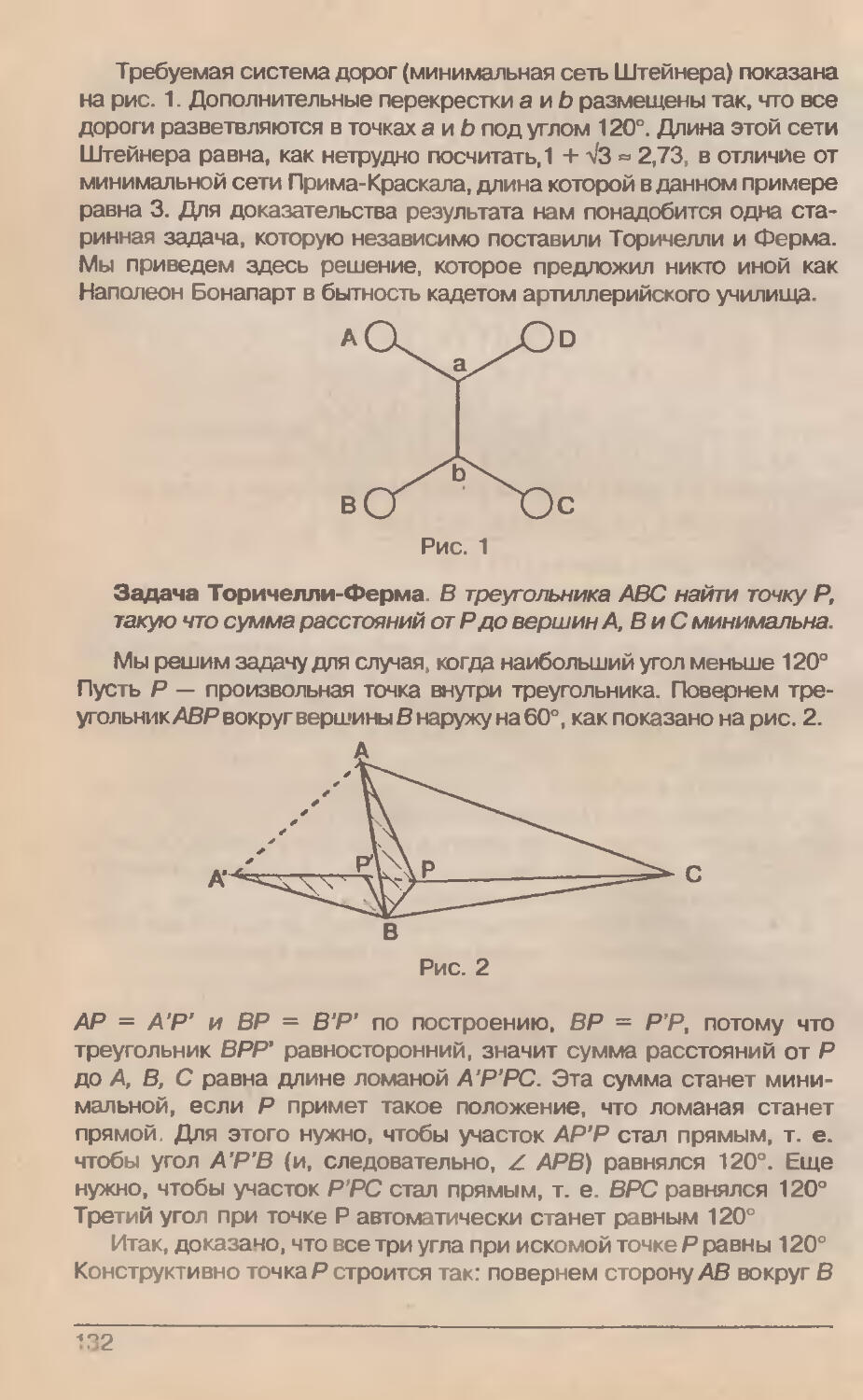
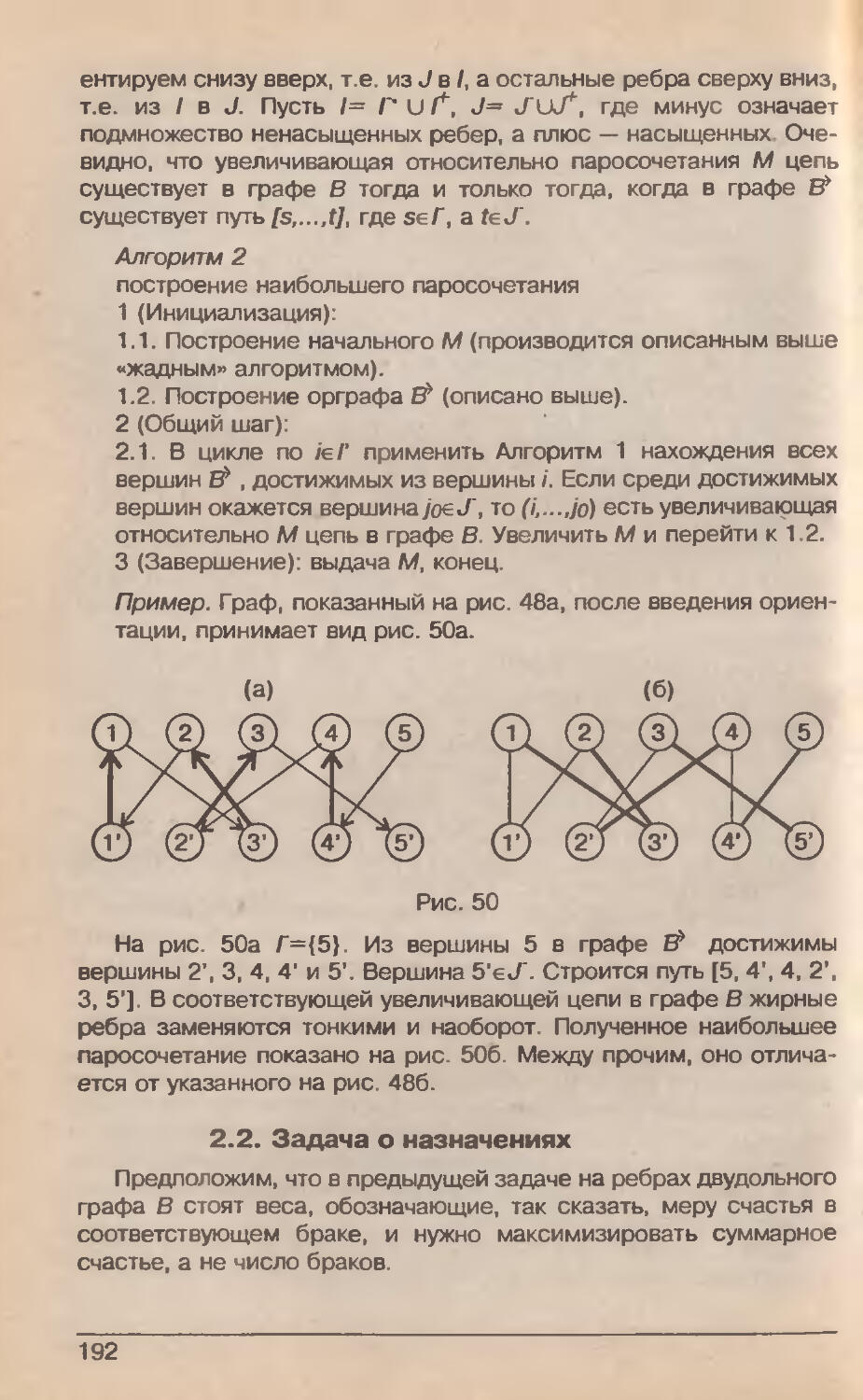
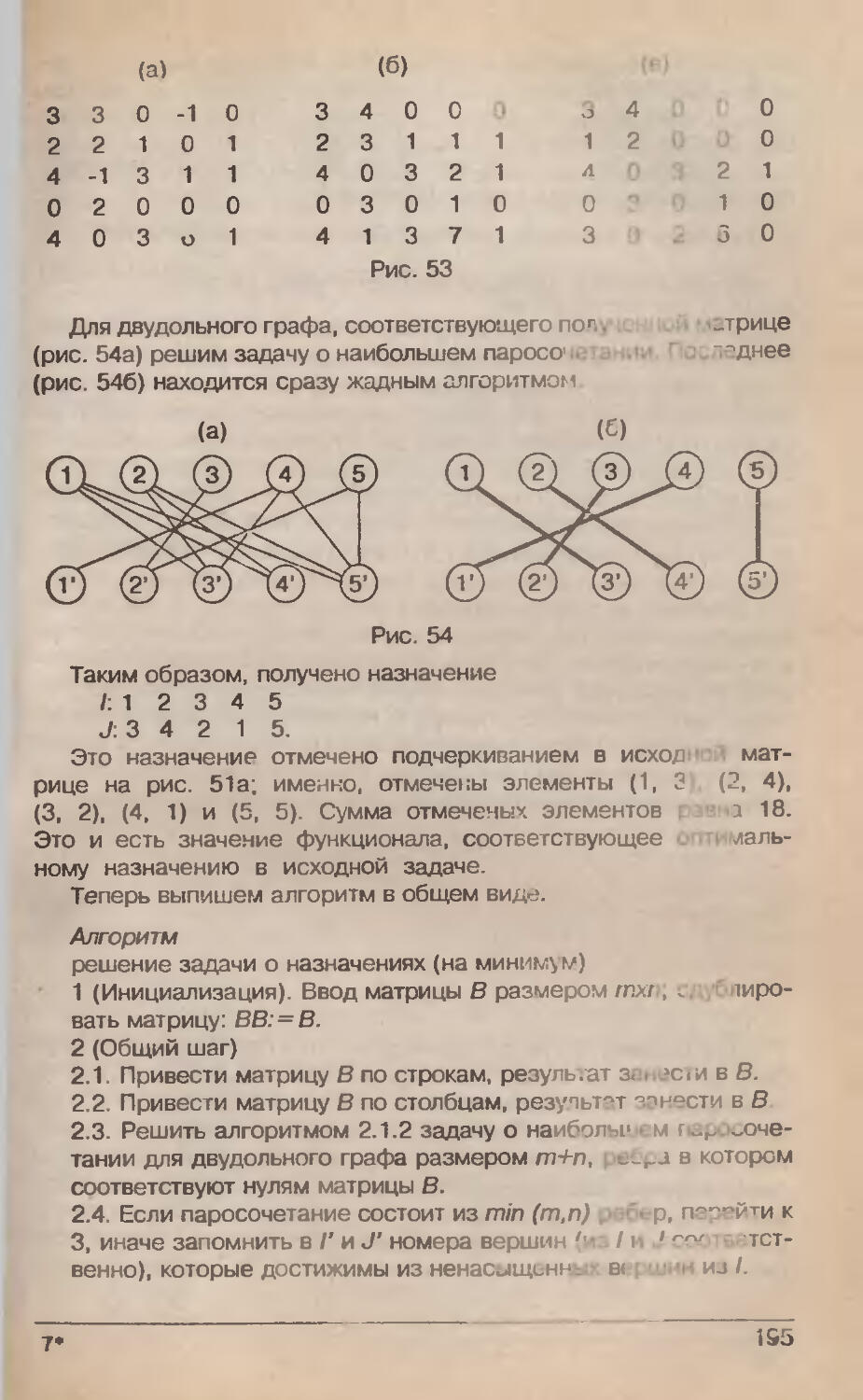
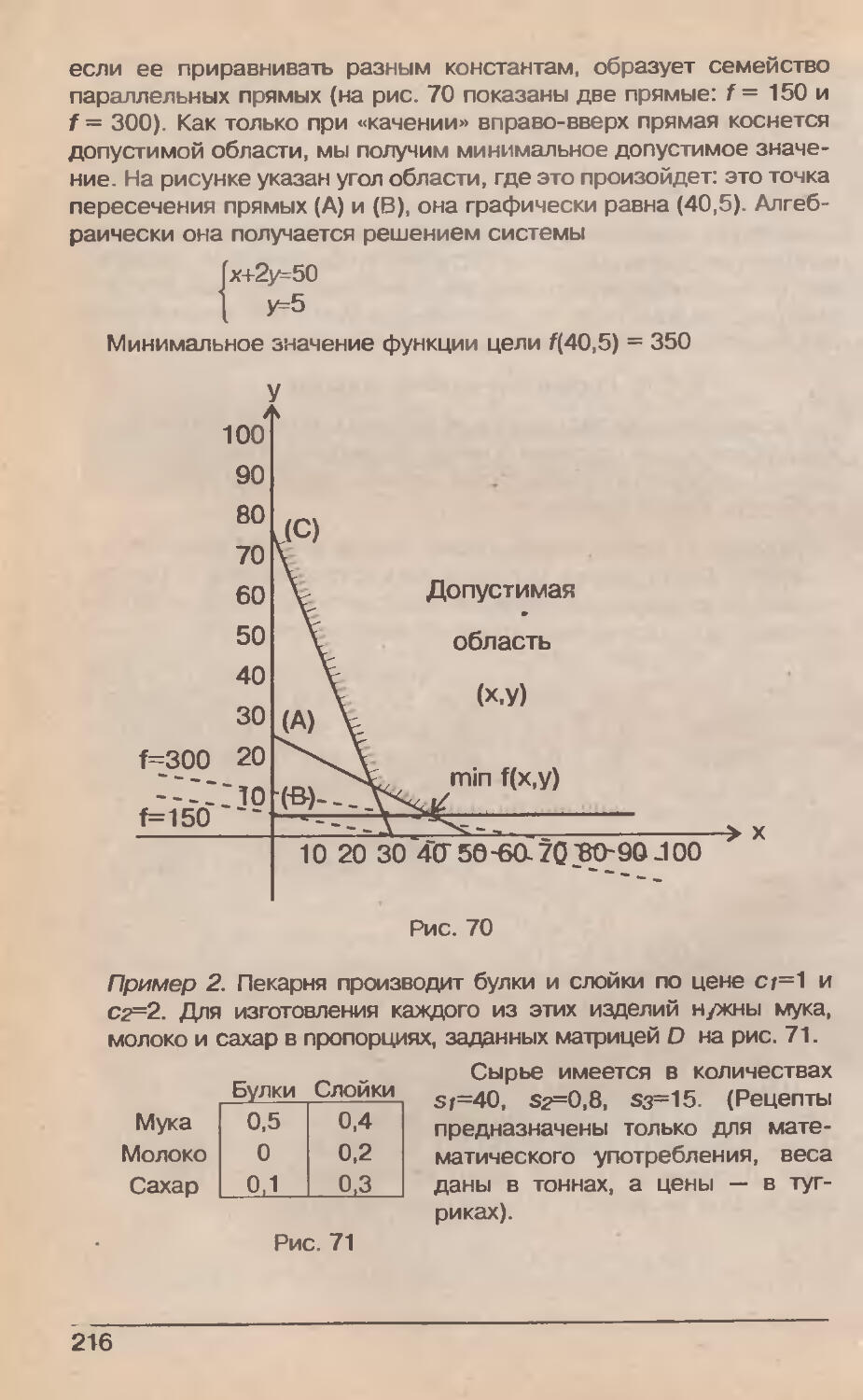
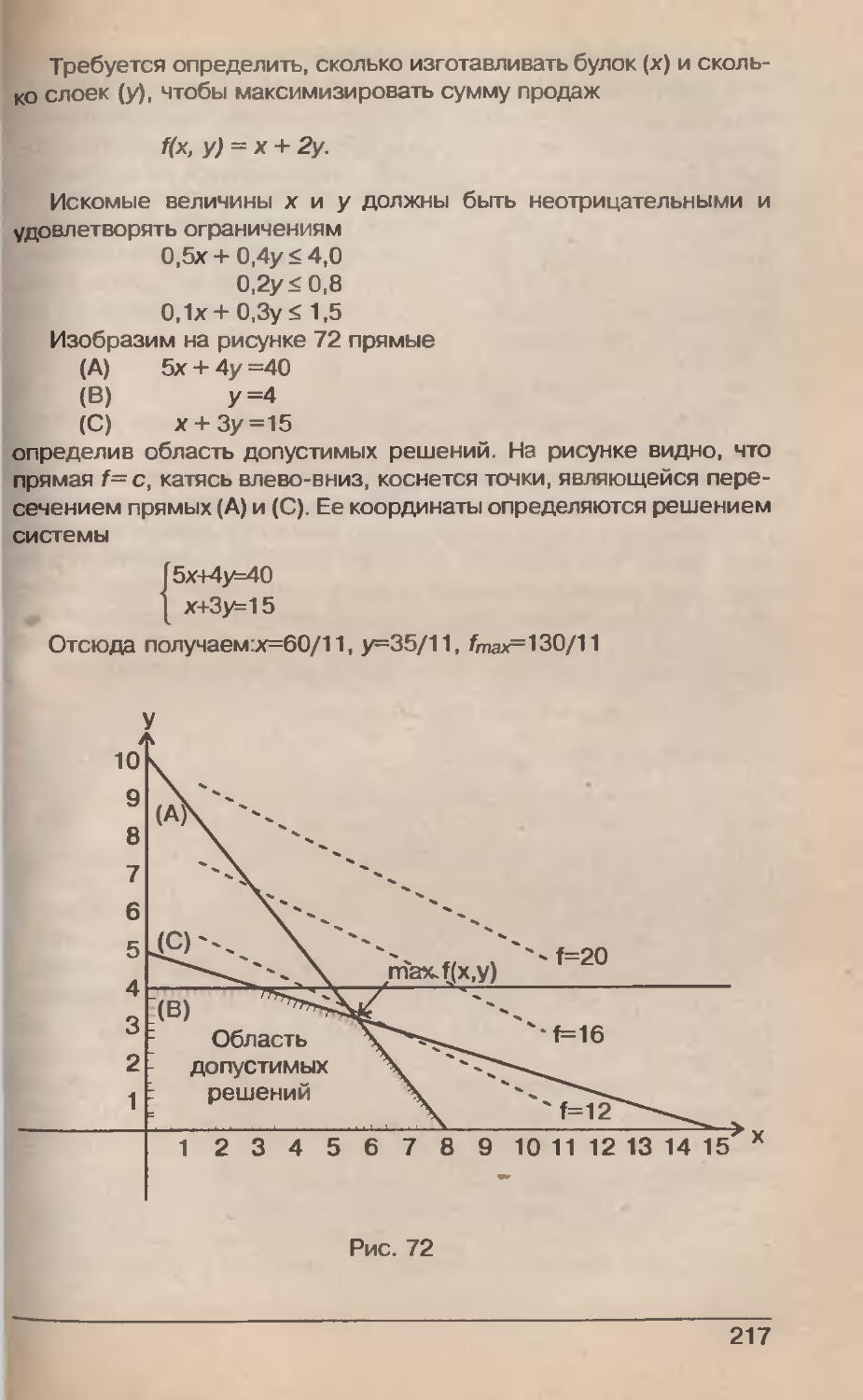
/
































































































































































































































































































































































Автор: Бондарев В.М. Рублинецкий В.И. Качко Е.Г.
Теги: программирование язык программирования паскаль
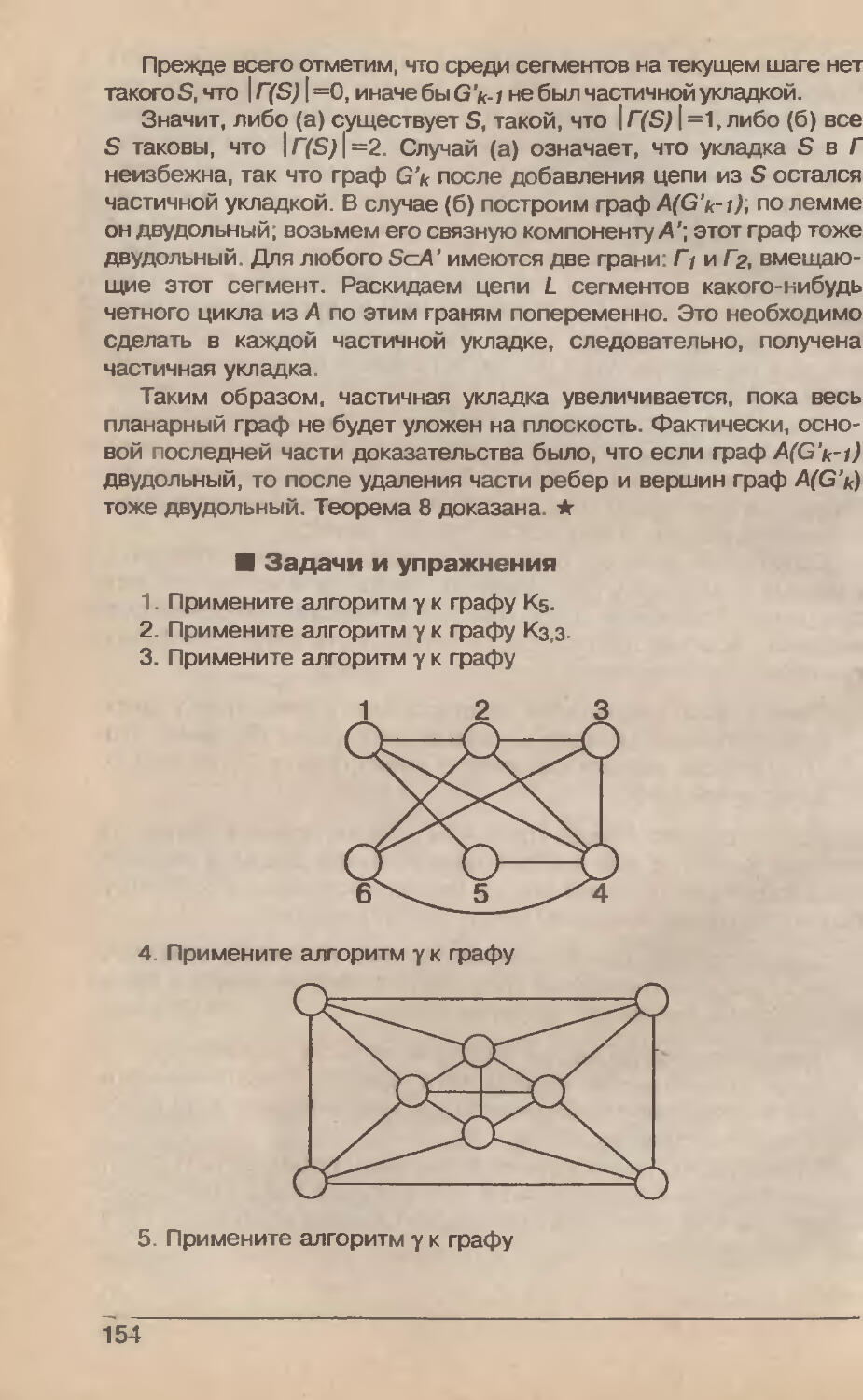
ISBN: 966-03-0313-0
Год: 1998




Текст
В.М. Бондарев
В.И. Рублинецкий
Е.Г. Качко
ПРОГРАММИРОВАНИЯ
Харьков «Фолио» Ростов на-Дону «Феникс» 1998
5БК 32.973-01
Б81
Художник-оформитель
С.А.Пятковка
Редактор
ЕЕ.Захаров
Бондарев В.М., Рублинецкий В.И., Качко Е.Г.
Основы программирования / Худож.-оформи-Б81 тель С.А.Пятковка. — Харьков: Фолио; Ростов н/Д:
Феникс, 1998. — 368 с.
ISBN 966-03-0313-0.
В компактной форме изложен мастерски написанный курс оиучения основам программирования. Первая часть книги представляет собой учебник Паскаля и тренировочный курс программирования вообще. Во второй части описаны разнообразные алгоритмы обработки данных. Часть третья представляет собой учебник по ассемблеру и системному программированию.
Книга предназначена для школьников старших классов, студентов и всех желающих освоить программирование. Специальных знаний для чтения книги не требуется.
Б 240401OOOO-QO1 Без объявл. 98
ISBN 966-03-0313-0
БЕК 32.973-01
© В. М. Бондарев, В. И. РуБлннсцкнн, Е. Г. Качко, 1998
© С Л. Пятковка тожес гвеннос оформление, 1998
ОТ ИЗДАТЕЛЯ
Что предлагается читателю? Три разные книжки под одной обложкой или единая книга, хотя и составленная из трех частей? Чтобы ответить на этот вопрос, придется вернуться немного назад.
Шесть лет назад благотворительным фондом «Профессионал» о Харькове был организован Компьютерный Лицей (ныне он называется лицей «Профессионал»). По плану основателей в Лицей следовало принимать способных школьников, отобранных по конкурсу после 9-го класса, и учить их два года, давая хорошее среднее и усиленное компьютерное образование. Я, тогда программист и руководитель отдела программирования на большом заводе, участвовал в организации лицея в качестве завуча по математике и программированию.
Дело пошло на удивление гладко. Желающих учиться оказалось много, удалось организовать необычно честный конкурс и в итоге из года в год отбирать сильных студентов. Получилась и вторая необходимая половина дела — удалось найти и перетянуть в Лицей учителей — опытных преподавателей и многоопытных прикладников, которые знали, чему нужно учить программиста не из программ министерства. Затем все вместе, методом, как говорил Александр Зиновьев, «пробок и ошибок», мы выработали и реализовали единый замысел обучения студентов основам компьютеристики. Замысел этот частично воплощен в предлагаемой книге.
Как научить молодых людей программировать? Что такое вообще хорошая ппограмма, и чем отличается наш подход от общепринятого? Чтобы лучше понять, о чем идет речь, передадим слово Кернигану и Ричи, создателям языка С и авторам соответствующего учебника:
3
«Первая программа, которая должна быть написана, — одна для всех языков — напечатать слова
HELLO, WORLD!
Это — самый существенный барьер; чтобы преодолеть его Вы должны суметь завести где-то текст программы, успешно его скомпилировать, загрузить, прогнать и найти, где оказалась Ваша выдача. Если Вы научились справляться с этими техническими деталями, все остальное сравнительно просто».
В общем, всех программистов так и учат. Этот метод изучения языка программирования, несомненно, правилен, когда обучаемый уже умеет программирова >, и ему важно, так сказать, поскорее узнать орфографию нового языка. Изучающий же первый язык (а часто второй, третий и т.д., равно, как и обучающий первому, второму и т.д. языку) программировать не умеет, т.е. не умеет тренированным умом разъять сложную мысль, которую ему предстоит записать в виде программы, в цепочки элементарных операций и сгустки процедур, закрученных, где надо, в циклы и разветвленных, где надо, условными переходами. Вот этому и нужно учить новичка, а здесь посыланием приветов не отделаешься — надо разбирать и придумывать (иногда записывая решение в виде программ, иногда нет) десятки разнообразных алгоритмов, пока не сформируется нужный навык.
Умение скомпилировать текст, загрузить, прогнать, поставить, где положено, точки, а где положено, запятые — имеет для новичка важность ничтожную. Его же обычно обучают именно этому — посыланию приветов. Считается, что выучить язык—дело длинное, и новичок по дороге сам научится танцевать. В результате получается «программист», которому нужен «алгоритмист», а тому нужен «постановщик» (именно такая иерархия царила в бывших советских конторах), причем друг друга они толком не понимали, особенно постановщики, которыми обычно служили инженеры, по старости негодные для выполнения основной работы — в колхозе.
Цель Лицея и этого учебника — воспитать компьютеристов широкого диапазона, которые смогут быть и программистами, и алгоритмистами, и — в какой-то степени, поскольку они изучают многие типичные прикладные задачи — постановщиками («постановщик», или, как говорят на Западе, system analist, — это действительно другая профессия, ее представители нуждаются в штучном таланте, этих учить — все равно что массово готовить клоунов).
Общий план достижения указанной цели следующий. Сперва студентам преподаются начала Паскаля, с множеством развивающих упражнений, которые учат их не только Паскалю, но и умению соображать по-программистски. Затем преподается параллельно продвинутый Паскаль, и — в специальном курсе — искусство
4
алгоритмирования на материале многих прикладных задач, а также элементы системотехники и функционирования PC. На втором году обучения, когда студенты прочно стали на программистские ноги, их учат элементам теории алгоритмов, системному программированию и языку ассемблер, программированию на языке С, знакомят с задачами разработки баз данных и некоторыми популярными СУБД, а также читают несколько спецкурсов для желающих в зависимости от вкусов и интересов студентов — по машинной графике, защите файлов от несанкционированного доступа, элементам численных методов и др. В течение двух лет каждый студент готовит три курсовые и дипломную работы.
Объем книги не позволяет предложить читателю все курсы Лицея, да это и не нужно: хороших книг, скажем, по базам данных, С, инструментальным средствам и системам программирования достаточно много. Мы поставили целью изложить в компактной форме курс обучения основам программирования в целом.
Выбор начального языка понятен — Паскаль прост, удобен для изучения; современные версии Паскаля годятся для многих серьезных приложений и имеют обещающее продолжение в Делфи Первая часть книги представляет собой мастерски написанный лаконичный учебник Паскаля и тренировочный курс программирования вообще. Дано систематическое описание конструкций языка, рассмотрены разнообразные алгоритмы и структуры данных. Уделено внимание разработке рекурсивных алгоритмов и решению переборных задач. Материал завершается введением в технологию объектно-ориентированного программирования.
Достойные изучения и подражания алгоритмы, начиная с алгоритма Евклида (4 век до нашей эры) и кончая алгоритмом Эль-Га-маля (1985 г.) собраны, сгруппированы, занимательно и понятно изложены (иногда в форме уже знакомого студентам Паскаля) и доказаны в части второй. Она не имеет аналогов в других изданиях по программированию. Здесь содержатся новейшие алгоритмы криптологии, которые позволят защитить свои программы и сообщения от взломщика, алгоритмы разноообразных прикладных задач теории графов, (и, в частности, задачи коммивояжера), теории расписаний, рассмотрена транспортная задача, вопросы сложности дискретных задач и дано введение в антимир алгоритмов.
Пройдя алгоритмическую выучку, можно приступать к углублен ному изучению программирования как ремесла, чтобы уметь использовать особенности операционной системы и системы машинных команд. Часть третья представляет собой учебник по ассемблеру и системному программированию, где мастерски излагается тщательно отобранный материал. Помимо описания кон
5
струкций языка дан обзор приемов программирования на ассемблере, рассмотрено модульное программирование и стыковка С-ассемблер.
Итак, у читателя в руках учебник основ компьютеристики в трех частях. Практика подтвердила, что учебник удался. Студенты Лицея никогда не возвращались с олимпиад без грамот и никогда не надрывались на программистских предметах при дальнейшем обучении в харьковских и закордонных вузах.
Автор этого введения смог оставить налаженный лицей и заняться издательской деятельностью. В этом качестве я рад предложить читателю эту талантливую книгу.
Е.Е. ЗАХАРОВ
В.М.БОЦДАРЕВ
vCHOBb программирования
ВВЕДЕНИЕ
Эта книга для тех, кто начинает изучать программирование. Из чего состоит этот предмет?
Центральным понятием программирования, бесспорно, является алгоритм. С него начинается работа над программой, а от качества алгоритма во многом зависит ее успешное завершение. Поэтому учиться программировать прежде всего означает учиться разрабатывать хорошие алгоритмы и применять те, что уже известны.
Алгоритм необходимо записать. Это можно сделать на русском языке, на языке графических схем, наконец, на алгоритмическом языке. Последний хорош тем, что записанный на нем алгоритм становится программой для ЭВМ, хотя у двух первых языков есть свои достоинства. Освоение алгоритмических языков — другая сторона изучения программирования.
Какой алгоритмический язык лучше изучать первым?
Он должен быть простым, у начинающего программиста и без того много трудностей. Алгоритмы, записанные на нем, должны быть понятны не только машине, но и человеку, ведь их придется анализировать и улучшать. Он должен быть современным и пригодным для профессиональной работы: кто захочет переучиваться, едва научившись!
К счастью, есть язык, который удовлетворяет всем этим требованиям. Он был создан Н.Виртом в начале 70-х годов специально для обучения программированию. Благодаря усилиям разработчиков систем программирования этот язык стал мощным инструментом профессиональных программистов, не утратив простоты и ясности, присущих ему от
9
рождения. В честь французского математика и физика, впервые создавшего механическое вычислительное устройство, язык называется Паскаль.
Чтобы скорее заняться активным программированием, вначале мы познакомимся с базовыми элементами языка, минимально необходимыми для написания законченных программ. Далее мы будем расширять и уточнять полученные сведения, иногда возвращаясь к уже знакомым понятиям.
В тексте книги встречаются вопросы, а в конце каждого раздела есть задачи. На вопросы нужно отвечать в процессе чтения, а задачи можно решать в любое время. Конечно, можно и не отвечать и не решать, но тогда вы приобретаете товар без гарантии. Программированию нельзя научить, а можно лишь научиться.
ОСНОВНЫЕ ПОНЯТИЯ ПАСКАЛЯ
1.1. Пример простой программы
Начнем знакомство с Паскалем с программы, которая вводит два числа с клавиатуры дисплея, складывает их и выводит сумму на экран.
program SUMMA; var X,Y,Z: integer; begin
read(X,Y);
Z := X + Y;
write (Z);
end.
СЛОВАРЬ:
program var
begin read write end
заголовок программы описание переменных начало программы ввод значений X и Y присваивание суммы вывод результата конец программы
программа переменные начало читать писать конец
На этом примере видны основные особенности записи программ:
1) всякая программа начинается с заголовка — слова program и следующего за ним названия программы;
2) после заголовка располагается описательная часть программы;
11
1.2. Имена и зарезервированные слова
Текст программы записывается при помощи латинских букв, цифр и знаков. Буквы допускаются прописные и строчные.
Особую роль в тексте программы играют имена и зарезервированные слова.
Имена применяют для обозначения программ, переменных и других объектов, определенных в программе. Имя может состоять из любого количества букв или цифр, но должно начинаться с буквы. В имя можно включать знак подчеркивания, который здесь считается буквой. В программе SUMMA есть четыре имени: SUMMA, X, Y, Z. Программисты часто используют осмысленные имена в своих программах Это всегда полезно, а в сложных программах совершенно необходимо. Вот еще несколько примеров имен: Flower, TU_104, pascal.
Зарезервированные слова применяют для обозначения операторов, описания переменных, заголовка программы и других элементов языка Паскаль. Их нельзя использовать в качестве имен и во всех программах они имеют одинаковый смысл. Зарезервированными словами в программе SUMMA являются слова program, var, begin, end.
1.3. Константы и переменные
Данные, которыми оперирует программа, могут быть определены в ней как неизменные, либо как способные изменять свое значение. Первые называются константами, а вторые переменными. И переменные и константы размещаются в памяти компьютера. В программе переменные должны быть описаны в предложении VAR (от слова VARIABLE — переменная), а константы — в предложении CONST.
1.4. Оператор присваивания
Оператор присваивания придает переменной конкретное значение, например:
X := 2; Y := 5.
Присваивание заполняет участок памяти, отведенный для переменной, новым значением, одновременно уничтожая старое. Поскольку задача любой программы — получить в определенном месте памяти нужное значение, редкая программа обходится без оператора присваивания.
12
Присваивать можно значение другой переменной или результат вычисления арифметического выражения.
А := В; А := В+С; X := Y+2-Z.
Общая схема оператора присваивания такова:
имя : = выражение
Все приведенные примеры укладываются в эту схему, т.к. и постоянные величины, и переменные являются частным случаем выражения.
ЗАМЕЧАНИЕ. Схема оператора — это заготовка для изготовления операторов. Чтобы превратить схему в оператор, надо заменить русские слова конкретными именами, выражениями и т.п.
ЗАДАЧИ
1. Поменяйте между собой значения двух переменных А и В, воспользовавшись третьей переменной R для временного хранения значения.
2. Поменяйте между собой значения трех переменных X, Y и Z по схеме тройного квартирного обмена:
X—>Y—>Z—>Х.
3. Присвойте переменной N ее собственное значение, увеличенное в N раз.
4. Чему равно X в результате выполнения программы
X := 2;
X := X + X;
X := X - X ?
2 АРИФМЕТИКА ПАСКАЛЯ
2.1. Тип INTEGER (целый)
И в жизни и в программировании очень полезно использовать понятие типа. Предположим, вам сказали, что некто или нечто носит имя Джой. Больше ничего не известно — сколько у него ног, как проводит свободное время, чем питается,— обо всем этом можно только гадать. В то же время очень многое можно сообщить, добавив лишь одно слово, определяющее тип объекта по имени Джой, например, Джой — собака, или Джой — человек, или Джой — компьютер.
Любая константа или переменная, использованная в программе, принадлежит к определенному типу. Тип задает множество допустимых значений переменных, внешний вид констант, возможные операции над значениями.
Значения целых величин в Паскале не могут быть меньше —32768 или больше 32767.
Константы целого типа (целые числа) записываются в виде последовательности цифр со знаком или без него, например:
5, 883, - 115, 32000.
Переменные должны быть перечислены в описательной части программы в предложении
VAR имя : INTEGER;
Над величинами целого типа допустимы арифметические операции: + (сложение), — (вычитание), * (умножение), div (деление нацело), mod (остаток от деления).
Все операц л вырабатывают результат целого типа Например,
14
15div4 = 3, 25 mod 4=1.
Ияд целыми определено и обычное деление Оно обозначается косой чертой «/» и дает частное вещественного типа.
2.2. Тип REAL (вещественный)
Константы вещественного типа (числа с дробной частью) изображаются с десятичной точкой: 12.3, —1.5, —0.75 или в показательной форме: — 0.45Е5, 6.7Е—10, 0.355Е6.
ВОПРОС. Какое из трех чисел: 0 0000000006 —45000 и 355000 обозначает каждая из констант в г оследнем примере 9
Вещественные переменные требуют описания предложением
VAR имя : REAL;
Над величинами вещественного тига допустимы арифметические операции: + (сложение), — (вычитание), * (умножение), / (деление).
2.3. Арифметические выражения
Арифметические выражения строятся из имен переменных, констант, знаков операций и круглых скобок так, как это принято в математике. При вычислении их значений раньше выполняются операции *, /, DIV, MOD, а затем + и —. Операции одинакового старшинства выполняются слева направо.
ВОПРОС. Каков результат вычисления арифметических выражений*
а) 5 MOD 3+1;
б) 2 * 6 / 2 / 3;
в) 2.4 / 2 - 24 DIV 20 ?
2.4. Функции
Наряду с переменными и константами в арифметические выражения можно включать функции. При определении значения выражения прежде всего вычисляются значения входящих в него функций В Паскале имеются стандартные (не требующие определения в программе) функции вещественного аргумента:
15
SQR(X) X в квадрате,
ABS(X) абсолютная величина X,
SIN(X) синус X (аргумент в радианах),
COS(X) косинус X (аргумент в радианах),
EXP(X) е в степени X,
t-N(X) логарифм натуральный X,
LOG(X) логарифм десятичный X,
SQRT(X) корень квадратный из X,
ARCTAN(X) арктангенс X.
К целому аргументу применимы лишь функции SQR и ABS. Тип значения этих двух функций совпадает с типом аргумента, а тип значения остальных функций — всегда вещественный.
2.5. Преобразование типов
Целое значение можно преобразовать в вещественное, присвоив вещественной переменной целое выражение. Например:
А := 3 + 5.
Противоположное преобразование выполняется при помощи стандартных функций:
TRUNC(X) целая часть аргумента,
ROUND(X) аргумент, округленный до ближайшего целого.
ВОПРОС. Чему равно:
a) TRUNC(3.6),
б) ROUND(3.6), в) TRUNC(36) ?
ЗАДАЧИ
1. Запишите на Паскале оператор, вычисляющий длину орбиты Земли. Указание считать орбиту окружностью с радиусом в 150 млн. км.
2. Найдите сумму членов арифметической прогрессии a, a+d, a+2*d, . , a+n*d
по заданным значениям a, d и п.
3, Вычислите расстояние между двумя точками с координатами Х1 Y1 й Х2, Y2.
16
4. Переменные А, В и С содержат длины сторон треугольника. Вычислите его площадь и сохраните ее в переменной S.
5. Поменяйте между собой значения двух переменных, не используя третьей переменной
6. Возведите число А в пятую степень, в шестнадцатую степень.
7. Переменная X содержит трехзначное целое число. Поместите в переменную S сумму цифр этого числа.
8. Дано вещественное число X (—1<=Х<=1). Вычислите значение функции arcsin X, используя для этого стандартные функции Паскаля.
9. Дано вещественное число X. Вычислите значение полинома
2х4 - Зх3 + 4х2 - 5х + 6,
выполнив для этого как можно меньше арифметических операций.
Зввод и вывод НА ДИСПЛЕЙ
3.1. Ввод и вывод
Мало программ обходятся без ввода данных и совсем нет таких, которые не выводят полученные результаты. Написать такую программу конечно, можно, но кому она понадобится ?
Ввод данных с клавиатуры дисплея выполняется оператором
READ (список переменных) ,
где список переменных — последовательность имен переменных, разделенных запятыми.
Например,
READ (X,Y,Z);
READ (BETA, GAMMA).
При выполнении оператора READ программа останавливается и ждет, пока нужное количество чисел не будет введено с клавиатуры. Вводимые числа разделяют пробелами или нажатием клавиши «Enter».
Заканчивают ввод всегда клавишей «Enter».
ВОПРОС. Какие значения получат вещественные переменные X.Y.Z после выполнения оператора READ (X.Y.Z), если на клавиатуре набрано: — 3. 5.6 1.0Е15?
Вывод данных на экран дисплея выполняется оператором
WRITE (список выражений) .
Выражения в списке разделяются запятыми. Значения выражений вначале вычисляются, а затем высвечиваются на экране.
18
Вслед за выражением после двоеточия можно указать ширину поля экрана, в котором разместится выводимое значение. Например, оператор WRITE (10:3, 55:6) высветит на экране .10..55 ( . оз ачает пустую позицию экрана). Вывод
происходит в том месте экрана, гдэ находится курсор.
При выводе вещественных значений можно указать, сколько десятичных цифр следует сохранить в дробной части числа. Количество цифр указывается венед за шириной поля после двоеточия. Например, если X = 3.14159, a Y = 2.71468, то оператор WRITE(X:6:2, Y:8:3) высветит на экране ..3.14....2,715.
Чтобы прокомментировать зыводимые значения, в список вывода можно помещать строки любых символов, заключенные в одинарные кавычки. Например,
WRITEfОтвет:’, Х:4,’ км/сек.’).
Эти строки появятся на экране без кавычек. Так при X = 3.5 предыдущий оператор выведет:
Ответ: 3.5 км/сек.
3.2. Дополнительные операторы ввода и вывода
Этс операторы readln (список ввода) и writein (список вывода).
Оператор readln отличается от read тем, что, введя необходимое количество данных, пропускает все остальные, набранные до нажатия клавиши «Enter».
ВОПРОС. На клавиатуре набраны две строки:
2345 6
Какие значения придаст переменным X и Y пара операторов:
a) read (X); read (Y);
б) readln (X); read (Y) ?
Оператор writein отличается от write тем, что после вывода всех значений переводит курсор в начало следующей строки. Можно использовать оператор writein без списка вывода. Он только перемещает курсор в начало следующей строки.
19
ЗАДАЧИ
1. Напишите программу, которая запрашивает два числа, находит остаток от деления первого на второе и выводит результат.
2. Напишите программу, которая вводит три числа, складывает их и выводит результат. Используйте как можно меньше переменных.
3. Введите число. Напечатайте 1, если число четное, и О, если число нечетное.
4. Выведите на экран первые десять степеней числа 2.
5. Напишите программу, которая выводит в центре чистого экрана каре из звездочек:
6. Выведите на экран слово ПАСКАЛЬ высотой в 8 строк.
7. Покажите на экране таблицы сложения и умножения одноразрядных двоичных чисел.
4 ЛОГИКА ПАСКАЛЯ
4.1. Условный оператор
До сих пор мы писали программы, которые выполняют свои операторы в том порядке, в каком они расположены. Такие программы похожи на автомобиль, способный ехать лишь в одном направлении. Далеко на таком автомобиле не уедешь. Чтобы изменять последовательность выполнения различных частей программы, применяют условный оператор.
Условный оператор позволяет выполнять или пропускать операторы программы в зависимости от некоторого условия. Схема условного оператора такова:
IF условие THEN оператор_1 ELSE оператор_2
Если условие истинно, выполняется оператор_1, иначе — выполняется оператор_2. В качестве условия применяют сравнения: =, О , <=, >=,>,<. Слева и справа от знака сравнения записывают арифметические выражения. Например, оператор
if X <> 0 then
Z := Y/X else м/Н1е(’Ошибка !’)
присвоит переменной Z значение частного Y/Х, если ХОО, в противном случае высветит на экране слово «Ошибка !».
Условный оператор может быть записан в односторонней форме:
21
IF условие THEN оператор
оператор выполняется, если условие истинно иначе — пропускается.
ВОПРОС. Какую из функций: SIN(X), ABS(X), TRUNC(X) можно заменить условным оператором
if X < О the: X := -X ?
4.2. Составной оператор
Составной оператор объединяет несколько операторов в один. Его схема:
BEGIN оператор ; оператор ; оператор :...оператор END
Составной оператор полезен, когда надо пропустить или выполнить несколько операторов подряд. Например:
if А < В then begin
R:=A;
А:=В; B:=R end
После выполнения такого оператора в переменной А будет большее, а в переменной В — меньшее их двух значений, находившихся там ранее.
4.3. Сложные условия
Сложные условия составляются из простых при помощи логических операций:
AND (и),
OR (или),
NOT (не).
Примеры сложных условий:
а) (0 < A) AND (А <= 1), б) (X = 0) OR (ABS(X) < 5), в) NOT (X = Y).
Сложные условия могут служить частями еще более сложных и т.д.
22
Истинность любого условия м жно вычислить при помощи таблиц значений логических операций:
ложь AND ложь = ложь ложь AND истина = ложь истина AND ложь = л жь истина AND истина = истина ложь OR ложь = ложь ложь OR истина = истина истина OR л жь = истина истина OR истина = истина
NOT ложь = истина NOT истина = ложь
ВОПРОС. Каково значение сложного условия (X > 5) and (Х<Х + 1)?
4.4. Тип BOOLEAN (логический)
Каждое сравнение вырабатывает одно из двух значений: TRUE (истина) либо FALSE (ложь). Например, сравнение 5 < 3 вырабатывает значение FALSE, сравнение 2 + 3 < = 5 вырабатывает значение TRUE.
TRUE и FALSE — константы логического типа.
Логические переменные должны быть описаны предложением:
VAR имя : BOOLEAN;
Над логическими значениями можно выполнять логические операции: AND, OR, NOT.
ВОПРОС. А и В — логические переменные. Всегда ли равнозначны логические выражения not (А or В) и not A and not В ?
Величины логического типа можно присваивать, выводить, но нельзя вводить оператором READ. Например:
X := TRUE: Y := 5 > 3; IF NOT X THEN ...
Из переменных, констант, сравнений, логических операций и скобок можно строить логические выражения. Сложные условия как раз и являются логическими выражениями.
При вычислении логического выражения операции выполняются в следующем порядке: NOT, AND, OR, сравнения, арифметические операции. Если нужно изменить порядок выполнения операций, применяют скобки.
ЗАДАЧИ
1. Ввести два числа. Напечатать сначала меньшее, затем большее.
23
2. Решить задачу 1, использовав только один оператор вывода.
3 Установить, истинны или ложны следующие условия:
a) NOT ((6 < 4) AND (4 > 8)),
б) (А <= А + 1) OR (12 - 3 > 0),
в) ((2 <= 2) AND (3 >= 3)) OR (15 > 25).
4. Даны три числа а, Ь и с (а О 0). Установить, имеет ли уравнение
ах2 + Ьх + с = 0
действительные корни и, если имеет, то найти их.
5. Ввести три числа. Выбрать и напечатать наибольшее из них.
6. Написать программу, которая требует ввода времени дня и, в зависимости от введенного значения, желает доброго утра, доброго дня, доброго вечера или спокойной ночи.
7. Даны действительные положительные числа х, у, z.
а) Выяснить, существует ли треугольник с длинами сторон х, у, z.
б) Если треугольник существует, то ответить, является ли он остроугольным.
8. Даны действительные числа х1, у1, х2, у2, хЗ, уЗ. Находится ли начало координат внутри треугольника с вершинами (х1,у1), (х2,у2), (хЗ,уЗ)?
5 циклы
5.1. Оператор цикла WHILE
Цикл — это замечательное изобретение, которое, в сущности, и делает компьютеры такими ценными. Он позволяет многократно повторить любую часть программы. Без такой возможности для одной секунды работы компьютера потребовалось бы писать десятки тысяч строк программы.
Схема оператора цикла такова:
WHILE логическое выражение DO оператор
Оператор будет повторяться, пока истинно логическое выражение. Перед каждым повторением оператора значение логического выражения перевычисляется. Если необходимо повторять несколько операторов, их следует объединить в составной оператор.
ПРИМЕР. Программа подсчета суммы S первых 1000 членов гармонического ряда 14-1/2 4- ...+ 1/N.
program Summa: var
S: real;
N: integer;
begin
S := 0;
N := 0;
while N < 1000 do begin
N := N + 1;
S := S + 1/N
end;
25
writeln(S) end.
ВОПРОС. Напишите оператор цикла, который:
а) не выполняется ни разу;
б) выполняется неограниченное число раз.
5.2. Оператор цикла REPEAT
Повторение группы операторов можно организовать и с помощью оператора
REPEAT оператор;оператор;...оператор UNTIL логич.выраж.
Часть программы, заключенная между ключевыми словами REPEAT и UNTIL, повторяется до тех пор, пока не станет истинным логическое выражение, стоящее после слова UNTIL.
В отличие от оператора WHILE вычисление логического выражения происходит не до, а после очередного повторения цикла. Из-за этого цикл REPEAT обязательно выполнится хотя бы раз, а цикл WHILE может не выполниться ни разу.
В программе подсчета суммы гармонического ряда оператор WHILE равносилен следующему оператору
repeat
N:= N+ 1;
S:=S+ 1/N
until N > 1000
ВОПРОС. Замените оператор «repeat A until В» равносильным фрагментом программы с оператором «while».
5.3. Поиск наибольшего числа
Предположим, нам необходимо ввести с клавиатуры N чисел, найти из них наибольшее и вывести его.
Для решения этой задачи предлагается следующий алгоритм.
1. Ввести первое число в переменную Мах.
2. Ввести следующее число в переменную Next.
3. Если Next > Мах, то Мах := Next.
Пункты 2 и 3 повторять, пока не будут введены все числа.
4. Вывести значение переменной Мах.
Действительно ли будет напечатано наибольшее из N чисел? Докажем это.
26
После выполнения первого пункта в переменной Мах находится наибольшее из уже введенных чисел. Эю справедливо, т.к. введено лишь одно число.
Повторение пунктов 2 и 3, в сущности, представляет собой цикл, который выполняется, пока не будут введены все числа. Если перед очередным повторением цикла в Мах находилось наибольшее из введенных чисел, то после выполнения пунктов 2 и 3 там снова будет наибольшее из введенных чисел.
ВОПРОС. Почему ?
Свойство переменной Мах содержать наибольшее из введенных чисел сохраняется после каждого повторения цикла (такие свойства называют инвариантом цикла). Естественно, инвариант цикла сохранится и после завершения цикла, т.е. после ввода всех чисел.
В последнем пункте значение Мах будет выведено.
Этот пример показывает, что алгоритм можно доказать, как доказывают математическую теорему. Программируя доказанный алгоритм, можно не опасаться ошибок в алгоритме, конечно, если нет ошибок в доказательстве.
5.4. Вложенные циклы
Оператор, повторяемый в цикле, сам может быть циклом.
ПРИМЕР.
var i,j: integer;
begn i := 0; while i < 10 do begin
I J := 0;
while j < 10 do begin write (i*10+j:4);
H j:=j+1; end {while j); writein;
| i := i + 1; end {while i) end.
ВОПРОСЫ. Что выведет на экран программа ?
Сколько раз выполнятся операторы, отмеченные одинарной линией, двойной линией ?
27
В Паскале нет с т количество и глубину вло-
жения циклов.
С А, .,
1. Введите с клаг латуры 6 ч. ал и определите их среднее арифметическое.
2. Напишите программу, которая вводит целые числа с клавиатуры и складывает их, пока не будет введено число 0.
УКАЗАНИЕ. Воспользуйтесь условием UNTIL X = 0.
3. Выведите на экран график функции sin(x) в интервале от 0 до 360 градусов.
УКАЗАНИЕ. Ссь абсцисс направьте по вертикали.
4. Вычислите:
a) sin х = х — х3 /3! + х5 /5! — х7 /7!...
б) п раз: sqrt (2+sqrt (2+sqrt (2 + ... + sqrt (2)))).
5. Напечатайте 20 первых степеней числа 2.
6. Найдите два целых трехзначных числа, частное которых приближает число «пи» с наибольшей точностью.
7 Замените оператор «if С then A else В» равносильным ему фрагментом программы, использовав оператор «while».
8. Напечатайте таблицу функции SIN(X+Y) для следующих значений аргументов: 0, 10, 20, 30, 40, 50, 60, 70. 80, 90.
9. Сосчитайте, сколько шестизначных чисел имеют одинаковые суммы трех первых и трех последних цифр.
10. Разбейте заданное число на 2 слагаемых всеми различными способами. Разбиения, отличающиеся лишь порядком слагаемых, разными не считать.
11. Сделайте то же для тоех слагаемых.
W МАССИВЫ
6.1. Одномерные массивы
До сих пор мы имели дело с простыми значениями — целыми, вещественными, логическими. Одномерный массив — это тип данных с составными значениями Они составлены из значений простого типа, который называют базовым. Точнее говоря, значениями массива служат последовательности значений базового типа одинаковой длины. Эту длину называют размером массива. Вот как может выглядеть значение массива из пяти целых чисел: (3,8,5,9,4).
Все элементы составного значения пронумерованы (проиндексированы). Благодаря этой нумерации можно выделить любой элемент составного значения и обращаться с ним, как с простым значением базового типа — целым, вещественным или логическим.
Переменный массив требует описания:
ARRAY [ тип индекса ] OF базовый тип
тип индекса — любой порядковый тип ( о порядковых типах будет сказано в разделе 8). Пока определение порядкового типа нам не знакомо, будем задавать тип индекса, указывая начальное и конечное значение отрезка целых чисел. Этот отрезок даст нам необходимое количество номеров для нумерации элементов составного значения, например отрезок 3..6 дает номера 3,4,5,6.
Операции над значениями массива — это операции над последовательностями. Разные значения одного массива можно сравнивать и присваивать. Вот несколько результатов сравнения значений массива array [1..5] of integer :
29
(1,3,5,2,8) <> (1,3,5,2,8) (8,6,3,7,4) < (8,6,4,2,1)
(5,2,4,3,9) <= (5 2,1,7,4) (3.5,4,2,1) = (2,6,4,2,1)
false true
true false
ВОПРОС. Изучив приведенные примеры, сформулируйте правило сравнения значений массива.
Переменному массиву можно присвоить значение другого Массива того же типа. Присвоением и сравнением исчерпываются допустиыыс ? ерации над значениями массива. Арифметические действия, звсд и вывод нельзя выполнять над последовательностями, но можно над их отдельными элементами. Элемент массива выделяется сонкрет-ным значением индекса. Например, имеется переменный массив, описанный как
var X: array [0..99] of real.
Тогда X[0] означает самый первый элемент массива, Х[1] — следующий за ним и т.д. При этом к Х[0], Х[1],..., Х[99] нужно относиться как к отдельным переменным базового типа, в данном случае real. В качестве индекса можно использовать любое выражение со значениями из отрезка 0..99.
ПРИМЕР. Ввод значений в массив М. var
М: array [1..10] of integer;
i: integer;
begin
i := 0;
repeat
i := i + 1;
read (M [i] )
until i = 10 end.
Любое? эпределение типа, данное в программе, можно либо непосредственно использовать в конструкции VAR для описания переменных, либо дать ему имя типа следующим образом:
TYPE имя типа = определение типа
Следующие два описания переменной М эквивалентны:
30
M: ARRAY [1 ..10] OF INTEGER;
и
TYPE ARR = ARRAY [1 ..10] OF INTEGER;
VAR M: ARR;
Заметим, что все описания должны предшествовать в программе их использованию.
6.2. Сортировка массивов
Массив — это настоящий склад данных в памяти ЭВМ. Иногда на складе необходимо навести порядок — расположить данные по их возрастанию или убыванию. Такая работа называется сортировкой массива.
Программистам известно много разных алгоритмов сортировки. Для начала познакомимся с сортировкой выбором.
Сортировка выбором
1. Установить номер наименьшего элемента массива.
2. Поменять местами наименьший и первый элементы массива.
3. Оставив в покое первый элемент, выполнить пункты 1 и 2 над остатком массива (массивом без первого элемента).
Пункт 3 повторять, пока остаток массива не сократится до одного элемента.
Вот как изменяется значение массива из пяти элементов (30, 20, 10, 50, 40) по мере повторения пункта 3:
40 50 10 20 30
10 50 40 20 30
10 20 40 50 30
10 20 30 50 40
10 20 30 40 50
Подчеркнута область поиска наименьшего элемента.
Из примера видно, что работа алгоритма состоит из последовательных шагов. На каждом шаге наименьший элемент области поиска перемещается в уже отсортированную часть массива, за счет этого упорядоченная часть массива растет, а неупорядоченная сокращается на 1 элемент Для сортировки массива из N элементов потребуется ровно N — 1 шагов алгоритма.
Время выполнения одного шага прямо пропорционально размеру неупорядоченной части массива.
31
ВОПРОС. Поиему ?
Размер неупорядоченной части равен N в начале работы и 2 — в конце. Общее время сортировки выбором
Т = k*N + k*(N—1) +...+ k*3 + k*2,
где k—коэффициент пропорциональности, не зависящий от N. По формуле для арифметической прогрессии получим:
Т= k*(N+2)*(N—1)/2,2
что примерно равно С * N, где С — константа, не зависящая otN.
Полученная формула не дает нам абсолютного значения времени, но показывает, как меняется продолжительность сортировки с изменением размера массива.
Зависимость вида
Т = f(N) ,
где N — объем входных данных, называется временной сложностью алгоритма.
О временной сложности сортировки выбором говорят, что она квадратичная, т.к. время сортировки пропорционально квадрату числа сортируемых элементов.
6.3 Обменная сортировка
Разберем еще один алгоритм сортировки массива. Как и предыдущий, он состоит из отдельных шагов. На каждом шаге проходят массив от начала к концу, сравнивая пары соседних элементов Если очередная пара нарушает требуемый порядок, ее элементы меняют местами. Шаги повторяют до тех пор, пока очередной проход не вызовет ни одного обмена.
Посмотрите, как изменяется значение массива из пяти элементов (30, 20, 10, 50, 40) на каждом шаге сортировки:
Исходное значение: 40 50 10 20 30
После 1-го шага : 40 10 20 30 50
После 2-го шага : 10 20 30 40 50
В отличие от сортировки выбором количество шагов обменной сортировки зависит от первоначального значения массива, поэтому попытаемся оценить временную сложность алгоритма в худшем случае (в лучшем случае она равна временной сложности одного шага)
32
ВОПРОС. Какова временная сложность одного шага ?
При обратном порядке чисел потребуется N шагов для сортировки массива из N элементов. Это и есть худший случай, т.к. за каждый шаг по крайней мере одно число «приезжает» на свое законное место. Значит, временная сложность обменной сортировки
Т = N * t (N)
Если вы правильно ответили на последний вопрос, то видите, что она тоже квадратичная.
ВОПРОС. Как можно ускорить приведенный алгоритм обменной сортировки ?
6.4. Многомерные массивы
Если элементы массива сами являются массивами, получается структура данных, которая в программировании называется двумерным массивом. Описать ее можно так:
ARRAY [тип индекса*!] OF ARRAY [тип индекса2] OF тип элементов
или
ARRAY [тип индекса*! ,тип i ндекса2] OF тип элементов
Обе формы описания равносильны, но вторая употребляется чаще.
Например,
VAR М2: ARRAY [-10.-10,1..50] OF REAL;
Обращаются к элементам двумерного массива, указывая не один, а два индекса: М2[4] [18] или М2[4,18]. Если в обращении указать только один индекс, это будет расценено как имя одномерного массива. Например, М2[10] означает массив из 50 вещественных переменных: М2[10,1], М2[10,2].
М2[10,50].
ПРИМЕР. Вывести на экран элементы двумерного массива вещественных чисел.
var
М2: array [1..10, 1..15] of real;
i,j: integer;
begin
i := 1;
while i <= 10 do begin
2 «Основы программирования»
33
j := 1;
while j <= 15 do begin
write (М2 [i,j] :5);
j := j + 1;
end {while};
writein;
i := i + 1;
end {while};
end.
Подобным же образом описывают трехмерные, четырехмерные и т.д. массивы. Обращаться к их элементам следует, указывая 3,4 и более индексов соответственно.
ВОПРОС. Сколько чисел можно записать в шестимерный массив X: array [0..1,0..1,0..1,0..1,0..1,0..1] of real ?
ЗАДАЧИ
1. Подсчитайте произведение элементов массива.
2. Вычислите значения функции Y=X*X для X = 2,4,6,8,...,36 и разместите их в одномерном массиве Y.
3. Измените порядок значений элементов массива на обратный.
4. «Сожмите» числовой массив, выбросив из него отрицательные числа.
5. Определите, является ли заданный массив упорядоченным.
6. Задан массив и некоторое число. Найти, на каком месте расположено число в массиве.
7. Напечатайте первую сотню простых чисел.
8. В массиве целых чисел найдите самую длинную плотную неубывающую последовательность.
9. Поверните квадратный массив на 90, 180, 270 градусов по часовой стрелке.
10. Выясните, есть ли одинаковые числа:
а) в одномерном массиве;
б) в двумерном массиве.
11. Подсчитайте количество уникальных чисел в массиве.
12. В массиве содержатся числа 0, 1, 2 и ничего кроме них. Упорядочить массив по возрастанию.
13. Задан массив чисел. Замените каждое число суммой предыдущих:
а) включая заменяемое;
б) исключая заменяемое.
34
7 ФУНКЦИИ И ПРОЦЕДУРЫ
7.1. Описание функций
Ранее мы познакомились со стандартными функциями Паскаля. Кроме них программист может воспользоваться своими собственными функциями, предварительно описав их в программе. Описание функции располагается до исполняемой части программы и является как бы маленькой программой внутри большой. Начинается описание заголовком функции
FUNCTION имя (параметры) : тип;
где имя — то имя, которое программист решил дать своей функции;
параметры — список переменных с указанием их типов, своего рода описание. В отличие от стандартных, функции программиста могут иметь любое число аргументов произвольных типов;
тип — это тип значения, которое вычисляет функция. Он обязан быть простым.
Заметим, что типы в заголовке функции можно обозначать только именами, поэтому тип массива требует предварительного переобозначения предложением type (см. раздел 6.1).
Вслед за заголовком располагается тело функции, которое по структуре ничем не отличается от программы, но заканчивается не точкой, а точкой с запятой. В теле функции должен присутствовать оператор присваивания, в левой части которого стоит имя функции, а в правой — выражение для возвращаемого значения.
2*
35
ПРИМЕР. Описание функции выбора большего из двух аргументов.
function МАХ (А,В: real): real;
begin
if А > В then MAX := A ' else MAX := В end;
ВОПРОС. Опишите функцию выбора меньшего из двух целых чисел.
7.2. Обращение к функции
После описания функции ее можно использовать в выражениях наряду со стандартными функциями. Аргументами при обращении могут быть любые выражения. Порядок следования и типы аргументов должны быть такими же, как у параметров в заголовке функции.
Вычисление выражений, содержащих обращение к функции, происходит по следующему алгоритму:
1) вычисляются выражения для аргументов функции;
2) значения аргументов присваиваются параметрам из заголовка описания;
3) выполняется тело функции и вычисляется ее значение;
4) значение функции ставится в исходное выражение на место обращения к функции;
5) вычисление исходного выражения продолжается.
Заметим, что если выражения для аргументов сами содержат обращения к функциям, то пункт 1) выполняется по приведенному алгоритму. В подобных случаях говорят, что алгоритм — рекурсивный.
Давайте посмотрим, что дает нам описание функции. Вы правы, если думаете, что без него можно обойтись, заменив обращения к функции переменными нужного типа и заранее вычислив их значения. Но тогда прийдется запрограммировать одни и те же вычисления столько раз, сколько раз мы обращались к функции. Программа удлинится, потеряет наглядность и утратит структуру, т.к. функция решает независимую от всего остального задачу, а мы «размажем» эту задачу по программе.
Такой образ действий повредит маленьким программам и катастрофически отразится на больших. Только разбив
36
ка задачи на множество относительно независимых подзадач позволяет программисту справляться со сложными программами.
7.3. Процедуры
Как быть, если выделенная нами подзадача не похожа на функцию, т.е. не возвращает ни одного или возвращает много значений ? Здесь нам пригодится процедура.
Процедура — это самостоятельная программная единица, которая выполняется по команде из другой программной единицы (программы, процедуры или функции). Процедура отличается от функции только заголовком и способом обращения к ней.
Схема заголовка процедуры следующая:
PROCEDURE имя (параметры);
Процедура не обязана возвращать значение, поэтому нет нужды указывать тип, как в заголовке функции.
Вот примеры заголовков процедур:
PROCEDURE ALPHA (X: INTEGER; Y: REAL; Z: CHAR); PROCEDURE BETA (M: ARR);
В том месте программы, где нужно выполнить действия, предусмотренные в описании процедуры, ставят оператор процедуры:
имя (аргументы) , где имя то же, что в заголовке процедуры;
ПРИМЕР. Описание и вызов процедуры, которая печатает сумму N первых элементов вещественного массива.
type
Arr = array [1..100] of real;
procedure PrintSum (R: Arr; N: integer); var
Summa: real;
i: integer;
begin
Summa := 0;
i := 1;
while i N do begin
Summa := Summa + R [i];
i := i + 1;
37
end;
writein (Summa); end;
var
A: Arr;
begin
PnntSum (A, 20);
end.
ВОПРОС. Что следует изменить в примере, чтобы печатать сумму элементов, начиная с N1 и кончая N2 ?
7.4. Параметры-переменные
Процедура может не только получать значения от вызывающей программы, но и возвращать в программу новые значения. Для этой цели служат параметры-переменные.
В то время, как параметр получает значение аргумента путем присваивания, параметр-переменная — это просто другое имя для аргумента. Под этим именем значение аргумента становится доступным в процедуре. Все преобразования, выполняемые в процедуре над параметром-переменной, выполняются, таким образом, над аргументом.
АР ГУ
ПРОГРАММА
МЕН
ТЫ
»> Параметр »> =Параметр-переменная=
ПА
РА
ПРОЦЕДУРА
МЕТ
РЫ
Рис.7.1
ВОПРОС. Почему при обращении к процедуре, аргумент, передаваемый параметру-переменной, может быть только переменной, а не константой или выражением ?
В списке параметров заголовка процедуры перед параметрами-переменными ставят слово VAR. Например,
procedure PrintSum (var R: Arr; N: integer);
38
Параметры-переменные можно использовать не только в процедурах, но и в функциях
7 5. Взаимодействие блоков
В некоторых вопросах различие между процедурами и функциями не играет роли. Обсуждая такие вопросы, будем называть их общим именем — блок.
В программе может быть описано сколько угодно блоков. Внутри этих блоков могут быть описания других блоков и т.д. без видимых ограничений. Важно знать, откуда какие блоки могут быть вызваны или, как говорят программисты, видны.
Для ответа на этот вопрос вообразите что блок — это дом с зеркальными стеклами в окнах. Изнутри через них видно все, что находится снаружи, внутрь же заглянуть нельзя.
Рис. 7.2
На рисунке изображен пример программы А, внутри которой описаны блоки В и С. Внутри В описаны D и Е, внутри С описан блок F, а в нем — G . Если вы пишете код блока F, то, согласно правилу зеркальных стекол, можете обращаться к бл экам В, С, а также G и даже самому блоку F.
Заметим, что обращение блока к самому себе называется рекурсией, и позже мы познакомимся с нею поближе.
ВОПРОС. Что видно из А ? Из D ?
Видимость — это свойство всех описаний, а не только блоков. Находясь в блоке, можно пользоваться всем, что видно из него. Так из блока F видны переменные, описанные в С и А, но не видны переменные, описанные в В, D, Е и G.
Объекты, описанные в блоке, называются внутренними, а те, что описаны в блоках, охватывающих данный, — внешними по отношению к блоку. Внешние переменные дают допол нительный канал связи между блоками (основным каналом следует считать параметры и параметры-переменные). Поль-
39
зеваться этим каналом надо осторожно, ибо он усиливает зависимость блоков друг от друга и этим затрудняет разработку программы.
Может статься, что имена разных внешних переменных совпадут. Какая из одноименных переменных будет видна из блока? Будет видна та, что описана в ближайшем из внешних блоков. Если же конкуренция возникнет между внешней и внутренней переменными, видна будет внутренняя.
ЗАДАЧИ
1. Определите функцию нахождения наибольшего из трех чисел.
2. Опишите процедуру, которая получает вещественный массив М из 100 элементов и возвращ ет S — сумму чисел, находящихся в массиве.
3. Опишите функцию вычисления среднего значения для N первых элементов вещественного массива W.
4. Определите функцию, вычисляющую, какой целой степенью числа 2 является ее аргумент.
5. Запрограммируйте сортировку выбором в виде процедуры. Поиск наименьшего числа сделайте ее внутренней процедурой.
6. Опишите массив размером 25 х 80 — образ экрана и определите процедуры построения:
1) горизонтальной линии;
2) прямой линии;
3) окружности;
4) прямоугольника;
5) закрашенного прямоугольника;
6) вывода на экран «графического» образа.
