, например х& у :: 1 Н [ v & Р ] = EQUIV( VAR( v ), Н [ Р ])
Рис. 8.2. Правила синтаксического разбора языка Норе.
Промежуточные формы 183
генерируемое каждым типом конкретного Норе-выражения.
Эти правила записываются в виде
Н [ hope-выражение ] = Абстрактное синтаксическое дерево
Мы используем биквадратные скобки [ и ], чтобы показать, что
аргумент Н является синтаксическим объектом.
8.3. Трансляция языка Норе
в промежуточный код
За исключением определений функций, ^-выражений и ква-
лифицированных выражений (let- и where-выражений), где ис-
пользуется сопоставление с образцом, все остальные выражения
языка Норе транслируются непосредственно в промежуточный
код. Трансляцию можно рассматривать как процесс выполнения
транслирующей функции Т, отображающей исходные выраже-
ния в выражения промежуточного кода. Мы будем выражать
правила функции Т на уровне синтаксических объектов, хотя
на практике в большинстве случаев в промежуточный код
транслируется не сам текст программы, а полученные из него
абстрактные синтаксические деревья. Мы будем записывать
каждое правило в следующем виде:
Т К исходное выражение ] = Выражение промежуточного кода
(Биквадратные скобки ([ и ]), как и ранее, показывают, что
аргумент Т является синтаксическим объектом). Правила транс-
ляции для подмножества выражений, не требующих сопостав-
ления с образцом, имеют следующий вид.
1. Литералы базовых, типов (например, целые числа, символы,
действительные числа и т. д.). Они не изменяются в процессе
трансляции.
T[n]] = n, и— это литерал
2. Идентификаторы. Если идентификатор является одной из
встроенных функций языка Норе, нужно выполнить отображе-
ние имен, чтобы гарантировать правильный выбор функции
промежуточного кода (одна и та же встроенная функция может
иметь разные имена в исходном тексте программы и в проме-
жуточном коде). В противном случае функция Т не изменяет
идентификатор. Мы будем обозначать через Bf эквивалент для
промежуточного кода встроенной функции f языка Норе:
T[f] = Bf (f — это идентификатор встроенной функции)
Т [ i ] = i (i — это любой другой идентификатор)
184 Часть II. Глава 8
Вспомним, что функции языка Норе не обладают свойством
карринга и имеют поэтому только один аргумент (который
может быть кортежем). Это означает, что примитивные функ-
ции, подобные функции «+», аргумент которых является кор-
тежем чисел, должны транслироваться в функции, явным обра-
зом разделяющие этот аргумент на части. Например, В+ =
= plus, где plus = Xt. + (INDEX 11) (INDEX 21). Определения
таких функций, как plus, могут быть явным образом включены
в транслируемую программу в качестве «библиотечных» опре-
делений. На практике, однако, разумно включать их в набор
констант. Другое решение состоит в том, чтобы выполнить не-
которую оптимизацию Т, позволяющую более пристально рас-
сматривать структуру применения функций в исходном тексте
и использовать «карринговые» версии примитивных функций
всякий раз, когда это возможно. Например:
T[ + (EIE2)] = plus T[EdT[E2]
Все сказанное выше, конечно, не относится к языкам, обладаю-
щим свойством карринга, для которых мы имеем просто
В+ = +•
3. Условные выражения. Они транслируются в вызов встроенной
функции COND. Предикат и выражения, идущие после then
и else, в свою очередь должны сами транслироваться с помощью
функции Т:
T[if-El then Е2 else E3] = COND Т[Е1]Т[Е2]Т|[Ез]|
4. Кортежи. Они транслируются непосредственно в вызов
встроенной функции TUPLE-n:
Т[(ЕЬ Е2, ..., En)l = TUPLE-п Т [ Е, ]Т [ EJ... Т [ Еп ]
5. Применения функций. Поскольку как функция, так и ее ар-
гумент являются выражениями, мы просто применяем Т к ним
обоим:
T[EiE2] = T[Ei]TIE2]
8. 3.1. Представление составных данных
Перед тем как перейти к рассмотрению трансляции сопо-
ставления с образцом, рассмотрим представление составных
данных. Метод, который мы собираемся использовать, состоит
в применении семейства функций кортежирования TUPLE-0,
TUPLE-1 и т. д., которые были введены в ^-исчисление в гл. 6.
Для того чтобы понять идею, рассмотрим пример определения
на языке Норе типа данных data для представления двоичного
Промежуточные формы 185
дерева:
data tree ===== empty 4—(- leaf( num) -|—(- node(tree # num =#= tree);
Это определение вводит три новых конструктора (empty — пу-
стое дерево, leaf — лист и node — узел), которые можно исполь-
зовать в процессе сопоставления с образцом для определения
типа дерева. При сопоставлении с образцом необходимо иметь
возможность различать применения различных конструкторов,
и, чтобы добиться этого, каждому из этих конструкторов надо
давать уникальную метку. (Эти метки должны быть уникаль-
ными только в рамках конкретного типа данных, так как
строгая типизация выражений исходного языка гарантирует,
что когда мы, например, ожидаем дерево, мы всегда его най-
дем.) Таким образом, мы будем связывать целые 0, 1 и 2
с конструкторами empty, leaf и node соответственно; причина
такого соглашения о нумерации станет ясна позднее. В общем
случае, если в определении типа данных имеется п конструк-
торов, мы будем использовать целые 0, 1, ..., п — 1.
Используя такие. метки, можем теперь представить приме-
нение конструктора арности п в виде кортежа из п + 1 элемен-
тов, первый элемент которого является меткой конструктора,
а остальные п элементов — это аргументы конструктора, на-
пример:
empty->TUPLE-1 О
leaf(n) -> TUPLE-2 1 T[n]]
node(x, у, z)->-TUPLE-4 2 T[x]T[у]T[z]
В общем случае применение Т к конструктору с имеет вид
Т[с(Еь ...,En)] = TUPLE-(n + l)NcT[E1] ... Т[ЕП]
8.4. Трансляция сопоставления с образцом
Рассмотрим теперь такие конструкции исходного языка,
выполнение которых основано на сопоставлении с образцом,
а именно: определение функций, квалифицированные выраже-
ния и Х-выражения. Для начала допустим, что образцы не пе-
рекрываются. Это означает, что ни одно выражение аргумента
не может соответствовать одновременно двум различным об-
разцам. Как увидим, это допущение значительно упрощает
процесс трансляции. Для полноты, однако, в разд. 8.5 рассмот-
рим обработку сопоставления с наиболее подходящим образ-
цом, где образцы могут перекрываться при условии, что набор
образцов является однозначным.
186 Часть II. Глава 8
Основную идею можно понять, рассмотрев определение
функции, которое в общем случае представляет собой набор
уравнений, включающих в себя образцы *>:
-----fP0 <= Ео;
-----fP1<=Ei;
-----fPn-i <= Еп-1;
где Pi — это образцы (O^i^n — 1). Как увидим позднее,
обработка квалифицированных выражений и ^-выражений
очень похожа на обработку определений этого сорта. Мы со-
бираемся оттранслировать этот набор уравнений в выражение
для вида f:
f = ла. промежуточный код для f
причем полный набор всех определений функций в исходной
программе будет представлен в виде letrec-выражения:
letrec f1 = Za. промежуточный код для f[
f2 = Xa. промежуточный код для f2
fN = Za. промежуточный код для fn
in промежуточный код для выражения верхнего
уровня
Конечно, новое имя аргумента а должно быть таким, чтобы не
было конфликта с уже существующими именами в программе.
Промежуточный код каждого определения функции состоит
из двух частей:
(1) код, определяющий, какое правило применимо к данному
аргументу;
(2) код для каждого выражения тела функции.
Чтобы определить применимое правило, нас интересует «форма»
аргумента, а не переменные, названные в образце. Например,
для следующего определения функции:
-----sum( nil) <= 0;
-----sum( х :: 1) <= х -р sum( 1);
нам нужно только знать, является аргумент пустым списком
(nil) или непустым списком вида Код, идентифицирую-
*> В дальнейшем эти уравнения называются правилами. — Прим, перев.
Промежуточные формы 187
щий форму аргумента, называется кодом сопоставления. После
определения применимого правила мы должны связать пере-
менные подходящего образца с соответствующими компонен-
тами аргумента. В первом правиле определения функции sum
образец не имеет переменных, поэтому мы транслируем выра-
жение тела непосредственно. Для второго правила мы должны
перед трансляцией его правой части x + sum(l) сгенерировать
связывающий код для переменных х и 1. Код тела функции
в этом случае является комбинацией связывающего кода и для
соответствующего выражения правой части.
Код сопоставления может последовательно соотнести каж-
дый образец с аргументом, чтобы определить, соответствуют ли
они друг другу, но на практике более эффективно слить все
эти тесты в единое дерево сопоставления. Это дерево опреде-
ляет часть промежуточного кода, который при выполнении воз-
вращает целое число, представляющее собой номер правила,
образец которого соответствует аргументу функции. Если ни
один образец не сопоставим с аргументом, возвращается —1.
Набор правил, определяющий упомянутую выше функцию f,
транслируется таким образом в единственное CASE-выражение,
выбирающее связывающий код, который соответствует номеру
правила, возвращаемому кодом дерева сопоставления:
Aa.CASE-n код для дерева сопоставления
ошибка
((связывающий код для правила 0) (код для Ео))
((связывающий код для правила 1) (код для Е[))
((связывающий код для правила и—1) (код для
En-i>)
Заметим, что если код сопоставления возвращает —1, то
ни один из образцов не соответствует аргументу. В этом случае
программа должна завершиться соответствующим сообщением
об ошибке. Все эти действия выполняются при выборе второго
аргумента CASE-n.
8.4.1. Генерация дерева сопоставления
Метод генерации дерева сопоставления из набора уравне-
ний, определяющих функцию, который мы здесь описываем,
является вариантом метода, описанного Хантом [49]. Детали
альтернативных подходов можно найти у Аугустсона [6] и
Уодлера [85]. Основная идея состоит в следующем: сначала
188 Часть II. Глава 8
мы генерируем отдельное дерево сопоставления для каждого
уравнения в определении функции, затем сливаем все деревья
в одно, которое транслируется в промежуточный код. Резуль-
тат выполнения этого кода равняется —1, если ни один образец
не соответствует аргументу, и к (к 0), если аргумент соответ-
ствует образцу к-го уравнения. (Как и ранее, предполагается,
что уравнения пронумерованы от 0 до п — 1.)
Каждое уравнение в определении функции f на языке Норе
имеет вид
------fPi<=E,;
где Р, — это образец, который может быть
(1) переменной, например х;
(2) подчеркиванием (-), которое с точки зрения генерации де-
рева сопоставления эквивалентно переменной;
(3) термом конструктора вида СР, где Р — это выражение об-
разца (вспомним, что такие конструкторы представляются в виде
кортежей, у которых первым компонентом является Nc); Р мо-
жет быть пустым, в этом случае С является константой данных;
(4) кортежем образцов вида (Рь Р2, ..., Рт), где Р, (1 «С
i т) — это выражение образца. (На этапе сопоставления
эквивалентность вида v&P — это то же самое, что и Р.) На
практике'мы также можем записывать литералы (например, 3)
в образцах, но здесь мы не будем рассматривать эту возмож-
ность, как не влияющую на понимание сути алгоритма. Мы
увидим, как обрабатываются выражения образцов, содержащие
литералы, в разд. 8.6.
Всякий раз, когда в образце встречается терм конструктора,
нужно проверять наличие этого конструктора в соответствую-
щей позиции аргумента. Этот тест представляется в дереве
сопоставления в виде внутренней вершины, имеющей форму
(позиция, список деревьев сопоставления)
«Позиция» — это спецификация пути, идентифицирующая про-
веряемый компонент аргумента. Она записывается в виде спи-
ска целых индексов: пустой список [ ] означает все выражение
аргумента функции; [i] означает i-й элемент кортежа аргумен-
тов; [i, j] означает j-й элемент i-ro элемента; [i, j,k] означает
k-й элемент j-ro элемента i-ro элемента и т. д. Например, для
уравнения
------g( х, Cj( у,, у2), С2( С3( z), п)) < — ... ;
где Ci и С2 являются конструкторами, [ ] означает весь кор-
теж аргументов; [1] означает первый элемент кортежа аргу-
ментов, т. е. х; [2] означает второй элемент кортежа аргумен-
Промежуточные формы 189
тов, т. е. С1(у1,у2); [2, 1] означает первый элемент второго
элемента кортежа аргументов, т. е. конструктор Сь и т. д. Спе-
цифицированный путь всегда ведет к коду конструктора (т. е.
его последний компонент всегда равен 1), который используется
для выбора одного из поддеревьев в «списке деревьев сопо-
ставления». Число поддеревьев в этом списке в точности совпа-
дает с числом конструкторов соответствующего типа данных.
Все, кроме одного, из этих поддеревьев соответствуют неудач-
ному сопоставлению, и мы будем представлять их в виде пустых
деревьев сопоставления. Одно поддерево, соответствующее слу-
чаю совпадения кодов конструкторов образца и аргумента,
строится по точно такому же принципу, как и все дерево со-
поставления: путем перебора всех конструкторов образца по
методу «в глубину слева направо». Чтобы сделать это объяс-
нение совершенно понятным, на рис. 8.3 показано дерево сопо-
ставления для следующего (i-ro) уравнения в определении
функции f:
------f( empty, node(leaf(x), k, node( empty, y, t)), nil) <= E1 ;
Тип этой функции имеет вид: tree # tree# list, где
tree — это тип данных, определенный нами выше. На рисунке
предполагается, что конструкторы списков nil и :: имеют коды
О и 1 соответственно, причем :: считается префиксным кон-
структором (вспомним также, что пустые конструкторы, та-
кие, как empty и nil, должны рассматриваться как кортежи из
одного элемента).
В этом примере порядок проверки конструкторов образца
определен в виде «в глубине слева направо». Символ X на ри-
сунке обозначает пустое дерево сопоставления, соответствующее
несовпадению образца и аргумента, а лист {i} обозначает
успешное совпадение аргумента и образца i-ro уравнения. Бу-
дем обозначать через
G[P]
дерево сопоставления, сгенерированное из образца Р, а через
Рт образец уравнения с правой частью Ет. Тогда дерево на
рис. 8.3 обозначается G[Pi].
После того как будет сгенерировано дерево сопоставления
для каждого уравнения в определении f, необходимо сделать
следующий шаг — слить эти деревья в одно. Для иллюстрации
этого процесса введем в наше определение f еще одно урав-
нение:
—-—f(leaf(x), leaf(y), х :: 1) <= Ej;
190 Часть П. Глава 8
Тестируемый конструктор
empty
node
leaf
node
empty
leaf
X X
Рис. 8.3. Дерево сопоставления для уравнения i.
Дерево сопоставления G[Pj] показано на рис. 8.4, а, а дерево,
получившееся в результате слияния G [Pi] и G [Pj], показано
б
Рис. 8.4. Слияние деревьев: а — дерево сопоставления для уравнения j; б —
дерево, полученное в результате слияния.
на рис. 8.4, б. Мы будем считать, что процесс слияния деревьев
выполняет функция М, поэтому дерево, изображенное. на,
Промежуточные формы 191
рис. 8.4, б, можно формально обозначить через
М( G [[ Pf J, G[Pj]|)
Операция слияния объединяет те вершины, которые проверяют
одинаковые компоненты аргумента. Чтобы определить опера-
цию М, необходимо упорядочить «позиции» каждой вершины
деревьев сопоставления. Отношение порядка на множестве по-
зиций соответствует принятому нами порядку тестирования
конструкторов образца по методу «в глубину слева направо»:
[] < [1] < [I, 1] < [1, 1, 1]< ... <[1,2] <[1,2, 1]< ,..[2]< ....
Правила слияния двух деревьев Ti и Т2 (обозначаемого
М(ТЬТ2)) можно записать следующим образом:
(1) Если одно из деревьев Tj или Т2 является пустым, опера-
ция М возвращает другое дерево. Это соответствует расшире-
нию дерева сопоставления по сравнению с тем, каким оно было
до слияния:
М(Х, Т) = Т
М(Т, Х) = Т
(2) Если Т) и Т2 являются вершинами (невисячими), то про-
цесс их слияния зависит от сравнения позиций (pi и р2), ука-
занных в этих вершинах. Если pi — р2, то обе вершины прове-
ряют один и тот же компонент в выражении аргумента, и по-
этому каждое поддерево Ti сливается с каждым поддеревом
Т2. Если pi < р2, то все вершины Т2 проверяют такой компо-
нент аргумента, который текстуально расположен справа от
компонента, указанного рь Следовательно, каждое поддерево
Т[ сливается с Т2. Если pi > р2, то каждое поддерево Т] сли-
вается с Т2:
М(Т1&(р„ [t10, tlb ..., tln_,]>, Т2&<р2, [t20, t21.....t2n_(]>) =
<P1, [M(t10, t20), M(tlb t2I), .. ,,M(tIn_i, t2n_i)]>, если Pl = p2,
<Pi, [M(tio, T2), M(tn, T2), . . .,M(tln_b T2)]>, если pi < p2,
(p2, [M(Tb t20), M(Tb t2I), ...,M(Tb t2n_i )]>, если pi > p2.
Символы =, < и > являются, конечно, булевыми функ-
циями на множестве позиций, а не на множестве целых
чисел.
Заметим, что у нас нет правила для слияния листьев, по-
скольку образцы не перекрываются, как мы предположили в
начале этого раздела. Поэтому листья сливаются по правилу
для пустых деревьев, приведенному выше (случай (1)). Подроб-
ное рассмотрение этого вопроса читатель найдет в разд. 8.5.
192 Часть II. Глава 8
Полное дерево сопоставления для множества образцов Pj,
Р2, ..., Рп-ь Рп определяется следующим образом:
М( G[PJ, М( G[P2], ..., М( G[Pn_,], G[Pn])...))
Мы завершаем обсуждение описанием правил преобразова-
ния результирующего дерева сопоставления в промежуточный
код. Правило трансляции назовем Е. Вспомним, что в резуль-
тате выполнения промежуточного кода выдается —1, если со-
поставление закончилось неудачей, и п, если аргумент соответ-
ствует образцу n-го уравнения.
Нам понадобится вспомогательная функция Р, транслирую-
щая «позицию» в промежуточный код, выбирающий компонент
аргумента, определяемый позицией. Например:
Р( а, [2, 3, 3])== INDEX 3 (INDEX 3 (INDEX 2 а))
где а — это имя аргумента. Правила для Е имеют следующий
вид (а снова обозначает имя аргумента):
Е( а, Х) = —1
Е(а, {п}) = п
Е(а, <р, [t0, t„ ...,!„_,]))
= CASE-n Р(а, p)®E(t0)E(tI)...E(tn_1)
где <8> обозначает пустое (ошибочное выражение). Оно не мо-
жет быть выбрано данным CASE-выражением, так как известно,
что программа правильно типизирована, что гарантирует код
выбора в CASE-выражении в пределах от 0 до п— 1.
Заметим, что код для дерева сопоставления используется
в качестве первого аргумента функции CASE верхнего уровня
по той простой причине, что в определении функции f может
быть несколько уравнений с одинаковой правой частью. Тогда,
если код для правых частей уравнений генерировать просто из
листьев дерева сопоставления, коды одинаковых правых частей
будут дублироваться. Однако совсем не трудно установить,
имеются ли в определении функции уравнения с одинаковой
правой частью, и если это так, тогда, конечно, нет никакой не-
обходимости в упомянутой функции CASE верхнего уровня.
8.4.2. Генерация связывающего кода
Код, получаемый из дерева сопоставления, выбирает одно
из уравнений определения функции исходя из анализа струк-
туры выражения аргумента. Но в выражении правой части
могут быть ссылки на переменные, содержащиеся в образце
выбранного уравнения. Цель связывающего кода состоит в том,
чтобы выбрать соответствующие этим переменным компоненты
Промежуточные формы 193
аргумента, для того чтобы их можно было использовать в вы-
ражении правой части. Поэтому с каждым листом дерева сопо-
ставления нужно связать некоторый дополнительный компонент.
При генерации дерева сопоставления для каждого уравнения
мы должны строить список связей вида «имя/позиция», где
имена являются идентификаторами, ссылки на которые имеются
в образцах, а позиции указывают положение соответствующих
этим идентификаторам частей аргумента и представляются, как
и ранее, в виде списка целых чисел. Этот дополнительный спи-
сок может храниться вместе с номером уравнения в листе
дерева сопоставления и используется при генерации связываю-
щего кода для промежуточного кода правой части этого уравне-
ния. Заметим, что символы, обозначающие произвольные пере-
менные (подчеркивания (_) в языке Норе), по очевидной при-
чине не следует включать в список связей.
Включение в листья списков связей требует косметической
модификации приведенного выше правила преобразования Е:
Е(а, {п, (список связей)}) = п
где {п, Ь} обозначает лист, содержащий номер уравнения и и
список связей Ь, требуемый для Е.
Чтобы сгенерировать связывающий код для уравнения к,
мы должны выделить список связей и использовать его при
генерации кода, выбирающего определенные компоненты выра-
жения аргумента. Рассмотрим общий вид k-го уравнения в
определении функции f:
------f( . . . Xj . . . х2 . . . xn . . . ) <= Ek
Список связей для уравнения к (обозначаемый здесь Lk) ука-
зывает нам позиции переменных х, в аргументе f. Его удобно
хранить в листе дерева сопоставления для уравнения к в виде
списка пар:
Lk = [(xb Pi), (х2, р2), ...,(хп, рп)1
(используя Норе-подобную нотацию-для записи списков). Про-
межуточный код, связывающий каждый Xi с соответствующим
компонентом аргумента, может иметь форму let-выражения.
Таким образом, обозначив функцию, генерирующую промежу-
точный код тела через В, мы получаем следующее правило:
В( а, Е', [(xi, pj), (х2, р2), ...,(хп, рп)]) =
let xj = Р( а, р!) in
let х2 = Р( а, р2) in
let хп — Р( a, Pn ) in Е'
13 — 1473
194 Часть II. Глава 8
где а — это имя аргумента, а Е7—^это промежуточный код пра-
вой части уравнения к. Конечно, если Xi упоминается в выра-
жении Е7 только один раз, мы можем удалить дополнительное
определение ... let xi = Р( a, pi) in и прямо заменить вхождение
Xi в Е7 на Р(а, pi). В результате этого получится не только
меньший по объему промежуточный код, но и более эффектив-
ный, так как в нем будет на одну связь меньше.
8.4.3. Квалифицированные и лямбда-выражения
Теперь, когда мы знаем, как транслируется сопоставление
с образцом в общем множестве определений, можем определить
правила трансляции для квалифицированных выражений и
лямбда-выражений. Как мы уже видели, нерекурсивные ква-
лифицированные выражения можно рассматривать как лямбда-
выражения:
T[let Р==Е, in Е2] = Т[(lambda Р=>Е2)Е1]
Т [ Е2 where Р == Е( ] = Т [(lambda Р = > Е2) Е[ ]
где Р — это выражение образца. Конечно, нет .необходимости
преобразовывать let-выражения в лямбда-выражения перед их
трансляцией, но эквивалентность этих двух форм служит не-
обходимой полноте спецификации трансляции. Код сопоставле-
ния и связывающий код можно получить «на месте», используя
правила трансляции для лямбда-выражений.
Сами лямбда-выражения являются частными случаями
определений функций. Главное отличие функции от лямбда-
выражения в том, что последнее является безымянным. Следо-
вательно:
Т [lambda Ро => Ео | ... | Pn_i => En_J =
Ла. CASE-n Е( а, М( G [Ро] ..., М( G [Рп_2]; G [Р„_,])...))
ошибка
(В( а, Т[Е01 Lo)
(В(а, T[En_,l Ln_j))
где Lt — это список связей для i-ro лямбда-правила Pi =>- Ei
(О i n—1). Это приводит нас к окончательному правилу
для Т, работающему также в случае рекурсивных квалифици-
рованных выражений. В качестве примера приведем одно из
таких выражений:
let (х, 1 :: у) === (1 :: х, х) in у
Промежуточные формы 195
(оно связывает х и у с бесконечным списком (1, 1, 1, 1, 1, ...]).
Любая из переменных левой части двойного равенства — =
встречается также в правой части. Из-за этого для данного
let-выражения не существует эквивалентного лямбда-выраже-
ния. Вместо него мы должны построить letrec-выражение, ком-
понентами которого являются промежуточный код для квали-
фикатора, связывающий код для каждой переменной в образце,
а также код сопоставления. Следовательно, данное выражение
нужно транслировать в промежуточный код вида
letrec Q = промежуточный код для (1 ::х, х),
х —INDEX 1 Q
у = INDEX 3 (INDEX 2 Q)
т=код сопоставления для (х, 1 ::у)
in COND ( = ш—1) ошибка у
Снова имена Q и т следует выбирать такими, чтобы не было
конфликта с существующими именами. Детали приведенного
правила для Т оставлены читателю в качестве упражнения.
8.5. Поиск наиболее подходящего образца
Описанный нами алгоритм трансляции работает с набором
образцов, которые не перекрываются друг с другом. Лучший
способ понять, что это значит, состоит в рассмотрении множе-
ства аргументов, соответствующих данному образцу. Если мы
обозначим образцы из набора определяющих функцию уравне-
ний через
Pb Р2> ...,Рп
а множество аргументов, которые соответствуют Pi через Si,
1 i п, тогда набор неперекрывающихся образцов характе-
ризуется тем, что никакие два образца не соответствуют од-
ному и тому же аргументу, т. е.
S^Sj^O, l<i, j<n, i#=j
В следующем примере в каждой строке записан набор непере-
крывающихся образцов:
nil хгу
empty nede(_, v, _) Ieaf( n)
( nil, x ) ( x .• 1, nil )
Поскольку предполагается, что образцы не перекрываются, нам
никогда не придется в процессе слияния деревьев, согласно
правилу М, сливать лист с другим листом или с внутренней вер-
шиной. Такое слияние противоречило бы условию неперекрывае-
13*
196 Часть II. Глава 8
мости образцов. Действительно, мы можем установить, пере-
крываются образцы рассматриваемого набора или нет, вклю-
чив в М следующие правила:
М({т}, {п}) = Образцы перекрываются!
М({п), (...)) = Образцы перекрываются!
М((...), {п}) = Образцы перекрываются!
Попытка выполнить каждое из этих слияний должна приводить
к сообщению об ошибке.
Некоторые языки, однако, допускают перекрываемость при
условии, что образцы являются однозначными. (Норе является
примером такого языка, как мы видели в гл. 2.) Для того чтобы
определить, что такое однозначность, мы должны ввести поня-
тие специализации образцов.
Образец Р| является специализацией образца Р, (или Pi яв-
ляется частным случаем Pj), если каждое выражение, соответ-
ствующее Р„ также соответствует Ръ но не наоборот, т. е. если
Si является строгим подмножеством Sj (Sj о SJ. Так, например,
nil — это специализация х, так как соответствует всем выраже-
ниям, которым соответствует nil, но не наоборот (так как х
также соответствует непустым спискам). Чтобы набор образцов
был однозначным, должно выполняться следующее условие:
Однозначность: Если какие-либо два образца перекрываются и ни один из
них не является специализацией другого, тогда для каждого выражения Е,
которое соответствует обоим образцам, должен существовать третий образец,
являющийся специализацией обоих, который также соответствует Е
Образцы, приведенные выше в качестве примера (т. е. nil и х),
являются однозначными, так как nil — это специализация х.
Более сложный набор образцов имеет вид:
(nil, х) (х, nil) (nil, nil)
Первые два образца перекрываются, и ни один не является
специализацией другого, но третий образец (nil, nil) является
специализацией первых двух. Он соответствует единственному
выражению, которое соответствует также первым двум образ-
цам, и, следовательно, образцы являются однозначными. Рас-
смотрим другой пример:
(х, nil) ( х :: 1, у)
Эти образцы перекрываются, так как оба они соответствуют
выражению вида ( а :: b, nil) для любых а и b и ни один не яв-
ляется специализацией другого. Поэтому, так как не существует
третьего образца, который был бы специализацией обоих, они
являются неоднозначными. Чтобы сделать их однозначными,
нужно ввести третий образец вида (х::1, nil), перекрывающий
выражения, соответствующие первым двум.
Промежуточные формы 197
В этом разделе мы рассматриваем вопрос о поиске наиболее
подходящего образца в том смысле, что, если некоторый аргу-
мент соответствует двум образцам, мы выбираем тот из них,
которому аргумент соответствует в наибольшей степени. Мы
всегда можем найти такой образец при условии, что набор об-
разцов обладает свойством однозначности. Если это не так,
тогда несколько образцов могут одинаково хорошо соответство-
вать аргументу и мы не сможем сделать выбор без введения
какого-либо искусственного упорядочения (например, лексико-
графического) множества образцов.
Поиск наиболее подходящего образца очень полезен, когда
мы хотим сказать что-то вроде
«Если аргумент соответствует этому образцу, тогда выполнить то-то, иначе
выполнить что-то другое.».
В случае неперекрывающихся образцов «иначе» заключается
в написании отдельного правила для каждой альтернативы слу-
чаю «тогда». Допустим в качестве простого примера, что мы
хотим определить функцию эквивалентности двух деревьев
IsEqualTree, которая берет два дерева ti и ta и возвращает
true, если ti = t2. (Эту функцию можно, конечно, определить,
используя оператор =, но для целей нашего обсуждения дадим
здесь рекурсивное определение.) Исходя из определения типа
данных «дерево» (tree), данного в разд. 8.3.1, нужно рассмот-
реть не менее девяти случаев-
dec IsEqualTree : tree # tree -»truval;
------IsEqualTree( empty, empty) <= true ;
------IsEqualTree) empty, leaf( — )) <= false ;
------IsEqualTree( empty, node( —, —, —))<= false;
------IsEqualTree(node( 11, vl, rl ), node( 12, v2, r2))<=
(vl=v2) and IsEqualTree( 11, 12)
and IsEqualTree(rl, r2);
В случае когда допускается, чтобы образцы перекрывались, и
мы ищем наиболее подходящий из них, требуется только четыре
уравнения:
------IsEqualTree( empty, empty) <= true ;
------IsEqualTree) leaf) m ), leaf( n)) <— m — n ;
------IsEqualTree) node( 11, vl, rl), node( 12, v2, r2))< =
(vl=v2) and IsEqualTree) 11, 12)
and IsEqualTree( rl, r2 );
------IsEqualTree(tl, t2)<= false;
198 Часть II. Глава 8
Последнее уравнение перекрывает шесть случаев, которые не
перекрываются первыми тремя.
Можно приспособить описанный выше алгоритм трансляции
для поиска наиболее подходящих образцов, изменив функцию
слияния М и структуру каждого листа. Здесь мы опишем моди-
фикацию алгоритма трансляции только в общих чертах; детали
можно найти в [33].
Первое, что мы должны уметь делать, — это сравнивать два
образца с целью определения того, что один из них является
частным случаем (специализацией) другого. Для этого мы опре-
делим функцию порядка так, что Р, Р, тогда и только
тогда, когда Sj zz> S,. Далее мы модифицируем структуру
листьев, позволив им содержать список номеров уравнений, а не
только один такой номер. Причина такой модификации состоит
в том, что теперь нам, возможно, придется сливать два листа,
и если окажется, что ни один из их образцов не является спе-
циализацией другого, то мы должны поместить в результирую-
щую вершину все номера уравнений сливаемых вершин, ожи-
дая, что в дальнейшем они будут заменены номером уравнения,
имеющего более специфичный образец. Если в конце процесса
слияния какой-либо лист результирующего дерева сопоставле-
ния будет содержать несколько номеров уравнений, тогда набор
образцов является неоднозначным. Из всего сказанного выте-
кают следующие дополнительные правила для М (для про-
стоты исключаем списки связей из листов):
М({М}, {N}) = {[n]}, если Рп Рт Для всех m в списке L,
m #= п,
{L} в противном случае, когда L = M<>N,
где < > — это функция присоединения списков, подобная ко-
торой имеется в языке Норе. Теперь стало возможным также
слияние внутренней вершины и листа (что было невозможно
в случае неперекрывающихся образцов)., Поэтому необходимы
два дополнительных правила для М. При слиянии внутренней
вершины N с листом L мы видим, что тесты конструкторов,
определенные в N и ее поддеревьях, просто накладывают до-
полнительные ограничения на структуру аргументов, соответ-
ствующих L. Это означает, что все уравнения, номера которых
содержатся в L, соответствуют заданному аргументу всегда, ко-
гда ему соответствуют уравнения, номера которых содержатся
в висячих вершинах поддерева N. Следовательно, дополнитель-
ные правила для М должны сливать L с каждым листом под-
Промежуточные формы 199
дерева, корнем которого является вершина N:
М({Ц, <р, [t,.....tn])) =
м«р, [t„ ..tn]>, {L}) =
<p, [M(tb {L}), .... M(tn{L})])
Слияние двух внутренних вершин остается таким же, как
раньше.
Для иллюстрации того, как работают введенные правила,
рассмотрим следующий набор определений. Хотя образцы дан-
ного набора перекрываются, он является однозначным:
------f( nil, nil) <= Е;;
------f( x, nil) <= E2;
------f( nil, x) <= E3;
Три образца соответствуют трем деревьям сопоставления:
([2,1], [ ])
[[3]] X
(ml, nil) (х, nil) (ml, x)
Слив второе и третье дерево, мы получим
<[1.1]. [ 1)
<[2,1],[ ])
[[2,3]]{[3]} {[2]} К
Заметим, что результат слияния внутренней вершины <[2,1],
[поддеревья]) с листом {[3]} получен путем слияния вершины
{[3]} с каждым из листьев поддерева, начинающегося в вер-
шине <[2, 1], [ ]>. Мы видим, что теперь самый левый лист со-
держит два номера уравнений; это отражает тот факт, что если
оба аргумента f равны nil, то такое выражение аргумента соот-
ветствует как второму, так и третьему образцу. Второй лист
слева содержит номер третьего уравнения. Это означает, что
третье уравнение соответствует всем кортежам аргументов,
200 Часть II. Глава 8
первый компонент которых равен nil. Слив данное дерево с де-
ревом сопоставления для первого уравнения, получим
{[2]}' X
Заметим, что, поскольку образец первого уравнения является
специализацией образцов второго и третьего уравнений, лист
{[1]} заменяет лист {[2,3]}. Поскольку теперь нет ни одного
листа, содержащего больше одного номера уравнений, мы за-
ключаем, что набор образцов является однозначным.
8.6. Литеральные образцы
В языке Норе, а также в некоторых других функциональных
языках возможно записать определение вроде
------f(3 ) <= Е ;
говорящее о том, что если аргумент равен 3, то результат дол-
жен быть равен Е. Аналогичные определения можно записать
для других литеральных образцов, таких, как символы или спи-
ски констант. Хотя наш алгоритм трансляции не допускает вы-
ражения, содержащие литеральные образцы, его можно соответ-
ствующим образом модифицировать, включив в дерево соответ-
ствия новый тип вершин. До сих пор внутренняя вершина
дерева сопоставления специфицировала проверку кода конструк-
тора того компонента аргумента, который определяется указан-
ной в данной вершине позицией. Чтобы иметь возможность ра-
ботать с литеральными образцами, мы должны определить
внутреннюю вершину, специфицирующую тест на равенство
между литералом и соответствующим компонентом аргумента.
Этот тест в конечном счете будет выполняться с помощью при-
митива EQ промежуточного кода. Мы будем записывать такую
вершину в следующем виде:
<<литерал, позиция, поддерево, поддерево))
где двойные скобки << и )) указывают, что эта вершина соот-
ветствует литеральному образцу. Позиция, как и раньше, опре-
деляет тестируемый компонент аргумента, литерал определяет
величину, которой должен быть равен выбранный компонент
аргумента, а два поддерева соответствуют случаям, когда тест
Промежуточные формы 201
завершается успехом и неудачей соответственно; последнее
поддерево’поэтому всегда должно быть пустым (X). Например,
дерево сопоставления для следующего выражения языка Норе:
------f(0, х::1) <=Е;
имеет вид
((2вГО,[1,1 ], [ ]))
([2.1]. [ ]) X
X ([к]}
где к — это соответствующий номер уравнения, a zero — это
промежуточный код, представляющий литерал 0. Если это един-
ственное уравнение для f (т. е. к == 1), то его промежуточный
код будет иметь вид
Ла.IF (EQ( INDEX 1 а) 0)
(CASE-2 (INDEX 1 (INDEX 2a))
ошибка (не может возникнуть, так как программа
правильно типизирована)
ошибка (при сопоставлении с образцом)
let х 1 = INDEX 2 (INDEX 2 а) in
letl = INDEX 3 (INDEX 2 a) in E')
ошибка (при сопоставлении с образцом)
где Е' снова обозначает промежуточный код для Е. Предпола-
гается, конечно, что дополнительное применение функции
CASE-1 с кодом варианта, получаемым из дерева сопоставле-
ния, отсутствует в приведенном выражении, поскольку в дан-
ном случае существует только одна копия Е'.
8.7. О порядке тестирования
В качестве отступления заметим, что мы в этой главе ис-
пользовали порядок тестирования в глубину слева направо в
предположении, что выбор конкретного порядка неважен, если
только этот порядок точно определен. В энергичной реализации
это действительно так, однако в ленивой реализации изменение
порядка тестирования может отразиться на результатах работы
программы. В качестве иллюстрации рассмотрим простой
пример:
—-----f( х, nil, a::b)<==Ej;
------f( a :: b, x, nil)<=E2;
------f(nil, a :: b, x)<=E3;
202 Часть П. Глава 8
Предположим, что мы тестируем аргументы этой функции в по-
рядке в глубину слева направо. Применение вида
((зацикливающее выражение, nil, ЕщгЕг) (1)
приведет к зацикливанию, тогда как применение
f(nil, ЕщгЕг, зацикливающее выражение) (2)
будет иметь значение Е3 (с соответствующими связями для а,
b и х). Теперь предположим, что мы поменяли порядок тести-
рования и тестируем аргумент в порядке справа налево. Выра-
жение вида (1) теперь будет иметь значение Еь тогда как вы-
ражение (2) приведет к зацикливанию.
Второе наше допущение состоит в том, что все образцы, яв-
ляющиеся кандидатами на соответствие аргументу, тестируются
(логически) одновременно, причем каждый тест, возможно, уда-
ляет некоторые образцы из множества кандидатов. В некоторых
языках, однако, образцы определяются таким образом, что тес-
тируются последовательно сверху вниз, причем каждый тести-
руется слева направо, пока либо не будет достигнут успех, либо
программа не зациклится. Примером такого языка является
Miranda. Такое изменение тестирования также изменяет резуль-
таты работы программы. Возвращаясь к нашему примеру, вы-
ражение (1) в этом случае будет иметь значение Еь а выраже-
ние (2) будет иметь значение Е3. (Описанный алгоритм транс-
ляции может быть легко изменен для поддержки этого порядка
тестирования путем изменения функции слияния деревьев сопо-
ставления— этот вопрос оставлен читателю в качестве упраж-
нения.) Порядок тестирования поэтому важен в ленивых языках,
и об этом нужно помнить при использовании сопоставления
образцов в исходной программе. Отличия алгоритмов сопо-
ставления строго описываются с помощью формальной семан-
тики. В приложении В мы строго описываем последовательную
схему тестирования сверху вниз, а относительно более сложную
семантику поиска наиболее подходящего образца можно найти
в [33].
На этом мы завершим наше описание механизма трансляции.
Заметим, что каждое определение функции транслируется в
Х-абстракцию с одной связанной переменной в случае языка
Норе. Это отражает тот факт, что функции языка Норе можно
строго рассматривать как имеющие один кортеж аргументов,
а не произвольное число отдельных аргументов. Если бы мы
транслировали в тот же самый промежуточный код языки, об-
ладающие свойством карринга (как Miranda), тогда каждая
функция была бы представлена в промежуточном коде в кар-
ринговой форме. Например, функция языка Miranda
f х у z = Е
Промежуточные формы 203
будет оттранслирована в следующее выражение промежуточ-
ного кода:
f = Хх. Ху. Хх. Е'
(где Е' — это промежуточный код для Е) внутри соответствую-
щего letrec-выражения. Мы 4 можем, конечно, представить
Hope-функцию в карринговой форме как функцию с числом
аргументов большие единицы, однако в этом мало смысла, так
как все применения Hope-функций являются полными, и нам
никогда не потребуется возможность представления частичного
применения функции. Трансляция таких языков, как Лисп и
FP, похожа на трансляцию языка Норе, за исключением того,
что отсутствует сопоставление образцов и что в этих языках
используются примитивы обработки списков (такие, как CONS,
HD, TL и т. д.) для построения и декомпозиции аргументов, а
не примитивы, работающие с кортежами, как в Норе. Симмет-
ричные функции обработки списков были бы, конечно, наибо-
лее удобны для трансляции языка FP.
Резюме
• Модифицированное Х-исчисление обеспечивает хороший про-
межуточный код общего назначения для функциональных
языков.
• Большинство конструкций языка высокого уровня трансли-
руются непосредственно в промежуточный код. Очевидным ис-
ключением является сопоставление образцов.
• Применения конструкторов' представляются применениями
функций построения кортежей (таких, как TUPLE-n), первый
элемент которых является кодом конструктора.
• Трансляция сопоставления с образцом включает построение
дерева сопоставления, из которого может быть сгенерирован
эффективный код, используемый для выбора варианта.
• Дерево сопоставления для набора образцов является резуль-
татом слияния деревьев сопоставления для отдельных образцов.
• Наряду с проверкой формы аргумента промежуточный код
для сопоставления с образцом должен также связывать пере-
менные, указанные в образце.
• Для языков, которые допускают только неперекрывающиеся
образцы, алгоритмы трансляции можно расширить с целью об-
наружения недопустимых перекрывающихся наборов образцов.
• При поиске наиболее подходящего образца в процессе сопо-
ставления допускается, чтобы образцы перекрывались, при
условии что набор образцов обладает свойством однозначности.
204 Часть II. Глава 8
• Алгоритм трансляции может работать с литеральными об-
разцами, если ввести в дерево сопоставления новый тип вершин
вместе с проверкой значения литерала.
Упражнения
8.1. а. Запишите абстрактное синтаксическое дерево для сле-
дующего уравнения:
------f(node(—, a, empty)) <= g( а + 1);
исходя из определения данных, приведенного на рис. 8.1.
б. В языке Норе мы можем передать конструктор в каче-
стве параметра в функцию высшего порядка (вспомните, на-
пример, обсуждение функции reduce в гл. 3). Более того, в язы-
ках, обладающих свойством карринга, конструктор можно при-
менить частично. Однако мы ничего не сказали о частичных
кортежах в нашем промежуточном коде. Значит ли это, что
конструкторы высших порядков невозможны при использова-
нии нашей схемы трансляции?
8.2. Запишите.на языке Норе определения операторов сравне-
ний позиций < , > и =, предположив, что позиции имеют тип
list [ num ).
8.3. Запишите на языке Норе определение данных для непере-
крывающихся деревьев сопоставления. Как можно расширить
это определение, чтобы оно включало символьные и целые ли-
тералы в образцах?
8.4. Рассмотрим следующее определение данных:
data funny == zero ++ one( funny) ++ two( funny #
funny) ++ three( funny # funny # funny);
а. Как можно представить в промежуточном коде следую-
щие выражения:
(i) zero
(ii) two( one( zero), zero)
(iii) three( three(zero, zero, one(zero), zero, zero)
б. Нарисуйте деревья сопоставлений для каждого уравнения
в следующем определении (предполагав алгоритм слияния для
неперекрывающихся образцов):
dec f: funny # funny # funny -► num;
------f( two( —, zero), zero, — )<=7;
------f(two(zero, one(zero)), —, three( —, —, x))<=g(x);
------f( —, zero, two( a, b))<=h(a, b, zero);
в. Получите дерево сопоставления для этого набора урав-
нений, слитое из отдельных деревьев сопоставления.
Промежуточные формы 205
г. Что представляют собой списки связей для каждого урав-
нения?
д. Запишите связывающий код, который будет сгенерирован
для третьего уравнения в определении f.
8.5. В языке Норе мы можем записать образец, в котором
кортеж аргументов конструктора имеет имя. Например, можно
записать
------f( ..., node Т, ... ) <== ...
где node определен в типе данных tree (см. разд. 8.3.1), а Т
обозначает кортеж аргументов node. Требует ли это возможно-
сти специального рассмотрения в алгоритме трансляции? Обос-
нуйте свой ответ.
8.6. а. Для функции IsEqualTree, приведенной в разд. 8.5, на-
рисуйте деревья сопоставления для каждого из 4 уравнений.
б. Слейте эти деревья одно за другим и обрисуйте в общих
чертах структуру результирующего промежуточного кода.
в. Вместо проведения проверки на специализацию (исполь-
зуя >>) всякий раз при слиянии двух листов мы можем просто
накапливать в листах список номеров перекрывающихся урав-
нений, а проверку на специализацию (и однозначность) прово-
дить после завершения слияния. Опишите в общих чертах тре-
буемую для этого модификацию функции слияния.
8.7. В определении однозначности говорится, что для двух пе-
рекрывающихся и неоднозначных образцов каждый образец,
уничтожающий эту неоднозначность, должен быть специализа-
цией обоих и соответствовать каждому аргументу, которому со-
ответствуют оба этих образца. Несмотря на то что алгоритм
слияния проводит проверку на специализацию, объясните, по-
чему нет необходимости проверять перекрываемость образцов.
8.8. До сих пор мы предполагали, что конструкторы nil и ::
в языке Норе следует рассматривать как конструкторы, опре-
деленные пользователем, т. е. что они нормальным образом
представляются с помощью кортежей с кодом конструктора,
равным 0 для nil и 1 для Теперь допустим, что nil представ-
ляется в промежуточном коде функцией NIL, а :: — функцией
CONS. Опишите в общих чертах необходимые для этого изме-
нения в алгоритме трансляции. Каково основное преимущество
использования такого представления nil и ::?
8.9. а. Какие изменения должны быть сделаны в алгоритме
трансляции сопоставления с образцом, чтобы он мог работать
с функциями, обладающими свойством карринга.
б. Почему «карринговые» конструкторы не являются про-
блемой?
Глава 9
МЕТОДЫ ИНТЕРПРЕТАЦИИ
Интерпретатор функционального языка является простейшей
формой реализации этого языка. Интерпретатор можно рас-
сматривать как функцию, которая берет абстрактное представ-
ление программы в качестве своего аргумента и находит конеч-
ное значение этой программы, т. е. ее слабую заголовочную
нормальную форму, в соответствии с определенным порядком
проведения преобразований. В этой главе мы исследуем раз-
личные методы интерпретации, используя определенный в пре-
дыдущей главе промежуточный код в качестве нашего предмет-
ного языка и, чтобы быть последовательными, Норе в качестве
определяющего языка. Мы могли бы, конечно, в качестве ин-
терпретируемого языка взять вместо промежуточного кода ка-
кой-либо исходный язык (например, Норе или Miranda), но
тогда многие' важные аспекты механизма интерпретации были
бы заслонены многочисленными малозначительными деталями.
Глава состоит из трех главных разделов. Раздел 9.1 вводит
тип данных языка Норе для представления абстрактных син-
таксических деревьев промежуточного кода, а в разд. 9.2 опи-
сывается -основной механизм интерпретации в случае энергич-
ного вычисления промежуточного кода программы. В разд. 9.3
мы модифицируем этот интерпретатор для поддержки вызовов
по имени и описываем различные способы реализации разделе-
ния, дающие в результате вызов по необходимости и, следова-
тельно, ленивое вычисление. Мы завершаем данную главу об-
щим обсуждением проблем, связанных с использованием интер-
претатора для определения операционной семантики языка.
9.1. Абстрактное представление
промежуточного кода
Абстрактное синтаксическое дерево для промежуточного кода
может быть представлено структурой данных языка Норе с по-
мощью оператора data. Оно может быть получено из промежу-
Методы интерпретации 207
точного кода, если мы напишем программу синтаксического раз-
бора. Другой путь заключается в непосредственной генерации
абстрактного синтаксического дерева для промежуточного кода
из абстрактного синтаксического дерева исходной программы.
Этот путь более предпочтителен, так как он исключает тексту-
альное представление промежуточного кода.
Тип данных, представляющих абстрактные синтаксические
деревья, будем называть ехр. Конструкторы, входящие в его
type id == list( char );
data exp ==VAR(id) H—H
I.AM(id#exp) + +
APP( exp # exp ) ++
LET( id # exp # exp ) -|—j-
RLET( list( id # exp ) # exp ) ++
INT(num) -j—j-
PRIM( id );
Рис 9.1. Тип данных языка Норе для абстрактных выражений.
определения, отражают различные типы выражений, определен-
ных в БНФ-описании промежуточного кода, вместе с выбран-
ными нами базовыми типами данных. Здесь мы ограничимся
целыми числами в качестве нашего единственного базового типа
и определенными на множестве целых чисел арифметическими
функциями и — в качестве единственных примитивов. Обес-
печив их реализацию, мы сможем в дальнейшем систематиче-
ски вводить другие базовые типы и примитивы. Определение
данных (на языке Норе) для абстрактного синтаксического де-
рева выражения промежуточного кода дано на рис. 9.1. Заме-
тим, что мы для ясности даем дополнительное определение типа
данных для идентификаторов, которые представляются стро-
ками символов.
Ниже приведено несколько примеров выражений промежу-
точного кода и соответствующие им абстрактные представления:
Выражение Абстрактное представление
+8 х АРР( АРР( PRIM( "+" ), INT( 8)), VAR( "х" ))
Xz.z 4 LAM("z", APP( VAR("z")), INT(4))
let p = + in( f p ) LET( "p", PRIM( "+" ), APP( VAR( "f" ), VAR( "p" ) ))
Из гл. 3 мы помним, что функция может применяться либо
энергично, либо лениво (т. е. используя передачу параметров
или по значению, или по необходимости), и для иллюстрации
практической реализации этих механизмов мы построим в сле-
дующих двух разделах разные интерпретаторы для этих двух
случаев.
Реализуя промежуточный код, интерпретатор, кроме того,
обеспечивает его операционную семантику. Он дает смысл
208 Часть II. Глава 9
промежуточному коду, описывая реализацию каждого свойства
этого кода. Однако здесь нам следует быть очень осторожными,
так как, чтобы определить точную семантику, необходимо иметь
детальное понимание определяющего языка, т. е. языка, на ко-
тором написан сам интерпретатор. В особенности, как увидим
далее, семантика вызовов в определяемом языке (промежуточ-
ный код в нашем случае) зависит от семантики вызовов в опре-
деляющем языке. В дальнейшем нашим определяющим языком
будет стандартная реализация языка Норе, в которой все кон-
структоры вызываются по необходимости, а все остальные функ-
ции— по значению. Об этом совершенно необходимо помнить,
потому что при использовании ленивой реализации языка Норе
для написания интерпретатора можно получить существенно
отличную реализацию промежуточного кода.
9.2. Энергичный интерпретатор
Основу большинства интерпретаторов функциональных язы-
ков составляют две функции, называемые Eval и Apply. Eval
вычисляет значение аргумента, преобразуя его к слабой заго-
ловочной нормальной форме, a Apply (которую можно рассмат-
ривать как вспомогательную функцию для Eval) вычисляет
значение применения функции с помощью преобразования этого
применения к слабой заголовочной нормальной форме. Постро-
енный с помощью этих функций интерпретатор по очевидной
причине называют Eval/Apply-интерпретатором. Первый такой
интерпретатор опцсан Маккарти [62].
Описываемый нами интерпретатор реализует применение
функции (т. е. p-редукцию), оставляя тело функции в непри-
косновенности и запоминая выражение, которое должно заме-
щать связанную переменную функции в специальной структуре
данных, называемой контекстом. При этом достигается такой же
эффект, как и при текстуальной подстановке аргумента в тело
функции, как это делается в %-исчислении. Мы коснулись вкрат-
це вопроса об использовании контекстов при обсуждении раз-
деления в разд. 6.6. Контекст просто обеспечивает связь между
именами (идентификаторами связанных переменных в нашем
случае) и выражениями. Таким образом, связь для данного ин-
терпретатора можно определить, найдя его в текущем контек-
сте и вернув соответствующее ему выражение.
Представление контекста не играет для нас здесь особой
роли, и потому будем рассматривать его просто как абстракт-
ный тип данных (называемый environment) с функциями до-
ступа для добавления именованных выражений и для поиска
выражения, связанного с данным именем. Будет полезным,
Методы интерпретации 209
однако, иметь некоторый конкретный способ представления свя-
зи, и поэтому мы будем писать
(п, е)
для обозначения того, что имя п связано с выражением е. (Эта
форма записи соответствует нотации языка Норе для пред-
ставления кортежей, которую будем использовать в самом ин-
терпретаторе.) Нам понадобятся следующие четыре функции
для работы с контекстом:
empty (Константная) функция, возвращающая пустой контекст
: + : Инфиксная функция вставки р : + : ( п, е ) обозначает контекст р
с дополнительной связью ( п, е )
: 4—|- : Функция подобна 4- ., но добавляет к контексту список связей
|] Инфиксная функция поиска. р||п обозначает величину, связанную
с идентификатором п в контексте р. Мы требуем, чтобы
( р : 4- • ( п, е )) Ц п = е
( р п, е )) || m = р || т, если п =/= т.
Заметим, что функция поиска возвращает самую последнюю
связь имени в случае, если были добавлены две различные
связи для одного и того же имени. Введем поэтому еще одну
аксиому:
(р: + :(п, е1)): + :(п, е2))||п = е2
Для простоты не будем рассматривать случай, когда функ-
ция поиска применяется к пустому контексту.
Теперь можно записать на языке Норе типы функций Eval
и Apply. Eval берет выражение (типа ехр, определенного на
рис. 9.1) и контекст и возвращает другое выражение — слабую
заголовочную нормальную форму выражения аргумента:
dec Eval : exp # environment * ехр;
Apply берет выражение функции и выражение аргумента и воз-
вращает результат применения функции к этому аргументу:
dec Apply : exp # exp -> exp;
Apply не рассматривает контекст в качестве своего аргумента
по причинам, которые станут понятны позднее.
В .соответствии со стилем программирования на языке Норе,
описанным в части I, определим теперь Eval и Apply, задав
по одному правилу для каждого возможного типа выражений
аргумента, т. е. по одному правилу для каждого конструктора
в типе данных ехр. Важно постоянно помнить, что все различ-
ные правила для Eval'и Apply должны приводить заданные
выражения к их слабым заголовочным нормальным формам.
14 — 1473
210 Часть II. Глава 9
Поэтому, если выражение уже в слабой заголовочной нормаль-
ной форме, мы должны вернуть его без изменений, иначе нужно
выполнить необходимые упрощения выражения.
9.2.1. Правила для Eval
Начнем с описания семи уравнений, определяющих функцию
Eval и соответствующих семи конструкторам типа ехр. Однако
нам потребуется также ввести два дополнительных конструк-
тора «внутренних типов выражений» для представления значе-
ний функции при рассмотрении интерпретации примитивных
функций и лямбда-абстракций. Итак, начнем описывать пра-
вила.
1. Применение функции (конструктор АРР)
Здесь мы сначала преобразуем выражения функции и аргу-
мента к их слабым заголовочным нормальным формам, а затем
используем Apply:
-------Eval(APP(El, Е2), env)<=
Apply( Eval( El, env), Eval( E2, env));
Заметим, что мы вычислили выражение аргумента до примене-
ния функции. Это соответствует вызову по значению, что нам
и требуется для энергичного интерпретатора. Однако следует
заметить, что Е2 вычисляется таким образом только потому,
что в стандартной реализации языка Норе функции вызываются
по значению. Мы вернемся к этому вопросу в разд. 9.3.1.
2. Целые числа (конструктор INT)
Здесь мы немедленно возвращаем целое число без измене-
ний, поскольку оно уже имеет слабую заголовочную нормаль-
ную форму:
-------Eval(e& INT(-), - )<=е;
(точно так же мы поступаем для любых других объектов базо-
вых типов).
3. Идентификаторы (конструктор VAR)
Значение, связанное с идентификатором, мы находим путем
поиска имени этого идентификатора в контексте:
•------Eval(VAR(v), env) <=env||v;
4. Примитивные функций (конструктор PRIM)
Примитивные функции представляют интересную проблему
при интерпретации, поскольку в общем случае необходимо иметь
Методы интерпретации 211
возможность представлять их частичное применение (оно не
может быть выражено непосредственно в языке Норе, но воз-
можно для промежуточного кода). Поэтому следует решить,
что возвращать в качестве результата вычисления выражения,
подобного следующему:
АРР(PRIM("+"), INT(l))
Мы не можем применить примитив, пока не будем иметь все
необходимые аргументы (два в случае функции «+»), и по-
этому должны построить специальную структуру для представ-
ления частичного применения функции. Эта структура будет
иметь форму тройки, включающей:
(1) имя примитивной функции (таким образом, мы знаем, ка-
кое правило применить, когда все аргументы будут в наличии).
Это аргумент конструктора PRIM;
(2) ожидаемое число аргументов этой функции (которое гово-
рит нам о том, сколько аргументов мы должны еще получить,
прежде чем сможем вычислить значение функции);
(3) список, содержащий уже полученные аргументы. Первона-
чально он пуст.
Заметим, что сумма длины списка (3) и числа ожидаемых
аргументов (2) является константой, равной арности рассмат-
риваемой примитивной функции. Поскольку эта тройка является
допустимым выражением, необходимо дополнить определение
данных ехр. Введем новый тип выражения с помощью конструк-
тора ОР:
data ехр== VAR( id) -|—. ++ RLET( list( id #ехр) # ехр)
++ ОР( id # num # 1 ist(exp));
Символ примитивной функции можно рассматривать как
частичное применение этого примитива без аргументов. Правило
для функции Eval, примененной к примитивной функции, имеет
следующий вид
------ Eval(e&PRIM(p), — )<=ОР(р, ArityOf(p), nil);
ArityOf — это вспомогательная функция, возвращающая ар-
ность заданного примитива. Она определяется просто:
dec ArityOf: id —> num ;
-----ArityOf ("+")<== 2;
-----ArityOf( "-")<= 2;
и т. д. для любых других примитивов, которые мы выберем.
Поскольку частично примененный примитив является слабой
14*
212 Часть II. Глава 9
заголовочной нормальной формой (вспомните обсуждение кар-
ринга в гл. 6), нам требуется следующее правило:
-----Eval(e&OP(—, —, — ), — )<=е;
Важно понять, что конструкторы ОР первоначально не входят
в программу на промежуточном коде; они генерируются интер-
претатором в качестве результата вычисления примитивной
функции.
5. Квалифицированные выражения (конструктор LET)
Здесь мы вычисляем выражение результата (Е2) в контек-
сте, дополненном связью новой переменной (v) с результатом
вычисления квалификатора (Е1):
-----Eval(LET(v, El, Е2), env)< =
Eval(E2, env:4-:(v, Eval(El, eval)));
Мы часто говорим, что квалифицированные выражения расши-
ряют текущий контекст, отражая тот факт, что их вычисление
приводит к включению дополнительной связи в контекст. Заме-
тим, что снова имеем энергичное вычисление, т. е. Е1 вычис-
ляется перед Е2. Это полностью соответствует нашим ожида-
ниям, поскольку выражение letx = EiinE2 эквивалентно приме-
нению ( Хх.Е2 ) El.
6. Лямбда-абстракции (конструктор LAM)
Это правило усложняется тем, что тело лямбда-абстракции
может содержать свободные переменные. Чтобы проиллюстри-
ровать проблему, рассмотрим вычисление следующего выраже-
ния, являющегося внутренней формой для выражения проме-
жуточного кода Хх. + х у:
LAM("x", АРР( АРР( PRIM( plus), VAR("x")), VAR("y'')))
(plus обозначает OP ( «+», 2, nil) ).
Проблема здесь в том, что связь для у нужно брать из того
контекста, который существует в момент вычисления данного
лямбда-выражения. Поскольку лямбда-выражение представляет
собой слабую заголовочную нормальную форму, необходимо
вернуть его без изменений, но при этом существует опасность,
что мы потеряем корректную связь свободной переменной у.
(Некоторые авторы называют это FUNARG-проблемой.) По
этой причине мы должны возвращать не только выражение, но
и контекст, дающий корректную связь для у. Такая составная
структура называется замыканием, поскольку она представляет
замкнутое выражение, т. е. выражение, не содержащее свобод-
Методы интерпретации 213
ных переменных (см. гл. 6). Здесь свободными мы называем
такие переменные, которые не имеют связанных с ними значе-
ний. Хотя возможно, что в теле замыкания содержатся пере-
менные, которые, строго говоря, являются свободными в том
смысле, что они не связаны соответствующими LAM-выраже-
ниями, каждая из них имеет связь в контексте. Следовательно,
такие переменные можно рассматривать просто как альтерна-
тивные представления тех значений, с которыми они связаны
в контексте. Более того, если бы мы занимались реализацией
интерпретатора, основанного на копировании, а не на контек-
сте, эти переменные были бы просто физически заменены соот-
ветствующими значениями аргументов и, следовательно, вообще
не присутствовали бы в лямбда-выражении.
Чтобы представить замыкание в нашем интерпретаторе, мы
должны добавить еще один конструктор к типу данных ехр:
data ехр ===== INT( num ) ++ ... + + ОР( id # num # list( exp))
+ + CLOSURE(exp # environment);
Правило для Eval в случае, когда выражение является Х-аб-
стракцией, имеет следующий вид:
-----Eval( е & LAM( —, — ), env) <= CLOSURE( е, env);
Поскольку замыкания представляют собой функции, а функции
являются слабыми заголовочными нормальными формами, мы
должны также включить правило для Eval в том случае, когда
выражение аргумента является замыканием:
-----Eval(e & CLOSURE( -, - ), -)<=е;
Как и частично примененные примитивы (конструктор ОР), за-
мыкания первоначально отсутствуют в промежуточном коде
программы и генерируются интерпретатором в качестве резуль-
татов вычисления лямбда-абстракций.
Заметим, что использование замыканий гарантирует, что пе-
ременные будут связаны статически, как это описано в гл. 3.
Если бы мы отказались от замыканий, интерпретатор выпол-
нял бы динамическое связывание переменных, так как контекст
(аргумент Eval) может только расти, пополняясь новыми (ди-
намическими) связями, заменяющими старые.
7. Рекурсивные let-выражения (конструктор RLET)
Обработка рекурсивных определений — это наиболее слож-
ная часть интерпретатора. Для простоты будем предполагать,
что каждое определение является лямбда-абстракцией (т. е.
функцией), поэтому нам нужно построить замыкание каждого
214 Часть II. Глава 9
определения и добавить соответствующие связи в контекст (это
требование можно немного ослабить — см. упражнение в конце
этой главы). Проблему, с которой мы при этом сталкиваемся,
можно понять, рассмотрев простой пример:
letrec f = Zy.g х, g = Zz.h f z
in f 1
Замыкания для f и g должны включать не только связи для
свободных переменных х и h, которые должны присутствовать
в контексте при вычислении выражения, но также связи для
самих f и g. Рассмотрим замыкание для f. Контекст для этого
замыкания должен быть текущим контекстом, дополненным
связями (f, Cf) и ( g, Cg ), где Cf — это замыкание для f, a Cs —
замыкание для g. Однако контекст внутри Cf должен также
содержать связи для f и g, которые сами являются замыкания-
ми. Поэтому они также должны содержать контекст, включаю-
щий связи для f и g и т. д. Процесс продолжается бесконечно.
Для решения этой проблемы нам необходим циклический
контекст, т. е. контекст, который логически замкнут сам на себя.
Мы видели, как строятся циклические структуры в гл. 4 с ис-
пользованием рекурсивных let- и where-выражений. Здесь бу-
дет использован тот же самый прием:
---— Eval( RLET( defs, Е), env) <= Eval( E, NewEnv)
where NewEnv == env map (lambda ( n, e)=>
(n, CLOSURE (e, NewEnv)), defs);
Вызов функции map в этом правиле приводит к построению
замыкания от каждой функции в списке определений (defs).
Контекстом каждого замыкания является NewEnv, следова-
тельно, имеет место цикличность В результате получается спи-
сок пар вида имя/замыкание, который добавляется к контек-
сту env с помощью функции доступа Все это основано
на том факте, что значение NewEnv не требуется немедленно,
поскольку аргументы конструктора CLOSURE не вычисляются
в точке вызова.
Теперь должно быть ясно, что для построения циклического
контекста мы использовали тот факт, что конструкторы в стан-
дартной реализации языка Норе являются ленивыми. Внима-
тельный читатель может спросить, что было бы, если в качестве
определяющего языка мы использовали строгий язык, напри-
мер строгий Лисп или FP. При использовании этих языков
нельзя построить циклический контекст, поскольку для его по-
строения совершенно необходимы ленивые вычисления в какой-
либо форме, чтобы программа не зациклилась. При отсутствии
Методы интерпретации 215
циклического контекста единственный путь, гарантирующий, что
связи не будут некорректно переопределены, заключается в пе-
реименовании переменных, введенных в RLET-выражениях, чтобы
сделать их имена уникальными по отношению к другим пере-
менным программы. Это должно быть сделано один раз и для
всех таких переменных перед вызовом интерпретатора. В этом
случае связь переменной может быть замещена только связью
той же самой переменной, что вполне безопасно, поскольку
свойство функциональности гарантирует отсутствие сторонних
эффектов. Правило для функции Eval, применной к RLET-вы-
ражению, выглядело бы в этом случае так:
-----Eval( RLET( defs, Е), env) <= Eval( Е, env H—h:defs);
Теперь мы рассмотрели все типы выражений и поэтому за-
канчиваем определение функции Eval и переходим к определе-
нию Apply.
9.2.2. Определение Apply
Чтобы определить Apply, нужно определить по одному урав-
нению для каждого возможного типа функций. Фактически су-
ществуют только два типа функций, которые нужно рассмот-
реть,— замыкания и примитивы. Это следует из рассмотрения
правых частей правил, определяющих Eval.
Чтобы применить замыкание (содержащее лямбда-выраже-
ние и контекст) к некоторому значению аргумента, мы просто
вычисляем тело лямбда-выражения в контексте замыкания, до-
полненном связью между связанной переменной (v) и значе-
нием аргумента (А):
-----Apoly(CLOSURE(LAM(v, В), env), А)<==
Eval( В, env:+ :(v, А));
Заметим, что функция Apply не требует, чтобы контекст был
ее аргументом, потому что как выражение функции, так и вы-
ражение аргумента вычисляются перед вызовом Apply. В рас-
сматриваемом интерпретаторе единственными вычисляемыми
выражениями, которые могут содержать (свободные) перемен-
ные, являются лямбда-абстракции, и связи для этих перемен-
ных даны в соответствующем замыкании. Заметим, что для
вычисления применения функции мы не используем непосред-
ственно функцию Apply, а используем Eval.
Нам осталось определить правило для обработки примити-
вов, представленных с помощью конструктора ОР (см. правило
вычисления примитивов). Если счетчик ожидаемых аргументов
216 Часть II. Глава 9
примитивной функции (который будем обозначать РАС) ра-
вен 1, нужно дополнить список аргументов и применить прими-
тивную функцию к этим аргументам. Если РАС больше 1, не-
обходимо сформировать новый примитив, РАС которого на еди-
ницу меньше, а список аргументов (arglist) соответствующим
type id —— Iist( char );
data exp ===== INT) num ) ++ VAR( id ) ++ PRIM) id ) + +
APP( exp # exp ) ++ LAM) id # exp ) 4—|-
LET( id # exp # exp ) + +
RLET( Iist) id # exp ) # exp ) ++ OP( id # num # list) exp )) +4-
CLOSURE( exp # environment);
dec Eval : exp # environment -> exp ;
dec Apply : exp # exp -> exp ;
dec ArityOf :id->num;
dec FunOf : id > ( list( exp ) -> exp );
-----Eval( App( El, E2 ), env ) <= Apply( Eval( El, env ),
Eval( E2, env ));
-----Eval) e & INT) _ ) <= e ;
-----Eval( VAR( v ), env ) <=env||v;
-----Eval) PRIM) p ), _ ) <= OP( p, ArityOf) p ), nil );
-----Eval) e & OP) _,_,_),_ ) <=e:
-----Eval) LET) v, El, E2 ), env ) <= Eval( E2, env : 4- :
( v, Eval) E2, env )));
-----Eval( e & LAM( _, _ ), env ) <= CLOSURE) e, env );
-----Eval) e & CLOSURE)____), _)<=e;
•----Eval) RLET) defs, E ), env ) <= Eva!) E, NewEnv )
where NewEnv ===== env 4-4--map (lambda ( n, e)=>
( n, CLOSURE) e, NewEnv)), defs);
-----Apply) CLOSURE) LAM) v, В ), env), A)<=Eva!(B, env:+:(v, A));
-----Apply) OP) p, РАС, args ), A ) <=
(if РАС = 1 then ( FunOt( p)) ( arglist) else OP) p, РАС — 1, arglist) )
where arglist == args () [A];
-----ArityOf) "4-" ) <= 2 ;
-----ArityOf) "-")<= 2;
-----FunOf) "+" ) <= lambda[ INT) a ), INT) b )J => INT) a 4- b );
-----FunOf) ) < = lambda[ INT) a ), INT) b )] => INT) a - b );
Рис 9 2 Энергичный интерпретатор.
образом расширен. Таким образом, результат частичного при-
менения примитивной функции сам является примитивной
функцией:
-----Арр1у(ОР(р, РАС, args), А)
<=(if РАС-1 then (FunOf(p))( arglist)
else OP(p, PAC-1, arglist))
where arglist ===== args () [A]
FunOf — это функция высшего порядка, которая возвращает
Hope-функцию, требуемую для реализации данного примитива
Методы интерпретации 217
(еще одно полезное применение функций высших порядков).
Ее объявление типа выглядит следующим образом:
dec FunOf: id -+ (list( exp) ->exp);
Возвращаемая функция должна быть написана так, чтобы при-
нимать аргументы примитива в виде списка выражений, по-
скольку в конструкторе ОР аргументы примитивной функции
накапливаются в виде списка (args). Здесь мы можем призвать
в помощь такое мощное средство языка Норе, как сопоставле-
ние с образцом:
-----FunOf("+") <=lambda[INT( а), INT( b)]=> INT( а + b);
-----FunOf("-")<=lambda[INT(a), INT(b)] = > INT(a-b);
Заметим, что аргументы этих функций вычислены заранее (т. е.
приведены к виду INT(x)), так как рассматриваемый интер-
претатор реализует передачу параметров по значению. Это объ-
ясняет, почему в каждом из записанных выше лямбда-выраже-
ний необходим только один образец.
Полный листинг интерпретатора на языке Норе приведен на
рис. 9.2. Простота результирующей программы еще раз под-
тверждает выразительную мощность функциональной нотации.
9.2.3. Обработка условных выражений
Построенный нами интерпретатор реализует вызов по зна-
чению для каждой функции. Это означает, что если мы реали-
зуем условные выражения в виде COND-функций, то будем вы-
числять выражения обеих ветвей условия, а также выражение
предиката всякий раз при применении таких функций. Это почти
наверняка приведет к тому, что программа не будет работать.
Традиционный путь решения этой проблемы заключается в осо-
бом рассмотрении условных выражений, что требует включения
дополнительного конструктора в определение ехр:
data ехр == INT( num) ++ ...
... ++CLOSURE(exp# environment )/
+ + COND(exp#exp#exp);
Это означает, что для данного интерпретатора выражение про-
межуточного кода
cond Е^Ез
необходимо транслировать в следующее абстрактное синтакси-
ческое дерево:
cond(e;, е;, е;)
218 Часть II. Глава 9
тогда как по общим правилам оно оттранслировалось бы в вы-
ражение
арр(дрр(арр( PRiM("cond"), е;), е'), е;)
где E'k—это абстрактное представление Ek. Если мы допустим
здесь, что true и false представляются целыми числами 1 и О
соответственно (на практике логические величины относятся
к отдельному базовому типу), то дополнительное правило для
Eval будет выглядеть следующим образом:
------Eval(COND(EI, Е2, ЕЗ), env)<=
if Eval(El, env) = INT(l) then EvaI(E2, env) else
Eval(E3, env);
Заметим, что этот дополнительный конструктор требуется
только в энергичной реализации; в ленивой реализации (один
из вариантов которой описан ниже), условные выражения мо-
гут транслироваться в вызовы примитивной функции cond.
9.3. Ленивый интерпретатор
Теперь мы модифицируем энергичный интерпретатор, опи-
санный в разд. 9.2, чтобы обеспечить вычисление нормального
порядка. Сначала мы реализуем вызов по имени, а в разд. 9.3.1
увидим различные пути реализации разделения и, следователь-
но, вызова по необходимости.
Первое и наиболее очевидное изменение, которое необходимо
сделать, касается правила для функции Eval, когда ее аргумен-
том является применение функции. Мы по-прежнему требуем,
чтобы функция была либо замыканием, либо примитивом, и
нам, следовательно, по-прежнему необходимо вычислять выра-
жение самой функции перед вызовом Apply. Однако теперь мы
хотим задержать вычисление аргумента до тех пор, пока нам
не потребуется его значение. Мы можем просто передать выра-
жение аргумента без изменений в функцию Apply, но это снова
поставит перед нами проблему, связанную со ссылками на пе-
ременные в выражении аргумента. Следовательно, мы должны
использовать структуру, подобную замыканию, чтобы запоми-
нать как само выражение аргумента, так и контекст, содержа-
щий корректные связи переменных этого выражения. Назовем
эту структуру задержкой, чтобы отразить тот факт, что она
представляет «отложенное» вычисление выражения, хотя ее час-
то называют также рецептом, отражая тот факт, что она пред-
ставляет рецепт для вычисления значения. Поэтому мы модифи-
Методы интерпретации 219
цируем определение данных ехр следующим образом.
data ехр == INT(num) ++ ...
... Ч—CLOSURE(exp # environment)
Ч—h SUSP(exp # environment);
Правило для Eval, когда ее аргумент является применением
функции, теперь принимает вид
-----Eval(APP(El, Е2), env)< =
Apply( Eval( El, env), SUSP(E2, env));
Теперь необходимо включить также правило для Eval в слу-
чае, когда аргументом является задержка. Оно требует, чтобы
выражение внутри задержки было вычислено с помощью ре-
курсивного вызова Eval:
-----Eval(SUSP(E, env), _)<=Eval(E, env);
Вследствие эквивалентности выражений letx = EiinE2 и
(Xx.E2)Ei мы должны также модифицировать правило для
Eval, когда ее аргументом является LET-выражение, по анало-
гии с тем, как это сделано в случае АРР-выражения:
-----Eval(LET(v, El, Е2 ), env)< =
Eval(E2, env:4-:(v, SUSP(E1, env)));
Как видим, теперь контекст может содержать задержки, по-
этому не гарантируется, что при поиске в контексте связи иден-
тификатора мы получим выражение в слабой заголовочной
нормальной форме. Следовательно, к каждому найденному вы-
ражению мы должны теперь применять Eval:
-----Eval(VAR(v), env) <= Eval(env||v, env);
Чтобы завершить модификацию Eval, следует расширить пра-
вило вычисления для RLET. Теперь, когда мы имеем задержки,
можно допустить любой набор взаимно рекурсивных определе-
ний (а не только рекурсивных функций) с помощью построе-
ния задержки для каждого рассматриваемого определения вме-
сто предположения о том, что определение является функцией,
и построения замыкания для каждого такого определения, как
ранее. Поэтому модификация Eval в случае, когда ее аргумен-
том является RLET-выражение, имеет простой вид:
-----Eval(RLET(defs, Е), env) <= Eval( Е, NewEnv)
where NewEnv —= env ++ : map( lambda (n, e)=>
(n, SUSP(e, NewEnv)), defs);
220 Часть II. Глава 9
Нам осталось изменить только правила для примитивных функ-
ций. Поскольку аргументы примитивной функции могут быть
задержками, их нужно вычислять в самом начале:
-----FunOf( "+")<== lambda [ х, у ] => INT( а + b);
where (INT(a), INT(b))==
( Eval( x, empty), Eval(y, empty));
-----FunOf("—") <— lambda {x, у ] => INT( a — b);
where (INT(a), INT(b))==
(Eval( x, empty), Eval(y, empty));
Заметим, что в каждом случае Eval вызывается с пустым кон-
текстом, поскольку контекст для вычисления каждого аргумента
содержится в соответствующей задержке. Полный листинг ле-
нивого интерпретатора приведен на рис. 9.3.
В качестве отступления заметим, что возможно представить
задержки с помощью замыканий. Имея выражение аргумента Е,
мы можем использовать (3-абстракцию, чтобы преобразовать Е
в выражение
(А.Х.Е )у
для любого у при условии, что ни х, ни у не являются свобод-
ными переменными в Е. Более того, если мы введем понятия
пустого параметра, обозначаемого ®, и пустого выражения,
обозначаемого ?, тогда можно записать выражение Е в виде
(Х®.Е)?
не заботясь больше об именах переменных. Сделав это, можно
сформировать замыкание результирующей функции (т. е.
Х®.Е) и, таким образом, промоделировать задержку. Итак, мы
пришли к следующей эквивалентности:
SUSP(E, env) CLOSURE) LAM(®, Е ), env)
История, однако, еще не закончена, поскольку мы должны яв-
ным образом «форсировать» вычисление Е всякий раз, когда
нам требуется значение Е. Чтобы сделать это, необходимо при-
менить замыкание для Е к пустому аргументу. Это должно быть
сделано только тогда, когда значение выражения действительно
необходимо, т. е. в процессе интерпретации строгих примитивов,
таких, как + и —. Поэтому, например, в случае примитива +>
мы имеем
-----FunOf() <= lambda [ х, у ] —> INT( а + b )
where (INT(a), INT(b))==(Eval(APP(x, ?), empty),
Eval(APP(y, ?), empty));
Методы интерпретации 221
type id ===== 1 ist( char );
data exp == INT( num ) H—h VAR( id ) ++ PRIM( id ) H—p
APP( exp # exp ) -p + LAM( id # exp ) -p-p
•LET( id # exp # exp ) + +
RLET( 1 ist( id # exp) # exp) ++ OP( id # num # 1 ist( exp )) + +
CLOSURE( exp # environment) + + SUSP( exp environment);
dec Eval : exp # environment -> exp ;
dec Apply : exp # exp -> exp ;
dec ArityOf : id -> num ;
dec FunOf : id > ( 1 ist( exp ) -> exp ) ;
Eval(APP(El, E2 ), env)
Eval(e & INT ( _ ), _ )
Eval( VAR( v), env)
Eval(PRIM(p), _ )
Eval( e &OP(
Eval( LET( v, El, E2), env)
Eval( e & LAM( _ ), env )
Eval(e & CLOSURE!
<= Apply! Eval( E1, env),
SUSP( E2, env ));
<= e;
<= Eval( env || v, env);
<=OP(p, ArityOf(p), nil)
<= e ;
<= Eval( E2, env : + :
( v, SUSP( El, env ) ) ;
<= CLOS URE( e, env);
< = e ;
•----Eval( SUSP( E, env ), _ ) <= Eval( E, env ) ;
-----Eval( RLET( defs, E ), env ) <= Eval( E, NewEnv )
where NewEnv == env : 4—p : map( lambda ( n, e ) =>
( n, SUSP(e, NewEnv)), defs);
-----Apply! CLOSUREf LAM( v, В ), env ), A ) < =
Eval( B, env : + : ( v, A ) ) ;
-----Apply! OP( p, РАС, args ), A ) < =
( if РАС = 1 then ( FunOf( p ) ) ( arglist) else
PRIM( OP( p, РАС - 1, arglist) ))
where argl ist == args ( ) [A];
-----ArityOf( "+") <=2;
-----ArityOf!"-") <=2;
-----FunOf( "+" ) <= lambda [x, y] => INT( a + b )
where (INT(a), INT( b )) == ( Eval( x, empty),
Eval( y, empty ));
-----— FunOf( "—" ) <= lambda [x, y] —> INT( a — b )
where ( 1NT( a ), INT( b )) == ( Eval( x, empty ),
Eval( y, empty ) ) ;
Рис. 9.3. Модифицированный интерпретатор.
Чтобы увидеть, что оба механизма эквивалентны, рассмотрим
работу Eval в обоих случаях. Для задержек имеем
Eval(SUSP(E, envl), env2 )
—> Eval( E, env’ )
Для замыканий имеем
Eval( APP(CLOSURE(LAM( ®, E), envl), ? ), env2 )
—* Apply( Eval( CLOSURE! LAM( E ), envl), env2),
CLOSURE! LAM(®, ?), env2))
222 Часть II. Глава 9
-> Apply( CLOSURE( LAM( ®, Е), envl),
CLOSURE(LAM( ®, ? ), env2))
->Eval(E, envl : + : ( ®, CLOSURE( LAM( ®, ?), env2))
= Eval( E, envl ))
поскольку ® является пустым идентификатором и, следова-
тельно, не расширяет контекст.
Заметим, однако, что если аргумент в теле функции встре-
чается больше одного раза, то для каждого вхождения аргу-
мента требуется вычисление задержки или применение соответ-
ствующего замыкания к пустому параметру. Таким образом,
требуется повторное вычисление аргумента всякий раз, когда
нам нужно получить его значение, и, следовательно, мы имеем
вызов по имени. Чтобы реализовать ленивое вычисление, мы
должны реализовать вызов по необходимости. Для этого тре-
буется разделять не только выражения аргументов, но и резуль-
таты вычислений этих выражений. Механизмы, реализующие
вызов по необходимости, рассмотрены в следующем подразделе.
9.3.1. Реализация вызова по необходимости
В гл. 6 мы рассмотрели следующее лямбда-выражение:
(/.х. + х х) Е
и показали, как с помощью контекста можно избежать созда-
ния двух копий Е. В нашем интерпретаторе мы имеем тот же
эффект, так чго после первого применения в контексте будут
существовать две ссылки на одно и то же выражение, т. е.
выражение является разделяемым.
Проблема, однако, заключается в том, что когда Е действи-
тельно приводится к слабой заголовочной нормальной форме
(после вычисления левого аргумента функции +, например),
контекст не изменяется. Это означает, что вычисление правого
аргумента функции + приведет к повторному вычислению Е.
Поэтому несмотря на тот факт, что мы создаем только одну
копию выражения аргумента, нам необходимы повторные вы-
числения Е, так что интерпретатор реализует вызов по имени.
Хотя может показаться, что для замещения в контексте за-
держки ее значением нам требуется что-то вроде оператора
присваивания, более удовлетворительное (с точки зрения функ-
циональности) решение состоит в использовании того факта,
что в стандартной реализации языка Норе конструкторы сами
вызываются по необходимости. Хитрость здесь в том, чтобы
вставить вызов функции Eval внутрь каждой задержки:
-----Eval(APP(El, Е2), env)< =
Apply(Eval(El, env), SUSP( Eval( E2, env)));
Методы интерпретации 223
(при этом требуется очевидная модификация ехр для измене-
ния аргументов SUSP-конструктора). Аргумент SUSP-конструк-
тора теперь является выражением, которое не будет вычис-
ляться, пока его значение действительно не потребуется,
а после вычисления это значение станет разделяемым. Правило
для функции Eval, применяемой к конструктору SUSP, прини-
мает следующий вид:
-----Eval(SUSP(E), _)<=Е;
Теперй давайте вернемся к нашему простому примеру. Когда
значение замыкания для Е потребуется в первый раз (т. е.
в процессе вычисления одного из аргументов функции -|-), вы-
ражение внутри задержки будет вычислено. При вычислении
второго аргумента функции -f- задержка будет повторно най-
дена в контексте, но на этот раз выражение внутри задержки
будет уже в слабой заголовочной нормальной форме. Поэтому,
хотя мы дважды ищем замыкание в контексте, вычисление вы-
ражения его аргумента будет проведено только один раз. Это
дает нам вызов по необходимости
Теперь посмотрим, что произойдет при использовании лени-
вой реализации языка Норе вместо стандартной. Вернемся
к энергичному интерпретатору из разд. 9.1 и к правилу для
функции Eval, аргументом которой является применение функ-
ции:
-----Eval(APP(El, Е2), env)< =
Apply( Eval( El, env), Eval(E2, env));
Мы видели, что E2 будет вычислено до применения функции,
поскольку в стандартной реализации языка Норе функции вы-
зываются по значению. При использовании ленивой реализации
языка Hope Е2 не будет вычислено немедленно, поскольку вы-
ражение Eval(E2, env) является параметром функции Apply,
который передается по необходимости. В результате контекст
будет содержать «задержанные» вызовы функции Eval. Эти
вызовы будут выполнены только при интерпретации строгих
операторов, таких, как
-----FunOf( "+")<= lambda [INT(a), INT(b)]=>
INT(a + b);
При применении этой функции выражения аргументов должны
быть вычислены, чтобы выполнить сопоставление с образцом,
и именно в этой точке задержанные вызовы Eval будут выпол-
нены. Более того, эти задержанные вызовы будут автоматически
заменены значениями INT(a) и INT(b), что соответствует
вызову по необходимости. Поэтому, хотя приведенное выше
224 Часть II. Глава 9
правило для Eval выглядит так, как если бы оно реализовывало
вызов по значению, на самом деле оно реализует вызов по не-
обходимости!
Это наблюдение поведения интерпретаторов ставит интерес-
ный вопрос: как можно реализовать вызов по значению, ис-
пользуя ленивый определяющий язык. Ответ состоит в том, что
это невозможно сделать без использования некоторых хитрых
искусственных приемов для «форсирования» вычисления аргу-
мента. Одним из таких приемов является сравнение аргумента
с самим собой;
----Eval(APP(E, A), env)< =
let E==Eval(A, env) in
if E = E then Apply( Eval( F, env), E)
else Apply) Eval(F, env), E);
Однако даже это не будет работать, если реализация исполь-
зует тот факт, что выражение Е = Е всегда истинно незави-
симо от значения Е. (Если мы определяем = как строгую
функцию, тогда _L = _L должно давать d_, а не true. Другими
словами, оба аргумента = должны в этом случае вычисляться,
и, значит, приведенное выше правило для Eval будет рабо-
тать.)
Все эти рассуждения можно обобщить следующим образом.
Используя полностью энергичный определяющий язык (даже
без ленивых конструкторов), мы можем без проблем интерпре-
тировать вызов по значению (хотя не сможем построить цикли-
ческий контекст, достаточный для поддержки произвольных ре-
курсивных определений). Мы можем также интерпретировать
вызов по имени с помощью задержек, но не можем выполнять
вызов по необходимости, поскольку не можем явно переписы-
вать контекст. Если определяющий язык поддерживает лени-
вые конструкторы и энергичные функции (как это сделано в
стандартной реализации языка Норе), тогда мы можем реали-
зовать и вызов по значению, и вызов по имени, и вызов по не-
обходимости, используя «энергичные» свойства функций и «ле-
нивые» свойства конструкторов. Если определяющий язык пол-
ностью ленивый (как ленивая реализация Норе), тогда мы
можем интерпретировать вызов по имени (используя приведен-
ную выше оригинальную версию SUSP-конструктора) и вызов
по необходимости, но вызов по имени возможен, только если
мы явным образом форсируем вычисление выражений с по-
мощью строгих операторов, таких, как =.
Теперь становится понятно, почему интерпретатор является
очень ненадежным средством описания языка. Интерпретатор
о многом может сказать, если мы в деталях понимаем семан-
Методы интерпретации 225
тику определяющего языка. Однако если мы неправильно пони-
маем этот язык, то не сможем правильно понять семантику
определяемого языка. Ситуация значительно ухудшается, если
интерпретатор для языка, скажем, L написан на самом языке
L (такой интерпретатор называется метациклическим). В этом
случае из правила для вычисления применения функций мы
не сможем сказать ничего о механизме вызова. Все это отно-
сится не только к семантике вызова функций. Каждая из кон-
струкций определяемого языка с необходимостью реализуется
в терминах конструкций определяющего языка, так что если мы
недостаточно хорошо понимаем эти конструкции, то не сможем
полностью понять семантику определяемого языка. Именно по
этой причине семантика языка программирования часто выра-
жается в неоперационном виде. Идея состоит в том, чтобы от-
казаться от определения языка в терминах другого языка и вы-
ражать семантику языка в терминах точных математических
понятий, что особенно подходит для функциональных языков.
Это уводит нас от операционной семантики в сферу денотацион-
ной семантики, которая определяет язык, явным образом уста-
навливая математическую величину для каждой языковой
конструкции, причем эта величина принадлежит хорошо специ-
фицированной области определения. Чтобы дать читателю неко-
торое базовое представление о предмете, в приложении В мы
коротко описываем, что такое денотационная семантика. Этот
материал предполагает некоторое минимальное понимание тео-
рии доменов и поэтому естественным образом следует за при-
ложением Б.
Резюме
• Программа на промежуточном коде может быть представ-
лена в абстрактной форме как структура данных.
• Интерпретатор приводит абстрактное представление выра-
жения промежуточного кода к слабой заголовочной нормаль-
ной форме.
• Значения всех свободных переменных выражения запоми-
наются в особой структуре, называемой контекстом.
• Различные механизмы вызова могут быть .реализованы с по-
мощью модификации правила для вычисления применений
функции.
• Замыкания используются для представления функций; они
запоминают значения свободных переменных тела функции пу-
тем включения в себя части контекста.
• Замыкания гарантируют статическое связывание; без них
мы получаем динамическое связывание.
15 — 1473
226 Часть II. Глава 9
• Задержки используются для представления невычисленных
выражений при ленивой реализации. Задержки также вклю-
чают в себя контекст и могут моделироваться с помощью за-
мыканий. Интерпретация letrec-выражений основана на исполь-
зовании циклического контекста.
• Операционная семантика определяемого языка полностью
зависит от семантики определяющего языка.
Упражнения
9.1. Для каждого из следующих выражений:
(О (Хх.Ху.х у у)(Хх.Ху.у)
(ii) (let х = 4 in Лу. 4-х 7)5
(iii) (Xf.Xg.Xx.f g(4-x l)2)*(Xx.x)
а) запишите абстрактное представление выражения в виде
терма составных данных языка Норе (типа ехр, определение
которого дано на рис. 9.1);
б) проследите вычисление выражения с помощью энергич-
ного интерпретатора из разд. 9.2.
9.2. а. Допустим, «контекст» имеет тип list( identifier# ехр ).
Запишите объявления и определения функций доступа empty,
:4~:> :4_4_; и 11-
б. Определите :4—Н через :4-:, используя функцию teduce
для списков.
в. Каковы будут определения функций empty, :4< и
если контекст представляется в виде функции типа identifier-►
expression (идентификатор -* выражение) ?
9.3. Расширьте интерпретатор, включив базовый тип truval,
булеву функцию > и логический оператор not. Запишите
абстрактное представление выражения (if( not( > 1 3 ) ) ( Хх.х )
( Хх. -j- 1 х ) )5 и проследите его вычисление.
9.4. Очевидно, нет необходимости формировать задержку, когда
выражение аргумента имеет слабую заголовочную нормальную
форму или само является задержкой. Предложите оптимиза-
цию интерпретатора, исключающую формирование таких избы-
точных задержек.
9.5. В наших интерпретаторах мы представляем частичное при-
менение примитивных функций в виде троек, описанных в
разд. 9.2.
а. Можете ли вы предложить другое представление, исполь-
зующее замыкания?
б. Каковы преимущества представления из разд. 9.2 с точ-
ки зрения пользователя интерпретатора? (Подсказка: рассмот-
Методы интерпретации 227
рите случай, когда результатом программы является частичное
применение примитива.)
9.6. Рассмотрим правило для функции Eval в случае RLET-вы-
ражений для энергичного интерпретатора из разд. 9.2. Здесь
мы предполагаем, что каждое определение вводит функцию
(мы встречали только замыкания в сконструированном цикли-
ческом контексте). В каком смысле это предположение является
избыточно ограничительным? Другими словами, каково общее
правило, регулирующее тип выражения в каждом определении
для энергичного интерпретатора? Используйте ваш ответ для
того, чтобы записать альтернативное определение для Eval
в этом случае.
9.7. а. Рассмотрим семейство функций кортежирования tuple-n,
п 0, которые использовались в предыдущей главе для пред-
ставления составных данных. Помня, что п может принимать
любое значение (^0), предложите, как эти функции можно
представить в абстрактном синтаксическом дереве промежу-
точного кода и как применения этих функций могут обраба-
тываться интерпретатором. (Предложение: ’введите новый тип
данных AllPrims, который содержит по одному конструктору
для каждого примитива, например:
data AllPrims == plus Н—|- minus -)—... ;)
б. Запишите новое правило для функции FunOf в случае
примитивной функции индексирования кортежей index для
выбранного вами представления кортежей.
в. Объясните, как ленивые конструкторы могут быть вклю-
чены в энергичный интерпретатор, представленный на рис. 9.2.
(Подсказка: рассмотрите дополнительное семейство примити-
вов lazytuple-n ( п 0 ), подобное семейству tuple-n, за исклю-
чением того, что каждая такая примитивная функция не яв-
ляется строгой по отношению ко всем своим аргументам.)
15*
Глава 10
РЕАЛИЗАЦИЯ НА ОСНОВЕ СТЕКОВ —
SECD-МАШИНА
Материал первой части этой книги позволяет читателю по-
нять концепции функционального языка и дает представление
о математических основах этих концепций. Описаны некоторые
свойства, необходимые для системы, вычисляющей функцио-
нальные выражения, например сохранение прозрачности ссылок
и корректная реализация порядка вычислений, выбранного для
данного языка. В предыдущей главе мы рассмотрели интерпре-
тацию функциональных языков и описали интерпретаторы, ко-
торые сами написаны на функциональном языке. Это позволяет
понять, как взяться за конструирование и реализацию функ-
ционального языка, чтобы обеспечить строгую спецификацию
высокого уровня Однако операционные характеристики таких
интерпретаторов основываются на возможностях того языка,
на котором написан сам интерпретатор, — вспомните обсужде-
ние «энергичности» или «ленивости» интерпретатора, написан-
ного на энергичном или ленивом языке. В этой главе мы начи-
наем обсуждение удобных абстрактных машин для выполнения
функциональных языков, использующих модель вычислений,
основанных на контексте.
Мы рассмотрим наиболее общую реализацию, основанную
на контексте, которая интерпретирует выражения Х-исчисления.
Как мы видели, Х-исчисление имеет достаточную мощность для
представления любого функционального языка и поэтому обес-
печивает хорошую основу для построения практических реа-
лизаций. Мы видели также, как функциональные языки транс-
лируются в такую форму, чтобы было возможно принять некото-
рый вариант Z-исчисления в качестве удобного промежуточного
кода для их реализации. Первый интерпретатор этого типа
был предложен в [59]. Он использует четыре стека, обозначае-
мые S, Е, С и D для обеспечения механического вычисления
%-выражений. В разд. 10.1 мы рассмотрим энергичную версию
Реализация иа основе стеков — SECD-машина 229
этой так называемой SECD-машины, а в разд. 10.2 опишем
модификации, необходимые для реализации ее ленивой версии.
Наконец, доказательство ее корректности будет дано в
разд. 10 3. Для установления корректности реализации тре-
буется по меньшей мере формальное доказательство того, что
семантика ее модели вычислений эквивалентна семантике язы-
ка. (В общем случае необходимо также доказать, что формаль-
ная спецификация реализации соответствует семантике модели,
но это относительно простая задача, если интерпретатор напи-
сан на функциональном языке, который сам может отражать
семантику модели Следовательно, это доказательство рассмат-
риваться не будет) Доказательство корректности, согласно
Плоткину [72], влечет за собой обеспечение формальной семан-
тики работы SECD-машины и затем показывает ее эквивалент-
ность семантике (3-редукции Оно дано для энергичной машины,
но модификации, требуемые для ленивой версии, достаточно
просты.
10.1. SECD-машина
SECD-машина Лэндина использует для вычисления Х-вы-
ражений четыре стека. Ее работу очень легко описать нефор-
мально Строгое описание работы SECD-машины основано на
представлении ее состояния в зависимости от содержимого ее
четырех стеков и заключается в описании переходов машины
из одного состояния в другое. Важность SECD-машины состоит
в том, что она лежит в основе многих методов практической
реализации. Ясно, однако, что без оптимизации SECD-машина
является далеко не самым эффективным средством реализации
функционального языка.
Начнем с описания энергичной системы, в которой пара-
метры передаются по значению, т. е. той, которая реализует
вычисление аппликативного порядка ^-выражений. В дальней-
шем мы покажем, как эта система может быть обобщена для
обеспечения ленивого вычисления Энергичную и ленивую вер-
сии SECD-машины часто называют машиной, управляемой
данными, и машиной, управляемой запросами, соответственно.
.Вспомним, что выражения в A-исчислении имеют следующий
БНФ-синтаксис:
(ехр) ::= Z {id).{ехр)| {id) |(ехр) {ехр)| ((ехр))\{соп)
где {id) представляет идентификаторы, а {соп)— произвольный
набор констант, таких, как атомы и примитивные функции.
Нам также понадобится рассмотреть замыкания в качестве
средства представления Л-абстракций вместе с соответствующими
230 Часть II. Глава 10
связями их свободных переменных (см. гл. 9). Замыкания
будут записываться в виде [id, ехр, env], где id — это иденти-
фикатор связанной переменной Х-выражения, ехр-—это тело
Л-выражения, a env-—контекст, содержащий связи свободных
переменных тела. Каждый элемент контекста — это пара вида
]id, value), где для энергичной SECD-машины value является
выражением в слабой заголовочной нормальной форме (СЗНФ).
Состояние SECD-машины — это четырехэлементный кортеж
(S, Е, С, D), где S — это стек объектов, используемый при вы-
числении рекурсивных выражений, Е— это контекст, т. е. спи-
сок пар вида идентификатор — объект, С — это управляющая
строка, т. е. оставшаяся часть вычисляемого выражения, D —-
это дамп, т. е. предыдущее состояние, используемое для воз-
врата из вызова функции.
Работа машины описывается в терминах переходов из од-
ного состояния в другое. Переходы мы определим с помощью
функции переходов из одного состояния в другое в следующем
разделе. Эта функция может быть использована для формаль-
ного определения операционной семантики реализации и дана
для случая аппликативного порядка вычислений.
В следующем разделе будет описана модификация, требуе-
мая для поддержки ленивого вычисления и, таким образом,
определена ленивая семантика. Работа машины каждого типа
проиллюстрирована примерами.
Перед тем как дать определение функции переходов, мы
введем некоторую систему обозначений. Функции-селекторы bv,
body, rator и rand для работы с компонентами составных вы-
ражений определяются следующим образом:
bv] кх.Е) = х
body] Хх.Е) = Е
rator] ErE2) = Е{
rand] E\E2) = E2
Каждый из компонентов состояния S, Е, С, D можно рас-
сматривать как стек или как список, где функция push соот-
ветствует функции cons (которую мы записываем с помощью
инфиксной функции ::), TOS соответствует hd и pop соответ-
ствует tl (возможно, вместе с присвоением головы списка не-
которому накопителю). Мы чаще будем использовать представ-
ление в виде списков, и в примерах, показывающих последова-
тельность изменения состояний, списки у нас растут влево, как
это принято для операции cons, т. е. самый левый элемент
списка считается вершиной соответствующего стека.
Реализация на основе стеков — SECD-машина 231
10.1.1. Функция переходов
Мы дадим сейчас спецификацию функции переходов для
SECD-машины, реализующей вычисление апггликативного по-
рядка. Реализующая эту функцию программа на языке Норе
type identifier data exp == char; ==ID (identifier )++ LAM ( char # exp ) ++ APP ( exp # exp ) -]—|-
data WHNF ==INT (num)++ PRIM ( WHNF -> WHNF ) ++ CLOSURE ( exp # char # list( char # WHNF ));
type Stack == list (WHNF);
type Environment == list ( char # WHNF );
type Control == list ( exp ); == list ( Stack # Environment # Control);
type Dump
type State == ( Stack # Environment # Control # Dump );
dec LookUp: identifier # Environment-> WHNF ;
— — LookUp( il, ( i2, W ) :: E )
<=if i 1 = i2 then W else LookUp(il, E);
dec Evaluate : State -> WHNF ;
------Evaluate ( Result:: S, E, nil, nil )
<— Result:
-------Evaluate ( x :: S, E, nil, ( SI, El, Cl ) :: DI )
< = Evaluate ( x :: SI, El, Cl, DI );
-------Evaluate ( S, E, ID(x)::C, D)
< = Evaluate ( LookUp( x, E ):: S, E, C, D);
-------Evaluate ( S, E, LAM( bv, body ) :: C, D)
< = Evaluate ( CLOSURE( body, bv, E ):: S, E, C, D);
---— Evaluate ( CLOSURE] body, bv, El ) :: ( arg :: S ), E, @ C, D )
< = Evaluate (nil,
( bv, arg ):: El,
[body],
(S, E, C)::D);
-------Evaluate ( PRIM( f ) :: ( arg :: S ), E, @ C, D )
< = Evaluate (f(arg)::S, E, C, D);
------Evaluate ( S, E, APP(fun, arg)::C, D)
<= Evaluate ( S, E, arg :: ( fun @ C )), D );
Рис. 10.1. Функция переходов для SECD-машины аппликативного порядка.
показана на рис. 10.1. Для данного текущего состояния (S, Е,
С, D) следующее состояние определяется управляющей стро-
кой С. Существует два случая, которые нужно рассмотреть,
причем первый из них имеет несколько вариантов.
232 Часть II. Глава 10
1. Если управляющая строка непустая и первым ее элементом
является X, т. е. X = hd(C), то мы имеем следующие четыре
варианта:
(а) X-—это константа или идентификатор. Величина, свя-
занная с X в текущем контексте, проталкивается в стек S,
и объект X удаляется из управляющей строки С. В случае если
X — это константа, величиной X является сама эта константа.
Величину X с учетом текущего контекста Е будем обозначать
valueof ( X, Е ). Таким образом, следующее состояние опреде-
ляется в виде
(valueof(X, E)::S, Е, ЩС), D)
(valueof (К, E)— К для константы К при любом контексте Е).
(b) X — это Х-абстракция. В этом случае мы формируем
замыкание, содержащее связанную переменную Х-абстракции,
тело Х-абстракции и контекст, включающий связи свободных
переменных тела Х-абстракции (все происходит точно так же,
как было описано в предыдущей главе). Следующее состояние
имеет вид
(>(Х), body(X), E]::S, Е, tl(C), D)
Заметим, что при корректной реализации для замкнутых вы-
ражений (без свободных переменных) все свободные перемен-
ные, встречающиеся в теле, должны иметь связанные с ними
значения в текущем контексте, поскольку мы приводим выра-
жение промежуточного кода к слабой заголовочной нормальной
форме. Конечно, при отсутствии свободных переменных в Х-вы-
ражении нет никакой необходимости формировать замыкание.
В этом случае Х-выражение может быть непосредственно при-
менимо к своему аргументу, если он есть, или возвращено в
качестве результата немедленно. Заметим, однако, что целью
SECD-машины не является обеспечение эффективной практиче-
ской реализации. Мы предоставляем читателю возможность
самому придумать необходимую оптимизацию в качестве про-
стого упражнения.
(с) X = FA, т. е. X — это применение выражения F (функ-
ции) к выражению А (аргументу). При энергичной реализации
выражения А и F вначале вычисляются, а затем величина F
применяется к величине А. Это выполняется с помощью замены
элемента FA в управляющей строке на три элемента A, F, @,
где @ —это специальный символ применения, который (как
увидим далее) при своем появлении в начале управляющей
строки вызывает применение верхнего элемента стека к эле-
менту, находящемуся непосредственно под ним. Таким образом,
Реализация на основе стеков — SEC D-машина 233
следующее состояние имеет вид
(S, Е, A::(F D)
(d) X = @, где @ — это специальный символ применения.
Выражение в вершине стека, скажем F, должно быть или при-
митивной функцией, или замыканием в соответствии с ранее
определенными преобразованиями состояний. Если стек S =
= f :: а :: S', то мы имеем два следующих подслучая:
(i) Если f — это примитивная функция, она применяется к а
(а —это голова хвоста S). Результат этого применения заме-
няет f и а в стеке S, а символ @ удаляется из управляющей
строки. Следующее состояние, таким образом, имеет вид
(f(a)::S', Е, tl(C), D)
(и) Если f — это замыкание [V, В,Е'], то выражение тела (В)
вычисляется в контексте Е, дополненном связью Уса. Однако
перед тем как сделать это, состояние машины нужно запомнить,
чтобы можно было продолжить работу после того, как вычисле-
ние В закончится. Это состояние представляет собой текущее
состояние машины (кортеж из четырех элементов) с удален-
ными верхним элементом управляющей строки и двумя верх-
ними элементами стека. Новый стек пуст, новый контекст пред-
ставляет собой контекст применяемого замыкания, дополненный
связью идентификатора связанной переменной с выражением
аргумента, а новая управляющая строка состоит из единствен-
ного элемента. Поэтому следующее состояние имеет вид
(( ), (V, ау.-.Е', В, (S', Е, tl(C), D))
2. В противном случае управляющая строка С пуста, поэтому
вычисление текущего (под) выражения считается законченным
и его результатом является единственный элемент стека S (для
синтаксически корректных выражений). Состояние, хранящееся
в вершине дампа D, восстанавливается, а только что получен-
ный результат проталкивается в новый стек. Если D — (S', Е',
С', D'), то следующее состояние имеет вид
(hd(S)::S', Е', С', D')
На основе приведенной спецификации можно легко написать
базовую реализацию энергичной SECD-машины на языке Норе,
определив тип данных для представления состояния машины
и функцию, реализующую переходы между состояниями. Про-
грамма, показанная на рис. 10.1, обеспечивает спецификацию,
которая является не только краткий и ясной, но и выполнимой.
Заметим, что в этой программе идентификаторы для про-
стоты представляются одним символом. Заметим также, что
234 Часть II. Глава 10
тип данных для представления дампа определен как список
троек, а не тетрад. Последняя альтернатива также была совер-
шенно правильной при условии включения пустого конструктора
дампа в соответствующее определение данных (сравните с кон-
структором nil для списков). Результатом программы в действи-
тельности является СЗНФ, а не «конечное» состояние. Вслед-
ствие рекурсивной природы функции Evaluate, однако, тип объ-
екта, возвращаемого этой функцией, полностью зависит от
первого из определяющих ее уравнений. Легко изменить это урав-
нение таким образом, чтобы функция Evaluate возвращала не
СЗНФ исходного выражения промежуточного кода, а полное
конечное состояние SECD-машины. В этом случае тип Evaluate
был бы State—>-State.
Теперь мы проиллюстрируем работу машины, показав после-
довательность переходов между состояниями при вычислении
выражения twice succ 0.
Затем расширим способности нашей машины, научив ее
обрабатывать другие примитивные конструкции, необходимые
в практических функциональных языках программирования, —
условные выражения и рекурсию. Поскольку рекурсия может
быть выражена в Х-исчислении с помощью У-комбинатора, мы
увидим, как машина обрабатывает применения рекурсивно-
определенных функций Однако мы увидим, что в этом случае
для энергичной SECD-машины имеют место определенные
трудности.
10.1.2. Пример вычисления
Выражение, вычисление которого будет рассмотрено в каче-
стве примера, имеет вид twice succ 0, где’функция twice опре-
делена в виде twice — kf.kx.f(fx), a succ — это уже известная
нам примитивная функция «следующий за», определенная на
множестве целых чисел. Итак, мы покажем, как SECD-машина
вычисляет выражение
(kf.hx.f(fx))succ 0
SECD-машина в начальном состоянии имеет это выражение
в качестве единственного элемента своего управляющего стека,
а стеки S, Е и D не содержат элементов, т. е. являются пустыми.
Последующие состояния машины показаны на рис. 10.2. Каждое
состояние получается из предыдущего в соответствии со специ-
фикацией, данной для функции переходов в предыдущем
разделе.
*> Это выражение детально определено в следующем разделе. — Прим,
перед.
3 E c £>
О () (( Xf .Kx.f( f x )) succ 0 ) ()
() () 0, (( Kf ,'/.x.f( f x)) succ ) & ( )
0 ( ) ((Xf.kx.fff X }) succ ), @ succ, Xf.Kx.f(f X ), @ bf.bx.f(f x), @, @ ( )
0 () ( )
succ, 0 [Д Ах./( f х), ( )], succ, 0 () ( )
( ) @, @ ( )
( ) ( f = SUCC ) Xx.f(f x) (0, (),«,())
[*, fU X), (f=succ)] (f = succ ) () ( 0, ( ), @, ( ) )
[x, fl f x ), (f = succ )], 0 ( ) @ ( )
( ) ( X ~ 0, f = succ ) f(f X) (()(),()())
() ( x ~ 0, f = succ ) f X, f, 0 X, f, @, f, @ ((),().(),())
( ) ( x == 0, f = succ ) ((),().(),())
0 ( x ~ 0, f = succ ) f, f, 0 ((),().(),())
succ, 0 ( x ~ 0, f — succ ) @, f, ® ((),().().())
1 ( x ~ 0, f = succ ) h ® (().().(),())
succ, 1 ( x = 0, f = succ ) @ ((),().(),()) ((),().()())
2 ( x = 0, f = succ ) ()
2 ( ) () ( )
Рис. 10.2. Последовательность состояний SECD-машины аппликативного порядка при вычислении выражения twice
succ 0.
Реализация на основе стеков — SECD-машина 235
236 Часть II. Глава 10
10.1.3. Специальные примитивные операции
в SECD-машине
Чистое Х-исчисление без типов является полным в том
смысле, что его средствами можно выразить и привести к нор-
мальной форме любое выражение, записанное на функциональ-
ном языке программирования. Однако для практических целей
чистое Х-исчисление требуется расширить множеством некото-
рых примитивов. Это относится по меньшей мере к примитиву
условного выражения, некоторым примитивным типам данных
(например, целым числам), примитивным функциям (например,
+, — ит. д.) и, возможно, средствам представления рекур-
сии, отличным от У-комбинатора Альтернативное представле-
ние таких примитивов в виде выражений чистого Х-исчисления
является не только малопонятным для программиста, но и неэф-
фективным при выполнении — в противоположность одной опе-
рации (абстрактной) машины, требуемой при выполнении при-
митива. Например, вспомним из гл. 6, что условная функция
представляется обычно в виде Хх Xt/.Xz.xyz, а логические кон-
станты true и false в чистом Х-исчислении выглядят как Хх.Ху.х
и кх.ку.у соответственно.
Строгие примитивные функции с одним аргументом не со-
ставляют проблемы, а примитивные функции с большим числом
аргументов считаются обладающими свойством карринга.
Частичное применение функции от п аргументов (п > 1 ) к
m < п объектам дает в результате замыкание; тело приме-
няемой функции не вычисляется, пока все аргументы не будут
в наличии Все эти механизмы присутствуют в только что опи-
санной SECD-машине, не считая соответствующих примитивных
операций, и для ленивой машины это все, что нам необходимо.
Однако в энергичной реализации возникают некоторые проб-
лемы, связанные с условными выражениями и рекурсией. Их
мы сейчас и рассмотрим.
Вычисление условных выражений
При аппликативном порядке вычислений обработка некото-
рых условных выражений может привести к неопределенному
результату. Например, определенное при всех целых значениях
а (кроме а — 0) выражение if а #= Othen 1/а else а приведет
к аварийному завершению программы при а = 0, так как при
аппликативном порядке вычислений выражения обеих ветвей
будут вычисляться независимо от результата вычисления преди-
ката (а #= 0) и при вычислении выражения 1/а произойдет
деление на нуль. Это не единственный случай, когда возникают
Проблемы. Вычисление некоторых обычным образом определен-
Реализация иа основе стеков — SECD-машииа 237
них рекурсивных функций также может привести к аварии или
к зацикливанию. Например, вычисление выражения факториала,
определенное в виде fac( п )= if п = 0 then 1 else п* fac (п— 1 ),
приведет к зацикливанию, так как ветвь else будет вычисляться
каждый раз независимо от значения предиката (п —0).
Одно решение проблемы заключается в преобразовании ус-
ловных выражений с использованием пустых функций либо без
аргументов, либо с одним пустым аргументом *>, если мы хотим
остаться в рамках синтаксиса Z-исчнсления, где все функции
имеют точно один аргумент. Это стандартный прием, который
можно использовать для обеспечения семантики нормального
порядка для выражений, которые должны иметь аппликативный
порядок вычисления. В частности, приведенное выше условное
выражение после преобразования имеет форму
(if а=/= 0 then Xdummy.f 1 a else /.dummy .a) any
где any может быть любым объектом. (Заметим, что здесь мы
вернулись к нормальной (карринговой) префиксной нотации
в выражении 1/а.) Данный эквивалент условного выражения
уже не может привести к аварии программы и является, кроме
того, более эффективным, особенно когда выражение отбрасы-
ваемой ветви условия является громоздким и требующим много
времени для вычисления (в предельном случае — бесконечно
много времени). Данный метод подобен описанному в гл. 9 для
реализации вызова по имени.
Более распространенный на практике подход к решению
проблемы заключается в определении нового типа выра-
жения:
{ехр) ::= ... | cond {ехр) {ехр) {ехр)
где аргументами cond являются соответственно then-выражение,
else-выражение и выражение предиката. Причина такого стран-
ного порядка аргументов в том, чтобы позволить обрабатывать
выражение вида cond ТЕР как обычное применение функции.
В результате данное выражение в начале управляющей строки
будет заменено следующими тремя элементами: Р, condTE, @.
Затем значение предиката Р будет помещено в вершину
стека S, а выражение condTE окажется в начале управляющей
строки.
Теперь мы можем расширить спецификацию функции пе-
реходов, включив один дополнительный вариант в случай 1:
*> Пустой аргумент обозначается в дальнейшем символом dummy.—
Прим, перед.
238 Часть П. Глава 10
(с) Если Х= cond В А, тогда следующее состояние имеет
вид
(t/(S), Е, В :: D), если hd( S) = true,
Е, A::tl(tl(C)), D), если hd(S) = false.
(Для программы, прошедшей на этапе компиляции Проверку
типов, других альтернатив быть не может.)
Таким образом, если мы имеем выражение вида cond В АР,
где В, А, Р также являются выражениями, когда значение Р
находится в вершине стека, а управляющая строка имеет вид
cond В А, @, ..., легко видеть, что расширенная функция пе-
реходов правильно найдет значение этого выражения (если,
конечно, Р имеет корректный тип). Можно было бы ввести
дополнительный подслучай в случай X = FA при условии Е =
= cond В, что привело бы к аналогичному результату.
Вычисление выражений, содержащих рекурсивные функции
Ниже мы рассмотрим два метода обработки рекурсии в
SECD-машине аппликативного порядка: метод использования
У-комбинатора и метод помеченных выражений. Заманчиво ис-
пользовать Y обычным образом для удаления явной рекурсии
из выражения, включающего рекурсивную функцию. После
этого полученное ^-выражение просто передается для обработки
в SECD-машину, которая в конце концов специально построена
так, чтобы иметь возможность обрабатывать такие выражения!
Таким образом, если рекурсивная функция определяется урав-
нением вида f(x) = E(f, х) для некоторого выражения Е, мы
можем записать
f = yA,g.Xx.E(g, х)
где У = Mi. (Кх. Л( хх)) (кх. h( хх)).
Например, мы можем записать версию функции для вычисле-
ния факториала в виде
fac — Ykf.kn. if (= п 2) then 2 else *n(f(pred и))
где pred— это известная нам примитивная функция предше-
ствования на множестве целых чисел. Взаимно рекурсивные
определения могут быть реализованы с помощью упаковки этих
определений в рекурсивно-определенные кортежи (или списки),
как описано в гл. 6.
