/










































































































































































































































































































































































































































































































































































































































































































































































Теги: компьютерные технологии оргсвязь программирование компьютерные сети
ISBN: 5-8046-0041-9
Год: 2004




Текст
77m Parker
and Karanjit S. Siyan
TCP/IP
Unleashed
3d edition
SAMS
ББК 32.988.02
УДК 681.324
П18
П18 TCP/IP. Для профессионалов. 3-е изд. / Т. Паркер, К. Сиян. — СПб.: Питер,
2004.— 859 с: ил.
ISBN 5-8046-0041-9
Главной особенностью этой книги является то, что материал в ней изложен с позиций, не
связанных с программированием. Авторы рассказывают о том, как работает протокол TCP/IP, как
он взаимодействует с другими протоколами своего семейства, какие функции выполняет.
Описания сопровождаются подробными инструкциями по установке и настройке протоколов и
служб, приводятся используемые для этого команды и примерные результаты их выполнения. Вы
узнаете, как организовать поддержку TCP/IP во многих операционных системах, включая
Windows 9x, Windows NT, Windows 2000, NetWare и в популярной системе Linux. В книге также
затронуты вопросы безопасности.
ББК 32.988.02
УДК 681.324
Права на издание получены по соглашению с Sams Publishing.
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного
разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как надежные. Тем не
менее, имея в виду возможные человеческие или технические ошибки, издательство не может гарантировать абсолютную
точность и полноту приводимых сведений и не несет ответственности за возможные ошибки, связанные с использованием книги.
© 2002 by Sams Publishing
ISBN 0-672-32351-6 (англ.) © Перевод на русский язык, ЗАО Издательский дом «Питер», 2004
ISBN 5-8046-0041-9 © Издание на русском языке, оформление, ЗАО Издательский дом «Питер», 2004
Краткое содержание
Благодарности 26
Введение 27
Глава 1. Открытые коммуникации 29
Глава 2. TCP/IP и Интернет 43
Глава 3. Общий обзор TCP/IP 57
Глава 4. Имена и адреса в сетях IP 70
Глава 5. ARP и RARP 99
Глава 6. DNS 123
Глава 7. WINS 138
Глава 8. Автоматизированная настройка TCP/IP 162
Глава 9. Обзор семейства протоколов IP 190
Глава 10. Протокол IP 204
Глава 11. Транспортные протоколы 248
Глава 12. IPv6 306
Глава 13. Маршрутизация в сетях IP 326
Глава 14. Шлюзовые протоколы 347
Глава 15. Протокол RIP 353
Глава 16. Протокол OSPF 385
Глава 17. Протокол IPP 408
Глава 18. Протоколы удаленного доступа 413
Глава 19. Брандмауэры 444
Глава 20. Сетевая и системная безопасность 457
Глава 21. Общая конфигурация 470
Глава 22. Настройка TCP/IP в Windows 95 и Windows 98 485
Глава 23. Настройка TCP/IP в Windows 2000 505
Глава 24. Поддержка IP в Novell NetWare 548
Глава 25. Настройка TCP/IP в системе Linux 563
Глава 26. Whois и Finger 584
Глава 27. Протоколы пересылки файлов 599
Глава 28. Telnet 620
Глава 29. Инструментарий удаленного доступа 636
Глава 30. Протоколы совместного доступа к файловой системе: NFS и SMB/CIFS . . . 648
Глава 31. Интеграция TCP/IP с прикладными службами 667
Глава 32. Почтовые протоколы Интернета 672
Глава 33. Служба HTTP 688
Глава 34. Служба сетевых новостей и протокол NNTP 704
Глава 35. Установка и настройка web-сервера 713
Глава 36. Настройка и оптимизация протоколов в системах семейства Unix .... 729
Глава 37. Реализация DNS 744
Глава 38. Управление сетью TCP/IP 756
Глава 39. Протокол управления сетью SNMP 777
Глава 40. Безопасность передачи данных TCP/IP 790
Глава 41. Инструментарий и методы диагностики 805
Приложение A. RFC и стандарты 828
Приложение Б. Сокращения и акронимы 837
Алфавитный указатель 846
Содержание
Благодарности . 26
Введение 27
От издательства 28
Глава 1. Открытые коммуникации 29
Эволюция открытых сетей 30
Многоуровневая структура коммуникаций 30
Эталонная модель OSI 32
1. Физический уровень 33
2. Канальный уровень 34
3. Сетевой уровень 34
4. Транспортный уровень 35
5. Сеансовый уровень 35
6. Представительский уровень 37
7. Прикладной уровень 37
Использование модели 37
Эталонная модель TCP/IP 40
Анатомия модели TCP/IP 40
Итоги 42
Глава 2. TCP/IP и Интернет 43
История Интернета 43
ARPANET 44
TCP/IP 44
NSF 45
Интернет сегодня 45
RFC и процесс стандартизации 46
Источники информации о RFC 47
Индексы RFC 48
Краткое знакомство со службами Интернета 48
Whois и Finger 48
FTP 48
Telnet 49
Электронная почта 49
World Wide Web 49
Usenet 49
Интрасети и эксграсети 50
Интрасети 50
Преимущества интрасетей 50
Области применения интрасетей 51
Предоставление внешнего доступа к интрасети 51
Будущее Интернета 52
NGI (Next Generation Internet) 52
vBNS 52
Internet2 A2) 53
Так кто же главный в Интернете? 53
ISOC (Internet Society) 53
IAB (Internet Architecture Board) 53
IETF (Internet Engineering Task Force) 54
IESG (Internet Engineering Steering Group) 54
IANA (Internet Assigned Numbers Authority) 54
ICANN (Internet Corporation for Assigned Names and Numbers) 54
InterNIC и другие регистрирующие органы 55
Редактор RFC 55
Поставщики услуг Интернета 55
Итоги 56
Глава 3. Общий обзор TCP/IP 57
Преимущества TCP/IP 57
Уровни и протоколы TCP/IP 58
Архитектура 58
TCP 59
IP 61
Прикладной уровень 63
Транспортный уровень 63
Сетевой уровень 64
Канальный уровень 64
Telnet 64
FTP 64
TFTP 65
SMTP 66
NFS 66
SNMP 67
Место TCP/IP в системе 68
Концепция интрасети 69
Итоги 69
Глава 4. Имена и адреса в сетях IP 70
Адресация в протоколе IP 70
Двоичная и десятичная запись 71
Форматы адресов IPv4 72
КлассА 73
КлассВ 74
Классе 74
Класс D 75
КлассЕ 76
Недостатки схемы адресации IPv4 76
Специальные IP-адреса 77
Адресация сети 78
Направленная широковещательная рассылка 78
Ограниченная рассылка 79
Нулевой IP-адрес 79
IP-адрес хоста в текущей сети 80
Обратная связь 80
Исключение в схеме адресации IP 81
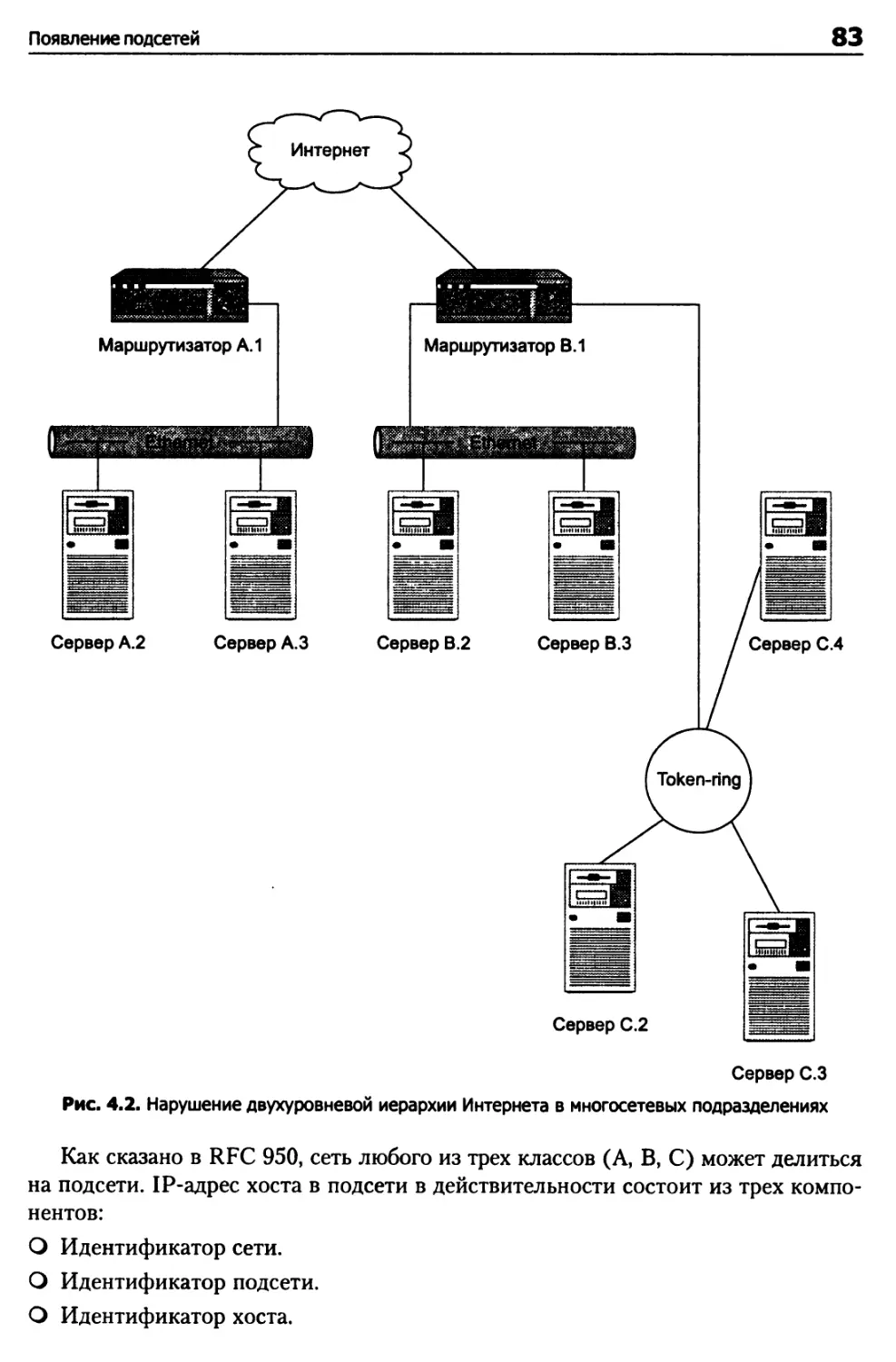
Появление подсетей 81
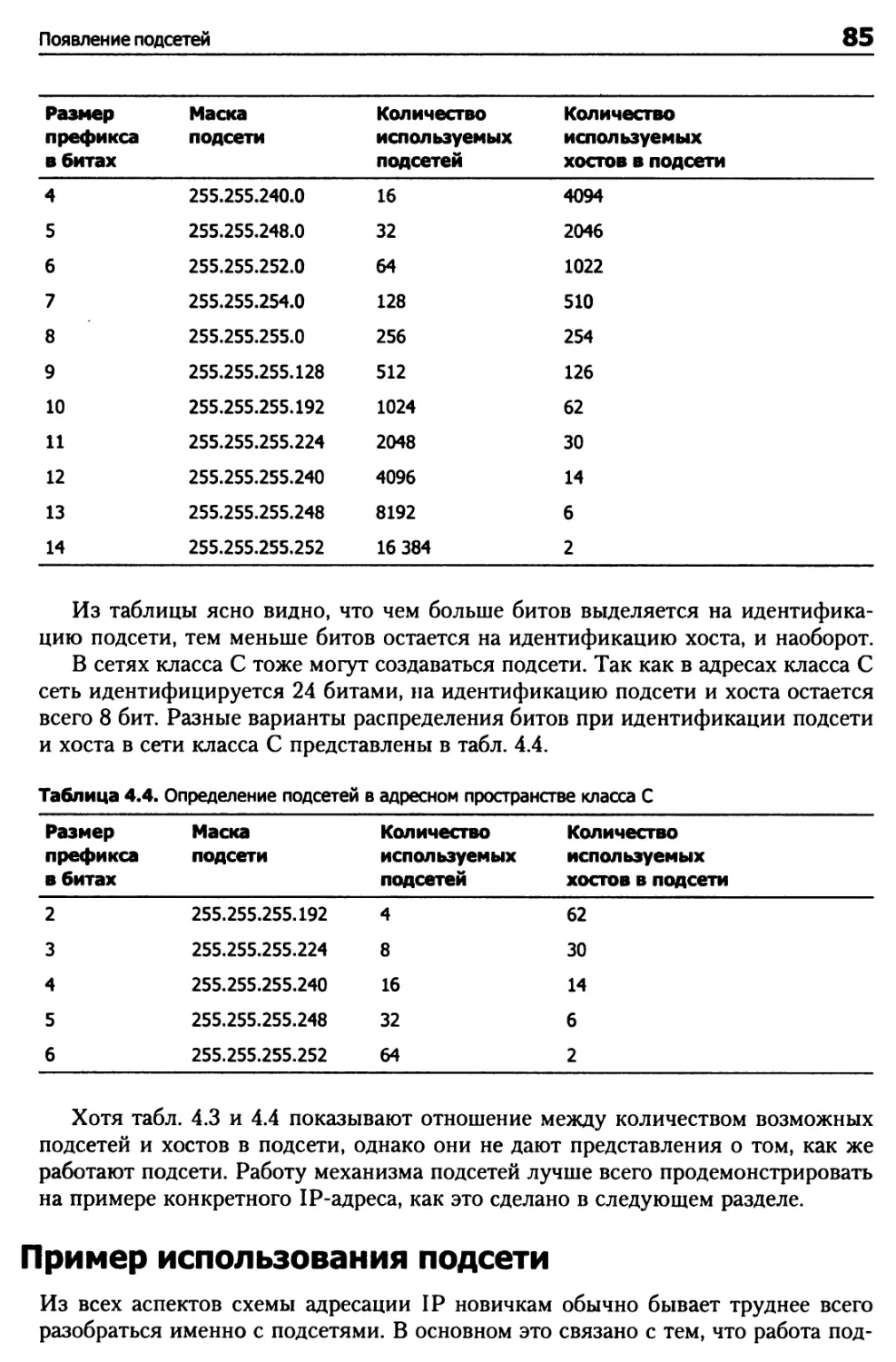
Подсети 82
Пример использования подсети 85
Маски подсети переменной длины 87
CIDR 88
Бесклассовая адресация 89
Расширенное агрегирование маршрутных данных 89
Суперсети 89
Принцип работы CIDR 90
Открытые адресные пространства 91
RFC 1597 и 1918 91
Адресация в частных сетях 92
Назначение адресов класса С 94
Настройка IP-адресов 95
Адресация в IP версии 6 96
Итоги 98
Глава 5. ARP и RARP 99
Механизмы адресации 99
Адресация в подсетях 100
Физические адреса 100
Адрес LLC 101
Сетевые кадры 102
IP-адреса 103
Общие сведения о протоколе ARP 104
toiuARP 105
Тип оборудования 106
Тип протокола 107
Длина аппаратного адреса (HLen) 108
Длина протокольного адреса (PLen) 108
Код операции 108
Аппаратный адрес отправителя 108
IP-адрес отправителя 108
Аппаратный адрес получателя 108
IP-адрес получателя 108
Схема работы ARP 109
Строение протокола ARP 110
Сетевой мониторинг с использованием ARP 111
Тайм-аут в кэше ARP 111
ARP в мостовых сетях ИЗ
Дублирование адресов и ARP 114
Дублирование IP-адресов клиентов TCP/IP 114
Дублирование IP-адресов на серверах TCP/IP 116
Проверка дублирования адресов ARP 117
Proxy ARP 117
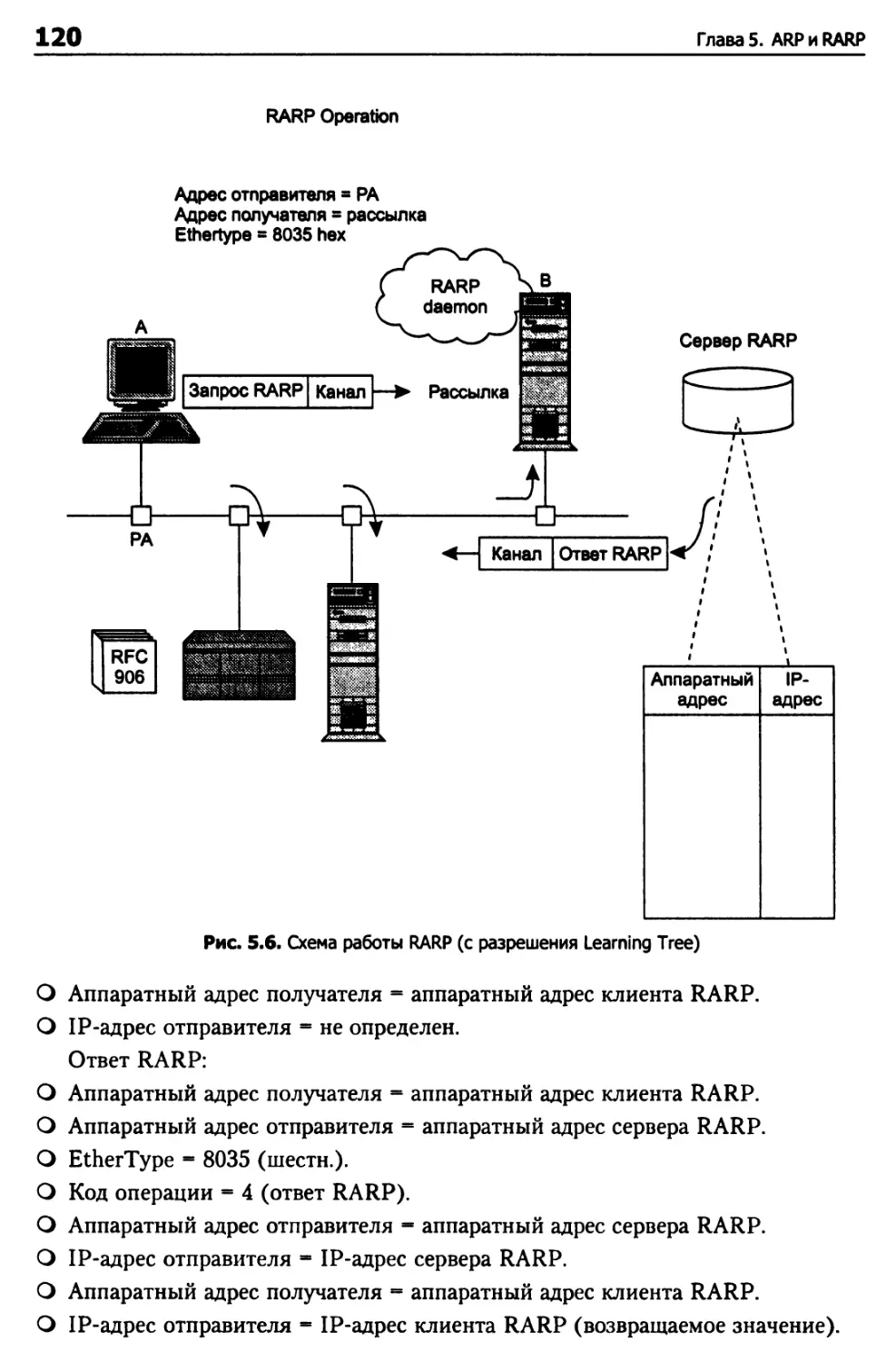
RARP 118
Схема работы RARP 119
Сбой сервера RARP 121
Основные и резервные серверы RARP 121
Команда ARP 122
Итоги 122
Глава 6. DNS 123
Система доменных имен: общие принципы 123
Иерархическое строение DNS 125
Делегирование полномочий 126
Распределенная база данных DNS 127
Домены и зоны 127
Домены верхнего уровня в Интернете 128
Выбор сервера имен 128
Процесс разрешения имен 128
Рекурсивные запросы 128
Итеративные запросы 129
Кэширование 129
Запросы на обратное разрешение 129
Безопасность DNS 129
Ресурсные записи (RR) 129
Ресурсные записи типа SOA 130
Ресурсные записи типа А 132
Ресурсные записи типа NS \ 132
Ресурсные записи CNAME 132
Ресурсные записи PTR 133
Делегированные домены 133
Ресурсные записи HINFO 133
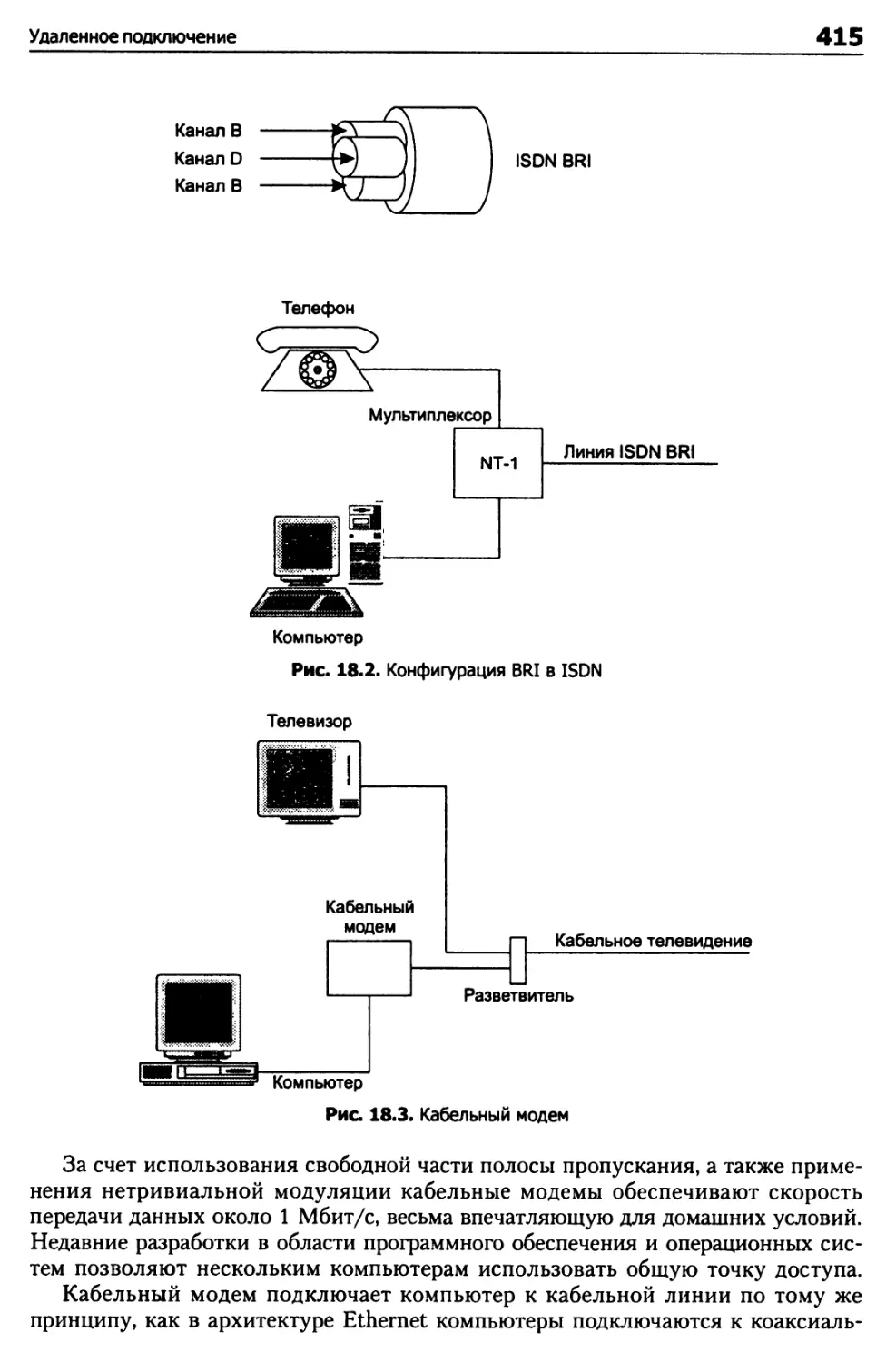
Ресурсные записи ISDN 134
Ресурсные записи MB 134
Ресурсные записи MG 135
Ресурсные записи MINFO 135
Ресурсные записи MR 135
Ресурсные записи MX 135
Ресурсные записи RP 136
Ресурсные записи RT 136
Ресурсные записи ТХТ 136
Ресурсные записи WKS 137
Ресурсные записи типа Х25 137
Итоги 137
Глава 7. WINS 138
NetBIOS 138
Разрешение имен в NetBIOS 141
Динамическое разрешение имен в NetBIOS 143
Преимущества WINS 144
Как работает WINS 144
Настройка клиентов WINS 146
Настройка WINS для прокси-агентов 147
Настройка прокси-агента в NT 4 148
Настройка прокси-агента в Windows 95/98 148
Настройка сервера WINS 148
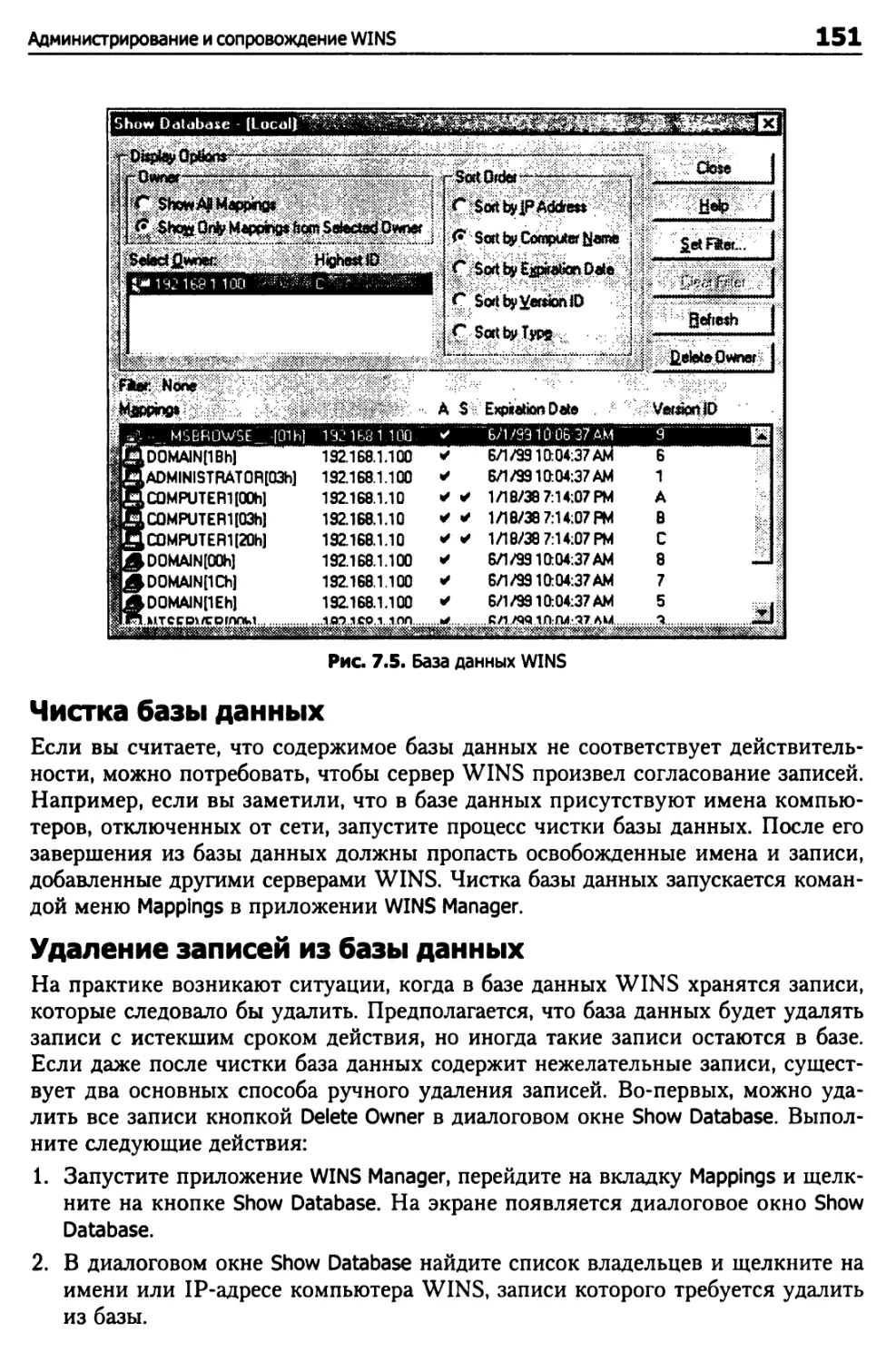
Администрирование и сопровождение WINS 149
Добавление статических записей 149
Сопровождение базы данных WINS 150
Архивация базы данных WINS 153
Архивация данных реестра 154
Восстановление базы данных WINS 154
Сжатие базы данных WINS 154
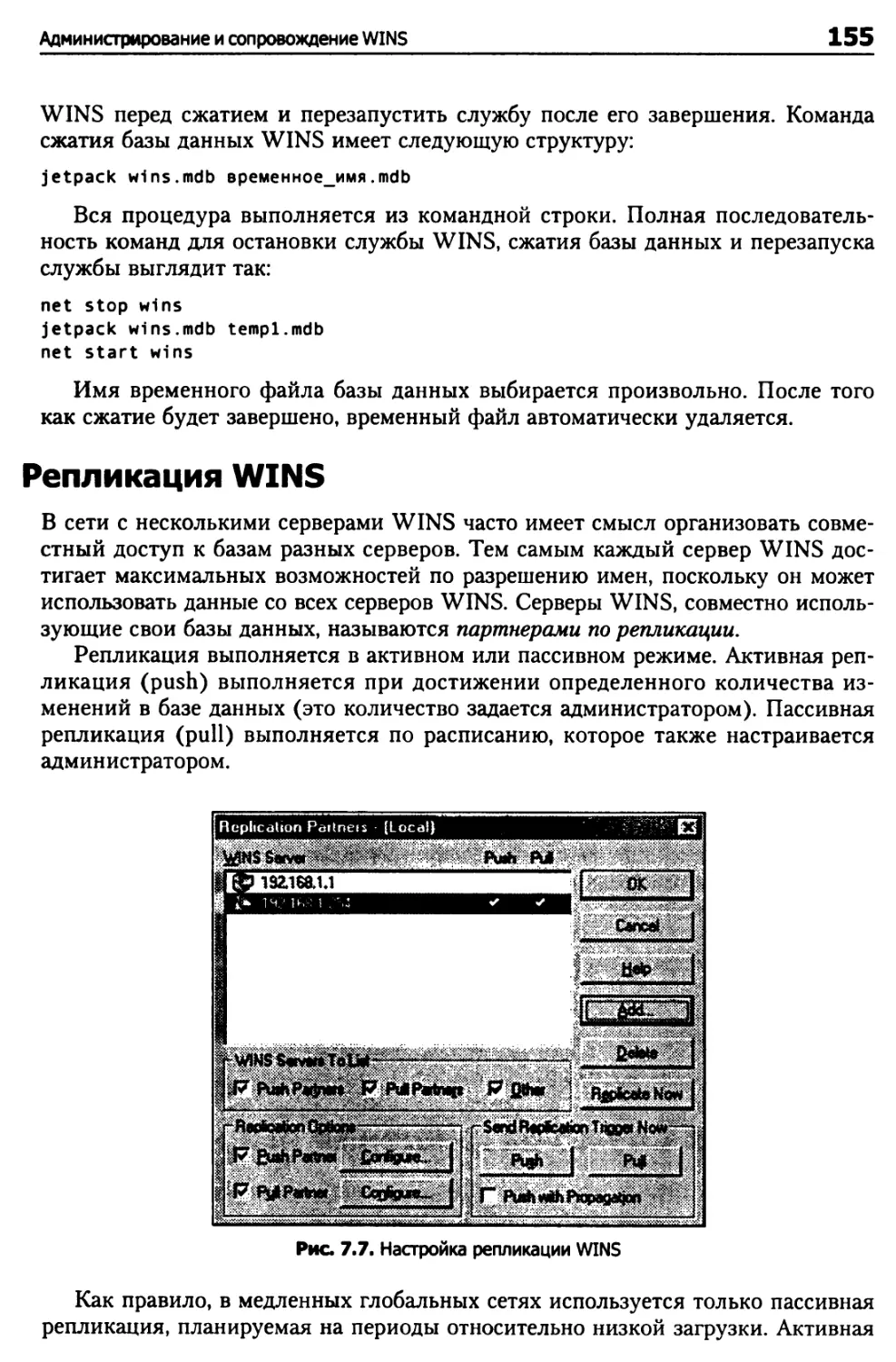
Репликация WINS 155
Рекомендации по реализации WINS 156
Интеграция служб разрешения имен 156
Предоставление данных WINS через DHCP 157
Разрешение имен NetBIOS через файл LMHOSTS 158
Итоги 160
Глава 8. Автоматизированная настройка TCP/IP 162
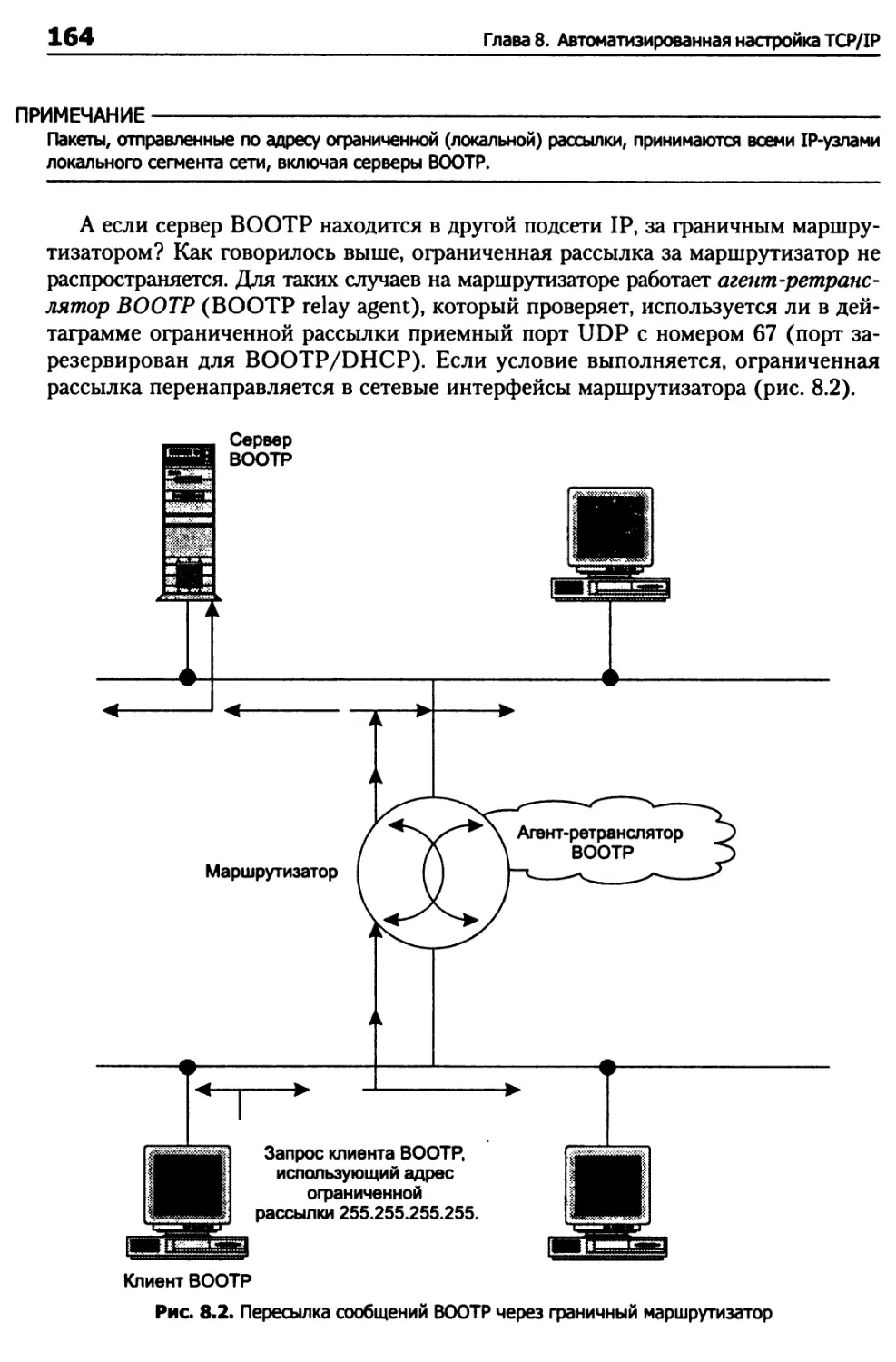
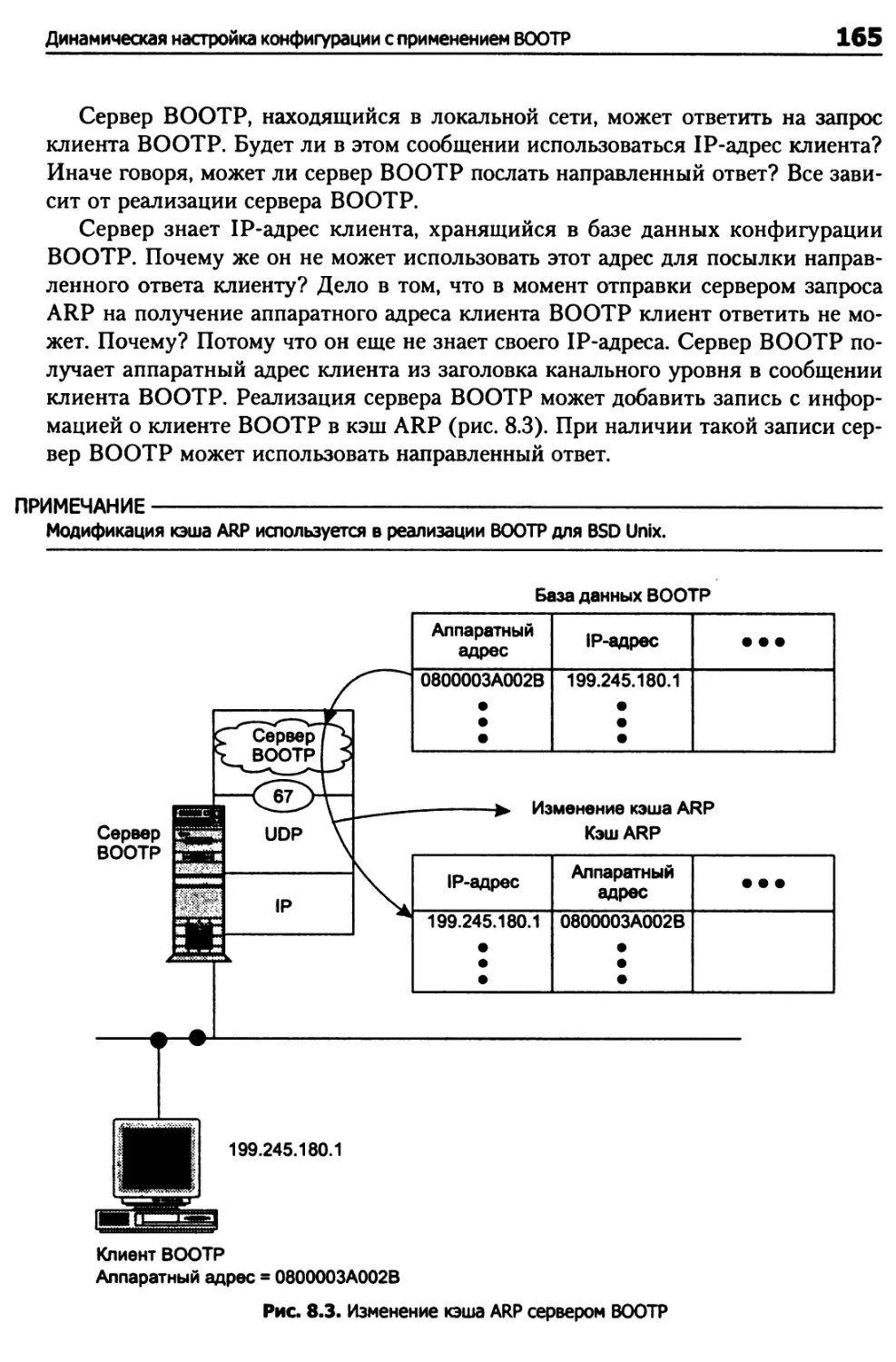
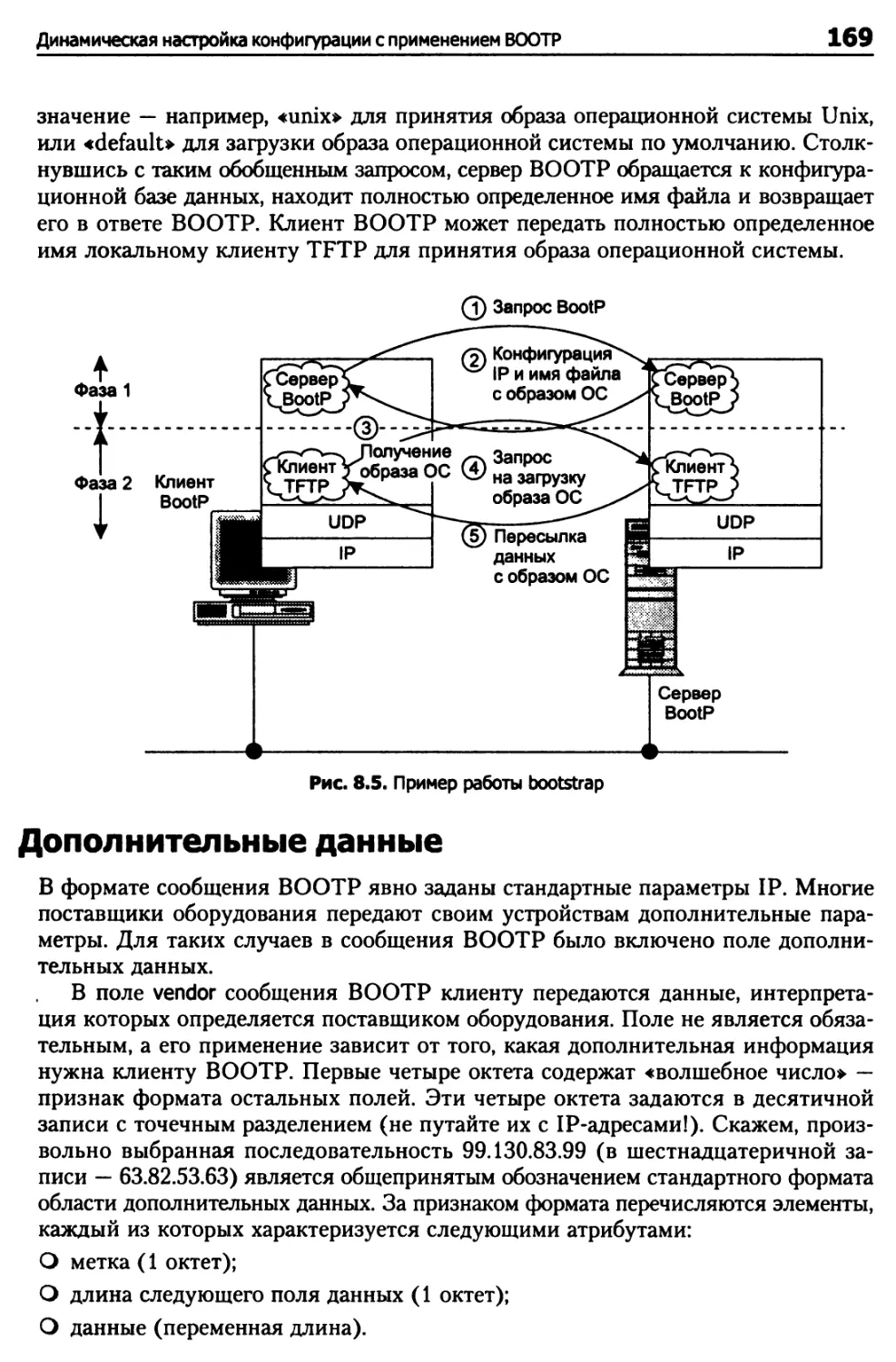
Динамическая настройка конфигурации с применением ВООТР 162
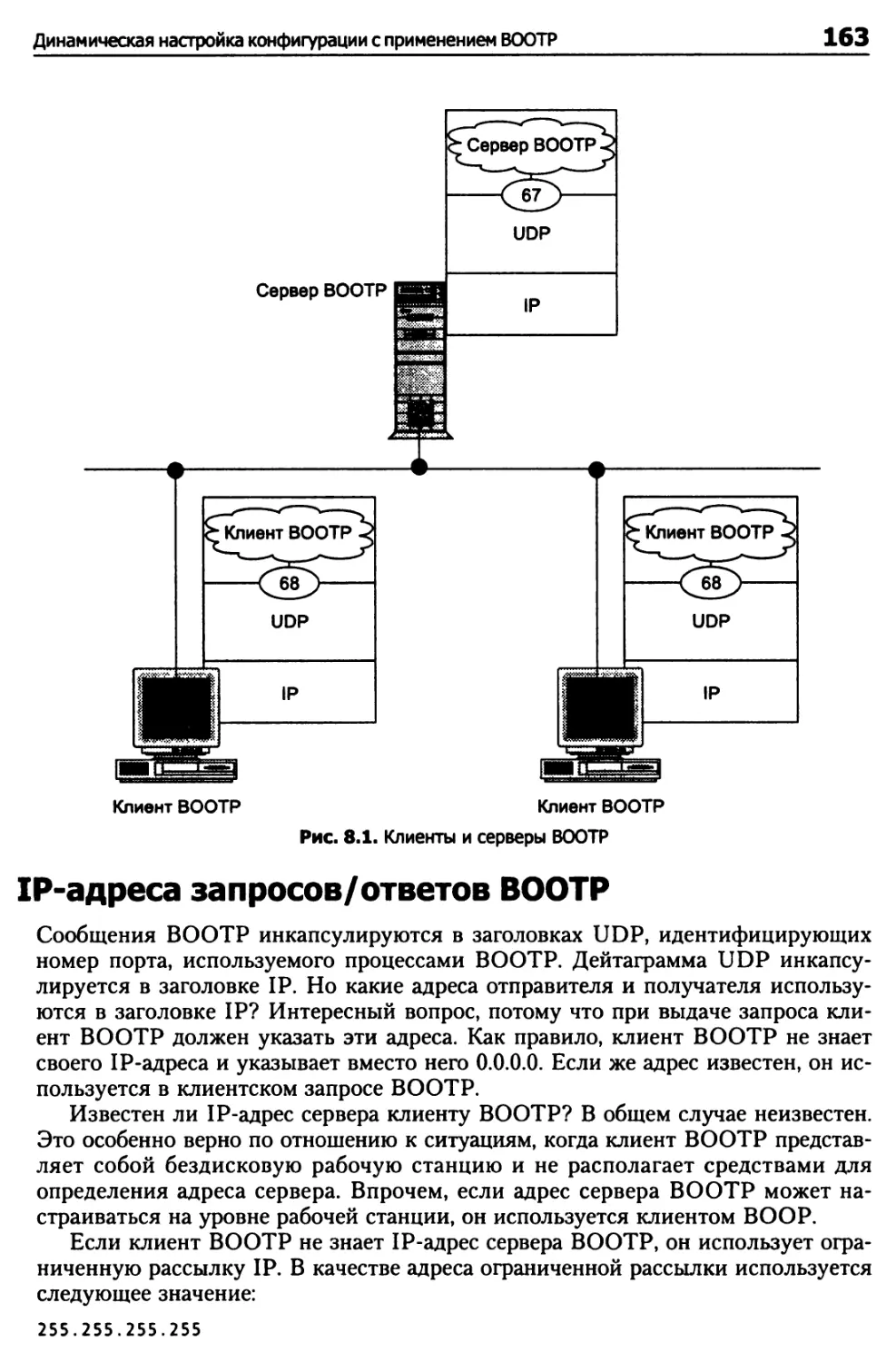
IP-адреса запросов/ответов ВООТР 163
Потеря сообщений ВООТР 166
Формат сообщения ВООТР 166
Фазы ВООТР 168
Дополнительные данные 169
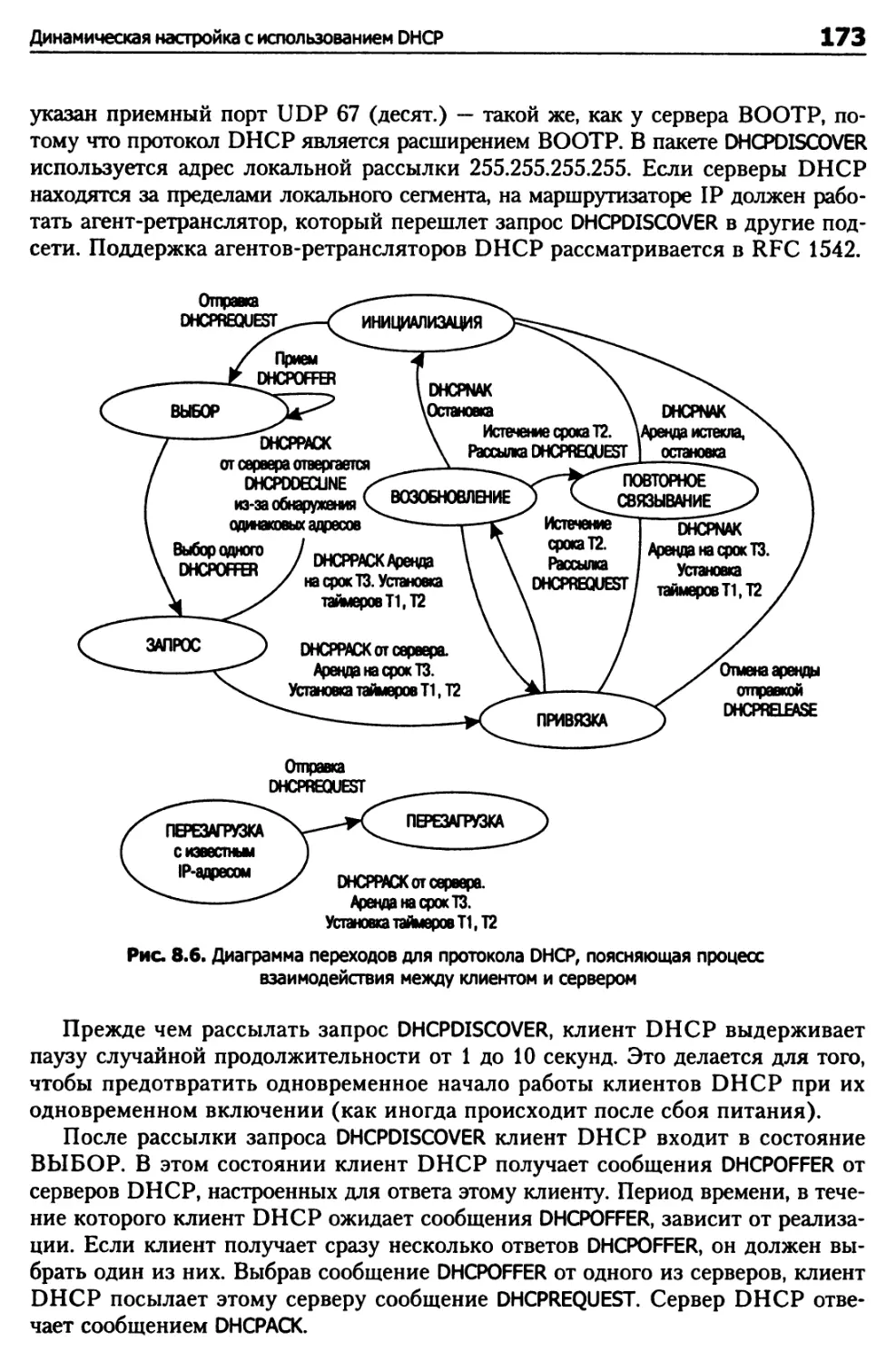
Динамическая настройка с использованием DHCP 171
Распределение IP-адресов в DHCP 171
Назначение IP-адресов в DHCP 172
Формат сообщения DHCP 175
Трассировка протокола DHCP 178
Итоги 189
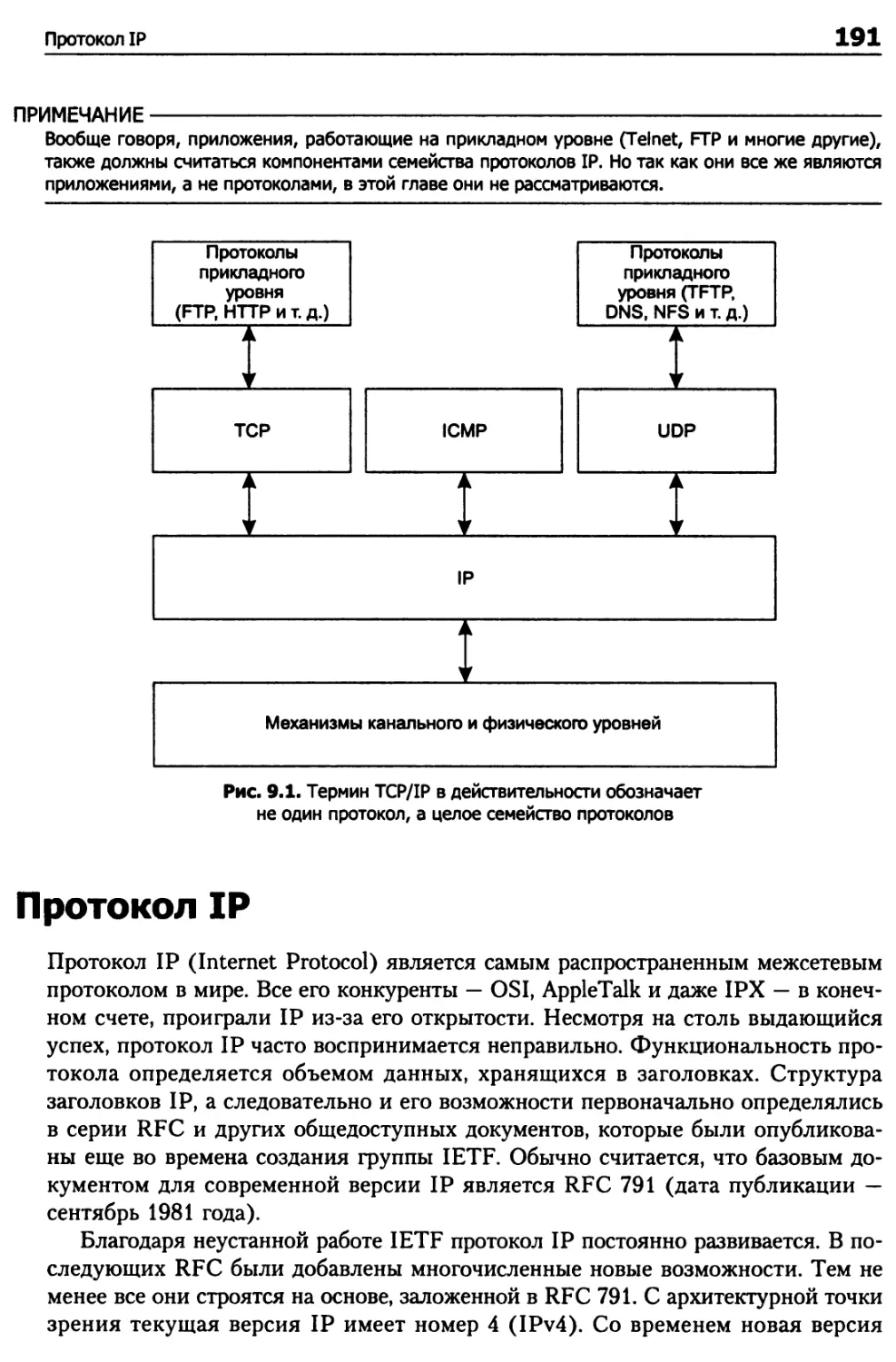
Глава 9. Обзор семейства протоколов IP 190
Модель TCP/IP 190
Семейство протоколов TCP/IP 190
Протоколе 191
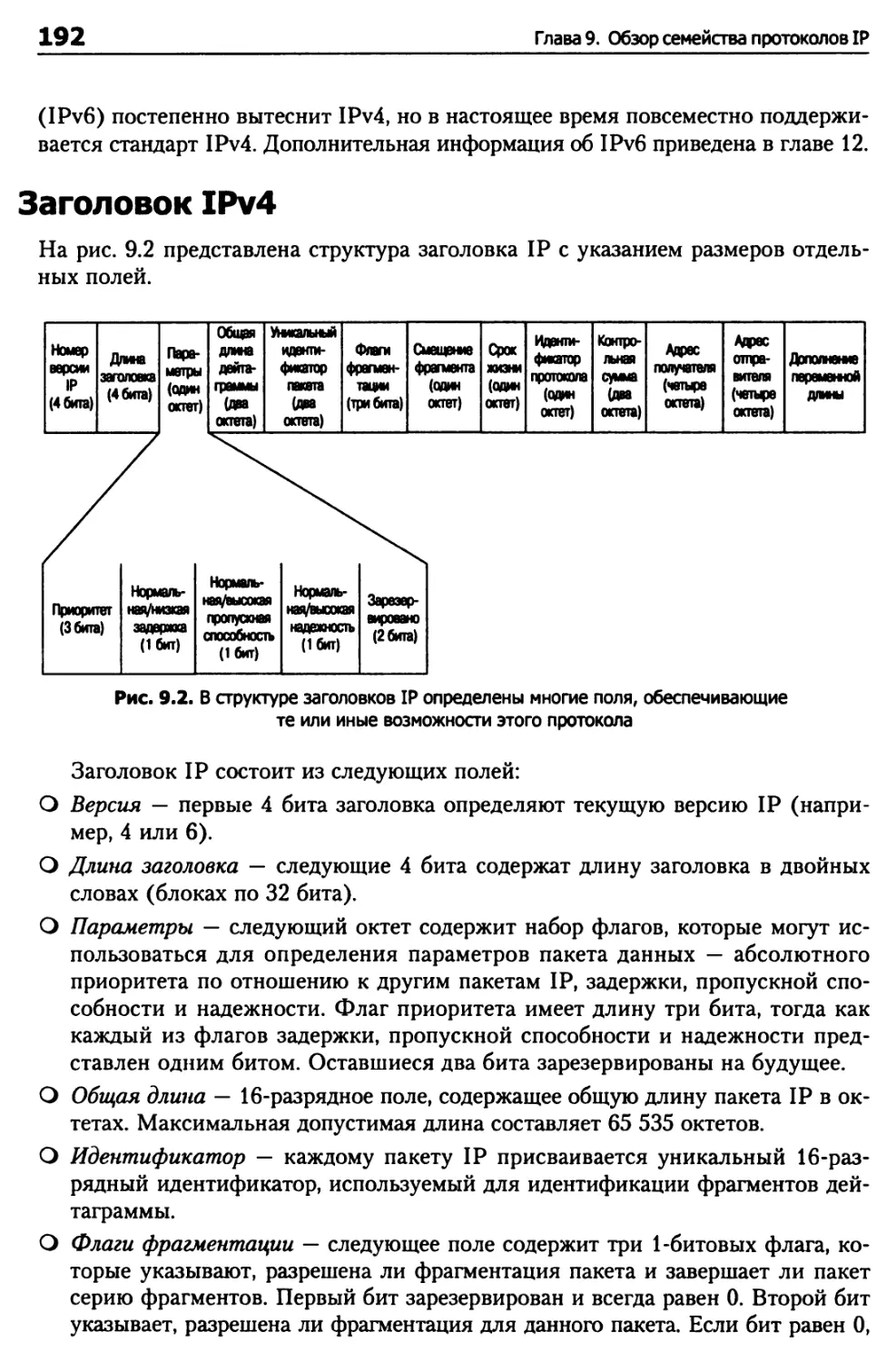
Заголовок IPv4 192
Задачи протокола IP 193
Поврежденные пакеты 194
Протокол TCP 195
Структура заголовка TCP 195
Задачи протокола TCP 197
Протокол UDP 200
Структура заголовка UDP 201
Задачи протокола UDP 201
Сравнение TCP с UDP 202
Итоги 203
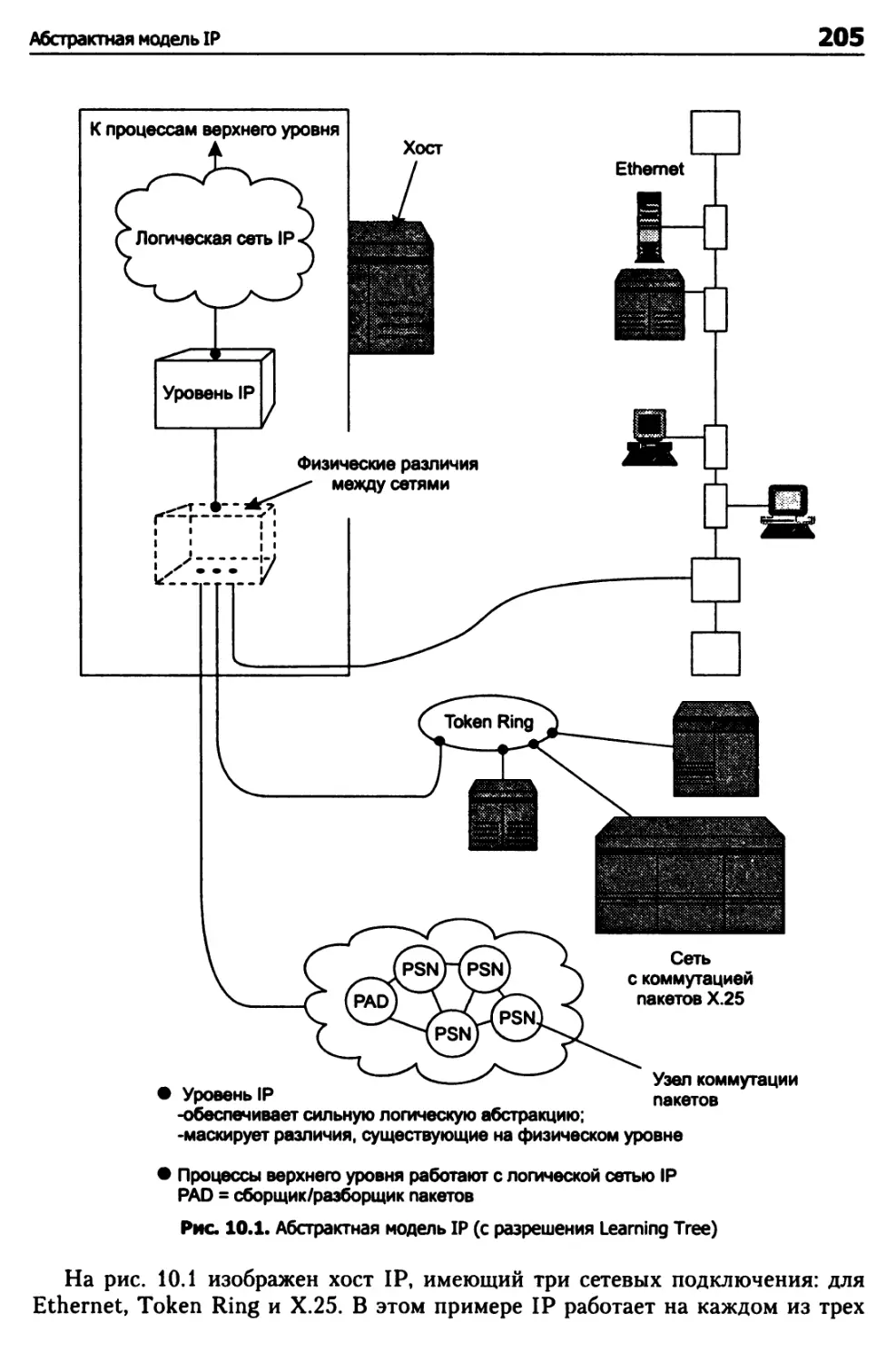
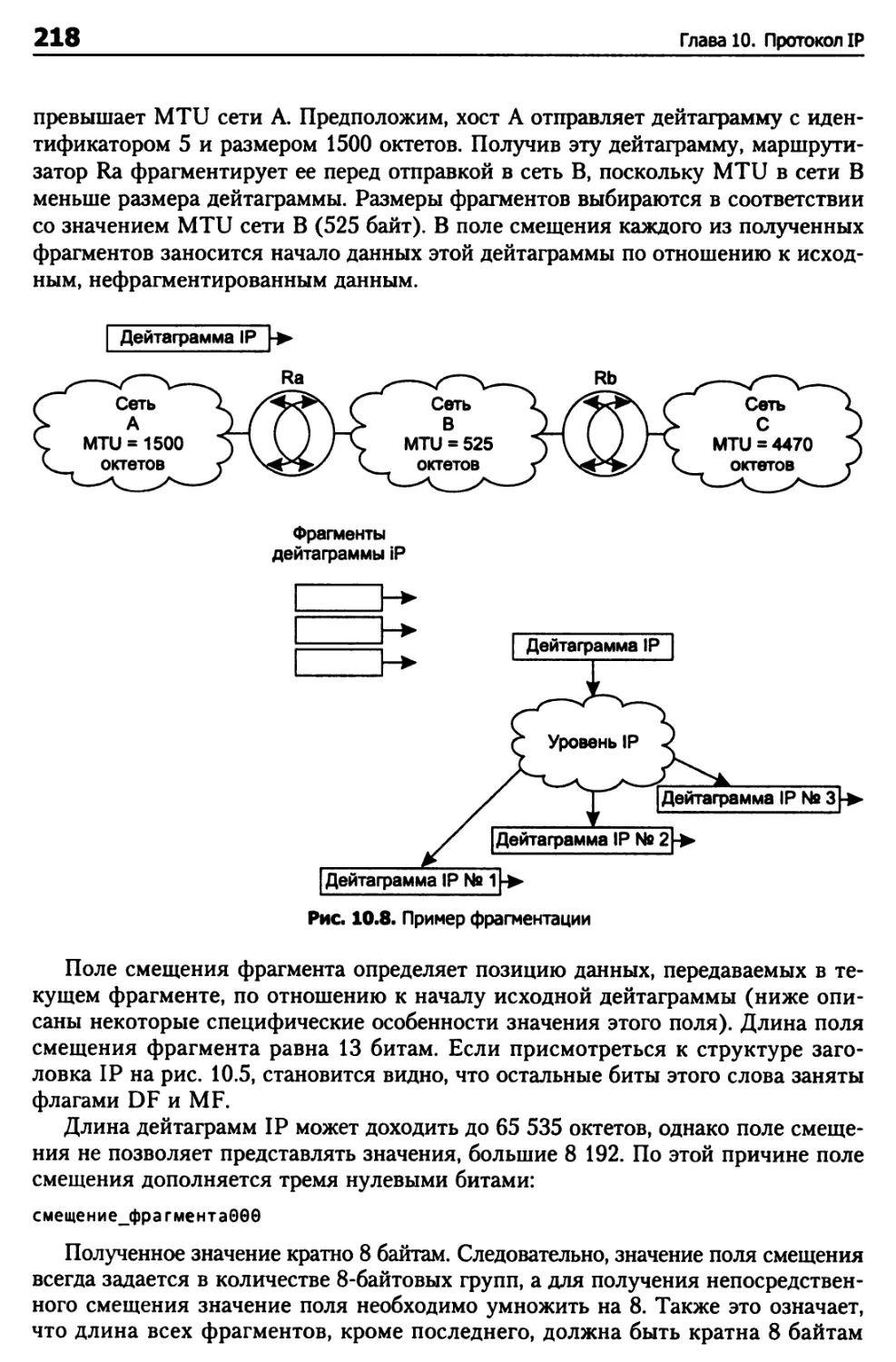
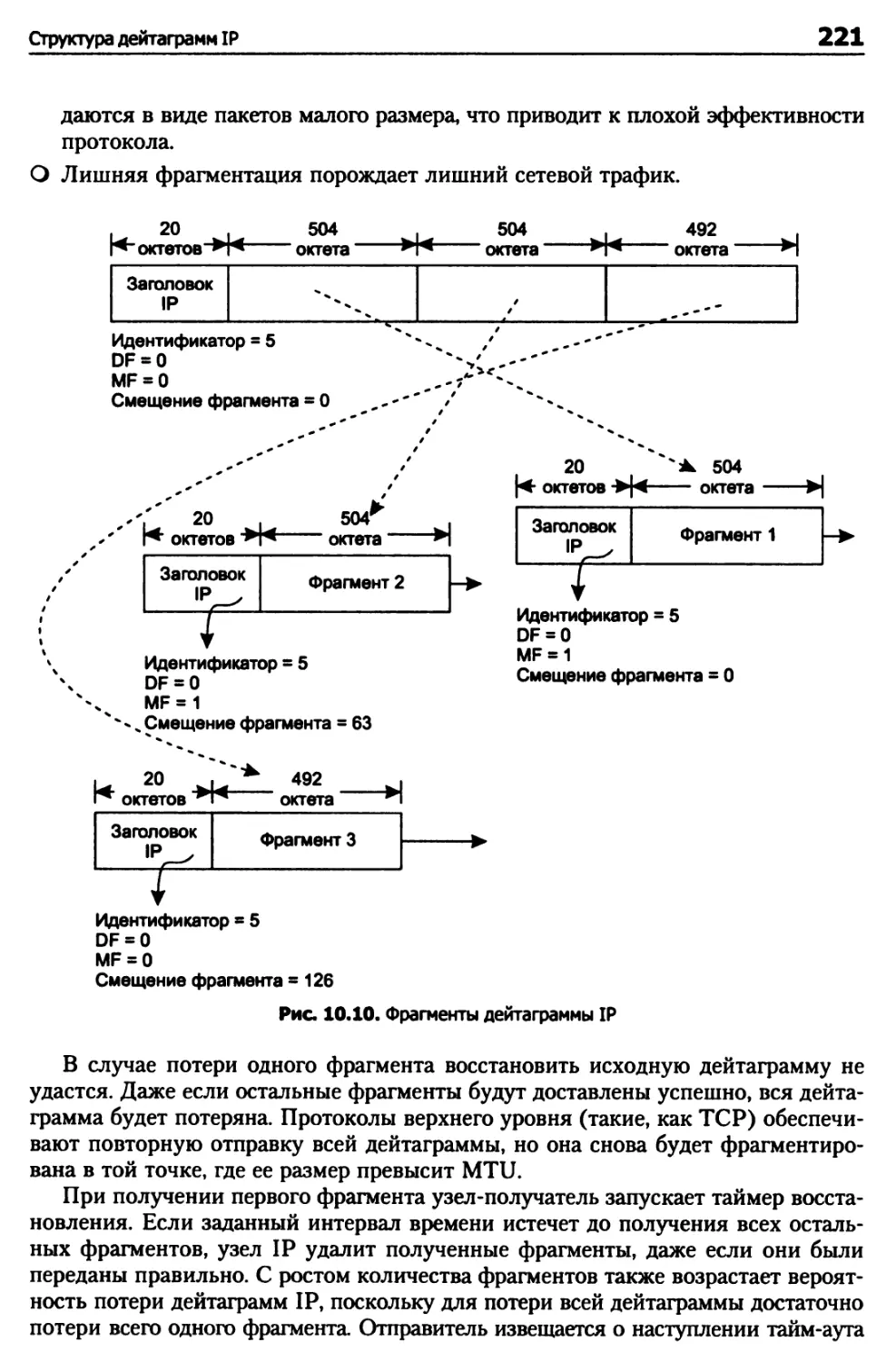
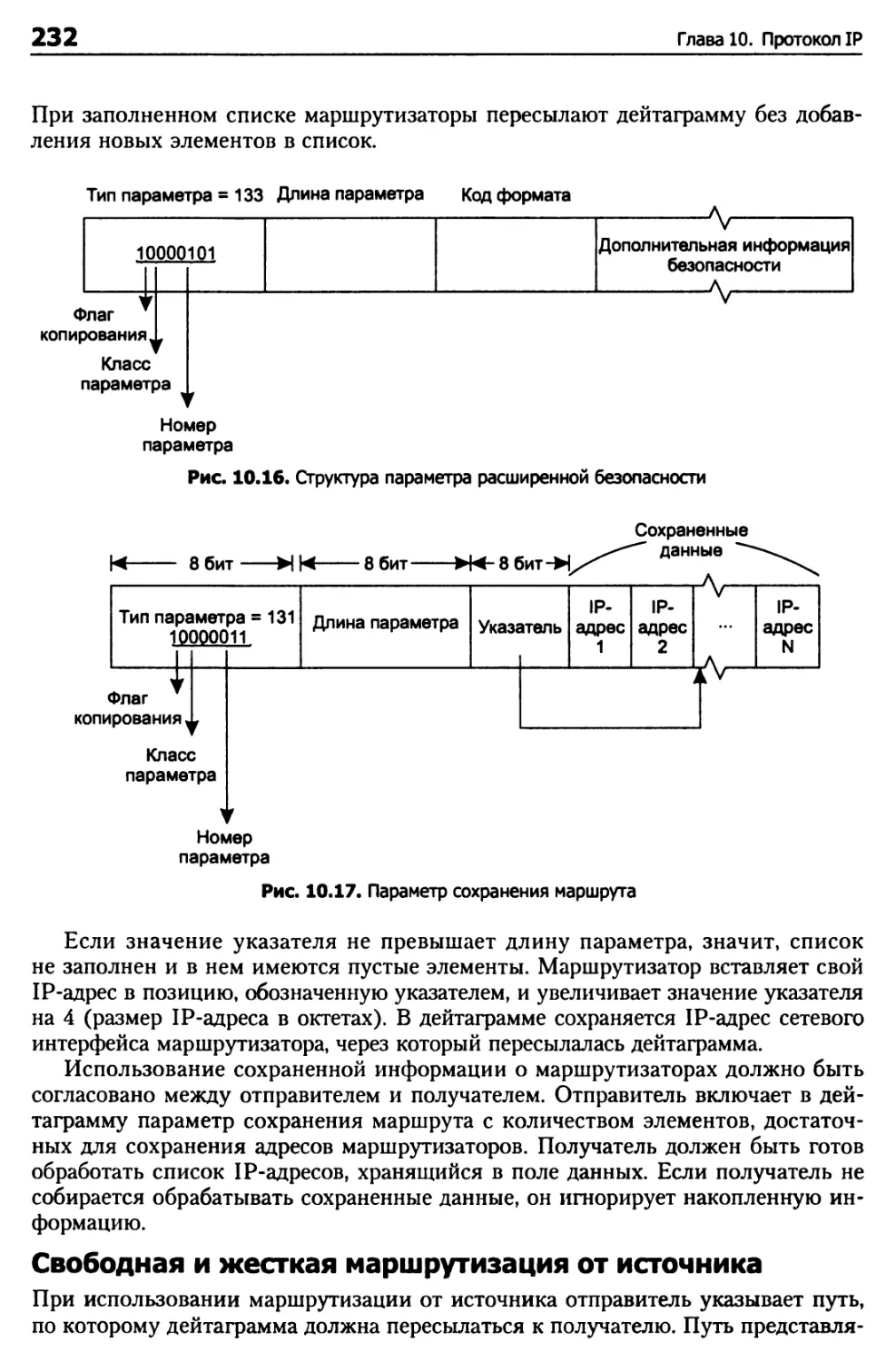
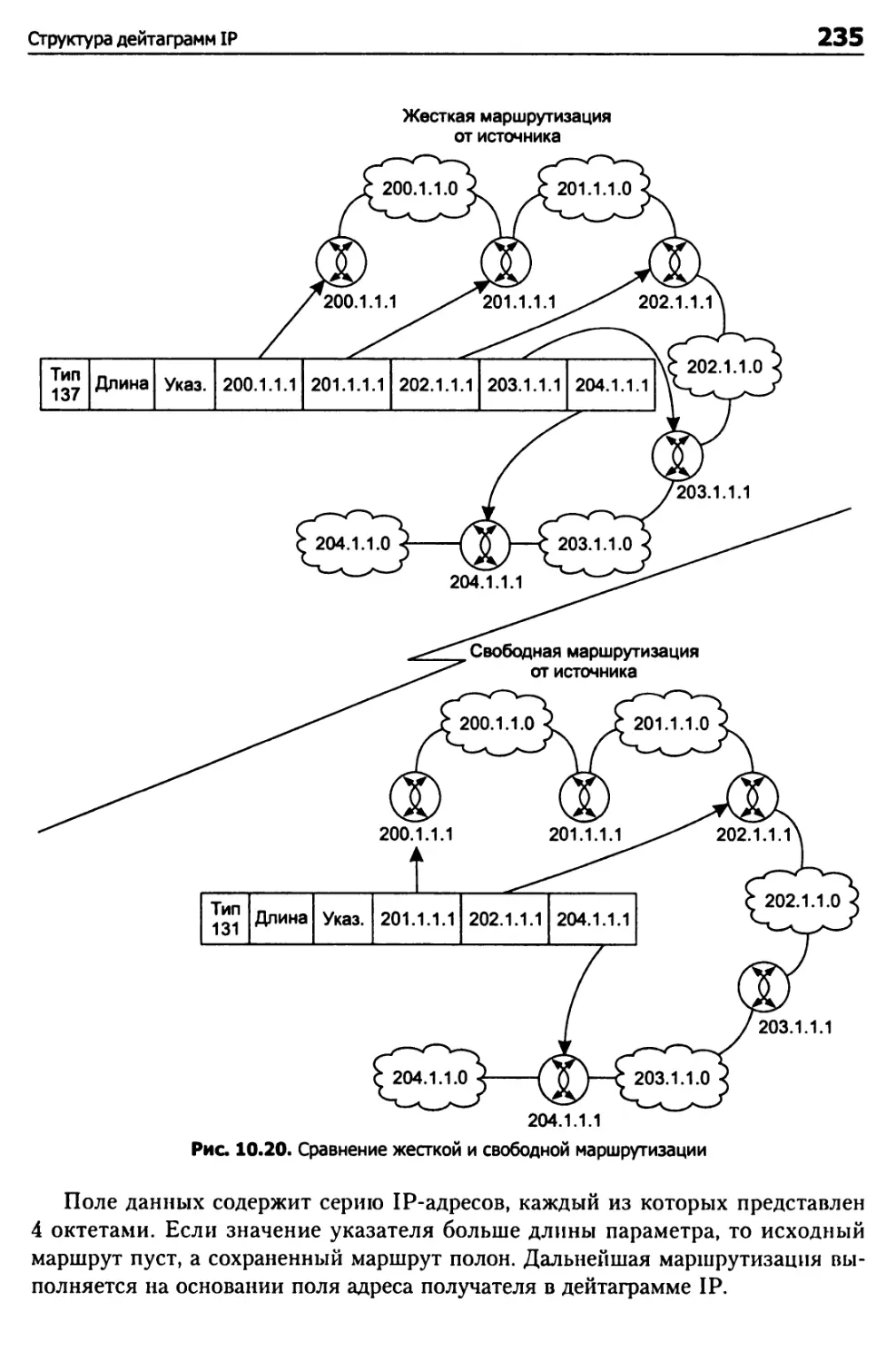
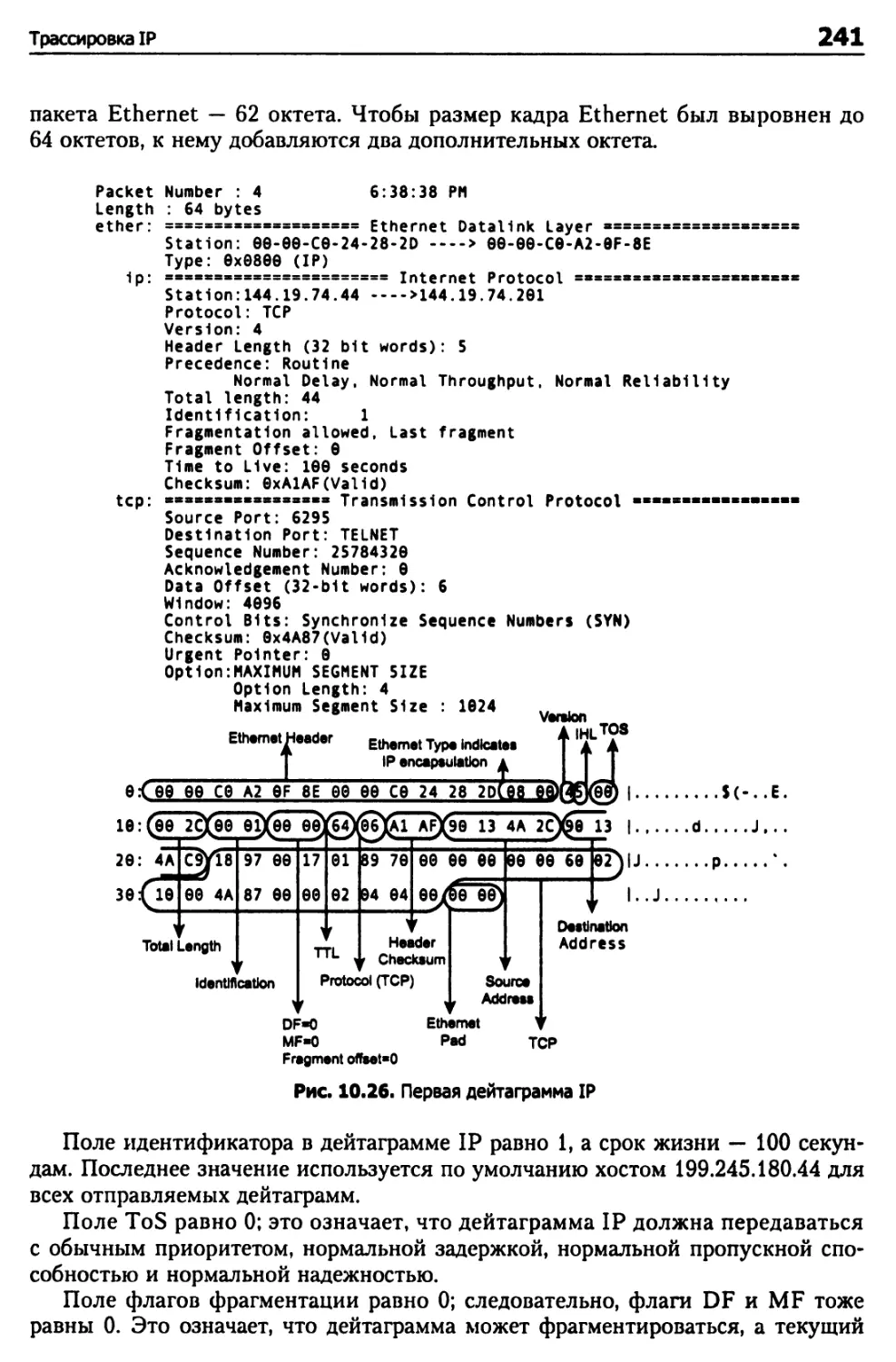
Глава 10. Протокол IP 204
Абстрактная модель IP 204
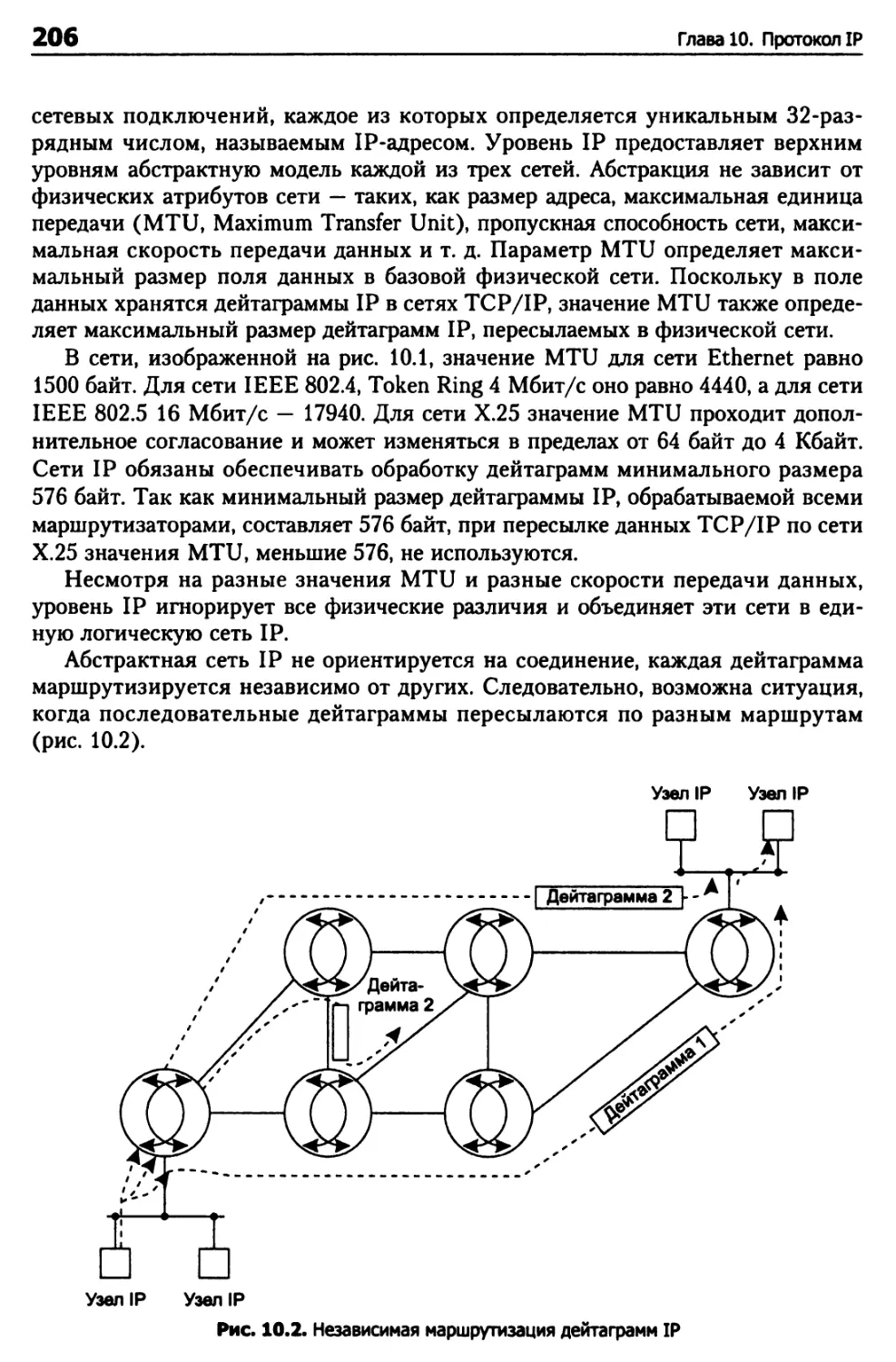
Размер дейтаграммы IP 207
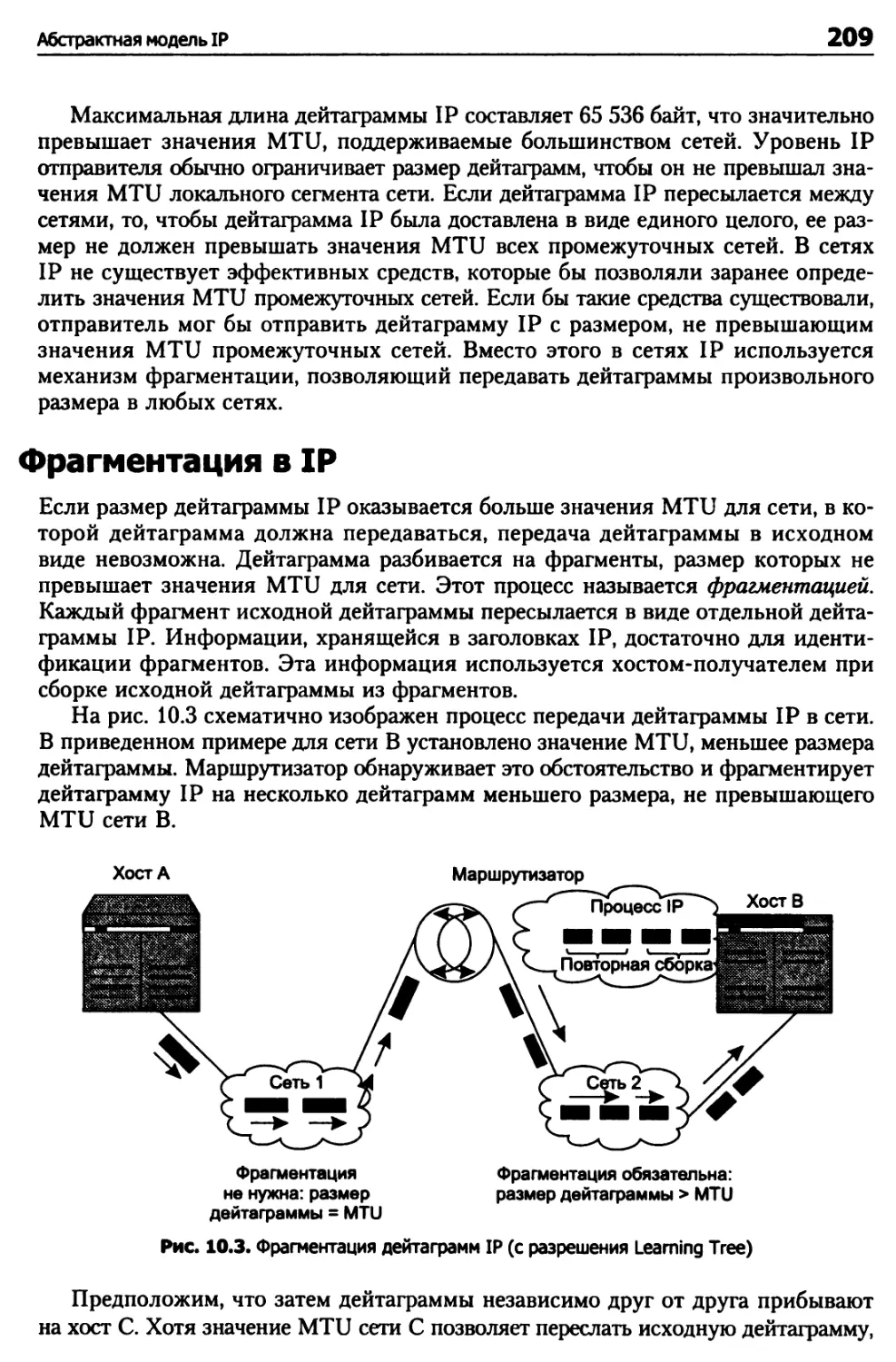
Фрагментация в IP 209
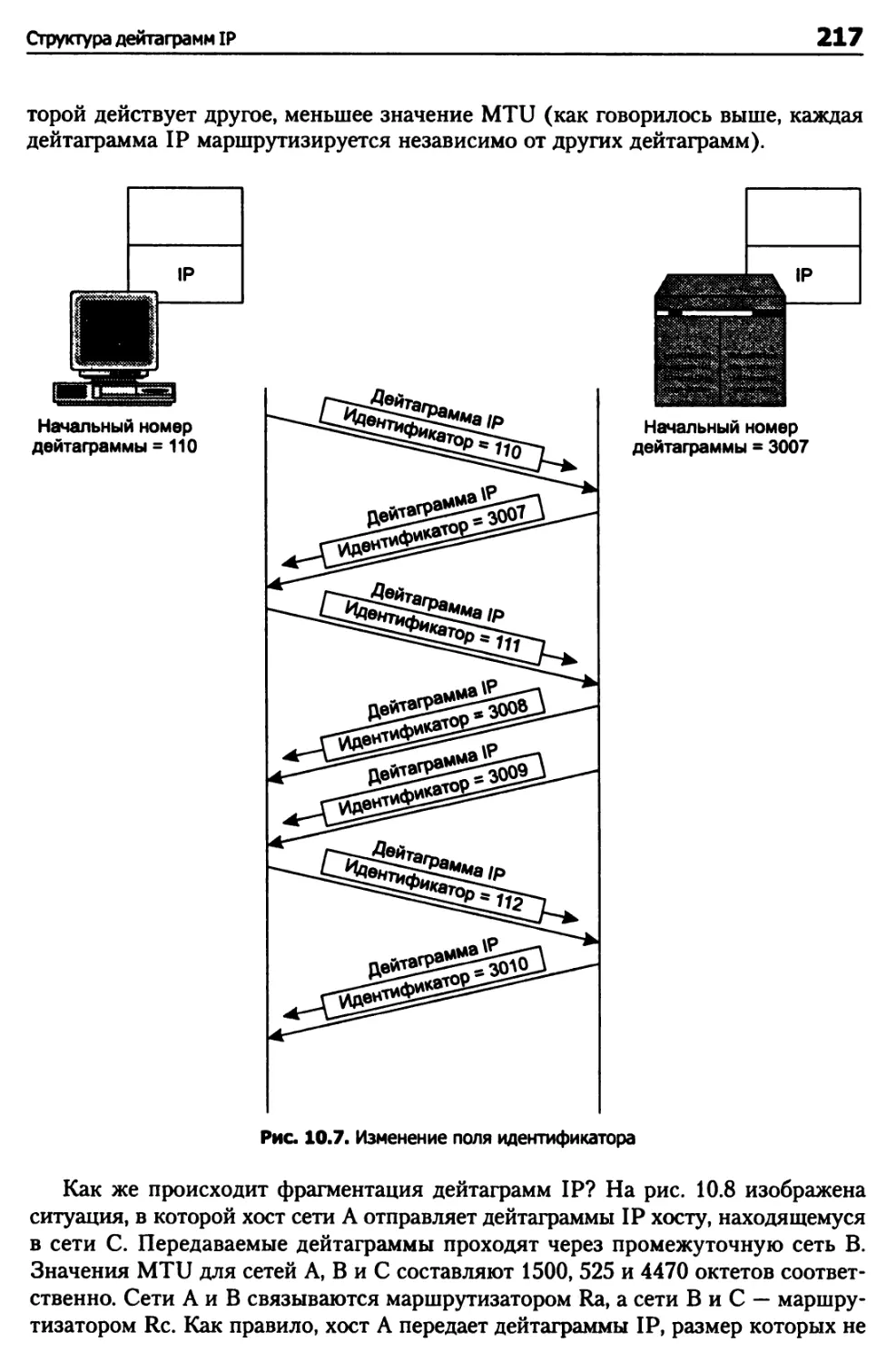
Структура дейтаграмм IP 210
Структура заголовка IP 211
Сетевой порядок байтов 238
Трассировка IP 239
Итоги 247
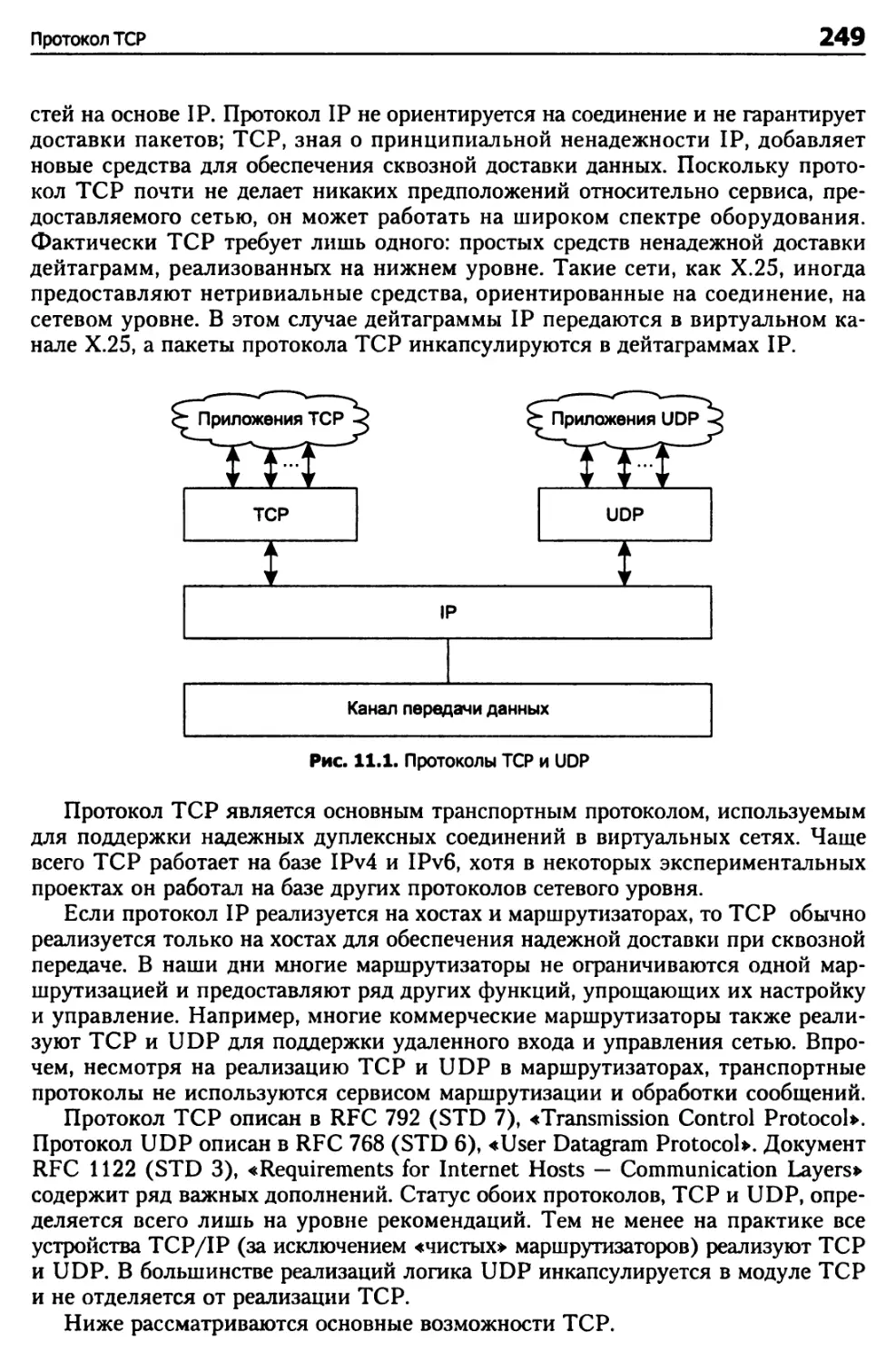
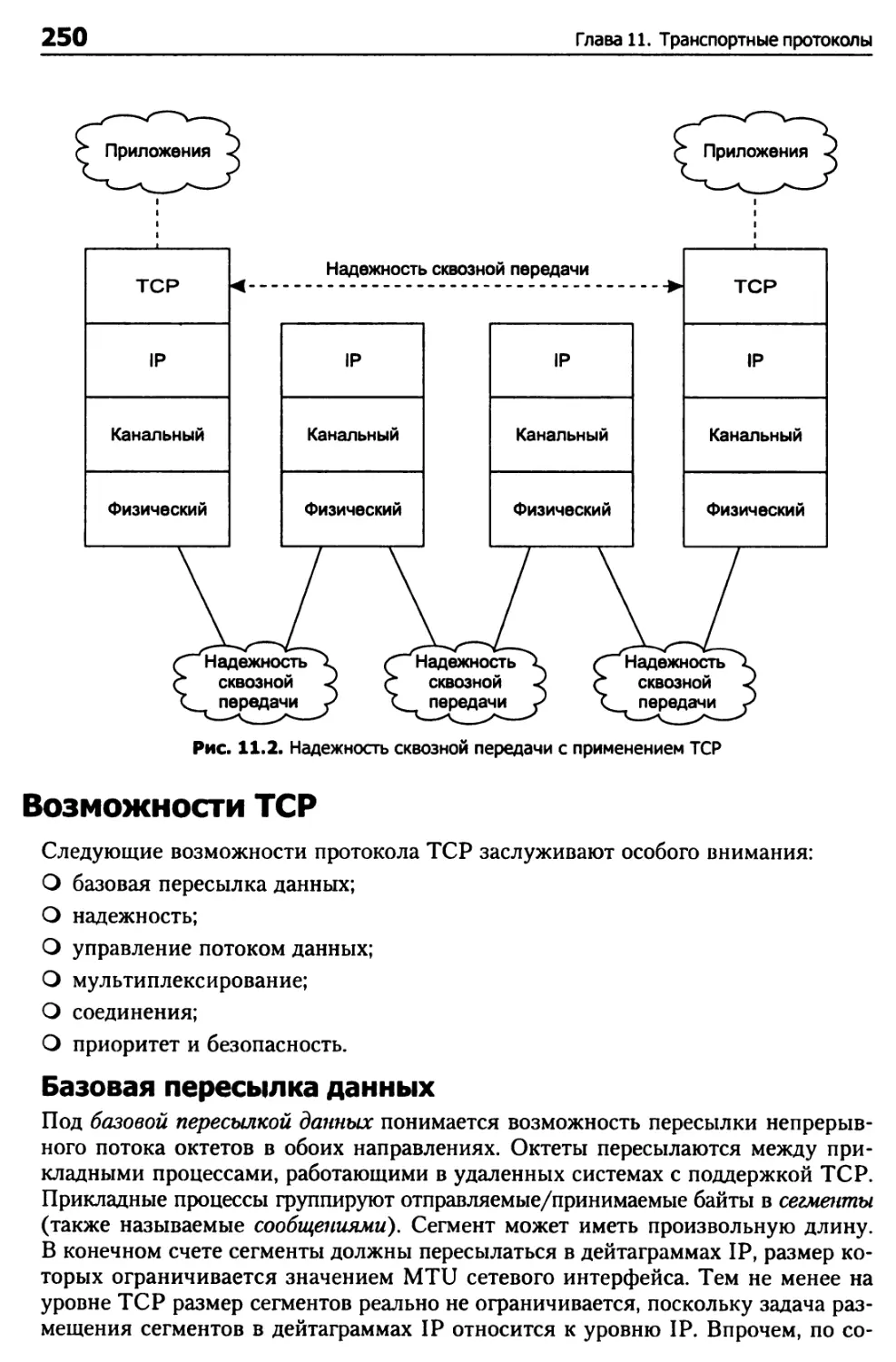
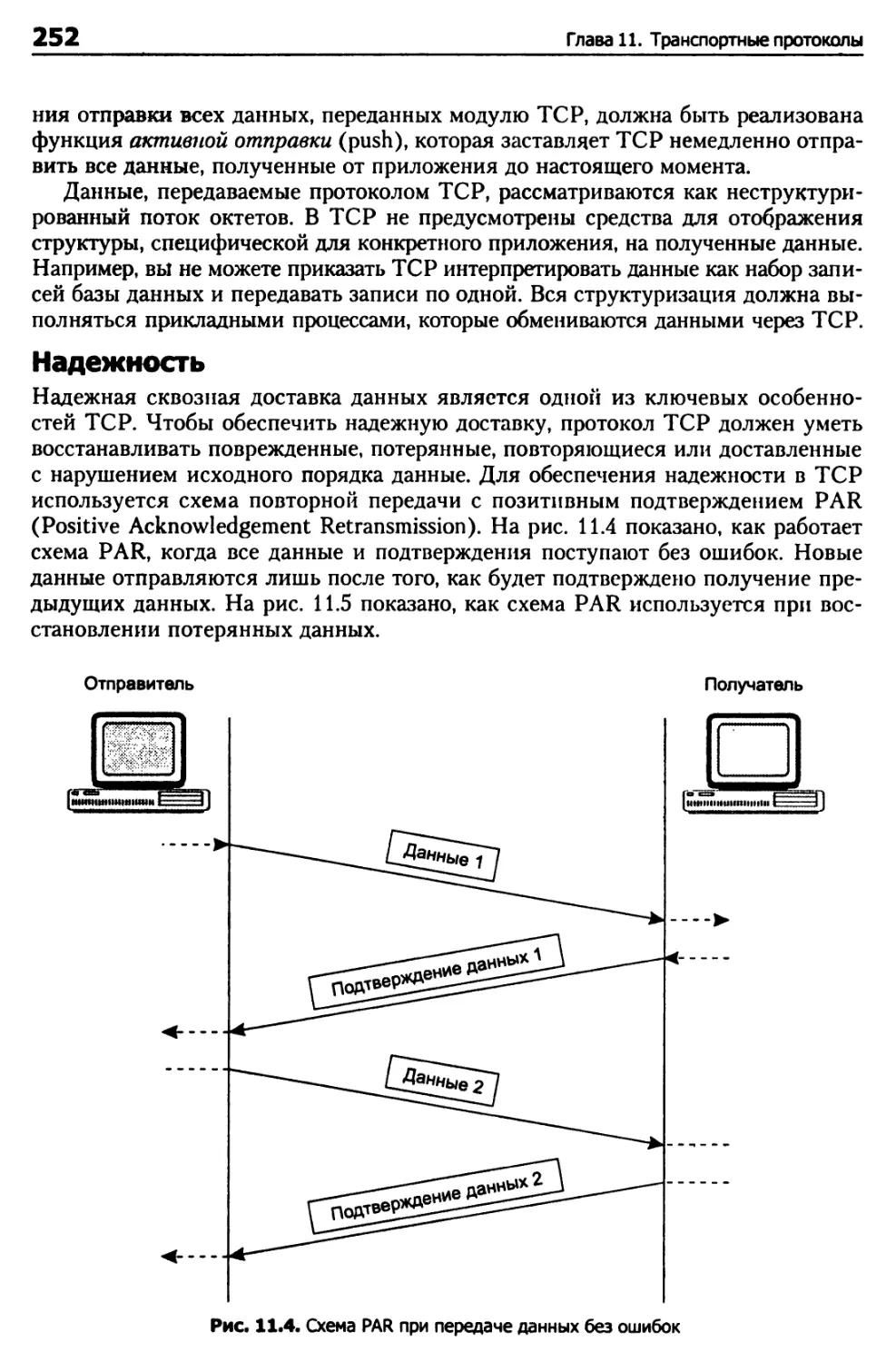
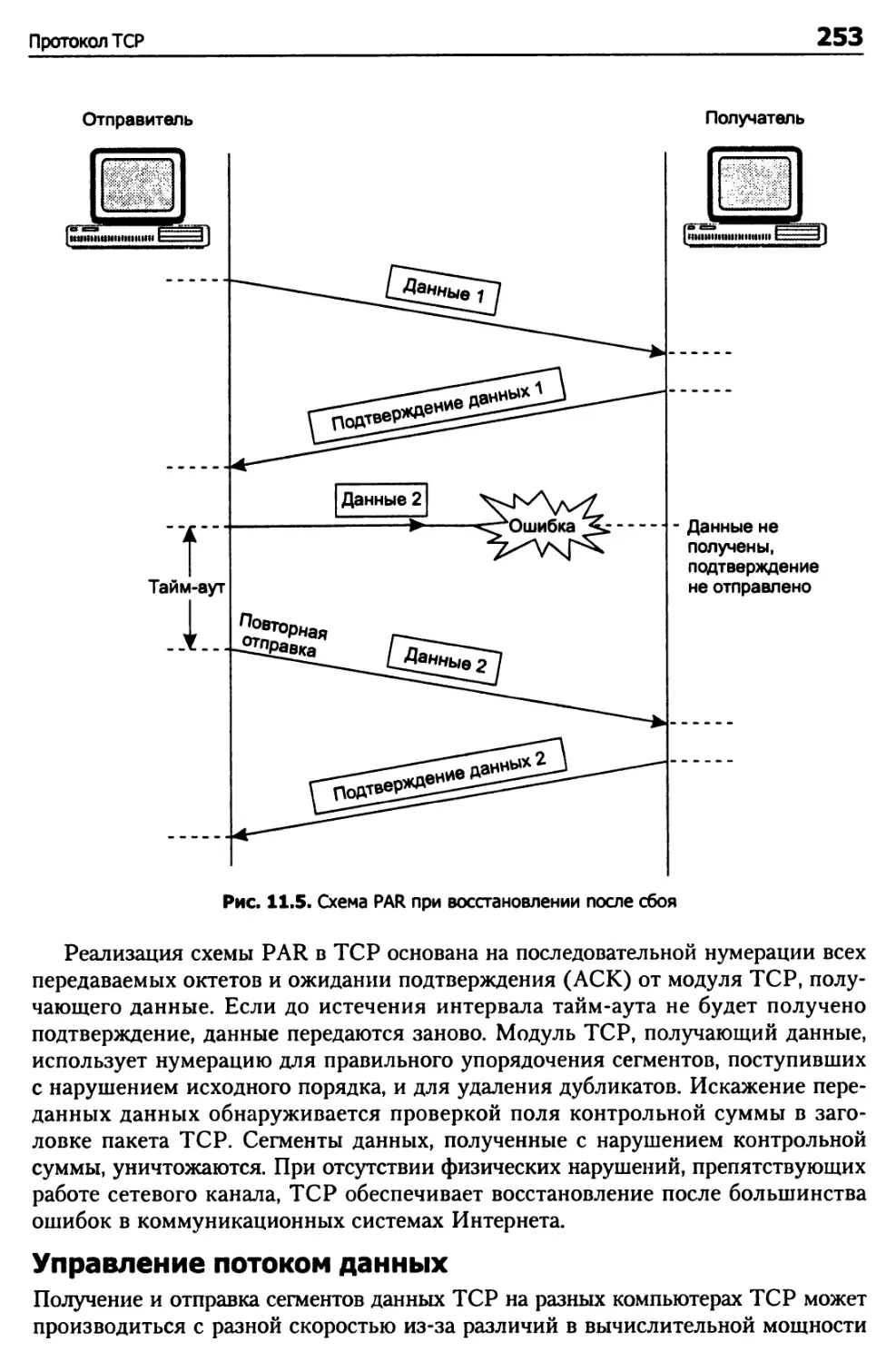
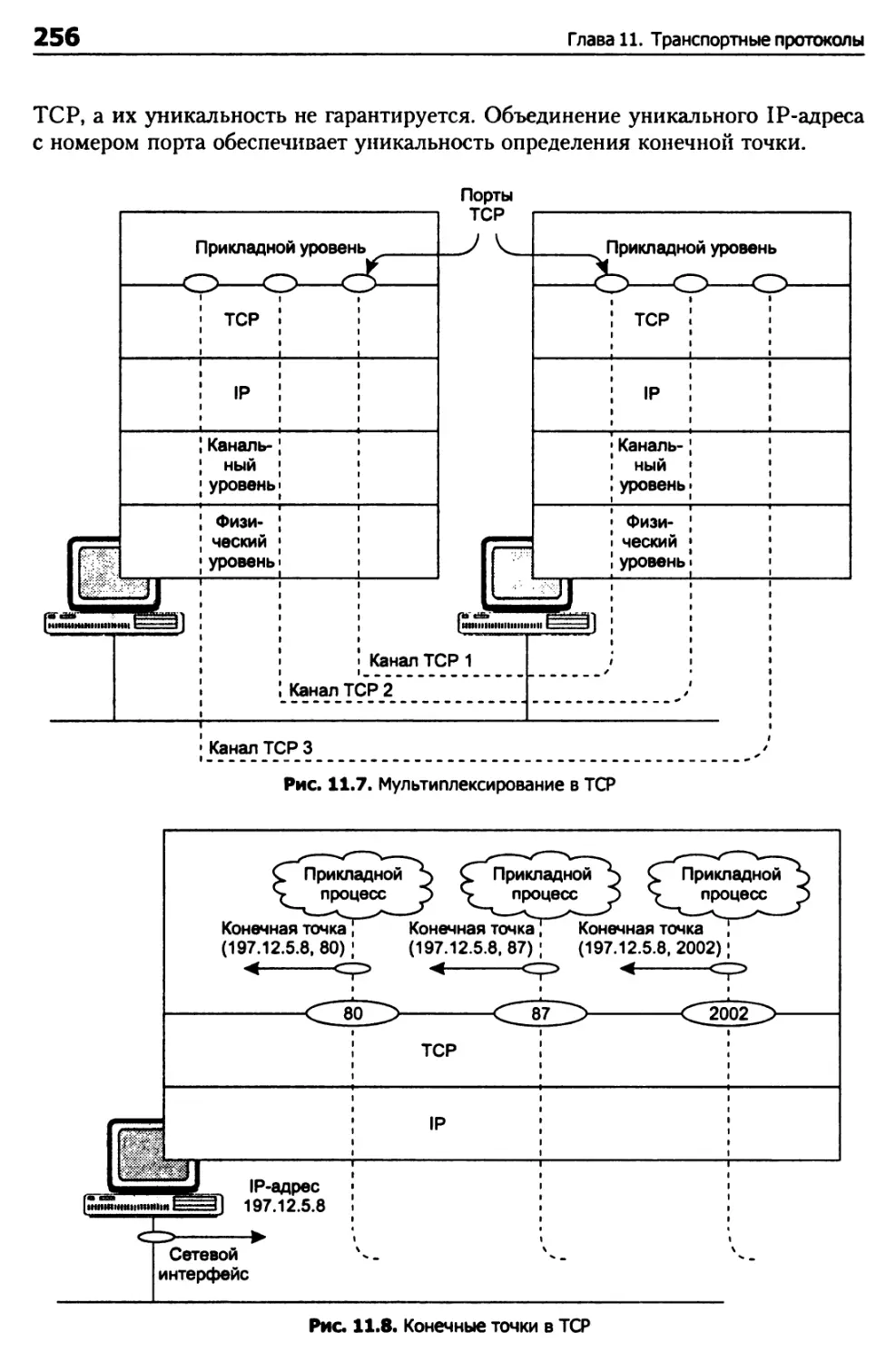
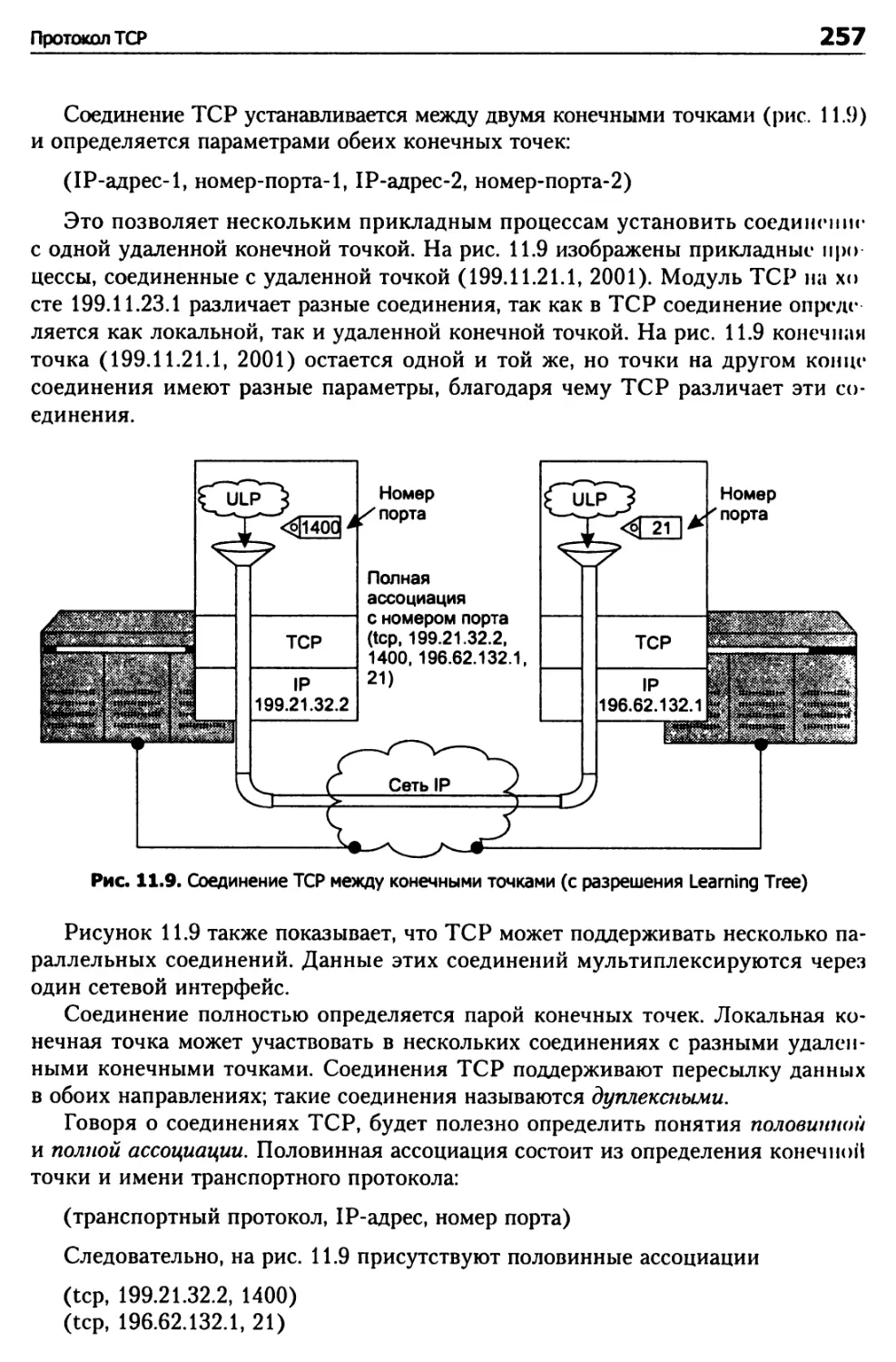
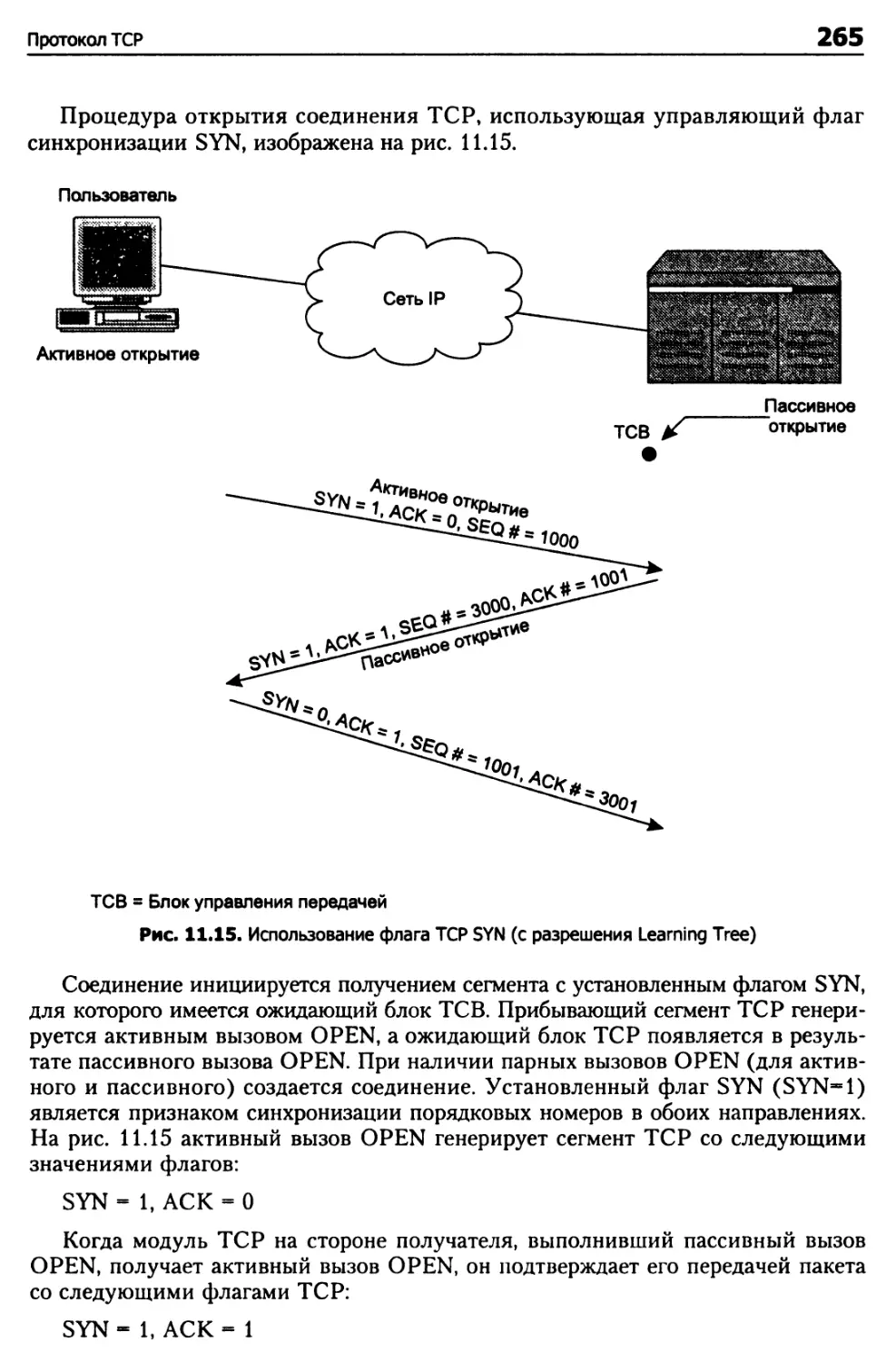
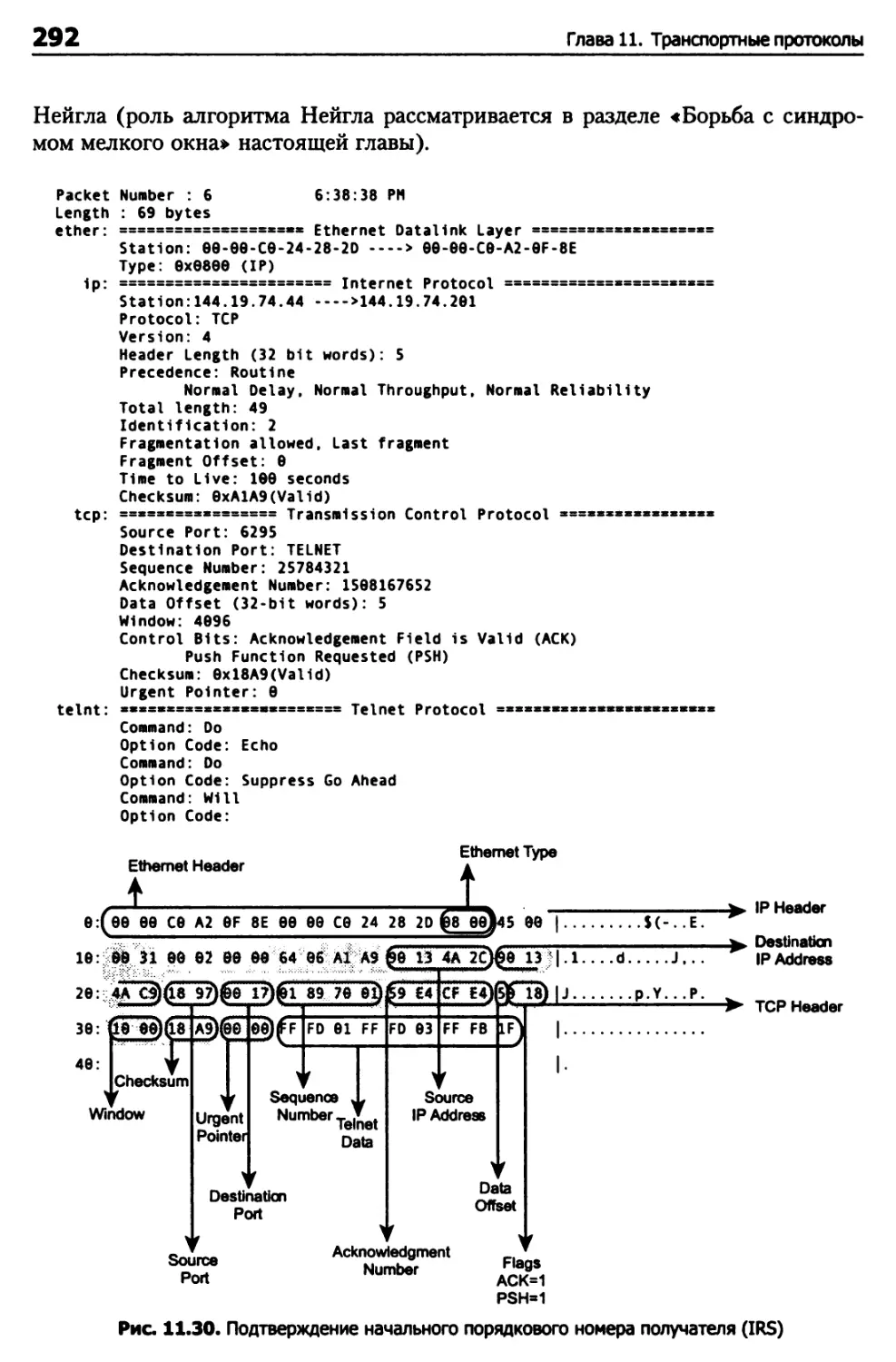
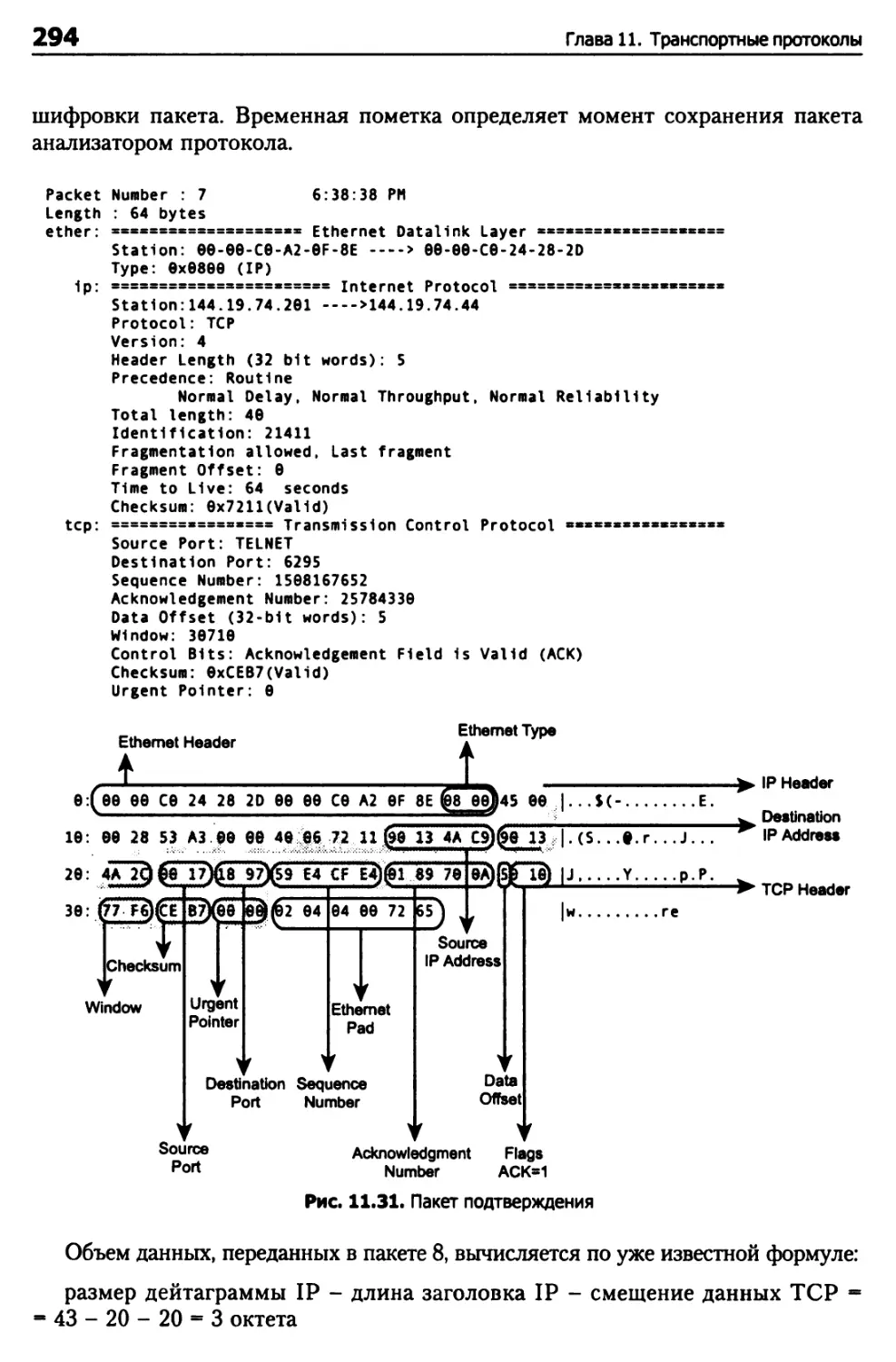
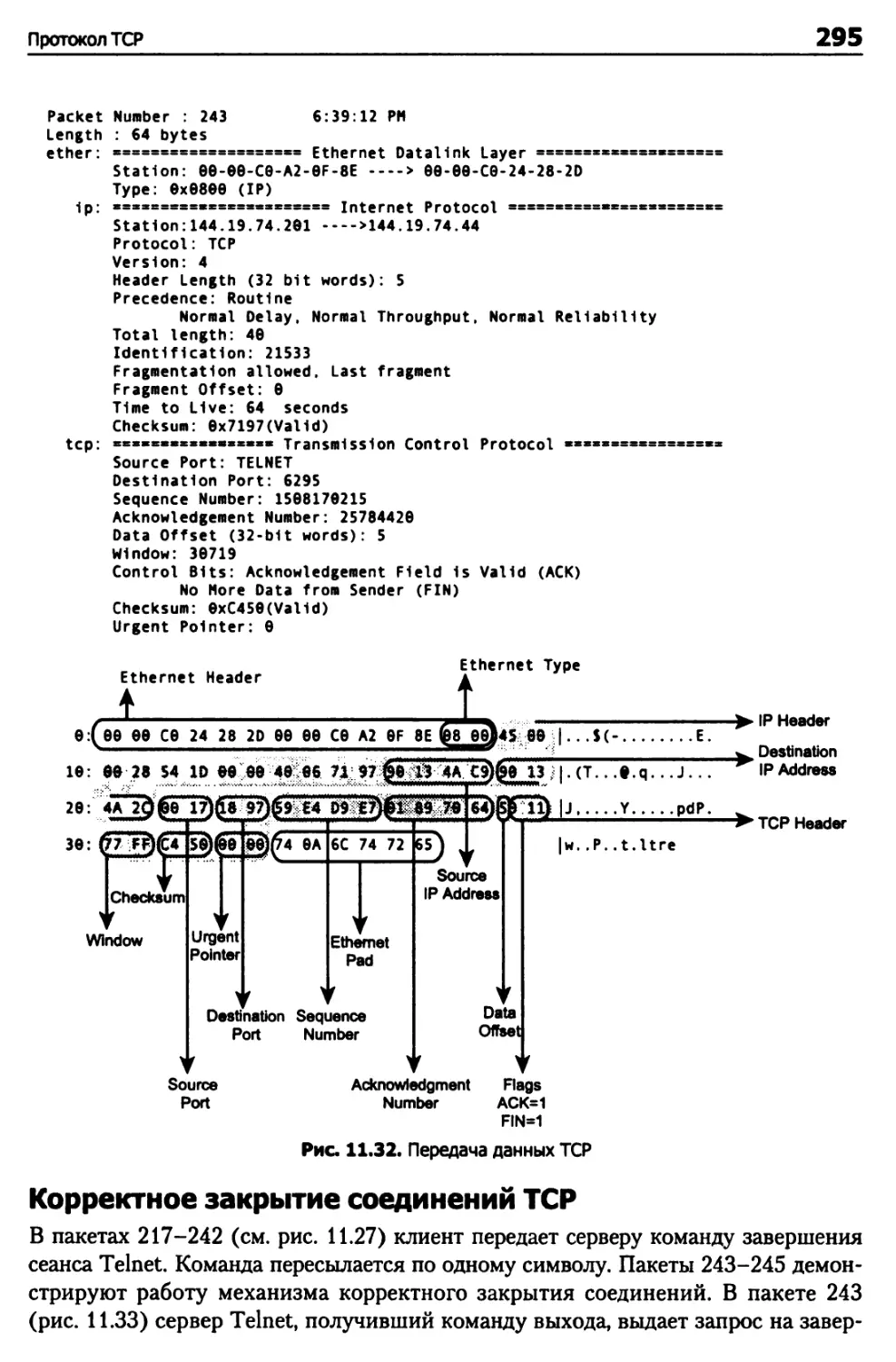
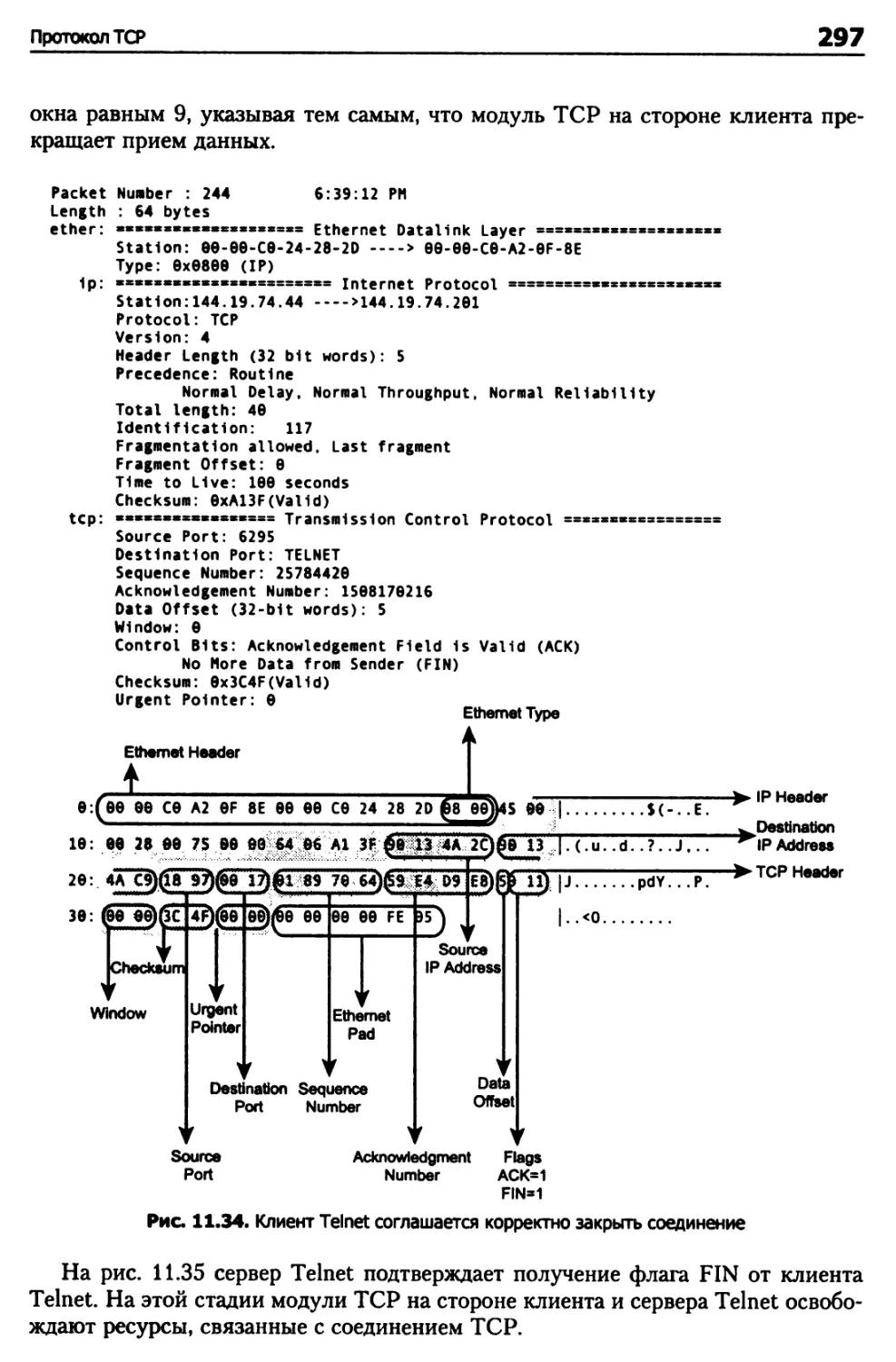
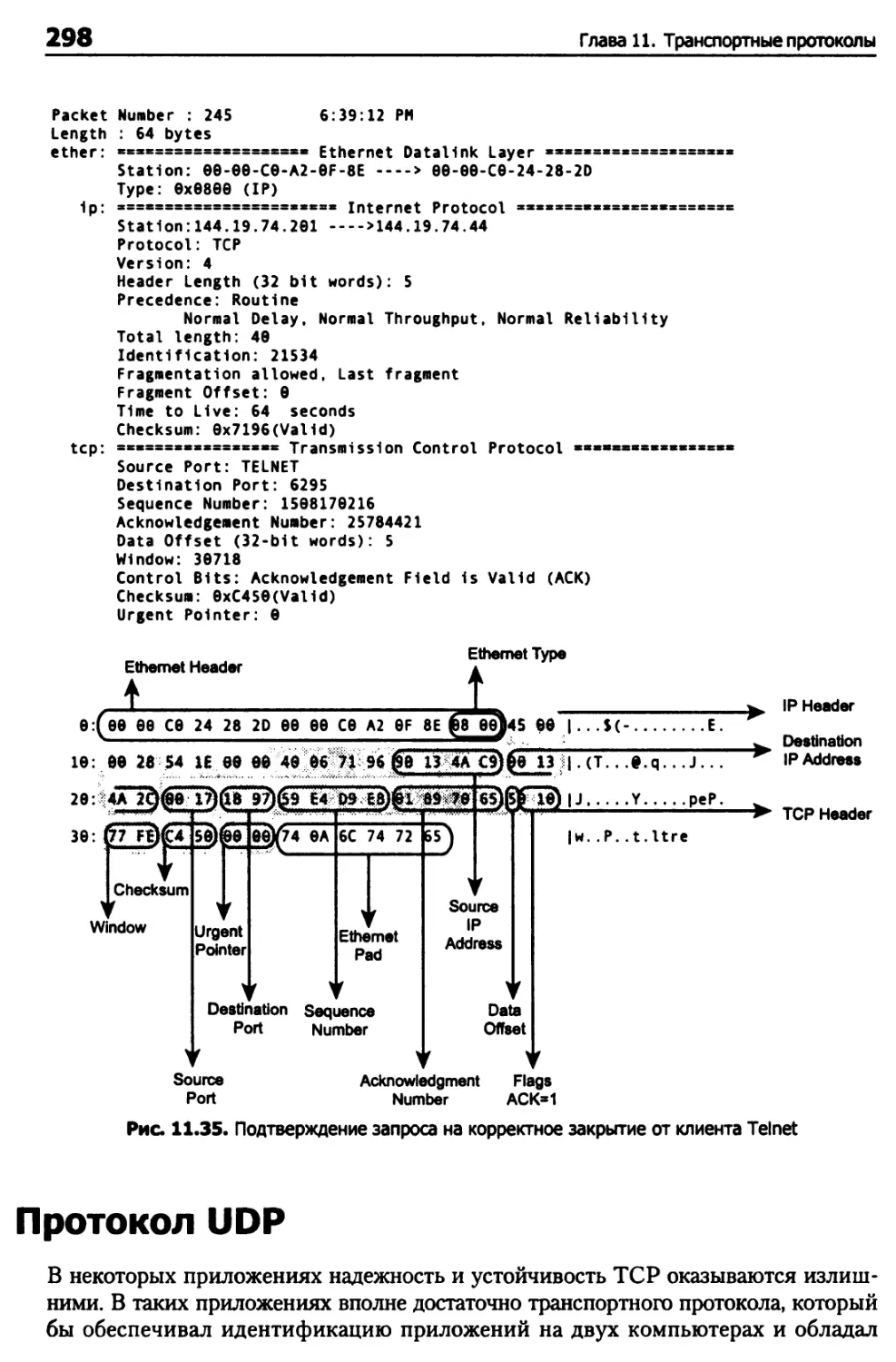
Глава 11. Транспортные протоколы 248
Протокол TCP 248
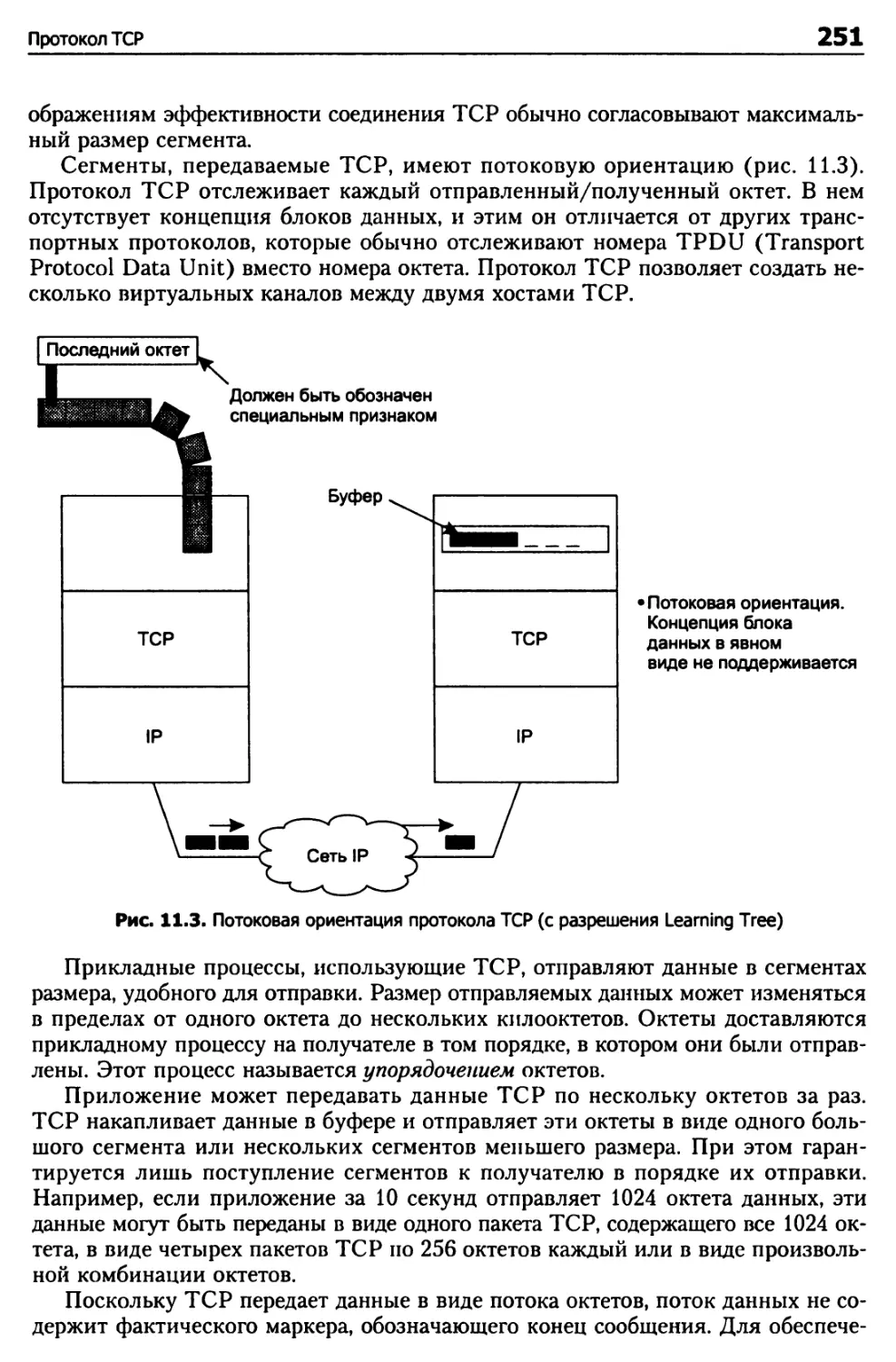
Возможности TCP 250
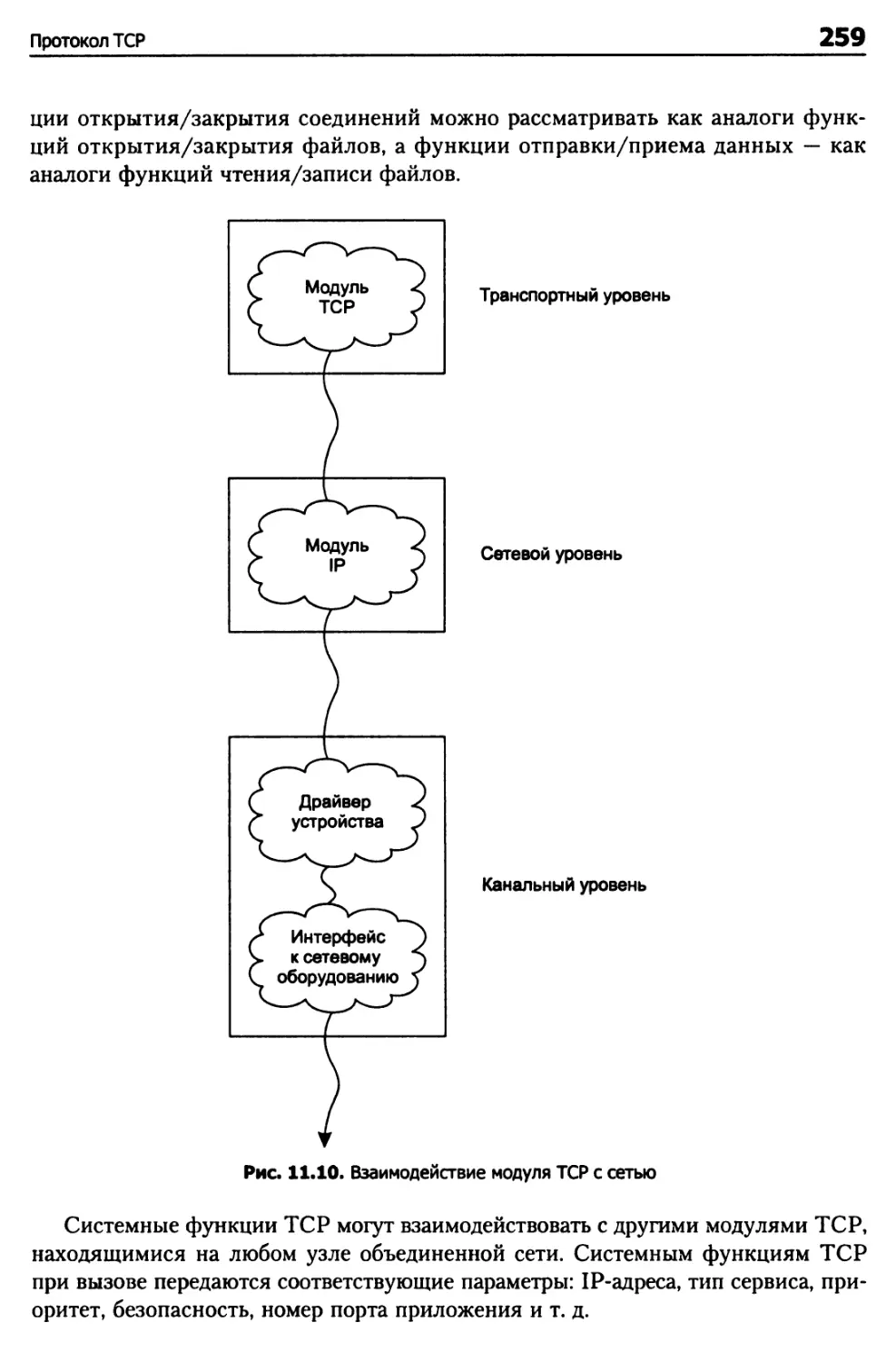
Программная среда хостов TCP 258
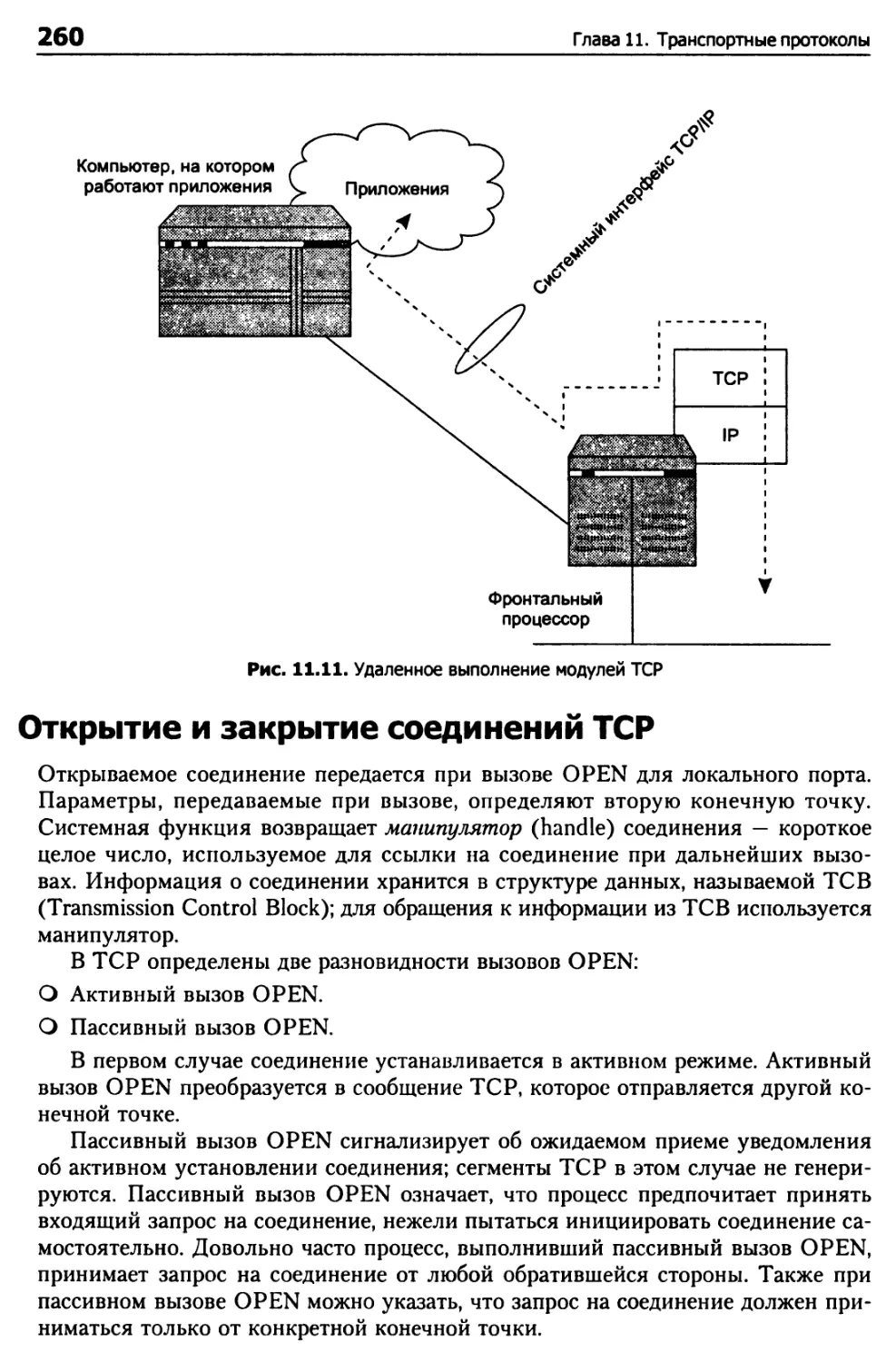
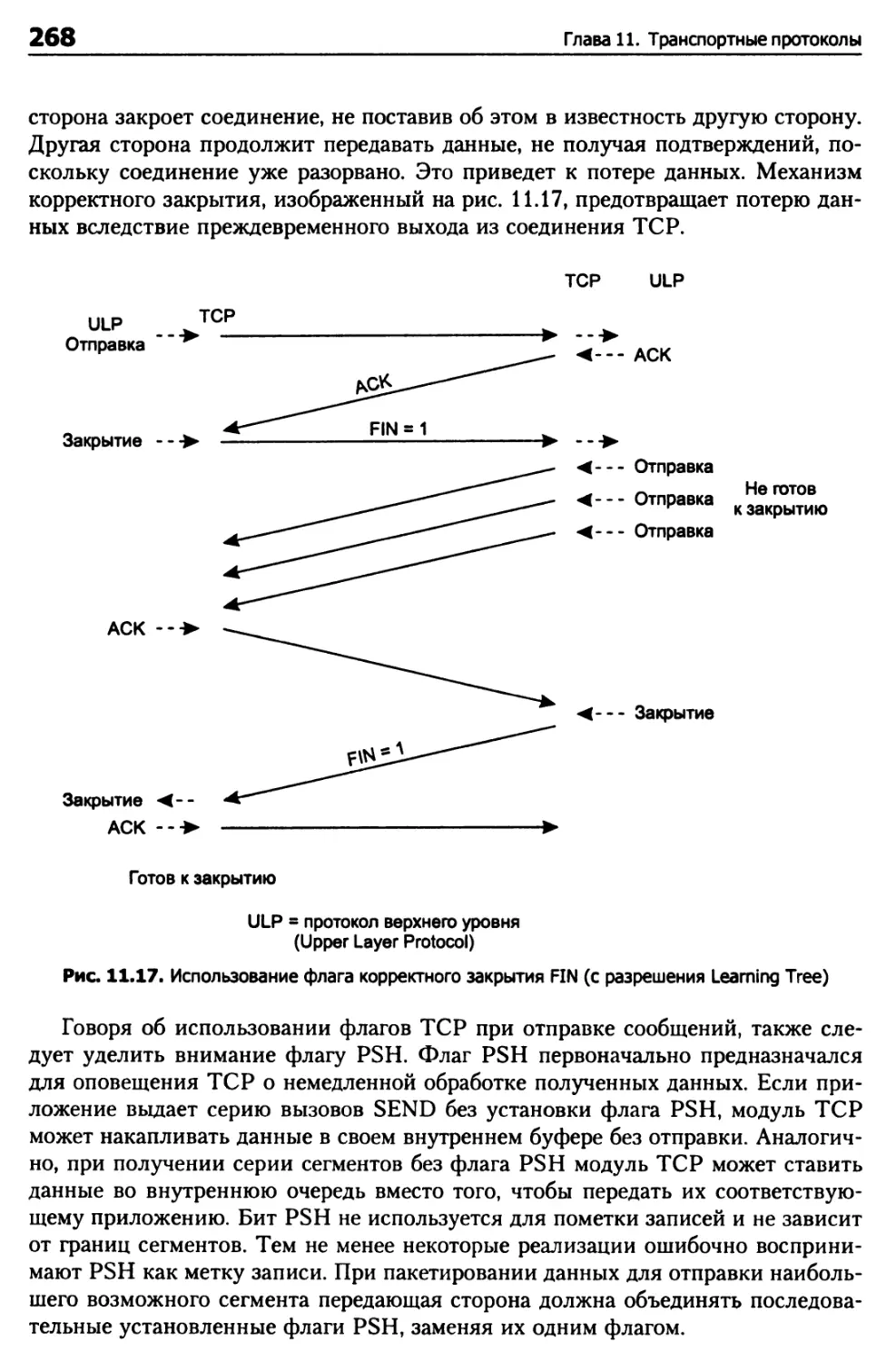
Открытие и закрытие соединений TCP 260
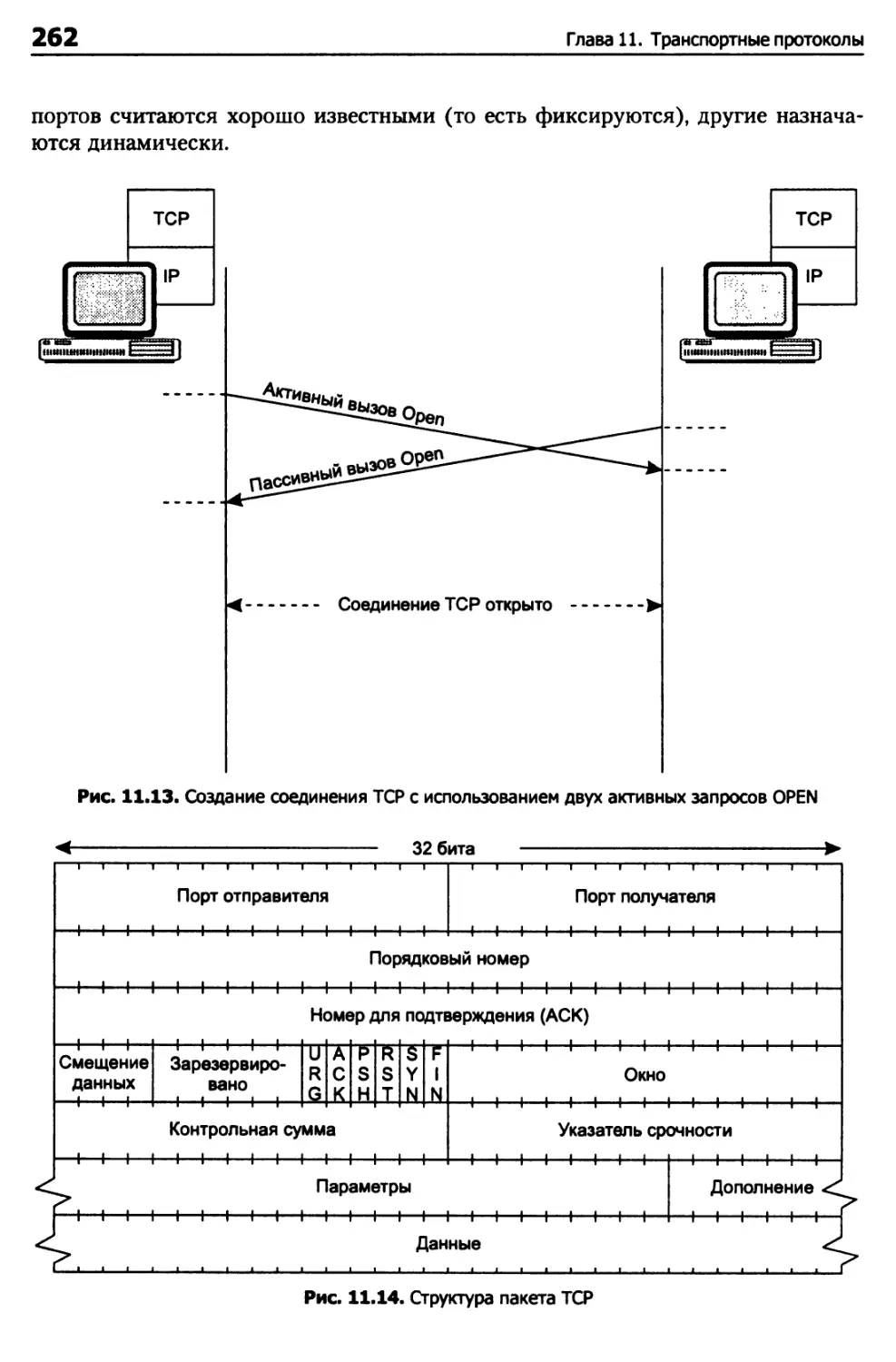
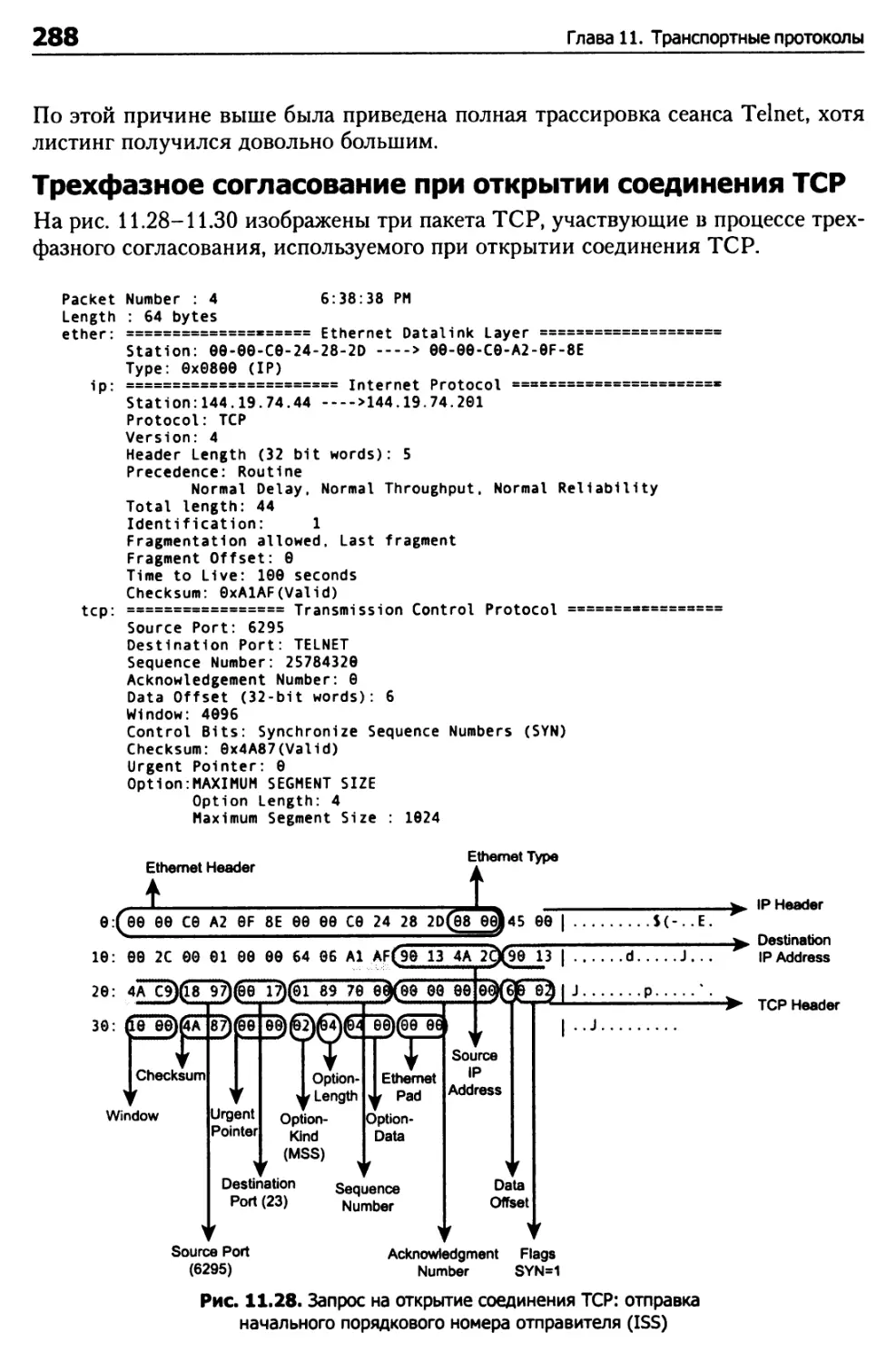
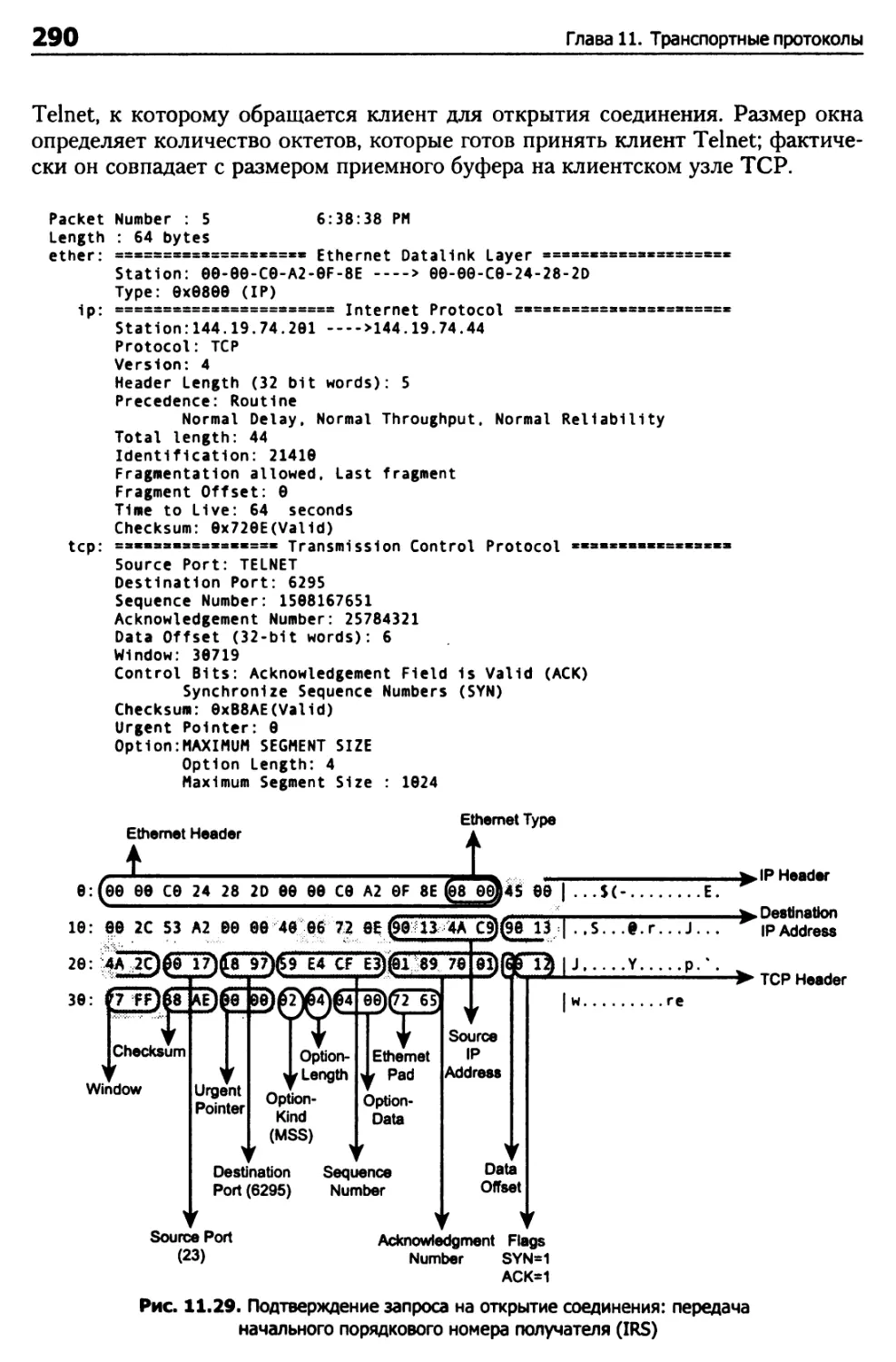
Структура пакета TCP 261
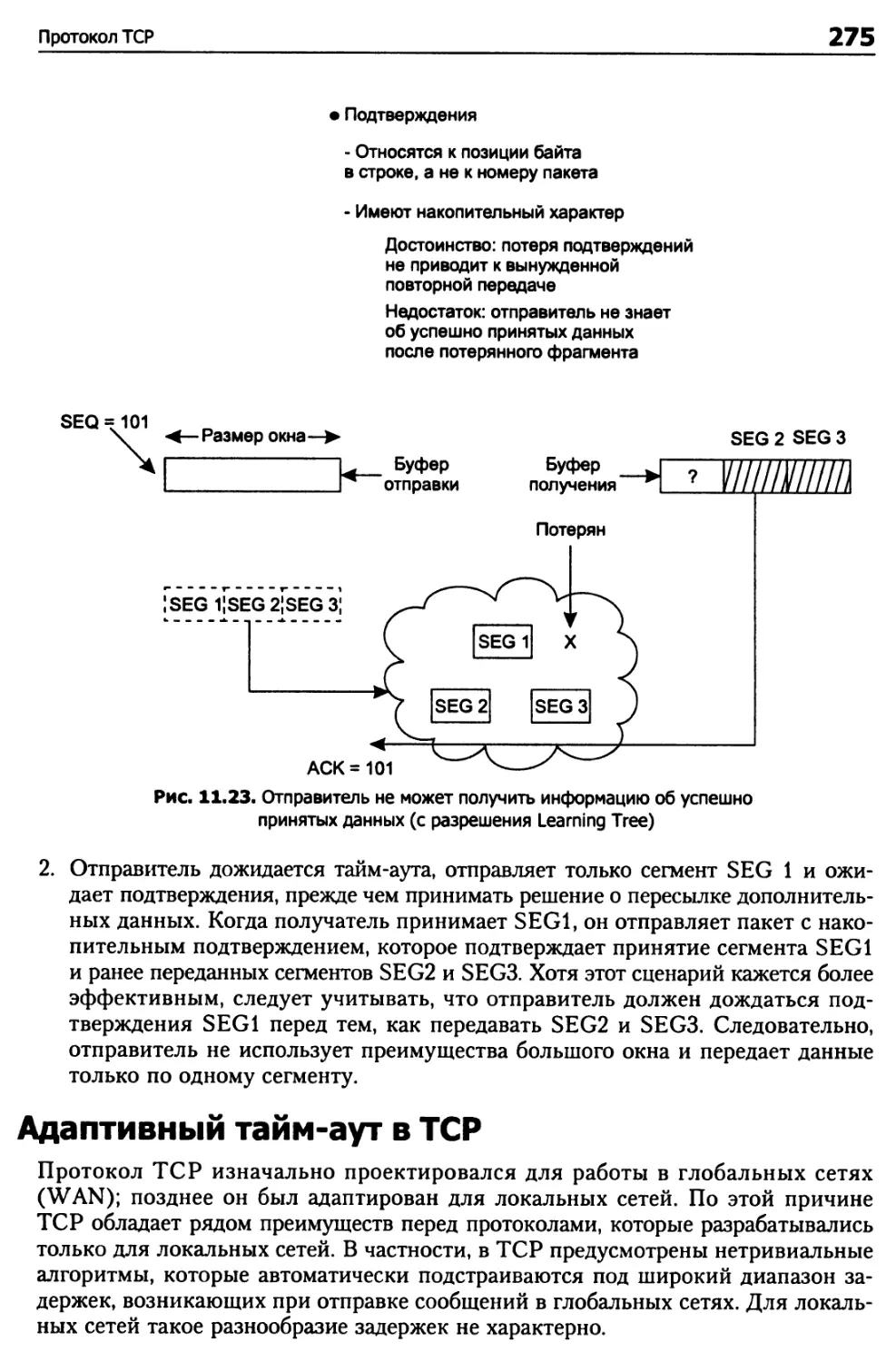
Адаптивный тайм-аут в TCP 275
Снижение последствий перегрузки сети в TCP 278
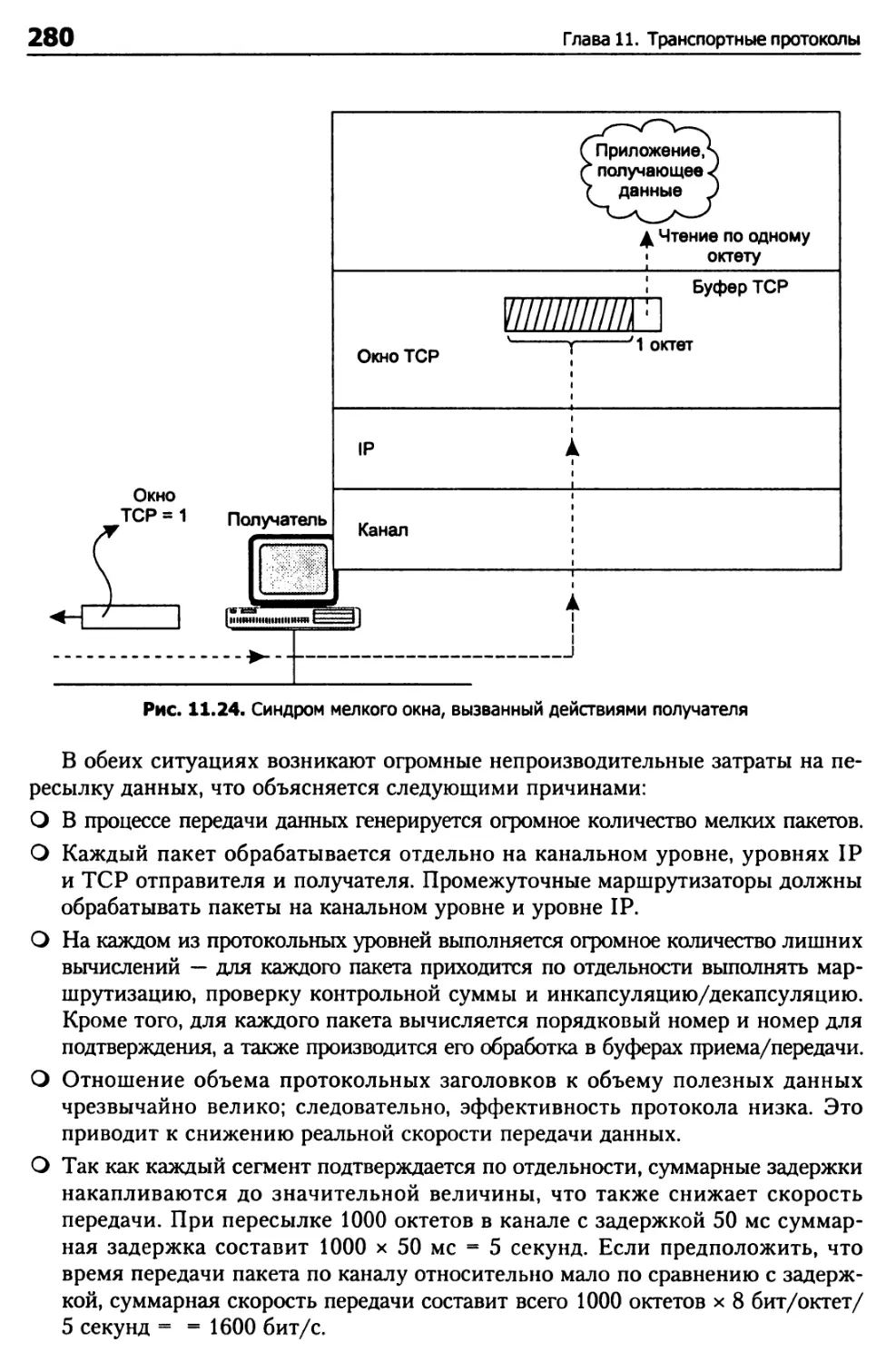
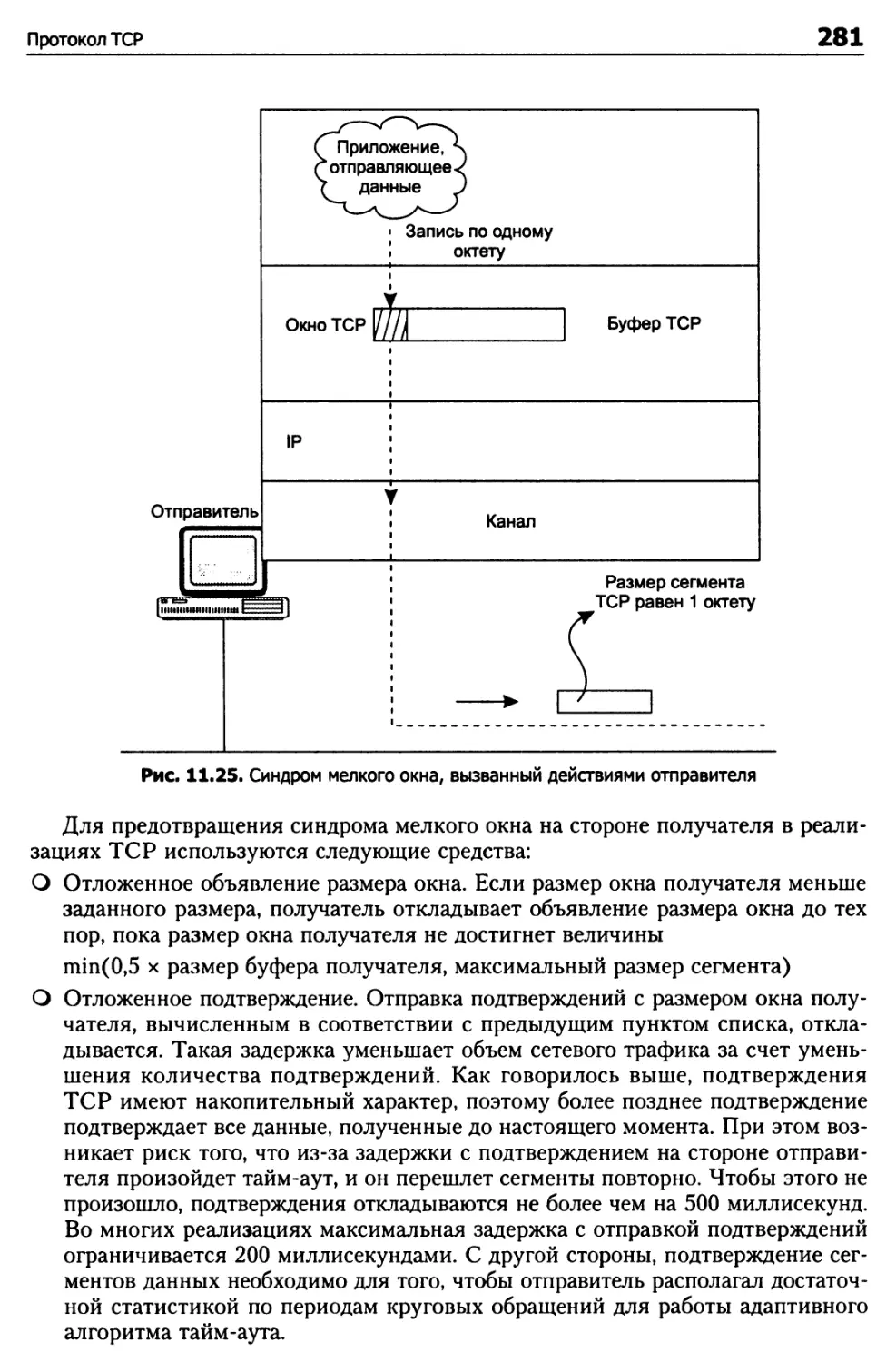
Борьба с синдромом мелкого окна 279
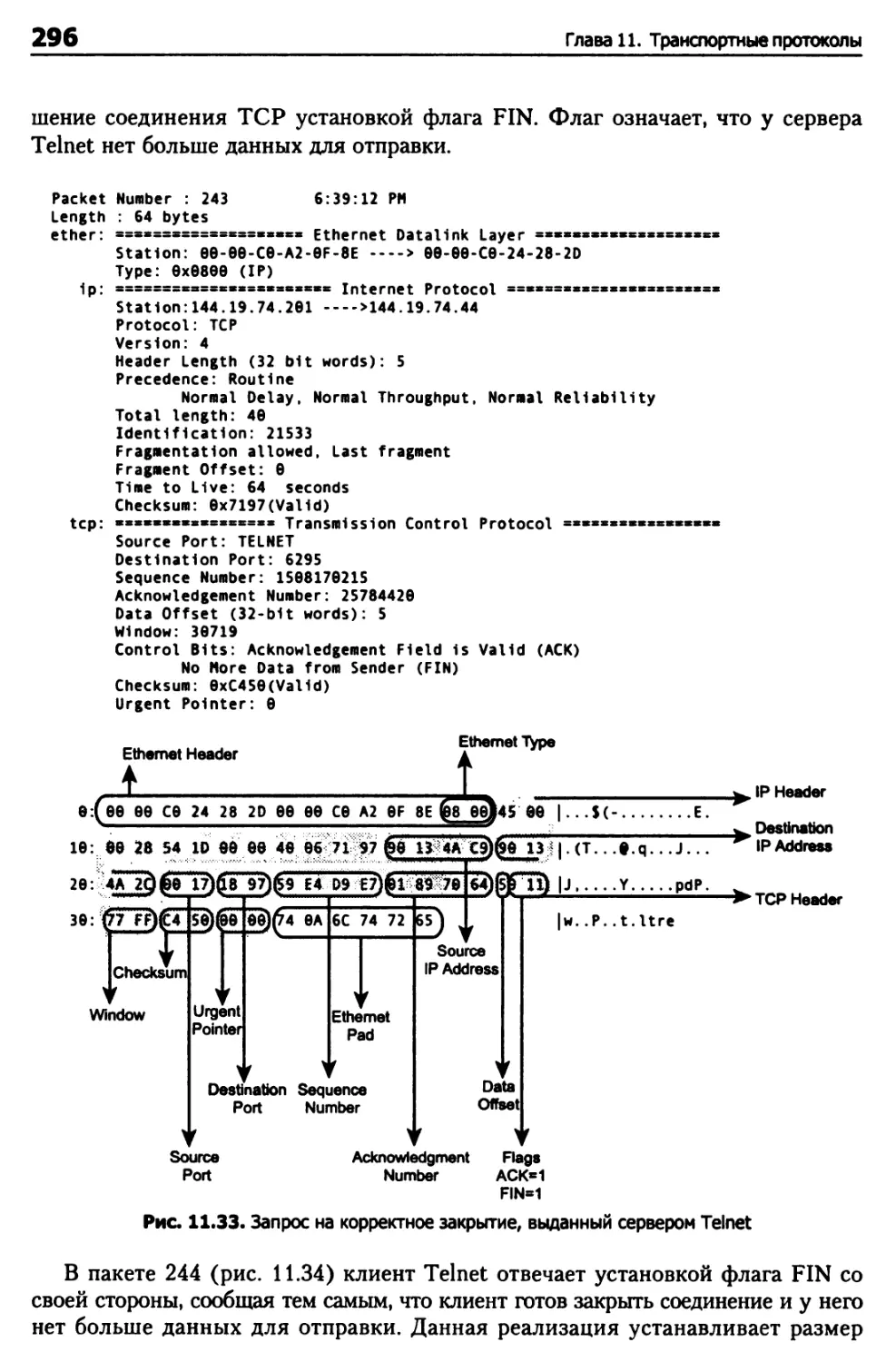
Разрыв соединений TCP 282
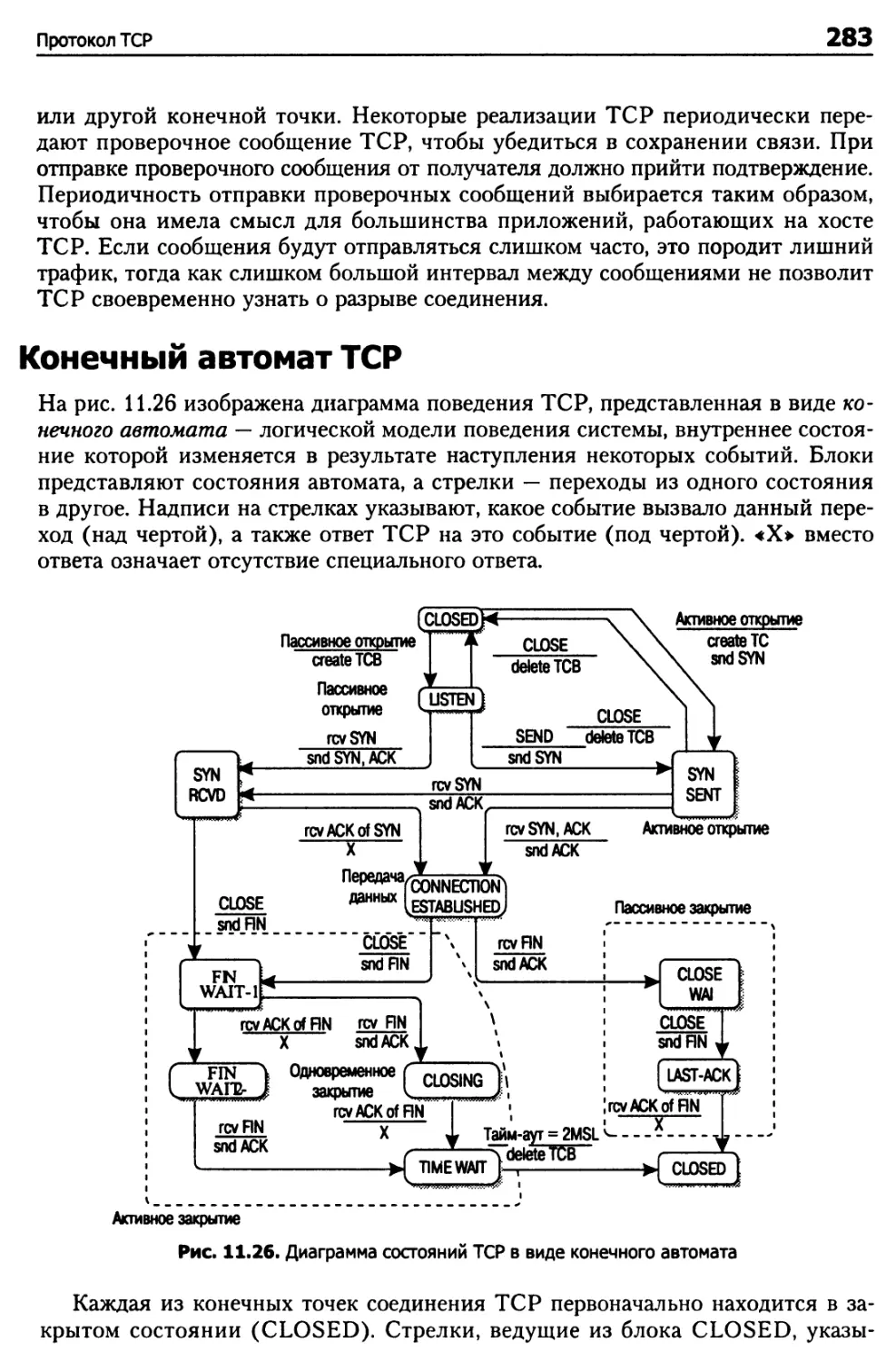
Конечный автомат TCP 283
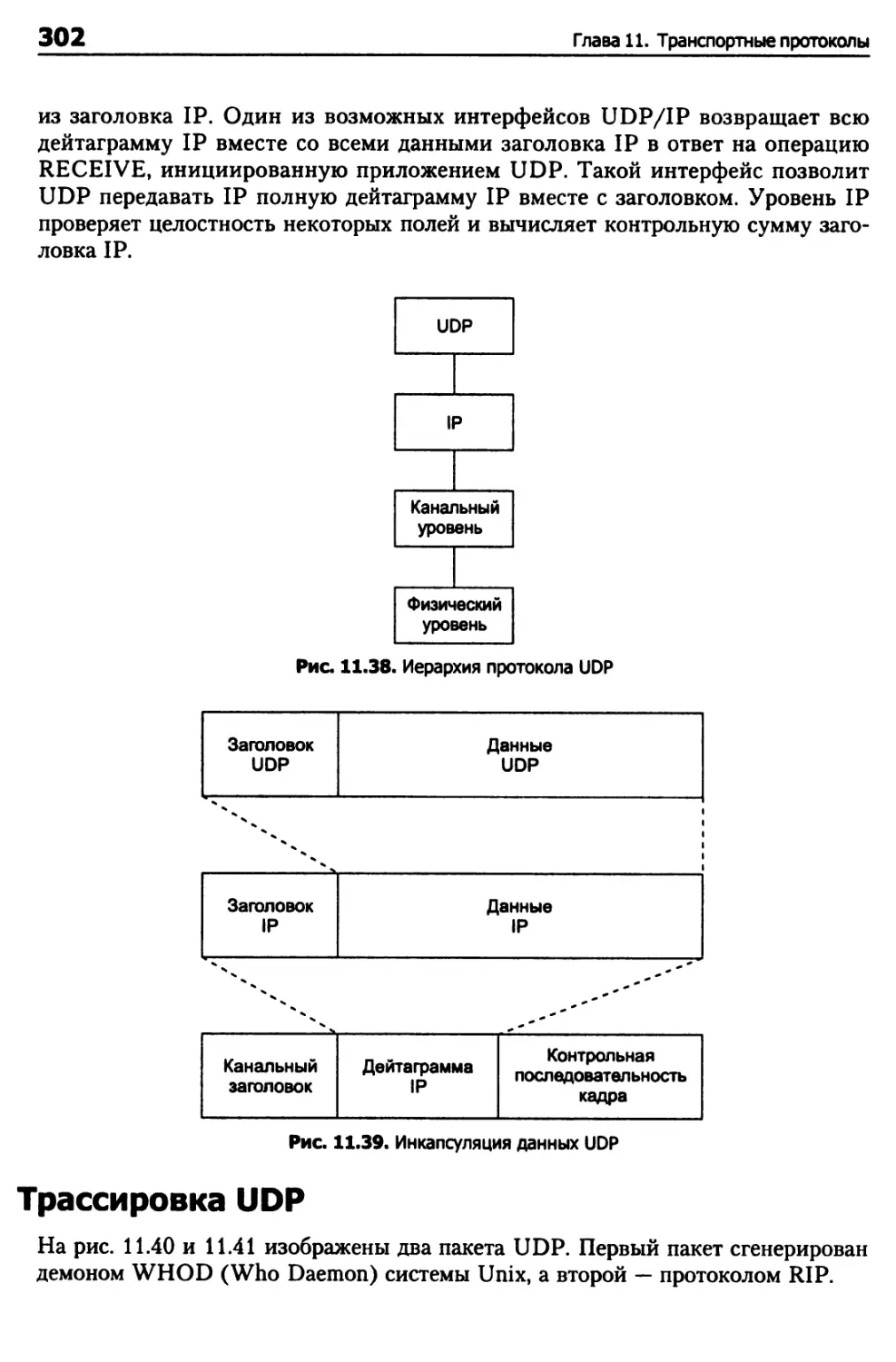
Протокол UDP 298
Структура заголовка UDP 300
Иерархия UDP и инкапсуляция 301
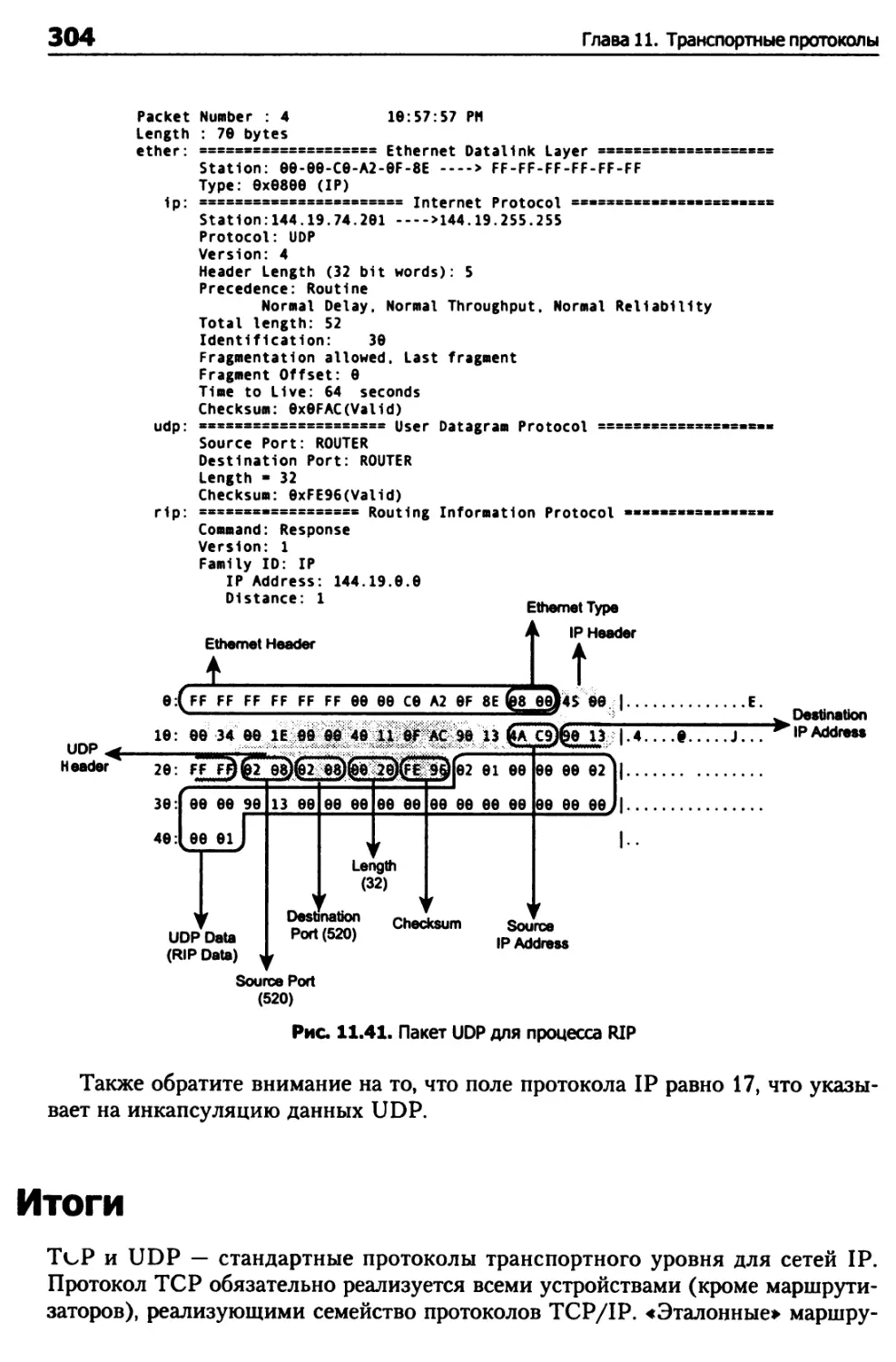
Трассировка UDP 302
Итоги 304
Глава 12. IPv6 306
Дейтаграмма IPv6 307
Классификация приоритетов 309
Потоковые метки 310
128-разрядные IP-адреса 311
Заголовки расширения IP 312
Хосты с несколькими IP-адресами 320
Направленные, групповые и альтернативные адреса 321
Переход с IPv4 на IPv6 323
Итоги 325
Глава 13. Маршрутизация в сетях IP 326
Основы маршрутизации 326
Статическая маршрутизация 327
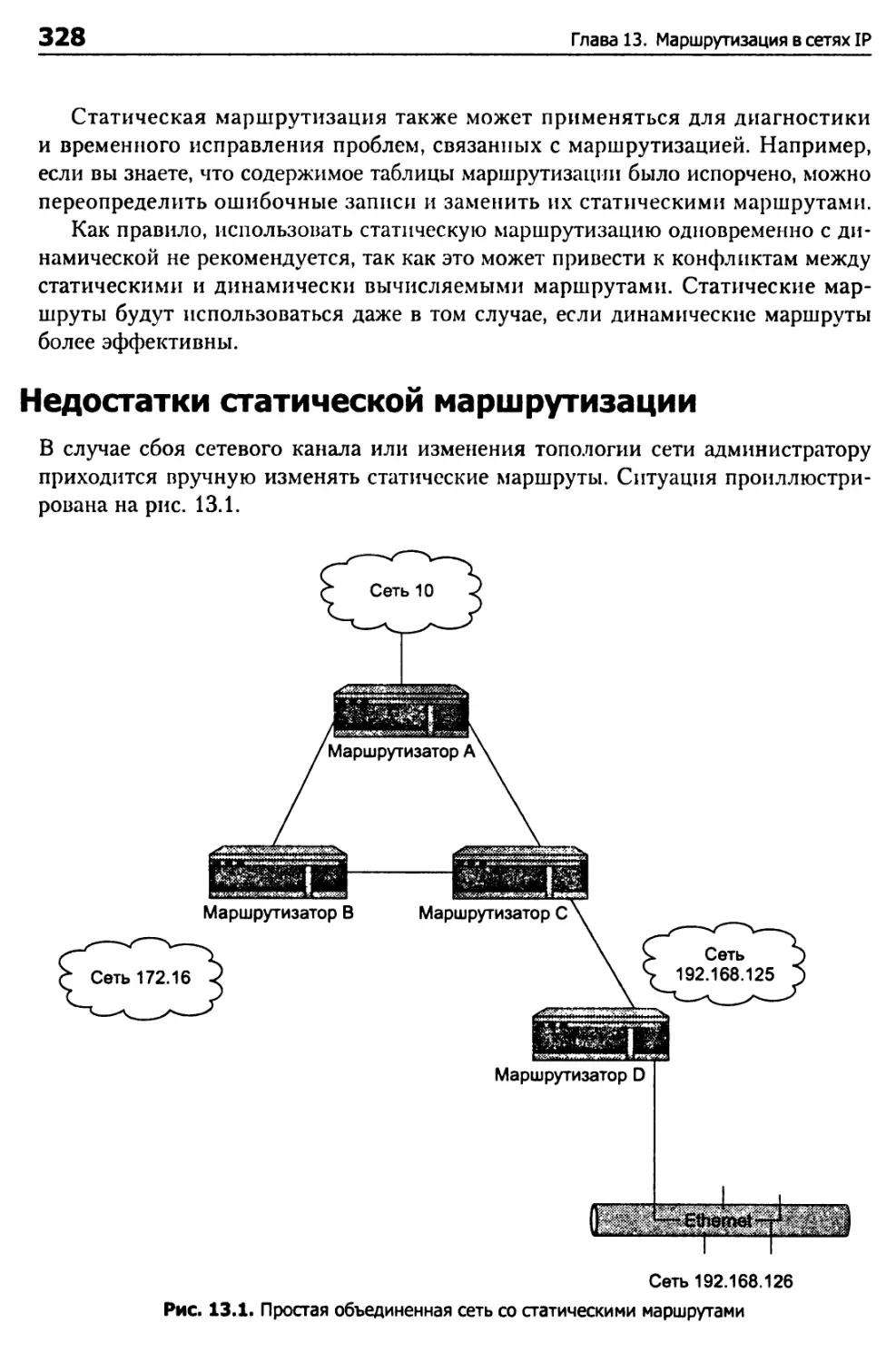
Недостатки статической маршрутизации 328
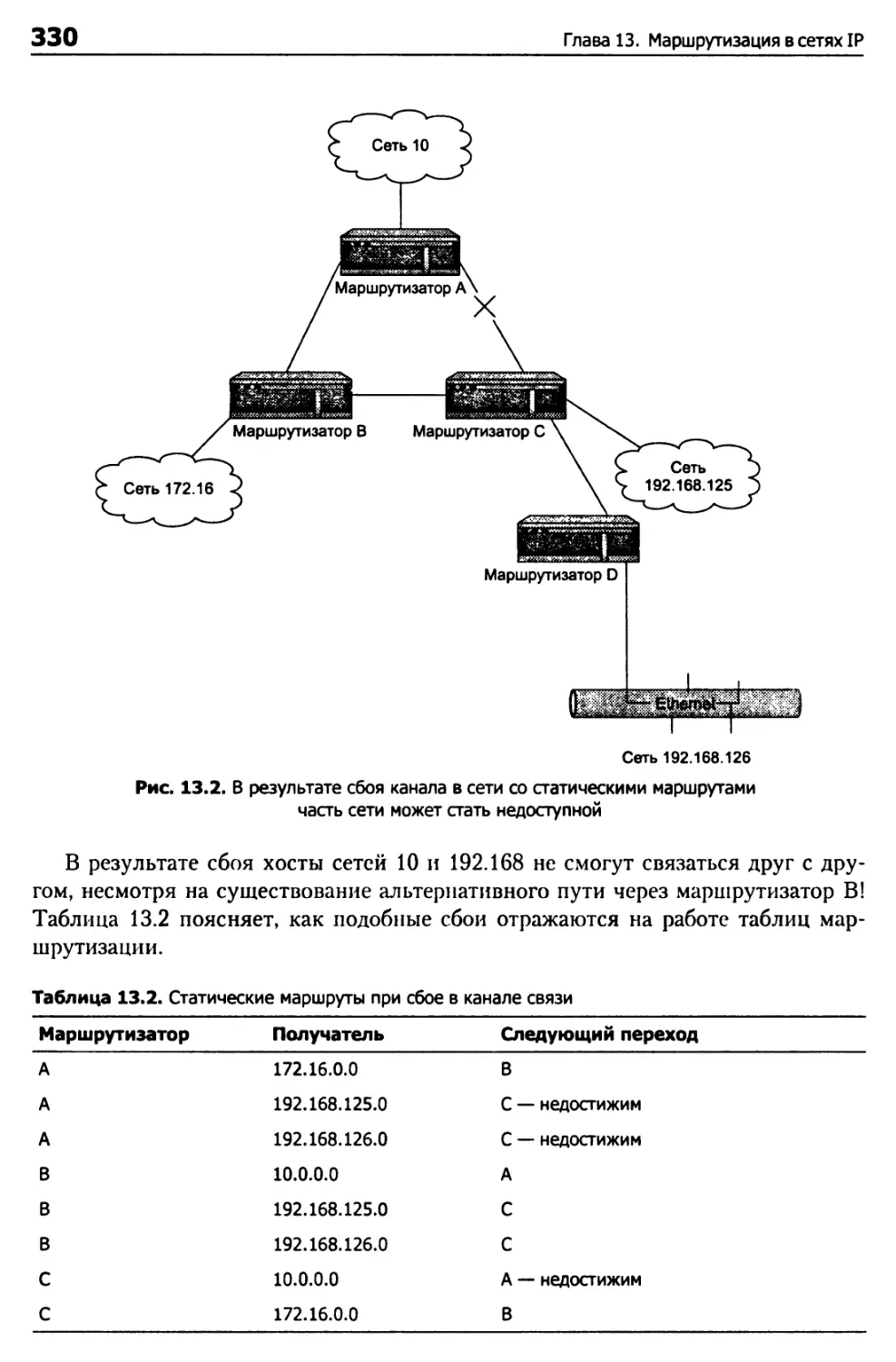
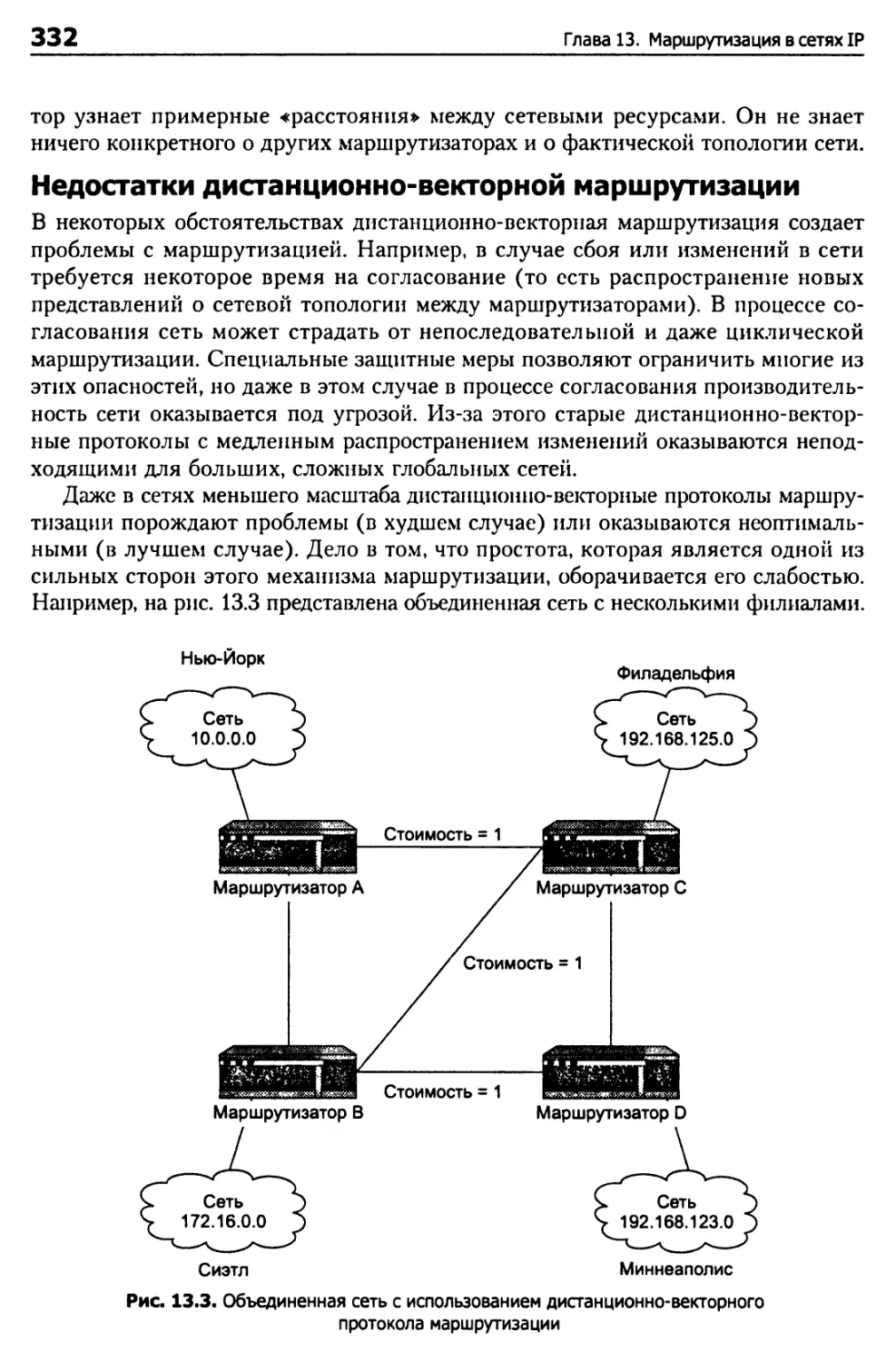
Дистанционно-векторная маршрутизация 331
Топологическая маршрутизация 334
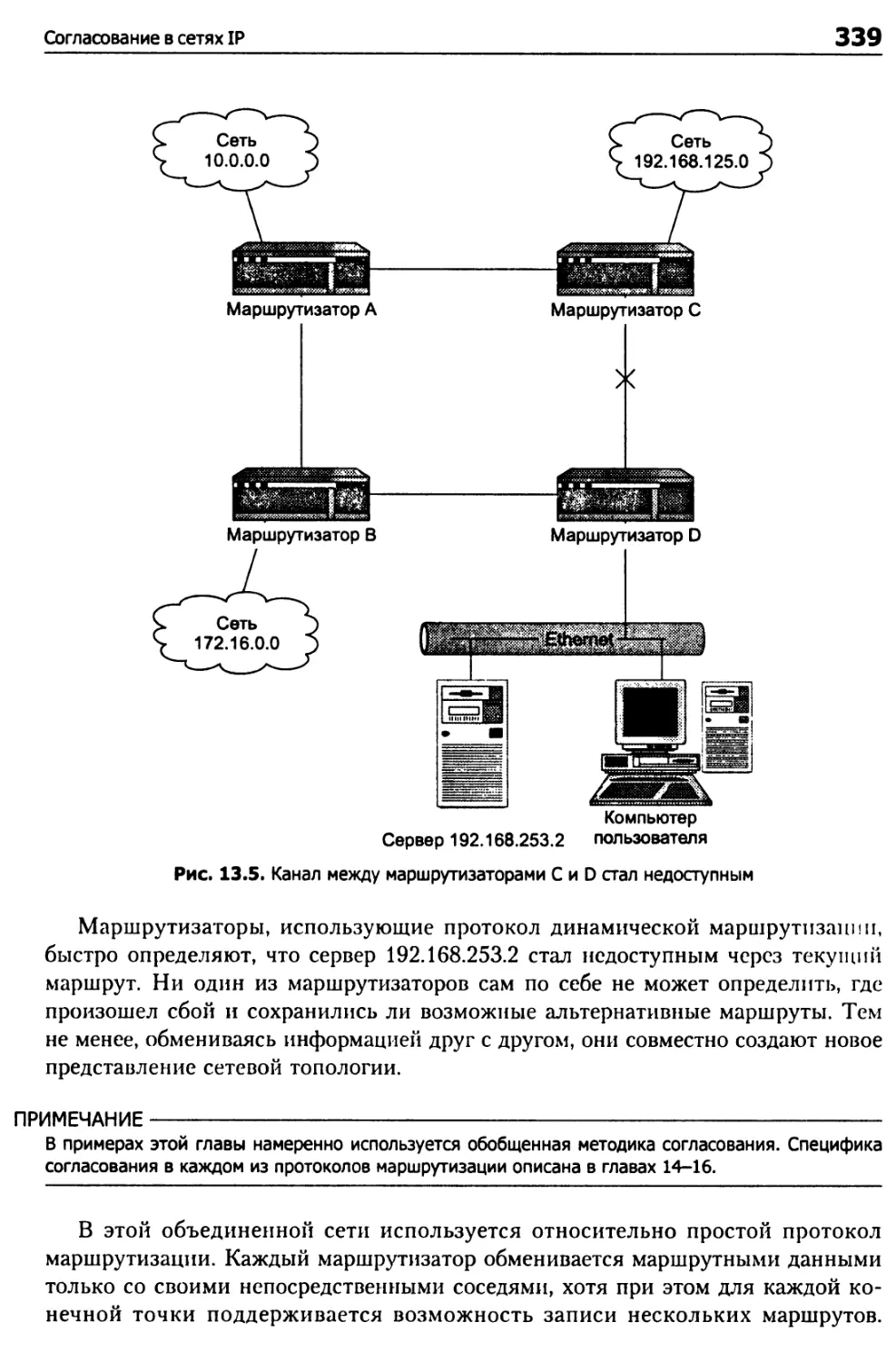
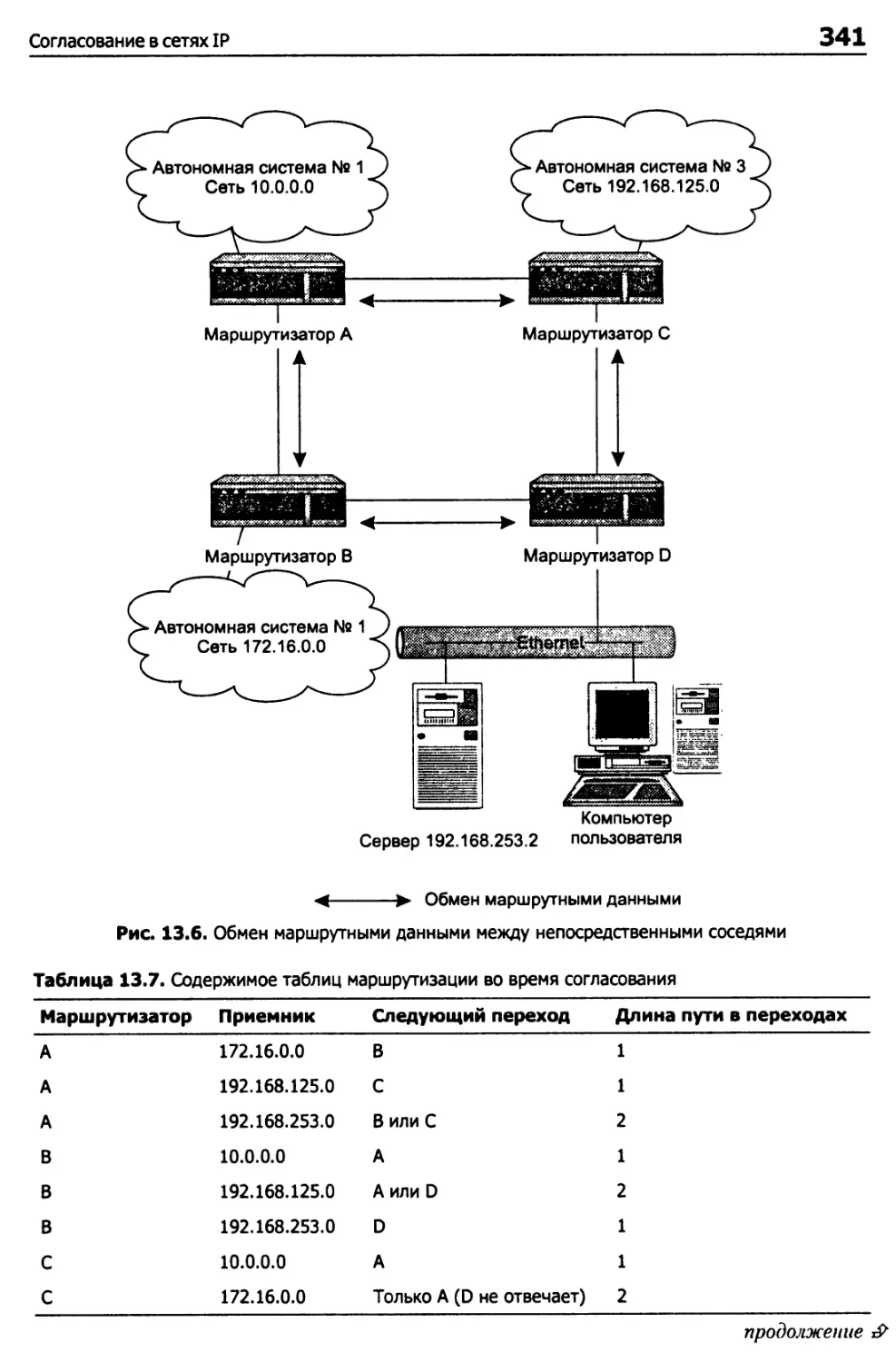
Согласование в сетях IP 336
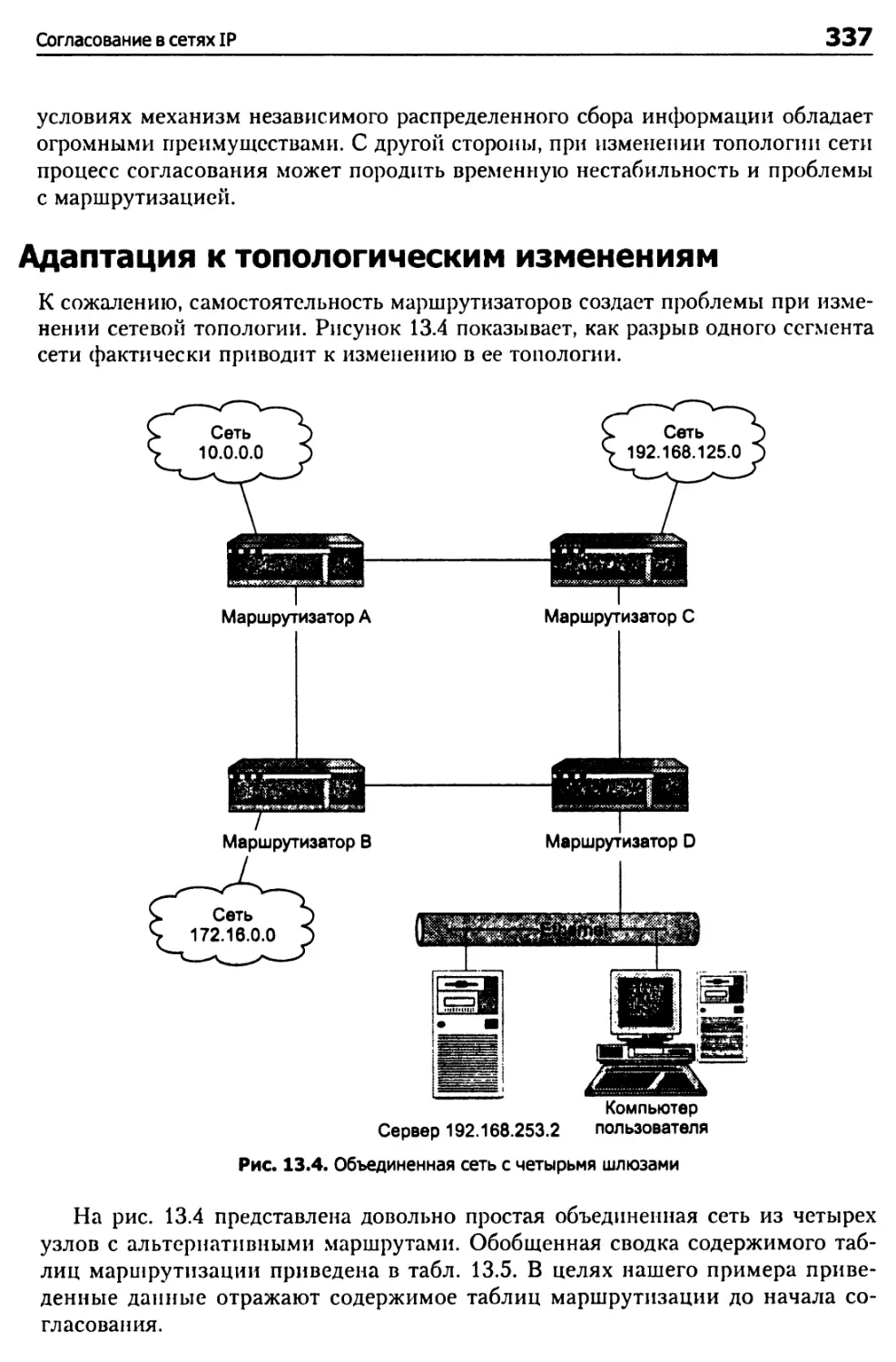
Адаптация к топологическим изменениям 337
Время согласования 342
Построение маршрутов в сетях IP 343
Хранение альтернативных маршрутов 344
Механизм инициирования обновлений 344
Маршрутные метрики 345
Итоги 346
Глава 14. Шлюзовые протоколы 347
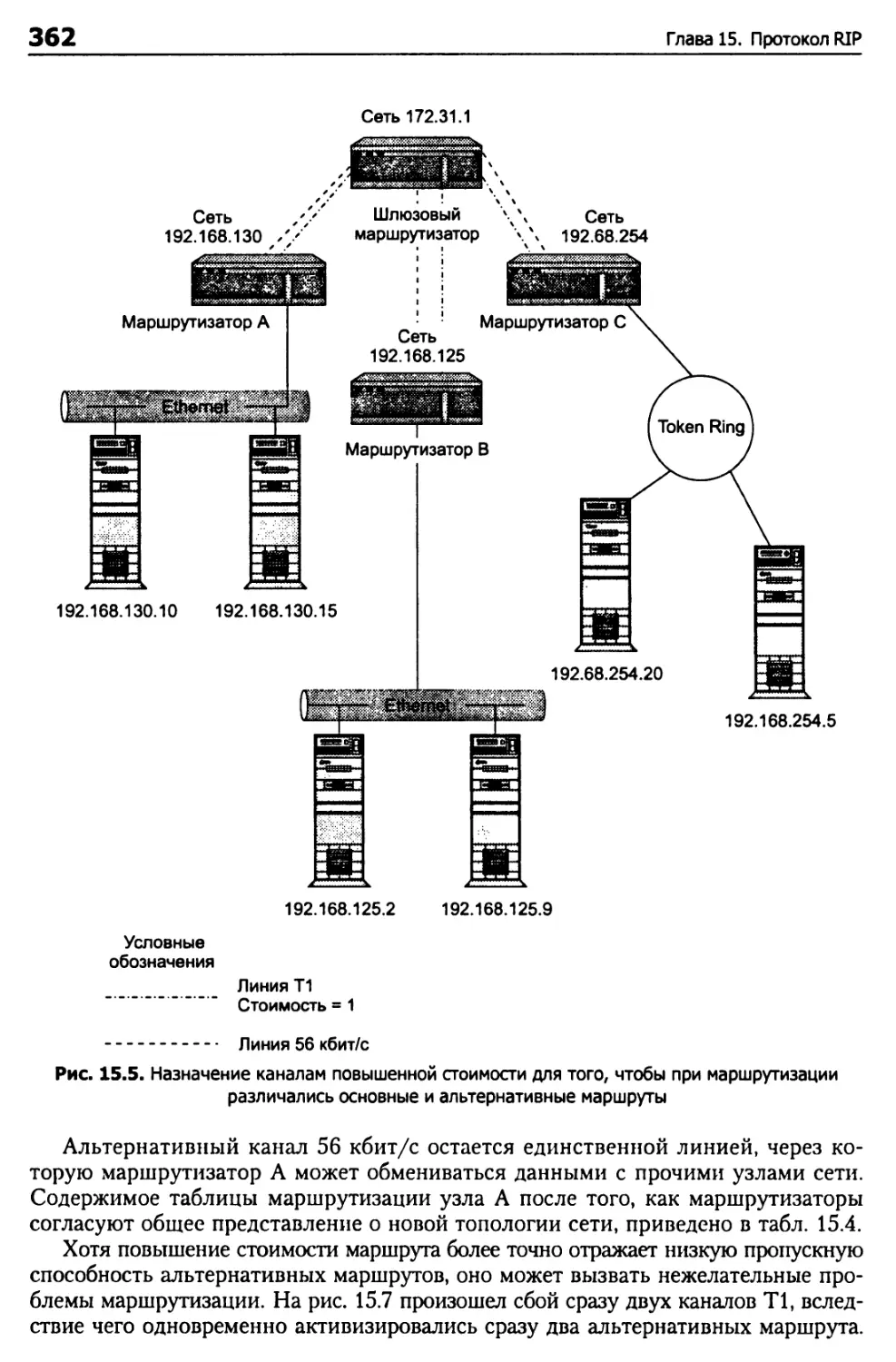
Шлюзы, мосты и маршрутизаторы 347
Шлюз 348
Мост 348
Маршрутизатор 349
Автономная система 349
Знакомство со шлюзовыми протоколами 349
Протоколы IGP и EGP 350
Протокол GGP 350
Протокол EGP 351
Протоколы IGP 352
Итоги 352
Глава 15. Протокол RIP 353
RFC 1058 353
Формат пакета RIP 354
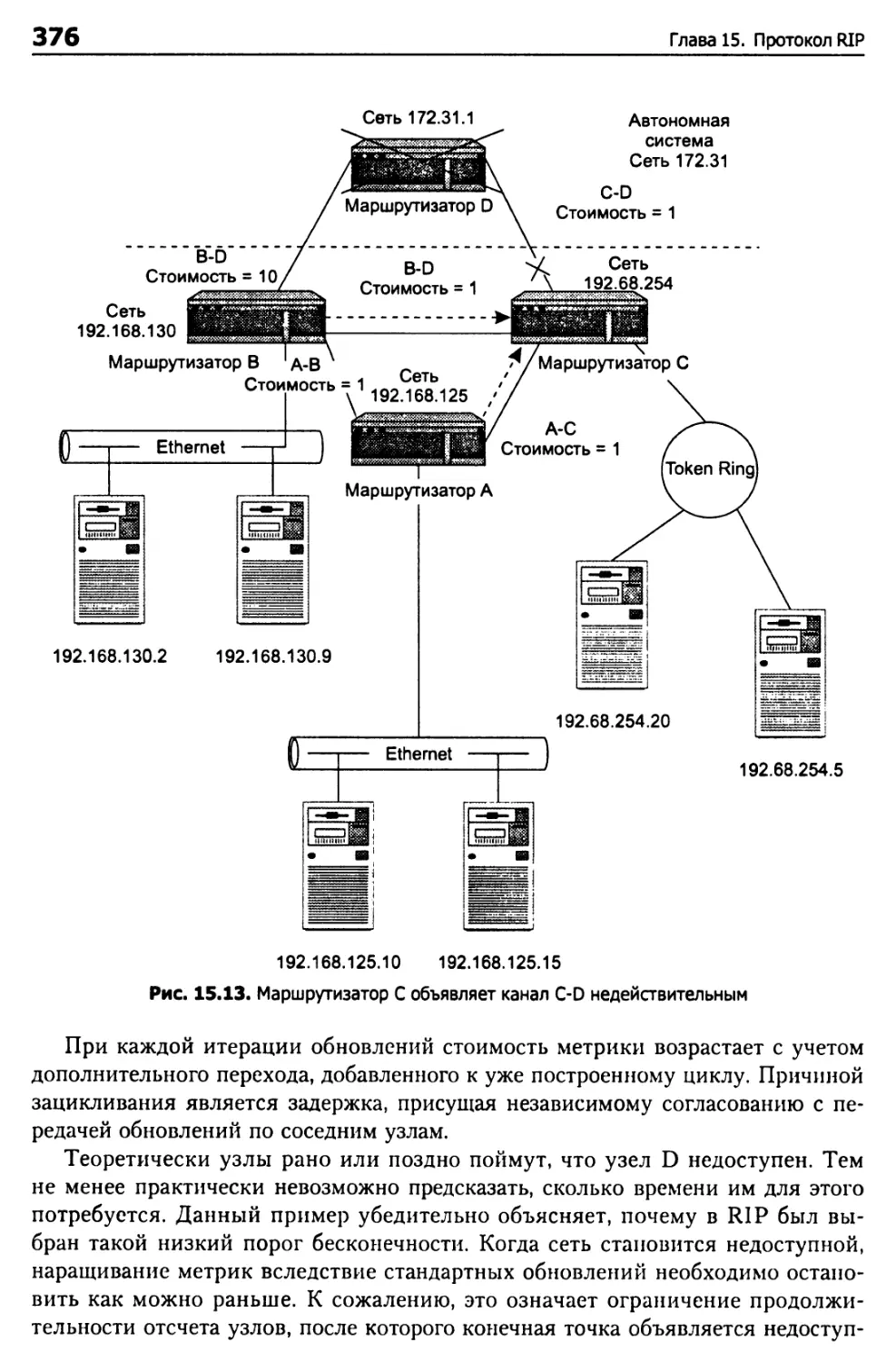
Таблица маршрутизации RIP 356
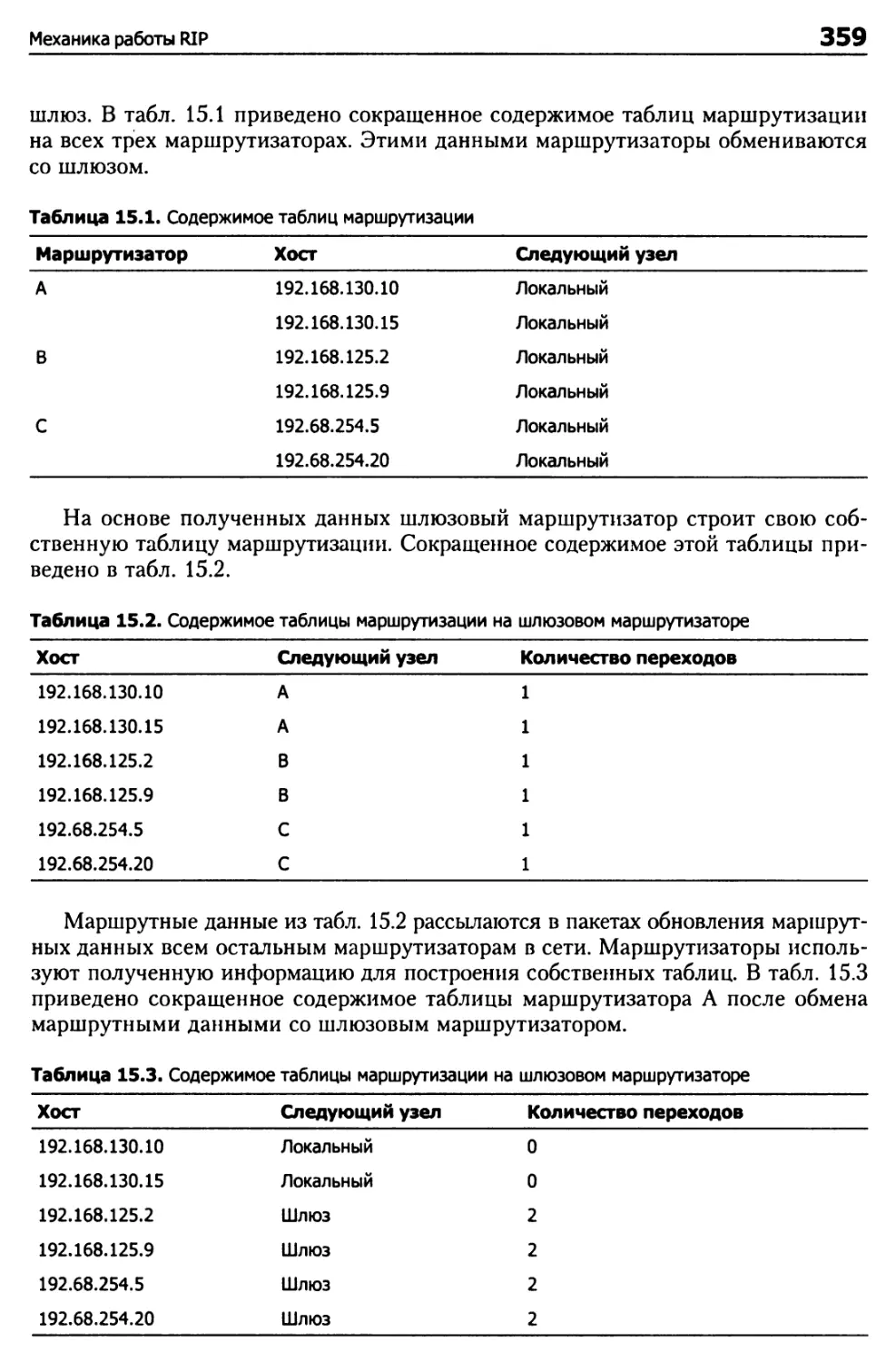
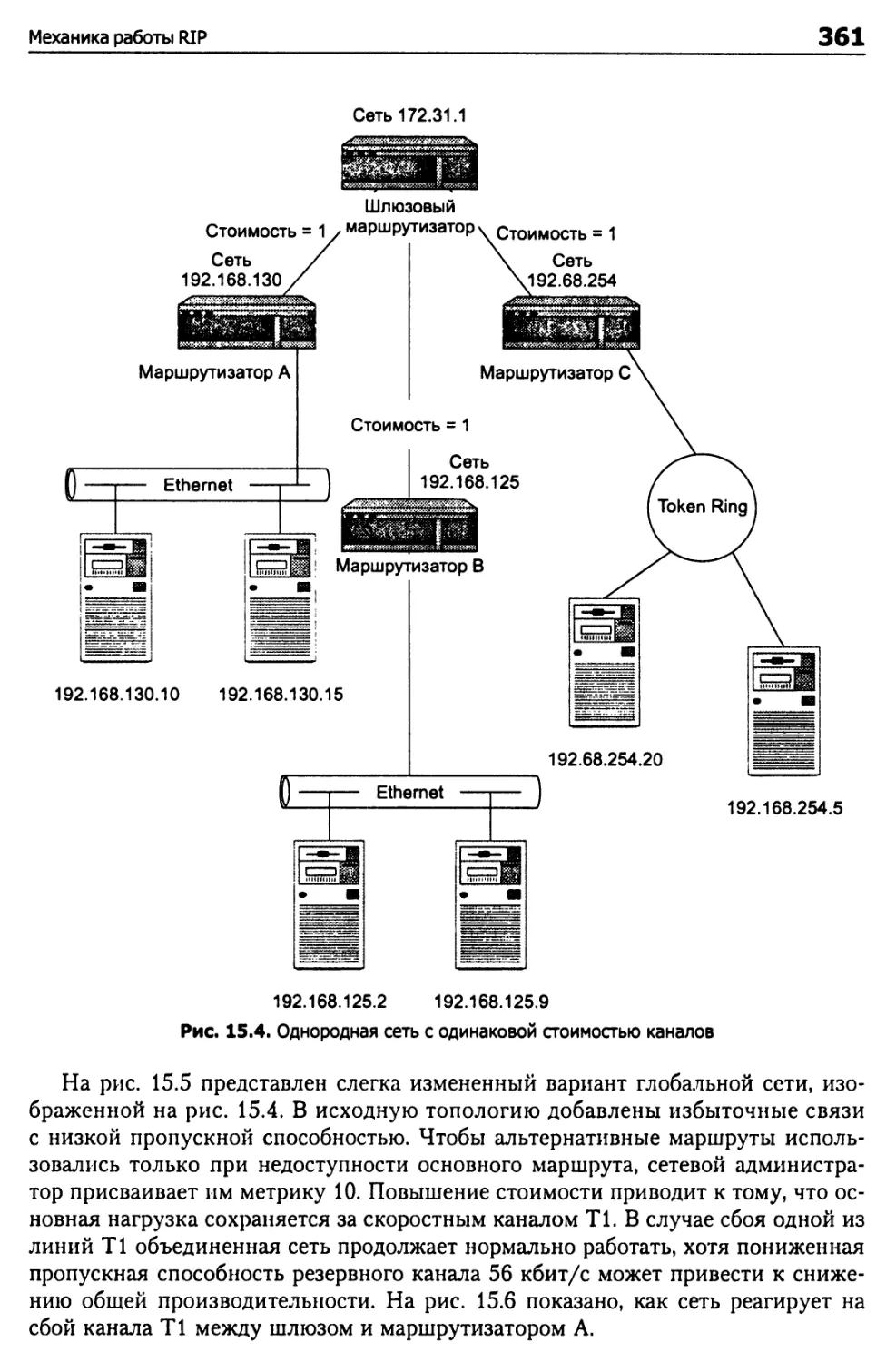
Механика работы RIP 358
Вычисление расстояний 360
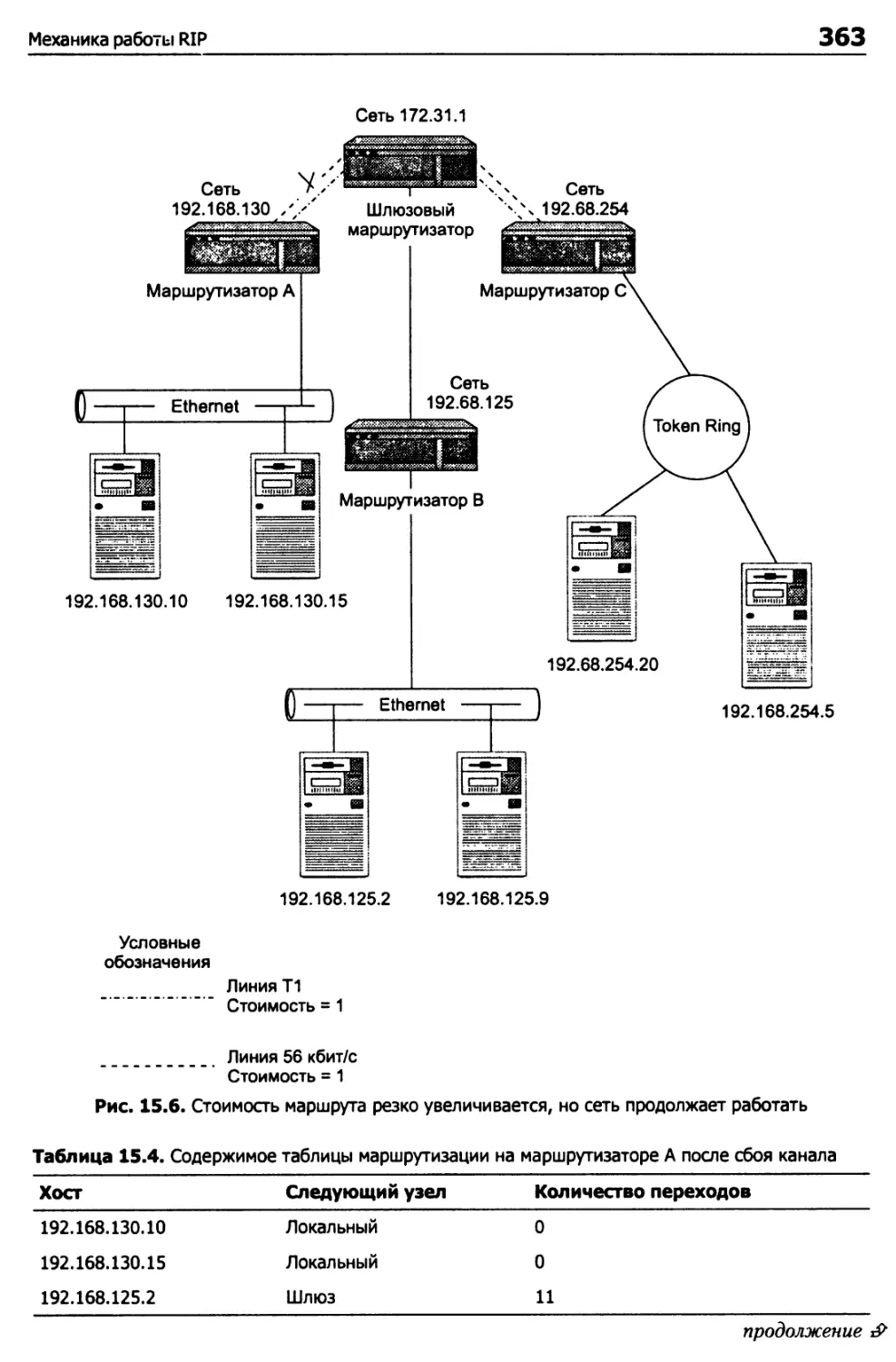
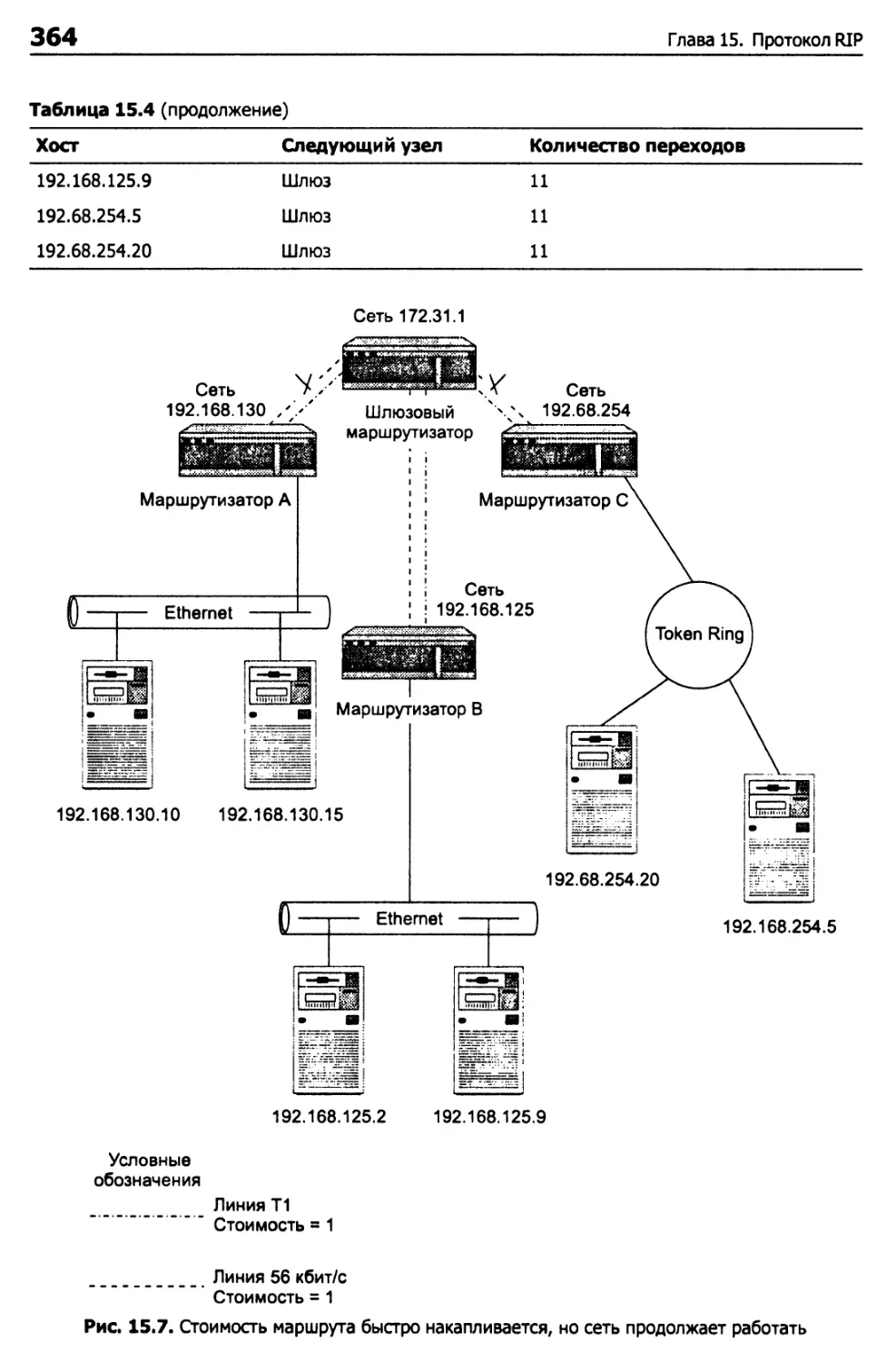
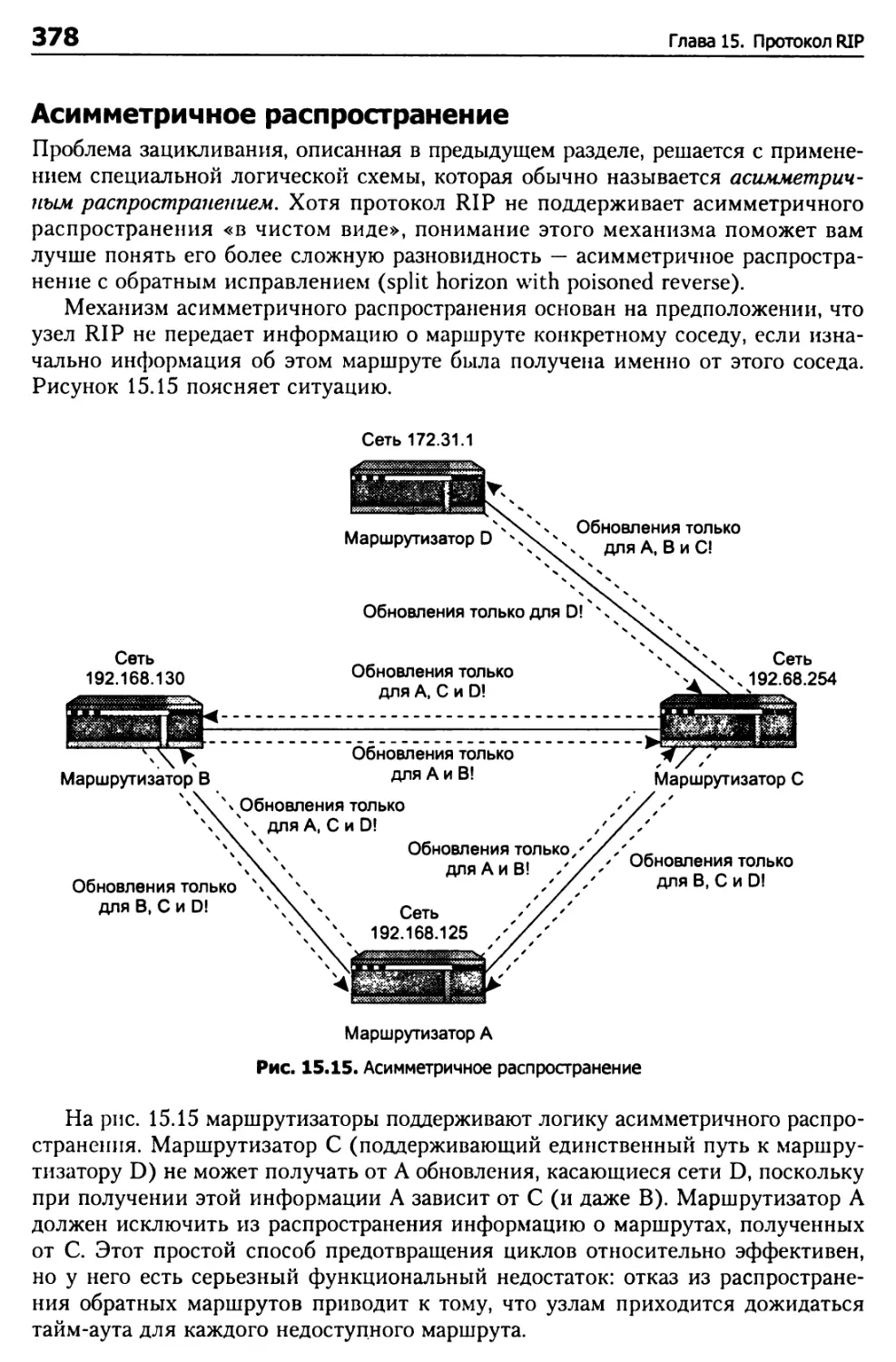
Обновление таблицы маршрутизации 365
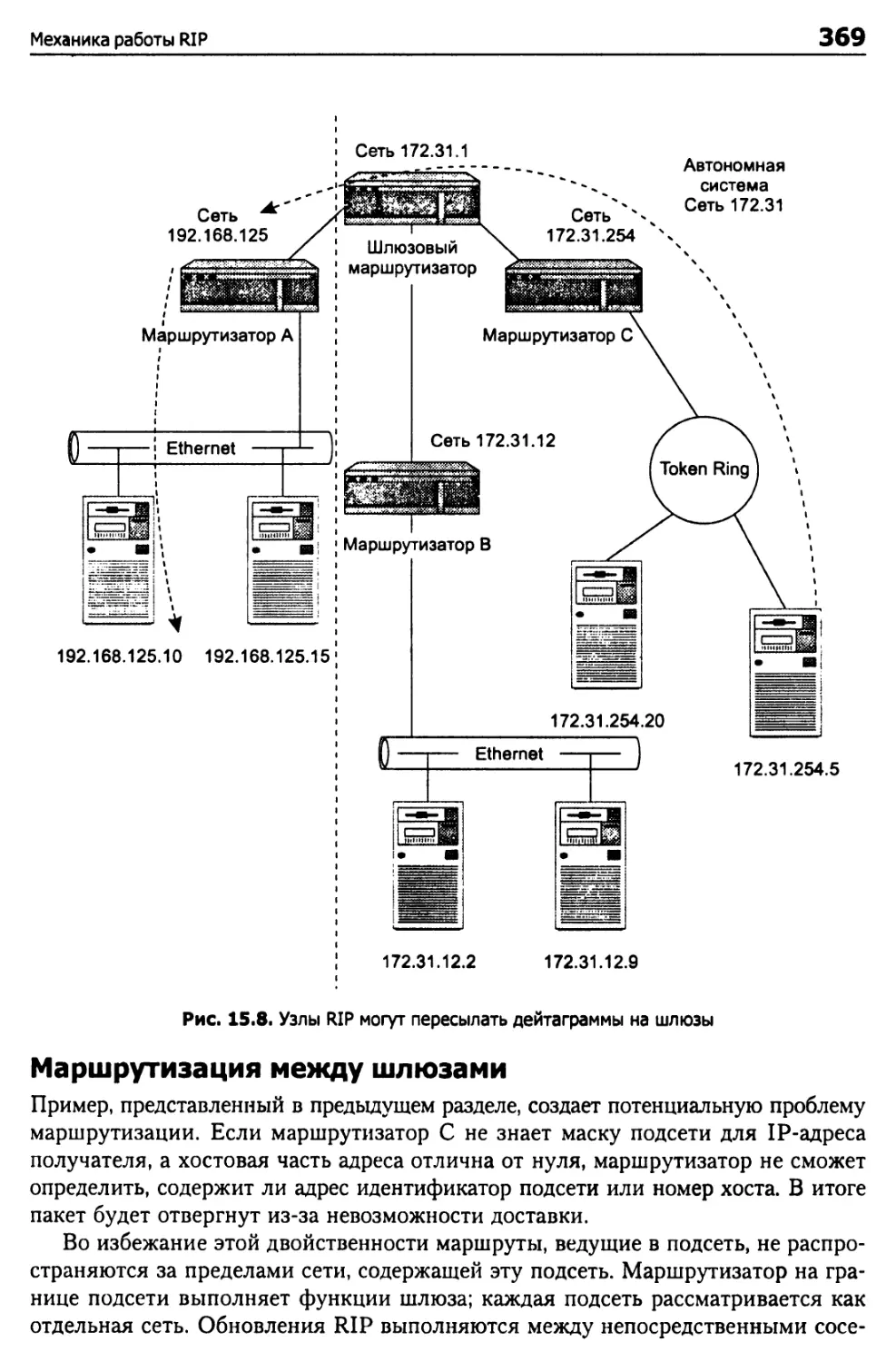
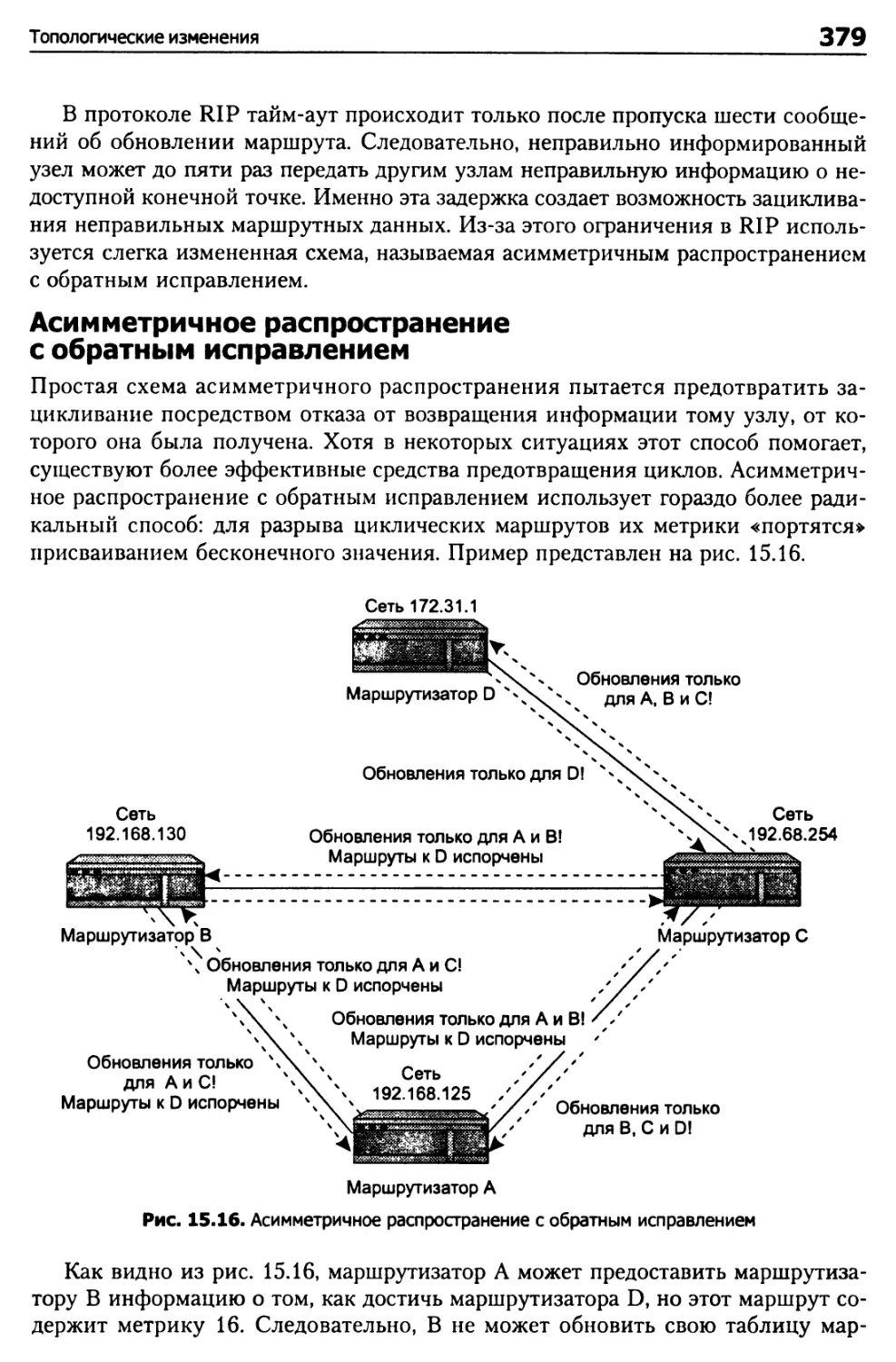
Проблемы адресации 367
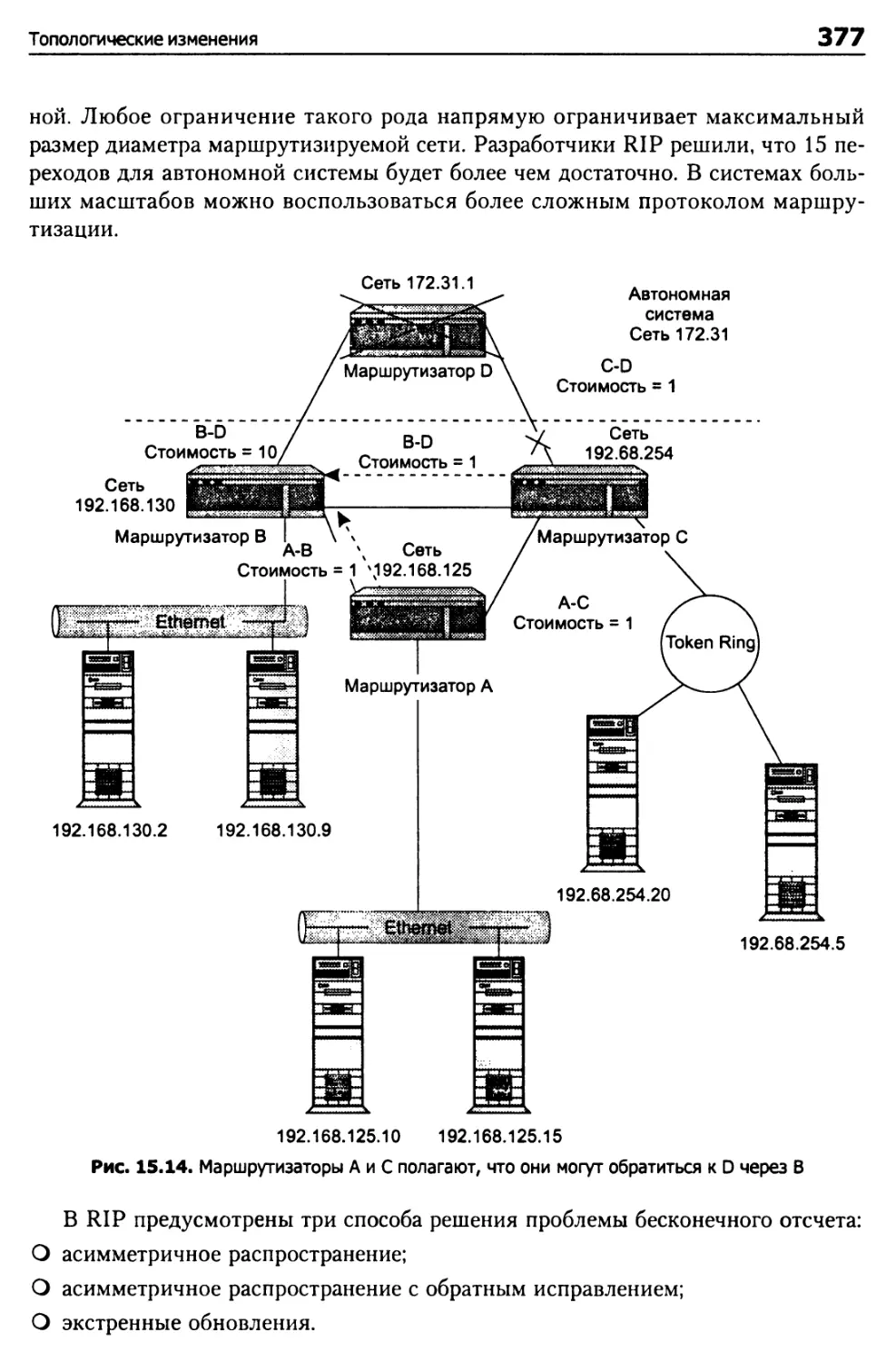
Топологические изменения 370
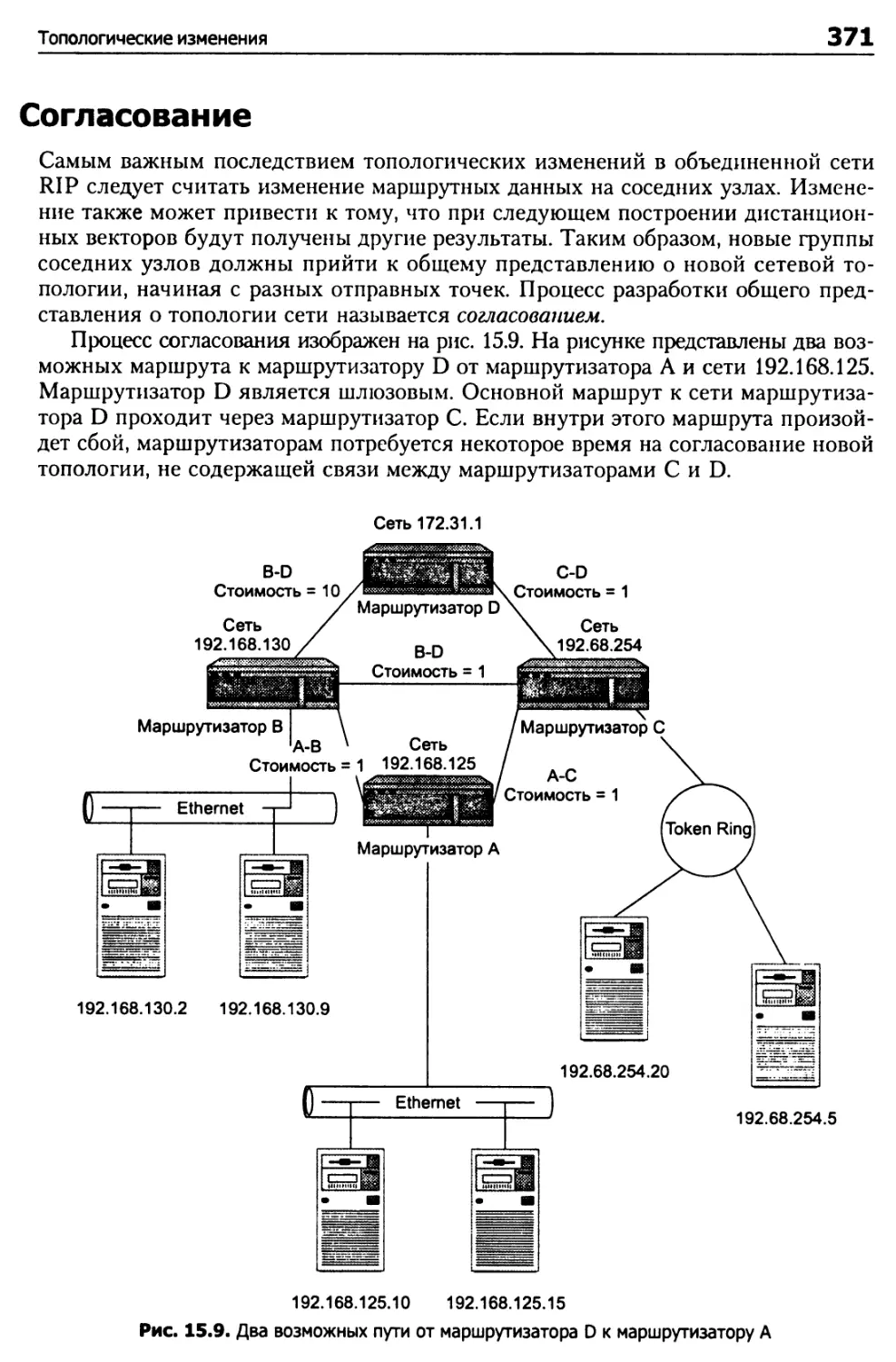
Согласование 371
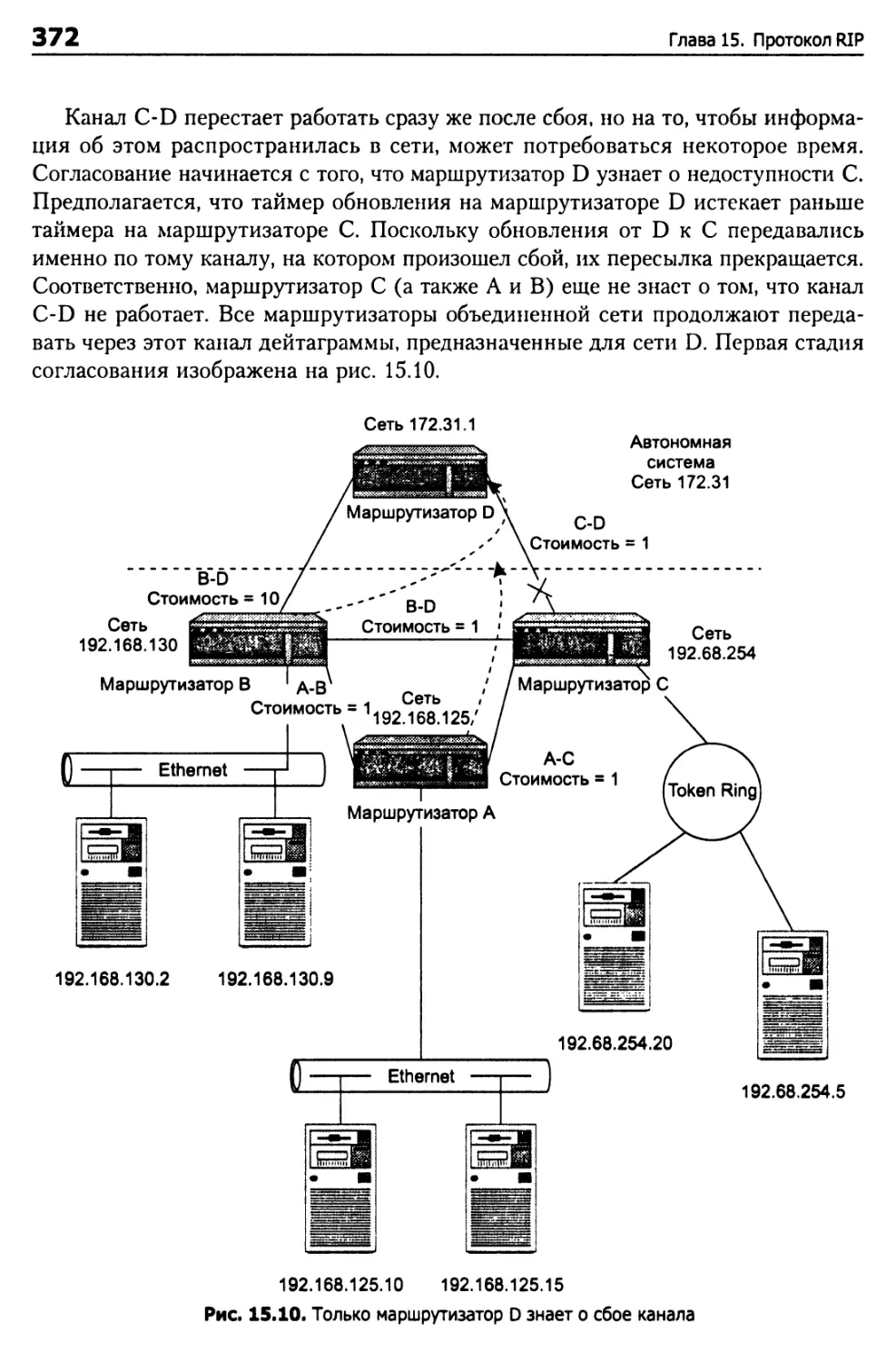
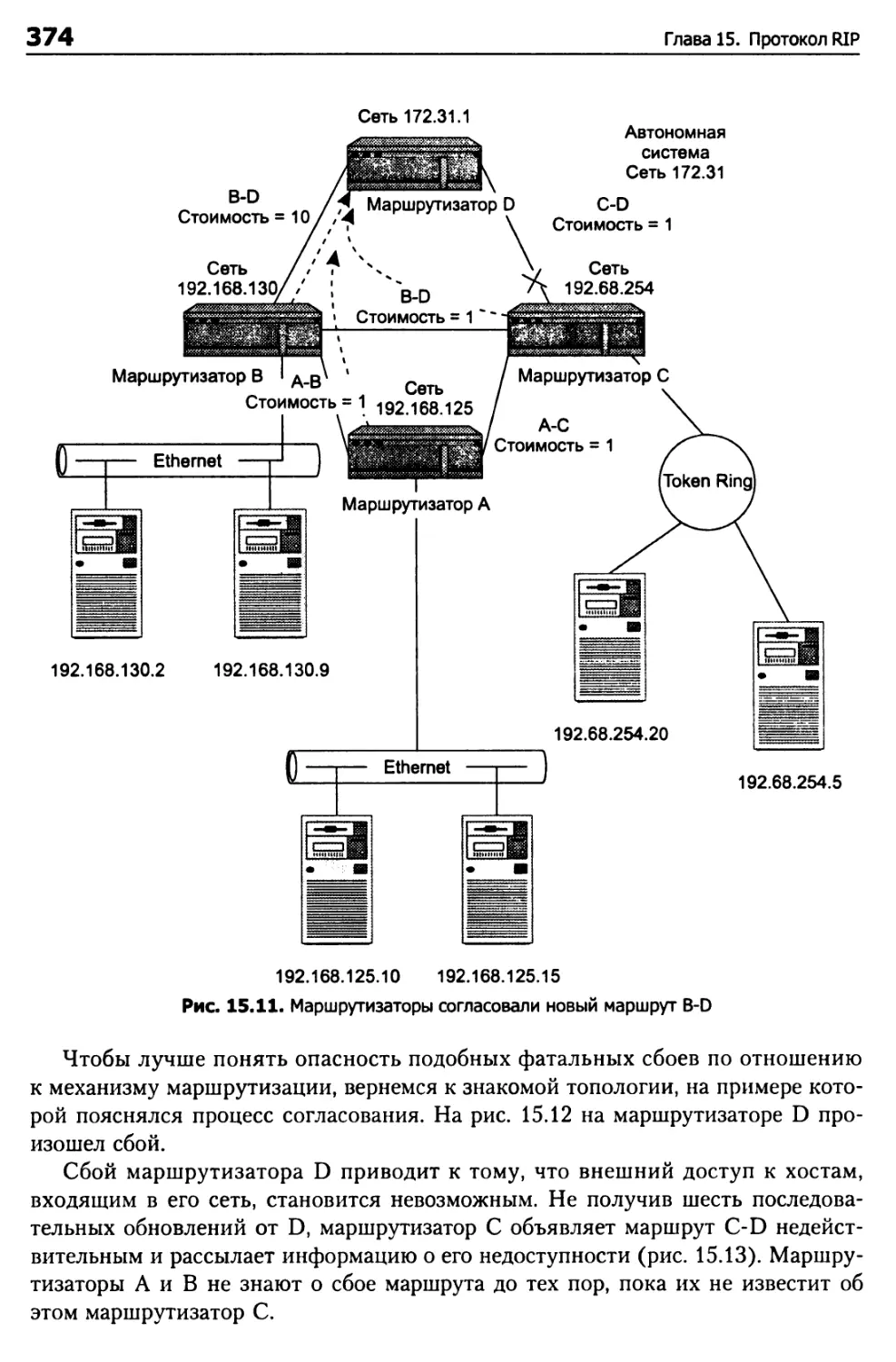
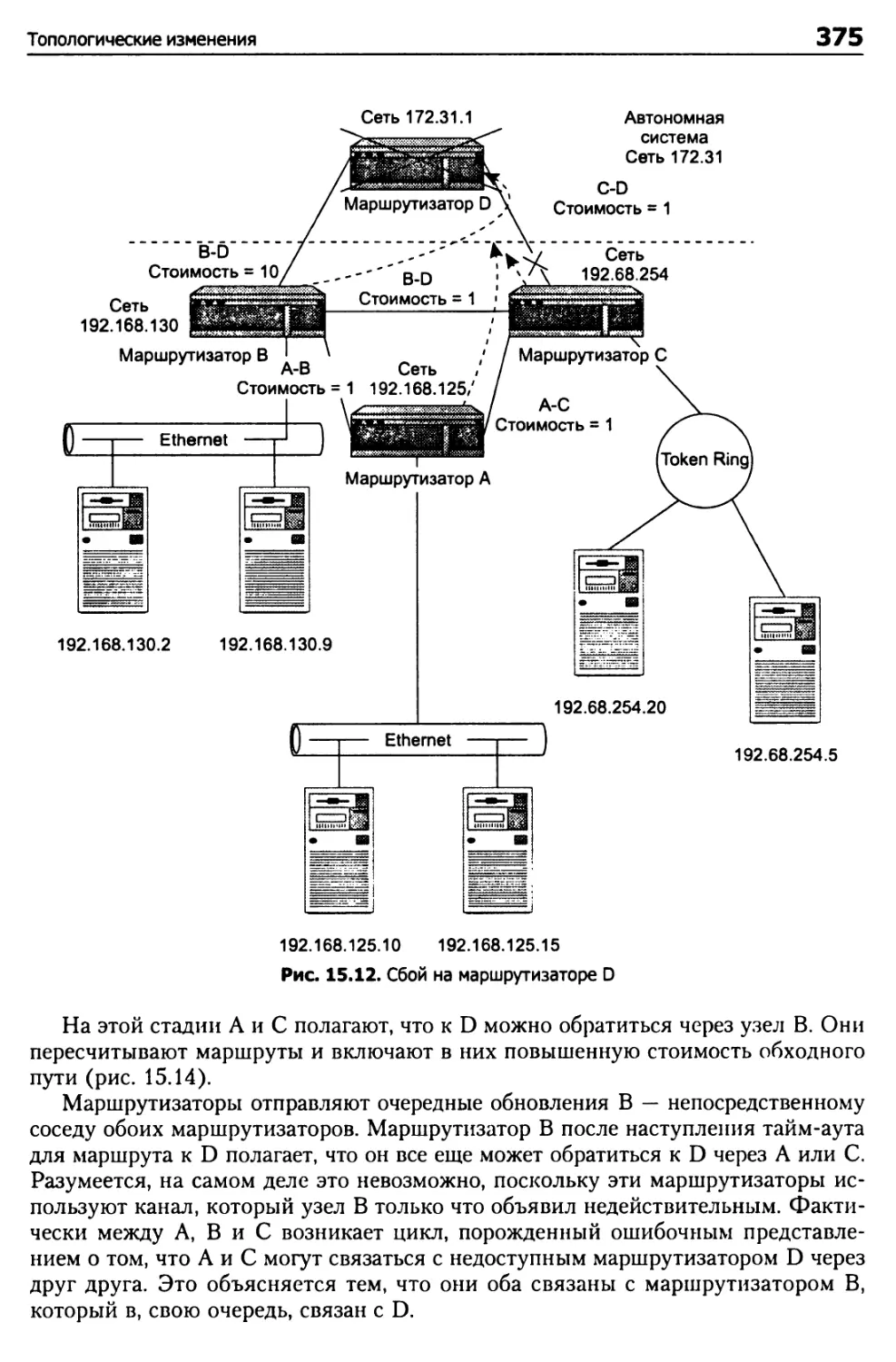
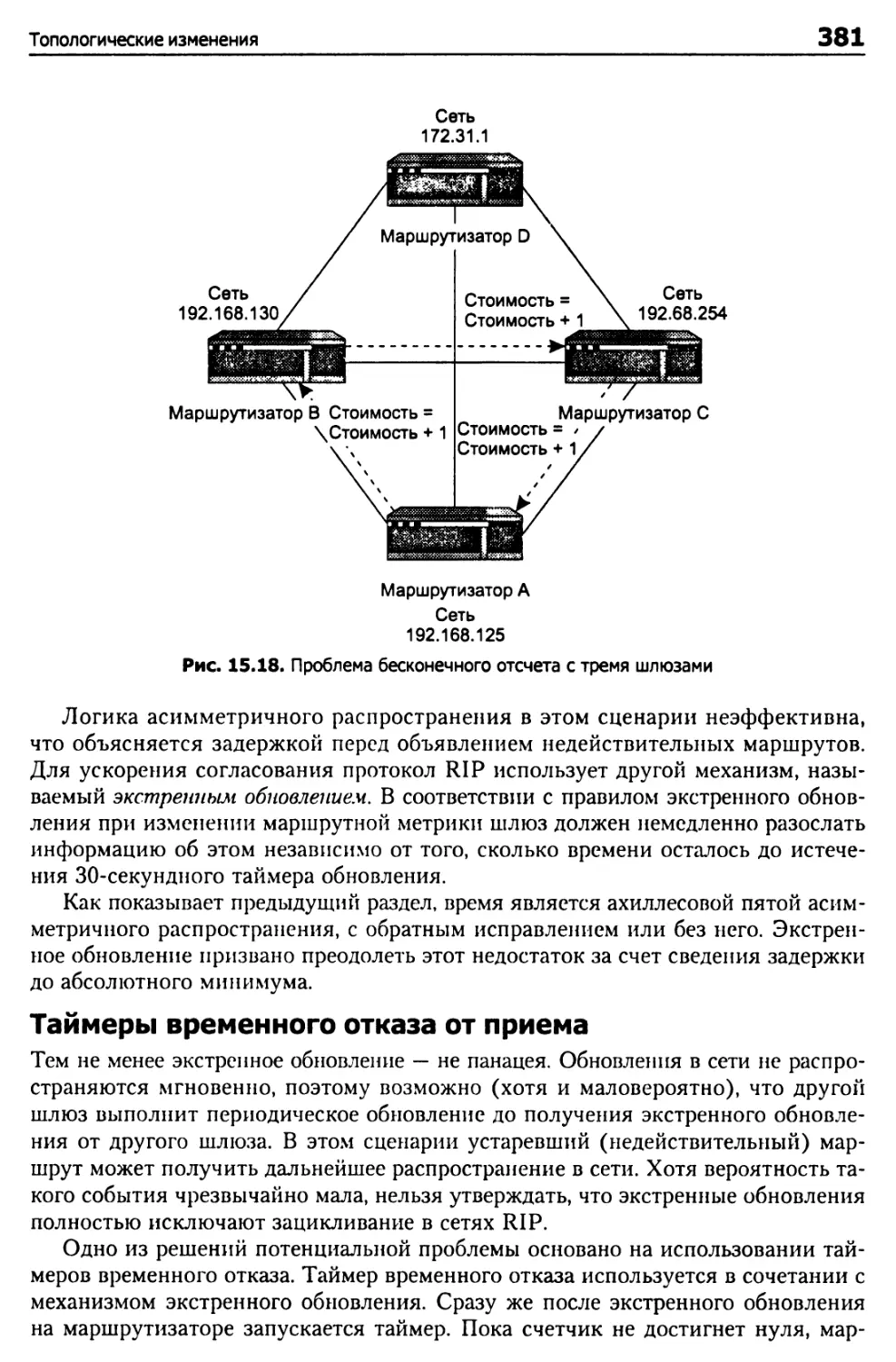
Проблема бесконечного отсчета 373
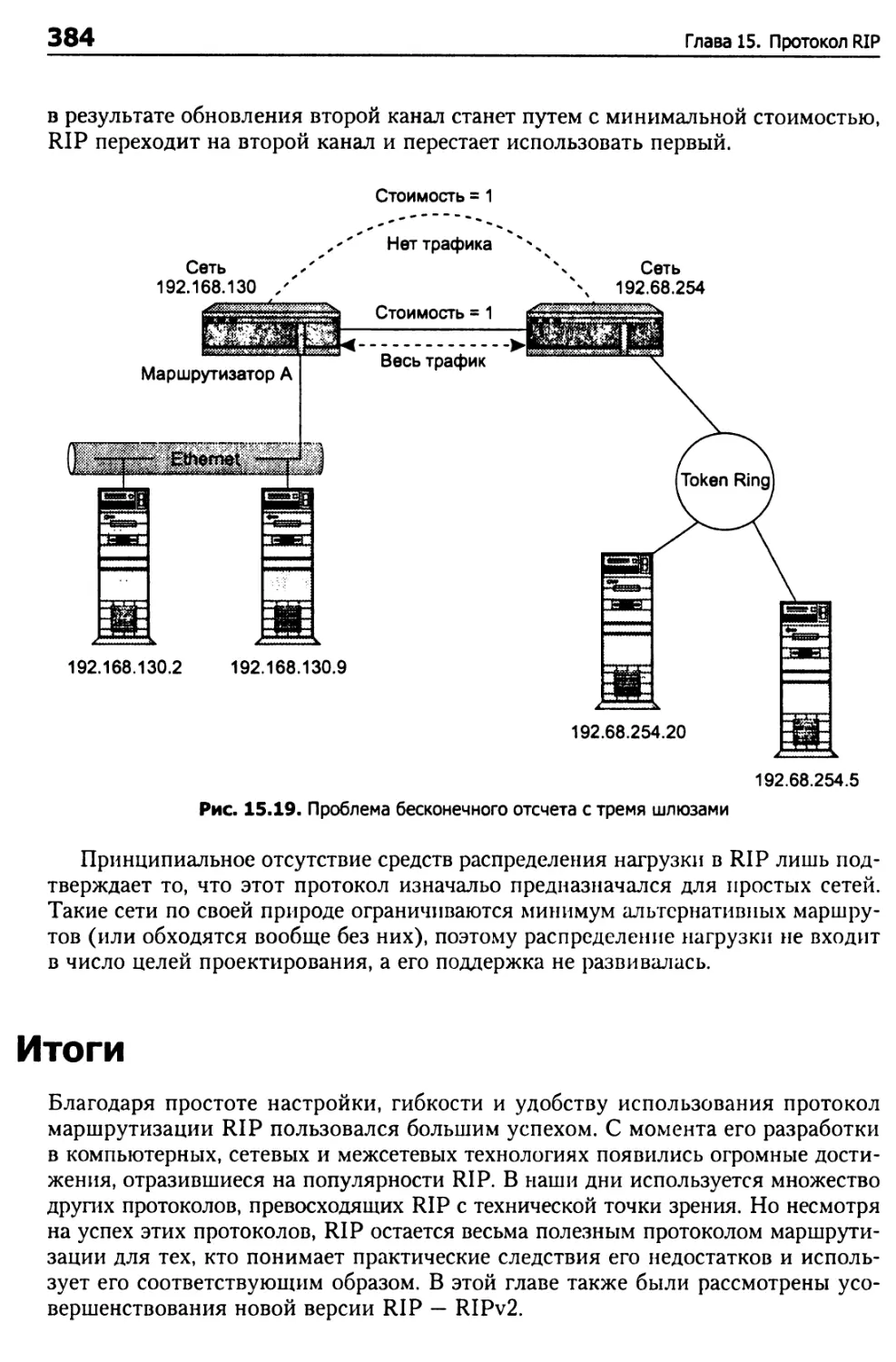
Недостатки RIP 382
Ограничение количества переходов 382
Фиксированные метрики 382
Высокий уровень трафика при обновлении таблиц 383
Медленное согласование 383
Отсутствие распределения нагрузки 383
Итоги 384
Глава 16. Протокол OSPF 385
Происхождение OSPF 385
Принципы работы OSPF 386
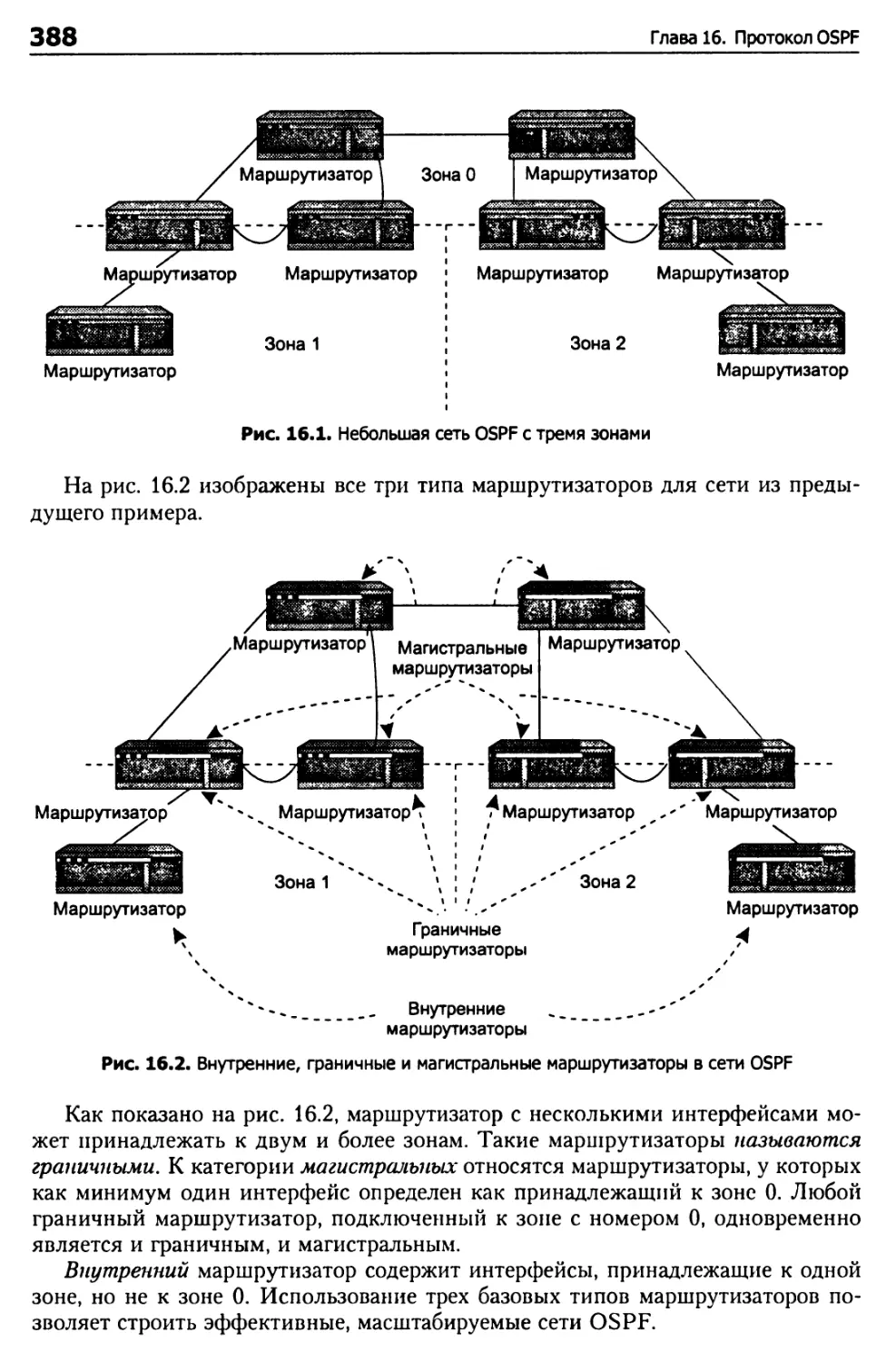
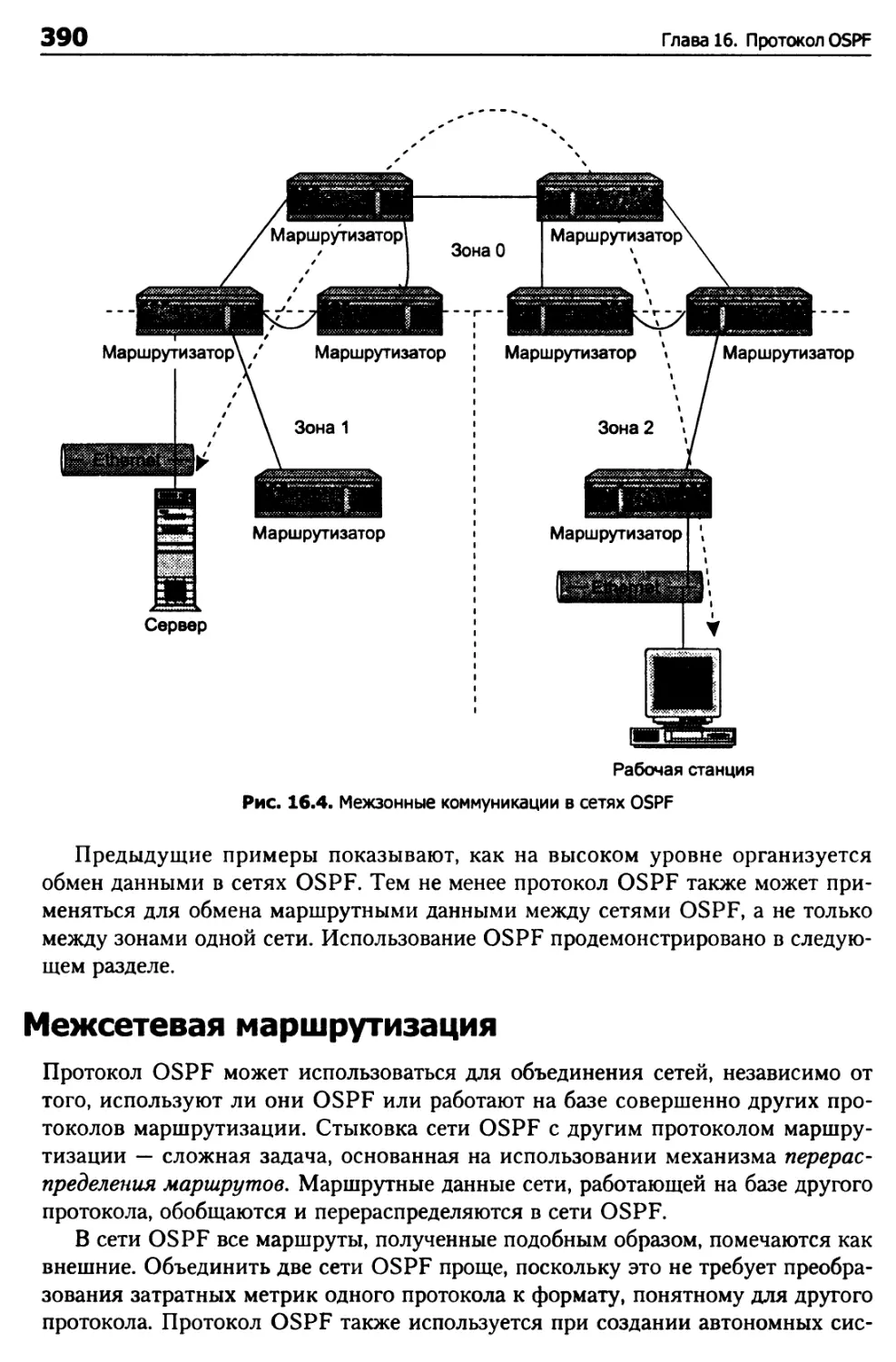
Зоны OSPF 387
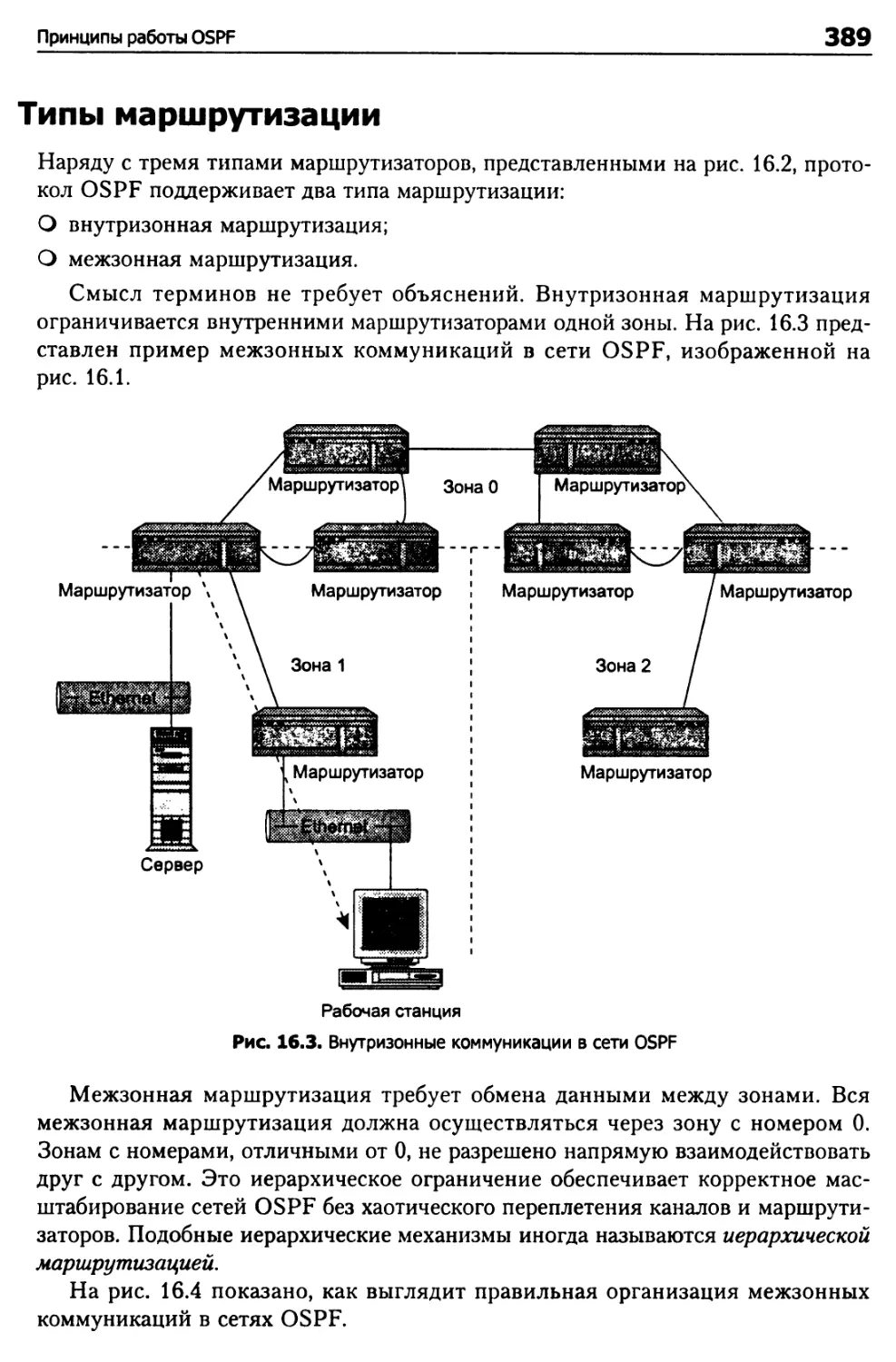
Типы маршрутизации 389
Межсетевая маршрутизация 390
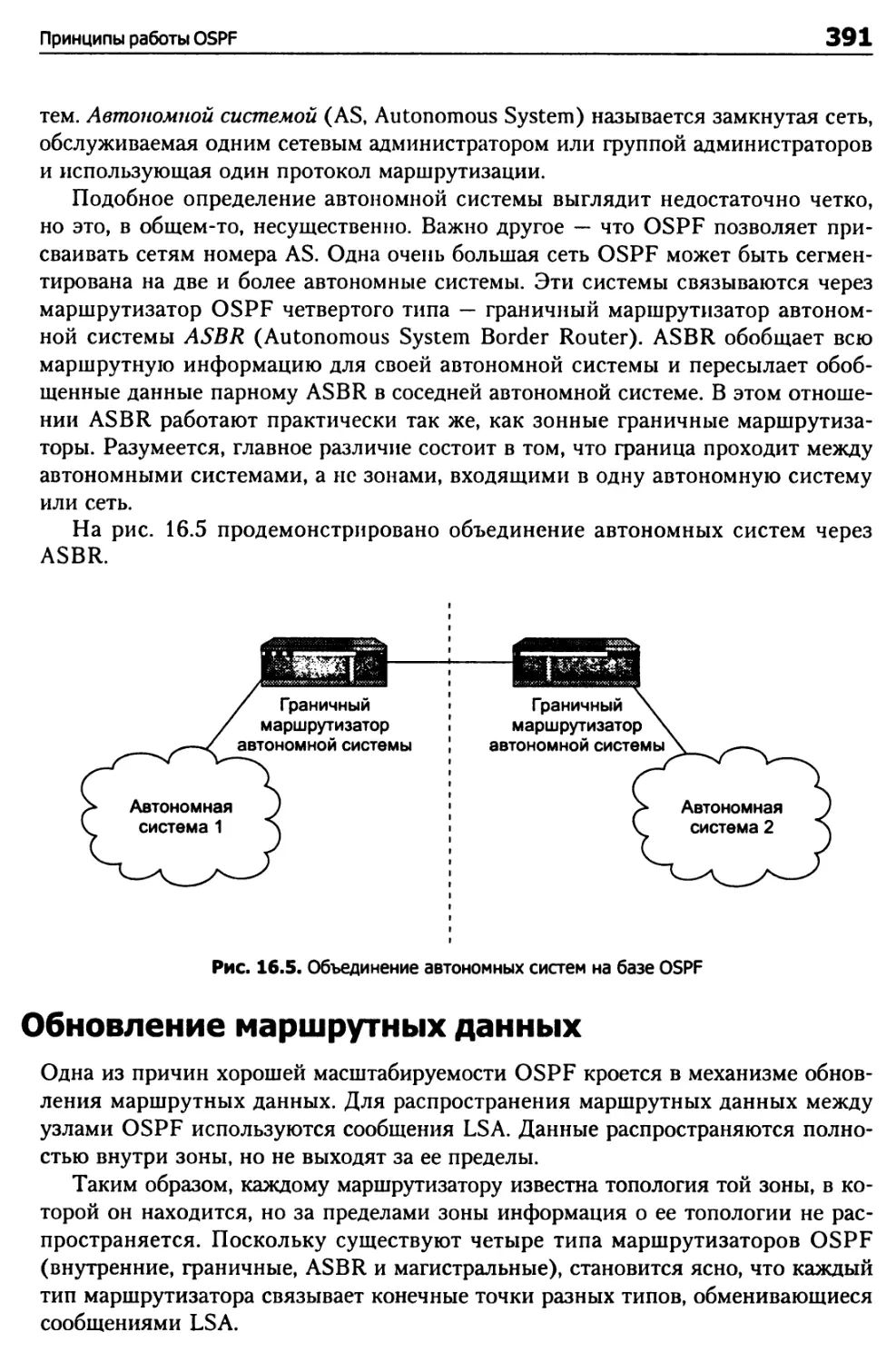
Обновление маршрутных данных 391
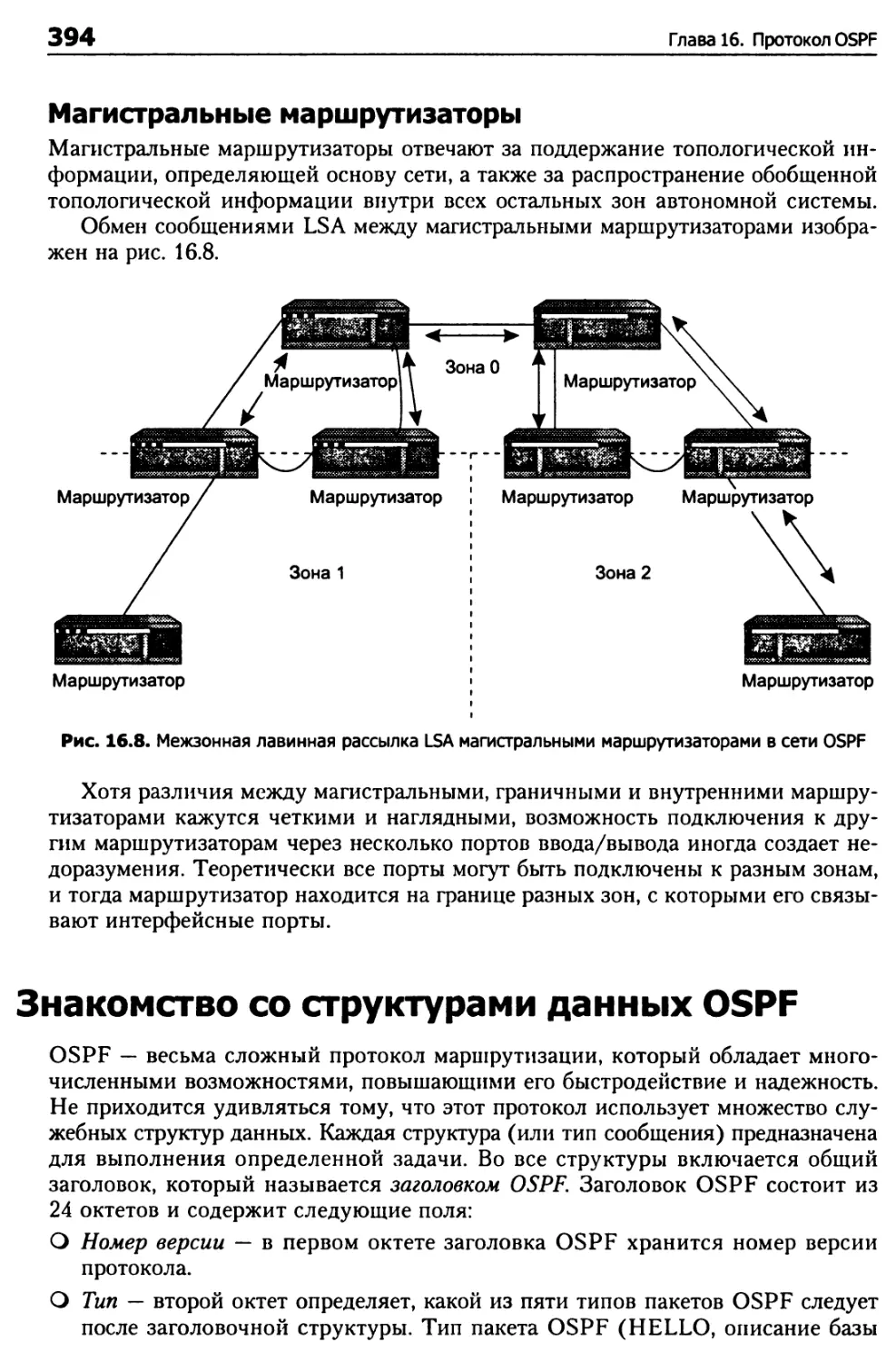
Знакомство со структурами данных OSPF 394
Пакет подтверждения состояния канала 400
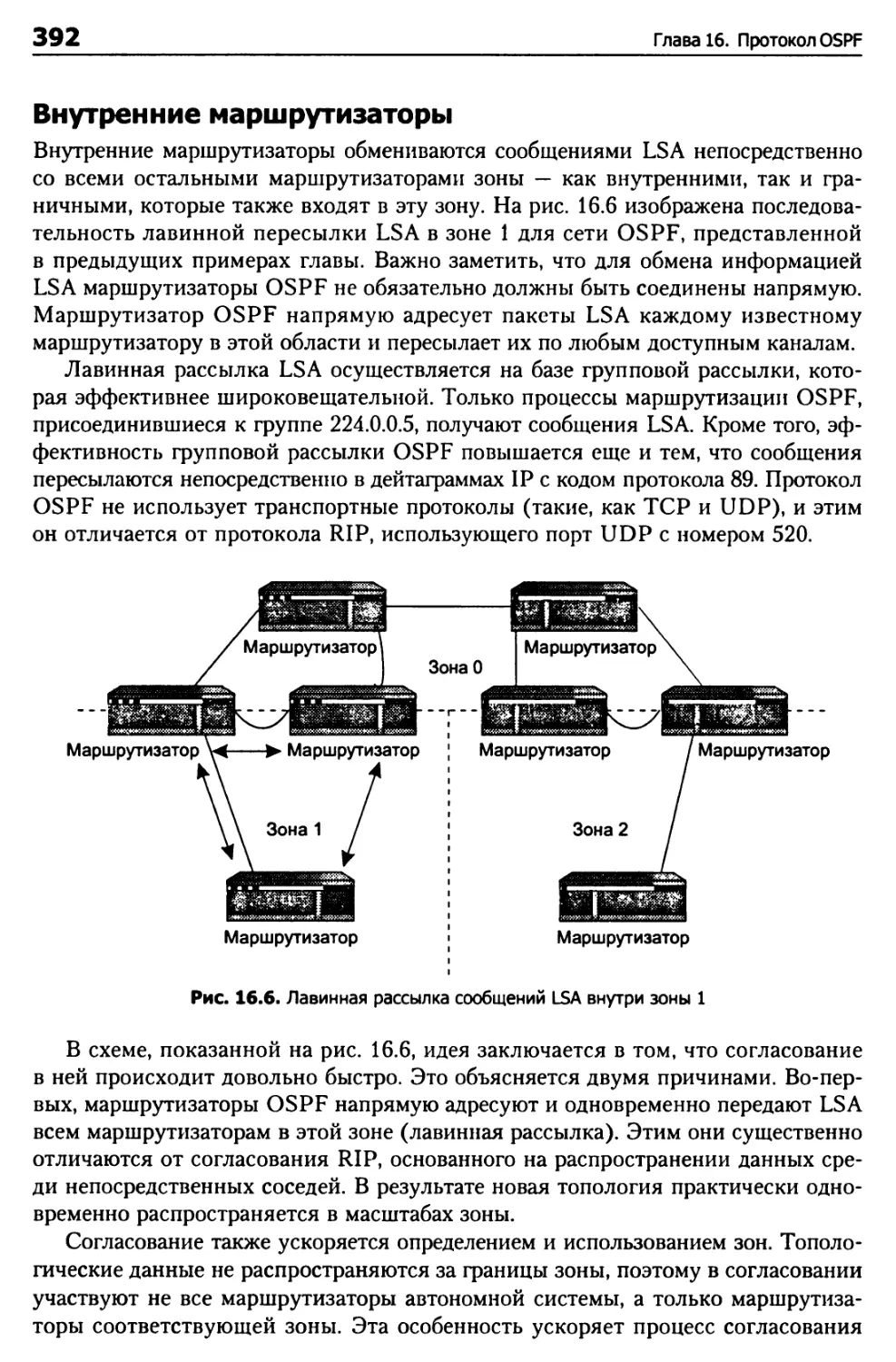
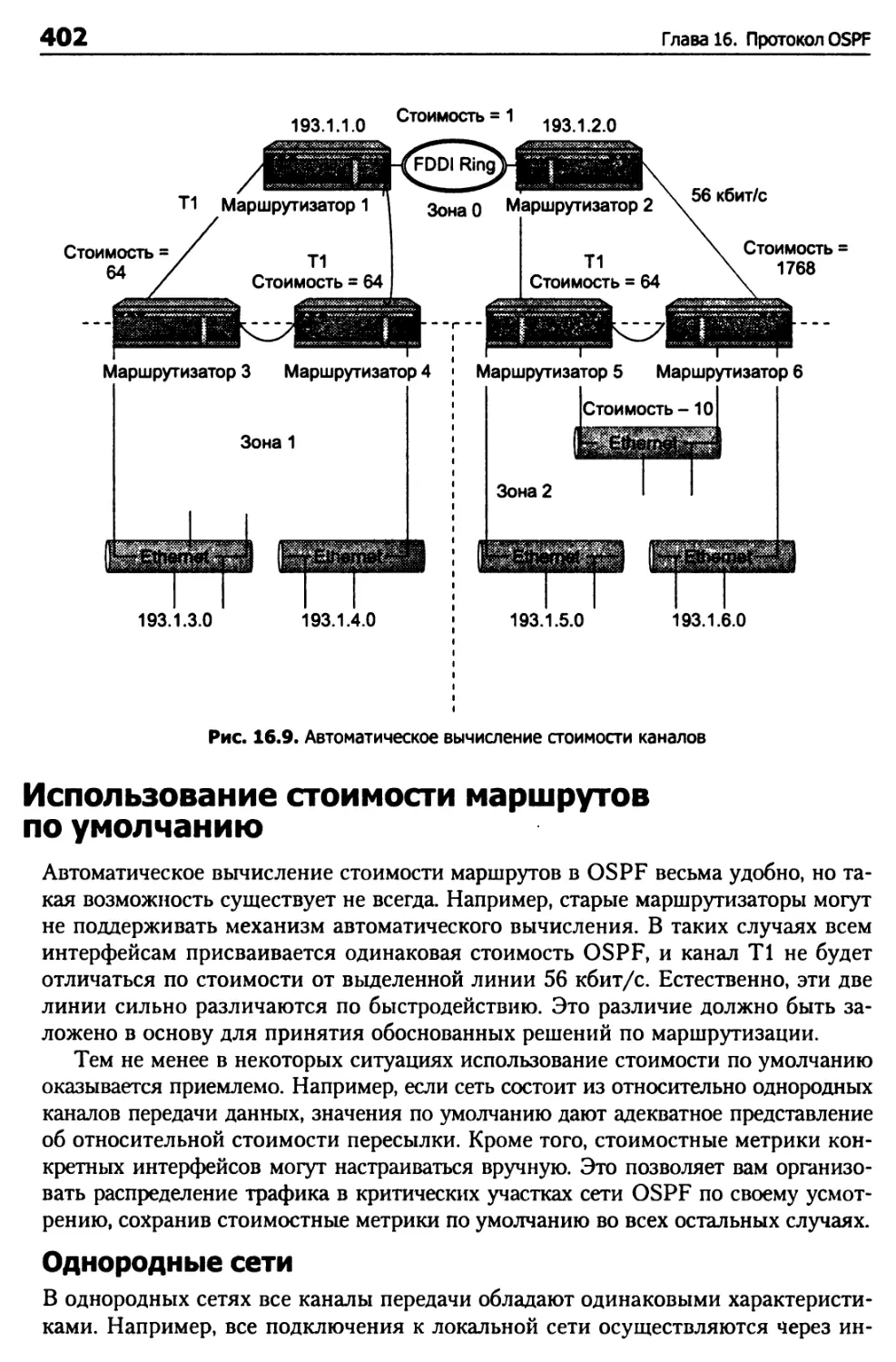
Построение маршрутов 401
Автоматическое вычисление 401
Использование стоимости маршрутов по умолчанию 402
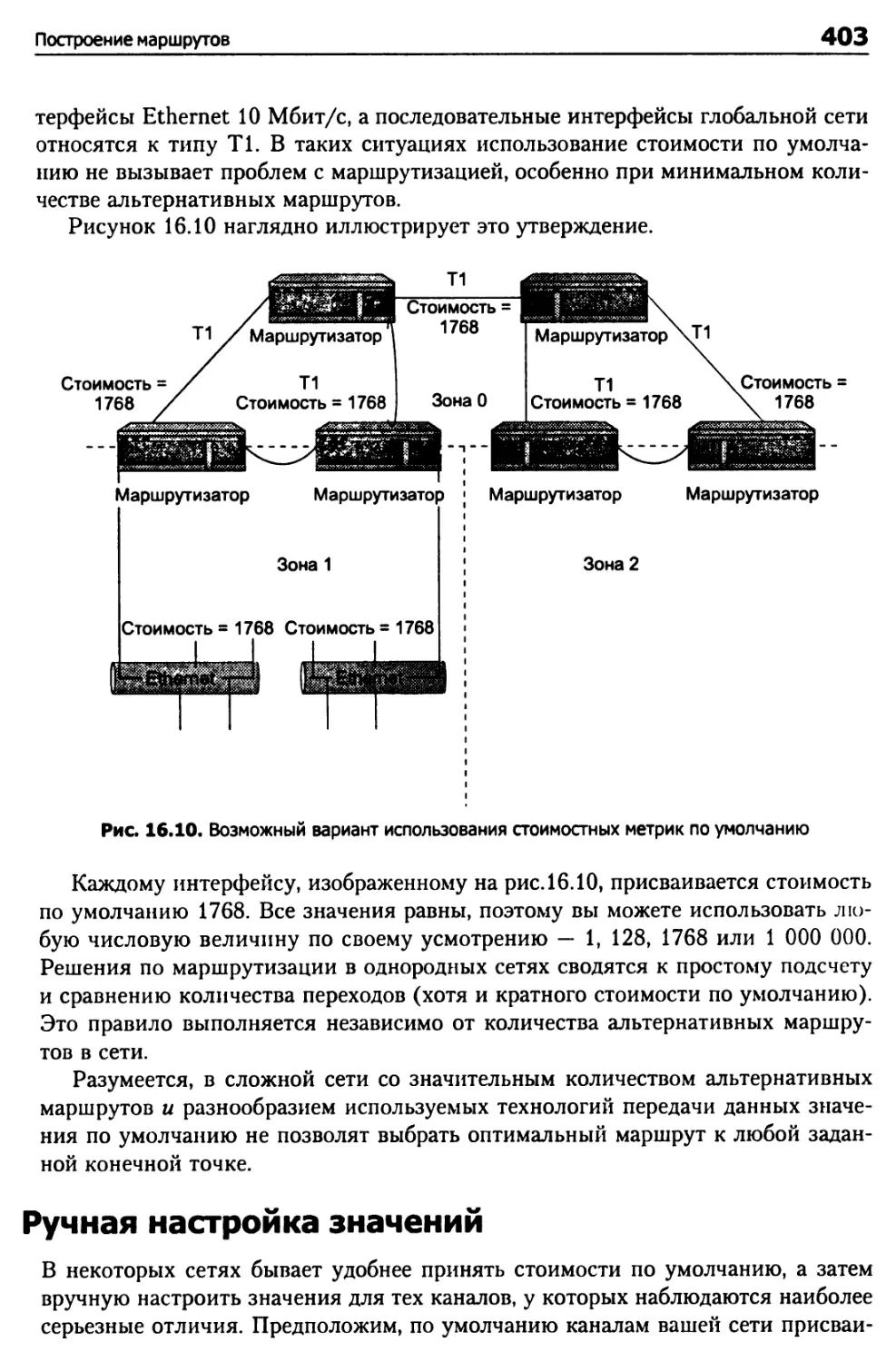
Ручная настройка значений 403
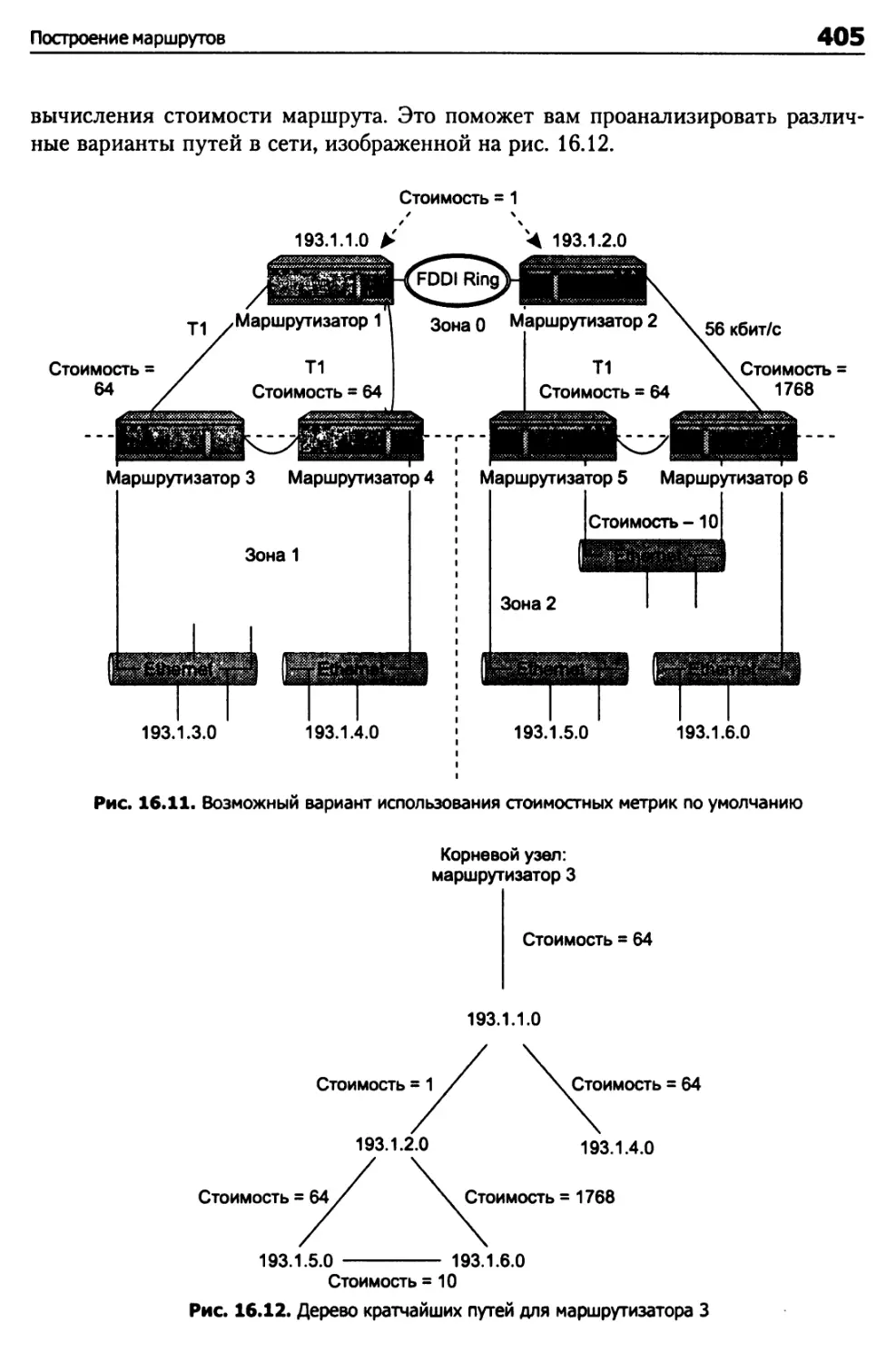
Дерево кратчайших путей 404
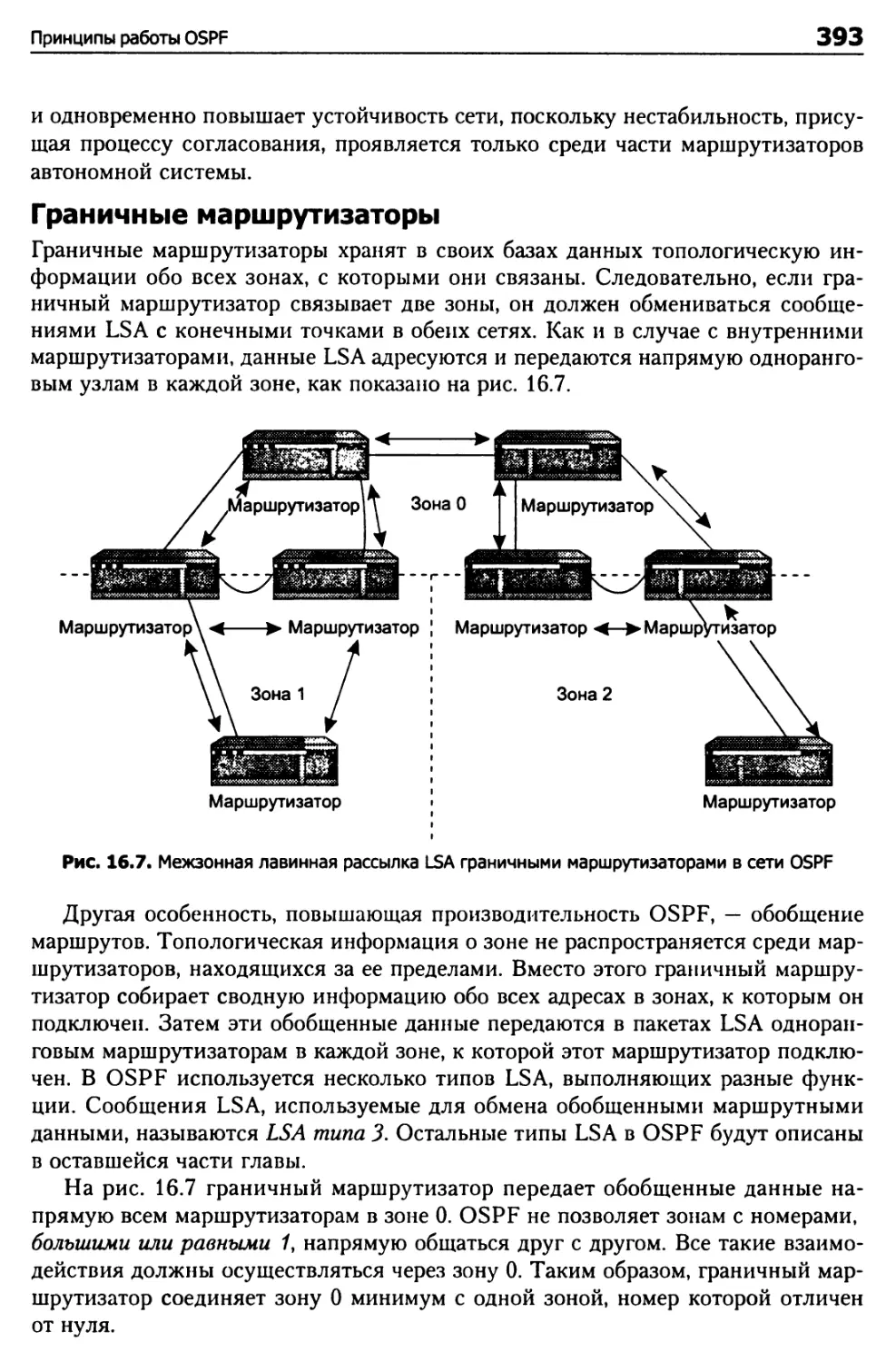
Дерево кратчайших путей для маршрутизатора 3 404
Дерево кратчайших путей для маршрутизатора 2 406
Итоги 407
Глава 17. Протокол IPP 408
История IPP 408
Протокол IPP с точки зрения пользователя 409
Реализация IPP от HP 411
Итоги 412
Глава 18. Протоколы удаленного доступа 413
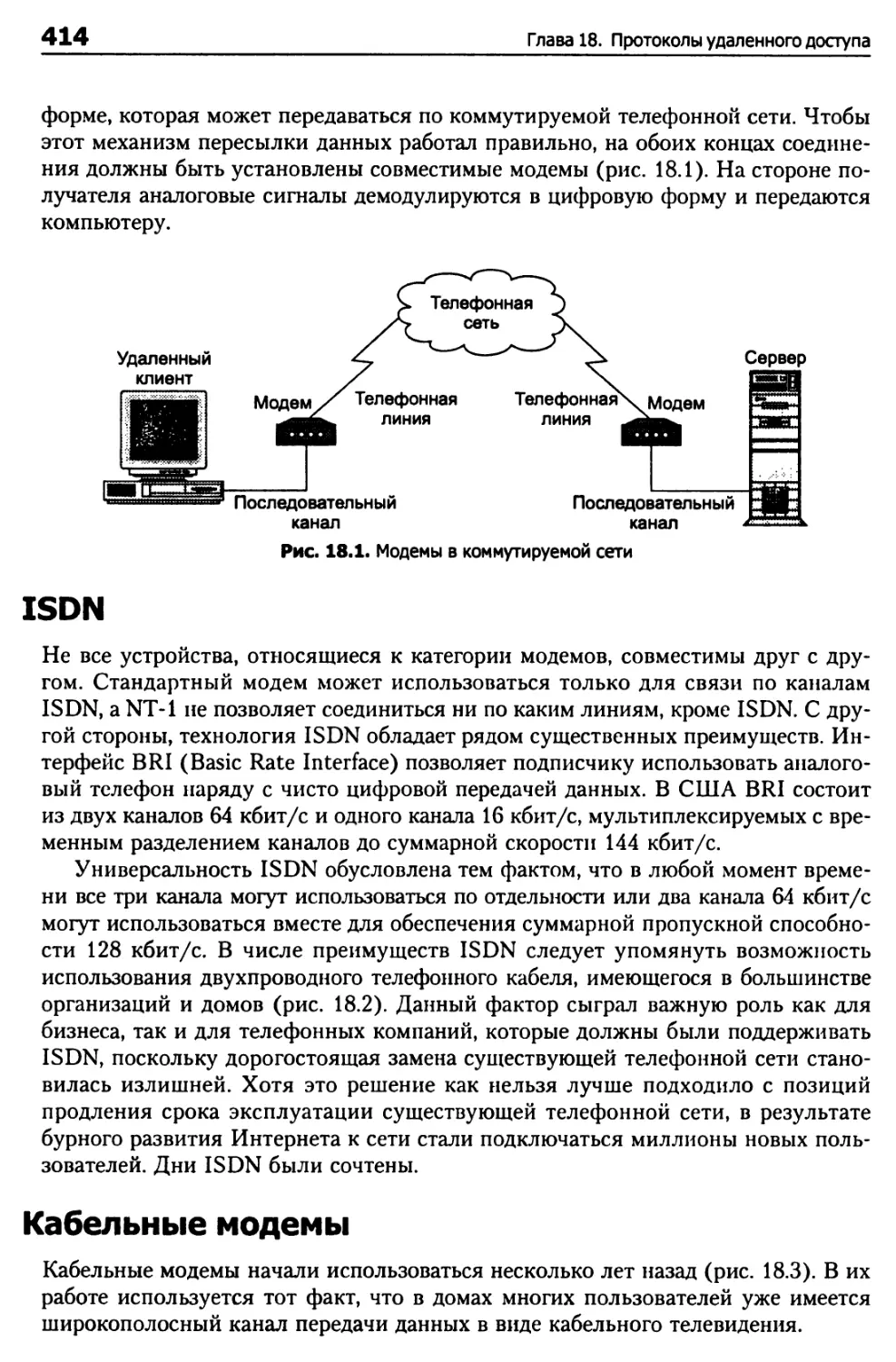
Удаленное подключение 413
ISDN 414
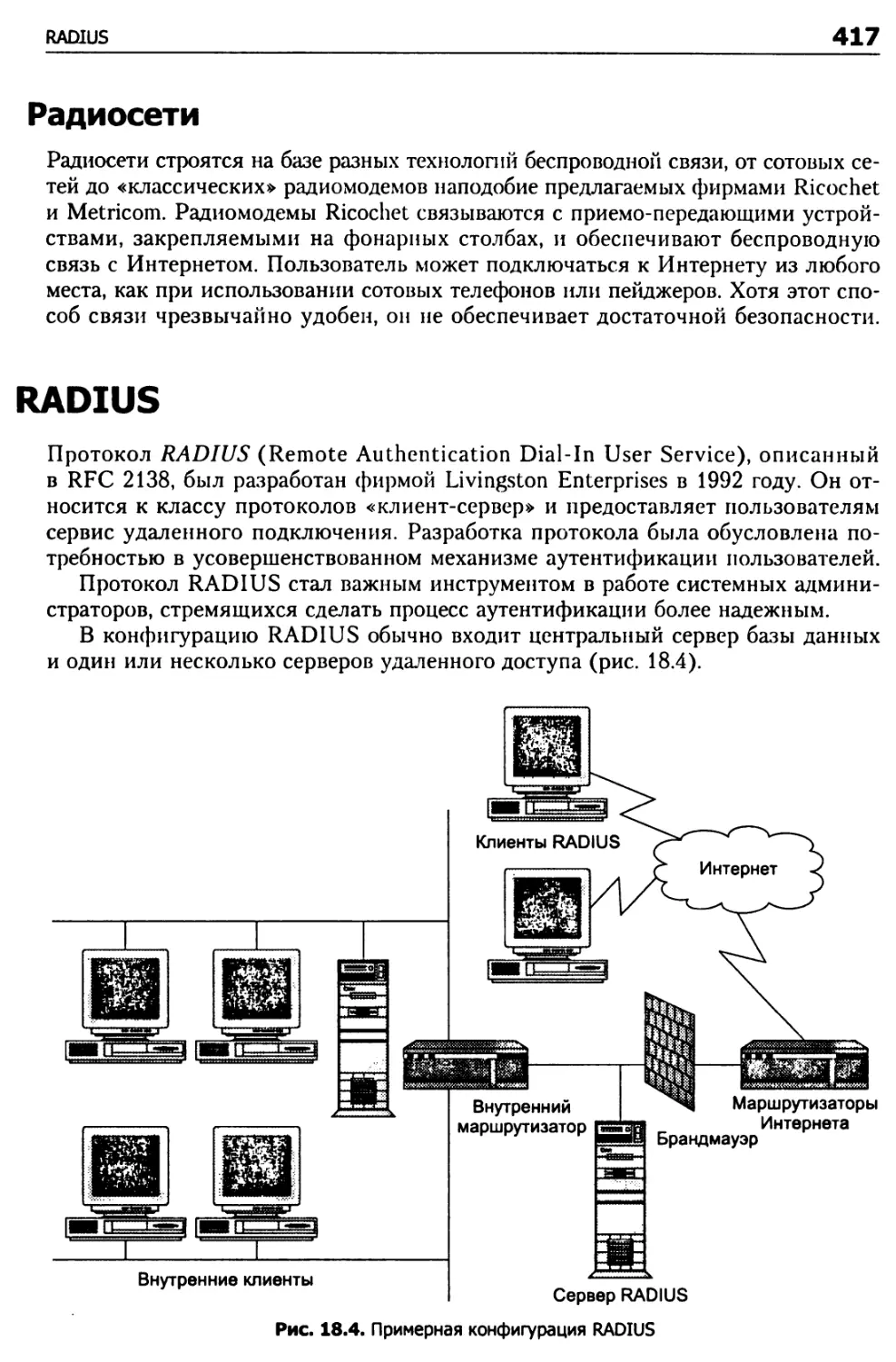
Кабельные модемы 414
DSL 416
Радиосети 417
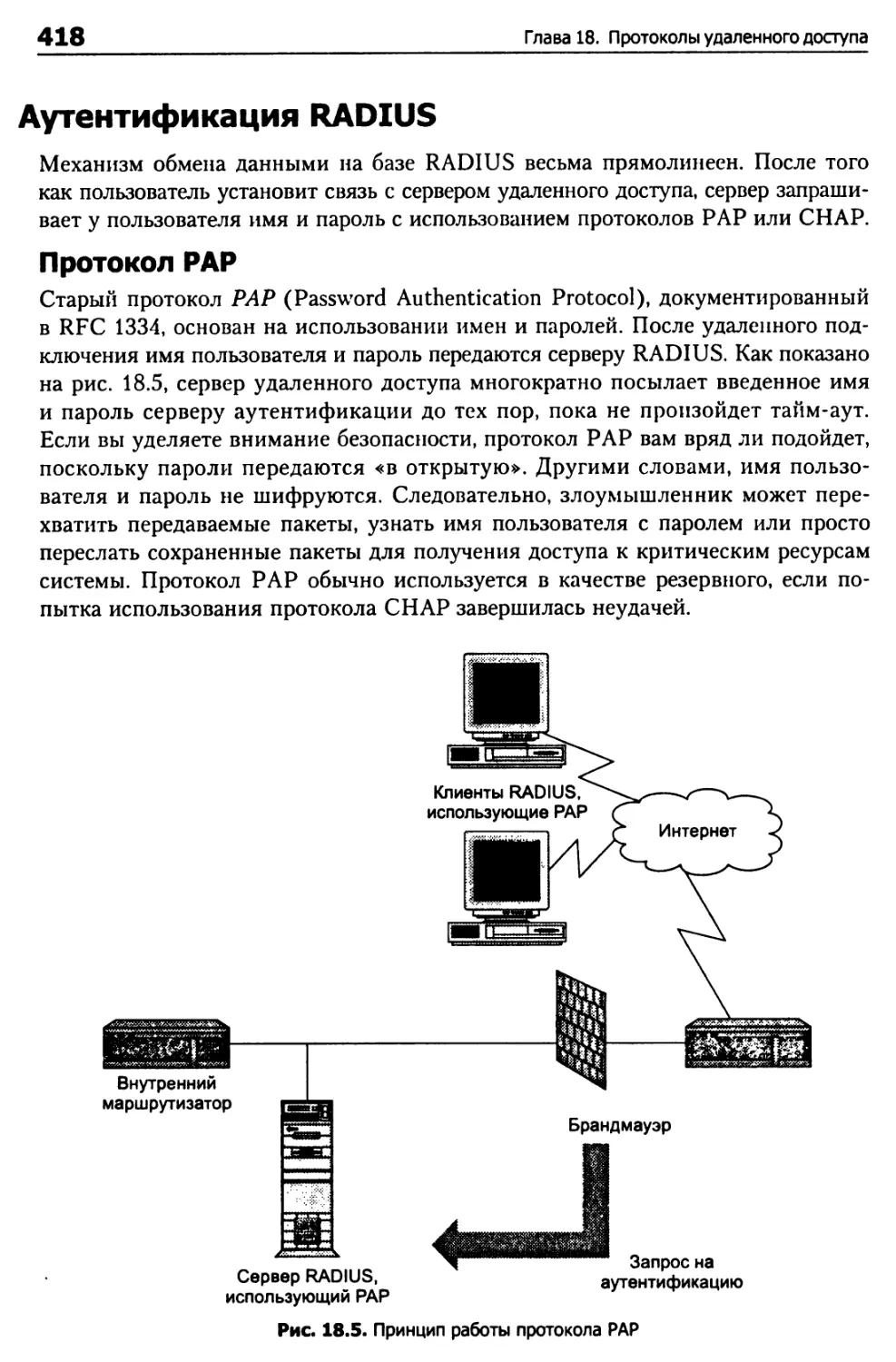
RADIUS 417
Аутентификация RADIUS 418
Транспортировка дейтаграмм IP в протоколах SUP, CSLIP и РРР 420
Протокол SLIP 420
Протокол CSLIP 421
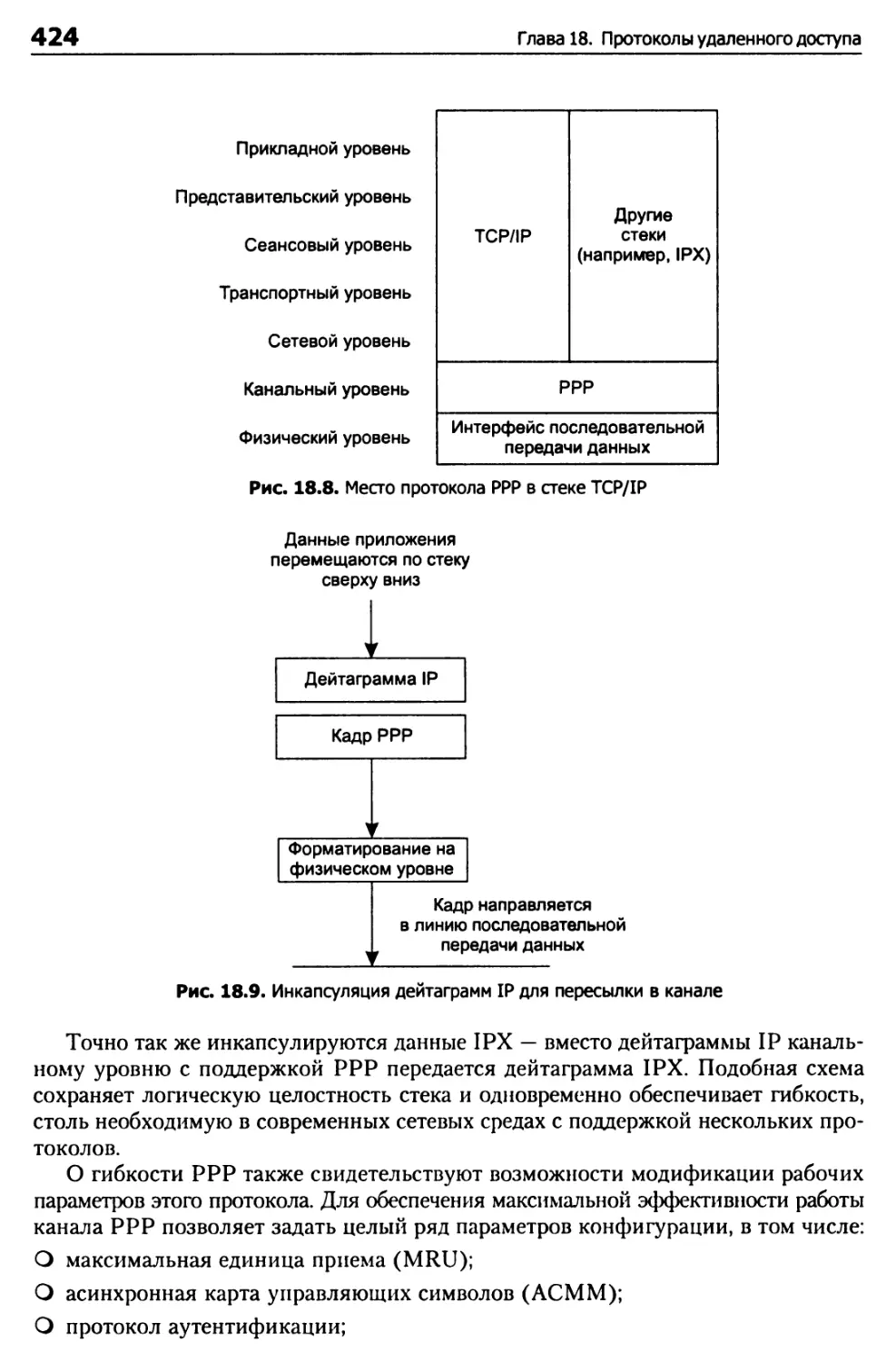
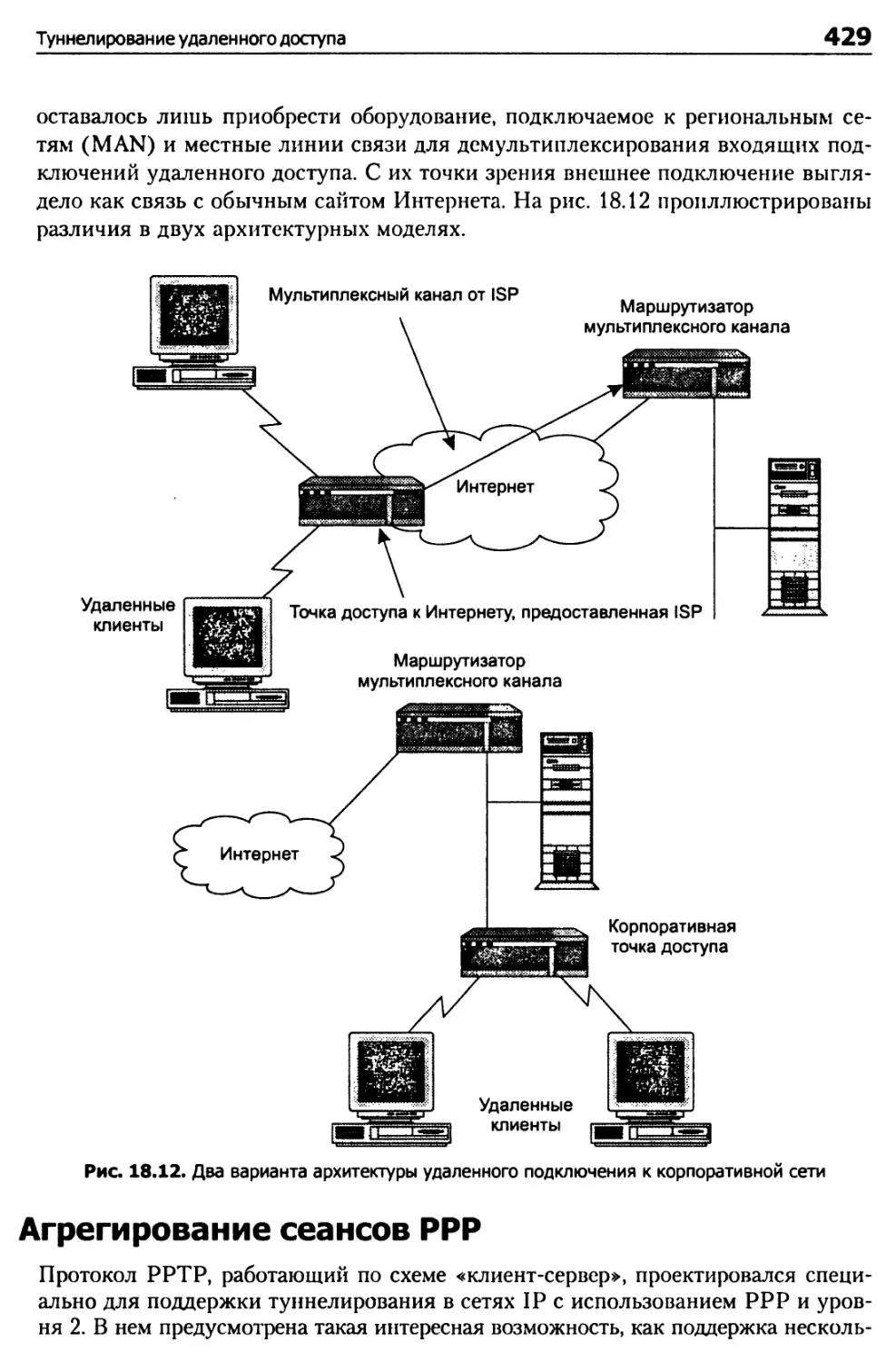
Протокол РРР 422
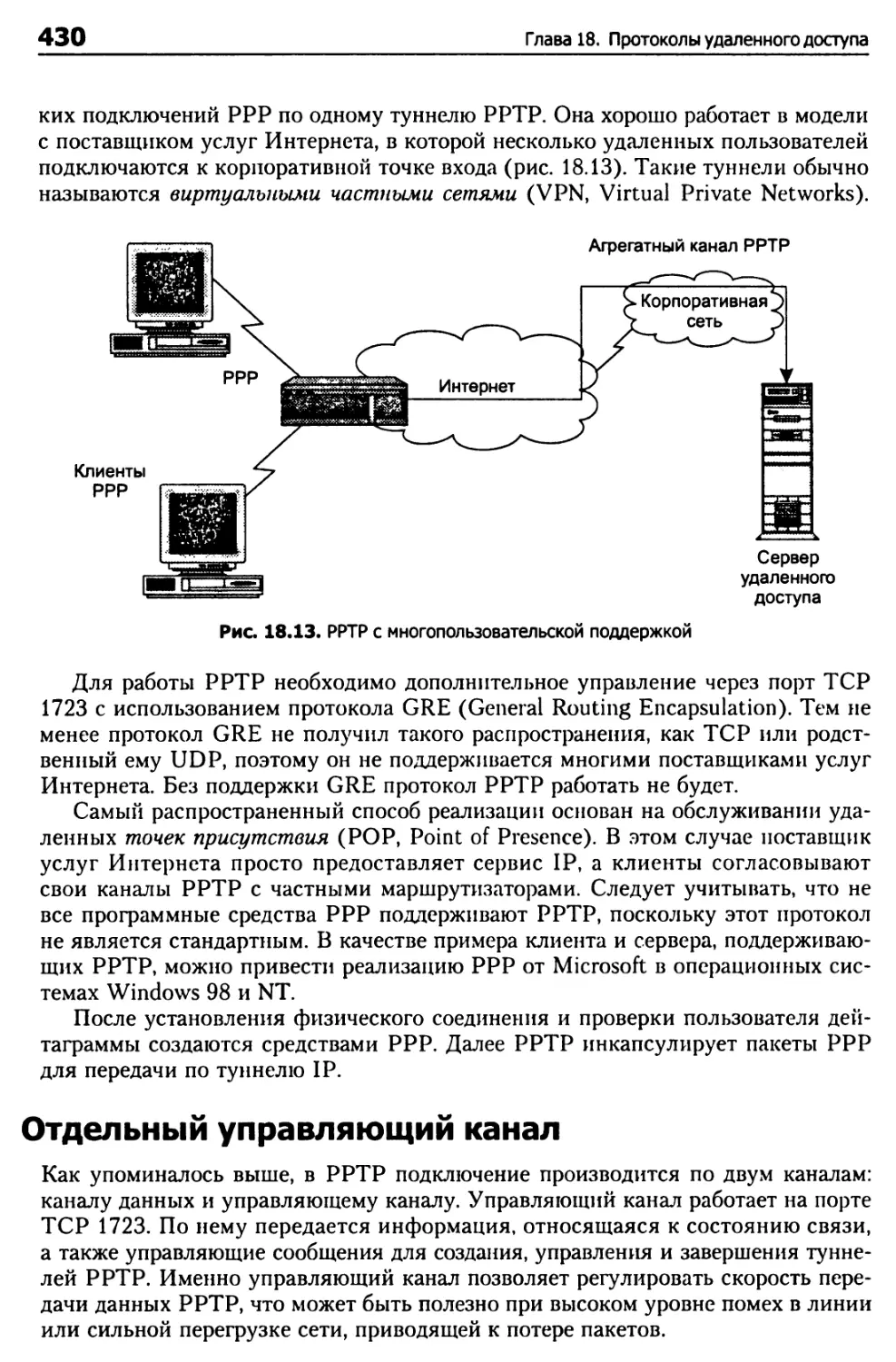
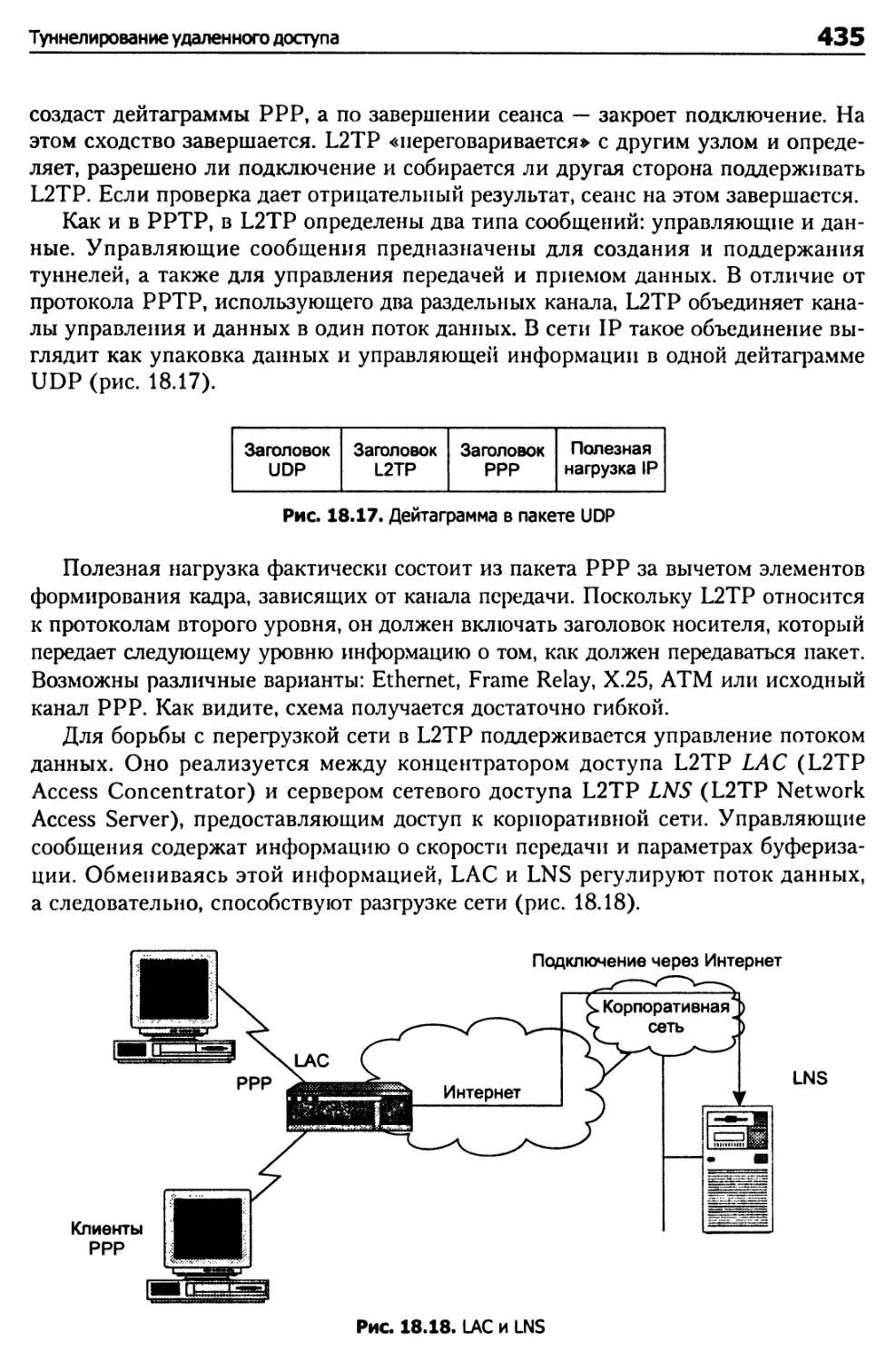
Туннелирование удаленного доступа 427
Протокол РРТР (Point-to-Point Tunneling) 428
Агрегирование сеансов РРР 429
Отдельный управляющий канал 430
Поддержка других протоколов 431
Аутентификация и защита 431
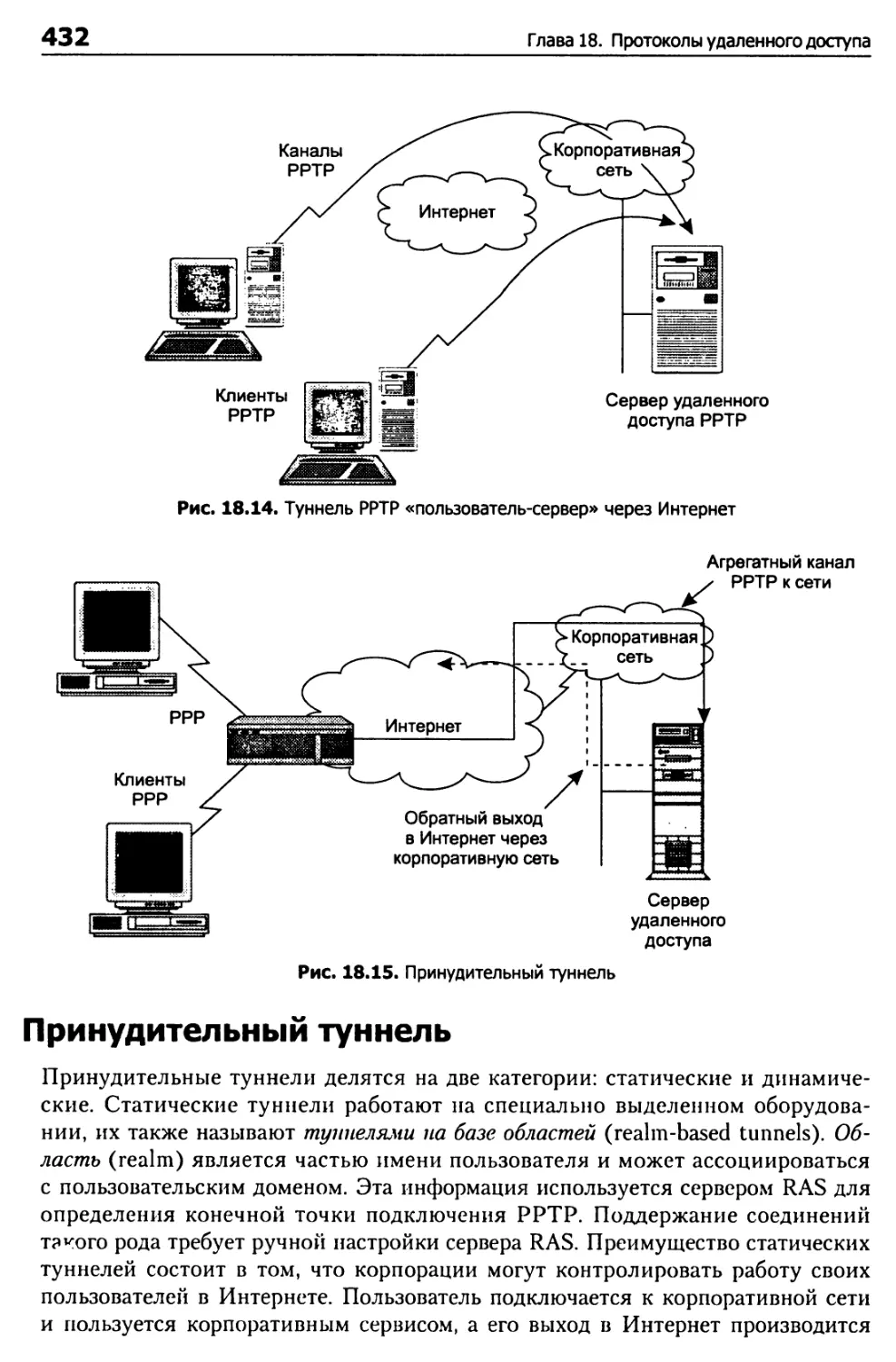
Типы туннелей РРТР 431
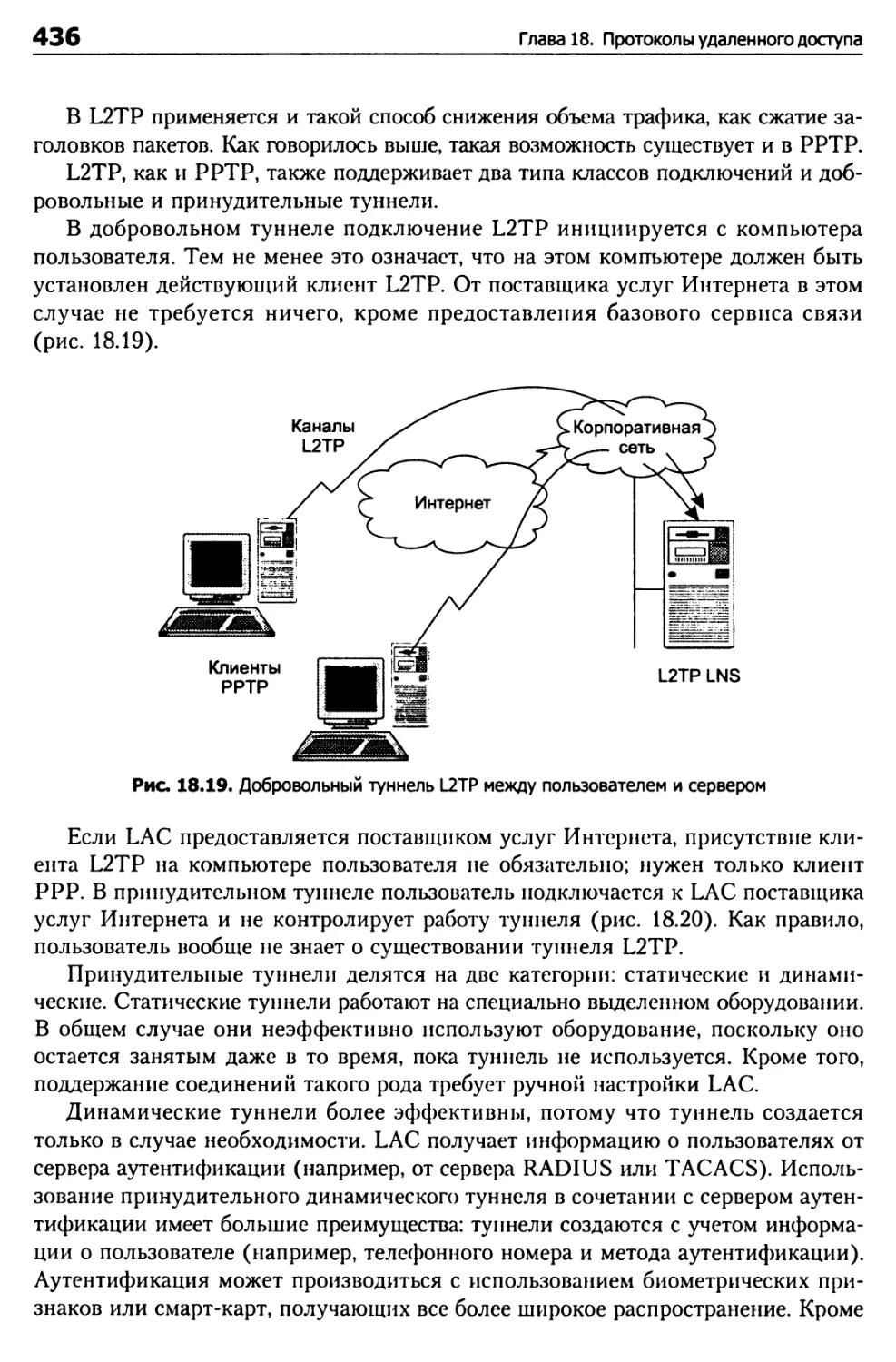
Добровольный туннель 431
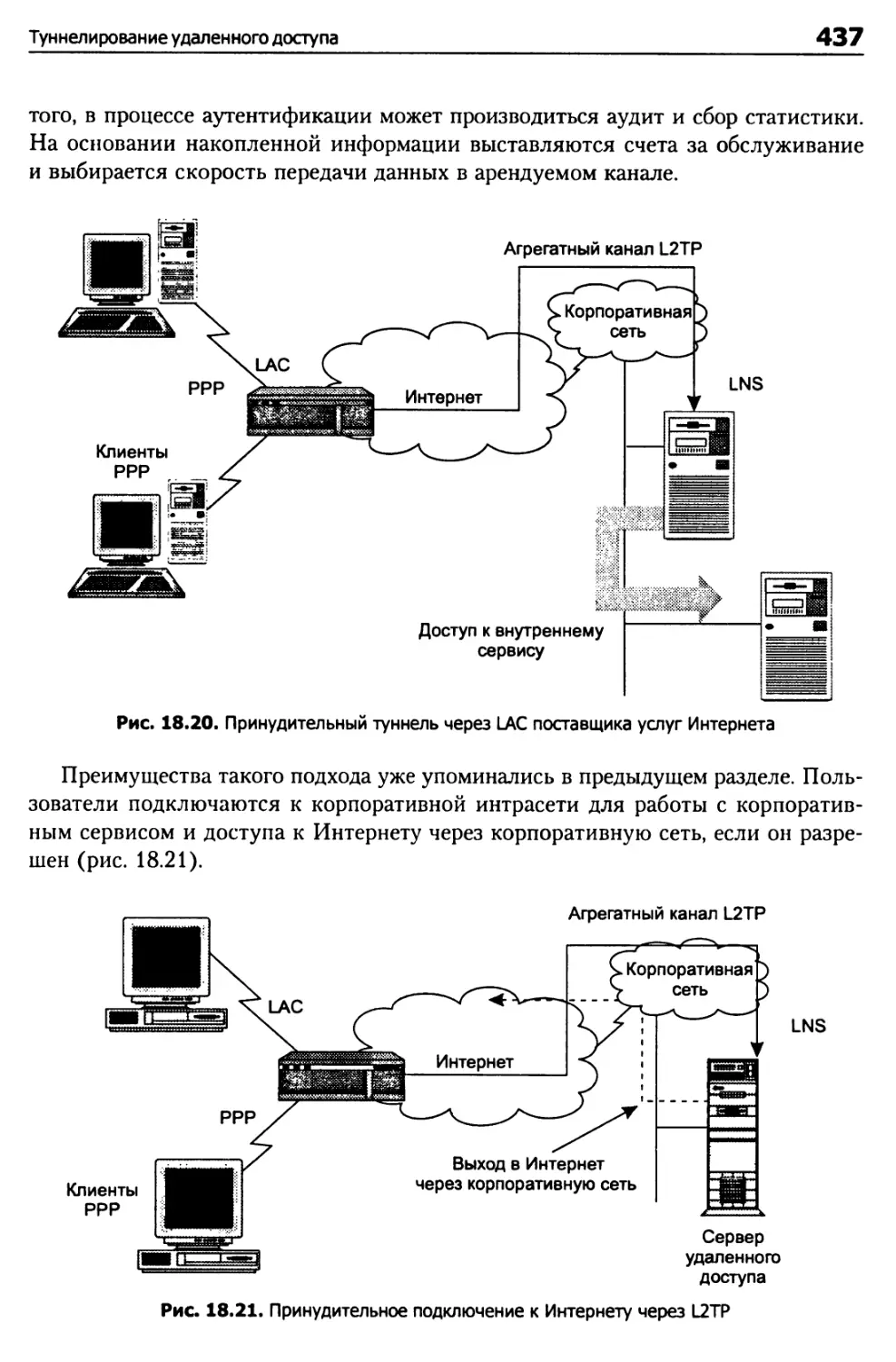
Принудительный туннель 432
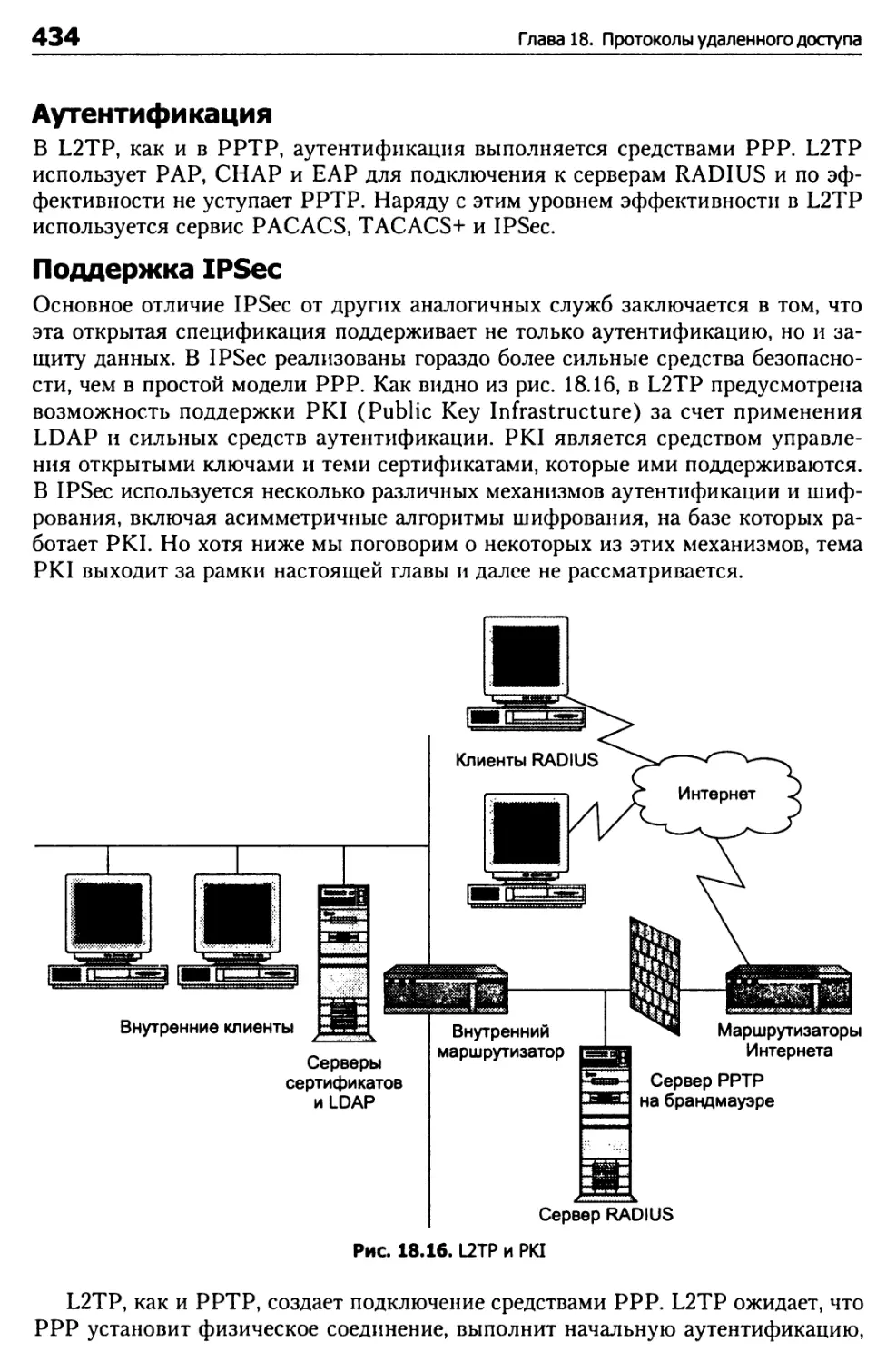
Туннельный протокол уровня 2 (L2TP) 433
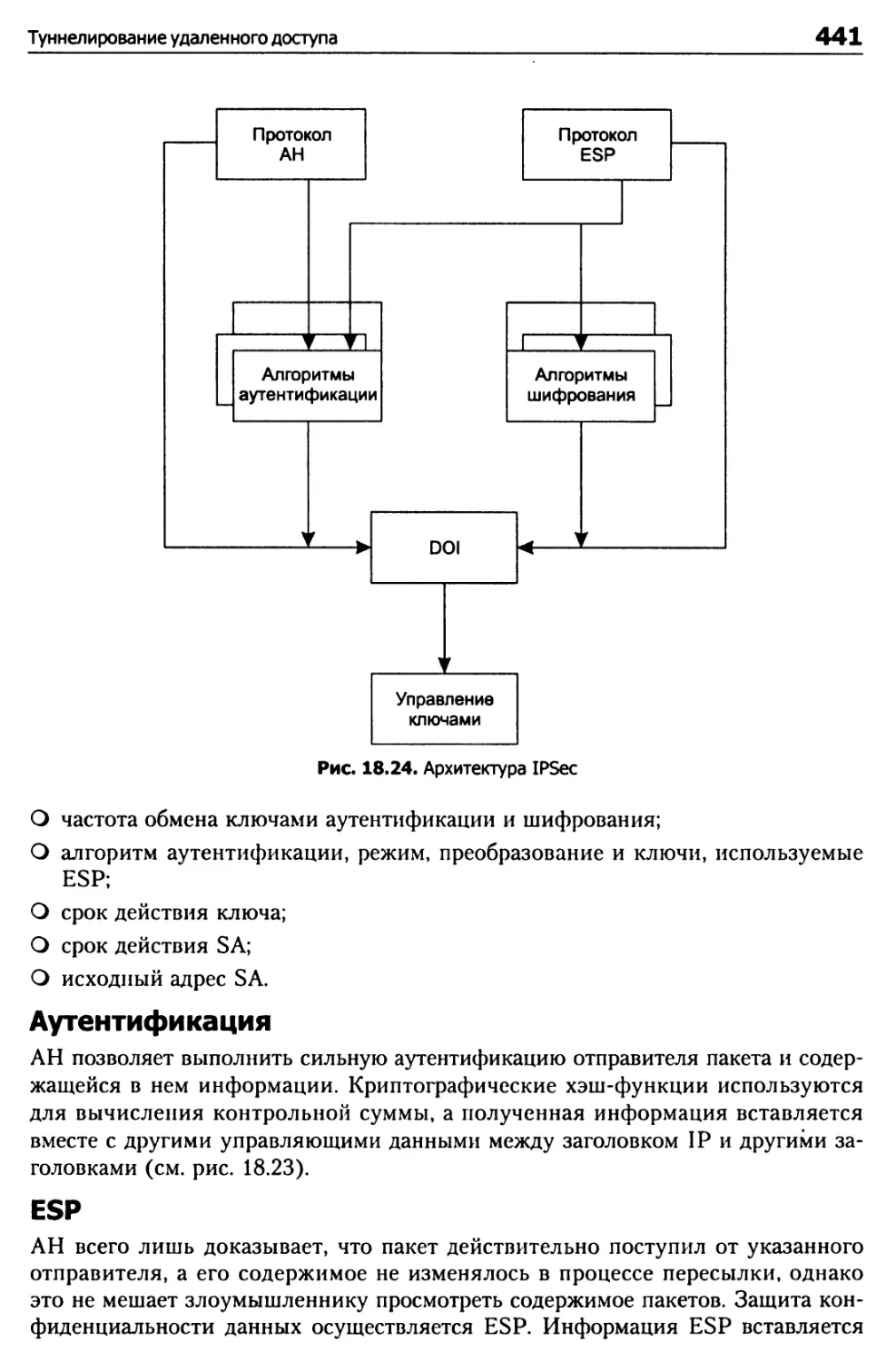
IPSec 439
Итоги 442
Глава 19. Брандмауэры 444
Безопасность сети 444
Функции брандмауэров 446
Использование брандмауэров 446
Прокси-серверы 447
Пакетные фильтры 448
Защита служб 449
Электронная почта (SMTP) 449
HTTP: World Wide Web 450
FTP 450
Telnet 451
Usenet: NNTP 452
DNS 452
Построение собственного брандмауэра 452
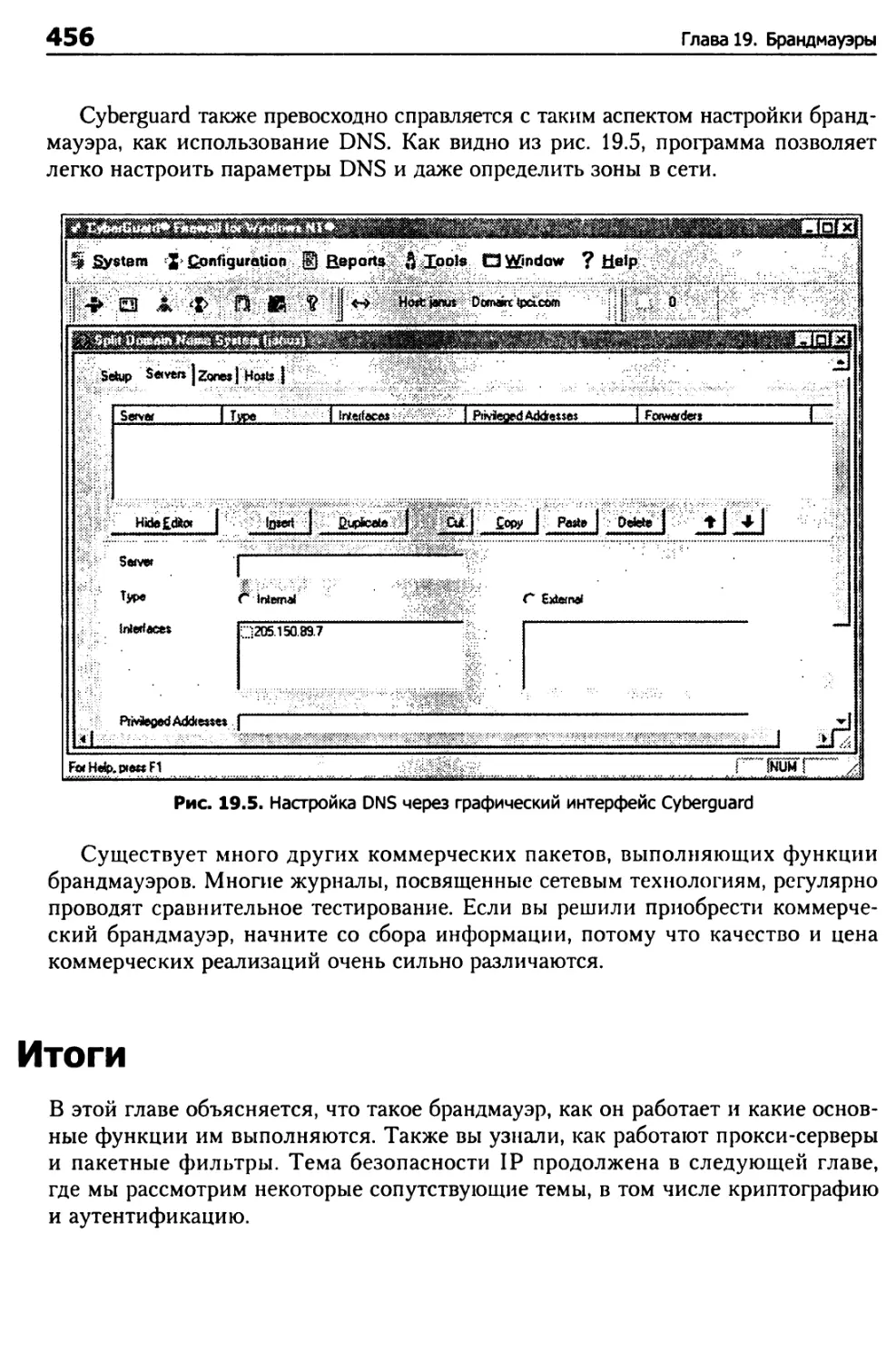
Использование коммерческих брандмауэров 453
Итоги 456
Глава 20. Сетевая и системная безопасность 457
Шифрование 458
Шифрование с парными ключами 459
Шифрование с симметричным закрытым ключом 460
DES, IDEA и другие 461
Аутентификация с применением цифровых подписей 463
Раскрытие шифров 464
Защита сети 465
Вход в систему и пароли 466
Разрешения доступа к файлам и каталогам 466
UUCP в системах Unix и Linux 468
Приготовьтесь к худшему 469
Итоги 469
Глава 21. Общая конфигурация 470
Установка сетевой платы 470
Сетевые платы 471
Настройка ресурсов 472
Установка программного обеспечения сетевой платы 473
Редиректоры и API 474
Службы 475
Сетевые интерфейсы 476
Сетевые и транспортные протоколы 476
Обязательные параметры конфигурации IP 476
Настройка адреса основного шлюза 478
Настройка адреса сервера имен 479
Настройка адреса почтового сервера 479
Регистрация доменного имени 480
Разновидности конфигурации IP 480
Настройка таблицы маршрутизации 481
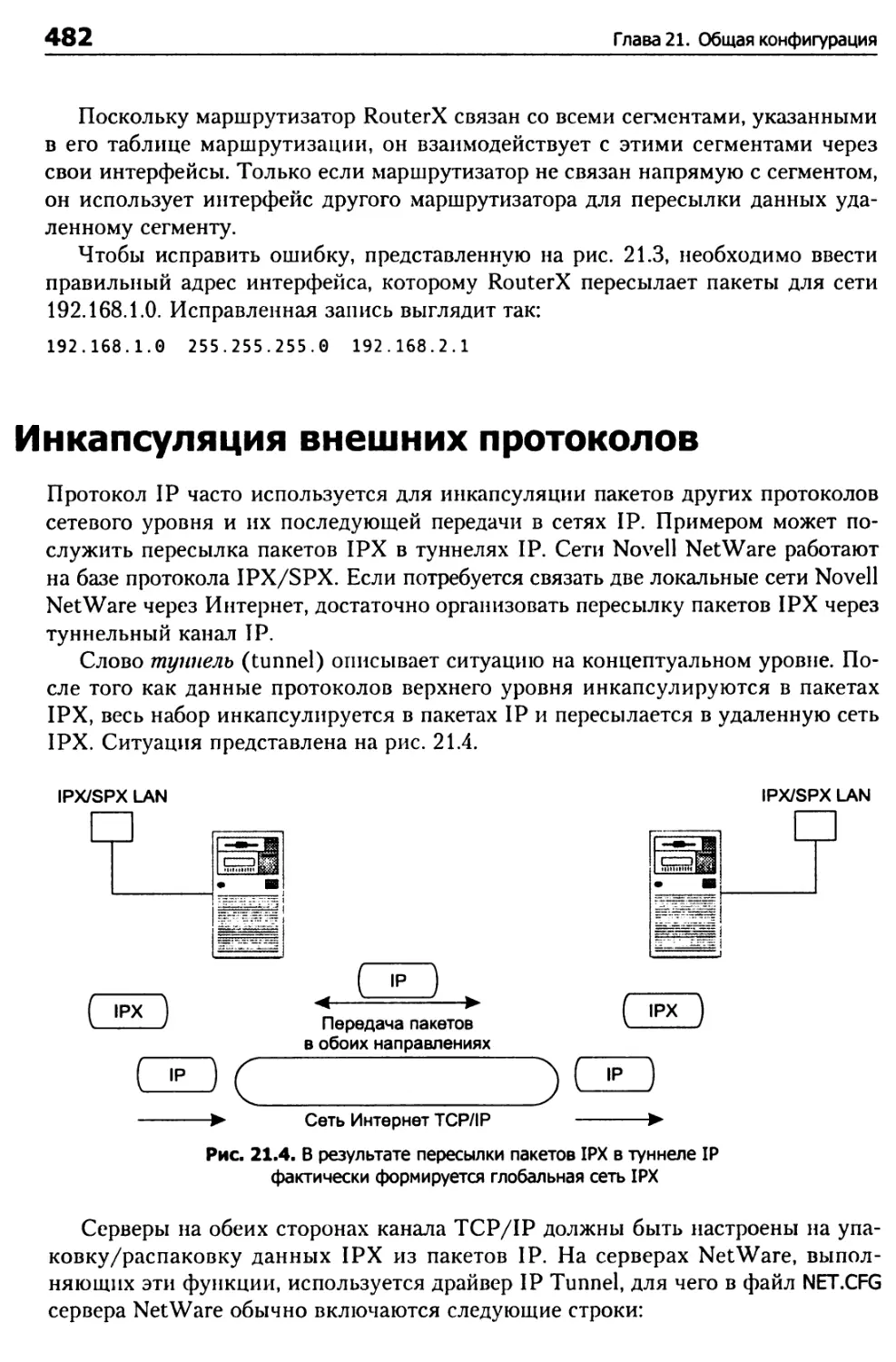
Инкапсуляция внешних протоколов 482
Итоги 483
Глава 22. Настройка TCP/IP в Windows 95 и Windows 98 485
Сетевая архитектура Windows 98 485
Установка сетевой платы 486
Мастер установки нового оборудования 487
Изменение параметров конфигурации сетевой платы 489
Если Windows 98 не загружается 490
Настройка TCP/IP в Windows 98 491
Сбор предварительной информации 491
Установка TCP/IP 492
Настройка реализации TCP/IP от Microsoft 492
Статические конфигурационные файлы 498
Настройка реестра 498
Тестирование TCP/IP 502
Итоги 504
Глава 23. Настройка TCP/IP в Windows 2000 505
Установка TCP/IP 505
Настройка IP-адреса 507
Назначение IP-адресов при отказе сервера DHCP 510
Настройка параметров DNS 510
Настройка адресов WINS 514
Безопасность и фильтрация TCP/IP 516
Настройка служб разрешения имен 518
Службы NetBIOS 519
Механизмы разрешения имен 521
Настройка кэша имен NetBIOS 523
Настройка широковещательных запросов на разрешение имен 524
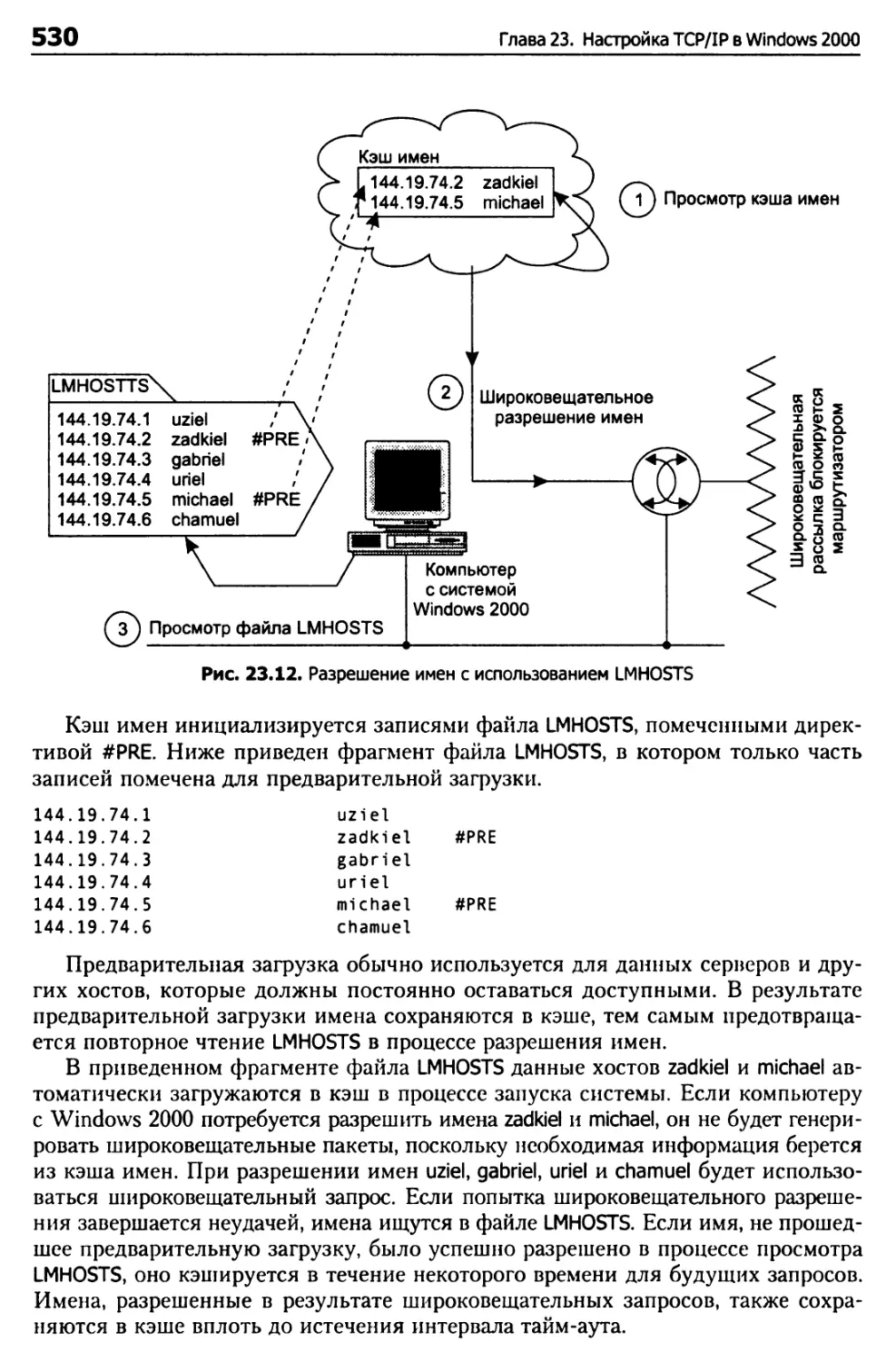
Настройка файла LMHOSTS 526
Настройка файла HOSTS 532
Другие служебные файлы TCP/IP 533
Файл NETWORKS 533
Файл PROTOCOL 534
Файл SERVICES 535
Установка и настройка службы сервера FTP 538
Установка и настройка службы сервера FTP на сервере Windows 2000 539
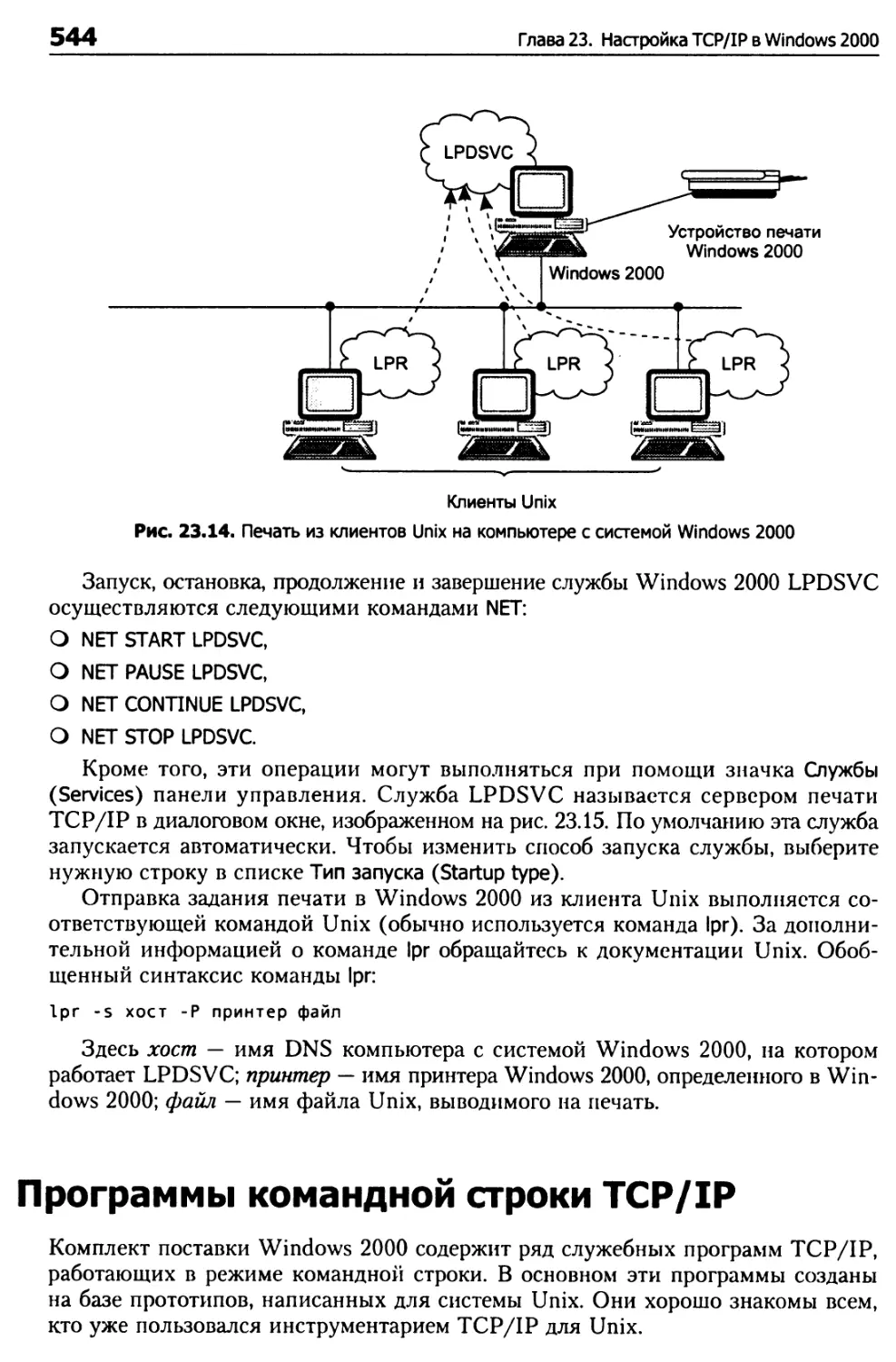