ПОРЯДКОВЫЕ
8 ТИПЫ ДАННЫХ
8.1. Тип CHAR (символьный)
Вычислительные машины имеют дело не только с числами. Едва ли не больше времени они бывают заняты обработкой текста. В Паскале для этого есть специальный тип данных, который называется CHAR (от слова character — символ). Его значениями явл <ются отдельные символы: буквы, цифры, знаки. Символьные константы заключаются в кавычки, например, ’А’, ’В ’С ’, ’4 ’, ’7
Символьные переменные описываются предложением
VAR имя: CHAR
Символьные значения можно вводить и выводить, присваивать, сравнивать. Ниже приведен пример, где выполняются все эти действия.
Var
X, Y: Char;
Begin
Read (X);
Y: = ’A’;
If X < Y then write (’X ')
End.
Сравнивать символы можно благодаря тому, что в машинной памяти они хранятся в виде целых чисел (кодов символов). Из двух символов большим считается тот, код которого больше. Для символов допустимы все шесть операций сравнения: =, <=, >=, с, >, о .
41
В Паскале имеются две стандартные символьные функции:
CHR(N) возвращает в программу символ с кодом N,
ORD (S) возвращает код символа S.
ВОПРОС. Что вернет функция CHR(ORD(X)) ?
Коды всех символов определяются стандартом, который называется ASCII — American Standard Code Information Interchange (читается «аски»), Первая половина таблицы стала международным стандартом, у второй есть разные варианты.
8.2. Перечислимый тип данных
Язык Паскаль позволяет программисту создавать собственные типы данных. Один из них называется перечислимый тип. Он задается программистом путем перечисления в круглых скобках всех допустимых значений типа.
(значение1, значение2...значением)
Значения не могут быть ничем, кроме имен. Их можно присваивать и сравнивать, но нельзя вводить и выводить операторами READ и WRITE. Из двух значений большим является то, которое в описании типа расположено правее.
ПРИМЕР. Работа с перечислимым типом данных.
type
season = (winter, spring, summer, outumn); var
X, Y: season;
begin
X: = winter; Y: = summer;
if X Y then write (’X Y’);
X := Y end.
8.3. Интервальный тип данных
Интервальный тип данных тоже «самодельный». Он определяется как интервал значений ранее определенного (базового) типа. Задается интервал своими крайними значениями.
42
значение1 ..значение2
Базовым может служить любой простой тип данных, кроме вещественного Например:
Туре
day = 1..31;
month = 1..12, letter = ’А ’Z ’
Именно интервальный тип до сих пор применялся нами для индексации массива.
8.4. Порядковые типы данных
Порядковыми называются все простые типы, значения которых можно расположить в возрастающем порядке. Типы INTEGER, CHAR, BOOLEAN, перечислимые и интервальные являются порядковыми. Типы REAL, ARRAY порядковыми не являются.
ВОПРОС. Почему ?
На любых порядковых типах определены функции:
PRED (X) возвращает значение, предшествующее К
К наименьшему значению не применима.
SUCC (X) возвращает значение, следующее за X.
К наибольшему значению не применима.
ORD (X) возвращает порядковый номер аргумента X Значения порядкового типа нумеруются числами
О, 1, 2,..., начиная с наименьшего. Исключение составляет тип INTEGER, для которого ORD(X)=X.
Теперь можно расширить определение массива (см. раздел 6.1) предложением: «Типом индекса массива может быть любой порядковый тип данных»
Вот примеры возможных описаний
array [(spring, summer, outumn, winter)] of real;
array [char] of integer;
array i’A’./Z'] of boolean.
Знакомство с порядковым типом позволяет нам узнать два полезных оператора Паскаля: FOR и CASE. Это подтверждает пользу знакомств.
43
8.5. Оператор FOR
Оператор FOR обеспечивает повторение цикла, управляемое переменной.
FOR переменная : = выражение! ТО выражение2 DO оператор ,
где переменная — переменная порядкового типа (но не параметр функции или процедуры);
выражение! и выражение^ того же типа, что и переменная.
Выполнение начинается с вычисления значений выражения! и выражения 2. Затем переменная получает значение выражения! и делается проверка, не превышает ли значение переменной выражения2. Если не превышает, выполняется оператор. После завершения оператора переменная получает следующее по порядку значение и все повторяется, начиная с проверки.
Когда значение переменной становится равным выраже-нию2, оператор выполняется последний раз. Например:
for i := 1 to 80 do V[i]: = 0
Возможен вариант оператора FOR, когда переменная принимает последовательно убывающие значения:
FOR переменная : = выражение! DOWNTO выражение2
DO оператор
В этом случае, чтобы цикл выполнился хотя бы раз, выражение! должно быть не меньше выражения2. Например:
for С := ’Z’ downto ’A’ do writein (С);
8.6. Оператор выбора
Если условный оператор напоминает дорожную развилку, то оператор выбора — это разделение пути на множество дорог, по одной из которых пойдет выполнение программы.
Вот схема оператора выбора:
CASE выражение OF
список констант: оператор;
список констант: оператор;
END
44
выражение порядкового типа вычисляется, и его зна 1ение отыскивается в одном из списков констант. После этого выполняется оператор, соответствующий списку.
Никакие два списка не должны иметь общих констант.
ПРИМЕР Число — прописью, var N: integer;
case N of
1: write (’один’);.
2: write (’два’);
3: write (’три’);
4,5,6,7,8,9: write (’много’) end;
Если значение выражения не найдено в списках, не выполняется ни один оператор.
ЗАДАЧИ
1. Определить значения следующих функций: PRED(spring) SUCC(summer) ORD(SUCC(winter)) SUCC(SUCC(outumn))
2. Напечатайте все трехзначные числа, у которых цифры разные.
3. Выведите на экран все символы и их коды.
4. Введите номер месяца. Напечатайте соответствующее
SUCC (2+3) PRED (0) PRED (’В ’) PRED (31.0)
месяцу время года : «зима», «весна», «лето», «осень».
5. Напишите программу, которая вводит русскую букву и сообщает, гласная она или согласная.
6. Введите строчную русскую букву. Выведите на экран такую же букву, но прописную.
7. Введите целое число. Выведите его на экран в шестнадцатиричной системе счисления.
Примечание. Для записи шестнадцатиричного числа используйте цифры 0, 1, 2, ..., 9, А, В, С, D, Е, F.
9 СТРОКИ символов
9.1. Значения и операции
Ci мвольный тип данных позволяет программисту работать с отдельными символами текста. Для обработки более крупных текстовых единиц — строк в Турбо-Паскале введен особый тип данных, который называется STRING (строка).
Значениями этого типа являются строки любых символов, заключенные в одинарные кавычки, например: 'Колледж', 'PASCAL', 'Курить — вредно’. Мы уже встречали их при организации вывода на экран (раздел 3.1), но официально не были знакомы.
Переменные строки должны быть описаны предложением
VAR имя: STRING
Строки можно присваивать, сравнивать всеми возможными способами, вводить, выводить и соединять. Соединение обозначается знаком «+». Вот примеры некоторых операций (справа — результат операции).
'стол' <= 'столик' 'АВС < 'ABDA' '12' < '2'
'Харь' + 'ков'
true true true 'Харьков'
ВОПРОС. На основе этих примеров сформулируйте правиле сравнения строк.
Среди всевозможных значений строк есть пустая строка. Она изображается двумя одинарными кавычками, между которыми ничего нет — ’.
Кавычка служит ограничителем строки. Чтобы не лишиться возможности иметь этот символ в составе строки, дого-
46
ворились повторять ее там дважды. Например, оператор write (’1м’’я’) выведет на экран: 1м’я .
9.2. Средства обработки строк
Турбо-Паскаль не только вводит дополнительный тип данных string, но и обеспечивает программиста готовыми функ-циями и процедурами для работы со строками.
Функции:
function Concat (s1, s2,..., sN: String) : String — соединяет последовательно строки si, s2,..., sN и возвращает полученное значение;
function Copy (S: String; Index: Integer; Count Integer): String — выделяет из строки S подстроку длиной в Count символов, начиная с позиции Index;
function Length (S: String) : Integer
возвращает длину строки;
function Pos (Substr: String; S: String) : Byte — возвращает позицию, с которой подстрока Substr первый раз встречается в строке S.
ВОПРОС. Что выведет функция
copy (X, pos(' ', X) + 1, 18), если X = ’Сила есть — ума не надо’ ?
Процедуры:
procedure Delete (var S: String; Index: Integer; Cointlnteger — удаляет из строки S Count символов, начиная с позиции Index;
procedure Insert (Source: String; var S: String; Index: Integer) — вставляет подстроку Source в строку S, начиная с позиции Index;
Для преобразования чисел в строки и обратно служат процедуры Str и Vai.
procedure Str (X [: Width [: Decimals ]]; var S : string) — преобразует число X в :троку S. Квалификаторы Width и Decimals выполняют ту же роль, что в операторе write. Квадратные скобки означают необязательность того, что в них заключено.
procedure Vai (S: String; var V; var Code: Integer) — преобразует строку S в значение числовой переменной V. Строка S должна быть корректной записью числа. Если это
47
нетак, переменная V=0, переменная Code <>0. В случае успешного преобразования Code = 0.
ВОПРОС. Почему процедура Str не имеет параметра, подобного параметру Code процедуры Vai?
На примере средств обработки строк видно, каким образом могут быть расширены возможности алгоритмического языка в любом направлении. Благодаря процедурам и функциям, каждый программист может сделать это для себя или для других.
9.3. Строка — составной тип данных
Программисту доступны отдельные символы переменной строки. С ними работают так, как если бы описатель STRING был равносилен описателю ARRAY [0..255] OF CHAR. Другими словами, если описана переменная X: STRING, то Х[1] — это символьная переменная со значением первого символа строки, Х[2] — символьная переменная со значением второго символа и т.д.
У X [0] особая роль — хранить длину строки. Значением X [0] является символ, код которого равен количеству символов в строке.
ВОПРОС. Чему равно значение X [0] после присваивания X := 'вопрос' ?;
Работая с отдельными символами строки, надо соблюдать осторожность, т.к. X [i] лишь тогда означает i-й символ строки, когда сама строка длиннее, чем I.
ЗАДАЧИ
1. Заменить в заданной строке первое вхождение слова «кот» словом «пес».
2. Сделать то же, но со всеми вхождениями.
3. Значением строки служит слово с дефисом. Обменять местами части слова до и после дефиса.
4. В строке — русское предложение. Выделить в отдельную строку первое слово предложения.
5. В строке — русское предложение, слова которого разделены одним или несколькими пробелами. Оставить по одному пробелу в качестве разделителя.
6. Удалить из строки все находящиеся в ней пробелы.
48
7. Определить, является ли заданная строка палиндромом (пример палиндрома: «А роза упала на лапу Азора»).
8. Рассматривая строку как массив символов, запрограммировать на Паскале следующие процедуры и функции:
1) length; 2) сору; 3) pos; 4) insert; 5) delete.
9. Запрограммировать на Паскале процедуры str и val.
10. Задан массив английских слов. Распечатайте все слова в алфавитном порядке.
11. Задан массив русских слов. Напечатайте все пары слов, образующих рифму.
W ОБРАБОТКА ЗАПИСЕЙ
10.1. Записи
В жизни встречается такая информация, которая состоит из данных разного типа. Это анкеты, таблицы, каталожные карточки и т.п. Для представления их в программе применяют записи.
Запись — это составной тип данных, который объединяет з себе разнотипные элементы (поля записи). Этот тип описывает конструкция:
имя типа = RECORD имя поля: тип поля; имя поля: тип поля;
имя поля: тип поля END
ПРИМЕР. Описание записи, содержащей сведения о книге.
type
Book = record
Tittle: string [80]; {название}
Author: string [20]; {автор}
Year : integer; {год издания}
end;
ВОПРОС. Чем отличаются и чем сходны запись и массив ?
Над записями допустимы операции присваивания, проверки на равенство и неравенство, ввода и вывода.
50
С полем записи в программе можно поступать, как с переменной того же типа, что поле. Обращаются к полю по составному имени:
имя записи.имя поля
ПРИМЕР. Работа с записями
var
X,Y: Book; {описание этого типа см.выше}
Z: array [1..100] of Book;
begin
X.Tittle := ' ТРИ МУШКЕТЕРА’;
X.Author := 'А.ДЮМА’;
X.Year := 1980;
Y := X;
writein (Y.Head, Y.Author);
Z [5] := X;
end.
Тип поля может быть любым, в том числе и записью. Например:
type
Full Name = record
Surname: string-
Name : string[20];
end;
Book = record
Tittle: string;
Author: Full Name;
Year: integer;
end
Если поле является записью, обращение к его элементам (полям поля) происходит по имени, состоящему из трех частей, например, X.Author.Surname. Глубина вложения описаний не ограничена.
10.2. Оператор WITH
Этот оператор для тех, кто не любит много писать. Он позволяет сократить обращение к полям записи. Его схема:
WITH имя записи DO оператор
Всюду внутри оператора можно опускать имя записи, в составном имени поля, транслятор добавит его сам.
51
ПРИМЕР. Применение оператора WITH, var X: Book;
with X do begin readln (Tittle, Author, Year); write (Tittle, Author, Year) end
10.3= Последовательный поиск
Компьютер идеально приспособлен для работы с большими объемами информации: телефонным справочником, адресной книгой, библиотечным каталогом. В фантастических романах суперЭВМ имеет сведения о каждом человеке на Земле.
Для хранения такой информации подходит массив записей.
ПРИМЕР. Описание библиотечного каталога
type
Book = record
Tittle: string [40];
Author: string [12];
Year: integer;
end;
Catalog = array [1..1000] of Book;
Посмотрим, как найти сведения о книге по заданному признаку, например, по фамилии автора. Найти, значит определить номер записи в массиве или сообщить об отсутствии такой записи.
Самый простой алгоритм поиска — последовательный. Он состоит в том, что у всех записей последовательно, начиная с первой, проверяется значение признака, по которому ведется поиск. Пусть требуется найти книгу, которую написал Вирт. Это можно сделать так
i := 1;
while (i <= 1000) and (Cat.Author О 'Вирт') do
i := i + 1;
где Cat — переменная типа Catalog
52
ВОПРОС. Как узнать, найдена запись или нет по завершении цикла ?
Рассмотренный алгоритм требует одного сложения и двух сравнений при каждом повторении цикла. До окончания поиска может выполниться очень много циклов, поэтому время поиска зависит от числа операций в одном повторении. Если, скажем, сократить число операций до двух, то время поиска уменьшится на 1/3.
Алгоритм поиска с двумя операциями в цикле существует. Его особенность в том, что запись с искомым признаком вносится в массив искусственно перед началом поиска.
ВОПРОС. Можете ли вы сами сформулировать такой алгоритм ?
10.4. Двоичный поиск
Общим свойством алгоритмов последовательного поиска является то, что время поиска прямо пропорционально количеству записей. Можно ли искать быстрее ? Оказывается, да, если массив записей отсортирован по значению искомого признака.
Рассмотрим следующий алгоритм поиска слова в словаре.
1.Открыть словарь посередине.
2.Сравнить искомое слово с тем, что в середине словаря.
З.Если слова совпадают, поиск завершен.
4.Если слово в середине больше искомого, продолжить поиск в первой половине словаря.
5.Если слово в середине меньше искомого, продолжить поиск во второй половине словаря.
Слова «продолжить поиск» означают применение алгоритма в целом к половине словаря, т.е. открыть ее посередине и т.д. В конце концов, либо слово будет найдено, либо делить пополам будет нечего, значит, слова в словаре нет.
ВОПРОС. Почему такой поиск называется двоичным ?
Словарь можно хранить в массиве записей, начало и конец области поиска запоминать в особых переменных. Запись словаря должна иметь отдельное поле, значением которого является слово.
ВОПРОС. Сформулируйте алгоритм двоичного поиска применительно к массиву записей.
53
Сравним скорость последовательного и двоичного поиска. Первый сокращает область поиска на одну запись за каждый шаг алгоритма. Второй за один шаг уменьшает область поиска в два раза. Следовательно, при удвоении числа записей время последовательного поиска возрастет в два раза, а время двоичного поиска увеличится лишь на один шаг алгоритма.
ВОПРОС. В массиве из N записей поиск в худшем случае продолжается 2 сек. Сколько времени он займет в массиве из 1024*N записей Дайте ответ для:
а) последовательного,
б) двоичного поиска.
ЗАДАЧИ
1. Перечислите качества, характеризующие программиста и предложите меру этих качеств. Опишите запись, предназначенную для хранения характеристики программиста.
2. Опишите массив записей, содержащих фамилию абонента и номер его телефона. Заполните несколько элементов этого массива фамилиями и телефонами своих знакомых.
3. Запрограммируйте поиск с порогом в телефонном справочнике.
4. Запрограммируйте двоичный поиск в телефонном справочнике.
5. Пропорциональный поиск отличается от двоичного тем, что область поиска делится на части, размер которых зависит от величин крайних и искомого ключей. Запрограммируйте пропорциональный поиск в телефонном справочнике.
6. - Индексом называется таблица, содержащая значения некоторых ключей и их местоположение в массиве записей. Индексом пользуются для ускорения поиска в массиве.
Запрограммируйте процедуры:
а) составления индекса;
б) последовательного поиска при помощи индекса.
Л РАБОТА С ФАЙЛАМИ
11.1. Файлы на магнитном диске
Данные, размещаемые программой в памяти компьютера, недолговечны; когда питание выключат, они исчезнут, если еще раньше их не сотрет следующая программа. Для сохранения информации всерьез и надолго ее записывают на магнитный диск.
Единицей хранения информации в библиотеке служит книга, единицей хранения информации на диске служит файл. Он имеет имя и занимает на диске область, размер которой зависит от объема файла. В файлах хранят документы, программы, изображения, — одним словом, все, что можно записать при помощи чисел или символов.
Различают два вида файлов: последовательного и произвольного доступа. Последовательные файлы состоят из элементов различной длины, между которыми стоят разделители. Чтобы найти элемент последовательного файла, надо просмотреть все, что ему предшествует.
Файлы произвольного доступа состоят из однотипных элементов, как массивы. Найти любой элемент можно по его порядковому номеру
В Паскале последовательные файлы называют текстовыми, а файлы произвольного доступа — типизированными.
Программа может обрабатывать существующий файл или создать новый файл. В любом случае работа с файлом складывается из трех пунктов:
1) открытие файла;
2) чтение или запись;
3) закрытие файла.
55
11.2. Текстовые файлы
Текстовые файлы хранят информацию в виде последовательности символов Символы составляют строки произвольной длины. В конце каждой строки находятся два особых символа: #13 #10, которые отделяют строку от следующей. Текстовые файлы широко распространены, их способен создавать любой экранный редактор.
В программе на Паскале текстовый файл представляет файловая переменная типа TEXT Ее описывают предложением
VAR имя: TEXT
Файловой переменной назначают имя файла при помощи оператора
assign (файловая переменная, имя файла), где имя файла — строка, содержащая дисковое имя файла.
Больше нигде в программе не появится имя файла, всюду его заменит файловая переменная.
Теперь файл необходимо открыть. Текстовый файл можно открыть:
для чтения — оператором
reset (файловая переменная);
для записи — оператором
rewrite (файловая переменная);
для пополнения — оператором
append (файловая переменная).
В файл, открытый для записи или пополнения, можно только писать, из файла, открытого для чтения, можно только читать. Если необходимо прочесть из файла, открытого для записи, его сначала надо закрыть оператором
close (файловая переменная),
а затем снова открыть уже для чтения.
11.3. Чтение из текстового файла
Чтение из файла выполняется хорошо знакомым нам оператором READ. Если перед списком ввода в операторе READ стоит файловая переменная, он вводит данные не с клавиатуры, а из файла. Например,
56
var
f: text;
a,b,c: Integer;
read (a,b,c); {ввод с клавиатуры} . read (f,a,b,c); {ввод из файла}
Текстовый файл для оператора READ такой же источник символов, как и клавиатура, только эти символы следуют друг за другом не во времени, а в пространстве файла. Во времени можно перемещаться лишь в одну сторону, по файлу — тоже. Движение допускается последовательное, от начала к концу, поэтому текстовые файлы называют последовательными.
Чтобы уяснить, что прочтет из файла тот или иной оператор READ, введем понятие указателя файла. Фактически указатель — это номер очередного символа файла, но лучше вообразить его в виде стрелки, направленной в определенную точку файла.
Сразу после открытия стрелка указывает на первый символ файла. Чтение очередной порции данных всегда выполняется, начиная с символа, на который показывает стрелка. После чтения стрелка автоматически передвигается вперед на длину прочитанного участка. Так продолжается, пока стрелка не достигнет конца файла. Дальнейшие попытки чтения вызовут сообщение об ошибке.
Как узнать, можно ли еще читать из файла ? Для этого в Паскале есть логическая функция
EOF (файловая переменная)
Она возвращает true, если достигнут конец файла, и false в противном случае. Название функции сокращает слова «End Of File» — конец файла.
Дополнительный оператор чтения READLN вводит все, предусмотренное списком ввода, и продвигает указатель до начала следующей строки.
ПРИМЕР. Чтение из текстового файла с выводом на экран.
var
f: text;
s: string;
begin
assign (f.’XXX.TXT’);
reset (f);
57
while not eof (f) do begin
readln (f, s); {ввод из файла} writein (s); {вывод на экран} end {while};
close(f) end.
ВОПРОС. Как подсчитать число строк в текстовом файле ?
11.4. Запись в текстовый файл
Запись в текстовый файл выполняется оператором WRITE, в котором перед списком вывода стоит файловая переменная. Выводимая информация присоединяется к той, что была выведена в файл с момента его открытия.
Желая создать новый файл, его открывают оператором REWRITE. Если же хотят дополнить уже существующий файл, открытие выполняют оператором APPEND. Открытие существующего файла оператором REWRITE приведет к потере того, что находилось там раньше.
Закончив запись в файл, вы должны его закрыть. Только после закрытия новый файл будет окончательно сформирован.
Дополнительный оператор записи WRITELN выводит все, предусмотренное списком вывода, и символы #13 #10 впри-дачу.
ПРИМЕР. Ввод с клавиатуры и запись в текстовый файла.
var
f: text;
s: string;
begin
assign (f.’XXX.TXT’);
rewrite (f); {открытие файла} readln (s); {ввод с клавиатуры} while s "do begin
writein (f,s); {вывод в файл} readln (s); {ввод с клавиатуры} end {while}, close (f) {закрытие файла}
end.
ВОПРОС. Что надо изменить в примере, чтобы программа копировала файл ХХХ.ТХТ в файл YYY.TXT ?
58
11.5. Устройства DOS
Кроме дисплея и дисков текст можно выводить на принтер, в коммуникационный порт, на пустое устройство. Операционная система выполняет роль посредника при обмене информацией между программой и любым из внешних устройств компьютера. Это выражается в том, что программис-ту предлагается работать не с самими устройствами со всей присущей им сложностью и разнообразием модификаций, а с логической моделью устройства в форме текстового файла.
Текстовые файлы, моделирующие устройства, существуют в виде распечатки, символов на экране, последова-тельнос-ти электрических сигналов и носят закрепленные за ними имена:
PRN принтер,
LPT1 синоним PRN,
LPT2 второй принтер,
LPT3 третий принтер,
CON консоль (дисплей+клавиатура),
СОМ1 первый коммуникационный порт,
COM2 второй коммуникационный порт,
NUL пустое устройство — игнорирует запись и ге-
нерирует сигнал, «конец файла» при чтении.
Работа с устройствами DOS ничем не отличается от работы с текстовыми файлами на дисках.
ПРИМЕР. Вывод на принтер
var
Lst: text;
begin
assign (Lst, ’PRN’);
rewrite (Lst);
' writeln (Lst, ’Hallo PRN !’); close (Lst);
end.
11.6. Стандартные фаиль ввода и вывода
Есть два текстовых файла, которые всегда к услугам программиста. Это стандартный вводной и стандартный вывод-н й файлы. Их файловые переменные носят имена Input и Output соответственно.
59
Чтение из стандартного вводного файла выполняется операторами read и readln без указания файловой переменной, запись в стандартный выводной файл Output делается такими же операторами write и writein.
В программе на Паскале молчаливо предполагается, что оба стандартных файла назначены на устройство ’CON’, т.е. Input — на клавиатуру Output — на дисплей. Это назначение можно изменить, например, так:
assign (Output, ’PRN’); rewrite (Output).
С этого момента вся информация, выводимая операторами write и writein, будет поступать не на экран, а на принтер. Чтобы восстановить существовавшее положение, надо выполнить операторы:
assign (Output, ’CON’);
rewrite (Output).
11.7. Типизированные файлы
Файлы произвольного доступа в ТП носят название типизированных. Элементами таких файлов могут быть числа, массивы, записи, но только не файлы.
Все элементы типизированного файла одного типа, а значит, и одного размера. Именно благодаря этому возможен произвольный доступ к элементам типизированного файла, т.к. по номеру элемента однозначно определяется его местоположение на магнитном диске. Нумеруются элементы файла целыми числами, начиная с нуля.
Типизированная файловая переменная описывается предложением
var имя: file of базовый тип
Связь файловой переменной с набором данных на диске выполняется, как и для текстовых файлов, оператором Assign.
В отличие от текстовых, типизированные файлы допускают чередование операций записи и чтения независимо от того, каким оператором, Reset или Rewrite, был открыт файл. Оператором Reset открываются уже существующие файлы, а оператором Rewrite — новые. Закрывается файл операторЬм Close. Внешне все четыре оператора не отличаются от таких же операторов для текстовых файлов.
60
Чтение из типизированного файла выполняется оператором
Read (файл, v1 [,v2...vN]),
запись — оператооом
Write (файл, v1 [,v2..vN]),
где v1,v2,...,vN — переменные базового типа.
Запись и чтение из типизированных файлов выполняются без преобразования данных, что существенно ускоряет эти операции. За это мы лишаемся важного преимущества текстовых файлов — возможности хранить в файле разнотипные данные.
Произвольный доступ к элементам файла выполняется оператором
Seek (файл, номер элемента: longint)
Этот оператор устанавливает указатель файла на элемент, номер которого является вторым параметром. Именно этот элемент будет считан или записан при очередном вводе или выводе.
Текущее положение указателя файла возвращается функцией
FilePos (файл) : longint, а общее количество записей — функцией
FileSize (файл) : longint
Как и для текстовых файлов, ситуация «конец файла» диагностируется функцией EOF (файл).
Поскольку типизированные файлы не нуждаются в разделителях элементов, функция EOF и дополнительные операторы ReadLn и WriteLn для них не имеют смысла.
ПРИМЕР. Работа с типизированным файлом.
var
f: file of real;
R: real;
i: integer;
begin
{создать новый файл по имени REAL-FILE.DAT)
assign (f, ’REALFILE.DAT’);
rewrite (f);
61
{сохранить вещественные числа в типизированном файле} for i := 1 to 5 do begin readln (R);
write (f,R);
end;
{записать последнее число на место первого} seek (f, fileSize (f) — 1);
read (f, R);
seek (f, 0);
write (f, R);
{дописать в файл число 5.5} seek (f, filesize (f));
R := 5.5;
write (f, R);
{вывести содержимое файла на экран} reset (f);
{без закрытия не будут видны изменения}
while not eof (f) do begin read (f,R);
writein (R); end {while};
{закрыть файл} close (f);
end.
ВОПРОС. Что выведет программа, если перед выводом содержимого на экран файл открыть оператором Rewrite?
ЗАДАЧИ
1. Создайте телефонный справочник в текстовом файле.
2. Запрограммируйте процедуру пополнения телефонного справочника сведениями о новом абоненте.
3. Введите фамилию абонента и выведите номер его телефона, найденный в справочнике. Предоставьте пользователю выбрать устройство вывода (экран, принтер или файл на диске).
62
4 Слейте два упорядоченных текстовых файла в один, сохранив порядок.
5. В файле хранится русский текст. Запрограммируйте процедуру, которая при каждом вызове возвращала бы очередное слово текста.
6. Укажите 8 отличий между текстовыми и типизированными файлами.
7. Типизированный файл состоит из записей, включающих фамилию спортсмена и результат бега на 100 м с барьерами. Определить фамилии бегунов, занявших первое, второе и третье места в соревновании.
8. В файле, состоящем из вещественных чисел, найти размер самой длинной неубывающей числовой последовательности.
9. Задан упорядоченный файл из целых чисел. При помощи генератора псевдослучайных чисел сделайте его неупорядоченным.
10. Запрограммируйте двоичный поиск в типизированном файле.
Ю ДИНАМИЧЕСКАЯ IX ПАМЯТЬ
12.1. Статические и д инамические перемежые
Все переменные, описанные в предложении VAR, размещаются в памяти перед выполнением программы и постоянно там находятся. Эти переменные называют статическими.
Во время выполнения программы можно размещать в памяти. новые переменные и освобождать память, когда необходимость в них отпадет. Такие переменные называют динамическими.
Динамические переменные безымянны, поэтому к ним обращаются не по имени, а по их адресу в памяти. Адреса хранятся в переменных особого типа — указателях. Для обращения к динамической переменой используют имя указателя, дополненное справа вертикальной стрелкой.
Не существует констант типа указатель, кроме одной — nil, которая обозначает «пустой» адрес. Различают указатели на целые, на вещественные, на массивы и вообще — на любой тип данных. Это различие проявляется в описании указателей, которое выглядит так:
''базовый тип
Например,
var
PI: ''integer; {указатель на целое)
PR: ''real; {указатель на вещественное)
РА: ''array[1..1000] of real; {указатель на массив)
ВОПРОС. Опишите указатель на указатель на целое.
64
12.2. Выделение и освобождение памяти
Выделение памяти для динамической переменной выполняется процедурой
NEW (указатель)
Процедура выделяет в памяти место, достаточное для хранения значений требуемого типа, и помещает адрес этого места в указатель.
ВОПРОС. Если все указатели хранят адреса, зачем разли чать типы указателей ?
ПРИМЕР. Работа с указателями, var Q Р
Р, Q : integer;
begin new(P);
Р": = 5;
Q: = P;
Р : = nil;
Q : = 8;
write (CT);
end.
Рис. 12.1
Процедура
DISPOSE (указатель)
освобождает память, на которую указывает ее параметр. Теперь эта память может быть распределена повторно.
Однотипные указатели можно сравнивать и присваивать.
Значение nil можно присвоить любому указателю.
ВОПРОС. Чем является указатель в процедурах new и dispose — параметром или параметром-переменной ?
3 «Основы программирования»
65
12.3. Массив указателей
Транслятор ограничивает суммарный объем статической памяти одним сегментом, т.е. 64 К. Объем динамической памяти ограничен лишь физическим ресурсом компьютера, а это гораздо больше.
Предположим, мы хотим запомнить как можно больше длинных строк символов. Размер строки — 256 байт, поэтому их предельное количество в статической памяти равно 64 * 1024 / 256 = 256.
Для хранения большего числа строк разместим статической памяти лишь указатели на них, а сами строки перенесем в динамическую память. Заметим, что размер одного указателя — 4 байта.
ПРИМЕР.
const
Maxitem = 2000;
type
PString = ''String;
TDinMas = array [1..Maxltem] of PString; var
p: TDinMas;
i: integer;
begin
for i := 1 to Maxitem do new (p [i]);
p [If:-Hallo»’;
end.
ВОПРОС. Дополните пример освобождением динамической памяти, занятой строками.
12.4. Динамические списки
В предыдущем примере на каждую динамическую переменную указывала одна статическая. Можно ли и указатели перенести в динамическую память? Да, если воспользоваться связанным списком.
Каждый элемент связанного списка, во-первых, хранит какую-то информацию, во-вторых, указывает на следующий за ним элемент. Лишь на самый первый элемент (голову списка) имеется отдельный указатель. Последний элемент никуда не указывает
66
nil
HEAD
Рис. 12 2
Элемент списка состоит из разнотипных частей (хранимая информация и указатель), и его естественно представить записью. Перед описанием самой записи описывают указатель не нее.
ПРИМЕР. Описание списка из целых чисел.
type
PEIement = "TEIement; {описание указателя)
TEIement = record {описание элемента)
Inf: integer;
Next: PEIement; end;
Число элементов связанного списка может расти или уменьшаться в зависимости от того, сколько данных мы хотим хранить в нем. Чтобы добавить новый элемент в список, необходимо:
1) получить память для него;
2) поместить туда информацию;
3) присоединить новый элемент к голове списка.
ПРИМЕР. Присоединение элемента к списку, var
X, Head: PEIement;
begin
new (X);
readln (X".lnf);
X".Next := Head; Head := X;
end.
Построение списка сводится к последовательному добавлению элементов в первоначально пустой список. На пустой список указывает пустой указатель (Head = nil).
Для удаления первого элемента из непустого списка необходимо:
1) передвинуть указатель с головы на следующий элемент;
з*
67
2) освободить память, занятую удаленным элементом.
ПРИМЕР Удаление элемента из списка.
var
X, Head: PEIement;
begin
X := Head;
Head := Head".Next;
dispose (X);
end.
Важно уметь перебирать последовательно все элементы списка, выполняя над ними какую-то операцию. Это называется прохождением списка.
ПРИМЕР. Пройти список, найдя сумму хранящихся в нем чисел.
var
X, Head: PEIement;
Summa: integer;
begin
Summa := 0;
X := Head;
while X nil do begin
Summa := Summa + X".lnf;
X := X".Next;
end {while};
end.
ЗАДАЧИ
1. Сохраните простой список в текстовом файле.
2. Восстановите простой список из текстового файла.
3. Опишите процедуры:
а) изменения порядка элементов списка на противоположный;
б) присоединения списка L2 к списку L1;
в) добавления элемента в конец списка,
г) удаления последнего элемента списка.
4. Опишите процедуру, которая формирует список L, включив в него по одному разу элементы, которые:
68
а) входят хотя бы в один из списков L1 и L2;
б) входят одновременно в оба списка L1 и L2;
в) входят в список L1, но не входят в список L2;
г) входят хотя бы в один из списков L1 и L2, но в то жр время не входят в другой из них;
5. Добавить элемент в список:
а) после элемента, на который указывает Р;
б) перед элементом, на который указывает Р.
6. Удалить элемент, стоящий:
а) после элемента, на который указывает Р;
б) перед элементом, на который указывает Р.
7. Отсортировать простой список по возрастанию поля Inf.
8. Многочлен Р(Х) = Ап * Хп +...+ Ai * X + Ао с целыми коэффициентами можно хранить в форме списка. Опишите функции:
a) equal (p,q), проверяющую на равенство многочлены р nq;
б) value (р,х), вычисляющую значение многочлена р в точке х;
в) summa (p,q,r), которая строит многочлен г = р + q.
13
РЕКУРСИЯ
13.1. Рекурсивные алгоритмы и рекурсивнь е определения
Программист разрабатывает программу, сводя исходную задачу к более простым. Среди этих задач может оказаться и первоначальная, но в упрощенной форме. Например, вычисление функции F(N) может потребовать вычисления F(N—1) и еще каких-то операций. Иными словами, частью алгоритма вычисления функции будет вычисление этой же функции.
Алгоритм, который является своей собственной частью, называется рекурсивным. Часто в основе такого алгоритма лежит рекурсивное определение какого-то понятия. I Например, о факториале числа N можно сказать, что
N! = 1 * 2 *...* (N—1) * N, или 1, если N = 0;
N! = (N — 1)! * N, если N!= 0.
Второе определение — рекурсивное.
Дадим рекурсивное определение списка: «Список — это пустая структура или элемент списка, указывающий на список». Пустой считается структура, на которую «указывает» nil.
Вот еще одно рекурсивное определение.
1. Стадо из п коров — это 3 коровы.
2. Стадо из п коров — это стадо из п—1 коровы и еще одна корова.
Попробуем применить это определение для проверки, является ли нечто стадом коров. Пусть это будет группа из пяти коров, обозначим ее К5. Объект К5 не удовлетворяет первому пункту определения, поскольку пять коров — это не три коровы. Согпасно второму пункту К5 — стадо, если
70
там есть одна корова, а остальная часть К5, назовем ее К4, — тоже стадо коров. Решение относительно объекта К5 откладывается, пока не будет принято решение относительно К4. Объект К4 снова не подходит под первый пункт, а второй пункт гласит, что К4 — стадо, если объект КЗ, полученный из К4 путем отделения одной коровы, тоже стадо. Решение о К4 тоже откладывается. Наконец, объект КЗ удов летворяет первому пункту определения, и мы можем смело заявить, что КЗ — стадо коров. Теперь и о К4 можно утверждать, что это стадо, а значит, и К5 является стадом коров.
Любое рекурсивное определение состоит из двух частей. Одна часть определяет понятие через него же, другая часть — через иные понятия.
ВОПРОС. Дайте рекурсивное определение целой степени числа R.
13.2. Рекурсивные процедуры и функции
Записать рекурсивный алгоритм на Паскале можно при помощи рекурсивной процедуры. Процедура является рекурсивной, если она обращается сама к себе прямо или
Заметим, что при косвенном обращении все процедуры в цепочке — рекурсивные.
Все сказанное о процедурах целиком относится и к функциям.
Вернемся к рекурсивному определению факториала. Достаточно переписать его на Паскале и получится описание рекурсивной функции.
ПРИМЕР
function Factorial (N: integer) : integer;
begin
if N = 0 then
Factorial := 1 else
Factorial := Factorial (N—1) * N end;
71
Рекурсивное определение списка позволяет по-новому определить прохождение списка. Пройти список означает посетить голову и пройти список, на который указывает голова (пройти хвост).
ПРИМЕР. Печать списка.
procedure PrintList (Head: PEIement);
begin
if Head nil then begin writein (Head".Inf); PrintList (Head".Next) end {if};
end;
ВОПРОС. Как изменится результат работы PrintList, если изменить порядок следования операторов
writein (Head".Inf);
PrintList (Head".Next)
на противоположный ?
13.3. Рекурсия изнутри
Это может показаться удивительным, но оамовызов процедуры ничем не отличается от вызова другой процедуры. Что происходит, если одна процедура (или программа) вызывает другую? В общих чертах следующее:
1) в памяти размещаются параметры, передаваемые процедуре (но не параметры-переменные!);
2) в другом месте памяти сохраняются значения внутренних переменных вызывающей процедуры;
3) запоминается адрес возврата в вызывающую процедуру (или программу);
4) управление передается вызванной процедуре.
Если процедуру вызвать повторно из другой процедуры или из нее самое, будет выполняться тот же код, но работать он будет с другими значениями параметров и внутренних переменных. Это и дает возможность рекурсии
Пусть рекурсивная процедура Power (X, N, У) возводит число X в целую степень N и возвращает результат У.
procedure Power (X: real; N: integer; var Y: real); begin
if N = 0 then Y := 1
72
else begin
Power (X, N — 1, Y); Y := Y * X end;
end
Проследим за состоянием памяти в процессе выполнения вызова Power (5, 3, Y). Стрелка «—>»означает вход в процедуру, стрелка «<—» означает выход из нее.
X N Y
—>Power(5,3,Y) X’ Y’ 3
—> Power(5,2,Y) |5|3| |_5]_2j X” Y" □
—> Power(5,1,Y) L513] UJ ш X'” V” Ш
—> Power(5,0,Y) 1513 I I5I2I I 5l 11 I 5I0I [7 I
<— Power(5,0,Y) L5]3j |_5[2] [511J □
<— Power(5,1,Y) I5J3J.L512J 0
<— Power(5,2,Y) <—Power(5,3,Y) [5j3j [ 25 125
Рис. 13.2
Число копий переменных, одновременно находящихся в памяти, называется глубиной рекурсии. Как видно из примера, сначала она растет, потом сокращается.
ВОПРОС. Какова наибольшая глубина рекурсии при прохождении списка из N элементов ?
13.4. Быстрая обменная сортировка
Теперь мы готовы к тому, чтобы познакомиться с алгоритмом сортировки массива, который во столько раз быстрее квадратичного, во сколько двоичный поиск быстрее последовательного. Он носит название быстрой обменной сортировки или сортировки Хоора.
1. Выбираем один из ключей массива в качестве разделителя.
73
2. Располагаем ключи, меньшие разделителя, до него, а большие — после.
3. Сортируем часть массива до разделителя.
4. Сортируем часть массива после разделителя.
Алгоритм выполняется, если размер сортируемой области больше 1
Пункт 2 можно выполнить, просматривая массив от краев к центру и меняя местами ключи, нарушающие порядок.
Пример перемещения ключей при выполнении пункта 2:
40 80 30 50 60 10 20
— > <
40 20 30 50 60 10 80
- > <
40 20 30 10 60 50 80
— < >
20 30 10 40 60 50 80
ВОПРОС. Какова временная сложность пункта 2 ?
ЗАДАЧИ
1. Вычислите произведение элементов массива:
А[1] * А[2] *...*A[N]
рекурсивным алгоритмом.
2. Определите рекурсивную функцию
function Sim(S:string; i, j: integer): boolean,
которая определяет, является ли симметричной часть строки S, начиная с i-го элемента и кончая j-м
3. Запрограммируйте рекурсивную функцию
function R (N:integer): boolean
проверки правильности имени в алгоритмическом языке Паскаль.
Имя расположено в N первых элементах символьного массива.
4. Запрограммируйте рекурсивный поиск наименьшего элемента массива.
74
6. Запрограммируйте алгоритм двоичного поиска в рекурсивной форме.
6. Напишите рекурсивную программу сортировки выбором.
7. Запрограммируйте рекурсивный алгоритм быстрой обменной сортировки.
8. Во входном файле записана формула следующего вида: формула :.= цифра | формула знак формула цифра ::= 0 | 1 |2|3|4|5|6|7|8|9.
Ввести эту формулу и вычислить ее значение.
9. Запрограммируйте процедуру, которая печатала бы все перестановки из заданных п символов.
14
ДЕРЕВЬЯ
14.1. Деревья вокруг нас
Дерево это иерархическая структура, состоящая из узлов и соединяющих их дуг. В каждый узел, кроме одного, ведет ровно одна дуга. Этот единственный узел называется корнем дерева.
Многие отношения, которые встречаются в жизни и в программировании, можно изобразить в виде деревьев. Например, вообразите себя корнем дерева. От вас ведут две дуги, к отцу и к матери. От них дуги ведут к их родителям и т.д. Получилось ваше генеалогическое дерево.
Посмотрим на колледж. В нем учатся два курса, на каждом курсе по две группы, в каждой группе по 18 учеников. Снова мы видим дерево.
___________КОЛЛЕДЖ__________
1 КУРС 2КУРС
‘---->-----1----------------,-----!----.
11 ГРУППА 12 ГРУППА 21 ГРУППА 22ГРУППА
। 1 I М I I I I I I I I I I I I *1 I I I ГТТТТТ1
УУУУУУУ УУУУУУУ УУУУУУУ УУУУУУУ
Рис. 14.1
Обратите внимание на компьютерную программу. Ее блоки составляют дерево, дуги которого означают вложенность. Взаимная вложенность операторов цикла, условных операторов, составных, — все это деревья. Даже арифметические выражения представляют собой деревья, в узлах которых операции.
76
((A+B)‘(C-D))/(F+G)
Рис. 14.2
Еще одно применение деревьев — это хранение и поиск информации, но с ним мы познакомимся немного позже.
14.2. Рекурсивное определение дерева
В начале предыдущего подраздела мы сказали, что дуги ведут к узлам дерева. Иная точка зрения состоит в том, что дуги ведут к частям дерева, которые сами являются деревьями. Она приводит к рекурсивному определению дерева: «Дерево — это пустая структура или узел, связанный дугами с конечным числом деревьев».
Пустое дерево — то же, что пустой список. Вообще, есть близкое родство между деревом и списком.
ВОПРОС. Как закончить фразу «Список — это дерево, в котором ...» ?
Рекурсивное и нерекурсивное определения дерева равносильны, но из второго можно извлечь много полезных алгоритмов.
14.3. Двоичные деревья
Деревья, в которых из каждого узла исходит не более двух дуг, называются двоичными. Такие деревья чаще других применяются для хранения и обработки информации.
Подобно элементам списка узлы дерева представляют в виде записей, хранящих некоторую информацию и два указателя.
ПРИМЕР. Описание узла дерева.
type
PNode = "TNode;
TNode = record
Inf: string;
Left, Right: PNode;
end;
77
В качестве хранимой инф рмации в примере выбра строка символов, но ничто не мешает хранить данные любого типа.
Отдельная переменная типа PNode должна указывать на корень дерева подобно переменной, указывающей на голову списка.
Прохождение дерева заключается в обходе всех его узлов. Сформулируем рекурсивный алгоритм прохождения бинарного дерева:
1. Посетить корень.
2. Пройти левое поддерево.
3. Пройти правое поддерево.
Обходя дерево (см. рис.) по этому алгоритму, мы посетим узлы в следующем порядке: А, В, С, D, Е, F, G.
А
।---1---1
В Е
С ' Ь F G
Рис. 14.3
ВОПРОС. Как следует изменить порядок пунктов алгоритма, чтобы пройти узлы в такой последовательности:
а) А,Е G P.B.D.C;
b) С D,B,F,G,E,A;
с) C,B,D,A,F,E,G ?
14.4. Двоичные упорядоченные деревья
В упорядоченных массивах можно быстро найти нужную информацию. Динамические списки можно быстро пополнить новыми элементами. Двоичные упорядоченные деревья соединяют в себе оба этих качества.
Двоичное дерево упорядочено, если все ключи левого поддерева каждого узла меньше, чем ключ узла, а ключи правого поддерева — больше (ключом называется признак, по которому ведется поиск).
Поиск в упорядоченном дереве выполняют рекурсивным алгоритмом очень похожим на алгоритм двоичного поиска.
1. Если дерево не пусто, то нужно сравнить искомый ключ с тем, что в корне дерева:
— если ключи совпадают, поиск завершен;
— если ключ в корне больше искомого, выполнить поиск в левом поддереве;
’8
— если ключ в корне меньше искомого, выполнить поиск в правом поддереве.
2. Если дерево пусто, поиск неудачен.
Продолжительность поиска определяется длиной одной ветви дерева. Если ветви примерно одинаковы (дерево сбалансировано), то время поиска в дереве с N узлами такое же, как время двоичного поиска в упорядоченном массиве из N элементов N—1
ВОПРОС. Если в дереве 15 узлов и все ветви одинаковой длины, какова длина ветви ?
Алгоритм поиска легко переделать в алгоритм включения нового узла в упорядоченное дерево. Для этого достаточно слова «поиск неудачен» заменить словами «включаем новый узел в качестве правого (левого) поддерева».
При удалении узла из дерева возможны следующие случаи:
1) удаляемый узел не имеет поддеревьев;
2) удаляемый узел имеет лишь одно поддерево;
3) удаляемый узел имеет оба поддерева.
В первом случае достаточно убрать ссылку на удаляемый узел в родительском узле. Во втором случае следует заменить в родительском узле ссылку на удаляемый узел ссылкой на его поддерево. В третьем случае надо заменить удаляемый узел самым левым узлом его правого поддерева или самым правым узлом его левого поддерева.
ВОПРОС. Каким алгоритмом можно найти узел для замены в третьем случае ?
ЗАДАЧИ
1. В бинарном дереве хранятся вещественные числа. Найдите их сумму.
2. Опишите рекурсивную функцию или процедуру, которая:
а) определяет, входит ли элемент Е в дерево Т;
б) определяет число вхождений элемента Е в дерево Т;
в) находит величину наибольшего элемента непустого дерева Т;
г) определяет максимальную глубину дерева Т;
д) подсчитывает число вершин на п-ом уровне непустого дерева Т.
3. Опишите процедуру copy (Т.Т1), которая строит Т1 — копию дерева Т.
79
4. Опишите логическую функцию same (Т), определяющую, есть ли в дереве Т хотя бы два одинаковых элемента.
5. Опишите функцию или процедуру, которая:
а) проверяет, входит ли элемент Е в упорядоченное дерево Т;
б) записывает в файл F элементы упорядоченного дерева Т по возрастанию;
в) добавляет новый элемент Е к упорядоченному дереву Т;
г) строит упорядоченное дерево Т из элементов, расположенных в файле F.
6. Постройте частотный словарь для английского текста в файле объемом не менее 30 К.
7. Опишите процедуру, которая выводит на экран дерево, показывая глубину узлов отступом от левого края экрана. Например, дерево
КОЛЛЕДЖ
1 КУРС 2КУРС
<----1------! <-----'-------1
11 ГРУППА 12 ГРУППА 21 ГРУППА 22 ГРУППА
будет выведено так:
11 группа
1 курс
12 группа
Колледж
21 группа
2 курс
22 группа
15
МНОЖЕСТВА
15.1. Значения типа множество
Наряду с числом множество является фундаментальным математическим понятием. К операциям и отношениям на множествах сводится большинство математических моделей. Тем не менее, Паскаль — один из немногих алгоритмических языков, который имеет встроенные средства для работы с множествами. В этом разделе мы посмотрим, как «переводятся» на Паскаль некоторые понятия теории множеств.
Паскаль
[1,2,3]
[’A'.’K'.'B'.’L’]
пустое множество []
[1..N]
В математике рассматривают конечные и бесконечные множества, состоящие из произвольных элементов В Паскале множества всегда конечные, причем состоят из небольшого числа элементов (в Турбо-Паскале — до 255 ). Все элементы множества должны быть одного порядкового типа.
Постоянные множества и в математике и в Паскале задаются перечнем их элементов.
Математика
{1, 2, 3}
{’A'/K’.’B’.'L’}
0
{1,2..N}
В квадратных скобках могут находиться не только константы, но любые выражения типа элементов множества, например, [2+Х, 8—3].
Переменные множества должны быть описаны предложением
VAR имя: SET OF базовый тип
81
множество прописных английских букв, множество целых чисел от 1 до 100,
ПРИМЕРЫ
set of ’A’..’Z’ set of 1..100 set of (winter, spring, summer, outumn)
множество времен года, set of char множество всех символов.
ВОПРОС. Чем похожи и чем отличаются множества и массивы ?
15.2. Отношения и операции на ножествах
Теперь переведем на Паскаль отношения и операции на множествах. Отношения рассматриваются в Паскале как операции, вырабатывающие логические значения.
Паскаль принадлежность х in А равенство А = В включение А < В нестрогое включение А <= В
В Паскале имеются также операции: > , >= и < >.
ВОПРОС. Какое значение у выражений:
Математика х 6 А А= В Ас В А^В
а) х in [х], б) [] <= [X, Y, Z], в) [s] = [s + 1], г) [х] <>[Х, X, X] ?
В Паскале определены три операции над множествами, которые вырабатывают значение того же типа, к которому принадлежат операнды.
Математика АиВ А п В А \ В
Паскаль объединение А + В пересечение А * В разность А — В
ВОПРОС. Запишите выражения, соответствующие заштрихованным участкам:
82
В заключение рассмотрим программу, которая печатает все простые числа из отрезка 2..N, действуя по методу решета Эратосфена.
ПРИМЕР. Решето Эратосфена.
const
N = 15;
var
S: set of 2..N;
{исходное множество чисел
i,k: integer;
begin
S := [2..N];
for i := 2 to N do
if i in S then begin
writeln (i);
{выводим наименьший из элементов S} {убираем из S числа, кратные i} for k := 1 to N div i do
S := S - [k*i];
end {if} end.
15.3. Внутреннее редставление множеств
Знакомство с внутренним представлением множеств поможет нам понять особенности и ограничения, присущие этому типу данных.
Все значения множества представляются в памяти последовательностями битов одинаковой длины. За каждое значение базового типа «отвечает» один бит. Если множество содержит некоторый элемент, в «ответственном» за него бите хранится 1, если не содержит — хранится 0.
ПРИМЕР.
var X: set of 1..15;
Внутреннее представление X
X := 0; 000000000000000>
X := [2,3,5]; 01 1010000000000>
X := [1..15]; 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 >
Операции над множествами сводятся к поразрядным логическим операциям над последовательностями битов, на
83
пример, объединение множеств выполняется путем поразрядного логического сложения битов:
X := [2,3,5]; 01 1010000000000>
Y := [3,5,7,8]; 0010101 10000000>
Z := X + Y; 011010110000000>
Поразрядные операции входят в набор команд процессора ЭВМ, поэтому выполняются быстро.
ВОПРОС. Какая поразрядная операция соответствует пересечению множеств, разности множеств ?
ЗАДАЧИ
1. Имеется группа студентов: A..F.
Male = [A..D]; Female = [E,FJ;
Aerob = [C,E]; Karate = [С..Е].
а) кто занимается аэробикой и каратэ ?
б) кто из мальчиков не занимается аэробикой ?
в) есть ли девочки, которые не занимаются каратэ ?
2. Дана непустая последовательность слов из строчных русских букв; между соседними словами запятая, за последним словом — точка. Напечатать в алфавитном порядке:
а) все гласные буквы, которые входят в каждое слово, б) все согласные буквы, которые не входят ни в одно слово;
в) все звонкие согласные буквы, которые входят хотя бы в одно слово;
г) все глухие согласные буквы, которые не входят хотя бы в одно слово;
д) все согласные буквы, которые вход ят только в од но слово;
е) все глухие согласные буквы, которые не входят только в одно слово.
3. Напишите процедуру, определяющую, является ли строка: а) именем, допустимым в Паскале;
б) целым числом;
в) вещественным числом в показательной форме.
W ПЕРЕБОРНЫЕ ЗАДАЧИ
16.1. Задача коммивояжера
Некоторые задачи решают, перебирая предполагаемые решения и проверяя, которое из них истинное. При этом надо позаботиться, чтобы истинное решение было среди предполагаемых, иначе его не найти. Если не известен иной способ решения задачи, ее называют переборной.
ВОПРОСЫ. Можно ли решить уравнение 3*Х — 12 = О перебором ? Является ли эта задача переборной?
Классическим примером переборной задачи служит задача коммивояжера. Дано множество из N городов, расстояния между которыми известны. В каком порядке должен посетить их коммивояжер, заезжая в каждый город лишь один раз, чтобы общий пройденный путь был кратчайшим?
Предполагаемыми решениями здесь являются перестановки из N городов. Из них*нужно выбрать ту, которая даст наименьшую суммарную длину маршрута.
ВОПРОС. Сколько существует перестановок из N городов?
Первое, что нужно сделать, решая задачу коммивояжера, это организовать перебор перестановок. Занумеруем города числами от 1 до N. Все перестановки можно получить, выбирая из множества [1..N] один элемент всевозможными способами и присоединяя к нему поочередно перестановки из оставшихся элементов. Это рекурсивный алгоритм, т.к. для построения перестановок из N элементов он нуж-
85
дается в перестановках из N—1 элемента. Добавим, что единственная перестановка из одного элемента — это сам элемент.
Запрограммируем получение перестановок в виде рекурсивной процедуры. Множество переставляемых элементов сделаем параметром процедуры. Другим параметром будет позиция перестановки, которая заполняется данным вызовом процедуры. Все перестановки будем поочередно строить во внешнем массиве из N целых чисел.
ПРИМЕР. Программа получения перестановок из множества чисел [1..N],
const
N = 5;
type
IntSet = set of 1..N;
var
A: array [1..N] of integer; {перестановка} procedure Perest (S: IntSet; K: integer);
var
i: integer;
begn
for i := 1 to N do if i in S then begin A [K] := i;
Perest (S - [i], К + 1)
end {if}
end;
oegin
Perest ( [1..N1, 1);
end.
Эта программа только строит перестановки в массиве А и больше ничего не делает, даже не выводит их на экран. Перестановка готова, когда S=[].
Дополним процедуру Perest подсчетом длины маршрута, заданного перестановкой, и выбором самого короткого из маршрутов. Для хранения кратчайшего из построенных маршрутов и его длины воспользуемся внешними переменными Amin и Lmin. Расстояния между городами содержатся в двумерном массиве Dist.
ПРИМЕР. Решение задачи коммивояжера
const
N = 5;
86
Dist array [1..N, 1..N] of integer = ((1,3,5,4,6), (3,2,5,4,7), (4,8,6,9,7), (3,4,2,7,6), (6,9,3,2,5));
type
IntSet = set of 1 ..N; var
A, Amin: array [1..N] of integer; {перестановки} Lmin: integer;
procedure Comm(S: IntSet; K: integer); var
L,i: integer;
begin if S = [] then begin
(подсчет длины маршрута L по перестановке А}
L := 0;
for i := 1 to N—1 do
L := L + Dist [A [i], A [i+1]];
{выбор кратчайшего маршрута} if (L < Lmin) then begin Lmin := L;
Amin := A end; (if) end {then} else for i := 1 to N do if i in S then begin A[K] := i;
Comi (S - [i], К + 1) end {if} end;
var i: integer; begin
Lmin := Maxi nt;
{самое большое целое число}
Comm ( [1..N], 1);
for i := 1 to N do writein (Amin [i]) end.
Программу можно улучшить, если подсчет длины маршрута делать одновременно с его построением. Переменную L в этом случае надо сделать внешней по отношению к процедуре Comm.
87
ВОПРОС. Что еще надо изменить в процедуре Comm ?
16.2. Метод ветвей и границ
Главная трудность переборных задач в том, что количество предполагаемых решений бывает в буквальном смысле необъятно. Сосчитайте, сколько существует перестановок, скажем, из 50 городов. Даже если компьютер сможет обрабатывать по миллиону перестановок в секунду (таких быстрых компьютеров пока нет), за все время существования вселенной он обработал бы такую ничтожную часть всех перестановок, что в языке нет названия для столь маленьких чисел.
Как же решают эти чудовищные переборные задачи ?
Один из подходов состоит в том, чтобы найти такую стратегию перебора и анализа возможных решений, когда можно отбрасывать их целыми группами, не занимаясь проверкой каждого в отдельности.
Например, если для коммивояжера найден маршрут длиной Lmin, а посещение первых К городов очередного варианта уже дает длину, большую, чем Lmin, незачем проверять не только этот вариант, но и все маршруты, которые совпадают с ним в первых К городах.
На рисунке показан план местности, где работает коммивояжер.
Рис. 16.1
Изобразим все мыслимые маршруты коммивояжера в виде деревьев.
2 3 4 5
13 4 5
Рис. 16.2
5
88
Перебор маршрутов можно рассматривать как движение по ветвям деревьев, а отбрасывание маршрутов — как отсечение ветвей дерева на границе достижения ими уже найденной минимальной длины маршрута. Этим объясняется название метода ветвей и границ.
ПРИМЕР. Метод ветвей и границ в задаче коммивояжера.
const
N = 5;
Dist: array [1..N, 1..N] of integer = ((1,3,5,4,6),
(3,2,5,4,7), (4,8,6,9,7), (3,4,2,7,6), (6,9,3,2,5));
type
IntSet = set of 1 ..N;
* var
A, Amin: array [1..N] of Integer, {перестановки}
L, Lmin: integer;
procedure Commi (S: IntSet; K: integer); var
i: integer;
begin
if S = [] then begin
{ выбор кратчайшего маршрута } if (L < Lmin) then begin Lmin := L; Amin := A end; {if} end {then} else for i := 1 to N do if i in S then begin A[K] := i;
if К > 1 then L := L + Dist [A [K— 1],i]; if L < Lmin then Commi (S — [i], К + 1); if К > 1 then L := L - Dist [A [K— 1 ],i]; end {if} end;
var
i: integer;
begin
Lmin := Maxlnt;
{самое большое целое число}
89
L:=0;
Commi ([1..N], 1);
for i := 1 to N do writein (Amin [i] ); end.
ВОПРОС. Каково значение переменной L после выполнения оператора Commi ( [1..N], 1) ?
Метод ветвей и границ не является алгоритмом решения переборных задач. Его можно считать идеей решения, которая нуждается в творческой разработке для каждой оригинальной задачи.
ЗАДАЧИ
1. Получить все расстановки 8 ладей на шахматной доске, при которых ни одна ладья не угрожает другой.
2. Сделать то же для 8 ферзей.
3. Обойти конем шахматную доску, не заходя на каждое поле более одного раза.
4. Лабиринт из N комнат задан таблицей соединений, в которой для каждой пары комнат указано, соединены ли они коридором. Построить путь из комнаты с номером i в комнату с номером j.
5. В данной последовательности N вещественных чисел выбрать возрастающую подпоследовательность наибольшей длины.
6. Имеется N предметов, веса которых равен А1, А2,...,Ап. Разделить эти предметы на две группы так, чтобы общий вес двух групп был максимально близким.
171 ПРОГРАММНЫЕ МОДУЛИ
17.1. Для чего нужны программные модули
Известно что при построении серьезной программы нельзя обойтись без процедур, которые заключают в себе ее отдельные части. Более крупными строительными единицами в Турбо-Паскале являются программные модули. Модуль имеет имя и может содержать описание многих процедур и функций, а также описания констант, типов данных и переменных.
Каждый программный м( дуль транслируется отдельно. Оттранслированные модули объединяются в выполнимую программу, этот процесс называется сборкой. Однажды написанный и оттранслированный модуль можно многокоатно использовать в различных программах, что экономит силы программиста, сокращает время трансляции и предохраняет от искажений исходный текст модуля. Иногда это даже помогает сохранить авторские права на программный модуль.
Чтобы подключить модуль к программе и сделать видимым его содержимое, достаточно упомянуть его имя в предложении
' USES имя модуля
USES должно быть первым предложением программы.
17. 2. Структура программного модуля
Любой программный модуль построен по следующей схеме:
UNIT имя модуля;
INTERFACE интерфейсный раздел
91
IMPLEMENTATION раздел реализации
BEGIN раздел инициализации
END.
Имя модуля используется в предложении USES при подключении модуля к программе.
В интерфейсном разделе перечисляется все, что должно быть видимым в модуле из программы, которая его использует. Константы, типы и переменные перечисляются в предложениях CONST, TYPE и VAR. Для процедур и функций даются только их заголовки.
В разделе реализации находится полное описание всех процедур и функций, а также описание констант, типов и переменных, которые нужны для внутреннего использования и не должны быть видны снаружи. Заголовки процедур и функций могут или полностью совпадать с заголовками из интерфейсного раздела, или отличаться от них полным отсутствием параметров.
Раздел инициализации содержит те операторы, что будут выполнены до начала программы, к которой подключен модуль. Если таких операторов нет, слово BEGIN писать не надо.
Модуль следует хранить в одноименном файле с расширением PAS.
17.3. Пример модуля
Ниже приведен пример модуля под названием Lists, который содержит средства работы со связанными списками из вещественных чисел. Модуль не ссылается на другие модули и не имеет раздела инициализации.
UNIT Lists;
INTERFACE
uses crt;
type
PList = "TEIement;
TEIement = record
{ описание элемента списка }
R: real;
Next: PList;
end;
procedure Push (var List: PList; R: real);
{ добавляет к списку List число R }
92
function Pop (var List: PList): real;
{ удаляет из списка List число R и возвращает его в программу}
procedure Nul (var List: PList);
{ создает пустой список List}
IMPLEMENTATION
procedure Push (var List: PList; R: real);
var P. PList;
begin
new (P);
P“.R := R;
P“.Next := List;
List := P;
end;
function Pop (var List: PList): real;
var P: PList;
begin
if List <> nil then begin
Pop := LisC.R;
P := List;
List := P“.Next;
dispose (P);
end (if);
end;
procedure Nul (var List: PList);
begin
List := nil;
end;
END.
Вот программа, которая использует модуль Lists. Она создает пустой список, добавляет к нему три числа, потом одно удаляет и выводит на экран:
uses Lists; var
L: PList;
R: real;
begin
Nul (L);
Push (L, 1.0);
Push (L, 2.0);
Push (L, 3.0);
writeln (Pop (L));
end.
93
17.4. Ссылки на модули
Модуль, как и программа, может использовать объекты, описанные в других модулях. Если эти объекты нужны в интерфейсном разделе, то он должен начинаться с предложения USES, в котором перечисляются имена всех необходимых модулей. Если на объекты есть ссылки только из раздела реализации, предложение USES может находиться в разделе реализации.
Предположим, в программе в предложении USES есть имя модуля А, который ссылается на модуль В. Это не означает, что в программе доступны объекты из В. Если в этом есть необходимость, в программе следует перечислить имена обоих модулей в предложении USES.
Взаимные ссылки двух модулей возможны только из разделов реализации.
Рис. 17.1
В разных модулях могут быть описаны одноименные объекты, например, и в модуле Айв модуле В может быть определена переменная V. Чтобы различить две такие переменные, к их именам добавляют имя модуля: A.V или B.V.
17.5. Стандартные модули ТП
Основная часть средств ТП расположена в стандартных модулях, которые поставляются в оттранслированном виде вместе с компилятором. Здесь мы рассмотрим некоторые из них.
В модуле SYSTEM содержатся средства ввода-вывода в текстовые и типизированные файлы, процедуры и функции для работы со строками, вещественными числами и динамической памятью. Модуль SYSTEM бывает нужен так часто, что он автоматически подсоединяется ко всем программам и модулям и вам незачем делать это явно.
В модуле CRT сосредоточены средства управления дисплеем в текстовом режиме, клавиатурой, динамиком. При
94
помощи имеющихся в нем процедур можно изменять цвета, выводить информацию в любом месте экрана, создавать окна, воспроизводить звуковые тоны различной высоты и длительности, обрабатывать расширенные коды клавиш.
Модуль DOS открывает доступ к возможностям операционной системы MS DOS. В нем находятся процедуры обработки даты и времени дня, анализа состояния магнитных дисков, средства работы со справочниками и отдельными файлами. Благодаря этому модулю из программы можно вызвать другую программу или сделать программу резидентной. Можно выполнить любую существующую процедуру обработки прерывания или написать свою собственную.
Модуль GRAPH содержит более 50 графических процедур, которые позволяют воспроизводить на экране точки, отрезки, многоугольники, окружности и другие фигуры различных цветов и размеров. Есть средства для разнообразных видов закрашивания и вывода текста в графическом режиме. Возможна работа с битовыми образами экрана и его частей. Работа с разнообразными адаптерами обеспечи ается набором графических драйверов, которые находятся в отдельных файлах.
Заметим, что модули SYSTEM, CRT и DOS обычно находятся в составе библиотечного файла TURBO.TPL, а модуль GRAPH представляет собой отдельный файл.
ЗАДАЧА
Разраб таите комплекс программных средств для работы со стеком и оформите в виде модуля. Включите туда процедуры удаления, пополнения, очистки стека, процедуры для обработки ошибок. Стек организуйте на базе массива чисел.
18
ВВЕДЕНИЕ
В ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ
ПРОГРАММИРОВАНИЕ
18.1. Зачем нужно ООП
Начиная с первого мнемокода, все средства разработки программ изобретались с единственной целью — чтобы проще было думать. ООП как технология программирования в этом смысле не является исключением.
Почему при помощи ООП думать проще ?
Программа, решающая некоторую задачу, заключает в себе описание части мира, относящейся к этой задаче. Описание действительности в форме системы взаимодействующих объектов, по-видимому, естественнее, чем в форме иерархии подпрограмм, поэтому ООП экономит мышление программиста больше, чем модульное программирование.
ООП возникло не вдруг. Среди его предпосылок можно назвать модульное программирование, абстрактные типы данных, ситуационное моделирование, фреймы. Первым алгоритмическим языком, где появились классы и объекты, был Simula-67. Окончательно принципы ООП оформились в языке Smalltalk-80.
18.2. Что такое объекты
Чтобы получить первое представление об объектах, рассмотрим домашний аквариум. Он населен рыбами, моллюсками, водорослями — все это объекты. Отдельные рыбки, улитки, водоросли — это экземпляры объектов.
Сосредоточимся на объекте «рыба». Она имеет размер, цвет, пол, местоположение и скорость. Кроме того, рыба способна выполнять определенные действия — плавать,
96
обозревать пространство перед собой, поедать корм или других рыб. Обобщая наши ихтиологические наблюдения, можно сказать, что объект имеет состояние (значения цвета, размера и т.д.) и методы (действия, на которые способен объект). Чтобы заставить объект что-то сделать, нужно послать ему сообщение.
Программируя объект, состояние можно хранить в наборе переменных, а методы реализовать в форме процедур. Объект представляет собой единство состояния и методов.
Попадая в среду развитого алгоритмического языка, понятия ООП оформляются в стиле этого языка. В ТП объект — это особый тип данных, а экземпляры объекта — переменные этого типа. Состояние характеризуется значениями полей объекта. Методами объекта являются ассоциированные с ним функции и процедуры, которым доступны поля. Передача сообщений объекту происходит в виде вызовов его методов с заданными параметрами.
18.3. Объект « числовой список»
Чтобы познакомиться с описанием объекта в ТП, представим в форме объекта динамический список из целыкчлеел. Элементами списка являются записи типа
PEIement = “TEIement;
TEIement = record
R: real;
Next: PEIement;
end;
Описание записи и указателя на запись не входит в описание объекта и предшествует ему.
Состояние списка характеризуется значением указателя на его голову и числом элементов списка. Со списком ассоциируются процедуры создания пустого списка, пополнения списка числом, удаления головного элемента списка.
type
TRealList = object
{ ПОЛЯ }
Head: PEement; {указатель на головной элемент) Number: integer; {число элементов списка }
{ МЕТОДЫ }
procedure Nul; {создает пустой список } procedure Add (R: real); {добавляет к списку
число R}
4 «Основы программирования»
97
function Del: real; {удаляет из списка число и возвращает его значение} end;
Описание методов должно располагаться позже, чем описание объекта. Имена методов составные, они складываются из имени объекта и названия метода. Вот пример описания метода Nul объекта TRealList:
procedure TRealList.Nul;
begin
Head := nil;
Number := 0;
end;
После того как объект описан, его экземпляры можно использовать в программе. Рассмотрим программу, которая создает пустой список, вносит в него три числа, последнее число удаляет и показывает его значение на экране.
var
L: TRealList;
begin
L.Nul;
LAdd (3.5);
LAdd (4.6);
LAdd (2.1); writein (LDel); end.
18.4. Инкапсуляция
Считается что объектам присущ ряд свойств, которые собственно и делают их объектами. Одно из них — скрывать в себе детали, которые несущественны для использования объекта — называется инкапсуляцией.
Чтобы увидеть, что такое инкапсуляция, спроектируем простое меню в одной строке экрана. Меню обеспечивает перебор пунктов нажатием клавиши Escape, позволяет зафиксировать выбор нажатием клавиши или отказаться от выбора нажатием клавиши Escape. После выбора одного из пунктов в программу воз зращается какое-то значение, связанное в выбранным пунктом, например, символ. При отказе от выбора в программу возвращается #27.
Перед началом работы меню ему надо передать названия пунктов и возвращаемые символы. Это можно сделать в форме строки вида
98
Первое (а) Второе (Ь) Третье (с)’, где за названием пункта следует в скобках возвращаемый СИМ1 ол.
Состояние меню характеризуется координатами меню на экране, номером отмеченного пункта, общим количеством пунктов, а также перечнем названий пунктов и возвращаемых символов.