Итак, можем ли мы реализовать рекурсивные функции не-
посредственно как наименьшие фиксированные точки? Ответом
на этот вопрос является нет, если мы используем аппликатив-
ный порядок вычислений. Проблема, состоит в том, что само-
Реализация на основе стеков — SECD-машина 239
применение замыкания, соответствующее терму хх, приводит
к зацикливанию — проверьте это! Однако можно модифициро-
вать определение У, чтобы обойти проблему, определив альтер-
нативный У-комбинатор следующим образом:
У' — Kh.(Кх.h{ Ку.хху))(Лх.h(Ky.хху))
У и У' эквивалентны, поскольку один можно получить из дру-
гого с помощью ^-преобразования (У' -<-► ЛУ). Если теперь вме-
сто У использовать У', самоприменение вычисляется, только
когда оно само применяется к аргументу, соответствующему
переменной у, например к целому аргументу функции fac. Если
применение функции, соответствующей й, например fac, к этому
значению аргумента не включает рекурсивный вызов, самопри-
менение не будет вычислено. Проверьте это тоже! Следует за-
метить, что этот метод, позволяющий обходить зацикливание
в вычислении аппликативного порядка, использует совершенно
такой же подход, как описанный нами в гл. 9 для достижения
семантики нормального порядка. Конечно, не возникает проб-
лемы при использовании нормального У-комбинатора в ленивой
SECD-машине, которая без необходимости не будет пытаться
вычислить самоприменение. Использование комбинаторов У
и У' для обработки рекурсии в SECD-машине является слож-
ным и неэффективным, хотя некоторая оптимизация дана в
[16]. Мы не будем здесь больше рассматривать этот вопрос
и перейдем к рассмотрению альтернативного метода.
Сначала добавим новый синтаксический тип «помеченное
выражение» к синтаксису выражения ехр:
(ехр)::=... I(((id), (id).(ехр)))
Теперь сделаем два расширения спецификации функции пере-
ходов. Первое включает дополнительную проверку первого
элемента управляющей строки X:
(е) Если X — это помеченное выражение «Л’’, L», тогда Х-аб-
стракция L связывается с именем N и добавляется в текущий
контекст. X затем заменяется Х-абстракцией L, и поэтому сле-
дующее состояние имеет вид
(S, (N, L)::E, L::tl(C), D)
Помеченное выражение можно рассматривать как стандартную
Л-абстракцию вместе с расширением текущего контекста связью
между именем и Х-абстракцией, входящими в помеченное вы-
ражение. Так, если помеченное выражение находится в начале
управляющей строки, оно заменяется своей %-абстракцией при со-
ответствующем изменении контекста. Любое последующее появ-
ление имени JV помеченного выражения в начале управляющей
240 Часть II. Глава 10
строки (в процессе применения его Х-абстракции L) приве-
дет к тому, что его Х-абстракция будет помещена в стек,
потому что контекст содержит соответствующую связь. По-
этому нам необходимо ввести новое правило переходов для слу-
чая, когда первым элементом управляющей строки является @,
а вершина стека S содержит Х-абстракцию. В этом случае
нужно преобразовать Х-абстракцию в замыкание перед ее при-
менением, так как она может содержать свободные перемен-
ные. Таким образом, мы добавляем к спецификации функции
переходов новое правило для случая, когда первый элемент
управляющей строки X — @, а стек имеет вид S — f :: а :: S'.
1. (d) (iii) Если f — это Х-абстракция, нужно протолкнуть ее
в С, чтобы при следующем преобразовании состояния было
сформировано замыкание этой Х-абстракции в S. Новое состоя-
ние имеет вид
(a:: S', Е, D)
Требуемое замыкание поэтому формируется за два шага. Оче-
видно, что использование помеченных выражений является не
самой эффективной реализацией рекурсии. В частности, замы-
кание, соответствующее Х-абстракции, известно уже при пер-
вом появлении помеченного выражения в начале управляющей
строки.
10.2. Ленивая SECD-машина
Чтобы реализовать вычисление нормального порядка, нужно
иметь возможность представлять вычисленные подвыражения
или задержки, которые «замораживают» выражение аргументов
до тех пор, пока их значения не потребуются при вычислении
тела функции. Как и в предыдущей главе, задержка состоит из
выражения вместе с контекстом, содержащим связи свободных
переменных этого выражения. Задержки представляют собой
еще один тип синтаксиса выражений, и мы будем записывать их
в виде пары выражение—-контекст, заключенной в фигурные
скобки, например {е, Е}, где е — это выражение, а Е-—контекст.
Функцию переходов для энергичной SECD-машины, опреде-
ленную в разд. 10.1.1, нужно изменить в трех местах, чтобы
получить реализацию с семантикой нормального порядка, ко-
торая может быть реализована либо через вызовы по имени,
либо через вызовы по необходимости. В первом случае функция
переходов может быть определена чисто функционально, но,
как мы уже видели, в этом случае имеет место неэффективное
повторное вычисление выражений аргументов, соответствующих
параметрам, которые многократно встречаются в теле Х-аб-
Реализация на основе стеков — SECD-машина 241
стракции. В случае вызовов по необходимости требуется, чтобы
выражения аргументов были разделяемыми, что можно сделать
только с помощью оператора присваивания, выполняемого для
задержек, представляющих невычисленные выражения аргумен-
тов. В любом случае модификация, необходимая для функции
переходов, относится к таким состояниям, которые имеют сле-
дующие три особенности:
(а) Применение в начале управляющей строки С. Когда
применение (КД) находится в начале управляющей строки,
необходимо вместо вычисления аргумента А сформировать за-
держку для А и протолкнуть ее в стек S. После этого вычис-
ляется F и применяется к этой задержке, как ранее.
(Ь) Примитивная функция, применяемая к задержке (сим-
вол @ находится в начале строки С). Если примитивная функ-
ция (в вершине S) является строкой, нужно инициировать вы-
числение задержки: при этом текущее состояние сохраняется
в дампе. После того как значение задержки вычислено, прими-
тивная функция применяется к этому значению. Следует отли-
чать элемент дампа для случая вычисления задержки от эле-
мента дампа для случая вычисления замыкания. Поэтому
каждый элемент дампа должен быть специальным образом по-
мечен— либо как дамп для замыкания, либо как дамп для
задержки. Это все, что необходимо для реализации вызова по
имени.
При ленивой реализации, однако, задержки в стеке объектов
представляются указателями ца их действительное местополо-
жение, и это местоположение должно также сохраняться при
инициации вычисления задержек. Затем, после завершения вы-
числения, полученное значение задержки записывается по ад-
ресу сохраненного местоположения задержки, что позволяет
всем остальным ссылкам на эту задержку разделять ее вычис-
ленное значение. Поскольку местоположение является частью
текущего состояния, оно запоминается в (расширенном) дампе.
Такой дамп (дамп задержки) часто называют дампом с при-
сваиванием.
(с) Строка С пустая. В случае вызова по имени, если мы
имеем дамп для задержки, состояние, сохраненное в этом дампе,
восстанавливается, причем величина аргумента (которая в ис-
ходном состоянии находится в вершине стека S) замещает за-
держку во втором сверху элементе стека S. Примитивная функ-
ция, вызвавшая вычисление задержки, будет теперь применена
к величине этой задержки, поскольку управляющая строка
после восстановления будет содержать в первой позиции сим-
вол @. Таким образом, мы имеем чисто функциональную спе-
цификацию функции переходов, но последующие применения
16 — 1473
242 Часть II. Глава 10
функций к той же самой задержке приведут к ее повторному
вычислению. В случае вызова по необходимости, если мы имеем
дамп для задержки, так что величина в вершине S будет ре-
зультатом вычисления задержки, местоположенйе, сохраненное
в дампе, при восстановлении заменяется этим результатом. За-
тем из дампа восстанавливается состояние SECD-машины, и
примитивная функция применяется к вычисленному значению
задержки.
Таким образом, при ленивой реализации как задержка, так
и значение этой задержки занимают одно и то же место в па-
мяти (это местоположение должно иметь пометку, указываю-
щую, что в данный момент является его содержимым), и доступ
к нему является косвенным При этом мы избегаем повторного
вычисления задержек, реализуя тем самым вызов по необходи-
мости. В гл. И мы увидим, что в вычислительной модели редук-
ции графов это соответствует замене вершин-редексов графа
результатами редукций подграфов. Итак, в ленивой SECD-ма-
шине нет повторного вычисления значений аргументов, по-
скольку p-редукция выполняется с помощью подстановки значе-
ний связанных переменных из текущего контекста.
Измененная спецификация функции преобразования состоя-
ний, которая обеспечивает семантику нормального порядка,
может быть записана следующим образом:
1. Если управляющая строка непустая и X = hd(C), то имеют
место четыре следующих варианта.
(а) Если X— это константа или идентификатор, следующее
состояние имеет вид
(vatueoftX, E)::S, Е, D)
точно так же, как в разд. 10.1.1.
(Ь) Если X — это Х-абстракция, следующее состояние имеет
вид
([НП body(X), E]::S, Е, D)
точно так же, как в разд. 10.1.1.
(с) Если X — FA, то в случае вызова по имени строится
задержка для А и проталкивается в стек S. Поэтому следующее
состояние имеет вид
({A, E}::S, Е, F :: (@ :: /Z(C)), D)
В случае вызова по необходимости построенная задержка запо-
минается где-либо вне стека, а в стек S проталкивается ука-
затель на нее.
(d) Если X = @, a S = f-л а S', мы имеем три подва-
рианта:
Реализация на основе стеков — SECD-машина 243
(i) Если f — это замыкание [V, В, Е'], следующее состояние
имеет вид
((), (V, а)::Е', В, (S', Е, П(С), D))
точно так же, как в случае энергичной спецификации.
(ii) Если f — это строгая примитивная функция, а а — это за-
держка {В, Е'} (или указатель на задержку при вызове по
необходимости), следующее состояние имеет вид
((), Е', В, (s, (S, Е, С, £>)))
Заметим, что в данном случае мы имеем дамп для задержки,
о чем говорит буква S. В случае вызова по имени поле, где
стоит буква S, просто содержит метку типа дампа, а в случае
вызова по необходимости оно будет содержать указатель на
задержку, т. е. а.
(Hi) Иначе, / — это примитив, который может быть применен
к аргументу а немедленно, независимо от того, является а за-
держкой или нет. Поэтому следующее состояние имеет вид
(для вызова по имени)
(f(a)-.-.S', Е, tl(C), D)
как и ранее. Для вызова по необходимости применение /(а)
нужно заменить на f(a\ ), где а/ означает содержимое области
памяти, на которую указывает а.
2. Если строка С пуста, мы имеем два варианта:
(а) Если D — это дамп с присваиванием ( у, (S', Е', С, D')),
в случае вызова по имени мы можем записать S' = f:: у :: S"
для некоторого стека S", и следующее состояние имеет вид
(f :: hd(S):: S", Е', С', D')
Для вызова по необходимости задержка, указываемая у,
должна быть заменена ее значением, и следующее состояние
имеет вид
(S', Е', С', D')
причем y:=hd(S). Здесь := — это разрушающий оператор
присваивания.
(Ь) Иначе, D — (S', Е', С', D') — это обычный дамп, и сле-
дующее состояние имеет вид
(hd(S)::S', Е', С', D')
как и для энергичной машины.
Теперь мы можем проиллюстрировать работу ленивой
SECD-машины, рассмотрев последовательность ее состояний
при вычислении головы ленивого списка, которое в общем
16*
244 Часть II. Глава 10
случае для энергичной реализации может продолжаться беско-
нечно. Вспомним также, что простые рекурсивные функции, та-
кие, как факториал, могут теперь применяться без использова-
ния модифицированного У-комбинатора, а условные функции
не нуждаются в таких замысловатых механизмах, как энергич-
ная реализация. Для представления списков используем кон-
станты nil и cons. Список
cons (cons 02 (cons а$ ... (cons ап nil) ... ))
будем записывать сокращенно в виде <аь ..., апу. Мы также
используем функцию-селектор hd, которая возвращает голову
S E c D
() EQ ( hd( cons x у )) DO
£1 EQ hd, @ DO
hd, LI EQ e DO
( ) EQ ( cons x у ) DI
£2 EQ cons x, Й DI
£3, L2 EQ cons, @ DI
cons, L3, L2 EQ @ DI
cons, L3, L2 EQ @ DI
{L3, L2} EQ () DI
hd, LI EQ @ DO
£3 EQ () DO
L \: {(cons x L2: {y, EQ} L3: {x, £0} J hd, L\), £0, @, y), £0} := <£3, £2)
где DI = ( LI, (I DO))
Рис. 10.3. Последовательность состояний ленивой SECD-машины при вычис-
лении выражения hdfcons (х, у)).
списка. (Конечно, можно было бы представлять списки сред-
ствами чистого Х-исчисления, как описано в гл. 6, без помощи
дополнительных примитивов.) На рис. 10.3 показана последо-
вательность состояний SECD-машины при вычислении выраже-
ния hd(consxy), где х и у являются произвольными, возможно,
бесконечными выражениями.
На этом рисунке £1, £2 и £3 обозначают местоположение
задержек, которые были заполнены где-то вне стека, когда их
выражения появились в качестве аргументов в применениях
функций в начале С. Заметим, что cons — это нестрогая функ-
ция и поэтому может быть применена к любому аргументу не-
медленно, выдавая невычисленный результат.
В первых двух разделах этой главы мы рассмотрели класси-
ческую SECD-машину, являющуюся самой первой реализацией
функциональных языков программирования, которая устанав-
ливает явный контекст для хранения значений свободных пере'
Реализация на основе стеков — SECD-машина 245
менных в подвыражениях. Существует много модернизаций, на-
чиная от простой, требующей только один стек для контекста,
машины для языков первого порядка и кончая более общим
МФП-компилятором (гл. 15) и категорийной абстрактной ма-
шиной (гл. 13). В следующей главе мы увидим, что существуют
альтернативные методы представления контекста, причем нет
определенного ответа на вопрос, какой подход является опти-
мальным.
10.3. Корректность реализации SECD-машины
Работа SECD-машины была определена в полуформальном
виде в терминах состояний и функции переходов, которая опре-
деляет одношаговые переходы из одного состояния в другое.
Эта машина вычисляет выражение языка, обозначаемого здесь
символом А, который является языком чистого Z-исчисления,
расширенного произвольным набором констант. Чтобы пока-
зать, что SECD-машина обеспечивает корректную реализа-
цию А, необходимо математически определить операционную
семантику и доказать, что она эквивалентна общепринятой (де-
нотационной) семантике А, определенной в терминах (3- и 6-ре-
дукций. Для этой цели мы принимаем метод доказательства,
предложенный Плоткиным (1975). Сначала мы дадим формаль-
ное определение составных частей SECD-машины, а затем опре-
делим для нее операционную функцию вычисления Eval. При
применении к выражению А эта функция возвращает значение,
вычисленное для этого выражения SECD-машиной. Мы опреде-
лим также функцию вычисления eval для языка А в терминах
подстановки (соответствующей p-редукции и 6-редукции) и за-
тем докажем, что две функции Eval и eval являются эквива-
лентными с точностью до a-преобразования, т. е. алфавитно-
эквивалентными. Доказательство является простым, но имеет
множество деталей, и доказательства двух лемм отнесены в ко-
нец этого раздела.
10.3.1. Обозначения и определения
Вначале мы введем некоторую систему обозначений:
М, N— термы А,
х, у — переменные,
а, b — константы данных,
f,g — константы примитивных функций.
Множество всех термов языка А обозначается словом Terms,
и FV(M) обозначает набор свободных переменных, встречаю-
щихся в терме М е А. Алфавитная эквивалентность термов М
и N обозначается М = aN и определена в гл. 6.
246 Часть II. Глава 10
SECD-машина задается набором своих состояний Dumps
вместе с функцией переходов, обозначаемой в инфиксной форме
через =>. Набор Dumps состоит из четырех элементных кор-
тежей, первые три компонента каждого из которых являются
членами множества стеков Stc, множества контекстов Env и
множества управляющих строк Cst соответственно. Множества
Stc и Env определены через другое множество Clos— множе-
ство замыканий. Множества Clos и Env определяются индук-
тивно следующим образом:
(1) Если %1, ..., хп — это различные переменные ( п 0 ) и
СЦ ( 1 i п) являются членами множества Clos, тогда Е =
= {<хг-, Cli} 11 i п} является членом множества контекстов
Env. Мы будем обозначать Dom(Е ) = {xi11 i п} и E(xt) =
= Clt ( 1 I 'С п ).
(2) Если Е — это контекст (т. е. член множества Env) и М —
это терм такой, что Dom( Е)э FV( М), тогда <М, Е) является
замыканием.
В базовом случае контекст Е = 0, т. е. п = 0 в (1), и за-
мыкание <Л4, Е> представляет константу, поскольку М не имеет
свободных переменных. Фактически в нашей формальной спе-
цификации SECD-машины константа а представляется в виде
<а,0). Вычисление замыкания, дающее Л-терм, представляется
функцией Real: Closure-^Terrns, которая индуктивно опреде-
ляется следующим образом:
Real( (Af, Е)) = [Real( Е( xt) )/xJ ... [Real( E( xn) )/x„] M.
где FV( M) = {xi 11 i n}.
Далее, введем символ Cl для обозначения замыкания и будем
обозначать через Е{С1/х} единственный контекст Е' такой, что
Е'(у) = Е(у), если у=/=х и Е'(х) = С1. Также введем индук-
тивно понятия ц-замыкания и и-контекста определяющие по
существу замыкания и контексты, которые мы использовали в
нашем неформальном описании энергичной SECD-машины.
(1) Замыкание <М, Е> является о-замыканием тогда и только
тогда, когда М является Х-абстракцией или константой, а Е
является ц-контекстом.
(2) Контекст Е является у-контекстом тогда и только тогда,
когда для каждой переменной хе Dom(E)-, Е(х) — это замы-
кание. Таким образом, пустой контекст является и-контекстом.
Теперь мы можем определить:
Stc — Clos*, множество всех последовательных замыканий,
Cts — (Terms{] {@})*
” и — первая буква английского слова value — значение. — Прим, перев.
Реализация на основе стеков — SECD-машина 247
Затем индуктивно определяется множество Dumps
(1) nil е Dumps
(2) Если SeStc, Ее Env, С е Cst, De Dumps и Dom(E ) =
э FV( С), тогда <S, Е, С, Dy е Dumps.
Теперь мы можем определить функцию переходов
=> : Dumps->Dumps. Поскольку мы собираемся анализировать
поведение SECD-машины как системы переписывания термов,
дадим здесь определение функции переходов в виде набора пра-
вил переписывания. Фактически это определение строго соответ-
ствует Норе-программе, данной в разд. 10.1. Имеется семь слу-
чаев:
(а) <С/:: S, Е, nil, {S', Е', С', D'yy=>{Cl:: S', Е', С', D'y
(b) {S,E,x::C,Dy^{E(x) ::S,E,C,Dy
(с) <S, Е, а :: С, Dy «а, 0> :: S, Е, С, Dy
(d) {S,E, (кх.М) :: С, Dy {{(Кх.М), Еу :: S, Е, С, Dy
(е) «(кх.М), Е'У -..Cl:-. S, Е, @:: С, Dy =>
=> {nil, E'{Cl/x}, М, {S, Е, С, Dyy
(f) «f, Е'У :: {a, E"):: S, E, @:: C, Dy => {{f(a),0y :: S, E, C, Dy
(g) <S, E, ( MN) :: C, Dy =>- <S, E, N :: M :: @ :: C, Dy
Можно считать, что функция => определяет правила переписы-
вания или одношаговые редукции термов, и мы вводим символ
=>* для обозначения /-шаговой редукции, т. е. преобразования,
соответствующего t применениям правил переписывания. Таким
образом, =>* определяется через =>' = =>- и =>'(£)) =
= =>(=><-1(D) ), где D~это дамп, />1. Мы также будем
обозначать через =>* произвольное положительное число пере-
ходов, т. е. произвольное число применений функции =>. Таким
образом, =>-* интерпретируется как «=>* для некоторого /».
10.3.2. Теорема эквивалентности
Сейчас, наконец, мы можем определить функцию вычисления
Eval для SECD-машины. Интуитивно эта функция представляет
загрузку машины термом из управляющей строки, работу ма-
шины с этим термом и затем выгрузку результата из стека ма-
шины. Таким образом, Eval формально определяется в терми-
нах двух вспомогательных-функций Load (загрузка) и Unload
(выгрузка) следующим образом:
Eval( M) = N
248 Часть II. Глава 10
тогда и только тогда, когда
Load(M )=>*£) и N ==Unload(D)
для некоторого дампа D, где Load и Unload определяются
в виде
Load( М) = (nil, <f>, М, nil)
Unload((Cl, ф, nil, nit)) = Real(Cl)
Гораздо проще определить семантическую функцию eval для
абстрактного вычисления термов с помощью p-редукции и
6-правил:
eval(a) =а, если а — константа,
eval( Lx .M) — Lx ,М,
eval(MN) = eval([N'/x] M'), если eval( М) = (Lx. М ’) и
eval( N) = N'
f(a), если eval(M) = f и
eval{ N) = a.
Чтобы сравнить эти функции вычисления, необходимо иметь
возможность соотнести значения выражений, выдаваемые се-
мантической функцией eval, с последовательностями переходов
SECD-машины из одного состояния в другое. Мы считаем зна-
чением замкнутого терма его СЗНФ (другой, единственный
терм) вместе с целым числом, соответствующим числу редук-
ций, необходимых для приведения этого терма к СЗНФ. Это
число, называемое временем, на единицу больше удвоенного
числа шагов редукции. Так, например, значением слабой заго-
ловочной нормальной формы является сама эта СЗНФ за вре-
мя 1. В общем случае мы определяем предикат «Л4 имеет зна-
чение N за время /» с помощью индукции по t для замкнутых,
термов М и /V следующим образом:
(1) а имеет значение а за время 1 и (Хх.М) имеет значение
( Lx.M) за время 1.
(2) Если М имеет значение (%х.Л1') за время t, N имеет зна-
чение N' за время t' и [N'/x]M' имеет значение L за время t",
то (MN) имеет значение L за время t + t' + t" + 1.
(3) Если М имеет значение f за время t и N имеет значение а
за время t', то, если f(a) определено, (AW) имеет значение
f( а) за время t + t' + 1.
В противном случае терм не имеет значения.
Отсюда можно показать (формально с помощью индукции),
что если М имеет значения N, N' за времена t, t', то N — N'
Реализация на основе стеков — SECD-машина 249
и t = t'. Следовательно, определение
eval(M) —N, если и только если М имеет значение N за неко-
торое время является корректным.
Мы будем использовать порядок, устанавливаемый парамет-
ром t предиката «М имеет значение N за время /» в приведен-
ных ниже индуктивных доказательствах лемм и теоремы, в ко-
торых последовательности редукций соотносятся с переходами
SECD-машины из одного состояния в другое. Поскольку имена
переменных не меняются в определении этого предиката, ясно,
что если М — аМ', то М имеет значение N за время t, если
и только если для некоторого N' =aN, М' имеет значение N'
за время t. Ясно также, что если eval(M) существует, то это
замкнутая величина. Утверждение о корректности SECD-реали-
зации дается в следующем виде:
Теорема 10.1. Для любого терма М имеет место равенство
Eval( M ) =aeval( М)
В доказательстве этой теоремы используются две леммы, кото-
рые мы сейчас сформулируем. Доказательства этих лемм при-
ведены в разд. 10.3.3.
Лемма 10.1. Допустим Е — это и-контекст, <Л1, Е> является
замыканием и М" — значение Real( <Л1, Е> ) за время t. Тогда
для любых S, Е, С, D при условии Dom( Е )э FV( С) и t' t
<S, Е, М::С, E')-.:S, Е, С, D)
где* (М', Е')— это v-замыкание и Real((M', Е')) =аМ".
Обозначения. Если для некоторого D^D', где D' не
имеет вид <С/, 0, nil, nil) и не существует дамп D" такой, что
D' => D", тогда говорят, что D попадает в ошибочное состоя-
ние D'.
Лемма 10.2. Допустим Е — это ц-контекст и (М, Е) является
замыканием. Если Real{(M, Е)) не имеет значения за любое
время 1), тогда для любых S, Е, С, D при условии
Dom(E)^3. FV( С) либо (S, Е, М :: С, D) попадает в ошибочное
состояние, либо <S, Е, М :: С, D) D' для некоторого D'.
Доказательство теоремы. Допустим, что eval(M) = М" и что
М" является значением М за некоторое время t. Из леммы 10.1
следует
(ш7, 0, М, nil)^*’ {{М', Е'}, 0, nil, nil)
для некоторого t' Z^zt, где Real((M', Е')) =аМ”. Следова-
тельно, Eval(M)=aM".
Если же М не имеет значения за любое время, то, согласно
лемме 10.2, либо (nil, 0, М, nil) попадает в ошибочное состоя-
250 Часть II. Глава 10
ние, либо для любого t существует дамп Dt такой, что {nil, 0,
М, пИ)=>1 Dt', т. е. вычисление никогда не кончается. В обоих
случаях E'val(M) не определена.
10.3.3. Доказательства лемм
Мы сейчас вновь сформулируем леммы, используемые при
доказательстве корректности энергичной SECD-машины, и до-
кажем их с помощью индукции по времени, понятие кото-
рого было введено в определении предиката «терм М имеет
значение N за время /». Читатели, не имеющие склонности
к строгим математическим выкладкам, могут опустить этот
раздел.
Лемма 10.1. Допустим Е — это и-контекст, <М, £> является
замыканием и М" — значение Real( {М, Е) ) за время t. Тогда
для любых S, Е, С, D при условии £от(£)э £Ё(С) и t't
<S, Е, М::С, D) = >е {(М', E')::S, Е, С, D)
где {М',Е’У—это ц-замыкание и Real( {М', Е') )=аМ".
Доказательство. Существуют четыре варианта в зависимо-
сти от вида М, которые нужно рассмотреть. Последний из них,
применение, разделяется на два подварианта, которые доказы-
ваются индукцией по t.
Вариант (1). М — это константа. Здесь FV(M) = 0, поэтому
М" = Real({M, Е} ) = М и t = 1. Поскольку <S, Е, М :: С, £>=>
=> «Л4, 0> :: S, Е, С, D}, мы имеем <ЛГ, £'> = <Л4, 0> и £=1.
Вариант (2). М — это абстракция. Здесь М" — Real( <М, Е~) )
и 1=1. Поскольку <S, £, М :: С, D) => «Л4, Е) ::S, Е, С, D), мы
имеем {№', Е'> = {М, £> и £ = 1.
Вариант (3). М — это переменная. Здесь М" = Real( Е( М ) )
и 1=1. Поскольку {S, Е, М :: С, D} => {Е(М) :: S, Е, С, D), мы
имеем (М', Е') = Е(М) и t' = 1.
Вариант (4). М = (М1М2) — это применение. Здесь Real({M,
E)) = NiN2, где = Real({Mi, £>) и N2 = Real{{M2, £>) и
имеются два случая.
Случай (i). Пусть имеет значение (kx.Ns) за время и, N2
имеет значение Nt за время и. Тогда М" является значением
[Ni/x]N2 за время w и t = u + v-irw-\-l. По предположению
индукции существуют и' и и v' v такие, что
(5, £, D)=>(S, Е, D}
^'{{М'2, E'2)-.-.S, Е, D)
Е'1у.-.{М'2, E'^-.-.S, Е, D)
Реализация на основе стеков — SECD-машина 251
где 2?eaZ( (М', Е' ) ) = а( Кх • N3 ) и Real( (М', Е'2}') = aN4, и
(М'г Е'{}— это и-замыкания.
Здесь M't = (Ку .М') для некоторого терма М3, и легко
видеть, что Real( ( М3, Е'((М', Е^у} ) ) = а[ ZV4/x ]Л^3. Следова-
тельно, поскольку [A^/xjA^ имеет значение М" за время w,
Real((M3, имеет значение, скажем, М" за
время w, где М" — аМ". Теперь
£{> £')::£, Е, @::С, D)
=>{nil, Е\{(М’2, Е'^/у}, М'3, (S, Е, С, D))
(<ЛГ, £'), Е\ {(М'2, Е'^/у], nil, (S, Е, С, £>))
для некоторого w' w согласно предположению индукции, где
<Л4', Е'у является и-замыканием таким, что Rea[((M', Е'У) —
= аМ" = аМ",
=>«ЛГ, E')::S, Е, С, D)
Таким образом,
<S, Е, М::С, О)^'((М', E')-.:S, Е, С, D)
где t' = и' + v' + w' + 3 > t-
Случай (ii). Пусть N\ имеет значение f за время и, N2 имеет
значение а за время v. Тогда f(a) = M" и / = и + и+1. По
предположению индукции существуют и' и, v' v и u-кон-
тексты Ei, Е2 такие, что
(S, Е, (ММ "С, D)=>(S, Е, М2-.: @ С, D)
=>D'«a, E2)::S, Е, Mi::@::C, D)
=>u'((f, Ei):-.(a, E2)-.-.S, E, @::C, D)
0)::S, E, C, D)
Отсюда мы имеем f = u' + и' + 2 > Z и <Л4', Е'У = (М", 0>,
что завершает доказательство.
Лемма 10.2. Допустим Е — это v-контекст и {М, Еу является
замыканием. Если Real((M, Еу) не имеет значения за любое
время t' t (t^ 1), тогда для любых S, Е, С, D при условии
Dom(E)s FV(С) либо <S, Е, М :: С, Dy наталкивается на оши-
бочное состояние, либо <S, Е, М :: С, Dy =>* D' для некоторого D'.
Доказательство. Эту лемму мы также докажем индукцией
по I, и для t = 1 результат тривиален.
Для /> 1, Real({M, Еу), а также М должны быть Х-приме-
нения, что следует из определения предиката, дающего значе-
252 Часть II. Глава 10
ние терма за время t, в предыдущем параграфе. Пусть М =
= Л11Л12- Тогда
(S, Е, (MiM2)::C, D) = >(S, Е, М2:: М\::@,-,:С, D}
Если Real((M2, £>) не имеет значения за любое время
— 1), результат следует из применения предположения ин-
дукции к (М2, Е). (Мы доказываем этот результат для всех
замыканий с указанными свойствами, поэтому <М2, Е), конечно,
является подходящим.)
Иначе допустим, что М" является значением Real((M2, £>)
за время v (t— 1). Согласно лемме 10.1,
(S, Е, М2::М,"@,::С, {(М'2, E^-.-.S, Е, Му-@::С, D}
где и' и, (М2, Е'у является и-замыканием и Real((M2,
Е'2^ — аМ2. Если v'^t—1, мы завершаем доказательство,
'поскольку при условии 1 sC s v' + 1 имеем <5, Е, М :: С, D}=>-
=^s Ds для некоторого Ds и можем выбрать s — t. Поэтому до-
пустим, что и' < t— 1.
Снова, если Real ((Mi, £>) не имеет значения за любое вре-
мя ^(/—1 — v'),- результат следует из применения предполо-
жения индукции к (Mi, Еу. Иначе, предположим, что М" яв-
ляется значением Real((Mi,Ey) за время и (/—1—v'). Со-
гласно лемме 10.1,
{(М'2, E'2\.:S, Е, Мх-.-.@-.-.С, D}^U’{(M\, Е'{)-.:
E'2)-.S, Е, @::С, D},
где и' ~^и, (Л!,, Е'у является v-замыканием и Real((M'lt
£[^) = aM". Если — v', мы снова завершаем дока-
зательство и поэтому предположим, что и' < t—1 — и'. При
этом возможны три варианта:
Вариант (/). M't — (^x.M3y Мы теперь имеем
«Лх.М', E2)::S, Е, @::С, D)=>
(nil, Е{{(М'2, Е'2)/х], М'3, (S, Е, С, D))
Если t = и' 4- v' + 2, мы завершаем доказательство, как и преж-
де, поэтому предположим обратное, и пусть Е'3 = Е\{(М2,
Е'у/ху Если Real((M3, Езу не имеет значения за любое
время =С(/ — и' — v' — 2), результат следует из предположения <
индукции, примененного к Е'^. Иначе, допустим что
Real( (Mj, Е'у ) имеет значение М" за время w^(t — и' —
— v' — 2). Тогда, как в доказательстве леммы 10.1,
Real((M, £» имеет значение М" = аМ3 за время u + t>4-w4-
Реализация на основе стеков — SECD-машина 253
+ 1 и' + v' -f- (t — и' — v' — что противоречит пер-
воначальному предположению леммы.
Вариант (2). М' и М'2 являются константной функцией и кон-
стантой данных соответственно. При этом Real((M, £>) имеет
значение за время и + v + 1 (и' + v' + 1) < t, что также яв-
ляется противоречием.
Вариант (3). Для всех других возможностей для М\ и М'2
имеет место ошибочное состояние.
Резюме
• SECD-машина является реализацией лямбда-исчисления, ос-
нованной на использовании стеков, которая применяет контекст
для хранения связей переменных, выполняя таким образом (3-ре-
дукцию. Работа этой машины описывается с помощью функ-
ции, определяющей переходы из одного состояния в другое.
.Эти состояния являются кортежами, состоящими из четырех
стеков.
• Существуют энергичный и ленивый варианты SECD-машины.
Энергичный вариант является наиболее естественным.
• Рекурсия реализуется с помощью У-комбинатора или с по-
мощью выражений нового типа, называемых помеченными вы-
ражениями.
• Специальные формы условного оператора и У-комбинатора
требуются для энергичной машины, чтобы избежать «зацик-
ливания».
• Семантику нормального порядка можно получить путем реа-
лизации вызовов по имени с помощью модификации функции
преобразования состояний энергичной машины. Однако семан-
тика вызовов по необходимости требует использования при-
сваивания и запоминания данных вне стека для обеспечения
разделения аргументов.
• Функциональная спецификация работы машины связана
с формальными доказательствами ее корректности.
• Операционная семантика, задаваемая функцией переходов,
эквивалентна семантике подстановок (3-редукции и 6-редукции
в лямбда-исчислении.
Упражнения
10.1. а. Покажите последовательность состояний энергичной
SECD-машины при вычислении лямбда-выражения ("кх.ку. -(-
+ ух) 23. Как эта последовательность изменится для ленивой
SECD-машины?
254 Часть II. Глава 10
б. Покажите последовательность состояний ленивой SECD-
машины при вычислении выражения
hd (from 1)
где функция from определена следующим образом:
from х = cons х (from ( +1 х)).
10.2. Объясните, почему реализация рекурсии в энергичной
SECD-машине с использованием У-комбинатора приводит к «за-
цикливанию». Имея определение функции
f(п) — cond 2 (* гс f( —п 1)) (=гс 2)
где cond — это условный оператор, определенный в разд. 10.1.3,
рассмотрите вычисление выражения f (3 ):
а) обоснуйте объяснение, данное вами выше, и покажите,
что при использовании Y' (определенного в разд. 10.1.3) вме-
сто У получается правильный результат. Покажите последова-
тельность состояний в этом случае. (На это потребуется неко-
торое время!)
б) проиллюстрируйте вычисление f'(3), где f' — это поме-
ченное выражение, которое эквивалентно f.
10.3. Модифицируйте Норе-программу, показанную на рис. 10.1,
которая реализует энергичную SECD-машину, так, чтобы вклю-
чить примитивный условный оператор cond и помеченные вы-
ражения, определенные в разд. 10.1.3.
10.4. Предложите оптимизацию реализации помеченных выра-
жений, требующую меньше переходов в SECD-машине.
10.5. Помеченные выражения адекватно представляют рекурсию,
выраженную в синтаксисе, используемом в этой главе, но не
реализуют должным образом статическое связывание в общем
случае, если допускаются взаимно рекурсивные определения.
Имея рекурсивное квалифицированное выражение
let f = Zx. cond 1 (g x) (=x 0)
g = hf.hf
h = ^y.f(—y 1)
in f 132
запишите помеченные выражения, представляющие функции f,
g, h, и покажите, что в применении f 132 вхождение f
в теле h связано некорректно. Как можно решить эту
проблему?
Реализация на основе стеков — SECD-машина 255
10,6. Модифицируйте Норе-программу на рис. 10.1, чтобы реа-
лизовать редукцию нормального порядка:
(а) используя вызовы по имени,
(Ь) используя вызовы по необходимости.
10.7. Доказательство корректности SECD-машины, данное в
разд. 10.3, предполагает энергичную семантику. Предложите,
как можно адаптировать это доказательство, чтобы показать,
что реализация, специфицированная для редукции нормального
порядка с вызовами по имени, также корректна.
Глава 11
ВВЕДЕНИЕ В РЕДУКЦИЮ ГРАФОВ
В предыдущей главе была рассмотрена основанная на ис-
пользовании стеков абстрактная машина для вычисления функ-
циональных выражений, написанных в соответствии с нотацией
Х-исчисления. Как мы видели, эта машина наиболее удобна для
реализации вычислений аппликативного порядка, соответствую-
щих вызовам по значению Расширение области применения
машины с целью поддерживать вызовы по необходимости тре-
бует введения дополнительных структур для явного представ-
ления задержек В этой главе будет рассмотрен совсем другой
подход к вычислению лямбда-выражений, при котором мы до-
пускаем представление выражений в виде графов, а не в виде
линейных текстовых строк. Результирующая модель вычисле-
ний по очевидным причинам называется редукцией графов.
Одно очевидное преимущество заключается в том, что в графо-
вом представлении легко выразить разделение; нам не нужна
дополнительная структура, такая, как контекст, для запомина-
ния связей (разделяемых) переменных, поскольку на (разде-
ляемый) подграф можно ссылаться любое число раз с помощью
указателей. Второе преимущество данного представления в том,
что вычисление нормального порядка в этом случае легко пред-
ставляется и относительно эффективно реализуется. Все это
делает редукцию графов особенно естественным инструментом
для поддержки вызовов по необходимости и, следовательно, ле-
нивого вычисления в функциональных языках.
Раздел 11.1 описывает, каким образом выражения, написан-
ные в нотации Х-исчисления, например введенный в гл. 8 про-
межуточный код, могут быть представлены в виде графов.
В разд. 11.2 мы описываем различные правила редукции этих
графов, используя вычисление нормального порядка. В частно-
сти, речь идет о правиле нахождения следующего редекса и
о применении к найденным редексам графового эквивалента
правил р- и б-редукции. Эти правила объединяются в форме
Введение в редукцию графов 257
алгоритма редукции графов, который представлен в разд. 11.3.
В разд. 11.4 мы рассматриваем проблему свободных перемен-
ных в выражениях и предлагаем различные пути преобразова-
ния этих выражений на этапе компиляции с целью удаления из
них свободных переменных. Это приводит нас к комбинаторным
реализациям, которые описаны в гл. 12 и 13.
11.1. Представление лямбда-выражений
в виде графов
До сих пор мы рассматривали только выражения, записан-
ные в текстовой форме, т. е. в виде строк символов. Хотя этого
совершенно достаточно, чтобы выразить правила преобразова-
ния лямбда-исчисления, мы указали некоторые проблемы, свя-
занные с данным представлением, в частности то, что трудно
в данном случае выразить разделение выражений аргументов.
В гл. 6 и позднее в гл. 9 и 10 мы использовали контекст для
запоминания связей каждой переменной в выражении. Две
ссылки на одну и ту же переменную в этом случае приводят
к тому, что из контекста дважды извлекается одна и та же
связь, и нет необходимости в ее дублировании. Второй метод
достижения разделения состоит в принятии графового пред-
ставления выражений. При этом множественные ссылки на одно
и то же выражение аргумента представляются множеством дуг,
идущих к единственной разделяемой копии соответствующего
графа аргумента. В этом разделе мы опишем, как различные
типы лямбда-выражений могут быть представлены в виде гра-
фов, и позднее покажем, как такие выражения могут быть ре-
дуцированы к слабой заголовочной нормальной форме (СЗНФ).
Как и в предыдущей главе, мы будем основывать наше обсуж-
дение на лямбда-исчислении и будем полагать, что let- и let-
гес-выражения были преобразованы в нашем промежуточном
коде. Обработка рекурсивных определений отложена до сле-
дующей главы.
Теперь рассмотрим каждый из возможных типов выражений
и покажем, как они представляются в виде направленных гра-
фов. Дуга из исходной вершины А в вершину назначения В
графа обычно обозначается стрелкой между этими двумя вер-
шинами:
А^В
Здесь, однако, мы не будем использовать это обозначение и счи-
таем, что каждая дуга выходит из вершины снизу и входит
в вершину сверху, т. е. имеет направление сверху вниз. Напри-
мер, мы можем нарисовать предыдущую дугу в следующем
17 — 1473
258 Часть II. Глава 11
виде:
Фактически каждый граф в этой главе будет направленным
ациклическим графом (НАГ). Под ацикличностью мы пони-
маем отсутствие циклов в графе, так что невозможно вернуться
в вершину, начав движение по любой из дуг, исходящих из этой
вершины. Однако это ограничение будет снято в гл. 12, чтобы
обеспечить эффективную обработку рекурсивных определений.
Нам нужно рассмотреть четыре типа выражений:
(1) Константы представляются просто в виде деревьев, состоя-
щих из одной вершины, которая содержит величину этой кон-
станты. Другими словами, константы появляются в графовом
представлении выражения в качестве листьев.
(2) Применения функций вида Е\Е2 представляются специаль-
ным типом вершин, называемых ©-вершинами, которые поме-
чаются символом @:
Еу Ег
Следует заметить, что примитивные функции, имеющие больше
одного аргумента, записываются в карринговой форме, как
описано в гл. 6. Например, выражение +13 интерпретируется
как (+1)3, где результатом применения функции + к аргу-
менту 1 является новая функция, эквивалентная функции «сле-
дующий за» на множестве целых чисел. Граф выражения +13
показан ниже:
определенная
в виде +1 (х) = х + 1
Введение в редукцию графов 259
(3) Лямбда-абстракции вида Хх.В представляются с помощью
второго специального типа вершин, называемых Х-вершинами.
При этом связанная переменная представляется листом, к ко-
торому ведет левая дуга, исходящая из Х-вершины, а поддерево,
представляющее выражение тела В, подвешено к правой исхо-
дящей дуге:
Выражение тела будет в общем случае иметь вхождения свя-
занной переменной и, возможно, также вхождения связанных
переменных других (внешних) Х-абстракций в качестве свобод-
ных переменных. Все такие ссылки на переменные представ-
ляются, как и ожидается, в виде листьев. Например, выраже-
ние Хх.Ку. + х( *уу) представляется в виде графа следующим
образом:
В качестве другого примера приведем граф для выражения
letx=linx, для которого предполагается, как мы указывали
ранее, что оно преобразовано в выражение (Хх.х) 1:
Мы могли бы, конечно, ввести новый тип вершин для Jet-выра-
жений этого вида, но это не является необходимым и привело бы
только к затуманиванию той простоты, которая присуща меха-
низму редукции графов. Обработка рекурсивных letrec-выра-
жений выполняется подобным образом, но использует так-
же У-комбинатор (который имеет свое собственное правило
17*
260 Часть II. Глава 11
преобразования графа). Мы отложим этот вопрос до гл. 12,
хотя коротко рассмотрим его в разд. 11.2.
(4) Следующий возможный тип вершин представляет состав-
ные данные, которые строятся с помощью функций-конструкто-
ров, таких, как cons. Без какого-либо специального рассмотре-
ния этих функций мы могли бы ожидать, что они обрабаты-
ваются подобно любой другой функции и что их применения
представляются с помощью @-вершин. Отличие состоит в том,
что эти функции не имеют соответствующих правил преобразо-
вания графа, поскольку любое их применение образует слабую
заголовочную нормальную форму. Например, выражение
cons Е nil можно было бы представить в виде
где cons и nil входят по предположению в предварительно
определенный набор констант. Мы могли бы даже обратиться
к определению cons в чистом Х-исчислении, а именно
кх.ку.кс.с х у, посредством чего устранили бы необходимость
любого специального типа вершины, но это весьма малопонят-
ное решение. Вместо этого мы выбираем альтернативное и бо-
лее эффективное представление применений конструкторов с по-
мощью нового типа вершины :: в следующем виде:
... вершина cons
Е nil
Заметим, что в этом графе конструктор cons представляется
уже не листом, как раньше, а внутренней вершиной, из которой
исходят дуги, ведущие к аргументам этого конструктора. Ту же
идею можно использовать при представлении любых других
примитивных конструкторов. Так, если бы мы рассматривали
семейство функций кортежирования, введенное в гл. 6, как
функции-конструкторы, то могли бы переписать применения
функций TUPLE-n, используя специальные вершины вида Тп,
например:
TUPLE-2 Е,
Введение в редукцию графов 261
Кортежи разного размера имеют теперь похожий формат,
отличающийся только числом дуг, исходящих из вершины Т;
это число указывается индексом Т. Соответствующая функция
индексирования кортежей в этом случае легко определяется,
поскольку n-й элемент кортежа, построенного с помощью
Тт (т^п), представляет собой просто n-й подграф, привя-
занный к вершине Тт.
Следует заметить, что.такая обработка примитивных кон-
структоров может быть распространена и на конструкторы,
определенные пользователем. Вспомним из гл. 8, что составные
термы могут быть представлены в виде кортежей из n + 1 эле-
ментов, где п — это арность соответствующего конструктора,
а первым элементом такого кортежа является код этого кон-
структора. Например, если С — это конструктор, определенный
пользователем, имеющий три аргумента и код с, то применение
С транслируется следующим образом:
С(х, у, г)—>~ТиРЬЕЛ с х' у' z'
где е'— это результат трансляции е. Однако мы могли бы
также хранить конструктор, определенный пользователем, в спе-
циальной предназначенной для этого вершине:
Здесь U — это просто метка, нужная, чтобы отличать такую
вершину от вершин других типов. Код конструктора, который
раньше можно было получить с помощью индексирования пер-
вого элемента кортежа, теперь можно получить из вершины,
имеющей метку Uc- Мы будем использовать это представление
в последующих обсуждениях, однако вместо символа U с ин-
дексом будем записывать имя конструктора, чтобы облегчить
понимание соответствующих графов. Это означает, что если
внутренняя вершина не является ни ©-вершиной, ни Х-верши-
ной, то она представляет имя какого-либо конструктора.
Однако при использовании таких вершин имеет место не-
большое затруднение, когда мы рассматриваем частичное при-
менение конструкторов, поскольку при этом мы не имеем
средств пометить результирующую специальную вершину как
функцию и не можем передать этой функции отсутствующие
аргументы. Для решения этой проблемы мы можем либо вер-
нуться назад к первоначальному карринговому представлению
частичного применения, либо ввести дополнительную Х-вершину
«вне» вершины-конструктора. В качестве примера рассмотрим
262 Часть II. Глава 11
выражение cons 7, представляющее частичное применение кон-
структора списков cons к числу 7. Карринговое представление
этого применения имеет вид
cons
Альтернативой является использование специальной вер-
шины :: и дополнительной Х-вершины:
Это оптимизированное графовое представление выражения
М.cons It, которое, как читатель может заметить, получается из
выражения cons! с помощью ^-преобразования. Дополнитель-
ная Х-вершина, требуемая в таких случаях, представляет собой
плату за выбранное нами удобное представление конструкторов.
Следует заметить, что подобным образом можно было бы
представлять и частичные применения примитивных функций, не
являющихся конструкторами, таких как +, хотя здесь мы вы-
брали для их представления карринговую форму. Другое пред-
ставление для конструкторов выбрано просто для того, чтобы
подчеркнуть, что они являются функциями со специальными
свойствами, а именно не имеют связанных с ними правил.
Теперь, дав представление каждого типа выражения нашего
языка, мы можем определить преобразования графов, соответ-
ствующие редукции выражений ^.-исчисления, точнее (3-редук-
ции, и применению примитивных функций согласно 6-правилам.
Как и в наших предыдущих обсуждениях, мы будем предпола-
гать, что все выражения необходимо редуцировать к их слабой
заголовочной нормальной форме (СЗНФ).
11.2. Правила редукции графов
Мы начинаем наше обсуждение редукции графов с рассмот-
рения функции, выполняющей редукцию, в качестве интерпре-
татора графов функциональных выражений. Перед выполнением
редукции необходимо сначала установить местоположение вер-
шины следующего редекса и определить, представляет эта вер-
шина (3- или 6-редекс. Наиболее общее выражение нашего про-
межуточного языка можно записать в виде Gej ... еп для не-
Введение в редукцию графов 263
которого неотрицательного целого п, где выражение G не яв-
ляется применением. Это выражение имеет графовое представ-
ление, показанное на рис. 11.1. Последовательность ©-вершин
вместе с корнем подграфа, представляющего G, найденная по-
следовательным движением по левым дугам из корневой вер-
шины графа (помеченной f), называется (левым) гребнем
этого графа.
Ясно, что определение местоположения самого внешнего ре-
декса, соответствующего редукции нормального порядка, за-
ключается в прохождении левого гребня графа до тех пор, пока
Рис. 11.1. Граф выражения для Get ... еп.
мы не попадем в вершину, не являющуюся ©-вершиной. При
этом для функции, представленной с помощью G, имеет место
один из четырех вариантов:
(1) G может быть атомарным объектом данных, например чис-
лом. В этом случае, если п — 0, выражение находится в СЗНФ,
и дальнейшая его редукция невозможна. Конечно, в случае
п > 0 имеет место ошибка типа, поскольку мы имеем выраже-
ние, где пытаемся применить объект данных к аргументам. Од-
нако мы будем предполагать здесь, что исходная программа
(и, следовательно, эквивалентный граф выражения) является
правильно типизированной, т. е. для нее была выполнена про-
верка типов, как описано в гл. 7. Поэтому рассматриваемый
вариант не может возникнуть при п > 0.
(2) G может быть составным объектом данных, т. е. корень
подграфа, представляющего G, является вершиной (примитив-
ного) конструктора. Как и в первом варианте, если п = 0, то
выражение находится в СЗНФ, поскольку для конструкторов
нет соответствующих правил редукции. В случае п > 0 имеет
место ошибка типа.
(3) G может быть Z-абстракцией. При этом если п = 0, то не
существует внешних ©-вершин, так что все выражение нахо-
дится в СЗНФ. Если 1, то подвыражение Get должно быть
264 Часть II. Глава 11
редуцировано, и соответствующая @-вершина помечается сим-
волом *, образуя очередной редекс.
(4) G может быть примитивной функцией арности k. При этом,
если k > п, выражение представляет частичное применение
этого примитива и, как мы отмечали в гл. 6, является СЗНФ,
поскольку такое применение примитива нельзя редуцировать,
пока отсутствуют недостающие k — п аргументов. Если k п,
то подвыражение Gei ... ё* редуцируется согласно б-правилу
для примитивной функции G. Например, если k = п, очередной
вершиной редекса является корнрвая вершина графа, помечен-
ная на рис. 11.1 символом ф. Если k < п, то результат приме-
нения примитивной функции сам должен быть функцией, т. е.
примитивная функция G должна быть функцией высшего по-
рядка.
Определив, как находить вершину очередного редекса на
каждом этапе вычислений, мы должны теперь определить пре-
образования графа, соответствующие редукциям подвыраже-
ний. Эти преобразования должны сохранять представление
графа, т. е. должны быть такими, чтобы граф правильно пред-
ставлял соответствующие выражения до и после преобразова-
ния. Мы уже видели, что все редексы являются ©-вершинами
и что каждое преобразование должно представлять либо 0-ре-
дукцию, либо применение б-правила. Другими словами, суще-
ствуют только два типа преобразования графа, которые нам
нужцо рассмотреть: применение подграфа 1-абстракции к под-
графу аргумента (1-применение) и применение вершины при-
митивной функции арности k к k подграфам аргументов.
11.2.1. Х-Применение
Применение подграфа 1-абстракции к подграфу аргумента
составляет графовое представление p-редекса. Результатом
1-применения является поэтому версия подграфа 1-абстракции
(графа функции), в которой каждый лист, представляющий
связанную переменную, каким-то образом заменен на (под)-
граф аргумента. Чтобы получить эффект разделения графов
аргументов, заменяем каждый указатель связанной переменной
в листах графа функции на указатель корневой вершины графа
аргумента, что в результате дает модифицированную копию
графа функции. Вершина редекса при этом заменяется резуль-
татом редукции, т. е. корневой вершиной модифицированного
графа функции. Чтобы проиллюстрировать этот механизм, на
рис. 11.2 показано преобразование графа, представляющее р-ре-
дукцию выражения (Xx.succх)3, где succ — это (примитивная)
Введение в редукцию графов 265
функция следования на множестве целых чисел. Исходный граф
показан слева, а преобразованный — справа.
Далее при ссылках на подграфы, представляющие опреде-
ленный тип выражений, таких как аргумент, тело функции, свя-
занная переменная, мы будем опускать слова «подграф», «граф»
Рис. 11.2. Простое преобразование графа, представляющее Х-применение.
или «лист» и ссылаться только на тип выражения. Теперь мы
рассмотрим в деталях модификации графа при подстановке
аргумента, замене вершины редекса и копировании тела
функции.
11.2.2. Подстановка аргументов
Как ранее установлено, замена связанной переменной аргу-
ментом достигается с помощью замены ссылки на связанную пе-
ременную указателем на граф аргумента. При этом в том слу-
чае, если тело функции содержит несколько ссылок на связан-
ную переменную, будет установлено несколько указателей на
единственную разделяемую копию графа аргумента. Пример,
приведенный на рис. 11.3, показывает преобразование графа,
соответствующее редукции
(Хх.+х х)(* 2 3)-> + (* 2 3)(* 2 3)
где подвыражение (*23) является разделяемым.
Таким образом, при графовом представлении разделение вы-
ражений представляется естественным образом без необходи-
мости введения явного контекста, что делает редукцию графов
жизнеспособной моделью для реализации функциональных язы-
ков. Первым этот факт отметил Уодсворт [86].
266 Часть II. Глава 11
Рис. 11.3. Преобразование графа, соответствующее p-редукции (Хх-+
хх)(» 2 3)->+(. 2 3) (* 2 3).
11.2.3. Замена корневой вершины редекса
После подстановки аргумента при выполнении р-редукции
редекс физически заменяется результатом этой редукции — либо
атомом, либо корневой вершиной упрощенного (редуцирован-
ного) выражения. Если вершина редекса сама является разде-
ляемой, тогда после замены каждая ссылка на нее соответ-
ствует уже вершине в редуцированной форме, и именно поэтому
операция замены обеспечивает реализацию семантики вызова
по необходимости. Как и в случае преобразования задержки
в дампе с присваиванием ленивой SECD-машины, замена вер-
шины редекса является сохраняющей значение в том смысле,
что значения заменяемого и заменяющего графов совпадают.
Другие вершины редекса не будут затронуты операцией заме-
ны, но будут «отрезаны» от корневой вершины и от графа в це-
лом. Если эти вершины не являются разделяемыми (т. е. они
не нужны больше при вычислении), тогда они образуют так
называемый мусор, и пространство, занимаемое ими, может
быть законным образом освобождено с использованием так
называемого сборщика мусора. Различные типы сборщиков му-
сора и методы их работы описаны в гл. 16. В примерах на
рис. 11.2 и 11.3 эти потенциально «мусорные» вершины не по-
казаны. На рис. 11.4, а снова показана редукция рис. 11.3, но
при этом показаны все «отрезанные» подграфы, которые могут
оказаться мусором. То же самое относится к следующему шагу
редукции, показанному на рис. 11.4,6.
Введение в редукцию графов 267
Рис. 11.4. Преобразование графа, при котором могут появиться мусорные
ячейки.
11.2.4. Копирование К-тела
Разделение при подстановке аргумента означает, что Х-аб-
стракция сама может быть разделяемой, являясь аргументом
некоторого Х-применения. Таким образом, в Х-применении необ-
ходимо заменить вершины, представляющие связанные перемен-
ные, внутри копии тела применяемой Х-абстракции. Для копии
тела требуются новые вершины графа для каждой вершины,
кроме корневой, которая записывается на место вершины ре-
декса.
Именно таким образом выполнялась p-редукция в приведен-
ных выше примерах, проиллюстрированных рис. 11.2—11.4.
Строго говоря, мы должны были показать отсоединенный под-
граф Х-абстракции Kx.succx на рис. 11.2, поскольку он продол-
жает существовать после редукции и может понадобиться на
каком-либо другом шаге вычисления. Однако такой отсоединен-
ный подграф показан на рис. 11.4 для Х-абстракции (Хх. + хх)
после ее применения к выражению *2 3.
Сейчас мы дадим более сложный пример, иллюстрирующий
основные положения этого раздела. Мы покажем редукцию
графа выражения промежуточного кода:
let twice = Xf.Хх.f(f x) in twice (Xx. +x 1)2
которое путем расширения определения функции twice может
быть представлено в эквивалентной форме следующим образом:
(X/. Хх. f (f х)) (Хх. + х 1)2
268 Часть II. Глава 11
Преобразования графа показаны на рис. 11.5. Мусор не пока-
зан, а корневая вершина очередного редекса помечена симво-
лом * в каждом графе. Самая верхняя вершина каждого графа
всегда одна и та же; она является корнем исходного выраже-
ния и в конце преобразования содержит результат 4. В первом
графе (а) редексом является Х-применение, тело которого имеет
два вхождения связанной переменной f. Подстановка приводит
к графу (б), где разделение выражения аргумента очевидно.
На следующем шаге редукции тело имеет только одно вхожде-
ние связанной переменной х, и в результате получается граф
(в). На следующем шаге редукции имеет место случай разде-
ляемой Х-абстракции. Здесь совершенно очевидна важность
копирования: одна и та же Х-абстракция используется и в каче-
стве применяемой функции, и как часть аргумента, подставляе-
мого в эту функцию. Последние три шага редукции опреде-
ляются правилами применения примитивных функций и могут
быть рассмотрены после прочтения следующего параграфа. Од-
нако преобразования графа являются очень простыми и вполне
очевидными: редекс графа (г) является первым аргументом
строгой примитивной функции +, а следующие две редукции
являются просто применениями примитивной функции (+)
к постоянным аргументам.
Проницательный читатель может заметить, что правила ре-
дукции Х-применений заставляют нас выполнять необязательное
копирование Х-тел как следствие разделения: почему мы не мо-
жем разделять Х-тела, только копируя каждый аргумент, яв-
ляющийся Х-абстракцией? Опровержение этой идеи заключается
в реализации рекурсии. Она обычно достигается с помощью
циклических графов (рассмотренных в следующей главе), так
что одна и та же функция может применяться несколько раз
к различным аргументам, и каждое применение поэтому требует
новой копии тела. Таким образом, альтернативная схема не
будет работать. Альтернативный подход может заключаться в
непосредственном использовании У-комбинатора, что дает со-
вершенно правильные Х-выражения и в случае нашей редукции
графов нормального порядка не приводит к проблеме зацикли-
вания вычислений (см. соответствующее обсуждение энергичной
SECD-машины в предыдущей главе). Однако в целом при ис-
пользовании У-комбинатора имеет место реализация самопри-
менения, включающего множество Х-абстракций в качестве ар-
гументов, которые будут копироваться в предлагаемой альтер-
нативной схеме. В следующей главе мы увидим, что наиболее
эффективная реализация применений У-комбинатора также ис-
пользует циклический граф. Поэтому предложенный нами метод
реализации Х-примёнений является предпочтительным.
Рис. 11.5. Редукция графа выражения
twice ( Хх. + х 1 ) 2.
270 Часть II. Глава 11
11.2.5. Применение примитивных функций
Правила преобразования графа, соответствующего примене-
нию примитивной функции, задаются б-правилами для этой
функции. Эти правила включают информацию о том, относи-
тельно каких аргументов функция является строгой (т. е. какие
аргументы нужно вычислить перед применением функции), а
также некоторую встроенную функцию, которая вычисляет ре-
зультат применения, когда все необходимые аргументы уже
вычислены.
Задав б-правила, которые нельзя детально специфицировать
в общем случае, мы можем теперь довольно просто определить
преобразование графа, соответствующее редукции редекса при-
менения примитивной функции. Для примитивной функции ар-
ности k:
(1) Вычислить строгие аргументы примитивной функции, со-
гласно б-правилам, с помощью рекурсивного применения функ-
ции редукции графа к соответствующим графам, начиная с тех,
которые обозначены ei, ..., ek на рис. 11.1, т. е. с тех, чьи кор-
невые вершины соединены с ©-вершинами, принадлежащими
гребню.
(2) Выполнить применение примитивной функции, используя
б-правило и вычисленные аргументы, и получить в результате
некоторый граф.
(3) Заменить вершину редекса графом, представляющим ре-
зультат. Эта операция отрежет от редекса некоторые подграфы,
порождая мусор, если только эти подграфы не являются разде-
ляемыми, точно так же, как в случае Х-применения.
Сейчас приведем два примера преобразования графов при при-
менениях примитивных функций. Первый — для арифметиче-
ской функции +, которая является строгой относительно обоих
своих аргументов, и второй — для условной функции — cond
в промежуточном коде.
Пример 1
Рассмотрим применение примитивной функции 4-1 (succ2), где
succ, как и прежде, является функцией следования на множе-
стве целых чисел. Это выражение имеет графовое представле-
ние, показанное на рис. 11.6, а. Редексом является корневая
вершина графа, соответствующая применению примитива 4~-
Поскольку 4- является строгой функцией по отношению к обоим
аргументам и только первый из аргументов находится в СЗНФ,
функция редукции графа вызывается рекурсивно для редуциро-
вания второго аргумента, который представлен правым подгра-
Введение в редукцию графов 271
фом вершины редекса. Результат этого рекурсивного вызова 3
заменяет ©-вершину второго аргумента функции +, как пока-
Рекурсивный вызов
для вычисления
Рис. 11.6. Редукция выражения 4-1 (succ 2).
зано на рис. 11.6, в. После этого функция + применяется, давая
в результате 4 в вершине редекса, как показано на рис. 11.6, г.
Пример 2
Теперь мы рассмотрим выражение
{kx.cond( negх)0( squareх))3, где neg и square заданы
в виде
neg = Кх. <х О
square = Лх. *х х
Фактически это выражение является Х-применением, и мы даем
читателю возможность самому получить граф, показанный на
рис. 11.7,а, выполнив один шаг редукции этого Х-применения
(расширения функций neg и square не показаны).
Следует заметить, что cond является строгой относительно
своего первого аргумента, поэтому преобразование, дающее
граф (б) из графа (а), получается с помощью рекурсивного
вызова функции рёдукции для вычисления выражения neg3.
Это вычисление дает в результате false, и поэтому S-правило
272 Часть II. Глава 11
для cond, выбирает подграф третьего аргумента в качестве ре-
зультата применения, давая граф, показанный на рис. 11.7, й. На-
конец, вычисляется крадрат числа 3 в результате редукции выра-
жения square 3, давая 9, как показано на рис. 11.7, г. (Заметим,
(Рекурсивный вызов
для вычисления
первого аргумента)
Рис. Р.7. Редукция выражения (r.x.cond ( neg х ) 0 ( square х ) ) 3.
что здесь false по предположению является константой, хотя
ее можно было бы закодировать каким-либо другим способом,
например как целое число.)
11.3. Интерпретаторы, основанные
на редукции графов
Теперь мы можем сконструировать вычислитель, приводящий
любое Z-выражение к СЗНФ, и ниже дадим неформальный ал-
горитм такого вычислителя для работы с графами, образец ко-
торых показан на рис. 11.1. Алгоритм представлен на доста-
точно абстрактном уровне, и детальные графовые манипуляции
скрыты в операциях высокого уровня. Например, определенные
проблемы, касающиеся функций-селекторов, разрешаются в
предложении «заменить вершину редекса». Подобным образом
явное управление рекурсивными вызовами, необходимыми для
Введение в редукцию графов 273
выявления аргументов примитивных функций, не специфициро-
вано? Эти два вопроса рассмотрены ниже. Для полноты мы
включили тесты, определяющие ошибки типов, хотя, как мы
отмечали ранее, это не обязательно, если для выражений была
предварительно выполнена проверка типов.
Чтобы редуцировать граф выражения
ПОВТОРИТЬ
(1) Последовательно идти вниз по левой ветви графа (спускать-
ся по левому гребню) до первой вершины, которая не является
©-вершиной
(2) Выполнить следующие действия в зависимости от типа теку-
щей рассматриваемой вершины:
(а) Если текущая вершина содержит атом или конструктор
данных, то
если текущая вершина является корнем графа (т. е.
имеется 0 аргументов)
то выражение находится в СЗНФ
иначе ошибка типа
(б) Если текущая вершина содержит примитивную функцию
от k аргументов, то
если k > числа ©-вершин в гребне
то выражение находится в СЗНФ
иначе найти, какие аргументы должны быть
вычислены, согласно соответствующему 6-правилу;
рекурсивно редуцировать подграфы этих аргумен-
тов к СЗНФ; выполнить примитивную функцию,
выдавая новый подграф в качестве результата;
заменить вершину редекса, являющуюся fe-й
©-вершиной вверх по гребню от текущей вершины,
этим результатом, т е. заменить ее корнем нового
подграфа (подняться по гребню)
(в) Если текущая вершина является Л-вершиной, то
если текущая вершина является корнем графа
то выражение находится в СЗНФ
иначе создать копию Х-тела, подставив в нее разделяемый
подграф аргумента вместо вершин связанной переменной
(имя связанной переменной подвешено к левой ветви
Л-вершины); заменить вершину редекса (первая ©-вер-
шина вверх по гребню) на результат, т. е. заменить ее
корнем копии Л-тела
ПОКА Выражение не находится СЗНФ
18 — 1473
274 Часть II. Глава 11
11.3.1. Функции проецирования
и вершины-синонимы
В этом разделе мы рассмотрим особенно сложный Допрос
в нашей схеме редукции графов, порождаемый применением
функций проецирования (или проекторов). Функцией проециро-
вания называется любая функция, возвращающая в результате
своего применения к выражению аргумента компонент этого
выражения, т. е. неизменный подграф нередуцированнога графа.
Например, функция тождества Хх.х, которую мы будем'обозна-
чать буквой I, является функцией проецирования, поскольку
возвращает граф своего аргумента без изменений. Еще один
класс примеров составляют все примитивные функции-селек-
торы, определенные на составных объектах данных, например,
примитивные функции hd и tl, которые соответственно выби-
рают голову и хвост списка.
Проблема, возникающая в описанной нами реализации, со-
стоит в том, что вершина редекса заменяется корневой верши-
ной (неизменного) результирующего подграфа, так что после
этого существуют две копии этого подграфа, в которых все
вершины, кроме корневых, являются разделяемыми. Поскольку
каждая корневая вершина может впоследствии стать редексом,
имеет место двойная редукция этого параграфа. Рисунок 11.8
показывает преобразования графов, соответствующие двум при-
менениям функций проецирования:
а) /(+ 1 2)
б) hd(cons(hd(cons 1 ш7))3)
Вершины-редексы снова помечены звездочкой *.
В каждом случае вершины, помеченные **, могут быть раз-
деляемыми, так что после редукции они не превращаются в
мусор, но могут стать редексами. Это может привести к по-
вторному вычислению выражения -|-12 (соответствующий под-
граф в случае (б) находится в СЗНФ), что является весьма
неэффективным. Существуют два решения этой проблемы, пер-
вое из которых основано на использовании так называемых
побочных вершин, или вершин-синонимов, помечаемых в графе
буквой 0. Если выражение представлено графом, корнем кото-
рого является побочная вершина, то оно интерпретируется
точно так же, как выражение, представленное графом, корнем
которого является вершина, подвешенная к побочной. Приме-
нение функции проецирования с вершиной редекса РА и вер-
шиной результата PR может теперь быть представлено с по-
мощью превращения РА в вершину-синоним, указывающую
Введение в редукцию графов 275
на PJ?, как показано на рис. 11.9 для примеров (а) и (б)
рис. у 1.8.
Недостаток этого подхода состоит в том, что вершины-си-
нонимы могут встречаться где угодно, появляясь всякий раз
при Применении функций проецирования, и, таким образом,-
могут образовывать цепочки — потенциальный источник неэф-
фективности. В общем случае мы не можем знать, станет ли
сама вершина PR синонимом после редукции результирующего
подграфа и станет ли синонимом вершина, на которую будет
указывать PR, и т. д. Это приводит ко второму решению проб-
лемы. Оно использует тот факт, что после применения функции
проецирования следующим редексом, который мы выберем, бу-
дет PR, если PR еще не находится в СЗНФ. Это следует из
определения нормального порядка редукций: если бы PR не
была самым внешним редексом после редукции РА, то РА
также не могла бы быть таковым, когда мы выбирали ее для
редукции. Отсюда заключаем, что PR гложет быть редуциро-
вана к СЗНФ до выбора РА в качестве очередного редекса,
а затем PR может быть скопирована в РА (т. е. редуцирован-
ная форма ** может быть скопирована в * на рис. 11.9) без
риска получить в дальнейшем двойную редукцию.
Отсюда следует, что если мы выбираем вершину-редекс PR
для редукции первой, то метод копирования, не требующий
каких-либо изменений алгоритма редукции графов, является
наилучшим. Однако метод побочных вершин также может ис
пользовать изменение порядка выбора редексов, поскольку если
PR редуцируется первой, то в момент замены РА будет уже
известно, является ли PR вершиной-синонимом. В этом случае
мы уже никогда не получим цепочку из нескольких вершин-
синонимов, поскольку если PR является синонимом, то она
копируется в РА (как при обычной редукции графов), иначе
РА становится вершиной-синонимом, указывающей на PR.
Эффективность метода побочных вершин (без цепочек) при-
мерно соответствует эффективности, достигаемой при методе
копирования. Выполняется одинаковое количество редукций,
поскольку в обоих случаях результирующий подграф (с корнем
PR) редуцируется к СЗНФ только один раз. Более того, в
обоих случаях требуется одинаковое количество памяти, по-
скольку обе схемы генерируют только одну избыточную вер-
шину: побочную вершину и дубликат вершины редекса соот-
ветственно. Недостатком метода побочных вершин без цепочек
является то, что каждая ссылка на РА требует повторного
доступа к вершине, чтобы получить содержимое PR. Однако
такие побочные вершины могут быть «замкнуты накоротко»
сборщиком мусора, который ответствен за обнаружение и
18*
276 Часть II. Глава 11
(Ъг.х)(+1 2)
nd (cons (nd (cons 1 ml))3)
6
Рис. 11.8. Редукция графов с помощью копирования при применении функ-
ций-проекторов.
«| б
Рис. 11.9. Редукция графов с использованием побочных вершин при примене-
нии функций-проекторов.
утилизацию неиспользуемых ячеек. Пример этого показан на
рис. 11.10, где изображен граф, представляющий выражение
append (cons (succ 1 ) nil) (cons (succ 1) nil), где append эквива-
лентна < > в языке Hope.
Недостатком метода побочных вершин является то, что каж-
дая вершина может быть синонимом, и должна выполняться
соответствующая проверка (с помощью просмотра поля-мет-
ки), прежде чем содержимое вершины может быть использо-
вано. Это требует небольшого, но постоянного дополнительного
времени на этапе выполнения. Однако существует одно до-
вольно тонкое преимущество, которое метод побочных вершин
имеет над методом копирования: он облегчает оптимизацию
Введение в редукцию графов 277
путем запоминания. Этот метод оптимизации будет обсуждаться
в гл. 19. Его сущность заключается в запоминании пар аргу-
мент— результат для функции, так что можно избежать по-
вторного вычисления, когда функция применяется несколько раз
к одному и тому же аргументу. Если существуют две копии
подграфа, представляющего одну и ту же функцию, как это
подлежит
обработке
сборщиком
мусора
Рис. 11.10. Обработка вершин-синонимов при сборке мусора.
может случиться в методе копирования при обработке приме-
нений проекторов, то список пар аргумент — результат должен
быть разделяемым или возможно включение в этот список двух
копий одной и той же пары. И тот и другой путь включают
значительные накладные расходы, тогда как если используются
вершины-синонимы, то будет только одна копия подграфа
функции и проблемы не возникает.
11.3.2. Доступ к гребню
и реверсирование указателей
Теперь мы опишем, как можно сконструировать функцию
редукции графов для вычисления выражений нашего расши-
ренного Х-исчисления, которое включает константы и примитив-
ные функции. Однако один вопрос, который до сих пор по-
дробно не рассматривался, — это вопрос о спуске по гребню
при применении примитивной функции и о подъеме (вверх по
гребню), необходимом при вычислении аргументов примитивной
функции для завершения ее применения. Одна из причин того,
что мы опустили детали реализации спуска/подъема, заклю-
чается в том, что простой метод, основанный на использовании
стека, хорошо работает в этом случае. Однако при редуциро-
вании графа уже имеется структура данных (сам граф), внутри
которой мы можем установить стек для управления спуском
278 Часть II. Глава 11
и подъемом. Метод, позволяющий закодировать такой стек в
графе, называется реверсированием указателей и основан на
выполнении простых локальных преобразований графа каждый
раз, когда' мы делаем шаг вниз или вверх по гребню.
Спуск и подъем с использованием стека
При вычислении применения примитивной функции мы идем
вниз по гребню подграфа, пока не окажемся в вершине, кото-
рая не является ©-вершиной, как показано на рис. 11.1. При
использовании стека мы просто движемся вниз по левому
гребню, проталкивая в стек каждую ©-вершину, которую про-
ходим (на практике мы проталкиваем в стек адрес ©-верши-
ны), пока не встретится Х-вершина или вершина примитивной
функции. При этом местоположение подграфов аргументов и
вершины редекса может быть найдено за постоянное время про-
стой индексацией от вершины стека. Заметим, что такой стек
необходим только из соображений эффективности. Если место-
положение вершины редекса при применении примитивной
функции известно и мы спустились вниз на п ©-вершин гребня
(до вершины примитивной функции), тогда подграф i-ro аргу-
мента может быть доступен через (п — /)-ю ©-вершину вниз
по гребню от вершины редекса.
Вычисление выражения верхнего уровня включает просто
спуск по гребню их графов для нахождения первого редекса
и его редуцирования. Это именно та редукция, которая порож-
дает дальнейшие редукции, возможно включающие рекурсив-
ные вызовы функции редуцирования. Теперь мы опишем в об-
щих чертах удобную схему использования стека, перечислив
операции, выполняемые при спуске по гребню (под) графа, ини-
циировании редукции подграфа аргумента и завершении редук-
ции (под)графа, следующим образом:
(1) Спуск является первой операцией, выполняемой при редук-
ции графа, представляющего выражение верхнего уровня или
новый подграф, и поэтому он использует новый сегмент стека,
называемый фреймом стека, который начинается в текущей
вершине стека (ВС) и, таким образом, строится на вершине
предыдущего фрейма стека. В процессе спуска позиция осно-
вания нового фрейма стека запоминается для дальнейшего
использования и указатели на каждую ©-вершину левого
гребня (под) графа последовательно проталкиваются в стек.
Число ©-вершин гребня является поэтому глубиной фрейма
стека по завершению спуска.
(2) Если вершина, куда мы пришли при завершении спуска,
является Х-вершиной, соответствующая редукция происходит,
как описано в предыдущих разделах этой главы, с использова-
Введение в редукцию графов 279
нием ВС для определения местоположения вершины-редекса.
Иначе, если это вершина примитивной функции арности п, ко-
торая меньше или равна глубине текущего фрейма стека (т. е.
числу имеющихся аргументов), то 6-правила для этой функции
просматриваются, чтобы определить, какие аргументы должны
быть вычислены. Если таковых нет, редукция выполняется в
соответствии с 6-правилами и завершается, как описано в (3).
Если существует хотя бы один строгий аргумент, его вычис-
ление инициируется с помощью рекурсивного повторного вы-
зова вычислителя после сохранения текущего состояния в стеке.
При этом сохраняется позиция текущего основания фрейма
стека (которая была запомнена ранее) и релевантная инфор-
мация о состоянии. Она должна включать идентификатор при-
меняемой примитивной функции вместе с позицией выполняе-
мого в данный момент 6-правила, указывающей, например, ка-
кие аргументы уже вычислены. Если требуется вычислить i-й
аргумент, его корневая вершина указывается правой дугой,
исходящей из ©-вершины, указанной i-м элементом стека ниже
ВС (до сохранения в стеке информации о текущем состоянии).
Вычислитель начнет редуцирование подграфа, протолкнув в
стек адрес его корневой вершины.
(3) После завершения редукции вычислитель возвращает
управление, заменив вершину редекса результатом, который
может быть либо атомарным, либо представлять собой корень
другого подграфа (например, в случае селектора или условной
функции). Стек очищается до основания текущего фрейма
стека, и, если оно является дном стека, вычисление завер-
шается; при этом вновь полученный редуцированный подграф
представляет слабую заголовочную нормальную форму выра-
жения верхнего уровня. Иначе, мы продолжаем работу с пре-
дыдущим фреймом стека, прочитав из стека информацию о со-
стоянии. Вычисление возобновляется в (сохраненной) точке
6-правил, в которой требовалось значение аргумента. Эту опе-
рацию иногда называют подъемом.
В качестве примера на рис. 11.11 показано состояние стека
при вычислении выражения
F(square 5) el е2
где F — это примитивная функция, строгая относительно своего
аргумента, a el и е2 являются произвольными выражениями.
Немедленно после инициации вычисления первого аргумента
стек и граф будут иметь вид, показанный на этом рисунке.
Спуск и подъем с использованием реверсирования указателей
Стек, используемый для управления доступом к гребню (под)-
280 Часть II. Глава 11
графа при вычислении аргументов для применений примитивных
функций, может быть физически размещен в вершинах самого
графа г очевидными выгодами с точки зрения эффективности
использования памяти. Из предыдущего раздела ясно, что на
каждом этапе вычисления выражения нам необходимо иметь
доступ только к текущей рассматриваемой вершине (и, следо-
вательно, к подграфам, доступным через ее исходящие дуги)
Рис. 11.11. Стек после рекурсивного вызова редуктора графов.
и к вершине, рассмотренной на предыдущем шаге. При этом
возможны обратный просмотр гребня для нахождения подгра-
фов аргументов и подъем при завершении применения прими-
тивной функции. Ценность такого способа в том, что стек как
бы размещается в самом гребне и моделируется путем ревер-
сирования входящей дуги рассматриваемой вершины, т. е. путем
изменения ее направления на противоположное. Так, при спуске
только что достигнутая вершина содержит в общем случае сле-
дующие указатели:
Введение в редукцию графов 281
Заметим, что после спуска и подъема гребень будет иметь
указатели во всех своих вершинах, реверсированные дважды,
что оставляет граф без изменений при возврате из вызова вы-
числителя (за исключением редукции соответствующей вер-
шины редекса к ее слабой заголовочной нормальной форме).
Теперь мы покажем, как работает реверсирование указателей
при редукции графов, обрисовав в общих чертах алгоритмы
и дав два примера, иллюстрирующие их основные особенности.
После этого нам будет просто расширить данный выше алго-
ритм редукции, чтобы включить в него реверсирование ука-
зателей.
При спуске и подъеме используются вершины гребня вместе
с тремя динамическими указателями: FORE (указатель на те-
кущую вершину), AFT (указатель на предыдущую вершину) и
TEMP (вспомогательный указатель), а также специальное зна-
чение указателя NULL для индикации конца цепочки. До на-
чала операции спуска, которая является первой операцией, вы-
полняемой вычислителем, мы присваиваем AFT := NULL и
FORE :== указатель на вершину редекса. Мы используем
LEFT ( и ) и RIGHT (п ) для обозначения соответственно левого
и правого указателей (исходящих дуг) вершины п. Алгоритм
спуска состоит в следующем:
СПУСК:
ПОКА FORE указывает на ©-вершину
TEMP :=FORE;
FORE := LEFT( FORE ); (FORE теперь ука-
зывает на сле-
дующую вершину
вниз по гребню)
LEFT( TEMP ) := AFT; (реверсирование
указателя; он те-
перь указывает на
предыдущую вер-
шину)
AFT := TEMP ; (AFT указывает на
начало цепочки
реверсированных
указателей)
КОНЕЦ
В конце спуска FORE указывает на первую вершину гребня,
которая не является ©-вершиной (G на рис. 11.1). AFT ука-
зывает на последнюю ©-вершину гребня, а левый указатель
каждой ©-вершины указывает на предыдущую ©-вершину, за
исключением вершины-редекса, левый указатель которой равен
282 Часть II. Глава 11
NULL. Подъем, в сущности, противоположен спуску; FORE
и AFT в алгоритме подъема обмениваются своими ролями.
Цикл прекращается после заданного числа шагов в случае на-
хождения вершины-редекса аргумента или, когда AFT примет
значение NULL при достижении редекса применения примитив-
ной функции после завершения ее вычисления.
Пример
Рассмотрим спуск по графу, представляющему выраже-
ние -J- 1 2:
Последовательные состояния гребня при спуске вместе со зна-
чениями указателей FORE и AFT показаны на рис. 11.12.
AFT -ь- NULL NULL NULL
I f
FORE - * @ -* 2 AFT —* ~* 2 (o> -* 2
I ' t
@ —1 FORE -* @ -* 1 AFT @ -* 1
I I
+ + FORE-* +
Рис. 1.12. Спуск по гребню графа выражения + 12: а — начальное состоя-
ние; б — один шаг вниз по гребню; в — конец спуска.
Для инициации вычисления i-ro аргумента применения при-
митивной функции мы просто выполняем подъемом через
i вершин вверх по гребню (считая от первой не ©-вершины)
и затем входим в гребень аргумента по правой дуге соответ-
ствующей ©-вершины. При этом мы реверсируем указатель,
чтобы обеспечить возврат к предыдущему гребню, следующим
образом:
TEMP :=FORE ;
FORE :=RIGHT( AFT);
RIGHT( AFT ):= TEMP;
Введение в редукцию графов 283
Заметим, что указатель AFT не изменяется, указывая на
©-вершину, к которой нужно вернуться после вычисления ар-
гумента. Подобным образом левый указатель этой вершины
по-прежнему направлен вверх по гребню в сторону вершины
редекса применения примитивной функции. Однако правый
указатель теперь направлен вниз по гребню. Аргумент, который
необходимо вычислить следующим (если он есть), будет опре-
делен б-правилами применяемой примитивной функции и теку-
щим состоянием при выполнении этих правил.
Теперь мы можем вызвать наш вычислитель для выполнения
редукции подграфа аргумента, но уже не можем использовать
специальный NULL-указатель для определения конца подъема,
поскольку указатель AFT уже использован нами. Мы предла-
гаем два способа решения этой проблемы. Первый, который мы
рассмотрим в оставшейся части этого раздела, заключается в
использовании одного дополнительного бита для пометки
©-вершины, указываемой AFT при входе в гребень подграфа
аргумента. Эта пометка проверяется при подъеме после того,
как значение аргумента вычислено и вычислитель пытается
заменить редекс этим значением и вернуть управление. Такая
проверка заменяет тестирование указателя AFT на значение
NULL. Второму методу требуется отдельный небольшой стек,
похожий на тот, что описан в предыдущем разделе, но содер-
жащий другую информацию. Туда может быть помещен ука-
затель на ©-вершину предыдущего гребня (т. е. значение
AFT), что дает возможность AFT быть инициализированным
значением NULL, как прежде. Другим решением является по-
мещение в стек числа ©-вершин гребня, пройденных при спуске,
что дает возможность при подъеме знать число шагов до дости-
жения редекса. Детали этих методов предлагаются читателю
в качестве упражнений.
Пример
Чтобы проиллюстрировать вычисление аргумента с исполь-
зованием реверсирования указателей, мы рассматриваем вы-
ражение + (+12)3 и показываем на рис. 11.13 состояние со-
ответствующего графа после спуска при входе в гребень пер-
вого аргумента и в начале спуска по новому гребню. Помеченная
вершина указывается символом ф.
В заключение рассмотрим действия, которые необходимо вы-
полнить при возврате управления вычислителем после выпол-
нения редукции вершины-редекса. Если значение указателя
AFT равно NULL, вычисление закончено, иначе известно
284 Часть II. Глава 11
только, что мы вычислили некоторый аргумент некоторого
применения примитивной функции. Чтобы возобновить при-
менение примитивной функции, вызвавшей вычислитель, необ-
ходимо найти ее идентификатор и определить, какой аргумент
NULL NULL
t t
@ — 3 @ -*3
t t
AFT @ 2 AFT —@+ FORE @ 2
I I I
FORE -* + @ ► 1 + @ 1
I I
+ +
a 6
NULL
I
@ —3
AFT
I
@ 2
FORE @ 1
I
+ +
e
Рис. 11.13. Вычисление аргумента с помощью реверсирования- указателей:
а — после спуска, б — вход в гребень подграфа аргумента; в — начало спуска
по новому гребню.
только что был вычислен. Теоретически мы можем получить
эту информацию, снова выполнив спуск по гребню до вершины
примитивной функции: если число выполняемых при спуске
шагов равно k, мы знаем, что только что был вычислен k-й ар-
гумент. Однако проще и эффективнее на этапе выполнения
запоминать в стеке идентификатор примитивной функции, но-
Введение в редукцию графов 285
мер вычисляемого аргумента, а также информацию о состоя-
нии выполнения 6-правил при входе в гребень аргумента. Когда
вычисление аргумента закончено, эта информация может быть
восстановлена из стека и использована для возобновления вы-
полнения 6-правил.
11.4. Проблема свободных переменных
Завершим эту главу тем, что укажем весьма серьезное пре-
пятствие для эффективности реализации, обусловленное нали-
чием свободных переменных в телах функций. В любом замкну-
том выражении (а именно такие выражения мы рассматриваем)
свободные переменные являются связанными переменными
внешних Х-абстракций внутри некоторой самой внешней
Z-абстракции, о чем говорилось детально в гл. 6. Фактически
проблема, указываемая здесь, является только примером (в
графовом представлении) той, которая раньше была представ-
лена в более абстрактной форме. Рассмотрим выражение
(Хх.Ку.х )EVE2, где £1 и Е2 являются произвольными выра-
жениями. Оно представляется следующим графом, в котором
вершина первого редекса, помеченная (1), является Х-приме-
нением. Этот же граф показан после одного шага редукции
(без мусора):
До сих пор не было копирования подграфов, за исключе-
нием шаблона Х тела, в котором связанная переменная была
замещена подграфом £1. Теперь рассмотрим следующую ре-
дукцию, соответствующую редексу, помеченному (2). Это также
^-применение, редукция которого, согласно правилам, данным
ранее в этой главе, включает создание копии подграфа, пред-
ставляющего Х-тело Е1 и замену вершины (2) корнем этой
копии — в данном случае тело не содержит связанных пере-
менных, которые необходимо замещать подграфом аргумента.
Ясно, что желательно разделять подграф, представляющий £1,
поскольку £1 может быть произвольно сложным, требующим
больших накладных расходов при копировании. Кроме того,
в результате копирования возможно дублирование редукций
286 Часть II. Глава 11
редексов Е1. Эта проблема возникла, поскольку тело Х-абстрак-
ции ку.х не содержит у. Мы уже встречали эту ситуацию
раньше в контексте функций проецирования и, следовательно,
можем попробовать решить проблему, как это делалось прежде.
Так, мы можем редуцировать Х-тело, не имеющее вхождений
связанной переменной, к СЗНФ до применения его Х-абстрак-
ции к аргументу, поскольку знаем, что оно в любом случае
будет следующим редексом после такого применения. Тогда
редукция выражения (кх.Е)Е', где х не входит в Е, может
иметь вид
Таким образом, этот метод работает хорошо, а предварительное
вычисление Х-тела увеличивает эффективность в случае, если
рассматриваемая Х-абстракция является разделяемой. Однако
при этом вычислитель должен проводить некоторый анализ для
обнаружения того, что Х-тело не содержит вхождений связанной
переменной.
К сожалению, существует более общая проблема свободных
переменных, снижающая эффективность, для решения которой
указанный метод не годится. Рассмотрим последовательность
редукций:
(Хх.(Ху. +х у) 1 ) 2 —> (Ху. 2 у) 1^+2 1
Эти редукции показаны графически на рис. 11.14.
Проблема состоит в том, что копии тела Ху. -\-ху различны
для различных связей переменной х. Поэтому никакое разде-
ление невозможно и, что более серьезно, не существует фикси-
рованной последовательности инструкций, которую можно ис-
пользовать для генерации копий, что создает трудности при
компиляции копирующей подпрограммы. Важность этих заме-
чаний относится к компиляции функциональных выражений для
выполнения на абстрактной машине, имеющей графовую ре-
дукцию в качестве модели вычислений. Подробный пример того,
о чем было сказано, дает рассмотрение G-машины в гл. 15.
Итак, имеются ли какие-либо решения проблемы свободных
переменных? К счастью, ответом является «да». Есть два под-
хода, которые можно выбрать. Первый заключается в разра-
ботке механизма, обеспечивающего прямой доступ к свободным
переменным, т. е. такого, который поддерживает явный кон-
текст. Это приводит к абстрактной машине типа SECD-машины,
Введение в редукцию графов 287
рассмотренной в предыдущей главе. Альтернативный подход
заключается в том, чтобы некоторым образом преобразовать
явные свободные переменные при компиляции — их присутствие
становится неявно распределенным при вычислении. Один спо-
соб добиться этого заключается в трансляции %-выражений
Рис. 11.14. Проблема свободных переменных в редукции графов.
в комбинаторную логику — смотрите, например, [43] — и в оп-
ределении машины редукции графов для комбинаторных гра-
фов. Второй метод состоит в трактовке всех свободных пере-
менных как аргументов дополнительных Х-абстракций; этот
метод называется Х-поднятием и применяется так же хорошо
к вложенным функциям высшего порядка (со ссылками на гло-
бальные параметры) в традиционных функциональных языках.
Существуют также более сложные методы, например использо-
вание суперкомбинаторов [46], и мы рассмотрим /подходы,
основанные на использовании комбинаторов, с целью найти
эффективные реализации редукции графов в следующих двух
главах. Дополнительная выгода решения проблемы свободных
переменных этим путем заключается в устранении ненужного
копирования и дублирования редукций, что придает реализации
свойство так называемой полной ленивости.
11.5. Параллельная редукция графов
Читатель мог заметить, что при редукции графа выражения
вполне возможно присутствие в этом графе множества редексов
в любой момент времени. Вследствие прозрачности ссылок мы
288 Часть II. Глава 11
знаем, что эти редексы будут всегда вычисляться с одинаковым
результатом независимо ог того, где и когда это вычисление
имеет место. Поэтому вполне возможно вычислять их одновре-
менно, разместив на отдельных процессорах. Каждый процес-
сор может затем приступить к редукции соответствующих ре-
дексов, возможно генерируя новые редексы и, таким образом,
создавая новые параллельные задачи. Тот факт, что граф
теперь редуцируется несколькими процессорами одновременно,
означает, что существуют дополнительные факторы, включен-
ные в процессе редукции, такие, как представление и синхрони-
зация задач и предотвращение повторного вычисления одного
и того же редекса двумя процессорами. Однако эти проб-
лемы могут быть решены, и мы отсылаем интересующегося
читателя к работе [22] для более полного обсуждения этих
вопросов.
Хотя параллельная редукция графов находится в «детском
возрасте», она представляет очень интересный новый подход
к параллельным вычислениям. Во время написания этой книги
исследования по параллельной редукции графов и разработке
машины такой редукции активно проводились несколькими
группами во всем мире Машины, описанные в [27, 44, 54] и
[71], все являются или машинами чистой редукции графов,
или основываются в своих операциях во многом на принципах
редукции графов. Машина ALICE для выполнения редукции,
описанная в [27], была действительно сконструирована и на-
чала работать в феврале 1986 г.
Резюме
• Лямбда-выражения могут быть представлены в виде графов.
• Применение правил редукции i-исчисления к графовому
представлению % выражений называется редукцией графов.
• Разделение легко выражается с помощью графового пред-
ставления.
• Редукция графов естественным образом является ленивой;
следующий редекс находится с помощью спуска по левому
гребню графа, пока не будет найдена вершина функции.
• Лямбда-применения включают копирование графа тела функ-
ции, подстановку графов аргументов вместо связанных пере-
менных и замену вершины редекса результатом.
• Применения примитивных функций включают (рекурсивную)
редукцию строгих аргументов примитива и проведение затем
примитивной операции в соответствии с б-правилами.
• Функции проецирования возвращают немодифицированный
компонент своего аргумента; без специального рассмотрения
Введение в редукцию графов 289
они могут вызвать дублирование редексов и, следовательно,
повторное вычисление.
• Проблему функций проецирования можно решить с по-
мощью побочных вершин и/или путем редукции выбранного
компонента аргумента до замены редекса.
• Спуск по левому гребню графа может быть выполнен либо
с использованием стека, либо с помощью реверсирования ука-
зателей.
• Свободные переменные в телах функций могут явиться при-
чиной ненужного копирования; эта проблема может быть ре-
шена или с помощью контекста, или путем преобразования
в форму без свободных переменных.
• Редукция графов может быть параллельной, с помощью раз-
мещения отдельных редексов на отдельных процессах для вы-
числения.
Упражнения
11.1. Для каждого из следующих выражений:
(i) (кх.ку.у (kh.h х))7(Хх.х)
(ii) (kf.(ky.f z/))(Zx4_+2 х)3
(iii) (кТ.Т T)(kf .кх .f (f x))S 0, где S = kx. + 1 x
а) нарисуйте граф, представляющий это выражение;
б) пометьте каждую вершину графа и затем редуцируйте
граф к СЗНФ, указывая на каждом этапе, какие вершины яв-
ляются новыми и какие становятся потенциальным мусором.
Идентифицируйте вершину редекса для каждой редукции.
11.2. Допустим, что выражение cons х у представлено с по-
мощью специальной вершины:
cons
х У
как описано в тексте. Покажите редукцию нормального порядка
графа для выражения
(kg.(Zs. + i (hd s))(g( cons 4)))(kf.f nil)
11.3. Имея обычное определение У-комбинатора
У = kh. (кх. /г( х х)) (кх. /г( X х))
а) нарисуйте граф, представляющий Yf, используя разделе-
ние для представления самоприменения в теле У;
19 — 1473
290 Часть II. Глава 11
б) покажите путем последовательных преобразований гра-
фа, используя разделение, когда это возможно, что Yf = f( Yf).
11.4. Рассмотрев выражение Х-исчисления
Е = (ка. -|-((Хх.х )п)а) ((Ху.//) 7)
а) нарисуйте граф для £;
б) редуцируйте этот граф с помощью обычных правил ре-
дукции графов и покажите, что вычисление выражения (Ху.у)7
выполняется дважды;
в) покажите, как можно использовать побочные вершины,
чтобы избежать избыточности в этом примере.
11.5. а. Предложите конкретное представление каждого типа
вершин графа. Вы должны рассмотреть следующие типы вер-
шин: @-вершины; Х-вершины; идентификаторы; константы; вер-
шины типа tuple-n-, cons-вершины. Для выбранного вами пред-
ставления нарисуйте конкретный граф выражения tuple-3
Ckx.cons( -]-1 х))2.
б. Каковы преимущества и недостатки специального пред-
ставления tuple-З, предложенного в разд. 11.1?
11.6. Предложите, как можно модифицировать алгоритм редук-
ции графов, описанный в разд, 11.3, чтобы реализовать вычис-
ление аппликативного порядка.
41.7. Проследите редукцию выражения -|-(—3 1) ((Хх.х) 1)
а) используя стек;
б) используя реверсирование указателей.
Для случая (а) укажите состояние, которое должно запоми-
наться в стеке каждый раз при инициации вычисления аргу-
мента примитива. В какой степени верно, что полное состояние
вычисления хранится в графе при использовании реверсирова-
ния указателей?
Глава 12
КОМБИНАТОРНАЯ РЕДУКЦИЯ
В предыдущей главе была рассмотрена вычислительная мо-
дель редукции графов в контексте Х-исчисления и показано, как
редукция нормального порядка реализуется путем редуцирова-
ния самого левого из самых внешних редексов с помощью
правил преобразования графов, соответствующих правилам ре-
дукции в Х-исчислении. Кроме этого была сформулирована
проблема, затрагивающая эффективность данной схемы, кото-
рая возникает при наличии свободных переменных во вложен-
ной Х-абстракции. Наличие свободных переменных означает, что
каждое применение данной функции должно порождать копию
тела этой функции, чтобы связать эти переменные с соответ-
ствующими значениями.
В этой главе будет рассмотрена комбинаторная '> реализа-
ция и, в частности, редукция графов комбинаторных выраже-
ний. При таком‘подходе каждое Х-выражение преобразуется
в эквивалентное выражение, построенное только из применений
примитивных функций и комбинаторов, каждый из которых
является замкнутым выражением, т. е. выражением без свобод-
ных переменных. В основе такого преобразования поэтому ле-
жит функция, которая абстрагирует свободные переменные вы-
ражения, оставляя после этого цепочку применений комбина-
торов.
В разд. 12.1 мы коснемся теории, лежащей в основе этого
типа реализации, и рассмотрим так называемую комбинатор-
ную логику [26]. Теоретически только два комбинатора, назы-
ваемые S и К, требуются для представления любого Х-выраже-
ния, хотя результирующая реализация является неэффективной
из-за того, что требуется очень большое число таких комбина-
В данном контексте комбинаторная реализация — это реализация на
основе комбинаторов, а комбинаторная логика — логика на основе комбина-
торов. — Прим, перев.
19*
292 Часть II. Глава 12
торов (и связанных с ними применений). Однако можно ввести
дополнительные комбинаторы, уменьшающие сложность резуль-
тирующих комбинаторных выражений, и в разд. 12.2 мы пока-
жем, как некоторые из них увеличивают эффективность резуль-
тирующей реализации. Затем мы увидим, как различными
способами с помощью У-комбинатора могут обрабатываться ре-
курсивные определения. В графовой форме У имеет особенно
эффективное представление, ведущее к очень элегантной обра-
ботке произвольных рекурсивных определений; более того, ре-
курсия может выражаться подобным образом в других формах
редукции графов, которые были рассмотрены в предыдущей
главе. В заключение мы по-другому посмотрим на реализацию,
использующую фиксированный набор комбинаторов, и опишем
метод, основанный на так называемых строках направляющих.
Он дает интуитивное понимание того, как работают фиксиро-
ванные комбинаторы, а также предлагает более эффективный
путь их представления.
12.1. Основы комбинаторной логики
и редукция
Комбинатором называется Х-выражение, не содержащее сво-
бодных переменных. Например, функция тождества кх.х яв-
ляется комбинатором и обозначается обычно буквой I. Другим
примером является комбинатор фиксированной точки, введен-
ный в гл. 6 и определяемый следующим образом:
У = X/i. ((Хх. /г( хх)) (Хх. й( хх)))
Двумя следующими примерами являются вычеркиватель К, за-
даваемый в виде К — kx.ky.x, и распределитель S, задаваемый
S = Xf.Xg.Xx.fx(gx). (Заметим кстати, что они имеют имена К
и 5, а не С и D потому, что были придуманы в Германии1’.)
Теперь, как мы увидим, любое Х-выражение Е может быть
преобразовано в аппликативное выражение, т. е. в выражение,
построенное целиком на применениях функций, где, таким об-
разом, отсутствуют Х-абстракции. Чтобы добиться этого, нам
требуется по меньшей мере два комбинатора (функции) S и К
в качестве дополнительных констант, включенных в синтаксис
выражения. Фактически Х-исчисление и комбинаторная логика
(КД), определенная на этих комбинаторных выражениях, яв-
ляются эквивалентными в следующем смысле. Существует на-
бор аксиом (их можно найти в [43]), с помощью которого
*>) Здесь речь идет о первых буквах соответствующих немецких и анг-
лийских слов — Прим, перев
Комбинаторная редукция 293
устанавливается эквивалентность двух комбинаторных выраже-
ний Мкл и Nrji, обозначаемая Мкл = кл^кл- Подобным обра-
зом в Х-исчислении эквивалентность выражений, обозначаемая
=х, интерпретируется как рефлексивное транзитивное замыка-
ние правил преобразования, данных в гл. 6. Затем, если Екл
и Ек представляют одно и то же выражение в этих двух логи-
ках, то можно показать, что Мкл = кл^кл тогда и только тогда,
когда Afj, = лЛ^л- В этом смысле комбинаторная логика может
рассматриваться как модель Х-исчисления.
В нашем представлении мы будем также использовать тож-
дественный комбинатор I, хотя следует заметить, что его можно
выразить через S и К с помощью тождества I = SKK. Оно
следует из аксиом КЛ, и его легко проверить в Х-исчислении;
это упражнение мы оставляем читателю.
Выражения в комбинаторной логике имеют следующий син-
таксис:
{КЛехр) ::== {identifier) | {КЛехр) {КЛехр) | ({ЕЛехр}) | {соп)
{соп) ::= 112|... | + |-1 ...|S|K|/
Заметим, что единственным механизмом сочетания выражений
является применение функции — отсюда термин «аппликативное
выражение», используемый для обозначения выражений в КЛ.
Константы (комбинаторы) S, К и / определены следующими
правилами редукции:
5 е f g->e g(f g)
Kef -+e
I e
В этом синтаксисе каждое выражение находится в чисто аппли-
кативной форме и поэтому может быть представлено графом,
в котором единственным типом внутренних вершин являются
©-вершины. Строго говоря, в этом случае не существует Х-вер-
шин, но мы по-прежнему можем допустить существование вер-
шин конструкторов данных. Однако единственными правилами
редукции, работающими с такими вершинами, являются при-
менения функций конструкторов и селекторов. В первом случае
будет создана новая вершина конструктора, а применение селек-
тора представляется точно так же, как применение любой дру-
гой примитивной функции или комбинатора. Никакого копиро-
вания не выполняется, и единственным специальным действием
является оптимизация, которая меняет порядок выбора редек-
сов и может вводить вершины-синонимы, как мы описывали в
предыдущей главе. Поэтому нет необходимости специально рас-
сматривать вершины конструкторов данных. (Фактически мы
294 Часть II. Глава 12
можем получить чисто аппликативную структуру комбинатор-
ных графов с помощью представления функций-конструкторов
как специальных примитивных комбинаторов, которые приме-
няются к аргументам как любые другие комбинаторы (через
@-вершины), однако для таких комбинаторов нет правил ре-
дукции. Мы уже рассматривали эту возможность в начале пре-
дыдущей главы, и в подходе, предложенном в [80] для пред-
ставления списков, используется комбинатор спаривания Р.)
Итак, все что нам нужно сделать — это определить правила
преобразования графов, соответствующие применениям 5, К,
и /, и объединить их с правилами применения примитивных
функций, чтобы получить упрощенную функцию редукции гра-
фов. Как и в случае редукции графов, в результате будет полу-
чена реализация, которая естественным образом является лени-
вой в том, что в качестве очередного редекса для упрощения
всегда выбирается самый левый из самых внешних редексов.
Перед спецификацией этих преобразований графов мы по-
кажем, как Х-выражения можно транслировать в комбинатор-
ную форму. Эта трансляция выполняется путем последователь-
ного абстрагирования (выделения) переменных из подвыраже-
ний, и мы определим сначала функцию абстрагирования abs,
которая имеет то свойство, что для переменной х и комбина-
торного выражения Е
abs(x, Е)х = Е
Таким образом, если результат абстрагирования х из Е приме-
нить снова к х, то мы получим Е. Поэтому определяем abs сле-
дующим образом:
abs( х, х ) = /
abs( х, k ) = Kk, если — это константа (напри-
мер, S или К)
abs( х, у ) = Ку, если у — это переменная, не рав-
ная х
abs(x, Et, Е2) = Sabs( х, Ei)abs(x, Е2) для Л-выражений Е{, Е2
abs(x, (£)) — (abs(x, £)) для Л-выражения Е
Выражение abs(x, Е) часто записывают в виде [х]£. Поэтому,
например, можно записать третье правило для abs как
[х]г/ = /Су
Функция трансляции comb, отображающая Х-выражения в эк-
вивалентную комбинаторную форму, определяется теперь в виде
comb( v ) = v для переменной v
comb( с ) = с для константы с
comb( Хх.Е ) = [х] comb( Е) для выражения Е
combi Е\Е2) = comb( Ei) comb{E2) для выражения Ei, Е2
combi (£)) = ( comb{ Е )) для выражения Е
Комбинаторная редукция 295
Нетрудно показать, что эта трансляция корректна в том смысле,
что если комбинаторы S и К заменить в comb (Е) на опреде-
ляющие их ^.-выражения, то результат sub ( comb ( Е )) окажется
равным Е (с точностью до а- и p-преобразования). Это следует
из индукции по структуре Х-выражения Е, и единственная хит-
рость заключается в доказательстве того, что sub ( [х] •
comb (Е )) = Хх.Е для всех переменных х и Х-выражений Е.
Это доказательство дано в качестве упражнения в конце главы.
Рассмотрим в качестве примера процесса абстрагирования
комбинаторную версию выражения Хх. (Ху.-f-ху ). Применяя
функцию трансляции comb к этому выражению, получим
comb (Хх. (Ху. -f- ху))
— [х] comb (Ку. + ху)
= [х] [у] comb(+xy )
— [•*] [у] comb ( +х) comb (у)
— [х] [у] comb ( + ) comb (х)у
= М Ы + ху
= М S [у] ( +х) [у] у
= [х] S (S [у] + [у] X) /
= [x]S(S(tf+ )(Кх)) I
= S[x](5(S(tf+)Ux)))M/
= 5(S[x]S[x](S(tf+)(Ax)))(A7)
= S(S(KS)(S[x](S(tf+))[x](Kx)))(K7)
= S(S(KS)(S(S[x]S[x](X+))(S[x]K[x]x)))(K/)
==S(S(KS)(S(SUS)(S[x]tf[x] + ))(S(KK)/))W)
= S(S(KS)(S(S(tfS)(S(TO(K+)))(S(W/)))(tfZ)
Это удивительно сложный способ записи функции сложения
двух чисел. Гораздо лучшим, но таким же правильным пред-
ставлением было бы +’ Тем не менее давайте посмотрим, как
этот «плюс-комбинатор» можно редуцировать после применения
к аргументу, скажем 2. Мы будем использовать нотацию = >
для обозначения комбинаторной редукции или, другими сло-
вами, p-редукции, состоящей из произвольного числа шагов.
Некоторые шаги, мы опускаем, а некоторые из наиболее непо-
нятных подвыражений выделяем подчеркиванием.
S (S(KS)(S(S(KS)(S(KK)(K+)Y)(S(KK)I)H (ЕП 2
= > s(KS)(S(S(KS)(S(KK)(K+)))(S(KK)I))2((КП2)
=> KS2 (S (S(KS)(S(KK)(K+)))(S(KK)I)2) I
=> S(S(KS)(S(KK)(K+))2(KK2(I2)))I
= >S(KS2(S(KK)(K+)2)(K2))I
=>S(S(KK2(K + 2))(K2))1
=>S(S(K+)(K2)'II
296 Часть II. Глава 12
Это выражение представляет частичное применение функции +
к аргументу 2, т. е. +2. Заметим, как атом 2 «привязался»
к комбинатору К, ожидая применения ко второму аргументу,
после чего, как скоро увидим, он встанет на нужное место. То
же самое относится к константной примитивной функции +,
и в общем случае выражение, связанное со свободной перемен-
ной, становится первым (или единственным) аргументом при-
менения К- Таким образом, контекст распределен по графу вы-
ражения, а значения, связанные с переменными, соединены
с К-вершинами. Чтобы закончить пример, мы можем применить
комбинаторное представление частичного применения +2 к це-
лому 3 следующим образом:
S(S(K+)(K2))Z3==>S(K+)(K2)3(/3)
=> к + 3(К 2 3)3
= > +23
=> 5
Основная привлекательность комбинаторного подхода за-
ключается в его математической элегантности и простоте вы-
числений, вытекающей из наличия только трех правил преобра-
зования графов (исключая те, что связаны с примитивными
функциями). Поскольку наиболее естественная реализация
основана на редукции графов, модель вычислений является ле-
нивой, а так как отсутствуют переменные, то нет необходимо-
сти рассматривать вопрос об их именах и контексте. К сожале-
нию, даже очень простое k-выражение имеет сложный экви-
валент в КЛ и, хотя отсутствуют переменные, уменьшение
накладных расходов из-за отсутствия контекста эффективно
компенсируется необходимостью передавать выражения аргу-
ментов в качестве параметров. Таким образом, этот «сырой»
подход не применим на практике без оптимизации с целью по-
вышения эффективности. В следующем разделе мы найдем
такую оптимизацию путем расширения набора постоянных ком-
бинаторов S, К и I.
12.2. Оптимизация Карри и редукция
комбинаторных графов Тернера
Хотя сложность выражений КЛ, использующих только ком-
бинаторы S, К и /, является недопустимо высокой для приме-
нения таких выражений в жизнеспособном методе реализациц,
некоторые структуры подвыражений имеют гораздо более про-
стую эквивалентную форму (имеется в виду отношение экви-
валентности в КЛ — кл). Более того, если мы введем два до-
Комбинаторная редукция 297
полнительных комбинатора в фиксированный набор комбина-
торов, то гораздо большее число выражений можно упростить
с помощью соответствующих новых тождеств. Эти новые комби-
наторы называются композитором, обозначаемым буквой В,
и перестановщиком, обозначаемым С, и определяются в A-ис-
числении в виде В = Xf.XxXy.f ( х у ) и С = kf.kxXy.f у х. Сле-
дующие равенства выполняются в комбинаторной логике, имею-
щей примитивные комбинаторы S, К, I, В и С:
S(K £1)(К £2)=«лК(£1 £2)
S(K Е\)1
S(K £1)Е2
S £1 (Д’ £2)
=хл£1
=КЛВ £1 £2
=хлС £1 £2
(правило 1)
(правило 2)
(правило 3)
(правило 4)
Эти равенства были введены Карри [26], и каждое из них дает
правило для упрощения применения S. Первые два обеспечи-
вают основные улучшения, в частности свойство «полной лени-
вости», гарантирующее отсутствие повторных вычислений под-
выражений. Эти равенства можно получить, если обратиться
к эквивалентности между A-исчислением и комбинаторной ло-
гикой и показать, что левая часть каждого превращается с по-
мощью p-редукции в правую часть при подстановке вместо ком-
бинаторов соответствующих A-выражений, например:
S(K £1) (К £2) Ах.К £1 х(К Е2 х), где К обозначает Ax.At/.x
—>рАх.£1 (К £2 х)
—>рАх.£1 £2
= К(£1 £2)
Иначе, мы можем доказать экстенсиональную истинность ра-
венств непосредственно в комбинаторной логике; мы говорим,
что М экстенсионально равно AZ, если Мх = Nx для любого х,
т. е. поведение М и N как функций совпадает. Мы поэтому
применяем обе части каждого из предложенных равенств к про-
извольному КЛ-выражению, используем правила переписыва-
ния для соответствующих комбинаторов и получаем требуемое
доказательство. Так, для первого уравнения мы получили бы
для левой части
S(K £1)(К £2)X=>SK Ех Х(К Е2 X)
— >к Е\Е2
й для правой части
#(£1 Е2)Х = >КЕ1Е2
298 Часть II. Глава 12
(индексы у каждой стрелки означают используемый комбина-
тор). Эти оптимизирующие равенства можно легко встроить
в функцию абстрагирования, которая теперь определяется
в виде
[х]х = /
\х\у~Ку, если у — это константа или переменная, не равная х
[х] ЕгЕ2 = if [х] Е{ = КМ
then if [х] Е2 = I
then М
else if [х] Е2 = KN
then К (ММ )
' else ВМ [х] Е2
else if [х] E2 = KN
then С[х]£!#
else S [x] Ei [x] E2
[x] (E) = ([x] E)
для ^.-выражений Ei, E2, E.
Легче проиллюстрировать применение новой функции аб-
страгирования к Х-выражению, используя строгое, а не ленивое
вычисление, когда каждое Х-выражение имеет соответствующее
КЛ-выражение, причем любой порядок вычислений приводит
к одинаковому результату. Так, рассмотренный нами пример,
где мы транслировали Х-выражение Кх.Ку. ~\-ху в комбинатор-
ное выражение, содержащее только применения S, К и /, те-
перь имеет вид
сотЬ{ Кх.Ку. + х у ) = [х] [у] + х у (точно таким путем, как ранее)
= [х] + х (поскольку [у] (+х ) = Л(+х ), так
как [//] + =/(+, [i/]x = Кх и [у]у =
= 1)
= + (поскольку [х] + = К+ и [х] X = I)
Таким образом, мы действительно получили оптимальную фор-
му функции «плюс» в этом простом примере, используя только
правила оптимизации 1 и 2. Более сложный пример показан
в разд. 12.2.2, после того как мы определим правила преобра-
зования графов для применений комбинаторов. Перед этим
в следующих двух подразделах рассмотрим оптимальное свой-
ство улучшенной системы, которая еще более упрощает транс-
ляцию Х-выражений в комбинаторную форму, а также дальней-
шую оптимизацию Тернера.
12.2.1. Аппликативные подвыражения
В этом разделе мы установим важное свойство оптимально-
сти улучшенного представления Х-выражений с помощью фик-
Комбинаторная редукция 299
сированного набора комбинаторов. Это свойство сохранения
аппликативных подвыражений, для которого требуется только
первое правило оптимизации из предыдущего раздела и не тре-
буются дополнительные комбинаторы В и С. В неоптимизиро-
ванном представлении с использованием {5, К, 1} это свойство
отсутствует. Рассмотрим, например, выражение кх. + 1 2, кото-
рое транслируется в КЛ-выражение S( 5( К + ) ( К1 ) ) ( £2)
при применении comb. Компоненты постоянного подвыражения
+ 12 распределяются по этому КЛ-выражению. Однако при
применении первого правила оптимизации, приведенного выше,
результирующее КЛ-выражение принимает вид К ( + 1 2 ), ос-
тавляя подвыражение +12 без изменений. Сохранение посто-
янных подвыражений особенно важно в случае постоянных ре-
дексов, и именно оно способствует их разделению в процессе
вычисления выражения. В результате становится возможным
избежать повторного вычисления таких редексов. Это способ-
ствует «полной ленивости»; данный термин иногда используют
для обозначения того, что никакое вычисление не выполняется
больше одного раза при выполнении функциональной про-
граммы.
В действительности аппликативные подвыражения (опреде-
ленные в синтаксисе КЛ-выражений в разд. 12.1) сохраняются
в общем случае в оптимизированном комбинаторном представ-
лении. Так, для A-выражения кх. + у2 подвыражение +«/2
было бы сохранено при применении comb и не сохранилось бы
при трансляции Z-выражения ку. + г/2, где переменная у свя-
зана.
Сохранение аппликативных подвыражений не является сразу
очевидным и требует более формального доказательства. Дока-
жем сначала следующие две леммы:
Лемма 12.1. Для аппликативного выражения Е, в котором пе-
ременная х не является свободной,
[х]Е — К.Е
Лемма доказывается индукцией по'числу применений в выра-
жении Е. В базовом случае Е является или константой, или
неравной х переменной и утверждение леммы выполняется по
определению. Если Е = Е\Е2, то £i и Е2 оба имеют меньше при-
менений, чем Е, и не имеют вхождений х. Поэтому по предполо-
жению индукции
[x]£==S[x] £, Jx] £, = S( К£,) (К£2 ) = £(£, £2)==К£
Лемма 12.2. Если £' является подвыражением аппликативного
выражения £, то оно также является подвыражением [х] £ для
всех переменных х, не входящих в Е'.
300 Часть П. Глава 12
Лемма снова доказывается индукцией по числу применений
в выражении Е. Прежде всего если Е' — Е, то [х]Е = КЕ со-
гласно лемме 12.1. При этом лемма 12.2, очевидно, справедлива.
Этот случай является базовым, в частности когда Е — это кон-
станта или переменная. В качестве шага индукции рассмотрим
случай E = EiE2, где Е' =/= Е, так что Е' является подвыраже-
нием Ег или Е2. Без потери общности допустим, что Е' — это
подвыражение Et. Тогда по предположению индукции Е' яв-
ляется подвыражением [х]/^ и, следовательно, [х] Е =
= S [х] Е] [х]£2- Заметим, что если Е = (Е"), [х]Е = ( [%]£"),
и результат следует аналогичным образом.
Теорема 12.1. Если Е' является аппликативным подвыражением
Х-выражения Е, то Е' сохраняется при применении comb, т. е.