Настройка TCP/IP для печати из Windows 2000 на принтерах Unix 541
Установка и настройка сетевой печати TCP/IP 541
Печать в Windows 2000 из клиентов Unix 543
Программы командной строки TCP/IP 544
Итоги 547
Глава 24. Поддержка IP в Novell NetWare 548
Novell иТСР/IP 548
IPnNetWare4 548
NetWare 5 и NetWare 6 549
Традиционные решения: IP в NetWare 3.x-4.x 550
IP Tunneling 551
IP Relay 551
LAN Workplace 552
IPX-IPGateway 552
NetWare/IP 553
NetWare 5/NetWare 6 — IP и все удобства Novell 554
Полноценная поддержка IP 554
Поддержка нескольких протоколов 554
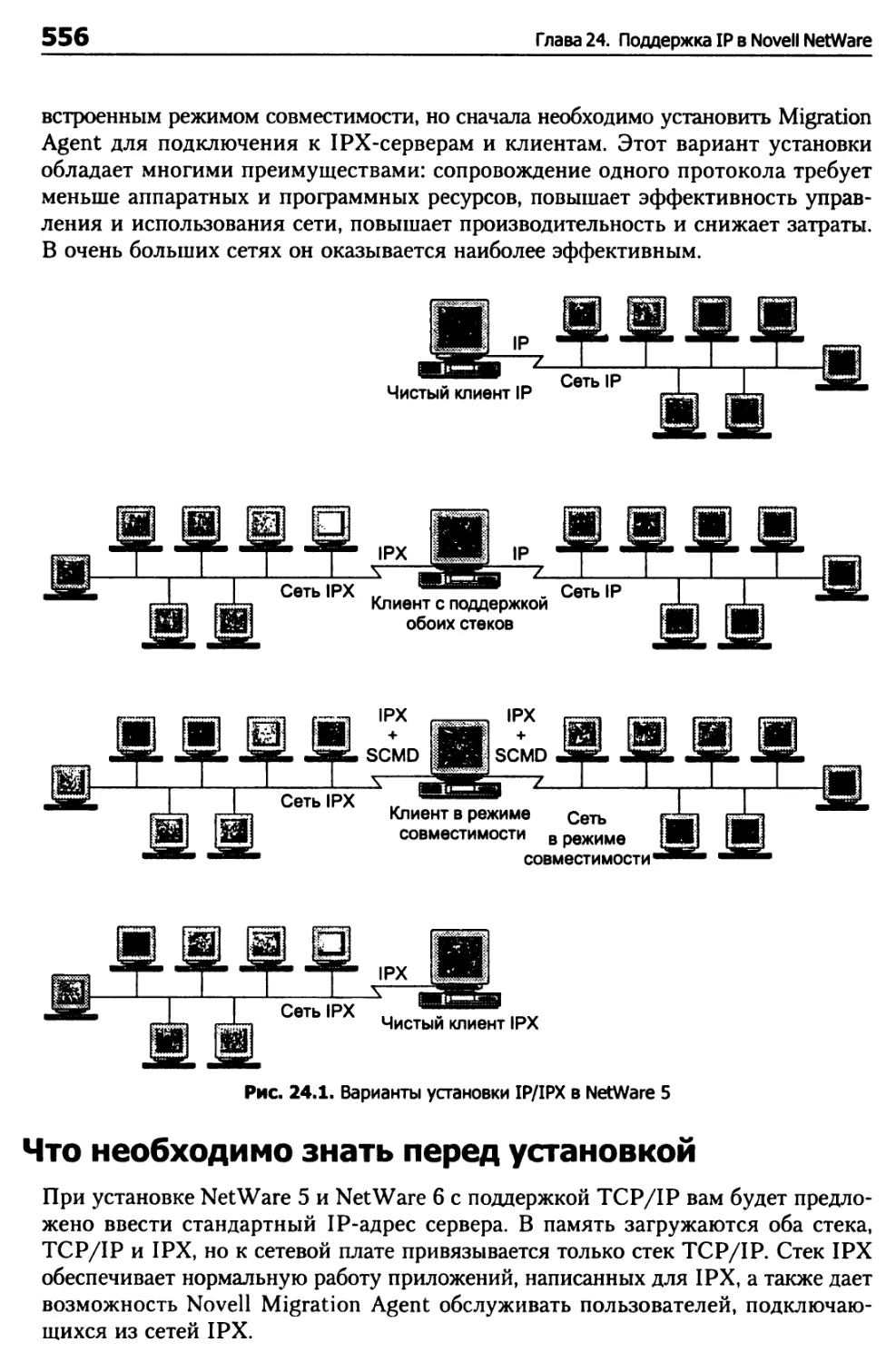
Варианты установки 555
Установка NetWare 5 и NetWare 6 для IP 555
Что необходимо знать перед установкой 556
Установка NetWare 5 и NetWare 6 для IPX 557
Что необходимо знать перед установкой 557
Смешанная установка IPX/IP 557
Что необходимо знать перед установкой 558
Средства, упрощающие переход на IP 558
NDS 558
DNS 559
DHCP 559
DDNS 559
SLP 559
Режим совместимости 560
Migration Agent 560
Стратегии перехода 560
Тестовая платформа 561
Возможные сценарии перехода 561
Итоги 562
Глава 25. Настройка TCP/IP в системе Linux 563
Подготовка системы к настройке TCP/IP 564
Доступ к сетевому интерфейсу 566
Настройка интерфейса обратной связи 567
Настройка интерфейса Ethernet 569
Служба имен 571
Шлюзы 573
Графические программы настройки сетевых интерфейсов 574
Программа netcfg 575
Программа linuxconf 575
Настройка SLIP и РРР 578
Настройка фиктивного интерфейса 579
Настройка SLIP 580
Настройка РРР 581
Итоги 583
Глава 26. Whois и Finger 584
Протокол Whois 584
Регистрация имен в Интернете 585
Базы данных Whois 586
Примеры 589
Расширения Whois 592
RWhois 592
WHOIS++ 592
Finger 592
Команда finger 593
Демоны Finger 595
Finger в других системах 596
Необычное применение Finger 596
Итоги 598
Глава 27. Протоколы пересылки файлов 599
Роль FTP и TFTP в современном мире 599
Пересылка файлов через FTP 600
Подключения FTP 600
Управляющий порт 601
Порт данных 602
Подключение с использованием клиентов FTP 603
Интерактивный режим FTP 604
Безопасность при использовании FTP 612
Серверы и демоны FTP 615
Анонимный доступ FTP 616
TFTP 618
Отличия TFTP от FTP 618
Команды TFTP 619
Итоги 619
Глава 28. Telnet 620
Знакомство с протоколом Telnet 620
Виртуальный терминал 622
Демон Telnet 623
Использование Telnet 625
Команда telnet в системе Unix 625
Графические клиенты Telnet 626
Команды Telnet 627
Примеры использования Telnet 629
Дополнительные возможности Telnet 630
Безопасность 630
Приложения Telnet 631
Работа с другими службами TCP/IP через Telnet 633
Итоги 635
Глава 29. Инструментарий удаленного доступа 636
R-команды 636
R-команды и безопасность 637
Запрет использования г-команд 637
Альтернативы для г-команд 640
Справочник г-команд 641
Демоны г-команд 641
rsh 641
rep 642
rlogin 642
rup 643
ruptime 643
rwho 643
rexec 644
Другие файлы 644
Функциональность г-команд на других платформах 646
Итоги 647
Глава 30. Протоколы совместного доступа к файловой
системе: NFS и SMB/CIFS 648
Что такое NFS? 648
Краткая история NFS 649
Почему NFS? 649
Реализация —как работает NFS 649
RPCnXDR 650
Жесткое и мягкое монтирование 650
Файлы и команды NFS 651
Демоны NFS 651
Служебные файлы NFS 654
Серверные команды NFS 656
Создание общих ресурсов 656
Отключение общих ресурсов 658
Клиентские команды NFS 659
Демонтирование ресурсов NFS 661
Пример: организация совместного доступа и монтирование файловой системы NFS . . . 662
Распространенные проблемы NFS и их решения 663
Ошибки при монтировании ресурсов 663
Ошибки при демонтировании ресурсов 664
Жесткое и мягкое монтирование 664
Другие протоколы и продукты 664
WebNFS 665
PC-NFS и другие клиентские программы 665
SMBhCIFS 665
Другие продукты 666
Итоги 666
Глава 31. Интеграция TCP/IP с прикладными службами ..... 667
Применение браузера на представительском уровне 668
Интеграция TCP/IP с унаследованными приложениями 669
Использование TCP/IP в других сетях 669
NetBIOS и TCP/IP 670
IPXnUDP 671
Итоги 671
Глава 32. Почтовые протоколы Интернета 672
Электронная почта 672
История электронной почты 672
Стандарты и их разработчики 673
Х.400 673
SMTP 675
MIME и SMTP 675
Другие стандарты кодировки двоичных данных 676
Команды SMTP 676
Коды состояния SMTP 677
Расширение SMTP 678
Заголовки SMTP 679
Достоинства и недостатки SMTP 679
Получение почты с применением POP и IMAP 680
Протокол POP 681
Протокол IMAP 681
Сравнение РОРЗ с IMAP4 682
Нетривиальные возможности электронной почты 683
Безопасность 683
Спам и другие нежелательные сообщения 686
Анонимный сервис электронной почты и пересылка 686
Итоги 687
Глава 33. Служба HTTP 688
Worldwide Web 688
Краткая история Web 688
Создатели и попечители Web 688
Стремительное развитие Web 689
Унифицированные указатели ресурсов 689
Web-серверы и браузеры 691
Протокол HTTP 692
НТТР/1.1 692
MIME и Web 695
Пример сеанса HTTP 696
Нетривиальные возможности Web 696
Средства, работающие на стороне сервера 697
SSLhS-HTTP 697
Языки Web 697
Будущее Web 701
HTTP-ng 701
ПОР 702
IPv6 702
IPP 702
XML 702
Итоги 703
Глава 34. Служба сетевых новостей и протокол NNTP 704
Usenet 704
Конференции и иерархии 705
Протокол NNTP 707
Получение списка конференций 708
Прием сообщений 709
Отправка сообщений 710
Спам и блокировка 711
Итоги 712
Глава 35. Установка и настройка web-сервера 713
Принципы работы web-серверов 713
Терминология web-серверов 714
Популярные web-серверы 716
Установка и запуск web-сервера Apache 717
Загрузка, установка и настройка Apache 717
Компиляция и установка Apache 719
Настройка Apache 720
Запуск и остановка Apache 722
Загрузка двоичных файлов Apache 723
Установка и настройка Apache в двоичном формате 725
Использование Apache для Windows 725
Другие web-серверы 727
Итоги 728
Глава 36. Настройка и оптимизация протоколов в системах
семейства Unix 729
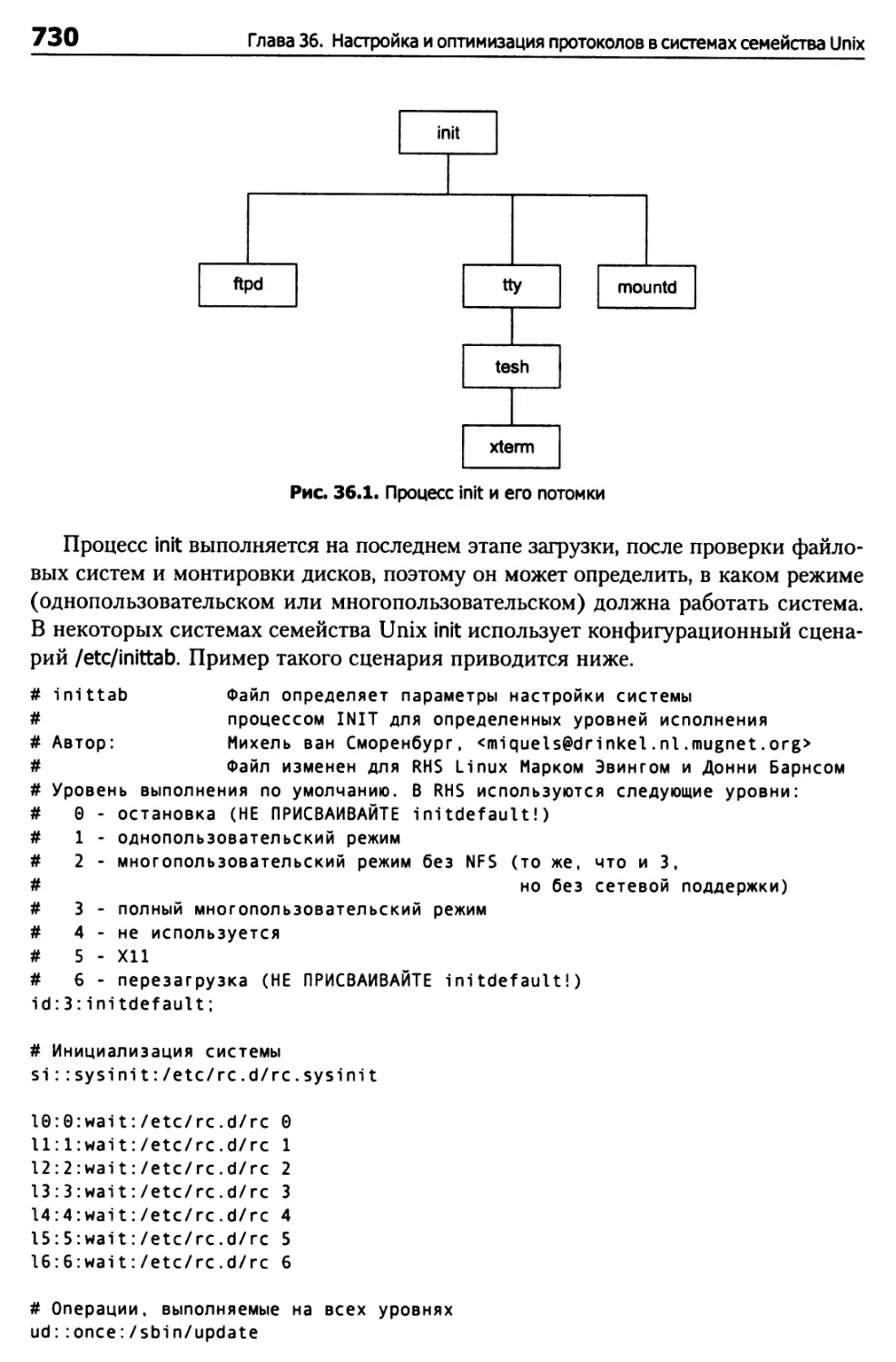
Инициализация системы 729
Процесс inlt и/etc/inittab 729
Сценарии гс 731
Конфигурационные файлы 735
Определение сетевых протоколов в/etc/protocols 735
Имена хостов в/etc/hosts 736
Клиент DNS и файл/etc/resolv.conf 742
Итоги 743
Глава 37. Реализация DNS 744
Серверы имен DNS 744
Ресурсные записи 745
Резольвер 747
Настройка сервера DNS в Unix и Linux 748
Ввод ресурсных записей 748
Остальные файлы DNS 749
Запуск демонов DNS 754
Настройка клиента 754
Windows и DNS 754
Итоги 755
Глава 38. Управление сетью TCP/IP 756
Разработка плана сетевого мониторинга 757
Анализ и диагностика сетевых проблем 758
Средства управления сетью 759
Анализаторы протоколов 759
Экспертные системы 761
Анализаторы на базе PC 762
Поддержка протоколов управления сетью 763
Интеграция со средствами сетевого моделирования 764
Настройка SNMP 765
Настройка SNMP в системе Windows 765
Настройка SNMP в системе Unix 767
Параметры безопасности SNMP 768
Управление сетью и агенты SNMP 768
Инструментарий и команды SNMP 770
RMON и другие модули MIB 771
Выработка требований 772
Построение подробного списка информации 772
Передача списка в службу поддержки 772
Формулировка стратегии построения отчетов 772
Определение показателей, используемых для оповещения об экстренных
ситуациях (в реальном времени) 772
Выбор информации для составления ежемесячных отчетов 773
Выбор информации для оптимизации 773
Обратная связь 773
Реализация требований 774
Оповещение служб поддержки 774
Повторный анализ требований 774
Информирование технической службы 774
Пробные проверки 774
Обучение технической службы 774
Документирование диагностических процедур 775
Упрощение систем управления элементами 775
Использование искусственного интеллекта 775
Итоги 776
Глава 39. Протокол управления сетью SNMP 777
ЧтотакоеБММР? 777
MIB 779
Использование SNMP 780
Unix и SNMP 781
Настройка SNMP в Unix и Linux 782
Команды SNMP 783
Windows и SNMP 784
Windows NT/2000 784
Windows9x/ME 786
Итоги 789
Глава 40. Безопасность передачи данных TCP/IP 790
Планирование сетевой безопасности 790
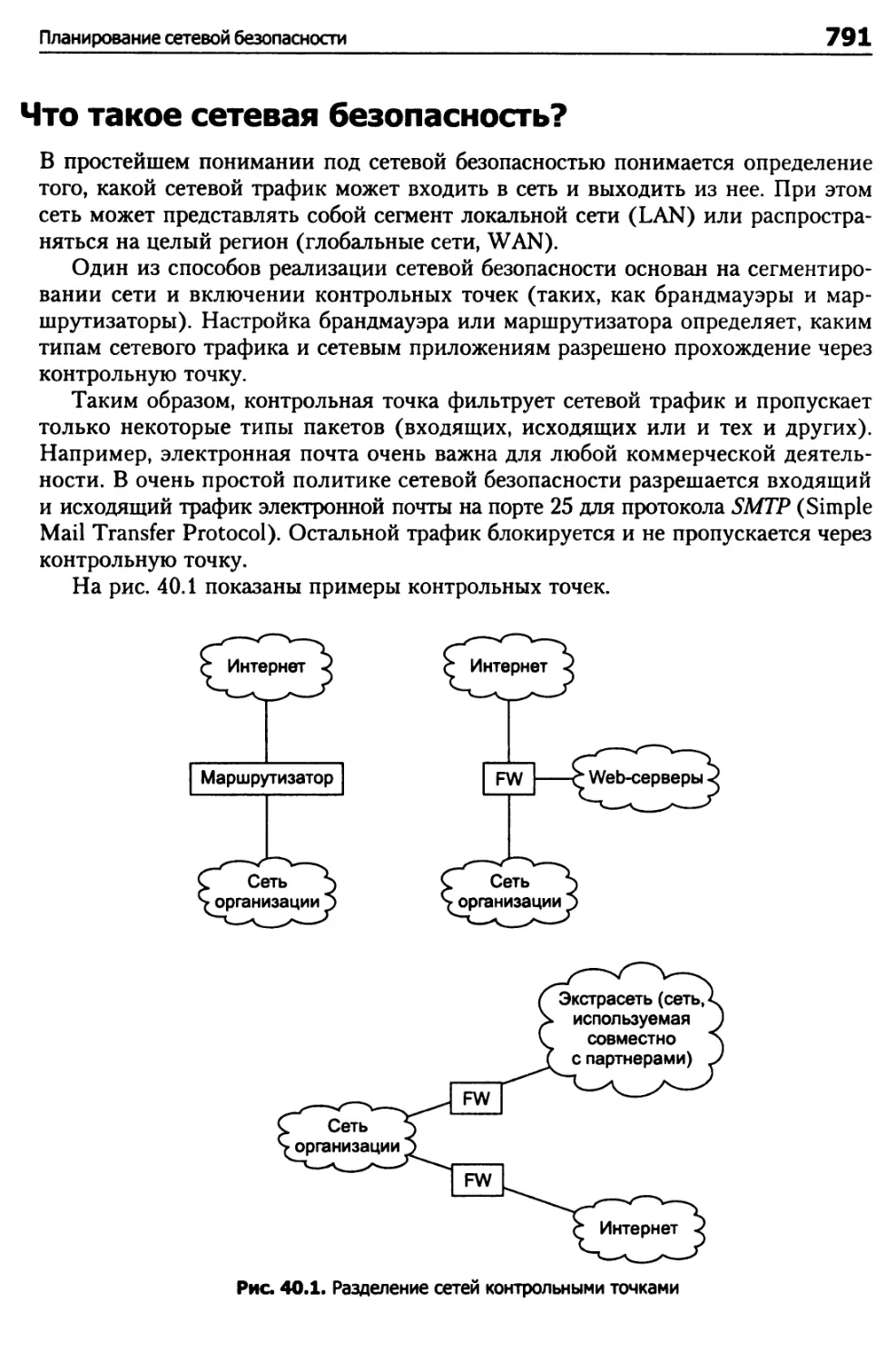
Что такое сетевая безопасность? 791
Почему важна сетевая безопасность? 792
Уровни безопасности 792
Пароли и файлы паролей 793
Ограничение доступа к паролям 794
Сетевая безопасность 795
Типы атак 795
Меры, обеспечивающие сетевую безопасность 797
Настройка приложений 799
Демон Интернета и файл /etc/inetd.conf 799
Программы шифрования 801
TCP Wrappers 802
Порты 803
Брандмауэры 803
Пакетные фильтры 804
Шлюзы приложений 804
Приложения-фильтры 804
Итоги 804
Глава 41. Инструментарий и методы диагностики 805
Наблюдение за состоянием сети 805
Стандартные утилиты 806
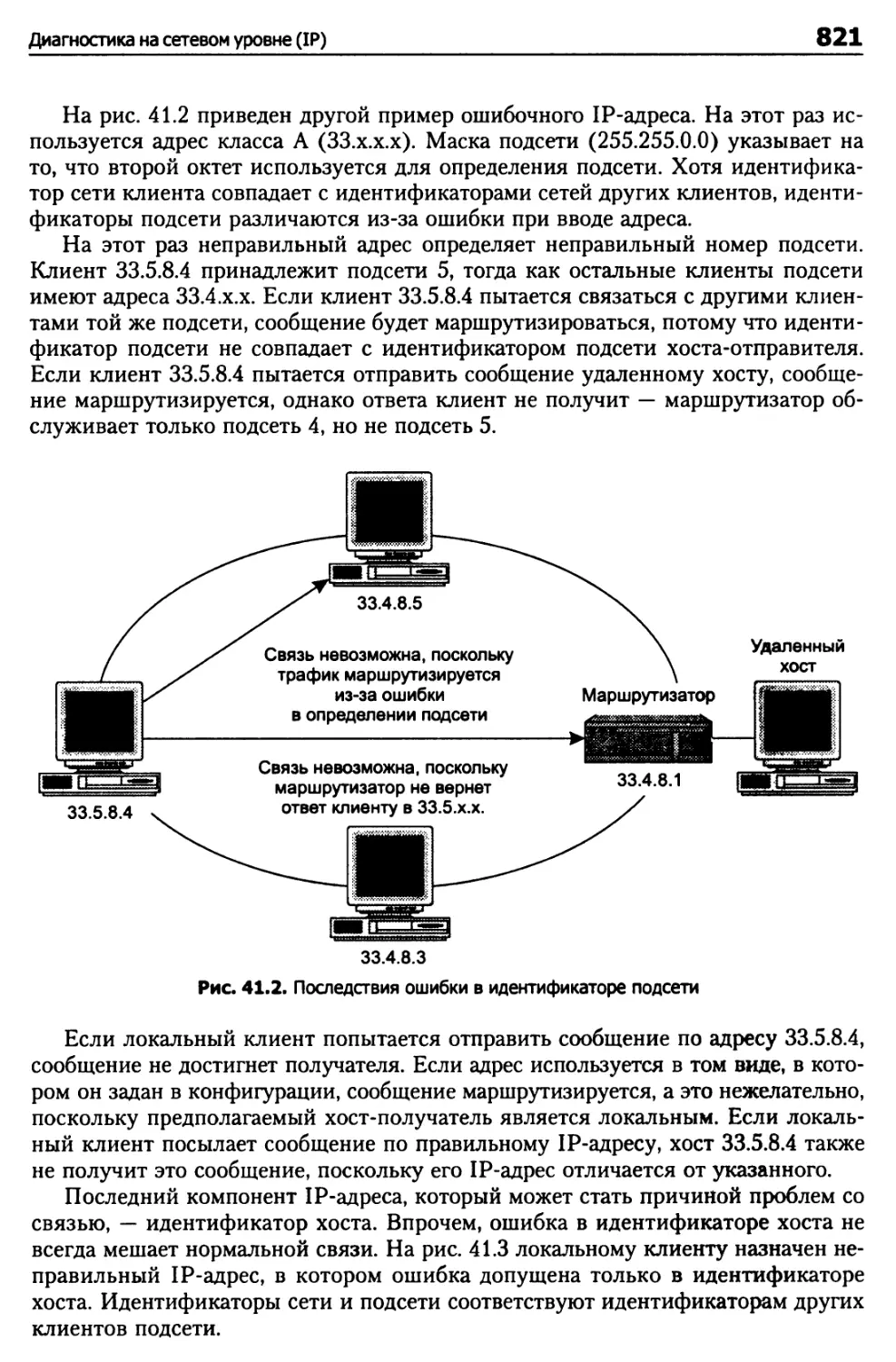
Проверка базового соединения 806
Диагностика проблем на сетевом уровне 810
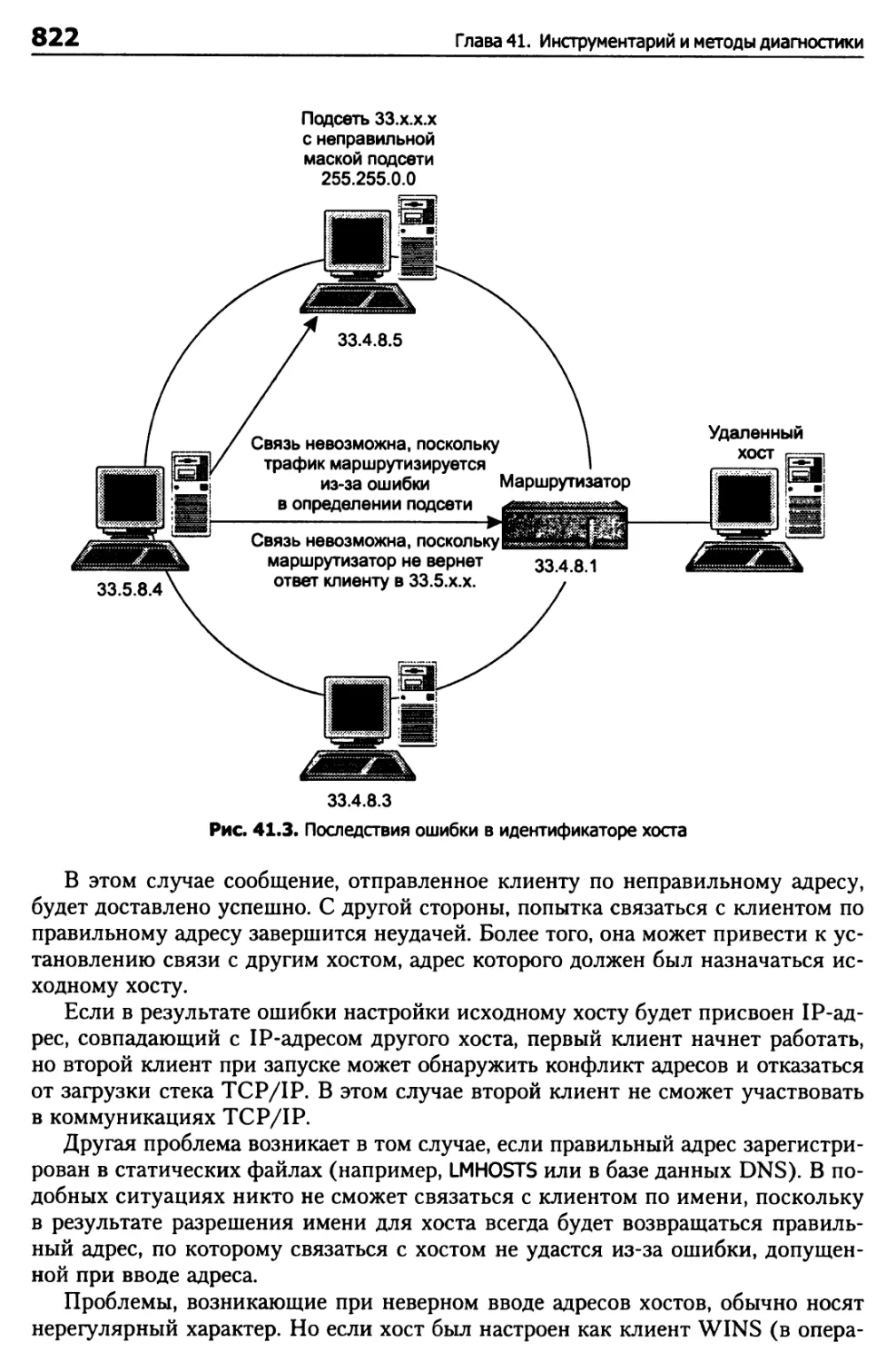
Проверка маршрутов 813
Проверка службы имен 817
Диагностика сетевого интерфейса 818
Диагностика на сетевом уровне (IP) 819
Параметры конфигурации TCP/IP 819
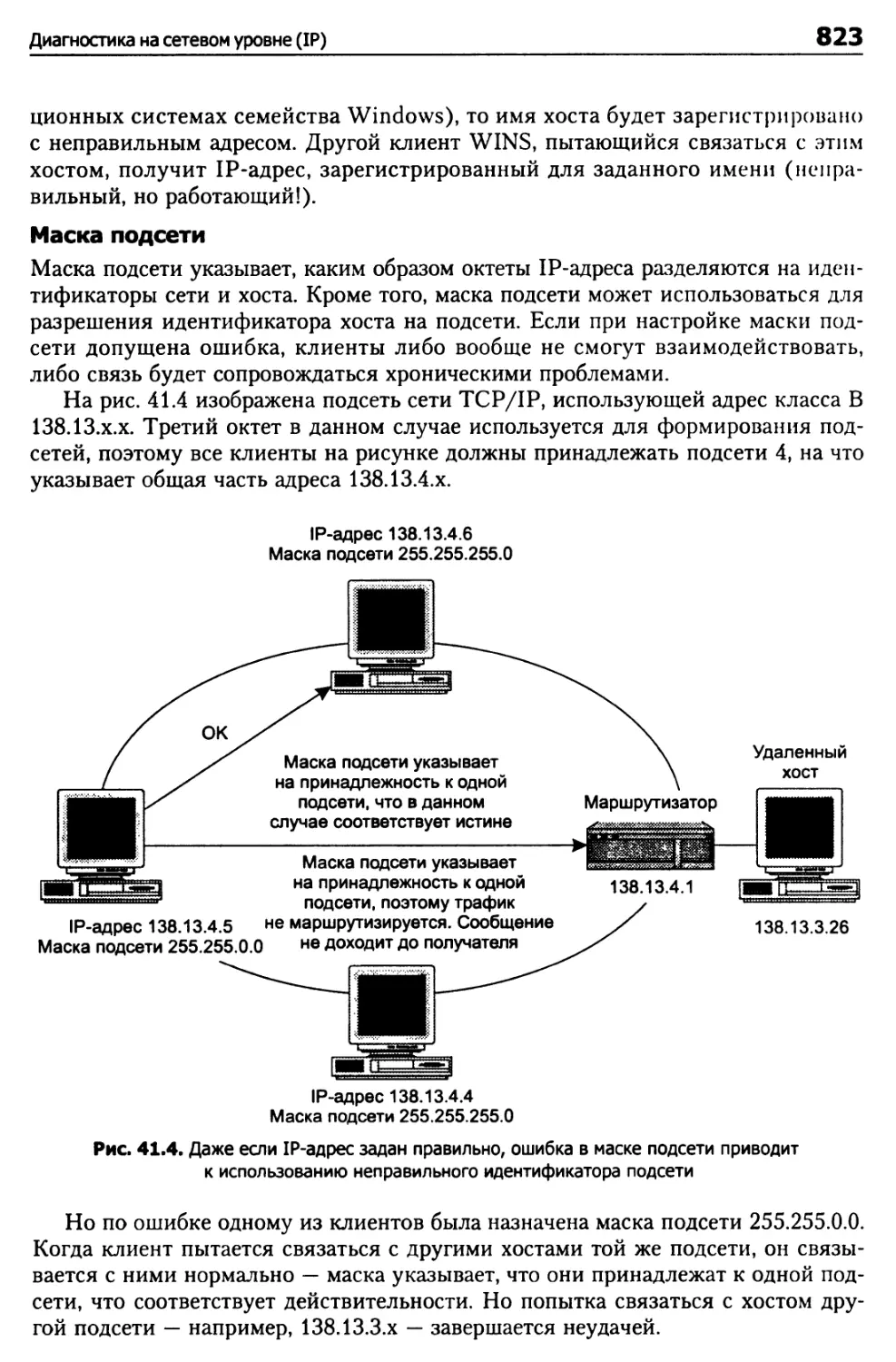
Диагностика проблем TCP и UDP 825
Проблемы с сокетами 825
Файл SERVICES 826
Диагностика на прикладном уровне 826
Проблемы разрешения имен 827
Итоги 827
Приложение A. RFC и стандарты 828
Информационные ресурсы 828
World Wide Web 828
FTP 829
Электронная почта 829
Бумажные копии 829
Тематический список полезных RFC 829
Общие сведения 830
TCPnUDP 830
IPhICMP 830
Нижние уровни 831
Загрузка 831
DNS 832
Пересылка и доступ к файлам 832
Электронная почта 832
Протоколы маршрутизации 832
Политика и производительность маршрутизации 833
Терминальный доступ 833
Другие приложения 834
Управление сетью 835
Туннелирование 835
OSI 836
Безопасность 836
Разное 836
Список RFC по номерам 836
Приложение Б. Сокращения и акронимы 837
Алфавитный указатель 846
радости в жизни, и моим родителям,
так много сделавшим для меня...
Благодарности
Одна из самых приятных обязанностей автора — выражение благодарности
людям, внесшим вклад в успех книги. Спасибо всем, кто был рядом со мной:
Харприт (Harpreet), Ахал Сингх (Ahal Singh), Теджиндер Каур (Tejnder Kaur),
Харджит (Harjeet), Джагджит 0а&Д0> Куки (Kookie) и Долли (Dolly). Я
особенно благодарен маме, Сен Жермен (Saint Germain), Эль Морья Хану (Е1 Могуа
Khan), Дживалу Кулу (Djwal Kul), Кутуми Лал Сингху (Kuthumi Lai Singh),
Куан-Йину (Kuan-Yin), Бхагавану Кришне (Bhagwan Krishna) и Бабаджи (Babaji).
Без их духовной поддержки эта книга никогда бы не появилась.
Я хочу поблагодарить Боба Санрегрета (Bob Sanregret) и Андерса Амундсо-
на (Anders Amundson), которые когда-то привлекли меня к написанию учебных
материалов на компьютерную тематику. Кроме того, спасибо сотрудникам Higher
Technology и Learning Tree за их помощь и поддержку в различных проектах.
Особую благодарность хочу выразить Филипу Вайнбергу (Philip Weinberg),
Ленин Бернстайну (Lenny Bernstein), доктору Дэвиду Коллинзу (Dr. David Collins),
Эрику Гарену (Eric Garen) и Джону Мориарти (John Moriarty).
Спасибо Дайну Исли (Dayna Isley) за сопровождение этого проекта и
выпускающему редактору Джинни Бесс (Ginny Bess). Также я благодарен Элизабет
Финни (Elizabeth Finney) и Уильяму Вагнеру (William Wagner) за помощь в
работе над книгой.
Введение
Протокол TCP/IP (Transmission Control Protocol/Internet Protocol) стал
фактическим стандартом не только для Интернета, но и для интрасетей. В интрасе-
тях протокол TCP/IP когда-то был лишь одним из многих и существовал
наряду с протоколами Novell IPX/SPX, Microsoft NetBIOS и NetBEUI, а также
AppleTalk. Хотя в наши дни в сетях по-прежнему встречаются другие
протоколы, основным коммуникационным протоколом стал TCP/IP.
Чем обусловлен переход на TCP/IP в интрасетях? Это происходило
постепенно. С развитием серверов Windows NT/2000 и Novell NetWare в них
появилась поддержка TCP/IP. Фирма Microsoft включила стек TCP/IP в Windows 9x
и NT/2000. Одним из преимуществ перехода на единый протокол является
расширение возможностей системной интеграции — например, компьютеры Unix,
Windows и Macintosh могут свободно общаться друг с другом. Переходу на
TCP/IP также способствовала возможность прямого подключения к Интернету
без необходимости преобразования сетевых протоколов. Из-за этого
большинство современных сетей (как гетерогенных, так и Windows-сетей) работает на
основе протокола TCP/IP. Протокол IPX/SPX занимает незначительный сектор
рынка, a NetBEUI используется только в малых и простых сетях Windows.
Впрочем, изменения оказались благоприятными. TCP/IP — один из самых
надежных сетевых протоколов, и он продолжает развиваться. Проблемы
безопасности TCP/IP хорошо известны и исследованы. Для повышения степени
защищенности TCP/IP были созданы новые стандарты (такие, как IPSec). Протокол
TCP/IP реализован почти на всех устройствах, подключаемых к сети. Наконец,
TCP/IP относится к числу открытых стандартов, а это означает, что все
спецификации опубликованы и доступны для всех желающих.
Естественно, развитие Интернета способствовало выдвижению TCP/IP на
ведущее место среди сетевых протоколов. В результате бурного роста World
Wide Web каждый компьютер должен поддерживать TCP/IP, чтобы общаться
с интернет-провайдером. Тем не менее протокол TCP/IP широко использовался
еще до начала революции Web, произошедшей всего несколько лет назад. Многие
из нас еще в начале 1980-х использовали TCP/IP для работы с электронной
почтой, FTP и Usenet на старых системах Unix и СР/М. Тогда для работы с TCP/IP
было недостаточно уметь нажимать две-три кнопки в графическом диалоговом
окне.
В наши дни полки магазинов забиты книгами о TCP/IP, многие из которых
повторяют друг друга. У протокола TCP/IP есть весьма странная особенность:
он очень прост и одновременно очень сложен. Если вам потребуется подключить
компьютер Windows к сети TCP/IP, это делается так просто, что описание
займет пару-тройку страниц. Но если вы захотите поближе познакомиться с
протоколами и стандартными утилитами семейства TCP/IP, для этого не хватит
тысячи страниц. Еще больше должен знать программист, занимающийся
разработкой приложений TCP/IP. Настоящее издание книги ориентируется на
читателя, который хочет познакомиться с протоколами и программами,
используемыми в работе TCP/IP, научиться подключать новые компьютеры к сетям
TCP/IP и знать то, на что следует обратить особое внимание; однако материал,
относящийся к программированию TCP/IP, в книге едва затронут.
Материал книги весьма обширен: мы подробно рассмотрим все базовые
протоколы TCP/IP. Вы увидите, как используются эти протоколы, как TCP работает
на базе протокола IP, который, в свою очередь, базируется на низкоуровневом
сетевом протоколе. В книге будут рассмотрены многочисленные приложения
базовых протоколов TCP/IP. Многие инструменты, используемые для
решения повседневных задач в крупных сетях — DNS (Domain Name System), NFS
(Network File System) и NIS (Network Information System), — работают на базе
протокола TCP/IP. Другие протоколы, предназначенные для
администраторов — такие, как SNMP (Simple Network Management Protocol) и ARP (Address
Resolution Protocol), — тоже основаны на базовых протоколах TCP. Даже такие
простые приложения, как почтовые клиенты, используют протоколы семейства
TCP. Вездесущий стек TCP/IP встречается при выполнении практически всех
повседневных задач. Понимание протокола и принципов его работы поможет
вам лучше разобраться в работе системы.
В этой книге мы постарались изложить материал с позиций, не связанных
с программированием. В книге показано, как работает протокол TCP/IP, как он
взаимодействует с другими протоколами семейства TCP/IP, какие функции он
выполняет в сети и как установить его поддержку на вашем компьютере.
Изложение сопровождается подробными инструкциями по установке и
настройке протоколов и служб. Мы приводим используемые команды и типичные
результаты, которые будут получены при их выполнении. Вы узнаете, как
организовать поддержку TCP/IP во многих операционных системах, таких как
Windows 2000, NetWare и Linux. В книге приводится информация о брандмауэрах
и безопасности. Короче говоря, в книгу включено все, что относится к TCP/IP,
кроме программирования приложений. Надеемся, книга вам понравится.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу электронной
почты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На web-сайте издательства http://www.piter.com вы найдете подробную
информацию о наших книгах.
1 Открытые
коммуникации
Марк А. Спортак (Mark A. Sportack)
Безусловно, протокол TCP/IP (Transmission Control Protocol/Internet Protocol)
можно считать самым успешным из всех когда-либо разрабатывавшихся
коммуникационных протоколов. В общем случае термин TCP/IP обозначает целое
семейство протоколов: TCP для надежной доставки данных, UPD (User
Datagram Protocol) для негарантированной доставки, IP (Internet Protocol) и других
прикладных служб.
Наглядным доказательством успеха TCP/IP является Интернет — самая
большая из когда-либо построенных открытых сетей. Первоначально Интернет
проектировался для упрощения оборонных исследований и для того, чтобы
правительство США сохранило систему связи даже в случае возможного ядерного
удара огромной разрушительной силы. Протокол TCP/IP был разработан именно
для этой цели.
Современный Интернет в большей степени ориентируется на коммерческие
и потребительские функции. Несмотря на столь радикальную смену ориентации,
все исходные атрибуты (то есть открытость, повышенная живучесть и
надежность) по-прежнему играют исключительно важную роль. Они обеспечивают
надежную доставку данных с использованием специально разработанных
протоколов (таких, как TCP), а также возможность автоматического обнаружения
и обхода сбойных участков сети. Но что еще важнее, TCP/IP является открытым
коммуникационным протоколом. Открытость означает, что он обеспечивает
связь в любых комбинациях устройств независимо от того, насколько они
различаются на физическом уровне.
Данная глава посвящена происхождению открытых коммуникаций и тем
концепциям, на которых базируется открытый обмен данными. Кроме того, в ней
представлены две основные модели, превратившие теоретические принципы
открытых коммуникаций в реальность: эталонная модель OSI (Open Systems
Interconnect) и эталонная модель TCP/IP. Эти модели существенно упрощают
понимание логики работы сети за счет ее разделения на функциональные
компоненты, объединенных в уровни. Хорошее знание этих уровней и концепции
открытых коммуникаций формирует основу для более осмысленного изучения
компонентов и областей применения TCP/IP.
Эволюция открытых сетей
В своем первоначальном варианте компьютерные сети представляли собой
системы, позволявшие соединять разнородные компоненты и обладавшие закрытой
архитектурой. Если в доисторические времена до появления персональных
компьютеров какая-либо компания пыталась автоматизировать обработку данных
или бухгалтерский учет, она обращалась к одному поставщику и приобретала
целый аппаратно-программный комплекс, готовый к эксплуатации.
В такой закрытой среде, ориентированной на определенную
фирму-поставщика, прикладные программы работали только в окружении, поддерживаемом
определенной операционной системой. Операционная систем работала только
в контексте безопасности оборудования, предоставленного тем же поставщиком.
Даже терминалы конечных пользователей и средства подключения к
центральному компьютеру были частью того же интегрированного решения,
разработанного конкретным поставщиком.
В эпоху безраздельного царствования интегрированных решений
Министерство обороны осознало необходимость надежной и защищенной от ошибок
коммуникационной сети, которая могла бы объединить все входящие в нее
компьютеры, а также компьютеры университетов, научных центров и
фирм-подрядчиков. На первый взгляд задача кажется не такой уж грандиозной, но это
впечатление обманчиво. На заре компьютерных технологий фирмы-поставщики
разрабатывали комплексы из программных, аппаратных и сетевых компонентов
с очень высокой степенью интеграции. Пользователю, пожелавшему