Работа с объектом-меню состоит из инициализации (метод Init) и выбора пункта (метод Select). Меню должно уметь рисовать себя на экране (метод Draw). Вспомогательный характер носят: определение начала и длины называния пункта в строке Items (методы LeftBoard и Len) и выделение возвращаемого значения для выбранного пункта меню (метод What-Sel).
type
TMenu = object
X,Y: integer; (координаты меню)
Items: string; (строка названий и возвращаемых символов}
Maxitem: integer; (общее количество пунктов) Selected: integer; {номер отмеченного пункта) procedure Init (Theltems: string); (заполняет поле Items, подсчитывает количество пунктов, делает выбранным первый пункт) procedure Select (var What: nteger); (позволяет тыбрать пункт меню и возвращает номер выбранного пункта. При казе от выбора возвращает 0) procedure Draw; (рисует меню, выделяя выбранный пункт цветом)
funct'on LeftBoard (Item: integer): integer; {возвращает начало названия пункта Item в строке Items)
function Len (Item: integer): integer; {возвращает длину названия пункта Item в строке Items}
function WhatSel: char, {возвращает символ выбранного пункта} end;
Полное описание методов TMenu находится в приложении к этому разделу.
Приведем пример программы, использующей такое меню.
4*
99
var
M: TMenu;
C: char;
begin
M.lnit (’Первое (а) Второе (b) Третье (c) );
M.Select (C);
end.
18.5. Объекты и модули
Сопоставляя объекты с модулями, можно найти нечто общее. Описание объекта напоминает интерфейсный раздел модуля, описание методов — раздел реализации. И модуль и объект обладают свойством инкапсуляции и объединяют в себе данные и процедуры. И модули, и объекты являются строительными блоками при создании программ. На этом их сходство заканчивается и начинается различие.
Объект, в отличие от модуля, не является единицей трансляции и должен быть описан внутри программы или модуля. Остальные отличия можно уяснить лишь продолжив изучение объектов.
18.6. Наследование
Наследование позволяет создавать новые объекты, изменяя или дополняя свойства прежних. Объект-наследник получает все поля и методы предка, но может добавить собственные поля, добавить собственные методы или перекрыть своими методами одноименные унаследованные методы.
Вернемся к объекту TMenu из раздела 4. После окончания работы с меню оно оставалось на экране, хотя уже никому не было нужно. Создадим новый объект TNeatMenu, наследующий TMenu, который в отличие от своего предка будет восстанавливать вид экрана. Для этого добавим новое поле Store, где будет храниться прежний экран во время действия меню, перекроем метод Init, и добавим метод Done.
type
TNeatMenu = object (TMenu)
Store: array [1..4000] of byte;
procedure Init (aX, aY: integer; Theltems:
string);
(сохраняет экран и вызывает Init предка}
100
procedure Done;
{восстанавливает состояние экрана}
end;
constructor TNeatMenu. Init (aX, aY: integer;Theltems: string);
begin
move (mem [$b800:0], Store, 4000);
TMenu.lnit (aX, aY, Theltems);
end;
destructor TNeatMenu.Done;
begin
move (Store, mem [$b800:0], 160*25);
end;
Как видно из примера, наследник не содержит описания полей и методов предка. Вместо этого просто указывается имя предка в скобках после слова object. Из методов наследника можно вызывать методы предка, чем мы и воспользовались, 41 об не переписывать Init полностью.
Объект TNeatMenu можно наследовать дальше, порождая разные виды меню, что мы будем делать в последующих примерах.
Отметим, что для создания наследника не требуется иметь исходный код преДка, достаточно, чтобы объект-предок был в составе оттранслированного модуля.
18.7. Виртуальные методы.
Конструкторы и деструкторы
Предположим, нам надоел прежний вид меню, и мы хотим видеть его в форме столбца в правой части экрана. Для этого достаточно изменить метод Draw объекта TNeatMenu.
Но если мы опишем потомка TNeatMenu (назовем его TVertMenu), который перекроет только метод Draw, то не достигнем цели. Дело в том, что методы Init и Select объекта TVertMenu унаследованы от TNeatMenu и будут вызывать не новый, а прежний Draw. Это естественно, т.к. во время трансляции объекта ТМепи в их код была заложена ссылка на TNeatMenu.Draw.
Как-то выйти из положения можно, перекрыв не только Draw, но также Select и Init. При этом мы не отделаемся простым вызовом метода предка из метода потомка, как в TNeatMenu, а будем вынуждены полностью воспроизвести код методов. Это не только громоздко, но и просто невоз
101
можно, когда исходного кода предка нет в нашем распоряжении.
Хороший выход из этой плохой ситуации открывают так называемые виртуальные методы. Если объявить методы Draw виртуальными, то связь между ними и вызывающими их процедурами будет устанавливаться не во время трансляции (раннее связывание), а во время выполнения программы (позднее связывание). Результат позднего связывания зависит от типа того объекта, чей метод обратился к виртуальному методу. Так экземпляр объекта TMenu вызовет TMenu.Draw и нарисует себя в верхней строке, а экземп-ляр объекта TVertMenu вызовет TVertMenu.Draw и нарисует себя в правой части экрана.
Чтобы воспользоваться виртуальными методами, надо соблюсти ряд формальностей.
Во-первых, в описании объекта после заголовка виртуального метода надо добавлять слово virtual.
Во-вторых, заголовки виртуальных методов предка и потомка должны в точности совпадать, причем оба метода должны быть виртуальными. Это означает, что, проектируя TMenu, мы должны были заранее предвидеть возможность его развития и сделать Draw виртуальным.
В-третьих, инициализация экземпляра объекта должна выполняться методом особого вида, который называется конструктор. Обычно на конструктор возлагается работа по инициализации экземпляра объекта: присвоение полям исходных значений, открытие файлов, первоначальный вывод на экран и т.п. В TNeatMenu роль конструктора исполнял метод Init.
Помимо действий, заложенных в него программистом, конструктор выполняет подготовку механизма позднего связывания виртуальных методов. Это значит, что до вызова любого виртуального метода должен быть выполнен какой-нибудь конструктор.
Превратить обычный метод в конструктор очень просто, надо лишь заменить слово procedure словом constructor в заголовке метода.
Упомянув о конструкторе, кстати познакомимся и с деструктором. Его роль противоположна роли конструктора — выполнять действия, завершающие работу с объектом: закрыть файлы, очистить динамическую память, восстановить экран и т.п. Заголовок метода-деструктора начинается словом destructor.
102
В объекте TMenu не г завершающих действий, а в объекте TNeatMenu есть, это восстановление экрана, которое выполняет метод Done. Если бы, проектируя объект TNeatMenu, мы уже знали о виртуальных методах, то описали бы его так:
type
TNeatMenu = object (TMenu)
Store: array [1..4000] of byte;
co structor Init (aX, aY: integer; Theltems: string);
destructor Done;
end;
a TVertMenu — так:
type
TVertMenu = object (TNeatMenu) procedure Draw; virtual;
end;
procedure TVertMenu.Draw; var
Item: integer;
begin
for Item := 1 to Maxitem do begin gotoXY (X, Y + Item—1);
if Item = Selected then TextColor (Yellow) else TextColor (White);
write (copy (Items, LeftBoard (Item), Len (Item)));
end {for};
gotoXY (80,25);
end;
Теперь работа с экземпляром М объекта TNeatMenu, состоит из трех частей:
M.lnit (’Первое (а) Второе (Ь) Третье (с)’);
M.Select (С);
M.Done;
Окончательно значение деструктора будет выяснено при рассмотрении объектов в динамической памяти.
18.8. Таблица виртуальных методов
Что же делает конструктор для подготовки позднего связывания ? Он устанавливает связь между экземпляром объекта и таблицей виртуальных методов (VMT) объекта.
103
Для каждого виртуального метода VMT содержит его адрес. Вызов виртуального метода делается не прямо, а через VMT: сперва по имени метода определяется его адрес, а затем по этому адресу передается управление.
У каждого объектного типа собственная таблица. Именно это позволяет одному и тому же оператору Draw вызывать совершенно разные процедуры, ведь VMT объекта TNeatMenu содержит адрес метода TNeatMenu.Draw, a VMT объекта TVertMenu содержит адрес метода TVertMenu.Draw.
Понять механизм раннего и позднего связывания поможет рисунок, который относится к рассмотренному примеру.
РАННЕЕ СВЯЗЫВАНИЕ
ПОЗДНЕЕ СВЯЗЫВАНИЕ
Рис. 18.1
18.9. Объекты в динамической памяти
Чтобы разместить объект в динамической памяти, надо описать указатель на него. Это похоже на описание динамических записей, например:
type
PMenu = "TMenu;
TMenu = object ...
Выделение памяти для динамического объекта выполняется процедурой NEW. Сразу после этого делается инициализация объекта, поэтому для объектов процедура NEW выглядит так:
NEW (указатель на объект, конструктор)
Высвобождение динамической памяти, занятой объектом, выполняется процедурой DISPOSE. Перед этим выполняются действия, завершающие работу с объектом, поэтому для объектов процедура DISPOSE выглядит так:
104
DISPOSE (указатель на объект, деструктор)
Нельзя освободить память, занятую динамическим объектом, если у него нет деструктора, хотя бы и пустого.
Вот пример работы с динамическим объектом типа TNeatMenu.
var
М: PNeatMenu;
п: integer;
begin
new (M, Init (’ Первое Второе Третье Десерт ’));
M.Select (п);
dispose (М, Done);
end.
18.10. Сложное меню в динамической памяти
Применим полученные знания для построения сложного иерархического меню. Нажатие клавиши будет разворачивать подсвеченный пункт в подменю или, если пункт находится на самом нижнем уровне, заканчивать работу. Нажатие клавиши Escape будет сворачивать подменю или заканчивать работу, если работа велась на самом верхнем уровне.
Для начала надо решить, каким образом задавать структуру иерархического меню. Сделаем это при помощи скобочной формы, смысл которой ясен из следующего примера.
СХЕМА ИЕРАРХИЧЕСКОГО МЕНЮ
Первое Второе 1 Третье ।
I I Борщ Окрошка (а) (Ь) ““1 1 Щи Каша (с) J. 1 Вареники (1) । 1 Ч ай Компот (g) (h)
1 Г речневая (d) МаЛная (е)
Рис. 18.2
Скобочная форма:
Первое (Борщ (а )Окрошка (Ь) Щи (с)) Второе (Каша (Гречневая (d) Манная (е)) Вареники (f)) Третье (Чай (д) Компот (h))
В скобочной форме за названием пункта меню следует описание соответствующего подменю, в такой же скобоч
105
ной форме. Если пункт конечный, в скобках после него указан возвращаемый символ.
Создадим составное меню в виде объекта TCompMenu, наследника TNeatMenu.
Несмотря на кажущуюся сложность поставленной задачи, потребуется перекрыть только два метода, Init и Select, и добавить лишь одно поле.
Теперь основная задача метода Init — разобрать скобочную форму, данную ему в виде параметра, заполнить поле Items, и сохранить описания всех подменю в специально предназначенном для этого поле SubMenus. SubMenus это массив строк, каждая из которых хранит описание одного подменю. Например, результатом разбора формы, приведенной выше, будет
Items =’ Первое ( ) Второе ( ) Третье (
SubMenus [1] = ’Борщ (а) Окрошка (Ь) Щи (с)',
SubMenus [2] = ’Каша (Гречневая (d) Манная (е)) Вареники (f)’, SubMenus [3] = ’Чай (g) Компот (h)’.
Метод TCompMenu.Select будет отличаться от Select предка только реакцией на нажатие клавиши. Она теперь зависит от того, является ли выбранный пункт конечным, или нет.
В первом случае, как раньше, надо закончить работу, вернув в программу номер пункта.
Во втором случае надо рекурсивным образом заставить отработать подменю выбранного пункта и только потом закончить работу.
Приведем описанный фрагмент метода Select:
#13: if pos (’(’.SubMenus [Selected] ) = 0 then
What := WhatSel else begin
X1 := X + LeftBoard (Selected);
{функция NEW }
SubMenu:=new (PCompMenu.lnit (X1.Y+1,SubMenus [ Selected]));
SubMenu "'.Select (WhatSub);
dispose (SubMenu, Done);
if WhatSub#27 then What := WhatSub;
end {else};
Пользуясь случаем, познакомимся с функциональной формой оператора NEW. Ее синтаксис задается схемой
NEW (тип указателя, конструктор): указатель на объект
Полный текст примера находится в приложении.
106
18.11. Полиморфизм
Для ООП характерен полиморфизм. Он выражается в том, что под одним именем скрываются различные действия, содержание которых зависит от типа объекта.
Впервые полиморфизм проявился, когда методы Select и Init, вызывая Draw, рисовали себя по-разному, в зависимости от типа владельца методов.
Полиморфизм полезен, т.к. позволяет весьма экономно делать некоторые вещи. Например, мы хотим, чтобы меню самого нижнего уровня были вертикальными. Для этого достаточно изменить в методе TCompSelect всего один оператор, вместо
SubMenu := new(PCompMenu,Init (X1.Y+1, SubMenus [Selected]));
надо написать
if pos (’)>’, SubMenus [Selected] ) = 0 then
SubMenu := new (PVertMenu, Init (X1, Y +1, SubMenus [Selected])) else
Subenu := new (PCompMenu, Init (X1, Y +1, SubMenus [Selected]))
Т.е., если дочернее меню не имеет подменю, выполнить TVertMenu.Init, иначе выполнить TCompMenu.lnit.
Конструктор устанавливает связь с соответствующей VMT и благодаря этому операторы
SubMenu".Select (WhatSub); dispose (SubMenu, Done);
будут вызывать виртуальные методы нужного объекта.
Вы, наверное, заметили, что полиморфизм является прямым следствием механизма позднего связывания.
18.12. Объекты изнутри
Содержание этого раздела носит частный характер и касается особенностей представления объектов в среде ТП.
Внутреннее представление объекта похоже на запись. Поля предка располагаются перед полями потомка. Если объект имеет виртуальные методы, конструктор или деструктор, транслятор добавляет 2-байтовое поле — смещение VMT в сегменте данных. Это поле располагается после обычных полей и наследуется потомками.
TMenu TNeatMenu
X,Y:integer; X,Y: integer;
107
Items: string:
Maxitem: integer;
Selected: integer;
Смещение VMT
Items: string;
Maxitem: integer;
Selected: integer;
Смещение VMT
Sto e: array [1..4000] of byte;
Конструктор сначала устанавливает указатель на VMT, а потом выполняет свои операторы. Это позволяет
вызывать виртуальные методы прямо из конструктора.
Каждый объект, имеющий виртуальные методы, констрак-торы или дестракторы, имеет и VMT, которая хранится в сег
менте данных.
1-е слово VMT содержит истинный размер экземпляров. Это необходимо для правильного распределения и освобождения динамической памяти.
2-е слово содержит отрицательный размер экземпляра. Оно используется для блокирования вызовов методов неинициализированного объекта. Перед вызовом виртуального метода проверяется, что первое слово VMT не равно нулю, а сумма первого и второго слова равна нулю.
Далее в VMT следуют указатели на виртуальные методы объекта.
Для работы с объектами в ТП имеются следующие стандартные функции.
SizeO f (переменная или тип) —
возвращает истинный размер объекта, который может быть больше от суммарного размера полей на 2 байта.
ТуреО f (переменная или тип) : pointer —
применяется только к объектам, имеющим VMT, и возвращает указатель на нее. Можно использовать для проверки совпадения типов: TypeOf (х) = TypeOf (у).
При инициализации объекта в динамической памяти возможны 2 вида ошибок констрактора:
1) он не смог распределить память для объекта.
Если функция обработки ошибок кучи возвращает 0, возникает ошибка времени выполнения. Если — 1, процедура NEW возвращает nil;
2) он не смог распределить память для динамических переменных. В этом случае функция Fail, которая вызывается только из констрактора, высвобождает занятую ранее память.
108
18.13. Взаимодействие объектов
Благодаря инкапсуляции объекты так хорошо изолируются друг от друга, что бывает нелегко заставить их сообщаться между собой в программе. Конечно, это касается независимых экземпляров объектов, а не тех, что являются полями или переменными методов других объектов.
Обычно связь в этом случае устанавливается при помощи указателей, что делает объектную программу похожей на структуру данных в динамической памяти. Наш опыт работы с такими структурами (массивами, списками, деревьями) показывает, что чем они регулярнее, тем проще с ними обращаться. Это относится к объектным программам и подтверждается практикой, например, пользовательский интерфейс, построенный при помощи известной библиотеки Turbo Vision, представляет иерархию экземпляров.
Непрямым способом обмена информацией между экземплярами объектов является передача через «карман» — внешнюю переменную, которой один объект присваивает значение, а другой считывает. Хотя этот способ прост, он лишает программу структурности, что не нравится многим программистам.
ЗАДАЧИ
1. Определите объект TFish — аквариумная рыбка. Рыбка имеет координаты, скорость, размер, цвет, направление движения. Методами объекта являются:
Init — устанавливает значения полей объекта и рисует рыбу на экране методом Draw.
Draw — рисует рыбу в виде уголка, с острием в точке Coord и направленного острием по ходу движения рыбы.
Look — проверяет несколько точек на линии движения рыбы. Если хоть одна из них отличатся по цвету от воды, возвращается ее цвет и расстоя ие до рыбы.
Run — перемещает рыбу в текущем направлении на расстояние, зависящее от текущей скорости рыбы. Иногда случайным образом меняет направление движения рыбы. Если рыба видит препятствие, направление движения меняется, пока препятствие не исчезнет из поля зрения рыбы.
2. Определите объект TAquarium, который является местом обитания рыб. Он представляет собой область экрана, наполненную водой. Рыбы живут в аквариуме, поэ
109
тому экземпляры объекта TFish должны быть полями объекта TAquarium.
Методы:
Init — включает графический режим, заполняет аквариум водой, скалами и рыбами.
Run — организует бесконечный цикл, в котором выполняется метод Run всех обитателей аквариума.
Done — выключает графический режим.
3. Определите два объекта TPike и ТКагр, которые наследуют объект TFsh. Оба они отличаются от TFish тем, что по-разному изображают себя на экране: TPike — в виде зеленой стрелки, а ТКагр — в виде красного треугольника. Воспользуйтесь виртуальными методами. Для этого вернитесь к определению TFish и откорректируйте его, сделав Draw пустым и виртуальным.
4. Объедините карпов и щук в две стаи. Стая — это связанный список рыб в динамической памяти. Для связи добавьте в объекты TPike и ТКагр поле Next — указатель на следующую рыбу в стае. Сделайте аквариум владельцем не отдельных рыб, а двух стай и позвольте пользователю пополнять стаи вводя рыб с клавиатуры.
5. Позвольте щукам проявить свой дурной характер и поедать карпов, как только они их увидят. Здесь возникнет проблема — установить, какого именно карпа видит щука. Она решается путем просмотра всей стаи карпов и поиска того, чьи координаты близки к координатам данной щуки. Найденный карп удаляется из стаи.
Приложение к разделу 18 < Введение в ООП»
uses crt;
type
TMenu = object
X,Y: integer;
Items: string;
Maxitem: integer;
Selected: integer;
constructor Init (aX, aY: integer; Theltems: string);
procedure Select (var What: char); virtual;
procedure Draw; virtual;
function LeftBoard (Item: integer): integer;
function Len (Item: integer): integer;
function WhatSel: char;
110
end;
constructor TMenu.lnit (aX, aY: Integer; Theltems: string); var
i: integer;
begin
X := aX; Y := aY;
Items := Theltems;
Selected := 1;
Maxitem := 0;
for i := 1 to length (Items) —1 do
if Items [i] = ’(’ then inc (Maxitem);
Draw;
end;
procedure TMenu.Select (var What: char); var
c: char;
begin
What := #0;
repeat
c := readkey;
case c of
’ begin
inc (Selected);
if Selected Maxitem then Selected := 1;
Draw;
end;
# 13: What := WhatSel;
# 27: What := #27;
# 0 : c := readkey;
end (case)
until What #0;
end;
procedure TMenu.Draw;
var
Xnext, Item: integer;
begin
Xnext := X;
for Item := 1 to Maxitem do begin
gotoXY (Xnext,Y);
if Item = Selected then TextColor (Yellow)
111
else TextColor (White);
write (copy (Items, LeftBoard (Item), Len (Item)));
inc (Xnext, Len (ltem)+2)
end {for};
gotoXY (80,25);
end;
function TMenu.LeftBoard (Item: integer): integer; var
i: integer;
begin
i := 1;
while Item 1 do begin
if ltems[i] = ’)’ then dec (Item);
inc (i);
end {while};
Left-Board := i;
end;
function TMenu.Len (Item: integer): integer;
var
i: integer;
begin
i := LeftBoard (Item);
repeat
inc (i);
until ltems[i] = ’(’;
Len := i — LeftBoard (Item);
end;
function TMenu.WhatSel: char;
begin
WhatSel := Items [LeftBoard (Selected) + Len (Selected) + 1]; end;
{}
type
PNeatMenu = "TNeatMenu;
TNeatMenu = object (TMenu)
Store: array [1..4000] of byte;
constructor Init (aX, aY: integer; Theltems: string);
destructor Done;
end;
112
constructor TNeatMenu.Init (aX, aY: integer;Theltems: string); begin
move (mem [$b800:0], Store, 4000);
TMenu.lnit (aX, aY, Theltems);
end;
destructor TNeatMenu.Done;
begin
move (Store, mem [$b800:0], 160*25);
end;
{........................................................}
type
PVertMenu = '"TVertMenu;
TVertMenu = object (TNeatMenu) procedure Draw; virtual;
end;
procedure TVertMenu.Draw;
var
Item: integer;
begin
for Item := 1 to Maxitem do begin
gotoXY (X, Y + Item-1);
if Item = Selected then TextColor (Yellow) else TextColor (White);
write (copy (Items, LeftBoard (Item), Len (Item))); end (for);
gotoXY(80,25);
end;
<--...................-.................-.....>
type
PCompMenu = '‘TCompMenu;
TCompMenu = object (TNeatMenu)
SubMenus: array [1..10]of string;
constructor Init (aX, aY: integer; Theltems: string);
procedure Select (var What: char); virtual;
end;
constructor TCompMenuJnit (aX, aY: integer; Theltems: string); var
i, bracket: integer;
begin
X := aX; Y := aY;
113
Maxitem := 0;
Items := ’ *;
bracket:= 0;
for i := 1 to length (Theltems) do begin
case Theltems [i] of
*(’: begin
inc (bracket);
if bracket = 1 then begin
inc (Maxitem);
SubMenus [Maxitem] := ”;
end {then} else
SubMenus [Maxitem] := SubMenus [Maxitem] + ’{’; end;
’)’: begin
dec (bracket);
if bracket 0 then
SubMenus [Maxitem] := SubMenus [Maxitem] + ’)’ else
if Theltems [i—1] = ’)' then
Items := Items + ’( )’
else
Items := Items + ’(’+ Theltems [i—1] + ')’; end;
else
if bracket = 0 then
Items := Items + Theltems [i]
else
SubMenus [Maxitem] := SubMenus [Maxitem] + Theltems [i];
end {case}
end {for};
Selected := 1;
move (mem [$b800:0], Store, 4000);
Draw;
end;
procedure TCompMenu.Select (var What: char);
var
WhatSub, c: char;
SubMenu: PNeatMenu;
X1: integer;
begin
What := #0;
114
repeat
с := readkey;
case c of
’ ': begin
inc (Selected);
if Selected Maxitem then Selected := 1;
Draw;
end;
#13: if pos (’(’.SubMenus [Selected]) = 0 then
What := WhatSel
else begin
X1 := X + LeftBoard (Selected);
SubMenu := new (PCompMenu,Init (X1, Y+1, SubMenus [Selected]));
(*
if pos(’))’, SubMenus [Selected]) 0 then
SubMenu := new (PCompMenu, Init (X1, Y +1, SubMenus [Selected])) else
SubMenu := new (PVertMenuJnit (XI, Y+1, SubMenus [Selected]));
*)
SubMenu".Select (WhatSub);
dispose (SubMenu, Done);
if WhatSub #27 then What := WhatSub;
end {else};
#27: What := #27;
#0 : c := readkey;
end {case}
until What #0;
end;
{- ..........-......-------------------------------}
var
M: PCompMenu;
n: char;
begin
clrscr;
new (M, Init (10, 5,
’Первое (Борщ (а) Окрошка (b) Щи (с)) Второе (Каша
(Гречневая (d)
Манная (е)) Вареники (f)) Третье (Чай (д) Компот (h))’ {’111111(1)222222(2)3333(3)’} ));
М".Select (п);
dispose (М, Done);
gotoxy (1,1); write (n); readln;
end.
ЗАДАЧИ
Здесь собраны более сложные задачи, чем те, что помещены в конце разделов. Каждая из них может чему-то научить, если решить ее самостоятельно или разобрать решение на занятиях в классе.
Большинство задач взяты из олимпиадных заданий по программированию и информатике.
НАИБОЛЬШИЙ ПРЯМОУГОЛЬНИК
Дана матрица, состоящая из нулей и единиц. Найти наибольший по площади прямоугольник, состоящий из одних единиц.
ПЕРИОД ДРОБИ
Найти период десятичной дроби, равной М / N, где М и N — натуральные числа.
НЕСОСТАВЛЯЕМОЕ ЧИСЛО
Задан массив натуральных чисел. Найти минимальное натуральное число, не представимое суммой чисел из массива. Каждый элемент массива может входить в сумму не более одного раза.
СООТВЕТСТВИЕ ШАБЛОНУ
Установить соответствие имени файла заданному шаблону. Шаблоном называется строка, в которой «?» означает любой символ, а «*» означает любую последовательность символов, в том числе пустую.
КОД ГРЕЯ
Построить N-разрядный код Грея.
Кодом Грея называется такая последовательность N-раз-рядных двоичных чисел, в которой два соседних, а также первое и последнее число отличаются одним разрядом. Например, для N = 2 один из кодов Грея таков: 00, 01, 11, 10.
116
БОЙ ШАШЕК
На доске стоят белые шашки и одна черная. Указать, какие шашки может побить черная за один ход.
МНОГОЧЛЕН
Вычислить коэффициенты а [0], а [1],..., а [п—1] много члена с заданными корнями х [1], х [2],..., х [п].
Напоминание. По теореме Безу
Р(х) = (х - х [1]) * (х - х [2]) * ...*(х - х [п]).
ПОКРЫТИЕ МАТРИЦЫ
Матрица содержит числа от 0 до 6. Покрыть матрицу костями домино из одного набора или сообщить, что это нельзя сделать.
ОБМЕН ЧАСТЕЙ МАССИВА
Задан одномерный массив и граница между двумя его частями. Поменять порядок расположения частей массива, не делая лишних присваиваний.
Например: 1234|567-»567[1234.
ПОДСЧЕТ СЛОВ
Сосчитать количество слов в файле с русским текстом, которые начинаются с заданного буквосочетания. Учесть возможность переноса слов.
ВЫРАВНИВАНИЕ ТЕКСТА
В ASCII файле находится русский текст. Выровнять его по левой и правой границам, добиваясь наиболее плотного и равномерного распределения слов в строках.
УПОРЯДОЧЕННЫЕ СУММЫ
Даны два массива А и В из целых чисел. Напечатать в порядке возрастания все суммы вида A [i]+B [j].
СЛОНЫ
Какое наименьшее количество слонов может держать под боем все шахматное поле ?
САМОРОДКИ
Есть множество золотых самородков известного веса. Разделить самородки на две кучи, наиболее близкие по весу.
РЮКЗАК
Имеется п предметов с известным весом и стоимостью. Необходимо выбрать такие предметы, чтобы их суммарный вес был менее 30 кг, а стоимость — наибольшей. Напечатать суммарную стоимость выбранных предметов.
ЛЕВЫЕ ПОВОРОТЫ
Ломаная задана координатами своих узлов. Сосчитать количество левых поворотов при движении вдоль ломаной.
117
ПЯТНА НА ШКУРЕ
Сосчитать количество черных пятен на белой шкуре. Шкуру представить в виде 0,1-матрицы, где 0 — белый, а 1 — черный цвет.
САМЫЙ ДЛИННЫЙ ПУТЬ
Найти самый длинный путь между двумя заданными вершинами в ориентированном графе без циклов.
НЕУБЫВАЮЩАЯ ПОДПОСЛЕДОВАТЕЛЬНОСТЬ
Найти самую длинную неубывающую подпоследовательность в последовательности целых чисел, избежав при этом полного перебора.
ТОЛКОВЫЙ СЛОВАРЬ
В толковом словаре одни слова определяются через другие так, что нигде нет порочного круга. Пронумеруйте слова таким образом, чтобы слова с большим номером определялись через слова с меньшими номерами.
МАТРИЦА ОТНОШЕНИЙ
Задана матрица вида
Х1 Х2 ХЗ ... Хп
Y1 R11 R12 R13 R1n
Y2 R21 R22 R23 R2n
Y3 R31 R32 R33 R3n
Ym Rm1 Rm2 Rm3 Rmn, где Xi, Yj целые числа, a Rij —
арифметические отношения: <, = ,>.
Найти значения Xi и Yj, которые удовлетворяли бы отношениям Rij.
КРАТЧАЙШИЙ ПУТЬ КОНЯ
Имеется бесконечная шахматная доска. За какое наименьшее число ходов конь сможет перейти с поля (xi.yi) на поле (Х2,уг> ?
ВЗАИМНЫЙ ЗАЧЕТ ДОЛГОВ^
Есть множество предприятии, которые должны друг другу. Произвести взаимный зачет долгов на максимальную сумму.
ТОЖДЕСТВО КОМПОСТЕРОВ
Имеется два автобусных талона. Установить, пробиты ли они одним компостером или разными. Талон можно вкладывать в компостер любой стороной так, чтобы края талона были параллельны краям компостера и все отверстия компостера помещались на талоне. Отверстия компостера размещаются на квадратной сетке размером М х N.
аиввивдий
L/RPHPMVJP в мир аягоритмов
ВВЕДЕНИЕ
Скотоводы, пчеловоды и прочие налогоплательщики кормят математиков за то, что математики решают задачи. Для решения задачи нужно придумать алгоритм, а для этого нужно тренироваться и знать много других алгоритмов, созданных мастерами. Конечно, нужно еще уметь придумывать удобные понятия и доказывать теоремы про их свойства, но все-таки, как ни крути, сердцевина математики — это алгоритмы, а остальное — достойная, но обслуга. Поэтому, казалось бы, людей, которых учат математике, следует, помимо прочего, специально учить алгоритмам.
Увы, в суете массового образования это здравое понимание забыто. Какие неочевидные алгоритмы проходят в школе? Ну, основные арифметические действия в столбик, извлечение квадратного корня, действия с дробями, Эвклидов алгоритм вычисления наибольшего общего делителя двух чисел и еще совсем немножко. Школьному учителю не до алгоритмов: он должен научить, как доказывать неравенство, где перепутаны модуль, пара тригонометрических функций и логарифм по основанию Зл/2. Другое популярное урокопрепровождение — это решение (и — главное! — правильно написанное объяснение) нуднейших стереометрических задач. Учитель не виноват: во-первых, его самого так учили, во-вторых, именно такие задачи спустят на экзамены из министерства, а не какие-то там алгоритмы.
Вот что говорит Дьедонне (1972), один из сильнейших математиков нашего времени: «Я прошу всех беспристрастно посмотреть на следующие темы, занимающие большое место в школьной математике:
...Свойства «традиционных» фигур, таких как треугольники, четырехугольники, окружности и системы окружностей... — все это
121
со всеми изощрениями, накопленными поколениями «геометров» и преподавателей в поисках подходящих экзаменационных задач.
...Весь псалтырь тригонометрических формул и их калейдоскопических преобразований, позволяющих находить великолепные «решения задач» на треугольники и — пожалуйста имейте в виду — «в форме, пригодной для логарифмирования»».
В институтском курсе математики тоже не до алгоритмов — учебное время уходит на то, чтобы вдолбить в студенческие головы длинные частоколы определений. «Задачи» имеют примерно такой вид: Придумайте какое-нибудь отношение толерантности.
В курсах программирования раньше изучали хоть алгоритмы сортировки, сейчас для сортировки вызывают готовую импортную программу. Не до алгоритмов сейчас: скопировано столько иностранных программных продуктов. Основная задача — научиться пользоваться хоть малой их толикой.
Изучающие алгоритмические языки — бывает — сами пишут программу, обычно, чтобы заставить компьютер сказать: «Привет!» Здесь большое разнообразие: в одних языках надо с авить запятую, в других точку, в третьих точку с запятой. Все это напоминает игру в теннис без мяча.
Такими негодными средствам развиваются навыки, иначе говоря, искусство составлять алгоритмы. Есть еще наука об алгоритмах, которая исследует, какие задачи решаются простыми алгоритмами, какие — сложными, а какие и вовсе не имеют алгоритмического решения. Этот круг вопросов полностью игнорируется стандартным образованием.
В такой ситуации становится очевидным, что алгоритмам нужно учиться в отдельном курсе. Настоящая книга задумана как простой, начальный учебник по алгоритмам.
Конечно, книги об алгоритмах, в том числе очень поучительные и простые, уже изданы, в том числе и на русском языке. Читателю рекомендуется изучить такие книги как
Н. Вирт. Алгоритмы и структуры данных. М.: «Мир», 1989 и
Ч. Уэзерелл. Этюды для программистов. М.. «Мир», 1982.
Эти книги, однако, не только про алгоритмы — они слишком перевиты с программированием, с такими вопросами, как грузить, хранить, упорядочивать и извлекать данные. О зависимости от программирования можно судить по тому, что книга Вирта существовала в первом варианте (Н. Вирт. Алгоритмы + структуры дан-ных=программы. М.: «Мир», 1985) ориентированной на Паскаль, а во втором варианте — на Модула-2. Эта переориентировка потребовала переработки книги.
122
В нашей книге алгоритмы будут рассматриваться в большем отрыве от про раммного воплощения, поэтому мы поработаем с интересными задачами из других ветвей математики. Именно, будут затронуты следующие темы:
— прикладная теория графов, ибо это — неиссякаемый источник задач любой сложности;
— «настоящее целочисленное программирование» (где при це лочисле» ном входе получают целочисленный выход) поскол ку содержательная, но не слишком сложная математика сочетается здесь с явной прикладной полезностью;
— теория расписаний, поучительная тем, что в ней, как вода и губка, перемежаются простейшие и NP-полные задачи;
— защи а данных: новые методы шифровки/дешифровки и взламывания кодов, поскольку эта область изобилует неожиданными и занимательными алгоритмами.
Что касается вопросов сложности решения задач, то они будут затрагиваться в соответствующих местах текста и подытожены в последней главе.
Курс лекций (годовой, при одной паре в неделю], более- иенее соответствующий этой книге, обкатывался на протяжении последних грех лет для старшего класса компьютерного лицея (-11-Й класс средней школы). Опыт показал, то большинство учеников усваивают курс, и это идет на пользу их математическому и программистскому развитию.
Разные читатели имеют разную подготовку и разные способности понимать чужое рассуждение. Мы будем считать читателя твердым «хорошистом», но пользоваться еще четырьмя знаками «д, ▲» и «☆, ★». Между треугольниками, начиная светлым и кончая черным, будет помешаться текст для «троечника»: определения сравнительно известных понятий, подробные разъяснения умозаключений, численные примеры, иллюстрирующие работу простых алгоритмов и т. п. Более подготовленный читатель места между треугольниками может пропускать или бегло просматривать.
Наоборот, тексты между пятиугольными звездочками предназначены для «отличников» — его читать не обязательно: там содержатся побочные заключения, расширения, обобщения и вообще необязательный для начинающего материал.
Если в треугольники или звездочки заключено заглавие пункта, параграфа или раздела, то это означает, что в такие знаки заключен весь соответствующий текст.
Мы будем пользоваться еще одним символом: |STOP |, который советует читателю отложить книгу и попробовать разобраться в обсуждаемом вопросе самому.
123
В книге, посвященной алгоритмам, вроде бы положено дать определение алгоритма как последовательности детерминированных действий, кои... Мы этого делать не станем. Приблизительно что такое алгоритм, понятно на примерах. Вот один из алгоритмов, списанный с пачки вермишели:
«Взять воды не меньше одного литра и положить 1/3 чайной ложки соли на каждые 100 г вермишели.
Вермишель высыпать в кипящую подсоленную воду и варить до готовности на слабом огне.
Готовую вермишель откинуть на дуршлаг и промыть водой»
Попытки давать слишком точные словесные определения объекта исследования мешают самому исследованию. Лингвистам известны две довольно толстые книжки: «Was ist ein Wort?» (Что такое слово?) и «Was ist ein Satz?» (Что такое предложение?), где собраны тысячи определений слова и предложения. Страшно подумать, сколько умственного труда угрохано на эту игру без малейших положительных результатов.
В этой книжке нет объяснений, что такое алгоритм, в каких формах его можно описывать, как его можно обобщить и тому подобных вопросов (кстати, они прекрасно изложены в книге Криницкого, 1977). В основном, здесь будут описаны, проанализированы и доказаны избранные (на вкус автора) алгоритмы.
В конце книги, когда возникнет нужда в точном определении алгоритма, он будет описан как машина Тьюринга.
Нумерация страниц и рисунков сплошная по всей книге, нумерация формул и теорем автономная в каждом разделе. Ссылки на литературу даются по фамилии первого автора сопровождаемой годом издания после запятой или в скобках. Большое количество возможных ссылок на иностранную литературу опущено как бесполезная демонстрация эрудиции автора — такая литература рядовому читателю стала совсем недоступна.
1 ПРИКЛАДНЫЕ ЗАДАЧИ ТЕОРИИ ГРАФОВ
1.1. Задача Прима-Краскала
Дана плоская страна и в ней п городов. Нужно соединить все города телефонной связью так, чтобы общая длина телефонных линий была минимальной
Всякую прикладную постановку задачи нелишне уточнить. Мы негласно подразумеваем, что города сравнительно со страной малы; поэтому мы пренебрежем величиной городов и будем изображать город (точнее: телефонную станцию, размещенную в городе) точкой. Введя подходящую систему декартовых координат, мы запишем положение /-го города, / = 1, .... л, парой координат (х/, yi). Условие, что страна плоская, означает, что dij — расстояние от /-го города, до /’-го, j = 1, .... л, задается формулой
dij = V(x, - xj) z+ (у, - у/) 2 (1)
В задаче речь идет о телефонной связи, т е. подразумевается транзитивность связи: если /-Й город связан с j-м, а /-й с k-м, то /-й связан с к-м. Подразумевается также, что телефонные линии могут разветвляться только на телефонной станции, а не в чистом поле. Наконец, требование минимальности (вместе с транзитивностью) означает, что в искомом решении не будет циклов. Если бы в минимальном решении был цикл, скажем, (/, /, k, I, i), то можно было бы убрать одно звено цикла, скажем, (/, к), причем связь между /’ и к сохранилась бы по другой стороне цикла, по пути (/, /', I, к). Но убирая одно звено, мы бы уменьшили минимальный цикл, что невозможно. Уточненную задачу можно теперь переформулировать в терминах теории графов.
125
Д Для этого придется ввести много терминов, которые пригодятся и дальше. Как говорил Берж, «во многих случаях жизни старая привычка толкает нас рисовать на бумаге точки, изображающие людей, населенные пункты, химические вещества и т. д.». Описанная картинка называется графом, точки (или маленькие кружки) — вершинами, линии — ребрами, стрелки — дугами. Если допустимо соединить две вершины кратными (т. е. несколькими) ребрами, то граф называется мультиграфом. Ребро, ведущее из вершины в нее же, называется петлей. Граф без кратных ребер и петель называется простым Поскольку дальше мы будем изучать преимущественно простые графы, то эпитет «простой» будет подразумеваться по умолчанию. Цепью между вершинами v и и называется последовательность ребер, соединяющих v и и (если вершины — это города, а ребра — дороги между соседи ми городами, то цепь — это дорога, соединяющая — может быть, не смежные — города v и и). Если граф ориентированный (орграф), в котором вместо ребер имеются дуги, то аналог цепи называется путем: в пути из v в и все дуги должны быть ориентированы «по ходу». Связный граф — это граф, где существует цепь между любой парой вершин v, и; иногда такой граф называют односвязным; если граф не связный и распадается на к, lot, компонент связности, то граф называется к-связным. Граф часто обозначают символом G(V,E), G от английского Graph, V от Vertices — вершины, Е от Edges — ребра. В приложениях часто рассматривают взвешенные графы, где каждому ребру приписывается вес (или длина). Взвешенные графы также называют сетями, их часто обозначают N(V,E,W), где N — от английского Network — сеть, а IV — от Weight — вес. Иногда надо рассматривать не весь граф, а его часть (часть вершин и часть ребер). Часть вершин и все инцидентные им ребра называются подграфом; все вершины и часть и цидентных им ребер называется суграфом. Циклом называется цепь из V в V. Деревом называется граф без циклов. Остовным деревом называется связный суграф графа, не имеющий циклов. Полным графом называется граф, в котором проведены все возможные ребра (в полном графе с п вершинами имеется п(п-1)/2 ребер).Л
В терминах теории графов задача Прима-Кра кала выглядит следующим образом:
Дан полный граф с п вершинами, длины ребер определяются по формуле (1), где х,, у, — координаты вершин. Найти остовное дерево минимальной длины.
В таком виде задача была поставлена и решена Примом (1961). Краскал, одновременно и независимо, поставил и решил задачу не для плоского случая, где расстояния определяются по формуле (1), а для произвольных положительных d,j, ij = 1.л. При этом для
126
некоторых пар индексов dj = что означает отсутствие ребра, т.е. рассматривается любой граф, а не только полный. Итак, вышеприведенный вариант есть, строго говоря, задача Прима, а задача Краскала звучит так:
Дан граф с п вершинами; длины ребер заданы матрицей {dtj}, i,j = 1, , п. Найти остовное дерево минимальной длины.
Обе перечисленные задачи решаются одним алгоритмом, причем алгоритмом самой примитивной разновидности.
Представим себе, что зимовщику оставлен некоторый запас продуктов, и его задачей является составление вкусного меню на всю зиму. Если зимовщик начнет с того, что сперва будет есть самую вкусную еду (например, шоколад), потом — вторую по вкусности (например, мясо), то он рискует оставить на последний месяц только соль и маргарин. Подобным образом, если оптимальный (для определенности, минимальный) объект строится как-то по шагам, то нельзя на первом шаге выбирать что-то самое малое, на втором шаге — оставшееся самое малое и т д. За такую политику обычно приходится жестоко расплачиваться на последних шагах. Алгоритм, который мы выше выругали, называется жадным.
Удивительно, но в задаче Прима-Краскала, которая не кажется особенно простой, жадный алгоритм дает точное оптимальное решение.
Как известно (это легко доказать, скажем, по индукции), дерево с л вершинами имеет п-1 ребер. Оказывается, каждое ребро надо выбирать жадно (лишь бы не возникали циклы).
Алгоритм Прима-Краскала
(краткое описание)
1. В цикле п-1 раз делай выбрать самое короткое еще не выбранное ребро при условии, что оно не образует цикла с уже выбранными.
Выбранные таким образом ребра образуют искомое остовное дерево
Описание алгоритма в таком виде несколько неудобно Оно слишком коротко и не раскрывает всех трудностей. Например, как конкретно следить, чтобы новое ребро не образовывало цикла со старыми9 Оказывается, это сделать просто До построения дерева окрасим каждую вершину i в отличный от других цвет г. При выборе очередного ребра, скажем (у), где i и / имеют разные цвета, вершина / и все, окрашенные в ее цвет (т. е. ранее с ней соединенные) перекрашиваются в цвет /. Таким образом, выбор вершин разного цвета обеспечивает отсутствие циклов После выбора п-1 ребер все вершины получают один цвет
127
Итак, более подробный алгоритм выглядит так.
Алгоритм Прима-Краскала
(среднеподробное описание)
1 (ввод). Ввести матрицу расстояний
D = {dij}, i,j = 1,.... n.
2 (инициализация). Приписать разные цвета всем вершинам: colj:=i; длина дерева L=0.
3 (общий шаг). В цикле по к:= 1 ton-1 do найти ребро минимальной длины между вершинами разного цвета; пусть это ребро (у). Запомнить результат: Res1[k]:=i; Res2[k]=j.
Перекрасить вершины:
П:= col[i]; j1:=col[j].
В цикле по m:=1 to n do
if col[m]=j1 then col[m]:=i1.
Нарастить длину дерева: L:= L+ d[i,fl.
Конец цикла по к.
4 (вывод). Вывести Rest, Res2.
На такой способ записи алгоритмов, где человеческий язык перемешан с условным алгоритмическим, а процесс разбит на пункты с возможными условными и безусловными переходами, к счастью, нет стандарта. Поэтому такой способ гибок, выразителен и повсеместно принят.
Можно, конечно, пойти дальше по пути увеличения точности (и уменьшения понятности) и записать алгоритм на каком-нибудь популярном языке, скажем, Паскале. Конечно, программа приводится не полностью, с купюрами касательно ввода/вывода, графики, открытия/закрытия файлов и т. п. Тогда алгоритм имеет примерно такой вид.
Алгоритм Прима-Краскала
(полное описание)
1. Описания
type.
DDAr=array[1..5O,1..5O] of real;
{матрица расстояний) var
D : DDAr;
X,Y : array[1..5O] of real;
col : array[1..5O] of integer; {цвет вершин)
Res : array[1..50,1..2] of integer; {перечень ребер дерева) dmin.l : real; {длина остовного дерева) N,k,m,j1 ,i,j: byte; {N — число вершин).
2. Ввод D[i,j].
128
3. Инициализация
for i:=1 to N do col[i]:= i;
k:= 0; L:= 0.
4. Общий шаг
while K<N-1 do
begin
dmin:= 30000;
for i1:=1 to N-1 do
for j1:=i1+1 to N do
if (D[i1,j1]<dmin) and (col[i1JOcol[j1]i then begin
dmin:= D[i1,j1],
i:= i1;
j:= Л
end;
k:= k+1;
L:= L+dmin;
Res[k,1]:= i;
Res[k,2]:= j;
j1:= co![j];
for m:=1 to N do
if col[m] = j1 then col[m]:=col[i]; end.
5. Вывод перечня ребер Res.
В дальнейшем изложении алгоритмы будут обычно опис ывагься неформальным способом средней подробности или, при простой структуре и сложных блоках, вообще вольным текстом.
Было объявлено, что описанный алгоритм получает в точности минимальное решение. Это нужно доказать.
А Для доказательства нам понадобится очень простое утверждение:
Если к дереву добавить ребро, то в дереве появится цикл, содержащий это ребро.
Действительно, пусть добавлено ребро (и, v) — «добавлено» означает, что ребро — новое, что раньше его в дереве не было. Поскольку дерево является связным графом, то существует цепь С(и, .... v) из нескольких ребер, соединяющая вершины и и v Добавление ребра (и, v) замыкает цепь, превращая ее в цикл. ▲
Теорема 1 Алгоритм Прима-Краскала получает минимальное остовное дерево.
Доказательство. Результатом работы алгоритма является набор из п-1 ребер. Они не образуют цикла, ибо на каждом из п-1 шагов
5 «Основы программирования»
129
соединялись вершины разного цвета, т. е. ранее не связанные. Этот граф связный, потому что после проведения 1-го ребра осталось п-1 разных цветов, .... после проведения (п-1 )-го ребра остался один цвет, т. е. одна компонента связности. Итак, полученный набор ребер образует связный граф без циклов, содержащий п-1 ребер, т. е. л вершин. Следовательно, граф есть остовное дерево. Осталось доказать что оно имеет минимальную длину.
Пусть {h, I2, In-i} ребра остовного дерева в том порядке, как их выбирал алгоритм, т. е. №j-i. Предположим для простоты доказательства, что все ребра сети имеют разную длину, т. е.
h<l2<...<ln-i (2)
Если полученное дерево не минимально, то существует другое дерево, задаваемое набором из п-1 ребер {di d2, , dn-i}, такое что сумма длин di меньше суммы длин //. С точностью до обозначений
di<d2<-.<dni (3)
Может быть, h=di, 1г =d2 и т.д., но так как деревья разные, то в последовательностях (2) и (3) найдется место, где ребра отличаются. Пусть самое левое такое место — к, так что d* (к может равняться единице, это не испортит доказательства). Поскольку 4 выбиралось по алгоритму самым 1алым из необразующих цикла с ребрами И, 1г, .... 1к-1, то lk<dk- Теперь добавим к дереву (3) ребро 1к, в нем появится цикл, содержащий ребро 4 и, может быть, какие-то (или все) ребра из h, I2,.... Ik-i, но они сами не образуют цикла, поэтому в цикле будет обязательно ребро d из набора dk, .... dn-i, причем d>lk- Выбросим из полученного графа с одним циклом ребро d; мы снова получим дерево, но оно будет на d-lk короче минимального, что невозможно. Полученное противоречие доказывает теорему для сети со всеми разными ребрами.
Если не предполагать, что все ребра разные, то в доказательстве могло бы получиться, что Ik =dk, и нам пришлось бы двигаться дальше по последовательностям (2) и (3), пока бы мы не нашли lk+m<dk+m- Это усложняет доказательство, но не меняет заключения.
В заключение анализа ал оритма надо оценить требуемую па мять и требуемое число операций. С памятью здесь все ясно: в варианте Прима надо хранить 2п координат точек, в варианте Краскала — п2 расстояний; в обоих вариантах удобно хранить 2(п-1) номеров вершин, т. е. п-1 ребер ответа. Всего требуется памяти 0(п2), т.е. порядка = л2, что, учитывая реальные величины л, необременительно. Для нахождения текущего минимального ребра
130
надо просмотреть О(п2) чисел и сделать это надо п-1 раз, так что временная сложность алгоритма О(п3). Это тоже реально. Задача Прима-Краскала относится к просто и точно решаемым.
Задачи и упражнения
1. Найти минимальное остовное дерево для сети с расстояниями
1 0 9,5 8,6 10,8 8,9 7,1 14
2 9,5 0 14,6 8,6 17 8,9 6,4
3 8,6 14,6 0 9,5 15 15,6 20,6
4 10,8 8,6 9,5 0 19,7 15 14,9
5 8,9 17 15 19,7 0 9,5 19,3
6 7,1 8,9 15,6 15 9,5 0 9,8
7 14 6,4 20,6 14,9 19,3 9,8 0
Ответ: длина дерева ЦТ) = 48,5
2 . Алгоритм Прима
1 (инициализация). Выбрать кратчайшее ребро.
2 (общий шаг), п-2 раза делай: выбрать кратчайшее ребро, одна вершина которого принадлежит уже выбранному дереву, а другая вершина принадлежит оставшейся части сети. Доказать, что этот алгоритм получает минимальное остовное дерево.
3 Алгоритм Краскала
1 (общий шаг). Пока возможно делай:
удалить из сети самое длинное ребро при условии, что сеть остается связной. Доказать, что этот алгоритм получает минимальное остовное дерево.
4. Оценить количество операций в алгоритме Прима (из задачи 2).
5. Оценить количество операций в алгоритме Краскала (из задачи 3).
1.2. Задача Штейнера
Предположим, что в плоской стране имеются четыре города, расположенные в вершинах единичного квадрата ABCD. Мы знаем, как соединить эти города кратчайшей телефонной сетью: нужно провести провода по линиям АВ, ВС и CD. А как соединить их кратчайшей системой дорог, чтоб можно было проехать из каждого города в каждый? Предполагается, что дороги отличаются от проводов тем, что они могут разветвляться в чистом поле.
| STOP|
5*
131
Требуемая система дорог (минимальная сеть Штейнера) показана на рис. 1. Дополнительные перекрестки а и b размещены так, что все дороги разветвляются в точках а и b под углом 120°. Длина этой сети Штейнера равна как нетрудно посчитать, 1 + ^3 <= 2,73, в отличие от минимальной сети Прима-Краскала, длина которой в данном примере равна 3. Для доказательства результата нам понадобится одна старинная задача, которую независимо поставили Торичелли и Ферма. Мы приведем здесь решение, которое предложил никто иной как Наполеон Бонапарт в бытность кадетом артиллерийского училища.
Задача Торичелли-Ферма. В треугольника АВС найти точку Р, такую что сумма расстояний от Рдо вершин А, В и С минимальна.
Мы решим задачу для случая, когда наибольший угол меньше 120° Пусть Р — произвольная точка внутри треугольника. Повернем треугольник АВР вокруг вершины В наружу на 60°, как показано на рис. 2.
АР = А’Р’ и ВР = В'Р’ по построению, ВР = Р’Р, потому что треугольник ВРР’ равносторонний, значит сумма расстояний от Р до А, В, С равна длине ломаной А’Р’РС. Эта сумма станет минимальной, если Р примет такое положение, что ломаная станет прямой. Для этого нужно, чтобы участок АР’Р стал прямым, т. е. чтобы угол А’Р’В (и, следовательно, Z АРВ) равнялся 120°. Еще нужно, чтобы участок Р'РС стал прямым, т. е. ВРС равнялся 120° Третий угол при точке Р автоматически станет равным 120°
Итак, доказано, что все три угла при искомой точке Р равны 120° Конструктивно точкаРстроится так: повернем сторону АВ вокруг В
наружу на 60° и проведем отрезок прямой А 'С Проделаем аналогичную операцию на любой из оставшихся сторон. Пересечение двух полученных прямолинейных отрезков даст Р
Комбинируя этот результат с легким перебором, нетрудно показать, что сеть, показанная на рис 1, — минимальна
Однако, в общем случае, когда расположение городов задается не вершинами квадрата, а произвольной сетью, никакого удачного алгоритма точного решения задачи Штейнера неизвестно.
Здесь мы впервые встречаемся с поучительным и приводящим к частым неудачам фактом: из двух на глаз похожих задач одна может решаться очень просто, а вторая — запредельно сложно Нужно специально учиться, чтобы отличать первые задачи от вторых.
Встает вопрос Что делать, если задача в разумное время точно не решается, а решать ее все равно надо? Ответ очевиден — решать неточно. Как это делается, мы покажем на задаче Штейнера. Мы изложим алгоритм ВЗЛ (Вайнера-Зайцева-Лившица), см. Вайнер, 1978. Этот алгоритм, в общем, организован так же, как алгоритм Прима-Краскала: в разных местах сети строятся локально-минимальные компоненты связности, которые по мере роста соединяются и образуют единую сеть Усложнение состоит в том, что элементарным действием является не соединение точек, а соединение компонент связности, поэтому нужно договориться, что такое компонента и что такое расстояние между компонентами.
Компонента состоит из некоторого числа вершин сети (городов) и некоторого числа промежуточных точек (развилок дорог), соединенных прямолинейными дорогами таким образом, что города и развилки, понимаемые как вершины, и дороги, понимаемые как ребра, образуют связной граф. Пусть имеются компоненты С и С. Расстояние между компонентами d(C,C’) равно длине кратчайшего прямолинейного отрезка, один конец которого является точкой х (городом или точкой дороги, все равно) из С, а другой конец является точкой у из С (короче, хе С, уеС).
Нахождение расстояний облегчает следующая
Теорема 2. Точка х или у или обе являются вершинами.
Доказательство. Предположим противное — какх, так и улежат не в вершинах, а внутри ребер, /х и 1У соответственно По построению, /х и 1у являются прямолинейными отрезками- они либо параллельны (рис. За), либо нет (рис. 36).
В случае (а), сдвигая отрезок ху параллельно самому себе и не увеличивая его, можно вывести один из его концов в конец одного из ребер, т е в вершину (или даже в две вершины, если отрезок достигнет их одновременно). В случае (б) нашелся бы параллель-
133
Рис. 3
ный сдвиг минимального отрезка ху, уменьшающий длину ху, что невозможно. Теорема доказана.
Алгоритм ВЗЛ, наподобие алгоритма Прима-Краскала, на каждом шаге соединяет две ближайшие компоненты связности (см. рис. 4а) по кратчайшему расстоянию, показанному штриховой линией. Города здесь показаны белыми кружками, а развилки — черными. Затем для развилки у решается задача Торичелли-Ферма, у перемещается в такое положение, что углы йух, uyv и vyx становятся равными 120° (рис. 46). Как найти такое положение точки у, решается посредством довольно громоздких формул аналитической геометрии, которые мы не станем здесь приводить.
(а)
Заметим, что нет гарантий, что алгоритм ВЗЛ дает оптимальное решение (тогда бы это был точный алгоритм). Более того, неизвестно, насколько полученное по алгоритму решен е отклонится от точного (если бы была известна нетривиальная оценка точности алгоритма, мы бы назвали его приближенным). В алгоритме ВЗЛ воплощены здравые идеи, которые, в общем, должны давать приличный результат. Такой алгоритм называется эвристичес им.
Задачи и упражнения
1. Доказать теорему 2 для треугольника, больший угол которого больше или равен 120°.
2 Доказать, что в минимальной сети Штейнера нет развилок, где расходится более трех дорог.
134
3 Доказать, что сеть Штейнера на рис. 1 оптимальна.
4. Доказать, что число развилок в минимальной сети Штейнера Q городами не превосходит п-2.
5. Записать кратко по пунктам алгоритм ВЗЛ.
6. Придумать пример, в котором алгоритм ВЗЛ не получает минимальной сети Штейнера.
1.3. Алгоритм Дейкстры
В предыдущем параграфе мы проводили дорожную сеть по бездорожью. Теперь мы п едположим, что дорожная сеть (произвольная, а не построенная по Штейнеру) уже есть, а нужно научиться искать в дорожной сети кратчайший путь между заданными точками. Для более точной постановки вопроса отождествим развилки и города: они будут вершинами сети, а дороги будут ребрами. Задача, которую нужно решить, — следующая:
Дана сеть N(V,E,W). Найти кратчайшую цепь между ч и v* (и, v* е V).
Можно предложить много процедур решения этой задачи, например, физическое моделирование такого рода: на плоской доске рисуется карта местности в города и развилки вбиваются гвозди, на каждый гвоздь надевается кольцо, дороги укладываются веревками, которые привязываются к соответствующим кольцам. Чтобы найти кратчайшее расстояние между кольцом i и кольцом к, нужно взять i в одну руку, взять к в другую и растянуть. Те веревки, которые натянутся и не дадут разводить руки шире, и образуют кратчайший путь между i и к. Однако, математическая процедура, которая промоделирует эту физическую, выглядит очень сложно. Известны алгоритмы попроще, из которых мы опишем алгоритм, предложенный Дейкстрой еще в 1959 г. Этот алгоритм решает более общую задачу:
В ориентирова шой, неориентированной или смешанной (т. е. такой, где часть дорог имеет одностороннее движение) сети найти кратчайший путь из заданной вершины во все остальные вершины.
Алгоритм использует три массива из л (= числу вершин сети) чисел каждый. Первый массив а содержит метки с двумя значения: О (вершина еще не рассм рена) и 1 (вершина уже рассмотрена); второй массив b содержит расстояния — текущие кратчайшие расстояния от Vi до соответствующей вершины; третий массив с содержит номера вершин — k-й элемент с* есть номер предпоследней вершины на текущем кратчайшем пути из v, в vk. Матрица расстояний D,i< задает длины дуг d*; если такой дуги нет, то d,k присваивается большое число Б, равное «машинной бесконечности».
Теперь можно описать
135
Алгоритм Дейкстры
1 (инициализация). В цикле от 1 до л заполнить нулями массив а; заполнить числом i массив с; перенести i-to строку матрицы D в массив Ь;
c[i]:=O {i — номер стартовой вершины)
2 (общий шаг). Найти минимум среди неотмеченных (т. е. тех к, для которых а[к] =0); пусть минимум достигается на индексе/, т. е. Д< bk-Затем выполняются следующие операции:
а[)]:=1\
если bk>bt+dik, то (bk:=bj+djk; Ck:=j)
{Условие означает, что путь v,... Vk длиннее, чем путь V»... v>v/<). (Если все а[к] отмечены, то длина пути от w до vk равна Ь[к]. Теперь надо перечислить вершины, входящие в кратчайший путь).
3 (выдача ответа). {Путь от v,до Vk выдается в обратном порядке следующей процедурой:}
3.1. z:=c[k];
3.2. Выдать z;
3.3. z:=c[z]. Если г = О, то конец,
иначе перейти к 3.2.
Для выполнения алгоритма нужно л раз просмотреть массив b
из л элементов, т. е. алгоритм Дейкстры имеет квадратичную сложность: О(гг).
ts. Проиллюстрируем работу алгоритма Дейкстры численным примером (рис. 5).
О 23 12 Б Б Б Б Б
23 0 25 Б 22 Б Б 35
12 25 0 18 Б Б Б Б
Б Б 18 О Б 20 Б Б
Б 22 Б Б 0 23 14 Б
Б Б Б 20 23 0 24 Б
Б Б Б Б 14 24 0 16
Б 35 Б Б Б Б 16 0
Рис. 5
Пусть, например, i = 3, т. е. требуется найти кратчайшие пути из вершины 3. Содержимое массивов а, Ь, с после выполнения п.1 показано на рис. 6.
1 2 3 4 5 6 7 8
0 0 1 0 0 0 0 0
12 25 0 18 Б Б Б Б
33033333
а b с
Рис. 6
136
Содержимое массивов меняется по мере выполнения общего шага, как показано на рис. 7.
1 2 3 4 5 6 7 8
а min bk = 12 b с 1 0 1 0 0 0 0 0 12 25 0 18 Б Б Б Б 33033333
а min bk = 1Е b с 1 0 1 1 0 0 0 0 12 25 0 1 Б 38 Б Б 33033433
a min bk = 25 b c 1 1 1 1 0 0 0 0 12 25 0 18 47 38 Б 60 33032432
a min bk = 38 b c 11110 10 0 12 25 0 18 47 38 62 60 33032462
a min bk = 47 b c 1111110 0 12 25 0 18 47 38 61 60 33032452
a min bk = 60 b c 1111110 1 12 25 0 18 47 38 61 60 33032452
Рис. 7
Длиннейший путь из 3, скажем, в 8 (8<-2<-3), получается, согласно п. 3 алгоритма. Л
Теорема 3. Алгоритм Дейкстры — корректен
Доказательство. «Корректен» означает, что алгоритм правильно решает задачу, т е в данном случае находит кратчайшие пути из vj во все vk-
Теорему докажем по индукции. Рассмотрим 1-й общий шаг, когда находится min bk(k*i), пусть минимум достигается на вершине j. Остальные bk (k*ij) пока лишь верхние оценки длин путей из и в Vk (обозначение: L [и .. v*]), они могут уменьшаться в ходе выполнения алгоритма, но bj — окончательная длина пути [v, vy], совпадающего с дугой [v;, vfl. Если бы существовал путь короче, он бы выглядел [V7, v* . vy], но уже первая его дуга не меньше, чем весь путь [v(, vy], а остальные дуги имеют положительную длину.
Мы разбили все вершины на два класса: С — неотмеченных вершин и С— отмеченных вершин. После 1-го общего шага Vj, Vj е С’, и, очевидно, все кратчайшие пути (пока «все» — означает
137
«один») из v/в v'gC’ не содержат вершины veC в качестве промежуточной.
Теперь сделаем индуктивный шаг Уже проделано s общих шагов, уже С'= {vj, v’,i, v’p, , v'jS}. при этом все кратчайшие пути из Vj в v’ не содержат вершин из С в качестве промежуточных.
Найдем минимальное Ь/ в неотмеченных столбцах; пусть минимум достигается на вершине Vj Соответствующий элемент с/, меняясь, мог принимать только номера отмеченных вершин, значит в вершину у/ идет путь, где все вершины, кроме конечной V/, — штрихованные, т е принадлежащие С Любой путь [к/ ... ^], содержащий хотя бы еще одну нештрихованную вершину, будет длиннее. Теорема доказана
Алгоритм Флойда-Уоршелла
Если надо узнать кратчайшие пути между всеми вершинами, то для решения этой задачи можно п раз повторить алгоритм Дейк-стры, принимая по очереди каждую вершину за стартовую; всего это потребует О(п3) операций. Однако, для решения этой задачи есть более экономный (по порядку тоже О(п3) но в константу раз экономней).
Алгоритм Флойда-Уоршелла
(столь элегантный, что он понятен прямо на машинном языке) for /с=1 to л do
for с=1 to л do
for /:=1 to л do
d[i,j]:=min(d[i,j], d[i,k]+d[k,j]);
Здесь d[i,j] — сначала длина дуги [i,j], а в конце — длина кратчайшего пути. Почему этот алгоритм корректен?
| STOP|
Мы не хотим лишать чи ателя удовольствия Разберитесь сами, почему корректен этот обворожительный алгоритм. Если не получится, воспользуйтесь следующим указанием
Указание Операцией треугольника для фиксированного к (см рис. 8) называется операция
z>ij:d[i,j]:=min(dflj,d[i,k] + d[k,j])
Эта операция заменяет d[i,j] на d[i,k]+d[k,y], если так короче.
Задачи и упражнения
1 Как будет работать алгоритм Дейкстры, если найдутся отрицательные «расстояния» d[i,k]2
☆ 2 Как будет работать алгоритм Флойда-Уоршелла, если найдутся отрицательные расстояния d[i,j]2 ★
138
1.4. Задачи трассировки
Мы только что научились находить путь в дорожной сети. На бездорожной плоскости, где всюду можно пройти, кратчайший путь — это прямолинейный отрезок между точками старта а и финиша z А как пройти (провести трассу) на местности, где имеются препятствия? Эта задача называется задачей трассировки.
Самые трудные задачи возникают здесь, когда препятствия по-разному трудно проходимы. Мы такие задачи рассматривать не будем, а решим две задачи, когда препятствия непроходимы полностью Различают две разновидности задач трассировки: стро ительную и электронную. В первой препятствиями чаще всего являются другие строения, реже иные искусственные (запретная зона, пруд) или естественные (гора, озеро) препятствия, но ранее проведенные трассы препятствиями не являются.
В электронной трассировке трассировка начинается на пустой плате с микроклеммами. Затем, согласно схеме, нужные клеммы соединяются напыленными на плату металлическими проводящими дорожками, и эти трассы являются препятствиями для следующих трасс: следующие не должны пересекать предыдущих.
1.4.1. Строительная трассировка
Мы будем приближенно изображать препятствия многоугольниками: это не слишком ограничительно, поскольку, если разрешается применять многоугольники произвольного вида с достаточным числом углов, всякое препятствие можно аппроксимировать с точностью, достаточной для приложений Итак, задача ставится так.
Дан всюду (кроме препятствий) проходимый участок местное ти, стартовая точка а и финишная г. Найти кратчайшую трассу из а в z.
Задача решается алгоритмом, который авторы (Бондарев, 1988) назвали алгоритмом Чучундры
Чучундра — это не имя автора алгоритма, а имя крысы из сказки Киплинга. Крыса предпочитала ходить вдоль стен.
139
Теорема 4. В случае препятствий-многоугольников кратчайшая трасса образует ломаную с узлами в вершинах много* угольников.
Доказательство. Представим, что трасса — это нить, туго натянутая между стартом а и финишем z. Ясно, что нить ляжет так, как утверждается в теореме. Пуристически настроенный читатель может сам математизировать это рассуждение.
Поскольку препятствия непреодолимы, звено ломаной — это либо сторона многоугольника (содержательно — трасса идет вдоль стены с внешней стороны препятствия), либо прямолинейный отрезок, проходящий вне многоугольников и соединяющий две вершины одного и того же или разных многоугольников
| STOP|
Идея алгоритма следующая нужно построить сеть, состоящую из сторон многоугольников и из прямоугольных отрезков, соединяющих вершины разных многоугольников или вершины одного многоугольника при условии, что они «простреливаются» друг из друга (препятствия считаются пуленепробиваемыми). Точки а и z, если они не вершины многоугольников, тоже нужно соединить с простреливаемыми из них вершинами. После того, как сеть построена, на ней нужно, пользуясь, например, алгоритмом Дейкстры, найти кратчайший путь из а в z
Формирование сети, т е. матрицы расстояний D размером л х п (п — общее число вершин всех многоугольников плюс два для учета старта и финиша) представляет собой тройной цикл. Внешний — по i — это перебор вершин, откуда стреляют; средний — по / (j: = i+1 to п, чтобы не повторяться) — это перебор вершин, куда стреляют, и внутренний - по к — это проверка, не пересекает ли к-я сторона какого-нибудь многоугольника (всего сторон столько, сколько углов) отрезок, по которому летят пули.
Последнее условие, в случае, как на рис. 9а, проверяется по стандартным формулам аналитической геометрии: выписывается уравнение прямой, проходящей через /, /, выписывается уравнение прямой, проходящей через концы отрезка к, решением системы из этих двух уравнений находится точка пересечения и устанавливается, лежит ли точка пересечения внутри рассматриваемых отрезков. Если да, то djj:= Б, конец цикла по к, если нет, продолжить цикл по к\ если нет пересечения по окончанию цикла по к, то вычисляется Евклидово расстояние dij, по формуле (1).
В случае, как на рис 96. ситуация сложнее: между i и j не проходит никакой стены, a j из / не простреливается. Чтобы преодолеть эту трудность, введем некую характеристику i угла препятствия: gj, положив
140
{О, если а; < п («вогнутый» угол) 1, если а, > л («выпуклый» угол)
Здесь а;есть внешний угол препятствия. Так, для угла с вершиной / на рис. 96 д, =1, а для угла с вершиной / gi = 0.
Для вычисления д, понадобится простое утверждение.
Теорема 5. Пусть Vj, vt+i, Vj+г, Ц+з — последовательные вершины многоугольника. Если крайние вершины и и vi+з лежат по одну сторону от прямой, проходящей через средние вершины Vi+i и Vi+г, то gi+i=gi+2 иначе gt+i* gt+2-
Доказательство. Пусть имеет место случай, показанный на рис. 10а. если препятствие лежит ниже ломаной, то а/+/ >п и а;+2 >п; если выше, то и ан-i <л и о.н-2 <л. В случае, показанном на рис. 106, если препятствие ниже ломаной, то ан-i >л и сц+2 <К иначе ан-i <п и а,+г >п. Утверждение доказано.
Положим gi = 1 и циклически проведем сравнение, описанное в теореме Для этого надо записать уравнение прямой, проходящей через вершины i+1 и i+2:
(Х-ХН1)(УН2 - Ун /) - (xi+2-Xi+i)(y-yi+f) = 0
(4)
Если при подстановке в (4) точек (х,, у) и (хнз, ун-з) в левой части получаются числа с одинаковым знаком, то g,+ i = днг, иначе Qi+i * gi+2- После этого цикла мы будем знать все д, точно или с
141
точностью до наоборот. Осталось абсолютно установить д,хотя бы для одной вершины Это легко сделать, потому что экстремальная вершина (например, с уо = max у,, где max берется по всем вершинам многоугольника) определенно имеет до = 1.
Теперь мы можем справиться с трудностью, показанной на рис. 96. Из вершины i (см рис 11а) не простреливается никакая вершина /, защищенная углом с вершиной / Чтобы исключить из рассмотрения загороженные вершины, отступим от вершины / по сторонам угла на величину е, заведомо меньшую, чем длина стороны, построив таким образом точки аир. Введем бинарную переменную В по следующему правилу:
g _ J1, если отрезки ар и ij пересекаются, [О, в противном случае
Тогда мы будем иметь следующие случаи, показанные на рис. 11.