Е' встречается также в качестве аппликативного подвыражения
в comb(E).
Докажем эту теорему индукцией по структуре выражения Е.
Во-первых, если Е' = Е, тогда Е является аппликативным вы-
ражением, так что Е' = Е == comb(E), и в этом случае теорема
справедлива.
Базовый случай следует немедленно, так как если Е яв-
ляется идентификатором или константой, то оно само является
единственным своим подвыражением, т. е. Е' = Е.
В качестве шага индукции нам необходимо рассмотреть
только случай Е'=/=Е, при этом существуют три варианта:
Вариант 1. Е = EiE2
Если Е' = Е, тогда Е' должно быть подвыражением Е} или Е2.
Тогда по предположению индукции Е' является подвыражением
comb (Ei) или comb (Е2). Но
comb( Е) = comb{ ЕУЕ^ = comb{ Е{) comb( Е2),
так что Е' также является подвыражением cornb(E).
Вариант 2. Е — ( Е" )
Е' должно быть аппликативным подвыражением Е" и, следова-
тельно, является подвыражением comb(E") по предположению
индукции. Но так как comb (Е) = ( comb (Е" ) ), Е' является
также подвыражением comb(E~).
Вариант 3. Е = 1.x.Е"
Е' должно быть аппликативным подвыражением Е" и, следова-
тельно, comb(E") по предположению индукции. Но comb(E")
является аппликативным 'выражением, и, согласно лемме 12.2,
Е' является подвыражением comb ( Е) = [х] comb (Е").
Перед тем как закончить рассмотрение вопроса об опти-
мальных свойствах, следует заметить, что правило оптимиза-
Комбинаторная редукция 301
ции 2 моделирует трредукцию. Это следует из
comb{ Кх.Е х) = [х] comb[ Е х ] = [х] (comb( Е) comb( х ))
= [х] ( comb( Е) х) = S [х] comb{ £)[х]х
Но, если х не входит в £, то он также не входит в comb(E),
поэтому, согласно лемме 12.1, [xjcomb (Е) = К. comb (Е). Та-
ким образом,
comb(Kx.E x) — S(K comb(E)) / — comb(E) (по правилу 2)
что можно было также получить, если бы мы сначала выпол-
нили Хх.£х-^л£.
12.2.2. Правила редукции графов
для комбинаторных выражений
Аппликативное комбинаторное выражение может быть пред-
ставлено в виде графа, содержащего только ©-вершины, как
определено в предыдущей главе. Таким образом, нам осталось
только дать правила преобразования графов, соответствующие
применению каждого из примитивных комбинаторов, а именно
S, К, /, в и С.
Эти правила изображены на рис. 12.1, где правило, соот-
ветствующее комбинатору А, помеченодля A—I, К, S, В, С.
Прописные буквы £, G, X и У обозначают корневые вер-
шины подграфов, представляющих выражения аргументов, к ко-
торым применяется соответствующий комбинатор. Заметим, что
в правилах для 1 и К не создается новых вершин, так как вер-
шина редекса (верхняя ©-вершина) просто заменяется содер-
жимым корневой вершины X. Так, для I две исходные вершины
могут стать мусором, а для К четыре исходные вершины могут
стать мусором. В случае правила для S создаются только две
новые вершины (нижние ©-вершины), при этом верхняя ©-вер-
шина является первоначальной вершиной редекса и может
быть получено до трех «мусорных» вершин. Подобным образом
только одна новая вершина создается в каждом из правил
В и С.
Любой граф, представляющий частичное применение, т. е.
содержащий недостаточное количество ©-вершин для выполне-
ния редукции, находится в СЗНФ, например следующий граф
@
@
square
302 Часть II. Глава 12
Рис. 12.1. Правила преобразования графов при редукции применений комби-
наторов.
представляет функцию, которая при применении к аргументу п
дает в результате п -|- п2.
В случае правила для S-комбинатора подграф, обозначае-
мый X и представляющий последний аргумент, является разде-
ляемым, и это пока единственная ситуация, в которой вводится
разделение в рассматриваемой комбинаторной реализации. Од-
Комбинаторная редукция 303
нако мы уже видели, что 5 появляется в нескольких местах
в комбинаторных формах многих Z-выражений и, более того,
именно применения S моделируют fl-редукцию, т. е. применение
Х-абстракций. Таким образом, разделение подграфов аргумен-
тов было введено для основного типа редукции графов, и
поэтому из такой простой оптимизации правила редукции
для S можно ожидать соответствующего увеличения эффек-
тивности.
Давайте теперь рассмотрим в качестве более сложного при-
мера трансляцию Х-абстракции Хх. 4~2(—хЗ) и преобразования
соответствующего графа при редукции применения этой аб-
стракции к константе 4.
comb( Хх. + 2 ( —х 3))
— [х] comb ( +2 ( —х 3))
= [х](+2(-х 3))
поскольку аргумент
comb является аппли-
кативным выражением
= S[х] (-}-2) [х] ( —х 3)
— S(K( 4-2))(S[х]( —х)(КЗ)) поскольку 4-2 является
аппликативным выра-
жением
= S(K(4-2))(S(S(K-)/)(tf3))
= S(/C(4"2))(S — (/СЗ)) согласно правилу опти-
мизации 2
= S (/С( 4-2)) (С — 3) согласно правилу опти-
мизации 4
= В(4~2)(С — 3) согласно правилу опти-
мизации 3
Обозначив Х-абстракцию Хх. 4-2 (—хЗ) буквой А, примене-
ние А в константе 4 можно представить комбинаторным выраже-
нием В(-|-2)(С — 3)4 (формально, потому что comb (А 4) =
— comb (А ) comb (4) и comb ( 4 ) = 4).
Редукция этого применения представлена последователь-
ностью графов, показанной на рис. 12.2.
Этот пример иллюстрирует трансляцию в оптимизированную
комбинаторную форму и действие правил 'преобразования гра-
фов. Однако мы еще не рассматривали рекурсивные функции.
Мы сделаем это в разд. 12.3, где дан намного более сложный
пример редукции комбинаторных графов, который должен про-
яснить все введенные принципы. В заключение этого раздела мы
еще раз рассмотрим проблему свободных переменных, для ре-
шения которой предназначен в первую очередь подход, излагае-
мый в этой главе.
304 Часть II. Глава 12
9 3
г
Рис. 12.2. Комбинаторная редукция графа выражения Хх. + 2 ( — х 3).
12.2.3. Дальнейшие оптимизации-
Существует множество оптимизаций различной важности,
которые могут быть получены добавлением новых комбинато-
ров к набору Карри/Тернера; набор комбинаторов, определен-
ный в [81], содержит более двенадцати.
Коммутативные операторы
Сначала мы укажем очень простую оптимизацию, относя-
щуюся к коммутативным примитивным функциям и С-комбина-
тору. Она задается равенством Ср=клр для коммутативной
примитивной функции р. Это равенство можно проверить, как
и правила оптимизации Карри, используя эквивалентность
между КЛ и Х-исчислением, поскольку Ср = ^‘кхХу.р у х =
— ‘kx.'ky.p х у (так как р является коммутативной) --пр. По-
другому, для любых КЛ-выражений X и Y С р X Y =>с р Y Х=
= pXY, следовательно, Ср экстенсионально равно р. Эту опти-
Комбинаторная редукция 305
мизацию очень просто включить в функцию абстрагирования
abs при условии, что известно, какие примитивные функции
являются коммутативными. Посредством этого можно удалить
некоторые вхождения комбинатора С.
Многократное абстрагирование переменных
Более тонкая оптимизация касается последовательного аб-
страгирования нескольких переменных из выражения. Хотя
оптимизация Карри обычно дает компактные выражения при
абстрагировании единичной переменной из аппликативного вы-
ражения, это не относится к случаю последовательного абстра-
гирования нескольких переменных. Например, рассмотрим аб-
страгирование переменных х, у и z из аппликативного выраже-
ния EiE2, где Ei содержит вхождения х, у и г. Для выражения Е
обозначим через Е', Е", Е’" соответственно абстракции [х] Е,
[у] [х]Е, [z] [у] [х]£. Тогда получим последовательные абстра-
гирования:
[х] ЕгЕ2 = SE\E’2
[«Д = S(BSEf)£"
[г] [у] [х] £,£2 = S(B S(B(B S}E'{"^E''r
Размер выражения (т. е. общее количество комбинаторов в
нем), получающегося при абстрагировании из соответствующего
^-выражения п переменных, является в общем случае по край-
ней мере квадратом п. Этот взрывной рост размерности можно
уменьшить, если ввести новый комбинатор S', определяемый
следующим правилом:
S' k х у z = k(x z)(y z)
S' подобен S, за исключением того, что не затрагивает доба-
вочный терм, примененный к аппликации остальных трех тер-
минов. Теперь мы можем ввести еще одно уравнение в опреде-
ление функции абстрагирования, а именно:
[х] АЕ{Е2 = S'X[x] Ei [х] Е2, если х не входит в А.
Правильность этого уравнения можно доказать, применив обе
части к выражению X, что дает [X/x]AEiE2 слева и
А [л/х] Ei [Х/х] Е2 справа. Это одно и то же выражение, если А
не содержит х. (Вспомним, что [E/x]Ei означает Et, где все
свободные вхождения х заменены на Е; это не следует путать
с функцией абстрагирования, например [х]£.) Переменная с ис-
пользованием S' абстрагируется уже не из применения двух
термов, как раньше с помощью S, а из применения трех термов,
если она не входит в первый из них. Часто случается, что
20 — 1473
306 Часть 11. Глава 12
первый терм в виде постоянного выражения, включающего толь-
ко комбинаторы, появляется раньше в процессе абстрагирования
переменных, при этом S', конечно, можно использовать. Для
нашего примера в этом случае мы можем получить
[х] EtE2 = SE'E'
[у][х]Е1Е2 =S'SE"E"
[z][y][x] Е,Е2 = S' (S'S) Е”’Е2'
И если бы мы захотели абстрагировать четвертую переменную
w, то получили бы
W [z] [//] [х] Е{Е2 = S' (S' (S'S)) Е'"'Е""
Таким образом, видим, что размеры последовательных выраже-
ний, из которых были абстрагированы п переменных, теперь
линейны относительно п. Первое постоянное выражение просто
увеличивается на одно вхождение S' при каждом абстрагиро-
вании.
Далее, похожее усовершенствование можно ввести, когда
абстрагируемая переменная входит только в одно из подвыраже-
ний применения. Мы определяем модифицированные комбина-
торы В и С:
В' kxyz = kx(yz)
С' k х у z — k(x z)y
Отсюда вытекают следующие правила оптимизации, которые
можно сравнить с правилами Карри в начале разд. 12.2:
S( В А Е1)Е2=клВ'АЕ1Е2
В(А Ei)E2 =кл В'АЕхЕ2
С(В А Е{) Е2=кдС' AEiE2
Функции от нескольких аргументов
В гл. 6 мы уже видели, что функцию от более чем одного
аргумента легко выразить в эквивалентной карринговой форме.
Однако мы также рассматривали «кортежированные языки»,
где функции применяются к единичным аргументам, являющим-
ся кортежами, причем компоненты этих кортежей доступны че-
рез соответствующие функции-селекторы. Подобный подход
можно применить в комбинаторном представлении функцио-
нальных выражений, если ввести комбинатор «разборки кор-
тежа», определяемый
t/Дх) = /х
L7(xb ..., xn) = fxl(x2, ...,хп) (п^2)
Комбинаторная редукция 307
где (%1, хт) является сокращенной формой записи для вы-
ражения Ттх\ ... хт и Тт — это комбинатор кортежирования,
строящий m-кортежи (тп^1), эквивалентный функции
TUPLE-tn, введенной в гл. 6.
Теперь функция f, определяемая уравнением /( Х\,..., хп ) = е,
где переменные Хь ..., хп могут входить в е, имеет комбинатор-
ную форму
comb( f) — U( [xj (U( [х2] (...((/([х„] comb( е)))...))))
12.2.4 . Снова о проблеме свободных переменных
Одна из причин, побудивших нас заняться комбинаторными
реализациями функциональных языков, была обусловлена про-
блемой свободных переменных, рассмотренной в конце преды-
дущей главы. В этом разделе мы вновь сформулируем эту про-
блему, а затем сделаем вывод о том, является ли полученное
нами решение удовлетворительным.
Рассмотрим Х-выражение (Хх'.Ху.Е ) A iА2, где Аь А2 являют-
ся выражениями аргументов, а Е содержит х в качестве свобод-
ной переменной. Система редукции графов, рассмотренная в
предыдущей главе, требует создания различных копий графа
подвыражения ку.Е для различных значений Ai, связанных с х,
если Х-абстракция 'Кх.'ку.Е является разделяемой. Теперь данное
выражение транслируется в
comb( (Л.х.Л.//.Е) А[А2) = сотЫ кх.Ку.Е) comb( А[) cotnb( А2)
и если Х-абстракция Ъх.'ку.Е является разделяемой в охваты-
вающем выражении (как аргумент некоторой другой функции),
то также будет разделяемым подвыражение comb (Кх.Ку.Е)
соответствующего комбинаторного графа. Однако последнее вы-
ражение не будет копироваться при вычислении применений,
поскольку оно не содержит переменных и, следовательно, необ-
ходима только одна его версия. Единственный недостаток за-
ключается в большей сложности комбинаторного представления
по сравнению с представлением Х-исчисления. Нетрудно видеть,
что вывод о необязательности копирования справедлив в любой
ситуации, где разделяемая ^-абстракция, содержащая свобод-
ные переменные, применяется к различным аргументам, и мы,
таким образом, действительно решили проблему свободных пе-
ременных. Однако существует еще одна проблема, с которой
мы столкнулись в предыдущей главе не только в контексте
свободных переменных, — это проблема функций-проекторов.
Она возникает, если в рассмотренном примере Е = х, вследствие
чего %-абстракция становится проектором, возвращающим один
20*
308 Часть II. Глава 12
из своих подграфов аргументов без изменений. В этом случае
comb (/.x.l.y.x) — К, как и ожидалось, но К —это также проек-
тор, что следует из его правила преобразования графа. Таким
образом, проблема проецирующих функций также присутствует
в комбинаторных реализациях при применениях как К, так и I.
Возможные решения, предложенные в гл. 11, например исполь-
зование вершин-синонимов, также хорошо применимы и в дан-
ном случае.
12.3. Представление рекурсии
Как было отмечено в гл. 11, рекурсию можно представить
в вычислительной модели ленивой редукции графов с помощью
непосредственного применения У-комбинатора, который являет-
ся совершенно правильным Х-выражением. Для применения
этого метода в комбинаторной реализации мы должны были бы
использовать КЛвыражение, соответствующее Z-выражению
для У, т. е. comb ( Xft. (‘kx.h (хх ) ) ( Хх.й( хх ) ) ). Сложность ре-
зультирующего выражения чрезмерно велика даже для пред-
ставления, основанного на расширенном фиксированном наборе
комбинаторов, хотя при немногим более эффективном подходе У
выражается с помощью комбинатора W = Mi/kx.hxx, для ко-
торого определено новое правило редукции. Этот подход рас-
сматривается в упражнении в конце главы. Мы, таким образом,
отвергаем непосредственное использование У в форме Х-выра-
жения в качестве практического метода реализации рекурсии
из соображений эффективности и опишем вместо этого два аль-
тернативных подхода. Один из них использует У-комбинатор
в качестве примитива, вводя дополнительное правило преобра-
зования графов, включающее цикл. Он является одновременно
эффективным и общеприменимым. Другой также включает цик-
лические графы и является гораздо более простым, но менее
общим. Мы опишем его в первую очередь.
12.3.1. Рекурсия верхнего уровня
Рассмотрим набор взаимно рекурсивных определений вида
letrec fi = Еь
fi —
fn = En
in E
Комбинаторная редукция 309
Наиболее простой путь представления рекурсии в этих опреде-
лениях заключается в построении п графов для каждого тела
функции и в соединении любой дуги, направленной к одной из
функций, с корневой вершиной соответствующего графа. Более
точно, определяющее выражение функции ft обозначим тогда
каждая /у может входить любое число раз в £, в качестве сво-
бодной переменной (или, эквивалентно, как константа) для
корневая вершина
дуги, идущие к вершинам,
соответствующим вхождениям
f в ее собственное определяющее
выражение, перенаправлены к
корневой вершине графа
Рис. 12.3. Представление рекурсивной функции, определенной в виде f=...f... .
(1 i, j ^м). Таким образом, каждая f, может входить любое
число раз в соответствующее комбинаторное выражение
comb(Et). Граф, представляющий эту систему взаимно рекур-
сивных определений функций, является объединением п отдель-
ных графов, представляющих выражения £ь ..., Еп, в кото-
рых каждая дуга, направленная к вершине, представляющей
переменную //, перенаправлена к корневой вершине графа,
представляющего Е/. В случае единственного рекурсивного
определения функции структура результирующего графа пока-
зана на рис. 12.3.
В качестве конкретного примера рассмотрим выражение
letrec f — кх.cons x(g х),
g — кх.cons(* х x)(f x)
in f2
310 Часть II. Глава 12
Оно генерирует бесконечный список [2, 4, 2, 4, ...]. В комбина-
торной форме эти определения имеют вид1)
f = сотЬ( &х. cons x(g х)) = [х] ( cons x(g x)) — S cons g
g = [x] (cons {square x)(f x)) = S(B cons square) f
Эти выражения, таким образом, представляются в виде графа,
показанного на рис. 12.4.
square
Рис. 12.4. Представление пары взаимно рекурсивных функций.
Заметим кстати, что с учетом оптимизации из разд. 12.2.3,
комбинаторную форму функции g можно преобразовать в
S' cons square f.
На рис. 12.5 показано графовое представление определения
факториала, имеющее комбинаторную форму:
factorial = S (С( В cond( =2)) 2) (S * ( В factorial^ С — 1)“)}
(см. упражнения в конце главы). На рис. 12.6 показаны пре-
образования, выполняемые при редукции выражения factorials.
Помеченные вершины будут указаны дугами в графах на
рис. 12.6, который иллюстрирует применение факториала, пред-
ставленного графом рис. 12.5, к константе 3. Это константа
физически занимает только одну вершину, помеченную # на
рисунке, хотя иногда в целях упрощения графов она копируется.
Заметим, что на этапе (h) в последовательности редукции,
показанной на рис. 12.6, подвыражение С—13 не было бы ре-
дуцировано в ленивой реализации. Однако эта редукция в конце
концов необходима и была выполнена на раннем этапе только
для упрощения графов на рисунке.
!) Здесь выражение (* х х) заменено эквивалентным выражением
( square х ), где square — это примитивная функция возведения в квадрат.
Иначе комбинаторная форма g имела бы гораздо более сложный вид. —
Прим, перев.
Комбинаторная редукция 311
Рис. 12.5. Представление факториала с помощью комбинаторного графа.
Это представление рекурсии годится для плоского или не-
вложенного набора функций, определенных пользователем, но
рекурсивные вспомогательные функции (определенные в рекур-
сивных let- или where-предложениях) не могут быть непосред-
ственно представлены этим методом. Поэтому в таких случаях
мы обращаемся к общему методу, использующему У-комбина-
тор вместе с соответствующим новым примитивным правилом
преобразования графов.
12.3.2. Эффективное представление рекурсии
с помощью Y-комбинатора
Мы видели в гл. 6, как любое рекурсивное выражение, за-
писанное на функциональном языке, можно выразить в Z-исчис-
лении с помощью У-комбинатора. В частности, если функция F
определена без использования квалифицированных выражений
в виде f(x) = E, где Е — это выражение, содержащее вхожде-
ние f, тогда f является наименьшей фиксированной точкой ^-вы-
ражения Эф.Кх.Е, т. е. f = У (kf.kx.E). Таким образом, f имеет
эквивалентное комбинаторное выражение У[/] [x]comb(E), так
как comb( У) = У.
Подобным образом предположим, что f определена с исполь-
зованием рекурсивного квалифицированного выражения, на-
пример
f = Кх. letrec g = Ei in Е2
где g входит в £i, f входит в Е2 и х входит в оба выражения
Е\ и Е2. Поскольку g рекурсивна, выражение, определяющее
312 Часть II. Глава 12
<Ч@ 3' (3)— (2) а граф 0 функции factorial, примененный к 3 ^3' @ @ В cond » 2 в редукция графа, помеченного * В (1 С' редукция графа, помеченного + * 3' с' (1) (2) \\*з * ""/'Г1) В*^ б S - редукция 2 2 cond @ ^3' 2 г В - редукция ~^з' > 1 д (1> 3*
В - редукция
Комбинаторная редукция 313
граф выражения Factorial (3) после вычисления
предиката функции cond
конец редукции factorial 2
6
о
конец последовательности редукций
Рис. 12.6. Последовательность комбинаторных графов при редукции выраже-
ния factorial 3.
314 Часть II. Глава 12
ее с помощью У, имеет вид: g = YLg.Ei, так что f определяется
в виде f — YXf.'kx. (Lg.E2) ( YTg.Et). Таким образом, комбина-
торная форма f имеет вид:
combi f) = У [f ] М ([g] comb(E2))(Y[g] combi£1))
Взаимная рекурсия может ^ыть представлена последователь-
ным выражением определенных функций в нерекурсивной фор-
ме (с помощью У) и подстановкой в определяющие выражения
всех других функций из набора. Однако при этом подстановка
выполняется для каждого вхождения имени функции в правую
часть каждого уравнения (кроме собственного уравнения этой
функции). Таким образом, в правых частях уравнений может
появиться несколько вхождений У. Например, два определения
f=...f...g...
g= ...f ...f ... g . . .
были бы преобразованы в нерекурсивную форму
f = YLf. ...f ...iYLg. ... YXf.E ... YLf.E ... g ...)...
g=yZg. ... (yZf.E) ... iYKf.E) ...g ...
где E = ... f ... g ... .
Другой метод, описанный в гл. 6, заключается в помещении
взаимно рекурсивных функций в единственный рекурсивный
кортеж с доступом к отдельным функциям с помощью функций
индексирования кортежа. Мы могли бы использовать здесь ана-
логичный метод, при этом абстрагирование происходило бы без
затруднений. При отсутствии семейства функций кортежирова-
ния TUPLE-n и функции индексирования INDEX можно было
бы обратиться к комбинатору разработки кортежа U, опреде-
ленному в разд. 12.2.3. Если мы имеем набор взаимно рекур-
сивных определений вида
letrec = Еъ
f2 =
in Е
то упаковываем Et в кортеж, который в комбинаторной форме
можно выразить с помощью U. Мы поэтому получаем опреде-
ление
(Л, ...,f„) = (£b ... ,Еп)
Комбинаторная редукция 315
и можем записать это равенство в виде
(Л, ...,/„) = [/(хл.(^(^2.(--.(^(^-(£1, ...
..))))(Л, ..-.fn)
следовательно,
(fb ...J„) = y(t7(^1.(t/(^2.(...((7(^„.(Eb ...,EJ)) ...)))))
Из определения комбинатора кортежирования Тп в разд. 12.2.3
можно вывести комбинаторную форму кортежа следующим об-
разом:
combi (e!t ..., еп)) = combi Тпех ... еп)
= Tncomb( в]) ... combi еп)
= (combi е J, .. ., combi еп))
для произвольных выражений eh ..., еп и п^1. Следова-
тельно, мы получим
comb( ...,fn)) = Y(U( [f,] (U( [f2] ( ... (Щ [f J (comb{ Ex), ...
..., combi £„))))• ••)))))
Правая часть этого определения имеет п вхождений U и
только одно вхождение Y. В рассмотренном нами примере,
Рис. 12.7. Правило преобразования графа для применения У.
предположив для простоты, что правые части уравнений яв-
ляются аппликативными выражениями, получаем намного более
простую комбинаторную форму
combiif, g)) =
-YiUi[f]iUi[g]i...f...g..., ...f...f...g...)))))
Теперь осталось определить эффективное преобразование графа
для представления применения У-комбинатора. К счастью, это
нетрудно сделать. Такое определение вытекает из определения
фиксированной точки, т. е. для любого Х-выражения X имеем
YX±=XiYX) = XiXiX ... XiYX)
Таким образом, циклический граф обеспечивает корректное
представление, как показано на рис. 12.7.
316 Часть II. Глава 12
Единственным вопросом, который можно теперь задать, яв-
ляется: действительно ли это представление наименьшей фикси-
рованной точки X? Ответом будет «да», но строгое доказатель-
ство этого утверждения выходит за рамки этой книги. Однако
заметим, что в семантическом домене Х-выражений (смот-
рите приложение Б) наименьшей фиксированной точкой (ве-
личины, обозначаемой X) является предел бесконечной последо-
вательности, получаемой повторяющимся применением X к не-
определенному элементу, т. е. Хотя ясно, что циклический
граф для YX представляет Х°°, он не имеет _1_, так что мы не
можем немедленно заключить, что он представляет наименьшую
фиксированную точку X.
Если рекурсивная функция f имеет определяющее комбина-
торное выражение YF, то выражение fk для выражения k
(которое мы для простоты считаем константой) имеет графо-
вое представление:
Следующее преобразование графа определяется структурой
подграфа, представляющего F. Результирующий граф будет со-
держать дуги, направленные к вершине, помеченной f, что
навсегда сохраняет цикличность, т. е. У никогда не будет при-
менен снова.
На этом заканчивается наше обсуждение реализации редук-
ции графов с помощью фиксированного набора комбинаторов.
Этот подход является, несомненно, математически элегантным,
устраняет проблему свободных переменных и может быть реа-
лизован относительно эффективно. Набор комбинаторов Тер-
нера делает данный подход жизнеспособным для некоторых
практических реализаций функциональных языков, а различ-
ные дальнейшие расширения этого фиксированного набора ком-
бинаторов привели к значительному повышению эффективности.
Проблемой, неотъемлемо присущей данному подходу, является
небольшой размер структурного элемента вычислений. Размер
структурного элемента является мерой сложности примитивных
операций, т. е. применений фиксированных примитивных ком-
бинаторов при выполнении редукции графов. Так, этот размер
предельно мал в случае {S, К, 1} — представления, и это приво-
дит к чрезмерно большим накладным расходам при вычисле-
нии. Размер структурного элемента остается маленьким, даже
когда мы расширяем набор примитивных комбинаторов, и аль-
Комбинаторная редукция 317
тернативный подход заключается в генерации более сложных
комбинаторов, «сделанных на заказ» для конкретных вычис-
ляемых выражений. Такие комбинаторы генерируются компиля-
тором и приводят к реализации, основанной на переменном на-
боре комбинаторов, которую мы обсудим в следующей главе.
12.4. Строки направляющих
Для читателя, незнакомого с идеей комбинаторов, общий
комбинаторный подход мог показаться чем-то необычным и
даже «мистическим» по природе. При первом чтении часто
очень тяжело увидеть, что в действительности происходит в про-
цессе абстрагирования и позднее, когда результирующие ком-
бинаторные выражения применяются к аргументам. Существует
однако интуитивная интерпретация правил редукции при при-
менении фиксированных комбинаторов, которая служит не
только объяснению того, что достигается с помощью комбина-
торов, но также естественным образом предлагает альтернатив-
ное и более эффективное представление комбинаторных выра-
жений. Первоначальная идея изложена в [56], хотя более де-
тальное обсуждение вопросов реализации можно найти в [76].
Сначала давайте рассмотрим снова выражение SE\E2, т. е.
применение комбинатора S к двум комбинаторным выражениям
Ei и Е2. Данное выражение можно рассматривать как помечен-
ное применение Ei к Е2, при этом пометка отражает присут-
ствие S-комбинатора. Такое помеченное применение мы пред-
ставим в виде графа.
(Причина выбора пометки ~ скоро станет ясна.)
Подобным образом мы помечаем граф применения СЕ1Е2
символом /, чтобы отразить тот факт, что применяемым ком-
бинатором является С, и получаем
Для В мы выбираем пометку \, поэтому граф, представляющий
выражение BEiE2, имеет вид
318 Часть II. Глава 12
При сравнении этих графов с теми из разд. 12.2.2, которые по-
лучены при применении правил, соответствующих комбинато-
рам, когда три выражения применяются к аргументу X, все
вдруг становится понятным. Пометки @-вершин в этих графах
можно рассматривать как механизмы подачи аргументов. Дру-
гими словами, когда выражение с помеченной корневой (^-вер-
шиной применяется к X, метка определяет, каким образом X
должен проходить через эту @-вершину: ''-пометка соответ-
ствует S-комбинатору, подающему х и к подграфу функции,
и к подграфу аргумента; /-пометка соответствует Скомбина-
тору, подающему х только к подграфу функции и оставляю-
щему подграф аргумента без изменений, и \-пометка соответ-
ствует S-комбинатору, подающему х к подграфу аргумента и
оставляющему подграф функции без изменений. Эти пометки
называются направляющими по очевидным причинам. Для пол-
ноты картины нам также требуется направляющий, соответ-
ствующий /(-комбинатору, который отбрасывает приходящий
аргумент; это требуется, когда на связанную переменную нет
ссылок в теле функции, как в случае, например,
Хх. 4- 1
Граф для этого выражения выглядит следующим образом:
+ 1
Конечно, цель подачи аргумента через граф заключается
в том, чтобы поставить аргумент на предназначенное ему место,
т. е. туда, где он должен был бы оказаться при использовании
обычной p-редукции. Таким образом, нам требуется специаль-
ный тип вершины, который действует как «отверстие», куда
помещается любой входящий в эту вершину аргумент, что со-
ответствует, как можно ожидать, /-комбинатору в эквивалент-
ном комбинаторном графе. В качестве простого примера рас-
смотрим выражение Хх.хх. Как читатель может проверить, оно
имеет комбинаторное представление S / / и, следовательно, аль-
тернативное графовое представление, использующее направляю-
щий ~ и /:
I I
Применение этого графа к выражению аргумента Е приве-
дет к тому, что Е будет подано по обеим дугам, исходящим из
Комбинаторная редукция 319
©-вершины и заменит собой два вхождения 1. Это даст выра-
жение ЕЕ, как и ожидалось.
Хотя направляющие работают вполне удовлетворительно
в случае единственной связанной переменной, ясно, что в слу-
чае многих связанных переменных и, следовательно, многих
входящих аргументов одного направляющего в каждой ©-вер-
шине недостаточно. Причина этого в том, что направления дви-
жения каждого входящего аргумента различны, так как каж-
дый аргумент требуется поместить в свою висячую вершину
графа. Для решения этой проблемы мы должны пометки в каж-
дой вершине заменить строками направляющих. Направляющий
в начале строки указывает, куда нужно послать первый аргу-
мент; следующий направляющий указывает, куда должен быть
послан второй аргумент и т. д. Для иллюстрации этого меха-
низма рассмотрим следующий пример:
'кх.'Ку. * ( + х х)у
Граф этого выражения, содержащий строки направляющих
в каждой ©-вершине, имеет вид
Теперь допустим, что первый аргумент (х) пришел в корневую
вершину графа. Первый направляющий / (т. е. первый направ-
ляющий в строке / \) направит этот аргумент по левой дуге,
исходящей из данной ©-вершины. По этому пути он войдет во
внутреннее применение функции +, где заменит оба вхожде-
ния I. Второй входящий аргумент теперь подчиняется направ-
ляющему \ (второй направляющий в строке/() и таким обра-
зом немедленно заменяет верхний I. Поскольку этот аргумент
никогда не будет передан по левой дуге корневой ©-вершины,
только один направляющий требуется для каждой ©-вершины
левой ветви. Поскольку существует только две связанные пере-
менные, для каждой строки требуется не более двух направ-
ляющих.
Мы можем выразить эффект направляющих более формаль-
но, дав правила редукции, соответствующие произвольной
320 Часть II. Глава 12
строке направляющих did2 dn в графе выражения вида
который мы представляем в виде выражения
( ®dtd2 ... dn^^2^X
Правила редукции выражаются рекурсивно с помощью записи
выражений, полученных для каждого возможного направляю-
щего в начале строки, следующим образом:
(@Л d ... d E\E‘2')X==@d ... d ( ^1X ) ( ^2X )
( ®!d ... d = ®d ... d ( E\X ) ^2
( ®\d2 ... d^l^Z^ ~ ®d2 ... dn^l(. ^2X )
(®-d2 ... dn^\^2^X~®d2 ... dn^^2
Кроме альтернативного представления графов фиксированных
комбинаторов, направляющие также дают нам понимание того,
как функция трансляции comb из разд. 12.1 для фиксирован-
ных комбинаторов может правильно моделировать р-редукцию.
Коротко говоря, функция трансляции удаляет (абстрагирует)
переменные из выражений, оставляя после себя что-то вроде
«маршрутной карты», закодированной в форме комбинаторов,
которая описывает, как входящий аргумент может быть пере-
дан обратно в первоначальную позицию (или позиции) абстра-
гированной переменной. Таким образом, из практики становится
ясно, почему только фиксированное число комбинаторов яв-
ляется теоретически необходимым: существует только фиксиро-
ванное множество путей, выходящих из каждой вершины графа.
Более того, появляется интуитивное понимание оптимизаций из
разд. 12.2, где вводятся комбинаторы В и С: если мы посылаем
аргумент по обеим ветвям @-вершины (S) и затем в одной из
ветвей отбрасываем его (К), то в качестве оптимизации его
вообще можно не посылать по ветви К, а вместо этого напра-
вить аргумент только туда, где он необходим.
Как читатель мог заметить, другим интересным свойством
строк направляющих является то, что они сохраняют первона-
чальную структуру графа (конечно, с удаленными %). Инфор-
мация, которая в другом случае заключена внутри сложного
Комбинаторная редукция 321
комбинаторного выражения, теперь содержится в первоначаль-
ных ©-вершинах в виде пометок. Это особенно важно с точки
зрения памяти: поскольку существуют только четыре типа на-
правляющих, каждый из них можно закодировать двумя би-
тами. Строка направляющих может быть сформирована из
«слов», содержащих число бит, кратное двум с возможным ме-
ханизмом связывания, обеспечивающим увязывание в цепочку
нескольких таких слов для запоминания длинных строк направ-
ляющих. Иначе необходимо установить предел числа «вложен-
ных» связанных переменных, необходимый для того, чтобы
строка направляющих могла разместиться в одном слове.
Строки направляющих, таким образом, ведут себя подоб-
но оптимизированным фиксированным комбинаторам. Действи-
тельно, сами строки можно рассматривать как явные комбина-
торы с помощью простого изменения соответствующих графов:
@<мг л @
где Cdld2...dn—это некоторый комбинатор. Правила редукции
для неявного набора комбинаторов
{СаЛ...4п|^еГ, /, \, 1
являются при этом простым перевыражением четырех (рекур-
сивных) правил редукции, данных выше. Например,
С/\а b с d = {a c)(b d)
Хотя теоретически величина п здесь неограниченна, на прак-
тике п может быть ограниченна. При этом неявный набор ком-
бинаторов сам будет «фиксированным» и конечным.
Резюме
• Аппликативные выражения можно эффективно реализовать,
не имея проблем со свободными переменными.
• Комбинаторная логика (КЛ) обеспечивает модель Л-исчис-
ления, в которой выражения являются аппликативными и стро-
ятся с помощью только S- и К-комбинаторов (вместе с кон-
стантами) .
• КЛ-выражения очень сложны, но могут быть оптимизиро-
ваны с помощью тождеств Карри и введения комбинаторов
В и С.
21 — 1473
322 Часть II. Глава 12
• С помощью первого из этих тождеств постоянные подвыра-
жения в Х-выражении могут быть сохранены (при трансляции
в КЛ), что способствует разделению и содействует ленивости.
® Дальнейшие улучшения можно получить с помощью введе-
ния дополнительных комбинаторов в этот набор.
® Рекурсия может быть реализована с помощью циклических
графов или с помощью У-комбинатора, который представляется
указателем из вершины на саму эту вершину.
• Направляющие дают модель комбинаторной редукции, в ко-
торой поток аргументов комбинаторов через граф представ-
ляется явным образом.
Упражнения
12.1. Преобразуйте следующие Х-выражения в S-K-7-комбина-
торную форму:
а) Хх. + х 1
б) Хх. х (Хх. х) 1
в) Хх. cond (= х 0) 1 (— х 1)
12.2. Докажите четыре тождества Карри для расширенного на-
бора комбинаторов S, К, I, В и С. Преобразуйте выражения из
упражнения 12.1 в оптимизированный комбинаторный код.
12.3. Имея следующие определения:
Х==(Хх.Х^.г/(х х z/))(Xx.Xr/.z/(x х у))
S — Xx.ky.hz.x z(y z)
B — kx.'ky.'kz.x (у z)
К — Хх.Хг/.х
а) покажите, что X является оператором фиксированной
точки;
б) докажите, что SKK = /, показав, что I является нормаль-
ной формой SKK в Х-исчислении, или с помощью правил редук-
ции для применений S и К, предполагая экстенсиональность
в КЛ.
в) покажите, что S ( KS ) К~ В.
12.4. Для комбинаторного выражения Е и переменной X дока-
жите индукцией по аппликативной структуре Е, что
sub( [х] Е) =а> р Хх. sub (Е)
где sub(E) обозначает Х-выражение, полученное из Е заме-
ной S, К и I на соответствующие Х-выражения. Следовательно,
Комбинаторная редукция 323
покажите, что
sub( [х] combf Е)) =а> р кх. Е
и что
sub( comb( Е)) =а, р Е
12.5. Модифицируйте функцию абстрагирования переменных
abs, чтобы включить в нее оптимизацию, которая использует
комбинатор S' вместо S при абстрагировании из тройного при-
менения всякий раз, когда это возможно. Выполните дальней-
шую оптимизацию abs, включив в нее В'и С'подобным образом.
12.6. Имея определение У-комбинаторов в Х-исчислении,
а) нарисуйте графовое представление Yf, используя разде-
ление для представления самоприменения в теле У;
б) покажите, что Yf — f(Yf) последовательным преобразо-
ванием графа.
12.7. Имея определение
factorial ri) = cond( = 2 п) 2 ( * n( factorial — n 1)))
а) покажите, что эквивалентное комбинаторное определение
имеет вид:
factorial = S(C(B cond( =2)) 2) (S * (В factorial^ С — 1)))
б) покажите, что эквивалентное нерекурсивное определение
имеет вид
factorial — Y(B(S(C(B cond (=2))2))
(B(S*)(C B(C-l))))
в) покажите последовательность редукции графов для вы-
числения выражения factorials, где factorial представляется
выражением, данным в б.
12.8. Комбинатор W определяется правилом редукции Whx =
— hxx.
а. Преобразуйте W в оптимизированную комбинаторную
форму (используя комбинаторы S, К, I, В, С) и покажите ре-
дукции графа, соответствующие вычислению выражения W-j-2.
б. Определите удобное примитивное правило преобразова-
ния графа для W, используя разделение.
в. Нарисуйте граф для E = S(BWB)(BWB).
г. Покажите, что Е эквивалентно У, проиллюстрировав, что
из графового представления для Ef с помощью последователь-
ных преобразований можно получить графовое представление
f(Ef).
21*
324 Часть II. Глава 12
12.9. Разработайте абстрактный алгоритм для генерации строк
направляющих из произвольного выражения чистого Х-исчис-
ления. (Подсказка: используйте функцию FV, данную в гл. 6,
которая возвращает набор свободных переменных для задан-
ного выражения.)
12.10. а. Рассмотрим выражение Xx.X.t/,7. Тело этого выражения
не может быть помечено направляющим «—», поскольку в нем
отсутствует @-вершина. Предложите метод решения проблемы.
б. Почему направляющие «—» встречаются только в кор-
невой вершине подграфа, представляющего Х-абстракцию?
12.11. Нарисуйте граф Х-выражения для У-комбинатора, содер-
жащий строки направляющих в каждой @-вершине.
Глава 13
НОВЕЙШИЕ КОМБИНАТОРНЫЕ РЕАЛИЗАЦИИ
Привлекательность комбинаторных реализаций в том, что
в этом случае все вычисляемые выражения находятся в чисто
аппликативной форме, фактически в константной аппликатив-
ной форме (КАФ), означающей аппликатнвную форму без пе-
ременных. Так, при редукции комбинаторных графов имеют
место только два типа преобразований, представляющих при-
менение комбинатора или примитивной функции к подвыраже-
нию, которое также находится в КАФ. Каждый комбинатор
является поэтому «чистой» функцией в том смысле, что его
применение зависит исключительно от значений его аргументов
и не зависит от значений любых свободных переменных его
тела. Таким образом, каждый комбинатор можно рассматривать
как константу в точности так же, как это имеет место с любой
примитивной функцией, например +•
В этой главе мы собираемся рассмотреть совершенно дру-
гой подход к комбинаторам, при котором каждое Х-выражение
транслируется в КАФ с использованием уникальных комбина-
торов, генерируемых непосредственно из рассматриваемого
Х-выражения. В результате для разных программ генерируется
не фиксированный набор, например такой, как описанный в
предыдущей главе набор Тернера, а различные наборы комби-
наторов. Причем, несмотря на то, что набор имеющихся у нас
комбинаторов теперь неограничен, преимущества комбинатор-
ного подхода сохраняются. Каждый комбинатор является
чистой функцией, и потому может рассматриваться как кон-
станта. Все выражения находятся в КАФ, так что реализация
по-прежнему свободна от контекста. Фактически преимущества
нового подхода перед подходом, использующим фиксированный
набор комбинаторов в том, что каждый генерируемый комби-
натор определенно будет «больше» фиксированных комбинато-
ров, поэтому выполнение одного и того же объема работ
потребует в данном случае меньшее количество применений
326 Часть II. Глава 13
комбинаторов. И мы говорим, что размер структурного эле-
мента каждого комбинатора увеличен.
Простейшее преобразование данного типа называется 1-уда-
лением и заключается в удалении свободных переменных из
каждого 1-тела, в результате чего получается один новый ком-
бинатор. Однако такое решение не дает максимально возмож-
ной эффективности, поскольку число применений в результи-
рующих выражениях (и, следовательно, число редукций гра-
фов, требуемых в процессе вычисления этих выражений) можно
уменьшить, а размер структурных элементов комбинаторов —
увеличить. Еще более серьезный недостаток состоит в том, что
полная ленивость может быть утрачена, и при этом возникает
вероятность, что в процессе вычисления выражения одно и то
же подвыражение будет вычислено более одного раза.
В разд. 13.2 описывается модификация простого 1-удаления,
основанная на так называемых суперкомбинаторах. При этом
подходе удаляются целые подвыражения, содержащие свобод-
ные переменные, а не сами свободные переменные, и сохра-
няется полная ленивость. Более того, увеличивается сложность
суперкомбинаторов, что в конечном счете ведет к уменьшению
числа требуемых применений функций. Предложения по даль-
нейшей оптимизации суперкомбинаторной реализации даны
в разд. 13.3.
Наконец, в разд. 13.4 мы рассматриваем реализацию, раз-
работанную в самое последнее время. Она основана на кате-
гориальной комбинаторной логике. Абстрактная машина для
комбинаторной редукции этого типа, называемая категориаль-
ной абстрактной машиной (КАМ), основана на прочном мате-
матическом фундаменте, способствующем достаточно высокой
степени оптимизации. Интересно, что ее работа описывается
в терминах переходов между состояниями, что очень напоминает
операционную семантику SECD-машины.
13.1. Абстрагирование свободных
переменных простым 1-удалением
Простейшая схема абстрагирования «вынимает» (удаляет)
свободные переменные из одного 1-тела за один шаг. 1-Аб-
стракция при этом заменяется частичным применением нового
комбинатора, имеющего на один параметр больше числа аб-
страгированных свободных переменных. Этот «дополнительный»
параметр соответствует связанной переменной 1-абстракции.
Для иллюстрации этой идеи рассмотрим 1-абстракцию L =
*’ В оригинале 1-lifting. — Прим. ред.
Новейшие комбинаторные реализации 327
= l.x. Е, где Е является аппликативной формой. Допустим, что
набор свободных переменных выражений Е, т. е. FV(E), имеет
вид vn}. Теперь определяем комбинатор а так, чтобы
av\v2 . vnx — Е, а после этого можем заменить L выражением
aViV2 ... vn поскольку для любого выражения аргумента Е'
имеем LE'— aViV2 VnE' в любом контексте, где о, связано
с выражением Vt а х связан с Е'. Рассматривая
комбинатор а в качестве нового примитива, можно считать, что
мы успешно заменим Х-абстракцию L аппликативным выраже-
нием. Получив новый комбинатор а, необходимо теперь опре-
делить правило преобразования графа, соответствующее при-
менению а к п+1 выражению аргументов. Это правило яв-
ляется контекстно-независимым по конструкции, в результате
чего а становится таким же, как любой другой комбинатор,
например S, К, I и т. д. Само правило должно быть определено
исключительно в терминах применений, включающих выраже-
ния аргументов, примитивных функций и предварительно опре-
деленных комбинаторов. Таким образом, имеется возможность
преобразовать все выражения в КАФ с помощью удаления пе-
ременных из самой внутренней Х-абстракции и продвижения по
направлению к внешним %-абстракциям. После каждого такого
шага в преобразованное выражение связанная переменная
больше не входит. В конце концов после удаления всех пере-
менных мы приходим к замкнутому выражению. Эта операция
удаления переменных выполняется с помощью функции lift,
которая отображает открытые Х-выражения в чисто апплика-
тивные выражения. Она определяется следующим образом:
lift( Е) = Е если Е в аппликативной форме
lifi( Кх.Е ) = aoi ... vn если Е — это аппликативное выражение,
причем FV(Kx.E) ~{vi ... оп},
где а определен в виде «гц ... vnx = Е
lift( 1.x. Е) = li t( 1.x.lift( Е )), если Е — это не аппликативное выражение
lift( Е\Е2 ) = lift( Ei ) hft( Ег) для Л-выражений Е\, Е2
hft( (Е)) = (И t(E)) для Л-выражений Е
Более общая функция Х-удаления определена в разд. 13.3.4.
Она удаляет свободные переменные из нескольких вложенных
Хгрыражений одновременно.
Для иллюстрации механизма Х-удаления рассмотрим сле-
дующую функцию (см. [46]) выбора n-го элемента из задан-
ного списка*
element — ‘kn.ks. cond( —п \)(hd s) (eletnent( —n 1 )(tl s))
Рекурсия (которую можно было бы выразить с помощью
вставки данного определения в letrec-выражение) выражается
328 Часть П. Глава 13
явно с помощью У-комбинатора следующим образом:
element = Y(Xel.kn. ks.cond(—nl)(hd s)(el(—n l)(tl s)))
Покажем сначала с помощью алгоритмического описания, как
удалением переменных из самой внутренней Z-абстракции (под-
черкнута в выражении, приведенном выше) на каждом шаге
удаления получается форма, не содержащая переменных. За-
тем покажем, как то же самое преобразование получается с по-
мощью применения функции lift. Фактически первый метод
показывает последовательность вычислений, которая соответ-
ствует энергичному применению lift к аргументу element. Обо-
значив самую, внутреннюю Х-абстракцию Е{ — %s.cond( ==п 1 )Х
%(hds) (el(—n\)(tls), мы сначала генерируем комбинатор
а, задаваемый
а п el s = cond(—n l)(hd s)(el(—n l)(tl s))
отсюда
lift( El) = a n el
и теперь
element = У(Хе/.Xn.a n el)
Новая самая внутренняя абстракция (с аппликативным телом)
снова подчеркнута, и мы обозначим ее Е2. Продолжая опера-
цию удаления, генерируем комбинатор р, задаваемый
Р el п = а п el
откуда
//f/(£2) = P el
и теперь
element = У(Ке1.^ el)
Наконец, обозначив единственную оставшуюся Х-абстракцию Е2,
генерируем комбинатор у, задаваемый
у el = р el
откуда
Z/M£3) = Y
и заканчиваем, получив
element = Yy
Новейшие комбинаторные реализации 329
где
у el = р el
$ el п =а п el
а п el s = cond(~n \)(hd s)(el(—n l)(tl s))
Теперь осталось только определить правила преобразования
графов, представляющие применения а, р и у к трем, двум и
одному аргументам соответственно. Ясно, что у = ₽, и пре-
образования графов, представляющих выражения $Е{Е2 и
Рис. 13.1. Правила преобразования графов для комбинаторов аир.
аЕхЕ2Е3 для выражений аргументов Е2, Е3 показаны на
рис. 13.1.
Тот факт, что размер структурного элемента увеличивается,
становится ясным из очевидной сложности правила редукции
для а. Интуитивно ясно также, что алгоритмическое описание
процесса удаления переменных действительно дает такой же ре-
зультат, как и применение функции lift к выражению element,
330 Часть II. Глава 13
которое выполняется следующим образом:
lift( element) = lift( Y ) lif t( 7.el .Kn.Ks. cond( — n l)(hd s)
(e/( — n l)(tl s)))
— Y lift( 7.el. lift( kn.ks. cond( = n l)(hd s)
(el( —n 1 )(tl s)))
— Y lift(kel ,lift(Kn ,lift(El)))
= Г lift(Kel,lift(E2))
= Г Uft(E3)
— Y у
где Ei, E2, E3 и у определены выше.
Хотя этот метод является достаточно элегантным и увели-
чивает размер структурного элемента, но для комбинатора а
он, конечно, не оптимален. Ясно, что поскольку новые комби-
наторы р и у эквивалентны, нет необходимости генерировать у.
Менее очевидно то, что р также не нужно было определять
из-за его схожести с а; эти комбинаторы отличаются только
порядком параметров. Гораздо менее ясно, что метод простого
Х-удаления может привести к дублированию редукций постоян-
ных подвыражений, при этом полная ленивость теряется. Рас-
смотрим, например, частичное применение elements, которое
вычисляется следующим образом:
element 2 = Xs.cond(~2 l)(hd s)(element(—2 l)(tl s))
= 7.s.cond false(hd s) (element \(tl s))
= 7.s.element l(tl s)
где постоянные подвыражения = 21 и —2 1 были вычислены
вначале и только один раз. (В ленивой реализации момент их
вычисления был бы конечно отложен, но результат по-преж-
нему мог бы быть разделяемым.) Однако применение данной
версии Х-удаления дает
element 2 = Yy2
—>rY element 2 по определению
Y
= >VP element 2 по определению у
= >p<z 2 element ng определению JP
Дальнейшая редукция невозможна пока выражение elements
не будет применено к аргументу (с которым нужно связать s
в правиле редукции для а). Таким образом, если частичное
применение elements является разделяемым, два постоянны^
подвыражения, указанные выше, будут вычисляться при каж>-
дом его применении к аргументу. В этом примере усилия при.
дублировании вычислений будут довольно незначительны. В об-;
щем случае, однако, повторно вычисляемые подвыражение
Новейшие комбинаторные реализации 331
могут быть произвольно сложными. Например, рассмотрим об-
щее выражение
f — кх.ку. + (BIG х) ( * у х)
где BIG — это сложная для вычисления функция, %-удаление
для этого выражения дает следующие комбинаторы:
₽х = ах
ах у = + (BIG х)(*у х)
Частичное применение f к аргументу А даст в результате
аЛ-частичное применение а. Каждое последующее применение
этой функции к аргументу, скажем В, даст выражение
+ ( BIG А ) ( * В А ), поэтому подвыражение BIG А будет вычис-
ляться каждый раз.
К счастью, повторное вычисление выражений достаточно
легко обойти. Любое непостоянное выражение Х-тела, не имею-
щее вхождений связанной переменной, будет кандидатом для
такой избыточности. Мы называем этот тип выражений свобод-
ными выражениями (аббревиатура — cb), и этот источник дуб-
лирования редукции выражений ведет нас к рассмотрению cb,
а не только переменных в качестве наших «единиц» удаления.
13.2. Суперкомбинаторы
Как мы видели в предыдущем разделе, при использовании
Х-удаления для преобразования Х-выражения в КАФ свободные
переменные аппликативных Х-тел представляются с помощью
параметров вновь сгенерированных комбинаторов. Эти изоли-
рованные свободные переменные являются минимальными не-
постоянными cb %-тел, поскольку они не содержат подвыра-
жений. В противоположность этому мы могли бы определить
новые комбинаторы, параметры которых представляют непо-
стоянные максимальные св (аббревиатура — мсв) соответствую-
щих Х-тел. Комбинаторы, полученные таким путем, называются
суперкомбинаторами, и были первоначально введены [46]
с целью преодоления некоторых трудностей, связанных с про-
стым ^-удалением, рассмотренным выше. В частности, при та-
ком подходе сохраняется полная ленивость, поскольку она
теряется, только когда свободная переменная, входящая в св
большего размера, удаляется из Х-тела. Поскольку в этой улуч-
шенной реализации все свободные выражения представляются
в виде (подвыражений) параметров суперкомбинаторов, гаран-
тируется, что их вычисленные значения будут разделяемыми;
332 Часть II. Глава 13
вспомним, что подграфы аргументов не копируются при реа-
лизации применения функции с помощью редукции графов.
Теперь мы представим суперкомбинаторное преобразование
Х-выражений в КАФ и проиллюстрируем этот метод, еще раз
рассмотрев функцию element из предыдущего раздела.
Суперкомбинаторное представление Х-абстракции с аппли-
кативным Х-телом достигается с помощью процедуры, приве-
денной ниже.
(1) Последовательно находим самые большие подвыраже-
ния, содержащие свободные переменные и не содержащие
связанную переменную Х-абстракции, используя стандартный
метод подсчета скобок и помня о «невидимых» скобках слева.
Другими словами, находим мсв. Рекурсивная функция mfes,
возвращающая набор мсв при применении к аппликативному
Х-телу со связанной переменной bv, определяется следующим
образом.
mfes(E) = 0, если FV{E) = 0 или FV{ Е) = {bv}
mfes{E) — {E}, если bv^E&FV{E)=£0
mfes{ElE2) — mfes{El){} mfes{E2), если bv e EXE2
mfes{ (E)) ----- mfes{ E)
(2) Последовательно заменяем каждое вхождение мсв в Х-теле
на новое имя параметра, т. е. на новую связанную переменную
суперкомбинатора. Если очередное мсв совпадает с ранее заме-
ненными, то заменяем его соответствующим предыдущим име-
нем параметра.
Функция mfelift, вынимающая мсв из Х-тел и генерирующая
суперкомбинаторные выражения, является, таким образом, мо-
дификацией функции Eft, данной в предыдущем разделе, и
определяется следующим образом:
mfeliftf Е) — Е, если Е в аппликативной форме
mfelift( Хх.Е) = ami • • m2, если Е — это аппликативное выра-
жение с
mfes( Е ) — {mt ... тп}, п О,
где а определена в виде apt ... рпх — [pi/mt.рп/тп]Е,
m'eli /(Хх .Е ) = mfelift{ Хх .mfelift( Е )) если Е не является аппликатив-
ным выражением
mfeli /( EiE2 ) = mfelift( Ei ) mfelift( E2) для Х-выражений Ei, E2
mfeli,t( (£)) = ( mfeli fi( E) ) для Х-выражения E
Заметим, что подстановку [pi/mj, ..., рп/тДЕ, не всегда про-
сто реализовать. В алгоритме, который определяет мсв, каж-
дое мсв заменяется на параметр, если мы не обнаруживаем
его в текущем списке уже найденных мсв. Модификация функ-
ции mfes с целью получить функцию, выполняющую требуе-
мую подстановку, оставлена читателям в качестве упражнения.
Новейшие комбинаторные реализации 333
Существует также более тонкая проблема, касающаяся мно-
гократных вхождений мсв. Предположим, что копия мсв,
а именно /Пь входит в качестве подвыражения в другое мсв т2.
В этом случае создаются два параметра pi и р2, соответствую-
щие Ш\ и т2, даже если свободные переменные т2 встречаются
только в его подвыражении пц. Например, мы можем иметь
rtii = —м 1 и т2 = cond( = (—п 1)1). Мы вернемся к этому во-
просу при рассмотрении оптимизации в следующем разделе.
А сейчас давайте вернемся к функции element и посмотрим,
как суперкомбинаторный подход сохраняет полную ленивость.
Покажем преобразование выражения для данной функции в
КАФ с помощью алгоритмического описания, что проще, чем
прослеживать вызовы функции в эквивалентном применении
mfelift. Начнем с определения:
element = Y(kel.hn.hs.cond( — п 1) (hd s)(el( — п l)(tl s)))
Все мсв самого внутреннего A-тела подчеркнуты, и мы связы-
ваем их с параметрами р и q суперкомбинатора а, который
определяется в виде
а р q s = p{hd s)(q(tl s))
откуда
element = Y(kel.kn.a(cond( = n l))(el(— n 1)))
Существует только одно мсв el в новом самом внутреннем
Х-теле, и мы генерируем суперкомбинатор р, определяемый
Р и п==а( cond( = п !))(«(— п 1))
откуда
element — Y(Kel. р el)
Наконец, генерируем у, который определяется
у el = PeZ
и получаем element — KY, где yel = $el, pun=a(cond(=n 1))Х
X ( и (—п 1)), а,р q s — p(hds) ( q(tls)).
Мы можем убедиться, что эта версия функции element яв-
ляется полностью ленивой, если рассмотрим результат ее при-
менения к целому числу 2, как это делалось в случае ее версии
для простого Х-удаления.
element 2 — Y у 2
= у element 2
= р element 2
= a (condl = 2 1)) (element^ —21))
334 Часть II. Глава 13
При первом вызове функции element 2, т. е. при первом приме-
нении выражения element 2 к аргументу, подвыражения = 21
и —2 1 будут вычислены. Если их вычисление выполняется
с помощью .редукции графов, то корневые вершины этих подвы-
ражений будут заменены значениями false и 1 соответственно.
Каждое из последующих разделяемых применений element 2
будет использовать эти значения, поэтому исходные подвыра-
жения не требуется вычислять заново. Отличие этого подхода
от Х-удаления заключается в том, что здесь разделяемые под-
выражения рассматриваются в качестве аргументов, а они есте-
ственным образом разделяются в редукции графов.
13.3. Оптимизация суперкомбинаторных реализаций
Существуют два потенциальных источника оптимизации
в суперкомбинаторной схеме преобразования. Первый заклю-
чается в выборе мсв аппликативного Х-тела, а второй — в при-
сваивании порядковых номеров параметрам генерируемых супер-
комбинаторов. Эти два источника не являются несвязанными:
выделение конкретного мсв влияет на структуру оставшейся
части Х-тела и, следовательно, на множество оставшихся
мсв. Довольно простой путь оптимизации, который мы уже ис-
пользовали, заключается в том, чтобы не рассматривать по-
стоянные подвыражения в качестве мсв. Если их рассматривать
как мсв, преобразованное суперкомбинаторное выражение бу-
дет, конечно, правильным, но каждое выделенное таким обра-
зом постоянное подвыражение станет постоянным аргументом
в процессе вычисления выражения, что приведет к необязатель-
ным накладным расходам по передаче параметров. К счастью,
нетрудно сделать так, чтобы компилятор выбирал в качестве
мсв только те выражения, которые содержат свободные пе-
ременные.
Мы начнем с того, что еще раз обратимся к потенциальной
проблеме, возникающей, когда копия одного мсв является под-
выражением другого. Затем рассмотрим упорядочивание пара-
метров суперкомбинаторов с целью максимизации размера
каждого мсв и, следовательно, окончательного размера струк-
турного элемента. В то же время мы будем стремиться мини-
мизировать число таких параметров, минимизируя таким обра-
зом накладные расходы по применению функции. Исключение
избыточных параметров и комбинаторов рассматривается в
разд. 13.3.3, и мы покажем, что порядок, максимизирующий
размер мсв, является также оптимальным для исключения этой
избыточности. В заключение рассмотрим дальнейшую оптими-
зацию суперкомбинаторной реализации, которая используется,
Новейшие комбинаторные реализации 335
'когда частично примененные функции не являются разделяе-
мыми. В этом случае несколько вложенных Х-абстракций пре-
образуются совместно, давая в результате один новый ком-
бинатор.
13.3.1. Многократные вхождения мсв
Допустим, как это было в разд. 13.2, что копия мсв гп.\ вхо-
дит в качестве подвыражения в мсв т2, и что создаются два
соответствующих параметра pi и р2. Обозначим эту схему реа-
лизации буквой А. Как мы уже видели, она приводит к неэф-
фективной генерации избыточного параметра. В качестве опти-
мизации можно было бы все вхождения mi в Х-теле заменить
после их обнаружения параметром pi и рассматривать pi точно
так же, как связанную переменную при нахождении оставшихся
мсв-. Таким образом pi не может в дальнейшем быть включено
ни в какое мсв. Обозначим эту схему реализации буквой В.
Если затем [pi/mt] m2 не имеет свободных переменных, .будет
сгенерирован только параметр pi, но не р2. Это решение опти-
мально по числу параметров, но в общем случае не оптимально
с точки зрения разделения. С другой стороны, может случиться,
что [pi/mi] m2 имеет два непостоянных мсв, например если
mi = q и m2 — р q г, где р, q, г являются свободными перемен-
ными. В этом случае в итоге были бы сгенерированы три пара-
метра, так что схема В в действительности дала бы менее
эффективный код, чем простая схема А.
13.3.2. Порядок параметров
и максимальные свободные выражения
В общем случае везде, где это возможно, нам бы хотелось,
чтобы размер генерируемых мсв был максимален, а их коли-
чество— минимально. Чем больше размер мсв, тем больше
свободных подвыражений оно будет содержать, и поэтому тем
больше будет возможностей для разделения, поскольку каждое
из таких свободных подвыражений можно вычислить, как
только его переменные будут связаны с соответствующими вы-
ражениями аргументов. Более того, поскольку каждое мсв
соответствует одному параметру суперкомбинатора, то чем
меньше будет создано мсв, тем меньше будут накладные рас-
ходы по передаче параметров.
Для иллюстрации влияния изменения последовательности
суперкомбинаторных параметров на число и размер каждого
генерируемого мсв рассмотрим два примера. Сначала допустим,
336 Часть П. Глава 13
что мы преобразуем следующее подвыражение выражения Е:
Е = ... (kn.a(hd s)n(tl s))...
где а — это предварительно определенный суперкомбинатор,
имеющий три параметра. Здесь существуют два мсв a(hds)
и (tls). Однако если в определении а поменять местами вто-
рой и третий параметры (порядок параметров может быть лю-
бым), то выражение Е примет вид
Е — ... (кп.а(hd s)(tl s)n) ...
где существует только одно мсв — a (lids) (tls), которое боль-
ше каждого из двух предыдущих, полученных при прежнем по-
рядке параметров для а. Порядок параметров поэтому имеет
важное влияние на создание мсв, хотя выбор такого порядка
произволен с точки зрения корректности реализации. Рассмот-
рим следующий пример. Предположим, что мы преобразуем
самое внутреннее %-тело выражения Е, имеющего вид
Е = ... (kz. у(* х z)) ...
Мы можем определить либо
а р q z — q(p z) с Е= ...а(* х) (+ у) ...
либо
а р q z — p(q z) с £=...а/(+ у)(* х) ...
Предположим, что х «более свободен», чем у, т. е. при про-
движении от самых внутренних Х-абстракций вовне у удаляется
из Е до удаления х. Тогда в теле связывающей у Х-абстракции
а(*х) будет мсв, если мы определим а, в противном случае
(*х) будет мсв, если мы определим а'. Следовательно, чтобы
максимизировать размер мсв, нам следует определить а. С дру-
гой стороны, если у более свободен, чем х, нам следует выбрать
генерацию а' и получить мсв а'( + г/) при удалении х. Таким
образом, интуитивно ясно, что для получения наименьшего ко-
личества мсв наибольших размеров нам следует назначать «са-
мым свободным» мсв самые левые позиции параметров. Перед
тем как показать, что это действительно оптимальный порядок,
дадим более строгое определение «свободы» мсв.
Формально глубина вложенности подвыражения задается
номерами уровня переменных, входящих в это подвыражение.
Если предположить, что все переменные имеют уникальные
Новейшие комбинаторные реализации 337
имена (так что определение корректно), то номер уровня пере-
менной х, входящей в выражение Е, обозначается ln(x, Е), где
функция In определена следующим образом:
1п(х, х) = О
1п(х, Ку.£) = 1
= 1 + 1п( х, Е)
1п(х, ЕгЕ2) = 1п(х, Et)
— 1п( х, Е2)
если х = у
если х Ф у
если х входит в Е\
если х входит в Е2
ln(x, (Е)) = ln(x, Е)
где Е, Ei, Е2 — это ^-выражения. Константы и свободные пере-
менные имеют по определению нулевой номер уровня, т. е.
1п(х, Е) = 0, если х — это константа или переменная, не вхо-
дящая в Е.
Подвыражение, например мсв, имеет теперь по определению
номер уровня, равный максимальному из номеров уровня пере-
менных, входящих в это подвыражение. Если этот номер боль-
ше нуля, то он равен номеру уровня связанной переменной са-
мой внутренней ^.-абстракции, в которой данное подвыражение
не является свободным.
Порядок выбора в первую очередь самых свободных мсв
определяется поэтому неоднозначно, поскольку два мсв могут
иметь один и тот же номер уровня. Однако в этом конкретном
случае это не имеет значения, и порядок выбора одного из
двух мсв может быть произвольным. Причем можно показать,
что выбор в первую очередь самых свободных мсв максимизи-
рует их число [46].
13.3.3. Избыточные параметры и комбинаторы
При рассмотрении в качестве примера функции element пре-
образование в суперкомбинаторную форму даст комбинатор у,
определенный yel=$el, где р— это предварительно определен-
ный комбинатор. Нетрудно видеть в этом случае избыточности,
что у = р (технически с помощью трпреобразования). В более
общем случае предположим, что суперкомбинатор р определен
в виде
₽Р1 • • • Рп = aej ... em (п, m > 1)
причем
Рп Pn-l^^^m—l...........Pk+l == &k+m—n+1
22 — 1473
338 Часть П. Глава 13
НО
Pk¥=ek+m^n для n>fe>max(0, п — т)
Тогда все параметры pk+i, рп являются избыточными, и мы
можем опустить их, дав эквивалентное определение 0 в виде
PPi • • • Pk = ctfi .. ек+т_п
Например, если мы имеем fiabcxyz —aele2xyz для произ-
вольных выражений el, е2, то можем вычеркнуть х, у и z из
обеих частей и получить fi a b с = ael е2. Заметим, что если
k = n— т^О, мы бы имели fipi ... рт-п = а, но а не содер-
жит свободных переменных и, значит, п = т (и k = 0), так как
иначе в левой части равенства имелись бы свободные перемен-
ные. Подобным образом если k = 0, то равенство принимает
вид 0 = aei ... ет-п, и, поскольку в левой части нет свободных
переменных, мы должны иметь т = п. Таким образом, диапазо-
ном допустимых значений для k является n^k>max{G,n—т),
иначе k = 0 и п — т и комбинатор 0 является избыточным,
с чем мы уже столкнулись при рассмотрении функции element.
Таким образом, мы видим, что порядок, определенный для
последовательных номеров параметров суперкомбинаторов
снова является важным; ясно, что только в некоторых случаях
можно вычеркнуть эквивалентные параметры в определяющих
равенствах. В действительности можно показать, что упорядо-
чивание по признаку наибольшей свободы позволяет максимизи-
ровать число параметров и, следовательно, комбинаторов, ис-
ключаемых из комбинаторных определений, а также максими-
зирует их число, как мы видели в предыдущем разделе [46].
В качестве примера рассмотрим применение mfelift к под-
выражению Кх.А некоторого выражения Е, где
А = ... ek (k > 0)
было получено с помощью предыдущего вызова mfelift при
трансляции некоторого выражения. 0 является предварительно
определенным комбинатором, и ..., ек имеют неубывающие
номера уровней в Е. Используя mfelift, мы определим новый
суперкомбинатор а, задаваемый
apt ... рпх = [pi/mb ..., рп/тп] (0е1 ... efe) для некоторого
целого п^О,
где mi, m2, ..., тп являются мсв в А. Теперь, если неверно, Что
ек = х, и х не входит в е/ для 1 k, то нельзя исключить
ни один параметр и, следовательно, нельзя выполнить каку!о-
либо оптимизацию. Допустим, что ек = х и х не входит в в}.
Новейшие комбинаторные реализации 339
Тогда параметр х можно исключить и существуют два случая,
которые нужно рассмотреть: k > 1 и k= 1.
• Если k > 1, то Pei ... вк-\ является единственным мсв, и мы
определяем арх = рх, так что а = 1 и может быть исключен.
Результатом применения mfelift является Pei ... ek-i.
• Если k = 1, то ах —fix, так что а = р и снова а можно ис-
ключить. Результатом применения mfelift является р, и в обоих
случаях все параметры, а также новый комбинатор а, могут
быть исключены.
Хотя такой порядок мсв является оптимальным для исклю-
чения избыточности, решение выбирать максимальные свобод-
ные выражения не является оптимальным в общем случае и
(забракованная нами) альтернатива простого Х-удаления пере-
менных (минимальных свободных выражений) является более
успешной. Чтобы увидеть это, допустим, что мы определили
новый комбинатор а, как и раньше, в виде
ар, ... рпх = [р^, ..., рп/тп] (fier ... ek)
и что вк = х. Теперь единственным препятствием для вычерки-
вания последнего параметра х является вхождение х в выра-
жения ei, ..., ek-i. Если бы мы удаляли только переменные,
то всегда имели бы е^ = х, если х входит в (tei ... ек, а также
были бы уверены, что е,- #= х для всех j < k, что позволяет ис-
ключить комбинатор а целиком. К сожалению, мы уже видели,
что простое %-удаление дает неадекватное разделение подвы-
ражений, и в результате может быть утрачена полная лени-
вость, обеспечение которой является главной целью суперком-
бинаторной реализации. Однако для облегчения этой ситуации
суперкомбинаторный метод можно несколько усовершенство-
вать.
Во-первых, не всегда хорошо даже с точки зрения разделения
удалять мсв, а не входящие в них переменные. В частности,
не дает никаких преимуществ удаление частично примененных
комбинаторов или строгих примитивных функций, поскольку
они не могут быть вычислены, пока не будут применены
к необходимому числу аргументов, позволяющему выполнить
редукцию применения функции в целом. Таким образом,
возможна ситуация, когда вычисленных подвыражений для
разделения может не существовать. Например, предположим,
что в некотором подвыражении существует несколько примене-
ний +х к различным выражениям аргументов, содержащим пе-
ременную у, которая менее свободна, чем х. Затем, если х свя-
зывается с константой 2 во время выполнения, мсв -|-2 не
22*
340 Часть II. Глава 13
может быть вычислено и, следовательно, его разделение никак
не повышает эффективность. '
Во-вторых, реализация должна гарантировать, что любое
мсв, являющееся переменной, скажем v, при удалении в ре-
зультате применения функции mfelift не входит в любое другое
мсв данного выражения, скажем Е. Как было отмечено в
разд. 13.3.1, это легко реализуется путем поиска v в Е, когда
и идентифицировано в качестве мсв-, по крайней мере такой
поиск осуществляется быстрее, чем поиск произвольного мсв.
В этом случае, если вк — х, то х не входит в выражение
Pei ... ek_.\, и поэтому исключение может быть выполнено.
13.3.4. Обобщенное к-удаление
и улучшенные суперкомбинаторы
В конце предыдущего раздела мы указали на конфликт
между двумя такими свойствами суперкомбинаторной реализа-
ции, наличие которых желательно — возможность разделения,
т. е. полная ленивость, и отсутствие избыточных комбинаторов.
Однако часто надобность в оптимизации с целью достижения
полной ленивости отпадает, поскольку те подвыражения, кото-
рые могут быть разделяемыми, являются подвыражениями мсв,
которые в свою очередь могут быть вычислены только после
приписывания значений их свободным переменным, т. е. после
применения. Таким образом, если функция никогда не приме-
няется частично, нет никакой необходимости рассматривать
разделение вообще.
Мы можем обобщить простой метод Х-удаления, описанный
в разд. 13.1, таким образом, чтобы несколько вложенных Х-аб-
стракций можно было преобразовывать совместно, получая
один новый комбинатор. Это преобразование мы называем об-
общенным Худалением. X-Абстракция, не являющаяся телом
другой охватывающей Х-абстракции, преобразуется в один и
тот же комбинатор, как простым, так и обобщенным Х-удале-
нием. Однако Х-абстракция, являющаяся телом другой Х-аб-
стракции, преобразуется с помощью обобщенного Х-удаления
в комбинатор, имеющий дополнительный параметр, соответ-
ствующий связанной переменной внешней Х-абстракции. То же
самое распространяется по индукции на любое число вложен-
ных Х-абстракций. X-Абстракция от m аргументов (т. е. m вло-
женных Х-абстракций), которая содержит п различных свобод-
ных переменных, преобразуется в комбинатор с п + m парамет-
рами, примененный к п свободным переменным в качестве
аргументов. Для краткости мы обозначим вложенную Х-абстрак-
цию ХхьХх2. • • - Ххт.£, где Е не является Х-абстракцией, через
Новейшие комбинаторные реализации 341
Хх). ... хт.Е. Обобщенная «удаляющая» функция, которую мы
назовем glift, имеет, таким образом, следующее определение:
glift(E) = E если Е в аппликатив-
ной форме
glifl(Xxi. ... хт.Е ) = аИ] ... и2 если Е является аппли-
кативным выражением
где а определяется в виде ащ ... vnXi ... хт = Е
и
{о,, ..., =
= £У(£)\{х„ ..., хт}
glift(kxi ... хт.Е) = glift(\xi. ... xm.glijt( £) ), если £ не является ни
аппликативным выра-
жением, ни Л-абстрак-
цией
gliftt Е\Ег) = glift( Ei) g/z'f/( £2 ) для Л-выражений £t, £2
glift( (£)) = ( glift( Е )) для Л-выражения £
Теперь давайте применим общее Х-удаление в случае нашей
функции element
element — У(Хе/ п s.cond( =п l)(hd s)(el( —п 1)(tl s)))
Она включает тройную вложенную Х-абстракцию, так что
glift( element) = Уа
где
a el п s = cond( =п \ )(hd s)(el( —п \)(tl s))
Таким образом, мы имеем один более сложный комбинатор, чем
два, полученных в результате (оптимизированного) суперком-
бинаторного преобразования; увеличение эффективности полу-
чено ценой потери возможности разделения, которая может
быть или не быть желательной. Здесь следует заметить, однако,
что простое Х-удаление вместе с упорядочиванием по признаку
наибольшей свободы параметров комбинаторов эквивалентно
обобщенному Х-удалению. Хотя при простом Х-удалении гене-
рируется несколько комбинаторов (один на каждую связанную
переменную), все они, кроме первого, являются избыточными
при таком порядке параметров.
Более общим примером является модификация функции
element, называемая sqelement и вычисляющая квадрат вы-
бранного элемента списка:
sqelement ~Y(kel п s,cond(=n l)((Xx. *x x)
(hd s))(el( —n \)(tl s)))
Теперь
glift( Kx. *x x) = а, где ax = * x x
342 Часть II. Глава 13
и, таким образом,
glift{ sqelement) = Y glift( Л el n s. condf =n 1)
(a(hd s))(el(— n l)(tl s)))
= У₽
где
P el n s = cond( = n i)(a(hd s))(el( — n l)(tl s))
и
ax = * x x
Хотя суперкомбинаторный подход имеет недостатки, указанные
выше, если разделение не требуется, он все-таки обладает не-
которыми достоинствами. Например, в некоторых ситуациях
он может генерировать меньшее число параметров за счет уда-
ления мсв, а не переменных. X-Удаление и преобразование в су-
перкомбинаторную форму представляют собой при компиляции
выражений в КАФ два крайних подхода с различными целями,
а именно минимизировать число комбинаторов и максимизиро-
вать разделение соответственно. Однако некоторые частичные
применения Х-абстракции могут быть разделяемыми, тогда как
другие могут не быть таковыми. Например, в выражении
let f = Kx.Ky.Kz.E in g(f 2 3)(f 2 5 7)
где g является некоторой функцией, частичное применение f 2
является разделяемым, но ни f 2 3, ни f 2 5 не являются та-
ковыми.
Это приводит к идее усовершенствованных суперкомбинато-
ров, генерируемых с помощью удаления максимальных свобод-
ных подвыражений из нескольких вложенных Х-абстракций за
один шаг. Этот метод является, конечно, расширением преобра-
зования обобщенным Х-удалением по аналогии с расширением
преобразования простым Х-удалением с помощью суперкомби-
наторной схемы. Он требует поэтому, чтобы только одно опре-
деляющее уравнение функции glift было изменено для получе-
ния расширенного определения функции, скажем mfeglift
mfeglift(7.x{ ... xk.E) = a,ni ... mn, если E является апплика-
тивным выражением с mfes( Хх; ...
. .. хк.Е) — {шх, ..., тп}, где а опре-
делен в виде ар{ ... рпхх ... хк =
= [Р\1ть ..., pn/mn]E
КАФ, генерируемая при применении mfeglift к Х-выражению,
дает наименьшее число суперкомбинаторов, которые сохраняют
полную ленивость при условии, если мы знаем, что ни одно
частичное применение абстракции никогда не может стать раз-
деляемым.
Новейшие комбинаторные реализации 343
13.4. Категорийные комбинаторы
Идея функционального языка без переменных была впервые
предложена Бэкусом [7], который ввел язык, называемый FP,
описанный в гл. 5. Мы уже видели преимущества реализаций,
где переменные не представлены явно: выражения являются
аппликативными, и их вычисление определяется наборами пра-
вил преобразования для применений операторов, являющихся
или комбинаторами, или примитивными функциями. Фактиче-
ски FP был предложен первоначально как основа языка про-'
граммирования для практического использования; утверждается,
что он обеспечивает естественные средства для специфициро-
ванных решений. Более того, формальное, свободное от пере-
менных определение языка приводит к «функциональной алгеб-
ре», которая упрощает формальные рассуждения о программах
и способствует оптимизации через преобразование программы,
что мы обсудим в гл. 18.
FP имеет довольно традиционный набор примитивных функ-
ций и небольшое число примитивных функционалов — «опера-
ций формирования программы» (ОФП), введенных в гл. 5, каж-
дый из которых определяет новую функцию согласно своим
собственным правилам переписывания. Поэтому эти функцио-
налы составляют фиксированный набор комбинаторов. В этом
разделе мы рассмотрим сначала подмножество первого порядка
языка FP и опишем неформально набор комбинаторов, есте-
ственных для определения функциональных выражений. От
этого неформального представления мы обратимся к результа-
там теории категорий для определения набора «категорийных
комбинаторов», который является полным В том смысле, что
соответствующая ему логика является моделью Х-исчисления,
так же как классическая комбинаторная логика КЛ. С более
практической точки зрения любой функциональный язык, та-
кой как Норе, просто транслировать в категорийную комбина-
торную форму. В гл. 18 можно найти описание трансляции
в FP функций первого порядка, использующих как сопоставле-
ние, с образцом, так и определенные пользователем составные
тиг/Ы данных; расширение для случая категорийных комбинато-
ров и функций высшего порядка является непосредственным.
13.4.1. Фиксированные комбинаторы FP
Языку FP требуются только три примитивных функционала:
композиция, конструкция и условное выражение вместе с пред-
ставлением для константных функций, чтобы выразить рекур-
сивные функции первого порядка. Функционал, называемый
344 Часть II. Глава 13
композицией, является в точности комбинатором В (компози-
тором), определенным в гл. 12. Нотация FP определена в гл. 5,
но в этом разделе мы обозначаем константную функцию «ка-
вычкой», за которой следует имя константы, а не подчеркива-
нием, как в других разделах этой книги. Это согласуется с [25],
и для объекта k мы определяем 'kx — k для всех объектов х.
Чтобы FP мог работать с функциями высших порядков, мы
сначала введем функцию применения арр в качестве дополни-
тельного примитива. Она определяется соотношением app(f,
х> — fx для функции f и объекта х, и поэтому мы имеем пра-
вило (арр ° [f, g] )х— (f х) (g х), так что арр эквивалентна
S-комбинатору.
В действительности некоторая форма примитивной функ-
ции арр является основой в любой модели Х-исчисления, и по-
скольку она имеет два аргумента, функционал, называемый
конструкцией (или по крайней мере операцией спаривания),
также является естественным примитивом. Каждая такая мо-
дель включает спаривание в той или иной форме. Например,
в КЛ оно принимает довольно непонятную форму карринга.
В следующем разделе мы обнаружим, что эти интуитивные со-
ображения имеют прочный математический фундамент.
Фактически арр—это почти все, что нам нужно, чтобы
выразить любую функцию, которую можно определить в %-ис-
числении. Но, к сожалению, у нас по-прежнему нет средств
выразить К-комбинатор. Мы могли дополнить FP K-комбина-
тором, но это противоречит задаче найти более естественное
представление, чем КЛ. Вместо этого получить новый комби-
натор мы можем, обратившись к теории замкнутых декартовых
категорий и к работе [25]. Тогда мы будем в состоянии пред-
ставить формальное описание механизма вычислений, основан-
ного на введенной в гл. 6 нотации де Брейна, который исполь-
зует эти теоретические результаты. Следующий раздел можно
опустить, если читатель не знаком с теоретическими основами
некоторых из правил переписывания, используемых для редук-
ции категорийных комбинаторных выражений. В любом случае
он найдет эти правила интуитивно достаточно ясными.
13.4.2. Категорийные комбинаторы [25]
В этом разделе мы кратко изложим результаты теории ка-
тегорий, необходимые нам далее. Категория С — это набор объ-
ектов obj(C), такой что
1. Если А, В obj (С), то существует набор стрелок из Л в В,
обозначаемый А^-В, и если f входит в набор А-*В, то мы го-
Новейшие комбинаторные реализации 345
ворим, что доменом f является А, а кодоменом / является Б,
или dotn (f) = A, cod(f) — В.
2. Для всех объектов А, В, С существует операция компози-
ции °, определенная на стрелках, которая ассоциативна, т. е.
если f входит в В-*-С и g входит вЛ->-В, тогда fog входит
в А —С и (f°g)°h = fo(goh) для всех стрелок f, g, h, так
что cod (h) = dotn (g), cod (g) = dotn (f).
3. Для каждого объекта А существует тождественная стрелка
id4, входящая в А->А, такая что для всех стрелок f, g, таких
что cod( f) = dotn (g) — A, idA <>f = f и g °idA — g.
Например, объектами категории могут быть множества,
а стрелками — отображения этих множеств друг в друга. Мы
Рис. 13 2. Конструкция произведения в декартовой категории.
будем ссылаться на определенную таким образом категорию
как на основную категорию.
В декартовой категории С существует конструкция, назы-
ваемая произведением, определенная следующим образом:
Для всех объектов А, В существует объект А X В и стрелки
FstA’B: АХ^->А, SndA'B: АХ^->В, называемые проекциями,
обладающие тем свойством, что для любого объекта С и стре-
лок f:C->A, g:C^>-B существует единственная стрелка С->
+АХВ, обозначаемая и называемая парой fug, имею-
щая свойство, что f = Fst ° (f, g), g = Snd°(f,g). (Мы опу-
стили верхние индексы у Fst и Snt там, где нет неоднозначности.
Угловые скобки не следует путать с ограничителями последова-
тельности в языке FP.)
Это определение проще всего видеть на диаграмме, приве-
денной на рис. 13.2. (Двоичное) произведение А и В опреде-
ляется тройкой (А X В, FstA’ в, SndA’ в) и дает формальное опи-
сание «конструкции» двух функций вместе со связанными
346 Часть II. Глава 13
функциями-селекторами, обозначаемыми 1 и 2. Из этого, в частно-
сти, следует, что <f, g) ° h — (f о h, goh} для всех стрелок h, та-
ких что cod(h)= С, и это будет одна из аксиом, используемых
для редукции в следующем разделе. Именно единственность
конструкции произведения гарантирует, что эвристическое по-
нятие спаривания функций действительно является корректно
определенным.
Представление Х-исчисления завершается введением двух
дополнительных конструкций в декартовы категории, а именно
Рис. 13.3. Конструкция экспоненциала в замкнутой декартовой категории.
применения и карринга, что ведет к следующему определению:
Декартовой замкнутой категорией (ДЗК) является катего-
рия, в которой для всех объектов А, В существует объект А В
и стрелка АррА’в : (Л => В)Х А -+В, называемая применением,
имеющая свойство, что для любого объекта С и стрелки f:CX
ХА-*-В существует единственная стрелка из С-*-А=>В, обо-
значаемая A(f) и называемая каррингом /, такая что f =
= Арр ° <A(f) oFst, Snd).
Это иллюстрируется рис. 13.3. Композируя правую часть по-
следнего равенства с {Idc,g}, получаем f ° <Jdc, g} = Арр о
°<A(f),g'>, что является аксиомой в логике, которую мы вве-
дем в следующем разделе.
Объект А =>- В представляет функциональное пространство,
определенное на Л и В, и пара (А => В, АррА’в) определяет
экспоненциал А к В. Уравнение, которому удовлетворяет един-
ственная стрелка, определяющая А(/), подразумевает, что для
элемента данных (х, у) из ОХА имеет место f(x, у) =
= Арр( A(f)x, у) = A(f) х у, что является обычным определе-
нием карринга. Снова именно единственность экспоненциала, га-
рантирует, что эвристическое понятие карринга действительно
является корректно определенным.
Два свойства единственности, приведенные выше, соответ-
ственно эквивалентны следующим двум равенствам, где f—ФтО
Новейшие комбинаторные реализации 347
любая стрелка соответствующего типа:
{Fst of, Snd°f) = f (сурьективное спаривание)
(поскольку Fst ° {Fst ° f, Snd of}— Fst ° f и аналогично для Snd),
или, эквивалентно, {Fst, Snd}= id и
Л( Арр o{f ° Fst, Snd)) = f (сурьективный карринг)
(поскольку A(f') = А [Арр ° {A(f')~° Fst, Snd}), и мы принимаем
f = A(f')).
Следующее равенство можно вывести, представив fog сна-
чала как А(Арр ° </ ° Fst, Snd})°g и затем как A(Appo{fo
ogoFst, Snd}), где f и g являются любыми стрелками соответ-
ствующих типов. Теперь, согласно правилам для произведений,
<f« Fst, Snd} ° <g о Fst, Snd}={f ° g ° Fst, Snd}, и, таким образом,
мы выводим, что Л (Арр о о Fst, Snd}) °g — A(Appo{foFst,
Snd} о {go Fst, Snd}). Обращаясь к единственности, затем по-
лучаем
Л( f) ° g = Л( f ° (g ° Fst, Snd))
для всех f, g соответствующих типов. Фактически это равен-
ство дает альтернативное определение экспоненциала и яв-
ляется немедленным следствием теорем адъюнкции теории
категорий.
Равенства, приведенные в этом разделе, способствуют тому,
чтобы ДЗК описывались только в виде равенств. В следующем
разделе мы будем использовать их для определения правил
переписывания для редукции выражений в терминах категорий-
ной комбинаторной логики (ККЛ) по аналогии с классической
КЛ, определенной в виде правил для S и К. Подводя итог, ска-
жем, что категорийная структура дает математическую стро-
гость, необходимую для формальной модели Х-исчисления, опре-
деленной в терминах естественных конструкций, выраженных
как комбинаторы в свободной от переменных форме — катего-
рийных комбинаторов.
13.4.3. Вычисление выражений
с помощью нотации де Брейна и ККЛ
Механизм, представленный в этом разделе, вычисляет запи-
санные в нотации де Брёйна выражения, используя категорий-
ные комбинаторы в качестве примитивов, ККЛ как основу для
правил переписывания и явный контекст. Читатель может по-
чувствовать здесь привкус SECD-машины. Описываемый в дан-
ном разделе аналогичный механизм будет «сильнее», достигая
348 Часть II. Глава 13
высшей точки при определении категорийной абстрактной ма-
шины в терминах переходов из одного состояния в другое. Пе-
ред тем как продолжить, читателю необходимо быть уверенным
в полном понимании описанной в гл. 6 нотации де Брёйна для
Х-исчисления.
В нотации де Брёйна имена переменных заменены их «сте-
пенями свободы» относительно уровня Х-тела, в которое они
входчт. Следовательно, при вычислении любого выражения наи-
меньший номер переменной всегда равен нулю, что соответ-
ствует связанной переменной, а номера остальных переменных
увеличиваются вплоть до максимального значения, являющегося
текущим уровнем вложенности редуцируемого Х-тела. Контекст,
который связывает значение с каждой свободной переменной,
таким образом, реализуется как простой список, голова кото-
рого находится справа. Так, контекст р имеет вид (...( (), vn )...
..., Vo), где vt — это значение переменной с номером I, т. е.
( ) является пустым контекстом, и если р является некоторым
контекстом, то ( р, d) — также контекст, где d — это некоторая
величина данных.
Вычисление Х-выражения де Брёйна задается поэтому сле-
дующей семантической функцией eval, которая отображает
пары выражение-контекст в значения, и определяется следую-
щим образом:
evallLO, (р, d)J = d
eval[L(n-\- 1), (р d) Ц — evalf Ln, р]
eval{k, р] — k, где & —константа
eval [ MN, р ] = eval [ М, р ] eval [ N, р ]
eval[L.M, p]d =eval[M, (p, d)]
Для начала введем три комбинатора:
1) 5, который эквивалентен обычному распределителю в КЛ;
2) Л, т. е. «карри», обсуждаемый выше;
3) ', т. е. «кавычка», обозначающая константные функции.
К этому добавляется бесконечное множество комбинаторов
{м'|м^гО}, используемых для индексации контекста. Функция
трансляции comb определяется теперь следующим образом:
comb( Ln) = nl
comb( k) = 'k, где k — это константный объект
comb^MN ) = S(comb{M), comb(N))
comb( X. M) = Л( comb( М))
Новейшие комбинаторные реализации 349
и правила редукции для комбинаторов имеют вид
0!(х, у) =У
( и + 1 )! (х, у) = п\ х
('х)у = х
S(x, y)z — х z (у z)
А(х)у z = х (у, z)
Теперь можно представить все эти комбинаторы в терминах ка-
тегорийных комбинаторов, введенных в предыдущем разделе,
после чего все механизмы ДЗК станут доступными нам, напри-
мер при оптимизации и доказательстве теорем эквивалентно-
сти между альтернативными наборами правил редукции. Так,
мы можем считать S(x, у) аббревиатурой для Арр о (х, у) и п!
аббревиатурой Snd°Fstn (где FsP = Id— тождественная функ-
ция и Fstn+1 = Fst ° Fstn), и мы приходим к следующим аксио-
мам комбинаторной логики:
(ass) (xoy)z —х(у г)
( fst ) Fst( x, у) = x
( snd ) Snd( x, у ) = у
(dpatr) (x, y)z = (xz,yz)
( dA.) A( ¥ ) yz = x(y, z)
( app ) App( x, у ) = xy
( quote ) ('x ) у = x
Заметим, что S-правило теперь представлено тремя правилами
арр, dpair и ass. Заметим также, что в действительности пра-
вило ( quote ) является избыточным, поскольку А(х ° Snd) yz =
= ( х о Snd ) (у z) = х z для всех х, у, z согласно ( JA ), ( ass )
и (snd). Таким образом, можем считать 'М аббревиатурой
Л( М ° Snd). Эти два выражения эквивалентны с точностью до
^-преобразования.
Шаги редукции при вычислении категорийных комбина-
торных выражений проиллюстрированы на следующем примере,
показывающем последовательность редукций (нормального по-
рядка) для выражения:
М — (кх.х 4((Ах.х)3)) +
В нотации де Брёйна оно превращается в М =
= ( А, Л04(( Х.ЛО )3))+. Затем мы получаем комбинаторную
форму
M' = comb(M) = S(A(S(0\, '4), S(A(0!), '3))), '+)
350 Часть II. Глава 13
Поскольку М' является замкнутым выражением, мы применяем
его к пустому контексту, что дает следующие редукции:
М'( )->sA(S(A В))( )(' + ())
где A = 5(0!, '4) и В = 5(Л(0!), '3)
>л S( А, В)С
где С = (( ), ('+( )))
->sS(0!, '4 ) С ( 5( Л( 0!), '3)С)
->.S.O! С ('4 С)(5(А(0!), '3)0
_>oi+('4C)(S(A(O!), '3)0
поскольку С >(( ), +)
+4($(Л(0!), '3)0
—>s+4 ( Л( 0!) С ('3 С))
->л+4(0!(С, ('3 С)))
—>oi4~4('3 С)
^,+4 3
->+7
Правила, данные выше, фактически определяют слабую катего-
риальную комбинаторную логику (СККЛ), которая является
слабой в том смысле, что не может редуцировать все Х-выра-
жения (или, точнее, результат применения comb к их версиям
де Брёйна) к их нормальной форме. Это можно видеть при рас-
смотрении Х-выражения Q = Хх. ( кх.х ) х, которое находится в
СЗНФ и имеет нормальную форму Хх.х. Версия де Брёйна для
Q имеет вид: Х.(Х.ЛО) L0, а его комбинаторная форма: Q'=
=comb ( X. ( X.LO ) L0 ) = Л ( S ( Л ( 0! ), 0! ) ). Таким образом, не
существует правила слабой редукцйи, применимого к Q'( ), по-
скольку dA-правило требует два аргумента для своего приме-
нения. То же самое будет справедливым для всех СЗНФ вида
Хх.е. В общем случае СККЛ не может вычислять выражения
внутри некоторой Х-абстракции и, более того, зависит в прове-
дении процесса редукции от применения своих выражений к кон-
тексту.
Существует, однако, сильная категорийная комбинаторная
логика ККЛ, которая берет в качестве своих аксиом результаты
теории декартовых замкнутых категорий, обсуждаемой в пре-
дыдущем разделе. Эти аксиомы, по существу, являются более
абстрактной формой правил СККЛ в том смысле, что примене-
ния функций к переменным, представляющим контексты, заме-
нены композициями с другими переменными функций. Это тре-
бует введения функции тождества Id вместе с двумя аксиомами,
соответствующими ее композиции слева и справа. Это представ-
ление было бы по-прежнему эквивалентно СККЛ, и для обес-
печения полного вычисления нормального порядка мы добав-
Новейшие комбинаторные реализации 351
ляем две аксиомы, моделирующие общую p-редукцию, которые
являются свойствами экспоненциальной конструкции, обсуждае-
мой в предыдущем разделе. Аксиомы ККЛ имеют, таким обра-
зом, следующий вид, где метки теперь начинаются с заглавной
буквы и источник каждого правила, могущий быть либо в ос-
новных категориях, либо в декартовых категориях, либо в ДЗК,
указан буквами С, СС и ССС соответственно.
(IdL) !d° x = x (C)
(IdR) x о Id = x (C)
(.Ass ) ( x° у )° z == x ° ( t/ ° z ) (C)
(Fst ) Fst ° (x, y) = x (CC)
( Snd ) Snd°(x, у) — у (CC)
(DPair ) (x,y)oz =(x°z,y°z) (CC)
(ОЛ) A( x )°y = A( x ° (у о Pst, Snd)) (CCC)
( Beta ) App°<A(x), y) (CCC)
Редукция рассмотренного выше выражения М = (Хх.х4Х
Х( (Zx.x) 3) )+, которое имеет комбинаторную форму
М' = Арр ° (A( X), Л( + ° Snd ))
где X = Арр ° (Y, Z)
Y = Арр ° (Snd, A(4°Snd))
Z = App°(A(Snd), Л(3 °Snd)}
теперь происходит непосредственно без применения М' к пус-
тому контексту, начинаясь следующим образом:
М' —^Beta X ° (Id, А( -f- ° Snd))
- ^Beta App°(Y, Snd ° (Id, A(3 ° Snd))) ° (Id, A( + ° Snd)}
— >snd App °(Y, Л( 3 о Snd)} о (Id, A( + ° Snd)}
~~*DPair App ° (Y о (id, A( + °Snd)}, A(3 ° Snd) ° (Id, A( + ° Snd)}}
~>dx App o(Y ° (Id, A( + °Snd)}, ,
Л( 3 о Snd ° ((Id, A( A~ ° Snd)} ° Fst, Snd}))
^Ass, snd Y^pp ° (Y ° (Id, A( + °Snd)}, A(3°,Snd))
-^DPair, Snd App ° (Арр о (A( + о Snd),
A( 4 ° Snd) о (Id, A( + °Snd))), A(3° Snd))
- +DA, Ass, Snd Арр о (Арр о (л( + ° Snd), А( 4 о Snd)), Л( 3 ° Snd))
->BetaAppo( + oSndo([d, Л(4оSnd)), А(3 ° Snd)}
^snd Арр ° <+ ° Л( 4 ° Snd), Л( 3 о Snd)),
= S( + °'4, '3) = S(S('+, '4), '3) = comb(+ 4 3)
Более того, теперь выражение Q, имеющее комбинаторную
форму Q' = А( Арр ° < Л( Snd), Snd)), может также быть ре-
дуцировано:
Q' ^Beta Л( Snd □ (Id, Snd) ) ^Snd Л( Snd )
352 Часть II. Глава 13
Таким образом, сильные правила редуцируют Q' к ККЛ-форме
Х-выражения Хх.х, которое также можно получить с помощью
Р-редукции из исходного Х-выражения. Однако, как мы заме-
тили выше, Q находится в СЗНФ, и потому не могло бы быть
редуцировано с помощью слабых правил.
Фактически в [25] показано, что СККЛ и ККЛ эквивалент-
ны в том смысле, что каждая СККЛ-редукция имеет эквива-
лентную ККЛ-редукцию, и обратное также справедливо с точ-
ностью до формы тгредукции. Другими словами ККЛ Н СККЛ
и СККЛ+ i]H ККЛ.
13.4.4. Категорийная абстрактная машина
Системы комбинаторной логики, определенные в предыду-
щем разделе, дают основу для вычисления Х-выражений во
многом таким же способом, как это делают комбинаторы S, К,
I, В, С в гл. 12. Подобным образом реализация может быть
основана на редукции графов, если определить правила преоб-
разования графов, соответствующие применениям каждого из
комбинаторов °, Fst, Snd, Id, Арр, A, < , >. Однако представ-
ление Х-выражений в категорийной комбинаторной форме не
только «естественно» в том отношении, что смысл таких выра-
жений ясен, но также и в том, что примитивные операции, тре-
буемые для механизма вычисления, вплотную соответствуют от-
дельным комбинаторам, формирующим выражение. Поэтому
вычислитель наиболее просто определить в терминах преобра-
зований некоторого состояния, представляющего частично вы-
численное выражение по мере просмотра вычисляемого выра-
жения. Это является основой категорийной абстрактной машины
(КАМ), [25, 64], спецификация которой напоминает SECD-ма-
шину, рассмотренную в гл. 10.
Состоянием КАМ является тройка (Г, С, S), где Т — это
терм, который представляет часть выражения, обрабатываемую
в данный момент (соответствующую элементам, близким к вер-
шине стека SECD-машины), С — это кодовая последователь-
ность категорийных комбинаторов (соответствующая управляю-
щей строке SECD-машины) и А — это стек (соответствующий
комбинации стека и дампа SECD-машины). Код представляется
в форме, данной в разд. 13.4.3, для слабой ККЛ с исключением
для композиции х ° у выражений х, у, представляющих функ-
ции. При вычислении применения (x°y)v для выражения v, х
должен быть применен к у v, и поскольку выражения просмат-
риваются слева направо, данное применение должно компили-
роваться в форму v(yx), т. е. порядок композируемых функ-
Новейшие комбинаторные реализации 353
ций должен быть изменен на обратный. Поэтому функция comb
для трансляции Х-выражений в КАМ-код имеет вид
cotnb( Ln) = FstnSnd
comb( k) — 'k (где k — это константа данных)
comb(f) — J\.(Sndf) (где f — это примитивная функ-
ция)
comb( MN ) = (comb( М ), comb( IV )) арр
comb{ А.. М ) = Л( comb( М ))
Новый постфиксный оператор арр теперь имеет строчную пер-
вую букйу, чтобы можно было отличать его от Арр.
Теперь мы можем формально описать работу слабой КАМ
в виде функции преобразования состояний =>: (терм X код X
X стек)—>-(терм X код X стек), определенной в инфиксной форме
следующим образом:
((S, О Fst ::С S ) — ^ > ( S С S, )
((S, t) Snd :: С S )=; > (* С S )
(S 'с :: С S )=> * ( с С S )
( S Л(С)::С1 S )=; > ((С s) С1 S )
( S (С S )=> > ( S с s:: S )
(г , ::С s :: S )=; > ( S с t :: S )
(1 )::С s :: S )=> (( S, t ) с S )
((С, 8, t) арр С1 S )=> ( ( s, t ) С()С1 S )
( т + -.-.с S )=> ( +т с 5 )
((т, п) + ..С 5 )=> > ( add( т, п ) с S )
где add обозначает 6-правило для «целого» сложения. Будет
замечено, что эти правила преобразования реализуют вычис-
ление аппликативного порядка, при котором аргументы функ-
ции вычисляются до ее применения. Однако это сделано исклю-
чительно ради эффективности и не является неотъемлемым свой-
ством лежащей в основе теории.
Символ < > обозначает присоединение, так что в третьем
снизу уравнении кодовые последовательности С и С1 соеди-
няются вместе. Последнее уравнение дает правило для приме-
нения примитивной функции «плюс»; ясно, что при введении
каждой новой примитивной функции должно добавляться по
крайней мере одно новое уравнение. Работа КАМ иллюстри-
руется редукцией в рамках слабой ККЛ выражения М, рас-
смотренного выше, которое применяется к пустому контексту.
Код, генерируемый для Л4, имеет вид
ЛГ' = (Л((А, В}арр), A(Snd + )}арр
где A = (Snd '4) арр и В = (A(Snd), '3)арр
Машина проходит следующую последовательность состояний.
(Для удобства записи элементы стека разделяются точками
с запятой или пробелами, когда нет неоднозначности. Поэтому
кодовая последовательность abed является сокращенной
23 — 1473
354 Часть II. Глава 13
-формой записи для а :: ( b :: ( с :: ( d:: nil))). Пустая последова-
тельность записывается [ ].)
О
{А, В} арр( )
О
+"
где +" = Snd + ( )
( <Л. В) арр ( );
(Snd + ( ), 4)
(О, 4)
4
Snd( (),+")
(Snd(( ), +"). 3)
((О, +"). 3)
3
(+4, 3)
(4, 3)
7
(Л( {А, В) арр ), Л( Snd + )) арр
Л( (А, В) арр ), Л( Snd + )) арр
, Л( Snd + ) > арр
Л.( Snd + ) > арр
> арр
арр
{А, В} арр
А, В > арр
Snd, '4 > арр, В > арр
, '4 > арр, В > арр
'4 > арр, В > арр
> арр, В > арр
арр, В > арр
Snd +, В > арр
+, В > арр
, В >-арр
В > арр
Л( Snd ), '3 > арр > арр
, '3 > арр > арр
'3 > арр > арр
> арр > арр
арр > арр
Snd > арр
> арр
арр
+
[ 1
(А, В}арр( )
{А, В) арр( )
((), +"); +4
(() +"); +4
Snd( (), +"); +4
Snd( (), +" ); +4
+4
+4
Мы описали машину, которая работает очень просто — в каче-
стве правил переписывания она использует аксиомы СККЛ.
Сильные правила также можно было бы использовать в каче-
стве основы для подобной системы. Заметим, что даже в слабой
версии они имеют важное значение в оптимизации определен-
ных кодовых последовательностей. Например, правило Beta
обеспечивает оптимизацию вспомогательных выражений, таких
как let х = М in М, которые не должны компилироваться как
(Хх.М)М, поскольку при выполнении последнего выражения
было бы сначала построено замыкание, а затем оно было бы
немедленно применено. Детали можно найти в [24].
Мы не упомянули рекурсию, поскольку она реализуется спо-
собами, подобными приведенным в гл. 10 для SECD-машины,
например с использованием У-комбинатора. Изящная оптимиза-
ция дана в [64]. Она использует «циклические контексты», на-
поминающие метод, описанный в гл. 9 для представления кон-
текстов в интерпретаторе. Мы в известном смысле завершили
рассмотрение группы основанных на контексте и основанных на
копировании реализаций, которые обсуждались во введении
к части II.
Новейшие комбинаторные реализации 355
13.5. Модификации КАМ
Работа КАМ, описанная в терминах преобразования состоя-
ний в предыдущем разделе, будет более эффективной, если при
практической реализации функциональных языков воспользо-
ваться рядом советов. В частности, некоторые часто встречаю-
щиеся последовательности переписываний рекомендуется пред-
ставлять новыми правилами, и можно показать, что существуют
правила, которые никогда не будут применяться на практике
Кроме того, способ доступа к контексту с помощью комбинато-
ров Fst и Snd является неэффективным, и, хотя «правило ка-
вычки», как было показано, является технически избыточным,
его альтернатива включает три переписывания вместо одного.
В следующем разделе мы приведем оптимизации из [61]
для «самой левой из самых внешних» редукции выражений
ККЛ, которые восстанавливают прямое правило для констант-
ных функций, обеспечивают более прямой доступ к- контексту,
комбинируют определенные правила в новое правило и исклю-
чают правила, которые становятся избыточными. Это приводит
к новой компилирующей функции и набору правил переписыва-
ния, которые приведены в разд. 13.5.2.
13.5.1. Оптимизированный набор правил
Первая оптимизация восстанавливает правило кавычки для
констант в его сильной форме:
'с ох=='с,
где с — это константный объект.
Каждая функция, определенная на константах, будет иметь
свои собственные законы, как мы видели в предыдущем раз-
деле. Например, в случае сложения целых чисел мы имели бы
дополнительный закон:
Арр ° (Арр ° (add, х), у) = х-\-у
В следующих трех оптимизациях необходимо различать выра-
жения ККЛ, которые получены непосредственно в результате
трансляции Х-выражений, от тех, которые не являются тако-
выми. Они называются ^-эквивалентными и промежуточными
выражениями соответственно. Промежуточные выражения воз-
никают при переписывании выражений ККЛ.
В ^-эквивалентном выражении комбинаторы Fst и Snd ис-
пользуются только для представления переменных, и для пере-
менных с номером уровня п 0 мы пишем
п=( ... ((Snd о Fst) ° Fst) о ... oFst)
23*
356 Часть II. Глава 13
где существует п вхождений Fst. Путем проверки взаимодей-
ствий между такими переменными и набором правил можно по-
казать, что правила (Fst) и (Snd) заменяются на правила
п ° (х, у) — (п — 1 )* ° х ( п > 0)
у) —У
которые являются сильными версиями правил, первоначально
введенных в разд. 13.4.3.
Третья оптимизация соединяет правила (DA) и (Beta),
поскольку
Арр о <Л( X ) О у, 2) = Х°(у, 2)
путем последовательного применения правил (£>Л), (Beta),
(Xss), (Dpair), (Xss), (Fst), (IdR), (Snd).
Мы можем поэтому ввести это правило в систему правил
переписываний, экономя семь переписываний всякий раз при
его применении. Более того, оно действительно может заменить
(£>Л) для всех практических целей. Это утверждение подтверж-
дается тем, что на практике выражения в результате вычисле-
ния становятся базовыми типами, т. е. значение вычисленного
выражения не является функцией и не содержит функцию в ка-
честве внутреннего подвыражения. Таким образом, для каж-
дого Л в ККЛ-выражении должен также существовать соответ-
ствующий комбинатор Арр, позволяющий удалить Л, поскольку
в окончательном результате нет ни одного Л. Отсюда следует,
что всякий раз, когда подвыражение А(х)°у может быть пе-
реписано, оно должно входить в (под) выражение вида Арр °
° <Л(х) ° y,z). Следовательно, мы можем обойтись без правила
(ДЛ).
В ^-эквивалентное выражение комбинаторы Арр могут вхо-
дить только в композиции с парой, и, изучив правила, включаю-
щие Арр, можно видеть, что Арр или исчезает (посредством
( Beta ) или нового правила, только что введенного выше), или
может быть переписано согласно (Лхх) и затем (Dpair). Это
дает
(Арр°(х, y))°z = Арр о (х о z, у ° z)
Таким образом, Арр всегда входит в композиции с парой во все
ККЛ-выражения, и если редуцируемое выражение само не яв-
ляется выражением типа произведения, правило (Dpair) не
может быть применено в любой другой ситуации. Так, обозна-
чая Арро(х,у} через <<x, t/», мы можем заменить (Dpair) по-
хожим правилом:
<(х, y))°z = ((xoz, y°z))
Новейшие комбинаторные реализации 357
Наконец, можно показать, что первые три правила {IdL),
(IdR) и (Ass) никогда нельзя применять при выполнении са-
мой левой из самых внешних редукций ^.-эквивалентных выра-
жений. Это можно доказать, показав, что их левые части не
могут встретиться ни в ^-эквивалентных выражениях (триви-
альное следствие из описания компилирующей функции в сле-
дующем разделе), ни в правых частях других правил [61].
13.5.2. Новые компилирующая функция
и правила ККЛ
Теперь мы можем определить оптимизированную систему
для «самой левой из самых внешних» редукций Х-эквивалент-
ных выражений ККЛ. Сначала компилирующая функция comb'
определяется в виде
comb'( А.. М) — Л( сотЬ'( М))
comb'( МН ) = ((comb'( М), comb\ N)))
comb'( Ln) = п
comb'( k)~'k, где k — это константа
Упрощенный набор правил переписывания имеет вид
(Opt. 1)
(Opt. 2)
(Opt. 3)
( Opt. 4)
(Opt. 5)
( Opt. 6)
n* ° (x, </) = ( n — 1 )* ° x ( n > 0 )
0*°(x, y) = y
((x, y))°z = ((x°z, y°z))
(<Л(х), у}) = x°{Id,y)
ЦА(х)°у, z)) = x°{y, z)
'k°x ='k, где k — это константный объект.
Можно показать, что этот набор правил минимален, если рас-
смотреть редукцию Х-выражения ( ( ( Lx.Ly.( ху) ) (Xz.c) )u),
представленного в ККЛ-форме, где с — это константа. Эта ре-
дукция, дающая в результате с, включает все шесть правил
переписывания. Оставляем ее читателю в качестве упражнения.
Резюме
• Свободные переменные можно «удалить» из Х-выражения,
чтобы получить константную аппликативную форму (КАФ), со-
держащую комбинаторы из переменного набора.
• Правила преобразования графа для каждого комбинатора
являются более сложными, чем в реализации, использующей
фиксированные комбинаторы, и должны генерироваться ком-
пилятором.
• Простое Х-удаление абстрагирует свободные переменные из
л-тел; при этом теряется полная ленивость.
358 Часть II. Глава 13
• При трансляции в суперкомбинаторную форму из Х-тел аб-
страгируются максимальные свободные выражения (мсв), что
гарантирует полную ленивость.
• Порядок выбора в первую очередь «самых свободных» па-
раметров дает в результате наименьшее число наиболее слож-
ных мсв. При этом исключается максимальное число избыточ-
ных параметров и суперкомбинаторов.
• Общее Х-удаление абстрагирует свободные переменные из
вложенных Х-абстракций, давая в результате меньше комбина-
торов, однако при этом полная ленивость снова не гаранти-
руется.
• Использование улучшенных суперкомбинаторов дает нам
меньшее число комбинаторов и сохраняет полную ленивость.
• Категорийные комбинаторы дают альтернативный (фиксиро-
ванный) набор комбинаторов, похожих на конструкции язы-
ка FP.
• Набор правил переписывания, основанный на категорийной
комбинаторной логике, редуцирует категорийные формы Х-вы-
ражений к СЗНФ и формирует основу категорийной абстракт-
ной машины.
Упражнения
13.1. а. Используйте простое Z-удаление для преобразования
следующего определения в константную аппликативную форму:
mult = YKm.Kx .Ку .cond ( = х \)у(т( — х 1) у)
б. Объясните, как ваше решение части (а) может привести
к тому, что одно и то же подвыражение будет вычислено более
одного раза. При каких обстоятельствах такая избыточность не
возникает? Подтвердите ваш ответ примером.
в. Выведите суперкомбинаторную форму mult и объясните,
как это представление исключает избыточность, о которой го-
ворилось в (б).
г. Покажите правила преобразования графа для каждого
комбинатора из части (в) в стиле рис. 13.1.
13.2. Выразите функцию
f = Кх.Ку.cond (< х y)x(f( — х у)у)
в суперкомбинаторной форме. Какие выгоды, относящиеся
к разделению, имеются в этом примере? Обоснуйте свой ответ.
13.3. Рассмотрим функцию f с вложенным определением
... let f xt х2 ... хп = Е in ...
Новейшие комбинаторные реализации 359
для некоторого выражения Е, в котором переменные Vi, ц2.
vm свободные.
а. Выразите это определение f в форме частичного примене-
ния комбинатора и определите этот комбинатор.
б. Каковы преимущества этого типа трансляции с точки
зрения эффективности функций высших порядков?
в. При каких обстоятельствах сохраняется полная лени-
вость, и какой анализ должен выполнить компилятор, чтобы
обнаружить это.
13.4. При каких условиях общее Х-удаление эквивалентно про-
стому Х-удалению с порядком параметров «самый свободный —
самый первый»? Приведите пример, когда этот случай не имеет
места.
13.5. В каком смысле комбинатор соответствует «чистому коду»?
Что это значит для комбинаторной реализации компилирую-
щего типа?
13.6. Для следующих выражений:
(i) (Xf .Kx.f х ( + 1 х)) + 2
(ii) (Хх.Ky.Kz. * (x z)(x(z/ z)))(Xx.x)(Ky. — у 1)4
а) преобразуйте их в нотацию де Брёйна;
б) представьте полученные выражения с помощью катего-
рийных комбинаторов;
в) редуцируйте результирующие комбинаторные выражения
к СЗНФ, используя аксиомы ККЛ.
13.7. Покажите, что Арр ° <Л( х) ° у, z} = х ° (у, z), используя
аксиомы ККЛ. Преобразуйте выражения из предыдущего
упражнения в оптимизированный КАМ-код разд. 13.5.
Глава 14
ПОТОКОВЫЕ РЕАЛИЗАЦИИ
Принципы работы большинства традиционных компьютеров
обычно описывают в виде последовательностей инструкций,
которые манипулируют данными и расположены в памяти либо
регистрах машины. Последовательность выполнения инструк-
ций контролируется с помощью специального регистра счетчика
команд. Говоря более абстрактно, такие архитектуры имеют
модель вычислений, определенную в терминах потока управле-
ния, и мы уже встречали такую модель для функциональных
языков. Например, функция переходов, используемая для опи-
сания SECD-машины в гл. 10, выполняет преобразования со-
стояния машины, заданного 4-элементным кортежем (Стек,
Контекст, Управляющая строка, Дамп), причем управление
процессом осуществляется с помощью Управляющей-строки,
содержимое которой определяет преобразование состояний.
В гл. 11 мы рассмотрели альтернативную модель вычисле-
ний, называемую редукцией графов, в которой основные пра-
вила редукции выражений лямбда-исчисления реализуются
непосредственно на графовом представлении выражения. Различ-
ные графовые преобразования могут заключаться либо в под-
становке аргумента вместо параметра, как при fl-редукции,
либо в применении примитивной функции согласно встроенным
правилам, как при б-редукции. Эту модель можно расширить
введением фиксированных или переменных комбинаторов, каж-
дый из которых будет иметь соответствующее правило, как мы
видели в двух предыдущих главах.
Альтернативный подход к определению модели вычислений
должен рассматривать данные как динамические, или активные,
сущности, которые текут по набору пассивных преобразовате-
лей, выполняющих соответствующие манипуляции всякий раз,
когда в них поступают соответствующие данные. В этом случае
операционные характеристики архитектуры специфицируются на
основании наличия операндов для заданного набора операторов
Потоковые реализации 361
и передачи данных между ними. Другими словами, вычисли-
тельная модель определяется в терминах потока данных, а не
потока управления или редукции графов, и программы на по-
нятийном уровне представляются потоковыми графами.
В данной главе в разд. 14.1 мы опишем базовую потоковую
абстрактную машину для вычисления функциональных выра-
жений. В этой модели выражение определяется набором вер-
шин, представляющих операторы, вместе с соединяющими ду-
гами, представляющими передачу данных между операторами.