организовать обмен данными с другой платформой, пришлось бы нелегко. Объяснялось
это очень просто: поставщики Министерства обороны хотели привязать к себе
заказчиков.
Заставить всех субподрядчиков Министерства обороны и связанные с ними
научные организации перейти на единый стандарт оборудования было абсолютно
нереально. Соответственно, возникла необходимость в средствах для соединения
разнородных платформ. Так появился первый протокол открытых
коммуникаций: IP (Internet Protocol).
Таким образом, открытой следует считать сеть, обеспечивающую
взаимодействие и совместное использование ресурсов на разнородных компьютерах.
Открытость достигается посредством объединенной разработки и сопровождения
технических спецификаций. Эти спецификации, также называемые открытыми
стандартами, свободно распространяются и доступны для всех желающих.
Многоуровневая структура коммуникаций
Открытые коммуникации возможны только при четком согласовании всех
функций, необходимых для взаимодействия и обмена данными между двумя
конечными системами. Идентификация этих важнейших функций и установление
порядка их выполнения закладывают основу для открытых коммуникаций. Две
системы смогут взаимодействовать только в том случае, если они договорятся
о том, как будет организовано это взаимодействие. Иначе говоря, они должны
следовать общим правилам получения данных от приложения и их упаковки для
передачи по сети. Никакие подробности, даже второстепенные, не могут считаться
сами собой разумеющимися или зависеть от случайностей.
К счастью, существует более или менее логичная последовательность
событий, необходимых для проведения сеанса связи. В минимальном варианте
необходимо выполнить следующие операции:
О Данные передаются от приложения коммуникационному процессу (также
называемому протоколом),
О Коммуникационный протокол должен подготовить данные приложения для
передачи по сети. Обычно при этом данные разбиваются на сегменты более
удобного размера.
О Сегментированные данные заключаются в служебную структуру данных
{конверт) для передачи по сети заданному устройству (или устройствам).
Дополнительная информация, содержащаяся в этой структуре, должна позволить
любому сетевому вычислительному устройству определить, откуда поступил
конверт и куда он передается. В зависимости от используемого протокола эта
структура может представлять собой кадр, пакет или ячейку.
О Кадры (или пакеты) преобразуются в физическое битовое представление для
передачи. Биты передаются в виде световых импульсов по оптоволоконным
сетям (например, FDDI) или в электронном состоянии (наличие/отсутствие
сигнала) по электронным сетям — например, Ethernet или любой другой сети,
в которой данные передаются в электрическом виде по металлическим
проводам.
В точке приема, то есть на компьютере-получателе, эти действия выполняются
в рбратном порядке.
Во время сеанса связи также может возникнуть необходимость и в других
операциях, координирующих действия отправителя и получателя и обеспечивающих
благополучное прибытие данных. К числу таких операций относятся следующие:
О Регулировка объема передаваемых данных, чтобы предотвратить перегрузку
получателя и/или сети.
Q Проверка целостности полученных данных, в ходе которой получатель
убеждается в том, что данные не были повреждены в процессе передачи.
Проверка осуществляется с использованием контрольных сумм — например, по
алгоритму CRC (Cyclic Redundancy Checksum). Полиномиальный
математический алгоритм вычисления контрольной суммы CRC позволяет
обнаруживать ошибки в передаваемых данных.
О Координация повторной передачи данных, которые либо не прибыли по месту
назначения, либо были получены в поврежденном виде.
О Наконец, получатель данных должен заново собрать сегменты в форму,
распознаваемую приложением-получателем. С точки зрения получателя,
принятые данные должны точно совпадать с данными, отправленными
приложением-отправителем. Иначе говоря, результат должен выглядеть так, словно
данные передаются напрямую между двумя приложениями. Данное свойство
называется логической смежностью.
Вероятно, основные принципы многоуровневых коммуникаций, включая
логическую смежность, лучше всего объяснять на примере эталонной модели OSL
Эталонная модель OSI
Международная организация по стандартизации (ISO, International Organization
for Stanartization) разработала эталонную модель взаимодействия открытых
систем (OSI, Open Systems Interconnection) в 1978/1979 годах для упрощения
открытого взаимодействия компьютерных систем. Открытым называется
взаимодействие, которое может поддерживаться в неоднородных средах, содержащих
системы разных поставщиков. Модель OSI устанавливает глобальный стандарт,
определяющий состав функциональных уровней при открытом взаимодействии
между компьютерами.
Эталонная модель OSI разрабатывалась почти 20 лет назад, и лишь немногие
коммерческие системы следовали ее спецификации. В то время производители
компьютерного оборудования стремились привязать клиентов к
запатентованным архитектурам, поддерживаемым одним поставщиком. С точки зрения
производителей конкуренция была нежелательна. Соответственно, все функции как
можно плотнее интегрировались в готовых решениях. Концепция
функциональной модульности или многоуровневой структуры казалась прямо
противоречащей намерениям любого производителя.
Следует заметить, что модель настолько успешно справилась со своими
исходными целями, что в настоящее время ее достоинства уже практически не
обсуждаются. Существовавший ранее закрытый, интегрированный подход уже
не применяется на практике, в наше время открытость коммуникаций считается
обязательной. Как ни странно, очень немногие продукты полностью
соответствуют стандарту OSI. Вместо этого базовая многоуровневая структура часто
адаптируется к новым стандартам. Тем не менее эталонная модель OSI остается
ценным средством для демонстрации принципов работы сети.
Несмотря на все успехи, с эталонной моделью OSI связан ряд устойчивых
заблуждений, поэтому в этом разделе придется привести ее очередной обзор
с указанием и исправлением этих заблуждений.
Первое заблуждение заключается в том, что эталонная модель OSI была
разработана Мелсдународной организацией стандартов (International Standards
Organization). Это не так. Эталонная модель OSI разрабатывалась Международной
организацией по стандартизации (International Organization for Standartization),
а эта организация предпочитает использовать мнемоническое сокращение
вместо акронима. Мнемоника основана на греческом слове isos, которое означает
«равный» или «стандартный».
Модель OSI разделяет процессы, участвующие в сеансе связи, на семь четко
различающихся функциональных уровней. Структура уровней соответствует
естественной последовательности событий, происходящих во время сеанса связи.
На рис. 1.1 изображена схема эталонной модели OSI. Уровни 1-3
обеспечивают доступ к сети, а уровни 4-7 посвящены логистике поддержки
коммуникаций сквозной передачи.
Уровень Номер
OSI OS1
Прикладной уровень 7
Представительский уровень 6
Сеансовый уровень 5
Транспортный уровень 4
Сетевой уровень 3
Канальный уровень 2
Физический уровень 1
Рис. 1.1. Эталонная модель OSI
1. Физический уровень
Нижний уровень модели называется физическим уровнем (physical layer) и
отвечает за передачу битового потока. Физический уровень получает кадры данных
от уровня 2 (канального уровня) и передает их структуру и содержимое; обычно
передача осуществляется последовательно по одному биту. Физический уровень
также отвечает за побитовый прием входящих потоков данных. Затем этот поток
передается канальному уровню для повторного формирования кадров.
В сущности, физический уровень имеет дело только с нулями и единицами.
Он не обладает механизмом интерпретации передаваемых или получаемых битов.
Все, что его интересует, — это физические характеристики электрических и/или
оптических средств передачи сигнала. В частности, сюда относится напряжение
электрического тока, используемого для передачи сигнала, тип носителя,
характеристики волнового сопротивления и даже физическая форма коннектора,
подключенного к передающей среде.
Основное заблуждение состоит в том, будто уровень 1 модели OSI включает
компоненты, способные генерировать или передавать коммуникационные сигналы.
На самом деле это не так, поскольку уровень 1 является всего лишь
функциональной моделью. Физический уровень ограничивается процессами и механизмами,
необходимыми для подачи сигнала в передающую среду и для приема сигналов
от этой среды. Его нижней границей является физический коннектор,
подключенный к передающей среде. Сама среда в этот уровень не входит, хотя
различные стандарты локальных сетей (LAN, Local Area Network), такие как 10BASET
и 100BASET, указывают тип передающей среды.
Все средства непосредственной передачи сигнала, сгенерированного
механизмами уровня 1 модели OSI, относятся к передающей среде. Среди примеров
передающей среды можно назвать коаксиальные кабели, оптоволоконные
кабели и витую пару. Вероятно, недоразумение обусловлено тем фактом, что
физический уровень определяет некоторые обязательные характеристики, которыми
должна обладать передающая среда для работы процессов и механизмов,
определенных на физическом уровне.
Соответственно, передающая среда остается за пределами физического уровня.
Иногда ее называют нулевым уровнем эталонной модели OSI.
2. Канальный уровень
Второй уровень эталонной модели OSI называется канальным уровнем (data link
layer). Его задачи, как и задачи всех остальных уровней, делятся на две
категории: прием и передача данных. Он отвечает за достоверность переданных
данных, обычно — по физическому каналу
На передающей стороне канальный уровень отвечает за упаковку
инструкций, данных и т. д. в кадры. Кадр (frame) представляет собой структуру данных,
специфическую для канального уровня; эта структура содержит информацию,
достаточную для успешной передачи данных по физическому каналу (например,
по локальной сети) к точке приема.
Успешная доставка означает, что кадр достигает положенного места
назначения без изменений. Следовательно, кадры также должны содержать
информацию для проверки целостности содержимого после доставки.
Гарантированная доставка происходит при выполнении двух условий:
О Узел-отправитель должен получить подтверждение того, что каждый кадр
был принят узлом-получателем без изменений.
О Перед тем как подтверждать прием кадра, узел-получатель должен проверить
целостность его содержимого.
По некоторым причинам переданные кадры могут не достигнуть места
назначения или их содержимое будет искажено и станет непригодным в процессе
передачи. Канальный уровень отвечает за обнаружение и исправление всех подобных
ошибок. Также он отвечает за повторную сборку двоичного потока, полученного
от физического уровня, и формирование кадров. Впрочем, если учесть, что в
кадрах передается как управляющая информация, так и содержимое, канальный
уровень на самом деле не восстанавливает кадры, а просто накапливает
поступающие биты до получения полного кадра.
Уровни 1 и 2 обязательны для всех типов коммуникаций, как в локальных,
так и в глобальных сетях. Как правило, функциональность уровней 1 и 2
реализуется сетевым адаптером, установленным внутри компьютера.
3. Сетевой уровень
Сетевой уровень (network layer) отвечает за установление маршрута между
отправителем и получателем. Этот уровень не располагает собственными средствами
обнаружения/исправления ошибок передачи, поэтому он использует средства
надежной пересылки данных уровня 2. Надежность сквозной передачи данных
по нескольким физическим каналам в большей степени относится к функциям
транспортного уровня (уровень 4).
Сетевой уровень используется для установления связи с компьютерными
системами, не входящими в местный сегмент локальной сети. Это возможно
благодаря его собственной архитектуре маршрутной адресации, независимой от
машинной адресации уровня 2. Подобные протоколы называются
маршрутизируемыми. К этой категории относятся протоколы IP, IPX (компания Novell)
и AppleTalk, хотя в этой книге будет рассматриваться исключительно протокол
IP, а также связанные с ним протоколы и приложения.
Использование сетевого уровня при коммуникациях не обязательно. Сетевой
уровень необходим лишь в том случае, если компьютеры находятся в разных
сегментах сети, разделенных маршрутизатором, или взаимодействующие
приложения должны использовать возможности сетевого или транспортного уровня.
Например, два хоста, напрямую подключенных к одной локальной сети, могут
взаимодействовать, ограничиваясь только механизмами локальной сети (уровни
1 и 2 эталонной модели OSI).
ПРИМЕЧАНИЕ
В наши дни необходимость в соединении сетей возникает так часто, что сетевой уровень уже не
считается необязательным. Работа старых протоколов, не обладающих собственной реализацией
сетевого уровня (например, NetBEUI), в современных сетевых архитектурах обеспечивается как
особый случай.
4. Транспортный уровень
Транспортный уровень (transport layer), как и канальный уровень, отвечает за
целостность передаваемых данных. Тем не менее транспортный уровень
способен выполнять эту функцию за пределами местного сегмента локальной сети.
Он обнаруживает пакеты, отвергнутые маршрутизатором, и автоматически
генерирует запрос на повторную передачу. Другими словами, транспортный уровень
обеспечивает настоящую надежность сквозной передачи.
Другая важная функция транспортного уровня — переупорядочивание
пакетов, поступивших с нарушением исходной последовательности. Нарушение
может происходить по разным причинам — например, из-за того, что пакеты
перемещались в сети по разным маршрутам или были повреждены в процессе
пересылки. Так или иначе, транспортный уровень способен определить
исходную последовательность пакетов и расположить их в этой последовательности
перед тем, как передавать их содержимое сеансовому уровню.
5. Сеансовый уровень
Пятое место в модели OSI занимает сеансовый уровень (session layer). Он
используется относительно редко, многие протоколы реализуют его функциональные
возможности на своих транспортных уровнях.
Основная функция сеансового уровня OSI — организация сеанса, то есть
передачи управления во время связи двух компьютерных систем. Сеанс
определяет направленность передачи данных (одно- или двусторонняя), а также
гарантирует завершение обработки одного запроса до принятия следующего.
Сеансовый уровень также может поддерживать некоторые из следующих
дополнений:
О Управление диалогом.
О Управление маркерами.
О Управление операциями.
В общем случае сеанс поддерживает двусторонний (дуплексный) режим обмена
данными. В некоторых приложениях вместо него может понадобиться
односторонний (полудуплексный) режим обмена. Сеансовый уровень позволяет выбрать
нужный режим, и эта возможность называется управлением диалогом.
Для работы некоторых протоколов очень важно, чтобы в любой момент
времени попытки выполнения критических операций могли выполняться только
одной из сторон. Чтобы обе стороны не пытались одновременно выполнить одну
и ту же операцию, необходимо реализовать специальный механизм
управления — например, основанный на использовании маркеров (tokens). В этом
случае выполнение операции разрешается только той стороне, которую в
настоящий момент удерживает маркер. Определение того, на какой стороне находится
маркер и как он передается между двумя сторонами, называется управлением
маркером. Функции управления маркером используются в протоколах
сеансового уровня ISO.
ПРИМЕЧАНИЕ
Не путайте термин «маркер» с похожим термином, существующим в архитектуре Token Ring.
Управление маркером на уровне 5 модели OSI происходит на значительно более высоком уровне.
Архитектура IBM Token Ring работает на 1 и 2 уровнях модели OSI.
Если передача файла между двумя компьютерами занимает один час, а
сетевые сбои происходят примерно каждые 30 минут, скорее всего, переслать файл
вообще никогда не удастся. После каждого аварийного завершения пересылку
приходится начинать заново. Для решения этой проблемы вся пересылка файла
рассматривается как одна операция, а в поток данных вставляются контрольные
точки. В этом случае при возникновении сбоя сеансовый уровень может
продолжить пересылку данных с предыдущей контрольной точки. Эти контрольные
точки называются точками синхронизации.
Точки синхронизации делятся на первичные и вторичные. Первичные точки
синхронизации, вставленные в поток данных любой из взаимодействующих
сторон, должны подтверждаться другой стороной, тогда как вторичные точки
синхронизации подтверждения не требуют. Часть сеанса между двумя первичными
точками синхронизации называется диалоговым блоком, а управление всем
процессом называется управлением операциями. Операция состоит из одного или
нескольких диалоговых блоков.
В сетях TCP/IP отсутствует общий протокол сеансового уровня. Это
объясняется тем, что некоторые характеристики сеансового уровня обеспечиваются
протоколом TCP. Если приложениям TCP/IP потребуются специальные
возможности сеансового уровня, они должны реализовать их самостоятельно. Например,
файловая система NFS (Network File System) самостоятельно реализует сервис
сеансового уровня — протокол RPC (Remote Procedure Call).
ПРИМЕЧАНИЕ
Протокол NFS также использует собственный сервис сеансового уровня — протокол XDR (External
Data Representation).
6. Представительский уровень
Представительский уровень (Presentation Layer) отвечает за управление
кодировкой данных. Во многих компьютерных системах используются разные
схемы кодировки, и представительский уровень должен обеспечить преобразование
между несовместимыми кодировками — такими, как ASCII (American Standard
Code for Information Interchange) и EBCDIC (Extended Binary Coded Decimal
Interchange Code).
Представительский уровень также может использоваться в качестве
промежуточного звена, обеспечивающего преобразование между форматами
представления вещественных чисел, числовыми форматами (например, поразрядным
дополнением до единицы или двойки), порядком следования байтов, а также
предоставляющего возможности шифрования/дешифрования данных.
Представительский уровень обеспечивает представление данных с единым
синтаксисом и семантикой. Если все узлы будут использовать этот общий язык
и понимать его, это предотвратит возможную неправильную интерпретацию
представления данных. Примером такого общего языка является рекомендуемый
OSI язык ASN.l (Abstract Syntax Representation, Rev.l). Кстати говоря, ASN.l
используется протоколом SNMP (Simple Network Management Protocol) для
кодирования данных высокого уровня.
7. Прикладной уровень
На самом верху эталонной модели OSI находится прикладной уровень (application
level). Несмотря на свое название, этот уровень не включает в себя
пользовательские приложения, а лишь обеспечивает взаимодействие этих приложений
с сетевым сервисом.
Этот уровень может рассматриваться как сторона, непосредственно
инициирующая сеанс связи. Предположим, почтовый клиент должен запросить новые
сообщения с почтового сервера. Клиентское приложение автоматически
генерирует запрос к соответствующему протоколу (или протоколам) 7 уровня и
инициирует сеанс связи для получения нужных файлов.
Использование модели
Вертикальное расположение уровней отражает функциональную структуру
процессов и данных, участвующих в передаче. Каждый уровень связывается со
смежными уровнями через интерфейсы. Связь между системами
обеспечивается передачей данных, инструкций, адресов и т. д. между уровнями. Различия
между логической и фактической последовательностю передачей управления во
время сеанса связи показаны на рис. 1.2.
ПРИМЕЧАНИЕ
Хотя эталонная модель состоит из семи уровней, это не означает, что все уровни задействованы
в каждом сеансе связи. Например, обмен данными через один сегмент локальной сети может
производиться исключительно на уровнях 1 и 2, без участия других уровней.
Номер Уровень Уровень Номер