(а) д,=1 (б) д,=0
Всего имеется четыре возможности:
на рис. 11а
1)6 = 1 ид; = 1,
2) В =0 и д, = Г,
на рис 116
3) В = 1 и д,; = О,
4) В = 0 и д, = О
Ясно, что вершина j не простреливается из i в случаях 1 и 4 (при четном В+д), простреливается — в случаях 2 и 3 (при нечетном в+д)
Характеристическая функция д позволяет сократить перебор, поскольку справедлива следующая
Теорема 6 Ни одна вершина ломаной, представляющей кратчайшую трассу, не может иметь g = О. (Исключение может иметь место, если в качестве старта и/или финиша назначены вершины eg - О).
I STOP|
142
Доказательство. Допустим противное: пусть в многоугольнике имеется внешний ZABCCn (см. рис. 12), и через него проходит кратчайшая трасса a-»...A->B->C-»...-»z, включающая стороны АВ и ВС. Поскольку есть свободная полоса между АВ, ВС и другими препятствиями, возможно вращать луч АВ вокругД, пока подвижный конец луча В’ не совместится с С или не коснется другого препятствия (точка D на рис. 12). Но АВ'+В'С< АВ+ВС. Нам удалось укоротить кратчайшую трассу, что невозможно.
Теорема доказана. По существу это геометрическое оформление механической аналогии с натянутой нитью.
Для иллюстрации работы алгоритма в качестве системы препятствий было выбрано нечто намеренно запутанное — известный лабиринт в Хэмптон-Корте, блуждания по которому описано у Джерома 1989 (глава 5). Кратчайшая трасса между случайно выбранными точками а и z показана на рис. 13.
Задачи и упражнения
1. В симметрической матрице D размером пхл почти половина памяти расходуется зря. Существенная информация хранится над главной диагональю; эту информацию можно хранить в линейном массиве £[1..п(п-1)/2]. Как пересчитывать индексы i,j матрицы D в индекс к массива L и обратно?
2. Если проекции отрезков на ось ох и оу не пересекаются, то и отрезки не пересекаются. Как использовать это для сокращения работы программы строительной трассировки9
1.4.2. Электронная трассировка
Плоский граф — это граф, нарисованный таким образом, что его ребра не пересекаются, например, как на рис. 14а. Плоский граф или граф, который можно перерисовать как плоский (еще говорят: который допускает плоскую укладку), называется планарным, как на рис. 146. Кстати, граф на рис. 14 называется полным четырехвершинником и обозначается К4.
143
Рис 13
144
Существуют и непланарные графы. На рис. 15 приведены два таких графа: полный пятивершинник К5 и полный двудольный граф из 3+3 вершин Кз.з.
Рис. 15
Д Двудольным графом называется граф, вершины которого разбиты на две доли (части), а ребра проходят только между вершинами из разных частей.А
При изготовлении электронных схем печатным способом электрические цепи наносятся на плоскую плату из изолирующего материала. Так как наносимые линии не изолированы, они не должны пересекаться. Если схема соединения образует непланарный граф, то схему надо напылять на несколько плат и соединять их перемычками. Здесь возникают сложные вопросы определения минимального числа плат (абстрактно: слоев графа). Мы в эти вопросы углубляться не станем, а займемся случаем одной платы, т. е. будет рассмотрена следующая задача:
Определить, является ли данный граф планарным и, если да, то произвести его плоскую укладку.
☆ Тех читателей, кто хочет больше узнать про электронную трассировку, мы отсылаем к книге Абрайтис, 1985.
Ясно, что если на ребра планарного графа нанести произвольное число вершин степени 2, то он останется планарным; равным образом, если на ребра непланарного графа нанести вершины степени 2, то он планарным не станет. (Степень вершины — это число ребер, к ней присоединенных).
145
В конце 1920-х годов Куратовский в Польше и Л.С. Понтрягин в СССР независимо доказали поразительную теорему, показавшую, что единственное, что мешает графу быть планарным, — это трудности, показанные на рис. 15.
Теорема 7 (Понтрягина-Куратовского). Граф планарен тогда и только тогда, когда он не содержит в качестве частей графы Ks и Кз,з (быть может с добавочными вершинами степени 2).
Мы опустим довольно сложное доказательство этой теоремы. Заинтересованный читатель может найти понятное доказательство в книге Емеличев, 1990. Не следует, однако, думать, что если трудностей всего две, то непланарных графов мало: при росте числа вершин непланарны почти все графы (Коршунов, 1985).
Критерий планарности, основанный на теореме Понтрягина-Куратовского не слишком практичен, потому что найти в графе части Ks и/или Кз,з не так просто. Например, так называемый граф Петерсена (рис. 16) не является планарным. Какой граф содержится в нем в качестве части: Кб или Кз,з?
Чтобы ответить на этот вопрос, надо убрать ребра (3,4) и (7,10), назначить вершины 1, 8 и 9 в одну долю и 2, 5,6 — в другую, после чего в графе Петерсена можно узреть Кз,з.
Поэтому для практической работы нужны более конструктивные критерии. ★
Для плоской укладки графа (и попутной проверке: планарен ли он?) удобно пользоваться алгоритмом у (Емеличев, 1990, §41).
Заметим, что в плоском графе можно говорить не только о вершинах и ребрах но и о гранях.
Грань — это часть плоскости, окруженная простым циклом (т. е. циклом без самопересечений) и не содержащая внутри себя других элементов графа. Удобно считать гранью также внешнюю грань, т. е. всю плоскость, окружающую плоский граф.
146
Нам понадобится также понятие мостика. Мостик — это ребро связного графа, такое, что при удалении этого ребра граф распадается на две компоненты связности.
Мы будем предполагать, что на вход алгоритма у подаются графы, обладающие следующими свойствами: (1) граф связный; (2) граф имеет хотя бы один цикл; (3) граф не имеет мостиков.
Если нарушено свойство (1), то граф нужно плоско укладывать отдельно по компонентам связности. Если нарушено (2), то граф — дерево, а дерево — это планарный граф и нарисовать его плоскую укладку тривиально. Если нарушено (3), то нужно «разрезать» мостик, произвести отдельно плоскую укладку каждой компоненты связности, а потом соединить их мостиком. Здесь может возникнуть трудность: в процессе укладки концевые вершины мостика могут спрятаться внутри плоского графа. Однако плоский граф легко перерисовать так, чтобы любая вершина вышла наружу. Это можно сделать посредством стереометрической проекции с северным полюсом внутри грани, ограниченной циклом, включающим выводимую наружу вершину, либо «прорезая к ней путь и связывая прорезанные ребра с другой стороны», как на на рис. 17.
Рис. 17
Сначала мы изложим алгоритм у на конкретном примере. Пусть на вход подан граф, показанный на рис. 18.
147
Инициализация алгоритма производится так: выбираем любой простой цикл; в нашем примере, скажем, цикл (123456781)и получаем две грани: Г j— внешнюю и Гг— внутреннюю (см. рис. 19).
Рис. 19
Представим себе, что граф состоит из колец-вершин, связанных веревочками-ребрами. Выбрав начальную грань, показанную на рис. 19, мы перережем все ребра у вершин, принадлежащих уже уложенной грани, но чтобы не забыть, в какую вершину шли перерезанные ребра, повесим на них квадратные ярлычки с номерами этих вершин. Оставшаяся часть графа распадется на связные куски — сегменты, показанные на рис. 20.
Если бы в каком-нибудь сегменте не было ни одного ярлычка, то
Рис. 20
граф до разрезания был бы несвязный; если бы был только один ярлычок, то граф имел бы мостик. Эти возможности заранее исключены, так что каждый сегмент имеет не менее двух ярлычков. Поэтому в каждом сегменте имеется цепь между любой парой ярлычков.
Если все ярлычки сегмента S имеют номера вершин какой-то грани Г, то мы будем говорить, что грань Г вмещает этот сегмент (или сегмент S вмещается в эту грань) и обозначать ЭсГ. Может быть, имеется не одна грань, вмещающая сегмент S, множество таких граней обозначим Г(5|, а число их | Г(Э) |. После инициализации для всех i справедливо I T(S) | =2. Потом, в ходе выполнения алгоритма, это свойство нарушится, и мы будем иметь | T(Sj) | = 0,1,2.
Общий шаг алгоритма следующий: обозреваются все сегменты Sj и определяются числа | l"(Si) |. Если хоть одно I ("(SO I = 0, то граф
148
не планарен, конец. Иначе, если есть хоть один сегмент с | T(Si) I =1, выбирается произвольный из таких сегментов. Найдем в этом сегменте цепь между какой-нибудь парой его ярлычков и совместим эти ярлычки с соответствующими вершинами единственной вмещающей грани. При этом вмещающая грань разобьется на две. Число граней, равно как и число ребер (и, может быть, число вершин) в уже уложенной части G’ увеличится. Наоборот, сегмент, из которого вынута цепь, исчезнет, или уменьшится, или развалится на меньшие сегменты с новыми ярлычками на ребрах, ведущих к вершинам, помещенным на этом шаге в G’. С измененной системой сегментов и достроенным G' нужно вернуться на общий шаг.
Если все | r(Sj) | = 2, то делается то же, что при | Г(Б<) I = 1, с единственным отличием, что теперь цепь можно помещать в любую из двух вмещающих граней.
В результате повторения общего шага либо будет получена плоская укладка, либо будет установлено, что граф G не планарный.
Вернемся к рассмотрению примера. Пока для любого i &с{Г1, Гг}, I T(Si) I = 2. Поэтому возьмем первый по номеру сегмент Si и в нем первую попавшуюся цепь (1, 9, 2); вставим эту цепь в грань Гг-Получим увеличенную уже уложенную часть G' и уменьшенную систему сегментов (рис. 21).
Рис. 21
Определим, какие грани вмещают новые сегменты БюГг: все остальные сегменты вмещаются в (П, Гг}.
Теперь имеется сегмент Sj, такой, что I T(Si) | = 1. Выберем в нем цепь, скажем (2, 10, 9) и поместим в грань Гг. Результаты показаны на рис. 22.
149
Читателю рекомендуется продолжить укладку самостоятельно.
д Продолжим укладку. Укладывая последовательно сегменты Si и Sy, вмещаемые одной гранью Гг, получим рис. 23.
Рис. 23
Й Й [б] [б] S, S, Ss S,
Теперь появился сегмент S2, вмещающийся только в одну грань Г1; уложим в нее цепь (3, 11, 5); результат показан на рис. 24.
Рис. 24
150
Все оставшиеся сегменты, кроме S4, вмещаются в одну грань Укладывая их, и уложив последним сегмент S4, получим плоскую укладку графа G, показанную на рис. 25.Л
8 7 6
Рис. 25
Еще раз опишем алгоритм у компактно и займемся его обоснованием.
Алгоритм у
1 (инициализация). Выберем любой простой цикл С исходного графа G; изобразим его на плоскости в виде грани, которую примем за уже уложенную часть G’; сформируем сегменты S/; если множество сегментов пусто, то перейти к 3.
2 (общий шаг):
2.1. Для каждого сегмента S найти множество F(S). Если существует сегмент S, для оторого Г(Б) | = 0, то граф не планарный, конец.
2.2. Если существует сегмент S, для которого |r(S>|= 1, то выбираем его, перейти к 2.4.
2.3. Для первого сегмента Si выбираем произвольную вмещающую его грань.
2.4. В выбранном сегменте выделим произвольную цепь между двумя ярлычками и уложим ее в выбранной (или единственной) вмещающей грани. Учтем изменения в системе сегментов. Перейти к 2.1
3 (завершение). Построена плоская укладка G’ исходного графа G, конец.
Теорема 8. Алгоритм у корректен
£ Доказательство Прежде всего нужно понять простой факт, что для любого сегмента |Г(Б)|< 2. Действительно, если все ярлычки одного сегмента принадлежат некоторой грани Г (точнее, циклу, окружающему эту грань), то они могут принадлежать все вместе только одной еще грани, внутренней или внешней.
151
Далее назовем сегменты Si и S конфликтующими относительно уже уложенной части G’, если: (1) существует грань, которая вмещает каждый из сегментов и (2) в сегментах есть две цепи (между ярлычками) Li и L2 (LicSi, L2CS2), такие, что их невозможно уложить в одну грань без пересечения. Конфликтующие сегменты Si и 5г обладают следующим свойством: если I l~(Si) | =2, и 1Г(5г)1=2, то r(Si) =Г(8г). Действительно, если бы r(Si)±T(S2), то, имея по определению одну общую вмещающую грань Гз, они бы имели еще по собственной грани Г» и Г? соответственно. Но тогда бы любая цепь из Si (соответственно, S?) могла разместиться в Г» (соответственно, Г?) (рис. 26, сплошные ребра), а, следовательно, и в Г3 (рис. 26, пунктирные ребра), но тогда бы Si и S2 не были конфликтующими. Значит, если имеется сегмент Si, и еще сегмент S2, конфликтующий с Si, затем сегмент S3, конфликтующий с S2 (но не с Si) и т. п., причем каждый вмещается в две грани, то эти грани общие для всех сегментов последовательности, и можно размещать цепь Li из Si в первую грань l~i, L2 из S2 в Гг, L3 из S3 снова в Г» и т. д. до конца последовательности. Если цепочка сегментов замыкается в цикл четной длины, то неприятностей не будет; если в нечетный цикл, то в конце окажется, что два конфликтующих сегмента нужно разместить без пересечений в общую грань, что невозможно.
Рис. 26
Сейчас нам понадобится в качестве вспомогательного утверждения теорема Кенига, которая полезна при решении и многих других задач.
Теорема 9 (Кенига). В двудольном графе все циклы четные; граф, в котором все циклы четные, — двудольный.
Доказательство. Первая часть теоремы совсем проста. Начнем цикл в верхней доли. Нужно пройти по четному числу ребер, чтобы подняться снова в верхнюю долю. Следовательно, при замыкании цикла число ребер будет четным.
Докажем вторую часть теоремы. Пусть граф связный (если нет, нужно повторить доказательство для каждой компоненты
152
связности). Выделим одну вершину и найдем какие-нибудь цепи (например, кратчайшие — по числу ребер — цепи, пользуясь алгоритмом Дейкстры) между vo и всеми остальными вершинами vj. Если одна цепь (vo, v/) нечетной длины, то и любая цепь (vo, v;) нечетная, иначе бы эти цепи образовали нечетный цикл. Аналогично, если одна цепь (vo, Vi) — четная, то любая цепь (vo, V,) — четная. Разобьем вершины на две доли: в одну войдет вершина vo и все, находящиеся от нее на четном расстоянии; в другую долю поместим все вершины, находящиеся от vo на нечетном расстоянии. Если вершины т и иг принадлежат одной доле то между ними не может быть ребра, иначе это ребро вместе с цепями (vo, ui) и (vo, иг) образовали бы нечетный цикл. Теорема Кенига доказана.
Продолжим доказательство теоремы 8. Частичной укладкой планарного графа G называется граф, который можно получить из какой-нибудь укладки G* графа G на плоскости удалением каких-то ребер и вершин. Таким образом, частичная укладка — это правильное начало укладки, в ней еще не сделано ошибок.
Сопоставим каждому сегменту на каком-то шаге алгоритма у (перед этим шагом уже уложен G') вершину в некотором постороннем служебном графе А(&), где вершины соединяются ребрами, если соответствующие сегменты являются конфликтующими.
Лемма. Если результатом некоторого шага алгоритма у является частичная укладка G' планарного графа G, такая, что |ffSj|=2 для всякого сегмента S относительно G’, то A(G) — двудольный граф.
Доказательство леммы. Пусть A(G) — не двудольный. Тогда, по теореме Кенига, в нем имеется цикл нечетной длины, и никакое продолжение не позволит плоско уложить оставшиеся сегменты, соответствующие нечетному циклу. Лемма доказана.
Теперь окончим доказательство теоремы 8, именно докажем, что если G — планарный граф, то результатом каждого шага алгоритма у является частичная укладка G.
Доказательство проведем индукцией по числу шагов.
Цикл, уложенный на первом шаге, должен присутствовать в любой укладке графа G. Следовательно, после первого шага получена частичная укладка.
Пусть граф G’k-i, полученный на предыдущем (к-1)-м шаге, является частичной укладкой. На текущем шаге к G'k-i присоединится цепь L: G’k = G’k-iUL. Докажем, что новый граф G'k — тоже частичная укладка.
133
Прежде всего отметим, что среди сегментов на текущем шаге нет такого S, что I l~(S) | =0, иначе бы G'k-1 не был частичной укладкой.
Значит, либо (а) суще твует S, такой, что |f(S21=1, либо (б) все S таковы, что |Г(Б;|=2. Случай (а) означает, что укладка S в Г неизбежна, так что граф G’k после добавления цепи из S остался частичной укладкой. В случае (б) построим граф A(G’k-i), по лемме он двудольный; возьмем его связную компоненту Д’; этот граф тоже двудольный. Для любого ScA’ имеются две грани: Г/ и Г?, вмещающие этот сегмент. Раскидаем цепи L сегментов какого-нибудь четного цикла из А по этим граням попеременно. Это необходимо сделать в каждой частичной укладке, следовательно, получена частичная укладка.
Таким образом, частичная укладка увеличивается п ка весь планарный граф не будет уложен на пло кость. Фактически, основой последней части доказательства было, что если граф A(G’k-i) двудольный, то после удаления части ребер и вершин граф A(G’k) тоже двудольный. Теорема 8 доказана. ★
Задачи и упражнения
1. Примените алгоритм у к графу К5.
2. Примените алгоритм у к графу Кз.з.
3. Примените алгоритм у к графу
1 2 3
4. Примени ге алгоритм у к графу
5. Примените алгоритм у к графу
154
☆ 6. Покажите, что граф в задаче 4 содержит К5 в качестве части. ★
1.5. Задачи размещения
Предположим, что имеется единственная дорога и п населенных пунктов вдоль неё. Размерами населенных пунктов мы пренебрежем, изображая их точками между населе <ными пунктам даны расстояния (по дороге). Мы хотим разместить в этой линейной стране некое обслуживающее устройство, скажем, школу. Найти для нее оптимальное место.
Сперва нужно договориться, что понимать под оптимальным размещением. Видимо, надо знать, сколько учеников живет в каждом пункте. Пусть такие данные известны: р,, /‘=1,2, .... л, — число учеников в /-м пункте. Предположим, что имеется всего два пункта: поселок, где живет тысяча учеников и отдаленный хутор, где живет один ученик. По-видимому, сдвигать школу в сторону хутора ienpa-вильно, нужно минимизировать сумму, так сказать, ученико-кило-метров, проходимых, например, утром, т. е. по доро е в школу.
Вернемся к постановке с л пунктами. Представим себе, что разместитель будущей школы двигается из пункта 1 в пункт л и к разместителю привязаны резинки: а штук к спине и b — к груди. Здесь а — число учеников, которые остались за спиной, а b — которые живут впереди, а + b = s. После того, как разместитель покинет первый пункт, pi резинок будет тянуть его назад a s-pi — вперед; если pi<s-pi, то равнодействующая будет тянуть вперед. Другими словами, после каждого шага размес-тителя, pi ученикам придется утром делать на один шаг больше, но зато s-pi ученикам — на один шаг меньше
Теорема 10. Школу надо ставить в населенном пункте.
Доказательство. Предположим, что точка остановки размести-теля случилась на дороге между двумя соседними пунктами с числом учеников с и d, соответственно. Сзади точки останова живет а учеников, а=а+с, а спереди Ь учеников, b =d+P; а = Ь. Пусть разместитель сделает шаг назад. Вследствие этого а ученикам
156
придется делать на шаг меньше, а b — на шаг больше, но так как а = Ь, то количество ученико-километров не изменится. Следовательно, разместитель может сделать еще шаг назад и т.д., пока он не войдет в предыдущий город. Здесь разместителя назад тянут а резинок, с резинок расслаблены, а b тянут вперед. Поскольку b>a, разместитель пойдет вперед, но тогда а+с=а резинок начнут тянуть назад и поскольку а=Ь, разместитель остановится. Таким образом, по описанным правилам движения, разместитель не мог уйти из пункта на дорогу.
Теорема доказана.
Теперь введем более реалистическую задачу. Наш мир станет двумерным, и пункты будут соединены нормальной дорожной сетью (однако, населенные пункты и перекрестки дорог будут в равной мере считаться вершинами сети).
Из доказательства теоремы 10 легко вывести следующее утверждение: В двумерной задаче школу надо размещать в вершине дорожной сети.
Действительно, если школа поставлена на дороге (на ребре, ограниченном вершинами ( v, v’)), то, с одной стороны дороги, из вершины v приходит а учеников, а с другой стороны, из вершины v‘ приходит b учеников. Буквально повторяя доказательство теоремы 10, можно сместить школу в v или v'.
Итак, в двумерной задаче размещения мы должны выбирать место для школы не из бесконечного числа точек, а из л точек, что делает полный перебор легко осуществимым.
Пример 1 Дана сеть, показанная на рис. 27. Число учеников в вершинах / = 1, ... 7 задано числами s = (80, 100, 140, 90, 60, 50, 40).
Рис. 27
Решение. Прежде всего, пользуясь алгоритмом Флойда-Уор-шелла или семь раз алгоритмом Дейкстры, найдем кратчайшие цепи из каждой вершины в каждую. Получится результат, записанный в следующей матрице А
156
1 2 3 4 5 6 7
1 0 9 10 15 11 17 24
2 9 0 5 6 5 10 17
3 10 5 0 7 10 11 14
4 15 6 7 0 8 4 11
5 11 5 10 8 0 6 19
6 17 10 11 4 6 0 13
7 24 17 14 11 19 13 0
Если поставить школу в вершине 1, то общее количество уче-нико-километров равно сумме произведений элементов первой строки матрицы на соответствующие числа массива р (скалярному произведению первой строки матрицы на вектор р), численно
7
fl = ^aiiPi = 6120. i= 1
Перебор по всем вершинам дает следующие численные данные
fl fz f4 fs f6 f7
6120 3440 3640 3800 4560 4930 8360
Таким образом, школу надо ставить в вершине 2.
Теперь, когда по существу все ясно, не помешает поставить и решить задачу формально:
Дана сеть Ncn вершинами, которым сопоставлены веса pi, рг, .... рп. Найти точку и на сети (в вершине или на ребре), такую что
п
f=^diupi=^ min, (5)
i= 1
где diu есть расстояние от i-й вершины до точки и.
В силу следствия из теоремы 10, минимизирующая функционал f точка находится в одной из вершин. Минимизирующая выражение (5) вершина находится перебором.
Д Функционал есть частный случай функции, когда аргумент не является числом (в данном случае — положением точки и), а значение является числом (в данном .случае — количеством учени-ко-километров). ▲
157
Поскольку в формуле (5) минимизируется сумма, задача о размещении называется минисуммной.
Теперь мы рассмотрим минимаксную задачу размещения.
Предположим, мы хотим разместить участок спецподразделе-ния полиции, задача которого выезжать по вызову, когда сработает сигнализация на охраняемом объекте. Считается, что срабатывание сигнализации — событие редкое, и главной целью является не постановка участка поблизости от сгущения охраняемых объектов (тогда к большинству охраняемых объектов полиция будет прибывать быстро, а в некоторые отдаленные — с недопустимым опозданием), а так, чтобы самый дальний охраняемый объект достигался в минимальное время.
Более точно, задача ставится следующим образом.
Дана сеть Ncn вершинами (= охраняемыми объектами). Найти точку и на сети (в вершине или на ребре), такую что
f = max diu => min (6)
1<i<n
Понятно, что если имеется всего два охраняемых объекта, то участок надо ставить между ними, так что теорема 10 или что-то подобное здесь не имеет места. В линейной стране, с которой мы начинали объяснение, участок следовало бы поставить посередине страны.
Рассмотрим пример и решим его, используя алгоритм Хакими (по-русски описанный, например, в книге Кристофидес, 1978).
Пример 2. Дана сеть, показанная на рис. 28. Найти место для полицейского участка.
1 2 3 4 5 6 max
1 0 6 8 12 9 7 12
2 6 0 2 6 3 8 8
3 8 2 0 4 5 9 9
4 12 6 4 0 9 5 12
5 9 3 5 9 0 5 9
6 7 8 9 5 5 0 9
Рис. 28
Решение. Прежде всего надо найти матрицу кратчайших цепей между всеми парами вершин D=(de), ij=1, .... п. Эта матрица показана тоже на рис. 28. Выпишем справа от матрицы в столбик наибольшие числа в соответствующей строке и найдем наименьшее число в ыолбце. Это 8, оно означает, что при размещении
158
участка в вершине 2 расстояние до самого дальнего охраняемого объекта равно 8 единицам, скажем, километрам. Для нашей задачи число 8 является оценкой сверху, ибо такое значение функционала уже получено, а, может быть, его удастся понизить, размещая участок на ребрах сети.
Следующий вопрос состоит в том, следует ли пробовать поставить участок на каждом ребре или некоторые ребра заведомо не годятся. На рис. 29 изображено ребро (i,j) и некоторая вершина k * ij. Если поставить участок и на ребре (i,j) в х км от /, т.е. в d9-x км от /, то расстояние от и до произвольного к * i,j через / равно duik = =x+dik', расстояние от и до к через/ равно dUjk = dij-x+d,k. Поскольку умные полицейские поедут по кратчайшей из двух дорог, то
dUk =min(x+dik, djj-x+dik) (7)
Величина
8ик =min(dik, d/к) (8)
очевидно является нижней оценкой для dUk, поскольку х>0 и dj-x>0. Эта нижняя оценка легко считается по матрице; получаем ее для всех ребер сети:
Ребро (i,j) (1.2) (1,6) (2.3) (2,5) (3,4) (4,6) (6,6)
&ик 7 8 8 6 8 7 7
Нижняя оценка ребер (1,6), (2,3) и (3,4) равна 8; это означает, что если на этих ребрах разместить участок, то f — кратчайшее расстояние до самого удаленного пункта — будет 8 или больше. Но мы уже имеем f =8, если разместить и в вершине 2 Следовательно, перечисленные три ребра можно не рассматривать
Из оставшихся ребер естественно начать с (2,5), так как оценка снизу для него — сама обещающая.
Теперь, собственно, начинается алгоритм Хакими, который определяет, где поставить и на выбранном из оценочных соображений ребре (2,5) Расстояние до вершины 1 по формуле (7) равно
dui =тт (x+d2i, d25-x+d5i)=min (х+6, 12-х)
Первое выражение под min как функция от х показано графически на рис. 29; второе значение на всем интервале изменения х больше первого — поэтому оно отбрасывается при выборе минимума. Аналогично получаем:
159
du2(x) = x;
du3(x) =x+2;
du4 (x) = 6+x;
dU5(x) =3-x;
dU6(x) =8-x.
Поскольку нам нужен максимум, мы берем верхнюю огибающую (показана жирными линиями). Поскольку нужен минимум максимума этой функции, находим минимум на огибающей. Получаем: minmax =7.
Теперь возвращаемся к нижним оценкам и видим, что на лучшее значение функционала надежды нет.
Итак, участок нужно разместить на ребре (2,5) в 1 км от пункта 2. Тогда расстояние до самого удаленного пункта равно 7.
Если надо поставить несколько пунктов обслуживания в минисуммной или минимаксной задаче, то применяются весьма сложные алгоритмы (см. Кристофидес, 1978). Здесь мы их рассматривать не станем.
Задачи и упражнения
1. Решить пример 1 на минимакс.
2. Решить пример 2 на минисумму.
☆ 3. Алгоритм Хакими удобен для ручного счета, но плохо программируется. Ниже приводится листинг программы на турбопаскале, где реализован другой алгоритм (D — матрица, задающая длины ребер, Р — матрица, задающая кратчайшие цепи).
Попытайтесь понять алгоритм и доказать его корректность.
160
Алгоритм решения минимаксной задачи.
{Преобразование матрицы расстояний в матрицу кратчайших путей} P:=D;
for k:=1 to N do
for i:=1 to N do
for j:=1 to N do
if P[i,j]>P[i,k]+P[k,j] then P[i,j]:=P[i,k]+P[k,j];
{Начинается выбор места для полицейского участка}
{Выбор в пунктах}
mima:=inf;
for i:=1 to n do
begin ma:=P[i,1];
for j:=2 to n do if p[i,j]>ma then ma:=P[i,j];
if ma<mina then begin ind:=i; mima:=ma end;
end;
writelnC Если полиция в пункте ind,’, то расстояние до’);
writeln(’ самого дальнего клиента равно', mima:5:2,’.’);
{Выбор на дорогах}
for i:=1 to п-1 do
for j:=H-1 to n do
begin if D[i,j]= inf then continue;
mai:=O; maj:=O;
for k:=1 to n do
begin if (k=i) or (k=j) then continue;
if P[i,k]<inf then di:=P[i,k];
if P[j,k]<inf then dj:=P[j,kj;
if di>dj then begin if dj>maj
then begin maj:=dj; inj:=k end
end
else begin if di>mai
then begin mai:=di; ini:=k end
end:
end {K};
dist:=(mai+D[i,j]+maj)/2;
if (dist<=mima) and (dist-mai>0) and(dist<mai+D[i,j]) then
begin
mima:=dist;
writein;
writein (' Если полиция между пунктами', i, ’ и ’, j, ',');
writein (’ на расстоянии’,(dist-mai):5:2, ’ от ’, i,’, то '); writein (’ расстояние до самых дальних пунктов ’, ini, ’ и ',inj, dist:5:2);
end;
end;
6 -Основы программирования»
161
1.6. СПУ — сетевое планирование и управление
СПУ впервые было опробовано в США в 1957-58 г.г. при разработке ракетной системы Полярис. Разработка состояла из нескольких десятков тысяч сравнительно простых работ, так что невозможно было ни оценить ее длительность, ни охватить умом, ни выделить те работы, которые нужно было особенно тщательно контролировать и усиленно финансировать.
Позднее, после того, как была развита методика управления столь большими проектами, и она положительно зарекомендовала себя в огромных разработках, ее стали с пользой применять и для гораздо меньших проектов, где число работ было порядка сотен, ибо оказалось, что человеку-администратору трудно полностью разобраться и в ситуации такой сложности. Мы же продемонстрируем основные алгоритмы СПУ на совсем игрушечных примерах (число работ п <10).
Рис. 30
Пусть разработка состоит всего из четырех работ: А, В, С, D. Их можно изобразить на ленточном графике Ганта (рис. 30). Предположим также, что между этими работами существуют следующие связи: В может начаться не раньше, чем будут выполнены первые 25% работы А; после выполнения 75% работы А можно начинать D; до выполнения последних 25% работы А нужно окончить В; окончить В нужно также до начала работ С и D; вторая половина работы D к ожет начаться лишь после выполнения работ А и С.
Ленточный график в совокупности с приведенным словесным описанием связей дает полное представление о разработке, но словесное описание связей очень громоздко даже в такой простой разработке, как в нашем минипримере. Поэтому мы изобразим графически описанные связи, дополнив ленточный график стрелками. В результате получится график, показанный на рис. 31.
162
Рис. 31
На рис. 31 почти также трудно разобраться в связях между работами, как и по словесному описанию. График станет гораздо более удобным, если разбить работы на более мелкие части, чтобы связи проводились только из концов частей и только в начала. В нашем примере для этого нужно разбить работу А на три части: (первые 25% работы), (последние 25%) и (остальные 50%), а работу D — на две: (первые 50%) и (последние 50%). Если обозначить работы нового набора кружками, а связи между ними стрелками, то получится график, показанный на рис. 32.
На новом графике хорошо видны связи, но исчез временной масштаб. Для компенсации этой потери поставим в кружках под чертой числа, указывающие длительности работ. Полученный график — это сетевой график на языке работ.
Сетевые графики составляют и другим, более традиционным способом, «на языке событий», когда длительность имеют стрелки,
6*
163
а не вершины. Однако при этом возникает много чисто практических неудобств, поэтому мы продолжим обсуждение «на языке работ». Подробное обсуждение выбора языка для сетевых графиков см. в статье Рублинецкого, 1966.
Сеть, представляющая разработку, является ориентированной. В ней имеются вершины, из которых стрелки только выходят (это — начальные работы} и вершины, в которые стрелки только входят (это конечные работы}. Вводя в сеть фиктивную работу нулевой длительности, из которой стрелки ведут только в началы- е работы, мы получим единственное начало. Аналогично, получим единственный конец. Впрочем, в нашем примере на рис. 31 изначально имеется одно начало и один конец.
Первая задача, которую мы рассмо рим, порождается издержками методики. Обычно граф большой разработки составляется разными специалистами, и они могут так определить связи между работами, что в сшитом графе могут появиться контуры (это же может произойти из-за простой технической ошибки).
Наличие контуров в сети недопустимо, так как одной из главных задач является определение критического пути — самого длинного пути из начальной работы в конечную, который определяет длительность всей разработки. Если есть контуры, то критический путь будет бесконечным.
Так возникает следующая задача:
Дан ориентированный граф. Определить, есть ли в нем контуры, и если есть, выделить их по одному или, хотя бы, группу связанных контуров.
Для ответа на вопрос, есть контуры или нет, служит следующий
Алгоритм удаления крайних вершин
1. Найти вершину, в которую не входит ни одной стрелки (дуги); удалить эту вершину и все выходящие из нее стрелки.Перейти к началу п.1. Если таких вершин не осталось, перейти к 2.
2. Найти вершину, из которой не выходит ни одной стрелки.Удалить ее и все стрелки, в нее входящие. Если таких вершин не осталось, перейти к 3.
3. Остались ли вершины? Если да, то через них проходит контур (или проходят контуры), иначе контуров нет.
Пример 1. Рассмотрим граф на рис. 32. Есть ли в нем контуры?
Решение. На первом шаге алгоритма будет удалена вершина Ai и выходящие из нее две стрелки, затем Аг, В, Аз, С, Di, D2, контуров нет, конец.
164
Пример 2. Рассмотрим граф на рис. 33. Есть ли в нем контуры’
Рис. 33
Решение. Применив алгоритм, на шаге 1 удалим вершину 1, затем на шаге 2 удалим вершину 7, затем на шаге 1 не найдем вершины, в которую не входит ни одной стрелки, перейдем на 2, затем на 3: в подграфе из вершин 2 — 6 есть контуры. Конец примера.
☆ Можно получить больше информации о контурах, используя понятие степени орграфа. Пусть имеется орграф Г По определению, к-тая степень графа Г, т.е. Г* , есть граф, в котором имеются те же вершины, что и в Г, сохраняются все стрелки и еще добавляются некие стрелки, такие, что если в Г вершина j достигается из i за к или меньше шагов, то в Г* вершина j достигается из / за один шаг. Так, см. рис. 34, Г выглядит как на рис. 34а, Г3— как на рис. 346 и Г3— как на рис. 34в.
В графе Г3 впервые появились петли на вершинах 2, 4 и 5. Это означает, что, скажем, вершина 2 за три шага достала самое себя, т.е. она лежит на контуре длины три. То же можно сказать о вершинах 4 и 5. Отсюда заключаем, что вершины 2, 4 и 5 образуют контур длины три; контур выдается пользователю для исправления связей. ★
Опишем теперь алгоритмы вычисления основных временных параметров сетевого графика.
165
Для простоты будем вести изложение на примере графика, изображенного на рис. 32, заменив лишь для краткости буквенные обозначения работ номерами и увеличив количество секторов в кружках (рис. 35). В верхнем секторе каждого кружка поставлен номер работы; номера расставлены так, чтобы каждая стрелка вела
Рис. 35
из рабо ы с меньшим номером в работу с большим номером — это значительно сокращает расчеты. Число в нижнем секторе кружка обозначает длительность работы. Значение остальных чисел на графике станет ясным из дальнейшего изложения.
Работу, из которой в данную идет стрелка, назовем работой, непосредственно предшествующей данной. Работа, в которую из данной ведет стрелка, будет называть работой, непосредственно следующей за данной. (Для краткости слово «непосредственно» будет обычно опускаться.)
Теперь можно приступить к определению раннего начала каждой работы Ь, то есть самого раннего срока для начала каждой работы, допускаемого длительностями работ di и связями, наложенными на график. Для начальной работы положим раннее начало равным нулю. Раннее начало любой работы определим как максимум ранних начал предшествующих работ вместе с их длительностями, то есть ti будем вычислять по формуле
h = 0 ti= max (tf^ dk,) к
(8)
где к,— ранние начала работ, предшествующих /-той, dr— длительности этих работ.
166
В нашем примере имеем
О =0,
t2 — t3 = t + di =3,
t4 = max (t2 + d2, ts + da) = 11 и т.д.
Ранние начала всех работ записаны в левом секторе кружков на рис. 35.
Алгоритм расчета данных начал можно представлять себе как обработку таблицы 1.
Таблица 1
I № работы,i 1 2 3 4 5 6 7
II № работ, следующих за данной 23 46 4,5, 6 7 7 7 —
III Длительность данной работы di 3 6 8 3 6 4 4
IV Ранее начало данной работы ti 0 3 3 11 11 11 17
Объясним, как получена строка IV.
Рассмотрим первую колонку таблицы: ti = 0, поэтому поставим О в строку IV. Все работы, следующие за первой (они указаны в строке II), будут иметь ранние начала не меньше, чем 3 = di (это число стоит в строке III). Поставим 3 в строку IV во второй и третьей колонке. Строка IV нашей таблицы приобретет такой вид:
||V I |о |з |з | | | I .1
Перейдем ко второй колонке. За второй работой следуют работы № 4 и 6 (эти данные опять берем из строки II). Значит, работы № 4 и 6 не могут начаться раньше, чем в t2+d2- Берем t? из строки IV, a d2 из строки III, складываем и ставим в колонки 4 и 6 строки IV Строка IV приобрела следующий вид:
11V I IО 13 13 19 I 19 I |
Перейдем к рассмотрению колонки 3. Как и прежде складываем 1з = 3 и d3 = 8; их сумму, равную 11, заносим в колонки 4, 5 и 6 строки IV. В колонках 4 и 6 уже стоит по девятке, но так как раннее начало определяется как максимум, большее число 11 вытеснит 9, и мы получим новый вид строки IV
Г IV I | о | 3 | 3 | 11 | 11 | 11 | 1
Переходим к колонке 4. Проделав все описанные операции, получим строку IV е следующем виде:
16'
’jV_ Г |o |з |з |и |11 111 114 I
После обработки колонки 5 строка IV будет иметь вид
IIV | |о |з |з |11 I11 111 117 |
(в последней колонке станет 17, так как 17 — число большее, и оно вытеснит 14).
Наконец, обработав колонку 6, получим тот же результат, так как te+de = 15 не вытеснит 17.
Вычисление ранних начал закончено.
Теперь можно вычислить продолж тельность всей нашей разработки — Т. Последняя, седьмая, работа начинается в 17-й день и длится четыре дня. Следовательно, Т = t/+d7 = 17 + 4 = 21. Продолжительность разработки равна длине критического пути. Таким образом, по таблице определена длина критического пути но еще не ясно, из каких работ состоит этот путь
Для определения состава критического пути и вычисления остальных параметров графика найдем вспомогательные величины — ранние начала работ нашего графика, при условии, что все стрелки в нем повернуты в обратную сторону. Тогда отношение предшествования в прямом графике превратится в отношение следования в обратном графике, и наоборот. Поэтому, чтобы составить таблицу обратного графика, нужно переписать табл. 1 (справа налево, так как конечная и начальная работы поменялись ролями), но в строке II вместо номеров работ, следующих за данной, нужно поместить номера работ, предшествующих данной. Получим таблицу следующего вида (табл. 2):
Таблица 2
I II № работы / № работ, следующих за данной 7 4.5, 6 6 2, 3 5 3 4 2, 3 3 1 2 1 1
III Длительность данной работы di 4 4 6 3 8 6 3
IV Раннее начало данной работы т; 0 4 4 4 10 8 18
Последняя строка заполняется с помощью уже описанного алгоритма. (Снова Т - xi+di =18 + 3 = 21).
Теперь у нас достаточно данных для вычисления всех остальных параметров графика. Вычислим эти параметры с помощью таблицы 3. Нам известны уже первые четыре строки этой таблицы, а значения чисел остальных строк и способы их получения мы объясним ниже.
168
Таблица 3
I № работы, / 1 2 3 4 5 6 7
II Длительность данной работы dj 3 6 8 3 6 4 4
III Ранее начало данной работы ti 0 3 3 11 11 11 17
IV Ранее начало работы в обратном графике т; 18 8 10 4 4 4 0
V Длина максимального пути mi 21 17 21 18 21 19 21
VI Полный запас времени работы z. 0 4 0 3 0 2 0
Нетрудно понять, что раннее начало работы равно длине максимального из путей, ведущих из начальной в эту работу (сама работа в путь не включается). Точно так же раннее начало работы в обратном графике равно длине максимального пути, ведущего в эту работу из конечной. Поэтому, если сложить &, т; и di, то получится длина максимального из всех путей, проходящих через / -тую работу. Обозначая эту величину через т/, имеем
т, = ti+Ti+di.
(9)
ггц — важный параметр графика сам по себе, так га< он в известной мере характеризует степень «критичности» работы. Кроме того, по т, легко определить, какие работы являются критическими, то есть лежат на критическом пути. Мы уже знаем длину критического пути, поэтому понятно, что все работы, у которых т( равны Т, лежат на нем. Критический путь на рис. 35 отмечен жирными линиями.
Назовем полным запасом времени данной работы величину, на которую работу можно отложить (или на которую можно уе еличить ее длительность) чтобы длина критического пути не увеличилась. Ясно, что критические работы нельзя откладывать, поэтому полные запасы их z(, равны нулю. Все остальные работы, у которых Т-гтц>0 можно откладывать как раз на величину этой разности, н<э увеличивая длину критического пути. Поэтому величина Zj вычисляется по следующей формуле:
Zi = T-mi (10)
По описанным формулам и вычислены параметры в таблице 3
169
Кроме того, Zi поставлены в правых секторах кружков на рис. 35. Этим завершается вычисление временных параметров сетевого графика на этапе планирования.
Затем наступает выполнение разработки и с ней этап управления Какие-то работы уходят в прошлое, появляются работы ранее непредвиденные, уточняются длительности и связи. Сетевой график часто обновляется и пересчитывается, что позволяет руководству концентрироваться на управлении только малой части из всех работ, а именно на работах, имеющих нулевые и малые запасы времени
Мы даже не упомянули о многих других задачах, которые решаются в хорошей системе СПУ: то нужно определить порядок выполнения работ, которые все проходят через одного исполнителя, то направить дополнительные средства на распараллеливание работ т е. на изменение следований, зависящих не от технологии, а от наличия ресурсов.
Задачи и упражнения
1. Составьте сетевой график разработки (а) ремонт стула; (б) ремонт кухни. Оцените длительность разработки.
2. Разберите приложенную процедуру MVon на турбопаскале Эта процедура переводит старые номера в новые (VON=Vocabu-lary:Old->New), чтобы получить правильную нумерацию, когда стрелка может вести только из меньшего номера в больший.
Procedure Mvon;
label out;
var mark array[1 ..n ] of boolean;
begin
B:=A;
k:=1;
for j:=1 to N do mark[j]:=Tnje;
for m:=1 to N do
for j:=1 to N do begin
if not (markfj]) then Continue
else for i:=1 to N do
if B[i,j]=i then goto out; mark[j]:=False;
for i:=1 to N do B[j,i]=O:
von[k]:=j;
k:=k+1;
out: end;
end;
☆ 3. Граф на рис. 34 возведите в куб пользуясь (а) матрицей инциденций, (б) списком вершин, следующих за каждой ★
170
1.7. Задача коммивояжера
1.7.1. Общее описание
Это знаменитая задача. Она была поставлена в 1934 г., и об нее, почти что как об Великую теорему Ферма, с тех пор обламывают зубы лучшие математики. В своей области (оптимизации дискретных задач) задача коммивояжера, ЗК, служит своеобразным полигоном, на котором испытываются все новые методы.
Наивная постановки задачи следующая.
Коммивояжер (бродячий торговец) должен выйти из первого города, посетить по разу в неизвестном порядке города 2, 3,... л и вернуться в первый город Расстояния между всеми городами известны. В каком порядке следует обходить города, чтобы замкнуты? путь (тур) коммивояжера был кратчайшим?
Чтобы, как говорят соискатели, обнаучить задачу, введем некоторые термины. Итак, города перенумерованы числами jeT = {1, 2, .... л). Тур коммивояжера может быть описан циклической перестановкой t=(ji, J2.jn, ji), пр1чем все л, jn — разные номера;
повторяющийся в начале и конце ji показывает, что перестановка зациклена. Расстояния между парами вершин сц образуют матрицу С. Задача состоит в том, чтобы найти такой тур t, чтобы минимизировать функционал п
L = = (11)
k=1
где jn+i=jn. Относительно математизированной формулировки ЗК уместно сделать два замечания.
Во-первых, в наивной постановке с(; означали расстояния, поэтому они должны быть неотрицательными, т.е. для всех /, /еТ
Cij — 0, Си = о° 12)
(последнее равенство означает запрет на петли в туре); симметричными, т.е. для всех i,j
с» = Ср \13)
и удовлетворять неравенству треугольника, т.е. для всех /, j, к
Cij + Cjk S Cik (14)
В математической постановке говорится о произвольней матрице С. Сделано это потому, что имеется много прикладных задач,
171
которые описываются основной моделью, но всем условиям (12)— (14) не удовлетворяют. Особенно часто нарушается условие (13) (например, если с,; — не расстояние, а плата за проезд: мы уже привыкли, что железнодорожный билет Харьков — Москва отличается по цене от билета Москва — Харьков). Поэтому мы будем различать два варианта ЗК симметричную задачу, когда условие (13) выполнено и несимметричную в противном случае. Условия (12) и (14) по умолчанию мы будем считать выполненными.
Второе замечание касается числа всех возможных туров. В несимметричной ЗК туры t =(jtj2, —,jn,ji) и ...j2.it) имеют
разную длину и должны учитываться оба. Разных туров очевидно
(п-1)!
Д Зафиксируем на первом и последнем месте в циклической перестановке номер ji, а оставшиеся п-1 номеров переставим всеми (п-1)! возможными способами. В результате получим все несимметричные туры.Л Симметричных туров имеется в два раза меньше, ибо каждый засчитан два раза: как f и как Г.
Можно представить, что С состоит только из единиц и нулей. Тогда С можно интерпретировать, как граф, где ребро (i,j) проведено, если Cij = 0 (нулю, а не единице как обычно) и не проведено, если = 1. Тогда если существует тур длины 0, то он пройдет по циклу, который включает все вершины по одному разу. Такой цикл называется гамильтоновым циклом (в орграфе — гамильтоновым контуром}. Незамкнутый гамильтонов цикл (соответственно, контур) называется гамильтоновой цепью (соответственно, гамильтоновым путем).
В терминах теории графов симметричную ЗК можно сформулировать так:
Дана полная сеть с п вершинами, длина ребра (!,)) равна сц. Найти гамильтонов цикл минимальной длины.
В несимметричной ЗК вместо «цикл» надо говорить «контур», а вместо «ребра» — «дуги» или «стрелки».
Некоторые прикладные задачи формулируются как ЗК, но в них нужно минимизировать длину не гамильтонова цикла (или контура), а гамильтоновой цепи (или гамильтонова пути) Такие задачи называются незамкнутыми. Некоторые модели сводятся к задаче о нескольких коммивояжерах, но мы ее здесь рассматривать не будем.
1.7.2. Два вида задач с переналадками и сведение этих задач к задаче коммивояжера
В начале этого параграфа мы приведем два конкретных примера задач с переналадками, а потом покажем, что для решения этих задач необходимо уметь решать задачу коммивояжера.
172
Задача о производстве красок. Имеется производственная линия для производства л красок разного цвета; обозначим эти краски номерами 1, 2, л. Всю производственную линию будем считать одним процессором, будем считать также, что единовременно процессор производит только одну краску, поэтому краски нужно производить в некотором порядке. Поскольку производство циклическое, то краски надо производить в циклическом порядке
После окончания производства краски / и перед началом производства краски j надо отмыть оборудование от краски /. Для этого требуется время Gj. Очевидно, что Gj зависит как от /, так и от j, и что, вообще говоря, Gj * Cji. При некотором выбранном порядке л придется на цикл производства красок потратить время п
f=YCii + ^tk
(Ц)чп К=1
где tk — чистое время производства k-ой краски (не считая переналадок). Однако вторая сумма в правой части постоянна, поэтому полное время на цикл производства минимизируется вместе с общим временем на переналадку, т.е. вместе с функционалом (11).
Таким образом, ЗК и задача о минимизации времени переналадок — это просто одна задача, только варианты ее описаны разными словами.
☆ Задача о дыропробивном прессе (Лурье, 1972). Дыропробивной пресс производит большое число одинаковых панелей — металлических листов, в которых последовательно по одному пробиваются отверстия разной формы и величины.
Схематически пресс можно представлять в виде стола, двигающегося независимо по координатам х,у, и вращающегося над столом диска, по периметру которого расположены дыропробивные инструменты разной формы и величины. Каждый инструмент присутствует в одном экземпляре, диск может вращаться одинаково в двух направлениях (координата вращения z). Наконец, имеется собственно пресс, который надавливает на подвешенный под него инструмент тогда, когда под инструмент подведена нужная точка листа.
Операция пробивки /-го отверстия характеризуется четвертой чисел (х/, у/, Zj, tj}, где, х/, у/ — координаты нужного положения стола, г; — координата нужного положения диска и tj — время пробивки /-го отверстия.
Производство панелей носит циклический характер; в начале и конце обработки каждого листа стол должен находиться в положении (хо уо), диск в положении zo, причем в этом положении
173
этверстие не пробивается. Это начальное состояние системы можно считать пробивкой фиктивного нулевого отверстия с параметрами (хо, уо, zo, 0).
Чтобы пробить j-oe отверс ие непосредс венно после /-го необходимо произвести следующие действия:
1 Переместить стол по осй х из положения х< в положение х/, затрачивая при этом время Iм (|х/-ху|) =tijx)
2. Проделать то же по оси у, за ратив время
3. Повернуть головку Гто кратчайшей из двух дуг из положения z/ в потожение z/, затратив время tt,/z)
4. Пробить j-e отверстие, затратив время tj.
Конкретный вид функций № зависит от механических
свойств пресса и достаточно громоздок; явно выписывать эти функции нет необходимости.
Действия 1 -3 (переналадка с /-го отверстия на j-e) происходят одновременно, и пробивка происходит немедленно после завершения самого длительного из этих действий. Поэтому
сц = max (tijx>, tijM, tijz))
(15)
Теперь, как и в предыдущем случае, задача составления оптимальной программы для дыропробивного пресса сводится к ЗК (здесь — симметрической).
1.7.3. Методы решения ЗК
Для начала любопытно попробовать, как поведет себя при решении ЗК жадный алгоритм, который так успешно решил задачу Прима-Краскала. В ЗК жадный алгоритм превратится в стратегию «иди в ближайший (в который еще не входил) город». Жадный алгоритм очевидно бессилен в этой задаче. Рассмотрим для примера сеть на рис. 36, представляющую «узкий» ромб. Пусть коммивояжер стартует из города 1 Алгоритм «иди в ближайший» выведет его в город 2, затем в 3, затем в 4; на последнем шаге придется платить за жадность, возвращаясь по длинной диагонали ромба. В результате получится не кратчайший, а длиннейший тур.
174
В пользу процедуры «иди в ближайший» можно сказа ь лишь то, что при старте из одного города она не уступит стратегии «иди в дальнейший» (Киржнер, 1973).
Как видим, жадный алгоритм ошибается. Можно ли доказать, что он ошибается умеренно, что полученный им тур хуже минимального, ну, скажем, всего в тысячу раз? Мы докажем, что этого доказать нельзя, причем не только для жадного алгоритм0, а для алгоритмов гораздо более мощных. Но сначала нужно договориться, как оценивать погрешность неточных алгоритмов, для определенности, в задаче минимизации. Пусть fe — настоящий минимум, известный в трудной задаче только Богу, a fa — тот квазиминимум, который получен по алгоритму. Ясно, что fa/fe>1. но это — тривиальное утверждение, что может быть погрешность. Чтобы оценить ее, нужно зажать отношение оценкой сверху:
fa/fe<1+e (16)
где, как обычно в высшей математике, е>0, но, против обычая, может быть очень большим. Величина е и будет служить мерой погрешности. Если алгоритм минимизации будет удовлетворять неравенству (16), мы будем говорить, что он имеет погрешность е.
Предположим теперь, что имеется алгоритм А решения ЗК, погрешность которого нужно оценить. Возьмем произвольный граф G(V,E) и по нему составим входную матрицу ЗК:
с . Г1, если ребро (/, /) е Е ’ |1+ ле в противном случае
Если в графе G есть гамильтонов цикл, то минимальн 1й тур проходит по этому циклу и тв = л. Если алгоритм Д тоже всегда будет находить этот путь, то по результатам алгоритма можно судить, есть ли гамильтонов цикл в произвольном графе. Однако, непереборного алгоритма, который мог бы ответить, есть ли гамильтонов цикл в произвольном графе, до сих пор никому не известно. Таким образом, наш алгоритм Д должен иногда ошибаться и включать в тур хотя бы одно ребро длины 1+пе. Но тогда fa>(n-1)+(1+ns) = п(1+е) так что fa/fe = 1+е, т.е превосходит погрешность е, заданную неравенством (16). О величине е в нашем рассуждении мы не договаривались, так что е может быть произвольно велик.
Таким образом доказана следующая
Теорема 11. Либо алгоритм А определяет, существует ли в произвольно 1 графе гамиль.онов цикл, либо погрешность А при решении ЗК може быть произвольно вел.ыа.
175
Это соображение впервые было опубликовано Сани и Гонзалесом (см. Рейнгольд, 1980).
Теорема Сани-Гонзалеса основана на том, что нет никаких ограничений на длину ребер. Теорема не проходит, если расстояния подчиняются неравенству треугольника (14).
Если оно соблюдается, можно предложить несколько алгоритмов с погрешностью 2. Прежде, чем описать такой алгоритм, напомним читателю одну старинную головоломку. Можно ли начертить одной линией (т.е. не отрывая карандаша от бумаги и не проводя линий повторно) открытый конверт? Рис. 37 показывает, что можно (цифры на отрезках показывают порядок их проведения). Закрытый конверт (рис. 38) одной линией нарисовать нельзя и вот почему. Будем называть линии ребрами, а их перекрестья — вершинами.
Когда через точку проводится линия, то используется два ребра — одно для входа в вершину, одно — для выхода. Если степень вершины нечетна — то в ней линия должна начаться или кончиться. На рис. 37 вершин нечетной степени две — в одной линия начинается, в другой — кончается. Однако на рис. 38 имеется четыре вершины степени три, но у одной линии не может быть четыре конца. Если же нужно прочертить фигуру одной замкнутой линией, то все ее вершины должны иметь четную степень.
Верно и обратное утверждение: если все вершины имеют четную степень, то фигуру можно нарисовать одной замкнутой линией. Действительно, процесс проведения линии может кончиться только если линия придет в вершину, откуда уже выхода нет: все ребра, присоединенные к этой вершине (обычно говорят: инцидентные этой вершине), уже прочерчены. Если при этом нарисована вся фигура, то нужное утверждение доказано; если нет, удалим уже нарисованную часть G'. После этого от графа останется одна или несколько связных компонент; пусть G” — одна из этих компонент В силу связности исходного графа G, G’ и G" имеют хоть одну общую вершину, скажем, — v. Если в G” удалены какие-то ребра, то по четному числу от каждой вершины. Поэтому G" — связный и
176
все его вершины имеют четную степень. Построим цикл в G" (может быть, не нарисовав всего G”) и через v добавим прорисованную часть G” к G’. Увеличивая таким образом прорисованную часть G’, мы добьемся того, что G' охватит весь G.
Эту задачу когда-то решил Эйлер, и замкнутую линию, которая покрывает все ребра графа, теперь называют Эйлеровым циклом. По существу, нами была доказана следующая
Теорема 12 (Эйлера). Эйлеров цикл в графе существует тогда и только тогда, когда (1) граф связный и (2) все его вершины имеют четные степени.
Теперь можно обсудить алгоритм решения ЗК через построение кратчайшего остовного дерева. Для краткости будем называть этот алгоритм деревянным.
Д Сперва обсудим свойства спрямления. Рассмотрим какую-нибудь цепь, например, как на рис. 40. Если справедливо неравенство треугольника, то d[ 1,3]<d[ 1,2]+d[2,3] и d[3,5]<d[3,4]+d[4,5]. Сложив эти два неравенства, получим d[1,3]+d[3,5]<d[1,2]+d[2,3]+d[3,4]+ +d[4,5]. По неравенству треугольника получим d[1,5]<d[1,3]+d[3,5]. Окончательно
d[1,5] < d[1,2]+d[2,3]+d[3,4]+d[3,5J.
Итак если справедливо неравенство треугольника, то для каждой цепи верно, что расстояние от начала до конца цепи меньше (или равно) суммарной длины всех ребер цепи. Это обобщение расхожего убеждения, что прямая короче кривой. ▲
Вернемся к ЗК и опишем решающий ее
Деревянный алгоритм
1. Построим на входной сети ЗК кратчайшее остовное дерево и удвоим все его ребра. Получим граф G — связный и с вершинами, имеющими только четные степени.
2. Построим эйлеров цикл G, начиная с вершины 1, цикл задается перечнем вершин.
3. Просмотрим перечень вершин, начиная с 1 и будем зачеркивать каждую вершину, которая повторяет уже встреченную в последовательности. Останется тур, который и является результатом алгоритма.
Пример 1. Дана полная сеть, показанная на рис. 39 (а — расположение городов, б — матрица расстояний С). Найти тур жадным и деревянным алгоритмами.
Решение. Жадный алгоритм (иди в ближайший из города 1) дает тур
177
1
2
3
4
5
6
(6)
1____2 3 4 5 6
- 6 4 8 7 14
6 - 11 7 10
4 7 - 4 3 10
8 11 4 - 5 11
7 7 3 5 - 7
14 10 10 11 7 -
1 -(4)-3-(3)-5-(5)-4-(11 )-6-(10)-2-(6)-1, где без скобок показаны номера вершин, а в скобках — длины ребер. Длина тура равна 39, тур показан на рис 39а.
2. Деревянный алгоритм сперва строит остовное дерево, показанное на рис. 40 штриховой линией, затем эйлеров цикл
1 2 1 3435653 1, затем тур 1 2 3 4 5 6 1 длиной 43, показан сплошной линией на рис. 40.
Теорема 13. Погрешность деревянного алгоритма равна 1.
Доказательство. Возьмем минимальный тур длины fe и удалим из него максимальное ребро. Длина получившейся гамильтоновой цепи Lhc меньше fe. Но эту же цепь можно рассматривать, как остовное дерево, ибо эта цепь достигает все вершины и не имеет циклов. Длина кратчайшего остовного дерева Lmt меньше или равна Lhc- Имеем цепочку неравенств
fB>Lnc Lmt
- (IE)
Но удвоенное дерево — оно же Эйлеров граф — мы свели к туру посредством спрямлений, следовательно, длина полученного по алгоритму тура удовлетворяет неравенству
2Lmt^ fA
(19)
Умножая (18) на два и соединяя с (19), получаем цепочку неравенств
2fe>2Z_HC >2Lmt> fA,
(20)
178
т.е. 2fe>ft», т.е. tn/fe >1+ е, е — 1-
Теорема доказана.
Выражаясь попроще, мы доказали, что деревянный алгоритм ошибается менее, чем в два раза. Это тоже не бог весть какое достижение, но алгоритмы такой точности уже обычно называют приблизительными, а не просто эвристическими.
Известно еще несколько простых алгори мов, гарантирующих в худшем случае е=1 (см., например, Рейнгольд, 1980). Понятно, что хотелось бы найти алгоритм поточнее. Поэтому мы зайдем с другого конца и для начала опишем «brute-force enumeration» — «перебор животной силой», как его называют в англоязычной литературе. Понятно, что полный перебор практически применим только в задачах малого размера. Напомним, что ЗК с л городами требует при полном переборе рассмотрения (п-1)1/2 туров в симметричной задаче и (п-1)! туров в несимметричной, а факториал, как показано в следующей таблице, растет удоучающе быстро:
С\1 й £ 1 10! -106 15! -1012 20! -1018 25! -1025 30! -1032 35! -ю40 40! -ю47 45! -1056 50! -1064
Чтобы проводить полный перебор в ЗК нужно научиться (разумеется, без повторений) генерировать все перестановки заданного числа m элементов. Это можно сделать несколькими способами, но самый распространенный (т.е. приложимый для переборных алгоритмов решения и других задач) — это перебор в лексикографическом порядке.
д Пусть имеется некоторый алфавит и наборы символов алфавита (букв), называемые словами. Буквы в алфавите упорядочены: например, в русском алфавите порядок букв: а«б« ...«я (символ ««» читается «предшествует»). Если задан порядок букв, можно упорядочить и слова. Скажем, дано слово u= (ui, иг..
Um) — состоящее из букв ui, иг, .... ит — и слово v= (vi, V2, .... vb). Тогда если ui<*vi, то и u«v; если же ui = vi, то сравнивают вторые буквы и т.д. Этот порядок слов и называется лексикографическим. Поэтому в русских словарях (лексиконах) слово «абажур» стоит раньше слова «абака»; слово «бур» стоит раньше слова «бура», потому что пробел считается предшествующим любой букве алфавита. ▲
Рассмотрим, скажем, перестановки из пяти элементов, обозначенных цифрами 1-5. Лексикографически первой перестан экой является 1 2 3 4 5, второй — 1 2354, .... последней — 5 4 3 2 1. Нужно осознать общий алгоритм преобразования любой перестановки в непосредственно следующую.
| STOP|
179
Правило такое: скажем, дана перестановка 1 3 5 4 2. Нужно двигаться по перестановке справа налево, пока впервые не увидим число меньшее, чем предыдущее (в примере — это 3 после 5). Это число, Pj-i надо увеличить, поставив вместо него какое-то число из расположенных правее, от Р,- до Рп- Число большее, чем Pi-i, несомненно найдется, т.к. Р/.»<Р/. Если есть несколько больших чисел, то, очевидно, надо ставить меньшее из них. Пусть это будет Р/, j>i-1. Затем число Р<-/ и все числа от Pi до Рп, не считая Pj нужно упорядочить по возрастанию. В результате получится непосредственно следующая перестановка, в примере — 1 4 2 3 5. Потом получится 1 4 2 5 3 (тот же алгоритм, но упрощенный случай) и т.д.
Нужно понимать, что в ЗК с л городами не нужны все перестановки из л элементов, потому что перестановки, скажем, 1 3542и35421 (последний элемент соединен с первым) задают один и тот же тур, считанный сперва с города 1, а потом с города 3. Поэтому нужно зафи сировать начальный город 1 и присоединять к нему все перестановки из остальных элементов. Этот перебор даст (п-1)! разных туров, т.е. полный перебор в несимметричной ЗК (мы по-прежнему будем различать туры 1 3 5 4 2 и 1 2 4 5 3).
Для разнообразия мы опишем этот алгоритм на Паскале. (В одной книге Набоков изложил кусочек учения Маркса стихами. «Чтобы не было так скучно», — пояснил он).
Алгоритм лексического перебора
all:-False; l:=maxint;
for i:=1 to n do P[i]:; {P — первый тур) repeat s:=0;
for i:=1 to n-1 do s:=s+C[P[i],P[i+1]];
s:=s+C[Pn],P[1]]; {посчитана стоимость 1-го тура} if l>s then begin
Tour:=P; l:=s end;
if P=final then begin {final — массив (1, n-1.2)}
for i:=1 to n do Write(P[i], ' ’);
Writein;
Writeln(’lenght=’,s);
repeat until KeyPressed; Rk:=ReadKey
end;
{Запомнили 1 -й тур, начали получать остальные}
for i:=n downto 3 do
180
begin
if P[i]<P[i-1] then continue;
min:=n+1;
k:=P[i-1];
{Ищем минимальное число из тех, что >к и правее} for j:=i to n do
if (P[j]>k and (P[j]<min then begin
min:fcP|j];
ind:=j end;
{Рокировка min и k}
P[i-1]:=min;
P[ind]:=k;
{Элементы на местах от i до n упорядочиваем по возрастанию}
for j:=i to n-1 do
begin
min:=n+1;
for k:=j to n do if min>P[k] then begin min:=P[k]; ind:=k end;
k:=P[j];
P|j] =min;
P[ind]:=k
end;
goto out
end;
all =True;
Writeln(’Получены все перестановки ’);
out until all.
Пример 2. Решим ЗК, поставленную в Примере 1 лексикографическим перебором. Приведенная выше программа напечатает города, составляюшие лучший тур:
126543
и сообщение: length=36
Получены все перестановки.
Желательно усовершенствовать перебор, применив разум вместо «brute force». В следующем пункте описан алгоритм, который реализует простую, но широко применимую и очень полезную идею.
181
1.7.4. Метод ветвей и границ
К идее метода ветвей и границ приходили многие исследователи, но Литтл с соавторами (Литтл, 1965) на основе указанного метода разработали удачный алгоритм оешения ЗК и тем способствовали популяризации подхода. С тех пор метод ветвей и границ был успешно применен ко многим задачам, для решения ЗК было придумано несколько других модификаций метода, но в большинстве учебников (исключение составляет, например, Кристофидес, 1978) излагается пионерская работа Литтла. Мы не отступим от этой традиции.
Общая идея метода тривиальна: нужно разделить огромное число перебираемых вариантов на классы и получить оценки (снизу — в задаче минимизации, сверху — в задаче максимизации) для этих классов, чтобы иметь возможность отбрасывать варианты не по одному, а целыми классами. Трудность состоит в том, чтобы найти такое разделение на классы (ветви) и такие оценки (границы), чтобы процедура была эффективной.
Мы изложим алгоритм Литтла с соавторами на конкретном примере, именно на ЗК, описанной в Примере 1 предыдущего пункта. Чтобы избавить читателя от перелистывания, мы повторно запишем матрицу на рис. 41а. Нам будет удобнее трактовать с,: как стоимость проезда из города / в город j. Допустим, что добрый мэр города j издал указ выплачивать каждому въехавшему в город коммивояжеру 5 долларов. Это означает, что любой тур подешевеет на 5 долларов, поскольку в любом туре нужно въехать в город/. Но поскольку все туры равномерно подешевели, то прежний минимальный тур будет и теперь стоить меньше всех. Добрый же поступок мэра можно представить как уменьшение всех чисел /-го столбца матрицы С на 5. Если бы мэр хотел спровадить коммивояжеров из /-го города и установил награду за выезд в размере 10 долларов, это можно было бы выразить вычитанием 10 из всех элементов/-й строки. Это снова изменило бы стоимость каждого тура, но минимальный тур остался бы минимальным. Итак, доказана следующая
Лемма. Вычитая любую константу из всех элементов любой строки или столбца матрицы С, мы оставляем минимальный тур минимальным.
Для алгоритма нам будет удобно получить побольше нулей в матрице С, не получая там, однако, отрицательных чисел. Для этого мы вычтем из каждой строки ее минимальный элемент (это называется приведением по строкам, см. рис. 416), а затем вычтем из каждого столбца матрицы, приведенной по строкам, его минимальный элемент, получив матрицу, приведенную по столбцам, см. рис. 41 в)
182
(а) (б) (з)
1 2 3 4 5 6 1 2 3 4 5 5 1 2 3 4 5 6
11 - 6 4 8 7 14 I- 2 0 4 3 l6j 4 - 0 0 3 3 6
2'6 - 7 11 7 10 I 0 - 1 5 1 4 6 0 - 1 4 1 0
3 I4 7 - 4 3 10 =41 4 - 1 0 7 3 => 1 2 - 0 0 3
4 I 8 11 4 - 5 11 7 0 - 1 7 4 4 5 0 - 1 3
5 I 7 7 3 5 - 7 I 4 4 0 2 - 4 3 4 2 0 1 - 0
6 И4 10 10 11 .1 l_7_ 3 з 4 0 - 7 7 I 3 3 0 -
2 1 4
Рис. 41
Прочерки по диагонали означают, что из города / в город / ходить нельзя. Заметим, что сумма констант приведения по строкам равна 27, сумма по столбцам 7, сумма сумм равна 34.
Тур можно задать системой из шести подчеркнутых элементов матрицы С, например, такой, как показано на рис. 41а. Подчеркивание элемента с,; означает, что в туре из /-го элемента идут именно в /гй. Для тура из шести городов подчеркнутых элементов должно быть шесть, так как в туре из шести городов имеется шесть ребер, каждый столбец должен содержать ровно один подчеркнутый элемент (в каждый город коммивояжер въехал один раз), в каждой строке должен быть ровно один подчеркнутый элемент (из каждого города коммивояжер выехал один раз), кроме того, подчеркнутые элементы должны описывать один тур, а не несколько меньших циклов. Сумма чисел подчеркнутых элементов есть стоимость тура. На рис. 41а стоимость равна 36, это тот минимальный тур, который получен лексикографическим перебором.
Теперь будем рассуждать от приведенной матрицы на рис. 41 в. Если в ней удастся построить правильную систему подчеркнутых элементов, т.е. систему, удовлетворяющую трем вышеописанным требованиям, и этими подчеркнутыми элементами будут только нули, то ясно, что для этой матрицы мы получим минимальный тур. Но он же будет минимальным и для исходной матрицы С, только для того, чтобы получить правильную стоимость тура нужно будет обратно прибавить все константы приведения, и стоимость тура изменится с 0 до 34. Таким образом, минимальный тур не может быть меньше, чем 34. Мы получили оценку снизу для всех туров.
Теперь приступим к ветвлению. Для этого проделаем шаг оценки нулей Рассмотрим i >уль в клетке (1,2) приведенной матрицы. Он означает, что цена перехода из города 1 в город 2 равна 0. Ну, а еспи мы не пойдем из города 1 в город 2? Тогда все равно нужно въехать в город 2 за цены, указанные во втором столбце; дешевле всего за 1 (из города 6) Далее, все равно надо будет выехать из
183
города 1 за цену, указанную в первой строке; дешевле всего в город 3 за 0. Суммируя эти два минимума, имеем 1+0=1: если не ехать «по нулю» из города 1 в город 2, то надо заплатить не меньше 1 Это и есть оценка нуля. Оценки всех нулей поставлены на рис. 42а правее и выше нуля (оценки нуля, равные нулю, не ставились).
Выберем максимальную из этих оценок (в примере есть несколько оценок, равных единице, выберем первую из них, в клетке (1,2)).
Итак, выбрано нулевое ребро (1,2). Разобьем все туры на два класса — включающие ребро (1,2) и не включающее ребро (1,2). Про второй класс можно сказать, что придется приплатить еще 1, так что туры этого класса «стоят» 35 или больше. Что касается первого класса, то в нем надо рассмотреть матрицу на рис. 426 с вычеркнутой первой строкой и вторым столбцом.