Вершины и дуги образуют направленный ациклический граф.
Хотя в предыдущих двух главах рассматривалось использование
НАГ для представления функциональных выражений в виде
графов, но здесь их использование существенно отличается,
поскольку дуги теперь моделируют динамический поток эле-
ментов данных, а не обеспечивают (статистическую) информа-
цию об аргументах функций, конструкторов данных и ^-аб-
стракций. Мы увидим также, что свойство ацикличности яв-
ляется важным; после того как данные поступят по входящим-
дугам и результат будет послан по выходящим дугам, вершина
может быть отброшена, а занимаемая ею память утилизирована
сборщиком мусора, от которого неоптимизированная модель
существенно зависит. Говорят, что базовая потоковая машина,
реализуя энергичное вычисление с помощью вызовов по значе-
нию, является управляемой данными. В разд. 14.2 мы опишем,
как из данной машины можно получить ее версию, управляемую
запросами, которая реализует ленивое вычисление с помощью
вызовов по необходимости. В разд. 14.3 подведем итог потоко-
вой модели и сравним ее с моделью редукции графов, описан-
ной в гл. 11.
14.1. Функциональный поток данных
аппликативного порядка
Наиболее естественная потоковая реализация длй функцио-
нальных языков — это машина, управляемая данными. Она
имеет семайтику аппликативного порядка, и именно эту модель
вычислений мы рассмотрим в первую очередь.
Функциональные выражения заданы здесь в терминах при-
митивных и определенных пользователем функций, а не в виде
выражений Z-исчисления, как при рассмотрении предыдущих
реализаций, и представлены направленными ациклическими
графами (НАГ), которые мы называем потоковыми графами
(ПГ^. Предполагается, что была применена операция, эквива-
лентная Х-удалению, так что все определенные пользователем
функции существуют на верхнем уровне и, возможно, определены
362 Часть II. Глава 14
в терминах вспомогательных комбинаторов. Все объекты,
имеющие в качестве своих значений функции, будут представ-
лены частичными применениями существующих функций. Это
значительно упрощает определение потоковой реализации без
какой-либо потери выразительной силы исходного языка за
счет небольших дополнительных усилий при компиляции.
14.1.1. Потоковые графы (ПГ)
ПГ — это граф, в котором вершины представляют операторы,
а дуги между вершинами представляют зависимости по дан-
ным между этими операторами. Дуги можно рассматривать
как пути, по которым данные «текут» с выхода одного опера-
тора на вход другого. В качестве простого примера здесь пока-
зан ПГ для выражения (2 * 3) + (1 * 4).
В описываемой нами потоковой модели существует шесть
различных типов вершин, пять из которых представляют при-
митивные потоковые операции, а шестой представляет (беско-
нечное) множество величин, включающее функции, определен-
ные пользователем, примитивные функции и константы, напри-
мер целые числа. С каждым типом вершин связан набор
правил, определяющих, по каким входящим дугам должны по-
ступать данные, чтобы соответствующий вершине оператор
мог вычислить результат (эти дуги соответствуют аргументам,
относительно которых оператор является строгим). Те же
правила определяют посылаемые по исходящим дугам значе-
ния, обусловленные входными данными. Для примитивных опе-
раторов эти правила эквивалентны б-правилам Х-исчисления.
У вершины-значения входящих дуг нет. Данные имеются только
на выходящей дуге. Вершины, представляющие конструкторы
данных, т. е. вершины-конструкторы, могут быть представлены
Потоковые реализации 363
с помощью специального типа вершин, как в гл. 11 для редук-
ции графов.
Дуга, направленная от вершины А к вершине В, представ-
ляет передачу результата, выданного оператором в вершине А,
в качестве аргумента для оператора в вершине В. Чтобы вер-
шина А могла вычислить результат, она должна быть обеспе-
чена всеми необходимыми аргументами, которые передаются
по соответствующим входным дугам А. Граф, представляющий
функциональное выражение, является ациклическим, так что
никакая дуга не передает данные более одного раза. Поэтому,
если вершина выдала данные и поместила их на свои выходя-
щие дуги, она уже не активизируется данными на своих вхо-
дящих дугах и, следовательно, удаляется, а занимаемая ею
память снова используется с помощью сборщика мусора
[см. гл. 16.]. (Конечно, можно придумать патологические вер-
шины, выполняющие несколько вычислений, используя незави-
симые входы и выходы, например если объединить две прими-
тивные вершины в одну. Однако мы не будем допускать таких
вершин.)
Тело или определяющее выражение функции пользователя
представляется в виде ПГ, имеющего по одной внешней входя-
щей дуге для каждого формального параметра функции и одну
внешнюю выходящую дугу, соответствующую результату этой
функции. Ссылки на эту функцию в ПГ других функций пред-
ставляются с помощью вершины-значения.
Теперь мы определим операции, связанные с каждым из
шести различных типов вершин. Это требует минимальных объ-
яснений. Исключением является вершина применения, с которой
связана операция подстановки ПГ, представляющего функцию
пользователя, и операция построения и применения частичных
применений, которые мы снова называем замыканиями. Опре-
делив все конституенты ПГ, мы покажем в качестве примеров
ПГ двух функций: функции первого порядка для вычисления
чисел Фибоначчи и функции высшего порядка тар, которая
применяет заданную функцию к каждому элементу заданного
списка.
Вершины в ПГ определяются следующим образом:
1. Вершина примитивной функции имеет одну входящую дугу
для каждого параметра этой функции и одну выходящую дугу.
Когда на всех входящих дугах, соответствующих строгим аргу-
ментам функции, имеются данные, результат применения функ-
ции к этим данным помещается на выходящую дугу. Вершина
помечена своим типом, а также идентификатором соответствую-
щей примитивной функции. Строгие аргументы и результат
применения определяются соответствующим данной функции
364 Часть П. Глава 14
6-правилом. Например, арифметическая функция имеет две
входящие дуги, по каждой из которых должны быть переданы
данные, чтобы операция была выполнена, после чего сумма
этих элементов данных (которые предполагаются числами) по-
мещается на выходящую дугу. Например,
х + у
2. Вершина копирования имеет одну входящую дугу и произ-
вольное число выходящих дуг. Она используется для дублиро-
вания входных данных, что всегда требуется, чтобы несколько
операторов в ПГ имели возможность работать с одной и той
же величиной. Например, как мы увидим, любой аргумент, по-
являющийся более одного раза в теле функции, должен дубли-
роваться таким образом:
копи-’
рова-
. ние j
3. Вершина-значение не имеет входящих дуг, но связанная с ней
величина, которая может быть либо константным элементом
данных (или структурой), либо примитивом, либо функцией
пользователя, представляется в виде замыкания, как описано
ниже. Эта величина или некоторое ее представление, например
адрес или указатель, помещается на единственную выходящую
дугу. В качестве примера здесь мы показываем вершину-значе-
ние для литерала 3:
(Причина включения вершин-значений, представляющих при-
митивы, состоит в том, чтобы допустить частичное применение
примитивов. В дальнейшем это станет ясным.)
Потоковые реализации 365
4. Вершина-переключатель используется для управления пото-
ком данных через ПГ в соответствии со значением булевого
элемента данных на ее «управляющей» дуге, которая по согла-
шению рисуется слева, как показано ниже. Оба входа необхо-
димы для выполнения операции переключения, и имеются две
выходящие дуги, помеченные Т и F.
Если по входящей управляющей дуге передается значение true
(более точно, величина, представляющая true), значение дан-
ных на второй входящей дуге, т. е. «входное значение», поме-
щается без изменений на выходную дугу, помеченную Т. По-
добным образом, если на управляющий вход поступает значение
false, вторая входная величина помещается на дугу, помечен-
ную F. (Мы предполагаем, что исходная программа не со-
держит ошибок, связанных с типами данных, так что никаких
других значений на управляющей дуге быть не может.)
5. Вершина слияния является дополнительной по отношению
к вершине-переключателю. Здесь опять имеется управляющий
вход, являющийся по соглашению первой входящей дугой, две
другие входящие дуги, помеченные Т и F, и единственная выхо-
дящая дуга. Данные необходимы на управляющем входе и на
одном из двух входов в зависимости от значения на управляю-
щей дуге.
два входных значения
Т F
управление \ слияние
366 Часть II. Глава 14
Если на управляющий вход поступает значение true, вели-
чина данных на входящей дуге, помеченной Т, помещается на
выходящую дугу, а если на управляющем входе значение false,
то на выходящую дугу помещается величина, поступающая по
дуге, помеченной F.
6. Вершина применения выполняет наиболее сложную опера-
цию, эквивалентную (3-редукции в Х-исчислении. Имеются две
входящие дуги. Первая из них, которая по соглашению ри-
суется с левой стороны, соответствует применяемой функции,
а вторая соответствует аргументу этой функции, как показано
ниже. Обе входящие дуги должны иметь данные в модели,
управляемой данными, а в ленивой модели, управляемой за-
просами, данные необходимы только на входной дуге, соответ-
ствующей функции. Результат применения в конце концов по-
мещается на выходящую дугу, иногда после подстановки под-
графа, представляющего тело функции пользователя, которая
подается на функциональный вход.
функция на первой
входящей дуге
аргумент на второй
входящей дуге
приме-
нение
результат применения
на выходящей дуге
Применяемая функция в этом случае всегда является за-
мыканием, которое мы будем представлять в виде пары [В,Е],
где В — это тело замыкания (ПГ), а Е — это контекст. Кон-
текст первоначально представляет собой список идентификато-
ров дуг (соответствующих идентификаторам аргументов), но
эти идентификаторы при появлении соответствующих значений
аргументов связываются с ними, давая в результате список пар
идентификатор — значение вида (ii = Vi..... in = vn). Когда
Потоковые реализации 367
все дуги имеют связанные с ними величины, ПГ тела замыка-
ния может быть вычислен путем мысленной замены каждой
входящей дуги на вершину-значение, представляющую соответ-
ствующий аргумент. Таким образом, все тела замыканий яв-
ляются статическими, и поэтому могут генерироваться на этапе
компиляции. Динамическим является только контекст, кон-
струируемый в процессе вычисления выражения. Поэтому ре-
зультат применения замыкания зависит от арности этого за-
мыкания, являющейся числом аргументов, к которым замыка-
ние должно быть применено, чтобы обеспечить связь для каж-
дого идентификатора в контексте.,
а. Если замыкание имеет арность 1, то в результате его при-
менения все идентификаторы в контексте связываются с неко-
торыми величинами, и функция, содержащаяся в замыкании,
будет применена путем помещения этих величин на входящие
дуги ее ПГ, как описано выше.
б. Если арность замыкания больше 1, то возвращается новое
замыкание, арность которого на единицу меньше и которое
имеет на одну связь больше в своем контексте. Чтобы проиллю-
стрировать механизм применения замыкания, рассмотрим
функцию (комбинатор)
f х у z = + ( + х y)z
ПГ тела f, которое мы обозначим Вц имеет вид
Первоначально замыкание для f выглядит следующим об-
разом:
f = [В£, (х, у, z)]
и именно это замыкание (или, точнее, указатель на него) пере-
дается по выходящей дуге вершины-значения, с которой свя-
зана величина f.
Частичные применения f представляются замыканиями, в
которых один или более идентификаторов дуг х, у и z связаны
368 Часть II. Глава 14
с соответствующими значениями, скажем X, Y и Z:
fX = [Bf, (х == X, у, z)]
fXY = [Bf, (х = Х, y = Y, z)]
fXYZ = IBf, (x = X, y = Y, z = Z)]
= + (+ X Y)Z
ПГ выражения +( + XY)Z эквивалентен исходному ПГ
для Bf, где входящие дуги X, Y и Z присоединены к вершинам-
значениям, содержащим величины X, Y и Z. Должно быть
ясно, что используемые здесь замыкания являются просто об-
общением замыканий, используемых в SECD-машине, поскольку
они моделируют частичные применения комбинаторов, имею-
щих несколько аргументов, вместо карринговых функций от
одного аргумента. Короче, подстановки конкретных значений
вместо переменных в Bf не выполняются до тех пор, пока все
значения аргументов не будут в наличии.
14.1.2. Примеры
Для того чтобы основной потоковый механизм стал более
понятным, рассмотрим два примера функций: функцию fib, вы-
числяющую числа Фибоначчи, и функцию тар, применяющую
некоторую функцию к каждому элементу заданного списка. Эти
функции имеют следующие определения:
fib x = cond(< х 2) 1 ( + (fib(— x 1))(fib( — x 2)))
map f s = cond (null s) s (cons (f ( hd s))(map f(tl s)))
ПГ для этих функций показаны соответственно на рис. 14.1
и 14.2. На этих рисунках для удобства ссылок на различные
части графов каждая вершина имеет свой номер.
В случае функции fib отметим, что у вершины-переключа-
теля 5 отсутствует выходная дуга, помеченная Т, поскольку
этот выход не требуется для результата применения fib, кото-
рый в этом случае равен константе 1. Если бы функция fib была
определена следующим образом:
fib x = cond (< х 2)x(4~(fib( — х 1 ))(fib( — x 2)))
тогда эта выходная дуга шла бы на вход Т вершины слия-
ния 17 и не существовало бы вершины-значения 15.
Функция тар является примером функции от нескольких
аргументов и поэтому требует каррингового применения, вклю-
чающего построение замыкания и его применение.
Потоковые реализации 369
Рис. 14.1. ПГ для функции fib.
24
1473
370 Часть II. Глава 14
Рис. 14.2. ПГ для функции тар.
Потоковые реализации 371
14.1.3. Работа абстрактной машины,
управляемой данными
В абстрактной машине, которую мы сейчас описываем, каж-
дая вершина в потоковом графе соответствует инструкции
в потоковой программе. Потоковая инструкция имеет четыре
поля, а именно:
1) идентификатор, например порядковый номер соответствую-
щей вершины потокового графа или адрес памяти в компьютер-
ной реализации;
2) список входов, представляющий последовательность величин
на входящих дугах соответствующей вершины;
3) тип вершины, т. е. вершина копирования, вершина-значение,
вершина слияния и т. д.;
4) список выходов, каждый элемент которого является парой,
состоящей из идентификатора вершины и номера входной дуги
Таблица 14.1. Потоковые инструкции для функции Фибоначчи
Идентификатор Размер списка входов Тип Список выходов
1 1 копирование (3.2, 5.2)
2 0 значение:2 (3.1)
3 •2 примитив : > (4.1)
4 1 копирование (17.1, 5.1)
5 2 переключатель (пусто, 6.1)
6 1 копирование (10.1, 9.1)
7 0 значение: 1 (9.2)
8 0 значение:2 (Ю.2)
9 2 примитив:— (12.2)
10 2 примитив:— (14.2)
11 0 значение: fib (12.1)
12 2 применение (16.2)
13 0 значение: fib (14.1)
14 2 . применение (16.1)
15 0 значение: 1 (17.2)
16 2 примитив : + (17.3)
17 3 слияние (выход)
этой вершины. В нашем определении ПГ только вершины ко-
пирования и вершины-переключатели могут иметь больше одного
элемента в своих списках выходов. В принципе несколько вы-
ходов могут иметь также некоторые примитивные функции,
с которыми мы, однако, здесь не работаем.
Заметим, что именно поле, содержащее список выходов (вме-
сте с любыми внешними входами) определяет связность соот-
ветствующего потокового графа, указывая, куда следует на-
править каждую выходящую дугу. Теперь мы можем записать
24*
372 Часть II. Глава 14
потоковые инструкции, представляющие любой заданный по-
токовый граф. Последовательность инструкции для определен-
ной ранее функции Фибоначчи показана в табл. 14.1. Анало-
гичная последовательность инструкций для функции шар может
быть легко получена, и мы оставляем это читателю в качестве
упражнения.
Элемент списка выходов вида i, к обозначает к-й вход ин-
струкции, имеющей идентификатор i. Для инструкций типа
значение соответствующая константа также указана в поле
типа. То же самое справедливо для инструкций типа примитив.
Значение fib в этом примере является ссылкой на первоначаль-
ное замыкание для fib, которое имеет вид [тело fib, 1.1 = ?].
Здесь «тело fib» представляет потоковые инструкции для fib,
а не ПГ этой функции, а символ ? указывает, что никакая ве-
личина не связана с входной переменной. Такое связывание
выполняется при применении (первоначального замыкания) fib
к аргументу.
Работа управляемой данными потоковой машины опреде-
ляется теперь следующим неформальным алгоритмом:
ПОВТОРИТЬ
Выбрать любую инструкцию, имеющую все необходимые
аргументы в списке входов;
Выполнить выбранную инструкцию;
Удалить эту инструкцию;
ПОКА имеется хотя бы одна инструкция
Заметим, что ПГ являются ациклическими, и поэтому ин-
струкция, соответствующая вершине в ПГ, после выполнения
удаляется, поскольку данные на ее входящих дугах появиться
не могут. Заметим также, что набор «все необходимые аргу-
менты» соответствует входам вершины ПГ, на которых нали-
чие данных обязательно, чтобы операция этой вершины могла
быть выполнена. Эти входы задаются правилами, специфиче-
скими для каждого типа инструкций. Такие правила указывают,
например, что значения данных должны быть на всех входах
для инструкций типа «копирование», «переключатель» и «при-
менение» (в последнем случае только для машины, управляе-
мой данными). В случае инструкции типа «слияние» необходим
первый (управляющий) вход, а также второй (Т) или третий
(F) в зависимости от того, имеется ли на первом входе значе-
ние true или false соответственно. В случае примитивной функ-
ции входы, на которых требуется наличие данных, соответ-
ствуют определяемым 6-правилами строгим аргументам этой
функции. Таким образом, в каждом случае все из необходимых
элементов входного списка известны. Заметим, что несколько
Потоковые реализации 373
инструкций могут иметь все необходимые аргументы в начале
нового цикла алгоритма. Поскольку функциональные выражения
обладают свойством прозрачности по ссылкам и ПГ явлдются
ациклическими, для выполнения может быть выбрана любая
такая инструкция (или инструкции), и в действительности лю-
бое число одинаковых алгоритмов может выполняться одновре-
менно, что очень способствует параллельной реализации.
В заключение этого раздела рассмотрим наиболее сложную
операцию нашего алгоритма, а именно «выполнить инструк-
цию». Она достаточно проста во всех случаях, кроме инструк-
ции применения, и определяется характеристиками типа рас-
сматриваемой инструкции. Например, инструкция «слияние» со
всеми необходимыми входами просто передает значение соот-
ветствующего входа (определяемое значением управляющего
входа) на вход, указанный единственным элементом списка вы-
ходов. Работа вершины применения в ПГ зависит от замыка-
ния, которое поступает по ее первой входной дуге.
Если в результате применения все переменные в контексте
замыкания оказываются связанными, то генерируется копия
тела функции, т. е. набор инструкций, представляющий ее ПГ.
Второй элемент списка входов инструкции применения запо-
минается при этом в поле входов копии тела, как специфициро-
вано в самом замыкании, а элемент списка выходов инструк-
ции применения запоминается в поле выходов копии тела.
(Вспомним, что в приведенном ранее примере программы для
fib поле выходов тела функции fib находится в списке выходов
последней инструкции «слияние»). Таким образом, функция
применяется к заданному аргументу, а ее результат направ-
ляется в нужное место назначения. Мы придерживаемся согла-
шения, что поле выходов тела функции соответствует полю вы-
ходов последней инструкции этого тела, как это имеет место
в примере для функции fib. Некоторые ограничения такого со-
глашения будут указаны ниже при обсуждении процедуры гене-
рации копий тел функций. Заметим, что в случае частично при-
мененной примитивной функции, такой как +, тело замыкания
будет состоять только из' одной вершины, которая заменит
соответствующую вершину применения после генерации ко-
пии тела.
Если, с другой стороны, замыкание имеет арность больше 1,
то значение аргумента (второй элемент списка входов в инструк-
ции применения) связывается со следующей переменной, кото-
рая не была связана в контексте замыкания. Результатом в
этом случае является копия старого замыкания, дополненная
этой новой связью.
374 Часть II. Глава 14
14.1.4. Оптимизированная реализация,
основанная на использовании стека
Неприятность, связанная с описанной в предыдущем раз-
деле реализацией, состоит в том, что новые «примеры» тел
функций, генерируемые при применении функции, должны быть
явным образом «встроены» в ПГ. При таком встраивании имеют
место значительные накладные расходы, и его можно избежать
в реализации, основанной на использовании стека. При этом
адресация инструкций является относительной, начиная с ад-
реса выполняемой в данный момент инструкции. Таким обра-
зом, в телах функций или замыканий нет абсолютных адресов
и, следовательно, нет необходимости преобразования адресов.
Эта идея ведет к следующей реализации, основанной на ра-
боте [34].
Инструкции, которые составляют потоковую программу для
вычисления функционального выражения, помещаются в стек,
и каждая инструкция в стеке имеет два поля: поле данных и
поле операции. Поле данных состоит из пары операндов или
входов, а поле операции состоит из кода операции (соответ-
ствующего типу вершины в ПГ) и двух относительных смеще-
ний в стеке от местоположения данной инструкции, указываю-
щих, куда поместить результат вычисления. Смещение +m.n
(п=1, 2) в поле операции инструкции в позиции i в стеке
ссылается на n-й операнд в поле данных инструкции, находя-
щейся на ш позиций ниже i, т. е. в позиции m i. Первона-
чально все поля данных являются пустыми, ожидающими дан-
ных от предшествующих инструкций (расположенных выше в
стеке), а стек содержит только те инструкции, которые исполь-
зуются в выражении «верхнего уровня», и не содержит ин-
струкций из тел любых функций пользователя. Вычисление про-
исходит путем выполнения инструкции в вершине стека, вытал-
кивания ее из стека и продолжения этого цикла до тех пор,
пока стек не станет пустым. Выполнение каждого типа инструк-
ции определяется точно так же, как мы видели для ПГ и на-
ших предыдущих форматов инструкций, но некоторое усовер-
шенствование в случае инструкции применения иллюстрирует
отличие данной реализации (и ее улучшенную производитель-
ность). Непосредственно перед выполнением инструкции при-
менения элемент в вершине стека будет иметь вид
| f | а | применение! +т,п |
где f является применением замыкания, а а — аргументом
этого замыкания. Результат применения помещается в n-ю по-
зицию операнда инструкции, расположенной на m позиций
ниже вершины стека. Первым делом инструкция применения
Потоковые реализации 375
выталкивается из стека. Остальные правила выполнения при-
менения аналогичны тем, которые были описаны ранее. Прежде
чем записать их, следует заметить, что контекст замыкания по
предположению состоит из списка значений аргументов, а не из
списка пар идентификаторов дуг и соответствующих значений,
как раньше, поскольку в оптимизированной реализации аргу-
менты функции соответствуют, по определению, входным полям
первых инструкций в списке инструкций; мы будем называть их
входными инструкциями. Все это, как вскоре станет понятно,
имеет отношение к использованию стека для хранения парамет-
ров функций. Правила применения имеют следующий вид:
Если замыкание f имеет арность 1, то копия тела f загру-
жается без изменений в стек. Значение аргумента запоминается
в поле первого операнда инструкции в вершине стека, а смеще-
ние +m n запоминается в выходном поле последней инструкции
данной копии (другими словами, оно запоминается в его соб-
ственной позиции в исходной инструкции применения!).
Если, с другой стороны, f является замыканием арности
р > 1, то создается новое замыкание (арности р — 1). Его
контекст дополнен значением аргумента а.
Мы заканчиваем этот раздел примером, иллюстрирующим
характерные особенности оптимизированной потоковой реализа-
ции. Рассмотрим выражение succ(f3), где succ — это прими-
тивная функция следования на множестве целых чисел, а функ
ция пользователя f определена в виде fx= -j-хх. Тело f имеет
следующие потоковые инструкции:
копирование + 1.1 + 1.2
примитив: (выход)
и ее первоначальное замыкание состоит из тела вместе с пу-
стым контекстом. Выражение верхнего уровня задается перво-
начальным стеком:
1) — — значение: 3 +2.2
— — значение: f + 1.1
— — применение +Е1
— — примитив: succ (выход)
Затем получаем следующие стеки:
2) - — значение: f + 1.1
— 3 применение + Е1
— — примитив: succ (выход)
3) [f, ( )] 3 применение +1.1
— — примитив: succ (выход)
376 Часть II. Глава 14
(Хотя во входном списке инструкции применения указано
замыкание [f, ( )], на практике был бы использован указа-
тель на это замыкание.)
4) 3 — копирование +1.1 +1.2
— — примитив: + +1.1
— — примитив: succ (выход)
(Заметим, что выходное поле новой копии тела функции
такое же, как выходное поле первоначальной инструкции
применения, т. е. +1.1)
5) 3 3 примитив: + +1.1
— примитив: succ (выход)
6) 6 — примитив: succ (выход)
7) выход = 7
Должно быть ясно теперь, что при таком подходе код для каж-
дой функции (поля операндов и списки выходов каждой ин-
струкции) не изменяется при вычислении функции. Отсюда
следует, что копирование тела применяемой функции в стек не
является необходимым. Вместо этого мы можем проходить че-
рез разделяемую копию тела функции, используя обычный
«счетчик команд». Применение функции теперь заключается
просто в выделении необходимого пространства в вершине
стека для хранения всех входов инструкций в теле функции
и в вызове кода функции, как если бы она была обычной под-
программой Помещение результата применения в «выходное»
поле тела функции соответствует в этом случае тому, что ре-
зультат остается в вершине стека, так что позиция результата 7
на приведенной выше диаграмме становится важной. Таким
образом, можно компилировать потоковые инструкции в обыч-
ный машинный код, где все примитивные операции берут свои
входные параметры из вершины стека.
Отметим также, что условные выражения в исходной про-
грамме будут транслироваться в последовательности инструк-
ций для предиката, true-ветви и false-ветви — с вершиной-пере-
ключателем, выбирающей одну из двух ветвей в зависимости от
значения предиката. К сожалению, описанная нами схема тре-
бует, чтобы все инструкции таких условных выражений обра-
батывались путем последовательного выталкивания их из стека,
тогда как нам необходимо обрабатывать только инструкции
одной из ветвей По этой причине мы должны использовать
идею знака вычеркивания, который при подаче на вход(ы)
инструкции приводит к тому, что эта инструкция удаляется без
выполнения. Когда значение предиката известно, знаки вычер-
Потоковые реализации 377
кивания должны подаваться на входы каждой инструкции той
ветви, которую мы не выбрали, так что когда эти инструкции
встречаются вычисляющему устройству, они просто игнори-
руются «Распространение» знаков вычеркивания достигается
путем передачи каждой инструкцией любого знака вычеркива-
ния с ее строгих входов на ее выход (ы). В этом случае вычер-
кивание одной из ветвей можно инициировать, поместив знак
вычеркивания на одну из выходных дуг соответствующей вер-
шины-переключателя. В качестве дополнительной оптимизации
в следующей реализации описанной здесь потоковой модели бу-
дет замечено, что инструкции каждой ветви являются непре-
рывными, и поэтому возможно достичь эффекта вычеркивания
путем «перепрыгивания» через всю ненужную нам ветвь с по-
мощью изменения указателя стека и счетчика команд. Это яв-
ляется потоковым аналогом инструкции «перехода» в тради-
ционном компьютере.
14.2. Функциональный поток данных 1
нормального порядка
Реализация, рассмотренная в предыдущем разделе, рабо-
тает по ..принципу, согласно которому вершины в потоковом
графе или инструкции в потоковой программе выполняются
всякий раз, когда данные имеются на необходимых входах, не-
зависимо от того, нужен или нет результат такого выполнения
другой части вычисления, т. е. другой вершине ПГ в качестве
входа. Поэтому такой управляемый данными режим выполне-
ния реализует редукцию аппликативного порядка, соответствую-
щую правилу вызова по значению Чтобы получить семантику
нормального порядка, применение функции должно выполнять-
ся, только когда его результат явным образом запрошен. Этот
запрос должен быть размножен в случае, когда вычисление
запрошенного применения требует результат другого Примене-
ния. Это размножение запроса в конце концов достигает ато-
марной вершины или дуги в ПГ, т. е. вершины-значения или
внешнего входа функции, после чего вершина может выпол-
ниться. Результирующий режим реализации называется пото-
ком данных, управляемым запросами, и в этом разделе мы
опишем модификации, необходимые, чтобы из версии, управ-
ляемой данными, получить версию, управляемую запросами.
Как обычно, по причинам эффективности нам необходимо га-
рантировать, чтобы выражения аргументов вычислялись не
более одного раза, т. е. мы требуем выполнение правила вызова
по необходимости, а не вызова по имени. Этого легко до-
биться в потоковой реализации, поскольку аргумент является
378 Часть II. Глава 14
разделяемым, будучи распределен с помощью вершины копиро-
вания, которая посылает его .результат по запросам на все свои
выходные дуги.
14.2.1. Работа потоковой машины,
управляемой запросами
Принцип работы машины, управляемой запросами, состоит
в том, что потоковая инструкция выполняется тогда и только
тогда, когда запрошен ее выход, а все необходимые входы вы-
числены и их значения имеются на входных дугах. Теоретически
это достигается поддержкой списка всех инструкций, выход
которых был затребован, но физически это можно реализовать
пометкой каждой инструкции, показывающей, был или не был
затребован выход этой инструкции. Отсюда немедленно следует
необходимость дополнительного поля в инструкции, содержа-
щего список идентификаторов тех инструкций, выход которых
необходим в качестве входа данной инструкции. Это поле мы
будем называть полем списка источников. Список источников
имеет один элемент для каждого строгого входа инструкции,
и каждый идентификатор в этом списке указывает инструкцию,
расположенную на другом конце соответствующей входящей
дуги. Вначале мы должны запросить выходную инструкцию,
связанную с выражением верхнего уровня. Она размножает
запрос, передавая его в направлении, противоположном на-
правлению потока данных. Физически инструкциям, требуемым
для вычисления выражения верхнего уровня, запросы пере-
даются с помощью идентификаторов в соответствующих спи-
сках источников, при этом устанавливаются метки запросов
этих инструкций. Как и ранее, инструкция после выполнения
удаляется (так как ПГ является ациклическим) и, будучи по-
меченной, вычеркивается из подразумеваемого «списка требо-
ваний». Главный цикл потоковой машины, управляемой запро-
сами, имеет вид
ПОВТОРИТЬ
Выбрать любую инструкцию, выход которой был запрошен,
с помощью тестирования ее метки;
если
Все необходимые аргументы находятся в поле списка,
входов;
то
Выполнить эту инструкцию;
Удалить эту инструкцию;
Известить о выполнении ту инструкцию, которая
запросила данную (чей идентификатор содержится в
списке выходов данной инструкции)
Потоковые реализации 379
иначе
Послать запрос соответствующим инструкциям, которые
указаны в списке источников данной инструкции;
Изменить статус инструкции; т. е. установить метку,
указывающую, что выполнение этой инструкции
не требуется
ПОКА
Существует хотя бы одна запрошенная инструкция
Нет необходимости перед выполнением данной инструкции
запрашивать все инструкции, идентификаторы которых ука-
заны в ее списке источников; это зависит от типа данной ин-
струкции. Термин «соответствующие» в приведенном выше ал-
горитме относится к инструкциям, определяемым списком
источников данной инструкции и исключает те инструкции, вхо-
ды от которых уже получены. Для инструкций копирования и
инструкций-переключателей все инструкции, указанные в списке
источников, должны быть запрошены. Для инструкции слияния
обязательно нужно запросить первую инструкцию из списка
источников, т. е. инструкцию, выходная дуга которой соединена
с управляющим входом. Затем запрашивается вторая или
третья инструкция в зависимости от того, получили мы на
управляющем входе значение true или false. Повторный запрос
посылается инструкцией слияния при повторном ее выборе для
вычисления после получения булевого результата от первой
инструкции, указанной в списке источников. Для инструкции
примитивной функции те инструкции из списка источников, ко-
торые должны запрашиваться при ее выборе для вычисления,
соответствуют строгим аргументам рассматриваемой примитив-
ной функции. Наконец, в случае инструкции применения за-
прашивается только первая инструкция из списка источников
(она соответствует применяемой функции). Эта функция при
необходимости сама пошлет запрос для своего аргумента, ис-
пользуя свою собственную копию второго элемента списка ис-
точников инструкции применения. Это станет ясным из описа-
ния работы инструкции применения, данного ниже.
После завершения выполнения инструкции ее можно удалить,
поскольку, как мы уже отмечали, ПГ является ациклическим.
Кроме этого, той инструкции, которая запрашивала выполнение
данной, посылается отклик, в результате чего она снова поме-
чается как требующая выполнения, имея теперь на входе тот
результат, который ждала. Конечно, если существует несколько
таких ожидаемых входов, то инструкцию по-прежнему невоз-
можно выполнить, и тогда она должна снова отложить свое вы-
полнение. Однако нетрудно разработать усовершенствованный
380 Часть II. Глава 14
интерпретатор, который не будет реактивировать ожидающую
инструкцию до тех пор, пока не будут получены все запрошен-
ные ею входы.
14.2.2. Выполнение инструкции применения
Как и в случае машины, управляемой данными, ключом
к пониманию принципов работы машины, управляемой запро-
сами, является то, как выполняется инструкция применения.
При первом выборе инструкции применения источнику приме-
няемой функции (связанному с первым входом) посылается
запрос, как описано в предыдущем разделе, а при втором вы-
боре выполняются следующие действия:
• Если первый вход является замыканием арности больше 1,
строится новое замыкание, как и в случае управления данными.
Однако теперь величины, связываемые с переменными кон-
текста, являются указателями на те инструкции, которые в ко-
нечном счете выдадут требуемые значения. В общем неоптими-
зированном случае каждая связь будет состоять из пары иден-
тификатор— исходная инструкция, хотя, как мы видели, можно
основываться на позиционном порядке входных дуг, используя
стек. Результирующее замыкание является результатом дан-
ного применения и запоминается в элементе списка входов, ко-
торый специфицирован обычным образом в списке выходов ин-
струкции применения.
• Если первым входом является замыкание арности 1, то ге-
нерируется соответствующим образом конкретизированная ко-
пия тела функции замыкания во многом подобно тому, как это
делается в случае машины, управляемой данными. Сначала все
инструкции тела функции воспроизводятся с новыми уникаль-
ными идентификаторами с модификацией всех элементов спи-
сков выходов и списков источников, кроме внешних выходов.
Конечно, при использовании стековой реализации, описанной
в разд. 14.1.4, нет необходимости в преобразовании адресов по
причинам, указанным выше. Затем выполняются следующие
четыре операции «соединения»:
1. Элемент списка выходов инструкции применения поме-
щается, как прежде, в выходное поле копии тела.
2. Элемент списка источников для каждой (внешней) вход-
ной дуги тела заменяется соответствующей связью из контекста.
Эта операция связывает с каждой входной дугой ту инструк-
цию, которая в конечном счете передает по этой дуге требуе-
мое значение.
Потоковые реализации 381
3. Элемент списка выходов каждой исходной инструкции,
на которую есть ссылка в контексте, изменяется так, что ука-
зывает на входную инструкцию, соответствующую данному эле-
менту контекста.
4. Выходная инструкция копии тела помечается как тре-
бующая выполнения, в результате чего начнется вычисление
вновь созданного применения функции.
Проницательный читатель должен был заметить, что нам те-
перь необходимо ввести небольшое ограничение. Если список
выходов инструкции содержит элемент, являющийся вторым
элементом списка входов вершины применения, то этот список
выходов должен состоять из одного элемента; в противном слу-
чае в п. 3 будет неизвестно, какой элемент списка нужно изме-
нить. Однако это ограничение можно обойти, сделав каждый
элемент списка источников парой, включающей исходную ин-
струкцию и номер элемента ее списка выходов.
14.3. Сравнение с другими моделями
Подобно другим вычислительным моделям, рассмотренным
в этой книге, таким как SECD-машина и редукция графов,
функциональная потоковая модель дает представление р-редук-
ции и 6-правил для поддерживаемых примитивных функций.
Эти примитивные функции включают условные выражения, ко-
торые, хотя и выражаются с помощью вершин-переключателей
и вершин слияния, могли бы точно так же рассматриваться
в терминах только двух дополнительных примитивных функций
и их дельта-правил. Более того, редекс такого применения
можно рассматривать как перезаписываемый в том смысле,
что входящие дуги его вершины применения перенаправляются
в тело функции.
Поэтому существует прямое соответствие между принципами
работы функционального потока данных и вычислительной мо-
дели редукции графов. Данное соответствие также распростра-
няется на графовое представление выражений, хотя это может
быть не очевидным с первого взгляда. Дуга в ПГ указывает
поток данных от исходной вершины к вершине, которая преоб-
разует эти данные, тогда как при редукции графов дуга ука-
зывает источник аргумента (и в действительности источник
функции). Таким образом, в двух вычислительных моделях дуги
указывают в противоположных направлениях, и по этой при-
чине поток данных часто называют «редукцией графов, пере-
вернутой вверх дном». Фактически при рассмотрении потоко-
вой модели, управляемой запросами, мы обнаруживаем, что
382 Часть II. Глава 14
запросы распространяются в направлениях, противоположных
направлениям дуг потока данных, т. е. в направлениях дуг соот-
ветствующих графов редукции. Подобно тому как граф редук-
ции может содержать много редексов, ПГ может содержать
много выполнимых инструкций, т. е. инструкций, имеющих
данные на всех требуемых входах. По этой причине потоковая
модель является особенно подходящей для параллельной обра-
ботки. Интересующегося читателя мы отсылаем к работам [4,
88], где описывается применение потоковых методов к парал-
лельной реализации языков с единичным присваиванием, напо-
минающих строгие функциональные языки первого порядка.
Более общие обзоры параллельных потоковых методов можно
найти в [30, 50].
Единственным существенным отличием графов редукции от
инвертированных ПГ является расщепление и соединение, вы-
полняемое вершинами-переключателями и вершинами слияния.
Оно также может быть устранено, если мы отбросим тип вер-
шин-переключателей и будем рассматривать вершины слияния
как вершины «условных выражений» с обычными тремя вхо-
дами: предикатом, следствием и альтернативой. Это привело бы
в модели, управляемой данными, к избыточному вычислению
подвыражений, так как нам в любом случае требуется либо
следствие, либо альтернатива. Причина существования вершин-
переключателей состоит в том, что необходимо гарантировать
выполнение только требуемых вычислений. Однако в модели,
управляемой запросами, инструкция выполняется, только бу-
дучи запрошенной, т. е. тогда, когда она необходима, поэтому
вершины-переключатели не нужны и инвертированный ПГ вы-
глядит точно так же, как граф редукции типа тех, что обсуж-
дались в гл. 11. Роль вершины-переключателя играют в модели,
управляемой запросами, дельта-правила вершины слияния, и
мы заключаем, что редукция графов и перевернутый поток
данных, управляемых запросами, — это, в сущности, одно
и то же.
Резюме
• Программы можно выразить графически с помощью потоко-
вых графов (ПГ).
• Вершины ПГ представляют операторы, а дуги между вер-
шинами— зависимости по данным.
• Наиболее естественная реализация потока данных является
управляемой данными. Это означает, что операторы выпол-
няются, как только все их необходимые входы будут в наличии.
• ПГ могут быть представлены наборами инструкций по одной
на каждую вершину графа.
Потоковые реализации 383
• Эти инструкции могут быть выполнены последовательно на
обычном компьютере, посредством чего выполняются операции,
специфицированные ПГ; входные данные для инструкций мож-
но хранить в стеке.
• Потоковую модель можно расширить для выполнения вы-
числения, управляемого запросами, которое соответствует ре-
дукции нормального порядка; это существенно усложняет
модель.
• Поток данных можно реализовать на параллельной машине
путем выполнения различных потоковых инструкций на различ-
ных процессорах.
Упражнения
14.1. Рассмотрим следующие функции
(i)fxyg = + (*2x)(gyyx)
(ii) g х у = —x(cond ( = х 0)0(g(— у 1)( — x 1)))
(iii) h x = f( — x 3)( + x)
а. Нарисуйте ПГ для каждой функции.
б. Для каждого из полученных ПГ запишите последователь-
ность потоковых инструкций, требуемую для реализации
функции.
14.2. Для функции F вида Fxix2 ... хп мы могли бы предста-
вить применение F, непосредственно связав выходную дугу ин-
струкции, генерирующей значение Xi с i-й входной дугой ПГ
функции F (l^i^n). Таким образом мы представили бы
применение F непосредственно с помощью ее ПГ, а не путем
формирования первоначального замыкания для F и применения
его затем с помощью последовательности вершин применения.
Какое ограничение накладывается при этом на способ исполь-
зования F? Обоснуйте свой ответ.
14.3. а. Каким образом выражение +ху может быть выражено
в виде ПГ в карринговой и в некарринговой форме?
б. Согласно нашему определению, вершина-значение для
примитивной функции Р выдает замыкание [Р, ()]. Допустим
теперь, что она вместо этого выдает соответствующий символ
функции Р. Расширьте правила для применения функции, дан-
ные в разд. 14.1, чтобы позволить функциональной дуге вер-
шины применения хранить такой символ примитивной функции.
14.4. Рассмотрим выражение верхнего уровня E = f(g3)7, где
f и g имеют вид
f h x = + (h х)х
g a b = —а 1
384 Часть II. Глава 14
а. Нарисуйте ПГ для Е, f и g.
б. Запишите соответствующие потоковые инструкции для Е,
f и g, используя нотацию из разд. 14.1.4
в. Покажите промежуточные стеки потоковых инструкций,
полученные при вычислении Е, основанном на использовании
стеков (предполагаем, что применение функции реализовано
с помощью копирования инструкций).
14.5. Объясните, почему посылка знака вычеркивания по отбра-
сываемой ветви ПГ условного выражения не приводит к появ-
лению этого знака на выходе этого ПГ. Объясните это на при-
мере ПГ для функции тар, приведенного на рис. 14 2.
14.6. Вернемся к примеру вычисления из разд. 14.1.4, который
показывает промежуточные стеки при вычислении выражения
succ(f3),. Как выходное поле (выход) можно выразить в виде
-|-m.n?
14.7. Предположим, что входные поля инструкций могут хра-
нить либо значение, либо идентификатор инструкции, которая в
конечном счете выдает это значение. Объясните, как эту воз-
можность можно использовать для реализации оптимизирован-
ной потоковой модели, управляемой запросами.
Глава 15
КОМПИЛЯЦИИ ФУНКЦИОНАЛЬНЫХ языков
Целью этой главы является объяснение того, как осуще-
ствляется трансляция функциональной программы, представ-
ленной в промежуточной форме, в последовательность команд
низкого уровня для обычного последовательного компьютера.
Часть обсуждения посвящена тому, как могут быть объединены
различные приведенные выше методики для наиболее эффек-
тивного применения языка. В этой главе устанавливается окон-
чательная связь между исходной программой и аппаратной
частью конкретного компьютера и в основном завершается опи-
сание применения функциональных языков.
Тот широкий набор способов трансляции, который мы пред-
ставили, дает создателю компилятора множество различных
возможностей, и вследствие этого конечный вид программы
будет лишь одним из многих возможных. Однако, к счастью,
многие основные методы компиляции исходного языка принци-
пиально схожи между собой, поэтому для хорошего по-
нимания их достаточно рассмотреть лишь один-два примера.
Помимо обсуждения общих вопросов компиляции (разд. 15.1),
большая часть этой главы связана с двумя работами по
изучению компиляторов функциональных языков, причем
особое внимание уделяется генерации машинных кодов и
абстрактным машинам, для которых производится эта ком-
пиляция.
Выбор именно этих двух примеров обусловлен тем, что они
представляют две крайности в области приложения функцио-
нальных языков, а именно — использование строгих языков,
основанных на оптимизированной SECD-машине, и использова-
ние ленивых языков на основе оптимизированной редукции гра-
фов. Обсуждение этих вопросов содержится в разд. 15.2 и 15.3.
Оба этих примера были использованы в качестве основы в
реальных компиляторах, а именно в компиляторе строгого
25
1473
386 Часть II. Глава 15
подмножества языка Норе, описанного в ч. I, для «ленивой»
версии функционального языка ML, описание которого можно
найти в [5].
15.1. Структура компилированной программы
На рис. 15.1 представлена общая структура типичного ком-
пилятора функционального языка. Суть представленных в верхней
части рисунка этапов должна быть знакомой по предыдущим
главам. В ч. I мы рассмотрели исходные языки програм-
мирования и то, как ими пользоваться. В гл. 8 описали проме-
жуточную форму, основанную на модифицированном лямбда-
исчислении, и показали, как осуществить перевод исходной
программы в подобную форму. В главах 12 и 13 мы рассмот-
рели комбинаторное представление и то, как его можно пере-
Исходная программа
Проверка грамматики и типов
Абстрактное синтаксическое дерево
Трансляция и удаление
сопоставления образцов
Промежуточная форма 1
Удаление лямбда-выражений
и генерация комбинаторов
Промежуточная форма 2
Генерация кода
Код абстрактной машины
Абстрактная машина
Рис. 15.1. Типичная схема компиляции.
Компиляции функциональных языков 387
вести в фиксированный набор комбинаторов или с помощью
лямбда-удаления в фиксированный набор суперкомбинаторов,
формируя тем самым «промежуточную форму 2». Фаза генера-
ции кода компилятором заключается в переводе этих (супер)-
комбинаторов в «чисто» кодовые последовательности, как это
было предложено в гл, 13. Мы предположили, что программа
в промежуточной форме поступает в генератор кодов в следую-
щем виде:
(описание комбинатора 1)
(описание комбинатора 2)
»
»
(описание комбинатора 7V)
(выражение, которое должно быть вычислено)
Это решение основано на предположении, что использование
(возможно, частичное) комбинаторов всегда более эффективно,
чем применение бета-поДстановки путем копирования, как в
лямбда-исчислении или в схеме графовой редукции, описаннрй
в гл. И. Это, разумеется, будет верно, если целевая ЭВМ яв-
ляется обычным последовательным компьютером, поскольку в
этом случае каждый комбинатор переходит в последователь-
ность машинных инструкций, которые, будучи инициирован-
ными, непосредственно реализуют операции, специфицирован-
ные данным комбинатором. Конечно, если целевой компьютер
был спроектирован с расчетом на копирование, то некоторые
специфические особенности его структуры могут быть исполь-
зованы для более эффективной реализации этого подхода, на-
пример путем использования параллелизма для выполнения
нескольких подстановок одновременно. Отметим, однако, что,
хотя мы не рассматриваем графовое копирование в последо-
вательных компиляторах, отсюда не следует, что мы не будем
использовать графовую редукцию вообще.
Заметьте, что если программа была транслирована в фик-
сированный набор комбинаторов, то промежуточная форма
программы будет иметь структуру, представленную на рис. 15.1,
а число N будет постоянным для всех программ.
Хотя на основании рис. 15.1 можно утверждать, что каждая
промежуточная форма существует исключительно во время
компиляции программы, на практике э’йо утверждение может
быть смягчено. Например, мы могли бы генерировать вторую
промежуточную форму непосредственно из абстрактного син-
таксического дерева, пропуская первую промежуточную форму,
25*
388 Часть II. Глава 15
или даже совсем отказаться от генерации обеих промежуточных
форм и непосредственно получить машинные коды. Конечным
выходом компилятора является последовательность инструк-
ций в машинных кодах в виде двоичных чисел, хранимых в глав-
ной памяти целевого компьютера, и поэтому мы можем заме-
нить на рис. 15.1 надпись «абстрактный компьютер» словами
«реальный компьютер», где в качестве последнего выступает,
например, VAX или другой микрокомпьютер. Недостатки ориен-
тации исключительно на один тип компьютеров очевидны, по-
этому мы будем использовать понятие абстрактной машины, для
чего постараемся определить примерную архитектуру абстракт-
ной машины и набор инструкций, достаточно общий для при-
менения одного компилятора на разных целевых компьютерах.
Это приводит к необходимости еще одного этапа трансляции,
на котором' команды абстрактной машины будут переводиться
в команды конкретного используемого компьютера. Последние
управляют конкретными структурами данных, которые пред-
ставляют компоненты архитектуры абстрактной машины, на-
пример стек; сами эти структуры хранятся в памяти целевой
машины.
В каждом из двух последующих разделов мы начнем рас-
смотрение с введения набора (возможно, рекурсивных) опре-
делений комбинаторов, получаемых из промежуточной формы
исходной программы путем лямбда-удаления (см. гл. 13).
Основное различие между двумя используемыми в этих главах
примерами определяется типами используемых абстрактных
машин и семантикой вызова функций, которую они поддержи-
вают. В первом случае, а именно в случае МФП-системы
(МФП — машина функционального программирования), абст-
рактная машина основана на принципах строгой SECD-машины,
которая была введена в гл. 10. В этом случае в компилирован-
ном коде программы используется энергичное вычисление. Мы
увидим, что существует тесная связь между архитектурами
абстрактной и конкретной машин, вследствие чего большинство
выражений напрямую переводится в последовательность ма-
шинных кодов и компиляция происходит достаточно эффективно.
Во втором случае, а именно G-машины, абстрактная машина
поддерживает (ленивую) редукцию графов нормального по-
рядка. Здесь все выражения транслируются в коды, управляю-
щие графом, представляющим выражение верхнего уровня.
Этот граф трансформируется из исходного состояния в состоя-
ние, представляющее выражение в СЗНФ, т. е. в окончатель-
ном виде. Различие в способах вычисления в G-машине и в це-
левой машине (графовое представление и выполнение команд
соответственно) означает, что программы G-машицы являются
Компиляции функциональных языков 389
частично «интерпретированными» в том смысле, что компили-
рованный код явно оперирует со структурой данных, представ-
ляющих некое выражение.
15.2. МФП-система
МФП является аббревиатурой термина «машина функцио-
нального программирования». Абстрактная МФП-машина осно-
вана на использовании стеков и может рассматриваться как
оптимизированный вариант SECD-машины. Существует генера-
тор кодов, который переводит программу в промежуточной
форме FC+ [10] в команды абстрактной МФП-машины (F-ko-
ды). Исходная программа транслируется в FC-форму путем
удаления сопоставления с образцом (см. гл. 8) и затем приме-
нением лямбда-удаления для каждой определенной пользовате-
лем функции с целью получения набора комбинаторов.
В связи с тем, что мы не используем лямбда-исчисление не-
посредственно, под «лямбда-удалением» мы понимаем удаление
вложенных функций. Вложенная функция транслируется в гло-
бальную функцию путем добавления к началу списка ее пара-
метров формальных параметров всех текстуально входящих
в ее тело функций (свободные переменные ее тела). После этого
удаляются все ссылки на эту гнездовую функцию путем приме-
нения ее трансформированной версии к дополнительным аргу-
ментам, соответствующим этим параметрам. Далее произво-
дится определение трансформированной функции на том же
уровне, что и остальные функции, так что в конце концов лик-
видируются все определения вложенных функций. Например,
определение вложенной функции в следующей функции Норе:
dec f: num #num -> (num -> num);
------f(x, y)<=Iambda z=> z*y + x;
окончательно транслируется в частичное применение с исполь-
зованием сгенерированной компилятором функции g:
f х у =g х у
g а b с = + ( * с Ь)а
Заметьте, что здесь мы записываем f как карринговую функ-
цию, хотя на самом деле она описана как функция от кортежа
из двух элементов. Аналогично g должна быть описана как
карринговая функция двух аргументов: пары (а, Ь), соответ-
ствующей аргументу функции f, и параметра с, соответствую-
щего связанной переменной z в лямбда-выражении.
390 Часть II. Глава 15
Исходная программа
Проверка грамматики и типов
Абстрактное синтаксическое дерево
Удаление сопоставления образцов
Лямбда-удаление
FC
Генерация кода
F - код
Абстрактная МФП-машина
Рис. 15.2. Схема МФП-компиляции.
В других языках, таких как Miranda, вложенные функции
могут встречаться в квалифицированных выражениях, например
в определение
f х у = х * у * ( g у) where g z = х + z
g является вложенным определением. Хотя g и не является
лямбда-выражением, лямбда-удаление все же применяется
к нему для получения уравнений
f х у = * х (* у (g' у х))
g' U V = + V U
МФП-система была разработана для поддержки оригиналь-
ной версии Норе [19], которую мы будем называть Е-Норе. Су-
ществуют два существенных различия между Норе и Е-Норе,
влияющие на соответствующие им генераторы кодов. Во-пер-
вых, Е-Норе является строгим языком, в котором как опреде-
ляемые пользователем функции, так и конструкторы вызы-
ваются по значению, и, во-вторых, вещественные числа не под-
Компиляции функциональных языков 391
держиваются в качестве основного типа чисел. Полная схема
компилляции приводится на рис. 15.2.
Трансляция из FC-формы в F-код содержит большое число
различных оптимизаций, многие из которых следует рассмат-
ривать лишь при более детальном изложении, поэтому мы опи-
шем упрощенную версию компилятора, которая выполняет
только некоторые из них. Это поможет нам полнее изложить
все принципиальные особенности МФП-системы и общие прие-
мы компиляции строгих языков программирования, не втяги-
ваясь в изучение множества несущественных деталей.
15.2.1. Промежуточный код
Программа на FC-этапе компиляции имеет вид S-выражения
(см. гл. 5). Программа состоит из списка определений комби-
наторов (comblist) и выражения верхнего уровня (ехр), опи-
сывающего вид результата работы программы. Каждое опре-
деление комбинатора (combdef) включает в себя определение
арности комбинатора (argcount)—целое число и выражение,
описывающее этот комбинатор. Существует шесть типов таких
выражений: константы (cv), локальные величины (lv), выраже-
ния с кортежами (mt), временные величины (tv), условия (if)
и применения функции (af). Есть три класса функций: встроен-
ные функции (bi) или примитивы; определяемые пользовате-
лем функции (ud), которые являются комбинаторами; и функ-
ции-выражения (fe), обработка которых в процессе компиляции
приводит к появлению замыканий. Формально синтаксис вы-
глядит так:
(program) :=( (comblist) (exp))
(comblist) := ((combdef) * )
(combdef) :=( (argcount) (exp))
(exp) :=( cv (con)) |( lv (argnum)) |
(mt (exp)+)|(tv (arity)(exp)
(exp)) |(if (exp) (exp)+ ) |
( af (funtag) (exp) * )
(con) ::= (integer) | ’(character)’ | (conlist) |(contup)
(conlist) ::=((con)*)
(contup) ::=[(con)*]
(funtag) ::=(bi (code))|(ud (funnum)) |(fe (exp))
(argcount), (argnum), (arity), (code), (funnum), (tag)
::= integers 0, 1, 2, . ..
M* означает ни одного или более М, а М+ — одно или более М.
Отметим, что цель синтаксического разделения выражений на
более мелкие заключается в более эффективной интерпретации
392 Часть II. Глава 15
FC-программ. Интерпретатор FC включен в полную систему
МФП, но в этой книге нами не описывается.
Теперь мы переходим к более детальному рассмотрению
особенностей указанных шести типов выражений.
Константы (cv)
Константы FC являются либо атомами, списками констант
в виде S-выражений, либо кортежами констант в виде S-в-ыра-
жений, заключенных в квадратные скобки. Типы списков и
кортежей в FC не определяются, но на практике все элементы
одного списка имеют один и тот же тип. Атомы являются це-
лыми числами или символами, а постоянные списки символов
могут быть записаны для удобства непосредственно в двойных
кавычках. Например,
(cv 12) (cv zx') (cv "Строка символов")
(cv[l ’a‘l) (cv(l 23)) (cv(2 "АБВ" [Tz 'Д' ZEZ]))
Локальные величины (Iv)
Выражение (Ivn) является ссылкой на n-й параметр комбина-
тора, в который оно входит. Например, для исходной функции
------f(x, у) <= ... х ... у ... ;
эквивалентный FC-комбинатор будет иметь размерность 2,
а ссылки на х и на у будут осуществляться с помощью (lv 1 )
и (Iv 2) соответственно. Фактические параметры комбинатора
хранятся в специальной структуре, называемой локальным кон-
текстом, которая будет описана ниже.
Конструкторы кортежей (mt)
Выражения типа mt используются для создания кортежей, яв-
ляющихся структурами данных с постоянным временем до-
ступа. Они используются в качестве составных блоков в опре-
деляемых пользователем структурах данных, как будет пока-
зано ниже. Например,
(mt(cv 1)(lv 3)(cv "Bill"))
образует кортеж размерности 3, в котором первым элементом
является число 1, вторым — величина третьего аргумента вы-
числяемого в данный момент комбинатора, а третьим — сим-
вольный список «Bill».
Временные величины (tv)
Выражения типа tv используются для введения новых локаль-
ных величин и соответствуют let-предложению. Например, вы-
Компиляции функциональных языков 393
ражение
(tv k Е, Е2 )
эквивалентно выражению
let ( хь х2, .. ., xfe ) = = Ei in Е2
Если k> 1, то Ei должно перейти в кортеж размерности к (по-
лучаемый с помощью mt), а элементы этого кортежа будут
в том же порядке добавлены к локальному контексту. Если
локальный контекст перед началом вычисления tv-выражения
содержал п входных параметров, то он будет дополнен к ве-
личинами (что даст в сумме п + к) для вычисления Е2. Ссылку
из Е2 на первый элемент этого кортежа даст выражение
(lvn-f-1), на второй—(lvn + 2) и т. д. Таким образом, вы-
ражение tv может быть использовано для разделения кортежа
на составляющие элементы.
Условные выражения (if)
Условные выражения в FC являются многовариантными в том
смысле, что одно условие может быть снабжено произвольным
количеством возможных выходов, а не только двумя. Вот при-
мер условного выражения:
(if S Е,Е2 ... Е„)
Вначале вычисляется значение селектора S, которое должно
быть в диапазоне от 0 до п—1. Если он равен к, то значение
всего условного выражения равно Ek+i. В стандартном двух-
вариантном условном выражении «false» соответствует нулю,
a «true» — единице. Заметьте, что строгая семантика вызова
функций в FC не позволяет поддерживать if в качестве встроен-
ной функции.
Применение функций (af)
Применения функций имеют следующий формат:
( bi с)
( af ( ud m ) EjE2 ... En )
(fe E)
Ei, ..., En обозначает выражения аргументов, к которым при-
меняется функция во втором поле данного формата. Поскольку
FC является строгим языком, то эти выражения вычисляются
до вызова функции. Если функция является встроенной, то с
обозначает код функции. Коды всех встроенных функций, ко-
торые мы будем использовать в этой главе, даны в табл. 15.1.
394 Часть II. Глава 15
Таблица 15.1. Список встроенных FC-функций
Код Имя Размерность Комментарий
1 plus 2 Функция сложения
2 mult 2 Функция умножения
3 greater 2 Функция сравнения
4 empty 0 Возвращает пустой список
5 cons 2 Функция работает со списком конструкто- ров
6 head 1 Возвращает головной элемент списка
7 tail 1 Возвращает последний элемент списка
8 isempty 1 Если данный список пуст, то возвращает 1, иначе 0
9 index 2 Возвращает элемент кортежа. Первый па- раметр— кортеж, второй — индекс элемен- та
Если функция является определяемой пользователем (ud), то
m обозначает m-ный комбинатор в списке комбинаторов, опи-
санных в программе.
Мы будем использовать термины «определяемая пользова-
телем функция» и «комбинатор» как взаимозаменяемые, хотя
необходимо помнить, что некоторые комбинаторы генерируются
компилятором в процессе лямбда-удаления; по сути под «опре-
деляемая пользователем» мы подразумеваем «невстроенная».
Если функция не является ни определяемой пользователем, ни
встроенной, то выражение Е обозначает выражение, результа-
том вычисления которого является функция и которое должно
переходить при его вычислении в замыкание. Генерация замы-
каний происходит при частичном применении функции, т. е.
если количество известных аргументов функции меньше ее ар-
ности. Арность каждой определяемой функции включена в ее
описание; арности встроенных функций являются предопреде-
ленными величинами и, таким образом, всегда известны ком-
пилятору; арность замыкания содержится в самом замыкании,
как это будет вскоре показано. В качестве примера частичного
применения можно привести функцию следования целых чисел,
которая может быть выражена с использованием встроенной
функции + (код равен 1)
( af (bi 1) (cv 1))
Это выражение обозначает функцию, добавляющую единицу
к некоторому аргументу; при вычислении оно даст замыкание.
Ниже приводится пример FC-программы, которая описы-
вает функцию тар для работы со списками из гл. 3 и пример
применения тар, в котором все элементы числового списка
увеличиваются на 1. Дается также эквивалентное описание для
Компиляции функциональных языков 395
Е-Норе (комментарии заключены в фигурные скобки {,}):
dec map : ( alpha —► beta ) # list( alpha ) -»1 ist( beta );
-----map(f, nil) <= nil;
------map(f, x :: 1) <=f((x):: map(f, 1);
dec succ : num num;
------succ( n) <= n + 1;
map( succ, [1, 2, 3 ]);
(
(2
(if(af(bi 8)(lv 2))
(af (bi 5)
(af (fe (lv 1))
(af (bi 6) (lv 2)))
( af (ud 1)
(lv 1)
( af (bi 7)(,lv 2)))
)
(af (bi 4))
)
)
(1
( af (bi 1) (lv 1 )(cv 1))
! Выражение верхнего уровня !
{ПРИМЕР ПРОГРАММЫ}
{map(f, 1)=}
{if not isempty(l)}
{then cons( }
{ f(head(l)),}
{ )
{ map(f, tail(l)))}
{ }
{ }
{ }
{else nil }
{succ(n)= }
{n+1 }
( af(ud l)(af(ud 2))(cv(l 2
{map(succ, [1, 2, 3])}
Заметьте, что работа co списками в FC происходит с помощью
встроенных функций empty (код 4), isempty (код 8), cons
(код 5), head (код 6) и tail (код 7). Транслятор из Е-Норе в
FC переводит функции обработки списков Е-Норе в соответ-
ствующие функции FC. Для представления более сложных
структур данных используются кортежи. В соответствии с под-
ходом, описанным в гл. 8, конструкторы в каждом типе данных
нумеруются числами от 0 до N — 1, где N — количество кон-
структоров в данном типе. Применение конструктора номер к
к аргументам Еь Е2, ..., Еп будет выглядеть, таким образом,
в виде следующего FC-выражения:
( mt( cv k)E,E' ... Е')
где Е{ является FC-представлением Еь Транслятор Е-Норе—>
->FC использует алгоритм трансляции сопоставления с образ-
цом, представленный в гл. 8, и многовариантные условные
выражения FC для реализации функции CASE-n, причем роль
396 Часть И. Глава 15
селектора играет код конструктора. Например, в данной ске-
летной программе Е-Норе
data Tl ==С1( ... )++С2(... )++ ... ++Ск( ... )р
dec f:Tl
-----f(Cl(...))<=E,;
-----f(C2(...)) <=Е2;
-----f(Ck(...))<=Ek;
сопоставление с образцом в f достигается с помощью един-
ственного условного выражения FC:
(if(af(bi 9) (lv l)(cv 1))EJE' ... E')
Условимся использовать запись E' для обозначения FC-пред-
ставления Ei. Функция index (код 9) с параметрами Ivl, cv 1
возвращает первый элемент кортежа, указываемого величиной
lv 1, который соответствует коду конструктора аргумента f.
Если это 0 (конструктор С1), то вычисляется Е[, если 1 (кон-
структор С2), то вычисляется Е' и так далее. Выбрав коррект-
ное правило для f, можно перестроить аргумент, используя одно
или более tv-выражение.
В МФП-системе код FC генерируется непосредственно из
программы на Е-Норе, однако можно создать и иные генера-
Таблица 15 2. Правила трансляции промежуточного кода в FC-код
Выражения промежуточного кода Эквивалентное FC-выражение
С С — константа х х-идентификатор Zxj.Xxa.... Лх„.Е (CV С') (1V Lx) Переводятся лямбда-удалением в FC комбинаторы
let х = Ei in Ez retrec Xi = Ei, x2 = E2 xn = En in E (tv ie[ е;) Е' Рекурсивные определения переводят- ся лямбда удалением в FC-комбина- торы
TUPLE-nE. E2> E„ ( mt EjEg ... e' ) или ( cv [ е[ Е2 ... ... Еп ] ), если все F, — константы
IF EiE2E2 P EiE2E3 Р-примитив (не кортеж) F EiE2 ... En F определяется поль- зователем E EtE2... En E — функциональное выражение ( if Е|Е2Е3) ( af ( bi Ср)е; е£... е') (af (ud Nf)e;e;...e' ) (af (fe e')e;e;...E;)
Компиляции функциональных языков 397
торы, например в табл. 15.2 сведены правила трансляции (см.
гл. 8) промежуточного кода в FC-код. СР обозначает код встро-
енной функции для примитива Р, NF обозначает номер комби-
натора (определяемой пользователем функции), соответствую-
щего F, и Lx обозначает номер локальной величины, связанной
с идентификатором х, например его положение в списке пара-
метров соответствующего комбинатора.
15.2.2. Абстрактная МФП-машина
Абстрактная МФП-машина имеет четыре компонента: па-
мять для хранения программы, содержащую компилированный
код всех комбинаторов; стек для вычислений, вмещающий аргу-
менты комбинаторов или временных величин (tv); стек вызо-
вов, содержащий адреса возврата и кучу, хранящую структуры
данных, создаваемые программой, и все замыкания, возникаю-
щие вследствие частичного применения функций.
Хранение программы
Генератор кода, который описывается ниже, транслирует каж-
дую введенную пользователем функцию в последовательность
команд абстрактной машины и последовательно заносит их в
память хранения программы. Начальный адрес каждого такого
блока кодов получает метку: FUN-1 для блока, соответствую-
щего первой введенной пользователем функции, FUN-2— для
второй и т. д. Ка.к и в обычном компьютере, программный счет-
чик всегда указывает на выполняемую команду. Набор компи-
лированных описаний функций образует глобальцый контекст
программы.
Стек вычислений
При вызове функции ее аргументы вычисляются и помещаются
в стек вычислений. Затем происходит вызов этой функции пу-
тем выполнения соответствующего ей компилированного кода.
Если данная функция была n-й определенной пользователем
функцией, то необходимо выполнить коды, начинающиеся с метки
FUN_n. Если функция является встроенной, то в соответствии
с ее кодом выполняется некоторая предопределенная инструк-
ция. Набор аргументов, созданный в стеке вычислений, соответ-
ствует локальному контексту вызванной функции. Локальный
контекст заменяется вычисленным этой функцией результатом
(это соответствует переписыванию редекса при графовой ре-
дукции).
Для иллюстрации работы стека вычислений предположим,
что определенная пользователем функция номер 4 оперирует
398 Часть II. Глава 15
с тремя аргументами, возвращая их сумму. На рис. 15.3 пока-
зано, как эта функция работает с числами 1, 2 и 3. FC-пред-
ставление здесь будет иметь вид
(af(ud 4)(cv 1)(cv 2)(cv 3))
Исхс снизу стек з эдный вверх, аполн; стек пс указат эется >казан ель с величг на рис тека и нами :. 15.3 зобра> трех , а; сте! кен ст, аргумс < нара ел кой штов щивает Cnpai функщ ся за СИ <
1
2 2
3 3 3 6
а б Рис. 15.3. Вызов функции. в г д
(рис. 15.3,б — г). Заметьте, что вначале вводится величина са-
мого правого аргумента, а затем величины аргументов слева
от него. Причины этого станут ясны ниже. Рис. 15.3, а показы-
вает завершенный локальный контекст вызываемый функции.
Вызов функции приводит к замене локального контекста вы-
численным значением — в данном случае числом 6 (рис. 15.3,5).
Ссылка на локальные величины (параметры функции) осуще-
ствляется путем индексирования локального контекста, начиная
от вершины стека. Локальный контекст может быть расширен
использованием tv-выражения в FC. В этом случае новая
величина (или величины) будет занесена в стек вычислений.
Например, выражение Е-Норе
let х == 1 in Е ^ (tv 1 (cv 1) Ez)
после выполнения компиляции даст код, записывающий еди-
ницу в стек вычислений (рис. 15.4).
При вычислении этого выражения мы предполагаем, что ар-
ность текущего комбинатора равна двум и что с помощью tv
уже создано и — 2 дополнительных локальных переменных, на-
чиная с lv3. Заметьте, однако, что эти локальные переменные
не обязательно должны занимать последовательные ячейки
стека, например если они генерируются в let-выражениях, ко-
торые являются аргументами функций в других let-выражениях.
Все ссылки на lvn+1 при компиляции будут заменены на
индексы, указывающие на место хранения 1 в стеке. После вы-
Компиляции функциональных языков 399
полнения Е результат заменит в стеке эту временную вели-
чину (1).
Стек вызовов
Стек вызовов аналогичен обычному стеку вызова подпрограмм.
При вызове функции в стек вызовов заносится адрес следую-
щей команды, которую необходимо выполнить после возврата
Iv n + 1 1
<
Iv п Iv n
Ivn -1 Iv n - 1
Iv 1 tv 1
Iv2 Iv2
До Рис. 15.4. Действие оператора tv. После
из функции. По завершении работы вызванной функции этот
адрес извлекается из стека и помещается в программный счет-
чик. После этого продолжается выполнение программы с этого
адреса.
Куча
Куча используется для хранения всех структур данных возни-
кающих при выполнении программы. Существуют три типа объ-
ектов кучи или ячеек: cons-ячейки, создаваемые встроенной
функцией работы со списками (код 5); кортежи, генерируемые
mt-выражениями, и замыкания, возникающие в результате ча-
стичного применения функции. Можно расширить возможности
абстрактной машины поддержкой задержек для обеспечения ле-
нивых вычислений, для чего потребуются дополнительные типы
объектов кучи. К этому вопросу мы еще вернемся позже. Фор-
маты описанных же структур представлены на рис. 15.5. Поле
РАЗМЕР в ячейках, соответствующих кортежам и замыканиям,
указывает на количество слов, занимаемых данной ячейкой.
Ячейки списков всегда состоят из двух слов, представляющих
хвост и голову списка.
Новые ячейки добавляются к куче путем ввода составляю-
щих их слов; другими словами, куча работает только как
400 Часть II. Глава 15
накапливающий стек, в котором доступ к ячейкам осуществляется
непосредственно по их адресу. Указатель кучи всегда указывает
на ее 'вершину и соответственно изменяется при вводе каждого!
слова или ячейки. В случае переполнения кучи инициируется/
«сборщик мусора», восстанавливающий неиспользуемые ячейку
кучи; различные способы такой «чистки» приводятся в гл. 16s.
Хвост А SIZE (п + 1) А SIZE (п + 3) А
Г олова А + 1 Элемент-1 А + 1 РАС А + 1
Элемент-2 А + 2 FUN@ А 1 2
... < Arg-1 А + 3
Элемент-п А + п + 1 Arg-2 А + 4
Arg-п А Ю + 2
Списки Крртежи Замыкания
Рис. 15.5. Структура ячеек кучи.
Ячейка-кортеж из п элементов хранится в виде массива из
n + 1 слов, в котором первое слово указывает на размер ячейки
(и + 1 слово), a (i+ 1)-е слово представляет i-й элемент кор-
тежа. Замыкание всегда обозначает частичное применение ка-
кой-либо функции — встроенной или определенной пользовате-
лем. Поле РАС содержит в себе количество недостающих аргу-
ментов замыкания (его размерность), равное числу аргументов
замыкания, которые должны быть получены для выполнения
соответствующей функции, т. е. РАС равно разности между ар-
ностью функции и числом уже имеющихся ее аргументов. Ком-
пилированный код этой функции хранится по адресу FUN@.
Остальные поля ячейки кучи определяют «частичный» локаль-
ный контекст функции. Этот контекст станет полным после при-
менения замыкания к РАС аргументам, после чего он поме-
щается в стек вычислений и происходит вызов функции по ад-
ресу FUN@. Если же количество известных аргументов меньше
значения РАС, например на к, то будет создано новое замыка-
ние, в котором новое значение счетчика РАС будет равно
РАС —• к, при этом к новому частичному контексту будет до-
бавлено к параметров. Рассмотрим пример. Пусть в седьмую
заданную пользователем функцию входят три аргумента, тогда
FC-выражение
( af (ud 7 ) ( cv 1 ))
приведет к созданию замыкания, показанного на рис. 15.6, а и
располагающегося в памяти, начиная, например, с адреса А.
Компиляции функциональных языков 401
Пусть это замыкание применяется к единственному аргументу
( af (fe (выражение, возвращающее это замыкание))( cv 2))
Тогда будет создано новое замыкание (рис. 15.6,6)—по ад-
ресу В, например. Если это новое замыкание в свою очередь
будет применено к еще одному аргументу — третьему, — то уже
произойдет вызов заданной функцйи путем переноса частичного
Рис. 15.6. Образование и применение замыканий.
контекста в стек вычислений и выполнения кодов, начиная с ад-
реса FUN-7. Заметьте, что в созданном полном контексте аргу-
менты в стеке располагаются так, что первый аргумент нахо-
дится ближе к вершине стека, чем остальные. Это и является
причиной того, что аргументы функции вычисляются справа
налево.
Все функции возвращают результат в стек вычислений в виде
единственного слова, которое представляет собой целое число,
символ или, возможно, ссылку на ячейку кучи — в том случае,
если результатом является кортеж, замыкание или другая со-
ставная структура. Поскольку исходные программы на языке
Е-Норе являются строго типизированными и мы предполагаем,
что для них была выполнена проверка типов, то для компили-
рованной программы отсутствует необходимость явно различать
эти типы слов. Однако для того чтобы программа сборщика
мусора могла бы отличить атомы (целые числа или символы)
от указателей, каждое слово в стеке вычислений и в куче снаб-
жается специальной меткой, занимающей два бита, обозначаю-
щих следующее:
00 — целое число
01—указатель (адрес)
10 — символ
11 — (не используется)
26 — 1473
402 Часть II. Глава 15
Таким образом, ячейки — указатели списков в куче — являются
легко отличимыми от кортежей и замыканий по метке 01,
связанной с первым словом этих ячеек. Поле размера
кортежа или замыкания имеет метку 00, поскольку размер
ячейки является целым числом. Различие же между симво-
лами и целыми числами не является существенным для гене-
ратора кодов.
Заметьте, что если с помощью tv-выражения вводится бо-
лее одной величины, то они будут храниться в куче в виде кор-
тежа. В этом случае кортеж должен быть распакован перед
тем, как его компоненты будут помещены в стек вычислений.
Связь с SECD-машиной
Аналогия между МФП- и SECD-машинами, изложенная в гл. 10,
сейчас становится более ясной: память хранения программы и
программный счетчик МФП соответствуют управляющему стеку
в SECD-машине. Однако в нашем случае программа хранится
в виде компилированного кода, а не в виде лямбда-выражений.
Стек вызовов служит для запоминания состояния вычислений
в точке вызова функции и восстановления этого состояния по
завершении работы вызванной функции. В этом плане он иг-
рает роль, аналогичную работе дампа в SECD-машине. Стек
вычислений в МФП в точности соответствует совокупности
стека и контекста в SECD-машине. В ней параметры функций
сохраняют свои имена, связи между именами и величинами
хранятся в контексте. В МФП, однако, все ссылки на пара-
метры функций при компиляции переходят к номера элементов
стека, и поэтому возникает необходимость в списке связей
имя — величина. И наконец, куча в МФП является лишь мес-
том хранения структур и замыканий. Например, если в гл. 10
мы говорим о том, что в SECD-машине возможно непосред-
ственное размещение замыканий в S-стеке, то в МФП они хра-
нятся в куче, а в стек помещается лишь указатель на место
хранения соответствующего замыкания, что, по существу, то же
самое. На самом же деле более близкое сходство можно уви-
деть при рассмотрении ленивой SECD-машины, в которой за-
держки рассматриваются как объекты кучи с косвенной адре-
сацией через указатель. В заключение добавим, что, _ хотя
SECD-машина может оказаться довольно неэффективной для
практических целей, ее значимость заключается в том, что она
хорошо описывает общую схему реализации функциональных
языков, которая может быть осуществлена различными путями.
МФП является лишь одной из возможных реализаций, основан-
ных на SECD-машине.
Компиляции функциональных языков 403
15.2.3. Простой генератор кода для МФП
Теперь мы переходим к обсуждению генератора кода, транс-
лирующего FC-выражения в команды F-кода. Назовем целевой
Таблица 15.3. Упрощенный набор команд F-кода
Команда Операнд Комментарий
PUSH #N $C @A % N * n Помещает целое N в стек вычислений Помещает символьное С в стек вычислений Помещает адрес А в стек вычислений Помещает N-e слово стека на его вершину Помещает n-й элемент таблицы констант в
стек
TABLE k Извлекает элемент стека и помещает его в k-ю позицию таблицы констант
COPY n Создает ячейку кучи, копируя верхние п элементов стека в кучу, добавляет поле размера ячейки, равное п + 1. Элементы стека заменяются ссылкой на ячейку кучи
DROP UNPACK m. n Сдвигает m элементов стека на п позиций вниз и изменяет указатель вершины стека Распаковывает кортеж, указываемый верх- ним элементом стека, на компоненты и по- мещает их в стек. Количество элементов кортежа находится в поле размера
JUMP A Переход по адресу А
CASE n Выталкивает число из стека и использует его как индекс таблицы адресов (таблицы переходов), расположенной после команды CASE. Выполнение команд продолжается с индексированной команды.
CALL RET A Вызов функции по адресу А. (Адрес воз- врата хранится в стеке вызовов.) Возврат после вызова функции в соответствии с хранимым в стеке вызовов адресом
APPLY n Применяет замыкание, указываемое верх- ним элементом стека к и аргументам, хра- нящимся ниже указателя стека
ADD, SUB, EMPTY и т. n. Встроенные функции. Аргумент(ы) — на вершине стека. Результат операции заме- щает аргумент в стеке
язык SIMPLE. Набор команд SIMPLE, который мы рассмот-
рим, является сокращенной версией полного набора команд
F-кода, состоящего из основных команд — их десять, и дополни-
тельных — по одной на каждую встроенную функцию. Все они
указаны в табл. 15.3.
Представим себе, что существует ассемблер F-кода, перево-
дящий'его команды в выполняемый двоичный код абстрактной
26*
404 Часть II. Глава 15
МФП-машины. В дополнение к существующим мнемоническим
командам добавим следующие:
ADDR А — адрес А
LABEL L — метка блока кодов. Операнд L в командах
или ADDR заменяется на адрес этого блока
RESERVE N — резервирует N последовательных слов памя-
ти для таблицы констант
На практике, команды F-кода рассматриваются как макро-
сы и могут быть макрорасширены в последовательности кодов
конкретной машины, например VAX. Для этого описания всех
макросов хранятся в макробиблиотеке.
Компиляция из FC в SIMPLE может протекать по одной
из пяти схем — D, Е, F, С и S, — которые осуществляют ком-
пиляцию описаний функций (D), выражений (Е), вызовов функ-
ций (F), констант (С) и структурных констант (S). D-схема
служит для компиляции определения функций пользователя в
последовательность команд SIMPLE. Генерированный код дол-
жен соответствовать условиям вызова функции МФП: в момент
входа в функцию ее аргументы должны располагаться на вер-
шине стека вычислений, а результат в свою очередь после вы-
числения замещает их. Для того чтобы вкратце показать, что
выполняют различные схемы компиляции, воспользуемся сокра-
щенной полуфункциональной записью. Для компиляции к-й
определенной пользователем функции мы пишем:
D [ (n е)]] k = LABEL FUN_n; (компилированное выражение, тела,
или е); DROP 1, n; RET
(Скобки [ ] используются для ограничения синтаксических объ-
ектов.) По схеме D возвращается в соответствии с описанием
входной FC-функции и номером функции к компилированный
код этой функции в виде последовательности команд SIMPLE
(под знаком «;» между командами следует понимать операцию
соединения последовательностей команд). Эту форму записи
мы будем использовать и далее, при описании G-машины в
разд. 15.3. Из записанного для D правила следует, что для ком-
пиляции описания k-й функции необходимо сперва образовать
метку кода FUN_k, затем откомпилировать тело функции е по
схеме Е. Поскольку возвращаемый результат будет помещен
на вершину стека, то необходимо также выработать команды,
переписывающие локальный контекст вместе с этим результа-
том— для этого'служит инструкция DROP. Возврат к вызы-
вающей части программы осуществляется с помощью RET.
Для компиляции выражений используется схема Е. Соответ-
ствующая процедура здесь немного сложнее, поскольку доступ
Компиляции функциональных языков 405
к элементам локального контекста, в котором вычисляется вы-
ражение, выполняется с помощью индексирования от вершины
стека вычислений. Всякий раз, когда мы помещаем что-либо на
вершину стека, например, когда мы создаем локальный кон-
текст для вложенного вызова функции, «расстояние» между
вершиной стека и содержимым локального контекста увеличи-
вается на одно слово. В связи с этим мы параметризуем Е
с помощью d-количества слов между вершиной стека и основа-
нием локального контекста (рис. 15.7, а). Далее, локальный
Рис. 15 7. Индексные
карты локальных величин.
контекст может быть расширен с помощью tv-выражения, что
может привести к тому, что входы локального контекста будут
разбросаны по различным участкам стека, поэтому мы также
должны параметризовать С с помощью «индексной карты» 1,
которая указывает на количество слов между основанием ло-
кального контекста и каждой локальной величиной; на
рис. 15.7,6 показан пример с тремя локальными величинами.
При каждом изменении локального контекста изменяется и эта
карта. Если 1 описывает положение п локальных величин, то
1 + + [к, ш] будет обозначать такое расширение карты 1, при
котором относительное положение локальной величины n + 1
будет равно m + 1 (отсчитывая от основания локального кон-
текста), для локальной величины п + 2 это будет т + 2 и так
далее до локальной величины п + к, которая будет отстоять на
m + k слов. На рис. 15.7, в показано состояние карты парамет-
ров после добавления двух локальных величин к стеку на
рис. 15.7,6. Необходимо помнить, что эта карта как структура
данных не возникает при непосредственной работе программы,
а существует лишь на этапе ее компиляции.
406 Часть IL Глава 15
При использовании Е-правила для компиляции тела выра-
жения возникает необходимость инициализации карты индексов,
содержащей смещение исходных локальных величин (аргумен-
тов функций). В исходной карте индексов, которую мы будем
обозначать как 1к, локальная величина i будет занимать отно-
сительное положение к — i (от основания локального контек-
ста). Правило для D-компиляции в полном виде будет выгля-
деть так:
D[(n е)] k = LABEL FUN_k; Е [ е] n — 1 ln; DROP 1, n; RET
Для каждого вида FC-выражений существует свое правило
Е-компиляции. Если выражение является константой, то ком-
пиляция выполняется по Е-схеме. Если константа является
атомом, то получаемый при компиляции код будет заносить вели-
чину этой константы в стек. Структурные константы компили-
руются в код инициализации программы и, таким образом, вы-
числяются лишь один раз до начала ее работы. По выполнению
кода инициализации указатель на вычисленную константу по-
мещается в таблицу констант, занимающую часть памяти хра-
нения программы (см. рис. 15.8). k-й элемент этой таблицы ука-
зывает на k-ю структурную константу, вычисленную таким об-
разом. Принципы работы S-схемы, генерирующей этот код,
будут описаны ниже. Итак, мы имеем
E[(cvk)]dl =C[k]
СГс'Л = PUSH $с
С[п] = PUSH#n (если п — целое)
(C["abcd ..."] ,~C[('a"b"c"d' ...)D
с[(е1е2...еп)]==спе;е;...е']]]
= (удаляет константу, чтобы откомпилиро-
вать позднее)
PUSH* к (если это к-я удаленная констан-
та)
Заметим, что последнее правило предполагает необходимость
в дополнительном параметре С (текущее число констант к)
и дополнительном результате, возвращаемом С (списке кон-
стант, которые будут прокомпилированы позже), однако здесь
для ясности мы об этом не упоминали.
Если компилируемое по Е-схеме выражение является ссыл-
кой на локальную величину, то параметры d и 1 используются
для определения ее относительного положения в стеке. Затем
это значение помещается на вершину стека:
E[(lv и)]d 1 = PUSH % (d — ln)
(где п-й элемент карты индексов обозначен как 1п).
Компиляции функциональных языков 407
Если это выражение является mt-выражением, то вначале
вычисляются элементы кортежа и помещаются в стек. Таким
образом, в стеке возникает копия элементов кортежа; затем
она перемещается в кучу командой COPY. Далее вырабаты-
ваются коды, проверяющие наличие свободного места в памяти
для хранения кортежа и автоматически добавляющие к ячейке
хранения кортежа еще один элемент — поле его размера. Эле-
менты стека замещаются указателем на место нахождения кор-
тежа в куче, и мы получаем
E[(mt EjE2 ... En)]d l = E[En]d 1; E[En_1]d+ 1 1; ... ;
E[E,]d + n-l 1;
COPY n
Если же в куче недостаточно места для хранения кортежа, то
инициируется сборщик «сборщик мусора» для повторного ис-
пользования пространства кучи (см. гл. 16).
Если выражение является tv-выражением, то происходит до-
бавление одной или более локальных величин к локальному
контексту; это приводит к необходимости соответствующего из-
менения 1 для вычисления результирующего выражения сле-
дующим образом:
E[(tv и E^Jld l = E[E]Jd 1;
if n > 1 then UNPACK;
E[E2]d + n 1 4-4- [n, d]; DROP 1, n
Заметьте, что если число локальных величин больше одного, то
результатом вычисления Е является кортеж, который должен
быть распакован и помещен в стек с помощью команды
UNPACK. Поскольку исходный язык является строго типи-
зированным, то величина п должна совпадать с содержи-
мым поля размера кортежа. Соответствующая проверка вы-
полняется компилятором и поэтому не поддерживается гене-
ратором кода.
Если выражение является многовариантным условным выра-
жением, то необходимо выработать код, вычисляющий преди-
кат, создать таблицу переходов и затем произвести компиляцию
всех ветвей этого условного выражения. Завершает послёдова-
тельность команд, соответствующих каждой ветви (кроме по-
следней), команда перехода JUMP, используемая для перехода
к метке выхода. Для обеспечения уникальности каждого номера
метки необходимо зарезервировать достаточное количество но-
меров меток до начала компиляции выражения. При этом мы
можем быть уверены, что использованные в разных ветвях
метки будут уникальными. Команда (Claim п> резервирует для
408 Часть II. Глава 15
этой цели п уникальных номеров меток. Метки имеют форму
Ь_<номер метки). Таким образом, получаем следующее:
Е [ (if Р EfE2 .. . En) ]d 1 = Е [ Р ] d 1; CASE и ;
(Claim n + 1) (предположим, что
b, b —1, ..., b + п зарезервирова-
ны)
L_b + 1; ADDR L_b + 2; ... ;
ADDR L_b + n;
LABEL L_b + 1 ; EfEJd 1;
JUMP L_b;
LABEL L_b + 2; E[E2]d 1;
JUMP L_b; ... ;
LABEL L_b + n; E[En]d 1;
LABEL L_b
И наконец, если выражение является вызовом функции, то
необходимо вначале выработать код для вычисления аргумен-
тов функции, а затем выработать код для вызова этой функции
по A-схеме. Если функция является замыканием, то исполь-
зуется команда APPLY. Если количество аргументов меньше,
чем арность функции, то создается замыкание путем помеще-
ния адреса функции и количества определенных аргументов на
вершину стека, а затем — с помощью COPY — это замыкайие
перемещается в кучу; в противном случае происходит вызов
функции. Для определения того, стоит ли формировать замыка-
ние, надо параметризовать А с помощью числа аргументов
функции. Обозначим арность функции f через Af, а инструк-
цию, соответствующую встроенной функции с через Мс. Тогда,
например, М] будет означать ADD, М2 — SUB и т. д. Отсюда
следует:
Е [(af F EfE2 ... En)]d 1 = Е [ Еп ] d 1; Е [ En_, ] d + 11;...;
E[Ej]d + n- 1 1;
А [ F ] d + n 1 n
A[(fe E)]d 1 n = E[E]d 1; APPLY n
A[(bi c)]d 1 n = if n = Ac
then Mc
else PUSH@Bl_c; PUSH Ac-n; COPY n + 2
A[(ud k)]d 1 n=if n = Ak
- then CALL FUN_k
else PUSH@FUN_k; PUSH Ak —n;
COPY n + 2
Заметьте, что если встроенная функция является частично-при-
мененной, то адрес функции, хранящийся в результирующем
замыкании, является адресом метки В1_с, где с — числовой
Компиляции функциональных языков 409
FC-код встроенной функции. Следовательно, помимо того, что
для каждой встроенной функции с существует своя команда,
необходимо также, чтобы по метке В1_с были расположены
коды, выполняющие то же, что эта единственная команда. На-
пример,
LABEL В1_1; ADD; RET
LABEL Bl_2; SUB; RET
и так далее.
Эти последовательности кодов аналогичны для всех компи-
лируемых программ и поэтому могут рассматриваться как биб-
лиотека определений. Они хранятся в ядре МфП-системы, кото-
рое будет рассмотрено ниже. Важно помнить, что обращение
к ним происходит, лишь если встроенная функция является час-
тично примененной; в том случае, когда сразу известны все ар-
гументы функции, выполняется та команда, которая соответ-
ствует этой функции. Это обусловлено тем, что поле адреса
функции в замыкании (FUN@) должно быть именно адресом —
мы не можем поместить в это поле непосредственно команду.
В завершение нам осталось описать S-схему, по которой ге-
нерируются (инициализирующие) коды создания постоянного
списка или кортежа, а соответствующий указатель помещается
в таблицу констант. Таблица констант предшествует кодам ини-
циализации, а место для нее резервируется командой RESERVE
ассемблера. Если в программе используются всего N констант,
то в последовательность кодов перед кодами инициализации
будет введена инструкция RESERVE N.
Правило S применяется ко всем константам программы
в порядке очередности. При компиляции k-й константы Ск вна-
чале генерируется код, создающий эту константу, а затем ука-
затель на нее помещается в k-ю позицию таблицы констант:
S [Си]; TABLE к
S определяется выражениями
S['c'] =PUSH $с
S [ n 1 = PUSH =$= n (п — целое)
( S [ "abed..."] ^SK'a' 'b' 'с' 'd' ... ) ])
S[(E, ... En_!En)] = EMPTY; S [ Еп ]; CONS;
SfEn-J; CONS; ... ;
S [ E, ]; CONS
S [[EtE2 ... EJ] =S [ En ]; S [ En_, ]; ...;
S[EJ; COPY n
(Заметьте, что оператор EMPTY помещает пустой список nil
на вершину стека.)
410 Часть II. Глава 15
Для компиляции выражения верхнего уровня мы должны вы-
звать Е-правило, которое должно быть соответствующим обра-
зом параметризовано, указывая на то, что локальный контекст
этого выражения является пустым
Е [выражение верхнего уровня]—1 1°
Следующие примеры иллюстрируют работу правил компи-
ляции в действии. В них запись 1п заменяет последовательность
пар (локальная величина, положение в стеке), заключенную
в квадратные скобки-
Г = [(1, n- 1), <2, п-2), 0)]
Пример 1
Допустим, что функция f (т, п) <= хт(+пт) была третьей
по счету определенной пользователем функцией:
D[(2(af(bi 2) (Iv 1 ) ( af ( bi 1 ) (iv 2)(Iv 1 ))))]3
= LABEL FUN_3;
E [ ( af ( bi 2 ) (Iv 1 )(af (bi 1) (Iv 2 ) (Iv 1 )))] 1 [(1, 1), (2, 0>];
DROP 1, 2; RET;
= LABEL FUN-3; E [ ( af (bi 1 ) (Iv 2)(lv 1 ))]1[(1, 1), <2, 0)];
E[(lv 1 )]2[<L, 1), (2, 0)]; MUL ; DROP 1, 2; RET;
= LABEL FUN_3; E[(lv 1 )] 1 [(1, 1), <2, 0)];
E H Iv 2 ) 1 2 [<1, 1), <2, 0)];
ADD; E[(lv 1 )]2[(1, 1), (2, 0)]; MUL; DROP 1, 2; RET;
=LABEL FUN_3; PUSH %0; PUSH %2; ADD; PUSH %1;
MUL; DROP 1, 2; RET;
Пример 2
Функция f (x) = if x > 4 then 2«x else x— седьмая определенная
пользователем функция:
D[( 1 (if (af (bi 3)(lv l)(cv 4)) (Iv 1) ( af (bi 2)
(cv 2)(lv 1 ))))]7
= LABEL FUN-7;
E [ (if ( af ( bi 3)(lv 1) (cv 4))(Iv 1)( af (bi 2)(cv 2)
(Iv 1 ))[0[<l, 0)];
DROP 1, 1; RET;
=LABEL FUN-7; E '( af ( bi 3)(lv 1 ) ( cv 4)) ] 0 [< 1, 0>];
CASE 2; ADDR L_2; ADDR L_3; (предполагаем,
что метки под номерами 1, 2 и 3 уже существуют)
LABEL L_2; Е [ (Iv 1 )]0[(1, 0)]; JUMP L_1
Компиляции функциональных языков 411
LABEL L_3; E[(af(bi 2)(cv 2)(lv 1))JO[<1, 0)];
LABEL L_l; DROP 1, 1; RET;
= LABEL FUN_7; PUSH #4; PUSH %1; GTR;
CASE 2; ADDR L_2; ADDR L_3;
LABEL L_2; PUSH %0; JUMP L_1 ;
LABEL L_3; E [ (lv 1 ) 10[<1, 0)]; E[(cv 2))] 1 [(1, 0)]; MUL;
LABEL L_1 ; DROP 1, 1; RET
=LABEL FUN_7; PUSH #4; PUSH %1; GTR; CASE 2;
ADDR L_2; PUSH %0; JUMP L_1 ;
LABEL L_3; PUSH %0; PUSH# 2; MUL;
LABEL L_1 ; DROP 1, 1 ; RET
Пример 3
Теперь рассмотрим функцию f ( a, g ) = let ( х, b ) = = g( а ) X
Xin(b, b), которую будем считать первой определенной поль-
зователем функцией.
D{(2(tv 2( af (feflv 2))(lv l))(mt(lv 4)(lv 4)))] 1
=LABEL FUN_1 ;
E[(tv 2)(af(fe(lv 2))(lv l))(mt(lv 4)(lv 4)))]1
[(1, 1>, <2, 0)];
DROP 1,2; RET
= LABEL FUN_1 ; E [( af (fe(lv 2)(lv 1))] 1 [<1, 1), <2, 0)];
UNPACK; E[(mt(lv 4)(lv 4))J3[(1, 1), <2, 0)] #+[2, 1];
DROP I, 2; DROP 1, 2; RET
= LABEL FUN_1; E[(lv 1 )]![<!, 1), <2, 0)];
A[(af(fe(lv 2))]2[(1, 1>, <2,0>] 2;
UNPACK; E[(mt(lv 4)(lv 4))]3 [<1, 1), <2, 0), <3, 2), (4, 3>];
DROP 1, 2; DROP 1, 2; RET
= LABEL FUN_1 ; PUSH %0; PUSH %2; APPLY; UNPACK;
PUSH %0; PUSH %1; COPY 2; DROP 1, 2; DROP 1, 2; RET
Очевидно, что существует большое количество различных
способов оптимизации работы генератора кодов. Обычно эти
оптимизации связаны с минимизацией обмена данными со сте-
ком и основаны на придании набору команд F-кода свойства
ортогональности для того, чтобы аргументы функции компили-
ровались непосредственно в операнды команд без обмена со
стеком. Подобные оптимизации являются низкоуровневыми и
зависят от типа используемого компьютера, так как основаны
на свойствах конкретного набора машинных команд. Однако
существуют способы и более высокоуровневой оптимизации.
Одна из простейших, рассматриваемая в упражнении в конце
этой главы, — избегать возникновения излишних ячеек кучи.
412 Часть II. Глава 15
'Для этого после каждого выполнения mt-команды следует опре-
делять, не является ли более оптимальным оставить компонен-
ты кортежа в стеке для хранения.
Другая применяемая оптимизация использует авторекурсию.
Напомним, что авторекурсивной функцией называется такая
функция, результат которой содержит вызов ее самой, как, на-
пример,
-----f(х, a) <=if х = 0 then a else f(x —1, а + х);
Предлагаемый способ оптимизации является общим в том смы-
сле, что он может применяться независимо от того, происхо-
дит ли рекурсивный вызов именно функции f или некоторой дру-
гой функции, например g.
Первое, в чем следует убедиться, — содержится ли резуль-
тат функции, код которой генерируется, в компилируемом вы-
ражении. Для этого мы вводим в Е-схему дополнительный па-
раметр, который равен Y, если это верно, и N — если нет. При
применениях функций этот параметр должен проверяться: для
определенных пользователем функций, если этот параметр ра-
вен Y, вместо обычного вызова может быть сделан переход
к вызванной функции. Однако, прежде чем это сделать, аргу-
менты вызываемой функции следует занести в стек на место
аргументов текущей функции — это предотвратит разрастание
стека при каждом рекурсивном вызове.
A[(ud k)]d 1 n Y = if n = Ak
then DROP n, d-n+1; JUMP FUN_k
else PUSH@FUN_k; PUSH Ak - n;
COPY n + 2; DROP 1, d-n
Этот дополнительный параметр должен быть соответствующим
образом введен во все схемы компиляции. Кзждое из правил
для Е должно при параметре, равном Y, обеспечивать то, чтобы
компилированный код каждого выражения помещал результат
своей работы в стек и осуществлял возврат к вызванной функ-
ции. Это позволяет избежать использования команд DROP и
RET в правиле для D-схемы, которые теперь будут выглядеть
так:
D[(n e)]k = LABEL FUN_k; Е[е]п - 1 Г Y
Читателю предлагается в качестве упражнения самостоятельно
расширить Е-схему для поддержки этого дополнительного па-
раметра.
Компиляции функциональных языков 413
15.2.4. Ядро МФП
Мы обсудили все основные составные части МФП-системы
и теперь нам остается объединить их вместе. Компоненты аб-
страктной МФП-машины вместе со всеми поддерживающими
Ядро МФП-системы < / Область хранения программы^ Стек вызовов Точка входа
Стек вычислений
Куча
Сборщик мусора
Библиотечные определения
Определение• встроенных функций
, Коды компилированных функций
Таблица констант
Код инициализации
Код выражения верхнего уровня
Рис. 15.8. Структура МФП-системы во время прогона.
Адрес А + N
414 Часть II. Глава 15
программами содержатся в ядре МФП, который включает
в себя:
1. Структуры данных абстрактной машины, такие как стек вы-
зовов, стек вычислений и куча. Память хранения программ со-
держит выполняемый двоичный код, генерированный компиля-
тором, и объединяется с ядром с помощью системно-зависимого
(например, VAX) загрузчика.
2. Сборщик мусора. Для большой эффективности он написан
на ассемблере конкретной машины (в нашем случае — VAX).
Сборщик мусора в МФП — это так называемый копирующий
сборщик. Он детально описан в гл. 10.
3. Набор библиотечных определений. Они включают в себя под-
программы для использования некоторых более сложных встро-
енных функций, например ввода/вывода и сложной обработки
списков, а также нужен для поддержки команд типа APPLY.
4. Определения встроенных функций, которые вызываются при
частичном приложении встроенных функций. Они также обра-
зуют библиотеку определений, на этот раз в форме:
LABEL В1_1 ; ADD; RET;
LABEL Bl_2; SUB; RET;
и т. д.
Точкой входа в полную систему, т. е. той частью кода, кото-
рая будет выполняться в первую очередь, является первая
команда кодов инициализации, которые создают таблицу струк-
турных констант (если такие существуют). Далее следуют ком-
пилированные коды выражений верхнего уровня, с которых на-
чинаются вычисления. Полная структура объединенных про-
граммы и ядра показана на рис. 15.8.
15.2.5. Ленивая версия МФП
Как мы уже упоминали, МФП-систему можно расширить
для поддержки ленивых вычислений путем включения задер-
жек в набор типов ячеек кучи. В самом деле, необходимые рас-
ширения аналогичны тем, которые были предложены с той же
целью для SECD-машины в гл. 10. Из нашего обсуждения
интерпретаторов в гл. 9 должно быть ясно, что задержки по
сути очень близки к замыканиям, если не считать того, что они
представляют полное применение функций, а не частичное. От-
сюда следует, что вид их представления аналогичен замыка-
ниям, только поле РАС уже не требуется (поскольку его содер-
жимое всегда равно нулю) и необходима специальная метка
для того, чтобы задержки можно было отличить от ячеек дру-
гих типов. Для того чтобы компилированный FC-код был бы
Компиляции функциональных языков 415
полностью ленивым, модифицированный компилятор должен из
каждого аргумента функции создавать задержку вместо вы-
числения аргументов перед вызовом функции, а встроенные
функции должны проверять (удостоверять), что их строгие ар-
гументы полностью вычислены, а не представлены в форме за-
держек перед применением правил редукции. Следующий блок
кодов ядра МФП выгружает аргументы задержек в стек, вы-
зывает задержанную функцию и затем заменяет первое слово
задержки результатом, что соответствует «вызову по необходи-
мости». Этот блок кодов используется только в том случае, если
примитив применяется к одному из своих строгих аргументов,
имеющему форму задержки. Требуется, следовательно, допол-
нительная метка для того, чтобы различать вычисленные и не-
вычисленные задержки.
Разумеется, число задержек, которые должны быть созданы,
проверены, вычислены и в конце концов удалены сборщиком
мусора, могло бы быть сокращено, если бы мы априорно знали
строгость каждой функции. В этом случае мы могЛи бы вычис-
лить некоторые или все аргументы до вызова функций, и с
этого момента мы можем быть уверены, что если произойдет
зацикливание при вычислении применения функции, то это про-
изойдет в связи с зацикливанием при вычислении собственно
функции. Это превращает вызов по необходимости в вызов по
значению. К счастью, строгость всех примитивов известна, и по-
этому можно избежать необходимости создания задержек для
строгих примитивов, а вместо этого вычислять аргумент до вы-
зова. Однако что касается функций, определяемых пользовате-
лем, то степень их строгости сразу не ясна, и поэтому, как нам
представляется, необходим так называемый анализатор стро-
гости. Для большого числа функций возможно автоматическое
определение того, является ли функция строгой по одному или
нескольким аргументам. Используя даваемую подобным анали-
затором информацию вместе с данными о строгости примити-
вов, мы можем существенно улучшить выполнение компилиро-
ванного кода путем более широкого использования передачи
параметров по значению. К этому вопросу мы еще вернемся
в гл. 20 при обсуждении общих приемов анализа, называемых
абстрактной интерпретацией, одним из которых является ана-
лиз строгости.
15.3. G-машина п
В этом разделе мы опишем компилированную ленивую реа-
лизацию для функционального языка, моделью вычисления для
о От слова graph (граф). — Прим, перев.
416 Часть II. Глава 15
которой является редукция графов, а отсюда и название «G-ма-
шина» [51]. Эта система является частично интерпретирующей
в том смысле, что графы, представляющие выражения, отра-
жают структуру исходного языка, однако сами представлены
и интерпретированы с использованием обычных машинных
команд. Как и в МФП-системе, конечным выходом являются
команды VAX-ассемблера, который генерируется с помощью
макрорасширения из целевого языка компилятора, включающим
макросы, определяющие императивную машину, основанную на
использовании стека. Однако коды, которые создают и преоб-
разуют графы во время прогона программы, компилируются из
выраж! ния верхнего уровня и выражений, определяющих функ-
ции, и если целевая машина специально создавалась с ориен-
тацией на преобразование графов выражений, то система будет
«полностью компилированной». Это происходит по той же са-
мой причине, почему мы можем назвать МФП-реализацию из
предыдущего раздела полностью компилированной; соответ-
ствующая ей абстрактная машина основана на стеке и, следо-
вательно, близка по структуре к целевой машине.
Большое количество особенностей низкого уровня, рассмот-
ренных в МФП-системе, в равной степени относится и к другим
абстрактным машинам, и поэтому при рассмотрении G-машины
мы не будем уделять им внимание. Мы не будем, например, рас-
сматривать физическое представление структур данных (на
этапе выполнения), способы организации кучи или построения
таблицы констант при инициализации.
Синтаксис функционального языка, который мы будем ком-
пилировать в этом разделе, в соответствии с промежуточной
формой 2 будет таким:
(выражение) ::= (константа) | (идентификатор) | (имя функции))
(выражение) (выражение) | (квалиф. выражение)
(квалиф выражение) ::= let (список лок. опред ) in (выражение),
letrec (список лок. опред.) in (выражение)
(список лок. опред.) ::=(лок. опред.) | (лок. опред.), (список лок. опред.)
(лок. опред.) ::= (имя переменной) — (выражение)
Мы опускаем выражения в скобках, поскольку они не важны
в данной реализации. Заметьте, что константы опять могут
включать и себя любыё базовые типы и примитивные функции,
хотя для простоты мы ограничиваемся использованием целых
чисел, булевых констант и списков, а также связанных с ними
функций. Главное различие между этим языком и FC, являю-
щимся основой МФП-системы, заключается в допущении рекур-
сивных квалифицирующих выражений (letrec-выражений). Хотя
все рекурсивные определения могут быть «подняты» на верхний
уровень, например, как дополнительные комбинаторы, рекурсив-
Компиляции функциональных языков 417
ные определения позволяют нам создавать циклические струк-
туры во время прогона программы. В качестве простого при-
мера можно заменить выражение
letrec cycle = cons a cycle
где а — свободная переменная, на выражение Са, где С — вспо-
могательная функция, определенная так:
С х = cons х ( С х)
Соответствующая этому выражению часть программы, однако,
будет работать по схеме нормальной рекурсии, так что цикл
не образуется. Причина того, что подобные выражения не воз-
никают в FC, заключается в том, что FC—строгий язык; функ-
ция cycle будет вычисляться бесконечно долго независимо даже
от того, будет ли она «поднята» для образования нового ком-
бинатора!
Приведем синтаксис определения функции:
(описание функции) ::=(имя функции) (список параметров) = (выражение)
(список параметров) (пусто) | (имя переменной) (список переменных)
Как и в МФП-системе, этот синтаксис предполагает, что все вы-
ражения уже транслированы и представлены в виде набора не-
ких комбинаторов (см. гл. 13).
Подобный синтаксис очень близок синтаксису промежуточ-
ного кода, описанного в гл. 8 (который в свою очередь соответ-
ствует «промежуточному коду 1» на рис. 15.1). Наиболее суще-
ственным различием же является то, что лямбда-абстракции
были удалены, так что выражение в промежуточном коде
f = Лх1.Лх2. ... А,хп.Е
при трансляции перейдет в определение функции (комбинатора)
fX|X2 ... xn = Е
Заметьте, что в этих кодах let-выражения включают список
локальных определений, а не одно-едцнственное определение,
как в гл. 8. Эта разница, однако, несущественна, так как
let Xj = еь х2 = е2, ..., хп = en in Е as
let X, == et in let x2==e2 in ... let xn = en in E
Условные выражения могут рассматриваться как примене-
ния примитивной функции cond в связи с «ленивой» семантикой
функционирования G-машины в МФП-системе, с другой стороны,
условные выражения рассматриваются как особый случай (по
этому вопросу см. также гл. 9).
27 — 1473
418 Часть II. Глава 15
До сих пор мы не рассматривали такие синтаксические типы,
как кортежи и составные данные. Кортеж длиной п 0 пред-
ставляется применением функции кортежирования типа
TUPLE-n из гл. 8, которая может рассматриваться так же, как
и все другие. Составные данные также представляются в виде
функций кортежирования (см. гл. 7), и здесь применимы при-
веденные в гл. 11 способы оптимизации, где конструкторы пред-
ставлены вершинами графа. Это, однако, находится вне нашего
рассмотрения.
Как и в случае с МФП-машиной, функционирование G-ма-
шины можно представить в виде четырех схем компиляции:
1. С-схема, генерирующая коды для конструирования графов,
представляющих выражения;
2. Е-схема, генерирующая коды для вычисления представлен-
ных графами выражений, созданных по С-схеме; по окончанию
работы устанавливается указатель на результат в вершине
стека вычислений;
3. F-схема, генерирующая тела функций, определенных пользо-
вателем, т. е. коды для редукции графов (созданных по С-схе-
ме), соответствующих применению функции;
4. В-схема, близкая к С-схеме, но служащая для вычисления
выражений, результатом которых будет целочисленная или бу-
лева константа с размещением результатов вычислений на вер-
шине другого стека, называемого дамп.
Это необходимо для повышения эффективности при примене-
нии примитивных функций, требующих строгой семантики и вы-
полняющих основные арифметические, логические и условные
операции. Их аргументы находятся на вершине дампа, что по-
могает сократить вычислительные затраты, связанные с кон-
струированием графов. Заметьте, что дамп хранит атомарные
данные и, как мы увидим ниже, информацию о состоянии про-
граммы в момент вызова функции, а стек содержит лишь ука-
затели на составные части графа выражения, редуцируемого
в данный момент. Подвыражения, представленные этими указа-
телями, также могут быть (косвенно доступными) атомами, но
чаще бывают списками или частично вычисленными примене-
ниями функции.
Выполнение компилированной программы G-машины осно-
вано на модели вычислений, описанной в гл. 11. Она использует
стек указателей для спуска и подъема по гребню графа и дамп
для вычисления применений функций. Единственной дополни-
тельной особенностью здесь является применение функций, опре-
деленных пользователем, для которых графы тела функции
должны быть означены подстановкой графов аргументов. Это
Компиляции функциональных языков 419
выполняется в соответствии с правилами, аналогичными прави-
лам p-редукции из гл. И, путем копирования шаблона, генери-
рованного по F-схеме для примененной функции, причем все
ссылки на аргументы являются косвенными, т. е. через указа-
тели стека. Этот вид «сращивания» близок по сути потоковой
модели вычислений из гл. 14.
В следующей главе мы введем несколько новых обозначений
и (абстрактных) примитивных инструкций G-машины в виде
макросов. В трех последующих разделах мы перейдем к обсуж-
дению четырех схем компиляции, введенных выше; Е-схема и
В-схема рассматриваются вместе. Схемы Е и F, объединенные
вместе, формируют eval/apply-реализацию, аналогичную рас-
смотренной в гл. 9.
15.3.1. Макросы G-машины
и общие обозначения
Примитивные операции, используемые абстрактной машиной,
могут быть разделены на 4 класса: операции со стеком и дам-
пом, создание и изменение вершин графа (и, таким образом,
графов), вызов функций и возврат из них, а также вычисление
применений примитивных функций. Каждая такая операция
представлена макросом в коде G-машины, генерированном ком-
пилятором; эти макросы образуют набор команд абстрактной
машины, который может быть реализован на любом компью-
тере, обладающем соответствующими языковыми средствами.
Например, макроинструкции PUSH и SLIDE требуют примене-
ния команд с индексированием. Таким образом, промежуточный
язык, основанный на макросах, является мобильным и может
быть реализован на выбранном компьютере с помощью обычных
языков программирования или машинного языка.
Макросы, соответствующие применению примитивных функ-
ций, используют подходящее дельта-правило этого примитива,
а полный набор макросов для операций со стеком и дампом,
работы с графами и для вызова функций и возврата описан
в трех следующих разделах. Однако, хотя смысл и сущность
этих операций станут ясны по мере их рассмотрения, эта часть
текста может быть пропущена при первом прочтении и исполь-
зоваться лишь для ссылок при необходимости. Сначала, однако,
следует ввести несколько общих обозначений.
Общие обозначения
• Обозначим указатель вершины стека как УВС, а текущую
глубину стека, т. е. число указателей в нем, как и. Таким
образом, УВС является п-ым указателем. Мы будем также
27*
420 Часть II. Глава 15
Таблица 15.4. Макросы для работы со стеком
PUSH m Помещает на вершину стека содержимое его элемента на
m ниже, чем УВС. Если m = 0, то PUSH 0 означает ’’сору УВС”
PUSHFUN f Помещает указатель на корневую вершину тела функции f
PUSHINT i Помещает указатель на новую вершину, содержащую це- лое число f
PUSHBOOL b Помещает указатель на новую вершину, содержащую бу- леву константу b
PUSHNIL Помещает указатель на новую вершину, содержащую пу- стой список
SLIDE m Копирует УВС в элемент (п — ш) стека, т. е. на m пози-
ций ниже УВС (УВС ’’переносится на m позиций вниз”)
обозначать элемент стека на m позиций ниже, чем УВС, т. е.
положение (п — т) как УВС — т.
• Контекст, связывающий выражения и имена переменных и яв-
ляющийся набором пар имя — число, обозначим г. Пустой кон-
текст, не содержащий таких пар, обозначим г0, а запись г{р/х}
будем использовать для обозначения контекста 2, дополненного
связью х := р.
• р-й элемент стека указывает на вершину графа, представ-
ляющую выражение, связанное с переменной х в контексте г.
Таблица 15.5. Макросы для работы с графами
МКАР
UPDATE m
ALLOC m
CONS
MKINT
MKBOOL
GET
Создает ©-вершину, для которой левым и правым указате-
лями являются УВС и УВС — 1 соответственно; дважды
выталкивает содержимое стека; помещает указатель на
новую ©-вершину на вершину стека (т. е. заменяет два
указателя на указатель ©-вершины)
Копирует содержимое вершины, указываемой УВС в вер-
шину, адресуемую через УВС — т; выталкивает верхний
элемент из стека
Устанавливает m ’’дырок” (т. е создает m новых вершин
с неопределенным содержимым); помещает в стеке после-
довательно m указателей на них
Создает новую cons-вершину, для которой левый (голов-
ной) и правый (хвостовой) указатели соответственно рав-
ны УВС и УВС—1; дважды выталкивает содержимое
стека; помещает указатель на новую cons-вершину на вер-
шину стека
Создает новую константную вершину, значение в которой
взято с вершины дампа; выталкивает содержимое вершины
дампа; помещает указатель на новую вершину в стек
Извлекает содержимое вершины, указываемой с помощью
УВС и выталкивает содержимое вершины стека; помещает
извлеченное значение в дамп
Компиляции функциональных языков 421
Другими словами, р ссылается на указатель, хранящийся в р-м
элементе стека. Тогда, например, в контексте г0{п/х} перемен-
ная х указывает на граф, в котором вершина редекса указы-
вается с помощью УВС. Элемент стека, связанный с перемен-
Таблица 15.6. Макросы для вызова функций и возврата
EVAL Помещает на вершину дампа остаток выражения, вычисляемого в
текущий момент (т. е. все символы, идущие в выражении после
этого EVAL), и весь стек, кроме его УВС; образует новый стек, в
котором единственным элементом является УВС; вычисляет новое
выражение, состоящее из единственного макроса UNWIND
UNWIND while УВС указывает на ©-вершину
do поместить указатель (правый) аргумента в стек
поместить (левый) указатель функции в стек
end-while
if УВС указывает на вершину определенной пользователем функ-
ции
then if число параметров в стеке арность функции
then считать тело функции вычисляемым сейчас выражением
else восстановить контекст (текущее выражение и стек),
выталкивая дамп (т. е. вернуться, так как частичное
находится в СЗНФ).
else if УВС указывает на вершину соответствующей примитивной
функции
then применить примитивную функцию согласно ее дельта-
правилам (например, вначале вычислить ее аргумен-
ты)
else ошибка типа
RET m Выталкивает тп элементов стека
if УВС указывает на © вершину или вершину-функцию
then UNWIND (результатом является функция, например, частич-
ное применение)
else извлечь и сохранить УВС; восстановить контекст (текущее вы-
ражение и стек) С помощью выталкивания элементов дампа;
поместить в стек сохраненный УВС (т. е. нормальный воз-
врат из функции, результат в УВС)
ной х в контексте г, обозначим как г(х) — для приведенного
выше примера г (х ) — р.
• Будем использовать двойные квадратные скобки для обозна-
чения синтаксических конструкторов, которые компилируются
по указанным четырем схемам. Например, Е[+2 3] обозначает
код, генерируемый для того, чтобы сложить константы 2 и 3;
указатель на вершину, хранящую результат (число 5), поме-
щается на вершину стека.