OSI OSI OSI OSI
7 Прикладной уровень Прикладной уровень 7
I 6 I Представительский уровень 1 логическая Представительский уровень I 6
5 Сеансовый уровень передача Сеансовый уровень Т 5
управления —
4 к Транспортный уровень м* hV Транспортный уровень \а 4
3 \ Сетевой уровень Сетевой уровень I/ 3
2 I \ Канальный уровень Канальный уровень /1 2
1 \ Физический уровень Физический уровень / I 1
I 1 ^ 1 I :_ ^—I 1
\
Ч
Хх Фактическая у'
х"^^ передача ^~''
*^-^ управления ^-'''
Рис. 1.2. Логическая и фактическая последовательность передачи
управления в многоуровневой коммуникационной модели
Хотя управление передается по вертикали, каждый уровень воспринимает
это так, словно он может напрямую взаимодействовать со своим аналогом на
удаленном компьютере. Чтобы создать логическую смежность уровней, каждый
уровень стека протоколов компьютера-отправителя добавляет свой заголовок,
который распознается и используется только этим уровнем или его аналогами
на других компьютерах. Стек протоколов компьютера-получателя
последовательно извлекает заголовки по уровням в процессе передачи данных приложению.
Этот процесс проиллюстрирован на рис. 1.3.
Например, сегменты данных упаковываются уровнем 4 компьютера-отправителя
для передачи уровню 3. Уровень 3 преобразует данные, полученные от уровня 4,
в пакеты, снабжает адресами и отправляет протоколу уровня 3
компьютера-получателя через свой уровень 2. Уровень 2 преобразует пакеты в кадры, снабженные
адресами, распознаваемыми локальной сетью. Кадры передаются уровню 1 для
преобразования в поток двоичных цифр (битов), передаваемых уровню 1 получателя.
На компьютере-получателе эта цепочка повторяется в обратном порядке, при
этом каждый уровень удаляет заголовки, добавленные аналогичными уровнями
на компьютере-отправителе. К тому моменту, когда данные достигнут уровня 4,
они имеют ту же форму, в которой они были представлены на уровне 4
отправителя. Соответственно, результат выглядит так, словно два протокола 4 уровня
являются физически смежными и обмениваются данными напрямую.
ПРИМЕЧАНИЕ
Следует учитывать, что многие современные сетевые протоколы используют собственные
многоуровневые модели. Эти модели различаются по степени соответствия стандартам разделения
функций, заявленным в эталонной модели OSI. Довольно часто эти модели объединяют семь
уровней OSI в пять и менее уровней. Кроме того, верхние уровни иерархий часто не соответствуют
в полной мере своим аналогам в модели OSI.
р71+рт| \ "*™»** 7 РтКРт]
I Data I J Hdr. | \ уровень / | Hdr. | | Data |
I Data J Hdr. J | Hdr. | \ W*** / | Hdr. | | Hdr. | Data |
I Layer I Layer I Layer I I Layer I \ rw*»^ / Г^*1 I Layer I Layer | Layer I
776 + 5 \ \^eT / 5 Г в 7 7
I Data J Hdr. [ Hdr. | | Hdr. | \ урмвнь / | Hdr. | | Hdr. | Hdr. | Data |
I Layer I Layer I Layer I layer I I Layer I \ т™шг™гт-^ / I 1дУвг I HwTlayeTTl^TlayeTl
7765 + 4 \ «ранспоршыи /4 + 5677
I Data I Hdr. I Hdr. J Hdr. | | Hdr. | \ уровень / | Hdr | | Hdr. | Hdr. | Hdr. | Data |
I Layer I Layer I Layer I Layer I Layer I I Layer I \ гшпш* /I layer I I Layer I Layer I Layer I Layer I Layer I
7 7 6 5 4 + 3 \ «^ / 3 + 4 5 6 7 7
| Data I Hdr. I Hdr. J Hdr. | Hdr. [ | Data | \ ypoeeHb / | Hdr. | | Hdr. | Hdr. | Hdr. | Hdr. | Data |
I Layer I layer I layer I layer I Layer I layer I [ Layer |\ йцапьмый A l*l&\ I Layer] Layer I Layer I layer I Layer I Layer I
7 7 I 6 5 I 4 3 + 2 \ \~~*ь / 2 + 345677
I Data J Hdr. J Hdr. | Hdr. J Hdr. J Hdr. | | Data | \ wuacno/ | Hdr. | | Hdr. | Hdr. | Hdr. | Hdr. | Hdr. | Data |
------ ------------- ---- -----^^--J^------------------------
layer Layer Layer Layer Layer Layer Layer Layer физи- Layer layer Layer Layer Layer layer layer Layer
7765432 И1 веский 1М2345677
I Data J Hdr. J Hdr. | Hdr. | Hdr. | Hdr. | Hdr. | | Data | ypo- | Hdr. | | Data | Hdr. | Hdr. | Hdr. | Hdr. | Hdr. | Data |
Рис. 1.З. Применение многоуровневых заголовков для поддержки
логической смежности уровней
На самом деле уровень 3 передает данные «вниз» уровню 2, который, в свою
очередь, преобразует кадры в битовый поток. После того как битовый поток
поступает устройству уровня 1 получателя, он передается уровню 2 для
повторного формирования кадров. После успешного завершения приема кадра
служебные данные удаляются, а хранящийся в кадре пакет передается уровню 3
получателя. Информация поступает точно в таком же виде, в котором она была
отправлена. С точки зрения уровня 3 передача данных производилась
фактически напрямую.
Возможность обмена данными между смежными уровнями (с точки зрения
этих уровней) стала одним из факторов, обусловивших успех модели.
Хотя эталонная модель OSI изначально предназначалась для определения
архитектуры протоколов открытых коммуникаций, в этом качестве ее ждал
бесславный провал. В сущности, модель почти полностью выродилась в
академическую абстракцию. Но зато эта модель великолепно подходит для
объяснения концепций открытых коммуникаций и логической последовательности
выполнения необходимых действий в сеансе связи. Для практических целей
существует другая, гораздо более содержательная модель — эталонная модель
TCP/IP. Она описывает архитектуру семейства протоколов IP, являющихся
основной темой настоящей книги.
Эталонная модель TCP/IP
В отличие от эталонной модели OSI, модель TCP/IP в большей степени
ориентируется на обеспечение сетевых взаимодействий, нежели на жесткое разделение
функциональных уровней. Для этой цели она признает важность иерархической
структуры функций, но предоставляет проектировщикам протоколов
достаточную гибкость в реализации. Соответственно, эталонная модель OSI гораздо
лучше подходит для объяснения механики межкомпьютерных взаимодействий, но
протокол TCP/IP стал основным межсетевым протоколом.
Гибкость эталонной модели TCP/IP по сравнению с эталонной моделью OSI
продемонстрирована на рис. 1.4.
Уровень I Номер I Эквивалентный
OSI | OSI J уровень TCP/IP
Прикладной уровень I 7 I
Прикладной
Представительский уровень б уровень
Сеансовый уровень 5
Межхостовой
Транспортный уровень 4 уровень
Сетевой уровень 3 Межсетевой уровень
Канальный уровень 2 Уровень сетевого
т : доступа
Физический уровень 1
Рис. 1.4. Сравнение эталонных моделей TCP/IP и OSI
Эталонная модель TCP/IP разрабатывалась значительно позже описываемого
ей протокола и отличается значительно большей гибкостью, чем модель OSI,
поскольку она в большей степени подчеркивает иерархическое расположение
функций вместо жесткого определения функциональных уровней.
Анатомия модели TCP/IP
Стек протоколов TCP/IP состоит из четырех функциональных уровней:
прикладного, межхостового, межсетевого и уровня сетевого доступа. Эти четыре
уровня приблизительно соответствуют семи уровням эталонной модели OSI с
сохранением общей функциональности.
Прикладной уровень
Прикладной уровень содержит протоколы удаленного доступа и совместного
использования ресурсов. Хорошо знакомые нам приложения — такие, как Telnet,
FTP, SMTP, HTTP и многие другие — работают на этом уровне и зависят от
функциональности уровней, расположенных ниже в иерархии. Любые
приложения, использующие взаимодействие в сетях IP (включая любительские и
коммерческие программы), относятся к этому уровню модели.
Межхостовой уровень
Межхостовой уровень IP приблизительно соответствует сеансовому и
транспортному уровням эталонной модели OSI. К функциям этого уровня относится
сегментирование данных в приложениях для пересылки по сети, выполнение
математических проверок целостности принятых данных и мультиплексирование
потоков данных (как передаваемых, так и принимаемых) для нескольких
приложений одновременно. Отсюда следует, что межхостовой уровень располагает
средствами идентификации приложений и умеет переупорядочивать данные,
принятые не в том порядке.
В настоящее время межхостовой уровень состоит из двух протоколов:
протокола управления передачей TCP (Transmission Control Protocol) и протокола
пользовательских дейтаграмм UDP (User Datagram Protocol). С учетом того, что
Интернет становится все более транзакционно-ориентированным, был
определен третий протокол, условно названный протоколом управления
транзакциями/передачей Т/ТСР (Transaction/Transmission Control Protocol). Тем не менее
в большинстве прикладных сервисов Интернета на межхостовом уровне
используются протоколы TCP и UDP.
Межсетевой уровень
Межсетевой уровень IPv4 состоит из всех протоколов и процедур,
позволяющих потоку данных между хостами проходить по нескольким сетям.
Следовательно, пакеты, в которых передаются данные, должны быть
маршрутизируемыми. За маршрутизируемое™ пакетов отвечает протокол IP (Internet Protocol).
Впрочем, функциональность межсетевого уровня не ограничивается
формированием пакетов. Уровень должен обладать средствами преобразования
адресов уровня 2 в адреса уровня 3, и наоборот. Эти функции обеспечиваются
одноранговыми (peer-to-peer) протоколами, описанными в главе 5.
Кроме того, межсетевой уровень должен поддерживать маршрутизацию и
функции управления маршрутами. Эти функции предоставляются внешними
протоколами, которые называются протоколами маршрутизации. К их числу
относятся протоколы IGP (Interior Gateway Protocols) и EGP (Exterior Gateway
Protocols). Хотя эти протоколы также находятся на межсетевом уровне, они не
являются «родными» протоколами семейства IP. Следует отметить, что многие
протоколы маршрутизации позволяют обнаруживать и строить маршруты в
архитектурах, использующих адресацию с несколькими протоколами маршрутизации.
Другими примерами протоколов маршрутизации с разными архитектурами
адресации являются IPX и AppleTalk.
Уровень сетевого доступа
Уровень сетевого доступа состоит из всех функций, необходимых для
физического подключения и передачи данных по сети. В эталонной модели OSI этот
набор функций разбит на два уровня: физический и канальный. Эталонная
модель TCP/IP создавалась после протоколов, присутствующих в ее названии,
и в ней эти два уровня были слиты воедино, поскольку различные протоколы
IP останавливаются на межсетевом уровне. Протокол IP предполагает, что все
низкоуровневые функции предоставляются либо локальной сетью, либо
подключением через последовательный интерфейс.
Итоги
Представленные в этой главе основные концепции сетей, их функции и даже их
возможные применения — всего лишь начало; эти «строительные блоки» будут
гораздо более подробно рассмотрены в книге. А эта глава всего лишь дает
читателю представление о некоторых основополагающих терминах и концепциях
открытых сетевых коммуникаций.
В главе 2 более подробно освещается роль TCP/IP в Интернете и
рассматриваются различные механизмы, благодаря которым TCP/IP по-прежнему
остается актуальным. Эталонные модели OSI и TCP/IP будут неоднократно
упоминаться в книге.
^ TCP/IP и Интернет
Нил Джеймисон (Neal S.Jamison)
Благодаря протоколу TCP/IP Интернет стал тем, чем он является сегодня. В
результате Интернет произвел в нашем стиле жизни и работы почти такие же
революционные изменения, как печатный станок, электричество или компьютер.
Настоящая глава посвящена истории Интернета, его попечителям и
перспективам будущего развития. В ней рассматривается процесс превращения идей
в стандарты, а также кратко представлены некоторые популярные протоколы
и службы, в том числе Telnet и HTTP.
История Интернета
История Интернета начинается с незапамятных времен. Рисунки на стенах
пещер, дымовые сигналы, голубиная почта — все эти виды связи наводили
наших предков на мысль, что должны существовать более совершенные способы.
Затем появился телеграф, телефон и трансатлантическая беспроводная связь...
и это уже было на что-то похоже. Потом были изобретены первые компьютеры —
громадные устройства, выделяющие уйму тепла. По своей вычислительной
мощности они уступали любому современному карманному калькулятору,
однако эти гиганты помогали выигрывать войны и использовались при переписи
населения. Впрочем, их было очень мало, никто не мог себе купить личный
компьютер и уж тем более — установить его дома.
В 1960-х годах на смену электронным лампам пришли транзисторы, размеры
и стоимость компьютеров начали падать, а интеллект и вычислительная мощность
этих машин стали расти. В это время группа ученых уже начала работать над
проблемой взаимодействия компьютеров. Леонард Клейнрок (Leonard Kleinrock),
в те времена аспирант MIT, предложил концепцию технологии коммутации
пакетов и опубликовал статью на эту тему в 1961 году. Тогда же Управление
перспективного планирования научно-исследовательских работ ARPA (Advanced
Research Project Agency) разрабатывало для себя (и для военных) новую систему
связи, и работа Клейнрока дала необходимый импульс. ARPA объявило конкурс
на создание первой сети с пакетной коммутацией. Контракт достался небольшой
фирме BBN (Bolt Beranek and Newman) из Массачусетса, занимавшейся
акустикой. Так родилась сеть ARPANET. Это произошло в 1969 году.
ARPANET
Исходная сеть ARPANET состояла всего из четырех хостов — по одному в
Калифорнийском университете Лос-Анджелеса, в Стэнфордском
научно-исследовательском институте, в университете Санта-Барбары и университете штата Юта.
Эта маленькая сеть на базе протокола NCP (Network Control Protocol) позволяла
своим пользователям регистрироваться на удаленных хостах, осуществлять
печать на удаленном принтере и передавать файлы. В 1971 году Рэй Томлинсон
(Ray Tomlinson), инженер из BBN, написал первую программу для работы с
электронной почтой.
TCP/IP
В 1974 году, всего через пять лет после рождения ARPANET, Винтон Серф
(Vinton Cerf) и Роберт Кан (Robert Kahn) разработали протокол управления
передачей TCP (Transmission Control Protocol). В начале 1980-х годов протокол
TCP/IP, спроектированный с расчетом на независимость от базового
компьютера и сети, заменил ограниченный протокол NCP, что позволило организовать
взаимодействие с другими разнородными ARPANET-подобными сетями (интер-
нетами). Так родился Интернет.
ПРИМЕЧАНИЕ
Термин «интернет» (со строчной буквы «и») обозначает сеть, состоящую из разнородных
компьютеров. Интернет (с прописной буквы «И») — ТА САМАЯ Сеть, объединяющая миллионы
компьютеров и пользователей.
Распространению TCP/IP способствовало Министерство обороны, которое
выбрало TCP/IP своим стандартным протоколом и потребовало его
обязательного использования фирмами-подрядчиками. Примерно в то же время
разработчики из Калифорнийского университета (Беркли) выпустили новую
разновидность операционной системы Unix, 4.2BSD (Berkeley Software Distribution),
которая распространялась бесплатно. Этот факт благотворно отразился на
протоколе TCP/IP, плотно интегрированном с 4.2BSD. Версия BSD Unix была
заложена в основу других систем семейства Unix, что объясняет господство TCP/IP
в мире Unix.
Протокол TCP/IP обеспечил надежность связи, необходимую для
начального развития Интернета, а ученые и инженеры начали включать в семейство
TCP/IP новые протоколы и приложения. FTP, Telnet и SMTP
поддерживались с самого начала. К числу новых пополнений семейства TCP/IP
относятся ШАР (Internet Mail Access Protocol), POP (Post Office Protocol) и,
конечно, HTTP.
NSF
Исключительно важная роль в становлении Интернета также принадлежит сети
NSFNet. Национальный научный фонд NSF (National Science Foundation)
оценил важность работ по созданию ARPANET и решил создать собственную сеть.
Сеть NSFNet соединяла несколько суперкомпьютеров, установленных в
университетах и правительственных учреждениях. Популярность сети росла, и в NSF
решили увеличить ее возможности за счет модернизации магистральных
каналов связи. Сеть NFSNet начиналась с линий со скоростью 56 кбит/с, перешла
на линии Т-1 A,544 Мбит/с), затем на Т-3 D3 Мбит/с) и вскоре стала самым
быстрым интернетом того времени.
На этом временном отрезке также создавались и другие сети, в том числе
BITNET (Because It's Time Network) и CSNET (Computer Science Research
Network). Сеть ARPANET продолжала расти невероятными темпами, с удвоением
количества хостов за каждый год.
В конце 1980-х и начале 1990-х годов сеть NFSNet заменила старую и более
медленную сеть ARPANET и стала официальной опорной сетью Интернета.
Интернет сегодня
В 1992 году Европейская организация ядерных исследований CERN (Conseil
Europeen pour la Recherche Nucleaire) и Тим Бернерс-Ли (Tim Berners-Lee)
выдвинули концепцию «Всемирной паутины» WWW (World Wide Web). Через
год была выпущена клиентская программа WWW, которая называлась Mosaic.
Эти два события превратили Интернет из текстовой среды, использовавшейся
преимущественно учеными и студентами, в графическую среду, которая сегодня
используется многими миллионами людей.
В апреле 1995 года сеть NFSNet была заменена более современной,
коммерческой опорной сетью. В результате ограничения на подключения к хостам в
Интернете были снижены и появился совершенно новый тип пользователей —
коммерческий пользователь.
Протокол РРР (Point-to-Point Protocol) был создан в 1994 году, а в 1995 году
он получил повсеместное распространение. РРР позволял использовать TCP/IP
в телефонных линиях, что облегчало доступ в Интернет для домашних
пользователей. В то же время стали появляться поставщики услуг Интернета (ISP, Internet
Service Providers), которые обеспечивали подключение к Интернету домашних
пользователей и организаций. Это привело к бурному росту количества
домашних пользователей.
Интернет развивался (и продолжает развиваться!) ошеломляющими
темпами — до 100 процентов в год.
В наши дни даже поверхностное знакомство с WWW наглядно показывает
важность эволюции Интернета. Использование Интернета вышло за рамки
академических и оборонных коммуникаций и научных исследований. Сейчас в
Интернете можно покупать товары и выполнять банковские операции, a Web откры-
вает доступ к всевозможной информации, от кулинарных рецептов до текстов
книг. Перспективы использования Интернета безграничны.
RFC и процесс стандартизации
В процессе эволюции Интернета новые идеи и комментарии представлялись
в виде документов, называемых запросами на комментарии, или RFC (Requests
for Comments). В этих документах обсуждаются многие аспекты коммуникаций,
связанных с Интернетом. Первый документ RFC (RFC 1) назывался «Host
Software» и был написан в апреле 1969 года Стивом Крокером (Steve Crocker),
аспирантом Калифорнийского университета в Лос-Анджелесе и автором восьми
из первых 25 RFC. Тексты первых RFC чрезвычайно интересны для всех, кто
интересуется историей Интернета. Спецификации протоколов Интернета,
определяемые IETF и IESG, также публикуются в форме RFC.
Редактором RFC называется лицо, публикующее RFC и отвечающее за
окончательное рецензирование документов. Роль редактора обсуждается ниже в этой
главе.
Хорошим источником информации обо всех типах RFC является сайт http://
www.rfc-editor.org/.
ПРИМЕЧАНИЕ
Джон Постел (Jon Postel) внес важный вклад в создание ARPANET, а следовательно, и в создание
Интернета. Он участвовал в создании системы доменных имен Интернета и в течение многих
лет занимался ее администрированием; эта система продолжает использоваться и сейчас. Джон
возглавлял Агентство по выделению имен и параметров протоколов Интернета IANA (Internet
Assigned Numbers Authority) и был редактором RFC. Джон скончался в октябре 1998 года. Его
памяти был посвящен RFC 2468 (Винтон Серф, октябрь 1998 года).
Документы RFC являются основным средством распространения новых идей
в области протоколов, исследований и стандартов. Если исследователь хочет
предложить новый протокол, научную работу или учебник по некоторой теме,
он оформляет их в виде документа RFC. Таким образом, к числу RFC
принадлежат описания стандартов Интернета, предложения по пересмотру старых и
внедрению новых протоколов, описания стратегий реализации, учебники, сборники
полезной информации и т. д.
Протоколы, которым суждено стать стандартами Интернета, проходят
несколько стадий в соответствии со степенью завершенности: предложенный