(б)
(а)
(о)
Дополнительно в уменьшенной матрице поставлен запрет в клетке (2,1), ибо выбрано ребро (1,2) и замыкать преждевременно тур ребром (2,1) нельзя. Уменьшенную матрицу можно привести на 1 по первому столбцу, так что каждый тур, ей отвечающий, стоит не меньше 35. Результат наших ветвлений и получения оценок показан на рис. 43. Кружки представляют классы: верхний кружок — класс всех туров; нижний левый — класс всех туров, включающих ребро (1,2); нижний правый — класс всех туров, не включающих ребро (1,2). Числа над кружками — оценки снизу.
Продолжим ветвление в положительную сторону: влево — вниз. Для этого оценим нули в уменьшенной матрице 0(1,2] на рис. 42в Максимальная оценка в клетке (3,1) равна 3 Таким образом, оценка для нижней правой вершины на рис. 44 есть 35+3=38. Для оценки нижней левой вершины нужно вычеркнуть из матрицы 0(1,2] еще строку 3 и столбец 1, получив матрицу С[(1,2),(3,1)] на рис. 45а. В эту
34
Рис. 43
184
матрицу нужно поставить запрет в клетку (2,3), так как уже построен
фрагмент тура из ребер (1,2) и (3,1), т.е. [3,1,2], и нужно запретить преждевременное замыкание (2,3). Эта матрица приводится по столб-
цу на 1 (рис. 456), таким образом, каждый тур соответствующего класса (т е. тур, содержащий ребра (1,2) и (3,1)) стоит 36 или более.
Оцениваем теперь нули в приведенной матрице С[(1,2),(3,1)]; нуль с максимальной оценкой 3 находится в клетке (6,5) Отрицательный вариант имеет оценку 38+3=41. Для получения оценки положительного варианта убираем строчку 6 и столбец 5, ставим запрет в клетку (5,6), см. рис. 45в. Эта матрица неприводима, следовательно, оценка положительного варианта не увеличивается (рис. 46).
(а) (б) (в) (Г)
3 4 5 6 3 4 5 6 3 4 6
2 - 4 1 0 2 - 3 1 0Г 2 - 3 О3 3 4
4 0 1 3 4 о1 - 1 3 4 О3 - 3 4 0 -
5 0 1 - 0 5 0 О2 - 0 5 0 О3 - 5 - 0
6 3 3 0 - 6 3 2 О3 -
1
34
Рис. 46
Рис. 45
Оценивая нули в матрице на рис. 45в, получаем ветвление по выбору ребра (2,6), отрицательный вариант получает оценку 36+3=39. а для получения оценки положительного варианта вычеркиваем вторую строку и шестой столбец, получая матрицу на рис. 45г.
В матрицу надо добавить запрет в клетку (5,3), ибо уже построен фрагмент тура [3,1,2,6,5] и надо запретить преждевременный возврат (5,3). Теперь, когда осталась матрица 2x2 с запретами по диагонали, достраиваем тур ребрами (4,3) и (5,4). Результат показан на рис. 47 Мы не зря ветвились по положительным вариантам. Сейчас получен тур
185
стоимостью в 36. При достижении низа по дереву перебора класс туров сузился до одного ту'а, а оценка снизу превратилась в точную стоимость. Теперь пора пожинать плоды своих трудов. Все классы, имеющие оценку 36 и выше лучшего тура не содержат. Поэтому соответствующие вершины на рис. 45 вычеркиваются. Вычеркиваются также вершины, оба потомка которой вычеркнуты. Мы колоссально сократили полный перебор. Осталось проверить, не содер-жит ли лучшего тура класс, соответствующий_матрице С[1,2], т.е. приведенной матрице С с запретом в клетке 1,2 (рис. 47а), приведенной на 1 по столбцу (что дало оценку 34+1=35), см. рис. 476. Оценка нулей дает 3 для нуля в клетке (1,3), так что оценка отрицательного варианта 35+3 превосходит стоимость уже полученного тура 36 и отрицательный вариант отсекается.
Для получения оценки положительного варианта исключаем из матрицы на рис. 476 первую строку и третий столбец, ставим запрет (3,1) и получаем матрицу на рис. 47в. Эта матрица приводится по четвертой строке на 1, оценка класса достигает 36 и кружок зачеркивается. Поскольку у вершины «все» убиты оба потомка, она убивается тоже. Вершин не осталось, перебор окончен. Мы получили тот же минимальный тур, который показан подчеркиванием на рис. 41а.
(а) (6) (в)
1 2 3 4 5 6 1 2 3 4 5 6
1 - - 0 3 3 6 1 CD СО СО Т) О 1 2 4 5 6
2 0-1410 2 О1 - 1 4 1 0 2 0-401
3 12-003 => 3 1 1 - О1 0 3 3 - 1 0 0 3
4 4 5 0 - 1 3 4 4 4 О1 - 1 3 4 4 4-13 1
5 4 2 0 1 - 0 5 4 10 1-0 5 4 11-0
6 7 1 3 3 0 - 6 7 О1 3 3 0 - 6 7 0 3 0 -
Рис. 47
Удовлетворительных теоретических оценок быстродействия алгоритма Литтла и родственных алгоритмов нет, но практика пока-311вает, что на современных машинах они часто позволяют решить ЗК с л=100. Это огромный прогресс по сравнению с полным перебором. Кроме того, алгоритмы типа ветвей и границ являются, если нет возможности доводить их до конца, эффективными эвристическими процедурами.
Итак, изучая методы решения ЗК, мы узнали, что такое алгоритм эвристический, приближенный и точный. Точные алгоритмы решения ЗК — зто полный перебор или усовершенствованный перебор; оба они, особенно первый, не эффективны при больших л.
166
Задачи и упражнения
1. Даны неотрицательные числа ai, аг,- ,ап, bi, Ьг.Ьп и мат-
рица С, dj-ai+bj. Решить ЗК с этой матрицей.
2. Задачу примера 1 п. 1.7.2 решить жадным алгоритмом, принимая по очереди за начальный города 1, 2,..., 6 и отбиоая
4. Алгоритм Карга-Томпсона
1 (инициализация). Возьмем две ближайшие вершины, скажем, / и /. Образуем (вырожденный) тур i-ц-и.
2 (общий шаг) Цикл по всем ребрам уже построенного тура Скажем, рассматривается ребро (i,j). Цикл по всем вершинам, еще не вошедшим в построенную часть тура. Выберем такую вершину к, чтобы Cik+Ckj-Cij было минимальным. Эту вершину к включим в тур между / и /. End цикла по ребрам.
3 (завершение) Когда все вершины войдут в тур.
Найти е для алгоритма Карга-Томпсона.
5. Имеется квадратная решетка размером лхл. Во всех внутренних, стенках каждой клетки есть по двери (так что из внутренней клетки можно попасть в четыре соседних) Коммивояжер стартует из произвольной клетки. Как он может обойти все клетки и вернуться в исходную? Решить задачу для л=9 и л=10.
☆ 6. Условия задачи 1, но сц= min (a^b/) Решить ЗК с этой матрицей. ★
2 ЦЕЛОЧИСЛЕННЫЕ ЗАДАЧИ ЛИНЕЙНОГО ПРОГРАММИРОВАНИЯ
2.1. Наибольшее паросочетание
Рассмотрим важную прикладную задачу:
Имеется m мужчин и п женщин. Каждый мужчина указывает несколько (может, нуль; может, одну; может, много) женщин, на которых он согласен жениться. Мнение женщин не спрашивают. Заключить наибольшее количество моногамных браков.
Можно поставить эту задачу в терминах теории графов.
Дан двудольный граф Вт,п- Найти наибольшее паросочетание.
Д Паросочетанием называется множество ребер, не имеющих общих вершин. ▲ На рис. 48а показан пример паросочетания, а на рис. 486 — пример наибольшего паросочетания.
(а)
(б)
Рис. 48
Эту задачу можно поставить еще одним способом. Обозначим возможные брачные связи матрицей А, где строки соответствуют мужчинам, столбцы женщинам,
_ (1, если брак возможен
* [0, если брак невозможен
i= 1, m; j= 1, n
188
Введем неизвестную величину х„ _ 11, если заключен брак (/, j) р
* [0, в противном случае
Помимо (1) величина хц удовлетворяет еще двум условиям:
yxj=1,/=1.....т, (2)
/ = 1
(любой мужчина женится только на одной женщине), т
£х/7=1./=1....л, (3)
i=1
(любая женщина выходит замуж только за одного мужчину). Чтобы было как можно больше браков, надо максимизировать функционал
У, Уа(/х,7->тах (4)
;=1у=1
Запись задачи состоит из оптимизируемого линейного функционала и нескольких условий (называемых ограничениями), которые линейны, как (2) или (3). Такая задача называется задачей линейного программирования. Без ограничения (1) задачи линейного программирования довольно просто решаются так называемым сим-плекс-методом. Добавление условия целочисленности (1) обычно делает задачу очень трудно решаемой. Однако имеется подкласс целочисленных задач линейного программирования, которые решаются вне рамок линейного программирования весьма остроумными алгоритмами. Такие задачи мы и рассмотрим в этом разделе. Задача о максимальном паросочетании — одна из таких задач.
Теперь вернемся к графской постановке.
Для решения задачи о наибольшем паросочетании применяется метод чередующихся цепей. Пусть М — паросочетание в двудольном графе В. Цепь, в которую поочередно входят ребра из М (жирные) и из не-М (тонкие) назовем чередующейся относительно М. Например, на рис. 48а цепь (1,1’, 2,3’) — чередующаяся. По определению, цепь, состоящая из одного ребра, тоже чередующаяся. Вершины, инцидентные ребрам из М назовем насыщенными, прочие — ненасыщенными. Очевидно, что если в графе существует чередующаяся относительно М цепь с ненасыщенными концевыми вершинами (т.е. тонкими концевыми ребрами), то в ней тонких ребер на одно больше, чем жирных. Если цепь «перекрасить», т. е. сделать все жирные ребра тонкими, а тонкие — жирными, то число жирных ребер, а, следовательно, и паросочетание, увеличатся на одно ребро. Чередующаяся
189
относительно М цепь с ненасыщенными концевыми вершинами называется увеличивающей относительно М цепью.
Теорема 1. Паросочетание М является наибольшим тогда и только тогда, когда нет увеличивающих относительно М цепей.
Доказательство. Необходимость очевидна, а достаточность докажем от противного. Пусть увеличивающихся относительно М цепей нет, а большее, чем М, паросочетание Мо есть. Рассмотрим граф Н, состоящий из ребер, входящих или в М, или в Мо, но не в оба вместе. Вообще, Н — необязательно связный, и в нем ребер из Мо больше, чем ребер из М. Любая вершина Н инцидентна самое большее одному ребру из М и одному из Мо. Связная компонента из Н может быть: (1) циклом; (2) цепью, у которой одно концевое ребро из М, а второе из Мо; (3) цепью, у которой оба концевых ребра из М; (4) цепью, у которой оба концевых ребра принадлежат Мо- Цикл в двудольном графе, очевидно, имеет четное число ребер, значит, в случае (1) число ребер из М равно числу ребер из Мо- То же соотношение верно для случая (2), а в случае (3) ребер из М больше, чем ребер из Мо- Но в графе Н ребер из Мо больше, чем из М, поэтому обязательно должен быть случай (4). Но цепь в этом случае является увеличивающей относительно М, что даст противоречие, доказывающее теорему
Теорема 1 служит основой для алгоритма нахождения наибольшего паросочетания. Но прежде, чем описывать этот алгоритм, мы выделим вспомогательный алгоритм 1 перечисления всех вершин орграфа, достижимых из данной вершины. В алгоритме 1 данная вершина — s, результат (в виде номера предыдущей вершины на пути достижения) записывается в массиве Р из л чисел, где л — количество вершин орграфа; еще используются рабочие массивы: byte О и Boolean R из л элементов каждый и два указателя (пойнтера) а и z, за сеющих соответственно начало и конец рабочей зоны массива Q.
Алгоритм 1:
Перечисление вершин орграфа, достижимых из s
1 (инициализация): a:=z:=1; Q[a]:=s. Для i=1,...,n все R[i]:= = false, P[i]:=-1.
2 (общий шаг):
2.1. В цикле рассмотрим все вершины в орграфе, непосредственно следующие за О[а]-й. Если для вершины k R[k]= false, то ?.=z+1; Q[z]:=k, Р[к]=О[в]; R[k]:=true.
2.2. a:=a+1. Если a < z, то перейти к 2.1.
3 (завершение): Выдача Р, конец.
Поясним алгоритм на примере. Дан орграф, показанный на рис. 49, найти все вершины, достижимые из s = 1.
190
5
QPf
Рис. 49
После шага 1 a:=1, z:-1 Q={1}... все P и R равны -1 и false, соответственно. Фигурные скобки в О для наглядности указывают границы рабочей зоны а и z. Для i=1,...,n P[i]= -1, что означает, что вершина i ниоткуда не достижима.
На шаге 2.1 рассматривается вершина к=2, рабочая зона О удлиняется на 1, туда заносится 2. P[2]:=Q[1]:=1. После шага 2.1 массивы Р, R и Q имеют вид: O={1,2}..., Р=(-1,1,-1,...), R=(f, t, f,...). После шага 2.2 Q=1, {2}...
После очередного шага 2 О =1, 2, {3 4}..., Р= (-1, 1,2, 2, -1,-1, -1) и R =(f, t, t, t, f...) (вершины 3 и 4 включены в рабочую зону Q, в R отмечено, что они достижимы из 2, а в R — что они уже были достигнуты.
После очередного шага 2 Q = 1, 2, 3, {4}..., Р=(-1, 1, 2, 2, -1, -1,-1)иЯ- не изменилось, так как после рассмотрения вершины 3 множество достижимых вершин не увеличилось, поскольку вершина 4 уже учтена как достижимая из 2.
После очередного шага 2 0=1, 2, 3, 4,{5}..., Р=(-1, 1,2, 2, 4, -1, -1) и Rs =true, так как стала достижимой вершина 5.
После очередного шага 2 0=1, 2, 3, 4, 5, .... Р=(-1, 1, 2, 2, 4, -1, -1), R как раньше, так как нет новых достижимых вершин и рабочая зона О закончилась, переход к 3.
Массив Р можно «раскрутить» как в алгоритме Дейкстры и узнать, по какому пути (кратчайшему по числу дуг) достижима каждая вершина. Скажем, массив Р показывает, что вершина 5 достижима из 4, 4 — из 2, 2 — из 1, т.е. имеется путь [1, 2, 4, 5].
Теперь вернемся к описанию алгоритма нахождения наибольшего паросочетания. Пусть /={1, 2, . , т] — номера верхних вершин, a J={1, 2,..., л} — номера нижних. Вначале все вершины ненасыщенные. Для построения начального паросочетания применим «жадный» алгоритм: будем просматривать по очереди вершины из / и, если из /е / ведут ребра в ненасыщенные вершины из J, будем жадно хватать и вводить в паросочетание первое попавшееся ребро, не думая о последствиях.
Далее, преобразуем двудольный граф В в орграф &, введя ориентацию следующим образом: все ребра, вошедшие в М, ори
191
ентируем снизу вверх, т.е. из J в /, а остальные ребра сверху вниз, т.е. из / в J. Пусть /= Г и f1', J= J'dJ1', где минус означает подмножество ненасыщенных ребер, а плюс — насыщенных Очевидно, что увеличивающая относительно паросочетания М цепь существует в графе В тогда и только тогда, когда в графе В* существует путь где sef, a teJ.
Алгоритм 2
построение наибольшего паросоч тания
1 (Инициализация):
1.1. Построение начального М (производится описанным выше «жадным» алгоритмом).
1.2. Построение орграфа Е? (описано выше).
2 (Общий шаг):
2.1. В цикле по ie/’ применить Алгоритм 1 нахождения всех вершин Е? , достижимых из вершины i. Если среди достижимых вершин окажется вершина joeJ', то (i,...,jo) есть увеличивающая относительно М цепь в графе В. Увеличить М и перейти к 1.2.
3 (Завершение): выдача М, конец.
Пример. Граф, показанный на рис. 48а, после введения ориентации, принимает вид рис. 50а.
(а) (б)
Рис. 50
На рис. 50а Г={5). Из вершины 5 в графе Е? достижимы вершины 2', 3, 4, 4‘ и 5'. Вершина 5'е J. Строится путь [5, 4', 4, 2’, 3, 5']. В соответствующей увеличивающей цепи в графе В жирные ребра заменяются тонкими и наоборот. Полученное наибольшее паросочетание показано на рис. 506. Между прочим, оно отличается от указанного на рис. 486.
2.2. Задача о назначениях
Предположим, что в предыдущей задаче на ребрах двудольного графа В стоят веса, обозначающие, так сказать, меру счастья в соответствующем браке, и нужно максимизировать суммарное счастье, а не число браков.
192
Формально задача запишется так: дана произвольная матрица д (или. менее общо, матрица из неотрицательных чисел), а дальше надо переписать формулы (1) — (4). Эту задачу обычно называют задачей о назначениях. Имеется в виду, что даны m кандидатов на п должностей, а матрица А характеризует меру полезности каждого кандидата при назначении его на каждую должность. Нужно найти назначение, максимизирующее суммарную полезность.
Почему-то чаще рассматривают в своем роде обратную задачу: матрица А выражает меру вредности каждого из m кандидатов при назначении на каждую из п должностей (например, это плата, которую нужно платить кандидату i за выполнение им работы j). Нужно найти назначение, минимизирующее суммарную вредность.
Ясно, что обе задачи решаются одним алгоритмом. В первой задаче нужно максимизировать:
m п
f = ^ У, а,, л,, => max
i = 1 j' = 1
Изменим матрицу А на А’ следующим образом: найдем в ней максимальный элемент (обозначим его г) и вычтем из него каждый элемент:
а 'у — г - atj.
Если А состояло из неотрицательных чисел, то Д' сохраняет это свойство.
f = Y а',,Ху = £ (г - a#) Xjj = £ г x,j - f = const - f
ij ij ij
Ясно, что максимизируя f, мы минимизируем Г и наоборот.
Ниже мы изложим алгоритм решения задачи о назначениях на минимум. Для большей понятности объясним алгоритм рассмотрением конкретного примера с матрицей А, показанной на рис. 51а. Будем пользоваться операцией приведения, которая описана в п. 1.7.4. Переделка обоснования этой операции с ЗК на задачу о назначениях очевидно. Приведенная матрица В показана на рис. 51 в — матрица на рис. 516 приведена только по строкам.
(а) (б) (в)
8 7 5 3 4 5 4 2 0 1 4 4 1 0 1
54423 32201 22101
82744 60522 50422
56544 12100 02000
83794 50461 40361
Рис. 51
7 Основы программирования'
193
Ясно, что если в задаче минимизации с неотрицательной матрицей удается провести «нулевое- назначение (только по тем клеткам, где bv—0), то будет достигнуто значение функционала f= 0, и меньше быть не может. Целью приведения было порождение большого числа нулей, чтобы попытаться найти нулевое назначение. Средство для получения наибольшего нулевого назначения мы уже имеем: нужно построить двудольный граф размера 5 + 5, где ребра соответствуют нулям (а не единицам, как в предыдущем параграфе) приведенной матрицы. Такой граф изображен на рис. 52а.
Наибольшее паросочетание, полученное алгоритмом 2.1.2 из предыдущего пункта, показано на рис. 526. Оно оставляет ненасыщенными две вершины из пяти. Чтобы увеличить паросочетание, нужно провести дальнейшие преобразования матрицы. Выше было показано, что минимум в задаче, где из всех элементов строки (или столбца) вычитается некоторое число, достигается на той же перестановке, что и в исходной задаче. Это свойство остается верным, если заменить вычитание сложением.
Пусть I’d, J’cJ и а — число. Будем говорить, что к матрице применяется операция Егервари Е(Г, J', а), если из каждой строки iel' вычитается а, а к каждому столбцу ieJ' прибавляется а. Эта операция не меняет оптимальной перестановки. Кроме того, элементы матрицы на пересечении строк из Г и столбцов J' не меняются, так как из них вычитается и прибавляется а.
Пусть Г vd' — множес ва вершин, достижимых из ненасыщенных вершин из / (множества/’ и J' получаются по алгоритму 2.1.2). В нашем примере из вершины 2 достижимы 4' и 1, а из вершины 5 достижимы 2' и 3. Таким образом, Г={1, 3}, J'={2‘, 4’}. Среди элементов Ь,;, где iel', aнайдем элемент минимального веса. В нашем примере — это Ь/з =1 Пусть а равно этому элементу: а=1 Преобразуем матрицу применив операцию Е(Г, J’, а). В результате матрица сперва примет вид, показанный на рис. 53а (а вычтена из строк 1 и 3), потом — вид на рис. 536 (а прибавлена к столбцам 2 и 4). Эту матрицу можно привести по строкам 2 и 5. Результат показан на рис. 53в.
194
(a)
3 3 0 -1 0
2 2 10 1
4-131 1
0 2 0 0 0
4 0 3 о 1
(б) (₽)
3 4 0 0 3 4 0
2 3 111 12 0
4 0 3 2 1 л 2 1
0 3 0 1 0 0 10
4 13 7 1 3 3 0
Рис. 53
Для двудольного графа, соответствующего пол. „трице
(рис. 54а) решим задачу о наибольшем паросо1 ~^днее
(рис. 546) находится сразу жадным алгоритмом
Рис. 54
Таким образом, получено назначение
/:1 2 3 4 5
J: 3 4 2 1 5.
Это назначение отмечено подчеркиванием в исход матрице на рис. 51а; именно, отмечены элементы (1, 3 (2, 4), (3, 2), (4, 1) и (5, 5). Сумма отмеченых элементов <а 18. Это и есть значение функционала, соответствующее сальному назначению в исходной задаче.
Теперь выпишем алгоритм в общем виде.
Алгоритм
решение задачи о назначениях (на минимум)
1 (Инициализация). Ввод матрицы В размером mxr, t тировать матрицу: ВВ: = В.
2 (Общий шаг)
2.1. Привести матрицу В по строкам, результат запасти в В.
2.2. Привести матрицу В по столбцам, результат занести в В
2.3. Решить алгоритмом 2.1.2 задачу о наибол-р ем i ар сочетании для двудольного графа размером т+п, еира в котором соответствуют нулям матрицы В.
2.4. Если паросочетание состоит из min (т,п) ,• юер, перейти к 3, иначе запомнить в /’ и J’ номера вершин (из / и ' оог тст-венно), которые достижимы из ненасыщс-нн- в ; '.инн из /.
Т
195
2.5. a: = min bjj , ie I, je J/j применить к В операцию Е(Г, J', а). Перейти к 2.1.
3. (Завершение). Вычислить f по ВВ согласно полученному паросочетанию. Вывод паросочетания и f.
Теорема 2. Алгоритм получает минимальное назначение.
Доказательство. Чтобы доказать корректность алгоритма, надо доказать два его свойства:
(1) применение пункта 2.5 оставляет матрицу В неотрицательной, (2) применение пункта 2.5 увеличивает паросочетание.
(1). Для простоты рассуждения можно считать, что множество /’ состоит из первых k= I/’ | элементов множества /, а множество J' из первых /= | J' | элементов множества J (это преобразование сводится к несущественной для нахождения минимального назначения перенумерации людей и работ). Тогда пункт 2.5 алгоритма можно представить схемой, показанной на рис. 55. Матрица В разбивается на четыре прямоугольника: I, II, III и IV. Из элементов прямоугольника I по строкам была вычтена а, а по столбцам прибавлена, поэтому элементы в прямоугольнике I не изменились. К элементам прямоугольника II прибавлена а, поэтому отрицательные числа там возникнуть не могли. Элементы прямоугольника III вообще не менялись. Из элементов прямоугольника IV вычиталась а, поэтому элементы его уменьшились. Однако а по определению равна минимальному числу, которое до применения операции а) стояло в этом прямоугольнике; поэ ому там появится новый ноль (или появятся новые нули), но отрицательных чисел возникнуть не может.
J'
/’ I IV
/"=///’ II III
Рис 55
(2). Докажем, что до операции E(I’,J', а) в прямоугольнике IV не было нулей, т.е. а>0. Действительно, если бы при ioe Г, Joe J”, bido=0, то вершина Jo была бы достижимой (из io) и не входила бы в J". При каждом применении операции E(I',J‘, а) в прямоугольнике IV возникает хотя бы один нуль, поэтому число достижимых (из множества ненасыщенных вершин, принадлежащих /) вершин, принадлежащих J, увеличивается по меньшей мере на единицу. Значит, сразу или через несколько (не более п-1) шагов будет достигнута ненасыщенная вершина из J, и сочетание увеличится. Теорема доказана.
196
Описанный алгоритм называется венгерским, потому что он основан на идеях работы венгра Егервари, написанной еще в 1931 г. Можно показать, что сложность венгерского алгоритма имеет порядок О(п4). Известны более экономные алгоритмы, основанные на теории потоков (см., например, книгу Форда и Фалкерсона, 1966); элементы этой теории будут изложены в 2.5.
2.3. Задача о назначениях на узкое место
Снова вспомним задачу о браках. Пусть ребра в двудольном графе имеют неотрицательные веса, — так сказать, коэффициенты счастья. В задаче о назначениях (на максимум) мы находили Tai ое паросочетание, чтобы максимизировать суммарное счастье, не принимая во внимание, как плохо придется некоторым индивидам. Сейчас мы зададимся другой целью — улучшить положение самых несчастных (из охваченных браком).
В терминах теории графов эта задача формулируется следующим образом:
Дан двудольный граф с весами. Найти такое паросочетание, чтобы минимальное ребро было как можно больше.
Задачу можно интерпретировать еще и так: имеется поточная линия, на которой п человек выполняют m операций — один человек выполняет одну операцию, b,j — время, которое /-й человек затрачивает на /-ю операцию. При назначении л /-й человек выполняет л (i)-K> операцию, причем человек т, такой, что Ьт,п(г) = minb/xo работает медленнее всех и определяет скорость всей поточной линии. Нужно найти назначение, чтобы максимизировать min bi,^ по всем возможным назначениям.
Алгоритм решения этой задачи указал Гросс (см. Форд, 1966). По этому алгоритму приходится решать серию задач нахождения наибольшего паросочетания.
Алгоритм Гросса
1 (Инициализация). Ввод матрицы В. Порождение начального назначения л=(1, 2, ..., п) (число на /-м месте показывает номер работы, на которую назначен i-й человек); начальный функционал f= f(n) = min ba.
1<&n
2 (Общий шаг).
2.1. Порождение матрицы А по правилу: для всех ij
(1, если by>f
а*- (0 в противном случае
197
2.2. Решение задачи о наибольшем паросочетании для матрицы А. Если полного паросочетания с л ребрами не получилось, перейти к 3; иначе запомнить в л новое паросочетание, в £=т1п(Ь,|Г/,)) и перейти к 2.1.
1</<л
3 . Вывести л, f: конец.
Корректность алгоритма очевидна.
Пример 1. Решить максимальную задачу о назначениях с матрицей, показанной на рис. 56а.
Решение. По шагу 1 л = (1, 2, 3,4, 5,6), 1=1. По шагу 2.1 получаем матрицу Ai (нули не проставлены) жадным алгоритмом получает я назначение л= (2, 1, 4, 3, 5, -), паросочетание неполное, которое перекраской увеличивающей цепи (6, 5’, 5, 6’) переводится в полное паросочетание л = (2,1,4, 3, 6, 5) с f= min(3,4, 5,4,4,7)=3. Переходя на шаг 2.1, получим матрицу Аг Получая наибольшее паросочетание по матрице Аг жадным алгоритмом, имеем л = (4,1,6,2,3,5) с /=min(6, 4,9, 5, 9,7)=4. Возвращаясь к шагу 2.1, полунаем матрицу Аз, которая не допускает полного паросочетания. Таким образом, ответом является паросочетание, полученное на предыдущем шаге с f=4.
2.4. Транспортная задача
Постановка задачи следующая:
Имеются m поставщиков одного товара, которые производят аь ....a,, ...,am единиц, и п потребителей, которым нужно bi,....
198
bj,.... bn единиц этого товара Пусть производство и потребление сбалансированы: ^3j=^bj. Заданы стоимость aj> О перевозки единицы товара от i-ro производителя к j-му потребителю. Считается, что перевозка х единиц товара в х раз дороже, чем перевозка единицы Найти, сколько товара каждый производитель должен направлять каждому потребителю, чтобы общая стоимость перевозок была минимальной.
Это — весьма реалистическая постановка задачи. Единственная натяжка — линейная зависимость цены перевозки от ее величины. Ну, скажем, если производители — это пекарни, а потребители — булочные, то нелепо утверждать, что Перевозка одной булки в два раза дешевле, чем перевозка двух булок. Однако, если считать товар не в булках, а в грузовиках, то линейность становится вполне реалистическим предположением.
Вообще нужно понимать, что линейные зависимости в мире довольно редки. Кэролловской Алисе задали задачу: кошка убивает крысу за минуту, за сколько минут кошка убьет 100 крыс? Алиса разумно ответила, что в этом случае крысы убьют кошку. Линейные зависимости так часто попадаются в математических моделях потому, что их легче считать. Постановщик задачи должен, если это возможно, оправдать линейную зависимость любыми корректными средствами, в частности, выбором единицы измерения.
В рамках линейного программирования транспортная задача ставится так: найти такие перевозки xj>0, чтобы минимизировать общую стоимость перевозок, m п
У У. сцхц-* min (19)
й1 /=1 при ограничениях п ^x^ai.i^..................m, (20)
/=1
(каждый поставщик вывезет весь товар);
m
^x„^bj,i=1.....n, (21)
»=1
(каждый потребитель получит по потребности).
Сейчас мы изложим алгоритм решения транспортной задачи, в котором не будет делений, так что если входные данные а, Ь, с — целочисленные, то и ответ х будет целочисленным.
Мы начнем развивать алгоритм издалека, вроде бы с посторонней задачи. Дана квадратная решетка с m строками и п столбцами. Некоторые узлы решетки помечены крестами. Цепью между крестами называется ломаная, такая, что (1) все ее звенья горизон
199
тальны или вертикальны; (2) все узлы излома — в точках, помеченных крестами. Циклом называется замкнутая цепь. Нас будет интересовать, каково максимальное количество крестов, которые можно разместить на решетке, чтобы через них нельзя было провести цикл.
На рис. 57а приведен пример цепи, а на рис. 576 — пример цикла.
(а) (б)
о я—о—в о о о я—о—я о о
о о я—я о о о о я—я о о Рис. 57
Ясно, что если поставить m крестов в левом столбце и л крестов в верхней строке (всего m+n-1, так как угловой крест засчитан дважды), то цикла не будет. А можно ли больше?
| STOP|
Пусть X — число крестов, а Хтах — максимальное число крестов, которые можно разместить на (т х л>-решетке без образования цикла. Рядом будем называть, как обычно, либо столбец, либо строку.
Лемма 1. Если Х=Хтах, то нет ряда без креста.
Доказательство. Пусть, для определенности, имеется строка без креста. Вставим в нее крест. В этот новый крест нельзя прийти по строке, может быть, можно по столбцу. Но тогда нельзя уйти по строке, а только по столбцу. Значит, на новом кресте не будет излома: цикла не было, и он не появился. Значит, с самого начала Х*Хтах. Полученное противоречие доказывает лемму.
Лемма 2. Если Х=Хтах, то любые два креста соединимы цепью.
Доказательство. Пусть + и х — любые два креста (см. рис. 58). Пусть они не соединимы цепью (следовательно, они не лежат в одном ряду). Поставим дополнительный «крест» * так, чтобы х* и +* были катетами прямоугольного треугольника с гипотенузой +х. Так как Х=Хтах, то с добавлением * возник цикл, проходящий через *. Рассмотрим четыре случая’
1. Цикл включил и х и +.
2. Цикл включил +, но не х
29Э
3. Цикл включил х, но не +.
4. Цикл не включил ни +, НИ X.
О О о о о о
о Ф о о о о
о о о о о о
о Ф о о в о Рис. 58
В случае 1 в качестве цепи (х...у) возьмем тот полуцикл, который не включает *. В случае 2 помимо * и х в их строке существует еще один крест (от которого цикл пошел в *); искомая цепь идет от х к этому кресту и далее по полуциклу, не включающему *, до +. Случай 3 аналогичен 2. Случай 4 означает, что в столбце *+ и в строке *х есть еще кресты. Через них + и х подключаются к циклу, из которого можно выделить цепь х+. Лемма доказана.
Теорема 3. Хтах=т+п-1.
Доказательство. Докажем по индукции по числу строк. Для т =1 это верно. Пусть это верно для к строк: Хтах =к+п-1. Добавим одну строку. В каждом столбце (к х лДматрицы есть по кресту по Лемме 1. Если поставить два креста в новую строку, то получится цикл, так как в меньшей матрице между крестами в тех же столбцах есть цепь. Один крест в новую строку, однако, доба ить можно. Теорема доказана.
Теперь вернемся к транспортной задаче. Ее условия по^но представить в виде таблицы на рис. 59.
Ь1 Ьг Ьп
а/ С11 С12 С1п
а2 С21 С22 С2п
Зт Ст1 Ст2 ^тп
Рис. 59
Строки соответствуют поставщикам, столбцы — потреби гелям, имеется тхп клеток, в северо-западном углу каждой клетки представлены цены перевозки, а процесс решения представляет собой заполнение клеток положительными числами х(;. Представьте себе, что узлы рассмотренной ранее решетки стоят в центре каждой
*201
клетки а положительные перевозки x(J>0 играют роль крестов, так что наборы перевозок в таблице могут быть циклическими (=кресты образовывают цикл) и нециклическими.
Теорема 4. Оптимальное решение достаточно искать на нециклических наборах.
Доказательство. Пусть в таблицу занесен допустимый, т.е удовлетворяющий ограничениям (20), (21) набор перевозок, и он весь или часть его образует цикл. В цикле, очевидно, четное количество крестов (=загруженных клеток); перенумеруем загруженные клетки числами 1,2,...,2k и разобьем клетки на два класса, с четными номерами и с нечетными. Пусть С+четн и С+нечетн — суммы Cij в клетках четного и нечетного класса соответственно Пусть, для определенности
С четн^ С нечетн (22)
Выберем минимальную перевозку в четном полуцикле; пусть ее величина г Отнимем г от каждой перевоз и четного полуцикла и прибавим г к каждой перевозке нечетного. В результате в наборе перевозок произойдут следующие изменения: 1) исчезнет одна или больше перевозок в четном полуцикле, т.е цикл разрушится, 2) стоимость перевозок по четному полуциклу уменьшится на С+чегнТ-к, а стоимость перевозок по нечетному циклу увеличится на С нечетн г к, т.е., в силу (21) уменьшится или, в крайнем случае останется прежней. Новый набор перевозок останется допустимым, так как в каждом ряду перевозка, уменьшенная на г, компенсируется перевозкой, увеличенной на г. Теорема доказана.
Начнем рассматривать пример, по дороге объясняя алгоритм и доказывая его свойства. Пусть входные данные задачи представ лены на рис. 60 (с,}=~ означает, что из i в / нет дороги).
f = 3 3+2 7+4 5+ +410+510+615+ +7 5 =258
202
Для инициализации проставляем перевозки жадным алгоритмом по строкам. Обратите внимание на хрб=0: мы пользовались жадным алгоритмом с одной поправкой — если при заполнении строки ставится пе евозка, причем одновременно исчерпывается мощность пос авщика и емкость потребителя, то жадный алгоритм продолжает работать, ставя фиктивную перевозку 0 в самую «дешевую» незанятую клетку. Это добавочное правило не относится к заполнению последней строки.
Теорема 5. Полученнь й набор — ациклический.
Доказательство. Перевозка, поставленная в ходе инициализации первой, не может входить в цикл, поскольку она либо единственная в столбце (если а>Ь), либо единственная в строке (если а<Ь). Удаляем из таблицы ряд, где первый элемент — единственный, и повторяем рассуждение.
Теорема 6. В ходе инициализации построен набор из п+т-1 загруженных клеток (включая фиктивные, загруженные нулем).
Доказательство. Алгоритм устроен так, что последняя запись в любой строке, кроме последней, не полностью удовлетворяет потребителя (при полном удовлетворении еще одному потребителю поставляется фиктивный нуль). Итак, число поставок, при которых потребитель полностью удовлетворяется, равно п — числу потребителей. Кроме того, в первых т-1 строках есть по одной неудовлетворяющей поставке, таких всего т-1. Общая сумма: п+т-1.
Теорема доказана.
Дальнейший ход алгоритма такой: выберем еще одну клетку для загрузки — и тогда возникнет циклический набор. Рассудим, какую дополнительную клетку выбрать. Для этого служат некие числа, которые приписываются каждой строчке щ, иг, .... ит, и каждому столбцу: vi, V2, .... vn. Они считаются следующим образом: сперва назначим щ=0 (число справа от первой строчки на рис. 60). Найдем в этой строке загруженные клетки (это клетки (1,1) и (1,3)) и подпишем под столбцом для каждой из этих клеток числа v, такие что для загруженной клетки (ij)
Ul+Vj =сц
(в примере под столбцом I поставлено 3, а под столбцом 3 поставлено 2). Теперь, зная vi, найдем в столбце 1 еще одну загруженную клетку (2,1) с сг<=4 и посчитаем иг=1, так что
С21~ 4 =иг + v/=1+3.
203
Далее, через загруженные клетки С24=4 и С2б=8 посчитаем V4=3 и V6=7. Потом через клетку сзб=7 посчитаем из=0, откуда через строку 3 посчитаем недостающие 1/2=5 и 1/5=6.
Нам удалось посчитать все и, и ц однозначно. Так и должно было случиться, как свидетельствует
Теорема 7. Изложенный алгоритм вычисляет все ui и vj, и присваивает каждому только одно значение.
Доказательство. Сначала докажем, что вычисляются все и, и Vj. Допустим противное: что р штук v и q штук и определить не удалось. С точностью до обозначений можно считать, что вычислены первые m-q штук и, и первые n-р штук ц (см. рис. 61).
п - р р
I IV
II III
Рис. 61
Это означает, что ни в блоке II, ни в блоке IV нет загруженных клеток. Набор нагруженных клеток — ациклический, поэтому в блоке III имеется не более p+q-1 загруженных клеток. Всего их было п+т-1, поэтому в блоке I их осталось самое меньшее
п+т -1- (p+q-1)=(n - р)+(т - q)
Для блока I это — слишком много загруженных клеток, получится цикл, а его быть не должно.
Вторая часть теоремы следует из хорошо известного факта. Уравнения для определения неизвестных имеют вид
Ui+Vj= Cjj.
Их т+п-1 штук по числу загруженных клеток. Неизвестных тоже т+п-1, поскольку щ насильственно назначен нулем. Если такая система имеет решение, то она имеет только одно решение.
Теорема доказана •
Возвратимся к алгоритму. Выберем какую-нибудь клетку (i,j), для которой u,+vj> Cjj. Это будет загруженная клетка, потому что для всех загруженных, по построению, игЩ-О. Теперь, вместе с остальными загруженными клетками, весь набор образует цикл и, как
204
легко видеть, только один. Допустим на минутку, что для новой клетки dj= Ui+vj. Дадим новой клетке номер 1 и двигаясь по циклу, перенумеруем остальные клетки числами 2,3,...,2k. Рассмотрим два класса клеток: нечет, куда входит новая клетка, и чет, вместе с суммами dj по этим классам С+чет и С+нечет- Какой-то элемент из класса чет имеет cab=ua+vb, он окаймлен по циклу элементами из другого класса, один в той же строке, другой — в том же столбце, значит в С+нечет входит и иа, и Vb- Развивая это рассуждение, можно понять, что как С+чет, так и С+нечет являются суммами тех же щ и ц, т.е. С+чет =С+нечет- Теперь вспомним, что в новой клетке Cij<Ui+Vj, поэтому С+чет >С+нечет- Теперь найдем минимальную перевозку г на более дорогом полуцикле чет, вычтем ее из всех перевозок этого полуцикла (при этом может получиться более одного нуля, но удалим только один — остальные останутся фиктивными перевозками), прибавим г ко всем перевозкам полуцикла нечет (-начит, новая клетка станет загруженной) и — с лучшим функционалом — вернемся к начальному положению — ациклическому набору из т+п-1 клеток.
Так мы будем действовать, пока сможем находить клетку с Ui+vj-Cjj=pij> 0 (между прочим, величина pij, из-за электрической аналогии, называется потенциалом, а излагаемый алгоритм называется методом потенциалов).
Опыт расчетов показывает, что итераций часто бывает меньше, если выбирать новую клетку не просто, чтобы ру было положительным, а чтобы pij было максимальным.
Теперь проделаем описанные действия над примером с рис. 60.
Потенциал ру максимален в клетке (1,5): р/5=0+6-3=3. Цикл образуют клетки (1,5) — (3,5) — (3,6) — (2,6) — (2,1) — (2,1) — (1,1) — —(1,5). К сожалению, в полуцикле чет есть фиктивная перевозка Х2б=0, поэтому прибавление/вычитание г =0 ничего не изменит в наборе перевозок, кроме того, что нулевая перевозка передвинется в клетку (1,5) и надо будет пересчитать потенциалы. Результат показан на рис. 62а.
205
(б)
f = 246
(в)
f = 221
Рис. 62
В этой таблице выбирается клетка (3,1) с рз,=3+3-2=4 и получается цикл (3,1) — (3,5) — (1,5) — (1,3) — (3,1). Из полуцикла чет вычитается х/з=3, к полуциклу нечет 3 прибавляется. В результате получаем набор перевозок, как на рис. 626. Общая стоимость перевозок f = 2 7+3 3+4 5+4 10+23+5 10 +6 12+7 5=246.
Результат следующей итерации показан на рис. 62в, и здесь оказывается, что клетки с положительным потенциалом нет. Таким образом, наилучший полученный результат f = 221 описанным способом улучшен быть не может Мы докажем, что он не может быть улучшен никаким способом.
Теорема 8. Если все потенциалы незагруженных клеток неположительны, то получена максимальная система перевозок
Доказательство. Рассмотрим немного измененную транспортную задачу, в которой единственное отличие состоит в том, что ее матрица С отличается от С, именно
C’ij= Cij-Uj-Vj,
где щ и ц — такие, как в последней неулучшаемой итерации. Окончательный набор Х={х«}, очевидно, является оптимальным для
206
измененной задачи, ибо все загруженные клетки имеют С'# =0, а в незагруженных клетках С’ц>0. Теперь возьмем произвольное допустимое (т.е. удовлетворяющее ограничениям (20), (21)) решение Х=М,)}.
В задаче с матрицей С
Я*) = X X С'7Х« i I
а в задаче с матрицей С’
ИХ) = X X Q - (ин- ц) Xif, i i
Разница между f и f
Д = f(X) - f (X) = £ £ (и, + Vj) Xij.
i i
Простыми выкладками, учитывая равенства (20) и (21), доказывается, что &=const. Действительно,
Л = X X х« + X vi= X и'Х х» + X X Чх’> = X Ui а‘+
i I j ' i I i i
+£ У Vj Xij = const! +У Vj^ Xi = const! +У Vj bi = const! + const 2 i / j I I
HiaK, всякое решение в задаче с С отличается от решения в задаче с С на константу. Мы получили решение X для задачи С, которое отличается от оптимального решения задачи с С на эту же контакту. Значит, мы получили оптимальный план для задачи с С.
Теорема доказана.
В Задачи и упражнения
1 Что делать, если ^а,
I i
2 . Можно ли с помощоЮ метода потенциалов решить задачу о назначениях?
2.5. Задача о максимальном потоке
Представим себе ветвящийся водопровод, вроде изображенного на рис. 63а. Если понимать его как сеть в теории графов, то ребра — это трубы, а числа на них — пропускные способности (измеряемые, скажем, в ведрах в минуту). Вершины бывают трех сортов: источники, стоки, просто соединения труб. Про источники (соответственно, стоки) известно, сколько ведер в минуту они
207
подают (соответственно, отводят). Задача — наладить максимальный стационарный поток из источников а стоки.
Не теряя общности, можно свести задачу к одному источнику одному стоку. Вводится один фиктивный источник бесконечной мощности и от него протягиваются трубы в настоящие источники с пропускной способностью равной мощности источника. Аналогичную процедуру проделывают со стоками (см. рис. 636). Теперь во все вершины, кроме источника s и стока t, в потоке должно столько же втекать, сколько и вытекать.
В сети на рис. 63 ясно видно, что максимальный поток равен 20, но вообще — это* задача, решение которой по мере роста сложности сети далеко не очевидно. Редко кто может сразу увидеть максимальный поток на рис. 64. Нужен алгоритм.
Назовем разрезом такое множество ребер, что если их разрезать, то сеть рас адется на две компоненты связности, в одной из которых будет источник, а в другой — сток. Пропускной способностью разреза назовем сумму пропускных способностей его ребер. Очевидно, что мощность максимального потока не превосходит пропускной способности минимального разреза: больший поток просто не пролезет в это сечение. А можно ли всегда так наладить поток, чтобы он был равен минимальному сечению? Оказывается, можно.
Теорема 9. Мощность максимального потока равна пропускной способности минимального сечения.
208
Доказательство. Пусть дан максимальный поток из источника s в сток t. Назовем ребро (i,j) насыщенным, если поток по нему равен пропускной способности: fg=Gj. Путь, состоящий из насыщенных ребер, будем называть насыщенным путем. Множество вершин S построим рекуррентно по следующим двум правилам:
1. Источник s принадлежит S; seS;
2. если veS и есть ненасыщенное ребро (v,u), то ueS.
Поскольку поток f максимальный, то teS, иначе бы нашелся ненасыщенный путь из s в t и по этому пути можно было бы увеличить поток. Таким образом, в S не вошла вершина t и, может быть, какие-то другие вершины; вершины, не вошедшие в S, образуют множество Т. Рассмотрим разрез S/Т, т.е. множество ребер, один конец которых принадлежит S, а другой — Т. Этот разрез состоит только из насыщенных ребер. Действительно, если бы нашлось ненасыщенное ребро, то его «Т-шный» конец должен бы принадлежать S по рекуррентному правилу построения S. Таким образом, мы выделили разрез, пропускная способность которого равна проходящему через него потоку. Значит, поток этот — максимальный, а разрез — минимальный.
Теорема доказана.
Из теоремы следует алгоритм построения максимального потока Мы сначала рассмотрим его на примере сети с рис. 636. Первым этапом алгоритма будет нахождение какого-нибудь ненасыщенного пути из s в t. Для этого построим таблицу, по длине равную числу вершин (включая источник и сток) из трех строчек. Верхняя строчка М для меток при номерах вершин, средняя W — для количества полученной воды, а третья V — для запоминания номера вершины, откуда получена вода.
М S'
(а) W оо Инициализация
V -
м S" Г 2' Из S вода
(б) W ~ 10 10 попала
V - S S в 1 и 2
М S" 1” 2’ 3’ 4' Из 1 вода
(в) IV ©о 10 10 10 5 попала
V - S S 1 1 в 3 и 4
209
М S“ 1" 2” 3’ 4’ Из 2 вода
(г) W оо 10 10 10 5 никуда не
V - S S 1 1 попала
М S" г 2" 3” 4' 5’ Из 3 вода
(Д) IV оо 10 10 10 5 10 попала
V - S S 1 1 3 в 5
М S” 1” 2” 3” 4" 5’ 6’ Из 4 вода
(е) IV оо 10 10 10 5 10 5 попала
V - S S 1 1 3 4 вб
М S” 1" 2” 3" 4” 5" 6‘ 7' Из 5 вода
(ж) IV ®о 10 10 10 5 10 5 10 попала
V - S S 1 1 3 4 5 в 7
М S" г 2” 3” 4” 5“ 6” 7* е Из 6 вода
(з) IV оо 10 10 10 5 10 5 10 5 попала в t,
V - S S 1 1 3 4 5 6 конец
Рис. 65
Вначале таблица имеет вид как на рис. 65а: рассматривается только источник (ш рих у S), в нем бесконечно много воды fWs=°o), она не пришла ниоткуда (прочерк в строке V). Первый общий шаг показан на рис. 656. За вершиной S следует две: 1 и 2, они получили метки; пропускная способность ребер (S, 1) и (S, 2) позволяет подать им по 10 ведер (IV/=10,Wz=10), вода подана из S (Vi-S, V2=S); затем S метится двойным штрихом, т.е. изымается из рассмотрения. Далее общий шаг производится из самой левой вершины, отмеченной одним штрихом.
Алгоритм общего шага таков:
Дана вершина i с одинарной меткой и IV.
1. В цикле рассмотреть каждую вершину к, связанную с / ребром.
1.1. Если вершина к имеет любую метку, — пропустить к\
1.2. Если ребро (i,k) насыщено, — пропус ить к\
1.3. Если ребро (i,k) пустое, — пустить по нему поток fifc=min (Wj, Cik),
т.е. отметить одинарной меткой номер столбца к, Wk=fik, Vk=i.
Дальнейшие действия алгоритма показаны на рис. 65. Общий шаг прекращается, как только вода попадает в t.
210
На следующем этапе алгоритма «задом наперед», как в алгоритме Дейкстры, строится путь из s в t: вершина t достигнута из 6, значит имеем фрагмент пути 6->t; вершина 6 достигнута из 4, значит, имеем больший фрагмент: 4—>6—и т.д. Окончательно получаем:
s—>1 ->4->6->Л
По второй строке узнаем, что из 6 в t протекло 5 ведер, из 1 в 4 — 5 ведер и т.д Минимум из всех этих величин — 5. Значит, уже можно наладить поток из s в t, равный 5, как показано на оис. 66 (числа в круглых скобках после пропускных способностей обозначают поток).
Рис. 66
Снова возвращаемся к алгоритму нахождения «прорыва» (ненасыщенного пути из s в /). Теперь п. 1.3 алгоритма слегка изменяется.
1.3. если ребро (/./^-ненасыщенное, то пусти ь по нему по’ ок
/;?юв<=т:п (W, сЛ - fik(CT3p>)
Этот пункт нужно сразу было сформулировать в таком виде, понимая, что вначале старый поток — нулевой.
В результате применения общего шага мы сперва найдем ненасыщенный путь s—>2^4—>6—и прокачаем по нему еще 5 ведер (больше не пропустит «полунасыщенное» ребро (4,6));потом мы найдем ненасыщенный путь s—>1—>3—>5—>7—>/ и прокачаем по нему еще 5 ведер (больше не пропустит «полунасыщенное» ребро (s, 1)). Мы получим поток, показанный на рис. 66 в к адратных скобках и равный 15. Это, очевидно, не максимум. Максимальный поток не использует перемычки (1,4) и равен 20. Нам нужно улучшить алгоритм, чтобы он мог отменять неудачные решения.
В алгоритме общего шага ничего не было сказано о том, что делать с вершиной к, из которой идет поток в /. Улучшенный алгоритм таков (курсивом отмечены улучшения).
1. Bl цикле рассмотреть каждую вершину к, связанную с / ребром:
1 Л. если к име =т любую метку — пропустить (i,k);
211
1.2. если ребро (i,k) насыщено и поток направлен из i в к, — пропустить к\
1.3. если ребро (i,k) ненасыщенное и поток направлен из 1вк, — пустить по нему поток (И4, сл - fu<CTap>)
1.4. если поток идет из кв i, то
fb(HOB)~fiJCTap} -min (fklCTap}, Ш)
При проведении шага 1.4 поток из /, который питался потоком из к не оскудеет, ибо есть И4, а завернутый поток, быть может, пробьется из к в t, минуя /.
Применяя новый алгоритм к сети на рис. 66, начиная с потока мощности 15, показанного в квадратных скобках, дойдем до положения, показанного на рис. 67а. Из вершины 4 ребра ведут в вершины 1,2 и 6. Поток в 2 закрыт по условию 1.1; поток в 6 закрыт по условию 1.2, но с вершиной 1 можно работать по шагу 1.4. После этого, общий шаг продолжает работать, как показано на рис. 676 — 67г (минус перед 1 в первой строке отмечает, что поток в 1 из Vi нужно будет вычитать).
После прорыва будет построен путь
S—>2—>4—>(вычитатъ)—>1 —>3—>7—
и окончательный поток (рис. 68) достигнет 20.
Остается вопрос, как останавливается описанный алгоритм.
Если с потока на рис. 68 снова начать общий шаг, то занеся s в первый столбец таблицы, мы не сможем далее ее заполнять.
212
Рис. 68
В общем случае, в первой строке некоторые вершины получат двойную метку, а остальные — никакой. Дважды отмеченные принадлежат множеству S, не отмеченные — множеству Т, а разрез S/T является минимальным. В нашем примере S={s}, Т={ 1, 2, 3, 4, 5, 6, 7, t}, разрез проходит по ребрам (s,1) и (s,2) с пропускной способностью 20.
Задачи и упражнения
1. Найдите максимальный поток для сети на рис. 64.
2. Что нужно изменить в алгоритме,чтобы он работал на ориентированной сети?
☆ 3. Придумайте, как решить задачу на рис. 48 посредством алгоритма построения максимального потока. ★
2.6. Общая задача линейного программирования и симплекс-метод
Мы уже долго ходим около общей задачи линейного программирования — пора о ней что-нибудь рассказать. Для примера мы рассмотрим две типичные задачи.
2.6.1. Задача о диете
Можно ли жить без борща? Можно, и без хлеба можно, и без шоколада. А вот без чего нельзя жить, то это без белков, жиров, витаминов и т.п. Назовем последние питательными веществами (короче, ПВ), а борщ и прочее назовем видами пищи (короче, ВП). Зависимость между ПВ и ВП задает разработанная диетологами матрица D, размеров тхл, где элемент dij определяет, сколько единиц измерения /-го ПВ содержится в единице /-го ВП. Пусть также даны цены с/, сг, .... сп всех ВП и биологические нормы bi, Ьг, bm, например, для человека, работающего на лесоповале, скажем, на месяц для каждого ПВ. Считается, что потреблять меньше нормы нельзя: человек перестанет валить лес и помрет. Пустьх/, Х2,.... хп — неизвестные нам количества ВП, которые надо купить.
213
Если будет куплено (и выдано!) х/, хг, .... хп ВП, то тем самым будет введено в диету количества ПВ всех видов, стоящие слева в неравенствах п ^dijxi>bj, i=1,m (23)
Справа в неравенствах стоят биологические нормы, служащие ограничениями снизу.
Понятно, что все х/ должны быть неотрицательными:
Xj>0J=1,n (24)
Если все, что нас интересует при составл нии диеты, — это соблюдение минимальной биологической нормы, то наГдем самую дешевую из допустимых диет, т.е. оптимизируем общую цену купленных продуктов:
п
У Cj Xj => min (25)
Задача (23) — (25), называемая задачей о диете, не рассматривает вкусовых качеств диеты, и в таком виде ею moi бы заинтересоваться разве что комендант концлагеря. Впрочем, некоторые вкусовые интересы учесть легко, например, заменив нули в (24) на положительные числа: хз>1000, где хз — количество шоколада. В таком виде задача о диете успешно применялась для составл эния дешевого рациона кормления цыплят и телят.
2.6.2. Задача об оптимальном ассортименте
Имеется производственное предприятие, скажем, пекарня, которая производит п видов сдобных изделий (короче, СИ), таких, как булки, пирожные и т.п., расходуя при этом т видов имеющегося сырья (короче ИС), такого, как мука, яйца и изюм. Составленная диетологами матрица D, размером тхл, задает зависимость между СИ и ИС: элемент dij определяет, сколько единиц измерения 7-го вида ИС надобно для производства вида /'-го вида СИ. Пусть даже даны а, сг, .... сп — продажные цены для каждого вида СИ и st, sz .... Sm — запасы каждого вида ИС.
Если произведен ассортимент СИ, состоящий из xt, хг, , хп видов СИ, то ен из-за ограниченности ресурсов должен удовлетворять неравен '.твам п
У dij X/ < Si, i=1,m (26)
#=1
Нужно, чтобы выполнялись условия неотрица ельности-
214
*j>0, j=1, n
(27)
и нужно оптимизировать сумму продаж
п
£с;Л)=япах (28)
^1
Имеется много подобных задач. Они отличаются от задач, изложенных в предыдущих параграфах этой главы тем, что неизвестны алгоритмы их решения, не содержащие деления. Мы рассмотрим, как решать две поставленные задачи с трех точек зрения: геометрической, алгебраической и экономической.
2.6.3. Геометрический подход
Геометрический подход не эффективен и может служить разве что для пояснения основных понятий. Если л =2, то можно решить задачу графически. Рассмотрим пример такой упрощенной до крайности задачи о диете.
Пример 1. Можно купить только хлеб и сало по цене с/=5 и сг=30. Диета должна удовлетворять органичениям по белкам, жирам и углеводам, которые содержатся в хлебе и сале в следующих (взятых с потолка) количествах (рис. 69).
Хлеб Сало Пусть биологическая норма такова* Ь/=5, Ьг=2,5, Ьз=15.Требует-
Белки 0,1 0,2 сясос авить допустимую диету (т.е.
Жиры 0 0,5 найти, сколько купить хлеба и сала,
Углеводы 0,5 0,2 чтобы соблюдалась биологическая норма) минимальной стоимости.
Рис. 69 Искомые неотрицательные х и у должны удовлетворять условиям
0,1х + 0,2у>5
0,5у>2,5
0,5х + 0,2у>15 или, в более удобном виде, (А) х + 2у>50 (В) у >5 (С) 5х + 2у>150
Изобразим декартову плоскость (рис. 70). Поскольку х и у — нео рицательны, искомое решение должно лежать в первом квадранте. Нарисуем прямые (А),(В) (С), заменив неравенства равенствами. Допустимая область лежит выше-правее этих прямых, как показано на рисунке 70. Минимизируемая функция цели
f(x,y) = 5х + ЗОу,
215
если ее приравнивать разным константам, образует семейство параллельных прямых (на рис. 70 показаны две прямые: f = 150 и f = 300). Как только при «качении» вправо-вверх прямая коснется допустимой области, мы получим минимальное допустимое значение. На рисунке указан угол области, где это произойдет: это точка пересечения прямых (А) и (В), она графически равна (40,5). Алгебраически она получается решением системы
х+2у=50
уб
Минимальное значение функции цели 7(40,5) = 350
Рис. 70
Пример 2. Пекарня производит булки и слойки по цене с/=1 и сг=2. Для изготовления каждого из этих изделий нужны мука, молоко и сахар в пропорциях, заданных матрицей D на рис. 71.
Мука Булки Слойки
0,5 0,4
Молоко 0 0,2
Сахар 0,1 0,3
Рис. 71
Сырье имеется в количествах s,=40, sz=0,8, S3=15. (Рецепты предназначены только для математического употребления, веса даны в тоннах, а цены — в тугриках).
216
Требуется определить, сколько изготавливать булок (х) и сколько слоек (у), чтобы максимизировать сумму продаж
/£х, у/ = х + 2у.
Искомые величины х и у должны быть неотрицательными и удовлетворять ограничениям
0,5х + 0,4у < 4,0
0,2у<0,8
0,1х+0,Зу< 1,5
Изобразим на рисунке 72 прямые
(А) 5х + 4у=40
(В) у =4
(С) х + 3у=15
определив область допустимых решений. На рисунке видно, что прямая f=c, катясь влево-вниз, коснется точки, являющейся пересечением прямых (А) и (С). Ее координаты определяются решением системы
(5х+4у=40
[ х+3у=15
Отсюда получаем:х=60/11, у=35/11, fmax= 130/11
217
2.6.4. Алгебраический подход
Д ром называется набор чисел, например, (1, 9, 9. 6). Число чиг ел в наборе называется размерностью вектора, приведенный для примера вектор — четырехмерный. Векторы одинаковой раз рности можно с. ""'.чвать: складываются их соответствующие июненты.
Нал эр, (1,9,9,6) + (- 1, ,- 2.5,1) = (0,9,6.5,7). Вектор можно умнож ь на число; для этого s :э компоненты умножаются на число. Наприк • (0,9,6.5,7) х 2 = (0,18,13,14). Поэтому можно взять
неско7. секторов, скажем,vi, V2, из и умножить их на числа с/, са сз и результаты сложить:
V4 = С1V1 + С2'-2 + C3V3
Получится вектор V4, являющийся линейной комбинацией векторов vi, V2, V3.
Известно, что если взять п штук m-мерных векторов (или, как еще гов< фят, п векторов из m-мерного пространства) и эти векторы неза^ кимы, т.е. ни один из них не является линейной комбинацией других, то эти векторы с 7разуют базис, т.е. любой вектор из этого пространства может бь > представлен как линейная комбинация векторов базиса. Дока но, что никакие т-1 векторов не образуют базиса в m-мерном пространстве, а любые т+1 векторов содержат вектор, линейно зависимый от остальных, скажем,
Vtn+1 = Civi + C2V2 +...+ CmVm
что можно переписать как
/71+1
Vi = 0
ы
где не все X, равны нулю, и говорить, что любые т+1 векторов представляют линейно-зависимую комбинацию.
Удобным является специальный базис, состоящий из т ортов: у /-го орта, i=1,m, i-я компонента равна 1, а все остальные равны 0.А
Опишем алгебраический прием, называемый заменой Жордана. Пусть дана таблица (см. рис. 73), устроенная следующим образом. Слева от таблицы в столбик приведены т векторов а/, аг, ..., ат, образующие базис. Над таблицей в строчку приведены п векторов из этого пространства bi, 62, .... bn, а столбец чисел под вектором bj образован из коэффициентов т,;, на которые н'.экно умножить соответствующие векторы бз?.иса, чтоб,. : мма этих произведений равнялась bj.
т
bj=^hjai, j=1,n (29)
г 1
>18
Рассмотрим такую задачу: нужно в базисе вместо вектора аг поставить один из векторов Ь/, Ьг, , Ьп, скажем, bs. Можно ли это сделать, т.е. образуют ли базис векторы
з/, аг, ..., аг-i, al+i, ..., ат
и, если да, то как из старых коэффициентов -ц получить новые коэффициенты T’j?
bi Ьг bs bn
а/ U1 U2 Us Un
Т21 T22 T2s T2n
Зг Tri Tr2 bs Trn
От Tml Tm2 Tms ... Tmn
Рис. 73.
Ответ на поставленные вопросы дает следующая
Теорема 10. Замену аг на bs проводить можно, если trs^O. Коэффициенты пересчитываются по форм лам
i — Г. t’ij — Tij/lrs,
(30 а)
i ф г. T’j- = tj-
T/s TH
Trs
(30 b)
Замечание: Формула выглядит страшнее, чем она есть на самом деле. При j=s коэффициент т'д=О для / = г, а тге=1. Таким образом, s-й столбец новых коэффициентов состоит из нулей, кроме «поворотного» элемента t7s = 1. Далее, г-я строчка новых коэффициентов получается делением старых на поворотный элемент. Что касается остальных коэффициентов t’(j, при i*r, j*s то они получаются так: рассмотрим прямоугольник с диагональю от элемента до поворотного элемента (см. рис. 74).
= с ttf=b
Vs = сТ'''''''- ъ;
Рис. 74
nj новый равен старый минус b d/c (bud лежат в других углах прямоугольника, на концах другой диагонали).
☆ Доказательство теоремы 10.
Чтобы доказать линейную независимость векторов нового базиса,
219
ai, аг, ., ar-i, bs, ar+i, .... am допустим противное: они независимы и их линейная комбинация равна 0:
а, + Це bs = 0 (31)
По старому базису вектор раскладывается так:
Ь, = ^t,s а, (32)
Подставляя (32) в (31), имеем
а; + ps bs) aj + р$ trsar — 0 (33)
Так как векторы а;, аг, .... ат независимы, все коэффициенты в (33) равны 0. В частности psTrs = 0, а так как trs * 0 (здесь нужно, чтобы поворотный элемент не был нулевым), то ps = 0. Поэтому все коэффициенты равны 0 и независимость доказана.
Теперь нужно показать, что новые коэффициенты — правильные, т.е. для любого j=1,п
bj = ^'ij а‘ + т'/7 bs (34>
Расписывая правую часть (34) через старые коэффициенты, получаем
V4 • «" » l z ^/s "tri .
У Т у 3i + Т rj bs—/ , (Ъ) — ) al + bs —
Trs Lrs
hr hr
- У (т« - 2) а‘ + z2- ( y,T's a»> • TfS Trs hr •
Собирая вместе коэффициенты при ah получаем
bj = у т>; ац + T/j вг
i*r
Этим заканчивается доказательство.*
2.6.5. Экономический подход
Общим рассуждением мы снова предпочтем рассмотрение примера, а именно, задачи о диете. Теперь мы не связаны требованием, чтобы геометрический образ задачи можно было изобразить на плоскости, поэтому можно ввести больше ВП.
Пример 3. Пусть в задаче о диете надо следить только за ограничениями по белкам, жирам и у леводам как в примере 1,
220
но теперь мы имеем возможность покупать следующие ВП: хлеб (с/=5), сало (С2=30), маргарин (сз=40), картофель (С4=5), яйца (С5= 180) и шоколад (Сб=400). По набору продуктов наш концлагерь становится трехзвездочным, поэтому повысим по сравнению с примером 1 также биологические нормы (Ь/=6), (Ьг=4), (Ьз=20).
Матрица D, задающая состав ПВ и ВП, показана на рис. 75.
"~\^ ВП ПВ^\ Норма Хлеб Сало Маргарин Картофель Яйца Шоколад
Белки 6 0,1 0,2 0 0 0,6 0,6
Жиры 4 0 0,5 0.8 0 0 0,2
Углеводы 20 0,5 0,1 0 0,5 0 0,2
Рис. 75
Теперь надо составить таблицу вроде показаной на рис. 73. Именно, нужно трактовать все ВП как трехмерные векторы, где первая компонента показывает долю белков, вторая — жиров, третья — углеводов. Нужно также найти какой-то базис и разложить все векторы по этому базису.
Удобно, что в нашем наборе есть ВП, содержащие только один вид ПВ: яйца, 10/6 кг которых заменяют 1 кг белков, маргарин, 10/8 кг которого заменяет 1 кг жиров и картофель, 2 кг которого заменяет 1 кг углеводов. Эти векторы мы поставим в базис, а остальные разложим по ним. С жестокой диетической точки зрения все равно, что съесть: 1 кг шоколада или смесь из 10/б-0,6 =1 кг яиц, 1% 0,2 =% кг маргар на и 2 0,2 = 0,4 кг картофеля. Разница только в цене: «искусственный» шоколад стоит
180-1 + 40 0,25 + 5 0,4 = 192,
а естественный — 400, так что первая цена минус вторая дает — 208.
Для ого, чтобы пересчитать коэффициенты по новому базису, нужно в таблице на рис. 75 первую строку умножить на 10/6, вторую — на 10/8, третью — на 2. Результат представлен на рисунке 76а. Заметим, что в таблице сверху показаны цены ВП, а снизу добавлена еще одна строка. Под столбцом «норма» мы записываем цену этой нормы из вектора базиса т.е.
180 10+ 40 5 + 5-40 = 2200
(эта цена некоторой диеты, которую, может быть, удастся снизить), а под остальными столбцами записывается разность между ценами искусственного и естественного продукта, вычисленная, как выше
221
Для шоколада. Ясно, что в столбцах векторов, совпадающих с базисными, стоят орты (чтобы получить 1 кг яиц, надо взять 1 кг яиц, 0 кг маргарина и 0 кг картофеля). В нижней строке в таких столбцах стоит 0, так как здесь искусственный продукт совпадает с естественным.
Рассмотрим таблицу на рис. 76 а.
Базис Цена Норма Хлеб 5 Сало 30 Марг. 40 Карт. 5 Яйца 180 Шок 400
Яйца 180 10 1/6 1/3 0 0 1 1
Марг. 40 5 0 5/8 1 0 0 1/4
Карт. 5 40 1 1/5 0 1 0 2/5
(а) 2200 30 56 0 0 0 -208
Яйца 180 22/3 1/6 0 -8/15 0 1 13/15
Сало 30 8 0 1 8/5 0 0 2/5
Карт. 5 192/5 1 0 -8/25 1 0 8/25
(6) 1752 30 0 -448/5 0 0 -928/5
Яйца 180 14/15 0 0 0 1
Марг. 30 8 0 1 0 0
Хлеб 5 192/5 1 0 1 0
(в) 600 0 0 - - 0 ►
Рис. 76. Жордановы замены.
Из нее видно, что естественный хлеб дешевле, чем равнопитательная смесь, составленная из яиц, маргарина и картофеля. Впрочем, аналогичная разница в цене на сало еще больше, поэтому попробуем ввести в базис сало, заменив какой-то вектор из базиса. Разберем, какой вектор из базиса нужно вытеснить. Если вводить такое количество сала, чтобы удовлетворить полностью потребность в белках (и, следовательно, избавиться от яиц), то надо ввести сала 10:(1/3) = 30 кг. Но при этом мы введем искусственного маргарина 30-5/8, а нужно его всего 5 кг — это неэкономно. Если вводить сало, чтобы заменить маргарин, то сала понадобится 5:(5/8) = 8 кг; если заменять картофель, то 40:1 = 40 кг. Из трех частных: 30, 8 и 40 выберем минимум (при условии, что он положителен). Таким образом, вектор сало вводится в базис вместо вектора маргарин. Поворотный элемент 5/8*0, поэтому это можно сделать, и делается замена по Жордану. Результат представлен на рис. 76 б.
Теперь остался один продукт — хлеб, который выгодно вставить в базис. Цена диеты снизилась до 1752. Определяем, как выше,
222
что хлеб надо вводить вместо картофел Результат показан на рис. 76в. Теперь цена диеты равна 600, и нет ни одного вектора, который было бы выгодно ввести в базис. Формирование диеты окончено.
Если решать задачу на максимизацию, наподобие примера 2, то в базис надо было вводить те столбцы, у которых разность цен в нижней строке была бы отрицательной.
В случае, если бы в первоначальном наборе в кторов bi, Ьг, Ьп не было ортов, их надо было бы ввести искусственно, назначив им очень большие цены в задаче минимизации и очень малые в задаче максимализаци i, чтобы в процессе счета они были вытеснены нефиктивными векторами.
Ради первого изложения, мы обошли некоторые технические трудности, связанные с вырождением матрицы D и кое-что еще. Но мы постарались донести до читателя главное содержание сим-плекс-алгоритма. Заинтересовавшийся читатель может ознакомиться с аналогичным описанием симплекс-алгоритма со всеми подробностями (включая недоказанную нами законность останова по замечательной книге Гейл, 1963).
Задачи и упражнения
1. Решить примеры 1 и 2 симплекс-алгоритмом.