Макросы для работы со стеком
Существует шесть стековых операций, макросы для которых
определены в табл. 15.4.
422 Часть II. Глава 15
Разумеется, что набор макросов PUSHINT, PUSHBOOL,
PUSHNIL может быть расширен соответствующими макросами
для дополнительных типов данных, например PUSHCHAR.
Макросы для работы с графами
Макросы для графов используются при генерации графов
тел функций и составных данных, а также при взаимодей-
ствии Е- и В-схем. Описание этих макросов представлено
в табл. 15.5.
Макросы для вызова функций и возврата
Они приводятся в табл. 15.6.
Редукция графов происходит с помощью именно этих мак-
росов. Макрос EVAL инициализирует вычисление выражения,
которое в ленивой системе является требуемым результатом,
если его вычисление не будет специальным образом форсиро-
вано. EVAL служит для вычисления выражений верхнего уровня
(см. разд. 15.3.3) и применений определенных пользователем
функций (см. разд. 15.3.3 и 15.3.4). Выполнение UNWIND и
RET всегда отчасти аналогично применению EVAL. Примене-
ние примитивных функций происходит по В-схеме (см.
разд. 15.3.3).
15.3.2. Генерация кода
для построения графов выражений — С-схема
С-схема компилирует код, создающий граф, представляю-
щий выражение, и помещает указатель на его вершину редекса
(корневую вершину) в вершину стека. Обозначим через
С[е]гп компилированный код для выражения е, где контекстом
является г, а глубина стека равна п. Во время прогона про-
граммы каждая переменная в г является формальным парамет-
ром функции, определенной пользователем, и должна иметь
в стеке соответствующий указатель на подграф аргумента. До-
ступ к указателям аргумента происходит с помощью макроса
PUSH, причем PUSHi помещает копию указателя в i-й, считая
от УВС, элемент стека. Поскольку доступ к указателям аргу-
мента происходит относительно вершины стека, то глубина
стека п также должна быть параметром С-схемы. Теперь можно
описать С с помощью анализа вариантов синтаксических типов
выражений, приведенных в начале разд. 15.3.
Для каждого основного типа (С-типа) определим макрос
PUSHCTYPE, который, будучи примененным к постоянному ар-
гументу С-типа, создает вершину, содержащую эту константу,
и помещает указатель на эту вершину в стек. Таким образом,
Компиляции функциональных языков 423
в общем случае для константы С-типа мы имеем
С [с] г n = PUSHCTYPE с
и, в частности,
С [ i ] г n = PUSHINT i для целого числа i
C[b]|r n = PUSHBOOL b для булевой константы b
С [nil] г n = PUSHNIL для пустого списка nil
(В последнем случае аргумент не нужен, так как мы лишь опре-
деляем одну константу списка.)
Как примитивная, так и определенная пользователем функ-
ция является константой и может рассматриваться как комби-
натор (см. разд. 15.2). В последнем случае его «значением»
будет его набор правил графовых преобразований, даваемых
компилированным по F-схеме кодом, а также его арность; это
«значение» хранится в глобальном контексте. Таким образом,
для функции f имеем
C[f]r n = PUSHFUN f
Переменные представлены своими связанными выражениями
в текущем контексте; для ссылок на них служат указатели
стека, как было сказано выше. Так, для переменной х
C[x]r n = PUSH (n —г(х))
где г(х) — положение указателя (стека) на граф выражения,
связанного с х в контексте г.
Компилированный код для общего применения вида eie2
состоит из трех частей. Вначале генерируется код для вычисле-
ния выражения е2, а указатель на корневую вершину результи-
рующего графа выражения помещается на вершину стека, глу-
бина которого увеличивается на 1. Затем генерируется код
выражения ei и команда для выполнения данного применения.
Получаем таким образом
(Де^Цг п = С[е2]|г n: СIех]|г(п4-1); МКАР
где макрос МКАР служит для создания ©-вершины и двух ука-
зателей— левого и правого, указывающих на графы, представ-
ляющие выражения et и е2 соответственно, а затем помещает
указатель на новую (©-вершину (заменяя вытолкнутые указа-
тели на графы ei и е2). Заметьте, что это не означает, что про-
исходит энергичное вычисление. Хотя и генерируется код созда-
ния графа выражения аргумента функции, но этот граф будет
редуцирован, только когда его корневая вершина станет редек-
сом, что задано макросом EVAL в Е-схеме. В следующем
424 Часть П. Глава 15
разделе увидим, что это не приводит к вычислению аргумента,
за исключением строго примитивных функций.
В случае функции конструкторов (здесь рассматривается
только cons) ситуация аналогична. Вначале компилируется код,
соответствующий двум аргументам — голове и хвосту списка,
так чтобы поместить в стек указатели на создаваемые ими гра-
фы. Однако вместо построения ©-вершины образуется специ-
ально помещенная cons-вершина, из стека выталкиваются два
указателя, а на вершину стека помещается указатель на новую
cons-вершину. Получаем
С [cons ele2U г n = C[e2]rn; C[eI]r(n+ 1); CONS
И наконец, мы подходим к квалифицированным выражениям,
для которых сначала рассмотрим простейший, нерекурсивный
случай. В выражении letxj = ei ine переменная X! может рас-
сматриваться как формальный параметр выражения е, а обра-
щение к ней будет происходить с помощью указателя на граф
выражения, причем текущий контекст будет изменен так, что
новый УВС будет связан с переменной хь После выполнения
кода выражения е указатель на граф квалифицированного вы-
ражения должен быть вытолкнут из стека до того, как его за-
менит указатель на граф, генерированный для е. Так компили-
руется нерекурсивное квалифицированное выражение:
C[let х1 = е1...xm = era tn е]г п —С[е,]|г п;
= С[е2]г(п + 1);
= C[em]r(n + m—1);
= С[е]|г/(п4-т);
= SLIDE т
где г' = г{( п + 1 )/xJ ... {(и + т )/хт}.
Теперь рассмотрим выражение letrec Xi — ei in e, в котором в
единственное рекурсивно описанное квалифицированное выра-
жение ei переменная X; входит по крайней мере один раз. В гра-
фе, генерированном для е, обращение к Х] может происходить
через измененный контекст, как и в нерекурсивном случае. Од-
нако так как ei благодаря Xi содержит ссылки на саму себя,
то и граф для е! также должен содержать соответствующие
указатели на свою вершину редекса. Для построения подобного
графа необходима генерация несколько своеобразного кода.
Особенность здесь заключается в том, что сперва надо создать
вершину-дырку, которая впоследствии станет редексом графа ei,
но оставить эту дырку пока пустой, чтобы заполнить после за-
вершения генерации кода для щ. Указатель на дырку поме-
щается в стек, а контекст изменяется так, чтобы в компилиро-
ванном для ei коде указатель (т. е. новый УВС) был связан
Компиляции функциональных языков 425
с переменной хь Этот код почти эквивалентен генерированному
по С-схеме с измененными контекстом и стеком, за исключением
того, что вершина-редекс, адресуемая УВС, не является заре-
зервированной для нее дыркой. Несмотря на это, ссылки на xj
на самом же деле компилируются в указатели дырок, так что
все, что остается сделать, — это скопировать содержимое ука-
зываемой УВС вершины в дырку, на которую указывает со-
седний с УВС элемент стека, и вытолкнуть элемент стека. Это
выполняется макросом UPDATE, a UPDATE m заменяет содер-
жимое вершины, адресуемой с помощью УВС — т, на содержи-
мое вершины, адресуемой с помощью УВС, и выталкивает эле-
мент стека. Создание дырок выполняется макросом ALLOC,
причем ALLOC ш создает ш дырок и помещает их указатели
в стек. Следовательно, имеем
С [ letrec Х[ = ej in е ] г n = ALLOC 1 ; С [ ej ] г'( n + 1);
UPDATE 1 ; C[e]r'(n+ 1);
SLIDE 1
где г' = г {(n + 1 )/xJ.
Рассмотрение кодов G-машины для выражений, содержащих
более одного рекурсивного квалифицированного определения,
предлагается читателю провести самостоятельно. Заметьте, что
использование рекурсивной версии всегда корректно, даже если
квалифицированное выражение нерекурсивно. Таким образом,
форма кода C[letrecxi = ец ..., xm = emine]rn является весь-
ма общей, позволяя корректно построить граф независимо от
того, есть ли или нет среди m квалифицированных выражений
такие, которые определены взаимно рекурсивно.
Мы завершим этот раздел двумя примерами, которые иллю-
стрируют важные свойства С-схемы.
Пример 1: letx = 5in + xx
Допустим, есть контекст г и стек глубиной п, тогда последо-
вательное применение уравнений, определяющих функцию С,
дает
С [let х = 5 in +х x]r n —C[5]jr п;
С[( + x)x]r{(n+ 1 )/x}(n + 1);
SLIDE I
= PUSHINT 5;
C[x]]r{(n + l)/x}(n+ 1);
С[ +x]r{(n + 1 )/x}(n + 2); MKAP;
SLIDE 1
= PUSHINT 5; PUSH 0;
426 Часть II. Глава 15
С [ х ] г {(n + 1 )/х) (п + 2);
С[ + ]г{(и + 1 )/х)(п + 3); МКАР;
МКАР; SLIDE 1
= PUSHINT 5; PUSH 0; PUSH 1;
PUSHFUN+ ; МКАР; МКАР;
SLIDE 1
Выполнение этого кода будет происходить следующим образом.
После выполнения первых четырех макроинструкций вид стека
и графа будет таким:
Заметьте, что мы рисуем здесь стек так, что он наращивается
вниз: причина этого заключается всего лишь в том, что стек
растет в сторону «раскрытия» графа выражения.
Выполнение следующей команды МКАР дает
Выполнение второго макроса МКАР приведет к следую-
щему:
Компиляции функциональных языков 427
И наконец, SLIDE 1 дает в результате
@
Пример 2: letrec х = f х in х х
Допустим опять, что есть контекст г и стек глубиной и.
Тогда последовательное применение уравнений, определяющих
функцию С, дает:
С[letrec х = f х in х х]г и
= ALLOC 1; C[f х ] г {(n + 1 )/х} (n + 1); UPDATE 1;
С[х xjr{(n+1 )/x}(n+1); SLIDE 1
= ALLOC 1; C[x]r{(n+l)/x}(n+1);
C[fjr{(n+l)/x}(n + 2); MKAP;
UPDATE 1; C[x]r{(n+l)/x}(n+1);
C[x]r{(n+ l)/x}(n + 2); MKAP; SLIDE 1
= ALLOC 1; PUSH 0; PUSHFUN f; MKAP; UPDATE I ;
PUSH 0; PUSH 1; MKAP; SLIDE 1
После выполнения первых трех макрокоманд вид стека
и графа будет следующим:
Следующий
Инструкция UPDATE 1 копирует содержимое вершины, отме-
ченной * (указываемой указателем УВС), в вершину, отмечен-
ную + (адресуемую с помощью соседней с УВС ячейкой).
428 Часть II. Глава 15
Получаем
Вершина, отмеченная *, становится несвязанной и может
быть устранена с помощью сборщика мусора, поскольку не яв-
ляется разделяемой. Выполнение двух следующих инструкций
PUSH 0 и PUSH 1 дает следующее:
а завершающих два макроса МКАР и SLIDE 1 приведут к ре-
зультату:
15.3.3. Генерация кода для вычисления
выражений — Е-схема
Е-схема компилирует код для вычисления выражения, пред-
ставленного графом, и помещает указатель на результат, т. е.
граф, представляющий выражение в СЗНФ, на вершину стека.
Если действовать по С-схеме, то подобная компиляция- очень
проста. Сначала вырабатывается код для построения графа,
представляющего вычисляемое выражение, например е, с по-
мощью вспомогательного контекста г и стека глубиной*п. Ре-
зультат обозначим С[е]гп. При прогоне, построив граф, необ-
ходимо затем редуцировать его, используя макрос EVAL, ко-
торый инициализирует спуск по гребню графа и выполняет
редукцию графа согласно изложенным в гл. 11 правилам. Таким
Компиляции функциональных языков 429
образом мы получаем определение Е-схемы, а именно
Е [ е ] г и = С [ е Л г n: EVAL
так что, например,
E[x]r n = PUSH(n — r(x)); EVAL для переменной х
Однако если выражение е находится в СЗНФ, то выполне-
ние макроса EVAL не дает никакого эффекта, как видно из его
определения в разделе 15.3.1, поэтому оно является в таких
случаях избыточным и, хотя во время компиляции нельзя опре-
делить, представлено ли выражение в форме СЗНФ, это всегда
верно для констант синтаксических типов, имен функций и (ле-
нивых) функций конструкторов (у нас это cons). Следовательно,
можно определить
Е [с] г п = С[с]г n = PUSHCTYPE с
для константы с, имеющей тип С, и в частности,
Е [ i ] г n =PUSHINT i, если i целое
E[b]r n =PUSHBOOL b, если b — булева величина
E[nil]r n = PUSHNIL
E[f]r n = PUSHFUN f, если f —имя функции
Аналогичным образом получаем
E[cons е^гЦг n = C[cons ехе2]1 г п = С[е2]|г п;
С[е1Цг(п4- 1): CONS
Существует еще один тип выражений, который мы можем
рассмотреть отдельно, а именно выражение, включающее при-
митивные функции. И опять мы можем совершенно обоснованно
предположить, что эти функции уже включены в описываемую
систему и находятся в листьях графов выражений, а их приме-
нение к аргументам инициируется макросом UNWIND. Тогда
соответствующие дельта-правила могут применяться так же, как
и в гл. 11. Однако в G-машине все применения строгих прими-
тивных (или «основных») функций обрабатываются по В-схеме
с использованием дампа в качестве отдельного стека. Эта схема
повышает эффективность работы, так как позволяет избежать
чрезмерного разрастания графовых конструкций. В отличие от
Е-схемы вычисление выражений, построенных по В-схеме, имеет
строгую семантику, так что аргументы примитивной функции
при ее применении являются полностью доступными и нахо-
дятся на вершине дампа в уже вычисленном виде как
430 Часть П. Глава 15
константы. Добавим к описанию Е-схемы компиляции еще пару,
уравнений;
E[4-eie2]r и — В [ -f-e(e2] г n; MKJNT
Ej[not в]]г n = Bj[not е!]г n; MKBOOL
по одному для каждой примитивной функции. Макрос MK.INT
(или MKBOOL соответственно) создает новую вершину графа,
содержащую константу, которую она выталкивает из вершины
дампа и помещает в стек указатель на новую вершину.
Для каждой строгой примитивной функции существует мак-
роинструкция, обозначенная тем же именем, что и функция, но
большими буквами, например макросы ADD и NOT соответ-
ствуют примитивным функциям + и not. Как и в Е-схеме, в
В-схеме существует по одному уравнению для каждой прими-
тивной функции в виде
В[ +eie2Цг n = B[e1]r n; В [ е2 ] г (п + 1); ADD
В К not е J г n = В [ е JJ г и; NOT etc.
Для любого другого выражения е, не являющегося приме-
нением примитивной функции
B[e]r n = E[e]r n; GET
где макрос GET извлекает содержимое вершины, на которую
указывает УВС, выталкивает элемент стека и помещает содер-
жимое вершины в дамп. В-схема обращается к Е-схеме для вы-
полнения выражения е, а Е-схема в свою очередь может подоб-
ным образом обратиться к В-схеме.
15.3.4. Компиляция тел функций — Y-схема
В гл. 11 мы увидели, как выбирается следующая вершина
редекса в графе выражения путем спуска по левому гребню
графа, а состояние стека G-машины после завершения спуска
по графу выражения Gei ... em показано на рис. 15.9. Спуск
происходит с помощью команды UNWIND, полностью описан-
ной в разд. 15.3.1. До начала спуска единственным элементом
стека является указатель на вершину редекса графа выраже-
ния, а потом, в процессе спуска, последовательные пары указа-
телей на аргумент и функцию заносятся в стек до тех пор, пока
на гребне не останется ни одной ©-вершины.
Применение определенной пользователем функции f с ар-
ностью гп будет редуцировано, только когда f будет приложена
к m аргументам; применение f к меньшему, чем ш, числу аргу-
ментов уже является СЗНФ и F-схема редуцирует граф, пред-
Компиляции функциональных языков 431
ставляющий применение fej ... em для произвольных выраже-
ний ei, ..., em без выполнения спуска по гребню этого графа.
Теперь корневая вершина ei адресуется указа-
телем в ячейке 2(т— i-J-1) стека, как показано на рис. 15.9.
Таким образом, если функция была задана как fxi ... xm = e,
где выражение е может содержать формальные параметры, т. е.
Рис. 15.9. Составление стека после раскручивания выражения Get ... еш.
переменные {xj J1 i т}, то результатом редукции этого при-
менения f ег ... ет будет величина е в контёксте
Г = Го {2m/xJ (2т — 2/х2) ... (2/хт)
со стеком глубиной (2т+1). Этот результат был бы получен
при выполнении кода E[e]r(2m-f-l) и хранится в новой вер-
шине, адресуемой указателем, помещенным на вершину стека,
т. е. в ячейке стека (2m+ 2). Однако при возврате из функ-
ции f этот результат должен заместить вершину редекса при-
менения функции, согласно обычным правилам, как редукции
графов; указатель на нее находится в ячейке, соседней (снизу)
с той, в которой хранится указатель на последний аргумент
применения, т. е. ячейка 1 стека. Таким образом, этот указатель
на (2m + 1) позицию ниже, чем УВС, так что для корректного
выполнения указанных операций достаточно воспользоваться
макросом UPDATE (2m -{- 1 ); помните, что UPDATE также
выталкивает элемент стека.
Теперь остается вытолкнуть из стека оставшиеся (2m) ука-
зателей, оставив УВС, указывающий на корневую вершину
432 Часть II. Глава 15
результирующего графа, и осуществить возврат из функции. Если
результатом ее выполнения является функция или применение
(частично примененная функция), то при возврате выполняется
инструкция UNWIND для обнаружения следующего редекса.
В противном случае из дампа извлекаются стек и вычисляемо^
выражение, а указатель результата помещается в этот стек.
Так происходит «нормальный» возврат из функции. Для выпол-
нения этих операций используется макрос RET 2m, полностью
описанный нами в разд. 15.3.L
Таким образом, мы определили F-схему так:
F [ fxj ... xm = е ] = Е [ е ] г (2m + 1); UPDATE( 2m + 1);
RET 2m
Пример: f x = cons x (f x )
В случае энергичного применения функции f ее вычисление
будет длиться бесконечно. Ленивая же семантика G-машины
позволяет получать значение отдельных частей бесконечного
результата. F-схема дает следующий код для f:
F[f х = cons x(f x)] = Efcons x (f x)]r13: UPDATE 3;
RET 2
поскольку здесь m = 1, а и = r0{2/x}, to
= C[f x]rj 3; ClxJrj 4; CONS; UPDATE 3; RET 2
= С[х]г! 3; C[f]r, 4; M.KAP; PUSH(4-ri(x)); CONS;
UPDATE 3 ; RET 2
= PUSH 1; PUSHFUN f; MKAP; PUSH 2; CONS;
UPDATE 3; RET 2
Как и в МФП-системе, каждый комбинатор ft обладает соот-
ветствующим ему элементом в глобальном контексте Ео, кото-
рый является парой, состоящей из значения арности функции
и кода, генерированного для нее по F-схеме. Поэтому в этом
примере окончательно получаем
Ео = {fi: (n( 1), F [ fjxj ... х„ (о = ej ]),
fra:(n(m), F[fmx, ... Xn(m) = em]|)
+ :(2. F[+x1x2 = ADD x,x2])
— : (2, F [ -{-XJX2 = SUB X]X2 ])
Компиляции функциональных языков 433
Примитивные функции +, —, not и т. п. появляются в двух
формах благодаря тому, что если они входят в выражения, ре-
дуцируемые по Е-схеме, то при достаточном количестве аргу-
ментов их применения будут обрабатываться по В-схеме, кото-
рая «знает» их дельта-правила. Использование больших букв
позволяет выделить истинно примитивные функции, которые
встречаются только лишь в редексах, а не в частичных приме-
нениях, которые представлены в СЗНФ. Действительно, если
все примитивные функции типа +, например входящие в выра-
жение верхнего уровня и тела функций, имеют по два аргу-
мента, то Е-схема прокомпилирует их, непосредственно исполь-
зовав инструкцию ADD в каждом случае, и элемент глобального
контекста для + никогда не будет достигнут при прогоне.
15.3.5. Оптимизация
Описанная в этой главе G-машина хотя и является хорошей
основой для полноценной реализации функционального языка,
но тем не менее существует несколько способов оптимизации,
выполнение которой целесообразно. Некоторые из способов
применимы к реализациям функциональных языков вообще и
используют методы преобразования и абстрактной интерпрета-
ции, рассмотренные в ч. III. В качестве примеров приведем
преобразование применения линейных функций в циклы для
экономии вычислительных ресурсов, связанных с вызовом функ-
ции, и модификацию авторекурсивных функций, разработанную
Джонсоном, который ввел новые инструкции MOVE, копирую-
щие данные в аккумуляторы циклов, и JFUN для выполнения
переходов. Далее, поскольку G-машина использует ленивую се-
мантику, то это приводит к значительным затратам на построе-
ние графов, представляющих невычисленные выражения аргу-
ментов (они непосредственно соответствуют задержкам). Од-
нако многие аргументы в конечном итоге все равно потребуются
в вычисленной форме, так что использования задержек в таких
случаях можно и избежать, передав аргумент по значению. На-
хождение этих строгих аргументов во время компиляции дало
бы значительное увеличение эффективности программы, и для
передачи их по значению генерируется соответствующий код.
Для этой цели используется анализатор строгости, обсуждае-
мый в гл. 20, призванный извлечь лучшее из двух альтернатив-
ных способов вычисления и повысить эффективность «ленивых»
вычислений до уровня «энергичных».
И наконец, здесь существует возможность и более специфи-
ческой оптимизации. Так, при построении графа количество вер-
шин может быть уменьшено использованием определенных
28 — 1473
434 Часть П. Глава 15
дополнительных макроинструкций. Такая возможность возникает
при построении графов, представляющих применение опреде-
ленных пользователем функций и рекурсивных квалифициро*
ванных выражений. Соответствующие последовательности кодов
оканчиваются инструкцией UPDATE m, где m > О, что приво/
дит к тому, что любая вершина, созданная предыдущей инструк]
цией, становится недоступной, а ее содержимое копируется в ка!
кую-либо вершину редекса где-нибудь в графе. Таким образом,
мы можем ввести макросы UPCONS и UPMKAP, такие что
UPCONS m и UPMKAPm будут замещать пары инструкций
CONS; UPDATE ( m + 1 ) и MKAP; UPDATE(m+l) соответ-
ственно без создания каких-либо промежуточных вершин. При-
менения этих оптимизаций можно найти в примерах в разд. 15.3.4
и 15.3.2 соответственно.
Резюме
• Функциональные программы, выраженные в подходящей
комбинаторной форме, могут быть транслированы в код аб-
страктной машины.
• Абстрактная машина может быть реализована на любом
компьютере, если рассматривать инструкции абстрактной ма-
шины как макросы.
• МФП является примером энергичной абстрактной машины
и может рассматриваться как оптимизированная версия
SECD-машины.
• В МФП исходные программы сперва компилируются в функ-
циональный код низкого уровня, называемый FC; затем они
транслируются в код МФП-машины с помощью различных схем
трансляции.
• G-машина является примером ленивой абстрактной машины;
она основана на редукции графов комбинаторных выражений.
В G-машине исходные программы компилируются в промежу-
точный код, напоминающий промежуточный код в гл. 8; затем
он транслируется в код G-машины по различным схемам ком-
пиляции.
• Код G-машины оперирует с графовой формой выражения
верхнего уровня; инструкция UNWIND всегда определяет са-
мый левый из самых внешних редексов.
Упражнения
15.1. Напишите в FC коде эквивалентные выражения для сле-
дующих функций (в каждом случае можно предположить, что
Компиляции функциональных языков 435
это первая описанная пользователем функция).
(a) f = Лх. + х( * х х)
(б) f = Xx.cond (= х 0)l(f(— х 1))
(в) f = Xx.Xy.let s = (+ х 1) in (tuple-3 s s у)
(г) f = Xx. Xy. Xg. case-3 (g x 1)0 y( — x 1)(* x y)
(д) f = Xx.Xg.cond (=xO)(g(Xy. *x(gy)))(f( — x 1)( + x y))
В (д) придется выполнить Х-удаление внутренней Х-абстракции,
создав одну вспомогательную функцию (комбинатор); предпо-
ложите, что она будет восьмой в списке определенных пользо-
вателем функций.
15.2. В каком смысле FC реализует ограниченную форму сопо-
ставления с образцом? В чем здесь заключается преимуще-
ство FC? {Подсказка-, следует рассмотреть выражение вида:
let х1 = Е1 in let х2 = Е2 in ... let xn = En in E
где Ej ссылается на элементы одного и того же кортежа.)
15.3. Напишите последовательности компилированного кода для
следующих FC-функций (п: стоящее перед функцией, указы-
вает на то, что номер функции равен п):
(а) 3 : (l(af(bi — )(cv 1)(Iv 1)))
(б) 5 : (2(tv 5(lv 1 )(mt(cv 4)(lv 2)(lv 7)(af(bi + )(lv 3)(lv 5)))))
(в) 6 : (2( if( af( bi < ) (1 v 1) (Iv 2)) (cv 0) ( af( ud 6)
(af(bi-)(lv l)(cv 1 ))(lv 2))))
15.4. Рассмотрите следующее FC-выражение
(tv 3(mt Е[Е2Ез)Е)
а. Напишите компилированный код (F-код) для этого выра-
жения, обозначая компилированный код для е через е'.
б. Известно, что компилированный код создает кортеж
в куче, а затем сразу же копирует его обратно в стек. Для оп-
тимальности было бы эффективным оставлять элементы кор-
тежа в стеке и избегать использования кучи. Какие свойства
mt-выражения позволяют это сделать?
в. Предложите соответствующее Изменение правил компи-
ляции, выполняющее эту оптимизацию. {Подсказка: добавьте
дополнительный параметр к Е, указывающий количество эле-
ментов, компилированный код которых должен оставаться в
стеке.)
15.5. В схемах компиляции для G-машины не рассматривалась
функция cond (условная функция). Это примитивная функция
28*
436 Часть II. Глава 15
от трех аргументов, из которых только первый является строгим
и представлен булевой величиной. Определите код G-машины
для вычисления выражения cond Е^гЕз в контексте г при стеке
глубиной п. {Подсказка-, рассмотрите код, генерированный для
cons, и используйте В-схему для вычисления первого аргумента.
Вам потребуется новый макрос COND для выбора нужной
ветви условного выражения.)
15.6. Напишите код G-машины для функции from, описываемой
так:
from n = cons n (from(succ n))
и получите граф для выражения (succO).
15.7. Рассмотрите вычисление кода G-машины
E[hd(tl(from 1 ) )]гоО, используя дополнительные правила:
E[hd e]r n = E[e]r n; HD ; EVAL
и Е [ tl e]r n = E[e]r n; TL; EVAL
где HD и TL — примитивные макроинструкции head и.tail, опре-
деление которых очевидно; функция from описана в упражне-
нии 15.6. Покажите, как выглядят стек и граф в ходе вычис-
лений.
15.8. Применение Y-комбинатора после Х-удаления может быть
выражено в виде Yf, где
Y X! = D Х1( D Х|)
D х, х2 = Х](х2 х2)
Получите код для Y (в контексте г со стеком глубиной п)
и покажите, как он генерирует граф, представляющий выра-
жение f ( Y f).
Глава 16
СБОРКА МУСОРА
Одно из главных достоинств функциональных языков заклю-
чено в том, что они освобождают программиста от необходимо-
сти планировать размещение программы и данных в памяти
компьютера. Мы описываем типы данных на абстрактном уров-
не, не заботясь о том, как эти данные представлены внутри ма-
шины; это происходит автоматически. Например, для создания
структуры данных мы применяем функции конструкторов для
построения нового типа данных из уже существующих типов,
не имея представления о том, как и где этот новый объект бу-
дет создан. Далее, время жизни этих объектов также несуще-
ственно, с точки зрения программиста, и поэтому мы не обя-
заны предусматривать, в какой момент объект перестает быть
необходимым программе. За столь высокий уровень абстрагиро-
вания при использовании различных типов данных приходится
расплачиваться увеличенной сложностью использующейся под-
системы управления памятью. Для новых элементов данных ав-
томатически выделяется место в памяти, а старые, неиспользуе-
мые, автоматически удаляются для того, чтобы область хране-
ния не переполнялась при работе.
Сложность систем управления памятью в основном опреде-
ляется механизмом удаления неиспользуемых ячеек памяти. Он
обычно известен под названием сборки мусора, и в этой главе
мы рассмотрим наиболее широко используемые сборщики му-
сора и опишем среду, в которой они используются. Некоторые
из них ориентированы на минимизацию времени, необходимого
для очистки неиспользуемых областей памяти; другие нацелены
на минимизацию размеров требуемой памяти; третьи стараются
собрать полезные данные вместе, т. е. в соседние ячейки па-
мяти, и так повысить их локализованность в системах виртуаль-
ной памяти; еще одна группа сборщиков мусора предназначена
для систем с распределенной памятью, например в многопроцес-
сорных системах.
438 Часть II. Глава 16
Существуют три основных класса сборщиков мусора, а имен-
но сканирующий сборщик, копирующий сборщик, а также сбор-
щик, основанный на подсчете ссылок. Они описываются в
разд. 16.2—16.4. Перед этим, однако, мы посвятим разд. 16.1
обсуждению некоторых «типичных» способов организации па-
мяти, на которые будем ссылаться в последующих разделах.
16.1. Организация памяти
При прогоне функциональной программы генерируются раз-
личные структуры данных. В их число входят структуры, со-
здаваемые самой программой (такие как списки и деревья), и
структуры, порождаемые конкретной реализацией (такие как
Рис. 16.1. Возможные виды организации кучи, основанной на списках.
замыкания, задержки и графы функций). Эти структуры обычно
создаются в области памяти компьютера, называемой кучей.
В самом общем виде куча состоит из набора слов памяти.
Структуры данных, возникающие при прогоне программы, со-
стоят из наборов отдельных ячеек, которые в свою очередь
состоят из наборов слов кучи. Эти ячейки могут быть как
фиксированного размера, как структуры хранения списков
(рис. 16.1, а), так и переменного (рис. 16.1,6). На рис. 16.1, а
граница между ячейками проходит после второго слова; для
рис. 16.1,6 эта граница должна задаваться с помощью указания
размера ячейки в первом ее слове или, иначе, поместив в пер-
вое слово ячейки адрес начала следующей ячейки.
Преимущество основанной на списках кучи заключается
в том, что ей требуется более простая подсистема управления
памятью. Поскольку все ячейки имеют фиксированный размер,
Сборка мусора 439
то границы между ними легко определить. Недостатком являет-
ся то, что все структуры данных должны тогда храниться как
списки. Это может быть удобным для таких языков, как Лисп,
но менее подходяще для языков типа Норе, которые допускают
произвольно большие определенные пользователем кортежи и
термы конструкторов. Использование ячеек переменного раз-
мера и стандартных методов индексации позволяет сделать
время доступа к элементам кортежей постоянным, просматри-
вая весь список, чтобы найти требуемый элемент.
16.1.1. Нахождение сво'бодного пространства
Перед тем как разместить ячейку кучи, необходимо выяс-
нить, какие места в куче не используются в данный момент.
Один из возможных вариантов заключается в создании свобод-
ного, списка, который представляет собой цепочку пустых ячеек,
на начало которой указывает регистр свободного списка. На
Рис. 16.2. Свободные списки.
рис. 16.2, а показана основанная на списках куча и регистр сво-
бодного списка, указывающий на список свободных ячеек, свя-
занных между собой с помощью хвостового слова каждой ячей-
ки. Затушеванные ячейки в данный момент заняты. Если куча
поддерживает ячейки переменного размера, то можно создать
различные свободные списки — по одному для каждого размера
440 Часть II. Глава 16
ячейки. Рисунок 16.2,6 иллюстрирует это для ячеек размером
по 2, 5 и 4 слова. В общем случае мы будем иметь вектор ука-
зателей, в котором i-й элемент указывает на список свободных
ячеек i-ro размера.
Когда программе требуется свободная ячейка, то выбирается
соответствующий ее размеру свободный список и его первая
ячейка предоставляется для размещения данных. После этого
До размещения ячейки
Рис. 16.3. Организация кучи в виде только накапливающих стеков.
После размещения
ячейки оазмером п
значение использованного регистра свободного списка изменя-
ется— он будет указывать на следующую ячейку списка. Каж-
дая ячейка должна включать в себя величину своего размера
для того, чтобы вернуться в свой свободный список после вы-
полнения процедуры сборки мусора.
Вариантом, альтернативным использованию свободного спи-
ска, является организация кучи в виде стека, в который эле-
менты только проталкиваются, т. е. в котором новые ячейки
всегда помещаются на его вершину. Все составляющие ячейку
слова заносятся в кучу так, как и в обычный стек. Здесь необ-
ходим регистр (обозначим его Т.), который всегда указывает на
«вершину» уже размещенных ячеек. При заполнении новой
ячейки размером п ее слова занимают последовательные ад-
реса над Т, после чего регистр соответственно изменяется. Это
показано на рис. 16.3.
Все ячейки кучи можно разделить на три категории: исполь-
зуемые в данное время программой — это активные ячейки; за-
нятые, но не используемые программой — мусорные ячейки; не-
занятые ячейки — свободные. Задачей сборщика мусора является
обнаружение и освобождение мусорных ячеек, их эффективное
превращение в свободные ячейки.
Сборка мусора 441
Для определения того, какие ячейки активны, необходимо
проанилизировать состояние процесса вычислений. Это состоя-
ние может быть представлено как стеком вычислений (как в
SECD-машине), так и единственным указателем на высокоуров-
невую ячейку графа вычислений (как при использовании ре-
дукции графов) либо каким-нибудь иным образом. Текущее со-
стояние и, следовательно, набор активных ячеек характери-
зуются несколькими внешними по отношению к куче словами,
Рис. 16.4. Слова состояния и указатели кучи.
которые мы будем называть словами состояния. Набор актив-
ных ячеек будет состоять из тех ячеек памяти, которые адре-
суются через эти слова состояния вместе с теми ячейками, ко-
торые доступны через эти ячейки кучи. Эта ситуация проиллю-
стрирована на рис. 16.4, где представлена единственная куча и
набор слов состояния, часть из которых указывает на ячейки
кучи.
Каждое слово состояния и каждое слово кучи может содер-
жать либо атом (т. е. целое число, символ и т. п., но не указа-
тель), либо указатель на ячейку кучи. Для нахождения свобод-
ных ячеек необходимо иметь возможность отличать атом от
указателя. Обычно это делается с помощью метки в каждом
слове. Различными метками можно пометить числа, символы,
булевы константы, указатели и т. п., но для сборщика мусора
важно лишь отличать атомы от указателей. Для этой цели мы
отведем один бит в каждом слове, который для атомов будет
равен 0, и 1 —для указателей.
Итак, процесс сборки мусора состоит из:
1) обнаружения тех ячеек, которые являются мусором, и
2) подготовки этих ячеек для последующего использования.
442 Часть II. Глава 16
Этот процесс может быть либо прерывистым, либо постоян-
ным: прерывающий сборщик мусора требует приостановки про-
цесса пользователя, а непрерывный сборщик позволяет вести
эти процессы параллельно. По понятным причинам первый на-
зван старт/стоп сборщиком, а второй — параллельным сборщи-
ком, или сборщиком реального времени.
16.2. Сканирующая сборка мусора
Для того чтобы в основном описать работу сканирующего
сборщика мусора, предположим, что у нас есть единственная
куча, основанная на списках, а регистр свободного списка ука-
зывает на начало цепочки свободных ячеек.
Предположим, что свободный список оканчивается пустым
указателем, т. е. указывающим на несуществующую ячейку по
адресу 0. Создание новой ячейки происходит при помощи реги-
стра свободного списка F, который затем изменяется для того,
чтобы указывать уже на следующую ячейку в цепочке. Если
при попытке размещения оказывается, что F равен нулю, то
это означает, что свободный список пуст и необходимо инициа-
лизировать сборщик мусора для того, чтобы из совокупности
всех мусорных ячеек создать новый свободный список. Если же
при этом не удается обнаружить ни одной мусорной ячейки, то
это означает, что резервы памяти полностью исчерпаны и про-
грамму следует прервать.
Алгоритм создания новых ячеек, который присваивает адрес
новой ячейки свободного списка переменной N, может быть не-
формально выражен так:
if F = 0 then сборка мусора;
N:=F; F:=tail(F)
Заметьте, что tail (F) дает адрес следующей свободной ячейки
свободного списка. Императивный характер описываемых в этой
главе алгоритмов отражает тот факт, что сборщик мусора яв-
ляется частью абстрактной машины, лежащей в основе реали-
зации; примитивные операции абстрактной машины всегда по
своей природе императивны, поскольку они влияют на ее со-
стояние.
При запуске сборщика мусора последовательно проверяется
каждое слово состояния. Если оно является указателем на
ячейку кучи, то адресуемая им ячейка маркируется, что гово-
рит о том, что она — активная ячейка. Этот процесс рекурсивно
повторяется для головы и хвоста ячейки. Если встреченная при
этом ячейка уже промаркирована, то этот процесс прекра-
' Сборка мусора 443
щается, поскольку все ячейки, в которые можно попасть из те-
кущей, уже промаркированы. Аналогично процесс будет прекра-
щен, если встречена ячейка-атом. После того как будут прове-
рены все слова состояний, все активные ячейки в куче окажутся
промаркированы, а мусорные, с другой стороны — нет. После
этого на фазе сканирования (называемой еще фазой сборки)
исследуются все ячейки кучи и строится новый свободный спи-
сок из тех ячеек, которые остались немаркированными на фазе
маркирования.
Для поддержки возможности маркирования в каждую ячей-
ку, как правило, включают дополнительный маркирующий бит.
Заметьте, что в отличие от битов меток, позволяющих отличать
атомные ячейки от указателей, маркирующий бит присваи-
вается ячейке в целом.
По мере сканирования ячеек и построения свободного спи-
ска необходимо изменять значение маркирующего бита в рас-
чете на последующие применения сборщика мусора в будущем.
Неформальное описание алгоритма маркирования будет вы-
глядеть так:
Для маркирования ячейки С:
if С еще не маркирована
then begin
установить маркирующий бит С в 1 ;
if первое слово С — указатель
then маркировать ячейку, -адресуемую -первым сло-
вом С;
if последнее слово С является непустым указателем
then маркировать ячейку, адресуемую последним сло-
вом С
end
Фаза сканирования заключается в построении нового сво-
бодного списка и установки всех маркирующих битов в 0:
Сделать свободный список пустым;
Для каждой ячейки кучи:
if маркирующий бит равен 1
then установить маркирующий бит в 0
else добавить ячейку к свободному списку;
Одна из проблем, возникающих при фазе маркирования, за-
ключается в рекурсивном просмотре всех активных ячеек. Спо-
собы реализации рекурсии достаточно просты, даже если сбор-
щик мусора создавался на уровне машинных кодов. Основная
проблема заключается в том, что для этого требуется дополни-
тельная память — для стека рекурсии. Размер этого стека
444 Часть II. Глава 16
должен быть по крайней мере не меньше, чем размер наибольшей
структуры кучи, который ограничен лишь общим объемом кучи.
Однако вспомним, что в гл. 11 мы говорили о том, что можно
просмотреть все вершины графа, используя перестановку ука-
зателя лишь с двумя регистрами FORE и AFT; этот же способ
можно применить для сканирования активных ячеек. Это позво-
лит избежать необходимости использования стека рекурсии.
Хотя реализация сканирующего сборщика мусора проста,
эта схема обладает тремя недостатками. Во-первых, поскольку
Ячейка
Немаркированная ячейка
Рис. 16 5. Формат маркирующего бита.
Ячейки
Маркированная ячейка
это старт/стоп сборщик, то необходимо время от времени пре-
рывать процесс пользователя. Это может быть незамеченным
для систем, работающих в пакетном режиме, но в системах
реального времени и в интерактивных системах такие паузы
в выполнении программы могут быть, заметны. Во-вторых, все
активные ячейки просматриваются дважды (вначале в фазе
маркирования, а затем в фазе сканирования), а все мусорные —
один раз (для создания свободного списка), это приводит к ро-
сту времени исполнения. И в-третьих, результатом является
свободный список, т. е. структура, ячейки которой произвольно
разбросаны по куче. Это не вызывает затруднений в системах
с реальной памятью, хотя и теряются преимущества хэширова-
ния. В системах с виртуальной памятью, однако, подобная фраг-
ментация не позволит локализовать ячейки одной структуры и
может привести к «молотилке», т. е. излишнему своппингу стра-
ниц памяти. Однако сканирующий сборщик может обрабаты-
вать циклические структуры данных, что является существен-
ным требованием ро многих реализациях, например в редукции
графов, при которой для осуществления рекурсии используются
циклические указатели.
16.3. Копирующие сборщики мусора
Как мы упоминали выше, главным недостатком сканирую-
щего алгоритма является то, что он фрагментирует кучу, рас-
пределяя в ней активные ячейки некоторым случайным обра-
Сборка мусора 445
зом. В копирующем же сборщике основной упор делается на
то, чтобы собрать вместе активные ячейки в некоторой области
памяти, оставляя свободное пространство в виде непрерывного
блока памяти. Это приводит к тому, что последовательные
ячейки располагаются по последовательным адресам кучи, что
помогает локализовать соседние ячейки структур данных внутри
кучи. Подобная локализованность очень важна в том случае,
если целевая машина использует виртуальную память.
В этом разделе мы опишем четыре типа копирующих сбор-
щиков: первый делит кучу на два подпространства и поочередно
перемещает активные ячейки из одного в другое. Второй яв-
ляется развитием этой схемы, позволяющим сборщику и про-
цессу пользователя протекать квазипараллельно. Третья схема
в свою очередь является оптимизированной версией второй.
Четвертый алгоритм выполняет то же самое, но использует лишь
одно неделимое пространство кучи.
16.3.1. Двухпространственная схема
В целях общности предположим, что куча содержит ячейки
переменного -размера, и каждая ячейка содержит поле размера,
указывающее, сколько слов содержится в ней. Разделим кучу
на две равные по размеру области. Будем называть их
SPACE 1 и SPACE2. Адреса нижнего и верхнего слов в каждой
области обозначим TOPI, BASE1, ТОР2 и BASE2 соответствен-
но. (Мы вводим эти четыре адреса только для удобства; TOPi
легко вычислить, зная BASEi и размер области.) В ходе ра-
боты программы все новые ячейки размещаются в одной из
двух областей; эта область называется текущей, а другая —
следующей областью. Граничные адреса текущей области обо-
значим CURTOP и CURBASE, а граничные адреса следующей
области —NEXTTOP и NEXTBASE.
Текущая область работает как стек, в который элементы
только проталкиваются; каждая новая ячейка помещается на
верх непрерывного блока активных ячеек, а доступ к ним про-
исходит не с помощью операции выталкивания, а с помощью
указателей. Адрес верхней текущей ячейки в текущей области
хранится в регистре Т. Условимся в будущем рисовать кучу
так, чтобы она росла на листе бумаги вверх и в сторону мень-
ших адресов памяти; помещение новых ячеек в кучу приводит
к уменьшению Т. В тот момент, когда остающейся свободной
части области недостаточно для размещения новой ячейки, про-
исходит инициация сборщика мусора. Этот момент может быть
зафиксирован путем сравнения Т и CURTOP перед размеще-
нием каждой новой ячейки, однако в нашем рассмотрении мы
446 Часть II. Глава 16
подпространство
Рис. 16.6. Организация кучи в виде двух подпространств.
Следующее
подпространство
предполагаем, что существует дополнительный регистр (NEW),
который содержит количество свободных слов в текущей обла-
сти. Эта ситуация показана на рис. 16.6.
При размещении новой ячейки ее слова последовательно за-
носятся в текущую область, а регистр Т уменьшается. Но перед
тем, как это будет сделано, мы должны проверить, достаточно
ли над Т места. Если ячейка содержит N слов, то следует вы-
полнить следующее:
NEW := NEW - N ;
if NEW < 0 then собрать мусор
При сборке мусора сборщик проходит по словам состояния
и находит ссылки на активные ячейки. Однако вместо простого
маркирования их, как в сканирующем сборщике, содержимое
этих ячеек физически переносится в другую область. При этом
текущая область называется FROMSPACE, а другая —
TOSPACE. Здесь требуется второй указатель (Т') для адреса-
ции верхнего слова в TOSPACE; перед началом цикла копиро-
вания он приравнивается к NEXTBASE и увеличивается каж-
дый раз, когда новое слово заносится в TOSPACE. При этом
первое слово в старой копии каждой ячейки и величина исход-
ного указателя на каждую перемещенную ячейку изменяются
так, чтобы указывать теперь на новое положение ячейки в
TOSPACE. Адрес, хранящийся теперь перед началом старой
копии ячейки, называется ведущим адресом, или невидимым
указателем, и используется для изменения всех ссылок на эту
ячейку, которые могут встретиться. В этом случае они будут
заменены на ведущий адрес, т. е. адрес новой копии ячейки.
Сборка мусора 447
Переме -
щаемая
ячейка
Рис. 16.7. Перемещение ячейки.
Так обеспечивается корректность системы ссылок при сборке
мусора, но для этого необходимо уметь отличать ведущий ад-
рес от слов другого типа, а это требует дополнительной метки
(один бит) в первом слове каждой ячейки, аналогично марки-
рующему биту в сканирующем сборщике. На рис. 16.7 пока-
заны состояние кучи и слово состояния W до и после того, как
ячейка размером N была скопирована в TOSPACE.
После того как ячейка скопирована, производится измене-
ние ссылок на все ячейки, связанные с данной, путем рекурсив-
ного инициирования сборщика аналогично тому, как это про-
исходит в сканирующем сборщике, и при этом столь же успешно
448 Часть II. Глава 16
применяется метод реверсирования указателей. В разд. 16.3.2
мы рассмотрим метод, позволяющий избежать подобной ре-
курсии.
Неформальное описание сборщика состоит в следующем:
Для сборки мусора:
Для каждого слова состояния S:
TRACE S
Что,бы выполнить операцию TRACE W:
if W — указатель на ячейку С
then if — первое слово С — ведущий адрес F
then W := F
else COPY С
Чтобы выполнить операцию COPY С :
протолкнуть все слова С в TOSPACE;
W:=T';
первое слово С (в FROMSPACE) :=| Т';
для каждого слова Wz в С:
TRACE W'
Заметьте, что f А обозначает ведущий адрес к ячейке под
номером А, т. е. это соответствующим образом помеченный
адрес А.
По завершении сборки мусора все активные ячейки из
FROMSPACE будут находиться в TOSPACE. Область над
этими ячейками образует новое свободное пространство. Коли-
чество свободных слов в этой области теперь заносится в NEW
(оно легко вычисляется по последнему значению Т' и
NEXTTOP), после чего происходит своппинг двух областей:
NEW := Т'— NEXTTOP
Т:=Т'
Поменять местами NEXTBASE и CURBASE
Поменять местами NEXTTOP и CURTOP
Заметьте, что, помимо преимуществ компактного хранения
данных, число обращений к каждой активной ячейке сократи-
лось от 2 в сканирующем сборщике до 1 здесь. Заметьте также,
что обращения к мусорным ячейкам в FROMSPACE вообще
не происходит. Другими словами, время сборки мусора по та-
кой схеме зависит только от количества слов состояния и ак-
тивных ячеек. Цена, которую приходится платить за все, — это
увеличенный объем требуемой памяти. Куча должна быть ровно
вдвое больше, чем в сканирующей схеме, а степень использова-
ния памяти никогда не может быть выше 50%. Запомним, од-
нако, что этот сборщик гораздо лучше подходит для систем
с виртуальной памятью, так что на практике требования допол-
Сборка мусора 449
нительной памяти могут и не вызывать серьезных осложнений.
Одним из основных недостатков этого алгоритма является то,
что он, как и сканирующий, является старт/стоп-сборщиком,
требующим прерывать процесс пользователя. В следующем раз-
деле мы опишем алгоритм Бэйкера, который, несмотря на то
что похож на этот, обладает тем преимуществом, что допускает
одновременное выполнение процесса пользователя и сборки
мусора.
16.3.2. Алгоритм Бэйкера [/2] ’>
Как и в предыдущем сборщике, куча делится на две обла-
сти. Работа процесса пользователя происходит обычным обра-
зом до того момента, пока одна из областей не заполнится,
тогда включается сборщик мусора. В отличие от предыдущего
алгоритма, где сборщик после запуска выполняет работу пол-
ностью, теперь он перемещает фиксированное число ячеек (к),
а затем передает управление основной программе обработки.
Когда при этом программе понадобится разместить новую ячей-
ку (например, после вызова CONS), то перед этим будут пере-
мещены другие к ячеек. Такое частичное перемещение, совмест-
ное с процессом пользователя, будет продолжаться до тех пор,
пока все активные ячейки FROMSPACE не будут переброшены
в TOSPACE, после чего работа по программе пользователя
продолжается дальше до тех пор, пока новая область не пере-
полнится. В неформальном виде алгоритм будет выглядеть так:
Для размещения ячейки:
if сборщик мусора не работает
then if есть место then разместить ячейку else включить
сборщик;
if сборщик мусора работает
then переместить к ячеек (или все оставшиеся, если их число
меньше к);
предоставить место новой ячейке;
if все ячейки перемещены then остановить сборщик
Действуя по этой схеме, процесс пользователя может встретить
ссылку на ячейку FROMSPACE до того, как она была пере-
мещена. Доступ к таким ячейкам, однако, возможен лишь для
примитивных функций типа head, tail, index и т. п., поэтому мы
можем создать иллюзию того, что они уже в TOSPACE, пере-
мещая их при каждом нахождении. Если результатом приме-
нения этих примитивов также является ссылка на ячейку, то
*> Рассматриваемый здесь сборщик мусора является на самом деле не-
ким обобщением предложенного Бэйкером сборщика. Их принципы, однако,
по существу одинаковы.
29 — 1473
450 Часть II. Глава 16
она также должна быть перемещена, а ее новый адрес (в
TOSPACE) возвращен в исполняемую программу. Это создает
иллюзию того, что все активные ячейки реально перемещены
в TOSPACE после начального вызова сборщика мусора. Сле-
довательно:
Для получения хвоста ячейки С1:
if работает сборщик мусора
then if Cl находится в FROMSPACE
then переместить Cl в TOSPACE
if ячейка Cl связана с ячейкой С2 в FROMSPACE
then переместить С2;
возвратить хвост С1
Аналогичные действия производятся для head, index и т. п.
При инициализации сборщика мусора он вначале производит
своппинг двух областей и устанавливает Т' таким, чтобы каж-
дая новая создаваемая программой ячейка размещалась бы
в TOSPACE, т. е. области, противоположной той, которая ис-
пользовалась до инициализации сборщика. Эта операция на-
зывается FLIP. После нее в словах состояния ищутся ссылки
на кучу. При обнаружении такой ссылки указываемая ячейка
перемещается в TOSPACE, а ведущие адреса заносятся, как
и прежде, в старую копию ячейки. В отличие от предыдущего
сборщика, однако, потомки перемещенных ячеек сразу не про-
слеживаются. Вместо этого вводится второй указатель S для
сканирования слов в TOSPACE снизу вверх (т. е. в направле-
нии размещения) с одновременным перемещением тех ячеек
FROMSPACE, которые связаны с TOSPACE. Таким образом,
сдвигаются все ячейки между S и Т', но их компоненты пока
еще остаются неизменными. Это будет сделано лишь тогда,
когда указатель S, поднимаясь вверх по TOSPACE, достиг-
нет Т'. При этом все ячейки ниже S будут перемещены, по-
скольку будут иметь всех своих прямых потомков Если S < Т',
то можно утверждать, что все активные ячейки из FROMSPACE
уже перемещены в TOSPACE и что во FROMSPACE содер-
жится лишь мусор. Таким образом, утверждения «все ячейки
перемещены» и «перемещено к ячеек» означают следующее:
все ячейки перемещены -> S < Т'
перемещено к ячеек —► итерация := 1 ;
while S^T' and итерация ^k do
if слово, адресуемое S, указывает на С
then переместить С;
итерация:—итерация Ц-1;
S :=S - 1
end
Сборка мусора
451
Использование подобным образом S и Т' позволяет
избежать рекурсивного вызова сборщика. Суть того, что
происходит в этом варианте сборщика, заключается в том,
что мы используем FROMSPACE как очередь в сборщике,
а не создаем отдельную буферную область хранения типа
стека сборщика (см. выше). По этой причине при пе-
реносе содержимого FROMSPACE в TOSPACE происходит
копирование в ширину, а не в глубину, как в рекурсивном
сборщике.
Подводя итоги, рассмотрим на рис. 16.8 три примера того,
как может переместиться ячейка С2. Необходимость сдвинуть
С2 может возникнуть в одном из трех случаев: во-первых, вы-
полняемой программе потребуется проиндексировать ячейку С1,
которая содержит ссылку на С2 (рис. 16.8, а), во-вторых, если
обнаружена ссылка на С2 при просмотре слов состояния после
операции FLIP (рис. 16.8,6) или, в-третьих, регистр сборщика
обнаружил ссылку на С при просмотре TOSPACE (рис. 16.8,в).
На рис. 16.8, г—е показаны состояния памяти, соответствую-
щие ситуациям на рис. 16.8, а — в соответственно после пере-
мещения ячейки С2.
Итак, произошло размещение всех новых ячеек в TOSPACE.
Это приводит к тому, что новые ячейки перекрываются со ста-
рыми, перемещенными сборщиком. Если при сканировании
TOSPACE регистр S обращается к такой новой ячейке, то ни-
чего существенного не произойдет, поскольку любой указатель
в этих ячейках будет указывать на новую ячейку, либо на ячей-
ку, которая уже была перемещена в TOSPACE. Это означает,
что для регистра S совсем необязательно проходить по этим
ячейкам и что это, с другой стороны, лишь замедляет сборку
мусора. Эта неоптимальность может быть устранена размеще-
нием всех новых ячеек на верхнем конце кучи, т. е. сверху вниз,
навстречу Т'. Это потребует ввести новый указатель ТОР на
текущую вершину свободной области. Он будет увеличиваться
каждый раз при размещении новой ячейки в этой области. Эта
ситуация показана на рис. 16.9.
Предположив теперь, что процесс пользователя и сборщик
располагают новые ячейки в TOSPACE перекрестным образом,
мы можем поинтересоваться, насколько велика должна быть
область TOSPACE, чтобы не произошло ее переполнение при
переносе ячеек из FROMSPACE. И наоборот, можно попробо-
вать определить, насколько велико может быть к для кучи дан-
ного размера, чтобы обеспечить то же самое.
Для простоты предположим, что размеры всех ячеек одина-
ковы и что после обмена областей в наличии оказалось N
'29*
452 Часть IJ. Глава 16
Рис. 16.8. Перемещения ячейки.
Свободно
Рис. 16.9. Размещение новых ячеек на вершине стека.
Сборка мусора 453
г де
Рис. 16 8 (Продолжение.)
доступных ячеек. Это означает, что при сборке мусора из обла-
сти FROMSPACE в TOSPACE было передвинуто N ячеек и N/k
ячеек (округленно до большего целого) было заново создано
процессом пользователя: заметьте, что размещение каждой но-
вой ячейки вызывает перемещение к активных ячеек в
TOSPACE. Это требует, чтобы объем одной области был
N + N/k ячеек, а всей кучи 2N ( 1 + 1/к) ячеек. Например, если
при введении одной новой ячейки перемещается одна старая
(т. е k= 1), то размер кучи должен быть 4N. С увеличением к
эта величина уменьшается. И с другой стороны, если максималь-
ное количество ячеек, необходимое программе, будет N, а каж-
дая область содержит М ячеек, то к должен быть не менее
N/(M — N).
454 Часть II. Глава 16
16.3.3. Фрагментированная куча
Очевидным недостатком предыдущих двух алгоритмов яв-
ляется то, что в каждый момент используется не более 50 %
пространства кучи. Кроме этого, при каждом цикле сборки
мусора перемещаются все активные ячейки. Одна из важных
эмпирических закономерностей позволяет утверждать, что
<наиболее «молодые» ячейки кучи содержат большую часть мусора)
или, другими словами, чем старше ячейка, тем выше вероят-
ность того, что она остается активной.
Такое предложение позволяет избежать основных недостат-
ков алгоритма Бэйкера путем деления кучи на большее, чем
два число областей с тем, чтобы производить сборку мусора
сразу для всей такой области, а более «молодые» области очи-
щать чаще, чем «старые» [60].
Таким образом, куча делится на к одинаковых областей, из
которых к—1 являются активными, а оставшаяся запасная
требуется для перемещения ячеек. Каждая область обладает
номером поколения, указывающим, как давно она стала исполь-
зоваться, т. е. когда выполняемая программа впервые начала ее
использовать. Чем выше номер поколения, тем моложе область.
Суть метода заключается в том, чтобы производить очистку
молодых областей (относительное количество мусора в которых
выше, чем в старых) более чаще, чем старых. Очистка состоит
в перемещении активных ячеек в запасную ячейку так, как
и в алгоритме Бэйкера. Функция частоты очистки определяет,
какая область будет очищена следующей, т. е. какую область
принять как следующую FROMSPACE. Так, мы можем очищать
область g вдвое чаще, чем область g—1, и т. д. Можно снаб-
дить каждую область еще одним параметром-номером версии,
который будет увеличиваться каждый раз при очистке области
в то время, как номер поколения остается при этом неиз-
менным.
Реализация этой схемы была бы достаточно очевидной, если
бы не тот факт, что не исключены ссылки на ячейки в
FROMSPACE из других областей кучи. В этом случае нам по-
может следующее эмпирическое наблюдение:
(большинство ссылок между областями приходится на старые области}.
Это говорит о том, что в большинстве случаев указатели связей
новой ячейки будут указывать на уже существующие ячейки.
Для того чтобы избежать просмотра всех старых областей, мы
создадим для каждой области таблицу входов, содержащую
полный набор указателей, входящих в эту область связей. (Все
указатели из старших областей указывают на .элементы кучи
Сборка мусора 455
Rk
Рис. 16.10. Таблицы входов.
через эти входные таблицы, что приводит к промежуточной
косвенной адресации в программе пользователя.) Теперь в
число областей, которые необходимо полностью просмотреть
в поисках указателей на очищаемую область, входят лишь мо-
лодые области. Поскольку молодые области очищаются чаще,
чем старые, то число областей, более молодых, чем очищаю-
щая, будет в среднем невелико. На рис. 16.10 показаны область
Rk и ее таблица входов Es (ниже мы увидим, что таблица вхо-
дов может перемещаться между областями, так что j и к не
обязательно должны быть равны).
Ведущие указатели f j, f2, ..., fn из старых областей направ-
лены в Rk через таблицу входов Ej. Теперь при очистке области
Rk по алгоритму Бэйкера для перемещения активных ячеек из
Rk в запасную область Rs необходимо лишь изменить указа-
тели в таблице Ej для необходимого изменения всего набора ве-
дущих ссылок.
По завершении перемещения Rk становится запасной об-
ластью. Таким образом, необходимо как-то зафиксировать тот
факт, что таблица входов Е, связана теперь с Rs, а не с Rk,
т. е. надо ввести таблицу, указывающую для каждой таблицы
входов, с какой из областей она связана. Такое использование
этих таблиц позволяет никогда не изменять внешние ведущие
ссылки fi, f2, ..., fn.
Этот метод создает лишь одну трудность: надо решить, на-
сколько велики должны быть таблицы входов. Изящное ре-
шение этой проблемы заключается в расположении таблицы
456 Часть П. Глава 16
m п
Рис. 16.11. Таблицы входов в виде стеков.
входов внутри самой области в форме стека, растущего от вер-
шины области вниз; ячейки же располагаются внизу области
[28]. Из-за того что таблица входов больше уже не отделена
от области кучи, она сможет автоматически перемещаться вме-
сте с ячейками этой области при ее чистке. Следовательно, те
ячейки старших областей, которые связаны указателями с таб-
лицей входов очищаемой области, тоже должны быть изме-
нены, для чего таблица входов должна содержать обратные
указатели на эти старшие ячейки. Это требует, чтобы каждый
элемент таблицы входов содержал бы два указателя: один,
указывающий внутрь очищаемой области, и второй — на ячейки
старшей области. Рис. 16.11 иллюстрирует это. На нем изобра-
жены область m и ведущие указатели из области п, указываю-
щие на таблицу входов области п.
Что может произойти в худшем случае? Область наполнится
активными ячейками, каждая из которых доступна из старшей
области, и поэтому в таблице входов должно быть столько же
элементов вход/выход, сколько ячеек содержится в области.
Например, если каждая ячейка состоит из двух слов и если
емкость области должна быть N ячеек, то общий размер об-
ласти должен быть 4N слов.
16.3.4. Алгоритм Морриса
В предыдущих разделах мы рассмотрели, как может быть
достигнуто сжатие за счет перемещения активных ячеек кучи
Сборка мусора 457
Рис. 16.12. Влияние алгоритма Морриса.
из одной области кучи в другую, «запасную область». Основ-
ной целью алгоритма сборки мусора Морриса является прове-
дение такого сжатия для той же самой области, где в данный
момент расположены активные ячейки [68].
Для лучшего представления о том, как происходит работа
по этому алгоритму, рассмотрим кучу до и после его примене-
ния. На рис. 16.12 представлена простая ситуация, в которой
два внешних указателя (слова состояния) указывают на две
структуры кучи с общими потомками и циклическим указа-
телем.
Заметьте, что после проведения сжатия направление всех
указателей сохраняется, т. е. если С1 выше С2 до сжатия, то
это же сохранится и после сжатия. Суть же того, что происхо-
дит здесь, заключается в устранении «мусорных ям» (на
рис. 16.12, а они выделены серым цветом) и в монолитной ком-
поновке активных ячеек в основании кучи.
Для осуществления этого для каждой данной ячейки необ-
ходимо знать все ее связи с другими ячейками, которые ссы-
лаются на нее для изменения всех указателей после перемещения
ячейки С. Задача здесь заключается в том, чтобы не использо-
вать дополнительную память (кроме небольшого количества
регистров). Для этого опять воспользуемся методом обработки
указателей, описанным в гл. 11. Предположим, что мы имеем си-
туацию, представленную на рис. 16.13, а. Ячейки А, В и С
458 Часть II. Глава 16
связаны с общей ячейкой S, содержащей в своем первом слове
элемент 1. Для запоминания всех ячеек, указывающих на S,
мы перевернем все указатели и сформируем цепочку, в которой
1 будет находиться в самом конце (рис. 16.13,6). Обратите
Рис. 16 13. Обращение указателя.
внимание, что при этом преобразовании не происходит потери
информации.
Осуществить это довольно просто: при обнаружении указа-
теля, как на рис. 16.14, а, мы «переворачиваем» его, занося
Рис. 16.14. Обращение одного из указателей.
содержимое адресуемой ячейки в ячейку указателя и записы-
вая адрес ячейки указателя в адресуемую (в прошлом) ячейку
(рис. 16.14,5). Заметьте, что для определения начала и конца
обратного указателя необходимо снабдить каждый такой ука-
затель дополнительной меткой из одного бита. Этот способ
маркировки представлен на рис. 16.14 затемненным треуголь-
ником внутри поля указателя. Заметьте также, что обратный
указатель указывает на отдельное слово внутри ячейки, а не
на ячейку в целом. Благодаря этому можно построить не-
Сборка мусора 459
сколько различных цепочек указателей так, чтобы разные
цепочки «проходили» бы через разные слова одной и той же
ячейки.
При работе сборщика мусора в фазе сборки предполагается,
что все активные ячейки были предварительно отмечены указа-
телями на них от слов состояния. В фазе маркирования под-
считывается общее число слов в активных ячейках (обозначим
Рис. 16.15. Взаимодействие ведущего и возвращающего указателей.
слов мусора G — путем простого вычитания А из общего раз-
мера кучи. Цель заключается в том, чтобы использовать G для
вычисления окончательного адреса каждой ячейки после их
перемещения. Если самое верхнее слово кучи находится по
адресу Т, то первая ближайшая к Т активная ячейка будет
оканчиваться по адресу Т + G, а следующая — по адресу
T + G4-S1 (где Si — размер первой активной ячейки), третья
аналогично— по адресу Т + G + Si + S2 и т. д.
Дальнейшая работа после того, как все активные ячейки
подсчитаны и промаркированы (как в сканирующем сборщике),
происходит в две фазы. В первой фазе все ведущие ссылки
(т. е. ссылки на ячейки, располагающиеся в куче ниже указа-
теля) заменяются адресами этих ячеек. Во второй фазе та же
операция производится с возвращающими указателями (т. е.
ссылки на ячейки, находящиеся выше, чем указатель), а ячей-
ка перемещается в свое окончательное положение. Для того
чтобы понять, почему необходимо сделать два отдельных «про-
хода» для изменения этих ссылок, рассмотрим ситуацию на
рис. 16.15, а и посмотрим, что может произойти, если попы-
таться сделать это только за один «проход».
460 Часть И. Глава 16
Встретив ссылку на ячейку С2, создадим новый обратный
указатель (см. рис. 16.15,6). Когда мы достигаем возвращаю-
щего указателя на ячейку С1, то аналогично формируем другой
обратный указатель, как показано на рис. 16.15, в. Может по-
казаться, что все ссылки ведут к С2, что, очевидно, неверно.
Трудность заключается в том, что мы создали обратный ука-
затель на слово, являющееся концом уже существующей це-
почки обратных указателей. Введение нового указателя приво-
дит к расширению исходной цепочки указателей, чего следует
избегать. Именно поэтому сборщик и должен работать-в два
этапа, чтобы не создавать обратных указателей на те ячейки,
которые уже были обработаны.
При первом прохождении вниз по куче мы опять подсчи-
тываем количество слов в активных ячейках по мере их обра-
ботки для того, чтобы определять окончательный адрес каждой
встречной ячейки (вспомним, что нам требовалось знать раз-
меры ячеек Si, S2, ..., или, точнее, общий размер ячеек Si +
+ S2 + ..., для подсчета этих адресов, что совершенно экви-
валентно тому, что дает подсчет слов активных ячеек, или
активных слов). Итак, если мы встречаем обратный указатель,
а число активных слов равно N, то все слова в цепочке обрат-
ных указателей должны быть заменены новым адресом Т +
+ G -|- N. Затем последнее слово цепочки обратных указателей
(узнаваемое по отсутствию установленного бита метки обрат-
ного указателя) заменяет первое слово этой цепочки. Если это
перемещение происходит для восстановления исходного поло-
жения другого ведущего указателя, то требуется дальнейшее
обращение указателей. На рис. 16.16 показан простой пример,
иллюстрирующий это.
Вначале имеется ячейка С1, связанная с двумя другими,
а ее первое поле указывает на ячейку С2, находящуюся в куче
ниже ее (рис. 16.16, а). Сборщик проходит по куче сверху
вниз и, встретив первую ссылку на С1, начинает создавать це-
почку обратных указателей (рис. 16.16,6). Когда находится
вторая ссылка на С1, то эта цепочка удлиняется (рис. 16.16,в).
Каждый раз, когда мы проходим через маркированное слово,
мы увеличиваем счетчик активных слов. Теперь предположим,
что, когда мы достигли первого слова в ячейке С1, значение
этого счетчика было равно N. Это говорит о том, что оконча-
тельное положение ячейки С1 будет по адресу Т + G + N. По-
этому, найдя в С1 обратный указатель (помеченный темным
треугольником), мы проходим по цепочке указателей, помещая
новый адрес Т + G + N в каждом ее слове. Этот процесс за-
вершится, когда мы достигнем слова, не содержащего уста-
новленного бита обратного указателя (клетка без темного тре-
Сборка мусора 461
Рис. 16.16. Демонстрация работы алгоритма Морриса.
угольника). Это поле заменяет первое слово в цепочке, а само
заменяется адресом T4-G + N. Так мы приходим к ситуации
на рис. 16.16, г. Завершая это рассмотрение, заметим, что эти
перемещения восстанавливают исходный указатель из С1 в С2.
Поскольку этот указатель является ведущим, мы должны на-
чать новую цепочку обратных указателей, и поэтому описанный
процесс возобновляется. Это показано на рис. 16.16, д. Этот
462 Часть II. Глава 16
алгоритм прямого поиска может быть неформально представ-
лен так:
N:=0; W := адрес первого слова кучи;
while W адрес последнего слова кучи do
if Wf помечена как активная
then if Wf есть .ведущий указатель Р
then t:=P*; {начать цепочку обратных указателей}
P}:=*-W;
W:== W + 1
else if Wf есть обратный указатель
then цепь (W, T-J-G + N, W);
N:=N+ 1
else W:=W+ 1
end
Здесь Af обозначает величину по адресу А,' а -*-А обозна-
чает обратный указатель на А (т. е. указатель, соответствую-
щая которому клетка на рисунке помечена темным треугольни-
ком). Оператор цепь (С, A, W) образует цепочку обратных
указателей, начинающуюся в С, устанавливает каждое слово
в цепочке равным А и заменяет слово по адресу W последним
значением в этой цепочке:
цепь (С, A, W) =
if Cf является обратным указателем
then next := Of ;
Cf :=А;
цепь (next, A, W)
else W := Cf
После завершения прохода от вершины кучи к ее основа-
нию этот процесс повторяется снова, на этот раз в противопо-
ложном направлении, для обработки возвращающих ссылок.
При этом осуществляется перемещение активных ячеек. Как
и прежде, работает счетчик активных ячеек, но на этот раз он
используется для перемещения ячеек в их новое положение.
Вначале значение счетчика равно А (общее количество актив-
ных ячеек) и уменьшается на единицу после обработки каждого
активного слова. Каждое активное слово перемещается на свое
новое место Т-(-G-f-N (где N — текущее значение счетчика).
После этого должны быть сформированы все цепочки обратных
указателей, начинающиеся с этого слова (это гарантирует, что
новая копия ячейки будет изменена, когда эта цепочка будет
наконец «раскручена»). По завершении второго прохода все
активные ячейки будут сгруппированы на дне кучи, а все ука-
Сборка мусора 463
затели установлены соответствующим образом. Алгоритм об-
ратного прохода неформально может быть описан так:
N:=A; W := адрес последней ячейки кучи
while W адрес первой ячейки кучи do
if Wt является активной
then копировать на адрес Т + G N ;
if Wf является возвращающим указателем Р
then (Т + G + N )f := Pf
pf ;= <-( Т + G + N );
W:=W— 1
else if Wj является обратным указателем
then цепь (W, T + G + N, W)
N:=N- 1
else W:=W — 1
end
Обратите внимание, что когда мы говорим «обратный ука-
затель», то подразумеваем под этим тот указатель, направле-
ние которого противоположно направлению движения при про-
ходе по куче.
Цена, которую приходится платить за этот вид сжатия дан-
ных, состоит в необходимости двух проходов по куче (сканиро-
вание как активных, так и «мусорных» ячеек), а также в час-
тичном поиске в куче активных ячеек для их маркировки.
Вследствие этого затраты времени здесь заметно больше, чем
в предшествующих копирующих сборщиках. Кроме этого, в
данном случае неприменим алгоритм Морриса в реальном вре-
мени, поскольку для прикладной программы, пока не окончи-
лась сборка всего мусора, не предоставляется место в куче для
расположения новых ячеек. Но с другой стороны, для некото-
рых вариантов реализации языка важным обстоятельством мо-
жет явиться то, что после сборки мусора порядок следования
активных ячеек остается неизменным.
16.4. Сборщики мусора с подсчетом ссылок
В рассмотренных нами сборщиках мусора поиск и обра-
ботка активных ячеек происходили в ходе процесса, логически
отделенного от процесса пользователя. Сканирование кучи на-
чинается от слов состояния и идет дальше по связывающим
указателям. Существующая альтернатива подобной двухпро-
цессной модели сборки мусора — это унифицированный под-
ход, при котором статус ячеек непрерывно изменяется в ходе
процесса пользователя. В отличие от предыдущих сборщиков,
где нас интересовала лишь активность каждой данной клетки,
464 Часть II. Глава 16
здесь мы снабдим каждую ячейку счетчиком, указывающим на
количество ссылок на данную ячейку; если показания этого
счетчика больше нуля, то ячейка активна по определению.
Таким образом, каждая ячейка будет содержать целочис-
ленное поле, называемое полем счетчика ссылок. Значение
числа в этом поле будет равно п, если для данной ячейки су-
ществует п ссылок от слов состояния и других активных ячеек.
При создании ячейки ее счетчик устанавливается равным еди-
нице, а потом он увеличивает свое значение на 1 каждый раз,
как только возникает новая ссылка на эту ячейку. С другой
стороны, как только устраняется какая-нибудь из ссылок, то
соответственно уменьшается и значение этого счетчика. Когда
оно достигает нуля, то это означает, что данная ячейка уже
больше не активна и может быть устранена. Однако до ее пе-
реработки уменьшаются на единицу счетчики всех ячеек, с ко-
торыми она связана (уничтожение этой ячейки означает уни-
чтожение по одной ссылке для каждой ячейки, на которые она
указывает). В результате счетчики некоторых из этих ячеек
также могут стать равными нулю, и потребуется соответственно
их уничтожение — возникает рекурсивный процесс. Заметьте,
что при использовании подобной схемы ячейки не перемещают-
ся, как было бы в результате сборки мусора. По этой причине
такие сборщики мусора обычно используют свободные списки.
После удаления ячейки, счетчик ссылок которой стал равен
нулю, она может быть добавлена к свободному списку.
Важной чертой этого вида сборки является то, что отсут-
ствует необходимость временного останова программы пользо-
вателя для проведения очистки кучи; сборка мусора здесь
является как бы функцией работающей программы. Другим
преимуществом этой схемы является то, что она способна рабо-
тать в распределенной среде. Уменьшение счетчика ссылок дан-
ной ячейки будет происходить в пределах одного из блоков памя-
ти, в то время как в других будут продолжаться вычисления.
Основным же недостатком этой схемы является то, что,
во-первых, она требует дополнительного места для размеще-
ния счетчиков ссылок в ячейках, а во-вторых, как и в скани-
рующем алгоритме, происходит фрагментация кучи, поскольку
активные ячейки не перемещаются. К другим недостаткам сле-
дует отнести то, что она не позволяет обрабатывать цикличе-
ские структуры, так как значение счетчика ссылок в такой
структуре данных всегда не меньше единицы (она указывает
сама на себя). Эту проблему, однако, можно решить, снабдив
счетчиком ссылок все максимальные циклические структуры
(циклические структуры, не являющиеся компонентами других
циклических структур). Графы таких структур обязаны быть
Сборка мусора 465
ациклическими, что означает их пригодность для описанного
способа обработки. Основная трудность заключается лишь в
нахождении этих максимальных циклов — подробное описание
этого можно найти в [47, 48].
16.4.1. Ленивая сборка мусора
Одна из трудностей стандартного подсчета ссылок заклю-
чается в том, что в процессе постепенного уменьшения количе-
ства ссылок на какую-нибудь ячейку, содержащую большую
структуру данных, она в определенный момент превращается
из активной в мусорную, поскольку ни одна из внутренних вер-
шин не является разделяемой, после чего процесс пользователя
прерывается для восстановления этой ячейки.
Здесь можно прибегнуть к помощи отдельного процессора
(или даже мультипроцессора). Однако все проблемы можно
решить и с помощью единственного процессора, реорганизовав
свободный список. Вместо удаления всех ссылок из ячеек му-
сора мы можем использовать «стек декрементации» (СД), со-
держащий адреса всех тех ячеек, счетчики ссылок которых
должны быть уменьшены [35]. Увеличение значения счетчиков
ссылок происходит обычным образом. Для уменьшения значе-
ния этого счетчика нам достаточно поместить адрес данной
ячейки в СД. Для размещения новой ячейки приходится при-
бегать к небольшой хитрости. Мы выталкиваем первое значе-
ние из СД и проверяем счетчик ссылок у адресуемой ячейки.
Если он равен 1, то это мусор (счетчик должен быть уменьшен
до 0). Следовательно, ячейка может быть размещена сразу же
после занесения всех ее полей указателей в СД — они также
должны быть уменьшены на 1. Исходное значение счетчика
ссылок созданной ячейки будет корректно установленным, т. е.
равным 1. Если же, с другой стороны, счетчик ссылок был
больше единицы, то его значение уменьшается на 1, как
обычно, а из СД извлекается следующее значение. Этот про-
цесс продолжается до тех пор, пока не станет возможным
требуемое размещение новой ячейки или не исчерпается СД —
в этом случае придется прибегнуть к использованию свободного
списка. Таким образом, предположив, что существует по край-
ней мере один элемент СД, соответствующий ячейке, у которой
счетчик ссылок равен единице, имеем
Для размещения ячейки:
while ячейка не размещена do
Р := pop СД ;
if RP= 1
30 — 1473
466 Часть II. Глава 16
then поместить все поля указателей Р| в СД
разместить Р
else RP:=RP — 1
end
Для дублирования- указателя С:
Rc := Rc + 1
Для уничтожения, указателя С:
поместить С в СД
Хотя теперь сборка мусора будет происходить в ленивом
режиме, не исключено, что в стеке может скапливаться боль-
шое число адресов ячеек, чьи счетчики ссылок больше единицы.
Однако существование таких длинных цепочек ссылок малове-
роятно вследствие важного вывода, сделанного на основе на-
блюдения за поведением функциональных программ, гласящего,
что счетчики ссылок большинства ячеек равны 1 [77]. Другими
словами, большинство ячеек не являются разделяемыми. Ре-
зультат наблюдения подсказал описываемую в следующем раз-
деле методику обработки счетчиков ссылок.
Несмотря на эту эмпирическую закономерность, в некото-
рых исключительных случаях все же может случиться так, что
на вершине СД соберутся указатели на длинную цепочку раз-
деляемых ячеек. Для решения этой проблемы мы можем объ-
единить СД с кучей обычного вида и установить ограничения
на количество выталкивания из СД при поиске мусорной ячей-
ки. Если мы установим этот предел равным к, т. е. если после
к последовательных выталкиваний из СД не будет обнаружена
мусорная ячейка или СД будет исчерпан, то ячейка разме-
щена в куче обычным образом. Это позволяет улучшить работу
сборщика в реальном времени. Однако если куча будет исчер-
пана, то в этом случае останется лишь продолжить поиск му-
сорной ячейки по СД путем выталкивания его элементов.
В том случае, если и куча, и СД будут исчерпаны, программу,
разумеется, следует прервать.
16.4.2. Однобитовые счетчики ссылок
Метод использования однобитовых счетчиков ссылок основан
на том упоминавшемся эмпирическом факте, что счетчики
большинства ячеек равны единице. Как видно из названия ме-
тода, здесь предлагается отвести под счетчик всего лишь один
бит вместо целого слова машинной памяти. Если этот бит ра-
вен 0, то существует одна ссылка на эту ячейку. При создании
новой ссылки на эту ячейку (т. е. когда эта ячейка станет
Сборка мусора 467
разделяемой) этот бит счетчика устанавливается в 1. Как
только это произойдет, мы уже не сможем вернуть его в 0, так
как нельзя быть уверенным, что остались лишь две ссылки —
их может быть и больше, информация о точном количестве
нигде не хранится. По этой причине, если счетчики всех ячеек
кучи станут равными 1, то необходимо применить сборщик
мусора второго типа. Однако благодаря упомянутому эмпири-
ческому факту этот сборщик теперь будет включаться гораздо
реже, чем если бы он просто работал сам по себе.
В качестве достаточно простой оптимизации этого метода
можно предложить поместить бит счетчика не в самой ячейке,
а в указателе на нее. Если этот бит равен 0, то этот указатель
лишь указывает на ячейку. При дублировании указателя на
ячейку (т. е. когда возникают связи с другими ячейками) этот
бит устанавливается в 1 как в исходном, так и в новом указа-
теле. Если мы уничтожаем указатель, счетчик которого равен
О, то мы знаем, что подобный указатель единственный и что
эта ячейка может быть сразу же переработана. Указатели вну-
три адресуемой ячейки должны проверяться аналогично; если
какой-нибудь из них имеет нулевой бит счетчика, то соответ-
ствующая ему ячейка также может быть очищена и т. д. За-
метьте, что дублирование указателя не требует обращения
к адресуемой ячейке—в этом и заключается преимущество хра-
нения бита счетчика внутри указателя, а не в самой ячейке.
В последовательных реализациях языка это экономит по од-
ному обращению к памяти при каждом копировании; в рас-
пределенной среде это помогает избежать установления (воз-
можно, протяженной) связи с соответствующей ячейкой.
16.4.3. «Взвешенные» счетчики ссылок
Представленный в предыдущем разделе подход, заключаю-
щийся в размещении счетчика ссылок внутри указателей, может
быть распространен на тот случай, когда значение счетчиков
превышает единицу. Излагаемый подход, иногда называемый
методом взвешенных счетчиков ссылок, был независимо разра-
ботан в работах [15, 78].
Основная мысль заключается в том, что теперь в ячейках
будет храниться обычный счетчик ссылок, а в указателях —
веса, сумма которых для каждой адресуемой с их помощью
ячейки равна значению счетчика этой ячейки. Будем считать,
что указатель с весом W эквивалентен W указателям с весами,
равными 1. Теперь при копировании указателя, как и в одно-
битовой схеме в разд. 16.4.2, обращения к ячейке можно из-
бежать; вместо этого вес данного указателя делится поровну
30*
468 Часть II. Глава 16
счетчик новой
ячейки = 1024
б
а
Рис. 16.17. Взвешенные счетчики ссылок.
между новым и исходным указателями, а счетчик в ячейке
остается неизменным. При удалении указателя его feec, однако,
должен быть вычтен из счетчика ссылок в ячейке согласно
основному правилу, по которому сумма весов равна значению
этого счетчика.
Пример функционирования этой схемы представлен на
рис. 16.17. Вначале (рис. 16.17, а) есть ячейка с исходным
счетчиком, равным 1024, и единственным указателем, хранящим
такой же вес. То, что произойдет при создании еще трех ссы-
лок на эту ячейку, показано на рис. 16.17,6. Счетчик ссылок
остается тот же, а вес исходного указателя поровну делится
между четырьмя указателями. Вес каждого указателя станет
равным 256, что в сумме дает 1024. Очевидно, что никакого
обращения к ячейке не требуется.
Рис. 16.17,в показывает, что произойдет после удаления
одного из указателей: показания счетчика ссылок ячейки умень-
шаются на величину веса удаленного указателя (т. е. на 256)
Сборка мусора 469
и становятся равными 768. Это число равно сумме весов остав-
шихся указателей. На рис. 16.17, г показана ситуация, возни-
кающая после дальнейшего дублирования одного из указателей.
Это приводит к увеличению числа указателей опять до четырех,
но веса нов'ого и исходного указателей будут равны половине
начального веса, т. е. 128 — это сохранит полный вес всех ука-
зателей 768. Совершенно очевидно, что обнуление счетчика ссы-
лок произойдет при полном удалении всех указателей, после
чего ячейка может обрабатываться сборщиком мусора.
Основным преимуществом хранения весов внутри указателей,
как и в методе однобитовых счетчиков ссылок, является то,
что отсутствует необходимость осуществления доступа к ячейке
при увеличении числа указателей на нее. Мы должны изменить
показания счетчика ссылок ячейки при удалении ссылок на
нее, но при этом обычно снимаются ссылки с указывающей
(адресующей) ячейки, так что доступ к адресуемой ячейке бу-
дет осуществлен в любом случае. Именно по этой причине ме-
тод взвешенных счетчиков ссылок особенно хорошо подходит
для распределенных версий реализации функциональных язы-
ков, где частота посылок сообщений сильно влияет на эффек-
тивность работы.
Резюме
• Сборка мусора — это процесс обнаружения и восстановления
неиспользуемых ячеек.
• Существуют три основных класса сборщиков мусора:
сканирующий, копирующий и сборщик на основе счетчиков
ссылок.
• Сборщик мусора, требующий остановки программы на время
своей работы, называется старт/стоп сборщиком; альтернати-
вой ему является параллельный сборщик.
• Сканирующий сборщик является старт/стоп сборщиком; он
прост, но неэффективен, поскольку требует от одного до двух
полных проходов по куче.
• Копирующие сборщики выполняют перемещение и компо-
новку активных ячеек; подобные сборщики более подходят для
систем с виртуальной памятью, чем сканирующие.
• Простейший копирующий сборщик является в принципе
старт/стопным сборщиком; он использует две подобласти и
работает путем копирования активных ячеек из одной в другую.
• Более сложные сборщики способны работать параллельно
с прикладной программой, использовать много областей или
одну-единственную область; они особенно эффективны для ма-
шин с малым размером памяти.
470 Часть II. Глава 16
• Сборщики на основе счетчиков ссылок работают параллель-
но, следя за количеством ссылок на каждую ячейку, но тре-
буют применения дополнительных приемов для обработки цик-
лических структур.
• Ленивые сборщики мусора на основе счетчиков ссылок мак-
симально оттягивают время обработки структуры и производят
это по частям, а не сразу.
• Однобитовые счетчики ссылок являются эффективными и мо-
гут храниться в указателях на ячейки; копирование указателя
на ячейку не требует обращения к ней. Это существенно для
распределенных систем.
• Метод взвешенных счетчиков ссылок является обобщением
метода однобитовых счетчиков.
Упражнения
16.1. Фред говорит: «При использовании копирующего сбор-
щика относительное количество времени, затрачиваемое при
сборке мусора, уменьшается (до нуля) по мере роста
размера кучи». Что имеет в виду Фред? Почему это
высказывание Фреда неверно для сканирующих сборщиков
мусора?
16.2. Почему все указатели в реализациях функционального
языка с вызовом по значению «направлены в прошлое», т. е.
указывают на более старые ячейки? Какие это дает преимуще-
ства при реализации алгоритма Бэйкера?
Дайте объяснение того, как в ленивой реализации функцио-
нального языка могут быть созданы «ведущие» ссылки, т. е.
ссылки на более молодые ячейки.
16.3. В чем состоит проблема самоадресующихся указателей в
алгоритме Морриса? Предложите путь решения этой проблемы.
16.4. а. Предложите, как должен быть изменен режим «Чтение-
Изменение-Запись» операций с памятью для уменьшения числа
обращений к памяти кучи с использованием СД. (Это вопрос
только для специалистов-по аппаратной части ЭВМ!)
б. Объясните, как можно применить СД в сборщике мусора на
основе однобитовых счетчиков ссылок для избежания обраще-
ний к ячейке при копировании и удалении указателей.
16.5. Для сборщика мусора со взвешенными счетчиками ссы-
лок:
а) предложите метод копирования указателей, вес которых ра-
вен 1;
б) в чем преимущество схемы, в которой число первоначально
установленных ссылок на ячейку равно целой степени 2;
Сборка мусора 471
в) рассмотрите следующую ситуацию:
где А, В, С и D являются ячейками; р, q и г — указатели,
а функция f имеет эквивалентное определение в Норе
-----f(x :: у) <=g(y);
Опишите, как сборщик мусора на основе взвешенных счет-
чиков ссылок изменит счетчики ссылок ячеек и указателей в
результате применения L
Часть III
ОПТИМИЗАЦИЯ
Введение
К настоящему моменту мы рассмотрели множество реали-
заций функциональных языков, интерпретационный и компиля-
ционный подходы, языки со строгой и ленивой семантикой,
основанные на вычислительных моделях, которые используют
определенный контекст, редукцию графов и комбинаторы раз-
личных форм. В каждом случае возникает возможность повы-
шения производительности выполнения программы и по вре-
мени выполнения, и по объему занимаемой памяти. Последний
вид повышения производительности относится и к вопросу
сборки мусора, рассмотренному в предыдущей главе, но подоб-
ный способ разрешения проблемы несколько похож на «запира-
ние конюшни после побега лошадей», поскольку в действитель-
ности хотелось бы прежде всего сократить потребность в какой-
либо сборке мусора до минимума. Аналогично можно отметить
определенную «локальную» оптимизацию, которая возникла в
некоторых связанных в основном с компилятором МФП-реали-
зациях, таких как компиляция авторекурсии в циклах. К. Дру-
гим случаям можно отнести использование стека в стиле
«TUKI» в потоковых машинах, включение дополнительных ком-
бинаторов в фиксированное SKIBC-множество и включение
дополнительных макросов в G-машину. Фактически часть рас-
смотренных реализаций была введена с целью показать реше-
ние ряда проблем низкой производительности, присущих их
предшественникам, выдвинутых сначала в качестве представле-
ния некоторой вычислительной модели. Например, проблема
свободных переменных в модели редукции графов для вычис-
ления лямбда-выражений приводит к реализациям на основе
комбинаторов, рассмотренных в гл. 12 и 13; и конечно, исполь-
зование лямбда-удаления и суперкомбинаторов мотивировано
именно этой же проблемой.
Настоящая часть книги связана скорее с более фундамен-
тальными формами, оптимизации, нежели тот локальный тин,
Введение 473
который рассматривался в предыдущем разделе. С одной сто-
роны, мы исследуем преобразование программ, при котором
может быть модифицирована вся структура функциональной
программы, а с другой стороны, можно управлять выполне-
нием программы, используя аннотации, порождаемые абстракт-
ной интерпретацией. К сожалению, в истории оптимизирующих
компиляторов бывало порождение кода, не всегда получающего
тот результат, на который была ориентирована исходная про-
грамма, т. е. компиляторы меняли семантику программ. Однако
для имеющих точную математическую семантику функциональ-
ных языков и преобразование, и абстрактная интерпретация
являются методами, способными обеспечить требуемый семан-
тически корректный тип оптимизации. Что касается термино-
логии, то существует мнение, что преобразование означает лю-
бую семантически корректную оптимизацию, поэтому абстракт-
ную интерпретацию можно было бы рассматривать только как
часть инструментального набора преобразований. В то же
время любой формальный статический анализ программ, вклю-
чая преобразование, является абстрактной интерпретацией.
Существует множество явных ограничений по производи-
тельности в неоптимизированых реализациях функциональных
языков, разумеется, для последовательных архитектур фон-
неймановского типа. Например, применение многих функций
при вычислении обладает «линейной» зависимостью от размера
аргумента (формальные определения в гл. 18) и в императив-
ном языке однозначно представлялось бы как цикл. Мы уже
увидели примеры этого в авторекурсии, которую, как показано
в гл. 15, относительно легко преобразовать в цикл во время
•компиляции, но классическим примером служат функции вида
факториала, которые не авторекурсивны, но все-таки линейны
и так же программируются с использованием циклов, что го-
ворит в пользу рекурсии в императивных языках. Аналогично
можно было бы ожидать, что при выполнении применения
функции Фибоначчи используется число вызовов функции, зави-
сящее экспоненциально от аргумента, тогда как два последо-
вательно накапливающих счетчика дают тот же результат за
линейное время и постоянное пространство в императивном
цикле. Вопрос, будет ли это несущественно в специализиро-
ванной, предположительно параллельной архитектуре, в значи-
тельной степени неуместен. С одной стороны, фон-неймановские
машины останутся и в ближайшем, и в далеком будущем, а в
любом случае параллельные машины — это набор последова-
тельных процессоров, каждый из которых лучше всего исполь-
зуется при выполнении нетривиальных преобразований. С дру-
гой стороны, препятствием оказываются накладные расходы на
474 Часть III
вызов функций — элементы вычислений становятся чересчур
малыми. Таким образом, оптимизация—это не просто жела-
тельное дополнение к направлению развития исследований в
области императивных языков, но существенный компонент
в любой жизнеспособной реализации функционального языка.
К счастью, подобные реализации императивного стиля часто
получаются полуавтоматически (требуя некоторой помощи от
программиста), а иногда и полностью автоматически, из опре-
делений заданных функций. Процесс порождения более эф-
фективных версий функциональных программ с сохранением
смысла относится к первой категории подходов к оптимизации,
которые мы рассматриваем, а именно к преобразованию, при
котором модифицируется внутренняя структура функций и
функциональных выражений. Некоторые преобразования просто
порождают в том же языке новые программы, которые эквива-
лентны семантически, но выполняются более эффективно. Такие
преобразования относятся к типу исходный — в исходный.
Обычно целевая программа является авторекурсивной, что счи-
тается эквивалентным циклу вследствие относительной легкости
компиляции применения авторекурсивной функции в итераци-
онную императивную форму. И наоборот, целевая программа
может вообще не выражаться в функциональном языке, а быть
непосредственно представлена, например, на императивном
языке. И все же термин преобразование обычно будем связы-
вать с вариантом исходный — в исходный.
Другое важное применение преобразования программ свя-
зано с эффективной реализацией абстрактных типов данных,
которые определяют структуры данных, используемые в про-
блемно-ориентированной высокоуровневой спецификации реше-
ния задач. Выразительная мощность определяемых пользовате-
лем типов данных при написании функциональных программ
раскрыта в первой части книги, и многие языки, включая Норе,
поддерживают их. Однако они обычно представляются в ЭВМ
блоками в памяти, которые взаимно связаны указателями,
в связи с чем, как установлено в гл. 15, все ссылки на эле-
менты, содержащиеся в структуре, косвенные. Это не самый
эффективный способ доступа к содержимому структур хране-
ния в машинах с прямой или индексной адресацией, для кото-
рых идеальной структурой данных является линейная струк-
тура, занимающая непрерывный участок памяти и ориентиро-
ванная на последовательный просмотр. В машинах же с
параллельной архитектурой оптимальная структура данных
может быть организована в виде двоичного дерева, дающего
возможность осуществлять доступ к различным частям струк-
туры данных со стороны различных процессорных элементов
Введение 475
распределенной среды. Следовательно, рассматривая такой про-
стейший пример абстрактного типа данных, как список, можно
преобразовать его представление для последовательной фон-
неймановской или параллельной машины в вектор или дерево
соответственно. Однако в идеальном случае программисту сле-
довало бы только определить функции на своих абстрактных
типах, оставляя (конкретные) определения соответствующих
реализационных типов (например, векторов или деревьев) ком-
пилятору. Синтез таких конкретных определений может также
осуществляться методами преобразований.
Хотя в этом кратком обзоре подходов к оптимизации особое
ударение делается на минимизацию времени выполнения, в ка-
честве вторичной оптимизации может быть получена и некото-
рая экономия пространства используемой памяти. Например,
так как в циклах используется обычное (разрушающее) при-
сваивание сцетчику (или нескольким счетчикам), то очевидно,
что они эффективны также и по отношению к использованию
памяти. Кроме того, разработаны и схемы преобразования,
имеющие в качестве главной цели оптимизацию используемой
памяти. Например, это может достигаться порождением для
данного множества функций эквивалентного множества, кото-
рое генерирует меньше промежуточных структур данных [14].
Эта задача — предмет проводимых в настоящее время иссле-
дований, в нашей же книге мы к ней больше обращаться
не будем.
Второй рассматриваемый нами подход к повышению эффек-
тивности выполнения функциональных программ использует
абстрактную интерпретацию для управления путем выполнения
программы без модификации ее определения. Механизм такого
управления формализуется аннотированием программы, специ-
фицирующим ее операционную семантику более точно, чем это
может быть сделано при определении только семантики для
языка в целом. Например, мы уже сталкивались в нескольких
случаях с семантикой энергичного и ленивого вычислений в
функциональных языках, в которых параметры всегда берутся
по значению и по необходимости соответственно. Однако нет
причины, почему бы не сделать некоторые применения функции
энергичными и их аргументы будут браться по значению, а дру-
гие— ленивыми и их аргументы будут браться по необходи-
мости. Требуется только однобитовая аннотация для каждого
параметра определения функции, указывающая, какая семан-
тика должна быть для каждого компилируемого применения
функции. Правда, практическая задача заключается прежде
всего в осуществлении правильного выбора. В идеале нам бы
хотелось, чтобы функциональный язык имел ленивую семантику
476 Часть III
по причинам корректности и способности работать со струк-
турами данных неограниченного размера (что обсуждалось
в гл. 4). К сожалению, ленивая реализация обычно менее эф-
фективна по сравнению со строгим вариантом вследствие не-
обходимости поддерживать задержки для представления невы-
численных выражений. Кроме того, строгая реализация может
использовать любой возможный параллелизм для одновремен-
ного вычисления аргументов при применении функции. Однако
для многих параметров энергичная и ленивая семантики при-
менения функции совпадают, приводя к одному результату
или зацикливанию. Таким образом, для достижения лучшего
результата нам бы хотелось идентифицировать во время ком-
пиляции, какие применения должны вычисляться лениво (для
сохранения семантической корректности), а какие могут вычис-
ляться строго (для повышения эффективности), анализируя
способ, которым осуществляется доступ к параметрам функций
в определяющих их выражениях.
Подобный анализ во время компиляции называют «анали-
зом строгости». Мы будем использовать его для иллюстрации
более общего метода абстрактной интерпретации, который,
говоря кратко,' выводит определенные свойства выполнения
программ, работая с «абстрактным доменом», гораздо более
простым, нежели (стандартный) семантический домен анали-
зируемых выражений. Другое применение абстрактной интер-
претации возникает в системах вывода типов, образующих
основу алгоритмов проверки типов, несмотря на то что термин
«абстрактная интерпретация» ещё не был введён в то время,
когда были написаны первые программы проверки типов. Про-
верка типов во время компиляции, разумеется, имеет отноше-
ние к оптимизации, но уже рассмотрена в гл. 7.
Третий вид оптимизации — это запоминание, которое можно
считать комбинацией методов преобразования и абстрактной ин-
терпретации. Лежащая в его основе идея чрезвычайно проста.
Каждая функция реализуется как соответствующая запомина-
ющая функция, которая вычисляет результаты применения
функции к новым аргументам обычным образом, но, кроме
того, сохраняет пару значений аргумент—результат в таблице,
называемой запоминающей (запоминающая таблица), так что
при повторном применении функции к этому аргументу резуль-
тат можно получить простым просмотром таблицы. (С функ-
циями от нескольких аргументов можно работать таким же
образом, рассматривая аргументы как отдельный кортеж.)
Описываемый метод основан на свойстве прозрачности ссылок
функциональных языков и мог бы обеспечивать большое повы-
шение производительности, если бы не потенциально взрыво-
Введение 477
подобный рост запоминающей таблицы во время выполнения,
которая способна не только занять чрезмерное количество па-
мяти, забирая в экстремальном случае всю свободную память,
но и сделать время доступа сравнимым с временем повторного
вычисления применения функции. Таким образом, основная
задача при реализации запоминания заключается в управлении
запоминающей таблицей, т. е. в определении либо момента,
когда элемент таблицы больше не нужен и должен быть уда-
лен, либо того, какой элемент наиболее подходит для его
замены при заполнении таблицы фиксированного размера.
Использование вместо функции эквивалентной ей запомина-
ющей функции 'может рассматриваться как результат преобра-
зования программы. Подобно этому, любое предсказание упо-
требимости образов значений аргументов в целях управления
таблицей можно рассматривать как вид абстрактной интерпре-
тации, и, разумеется, всякое формальное доказательство семан-
тической корректности реализации запоминания для заданной
стратегии замещения элементов таблицы потребует методов по-
добного вида.
В первой главе этой части мы сначала рассмотрим опера-
ционное представление преобразования программ и опишем
методологию последовательного конвертирования определения
функции в более эффективную версию, сохраняющую смысл,
с использованием шести различных правил. Затем покажем,
как эту методологию можно применить к преобразованию ти-
пов данных. В гл. 18 предлагается альтернативный алгебраи-
ческий подход к преобразованию, в котором эквивалентные
функции получаются для родовых классов функции, сводя
трансформационный процесс к распознаванию примеров «тео-
рем» (устанавливающих такие эквивалентности) и последу-
ющему применению теорем к преобразуемой функции. В этом
подходе осуществляется анализ свободных от переменных вы-
ражений, записанных в стиле FP, описанном в гл. 5. Подобный
анализ так называемого функционального уровня основан на
функциональной алгебре Бекуса, полезные результаты которой
вводятся в начале гл. 18. В гл. 19 мы рассматриваем метод
запоминания, обращаясь ко многим вопросам, возникающим
при управлении запоминающей таблицей, и предлагаем не-
сколько примеров его применения, включая преобразование
вида исходный — в исходный. Наконец, в гл. 20 обсуждается
абстрактная интерпретация. Неформально, с помощью простого
численного примера вводится основная идея, затем в качестве
типичного примера применения абстрактной интерпретации рас-
сматривается анализ строгости.
Глава 17
ПРЕОБРАЗОВАНИЕ ПРОГРАММ
И ОПЕРАЦИОННЫЙ ПОДХОД
Цель создания программы, корректной и легко понимаемой,
часто вступает в конфликт с одновременно выдвигаемым требо-
ванием эффективности ее выполнения, т. е. за короткое время
и с использованием возможно меньшего объема памяти. Таким
образом, идеальным было бы желание получить начальное ре-
шение, концентрируясь на ясности и корректности и практи-
чески не обращая внимания на его эффективность, а затем
преобразовать это решение в эффективную форму, используя
манипуляции, гарантирующие сохранение смысла программы.
Такой трансформационный подход хорошо соответствует функ-
циональным языкам, поскольку они чисто декларативны, обла-
дая свойством прозрачности ссылок, что обсуждалось в первой
части книги. Относительно легко породить сохраняющие смысл
преобразования, используя естественное отношение равенства;
подобные синтаксические выражения всегда принимают одина-
ковые значения, т. е. являются семантически во всех контек-
стах подобными. Императивные же языки не обладают свой-
ством прозрачности ссылок вследствие допущения глобальных
переменных и разрушающего присваивания, в результате чего
выражения могут принимать различные значения в разных
контекстах И использование равенства в математическом смыс-
ле осуществляется с гораздо большим трудом.
Мы рассмотрим два различных типа преобразований. Сна-
чала, в этой главе, мы рассмотрим трансформационную мето-
дологию Берсталла и Дарлингтона [18], которая представляет
небольшое множество сохраняющих смысл правил порождения
новых рекурсивных уравнений. Полученные уравнения можно
использовать для определения новых функций или переопреде!-
ления существующих функций в другой, желательно более
эффективный вид. Методология точно не предписывает выбор
последовательности применяемых правил, очередное применя-
емое правило в любом процессе преобразования выбирается'
Преобразование программ и операционный подход 479
разработчиками программы, возможно руководствующимися
определенной неформальной эвристикой преобразования. В свя-
зи с этим трансформационная методология очень гибка, разре-
шая широкий диапазон оптимизаций, каждая из которых га-
рантированно является семантически корректной. Ее можно
рассматривать как представление операционного описания пре-
образования программы. В противовес этому второй стиль пре-
образования, который мы рассмотрим (в следующей главе),
аЛгебраичен по природе и основан на теоремах, устанавли-
вающих обобщенные эквивалентности, т. е. семантические по-
добия между классами функций. Выражения в функциональной
программе могут быть переписаны в более эффективный экви-
валентный вид, задаваемый одной из теорем. Таким образом,
процесс преобразования превращается в процесс распознава-
ния примеров теорем, в связи с чем алгебраический подход в
большей степени пригоден для автоматизации.
Однако для профессионала трансформационная методоло-
гия является более гибкой, разрешая целый класс преобразова-
ний, выражаемых в виде последовательностей примитивных
правил, включая и те, которые можно представить как при-
меры алгебраических теорем. Алгебраический же подход для
каждого нового класса преобразований требует изобретения
новых теорем до того, как станет очевидным его преимущество.
Для разработки практической системы преобразования, осно-
ванной на операционном подходе, необходимо ввести метаязык,
в котором последовательности требуемых в преобразовании
программы шагов пользователь может специфицировать в мета-
программе, или сценарии. Более того, сценарии в равной сте-
пени могут использоваться в пользовательском интерфейсе и
для алгебраического подхода — теоремы выступили бы в ка-
честве новых, высокоуровневых примитивов, — что позволяет
унифицировать трансформационные системы. Использование
метапрограммирования для методологии раскрутки/скрутки слу-
жит предметом разд. 17.2.
В разд. 17.3 рассматривается преобразование абстрактных
типов данных в конкретные типы, которые могут быть эффек-
тивно реализованы. Мы используем подход раскрутки/скрутки
и иллюстрируем на двух примерах соответствующие методы.
И снова увидим, что эта методология обладает значительной
гибкостью, но в общем случае еще более трудно поддается
автоматизации. Если бы даже соответствующий алгебраический
подход был более подвержен автоматизации, возросшая слож-
ность преобразований требует более обоснованных теорети-
ческих результатов, и мы не раскрываем его в этой книге.
480 Часть III. Глава 17
17.1. Трансформационная методология
раскрутки/скрутки
Прежде чем изложить множество правил, определяющих
методологию, рассмотрим сначала простейший пример, иллю-
стрирующий исследуемый тип оптимизации. Предположим,
имеется следующее наивное определение в языке Норе функ-
ции g, вычисляющей сумму списка удвоенных чисел:
dec sum : list( num) —> num ;
------sum( nil) < = 0;
------sum( x :: 1) <= x + sum( 1);
dec double : 11 st( num) -> 1 ist( num );
-----double( nil) <= nil;
------double( x :: I) <= ( 2 * x):: double( 1);
dec g : list( num ) —> num ;
•-----g( 1) <= sum( double( 1));
Эти определения — явно неэффективное решение задачи, в
котором осуществляется проход по двум спискам: по первона-
чззьному списку, элементы которого удваиваются, и результи-
рующему списку, элементы которого суммируются. Можно вы-
вести новую версию g, которая осуществляет проход по списку
только один раз, применяя следующие три правила (названия
которых приводятся курсивом):
------g( nil) <= sum( double( nil));
< - sum( nil);
<=0
-----g(x:: 1) <= sum(double(x:: 1));
<— 'um((2 * x):: double( 1));
<=(2*x) + g(l);
подстановка в
определение g,
конкретизация
применение первого
рекурсивного
уравнения для
функции double,
раскрутка
раскрутка
конкретизация
раскрутка
раскрутка
применение
рекурсивного
уравнения
для функции g,
скрутка
Заметим, что оба правила раскрутки и скрутки заключаются
в подстановке одной части рекурсивного уравнения вместо дру-
Преобразование программ и операционный подход 481
гой: правой вместо левой в случае раскрутки и левой вместо
правой в случае скрутки. Новая полученная нами программа,
являющаяся семантически эквивалентным определением g,
имеет вид
dec g : Iist( num) -> num;
------g(nil) <=0;
------g(x::l) <=(2*x) + g(l);
Система раскрутки/скрутки Берсталла и Дарлингтона [18]
состоит в самом деле из шести правил, разрешающих вводить
новые уравнения, являющиеся следствиями существующих урав-
нений. В формулировке этих правил мы используем термин эк-
земпляр выражения, который означает любое выражение, по-
лученное из упомянутого выражения подстановкой для каждой
переменной выражений, таких как константы. Система раскрут-
ки/скрутки включает следующие правила:
1. Определение. Вводим новое рекурсивное уравнение, выраже-
ние в левой части которого не является экземпляром выра-
жения левой части какого-либо из имеющихся уравнений.
Новое уравнение, следовательно, определяет новую функцию
или расширяет область определения существующей функции,
обычно введенной ранее этим же самым правилом.
2. Конкретизация. Осуществим подстановку экземпляра имею-
щегося уравнения, т. е. уравнение получается подстановкой
частных выражений (например, констант) вместо перемен-
ных в существующее уравнение.
3. Раскрутка. Если существуют уравнения Е <=Е' и F<=F/
и имеется некоторое вхождение экземпляра Е в F', заменим
это вхождение соответствующим экземпляром- Е', получая F*,
и введем уравнение F < = F*. Таким образом, F* = [Е'/Е] IF',
где верхний индекс । обозначает подстановку экземпляра
в уравнение Е <= Е'.
4. Скрутка. Если имеются уравнения Е<=Е' и F < = F' и
существует некоторое вхождение экземпляра Е' в F', заменим
это вхождение на соответствующий экземпляр Е, получая F+,
и введем уравнение F<=F+, где F+ = [E/E']IF' (нотация
аналогична (3)).
5. Абстракция. Вводим where-предложение (квалифицирован-
ное выражение), порождая из имеющегося уравнения
Е <= Е' новое уравнение
Е <=[u;/F|, ...,un/Fn]E' where(ub ..., un) = (Fb ...,Fn)
6. Законы. Мы можем преобразовать уравнение, применяя к вы-
ражению правой части какие-либо законы, действующие по
31 — 1473
482 Часть III. Глава 17
отношению к содержащимся в нем примитивам, например
законы ассоциативности, коммутативности и т. п. Новое урав-
нение получается как математическое равенство между вы-
ражениями, тождество которых определяется законом, на-
пример х + (у + z) = (х + у) + z. Каждое правило является
равенством, так что смысл функциональной программы, преоб-
разуемой по методологии раскрутки/скрутки, действительно
гарантированно сохраняется, по крайней мере частично. Рас-
смотрим сначала чуть более сложный пример — функцию,
вычисляющую среднее списка чисел, в преобразовании кото-
рой используются все первые пять правил. Исходное, наив-
ное, но ясное и очевидно корректное решение имеет вид
dec average : list(num)—>num ;
------average( 1) <= sum( 1) div iength(l);
------sum(nil) <= 0 ;
------sum( n :: 1) <= n + sum( 1);
------length( nil) <= 0;
------length( n :: 1) <= 1 + length( 1);
Как и в первом примере, осуществляются два прохода по спис-
кам, на этот раз по одному списку, для которого раздельно
определяются сумма и число элементов, которые затем уча-
ствуют в операции деления для вычисления функции среднего.
Нам бы хотелось выполнить обе операции вместе за один про-
ход списка. Можно получить семантически эквивалентную функ-
циональную программу, которая делает это, используя методо-
логию раскрутки/скрутки следующим образом:
dec av : list(num)->num#num ;
------av(l) <=(sum(l), length(l)); определение
------av(nil) <=(sum nil, length nil); конкретизация
= (0, 0);
раскрутка
------av(n::l) <= (sum(n :: 1), length(n :: 1)); конкретизация
<= (n + sum( 1), 1 + length( 1));
раскрутка
= (n + u, 1 + v)
where (u, v)==(sum(l), length(l));
абстракция
= ( n + u, 1 + V )
where (u, v) == av( 1); скрутка
Преобразование программ и операционный подход 483
------average( 1) <= sum( 1) div length( 1);
<=u div v
where (u, v) == ( sum( 1), length( 1));
абстракция
<=u div v
where (u, v) == av( 1); скрутка
В результате получаем преобразованную программу:
dec average : list( num )-> num ;
dec av ’• list( num) -► num # num ;
------average( 1) <= u div v
where (u, v) —— av( 1);
------av( nil) <= (0, 0);
------av(n::l) <=(n + u, 1 +v)
where (u, v) == av( 1);
При выполнении применения к списку чисел функции average,
определенной в окончательной программе, согласно нашим на-
мерениям, только один раз осуществляется проход по списку,
при котором последовательно накапливаются, а при достижении
конца списка участвуют в операции деления сумма и длина
списка. Примером с более впечатляющим ростом эффективности
служит преобразование функции Фибоначчи, которая, будучи
нелинейной, требует экспоненциального числа вызовов по отно-
шению к величине ее аргумента (т. е. пропорционального ее
результату). Функция может быть определена следующим об-
разом:
dec fib : num num;
------fib(O) <= 1 ;
------fib( 1)<=1;
------fib( n + 2) < = fib( n + 1) + fib( n );
В этом определении используется нестандартный синтаксис для
образцов: образец n + к просто указывает, что аргумент дол-
жен быть больше или равен к (п больше или равно 0). Следует
отметить, что, хотя запись сделана не на стандартном языке
Норе, некоторые компиляторы Норе расширены с целью вос-
принимать такие определения. В общем случае подобные опре-
деления должны формулироваться с использованием перекры-
вающихся образцов. В третьем уравнении для fib следовало бы
тогда использовать образец п, учитывая, что и 0 и 1, более кон-
кретные, чем п (см. гл. 8), и, следовательно, будет выбираться
первое уравнение, если аргументом будет 0, и второе, если ар-
гументом будет 1.
31*
484 Часть III. Глава 17
Нелинейность такого определения fib обусловлена двумя ре-
курсивными вызовами в выражении в правой части третьего
уравнения, порождающими двоичное дерево для представления
частично вычисленных применений. Преобразованная же вер-
сия выполняется за линейное время, или, говоря более точ-
но, требует числа вызовов функции, зависящего линейно от ве-
личины аргумента. Методология раскрутки/скрутки приводит
к следующему преобразованию:
dec g : num -» num # num;
-----g(n) <=(fib(n-f-1), fib(n)); определение
-----g(0) <=(fib( 1), fib(O)); конкретизация
<=(1, 1); раскрутка
-----g(n+l) <= (fib(n 2), fib(n-f-l)); конкретизация
<= (fib( n + 1) + fib( n), fib( n + 1 ));
раскрутка
<=(vl + n, u)
where (u, v)==(fib(n + 1), fib(n));
абстракция
<=(u + v, u)
where (u, v)==g(n); скрутка
-----fib(n + 2) <=fib(n + 1 ) + fib(n);
<= u + v
where (u, v) —— (fib(n + 1), fib(n));
абстракция
<= U + V
where (u, v)==g(n); скрутка
В результате получается следующая преобразованная версия
функции Фибоначчи:
dec fib : num -> num;
dec g : num -> num # num;
-----fib(O) <= 1 ;
-----fib( 1)<=1;
-----fib(n-|-2)<=u + v
where (u, v)==g(n);
-----g(0)<=(l, 1);
-----g(n4- l)<=(u + v, u)
where (u, v)==g(n);
Очевидно, что время выполнения применения g(N) и, следова-
тельно, fib(N) порядка O(N), т. е. преобразованная функция
Фибоначчи действительно линейна по отношению к величине ар-
гумента. Существует множество примеров функций, которые
Преобразование программ и операционный подход 485
можно преобразовать таким же образом, некоторые из них
можно найти в упражнениях в конце этой главы. В этом раз-
деле мы больше не предлагаем примеров, но подобная методо-
логия будет применяться к преобразованию типов данных в
разд. 17.3.
Ключевыми шагами в рассмотренном выше примере были
выбор определения g в терминах fib, следующие далее абстрак-
ция where и скрутка в получении уравнения рекурсии для
g(n+l). Пара следующих друг за другом шагов, включаю-
щих абстракцию where и скрутку, иногда рассматривается как
составной шаг и называется формированной скруткой. В об-
щем и, разумеется, в этом примере на долю программиста вы-
падает необходимость в проявлении изобретательности, которая
требуется при выборе соответствующих определений (g в на-
шем примере) и кортежей для абстракции в форсированной
скрутке, (f (п + 1 ), f(n)) в нашем примере. В связи с этим
подобные шаги принято называть эвристическими заодно с дру-
гими, требующими творческих проявлений интеллекта, необхо-
димость которых при применении трансформационных систем
обусловлена их природой. Таким образом, имея, несомненно,
весьма широкую применимость, методология раскрутки/скрутки
требует точных действий от программиста. Использование ее
имеет поэтому сходство с проектированием программ в обще-
принятом смысле. Полная автоматизация в применении мето-
дологии представляется весьма трудной, хотя вполне возможна
поддержка различных наборов стандартных последовательно-
стей правил, собранных в «библиотеку преобразований», ори-
ентированных на применение в качестве высокоуровневого сред-
ства трансформационной тактики. Прежде чем принять и рас-
смотреть такую точку зрения в следующем разделе, обсудим
сначала вопросы корректности и полноты трансформационной
системы раскрутки/скрутки.