стандарт, проект стандарта и стандарт. По мере развития стандарта объемы
аналитических и тестовых данных растут. После завершения этого процесса протоколу
присваивается определенное число STD, то есть номер нового стандарта.
По мере совершенствования технологий некоторые протоколы заменяются
своими улучшенными версиями или перестают использоваться. Такие протоколы
помечаются как «исторические» («historic»). В некоторых RFC документируются
результаты анализа и разработки новых протоколов, которые помечаются как
«экспериментальные» («experimental»).
Протоколы, разработанные другими стандартизирующими организациями,
конкретными фирмами-поставщиками или частными лицами, также могут
представлять интерес и рекомендоваться для применения в Интернете.
Спецификации таких протоколов также публикуются в виде RFC для удобства и простоты
распространения в Интернет-сообществе. Такие протоколы помечаются как
«информационные» («informational»).
Иногда протоколы получают широкое распространение без одобрения или
участия IESG. В частности, это может быть связано с эволюцией протоколов
по маркетинговым или политическим причинам. Некоторые из этих
протоколов даже начинают играть важную роль в Интернет-сообществе, поскольку
коммерческие организации используют их в своих интрасетях. Согласно
официальной позиции IAB, при эволюции протоколов рекомендуется
использовать процесс стандартизации; тем самым обеспечивается максимальный
уровень совместимости и предотвращается возникновение конфликтных
требований к протоколам.
Не все протоколы должны быть обязательно реализованы во всех системах,
потому что из-за огромного разнообразия существующих систем в некоторых
случаях реализация протоколов не имеет смысла. Например, к таким
устройствам Интернета, как шлюзы, маршрутизаторы, терминальные серверы, рабочие
станции и многопользовательские хосты, предъявляются совершенно разные
требования. Не для всех из них нужны одни и те же протоколы.
Источники информации о RFC
Тексты RFC хранятся в нескольких архивах. Возможно, поиски следует
начинать с индекса RFC. Список индексов приведен в следующем разделе.
Существует несколько способов получения RFC: Web, FTP, Telnet и даже
электронная почта. В табл. 2.1 перечислены некоторые архивы RFC, доступные
через FTP.
Таблица 2.1. Архивы RFC, доступные через FTP
Сайт Имя/Пароль/Каталог
ftp.isi.edu anonymous/name@host.domain/in-notes
wuarchive.wustl.edu anonymous/name@host.domain/doc/rfc
Некоторые архивы также рассылают RFC по электронной почте. Например,
вы можете отправить сообщение по адресу nis-info@nis.nsf.net с пустой строкой
темы и текстом «send rfcnnnn.txt», где пппп — номер нужного RFC.
Как и следовало предполагать, многие архивы также предоставляют доступ
к документам через Web. Если вы захотите воспользоваться этой возможностью,
поиски можно начать с сайта http://www.rfc-editor.org.
За дополнительной информацией о получении RFC обращайтесь по адресу
http://www.isi.edu/in-notes/rfc-retrieval.txt.
Индексы RFC
Полный индекс документов RFC занимает слишком много места, чтобы
приводить его здесь. Впрочем, в Web представлены индексы в форматах ASCII, HTML
и в специальном поисковом формате. Ниже перечислены некоторые примеры:
О Текстовый формат: ftp://ftp.isi.edu/in-notes/rfc-index.txt.
О HTML: ftp://ftpeng.cisco.com/fred/rfc-index/rfc.html.
О HTML by Protocol: http://www.garlic.com/~lynn/rfcprot.htm.
По адресу http://www.rfc-editor.org/rfcsearch.html находится поисковый
механизм RFC.
Краткое знакомство со службами Интернета
Без популярных протоколов и служб — таких, как HTTP, SMTP и FTP —
Интернет был бы просто большим количеством компьютеров, связанных в
бесполезный клубок. В этом разделе кратко описаны самые распространенные (и самые
полезные) протоколы Интернета со ссылками на главы, в которых вы найдете
дополнительную информацию.
Whois и Finger
Служба и протокол Whois предназначены для получения информации о хостах
и доменах Интернета. Обращаясь с запросом к любому из серверов баз данных
Whois, клиенты Whois могут получить разнообразные сведения — контактные
данные узлов и доменов, географические адреса и т. д. Whois используется в
некоторых организациях (особенно в университетах) в качестве электронного
каталога персонала.
Whois находится на хорошо известном порте TCP с номером 43. Подробное
описание приведено в RFC 954.
Служба/протокол Finger предназначены для сбора информации о пользователе
Интернета. В частности, вы можете узнать адрес электронной почты
пользователя, определить, имеются ли у него непрочитанные сообщения и подключен
ли он к Интернету в данный момент, и даже получить частичную информацию
о том, над чем он в данный момент работает. Ввиду специфики этой службы
некоторые администраторы предпочитают отключать ее на своих хостах. Finger
ведет прослушивание на порту TCP с номером 79, а подробное описание
приведено в RFC 1288.
За дополнительной информацией об этих службах обращайтесь к главе 29.
FTP
Служба/протокол FTP (File Transfer Protocol) обеспечивает пересылку файлов
по Интернету. Протокол FTP также относится к числу ранних протоколов, он
появился еще в 1971 году. В наше время FTP повсеместно используется для
предоставления открытого доступа к файлам (через анонимный вход).
Протокол FTP работает на хорошо известных портах TCP с номерами 20 и 21.
Подробное описание приведено в RFC 959.
За дополнительной информацией о FTP и других протоколах пересылки
файлов обращайтесь к главе 30.
Telnet
Программа Telnet предназначена для эмуляции терминала в Интернете. Проще
говоря, Telnet позволяет регистрироваться на удаленных хостах, не беспокоясь
о совместимости терминалов. Telnet также принадлежит к числу самых первых
протоколов и служб раннего Интернета (см. RFC 15). Telnet работает на хорошо
известном порте TCP с номером 23. Подробное описание приведено в RFC 854.
За дополнительной информацией о Telnet обращайтесь к главе 31.
Электронная почта
Протокол SMTP (Simple Mail Transfer Protocol) определяет Интернет-стандарт
для работы с электронной почтой. Многие пользователи ежедневно используют
этот протокол, даже не осознавая этого. SMTP дополняется другими протоколами
и службами (такими, как РОРЗ и ШАР4), позволяющими выполнять операции
с сообщениями на почтовом сервере и загружать их на локальный компьютер
для чтения. Протокол SMTP работает на хорошо известном порте TCP с
номером 25. Подробное описание приведено в RFC 821.
За дополнительной информацией о SMTP, а также других протоколах и
службах для работы с электронной почтой обращайтесь к главе 35.
World Wide Web
Протокол HTTP заложен в основу работы World Wide Web. В сущности, именно
HTTP принадлежит основная заслуга в бурном развитии Интернета в
середине 1990-х годов. Сначала появились первые клиенты HTTP (такие, как Mosaic
и Netscape), которые позволяли наглядно «увидеть» Web. Вскоре стали
появляться web-серверы с полезной информацией. В наше время в Интернете
существует более шести миллионов web-сайтов, работающих на базе HTTP.
Протокол HTTP работает на хорошо известном порте TCP с номером 80, а подробное
описание его текущей версии, HTTP/1.1, приведено в RFC 2616.
За дополнительной информацией о HTTP, а также других протоколах и
службах для работы в Web обращайтесь к главе 36.
Usenet
Служба/протокол NNTP (Network News Transfer Protocol) обеспечивает
публикацию, прием и пересылку новостей Usenet. Несомненно, Usenet — явление
историческое. Это доска объявлений в масштабе Интернета, состоящая из конфе-
ренций (newsgroups) — форумов, в которых обсуждаются всевозможные темы.
Протокол NNTP работает на хорошо известном порте TCP с номером 119, а его
подробное описание приведено в RFC 977.
За дополнительной информацией о NNTP обращайтесь к главе 31.
Интрасети и экстрасети
После произошедшей в 1991 году коммерциализации Интернета корпорации
довольно быстро открыли новые возможности использования Интернета, его
служб и технологий для экономии времени и денег, а также для получения
стратегических преимуществ. Одним из самых масштабных применений этой
технологии в наши дни стали интрасети.
Интрасети
Интрасетью (intranet) называется корпоративная локальная сеть, в которой
основным коммуникационным протоколом является TCP/IP. Прикладные службы
интрасетей основаны на стандартных службах Интернета — HTTP, FTP, TELNET,
SSH и т. д.
Проще говоря, интрасеть представляет собой конечную, замкнутую сеть,
использующую технологии Интернета для совместного использования данных.
Интрасеть может быть подключена к Интернету с установлением контрольных
механизмов, предотвращающих несанкционированный доступ. Впрочем,
интрасеть может вообще не иметь выхода в Интернет.
Преимущества интрасетей
Корпоративные интрасети обладают многими преимуществами. Относительно
низкая стоимость реализации и сопровождения обеспечивает компаниям очень
высокий уровень прибыли на инвестированный капитал. Среди основных
преимуществ интрасетей стоит выделить следующие:
О Интрасети просты в использовании. Пользовательский интерфейс
интрасетей основан на обычном web-браузере, поэтому затраты на обучение
персонала близки к нулю.
О Интрасети упрощают доступ работников к информации. Интрасети позволяют
чрезвычайно эффективно организовать доступ работников к необходимой
информации, будь то одностраничный служебный меморандум или 500-стра-
ничный телефонный справочник.
О Интрасети снижают затраты на подготовку печатных материалов.
Распространение информации в крупной компании или организации традиционно
считалось не только организационно сложной, но и очень дорогой задачей.
О Интрасети расширяют возможности традиционных документов. Найти имя
или название товара в бумажном справочнике или каталоге не так уж сложно,
однако этот процесс часто бывает утомительным и занимающим много
времени.
О Интрасети повышают актуальность данных. После вывода на печать
документ может устареть. Таким образом, возникает опасность распространения
копий устаревших и, возможно, — недостоверных документов.
Приведенный список не исчерпывает всех преимуществ интрасетей.
Компании, установившие у себя интрасети, открыли для себя гораздо больше новых
возможностей, чем перечислено выше. А при использовании таких
Интернет-технологий и служб, как браузеры и web-серверы с открытыми исходными текстами,
все эти преимущества удается реализовать с относительно низкими затратами.
Области применения интрасетей
Возможности применения интрасетей, повышающие эффективность и
производительность труда в организациях, практически безграничны. Ниже перечислены
некоторые популярные области применения интрасетевых технологий.
О Управление кадрами. Многие компании распространяют объявления о
вакансиях, ведут базы данных с информацией о сотрудниках, распространяют
всевозможные документы вроде анкет, табельных листков, отчетов о затратах
и даже уведомлений о перечислении зарплаты на счет — и все это делается
при помощи интрасетей.
О Управление проектами. Руководители проектов могут просматривать и
обновлять электронные таблицы и графики Гантта, опубликованные в интрасети.
Отчеты о состоянии проекта тоже могут публиковаться в интрасети для их
просмотра и рецензирования руководителями.
О Инвентаризационный учет. Публикация инвентарных баз данных в
электронном виде с доступом либо на уровне собственных форматов данных,
либо через специальные приложения.
О Управление файлами. После установки мощного сервера интрасети,
работающего на базе web-технологий, надобность в старом файловом сервере отпадет.
Интрасети удобны для корпоративных пользователей, однако предоставление
доступа к корпоративным интрасетям внешним клиентам тоже приносит пользу.
Так появились экстрасети, описанные в следующем разделе.
Предоставление внешнего доступа к интрасети
Интрасети предназначены для совместного использования информации в
рамках компании или организации. Следующим шагом в развитии этой идеи стали
экстрасети. Экстрасеть (extranet) представляет собой интрасеть,
предоставляющую контролируемый доступ определенной группе внешних пользователей. На
практике экстрасети используются для обмена информацией со стратегическими
партнерами (клиентами, поставщиками или службами доставки). Короче
говоря, экстрасети относятся к сетям класса «бизнес-бизнес».
Некоторые области применения экстрасетей:
О проведение деловых операций на базе EDI (Electronic Data Interchange) или
других технологий;
О взаимодействие с другими организациями в работе над совместными
проектами;
О обмен новостями или другой информацией с партнерами.
Пример: крупная компания, занимающаяся доставкой товаров, может
предоставить торговой компании доступ к своей интрасети, чтобы торговая компания
могла согласовать данные о сроках поставки со своими покупателями.
Будущее Интернета
По мере роста популярности и расширения областей практического применения
Интернета совершенствуются и интернет-технологии. В настоящее время
существует ряд проектов, направленных на улучшение этих технологий. Наиболее
перспективными являются следующие проекты:
О NGI (Next Generation Internet);
О vNBS (Very high-speed Backbone Network Service);
О Internet2 A2).
Все эти проекты более подробно рассматриваются в следующих подразделах.
NGI (Next Generation Internet)
Как сообщил президент Клинтон в своем докладе о положении страны в 1998 году,
инициатива Интернета следующего поколения NGI (Next Generation Internet)
обеспечивает финансирование и координацию работы академических и
федеральных учреждений, направленных на финансирование и построение
интернет-сервиса следующего поколения.
За дополнительной информацией об инициативе NGI обращайтесь на сайт
http://www.ngi.gov.
vBNS
Национальный научный фонд начал работу над созданием экспериментальной
опорной сети с огромной скоростью передачи данных. Этой опорной сети,
оператором которой является MCI WorldCom, было присвоено название vBNS (Very
high-speed Backbone Network Service). В ближайшем будущем vBNS послужит
платформой для тестирования новых, высокоскоростных интернет-технологий
и протоколов. В настоящее время сеть соединяет несколько суперкомпыотер-
ных центров и точек доступа к сети на скоростях ОС-12 F22 Мбит/с) и выше.
В феврале 1999 года компания MCI WorldCom объявила об установке канала
связи ОС-48 B,5 Гбит/с) между Лос-Анджелесом и Сан-Франциско.
Обращайтесь на сайт http://www.vbns.net за дополнительной информацией
о vBNS.
Internet2 A2)
Испытательная сеть Internet2 была создана для того, чтобы университеты,
правительственные и промышленные организации могли совместно разрабатывать
новые интернет-технологии. Партнерские организации связывались
высокоскоростной сетью Abilene (до 9,6 Гбит/с). В 12 также задействована сеть vBNS,
упомянутая в предыдущем разделе.
Обращайтесь на сайт http://www.internet2.edu за дополнительной информацией
о 12. Информация о сети Abilene находится по адресу http://www.ucaid.edu/abilene.
Так кто же главный в Интернете?
Огромные масштабы Интернета и множество высокотехнологичных инициатив,
направленных на его совершенствование, наводят на мысль, что группа,
ответственная за Интернет, трудится не покладая рук. Это не совсем так: никакой группы,
«ответственной» за Интернет, не существует. У Интернета нет директора,
главного администратора или даже президента. Оказывается, Интернет процветает
в условиях анархической, неофициальной культуры 1960-х, в которых он был
рожден. Тем не менее существует ряд групп, которые помогают следить за
развитием технологий Интернета, за процессами регистрации и общими проблемами,
связанными с управлением сетью таких огромных масштабов.
ISOC (Internet Society)
Общество Интернета ISOC (Internet Society) объединяет на профессиональной
основе свыше 150 организаций и 6000 физических лиц из более 100 стран мира.
Эти организации и лица совместно решают вопросы, от которых зависит
нормальная работа Интернета и его будущее. ISOC состоит из нескольких групп,
отвечающих за стандарты инфраструктуры Интернета, в том числе IAB (Internet
Architecture Board) и IETF (Internet Engineering Task Force).
Web-сайт ISOC находится по адресу http://www.isoc.org.
IAB (Internet Architecture Board)
Координационный совет по архитектуре Интернета IAB (Internet Architecture
Board) выполняет функции технического советника при Обществе Интернета.
Эта небольшая группа (кандидаты в члены IAB представляются IETF и
одобряются Советом попечителей ISOC) проводит регулярные заседания, на которых
рассматриваются и вносятся новые идеи и предложения для последующей
разработки в IETF и IESG.
Web-сайт IAB находится по адресу http://www.iab.org.
IETF (Internet Engineering Task Force)
Проблемная группа проектирования Интернета IETF (Internet Engineering Task
Force) является открытым сообществом сетевых проектировщиков,
поставщиков и ученых, работающих над развитием Интернета. IETF проводит заседания
только три раза в год, а большая часть работы выполняется через электронные
списки рассылки. IETF делится на несколько рабочих групп, каждая из которых
занимается определенной темой. К числу рабочих групп IESG принадлежат
группы разработчиков HTTP (Hypertext Transfer Protocol) и IPP (Internet
Printing Protocol).
Группа IETF открыта для всех желающих. Ее web-сайт находится по адресу
http://www.ietf.org.
IESG (Internet Engineering Steering Group)
Исполнительный комитет IETF — IESG (Internet Engineering Steering Group) —
отвечает за техническое руководство деятельностью IETF и процессом выработки
новых стандартов Интернета. IESG также следит за соблюдением правил ISOC
в деятельности IETF. Кроме того, IESG окончательно утверждает спецификации
перед тем, как они принимаются в качестве стандартов Интернета.
За дополнительной информацией о IESG обращайтесь по адресу http://www.
ietf.org/iesg.html.
IANA (Internet Assigned Numbers Authority)
Агентство по выделению имен и параметров протоколов Интернета IANA
(Internet Assigned Numbers Authority) отвечает за назначение IP-адресов и
управление пространством имен доменов. IANA также определяет номера портов
протокола IP и другие параметры. Деятельность IANA осуществляется под
патронажем ICANN.
Web-сайт IANA находится по адресу http://www.iana.org.
ICANN (Internet Corporation for Assigned
Names and Numbers)
Корпорация по выделению имен и параметров протоколов Интернета ICANN
(Internet Corporation for Assigned Names and Numbers) создавалась как часть
проекта по переводу администрирования доменных имен и пространства
IP-адресов на интернациональную основу. Основной целью ICANN является перевод
администрирования доменов и IP-адресов из правительственного в частный
сектор. В настоящее время ICANN участвует в работе над системой SRS (Shared
Registry System), благодаря которой процесс регистрации доменных имен
должен стать открытым для честной конкуренции. Дополнительная информация
о SRS приводится в следующем разделе.
За дополнительной информацией о ICANN обращайтесь по адресу http://
www.icann.org.
InterNIC и другие регистрирующие органы
Информационный центр Интернета InterNIC (Internet Network Information
Center), работающий под управлением Network Solutions, Inc., был основным
регистратором доменов верхнего уровня (.com, .org, .net, .edu) с 1993 года. Надзор
за деятельностью InterNIC осуществляется Национальной администрацией по
телекоммуникациям и информации NTIA (National Telecommunications &
Information Administration), подгруппой Министерства торговли. InterNIC передал
часть полномочий другим официальным регистрирующим органам (таким, как
информационные центры Министерства обороны и Азиатско-тихоокеанского
региона). В последнее время появились новые инициативы, направленные на
дальнейшее разделение полномочий InterNIC. Одна из таких инициатив, SRS
(Shared Registry System), направлена на внесение открытой и честной
конкуренции в процесс регистрации доменов. В настоящее время свыше 60 компаний
выполняют регистрирующие функции в рамках этой инициативы.