☆ 2. Доказать, что элементы последней строки на рис 766, и 76в тоже считаются по формуле (30.в).*
3 ТЕОРИЯ РАСПИСАНИЙ
Теория расписаний занимается задачами, от которых болит голова, скажем, у владельца маленькой автомастерской, где работает только он сам. Какое-то число автомобилей ждет ремонта, он их чцнит по одному, поэтому сроки окончания ремонта каждой машины зависит только от порядка, в котором они будут ремонтироваться. Со сроками окончания связаны выплаты, премии, потеря престижа и прочее. Нужно определить наилучший порядок ремонта машин. Вместо автомеханика и машин можно говорить о верфи и авианосцах, машинистке и рукописях, центральном процессоре компьютера и заданиях и т.д. Мы будем говорить общо: исполнитель делает работу.
Описанная схема — самая примитивная. Есть задачи более сложные, например, когда исполнителей несколько. Тогда задача состоит в том, чтоб раскидать работы по исполнителям и упорядочить работы для каждого исполнителя. Мы рассмотрим эти и другие обобщения. Некоторые задачи теории расписаний решаются простыми и изящными алгоритмами, большинство задач — неприступно. Изящные алгоритмы будут изложены, и узнать их полезно и приятно. Однако основная педагогическая цель данного раздела — показать, как из очень похожих на первый взгляд задач одни относятся к простым, другие — к запредельно сложным. Интуиция и выработанные приемы для распознавания сложных задач очень важны для разработчика алгоритмов, ибо неисчислимы потери времени и сил от того, что сложные задачи пытались решить просто.
Начнем с задач, где имеется один исполнитель.
224
3.1. Задачи одного исполнителя на минимакс
Мы условимся, что работы неделимы, каждая /-я работа имеет известную длительность р/, работы можно выполнять в любом порядке, каждая работа пребывает в системе с самого начала и может начаться в произвольный момент. Исполнитель может делать работы в любое время, начиная с (=0, без перекуров и поломок. Общие правила игры таковы, что чем скорее будет выполнена любая работа, тем лучше, поэтому исполнитель должен быть занят все время, а разрывы в исполнении работ невыгодны (если подтянуть оторванное начало какой-то работы к концу, то она окончится в то же время, а некоторые предыдущие можно будет сдвинуть по оси времени влево, т.е. они окончатся раньше). Окончания работ tj зависят от перестановки л — от порядка выполнения. Т(л)=(Г/(л), (г(л), .... tn(n}} называется расписанием.
Задача красильщика
Красильщик должен окрасить п предметов; для окраски j-ro требуется время р,. По окончании окраски j-й предмет должен еще сохнуть время bj, после чего он считается готовым. В каком порядке нужно красить предметы, чтобы последний в просушке был готов как можно раньше?
Можно поставить задачу чуть более общим образом: j-й работе сопоставлена штрафная функция w(t)=tj+bj. Найти такое расписание Т(л), чтобы минимизировать /=тах ад.
| STOP|
Задача красильщика решается просто — нужно упорядочить работы по убыванию bj (длительностей просушки), т.е. расположить их в таком порядке , что
Ьл'( 1 )>bit’(2)S..Sbit,(n), (1)
где bnw означает параметр b для работы, стоящей /-й в перестановке л.
Теперь докажем, что указанный выше алгоритм дает оптимум.
Теорема 1. Оптимальное расписание в задаче красильщика получается упорядочением работ по убыванию bj.
Доказательство. Пусть л’ не оптимальная перестановка. Тогда существует оптимальная перестановка ло*л’ такая, что KT(no))<f(T(n’)) или, короче, /(ло)</(л’)
Так как ло*л’, то в перестановке или, допуская вольность речи, в расписании по найдется пара работ, скажем, аир таких, что а«р
8 «Основы программирования*
225
(а. непосредственно предшествует Р), но ba<bp. Пусть суммарная длительность работ, стоящих в расписании по перед работой а, равна т. Тогда под знак максимума в функционале f работа а дает вклад т+pa+Oa, а работа р — вклад т+pa+pp+bp. Поскольку Ьр>Ьа, то
max (l+Pa+ba, T+Pa+PBT-bp)=T+pa+pp+b|J.
Составим перестановку iti, которая совпадает ело, но а и р переставлены. Тогда вклад в f от работы р равен т+рр+Ьр, а от работы а равен t+pp +ра+Ьа- Но т+рр+Ьр<т+рр +ра+Ьа поскольку ра>0, а т+рр +ра+Ь(1<т+ра+рр+Ьр, поскольку Ьр>Ьп. Итак, вклад от этой пары работ под знак максимума не увеличился, т.е. /(7ц)</(по). Если в перестановке щ есть пара, нарушающая условие (1), то проделаем с тц то, что было проделано с по, и получим перестановку кг, такую что ^K2)</(ni), и т.д. В конце концов мы получим перестановку, удовлетворяющую условию (1), которая в смысле f не хуже, чем оптимальная перестановка Теорема доказана.
Вообще допущение о том, что все работы могут начаться в любое время, начиная с t=0, нереалистично, поскольку работы приходят из внешнего мира тогда, когда они приходят, скажем, в моменты г/, не все равные нулю.
Как решить задачу красильщика, если у-й работе сопоставлен не только «хвост» bj, но и раннее начало г/?
Оказывается, что эту задачу, как будет показано в разделе 5, можно решить только перебором.
Введем важные понятия, часто используемые в календарном планировании. Во многих моделях каждой работе сопоставляется величина dj(dj>0), которая интерпретируется как директивный срок выполнения работы j. Пусть по расписанию Тработа; заканчивается в момент tj(T). Назовем отклонением от директивного срока или, короче, отклонением величину
lj(T) =tj(T) - dt (2)
Поскольку возможны случаи /;>0 и //<0, но такие величины разумно вводить в модель, если выполнение работы до директивного срока вознаграждается, а после штрафуется. Назовем запозданием работы / величину
о)
Рассмотрение этой величины оправдано в тех ситуациях, когда выполнение работы до директивного срока расценивается так же, как и выполнение в срок, а выполнение работы после dj штрафует
226
ся. В принципе возможна ситуация, когда выполнение работы раньше директивного срока н желательно, равно как и выполнение после директи зного срока (например, если выполнение работ раньше своих директивных сроков приводит к издержкам на хранение готовой продукции), но акие задачи мы исключили из рассмотрения.
Как построить порядок выполнения работ, чтобы минимизировать сумму отклонений?
| STOP,
Эту задачу поставил Джексон и нашел, что она решается упорядочением работ по возрастанию их директивных сроков, т.е. расположением в таком порядке л', что
dK’( 1) <S ... s dn(n)
Теорема 2. Оптимальное расписание в задаче Джексона достигается уп рядочением работ по возрастанию их директивных сроков.
Доказательство. Предположим, как в доказательстве теоремы 1, существование ло*л’, такого что /(ло)<7(л‘) и что а«р, тогда как da>dp. В расписании Г(по)
/а(ло) = т+Ра - da= yi,
/р(Ло) = т+Ра+рр - dp = У2
В расписании Г(л')
/а(л') = Т+рр+Ра - da= VI,
/р(л’) = т+рр - dp= V2
Ясно, что max (У1,У2)=У2, кроме того, y?>vj и y2>v2. Доказательство завершается так же, как и доказательство теоремы 1.
Можно было бы изложить еще несколько задач, решаемых своими простыми алгоритмами, но в этом нет нужды, поскольку есть общий алгоритм решения задачи минимизации максимума неубывающих ч/ДГ), предложенный Э.М. Лившицем (1969).
Алгоритм Лившица
Оптимальный порядок работ строится, начиная с конца. При любом порядке последняя работа окончится в момент ш = у р/.
i
Пусть min у/ (ш) = у* (ш).
i
Положим к’(п)=к и перейдем к задаче меньшего размера, полагая п:=п-1; ш:=(о -рк, J:=J\K. Повторяя эту процедуру п раз, найдем оптимальную перестановку л'.
8
227
Теорема 3. Алгоритм Лившица корректен.
Доказательство. Пусть порядки л’ и по имеют в конце несколько (может быть, нуль) работ одинаковых и одинаково упорядоченных, так что, считая справа, аир — первые неодинаковые работы в перестановках л’ и по соответственно (см. рис. 77). Значит, работа а лежит в перестановке по где-то левее. Построим перестановку Hi такой, как показано на рисунке. Перестановка m не хуже по, так как
1) а не дает большего вклада в максимум по построению л’;
2) р не дает большего вклада, поскольку в m Р расположена левее, чем в по;
3) блок, который стоял между а и р в по, сдвинут влево.
Общий конец у л’ и Л1 вырос. Действуя далее в таком духе и не увеличивая функционала, получим л’.
<о' <0
« I " к j
а р общий ;
* 17 7 7 17 ----V. V//J11111111111111 Ib wx \ j ~Т]
". Г---7-7 11П111111111111'? XX 'У///A I
Рис. 77
3.2. Задачи одного исполнителя на минисумму
Как и.в предыдущем подразделе, мы начнем с рассмотрения простых задач, но не из дидактических соображений, а потому, что здесь есть сложные задачи, которые решаются не иначе, чем перебором.
Для начала разберем задачу минимизации среднего времени пребывания работ в системе. Будем считать, что все л работ находятся в системе с момента t=0 и что /-я работа покидает систему в момент tj(T). Тогда среднее время пребывания работ в системе равно
i
Эта задача решается упорядочением работ по возрастанию длительностей работ, т.е. построением перестановки л' такой, что
Рп (Ц^Рл-(2)< Рк'(п)
Теорема 4 (Смит). Задача минимизации среднего времени решается упорядочением работ по возрастанию длительностей.
228
Доказательство. Рассуждение проводится по обычной схеме. Пусть существует перестановка то*л', f(no)<f(n’) и в то есть пара акр, такая, что ра>рр. Построим ni отличающуюся от то только тем, что в Л1 р«а, и докажем, что f(rti )< В расписании Г(то)
f(TO) = ^+(т+р(1)+(Т+р(1+рр)
(здесь и далее fap — вклад в функционал f от всех работ, кроме а и Р), а в расписании Г(л1)
f(ni) = <ф+(т+рр)+(т+рр+ра)
Возьмем разность f(no)-f(ni)
Лто)- фи) = ра- pp>0, что и требовалось доказать. Дальше, как обычно строим цепочку
то—> Л1—>...—»то =л’,
доказывая
/(то)>П^1 )>••> ffa’)
Следующая задача учитывает разную стоимость пребывания рабо ы в системе обслуживания. В ней надо минимизировать
f(n) =£ Ci ti
| STOP|
Мак-Нотон предложил решать ее упорядочением работ по возрастанию параметра pj/cj. Мы оставляем читателю простое доказательство корректности этого алгоритма (упражнение 3).
Вспомним теперь о введенных ранее понятиях: отклонениях /; и запозданиях z, (см. формулы (2) и (3)).
Более реалистично взвешивать их, т.е. умножать для /-й работы на коэффициент с/. В первой задаче нужно минимизировать
/ i
а во второй — функционал
I i
Задача минимизации fi решается как задача Мак-Нотона, так как функционалы в этих задачах отличаются на константу.
Задача минимизации fz решается только перебором, как будет доказано в разделе 5.
229
В приложениях встречаются также и разрывные функции штрафа. Допустим, для примера, следующую ситуацию. Работа/состоит в том, чтобы изготовить и доставить инструменты для наблюдения астрономического явления, которой произойдет в заранее известный момент dj. Тогда окончание этой работы в любой момент позднее d, одинаково бессмысленно и должно штрафоваться одинаково Примеры такового рода встречаются не только в астрономии, но и в других, вполне земных ситуациях Их можно моделировать штрафными функциями вида
Эту задачу о минимизации числа запоздавших работ поставил Мур, а Ходжсон предложил простой алгоритм ее решения.
| STOP|
(4)
Алгоритм Ходжсона
1. Упорядочить все работы в порядке возрастания d,; для определенности, если di=dj, то первой ставится работа с меньшим номером Получается перестановка
л = (л(1), я(2)..к(к)....л(л))
2. /с:=0;
3. fc=fc+1. Если работа к — отмечена или к>п, то полученная перестановка л’ — оптимальная, конец.
4. Если dn(k), то перейти к 3.
5. В случае, если tn(k)>dn{i<), найти из работ п(1), л(2), .... л(к} работу самой большой длительности. Пусть это будет работа j =п(1). Поставить работу j в конец, а следующие за ней до к(к)-й включительно сдвинуть к началу, т.е. порядок
тс(1), тг(2), .... /'= л(/), к(/+1), .... тг(/г).п(п)
преобразовать в порядок
л(1), л(2), ..., л(/-1), л(/+1), .... п(к) , л(л),/
Отметить работу /. Перейти к 3.
Справедливость такого алгоритма доказывает следующая
Теорема 5. Алгоритм Ходжсона дает оптимальное расписание в задаче Мура.
Доказательство, известное автору, настолько длинное и скучное, что читатель его все равно забудет. Лучше читателю самому попробовать доказать эту теорему коротко и остроумно.
Формула (4) годится не для всех прикладных ситуаций, потому что штрафы за выполнение работ после их директивных сроков
230
чаще всего зависят от вида работ Поэтому более реалистично ввести штрафные функции вида
,5>
Однако задача о взвешенном числе запоздав их работ, которую также поставил Дж. Мур, является универсальной задачей перебора, как будет показанс в разделе 5.
3.3. Задачи о нескольких исполнителях
В начале раздела говорилось, что если имеется несколько исполнителей, то работы надо сперва разбро ать по нескольким исполнителям, а потом упорядочить для каждого. К сожалению, за словом «разбросать» кроется очень неприятная задача.
Упростим ситуацию предельно. Имеется два идентичных исполнителя и п работ с длительностями pi, рг . Рп- Нет никаких
ограничений ни на разбрасывание, ни на порядок. Нужно лишь минимизировать время, когда закончит работу последний из двух исполнителей. Чтобы решить эту задачу, нужно разбросать работы так, чтобы суммы длительностей работ доставшихся каждому исполнителю были как можно более одинаковыми.
Эту задачу обычно называют задачей о камнях, имея в виду такую словесную формулировку:
Дана куча из п камней веса pi, рг. рп' разбросать ее на две
кучи максимально равного веса.
Эта задача, несмотря на обманчивую простоту формул кровки, — очень сложна; точно она не решается иначе, чем перебором. Почти каждая задача о нескольких исполнителях включает решение о раз-бра ывании работ (=камней), и поэтому она не может иметь простого решения. Что неожиданно, все задачи об одном процессоре, которые выше мы объявили трудными, тоже содержат задачу о камнях.
Тем не менее имеется одна нетривиальная просто решаемая задача о двух исполнителях (в ней принято говорить — «станках»). Это задача С. Джонсона.
Постановка задачи следующая:
На двух разных станках Mi и Мг нужно изготовить п деталей. Для изготовления j-й детали нужно проделать две операции — сначала первую на станке Mi с длительностью aj, а потом (возможно, после перерыва) — вторую, на станке Мг с длительностью bj. Требуется найти такие порядки выполнения операций на обоих станках, чтобы как можно раньше изготовить все детали.
231
Как видим, здесь нет раскидывания по станкам, так что есть шанс решить задачу без перебора.
Решение задачи очень просто в вычислительном отношении, но логически отнюдь не просто. ☆ Мы подробно изложим и докажем решающий ее алгоритм, следуя, в основном, изложению самого Джонсона (Джонсон, 1960). Для краткости, мы будем обозначать операции /-й работы через ц и р/, их длительности — через а, и Ь/ (в трехоперационных задачах, операции будут о/, р/, yj, а их длительности — а/, bj и Cj). Для начала мы докажем, что если ла и пр — порядки выполнения операций аир — различны, то в задаче Джонсона их можно без увеличения функционала сделать одинаковым.
Лемма 1. пр))^ /(Г(Ла, к»))
Доказательство. Пусть
Pa=O/1, Oj2.Ojn
₽P=Pi/, Pi2, .... P/n
Допустим, что согласно порядкам л«, пр первые s-1 операции производятся в одинаковом порядке (1<s<n), a s-e операции для разных процессоров уже относятся к разным работам (см. рис.78).
~'J Yi 8.
м„ / Г~^-У//7Л __________>t
, Начало с \ * , _
х • блок D
। одинаковым '
' порядком г-н-----1
----------------IFF”
Рис. 78
На рис 78 штриховой линией окружено множество В начальных операций с одинаковым порядком, последняя операция множества В на оси Mi кончается в момент т/, а на оси Мг — в момент тг. Операция у/ — s-я по порядку на оси Mi — должна начинаться в момент т/ — иначе все операции, кроме принадлежащих В, можно было бы сдвинуть влево на зазор между т/ и началом у/, и тем самым уменьшить f(T). Операция у?, продолжающая у/, должна стоять на оси Мг правее, чем на s-м месте. Пусть 5г — первая после В операция на оси Мг. Ей должна предшествовать операция 8» на оси Mi, и должна стоять правее у/. Возможны два варианта: I — операция 5/ заканчивается позже хг, II — операция 5/ заканчивается раньше Т2- На рис. 78 показан вариант I.
232
Преобразуем расписание Т(Па, пр) в Т’(п’а, л’р), для чего произведем следующие действия:
1) «вынем» операцию уг, образовав на оси Мг просвет величиной в дг;
2) сдвинем операции блока D вправо на дг, отчего непосредственно после момента окончания операции 5/ образуется просвет на оси Мг, величиной в дг (ясно, что этот сдвиг оставит расписание допустимым);
3) в этот новый просвет вставим операцию уг',
4) если возможно (в варианте I это возможно) сдвинем операцию уг влево до «упора», т.е. до момента max (t(yi), тг), где t(yi) — момент окончания операции yi Затем сдвинем все операции, следующие за yi на оси Мг влево до своих упоров.
Легко видеть, что вследствие указанных действии функционал f(T) мог разве что уменьшиться, а множество В возросло. Действуя и далее таким способом, добьемся того, что пр совпадает с тса. Лемма доказана.
Из леммы 1 следует, что оптимальное расписание в двухоперационной задаче Джонсона достаточно искать на подмножестве расписаний, где Ла=лр=л.
Обозначим через х/,(х/>0) время простоя процессора Мг непосредственно перед началом выполнения операции р/. Если, например, л =(1, 2, .... л), то график выполнения операций будет иметь такой вид, как показано на рис. 79.
Рис. 79
На рисунке легко усмотрет что
х»=а/,
хг =тах (а/+аг - bi - х», 0)
xj+x2=max (а/+аг - Ь/, а/)
хз =тах (а/+а2 +аз -Ь/ Ьг - х/- хг, 0)
х/+х2+-хз=тах (а/+аг +аз -bi- Ьг, ai+аг - bi, ai)
Вообще п
V х/ = max Su, 1<u<n
233
и и-1
где su=£ а; - у Ь,
Для того, чтобы минимизировать срок окончания последней операции на процессоре Мг, нужно минимизировать л
У Xj ; а для этого нужно минимизировать max 5U;
Ml 1<Ц<П
верно и обратное утверждение Поэтому вместо первоначальной минимизационной задачи можно рассматривать эквивалентную задачу минимизации
f(n) = max 5u->min 1< и< п
Пусть л — некоторый порядок операций, а л' — порядок, отличающийся от л лишь парной транспозицией операций /и Н-1. Выражения, аналогичные su для перестановки л’, обозначим Su’. Ясно, что для и<1 имеет место равенство Su=su’, поскольку суммы в этих выражениях не «достают» до переставленных индексов. С другой стороны для и>/+1 также имеет место равенство su=su', поскольку оба переставленных индекса входят в суммы, где действует перестановочный закон. Отличаются только выражения для
/ f-1 Л-1 Л-1
Sj =У Эк — У bk, 5/'=У 3k + Ян-1 — У bk',
fc=1 fc=1 fc=1 k=1
hT i н-1 /-1
s/+i=£ a* - У bk, s*H-i=y ak - У. bk -bltv, k=1 k=1 k=1 k=1
Ясно, что если max(si, Si+i)=max(s,'. s’i+i), to
Теорема 6. Оптимальный порядок л' строится по следующему правилу: i-я операция предшествует (/+1)-й, если
max(s,, Si+i)<max(sA s'h-i)
(6)
Доказательство. Если имеет место равенство, то любой порядок оптимальный, и требуется выполнение некоторых дополнительных условий (см. случай 4 в Лемме 2). Вычитая н-i м
у ak - У bk k=1 k=1
из каждого члена равенства (1), получаем
234
max (-ан-ъ -bi)<max (-а;, -Ьн-i)
или
min (а/, Ья-i )<min (a»+i, bi) 17)
Это упорядочение транзитивно (доказано ниже в Лемме 2) и ведет к построению порядка л’, единственного с точностью до не ущественных инверсии
Неравенство f(n')<f(n) выполняется, так как л' может быть получено из л путем последовательных парных транстоэиций соответственно с (7), причем каждая транспозиция разве что уменьшает f.
Лемма 2. Соотношение (7) тран итивно.
Доказательство. Пусть, не ограничивая общности
min (а/, t>2)<min (аг, bi)
min (аг, ba)<min (аз, Ьг)
Нужно доказать, что min (а/, Ьз)^т!п (аз, bi) за исключением возможного случая, когда перестановка второй операции с первой или третьей несущественна.
Рассмотрим возможные случаи.
Случай 1. а1<Ьг, аг, Ьг, аг£Ьз аз Ьг- Тогда а1<аг^аз, ai<bi, так что а/< min (аз, bi).
Случай 2. Ьг<а1, аг, bi; Ьз^аг, аз, Ьг. Тогда Ьз<Ьг<Ь1, Ьз<аз. так что Ьз< min (аз, bi).
Случай 3. ai<b2, аг, bi; Ьз^аг, аз, Ьг. Тогда ai<bi, Ьз^аз.так что min (а/, бз)< min (аз, bi)
Случай 4 Ьг<31, аг, bi; аг^Ьз. аз, Ьг. Тогда аг=Ьг и перестановка второй операции не влияет на f. В этом случае первая операция может выполняться до или после третьей, но это не противоречит транзитивности, если мы упорядочим сначала первую и третью операции, а затем поместим произвольным образом вторую операцию. *
Используя (7) получаем простой алгоритм упорядочения, требующий О(п) вы ислительных операций.
Алгоритм 1 (Джонсон). Нахождение оптимального расписания в двухоперационной задаче Джонсона.
Входные данные. Количество работ п, массивы длительностей операций на первом процессоре а/ и на втором процессоре Ь/, /е J. Результат работы. Перестановка л, указывающая порядок выполнения работ на процессорах.
235
Описание алгоритма.
1. Выбрать среди невычеркнутых входных данных at, аг.ап;
bi, Ьг..Ьп минимальное число.
2. Если минимальное число принадлежит массиву а, скажем, есть число а,, то /-ю операцию назначить первой среди невычеркнутых, а в противном случае — последней среди невычеркнутых. Вычеркнуть соответствующие а/ и Ь, из массива входных данных.
3. Если все а и b вычеркнуты, то конец. Иначе вернуться к 1.
Замечание. Если применение пункта 1 дает несколько операций, поставить их для определенности в порядке номеров.
Пример. Пусть входные данные задаются следующей таблицей
Г. 1 2 3 4 5
аг. 4 4 30 6 2
Ьц 5 1 4 30 3
Применение алгоритма Джонсона даст оптимальный порядок л'= (5, 1, 4, 3, 2), f = 47. При обратном порядке л = (2, 3, 4, 1, 5) f=78 — наихудшее из всех возможных значений функционала.
Задачи и упражнения
1. Придумайте алгоритм минимизации максимума (а) запозданий, (б) взвешенных запозданий.
☆ 2. Придумайте алгоритм минимизации суммы штрафных функций
tpi (f) = с/ exp (X tj) + bj ★
3. Доказать алгоритм Мак-Нотона в задаче минимизации
f(n)=£ су tj => min
/
4. Печатный цех параллельно печатает п книг, длительность печати у-й книги — pj\ потом все книги последовательно проверяет один корректор. В каком порядке он должен проверять книги, чтобы последняя была откорректирована как можно раньше?
КРИПТОЛОГИЯ
С древних времен люди испытывали потребность как-то зашифровывать послания. Согласно легенде, самый древний способ тайнописи был такой: обривали голову раба, писали на коже головы нужное послание, ждали пока вырастут волосы и слали к адресату. Расшифровка походила на зашифровку: обривали раба и т.д.
Юлий Цезарь был, якобы, первым, кто придумал собс венно шифр. Алфавит размещается на круге по часовой стрелке (при этом в русском алфавите, после А идет Б, а после Я — А). Для зашифровки буквы текста заменяются буквами, отстоящими по кругу на заданное число букв дальше по часовой стрелке. Если, скажем, сдвиг на 3, то вместо /-й используется (i+3)-n буква, например, вместо А пишется Г, а вместо Я пишется В. При расшифровке наоборот берут букву на заданное число букв ближе, т.е двигаясь против часовой стрелки.
Шифр Цезаря расшифровать легко. Известны вероятности букв Pi, /=1, .... л, в языке сообщения (л — число букв в алфавите). Посчитаем частоты букв fi в зашифрованном сообщении Если оно не очень короткое, то fj должны сравнительно хорошо согласовываться с р,: fi ^pi. Затем начнем делать перебор по сдвигам. Когда сдвиг не угадан, общее различие между р, и равное п
A(s) = y| pi-fj(s)\
i=1
будет велико, а когда сдвиг угадан — мало. Минимизация A(s) по всем s =1, 2..л дает ключ к расшифровке кода Цезаря.
Позднее были построены другие, много более трудные для взлома шифры. Терминология здесь такова: законный адресат расшифровывав сообщение, а «враг», не имея ключа, взламывает
237
шифр. Создание шифров и законное ими пользование — это объект криптографии, взлом шифра — это криптанализ, криптология объединяет криптографию и криптанализ. Например, обобщением шифра Цезаря является шифр Виженера. Он устроен следующим образом. Сопоставим каждой букве алфавита цифру (например, в английском алфавите буквы нумеруются от А=0 до Z=25). Ключ задается словом из d букв (=чисел). Слово повторно записывается под шифруемым сообщением, и в /-м столбике из двух букв буква сообщения пц складывается по модулю 26 со стоящей под ней буквой ключа kr. 1г=пц+к) mod dr, здесь буква /( — это буква криптограммы. Например,
Сообщение Повторяемый ключ Криптограмма
NOWISTHE...
GAHGAHGA...
TODOSANE...
Расшифровка осуществляется вычитанием клю а по модулю 26 При d=1 шифр Виженера становится шифром Цезаря.
Шифр Виженера взломать гораздо труднее, но с помощью компьютера это возможно. Крупным недостатком таких систем шифрования является то, что отправитель криптограмм должен передавать получателю ключ, который может по дороге быть потерян, продан, украден и т.п.
К середине 70-х годов на базе компьютеров были построены глобальные системы электронной связи. Электронная связь теснит бумажную, и ясно, что последняя доживает свое. Однако у бумажной почты есть преимущество: письмо заключается в конверт и закрытость конверта охраняется законом. Электронная почта открыта для перехвата, ее нельзя поместить в конверт, ее можно защитить только зашифровкой. Учиты ая размах и интенсивность электронной связи, вопрос о пересылке ключей стал еще болезненней: ведь ключи для надежности нужно часто обновлять. И что делать, если посылатель обращается к получателю впервые?
В 1976 г. американцы Диффи и Хеллман предложили удивительный способ выработки секретного ключа без всякого предварительного сговора путем обмена информацией по открытому каналу. Это открытие решило вопрос с ключами и начало качественно новый этап компьютерной технологии. Кроме того, Диффи и Хеллман обсудили совершенно новый принцип шифровки, где умение зашифровывать не влекло умение расшифровывать. Конкретная реализация такой идеи позволяет перейти к так называемому открытому шифрованию. Абонент электронной сети открыто сообщал о том, как зашифровать к нему сообщения; однако расшифровать их мог только он сам.
238
Первый конкретный алгоритм для открытого шифрования предложили в 1978 Райвест, Шамир и Эйдлман. Эта криптографическая система называется RSA (Rivest-Shamir-Adleman), и она широко используется по настоящее время. Позднее были предложены другие системы открытого шифрования, но мы их здесь обсуждать не будем — вокруг RSA достаточно задач и алгоритмов. Однако прежде чем заняться этой системой, нужно ввести самые элемен тарные понятия теории чисел.
А 4.1. Элементы теории сравнений
То, что изложено в этом пункте, занимает несколько страниц в популярной книжке Оре. 1980. Далее все числа, если не оговорено противное, — целые.
По определению а^Ь mod т (читается а сравнимо с b по модулю т), если а и b дают одинаковый остаток при делении на т, или, другими словами, a^b mod т тогда и только тогда, когда а-Ь делится на т (обозначение- т | а-Ь)
Утверждение 1. Если a=b mod р и a=b mod q, и р. q — взаимно просты, то a=b mod pq.
Утверждение 2. Если а^Ь mod m, и c^d mod m, то ac^bd mod m.
Раз так, то из a=b mod m следует a%bs mod m, где s — любая степень.
Утверждение 3. Если a=b mod m, и csd mod m, то a+&=b+d mod m.
Отсюда и из утверждения 2 следует, что в любом арифметическом выражении из переменных или констант, связанных операциями сложения и умножения, можно вместо любой величины ставить другую величину, с ней сравнимую.
Утверждение 4. Обе части сравнения можно делить на число г, если:
(а) в обеих частях сравнения после деления останутся целые числа;
(б) г и модуль m — взаимно простые.
Доказательство, cr^dr mod m <-> m I cr-dr <-> m I r(c-d).B силу (6) m | c-d, csd mod m
Все эти утверждения легко выводятся из определения сравнения.
Нам понадобится еще малая теорема Ферма.
239
Теорема 1. Если а не делится на простое число р, то aP^sl mod р.
Доказательство. Пусты/, гг,.... Гр-1 — полная система вычетов, г.е. всевозможные остатки 1, 2, р-1 при делении на р. Если а
не кратно р, то числа аг/, агг, .... агр./ все попарно несравнимы. Допустим противное, что аи=агг mod р. Тогдар\ап-агг, т.е. р|а(г/--Г2), и так как р не делит а, то р делит п-гг, т.е. г/^гг mod р, противоречие. Тогда аг/, агг, .... агр./ тоже полная система вычетов, но взятая в другом порядке, т.е. по mod р
г/^ап/
Г1=апг
Tpt^aripi
Перемножая левые части и правые, получим
г/Г2.. .гр. /=а ₽' '(п/П2. г/р. /)=а ₽' '(г/гг.. .гр. /)
Поскольку произведение rir2...rp-i не делится на р, можно сокращать Получим а₽’,= / mod р. ▲
4.2. Выработка секретного ключа по Диффи-Хеллману
Основную роль здесь и в подобных задачах играют математические операции, когда прямая операция сравнительно проста, а обратная — запредельно сложна (по-английски они называются one-way functions). Такие операции известны и в жизни, и в математике. В жизни, например, слить/разделить вино и воду. Из математических операций такого рода нам понадобятся две:
(1 ) легкая операция: перемножить два больших числа P Q=N; трудная операция: разложить N на множители
(2 ) легкая операция: возвести основание а в степень р и взять остаток по модулю m: L=ap mod m.
трудная операция: найти р, зная L, а и m
Обе трудные задачи, в общем, решаются перебором по р и, следовательно, практически не решаются, если р — очень большое.
Предположим, что в компьютерной сети, где происходит общение, общеизвестны основание а и модуль р (это не является предварительным сговором, поскольку аир можно послать корреспонденту открытым текстом).
240
Схема Диффи-Хеллмана
Этап Отправитель Враг Получатель
1. Вырабатывает П
случайное число х, Е
1< х< т ; Р
вычисляет Li=ax mod т Е
и посылает U X Получает L
получателю В вырабатывает
А случайное число у
Т 1 <у<т;
ы вычисляет
в Lj=ay mod т
А и посылает Lj
Получает Ц Е отправителю
2. Вычисляет Т Вычисляет
Kj= L?= af* mod т Kj= L/=a>(y mod т
В силу утверждений 2 и 3, Ki=Kj. Это число, вычисленное как отправителем, так и получателем является общим секретным ключом. Враг перехватил L» и Lj, но не смог узнать х и у.
Пример. Пусть а =2, т = 601.
1. Отправитель генерирует число х =178 и посылает получателю
Li =21'8=8 mod 601. Получатель генерирует у =302 и посылает отправителю L; =2302=4 mod 601.
2. Отправитель вычисляет Ki =4178=64 mod 601. Получатель вычисляет К) =8302^64 mod 601.
4.3. Система RSA
Открытыми ключами является число п (вообще говоря, огромное, занимающее не меньше 512 бит) и зашифровывающий (encryption) ключ е. Число п является произведением двух простых чисел: n=pq, но числа pnq держатся в секрете. Секретным является и расшифровывающий (decryption) ключ d. Ключи d и е удовлетворяют сравнению de=1 mod (р-1 )(q-1). Теперь понятно, почему надо держать в секрете (или просто забыть) р и q. Причина в том, что зная е, р и q, можно из последнего сравнения восстановить d.
Зашифрованный текст является последовательностью алфавитно-цифровых символов, скажем, в коде ASCII; кодам соответствуют числа. Таким образом текст есть последовательность трехзначных чисел, т.е. длинное число т. Пусть т такое, что 1< т< п (если т>п, разобьем текст на меньшие куски). Схема передачи сообщения в системе RSA имеет такой вид
241
Этап Отправитель Враг Получатель
1. Зашифровывает П
сообщение т. Е
1< m< п так: Р
csm® mod n Е
Посылает с X
2. В А Т ы В А Е Т Получает с и расшифровывает его так: m=cd mod n 1< m<n
Враг знает п и е из общедоступного справочника, но, перехватив с=тв mod п, он не может восстановить сообщение т, ибо слишком много разных т, будучи возведены в степень по модулю п, дают с. Напротив, получатель, зная d, расшифровывает т однозначно.
Пример. Пусть п =3 5, е=3, d=3, т=3, ed=1 mod 2 4. При зашифровке c^me=27s12 mod 15. Приняв с=12, получатель производит расшифровку: т =123 =144 12=912=108^3 mod 15.
В общем случае справедлива следующая
Теорема 2. Еслип=pq, ecfel mod(p-1)(q-1), тот, 1<т< п, т.п — взаимные простые, обладает свойством (me)d=medsm mod п.
Доказательство. По малой теореме Ферма
тр,«1 mod р
Возведя обе части в степень q-1, получаем
moCi р
Аналогично (возводя обе части еще в степень к}
П7('р-»Хч-»М=1 mod q
Перемножая модули в двух последних сравнениях, имеем т<р-»Яч-О*=^ modpq=n
Несомненно,
rmm mod n
Перемножая последние два сравнения, имеем
242
m(P 1)(q- №+mod п (1)
С другой стороны, ed=1 modjp- 1)(q-1), т е. (р- 1)(q-q) I ed-1, т.е. ed-1—k(p-1)(q-1), т.е. ed=(p-1)(q-1)k+1
Это — экспонента в левой части (1), и (1) можно переписать так
т^^т mod п,
что и требовалось доказать.
Чтобы взломать шифр RSA, надо уметь найти d, для этого достаточно найти сомножители р и q, образующие п или, как говорят, факторизовать п. Этим мы и будем заниматься до конца раздела
4.4. Алгоритмы факторизации п
4.4.1. Прямой перебор
В классических трудах П Л. Чебышева, Сильвестера, Эрмита и др. была получена знаменитая оценка для п(х) — количества простых чисел, предшествующих числу х:
X
X -> «О
Поскольку наименьший делитель числа л не превосходит
L=[^n]
то при факторизации методом прямого перебора придется делить л в предельном случае на n(L)=L/lnL первых чисел. Для применяемых л это практически невыполнимо. Однако прямой перебор может использоваться как часть других, более сложных алгоритмов.
4.4.2. Алгоритм Евклида
Все рассматриваемые ниже алгоритмы факторизации содержат процедуру нахождения наибольшего делителя двух чисел: НОД(а/, аг), что наиболее эффективно выполняется использованием алгоритма Евклида. Рассмотрим его подробнее.
Алгоритм Евклида
1. Если аг=аг, то НОД:=а,, конец алгоритма, иначе а/:=тах (аг, аг), аг~ min (а/, аг)-
2. а/ целочисленно делится на аг, остаток заносится в аз-
3. Если аз=0, то НОД:=аг, конец алгоритма.
4. аг=аг\ аг-аз', иди в 2.
Вычислительная сложность алгоритма может быть оценена с использованием теоремы 3
243
Теорема 3. Алгоритм Евклида требует меньше, чем 21дг(тах (ai, аг)) целочисленных делений.
Доказательство. Можно считать, что алгоритм Евклида порождает следующие равенства:
ai=biаг+аз аг=Ьгаз+а4 аз=Ьза4+а5
(2)
ап-2—Ьп-гап- i+an
В последнем равенстве ап=0 и НОД (ai, аг)=ап-1. Из первой строки видно, что аз<а//2; вообще аь+г<ак/2.
Элементы левого столбца а/, аг, к, ап-г, взятые через один, убывают быстрее, чем при делении на 2 (при дихотомии); поэтому число строк, т.е. число итераций (делений) меньше, чем 21д2(тах(а/, аг)).
4.4.3. Алгоритм Полларда
Пусть р — наименьший простой сомножитель факторизуемого числа л, и пусть в результате случайного генерирования чисел удалось получить а и Ь, такие что
а^Ь mod р
(3)
Тогда очевидно р является делителем а-b, и р может быть получено вычислением НОД (а-b, п).
Таким образом, факторизацию л можно свести к получению двух чисел а и Ь, дающих при делении на р одинаковые остатки. По принципу Дирихле это всегда можно сделать, породив р+1 разных чисел.
К счастью, получить такие а и b с большой вероятностью можно гораздо раньше.
Зададимся числом г, г<р, и оценим вероятность того, что случайно породив г разных чисел, мы получим их все с разными остатками при делении на р. Эта вероятность (см. Феллер, 1964, стр. 44-45) У(г,р), зависящая от г и р, равна
V(r D}_ РФ ~1ХР ~2)--(Р ~ г+1) _ Р Р-1 Р-2 (,Р) рг Р Р Р
р-2+1 ,1,2
Р (1 P)(1 Р
Р
Оценим логарифм этой вероятности:
244
In V(r, P)=X In (1- £)<-££= - r(^1) = -/-1 i-1
В последней выкладке используется неравенство
Vxe(O, 1): In (1-х)<-х
Это неравенство (см. рис. 80) эквивалентно утверждению, что |ДВ| > |ДС|, что верно, поскольку точка В лежит ниже касательной к кривой Inx в точке С=(0,1), а касательная к Inx наклонена под углом 45".
При росте г вероятность V(r,p) падает быстро; при г=у!р имеем « и ,
1пУ= — - лГу => I-0,5» 0,61, а при г=^2р имеем 1пУ=-1 и V~e =0.37.
Соответственно, вероятности найти а и Ь, удовлетворяющие условию (3), равны 0,39 и 0,63. Поскольку р^п, есть хорошие шансы факторизовать л за ^Гп попыток. Рассмотрим, как реализовать этот процесс Вначале необходимо сформировать последовательность случайных чисел по модулю л. Приведенный ниже датчик порождает необходимую нам последовательность псевдослучайных чисел.
245
Алгоритм генерации псевдослучайных чисел
1 (инициализация). В датчик вводится любое число хое[1,п-1].
2 (общий шаг). На k-том шаге, к=1,2,..., порождается число x*=P(Xfc-i), где Р — полином.
В качестве Р можно выбрать различные функции, но для уменьшения вычислительной сложности выберем в качестве Р очень простую функцию, например, ^(х)=х2+1. Используя описанный датчик, порождаем случайную последовательность
XI, Х2,.., Хк.
Последнее полученное число х* надо проверить на выполнение условия
xi^xj mod р
для всех ранее полученных xj, j<k.
Для выполнения проверки необходимо осуществить квадратичный перебор. Обойти его можно, воспользовавшись результатами следующей теоремы.
Теорема 4. Пусть Хк и х; порождены полиномиальным датчиком с m
p^aif-'
i=1
и xi^Xj mod p. Тогда для любого а>0 справедливо сравнение Xj+a^Xk+a mod р.
Доказательство. Сначала проведем доказательство для а=1.
Пусть, для определенности, Xk>Xj. Тогда
Xk+i = aoxkrn+aiXkrn',+...+am-iXk+arn
Xj+i = aox/n+aix/n1+...+am-iXi+am
Нужно доказать, что если p\xk-xj, то p\xk+i-Xj+i. Вычитая нижнее равенство из верхнего, имеем
т-1
Xk+i- Xy+i=^ at (хУ“- х^4)
>=о
Это число явно делится на Xk-Xj и, следовательно, на р.
Если Xk^Xf, то Xk+i^Xj+i, то Xk+^Xj+2 и т.дТеорема 4 доказана.
Из приведенного следует, что для факторизации числа достаточно найти пару х*. xt с нужной разностью индексов Теперь можно окончательно сформировать
р-алгоритм Полларда
1 (инициализация). Случайно породить хо, к:=0.
2. к.=к+1.
246
3. Xk =P(Xk-i).
4. Если к — нечетное, иди в 2.
5. j:=k/2. Найти НОД (n, | Xk-Xj I).
6. Если НОД=1, иди в 2.
7. Если НОД <л, то р:= НОД конец.
8. (Если НОД делится не только на р, но и на л). Иди в 1.
В пунктах 4 и 5 алгоритма
хг сравнивается с х/, разность индексов 1;
Х4 сравнивается с хг, разность индексов 2;
хе сравнивается с хз, разность индексов 3 и т.д., пока не будут найдены х* и х/ с нужной разностью в индексах.
Алгоритм назван греческой буквой р потому, что хотя последовательность Хк бесконечная, но по конечному модулю р она является периодической, образуя петлю в виде буквы р (рис. 81).
Рис. 81
При анализе донорской крови на редкий вирус проверяют не каждую порцию, а смесь, образованную по капле из каждой порции. Обычно результат анализа отрицательный, а если он положительный, то тогда уже индивидуально анализируются все представленные в смеси порции. Аналогичный трюк можно проделать с разностями d/=|xk-Xy|, получаемыми в р-алгоритме. Вместо того, чтобы для каждой разности считать НОД (л, |х/<-х;|), формируется произ
247
ведение d=did?—dv mod n. После того, как наберется v сомножителей, считается НОД (d,n). Обычным результатом будет НОД=1, после чего нужно продолжать алгоритм и формировать новое d. При удачном исходе НОД =р и задача решена. Но может оказаться, что НОД = п. Тогда нужно проанализировать индивидуально все сомножители d, тж. может быть, что среди них есть один, делящийся на р и другой, делящийся на q.
Пример 1. Разложить 209, используя РчЛн ихо=17.
Все числа ниже взяты по модулю 209
xq=17
х/=81
Х2=83, di= |83-811 =2, НОД(2,209)=1
хз=202
х4=50, dz=| 50-831 =33, НОД(33,209)=11, 209=11-19.
4.4.4. Алгоритмы, основанные на сравнимости квадратов
П едположим, что удалось найти два разных по модулю п числа х и у, таких, что
х^у2 mod п (х>у) (4)
Тогда (х2-у2)=(х-у)(х+у) делится на л, и, если n=pq, могут представиться четыре варианта:
(1)pq|x-y;
(2)ра\х+у, (3)р х-уир|х+у (4) р х+уир|х-у.
В двух последних вариантах, находя соответствующий НОД, можно факторизовать л. К сожалению, трудно получить х и у, удовлетворяющие условию (4), если не известно разложение л. Одна из удачных идей получе ия нужных х и у — следующая.
Базой В назовем множество чисел ро, pi, рг, рь, где ро=-1, а pt, рг рь — Ь штук простых чисел, начиная с 2 в порядке возрастания. Пусть Z.=[Vn]. Для каждого числа aj=L+i, /=1, 2,..., вычислим qt — наименьший по абсолютной величине остаток по модулю п числа а2. Затеи попробуем разложить q, на множители из базы В.
Далее для ясности поясним алгоритм на примере. Пусть надо разложить л=221, так что L=14, а/=15, q/=4. Остаток qj раскладывается на множители базы именно <?/=р/2; степень 2 заносим в соответствующий столбец таблицы и начинаем обрабатывать
248
ap=16, надо продолжать таблицу пока в последнем столбце не окажется b +2 прочерков (в нашем примере 6 прочерков).
Разложение п =221, L=14, b =4
i а,= L+i Qi^i mod n оазложение на
-1 2 3 5 7 иные множит
1 15 4 2 —
2 16 35 1 1 —
3 17 68 2 17
4 18 103 103
5 19 -81 1 4 —
6 20 -42 1 1 1 1 —
7 21 -1 1 —
8 22 42 1 1 1 —
Степени при множителях из базы (4-й столбец таблицы, нули в незаполненных клетках, выбираются только строки, где в последнем столбце стоит про ерк) образуют матрицу D размером (Ь +1 )х(Ь +2) = 5x6:
(02000) 000 1 1 1 0400 1110 1 1 0000 I01101J
Теперь надо из матрицы D выделить подматрицу D’ из всех столбцов и части строк, чтобы сумма элементов в каждом столбце подматрицы была четной.
Это простая задача линейной алгебры. Нужно заменить в D все четные числа нулями, а нечетные — единицами и ввести сложение по модулю 2. Все привычные свойства останутся, и нужно будет найти линейно-зависимые строки, что в пространстве размерности п при числе векторов-строк п+1 всегда возможно.
Найдем такую линейную комбинацию, по ней выделим подматрицу D’.
Выделим, например, в качестве подматрицы D' три нижних строки матрицы D. Они соответствуют строкам 6, 7, 8 таблицы, т.е.сравнениям
20^(-1)237
212=-1
222е 237
249
Перемножая эти сравнения, получим (20 21 22)2=(2 3 7)2
Четность степеней справа обеспечил выоор матрицы D’. Пере ходя к наименьшим ос аткам по модулю 221, имеем
(-43)2=43
Это один из неудачных вариантов отношений (4). Чтобы найти удачный вариант, надо найти другую подматрицу D', например, состоящую из строк 3 и 5 матрицы D, т.е. соответствующую строкам 5 и 7 таблицы:
192Н-1)34
212Н-1)
Перемножая эти сравнения, имеем
(19 21 )2^92 432=92
Теперь надо искать НОД (221, 43-9) = НОД (221, 34) = 17. Соответственно НОД (221, 43+9) = НОД (221, 52) = 13. Мы нашли оба сомножителя числа 221=1317.
Если бы удачной подматрицы найти не удалось, можно было бы получить в таблице еще одну строку с прочерком в последнем столбце.
Можно теперь записать в общем виде
Алгоритм разложения квадратичных вычетов
1. Ввод л; задается Ь, строится база В ={-1, р/, .... рь}; Е:=[^л], k:=0, i:=0.
2. k:=k+1. В цикле порождается абсолютно наименьший остаток (АНО) Tk modn, затем число Bk=L+ Тк, затем квадратичный вычет qk (тоже АНО).
3. АНО qk делится на все множители базы В. Если qk не раскладывается полностью на множители базы, иди в 2. Иначе /:=/+1 и формируется i-я строка матрицы D — если в разложении qk j-й множитель стоит в степени бу, то df=8i; если после заполнения i-й строки, КЬ+2, иди в 2.
4. Найти подматрицу D', D'cD, такую что все суммы по столбцам Sj четные.
5. Перемножить mod п все х2, соответствующие строкам D’, что даетх2.
б. у2^ poSo...pis'..ppSs mod п
1. Найти НОД (х-1,п). Если НОД=1, иди в 4.
8. НОД — делитель т, конец.
250
Описанный алгоритм дает один из многих подходов к использованию условия (4). Алгоритм можно варьировать в пп. 1 — 4.
В п 1 можно отказаться от немедленного построения базы В, задав только ее верхнюю границу, а по олнять ее элементами по мере разложения q\ не обязательно порождать а*, начиная с 'tn. В п. 2 можно наладить порождение qk принципиально другим методом. В п. 3 можно применить так называемое «квадратичное решето», не пробуя делить те qk, которые не делятся на фиксированный множитель pf, кроме того, можно породить больше, чем Ь+2 строк, чтоб легче получать подматрицы. В п. 4 можно искать подматрицу D' после заполнения каждой очередной строки D.
По результатам факторизации больших чисел, группа алгоритмов, опирающихся на условие (4), по-видимому, является пока самой эффективной. Все последние рекорды факторизации держит алгоритм QS (quadratic seve = квадратичное решето). Эти рекорды представлены в следующей таблице.
Рекорды факторизации чисел общего вида
Год установления 1983 1985 1987 1989 1993 1994
Количество десятичных знаков в числе 71 80 88 100 120 129
Рекорды факторизации чисел специального вида, например, имеющих вид 22 - 1 (числа Ферма), много выше. Чтобы представить объем вычислений, связанных с этими рекордами, нужно знать, что для установления рекорда 1993 г. понадобилось 0,5 мивс-года (мивс — миллион инструкций в секунду; это количество операций, которое выполняет машина с быстродействием в 1 мивс в 1 год т.е. свыше З Ю13 операций), а для установления рекорда 1994 г. понадобилось около 5000 мивс-лет. Последний рекорд установлен добровольцами—членами сети InterNet, работавшими с августа 1993 по апрель 1994 г. Впрочем у алгоритма QS появился грозный соперник — алгоритм NFS (number field sieve), сила которого проверяется во время написания этих строк. Добавление к верстке: в апреле 1996 г. с помощью NFS удалось факторизовать 130-значное число за примерно 500 мивс-лет...
Имеется много других занятных алгоритмов факторизации, но на эту тему на русском языке пока нет доступной литературы (читатель может поискать книгу Гайкович, 1994 или недавно появившуюся книгу Жельников, 1996).
Задачи и упражнения
1. Разберите программу
Program letter_frequency;
251
{Программа находит частоты бука а текстах английского языка и заносит их в файл FRinLA, причем на первом месте ставится чвстота пробела} var f:text
ch:char;
iJongint;
freq: array [7V„ ’Z'] of longint;
begin
for ch:=H’ to 'Z' do freq[ch]:=0;
i:=0;
assign (f, Paramstr(1) );
reset(f);
while not eof(f) do begin
read(f, ch);
ch:= UpCase(ch);
if ch in [TV.. 'Z'] then begin
inc(freq[ch]);
inc(i);
end;
end;
close(f);
assign (f, 'GFRinLA.txt');
rewrite(f);
{ch: =0.222
writeff, ch);}
for ch:=7V to ’Z’ do write (f, freq[ch]/i);
writein (’frequencies:'};
for ch:=H’ to 'I' do write (f, freq[ch]/i:6:3, ' ’); writein;
for ch:=’J’ to 'R' do write (f, freq[ch]/i:6:3, ’ ’); writein;
for ch =’S’ to 'Z' do write (f, freq[ch]/i:6:3, ’ ')i writein; close(f);
end.
2. Напишите и испытайте программу взлома шифра Цезаря.
3. Напишите и испытайте программу взлома шифра простой подстановки: a-^li, 6-^2,—, где //, 1г,... разные буквы русского алфавита.
4. Докажите, что из п любых целых чисел можно набрать сумму, делящуюся на п без остатка.
5. Разложите на множители перебором и всеми другими описанными методами следующие числа (все они являются произведениями двух простых):
а) 200819
б) 141467
в)3121133
г) 2187433
☆5 О СЛОЖНОСТИ ЗАДАЧ *
Черная звездочка стоит после заголовка; это значит, что весь раздел 5 — не для первого чтения.
В математике почти нет результатов, касающихся абсолютной сложности задач. Это неудивительно, потому что оценивать абсолютную сложность задачи — это значит оценивать ее при абсолютно любом методе решения, а кто знает еще неизвестные методы? Реальный подход здесь — это сравнивать задачи по сложности.
Описывая задачи теории расписаний с несколькими исполнителями, мы упомянули две задачи: одна о разделении работ между двумя исполнителями, друга — о разделении камней на две максимально равные кучи. Ничего не зная о сложности этих задач, можно уверенно сказать, что сложность одинакова, ибо в сущности это одна задача Z/, изложенная разными словами. Рассмотрим чуть более общую задачу Z?:
Даны п камней весом pt, рг, .... Рп, п
Р=Хрп i= 1
набрать из них кучу общим весом И/, И/<Р.
Алгоритм Аг, решающий Zz, обязательно решит Zf, обратное утверждение не гарантируется. Значит, Z? сложнее (или, может быть, не проще) Zi. Эго отношение мы будем обозначать Zz>Zi (или Z&Zt).
Рассмотрим еще одну задачу Z3 (задачу о ранце): даны п предметов; каждый имеет вес р, и стоимость v;; набрать из них кучу весом не больше W, чтоб общая стоимость была максимальной.
253
Если взять 2з с v( =кр,, то максимальная стоимость достигается при максимальном весе, не превосходящем W, и нахождение такой кучи есть задача Z?. Значит, Z3&Z2.
Вообще опыт решения задач учит, что если алгоритм требует О (nconst) операций, то решить такую задачу реально (такие задачи называются задачами полиномиальной сложности). Конечно, если const в экспоненте равна тысяче, то радости мало, но опять же экспериментальным фактом является то что человеческий ум редко выдумывает алгоритмы сложнее О(п3) и почти никогда сложнее О(п5), так что практически тезис о легкой решаемости задач полиномиальной сложности оправдывается. Иное дело — экспоненциальная сложность: сп, лп, л! и даже 2”. Такие задачи приличного размера в лоб практически не решаются.
Вернемся к обсуждению сравнительной сложности. В теории графов известно такое понятие — клика. Кликой называется подграф, в котором все вершины связаны между собой. Рассмотрим задачу Z4: найти максимальную клику в данном графе. Известно другое понятие — независимое множество. Это множество вершин, такое, что ни одна пара вершин из него не связана ребром. Рассмотрим задачу Z5: найти максимально независимое множест во. Что можно сказать о сравнительной сложности Z4 и Z5?
I STOP|
Ответ — следующий. Предположим, мы располагаем алгоритмом А4, решающем задачу Z4. Нетрудно вообразить гго если надо решить задачу Z5 — для графа G нужно преобразовать его в граф G’ с теми же вершинами, но в G’ ставится ребро там, где его не было в G и удаляется ребро там, где оно было в G. Если подать G’ на вход алгоритма А4, он найдет максимальную клику, которая соответствует максимальному независимому множеству в G. Верно и обратное рассуждение о том, как применять алгоритм As — для решения задачи Z4. Поэтому задачи Z4 и Z5 эквивалентны по сложности с точностью до простого преобразования входных и выходных данных. Пренебрегая простыми преобразованиями, можно считать, что Z4 эквивалентна по сложности Z5, что обозначается следующим образом: Z^Zs.
В общей теории сравнения задач по сложности пренебрегают преобразованиями любой полиномиальной сложности, но мы пока ограничимся преобразованиями попроще.
Повторим и уточним методику сравнения (см. рис. 82).
Если возможно пройти эту схему не только по пути 1-»2, но и по пути 1-»3-»4-»2, то говорят, что задача Р сводится к задаче Q. Однако одного этого обстоятельства мало, чтобы утверждать, что Q сложнее (или не проще) задачи Р, потому что нужно учитывать
254
сложность преобразовании 1-»3 и 4-»2. Поясним сказанное примером. Пусть Р — задача коммивояжера, a Q — задача bi i6opa лучшего из двух заданных туров. Зада у Р можно решить, используя алгоритм решения Q. Для этого нужно потребовать, чтобы преобразование 1 -»3 нашло минимальный тур и произвольный тур. После этого О найдет минимальный тур и, не преобразов вая его (преобразование 4-»2 тождественное), пошлет решение на выход О. Это случилось потому что преобразование 1->3 имело экспоненциальную сложность, чего мы допускать не будем. Однако, применяя описанную схему к Z4 и Z5 мы получим Z4&Z5 и Z5&Z4, т.е Z^Zs.
1. Вход Р
Алгоритм
пре образование входа
решения Р
2. Выход Р
пр ^образование
3. Вход Q
Алгоритм
выхода
решения Q
4. Выход О
Рис. 82
Можно установить равенство задач по сложности не путем установления двух противоположных неравенств, а наблюдая на приведенной схеме за линией преобразования вход »вход. Пусть, скажем, P—Z4 и O=Zs-
Входом Z4 может быть любой граф G, на вход Z5 по линии 1 -»3 подается обратный граф G'. Но каждый граф является обратным к какому-то другому, поэтому вход Z5 будет принимать по линии 1 -»3 всевозможные графы, к чему он и при пособлен в, так сказать нормальном режиме, обслуживая задачу Z5. Входы задач Z4 и Z5, равно как и выходы, равнообъемны, поэтому Z^Zs- Если же P=Z?. a Q-Z3 то по линии 1-»3 будут идти задачи, в которых стоимости всегда пропорциональны весам. Это — подзадача, т.е. часть всевозможных задач о ранце. Алгоритм решения задачи Z3 явно умеет больше, чем алгоритм решения задачи Z2. В этих случаях мы будем говорить, что Z$>Z2. Отношение же «не проще», обозначаемое «£>», мы оставим для грубых сравнений, когда все задачи полиномиальной сложности равны.
5.1. Исследование сложности некоторых задач теории расписаний
Теперь, пользуясь обсужденными выше понятиями, мы установим сравнительную сложность нерешенных задач теории расписаний с задачей о камнях Z/. При этом будут позволены очень
255
простые (линейной сложности) преобразования вход — вход и выход — выход. В изложении мы будем следовать работе Лившиц, 1972.
Будут проанализированы следующие задачи:
1. Задача о красильщике, когда rj>0, т.е. случай, когда часть работ появится в системе позже t=0.
2. Задача о минимизации суммы взвешенных запозданий.
3. Задача Мура со взвешенным числом запоздавших работ.
4. Задача С. Джонсона о трех станках.
п
В Z/ будем обозначать w =
j=i
Теорема 1. Задача красильщика с г/20 сложнее задачи о камнях Zi.
Доказательство. Обозначим через Р' задачу с п+1 работой, где
го =w, rj =0,
4>o(t)=to+w, <Р/(0=(/. (1)
т. е. bo=w т. е. bj=O.
Очевидно, что Р’ является подзадачей обсуждаемой задачи красильщика.
Идея доказательства (см рис. 83) состоит в том, чтобы работы 1,2,.... п разбить на две минимально различающиеся по суммарной длительности кучи hi и hz, после чего поставить работы из hi до rcf=w, а работы из hz поставить после окончания нулевой работы. При этом функционал будет равен f=(po+2iv)+A, где po+2w оценка для f снизу, получаемая при условии, что имеется всего одна (нулевая) работа, а А — это разность между весом большей кучи и точной половиной IV.
Теорема 2. Задача о минимизации суммы взвешенных запозданий сложнее задачи Zi.
256
Доказательство. Построим подзадачу с п+1 работой, произвольными pi и
[O.foSW + PO ID\
4)0 [2Po(to- (w + Po)), to >w + Po, % ‘
Это — подзадача обсуждаемой задачи, когда со=2ро, Cj=pj, do=w+po, dj=O.
Пусть п ={ji, J2,ik, О, jk+1. ik+2, .... jn) — порядок, определяющий расписание Т(к). Посчитаем функционал f(T(n))=f(n). Сначала подсчитаем 7(л, hi} вклад в функционал от работ hi={ji, /2, .... /*}. Для краткости записи через ри (соответственно, «род) будем обозначать длительность (соответственно, штрафную функцию) работы, стоящей /-й по порядку в перестановке л т.е.р[(]=рп(0. В этих обозначениях
f(n, /7l)=£<P[il(t) =Р[1] Р(1]+ (Р{1]+P[2])P[2]+ ...+ (P[1]+ - +P[k])P(*] = le/ij
=Zp£j+ PW= ^(£p&+£ph pw)+
iehi hj i hi i ieh,
fat-
iehy к hy
где ivi — вес кучи hi.
Аналогично вычисляется f(n, h2) — вклад в функционал от работ tl2={jk+1, ik+2, .... in}
Дл, = (to+ Plfc+1])P[k+1 ]+ (to+ P[Jr+1j+ P[k+2])P[lr+2]+
iehz
+ (to+ P(fc+1]+ ...+ Р[п])Р(л]= £p(j]+ t0(P[k+1]+ -.+ P[k+u]) +£p[i) P[/]=
i hj
= ^<ХрЙ)+ t0W2+|w^, ieti2
где W2 — вес кучи h2, a to=wi+po — время окончания нулевой работы.
Окончательно,
п
Г(л)=/(л, hi) + <po(to) + f(n2, h2)= ^(w^+ w^) + -^P?+ <po(to) + tows= ы
= И^) + constl + <po(to) + (W1+ Po) W2= 2W1W2+ wi) +
1 9
+ constl + <po(to) + P0W2= const) + —(IY1+W2) + <po(fo) + P0W2=
= const2 + <po(to) + P0W2.
9 *Ооноаы программирования»
257
Рассмотрим два случая:
1. wi<w. Тогда w/=w-A, W2=w+A,<po(fo)=0.
В этом случае
fi=const2+(w+&)pa= const3+po&-
2. wf>w. Тогда wj=w+A, W2=w-A, fo=w+A+po, <po(fo)=2poA- В этом случае
(?=consf2+(w-A)po+2poA= consf3+poA.
Как видим, выражения для fi и fg совпадают и минимизируются вместе с А, минимизируемой функционалом в задаче Zi.
Преобразования входа и выхода линейны по сложности.
Теорема 3 Задача минимизации взвешенного числа запоздавших работ не проще задачи о камнях.
Доказательство. Выделим в задаче следующую подзадачу с п+1 работой с произвольными р/, /=1, 2, .... л с pcp=2w и такими штрафными функциями:
[О, to< 3w [О, t< 2w “ |3о, fo>3iv “ \pj, t/>2w
Функционал f(n), как и в предыдущий теореме, слагается из трех величин:
(3)
Гц) + <po(wi+po) + f(n, h2)
Рассмотрим два случая:
1. w/<w. Тогда f(n, hi)=O и <po(w/+po)=<p(3w-A)=O, но любая работа из бг запаздывает, так что
= W2= w +Д
te/>2
2. w/>w. Тогда по-прежнему f( л, h/)=0, но <ро(и/,+ро)=<ро(ЗиН-д)= =3iv и к тому же любая работа из ю? запаздывает, так что
f2 = 3w+W2=4w-A
Так как w>A, то fi<f? и минимум Т(л) достигается в случае (1). Но f(n) минимизируется вместе с А. что и доказывает теорему
Теорема 4. Задача Джонсона с тремя станками сложнее задачи Zi.
Напомним, что длительности операций на первом, втором и третьем станке обозначаются соответственно через а/, bj и с/. Мы
258
рассмотрим задачу с п+1 работой, так что появятся операции длительности ао, Ьо, со-
Возьмем подзадачу, где Ьо и bj, (/=1,2, .... л) произвольные положительные числа, но ^bj=2w; aoF=w, co^w, а7=0, с/=0. Изготовление лишь детали 0 займет w+bo+w времени, а во всей подзадаче нужно еще раскидать операции длительности ty на две кучи hi и /?2. выполняемые до и после операции 0 соответственно Если iv/=W2, функционал t=2w+bo, если | w/-w| = |w2-w|=A, то f=2w+bo+&-
Теорема доказана.
5.2. Псевдополиномиальные алгоритмы
Задача Z2 — набрать из камней весом pi, рг....... Рп кучу
заданного веса w или, если это невозможно, максимально близкую к iv снизу — воплощает в чистом виде задачу комплектации. Алгоритм ее решения нужен как составная часть многих алгоритмов. Поэтому хотелось бы иметь хоть какой-нибудь алгоритм решения Z2-
Для решения задачи Z?, а лучше мы напишем Zs{n,w), чтобы помнить, что есть л камней, и надо набрать вес w, построим и заполним таблицу Тел строками и w+1 столбцами. Перед строкой /, i=1, 2,.... п напишем р, — вес /-го камня, над столбцами напишем числа О, 1w. В клетку T[i,j] таблицы будем ставить оптимальное решение задачи Zgfij], т.е. задачи, когда даны камни 1, 2, ..., / с весами pi, рг, .... pt, а нужно укомплектовать вес w=j.
На первый взгляд мы не очень упростили ситуацию — теперь вместо исходной задачи нужно решать n(w+1) задач такого же типа, включая исходную. Оправданием может служить два соображения: а) при простых исходных данных задачи будут просто решаться; б) удастся просто переходить от простых задач к более сложным.
Эти соображения — правильные. Действительно, первый слева столбец (над ним стоит нуль и мь будем впредь называть его нулевым столбцом), как легко сообразить, надо заполнить нулями. Первую строку надо сначала заполнить нулями, а, начиная с клетки (1, pi) включительно, числами р(.
Теперь будем заполнять 2-ю, 3-ю и т.д. строки таблицы, каждую слева направо. Клетку T[i,j], i,j>1, будем заполнять по правилу
1. Если j-pi>0, то t:=T[i-1, j-pi), иначе t:=0; (4)
2. T[i,j]:=max(T[i-1,j], t+pi)
Первая часть правила гласит, что слева от таблицы Тпростирается сплошное поле нулей. Вторая часть означает, что: Тр-1, j] — это
9'
259
оптимальная комплектация веса / из камней весом pi,..., Pi-i. Если поставить T[i-1, j] в клетку (ij) — это значит при решении задачи Zs(i,j) обойтись без /-го камня. Если T[i-1, j-pi] — внутри таблицы, это наилучшая комплектация веса j-pi из камней 1, 2, .... i-1. Добавляя Pi, получаем комплектацию.
Теорема 5. В клетке T[i,j], i,j>1, общий шаг (4) записывает максимальный вес w в задаче Zsfij).
Доказательство. Либо в оптимальный комплект входит камень pi, либо нет. Вот втором случае максимальный вес уже был бы записан в клетке T[i-1, j] по индуктивному предположению, что предыдущие задачи решены оптимально. В первом случае, если бы максимальный вес был больше, чем t+pi, то без pi максимальный вес предыдущей задачи Zz(i-1, j-pt) был бы больше, чем содержимое клетки T[i-1, j-pi], что тоже невоз-можно.Теорема доказана.
Продолжая заполнять таблицу Т по правилу (4), мы дойдем до юго-восточного угла, где запишется вес (но не состав) максимальной кучи.
Пример 1. Даны камни весом р/=3, рз=5, рз=7, Р5=11. Надо набрать w=13. Таблица Т примет такой вид
0 1 2 3 4 5 6 7 8 9 10 11 12 13
3 0 О’ 0 3 3 3 3 3 3 3 3 3 3 3
5 0 0 0 3 3 5 5” 5 8 8 8 8 8 8
7 0 0 0 3 3 5 5 7 8 8 10 10 12 12"
9 0 0 0 3 3 5 5 7 8 9 9 10 12 12’
11 0 0 0 3 3 5 5 7 8 9 9 11 12 12’
Ответ — нет кучи, весящей 13’ ближе всего снизу — 12.
Однако, нужно установить и состав оптимальной кучи. Это делает следующий
Алгоритм восстановления кучи
(Вводятся две метки ml и m2}
1 (инициализация). Клетка в юго-восточном углу таблицы Т отмечается меткой m 1
2 (общий шаг). Обозревается клетка T[i,j], Если T[i-1, j]=T[i,j], то перейти на 3, иначе перейти на 4.
3. k=i-1; если i-1 и T[i,j]>0, то метим T[i,j] меткой m2 и переходим на 5; если i=1 и T[1j]=O, то переходим на 5; если i>1, то метим T[i,j] и переходим на 2.
4. Метим T[i,j] меткой m2; j~j-Ph перейти на 3.
5 Вывести номера строк, где стоят клетки с меткой m2.
260
Пример 2. Алгоритм восстановления кучи применяется к таблице примера 1; метка т1 обозначается одним штрихом, метка m2 — двумя.
При инициализации Т[5,13] получает штрих.
Затем п. 2 направляет в 3, метим одним штрихом Т[4,13] и переходим к 2; п. 2 снова направляет в 3, метим одним штрихом Т[3,13], возвращаемся в 2; п. 2 теперь отсылает на 4. В п. 4 метим двойным штрихом Т[3,13], переходим к Т[3,13-7]=Т[3,6] и переходим к 3; п. 3 преобразует Т[3,6] в Т[2,6], метит Т[2,6] одним штрихом и переходит в 2; п. 2 отсылает в 4, метим Т[2,6] двойным штрихом, меняем Т[2,6] на Т[2,1] и переходим к 3; п. 3 меняет Т[2,1] на Т[1,1], поскольку Т[1, /7=0, метки не ставим, переходим на 5; п. 5 выдает 2 и 3 — номера камней, чей суммарный вес равен 5+7=12.
Читатель может сказать, что ему много говорено о запредельгой сложности задачи Z?, а она решается не то, что полиномиально, а за O(nw) операций. Здесь нужно обратить внимание, что мы раньше в такие игры не играли: сложность подсчитывалась в теоминах п, т.е. количества чисел на входе, а вовсе не от размера чисел, как в данном случае. Такие алгоритмы, как изложенный называются псевдополиномиа 1ьными.
Тем не менее для практических надобностей такие алгоритмы очень полезны — как точные, если входные числа малы, и как приближенные, если большие входные числа приходится огрублять до малых.
Задачи и упражнения
1. Определите по таблице примера 1 состав куч для Т[5,11] и Т[3,10].
2. Какую погрешность можно гарантировать, есл1 входные данные задачи Z? уменьшены в 10 раз и округлены.
3. Измените алгоритм, чтобы он решал задачу Za о ранце.
5.3. Труднорешаемые задачи
В конце 60-х — начале 70-х годов в теории дискретных оптимизационных задач произошел чрезвычайно важный прорыв. Кук (1975), Карп (1975) и другие исследователи показали, что если позволить преобразования вход-»вход 1-»3 и выход-»выход 4-»2 не только линейные, но и полиномиальные, то возможно взаимно свести друг к другу почти все наиболее известные и не решаемые иначе, чем перебором, задачи, хотя над многими из них первоклассные математики бились около столетия. Почин Кука и Карпа был подхвачен, список взаимно сводимых, т.е. эквивалентных по сложности задач активно пополнялся (и пополняется), и сейчас их
261
более двух тысяч. По причинам которые здесь не стоит объяснять, поскольку это связано с другим, более сложным способом объяс нения материала, их назвали WP-полными (а, в некотором смысле, худшие из них — NP-трудными).