Поскольку правила методологии раскрутки/скрутки основа-
ны исключительно на эквивалентных рассуждениях, т. е. на
использовании математического равенства, «неправильные» ре-
зультаты, т. е. противоречивое множество новых функций, по-
лучить невозможно. Однако можно породить новые функции,
которые не завершаются. Например, из уравнения
------f( х) <=х;
можно получить, используя скрутку, преобразованное уравнение
------f(x)<=f(x);
которое, очевидно, при выполнении не завершится. В действи-
тельности можно показать, что система раскрутки/скрутки
486 Часть III. Глава 17
сохраняет частичную корректность: если преобразованная про-
грамма завершается, гарантируется возврат тех же результа-
тов, что и у исходной программы (для соответствующих под-
разумеваемых областей определения объектов). Это справед-
ливо вследствие того, что функции, определенные исходным
множеством уравнений рекурсии, являются наименьшими реше-
ниями этих уравнений, заданных наименьшими фиксированными
точками соответствующего множества функциональных уравне-
ний. Поскольку все преобразованные уравнения получаются по-
следовательной подстановкой вместо подвыражений, присут-
ствующих в существующих уравнениях, равных выражений,
эти решения должны также удовлетворять и результирующему
множеству уравнений. Другими словами, они являются также
и решениями множества уравнений, определенного преобразо-
ванными функциями, но не обязательно наименьшими реше-
ниями этих уравнений. Таким образом, определенная преобра-
зованными уравнениями функция слабее (в смысле связанного
функционального пространства), чем соответствующая функция,
определенная исходными уравнениями.
Если f— функция между доменами D, С и С — плоский,
т. е. х < у, если х = _1_ или х = у для х, у е С, мы можем
немедленно убедиться в частичной корректности, даже если
функциональное пространство [£>->(?] в общем случае неплос-
кое. Если f'— преобразованная версия f и f' должна быть сла-
бее f, тогда для всех объектов xeD имеет место f'x < fx, по-
этому если f'x завершается, т. е. f'x =£ _1_, должно выполняться
равенство fx = f'x. Далее, если f определена на том же множе-
стве объектов, что и ее преобразованная версия f', т. е. fx = _1_
тогда и только тогда, когда f'x < fx для объектов х е D, то
обеспечивается и полная корректность, поскольку f'x < fx, и
поэтому или f'x = ± = fx по предположению, или f'х = fx. Эти
условия достаточны для полной корректности методологии рас-
крутки/скрутки, но, очевидно, они не являются необходимыми.
Формальный анализ корректности можно найти в [58]. Может
случиться, что некоторых читателей озаботит выявившееся от-
сутствие симметрии в том аргументе, и поскольку все шаги
преобразования — это применение математического равенства,
то любое решение для определенной преобразованными уравне-
ниями функции должно быть также и решением для исходных
уравнений и поэтому больше, чем их наименьшее решение. Это
приводит к эквивалентно преобразованным функциям и полной
корректности. Однако обратный аргумент не всегда верен, по-
скольку правила преобразования необращаемы. Это означает,
что не всегда возможно определить сохраняющее смысл преоб-
разование, которое покрывает уравнение из уравнения, получен-
Преобразование программ и операционный подход 487
ного применением к нему одного из шести правил, как мы это
видели в примере с незавершением. Иначе говоря, асимметрия
возникает вследствие однонаправленности самих правил преоб-
разования.
Полная корректность может быть установлена отдельным
доказательством завершимости конечной, преобразованной про-
граммы или гарантирована наложением определенных ограниче-
ний на применение правил скрутки и раскрутки. Что касается
последнего случая, то Коттом показана «надежность» в смысле
сохранения полной корректности преобразований, которые, не-
строго говоря, включают больше раскруток, чем скруток.
Что касается полноты, то формально трансформационная
система раскрутки/скрутки неполна, т. е. существуют опреде-
ленные эквивалентные множества рекурсивных уравнений, ко-
торые нельзя преобразовать одно в другое последовательным
применением правил. Например, уравнения
-----f(0)<=0;
-----f(x+l)<=l+f(x);
эквивалентны уравнению
-----f(x) <=х;
но не существует способа, посредством которого последнее урав-
нение порождается из первых двух с помощью шести правил
методологии раскрутки/скрутки. Однако такие примеры отно-
сятся скорее к патологическим случаям. Можно сказать, что
для всех практических целей методология полна. Реальная же
проблема состоит в том, что она в лучшем случае только полу-
автоматизируема и требует интеллектуальных усилий от про-
граммиста, т. е. является по существу инструментом проектиро-
вания программ. Здесь наблюдается аналогия с доказатель-
ством теорем, где используемые для доказательства аксиомы
или правила очень просты и обычно требуется много усилий
для поиска в базе данных соответствующей последовательности
шагов доказательства, или, иначе, помощь пользователя. Не-
смотря на то что альтернативный алгебраический подход к пре-
образованию программ более расположен к автоматизации, под-
ход раскрутки/скрутки обладает большей гибкостью вследствие
своей почти полноты, и, конечно, в общем он более применим,
чем множество известных сейчас теорем. Таким образом, важно
развивать метаязыковые системы, посредством которых про-
граммист сможет специфицировать желательные шаги преобра-
зования. Подобная система смогла бы помочь разработке окон-
чательной реализации прикладной программы пользователя, и
488 Часть III. Глава 17
поэтому ее следует рассматривать как неотъемлемую часть
среди поддержки функционального программирования. Этот
вопрос является предметом следующего раздела, а дальнейшее
применение методологии раскрутки/скрутки к преобразованию
типов данных мы рассмотрим в разд. 17.3.
17.2. Управление системой раскрутки/скрутки
— метаязык преобразований
Функция, написанная на метаязыке, — метафункция или ме-
тапрограмма— оперирует программой, написанной на функ-
циональном языке, которая должна быть преобразована; подоб-
ные программы являются объектами метаязыка. Очевидным
примером метафункции служит редактор программ, имеющий
тип
программа # список, команд программа
где тип программы указывает на некоторое абстрактное пред-
ставление программы (см., например, гл. 8, в которой дается
определение данных для абстрактных синтаксических деревьев
в языке Норе на самом Норе).
Можно выразить преобразования как метафункцию типа
программа—»-программа. Для функционального языка, такого
как Норе, программный тип — это множество уравнений, а тип
для уравнения задается в терминах некоторого абстрактного
синтаксического дерева. Метафункции преобразования опреде-
ляются в свою очередь как композиции других метафункций
первого уровня, которые оперируют с уравнениями и выраже-
ниями, образующими программу. Следовательно, для реализа-
ции преобразований раскрутки/скрутки с помощью метаязыка
необходимо определить шесть функций первого уровня, принад-
лежащих метаязыку, — по одной на каждое правило преобра-
зования. Программист специфицирует требуемые шаги преоб-
разования, используя выражения метаязыка; генерируемые
метапрограммой последовательности правил будут подобны
показанным в примерах в предыдущем разделе.
К сожалению, методология раскрутки/скрутки, как уже го-
ворилось, требует существенных усилий на программирование
пользователем на метауровне — в действительности, вероятно,
больше, чем требуется для первоначального получения исход-
ного решения. Это и не очень удивительно, ведь исходная про-
грамма представляет «высокоуровневую» спецификацию реше-
ния задачи, которая, как нам хочется думать, может быть вы-
ражена ясно и кратко, но без заботы об эффективности. Однако
требует больших усилий метапрограммирование, и мы вынуж-
Преобразование программ и операционный подход 489
дены искать более эффективные пути применения правил пре-
образования или альтернативную основу для выполнения пре-
образования.
Описываемая в этой главе методология вызывает беспокой-
ство в том аспекте, что ее правила, будучи связаны с конкрет-
ными уравнениями, определяющими функции, действуют на
слишком низком уровне детализации. Следовательно, один из
подходов к созданию практической системы сохраняющих
смысл преобразований заключается в попытке построения струк-
турных метапрограмм нисходящим образом, который пропове-
дуется многие годы специалистами по технологии программи-
рования. Высокоуровневые функции можно было бы применить
для генерации низкоуровневых шагов преобразований, необхо-
димых для достижения цели преобразования, но сложность этих
последовательностей шад'ов была бы уже скрыта от пользова-
теля. Естественно, многие функции с такой структурой по-
требуют для преобразования подобные последовательности ша-
гов. Такие структурные сходства могут идентифицировать ро-
довые классы функций, которые можно трансформировать
одними и теми же метафункциями.
Однако в общем для высокоуровневой метафункции будет
недостаточным являться просто макросом, т. е. фиксированной
последовательностью примитивных правил, удобно параметри-
зованной в терминах имен функций, имен переменных и кон-
стант, встречающихся в уравнениях преобразуемой программы.
Для того чтобы быть достаточными, функциям в родовых клас-
сах следовало бы быть изоморфными, а не просто «подобными».
В практических целях высокоуровневые метафункции должны
были бы не только включать полностью определенные описания
преобразований — в терминах известных априори последователь-
ностей правил методологии раскрутки/скрутки, — но применять
также и тактику эвристического поиска среди различных воз-
можных последовательностей правил в надежде найти прием-
лемо оптимизированные определения функций. Они должны бы
также быть способными учитывать «советы» пользователя, пред-
лагаемые в идеальном случае интерактивно, в форме выбора
из меню применимых метафункций, что полезно в силу невоз-
можности автоматизации применения методологии. Алгебраиче-
ские схемы гораздо более перспективны для автоматического
преобразования определенных функций, и эти схемы можно
было бы объединить в тактическое средство второго уровня в
предлагаемой метасистеме. В действительности оказывается,
что «линеаризация» (см. гл. 18) была бы наилучшим примером,
как и «преобразование в итерационную форму», направленное
на генерацию авторекурсивных версий функций.
490 Часть III. Глава 17
17.3. Преобразование типов данных
Использование абстрактных типов данных в языках про-
граммирования как функциональных, так и императивных стало
обычным явлением, поскольку обеспечивает программиста бо-
лее мощными выразительными средствами, разрешая описывать
объекты, с которыми работает программа, наиболее естествен-
ным для решаемой задачи способом. Эти преимущества хорошо
известны, и, в частности, в первой части книги были разъяснены
достоинства сильно типизированного функционального языка.
Здесь мы не повторяем этих аргументов. К сожалению, прису-
щие абстрактным типам структуры редко соотносятся с обычно
очень ограниченной структурой областей хранения в памяти ма-
шины, поэтому реализация их неэффективна как по объему па-
мяти, необходимому для объектов этих типов, так и по времени
выборки элементов из таких объектов. Неоптимизированное
представление составных объектов данных в памяти просто свя-
зывает ячейки памяти в точном соответствии со структурой типа
объекта с использованием указателей и кучи, как обсуждалось
в гл. 15. Однако в некоторых структурах данных имеется опре-
деленное упорядочение объектов и доступ к структурам осуще-
ствляется в соответствии с этим упорядочением — самым оче-
видным примером являются списки. В таких случаях, очевидно,
было бы наиболее эффективным применение естественного по-
рядка элементов памяти путем занесения последовательных аб-
страктных объектов в смежные блоки памяти, что ускоряет и
операцию запоминания, обычно реализуемую машинной опера-
цией MOVE, и операцию выборки элемента, использующей ин-
дексацию. Конечно, не для всех компьютеров смежное разме-
щение элементов хранения является обязательно оптимальным.
Для машин с параллельной архитектурой, например, более под-
ходящей структурой для динамических объектов может быть
бинарное, дерево, с которым стал бы возможен независимый,
одновременный доступ к его компонентам со стороны несколь-
ких процессоров. Для структурированных данных с компонента-
ми, которые можно обрабатывать в любом порядке, такое ре-
шение было бы действительно оптимальным, и поэтому можно
было бы список представить подобным деревом.
Затруднение заключается в том, что у программиста, же-
лающего повысить производительность программы за счет ис-
пользования свойств архитектуры машины, нет альтернативы
кроме определения всех его типов данных машинно-ориентиро-
ванным способом и написания всех функций для манипулиро-
вания этими типами. В лучшем случае программисту необхо-
димо определить только множество абстрактных типов, множе-
ство конкретных типов, в которых объекты абстрактных типов
Преобразование программ и операционный подход 491
^представляют во время выполнения, и отображения между со-
ответствующими конкретными и абстрактными типами. Тогда
достаточно определить только функции манипулирования аб-
страктными типами, оставляя компилятору синтез соответствую-
щих функций манипулирования конкретными типами. В этом
случае вообще нет необходимости представлять явно абстракт-
ные типы во время выполнения, при этом программисту остают-
ся достоинства программирования на прикладном уровне. Та-
ким образом, под «преобразованием типов данных» мы на са-
мом деле понимаем синтез конкретных функций, определенных
на конкретных типах, соответствующих абстрактным функциям,
определенным на абстрактных типах.
Такая идеалистическая ситуация достигается не так легко,
автоматическая генерация реализации абстрактной программы,
манипулирующей конкретными объектами с максимальной эф-
фективностью, требует колоссальной трансформационной систе-
мы компилятора, если таковая вообще возможна. Тем не менее
в определенных случаях такие схемы преобразований могут
быть получены и на основе подхода раскрутки/скрутки, и на
основе алгебраического подхода. Правда, последовательности
требуемых шагов еще более не ясны, чем те, о которых шла
речь в разд. 17.1, поэтому для применения этой методологии
необходимо дополнительное взаимодействие с пользователем.
Методологию раскрутки/скрутки можно применить к преоб-
разованию типов данных без отклонений, за исключением вве-
дения новых «законов», соответствующих свойствам рассматри-
ваемых типов, от описанной в разд. 17.1 схемы, поддерживае-
мой метасистемой примерно такого вида, который был обрисован
в разд. 17.2. Как мы уже замечали, требуемые в трансфор-
мационном процессе шаги — это нечто неясное, особенно это ка-
сается шагов определения, скрутки и абстракции, но для отно-
сительно простых примеров схема практична и гарантирует, что
любое порождаемое преобразование (частично) корректно. Сей-
час мы рассмотрим два примера, призванные иллюстрировать
известные в настоящее время возможности, но заметим, что, по
крайней мере на момент написания книги, подобная система
еще не была реализована.
Пример 1. Представление деревьев массивами
Предположим, что имеется обычное полиморфное определе-
ние типа данных дерево ’> на языке Норе:
data tree( alpha) == leaf( alpha) -]—(- node( tree
( alpha )# alpha # tree( alpha ));
*> Имеется в виду двоичное дерево. — Прим, перев.
492 Часть III. Глава 17
которое мы хотим представить массивом троек, каждая из ко-
торых включает элемент данных типа alpha, хранимый в соот-
ветствующем узле абстрактного дерева, и два числа, опреде-
ляющие связность узлов дерева через индексацию массива. Для
листьев оба числа равны нулю, другим узлам соответствуют
тройки, индексируемые в массиве, первым и вторым числами,
указывающими на корневые узлы левого и правого поддеревьев.
,7.
Строка 17 2 3
5^ Строка 2 5 0 0
Строка 3 9 4 5
3 4 Строка 4 3 0 0
Строка 5 4 0 0
Абстрактный тип дерево
Конкретный тип- двумерный массив
Рис. 17 1. Представление дерева массивом.
Конкретный тип имеет в соответствии с этим следующее объ-
явление:
type row_num == num ;
data array( alpha) == empty_array + + assign( array #row_num
# alpha # num # num);
Пустой массив (empty_array) и представляет какое-либо де-
рево, а второй подтип представляет массив, образованный из
массива, являющегося первым аргументом конструктора assign,
занесением в строки, нумеруемые вторым аргументом троек,
компонентами которых служат соответственно третий, четвер-
тый и пятый аргументы. Следовательно, дерево, показанное на
рис. 17.1, представляется массивом, изображенным рядом с де-
ревом, а массив записывается (неоднозначно) следующим об-
разом:
assign(assign(assign( assign (assign(empty_array, 1, 7, 2, 3),
2, 5, 0, 0), 3, 9, 4, 5), 5, 4, 0, 0), 4, 3, 0, 0)
С конкретной формой абстрактного типа связаны селекто-
ры— функции выборки, которые определяют, как осуществляет-
ся доступ к элементам данных, хранимых в объектах, т. е.
представляют операции индексирования. Эти селекторы обычно
рекурсивны и могут быть записаны программистом в форме
рекурсивных уравнений. Вследствие рекурсивности их нельзя
представить обычным сопоставлением с образцом. Если тип
данных считается аксиоматическим, определяющие уравнения
для функций селекторов фактически устанавливают эти аксио-
мы. Определим для нашего примера функции read-data,
Преобразование программ и операционный подход 493
read_left и read-right, находящие элемент данных, левый и пра-
вый указатели соответственно в тройке массива, представляю-
щий узел следующим образом:
dec read_data : array( alpha) # num —> alpha ;
------read_data( assign( ar, n, a, i, j)<=if m = n
then a else read_data( ar, m);
dec read_left: array( alpha) # num —> num ;
------read_left( assign( ar, n, a, i, j), m)<=if m = n
then i else read_left( ar, m);
dec read-right: array( alpha) # num -> num;
------read_right( assign( ar, n, a, i, j), m)<=if m = n
then j else read_right( ar, m);
(Мы опустили уравнения c empty_array в образцах, что в прин-
ципе ошибочно, поскольку функции не определены на пустых
массивах.)
Последнее, что обязан программист, — это подготовить ото-
бражения между конкретным типом и исходный абстрактным
типом. Назовем его для отображения «абстракция» abs и опре-
делим следующим образом:
dec abs : array( alpha # num) -> tree( alpha);
dec abs 1 : array( alpha #num) -> tree( alpha);
------abs( ar) <= absl( ar, 1);
------absl(ar, rn)<=if read_left( ar, rn) = 0
then leaf( read_data( ar, rn))
else node( absl( ar, read_left( ar, rn)),
read_data( ar, rn),
absl(ar, read_right( ar, rn)));
Заметим, что выражение abs I ( ar, rn) имеет в качестве значе-
ния поддерево с корневым узлом, представляемым строкой
с номером rn в массиве аг.
Получив эти определения, программист освободится от не-
обходимости написания каких-либо функций по абстрактному
типу tree, а трансформационная система должна будет синтези-
ровать соответствующие функции на конкретных массивах. При-
нимая, что и абстрактный, и конкретный типы для чисел имеют
тип num, рассмотрим функцию sum, которая складывает числа
в дереве, и применим методологию раскрутки/скрутки для по-
лучения конкретной версии suim Абстрактная функция опреде-
ляется следующим образом:
dec sum 1 tree( num) —>-num ;
——— sum(leaf(n)) <=n;
------sum(node(tl, n, t2)) <= sum( tl)-|-n + sum( t2);
494 Часть III. Глава 17
Преобразование абстрактной функции sum в ее конкретную
функцию concsum осуществляется через выполнение следую-
щих примитивных шагов, которое может поддерживаться мета-
системой вида, описанного в разд. 17.2. Начнем с введения но-
вого, конкретного определения функции в терминах абстракт-
ной функции:
dec concsum аггау( num) -> num;
------concsum( at) <— sum( abs( ar));
<= sum( absl( ar, 1)); раскрутка
В соответствии c abs 1 введем функцию concsum 1:
dec concsum 1 : array( num) # num-> num ;
------concsuml(ar, rn) <= sum( absl( ar, rn)); определение
откуда
-----concsum 1( ar, 1) <— sum( absl( ar, rn)); конкретизация
поэтому
------concsum( ar )<= concsum 1( ar, 1); скрутка
Теперь, раскручивая определение abs1 в управлении для
concsum 1, получим
------concsjiml( ar, rn)<=sum(
if read_left( аг, rn) = 0
then leaf(read_data( ar, rn)),
read_data( ar, rn),
absl(ar, read_right(ar, rn)));
<== if read_Ieft( ar, rn) = 0
then sum(leaf(read_data(ar, rn)))
else sum(node( absl( ar, read_left( ar, rn)),
read_data( ar, rn),
absl(ar, read_right( ar, rn))));
используя дистрибутивный закон, действующий для конструк-
ции if_then_else. Он устанавливает справедливость для функ-
ции f и выражений А, В, С тождества
f( if A then В else C) = if A then f( В) else f(C)
Таким образом, раскрутка sum дает
------concsuml(ar, rn)<=
if read_left( ar, rn) = 0
then read_data( ar, rn)
else sum(absl(ar, read_left(ar, rn)))
+ read_data( ar, rn)
-j- sum( absl( ar, read_right( ar, rfi)));
Преобразование программ и операционный подход 495
и, наконец, скрутка concsum 1 приводит к уравнению
------concsum 1( аг, гп)< =
if read_left(ar, rn) = O
then read_data( ar, rn)
else concsum 1(ar, read_left( ar, rn))
+ read_data( ar, rn)
4-concsum 1(ar, read_right(ar, rn)));
Итак, можно определить суммирование элементов данных в аб-
страктном дереве исключительно в терминах конкретных пред-
ставлений этого дерева, а именно массива троек и определен-
ных на них функциях, уравнением:
------concsum( аг) <== concsum l(ar, 1);
в котором правая часть определена уравнением для concsum1,
порожденным преобразованием.
Пример 2. Обращение списка, представленного деревом
В предыдущем примере диапазоны значений абстрактной
функции sum и ее конкретной версии concsum совпадали, а
именно представляли собой множество чисел, и, формулируя
иначе результат, мы могли бы убедиться, что отображение аб-
стракции между типами диапазонов значений есть функция
тождества В следующей главе мы увидим, что подобный вид
преобразования можно рассматривать как «треугольный», вер-
шинам треугольника соответствуют абстрактный тип области
определения, конкретный тип области определения и общий
тип диапазона значений функции. В этом примере мы рассмат-
риваем полный «квадрат», хотя типы области определения и
диапазона значений абстрактной функции (а следовательно,
также связанной с ней конкретной функции) совпадают. Од-
нако полностью общий пример, включающий различные аб-
страктные типы области определения и диапазона значений, ко-
торые отличаются также от их конкретных партнеров, был бы
гораздо утомительнее, но не дал бы более глубокого проникно-
вения в проблему.
Предположим, что необходимо представить список деревом,
возможно, с целью реализации параллелизма, в результате чего
несколько процессоров смогут манипулировать одновременно
различными, независимыми сегментами списка, которые Пред-
ставляются непересекающимися поддеревьями. Например, список
496 Часть III. Глава 17
в языке Норе [2, 8, 4, 6, 9] можно представить деревом:
Формально определим в Норе конкретный тип данных tree
объектов полиморфного типа alpha:
data tree( alpha) —— empty ++ node( tree( alpha) =#= alpha #
tree( alpha ));
Заметим, что это дерево не вполне совпадает с деревом из пре-
дыдущего примера, а именно различны базовые типы; здесь
пустое дерево, а там дерево из одного узла, или, иначе говоря,
«листа», содержащего элемент данных. Функция абстракции abs,
отображающая конкретное дерево в абстрактный список, опре-
деляется программистом следующим образом:
dec abs : tree( alpha) 1 ist( alpha );
------abs( empty) < = nil;
------abs(node(tl, n, t2)) <=abs(tl)( >[n]( )abs(t2);
где инфиксный оператор < > обозначает определенную на спи-
сках функцию присоединения, а [п] обозначает одноэлементный
список, состоящий из элемента п.
Предположим теперь, что абстрактная функция reverse, для
которой необходимо синтезировать конкретную форму revtree,
определена следующим образом:
dec reverse : list( alpha) -> 1 ist( alpha );
------reverse( nil) < = nil;
------reverse( x :: 1) < = reverse( I) ( ) [ x ];
Тогда функция revtree специфицируется следующим образом:
dec revtree tree( alpha) -> tree( alpha);
------revtree(t) <=tr st abs tr = reverse( abs t);
Связка st означает «такой, что», т. е. использован не стан-
дартный синтаксис языка Норе, но поддерживаемый расширен-
ным функциональным языком UnifHope, который упоминался
в гл. 5. Хотя эта спецификация и выполняема в UnifHope, здесь
мы поставим цель удали,ть связку st из определения функции
revtree с помощью шагов скрутки в последовательности преоб-
разований.
Преобразование программ и операционный подход 497
Для базового случая revtree преобразование выполняется
следующим образом:
-----revtree(empty) <= tr
<=tr
<= tr
st abs( tr ) = reverse( abs( empty));
конкретизация
st abs(tr) = reverse(nil);
раскрутка abs
st abs( tr) = nil;
раскрутка reverse
<=tr st abs( tr ) = abs(empty);
скрутка abs
<=tr st tr = empty; закон*
<= empty;
Достаточным условием для применения закона, обозначенного
*, в показанном шаге была бы взаимная однозначность функ-
ции abs, но нам необходимо лишь, чтобы abs (tr) =^= nil, если
tr #= empty, что очевидно. Преобразование рекурсивной части
revtree включает следующие шаги, связанные с более тонкими
рассуждениями:
------revtree(node(tl, n, t2))
<=tr st abs(tr) = reverse( abs(node(tl, n, t2)));
конкретизация
<= tr st abs( tr) = reverse( abs( tl) ( ) [ n ] ( ) abs (t2));
• " раскрутка abs
< == tr st abs( tr) = reverse( abs( t2)) ( ) [ n ] ( )
reverse( abs( tl )); закон для reverse^
< = tr st abs( tr) — abs( revtree( t2)) ( ) [ n ] ( )
abs( revtree( tl)); скрутка revtree1-
<=tr st abs( tr) = abs( node( revtree] t2), n,
revtree( tl ))); скрутка abs
< = tr st tr = node( revtree] t2), n, revtree(tl)); закон#
<= node( revtree( t2), n, revtree( tl )); 7
Таким образом, мы получили полное определение revtree кон-
кретной версии reverse, сформулированное исключительно в тер-
минах конкретного типа tree и функций, манипулирующих с объ-
ектами этого типа. Однако три шага из нашего преобразования,
обозначенные $, 1‘, #, не вполне объяснены и даже не являются,
как оказывается, обязательно справедливыми. Рассматривая
сначала последний из них, легко можно видеть, что функция abs
не является взаимно однозначной, поскольку, например, известно
два представления деревом списка [1,2]. Следовательно, мо-
жет показаться, что мы не вправе снять функции abs в правой
части уравнения, как это было сделано. Тем не менее оче-
видно, что получившееся в результате этого шага уравнение
32 — 1473
498 Часть III. Глава 17
справедливо, поэтому окончательное рекурсивное уравнение, фор-
мулирующее определение функции revtree, правильно представ-
ляет reverse в конкретной области определения. Конечно, данный
список будет представлять только одно (каноническое) дерево,
например наиболее сбалансированное дерево (с числом элемен-
тов в каждом левом поддереве, не меньшим, чем в соответ-
ствующем правом поддереве, если число элементов не является
степенью 2). Если это так, то abs — взаимно однозначная функ-
ция, и поэтому проблем не возникает.
В шаге, отмеченном +, просто берется функция abs в обеих
частях уравнения, определяющего revtree, в результате чего
получается
------abs( revtree( t)) < = abs( tr) st abs( tr) = reverse( abs (t));
<= reverse( abs( t)); no определению,
и преобразование выполняется скруткой.
Закон, связанный с отмеченным 5 шагом преобразования,
устанавливает, что для всяких списков А и В
reverse(A ( ) В ) = reverse В ( ) reverse А
По существу этот закон эквивалентен уравнению рекурсивного
определения reverse и вместе с законом reverse (nil ) = nil мог
бы использоваться в качестве альтернативной формулировки.
Тем не менее можно строго вывести это утверждение из рекур-
сивных уравнений, определяющих < > и reverse, используя
только примитивные шаги преобразования и структурную ин-
дукцию по списку А следующим образом.
В базовом случае А — nil. Следовательно,
reverse( А { ) В) = reverse( nil { ) В )
= reverse(B) раскрутка ()
= reverse(B)( >nil индукцией по В
= reverse^ В ) { ) reverse( А) скрутка reverse
Примем для индуктивного шага, что результат верен для спи-
ска А, и рассмотрим выражение
reverse( (а::А)()В) = reverse( а :: (А ( } В )) раскрутка { }
= reverse( А ( ) В ) ( ) [а] раскрутка reverse
= (reverse( В) ( ) reverse( А)) ( )
индуктивное предположение
= reverse(В)( ) (reverse(А)( )
ассоциативность
= reverse( В) () reverse( а :: А)
скрутка reverse
что завершает доказательство.
Преобразование программ и операционный подход 499
Рассмотренные два примера намного сложнее всех преоб-
разований, которые были обсуждены ранее в этой главе. Струк-
тура преобразований затуманена наличием объектных перемен-
ных, которые могут, например, препятствовать установлению
упрощающих законов. Отсутствие объектных переменных в ал-
гебраическом подходе, которое частично способствует его боль-
шей автоматизируемости, и соответствующий стиль преобразо-
ваний— это предмет следующей главы.
Резюме
• Преобразование программ представляет способ оптимизации
функциональных программ, гарантирующий сохранение их
смысла.
• Трансформационная методология раскрутки/скрутки осно-
вана на множестве из шести базовых правил.
• Применение последовательностей этих правил порождает
весьма широкий спектр преобразований, являющихся коррект-
ными с точностью до незавершения (т. е. частично коррект-
ными) .
• Последовательности правил подготавливаются программи-
стом, т. е. являются частью процесса разработки программы.
• Для поддержки этого процесса можно использовать мета-
язык, позволяющий программисту специфицировать преобразо-
вания в виде метапрограмм.
• Методологию раскрутки/скрутки можно принять для преоб-
разования абстрактных типов данных и определенных на них
функций в альтернативные конкретные формы.
Упражнения
17.1. Следующая программа на языке Норе определяет функ-
цию treeaverage, которая вычисляет среднее чисел дерева:
data tree( alpha) == tip( alpha ) ++ node( tree( alpha ) Ф
tree( alpha ));
dec treeaverage, sum, count: tree( num )—»• num;
------- sum( tip( n)) < = n ;
------sum( node( 11, t2)) < = sum( 11) + sum( t2);
------count( tip( n)) <= 1;
------count! node( 11, t2)) < — count( 11 ) 4- count( t2);
------treeaverage(t) <=sum(t) div count(t);
где div — примитивная функция деления. Используя методоло-
гию раскрутки/скрутки, преобразуйте определение treeaverage
32*
500 Часть III. Глава 17
в более эффективную форму, требующую только одного про-
хода по дереву.
17.2. Даны определения в языке Норе:
dec addn : num # 1 ist( num) —> list (num);
dec sum : list( num) -> num ;
-----addn(n, nil) <=nil;
---—addn(n, m :: z) <= (n + m):: addn(n, z);
-----sum( nil) < = 0 ;
-----sum( n :: z) < = n + sum( z);
dec g : num # list( num) -> 1 ist( num);
———g(n, z) <= sum( addn( n, z));
Преобразуйте определение g в форму, в которой нет вызовов
ни addn, ни sum.
17.3. Выражение listo(n) имеет в качестве значения список це-
лых от 1 до п включительно и определяется следующим об-
разом:
dec listo : num --> list( num);
dec append : 1 ist( alpha ) # list( alpha ) -> list( alpha );
---— listo( 0) < = nil;
-----listo( n + 1) <== append( listo( n), (n + 1):: nil);
•----append(nil, z)<=z;
-----append( x :: zl, z2) < = x :: append( zl, z2);
Эта программа неэффективна вследствие повторных обращений
к append, обусловленных копированием ее первого аргумента.
Получите более эффективную версию listo, которая не исполь-
зует append. (Подсказка: определите вспомогательную функцию
и используйте ассоциативность append.)
17.4. Объясните, почему важно устранение отождествления1)
в преобразовании абстрактных типов данных. Используя мето-
дологию раскрутки/скрутки, устраните оператор st (и, следо-
вательно, отождествление) из следующего определения функ-
ции g, тщательно объясняя справедливость каждого шага пре-
образования:
dec g : num -»1 ist( num);
dec forall : 1 ist( alpha ) =#= ( alpha -* truval) —► truval;
dec length : list( alpha )-> num;
dec isone : num -> truval;
-----g(n)<=z st (length( z) = n, forall(z, isone) = true);
-----forall( nil, p)<=true;
о Типа st. — Прим, перев.
Преобразование программ и операционный подход 501
------forall(x::z, р)<=р(х) and forall( z, р);
------length(nil) <= 0 ;
------length( х :: z) <= 1 + length(z);
------isone( x) < = x = 1 ;
17.5. Функция factlist, создающая список факториалов, опреде-
лена на языке Норе следующим образом:
dec factlist: num —> list( num);
dec factorial: num —► num ;
------factlist( 0) <= [1];
------factlist( n + 1 ) <= factorial n 1 ):: factlist( n);
------factorial0) <= 1 ;
------factorial n + 1) < = (n + 1)* factorial n);
Почему это определение factlist неэффективно? Определив под-
ходящую вспомогательную функцию, преобразуйте это опреде-
ление в форму, не осуществляющую избыточных вычислений.
Глава 18
АЛГЕБРАИЧЕСКОЕ ПРЕОБРАЗОВАНИЕ ПРОГРАММ
Несмотря на близость к полноте, трансформационная ме-
тодология раскрутки/скрутки в ограниченной степени допускает
автоматизацию, необходимую, как мы увидели в предыдущей
главе, для жизнеспособных трансформационных систем. Рас-
сматриваемые в этой главе преобразования основаны на при-
менении аксиом и теорем, устанавливающих равенство между
выражениями и имеющими некоторую структуру определения-
ми функций, отсюда проистекает термин алгебраическое пре-
образование. Экземпляры левой (или правой) части этих урав-
нений идентифицируются при разборе выражений как подвы-
ражения, и любой экземпляр может быть заменен на любой
соответствующим образом созданный экземпляр правой (или
левой) части (вследствие прозрачности по ссылкам). Оптими-
зация в связи с этим является следствием глубинного анализа,
приводящего к теоремам, устанавливающим равенство между
«исходными», определенными пользователем функциями и их
более эффективными версиями. Типичная аксиома, выраженная
в объектно-ориентированном стиле языка Норе, имеет следую-
щий вид:
f( if р(х) then q(x) else r(x)) =
if p(x) then f(q(x)) else f(r(x))
для всех функций f, p, q, г и всех объектов х. Подобно этому,
теорема, например, может устанавливать равенство между ба-
зовой функцией Фибоначчи и ее линейной версией:
fib( n) — let (u, v)==g(n) in v
где fib и g — определенные в предыдущей главе функции. Та-
ким образом, основанное на объектно-ориентированном пред-
ставлении преобразование требует анализа выражений, вклю-
чающего рассмотрение и вызываемых функций, и конкретных
Алгебраическое преобразование программ 503
аргументов, к которым они применяются. Однако рассмотрение
области определения объектов не должно быть критическим для
анализа функций, действительная цель которого заключается
в оптимизации, и можно практически не раскрывать ее. Рас-
суждая на уровне функций, на котором переменные абстраги-
руются, нет необходимости касаться дополнительных областей
определения объектов, структура функциональных выражений
получается более простой, а равенства функциями могут быть
выражены более компактно и легче распознаются. В результате
вследствие более простого синтаксиса функциональных выра-
жений можно относительно легко получить преобразования, ко-
торые можно использовать более широко. Что же касается
трудностей в автоматизации методологии раскрутки/скрутки,
то они в действительности связаны с ориентацией на объекты,
что скрывает определенные функциональные взаимосвязи.
Известно несколько схем преобразований, основанных на
алгебраическом подходе к FP, и для того чтобы описать их все
с какими-либо деталями, потребовалась бы отдельная книга.
Одна из схем связывает преобразование функций с циклами
в императивных языках или, что то же самое, с авторекурсией,
рассматривая сначала класс линейных функций (кратко го-
воря, при выполнении линейной функции осуществляется число
вызовов, пропорциональное размеру аргумента). Существуют
такие схемы, которые преобразуют нелинейные функции опре-
деленных классов в линейную форму и, следовательно, в авто-
рекурсию, примером служит функция Фибоначчи. Применяя
расширенную алгебру, которая включает аксиомы для много-
значных функций, можно механически синтезировать обратные
функции для рекурсивных функций широкого спектра. Напри-
мер, функцию split можно получить как обратную для append,
функция дает множество всех пар списков, которые, присоеди-
няясь, образуют весь список. Обратные функции имеют в функ-
циональных языках важное значение при оптимизации с отож-
дествлением и при синтезе эффективных конкретных версий
абстрактных типов данных, как мы увидим в разд. 18.5.
В этой главе, однако, нам главным образом будет интере-
сен вопрос преобразования линейных функций в циклическую
или авторекурсивную форму. Что касается других схем, то мы
просто осветим основные принципы и укажем ссылки на пуб-
ликации по соответствующим исследованиям. Прежде чем при-
ступить к этим вопросам, опишем сначала процесс абстрагиро-
вания от переменных, который позволяет конвертировать про-
граммы на языке Норе с определенными пользователем типами
данных в программы на FP. Затем введем аксиомы функцио-
нальной алгебры для FP, дав несколько примеров их
504 Часть III. Глава 18
применения, и перейдем к рассмотрению функциональных форм,
в частности их линейного подмножества. Оно в свою очередь
приведет к линейным функциям, удовлетворяющим теореме
о линейном расширении, на которой основана главным образом
теоретическая часть этой главы. Затем будет дан обзор неко-
торых из более мощных методов, упомянутых выше. И наконец,
заканчивая главу, опишем альтернативный подход к преобра-
зованию, который также алгебраичен по природе, но представ-
лен на объектном уровне. Он основан на идее передачи
продолжений, которые являются по существу функциями, пред-
ставляющими работу, «оставшуюся для выполнения» в час-
тично вычисленном применении функции. Такой путь даст воз-
можность найти с использованием нескольких эвристических
шагов авторекурсивные версии многих функций. Однако проб-
лемой остается эффективное представление продолжений в виде
структур данных, поскольку они вполне могут оказаться слож-
ными функциями.
18.1. Абстрагирование от переменных
Алгебраический подход к преобразованию использует тео-
ремы, устанавливающие родовые тождества между функциями,
в связи с чем преобразование становится скорее примером
применения теоремы, чем предписанием для определения при-
менения следующего правила в алгоритме трансформации.
Первой задачей поэтому является представление всех функ-
циональных выражений в форме, свободной от переменных,
т. е. абстрагирование от всех переменных в программе. Выше
мы уже встречались с этой проблемой и должны сначала
устранить всякое сопоставление с образцом, которое может
присутствовать, как это было в гл. 8, а уже затем применить
функции абстрагирования некоторого вида для порождения
выражений в форме комбинаторов. Один из возможных ва-
риантов— функция абстрагирования, введенная в гл. 12 для
получения аппликативных выражений, содержащих только при-
митивные комбинаторы S, К и / (вместе с другими, такими
как В и С, в оптимизированной реализации). В этой главе,
однако, мы коснемся только функций первого порядка, поэтому
наиболее удобным средством для их представления с точки
зрения устанавливаемых им аксиом и функциональной алгебры
является подмножество функционального языка FP, описан-
ного в гл. 5.
Абстрагирование от переменных в языке без сопоставления
с образцом и определяемых пользователем типов данных осу-
ществляется легко и по существу вытекает из метода, рассмот-
Алгебраическое преобразование программ 505
ренного при обсуждении CAM-машины в конце гл. 13. Компи-
ляция сопоставления с образцом в условные деревья была
рассмотрена в гл. 8. Рассмотрим здесь, как представляются
в FP определяемые пользователем типы. Для иллюстрации ме-
ханизма абстрагирования предположим, что имеется следующее
предположение, определяющее синтаксис выражения первого по-
рядка:
Е ::= константа [идентификатор \ЕЕ\{ )\(Е {, Е}*)
где, как обычно, Л1* означает нуль или несколько присутствий
М. Применение функции записывается в инфиксной нотации
с использованием двоеточия. С целью приближения к соглаше-
ниям по FP при обозначении последовательностей будем ис-
пользовать угловые скобки. Функция абстрагирования abs
для рассматриваемого синтаксиса описывается уравнением
abs( х, Е ): х = Е. Функцию f арности m можно выразить в
форме, свободной от переменных, следующим образом. Пусть
дано определение f(xi, ..., xm ) = Е, на функциональном уров-
не f имеет форму f = abs(z, [(l:z)/xi, ..., (m t z)/хт]Е),
поскольку определение на объектном уровне можно представить
как f(z) = E, где z = (xi, ..., хт), т. е. где xl = i:z.
Функция абстрагирования определяется уравнениями:
abs( х, х ) = id
abs( х, у)=у для объекта у (в общем случае, если используются функ-
— ции более высокого порядка, результатом
будет Ку)
abs(x, f: Е ) — f ° abs( х, Е) для функций f, которые нельзя выразить
с помощью объектов FP первого порядка
abs( х, {Ej, ..., Еп)) = [абз( х, £i ), ..., abs{ х, Еп )]
(В общем случае abs ( х, Et : £2) = apply ° [abs (х, Bi), abs-
(х,Е2)[, где apply — примитивный функционал, не принадле-
жащий FP первого порядка, определяемый как apply : <f, х> =
= f: х для функционального выражения f объектного выраже-
ния х. Таким образом, функция apply эквивалентна комбина-
тору А в том, что (apply ° [Д g]): х = (f : х): (g : х). Однако мы
обойдемся без этого в своем анализе функций первого по-
рядка.)
Учитывая, что мы уже можем компилировать сопоставление
с образцом в условные деревья, рассмотрим сейчас, как обес-
печивается в FP представление определяемых пользователем
типов данных. Примем тот же подход, что и в гл. 8, за исклю-
чением использования для представления составных данных по-
следовательностей вместо кортежей. Каждый конструктор типа
данных Норе задается уникальным признаком, например це-
лым числом, а структура, образованная применением п-арного
506 Часть 1П. Глава 18
конструктора, представляется последовательностью длины
п+1, первым элементом которой является признак конструк-
тора. Доступ к коду конструктора осуществляется поэтому пу-
тем выделения первого элемента представления последова-
тельности составного объекта. Выбор конкретного компонента
структуры представляется применением функции селектора FP,
которая имеет значение на единицу больше номера позиции
этого компонента в определении конструктора. Предположим,
например, что имеется следующее определение типа в языке
Норе:
data tree( alpha )== leaf) alpha) -|—|- node) tree( alpha ), alpha,
tree) alpha));
leaf и node будут задаваться признаками 0 и 1 соответственно,
так что, например, выражение leaf (39) будет представляться
в FP последовательностью <0,39). Аналогично объект node-
(leaf) 8), 7, leaf (9)) представится как <1, <0, 8\ 7, <0, 9>>.
Теперь мы можем легко перевести функцию, определенную на
дереве, из языка Норе в язык FP. Например, функция depth,
определяемая уравнениями
-1----depth) leaf) х)) < = 0 ;
------depth) node) 1, х, г)) <=1 + max) depth) 1), depth) г ));
имеет следующее эквивалентное определение в FP:
depth = eq ° [1, 0]—>0; + °[1, max ° [depth ° 2, depth ° 4]]
Таким образом можно получить эквиваленты в FP для любых
функций первого порядка Норе; для трансляции функций выс-
шего порядка не требуется нового метода, если, как обсужда-
лось в конце гл. 13, включить в язык FP дополнительные ком-
бинаторы, такие как apply и К.
18.2. Аксиомы алгебры FP
и уравнения функционального уровня
Функциональная алгебра FP основана на наборе аксиом,
получаемых из примитивных функций и функционалов (комби-
нированных форм). Читателя, не знакомого с языком FP, от-
сылаем к гл. 5, где определяется вариант нотации FP. С каж-
дым примитивом связано множество аксиом, соответствующих
его семантике, в котором есть и аксиомы, связанные с абстракт-
ными типами данных. Аксиомы представляются уравнениями
в свободной от переменных форме, что дает функциональной
алгебре полную независимость от области определения объек-
тов, поэтому всякое множество аксиом, не приводящих к про-
Алгебраическое преобразование программ 507
тиворечию, может определять алгебру. Однако, для того чтобы
быть полезным, уравнение, получаемое при применении обеих
частей уравнения аксиомы к одному и тому же произвольному
объекту, должно быть известным как справедливое и на объект-
ном уровне. Например, аксиома, соответствующая функции
выбора первого элемента последовательности, может иметь вид:
hd ° cons ° [f, g] = f для функций f, g, где диапазон значений
g — это множество последовательностей. При применении ее
к объекту х получаем уравнение hd:cons: (f:x, g :x> = f : x,
которое, как мы знаем, справедливо. Этот же аргумент при-
меним ко всем аксиомам, список которых дается ниже. Можно
допустить существование и каких-либо других примитивных
типов данных, каждый из них сделает свой вклад в множество
аксиом, но мы ограничиваемся только аксиомами для последо-
вательностей. Включение аксиом для нового типа — это простое
упражнение в спецификации абстрактных типов данных. Сей-
час мы приведем множество аксиом, которое будет использо-
ваться в этой главе в рассуждениях функционального уровня.
Все переменные имеют диапазоны значений на множестве
функций FP, за исключением лежащих в основе функций, пред-
ставляющих собой константы', в этом случае переменные будут
рассматриваться как возвращаемые в результате объекты.
18.2.1. Аксиомы для примитивных функций
Первые две аксиомы не зависят от типа:
id ° х = х ° id = х, где id — функция тождества
х ° у = х для константной функции х, в об-
ласти определения которой опреде-
лен у
Для функций, манипулирующих последовательностями, су-
ществуют симметричные наборы «левых» и «правых» аксиом,
соответствующие симметрии определения последовательностей
в FP. К левым аксиомам относятся следующие:
cons°[x, [уь = [х, У\, ...,Уп\ (и>0)
hd°{x\, ..., Хп\ = х, в области, в которой определена [х2, . ..,хп]
</о[хь ..., хп] = [х2.........хп} (га^1) в области, в которой определе-
на х,
A’fXj.....хд] ~xk в области, в которой [хр ..., xft),
xft + ), ...,xj определена
(Следовательно, функция селектора k = hd ° tlk~l для £^1.)
О функция f определена в домене D, если для xeD, f :x=/=_L для x#=_L.
508 Часть III. Глава 18
Соответствующие правые аксиомы имеют вид
consr °[[z/l,
hr ° [Xi, ..
tr°[xi..........
,Уп],х] = [yi...уп, х] ( л>0)
хп] = хп в области, в которой определена [хь
хп] = [Х|, ..., xn~i] (n^l) в области, в которой опреде-
.....Хп1
лена хп
— xn_fe + 1 ( 1 k п ) в области, в которой определена
Гх., .. , х ., х . , п, ..х 1
L 1’ ’ п—« п~ k+2 ’ nJ
(следовательно, функция селектора kr == hr°trk 1 для k 75= 1)
Примитивная функция null проверяет последовательность
на пустоту и поэтому порождает следующую аксиому
null о [ ] = Т
Заметим, что [ ] означает пустую конструкцию, которая при
применении к объекту х дает пустую последовательность < >.
Наконец, имеем
null ° (cons ° [х, у]) = F в области, в которой определена
cons ° [х, у]
Существуют также аналогичные правые аксиомы.
18.2.2. Аксиомы для комбинированных форм
Аксиомы, связанные с примитивными функционалами FP,
будут использоваться чрезвычайно широко, поскольку они
определяют структуру определений функций, подлежащих пре-
образованию Предлагаемое множество аксиом не является
полным в том смысле, что существуют равенства между функ-
циями, невыводимые из аксиом. Наиболее важные аксиомы
связаны с комбинированными формами из композиции, условия
и конструкции, существенных для определения полезных функ-
ций первого порядка. Любое, включающее другие комбиниро-
ванные формы, выражение эквивалентно одному из определен-
ных в терминах явно рекурсивных функций, которые исполь-
зуют только эти три формы, использование функций высшего
порядка обсуждалось в гл. 5. Мы не включили в множество
аксиом какие-либо аксиомы, связанные с «применимым ко
всему» функционалом а, но аксиомы функционалов «включе-
ния»/ и \ нам будут необходимы:
/°(£°Л)
/°( р-*<7; г)
(; r)°f
Р-> qp->r, s
l/i.
= (f°g)°ft (ассоциативность композиции)
= p-*f°p; f°r
— P°f >q“f, r°f
= p^q-, s
= [fi°g. --.,fn°g]
Алгебраическое преобразование программ 509
[... (p->f , g) ...] = р->[ . g ...]
= f°[xI, If°[x2, ...,**11 (n>2)
= f°[\f °[*i. • • xn_,J, xn] ( n >2)
/fo[x] = \fo[x]
/fo[xb ...,Xn]
\f° [X1....Xn]
Если ранее в языках объектного уровня мы определяли функ-
цию как выражение, дающее результат в терминах ее формаль-
ных параметров, то теперь определим функционал, исходя из
порождаемых им результатов при применении его к формаль-
ным функциональным параметрам. В этой главе рассматри-
ваются только функционалы с одним параметром, применение
функционала Н к функции f обозначается как H(f), или для
кратности Hf, используя положение символов рядом друг
с другом. Выражение Hf с переменной f часто называют фор-
мой в отличие от термина «функционал», примером которого
является Н. Функционал же Gen переменными будет опреде-
ляться формой G (fi, ..., fn).
Будем рассматривать далее в нашем исследовании методов
алгебраического преобразования функции, определяемые урав-
нением вида
f = p-+q; Hf
для некоторого функционала Н и фиксированных функций р
и q. Свойства таких функций, очевидно, определяются структу-
рой Н, которая часто выражается с помощью функциональных
композиций. Композиция функционалов Hi и Н2 также запи-
сывается как Н = HiH2, что для функциональной переменной f
определяется как Hf = Hi(H2f). Тождественный функционал
будет обозначаться через ID, определяемый как lD(f) — f, т. е.
IDH = HID — H. Через Нп обозначается л-кратная функцио-
нальная композиция, определяемая следующим образом: Н°—
= IDHnf = H(Hn~lf) для п Js 1.
В качестве простого примера рассуждений на функциональ-
ном уровне, используемого нами и далее, рассмотрим выраже-
ние Нп1, где Н определяется как Hf = f ° [/ ° 1, k], а / и k —
фиксированные функции. Для п = 1 результатом будет 1 °J
° [/° 1, £] = / ° 1, что вытекает из аксиом для последовательно-
сти. Следовательно, для п ~ 2 результатом будет
о [/ о 1, &] — /2 о 1, и по индукции мы можем доказать, что Нп\ =
=-fn°\. Базовый случай уже имеем, и предположим, что
Нп\ = jn ° 1 для п 0. Тогда
Яя+'1 =Я(Ял1) = (//п1)»[/о1, й]
= /л° 1 о[/□ 1, ft]
= /по/о 1
= ;rt+1ol
по индуктивному предположению
по аксиомам для последовательности
что м показать
510 Часть III. Глава 18
Сейчас мы приступим к рассмотрению специального случая,
в котором функционал Н линеен (что формально определяется
в следующем разделе), т. е. дает линейную функцию f и при-
водит к циклическому представлению f.
18.3. Линейные функции и теорема
о линейном расширении
Интуитивно линейная функция — это такая функция, кото-
рая при выполнении порождает число вызовов себя, растущее
линейно в зависимости от величины аргумента, к которому она
Рис. 18.1. «Гребневидное» дерево редукции для линейной функции.
применяется. Отсюда, разумеется, вытекает, что авторекурсив-
ные функции линейны, они определяются в обозначениях пре-
дыдущего раздела уравнениями вида f — р q\ f°x для неко-
торой фиксированной функции х, что соответствует функцио-
налу Н, определяемому как Hf = f°x. Однако авторекурсивные
функции образуют лишь небольшое подмножество линейного
класса, и любая функция с «гребневидным» деревом редукции,
т. е. деревом, которое растет однонаправленно вниз вдоль сво-
его левого ответвления, как показано на рис. 18.1, должна
быть линейна; типичнейшим примером является функция фак-
ториала.
В дереве на рисунке узлы, помеченные символом а, пред-
ставляют вызовы двухместной функции а, которая имеется
в уравнении, определяющем линейную функцию, скажем f,
а подчиненные поддеревья каждого узла представляют выра-
жения ее аргументов. Узлы дерев-а, помеченные е,
обозначают выражения, которые еще не специфицированы, но
уже не включают вызовов f; при вычислении аппликативного
порядка они становятся листьями *>. Лист b соответствует при-
менению базового случая f, например <?; величина же п про-
о С точки зрения теории графов, эти узлы всегда листья. Здесь имеет-
ся в виду, что они становятся узлами, для которых известно значение соот-
ветствующего выражения. — Прим, перев.
Алгебраическое преобразование программ 511
порциональна некоторой мере от величины аргумента, которой
может быть, например, величина целого числа (для случая
факториала) или длина списка (для случая обращения списка).
В случае применения функции факториала к аргументу х имеем
п = х, ei = n, е2 = п—1, ел = Ь = 1, а а — *, т. е. опе-
ратор умножения, граф имеет вид
Теперь поставим вопрос так: какое свойство Н мы можем
определить для данной функции f, определяющейся уравнением
f = p-^q', Hf, которое бы показывало линейность f в указанном
смысле? Для ответа на него рассмотрим следующие нерекур-
сивные расширения f.
Пусть дано выражение f — p^q-, Hf. Получим расширен-
ную версию подстановкой определения f вместо вхождения f
в правой части. Это приводит к уравнению
f=p-><T, H{p^q- Hf)
повторение операции дает
H(p>q; H(p^q; Hf))
и так далее. Так этот процесс может продолжаться до беско-
нечности, а число термов может расти в высшей степени нели-
нейным образом в зависимости от определения Н. Например,
функция Фибоначчи интуитивно явно является нелинейной,
имея сбалансированное дерево редукции. Здесь каждое при-
менение Н в выражении приносит еще два Н, поэтому число
термов растет экспоненциально с ростом числа подстановок для
f, выполняемых в правой части. Для получения линейно расту-
щего числа термов необходимо распределить функционал Н
через условное выражение и достаточно, чтобы для всех функ-
ций а, Ь, с выполнялось свойство
H(a->b-, c) = Hta^Hb; Нс
для некоторого функционала Ht, который называется преди-
катным преобразователем Н. Это свойство определяет функцио-
нал Н как линейный и, что эквивалентно, форму Hf как ли-
нейную. (В действительности, для того чтобы убедиться
512 Часть III. Глава 18
в сходимости расширения, ниже будет использовано дополнитель-
ное условие, которому должен удовлетворять линейный функцио-
нал Н, а именно следующее: если для любого объекта х
/7 _L : х =]= _1_, то для любой функции а имеет место Hta-.x =
= Т. Очевидно, что это условие выполняется, если функционал
Н строгий, т. е. Н _L = J_ )
Тогда для линейного функционала Н вышеприведенное рас-
ширение упрощается до
f = p-+q; Htp-+Hq-, ...; Hntp^Hnq-, Hn+lf
для всех п 0. Таким образом, мы приходим к теореме о ли-
нейном расширении (ТЛР):
Если Н — непрерывный линейный функционал, тогда функ-
ция /, определенная как f — p-^-q-, Hf для фиксированных
функций р, q, задается следующим образом:
f = p^q; Htp^Hq- ...; Hfp^Hnq-, ...
Условие линейности H(a-+b\ с) = Hta^ НЬ ; Нс, конечно,
является достаточным для того, чтобы /' имела нерекурсивное
расширение, но оно не является необходимым. Свойство, по
которому //(а—>-6; с) — Нta->H\b, для некоторого функцио-
нала А/j было бы также достаточным, но в действительности
оно также не является необходимым. Теоремы о расширении
для определенных классов нелинейных функций рассматривают-
ся в [37,90].
Будучи вполне корректной, наша формулировка ТЛР не-
сколько неточна. Для склонного к математической точности
читателя сформулируем теорему более строго. Если определить
последовательность функций /,• как
А>=±
fn+l = р ~>q\ Htp-> Hq\ ... ; Htp-+Hnq-, J_ для n>0
то ТЛР утверждает, что для линейного Н наименьшим реше-
нием уравнения f = p—^q-, Hf является
ИгП(1->оо) f i
Справедливость этого результата докажем, установив сна-
чала рекуррентное соотношение
fn+i = P^q\ Hfn
Разумеется, оно справедливо, если функционал Н строгий. Если
Н не является строгим, то для всякого объекта х или
Алгебраическое преобразование программ 513
ИЛИ
Н ± : х =/= ± и Htp : х = Т, так что Hfn ' х = Hq х
В любом случае fn+i: х = (р-+- q ; Hfn):x, что и требовалось
доказать.
Теперь, поскольку последовательность (f0, fit ...) возрас-
тающая (в смысле увеличения цепи Клини), она должна иметь
предел в пространстве функции, которое является законченным
частичным упорядочением (домена), а этот предел — по тео-
реме о фиксированной точке (см. приложение Б) — наимень-
шая фиксированная точка уравнения для Д
' Согласно аксиоме дистрибутивности для условных выраже-
ний, порождаемых ТЛР, бесконечные условные выражения
представляются для композиции с непрерывной функцией g
как
. .. ; Hntp->Hnq-, ... )<•§ =
= р<,£•-► (jog; ...
и
g’°(p-*7; •••; Hlp^Hnq\ ...) =
= p-+g°q; Hntp^g°(Hnq'y, ...
Это справедливо тогда и только тогда, когда (limfi) °g=z
= lim(ft°g) и g°limft — Hm(gofi), что выполняется вслед-
ствие непрерывности функционала композиции и функции g.
Сейчас мы в состоянии легко идентифицировать базисное
множество элементарных линейных форм, проверяя на линей-
ность условные выражения. Но еще более важным выводом
является то, что множество линейных форм замкнуто: если
функционалы Н и G линейны, то линейна и их композиция HG,
а предикатный преобразователь HtGt является композицией пре-
дикатных преобразователей Н и G соответственно. Этот резуль-
тат называется теоремой о композиции функционалов [8]. Если
L = HG, то можно легко показать, что для произвольных функ-
ций а, Ь и с
L(a->b; с) = Lta^> Lb; Lc
где Lt = HtGt:
L(a->b; c) — H(G(a—> b ; c))
— H(Gta -> Gb; Gc), поскольку G линеен
= Ht( Gta) -> H(Gb); H(Gc), поскольку H линеен
— Lta->Lb; Lc
Сложная часть доказательства теоремы заключается в под-
33 — 1473
514 Часть III. Глава 18
тверждении дополнительного условия для L, которое мы упо-
мянули выше при определении линейного функционала, мы
опускаем эту часть.
Базисный набор линейных функционалов, называемых про-
стыми линейными функционалами, или для краткости ПЛФ,
приведен вместе с соответствующими предикатными преобразо-
вателями в табл. 18.1. Символы f и а используются для обозна-
чения функциональных переменных, другие символы обозна-
чают произвольные фиксированные функции, многоточие обо-
значает конечную последовательность фиксированных функций,
например ..., гп для пг^О.
Таблица 18.1. Простые линейные формы
Линейная форма, Hf Форйа предикатного преобразователя, Н^а
Г т
for aor ( Hj = Н)
Г ** f a (Ht = lb)'
[..., А...1 a (Hf-ID)
{например, обычными являются f присутствие! в конструкции только один
16 г] и Hf = [r, fl) раз
Р —> р —► Т ; а
Р —> f'.r р —> а; Т
f — г a (Ht = ID)
Линейность каждой из перечисленных в таблице форм показы-
вается весьма легко. Например, в случае первой формы для
произвольных функций а, Ь, с:
Н(а-+Ь\ c) — r = T-+r; r = Hta-»Hb-, Нс
В действительности вместо Т-*~г; г можно было бы написать
и F->r; г или Ь-+г; г, где b — любая булева функция. Следо-
вательно, предикатный преобразователь Т, приведенный в
табл. 18.1, неоднозначен. Во втором случае имеем
Н(а-+Ь; с) = (а->Ь-, с)°г
— a°r->b°r; со г по аксиомам для условных
выражений
~На-->НЬ\ Нс т. е. Ht = H
Доказательства для других случаев в такой же степени про-
сты, и мы оставляем их в качестве упражнений. Хотя эти до-
казательства достаточны для строгих функционалов Н (а Н
всегда является строгим в случаях Hf — for, г of и [..., f, ...]),
в общем случае необходимо также показать выполнимость вто-
Алгебраическое преобразование программ 515
рого условия для линейности. Это доказательство также остав-
ляется в качестве упражнения.
Применяя теорему о композиции к этим ПЛФ, можно уста-
новить весьма богатый класс линейных форм и соответствую-
щих предикатных преобразовдтелей. Он представляет линейные
функции, которые мы в следующем разделе преобразуем в
итерационную форму: в циклы или авторекурсивные функции.
Заметим, что все построенные из трех примитивных функциона-
лов: композиции функций, конструкции и условного выраже-
ния, формы Hf, содержащие единственное присутствие функцио-
нальной переменной f, должны быть линейны.
Таким образом, например, форма Нf = h ° [i, f о/] линейна
и имеет предикатный преобразователь, определенный как Hta ~
= ао]. Это следует из того, что Н = Н1Н2Н3, где Hif — h°f,
H2f = [i,f], H3f = f°j. Отсюда H\t = ID, H2t = ID, H3ta = a » j,
a Ht = ID.ID.H3t = H3t. На самом деле подобная форма может
быть сразу же идентифицирована как линейная применением
упомянутого выше эвристического правила, а ее предикатный
преобразователь получен нахождением «композиции всех функ-
ций, участвующих в композиции с f справа». Значимость этого
примера определяется тем, что он охватывает и рассмотренный
уже пример факториала. Если f — p-^q- Hf, то, присваивая
функции р значение eq 0, q—1, h — *, i — id, j — sub 1, полу-
чаем определение факториала. Но, кроме того, эта форма по-
крывает и другие функции. Например, присваивание р значе-
ния null, q— [ ], h — consr, i — hd, j—• tl приводит к функции
reverse, которая обращает заданную последовательность.
Несмотря на удобство приведенной эвристики для ручных
выкладок, очевидно, систематическая декомпозиция формы в
ПЛФ более всего подходит для автоматической компиляции.
Фактически в точности такую декомпозицию должен выполнять
синтаксический анализатор в любой реализации подобных вы-
ражений, и для получения предикатных преобразователей необ-
ходимы минимальные дополнительные усилия. Мы продолжаем
обсуждение этого вопроса в следующем разделе, где в процессе
синтаксического анализа будут также строиться циклы, соот-
ветствующие линейным функциям.
18.4. Итерационные формы линейных функций
Используя теорему о линейном расширении, можно сформи-
ровать итерационную реализацию, соответствующую линейной
функции, определяемой в форме f — p^-q-, Hf. Эта реализация
может принимать форму или цикла (или пары циклов), опре-
деленного объекта, или эквивалентной авторекурсивной версии f.
33*
516 Часть III. Глава 18
Рассмотрим первую альтернативу, которая несколько проще и
не требует дальнейшего преобразования в императивную реа-
лизацию; исследование второй можно найти в [40].
Если для заданного в качестве аргумента объекта опреде-
лена функция f:x, то по ТЛР f : x — (Hnq) : х, где п — такое
наименьшее целое, что (JHntp) : х = Т. Следовательно, для при-
менения f к х функция f в принципе может быть «вычислена»
итерационно в цикле. При этом начинаем с известной функ-
ции g в накопителе и применяем И к накопителю п раз. При-
менение окончательного содержимого накопителя к х даст
результат. Конечно, в общем случае увеличение сложности функ-
ций в последовательности q, Hq, H2q, ... делает этот подход не-
практичным, и необходимо произвести более сложную работу
для нахождения цикла на объектном уровне. Лежащая в основе
предлагаемого метода анализа идея заключается в том, что
если для выражения f: х действительно существует реализация
циклом, то цикл должен включать присваивание накопителю
значения выражения, которое зависит от двух параметров: те-
кущего состояния накопителя и от некоторой входной перемен-
ной цикла задаваемой счетчиком цикла t на i-й итерации.
С целью получения такого выражения введем обозначение
rl = {Hiq)‘. xt для 0 i <? п и некоторого множества {х, 10
х„ = х, где п — определенное выше целое. Тогда по
ТЛР rn = f:x и можно найти соответствующее Н выражение
объектного уровня Ен, обладающее таким свойством, что п =
= Ец( ri-i, xt) для 1 sC i ss? п. Множество объектов {г, 11 sC [
п} можно вычислить итерационно в цикле с использованием
присваивания накапливающей переменной г := Ен( г, xi), при-
водя к г = гп в накопителе, что и требуется в результате по-
следней итерации. Следовательно, Ен можно рассматривать как
метку для узлов в графе линейного выражения на рис. 18.1.
Если функционал Н полностью построен из ПЛФ, то, как мы
увидим, п и {xi} можно вычислить для любого объекта х из р
и Ht, который получается описанным в предыдущем разделе
способом. Поскольку мы знаем также, что начальное значение
накопителя г — r0 =q : х0, остается только определить выраже-
ния Ен ( и, v ) для объектных переменных и, v.
Определим сначала выражение Ен, когда Н является ПЛФ,
а затем уже определим выражение для случая, когда Н — ком-
позиция ПЛФ. Если Н = Hi ... Нп, где каждый Hi есть ПЛФ
(l^ts£n), Ен определяется через ЕН\, .... ЕНп (и по суще-
ству через Ни, ..., Hnt). В целях простоты рассмотрим только
функционалы С, являющиеся композициями следующих трех
введенных в предыдущем разделе ПЛФ: Hf — for, Hf = r°f и
Hf— [..., f, ...], где г — произвольная фиксированная функ-
Алгебраическое преобразование программ 517
ция. а многоточие обозначает конечную последовательность фик-
сированных функций. Будем называть функционалы С такого
типа композиционными линейными функционалами (КЛФ).
Случай ПЛФ, когда Hf = г для всех функций f, тривиален —
функция, определяемая уравнением f = p-^q\ г является не-
рекурсивной; то же самое справедливо, когда Н— композиция
из КЛФ, включающих функционал такого типа. Композицион-
ные линейные функционалы, содержащие условные выражения,
анализируются аналогично третьему рассматриваемому типу
КЛФ, включающему конструкции. В действительности в [39]
рассмотрено более широкое множество простых линейных функ-
ционалов, включающее, например, функционал Н, определяе-
мый как Hf — [..., Af, .Bf, ...], где А и В — линейные функ-
ционалы с равными предикатными преобразователями At = Bt.
В этом случае класс линейных функций, преобразуемых в ите-
рационную форму, гораздо более широк, нежели тот класс,
к которому мы обращаемся здесь. Тем не менее рассматривае-
мый нами пример обладает достаточной степенью общности
для того, чтобы объяснить затронутые принципы.
Сначала покажем справедливость следующей важной леммы,
используемой в доказательстве излагаемой ниже теоремы.
Лемма 18.1. Для заданного КЛФ при любых функциях f
Htf = f°Htid.
Доказательство. Обозначим функцию Htid через j и прирав-
няем ее к j в случае факториалоподобной формы Hf~h°
•° U, f ° /] • Доказательство леммы проведем индукцией по числу
ПЛФ в композиции Н. (Предикатные преобразователи для каж-
дой из рассмотренных ПЛФ приведены в табл. 18.1.)
Базовый случай. Если Hf = f°r, то j — Had = id°r = г.
Следовательно, Htf — for = f°j.
Если Hf = r of, to / = Htid = id. Следовательно, Htf = f =
= f ° /•
Если Hf = [..., f, ...], to j = Htid=id. Следовательно,
Htf = f = f°j.
Индуктивный шаг. Предположим, что Н = Н\ ... Нт для
т 2, и пусть L = Н\ ... Нт-\. Примем индуктивно, что
— f ° Ltid для всех функций f. Но
= Hmif)
— Н mtf ° Lyd
= f ° Lfid
~f°Lt( Hmtid)
— f°Htid
по теореме о композиции функционалов
по индуктивному предположению
по равенству из базового случая
по индуктивному предположению
по теореме о композиции функционалов,
Это завершает доказательство.
518 Часть III. Глава 18
Рассмотрим теперь функцию, определяемую уравнением f =
= р-><7; Hf, и применение f:x к, значению, не являющемуся
основанием. Первое следствие из леммы заключается в том, что
наименьшим целым п, таким, что Н1р:х = Т, является такое
наименьшее п, что р: jn:x = Т, которое легко вычисляется в
простом цикле «пока» последовательным применением / к х,
а затем р — к результату. Осуществим дальнейшее использова-
ние этого же цикла «пока», определяя множество {х,-10 i п}
как хп = х и x(-i = / : х( = jn-‘+l _ х для 1 i п. Это множе-
ство, как мы увидим, действительно потребуется в следующей
теореме.
Нам уже известно из предыдущего раздела, как вычислять
предикатный преобразователь Ht КЛФ Н. Теперь нам нужно
определить аналогичным образом выражение Ен. Ключевое
свойство, которым должно обладать это выражение, заклю-
чается в том, что ( Hf): х — Ен(( Htf): х, х) для всех функ-
ций f и объектов х. Сформулируем теперь теорему.
Теорема 18.1. Пусть для данных КЛФ Н, целого п>0 и
объекта г0 множество {rt 11 i п} определяется через п =
= {H'q) :xi, где {xjO^i^n}—определенное выше множе-
ство. Тогда ri = Ен(Г1-1, хг) для 1 I п.
Доказательство:
ri = (Hiq):xl = (H(Hc ’y)):xz
для 1 'C i :C n
= E((/Zz(/Z'-|?):xz, Xi)
по предположению, подставляя Hl~lq
вместо f и заменяя для краткости Eff
на Е
= E^Hl~rqaHtid):Xi, Xi)
= E((Hl~lq):xi^i, xt)
= Е(гг_ь Xi)
по лемме 18.1, подставляя Нг
вместо f
по определению xz_i для Z^l
по определению ri для i 1
Отсюда непосредственно следует итерационная реализация вы-
ражения f:x в виде пары циклов: упомянутого выше цикла
«пока», вычисляющего п и множество {xz| 0 i п} и цикла
«для», который пускается п раз для вычисления f:x через г,
начиная с гq :xq и последовательно присваивая (п раз)
г :=Е( г, Xi).
Таким образом, нам следует только определить соответствую-
щие выражения Ен для произвольных КЛФ Н, удовлетворяю-
щих условиям. Требуемые определения (справедливость их до-
Алгебраическое преобразование программ 519
называется в приводимой ниже лемме) выражаются следую-
щим образом:
Если Hf = f°r, то Ен{и, v ) = и для объектных переменных и, о
Если Hf = rof, то Ед(и, v) = r:u для объектных переменных и, v
Если = .........г,, f, rz+1, то
£я(и, о) = (г1:о..r{:v, и, r< + ,:v.rn:v)
для объектных переменных
Если Н = ВС, где В — одна из трех рассматриваемых здесь ПЛФ, а С —
КЛФ, то ЕД и, v) — ЕД ЕДи, В yd : v ), v )
Для завершения теоретической части раздела рассмотрим
следующую лемму.
Лемма 18.2. Приведенное выше определение выражения Ен,
связанного с КЛФ Н, удовлетворяет условию (Hf):x =
= Ен( (Htf) :х, х) для всех функций f и объектов х.
Доказательство. Используем снова индукцию по числу ПЛФ
в композиции Н.
Базовый случай.
Если Hf = f°r, то HJ : х, х ) = H}f : х = (f°r):'x = Hf: х
Если Hfi=r°f, то Е H(Htf : х, х ) = г : (Я tf : х ) = г : (f: х) = (г® f ): х =
= Hf:x
Если Hf = ., rt,f, ..г„], то Ен (Hff : x, x ) = [г(: x.r, : x
Htf-.x, ri + 1:x>...,rn:x] = [r1,...,rl, ID( f), r; + 1, ..r„] : x = Hf : x
Индуктивный шаг. Предположим, что Н = АВ, где А —ПЛФ
из базового случая, а В — КЛФ. Тогда
ЕДНД.х, х) = ЕДЕДНД.х, Ayd'.x), х) по определению ЕАд
= ЕД ЕД Btf : Ayd : х, Ayd : х ), х )
Htf = At( B/f ) по теореме о функциональной композиции
= Вtf : Afid по лемме 18.1
Следовательно,
Eff( Ну : х, х ) = ЕД Bf : Ayd : х, х) по индуктивному предположению
= £4((Bf°A/zd):x, х)
= ЕД At( Bf ): х, х) по лемдое 18.1
= Л( Bf ): х так как А — ПЛФ из базового случая
— Hf:x
что завершает доказательство.
Таким образом, всякую линейную рекурсивную функцию,
определяемую уравнением вида f = рq; Hf, где Н—КЛФ,
действительно можно реализовать парой описанных выше цик-
лов, цикла «пока» и цикла «для», которые просто записываются
520 Часть III. Глава 18
в терминах р, q, Htid и Ен (что оставляется читателю в каче-
стве упражнения).
Рассмотрим, как работает преобразование, взяв в качестве
примера обобщенную функцию факториала. Она задается урав-
нением f = p^q-, Hf, где Hf = h°[i, f°j], Как и в предыду-
щем разделе, запишем Н — Н\Н2Н3, где Hif = h ° f, H2f — (i, fl,
H3f — f°j, Нц = ID, H2t = ID, H3t = H3 и поэтому Htid = j.
Теперь мы имеем для ПЛФ Н\, Н2, Н3 соответствующие выраже-
ния Ei(u, v) = h:u, Е2(и, v) = {i:v, u>, E3(u, v) = u. Отсюда
по теореме 18.1 предложение присваивания в цикле имеет вид
r-.= EHfr, xi) = £I(£'2(£3(r, HuH2tid:Xi), x( )
= £1(£2(£з(г’ xz)- хЛ \ )
= £.(£2('> ХЛ xj подставляя предикатные преобразователи
= £1(<г:х1, г), х/)
т. е.
г := h : (i: xt, г)
Следовательно, в случае факториала, для которого p = eqft,
q = 1, h = *, i = id и j — sub 1, получаем присваивание в цикле
r:=*:<x„ г> и Htid — j = subl. Для функции обращения, где
р = null, q = [ ], lt=consr, i = id, a j = tl, получаем r :=
:= consr : {hd :xt, г) и Htid = j = tl.
Рассмотренные преобразования обеспечивают по существу
только минимальное повышение производительности, поскольку
устранены только вызовы рекурсивной функции. Однако это не
удивительно, принимая во внимание общность схемы, примени-
мой ко всем линейным рекурсивным функциям, определяемым
КЛФ, часть из которых вообще неоптимизируема, а примером
служит функция обращения элементов заданной последователь-
ности. При выполнении этой функции необходимо сначала
породить последовательность ее рекурсивных вызовов, продол-
жающуюся до достижения базового случая, а затем завершить
соответствующие применения функции, используя аргументы, ко-
торые должны были быть сохранены в начальной последова-
тельности вызовов. Если невозможно перестроить эти аргумен-
ты, начиная с аргумента базового случая и повторно применяя
некоторую фиксированную функцию, то не существует ясной
альтернативы реализации применения функции за два прохода:
первый — для предвычисления и занесения в стек всех аргумен-
тов вплоть до базового случая, второй — для последовательного
завершения вычисления конкретизированных значениями аргу-
ментов из стека выражений, определяющих функцию. В случае
функции обращения каждый помещаемый в стек после первого
(того, что применяется на верхнем уровне) аргумент является
хвостом списка для предыдущего, который поэтому нельзя ре-
Алгебраическое преобразование программ 521
конструировать из-за разрушительной природы функции tl, ко-
торая отбрасывает голову списка своего аргумента. Однако
в случае факториала следующий помещаемый в стек аргумент
является Целым числом, на единицу меньшим текущего аргу-
мента, поэтому в этом случае предыдущий аргумент можно ре-
конструировать путем прибавления единицы. Таким образом,
в реализации функции факториала нет нужды в хранении в
стеке аргументов.
В общем случае «следующий» аргумент получается путем
применения известной функции j = Htid к «текущему». Следо-
вательно, можно избежать построения стека, если мы знаем, что
функция / имеет обратную функцию /_| и способы определить
ее. В этом случае не строится промежуточный стек, но нельзя
полностью обойтись без цикла «пока», поскольку необходимо
узнать число итераций п, требуемое в цикле «для», а также зна-
чение аргумента хо в базовом случае. Для определенных функ-
ций, правда, эти два значения можно узнать, не прибегая к вы-
полнению цикла «пока». Например, если предикатная функция
p = eqQ, a j = sub\, то п — х (аргумент верхнего уровня),
а хо = 0. Аналогично если p = null, а / = tl, то n = length(x),
а Хо =< >, где применение функции length является простой
операцией, если длина списка поддерживается в его дескрип-
торе. Однако напоминаем, что в последнем случае мы не знаем
и поэтому не можем обойтись без цикла «пока». Единствен-
ным выигрышем будет упрощение его тела, вызванное ненуж-
ностью обновления счетчика.
Итак, можно удалить; цикл «пока» только в случае, когда
/ имеет известную обратную функцию, и, компилируя, можно
сгенерировать код, необходимый для получения, х0 и л во
время выполнения. На практике функция / обычно имеет
весьма простую структуру, например она может быть такой
примитивной, как sub 1 или tl в наших примерах. Более того,
можно использовать упоминаемую в этой главе теорию обрат-
ных функций для значительного расширения диапазона таких
функций, для которых может быть найдена обратная функция.
Таким образом, при выполнении указанных условий результи-
рующий цикл, соответствующий применению к аргументу а функ-
ции определяемой как f = p-+q-, Hf, имеет следующий вид:
и := NumberOfIterations(j, р, а);
х := BaseValue(j, р, а);
г := q : х ;
for i1 to n
x := j-1: x;
r:=EH(r, x)
end
522 Часть III. Глава 18
Код для функций Numberoflteratins (Число Итераций) и
BaseValue (Базовый Случай), как и для функции Ен, генери-
руется компилятором. В случае факториала цикл имеет вид
п := а;
х := 0;
г := 1;
for i :== 1 to n
x :== addl : x;
r := * : (г, x)
end
Это обычная императивная реализация факториала, рабо-
тающая в направлении от базового случая вверх к а. Заметим,
что в равной степени общепринятая реализация цикла рабо-
тает в направлении от аргумента верхнего уровня вниз, т. е.
в обратном направлении. Возможность такого обращения цикла
определяется свойствами ассоциативности и коммутативности,
которыми здесь обладает примитивная функция умножения *.
В общем случае можно обойтись без цикла «для» обращением
цикла «пока», если выполняется подобное, менее ограничитель-
ное свойство ассоциативности, естественно согласующееся с при-
веденной выше схемой преобразования. Это условие связано
с функцией Ен, и у нас нет нужды в обладании обратной функ-
цией по отношению к поскольку цикл «пока» ис-
пользует эту функцию как отвечающую за порождение его ите-
раций. Сформулируем результат, основанный на работе [39],
используя определенную выше нотацию:
Пусть а0 = у0 = х и = £я(у., а(-_| ), 1/г = /: Уг-1( t > 1 )•
Тогда Hf:x — Ен( q : у п, ап_х ), где п = minl { р: : х = 7’},
если Ен(и, EH(v, w)) = £я( Ен( и, v), га) для всех объектов и, v, w.
Можно аналогично показать, что при этом условии функ-
ция f имеет следующую авторекурсивную форму:
f = p->q- Eo[qojol, 2]°g°[j, id]
где
g = p°l-+id; g°[j°l, £]
и функция E в FP определяется как Е: <u, v) — EH(u,v).
Результат Кьебурца и Шультиса [57], который при опреде-
ленных условиях дает авторекурсивную форму для функций
определенного выше факториального класса, действительно
устанавливает особый случай этого преобразования, а точнее
Алгебраическое преобразование программ 523
непосредственное обобщение его. Этот результат устанавливает
для заданных функций f и f*, определенных как
f = p^-q\ h°[i, f ° j] и /’ = p ° 1 -» h о [2, q о 1 ];
f* о [j о 1, h ° [2, 1]]
где фиксированная функция h ассоциативна по отношению к ле-
вому единственному объекту и справедливо f = f*°[id, и].
(Объект и является левой единицей функции h тогда и только
тогда, когда h° [и, х] = х для всех функций х.)
Теперь докажем этот результат, используя ТЛР и сравни-
вая общие члены выражений в обеих частях предложенного
равенства. Если для каждой пары соответствующих членов
можно показать, что они равны, тогда и (сходящиеся) расши-
рения, а следовательно, и их функции должны быть равны.
Рассматривая сначала левую часть, определим функцио-
нал Н как Нх = h о [i, х »/], где х — функциональная перемен-
ная, поэтому, как мы видели в разд. 18.3, Htx = xoj. Отсюда
Htp = р° ] .
Теперь
Hnq — Л°[/, (Hniq)°j] для п 2* 1
= h<> [z, ho [z, ( Hn~2q )° /] ° j] длял>2
= h ° [/, h ° [i о ( Hn~2q ) о j2]] по аксиоме конституции/композиции F P
= ho [z, h ° [zо h° [zо j2, ..., h° [i° jn~h° [z® Jn-1, ( H°q )°/n] ... ]]]
= /ho [i, iо jt ...t iо jn~11 qо jra] для n 0
что можно строго доказать индукцией по п. Заметим, что этот
результат верен для п = 0, если условиться, что последователь-
ность iri°j, ..., iojn-1 в этом случае пуста, приводя к /h°[q\,
что равно q по определению /h. Таким образом, общий член
для левой части имеет вид
ро jn jha [i, io j, . . io q □ jn] для n > 0
Обратимся сейчас к правой части, определив функционал G
как Gx = xok, где фиксированная функция k = [j°\, h ° [2,
io 1]], откуда следует равенство Gt — G. Тогда, если q* = ho [2,
<7 о 1 ], функция f* определяется уравнением f* = р о\^>- q*-, Gf*,
а предикат общего члена в ее выражении имеет вид
G"( po\) = polok’1 — pojn о I, что следует из полученного в
разд. 18.2 результата.
Теперь
Gnq* = q*okn
= h°[2okn, <7“1о/гп] по аксиоме конструкции/композиции FP
= ho[2okn, qojno 1] до тому же результату из разд. 18.2
524 Часть III. Глава 18
Но
2°£л=/1о[2, z°l]%n-1 ( п > 1 )
= Л=[2 = А:П-1, jof-’ol] используя тот же самый результат
= Л» [ft° [2*fen-2, z’°/n-2°l], i°/re-1ol]
= \Л°[2, z’°l, i»j°l......i°jn~1 ° 1] (n.^0)
повторяя тот же аргумент. Снова легко доказать этот резуль-
тат, строго используя индукцию по п, оставим читателю это
доказательство в качестве упражнения.
Таким образом,
Gnq' = h° [\h. о [2, i ° 1, i ° j ° 1, ..., i ° jn ~1 ° 1], q ° jn о 1] (га 0)
= \h ° [2, i ° 1, i ° j’ ° 1, .. ., i о jn~1 о 1, q о jn о 1 ]
Общий член в правой части поэтому имеет вид;
ро jno 1 о [id, и] ->\h« [2, z’° 1, i ° j» 1, .... I ° jn~1 ° 1, q о jno 1] о [id, u] ( n 0 )
t. e. poj ->\n ° [u, 1, 1 ° ].i°j по аксиоме селектора/конструк-
ции FP
т. e. p° jn /h°[u, i, i° j, ..i° jn~l, q° jn] поскольку h ассоциативна
т. e. p° jn -+ h° [zz, lh° [z, i ° j, ..., i° jni, q° j"]]
л ,, r. . . . -n-l .»!
т.е.р°1 ->/Ло [z, z°/, ..., z°/ , <7°/ J поскольку zz есть левая едини-
ца h
Это выражение совпадает с тем, что мы получили для левой
части для всех п 0, следовательно, равенство доказано.
Интуитивно можно догадаться, что второй аргумент функ-
ции f* соответствует накапливающей переменной в императив-
ном цикле «пока», установим его начальное значение равным
единичному объекту функции h в соответствии с композицией f*
с конструкцией [id, и]. Первый аргумент соответствует входной
переменной цикла, начальное значение которой задается рав-
ным аргументу f опять-таки в соответствии с композицией f*
и. [id, и], и последовательно «уменьшается» (при рекурсивных
вызовах f*, соответствующих итерациях цикла), пока не вы-
полнится условие выхода из цикла.
Для функции факториала, например, будем иметь p = eq0,
h = *, j — sub 1, i = id., u=l, поэтому f* определяется следую-
щим уравнением;
f* = eq0 о 1 -> * о [2, 1]; f*o[swbl°l, * ° [2, 1]]
Выражение /* ° [t<7, 1] представляет обычйый цикл, начинаю-
щийся с 1 в накопителе и со значения входной переменной, рав-
ной аргументу выражения верхнего уровня. Затем в цикле по-
Алгебраическое преобразование программ 525
следовательно умножается накопитель на входную переменную,
которая уменьшается, пока не станет равной нулю (условие
выхода).
18.5. Другие применения
Привлекательность алгебраического подхода к преобразова-
ниям на функциональном уровне заключается в его применимо-
сти к реальным классам функций. Мы рассмотрим только часть
линейного класса, для которой преобразования выполняются
механически. Всю информацию, необходимую для трансляции
рассмотренных в этой главе функций линейного класса в итера-
ционную форму, можно, например, получить при синтаксиче-
ском анализе определяющих функции уравнений, который все
же необходим в любой реализации. Однако этот подход, разу-
меется, не ограничен линейными функциями, многие нелиней-
ные функции имеют эквивалентные линейные версии, по кото-
рым, согласно приведенным выше результатам, получаются
итерационные реализации. Назовем такое преобразование линеа-
ризацией, а указанные нелинейные функции — вырожденными
мультилинейными. Уравнение, определяющее такую функцию f,
имеет форму f = p^>-q; Hf, где Hv = M(v, v), v — функ-
циональная переменная, a M — мультилинейный функционал от
п параметров; мультилинейная форма M(fx, ..., fn) независимо
линейна по каждому рассматриваемому по отдельности аргу-
менту, т. е. для 1 i п
M(fi, h-t, a~+b\ с, fi+l, ...,fn) =
— М^а.-*-NL(fx, ...,fi-x, b, fi+l,
..„fi-ь c, fi+x, ...,fn)
для некоторых фиксированных функционалов Mi. (В действи-
тельности, как и в случае определения линейных форм, мы тре-
буем, чтобы из существования объекта х, такого, что M{fx, ...
..., ft-i, _L, fl+x, ..., fn) :х = _1_, следовало, что для всех функ-
ций a, Mta:x = T, что всегда выполняется, если М — строгий
функционал.)
Мы не рассматриваем здесь детали, которые довольно гро-
моздки и которые можно найти в работе [37], но просто иллю-
стрируем преобразование, рассматривая пример функции Фи-
боначчи, являющейся вырожденной билинейной (2-мультили-
нейной):
fib — le 1 -> 1 ; -фо [fib о sub 1, fib ° sub2]
526 Часть III. Глава 18
где le 1 определяется как 1е1:х = Т, если и F, если
х > 1 для целого х. Уравнение можно переписать следующим
образом:
fib = le 1 ->j_; G(f, f )
где
G(u, v ) = + о [uosubl, v<>sub2]
Легко видеть, что функционал G— билинейный, предикат-
ные преобразователи Gi, G2 определяются для функциональной
переменной а как G\a = a<>sub\ и G2a = a°su6 2 соответ-
ственно. Несложно показать, что для G выполняются условия
главной теоремы о линеаризации для мультилинейных функ-
ций, в частности, вследствие того, что G2 есть степень Gi, т. е.
G2 = G? для некоторого целого п 2, здесь п = 2. (Читатель
должен, вероятно, заметить, что это свойство является доста-
точным для одного из условий теоремы, соответствующее не-
обходимое условие несколько более общо. Кроме того, как
можно легко показать, что в случае п = 1 функция будет уже
линейной. Теорема о линеаризации имеет несколько более сла-
бые условия, но мы здесь не затрагиваем их.)
Определим для заданной вырожденной билинейной функции,
удовлетворяющей условиям теоремы, линейную функцию g сле-
дующим образом:
g-==p->[?, Gxq]; [G'(I°g, 2og), GXlog)]
где G'( и, Giv ) — G(u,v) для функциональных переменных и, v
(то, что такой функционал G' существует, является одним из
«более слабых» условий). Тогда f= 1 °g. Следовательно, в слу-
чае fib имеем G'(u, v) — + ° [и о sub 1, u°su&l], р = 1е\ и
q= 1, а линейная форма определяется как
fib = 1 о g
где
g = /el->[l, 1]; [4- о [1 ogosubl, 2og°sub\], logosuM]
после прямой подстановки. С помощью обобщенной схемы пре-
образований линейных функций в циклы, рассмотренной в пре-
дыдущем разделе, действительно можно было бы получить сей-
час обычную циклическую реализацию ряда Фибоначчи, но не-
посредственное упрощение выражения дает
g = le\->[£, И; [+ о[1, 2], l]ogos«M
Таким образом, получаем g = le 1 ->-[1,1] ; [+, 1] og°sub 1,
учитывая то, что [l,2] = td для корректных выражений, т. е.
Алгебраическое преобразование программ 527
выражений, обе части которых применяются к последователь-
ности из двух элементов. Применяя к этой функции теорему
о линейнйм расширении, получаем
fib: X = 1; (g: х)
— 1 ;(Я"[1, 1] : х) где n = nun( {/el : sub\l: х = Т}
— 1 1]" : [1, 1]: sub\n : х) где я=тй( {х — i 1 = Т}
= 1 ’-К [ + , I]*-1 • (!, О) поскольку п — х— 1
= !:([+, 1Г2:(2, 1>)
= !:([+, 1Г3:<3, 2))
= !:([+, 1Г4:(5, 3))
Эта последовательность в точности соответствует итерацион-
ной реализации функции Фибоначчи, которая использует пару
накопителей, повторно добавляя в них значения.
Более важным применением алгебраических методов слу-
жит синтез рекурсивно определенных обратных функций. Этот
сложный вопрос является скорее предметом, лежащим за пре-
делами данной книги, поскольку обращение функции может
быть неоднозначным отображением, рассматривающая их тео-
рия использует логические функциональные переменные и за-
трагивает степени доменов. Может показаться странным же-
лание синтезировать обращение для данной функции. Однако
существуют по крайней мере две важные роли преобразований
такого типа. Одна из них связана с повышением производи-
тельности программирования на функциональных языках, пре-
доставляющих расширенные средства, которые позволяют ис-
пользовать функции как отношения в любом их виде, как в
логическом программировании. Например, можно определить
функцию append, осуществляющую обычную конкатенацию
двух списков, но может потребоваться также и функция, кото-
рая при применении к списку как к аргументу возвращает все
пары списков, порождающих при присоединении (append) этот
аргумент. Эта функция, назовем ее split (расщеплять), могла бы
быть написана независимо, но она уже полностью определена
через append и в этом смысле избыточна и приводит к не-
обязательным усилиям со стороны программиста. Опреде-
ление
split(х) = {(у, z), такая, что append(y, z) = x)
достаточно с программистской точки зрения. Аналогично мо-
жет быть полезной функция разности между двумя списками,
528 Часть III. Глава 18
определяемая как список, который при добавлении справа ко
второму списку дает первый:
difference(x, y) = z, такой, что append(y, z) — x
И снова эта функция полностью специфицирована функцией
append, и поэтому программисту не обязательно определять
одну логическую функцию или скорее отношение два или три
раза.
К сожалению, в реализациях расширенных функциональных
языков применения неявно определенных функций, таких как
split и difference, должны вычисляться с использованием отож-
дествления, как это делается в реализациях логических языков,
подобных Прологу, который обычно менее эффективен, чем
основанное на реализации вычисление функциональных выра-
жений. Более того, часто известно, что существуют, как и в на-
шем примере, рекурсивные, чисто функциональные реализации.
Если бы можно было компилировать рекурсивно определенное
обращение функции, задавая один из видов соответствующего
отношения, тогда все его виды можно было бы реализовать, не
прибегая к отождествлению во время выполнения. Например,
split-append-^, a difference тогда можно синтезировать из этой
формы. Современные методы действительно позволяют синтези-
ровать рекурсивное определение для append-1, как и для зна-
чительного класса других рекурсивно определенных функ-
ций [38].
Вторая важная область применения обратных функций свя-
зана с преобразованием абстрактных типов данных, рассмот-
ренным в предыдущей главе. Можно выразить эту задачу в
терминах коммутативных квадратов функций между абстракт-
ными и конкретными типами. Оказывается, что естественное
решение можно получить, используя композицию функций и
обратные функции, т. е. с помощью алгебраического под-
хода.
Предположим, имеется пара определенных пользователем
абстрактных типов данных а, 0 и соответствующая конкретная
пара типов а', 0', которые служат реализацией а и 0 соответ-
ственно. Тогда для всякой функции /:а->0 необходимо син-
тезировать соответствующую функцию, скажем f': а'-+[}', ко-
торая выполняет операции на объектах типа а', изоморфные
в определенном смысле операциям, выполняемым и функцией f
на соответствующих объектах типа а. Функция f' поэтому яв-
ляется конкретной «реализационной версией» f, которую мы
ищем. Введенные понятия связаны на коммутативном квадрате,
Алгебраическое преобразование программ 529
изображенном на следующей диаграмме.
absu
absp
Здесь функция абстрагирования для абстрактного типа ст
обозначается как absa: ст'->- о, где ст7 — конкретный тип, соот-
ветствующий ст. Следовательно, в нотации функциональной ал-
гебры FP / ° absa = abs$ о f' или f' = abs$ 1 ° f □ absa, принимая, что
существует обратная функция abs^. В частном случае, когда
Р = Р', т. е. конкретный тип диапазона значений совпадает
с абстрактным типом диапазона значений, имеем треугольник:
из которого следует, что f — f ° abs. Подобная ситуация могла
бы возникнуть, например, если бы р был базовым типом, таким
как целые, — этот случай мы имеем в первом примере преоб-
разования типов данных, рассмотренном в предыдущей главе.
Простая идея коммутативного квадрата образует платформу
всего алгебраического подхода к преобразованию типов дан-
ных [40]. Такая трансформационная система действует путем
последовательного переписывания выражений, определяющих
функции abs~l и f' с использованием множества аксиом, кото-
рое включает аксиомы FP и аксиомы, связанные с обращением
функций. К тому же в качестве дополнительных аксиом для
конкретных преобразований применяются также сформулиро-
ванные пользователем определения абстрактных типов данных;
это осуществляется таким же образом, как и в случае описан-
ного в разд. 17.3 подхода раскрутки/скрутки к этой задаче.
Таким способом многие функции /7:а7->р7, соответствующие
сформулированным программистом функциям можно
синтезировать механически, обходясь без эвристических шагов,
34 — 1473
530 Часть III. Глава 18
не считая спецификации аксиом, соответствующих определен-
ным пользователем типам. Алгебраический подход легко при-
меним, в частности, к примерам из разд. 17.3.
Итак, мы увидели, что алгебраический подход к преобразо-
ванию программ обеспечивает осуществляемую оптимизацию
для множества классов функциональных программ, вся тре-
буемая информация для этого может быть получена( на этапе
синтаксического анализа. Если сравнить два разных подхода,
то с помощью методологии раскрутки/скрутки так|ке можно
было бы вывести в результате соответствующих Шагов, опи-
санных в предыдущей главе, всякое функциональное равенство,
получаемое с применением алгебраического подхода. Однако
как правильно выбрать «подходящие шаги» без помощи интуи-
ции— это существенный вопрос, и выбор этот, оказывается,
весьма трудно поддается, если вообще поддается, автоматиза-'
ции с требуемой степенью общности. Пока же наиболее эффек-
тивным решением представляется компромисс, согласно кото-
ррму трансформационная метасистема вида, рассмотренного в
разд. 17.2, расширяется включением новых высокоуровневых
шагов или тактик, что позволяет применять алгебраические
равенства между функциями (или между функциями и цик-
лами). Таким способом можно увеличить автоматизируемость
алгебраического подхода, сохраняя в то же время почти пол-
ноту методологии раскрутки/скрутки. В самом деле, этот под-
ход может предоставить даже средства, с помощью которых
в метасистеме могут быть сгенерированы новые тактики, а воз-
можно, и новые функциональные эквивалентности.
18.6. Преобразование передачей продолжений
Другой подход к преобразованию программ упрощает ме-
ханизм вызова рекурсивной функции, платя за это введением
функций высших порядков, которые он затем пытается эффек-
тивно представить. Для функции одного аргумента идея заклю-
чается в нахождении эквивалентной авторекурсивной функции
двух аргументов, один из которых является объектом данных
того же типа, что и аргумент исходной функции, а второй —
функцией, называемой продолжением. В общем случае про-
должение можно рассматривать как отображение. При приме-
нении к объекту, представляющему некоторое «текущее состоя-
ние», оно дает определенное «конечное состояние», из которого
может быть извлечен желаемый результат. В последователь-
ности пар состояние/продолжение, для каждой из которых воз-
можно достижение конечного состояния путем применения про-
должения к данному состоянию, пары могут рассматриваться
Алгебраическое преобразование программ 531
как определение инварианта итерационного процесса. Продол-
жения были введены первоначально на основе этой идеи
с целью обеспечения денотационной семантикой предложений
goto в императивных языках; эта семантика может быть задана
в терминах состояний программы, связывающих значения с пе-
ременными программы.
Обычно бывает не слишком трудно определить новую авто-
рекурсивную функцию независимо от исходной функции и, как
мы увидим, всегда можно определить ее взаимно рекурсивной.
Но платой за такое легкое порождение итерационной реализа-
ции будут требуемые продолжения, являющиеся функциями
высших порядков. Как мы видели, подобные объекты гораздо
менее эффективны для реализации по сравнению с данными,
и передаваемые как параметры в применении преобразуемой
функции продолжения становятся чрезвычайно сложными, что
лишает смысла само преобразование. Что обычно случается,
так это то, что авторекурсивная версия f-lr функции f сначала
применяется к аргументу f и берется простое продолжение, та-
кое как функция тождества id. Она последовательно приме-
няется к парам объект/продолжение, в которых объект стано-
вится проще, в конце концов достигая . базового случая, на
котором завершается вычисление, а сложность продолжения
возрастает. Выигрыш этот метод дает, только когда продолже-
ния можно представить такими простыми структурами данных,
как счетчики или списки. В этом случае продолжение аналогично
накопителю.
Допустим теперь, что функция f определяется как f(x) =
— if р then q else E, где переменная может встретиться в любом
из выражений р, q и Е, а- Е имеет вхождение функции, приме-
няемой к подвыражению s(x), т. е. /(s(x))— подвыражения
Е. Тогда, если f применяется к аргументу а небазового случая
(т. е. [а/х]р имеет значение false), вычисление продолжается
применением сначала f к s(a), что дает, скажем, результат г,
а затем вычислением выражения, получаемого из Е подстанов-
кой г вместо f(s(x)). Это дает в результате f(a) = Er, где
используется обозначение Ew = [w/f( s (х)) ] Е для переменной
w. Другой способ выражения этого результата —• сказать, что
функция у = lw.Ew применена к аргументу г — f(s(a)). Эта
функция у, являясь продолжением, представляет оставшееся
вычисление, которое необходимо выполнить для нахождения
f(a) после того, как будет завершено вычисление f(s(a)).
Таким образом, эквивалентным определением f является
f(x) = f-fr(x, id)
*> tr — аббревиатура от tail-recursive (авторекурсивный).—Прим, перев.
34*
532 Часть III. Глава 18
где
f-tr(x, у) = у(Дх))
= if p then y(<?) else f-/r(s(x), лю.уЕ^,)
Справедливость этого уравнения будет очевидна опытному раз-
работчику функциональных программ, а мы докажем нефор-
мально это равенство, показав f-tr ( х, у ) = у ( f (х) ) по индук-
ции следующим образом. Прежде всего если х таков, что р
имеет значение true, то f-tr( х, у ) = у ( q) = у( f ( х ) ). В про-
тивном случае
f-tr( х, у) = f-tr( s( х ), 7.w.yEw)
= ( kw.yEw ) f( s( x ) ) по индуктивному предположению
= у( E ) по определению Ew
= y(f(x)) согласно базовому случаю
Мы не определили применяемый механизм индукции, в частно-
сти лежащий в его основе порядок, но по существу метод яв-
ляется методом индукции подцелей, использованным в тех же
целях в работе [87].
Типичный пример преобразования такого стиля — это пре-
образование функции rev, которая обращает список, определен-
ной следующим образом:
rev(x)<=if null(x)
then nil
else rev( tl( x)) ( ) [hd( x)];
Здесь при применении к непустому (не nil) списку функция
сначала вызывает сама себя с аргументом tl (х ), а затем при-
меняет продолжение Xw.w( >[AtZ(x)]. Следовательно, авторе-
курсивная версия имеет вид
rev(x) <= rev-tr(х, id);
где
rev-tr(x, у) <— if null(x)
then y( nil)
else rev-tr(tl(x), Zw.y(w( )[hd(x)]));
Продолжения в этом случае можно представить списками,
поскольку все они имеют вид для определенного k.
Для доказательства этого факта сначала заметим, что id при-
нимает вид (k — nil), и примем индуктивно, что у = ~)k.
Тогда
hw. у( w { ) [hd х]) = Хщ. (w ( ) [hd х]) ( ) k (р-редукция)
— ‘kw.w{ )cons(hd(x), k) (по свойству
ассоциативности
определения append)
Алгебраическое преобразование программ 533
что и требовалось; следующее продолжение передается с ис-
пользованием его представления в виде списка hd(x) ::k. Сле-
довательно, вместо передачи продолжения у — >& можно
передать представляющий его список k. Таким образом, заме-
тив, что в базовом случае ( >&) (ш7) = k, получаем обыч-
ную авторекурсивную функцию, обращающую списки:
rev( х) < — rev-tr *( х, nil);
rev-tr’(x, k) <=if null(x)
then k
else rev-tr *(tl(x), hd(x)::k);
В действительности этот результат легко обобщается
подобным образом до установления утверждения об обра-
щении циклов, которое мы получили в разд. 18.4, используя
ТЛР.
Применимость метода передачи продолжений не ограничена
функциями с одним присутствием ее имени в правой части
уравнения, определяющего функцию. Получим сейчас с исполь-
зованием его итерационную форму функции Фибоначчи. Начнем
с определения
fib(x) <= if х 1
then 1
else fib( x — 1) + fib( x — 2);
При вычислении функции fib(n) для аргумента п>1 сна-
чала fib применяется раздельно к (п—1) и (п — 2), что дает
результирующую пару (fib ( п—1), fib ( п — 2)). После этого
вычисление завершается применением продолжения Kuv. (u +
+ v), где huv. обозначает лямбда-абстракцию пары (u, v).
Следующий шаг в некоторой степени трюковый. Поскольку
правая часть вычисления породила пару, нам нужна новая функ-
ция, которая бы порождала подобную пару более предпочти-
тельным способом по сравнению с fib, что вызвано необходи-
мостью применения продолжений к парам (они имеют ар-
ность 2). Таким образом, определяем
g( х) <= (fib( х), fib( х — 1));
<= if х 1
then (1, 1)
else (fib( x — 1) + fib( x — 2), fib( x — 1));
Применяя ту же стратегию продолжения, что использова-
лась выше для fib(n), получаем подобную результирующую
пару (fib(п — 1), fib( п — 2)), но теперь продолжение имеет
534 Часть III. Глава 18
вид: kuv. (u + и, и). После этого эвристического шага легко
получить авторекурсивную форму для g, из которой fib можно
выделить следующим образом:
g(x) <=g-tr(x, id);
g-tr( x, у) < = if x 1
then y(1, 1)
else g-tr(x— 1, Xuv.y(u 4~ v, u));
Далее kuv.y{ и + v, и ) = у °kuv.{ и + и, и) и все продолжения
имеют форму {кии. ( и + и, и)}п, т. е. [+, 1]л в нотации FP.
(Это можно доказать строго, как и раньше, по индукции.) Пере-
даваемое продолжение можно поэтому заменить на п, получае-
мое простым счетчиком. Получаем
g(x) <=g-tr*(x, 0);
g-tr’(x, n) <= if x^l
then [+, 1 ]n( 1, 1) ,
else g-tr*( x — 1, n + 1);
Наконец, получаем результат g( x ) — [ +, 1 ] x( 1, 1), как и с ис-
пользованием методологии раскрутки/скрутки и алгебраиче-
ского подхода.
На самом деле стиль передачи продолжения с определенным
успехом можно применить также и к несколько необычным
функциям. Рассмотрим пример в высшей степени нелинейной
«91-функции» Мак-Карти, определенной следующим образом:
f(x) <=if х > 100
then х — 10
else f(f(x + И ))’>
Можно сразу же выразить это определение в форме авторе-
курсивной передачи продолжения:
f(x) <=f-tr(x, id);
f-tr( x, у) <= if x > 100
then y( x — 10)
else f-tr(x + 11, Zw.y(f(w)))
Здесь, однако, мы не избавились от присутствия f в ее ав-
торекурсивной версии, но можно получить простое выражение
для передаваемого продолжения: оно имеет вид kw.f(f(...
... f{w) ...)) для некоторого числа применений f, которые
снова можно представить счетчиком. Задача не полностью без-
надежна, поскольку необходимо иметь способ моделировать
многократные применения f для вычисления у{х—10). Это
Алгебраическое преобразование программ 535
можно сделать, введя вспомогательную функцию sim-app
f(x) <= f-tr*(х, 0);
f-tr’(x, i) <=ifx>100
then sim-app(x — 10, i)
else f-tr*( x + 11, i + 1);
sim-app(v, i) <= if i = 0
then v
else f-tr*( v, i — 1)
Корректность взаимной рекурсии можно показать, заметив,
что f-tr* (х, i) = у (f (х ) ) = f (f (х) ).
Стиль преобразования передачей продолжения применим ис-
ключительно широко, но требует нахождения эффективного
представления генерируемых продолжений, поскольку в против-
ном случае всякое повышение эффективности было бы направ-
ленным вследствие высоких накладных расходов, обусловлен-
ных работой с обременительными функциями высших порядков.
Часто такого представления, что в действительности и не уди-
вительно, найти не удается либо из-за того, что некоторые ре-
курсивные функции оптимальны или почти оптимальны, либо
вследствие трудностей, обусловленных природой решаемых за-
дач, связанных, например, с обработкой деревьев. Когда же
удобное представление для продолжений найти удается (это
может быть простой счетчик или список), то судя по рассмот-
ренным нами в общем несложным примерам, для этого тре-
буются эвристические шаги. На основе передачи продолжений
можно построить трансформационную систему, действующую
чуть более механически, нежели методология раскрутки/скрут-
ки, и более широко применимую, чем алгебраические методы,
наиболее подходящие для автоматизации. Во всяком случае,
этот стиль представляет новый интересный подход со своими
возможностями.
Резюме
• Алгебраический стиль преобразования программ основан на
нахождении равенств для родовых классов функций.
• Формальный анализ удобно производить в форме, свободной
от переменных.
• Аксиомы FP способствуют проведению манипулирования про-
граммами более механически.
*> sim-app — аббревиатура от simulate-applications (моделировать приме-
нения).— Прим, перев.
536 Часть III. Глава 18
• Линейные функции образуют большой класс, замкнутый от-
носительно операции композиции функционалов.
• Линейные функции можно преобразовать, используя теорему
о линейном расширении, в циклы или авторекурсивную форму.
• Если выражение, определяющее линейную функцию, обла-
дает соответствующим свойством ассоциативности, можно про-
извести обращение цикла.
• Вырожденные мультилинейные функции являются нелиней-
ными, однако при определенных условиях они могут быть пре-
образованы в линейные.
• Можно синтезировать множество рекурсивных обратных
функций и использовать их для автоматизации преобразований
типов данных и для устранения отождествления.
• Можно найти авторекурсивную форму высшего порядка, ко-
торая в вызовах самой себя использует функцию, называемую
продолжением.
• Продолжение может иногда представляться структурой дан-
ных, что делает реализацию функции более эффективной.
Упражнения
18.1. Докажите, что каждый из функционалов в табл. 18.1 ли-
неен и что предикатные преобразователи именно такие, как
определено. Если все функции FP строгие, то какие функцио-
налы должны быть всегда строгими и почему?
18.2. Докажите для каждого из следующих случаев, что функ-
ционал Н с функциональной переменной f линеен, и найдите
соответствующий предикатный преобразователь:
a) Hf = Pf-+ k ; h, где P — линейный функционал, a k и h —
фиксированные функции;
б) Hf—Pf^>~Af; Bf, где Р, А, В — линейные функционалы
с Pt = At = Bp,
в) Hf = Pf-+Af; k, где P, A—линейные функционалы c Pt —
= At, a'k— фиксированная функция;
г) Hf = p—>~q; Af, где A — линейный функционал, a p и q —
фиксированные функции;
д) Hf = p-^Af; Bf, где A, В — линейные функционалы, ар —
фиксированная функция.
18.3. При каких условиях Ht = At, если Hf = p->-Af; Bf, где
р — фиксированная функция, а А, В — линейные функционалы
с =
18.4. Докажите индукцией по п для заданного функционала,
определенного как Hf = h° [i, f ° j], где h, i, j — фиксированные
функции, что Hnf=/h ° [i, i ° /, ... , i-° jn~', f ° /"] для n 0. Ка-
кой результат был бы в случае Hf = h.° [f°j, i]?
Алгебраическое преобразование программ 537
18.5. Докажите индукцией по п, что 2 ° kn = \ft ° [2, i°l, i°f°
° 1, ..., i ° ° 1] для n > О, где k = [j ° 1, ft ° [2, i ° 1] ]. Иначе
говоря, покажите, что
ft ° [2, q ° 1 ] ° kn = \h ° [2, i ° 1, i ° j ° 1, ..., i ° jn~1 ° I, q ° jn ° 1 ].
18.6. Покажите, что для данной билинейной формы G(u,v)
с G1 = G2 функционал Н, определяемый как Hf = G(f,f), ли-
неен. Обобщите этот результат на случай п-мультилинейной
формы.
18.7. Покажите, что функционал И, определяемый как Hf =
= Pf-+Af; Bf, линеен, если функционалы Р, А, В линейны
и имеют равные предикатные преобразователи. Теорему 18.1
можно обобщить до применения к этому функционалу И, если
Р, А, В есть КЛФ, и определить
Ен(и, v) = if ЕР(и, v) then ЕА(и, v) else Ев(и, v)
Покажите, используя этот результат или как-нибудь иначе, что
функция sqrt приближения к квадратному корню линейна, если
определяется как
sqrt( а, е) = if а < е
then О
else if square( х + е) а
then х + е
else х
where х = sqrt( а, 2 * е)
(square — примитивная арифметическая функция возведения в
квадрат: square (х) = х*х).
18.8. Функция Фибоначчи определяется в FP следующим об-
разом:
/zft = /el->l; -j- о [fib, fibosubl]°subl
Покажите, что если g = [fib, fib ° sub 1], то g = lel-+-
где H— линейный функционал. Дайте определение Н
и покажите, как строится циклическая реализация g и, следо-
вательно, fib.
18.9. Функция factlist определяется в FP следующим образом:
factlist = eqQ -> [ 1 ]; cons ® [factorial, factlist ° sub 1 ]
factorial — eqO —> 1 ; * ° [id, factorial ° sub 1 ]
Дайте рекурсивное определение функции ft = [factlist, factorial]
и покажите, что функция й — вырожденная мультилинейная,
но не. линейная. Далее, пусть f = factlist ° sub 1. Покажите, что
538 Часть III. Глава 18
функция h' — [f, factorial] линейная, и найдите ее предикатный
преобразователь.
{Подсказка. Установите сначала, что предикат в определении
функции factorial можно заменить на eq 1.) Покажите, .как по-
лучается циклическая реализация factlist.
18.10. Выразите следующие функции в форме передачи продол-
жений:
а) функцию listo, определенную в упражнении 17.3;
б) функцию factorial.
Найдите в каждом случае эффективное представление продол-
жения, формируя его свойства, требуемые для использованных
примитивных функций.
Глава 19
ЗАПОМИНАНИЕ
Методика, названная запоминанием, была первоначально
предложена в [65] и основана на замене определенных нели-
нейных определений функций соответствующими мемо-функция-
ми. Мемо-функция близка к обычной функции; отличие же
состоит в том, что она «помнит» некоторые или все свои аргу-
менты, к которым она была применена, а также соответствую-
щие полученные при этом результаты благодаря хранению
необходимых пар величин в специальной таблице — мемо-таб-
лице. Если мемо-функция повторно применяется к тому же аргу-
менту, то она не будет пересчитывать результат заново, а просто
воспользуется ранее вычисленным. Корректность этого гаран-
тируется ссылочной прозрачностью по ссылкам функциональ-
ных языков, так что побочных эффектов не возникает. В каче-
стве простого примера приведем функцию power, определенную
так:
------power(O) <= 1;
------power( i) <= power( i — 1) + power( i — 1);
Она возвращает 2n при аргументе, равном и. При обычной реа-
лизации этой функции этот расчет потребует 1 + 2П вызовов
функции power. Если же, однако, power будет мемо-функцией,
то второй ее вызов сведется к простому поиску только что по-
лученного результата в мемо-таблице, а последующие вызовы
будут не нужны. Таким образом будет сделано лишь 1 4- п вы-
зовов.
Таким образом, запоминание поможет заменить потенциаль-
но дорогостоящие вычисления простым просмотром таблицы,
позволяя использовать неэффективные версии функций, близ-
ких к своим спецификациям, в качестве альтернативы преобра-
зования исходного текста программы. В самом деле, возможно-
сти применения запоминания более широки, чем у такого
540 Часть III. Глава 19
преобразования. Любую функцию можно сделать мемо-функ-
цией. Для этого годится любая функция, хотя эффект исполь-
зования запоминания не всегда может быть положительным.
Примером могут служить линейные функции, такие как факто-
риал, в которых аргументы не используются более одного раза
при каждом обращении к функции. (Заметьте, однако, что в тех
функциях, которые осуществляют несколько вызовов факто-
риала, например в комбинаторике, выигрыш в эффективности
может быть значительным.) Можно также утверждать, что унич-
тожение исходного описания функции при преобразовании про-
граммы является недостатком, которого можно избежать при
запоминании, но это не столь очевидно, поскольку оптимизиро-
ванная версия функции не всегда будет доступна программисту
или использоваться им. И наоборот, сторонники строгости мо-
гут возразить, что реализация мемо-функций обычно требует
нефункциональных операций, а именно динамического измене-
ния мемо-таблиц разрушающим присваиванием. Альтернатив-
ная, чисто функциональная реализация требует, чтобы мемо-
таблица поступила в мемо-функцию и возвращалась обнов-
ленной в качестве результата. Этот подход, конечно, более
компактен, чем метод разрушающего присваивания, хоть и
менее эффективен. Соответствующее рассмотрение содержится
в разд. 19.3.3, где для запоминания мы получим способ
преобразования текста программ, эквивалентный запоми-
нанию.
19.1. Принцип работы и основные трудности
Функция Фибоначчи fib является классическим примером
функции, эффективность которой заметно возрастает при при-
менении метода запоминания. Каждый вызов fib генерирует два
последующих вызова, так что стоимость вычисления fib(n)
экспоненциально зависит от и, а мемо-версия fib(n) — только
линейно, поскольку для каждого п функция fib(n) будет вы-
числяться только один раз. Мемо-функцию fib можно предста-
вить в таком виде:
memo_fib п <=if in_memo_table(n)
then lookup(n)
else insert(fib(n))
Вспомогательные операции in_memo_table, lookup и insert ра-
ботают с мемо-таблицей. Хотя первые две операции могут рас-
сматриваться как функции, insert добавляет (нефункционально)
Запоминание 541
К мемо-таблице новую пару (и, fib(n) ), а в качестве резуль-
тата возвращает fib(n). Конечно, эти вспомогательные опера-
ции не видны программисту и не будут, как правило, реализо-
вываться как истинные функции во время прогона программы.
Мы приведем еще одну, но чисто функциональную версию
memo .fib, когда будем рассматривать преобразование исходного
текста в разд. 19.3.3. В любом случае при наличии обычного
определения fib вызов memo_fib всегда будет давать тот же
результат, что и вызов fib с тем же аргументом, т. е.
memo_fib ( и ) = fib( п ) для всех п, так что memo-fib имеет
ту же семантику, что и fib; очевидно, что это относится ко всем
мемо-функциям. Причина этого заключается в прозрачности по
ссылкам и в одинаковой мере справедливо как для передавае-
мых по значению, так и для передаваемых по необходимости
параметров (для семантики аппликативного и нормального по-
рядка соответственно). В последнем случае ни величины аргу-
ментов, ни результаты, хранящиеся в мемо-таблице, не будут
вычислены полностью; ленивое запоминание в полном объеме
будет обсуждаться в следующем разделе.