Основные регистрирующие органы перечислены в табл. 2.2.
Таблица 2.2. Основные регистрирующие органы Интернета
Имя URL
InterNIC http://www.jnternic.net/
Информационный центр Министерства обороны http://nic.mil
Федеральный регистр США http://nic.gov
Информационный центр Азиатско-тихоокеанского региона http://www.apnic.net
RIPE (Rftseaux IP Europeftns) http://www.ripe.net
Совет регистрирующих органов (CORE, Council of Registrars) http://www.corenic.org/
Register.com http://register.com
Редактор RFC
Запросы на комментарии (RFC) представляют собой серию документов,
которые, среди прочего, определяют стандарты Интернета. Дополнительная
информация о RFC приведена в разделе «RFC и процесс стандартизации» выше в этой
главе.
Редактором RFC называется лицо, публикующее RFC и отвечающее за
окончательное рецензирование документов.
За дополнительной информацией о редакторе RFC обращайтесь на сайт
http://www.rfc-editor.org/.
Поставщики услуг Интернета
Коммерциализация Интернета в 1990 году была радостно встречена
многочисленными поставщиками услуг Интернета, которые горели желанием приобщить
к Интернету миллионы домашних пользователей и организаций. Поставщиком
услуг Интернета, или ISP (Internet Service Provider), называется коммерческая
организация, которая устанавливает интернет-серверы в своих офисах или
машинных залах. Серверы оснащаются модемами и обеспечивают поддержку
протоколов РРР (Point-to-Point Protocol) или SLIP (Serial Line Internet Protocol),
при помощи которых удаленные пользователи подключаются со своих
персональных компьютеров к Интернету.
Поставщики услуг Интернета на коммерческой основе предоставляют
удаленным пользователям доступ к Интернету. Большинство поставщиков также
предоставляет учетную запись электронной почты на своем сервере, а некоторые
даже открывают доступ к командному процессору системы Unix.
Более крупные поставщики обеспечивают коммерческие организации и
других поставщиков высокоскоростными средствами связи (ISDN, усеченными
каналами Т-1 и даже выше).
Итоги
В этой главе рассматривалась история Интернета, путь его развития и другие
сопутствующие темы. Также она дает краткое представление о современном
использовании интернет-технологий, интрасетях и экстрасетях.
Описание процесса стандартизации на базе RFC сопровождается ссылками,
по которым вы найдете тексты RFC для дальнейшего изучения.
Также были описаны самые популярные службы Интернета со ссылками на
последующие главы книги, содержащие дополнительную информацию.
Вы познакомились с организациями, которые привели Интернет к его
современному состоянию и продолжают развивать его в соответствии с изменениями
в технологиях и потребностях пользователей. Трудно предсказать, что ждет
Интернет в будущем. Всего за несколько лет Интернет вырос из крошечной
экспериментальной сети, использовавшейся немногочисленными учеными, в
глобальную сеть с миллионами компьютеров и пользователей. Уверенно можно
сказать только одно: с такими проектами, как NGI, 12 и vBNS, мы еще только
начинаем видеть потенциальные возможности и области практического
применения этой пленительной технологии.
*J Общий обзор TCP/IP
Рима С. Регас (Rima S. Regas)
Протокол TCP/IP встречается повсеместно. Это семейство протоколов, благодаря
которым любой пользователь с компьютером, модемом и договором, заключенным
с поставщиком услуг Интернета, может получить доступ к информации по всему
Интернету. Пользователи служб AOL Instant Messenger и ICQ (также
принадлежащей AOL) получают и отправляют свыше 750 миллионов сообщений в день.
Большая часть этого немыслимого объема информации передается по Интернету.
Именно благодаря TCP/IP каждый день благополучно выполняются многие
миллионы операций — а возможно, и миллиарды, поскольку работа в Интернете
отнюдь не ограничивается электронной почтой и обменом сообщениями. Более
того, в ближайшее время TCP/IP не собирается сдавать свои позиции. Это
стабильное, хорошо проработанное и достаточно полное семейство протоколов,
и в этой главе мы познакомимся с основными принципами его работы.
Все рутинные операции по управлению общим перемещением пакетов
данных в Интернете выполняются TCP и IP — двумя разными протоколами,
работающими в едином комплексе. Оба протокола используют специальные
заголовки, определяющие содержимое каждого пакета, а если пакетов несколько —
сколько еще их следует ожидать. Протокол TCP ориентирован на обеспечение
связи с удаленными хостами. Протокол IP обеспечивает адресацию, чтобы
сообщения доставлялись в точности туда, куда они были адресованы. Преимущества
TCP/IP описаны в следующем разделе.
Преимущества TCP/IP
Протокол TCP/IP обеспечивает возможность межплатформенных сетевых
взаимодействий (то есть связи в разнородных сетях). Например, сеть под
управлением Windows NT/2000 может содержать рабочие станции Unix и Macintosh
и даже другие сети более низкого порядка. TCP/IP обладает следующими
характеристиками:
О Хорошие средства восстановления после сбоев.
О Возможность добавления новых сетей без прерывания текущей работы.
О Устойчивость к ошибкам.
О Независимость от платформы реализации.
О Низкие непроизводительные затраты на пересылку служебных данных.
Протокол TCP/IP изначально проектировался для задач Министерства
обороны, поэтому все перечисленные достоинства скорее относятся к постановке задачи
на проектирование. Например, наличие хороших средств восстановления после
сбоев означает, что в случае уничтожения части сети из-за вторжения или удара
противника ее оставшиеся компоненты должны сохранить полную
работоспособность. То же самое относится и к добавлению новых сетей без прерывания
текущей работы. Устойчивость к ошибкам была реализована таким образом, что в
случае потери информационного пакета на одном маршруте специальный механизм
должен был направить пакет к месту назначения по другому маршруту.
Независимость от платформы означает, что сети и клиенты могут работать под управлением
Windows, Unix, Macintosh, а также любой другой платформы или комбинации
платформ. Эффективность TCP/IP обусловлена главным образом с его низкими
непроизводительными затратами. Производительность играет основную роль
в любой сети, а протокол TCP/IP не имеет себе равных по скорости и простоте.
Уровни и протоколы TCP/IP
Протоколы TCP и IP совместно управляют потоками данных (как входящими, так
и исходящими) в сети. Но если протокол IP просто передает пакеты, не обращая
внимания на результат, TCP должен проследить за тем, чтобы пакеты прибыли
в положенное место. В частности, TCP отвечает за выполнение следующих задач:
О Открытие и закрытие сеанса.
О Управление пакетами.
О Управление потоком данных.
О Обнаружение и обработка ошибок.
Архитектура
Сетевая среда TCP/IP выполняет все операции, перечисленные выше, и
координирует их с удаленными хостами. Протокол TCP/IP проектировался по
модели Министерства обороны, которая состояла только из четырех уровней
вместо семи, как в модели OSI.
Главное различие между структурой уровней OSI и TCP/IP заключается
в том, что транспортный уровень не всегда обеспечивает гарантированную
доставку. На транспортном уровне TCP/IP также поддерживается более простой
протокол UDP (User Datagram Protocol).
Прикладной уровень
Прикладной уровень состоит из таких протоколов, как SMTP, FTP, NFS, NIS,
LPD, Telnet и Remote Login. Области применения этих протоколов хорошо
знакомы большинству пользователей Интернета.
Транспортный уровень
Транспортный уровень состоит из протоколов UDP и TCP. Первый доставляет
пакеты почти без проверки, а второй обеспечивает гарантию доставки.
Сетевой уровень
Сетевой уровень состоит из следующих протоколов: ICMP, IP, IGMP, RIP, OSPF,
EGP и BGP. Протокол ICMP (Internet Control Message Protocol) используется
для передачи информации о проблемах уровня IP и получения значений
параметров IP. Протокол IGMP (Internet Group Management Protocol) предназначен
для управления групповой рассылкой. Протоколы RIP, OSPF, EGP и BGP4
относятся к числу протоколов маршрутизации.
Канальный уровень
Канальный уровень состоит из протоколов ARP и RARP и подсистемы
формирования кадров, обеспечивающей пересылку пакетов.
TCP
Протокол управления передачей TCP (Transmission Control Protocol)
обеспечивает гарантированную доставку пакетов данных и предоставляет услуги связи
приложениям. TCP использует упорядоченное подтверждение приема и при
необходимости организует повторную передачу пакетов.
Заголовок TCP имеет следующую структуру:
16 бит 32 бит
Порт отправителя Порт получателя
Порядковый номер
Номер для подтверждения (АСК)
Смещение зарезервировано U A P R S F Окно
Контрольная сумма Указатель срочности
Параметры и заполнители
Смысл полей заголовка поясняется ниже.
Порт отправителя
Номер порта, с которого был отправлен пакет.
Порт получателя
Номер порта, которому отправлен пакет.
Порядковый номер
Порядковый номер первого октета данных в сегменте.
Номер для подтверждения (АСК)
При установленном бите АСК это поле содержит следующий порядковый
номер, который ожидает получить отправитель сегмента в подтверждение того,
что все предыдущие порядковые номера были переданы успешно. После
установления связи это значение передается всегда.
Смещение
Смещение начала данных (длина заголовка).
Зарезервировано
Поле зарезервировано и не используется, но должно быть обнулено.
Управляющие биты
Список управляющих битов приведен в следующей таблице.
U (URG) Указатель срочности содержит значимые данные
А (АСК) Номер для подтверждения содержит значимые данные
Р (PSH) Функция немедленной доставки
R (RST) Сброс соединения
S (SYN) Синхронизация порядковых номеров
F (FIN) Конец данных
Окно
Количество октетов данных (начиная с указанного в поле АСК), которые могут
быть отправлены без подтверждения успешного приема ранее переданных данных.
Контрольная сумма
16-разрядное дополнение суммы всех 16-разрядных слов заголовка и текста.
Если сегмент содержит нечетное число октетов, последний октет дополняется
нулями для формирования 16-разрядного слова, используемого при вычислении
контрольной суммы. Обратите внимание: заполнители не пересылаются вместе
с сегментом.
Указатель срочности
Управляющее поле, содержимое которого имеет смысл лишь при установленном
бите URG. Указатель срочности обозначает октет данных, связанный со
срочным вызовом отправителя.
Параметры
В конце заголовка могут пересылаться дополнительные параметры. Длина каждого
параметра должна быть кратна 8 битам. Существует два формата параметров:
О Тип параметра (один октет).
О Тип параметра (один октет), длина параметра (один октет) и собственно
данные параметра.
В поле длины параметра учитываются все три поля (то есть тип, длина и
данные). В поле данных содержится вся информация, пересылаемая в качестве
значения параметра. В табл. 3.1 приведены значения полей для трех основных типов
параметров. Параметры учитываются при вычислении контрольной суммы
заголовка IP. Длина списка параметров может быть меньше указанной в поле
смещения, в этом случае оставшаяся часть заголовка после параметра с типом О
заполняется нулями.
Таблица 3.1. Формат параметров
Тип Длина Описание
0 - Конец списка параметров
1 - Нет операции
2 4 Максимальный размер сегмента
Параметр типа 0 обозначает конец всего списка параметров (а не каждого
параметра по отдельности!). Его присутствие обязательно только в том случае,
если список параметров завершается раньше конца заголовка.
Параметр типа 1 предназначен для выравнивания следующего параметра по
границе слова. Никакой полезной информации он не несет.
Параметр типа 2 определяет максимальный размер принимаемых сегментов.
Если параметр не указан, размер сегмента не ограничивается.
IP
Протокол IP управляет доставкой пакетов между серверами и клиентами.
Заголовок IP имеет следующую структуру.
4 бит 8 бит 16 бит 32 бит
Версия Длина ^nlU'iL Общая длина
г заголовка службы -* «-
... ^ Смещение
Индетификатор Флаги фрагмента
СР°К Протокол Контрольная сумма
жизни
Адрес отправителя
Адрес получателя
Параметры и заполнители
Каждое поле содержит информацию о передаваемом пакете IP. Смысл полей
заголовка поясняется ниже.
Версия
Номер версии IP, используемой данным пакетом. В настоящее время повсеместно
используется протокол IP версии 4 (IPv4).
Длина заголовка
Общая длина заголовка. По содержимому этого поля получатель определяет,
когда нужно прекратить чтение заголовка и перейти к чтению данных.
Тип службы (сервиса)
Это редко используемое поле содержит ряд параметров, включая числовой
приоритет пакета. Более высокие значения указывают на необходимость
первоочередной обработки.
Общая длина
Общая длина пакета в октетах. Значение не может превышать 65 535; в
противном случае получатель считает, что содержимое пакета испорчено.
Идентификатор
Идентификатор, назначаемый отправителем для сборки пакета из фрагментов.
Флаги
Первый бит зарезервирован и игнорируется. При установленном флаге DF (Do
Not Fragment) пакет ни при каких условиях не должен фрагментироваться.
Установленный флаг MF (More Fragments) означает наличие других
фрагментов, а в последнем фрагменте этот флаг равен нулю.
Смещение фрагмента
При установленном флаге MF поле определяет позицию текущего фрагмента
в исходном пакете.
Срок жизни
Максимальная продолжительность пересылки пакета. Обычно срок жизни
составляет от 15 до 30 секунд. Если пакет будет отвергнут или потерян при
пересылке, отправитель оповещается об утрате и получает возможность отправить
пакет заново.
Протокол
Числовое обозначение протокола, который должен использоваться при
обработке пакета.
Контрольная сумма
Контрольная сумма, используемая для проверки целостности заголовка.
Адрес отправителя
Адрес хоста, отправившего пакет.
Адрес получателя
Адрес хоста, которому предназначен пакет.
Параметры и заполнители
Поле параметров не является обязательным. Если оно используется, в
параметрах передается информация об использовании защиты, жесткой или свободной
маршрутизации, отслеживания маршрута и временной пометки. Формат
поддерживаемых параметров описан в табл. 3.2. Заполнители обеспечивают
выравнивание конца заголовка по границе двойного слова.
Таблица 3.2. Формат параметров
Класс Номер Описание
О 9 Конец списка параметров
О 2 Защита данных по стандартам Министерства обороны
О 3 Свободная маршрутизация
О 7 Отслеживание маршрута
О 9 Маршрутизация только через заданные узлы
2 4 Временная пометка
Услуги протокола TCP/IP предоставляются через «стек» промежуточных
уровней. Поскольку TCP и IP — это два разных протокола, им нужна общая
среда для выполнения промежуточных преобразований. Как упоминалось ранее
в этой главе, в отличие от семиуровневой модели OSI стек TCP/IP состоит всего
из четырех уровней:
О Прикладной уровень.
О Транспортный уровень.
О Сетевой уровень.
О Канальный уровень.
Ниже кратко описаны основные задачи каждого уровня.
Прикладной уровень
Прикладной уровень объединяет несколько задач, разделенных в иерархии OSI
на три уровня. Все эти задачи (аутентификация, обработка и сжатие данных)
относятся к работе конечного пользователя. Именно на этом уровне
устанавливается связь в почтовых клиентах, браузерах, клиентах Telnet и другие
интернет-приложениях.
Транспортный уровень
Стоит еще раз напомнить, что в отличие от OSI этот уровень не отвечает за
гарантированную доставку пакетов. Его основной задачей является управление
передачей пакетов между отправителем и получателем. Модель OSI гарантирует
проверку пакетов и в случае нарушения их целостности — их повторный запрос
у отправителя.
Сетевой уровень
Сетевой уровень занимается исключительно управлением маршрутизацией
пакетов. На этом уровне принимаются решения о том, куда следует отправить
пакет на основании полученной информации.
Канальный уровень
Канальный уровень управляет сетевыми соединениями и обеспечивает пакетный
ввод/вывод на уровне сети, но не на уровне приложения.
Теперь, когда вы достаточно хорошо представляете, что такое TCP/IP и что
он может, мы переходим к следующей, более осязаемой теме — возможностям,
которые перед вами открывает TCP/IP.
Telnet
Термин «Telnet» (сокращение от «TELecommunications NETwork») обычно
используется для обозначения как приложения, так и самого протокола, что
наделяет его двойным смыслом. Telnet предоставляет в распоряжение пользователя
средства для удаленного входа и прямого выполнения терминальных операций
по сети. Иначе говоря, Telnet обеспечивает прямой доступ к удаленному
компьютеру. Telnet работает на порте 23.
На хосте должен работать сервер Telnet, ожидающий аутентифицированного
удаленного входа. В Windows 9x/NT/2000, BeOS, Linux и других операционных
системах на платформе х86 необходимо установить отдельный сервер Telnet,
настроить его и запустить на прием входящих запросов. Системы на базе MacOS
также требуют отдельного сервера Telnet. Только в системах семейства Unix
имеется собственный сервер Telnet, который обычно называется telnetd (буква
«d» означает «daemon», то есть «демон» — так называется серверное
приложение, работающее в фоновом режиме). На другом конце соединения работает
приложение Telnet, обеспечивающее текстовый или графический интерфейс
для пользовательского сеанса.
ПРИМЕЧАНИЕ
Вообще говоря, в Windows 2000 имеется встроенный сервер Telnet, который вызывается по ссылке
или вводом команды telnet в консоли. Таким образом, в Windows 2000 устанавливать внешний
сервер Telnet не нужно.
FTP
В отличие от протокола Telnet, позволяющего работать на удаленном хосте,
протокол FTP играет более пассивную роль и предназначается для приема и
отправки файлов на удаленный сервер. Такая возможность идеально подходит
для web-мастеров и вообще для всех, кому потребуется пересылать большие
файлы с одного компьютера на другой без прямого подключения. FTP
обычно используется в так называемом «пассивном» режиме, при котором клиент
загружает данные о дереве каталогов и отключается, но периодически
сигнализирует серверу о необходимости сохранять открытый порт.
ПРИМЕЧАНИЕ
Серверы FTP настраиваются по усмотрению web-мастера. Одни серверы предоставляют
анонимным пользователям доступ ко всем областям сервера без ограничений; другие ограничивают
доступ аутентифицированными пользователями; третьи ограничивают анонимный доступ очень
коротким тайм-аутом. Если пользователь не выполняет активных действий, сервер автоматически
разрывает соединение. Если пользователь пожелает продолжить работу на сервере, ему придется
подключиться заново.
В системах семейства Unix поддержка FTP обычно обеспечивается
программами ftpd (буква «d», как и в предыдущем случае, означает «демон») и ftp
(клиентское приложение). По умолчанию протокол FTP работает на портах 20
(пересылка данных) и 21 (пересылка команд). FTP отличается от всех остальных
протоколов TCP/IP тем, что команды могут передаваться одновременно с
передачей данных в реальном времени; у других протоколов подобная возможность
отсутствует.
Клиенты и серверы FTP в той или иной форме существуют во всех
операционных системах. Приложения FTP на базе MacOS имеют графический
интерфейс, как и большинство приложений для системы Windows. Преимущество
графических клиентов FTP заключается в том, что команды, обычно вводимые
вручную, теперь автоматически генерируются клиентом, что снижает
вероятность ошибок, упрощает и ускоряет работу. С другой стороны, серверы FTP
после первоначальной настройки не требуют дополнительного внимания, поэтому
графический интерфейс для них оказывается лишним.
TFTP
Название протокола TFTP (Trivial FTP) выбрано весьма удачно. TFTP является
«бедным родственником» FTP и поддерживает лишь малое подмножество его
функций. Он работает на базе протокола UDP, который в продолжение нашего
сравнения можно назвать «бедным родственником» TCP. TFTP не следить за
доставкой пакетов и практически не обладает средствами обработки ошибок.
С другой стороны, эти ограничения снижают непроизводительные затраты при
пересылке. TFTP не выполняет аутентификации; он просто устанавливает
соединение. В качестве защитной меры TFTP позволяет перемещать только
общедоступные файлы.
Применение TFTP создает серьезную угрозу для безопасности системы.
По этой причине TFTP обычно используется во встроенных приложениях, для
копирования конфигурационных файлов при настройке маршрутизатора, при
необходимости жесткой экономии ресурсов, а также в тех случаях, когда
безопасность обеспечивается другими средствами. Протокол TFTP также
используется в сетевых конфигурациях, в которых загрузка компьютеров производится
с удаленного сервера, а протокол TFTP может быть легко записан в ПЗУ сетевых
адаптеров.
SMTP
Протокол SMTP (Simple Mail Transfer Protocol) является фактическим
стандартом пересылки электронной почты в сетях, особенно в Интернете. Во всех
операционных системах имеются почтовые клиенты с поддержкой SMTP, а
большинство поставщиков услуг Интернета (если не все) использует SMTP для
работы с исходящей почтой. Серверы SMTP существуют для всех
операционных систем, включая Windows 9x/NT/2K, MacOS, семейство Unix, Linux, BeOS
и даже AmigaOS.
Протокол SMTP проектировался для транспортировки сообщений
электронной почты в разных сетевых средах. В сущности, SMTP не следит за тем, как
перемещается сообщение, а лишь за тем, чтобы оно было доставлено к месту
назначения.
SMTP обладает мощными средствами обработки почты, обеспечивающими
автоматическую маршрутизацию по определенным критериям. В частности,
SMTP может оповестить отправителя о том, что адрес не существует, и вернуть
ему сообщение, если почта остается недоставленной в течение определенного
периода времени (задаваемого системным администратором сервера, с которого
отправляется сообщение). SMTP использует порт TCP с номером 25.
NFS
Файловая система NFS (Network File System) создавалась компанией Sun
Microsystems, Inc. для решения проблем в сетях с несколькими операционными
системами. NFS поддерживает только совместный доступ к файлам и является
компонентом многих операционных систем семейства Unix. Кроме того, NFS
хорошо поддерживается большинством других операционных систем.
В NFS версий 1 и 2 в качестве основного транспортного протокола
использовался протокол UDP. Поскольку UDP не обеспечивает гарантированной
доставки, для ненадежных каналов эта задача должна решаться на уровне NFS, а не
на уровне протокола. Из-за этого в некоторых ранних реализациях NFS
существовали проблемы с порчей содержимого файлов.
Начиная с NFS версии 3, в качестве транспортного протокола может
использоваться TCP. Впрочем, появившаяся в NFS 3 поддержка TCP не
оптимизирована. При использовании TCP в качестве транспортного протокола NFS может
использовать надежность TCP для повышения качества доставки по ненадеж-
ным каналам. Соответственно, NFS версии 3 лучше работает в глобальных сетях
и в Интернете.
ПРИМЕЧАНИЕ
Был предложен стандарт NFS версии 4, но в большинстве коммерческих реализаций используется
NFS версий 2 и 3.
«Чистая» реализация NFS не может предотвратить одновременную запись
в файл со стороны нескольких пользователей, что легко приводит к порче
данных, если пользователи не знают о параллельном выполнении операций с файлом.
Тем не менее механизм блокировки файлов, реализованный протоколом NLM
(Network Lock Manager), может использоваться в сочетании с NFS для
организации совместного чтения и записи в файл.
Механизм доступа к файлам через NFS прямолинеен и прозрачен. После
монтирования том NFS становится частью системы конечного пользователя.
Никаких дополнительных шагов не требуется — естественно, не считая
процесса экспортирования, необходимого для синхронизации конфигурации NFS
на сервере и у клиентов. Впрочем, простота этой системы и удобство ее
администрирования оставляют желать лучшего.
SNMP
Протокол SNMP (Simple Network Management Protocol) реализует простые
средства сбора данных о работе маршрутизатора и управления им с
использованием различных протоколов — таких, как UDP, IPX и IP. При любом
обсуждении SNMP важно помнить, что первая буква в названии протокола означает
«Simple», то есть «простой». Действительно, SNMP — само воплощение
простоты. Во-первых, протокол поддерживает только четыре команды — GET,
GETNEXT, SET и TRAP. Первые две команды предоставляют доступ к
информации, а третья позволяет осуществлять удаленное управление некоторыми
функциями маршрутизаторов. Команда TRAP включает режим получения от
устройства информации о проблемах или происходящих событиях.
Сетевые устройства передают информацию о себе через базу управляющей
информации MIB (Management Information Base). Эти данные, описывающие
устройство, передаются станции управления SNMP (SNMP Management Station),
которая поочередно идентифицирует каждое устройство и сохраняет
информацию о нем. Станция управляет всеми SNMP-совместимыми устройствами.
Для каждого устройства запускается агент SNMP, представляющий клиентскую
сторону операций с устройствами. Когда станция управления запрашивает
информацию о порте командой GET, агент возвращает эту информацию.
Протокол SNMP не предназначен для управления всеми сетевыми
устройствами с возможностью точного описания операций. Это простой протокол для
повседневной работы, который позволяет получить нужную информацию без
загрузки 5—6 управляющих интерфейсов. Для отправки сообщений SNMP
использует транспортный протокол UDP.
Место TCP/IP в системе
Итак, теперь вы знаете, какие услуга предоставляет протокол TCP/IP, и
убедились в его гибкости и повсеместном распространении как промышленного
стандарта. TCP/IP используется в Интернете, поэтому в сетях на базе TCP/IP нет
очевидных ограничений на пропускную способность каналов или размер сети.
Вы знаете, какие факторы обусловили успех TCP/IP и какими достоинствами
обладает этот протокол.
Если вы работаете в сети на базе Windows или Unix, то с большой
вероятностью вы уже используете TCP/IP. В ранних версиях NetWare (таких, как
NetWare 2 и 3) используется протокол IPX/SPX. В NetWare 3 была добавлена
серверная поддержка TCP/IP и шлюз IPX-TCP/IP для подключения к
Интернету. В версии 4 появилась более качественная поддержка TCP/IP. NetWare
версий 5 и выше позволяет заменить IPX протоколом TCP/IP и обладает
полноценной поддержкой TCP/IP.
Также стоит рассмотреть возможность модернизации системы, использующей
AppleShare в сетях AppleTalk (версии менее 6.x). К AppleShare IP это не
относится, поскольку в этом серверном пакете протокол TCP/IP уже реализован,
однако в этом случае приходится учитывать фактор затрат. TCP/IP
предоставляет в ваше распоряжение широкий ассортимент возможностей, серверов, служб,
клиентов и т. д. бесплатно или за минимальные деньги.
На установку интрасети TCP/IP можно потратить огромную сумму, но того
же эффекта можно добиться и при гораздо меньших затратах. Начните с выбора
серверной операционной системы — например, Linux. Система распространяется
бесплатно или почти бесплатно, если вы купите один из комплектов поставки.
Наибольшей популярностью пользуются поставки Red Hat, Debian, Mandrake
и Caldera. Система Linux остается бесплатной, но при покупке
перечисленных поставок вы также приобретаете обслуживание и поддержку, специальные
установочные программы и другие дополнения, не входящие в стандартную
поставку Linux.
ПРИМЕЧАНИЕ
Если вы не захотите тратить $60, RedHat Linux можно загрузить бесплатно с сайта, но загрузка
по модему займет очень много времени — поставка RedHat занимает более 160 Мбайт. Быстрее
и проще купить готовую поставку.
Также можно использовать существующую операционную систему, поскольку
для MacOS, Windows 9x/NT/2000/XP написано немало серверов. Одни
распространяются бесплатно, другие стоят от $30 до $2500 в зависимости от
функций, выполняемых продуктом, и типа лицензии. Заодно можно сменить
коммуникационное оборудование, но и того, что у вас есть, должно хватить —
конечно, если вы не собираетесь переходить с текстовых приложений на
графические приложения с трехмерной анимацией, работающие в круглосуточном
режиме.
Концепция интрасети
Преимущественное использование протокола TCP/IP в современных интрасетях
объясняется тремя факторами: затратами на реализацию, скоростью и
возможностью расширения. Реализация TCP/IP может обойтись минимальными
затратами. TCP/IP может работать параллельно со старыми протоколами (AppleTalk,
IPX и т. д.) вплоть до полного завершения перехода; TCP/IP работает быстро
и эффективно, с использованием надежных и проверенных протоколов;
наконец, благодаря удобному механизму пакетной коммутации этот протокол можно
в любой момент расширить.
Кроме того, ваша компания или сеть получит доступ к огромным ресурсам
Интернета. В наше время самым распространенным применением Интернета
является электронная почта, которая по популярности превосходит даже
просмотр web-страниц. Ежедневно в Интернете передаются миллиарды сообщений,
а миллионы интернет-терминалов предоставляют пользователям доступ к
ресурсам, опубликованным в Интернете.
Существует много способов подключения к Интернету, но в настоящее время
чаще всего используется модемное подключение, а в некоторых регионах — DSL
(Digital Subscriber Line) и кабельные модемы. Любой пользователь с аналоговым
модемом может связаться с модемом поставщика услуг Интернета и
подключиться к Интернету, далее остается лишь использовать нужные ресурсы. Самый
популярный протокол канального уровня для модемного подключения
называется РРР (Point-to-Point Protocol). Старый протокол SLIP (Serial Line Interface
Protocol) позволяет создать последовательное подключение к Интернету из
клиентской программы. Позднее протокол SLIP был доработан для сжатия заголовков
TCP/IP; это привело к появлению новой разновидности SLIP, которая
называлась CSLIP (Compressed SLIP). В наше время оба протокола, SLIP и CSLIP,
в основном были вытеснены РРР.
Итоги
Как было показано в этой главе, при пересылке пакета между компьютерами
необходимо учитывать очень много факторов. Вот почему протоколы TCP и IP
работают в столь тесном взаимодействии. Оба протокола выполняют важные
операции, обеспечивающие успешное функционирование Интернета. Также вы
узнали, что стек TCP/IP состоит из нескольких уровней и что каждый уровень
выполняет определенную функцию. Если одно из звеньев этой цепочки даст
сбой, вся работа протокола будет парализована. К счастью, такое происходит
очень редко. Именно из-за своей надежности протокол TCP/IP в той или иной
форме доступен во всех операционных системах.
При этом протокол TCP/IP обладает хорошими характеристиками
масштабируемости и мобильности. Во многих ситуациях, в которых уместно применение
TCP/IP, часто выясняется, что соответствующая поддержка уже существует.
Главное — проанализируйте все активные протоколы, используемые сетевым
объединением, и убедитесь в том, что переход на TCP/IP не приведет к непоправимым
последствиям для пользовательского доступа. В остальном все проще простого.
4 И мена и адреса
в сетях IP
Марк А. Спортак (Mark A. Sportack)
Необходимым условием межсетевого обмена является наличие эффективной
схемы адресации, которая должна соблюдаться всеми участниками. Существует
множество разновидностей схем адресации. Сетевые адреса всегда имеют
числовую форму, но могут выражаться в двоичной, десятичной и даже шестнадцате-
ричной системе счисления. Схема адресации может быть закрытой
(запатентованной) или открытой, чтобы ее могли реализовать все желающие. Кроме того,
она может обеспечивать высокий уровень масштабируемости или намеренно
ограничиваться небольшим сообществом пользователей.
В этой главе рассматривается схема адресации, реализованная в протоколе
IP (Internet Protocol). За последние 20 лет протокол IP прошел серьезный путь
развития, и вместе с ним развивалась схема адресации. В этой главе описана
эволюция схемы адресации IP, а также объясняются ее важнейшие концепции,
в том числе классификация IP-адресов, бесклассовые адреса междоменной
маршрутизации (CIDR), маски и адреса подсетей, а также маски подсетей
переменной длины.
Адресация в протоколе IP
Проблемная группа проектирования Интернета (IETF), занимающаяся развитием
Интернета и IP, решила использовать для идентификации сетей и хостов IP
числовые адреса, удобные для машинной обработки. Таким образом, каждой
сети в Интернете присваивается уникальный числовой идентификатор.
Администратор этой сети должен позаботиться о том, чтобы каждому хосту в сети
также был присвоен уникальный идентификатор.
В исходном варианте — IP версии 4 (IPv4) — используются 32-разрядные
двоичные адреса. IP-адреса обычно записываются в виде четырех десятичных
чисел, разделенных точками (так называемая десятичная запись с точечным
разделением). Каждый компонент IP-адреса представляется одним октетом, то
есть 8-разрядным двоичным числом. Двоичная запись удобна для машинной
обработки, но не для пользователей, поэтому сетевые адреса обычно
записываются в более понятной десятичной форме. По этой причине необходимо хорошо
понимать различия между десятичной и двоичной системами счисления,
поскольку на них базируется вся схема адресации IP. Преобразования между
двоичной и десятичной системами счисления рассматриваются в разделе
«Двоичная и десятичная запись».
Исходная 32-разрядная схема адресации IPv4 означает, что в Интернете
может существовать не более 4 294 967 296 возможных IP-адресов — когда-то
это число B в 32 степени) казалось немыслимо огромным. Неэкономное
расходование адресов (резервирование больших адресных блоков без их
фактического использования, использование классовых адресов и неправильных
масок подсетей и т. д.) оказалось слишком расточительным. Возникла нехватка
адресов. Многие случаи неэкономного расходования, а также меры по
исправлению ситуации станут более понятными после знакомства со схемой
адресации IPv4.
ПРИМЕЧАНИЕ
Работа над новой версией IP близится к завершению. Новая версия, IPv6, использует
принципиально иную схему адресации и шестнадцатеричное представление компонентов, разделяемых
двоеточиями. В IPv6 длина адресов равна 128 байтам, а новая система классификации повышает
эффективность их использования. Учитывая, что на широкое распространение новой версии IP
потребуется несколько лет, в этой книге все примеры приводятся в схеме адресации IPv4.
Дополнительная информация о IPv6 приводится в главе 12.
Двоичная и десятичная запись
В двоичной системе счисления значение, представляемое единичным битом,
зависит от ее положения в числе. В этом отношении она похожа на
общепринятую десятичную систему, в которой крайняя правая цифра определяет
количество единиц в числе, вторая цифра справа — количество десятков, третья —
количество сотен и т. д. По своей значимости каждая цифра в 10 раз превышает
цифру, находящуюся справа от нее.
Но если в десятичной системе используются десять цифр, представляющих
разные значения разрядов (от 0 до 9), то в двоичной системе существует всего
две цифры: 0 и 1. Значение, представляемое этими цифрами, также зависит
от их позиции в числе. Крайняя правая позиция числа представляет значение 1
(в десятичном эквиваленте). Вторая цифра справа представляет значение 2,
третья — 4, четвертая — 8 и т. д. Значимость каждой позиции вдвое превышает
значимость позиции, находящейся справа.
Десятичное представление двоичного числа вычисляется суммированием
десятичных эквивалентов по всем разрядам, содержащим единицы. С
математической точки зрения максимальное значение каждого из четырех октетов адреса
IPv4 в десятичной системе равно 255. Двоичный эквивалент десятичного числа
255 состоит из 8 разрядов, заполненных единицами. Связь между двоичным
и десятичным представлением числа продемонстрирована в табл. 4.1.
Таблица 4.1. Двоичное A1111111) и десятичное B55) представление октетов
8 7 65 4321
Двоичная цифра 1 1 111111
Десятичное значение цифры 128 64 32 16 8 4 2 1
Как видно из таблицы, все биты двоичного адреса заполнены единицами,
поэтому десятичное представление двоичного числа определяется суммированием
десятичных значений, соответствующих восьми столбцам: 128+64+32+16+8+
+4+2+1 = 255.
В табл. 4.2 представлен другой пример преобразования из двоичной системы
в десятичную. На этот раз пятый разряд справа равен нулю, эта позиция
соответствует десятичному значению 16. Следовательно, полученное двоичное число
будет на 16 меньше 255: 128+64+32+8+4+2+1 = 255.
Таблица 4.2. Двоичное A1101111) и десятичное B39) представление октетов
8 7 65 4321
Двоичная цифра 11 101111
Десятичное значение цифры 128 64 32 16 8 4 2 1
Понимание многих аспектов схемы адресации IP, в том числе масок
подсетей, VLSM и CIDR, требует перехода от десятичной системы к двоичной.
Следовательно, для изучения различных вариантов адресации в сетях IP необходимо
хорошо разбираться в этих системах счисления.
Форматы адресов IPv4
Протокол IP был стандартизирован в сентябре 1981 года. В его схеме адресации
учитывалось текущее состояние дел в области информационных технологий, но
ее постарались по возможности ориентировать на будущее развитие. Базовый
IP-адрес представлял собой 32-разрядное двоичное число, разбитое на четыре
октета (8-разрядных двоичных числа).
Для удобства двоичные адреса обычно преобразуются в более знакомую
десятичную систему. Каждый из четырех октетов IP-адреса представляется
десятичным числом от 0 до 255, которые при записи разделяются точками
(десятичная запись с точечным разделением). Таким образом, наименьший адрес,
который может быть представлен в схеме IPv4, равен 0.0.0.0, а наибольший адрес
равен 255.255.255.255. Тем не менее оба эти значения зарезервированы и не
могут назначаться конечным системам. Причины становятся понятны лишь
после знакомства с особенностями реализации структуры этого базового адреса
в протоколе.
Адреса IPv4 делятся на классы в соответствии с размером сети (крупная,
средняя или мелкая). Классы различаются по количеству бит, выделенных для
идентификации сети и хоста. Существует пять классов IP-адресов,
обозначаемых одной буквой алфавита:
О Класс А.
О Класс В.
О Класс С.
О Класс D.
О Класс Е.
IP-адрес состоит из двух частей: идентификатора сети и идентификатора
хоста. Пять классов представляют разные степени компромисса между
количеством сетей и хостов, описываемых этими идентификаторами.
Класс А
Адреса IPv4 класса А предназначены для поддержки очень больших сетей.
Поскольку на момент стандартизации потребность в крупномасштабных сетях
считалась минимальной, структура этих адресов увеличивала до максимума
количество возможных адресов хостов, но существенно ограничивала количество
возможных сетей класса А.
В IP-адресах класса А для определения сети используется только первый октет.
Три оставшихся октета определяют хост. Первый бит адреса класса А всегда
равен 0, поэтому допустимые значения идентификаторов сетей класса А могут
лежать в интервале от 0 до 127 F4+32+16+8+4+2+1 — из суммы исключается
крайний левый разряд, представляющий число 128). Следовательно, в этой схеме
адресации возможно существование не более 127 сетей IP класса А.
Последние 24 бита (то есть три десятичных числа, разделенных точками)
в классе А представляют идентификатор хоста. Таким образом, IP-адреса класса А
лежат в интервале от 1.0.0.0 до 126.255.255.255.
Обратите внимание: идентификатор сети хранится только в первом октете,
а остальные три октета определяют уникальный идентификатор хоста в границах
сети. При определении адресных интервалов они обычно заполняются нулями.
ПРИМЕЧАНИЕ
С технической точки зрения адрес 127.0.0.0 также является адресом сети класса А, но он
зарезервирован для целей тестирования с обратной связью и не может быть присвоен конкретной сети.
Оглядываясь назад, следует признать это решение неудачным, поскольку оно исключает из
использования целую сеть класса А с огромным количеством IP-адресов.
Каждая сеть класса А может поддерживать до 16 777 214 уникальных хостов.
Эта величина была получена возведением 2 в 24 степень с последующим
вычитанием 2. Вычитание необходимо из-за того, что в IP адрес, состоящий из одних
нулей, используется для идентификации сети, а адрес из одних единиц — для
групповой рассылки в этой сети. Структура IP-адреса класса А с выделением
октетов, представляющих идентификаторы сети и хоста, представлена на
следующем рисунке.
Сеть Хост
Октет 12 3 4
ПРИМЕЧАНИЕ
Класс А обычно используется для очень больших сетей — таких, как исходная сеть ARPANET.
Большинство адресов класса А уже выделено, поэтому получить от InterNIC новый адрес сети класса А
очень трудно (если вообще возможно).
Класс В
Адреса класса В предназначены для поддержки средних и крупных сетей.
Допустимые адреса класса В лежат в интервале от 128.1.0.0 до 191.255.255.255.
Математическая логика, лежащая в основе адресации, довольно проста.
Первые два октета в IP-адресе класса В используются для представления
идентификатора сети, а два других октета содержат идентификатор хоста. Первые два
бита первого октета адреса класса В равны 10. Остальные шесть битов содержат
нули или единицы. На математическом уровне первый октет адреса класса В
должен быть меньше либо равен 191 (сумма 128+32+16+8+4+2+1).
Последние 16 бит B октета) определяют идентификатор хоста. Каждая сеть
класса В может содержать до 65 534 уникальных хостов. Эта величина была
получена возведением 2 в 16 степень с последующим вычитанием 2 (адреса,
зарезервированные IP для служебного использования). Данная схема позволяет
определить не более 16 382 сетей IP класса В.
Структура IP-адреса класса В представлена на следующем рисунке.
Сеть I Хост
Октет 12 3 4
ПРИМЕЧАНИЕ
Адреса класса В широко применяются в сетях средних размеров. Многие крупные организации
получили адреса класса В.
Классе
Адреса класса С предназначены для поддержки большого количества мелких
сетей. По своей структуре адреса этого класса противоположны адресам
класса А. Если в классе А сеть задается одним октетом, а остальные три октета
определяют хост, то в адресном пространстве класса С три октета используются для
идентификации сети, а хост задается всего одним октетом.
Первые три бита первого октета адреса класса С равны ПО, что соответствует
десятичному числу 192 A28+64). Таким образом, это число определяет нижнюю
границу адресного пространства класса С. Третий бит соответствует десятичному
числу 32. Равенство этого бита нулю определяет верхнюю границу адресного
пространства. После исключения третьего бита максимальное значение октета
остается равным 223, то есть 225-32. Таким образом, IP-адреса класса С лежат
в интервале от 192.0.0.0 до 223.255.255.255.
Последний октет используется для идентификации хоста. Теоретически
IP-адрес класса С способен поддерживать до 256 уникальных хостов (от 0 до 255), но
на практике остается всего 254 адреса, поскольку значения 0 и 255
зарезервированы. Максимальное количество сетей класса С равно 2 097 150.
ПРИМЕЧАНИЕ
В схеме адресации протокола IP идентификаторы хостов, все компоненты которых равны 0 или
255, зарезервированы. IP-адрес, у которого все биты идентификатора хоста равны 0, определяет
всю сеть. IP-адрес, у которого все биты адреса хоста равны 1, используется для групповой рассылки
по всем системам, входящим в заданную сеть.
Структура IP-адреса класса С представлена на следующем рисунке.
Сеть Хост
Октет 12 3 4
Класс D
Класс D создавался для поддержки групповой рассылки в сетях IP. Этот
механизм используется приложениями, построенными на основе активной рассылки
сообщений группам узлов. Групповой (multicast) адрес представляет собой
уникальный сетевой адрес, отправленные по которому пакеты направляются
заранее определенной группе IP-адресов. Таким образом, одна станция может
сгенерировать серию пакетов, которые будут маршрутизированы нескольким
получателям одновременно. Такой подход гораздо эффективнее, чем создание
отдельной серии пакетов для каждого получателя. Групповая рассылка в сетях IP
давно считается полезным средством из-за заметного снижения сетевого трафика.
Протокол IPv6 также использует групповую рассылку во многих аспектах своей
работы.
Адресное пространство класса D, как и остальные адресные пространства,
ограничено. Первые четыре бита адреса класса D должны быть равны 1110.
Установка первых трех бит первого октета означает, что адресное пространство
начинается с 128+64+32, то есть 224. Исключение четвертого бита означает,
что адреса класса D ограничиваются максимальным значением 128+64+32+8+
+4+2+1=239. Таким образом, IP-адреса класса D лежат в интервале от 224.0.0.0
до 239.255.255.255.
На первый взгляд этот интервал выглядит несколько странно, если учесть,
что верхняя граница задается всеми четырьмя октетами. В обычной
интерпретации это означало бы, что октеты, содержащие идентификаторы хоста и сети,
совместно определяют идентификатор сети. Однако для этого есть причины!
Адресное пространство класса D не используется для связи с отдельными
хостами или сетями.
Адреса класса D предназначены для доставки сообщений группе хостов с IP-
адресами в частных сетях. Следовательно, делить адрес на адреса сети и хоста
по октетам или битам нет смысла. Вместо этого все адресное пространство
используется для идентификации групп IP-адресов (классов А, В и С). В наши
дни предложено несколько новых схем, позволяющих выполнять групповую
рассылку в сетях IP без сложностей, связанных с использованием адресного
пространства класса D.
Структура IP-адреса класса D представлена на следующем рисунке.
Хост
Октет 12 3 4
Класс Е
Адреса класса Е были определены, но IETF зарезервировала их для
собственных исследований, поэтому в Интернете адреса класса Е не выделялись. Первые
четыре бита в адресе класса Е всегда содержат единицы; следовательно,
IP-адреса класса Е лежат в интервале от 240.0.0.0 до 255.255.255.255. Поскольку этот
класс был определен для исследовательских целей, а его использование
ограничивается рамками IETF, дальнейшее изучение этих адресов не обязательно.
Недостатки схемы адресации IPv4
В результате больших различий между количествами IP-адресов в классах
многие потенциальные адреса оставались неиспользованными. Для примера
рассмотрим компанию среднего размера, которой требуется 300 IP-адресов. Одной сети
касса С B54 адреса) недостаточно. В двух сетях класса С адресов более чем
достаточно, но это приводит к созданию двух отдельных сетей в компании и как
следствие — увеличению размеров таблиц маршрутизации в Интернете (для
каждого адресного пространства в таблице создается отдельная запись, даже
если они принадлежат одной организации).
Другой вариант: назначение сети класса В предоставляет все необходимые
адреса в одном домене, но при этом 65 234 адреса остаются неиспользуемыми.
Раньше адреса класса В слишком часто раздавались любым сетям, содержащим
более 254 хостов. Из-за этого адресное пространство класса В стало истощаться
быстрее, чем в других классах.
Возможно, наиболее расточительной практикой была раздача адресных
пространств по запросу. Любая организация, которой требовалось адресное
пространство, просто запрашивала его и заполняла анкету с указанием количества
сетей и хостов в сети. Никто не пытался проверять заявленные цифры, и
многие организации блокировали большие части адресного пространства IPv4
просто на случай, если в будущем возникнет какая-нибудь непредвиденная
потребность.
К счастью, сейчас эта проблема осталась в прошлом. Были разработаны
многочисленные расширения IP, специально предназначенные для повышения эффек-
тивности использования 32-разрядного адресного пространства. Самыми
важными являются следующие расширения:
О Маски подсетей.
О Маски подсетей переменной длины (VLSM, Variable Length Subnet Masks).
О CIDR.
Эти разные механизмы разрабатывались для решения разных проблем. Маски
подсетей фиксированной и переменной длины разрабатывались для того, чтобы
в одной физической сети, подключенной к Интернету, могли существовать
несколько логических сетей. Маски более подробно описаны ниже, в разделе «Маски
подсети переменной длины» этой главы.
Механизм CIDR (Classless InterDomain Routing) предназначался для того,
чтобы ликвидировать неэффективность исходной жесткой схемы разбиения
адресов на классы. Это позволило маршрутизаторам объединять несколько
разных сетевых адресов в одну запись таблицы маршрутизации.
Учтите, что эти два механизма не являются взаимоисключающими; они
могут и должны использоваться вместе.
ПРИМЕЧАНИЕ
Стабильная работа Интернета напрямую зависит от уникальности сетевых адресов, находящихся
в широком использовании. Следовательно, был необходим механизм, который бы гарантировал
эту уникальность. На первых порах ответственность за проверку была возложена на организацию
InterNIC (Internet Network Information Center). Затем эта организация прекратила существование,
а ее обязанности были переданы IANA. Потом агентство IANA также было ликвидировано, и новым
хранителем имен и адресов Интернета стала Корпорация по выделению имен и параметров
протоколов Интернета (ICANN). В настоящее время ICANN создает структуру конкурентной регистрации,
которая позволит коммерческим организациям конкурировать друг с другом за имена и адреса IP.
При этом очень важно проследить за тем, чтобы не происходило дублирование адресов массового
пользования. Дублирование нарушит нормальную работу Интернета и помешает доставке пакетов
по повторяющимся адресам.
Хотя сетевой администратор может произвольно выбрать незарегистрированный IP-адрес,
поступать подобным образом не рекомендуется. Нормальный доступ к хостам с фиктивными
IP-адресами будет возможен только в пределах сети, к которой принадлежат эти хосты. Подключение
к Интернету сетей, содержащих фиктивные адреса, создает потенциальную опасность конфликтов
с организациями, которым это адресное пространство принадлежит по праву. Дублирование
адресов создает проблемы с маршрутизацией и мешает доставке пакетов в правильную сеть.
При наличии брандмауэра в частных сетях могут использоваться дублирующиеся адреса, поскольку
в результате преобразования вместо адресов частной сети подставляется адрес открытого
интерфейса брандмауэра. В этом случае адрес частной сети может иметь дубликат в Интернете.
Некоторые адреса — а точнее, один адрес класса А A0.0.0.0), 16 адресов класса В A72.16.0.0- 172.31.0.0)
и 256 адресов класса С A92.168.0.0-192.168.255.0) — зарезервированы для закрытого
использования в частных сетях.
Специальные IP-адреса
В схеме адресации IP определено несколько специальных адресов. В RFC 1700
приводится специальная запись для представления специальных IP-адресов:
IP-адрес ::= { <идентификатор-сети>, <идентификатор-хоста> }
В этой записи IP-адрес определяется парой чисел: идентификатором сети
и идентификатором хоста.
Значение «-1» означает, что поле заполнено единицами, а значение «О»
указывает на то, что поле заполнено нулями.
Определены следующие специальные IP-адреса:
О { < идентификатор-сети >, 0 }
О { < идентификатор-сети>, -1 >
О { -1, -1 }
О { 0, 0 }
О { 0, <идентификатор-хоста > }
О { 127, < произвольно }
Адреса, в которых поле <идентификатор-хоста> заполнено только нулями или
единицами, не могут использоваться в качестве самостоятельных IP-адресов.
Следовательно, если номер хоста состоит из N бит, для назначения в сети
свободно только 2N - 2 IP-адресов.
Специальные адреса рассматриваются в нескольких ближайших подразделах.
Кроме специальных адресов, перечисленных выше, специальные адреса также
применяются при широковещательной рассылке в подсетях. В этой вводной главе,
содержащей общие сведения об адресации IP, подсети не рассматриваются.
Адресация сети
Хосту TCP/IP не может быть присвоен идентификатор, состоящий из одних
нулей. IP-адреса с нулевым идентификатором хоста обозначают всю сеть.
Специальные адреса этой категории обозначаются записью
{ <идентификатор-сети>, 0 }
Возьмем IP-адрес 137.53.0.0, принадлежащий сети класса В. Как говорилось
выше, в сетях класса В поле <идентификатор-сети> занимает 16 бит B байта, или
первые два десятичных числа в десятичной записи с точечным разделением),
а <идентификатор-хоста> — оставшиеся 16 бит адреса. Следовательно,
специальный адрес 137.53.0.0 определяет всю сеть класса В 137.53.
В адресах класса В 137.53.0.0 и 141.85.0.0 идентификатор хоста равен «0.0».
Таким образом, эти адреса определяют все узлы, входящие в сеть. Адреса {
<идентификатор-сети >, 0 } не могут использоваться в качестве адресов отправителя
или получателя.
Направленная широковещательная рассылка
Идентификатор хоста, заполненный единицами, является признаком адреса
направленной широковещательной рассылки. Такие адреса могут указываться в
дейтаграммах IP как адреса получателя, но ни при каких условиях — как адреса
отправителя. Этот специальный адрес обозначается записью
{ <идентификатор-сети>, -1 }
Адрес направленной широковещательной рассылки описывает все узлы,
входящие в заданную сеть. Таким образом, для сети 137.53 адрес
широковещательной рассылки имеет вид 137.53.255.255. Сеть 137.53 относится к классу В, поле
<идентификатор-хоста> в этом классе занимает 16 бит B байта, или два
последних десятичных числа в десятичной записи с точечным разделением). Если все
16 бит поля < идентификатор-хоста> заполняются единицами, результат
соответствует десятичному значению 255.255.
В примере с сетью 137.53 сетевое оборудование обеспечивает эффективное
выполнение рассылки на аппаратном уровне. В других сетях (например, типа
«точка-точка») эффективная аппаратная поддержка рассылки отсутствует. В этом
случае рассылка реализуется на уровне программных средств IP за счет
дублирования дейтаграммы IP по всем возможным получателям.
Данные направленной рассылки отправляются в сеть, заданную полем <иден-
тификатор-сети>. Если настройка маршрутизаторов разрешает пропускать
направленную рассылку, дейтаграмма IP передается последнему маршрутизатору,
подключенному к итоговой сети с заданным идентификатором. Маршрутизатор
обязан разослать дейтаграмму IP всем узлам сети. Если в итоговой сети
предусмотрена соответствующая аппаратная поддержка, она задействуется для
рассылки дейтаграммы IP.
Если рассылка в других сетях запрещена, маршрутизатор можно настроить
так, чтобы он не пропускал направленную рассылку.
Ограниченная рассылка
Адрес 255.255.255.255 представляет рассылку другого типа — так называемую
ограниченную, или локальную рассылку. Специальный адрес определяется записью
{ -1. -1 }
Ограниченная рассылка может применяться в локальных сетях, когда
рассылаемые дейтаграммы не выходят за пределы маршрутизатора.
При направленной рассылке отправитель должен задать идентификатор сети.
Если рассылка выполняется внутри локальной сети, можно воспользоваться
ограниченной рассылкой, для которой знать идентификатор не обязательно.
Адрес ограниченной рассылки никогда не может указываться как IP-адрес
отправителя; допускается только его использование вместо адреса получателя.
Нулевой IP-адрес
Нулевой IP-адрес представляет собой специальный адрес вида
{ 0. 0 }
Идентификатор сети равен нулю, что соответствует текущей сети. Нулевой
идентификатор хоста представляет текущий хост. Обычно этот специальный
адрес используется тогда, когда узел IP пытается определить собственный
IP-адрес. Например, узлы сети могут использовать протокол ВООТР для назначения
IP-адреса с центрального сервера ВООТР.
При отправке исходного запроса серверу ВООТР узел IP еще не знает свой
IP-адрес и поэтому указывает в адресе отправителя нулевые идентификаторы
узла и хоста. После того как узел узнает свой IP-адрес, он перестает
использовать адрес 0.0.0.0.
Адрес 0.0.0.0 также используется в таблицах маршрутизации для
обозначения IP-адреса маршрутизатора по умолчанию (часто называемого основным
шлюзом).
IP-адрес 0.0.0.0 может использоваться только как отправитель и никогда
не указывается в качестве получателя. Учтите, что в некоторых устаревших
системах адрес, состоящий из одних нулей, используется для локальной
рассылки.
IP-адрес хоста в текущей сети
Если идентификатор сети равен нулю, а идентификатор-хоста отличен от нуля,
адрес относится к заданному хосту в текущей сети.
{ 0, <идентификатор-хоста> }
Если узел сети получает пакет, у которого в IP-адресе получателя
идентификатор сети равен нулю, а идентификатор хоста совпадает с его собственным
идентификатором хоста, узел принимает этот пакет. В этом случае нулевой
идентификатор сети интерпретируется как признак текущей сети.
Обратная связь
Идентификатор сети 127 зарезервирован для адресов обратной связи. Адресом
обратной связи называется специальный адрес вида
{ 127, <произвольно> }
Любой пакет, отправленный приложением TCP/IP по адресу 127.ХХ.Х, где
X — число от 0 до 255, не достигает передающей среды и возвращается
приложению. Пакет копируется из буфера передачи в буфер приема на том же
компьютере, поэтому IP-адрес 127.ХХХ называется адресом обратной связи. Адрес
обратной связи позволяет быстро проверить правильность конфигурации
программных средств TCP/IP. Например, при помощи утилиты ping можно убедиться
в том, что программы уровня IP работают на некотором базовом уровне. Утилита
ping посылает эхо-пакет ICMP по заданному IP-адресу (в данном случае — по
адресу обратной связи). Уровень IP поэтому отвечает на входящий эхо-пакет
и отправляет ответный пакет ICMP.
Обратная связь бывает полезной и в других ситуациях — например, когда
клиент работает на одном компьютере со службой TCP/IP. В этом случае к службе
можно обратиться по адресу обратной связи. Например, типичные команды для
подключения к серверу Telnet или FTP, находящемся на одном компьютере с
клиентом, выглядят так:
telnet 127.0.0.1
ftp 127.0.0.1
Исключение в схеме адресации IP
Выше упоминалось о том, что идентификатор хоста, состоящий из одних
единиц, используется для широковещательной рассылки. Важным исключением
из этого правила составляют программные средства TCP/IP, произошедшие от
BSD 4.2. Многие коммерческие реализации создавались на базе BSD 4.2. При
использовании очень старых программ TCP/IP вы можете столкнуться с этим
исключением.
В BSD Unix для задания адреса широковещательной рассылки
идентификатор хоста заполнялся нулями. На момент написания BSD 4.2 в документах RFC
недостаточно четко определялись правила широковещательной адресации.
Недостаток был исправлен в более поздних RFC, где было сказано, что в адресах
широковещательной рассылки идентификатор хоста должен заполняться
единицами. Версия BSD 4.3 была модифицирована в соответствии с RFC. Программы,
написанные для BSD 4.2 и не исправленные впоследствии, могут использовать
схему с нулями. Если хосты, использующие нули в широковещательных
адресах, находятся в одной физической сети с хостами, использующими единицы,
механизм широковещательной рассылки может работать не так, как ожидается,
что приведет к ошибкам в работе приложений TCP/IP в этой сети.
Появление подсетей
Первоначально в Интернете использовалась двухуровневая иерархия, а адреса
состояли только из идентификаторов сети и хоста. На рис. 4.1 изображена
небольшая и простая двухуровневая сеть. Подобная иерархия предполагает, что
в каждом подразделении работает только одна сеть. Следовательно, для каждого
подразделения достаточно одного подключения к Интернету. На первых порах
эти предположения были вполне реальными, но постепенно сети развивались
и расширялись. В 1985 году уже нельзя было с уверенностью предполагать, что
организация использует только одну сеть или будет довольствоваться одним
подключением к Интернету.
По мере появления подразделений с несколькими сетями появилась очевидная
необходимость в механизме, который бы различал логические сети, создаваемые
в подразделениях второго уровня Интернета. Отсутствие такого механизма делало
невозможной эффективную маршрутизацию данных в подразделениях с
несколькими сетями. Ситуация продемонстрирована на рис. 4.2.
Одно из возможных решений заключалось в предоставлении каждой
логической сети (или подсети) отдельного диапазона IP-адресов. Такое решение
работает, но оно привело бы к чрезвычайно неэффективному использованию
адресного пространства IP. По прошествии некоторого времени все
нераспределенные адреса IP были бы полностью исчерпаны. Еще быстрее проявилось бы
другое последствие — увеличение объема таблиц на маршрутизаторах Интернета,
поскольку каждой сети потребовалась бы отдельная запись в таблице
маршрутизации. Очевидно, приходилось искать более удачное решение.
Маршрутизатор А. 1 Маршрутизатор В. 1
ВЯвЯЯ ИВВЯН ИшиВД ПЯ85И
ifiitiri I.! Щш А I' ЮЙ "I
„ ,-,.,L Ш1 Ш л^л
Сервер А.2 Сервер А.З Сервер В.2 Сервер В.З
Рис. 4.1. Первоначальная двухуровневая иерархия Интернета
Было решено произвести иерархическую группировку логических сетей и
организовать маршрутизацию между ними. С точки зрения Интернета
подразделение с несколькими логическими сетями интерпретируется как одна сеть, а
следовательно, использует единый диапазон IP-адресов. Тем не менее каждой сети
требовался свой уникальный диапазон адресов.
Подсети
В середине 1980-х годов были выпущены RFC 917 и 950. В этих документах
предлагалось решение постоянно нарастающих проблем, обусловленных
относительно плоской, двухуровневой иерархией IP-адресов. Таким решением стали
подсети (subnets). Концепция подсети была основана на необходимости третьего
уровня в иерархии Интернета. По мере развития межсетевые технологии
становились все более распространенными и использовались все чаще. В результате
наличие нескольких сетей в средних и крупных организациях стало обычным
явлением. Часто эти сети были локальными. Каждая локальная сеть может
интерпретироваться как подсеть.
В таких многосетевых средах каждая подсеть подключалась к Интернету
через общую точку — маршрутизатор. Подробности строения сетевой среды для
Интернета были несущественными. Суть оставалась неизменной: имеется
некоторая частная сеть, обеспечивающая доставку своих дейтаграмм. Таким образом,
Интернету оставалось позаботиться лишь о том, как связаться со шлюзовым
маршрутизатором этой сети через Интернет. Внутри частной сети хостовая часть
IP-адреса проходила дополнительное деление для идентификации подсети.
Маршрутизатор А. 1 Маршрутизатор В. 1
!• ш\ • в • и; • ш\ • ш\
Сервер А.2 Сервер А.З Сервер В.2 Сервер В.З / Сервер С.4
( Token-ring j
crgfl \
Сервер С.2 = 1
Сервер С.З
Рис. 4.2. Нарушение двухуровневой иерархии Интернета в многосетевых подразделениях
Как сказано в RFC 950, сеть любого из трех классов (А, В, С) может делиться
на подсети. IP-адрес хоста в подсети в действительности состоит из трех
компонентов:
О Идентификатор сети.
О Идентификатор подсети.
О Идентификатор хоста.
Идентификаторы подсети и хоста содержатся в идентификаторе хоста
исходного IP-адреса. Таким образом, возможность создания подсетей напрямую
зависит от типа IP-адреса. Чем больше бит содержит хостовая часть IP-адреса, тем
больше подсетей и хостов можно создать. Тем не менее создание подсетей
уменьшает количество адресуемых хостов. Фактически вы забираете часть битов хос-
тового идентификатора для идентификации подсети. При этом используется
специальный псевдоадрес IP, называемый маской подсети.
Маска подсети представляет собой 32-разрядное двоичное число, которое
может выражаться в десятичной записи с точечным разделением. Маска сообщает
конечным системам сети (включая маршрутизаторы и другие хосты), какие биты
IP-адреса используются для идентификации сети и подсети. Эти биты называются
расширенным сетевым префиксом. Остальные биты идентифицируют хосты в
подсети. Биты маски, идентифицирующие сеть, равны 1, а хостовые биты равны 0.
Например, маска 11111111.11111111.11111111.11000000 B55.255.255.192 в
десятичной записи) позволяет использовать 64 хостовых идентификатора в подсети.
Значения шести правых битов (нулевых битов маски) в десятичном
представлении равны 64. Следовательно, в этой подсети можно однозначно
идентифицировать не более 64 устройств. Реально использоваться могут лишь 62
идентификатора, два оставшихся зарезервированы. Первый идентификатор хоста в подсети
всегда резервируется для идентификации самой подсети. Последний
идентификатор тоже резервируется для использования в широковещательных рассылках.
Помните, что максимальное количество реально используемых идентификаторов
хостов в подсети всегда на два меньше максимального количества хостов.
Однако количество возможных подсетей зависит от класса адреса IP. В
разных классах для идентификатора сети резервируется разное количество битов,
поэтому количества битов, используемых для определения подсети, тоже
различаются. В табл. 4.3 продемонстрировано отношение между количеством подсетей
и количеством хостов в подсети для IP-адресов класса В. В адресах класса В 16 бит
определяют сеть, а другие 16 бит определяют хост. Из таблицы видно, что
наименьшее количество битов сетевого префикса равно 2, а наибольшее равно 14.
Причина проста: сетевой префикс из одного бита позволяет определить всего два
идентификатора подсети, 0 и 1. Исходные правила определения подсетей
запрещали использовать идентификаторы подсетей, состоящие только из одних
нулей или единиц. Тем не менее многие коммерческие маршрутизаторы разрешали
использовать такие идентификаторы подсетей. Один из последующих RFC A812)
внес ясность в этот вопрос. Сейчас использование идентификаторов подсетей,
состоящих только из нулей или единиц, разрешено, хотя во многих старых книгах
утверждается, что такие идентификаторы недопустимы.
Сетевой префикс из 2 битов позволяет определить четыре идентификатора
подсети: 00, 01, 10 и И.
Таблица 4.3. Определение подсетей в адресном пространстве класса В
Размер Маска Количество Количество
префикса подсети используемых используемых
в битах подсетей хостов в подсети
2 255.255.192.0 4 16 382
3 255.255.224.0 8 8190
Размер Маска Количество Количество
префикса подсети используемых используемых
в битах подсетей хостов в подсети
4 255.255.240.0 16 4094
5 255.255.248.0 32 2046
6 255.255.252.0 64 1022
7 255.255.254.0 128 510
8 255.255.255.0 256 254
9 255.255.255.128 512 126
10 255.255.255.192 1024 62
11 255.255.255.224 2048 30
12 255.255.255.240 4096 14
13 255.255.255.248 8192 6
14 255.255.255.252 16 384 2
Из таблицы ясно видно, что чем больше битов выделяется на
идентификацию подсети, тем меньше битов остается на идентификацию хоста, и наоборот.
В сетях класса С тоже могут создаваться подсети. Так как в адресах класса С
сеть идентифицируется 24 битами, на идентификацию подсети и хоста остается
всего 8 бит. Разные варианты распределения битов при идентификации подсети
и хоста в сети класса С представлены в табл. 4.4.
Таблица 4.4. Определение подсетей в адресном пространстве класса С
Размер Маска Количество Количество
префикса подсети используемых используемых
в битах подсетей хостов в подсети
2 255.255.255.192 4 62
3 255.255.255.224 8 30
4 255.255.255.240 16 14
5 255.255.255.248 32 6
6 255.255.255.252 64 2
Хотя табл. 4.3 и 4.4 показывают отношение между количеством возможных
подсетей и хостов в подсети, однако они не дают представления о том, как же
работают подсети. Работу механизма подсетей лучше всего продемонстрировать
на примере конкретного IP-адреса, как это сделано в следующем разделе.
Пример использования подсети
Из всех аспектов схемы адресации IP новичкам обычно бывает труднее всего
разобраться именно с подсетями. В основном это связано с тем, что работа под-
сети выглядит логично лишь в двоичном представлении, не особенно удобном
для человеческого восприятия. Допустим, вам потребовалось определить
подсеть для адреса класса С 193.168.125.0. Это базовый адрес, используемый при
построении маршрутов в Интернете. Если вы захотите разбить его на восемь
подсетей, по крайней мере три из 8 битов идентификатора хоста придется
выделить на создание уникального префикса для каждой из восьми подсетей: 000,
001, 010, 011, 100, 101, 110 и 111. Последний октет адреса разбивается на две
части: 3 бита добавляются к идентификатору сети и образуют расширенный
сетевой префикс, а оставшиеся 5 битов используются для идентификации хостов.
Формирование адресов подсетей продемонстрировано в табл. 4.5.
В табл. 4.5 расширенные сетевые префиксы (состоящие из идентификатора
сети IP и идентификатора подсети) выделены жирным шрифтом.
Идентификаторы подсети дополнительно оформлены курсивом. Идентификаторы хостов
выводятся нормальным шрифтом и отделяются от расширенного сетевого
префикса дефисом. Такая система обозначений помогает понять, как происходит
деление базовых сетевых IP-адресов на подсети.
Таблица 4.5. Формирование подсетей
Сеть Двоичный адрес Десятичный адрес
Базовая 11000001.10101000.01111101.00000000 193.168.125.0
Подсеть 0 11000001.10101000.01111101.000 00000 193.168.125.0
Подсеть 1 11000001.10101000.01111101.001 00000 193.168.125.32
Подсеть 2 11000001.10101000.01111101.010-00000 193.168.125.64
Подсеть 3 11000001.10101000.01111101.011-00000 193.168.125.96
Подсеть 4 11000001.10101000.01111101.100 00000 193.168.125.128
Подсеть 5 11000001.10101000.01111101.101-00000 193.168.125.160
Подсеть 6 11000001.10101000.01111101.110-00000 193.168.125.192
Подсеть 7 11000001.10101000.01111101.111 00000 193.168.125.224
Идентификатор подсети определяется первыми тремя битами последнего
октета. Десятичные представления этих цифр равны 128, 64 и 32 соответственно.
В третьем столбце приводятся начальные IP-адреса каждой подсети. Как и
следовало ожидать, они увеличиваются с приращением 32 (крайний правый бит в
идентификаторе подсети).
ПРИМЕЧАНИЕ
Подсети 0 и 7 возможны с математической точки зрения, но когда-то они были запрещены даже
при наличии соответствующих записей на маршрутизаторе. Сейчас такие идентификаторы
подсетей разрешены, их идентификаторы подсетей равны 000 и 111 соответственно.
Хосты в каждой подсети определяются оставшимися пятью битами
последнего октета. Существуют 32 возможные комбинации из пяти нулей и единиц;
минимальное и максимальное значения зарезервированы, для использования
остается до 30 хостов в каждой подсети. Устройство с IP-адресом 193.168.125.193
будет первым хостом, определенным в подсети 6. Дальше нумерация хостов
продолжается до 193.168.125.222, и на этом подсеть окончательно заполняется.
Дальнейшее включение хостов в нее становится невозможным.
Маски подсети переменной длины
Хотя механизм определения подсетей стал ценным усовершенствованием схемы
адресации в Интернете, ему был присущ один принципиальный недостаток: вся
сеть ограничивалась одной маской подсети. Таким образом, после выбора маски
подсети (определяющей количество хостов в подсети) вы уже не могли
организовать поддержку подсетей другого размера. Если размер подсети требовалось
увеличить, приходилось изменять маску для всей сети. Не стоит и говорить, что
это весьма сложная и длительная процедура.
Решение этой проблемы было предложено в 1987 году. IETF опубликовала
документ RFC 1009, в котором определялся механизм поддержки нескольких
масок в одной подсети. На первый взгляд эти маски подсетей имели разные
размеры, но их нельзя было считать разными масками — сетевые префиксы были
идентичны. Из-за этого новой методике определения подсетей было присвоено
название «масок подсетей переменной длины» VLSM (Variable Length Subnet
Masks).
VLSM повышает эффективность использования адресного пространства IP
в границах организации, поскольку сетевому администратору предоставляется
возможность настройки маски по конкретным требованиям каждой подсети.
Для наглядности предположим, что у нас имеется базовый IP-адрес 172.16.0.0.
Это адрес класса В, в котором используется 16-разрядный идентификатор
подсети. В результате расширения сетевого префикса на 6 бит создается
22-разрядный расширенный сетевой префикс. С математической точки зрения существует
64 идентификатора подсетей, каждая из которых содержит до 1022 хостов.
Подобная схема вполне разумна, если организации требуется более 30
подсетей с более чем 500 хостами в каждой. Тем не менее, если организация состоит
из нескольких больших филиалов, сети которых содержат более 500 хостов, и
множества мелких филиалов с 40-50 хостами, многие потенциально возможные
адреса останутся неиспользованными. Каждому филиалу независимо от его
потребностей будет выделена подсеть с 1022 хостами, и каждый мелкий филиал
будет попусту расходовать около 950 адресов. При использовании одной маски
подсети фиксированной и заранее определенной длины подобное расходование
адресов неизбежно.
Теоретически механизм определения подсетей был идеальным решением
серьезной проблемы быстрого истощения конечного адресного пространства IP.
Возможность разбиения идентификатора хоста в IP-адресе на идентификаторы
подсети и хоста значительно сократила бесполезное расходование IP-адресов.
К сожалению, в реальном мире потребности в подсетях носят неравномерный
характер. Нельзя ожидать, что организация или все ее сети будут делиться на
субкомпоненты равного размера. Гораздо более вероятна ситуация, при которой
потребуется создавать филиалы (и подсети) любых размеров, и применение
маски подсети фиксированной длины приведет к напрасному расходу
IP-адресов, как в предыдущем примере.
ПРИМЕЧАНИЕ
Размер расширенного сетевого префикса указывается после символа / в конце IP-адреса. Таким
образом, запись 193.168.125.0/27 обозначает адрес класса С, в котором расширенный сетевой
префикс занимает 27 битов.
Для решения этой проблемы было разрешено гибкое создание подсетей в
адресном пространстве IP с возможностью определения сетевых масок переменного
размера. Так, в предыдущем примере сетевой администратор может разбить
базовый IP-адрес на маски подсетей разного размера. Несколько крупных
филиалов могут продолжить использование 22-разрядных сетевых префиксов, а мелким
филиалам может быть назначен 25- или 26-разрядный префикс. 25-разрядный
префикс позволит создавать подсети, содержащие до 126 хостов, а 26-разрядный
префикс ограничивает размер сети 62 хостами. Методика, на которой основано
решение, называется VLSM.
CIDR
Механизм бесклассовой междоменной маршрутизации CIDR (Classless Interdomain
Routing) принадлежит к числу относительно новых дополнений схемы
адресации IP. Он был порожден кризисом, который сопровождал период бурного роста
Интернета в начале 1990-х годов.
Еще в 1992 году участники IETF были обеспокоены способностью Интернета
масштабироваться в соответствии с потребностью в его использовании. Особую
озабоченность вызывали следующие проблемы:
О Исчерпание резерва оставшихся сетевых адресов IPv4. Особенно серьезная
угроза исчерпания существовала для адресного пространства класса В.
О Быстрый и существенный рост размеров таблиц маршрутизации в результате
расширения Интернета.
Все признаки указывали на то, что по мере подключения новых коммерческих
предприятий быстрый рост Интернета продолжится.. Более того, некоторые члены
IETF даже предсказывали наступление «Судного дня» в марте 1994 года, когда
должно было произойти предполагаемое исчерпание адресного пространства
класса В. Отсутствие других механизмов адресации представляло серьезную угрозу
для масштабируемости Интернета. Еще более угрожающе выглядела
перспектива того, что механизмы маршрутизации в Интернете рухнут еще до наступления
«Судного дня» под весом постоянно увеличивающихся таблиц маршрутизации.
Интернет становился жертвой собственной популярности. В IETF решили,
что для предотвращения краха Интернета необходимы как краткосрочные, так
и долгосрочные меры. В перспективе единственным приемлемым решением была
абсолютно новая версия IP со значительно расширенным адресным пространством
и схемой адресации. В итоге это решение стало известно под названием IPng
(Internet Protocol: Next Generation) или более формально — IP версии 6 (IPv6).
Более неотложное, краткосрочное решение требовало замедлить раздачу
существующих свободных адресов. Оно было основано на исключении
неэффективных классов адресов в пользу более гибкой архитектуры адресации.
Результатом стал механизм CIDR. В сентябре 1993 года проект CIDR был опубликован
в документах RFC 1517, 1518, 1519 и 1520.
CIDR обладает рядом ключевых аспектов, которые оказались бесценными для
замедления процесса опустошения адресного пространства:
О Исключение классовой адресации.
О Расширенное агрегирование маршрутных данных.
О Суперсети.
Общим эффектом этих нововведений стало устаревание схемы классовой
адресации. Возможно, такие адреса все еще используются в отдельных местах, но
бесклассовые адреса (несмотря на негативные ассоциации!) обладают гораздо
большей эффективностью.
Бесклассовая адресация
С математической точки зрения адресное пространство IPv4 все еще содержало
значительное количество свободных адресов. К сожалению, многие из этих
потенциальных адресов оказались заблокированными в назначенных блоках (или
классах) назначаемых адресов. Ликвидация классов не обязательно приводит к
возвращению адресов, заблокированных в уже выделенных адресных
пространствах, но значительно повышает эффективность использования оставшихся
адресов. Ожидается, что эта временная мера обеспечит время, необходимое на
разработку и запуск в эксплуатацию протокола IPv6.
Расширенное агрегирование маршрутных данных
CIDR позволяет маршрутизаторам Интернета (а также любым CIDR-совмес-
тимым маршрутизаторам) более эффективно использовать агрегирование
маршрутных данных. Другими словами, одна запись в таблице маршрутизации
может представлять адресные пространства нескольких сетей. Это
обстоятельство существенно уменьшает объем таблиц маршрутизации в каждом
конкретном межсетевом образовании, что непосредственно способствует улучшению
масштабируемости.
Механизм CIDR был реализован в Интернете в 1994-1995 годах и
немедленно оказался эффективным средством против разрастания таблиц
маршрутизации. Если бы не CIDR, вряд ли Интернет продолжал бы расти прежними
темпами.
Суперсети
К числу преимуществ CIDR также относится возможность использования
суперсетей. Суперсеть представляет собой не что иное, как несколько смежных блоков
адресных пространств класса С, имитирующих одно адресное пространство
большего размера. Если вам удастся получить достаточно смежных блоков адресов
класса С, вы сможете переопределить распределение битов между
идентификаторами хоста и сети и имитировать сеть класса В.
Суперсети проектировались как временная мера борьбы с быстрым
исчерпанием адресного пространства класса В, которая предоставляла в распоряжение
пользователей более гибкую альтернативу. Использовавшаяся ранее классовая
схема адресации страдала от огромных различий в масштабах сетей классов В
и С. Если размер сети превышал ограничение в 254 хоста, установленное для
класса С, приходилось выбирать один из двух вариантов, каждый из которых
оставлял желать лучшего:
О Использование нескольких сетей класса С (с необходимостью
маршрутизации между сетевыми доменами).
О Переход на сеть класса В с 65 534 возможными хостами.
Чаще использовалось второе, более простое решение, несмотря на то, при нем
напрасно расходовались десятки тысяч IP-адресов.
Принцип работы CIDR
Механизм CIDR нарушил старые традиции и ознаменовал полный отказ от
жесткой схемы классовой адресации. В исходной схеме адресации IPv4 в адресах
класса А используется 8-разрядный идентификатор сети, в адресах класса В —
16-разрядный, а в адресах класса С — 24-разрядный идентификатор сети.
Механизм CIDR заменил эти категории обобщенным сетевым префиксом
произвольной длины, не обязательно кратной 8 битам. В результате появилась
возможность планировать адресные пространства сетей в соответствии с размерами
сети, вместо того чтобы принудительно подгонять сети под адресные
пространства заранее определенного размера.
Каждый CIDR-совместимый сетевой адрес описывается битовой маской,
определяющей длину сетевого префикса. Например, запись 192.125.61.8/20 обозначает
адрес CIDR с 20-разрядным идентификатором сети. Теперь допускается
использование любых IP-адресов независимо от того, к какому классу они принадлежали:
А, В и С! Маршрутизаторы с поддержкой CIDR определяют идентификатор сети
по числу, следующему за /. Таким образом, бывший адрес класса С 192.125.61.8
ранее состоял из идентификатора сети 192.125.61 и идентификатора хоста 8.
В сетях класса С можно было назначить адреса не более чем 254 хостам. При
использовании CIDR ограничения на выравнивание компонентов адреса по
8-разрядной границе снимаются. Чтобы лучше понять, как работает этот механизм,
необходимо преобразовать десятичное представление адреса в двоичную систему.
В двоичном виде сетевая часть этого адреса имеет вид 11000000.01111101.
00111101. Первые 20 бит этой последовательности определяют идентификатор
сети. Разбиение адреса на компоненты продемонстрировано в табл. 4.6.
Таблица 4.6. 20-разрядный идентификатор сети CIDR
Идентификатор сети Идентификатор хоста
Двоичное представление адреса 11000000.01111101.0011 1101.00001000
Обратите внимание: деление адреса на идентификаторы сети и хоста
проходит в середине третьего октета. Биты, не использованные для идентификации
сети, используются для идентификации хоста. Таким образом, в адресе IPv4
с 20-разрядным сетевым префиксом остается 12 бит на идентификацию хоста.
С математической точки зрения 12-разрядное двоичное число позволяет
представить 4094 пригодных к использованию хостов. Поскольку ни один бит в
левой части не должен принимать стандартные значения (ранее необходимые для
идентификации классов), в сети CIDR может использоваться практически весь
диапазон адресов. Следовательно, 20-разрядный сетевой префикс может
принимать значения, ранее зарезервированные для сетей класса А, В и С.
Открытые адресные пространства
Если глобальная сеть (WAN) не подключена напрямую к Интернету или к любой
другой сети, межсетевые адреса могут выбираться произвольно. Вообще говоря,
произвольный выбор межсетевых адресов считается вопиющим проявлением
близорукости и халатности. С учетом сказанного, в мае 1993 года был
опубликован документ RFC 1597, в котором был предложен выход из положения.
RFC 1597 и 1918
RFC 1597 был заменен RFC 1918 в феврале 1996 года. Тем не менее новый
документ ограничивался минимальными изменениями в исходной спецификации.
Самым существенным из этих изменений был отказ от алфавитных классов А,
В и С. Вместо этого в RFC 1919 было выдвинуто предложение об
использовании адресации по схеме CIDR. Как объяснялось в предыдущем разделе, CIDR
не использует классовые адреса. Вместо этого количество битов,
зарезервированных для идентификатора сети, указывается за символом /. Таким образом,
идентификатор 10 класса А записывается в виде 10/8, поскольку только 8 бит
используются для идентификации сети. Что еще важнее, хостовой
идентификатор может начинаться на границе любого бита, в отличие от существовавшей
ранее классовой адресации, при которой начало идентификатора хоста
обязательно выравнивалось по 8-битной границе.
Также были определены и зарезервированы три диапазона адресов, которые
могли использоваться только для внутренних целей, по одному от каждого из
классов IPv4 А, В и С:
О 10.0.0.0-10.255.255.255.
О 172.16.0.0-172.31.255.255.
О 192.168.0.0-192.168.255.255.
Эти диапазоны были зарезервированы IANA для частных сетей. Одно из
положений RFC 1597 гласило, что эти адреса не могут использоваться при
непосредственных обращениях к Интернету. Компании, использовавшие эти адреса
и впоследствии пожелавшие получить выход в Интернет, оказались в трудной
ситуации. Они могли перенумеровать все свои устройства в соответствии с
требованиями IANA или же установить между интрасетью и Интернетом промежуточ-
ное звено — прокси-сервер или преобразователь сетевых адресов NA T (Network
Address Translator). Применение подобных устройств позволило бы компании
продолжить работу с фиктивными адресами без ущерба для доступа к Интернету
(и из него).
Если вы захотите использовать зарезервированные адреса RFC 1597 в своей
интрасети, необходимо учитывать долгосрочные последствия этого решения.
Возможно, со временем вам понадобится подключиться к сетям других
компаний через экстрасеть или через Интернет. В любом из этих случаев уникальность
фиктивных адресов не гарантируется.
Наконец, при использовании адресов из диапазонов, зарезервированных для
частных сетей в RFC 1918, вы по-прежнему должны гарантировать уникальность
адресов устройств в рамках домена закрытой сети. Адреса ни будут уникальными
в глобальном отношении, но они должны быть уникальны хотя бы локально.
Адресация в частных сетях
Для снижения потребности в новых IP-адресах в марте 1994 года был
опубликован документ RFC 1597, посвященный назначению IP-адресов в частных
сетях. Частными (private) называются сети, не подключенные к другой сети или
содержащие хосты и службы с ограниченными возможностями взаимодействия
с Интернетом. Хосты частных сетей делятся на три категории:
О Хосты, не нуждающиеся в доступе к Интернету.
О Хосты, нуждающиеся в доступе к ограниченному набору внешних служб —
электронной почте, FTP, новостям, удаленному входу и т. д, которые могут
обрабатываться шлюзом прикладного уровня.
О Хосты, нуждающиеся во внешнем доступе сетевого уровня. Задача решается
средствами IP, и в ее решении должны быть задействованы маршрутизаторы
или хосты, видимые для внешних сетей.
Хостам первой категории могут назначаться IP-адреса, уникальные в
границах частной сети, но не уникальные в Интернете. Такие хосты не обмениваются
пакетами с хостами за пределами частной сети, поэтому проблема дублирования
IP-адресов не возникает.
Для хостов второй категории, изолированных от внешнего доступа в
Интернет шлюзом прикладного уроня, уникальность IP-адресов не обязательна. Это
объясняется тем, что шлюз прикладного уровня маскирует IP-адреса этих
хостов от внешней сети.
Только хостам третьей категории должны назначаться IP-адреса, глобально
уникальные в Интернете.
При ведении нормальной документации по сети идентификация хостов
категорий 1 и 2 выполняется относительно легко. Эти хосты не нуждаются в
подключениях сетевого уровня за пределами корпоративной сети.
В RFC 1597 приводятся следующие примеры хостов категорий 1 и 2:
О Крупный аэропорт с несколькими электронными табло, на которых
отображается время вылета/прибытия, адресуемыми через TCP/IP. Крайне
маловероятно, чтобы к этим табло потребовался прямой доступ из других сетей.
О Крупные организации (такие, как банки и сети розничной торговли)
переходят на TCP/IP в своих внутренних коммуникациях. Локальным рабочим
станциям — кассам, банкоматам и т. д. — внешний доступ обычно не нужен.
О По соображениям безопасности во многих организациях внутренние сети
подключаются к Интернету через шлюзы прикладного уровня (например,
через брандмауэры). Внутренняя сеть обычно не имеет прямого доступа к
Интернету, а из Интернета видны только хосты брандмауэров (один или более).
В этом случае во внутренней сети допускается использование не-уникаль-
ных IP-адресов.
О Если две организации общаются между собой по частному каналу, обычно
каждое из них имеет доступ к очень ограниченному набору хостов на другом
конце канала. Только этим хостам должны назначаться глобально
уникальные IP-адреса.
О Маршрутизаторы частной сети обычно не должны быть напрямую доступны
за пределами организации.
На основании запроса авторов RFC 1597 ICANN зарезервировала для
частных сетей следующие три блока адресного пространства IP, которые могут
назначаться хостам категорий 1 и 2:
О 10.0.0.0-10.255.255.255 - 1 сеть класса А.
О 172.16.0.0-172.31.255.255 - 16 сетей класса В.
О 192.168.0.0-192.168.255.255 - 256 сетей класса С.
Предприятие, желающее использовать IP-адреса из перечисленных адресных
пространствах, может делать это без координации с ICANN или реестра
Интернета. Таким образом, эти адресные пространства могут использоваться многими
предприятиями, что сокращает необходимость в выделении новых
идентификаторов сетей. Адреса в частных сетях уникальны в границах предприятия, но не
в границах сети.
Если предприятие нуждается в глобально-уникальных адресах для
приложений и устройств, подключенных на уровне IP, ему приходится получать такие
адреса от реестра Интернета. ICANN не распределяет IP-адреса из адресного
пространства частных сетей.
Поскольку частные адреса не имеют глобального смысла, маршрутные
данные частной сети не должны выходить за пределы организации.
Маршрутизаторы сетей, не использующих частное адресное пространство (например, сетей
поставщиков услуг Интернета), должны быть настроены таким образом, чтобы
они отвергали маршрутные данные частных сетей. Фильтрация этих данных не
должна сопроволсдаться сообщениями об ошибке протокола маршрутизации.
Чтобы использовать частное адресное пространство, предприятие должно
определить, какие хосты не нуждаются в связи на сетевом уровне. Если для
внешней сети потребуется изменение конфигурации хостов и средств связи
сетевого уровня, должны быть присвоены глобально-уникальные адреса. Иначе
говоря, IP-адреса этих хостов должны быть переведены из частного адресного
пространства в открытое адресное пространство. Если организация не будет
должным образом следить за изменением требований к хостам, она может
случайно создать ситуацию с дублированием IP-адресов. Возможно, по этой
и по некоторым другим причинам в июле 1994 года был выпущен документ
RFC 1627.
Авторы RFC 1627 указывают на то, что рекомендации RFC 1597 уменьшают
надежность и безопасность работы сети и слишком дорого обходятся из-за
множества возникающих проблем. Например, если двум организациям,
использующим частные адресные пространства, потребуется связаться напрямую, по
крайней мере одной из них придется изменить свои назначенные IP-адреса. В RFC
1627 утверждалось, что «RFC 1597 создает иллюзию решения проблемы за счет
формализации традиционно неформальной практики. На самом деле эта
формализация только отвлекает от необходимости решать насущные проблемы и даже
не предоставляет существенной помощи в краткосрочной перспективе». Кроме
того, в RFC 1627 утверждается, что ICANN превысила границы своих
полномочий, порекомендовав RFC 1597 без обычного открытого обсуждения и
одобрения со стороны IETF и IAB.
Так что же делать простому проектировщику сети, оказавшемуся в центре
противоречий, связанных с использованием частных адресов? Если вы
собираетесь последовать рекомендациям RFC 1597, будьте очень осторожны. Убедитесь
в том, что вы располагаете всей необходимой документацией и хорошо знаете,
какие службы видны или не видны для внешнего мира. Прочитайте RFC 1627
и разберитесь в сути выдвинутых возражений.
Назначение адресов класса С
Адреса класса С в диапазоне 192.0.0 до 223.255.245 были разделены на восемь
адресных блоков (табл. 4.7). За распределение адресов из этих блоков отвечают
региональные полномочные организации.
Таблица 4.7. Распределение адресов класса С
Диапазон адресов Регион
192.0.0-193.255.255 Внерегиональные адреса. Диапазон включает адреса, использовавшиеся
до появления схемы регионального назначения адресов
194.0.0-195.255.255 Европа
196.0.0-197.255.255 Используется при назначении IP-адресов независимо от региона
198.0.0-199.255.255 Северная Америка
200.0.0-201.255.255 Центральная и Южная Африка
202.0.0-203.255.255 Побережье Тихого океана
204.0.0-205.255.255 Используется при назначении IP-адресов независимо от региона
206.0.0-207.255.255 Используется при назначении IP-адресов независимо от региона
208.0.0-223.255.255 Доступные адреса
Информация, приведенная в табл. 4.7, может пригодиться в том случае, если
у вас имеется протокол трассировки пакетов, входящих в сеть, и вы хотите
определить, из какой географической зоны приходят пакеты.
Настройка IP-адресов
Настройка хостов в сетях TCP/IP должна производиться с использованием
правильных IP-адресов. Конкретная процедура настройки зависит от
операционной системы, но в целом процессы делятся на следующие категории:
О Настройка в командной строке.
О Настройка с использованием меню.
О Настройка с использованием графического интерфейса.
О Динамическое назначение адреса при загрузке хоста с центрального сервера.
В табл. 4.8 приведены примеры операционных систем, относящихся к
различным категориям.
Таблица 4.8. Настройка IP-адреса и других параметров хостов
Методика Операционная система/протокол
Режим командной строки Unix, VMS, устройства маршрутизации, MS-DOS
Меню Устройства маршрутизации, Unix, серверы NetWare, MS-DOS
Графический Интернет Unix, Microsoft Windows
Динамическое назначение Протоколы DHCP и ВООТР. Поддерживаются почти всеми
основными операционными системами
Во многих системах существуют команды модификации IP-адресов, часто
включаемые в стартовый сценарий операционной системы. Интерфейс меню
строится с использованием псевдографики из расширенного набора символов,
в нем вам предлагается ввести IP-адрес и другие параметры IP. Графический
интерфейс предназначен для систем, поддерживающих графический вывод на
уровне пикселов. Примерами таких систем являются X-Window и операционные
системы семейства Microsoft Windows. Динамическое назначение IP-адресов
используется в сочетании с протоколами ВООТР и DHCP. Устройство при
запуске запрашивает IP-адрес и другие параметры с центрального сервера,
который передает эти сведения по протоколу ВООТР и DHCP.
Информация об IP-адресе хоста регистрируется в нескольких местах.
Введенный IP-адрес кэшируется в памяти и остается доступным для использования
программным обеспечением TCP/IP. Кроме того, эти данные иногда
сохраняются в системных файлах операционной системы. Информация об IP-адресах
других систем может быть получена из специального файла, который обычно
называется hosts, или при помощи протокола DNS. Как правило, сервис DNS
используется для получения IP-адреса хоста по его символическому имени
DNS. В некоторых системах реализованы специальные запатентованные
протоколы для получения IP-адресов в сети (пример — служба WINS в
операционных системах Microsoft).
Адресация в IP версии 6
Как упоминалось выше в этой главе, по мере расширения Интернета
32-разрядное адресное пространство IP-адресов постепенно подходит к концу. Невзирая
на RFC 1597, для каждого сетевого подключения к Интернету нужен
уникальный IP-адрес. Некоторые устройства имеют несколько сетевых подключений,
что приводит к быстрому поглощению доступных IP-адресов.
Считается, что 32-разрядные IP-адреса (так называемая адресация по схеме IP
версии 4) могут обеспечить более 2 100 000 сетей, содержащих в общей
сложности 3720 миллионов хостов. Тем не менее схема распределения адресов IP
недостаточно эффективна, поскольку для соединения сетей через устройства
ретрансляции, работающие на сетевом уровне (в частности, маршрутизаторы), обычно
требуются новые сетевые адреса.
В результате стала быстро возникать нехватка IP-адресов. Для решения этой
проблемы группа IETF проанализировала методы решения проблемы адресного
пространства и внесла в протокол изменения, повышавшие эффективность его
работы в условиях новых сетевых технологий. После изучения различных
предложений по преодолению ограничений текущей версии протокола IP
(называемой IP версии 4, или IPv4), было решено перейти на протокол IP нового
поколения — «IP Next Generation», также называемый IPng или IPv6. Одной из
целей, поставленных при проектировании IPv6, должна была стать поддержка
минимум одного миллиарда сетей. Чтобы соответствовать этому критерию, IPv6
использует 128-разрядные адреса, длина которых вчетверо превышает длину
адресов IPv4. IPv6 тоже использует концепции идентификаторов сетей и
хостов, но расширяет ее на несколько уровней. Иерархическая адресация IPv6
обеспечивает более эффективную маршрутизацию. Адрес IPv6 может содержать
32-разрядный адрес IPv4, который размещается в младших 32 битах адреса IPv6
с заполнением 96 старших битов фиксированным префиксом из 80 нулевых битов,
за которыми следуют 16 единичных или нулевых битов.
IPv6 позволяет использовать незарегистрированные адреса IPv4; для этого
в адрес добавляется уникальный зарегистрированный модификатор, вследствие
чего весь адрес IPv6 становится уникальым.
Схема адресации IPv6 проектировалась с расчетом на взаимодействие с
системами на базе IPv4. Таким образом, становится возможным сосуществование двух
схем адресации IP в течение некоторого периода. Для передачи информации
между сетями, работающими на базе IPv4 и более нового протокола IPv6, могут
использоваться маршрутизаторы с поддержкой обоих протоколов, IPv4 и IPv6.
Протокол IPv6 включает поддержку мобильных портативных систем. В
частности, это позволяет пользователям портативных компьютеров и других устройств
подключаться к любой точке сети без ручной перенастройки. Мобильные системы
автоматически устанавливают связь при подключении к сети в другой точке.
Автоматическая настройка применяется не только для мобильных систем, но
и для обычных рабочих станций. IPv6 поддерживает шифрование данных и
обладает улучшенной поддержкой трафика в реальном времени (то есть обеспечивает
определенные гарантии максимальной задержки при передаче дейтаграмм по сети).
Адреса IPv6 имеют длину 128 байт, поэтому десятичная запись с точечным
разделением для них неудобна — представьте, что вам придется записывать
строку из 16 десятичных цифр, разделенных точками!
Рассмотрим следующее двоичное представление адреса IPv6:
01011000 00000000 00000000 11000000
11100011 11000011 11110001 10101010
01001000 11100011 11011001 00100111
11010100 10010101 10101010 11111110
Адрес IPv6 состоит из 128 бит и записывать его в двоичной системе крайне
неудобно. В десятичной записи с точечным разделением этот адрес выглядит так:
88.0.0.192.227.195.241.170.72.227.217.39.212.149.170.254
Такая запись получается недостаточно компактной. Для записи этих двоичных
последовательностей проектировщики остановились на шестиадцатеричпой записи
с разделением двоеточиями. Адрес разбивается на 16-разрядные группы,
разделенные символом «>. Так, адрес из предыдущего примера записывается в виде:
5800:00C0:E3C3:F1AA:48E3:D927:D495:AAFE
Использование этой формы записи уменьшает количество цифр и
символов-разделителей, но это не все: существует два приема сокращенной записи,
которые могут применяться для дальнейшего уменьшения количества символов.
Во-первых, начальные нули можно не указывать. Для примера возьмем
следующий адрес IPv6:
48А6:0000:0000:0000:0000:0DA3:003F:0001
С пропуском начальных нулей возможна следующая упрощенная форма
записи:
48А6:0:0:0:0:DA3:3F:1
Последовательность 0000 заменяется 0, 0DA3 заменяется на DA3, а 0001 —
на 1. Во всех перечисленных случаях исключение начальных нулей уменьшает
количество символов в адресе.
Во-вторых, правило сжатия нулей позволяет заменить последовательность
повторяющихся нулей двойным символом двоеточия (:: ). Так, в приведенном
выше адресе IPv6 присутствует последовательность из четырех нулей @:0:0:0),
которая может быть заменена на «::». Таким образом, предыдущий адрес IPv6
записывается в виде
48А6::DA3:3F:1
При расширении адреса, содержащего сжатые нули, часть адреса,
находящаяся слева от двоеточий, выравнивается по начальным 16-разрядным словам
адреса, а часть, находящаяся справа, выравнивается по конечным 16-разрядным
словам адреса. Оставшиеся 16-разрядные слова адреса заполняются нулями.