Поскольку все WP-полные задачи полиномиально сводимы друг к другу, то это означает, что если будет доказано, что хоть одна WP-полная задача не решается проще, чем перебором (т.е. решается алгоритмом с экспоненциальной или выше сложностью), то из эквивалентности по сложности последует, что все WP-полные задачи абсолютно сложны; наоборот, если хоть одна WP-полная задача будет решена полиномиальным алгоритмом, то сразу все WP-полные задачи будут решены этим алгоритмом, после всего лишь полиномиально сложного сведения к задаче, оказавшейся простой. Последняя возможность всем исследователям в этой области представляется чрезвычайно неправдоподобной. Поэтому в качестве естественно-научной гипотезы разумно принять следующий тезис: точное решение любой NP-полной задачи невозможно получить алгоритмом полиномиальной сложности
Именно с опорой на этот тезис в разных местах книги про какие-то задачи говорилось, что они не решаются иначе, чем перебором
Что касается конкретного сведения одних WP-полных задач к другим, решено этот материал в книгу не включать. Сведение осуществляется искусственными и громоздкими приемами роде тех, что были использованы в подразделе 5.1, но только сложнее. Основные сведения есть в книгах Рейнгольд, 1980, и особенно подробно в книге Гэри, 1982, где собрано более 300 WP-полных задач. Если у читателя не будет получаться простое решения дискретной задачи, всегда стоит заглянуть в книгу Гэри и Джонсона, — может быть, не стоит тратить силы
5.4. Как решать труднорешаемые задачи
Хотя значительную часть дискретных задач по теории точно решить невозможно, на практике их решать нужно. Поэтому, пожалуй, стоит высказать несколько резюмирующих соображений по этому поводу.
Во-первых, из массовой труднорешаемой задачи удае ся выделить легкоразрешаемую подзадачу (например, задачу Джонсона о двух станках из задачи об п станках).
Во-вторых, если приходится решать массовую задачу во всей бщности, то для практического решения используются чаще всего:
— эвристические процедуры (например, «иди в ближайший непройден ый город» в задаче коммивояжера);
262
— приближенные процедуры (например, «деревянный алгоритм» в задаче коммивояжера);
— метод ветвей и границ (например, метод Литтла и соавт. в задаче коммивояжера);
— пселдополиномиальные методы и вообще динамическое программирование, в которое псевдополиномиальные методы входят (например, описанное выше решение задачи Zg).
В связи с приближенными процедурами возникает естественный вопрос: а нельзя ли, постепенно усложняя приближенный алгоритм, получать все более точное решение, такие прецеденты известны. Например, для решения задачи Zg Д.Джонсон предложил следующее семейство алгоритмов по параметру т.
Алгоритм Джонсона
Вход: положительные числа pi, pg....рп (веса камней), w
(набираемый общий вес), целочисленный параметр т>2.
Определение: Назовем камень к большим, если рк> w/(m+1)
1. Перебрать все подмножества из больших камней и найти множество больших камней с весом w', такое что
w’< w и д= w-w" => min
2. Если д=0, конец, выдача h и w‘.
3. Перебрать все малые камни в порядке убывания веса. Если очередной j камень имеет вес р/, такой что pt < Д, то
h:=hVj; w:=w'+pj; A.^h-pj
Продолжать перебор по малым камням.
4. Перебор по малым камням закончен. Выдача Лии/, конец
Теперь оценим сложность и точность этого алгоритма при фиксированном т.
Поскольку рк> w/(m + 1), го т + 1 больших камней тяжелее w. Значит предельное число камней в куче — т. Отсюда ограничение в п. 1 алгоритма.
Пусть Ь, Ь<п, — число тяжелых камней. Куч, состоящих меньше, чем из т +• 1 камней имеется
Сь1+ Сь2+...+ Cbm = O(bm)<;O(nm)
таким образом, перебор имеет полиномиальную, возрастающую с т сложность.
Теперь обсудим точность алгоритма. Если на входе вообще не было малых камней, то w' — максимум уже после шага 1.
Если малые камни были, то либо они все были положены в кучу на шаге 3 (и тогда w'— максимум), либо не все. В таком случае на
263
шаге 3 невязка Д стала меньше какого-то малого камня С (по этой причине его нельзя было положить в кучу) Таким образом, после окончания шага 3
w w -w- д^---
т +1
Деля на w, получаем
w'^ 1
w т +1
т.е.
1___1—
т +1 w
Точное максимальное решение w” расположено между w' и w. w’< w"< w. Таким образом, чем больше т, тем меньше относительная погрешность:
1-—
т +1
К сожалению, такие алгоритмы — большая редкость. Обычно для труднорешаемой задачи известен простой алгоритм с плохой точностью, перебор на другом конце и ничего посередине. Некий выход представляют рандомизированные алгоритмы, где решение набрасывается случайно, но не равномерно, а пропорционально эвристическим предпочтениям. Лучший результат из случайных можно выбирать очень долго.
5.5. Совсем нерешаемые задачи
Дальнейший текст — это уже введение в антимир алгоритмов, причем очень краткое и изложенное, как говорят физики, «на пальцах». Из мощностных соображений ясно, что множество трансцендентных чисел много больше счетного множества, скажем, целых чисел, но оказалось очень трудным найти конкретные числа, такие, как е и я, про которые удалось доказать, что они трансцендентные. Так и с нерешаемыми задачами: мир математических объектов, мир непоставленных и нерешенных задач образует бесконечную шкалу все «более бесконечных» бесконечностей, а человечество за все время своего существование породит лишь конечное множество букв математических текстов. Найти же конкретную нерешаемую задачу трудно.
Здесь нужно твердо понимать, что надо искать. Задача всегда массовая: нет задачи «2 умножить на 2», есть задача умножения любых чисел (ну, если подумать, конечного числа чисел конечной
264
длины), и это — задача решаемая, — известен алгори м умножения в столбик. Нерешаемая задача — тоже массовая может быть, конкретные задачи, вроде «2 х 2», решаются, может быть решаются массовые подзадачи, вроде «умножить на 2», но общего алгоритма решения всей задачи нет.
далее, нужно точно определить, что такое алгоритм, ибо если он существует, его нужно просто предъявить, а если нет, то для доказательства несуществования нужно точно знать, чего нет
В 1930-х годах когда компьютеров еще не было, Тьюринг предложил идеальную машину, которая схематически изображена на рис. 84.
Машина Тьюринга (короче, МТ) состоит из головки и бесконечной в обе стороны ленты, разграфленной на клетки, в каждой из ко орых можно поместить один символ из заданного алфавита. Головка имеет колеса 1, чтобы передвигаться по ленте (на одну клетку в каждый такт времени), глаз 2, чтобы видеть, что написано в единственной клетке, над которой зависла головка, руку 3, чтобы стереть и/или написать один алфавитный символ в этой клетке и, разумеется, мозг 4. Барыня, которая обидела Герасима, который обидел Муму на один и тот же вход (Герасима со стаканом воды) реагировала по-разному, так как барыня пребывала в разных внутренних состояниях. Мозг 4 устроен примерно как мозг указанной барыни: он пребывает в конечном числе состояний qi, qg, ..., qm и, видя в обозреваемой глазом 2 клетке символ из конечного алфавита а/, ag, .... ап, выдает реакцию r(a,q). Реакция состоит из трех действий A, Q, М: А — написание нового символа взамен старого (в частности, оставление символа неизменным), О - переход из старого состояния в новое (в частности, оставление старого состояния), М — движение: Я — на одну клетку вправо, L — на одну клетку влево, S — стоять на месте.
Как всякая порядочная машина для обработки информации, МТ имеет вход, записанный на ленту по букве на клетку подряд слева направо. Считается, что в начале работы головка стоит в стартовом состоянии qi над первой буквой входа. От МТ требуется в конце работы иметь чистую ленту, со стертым входом и всеми промежуточными вычислениями; на ленте остается только выход и головка
265
стоит у левой буквы выхода в финальном состоянии, обычно обозначаемым восклицательным знаком. Весь умственный багаж МТ для решения конкретной задачи обработки информации (т.е. программу) можно изобразить таблицей с двумг входами: а/ и qj с тройкой А, О, М в каждой клетке. Последняя условность: будем обозначать содержимое пустой клетки буквой X.
Хотя МТ устроена просто, она может решать кое-какие задачи по переработке информации.
Задача 1 Стереть двоичный массив.
Решение. Программе нужна команда типа «видишь 0 — заменяй на X и двигайся вправо», в принятых обозначениях (0, qi)-»(Х, qi, R). Для экономии письма принято в правой части команды не указывать буквы алфавита (или состояния), если они не изменяются; символ движения опускается, если надо остаться на месте. Таким образом, команда пишется короче: (0, qi)—>(Х, Я). То же надо сделать с 1: (1, 4/)->(Х, Я). Еще надо остановиться за очищенным массивом: (К q/)-»(l). Собранная в таблицу, программа выглядит так:
qi
О 1
X
хя хя
Задача 2 Скопировать двоичный массив.
Решение. Нужна команда типа «видишь 0, запомни с номером состояния, иди вправо, пропуская 0 и 1 до X, там поставь 0»; в обозначениях (0, q/)->(Q2, Я); в Q2 помнится, что головка несет 0, чтобы пропус кать, нужно чтобы (О, 42)-»(Я), (1, 4г)->(Я), (X, 4z)-»(0, 43. L) где 43 — состояние возврата влево. Однако в таких командах не хватает останова, они будут бесконечно распространять 0 и 1 вправо. Для организации останова нужно ввести знак конца массива наприм р символ * Окончательная программа выглядит, например, так:
а\_ qi q2 Q3 q4 Q5 Q6
0 R L z, Q4, R R R L
1 R L u, 45, Я R R
X *, q2, l q3, R 1 R 0, 46, L 1. 46, L
* — — L Я R L
Z — — 0. L — — Q3, Я
и — — 1. L — — 43. Я
266
объяснения. Первый столбец описывает постановку, звездочки * в конце массива: головка пропускает 0 или 1 двигаясь вправо, пока не дойдет до X на правом краю массива; там ставится звездочка, головка переходит в состояние возврата q? и начинает обратное движение. На буквы г и и ни головка, ни читатель не должны пока обращать внимания: этих букв еще нет на ленте. Второй столбец описывает состояние возврата дг В том состоянии головка движется налево, пропуская нули и единицы, пока не достигнет пустой клетки на левом <раю массива; здесь головка смещается на клетку вправо, устанавливаясь над первым элементом массива и переходя в рабо ее состояние дз. Фактически возникла начальная ситуация, только теперь в конце массива стоит * Тре ий столбец описывает действия в состоянии дз видя 0, головка запоминает это переходом в Q4 (видя 2 — переходом в дз), заменяет 0 на символ г, чтобы не скопировать еще раз (1 заменяет на и) и начинает движение вправо. На реакцию в состоянии дз на остальные буквы можно пока не смотреть. Состояния q4 и qs обеспечивают движение вправо через 0, 1 и *, копирование по достижении пустой клетки и переход в состояние возврата qe- В состоянии qe головка идет влево до первой встреченной буквы и или z и во вращается в состояние дз По окончании копирования головка окажется в состоянии дз на звездочке *. Тогда (теперь надо читать нижние четыре команды в третьем столбце) оставляется звездочка, идет движение влево с обратной заменой z на О и и на 1, пока не попадется пустая клетка слева Здесь делается шаг вправо и останов.
Читатель, дошедший до этого места в книге, несомненно является ловким програм истом Он, конечно, сможет сложи ь на МТ два двоичных числа (указание: проще циклически уменьшать на 1 правое число и увеличивать на 1 левое) умножа ь числа, считать, сколько единиц в двоичном числе и т.п
Потом полезно построить условный переход
(1.Р)-»(Р’.Я), (O,q)-»(q",L)
(если в клетке — 1, перейти в состояние q’ и пойти налево, если в клетке — 0, перейти в состояние д" и пойти направо), потом легко придумать, как вызывать одни программы из других и т.п
Вскоре станет ясно, что МТ может делать элементарные опера ции, которые может делать хардв р h rdware) современного компьютера, а остальное — дело софтвера (software — программное обеспечение) В отличие от современников Тьюринга нас не удивляет что современный компьютер, снабженный развитым программным обеспечение (а, следовательно и МТ) может делать очень многое К гаму же МТ выгодно отличается от любого компьютера тем, что у МТ нет ограничений на памя ь
26
Тезис Тьюринга (зто не теорема, тут нельзя доказывать 7ж«ти дать фундаментальное, исходное определение) состоит в том, что алгоритмически разрешимо то, что может сделать машина Тьюринга.
Были сделаны еще две совершенно разные попытки описать алгоритмически разрешимое через рекурсивные функции и через преобразование слов в алфавите. Позже удалось доказать, что описываемые во всех трех подходах множества алгоритмически разрешимых задач эквивалентны. Это подтвердило правильность выбранного определения. Можно сказать по-современному: алгоритмически разрешимо то, что разрешимо на современных компьютерах, если есть нужные программы и нет ограничений на время обработки информации и используемую память. МТ удобна тем, что она просто устроена и про ее действия легче доказывать теоремы.
Теперь перейдем к построению нерешаемой задачи. Вообще положение такое: мы что-то пишем на ленте МТ в качестве входа, устанавливаем головку над левой буквой входа и запускаем машину. Если через конечное время МТ остановится, мы говорим, что программа, введенная в машину, или — короче — машина применима ко входу. Но машина может никогда не остановиться (например, если в таблице-программе первый столбец, описывающий начальное состояние, содержит только букву Я, — тогда головка, ничего не делая, будет неограниченно двигаться вправо). Тогда МТ не применима ко входу. В качестве входа можно записать на ленту каким-нибудь образом закодированную в строку программу самой машины. Задача состоит в том, чтобы создать алгоритм, который по любому коду машины должен установить, к какому классу относится машина: к классу самоприменимых или несамоприменимых. Это проблема распознавания самоприменимости.
Теорема 6 (Тьюринг). Проблема самоприменимости алгори -мически неразрешима.
Доказательство Предположим противное: такая машина А существует. Тогда в А всякий самоприменимый код перерабатывается в символ Y (да), а всякий несамоприменимыи код — в символ N (нет). Машину А нетрудно переделать в машину В, которая перерабатывает несамоприменимые коды в N, а к самоприменимым кодам В уже не применима (вместо команды типа (a,q)-*(Y,!) надо поставить (a,q)-+(a,q), обеспечив зацикливание).
Таким образом. В применима ко всякому самонеприменимому коду и не применима ко всякому самоприменимому. Это — противоречие. Действительно. 1) пусть машина В самоприменима, тогда она применима к своему коду В’ и напечатает N, что означает, что
268
она несамоприменима; 2) пусть В — несамоприменима, тогда она применима к В', что означает, что она самоприменима.
Полученное противоречие доказывает теорему.
Неразрешимые проблемы найдены не только в «сфере самообслуживания» машин Тьюринга, а в посторонней математике.
Заинтересовавшийся читатель может начать ознакомление с антимиром алгоритмов с популярных брошюр: Трахтенброт, 1957; Успенский, 1979 и 1982
ЛИТЕРАТУРА
Дж Муди
Родился в Лондоне в округе Св. Клемента, умер 26 декабря 1812 г. 85 лет отроду
Его мемуары см.«European Magazine».
О его актерской деятельности см. «Churchill Rosciad»
Плита на могиле Дж Муди
1. АЬрайтис Л.Б. Автоматизация проектирования топологии цифровых интегральных микросхем. — М.. Радио и связь, 1985, 198 с
2. Бондарев В.М.. Рублинецкий В.И., Сигалов В.Л. Точное решение задачи строительной трассировки — ДАН УССР. 1988, № 6, сер. «А», стр. 67—70.
3. Вайнер В.Г., Зайцев И.В.. Лившиц Э.М. Алгоритмы построения связывающих сетей. — Автоматика и телемеханика, 1978, №7, с. 153 - 162
4. Гайкович В., Першин А. Безопасность электронных банковских систем. — М.: Компания «Единая Европа», 1994, 360 с.
5. Гейл Д. Теории линейных экономических моделей. М. Изд иностранной литературы, 1963, 418 с.
6. Гэри М., Джонсон Д. Вычислительные машины и труднорешаемые задачи. — М.: Мир, 1982, 416 с
7. Джонсон С. Оптимальное расписание для двух- и трехступенчатых процессов с учетом времени наладки. Кибернетич. сб., М.: Мир, 1960, вып. 1, с. 78 — 86.
* Автор с первого раздела хотел ставить эпиграфы, но боялся вызвать раздражение серьезного читателя. Дальше отступать некуда.
270
8. Дьедонне Ж. Линейная алгебра и элементарная геометрия. — М.: Наука, 1972, 346 с.
9. Емеличев Р.И., Мельников О.И., Сарванов В.И., Тышкевич Р.И. Лекции по теории графов. — М. Наука, 1990, 383 с.
10. Жельников В. Криптография от папируса до компьютера. — М.: ABF, 1996, 352 с.
11. Карп Р.М. Сводимость комбинаторных проблем. — Киберне-тич. сб., М., Мир, 1975, вып. 12, с. 16 — 39.
12. Киржнер В.М., Рублинецкий В.И. О процедуре «иди в ближайший» в задаче коммивояжера. — Выч мат ивыч техн., Харьков, 1973, вып. IV. с 40-41
13 Коршунов А.Д. Основные свойства случайных графов с большим числом вершин и ребер — УМН. 1985, т 40, вып 1, с. 107 - 173
14. КофманА. Методы и модели исследования операций — М Мир, 1966 - 480 с.
15. Криницкий Н.А. Алгоритмы вокруг нас - М Наука, 1977, 225 с.
16. Кристофидес Н. Теория графов. Алгоритмический подход. — М.. Мир, 1978 - 432 с.
17 Кук С.А. Сложность процедур вывода теорем. — Кибернетич. сб , М. Мир, 1975, вып. 12, С. 5 — 15.
18 Лившиц Э М. Минимизация максимального штрафа в задаче одного станка. — Труды I зимней школы по мат прогр., М , 1969, вып. 3
19 Лившиц Э.М., Рублинецкий В. И. О сравнительной сложности некоторых задач дискретной оптимизации — Выч мат ивыч техн. Харьков, 1972, вып. Ill, с 78 — 85
20 Литтл Дж.. Мурти К, Суини Д., Кэрел К Алгоритм решения задачи коммивояжера. - Экономика и мат методы, 1965, №1, с. 13 - 22
21 Лурье З.Я., Рублинецкий В.И., ТомчукЕ.Я. Оптимизация управляющей программы автоматизированного привода одного класса механизмов. Изв. ВУЗов, сер. Электромеханика, 1972, №4, с. 27 — 32.
22. Оре О. Приглашение в теорию чисел — (Библиотечка «Квант», вып 3) М. Наука. 1980 — 127 с
23 Прим РК Кратчайшие связывающие сети и некоторые обобщения. — Кибернетич. сб . М., Мир. 1961, вып 2. с 95 — 107
24 Рейнольд Э.. Нивергельт Ю., Део Н Комбинаторные алгоритмы. Теория и практика - М Мир. 1980, 476 с
25 Рублинецкий В. И Постановка оптимизационных задач и способ изображения сетевых графиков - Сб «Методы кибернетики в планировании и управлении строительством» Таллин 1966, с 207-214
271
26. Трахтенброт Б.А. Алгоритмы и машинное решение задач. (Популярные лекции по математике, вып. 26). — М.. Техтеориздат, 1957, 95 с.
27 Успенский В.А. Машина Поста. (Популярные лекции по математике, вып. 54). — М. Наука, 1979, 95 с.
28. Успенский В.А. Теорема Геделя о неполноте. (Популярные лекции по математике, вып. 57). — М. Наука, 1982, 111 с.
29. Феллер В. Введение в теорию вероятностей и ее приложения. — М.: Мир, 1964, 498 С.
30. Форд Л., Фалкерсон Д. Потоки в сетях. — М.: Мир, 1966, 276 с.
Е.Г.КАЧКО
элементы afa прооессионального н п зограммирования
ВВЕДЕНИЕ
Г Io определению ассемблер — это язык, в котором каждой команде машинного языка соответствует один оператор на языке ассмеблер. Это определение подчеркивает близость машинного языка и языка ассемблер.
Зачем программировать на языке ассемблер? Программирование в машинных кодах затруднено в связи необходимостью задавать коды команд и адреса данных во внутреннем представлении. Например, для пересылки данных из регистра СХ в ВХ используется машинная команда 8В D9, в которой старший байт (8В) определяет код операции, а младший байт (D9) определяет номера используемых регистров (011 — ВХ, 001 — СХ) и способ адресации (регистровый — 11). На ассемблере эта команда имеет вид MOV ВХ,СХ. Писать программы на ассемблере проще, чем в машинных кодах, но труднее, чем на языках высокого уровня. Поэтому ассемблер используют лишь в некоторых случаях, когда, например, должен быть написан драйвер для управления внешним устройством, или программа, сделанная на языке высокого уровня, не удовлетворяет пользователя по быстродействию и/или требуемой памяти, или когда язык высокого уровня не поддерживает те возможности машины, которые необходимо использовать (защищенный режим процессоров, 32-битные сегменты и др.).
Даже если Вам никогда не придется решать перечисленные выше задачи, изучение ассемблера поможет писать профессиональные программы на языках высокого уровня.
275
ПРОСТЕЙШИЕ КОНСТРУКЦИИ ЯЗЫКА
1.1. Первая программа
Пусть необходимо составить программу для вычисления z=x+y для целых х, у, z.
Операторы языка ассемблер делятся на команды и директивы. Директива задает необходимую информацию транслятору.
.MODEL SMALL .DATA
X DW 5
У DW 3
Z DW ?
.CODE
begin: MOV AX,@DATA
MOV DS,AX
MOV AX,X ; X=>AX
ADD AX,Y ; X+Y=>AX
MOV Z,AX ; AX=>Z
MOV AH.4CH
INT 21H
END begin
Первая директива программы — .MODEL. Директива задает механизм распределения памяти под данные и команды. Аналогична моделям памяти в языках высокого уровня. Имена моделей памяти в С и ассемблере одинаковы (TINY, SMALL, COMPACT, MEDIUM, LARGE, HUGE).
Директива .DATA определяет начало участка программы с данными (сегмент данных, соответствует области описания данных в языках высокого уровня).
276
Директивы -Л’ задают типы переменных (Define Word), их значения (для переменных х, у). Для переменной z начальное значение не определено (?).
Директива .CODE определяет начало участка программы с командами (кодовый сегмент). Для правильного обращения к переменным из сегмента данных адрес этого сегмента должен быть записан в регистр DS (Data Segment). Это выполняют команды
MOV AX,@DATA
MOV DS,АХ
Для вычисления z используются команды
MOV АХ,Х ADD AX,Y MOV Z,AX
;X=>AX
;X+Y=>AX ;X+Y=>Z
Напоминаем, что команды не допускают использование обоих операндов из памяти, т.е. команда ADD X.Y не допустима!
Для возврата в программу, из которой вызывается наша программа, используется системный вызов (INT 21Н), в регистре АН задан код функции выхода из программы (4С) в шестнадцатиричной системе счисления (буква Н)
В директиве END задана метка первой выполняемой команды программы begin (адрес точки входа).
Пусть программа имеет имя FIRST.ASM. Для трансляции программы используем программу TASM.EXE, задав следующие ключи:
/I — формирование листинга
/zi — формирование отладочной информации (она потребуется при работе с отладчиком)
Таким образом, командная стоока для трансляции программы first.asm имеет вид:
tasm /I /zi first.asm
Заметим, что расширение asm можно не задавать, оно принято по умолчанию.
Если ошибок нет, транслятор выдаст сообщение об отсутствии ошибок и сформирует файл first.obj. Если есть ошибки (предупреждения), транслятор указывает номера строк и информацию об ошибках. В файле first.lst, который формируется по ключу /I, можно посмотреть оператор, к котор >му относится ошибка, а также внутреннее представление команд и данных программы.
277
Если файл first, obj сформирован, выполним компоновку т.е. объединение сегментов. Для компоновки используется программа tlink.exe. Командная строка имеет вид:
tlink /v first,
где v — ключ для трансляции, позволяющий получить полную отладочную информацию.
В результате этого шага получим first.exe — файл с полной отладочной информацией. Программа tlink выдаст предупреждение об отсутствии стека, которое можно игнорировать.
Чтобы каждый раз не повторять указанные выше команды, можно составить командный файл для формирования ехе-файла. Ниже приведен пример такого файла ta.bat;
tasm /I /zi %1
tlink /v %1
При вызове этого файла с помощью командной строки ta first получим first.exe. Очевидно, что в комадный файл можно включить обработку ошибок на каждом шаге (Сделайте это!).
Чтобы просмотреть ход выполнения программы, используют отладчик (например, Turbo Debugger, программа td.exe):
td first
В Turbo Debugger'e используется знакомая среда для работы с языками высокого уровня:
пошаговое выполнение — F7
выполнить до курсора — F4
просмотреть значения переменных — Ctrl/F7 и т.д.
1.2. Структура оператора ассемблера
Программа состоит из операторов. Каждый оператор занимает одну строку.
Общий вид оператора:
[имя или метка:] мнемокод [оп1[,оп2х[,...]]] [комментарий]
Имя используется с директивами, метка — с командами. Обращаем Ваше внимание на различие между ними: с меткой используется символ . В качестве имени (метки) используются идентификаторы (не могут начинаться с цифры, могут содержать символы: ,А,..’2’,’а’,..’г’,_,@,$,?,0..9...3аметим, что использование ’.’в качестве первого символа нежелательно.
278
т.к. с точки начинаются обычно директивы. В качестве имени (метки) нельзя использовать зарезервированные слова (мнемокоды, обозначения операций).[3].
Примеры операторов:
х dw 5
begin: mov ах, х ; х=>ах
При записи зарезервированных сл )в их можно задать как маленькими, так и заглавными латинскими буквами.
Директивы определения данных используются для определения типа данных, резервирования памяти для них и записи значений данных (последнее не обязательно, значение Z в примере первой программы мы не задали). Для задания типа данных используются ключевые слова:
db — определить байт;
dw — определить слово(2 байта);
dd — определить двойное слово(4 байта);
dq — определить данные длиной 8 байтов;
dt — определить данные длиной 10 байтов;
Для 32-разрядных процессоров дополнительно используются директивы df.dp (определяют 6 байт).Эти директивы обычно используются для определения дальних адресов для 32-битных сегментов.
Директива определения данных имеет вид
[ имя данного ] имя типа значение 1 [.значение 2 [,...]]
В качестве имени данного можно использовать любое имя, кроме зарезервированных слов. Имя типа должно быть одним из заданных выше (db,dw..dt).
Правила задания значений зависят от их типа.
1.2.1. Задание целых чисел
Значение числа может быть задано в 10-ой, 2-ой, 8- й или 16-ой системах счисления.
Для определения системы счисления используются символы :
Ь(В) — двоичная;
о(О) — восьмеричная;
d(D) — десятичная;
h(H) — шестнадцатиричная.
Эти символы записываются после числового значения без пробела.
279
. Примеры определения данных с указанием системы счисления:
dw 10d, 8ch, 10b, 27o
В этом примере определены 4 числа, для каждого задана система счисления.
Если шестнадцатиричная константа начинается с буквы, необходимо начать это число с нуля, например: dw Offh
Если система счисления не задана, она определяется по умолчанию. Для этого используется директива .RADIX:
.RADIX { 28 10 16 } ,
где число в скобках определяет принятую по умолчанию систему счисления.
Сама система счисления всегда задается в 10-ой системе.
ПРИМЕР:
.RADIX 2
dw 10, 11, 011, 111
В этом примере все числа двоичные, т.к. задана двоичная система счисления (.RADIX 2).
В программе может быть задано несколько директив .RADIX. Действие очередной директивы распространяется до новой директивы .RADIX или до конца программы. Если задана директива .RADIX и определена система счисления с помощью символа в конце числа, то последнее определение имеет больший приоритет.
ПРИМЕР:
.RADIX 8
dw 5, OAH, 12, 10В
В директиве первое и третье числа восьмеричные, второе — шестнадцатиричное, а последнее — двоичное. Необходимо быть внимательным если в директиве .RADIX задана шестнадцатиричная системя счисления. Так в директивах
.RADIX 16
dw 10В
определена двоичная константа 10, а не шестнадцатиричная 10В!
Если директива .RADIX не задана, принята десятичная система счисления.
В табл 1.1 представлены диапазоны целых чисел в зависимости от выбранной директивы.
280
Таблица 1.1
Длина константы (байт) Диапазон представления
Число со знаком Число без знака
1 -128, 127 0, 255
2 -32768, 32767 0, 65535
4 -2'31, 2'31-1 0, 2'32-1
8 -2'63, 2'63-1 0, 2'64-1
Наряду с числовыми значениями можно использовать константные выражения, т.е. выражения, значения которых можно вычислить на этапе трансляции.
ПРИМЕР:
dw 32765/5 ; Деление нацело
В выражении можно использовать:
знаки арифметических действий (+, *, /);
знаки логических действий (and, or, not, xor);
знаки отношений (LT—< , LE—<=, EQ —=, NE—<>, GT — >, GE—>=);
специальные операции (TYPE и др.);
Операции +,-,*,/ возвращают целые значения, выполняются над целыми числами.
Логические операции выполняются побитово. Результатом выполнения операций являются значения: истина(О), ложь (OFFFFH).
Операция TYPE возвращает число байт, отводимых для единицы данных выбранного типа.
ПРИМЕРЫ:
a db 3,5 ; TYPE(a)=1 (db — байт)
b dw 4,12 ; TYPE(b)=2 (dw — слово);
t dt 5 ; TYPE(t)=1O (dt — 10 байт);
Другие операции используются редко.
1.2.2. Задание чисел с плавающей точкой ♦
Поддерживается три формата задания чисел с плавающей точкой. В табл. 1.2 приведены граничные значения констант в зависимости от формата.
281
Таблица 1.2
N форм. Длина константы (байт) Точность(кол-во двоичных цифр мант.) Диапазон пред тавления
1 4 24 10~-38, 10~38
2 8 53 10'"-308, 10~308
3 10 64 10~-4932, 10~4932
Как следует из табл. 1.2, для задания чисел с плавающей точкой используются 4, 8 или 10 байтов, т.е. директивы dd, dq или dt соответственно. Само значение записывается в формате с десятичной точкой или в нормальной форме, т.е. с мантиссой и порядком (как в языках высокого уровня).
ПРИМЕРЫ:
dd 5.7, -3.52, 1е-5
dq 50, 51.35, -4., 25.0
dt 15.7е-1000, 15.7е1000
; под число отводится 4 байта
• под число отводится 8 байт
; под число отводится 10 байт
Заметим, что последние константы можно записать, отводя для них максимальную память1 Число 50 во 2 строке будет записано как число целое , а число -4 в той же строке — как число с плавающей точкой, т.к. в записи есть точка.
Числа с плавающей точкой можно задавать, используя для задания внутреннее представление. Признаком внутреннего представления служит символ г в конце числа.
ПРИМЕР: dd 40000000г; число 2 в формате с плавающей точкой.
Цифры числа в этом случае шестнадцатиричные. Преобразование чисел во внутреннее представление показано в [1,с.445].
1.2.3, Задание чисел в упакованном формате
Упакованный (двоично-десятичный) формат используется, если необходимо обрабатывать большое число данных, а количество выполняемых операций невелико. В этом случае перевод чисел из десятичной системы счисления в двоичную при вводе и обратный перевод при выводе становится слишком накладным. Для задания двоично-десятичных чисел используется тип dt.
282
ПРИМЕР:
dt 1800 ; число 1800 задается в 2-10 формате dt -1800 ; число -1800 задается в 2-10 формате ; знак минус задается байтом 80h
1.2.4. Определение переменных и массивов
Пусть в программе необходимо определить значения переменных х=5, у=50, z=500 u-50.5, используя для каждой переменной минимальную память.
х db 5
у db 50 z dw 500 u dd 50.5
Для определения требуемого типа данных используют диапазон представления целых чисел (табл. 1.1) и чисел с плавающей точкой (табл. 1.2).
Рассмотрим задание массива. По определению массив содержит данные одного типа. Пусть необходимо определить массив целых чисел со значениями элементов: 5, 50, 500, 5000 (всего 4 числа). Сначала определим тип элементов массива (требуемая память определяется максимальным числом). В нашем примере максимальное число 5000 требует двух байт, т.е. это данные типа dw.
array dw5, 50, 500, 5000;
Если числа массива не помещаются в одной строке, используются дополнительные строки без определения имени.
Пример массива с двадцатью элементами :
array_20 db 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 db 11, 12, 13, 14, 15, 16, 17, 18, 19, 20
Количество дополнительных строк может быть любым.
Для задания двумерных массивов, по возможности, одной строке программы соответствует строка массива .
ПРИМЕР: Задать двумерный массив
1. 2, 3, 4 matr = 5, 6, 7, 8 9,10,11,12
283
; Задание матрицы в программе
matr db 1, 2, 3, 4
db 5, 6, 7, 8 db 9, 10, 11, 12
Если элементы массивов повторяются, можно определить группу одинаковых элементов.
ПРИМЕР: Задать одномерный массив: 1,3,3,3,3,5,5,5,5,5
ByteAr db 1, 4 dup(3), 5 dup(5)
Ключевое слово dup означает повторить в памяти, коэффициент перед словом определяет число повторений, а число в скобках задает значение, которое повторяется. Группа повторяющихся значений может содержать более одного значения. После коэффициента повторений должен быть хотя бы один пробел.
ПРИМЕР:
WordAr dw 10 dup( 1,3,5)
В примере задано 30 чисел (10 групп, в каждой группе 3 числа(1,3,5).
Для резервирования памяти под массив используется также ключевое слово dup.
ПРИМЕР:
VideoMemory dw 25*80 dup(?) ; Память для содержимого ; экрана, содержащего ; 25 строк по 80 элементов ; в каждой строке
1.2.5. Особенности определения символьных данных и строк
Для задания символа используется запись вида : db ’А'.
Для задания строки символов ’abed’ используется директива
db 'a', ’b’, ’с’, ’d’ или
db ’abed’
Обе директивы с точки зрения выполняемых действий эквивалентны.
В строке можно задать признак конца, например, символ с кодом 0:
db ’abcd’,0
284
Если задается строка для вывода на принтер, в конце должны быть заданы символы возврата каретки(13) и перевода строки(Ю):
db ’abed’,13,10
Для резервирования памяти под строку используется ключевое слово dup.
ПРИМЕРЫ:
string db 80 dup(?) ; Память под строку длиной
; 80 символов
text db 80*25 dup(?) ; Память под 25 строк длиной
; 80 символов.
1.2.6. Особенности определения адресов
Адреса данных используются для организации циклов, передачи параметров и в других случаях. Напоминаем, что адреса бывают ближние(пеаг) и дальние(Таг).
Near-адрес задает смещение внутри сегмента. Far-адрес задает адрес начала сегмента и смещение внутри него (2 компонента).
Для 16-битных сегментов near-адрес занимает 2 байта, а far-адрес — 4.
Для 32-битных процессоров можно использовать 32-битный сегмент, в этом случае near-адрес занимает 4 байта, а far-адрес — 6 байтов.
Для определения адреса в поле значения задается имя переменной, а тип адреса определяется директивой.
ПРИМЕР:
х dw
near_addr dw
far_addr dd
5,3;
x ; пеаг-адрес x
x ; far-адрес x
В рассмотренном примере предполагается, что сегмент 16-битный.
Допускается использовать имя переменной в выражении, например:
у dw 1,3,5
number dw(number-y)/2
В поле number будет записано количество чисел в массиве у. Действительно, number-y — число байт в массиве у, 2 — длина элемента массива.
285
1.2.7. Структуры (STRUC) (аналогичны записям PASCAL или структурам С)
Общий вид определения типа структуры:
имя struc
поле 1
поле 2
поле 3
имя ends
Каждое поле — это определение данных (директивы db, dw, ... возможно, с заданиями значений )
ПРИМЕР: Описать структуру, содержащую фамилию (20 символов) и возраст, data struc fio db' age dw data ends
Описание структуры эквивалентно определению типа в Паскале. Может быть записано в любом месте программы, как внутри, так и вне сегмента. Для резервирования памяти под структуру используется директива
имя данного имя структуры <[значения полеи]>
ПРИМЕР:
datajvanov data <’Иванов И.И.', 20>; Если строка содер-; жит больше символов ; чем допустимо, то ; ошибка.
Значения полей можно не задавать, в этом случае возможны два вариан а
1. Значение поля задано в определении типа => оно переносится в определение данного.
2. Значение поля не задано => оно обнуляется.
ПРИМЕР:
Not_Know data < >
Если необходимо задать только некоторые поля, должны быть заданы соответствующие запятые:
286
Data_age data <, 25>
Можно определить массив стуктур, например:
Students data 25 dup(< >)
Рассмотрим доступ к элементам структуры.
1. Доступ к элементам структуры задается аналогично доступу в языках высокого уровня, т.е. задается имя данного.имя поля.
ПРИМЕР: Сравнить поле age datajvanov с 25 годами, и, если его возраст меньше, то перейти к метке YES, иначе NO.
cmp datajvanov.age, 25
jl YES
NO:
YES:
2. Если адрес структуры находится в регистре, для доступа к полю используются символы или ’+'.
ПРИМЕР: В первую строку массива Students записать воз раст 18 лет.
lea bx, students
mov [bx].age, 18;
или
mov [bx.age],18
или
mov [bx+age],18
или
mov [bx]+age,18
Недостаток структур: имена полей рассматриваются как имена данных, т.е. должны быть уникальны, а значит, имя аде нельзя больше использовать при определении простых переменных или структур.
Структуры могут быть вложены, но рекурсия не может быть применена.
ПРИМЕР: В структуре data определить аде как день, месяц, год.
Определение внутренней структуры:
age struc
day dw ?
287
month dw ?
year dw ?
age ends
; Определение внешней структуры
data struc
fio db ’ ’
age < > data ends
Students data 25 dup(< >)
ПРИМЕР: Определить месяц рождения первого человека списка, lea bx, students mov ах, [bx].age.month
Операция Size для структур определяет длину структуры. Так size data = 26 байт.
1.2.8. Объединения (UNION)
Используются, если необходимо выделить одну и ту же память для данных разного типа.
Структура UNION:
имя UNION поле 1 поле 2
поле п имя ends
При работе с клавиатурой может использоваться обычный или расширенный коды.
ПРИМЕР: Выделить память под код нажатой клавиши.
; определение типа code UNION spec dw ordinary db ?,7 code ends
; выделение памяти
cd code <>
Доступ к полям такой же, как для структуры, например:
288
mov cd.spec, 3B00h; код клавиши F1
mov cd.ordinary, ’1’ ;код клавиши '1'
Объединения могут быть вложены в структуры и наоборот, структуры могут вложены в объединения. Если объединение вложено в структуру, получаем структуру с вариантами.
ПРИМЕР: Пусть для элементов списка требуется информация
имя переменной, тип, адрес или значение
32 байта 1 байт 4 или 6 байт 2 байт
address UNION
addr_32 df
addr_far dd
value dw
address ends
string struc
nam db 32 dup(?)
typ db ?
adr address < >
string ends
; Резервирование памяти под список.
tabl string 200 dup(< >)
1.2.9. Записи (RECORD)
Используются для определения битовых полей внутри байта(слова).
Общий вид записи:
имя_типа RECORD поле_1, поле_2, ...
Поле задается в виде
имя_поля- длина_поля в битах [=значение]
Поля задаются, начиная с крайних слева, т.е. полей, занимающих старшие биты. Если общее количество битов, занимаемых полями, меньше 8(16) битов, то свободными остаются старшие биты байта(слова).
Примеры использования записей:
ПРИМЕР 1: Пусть в байте необходимо задать 3 поля р, q, г (Рис.1)
10 «Основы программирования»
289
7 6 5 4 3 2 1 О
Рис. 1
byte_record RECORD р:2, q:2, r:3
(Старший бит не используется).
ПРИМЕР 2: Пусть в слове необходимо записать 3 поля (Рис. 2):
54321 0987654321 0,
I I I I I I I 1 1 1 1 I 1 1 1 1 1 1 1 1 1 1 1 1 1 I 1 1 1 1 1 1 1 1 1 1
I I 1 часы 1 1 1 1 минуты 1 I секунды I i I
Рис. 2
Time_record RECORD h:5, m:6,s:5
Вы не знаете, почему имя типа в последнем примере задано так ? Именно такую структуру имеет время создания файла в каталоге (MS DOS). Под поле секунд отводится только 5 битов, поэтому значение секунд задается уменьшенным в два раза.
Заметим, что оператор RECORD означает только определение типа, для резервирования памяти используем оператор :
имя.данного имя_типа <[[значение поля 1],[значение поля 2],...]>
Если значение поля не задано, оно выбирается таким, каким задано в определении типа. Значение поля может быть неоп-ределено.
ПРИМЕР 3: Задать время создания файла 11 часов 50 минут 21 секунда.
t time_record <11, 50 10>
Еще раз обратите внимание на задание поля секунд !
Операции для работы с данными
1. SIZE имя типа ; возвращает длину записи в байтах.
2. WIDTH (поле, имя записи); возвращает размер поля или размер записи в битах.
290
3. MASK {имя типа, поле}; возвращает 'маску' для выделения записи или заданного поля, т.е. двоичное число, равное '1' в битах, соответствующих данному полю, и '0' во всех остальных битах.
Для загрузки всей записи задается ее имя. Если в команде задано имя поля, то определяется число битов, на которые необходимо сдвинуть запись, чтобы поле стало крайним справа.
Примеры команд для работы с полями записи.
ПРИМЕР 1:
mov ax,t ; загрузим в ах время создания файла
mov bl,s ; Ы=0, т.к. поле секунд крайнее правое
mov bh,m ; bh=5, т.к. поле минут необходимо сдвинуть
; на 5 битов вправо, чтобы оно стало крайним
; справа
cmp ах, time_record <14, 15, 15> ; сравнение времени ; создания файла из ах с новым временем, ; заданным непосредственно в команде
mov cl, width h ; cl=5 ширина поля часов
mov ch width byte_record ; ch=7 — число битов во всей
;записи
mov cl, mask q; cl=00011000 — маска для выделения ; поля q
mov ch, mask byte_record ; ch=01111111 — '0' соответ-; ствует неиспользуемому полю
Допускается использовать массив записей. В этом случае используется ключевое слово dup.
ПРИМЕР 2:
array_of_records time_record 100 dup(<>)
Выделенную в этом примере память можно использовать для задания времени создания для 100 файлов.
Анализ простейших конструкций показал, что допускается выделение памяти для простых переменных, массивов, структур, объединений и данных с битовыми полями. Выделенная память может быть инициализирована, т.е. заданы начальные значения. Сравнительный анализ простейших конструкций ассемблера и языков высокого уровня, например, С, демонстрирует совпадение их основных типов. Паскаль обычно не охватывает всех типов, допустимых в ассемблере (нет объединений, битовых структур).
Ю
291
2
ОБЗОР ПРИЕМОВ ПРОГРАММИРОВАНИЯ
НА АССЕМБЛЕРЕ
2.1. Программирование арифметических выражений.
Напоминаем, что допускается использование целых (двоичных и двоично-десятичных) и чисел с плавающей точкой. В данном учебнике рассмотрена арифметика для целых двоичных чисел. В табл. 2.1 представлены основные команды для выполнения арифметических операций, а в табл. 2.2 — дополнительные.
Таблица 2.1
Назначение Общий вид команды Выполняемые действия Флаги
Сложение add оп 1, оп 2 (on 1) + (on 2) => on 1 о, s, z, a. p. c
Вычитание sub оп 1, оп 2 (on 1) - (on 2) => on 1 o, s, z, а. о. c
Умножение беззнаковое Умножение знаковое mul оп imul on { al } { ax } {ax)*(on)=> {dx, ax } {ea x} {edx, eax} 0, c
Деление беззнаковое Деление знаковое div on idiv on ax - dx,ax .edx,eax, (al, ah 7(on)=> <ax, dx |gax,ed>s —
Обозначения, используемые в таблице :
оп 1, оп 2, оп — операнды, т.е. содержимое, стоящее по первому (оп 1), второму (оп 2) адресам или единствен-
292
ный операнд (on); al, ah, ax, dx, eax, edx — регистры, г.ри-чем eax, edx допустимы только для процессоров 80386 и выше.
Как видно из табл. 2.1 в командах умножения и деления задается один операнд, второй сомножитель или делимое в фиксированных регистрах. Команда умножения возвращает результат в два раза длиннее сомножителей, команда деления требует, чтобы делимое было в два раза длиннее делителя. Результатом выполнения команды деления являются частное(ре-гистр, записанный первым в таблице) и остаток(регистр, записанный вторым).
Если перед кодом стоит буква i (imul, idiv, i-integer-целый), операции выполняются с учетом знаков исходных данных, в противном случае — беззнаковые операции.
ПРИМЕР: Вычислить значение выражения x=y+(z-u*v)/w, если исходные данные занимают одно слово.
.MODEL SMALL
.DATA
X dw ? ; резервирование памяти под результат
У dw 1 ; резервирование памяти под исходные
; данные
z dw 2
u dw 3
w dw 4
V dw 5
.CODE
beg n:mov ax,©DATA
mov ds,ax
mov ax,u
mul v ; u*v - dx.ax ;t.k. u*v меньше максималь-
; ного целого в слове,
mov Ьх,ах ; содержимое регистра dx дальше
; не учитывается
mov ax,z
sub ax.bx ; z-u*v
swd ; подготовка команды деления
idiv w ; (z-u*v)/w
add ах,у ; y+(z-u*v)/w
mov х,ах ; х
mov ah, 4ch
int 21h
end begin
293
'Узелки" на память
Данные, участвующие в операциях, должны быть одной длины (байт-байт, слово-слово, двойное слово-двойное слово).
Команда умножения изменяет содержимое регистра dx,(edx) даже если сомножители дают произведение, которое помещается в ах(еах).
Команда деления требует дополнительной подготовки т.е. увеличения длины делимого(длина делимого должна быть в 2 раза больше длины делителя). Для расширения делимого в ah, dx, edx(flnfl байта, слова и двойного слова соответственно) записывается знаковый разряд.
Рекомендуем просмо реть выполнение программы с помощью отладчика!
Таблица 2.2 Двоичная арифметика(дополнительные команды
Назначение Общий вид команды Выполняемые действия 1 Флаги
Увеличение на 1 inc on on = on + 1 о, s, z, a, p
Уменьшение на 1 dec on on = on - 1 o, s, z, a, p
Изменение знака на противоположный neg on on = - on с (c = 0, если I результат = 0)
Расширение делимого cbw cwd cdq al => (ah, al) ax => (dx, ax) eax => (edx, eax)
Сложение с переносом adc on1, on2 on1 = on1 + оп2 + c о, s, z, a, p, c
Вычитание с переносом sbb on1, on2 on1 = on1 - on2 - c o, s, z, a, p, c
Заметим, что команды inc(dec) используются вместо add(sub), если нельзя менять флаг переноса; команды adc(sbb) используются для вычислений с многократной точностью.
294
2.2. Организация разветвлений и циклов
При изложении этого вопроса мы предполагаем, что программа одномодульная.
Для организации разветвлений используются команды условных и безусловных переходов. Команды условного перехода имеют ограниченную область доступа -128.. 127 байт, т. е. разность между адресом очередной команды и адресом перехода должна быть в этом диапазоне.
Если необходимо перейти к команде вне области действия команды перехода, команда условного перехода комбинируется с командой безусловного перехода.
ПРИМЕР: Реализовать на ассемблере оператор if ( х < 3 ) goto m, если m-метка вне области действия оператора if.
Решение 1
mov ах, х ; х => ах стр ах, 3 ; х < 3 ?
jl т ; if( х < 3 ) goto т
Предложенное решение НЕ ВЕРНО, транслятор сообщит об ошибке, если m вне области действия оператора if.
Решение 2
mov ах, х стр ах, 3 jge continue jmp near ptr m continue:........
; x => ax
; x<3?
; if (x=3) goto continue
; if (x<3) goto m
Решение ВЕРНО. Здесь используется команда безусловного перехода с префиксом near ptr. Префикс определяет область действия команды безусловного перехода и принимает значения:
short область действия -128..127 байт
near ptr область действия -32768..32767 байт
far ptr область действия распространяется на другие модули программы.
295
При использовании команд перехода необходимо правильно выбирать требуемые команды с учетом работы со знаковыми и беззнаковыми данными.
Таблица 2.3
Основные команды условного перехода
Знаковые данные Беззнаковые данные Не зависят от типа
]1(]'пде)-меньше ]Ь(]па1)-ниже je(jz)-paBHO
|д(]п1е)-больше ia(inbe)-Bbiuje jne(;nz)-He равно
]1е(]пд)-не больше jbe(jna)-He выше jo-переполнение
jge(jnl)-He меньше jae(jnb)-He ниже jno-нет переполнения
js отрицательное jc-перенос
jns не отрицательное jnc-нет переноса
Примеры команд с использованием команд перехода.
ПРИМЕР 1: Вычислить z=max(x,y) с учетом знака чисел х, у
mov ах, х ; х => ах
стр ах, у ; х сравнивается с у
jge хдеу
mov ах, у ; у => ах
хдеу: mov z, ах >
В этом примере хдеу — метка с адресом перехода, если х >= у.
ПРИМЕР 2: Очистить область памяти, ограниченную адресами начального и конечного cnoB(begin_addr, end_addr).
mov bx, begin_addr ; begin_addr => bx
for: mov word ptr [bx], 0 add bx, 2 cmp bx, end_addr jbe for
* Для 32-разрядных прцессоров область действия команд условного перехода может быть расширена для работы с 32-битными сегментами.
296
Адрес области памяти — число без знака, поэтому используется команда jbe, а не jle. Обратите внимание на префикс word ptr в команде с меткой for. Этот префикс необходим, чтобы указать транслятору на необходимость записи нуля в 2 байта. Вместо word ptr при необходимости можно использовать byte ptr, dword ptr.
Последний пример — циклическая программа.
Для организации циклов с известным числом повторений используется команда loop или ее модификации. Область действия команды и ее модификаций такая же, как у команд условного перехода (-128..127).
Циклический участок программы обычно имеет следующую структуру:
; Инициализация цикла
mov сх, число повторений
jcxz метка_после_цикла
;Команды, которые должны быть выполнены в цикле метка: ...........
loop метка
метка_после_цикла :
Команда jcxz означает переход при сх=О, т.е. цикл не нужно выполнять ни разу. Напоминаем, что по команде loop содержимое сх уменьшается на 1 и, если сх<>0, то переход к метке, заданной в команде loop, в противном случае — выход из цикла.
Если выход из цикла определяется не только числом повторений, вместо команды loop можно использовать ее разновид ности
{ loope } повтор цикла, если счетчик не исчерпан и фла|
{ loopz } нуля установлен
{ loopne } повтор цикла, если счетчик не исчерпан и флаг { loopnz } нуля не установлен
ПРИМЕР: Составить программу для вычисления контрольной суммы заданной области памяти. Область задается начальным begin-addr и конечным end-addr адресами. Контрольная сумма — сумма всех байт области. Результат записывается в один байт, биты переноса игнорируются.
297
; Определение числа повторений цикла
; end_addr begin_addr + 1
; установка начального значения адреса
; Установка начального значения суммы mov ex, end_addr sub ex, begin_addr inc ex sub al,al ; для суммы mov bx, begin_addr
; Если цикл выполнять не нужно, то выход jcxz break
; Циклический участок программы
for: add al, [bx]
inc bx loop for
; Выход из цикла
break: mov s, al
2.3. Обработка массивов
2.3.1. Задание адреса
При работе с массивами возникают проблемы задания адреса элемента массива и его изменения. Рассмотрим различные способы задания адреса сначала для одномерного массива а затем и в общем случае.
Пусть заданы массивы
barray warray s u V w s sarray db10dup(?) ; массив байт dw10 dup(?) ; массив слов struc dw? db? db? ends s 10 dup(<> ); массив структур
Адреса первых трех элементов массивов приведены в таблице 2.4.
298
Таблица 2.4
Адресация элементов массивов
Г имя массива Адрес 1 элемента Адрес 2 элемента Адрес 3 элемента
barray barray barray + 1 barray + 2
warray warray warray + 2 wa ray + 4
sarray sarray sarray + 4 sarray + 8
В общем случае для n-ого элемента массива адрес равен
Адрес(Ап)=Адрес(А1) + (n-1)*length, (2.1)
где length — длина одного элемента массива
Если предположить, что нумерация элементов массива начинается с нуля, то формула (2.1) упрощается
Адрес(Ап)=Адрес(АО) + n*length (2.2)
Именно такая формула используется для вычисления адреса элемента массива транслятором с языка С.
Если адрес начала массива находится в регистре (такой регистр называют базисным), то в команде адрес элемента массива задается так:
[Смещение] [Регистр с адресом начала массива]
ПРИМЕР: Поместить адрес начала массива sarray в регистр Ьх и задать адрес начала последнего элемента массива структур
lea bx, sarray ; адрес начала массива или
mov bx, offset sarray
Обратите внимание, что команда
mov bx, sarray
недопустима для решения поставленной задачи !!!
Адрес последнего элемента массива:
[9*4][Ьх] или [36][Ьх] или [Ьх+36] или 36[Ьх], — это все эквивалентные способы задания
Если необходимо каждый раз задавать разный элемент, смещение может быть задано в регистре (такой регистр называют индексным). В этом случае адрес задается с помощью двух регистров
[ Индексный регистр ] [ Базисный регистр ]
299
ПРИМЕР: Задать адрес последнего элемента массива sar-гау, если адрес его начала в оегистре Ьх, а смещение поместить в регистр si
mov si, 36 ; 36 => si (Величина смещения для последнего элемента)
Адрес последнего элемента массива:
[bx][si] или [bx+si] или [si][bx],...
Наконец, адрес текущего элемента массива может быть вычислен заранее и помещен в регистр, в этом случае используется только этот регистр — однокомпонентный адрес.
ПРИМЕР: Задать адрес последнего элемента массива sar-гау, вычислив его и поместив в регистр si.
lea si, sarray; A(0)
add si, 36 ; + смещение
Адрес последнего элемента массива: [si].
Адресация элементов многомерного массива
Формулы (2.1-1.2) пригодны для многомерного массива. В этих формулах п означает номер элемента в массиве. Для многомерных массивов такой номер называется приведенным индексом. Можно доказать, что адрес элемента п-мер-ного массива с индексами i[0], i[1],... вычисляется по формуле (предполагаем, что начальные значения всех индексов равны нулю):
Адрес (A i[0], i[1],..., 1[п-1])=Адрес(А [0] [0]...[0])+ (2.3)
i[0]*h[0]+i[1]*h[1]+...+i[n-1]*h[n-1]
Где i[0],i[1],...i[n-1] — индексы для текущего элемента; h[0],h[1],...h[n-1] — шаги изменения адреса при изменении индексов.
Если предположить, что первым изменяется последний индекс, то шаги изменения адреса можно вычислить по рекурент-ным формулам
h[n-1] = length;
h[n-2] = h[n-1] * р[п-1]; (2.4)
h[k] = h[k+1] * p[k+1];
hi6j = h[i]"; p[i]
300
Здесь р[1],р[2],... — число элементов для 1, 2... п-1
размерностей.
ПРИМЕР: Составить формулу для вычисления адреса элемента массива Arrayfi, j, к], если каждая размерность изменяется от О до 9.
По формуле (2.3) для 3-х мерного массива получим
Адрес(Аггау[1, j, к])=Адрес(Аггау[0,0,0])+ (2.5)
+i*h[0]+j*h[1]+k*h[2]
Определим h[0], h[1], h[2] (по формуле 2.4)
h[2] = length,
h[1] = h[2]*10=length*10
h[0] = h[1]*1O=length*1OO
Подставив h[0], h[1], h[2] в формулу (2.5), получим
Адрес(Аггау[1, j, k])=Aflpec(Array[0,0,0]+i*length*100+ +j*length*1O+k*length) (2.6)
Анализ формул (2.3-2.4) показывает, что использование индексных переменных в программе требует больших затрат для вычисления их адреса. Это следует помнить при программировании на любом языке программирования и минимизировать количество индексных переменных в программе.
В ассемблере обычно используются специальные приемы для работы с многомерными массивами, они будут рассмотрены ниже.
2.3.2. Обработка одномерных массивов
Ниже приведены приемы программирования для случая, когда индекс массива изменяется монотонно (увеличивается или уменьшается) с постоянным шагом. Такая программа является циклической.
Рассмотрим правила обработки переменной в зависимости от ее функций.
1. Если переменная является индексом элемента массива, формируется адрес соответствующего элемента массива.
2. Если переменная является параметром цикла, т.е. определяет, выходить из цикла или нет, формируется число повторений цикла.
3. Если переменная используется для вычислений (будем ее называть обычной переменной), формируется ее значение.
301
Приведенные правила позволяют значительно упростить составление программ для обработки массивов.
ПРИМЕР 1: Составить программу для вычисления суммы элементов одного массива.
begin: .MODEL SMALL .DATA array dw 5,3,1,7 numbers dw 4 s * dw ? .CODE mov ax, @daia mov ds, ax
; for(s= =0; i<numbers; i++) ,
s+=array[i];
s — простая переменная
i — параметр цикла и индекс
for: sub ax, ax ; for(s=i-0; i<numbers; i++) tea bx, array ; mov ex, numbers; add ax, [bx] ; s+=array[i]
add bx, 2 ; i++
loop for ; if(i<numbers) go to for mov s, ax
mov ah, 4ch
int 21 h
end begin
В программе для промежуто1 ного значения суммы используется регистр, это позволяет ускорить вычисление суммы.
ПРИМЕР 2: Составить программу для переписывания символов строки в обратном порядке*
.MODEL SMALL
.DATA
string db ’abcde’
* Соответствие между операторами языка высокого уровня и ассемблера не строгое. Оператор типа for проверяет условие до входа в цикл.
302
numbers dw 5 res db 5 dup(?)
.CODE
begin: mov ax, @data
mov ds, ax
for(i=4,j=0;j<5,j++) res[i—]-string[j]
i — индекс в массиве res
j — индекс в массиве string и параметр цикла
lea di, es for(i=4,j=0;j<5;j++)
add di, 4 ; адрес последнего символа в res
mov ex, 5
lea si, string
for: mov al, [si] ; res[i]=string[j];
mov [di], al
dec di i—
inc si j++
loop for Оставаться в цикле
mov ah 4ch
int 21h
end begin
ПРИМЕР 3: Составить программу для вычисления ма <си мального числа и его номера(элементы массива — 2-х байтовые числа)
.MODEL SMALL
.DATA
warray dw 1,7,3,-8,4
numbers dw 5
max dw ?
numb dw ?
.CODE
begin: mov ax, (gJoata
mov ds, ax
max=warray[numb=O];
for(i=1;i<numbers; i++)
if(max<array[i])
max=warray [numb=i];
i — индекс, параметр цикла и простая переменная
303
mov ax, wan / ; max-array[numb=O];
mov numb, 0
mov ex, num jars ; for(i-1;i<numbers; i++);
dec ex ; число повторений цикла
lea bx, warray+2 ; agree warray[1]
mov dx, 1 J i=1
for; cmp ax, [bx] ; if(max<array[i]) ...
jge nexti
mov ax, [bx] ; max=warray[numb=i];
mov numb, dx ; numb=i;
nexti: add bx, 2 ; i:=i+1 i++
add dx, 1
loop for
mov max, ax
mov ah, 4ch ;выход из программы
int 21h
end begin
Рассмотренные примеры показывают применение правил составления программ при монотонном изменении параметров.
Если в программе обрабатываются несколько массивов, причем индексы в массивах изменяются синхронно, используют прямую адресацию с индексным регистром, т.е. адрес в команде задают так: имя массива [индексный регистр]. В индексный регистр записывается смещение первого используемого элемента относительно начала массива.
ПРИМЕР 4: Вычислить u[i]=x[i]+y[i]-z[i] (i=0..n-1)
В этом примере используется 4 массива с синхронным изменением индексов.
.MODEL SMALL .DATA
X У z п u dw 5, 7, 12, 4, 3 dw 1, 2, 3, 4, 5 dw 7, -7, 7, -7, 7 dw 5 dw 5 dup(?) .CODE
begin: mov ax, @data mov ds, ax
for(i=0; i<n; i++) u[i]=x[i]+y[i]-z[i]
i — параметр цикла и индекс
304
mov сх, n; счетчик
sub si, si; si=0 ; индексный регистр - смещение
; первого элемента
; относительно начала массива
for: mov ах, x[si] ; x[i] = ах
add ах, y[si] ; x[ij+y[i] = ах
sub ах, z[si] ; x[i]+y[i]-z[i] = ах
mov u[si], ах ; u[i]=x[i]+y[i]-z[i]
add si, 2 ; i++
loop for
mov ah, 4ch
int 21h
end begin
"Узелки" на память
В качестве индексного регистра можно использовать регистры si, di (ограничение снято в 80386 и выше).
Адрес элемента массива при косвенной адресации может быть в регистрах bx, si, di, bp. Если использовать регистр Ьр, данные извлекаются из стека, во всех остальных случаях — из сегмента данных (ограничение снято в 80386 и выше).
Если для адресации элемента массива используется базисный и индексный регистры, то в качестве базисного используют bx, Ьр, а в качестве индексного si, di.
2.3.3. Реализация вложенных циклов
Пусть необходимо реализовать алгоритм вида
for (i=0;i<n; i++){
for (j=O;j<m;j++){
}
}
Переменные i, j в программе — параметры цикла. С циклом связан единственный регистр сх. Для реализации вложенных циклов обычно используется такая последовательность операторов:
; Формирование счетчика для внешнего цикла mov сх, п ; число повторений внешнего цикла
; Формирование счетчика для внутреннего цикла fori: push сх ; сохранение счетчика для внешнего цикла mov сх, т; число повторений внутреннего цикла
305
forj: ........................
; Конец внутреннего цикла
loop forj
pop сх ; вое тановление счетчика для внешнего цикла
; Конец внешнего цикла loop fori
При программировании вложенных циклов используется стек. Для задания стека применяют директиву .STACK <раз-мер>, где <размер> — размер стека в байтах.
ПРИМЕР: Заданы две строки. Скопировать в третью с року те символы первой строки, которые есть во второй строке. Определить число символов в результирующей строке.
.MODEL SMALL .STACK 256 .DATA
string 1 string2 п1 п2 res п db ’ab123cd45’ db ’0123456789’ dw 9 ; длина первой строки dw 10 ; длина второй строки db 9 dup(?) ; память для результирующей dw ? строки и ее длины .CODE
begin: mov ах, @data mov ds, ax
; for(k=i=0;i<n1;i++)
; for(j=0;j<n2;j++)
; if (stringl [i]==string2[j] {
; res[k++] “String 1[i];
; break;
; }
; n=k;
; k — индекс массива res и обычная переменная (оператор n=k)
; i, j — индексы массивов и параметры циклов
lea di, res ; for(k=i=0; i<n1; i++)
mov ax,0
mov ex, n1
lea si, string 1
fori: push ex ; for(j=0;j<n2; j++) {
lea bx, string2
mov ex, n2
306
forj: mov dl, [si] ; if (stringl [i]==string2[j]) {
cmp dl, [bxl
jne nextj
mov [di], dl ; res[k++]=string1 [i]
inc ax
inc di
jmp breakj
nextj: inc bx
loop forj
breakj: Pop ex
inc si
loop fori
mov n,ax
mov ah, 4ch
int 21h
end begin
Просмотрите выполнение программы с помощью отладчика. Обратите внимание на изменение содержимого сх для каждого цикла!
Очевидно, что предложенный прием можно использовать для циклов с любым уровнем вложенности.
2.3.4. Обработка многомерных массивов
При рассмотрении приемов работы с одномерными массивами были предложены способы использования базисных или индексных регистров. В случае двумерных массивов оба регистра используются для задания адреса элемента массива. Адрес задается так:
[ Индексный регистр] [ Базисный регистр ]
Напоминаем, что в качестве индексного используются регистры si, di, базисного — bx, bp.
В базисный регистр записывается адрес начала массива, а в индексный — смещение относительно его начала. При изменении одного индекса изменяется содержимое базисного регистра, а при изменении дру ого — индексного*.
ПРИМЕР: Составить программу для вычисления сумм столбцов матрицы.
.MODEL SMALL
.STACK 256
.DATA
* В процессорах 80386 и выше можно в качестве базисного и индексного использовать любые общие регистры.
307
.natr dw dw 1, 2, 3, 4, 5 1. 2, 3, 4, 5 ; Исходная матрица
sum dw 5 dup(?)
n dw 2 ;число строк матрицы
m dw 5 .CODE ;число столбцов матоицы
for (i=0; i<5; i++) {
sum[i]=0;
for (j=0; j<2; j++) sum [i]+=matr[j] [i];
}
i — параметр цикла, индекс массивов sum и matr j — параметр цикла, индекс массива matr
begin: mov mov ax, @data ds, ax
fori: mov lea lea sub ex, 5 ; for (i=0; i<5; i++) bx, matr ; базисный регистр для matr di, sum ; базисный регистр для sum ax, ax ; текущее значение суммы
forj: push mov sub add сх ; for (j=0; <2j; j++) ex, 2 si, si ; индексный регистр для matr ax,[si][bx]
add si, 10 ; j:=j+1 loop forj mov [di], ax ; sum[i]=ax; pop ex add bx, 2 ; i=i+1; add di, 2 loop fori mov ah, 4ch int 21 h end begin
Заметим, что изменение индекса требует изменения адреса. Шаг изменения адреса при переходе внутри строки равен длине элемента массива (2), а шаг для перехода на соседнюю строку равен длине строки в байтах (5*2=10).
Рассмотренный выше прием удобен, если количество одновременно обрабатываемых массивов невелико. Это связано с ограничением на допустимые регистры для индекса (базы). Решение такой несложной задачи как перемножение матриц (одновременно работаем с тремя двумерными массивами) потребует сохранения и восстановления регистров для индексации. Кроме
308
того метод не пригоден, если размерность массивов более двух.
Для упрощения работы с двумерными массивами и обеспечения возможности работы с массивами произвольной размерности испол .зуется метод связанных индексов.
Суть метода. Индексу ставится в соответствие базисный регистр. При задании значения индекса в этот регистр записывается адрес элемента массива, с которого начинается обработка. При задании каждого очередного индекса запоминается заданный адрес в стеке. После задания последнего индекса для всех старших индексов в стеке будут храниться адреса первого обрабатываемого элемента.
При изменении индекса адрес, соответствующий этому индексу, изменяется на величину шага изменения адреса. Для вычисления шагов применяются формулы (2.4). Т.к. шаги изменения адресов не зависят от параметров цикла, они задаются вне циклов.
Ниже представлена структура программы для работы с
многомерным массивом, type аггау[..
for (i=...; i...; i+=...) {
for (j=...; j...; j+=...) {
for (k=...; k...; k+=...) {
array[i][j]. ..=...;
'}......................
}
}
; Вычисление шагов
H1=...; H2=...; ... Hk=...
mov сх, ...
mov bx, адрес первого
обрабатываемого элемента
fori: push сх
push bx
mov ex, ...
forj: push ex
push bx
mov ex, ...
fork: mov word ptr[bx], ...
; endk add bx, Hk loop fork ; endj pop ex pop bx add bx, Hj loop forj ; endi pop ex pop bx add bx, Hi loop fori
309
ПРИМЕР: Составить программу для вычисления сумм слоев в трехмерном массиве.
Пусть исходный массив X и результирующий массив S
int х[5][2][10];
int s[10];
Необходимо на ассемблере реализовать программу
for (1=к=0; к<10; к++) {
s[l]=0
for (i=0; i<5; i++) {
for (j=0; j<2; j++) { s[l]+=x[i][j][k];
I++;
}
1. Выделим память под исходные данные и результаты.
.STACK 256
.DATA
х dw (5*2*10) dup(1)
s dw 10dup(?)
HI dw ?
HJ dw ?
Hk dw ?
2. Вычислим шаг изменения адреса по каждому индексу:
Hk=2 ; HJ=10*Hk=20 ;
HI=2*HJ=40
3. Запишем кодовый сегмент для программы
.CODE
begin: mov ax, @data
mov ds, ax
mov HI, 40
mov HJ, 20
mov Hk, 2
lea di, s ; l=0
mov ex, 10 ; for(k=0; k<10; k++)
lea bx, x
fork: sub ax, ax ; s[l]=0
; промежуточное значение суммы
push сх
mov сх, 5 ; for(i=0: i<5; i++)
push bx
fori: push ex ; for(j=1; j<2; j+-r/
310
forj:
mov ex, 2 push bx
add ax, [bx] ; s[l]+=x[i][j][k];
add bx, HJ ;j++;
loop forj
pop bx
add bx, HI ; i++
pop ex
loop fori
mov [di], ax
add di, 2
pop bx
add bx, Hk ; k++
pop ex
loop fork
mov ah, 4ch
int 21h
end begin
Посмотрите внимательно, как изменяется адрес для каждого индекса!
Приведенный метод можно использовать для массивов любой размерности, т.к. в нем этот массив приводится к одномерному массиву, элементами которого являются данные разной длины. Именно этот принцип заложен в основу обработки массивов в С, поэтому размерность массивов в языке С неограничена.
2.3.5. Особенности обработки массивов с произвольным изменением индексов
Способ обработки массивов, рассмотренный выше, используется для массивов любой размерности выше единицы. Но использовать этот способ для работы с массивами, если индексы изменяются немонотонно, нельзя. В этом случае адрес текущего элемента вычисляется каждый раз заново. Для вычисления адреса используются формулы (2.3-2.4)
Ниже представлена структура программы для случая произвольного изменения индекса.
;Вычисление шагов изменения адреса
; Н1, Н2, ... Формула(2.4)
; Формирование значений индексов ; (зависит от программы)
311
; Вычисление адреса элемента массива
; Формула(2.3)
; Использование элемента массива
; (зависит от программы)
ПРИМЕР: Задана матрица, в которой есть много нулевых элементов. Для экономии памяти для матрицы заданы только ненулевые элементы. Для каждого элемента задаются номер строки, номер столбца и значение элемента. Преобразовать матрицу к естественному виду, т.е. записать ее в виде
( 00 00...0 ) ( .... 0. ... 0000) (000....00...0 ) (00....00...0.)