Пример с функцией Фибоначчи является несколько специ-
фичным, поскольку его аргументы являются атомами и запо-
минание может также с большим успехом применяться для
того, чтобы избежать избыточность при обработке структур
данных, т. е. чтобы не «проходить» по одной и той же части
структуры дважды. Это особенно эффективно проявляется в
вычислителях выражений, таких как рассмотренный в гл. 9
интерпретатор eval-apply, где выражение аргумента не вычис-
ляется до тех пор, пока оно впервые не потребуется в опреде-
ляющем выражении примененной функции, но будет вычис-
ляться каждый раз, когда потребуется его значение. Мы рас-
смотрим этот пример в разд. 19.2, где будем использовать
указатели для обеспечения эффективного представления невы-
численных аргументов.
Помимо положительных сторон, использование мемо-функ-
ций приводит к серьезным трудностям при их реализации. Во-
первых, сопоставление аргументов с элементами мемо-таблицы
является неэффективным, если данный аргумент является со-
ставной структурой данных, например деревом. Мемо-функция
проверяет аргументы и каждый элемент на равенство, исполь-
зуя рекурсивную процедуру тестирования каждой подструктуры
объекта с рекурсивно определенным типом данных. Например,
если есть такое описание типа данных:
data tree === leaf(num) ++ node( tree # num # tree);
542 Часть III. Глава 19
то функция, проверяющая два объекта типа tree на равенство,
будет такой:
dec compare : (tree # tree) -> truval;
------compare(leaf(n), leaf(m)) <=(n = m);
------comparedtree(s, n, t), tree(u, m, v))<=(n = m) and
compare (s, u)
and
compare(t, v);
------compare( leaf( n), tree(u, m, v)) <= false;
------------------------------------------compare( tree( u, m, v), leaf(n)) <= false;
Стоимость таких проверок высока, а выполняться они должны
при каждом вызове мемо-функции, возможно, несколько раз
по мере роста мемо-таблицы. Проблема усугубляется тем, что
применение сложных методов для обработки составных струк-
тур затруднительно, например использование хэширования для
оптимизации поиска в мемо-таблицах или для формирования
этих таблиц в виде упорядоченных деревьев. В любом случае
получение необходимой и уникальной характеризации структуры
данных требует создания рекурсивной функции. Другим недо-
статком этого вида запоминания является то, что при проверке
на равенство необходимо полное вычисление всех аргументов,
и поэтому мы ограничены вычислениями аппликативного по-
рядка.
Однако наиболее серьезным ограничением запоминания яв-
ляется то, что мемо-таблицы бесконечно наращиваются при
добавлении каждого нового элемента, и даже если данный
аргумент никогда больше не будет использован мемо-функцией,
он все равно продолжает храниться в таблице. Довольно
трудно понять, стоит ли удалить данный элемент мемо-таб-
лицы, т. е. когда он перестает быть необходимым, поэтому
непрерывный рост мемо-таблицы может в конце концов при-
вести к тому, что вся доступная память будет исчерпана и вы-
числение выражений прекратится; кроме этого, затраты на
просмотр мемо-таблицы также возрастают с увеличением ее
размера.
Ниже в этой главе мы рассмотрим, как эти недостатки мо-
гут быть в большой мере исправлены, что позволит осуществить
успешную реализацию. Затруднения с составными аргументами
можно преодолеть, если воспользоваться ленивыми мемо-функ-
циями [48],— с этого мы начнем обсуждение; потом мы рас-
смотрим способ контроля роста мемо-таблиц. И наконец, мы
обсудим некоторые проблемы, возникающие при сборке мусора
в мемо-таблицах.
Запоминание 543
19.2. Ленивые мемо-функции
Ленивые мемо-функции были введены для использования их
в ленивых реализациях функциональных языков; они упрощают
представление в мемо-таблицах тех аргументов, хранение ко-
торых в полном вычисленном виде больше не является необхо-
димым. При этом устраняются многие трудности, связанные
с рекурсивной проверкой на равенство и хэшированием, так что
эта методика также годится и для строгих реализаций. Основ-
ная мысль заключается в смягчении тех требований, которым
должна удовлетворять мемо-функция; мы скоро увидим, что все
мемо-функции могут быть заданы через ленивые мемо-функции;
другими словами, использование ленивой методики не приводит
к потере общности. Обычные мемо-функции, которые мы будем
называть полными мемо-функциями, требуются для повторного
использования уже вычисленных результатов, если они приме-
няются к аргументам, равным тем, которые были использованы
накануне. Ленивые мемо-функции, однако, должны так дей-
ствовать, лишь только если их аргументы идентичны предыду-
щим, т. е. хранящимся в том же месте в памяти. Таким образом,
два объекта идентичны, если
(1) они хранятся по одному адресу, т. е. доступны по од-
ному указателю;
(2) они являются атомами одинаковых типов, например це-
лыми, символами, булевыми константами и т. п.
Видно, что в любом применении, в которое входит запоми-
нание, сравнение указателей должно входить в число прими-
тивных операций. Заметьте, что атомы также проверяются на
равенство, поскольку они не имеют ассоциированного адреса;
мы можем с тем же успехом считать, что каждый атом имеет
уникальный (неявный) адрес, тогда одинаковые (равные) атомы
будут идентичны согласно данному выше определению. Теперь
уже нет необходимости в проведении рекурсивной проверки ра-
венства, на смену которой приходит простое сравнение указа-
телей; мемо-таблицы могут быть организованы как таблицы
хэширования или упорядоченные двоичные деревья для обеспе-
чения удобства поиска аргумента (атома или указателя). На-
пример, индекс хэширования может быть вычислен исходя из
адреса или состояния битов указателя с помощью обычных ме-
тодов. Кроме этого, подобное применение указателей для пред-
ставления аргументов в мемо-таблицах облегчает сборку му-
сора. Мы еще встретимся с этим в разд. 19.4, но уже сейчас
необходимо заметить, что при устранении аргумента, храняще-
гося в мемо-таблице, его ячейка также может быть удалена из
мемо-таблицы, поскольку хранящаяся в ней величина не будет
544 Часть III. Глава 19
использоваться в качестве аргумента ни в одной из функций.
При таком подходе разрастание ленивых мемо-таблиц может
быть в некоторой мере ограничено.
Важной чертой этого вида запоминания является то, что он
поддерживает циклические структуры. Они используются для
представления в связанном пространстве бесконечных объектов,
состоящих из повторяющихся конечных образцов, т. е. цикличе-
ских объектов. Например, бесконечный список, состоящий из
единиц (ones), представленный рекурсивным равенством
------ones < = 1 :: ones ;
может быть представлен единственной cons-ячейкой:
Другими словами, циклические структуры обеспечивают опти-
мизацию определенного класса бесконечных объектов. Вслед-
ствие этого ими можно манипулировать с помощью обычных ле-
нивых методов и использовать для представления невычисленных
выражений с бесконечными значениями. Например, выра-
жение hd (tl (tl (tl ( ones ) ) ) ), вычисление которого дает еди-
ницу, требует четырех вызовов функции ones, если не исполь-
зуется циклическое представление, но если оно было использо-
вано, то вызовов не потребуется вообще, поскольку компиляция
выражения уже дала бы циклическую форму. Таким образом,
даже если результат применения функции к циклической струк-
туре также может быть представлен как циклическая структура,
то обычные ленивые вычисления дадут в общем случае в каче-
стве результата бесконечную структуру, т. е. включающую не-
вычисляемое бесконечное выражение. Примером этого является
выражение для вычисления бесконечного списка двоек (twos ):
------twos' <= map double ones;
------double x < = 2 * x ;
При нормальной ленивой реализации циклическая структура
ничем не отличается от любой другой, поскольку просмотра
содержимого ячейки, представляющей рекурсивную часть выра-
жения, не происходит. Здесь ленивое вычисление функции twos
дает 2:: map double ones, а подвыражение тар double ones не
будет редуцировано и, конечно, не будет идентифицировано
с корневой ячейкой всего выражения twos.
Важность хранения бесконечных циклических структур за-
ключается не только’в их компактности, но и в том, что для
Запоминание 545
их создания требуется конечный объем вычислительной работы.
Далее, доступ к ним в отличие от бесконечных объектов доста-
точно прост и дешев, не требует дополнительных вызовов функ-
ций. Во многих случаях ленивое запоминание автоматически
поддерживает цикличность циклических структур путем иден-
тификации указателя аргумента с указателем на включающее
выражение. Например, ленивое вычисление выражения шар
double ones дает структуру
map double ones
2
тар double ones
Теперь аргументы рекурсивного вызова тар идентичны ар-
гументам вызова высокого уровня, так что если тар станет
мемо-функцией, то исходный результат будет использован вновь.
Это приведет к генерации циклической структуры
map double ones
которая является оптимальной. Таким образом, мы видим, что
запоминание автоматически позволяет представлять многие бес-
конечные объекты с помощью циклических структур максималь-
но компактного вида; для более сложного примера мы отсы-
лаем читателя к упражнению с функцией zip в конце главы.
Запоминание с использованием ленивых мемо-функций
особенно эффективно при реализации интерпретаторов и компи-
ляторов, манипулирующих абстрактными синтаксическими де-
ревьями и неоднократно использующих многие сложные подде-
ревья. В качестве примера рассмотрим очень простой интер-
претатор для (чистого) лямбда-вычисления, выполняющий
применение функций путем явной р-подстановки:
data ехр ===== id( char)++арр( ехр, ехр)-|—|-lam(char, ехр);
dec eval: ехр -> ехр;
dec apply : (exp#ехр)—>ехр;
------eval(app(f, х)) <= apply( eval( f), х);
------eval(id(c)) <=id(c);
------eval(lam(c, e)) <=lam(c, e);
—-----apply(lam(c, e ), a ) <= eval( subst( c, a, e));
------apply(id(c), a) <=app(id c, a);
------apply(app(f, x), a) <= app( app( f, x), a);
35 — 1473
546 Часть III. Глава 19
где subst (с, а, е) замещает все (свободные) вхождения с в е
на а. Здесь обеспечивается семантика нормального порядка, по-
скольку аргументы не вычисляются перед тем, как будут под-
ставлены в тела функций, применяемых к ним, а нормальные
формы (СЗНФ) являются либо лямбда-абстракциями с кон-
структором 1am, либо применением идентификатора с конструк-
тором id к произвольному числу (включая нуль) аргументов.
Хотя выражение в аргументе не вычисляется до тех пор, пока
его значение не потребуется в теле примененной лямбда-аб-
стракции, оно будет вычисляться вновь и вновь для каждого
его вхождения в тело абстракции. Однако если eval является
ленивой мемо-функцией, то адрес и значение вычисленного вы-
ражения аргумента будут храниться в мемо-таблице и при не-
обходимости значение просто отыскивается в этой таблице.
Таким образом запоминание обеспечивает реализацию вызова по
необходимости с помощью функционально определенного интер-
претатора с семантикой вызова по имени. В гл. 9 мы видели,
что свойство разделения, необходимое в ленивом интерпрета-
торе, трудно обеспечить чисто функциональным путем — для
этого необходимы ухищрения с ленивыми конструкторами Норе;
кроме этого, в гл. 10 нам пришлось ввести разрушающее при-
сваивание для обеспечения реализации ленивой SECD-машины.
Здесь, однако, мы обнаружили, что ленивое запоминание авто-
матически обеспечивает эту эффективность, модулируя обычные
механизмы ленивых вычислений; разделение происходит кос-
венным образом через мемо-таблицу с эффективностью, не-
сколько превышающей эффективность разрушающего присваи-
вания.
В качестве простого примера приведем инкрементальный
компилятор, создающий представление программы пользователя
вместе с компилированным кодом. При редактировании поль-
зователем программы выполняется минимально возможная ее
перекомпиляция, так как компилятор следит за той частью ко-
дов, которые подвергались изменению и должны быть генери-
рованы вновь. Мемо-функции дают эту информацию автомати-
чески. Например, если к обычному компилятору был добавлен
структурный редактор для изменения абстрактных синтаксиче-
ских деревьев, а также было осуществлено превращение функ-
ций генерации кода в мемо-функции, то в результате получится
инкрементирующий компилятор. Генератор кода может в любой
момент обработать все абстрактное синтаксическое дерево, но
новый код будет выработан лишь для тех частей, которые были
изменены.
В завершение обсуждения ленивых мемо-функций мы рас-
смотрим, как при помощи ленивых мемо-функций может быть
Запоминание 547
достигнуто полное запоминание. Основное здесь заключается
в обеспечении того, чтобы проверка на идентичность стала бы
эквивалентной проверке на равенство. Это уже верно для ато-
мов и может быть распространено на все структуры данных,
если они хранятся только в одном месте. Это означает, что лю-
бые две одинаковые структуры данных независимо от того, яв-
ляются ли они аргументами мемо-функций, должны разделять
одни и те же ячейки памяти, приводя к существенным наклад-
ным расходам при вычислении выражений. Однако при таком
подходе мы можем определить полные мемо-функции через ле-
нивые, используя хэширующий конструктор cons [74].
Хэширующий cons (hcons) аналогичен функции конструк-
тора cons, но не производит размещения новой ячейки, если уже
существует ячейка, у которой головное и хвостовое поля иден-
тичны ее соответствующим полям. Хэширующая версия, есте-
ственно, может быть определена для каждой функции конструк-
тора, но мы для простоты ограничимся рассмотрением только
конструктора списков cons. Мы можем определить hcons как
ленивую мемо-функцию; будем использовать обозначения Норе
и, кроме этого, обозначать строку объявления словом- мемо для
указания на то, что функция должна быть мемо-функцией:
dec memo hcons ( alpha # list] alpha)) -> list] alpha);
------hcons] a, b) <= a :: b ;
Теперь, используя hcons, мы можем определить функцию unique,
которая будет производить уникальное копирование объекта
dec unique : alpha -* alpha ;
------unique( a :: b) <= hcons( unique] a), unique] b));
------unique] x) < = x;
(Заметьте, что в этом определении присутствуют образцы.) Та-
ким образом, если а и b являются двумя эквивалентными
структурами, то unique] а) и unique] Ь) будут идентичными,
что следует из структурной индукции; утверждение является ис-
тинным по определению атомарных а и Ь. Для преобразования
функции f: а -+ 0 в полную мемо-функцию f' мы должны теперь
превратить f в ленивую мемо-функцию и применить f' к уни-
кальным аргументам, получая таким образом:
dec memo f: а-> 0;
dec f': а-> 0
------f' x<=f( unique x);
35*
548 Часть III. Глава 19
Когда Г применяется к аргументу, который эквивалентен пре-
дыдущему, то unique обеспечивает то, что ленивая мемо-функ-
ция f будет применена к соответствующим идентичным аргу-
ментам, так что повторных вычислений не произойдет. Разу-
меется, недостатки этой схемы те же, что и в любой другой
схеме, поддерживающей мемо-функции, а именно: полное вы-
числение аргументов, неэффективность в сравнении величин ар-
гументов (unique является рекурсивной функцией) и повышен-
ная трудность управления размером мемо-таблицы.
19.3. Управление размером мемо-таблицы
Если не предпринимать никаких действий для удаления не-
используемых элементов из мемо-таблицы, то ее наращивание
будет происходить непрерывно; при применении ассоциирован-
ной с ней функции к новому аргументу к ней будет прибав-
ляться новый элемент. Именно эти излишние затраты памяти
помешали запоминанию сразу же стать широко используемым
видом оптимизации; в последнее время в решении этой про-
блемы достигнуты некоторые успехи. Существуют два пути кон-
троля роста мемо-таблицы. Первый состоит в расширении функ-
ций сборщика мусора для восстановления неиспользуемых эле-
ментов мемо-таблицы; мы обсудим это в разд. 19.4.
Другой заключается в сообщении мемо-функциям информа-
ции о том, какие элементы мемо-таблицы значений аргументов
можно удалить и при каких условиях это удаление будет без-
опасным, т. е. существует гарантия, что эти элементы больше
никогда не потребуются. Часто программист способен дать та-
кую информацию, которую компилятор без труда соответствен-
ным образом закодирует. Более того, в отличие от других опти-
мизаций, осуществляемых программистом, любая ошибочная
стратегия удаления может повлиять не на корректность про-
граммы, а только на ее эффективность, поскольку при необос-
нованном удалении элементов мемо-таблицы может возникнуть
необходимость в их повторном пересчете.
В частности, программисту может быть хорошо известно,
когда мемо-таблица может быть очищена, т. е. полностью устра-
нена. В нашем примере с циклическим списком единиц в пре-
дыдущей главе очень важно, чтобы мемо-таблица оставалась
неповрежденной в течение времени обработки данной цикличе-
ской структуры некоторой функцией. С другой стороны, беско-
нечный список может быть вычислен обычным путем, без ис-
пользования запоминания. Однако после завершения отображе-
ния этого списка все его элементы можно удалить — даже если
программист уверен, что тар будет применяться вновь к идеи-
Запоминание 549
тичной функции или списку; основное внимание следует уделять
тому, чтобы циклические структуры использовались как можно
шире при последующих применениях и при минимальных за-
тратах. В этом случае достаточно создать локальную мемо-таб-
лицу для каждого применения функции тар верхнего уровня,
которую можно полностью уничтожать при возврате. Таким об-
разом, мы можем определить локальную мемо-функцию m для
тар, соответствующую той определенной функции, которая ото-
бражается в данный момент. Для этого составляем следующее
квалифицированное выражение (опуская объявления Норе):
—-----map(f, z)<=m(z)
where memo m== lambda nil => nil |
a :: x =>
f(a)::m(x);
19.3.1. Динамическое управление мемо-таблицами
Описанный выше вид локального запоминания не позволяет
осуществлять динамическое управление мемо-таблицами, при
котором по мере добавления новых элементов таблицы устарев-
шие и ненужные элементы удаляются из нее, причем полного
разрушения таблицы при этом не происходит. Это позволяет
сохранять размер мемо-таблиц в разумных контролируемых
пределах; во многих случаях это небольшое фиксированное
число элементов. Мы сосредоточим наше внимание главным об-
разом на локальном запоминании, при котором мемо-таблица
создается для каждого применения верхнего уровня мемо-функ-
ции, а запоминание происходит лишь для применений этих
функций, входящих в описывающие ее уравнения, а также в
уравнения других функций, вызываемые из них. Некоторая огра-
ниченность подобного подхода проявляется, например, в том,
что два применения верхнего уровня функции fib (20) будут
выполняться за линейное время каждая при локальном запо-
минании в то время, как второе применение может быть выпол-
нено за постоянное время при простом поиске и нахождении
своего результата в мемо-таблице первой функции, если эта
таблица не была разрушена. Далее мы увидим, что при этом
ограничении компилятор способен во многих случаях автомати-
чески определять стратегию динамического удаления путем про-
стого грамматического анализа выражения, описывающего ме-
мо-функцию.
Сначала, однако, мы рассмотрим дополнительные примити-
вы, необходимые для реализации подобного управления табли-
цами, и то, как программист может использовать их. Удаление
650 Часть III. Глава 19
элементов мемо-таблицы выполняется функцией, называемой
table manager (регулировщик таблиц), которую может создать
пользователь или для определенных классов функций генериро-
вать компилятор. Регулировщик таблиц функции f типа а->-р
имеет тип а—>-list а и выполняется сразу после вычисления ре-
зультата f до создания нового элемента в мемо-таблице функ-
ции f. Она находит те величины аргументов, ячейки которых
могут быть удалены (или переписаны) из мемо-таблицы, при-
чем осуществление этого будет безопасно в том смысле, что в
текущем вызове верхнего уровня эти аргументы больше не бу-
дут использоваться функцией f. Например, можно ожидать, что
функция регулировщика таблиц для fib будет lambda х=>
=> [х — 2] в синтаксисе Норе, поскольку для вычисления каж-
дого числа Фибоначчи требуются лишь значения предыдущих
двух. В этом примере мы вводим список с единственным эле-
ментом, но для функции, манипулирующей деревьями, регули-
ровщик таблиц может иметь вид
lambda leaf(x)=> nil |node(l, x, r)=> [1, r]
В последнем случае, если текущий аргумент заменяется на ука-
затель ptr на ячейку вершины (дерева), то применение регу-
лировщика таблиц будет указывать, что элементы мемо-таблицы
с ключами (компонентами аргумента), равными ptr.left или
ptr.right (указатели на левое и правое поддеревья ячейки соот-
ветственно), больше не являются необходимыми и поэтому мо-
гут быть удалены. Операция вставки не требует сканирования
всей таблицы для удаления элементов, указанных регулиров-
щиком таблиц. Достаточно лишь осуществить просмотр таблицы
для обнаружения всех удаляемых элементов, применив методы
хэширования или реорганизации дерева таблицы.
Выигрыш пространства, даваемый динамическим регулиро-
ванием мемо-таблиц, достигается за счет небольшого увеличе-
ния стоимости выполнения операции вставки, так как теперь
необходимо каждый раз инициировать регулировщик таблиц.
Однако для работы регулировщиков таблиц не требуется допол-
нительных (инструментальных) средств, поскольку они просто
выражены в компилируемом функциональном языке и являются
нерекурсивными. При выполнении мемо-функции основные ус-
ловные выражения проверяются до выполнения просмотра. При
истинности данного условия мемо-функция возвращает резуль-
тат базового случая и не изменяет мемо-таблицу. В противном
случае выполняется просмотр для установления того, известен
ли данный результат. В связи с тем что элементы, относящиеся
к базовому случаю, никогда не заносятся в мемо-таблицу, то
для регулировщика таблиц нет необходимости проверять их.
Запоминание 551
Таким образом, для неопределенной выше функции манипуляции
деревом регулировщик таблиц будет иметь вид lambda node (1,
х, г) =>-[ 1, г ], поскольку мы ^наем, что регулировщик никогда
не применяется к листу.
19.3.2. Автоматическая генерация
регулировщиков таблиц
Для важного класса нелинейных функций возможен не
только автоматический синтез компилятором регулировщиков
таблиц мемо-функций, но и ограничение размеров мемо-таб-
лицы некой постоянной величины, определяемой на этапе ком-
пиляции. Можно показать, что это возможно для любой функ-
ции, описанной FP-равенством вида f = р -> q; M(f, ..., f),
где М — это шмультилинейный функционал, описанный в
разд. 18.5, с предикатными преобразователями Мь . .., Мт,
являющимися положительными степенями некоторого функцио-
нала Мо, называемого наибольшим общим генератором. Макси-
мальный размер, которого может достигать мемо-таблица, будет
наименьшей общей суммой (НОС) этих степеней, где наи-
меньшей общей суммой набора целых чисел {ai, ..., ап} яв-
ляется такое наименьшее целое L, что L — а; может быть пред-
ставлено в виде kfUf ... + knan для некоторых неотрицатель-
ных целых k\, ..., kn (1 — сравните это определение
с определением «наименьшего общего делителя».
Генерированный для f регулировщик таблицы тогда будет
lambda х => [ТССх], где LCC — M^id (другими словами, LCC
является видом «наименьшей общей композиции» функциона-
лов Mi, ..., Mm). Таким образом, как только мемо-таблица до-
стигает своего максимального размера, то при добавлении но-
вого элемента будет удаляться один старый, или, альтернатив-
но, старый элемент таблицы будет заменяться новым.
Функция Фибоначчи, естественно, удовлетворяет этим усло-
виям, как мы указывали выше LCC = sub2, мемо-таблица не
содержит более двух элементов, а время выполнения функции
линейно зависит от аргумента. В разд. 18.5 мы также увидели,
как достичь этого при линеаризации, а мемо-функция будет ра-
ботать несколько медленнее, чем соответствующая линейно-пре-
образованная функция из-за большего набора выполняемых ею
при прогоне действий. Это же относится и ко всем другим функ-
циям, удовлетворяющим условиям теоремы о линеаризации —
эти условия включают в себя условия, необходимые для запо-
минания и некоторые другие. Таким образом, любая линеари-
зуемая этим путем функция может быть также обращена и в
мемо-функцию, причем проверка необходимых условий для
552 Часть III, Глава 19
этого более проста. В этом аспекте запоминание является более
практически пригодной альтернативой, нежели преобразование
нелинейных функций. Автоматическая генерация регулировщи-
ков таблиц и ограничителей размеров мемо-таблиц фактически
может быть расширена для вырождения мультилинейных функ-
ций с предикатными преобразователями, которые являются не-
совместимыми, т. е. которые не имеют максимального общего
множителя. Регулировщик таблиц находит один удаляемый эле
мен г для каждого набора предикатных преобразователей, кото-
рые имеют максимальный общий множитель, причем каждый
совместимый набор будет иметь ровно один член, являющийся
одновременно наибольшим общим множителем этого набора и
его LCC. Таким образом, один элемент мемо-таблицы будет
удален для каждого предиката преобразователя, что вполне же-
лательно с точки зрения контроля за размером таблицы, но
фактически является несущественным, так как при этом мемо-
функция никогда не сможет быть вновь применена к тому же
аргументу.
Локальная мемо-функция может быть применена к тому же
аргументу лишь тогда, когда он поступает к различным вхож-
дениям функции в описывающем ее выражении, соответствую-
щем различным предикатным преобразователям. Они должны
находиться в одном совместимом наборе, поскольку в другом
случае одинаковые аргументы не смогут генерироваться при
вычислении одного высокоуровневого применения функции. За-
дачей компилятора является определение того, какие из преди-
катных преобразователей являются совместимыми, а какие —
нет. Некоторые из них описываются довольно сложными выра-
жениями, и поэтому не всегда их можно достаточно упростить
для определения их совместимости. Таким образом, при нали-
чии набора неизвестных, совместимость которых не ясна, удале-
ние каких-либо элементов мемо-таблицы было бы необоснован-
ным, хотя, конечно, это и не привело бы к вычислению некор-
ректных результатов, а лишь повлекло бы за собой излишние
повторные вычисления.
В качестве примера этого типа запоминания рассмотрим
сначала следующее простое определение функции depth, кото-
рая вычисляет глубину дерева как максимальное расстояний от
его корневой вершины до отдельных листьев:
dec depth : tree—> num ;
------depth( leaf( n)) <= 0;
------depth(node(l, n, r))<=if depth( 1) > depth(r)
then 1 + depth( 1)
else 1 -j- depth( r);
Запоминание 553
Для трансляции этого определения в FP-форму мы в соот-
ветствии с разд. 18.1 вначале припишем метки 0 и 1 конструк-
торам leaf и node соответственно. При этом получим FP-опре-
деление
depth = eq® о 1 -> 0 ; gt ° [depth ° 2, depth ° 4] -> + о [ 1, depth о 2];
+ о [1, depth о А}
которое может быть записано в виде depth = eqQ ° 1 ->0;
Hdepth, где функционал Н является вырожденной 4-мультили-
нейной функцией, определяемой Hf = M(f, f, f, f), где M(a, b,
c, d) = gt ° [a о 2, b ° 4]->- + о [ 1, co 2]; + » [1, d°4] для пере-
менных f, a, b, c, d.
Теперь Mif = M3f = f ° 2, a M2f = M4f = f о 4 (см. упражне-
ния в гл. 18), так что мы имеем два совместимых набора пре-
дикатных преобразователей, каждый из которых имеет только
один определенный член. Следовательно, регулировщик таблиц
для мемо-функции depth будет lambda х=>- [2 ::х, 4::х], а со-
ответствующая функция для исходного определения Норе будет
lambda node (1, n, г) =>- [ 1, г ].
Более сложным примером является функция deepest, возвра-
щающая для данного дерева список всех величин, хранящихся
в листьях дерева на его максимальной глубине. Эта функция
определяется ниже через функцию depth, которую мы теперь
уже записываем в более сокращенном виде:
dec depth : tree -> num ;
------depth( leaf( x)) <= 0;
------- depth(node(l, n, r)) <= 1 + max( depth( 1), depth(r));
dec deepest: tree -> 1 ist( num);
------deepest( leaf( x)) <= [x];
------deepest(node( 1, n, r)) <=if depth( 1) > depth(r)
then deepest( 1)
else if depth( 1) < depth( r )
then deepest(r)
else deepest( 1) ( )
deepest( г);
В этом случае мы не можем осуществить простого локаль-
ного запоминания depth, так как повторное использование тех
же аргументов происходит не в одном высокоуровневом приме-
нении depth, а в разных, но в рамках единого высокоуровне-
вого применения deepest. Мы можем пожелать более полного
запоминания функции depth, но только для вызовов ее
из deepest. В этом случае мемо-таблица для depth должна
554 Часть HI. Глава 19
уничтожаться по завершении функционирования высокоуровне-
вого применения deepest.
Взаимно определенные функции часто могут быть альтер-
нативно оптимизированы путем объединения их в единое опре-
деление функции, например h, где h является конструкцией из
двух функций, если пользоваться FP-терминологией. Говоря
вкратце, здесь h определяется как h = [depth', deepest'], где
depth' и deepest' являются определяющими depth и deepest
FP-выражениями, в которых depth и deepest заменены на l_°ft
и 2 »h соответственно. При этом новыми FP-определениями для
depth и deepest станут depth = 1 ° h и deepest =? 2 °ft. Теперь
можно показать, что ft является вырожденной мультилинейной
функцией (см. упражнения). Таким образом, локальное запо-
минание может использоваться для эффективной реализации
функции ft и генерирует регулировщик таблиц lambda node-
• (1, п, г ) =>[!, г], как мы уже предположили выше.
При' применении к дереву мемо-версии, составленной из
функций depth и deepest, происходит последовательное вычис-
ление величин depth и deepest для поддеревьев, начиная
с листьев. Затем, двигаясь вверх по дереву, вычисляются соот-
ветствующие величины для внутренних вершин путем операции
просмотра для получения результатов для их ближайших
потомков. Это приводит к эффективной реализации, ограничи-
вающей размер таблицы глубиной дерева, поскольку при зане-
сении результата для данной внутренней вершины в мемо-таб-
лицу удаляются два ее элемента и остается только один
элемент, соответствующий всему поддереву, для которого дан-
ная внутренняя вершина является корневой.
19.3.3. Запоминание как преобразование
исходного текста
В приведенном выше представлении запоминания мы пред-
полагали, что во время прогона поддерживаются все прими-
тивы, необходимые для доступа и создания мемо-таблиц, а имен-
но операции m_memo_table, lookup и insert. Можно объединить
первые две из этих операций в одну функцию, возвращающую
пару величин: булеву величину, указывающую, насколько
успешно прошел просмотр таблицы (был ли успешным про-
смотр или нет), и результат, если он был обнаружен, а в про-
тивном случае — неопределенное значение. Операция вставки
insert должна использовать регулировщик таблиц, созданный
для этой мемо-функции (либо непосредственно программистом,
либо компилятором для вырожденной мультилинейной функ-
ции), а затем создать новый элемент таблицы после, возможно,
удаления одного старого. Наиболее эффективная реализация
Запоминание 555
этой операции является нефункциональной и использует разру-
шающее присваивание, однако в принципе возможно функцио-
нальное моделирование ее путем такой модификации мемо-функ-
ции, что мемо-таблица становится ее дополнительным аргумен-
том, а дополнительным возвращенным результатом является
измененная версия этой таблицы. При таком подходе мы можем
представить мемо-версию функции при помощи исходного язы-
ка в ее оригинальном определении; Норе-версия мемо-функции
Фибоначчи приведена ниже. Некоторые используемые ниже
определения считаются уже описанными, а наиболее очевидные
равенства опущены.
type arg_type ===== alpha ;
type res_type == beta ;
type table ===== list( arg_type # res_type );
type manager == arg_type —> list( arg_type);
dec lookup : table =#= arg_type —> truval =#= res_type ;
(возвращает значение true и результат, если обнаружен
элемент таблицы, соответствующий данному аргументу,
или false в противном случае)
dec delete_entry : table # 1 ist( arg_type) —table ;
(находит элементы, соответствующие данным аргументам,
и, если они существуют, удаляет их из таблицы)
dec insert: table =#= ( arg_type # геэ Луре ) =#= manager -> table ;
------insert(tab, (arg, res), man) =
(arg, res ):: delete_entry( tab, man(arg));
Перестроенное Норе-определение для fib будет теперь выгля-
деть так:
------fib( х) = let (FinalTab, Answer )==Mfib( nil, x) in
Answer
где Mfib — это мемо-версия fib и определяется так:
------Mfib( tab, x)<=
if x==< 1
then (tab, 1)
else let ( Knowlt, res) == lookup( tab, x) in
if Knowlt
then (tab, res)
else let (tabb Aj) ===== Mfib(tab, x—1) in
let (tab2, A2) =—Mfib( tabj, x —2) in
let TheAnswer ===== Ai + A2 in
(insert(tab2, (x, TheAnswer), lambda y=>
[y — 2]), TheAnswer);
556 Часть III. Глава 19
19.4. Сборка мусора для мемо-таблиц
При полном запоминании не представляется возможным пред-
сказать для данной функции, что она никогда не будет исполь-
зовать аргумент, равный тому, который уже соответствует не-
которому элементу мемо-таблицы; кроме этого, мы показали,
что подобное предсказание возможно лишь при локальном
запоминании и только для определенного класса вырожденных
мультилинейных функций, а также для тех функций, для кото-
рых программист может создать соответствующий регулиров-
щик таблиц. Однако в случае ленивого запоминания, если
сборщик мусора обнаруживает, что объект, идентичный аргу-
менту элемента мемо-таблицы, может быть удален, поскольку
ссылки на него отсутствуют, то и этот элемент больше не нужен
и поэтому также может быть удален сборщиком мусора. Од-
нако по определению все аргументы, имеющие соответствующие
элементы в доступных мемо-таблицах, также являются до-
ступными, и поэтому стандартный сборщик мусора, сохраняю-
щий все доступные структуры данных, не может обрабатывать
их. Вследствие этого он должен игнорировать ссылки элемен-
тов мемо-таблиц на хранящиеся аргументы, но, кроме этого,
остаются трудности со ссылками от элементов мемо-таблицы на
хранящиеся результаты. Если аргумент остается для хранения,
то и соответствующий ему результат также должен быть со-
хранен, так чтобы он мог быть найден, когда мемо-функция
будет применена к этому аргументу, и наоборот, если аргумент
удаляется, то и ссылка на его результат тоже должна быть
устранена.
Итак, мы оказались перед замкнутым кругом проблем. Если
сборщик мусора просматривает мемо-таблицу и если он еще
не достиг какой-либо из хранящейся в ней структуры аргумен-
тов, он не знает, какие из хранящихся структур результатов
стоит сохранить, за исключением тех, которые уже были от-
мечены как достижимые до обращения к этой мемо-таблице.
С другой стороны, некоторые структуры данных, включая ар-
гументы, имеющие свои элементы в мемо-таблице, могут быть
доступны только через структуры результатов, хранящиеся в
мемо-таблице. Поэтому просто отложить проверку мемо-таблиц
до конца сборки мусора было бы недостаточно. Это может при-
вести к тому, что некоторые элементы мемо-таблицы будут
удалены, причем их аргументы будут оставаться доступными
для мемо-функций через результат, хранящийся в нестертой
ячейке, находящейся ниже в таблице. Последствия этого не
будут фатальными с точки зрения корректности программы, но
это может привести к значительному снижению эффективности
Запоминание 557
вследствие потери преимуществ запоминания. На самом же
деле, как мы увидим, модификация сборщика мусора, необхо-
димая для корректной обработки им элементов мемо-таблиц
и их результатов, не является чрезмерно сложной. В качестве
иллюстрирующего это примера мы проведем модификацию ска-
нирующего сборщика мусора, следуя основному подходу, заим-
ствованному в [47].
Рассмотрим простую систему, в которой все ячейки,
предназначенные для хранения составных данных, содержат
поля для двух указателей и метки, указывающие на их тип.
Предположим, что мемо-таблица имеет вид списка элементов
и что головная ячейка имеет тип memo table. Поскольку ячейки
состоят лишь из двух указателей и метки, то список мемо-таб-
лицы будет представлен как Отдельная структура, в которой
поле первого указателя будет связывать элементы списка,
а второго — указывать на ячейку типа entry, представляющую
вход мемо-таблицы. На практике более подходящей структурой
было бы двоичное дерево благодаря дополнительному полю
ячейки-указателя, так как в противоположном случае для каж-
дой вершины было бы необходимо иметь две связанные ячейки.
Эффективность также можно увеличить, если бы элементы
мемо-таблицы были объединены в ячейки, образующие список
или древовидную структуру мемо-таблицы вместо необходимо-
сти осуществлять косвенный доступ к ним, а в практических
реализациях использовались бы ячейки переменного размера;
в этом случае указателей было бы четыре или для древовид-
ной мемо-таблицы-—пять.
В фазе маркирования, когда сборщик мусора находит ячей-
ку типа memo table (головная ячейка списка или корневая —
для дерева), он маркирует ее, а затем сканирует мемо-таблицу.
Для каждой ячейки мемо-таблицы он извлекает связанный
с нею элемент (представленный ячейкой типа entry, указывае-
мой этой ячейкой) и исследует его аргумент. Если аргумент
является атомом или уже маркирован, то и этот элемент, и его
результат маркируются. В противном случае мы имеем струк-
туру, показанную на рис. 19.1, а, и сборщик мусора меняет
местами указатель на аргумент в этом элементе (в поле его
первого указателя) и первый указатель в аргументе, приводя
к возникновению структуры, изображенной на рис. 19.1,6.
Если несколько элементов в различных мемо-таблицах ука-
зывают на один и тот же немаркированный аргумент, то ука-
занная процедура дает список, в котором немаркированные
элементы образуют хвост, а аргумент — голову, как показано
на рис. 19.2. Новый добавляемый элемент мемо-таблицы
вставляется сразу же после ячейки аргумента, т. е. во вторую
558 Часть III. Глава 19
позицию списка, а первый обнаруженный элемент всегда яв-
ляется последним в списке. Эта ячейка хранит исходное содер-
жимое поля первого указателя ячейки аргумента.
Теперь, когда сборщик мусора промаркировал ячейку (пер-
вый указатель на ячейку типа entry), он начинает маркировать
в
Рис. 19.1. Обращение указателя при обнаружении немаркированного аргу-
мента: а — элемент мемо-таблицы с немаркированным аргументом; б — после
обращения указателя.
все элементы в списке и их результаты и восстанавливает ис-
ходное состояние первых указателей во всех ячейках списка.
Таким образом, ячейка аргумента будет восстановлена с исполь-
зованием указателя, хранимого в последней ячейке списка,
Рис. 19.2. Цепочка аргументов с неразделяемым немаркированным аргу-
ментом.
а каждая ячейка будет теперь указывать на ячейку аргумента.
Первый указатель, хранящийся в каждой ячейке, может быть
особым образом помечен (если есть свободный бит), так чтобы
можно было избежать косвенных обращений при проверке того,
указывает ли данная ячейка на ячейку типа entry. В конце
фазы маркирования все достижимые элементы, аргументы и
результаты будут промаркированы, а фаза сканирования будет
выполняться в нормальном режиме и лишь с тем дополнением,
что в списках (или деревьях) мемо-таблиц будут удаляться все
ячейки, указывающие на немаркированные (удаленные) эле-
менты. Любой такой элемент мемо-таблицы будет некорректен
из-за обратимости указателей и, разумеется, не может уже
потребоваться.
Запоминание 559
Резюме
• Запоминание осуществляется путем сохранения результатов,
вычисленных функцией для всех тех аргументов, к которым она
применялась; при этом пары аргумент-результат заносятся
в мемо-таблицу.
• Когда мемо-функция вновь применяется к тому же аргу-
менту, то результат ищется в мемо-таблице, а не вычисляется
заново.
• Ленивые мемо-функции проверяют аргументы на идентич-
ность, а не на равенство и обеспечивают ленивую семантику,
а также более эффективное сравнение аргументов.
• Ленивые мемо-функции особенно эффективны для представ-
ления циклических структур.
• Полное запоминание может быть реализовано на основе ле-
нивого запоминания с «хэширующими» конструкторами.
• Регулировщики таблиц регулируют рост мемо-таблиц путем
удаления определенных элементов таблиц при вводе новых.
• Для определенных вырожденных мультилинейных функций
размер мемо-таблицы можно ограничить некоторым постоян-
ным числом элементов, определяемым при компиляции.
• Мемо-таблицы и их элементы рассматриваются сборщиком
мусора как ячейки особого вида.
Упражнения
19.1. Функция zip, формирующая список соответствующих пар
из двух списков аргументов, определяется так:
------zip([], [])<=[];
------zip(a::x, b::y)<=[a, b]:: zip(x, у);
Для циклических списков ab = a::b::alr и abc = а ::b ::
::c:-.abc найдите ленивую форму представления zip(ab, abc)
после шести применений zip и покажите, как она может быть
выражена через циклическую структуру системой, поддержи-
вающей ленивые мемо-функции. Какая циклическая структура
может служить для представления выражения zip(ab, аЬ)?
19.2. Определяемая ниже функция comb для данного целого п
возвращает все комбинации чисел 2, 3 и 5, которые склады-
вает с п:
data combination == с235(num # num # num);
dec addon : num # list( combination) —> 1 ist( combination);
dec g, comb : num—>list(combination);
------addon( a, nil) <=nil;
------addon(2, c235((x, y, z)::L))<=
c235(x-j-l, y, z):: addon(2, L);
560 Часть III. Глава 19
------addon(3, с235((х, у, z)::L))<=
с235(х, у+1> z)::addon(3, L);
------ad'don(5, с235((х, у, z)::L))<=
с235(х, у, z + 1):: addon( 5, L);
------g 2<=[с235( 1, 0, 0)];
------g 3<=[с235(0, 1, 0)];
------g 4<=[с235(2, О, 0)];
------g 5 <=[с235(0, О, 1), с235( 1, 1, 0)];
------comb n<=if n<15 then g n else addon(5,
comb( n — 5)) (*)
addon( 3,
comb( n — 3)) (*}
addon( 2,
comb( n — 2));
где инфиксная функция <*> соединяет два списка с исключе-
нием возможных повторений. Дайте свободное от переменных
определение comb и определите функцию ее регулировщика
таблицы. Каков будет максимальный размер мемо-таблицы при
вычислении comb?
19.3. Дайте FP-определение функции deepest, описанной в
разд. 19.3.2 и на основе его создайте FP-уравнение для опре-
деления функции h = [depth, deepest]. Докажите, что h яв-
ляется вырожденной 8-мультилинейной функцией с двумя клас-
сами предикатных преобразователей, и дайте определения для
одного предикатного преобразователя из каждого класса. По-
кажите, что регулировщик таблиц для h в обозначениях Норе
имеет вид
lambda node(l, п, г )=>[!, г]
19.4. Вырожденная билинейная функция f, вычисляющая бино-
миальные коэффициенты, может быть представлена так:
f = (or°[=, е<70°2])-> 1 ; + ° [f °[subl ° 1, subl°2],
f O [siz&l О 1, 2]]
Как можно описать предикатные преобразователи Mi и М2,
связанные с этим определением? Покажите, что М’М2 = M2Mi.
Рассмотрим теперь функцию g, такую, что:
£ = />-*<7; aofgoft, g°c]
где b °с = с °b для фиксированных функций р, q, а, Ь, с. Если
предикатные преобразователи не имеют ни одного общего ге-
нератора, т. е. не существует целых п, т, таких, что Ьп = ст,
то как много раз g может быть применена к одному произволь-
ному аргументу в применении верхнего уровня? Могли бы вы
предложить подходящую стратегию удаления элементов мемо-
таблицы?
Глава 20
АБСТРАКТНАЯ ИНТЕРПРЕТАЦИЯ
Вместо того чтобы преобразовывать исходную программу
в другую эквивалентную программу, которая на данном ком-
пьютере будет выполняться более эффективно, возможен и
второй путь оптимизации, заключающийся в определенном ан-
нотировании программы, принуждающем ее выполняться не-
которым заданным образом, при котором не изменяются конеч-
ные выдаваемые результаты. Эти два подхода не исключают
друг друга и одна из стратегий оптимизации функциональных
программ заключается сначала в преобразовании программы,
согласно рассмотренным в первых главах методом, а затем
в выборке семантически корректных аннотаций для управления
ее работой. Основной трудностью, с которой сталкивается аб-
страктная интерпретация, заключается в определении того,
когда рабочие характеристики программы могут быть обос-
нованно изменены, т. е. изменены так, чтобы сохранилась
семантика программы. Классическим примером является
анализ строгости, как мы уже упоминали во введении к ч. III;
более глубокому изучению этого посвящен разд. 20.2. Для
начала, однако, - перейдем к введению более общего ха-
рактера.
20.1. Общие принципы
Семантика любого функционального языка выражается в
терминах доменов таких объектов, как целые числа, логические
величины, символы и ▼. д., или через объединения любых из
них и непрерывные функции, определенные на них. Следова-
тельно, любой формальный анализ выполнения программы
также должен вестись в терминах этих доменов, а не множеств.
При абстрактной интерпретации анализируются определенные
свойства процесса вычисления функционального выражения
36 - 1473
562 Часть III. Глава 20
путем определения вначале «абстрактного домена», который го-
раздо проще, нежели стандартный семантический домен этого
выражения, и структура которого является минимально необ-
ходимой для поддержки этих свойств На абстрактном домене
определяются абстрактные версии каждой из функций, входя-
щих в это выражение; затем эти версии применяются к аб-
стракциям аргументов и дают результаты также из абстракт-
ного домена, по которым могут быть получены требуемые свой-
ства реальных применений функции. Смысл заключается в
том, что «применения» в абстрактной области обычно гораздо
проще, чем во время компиляции, поэтому соответственно об-
легчается аннотирование, необходимое для управления выпол-
нением реального выражения. В этом случае может быть
определена эквивалентная операционная семантика рассматри-
ваемого выражения, являющаяся более эффективной, чем стан-
дартная семантика, а также может быть установлена коррект-
ность этого аннотирования
Хорошей иллюстрацией этой общей идеи может послужить
простой арифметический пример, в котором на самом деле мы
могли бы использовать множества вместо доменов объектов.
Рассмотрим набор целых чисел Z и функцию умножения *
и предположим, что мы хотим узнать знак произведения чисел
762 и —957. Один из способов сделать это — получить произ-
ведение (—729234) и установить, что оно является отрицатель-
ным числом. Поэтому ответ будет «отрицательный». Однако
вряд ли кто-нибудь на самом деле будет производить эти вы-
числения; вместо этого легче, конечно, воспользоваться «пра-
вилом о знаках», гласящим, чго произведение двух чисел с про-
тивоположными знаками отрицательно. Это правило является
видом абстрактной интерпретации, использующей абстрактный
набор Z* = {плюс, минус, нуль}, соответствующий возможным
знакам целых чисел. Функция абстракции absz'.Z->Z* будет
определяться так:
absz{ х) = плюс, если х > 0
= минус, если х < 0
= нуль, если х = 0
а функция абстракции для пар целых чисел (область определе-
ния *) является ее расширением: absZzz : Z X Z-*Z* X Z*
и определяется так:
abszxz{x, y) — (absz(x), absz(y))
Абстрактная интерпретация 563
Если абстрактную версию * обозначить как *+, то правило
о знаках можно представить следующим образом:
**(плюс, плюс) = ** (минус, минус) = плюс
*#(плюс, минус ) = ** (минус, плюс) = минус
*# (нуль, а) = ** (а, нуль) = нуль (a^Z#)
Обычно символ # используется для обозначения постфикс-
ных форм как функций, отображающих обычные функции, та-
кие как * к их абстрактным версиям (**), так и функций
типа absz, которые отображают объекты. Поэтому в первом
случае # имеет тип ( Z X Z —> Z ) -> ( Z# X 2* -> Z* ), а во вто-
ром Z—>Z#- Теперь мы имеем х* = плюс для х > 0, х* =
= минус для х < 0 и 0* = нуль и, как легко заметить, для
любых х, у е Z
*#(х*, у*) = (*(х, у))#
что следует из рассмотрения всех шести возможных случаев
х, у > 0, <0, =0. Другими словами, квадрат функций комму-
тативен или в FP-обозначениях:
absz о * = ** о abszxz
*
Z XZ---------► Z
SlbSz х z 3bsz
Z'XZ*-----—► z*
*
Это равенство является одним из гарантирующих коррект-
ность правилом о знаках, и можно заметить, что оно всегда
приводит к определенному ответу, т. е. мы можем всегда при-
менить это правило для получения знака произведения, не вы-
числяя его.
Теперь предположим, что мы имеем операцию сложения,
определенную на Z, и хотим вывести соответствующее правило
о знаках и для него. Мы можем сразу записать:
-\-*(плюс, плюс) — +# (нуль, плюс) — +# (плюс, нуль) =
= плюс
+ # (минус, минус) = -\-# (нуль, минус) — (минус, нуль) =
= минус
-]-*(нуль, нуль) = нуль
36*
564 Часть III. Глава 20
но мы не можем ничего определить для + (плюс, минус) и
+ (минус, плюс). Они не могут гарантировано приводить
к плюсу, минусу или нулю, поскольку для каждого варианта
ответа можно найти противоположный пример, подтверждаю-
щий корректность обратного утверждения + *(х*, у#) =
==(+(x,z/))*. Например, если мы решили, что-}-* (плюс, мину с)—
= плюс, то при х = 1, у — —2 слева будет плюс, хотя правая
часть дает (—1)* = минус. Поэтому мы должны добавить
к нашему абстрактному набору (по крайней мере) элемент
неизвестно.
Говоря точнее, необходимо с каждым элементом из абстракт-
ного домена Z* связать подмножество стандартной области
определения Z, которое этот элемент представляет. В нашем
случае мы свяжем плюс с множеством {п|п>0}, минус с
{п|п<;0}, а нуль с {0}. Абстрактная интерпретация будет кор-
ректной и, как говорится, надежной, если реальный результат
применения функции находится в наборе, выраженном резуль-
татом соответствующего применения абстрактной функции.
Вследствие этого уравнение корректности должно быть заме-
нено критерием надежности:
abs о * cz *# ° abs
где знак включения множества относится к множествам, свя-
занным с рассматриваемыми абстрактными величинами. Из
нашего первого примера видно, что поддержка этого свойства
осуществляется благодаря равенству abs ° * = ** ° abs, но во
втором примере для обеспечения надежности необходимо свя-
зать элементы +#(плюс, минус )= -)-#( минус, плюс) со всем
множеством Z. Следовательно, мы получаем дополнительный
элемент в Z# — назовем его Ф, — связанный с Z, и дополни-
тельные правила для абстрактной функции -f-#
-}-*(плюс, минус) = 4-# (минус, плюс) = +* (а, Ф) =
= +#(Ф, а) = Ф
для а е { плюс, минус, нуль, Ф}.
(Мы должны также определить новые правила для **, а именно
*#(а, Ф) = **( Ф, а) = Ф, чтобы можно было определить зна-
ки произвольных арифметических выражений, включающих
как сложение, так и умножение.)
При отображении- определенных выражений в Ф для обес-
печения надежности мы отбрасываем некоторую информацию,
что приводит к тому, что определение знаков некоторых выра-
жений становится невозможным без их вычисления. Если аб-
страктное значение выражения будет Ф, то осуществление его
Абстрактная интерпретация 565
абстрактной йнтерпретации не поможет нам узнать его знак!
Например, вычислений при определении знака выражения
39 — 24 можно избежать. (В частности, мы не сможем опреде-
лить, что выражение 39—24 положительно.) К сожалению, си-
туация подобного рода неизбежно возникает почти во всех опти-
мизациях, основанных на абстрактной интерпретации; «почти»—
так как правило о знаках для умножения способно дать
исчерпывающую информацию, но это является исключением.
Причина заключается в том, что нам необходимо абстрагиро-
вать те свойства, которые являются неопределенными, а для
уверенности в корректности, т. е. надежности, мы должны рас-
сматривать все возможные результаты вычислений, представ-
ленные данными абстрактными значениями, из которых только
один будет иметь место в любом конкретном случае. Таким
образом, при анализе строгости мы должны найти все случаи,
в которых аргумент, который может быть передан по значению,
не будет определен как строгий, но мы уверены, что любой
аргумент, который должен быть передан по необходимости, ко-
нечно, не будет определен как строгий Разумеется, при доста-
точном расширении абстрактной области определения мы мо-
жем в полной мере представить любое свойство, делая возмож-
ным точное предсказание, но в конце концов мы можем и
вернуться к стандартной области определения и проделать все
вычисления полностью. Так было в том примере, где мы рас-
сматривали правило знаков для сложения.
20.2. Анализ строгости
Впервые мысль о применимости абстрактной интерпретации
для анализа строгости была высказана в [69], который исполь-
зовал эту методику также для исследования проблемы уста-
новления условной конечности времени вычисления выражения.
Основной задачей здесь является повышение эффективности
ленивой реализации функционального языка путем поиска воз-
можности доступа к аргументам по значению, а не по необхо-
димости без изменения условий окончания работы программы.
Как мы видели в предыдущих главах, это устраняет необхо-
димость в создании задержек для аргументов в SECD-машине
и в то же время уменьшает количество структур данных, соз-
даваемых во время прогона программы и обрабатываемых в
дальнейшем сборщиком мусора. Более того, если при парал-
лельной редукции графов известна строгость каждой опреде-
ленной пользователем функций, то это позволяет производить
вычисление строгих аргументов параллельно с вычислением
функции, увеличивая тем самым степень параллелизма.
566 Часть HI. Глава 20
Майкрофт начинал свои исследования с функций первого
порядка и плоских доменов; в нашем обсуждении мы будем
основываться на этом же подходе. Для функций более высокого
порядка он может быть обобщен в рамках типизированного
лямбда-исчисления (см. [17]), и в следующем разделе мы бу-
дем использовать основы этого подхода при рассмотрении во-
просов, связанных с доказательством надежности.
Итак, функция f арностью п будет строгой относительно
i-ro аргумента тогда и только тогда, когда
f(xb . . ., Xi _b _L, xi + 1, ..., x„)= ±
для всех объектов xi, x,_t, xl+i, ..., xn в плоском домене
A (1 ^i^n). Для такой функции можно безопасно вычислять
i-й аргумент до применения этой функции ко всем п аргументам,
так как если процесс этого вычисления не закончится, т. е.
имеет значение _!_ в семантическом домене, тогда то же самое
относится и к применению функции f и полному набору аргу-
ментов и в соответствии с любым правилом вычислений с опре-
деленной стандартной семантикой. Таким образом, мы можем
передавать i-й аргумент по значению и соответствующим обра-
зом аннотировать определение f для отражения этой инфор-
мации.
Как будет ясно из приложения Б, плоский домен А является
частично упорядоченным множеством (Sj_, < ), где 3 — любой
набор атомарных данных, доступных в типичном языке про-
граммирования, такой как объединение логических величин,
целых чисел и символов и Sx = S|J{±}. Порядок ( < ) опре-
деляется выражениями ± < а и а < а для всех aeS; < не
определяется для различных элементов, не являющихся рав-
ными ±. (В техническом аспекте, заметим, это приводит к
«объединенной» сумме доменов, обозначаемой Ф, которые
имеют единственный общий элемент «основание». «Объединен-
ная» сумма доменов D = (S±, <d) и Е = (7’х, <е) есть до-
мен D Ф Е = ((S U Т) х, <), упорядоченный согласно правилу,
что х < у тогда и только тогда, когда х— ± или x<Zoy, или
x<Zsy, так что «объединенная» сумма для плоских доменов
также является плоской, поскольку для х, y^S, x<Zny тогда
и только тогда, когда х = у, и аналогично для х, у е Т. Хотя
при этом выражения будут не типизированы, здесь это являет-
ся несущественным, и вместо этого мы могли бы определить
разъединенную сумму, в которой наименьший элемент в каждой
области удаляется для хранения и вводится новый элемент
«основание», меньший, чем любой наименьший элемент слагае-
мых доменов. При этом подтипы будут выражены через полные
домены, а не через множества.)
Абстрактная интерпретация 567
Для нужд анализа строгости определим абстрактный домен
для А как Л#=={0, 1), где 0 является нижним элементом, ко-
торый связан с множеством {-L}, 1 связан с Л и порядок в А#
такой: 0 < 1. Мы будем выражать бесконечно вычисляемое вы-
ражение через 0, а выражения, вычисление которых может быть
конечным (но может и не быть таким), через 1, так что функ-
ция абстракции dbsA'.A~^-A* будет определяться
absA( JL ) = О
absA(а) = 1 (а=А= _|_, ае ,4)
Мы будем рассматривать функции с произвольным количе-
ством аргументов, т. е. функции вида f:An-*~A с арностью
п 2, и поэтому мы расширим нашу область А для включения
кортежей. Определим результирующую область Ап как {(fli, ...
..., О-n) | at е А, а, #= ±, 1 i п} J {_!_}, т. е. мы будем ис-
пользовать объединенное произведение, в котором компоненты
кортежа не равны основанию. Таким образом, мы рассматри-
ваем домен D, являющийся (объединенной) суммой доменов
Ап для п 0, обозначаемой D = А ф А2 ®‘ ... . Отношение
порядка < очевидным образом расширяется для поддержки
кортежей в D (см. о декартовых произведениях в при-
ложении В) путем определения (dj, ..., dn)<Z(ei, ..., ет)
тогда и только тогда, когда п = т и dt et для 1 sC I п,
т. е. dt — ei, поскольку домен А является плоским и d;^±.
Таким образом, отношение порядка для кортежей является от-
ношением равенства, и поэтому домен D тоже плоский. Теперь
мы можем работать в рамках несколько более общего подхода
и допускаем функции типа D—>-£), которые могут возвращать
в качестве результата кортежи.
Абстрактным доменом, соответствующим D, теперь будет
D# — А#2ф ..., а функцию абстракции мы можем рас-
пространить и на кортежи, представив absAn : Ап—>А#п как
absAn(a,, ..., ап) = (abs( аг), ..., abs( ап ) ) (а{, ...,апе=А)
так что теперь можно определить функцию абстракции
abs : £)-*£>* (опуская индекс D) через
abs( d) — absA( d), если d e A '
= absAn( d), если d e An
568
Часть III. Глава 20
Функция «верхнего индекса» [Z)—>£>]—>[ Z)#—►£>*]» отобра-
жающая функцию f в f# такова, что показанный ниже квадрат
abs abs
D*----------► О*
и f*
обладает следующим свойством: /*( abs( d)) о abs{ f( d)) для на-
дежной абстрактной интерпретации. Мы будем также исполь-
зовать знак # для обозначения abs, т. е. d# =abs(d), и по-
этому # о f cz f# о Эту связь можно использовать для упро-
щения наших проверок строгости следующим образом.
Если abs(f(xi, ..., xt-i, ±, x,+i, ..., х„))=0 для всех
объектов Xi, ..., Хг-ь Хг+ь ..., х„е/1, то по определению abs
мы получаем, что f(xi, ..., x»—i, ±, хн-ь ..., хл) = ±, так как 0
связан с одноэлементным набором {J_}. Поэтому f будет стро-
гой по Ему аргументу. Предположив, что имеет место надеж-
ная абстрактная интерпретация, из этого условия получим, что
f#(x*, ..., х*_р 0, х*+1. ..., х*) = 0- Таким образом, крите-
рий строгости может быть сведен к f*( 1, . .., 1, 0, 1, ..., 1) =
— 0, где 0 стоит в Ей слева позиции. Это будет выполняться,
если f и # являются непрерывными, поскольку при этом f#
также непрерывна, и поэтому
f*(X]#, . ...Х,-!*, 0, xi+1*, ...,х„#)<
< f*( 1, ..., 1, О, 1, ..., 1 ) = 0
для всех X], ..., х,_ь х/+1, . .., х„ е А,
так как (хГ, ..., х*_ь 0, x*+i....х* ) < (1, ..., 1, 0, 1, ..., 1).
Разумеется, при такой интерпретации абстрактная величина
1 будет иногда ассоциироваться с выражением, вычисление ко-
торого будет бесконечно, что приведет к тому, что строгость
некоторых определенных аргументов не будет установлена —
это является платой за надежность при простом абстрактном
домене. Вообще же мы ожидаем, что значительная часть стро-
гих аргументов будет корректно идентифицирована, и с точки
зрения работы программы это лучше, чем ничего.
Теперь мы можем определить, в чем заключается абстрак-
ция определений функции, т. е. завершить определение функ-
Абстрактная интерпретация 569
ции #. Как мы увидим ниже, наши действия состоят в опреде-
лении абстрактных версий примитивных функций, а затем
правила для получения примитивных абстрактных вершин вы-
ражений первого порядка, сформированных с помощью прими-
тивных функций объектов и рекурсий. В разд. 20.3 мы вкратце
представим все шаги, необходимые для осуществления формаль-
ного доказательства надежности абстрактной интерпретации, от-
сылая читателя к соответствующим ссылкам на литературу для
ознакомления с более подробными деталями, приводящими к не-
которым достаточно сложным алгебраическим выкладкам.
20.2.1. Абстракция выражений первого порядка
Условимся рассматривать только такие строгие бинарные опе-
раторы нашего языка, как -|-, —, = и т. п. Поскольку они яв-
ляются строгими по отношению к своим обоим аргументам, то
все их абстрактные версии будут обладать свойствами логиче-
ской конъюнкции А в > соответствии со следующими равен-
ствами:
1 Л 1 = 1
1 Д0 = 0
ОД 1=0
0 Д 0 = 0
Другими словами, +# = Л, — * = Л и т. д.
Теперь если условное выражение Е имеет вид if х then у else z,
то наше положение несколько усложняется. Если вычисление х
бесконечно, то и Е также не будет вычислено никогда. Если же,
однако, х может быть вычислено за конечное время, мы можем
быть уверены, что вычисление Е будет бесконечным, если и у,
и z не будут вычислены, так как мы не знаем, какой из двух
вариантов будет выбран, не имея пока более точной информа-
ции о х. Вследствие этого абстрактная версия условной функ-
ции будет определяться через if* р then* q else* г = р/\( qVr)
для объектов р, q, г^А*> где V определено так:
1 V 1 = 1
1 V 0= 1
0 V I = 1
0 V 0 = 0
Поскольку мы рассматриваем только функции первого по-
рядка, то можно считать, что все они имеют свои имена и
570 Часть 111. Глава 20
существуют в некоторой функциональной среде, так что нам
необходимо рассмотреть только их применения. Так, любое вы-
ражение Е является либо константой, для которой мы ввели
определение функции abs, либо применением вида Е\Е2, введем
определение( EiE2 )*=£'*•£*• (Для применения Е\Е2 и для функ-
ций первого порядка Е\ будет являться либо примитивной функ-
цией, либо именем функции, определенной пользователем; на
самом же деле абстракция, введенная для применения, поддер-
живает функции и более высокого порядка.)
Если предложить, что нижеследующее определение # обес-
печивает надежную абстрактную интерпретацию, то мы получим
все необходимое для того, чтобы конвертировать произвольное
выражение первого порядка в абстрактную форму, с помощью
которой можно установить конечность вычислений и их стро-
гость Рассмотрим в качестве примера функцию трех аргумен-
тов ), которая задается следующим равенством:
-----f(x, у, z) <= if х = 0 then y + z else x —у;
Для получения абстрактной формы мы просто «вставим #
в применение функции» в соответствии с приведенным выше
правилом и применим правило для абстрагирования условных
выражений
/*(Х, У, Z) = (x = 0)*A((Hz)*V(x-?)*)
где X представляет х# и аналогично для У и Z. Теперь
(х = 0)# = ХА1, так как является строгой по обоим аргумен-
там, и 0* = 1, так как 0 — константа При тех же аргументах
в (у + г) и (х — у) мы получим
f#(X, У, Z) = (XA 1)А((УА2)У(ХАУ))
= X /\ У после некоторых упрощений
Разумеется, всегда можно подобрать соответствующие пара-
метры х, у и z для получения желаемых X, У и Z в D# (т. е.
х = J_ дает X = 0, у = 3 дает У = 1). Следовательно, X, У и Z
могут рассматриваться как формальные параметры функции
/*• Таким образом, окончательно мы имеем/#(0, 1, 1) =
f*(l, 0, 1 ) = 0 и f#( 1, 1, 0)= 1, на основании чего можно
заключить, что f является строгой только по первым двум своим
аргументам
Рассмотрение этого примера приводит к разнообразным вы-
водам. Первый заключается в том, что, хотя данный результат
мог бы быть получен путем наблюдения, использованный метод
может быть алгоритмизован и гарантирует корректность своей
Абстрактная интерпретация 571
работы, поскольку его надежность уже была доказана. Второй
состоит в том, что мы осуществили несколько интеллектуальных
шагов при упрощении логических выражений, что в более об-
щем случае не всегда может быть сделано столь же просто,
не говоря уже об автоматизации этого процесса. Однако, учи-
тывая малые размеры абстрактного домена, часто бывает по-
лезно использовать таблицы истинности для выполнения необ-
ходимых логических вычислений, особенно при отсутствии
рекурсивных выражений. Здесь, например, у нас есть три аргу-
мента, каждый из которых может принимать одно из двух зна-
чений, т. е. таблица истинности будет состоять лишь из восьми
строк. И наконец, третий наш вывод будет заключаться в том,
что этот метод легко применим для определения строгости лю-
бой нерекурсивной функции первого порядка, но в этом отно-
сительно тривиальном случае оптимизация либо почти, либо
совсем не нужна, а рекурсия является практически неотъемле-
мой особенностью функциональных программ, что мы и рас-
смотрим в следующем разделе.
20.2.2. Выражения с рекурсией
Абстрагирование выражений, описывающих рекурсивные
функции, мы будем производить точно так же, как и в нере-
курсивном случае, и неизбежно при этом получим соответ-
ствующее рекурсивное уравнение для абстрактной функции.
Эта функция, однако, будет определена на очень малой обла-
сти, чем мы и будем пользоваться при вычислении наименьшей
фиксированной точки функции, используя ее рекурсивное урав-
ние и теорему о фиксированной точке, представленную в при-
ложении Б. Мы опять рассматриваем пример, который позво-
ляет представить этот метод достаточно подробно. Предполо-
жим, что функция f определяется следующим выражением:
-----f(x, у) <=if х = 0 then у else f(х — 1, у);
Используя метод из предыдущего раздела, мы получим для
абстрактной функции такое уравнение:
f#(X, У) = (х = 0)#Д(г/* Vf*((x-1)*, у*)
= Х /\(YVf*(X, Y))
где опять х# и г/* будут заменены на формальные параметры X
и У. Поскольку f# непрерывна (так как f непрерывна и можно
показать, что # — тоже непрерывна), то мы можем вычислить
ее для нахождения наименьшей фиксированной точки с помощью
прямой итерации. Это вычисление обязательно будет конечным,
572 Часть III. Глава 20
так как домен D* имеет конечную глубину, является плоским,
не имеет бесконечно возрастающих последовательностей, а ме-
тод является непригодным для маленьких доменов. Следова-
тельно, в общем случае, функция /*> определяемая выраже-
нием
f#(A\, где /* входит в Е (как Xh ...,Хп)
может быть получена на этапе компиляции с помощью следую-
щей итерации. Пусть
Тогда f* = fn для таких п, что fn(X}, ..., Хп) = Xi, ...
..., Хп ) для всех Хь . .., Хп <= £>*•
В нашем примере, следовательно, мы получим
Y) — 0
f*(X, У) = ХД(У V0) = XAK
f*(X, Y) = X A(KV (ХДУ)) = ХДУ
и поэтому можно заключить, что/*(.¥, У) = ХДУ.
Функции f* будут выражены в виде таблицы, которая пол-
ностью определяет отображение, и итерации будут прекращены
лишь после того, как таблица при очередной итерации оста-
нется неизменной. Важно избежать генерации таких последо-
вательностей, как /*(0, 1, 1, ..., 1^, п 0, при проверке стро-
гости первого аргумента и остановиться при равенстве по-
следовательных величин. Это необязательно будет происходить
в результате применения фиксированной точки к одинаковым
аргументам, так как эта последовательность не служит вычис-
лению f#- Единственный способ выполнения проверки строго-
сти заключается в нахождении полного определения фиксиро-
ванной точки путем вычисления, если это необходимо, всей
таблицы, хотя помимо последовательных применений аппрокси-
маций ко всем возможным комбинациям аргументов разрабо-
таны и более эффективные методы [71].
20.3. Доказательства надежности
В завершение нашего обсуждения приемов абстрактной ин-
терпретации и их применения для анализа строгости мы вкратце
рассмотрим основные результаты, которых мы достигли в фор-
Абстрактная интерпретация 573
мальном обосновании надежности абстрактной интерпретации.
Корни теории абстрактной интерпретации находятся в теории
доменов, и поэтому полное рассмотрение не только выходит за
рамки этой книги, но само по себе требует отдельной книги.
В предыдущих разделах мы рассматривали главным образом
два семантических направления: стандартную семантику, опре-
деленную на стандартном домене D2 и абстрактную семантику
с абстрактной областью D*- Таким образом, мы должны рас-
сматривать две семантические функции, отображающие син-
таксис данных выражений в величины в стандартных и
абстрактных доменах соответственно, а также подходящую
функцию абстракции absp, для которой выполняется условие
надежности. Следующее описание полностью основано на под-
ходе, описанном в [17], и применяется к функциональным
языкам вообще с функциями более высоких порядков, хотя
в указываемой работе не рассматриваются неплоские до-
мены.
Предположим, что интерпретация I функциональных выра-
жений с данным синтаксисом происходит на семантическом до-
мене D', что его семантической функцией является sem' и что
функция среды, отображающей имена переменных на величины
из D', является р'. В нашем случае / будет либо стандартной,
либо абстрактной интерпретацией, соответственно D1 будет либо
D, либо D#’ a sem' и р' будут соответствовать стандартной
или абстрактной семантике и среде. Семантические функции
отображают синтаксические конструкции и среду на величины
из семантических доменов и обычно являются карринговыми,
так что sem1 имеет тип выражение-> среда' D', где среда1 ~
= [переменные->£>'], а выражения и переменные соответствуют
некоторому синтаксису.
Использование лямбда-вычисления является достаточным
для нашего синтаксиса выражений, так как нам известно, что
с его помощью можно представить любой функциональный
язык и соответствующий способ трансляции. Для представле-
ния функций от более чем одного параметра, мы можем ввести
в лямбда-вычисления кортежи, как было предложено в гл. 6.
Однако при доказательстве надежности, основанном на пред-
лагаемом ниже подходе, в любом случае допускается наличие
функций высшего порядка и предполагается, что все функции
представлены в карринговой форме. Таким образом мы опре-
делим sem':
sern'xp = рх
sem'ср = с
574 Часть III. Глава 20
где с является постоянным выражением, а с — соответствующее
значение, выбранное в D1:
sem'{ MN ) р = (semJMp) (sem‘Np)
sem/( kx. M) p = kd. setn'Mp {djx}
где {d/x} расширяет p так, что x будет связано c d.
Таким образом интерпретация / зависит исключительно от
области D' и величин, присвоенных константам. (Случай функ-
ций более высоких порядков был разобран в [17] с помощью
типизированного лямбда-исчисления; для различных типов
устанавливались различные домены. При этом D' будет их разъ-
единенной суммой и интерпретация будет зависеть лишь от до-
менов, связанных с базовыми типами, и от величин, присваивае-
мых константам.)
Например, в предыдущем разделе при стандартной интерпре-
тации мы имели бы следующее определение семантики услов-
ных выражений:
semst( if р then х else y) = COND(p, х, у)
где COND : А3 -> А определяется так:
COND{p, х, у) = X, если р ф {true, false}
COND{ true, x, y) = x
COND{ false, x, y) = y
При абстрактной интерпретации мы будем иметь:
sem*{it р then х else y) = COND*{p, х, у)
где COND* : А*3 —> А* определяется так:
COND*{0, х, у) = 0
COND*( 1, х, r/) = x V у
где V — оператор наименьшей верхней границы, эквивалентный
«логическому ИЛИ», использованному в разд. 20.2.1.
Абстрактная функция # должна связывать стандартную се-
мантику и абстрактную семантику таким образом, чтобы была
возможность корректно получать обоснованные сведения
о строгости данной функции f путем вычисления в абстрактном
домене выражений, полученных применением абстрактной се-
мантической функции к выражениям f(xIt ..., _1_, ..., х„),
где f имеет арность п. Это понятие корректности является бо-
лее строгим, нежели свойство надежности, обсужденное нами
в разд. 20.1, и называется полнотой.
На самом деле для выражений типизированного лямбда-ис-
числения полнота этой абстрактной интерпретации может быть
установлена выбором соответствующего описания каждой ти-
Абстрактная интерпретация 575
пизированной функции абстракции absa : Da ->D*’ удовлетво-
ряющей следующим условиям:
1. absa(d) = J_* тогда и только тогда, когда d = _La. Это гаран-
тирует то, что основание абстрактного домена будет ассоцииро-
вано с множеством {_!_}.
2. Для всех выражений Е типа ст и контекста р:
absa{ setnstEp) < sem*( Eabs0 ° p)
3. abs-tifd) <tz6sa->T(f )absa(d).
При этих условиях мы получаем следующую теорему пол-
ноты [17]. (Для простоты мы рассматриваем замкнутые выра-
жения, т. е. выражения, не содержащие свободных переменных,
и опускаем члены, представляющие пустой контекст.) Суть этой
теоремы заключается в том, что для закрытого члена М : стг~> ...
... -*стл->Л верно следующее:
( sem#M ) Т*! ... ±*; ... = 0 =>
( semstM ~)di ... doi ... dn = ±А
для всех di е DCTi, • • •, dn^ Dan.
Член T*j обозначает верхний элемент домена, представляю-
щего тип ст, (l^/'^rt), который является большим среди
всех элементов домена, расставленных в порядке возрастания,—-
подобные домены являются решетками. Домен А является объ-
единенной суммой каждого домена, представляющий базовый
тип, и, следовательно, совпадает с доменом А из предыдущего
раздела. Этот результат полностью аналогичен тому, который
был необходим для обоснования метода, использованного ра-
нее для анализа строгости. Ход доказательства достаточно ясен
при данных условиях, накладываемых на функции абстракции,
однако найти их и доказать выполняемость этих условий не-
просто. Для базовых типов наше определение из предыдущего
раздела является достаточным для анализа первого порядка,
а именно absA(d) = 0, если d — Л-А, и 1 в противном случае.
Соответствующее расширение на типы более высоких порядков
будет гораздо сложнее и является предметом рассмотрения
[1, 17], которые дали развитие этим идеям.
20.4. Другие применения для оптимизации программ
В настоящее время абстрактная интерпретация является ак-
тивно развиваемой областью знаний [2], и до сих пор един-
ственным способом оптимизации, в котором она практически
использовалась, был только анализ строгости, в той или иной
576 Часть HI. Глава 20
мере рассмотренный нами. Существует, однако, большое число
иных возможностей ее использования при оптимизации функ-
циональных программ путем семантически корректной аннота-
ции. Мы уже встречались с одним примером, который может
рассматриваться как абстрактная интерпретация в системе вы-
вода типов, обсужденной в гл. 7, которая образует основу ал-
горитмов проверки типов. Проверка типов является полностью
статичным анализом, проводящимся на этапе компиляции и
может быть сформулирована в терминах отображений между
различными семантическими доменами, что является сутью аб-
страктной интерпретации. После этого могут быть установлены
надежность и полнота.
Второе дополнительное применение связано с использова-
нием деструктивного присваивания при выполнении функцио-
нальной программы, называемого «изменением на месте». Бла-
годаря ссылочной прозрачности возможности вторичного ис-
пользования ячеек хранения являются ограниченными для не-
посредственной реализации функциональных языков. На самом
деле независимо от разделения повторяющихся аргументов в
реализации языка с вызовами по необходимости повторное ис-
пользование ячеек хранения происходит только при манипуля-
ции стеком и косвенным образом при сборке мусора. Однако
сборка мусора существенно замедляет вычисление выражений
и от ее применения необходимо воздержаться до тех пор, пока
это возможно. Следовательно, более желательно разрушить объ-
ект данных путем переписывания его содержимого либо доба-
вить его к свободному списку после того, как он станет недо-
стижимым. Например, функция squall, вычисляющая квадраты
для всех элементов из целочисленного списка
dec squall: list( num) > 1 ist( num);
------squall( x) <— map( square, x);
где map и square являются примитивными функциями, дает но-
вый список при непосредственной реализации, хотя после вы-
числения квадрата элемента последний становится недостижи-
мым до тех пор, пока он не потребуется в другой части вычис-
лений. Поэтому идеальной представляется ситуация, когда при
прохождении по списку аргументов функции squall все элементы
будут переписаны, а все его cons-ячейки будут оставлены без
изменений. Указатель на результат будет при этом таким же,
каким был и указатель на аргумент в момент вызова функции.
Рассматривая различные свойства разделения, которыми может
обладать вершина в графе выражения из гл. II, такие, как
Абстрактная интерпретация 577
«единственно адресуемая», «не обязательно единственно адре-
суемая», абстрактная интерпретация на этапе компиляции мо-
жет идентифицировать и соответственно аннотировать опера-
ции, ликвидирующие ссылки, т. е. те, которые обращаются
к ячейке с единственной ссылкой, это сразу же сделает эту
ячейку доступной для повторного использования, возможно,
даже в той же правой части рекурсивного уравнения. Напри-
мер, в уравнении map (f, а :: у) <= f (а):: map (f, у) cons-ячей-
ка, адресуемая в левой части, станет недостижимой после вы-
числения аргументов cons в правой части до тех пор, пока не
будет использована в каком-либо другом месте. Благодаря
этому подходу были достигнуты некоторые успехи. Так, Худак
опубликовал функциональную версию алгоритма быстрой сор-
тировки Quicksort, который действует в линейном простран-
стве [2].
Другие приложения, которые различаются главным образом
по времени, необходимом для их создания, включают в себя
«анализ высказываний» и «анализ сложности». Первый связан
с определением того, какое из рекурсивных уравнений в опи-
саниях функции потребуется при данном вызове этой функции.
Это важно в компьютерах с параллельной архитектурой, в ко-
торых может быть необходим удаленный доступ к разделяемым
кодам. Путем определения того, какие части этого кода необ-
ходимы (высказывания), можно значительно сократить количе-
ство сообщений, которые эти высказывания пересылают. Анализ
сложности также важен для параллельных машин, особенно для
машин с улучшенными структурными элементами. Если выра-
жение содержит подвыражение, которое может быть вычислено
независимо, например аргументы применения функции или вы-
ражение, значением которого является функция и которое при-
меняется к выражению аргумента, то независимые вычисления
могут быть поручены («разбросаны») различным процессорам
для параллельного выполнения. Однако такое распределение
приводит к дальнейшему росту обмена информацией, и если
стоимость разделения вычислений преобладает над выигрышем
по времени выполнения вычислений, то смысла увеличивать сте-
пень параллелизма таким образом нет. Задача, поэтому, заклю-
чается в том, чтобы заранее, на этапе компиляции, знать, как
долго будет происходить вычисление подвыражений. Возможно,
что на это будет указывать некая мера сложности, определен-
ная для выражений, и если они были выражены в терминах
некой нестандартной семантики и домена, то абстрактная ин-
терпретация может стать формальной основой для подобного
анализа.
37
,473
578 Часть III. Глава 20
Резюме
• Абстрактная интерпретация помогает определить характери-
стики работы программы, что позволяет модифицировать пра-
вила для ее вычисления без изменения ее семантики.
• Арифметическое «правило знаков» является прототипным
примером.
• Основным применением является анализ строгости, который
позволяет определить те аргументы, которые необходимы и
поэтому могут быть переданы по значению.
• В плоских доменах абстрактные формы функций первого по-
рядка получаются с помощью замещения (стандартных) при-
митивных операторов в определяющих их выражениях на аб-
страктные версии.
• Рекурсивно определенные абстрактные функции вычисляют-
ся во время компиляции путем итеративного нахождения их
наименьших фиксированных точек.
• Основной анализ строгости может быть естественным обра-
зом обобщен для функций высшего порядка и неплоских до-
менов.
• Доказательство надежности абстрактных интерпретаций от-
носится к области денотационной семантики.
• Другие применения абстрактной интерпретации состоят в «из-
менении на месте» структур данных, анализе сложности и ана-
лизе высказываний.
Упражнения
20.1. В обычной целочисленной арифметике мы пользуемся
«правилом знаков», позволяющим определять знак результата
без осуществления вычислений. Аналогичным образом мы мо-
жем использовать правила для определения «порядка величи-
ны» результата, т. е. количества знаков, из которых он состоит,
иногда точно, а иногда указывая диапазон возможных зна-
чений.
а. Каким будет абстрактный набор А, представляющий все воз-
можные «порядки величины»?
б. Для данных целых чисел х, у и абстрактных интерпретаций
X, Y е 2А (набор степеней А) определите абстрактные версии
операторов сложения и умножения + * и *# путем определе-
ния двух подмножеств А : % + # У и X ** Y.
в. Каким будет прогноз вашей методики абстрактной интерпре-
тации по поводу количества знаков в величине — результате
вычисления выражения (—9*100)+ 99?
Абстрактная интерпретация 579
20.2. Объясните, что понимается под «надежностью» абстракт-
ной интерпретации, и дайте формальное описание в терминах
соответствующих семантических доменов. Докажите, что в уп-
ражнении 20.1 пример с «порядком величины» является на-
дежным.
20.3. Определите аргументы, при которых следующие функции
будут строгими:
а) f(х, у, z) = if х у then 1 else if у = f( х — 1, у, z)
then у else z * f(x, у -1- 1, z + 1)
6) f(x, y, z) = if x у then z else if y = f(x — 1, y, z)
then у else z * /(x, у + 1, z -j- 1)
Приложение Л
КРАТКОЕ ОПИСАНИЕ ЯЗЫКА НОРЕ
А.1. БНФ языка Норе
Язык, описанный в книге, является расширением эдинбургского языка
Норе и официально известен как Норе+. Приведенная ниже БНФ является
полной и включает некоторые особенности, о которых не говорилось в ч. I
данной книги. Они пронумерованы и кратко прокомментированы ниже. В ис-
пользуемой нотации БНФ {Е} + означает одно или несколько вхождений Е;
{Е}* означает нуль или больше вхождений Е; [Е] указывает, что Е яв-
ляется необязательным. Зарезервированные слова выделены шрифтом ’>
(программа)
(модуль)
(оператор)
(свободное врж)
(имя модуля)
(дек)
(дек оператора)
(имя оп)
(приоритет)
(дек типа)
(дек данных)
(дек синонима)
(дек конструктора)
= {(модуль); }* {(оператор)}+
= module (имя модуля) {; (дек)* 2'}4- end (la)
— {(дек) [ (свободное врж)} ;
= (врж)
= (идентификатор)
= (дек типа)
(дек переменной типа)
(дек объекта)
(уравнение)
(дек оператора)
(дек импорта)
(дек экспорта)
::= infix (имя оп): (приоритет)
| infixrl (имя оп): (приоритет) (2)
::=(имя объекта) | (конструктор данных)
::= 11 ... 19 110
(дек данных)
|(дек синонима)
| (дек конструктора)
::= data (дек типа данных)
{with (дек типа данных)}* (3)
::= type (имя типа) == (врж типа)
::=type (конструктор типа) (параметры типа)==
(врж типа)
’> Материал этого приложения основан на определении языка Норе+ [70]
и включает части, взятые непосредственно из текста этого определения. Этот
материал воспроизводится с любезного разрешения Найджела Перри и фир-
мы International Computers Ltd (ICL.)
2) дек — сокращение слова «декларация»; врж — сокращение слова «вы-
ражение». — Прим, перев.
Краткое описание языка Норе 581
(дек типа данных)
(дек переменной типа)
(переменная типа)
(параметры типа)
(имя типа)
(конструктор типа)
(параметр типа)
(элемент данных)
(врж применения)
(уравнение)
::=(имя типа) ===== (элемент данных)
{-|—(элемент данных)}*
| (конструктор типа) (параметры типа)==
(элемент данных) {-j—{-(элемент данных)}*
::= typevar (переменная типа) {.(переменная типа)}*
::= (идентификатор)
::= (параметр типа)
{((параметр типа) {.(параметр типа)}*)
;:= (идентификатор)
::= (идентификатор)
::= (идентификатор)
::= (константа данных)
{(конструктор данных) (врж типа)
(врж типа) (конструктор данных) (врж типа)
(врж типа) :== (переменная типа)
(тип кортежа) (хэш-символ) (тип функции) (константа данных) (конструктор данных) (дек экспорта) (имя типа) (тип кортежа) (тип функции) ((врж типа)) (конструктор типа) (врж типа) :=(врж типа) {(хэш-символ) (врж типа)}+ :=#|Х :=(врж типа)-*(врж типа) := (идентификатор) := (идентификатор) .:= pubtype (имя типа){,(имя типа)}* (16)
(дек импорта) | pubconst (идентификатор данных) {.(идентификатор данных)}* (1в) | pubfun (имя объекта) {.(имя объекта)}* (1г) .:= use (имя модуля) {.(имя модуля)}* (1д)
(идентификатор данных) (дек объекта) (имя объекта) (врж) ::= (константа данных) | (конструктор данных) := dec (имя объекта): (врж типа) := (идентификатор) ::= ((врж)) (литерал)
( (врж) {,(врж)}+ )
(константа данных)
(конструктор данных) (врж)
if (врж) then (врж) else (врж)
let (образец) ===== (врж) in (врж)
otherwise (врж) (4)
(врж) where (образец) ===== (врж) end (5)
lambda (образец) => (врж)
{| (образец) => (врж)}* end (5)
(врж) (врж)
(врж)(имя оп)(врж)
(врж)((врж аргумента){,(врж аргумента)}*)
(имя объекта)
(переменная образца)
error (врж)
::= (врж) | ? (6)
::= —-----(имя объекта) [(образец)] <= (врж)
| —----(образец) (имя объекта)
(образец) <=(врж)
582 Приложение А
(образец) ::= (образец) {.(образец)}*) (конструктор данных) (образец) (переменная образца) (литерал) (константа данных) error (образец) (7)
(переменная образца) ::= (литерал) :: = (переменная образца) & (образец) {идентификатор) {целый литерал) (вещественный литерал) (символьный литерал) (истинностный литерал) (пустой литерал)
(целый литерал) ::= (вещественный литерал) (цифра) ::= (символьный литерал) ::= —] (цифра) {(цифра)}* [ —] (цифра) {(цифра)}*, (цифра) {(цифра)}* 0| ... |9 .одиночная кавычка) (представление символа) 'одиночная кавычка)
(одиночная кавычка) (представление символа) ::= / (графический символ) (новая строка) (табуляция) (двойная кавычка) (перевод формата) (обратный слэш) (шестнадцатеричное представление)
(графический символ) ::= любая печатная графическая буква (включая
(новая строка) (табуляция) (перевод формата) (двойная кавычка) (обратный слэш) пробел), кроме обратного слэша ::=\п ::=\t ::=\f "=\" ::=\\
(шестнадцатеричное представление) ::= \ (шести. цифра) (шести, цифра)
(шести, цифра) (пустой литерал) : (истинностный литерал; : (идентификатор) : = 0 | ... 19 iА I ... IF = ( ) , (8) = true 1 false = (буква) {(буква) | (цифра)}*
(буква) : | {(составной символ))* = а| ... | z | А| ... | Z | (другие алфавитные знаки из стандартного
(составной символ) : набора) = @ | S | $ | % 1 ~ 1 & 1 * 1 - J + 1/1\|:|<1>1 = 1‘П1’1~ | (другие символьные знаки из стандартного набора)
Замечания к БНФ
1. Декларации могут объединяться в модули, которые компилируются по
отдельности. Модули могут экспортировать некоторые или все объявленные
в них типы и объекты и могут импортировать объекты и типы из других
модулей. Модули и операторы объединяются в программу,, которая является
основной единицей на этапе выполнения. Модуль может быть объединен с
другими предварительно скомпилированными модулями для формирования
программы.
Краткое описание языка Норе 583
1а. Имя модуля идентифицирует модуль. Если в модуле встречается деклара-
ция объекта, то его определяющие уравнения должны быть в том же мо-
дуле. (Замечание', модули не могут содержать другие модули.)
16. Типы, объявленные в модуле, могут быть экспортированы из него с по-
мощью декларации pubtype.
1в. Если экспортируемый тип является сконструированным, его константы
данных и конструкторы не экспортируются вместе с типом. Константы и
конструкторы данных, объявленные в модуле, могут экспортироваться с по-
мощью декларации pubconst.
1г. Функции, объявленные в модуле, могут экспортироваться с помощью де-
кларации pubfun.
1д. Все элементы, экспортируемые некоторым модулем, могут быть импорти-
рованы другим модулем с помощью декларации use. Импортирующий модуль
может затем ссылаться на эти элементы.
2. infixrl — это то же самое, что и infix, но объявленный оператор выпол-
няется справа налево. Например, мы могли бы объявить : : с помощью infixrl.
При этом мы могли бы записать 1 : : 2 : : nil, опустив скобки, которые в
противном случае необходимы вокруг 2 : : nil.
3. with используется для определения взаимно рекурсивных типов данных.
Например:
data D1 == ... D2 ... with D2 == ... DI ... ;
4. Если образец в квалифицированном выражении оказался несопоставлен-
ным, то вычисляется выражение после ключевого слова otherwise, которое
является необязательным. Например, let х • : 1 = — Е in El otherwise Е2
дает результат вычисления Е2, если Е — это nil.
5. Ключевые слова end в БНФ могут быть опущены в некоторых реализа-
циях, и именно так сделано в тексте данной книги. Эти ключевые слова не
являются частью первоначального языка Норе, и возможность опускать их
объясняется желанием сделать Норе+ совместимым с Норе.
6. ? используется в сокращенной записи lambda-выражений. Например,
f (а, ?, Ь, ?) эквивалентно lambda(х, у)=> f (а, х, Ь, у).
7 Норе имеет ошибочную величину, которая является членом каждого воз-
можного типа, error можно рассматривать как конструктор, аргумент кото-
рого представляет собой список пар: номер ошибки, сообщение об ошибке
(типа list ( num # list (char )) ). Ошибка, появляющаяся при применении
функции f, может быть «отловлена» сопоставлением результата применения
с образцом вида error (m), где m — это текущий список сообщений. По-
следующие сообщения об ошибках могут добавляться к существующему спи-
ску путем формирования нового error-выражения, например еггог( ( 13, ’’Some-
thing is wrong”) ::m).
8. «пустой» (void) — это специальный тип, который можно рассматривать как
пустой кортеж.
А.2. Предварительно определенные типы и функции
Переменные типа
alpha, beta
Типы
num, real, char, void, truval, list( alpha), filename, file
(infix::: 7; data 1 ist( alpha ) == nil —|- alpha :: 1 ist( alpha ); )
584 Приложение А
Функции преобразования «символ -<—>- код»
dec ord: char -> num ;
dec chr : num -> char ;
Функции преобразования вещественных чисел в целые и обратно
dec floor, ceil, trunc, round : real -> num;
dec float: num -> real;
Арифметические функции (обратите внимание на использование одинаковых
имен для функций разного типа)
infix +, — : 5 ;
infix * : 6;
infix '': 7;
dec +, —, *, : num # num-> num;
dec +, —num # real -> real;
dec +, —, ~ : real # num -> real;
dec +, —, : real # real -> real;
infix div, mod, divmod:6;
dec div : num # num -> num ;
dec mod : num # num -> num ;
dec divmod : num # num -> num # num ;
infix /: 6;
dec / : num # num -> real;
dec / : num # real -> real;
dec / : real num -> real;
dec / : real # real -> real;
dec — : num -> num ;
dec — : real -> real;
Булевы функции
infix <, >, >=:4;
dec <, =<, >, >=: truval;
dec <, =<, >, >=: real real -> truval;
dec <, =<, >, >=: char # char-> truval;
dec <, =<, >, >=: list( char )# list! char )-> truval;
nil (op) nil <= true ;
nil (op) <= ((op) = < ) or ((op) == < );
(op) nil <= ( (op) == > ) or ((op) == >= );
( h :: t) (op) ( g :: s ) <= if h (op) g then t (op) s else false;
infix =, /=: 3; dec =, /= : alpha # alpha -> truval;
Краткое описание языка Норе 585
Функции обработки списков
infix ():5;
dec ( ): 1 ist( alpha ) # list( alpha ) -> list( alpha );
Функции ввода/вывода
dec fromfile: filename -* 1 ist( char );
(Возвращает содержимое файла с именем filename)
dec tofile: filename # 1 ist( char ) ->file;
(Создает новый внешний файл и устанавливает его значение равным списку
символов. Возвращает внутреннюю величину типа file)
dec fromfile: file-* list( char );
(Возвращает список символов, связанный с данным файлом)
Приложение Б
ОСНОВЫ ТЕОРИИ ДОМЕНОВ
Б.1. Введение
Наше обсуждение лямбда-исчисления в гл. 6 было чисто синтаксическим
по характеру. Мы определили только то, какую структуру должны иметь
Х-выражения и как определенные выражения и подвыражения можно тексту-
ально заменить другими согласно правилам редукции. То же самое замечание
справедливо по отношению ко всем языкам программирования, и одного
синтаксиса недостаточно, чтобы полностью объяснить эффект выполнения
программы. Теория доменов и денотационная семантика (которая рассматри-
вается в приложении В) были введены, чтобы дать смысл синтаксическим вы-
ражениям и, следовательно, рекурсивным программам на функциональных
языках в частности. Формально мы рассматриваем смысл выражения как
величину, взятую из некоторого множества или домена, обладающего хорошо
понятными математическими свойствами. Например, выражения могут стро-
иться из пяти римских цифр I, II, III, IV, V и оператора плюс. Хотя мы
определяем, что является грамматически корректными выражениями, такими
как II плюс II или V, мы еще не знаем, как интерпретировать эти симво-
лы— что такое, например, IV? В типичном случае мы можем говорить о яб-
локах. Тогда смысл символа IV в том, что мы имеем в руках четыре яблока,
в чем можем убедиться, сосчитав их. При обычной интерпретации оператора
плюс можно ожидать, что I плюс III (одно яблоко в одной руке и три в
другой) и II плюс II (по два яблока в каждой руке) означают то же са-
мое— четыре яблока всего, т. е. имеют смысл символа IV.
В более абстрактных терминах смысл таких выражений может зада-
ваться целыми 1, 2, 3, 4, 5, которые представляют цифры I, II, III, IV, V
соответственно. Что касается терминологии, мы также говорим, что I обозна-
чает 1 и т. д., поскольку цифровые выражения являются конкретными объ-
ектами, которые могут быть записаны, тогда как целые — это математиче-
ская абстракция и не единственно возможное представление. При таком на-
боре величин смыслом оператора плюс может вполне естественно быть сло-
жение по модулю 5, т. е. смыслом выражения Е плюс F является сумма по
модулю 5 целых, представляющих Е и F. При таком определении смысл вы-
ражений I плюс III, II плюс II, IV один и тот же — целое 4.
В качестве первой попытки найти удобные домены величины для пред-
ставления смысла синтаксических выражений можно попробовать положить
в основу нашей теории обычные множества и определенные на них функции,
но мы немедленно перейдем к противоречиям. Например, мы могли бы иметь
синтаксически корректное определение функции silly *> на языке Норе:
dec silly : truval -> truval ;
------si 1 ly( x ) <= not ( silly x );
Слово silly означает «глупый». — Прим, перев.
Основы теории доменов 587
Если мы рассмотрим тип truval как множество Bool — {true, false} и not
как оператор логического отрицания neg, то не сможем найти ни одной
функции /: Bool —> Bool, удовлетворяющей представляющему silly уравнению,
т. е. такой, чтобы f ( х ) — negl f( х) ) для х е Bool. Например, если f true =
= true, то f true neg( f true ), что противоречит определяющему уравнению,
и аналогично для f true = false. На практике если silly будет применена к
любому объекту типа truval, то вычисление никогда не завершится, но в
множестве Bool не существует представления для такого бесконечного вы-
числения.
Если теперь добавить один новый элемент _1_ (читается «основание»)
к множеству Bool, получив множество Воо1± (где для любого множества S,
S± обозначает множество S (J {□_}), то можно выйти из положения, сделав f
(и, следовательно, silly) правильно определенной функцией. Для этого нужно,
чтобы мы соответствующим образом расширили определение neg, т. е. чтобы
мы определили neg _1_ = _1_, и тогда определение f, удовлетворяющее уравне-
нию для silly, имеет вид /х = _1_ для всех х е BoolПоскольку основание
_1_ представляет неопределенную величину или незавершенке, оно включает в
себя меньше информации, чем элементы Bool, и путем определения на мно-
жестве Bool такого «информационного порядка» Bool ± становится домейом.
Фактически для функций, определенных только на множествах, не включаю-
щих составные данные, такие как списки, эта конструкция домена достаточна
для определения непротиворечивой семантики, как мы скоро увидим при рас-
смотрении плоских доменов в следующем разделе.
Б.2. Законченный частичный порядок
и непрерывные функции
Как мы только что видели, мы можем сконструировать некоторые до-
мены, чтобы обеспечить непротиворечивую семантику, просто «подняв» мно-
жество величин над неопределенным элементом (основанием). Однако для
многих правил редукции с различными ассоциированными нормальными фор-
мами ситуация является не просто черной или белой, т. е. что результат
редукции может быть ни полностью вычисленным выражением, ни неопреде-
ленным, а частично вычисленным. Например, бесконечный список единиц,
определенный
-----ones <= 1 :: ones ;
имеет бесконечно много частично вычисленных результатов: ones, l::ones,
1 :: ( 1 :: ones), 1 :: ( 1 :: ( 1 .: ones) ) и т. д. Таким образом, если наш домен
будет правильно представлять результаты всех вычислений, он должен вклю-
чать частичные элементы, представляющие приближения к полностью вычис-
ленным, или полным, элементам. Они могут быть бесконечными, как в случае
функции ones, например. Таким образом, нам необходимо отношение порядка
< на множестве элементов домена, чтобы показать, какие элементы являют-
ся приближенными, а какие — приближенно представляемыми. Запись а < b
означает, что а является приближением b и читается ”а аппроксимирует Ь”.
Мы также требуем, чтобы домены включали пределы бесконечных цепочек
аппроксимирующих частичных элементов, например nil < [1] < [1, 1] <
< [1, 1, I] <... . Этч пределы являются полными элементами, и в приве-
денном примере нам бы хотелось, чтобы бесконечный список единиц был
представлен членом домена, представляющего списки, — в конце концов это
истинное значение функции ones.
В случае плоского домена 4^ порядок < очень прост и определяется
следующим образом: _1_ < а для всех и для а, b е А, а <. b тогда
и только тогда, когда а = Ь. Говорят, что множество А «поднимают» для
588 Приложение Б
того, чтобы сформировать домен А т. е. поднимают над основанием —
новым элементом _1_. Различные члены подмножества А домена не связаны
отношением порядка, и именно из-за этого единообразия всех элементов,
кроме основания, домен называется плоским Так, множество Bool j_, введен-
ное выше, является плоским доменом, и домен целых чисел (где Z —
= {1,2, также плоский: различные целые несравнимы между собой, т.е.
не могут аппроксимировать друг друга, и мы имеем только 1 < 1, 2 < 2, ...
для введенного отношения порядка на Z
В общем случае домен должен удовлетворять следующим двум аксио-
мам, вторая из которых является следствием первой для плоских доменов:
1. Домен является частично упорядоченным множеством (£>, <) с наимень-
шим элементом _1_о таким, что J_D < d для всех d е D, где отношение по-
рядка < является
(i) рефлексивным, т. е. d < d для всех deD,
(й) транзитивным, т. е. если d < е и е < f для d, е, f е D, то d < f,
(ill) антисимметричным, т. е. если d < е для d е.е £), то неверно, что
е <Z d.
2. Для каждой возрастающей последовательности Xi < х2 < ... < хп < ...
в D наименьшая верхняя граница Lin>i хп е ® существует. Этим утверж-
дается, что домен является законченным частичным порядком (или зчп). Наи-
меньшая верхняя граница приведенной выше последовательности опреде-
ляется следующим образом:
(i) Она является верхней границей, т. е. для всех п 1 имеет место
х < LL , х .
п п.
(й) Она является наименьшей, т. е. если х„ < и для всех л > 1 и неко-
торого и е D, то Un>i хп < “•
Нелегко в нескольких предложениях дать интуитивное объяснение необхо-
димости аксиомы 2, и мы отсылаем читателя к работе [75]. Однако можно
привести аналогию, включающую рациональные числа. Рассмотрим множе-
ство Q рациональных чисел в замкнутом действительном интервале /=[0,3],
т. е. рациональные числа г такие, что 0 si г si 3. Тогда если si обозначает
порядок «меньше или равно», определенный для действительных чисел, то
легко проверить, что (Q, si) является частично упорядоченным множеством.
(Однако заметим, что этот порядок не является аппроксимирующим поряд-
ком, определенным выше; для этой цели снова нужно было бы использовать
плоский домен.) Теперь рассмотрим последовательность 1, 1 + 1, 1 + 1
+ 1/(21), 1 + 1 + 1/(2!) + 1/(31), .... Очевидно, что эта последовательность
возрастающая, элементы ее являются рациональными числами и л-й элемент
равен 1 — 1)! Однако ее предел является иррациональным чис-
лом е, которое не принадлежит Q. Таким образом, (Q, si) не является зчп,
но (/, ^) является зчп, поскольку это множество включает все такие пределы.
Домены обеспечивают удобное абстрактное представление объектов дан-
ных, которые мы рассматривали, и мы теперь обратим наше внимание на
функции, определенные на доменах. Говоря неформально, все, что мы тре-
буем, состоит в том, чтобы вычислимые функции между доменами сохраняли
структуру этих доменов, т е. их упорядоченность, так что чем больше инфор-
мации дано функции (чем лучше аппроксимация ее аргумента), тем больше
информации она возвращает (тем лучше аппроксимация ее результата).
В частности, вычислимые функции должны быть монотонными. Определение
монотонности имеет вид:
является монотонной тогда и только тогда, когда
для любых d, е е D, если d < е, то f( d ) < f( е ).
Основы теории доменов 589
Однако для неплоских доменов мы требуем также сохранения границ, и
это требование включается в третью аксиому:
3. Вычислимые функции являются непрерывными, где f: D-+E является не-
прерывной тогда и только тогда, когда для каждой возрастающей последо-
вательности xt < хг •<...< хп < ... в D,f ( U„>1 хп ) Un> 1 f ( хп )•
Мы можем использовать наш пример с интервалом действительных чисел
в качестве аналогии для объяснения причин введения этой аксиомы. Аргу-
менты, относящиеся к понятию вычислимости, можно снова найти в работе
[75]. Предположим, мы имеем рациональную последовательность tn (я 0),
где /0 = 3 и tn = tn-i + 2_/" для л > 0, так что предел этой последователь-
ности равен 4. Теперь допустим, что функция f : Q —Q определена в виде
f(tn) = tn— 1, и допустим, что мы хотим расширить f, чтобы иметь отобра-
жение [3,4]-+• [2,4], причем структура отображаемых областей должна со-
храниться. Как мы определяем [(4)? Мы могли бы выбрать любое действи-
тельное число в замкнутом интервале [3, 4] и сохранить при этом f монотон-
ной. Но если бы мы выбрали /(4) = 4, то в области значений f мы имели бы
возрастающую последовательность f(t„) (я^О), все ближе и ближе при-
ближающуюся к 3 при увеличении л и стремлении tn к 4, однако в точке 4
был бы «скачок» в величине f с 3 до 4. Непрерывность по существу говорит,
что скачков быть не должно.
Заметим, что непрерывность предполагает монотонность, поскольку, если
d < е для d,e е D, мы можем рассмотреть последовательность d < е <
<е < е < ..., которая имеет наименьшую верхнюю границу е. Затем, если
f непрерывна, мы имеем [(е ) = U{f(d). но f(d) < LJ{f( d ), [(e)]
по определению, и поэтому /(d) < /( е ).
Б.З. Конструкции на доменах:
новые домены из старых
Имея домены D и Е, мы можем конструировать новые домены, и мы
определим четыре конструкции, необходимые в разных местах этой книги:
декартово произведение Ь'^Е, соответствующее кортежам в языке Норе,
функциональное пространство [D Л], разъединенную сумму D + Е, пред-
ставляющую объединение типов данных, и объединенную сумму D Ф Е, ко-
торую мы использовали при обсуждении абстрактной интерпретации в гл. 20.
Произведение D\E— это множество пар {(d, е) \deD, ее£}. Оно
имеет порядок, определенный следующим образом: (а, b ) < (d, е) тогда
и только тогда, когда a<dH6<e8 доменах D и Е соответственно. Наи-
меньший элемент J_D хе = (_Ld, ~1~е), и, имея возрастающую последователь-
ность {(d„, ) | л 2&1}, мы должны иметь возрастающие последовательно-
сти {d„ I п 1} и {еп | я 1} в D и Е соответственно. Поэтому мы опреде-
ляем наименьшую верхнюю границу возрастающей последовательности
(dt, е\) < (dz, е2 ) < ... в DXE в виде
Un>t ( dn' еп ) = ( Un>i dn, Un>i en )
Аналогично определяется m-местиое произведение Dt X• • - X Dm = {(di, ...
..., dm ) | di e Dit 1 sg i -^2 m] с аналогичным отношением порядка, наимень-
шим элементом и наименьшей верхней границей.
Функциональное пространство [£>->£] — это множество всех непрерыв-
ных функций между D и Е, упорядоченных следующим образом: f < g тогда
и только тогда, когда f(d) < g(d ) для всех d^D. Наименьшим элементом
является Ad. _Lc, и наименьшая верхняя граница возрастающей последова-
590 Приложение Б
тельности {fn | п 1} в [D —>-£] определяется следующим образом:
(Un>1 fn)(d) = un>lfn(d).
Разъединенная сумма доменов определяется в терминах операции непе-
ресекающегося объединения U над множествами. Непересекающееся объеди-
нение отличается от обычного объединения множеств тем, что каждый его
элемент остается связанным с исходными множествами, к которым он при-
надлежит, т. е.
Л1 U • • U Ат = {х( а ) | а = Ai, х е а, 1 sg i 'С т}
Таким образом, если элемент является членом п gs 1 исходных множеств, он
будет присутствовать п раз в непересекающемся объединении, т. е. если
.ге/1 и хе'В, то х(Л) У=х(В) в А{)В. Там, где не будет двусмысленно-
сти, мы будем слегка пренебрегать нашей нотацией и ссылаться на исходное
множество, связанное с элементом z е Л( J U Ап в виде если z =
= х( Ai ) для некоторого х е А, (1 : Eg ш).
Разъединенная сумма £>i + ... + Dm = (Dt U • U Dm) . где J_ — это но-
вый наименьший элемент, т. е. слагаемые Dt.....Dm подняты над _1_. Отно-
шение порядка на Dt + ... + Dm определяется в виде: а < b тогда и только
тогда, когда а = J_ или а е D,, h <= D, и а < b в слагаемом Di для неко-
торого i, 1 • iт.
Тогда, имея возрастающую последовательность {d„ | п 1} в Dt
... + Dm, мы имеем или dn — J_ для всех n 1 (в этом случае мы опреде-
ляем наименьшую верхнюю границу данной последовательности равной _L),
или, иначе, существует А 1 такой, что для всех п N, id„e[): для неко-
торого i, 1 sg i Eg и мы можем определить наименьшую границу равной
границе соответствующей последовательности в D„ Un>W dn- Более точно,
мы имеем определение
dn = U хп
где для N, dn = х„( Dt) для некоторого i (1 sg i Eg Af) и I I (i) обозна-
чает оператор наименьшей верхней границы на множестве £>,.
Заметим, что в конструкции разъединенной суммы два слагаемых Di
(1 i zn) могут быть одним и тем же доменом. Другими словами, мы
можем иметь £>, = D, для некоторых i =/= /, при этом каждый элемент Di
дважды встречается в непересекающемся объединении, например мы можем
определить D D. Обычно каждый элемент разъединенной суммы явным об-
разом помечают, получая
Di + • • + Dm = {_L} (J {(/, di) | di £= Di, 1 "Eg i sg m}
где элементы являются ясно различимыми.
Строго говоря, если d е Dt 4- ... + Dm, мы не должны писать d е Dt
для любого слагаемого Dt, 1 Eg i Eg т, а должны вместо этого использовать
функции инъекции и проекции, in и | соответственно, которые обычно записы-
ваются в инфиксной форме. Если D — это сумма, тогда эти функции опреде-
ляются в виде:
1. Если d' е D' и D' является слагаемым D, тогда d' in D является образом
d' при инъекции D' в D, т. е. d' in D = d'(D'). Например, если D' — это
первое слагаемое и мы пометили элементы в D, то d' in D =
2. Если d e D, to d | D' — d', если d = d' in D, J_D'.
Поэтому вместо d e Di нам следует писать d = di in Dt -|- ... -J- Dm для
некоторого d,^D„ 1 Eg i Eg m, но это не является необходимым, когда нет
неоднозначности при использовании оператора е.
Основы теории доменов 591
Существует также другой тип суммы — объединенная сумма D, ф .. .
... © Dm, в которой новый наименьший элемент не вводится, а наименьшие
элементы всех слагаемых заменяются одним наименьшим элементом J_ объ-
единенной суммы. При этом определения отношения порядка и наименьшей
границы становятся проще. Различия между двумя типами сумм проиллю-
стрированы на рис. Б.1.
В качестве простого упражнения мы предлагаем читателю самому пока-
зать, что определения этих четырех конструкций удовлетворяют аксиомам,
Объединенная сумма DIE
Разъединенная сумма D®E
Рис. Б.1. Разъединенная и объединенная суммы доменов D и Е.
данным для доменов. Выполнение этого упражнения позволит читателю хо-
рошо освоить введенную нотацию.
Б.4. Наименьшие фиксированные точки
Мы завершаем наше краткое введение в теорию доменов теоремой, по-
ясняющей смысл синтаксического понятия рекурсивной функции и комбина-
тора фиксированной точки в Х-исчислении. Это обусловлено содержанием
гл. 6, и теорема формулируется следующим образом:
Теорема о фиксированной точке. Если f : D D является непрерывной функ-
цией на домене D, тогда
1) f имеет наименьшую фиксированную точку d<f=D. т. е. d удовлетворяет
условиям f( d )= d, и если /( е ) = е для некоторого eeD, то rf< е;
2) наименьшая фиксированная точка d е D функции [ определяется соотно-
шением d =Un>ofn(-LD).
Доказательство. Доказательство, которое использует все аксиомы для доме-
нов и определенных па них вычислимых функций, рассматривает элементы
(k 0) и использует индукцию по k. Сначала мы покажем индук-
тивно. что {/* (_!_/>) | k 0} является возрастающей последовательностью
и что ее наименьшая верхняя граница d является фиксированной
точкой.
В базовом случае =J_o < [(-Ln), поскольку J_o—это наимень-
ший элемент.
Для шага индукции, допустив, что <fk+,(J-n) для k 0, мы
имеем
поскольку функция [ монотонна, т. е.
592 Приложение Б
Таким образом, последовательность {f*(J_o) | k 0} является возрастаю-
щей с наименьшей верхней границей, скажем, d. Но
) = f( Un>o f”( -Lo ) ) = Un>) Г+‘( -Lo ). поскольку f непрерывна, (
= Un>0 f ( )> поскольку f ( _1_д ) < Lln>0 f ( -l-x>)
= d
Такйм образом, d является фиксированной точкой.
Теперь предположим, что х— также фиксированная точка f. Тогда
JLo) < х для всех k 0, что также можно показать по индукции. В ба-
зовом случае _Ld < х, поскольку _Ld является наименьшим элементом. Да-
лее, если f" (-Ld) < f (х) = х для k > 0, то f‘+1 (J_D) < f (х) = х, по-
скольку f монотонна и х является фиксированной точкой f по предположе-
нию.
Таким образом, х является верхней границей возрастающей последова-
тельности {Jк (_1_о) | k 0} и, значит, находится «выше» ее наименьшей
верхней границы, т. е. |_|п>0 ("( -*-£>)< х- Поэтому fn( _1_р ) является
наименьшей фиксированной точкой f.
Вследствие теоремы о фиксированной точке мы можем теперь интерпре-
тировать рекурсивно-определенные функции как наименьшие фиксированные
точки и можем дать смысл операторам фиксированной точки, в частности
комбинатору наименьшей фиксированной точки, Y.
Приложение В
ФОРМАЛЬНАЯ СЕМАНТИКА
Многие проблемы, касающиеся реализаций языков программирования,
возникают из-за того, что некоторые семантические особенности не являются
полностью специфицированными в определениях языков Одним простым при-
мером, типичным для императивных языков, является то, что переменные мо-
гут иметь или не иметь предварительно присвоенные значения при своем
первом использовании. Вторым примером является то, что доступ к массиву
со значением индекса, лежащим вне допустимых пределов, может не быть
обнаружен во время выполнения, что дает непредсказуемые результаты, воз-
можно включающие разрушение самой скомпилированной программы. Подоб-
ным образом мы были не в состоянии достичь строгого вычисления, исполь-
зуя интерпретатор, написанный на ленивом функциональном языке, поскольку
мы определяли семантику нашего исходного языка в терминах другого
функционального языка Хотя интерпретатор, очевидно, дает точное определе-
ние семантики языка, это определение зависит также от семантики второго
языка, используемого для реализации. Поэтому семантика должна быть так-
же формально определена, если мы должны получить полное и однозначное
определение для исходного языка
Для строгого решения этих вопросов, а также других, таких как вопрос
о сохраняющих смысл оптимизациях, рассмотренных в ч III данной книги,
каждый язык программирования должен быть обеспечен математической се-
мантикой. Функциональные языки программирования вследствие прочного
теоретического фундамента хорошо подходят для этого Имеют место не-
сколько альтернативных подходов к формальной семантике Операционная
семантика предписывает, как вычисляются выражения в терминах переходов
между состояниями, определенными таким образом, чтобы представлять час-
тично вычисленные выражения Конец последовательности переходов пред-
ставляет некоторую полностью редуцированную величину Другой подход,
который был использован для описания семантики императивных языков,
является аксиоматическим. В этом случае каждому типу синтаксического
оператора соответствует аксиома Имея набор допущений, представляющих
состояние выполнения программы в точке непосредственно перед выполняе-
мым оператором, набор допущений в точке непосредственно после его выпол-
нения может быть выведен из аксиомы, связанной с этим оператором. Од-
нако, поскольку в декларативной программе не существует естественного
понятия «точка программы» (если ее последовательность вычислений не пред-
ставлена ясно), аксиоматический подход трудно применить для функциональ-
ных языков.
Для функциональных языков мы рассмотрим здесь денотационную се-
мантику, которая определяет отображение, чтобы связать с каждым синтак-
сически корректным выражением величину в некотором правильно определен-
ном математическом домене типа тех, что были рассмотрены в предыдущем
ЗЧ — 1473
594 Приложение В
приложении. Поэтому можно сказать, что выражения обозначают их величи-
ны ”, при этом абстрактный домен таких величин будет изоморфен по отно-
шению к машинному представлению результатов вычисления выражений. На-
пример, домен (конечного подмножества) целых чисел с неопределенным
элементом изоморфен множеству битовых образов, используемых для пред-
ставления этих чисел, вместе с возможностью незавершения.
Поэтому денотационная семантика языка точно специфицирует что яв-
ляется величиной любого исходного выражения в истинном духе функцио-
нального программирования, тогда как операционная семантика предписы-
вает как выражения вычисляются и в наибольшей степени подходят для раз-
работки интерпретатора. Однако, если в нашем распоряжении имеется суще-
ствующая реализация функционального языка, денотационная семантика
также может быть использована непосредственно в качестве интерпретатора,
и это по существу то, что мы делали в гл. 9. В настоящее время один из
ключевых вопросов теории языков программирования заключается в том,
чтобы доказать, что операционная семантика языка, основываясь на которой
мы хотим строить реализации, эквивалентна его денотационной семантике,
которая должна быть частью определения языка. Такие эквивалентности уста-
навливаются формально в виде теорем соответствия, которые по существу
доказывают корректность интерпретаторов в предположении, что эти про-
граммы на самом деле приведены в соответствие с операционной семантикой.