В качестве примера рассмотрим следующую запись:
5400:FD45::FFFF:3AFE
После расширения адрес принимает вид
5400:FD45:0:0:0:0:FFFF:3AFE
Последовательность «:> может встречаться в адресе только один раз, чтобы
обеспечить однозначную интерпретацию. Следующая запись IPv6 недопустима —
по ней невозможно определить, какое слово занимает последовательность 45А1:
5400::45А1::23Аб
Наконец, последовательность «:> может использоваться в качестве префикса
или суффикса. Рассмотрим следующее представление адреса IPv4 170.1.1.1
в формате IPv6:
0:0:0:0:0:0:АА01:101
Итоги
Хорошее знание схемы адресации IP абсолютно необходимо для понимания
основных принципов межсетевой связи на базе IP. Базовый материал,
представленный в настоящей главе, поможет вам лучше разобраться в этой теме. Многие
из упоминаемых архитектурных решений (CIDR, маски подсетей, VLSM)
используются настолько широко, что их недостаточное понимание сильно затруднит
вашу работу по поддержке и проектированию межсетевых образований. Кроме
того, в этой главе рассматриваются частные адреса и области их применения,
а также в общих чертах описана структура адресов IPv6.
В следующих главах этой части книги рассматриваются другие аспекты выбора
имен и адресов в сетях IP, в том числе механизм установления соответствия
между IP-адресами и аппаратными адресами локальных сетей, а также
преобразование удобных символических имен в IP-адреса.
|- ARP и RARP
IP-адреса являются общим средством идентификации хостов в TCP/IP, но для
того, чтобы дейтаграмма была доставлена получателю, одного IP-адреса
недостаточно. В доставке задействована сетевая система, поведение которой обычно
зависит от сетевой операционной системы и типа оборудования. Чтобы хорошо
понимать механизм маршрутизации данных от отправителя к получателю,
необходимо разобраться в том, как организовано взаимодействие компьютеров,
входящих в сеть. Глава начинается с общего обзора типичных сетевых архитектур
(в особенности Ethernet) и дает представление о том, как в TCP/IP происходит
преобразование IP-адресов в канальные адреса, используемые на уровне сети.
Преобразование IP-адреса в канальный адрес выполняется при помощи протокола
ARP (Address Resolution Protocol). Парный протокол RARP (Reverse Address
Resolution Protocol) решает обратную задачу — преобразование канальных
адресов в IP-адреса.
Механизмы адресации
IP-адреса используются TCP/IP для доставки дейтаграмм заданному получателю.
При описании механизмов адресации часто встречаются три стандартных
термина: имя, адрес и маршрут.
Имя представляет собой символическое обозначение компьютера, пользователя
или приложения. Обычно имена являются уникальными и обозначают
конечного получателя дейтаграммы. Адрес обычно определяет физическое или
логическое местонахождение получателя в сети. Маршрут содержит информацию
о том, каким образом дейтаграмма должна доставляться по нужному адресу. При
использовании термина «адрес» необходима осторожность, потому что этот
термин часто используется в коммуникационных протоколах для обозначения
множества разных понятий. В частности, он может обозначать хост, порт
компьютера, адрес памяти, приложение и многое другое. В общем случае каждый уровень
модели OSI использует собственные адреса. Например, в сети Ethernet адресом
канального уровня является аппаратный адрес Ethernet, уникальный для каждого
сетевого адаптера, а адресом сетевого уровня является IP-адрес
соответствующего узла TCP/IP.
В процессе доставки ключевую роль обычно играет регистрационное имя
получателя. Пакет сетевого программного обеспечения, называемый сервером имен,
строит адрес и маршрут по именам пользователя и компьютера, скрывая этот
аспект маршрутизации TCP/IP и доставки от приложения. Помимо
прозрачности адресации и маршрутизации с точки зрения приложений, серверы имен
обладают другим существенным преимуществом: они позволяют системному или
сетевому администратору достаточно свободно изменять параметры сети без
перенастройки каждого компьютера по отдельности. Пока в сети имеется
работающий сервер имен, приложения и пользователи могут игнорировать
изменения в маршруте.
Адресация в подсетях
Пересылка данных на другой компьютер обычно осуществляется по IP-адресу.
Хотя протокол TCP/IP проектировался для работы с IP-адресами, реальным
сетевым программным и аппаратным обеспечением эти адреса не
поддерживаются. Вместо этого сетевые программные средства идентифицируют
компьютеры по физическим адресам, которые кодируются в сетевых устройствах,
устанавливаемых на компьютерах. Установление соответствия между IP-адресом
и физическим адресом не входит в обычный круг задач протокола TCP/IP,
поэтому для решения этой задачи было разработано несколько специальных
протоколов. Эти протоколы будут рассмотрены в следующем разделе, но сначала
мы обсудим структуру физических адресов сети.
В отдельной локальной или глобальной сети для правильной доставки
дейтаграмм необходимо знать несколько атрибутов, прежде всего — физический
и канальный адрес получателя. Эти адреса достаточно важны и заслуживают
более внимательного рассмотрения.
Физические адреса
Каждое устройство в сети характеризуется уникальным физическим адресом,
который также называется аппаратным адресом. Физические адреса обычно
кодируются на уровне сетевого адаптера, иногда они могут настраиваться пользователем
при помощи переключателей или специальных программ. Но чаще физические
адреса жестко кодируются в ППЗУ адаптера; производители сетевого
оборудования часто совместно работают над тем, чтобы предотвратить возможное
дублирование физических адресов. В любой отдельной сети каждый физический
адрес может существовать только в одном экземпляре, иначе сервер имен не
сможет однозначно определить получателя. Длина физического адреса
изменяется в зависимости от сетевой архитектуры. Например, в Ethernet и ряде других
сетевых архитектур адреса имеют длину 48 бит. Обмен данными по сети требует
указания двух сетевых адресов: передающего и принимающего устройства.
В настоящее время назначением единых физических адресов подсетей
занимается IEEE (раньше этим занималась фирма Xerox, исходный разработчик
Ethernet). Для каждой подсети IEEE назначает 24-разрядный идентификатор
OUI (Organization Unique Identifier), остальные 24 бита адреса организация
может использовать по своему усмотрению. Вообще говоря, два из 24 битов
OUI являются управляющими, поэтому подсеть определяется только 22 битами.
Формат идентификатора OUI показан на рис. 5.1. Комбинация из 24 битов OUI
и 24 битов, присвоенных локально, называется адресом MAC (Media Access Control).
При сборке пакета данных для передачи в объединенной сети используются два
адреса MAC — по одному для отправителя и для получателя.
22 бита 24 бита
1бит 1бит| | |
И/Г У/Л Адрес подсети, назначенный IEEE Физический адрес, назначенный локально
0 = Индивидуальный 0 = Универсальный
1 = Групповой 1 = Локальный
Рис. 5.1. Структура идентификатора ОЮ
Крайний левый бит числа называется признаком индивидуального или
группового адреса (I/G). Если бит равен 0, то остальные биты определяют
индивидуальный адрес; значение 1 указывает на то, что остальные биты определяют
групповой адрес, нуждающийся в дальнейшей обработке. Если все 24 бита ОШ
заполнены единицами, то получателями являются все станции сети.
Второй бит структуры ОШ называется локальным или универсальным битом
(U/L). Если он равен 0, то значение OUI было задано административным органом
(именно этот вариант используется в OUI, назначаемых в IEEE). Если второй
бит равен 1, значит, идентификатор OUI был назначен локально, и его
интерпретация как адреса, присвоенного в IEEE, может вызвать проблемы. Обычно
применение структур, у которых второй бит равен 1, ограничивается локальными
и глобальными сетями и не передается в другие сети, которые могут следовать
формату адресации IEEE.
ПРИМЕЧАНИЕ
Некоторые старые протоколы (такие, как DECNet Phase IV) использовали локально
назначенные адреса, в которых биты локально назначенного физического адреса заполнялись сетевым
адресом DECNet.
Оставшиеся 22 бита структуры OUI содержат физический адрес подсети,
назначенный IEEE. Вторая группа из 24 бит идентифицирует адреса внутри
локальной сети и администрируется локально. 24 бита позволяют представить
около 16 миллионов адресов, но если физических адресов вдруг окажется
недостаточно, IEEE может выделить второй адрес подсети.
Адрес LLC
В стандартах IEEE Ethernet используется другой адрес, называемый адресом
канального уровня (обычно применяется сокращение LSAP от «link service access
point»). Канальный уровень в сетях IEEE делится на верхний подуровень LLC
(Logical Link Control) и нижний подуровень MAC (Media Access Control), на
котором реализуются аппаратные связи. Адреса протокола подуровня LLC
называются адресами SAP (Service Access Points) или LSAP (Logical Service Access
Points).
Адрес LSAP определяет тип протокола, используемого на канальном уровне.
Как и в случае физических адресов, дейтаграмма содержит адреса LSAP как
передающей, так и принимающей стороны.
Сетевые кадры
Структура информации в передаваемых пакетах данных зависит от протокола,
используемого сетью. Тем не менее будет поучительно проанализировать один
из вариантов структуризации и увидеть, как в дейтаграмму перед отправкой по
сети включаются упоминавшиеся выше адреса, а также другая дополнительная
информация. В качестве примера будет использована архитектура Ethernet,
широко используемая в сочетании с TCP/IP. С другими системами общий
принцип сохраняется, хотя конкретная структура заголовков может быть несколько
иной. Помните, что упаковка заголовков TCP/IP производится сетевыми
протоколами и не имеет отношения к уровню TCP/IP. Типичный кадр Ethernet
(этим термином обозначается дейтаграмма, готовая к пересылке по сети)
изображен на рис. 5.2.
| Преамбула |п^4я1отпХСеля1 Т™ [ **»»"* \ <*С [
64 бит 48 бит 48 бит 16 бит Переменная 32 бит
| I J длина
Рис. 5.2. Структура кадра Ethernet
64-разрядная преамбула предназначена в первую очередь для
синхронизации процесса и борьбы со случайным шумом в нескольких первых
отправляемых битах. В механизмах адресации и маршрутизации преамбула не
используется. В конце преамбулы находится последовательность битов SFD (Start Frame
Delimiter), после которой и начинается кадр.
Адреса получателя и отправителя в структуре кадра Ethernet хранятся в
48-разрядном формате IEEE. За ними следует 16-разрядный признак типа протокола.
После типа следуют фактические данные (дейтаграмма TCP/IP). Поле данных
в стандартной архитектуре Ethernet имеет длину от 64 до 1500 байт. Если длина
данных меньше 64 байт, они дополняются нулями. Дополнение до минимальной
длины 64 байта выполняется для того, чтобы упростить обнаружение коллизий.
В конце фрейма Ethernet находится контрольная сумма CRC (Cyclic
Redundancy Check), используемая для проверки того, что содержимое кадра не было
изменено в процессе пересылки. Каждый компьютер, входящий в маршрут
пересылки, вычисляет контрольную сумму кадра и сравнивает ее со значением
в конце кадра. Если два числа совпадают, данные кадра считаются
действительными и пересылаются дальше по сети или в подсеть. Если данные различаются,
значит, содержимое кадра было искажено, поэтому кадр отвергается, после чего
может быть послан запрос на повторную передачу.
В некоторых протоколах, имеющих отношение к Ethernet (например, IEEE
802.3), общее строение кадра остается прежним, но содержимое несколько
отличается. Так, в 802.3 16 бит, используемые в Ethernet для идентификации типа
протокола, заменяются 16-разрядной длиной блока данных. Кроме того, новое
поле следует непосредственно за областью данных.
ХР-адреса
Как упоминалось выше, в TCP/IP используются 32-разрядные адреса,
позволяющие идентифицировать любой компьютер сети и сеть, к которой он подключен.
IP-адрес определяет подключение компьютера к сети, а не сам компьютер; это
важное различие и о нем следует помнить. Изменение местонахождения
компьютера в сети иногда приводит к смене IP-адреса (в зависимости от настройки
сети). IP-адрес представляет собой набор чисел, однозначно определяющих
устройство; многие читатели часто видят эти обозначения вида 128.40.8.72 на
своих рабочих станциях и терминалах. IP-адрес состоит из четырех 8-разрядных
групп, его общая длина составляет 32 бита. IP-адреса назначаются центром NIC
(Network Information Center), хотя если сеть не подключена к Интернету, адреса
могут определяться произвольно. Общепринятый способ записи IP-адресов
называется десятичной записью с точечным разделением.
IP-адреса делятся на четыре категории в зависимости от размера сети.
Структура адресов разных категорий (от класса А до класса D) показана на рис. 5.3.
Класс определяется последовательностью начальных битов, содержащей от
одного (класс А) до четырех битов (класс D). Класс можно определить по первым
трем (старшим) битам. На практике обычно бывает достаточно двух битов,
поскольку адреса класса D используются редко.
Го | Сеть G бит) | Адрес B4 бит) |
По | Сеть A4 бит) | Адрес A6 бит) |
рГГо | Сеть B1 бит) I Адрес (8 бит) |
| 1110 | Групповой адрес B8 бит) |
Рис. 5.3. Структура четырех классов IP-адресов
Адреса класса А предназначены для крупных сетей с большим количеством
хостов. В них используется 24-разрядный локальный адрес (часто называемый
идентификатором хоста). Идентификатор сети ограничен 7 битами, что серьезно
ограничивает количество представляемых сетей.
Адреса класса В предназначены для средних сетей. В них используется
16-разрядный идентификатор хоста и 14-разрядный идентификатор сети.
В адресах класса В идентификатор хоста представлен всего 8 битами, поэтому
количество устройств ограничивается 256. Идентификатор сети содержит 21 бит.
Наконец, адреса класса D используются для групповой рассылки, когда
пакет передается нескольким устройствам.
По IP-адресу сетевой шлюз может определить, будут ли данные отправлены
в Интернет (или другое межсетевое образование) или останутся в локальной
сети. Если сетевая часть адреса получателя совпадает с идентификатором сети,
к которой подключен отправитель (пересылка в пределах сети), значит, получатель
находится в одной сети с отправителем и межсетевая пересылка не производится.
Все остальные сетевые адреса обрабатываются маршрутизатором (традиционно
называемым интернет-шлюзом), чтобы данные могли выйти за пределы
локальной сети.
Компьютер (а особенно маршрутизатор), подключенный к нескольким сетям,
может иметь несколько IP-адресов. Такие компьютеры называются
многоадресными, поскольку они имеют уникальный адрес в каждой сети, к которой он
подключен. Две сети, соединенные шлюзом, могут иметь одинаковый идентификатор,
что создает проблемы с адресацией, потому что шлюз должен быть способен
различить, к какой сети относится физический адрес. Проблема решается при
помощи специального протокола ARP (Address Resolution Protocol),
занимающегося только разрешением адресов.
Общие сведения о протоколе ARP
Чтобы отправить дейтаграмму с одного компьютера на другой в локальной или
глобальной сети, отправитель должен знать физический адрес получателя.
Должен существовать механизм преобразования IP-адресов, задаваемых
приложениями, в физические адреса устройств, соединяющих компьютеры с сетью.
Задачу преобразования IP-адресов в физические адреса можно решить
методом «грубой силы» и хранить таблицу преобразований на каждом компьютере.
Когда приложению потребуется отправить данные на другой компьютер,
программа просматривает таблицу преобразований и ищет в ней физический адрес.
Подобный метод создает множество проблем, потому им почти никто не
пользуется. Главным недостатком является необходимость постоянного обновления
таблицы адресов на каждом компьютере при внесении любых изменений.
Для решения этой проблемы был разработан протокол ARP. Этот протокол
преобразует IP-адреса в физические адреса (сетевые и локальные) и тем самым
избавляет приложения от необходимости знать что-либо о физических адресах.
Проще говоря, ARP ведет таблицу соответствия между IP-адресами и
физическими адресами, называемую таблицей ARP. Таблица ARP обычно строится
динамически, хотя существует возможность добавления статических записей для
диагностических целей и для исправления проблем с порчей данных.
Структура таблицы ARP изображена на рис. 5.4. Кроме того, ARP
поддерживает кэш записей, называемый кэшем ARP. Обычно поиск начинается с кэша
ARP, и только в случае неудачи данные ищутся в таблице ARP. Динамически
сгенерированные записи кэша ARP становятся недействительными при
истечении интервала тайм-аута, тогда как на статические записи тайм-аут не должен
распространяться. Уничтожение статических записей в результате тайм-аута
является признаком порчи данных в кэше ARP.
,^ Физический ID в„ЛЛЛ т
ИФ адрес IP-адрес Тип
Запись 1 I
Запись 2
Запись 3 1
Записи п
Рис. 5.4. Структура таблицы ARP. Каждая строка таблицы представляет одно устройство
KauiARP
Каждая строка кэша ARP соответствует одному устройству и содержит четыре
атрибута, хранящихся для каждого устройства:
О ИФ — физический порт (интерфейс).
О Физический адрес — физический адрес устройства.
О IP-адрес — IP-адрес, соответствующий физическому устройству.
О Тип — Тип записи.
Поле типа принимает четыре возможных значения:
О 2 — запись недействительна;
О 3 — соответствие устанавливается динамически (то есть запись может
измениться);
О 4 — статическое соответствие (запись не изменяется);
О 1 — ни один из перечисленных вариантов.
При получении IP-адреса, для которого нужно найти соответствующий
физический адрес, ARP просматривает кэш и таблицу ARP в поисках совпадения.
Если совпадение будет найдено, ARP возвращает физический адрес стороне, от
которой был получен IP-адрес. Если информация не обнаружена, в сеть отправ-
ляется запрос ARP — специальное широковещательное сообщение, получаемое
всеми устройствами локальной сети.
Запрос ARP содержит IP-адрес предполагаемого получателя. Если устройство
опознает IP-адрес как принадлежащий ему, оно отправляет ответное сообщение
со своим физическим адресом тому компьютеру, который сгенерировал запрос
ARP. Полученная информация сохраняется в таблице и кэше ARP для будущего
использования. Таким образом, ARP может определить физический адрес любого
компьютера на основании его IP-адреса.
Структура запросов и ответов ARP представлена на рис. 5.5. При отправке
запроса используются все поля структуры, кроме поля аппаратного адреса
получателя (который, собственно, и пытается определить этот запрос). В ответах
ARP используются все поля.
Тип оборудования A6 бит)
Тип протокола A6 бит)
Длина аппаратного Длина протокольного
адреса адреса
Код операции A6 бит)
Аппаратный адрес отправителя
IP-адрес отправителя
Аппаратный адрес получателя
IP-адрес получателя
Рис 5.5. Структура запросов и ответов ARP
Многие поля запросов и ответов ARP принимают значения из ограниченного
набора. В оставшейся части этого раздела мы более подробно рассмотрим каждое
поле и познакомимся с его назначением.
Тип оборудования
Первое поле определяет тип аппаратного интерфейса. Допустимые значения
перечислены в следующей таблице.
Значение Описание
1 Ethernet
2 Experimental Ethernet
3 Х.25
4 Proteon ProNET (Token Ring)
5 Chaos
6 IEEE 802.X
7 ARCnet
Значение Описание
8 Hyperchannel
9 Lanstar
10 Autonet Short Address
11 LocalTalk
12 LocalTalk
13 Ultra link
14 SMDS
15 Frame Relay
16 ATM (Asynchronous Transmission Mode)
17 HDLC
18 Оптоволоконная линия
19 ATM (Asynchronous Transmission Mode)
20 Последовательная линия
21 ATM (Asynchronous Transmission Mode)
Тип протокола
Второе поле определяет тип протокола, используемого
устройством-отправителем. В сочетании с TCP/IP обычно используется семейство EtherType, а
допустимые значения поля перечислены в следующей таблице.
Значение Описание
512 XEROX PUP
513 PUP Address Translation
1536 XEROX NS IDP
2048 IP (Internet Protocol)
2049 X.75
2050 NBS
2051 ECMA
2052 Chaosnet
2053 X.25 Level 3
2054 ARP (Address Resolution Protocol)
2055 XNS
4096 Berkeley Trailer
21000 BBN Simnet
24577 DEC MOP Dump/Load
Значение Описание
24578 DEC MOP Remote Console
24579 DEC DECnet Phase IV
24580 DEC LAT
24582 DEC
24583 DEC
32773 HP Probe
32784 Excelan
32821 RARP (Reverse ARP)
32823 AppleTalk
32824 DEC LANBridge
Если протокол не относится к семейству EtherType, допускаются другие
значения.
Длина аппаратного адреса (HLen)
Третье поле содержит длину каждого аппаратного адреса в дейтаграмме (в
байтах). Для сетей Ethernet это поле равно 4 байтам.
Длина протокольного адреса (PLen)
Четвертое поле содержит длину протокольного адреса в дейтаграмме (в байтах).
Для протокола IP это поле равно 4 байтам.
Код операции
Пятое поле определяет, является ли дейтаграмма запросом или ответом ARP. Для
запросов ARP его значение равно 1, а для ответов ARP используется значение 2.
Аппаратный адрес отправителя
Шестое поле определяет аппаратный адрес устройства-отправителя.
IP-адрес отправителя
Седьмое поле определяет IP-адрес устройства-отправителя.
Аппаратный адрес получателя
Восьмое поле определяет аппаратный адрес устройства-получателя.
IP-адрес получателя
Девятое поле определяет IP-адрес устройства-получателя.
Схема работы ARP
При отправке пакета IP через сетевые уровни узлов в объединенных сетях TCP/
IP компонент сетевого уровня, осуществляющий маршрутизацию, определяет
IP-адрес следующего маршрутизатора.
Маршрутизирующий компонент сетевого уровня проверяет, находится ли
хост, которому пересылается дейтаграмма IP, в локальной сети или в другом
сетевом сегменте.
Если хост-отправитель определяет, что получатель находится в локальной
сети, он должен получить аппаратный адрес получателя. Если получатель
находится в удаленной сети, то отправителю необходимо узнать аппаратный адрес
порта маршрутизатора, на который должна быть отправлена дейтаграмма IP.
В широковещательных сетях для получения аппаратных адресов,
принадлежащих локальной сети (как узлов-получателей, так и портов маршрутизатора),
применяется протокол ARP.
Протокол ARP реализуется в составе модуля IP в сетях, использующих сервис
разрешения адресов — таких, как широковещательные локальные сети (Ethernet,
Token Ring и т. д.) Протокол ARP инкапсулируется протоколом канального
уровня, но не протоколом IP. Таким образом, протокол ARP не может
маршрутизироваться, то есть никогда не выходит за граничный маршрутизатор.
Прежде чем отправлять запрос, модуль ARP пытается найти нужный адрес
в локальном кэше. Кэш ARP содержит пары, содержащие информацию о
соответствии IP-адресов и аппаратных адресов.
Если искомый IP-адрес присутствует в кэше ARP, протокол находит
соответствующий аппаратный адрес и возвращает его модулю ARP. Модуль ARP
возвращает аппаратный адрес сетевому драйверу, выдавшему заявку на определение
аппаратного адреса целевого узла. Затем сетевой драйвер передает кадр
канального уровня, содержащий дейтаграмму IP, в которой поле аппаратного адреса
получателя заполнено найденным адресом. В этом сценарии запрос ARP не
генерируется, поскольку нужные данные берутся из локального кэша.
Но что произойдет, если аппаратный адрес получателя отсутствует в кэше
ARP? В этом случае модуль ARP генерирует кадр канального уровня с
запросом ARP на получение аппаратного адреса заданного узла. Запрос ARP
рассылается на канальном уровне по всем узлам локального сетевого сегмента. Как
упоминалось выше, запросы/ответы ARP ограничиваются локальным сетевым
сегментом и не выходят за граничный маршрутизатор.
При получении запроса ARP канальный уровень искомого узла передает
пакет модулю разрешения адресов. Запрос ARP рассылается на канальном уровне,
поэтому его получают все узлы локальной сети. Тем не менее на запрос ARP
отвечает только тот узел, IP-адрес которого соответствует искомому IP-адресу.
Ниже описана последовательность действий модуля ARP на узле-получателе.
1. Сначала узел проверяет тип оборудования, указанный в соответствующем
поле запроса ARP. Если тип оборудования успешно опознан, производится
необязательная проверка поля длины аппаратного адреса в запросе ARP.
2. Узел решает, поддерживает ли он тип протокола, указанный в
соответствующем поле запроса ARP. Если ответ положителен, производится
необязательная проверка поля длины протокольного адреса в запросе ARP.
3. Флагу слияния присваивается значение false.
4. Если пара <тип протокола, протокольный адрес отправителя> уже
присутствует в кэше ARP узла, поле аппаратного адреса отправителя обновляется по
данным пакета, а флаг слияния устанавливается в положение true.
5. Затем узел решает, принадлежит ли ему указанный протокольный адрес. Иначе
говоря, он проверяет, соответствует ли его IP-адрес целевому IP-адресу,
указанному в запросе. Если ответ будет положительным, проверяется флаг
слияния, и если он равен false — триплет <тип протокола, протокольный адрес
отправителя, аппаратный адрес отправителя> добавляется в кэш ARP.
6. Наконец, узел проверяет поле кода операции и решает, является ли
полученный пакет запросом. Если ответ будет положительным, поля аппаратного
и протокольного адресов меняются местами, а в поля отправителя заносятся
локальные значения аппаратного и протокольного адресов (см. описание
поля «Код операции» в ответе ARP). Пакет отправляется по новому
аппаратному адресу с того устройства, на котором он был получен.
В описанном алгоритме перед анализом кода операции триплет <тип
протокола, протокольный адрес отправителя, аппаратный адрес отправителя>
включается в кэш ARP только в том случае, если IP-адрес отправителя отсутствует
в кэше ARP. Обновление производится только в кэшах ARP, содержащих
запись с IP-адресом отправителя.
Обновление или добавление записей в кэше ARP производится потому, что
отправителю запроса ARP с большой долей вероятности могут ответить верхние
уровни узла-получателя; когда получатель генерирует кадр канального уровня,
он обращается к кэшу ARP и обнаруживает, что аппаратный адрес отправителя
уже известен. В этом случае запрос ARP на получение аппаратного адреса
отправителя не требуется.
Если в кэше получателя уже присутствует запись для пары <тип протокола,
протокольный адрес отправителя^ то старый аппаратный адрес в кэше
заменяется новым. Это может произойти в следующих ситуациях:
О На узле, отправившем запрос ARP, произведена замена оборудования. В этом
случае изменяется аппаратный адрес того же узла.
О Произошло переназначение IP-адресов, и IP-адрес узла, отправившего запрос
ARP, отличен от того, который хранится в кэше ARP получателя.
Аппаратный адрес отправителя ARP изменяется потому, что это другой узел.
О В сети возникла проблема с дублированием адресов. Другой узел утверждает,
что он обладает тем же IP-адресом, который хранится в кэше получателя.
Первые два случая вполне обычны, но дублирование IP-адресов является
ошибкой и подробно рассматривается в соответствующем разделе этой главы.
Строение протокола ARP
Теоретически поля HLen и PLen в формате пакета ARP являются
избыточными, поскольку длина адресов, аппаратного и протокольного, определяется
значениями полей типа оборудования и типа протокола. Например, если поле
типа оборудования содержит значение 1 (признак кадра Ethernet), из этого
следует, что поле HLen должно содержать 6, поскольку длина адресов Ethernet равна
6 октетам. Аналогично, если во втором поле указан протокол IP, значение PLen
должно быть равно 4, поскольку IP-адреса состоят из 4 октетов.
Избыточные поля HLen и PLen включены для дополнительной проверки
целостности данных, а также для применения средств сетевого мониторинга.
Код операции определяет, является ли пакет запросом или ответом на
предыдущий запрос. Учитывая количество существующих кодов операций,
использование поля из двух октетов выглядит излишним. Вполне хватило бы и одного
октета.
Поля аппаратного адреса и IP-адреса отправителя нужны для их сохранения
в кэше ARP получателя. В запросе ARP поле аппаратного адреса получателя
остается пустым, поскольку именно эта величина возвращается в поле
аппаратного адреса отправителя в ответе ARP. Аппаратный адрес получателя
включается для полноты и для применения средств сетевого мониторинга.
Присутствие IP-адреса получателя в запросе ARP необходимо для того,
чтобы компьютер мог определить, является ли он получателем запроса и нужно ли
отправлять ответ. Поле IP-адреса получателя в ответе ARP в действительности
не обязательно, если предполагается, что ответ инициируется только при
получении запроса. Тем не менее это поле может использоваться при сетевом
мониторинге, а также для упрощения алгоритма обработки запросов/ответов в ARP.
Сетевой мониторинг с использованием ARP
Протокол ARP может использоваться устройством мониторинга для сбора
информации о протоколах более высокого уровня посредством простого анализа
заголовков кадров ARP. Например, анализируя поле типа протокола,
устройство сетевого мониторинга может определить, какие протоколы используются
в сети. Устройство мониторинга должно быть спроектировано с учетом
рекомендаций, приводимых в этом разделе.
При получении пакета ARP устройство мониторинга может сохранить в
таблице тип протокола, протокольный и аппаратный адреса отправителя. Кроме
того, оно может определить длину аппаратного и протокольного адреса по
содержимому полей HLen и PLen пакета ARP. Обратите внимание: пакеты ARP
пересылаются на канальном уровне, и монитор получает все запросы ARP.
Если код операции указывает на то, что пакет содержит запрос ARP, а
протокольный адрес получателя соответствует протокольному адресу монитора,
монитор отправляет ответ ARP точно так же, как бы это сделал любой другой
узел. Монитор не получает ответы ARP, так как они передаются
непосредственно хосту, отправившему запрос.
Тайм-аут в кэше ARP
В реализации кэша ARP часто поддерживается механизм тайм-аута, основанным
на временной пометке записей кэша. Ниже обсуждаются некоторые проблемы,
связанные с тайм-аутом в таблицах ARP.
При перемещении на узле обычно отключается питание, что приводит к
очистке кэша ARP и предотвращает конфликты со старыми записями. Другим
узлам сети обычно ничего не известно о перемещении или отключении
некоторого узла.
Если узел перемещается в пределах сегмента сети, информация об этом узле
в кэше ARP остается действительной, потому что аппаратный и IP-адрес
перемещенного узла остаются прежними.
Если узел отключается, другие узлы не смогут связаться с ним. Они
используют информацию из кэша ARP для обращения к узлу, но не смогут установить
связь. Неудача при установлении связи с узлом может использоваться
реализацией протокола для удаления сведений об узле Перед тем как принять решение
о неудаче, реализация может попытаться отправить еще несколько запросов ARP.
При перемещении в другой сегмент сети узел оказывается за граничным
маршрутизатором. Поскольку IP-адрес содержит информацию о сегменте сети,
к которому подключен узел, IP-адрес перемещенного узла должен измениться
даже в том случае, если его аппаратный адрес остается прежним. Вспомните,
что пересылка данных ARP не выходит за граничный маршрутизатор. На
практике можно считать, что узел был отключен или стал недоступен.
При использовании записи в кэше для пересылки пакетов узлу реализация
ARP обычно обновляет временную пометку этой записи. Пометки также
обновляются при получении запросов ARP от узла, для которого существует запись
в кэше ARP. Если в течение достаточно долгого времени, называемого интервалом
тайм-аута ARP, от узла не поступало ни одного пакета, запись удаляется из кэша.
Реализация ARP также может включать независимый процесс (так
называемый демон). Независимый процесс периодически проверяет кэш ARP и удаляет
старые записи по тайм-ауту. Во многих реализациях TCP/IP по умолчанию
используется интервал тайм-аута продолжительностью 15 минут, а в некоторых
реализациях это значение может задаваться системным администратором.
В усовершенствованном варианте этой схемы демон ARP сначала отправляет
запрос ARP узлу. Если после нескольких повторных попыток ответ ARP не
приходит, запись удаляется. В этом случае запрос ARP отправляется узлу
напрямую и не рассылается в сети, потому что аппаратный адрес узла известен из
кэша ARP. Данная схема стандартна в реализациях ARP для Linux.
Многие реализации TCP/IP позволяют вручную создавать записи в кэше
ARP. Обычно в ручном создании записей нет необходимости, поскольку связи
между IP-адресами и аппаратными адресами определяются протоколом ARP
в динамическом режиме. Записи, созданные вручную, не устаревают по тайм-ауту
и могут использоваться для решения проблем с ошибочными записями в таблице
ARP, возникающими из-за дублирования IP-адресов или неправильной работы
программ. В разных операционных системах для просмотра или внесения
изменений в кэш ARP используются разные программы — как графические, так
и работающие в режиме командной строки. В операционных системах Windows
NT/XP и Unix для этой цели используется утилита ARP. Ниже приведен
синтаксис команды ARP для Windows XP.
Отображение и изменение таблиц преобразования IP-адресов в физические,
используемые протоколом разрешения адресов (ARP)
ARP -s inet_addr eth_addr [if_addr]
ARP -d inet_addr [if_addr]
ARP -a [inet_addr] [-N if_addr]
-а Отображает текущие ARP-записи, опрашивая текущие данные
протокола. Если задан inet_addr, то будут отображены IP
и физический адреса только для заданного компьютера.
Если более одного сетевого интерфейса используют ARP,
то будут отображаться записи для каждой таблицы.
-g To же, что и ключ -а.
inet_addr Определяет IP-адрес
-N if_addr Отображает ARP-записи для заданного в i faddr сетевого
интерфейса.
-d Удаляет узел, задаваемый inet_addr. inet_addr может содержать
символ шаблона * для удаления всех узлов.
-s Добавляет узел и связывает internet адрес inet_addr
с физическим адресом eth_addr. Физический адрес задается
6 байтами (в шестнадцатеричном виде), разделенными дефисом.
Эта связь является постоянной.
eth_addr Определяет физический адрес.
if_addr Если параметр задан, он определяет интернет-адрес интерфейса,
чья таблица преобразования адресов должна измениться.
Если не задан, - будет использован первый доступный интерфейс.
Пример:
> агр -s 157.55.85.212 00-аа-00-62-с6-09 ... Добавляет статическую запись
> агр -а ... Выводит ARP-таблицу.
ARP в мостовых сетях
Сети соединяются при помощи мостовых устройств, работающих на уровне 2 OSI,
и маршрутизаторов, работающих на уровне 3. Мосты расширяют область
действия локальной сети. Работа ARP в локальных сетях требует особого
обсуждения, которое станет темой этого раздела.
Когда попытка установить связь TCP/IP завершается неудачей, протокол
TCP, отвечающий за надежную доставку, пытается переслать пакеты заново.
Если неудача была обусловлена физическим сбоем канала, а к получателю ведут
другие пути, дейтаграмма IP маршрутизируется в обход сбойного участка. Если
TCP не удается восстановить связь, восстановление продолжается на более
низких уровнях, где модуль ARP пытается восстановить связь, производя
широковещательную рассылку запросов ARP. Если получатель находится в локальном
сегменте сети, подобный способ восстановления приемлем. Впрочем, когда
несколько узлов начинают одновременно рассылать широковещательные запросы
ARP, возникают проблемы. Рассмотрим ситуацию, когда центральный хост
становится недоступным из-за сбоя канала или оборудования. Если 100 станций
подключены к центральному хосту в сети и связь с хостом вдруг прерывается,
все 100 станций начинают одновременно передавать широковещательные
запросы ARP. В некоторых системах запросы ARP отправляются каждую секунду;
следовательно, ежесекундно в системе будет генерироваться сто
широковещательных запросов. В результате создается значительный объем сетевого трафика,
который отрицательно влияет на доступность сети для других узлов.
Широковещательный трафик даже может замедлить работу узлов, которые
в настоящий момент не обращаются к сети. Дело в том, что сетевой адаптер и
связанный с ним программный драйвер должны анализировать каждый
широковещательный пакет. В случае с запросами ARP для каждого широковещательного
запроса также должен выполняться модуль ARP. Обработка даже 50 запросов
ARP в секунду требует заметных вычислительных мощностей и замедляет работу
узла. В результате возникает впечатление, что все узлы сети замедляются.
Повторение широковещательных запросов ARP создает дальнейшие
затруднения в мостовых сетях. Сетевые сегменты, разделенные мостами, считаются
частью одного домена MAC, а запросы/ответы ARP должны передаваться через
мосты. Распространение широковещательного трафика за границы мостов
приводит к дальнейшему нарастанию его объема. В таких условиях создание
больших или сложных сетевых топологий с использованием мостов нежелательно.
Дублирование адресов и ARP
IP-адреса в сети должны быть уникальными. Но как обеспечить эту
уникальность? За счет хорошо организованного документирования и правил назначения
IP-адресов. Но так как в назначении IP-адресов участвует человеческий фактор,
нельзя исключать появления в сети узлов с одинаковыми IP-адресами. Если это
произойдет, в сети возникает хаос; сетевые приложения начинают вести себя
непредсказуемо или вовсе прекращают работать.
Чтобы вы лучше поняли последствия от дублирования IP-адресов, в
следующих разделах будут рассмотрены два сценария:
О дублирование IP-адресов клиентов TCP/IP;
О дублирование IP-адресов серверов TCP/IP.
Дублирование IP-адресов клиентов TCP/IP
Предположим, два клиента TCP/IP (далее — «клиент 1» и «клиент 2»)
обращаются к центральному серверу TCP/IP по IP-адресу 144.19.74.102. Аппаратный
адрес сервера равен 080020021545.
Клиенты 1 и 2 используют один и тот же IP-адрес 144.19.74.1. Их
аппаратные адреса равны 0000С0085121 и 0000С0075106 соответственно.
Клиент 1 начинает сеанс FTP на сервере TCP/IP. Перед началом сеанса FTP
клиент 1 рассылает широковещательный запрос ARP для получения аппаратного
адреса сервера TCP/IP. При получении запроса ARP сервер TCP/IP добавляет
в кэш ARP запись для отправителя запроса (клиента 1) и отправляет ему ответ
ARP. При получении ответа ARP клиент 1 добавляет запись для сервера TCP/IP
в свой локальный кэш ARP. На этой стадии кэши ARP на сервере TCP/IP и на
клиенте 1 находятся в следующем состоянии.
Сервер TCP/IP:
IP-адрес Аппаратный адрес
144.19.74.1 0000С0085121
Клиент 1:
IP-адрес Аппаратный адрес
144.19.74.102 080020021545
Во второй фазе клиент 2 пытается открыть сеанс TCP/IP (например, другой
сеанс FTP) с тем же сервером TCP/IP.
Прежде чем устанавливать связь, клиент 2 должен узнать аппаратный адрес
сервера TCP/IP. Он пытается сделать это, отправляя запрос ARP. При
получении запроса ARP сервер TCP/IP должен занести информацию об отправителе
запроса (клиенте 2) в кэш ARP и вернуть ему ответ. Сервер TCP/IP
обнаруживает, что в кэше ARP уже имеется запись для адреса 144.19.74.1. В соответствии
с RFC 826 сервер TCP/IP должен заменить существующую запись новой.
Большинство реализаций TCP выполняет замену автоматически, без
предупреждения о возможности потенциального дублирования IP-адресов, хотя некоторые
реализации выдают такое предупреждение. Сервер TCP/IP отвечает на запрос
ARP от клиента 2. При получении ответа компьютер 2 добавляет запись с
данными сервера TCP/IP в свой локальный кэш ARP. На этой стадии кэши ARP
на сервере TCP/IP и на клиенте 2 находятся в следующем состоянии.
Сервер TCP/IP:
IP-адрес Аппаратный адрес
144.19.74.1 0000С0075106
Клиент 1:
IP-адрес Аппаратный адрес
144.19.74.102 080020021545
Когда сервер TCP/IP захочет отправить данные клиенту 1, он ищет
аппаратный адрес клиента 1 по IP-адресу 144.19.74.1 в локальном кэше ARP и
отправляет данные по найденному адресу. К сожалению, этот аппаратный адрес
принадлежит клиенту 2, поэтому данные будут отправлены клиенту 2. Клиент 1, не
получив ожидаемые данные, пытается повторить последний запрос, но сервер
TCP/IP снова отправит ответ клиенту 2. Клиент 1 «виснет» в ожидании ответа.
Со временем операция будет отменена по тайм-ауту, или компьютер придется
перезагрузить. Так или иначе, приложение, которое раньше благополучно
работало, вдруг перестает работать, к немалому удивлению пользователя и
системного администратора.
Клиент 2 неожиданно для себя получает данные, предназначенные для
клиента 1. Вероятно, он отвергнет эти данные, может быть сгенерирует сообщение
об ошибке и продолжит свой сеанс с сервером TCP/IP. Также не исключено,
что компьютер придет в замешательство и «зависнет».
Если пользователь клиента 1 перезагрузит «зависший» компьютер и
попытается снова подключиться к серверу TCP/IP, данные кэша клиента 2 на сервере
TCP/IP будут заменены данными клиента 1. Теперь «зависает» клиент 2, и
ситуация повторяется до тех пор, пока пользователи не оставят свои попытки.
Если пользователи клиентов 1 и 2 не обмениваются информацией о
возникающих проблемах, каждый пользователь видит происходящее лишь со своей
стороны — его клиент «виснет» на середине сеанса работы с сервером TCP/IP.
Если обращения к серверу происходят в разное время, не исключено, что
проблема не проявится, а дублирование IP-адресов останется незамеченным. Если
же пользователи будут сталкиваться с проблемой время от времени, они решат,
что происходящее вызвано какими-то сетевыми сбоями и не станут сообщать
о проблеме. Дублирование адресов снова останется незамеченным.
Дублирование IP-адресов на серверах TCP/IP
Теперь рассмотрим несколько иную ситуацию. Имеются два сервера TCP/IP
(далее — «сервер 1» и «сервер 2»), которым были присвоены одинаковые IP-адреса
144.19.74.102. Аппаратные адреса серверов равны 080020021545 и АА0004126750.
Клиент с IP-адресом 144.19.74.1 пытается обратиться к серверу TCP/IP по
адресу 144.19.74.102. Аппаратный адрес клиента равен 0000С0085121.
Клиент пытается соединиться с сервером 2. Прежде чем создать соединение
TCP/IP, клиент генерирует широковещательный запрос ARP для получения
аппаратного адреса сервера TCP/IP. Один и тот же аппаратный адрес 144.19.74.102
присвоен двум серверам TCP/IP. При получении запроса ARP оба сервера
создают записи для отправителя запроса ARP (клиента) в своих локальных кэшах
ARP и отправляют ему ответ ARP. Клиент принимает первый ответ ARP и молча
игнорирует второй ответ. Если ответ сервера 2 достигнет клиента первым,
клиент включит в локальный кэш запись для сервера 2. На этой стадии кэши ARP
на серверах и клиенте находятся в следующем состоянии.
Сервер 1:
IP-адрес Аппаратный адрес
144.19.74.1 0000С0085121
Сервер 2:
IP-адрес Аппаратный адрес
144.19.74.1 АА0003126750
Клиент 1:
IP-адрес Аппаратный адрес
144.19.74.102 080020021545
Клиент продолжает работать с сервером 2, а не с сервером 1, как
предполагалось изначально. Если нужная служба отсутствует на сервере 2, подключение
завершается неудачей, а пользователь неожиданно получает сообщение о том,
что служба не поддерживается сервером. Это сильно озадачит пользователя,
особенно если раньше он успешно пользовался услугами сервера 1.
Если на сервере 2 имеется нужная служба, пользователь пытается
подключиться к ней. Для таких служб, как Telnet и FTP, требуется ввести имя и пароль.
Только особенно внимательный пользователь заметит, что имя/номер версии
сервера FTP или Telnet, выводимый на экране, отличается от предполагаемого.
Если на сервере 2 не существует учетной записи с таким же именем и паролем,
как на сервере 1, попытка подключения будет отвергнута. Если имя и пароль
совпадают на обоих серверах, пользователь подключится не к тому серверу, к
которому он собирался подключиться. Возможны разные последствия — например,
пользователь может не найти нужных файлов или данных.
Если сервер является многоадресным (сервер с несколькими сетевыми
подключениями) и выполняет функции маршрутизатора, ситуация может оказаться
еще более запутанной — пакеты, предназначенные для внешней сети, могут
следовать по другому маршруту или не будут доставлены из-за того, что они будут
приняты не тем сервером.
Проверка дублирования адресов ARP
Многие реализации TCP/IP при запуске производят широковещательную
рассылку запроса ARP. В рассылаемом запросе поле IP-адреса получателя
заполняется IP-адресом запускаемого узла.
Исходный запрос ARP проверяет, имеются ли в сети узлы с одинаковым
IP-адресом. Если узел получит ответ ARP, значит, IP-адрес другого узла
(сгенерировавшего ответ ARP) совпадает с IP-адресом запускаемого узла.
Запускаемый узел должен сообщить о дублировании IP-адресов каким-либо подходящим
способом. Узел, отвечающий на запрос ARP, даже может дополнительно
проверить поле IP-адреса отправителя и сравнить его с собственным IP-адресом.
Если IP-адреса отправителя и получателя совпадают, то отвечающий узел может
сгенерировать сообщение о дублировании IP-адресов.
Кадр ARP, структура которого была описана выше, позволяет обнаруживать
только дублирующиеся IP-адреса в том же сегменте сети. Поскольку пакеты
ARP не выходят за маршрутизатор, они не позволяют обнаружить проблемы
с дублированием IP-адресов в сегментах сетей, соединенных маршрутизаторами.
Исходный широковещательный запрос ARP также предназначен для узлов,
приступающих к обновлению кэша ARP, у которых имеется запись для
запускаемого узла. Если аппаратный адрес запускаемого узла изменился (из-за смены
сетевого оборудования), то все узлы, получившие запрос, должны удалить старый
аппаратный адрес и обновить свои кэши ARP новым адресом.
Proxy ARP
Ранее в этой главе было показано, что две сети, соединенные через шлюз, могут
содержать одинаковые сетевые адреса. Шлюз должен определить, к какой из сетей
относится физический или IP-адрес входящей дейтаграммы. Для этого он
может воспользоваться модифицированной версией ARP, называемой Proxy ARP.
Proxy ARP строит кэш ARP, состоящий из записей обеих сетей. Шлюз должен
управлять запросами и ответами ARP, пересекающими границу между сетями.
Объединяя два кэша ARP, Proxy ARP вносит дополнительную гибкость в
процесс разрешения адресов и предотвращает появление лишних дейтаграмм с
запросами/ответами ARP, когда адрес находится за границей шлюза.
RARP
Если устройство не знает свой IP-адрес, оно не сможет сгенерировать запросы
и ответы ARP. Подобные ситуации характерны для таких устройств, как
бездисковые рабочие станции в сети. Единственный адрес, известный устройству, — это
физический адрес, установленный на сетевом адаптере.
Простейший выход из ситуации заключается в использовании протокола RARP
(Reverse Address Resolution Protocol), который по выполняемым функциям
противоположен ARP. Компьютер отправляет физический адрес и ожидает получить
обратно IP-адрес. Ответ, содержащий IP-адрес, отправляется сервером RARP —
хостом, который может предоставить эту информацию. Хотя
устройство-отправитель передает сообщение в широковещательном режиме, в правилах RARP
сказано, что только сервер RARP может сгенерировать ответ. Во многих сетях
используется несколько серверов RARP, как для распределения нагрузки, так
и для выполнения резервных функций при возникновении проблем.
RARP часто используется «бездисковыми станциями», не имеющими
локальных накопителей. На самом деле современные бездисковые станции часто
оснащаются локальным диском, но он используется только для ускорения работы
операционной системы, но не для хранения параметров TCP/IP, хранящихся на
удаленном сервере. Например, на локальном диске может храниться локальный
файл подкачки, необходимый для реализации виртуальной памяти в
операционной системе.
На бездисковых станциях также имеется копия операционной системы,
хранящейся на удаленном сервере. При запуске бездисковая станция загружает
копию операционной системы с удаленного сервера в память. Но чтобы станция
могла начать загрузку образа операционной системы с использованием
протоколов передачи файлов TCP/IP, ей нужно знать свой IP-адрес. Этот адрес не
может быть произвольной величиной; он должен быть уникальным и иметь тот же
префикс, что и IP-адреса других узлов сегмента сети. Например, если другие
станции сети имеют IP-адреса 199.245.180.1, 199.245.180.5 и 199.245.180.7, то
общий префикс имеет вид «199.245.180». Бездисковая станция тоже должна иметь
тот же префикс. Общий префикс необходим из-за того, что он определяет
маршрут пакета в сегменте сети.
Обычно бездисковые станции получают свой IP-адрес, отправляя запрос
серверам текущего сегмента сети. Поскольку информация об адресе удаленного
сервера тоже недоступна, запрос отправляется в виде широковещательной
рассылки канального уровня. Один из механизмов получения IP-адресов от
удаленных серверов основан на использовании протокола RARP (Reverse Address
Resolution Protocol). Этот протокол называется «обратным» (reverse), потому
что он выполняет преобразование адреса, обратное тому, которое выполняется
протоколом ARP.
Бездисковые станции используются для снижения стоимости оборудования,
упрощения конфигурации и обновления узлов за счет централизованного
хранения важнейшей информации, а также снижения вероятности проникновения
вирусов в систему, поскольку конечный пользователь не может легко установить
свою программу на бездисковую станцию.
Схема работы RARP
Узел, желающий узнать свой IP-адрес (клиент RARP), рассылает
широковещательный запрос, называемый запросом RARP. Запрос RARP рассылается на
канальном уровне, потому что клиент RARP не знает адрес (аппаратный или IP)
удаленного сервера. Удаленный сервер, обрабатывающий запрос RARP,
называется сервером RARP.
При наличии нескольких серверов RARP все серверы пытаются обработать
запрос RARP. Обычно клиент RARP принимает первый полученный ответ и
игнорирует остальные.
Сервер RARP содержит таблицу IP-адресов для узлов сегмента сети. Таблица
индексируется по идентификатору, уникальному для каждого компьютера. Этот
уникальный идентификатор передается в запросе RARP. Для бездисковых
станций этот уникальный идентификатор должен представлять собой некий
аппаратный и достаточно легко определяемый параметр. Идентификатор не может
храниться локально, на бездисковых станциях отсутствует локальный диск,
который бы мог использоваться для этой цели. Проектировщики RARP (см. STD 38,
RFC 903) решили использовать для идентификации аппаратные адреса, поскольку
они уникальны в границах сегмента сети и легкодоступны для сетевых драйверов.
Получая запрос RARP, сервер RARP просматривает таблицу ассоциаций
между IP-адресами и аппаратными адресами (рис. 5.6). Если в процессе просмотра
будет найдена запись, соответствующая аппаратному адресу в запросе RARP,
протокол возвращает найденный IP-адрес в ответе RARP. Ответ RARP не
рассылается в широковещательном режиме; сервер берет аппаратный адрес клиента
RARP из запроса RARP.
Пакеты запросов и ответов RARP имеют такую же структуру, как пакеты ARP.
ARP и RARP различаются по значениям, содержащимся в полях. Если пакет
RARP передается в кадре Ethernet, используется код EtherType 8035 (шести.).
Ниже перечислены значения отдельных полей в пакетах RARP.
Запрос RARP:
О Аппаратный адрес получателя = рассылка.
О Аппаратный адрес отправителя = аппаратный адрес клиента RARP.
О EtherType «= 8035 (шести.).
О Код операции = 3 (запрос RARP).
О Аппаратный адрес отправителя = аппаратный адрес клиента RARP.
О IP-адрес отправителя * не определен; обычно используется 0.0.0.0.
RARP Operation
Адрес отправителя = PA
Адрес получателя = рассылка
Ethertype = 8035 hex
С RARP ^^L
( daemon Д1
^—/"~*^ВЭ Сервер RARP
| Запрос RARP | Канал [—► Рассылка ШШ Г "Ч
Г ^ ^ л А
—£—У*—У* ;—°— /; \
<—| Канал | Ответ RARP \<r ! \
шШШШШШ ШИ | адрес | адрес |
Рис. 5.6. Схема работы RARP (с разрешения Learning Tree)
О Аппаратный адрес получателя = аппаратный адрес клиента RARP.
О IP-адрес отправителя = не определен.
Ответ RARP:
О Аппаратный адрес получателя = аппаратный адрес клиента RARP.
О Аппаратный адрес отправителя = аппаратный адрес сервера RARP.
О EtherType = 8035 (шести.).
О Код операции = 4 (ответ RARP).
О Аппаратный адрес отправителя = аппаратный адрес сервера RARP.
О IP-адрес отправителя = IP-адрес сервера RARP.
О Аппаратный адрес получателя = аппаратный адрес клиента RARP.
О IP-адрес отправителя = IP-адрес клиента RARP (возвращаемое значение).
Поле аппаратного адреса получателя в запросе заполняется аппаратным
адресом клиента RARP. Это делается для удобства сервера, чтобы ему не пришлось
заполнять это поле, которое должно содержать аппаратный адрес клиента RARP
в ответе.
Сетевой драйвер анализирует поле EtherType, определяет, что пакет является
пакетом RARP (EtherType - 8035 шести.) и отправляет запрос модулю RARP.
Запросам RARP соответствует код операции 3, а ответам RARP — код операции
4. Содержимое этих полей также может использоваться для того, чтобы отличить
пакеты RARP от пакетов ARP. Тем не менее такой подход недостаточно
эффективен. Модулю ARP пришлось бы анализировать поле кода операции в пакете,
и если код указывает на пакет RARP — передать пакет модулю RARP.
Использование поля EtherType позволяет более эффективно выполнить
демультиплексирование на низком уровне.
ПРИМЕЧАНИЕ
Во многих реализациях поддержка RARP не интегрируется в модулях ARP и IP. Ее необходимо
запускать в виде отдельного процесса (например, демона) на компьютере, выполняющем функции
сервера RARP.
Сбой сервера RARP
Если сервер RARP становится недоступным из-за сбоя сетевого соединения или
из-за выхода компьютера из строя, клиенты RARP не смогут нормально
загрузиться. Они будут снова и снова рассылать широковещательные запросы RARP.
Одновременная рассылка запросов многими клиентами RARP серьезно
увеличивает сетевой трафик.
Отсутствие ожидаемого ответа RARP приводит к более серьезным
последствиям, нежели для протокола ARP. Отсутствие ответа ARP означает лишь то, что
конкретный хост и его службы недоступны в настоящий момент — клиент ARP
может попытаться обратиться к другим узлам сети. Тем не менее при отсутствии
ответа RARP клиент не сможет загрузиться. Многие клиенты RARP продолжают
рассылать широковещательные запросы в течение неопределенно долгого времени
в надежде, что сервер RARP когда-нибудь снова станет доступным. Следовательно,
повторение широковещательных запросов RARP порождает больше проблем, чем
повторение запросов ARP, из-за возрастания сетевого трафика.
Основные и резервные серверы RARP
Чтобы сделать работу RARP более надежной, можно использовать несколько
серверов RARP. Если в сети работает несколько серверов RARP, при получении
широковещательного запроса каждый сервер попытается ответить на этот запрос.
Только один ответ используется клиентом RARP; все остальные ответы
игнорируются. Для предотвращения рассылки множественных ответов RARP
применяется схема, при которой один сервер RARP назначается основным, а все
остальные — резервными.
Получив запрос RARP, основной сервер отвечает на него. Резервные серверы
не отвечают, но регистрируют время прибытия запроса. Если основной сервер
не ответит в течение интервала тайм-аута, то резервный сервер RARP считает,
что основной сервер недоступен, и отвечает на запрос.
Если в сети работает несколько резервных серверов, все резервные серверы
попытаются ответить одновременно. В усовершенствованном варианте этой схемы
резервный сервер отвечает не сразу, а ожидает в течение случайного интервала
времени. При нормальной работе основного сервера дополнительных задержек
с отправкой ответа RARP не будет. Если основной сервер вышел из строя,
возможна небольшая случайная задержка перед тем, как ответит один из резервных
серверов RARP.
Команда ARP
Многие (но не все) реализации TCP/IP предоставляют средства для проверки
содержимого кэша. В Unix и Windows NT/2000/XP существует команда агр,
выводящая все содержимое кэша ARP. Для просмотра кэша команда вводится
с ключом -а:
$ агр -а
brutus <205.150.89.3> at 0:0:d2:03:08:10
В данном примере кэш содержит данные компьютера brutus с IP-адресом
205.150.89.3 и адресом MAC 0:0:d2:03:08:10.
Команда агр обычно используется только тогда, когда администратор сети
пытается решить проблемы с дублированием IP-адресов. Если в сети имеются
два компьютера с одинаковыми IP-адресами (но разными адресами MAC),
информация о них будет присутствовать в кэше ARP.
Итоги
В этой главе были рассмотрены самые распространенные протоколы
разрешения адресов: ARP, Proxy ARP и RARP. Глава начинается с описания того, как
дейтаграммы TCP/IP собираются в кадры Ethernet. После знакомства со всеми
иерархическими уровнями, задействованными в работе межсетевых объединений,
вы получили достаточно хорошее представление о том, как работает TCP/IP
и как происходит передача данных по сети заданному хосту.
fZ DNS
Рима С. Регас (Rima S. Regas)
Каранжит С. Сиян (Karanjit S. Siyan)
На ранней стадии развития ARPANET, когда сеть оставалась относительно
небольшой, пользователи сети должны были поддерживать конфигурационный
файл HOSTS с информацией о рабочих станциях, входящих в сеть. Файл был
необходим для взаимодействия с другими системами в сети. Тем не менее такое
решение создавало немало проблем, поскольку файл HOSTS приходилось
обновлять вручную на каждом компьютере. Автоматизация настройки конфигурации
практически отсутствовала, вследствие чего обновление файла было
утомительным и долгим процессом.
Файл HOSTS содержит информацию о том, какой IP-адрес связывается с тем
или иным именем. Когда компьютеру требовалось найти другой компьютер в сети,
он обращался к локальному файлу HOSTS. Компьютер, не имеющий записи в
файле HOSTS, фактически не существовал для сети. Служба DNS (Domain Name
System) кардинально изменила эту ситуацию. У системных администраторов
появляется возможность использования сервера в качестве хоста DNS.
Например, когда компьютеру в сети потребуется узнать данные другого сервера, он
обращается к файлу HOSTS.
В наше время файл HOSTS продолжает использоваться, но обычно только для
того, чтобы предотвратить поиск локальных компьютеров средствами DNS.
Выборка информации из файла происходит гораздо быстрее. Короче говоря,
сетевое программное обеспечение компьютера настроено таким образом, чтобы оно
просматривало локальный файл HOSTS перед тем, как обращаться к серверу DNS.
При обнаружении информации в файле клиентская программа продолжает
работать с удаленным хостом, что существенно уменьшает затраты времени по
сравнению с получением IP-адреса средствами DNS.
Система доменных имен: общие принципы
Как известно, имена запоминаются проще, чем числа. Многие люди обладают
феноменальной способностью запоминать телефонные номера, адреса,
денежные суммы и другие числа, но в настоящее время существует слишком много
IP-адресов, чтобы можно было запомнить хотя бы их малую часть. По этой
причине была разработана методика присваивания имен IP-адресам,
основанная на мнемоническом принципе. Например, C|Net было присвоено доменное имя
www.cnet.com (обратите внимание на отсутствие вертикальной черты и
прописных букв). По сравнению с именем сайта оно выглядит невыразительно, но тем
не менее оно работает и прекрасно ассоциируется с именем сайта. C|Net — один
из самых больших и посещаемых сайтов в мире.
Система DNS появилась из-за очевидной необходимости в системе, которая
бы транслировала символические имена в IP-адреса. В результате трансляции
или разрешения доменного имени сайта (например, www.cnet.com) возвращается
IP-адрес B04.162.80.181), который используется для обращения к данным. Именно
таким образом в ваш браузер доставляется запрашиваемая информация. Процесс
требовал создания сети систем, которые назывались серверами DNS (Domain
Name Service).
Частью работы по поддержанию системы DNS в Интернете является
поддержка первичных (корневых) доменных серверов, к которым остальные серверы
DNS обращаются для получения информации о доменах верхнего уровня,
зарегистрированных в Интернете. Информация DNS распределяется по
большому количеству серверов DNS. Если ваш сервер DNS не может преобразовать
доменное имя в IP-адрес, он обращается к другому серверу DNS, который, как
предполагается, обладает более полной информацией о преобразуемом имени.
Если этот сервер тоже не справляется с преобразованием имени, он может
вернуть ссылку на другой сервер DNS, который может знать ответ. Процесс
повторяется до тех пор, пока не произойдет тайм-аут. В этом случае исходному узлу
возвращается признак ошибки и выводится соответствующее сообщение (если
такая возможность поддерживается клиентом). Если поиски web-сайта
завершаются неудачей, браузер выводит сообщение о том, что сайт найти не удалось
или произошла ошибка DNS.
Ссылочный механизм, описанный выше, обычно используется серверами
DNS при обращении с запросами к другим серверам DNS. Подобный тип запроса
DNS называется итеративным. Резольвер DNS (другое название клиента DNS)
находится на узле, выдавшем запрос DNS. Резольвер не генерирует итеративные
запросы, вместо этого он выдает запрос другого типа — так называемый
рекурсивный запрос. Узел, отправивший рекурсивный запрос серверу DNS, ожидает,
что последний вернет окончательный ответ или информацию о том, что имя
разрешить не удалось. Получив рекурсивный запрос, сервер DNS не возвращает
ссылку на другой сервер DNS; он должен самостоятельно сгенерировать
итеративные запросы для получения окончательного ответа.
Система DNS начинается с корневых серверов DNS верхнего уровня, далее
информация об именах и IP-адресах распространяется по серверам DNS,
расположенным по всему миру. Иерархическое строение системы, непосредственно
обусловленное ее организационной структурой, наглядно демонстрирует
простой пример — отсутствие локальной информации о преобразовании на сервере
DNS. Если сервер не может найти нужный IP-адрес в собственной базе данных,
он обращается к другому серверу DNS; это продолжается до тех пор, пока
информация не будет найдена или не произойдет тайм-аут. В следующем разделе
приводится более подробное описание структуры DNS, поскольку
иерархическое строение системы имеет другой, очень важный аспект.
Иерархическое строение DNS
В исходном документе RFC 819, опубликованном в 1982 году, Зав-Синг Су
(Zaw-Sing Su) и Джон Постел (Jon Postel) изложили основные планы и
концепции DNS. Ниже приведен фрагмент, который дает представление об уровне
изложения.
«...Совокупность доменов формирует иерархию. Используя представление
из теории графов, эту иерархию можно смоделировать в виде направленного
графа. Направленный граф представляет собой набор узлов и ребер, при этом
ребра определяются упорядоченными парами узлов [1]. Каждый узел графа
представляет домен. Упорядоченная пара (В, А), то есть ребро, следующее от
В к А, означает, что В является субдоменом А, а В является простым именем,
уникальным в А».
Понять такой текст непросто, поэтому мы воспользуемся более простым
объяснением. Основной принцип прост: имеется некий домен верхнего уровня —
например, com или edu. Домены com и edu находятся на верхнем уровне и не
имеют вышестоящих доменов. Впрочем, существует одно исключение: на самом
деле после com должна стоять точка (com.). Она обозначает домен еще более
высокого уровня, чем com, который называется корневым доменом. Домены
верхнего уровня (такие, как com, edu и org) называются универсальным
множеством имен, потому что они содержат домены и субдомены, расположенные на
более низких уровнях иерархии.
После верхнего уровня следуют промежуточные домены, или домены второго
уровня. В качестве примеров промежуточных доменов можно привести домены
coke.com, whltehouse.gov и disney.com. Эти домены также могут регистрироваться,
но обычно это делается только для того, чтобы зарезервировать целый
диапазон логически связанных доменных имен. На практике чаще встречается
регистрация субдоменов, или конечных (endpoint) доменов, как их называли Су
и Постел. Примеры — www.coke.com, www.whitehouse.gov и www.disney.com.
Разумеется, все эти домены типичны для регистрационной системы InterNIC. В
других системах, находящихся за пределами Соединенных Штатов, используются
различные схемы обозначения направленности и страны, к которой относится
домен. Например, имя www.bbc.co.uk указывает на то, что сайт ВВС имеет
коммерческую направленность (со, аналог com) и находится в Соединенном
Королевстве (uk).
Имена субдоменов выбираются почти произвольно. Примеры — www.netscape.
com, home.netscape.com, wwwl.netscape.com. Они могут находиться в разных местах
Интернета и содержать разную информацию. Конечно, если web-мастер сочтет
нужным, несколько имен могут ссылаться на один сайт и одну страницу. Именно
так обстоит дело с сайтом Netscape; к нему можно обратиться по любому из
перечисленных URL.
U
III U: Универсальное множество имен
I E | I: Промежуточный домен
/\ Е: Конечный домен
Е Е I
Е Е Е
Рис. 6.1. Исходная иерархия доменов
ПРИМЕЧАНИЕ
Другой пример: Webopaedia также решила зарегистрировать субдомен webopedia.com, поскольку
у многих пользователей возникали проблемы с дифтонгом аэ.
Делегирование полномочий
Устройство системы DNS позволяет серверам, подчиненным по отношению к
корневым серверам имен, контролировать заданный домен. Хорошим примером
является локальный поставщик услуг Интернета, который обеспечивает хостинг
web-сайтов для отдельных лиц и организаций. Когда некая организация X
регистрирует в InterNIC свое доменное имя (www.companyx.com), она включает в заявку
первичный и вторичный серверы DNS своего поставщика. InterNIC заносит эту
информацию на свой корневой сервер .com и обеспечивает ее дальнейшее
распространение.
ПРИМЕЧАНИЕ
Серверы DNS периодически синхронизируют свои локальные базы данных с базами данных других
серверов DNS и проверяют, не появились ли новые записи на корневых серверах. Этот процесс
называется распространением (propagation). Регистрация доменных имен требует некоторого
времени, но зарегистрированное имя распространяется в Интернете в течение примерно трех-четы-
рех дней и становится доступным во всем мире.
Чтобы эта система нормально работала, возникла потребность в средствах
определения местонахождения компьютера в сети. Из этой потребности стала
развиваться иерархия систем и механизмы классификации компьютеров по
выполняемым функциям. Например, если компьютер находится в учебном
заведении, он принадлежит к домену верхнего уровня .edu. Сайты коммерческой
направленности принадлежат к домену верхнего уровня .com и т. д. Данная
концепция формирует основу логической иерархии DNS, но не определяет
структуру корневых серверов имен (вскоре мы вернемся к этой теме).
Распределенная база данных DNS
Архитектура распределенной базы данных, заложенная в основу DNS, обладает
большими возможностями. Как упоминалось выше, полномочия делегируются
другим серверам, местонахождение которых лучше подходит для обработки
трафика некоторого домена или субдомена. Распространение информации по
серверам происходит по хорошо продуманному плану.
Каждому домену назначается владелец. Информация о владельце
определяется как часть доменных данных SOA (Start of Authority), которые будут более
подробно рассмотрены ниже. Домен верхнего уровня — например, com. —
делегирует полномочия контроллера для некоторого доменного имени (скажем,
disney.com) серверам DNS, указанным в качестве первичных. Тем самым
контроллер домена верхнего уровня освобождается от необходимости обрабатывать
каждый запрос DNS в Интернете.
После того как с контроллером домена будут связаны данные SOA, он сможет
делегировать полномочия контроллера для субдоменов другим серверам DNS
и т. д. По этому принципу организуется делегирование полномочий в иерархии
серверов DNS от верхнего уровня до нижнего.
Домены и зоны
Домены и зоны часто работают вместе, но между ними существует тонкое
различие. Зоной (zone) называется первичный домен универсального множества имен,
делегированный другому серверу DNS для административных целей. Например,
Disney.com — это зона, а www.disney.com — хост, находящийся в этой зоне. Зона
может состоять из одного домена или нескольких субдоменов. Например, студия
Диснея может создать субдомены с именами east-coast.Disney.com и west-coast.
Disney.com. В случае делегирования эти субдомены образуют отдельные зоны
с именами east-coast.Disney.com и west-coast.Disney.com, которые будут иметь
собственные серверы DNS. Без делегирования эти субдомены останутся частью
зоны Disney.com и будут обслуживаться серверами DNS сервера Disney.com.
Административные обязанности делегируются первичному серверу DNS.
Первичный сервер DNS сайта Диснея, huey.disney.com, имеет IP-адрес 204.128.192.10.
Поскольку Huey назначается первичным сервером DNS для домена Disney, он
также является первичным сервером DNS для зоны Disney.com. Назначенный
владелец этого сервера имеет адрес root@huey.disney.com, который хранится в SOA
в виде root.huey.disney.com.
ПРИМЕЧАНИЕ
Учтите, что в правильно отформатированных данных SOA символ @ в адресе электронной почты
администратора заменяется точкой. В некоторых компаниях используются адреса электронной
почты, в которых перед @ стоит дополнительный разделитель. В этом случае возникнут проблемы,
потому что адрес вида host.admin@example.com будет храниться в SOA в виде host.admin.
example.com. Любая система, пытающаяся преобразовать этот адрес, интерпретирует его в виде
host@admin.example.com, что приводит к ошибке DNS (если ошибочно интерпретированный
адрес не существует).
Домены верхнего уровня в Интернете
Существует несколько доменов верхнего уровня, из которых наибольшей
известностью пользуются домены COM, EDU, GOV, MIL, NET и ORG. Тем не менее
существует множество других доменов, большинство из них находится в других странах.
Каждой стране присвоен домен верхнего уровня, имя которого состоит из двух
букв. Так, Великобритании присвоен домен UK (на самом деле официальный
домен верхнего уровня этой страны называется GB, но это имя используется
редко); Новой Зеландии — домен NZ, Японии — JP и т. д. Пример использования
национального домена верхнего уровня приводился выше — www.bbc.co.uk.
ПРИМЕЧАНИЕ
В адресах, находящихся за пределами США, используются и другие домены. Так, домен СО,
означающий коммерческую направленность, является близким аналогом домена InterNIC COM.
ВНИМАНИЕ
Ничто не мешает регистрировать домены в других странах, даже если сервер находится вдали
от страны, указанной в URL.
Выбор сервера имен
Серверы имен существуют на многих платформах, включая Windows NT/2000/
ХР, Unix, NetWare, Macintosh и т. д. В Windows NT/2000 имеется готовая
реализация сервера DNS. Для Apple существует бесплатный сервер DNS, который
называется MacDNS. В системах семейства Unix присутствует широко
распространенный и надежный сервер BIND. Тем не менее существует ряд мощных
серверов DNS, разработанных независимыми фирмами.
Оценку различных серверов DNS можно найти на таких сайтах, как Dave Central
(www.davecentral.com) и Tucows (www.tucows.com, также существует ряд местных
филиалов). Эти сайты рецензируют практически все программное обеспечение,
проходящее через них, и дают хорошее представление о различных реализациях.
Процесс разрешения имен
Когда клиент (например, браузер) выдает запрос к некоторому URL, этот
запрос передается локальному серверу DNS, который пытается преобразовать имя
в IP-адрес. Если преобразование проходит успешно, данные передаются дальше,
а сервер получает следующий запрос. Если сервер не находит адрес, у него есть
два варианта дальнейших действий в зависимости от настройки.
Рекурсивные запросы
Наиболее типичными являются рекурсивные запросы. Если запрос поступает
на сервер и в кэше сервера обнаруживается запись А (см. ниже), поиск на этом
останавливается. В противном случае сервер должен обратиться с запросом к
другому серверу, то есть передать запрос на более высокий уровень. При этом также
учитывается значение TTL (срока жизни) запроса. Если поиск записи А
занимает слишком много времени, запрос «умирает», а исходный сервер DNS
возвращает ошибку «address not found».
Итеративные запросы
Итеративные запросы должны оставаться локальными по нескольким
причинам, чаще всего из-за недоступности другого сервера DNS. Иногда рекурсия
отключается на сервере DNS, к которому вы обращаетесь, но это маловероятно.
Сервер прилагает все усилия к тому, чтобы найти в своем кэше лучшее возможное
совпадение. Но если данных нет — значит, их нет, и тогда возвращается ошибка.
Кэширование
По мере выполнения своих текущих задач сервер DNS собирает информацию
и сохраняет ее в виде ресурсных записей (RR, Resource Records), содержащих
сведения о запрашиваемых URL. При этом также учитывается значение TTL.
Сервер кэширует столько информации, сколько ему разрешено кэшировать,
и хранит ее, пока информация остается действительной.
Запросы на обратное разрешение
Типичный «прямой» запрос пытается найти IP-адрес по известному URL. При
обратном разрешении решается противоположная задача — поиск URL по
известному IP-адресу. В настоящее время существует несколько утилит,
выполняющих поиск подобного рода. Для системы Windows лучшей программой
такого рода является CyberKit Люка Ниенса (Luc Niejens) — бесплатная сетевая
утилита, которую можно загрузить по адресу www.ping.be/cyberkit.
Безопасность DNS
Клиенты могут производить безопасное обновление данных на динамическом
сервере DNS, чтобы их записи автоматически обновлялись без участия
администратора.
Ресурсные записи (RR)
Все типы ресурсных записей DNS имеют сходный формат. Хотя в файлах DNS
существует множество сокращенных обозначений и аббревиатур, в следующих
примерах для предотвращения путаницы и неоднозначной интерпретации
используется простейшая схема записи.
Первое поле в записи DNS всегда содержит IP-адрес или имя хоста. Если
данные отсутствуют, подразумевается имя или адрес из предыдущей записи.
Обратите внимание: все имена и адреса завершаются символом «точка» (.).
Это обозначение означает, что имя или адрес является абсолютным, а не
относительным. Абсолютные адреса, также называемые полностью определенными
доменными именами, задаются по отношению к корневому домену, тогда как
относительные адреса задаются по отношению к основному домену (который может
быть как корневой, так и иной домен). За этим полем может следовать
необязательное значение TTL, которое указывает, в течение какого промежутка времени
информация в этом поле должна считаться действительной.
Во втором поле указывается тип адреса. В современных базах данных DNS
обычно встречается строка «IN», признак интернет-адреса. Данное поле
присутствует по историческим причинам и для сохранения совместимости со старыми
системами.
Третье поле содержит строку, определяющую тип ресурсной записи. За ним
следуют необязательные параметры, специфические для данного типа записи.
Ресурсные записи типа SOA
Запись SO A (Start of Authority) означает, что сервер имен DNS является
лучшим источником информации для этого домена. Записи SOA также содержат
адрес электронной почты ответственного лица для зоны, признак модификации
зонного файла базы данных, а также используются для установки таймеров,
определяющих периодичность обновления копий зонной информации другими
серверами.
В записи хранится имя системы DNS и имя лица, ответственного за ее
работу. Ниже приведен пример записи SO А:
; Start of Authority (SOA) record
dns.com. IN SOA dnsl.dns.com. owner.dns.com. (
000000001 ; serial # (counter)
10800 ; refresh C hours)
3600 ; retry A hour)
604800 ; expire A week)
86400) ; TTL A day)
Обратите внимание: адрес владельца задается в формате owner.dns.com, что
следует читать как owner@dns.com. Строка завершается открывающей круглой
скобкой, парная закрывающая скобка находится в последней строке после
значения TTL. Запись может быть представлена в следующем формате, который
также вполне допустим:
Dns.com. IN SOA dnsl.dns.com. owner.dns.com.
@00001 10800 3600 604800 86400)
Точка с запятой (;) начинает комментарий. Все символы строки, следующие
после нее, игнорируются. Также следует заметить, что все числовые данные
задаются в секундах. Компоненты записи SOA рассматриваются в следующих
разделах.
Порядковый номер
Порядковый номер (serial number) определяет текущую версию базы данных
DNS. При обновлении базы данных ее порядковый номер должен увеличиваться,
чтобы вторичные серверы знали о том, что им также следует обновить базу
данных.
Порядковый номер управляет зонной пересылкой данных между первичным
и вторичным серверами имен DNS. Сервер вторичного имени периодически
связывается с первичным сервером и запрашивает порядковый номер зонных
данных первичного сервера. Если оказывается, что порядковый номер на
первичном сервере больше порядкового номера на вторичном сервере, значит,
зонные данные устарели и вторичный сервер принимает новую копию зонных
данных с первичного сервера. Пересылка информации с первичного сервера на
вторичный называется зонной пересылкой.
Порядковый номер может быть реализован в виде простого счетчика, но
чаще используется временная пометка, поскольку при внесении изменений в базу
данных на первичном сервере ее значение всегда увеличивается.
Период обновления
Период обновления (refresh) определяет интервал между последовательными
обновлениями информации на вторичных серверах имен A0 800 секунд
соответствуют трем часам).
Значение этого поля определяет, как часто вторичные серверы DNS должны
проверять зонные данные на первичных серверах DNS. По умолчанию период
обновления равен трем часам; если вторичные серверы принимают оповещения
об изменениях, вы можете смело увеличить продолжительность интервала (до
суток и более), чтобы снизить количество опросов. Такая возможность особенно
полезна при использовании медленных линий и при установлении связи по
требованию.
Период повтора
Если вторичному серверу имен не удается связаться с первичным сервером,
он пытается заново установить соединение через заданное количество секунд
C600 секунд соответствуют одному часу).
Значение поля определяет, как часто вторичный сервер будет пытаться
восстановить утраченное соединение. Период повтора обычно короче периода
обновления. По умолчанию период повтора равен 60 минутам.
Период актуальности
Если вторичному серверу имен не удается связаться с первичным сервером в
течение заданного промежутка времени (в секундах), вторичный сервер перестает
отвечать на запросы об этом домене. На какой-то стадии данные настолько
устаревают, что могут оказаться потенциально вредными, и даже полное отсутствие
информации лучше, чем дезинформация. 604 800 секунд в приведенном выше
примере соответствуют одной неделе.
Значение поля определяет период времени, в течение которого данные
вторичного сервера считаются достоверными. Если вторичному серверу DNS долго
не удается связаться с первичным сервером, его данные могут стать
недействительными. По умолчанию период актуальности равен трем дням, причем по
длительности он может превышать как минимальный срок жизни, так и период
повтора.
Срок жизни
Срок жизни данных, или TTL (Time to Live), возвращается при всех запросах
к базе данных и указывает запрашивающей стороне (или другим серверам),
в течение какого времени возможно безопасное кэширование информации
(86 400 секунд в приведенном примере соответствуют одному дню). Это
значение используется по умолчанию для всех записей файла, но оно может быть
переопределено на уровне отдельной ресурсной записи.
Минимальный срок жизни, используемый по умолчанию, оказывает
громадное воздействие на трафик DNS. Он указывает, в течение какого времени
сервер-получатель может квитировать данные. Каждый ответ на запрос возвращается
с определенным значением TTL, которое по умолчанию равно 24 часам. Если
вы собираетесь вносить существенные изменения в зонную информацию DNS,
временно установите более короткий срок жизни данных (например, один час),
но изменения следует вносить лишь по прошествии периода времени,
определяемого предыдущим значением TTL. После того как вы убедитесь в
правильности внесенных изменений, увеличьте TTL до предыдущей величины.
Соблюдение этого правила значительно повышает эффективность распространения
данных в Интернете и сокращает время, в течение которого устаревшие данные
могут оставаться в кэшах других серверов.
Ресурсные записи типа А
Ресурсная запись типа А содержит IP-адрес, ассоциируемый с именем хоста,
которое указывается в первом поле записи.
Записи типа А составляют самую распространенную разновидность
ресурсных записей, встречающихся в файлах данных.
Ресурсные записи типа NS
Запись NS содержит адрес сервера имен, обслуживающего домен. В нашем
примере используются два сервера имен с информацией DNS для домена foo.com.
Запись NS определяет уполномоченный сервер DNS для домена DNS.
Каждый домен должен иметь минимум два таких сервера. Запись NS состоит всего
из двух полей.
Ресурсные записи CNAME
Запись CNAME определяет псевдоним, ассоциируемый с именем хоста, которое
указывается в первом поле записи. Хотя одной системе может быть назначена
одна запись А с несколькими записями CNAME, при использовании записей
CNAME необходима осторожность. Например, некоторые почтовые программы
при попытке разрешения имени хоста MX, использующего запись CNAME
вместо записи А, ведут себя непредсказуемым образом.
Записи CNAME используются для маскировки подробностей реализации сети
от клиентов, которые к ней подключаются. В качестве псевдонимов могут исполь-
зоваться сокращенные формы имен. Скажем, хосту с именем publicl.business.com
можно назначить псевдоним www.business.com.
Ресурсные записи PTR
Записи PTR связывают IP-адрес с именем хоста в домене обратного поиска
(in-addr.arpa). Запись содержит IP-адрес и имя хоста, соответствующее этому
адресу. Имя хоста задается в формате полностью определенного доменного имени.
Многие сайты в качестве меры безопасности запрещают доступ со стороны
компьютеров, у которых существуют расхождения между записями А и PTR, поэтому
следите за тем, чтобы содержимое записей PTR синхронизировалось с записями А.
Запрос обратного поиска, иногда называемый запросом PTR, также может
использоваться для идентификации организации, ответственной за IP-адрес. Как
говорилось выше, результат запроса PTR включает полностью определенное
доменное имя, в котором присутствует имя домена.
Делегированные домены
Механизм делегирования снимает основную ответственность за
администрирование домена и передает ее от основного сервера другому, подчиненному. ICANN
осуществляет административный контроль над .com и делегирует права по
администрированию всех доменов следующего уровня их соответствующим доменам.
На практике большинство сайтов работает на базе хостинга, то есть серверное
пространство арендуется внешним пользователем, и владельцу сайта не приходится
следить за оборудованием — этим занимается техническая служба хостинга.
Для сайтов, работающих на базе хостинга, контроль над доменами часто
поручается администратору сервера DNS. Впрочем, вы также можете воспользоваться
бесплатным сервером DNS, доступным по адресу http://soa.granJtecanyon.com.
Ресурсные записи HINFO
Запись HINFO определяет тип оборудования и операционную систему хоста.
Стандартные сокращенные обозначения операционных систем опубликованы
в RFC 1700 (на момент написания книги), в разделе «System Names List».
Сокращенные обозначения типов оборудования, используемого на хостах,
определяются в этом же документе RFC. Идентификаторы типов процессора определяются
в разделе «Machine Names List». Небольшое подмножество типов, определенных
в RFC 1700, приведено в табл. 6.1.
Имена содержат до 40 символов, среди которых могут быть буквы и цифры,
а также символы - и / (дефис и косая черта). Имя начинается с буквы и
заканчивается буквой или цифрой. Некоторые администраторы предпочитают не
раскрывать эту информацию на общедоступных серверах DNS, поскольку она
упрощает несанкционированный доступ к системе — например, за счет
использования известных дефектов в средствах безопасности конкретного типа системы.
Если вы используете записи HINFO, позаботьтесь о том, чтобы ваша система
соответствовала рекомендациям CERT в области безопасности.
Таблица 6.1. Стандартные обозначения основных операционных систем
и типов процессора в RFC 1700
APOLLO OPENVMS TANDEM
AIX/370 OS/2 UNIX
DOMAIN PCDOS UNIX-BSD
DOS SCO-OPEN-DESKTOP-2.0 UNIX-PC
INTERLISP SCO-OPEN-DESKTOP-3.0 UNKNOWN
ITS SCO-UNIX-3.2V4.0 VM
LISP SCO-UNIX-3.2V4.1 VM/370
MSDOS SCO-UNIX-3.2V4.2 VMS
MULTICS SUN WANG
MVS SUN-OS-3.5 WIN32
NONSTOP SUN-OS-4.0 X11R3
OS86 IBM-RS/6000 SUN-4/200
APPLE-MACINTOSH INTEL-386 SUN-4/390
APPLE-POWERBOOK M68000 SYMBOLICS-3600
CRAY-2 MAC-II UNKNOWN
DECSTATION MAC-POWERBOOK VAX
DEC-VAX MACINTOSH VAX-11/725
DEC-VAXCLUSTER MICROVAX VAXCLUSTER
DEC-VAXSTATION PDP-11 VAXSTATION
IBM-PC/AT SILICON-GRAPHICS
IBM-PQ/XT SUN
Ресурсные записи ISDN
Записи ISDN связывают имя хоста с адресом ISDN. Номер ISDN также может
включать номер DDI (Direct Dial In). Субадрес ISDN не является обязательным.
Записи ISDN имеют несколько возможных применений. В частности, они
предоставляют простой механизм документирования адресов для использования
в статических конфигурациях приложений ISDN. Возможно, в дальнейшем они
будут автоматически использоваться маршрутизаторами Интернета.
Ресурсные записи MB
Запись MB (Mailbox) определяет почтовый ящик, ассоциируемый с хостом.
В полях записи должно быть указано имя почтового ящика и полностью
определенное доменное имя хоста, содержащего этот почтовый ящик. Пока данный
тип записи используется только в экспериментальных разработках.
Ресурсные записи MG
Запись MG определяет почтовый ящик, входящий в групповой список рассылки
для заданного доменного имени. Имя почтового ящика должно быть указано
в формате полностью определенного доменного имени. Пока данный тип записи
используется только в экспериментальных разработках.
Ресурсные записи MINFO
Запись MINFO содержит информацию о почтовом ящике или списке рассылки.
Она состоит из двух полей. Первое поле содержит полностью определенное до^
менное имя почтового ящика, ответственного за список рассылки, указанный
в ресурсной записи. Второе поле содержит полностью определенное доменное
имя почтового ящика, которому должны отправляться сообщения об ошибках,
связанных с ведением списка рассылки. Хотя эти записи могут быть связаны
с одним и тем же простым почтовым ящиком, они обычно используются для
списков рассылки, в которых задействованы разные почтовые адреса для
решения административных задач (например, подписки) и для оповещения об
ошибках типа «mail not deliverable».
Ресурсные записи MR
Запись MR используется для переименования почтового ящика. В поле замены
вводится полностью определенное доменное имя нового почтового ящика. Если
ящик перемещается с одного хоста на другой, можно использовать псевдоним.
Пока данный тип записи используется только в экспериментальных разработках.
Ресурсные записи MX
Запись MX (Mail eXchanger) определяет имя обработчика почты (сервера,
обрабатывающего или пересылающего почту) для данного домена или хоста. Имя
обработчика должно быть задано в формате полностью определенного доменного
имени. Запись MX состоит из следующих полей:
О Имя хоста или домена, обслуживаемого обработчиком почты.
О Полностью определенное доменное имя обработчика почты.
О Приоритет обработчика почты.
Приоритет представляет собой число от 0 до 65 535, которое определяет
очередность обработки почты для заданного хоста или домена. Высокий приоритет
соответствует минимальным числовым значениям, а наивысший приоритет
равен 0. Абсолютное значение приоритета несущественно, важна лишь его
относительная величина по сравнению с другими приоритетами. Доставка почты
начинается с обработчика, обладающего минимальным числовым кодом приоритета.
Если попытка оказывается неудачной, в следующей попытке участвует сервер
со следующим по возрастанию кодом приоритета. Если два или более
серверов-обработчиков почты обладают одинаковым приоритетом, почтовая
программа должна сама решить, какой из них следует опробовать в первую очередь.
Тем не менее переход к следующему уровню приоритета происходит лишь
после того, как будут опробованы все обработчики предыдущего уровня. Обычно
наиболее желательному серверу присваивается приоритет 10, следующему —
приоритет 20, затем 30 и т. д. Подобная схема позволяет при необходимости
легко включить новый обработчик почты в цепочку между действующими
обработчиками.
Поиск по записям MX не рекурсивен. После того как запись MX определит
наилучший приемник почты для хоста, дальнейшие поиски ограничиваются
выборкой записи А для обработчика почты. Записи MX, относящиеся к самому
обработчику почты, игнорируются, если только почта не была адресована
непосредственно ему.
Ресурсные записи RP
Запись RP (Responsible Person) определяет лицо, ответственное за устройство
с заданным именем DNS. Хотя запись SOA указывает, кто является
ответственным за зону, а также предоставляет контактные данные для решения проблем,
связанных с DNS, различными хостами внутри домена обычно управляют
разные люди. Запись RP позволяет указать, с кем следует связаться при
возникновении проблем с устройством, которому соответствует указанное имя DNS.
Типичные проблемы — недоступность важного сервера или подозрительные
действия хоста, замеченные с другого сайта.
Запись RP содержит адрес электронной почты и полностью определенное
доменное имя, по которому следует обращаться за дополнительной
информацией. Адрес электронной почты задается в стандартном формате доменных имен,
но символ @, встречающийся в большинстве адресов, заменяется точкой.
Ссылка на дополнительную информацию представляет собой доменное имя,
указывающее на ресурсную запись ТХТ. Эта запись может содержать контактные
данные (полное имя, номер телефона или пейджера) в произвольном формате.
Ресурсные записи RT
Запись RT (Route Through) определяет промежуточный хост, который
маршрутизирует пакеты для хоста, не имеющего собственного прямого
подключения. Имя промежуточного хоста, принимающего пакеты другого хоста, должно
быть представлено в формате полностью определенного доменного имени. Как
и в случае с обработчиком почты, при определении промежуточных хостов
допускается только один уровень косвенных ссылок; иначе говоря, путь к
промежуточному хосту не может проходить через другой промежуточный хост.
Ресурсные записи ТХТ
Запись ТХТ содержит информацию, представленную в форме простого текста.
Часто в этих записях хранятся сведения о контактных лицах, имена и телефоны
и другая информация такого рода. Длина строки текста должна быть менее
256 символов.
Ресурсные записи WKS
Запись WKS (Well-Known Service) описывают службы, предоставляемые
некоторым протоколом через некоторый интерфейс, по IP-адресу. К числу таких служб
относятся Telnet и FTP. Протокол определяется значением одного из полей
записи. На практике использовать эти записи не рекомендуется (RFC 1123).
Ресурсные записи типа Х25
Записи типа Х25 похожи на ресурсные записи А, но они связывают имя хоста
не с IP-адресом, а с адресом Х.121. Адреса Х.121 являются стандартной формой
адресации в сетях Х.25. Адрес PSDN (Public Switched Data Network) начинается
с кода DNIC (Data Network Identification Code), состоящего из четырех цифр.
Код определяется в рекомендациях по реализации X .121, разработанных
Международным консультативным комитетом по телеграфии и телефонии (CCITT).
Адрес не должен содержать национальных префиксов. Ресурсная запись Х25
проектировалась для использования в сочетании с ресурсной записью RT.
Итоги
В этой главе читатель познакомился с иерархической структурой системы
доменных имен (DNS) Интернета. Эта система была разработана для того, чтобы
основной формой адресации интернет-ресурсов были символические имена.
Также было показано, что DNS использует несколько способов определения
IP-адреса по доменному имени. Следует помнить, что эта система, как и любая
другая, может давать сбои. Если материал этой главы остался для вас
непонятным или вы запутались в его структуре, предоставьте эти хлопоты вашему
поставщику услуг Интернета. Кстати говоря, DNS используется при любом
обращении к web-сайтам или загрузке ресурсов по другим протоколам.
-"* WINS
Курт Хадсон (Kurt Hudson)
Служба имен Интернета для Windows WINS (Windows Internet Name Service)
также называется службой имен NetBIOS, поскольку она преобразует имена
NetBIOS в IP-адреса. Система NetBIOS (Network Basic Input/Output System)
является совместной разработкой IBM и Microsoft. Позднее фирма Microsoft
приобрела права на NetBIOS, чтобы использовать систему в своем продукте
LANManager (в настоящее время устаревшем). Сейчас NetBIOS существует в
сетевых операционных системах Microsoft, предшествующих Windows 2000 (то есть
NT 5.0). В сетях на базе Windows 3.x, Windows 95, Windows 98 и Windows NT 4.0
используются сетевые средства NetBIOS. Каждый администратор,
поддерживающий работу сети с этими операционными системами, должен быть знаком с
механизмом разрешения имен NetBIOS и особенно хорошо разбираться в WINS.
В этой главе рассматривается процесс настройки NetBIOS и ограничения,
присущие этому механизму. В частности, в ней описаны такие средства
разрешения имен NetBIOS, как файл LMHOSTS и WINS. Особое внимание уделяется
разрешению имен в WINS, клиентской и серверной конфигурации, а также
администрированию WINS.
ПРИМЕЧАНИЕ
Фирма Microsoft исключила NetBIOS семейства Windows 2000. По официальным данным,
будущие операционные системы будут поддерживать имена NetBIOS для сохранения совместимости,
но не будут зависеть от них. По этой причине WINS рассматривается в контексте Windows 9x и
Windows NT. Хотя сервер Windows 2000 может быть настроен на выполнение функций сервера
WINS, обычно это делается лишь для обеспечения совместимости.
NetBIOS
С точки зрения Microsoft, NetBIOS представляет собой интерфейс прикладного
программирования (API). В сущности, любой интерфейс такого рода может
рассматриваться как прослойка между компонентами. Уровень NetBIOS
располагается между прикладным и транспортным уровнями стека протоколов TCP/IP
от Microsoft (рис. 7.1).
Прикладной уровень
—■— NetBIOS —
Транспортный уровень
Межсетевой уровень
Сетевой интерфейс
Рис. 7.1. NetBIOS в стеке протоколов TCP/IP от Microsoft
Главная функция NetBIOS — обеспечение независимости между
прикладным и транспортным уровнями. Это делается для того, чтобы разработчик при-*
ложения мог написать программу с сетевой поддержкой, не разбираясь во всех
тонкостях базового протокола. Кроме того, наличие дополнительной прослойки
NetBIOS позволяет использовать приложение с разными транспортными
протоколами. Разработчик должен лишь написать приложение, работающее на уровне
NetBIOS и не рассчитанное на конкретный протокол.
ПРИМЕЧАНИЕ
В продуктах Microsoft также поддерживается интерфейс Windows Sockets (также называемый
WinSocks). Как и NetBIOS, этот интерфейс расположен между прикладным и транспортным
уровнями. NetBIOS и WinSocks не связаны друг с другом, это два разных пути реализации
коммуникаций. Microsoft мог использовать существующие средства Интернета, работающие с интерфейсом
сокетов (и написанные в основном для системы Unix).
При установке сетевых операционных систем Microsoft программа установки
требует ввести имя компьютера. Имя, вводимое на этой стадии, является
именем NetBIOS. Имена NetBIOS должны быть уникальны в пределах сети, то есть
имя не может использоваться ни одним из существующих компьютеров сети.
Имена NetBIOS имеют длину до 15 символов и не могут содержать следующие
символы:
О обратная косая черта (\);
О пробел ( );
О дефис (-);
О апостроф О;
О знак «at» (@);
О процент (%);
О восклицательный знак (!);
О амперсанд (&);
О точка (.).
Во всех сетевых операционных системах от Microsoft, использующих TCP/IP
(до Windows 2000), поддерживаются как имена NetBIOS, так и имена хостов.
Имя хоста настраивается в свойствах протокола TCP/IP. По умолчанию имя
хоста совпадает с именем компьютера в NetBIOS. Рекомендуется оставить эти
имена одинаковыми, иначе вы усложните процесс диагностики. Например, такие
утилиты, как ping, работают с именами хостов, а при отображении диска на
сервер Microsoft используется имя NetBIOS. В случае если имена различаются,
вам придется рассматривать каждое имя и каждое соединение по отдельности.
Но если компьютер будет использоваться в Интернете, для имен хостов TCP/
IP устанавливаются дополнительные ограничения, которые должны учитываться
при выборе имен компьютеров NetBIOS. Такие имена состоят только из
символов A-Z, a-z, 0-9 и дефисов (-), причем первый и последний символы имени
хоста TCP/IP должны быть алфавитно-цифровыми (то есть A-Z, a-z или 0-9).
В операционных системах Microsoft имя компьютера определяется именем
NetBIOS, как показано на рис. 7.2. На рисунке приведено имя NetBIOS в системе
Windows 98, но в системе Windows 95 дело обстоит аналогично.
ЦДЗДДД- - -щ^^^ш^^ШмШШ^^^^^щ^ i xij
k Idartificatior* |$«vicej| Protocols) Ad*tf*t] Ъг*$гф\ ч Л ] \
\k £311 Window* u$e*ttefo8ov^ II
vs ^S£i^ tfu$Ort^#otOier>afr*ofthe domain ihtf&mwjje* [j
U * D*put«N«n*y * JNTSERVEft • "^\ "*C:%vV * -> о '' * I
-. "^ f .»■» HiWHIHiH <W>llll*llW>Hl>im>*IU»^lll*ll>4l>M<l <A\
L 1УОпшч I j
L* II
OK I C»**i [1
Рис. 7.2. Имя компьютера является именем NetBIOS
Чтобы вызвать это диалоговое окно в Windows 95/98, щелкните правой
кнопкой мыши на значке Сетевое окружение (Network Neighborhood) и выберите в
контекстном меню команду Свойства (Properties). Затем откройте вкладку Идентификация
(Identification) в диалоговом окне Сеть (Network). В Windows NT 4 используется
аналогичная процедура, но вкладка называется Общие (General) и открывается
по умолчанию.
Имя хоста TCP/IP является частью конфигурации TCP/IP в
операционных системах Microsoft, как наглядно показывает диалоговое окно Microsoft
Windows NT, изображенное на рис. 7.3.