Алгоритм решения :
1. Обнуление всех элементов результирующей матрицы
2. Запись ненулевых элементов в матрицу
elem . MODEL SMALL . STACK 256 . DATA . 386 struc ; определение структуры
string col value elem NUMBER ; элемента матрицы dw ? dw ? dw ? ends equ 100 ; Максимальное число ненулевых ;элементов
tabl <2, 3, -5>, <1,4, 2>, (NUMBER-2) dup (<0, 0, 0>)
MAXCOL MAXSTRING matr equ 10 ; Максимальное число колонок equ 10 ; Максимальное число строк dw (MAXCOL*MAXSTRING) dup (?) ; результирующая матрица
H1 H2 LIMITS1 LIMITS2 dw ? ; шаги изменения адреса dw ? ; в матрице dw 0, MAXSTRING dw 0, MAXCOL . CODE
begin: mov ax, @data mov ds, ax
312
/* Очистка матрицы */ for (i=0; KMAXSTRING; i++) for (j=0; j<MAXCOL; j++) matr[i][j]=O; /* Заполнение результирующей матрицы */ i=0; While (v=tabl[i].value) { c=tabl[i].col; s=tabl[i].string; matr[s][c]=v; i++; } Переменные i, j — индексы и параметры цикла с, s — индексы v — простая переменная
Вычисление шагов изменения адреса в матрице mov Н2, 2 ; элементы матрицы ; длиной 2 байта mov ах, MAXCOL add ах, ах mov Н1,ах ; H1=2*MAXCOL ; Обнуление исходной матрицы — обнуление ; последовательных ; MAXCOL*MAXSTRING элементов mov ах, MAXCOL
mul MAXSTRING; Общее число элементов ; не больше 65535 mov сх, ах ; счетчик sub ах, ах lea di, matr for: mov [di], ax add di, H2 loop for ; Заполнение матрицы lea si, tabl ; i=0
whil: mov bx, [si].value ; while (v=tabl[i].value) and bx, bx je break mov ex, [si].col ; c=tabl[i].col bound cx.dword ptr LIMITS2 mov ax, [si].STRING ; s=tabl[i].string bound ax.dword ptr LIMITS1
313
break:
lea di. matr
-nul H1 ; вычисление адреса
add di, ax ; matr[s][c]
mov ax, ex
mul H2
add di, ax
mov [di], bx ; matr[s][c]=v
add si, SIZE elem ; i++
jmp whil
mov ah, 4CH
int 21 h
end begin
В этом примере показана работа с массивом структур и двумерным массивом, индексы при формировании которого изменяются по произвольному закону. Директива .386 разрешает команды проиессора 80386 и связана с командой bound. Эта команда проверяет правильность задания индекса в массиве. Если индекс не удовлетворяет интервалу, программа прерывается.
2.3 6. Использование команд для работы с блоками
В большинстве прграмм, связанных с массивами, приходится выполнять такие действия:
формировать адрес, с которого начинается обработка ; изменять этот адрес в сторону увеличения или уменьшения. Для упрощения программирования этих действий используются команды для работы с блоками. Напоминаем наиболее важные особенности этих команд.
1. Адрес первого обрабатываемого элемента для исходного блока (источника) должен быть записан в регистры ds: si , а результирующего (приемника) — в es; di. Присутствие сегментного регистра в адресе расширяет область действия команд на блоки из разных сегментов. Если исходный и результирующий блоки в одном сегменте (стандартном), используются такие команды:
push es ; Сохранение содержимого es
push ds
pop es : es=ds
2. В качестве элементов блока используются байты, слова. Для 32-битных процессоров элементом блока может быть
314
двойное слово. Длительность выполнения команды не зависит от длины элемента блока. Поэтому желательно выбирать эту длину максимально допустимой.
3. Элементы блока могут обрабатываться, начиная с начала или конца блока.
Переход к очередному элементу выполняется автоматически. Дл! установки направления обработки используются команды:
cld ; Блок обрабатывается с начала, после обработки адрес увеличивается на длину элемента блока
std ; Блок обрабатывается с конца, после обработки адрес уменьшается на длину элемента блока
4. Число элементов блока обычно записывается в регистр сх. В этом случае для организации цикла можно использовать команду loop или префиксы гер (повторить), гере (повторить, пока равно, repZ-синоним), герпе (повторить, пока не равно, repnZ-синоним).
В таблице 2.5 приведены команды для работы с блоками.
Последняя буква кода определяет длину элемента блока. В — блок байтов, W — блок слов, D — блок двойных слов. Если используется одна из команд MOVS, CMPS LODS, STOS, SCAS, то должны быть заданы операнды. Они используются транслятором для определения длины элемента.
Таблица 2.5
Команды для работы с блоками
Назначение Общий ВУД команды Выполняемые действия Флаги
Копирование MOV3B MOVSW MOVSD MOVS оп1,оп2 источник => приемник нет
Сравнение CMPSB CMPSW CMPSD CMPS оп1,оп2 Сравнение элементов источника и приемника о, S, Z, а, р, с
Загрузка LODSB LODSW LODSD LODS оп Элемент блока-источника загружается в регистр al, ах, еах (в зависимости от длины элемента) нет
315
Г Назначение Общий вид команды Выполняемые действия Флаги
Запись в память STOSB STOSW STOSD STOS on Содержимое регистра al, ах, еах (в зависимости от длины элемента) записывается в память с адресом es:di нет
Сканирование SCASB SCASW SCASD SCAS on Содержимое регистра al, ах, еах (в зависимости от длины элемента) сравнивается с элементом блока приемника N о со а о" со
Адреса блоков в соответствующие регистры должны быть загружены в программе. Поэтому мы рекомендуем использовать команды с явным заданием длины.
Рассмотрим примеры использования команд.
ПРИМЕР 1: Составить программу для записи содержимого экрана в память (текстовый режим, цветной дисплей).
.MODEL SMALL .386
.STACK 100Н .DATA
screen dw 25*80 dup (?)
.CODE
begin: mov ax, @data
mov ds, ax
; Подготовка для работы с блоками
push es cld push ds
pop es ; сегментный адрес
; приемника
push ds
mov ax, 0B800H
mov ds, ax ; сегментный адрес
; источника
sub si, si ; смещение источника
lea di, screen ; смещение приемника
316
mov ex, 25*80*2/4 ; количество 4-х байтовых ; элементов в блоке
rep pop pop mov int end movsd ds es ah, 4ch 21h begin
В этом примере использована директива .386, которая дает возможность задать длину элемента блока равной 4 байтам. Напоминаем, что задание максимальной длины блока позволяет сократить время пересылки. Команда rep movsd пересылает столько элементов, сколько задано в сх.
ПРИМЕР 2: Составить программу для сравнения двух "длинных" чисел, каждое занимает п двойных слов, числа без знака. Программа должна записывать в регистр ах значение 0. меньше 0 или больше 0, если первое число равно второму, меньше второго или больше второго соответственно.
arrayl аггау2 number
begin:
.MODEL SMALL .386 .STACK 100H .DATA
dd 12345678h, 90123456h
dd 87654321h, 65432109h
dw 2 .CODE mov ax, @data
mov ds, ax
for (i=1; i>=0; i-)
if (arrayl [i] > array2[i] ) { ax=1 ; break;
}
else
if (arrayl [i] < array2[i]) { ax=-1; break;
}
} if (i<0) ax=0;
std
push ds
POP es; es=ds
lea si, arrayl
317
add si, 4 ; начинаем co старшего
a элемента блока
lea di, array2
add di, 4
mov ex, 2 ; число элементов в блоках
repe empsd ; сравниваем, пока равны
jexz equal
jb fits
mov ax, 1
jmp short cont
fits: mov ax, -1
jmp short cont
equal: sub ax, ax
cont: mov ah, 4ch
int 21h
end begin
ПРИМЕР 3: Составить программу для очистки экрана (записи пробелов с атрибутом 70h).
.MODEL SMALL .386 .CODE
begin: mov ax, 0b800H mov es, ax cld sub di, di mov eax, 070207020h ; 70h — атрибут, ; 20h — код пробела mov ex, 25*80*2/4 ; количество элементов
rep stosd mov ah, 4ch int 21 h end begin
ПРИМЕР 4: Составить программу для преобразования всех строчных латинских букв в строке в прописные. Результат получить в той же строке. Признак конца строки — символ с кодом 0.
.MODEL SMALL
.STACK 100Н
.DATA
string db ’AaaaBbbCc’, 0
.CODE
begin: mov ax, @data
mov ds, ax
318
cld push es push ds pop es lea si, string mov di, si
for: lodsb and al, al je break cmp al, ’a’ ; if (маленькая латинская буква) jb notletter cmp al, ’z’ ja notletter sub al, ’a’ ; изменяем ее на заглавную add al, 'A'
notletter. stosb jmp for
break: pop es mov ah, 4ch int 21 h end begin
ПРИМЕР 5: Составить программу для нахождения в заданном массиве номера первого числа, равного 0 (массив двухбайтовых чисел).
.MODEL SMALL .STACK 100Н .DATA
аггаук dw 1, 2, 3, 4, 0, 5, 6, 7 ; исходный массив
numbers dw 8 ; количество чисел в массиве
num dw ? ; память для результата
.CODE
begin: mov ах, @data
mov ds, ах
push es
push ds
pop es
lea di, array
sub ax, ax
mov ex, numbers
mov num, -1
repne scasw ' ; сканировать массив, пока элемент ; блока не равен ах
jcxz lend
mov ах, numbers
sub ах, сх ; номер числа в массиве
319
es
ah, 4ch
21 h
pop
lend: mov
int end begin
Рассмотренные примеры демонстрируют использование команд для работы с блоками при обработке массивов.
2.5. Побитовая обработка
При составлении системных программ часто приходится обрабатывать состояния внешних устройств, признаки завершения, флаги* и другую системную информацию. Как правило, элемент информации составляет не целый байт (слово). Для работы с элементами байта (слова) используются данные типа RECORD (см. 1.3.9 ) и команды для побитовой обработки**.
Основные команды побитовой обработки, допустимые для всех процессоров, приведены в таблице 2.6, а дополнительные команды для процессоров 80386 и выше — в таблице 2.7. Команды, в которых используются номер разряда, предполагают стандартную их нумерацию, т.е. нулевой — это младший разряд.
Таблица 2.6
Основные команды побитовой обработки
Назначение Общий вид Выполняемые действия Флаги
Логическое умножение and (оп1)&(оп2) => оп1 о=0, s, z, Р, с=0
Логическое сравнение test (оп1 )&(оп2) о=0, с=0, s, z„ р
Логическое сложение or (оп1) | (оп2) => оп1 о=0, с=0
Отрицание not "оп1 —
* Флаг переполнения 0 устанавливается только при сдвиге на один разряд.(см. с. 332)
** Выполняемые действия команд ror, rol, rcl, гсг описаны для случая сдвига на один разряд. При сдвиге на несколько разрядов во флаг переноса записывается последний разряд, оказавшийся за разрядной сеткой.(см. с. 332)
320
Назначение Общий вид Выполняемые действия Флаги
Сложение по модулю 2 хог (оп1)~(оп2) => оп1 о*), с
Сдвиг арифметический (влевог вправо) sal sar ((signed)onl) {«} {const} {»}{(cl) О*), S, Z, р, с
Логический (влево, вправо) shl shr (unsigned)onl {«} {const} {»}{(cl) },
Циклический (влево, вправо) гоГ*) ror**) с = старшему разряду оп1=(оп1«1)|с с = младшему разряду оп1 =(оп1 »1) | (с«п***)) о, с
Циклический со сдвигом rd**) rcr**) c(new) = старшему разряду оп1 = (оп1 «1) |c(old) c(new) = младшему разряду оп1 = (on1»1)|c(old)«n***).
Таблица 2.7
Дополнительные команды побитовой обработки
Назначение Код Выполняемые действия Флаги
Проверка битов, начиная с младшего BSF оп1, оп2 if(Bce биты оп2 нулевые) { оп1=0; флаг z=0; else { оп1=номеру ненулевого бита; флаг z=1; } Z
Проверка битов, начиная со старшего BSR оп1, оп2 Такие же, как для BSF, только изменяется направление просмотра Z
Проверка бита с заданным номером ВТ оп1, оп2 Флаг с=значению бита в оп1 с номером, заданным оп2 с
11 «Основы программирования»
321
Назначение Код Выполняемые действия Флаги
Установка бита с заданным номером BTS оп1, оп2 Флаг с=значению бита в оп1, с номером заданным оп2. Бит в оп1 устанавливается равным 1 с
Сброс бита с заданным номером BTR оп1, оп2 То же, что BTS, но заданный бит устанавливается в 0 с
Инвертирование бита с заданным номером ВТС оп1, оп2 То же, что предыдущие две команды, но содержимое бита инвертируется с
Команды, заданные в таблице 2.7, действуют на слова и двойные слова. В командах, требующих задания номера разряда, его можно не указывать, т.е. в команде задавать только один операнд, в этом случае используется нулевой разряд.
Примеры использования команд побитовой обработки.
ПРИМЕР 1: Реализовать дополнительные команды (табл. 2.7), используя основные команды побитовой обработки, используя для работы двух-байтовые слова.
; Команда BSF. Определение номера младшего
; ненулевого бита
; for (i=0; i<16; i++){
; if (wrd & (1«i)){
; res=i ; флаг z=1; break;}
; } if (i==16){ res=O; флаг z=0}
; i — параметр цикла и простая переменная
mov mov mov
forbsf: mov
and je mov lahf or sahf jmp
continuebsf: inc shl loop
bx, 1 ;для сдвига
dx, 0 ; i=0
ex, 16 ; счетчик
ax, wrd
ax, bx
continuebsf
res, dx
; загрузка регистра флагов в АН ah, 40h ; установка флага z
exitbsf
dx
bx, 1
forbsf
322
mov res О
lahf
and ah, 10111111b ; сброс флага z
sahf
exitbsf:
Команда BSR. Определение номера старшего
ненулевого бита
for (i=15; i=>0; i—) { b=0x8000;
if (wrd & b){
res=i; флаг z=1; break;}
b»1;
if (i) { res=O; флаг z=0
mov bx, 8000h ; для сдвига
mov dx, 15 ; i=15
mov ex, 16
forbsr: mov ax, wrd
and ax, bx
je continuebsr
mov res, dx
lahf
or ah, 40h
sahf
jmp exitbsr
continuebsr: shr bx, 1
dec dx
loop forbsr
mov res, 0
lahf
and ah, 10111111b
sahf
exitbsr:
; Команда BTS . Установка бита с заданным номером
; Флаг с = старому значению устанавливаемого бита
; c=word & (1«i) ? 1:0;
; word l=(1«i);
mov dx, 1 ; установка и сохранение флага с mov cl, number
shl dx, cl
test dx, wrd
je debts stc pushf
jmp short continuebts
11
323
debts: clc
pushf
continuebts: or wrd, dx ; установка заданного бита popf ; восстановление регистра флагов
; Команда BTR. Сброс бита с заданным номером
; Флаг с равен старому значению сбрасываемого бита
; флаг c=wrd & (1«i) ? 1:0 ;
; word &=“(1«i);
mov dx, 1
mov cl, number shl dx, cl test dx, word je elebtr stc
pushf
jmp short continuebtr
elebtr: clc
pushf
continuebtr: not dx and wrd, dx popf
. Команда BTC. Инвертирование бита с заданным ; номером.
; Флаг с равен старому значению инвертируемого бита
; флаг c=wrd & (1«i) & 1:0 ;
; word~=(1«i);
mov dx, 1
mov cl, number shl dx, cl test dx, wrd je elebte stc
pushf
jmp short continuebtc elebte: clc
pushf
continuebtc: xor wrd, dx popf
ПРИМЕР 2: Определить тип процессора, используя для определения алгоритм, предложенный в жур але д-ра Добба (№2, 1991, с.54).
324
Если используется процессор 8086-80186, то при извлечении регистра флагов из стека, биты 12-15 установлены в "1”.
Если процессор 80286, то те же биты установлены в "0".
Если процессор 80386, то бит 15 в "0", остальные в ”1".
.MODEL SMALL
.STACK 100H .DATA
msg86 db 'Процессор 8086-80186’, 13, 10,
msg286 db ’Процессор 80286', 13, 10, '$'
msg386 db 'Процессор 80386’, 13, 10, ’$’
msg db 'Тип процессора неопределен', 13, 10, '$' .CODE
begin: mov ax, @data mov ds, ax xor ax, ax push ax popf ; запись в регистр флагов нулей pushf pop ах ; ах = содержимое регистра флагов and ах, 0F000H ; анализ старших четырех цифр cmp ах, 0F000H je р8086 стр ах, 0 je р80286 стр ах, 08000Н je р80386 lea dx, msg ; сообщение о неизвестном ; процессоре jmp short print
pr8086: lea dx, msg86 ; сообщение о 8086-80186 ; процессоре jmp short print
P80286: lea dx, msg286 ; сообщение о 80286 ; процессоре jmp short print
p80386. lea dx, msg386 ; сообщение о 80386 , процессоре
print: mov ah, 9 ; вывод сообщения int 21 h mov ah, 4ch int 21 h end begin
В данном примере выводится строка. Для вывода используется функция DOS (ah=9), адрес начала выводимой
325
строки должен быть в регистрах ds:dx. Т.к. выводг мые строки в сегменте данных и ds указывает на этот сегмент, то достаточно смещение для сообщения поместить в dx (команды lea).
ПРИМЕР 3: Вычислить значение булевского выражения
Ь=а[7]а[6] а[5]а[4]~а[3]а[2]а[ 1 ]а[0] | | -а[7]-а[6]а[5]а[4] | -а[3]-а[2]'а[1 ]
“ — знак отрицания;
а[7], а[6]...а[0] — значения битов с соответствующим
номером.
Алгоритм вычисления.
1. Т.к. при умножении на 1 произведение не изменяется, считаем, что все несуществующие сомножители равны "1", т.е. формируем маски
для 1 слагаемого : 00000000 — все сомножители (все буквы) присутствуют;
для 2 слагаемого : 00001111 — нет букв а[3], а[2], а[1], а[0];
для 3 слагаемого : 11110001 — нет букв а[7], а[6], а[5], а[4], а[0] ;
2. Каждое слагаемое складываем по модулю 2 с константой, в которой "1” соответствует переменной без отрицания и отсутствующей переменной, а 0 — переменной с отрицанием.
Получаем константы
для 1 слагаемого — 11110111 ;
для 2 слагаемого — 00111111 ;
для 3 слагаемого — 11110001 .
3. Если хотя бы одно слагаемое равно 1, то значение логического выражения равно 1, в противном случае — 0 .
Программа:
; Вычисление значения булевского выражения
; Ь=а[7]а[6]а[5]а[4]“а[3]а[2]а[1]а[0]|
: | -а[7]-а[6]а[5]а[4] | -а[3]’а[2]-а[ 1 ]
; ответ в регистре al ( 0 или 1 )
.MODEL SMALL
.DATA
a db 10110111b
b db ?
.CODE
begin: mov ax, @data
326
mov ds, ax
mov al, a
mov ah,00000000b
or ah, al ; для 1 слагаемого
mov Ы 00001111b
or Ы, al ; для 2 слагаемого
mov bh,11110001b
or bh, al ; для 3 слагаемого
; Определяем значения слагаемых
xor ah, 11110111b
jz true ; 1 слагаемое =1
xor Ы, 00111111b
jz true ; 2 слагаемое = 1
xor bh,11110001b
jz true
zero: sub al, al
jmp short false
true: mov al, 1
false: mov ah, 4ch
int 21h
end begin
ПРИМЕР 4: Составить программу для определения подключенного к ЭВМ оборудования, если информация находится в ячейке 410Ь(слово) и имеет такую структуру:
I-1---1--1--1--1--1--1---1--1--1--1 I I ПП I
I I I I I I I I I I I I__I__I__Ь_1___I
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
1-2 — число присоединенных принтеров
3 — не используется
4 — есть игровой адаптер
5-7 — число последовательных портов
8 — не используется
9-10 — число накопителей на гибком диске
11-12 — тип видеоадаптера
13-14 — не используется
15 — есть сопроцессор
16 —есть НГД
.MODEL SMALL
.DATA EQUIP RECORD P1:2, UP1:1, P2:1, P3:3, { UP2:1, P4:2, P5:2, UP3:2, P6:1, P7:1 }
msg1 db 'Число присоединенных принтеров: 13, 10, ’$’
msg21 db 'Игровой адаптер ’, 13, 10, '$'
327
msg3 db 'Число последовательных портов: 13, 10,
msg4 db 'Число НГД: ', 13, 10,
msg51 db 'Тип видеоадаптера : ’, 13, 10,
msg61 db 'Сопроцессор есть’, 13, 10,
msg62 db 'Сопроцессора нет’, 13, 10, '$'
msg71 db 'НГД : есть ', 13, 10, '$'
msg72 db 'НГД : нет ’, 13, 10, '$’
msg52 db 'Тип видеоадаптера : цветной ’, 13, 10,
msg22 db 'Игрового адаптера нет ', 13, 10, .CODE
begin: mov ах, @data mov ds, ax ; связь с сегментом данных mov ах, 0 mov es, ах ; сегмент ячейки 41 ОН mov si, 41 Oh ; смещение для ячейки 41 ОН mov ах, es:[si] and ах, 1 ; Формирование и вывод jne ngd ; информации о наличии lea dx, msg72 ; гибких дисков jmp short printgd
ngd: mov dx, msg71
printgd: mov ah, 9
int 21 h
1 mov ax, es:[si] mov cl, рб ; формирование и вывод mov bx, mask рб ; информации о наличии and bx, ax ; сопроцессора shr bx, cl and ax, 1 jne sopr lea dx, msg62 jmp short printsp
sopr: mov dx, msg61
printsp: mov ah, 9
int 21 h
1 mov ax, es:[si] mov cl, p5 ; формирование и вывод mov bx, mask p5 ; информации о типе and bx, ax ; видеоадаптера shr bx, cl cmp bx, 3 jne color lea dx, msg51 jmp printVA
328
printVA: lea mov int dx, msg52 ah, 9 21h
1 mov mov mov and shr inc lea add mov ax, es:[si] cl, p4 ; формирование и вывод bx, mask p4 ; информации о количестве НГ j bx, ax bx, cl bx dx, msg4 bl, 'O' msg4+10, Ы
mov ax, es:[si] mov cl, рЗ ; формирование и вывод mov bx, mask рЗ ; информации о количестве and bx, ax ; последовательных портов shr bx, cl inc bx leadx, msg3 add bl, ’0’ mov msg3+30, Ы mov ah, 9 int 21 h
» play: mov mov mov and jne lea jmp mov mov int ax, es:[si] cl, p2 ; формирование и вывод bx, mask p2 ; информации об игровом Jbx, ax ; адаптере Play dx, msg22 short play dx, msg21 ah, 9 21h
1 mov mov mov and inc lea add mov mov ax, es:[si] cl, p1 ; определение числа bx, mask p1 ; присоединенных принтеров bx, ax bx dx, msg1 bl, '0' msg1+31, Ы ah, 9
329
int 21h
mov ah, 4ch
int 21h end begin
В этом примере показан доступ к полям записи, проиллюстрирована возможность изменения выводимой строки. Заметим, что при перераспределении битов между полями достаточно будет изменить описание записи RECORD, программа при этом не изменится.
_ МОДУЛЬНОЕ
О ПРОГРАММИРОВАНИЕ О НА АССЕМБЛЕРЕ
3.1. Структура исполняемых программ
Исполняемые программы делятся на позиционно-зависимые и позиционно-независимые программы. В позиционно-зависимой программе есть команды, зависящие от адреса начала программы. Все написанные до сих пор программы позиционно-зависимые, т.к. в них присутствует команда mov ах, @data, в которой — @data — адрес начала сегмента данных, при изменении этого адреса изменяется внутреннее представление команды.
Позиционно-независимая программа состоит из одного сегмента (.CODE), в котором расположены и данные, и команды. В этом случае не требуется связи между сегментами. Регистры ds, cs указывают на адрес начала общего сегмента. Не требуется корректировка команд после их загрузки в память. Такая программа наиболее проста с точки зрения загрузчика, содержит только команды и данные, т.е. имеет минимальный размер. Позиционно-независимые программы имеют расширение .сот. Ограничения на .com-файлы: длина ограничена размером одного сегмента!
Позиционно-зависимая программа (.ехе-файл) должна содержать информацию обо всех ее сегментах (данных, стека,...) и позиционно-зависимых командах, необходимую загрузчику для правильной настройки таких команд. Эта информация записывается в так называемый заголовок .ехе-файла, содержащий 256 б, поэтому .ехе-файл всегда больше соответствующего .сот-файла.
331
При программировании на ассемблере можно составить программу таким образом, чтобы затем получить как .ехе-, так и .com-файл. Ранее была описана процедура для получения .ехе-файла. Рассмотрим структуру ассемблер-программы для получения .сот-файла.
.MODEL имя
.CODE
org 100 h begin: jmp short first
; определение данных программы
first: ; начало команд программы
int 20h end begin
В качестве модели памяти можно использовать TIN4 (крошечную) или SMALL(Manyio) модель. Использование других моделей не имеет смысла, т.к. они предполагают существование нескольких сегментов, в т.ч. сегмента стека.
Т.к. в программе допустим только один сегмент, этим сегментом является сегмент команд (.CODE).
При загрузке любой программы в память ей сообщается дополнительная информация для связи программы с операционной системой. Эта информация задается в заголовке ( program segment prefix—psp). Размер этого заголовка 2566(100h). Т.к. команды программы для .сот файла после загрузки не модифицируются, необходимо указать транслятору, что первая команда смещена относительно начала программы на величину заголовка (директива org 100h).
В командах программы необходимо знать тип используемых данных, например, по команде mov х, 5 в поле х может быть записано число 5 как байт или слово. Поэтому данные предшествуют командам программы. Чтобы данные не интерпретировались как команды, команда jmp используется для обхода области данных.
Для выхода из программы используется более простой способ — команда int 20h, которая обеспечивает возврат в вызывающую программу.
ПРИМЕР: Составить программу вычисления z=x+y для формирования .com-файла (файл summa.asm).
332
.MODEL SMALl .CODE
org 100h
begin: jmp short first
X dw 5
У dw 3
Z dw ?
first: mov ax, x
add ax, у
mov z, ax
int 20h
end begin
Для трансляции программы используется стандартная командная строка
tasm summa.asm
Для компоновки задается специальный ключ /t, который обеспечивает формирование .сот-файла:
tlink /t summa obj
Заметим, что для .com-файла отладочная информация не записывается в файл, поэтому отладку можно вести в пошаговом режиме, без указания имен данных. Если программа сложная, рекомендуется ее отладить как .ехе-программу, а затем преобразовать ее в .com-файл. Для преобразования можно изменить структуру программы, перетранслировать и перекомпоновать или использовать стандартную утилиту exe2bin.
Файлы типа .сот используются, если необходимо получить программу минимального размера.
3.2. Процедуры и функции
Процедуры и функции позволяют оформлять независимые участки программы в виде отдельных модулей, что значительно упрощает отладку программы и уменьшает ее размер. Ниже будут рассмотрены команды для работы с процедурами (функциями), структура процедур (функций) и способы передачи параметров. В начале даются общие положения для процедур и функций. Особенности функций (они незначительны) рассмотрены в конце.
333
3.2.1. Команды для работы с процедурами (функциями)
Команды для работы с процедурами (функциями) приведены в табл. 3.1
Таблица 3.1
Команды и директивы для работы с процедурами (функциями)
Назначение Общий вид команды Выполняемые действия Флаги
Запись в стек push операнд * [—sp]=val; val-слово или дв. слово* 1 —
Чтение из стека pop операнд val=*(sp)++; val-слово или дв. слово*) —
Вызов процедуры (функции) call операнд push адрес возврата jmp оп, где оп -операнд команды call, может быть задано имя процедуры (прямая адресация) или адрес (косвенная)
Возврат в вызывающую программу геЦчисло] ге1:п[число] геН{число] pop адрес возврата jmp адрес возврата retn-ближняя процедура (адрес возврата - одно слово) retf-дальняя процедура (адрес возврата- два слова) ret-тип прцедуры определяется моделью памяти и содержимым директивы proc
Директива начала процедуры (функции) имя ргос[пеаг] имя procffar] Задает начало процедуры и ее атрибут дистанции. Если не задан, то определяется моделью памяти (near - tiny,small,compact)
334
Назначение Общий вид команды Выполняемые действия Флаги
Директива конца процедуры (функции) имя endp Задает конец процедуры с заданным именем —
Общий вид прцедуры :
имя proc
имя endp
Процедура должна быть частью сегмента кодов. Она может быть записана либо в о дельном файле, либо в том же что и вызывающая программа. Может быть задано несколько процедур последовательно. При выполнении программ переход к процедуре желательно выполнять только по команде call, а не в результате естественного выполнения команд, поэтому процедуры помещаются или в начало сегмента кода до точки входа, или в конце после команд для выхода из программы, или в отдельном файле.
ПРИМЕР: Составить процедуру для вычисления длины строки, последний символ которой имеет код 0. Пусть адрес начала строки в регистре ВХ, а длина строки возвращается через регистр АХ.
.MODEL SMALL .DATA
str1 db 'Это первая строка’, 0
str2 db 'А это вторая’, 0
п dw 7 7 • » •
.CODE
begin: mov ах, @data
mov ds, ах
lea bx, str1
call strlen
mov lea n, ax bx, str2
call strlen
mov n+2, ax
mov ah, 4ch
int 21h
srrlen proc near , near можно не писать
xor ax, ax
for: mov cl, [bx] while (str[i])ax++;
335
and cl, cl
je lend ; конец строки
inc ax
inc bx
jmp for
lend: ret
strlen endp
end begin
В данной процедуре параметры задаются в регистрах. Т.к. вызывающая программа и процедура находятся в одном файле, процедура может использовать имена переменных программы. Если параметров много, для их передачи используется стек или переменные вызывающей программы записываются в область памяти, доступную другим программам (передача параметров через внешние переменные). Эти способы передачи обычно используют.для внешних процедур, которые находятся не в том файле, что и вызывающая программа. Наиболее часто параметры передаются через стек
3.2.2. Передача параметров через стек
При передаче параметров через стек возникает проблема доступа к ним. Рассмотрим способы адресации (табл. 3.2). Из всех режимов адресации выберем режим, связанный с адресацией в стеке. В этом режиме в качестве базисного регистра используется регистр Ьр, именно этот регистр будем применять для задания элемента стека. С другой стороны, указатель стека, т.е. адрес последнего занесенного элемента в стек, расположен в регистре sp. Чтобы иметь доступ к данным стека, используются команды
push bp ; сохранение bp
mov bp, sp ; bp=sp
Эти команды должны присутствовать в любой процедуре, в которой параметры передаются через стек.
Чтобы изучить механизм передачи параметров через стек, рассмотрим сначала внутренние процедуры, а потом внешние.
Будем считать, что все параметры передаются через стек. Параметры можно разделить на параметры-исходные данные и параметры-результаты. Для первых передаются значения, а для вторых — адреса. Чтобы уменьшить число передаваемых параметров, для массивов передаются адреса, а не значения элементов, даже для массивов исходных данных. При трансля
336
ции с языков высокого уровня параметры заносятся в стек в порядке их следования в списке в PASCALe и в обратном порядке в С.
Таблица 3.2
Способы адресации данных в памяти
Сегментный регистр, используемый при формировании адреса Общие регистры, используемые для задания адреса Местонахождение данных
DS ВХ Сегмент данных
DS SI Сегмент данных
DS DI Сегмент данных
SS ВР Стек
DS SI, ВХ Сегмент данных
DS DI, ВХ Сегмент данных
SS SI, ВР Стек
SS DI, ВР Стек
В ассемблере можно использовать любой порядок.
Чтобы стек не переполнялся, после использования параметры должны быть извлечены из стека. Эту функцию, называемую очисткой стека, может выполнить вызывающая программа после возврата ей управления или вызываемая непосредственно перед завершением. В С очистку стека выполняет вызывающая программа, т.к. число параметров может быть переменным и только вызывающая программа "знает", сколько параметров она передала. В Паскале очистку выполняет вызываемая программа, т.к. число параметров неизменно. Для очистки стека внутри процедур используется команда ret п, где n-число байт стека, которые должны быть очищены.
Ниже рассмотрены примеры использования процедур с передачей параметров через стек. Примеры отражают приемы передачи простых переменных (исходных данных и результатов), массивов, структур и объединений.
ПРИМЕР 1: Составить процедуру вычисления z=x+y и использовать ее для вычисления c=a+b; f=d+e.
.MODEL SMALL
.STACK
.DATA
a dw 5
b dw 3
337
с d ow ?
dw 4
е f begin: dw -5 dw ? .CODE mov ax, ©data mov ds, ax push a ; передача параметров a, b
push b lea ax, c push ax ; передача адреса с call summa ; вызов процедуры pop ax ; очистка стека pop ax ; (3 параметра) pop ax push d ; передача параметров d, e
summa push e lea ax, f push ax call summa ; вызов процедуры pop ax ; очистка стека pop ax ; ( 3 параметра) pop ax mov ah, 4ch int 21 h proc ; Состояние стека после
push bp ; обращения к процеду- mov bp, sp ; pe summa для вычис- mov ax, [bp+8] ; a ; ления c~a+b add ax, [bp+6] ; a+b q mov bx, [bp+4] ; &c P — mov [bx], ax ; c=a+b I &возврата 2 Pop bp ; &c 4 ret ; b 6 summa endp * end begin ; a 8
В примере показана передача простых переменных(исходных данных и результатов). Показано состояние стека после обращения к процедуре summa для вычисления с=а+Ь. Анализ программы показывает, что передача параметров с последующей очисткой стека, передача управления процедуре требует дополнительных команд. Эти же действия выполняются при программировании на языке высокого уровня. Поэтому преж
338
де чем писать процедуру на любом языке, подумайте, эффективна ли она! Решение предыдущего примера без процедуры явно предпочтительней!
ПРИМЕР 2: Составить процедуру для объединения двух строк и использовать се для объединения строк, содержащих слова "first ” и "second " в одну строку. Вывести результат на дисплей.
.MODEL SMALL
.STACK 100Н
.DATA
Str1 db ’first ’, 0
str2 db ’second’, 13, 10, ’$’, 0
rez db (rez-str1) dup (?) .CODE
begin: mov ax, @data
mov lea push lea push lea push call ds, ax ax, str1 ; передача адресов массивов ax ax, str2 ax ax, rez ax strcat ;вызов процедуры
pop ax ; очистка ci pop ax pop ax lea dx, rez mov ah, 9 int 21 h mov ah, 4ch int 21 h strcat proc push bp mov bp, sp mov si, [bp+8]; &str1 mov di, [bp+4] ; &res againl: mov al, [si] and al, a! ie second ека Состояние стека
bp 0 2 4 6 8
&возсрата
&res
&str2
8str1
mov [di], al inc si inc di jmp againl
339
second: again2: mov si, [bp+6] ; &str2 mov al, [si] mov [di], al and al, al je all inc si inc di jmp again2
all: pop bp ret strcat endp end begin
В этим примере признаком конца исходных данных является нулевой завершитель (символ с кодом 0). В результирующую строку завершитель записывается после копирования второй строки. Для массивов исходных данных (str 1, str2) и массива результата (rez) передаются адреса. Это делается для экономии стекового пространства и числа команд, необходимых для передачи параметров.
ПРИМЕР 3: Составить процедуру для обмена местами нулевой и первой страниц видеопамяти в текстовом режиме. В качестве параметра использовать номер режима, который задает адрес начала видеопамяти (если режим = 7 (моно), то адрес-OBOOOOOOOh, иначе адрес = 0B8000000h). Номер режима определять с помощью прерывания 10h, функции ofh, которая возвращает номер режима в регистре al.
.MODEL SMALL
.386
.STACK 100Н
.CODE
begin: mov ah, OFH
int 10h ; Определение видеорежима push ax ; Передача видеорежима
call pop mov int swap video „ ax ~ ; Состояние стека после 4Сь ; обращения к проце- 21 h !ДУРе
swap_video proc bp 0
pusn mov Dp bp, sp ds J &возврата 2
push № режима 4
push es
340
mov ax, [bp+4] ; текущий видеорежим
mov cmp jne mov color: mov dx, 0B800H al, 7 color dx, 0B000H ds, dx
mov mov sub mov for: mov es, dx ; Адрес сегмента для страниц si, 4096 ; смещение для 2 страницы di, di сх, 1000 еах, [si] ; Обмен страниц
mov ebx, [di] mov [si], ebx mov [di], eax add si, 4 add di, 4 loop fqr pop es pop ds pop bp ret swap_video endp
end begin
Если используется 16-битный процессор, необходимо:
1) Удалить директиву .386;
2) команду mov сх, 1000 заменить командой mov сх, 2000 (число 2-х байтовых слов для обмена); |
3) вместо регистров еах, ebx использовать регистры ах, Ьх
4) команды add si, 4 и add di, 4 заменить командами add si, 2 и add di, 2 соответственно.
3.2.3. Особенности использования функций
Функции в языке высокого уровня отличаются от процедуры способом их использования в программе. Результат не задается в списке параметров, он "передается через имя", т.е. обращение к функции используется в выражении, как обычная переменная. Это достигается за счет передачи результата через фиксированные регистры. При программировании на ассемблере функцией будем считать процедуру, в которой вычисляется результат, возвращаемый в вызывающую программу через регистр. Выше была составлена процедура вычисления z=x+y. Составим функцию для вычисления z.
.MODEL SMALL
.STACK 100H
.DATA
341
X
У z
begin:
summa
dw 5
dw 6 dw ? .CODE mov ax, @data mov ds, ax push x push у ; z не пересылается в стек call summa pop ex pop ex mov z, ax ; результат возвращается через ax mov ah, 4ch int 21 h proc ; Состояние стека
push bp mov bp, sp mov ax, [bp+4] ; у ; bp 0
&возврата 2
add ax, [bp+6] ; x+y У < 4
pop bp ret x 6
endp
end begin
summa
Сравнение процедуры и функции показывает, что использование функции более эффективно. В дальнейшем для возврата единственного результата будем использовать функции.
ПРИМЕР: Составить функцию для сравнения "длинных” чисел без знака.
x .MODEL SMALL .DATA dw 5768h, 3452h, 1234h, Offffh ; Числа записаны,
У msg1 msg2 msg3 ; начиная с младших цифр dw Offffh, 1234h, 3452h, 5768h db ’ Первое число меньше второго’, 13, 10, ’$’ db 'Первое число больше второго’, 13, 10, ’$’ db ’Первое число равно второму’, 13, 10, ’$’ .CODE
begin: mov ах, @data mov ds, ax mov ax, offset x push ax ; адрес первого числа mov ax, offset у push ax ; адрес второго числа mov ax, 4 ; Длины чисел push ax
342
call cmpd
add sp, 6
and ax, ax
jl below
jg above
mov dx, offset msg3
jmp write
beiow: lea dx, msg1
jmp write
above: lea dx, msg2
write: mov ah, 9
int 21h
mov ah, 4ch
int 21 h
cmpd
proc ; Состояние стека
push bp
mov bp, sp 1 bp 0
mov si, [bp+8 &возврата 2
mov di, [bp+6]
mov ex, [bp+4] n 4
mov bx, ex ; &y 6
dec bx
shl bx, 1 &x 8
for:
bel:
ab: return:
cmpd
add si, bx ; Адреса "старших" цифр чисел add di, bx mov bx, [si] cmp bx, [di] jb bel ja ab sub si, 2 sub di, 2 loop for xor ax, ax jmp return mov ax, -1 jmp return mov ax, 1 pop bp ret endp end begin
В рассмотренной выше функции в регистре ах формирует >я О, -1, 1, если первое число равно, меньше второго или больше второго числа соответственно. Главная программа выводит соответствующее сообщение. При сравнении чисел учитывается, что младшие байты памяти соответствуют младшей части
343
числа. Ожидаемый результат для чисел программы: первое число больше второго.
Если вызывающая программа и подпрограмма на ассемблере, для результата можно использовать любой регистр, известный вызывающей программе. Если программы составлены на разных языках, имеются стандартные соглашения о регистрах (см. раздел "Стыковка Ассемблер — С")
3.2.4. Особенности использования внешних процедур (функций)
Внешняя процедура (функция/ транслируется отдельно от вызывающей программы. Это позволяет не транслировать каждый раз модули, в которых не было изменений. Упрощается изолированная от всей системы отладка отдельных модулей, что допускает участие в разработке системы группы программистов. Не следует заботиться о локальных именах программы, например, о метках, которые могут совпадать для различных модулей. И, наконец, появляется возможность стыковки разноязыковых модулей.
Чтобы объединить несколько модулей (эту функцию выполняет компоновщик) в одну программу, необходима специальная информация для вызывающей и вызываемой программ. Рассмотрим эту информацию.
Вызывающая программа
1. Необходимо знать, что вызываемый модуль является внешним, а также знать его тип.
Для этого используется директива
extrn имя процедуры : тип
где тип определяет атрибут дальности и задается словами: near, far или proc. Если задано слово proc, атрибут дальности (near, far) определяется моделью памяти (напоминаем, что модели tiny, small, compact соответствуют атрибуту near).
Директива записывается вне сегментов, в этом случае компоновщик будет искать определение этого имени во всех сегментах, пока не найдет. Можно директиву задать внутри сегмента .CODE, это указывает компоновщику на необходимость поиска этого имени в сегменте кодов. Это ускорит компоновку, но этот способ нельзя использовать для случая, если используется несколько кодовых сегментов.
344
2. Если вызывающая программа резервирует память под данные, которые должны использоваться в процедуре (функции), адреса этих данных должны быть определены как адреса типа public, т.е. доступные (известные) другим сегментам.
Общий вид директивы public
public имя1, имя2..
Если все данные сегмента должны быть доступны процедуре (функции), сам сегмент объявляется как сегмент типа public. При задании малой модели (.MODEL SMALL) сегмент данных по умолчанию является сегментом типа public, поэтому директива public для данных из сегмента .DATA не обязательна!
Директива public, если она необходима, задается в том сегменте, где определено это имя. Директиву можно использовать не только для переменных, но и для меток.
Вызываемая программа
1. Имя процедуры (функции) должно быть задано в директиве public:
public имя процедуры (функции)
2. Если процедура (функция) использует данные, память под которые выделена в другой программе, то в этой программе используется директива
extrn определение!, определение2,...
Общий вид определения для передаваемых данных:
имя : тип : количество , где
имя — имя данного, память под которое выделена в другом модуле;
тип — тип данного, используется для определения длины данного в байтах, для задания используются ключевые слова: byte, word, dword, fword, qword, tbyte или имя структуры для 1-, 2-, 4-, 8-, 10-байтовых данных и данных, определенных пользователем. Если в качестве внешнего имени используется имя, определенное в директиве equ, его тип — abs;
количество — задает число элементов данного типа, используется, если в качестве внешнего передается массив, позволяет применять в процедуре (функции) операции SIZE, LENGTH.
345
Таким образом, имена используемых, но не определенных данных должны определяться директивой extrn, а имена определенных данных, которые могут использоваться другими модулями, определяются директивой public. Чтобы обеспечить возможность одинаково задавать данные в различных модулях, используется директива global. Общий вид директивы:
global определение!, определение2, ...
Определения задаются так же, как для директивы extrn.
Чтобы определить функции global, транслятор "смотрит", выделена ли память для данного в этом модуле. Если выделена, директива эквивалентна директиве local, в противном случае — extrn. Использование global делает возможным сделать общим определение для нескольких модулей. Общая часть может быть помещена в файл, который подключается к модулям с помощью директивы include.
Общий вид директивы:
include имя файла
Для файла может быть задано его полное имя.
Т.к. внешняя процедура (функция) может использоваться другими программами, о которых разработчик заранее может не знать, эта программа не должна "портить" содержимое ресурсов общего пользования.
С учетом рассмотренных выше требований общий вид внешней процедуры (функции) следующий:
.MODEL имя
.CODE
имя_проц. ргос public имя
; Сохранение используемых регистров
; Реализация алгоритма
; Восстановление используемых регистров
ret
имя endp end
В процедуре, в отличие от главной программы, в директиве end адрес точки входа не задается.
346
Общий вид вызывающей программы : .MODEL имя
extrn имя_проц: proc
.CODE begin:
end begin
Директивы public и extrn в этих программах можно заменить директивой global имя_проц:ргос. Но мы все-таки рекомендуем Вам использовать директивы public и extrn, т.к. они позволяют более глубоко изучить механизм связи модулей. Именно эти директивы наиболее часто используются в опубликованных программах. После того, как Вы уверенно почувствуете себя в использовании этих директив, можно их заменить директивой global.
Для создания исполняемой программы из нескольких модулей, выполняется раздельная трансляция для каждого модуля (tasm имя_модуля1, tasm имя_модуля2,...) и компоновка всех модулей вместе (tlink имя_модуля1 имя_модуля2 ...). Для формирования отладочной информации используются те же ключи, что и для одномодульных программ.
Примеры'составления и использования внешних процедур.
ПРИМЕР 1: Составить внешнюю процедуру для вычисления z=x+y. Параметры передавать через стек.
; файл main.asm
.MODEL SMALL
.STACK 100H extern summa: proc .DATA
x dw 5
у dw 3
z dw ?
.CODE
begin: mov ax, @data
mov ds, ax
lea ax, z
push ax
push у push x
347
call summa
add sp, 6
mov ah, 4ch
int 21h
end begin
; файл stimma.asm
.MODEL SMALL .CODE
summa proc public summa push bp mov bp, sp mov ax, [bp+4] add ax, [bp+6] mov bx, [bp+8] mov [bx], ax pop bp ret
; x
; x+y
;z=x+y
Состояние стека
bp 0
&возврата 2
X 4
У 6
&z 8
summa endp end
Для трансляции этих файлов используются команды:
tasm /zi main
tasm /zi summa
tlink /v main summa
В результате выполнения этих команд получим файл main.exe.
4 СТЫКОВКА С — АССЕМБЛЕР
Существует три способа стыковки:
1. Вставка в С-программу команд на ассемблере;
2. Программа на С вызывает процедуру на ассемблере;
3. Программа на ассемблере вызывает процедуру на С;
Последний способ чаще всего используется для применения стандартных функций С при программировании на ассемблере.
4.1. Вставка в С программ на ассемблере. Рекомендации и правила записи вставок
1. Команда должна начинаться с ключевого слова asm. При использовании C++ несколько подряд идущих команд могут быть объединены в блок
asm {
}
При использовании TURBO С перед командой должно быть слово asm.
2. Вставлять можно все допустимые машинные команды и директивы, не определяющие работу транслятора. Так не допускаются директивы
segment и ends;
proc и endp;
assume и end
и др.
3. В ассемблерной части программы допускается использование данных С-программы всех классов (локальные,
349
внешние, статические, регистровые). Данные могут быть объявлены в ассемблерной части программы, при этом их класс определяется местом программы, где они определены. Данные объявляются по правилам объявления данных в ассемблере.
ПРИМЕР: asm х db ?
4. Если в ассемблерной части есть команда перехода, то метка записывается по правилам С, например
asm jmp label
label: asm xor ax, ax
5. Комментарии записывают по правилам С. Символ используется в качестве конца команды, а не начала комментария. В строке может быть записано несколько команд, например:
asm push ах; asm push bx; asm push ex
или для C++
asm {push ax; push bx; push ex)
После последней или единственной командной строки можно не ставить.
6. В ассемблерной части программы нельзя изменить содержимое регистров cs, ds, ss, sp, bp, а также si, di, если используются регистровые переменные.
7. Если встречается хотя бы одна ассемблерная вставка, необходим дополнительный шаг трансляции с языка С на ассемблер. Для задания транслятору режима перевода в ассемблерный код используется директива
# pragma inline
Если директивы нет, требуется повторная трансляция, если встречена команда на ассемблере.
8. Программа с ассемблерными вставками не может быть оттранслирована в интегрированной среде (turbo с). Требуется tcc. Это ограничение снято в C++. Пример программы с ассемблерными вставками :
# pragma inline
int summa (int x, int y){
int z;
asm mov ax, x
asm add ax, у
350
asm mov z, ax
return z;
}
main(){
printff" сумма = % d\n", summa(5, 3));
}
Пусть программа в файле prog.c, библиотеки в подкаталоге LIB, а заголовочные файлы в подкаталоге INCLUDE, тогда для формирования .ехе файла используется команда
bcc -LLIB -IINCLUDE prog.c для Borland С++ или
tcc -LLIB -IINCLUDE ргос.с для Tu bo C++
Недостаток этого способа стыковки:
Невозможна отдельная компиляция С и ассемблер-программ.
«
4.2. Вызов из С процедур на ассемблере
Требования к процедуре на ассемблере
1. Имя процедуры дожно начинаться с символа подчеркивания, т.к. этот символ добавляется по умолчанию при трансляции программ.
2. Для ассемблер-программы необходимо использовать ту же модель памяти, пои для вызывающей программы.
3. Для обеспечения возможности связывания программ на этапе компоновки имя процедуры должно быть задано в директиве public.
Таким образом структура процедуры :
.MODEL имя_модели
_имя proc
риЫю_имя
_имя endp •
end
Способы передачи параметров:
1. Передача параметров через список. При изложении этого вопроса предполагается, что используется принятый по умолчанию в С способ записи параметров в стек. В этом случае параметры записаны в стек в порядке, обратном их расположению в списке. Таким образом, при обращении к процедуре стек имеет такую структуру:
351
SS:SP =>
Адрес возврата
1 -й параметр процедуры 2-й параметр процедуры
Для доступа к параметрам без их извлечения из стека используется регистр Ьр.
последний параметр
SS:SP =>
bp
Адрес возврата
1 -й параметр процедуры 2-й параметр процедуры
последний параметр
Для сохранения содержимого Ьр, его содержимое записывается в стек, который после этого имеет такую структуру.
Структура процедуры с параметрами:
.MODEL имя_модели _имя proc
риЫ!с_имя
push bp mov bp, sp
pop bp ret _имя endp
end
ПРИМЕР: Составить главную программу и процедуру для вычисления z=x+y для целых х, у, z.
# include <stdio.h>
/*файл prog.c*/
extern "С"
void summa (int x, int y, int*z);
int c;
main(){
summa(2, 3, &c);
printff’сумма = %d\n", c);
}
; Файл proc, asm
.MODEL SMALL .CODE
.umma proc
352
public _summa push bp mov bp, sp push ax
mov ax, [bp+4] add ax, [bp+6] push bx
mov bx, [bp+8] mov [bx], ax pop bx pop ax pop bp
ret
summa endp end
; Состояние стека
SP=> 2 • 2+3 ; » 1 » bp "о 2 4 6 8
&возврата
2
3
&с
Для получения .exe файла необходим оператор :
bcc -linclude -Llib prog proc.asm
или выполнение проекта в интегрированной среде.
Обратите внимание на величины смещений для параметров и особенность передачи параметра-результата!
При использовании больших моделей, для которых адреса, в том числе адрес возврата и адрес результата, являются дальними адресами, смещения будут другими.
Рассмотрим процедуру summa для модели LARGE.
.MODEL LARGE
summa proc ; no умолчанию дальняя public _summa push bp SP =>• mov bp, sp push ax '• mov ax, [bp+6] ; add ax, [bp+8] ’ push bx • push es ;
lesbx, [bp+1O] mov es:[bx], ax ’ pop es ; pop bx pop ax pop bp ret
___________bp____________
Адрес возврата (смещение) Адрес возврата (сегмент) ______2__________________ ______3__________________ ______&с (смещение)______ ______&с (сегмент)_______
summa endp end
12 «Основы программирования»
О
2
4
6 8 .10 12
353
Чтобы не вычислять величины смещений для параметров, используется директива arg:
arg имя : тип [:количество], имя : тип ^количество], ...
Имена параметров задаются в том порядке, в котором они следует в операторе вызова.
Тип определяет длину параметра и задается ключевыми словами :
byte , word dword , qword , tbyte
Если параметр является массивом, то тип определяет длину одного элемента и количество таких элементов.
Для предыдущей программы директива arg имеет вид:
arg a.word, b:word, addr_c:word
После директивы в командах можно использовать имена параметров вместо их адресов в стеке, т.е.
mov ах, а add ах, b mov bx, addr_c mov [bx], ax
2 Передача параметров через внешние переменные.
Сначала напомним, что внешние переменные в программе на С должны быть описаны вне функции. В процедуре на ассемблере эти переменные должны быть заданы с символом подчеркивания и указаны в директиве extrn
extrn имя:тип, имя:тип, ...
Директива означает, Что память под заданные переменные выделена в другом месте (в программе на С). Тип задается ключевыми словами : byte, word, dword, qword, tbyte и определяет длину одного данного.
Пример директивы extrn для предыдущей программы:
extrn _х: word, _у: word, _z: word;
Для обращения к внешним переменным для малых моделей можно задавать имена этих переменных, для больших — необходимо задать сегментный компонент и смещение, определяемое именем.
354
ПРИМЕР: Главная программа на С и процедура на ассем блере при передаче параметров через внешние переменнь»-
#include <stdio.h>
/‘файл prog.с*/
extern "С”
void summa(void);
int x, у, z; /‘Внешние переменные*/ main(){
х=2; у=3;
summa();
printf(''cyMMa=%d\n", z);
}
; файл proc.asm
extrn _x: word , _y: word , _z: wore .MODEL SMALL €
.CODE
_summa proc
public_summa push ax mov ax, _x add ax, _y pop ax mov z, ax ret
_summa endp end
Для больших моделей ниже приведен пример
; файл procj.asm
extrn _х: word, _у: word, _z: word .MODEL LARGE
_summa proc
public _summa push ax
push es
mov ax, seg _x
mov es, ax
mov ax, es:_x
mov bx, seg _y
mov es, bx
add ax, es:_y
mov bx, seg _z
mov es, bx
mov es:_z, ax
pop es
12»
355
pop ax ret summa endp
end
Сравнительный анализ способов передачи параметров показывает, что первый способ обеспечивает независимость процедуры от имен параметров в вызывающей программе, а второй нет. Последний способ проще с точки зрения программиста и не требует дополнительных команд для пересылки параметров.
Особенности составления функций.
Вспомним, чем процедура отличается от функции? У функции один (чаще всего единственный ) результат не задается в списке, т.е. при обращении к процедуре мы пишем:
summa(x, у, &z);
а при обращении к функции
z=summa(x, у);
Вы видите, что результат исключен из списка параметров. Т.к. функция не знает адреса, куда записать z, то она помещает его всегда в фиксированное место, о котором знает вызывающая программа. Это место зависит от типа результата и его длины.
Таблица соответствия места результата и типа данных
Тип результата Место результата
[unsignedlchar al
[signed char al
[unsigned]int ax
[signed int ax
Тип результата Место результата
[unsigned]long dx, ах(ах-младшее слово)
[signedllonq dx, ах(ах-младшее слово)
float вершина стека сопроцессора
[long]double вершина стека сопроцессора
адрес типа near ах
адрес типа far, huge dx, ах(ах - смещение)
356
тип результата место результата
структура длиной,
1 байт al
2 байта ах
4 байта dx, ах (ах-младшее слово)
3 или > 4 байт выделяется память в сегменте данных и адрес выделенной области в ах или (dx, ах) в зависимости от типа адреса по умолчанию.
ПРИМЕР: Составить программу и функцию вычисления z=x+y
#include <stdio.h> , ,
/* файл prog.c */
int summa (int x, int y);
main(){
printf(,,cyMMa=%d\n”, summa(2, 3));
}
/* файл p func.asm */ .MODEL SMALL .CODE
_summa proc
public _summa push bp mov bp, sp mov ax, [bp+4] add ax, [bp+6] pop bp ret
_summa endp end
Ьр 0
йвозврата 2
2 4
3 6
Использование локальных переменных в процедурах (функциях) на ассемблере.
Пусть в процедуре (функции) необходимо выделить память под вспомогательные переменные. Как мы это делаем, работая с языком С? Описываем переменную внутри процедуры и память под них выделяется в стеке. Почему эти переменные не задаются как внешние? Нам необходимо, чтобы память, выделенная под вспомогательные переменные, освобождалась при выходе и выделялась при каждом повторном входе. Это делает процедуру повторно-входимой или реентерабельной.
357
Память в ассемблерной процедуре выделяется в стеке так же, при этом получаем стек, имеющий такую структуру:
сохраненные регистры локальные переменные Ьр адрес возврата параметры
Как зарезервировать память в стеке под локальные переменные? Для этого достаточно определить, сколько байтов требуется для локальной области и изменить содержимое регистра sp на эту величину. Так, если для локальной области требуется п байтов, то для выделения памяти требуется команда
sub sp, п
Для освобождения памяти в этом
случае используется команда add sp, п
ПРИМЕР: Реализовать на ассемблере функцию, которая вызывается программой на С.
Определение функции на языке С :
it fun(int a, int b){
int m, n;
m=2*a+b; n=3*b;
return(m/n);
}
; файл proc.asm
.MODEL SMALL
.CODE
_ un proc Состояние стека
public push mov _fun bp bp, sp m
n
sub push mov sp, 4 ; m, n dx ax, [bp+4] ; a ax, 1 ; 2*a ax, [bp+6] ; 2*a+b [bp-4], ax ; m ax, 3 word ptr[bp+6] ; 3*b [bp-2], ax ; n bp 0
&возврата 2
sal add mov a 4
b 6
mov mul mov cwd
div word ptr[bp-2]
pop dx
add sp, 4
pop bp
258
l
ret _fun endp end
Проанализируйте каждую команду программы!
Для упрощения работы с локальными переменными в процедуре используется директива LOCAL :
LOCAL имя: тип[:к-во], имя: тип[:к-во], ...
имя — имя очередной локальной переменной; тип — {BYTE, WORD, DWORD, QWORD, TBYTE} k-bo — определяет число данных этого типа и используется, если локальное данное является массивом;
=имя — определяет имя переменной, куда записывается число байт, отводимых для локальной области. Это имя используется в командах резервирования и освобождения памяти для локальных данных.
ПРИМЕР: Составить предыдущую программу, используя директивы ARG и LOCAL.
; файл proc.asm
.MODEL SMALL _fun proc public _fun ARG a:word, b:word LOCAL m:ord, n:word=SIZ push bp mov bp, sp sub sp, SIZ ; резервирование памяти push dx mov ax, a sal ax, 1 add ax, b mov m, ax mov ax, 3 mul b mov n, ax mov ax, m cwd div n pop dx add sp, SIZE pop bp ret _fun endp end
359
Сравните последние две програ’ммы:
Вызывающая программа для _fun обоих вариантов;
/* файл prog.c */
main(){
рппМ("результат=%с1\п", fun(5, 2));
}
Команда для получения .ехе файла
bcc -linclude -Llib prog.c proc.asm
Итак, повторим основные моменты, о которых необходимо помнить, если процедура на ассемблере вызывается из про граммы на С:
1. Имя функции начинается с символа подчеркивания и должно быть задано в директиве public.
2. Для доступа к параметрам из списка используется регистр Ьр.
3. При передаче внешних переменных они должны быть с символом подчеркивания и заданы в директиве public или extrn, если память выделена в программе на ассемблере или С соответственно.
4. Если есть локальные переменные, память под них выделяется в стеке. Только недостаточный размер стека может быть основанием выделения памяти в сегменте данных.
5. Рекомендуется использовать директивы arg, local, которые делают программу нагляднее.
4.3. Вызов из ассемблера процедур на С
Для \спешной работы функций языка С могут потребоваться константы, генерируемые программой начальной инициализации. Поэтому рекомендуется использовать Ьсс или проект даже в том случае, если главная программа написана на языке ассемблер, Ьсс подключает модуль начальной инициализации при компоновке программы.
Мы сейчас рассматриваем вариант, когда программа на ассемблере обращается к функции (стандартной или нестандартной) языка С.
Программа на ассемблере должна выполнить следующее: сформировать требуемый список параметров в стеке;
вызвать функцию, используя правильный атрибут дальности
(call far..., call near...);
очистить стек.
^6и
ПРИМЕР: Для заданных значений х, у вычислить z=x+y; u=x-y и отпчатать z, <j в виде г=число ; и=число. Вычисления делать на ассемблере, а результат печатать с помощью функции printf.
extrn printf: near .MODEL SMALL .DATA
X У Z U V string _main dw 5 dw 3 dw ? dw ? dw ? db ’z=%d ; u=%d\n’ .CODE proc public _main
begin: mov ax, @data t mov ds, ax mov ax, x add ax, у mov z, ax mov ax, x sub ax, у mov u, ax ; Формирование списка параметров push v push u lea ax, string push ax ; Обращение к функции call _printf ; Очистка стека add sp, 6 ; Выход из программы mov ah, 4ch int 21 h _main end end main
Для формирования .ехе файла требуется команда
bcc -Llib prog.asm
Параметр (include не нужен, т.к. нет заголовочных файлов.
Итак, рассмотрены три способа стыковки. Рекомендуем тщательно разобраться во всех приведенных примерах, используя для отладки программы td.exe, а затем использовать
361
приведенные способы стыковки при решении практических задач.
Поздравляем Вас с вступлением в когорту профессиональных программистов и рекомендуем изучить основные положения книги :
Касаткин А.И. Профессиональное программирование на языке С. Системное программирование. — Мн: Высш.шк., 1993.— 301с.
Список литературы
1. Лю Ю-Чжен, Гибсон Г. Микропроцессоры семейства 8086/8088. Архитектура, программирование и проектирование микрокомпьютерных систем. — М.: Радио и связь, 1987.— 512 с.
2 Абель Г. Язык ассемблера для IBM PC и программирование. — М.: Высшая школа, 1992. — 314 с.
3. Использование Turbo Assembler при разработке программ. — Киев: Диалектика, 1994. — 288 с.
СОДЕРЖАНИЕ
ОТ ИЗДАТЕЛЯ t
В. М. Бондарев.
ОСНОВЫ ПРОГРАММИРОВАНИЯ
ВВЕДЕНИЕ 9
1. ОСНОВНЫЕ ПОНЯТИЯ ПАСКАЛЯ
1.1 Пример простой программы....................... 11
1.2. Имена и зарезервированные слова............... 12
1.3. Константы и переменные........................12
1.4. Оператор присваивания.........................12
Задачи............................................. 13
2. АРИФМЕТИКА ПАСКАЛЯ
2.1. Тип INTEGER (целый)...........................14
2.2. Тип REAL (вещественный).......................15
2.3 Арифметические выражения ......................15
2.4. Функции..................................... 15
2.5. Преобразование типов......................... 16
Задачи........................................... 16
3. ВВОД И ВЫВОД НА ДИСПЛЕЙ
3 .1 Ввод и вывод ............................... 18
3 2 Дополнительные операторы ввода и вывода. ... 19
З адачи........................................ 20
4. ЛОГИКА ПАСКАЛЯ
4.1 Условный оператор .............................21
4 2 Составной оператор.............................22
4 3 Сложные условия .............................. 23
4 4 Тип BOOLEAN (логический) ..................... 23
Задачи.............................................23
5. ЦИКЛЫ
5.1 Оператор цикла WHILE........................ 25
5.2 Оператор цикла REPEAT ................... .. . 26
363
5.3 . Поиск наибольшего числа..........................26
5.4 . Вложенные циклы..................................27
Задачи.................................................28
6. МАССИВЫ
6.1 Одномерные массивы...... 29
6.2. Сортировка массивов...............................31
6.3. Обменная сортировка ..............................32
6.4. Многомерные массивы...............................33
Задачи.................................................34
7. ФУНКЦИИ И ПРОЦЕДУРЫ
7 1. Описание функций.................................35
7.2. Обращение к функции...............................36
7.3. Процедуры ........................................37
7.4. Параметры-переменные..............................38
7.5. Взаимодействие блоков.............................39
Задачи.................................................40
8. ПОРЯДКОВЫЕ ТИПЫ ДАННЫХ
8.1 Тип CHAR (символьный)............................ 41
8.2. Перечислимый тип данных...........................42
8.3. Интервальный тип данных...........................42
8.4. Порядковые типы данных............................43
8.5. Оператор FOR......................................44
8.6. Оператор выбора...................................44
Задачи.................................................45
9. СТРОКИ СИМВОЛОВ
9.1. Значения и операции...............................46
9.2. Средства обработки строк..........................47
9.3. Строка — составной тип данных.................... 48
Задачи................................................ 48
10. ОБРАБОТКА ЗАПИСЕЙ
10.1. Записи...........................................50
10.2. Оператор WITH....................................51
10.3. Последовательный поиск ..........................52
10.4. Двоичный поиск...................................53
Задачи.................................................54
11. РАБОТА С ФАЙЛАМИ
11.1. Файлы на магнитном диске.........................55
11.2. Текстовые файлы..................................56
11.3. Чтение из текстового файла.......................56
11.4. Запись в текстовой файл..........................58
11.5. Устройства DOS...................................59
11.6. Стандартные файлы ввода и вывода.................59
11.7. Типизированные файлы.............................60
Задачи.................................................61
12. ДИНАМИЧЕСКАЯ ПАМЯТЬ
12.1. Статические и динамические переменные............64
12.2. Выделение и освобождение памяти..................65
12.3. Массив указателей................................66
364
12.4. Динамические списки..............................66
Задачи.................................................68
13. РЕКУРСИЯ
13.1. Рекурсивные алгоритмы и рекурсивные определения..70
13.2. Рекурсивные процедуры и функции..—...............71
13.3. Рекурсия изнутри............................... 72
13.4. Быстрая обменная сортировка......................74
Задачи.................................................74
14. ДЕРЕВЬЯ
14.1. Деревья вокруг нас.............................. 76
14.2. Рекурсивное определение дерева.................. 77
14.3. Двоичные деревья.................................77
14.4. Двоичные упорядоченные деревья.................. 78
Задачи.................................................79
15. МНОЖЕСТВА
15.1. Значения типа множество..........................81
15.2. Отношения и операции на множествах...............82
15.3. Внутреннее представление множеств................83
Задачи.................................................84
16. ПЕРЕБОРНЫЕ ЗАДАЧИ
16.1. Задача коммивояжера............................. 85
16.2. Метод ветвей и границ............................88
Задачи.................................................90
17. ПРОГРАММНЫЕ МОДУЛИ
17 1. Для чего нужны программные модули...............91
17.2. Структура программного модуля....................91
17.3. Пример модуля....................................92
17.4. Ссылки на модули.............................. ..94
17.5. Стандартные модули ТП............................94
Задачи.........................*.......................95
18. ВВЕДЕНИЕ В ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ ПРОГРАММИРОВАНИЕ
18.1. Зачем нужно ООП..................................96
18.2. Что такое объекты................................96
18.3. Объект «числовой список».........................97
18.4. Инкапсуляция.....................................98
18.5. Объекты и модули................................100
18.6. Наследование....................................100
18.7. Виртуальные методы. Констракторы и дестракторы..101
18.8. Таблица виртуальных методов.....................103
18.9. Объекты в динамической памяти...................104
18.10. Сложное меню в динамической памяти.............105
18.11. Полиморфизм....................................107
18.12. Объекты изнутри................................107
18.13. Взаимодействие объектов........................109
Задачи................................................109
Приложение к разделу 18 « Введение в ООП».............110
ЗАДАЧИ 116
365
В.И.Рублинецкий. ВВЕДЕНИЕ В МИР АЛГОРИТМОВ ВВЕДЕНИЕ 121
1. ПРИКЛАДНЫЕ ЗАДАЧИ ТЕОРИИ ГРАФОВ 1.1 Задача Прима-Краскала.................................125
Задачи и упражнения....................................131
1.2. Задача Штейнера...................................131
Задачи и упражнения....................................134
1.3. Алгоритм Дейкстры.................................135
Задачи и упражнения....................................138
1.4. Задачи трассировки................................139
Задачи и упражнения....................................154
1.5. Задачи размещения.................................155
Задачи и упражнения....................................160
1.6. СПУ — сетевое планирование и управление...........162
Задачи и упражнения....................................170
1.7. Задача коммивояжера...............................171
Задачи и упражнения....................................187
2. ЦЕЛОЧИСЛЕННЫЕ ЗАДАЧИ ЛИНЕЙНОГО ПРОГРАММИРОВАНИЯ
2.1. Наибольшее паросочетание.............................188
2.2. Задача о назначениях..............................192
2.3. Задача о назначениях на узкое место...............197
2.4. Транспортная задача...............................198
Задачи и упражнения....................................207
2.5. Задача о максимальном потоке......................207
Задачи и упражнения....................................213
2.6. Общая задача линейного программирования и симплекс-метод.213
Задачи и упражнения....................................223
3. ТЕОРИЯ РАСПИСАНИЙ
3.1. Задачи одного исполнителя на минимакс................225
3.2. Задачи одного исполнителя на минисумму............228
3.3. Задачи о нескольких исполнителях..................231
Задачи и упражнения....................................236
4. КРИПТОЛОГИЯ 237
4.1. Элементы теории сравнений.........................239
4.2. Выработка секретного ключа по Диффи-Хеллману......240
4.3. Система RSA.......................................241
4.4. Алгоритмы факторизации п..........................243
Задачи и упражнения....................................251
5 О СЛОЖНОСТИ ЗАДАЧ
5.1. Исследование сложности некоторых задач теории расписаний......................................255
5.2 Псевдополиномиальные алгоритмы.....................259
Задачи и упражнения.................................. 261
5.3. Труднорешаемые задачи............................ 261
5.4. Как решать труднорешаемые задачи..................262
5.5. Совсем нерешаемые задачи..........................264
1ИТЕРАТУРА 270
366
Е.Г.Качко.
ЭЛЕМЕНТЫ ПРОФЕССИОНАЛЬНОГО ПРОГРАММИРОВАНИЯ
ВВЕДЕНИЕ 275
1. ПРОСТЕЙШИЕ КОНСТРУКЦИИ ЯЗЫКА
1.1. Первая программа............................ 277
1.2. Структура оператора ассемблера .....-........279
Операции для работы с данными.................... 291
2. ОБЗОР ПРИЕМОВ ПРОГРАММИРОВАНИЯ НА АССЕМБЛЕРЕ
2 1. Программирование арифметических выражений .. . 293
“Узелки" на память.. ........................... -295
2 2. Организация разветвлений и циклов 296
2 .3. Обработка массивов .....
2 .5. Побитовая обработка .................... 321
3. МОДУЛЬНОЕ ПРОГРАММИРОВАНИЕ НА АССЕМБЛЕРЕ
3 .1. Структура исполняемых программ............ 332
3 2. Процедуры и Функции.........................334
4. СТЫКОВКА С - АССЕМБЛЕР
4.1. Вставка в С программ на ассемблере. Рекомендации и правила записи вставок........... -349
4.2. Вызов из С процедур на ассемблере . 351
4.3. Вызов из ассемблера процедур на С 360
ЛИТЕРАТУРА 362
СОДЕРЖАНИЕ 363
Учебное издание
БОНДАРЕВ Владимир Михайлович РУБЛИНЕЦКИЙ Владимир Ильич КАЧКО Елена Григорьевна
ОСНОВЫ
ПРОГРАММИРОВАНИЯ
Главный редактор В.И.Галий Художественный редактор
Б.Ф.Бублик Технический редактор
Л.Т.Ена
Сдано в набор 03.02.96. Подписано в печать 08.01.98. Формат 84x108 1/32. Бумага типогр.
Гарнитура Прагматика. Печать высокая с ФПФ.
Усл. печ. л. 19,32. Усл. кр.-отт. 20,16. Уч.-изд. л. 22,8. Тираж 25 000 экз. (3-й завод 17 001—22 000 экз.). Заказ № 7-89.
«Фолио»
310002, Харьков, ул. Артема, 8
Отпечатано с готовых позитивов на книжной фабрике им. М. В. Фрунзе, 310057, Харьков, ул. Донец-Захаржевского, 6/8
В.М.Бондарев В.И.Рублинецкий
Е.Г.Качко
ОСНОВЫ
ПРОГРАММИРОВАНИЯ
Основы Паскаля
Разработка алгоритмов
1ШНН* Элементы профессионального программирования