Однако эти доказательства являются длинными, и требуется еще много ис-
следований, чтобы данный подход стал практическим методом разработки
программного обеспечения.
Вместо этого здесь мы рассмотрим семантику некоторых характерных
особенностей типичных функциональных языков, таких как Норе, показав,
например, как мы можем различать редукцию аппликативного и нормального
порядка. Заметим, однако, что передачи параметров по имени и по необхо-
димости дают одинаковое значение для каждого выражения, поскольку каж-
дая реализует редукцию нормального порядка. Эти два правила вычислений
являются поэтому семантически идентичными с точки зрения денотационной
семантики, но отличаются с точки зрения операционной семантики. Мы начи-
наем с рассмотрения 1-исчисления, поскольку все функциональные языки
математически эквивалентны ему и его семантика обеспечивает относительно
простое введение в предмет нашего обсуждения.
В.1. Денотационная семантика 1-исчисления
Существует фундаментальный вопрос, на который нужно ответить, пре-
жде чем может быть определена любая осмысленная семантика для лямбда-
исчисления. То же самое относится к любому функциональному языку, в
особенности такому, где нет ограничений на использование функций высших
порядков. Проблема состоит в том, что все правила преобразования, опреде-
ленные для 1-исчисления, имеют отношение к парам синтаксических выраже-
ний, так что правила редукции любого интерпретатора, основанного исклю-
чительно на правилах преобразования 1-исчисления, выполняют только
синтаксические манипуляции. Эта проблема может представлять чисто акаде-
мический интерес, но для практических целей мы обычно требуем, чтобы объ-
екты данных в программе имели конкретную интерпретацию, например целые,
символы и, вообще говоря, функции (высших порядков) тоже. На основа-
нии того, что уже изучено, мы не можем даже быть уверенными, что суще-
ствует множество величин, скажем D, изоморфное полному множеству нор-
мальных форм 1-исчисления. В случае чистого 1-исчисления все эти нормаль-
” Глагол «обозначать» соответствует английскому to denote. Отсюда
название- денотационная семантика. — Прим, персе.
Формальная семантика 595
ные формы являются функциями, и поэтому D должно быть изоморфным
своему собственному функциональному пространству, но если в этом про-
странстве допустимы все функции, изоморфизм невозможен, если только D
не состоит из единственного элемента. (Это обусловлено исчислимостью и
мощностью множества аргументов.) В этом случае единственная семантика
Х-исчисления, которую мы были бы в состоянии найти, состоит в том, что
каждое выражение обозначает одну и ту же величину!
Это оказалось фатальным пороком Х-исчисления на долгие годы, пока
на функции, допустимые в функциональном пространстве, не были наложены
определенные ограничения, относящиеся к вычислимости. Если мы требуем,
чтобы D являлось зчп (определенном в приложении Б) и чтобы все функции
были непрерывными, то мы можем найти нетривиальные решения «доменно-
го» уравнения £>=[£)-►£)] и его обобщения вида О = А[£)->-£>], где А
является доменом атомарных данных, таких как целые числа (с неопределен-
ным элементом).
Одним семантическим доменом D для Х-выражений является подмноже-
ство .'Ао (где -Ры—это множество всех множеств неотрицательных целых
чисел) с включением подмножества для его упорядочения. Может быть сфор-
мулирована теория непрерывных функций на З’ш, где каждая такая функция
отождествляется с некоторым элементом и, основываясь на этом, может
быть определена модель Х-исчисления. В этой модели существуют оператор
абстракции и оператор применения, которые подчиняются тем же самым пра-
вилам преобразования, что и соответствующие операторы, задаваемые в Х-ис-
числении с помощью X и с помощью записи одного выражения следом за
другим.
Мы не будем здесь больше рассматривать этот вопрос, отсылая читателя
к работе [75], но снова подчеркиваем важность знания того, что некоторая
нетривиальная модель существует. Если бы это было не так, приведенные
ниже семантические уравнения были бы совсем пустыми, отражающими про-
сто преобразование одного синтаксиса, где мы пишем X для оператора аб-
стракции, в другой синтаксис, где тот же самый оператор мы обозначаем А!
Теория доменов и денотационная семантика — это очень существенный пред-
мет, изучение которого было начато в работах Стрэчи, Скотта, Плоткина
и др. в начале семидесятых годов. Прекрасное описание этого вопроса с хо-
рошими рассуждениями на интуитивном уровне дано в работе [75].
Теперь мы готовы определить семантику для лямбда-исчисления — как
чистого, так и расширенного примитивными типами данных и функциями.
Здесь мы используем следующий синтаксис выражений для чистого Х-исчис-
ления:
Е х | Хх.Е\ЕЕ'
где х е Iden (множество идентификаторов) является именем переменной. Те-
перь в предположении, что мы имеем нетривиальный семантический домен D
с удобным представлением абстракции и применения функций (’Т?а>-модель”
является одним из примеров), достаточно трех уравнений (по одному для
каждого синтаксического типа), чтобы определить требуемую семантическую
функцию. Мы используем имя d для обозначения переменной, представляю-
щей величину в D, и р: lden-^-D для обозначения контекстной функции (в
множестве контекстов Env), которая отображает синтаксические имена пере-
менных в величины из D.
Семантическая функция S : Ехр-+ Env D (где Ехр — это множество
синтаксических выражений) определяется следующим образом:
S[x]p =р[х]
S[ Хх.Е]р = Ad.S [ Е] ( р {d/x} )
SIEE'U =(S[£]p)(S[E']p)
38*
596 Приложение В
где Л — это семантический оператор абстракции и p(d/x}—это контекст р,
расширенный включением связи х с d и определенный в виде
р { d/x } у = if х = у then d else ру
Применение функции в D обозначается с помощью записи аргумента
следом за функцией, так же как в рассматриваемом синтаксисе. Мы будем
также придерживаться соглашения о заключении синтаксических конструкций
в двойные квадратные скобки. Заметим, что эти уравнения определяют се-
мантику нормального порядка вследствие определения Л и связанного с ним
правила для p-редукции. Как мы увидим в следующем примере, соответ-
ствующая семантика аппликативного порядка может быть получена с по-
мощью модификации уравнения для Х-абстракции.
Если мы добавляем константы в наш синтаксис, получая Е :: =
::= х | k | 7.x.£ | ЕЕ', наш семантический домен становится наименьшим ре-
шением уравнения вида D = А + [D -> £>], где А — это множество примитив-
ных величин. Поскольку этот домен является разъединенной суммой с более
чем одним компонентом, нам будет необходимо использовать функции про-
екции и инъекции, обозначаемые в инфиксной форме | и in соответственно,
для того, чтобы иметь возможность рассматривать элемент или в Р, или в
его собственном компоненте, А или [£>—*-£>]. Наши уравнения для функции S
в этом случае принимают вид:
5[х]р = р[х]
S[MP = £[*]
S [ Лх.£] р = Ad.S [£]( р {d/x}) in D
S [ ££'] р = ( S [£] p | [D—>£)])( S [£'] p )
где К : Const -> D — это некоторое отображение, заданное для синтаксических
констант (в множестве констант Const). Заметим, что областью значений £
не обязательно является А, поскольку некоторые примитивные функции так-
же могут быть константами; вспомним из гл. 3, что множество констант
может включать как базовые типы, например целые числа, так и связан-
ные с ними операторы, в частности +•
Приведенные выше уравнения снова определяют семантику редукции
нормального порядка (согласно определению Л), и, чтобы дать соответствую-
щие уравнения для редукции аппликативного порядка, мы используем функ-
цию strict: ( D D ) -> D D, определенную в виде
strict f х = f х, если х =£ J_
strict f J_ = I
Затем мы изменяем уравнение, определяющее величину абстракции, следую-
щим образом:
S [ Хх.£ ] р = (stricti, Ad.S [ £ ] р {d/x})) in D
Однако эта модификация, которая выглядит довольно невинно, ведет к про-
блемам, связанным с ^-преобразованием, и комбинатор фиксированной точ-
ки Y не вычисляет больше фиксированные точки, а дает всегда _L с очевид-
ными последствиями для свойств рекурсивно-определенных функцией (вспо-
мните SECD-машину из гл. 10). Это является источником теоретических воз-
ражений против интерпретаторов аппликативного порядка.
Формальная семантика 597
В.2. Денотационная семантика
функциональных языков программирования
Анализ, проведенный для Z-исчисления в предыдущем разделе, обеспечи-
вает фундамент для денотационной семантики используемых на практике
функциональных языков программирования, таких как Норе. Однако мы рас-
смотрим только наиболее важные особенности таких языков и покажем, как
получить соответствующие им семантические уравнения, поскольку было бы
слишком серьезным делом давать здесь полную семантику такого сложного
языка, как Норе. Некоторые из этих особенностей не требуют новых мето-
дов, поскольку непосредственно могут быть представлены в Х-исчислении. На-
пример, функции арности больше единицы могут быть определены в каррин-
говой форме с формальными параметрами, представленными в виде связан-
ных переменных Х-абстракций, а рекурсия может быть выражена с помощью
У-комбинатора. С другой стороны, сопоставление с образцом требует спе-
циальной обработки, и мы рассмотрим этот вопрос позднее, в разд. В.4.
Здесь мы дадим семантическую функцию S для синтаксиса типичного
функционального языка программирования, включающего кортежи, обозна-
чаемые заключенными в скобки последовательностями выражений, но пока не
включающего сопоставления с образцом. В этом языке все функции имеют
только один аргумент, который может быть кортежем; т. е. функция арности
п Эг 2 применяется к кортежу из п компонентов. Эта схема соответствует
функциональному языку Норе, но мы точно так же могли бы посредством
карринга ограничиться только функциями от одного аргумента. В этом слу-
чае функция арности п поочередно применялась бы к каждому из своих ар-
гументов.
Поэтому рассмотрим синтаксис
Е ::== х | ЕЕ' | И Е then Е' else Е" | ( Е,, ..Е„ ) | Лх.Е | fix x.E|let х = Е
in Е'| v( xi, ..., хге ).Е | let ( хь ..xn ) = E in E'
где x, xt, ..., xn (n 2) являются именами переменных. Так же как в
гл. 7, мы используем оператор «ню-абстракции» v для обозначения некаррин-
говой функции от нескольких аргументов; если функция f арности п опреде-
лена в виде f ( xi, ... , хп ) = Е, тогда мы пишем f = v (xi, ... , xn ).E. Выра-
жение fix x.E обозначает наименьшую фиксированную точку уравнения
f= [f/x]E, так что функции, определенные с помощью выражений вида
f у — Ej, где f входит в Ef, записываются как f = fix f. (Xy.Et) в данном
синтаксйсе Заметим также, что мы включили условные выражения в каче-
стве отдельного синтаксического типа, хотя могли бы определить вместо
этого примитивную условную функцию от трех аргументов.
Мы считаем наш семантический домен D разъединенной суммой (опре-
деленной в приложении Б), где слагаемыми являются базовые домены
Во.....Вт, домен W, состоящий из единственного элемента и представляю-
щий ошибку, домены кортежей с двумя или более компонентами и (непре-
рывное) функциональное пространство F — [£)->£)]. Мы выбрали разъеди-
ненную сумму вместо объединенной, так что каждое слагаемое является
доменом, представляющим полный тип объектов со своим собственным не-
определенным элементом. Теперь мы опишем эти слагаемые по отдельности.
1. Во является плоским доменом логических величин {JLbo, true, false}, а для
1 sc i m, В, представляет некоторый базовый тип, такой как числа, сим-
волы и т д.
2. W является доменом, состоящим из единственного элемента {_Lw}. Мы
могли бы исключить W из нашего определения D и представлять ошибки
как J_D. Однако в этом случае мы не могли бы отличить ошибку типа от
бесконечного вычисления.
598 Приложение В
3. Для я > 2 мы определяем домен Un, представляющий кортеж из п ком-
понентов в виде «-местного декартова произведения.
4. Определение пространств непрерывных функций F = [£>-»-/)] было дано
в приложении Б.
Таким образом, домен D определяется набором «доменных» уравнений:
D = В 0 + ... + Вт -|- W + F -|- U 2 + U з + ...
где W = {Х^,}, Un = D/ ...XD (п>2)
и F = [О >/)]
Теория доменов говорит нам о том, что эти уравнения имеют решение.
В нашем семантическом домене мы будем использовать карринговую ус-
ловную функцию cond : Во^>- D —> D —> D, и запишем cond р d а' в виде
if р then d else d', где
if true then d else d' = d
if false then d else d' = d'
if _LB0 then d else d' = XD
Мы будем использовать также определенные в приложении Б функции инъ-
екции и проекции in и 1 соответственно и функцию индексирования
j: ( D X 2+ ) —> D, которая выбирает компоненты кортежей из D и опреде-
ляется следующим образом:
( й], .. ., ет ) 4. i = е,, если 1 X iт
= Х^. in D в противном случае
d ф i = Хде, in D, если d & U для любого т
Чтобы определить нашу семантическую функцию, необходимо проверять, при-
надлежит ли элемент d домена D некоторому слагаемому, скажем S, из опре-
деления D. Однако если d является х, то такой тест никогда не закончится,
так что его результатом является X. Таким образом, мы будем использо-
вать функцию Е принадлежности домену, которая определяется в виде:
dES = true, если d = s in D для некоторого s <= S
= X, если d = X
= false в противном случае
(Проницательный читатель уже заметил, что мы по существу уже ис-
пользовали функцию Е в нашем определении разъединенной суммы в прило-
жении Б. Однако там мы не вводили новое обозначение и использовали обыч-
ный символ ее принадлежности множеству.)
Теперь мы готовы определить семантику для нашего синтаксиса функ-
ционального языка. Имея функцию контекста р: Iden-+- D и временно не
рассматривая последние два синтаксических типа, определяем семантическую
функцию <S : Ехр -> Env D с помощью следующих уравнений:
УЦ х ] р = Р[х]
<НЕЕ']Р = _if dEF
then if d'EUZ then _LW else ( d | F ) d'
else X^
где d = S [ E ] p, d' = S [ E' ] p
Формальная семантика 599
I if Е then Е' else E"Jp = if dEB0
= then if d | Bo then $ [ E' ] p else [ E" ] p
else J_r
где d = S [ E ] p
Г[(ЕЬ ...,En)Jp =(«’[E,]p, ...,<Г[Еп]1р) in D
<Г[(Лх.Е]р = (Ad.<y[E]p{d/x)) in D
[ fix x. E ] p > — K( Ad.<? [ E ] p (d/x))
S [ let x = E in E' ] p = if dEUZ then d.^, else S [ E' ] p {d/x}
где d = 8 [ E ] p
где Л является оператором абстракции, определенным на D, и Y-.F-+D—
это оператор наименьшей фиксированной точки D (который всегда суще-
ствует). Заметим, что семантика, данная для применения ЕЕ', является энер-
гичной, т. е. она соответствует редукции аппликативного порядка, поскольку
проверка d' £ IV' гарантирует, что семантической величиной ЕЕ' является _1_D
всякий раз, когда эту же семантическую величину имеет Е', согласно нашему
определению условной функции на D. Мы можем получить семантику вызова
по имени/необходимости, соответствующую редукции нормального порядка,
если уберем эту проверку. '
Если бы мы считали, что все функции обладают свойством карринга, при-
веденных выше уравнений было бы достаточно для обеспечения полной семан-
тики для языка с функциями более чем от одного аргумента. Однако наше
использование кортежей для этой цели приводит к появлению двух дополни-
тельных синтаксических типов и, следовательно, еще двух семантических
уравнений:
v (хь . . ., хп ).Е ] р — ( AdEUn.8 [ Е ] р {( d у i )/xi | 1 < i < /г} ) in D
8 [ let ( xj, ..., xn ) = E in E' J p
— if dEUn then 8 [ E' ] p {( d * i )/x, | 1 + i + "} else 1^,
где d = <¥“[[ E Ц p,
а типизированная версия оператора абстракции Л определяется в виде
AdES.e = Ad.( if dES then e else _LW )
для слагаемого (домена) S и e e D.
Так,- например, величиной выражения (v(x, у).х + у)(2, 3) является
( AdEt/2. [ х + у ] р {( d j 1 )/х} {( d | 2 )/у}) ( 2, 3 )
= ( AdEZ72.( d ф 1 ) + (d;2))(2, 3)
= ( (2, 3);i) + ((2, 3 ) ф 2-)
= 2 + 3
= 5
В действительности мы могли бы представлять функции от двух и более ар-
гументов как карринговые функции в нашем семантическом домене, просто
добавив следующее уравнение:
8 [ v( X], ..., xn ).Е ] р = ( Adi • • Adn.<y [ Е ] р {dt/xf | 1 < i < п.}) in D
Однако при этом допускалось бы частичное применение функции арности
п + 2 к менее чем п аргументам, дающее в результате функцию высшего
порядка. Это допустимо для некоторых языков, но не допустимо в языке
600 Приложение В
Норе, где частичное применение должно быть выражено явно с помощью
лямбда-оператора (см. гл. 4).
Исключая случаи небулева предиката и применения выражения, которое
не является функцией, ошибка типа обнаружилась бы в денотационной семан-
тике только при применении примитивной функции к объекту неподходящего
типа; при этом допустимые типы аргументов задаются спецификациями при-
митивных функций. Однако мы видели в гл. 7, что любое правильно типизи-
рованное выражение (в соответствии с Ж”, например) не может привести
к такой ошибке типа, и поэтому приведенные выше уравнения являются дей-
ствительно достаточными. Фактически программа проверки типов, конечно,
нашла бы любую ошибку типа, возникающую при применении выражения,
не являющегося функцией, и если бы мы представляли условные выражения
с помощью примитивной функции от трех аргументов cond : truval ->• а а
—г- а, то могли бы вообще не говорить о типах в семантических уравнениях;
программа проверки типов нашла бы также любые ошибки типов в условных
выражениях. Однако это не означает, что семантика типов не является важ-
ной. Наоборот, приведенные выше аргументы зависят от теоремы семантиче-
ской правильности для правильно типизированных выражений, при доказа-
тельстве которой типы представляются как поддомены семантического до-
мена D с определенными свойствами. Читателя, интересующегося этим вопро-
сом, мы отсылаем к работе [66).
В.З. Конструируемые типы данных
Конструктивный терм данных выражается с помощью применения функ-
ции-конструктора к соответствующему числу аргументов соответствующих
типов. Мы представляем типы таких элементов с помощью новых доменов,
определенных доменными уравнениями, соответствующими объявлениям со-
ставных типов. Допустим, мы имеем объявление
data t==c1(x1]#...#T1_ aJ++ ... ++сп(тп1#...#т„,ап);
где aj —это арность конструктора cj( a Tjk являются типами (1 si j п,
1 k sg aj). Эти типы могут включать t, давая рекурсивное определение.
Пусть С,к является доменом, представляющим тип т,&. Тогда домен Т, пред-
ставляющий тип t, является (наименьшим) решением следующего доменного
уравнения:
T~(CI1X...XCI>Oi)+...+(CnlX...XC„taJ
Доменное уравнение для D теперь принимает вид:
D = Во + ... + Bm + W + К + £72+^з + ••• + Л + — Л-Т и
где слагаемые Т, представляют все определенные пользователем составные
типы, такие как Т (1 i и).
Например, списки истинностных величин могут быть объявлены в виде
data listbool ==nilbool -|—|- consbool( truval, listbool);
так что домен таких списков является решением уравнения Т = N +(ВоХ Т),
где W— это домен, состоящий из одного элемента (как IJ7), представляющий
пустой булев список.
Если задан тип t и соответствующий ему домен Т, то смысл конструк-
тора с, типа t задается элементом X ••• X С1а_ -> Т, а именно:
#[cJp = (AdECnX ... XCfaJ.(d|l........d\at) |Т) in D
Все это справедливо для мономорфных типов. Для полиморфных типов
мы получаем семейство доменных уравнений по одному для каждого значе-
Формальная семантика 601
ния переменных типа, содержащихся в объявлении. Таким образом, имея
объявление
data р(аг ..., ат ) == с,( ти # ... # т1г ) ++ ...
++<=n( Tni# ••• #гп, ап )!
где переменные типа ai ( 1 i ) входят в правую часть, мы получаем
бесконечное число доменных уравнений, соответствующих присваиванию лю-
бого монотипа каждому at. Конечно, мы могли бы определить домен, содер-
жащий каждый домен, соответствующий полиморфному типу р, а именно
Р D 1 + ... + D л,где D‘ является (-местным декартовым произведением
D X • • • X D, но при этом можно было бы представить много типов выра-
жений, которые не определены в синтаксисе, например списки элементов раз-
личных типов. Семантика полиморфных типов лежит за пределами этой
книги, и интересующегося читателя мы отсылаем к работе [53].
В.4. Сопоставление с образцом
Функция, которая (частично) определена рекурсивным уравнением, со-
держащим образец для сопоставления, может быть выражена с помощью
оператора v-абстракции, введенного в гл. 7. Имея функцию f, определенную
уравнением IP = Е, мы пишем f = vP.E для образца Р. Так, если Р являет-
ся идентификатором переменной, то имеем v = X, и мы уже дали семантику
для f, когда Р является кортежем переменных (в разд. В.2). В этом разделе
мы сначала дадим денотационную семантику для функций, определенных
только одним уравнением, содержащим образец, а затем сделаем обобщение
на случай нескольких уравнений. Для этого введем семантический оператор V,
дающий результат сопоставления с образцом всех определяющих уравнений
функции, когда она применяется к аргументу (или аргументам).
Существует два синтаксических типа образца: идентификатор переменной
и применение функции конструктора арности i 0 к i образцам. Для целей
данного обсуждения константа определяется как конструктор арности 0. (Это
математически удобно, но не является определением, используемым в осталь-
ной части данной книги.) Сначала мы рассмотрим функцию f, определенную
единственным уравнением fP = Е, где выражение Р является образцом. Вы-
ражение fA редуцируется к UE, где, согласно нотации из гл. 7, и=У°(Р, А)
является подстановкой для идентификаторов, входящих в Е, которая опреде-
ляется путем отождествления Р и А при условии, что такое отождествление
возможно. Например, если Р является формальным параметром х, то можно
сказать, что f А редуцируется к [А/х] Е, что, как и ожидалось, является
просто синтаксической формой p-подстановки. Если отождествление заканчи-
вается неудачей, то образец несопоставим с аргументом. В этом случае, если
нет других определяющих уравнений для f, возникает ошибка типа, т. е. тип
функции несовместим с типом аргумента. Однако, поскольку все эти интуи-
тивные рассуждения относятся только к синтаксису, они неприменимы непо-
средственно к нашему рассмотрению денотационной семантики.
Поэтому мы дадим определение функции, соответствующей f в семанти-
ческом домене D с контекстом р, и определим таким образом семантику v
в виде
^"[vP.E]p=(7Aa.(g’|[E]]p*) in D, если отождествление, приведенное
ниже, успешно,
где U = 7( (Й’Г Р] р»), а), р* = р {d./х,} ... {d„/xn}
и Х|, ...,хп являются переменными, входящими в Р.
692 Приложение В
Для неудачного отождествления нам необходима специальная величина
в D, которую мы обозначим wrong и которая представляет неудачное сопо-
ставление с образцом В качестве этой величины мы выбираем наименьший
(и единственный) элемент ±ip слагаемого W из определения D, так что
== wrong.
Заметим, что отождествление теперь выполняется над термами в D, да-
вая подстановку U для семантических переменных dt, представляющих вели-
чины в D, т е. мы просто переименовали переменные х, точно так же, как
ранее мы переименовали х в d в правиле для ^.-абстракции.
В частном случае, когда Р является идентификатором х, мы имеем р* =
= p{d/x}, так что U = 7“( ( ^ I х ] р {d/x} ), а ) = [a/d] и
<HvP.E]p = Aa.[a/d](£’[E]|p*) in D
=а A.d.( £ I E ] p*) in D (а-преобразование)
= £ [ Лх. E ] p согласно уравнению для £,
данному в предыдущем разделе
Отождествление при сопоставлении с образцом является частным слу-
чаем отождествления, поскольку при этом все переменные входят только в
один из термов — образец — и мы можем записать семантические уравнения
для v непосредственно в виде набора рекурсивных уравнений:
£ [ vx. Е ] р = ( &.d.£ [ Е ] р {d/x}) in D для идентификатора х,
£ [ v( с( Pi, ..Pn ) ).Е ] р = AdEC.( £ [ vPi, ..., vPn.E ] р )
( d | 1 ) ... ( d ф n) in D
где c — это конструктор арности n с соответствующим семантическим доме-
ном С и Pi, ..., Рп являются образцами. Если п = 0 (константный обра-
зец),то второе уравнение принимает вид
[ vc. Е ] р = AdEC.^" [ Е ] р
(отныне мы для краткости будем опускать инъекции в D), где С — это до-
мен из одного элемента {Кс}. Обозначив величину через /, мы имеем для
е е D
fe = if еЕС then [e/d] £ [ Е ] р else
так что если не выполняется условие е = Кс, то сопоставление заканчивается
неудачей, как и требуется. (Заметим, что мы по-прежнему не допускаем
частичных применений из-за типизированной Л-абстракции.)
Например, функция, преобразующая список списков в список атомов,
может быть определена следующими уравнениями-
-----f nil <= nil ;
-----f(nil::z) <=f(z);
-----f( ( x:: у ):: z) < = x:: (f (у :: z));
„ /
Взяв третье уравнение, мы получаем
S’! v( ( х:: у ) z ).( х :: ( f у :: z ) ) ] р
= AdELzsts. ( £ [ v( x :: у ). vz. ( x :: (f у :: z )) ]] p ) d ф 1 d 12
= AdELzsts. ( AeE£zs/s.( £ [ vx.vy. vz( х::(!у::г))]р)е|1е|2)<1ф1 d ф 2
На этом этапе символы v можно заменить на %, и мы возвращаемся к слу-
чаю, когда нет никакого сопоставления с образцом. Читателю, который за-
метил, что переменная f является свободной в правой части, не следует бес-
покоиться, поскольку в действительности она была бы связана, если бы мы
Формальная семантика 603
дали полную семантику рекурсивной функции f, как это показано ниже.
В заключение мы обобщим приведенные выше результаты, чтобы дать
полную семантику для функций, определенных одним или несколькими урав-
нениями, включающими образцы. Для этого определим функцию V
D, чтобы объединить сопоставление с образцом при применении функции:
V ( d, е ) — d, если d wrong и d У= J-
V ( wrong, е) = е
V ( _!_, е ) = -L
Применение V представляет последовательное сопоставление двух образцов
из определяющих функцию уравнений, когда эта функция применяется к ар-
гументу. Если образец первого уравнения сопоставим с аргументом, это
уравнение используется для вычисления результата, иначе используется вто-
рое уравнение. Если процесс сопоставления «зацикливается», результатом
применения функции также должно быть незавершение Ясно, что V является
ассоциативной, и мы будем использовать ее в инфиксной форме без скобок
(не боясь неоднозначности) для получения функции, определенной любым
числом уравнений.
Если функция f определена m рекурсивными уравнениями fР, < = Ei,
где Р| является образцом, a Е,— выражением (1 sj i sg m), то семантиче-
ское уравнение для f имеет вид:
I П Р = /V ° (( ё [ vP>. Е, ] р ),...,(«[ vPm ,Em ] р ))
где / и ° обозначают операторы редукции (или вставки) и композиции
соответственно, так что
(/V°(d,, ..., dn))e = (d>e) V ... V (dne)
(Сравните с языком FP, описанным в гл 5 )
Теперь нам осталось рассмотреть только случай, когда f определена ре-
курсивно, т. е когда f входит в выражения £,. В этом случае необходимо
использовать семантический оператор фиксированной точки У следующим об-
разом:
ё[ f J р = Ykd. ( ё [ vPi. Еi ] р {d/f}) V ... V («О vPm• Em ] р {d/f})
РЕШЕНИЕ НЕКОТОРЫХ УПРАЖНЕНИЙ
Глава 2
2.1. а.------convert(n) <=if n = 0 then 0 else convert(n div 2)»10-f-
if ( n mod 2 ) = 0 then 0 else 1 ;
6.-------sum ( m, n ) < = sum 2 ( m, n, 0 ) ;
-------sum2(m, п, c ) < =
if n = 0 then c
sum2(mdiv 2, n div 2, c2)*10-f-s2
where (c2, s2) = = (total div 2, total mod 2)
where total = = ( n mod 2 ) + ( m mod 2 ) + c ;
2.3. type bag ( alpha) = = list (alpha # num) ;
-------add( e, nil ) < = [( e, 1 )] ;
-------add ( e, (entry & ( x, n ) ) :: s ) < = if e = x then( x, n -|- 1) :: s
else entry :: add(e, s ) ;
-------remove( (x, n ) :: s ) < = (x, if n — 1 then s else(x, n — 1 ) :: s ) ;
будем предполагать, что мешок непуст
-—-----union ((xl, nl ) :: si, s2 ) С = if nl = 0 then union(sl, s2 )
else union( ( xl, nl — 1 ), add( xl, s2 ) ) ;
-------union (nil, s) < = s ; не самая эффективная, но интересная
версия!
2.5. dec isort: list ( num ) -> list ( num ) ;
dec insert: num # list ( num ) list ( num ) ;
-------isort(nil) < = nil ; эта версия работает в «обратном направле-
нии» по отношению к версии, предложенной в тексте данного упражне-
ния, но является немногим более простой
-------isort ( х :: s ) < = insert (х, isort ( s ) ) ;
2.7. data truval = = true —(- false ;
-------^and( false, false) <= false ; (объявление очевидно)
-------and (true, true ) <=true ; и аналогично для (true, false) и
(false, true). Оба этих варианта дают false.
2.8. а. Это только одно из многих возможных решений'
type name = = list ( char ) ; data sex = = male ++ female ;
type date = = ( num # num # num) ;
type DateOfBirth = = date ; type EnrolmentDate = = date ;
type address = list (char ) ;
type Staffinfo = = ( name # sex # DateOfBirth # EnrolmentDate #
address ) ;
type course = = num ;
data Section = = Systems ++ Software ++ Theory ;
data Supportclass = = Secretarial ++ ComputerSupport ++ Mainten-
ance ;
data StaffRecord = = Teacher( Staffinfo # Section #
list ( course ) ) 4—|- Support ( Staff Info Supportclass ) ;
type Database == list( StaffRecord ) ;
Решение некоторых упражнений 605
б. (i) dec CountTeachers : Database —► num ; аналогично для обслуживаю-
щего персонала
---— CountTeachers ( nil) < = 0;
------CountTeachers ( Teacher _) :: Rest) < =
1 -|- CountTeachers ( Rest) ;
------CountTeachers( Support( Rest )< =
CountTeachers ( Rest) ;
2.9. Ассоциативность доказывается аналогично тому, как это делается для
функции Join, приведенной в тексте данной главы. Для доказательства ком-
мутативности докажем сначала индукцией по ш, что add( n, succ( m )) =
add(succ(n), m) для всех n, m типа nat. В базовом случае m = zero, и
мы имеем add( n, succ( zero ) ) = succ( add( n, zero ) ) = succ( n ) =
add(succ(n), zero) для всех п типа nat.
Теперь допустим, что add( n, succ( и ) ) — add( succ( n ), и ) для всех п,
и типа nat. Тогда add( n, succ( succ( и ) ) ) = succ( add ( n, succ( и ) ) ) —
succ( add( succ( n ), и ) ) по предположению индукции = add(succ( n ),
succ(u) ), что и требовалось доказать.
Коммутативность теперь доказывается индукцией по п. Для n = zero,
add ( zero, m ) = add ( m, zero ), что можно показать индукцией по m, ис-
пользуя только что полученный результат. Наконец, предполагая, что
add ( u, m ) = add ( m, и ) для всех и, т : nat, add( succ( и ), т ) = add( и,
succ(m)) согласно полученному ранее результату = succ( add( и, m ) ) =
succ(add(m, и)) по предположению индукции =add(m, succ(u)), что и
требовалось доказать.
Заметим, что более простое доказательство использует индукцию по па-
рам ( п, m ) с базовым случаем (zero, zero). Затем делается предположение
об (n, m ) и рассматриваются пары (succ(n), m) и (n, succ(m)). По-
прежнему необходимо воспользоваться подсказкой.
Глава 3
3.1.----- — map( f, 1 ) < = reduce(lambda( х, у ) = > I ( х ) :: у, nil, 1);
------И ( ) 12 <= reduce(12, 11 ) ;
3.3. gen ( n ) < = тар (lambda х — > lambda у = > у + x,f гот (1, п));
------Тгот( п. т) < = if п > т then nil else n :: from( n + 1, m ) ;
(функции должны быть подходящим образом объявлены).
3.4. в. C(F) < = reduce ( compose, lambda у = > у, F ) ;
3.5. а. Данная функция аналогична reduce, за исключением того, что функция
reduce имеет тип а 0 0, а не а # 0 0. / возвращает функцию, кото-
рая при применении к «базовому случаю» дает результирующий редуциро-
ванный список.
б. — — — sum (1) < = ( (lambda а = > lambda b=>a-|-b)/l) 0;
в. —-----add ( n ) < = lambda nil = > nil (
x :: s = > if n < x then n :: ( x :: s ) else x :: ( add ( n ) ( s ) ) ;
r. (add/[4, 2, 7, 3] ) 0
Глава 4
4.1. Мы можем определить функцию, которая генерирует бесконечный список
случайных чисел, например:
dec Randoms : real l?st( real) ;
— -----Randoms ( seed ) < = let ( next, newseed) = =
Generate / seed)
in next:: Randoms ( newseed ) ;
Его можно передавать всем функциям, которым требуются случайные числа;
очередное случайное число можно получить, взяв голову этого бесконечного
списка.
606 Решение некоторых упражнений
4.4. а.-------pipe(F) < = lambda stream =>
reduce( compose, lambda y=>y, StreamFuns )
where StreamFuns == map ( lambda f =>
( lambda s = > map( f, s ) ),F ) ;
StreamFuns просто транслирует каждую функцию f из F (типа а-* а) в
функцию обработки потока (типа list( а )->-list( а ) ) с помощью map(f, s ),
где s — это аргумент из потока, к которому f в конечном счете применяется
с помощью reduce. С помощью последовательно ленивого вычисления, оче-
видно, нельзя получить ничего похожего на конвейер: каждая величина из
входного потока будет обрабатываться каждой функцией из F до того, как
начнет обрабатываться следующая величина. Однако список функций обра-
ботки потока можно рассматривать как описание физического конвейера про-
цессов, и каждая такая функция могла бы быть реализована на отдельном
процессоре. В этом случае возможно получить параллелизм, присущий кон-
вейеру.
б.-------Intersection ( S, Т ) ,< = Filter ( pipe( F ) (map{ lambda s = >
( 1, false ), S ) ) )
where F = = map (lambda x — > lambda ( v, f) = >
( v, if v = x then true else f ), T ) ;
-------Filter ( nil ) < = nil ;
------Filter ( ( v, b ) :: s ) < = (if b then v :: r else г )
where r = = Filter(s) ;
Глава 5
5.3. Это зависит от того, как мы определяем лямбда-выражение. Ясно, что
любая функция может быть записана в карринговой форме с помощью не-
скольких вложенных друг в друга лямбда-выражений, например f х у = Е
в языке Miranda превращается в f = lambda х = > lambda у = > Е в язы-
ке Норе. Однако если в языке Miranda мы имеем f х у z = Е, что соответ-
ствует ------f'(x, у, z) < = Е з языке Норе, тогда G = f а не всегда
то же самое, что и Н = lambda(х, у ) = > f'( а, х, у ). Это зависит от того,
как используется G. Если G всегда применяется к двум аргументам, то G и
Н эквивалентны- G а Ь = Н(а, Ь); однако если функция G применена ча-
стично, как в случае G Ь, тогда лямбда-нотация требует, чтобы такое ча-
стичное применение было записано в виде lambda у=>Н(Ь, у). В этом
смысле карринг является более общим; однако делает ли карринг программы
более ясными — это дело вкуса.
5.5. б. Def арр = /cons ° consr
Глава 6
6.2. а. Вариант (in). Мы будем редуцировать на каждом шаге самый ле-
вый из самых внешних редексов.
( ХЛ. ( Xx./i( х х ) ) ( 7.x.hA х х ) ) ) ( ( ХаМ.а ) (+ 1 5 ) )
- > ( Хх.( ( ( ka.t.b.a ) ( + 1 5))(х х)))(Хх. ( ( Ха.ХЬ.а ) ( + 1 5 ) ) (х х) ) )
- >-((( Ха.Х&.а ) ( + 1 5 ) ) (Хх. ( ( Ха.Хй.а ) ( + 1 5) ) ( х х ) ) )
( (Хх.( (Ха.Х&.а ) ( + 1 5))(хх))))))
( ( (Х6.( + 1 5 ) ) ) ( Хх.( ( Ха.Хб.а ) ( + 1 5 ) ) ( х х ) ) )
( (Ха.( (Ха.Х& -а)(+ 1 5) )(х х) ) ) ) ) )
- <+ 1 5)
- >6
6.4. (ХД+ (f l)(f 2) )(Xx.(Xt/.y) 7)
- >- + (/ 1 ш 2 ) where f = ( Хх. ( Ky.y ) 7 )
- >+( (Xx.(Xy.v) 7) I )(f 2) where f = ( Xx.( t.y.y ) 7)
- *- + (( Ц-У ) 7 ) ( f 2 ) where f = (Xx. ( 7.y.y ) 7 )
where f = ( Xx. ( Xy.y ) 7 )
Решение некоторых упражнений 607
* -* + 7(f 2)
— >• + 7 ( (Кх.(Ку.у) 7)2)
* -> + 7( (Ку.у) 7)
- + + 7 7
- + 14
При выполнении шагов, отмеченных *, (Ку.у) 7 редуцируется дважды. Мы
можем избежать этого, выполнив редукцию тела функции до завершения
применения. Этот порядок редукций называется редукцией внутреннего греб-
ня. При этом редексы тела редуцируются один раз, однако требуется выпол-
нить редукцию, «пройдя через символы л», что снова приводит к появлению
проблем свободных переменных и конфликта имен. Отсюда следует непри-
годность данного метода для практического использования.
6.5. a. (i)Xx.x, (ii) z.x.6
б. JL, поскольку *J__L = J_ и J_ является наименьшим элементом по
определению (см. приложение Б). Другими фиксированными точками яв-
ляются 0 и 1.
в. В упражнении 6.2. в (iii) вычисляется наименьшая фиксированная
точка выражения ( Кх.Ку.х ) ( + 1 5), т. е. Х.х.6, поскольку применяемая
функция является версией У-комбинатора в Х-исчислении. Это объясняет,
почему ответом является 6.
6.7. a.' (i) NOT = Кх.х FALSE TRUE
(ii) XOR = Ka.Kb.a( NOT b )b
6.8. 6. K.(K.L0 L0)(K.L0(K.L\ ) )
Глава 7
7.1. а. Для предиката a( b ) : truval — > b : fl, a : p -+ truval
Для следствия [с] : list( a), c : a,
Для альтернативы [b :: c] : list (у ), b : у, c . list { у )
= > у = P, a = list ( у ) = list ( p )
Следовательно, f : ( ( P truval) # p # list( P ) ) -> list (list ( P ) )
6. (a ( a -> truval) )-*- (a truval)-»- a -> truval (вспомним, что
следствие и альтернатива всегда имеют одинаковый тип в условном выра-
в. (a # ( (a # пит )->Р)#(Р->а-^у) ) -»list ( а -+ ( р # у ) )
7.2. Начинаем с применения правила (d):
ТГ( nil, Kf.Kg.Ka.Kb.pair( fa)(gb)) = (Ri, RiPi -> pi )
где Pi—это новая переменная типа и
( R\, pi )= »°(f : р, Kg.Ka.Kb.pair( f a)(g b) )
В результате наш алгоритм дает следующий результат:
funpair : ( р ) -* (б ) ^ a-+y -+ ( р X 6 )
Подобным образом
tagpair :a^p->p->((aXP)X(aXP))
7.3. а. apply :((a-<-p)Xa)-^p
б.------apply (tuple-2 f x ) < — f x
в. В общем случае мы имеем v( tuple-n Xi... x„ ) вместо v( Xi, .... xn )
и для вывода типа образца используем допущение для tuple-n вместо пра-
вила (g).
7.4. сиггуЗ f < = lambda х = > lambda у = > lambda z = >
f (X, у, z ) ;
сиггуЗ : ( /аХ fiX}'}+ И)+ a + ft + y + 6
7.5. Для конструктора с арности п > 0 У( A, v( cpi... рп ) е ) = t/p-> U<j,
где U=Т (у, Р1->...-*р„^-Р), ЗГ(Л, с) = (/, у) и X (Л, vpi... vpn.e ) =
608 Решение некоторых упражнений
= ( R, pi -► ... ->р„ о). Базовые случаи: для конструктора с арности 0
Ж” ( А.с : у, vc.e ) = (s, sy g )
где (S, о) = -)Г(А.с:у, e)
для переменной х, vx.e = кх.е и применяется правило ( d ).
(Заметим, что fpi.. рп представляется как f = vpi... vp„.e.)
7.6. а. «Проверка Ьхождения» для несогласованной пары (пит, пит^-х)
б. «Проверка вхождения» для несогласованной пары ( bool, bool -> т )
Глава 8
8.1. б. Конструкторы могут передаваться в качестве аргументов и возвра-
щаться в качестве результатов. Для карринговых языков мы опираемся на
тот факт, что функция TUPLE-n сама является карринговой. Например, кон-
структор списков cons может быть оттранслирован в частичное применение
TUPLE-3 1, где 1 является внутренним кодом для cons. В языке Норе мы
могли бы использовать двухъярусное представление для составных данных,
так что cons х у был бы представлен в виде TUPLE-2 1 (TUPLE-2x у).
В этом случае при передаче в качестве параметра его следует передавать в
виде TUPLE-2 1, при этом его применение к кортежу, содержащему х и у,
дает требуемый результат. При использовании нашего представления мы
должны декомпозировать кортеж, к которому cons в конце концов приме-
няется. В этом случае cons передается в виде XT.TUPLE-3 1 ( INDEX 1 t)
(INDEX 2 t)
8.3. data Tree = — NoMatch —(- Leaf (list ( EquationNumber ) ) -|—Node( Po-
sition # list(Tree )) ; с соответствующим образом определенным Equation-
Number (номер уравнения) и Position (позиция). Для расширения, включаю-
щего символьные и целые литералы, требуется дополнительный тип вершины:
data Tree = = .. -|—Literal ( Expression #Tree #Tree ) ;
8.4. a. (ii) TUPLE-3 2 ( TUPLE-2 1 ( TUPLE-1 0 ) )’ ( TUPLE-1 0)
В качестве отступления заметим, что существует основанный на %-исчислении
промежуточный язык, называемый FLIC, который очень похож на язык,
определенный нами в этой главе. Одним из главных отличий является то,
что FLIC поддерживает кортежи с метками, в которые можно вставлять
метки с помощью специальных функций инъекции. Эту возможность можно
использовать для пометки аргументов конструктора меткой кода конструк-
тора. При этом код конструктора не является больше компонентом соответ-
ствующего кортежа, так, что, например, конструктор zero в этом случае был
бы представлен кортежем арности 0 с внутренними метками.
г. Списки связей пусты для первых двух уравнений; третье имеет список
связей вида [("а”, [3, 2] ), ("Ь", [3, 3] )].
8.5. Да! Величина node v представляется четырехэлементным кортежем, пер-
вый элемент которого является меткой конструктора node, а остальные три
элемента являются элементами v. Поэтому, чтобы связать Т с v, мы должны
выделить эти три элемента и построить новый трехэлементный кортеж. Про-
стейший путь сделать это заключается в замене Т в образце на кортеж пере-
менных, например (х(, х2, х3) для целей трансляции. Альтернативой могло
бы быть представление всех данных, построенных с помощью конструкторов
в виде пар, где первый элемент является меткой конструктора, а второй —
аргументом конструктора (который конечно, может быть кортежем). Констан-
ты данных снова могут быть представлены кортежами из одного элемента.
8.7. Потому что если мы сливаем две вершины, одна из которых является
листом, то уравнения, связанные с этими вершинами, должны перекрываться:
если бы они не перекрывались, мы не сливали бы соответствующие вершины.
8.8. Тест наличия конструкторов nil/cons вызов функции isempty; индекса-
ция для доступа к головному и хвостовому элементам -> непосредственные
вызовы функций head и tail. Преимуществом является эффективность; в дан-
ной реализации функции обработки списков должны, вероятно, быть в вы-
сокой степени оптимизированы.
Решение некоторых упражнений 609
8.9. Модификации являются тривиальными. Вместо одного символа для каж-
дой функции мы вводим отдельный символ к для каждого аргумента функ-
ции При рассмотрении дерева сопоставления мы по-прежнему можем счи-
тать, что аргументы образуют кортеж. Единственное изменение, которое тре-
буется в данном случае, касается окончательной трансляции позиций. Пози-
ция [п] теперь указывает n-й аргумент/связанную переменную (скажем, ai),
а не n-й элемент кортежа аргументов. Каррииговые конструкторы не пред-
ставляют проблемы. К моменту вызова функции все аргументы составных
данных запомнены в виде кортежей, и описанный нами метод индексации
по-прежнему работает.
р л Д. В я ф
9.1. a. (ii) LET("x", INT(4), LAM( "у", АРР( APP(PRIM( "+" ),
INT(7) ), INT(5) ) ) )
9.2. в.------empty <= lambda i=>i; этот вариант не может возник-
нуть, поскольку все выражения являются замкнутыми
-------Е (v, е) < = lambda i = if i = v then e else E (i) ; за-
тем следует определение
9.5. а. Мы могли бы представить применения примитивных функций с по-
мощью специального типа вершин, называемого PRIMAPP, например
+ х у -► PRIMAPP ( [х, у]). В этом случае частичные применения
примитивов должны быть представлены с помощью замыканий, чтобы реа-
лизовать карринг, например 4-6 —CLOSURE! LAM( "х", *PRIMAPP(
[INT( 6 ), VAR("x")] ) ), empty)
б Все очень хорошо, за исключением того, что теперь нет различий
между тем, как внутри интерпретатора представлены выражения +6 и
Хх + 6 х. Если программа выдаст такое выражение в качестве результата
и попытается напечатать его, пользователь всегда будет получать ответ
Хх. + 6 х. Это может удивить его, если он ввел + 6 в качестве выражения,
которое необходимо вычислить.
9.7. a data AllPrims = = plus -|—minus -)—f- ... -|—F tuple ( num )++ ...;
Здесь ” представляется с помощью конструктора plus, "—" — с по-
мощью minus, .. , tuple-n — с помощью tuple ( п) и т д. Необходимо соот-
ветствующим образом модифицировать функцию ArityOf: ArityOf ( plus ) = 2 ;
...; ArityOf (t uple( n ) ) < = n. Основной механизм применения остается та-
ким же, как раньше, за исключением того, что нам необходимо представление
для кортежей поскольку мы теперь поддерживаем их в качестве нового ба-
зового типа. Достаточно дополнить наш список выражений следующим об-
разом:
data ехр === INT( num ) ++ VAR( id ) ++ ... +4- TUPLE( list (exp ));
6. FunOf (typle ( n ) ) < = lambda Args = > TUPLE (Args ) ;
в. Нам необходимо использовать свойства обоих рассмотренных интер-
претаторов: если применяемой функцией является lazytuple-n, то мы должны
сформировать задержку из ее аргументов, иначе необходимо вычислить эти
аргументы, как в случае энергичного интерпретатора.
-------Eval ( АРР (F, A), Env) <= Check ( Evalf F, Env), A, Env);
-------Check( F & OP( lazytuple( _ ), _, - ), A, Env )< =
Apply ( F, SUSP( A, Env ) ) ;
-------Check (F, A, Env ) < = Apply ( F, Eval ( A, Env ) ) ;
используя перекрывающиеся образцы.
Глава 10
10.1. Аналогично примерам, приведенным в гл. 10.
39 — 1473
610 Решение некоторых упражнений
10.2. Энергичное использование Y = Xh. ( Xx.h( хх ) ) ( Xx.h( хх ) ) приводит к
тому, что применение хх редуцируется, как только х становится связанным.
а. При энергичном вычислении Y f 3, 3 уже находится в СЗНФ и Y f
редуцируется к DD, где D = (Хх. ( Xf.Xn.cond ... ) ( хх ) ). Это выражение ре-
дуцируется к (Xf.Xn.cond ...) (£>£)), и снова вычисляется аргумент DD и
так далее до бесконечности.
При использовании Y' мы получаем выражение D'D' при вычислении
Y'f, где D' = (Хх.( Xf.Xn.cond ... ) ( Xz.xxz ) ), которое редуцируется к
(Xf.Xn.cond ... ) (Xz.D'D'z). Последнее выражение находится в СЗНФ. Та-
ким образом, при применении этого выражения к 3, мы получаем в else-ча-
сти подвыражение ( XzD'D'z) 2-►/)'£)' 2, которое обеспечивает проведение
рекурсии. Однако в базовом случае подвыражение ( Xz.D'D'z) отсутствует.
б. f' = (f, Xn.cond 2 (* n(f( — n 1 ) ) )( = n 2) ). Начальное состоя-
ние имеет вид
( )( )(ГЗ)( )->( )( )(3, Г, @)( )
(3) ( ) (Г, е) ( )
—( 3 ) ( f = Xn.cond... ) (Xn.cond .... @ ) ( )
( fn, cond ..., ( f = Xn. cond ...)], 3 )
( f = Xn cond... ) (@ ) ( )
—> ...
f' больше недоступна.
10.4. Поместите замыкание, соответствующее лямбда-выражению помеченного
выражения, в контекст немедленно — связи свободных переменных не изме-
нятся при редукции к СЗНФ.
10.5. Lf = (f, Xx.cond 1 ( g x ) ( = x 0 ))
g = tf.h f
При вычислении Lf 132 переменная x связана с 132, следовательно, f
связана с 132 в применении g. Таким образом, в теле h. f связана с 132,
тогда как Ъна должна быть связана с Xx.cond ... . Проблему можно обойти,
если использовать уникальные имена. ,
10.7. Необходимо изменить правила переходов между состояниями (сравните
с реализацией вызовов по имени, описанной в тексте главы) и семантическую
функцию eval, определяющую правила подстановки для |J- и 6-редукции.
В остальном доказательство аналогично приведенному в тексте главы.
Глава 11
11.1. (i)
* обозначает первый редекс , f обозначает второй редекс
Решение некоторых упражнений 611
Варианты (ii) и (iii) выполняются аналогично.
11.2. Представьте cons 4 в виде (Xx.Xy.cons х у )4 или в виде Ку.cons 4 у.
Затем выражение редуцируется но обычным правилам.
11.5. а. Каждый тип вершины содержит поле метки и другие поля, как по-
казано ниже (существуют различные оптимизации):
@-вершина : два указателя
идентификатор : id
cons : два указателя
Х-вершина : id и указатель
константа :значение
tuple-n :вектор из п указателей
где id является некоторым подходящим числовым кодом идентификатора.
В каждом случае слева от знака : показана метка соответствующей
ячейки.
б. Основное преимущество в том, что элементы кортежа могут быть
доступны за постоянное время. Недостатком является необходимость ячеек
переменного размера; для некоторых реализаций (в частности, для парал-
лельных реализаций) это может существенно усложнить управление памятью
и сборку мусора.
11.6. При редукции графа нормального порядка мы находим следующий ре-
декс путем сканирования графа в глубину слева направо. Чтобы сначала
вычислить аргументы, мы должны от каждой @-всршины графа идти вправо,
пока это возможно. Таким образом, необходим просмотр графа в глубину
справа налево.
Глава 12
12.1. a. comb( Хх. X х 1 ) = [x]comb ( + х 1 ) = [х](-|- х 1 )
= S[x](+ x)[x]l=S(S[x] + [x]x)(K 1)
= S(S(tf+)/)(K 1 )
б. S(S /(К/) )(К 1 )
B.S(S(S(K cond1(S(S(K=-)l(K 0) ) )(tf l))(S(S(K-)/)(K 1))
12.3. а. X = ZZ, где Z — Хх.г.у.у (х х у). Таким образом, для Х-выраже-
ния Е X E=(Z Z)E = (Ку.у (Z Z у) )E = E(ZZE)=E( ХЕ)
б. Для всех М, S ККМ = КМ~(КМ)=М = 1М
в. Для всех М. N, Р
S(K S)K М N Р = К S М(К M)N P = S(K M)N Р
= к м Р (N Р)=М (К Р) = В М К Р
12.4. Базовые случаи:
(i) sub ( [х] х ) — sub (I) = Xz.z = a 7.x.sub ( x )
(ii) Для константы m или переменной m=^=x sub( [x]m )=sub(K m) =
( Xx.Xt/.x ) m — ffiy.m = aXx.su6 ( m )
Шаг индукции:
sub( [x]AB)= sub(S[x]A[x]B)= sub(S)sub( [x]A )
— asub ( S ) (kx.sub ( A ) ) (Xx.sub ( В ) ) (по предположению ин-
дукции)
= Xz. ( Xx.suftf A ) )z( 7.x.sub( В )z) =
p Xz. [z/x] sub (A ) [z/x] sub ( В )
= Xz. [z/x] ( sub( A )sub( B) ) = Xz. [z/x]sub (A В )
~ aXx.sub( AB)
Далее доказательство выполняется, как описано в гл. 12.
12.7. comb(W) = SS (KI).
а. Очевидно.
39*
612
Решение некоторых упражнений
б.
Редукция графа выражения W' -f- 2 очевидна,
в. Е имеет граф
г. Преобразования графов очевидны.
12.9. Функция абстракции abs может быть определена следующим образом:
abs( Xv.v ) = 1
abs ( Xv.w ) = <а К w
(для идентификатора ш =/= v) *
abs( Kv Kw.E ) = abs( Kv.absf Kw.E ) )
abs( Kv.9$EiEz ) = ®/$ abs (Xv.Et )Е2 если v e fl'V E,| и v /-'H E: )
= &\$Etabs (Ky.Ez ) если v & FV( E\ ) н v FV(Ег\
= $abs( Xv.Ej )abs( Xv.E2) если xe FVIEFjtiv e FV( E;}
= 9— $EtEz) если v FV( £\)и v ф FV( E2 )
12.9. а. Используйте Л'-комбинатор. Kx Ку 7 = $Kx.K 7.
б. Через эту вершину переменные связываются с аргументами. Если
связанная переменная не встречается в теле, мы используем направляющий
"—" в корневой вершине. В графе тела направляющие только посылают
аргумент на нужное место; таким образом, если переменная не встречается
ниже данной вершины, ее не следует передавать этой вершине, поэтому нет
необходимости в направляющем ”—".
Глава 13
13.1. a. mult = YKm.KxKy.cond ( = xl)y(m(— х 1 )у. Самая внутренняя
Х-абстракция (подчеркнута) может быть записана в виде а. т х, где а опре-
деляется следующим образом.
а и v w =£= cond( = v 1 )w ( и ( — v 1 ) ш )
Далее, mult = YKm Кх.а т х, и мы определяем 0 в виде £ и v = а и v,
поэтому [J = а, что дает mult = Y Кт.ат — Ya (с помощью ^-преобразова-
ния). Заметим, что вам бы понадобился еще один комбинатор, если бы вы
изменили порядок двух первых параметров а (см также упр. 13 5).
б. Y а 3—>-a mult 3, что является частичным применением и не может
быть редуцировано далее. Однако
mull3 — Ку.cond ( — 3 1 ) у ( mult ( — 3 1 ) у )
— Ку.cond false у ( mult 2 у ) = Ky.mult 2 у
так что значения двух постоянных подвыражений =3 1 и —3 1 могут быть
разделяемыми при втором применении mult 3. Эта возможность разделения
теряется при Х-удаленни.
Решение некоторых упражнений 613
в. Мсв в подчеркнутом выражении — это cond (=х 1) и т (— х 1),
и мы имеем
mult = У Хот.Хх.о( т( — х 1 ) ) ( cond ( = х 1))
где ouvw — vw(u w). Единственным мсв нового самого внутреннего Х-тела
является т, и мы имеем
mult = У Хш хт — Ут
где xuv — <з(и( — v 1 ) ) ( cond( = v 1 ) )
Теперь частичное применение mult дает
т mult 3 = а ( mult( — 3 1 ) ) (cond ( = v 1 ) )
Поэтому значение постоянных подвыражений могут быть разделяемыми.
г. Только правило для -г
13.2. f =# YXf.Xx.Xy.cond( <; х y)x(f(— х у)у) и мсв являются <х, х, f,
—х. В данном случае никаких выгод по сравнению с Х-удалением нет, по-
скольку частичные применения — это единственные мсв, не являющиеся пере-
менными. Эти частичные применения примитивных функций не могут быть
редуцированы, поскольку для редукции требуются все аргументы. Более
того, в данном случае имеем 4 параметра вместо двух при простом Х-уда-
лении.
13.3. a. f = Xxi.Xx2. . Ах„ Е — avi.. vm, где avi... vmxt... х„ == £ (общее
лямбда-удаление).
б. Все объекты, имеющие в качестве своих значений функции, становят-
ся частичными применениями комбинаторов. Это означает, что мы можем
«накапливать» аргументы комбинатора и применять комбинатор, только когда
все его аргументы будут в наличии (сравните с обычным механизмом кар-
рингового применения функции).
в. Полная ленивость сохраняется, если никакое частичное применение f
не становится разделяемым. Иначе возможно, что подвыражение внутри тела
комбинатора будет вычисляться каждый раз при применении разделяемого
частичного применения. Компилятор может определить, будет ли f приме-
няться. частично, и если да, то будет ли это частичное применение разделяе-
мым. Если разделение не имеет места, соответствующий комбинатор можно
оставить без изменения, не боясь потерять полную ленивость. Если же он
может стать разделяемым, то мсв-удаление должно применяться в таком
виде, как описано в разд. 13.2. При этом появляется по крайней мере один
новый комбинатор.
13.4. Нам необходимо рассмотреть только выражения вида X — Хх<... лх„.£,
где выражение Е является а'ппликативным, поскольку в противном случае мы
можем сделать индуктивное предположение о том, что результат справедлив
для £ (и аналогично для выражений, не являющихся лямбда-абстракциями).
Для общего лямбда-удаления мы получаем glift( X ) = avt... vm, где
avi... vmxi... x„ = £ и Vj... vm являются свободными переменными в X.
Для простого лямбда-удаления (с порядком параметров «самый свобод-
ный— самый первый») мы получаем slift( Хх« £ ) = a'wt ... wmxi ... Xn-t
(при условии, что каждый х,, ..., х„-, входит в £), где a'w,... wmx,... хл =
= Е и Wt, ..., w„ являются переменными vt, ..., vm, расположенными в
порядке «самый свободный — самый первый». Но
ХХ| ... Xxn-i.a't»! ... WmXi ... xn-i = a'wt ... w„
614 Решение некоторых упражнений
(^-преобразование), и потому достаточными условиями являются то, чтобы
при общем лямбда-удалении параметры, соответствующие свободным пере-
менным, также располагались в порядке «самый свободный<—самый первый»,
и то, чтобы каждая переменная, имеющая подвыражение Е в своей области
действия, входила в это выражение. При невыполнении последнего условия
мы имеем, например, выражение X — Хх Ху Xz.z х, для которого простое
Х-удаление дает X = р, где [)ху = аиахг = гх, а общее лямбда-уда-
ление дает единственный комбинатор.
13.6. (Только случай (i).)
a. (X.X.L1 L0 ( + 1 L0) ) + 2
б. S(S (A(A(S(S( 1!,0!), S(S('+,'l), 0!)))),' + ), '2 )
в СККЛ или
Арр ° (А, В) , где А == Арр ° <С, D), В = А( 2 ° Snd )
где С —- А( А( Арр ° (В, F) ) ), D = А( + ° Snd )
где Е = Арр ° {Snd ° Fst, Snd}, F — Арр ° (G, Snd)
где G = Арр ° (A( + ° Snd ), A( 1 ° Snd ))
в. СЗНФ, равная 5, получается просто, как в примере из гл. 13, с по-
мощью либо правил СККЛ (применяя выражение к пустому контексту),
либо правил ККЛ.
Глава 14
14.1. б. Используем формат табл. 14.1, но не указываем размер списка вхо-
дов инструкций.
(i) 1 копирование (4.2, 7.2) (iii) 1 копирование (3.1, 5.2)
2 копирование (5.2, 6.2) 2 значение: 3 (3.2)
3 значение:2 (4.1) 3 — (7.2)
4 * (8.1) 4 значение:+ (5.1)
5 применение (6.1) 5 применение (8.2)
6 применение (7.1) 6 значение:f (7.1)
7 применение (8.2) 7 применение (8.1)
8 + (выход) 8 применение (выход)
14.2. Ограничением при использовании F является в этом случае запрет ча-
стичного применения F. Если мы применяем F частично, то не имеем механиз-
ма, с помощью которого можно ссылаться на результирующую функцию, и
не имеем механизма применения такой функции. Тем не менее именно таким
путем реализуется применение функций во многих традиционных потоковых
машинах. Невозможность поддерживать (по крайней мере, простым спосо-
бом) функции высшего порядка делает эти машины очень неудобными для
реализации функциональных языков.
14.3. а. См. предыдущий пример.
б. Символ примитивной функции может теперь появиться на функцио-
нальном входе вершины применения. Поэтому правила для вершины такого
типа должны быть соответствующим образом расширены.
14.5. Потому что две ветви условного выражения соединяются с помощью
вершины-слияния, которая не является строгой по входам F и Т. Если на
управляющий вход поступает true, знак вычеркивания на входе F будет
проигнорирован, и аналогично для false и входа Т.
14.6. 0.2 соответствует вершине стека, когда она появляется в списке выхо-
дов последней инструкции.
14.7. Таким образом мы просто можем использовать входцые поля инструк-
ций для хранения элементов списка источников.
Глава 15
15.1. г. ( 3( if ( af ( fe( Iv 3 ) ) (Iv 1 ) (cv 1 ) ) (Iv 2) ( af (bi — ) (Iv 1 ) ( cv 1 ) )
( af(bi »)(lv 1 )(lv 2) )) )
Решение некоторых упражнений 615
15.2. tv-выражения могут осуществлять распаковку кортежей; в этом ас-
пекте они могут рассматриваться как непосредственные реализации выраже-
ний типа let ( Xi, х2, ..., хп ) = = Т in ... .
15.4. б. Важное свойство промежуточных кортежей состоит в том, что они
не являются разделяемыми. В действительности это сокращение для выраже-
ния (tv 1 Ei (tv 1 Ег (tv 1 Е3 Е ) ) ).
в. Мы могли бы транслировать это выражение в эквивалентную «длин-
ную» форму. Однако при непосредственном использовании кортежей в гене-
раторе кодом мы можем прийти к более общему решению. Например, если
было дано выражение (tv 3 (if (...) (lv 4 ) ( mt EiE2E3 ) )Е ), то мы не
сможем столь же легко применить трансляцию FC-*FC. Требуемое расшире-
ние достаточно просто: к функциям компиляции надо лишь добавить другой
параметр п, уведомляющий основное правило о том, то если п > 1, то ре-
зультатом вычисления выражения будет кортеж размерности п, который
должен быть оставлен в стеке. Этот параметр распространяется по всем вет-
вям условного выражения до результата в tv-выражении. «Базовым случаем»
будет являться правило для mt-выражения, в котором дополнительный па-
раметр определяет, куда должен быть помещен результирующий кортеж.
Двумя наиболее интересными правилами являются следующие:
E[(mt Е(Е2... E„)]d 1 п = E[En]d 1; Е[E„_i]d + 1 1 ;
...; E[Ei]d + n— 1 1;
if n = 1 then COPY n
E[(tv k Ei E2 )]d 1 n = E[E,]d 1 k;
= E[E2]d + k 1 ++ [k, d] ; DROP n, k
15.6. F [ from n = cons n from( succ( n )) ] = E [ cons n from( succ( n )) ] Г) 3 ;
UPDATE 3; RET 2
согласно F-схеме, где п = r0{2/x}, то г0 является пустым контекстом. Приме-
няя правила для Е- и С-схем, мы получаем
PUSH 1; PUSHFUN succ; MKAP; PUSHFUN from;
MKAP; PUSH 2; CONS; UPDATE 3; RET 2
Граф для from( succ( 0 ) ) строится с помощью кода
С [ from( succ( 0 )) ] гоО = PUSHINT 0; PUSHFUN SUCC;
MKAP; PUSHFUN from; MKAP-
С помощью этого легко получить стек и граф.
15.7. E[hd(tl(from 1 )) ] гоО
= Е [ tl ( from 1 ) ] roO ; HD ; EVAL
= E [ from 1 J roO; TL ; EVAL ; HD ; EVAL ;
= C [ from 1 ] roO ; EVAL ; TL ; EVAL ; HD ; EVAL ;
= ... = PUSHINT 1 ; PUSHFUN from ; MKAP ;
EVAL; TL; EVAL; HD; EVAL
После операций раскручивания (в первой инструкции EVAL) вычисляемое
выражение станет PUSH 1 ; PUSHFUN succ; ...; RET 2, как и в приме-
ре 15.6, а граф и стек будут выглядеть так:
from
616 Решение некоторых упражнений
После выполнения RET 2 выражение TL ; EVAL ; HD ; EVAL будет восста-
новлено, а стек и граф станут такими:
Вычисление хвостовой части (даваемой TL) использует вызов второй функ-
ции— from 2, а вычисление головной части результата (последний EVAL)
даст ноль, так как граф будет состоять из единственной вершины 2, т. е. уже
в СЗНФ.
15.8. Yf = let D xt Хг = Xj( Х2 х2) in D f ( D f ), а затем применить, как
обычно, правила компиляции для c[Y f ] г п.
Глава 16
16.1. Важным свойством копирующего сборщика мусора является то, что он
проходит только по активным ячейкам. Число активных ячеек, необходимых
в данный момент при выполнении программы, не зависит от общего размера
кучи. Следовательно, если увеличить размер каждого подпространства кучи
в N раз, то сборщик мусора будет включаться примерно в N раз реже, но
время его работы сохранится тем же. Таким образом, время, уходящее на
сборку мусора, стремится к нулю по мере увеличения N. Для сканирующего
сборщика эти рассуждения неприменимы, так как здесь просматриваются
все ячейки кучи, поэтому время сборки мусора растет линейно вместе с N.
16.2. а. Это вызвано тем, что элементы кортежей и аргументы конструктора
вычисляются перед тем, как будет создана ячейка кортежа или конструктора.
При использовании данной версии алгоритма Бэйкера это означает, что таб-
лицы отражения не требуются, поскольку все указатели направлены либо
к ячейкам той же области, либо к ячейкам старших областей.
б. Это может произойти при ленивой реализации, когда задержка или
редекс графа заменяется результатом вычисления задержки или редекса.
Этим результатом может быть другая структура кучи, построенная спустя
некоторое время после создания задержки или вершины редекса.
16.4. При проталкивании стека декрементации в поисках свободной ячейки
мы можем вытолкнуть очередной адрес, а затем прочитать содержимое
ячейки по этому адресу. Затем оно может быть изменено двумя путями:
уменьшением счетчика ссылок этой ячейки, если его текущее значение боль-
ше 1, или заменой содержимого ячейки на новое, если этот счетчик равен
нулю (поля указателей также должны быть помещены в стек декремента-
ции). После этого измененная ячейка переносится на старое место, и весь
процесс занимает один цикл чтения/изменения/записи.
16.5. а. Создайте косвенную ячейку (ячейку-синоним), которая содержит
единственный указатель на требуемую ячейку с весом, равным 1.
б. Если исходное значение счетчика ссылок равно 2" для некоторого п,
то вес в каждом указателе требует лишь log2 п бит памяти для хранения.
Дублирование указателей соответствует уменьшению веса на 1 и помещению
этого веса в оба указателя. Ячейка должна иметь поле счетчика ссылок дли-
ной в п бит; если ячейка с нормированным весом, равным к, будет удалена,
ТО счетчик ссылок должен быть уменьшен на 2к.
Решение некоторых упражнений 617
б. Пусть wP— вес указателя р, а гс — счетчик ссылок ячейки с. По
завершении переписывания счетчики и веса будут выглядеть следующим
образом:
WP : = wp ; wp := wr — (wr div 2 ) ; wr : = wr div 2 ; DEC ( B, WP )
где DEC(c, n) уменьшает содержимое счетчика ссылок ячейки с на п и,
возможно, подвергает ячейку с обработке как мусорную. Это можно оптими-
зировать, непосредственно рассмотрев счетчик ссылок В:
гв := гв — wp;
if гв = 0 then В не является разделяемой и поэтому должна быть возвра-
щена в свободный список
wp : = wr;
DEC (С, wq)
else В является разделяемой
wp : = wr — ( wr di v 2 ) ;
wr := wrdiv 2 ;
Глава 17
17.1.-------g( t) < = ( sum( t), count( t) ) ;
-------g( tip( n ) ) <= ( sum( tip(n ) ), count( tip(n ) ) ) ;
<= (n, 1 )
-------g( node( tl, t2 ) ) < = ( sum( node( tl, t2 ) ),
count( node( tl, t2 ) ) ) ;
< = ( sum (tl ) + sum( t2 ),
count( tl ) + count( t2 ) ) ;
< ' = (u + x, v + y) where ( u, v, x, y) = =
( sum( tl ), count( tl ), sum( t2 ),
count( t2 ) )
< = (u + x, v + y)
where( (u, v),(x, y) ) = =
(g( tl ), g(t2) ) ;
-------treeaverage (t) < = u div v where ( u, v ) = =
( sum( t), count (t) ) ;
< = u div v where (u, v ) = = g (t) ;
17.3. (Далее названия шагов преобразования будут опущены.)
— -----listo( п ) < = g( n, nil ) ;
-------g( n, 1 ) < = append( listo( n ), 1 ) ;
-------g( 0, 1) <" append( listo( 0 ), I ) <' = append( nil, 1) <" = 1
------g( n + 1, 1)<= append( listo( n + 1, 1 )
< = append( append( listo( n ), ( n + 1 ) :: nil ), 1)
(так как append — ассоциативная функция)
< = append( listo( п ), ( п + 1 ) :: append( nil, 1))
< = append( listo( n ), (n + 1 ) :: 1 )
< = g(n, (n + 1 ) :: 1 ) ;
17.4.-------g( 0 ) <; = z st (length( z ) = 0, forall ( z, isone ) )
< = nil ; (объединим с первыми уравнениями, описываю-
щими функции length и forall)
-------g( n + 1) < = z st ( length z ) = n 4- 1, forall ( z. isone ) ;
< = x :: z' st (length( x :: z' ) = n + 1, forall ( x :: z',
izone)) (z не может быть nil, поэтому объеди-
ним с другими уравнениями)
< = х :: z' st ( 1 + length( г') = n + 1, isone( x ),
forall(z', isone)) (раскрутка)
< = 1 :: z' st (length( z') = n, forall ( z', isone ) )
(isone ( x ) iff x = 1)
<=l::g(n) (скрутка)
618 Решение некоторых упражнений
Глава 18
18.1. Первая часть очевидна — как в гл. 18. X ° а = X по определению X,
а о X = X, если а строгая, [, X, ...]= X, если последовательность являет-
ся строгой. Следовательно, функционалы, определяемые через композицию и
конструирование, должны всегда быть строгими.
18.2. б. Щ а-гЬ ; с )
= Р(а->6 ; с) ->А(а^6 ; с); В(а-^Ь;с)
= (Р,а->РЬ; Рс)-^ (А,а->А1>; Ас) (Вщ-э-ВЬ; Вс)
= Р,а->(Рй->Ай ; ВЬ ) ; (Рс^Ас; Вс )
= Pta^Hb ; Нс
поэтому Hi = Pt в случае, если выполняется последнее условие.
Н X : х X = > Р X : х =/= X = > Pta : х = PVa => Н ta : х — ТУ а.
Остальное аналогично.
18.3. Hta = р-+ Ata\ Bta Если At = В/, то Ht = At, если p : x {T, F} = >
Ata : x = X.
18.4. n = 0 : Haf = /h° [/] = f.n — 1 : истина по определению H.
Шаги индукции:
[h. ° [i, i ° j, ..., i ° jn, f ° /”+1]
= h ° [f, /h ° [i ° j, , i ° f ° /л+1] ]
= h» i, /h ° [i........i ° j"-', f ° /"] ° /]
= h ° [i, Hnf ° j] (по предположению индукции)
= H(H"f)= H“+'f
Если Hf = h ° [f ° j, i], H"f = \h ° [f о jn, i □ jn~i, ..., i° j, t].
18.6. H( a-»- b ; c )= G ( a -* b ; c,a-+b ; c )
= Gta-*- G ( b, a-+ b ; c); G (c, a—>~ b ; c)
= Gta->- ( G2a -> G ( b, b ) ; G ( b, c ) ) ;
(G2a-^G(c, 6) ; G(c, c) )
= Gta -> G ( b, b ) ; G ( с, с ), поэтому Gt = G2
Если ЯХ:х=/=Х, то G(X, X ) : x = X, поэтому Gia:x = 7Va. Таким
образом, H — линейный функционал с предикатным преобразователем G(.
Аналогично если М есть n-мультилинейный функционал, а Mt = ... Мп, то
M(f,'...,f) будет линейна относительно f с предикатным преобразовате-
лем Mi.
18.8. Поскольку fib ° sub 1 = le 1 1 ; fib ° sub 1,
g = le 1 [ 1, 1 ] ; [-f- ° [fib, fib о sub 1 ] ° sub 1, fib ° sub 1 ]
— lei->- [1, 1] ; [+ ° g° sub I, l«g»s«61]
Таким образом, g = le 1 [1, 1] ; Hg, где Hg = [+, 1] ° g ° sub 1. Реализа-
ция цикла описана в гл 18.
18.9. h = eg 0 [ [1], 1] ; [cons ° [2 ° ft, 1 ° ft ° sub I], * ° [id, 2 ° h° sub 1]]
ft' = e<?l-^[[i],"i] ; Hh'
где ~
Hv = [cons ° [2 ° v ° sub 1, 1 ° v ° sub 1], » ° [id, 2 ° v ° sub 1]]
для переменной v. Таким образом, H является линейным функционалом (так
как он вырожденный мультилинейный функционал с равными предикатными
преобразователями, см. упр. 18.6) с Hta =А= а ° sub 1.
18.10. а. listo( х ) = listo-tr( х, id ), где
listo-tr( х, у ) = if х = 0
then у ( nil)
else listo-tr ( x— 1, Xw.y( w ( ) ( x :: nil) ) )
Как и в примере обращения в гл. 18, запишем продолжение с помощью спи-
сков и получим
listo ( х ) = listo* ( х, nil)
listo* (x, k ) = if x = 0
then k
else listo*(x—1, x::k)
Решение некоторых упражнений 619
б. fac( х ) = fac-tr( х, id )
fac-tr (х, у ) = if х = О
then у( 1 )
else fac-tr(x—1, Xw.\(w»x ) )
На этот раз мы выразим продолжение через мультипликативный аккуму-
лятор а : у = A.v.v*a Поэтому, поскольку /.ы’у(ю*х) = Kw. (w»x)*a =
Kw.w*(x*a). согласно ассоциативности *, мы получим
fac( х ) = fac* ( х, 1 )
fac* ( х, a ) = if x = 0
then a
else fac* ( x — 1, x*a )
Глава 19
19.1 . zip( ab, abc ) = zip( a :: b :: ab, a :: b :: c :: abc )->
[a, a] :: zip( b :: ab, b :: c :: abc ) ->...
->[a, a] :: [b, b] :: [a, c] :: [b, a]
: [a, b]:: [b, c] :: zip( ab, abc )
после шести редукций. Аргументы вызова zip теперь идентичны исходным
аргументам, и поэтому при следующей редукции происходит просмотр мемо-
таблицьг. Это приводит к появлению циклической структуры вида
z = [а, а] :: [Ь, Ь] :: [а, с] :: [Ь, а]:: [а, Ь]:: [b, с]:: z
Для zip( ab, ab ) мы аналогично получаем
z = [а, а] :: [b, b] :: z.
19.2 . comb=le5—>g ; (*) ° [addon ° [5, comb ° sub 5],
(*) ° [addon ° [3, comb ° sub 3],
addon ° [2, comb ° sub 2]]]
(Здесь мы используем префиксную форму (*) .)
Это вырожденный 3-мультилинейный функционал с совместимыми предикат-
ными преобразователями М], М2, М3, определяемыми равенствами Мщ =
а ° sub 5, М2а = а ° sub 3, М3а = а ° sub 2, так что наименьшая общая сумма
будет 5, a LCC = sub 5. Следовательно, регулировщиком таблиц будет
lambda х = >[х — 5], а мемо-таблица никогда не будет содержать более
5 элементов.
19.4. Mia = а ° [s ° 1, s ° 2], ЛДа = а ° [s ° 1, 2], где s = sub 1. Поэтому
MiM2a = а ° [s ° s ° 1, s»2] = M2MiaVa
Следовательно, MiM2 = M2Mi. Для данного g и если b° с = с° b, предикат-
ные преобразователи заменяются аналогично, и если не существует общего
генератора, то граф вызова аргумента выглядит так:
Следовательно, внутренние вершины встречаются дважды, а боковые — толь-
ко один раз. Отсюда следует стратегия удаления, согласно которой элемент
таблицы удаляется после того, как он встретится в первый раз.
620 Решение некоторых упражнений
Глава 20
20.1. а А является набором неотрицательных целых чисел, и если число х
состоит из d цифр, то его абстрактное значение в А будет (d—1 ). Аб-
страктной областью определения является 2Л, а хч — { d— 1}
б. X + *У = U {т + 1, т, т — 1 | т — тах( х, у )}
х<=Х
у^у
b.X*#Y = U {х + у, х + у + 1}
х <= X
У е= Г
г. ( —9 * 100 ) + 99 => ( {0} * #{2}) + #{1} =
= {2, 3} + * {1} = {3, 2, 1, 4, 3, 2} =
= {1, 2, 3, 4}
20.3. a [#(Х, У, Z) = (XA Y)A(true\J( (Y/\f#(X, У, Z) )Д
(У V(ZAf*(*. Y, X) ) ) ) )
(пропуская некоторые шаги) Следовательно f*(X, У, Z) = X Д У, поэтому
f является строгой относительно первых двух аргументов
б f#(X, Y, Z) = (XAY)A(ZV ((YAf#(X, У, Z) )Л
(У V (ZA #(Х, У, Z) ) ) ))
Пусть f * (X, У, Z)=0 для всех X, У, Z (где 0 обозначает величину
false) Подставим это в правую часть, получим f* = (ХДУ)Д(г\/0) =
X Л У Л X Повторение этого даст f* = X A Y А X, а в пределе получим
f# = X AY А X, поэтому f является строгой по всем своим аргументам.
Литература
I Abramsky, S, (1985) ‘Strictness analysis and polymorphic invariance’ In
Programs as data objects LNCS HI Springer Verlag
2 Abramsky, S , Hankin, C L (eds ), (1987) Abstract interpretation of declarative
languages Ellis Horwood
3 Aho, A V , Hopcroft, J E , Ullman, J D . (1983) Data structures and algorithms.
Addison-Wesley
4 Arvind, Kathail, V , Pingall, К , (1980) ‘A dataflow architecture with tagged
tokens’ Proc International Conference on Circuits and Computers
5 Augustsson, L , (1984) ‘A compiler for lazy ML’ In Proc ACM Symposium on
Lisp and Functional Programming, Austin, 218-27
6 Augustsson, L, (1985) ‘Compiling pattern matching’ In Proc Conference on
Functional Programming Languages and Computer Architecture, Nancy,
368-81 LNCS 201 Springer Verlag
7 Backus, J W , (1978) ‘Can programming be liberated from the von Neumann
style9 A functional style and its algebra of programs’, Communications of the
ACM, 21, 613-41
8 Backus, JW, (1981) ‘The algebra of functional programs function-level
reasoning, linear equations and extended definitions’ LNCS 107, 1-43.
Springer Verlag
9 Backus, JW, Williams, JH, Wimmers, EL (1987) FL language manual
(preliminary version) IBM research report number RJ 5339 (54809)
10 Bailey, R , (1985) FP/M abstract syntax description Internal report, Department
of Computing, Imperial College, University of London
11 Bailey, R, (1987) ‘Functional programming using abstract data types’ In S
Etsenbach (ed ) Functional programming languages tools and architectures
57-68 Ellis Horwood
12 Baker, H , (1978) ‘List processing in real time on a serial computer’ Communi-
cations of the ACM, 21(4), 280-94
622 Литература
13. Barendregt Н.Р., (1984). the lambda calculus - its syntax and semantics. North)
Holland !
14. Bellegarde, F., (1984). ‘Rewriting systems on FP expressions that reduce the
number of sequences they yield’. In Proc. Conference on LISP and Functional
Programming, 63-73. (Also in Science of Computer Programming, 6(1),
11-34, January 1986.)
15. Bevan, D.I., (1985). Distributed garbage collection using reference counting.
Research report, GEC Research Ltd; Hirst Research Centre, and also in
PARLE 1987
16. Burge, W.H., (1978). Recursive programming techniques. Addison-Wesley
. 17. Bum,' G., Hankin, C.L., Abramsky, S., (1985). The theory and practice of
strictness analysis of higher-order functions. Internal report no. DoC 85/6,
Department of Computing, Imperial College, University of London
18. Burstall, R.M., Darlington, J., (1977). ‘A transformation system for developing
recursive programs’. JACM, 24(1), 44-67
19. Burstall, R,M., MacQueen, D.B., Sanella, D.T., (1980). Hope: an experimental
applicative language. CSR-62-80, Department of Computer Science, Univer-
sity of Edinburgh
20. Cardelli, L., (1984). ‘Basic polymorphic type checking’. Science of Computer
Programming, 8(2), 147-72, April 1987
21. Church, A., (1941). The calculi of lambda conversion. Princeton University Press
22. Clack, C.D. and Peyton Jones, S.L., (1986). ‘The four-stroke reduction engine’.
Proc, of the ACM Conference on LISP and Functional Programming, Boston,
220-32
23. Colmerauer, A., Kanoui, H., Pasero, R., Roussel, P. (1973), Un systeme de
communication homme-machine en Frqncais. Rapport, groupe intelligence
artificielle, Universite d’Aix Merseille, Luminy
24. Cousineau, G., Curien, P-L., Mauny, M., (1985). ‘The categorical abstract
machine’. In Proc. Conference on Functional Programming and Computer
Architecture, Nancy, 50-64, LNCS 201. Springer Verlag. (Also in Science of
Computer Programming, 8(2) 173-202, April 1987.)
25. Curien, P-L., (1986). Categorical combinators, sequential algorithms and func-
tional programming. Pitman/Wiley
26. Curry, H.B., Feys, R., (1958). Combinatory logic. Vol. 1. North Holland
27. Darlington, J., Cripps, M.D., Field, A.J., Harrison, P.G., Reeve, M.J., (1987).
‘The design and implementation of ALICE: a parallel graph reduction
machine’. To appear in IEEE Press edition on Dataflow and reduction
architectures, ed. by S. Thakkar
28. Davies, I.L., PhD Report 1 (for R. Bailey). Research proposal, April 1985.
Department of Computing, Imperial College, University of London
Литература 623
29. De Bruijn, N.G., (1972). ‘Lambda calculus notation with nameless dummies’.
\ Indagationes Mathematicae. 34, 381-92
3(X Dennis, J.B.,( 1980).‘Data flow supercomputers’. IEEE Computer, 13(11), 48-56
31 Dijkstra, E.J.W., (1976). A discipline of programming. Prentice-Hall
32. Fairbairn, J. (1982). The design and implementation of a simple untyped language
based on the lambda calculus. PhD thesis, University of Cambridge
33. Field, A.J., Hunt, L.S., While, R.L., (1988). Best-fit pattern matching for
functional languages, Internal report, Department of Computing, Imperial
College
34. Glaser, H., Hayes, S., (1986). ‘Another implementation technique for applicative
languages’. Proc. European Symposium on s Programming, Saarbrucken,
70-81. LNCS 213. Springer Verlag
35. Glaser, H.W., Thompson, P., (1985). ‘Lazy garbage collection’. Software -
Practice and Experience, 17( 1), 1-4
36. Gordon M.J., Milner, A.J., Wadsworth, C.P., (1979). ‘Edinburgh LCF’. LCNS
78. Springer Verlag
37. Harrison, P.G., (1985). Linearisation: An optimisation for non-linear functional
programs. Research report, Department of Computing, Imperial College.
(Also to appear in Science of Computer Programming, 1988).
38. Harrison, P.G., (1988). ‘Functional inversion.’ Proc. Workshop on Partial
Evaluation and Mixed Computation, Denmark, 1987, North-Holland
39. Harrison, P.G., Khoshnevisan, H., (1986). ‘Efficient compilation of linear
functions into object-level loops’. SIGPLAN '86 Symposium on Compiler
Construction, Palo Alto
40. Harrison, P.G., Khoshnevisan, H., (1988). On the synthesis of function inverses.
Research report, Department of Computing, Imperial College, University of
London
41. Henderson, P.,(1982). ‘Purely functional operating systems’. In J. Darlington, P.
Henderson & D. Turner (eds.), Eunctiona! programming and its applications,
177-92. Cambridge University Press.
42. Henderson, P., Jones, G.A., Jones, S.B. (1983). The LispKit manual, Vol. 1.
Technical monograph PRG-32(1), Oxford University Computer Laboratory,
Programming Research Group
43. Hindley, J.R., Seldin, J.P., (1986). Introduction to combinators and X-calculus.
Cambridge University Press
44. Hudak, P., (1985). Para-functional programming - a paradigm for programming
multiprocessor systems. Internal report no. YALEU/DCS/RR-390. Depart-
ment of Computer Science, Y ale University (Also in IEEE Computer, 60-70,
August 1986)
624 Литература
45. Hudak, Р., Goldberg, В., (1985). ‘Serial combinators: optimal grains of paral-
lelism’. Proc. Conference on Functional Programming and Computer Archi-.
tecture, Nancy, 382-99, LNCS 201. Springer Verlag
46. Hughes, R.J.M., (1984). The design and implementation of programming
languages. PhD thesis, University of Oxford
47. Hughes, R.J.M., (1985a). ‘A distributed garbage collection algorithm’. Proc.
Conference on Functional Programming and Computer Architecture, Nancy,
256-72, LNCS 201. Springer Verlag
48- Hughes, R.J.M., (1985b). ‘Lazy memo functions’. In Proc. Conference on
Functional Programming and Computer Architecture, Nancy, 129-46, LNCS
201. Springer Verlag
49- Hunt, L.S., (1986). A Hope to FLIC translator with strictness analysis. MSc
dissertation, Department of Computing, Imperial College, University of
London
50. IEEE Computer, (1982). Special edition on Data Flow Systems, 15(2), February
1982
51. Johnsson. T., (1984). ‘Efficient compilation of lazy evaluation’. In Proc. ACM
Conference on Compiler Construction, Montreal, 58-69
52. Johnsson, T., (1985). ‘Lambda lifting: transforming programs to recursive
equations’. In Proc. Conference on Functional Programming Languages and
Computer Architecture, Nancy, 190-203
53. Kahn, G., MacQueen, D.B., Plotkin, G. (eds.), (1984). ‘Semantics of Data Types’.
Proc. International Symposium, Sophia-Antipolis, LNCS 173, Springer
Verlag
54. Keller, R.M., (1985). Rediflow architecture prospectus. Internal report no. UUCS-
85-105, Department of Computer Science, University of Utah
55. Kelly, P.H.J. (1987). Functional languages for loosely-coupled multiprocessors.
PhD thesis, Imperial College, University of London
56. Kennaway, J.R., Sleep, M.R.. (1982). Director strings as combinators. Internal
report, Computing Studies Sector, University of East Anglia
57. Kieburtz, R.B., Shultis, J., (1981). ‘Transformations of FP program schemes’. In .
Proc. ACM Conference on Functional Languages and Computer Architecture,
Portsmouth, New Hampshire
58. Kott. L., (1978).‘About a transformation system: a theoretical study'. In Proc. 3rd
Symposium on Programming, Pans
59. Landin, P.J., (1964). ‘The mechanical evaluation of expressions’. Computer
Journal, 6, 308-20
60. Lieberman, H., Hewitt, C., (1983). ‘A real-time garbage collector based on the
lifetime of objects’. Communications of the ACM, 26(6), 419-29
Литература 625
61. Lins, R.D., (1986). ‘A new formula for the execution of categorical combinators’.
In Proc. 8th International Conference on Automated Deduction, LNCS 230,
89-98. Springer Verlag
^2. McCarthy, J., (1960). ‘Recursive functions of symbolic expressions and their
computation by machine’. Communications of the ACM, 3(4), 184-95
6$. McCarthy, J., Abrahams, P.W., Edwards, D.J., Hart, T.P., Levin, M.I. (1962).
LISP 1.5 programmers manual, MIT Press, 1962
б4маипу, M., Suarez, A., (1986). ‘Implementing functional languages in the
categorical abstract machine’. In Proc. Conference on Lisp and Functional
Programming
65. Michie, D., (1968). ‘“Memo” functions and machine learning’, Nature, 218,
19-22
66. Milner, R., (1978). ‘A theory of type polymorphism in programming’. Journal of
Computer and System Science, 17, 348-75
67. Minsky, M.L., (1967). Computation: finite and infinite machines. Prentice-Hall
68. Morris, F.L., (1978). ‘A time-and space-efficient garbage compaction algorithm’,
Communications of the ACM, 21(8), 662-5
69. Mycroft, A. (1981). Abstract interpretation and optimizing transformations for
applicative programs. PhD thesis, Department of Computer Science, Univer-
sity of Edinburgh
70. Perry, N., (1987). Hope+. Internal research report ref. IC/FPR/LANG/2.5.1/7,
Functional Programming Section, Department of Computing, Imperial
College, University of London
71. Peyton Jones, S.L., Clack, C.D., Salkild, J., (1985). GRIP - a parallel graph
reduction machine. Internal report, Department of Computer Science,
University College, London
72. Plotkin, G.D., (1975). ‘Call-by-name, call-by-value and the lambda calculus’.
Theoretical Computer Science, 1, 125-59
73. Robinson, J.A., (1965). ‘A machine-oriented logic based on the resolution
principle’. Journal of the ACM, 12(1), 23-41
74. Spitzen, J.M., Levitt, K.N., (1978). ‘An example of hierarchical design and
proof’. Communications of the ACM, 21(12), 1064-75
75. Stoy, J.E., (1977). Denotational semantics: the Scott-Strachey approach to
programming language theory. MIT Press
76. Stoye, W.R., (1985). The implementation of functional languages using custom
hardware. PhD thesis, University of Cambridge
77 Stoye, W.R., Clarke, T.J.W., Norman, A.C., (1984). ‘Some practical methods for
rapid combinator reduction’. Proc. ACM Symposium on Lisp and Functional
Programming, Austin, 159-66
40
1473
626 Литература
78. Thomas, R E , (1981). A dataflow computer with improved asymptotic perfor-
mance. MIT Laboratory for Computer Science report MIT/LCS/TR-265
Turner, D.A., (1976). The SASL language manual. University of St Andrews
80. Turner. D A , (1979). ‘A new implementation technique for applicative langua/
ges’. Software - Practice and Experience, 9, 31 -49
81. Turner, D A., (1981). Aspects oj the implementation of programming language^.
PhD thesis, University of Oxford
82. Turner, D A , (1982). ‘Recursion equations as a programming language’. In J.
Darlington, P. Henderson & D. Turner (eds.), Functional programming and
its applications, 1-28, Cambridge University Press
83. Turner, D.A., (1985).‘Miranda - a non-stnct functional language with polymor-
phic types’. In Proc. Conference on Functional Programming Languages and
Computer Architecture, Nancy, 1-16., LCNS 201, Springer Verlag
84. Wadler, P., (1985) An introduction to Orwell. Programming Research Group,
University of Oxford
85. Wadler. P., (1987). ‘Efficient compilation of pattern matching’. In S Peyton
Jones (ed.) The implementation of functional programming languages
(Chapter 5), 78-103 Prentice Hall
86. Wadsworth, C.P., (1981). Semantics and pragmatics of the lambda calculus. PhD
thesis,,University of Oxford (Chapter 4)
87 Wand, M., (1980). ‘Continuation-based program transformation strategies’,
J ACM 27(1), 164-80
88. Watson, I. Gurd, J, (1979). ‘A prototype data flow computer with token
labelling’, Af-IPS Conference Proceedings, 48. 1979 National Computer
Conference
89 Watson, P , Watson, I., Woods, V.,(1986). A model of computation for the parallel
evaluation of functional languages based on a canonical representation of
variables. Internal report No. PMP/MU/PW/000001, Department of Com-
puter Science, University of Manchester
90. Williams, J.H., (1982). ‘On the development of the algebra of functional
programs’. ACM Transactions on Programming Languages and Systems, 4,4
Предметный указатель
Абстрагирование 305
от переменных 504
при лямбда-поднятии 326
Абстрактная
интерпретация 473
анализ строгости 565
доказательство надежности 572
полнота 573
правило знаков 562
машина 387
Абстрактное синтаксическое дерево
181
Абстрактный
домен 562, 566
тип данных 474
Авторекурсивная функция 42
Аксиомы 161
Активная ячейка 440
Алфавитная эквивалентность 125, 133
Анализ сложности 577
Анализ функционального уровня 477,
503
Аннотация 472, 474, 561
Аппликативное выражение 292
Аппликативный язык программирова-
ния 9
Аппроксимация Ньютона — Рафсона
76
Аргумент 14
Ассоциативность (функции Join) 25
Базовый тип 154
Бесконечная структура 74
Бета-
абстракция 135
редукция 125
40*
Ведущий адрес 446
Вершина 46
копирования 364
применения в потоковом графе 366
в редуцируемом графе 258
примитивной функции в ПГ 365
синоним 274
Взаимная рекурсия 142, 174
Взаимно рекурсивные функции
проверка типов 174
Взаимодействие ведущего и возвра-
щающего указателей 459
Взвешенный счетчик ссылок 467
Вид рекурсии 27
Встроенная (примитивная) функция
16
Входные инструкции 375
Вызов
по значению 71
по текстовой замене 139
Вычисление 119, 238
лямбда-выражений 123
основанное на контексте 228
Г-машина 415
генератор кода 422
генерация кода 422
Генерация кода 386
для МФП 403
Гребень графа 263
доступ при редукции графа 277
Дамп с присваиванием 241
Дерево 45
628 Предметный указатель
двоичное 46
сопоставления 187
Декартова категория 345, 346
Дельта-правило 124
Денотационная семантика 593
Динамическое связывание 61
Доказательство 154
Домен
плоский 11
области определения функции И, 586
теория 586
EQ/eq 123
Eval/Apply-интерпретатор 208
Eta-редукция 125
Завершение 72
сопоставления образцов 201
Зависимость по данным 362
Завязывание узлов 81
Заголовочная нормальная форма
(ЗНФ) 136
Задержка 218
Заключение в скобки
аргументов 18
применений 91, 123
Законченный частичный порядок 587
Запоминание
для циклических структур 544
как преобразование исходного тек-
ста 554
Знак вычеркивания 378
1-комбинатор 292
INDEX/index 124
Идентификатор 210
трансляция 183
Изменение на месте 577
Императивный язык 8
Интерпретация 207
идентификаторов 212
let-выражений 213
letrec-выражений 215
абстракций 213
базовых величин 211'
применений 211, 224, 225
примитивных функций 212
Инфиксная функция/оператор 22, 29
Истинностная величина 26
К-комбинатор 292
Каноническое лямбда-исчисление 149
Карринг 91, 123
в декартовой замкнутой категории
347
Категорийная
абстрактная машина (КАМ) 149
комбинаторная логика (ККЛ) 326
Категорийный комбинатор 346
Категория 344
Квалификатор 31
Квалифицированное выражение 31,
212
трансляция 194
Квалифицирующее выражение 31
Код сопоставления 187
Кодомен 12, 346
Комбинатор 291
В 296
В' 306
С 296
С' 306
I 292
К 292
S 292
S' 305
U 306
W 322
Y 141, 144, 239
Y' 240
категорийный 346
создаваемый лямбда-удалением 327
Комбинаторная логика 292
Комбинирующая форма 107
Компиляция 386
G-машины 423
МФП-схемы 405
Композитор 297
Композиция 14, 108, 345
функционалов 510
Константа 108, 392
данных 34
Константная аппликативная форма
(КАФ) 325
Конструктор
данных 34
хэширования 548
Конструкция 108
Контекст 138
Копирование
лямбда-тел 126, 267
потоковых конструкций 376
Кортеж 23, 143
вершины графа представления 261
проверка типов 172
трансляция 185
Кортежирование 142
Куча 399, 438
Предметный указатель 629
LAMBDA 57, 91, 99
абстракция 212
вершина 260
исчисление 118, 121
исчисление Де-Брейна 149
чистое 145
связанная переменная 156
удаление 327, 363, 390
общее 341
LETREC 417
LET-связанная переменная 155
letrec/whererec 58
Ленивое вычисление 71, 130, 141
Ленивый
гребень графа 263
конструктор 85, 140
сборщик мусора 465
Линеаризация 525
функции 525, 534
Лисп 95
атом 95
IF 98
LAMBDA 99
LETREC 98
лист 95
QUOTE 98
Литерал в образцах 41, 200
трансляция 184
Локальный контекст 392
Miranda 89
where 92
абстракция списков 94
арифметическая последовательность
91
включение списков 94
переменная типа 95
список 91
МФП
архитектура абстрактной машины
396
генератор кода 402
индексные карты 406
ленивая версия 414
оптимизация авторекурсии 413
система 389
структура ядра 413
форматы кучи 400
Макроинструкции G-машины 419
Максимальная циклическая структу-
ра 464
Максимальное свободное выражение
332
Мемо
таблица 476, 540
автоматическая генерация 552
контроль размера 549—557
локальная 549
просмотр аргументов 542
сборка мусора 557
функция 476, 505
ленивая 544—549
полная 543, 547
Метациклический интерпретатор 226
Механизм вызова 138
Минимальное свободное выражение
332
Мономорфный тип 156
Монотип 155
Мусор 266
Мусорная ячейка 441
NIL/nil 125
NULL/null 125
Набор допущений 161
инструкций языка SIMPLE 403
Наивысший общий генератор 552
Наименьшая фиксированная точка
141
Накапливание параметров 40
Накапливающий параметр 39
Направленный ациклический граф
(НАГ) 258
Направленный граф 53, 257
Невидимый указатель 446
Неопределенная функция 13
Неперекрывающиеся образцы 186, 195
трансляция 186
Неродовые переменные типа 191
Несогласованная пара 165
Номер уровня 336
Нормальная форма 122, 128
единственность 133
Нормальный порядок рекурсии
(НПР) 129, 140
Ню-абстракция 173
Область
определения функции 11
значений функции 11
Образец 38
в лямбда-выражениях 58
Общее лямбда-удаление 341
Одношаговая редукция 131
Операционная семантика 119, 226
630 Предметный указатель
Операция формирования программы
107
Оптимизирующий компилятор 473
Организация памяти 441
Отношение 528
PRED/pred 125
PROLOG 88
Параллельная
машина 287, 382, 474, 475
редукция графов 287
Параллельный сборщик мусора 443
Параметр 13
Перекрывающиеся образцы 38
Переменная
свободная 132
связанная 132
лямбда-связанная 159
Перестановщик 297
Побочная вершина 274
Побочные эффекты 17
Поверхностный тип 17
Подпространство 445
Подстановка 132
Подсчет скобок 332
Подчеркивание (__) в образцах 41,
187, 193
Подъем по гребню графа 279
Полиморфный тип' 35, 38
Политип 154
Полная
ленивость 287, 327, 332, 333
функция 13
Полнота 575
Помеченное выражение 238
Порядок
вычислений 71
редукций 128
Поток 359
управляемый данными 360
управляемый запросами 377
Потоковый граф (ПГ) 360
Правила
знаков 563
переписывания 38
преобразования при редукции гра-
фов 370
редукции комбинаторов 293
Правильно
обоснованная индукция 12
определенная функция 12
типизированное выражение 164
Правильный тип 164
Предикатный преобразователь 511
Предыстория вычислений 17
Преобразование 473
алгебраическое 502
мета-язык 480, 489, 531
методология 479
передачей продолжений 531
программы 473
раскрутка/скрутка 481
дополнительные правила 483, 493,
495, 499
основные правила 482
частичная корректность 486
типов данных 490
тактика 485, 531
Префиксная
нотация 29
функция 22
Применение 14, 210, 346, 393
в декартовой замкнутой категории
347
Применить ко всем 108
Примитивная функция 22, 210
Примитивы 14
Приоритет операторов 30
Присваивание 18
Проблема свободных переменных в
редукции графов 284
Проверка вхожденья Ю6
Продолжение 530
Проектор 274
Проекция 346
Прозрачность по ссылкам 17
Произведение 345
Промежуточный
код 181, 208
FC-код 391
Процесс пользователя 442
Разделение 138
в интерпретаторе 224
в редукции графов 258, 260
предложения на лексемы 42
Разделяемая совокупность потоковых
инструкций 377
Размер структурного элемента 316
Разрушающее присваивание 18, 244
Реализация
линейной функции с помощью цик-
лов 516, 539
основанная на контексте 117
Реверсирование указателя 278
Редекс 127, 263
самый внешний 129
самый внутренний 129
Предметный указатель 631
самый левый 129
самый правый 129
Редукция 125
аппликативного порядка 129, 140
Д-126 (бета-)
графов 138, 256, 288
комбинаторных выражений 300
параллельная 287
при применении примитивной функ-
ции 270
6-125 (дельта-)
т)-136 (ню-)
строк 137
Результат/квалификатор 31
Рекуррентное соотношение 28
Рекурсивное iet/where 213
Рекурсия 27
в лямбда-исчислении 141
в SECD-машине 239
в редукции графов 307
Рефлексивное транзитивное замыка-
ние 130
Рецепт 218
Решение проблемы перекрывающихся
образцов 195, 203
Решето Эратосфена 76
Родовой тип 35
переменная 159
Ромбическое свойство 130
Самоприменение 176
Самый левый из самых внутренних/
самых внешних 129, 140
Сборка мусора 437
по алгоритму Бейкера 449
Морриса 456
с подсчетом ссылок 226
Сборщик мусора 266
копирующий 444
реального времени 443
сканирующий 442
Свободная
переменная 132
ячейка 439
Свободное выражение 331
Свободный список 439
Связанная переменная 132
Связанное вхождение 132
Связывание 33, 62, 103
Связывающий код 187
генерация 193
SECD-машина 230
взаимосвязь с КАМ 348, 353
доказательство корректности реали-
зации 247
ленивая 240
обработка условных выражений 238
семантика 248
состояние машины 231
управляемая данными 229
управляемая запросами 229
функция переходов 233
энергичная 231
Семантика 593
аксиоматическая 593
денотационная 593
лямбда-исчисления 594
операционная 593
SECD-машины 248
функционального языка
Семантическая функция 573
Семантический домен 594
Сети процессов 80
Символьное S-выражение 96
Синтаксический разбор 181
Сканирующая сборка мусора 443
Слабая
заголовочная нормальная форма
(СЗНФ) 135
категориальная комбинаторная логи-
ка (СККЛ) 351
Слабое ромбическое свойство 133
Слияние деревьев сопоставления 199
Слово состояния 441
Совмещение 126, 165, 266
Сопоставление с образцом 3, 601
семантика 601
трансляция 186
Составные данные 35
вершина графа 261
Сохранение аппликативного выраже-
ния 298
Специализация образцов 196
Список 34
источников 378
Спуск по гребню графа 263
Статическое связывание 61
Стек 231. 278, 374, 398
дампа SECD-машины 230
Строгая типизация 19, 90
Строгость 72
анализ 565
Строка направляющих 317
Структурная индукция 46
Структурный элемент 316
Сумма
объединенная 591
разъединенная 590
Суперкомбинатор 287, 326, 331
улучшенный 341, 344
Суръективное спаривание 347
632 Предметный указатель
Суръективный карринг 348
Счетчик ссылок 464
TL/tl 125
TRUE/true 125
TUPLE-n/tuple-n 125
Treesort 41, 67
Таблица входов 454
Тело
лямбда-абстракции 123
функции 22
Теорема
Черча — Рассера 130
о линейном расширении 505, 512—513
стандартизации 130
эквивалентности 249
композиции функционалов 513
Тип 21, 155
высший
данных, определяемых пользователем
33, 95
неповерхностный 161
поверхностный 161
полиморфный 35
Типа
вывод 160
неродовая переменная 159
переменная 36, 155
проверка 154
родовая переменная 159
свободная переменная 161
связанная квантором переменная 161
Типизированное лямбда-исчисление
576
Трансляция применения 185
Улучшенный суперкомбинатор 341,
344
Уплотняющий сборщик мусора 445
Упорядоченное двоичное дерево 42
Управляющий стек (в SECD-маши-
не) 232
Уравнение 38
Условное выражение 108, 393
Условный оператор 23
в SECD-машине 238
интерпретация 218
трансляция 185
F-код 389
FALSE/false 125
FP 103
алгебра 503, 507
FUNARG 214
Фактический параметр 13
Фиксированная точка 141
наименьшая 141
комбинатор 142, 292
Форма функционала 510
Формальный параметр 13, 123, 126
Форсированная скрутка 485
Форсированное вычисление 222
Фрейм стека 278
Функционал 343, 509
билинейный 526
линейный 512
мультилинейный 526
простой линейный 526
теорема композиции 513
Функциональная
алгебра 477
форма 107
экстенсиальность 133
Функциональное пространство 346
Функциональный язык 9
Функциональность 17
Функция 12
Apply 209, 216
Eval 209, 211
abs 294
авторекурсивная 39, 412, 516
высшего порядка 55, 92, 102, 128
детерминированная 12
инъекции 598
итерационная 516
конструирующая 34
линейная 474, 503, 510—525
первого порядка 55
проекции 273
удаления lift 328
Норе 19
if . . . then ... else 23
char 26
data 35
dec 21
infix 30
lambda 57, 123
let/where 32
list 36
map 57
num 21
reduce 60
truval 26
type 37
typevar 36
выражение типа 21
конкатенация списков 38
кортеж 23
объявление типа 21
приоритет оператора 30
Предметный указатель 633
Числовое S-выражение 96, 391
Чистое лямбда-исчисление 145
Циклическая структура данных 78
Циклический граф 268
Частичная функция 13
Частичное применение 92, 327
Эвристические шаги 485
Эквивалентность образцов 40, 183,
189
Экспоненциал 346
Экстенсиональность 136, 297
Энергичное вычисление 71, 130, 140
СОДЕРЖАНИЕ
Предисловие редактора перевода ...................................... 5
Предисловие .................................................. . 6
Часть I. Программирование с помощью функций........................ 8
Введение .......................................................... 8
Глава 1. Введение в функции.................................... 11
1.1. Чистые функции......................................11
1.2. Функциональность....................................17
Резюме.................................................. 19
Глава 2. Введение в функциональное программирование. Язык Норе 20
2.1. Введение понятия функции............................20
2.2. Кортежи . 23
2.3. Рекурсивные функции . 27
2.4. Объявляемые инфиксные операторы.....................29
2.5. Квалифицированные выражения.........................30
2.6. Типы данных, определяемые пользователем.............33
2.7. Доказательства по индукции..........................49
Резю ме . 52
Упра жнения . 52
Глава 3. Функции высшего порядка ........................... 55
3.1. Примеры рекурсии . 56
3.2. Связывание .... 61
3.3. Другие примеры рекурсии.............................61
3.4. Пример применения...................................64
Резюме...................................................69
Упражнения...............................................69
Глава 4. Виды вычислений...................................... 71
4.1. Понятие строгости...................................72
4.2. Обработка «бесконечных» структур данных.............74
4.3. Сети процессов......................................79
4.4. Вычисление с «неизвестным»..........................83
Резюме............................................... . 85
Упражнения...............................................86
Глава 5. Другие стили функционального программирования..........88
5.1. Miranda.............................................89
Содержание 635
5.2. Лисп....................................................95
5.3. FP......................................................ЮЗ
Резюме.......................................................115
Упражнения...................................................115
Часть II. Реализация • ..................................1'7
Введение.................................. . .................117
Глава 6. Математические основы: 1-исчисление.................. 120
6.1. Введение и синтаксис...............................121
6.2. Вычисление 1-выражений.............................123
6.3. Порядок редукций и нормальные формы................127
6.4. P-Редукция и проблема конфликта имен...............132
6.5. Обход проблемы конфликта имен......................135
6.6. Эффект разделения..................................137
6.7. Рекурсивные выражения..............................140
6.8. Чистое 1-исчисление................................144
6.9. 1-исчисление де Брейна .......................... 148
Резюме..................................................149
Упражнения..............................................150
Глава 7. Система вывода типов и проверка типов .................153
7.1. Неформальное введение в проверку типов.............154
7.2. Система вывода типов...............................160
7.3. Алгоритм проверки типа 7Г..........................164
7.4. Расширения Ж для практической проверки типов .... 172
7.5. Ограничения W......................................175
Резюме..................................................176
Упражнения..............................................177
Глава 8. Промежуточные формы.................................. 179
8.1. Промежуточный код для функциональных языков .... 180
8.2. Абстрактные синтаксические деревья.................181
8.3. Трансляция языка Норе в промежуточный код..........183
8.4. Трансляция сопоставления с образцом................185
8.5. Поиск наиболее подходящего образца.................195
8.6. Литеральные образцы................................200
8.7. О порядке тестирования........................... 201
Резюме..................................................203
Упражнения..............................................204
Глава 9. Методы интерпретации.....................................206
9.1. Абстрактное представление промежуточного кода . . . 206
9.2. Энергичный интерпретатор...........................208
9.3. Ленивый интерпретатор..............................218
Резюме.................................................225
Упражнения..............................................226
Глава 10. Реализация на основе стеков — SECD-машина...............228
10.1. SECD-машина......................................229
10.2. Ленивая SECD-машина..............................240
636 Содержание
10.3. Корректность реализации SECD-машины.........................245
Резюме............................................................253
Упражнения........................................................253
Глава 11. Введение в редукцию графов...................................... 256
11.1. Представление лямбда-выражений в виде графов . . . 257
11.2. Правила редукции графов ....................................262
11.3. Интерпретаторы, основанные на редукции графов . . . 272
11.4. Проблема свободных переменных...............................285
11.5. Параллельная редукция графов................................287
Резюме . . . .'...................................................288
Упражнения........................................................289
Глава 12. Комбинаторная редукция ......................................... 291
12.1. Основы комбинаторной логики и редукция.............292
12.2. Оптимизация Карри и редукция комбинаторных графов
Тернера ............................................ 296
12.3. Представление рекурсии......................................308
12.4. Строки направляющих.........................................317
Резюме............................................................321
Упражнения........................................................322
Глава 13. Новейшие комбинаторные реализации . . .-.........................325
13.1. Абстрагирование свободных переменных простым /.-удале-
нием .............................................. 326
13.2. Суперкомбинаторы.................................331
13 3. Оптимизация суперкомбинаторных реализаций............334
13.4. Категорийные комбинаторы....................................343
13 5. Модификации КАМ.............................................355
Резюме............................................................357
Упражнения..................................... .......358
Глава 14. Потоковые реализации .......................................... 360
14.1. Функциональный поток данных аппликативного порядка 361
14.2. Функциональный поток данных нормального порядка . . 377
14.3. Сравнение с другими моделями . . . . ..381
Резюме............................................................382
Упражнения .......................................................383
Глава 15. Компиляции функциональных языков .. 385
15 1. Структура компилированной программы.........................386
15.2. МФП-система.................................................389
15.3. G-машина.................................................. 415
Резюме............................................................434
Упражнения........................................................434
Глава 16. Сборка мусора ................................................. 437
16.1. Организация памяти......................................... 438
16.2. Сканирующая сборка мусора...................................442
16.3. Копирующие сборщики мусора..................................444
16.4. Сборщики мусора с подсчетом ссылок..........................463
Резюме............................................................469
Упражнения........................................................470
Содержание 637
Часть III. Оптимизация............................................472
Введение..................................• . . - ............. 472
Глава 17. Преобразование программ и операционный подход .... 478
17.1. Трансформационная методология раскрутки/скрутки . 480
17.2. Управление системой раскрутки/скрутки — метаязык пре-
образований ................................... .... 488
17.3. Преобразование типов данных.......................490
Резюме................................................ 499
Упражнения............................................ 499
Глава 18. Алгебраическое преобразование программ..................502
18.1. Абстрагирование от переменных.....................504
18.2. Аксиомы алгебры FP и уравнения функционального
уровня................................................ 506
18.3. Линейная функция и теорема о линейном расширении . . 510
18.4. Итерационные формы линейных функций . . .... 515
18.5. Другие применения.................................525
18.6. Преобразование передачей продолжений..............530
Резюме............................................... 535
Упражнения............................................ 536
Глава 19. Запоминание 539
19.1. Принципы работы и основные трудности..............540
19.2. Ленивые мемо-функции..............................543
19.3. Управление размером мемо-таблицы..................548
19.4. Сборка мусора для мемо-таблиц.....................556
Резюме..................................................559
Упражнения . . . ................................... . 559
Глава 20. Абстрактная интерпретация...............................561
20.1. Общие принципы....................................561
20.2. Анализ строгости..................................565
20.3. Доказательства надежности.........................572
20.4. Другие применения для оптимизации программ .... 575
Резюме..................................................578
Упражнения..............................................578
Приложение А. Краткое описание языка Норе...................... 580
А.1. БНФ языка Норе ... .......................... . 580
А.2. Предварительно определенные типы и функции .... 583
Приложение Б. Основы теории доменов.............................. 586
Б.1. Введение......................................... 586
Б.2. Законченный частичный порядок и непрерывные функции 587
Б.З. Конструкции на доменах: новые домены из старых . . . 589
Б.4. Наименьшие фиксированные точки.....................591
•
Приложение В. Формальная семантика 593
В.1. Денотационная семантика Л-исчисления..............594
В.2. Денотационная семантика функциональных языков про-
граммирования ...........................................597
638 Содержание
В.З. Конструируемые типы данных........................600
В.4. Сопоставление с образцом..........................601
Решение некоторых упражнений....................................604
Литература..................................................... 621
Предметный указатель .......................................... 625
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги,
ее оформлении, качестве перевода и
другие просим присылать по адресу:
129820, Москва, И-110, ГСП, 1-й Риж-
ский пер., 2, изд-во «Мир».
Научное издание
Антони Филд, Петер Харрисон
ФУНКЦИОНАЛЬНОЕ ПРОГРАММИРОВАНИЕ
Заведующий редакцией Э Н Вадиков
Ведущий редактор Т Н Шестакова
Мл научный редактор В Н Соколова
Художественные редакторы Н М Иванов, О Н Адаскина
Технический редактор И М Кренделева
Корректоры С С Суставова, Н А Гиря
ИВ № 7461
Сдано в набор 21.09.90. Подписано к печати 02.09.91. Формат 60x881/16. Bywaia
кн.-журн. Печать офсетная. Гарнитура латинская. Объем 20,0 бум. л. Усл. печ
л. 39,2. Усл. кр.-отт. 39,2, Уч.-изд. л. 37,22. Изд. № 6/7100. Тираж 6000 экз.
Зак. 1473. С060.
Издательство «Мир» Министерства печати и информации Российской Федерации.
129820, ГСП, Москва, И-110, 1-ый Рижский пер., 2.
Московская типография № 11 Министерства печати и информации Российской
Федерации, 113105, Москва, Нагатинская ул., д. 1.