IP Address ONS | WINS Acttesi | DHCP Rel^ | Roufire | .. .
Domain Name System |ONS) II
£lost Name: . . Ogrodk -' II
jJSSZS | domain, com I 1
. "DNS Service Search Older * • ....:.,.^..v:.... J j
: j • /yl ; ti.' J,|
Add-: 1 ft**- 1 Remote I ; \ I-
- DomamSuffat Search Order •■-\ \\
\ " " _-—ii И
i>jjl!'''.^'.'l.'^J ;!.[
; . | OK | Cancel | Apply И
Рис. 7.3. Настройка имени хоста TCP/IP в Windows NT Server
NetBIOS является неотъемлемой частью сетевой конфигурации Microsoft,
поэтому реализация протокола TCP/IP в операционных системах Microsoft
обозначается специальными акронимами NBT и NetBT. Оба акронима обозначают
одно и то же — NetBIOS через TCP/IP. Удаление NetBIOS из системы
приведет к нарушению работы сетевых компонентов операционных систем Microsoft.
Разрешение имен в NetBIOS
Имена NetBIOS, как и имена хостов, должны быть преобразованы в IP-адреса
при использовании в сетях TCP/IP. Существует несколько способов
преобразования имен NetBIOS в IP-адреса. В операционных системах Microsoft
используются следующие способы разрешения имен NetBIOS (то есть их
преобразования в IP-адреса):
О Кэш имен — клиенты Microsoft поддерживают кэш имен NetBIOS с именами
компьютеров и IP-адресами, которые ранее были разрешены данным
клиентом. Чтобы просмотреть содержимое кэша имен, введите команду NBTSTAT -с
в режиме командной строки сетевой операционной системы Microsoft,
использующей TCP/IP.
О Сервер WINS — сервер WIN поддерживает базу данных с информацией о
связях имен компьютеров с IP-адресами. Чтобы преобразовать имя компьютера
в IP-адрес, клиент обращается к серверу WINS с запросом. Также
используется термин «сервер имен NetBIOS», или NBNS (NetBIOS Name Server).
О Широковещательная рассылка — клиент сети Microsoft может разослать
запрос в локальном сегменте сети, чтобы узнать, принадлежит ли разрешаемое
имя этому сегменту.
О Файл LMHOSTS — статический файл, публикуемый централизованно или на
уровне отдельной системы. Файл содержит список IP-адресов с
соответствующими им именами компьютеров.
О Файл HOSTS — другой статический файл, который также может
публиковаться централизованно или на уровне отдельной системы. Формат этого
текстового ASCII-файла соответствует формату файла UNIX\etc\hosts в BSD
(Berkeley Software Distribution) 4.2. Файл содержит список имен хостов
Интернета в формате полностью определенных доменных имен (FQDN, Fully
Qualified Domain Name) и соответствующих им IP-адресов.
О Сервер DNS — для разрешения имен WINS клиенты WINS могут
использовать сервер DNS. Этот вариант, настройка которого производится на уровне
клиентской системы, позволяет выполнять разрешение имен NetBIOS через
сервер DNS вместо сервера WINS.
Очередность, в которой клиентская система пытается разрешить имя NetBIOS,
зависит от типа узла NetBIOS. Существуют четыре типа узлов NetBIOS:
О В~узел — узлы этого типа называются широковещательными (Broadcast),
поскольку компьютер осуществляет разрешение имен NetBIOS только
посредством рассылки запросов в локальном сегменте. Вообще говоря, в системах
Microsoft используются расширенные В-узлы, которые ищут информацию
в файле LMHOSTS, если имя не было найдено в локальном сегменте.
О Р-узел — разрешение имен выполняется точечным (Point-to-point)
обращением к серверу WINS, широковещательная рассылка в локальном сегменте
не используется.
О М-узел — смешанные (Mixed) системы сначала рассылают запрос в
локальном сегменте, а затем обращаются за разрешением имени к серверу WINS.
О Н-узел — гибридные (Hybrid) системы сначала обращаются за разрешением
имени к серверу WINS. Если получить ответ не удается, Н-узел рассылает
запрос в локальном сегменте.
Прежде чем выполнять любые попытки разрешения имен в NetBIOS, все
клиенты Microsoft сначала проверяют содержимое кэша имен. По умолчанию в
операционных системах Microsoft используются узлы типов В и Н. Расширенные
В-узлы используются по умолчанию для всех компьютеров, на которых не задан
адрес сервера WINS. При наличии адреса сервера WINS по умолчанию
используется Н-узел. Процесс настройки клиента рассматривается ниже в этой главе.
ПРИМЕЧАНИЕ
Чтобы изменить тип узла NetBIOS на Р или М, необходимо отредактировать реестр Windows. За
дополнительной информацией о настройке TCP/IP в Windows NT (в том числе и о модификации
типа узла NetBIOS) обращайтесь на сайт Microsoft http://www.microsoft.com или найдите
компакт-диск TechNet от Microsoft. Статья, посвященная настройке TCP/IP в Windows 95/98,
называется «MS TCP/IP and Windows 95 Networking». Чтобы найти информацию о настройке TCP/IP
в Windows NT, проведите поиск по строке «Q120642». В этих статьях также описано множество
других параметров Microsoft TCP/IP.
Существует несколько типов имен NetBIOS, которые могут использоваться
во всех операционных системах Microsoft. Уникальность этих имен
обеспечивается присоединением к имени компьютера шестнадцатеричного идентификатора.
Каждое уникальное имя описывает уровень сервиса, поддерживаемого
компьютером. Например, во всех операционных системах Microsoft поддерживается имя
рабочей станции; этот уровень сервиса позволяет компьютерам
взаимодействовать по сети. Если операционная система также предоставляет другие виды
сетевого сервиса (например, совместный доступ к файлам или принтерам), ей также
будет присвоено серверное имя. В табл. 7.1 перечислены стандартные имена
NetBIOS, используемые в операционных системах Microsoft.
Таблица 7.1. Имена NetBIOS с шесгнадцатеричными идентификаторами
Имя NetBIOS Описание
и шестнадцатеричный
идентификатор
Имя компьютера[00п] Функциональность рабочей станции на клиенте WINS
Имя компьютера[03п] Функциональность передачи сообщений
на клиенте WINS
Имя компьютера[20п] Функциональность сервера на клиенте WINS
Имя пользователя[03п] Зарегистрированное имя текущего пользователя
Имя домена[1Вп] Функциональность главного контроллера домена (PDC,
Primary Domain Controller)
Как видно из табл. 7.1, каждая операционная система Microsoft в сети обычно
регистрирует несколько имен компьютеров. Существует два способа
регистрации имен: если система является клиентом WINS, она регистрирует все свои
имена NetBIOS на сервере WINS. Системы, являющиеся клиентами WINS,
рассылают имена в локальном сегменте сети. Если другая система не отвечает на
разосланные запросы, информируя о том, что запрашиваемые имена уже заняты,
имена считаются зарегистрированными. Если имена NetBIOS уже используются
другим компьютером локального сегмента, система, пытающаяся их
зарегистрировать, автоматически отключается от сети. Далее системный администратор
должен выбрать для одной из конфликтующих систем другое имя.
Динамическое разрешение имен в NetBIOS
Единственный динамический способ преобразования имен NetBIOS в IP-адреса
в сетях Microsoft TCP/IP основан на использовании WINS. Сервер WINS
получает запросы на регистрацию имен, отправляемые клиентами WINS при запуске.
При отключении клиенты отправляют серверу WINS запросы на освобождение
имен. Таким образом, содержимое базы данных WINS синхронизируется с
текущими именами активных компьютеров в сети.
Функциональность WINS реализуется службой, работающей на серверах
Windows NT. Для хранения регистрационных данных и разрешения имен служба
использует базу данных Microsoft Access.
Преимущества WINS
Применение серверов WINS для разрешения имен NetBIOS в сетях Microsoft
обладает рядом преимуществ, часть из которых перечислена ниже.
О WINS сокращает объем широковещательного трафика при разрешении имен.
Вместо того чтобы рассылать запросы в локальном сегменте, клиент WINS
напрямую связывается с сервером WINS.
О Клиенты WINS могут связываться с серверами WINS в удаленных сегментах.
Маршрутизаторы обычно фильтруют широковещательный трафик, поэтому
рассылка запросов на разрешение имен ограничивается локальной подсетью.
Клиенты WINS связываются с серверами WINS посредством направленного
запроса по IP-адресу сервера. Хотя маршрутизатору можно разрешить
пересылку широковещательных запросов на разрешение имен посредством
активизации портов UDP 137 и 138, делать это обычно не рекомендуется из-за
повышения объема трафика.
О WINS работает в динамическом режиме. Клиенты WINS автоматически
регистрируются на сервере WINS при запуске, администратору не приходится
вводить пары «IP-адрес — имя NetBIOS».
О WINS упрощает ведение списков просмотра (browse lists). Системы Microsoft
поддерживают большие списки ресурсов, доступных через сеть (например,
совместных файлов или принтеров), эти списки называются «списками
просмотра». Сервер WINS облегчает задачу документирования доступных
ресурсов за счет получения информации об именах NetBIOS на каждом компьютере.
Если бы сеть полагалась только на широковещательный трафик, в
многосегментных сетях списки были бы неполными.
Как работает WINS
Сервер WINS собирает данные и поддерживает централизованную базу данных
с активными именами NetBIOS. Сервер WINS обрабатывает заявки на
регистрацию/освобождение и разрешение имен, поступающие от клиентов WINS. Как
упоминалось выше, сервер WINS рассчитывает на то, что клиенты WINS
зарегистрируют свои имена на сервере WINS при запуске. Также предполагается,
что клиенты освобождают свои имена при отключении. Поскольку все клиенты
WINS регистрируют и освобождают свои имена через сервер WINS, последний
может обеспечить достоверное преобразование IP-адресов в имена NetBIOS по
запросу клиента.
Регистрация имен
При запуске клиент WINS должен зарегистрировать свое имя NetBIOS на
сервере WINS. Запросы на регистрацию имен отправляются непосредственно
серверу WINS, который либо регистрирует имя, либо отказывает в регистрации.
Если имя не используется другой системой, сервер WINS регистрирует имя
и посылает пакет подтверждения клиентской системе. Пакет подтверждения
содержит зарегистрированное имя и его срок жизни (TTL) — интервал времени,
зарезервированный для клиента, в течение которого имя должно быть
перерегистрировано. Если клиент WINS не перерегистрирует имя до истечения срока жизни,
имя удаляется из базы данных WINS и может быть зарегистрировано другой
системой. Ограничение срока жизни гарантирует, что системы,
зарегистрировавшие имена и затем отключенные вследствие аварийного завершения или сбоя
питания, не будут занимать имена NetBIOS во время отключения от сети.
Если клиент WINS пытается зарегистрировать имя NetBIOS, уже
встречающееся в базе данных WINS, сервер возвращает клиенту пакет с приказом на
ожидание. Далее сервер убеждается в том, что имя действительно используется
в сети, для чего зарегистрированному владельцу имени отправляется пакет с
запросом на подтверждение. Если сервер WINS получает ответ от системы,
зарегистрировавшей имя, то запрос второго компьютера на регистрацию имени
отвергается. Если ранее зарегистрированный владелец имени не отвечает, сервер
WINS повторяет запрос еще два раза. Если предыдущий владелец не ответил ни
на один запрос, сервер WINS освобождает имя и предоставляет его той системе,
которая его запросила.
ПРИМЕЧАНИЕ
Если клиент WINS в процессе запуска не получает ответа от основного сервера WINS после трех
попыток, он связывается с одним из альтернативных серверов WINS. Если оба сервера WINS,
основной и альтернативный, не отвечают, клиент WINS регистрирует свое имя NetBIOS посредством
широковещательной рассылки.
Обновление имен
По полученному значению TTL клиент WINS определяет, в течение какого срока
имя NetBIOS должно быть обновлено на сервере WINS. По умолчанию срок
жизни имен WINS равен шести дням, или 518 400 секундам. Клиенты WINS
пытаются обновить свои имена после истечения одной восьмой срока. Если
клиенту не удается связаться с основным сервером WINS в течение этого
времени, он пытается обновить имя через альтернативный сервер. После того как
имя будет обновлено, клиент ожидает истечения половины TTL и снова пытается
обновить имя. Если все попытки обновления окажутся безуспешными, имя
NetBIOS освобождается.
Запросы и ответы
Как объяснялось выше, клиентам WINS по умолчанию назначается гибридный
тип узла, то есть когда клиенту потребуется разрешить некоторое имя, он
обращается к серверу WINS. Например, если клиент WINS пытается связаться
с компьютером HOSTX, он сначала ищет это имя в своем кэше имен. Если
соответствие не найдено в локальном кэше, клиент обращается к серверу WINS за
определением IP-адреса HOSTX. Если после трех повторных попыток ему не
удастся найти основной сервер WINS, клиент пытается обратиться к
альтернативному серверу. Если все серверы WINS недоступны или у ответивших серве-
ров отсутствует информация об указанном имени NetBIOS, клиент WINS
рассылает в локальной подсети широковещательный запрос на разрешение имени.
Освобождение имен
Перед отключением клиент WINS обязательно должен выдать запрос на
освобождение имени. Для каждого имени, зарегистрированного клиентом, серверу
WINS передается непосредственный запрос. Пакет содержит освобождаемое
имя NetBIOS и соответствующий ему IP-адрес.
Сервер реагирует на полученный запрос и возвращает пакет, содержащий
отрицательное или положительное подтверждение. Если сервер WINS
обнаруживает конфликт в базе данных (например, если попытка освобождения имени
выполняется не тем компьютером, которым это имя было зарегистрировано), ответ
будет отрицательным. На отключение клиента WINS это никак не влияет,
поскольку клиент игнорирует содержимое ответного пакета и отключается как
при положительном, так и отрицательном ответе.
Настройка клиентов WINS
Настройка Windows NT или Windows 95 для использования WINS сводится
к простому вводу IP-адреса сервера WINS. Настройка в обоих семействах
операционных систем выполняется в диалоговом окне свойств протокола TCP/IP,
на вкладке Конфигурация WINS (WINS Configuration) в Windows 95/98 или на
вкладке WINS в Windows NT. На рис. 7.4 изображена конфигурация WINS в системе
Windows 98.
Чтобы активизировать разрешение имен через WINS на клиентском
компьютере, достаточно ввести IP-адрес одного сервера WINS. Если клиент WINS
будет работать с несколькими серверами WINS, в диалоговом окне конфигурации
вводятся дополнительные IP-адреса. В системах семейства Windows NT адреса
основного и альтернативных серверов WINS вводятся только через этот
интерфейс. По умолчанию обращение к альтернативному серверу WINS происходит
только в том случае, если клиент не находит основной сервер WINS в сети.
Следующие операционные системы могут настраиваться как клиенты WINS:
О Windows NT Server 4.0, 3.5х;
О Windows NT Workstation 4.0, 3.5x;
О Windows 95/98;
О Windows for Workgroups 3.11 с Microsoft TCP/IP-32;
О Microsoft Network Client 3.0 для MS-DOS;
О LAN Manager 2.2c для MS-DOS.
Как упоминалось выше, при настройке клиента на адрес WINS В-узлы
автоматически преобразуются в Н-узлы. В этом можно убедиться, вводя команду
ipconfig /all в режиме командной строки Windows NT. Чтобы проверить
конфигурацию IP для систем Windows 95/98, введите в командной строке команду
winipcfg. Для получения информации о типе узла щелкните в открывшемся окне
на кнопке Сведения (More Info).
ррл-iffito&r-;:'t\;.. - ?;Actahced '■ :- J ' ' NetBIOS -. }
:y DNS Con^^ J &rf*w*y ^NS Confi»»^ion } JP Address |
: :^ j I
,;V configure^ jj
• • Г S^&eWI^Resolution
К r-^SSefvefc$^ch0^er: {'•.'
[192.168. 1 .200 | &dd | j
• ;.i::'Sfiopfjp:.'j j j
■■'. j OK I Caned j
Рис. 7.4. Настройка WINS в Windows 98
Настройка WINS для прокси-агентов
Системы Windows 95, Windows 98 и Windows NT также могут настраиваться на
выполнение прокси-функций WINS. Клиент WINS, настроенный на
выполнение прокси-функций, называется прокси-агентом WINS. Прокси-агент WINS
связывается с сервером WINS для разрешения имен по поручению систем,
находящихся в локальном сегменте и не являющихся клиентами WINS. Таким
образом, системы, не являющиеся клиентами WINS, также могут пользоваться
преимуществами разрешения имен NetBIOS, предоставляемыми WINS.
Процесс настройки почти не отличается от обычного процесса разрешения
имен WINS. Когда компьютер, не являющийся клиентом WINS, рассылает
широковещательный запрос на разрешение имени в локальной подсети, прокси-агент
WINS получает запрос и пересылает его серверу WINS. Если сервер WINS
может преобразовать имя NetBIOS в IP-адрес, прокси-агент WINS пересылает
ответ компьютеру, не являющемуся клиентом WINS.
При настройке систем для выполнения функций прокси-агентов WINS
следует помнить, что прокси-агенты могут увеличивать сетевой трафик из-за
повторения запросов на разрешение имен. Microsoft не рекомендует использовать
более двух прокси-агентов WINS в каждой подсети, содержащей компьютеры,
которые не являются клиентами WINS. Если все компьютеры сети будут
настроены как прокси-агенты, широковещательный запрос на разрешение имени
будет продублирован на каждом компьютере в сети.
Настройка прокси-агента в NT 4
Настройка системы на базе Windows NT 4 для выполнения функций прокси-
агента WINS производится следующим образом:
1. Запустите редактор реестра Windows NT 4 командой regeditexe или regedt32.exe.
2. Найдите подраздел Parameters в разделе HKEY_LOCAL_MACHINE\SYSTEM\
CurrentControlSet\ Services\NetBT.
3. Дважды щелкните на параметре EnableProxy и задайте ему значение 1.
4. Закройте редактор реестра.
5. Перезапустите компьютер.
Настройка прокси-агента в Windows 95/98
Настройка системы на базе Windows 95/98 для выполнения функций прокси-
агента WINS производится следующим образом:
1. Запустите редактор реестра Windows 95/98 командой regedit.exe.
2. В разделе HKEY_LOCAL„MACHINE\SYSTEM\CurrentControlSet\Services\VxD найдите
подраздел MSTCP.
3. Щелкните на подразделе MSTCP, чтобы выделить его.
4. Выполните команду меню Правка ► Создать ► Строковый параметр (Edit ► New ►
String Value).
5. Введите имя нового параметра EnableProxy.
6. Дважды щелкните на строке EnableProxy; на экране появляется диалоговое
окно Изменение строкового параметра (Edit String).
7. Введите 1 в поле Значение (Value) и щелкните на кнопке ОК.
8. Закройте редактор реестра и перезапустите систему.
Настройка сервера WINS
После того как служба сервера WINS будет установлена на сервере Windows NT,
последний начинает выполнять функции сервера WINS. Программное
обеспечение сервера WINS входит в комплект поставки Windows NT Server, но не
устанавливается в стандартном варианте установки.
Установка службы сервера WINS в системе на базе Windows NT 4
выполняется следующим образом:
1. Щелкните правой кнопкой мыши на значке Сетевое окружение (Network
Neighborhood) и выберите в открывшемся контекстном меню команду Свойства
(Properties).
2. Щелкните на вкладке Services.
3. Щелкните на кнопке Add.
4. Выберите в списке служб строку Windows Internet Name Service и нажмите
кнопку ОК.
5. Вам будет предложено задать путь к исходным файлам Windows NT.
Убедитесь в правильности введенного пути и щелкните на кнопке ОК.
6. После завершения установки службы щелкните на кнопке ОК и перезапустите
компьютер, как будет предложено.
После перезапуска системы:
1. Откройте панель управления, чтобы подтвердить установку. Для этого
выполните команду Пуск ► Настройка ► Панель управления (Start ► Settings ► Control
Panel).
2. Дважды щелкните на значке Службы (Services) на панели управления, чтобы
просмотреть список установленных служб.
Если служба WINS была успешно установлена, она будет находиться где-то
в конце списка установленных служб. Из этого мини-приложения вы можете
запускать и завершать WINS и многие другие службы, временно останавливать
их работу, а также настраивать параметры запуска.
Администрирование и сопровождение WINS
После установки службы WINS в группе Administrative Tools меню Пуск (Start)
Windows NT должно появиться приложение WINS Manager. Выполните команду
Start ► Programs ► Administrative Tools и выберите строку WINS Manager.
Диспетчер WINS предназначен для выполнения административных операций
на сервере WINS. Например, вы можете включить в базу данных WINS
статические отображения для компьютеров, не являющихся клиентами WINS. Кроме
того, приложение позволяет заархивировать базу данных WINS, настроить
партнеров по репликации WINS и просмотреть текущее содержимое базы.
Добавление статических записей
Если в сети работают компьютеры, не являющиеся клиентами WINS, и вы хотите,
чтобы сервер WINS мог преобразовывать имена таких компьютеров в
IP-адреса, следует произвести настройку статических отображений. Статические
отображения вручную добавляются в базу данных WINS для того, чтобы сервер
мог разрешать имена NetBIOS компьютеров, не являющихся клиентами WINS.
Чтобы включить в базу данных статическое отображение, выполните следующее
действие:
1. Запустите WINS Manager.
2. Откройте меню Mappings и выберите команду Static Mappings.
3. Щелкните на кнопке Add Mappings.
4. В диалоговом окне Add Static Mappings введите имя и IP-адрес компьютера,
данные которого должны храниться в базе данных в статическом виде.
5. Выберите тип имени для компьютера. Предлагаются следующие варианты:
□ Unique — используется для разрешения имени отдельного компьютера.
□ Group — используется в качестве «обычного группового» имени. IP-адреса
отдельных членов группы не хранятся в базе, поскольку обмен
информацией в группах осуществляется посредством широковещательной рассылки
пакетов.
□ Domain Name — используется для ввода доменных имен. Этот вариант
предназначен для ввода информации о доменных контроллерах
Windows NT.
□ Internet Group — позволяет группировать ресурсы (например, принтеры)
для целей просмотра.
□ Multihomed — используется для поддержки многоадресных компьютеров,
имеющих несколько IP-адресов. Как правило, на таких компьютерах
устанавливается несколько сетевых адаптеров, но используется только одно
имя. Данный тип записи делает возможной такую конфигурацию,
позволяя отобразить несколько IP-адресов на одно имя компьютера NetBIOS.
□ Щелкните на кнопке Add.
□ Повторите описанную процедуру для всех остальных записей. После
завершения ввода статических данных щелкните на кнопке Close.
Поскольку категории Domain Name, Internet Group и Multihomed состоят из
нескольких записей, при их выборе появляется дополнительное диалоговое окно.
В каждую категорию может входить до 25 записей. Клиентские компьютеры
WINS не могут зарегистрировать имена, статически зарегистрированные на
сервере WINS.
Сопровождение базы данных WINS
С базой данных WINS можно выполнять некоторые служебные операции, в том
числе — архивацию, восстановление, сжатие и согласование записей.
Для просмотра записей базы данных WINS используется программа WINS
Manager. Чтобы просмотреть содержимое базы, откройте меню Mappings и
выберите команду Show Database. Предусмотрены режимы просмотра как всех записей,
так и записей, принадлежащих указанному владельцу (серверу WINS). Если
несколько серверов WINS используются в качестве партнеров по репликации,
каждый партнер может просматривать записи, хранящиеся в базах данных остальных
партнеров. Настройка репликации WINS рассматривается ниже в этой главе.
Отображаемые записи сортируются по IP-адресу, имени компьютера, сроку
жизни, идентификатору версии и типу (рис. 7.5).
Окно Mappings также позволяет узнать, является ли запись активной или
статической. Для статических записей в столбце S присутствует пометка; для
активных записей пометка имеется в столбце А. Записи, не помеченные как
активные или статические, не проверяются и ожидают удаления.
С;- [r'^i^^ionJO •"•' .^i-'yvv'^ii^yv:;'::1.'!.
: A•:€• •'?«? ty. TV№; ::;. •.••:. 7 J£:j-!-.- .•..'..' •- —: l
.'МйЛо* • V:; -:- A! .$ V- Expeatoi Date . . • Vernon ID •
• •• РзЯЯшШШшШмня I
|MD0MAIN[1Bh] 19Z16&V1Q0 * Б/1/9910:04:37 AM Б '."j::
IMADMINISTRAT0R[03h] 192.168.1.100 * 6/1/9910:04:37 AM 1
l©COMPUTER1[00h] 192.168.1.10 * * 1Л 8/38 7:14:07 PM A
IMcOMF4JTER1[03h] 192.168.1.10 « *> 1Л8/387:14:07PM В :
|gCOMPUTER1[20hJ 192.168.1.10 * * 1/18/38 7:14:07PM С •
»DOMAIN[00h] 192.168.1.100 * 6Л/9910:04:37 AM 8 -J
|y^D0MAIN{1Ch) 192.168.1.100 « 6/1/9910:04:37 AM 7
|AD0MAIN[1Eh] 192.168.1.100 * 6/1/991004:37 AM 5 ,
ШЙмтсср^лгогппи .ncn ico lion * сл/адтгмгглм ^ JU.j
Рис. 7.5. База данных WINS
Чистка базы данных
Если вы считаете, что содержимое базы данных не соответствует
действительности, можно потребовать, чтобы сервер WINS произвел согласование записей.
Например, если вы заметили, что в базе данных присутствуют имена
компьютеров, отключенных от сети, запустите процесс чистки базы данных. После его
завершения из базы данных должны пропасть освобожденные имена и записи,
добавленные другими серверами WINS. Чистка базы данных запускается
командой меню Mappings в приложении WINS Manager.
Удаление записей из базы данных
На практике возникают ситуации, когда в базе данных WINS хранятся записи,
которые следовало бы удалить. Предполагается, что база данных будет удалять
записи с истекшим сроком действия, но иногда такие записи остаются в базе.
Если даже после чистки база данных содержит нежелательные записи,
существует два основных способа ручного удаления записей. Во-первых, можно
удалить все записи кнопкой Delete Owner в диалоговом окне Show Database.
Выполните следующие действия:
1. Запустите приложение WINS Manager, перейдите на вкладку Mappings и
щелкните на кнопке Show Database. На экране появляется диалоговое окно Show
Database.
2. В диалоговом окне Show Database найдите список владельцев и щелкните на
имени или IP-адресе компьютера WINS, записи которого требуется удалить
из базы.
3. Щелкните на кнопке Delete Owner.
4. Подтвердите удаление, щелкнув на кнопке Yes в диалоговом окне с
предупреждением. Следующее окно сообщает, что согласование записей с этой базой
данных WINS невозможно до тех пор, пока записи не будут построены заново.
После того как из базы данных будут удалены все записи, каждый клиент
WINS должен заново зарегистрировать свое имя в базе данных WINS. При
перегрузке компьютеров в сети это происходит автоматически.
Во втором варианте удаление записей из базы данных WINS производится
избирательно. При этом используется утилита winscl.exe из пакета Windows NT 4.0
Resource Kit.
Выбор интервала для автоматического
выполнения операций
Сервер WINS автоматически выполняет многие операции по сопровождению
базы данных с заданной частотой. Интервал выполнения этих
автоматизированных операций задается в диалоговом окне WINS Server Configuration. Чтобы
вызвать это окно, выполните команду Server ► Configuration в WINS Manager и
выберите Configuration (рис. 7.6).
Y^$$«uw$$^ j—jjz—j
л.ф^?^^^^:. ^|ffi^;p|^g \ ]}———>
'Доорммод^, - ■. 1*рЭД»ЭСТ - | гУТ* ,1
I] Ч Л - \s ^v^""* i^^T,' V?, " j I I I
rPuflPafametett-"-~:—k : -PutHP&wMtoi— ;
J P InitialRepicafcry : ч Г Ij^^feeOort . |
j RetiyCoMtf: [5 § . - Г Reflate on Addrw* Chang» |
Рис. 7.6. Диалоговое окно WINS Server Configuration
В окне WINS Server Configuration задаются следующие интервалы:
О Renewal Interval — срок жизни зарегистрированного имени. Клиент WINS
должен обновить имя до истечения заданного срока. По умолчанию значение
равно 144 часам F суток).
О Extinction Interval — промежуток (по умолчанию — 144 часа) между
освобождением имени и моментом, когда оно становится недействительным. По
истечении этого периода имя компьютера считается устаревшим.
О Extinction Timeout — промежуток времени между устареванием имени и его
фактическим удалением из базы данных. По умолчанию равен 144 часам.
О Verify Interval — записи, поступающие с других серверов WINS, по умолчанию
проверяются каждые 576 часов B4 дня). Подобной проверке подлежат
только записи других серверов WINS.
Дополнительная настройка сервера WINS
Кнопка Advanced в диалоговом окне WINS Server Configuration открывает диалоговое
окно дополнительной настройки сервера WINS. Это окно управляет ведением
журналов работы сервера, архивацией и другими служебными операциями. Ниже
перечислены основные управляющие возможности этого окна.
О Logging Enabled — журнал изменений в базе данных по умолчанию хранится
в папке %system_root%/system32/wins. WINS использует этот файл для
восстановления данных после сбоев.
О Log Detailed Events — WINS сохраняет подробную информацию обо всех
выполняемых операциях. Если у вас возникают трудности с регистрацией имен
на сервере WINS, попробуйте включить этот режим. Поскольку сохранение
подробной информации замедляет работу WINS, его рекомендуется включать
только при диагностике проблем с регистрацией. Чтобы просмотреть
подробную информацию, воспользуйтесь разделом System Log приложения Event Viewer.
О Replicate Only With Partners — по умолчанию сервер WINS выполняет
репликацию только с серверами WINS, указанными в качестве партнеров по
репликации. Если снять этот флажок, сервер WINS можно настроить для обмена
данными с серверами WINS, отсутствующими в списке партнеров.
О Backup on Termination — база данных WINS архивируется при завершении
работы WINS Manager.
О Migrate On/Off — клиентам WINS разрешается перезаписывать статические
данные. Эта возможность используется в ситуациях, когда для компьютеров,
которые не являлись клиентами WINS, были созданы статические записи, после
чего эти компьютеры были преобразованы в клиентов WINS. Перезапись
статических данных позволяет новым клиентам WINS динамически регистрировать
свои имена компьютеров (с перезаписью существующих статических записей).
Включите этот режим при модернизации более старых систем до Windows NT.
О Starting Version Count — значение, используемое для контроля версии базы
данных. Если база данных WINS будет безвозвратно испорчена, введите
нулевой номер версии, чтобы обновить базу данных.
О Database Backup Path — каталог, в котором хранятся архивы базы данных.
Архивы используются для восстановления данных в случае сбоя WINS или
системного сбоя. Важная подробность: не используйте сетевые каталоги для
архивации базы данных WINS! В случае нарушения работы сети вы не
сможете обратиться к базе данных WINS или восстановить ее.
Архивация базы данных WINS
Каждые 24 часа база данных WINS автоматически архивируется. Тем не менее
для этого необходимо задать каталог для хранения архивов. Выполните
следующие действия:
1. Откройте меню Mappings и выберите команду Back Up Database.
2. Введите каталог для хранения архивов.
3. Щелкните на кнопке ОК.
Архивация данных реестра
В процесс сопровождения WINS также может входить архивация данных реестра,
относящихся к серверу WINS. Выполните следующие действия:
1. Запустите редактор реестра Windows NT 4 командой regeditexe или regedt32.exe.
2. Найдите подраздел WINS в разделе HKEYJXX^JW(>IINE^
Services\.
3. Откройте меню Реестр (Registry) и выберите команду Экспорт ветви реестра
(Save Key). На экране появляется соответствующее диалоговое окно.
4. Введите каталог, используемый для архивации, и щелкните на кнопке
Сохранить (Save).
5. Закройте редактор реестра
Восстановление базы данных WINS
Если WINS перестает нормально работать, вероятно, целостность данных в базе
WINS была нарушена. При обнаружении порчи данных WINS автоматически
восстанавливает базу данных. Также можно остановить и перезапустить службу
WINS — возможно, сервер обнаружит и исправит ошибку. Это делается так:
1. Откройте панель управления. Для этого следует выполнить команду Пуск ►
Настройка ► Панель управления (Start ► Settings ► Control Panel).
2. Дважды щелкните на значке Службы (Services).
3. Найдите в списке служб строку Windows Internet Name Service.
4. Щелкните на кнопке Stop.
5. Щелкните на кнопке Start.
Если WINS обнаруживает порчу данных в базе, воспользуйтесь приложением
Event Viewer и убедитесь в том, что восстановление прошло успешно. Если WINS
не обнаруживает порчу данных и не восстанавливает базу после перезапуска,
восстановление можно провести вручную. Это делается так:
1. Откройте меню Mappings и выберите команду Restore Database.
2. Введите каталог, в котором хранится архив.
3. Щелкните на кнопке ОК.
Если команда восстановления базы данных недоступна, значит, база данных
WINS ранее не архивировалась. В этом случае содержимое базы данных следует
удалить (кнопка Delete Owner — см. выше) и построить базу заново. При этом
все клиенты должны повторно зарегистрироваться в WINS, что происходит
автоматически при перезагрузке клиентских систем.
Сжатие базы данных WINS
Когда база данных WINS (wins.mdb) достигает объема в 30 Мбайт и более, ее
рекомендуется сжать. Ручное сжатие базы данных WINS производится утилитой
jetpack.exe из режима командной строки. По умолчанию база данных WINS
хранится в каталоге C:\WINNT\SYSTEM32\WINS. Не забудьте завершить работу службы
WINS перед сжатием и перезапустить службу после его завершения. Команда
сжатия базы данных WINS имеет следующую структуру:
jetpack wins.mdb временное_имя.mdb
Вся процедура выполняется из командной строки. Полная
последовательность команд для остановки службы WINS, сжатия базы данных и перезапуска
службы выглядит так:
net stop wins
jetpack wins.mdb templ.mdb
net start wins
Имя временного файла базы данных выбирается произвольно. После того
как сжатие будет завершено, временный файл автоматически удаляется.
Репликация WINS
В сети с несколькими серверами WINS часто имеет смысл организовать
совместный доступ к базам разных серверов. Тем самым каждый сервер WINS
достигает максимальных возможностей по разрешению имен, поскольку он может
использовать данные со всех серверов WINS. Серверы WINS, совместно
использующие свои базы данных, называются партнерами по репликации.
Репликация выполняется в активном или пассивном режиме. Активная
репликация (push) выполняется при достижении определенного количества
изменений в базе данных (это количество задается администратором). Пассивная
репликация (pull) выполняется по расписанию, которое также настраивается
администратором.
■ -jflgyiS S^^fwyytM:;. ";; ^' "• •- rVm »fl -::.- ^ • •••■>•:.,■•;■■•:•;;• :.">.„••;{
в^У|.л:1'..^У^=.'^^л.Г:1
Рис. 7.7. Настройка репликации WINS
Как правило, в медленных глобальных сетях используется только пассивная
репликация, планируемая на периоды относительно низкой загрузки. Активная
репликация (наряду с пассивной) обычно применяется в локальных сетях с
относительно быстрыми подключениями. Она гарантирует, что между
последовательными обновлениями содержимое базы данных WINS не изменится слишком
значительно. С другой стороны, система пассивной репликации гарантирует, что
обновления будут происходить регулярно, даже при минимальных изменениях.
Чтобы настроить механизм репликации, запустите приложение WINS Manager,
откройте меню Server и выберите команду Replication Partners.
В диалоговом окне Replications Partners настраиваются активные и/или
пассивные партнеры по репликации. Кнопка Replicate Now выполняет немедленную
репликацию. Флажок Push with Propagation передает изменения партнерам по
репликации и инициирует «цепную реакцию»: обновляются не только
непосредственные партнеры по репликации, но также все партнеры следующего уровня
(то есть «партнеры партнеров»).
Рекомендации по реализации WINS
Хотя для предоставления сервиса WINS в сети достаточно одного сервера,
Microsoft рекомендует использовать минимум два сервера. Второй сервер WINS
обеспечивает дополнительную защиту от ошибок на случай сбоя первого сервера.
Помимо повышения устойчивости, второй сервер WINS отчасти способствует
распределению нагрузки. Чтобы работа более равномерно распределялась между
серверами, разделите клиентов на две равные группы и назначьте им разные
серверы WINS в качестве основного сервера. Другой сервер WINS назначается
альтернативным, или вторичным, чтобы каждый клиент пользовался
преимуществами повышенной надежности. Кроме того, не забудьте убедиться в том, что
серверы WINS выполняют функции партнеров по репликации.
Для нормальной работы системы WINS на каждые 10 000 обслуживаемых
клиентов WINS необходимо устанавливать дополнительный сервер. Если
потребуется повысить производительность работы отдельного сервера WINS,
отключите режим ведения журнала. Сбой сервера WINS приведет к утрате последних
изменений в базе данных, но сервер будет работать быстрее. Чтобы повысить
производительность за счет установки нового оборудования на сервере,
рассмотрите возможность использования многопроцессорной системы. Microsoft
утверждает, что каждый дополнительный процессор примерно на 25 % ускоряет
работу сервера WINS.
Интеграция служб разрешения имен
Помимо сервера WINS, клиент сети Microsoft может обратиться за разрешением
имен NetBIOS к серверу DNS. В системах Windows NT 4.0 этот режим
включается установкой флажка Enable DNS for Windows Resolution (рис. 7.8). Если флажок
установлен, то после неудачной попытки разрешения имени через сервер WINS,
широковещательный запрос или файл LMHOSTS/HOSTS, клиент WINS
обращается к серверу DNS.
IPAdcfo**| DNS ;. ед$^геи ]DHCPReJay | Bouting J
: r window* и^$$й$*?«** CWWS]—'—^^ггг:~?—: I
;. | j[1] Novell NE2000 Adapter 3 j I
■■• I p^aryWins $Ш£й: J192 .168 .1 Too": :- Ir :•=
,^Д||' : OK | Cancel ; [ '.- &apfc»" £• j J
Рис. 7.8. Включение разрешения имен через сервер DNS в клиенте WINS
Серверы DNS от Microsoft также могут настраиваться на разрешение имен
через WINS (рис. 7.9). При этом сервер WINS используется только для
разрешения хостового имени компьютера в сети. Это означает, что сервер DNS
должен быть способен разрешить имя домена и любых субдоменов перед
обращением к серверу WINS.
Предоставление данных WINS через DHCP
Сервер DHCP тоже можно настроить так, чтобы возвращаемая клиенту
информация не ограничивалась возвращением IP-адреса и маски подсети. Клиент DHCP
также может получать от сервера DHCP данные WINS. Точнее, для клиента
DHCP можно задать адреса серверов WINS (основного и вторичного) и тип
узла NetBIOS.
Четыре типа узлов NetBIOS — В, Р, М и Н — описаны выше в этой главе. На
рис. 7.10 изображено диалоговое окно настройки этих параметров для сервера
DHCP от Microsoft. Настройка DHCP описана в главе 8.
ПРИМЕЧАНИЕ
IP-адреса, настроенные на основном и вторичном серверах WINS, имеют более высокий
приоритет, чем аналогичные параметры, настроенные в DHCP.
Genmi J SOA Record | Noty WINS Lookup j
& |fe£\^NS]RjSc£i55rj Г Setting on^ «Ifect tecel *eryer:, 1
r-^fNS Server* ~~~- -.— '■—-: —■■— -—. .~~r™.^-~™ 1.
l-i :■ ■ ■.^■w;r?:f
: r: 1192.168.1.100 Л #&№'■■{■■'.'. i! ••
I { I '".... 1 : ■'•$■• I 1
J I ■ "I ИГ, I -Г .11 -I ■■■!- . | II
. I :.• .., .;: :.;: ^lll...^.... 11.: i'J:.'.^ j
Advanced .♦ i-j |
■■.■■■ ^••••^•■:p.:-' OK | &noe* | 1
Рис. 7.9. Активизация обращения к серверу WINS в сервере DNS
Option*tot: П92.168t*!;t3J"-"-4"J :'"'У:' :УЖ&^УУ- '''":'""rУ"- I OK J:
JUnussdOgfom: . , ■,,,>..,;:/:>x„ ,,■ ReliveOfi^oj»:;• = ••:. . .-. •*
1002 Time Offset 3 • • '^': • ' 1003 Routw ' 3 С^псЫ f
004 Time Server w^$&4-. 1 Ш°^$^*** 1
007 Log Servers -t ■'.'.'r^'^. i \ШШ^ВиШб\ур& ^J2S-J
: 008 Cookie Servers . ,^fi*t^li047 NetBIOS Scope 10 .\ ::•'• :' :
]009 LPR Servers iJ..'r—Z .'"Tj *J. ■ . ц^ . t\
Comment: NBN5Addfe^e4)iripf*o#0«fet . :
; iPAdde«* jmmuoo "''. У ■ .,-\.:^;%. ..-.: 3
|. £dftAtray.u | j
: I . JrJ J
Рис. 7.10. Серверы DHCP могут предоставлять сведения о конфигурации WINS
Разрешение имен NetBIOS
через файл LMHOSTS
Преобразование имен NetBIOS в IP-адреса также может производиться на
основании содержимого файла LMHOSTS. Тем не менее файл LMHOSTS приходится
создавать и обновлять вручную. В сущности, файл представляет собой статическую
таблицу, устанавливающую соответствие между именами компьютеров и
IP-адресами. Фирма Microsoft включила пример файла LMHOSTS в комплект поставки
операционных систем Windows NT и Windows 95/98. В Windows 95/98 файл
LMHOSTS.SAM находится в каталоге c:\windows. В Windows NT файл LMHOSTS.SAM
следует искать в каталоге c:\winnt\system32\drivers\etc.
В файле LMHOSTS.SAM подробно объясняется, как создать файл LMHOSTS. Тем
не менее, чтобы файл LMHOSTS активно использовался, он должен называться
просто LMHOSTS (без расширения). Примерный файл LMHOSTS показан на рис. 7.11.
НЕ*» £<*.&ммЬ и* • ^ , ?;■*.£: •• :;- • ; • '. • ••
N192.168.1.27 servers «PRE 800H:donainM1 *DC for MasteM Domain 3j
1192.168.2.101 files «PRE ifile server jj
1192.168.3.105 serueM tPRE ^used for include below II
|192.168.1.102 seruer2 II
1192.168.1.103 seruer3 |j
1192.168.1.1011 server* jj
|tBECIN_ftLTERNATE II
IlilNCLUDE \\seruer1\public\lnhosts jj
lit INCLUDE \\seruerS\public\lmhosts Jj]
|j«EHO_ftLTERNflTE
Рис. 7.11. Пример файла LMHOSTS
Помимо отображения IP-адресов на имена компьютеров NetBIOS, файл
LMHOSTS содержит специальные директивы, расширяющие его возможности.
Например, записи LMHOSTS, завершающиеся директивой #PRE, заносятся в кэш
имен NetBIOS при запуске компьютера. Тем самым ускоряется процесс
разрешения имен, поскольку клиенты Microsoft всегда начинают попытки
разрешения с поиска в кэше имен.
В табл. 7.2 перечислены специальные директивы, используемые в файле
LMHOSTS.
Таблица 7.2. Директивы и описания LMHOSTS
Директива Описание
#PRE Записи с директивой #PRE предварительно загружаются в кэш
имен NetBIOS
#ООМ:имя_домена Директива #DOM определяет имя домена. Запись необходима
для работы контроллера домена (например, синхронизации
и просмотра баз данных)
#ШО.и0Е<имя_файла> Дополнительные файлы, используемые для разрешения имен.
Допускается использование файлов LMHOSTS, находящихся
на удаленных компьютерах (по ссылке в формате UNC). Если вы
используете файлы LMHOSTS на других компьютерах, то эта
запись работает только в том случае, если для удаленного
компьютера было заранее создано отображение
продолжение £
Таблица 7.2 (продолжение)
Директива Описание
#BEGIN_ALTERNATE Директивы #BEGIN_ALTERNATE и #END_ALTERNATE
#END_ALTERNATE позволяют включить в файл LMHOSTS несколько записей
#INCLUDE. Таким образом, файл LMHOSTS работает
с несколькими удаленными файлами LMHOSTS так,
как если бы они были локальными
#МН Директива #МН используется для многоадресных (MultiHomed)
компьютеров, обладающих несколькими IP-адресами,
отображаемыми на одно имя компьютера
комментарий Комментарий, включаемый в файл LMHOSTS после любой
информационной записи или в отдельной строке
Вероятно, самым важным из перечисленных директив следует считать
директиву #PRE, поскольку она в наибольшей степени влияет на скорость
разрешения имен в сети. Вторая по важности директива #DOM определяет
контроллер домена. Присутствие записей #PRE и #DOM на всех контроллерах доменов
повышает скорость административного обмена данными между контроллерами.
Кроме того, наличие на клиентском компьютере файла LMHOSTS, добавляющего
IP-адреса контроллера домена в кэш имен, ускоряет вход в систему, поскольку
в клиентской системе уже имеется готовый IP-адрес контроллера домена.
ПРИМЕЧАНИЕ
Файлы HOSTS и LMHOSTS очень похожи. Файл LMHOSTS предназначен для разрешения имен
NetBIOS, а файл HOSTS предназначен для разрешения имен хостов (см. главу 6).
Итоги
Имена NetBIOS использовались в сетях Microsoft до выхода Windows 2000.
В сетях TCP/IP для обмена данными между двумя компьютерами эти имена
должны быть преобразованы в IP-адреса. Существует несколько механизмов
разрешения имен, но динамический механизм всего один — использование WINS.
WINS работает как внутреннее приложение типа «клиент-сервер»,
встроенное в операционную систему Microsoft. При запуске клиент WINS регистрирует
свое имя и IP-адрес на сервере WINS. Имена освобождаются при завершении
работы клиента. Это позволяет серверу WINS вести базу данных имен, реально
используемых в сети. Когда клиент WINS хочет связаться с другим
компьютером сети, он обращается к серверу WINS с запросом на преобразование имени
NetBIOS в IP-адрес.
Чтобы компьютер мог стать клиентом WINS, он должен знать IP-адрес как
минимум одного сервера WINS. Данные вводятся в диалоговом окне настройки
TCP/IP для клиента WINS. Для повышения устойчивости системы клиенту
WINS можно назначить адреса нескольких серверов WINS. Если основной
сервер WINS недоступен, клиент попытается связаться с вторичным сервером WINS.
Функциональность WINS также может использоваться компьютерами, не
являющимися клиентами WINS. Такие компьютеры обслуживаются прокси-аген-
тами WINS. Прокси-агент получает локальные широковещательные запросы на
разрешение имен и пересылает их серверу WINS, после чего возвращает ответ
сервера компьютеру, от которого поступил запрос.
Многие административные и служебные операции выполняются сервером
WINS автоматически. Тем не менее архивацию базы данных на сервере WINS
следует включить отдельно в приложении WINS Manager. Сервер WINS
автоматически восстанавливает испорченную базу данных после перезапуска (конечно,
при наличии архивной копии). Восстановление базы данных также можно
выполнить вручную из приложения WINS Manager. Для сжатия базы данных сервера
WINS используется утилита командной строки jetpack.exe.
Партнерами по репликации называются серверы WINS, настроенные для обмена
информацией из баз данных WINS. По типу обмена данными партнеры делятся
на два класса: активные и пассивные. Пассивные партнеры хорошо подходят для
медленных глобальных сетей. В относительно быстрых локальных сетях можно
настроить как активный, так и пассивный обмен, чтобы базы данных WINS
содержали самую свежую информацию.
Файлы LMHOSTS также упрощают разрешение имен NetBIOS. В отличие от
WINS файлы LMHOSTS содержат статическую информацию и обновляются
вручную, но несмотря на это, они обладают определенными преимуществами. Записи
файла LMHOSTS могут загружаться в кэш имен NetBIOS, для этого запись
снабжается директивой #PRE. Тег #DOM в файлах LMHOSTS используется для
идентификации контроллера домена.
8 Автоматизированная
настройка TCP/IP
Карапжит С. Сияй (Karajit S. Siyan)
Настройка параметров TCP/IP для каждой станции в большой сети обычно
сопряжена с тяжелой и долгой работой, особенно когда возникает необходимость
в изменении таких параметров TCP/IP, как IP-адреса и маски подсетей.
Изменения могут быть обусловлены кардинальной реструктуризацией сети или
наличием в ней многочисленных мобильных пользователей с портативными
компьютерами, которые могут подключаться к любому сегменту сети.
Возможны как физические, так и беспроводные подключения. Поскольку параметры
конфигурации TCP/IP компьютера зависят от того, к какому сегменту он
подключен, переход компьютера в другой сегмент сети должен сопровождаться
соответствующим изменением параметров.
Только компетентный сетевой администратор хорошо понимает все
последствия, к которым приводит изменение параметров TCP/IP. Группа IETF
разработала для объединенных сетей TCP/IP несколько протоколов
автоматической настройки, в том числе ВООТР (Boot Protocol) и DHCP (Dynamic Host
Configuration Protocol).
Динамическая настройка конфигурации
с применением ВООТР
Протокол ВООТР проектировался для того, чтобы протоколы IP (Internet
Protocol) и UDP (User Datagram Protocol) могли использоваться для передачи
информации компьютерам, желающими настроить свою конфигурацию. Компьютер,
сгенерировавший запрос, называется клиентом ВООТР, а компьютер, ответивший
на запрос клиента, называется сервером ВООТР (рис. 8.1).
Целью клиентского запроса ВООТР является получение значений
параметров IP для компьютера, на котором работает клиент ВООТР.
Протокол ВООТР описан в RFC 951. Обновленная информация содержится
в RFC 2132, RFC 1532, RFC 1542 и RFC 1395. Принципы действия ВООТР
изложены в следующем разделе.
^Сервер ВООТР^
UDP
Сервер ВООТР Дщ
. т .
р£ Клиент ВООТР Ц к£ Клиент ВООТР i
—OjD— —C?l)—
UDP UDP
h^^^^H ' l^^^^H
l~—■-=="—" ■■■■ -Д ' i i <^1?"..'..H Л
Клиент ВООТР Клиент ВООТР
Рис. 8.1. Клиенты и серверы ВООТР
IP-адреса запросов/ответов ВООТР
Сообщения ВООТР инкапсулируются в заголовках UDP, идентифицирующих
номер порта, используемого процессами ВООТР. Дейтаграмма UDP
инкапсулируется в заголовке IP. Но какие адреса отправителя и получателя
используются в заголовке IP? Интересный вопрос, потому что при выдаче запроса
клиент ВООТР должен указать эти адреса. Как правило, клиент ВООТР не знает
своего IP-адреса и указывает вместо него 0.0.0.0. Если же адрес известен, он
используется в клиентском запросе ВООТР.
Известен ли IP-адрес сервера клиенту ВООТР? В общем случае неизвестен.
Это особенно верно по отношению к ситуациям, когда клиент ВООТР
представляет собой бездисковую рабочую станцию и не располагает средствами для
определения адреса сервера. Впрочем, если адрес сервера ВООТР может
настраиваться на уровне рабочей станции, он используется клиентом ВООР.
Если клиент ВООТР не знает IP-адрес сервера ВООТР, он использует
ограниченную рассылку IP. В качестве адреса ограниченной рассылки используется
следующее значение:
255.255.255.255
ПРИМЕЧАНИЕ
Пакеты, отправленные по адресу ограниченной (локальной) рассылки, принимаются всеми IP-узлами
локального сегмента сети, включая серверы ВООТР.
А если сервер ВООТР находится в другой подсети IP, за граничным
маршрутизатором? Как говорилось выше, ограниченная рассылка за маршрутизатор не
распространяется. Для таких случаев на маршрутизаторе работает
агент-ретранслятор ВООТР (ВООТР relay agent), который проверяет, используется ли в
дейтаграмме ограниченной рассылки приемный порт UDP с номером 67 (порт
зарезервирован для BOOTP/DHCP). Если условие выполняется, ограниченная
рассылка перенаправляется в сетевые интерфейсы маршрутизатора (рис. 8.2).
Сервер
ИВН воотр
4J . 1
< 1 < т H ►
1
(^Х/""*~^\ Агент-ретранслятор ^)
Д \ BOOTP p
( ) r-y_^y_ _^~——^
T
# ' •
_lT~* —" _L
j Запрос клиента BOOTP, r~jjjj~j~j
использующий адрес I^^^B
офаниченной H^^^H I
1 рассылки 255.255.255.255. [жННШ
Клиент BOOTP
Рис. 8.2. Пересылка сообщений ВООТР через граничный маршрутизатор
Сервер ВООТР, находящийся в локальной сети, может ответить на запрос
клиента ВООТР. Будет ли в этом сообщении использоваться IP-адрес клиента?
Иначе говоря, может ли сервер ВООТР послать направленный ответ? Все
зависит от реализации сервера ВООТР.
Сервер знает IP-адрес клиента, хранящийся в базе данных конфигурации
ВООТР. Почему же он не может использовать этот адрес для посылки
направленного ответа клиенту? Дело в том, что в момент отправки сервером запроса
ARP на получение аппаратного адреса клиента ВООТР клиент ответить не
может. Почему? Потому что он еще не знает своего IP-адреса. Сервер ВООТР
получает аппаратный адрес клиента из заголовка канального уровня в сообщении
клиента ВООТР. Реализация сервера ВООТР может добавить запись с
информацией о клиенте ВООТР в кэш ARP (рис. 8.3). При наличии такой записи
сервер ВООТР может использовать направленный ответ.
ПРИМЕЧАНИЕ
Модификация кэша ARP используется в реализации ВООТР для BSD Unix.
База данных ВООТР
^Аппаратный I ,р.адоес |^ ллл \
адрес 1^-адрес •••
И/ Н 0800003А002В 199.245.180.1
У I • I • I
\*> ^—ч-J^ I I • I • I
£ Сервер / М I • I * I
pX^JtoOTPJJ^ ' ' ■ '
^ ^ \L-——■ ► Изменение кэша ARP
UDP \| Кэш ARP
ВООТР \ТМТ] \ | 1 1 1
И—7Р—К. |Р"адрес ^^ *"
| ^ 199.245.180.1 0800003А002В
[ # *
m i% I • I • I
• • | |
—Т"-*"^
р^^И 199.245.180.1
Клиент ВООТР
Аппаратный адрес = 0800003А002В
Рис. 8.3. Изменение кэша ARP сервером ВООТР
Если сервер ВООТР не изменяет содержимое кэша ARP, ответ рассылается
в широковещательном режиме.
Потеря сообщений ВООТР
В своей работе ВООТР использует протоколы UDP и IP, не гарантирующие
доставки сообщений. В результате возможна потеря, задержка, дублирование
или нарушение последовательности сообщений ВООТР. Поскольку
контрольная сумма IP обеспечивает проверку целостности только заголовка, но не поля
данных, реализация ВООТР может потребовать активизации контрольной суммы
UDP, защищающей от ошибок во всем сообщении ВООТР.
При отправке запросов клиент ВООТР устанавливает флаг запрета
фрагментации (DF), чтобы упростить обработку ответов ВООТР, а также на случай
нехватки памяти для сбора фрагментированных дейтаграмм.
Для борьбы с потерей сообщений в ВООТР используется механизм тайм-аута
с повторной передачей. Отправляя запрос, клиент ВООТР запускает таймер.
Если ответ ВООТР будет получен до истечения интервала тайм-аута, отсчет
прекращается; в противном случае ВООТР передает запрос заново.
Одновременный запуск нескольких клиентов ВООТР может привести к
переполнению сети широковещательными запросами ВООТР. Чтобы этого не
произошло, в спецификации ВООТР рекомендуется использовать случайную
задержку, начальная продолжительность которой составляет от нуля до четырех
секунд. При каждой последующей повторной отправке интервал удваивается до
тех пор, пока он не достигнет достаточно большой величины (например, 60
секунд). При достижении верхней границы продолжительность интервала
перестает удваиваться, но случайная задержка в итоговом интервале продолжает
применяться. Внесение случайной задержки помогает предотвратить
одновременное поступление запросов со стороны клиентов ВООТР, повышающих нагрузку
на сервер и порождающих конфликты пакетов в Ethernet. Удвоение
продолжительности случайного интервала предотвращает перегрузку сети
многочисленными широковещательными запросами со стороны многих клиентов ВООТР.
Формат сообщения ВООТР
На рис. 8.4 изображена структура сообщения ВООТР. Отдельные поля
сообщения описаны в табл. 8.1.
Таблица 8.1. Поля сообщений ВООТР
Поле Длина Описание
в октетах
ор 1 Тип сообщения: 1 — запрос (BOOTREQUEST), 2 — ответ (BOOTREPLY)
htype 1 Тип аппаратного адреса. Значения совпадают со значениями
аналогичного поля в пакетах ARP. Например, код 1 соответствует
сети Ethernet 10 Мбит/с
Ыеп 1 Длина аппаратного адреса в октетах. Аппаратные адреса Ethernet
и Token Ring имеют длину 6 байт
Поле Длина Описание
в октетах
hops 1 Поле обнуляется клиентом ВООТР. Может использоваться
агентом-ретранслятором, работающим на маршрутизаторе,
при пересылке сообщений ВООТР
xid 1 Код транзакции — случайное число, задаваемое клиентом ВООТР
при построении сообщения. Сервер ВООТР использует код транзакции
в своих ответах клиенту. Наличие кода xid позволяет клиентам
и серверам ВООТР связать сообщение ВООТР с ответом
sees 1 Заполняется клиентом ВООТР. Содержит количество секунд,
прошедших с начала загрузки клиента
— 2 Не используется
ciaddr 4 IP-адрес клиента ВООТР. Заполняется клиентом в сообщении
BOOTREQUEST, предназначенном для проверки использования ранее
назначенных параметров конфигурации. Если клиент не знает свой
IP-адрес, полю присваивается О
yiaddr 4 IP-адрес клиента ВООТР, возвращаемый сервером ВООТР
sladdr 4 IP-адрес сервера. Значение присваивается клиентом ВООТР, если
клиент хочет связаться с конкретным сервером ВООТР. IP-адрес
сервера ВООТР может храниться в конфигурационной базе данных
TCP/IP на клиенте ВООТР. Сервер может вернуть адрес следующего
сервера, с которым следует связаться в процессе загрузки, —
например, адрес сервера, на котором хранится загрузочный
образ операционной системы
giaddr 4 IP-адрес маршрутизатора, на котором работает агент-ретранслятор
ВООТР
chaddr 16 Аппаратный адрес клиента ВООТР. 16 октетов зарезервированы
для того, чтобы данное поле позволяло представлять различные
типы аппаратных адресов. В архитектурах Ethernet и Token Ring
используются только 6 октетов
sname 64 Необязательное имя сервера (если оно известно клиенту ВООТР).
Хранится в формате строки, завершенной нуль-символом
file 128 Имя загрузочного образа. Хранится в формате строки, завершенной
нуль-символом. Если клиент ВООТР хочет загрузить образ операционной
системы, принятый с сетевого устройства, он может задать обобщенное
имя — например, «unix» для загрузки образа Unix
На сервере ВООТР может храниться дополнительная информация
о конкретной операционной системе, необходимой для этой рабочей
станции. Ответ, полученный от сервера ВООТР, содержит полностью
определенное имя файла
vendor 64 Дополнительные данные, смысл которых определяется поставщиком.
Например, при запросе в этом поле может передаваться тип/серийный
номер устройства, а при ответе — информация о поддержке некоторых
возможностей или идентификатор удаленной файловой системы.
Информация может быть зарезервирована для использования
ядром или загрузчиком третьей фазы
0 12 3
01234567890123456789012345678901
Г орA) | htypeA) | hlen A) | hopsA) l
xidD) 1
sees B) | flags B) . [
| ciaddr D) |
| yiaddr D) |
| siaddr D) |
I giaddr D) |
chaddrA6)
I sname F4) |
file A28)
| vendor F4) I
В круглых скобках указывается
длина поля (в октетах)
Рис. 8.4. Формат сообщения BOOT?
Фазы ВООТР
Несмотря на свое название, протокол ВООТР не используется для фактической
пересылки образа операционной системы клиенту ВООТР. Пересылка образа
осуществляется отдельным протоколом TFTP (Trivial File Transfer Protocol),
который использует в качестве транспорта протокол UDP. Бездисковые
рабочие станции загружают образ операционной системы с сервера; другие станции
просто используют ВООТР для централизованного назначения IP-адресов, без
загрузки системы.
На рис. 8.5 изображены фазы, из которых состоит процесс загрузки образа
операционной системы. На шаге 1 клиент ВООТР выдает запрос на получение
данных конфигурации IP. На шаге 2 сервер ВООТР возвращает данные
конфигурации IP и имя загружаемого файла с образом операционной системы. На шаге 3
клиент ВООТР посылает запрос на загрузку образа операционной системы
клиенту TFTP. На шаге 4 клиент TFTP посылает серверу TFTP запрос на загрузку
образа операционной системы. На шаге 5 сервер TFTP возвращает серию
пакетов данных, содержащих образ операционной системы. После принятия образа
ВООТР загружает его в память и инициализируется.
Отделение ВООТР от механизма пересылки образа операционной системы
обладает тем преимуществом, что сервер ВООТР не обязан работать на том
компьютере, на котором хранятся образы операционных систем (то есть
сервере TFTP). Кроме того, это позволяет использовать ВООТР в ситуациях,
когда с сервера принимаются только данные конфигурации, без пересылки образа
операционной системы.
Возможна ситуация, в которой администратор настраивает рабочую станцию
на загрузку разных операционных систем в зависимости от пользователя. В этом
случае запрос ВООТР может содержать в поле имени файла обобщенное обо-
значение — например, «unix» для принятия образа операционной системы Unix,
или «default» для загрузки образа операционной системы по умолчанию.
Столкнувшись с таким обобщенным запросом, сервер ВООТР обращается к
конфигурационной базе данных, находит полностью определенное имя файла и возвращает
его в ответе ВООТР. Клиент ВООТР может передать полностью определенное
имя локальному клиенту TFTP для принятия образа операционной системы.
A) Запрос BootP
* ^*^ B) Конфигурация^^-
t ГСерверХТ IP и имя файла Тб^^Х
фа?а1 ЧЁ°^Е^г^^_ с образом OC/KgootPj)
-X ®^5Ф~====^^ -
Т Ьр^-чПолучение запрос ^lUr^^-^
СКлиент Уобоаза ОС DJ *^ ъ Клиент1)
Фаза 2 Клиент В TFTP V>opa3a V ^ на загрузку Jt Tfjp j
I BootP S-Q—r^-^ ^ J образа OC^ 4^^^/
I njj|g UDp ^4— —;—m J UDP
▼ H^^l \§) Пересылка IB ■
|^^___!£ I данных P§ »P I
Сервер
BootP
1 1
Рис. 8.5. Пример работы bootstrap
Дополнительные данные
В формате сообщения ВООТР явно заданы стандартные параметры IP. Многие
поставщики оборудования передают своим устройствам дополнительные
параметры. Для таких случаев в сообщения ВООТР было включено поле
дополнительных данных.
В поле vendor сообщения ВООТР клиенту передаются данные,
интерпретация которых определяется поставщиком оборудования. Поле не является
обязательным, а его применение зависит от того, какая дополнительная информация
нужна клиенту ВООТР. Первые четыре октета содержат «волшебное число» —
признак формата остальных полей. Эти четыре октета задаются в десятичной
записи с точечным разделением (не путайте их с IP-адресами!). Скажем,
произвольно выбранная последовательность 99.130.83.99 (в шестнадцатеричной
записи — 63.82.53.63) является общепринятым обозначением стандартного формата
области дополнительных данных. За признаком формата перечисляются элементы,
каждый из которых характеризуется следующими атрибутами:
О метка A октет);
О длина следующего поля данных A октет);
О данные (переменная длина).
Метки элементов ВООТР описаны в RFC 1497, «ВООТР Vendor Information
Extensions». С появлением протокола DHCP дополнительные данные ВООТР
и поле параметров DHCP были приведены к общему формату, описанному
в RFC 2132, «DHCP Options and BOOTP Vendor Extensions». Некоторые часто
используемые значения меток приведены в табл. 8.2.
Таблица 8.2. Стандартные метки дополнительных данных ВООТР
Метка Длина данных Интерпретация
0 - Используется только в целях выравнивания, чтобы следующие
поля начинались с границы слова
1 4 Маска подсети
2 4 Смещение географической зоны, в которой находится подсеть
клиента, от стандартного времени UTC (Coordinated Universal Time).
Смещение выражается 32-разрядным целым числом со знаком
3 N Список IP-адресов маршрутизаторов в подсети клиента.
Маршрутизаторы перечисляются в порядке предпочтительности.
Минимальная длина списка равна 4 октетам, а общая длина
должна быть кратна 4
4 N Список серверов времени (RFC 868), доступных для клиента.
Серверы перечисляются в порядке предпочтительности.
Минимальная длина списка равна 4 октетам, а общая длина
должна быть кратна 4
5 N Список серверов имен (IEN 116), доступных для клиента. Серверы
перечисляются в порядке предпочтительности. Минимальная длина
списка равна 4 октетам, а общая длина должна быть кратна 4
6 N Список серверов DNS (STD 13, EFC 1035), доступных для клиента.
Серверы перечисляются в порядке предпочтительности.
Минимальная длина списка равна 4 октетам, а общая длина
должна быть кратна 4
7 N Список журнальных серверов (MIT-LCS UDP), доступных для
клиента. Серверы перечисляются в порядке предпочтительности.
Минимальная длина списка равна 4 октетам, а общая длина
должна быть кратна 4
8 N Список серверов cookie (RFC 865), доступных для клиента.
Серверы перечисляются в порядке предпочтительности.
Минимальная длина списка равна 4 октетам, а общая длина
должна быть кратна 4
9 N Список серверов построчной печати LPR (RFC 1179),
доступных для клиента. Серверы перечисляются в порядке
предпочтительности. Минимальная длина списка равна
4 октетам, а общая длина должна быть кратна 4
10 N Список серверов Imagen Impress, доступных для клиента.
Серверы перечисляются в порядке предпочтительности.
Минимальная длина списка равна 4 октетам, а общая длина
должна быть кратна 4
Метка Длина данных Интерпретация
И N Список серверов местонахождения ресурсов (RFC 887),
доступных для клиента. Серверы перечисляются в порядке
предпочтительности. Минимальная длина списка равна
4 октетам, а общая длина должна быть кратна 4
12 N Имя хоста, соответствующее данному клиенту, с возможным
уточнением имени локального домена. Допустимые символы
описаны в RFC 1035. Минимальная длина поля данных равна
1 октету
13 N Размер загрузочного файла. Определяет длину загрузочного
образа, используемого клиентом по умолчанию,
в 512-килобайтных блоках. Длина файла задается
16-разрядным целым числом без знака
128-254 Не определена Интерпретация зависит от реализации
255 - Признак конца информации в поле дополнительных параметров.
Дальнейшие октеты должны быть заполнены нулями
Динамическая настройка
с использованием DHCP
Протокол DHCP (Dynamic Host Configuration Protocol) является расширением
протокола ВООТР и обладает более гибкими возможностями управления
IP-адресами. DHCP может использоваться для динамической настройки основных
параметров TCP/IP хостов (рабочих станций и серверов), работающих в сети.
Протокол DHCP состоит из двух компонентов:
О механизм назначения IP-адресов и других параметров TCP/IP;
О протокол согласования и передачи информации о хостах.
Хост, запрашивающий данные о конфигурации TCP/IP, называется клиентом
DHCP, а хост TCP/IP, предоставляющий эту информацию, называется сервером
DHCP.
Протокол DHCP описан в RFC 2131, «Dynamic Host Configuration Protocol».
Принципы работы DHCP описаны ниже.
Распределение IP-адресов в DHCP
В DHCP используются три способа назначения IP-адресов:
О ручное назначение;
О автоматическое назначение;
О динамическое назначение.
При ручном назначении IP-адрес клиента DHCP вводится вручную сетевым
администратором на сервере DHCP, после чего передается клиенту через
протокол DHCP.
При автоматическом назначении ручная настройка адресов не нужна.
Клиент DHCP получает IP-адрес при первом обращении к серверу DHCP. IP-адреса,
назначенные этим способом, закрепляются за клиентом DHCP и не используются
другими клиентами DHCP.
При динамическом назначении клиент получает IP-адрес на временной основе
или «арендует» его на определенный срок. По истечении этого срока IP-адрес
отзывается, и клиент DHCP должен перестать его использовать. Если клиент
DHCP по-прежнему нуждается в IP-адресе для выполнения своих функций, он
должен запросить другой адрес.
Из трех описанных методов только динамическое назначение позволяет
организовать автоматическое повторное использование IP-адресов. Если клиент
DHCP перестает использовать IP-адрес (например, при корректном
отключении компьютера), он возвращает его серверу DHCP. После этого сервер DHCP
может назначить тот же IP-адрес другому клиенту DHCP, обратившемуся с
запросом на получение адреса.
Метод динамического назначения адресов особенно удобен для клиентов
DHCP, нуждающихся в IP-адресе для временного подключения к сети. Для
примера рассмотрим сеть класса С, к которой могут подключаться до 300 мобильных
пользователей с портативными компьютерами. Сеть класса С может содержать
до 253 узлов B55 - 2 специальных адреса = 253). Поскольку компьютеры,
подключающиеся к сети через TCP/IP, должны обладать уникальными IP-адресами,
все 300 компьютеров не могут подключиться к сети одновременно. Тем не менее,
если в любой момент времени в сети возможно не более 200 физических
подключений, появляется возможность переназначения неиспользуемых адресов
класса С за счет применения механизма динамического назначения адресов DHCP.
Динамическое назначение адресов также хорошо подходит для назначения
IP-адресов новым хостам с постоянным подключением в ситуациях, когда
свободных адресов не хватает. По мере отключения из сети старых хостов их
IP-адреса могут немедленно назначаться новым хостам.
ПРИМЕЧАНИЕ
Какой бы из трех способов назначения IP-адресов ни был избран, вы все равно сможете один раз
настроить параметры IP на центральном сервере DHCP вместо того, чтобы повторять настройку
конфигурации TCP/IP для каждого компьютера по отдельности.
Назначение IP-адресов в DHCP
Обратившись с запросом к серверу DHCP, клиент DHCP проходит ряд
внутренних стадий, во время которых он согласовывает с сервером срок и область
использования IP-адреса. Процесс получения IP-адреса клиентом DHCP лучше
всего объяснить на диаграмме переходов (то есть конечного автомата). На рис. 8.6
изображена диаграмма, поясняющая процесс взаимодействия между клиентом
и сервером DHCP.
При первом запуске клиент DHCP находится в состоянии
ИНИЦИАЛИЗАЦИЯ. На этой стадии клиент DHCP еще не знает своих параметров IP, поэтому
он рассылает запрос DHCPDISCOVER, инкапсулированный в пакете UDP/IP. В пакете
указан приемный порт UDP 67 (десят.) — такой же, как у сервера ВООТР,
потому что протокол DHCP является расширением ВООТР. В пакете DHCPDISCOVER
используется адрес локальной рассылки 255.255.255.255. Если серверы DHCP
находятся за пределами локального сегмента, на маршрутизаторе IP должен
работать агент-ретранслятор, который перешлет запрос DHCPDISCOVER в другие
подсети. Поддержка агентов-ретрансляторов DHCP рассматривается в RFC 1542.
Отправка ^*~ ^
DHCPREQUESl^ Г ИНИЦИАЛИЗАЦИЯ ^==^^^
/ Прием Ц >v \^^
^"— IL^OFFffi IrjHCPNAK \ ^\
С ВЫБОР J*r ^Остановка \ DHCPNAKN.
^—-, -^гооАГк' \ Истечение срока Т2. \ Аренда истекла, \
/ uhuwauk \ рассылка DHCPREQUEST остановка \
/ от сервера отвергается . \ . ^ .^ '—— _ \
/ DHCPDDBCUNE S* ^^Х^Г"^ ПОВТОРНОЕ ^Ч \
ю«обнвиши|(чВОаОБНОШ1В^ Ч^ЯЗМАНИЕ^
1 одинаковых адресов г—г""^ Истечение [ ffiCPNAK /
\ЕёЙЖ J"™**~ \ \ ££ «-кг* /
\ / на срок ТЗ. Установка \ \ DHCPREQUEST/ таймеоовТ! Т2 /
^ >/ таймеровТ1,Т2 \ \ / ^^ ' /
С ЗАПРОС J) DHCPPACK от сервера. \\ / /
<^^ Аренда на срок ТЗ. \.1 / ./Отмена аренды
\v. Установка таймеров Т1.Т2 S^ ^-— / отправкой
^^-----____-^<^вяз^; DHCPREL£ASE
Отправка
DHCPREQUEST
I с известным J
\\Р-арресш ^у онсрраСК от сервера.
— -^ Аренда на срок ТЗ.
Установка таймеров Т1, Т2
Рис. 8.6. Диаграмма переходов для протокола DHCP, поясняющая процесс
взаимодействия между клиентом и сервером
Прежде чем рассылать запрос DHCPDISCOVER, клиент DHCP выдерживает
паузу случайной продолжительности от 1 до 10 секунд. Это делается для того,
чтобы предотвратить одновременное начало работы клиентов DHCP при их
одновременном включении (как иногда происходит после сбоя питания).
После рассылки запроса DHCPDISCOVER клиент DHCP входит в состояние
ВЫБОР. В этом состоянии клиент DHCP получает сообщения DHCPOFFER от
серверов DHCP, настроенных для ответа этому клиенту. Период времени, в
течение которого клиент DHCP ожидает сообщения DHCPOFFER, зависит от
реализации. Если клиент получает сразу несколько ответов DHCPOFFER, он должен
выбрать один из них. Выбрав сообщение DHCPOFFER от одного из серверов, клиент
DHCP посылает этому серверу сообщение DHCPREQUEST. Сервер DHCP
отвечает сообщением DHCPACK.
Дополнительно клиент DHCP может проверить IP-адрес, переданный в
сообщении DHCPACK, и убедиться в том, что этот адрес не используется. В сетях
с широковещательной рассылкой клиент DHCP может отправить по указанному
адресу запрос ARP и проверить наличие ответа ARP. Получение ответа ARP
означает, что предложенный IP-адрес уже используется; в этом случае ответ
DHCPACK от сервера игнорируется, отправляется ответ DHCPDECLINE, а клиент
DHCP переходит в исходное состояние ИНИЦИАЛИЗАЦИЯ и пытается
получить свободный IP-адрес. При рассылке запроса ARP в локальной сети клиент
указывает в пакете ARP собственный аппаратный адрес в поле аппаратного
адреса отправителя, но в поле IP-адреса отправителя заносится нулевое
значение. Нулевой IP-адрес используется вместо предложенного IP-адреса, чтобы
избежать возможной путаницы с кэшами ARP других хостов TCP/IP (в том
случае, если предложенный IP-адрес уже используется).
Когда клиент получает от сервера DHCP сообщение DHCPACK, он определяет
три временных интервала и переходит в состояние ПРИВЯЗКА. Первый
интервал Т1 определяет срок возобновления аренды; второй интервал Т2 определяет
срок повторной привязки; третий интервал ТЗ определяет продолжительность
аренды. С сообщением DHCPACK всегда возвращается значение ТЗ, то есть
продолжительность аренды. Значения Т1 и Т2 настраиваются на сервере DHCP,
а если они не были заданы, используются значения по умолчанию, основанные
на продолжительности срока аренды, рассчитанные по следующим формулам:
О Т1 = интервал возобновления;
О Т2 - интервал повторной привязки;
О ТЗ - продолжительность аренды;
О Т1 - 0,5 х ТЗ;
О Т2 - 0,875 х ТЗ.
Моменты времени, в которые происходит тайм-аут, вычисляются
прибавлением интервала ко времени отправки сообщения DHCPREQUEST, по которому
было сгенерировано подтверждение DHCPACK. Если запрос DHCP был
отправлен в момент ТО, то моменты тайм-аута по всем трем интервалам вычисляются
по следующим формулам:
О тайм-аут по Т1 = ТО + Т1;
О тайм-аут по Т2 - ТО + Т2;
О тайм-аут по ТЗ в ТО + ТЗ.
ПРИМЕЧАНИЕ
В RFC 2131 рекомендуется увеличивать Т1 и Т2 на величину случайной задержки, чтобы
предотвратить одновременное наступление тайм-аута на нескольких клиентах DHCP.
При истечении интервала Т1 клиент DHCP переходит из состояния
ПРИВЯЗКА в состояние ВОЗОБНОВЛЕНИЕ. В этом состоянии клиент DHCP
должен согласовать с сервером DHCP, выдавшим исходный IP-адрес, новый
срок аренды для назначенного IP-адреса. Если исходный сервер DHCP
отказывается возобновить аренду, он посылает сообщение DHCPNAK; клиент возвраща-
ется в состояние ИНИЦИАЛИЗАЦИЯ и пытается получить новый IP-адрес.
Если исходный сервер DHCP отправляет сообщение DHCPACK, в этом
сообщении указывается новая продолжительность аренды. Клиент DHCP снова
устанавливает интервалы Tl, T2 и ТЗ и переходит в состояние ПРИВЯЗКА.
Если интервал Т2 истекает в тот момент, когда клиент DHCP в состоянии
ВОЗОБНОВЛЕНИЕ ожидает сообщения DHCPACK или DHCPNAK от исходного
сервера DHCP, клиент переходит из состояния ВОЗОБНОВЛЕНИЕ в
состояние ПОВТОРНОЕ СВЯЗЫВАНИЕ. Исходный сервер DHCP может не ответить
из-за того, что он временно недоступен или из-за сбоя в сетевом канале. Из
приведенных выше формул видно, что Т2 > Т1, поэтому клиент DHCP
дополнительно ждет возобновления аренды в течение времени Т2-Т1.
При истечении интервала Т2 в сети рассылается широковещательный запрос
DHCPREQUEST для всех серверов DHCP, способных возобновить аренду; клиент
DHCP находится в состояние ПОВТОРНОЕ СВЯЗЫВАНИЕ. Рассылка запроса
объясняется тем, что после ожидания Т2-Т1 секунд в состоянии
ВОЗОБНОВЛЕНИЕ клиент DHCP приходит к выходу, что исходный сервер DHCP
недоступен, и пытается связаться с любым сервером DHCP, способным ему ответить.
Если сервер DHCP отвечает сообщением DHCPACK, клиент DHCP возобновляет
аренду (ТЗ), задает интервалы Т1 и Т2 и переходит в состояние ПРИВЯЗКА.
Если ни один сервер DHCP не сможет возобновить аренду до истечения
интервала ТЗ, аренда становится недействительной и клиент DHCP переходит в
состояние ИНИЦИАЛИЗАЦИЯ. Обратите внимание: к этому моменту клиент DHCP
уже дважды пытался возобновить аренду — сначала с исходного сервера DHCP,
а затем с любого сервера DHCP в сети.
При истечении срока аренды (ТЗ) клиент DHCP должен прекратить
использование IP-адреса и все сетевые операции с этим IP-адресом.
Чтобы прекратить использование IP-адреса, клиент DHCP не обязан
дожидаться истечения срока аренды (ТЗ). Он может намеренно отказаться от
использования IP-адреса, отменив аренду. Предположим, пользователь с портативным
компьютером подключился к сети для выполнения некоторой операции. Сервер
DHCP в сети предоставил ему IP-адрес сроком на один час. Пользователь
закончил свою работу за 30 минут и теперь хочет отключиться от сети. В процессе
корректного отключения компьютера клиент DHCP посылает серверу
сообщение DHCPRELEASE, чтобы сервер отменил аренду досрочно. Возвращенный
IP-адрес в дальнейшем может использоваться другим клиентом.
Если клиент DHCP работает на компьютере, оснащенном жестким диском,
то IP-адрес может храниться на этом диске и при запуске компьютера клиент
может запросить использовавшийся ранее адрес. На рис. 8.6 этой ситуации
соответствует состояние «ПЕРЕЗАГРУЗКА с известным IP-адресом».
Формат сообщения DHCP
Структура сообщения DHCP изображена на рис. 8.7. В сообщениях DHCP все
поля имеют фиксированный формат, кроме поля дополнительных данных,
минимальный размер которого равен 312 октетам. Читатели, знакомые с прото-
колом ВООТР, увидят, что сообщения DHCP и ВООТР имеют почти
одинаковый формат, не считая полей флагов и дополнительных параметров. Более того,
сервер DHCP может быть настроен на обработку запросов ВООТР (процедура
настройки зависит от операционной системы).
0 1 2 3
01234567890123456789012345678901
] I I I I I I I—«—I I I I I I I I I НН 1 I I I—f—I—I—Ы—ММ
орA) htypeA) hlen A) hopsA)
Г xidD)
1 sees B) | flags B) |
| ciaddr D) |
I yiaddr D) |
siaddr D) |
| giaddr D) |
chaddrA6)
I sname F4) |
Г file A28)
I vendor F4) |
В круглых скобках указывается
длина поля (в октетах)
Рис. 8.7. Формат пакета DHCP
Отдельные поля сообщений протокола DHCP описаны в табл. 8.3. В поле
флагов используется только крайний левый бит (рис. 8.8), остальные биты
должны быть равны нулю.
в р р р р о о р р о р р о о р р
В = 1 Широковещательный
В = 0 Направленный
Рис. 8.8. Формат пакета DHCP
Таблица 8.3. Поля сообщений DHCP
Поле Длина Описание
в октетах
ор 1 Тип сообщения: 1 — запрос (BOOTREQUEST), 2 — ответ (BOOTREPLY)
htype 1 Тип аппаратного адреса. Значения совпадают со значениями
аналогичного поля в пакетах ARP. Например, код 1 соответствует
сети Ethernet 10 Мбит/с
hlen 1 Длина аппаратного адреса в октетах. Аппаратные адреса Ethernet
и Token Ring имеют длину 6 байт
Поле Длина Описание
в октетах
hops 1 Поле обнуляется клиентом DHCP. Может использоваться агентом-
ретранслятором, работающим на маршрутизаторе, при пересылке
сообщений DHCP
xid 1 Код транзакции — случайное число, задаваемое клиентом DHCP при
построении сообщения. Сервер DHCP использует код транзакции в своих
ответах клиенту. Наличие кода xid позволяет клиентам и серверам DHCP
связать сообщение DHCP с ответом
sees 1 Заполняется клиентом DHCP. Содержит количество секунд, прошедших
с начала загрузки клиента
flags 2 Если крайний левый бит равен 1, сообщение является
широковещательным. Все остальные биты должны быть равны О
ciaddr 4 IP-адрес клиента DHCP. Заполняется клиентом в сообщении
DHCPREQUEST, предназначенном для проверки использования ранее
назначенных параметров конфигурации. Если клиент не знает свой
IP-адрес, полю присваивается О
yiaddr 4 IP-адрес клиента DHCP, возвращаемый сервером DHCP
siaddr 4 IP-адрес сервера. Значение присваивается клиентом DHCP, если клиент
хочет связаться с конкретным сервером DHCP. IP-адрес сервера DHCP может
быть получен при помощи сообщений DHCPOFER и DHCPACK, ранее
возвращенных сервером. Сервер может вернуть адрес следующего сервера,
с которым следует связаться в процессе загрузки, — например, адрес
сервера, на котором хранится загрузочный образ операционной системы
giaddr 4 IP-адрес маршрутизатора, на котором работает агент-ретранслятор DHCP
chaddr 16 Аппаратный адрес клиента DHCP. 16 октетов зарезервированы для того,
чтобы данное поле позволяло представлять различные типы аппаратных
адресов. В архитектурах Ethernet и Token Ring используются только 6 октетов
sname 64 Необязательное имя сервера (если оно известно клиенту DHCP).
Хранится в формате строки, завершенной нуль-символом
file 128 Имя загрузочного образа. Хранится в формате строки, завершенной
нуль-символом. Если клиент DHCP хочет загрузить образ операционной
системы, принятый с сетевого устройства, он может задать
в DHCPDISCOVER обобщенное имя — например, «unix» для загрузки
образа Unix. На сервере DHCP может храниться дополнительная
информация о конкретной операционной системе, необходимой для
этой рабочей станции. Ответ сервера DHCP может возвращаться в виде
полностью определенного имени файла в сообщении DHCPOFFER
options 312 Дополнительные параметры
Большинство сообщений DHCP, передаваемых сервером DHCP клиенту,
являются направленными (то есть посылаются на один конкретный IP-адрес). Это
объясняется тем, что сервер DHCP узнает адрес клиента DHCP из сообщений,
отправляемых клиентом серверу. Клиент DHCP может потребовать, чтобы
сервер отвечал по адресу широковещательной рассылки, для чего крайний левый
бит поля options устанавливается в 1. Клиент DHCP поступает подобным образом,
если он еще не знает своего IP-адреса. Модуль IP на клиенте DHCP отвергает
полученную дейтаграмму, если IP-адрес получателя, указанный в дейтаграмме,
не совпадает с IP-адресом сетевого интерфейса клиента DHCP. Если IP-адрес
сетевого интерфейса неизвестен, дейтаграмма также отвергается. С другой
стороны, модуль IP принимает любые широковещательные дейтаграммы DHCP.
Следовательно, чтобы модуль IP заведомо принимал ответ сервера DHCP,
когда IP-адрес еще не настроен, клиент DHCP должен потребовать, чтобы сервер
отправлял широковещательные сообщения вместо направленных.
Поле options имеет переменную длину. Его минимальный размер увеличен до
312 октетов, чтобы общий минимальный размер сообщения DHCP составлял
576 октетов — минимальный размер дейтаграммы IP, принимаемой хостом. Если
клиент DHCP должен использовать сообщения большего размера, он
согласовывает максимальный размер при помощи специального параметра. Поскольку
поля sname и file довольно велики, но используются не всегда, область
параметров можно расширить в эти поля при помощи параметра Option Overload. Если
этот параметр присутствует, обычный смысл полей sname и field игнорируется
и в этих полях ищутся параметры в формате TLV (Type, Length, Value).
Из рис. 8.9 видно, что в DHCP параметр представляется полем типа A октет),
за которым следует поле длины A октет). Значение поля длины определяет
размер поля значения. Различные сообщения DHCP представляются
специальным кодом типа 53. Значения параметров, определяющих сообщения DHCP,
приведены на рис. 8.10.
1 октет 1 октет N октетов д
Тип Длина (N) Значение
i—i—и—%—i
CD
Рис. 8.9. Формат параметра в сообщениях DHCP
Трассировка протокола DHCP
В этом разделе описан формат сообщений DHCP для пакетов, используемых
в реально существующей сети. Помимо указанных в табл. 8.3, на последующих
рисунках вам встретятся обозначения:
О Destination IP Address — IP-адрес получателя;
О Source IP Address — IP-адрес отправителя;
О Ethernet Header — заголовок Ethernet;
О UDP Header — заголовок UDP;
О UDP Source Port — UDP-порт отправителя;
О UDP Destination Port — UDP-порт получателя;
О Ethernet type — тип Ethernet.
1 октет 1 октет 1 октет
DHCPDISCOVER | ff„ | ^ | 3^^ |
DHCPOFFER [ Тип [ Длина | Значение |
DHCPREQUEST | ff„ [ д^ | 3^^ |
DHCPDECLINE | g„ | ^ \ 3Jeme\
DHCKACK I Тип | Длина | Значение |
53Ii I1 I
DHCPNAK J Тип | Длина | Значение |
DHCPRELEASE | *, | ^ | Знач1ение |
Рис. 8.10. Значения параметров в сообщениях DHCP
Поскольку протокол DHCP и формат его пакетов являются расширениями
ВООТР, в этом разделе будет обсуждаться только трассировка DHCP. Клиенты
и серверы DHCP используют те же номера портов, что и клиенты и серверы
ВООТР, то есть клиенты DHCP использует порт UDP с номером 68, а серверы
DHCP — порт UDP с номером 67. Большинство анализаторов протоколов
расшифровывает сообщения DHCP и BOOT в одном формате.
Широковещательный запрос DHCP (рис. 8.11) имеет следующие параметры:
О ор - 1;
О htype - 1;
О Ыеп - 6;
О hops = 0;
О xid - 826E7769 (шести.);
О sees = 0;
О flags = 0;
О ciaddr - 0.0.0.0;
Packet Number : 4 7:28:11 PM
Length : 346 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-A0-24-AB-D1-E6 > FF-FF-FF-FF-FF-FF
Type: 0x0890 (IP)
ip: ======================= Internet Protocol =======================
Station:©.0.0.0 >255.255.255.255
Protocol: UDP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput. Normal Reliability
Total length: 328
Identification: 0
Fragmentation allowed, Last fragment
Fragment Offset: 0
Time to Live: 128 seconds
Checksum: 0x39A6(Valid)
udp: ===================== User Datagram Protocol ====================
Source Port: BOOTPC
Destination Port: BOOTPS
Length = 308
Checksum: 0xA382(Valid)
Data:
0: 01 01 06 00 82 6E 77 69 00 00 00 00 00 00 00 00 | nwi
10: 00 00 00 00 00 00 00 00 00 00 00 00 00 A0 24 AB | $
20: Dl E6 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
30: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
60: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
70: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
90: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
A0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
B0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
C0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
D0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
E0: 00 00 00 00 00 00 00 00 00 00 00 00 63 82 S3 63 | C.Sc
F0: 35 01 01 3D 07 01 00 A0 24 AB 01 E6 0C 06 54 59 |5..= S TP
100: 4E 54 57 00 37 07 01 0F 03 2C 2E 2F 06 FF 00 00 |NTW.7 /
110: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
120: 00 00 00 00 00 00 00 00 00 00 00 00 j
Destination UDP UDP ^^ Ethernet
IP Source Destination UDP Ethernet ««jce Type
Address Port Port Header Header мЛпл» 4
t t t t »t | j
0: FF FF FF FF FF FF 00JA0 24 AB Dl Е6Г08 0§ 45 90 | S E. ,P
I I I Г ^Header
10:01 48 09 90 00 00 80j11 39 A6€00 99 00 OflCFF FF i .H 9
20: FF РРЙОФПбо^зУО! 34 A3 82 (о1Хо7Уо1Х^82 6E | . . .D.C.4 n > **
30: 77 69)gF00fe0 00^00 00 00 00100 00 00 0"OT00 00 | wi * *****
40: 00 РОТОР 00 00 Ю9Х00|А0 24 AB Dl E6 00 Ofl 00 00 | $ > ***"'
50: 00 00 00 00 00 ЮОУОО 00 00 00 00 00 00 Ofl 00 0011
I 1 I I I I I I ►sname
6©: '00 00 loo 00 00 loo 00 00 о© 00 00 O0 воI ea 00 00JI
I ▼ I I T
1 T T Htype Hop8
««ни, Flaee Addr I
giaddr ci T T
OP Hlen I
T
ytaddr
a
Рис. 8.11. Широковещательный запрос DHCP
70:1 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ||
I > sname
80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00J|
90: [o0 00 00 00 00 00|00 00 00 00 00 00 00 00 00 2><d)\
A0: [000000000000 00 00 00 00 00 00 00 00 00 00 ||
B0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
► file
C0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ||
00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
E0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
F0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ||
100: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00J|
110:^00 00 00 00 00 00j^3 82 S3 63J 35 01 01 30 07 рГ|[ c.ScS..-.. ^JJSkta
120:f©0 A0 24 AB 01 E6 0C 06 54 50 4E 54 57 00 37 07 |..$ TPNTW.7.
130: 01 0F 03 2C 2E 2F 06 FF 00 00 00 00 00 00 00 00 | ...,. /
I ► options
140: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
150: 00 00 00 00 00 00
Рис. 8.11. Широковещательный запрос DHCP (продолжение)
О yiaddr = 0.0.0.0;
О siaddr - 0.0.0.0;
О giaddr = 0.0.0.0;
О chaddr - 00A024ABD1E6 0000000000000000000;
О sname - 0 F4 октета);
О file-0 A28 октетов);
О options - 0 C12 октетов).
Направленный ответ DHCP (рис. 8.12) имеет следующие параметры:
О ор - 2;
О htype e 1;
О Ыеп - 6;
О hops - 0;
О xid = 826E7769 (шести.);
О sees в 0;
О flags - 0;
О ciaddr - 0.0.0.0;
О yiaddr = 199.245.180.41;
О siaddr = 199.245.180.0;
О giaddr - 0.0.0.0;
О chaddr - 00A024ABD1E6 0000000000000000000;
О sname = 0 F4 октета);
О file = 0 A28 октетов);
О options = «волшебное число» 63 82 53 63 (шести.).
Packet Number : 5 7:28:11 РМ
Length : 594 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-00-C0-DD-14-5C > 00-A0-24-AB-D1-E6
Type: 0x0800 (IP)
ip: ======================= internet Protocol =======================
Station:199.245.180.10 >199.245.180.41
Protocol: UDP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput. Normal Reliability
Total length: 576
Identification: 47444
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 128 seconds
Checksum: 0x8739(Valid)
udp: ===================== User Datagram Protocol ====================
Source Port: B00TP5
Destination Port: BOOTPC
Length = 556
Checksum: 0x0000(checksum not used)
Data:
0: 02 01 06 00 82 6E 77 69 00 00 00 00 00 00 00 00 | nwi
10: C7 F5 84 29 C7 F5 B4 0A 00 00 00 00 00 A0 24 AB |...) $.
20: Dl E6 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
30: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
60: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
70: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
90: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
АО: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
B0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
CO: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
D0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
E0: 00 00 00 00 00 00 00 00 00 00 00 00 63 82 53 63 | с. Sc
F0: 35 01 02 36 04 C7 F5 B4 0A 33 04 00 00 0E 10 ЗА |5..6 3
100: 04 00 00 07 08 3B 04 00 00 0C 3C 01 04 FF FF FF | ; <
110: 00 06 04 C7 F5 B4 0A 0F 0C 6B 69 6E 65 74 69 63 | kinetic
120: 73 2E 63 6F 6D FF 00 00 00 00 00 00 00 00 00 00 |s.com
130: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
140: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
150: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
160: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 j
170: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
180: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
190: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1A0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1B0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 j
1C0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1D0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1E0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1F0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
200: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
210: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 j
220: 00 00 00 00
Рис. 8.12. Направленный ответ DHCP
Htype
A
U DP U DP I Ethernet
Source Destination UDP Ethernet Type
Port Port Header Header OP Hlen A ^Jj0
i t t f t L Li t -^ > *
0: 00 A0 21 AB Oil E6 00 00 C0 DD 14 BCflSOffy 45 00 | ..$ \..E. * Header
10: 02 40 Bf> 54 00 00 80 11 87 39 Q7 F5 B4 0AXC7 F5 | .@.T 9 Sou"»
г г I -TLL ' ► IP
20: 04 29)р*43^'б> 44H2 2C 00 09p2X91J0?)PX8TTE \ .).C.D n AddPMi
30: 77 69]gF00^0 00jp0 00 00g7 F5 B4 29JC7 F5 | wi )..
I I 11 ъ yiaddr
40: B4 ОАХШёо eeioejp ao p4 ab pi E6 00 00 00 00 i $
I I I ""^ ► chaddr
50: 00 00 00 00 00 00lfe0 09 [90 00 00 00 00 00 09 09] |
I 11 I ^ ciaddr
69: fee lee eeleeleo lee 00 00 00 00 00 00 00 00 00 0011
II II ' I ► flags
70: bo lee ее lee lee 00 09 00 00 00 00 09 99 99 99 99 1
I J I ' I ' > giaddr
89: be 99 99 99 99 99 99 90 99 99 99 99 99 99 99 99] |
I I f^ ►sees
99: |P0|0Q 99 99 99 99j|90 99 99 90 99 90 99 09 90 00] |
"l ' -* ► siaddr
A0: kh 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0011
| I | > sname
B0: BO 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0011
I > file
C0: BO 00 00 00 00 00 00 09 99 99 99 99 99 99 99 99 I
D9: BO 99 99 99 99 99 99 00 00 09 99 99 99 09 90 99 |
E9: be 99 99 99 99 99 99 99 90 00 00 00 99 99 90 09 |
F9: BO 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
100: Ье 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
110: |Э0 00 00 00 00 8eJj^T 82 53 63K5 01 02 36 04 C^| c.Sc5..6..
^ —^1 i | ^ magic cookie
120: f5 B4 0A 33 04 00 00 0E 10 ЗА 04 00 00 07 08 3B | ...3 ;
130: Ю4 00 00 0C 3C 01 04 FF FF FF 00 06 04 C7 F5 B4 | . . . . <
140: Ьа 0F 0C 6B 69 6E 65 74 69 63 73 2E 63 6F 6D FF | ...kinetics.com.
150: be 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0011
160: Б0 00 00 00 00 00 00 09 99 99 99 99 90 00 00 00 |
| > options
170: be 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0011
180: 1Э0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
190: be 00 00 00 99 99 00 00 00 00 00 00 00 00 00 00 |
1A0: be 00 00 00 00 00 00 00 00 00 99 99 99 99 99 99 |
1B9: be 00 00 00 00 00 00 00 00 00 00 00 00 00 00 90 |
1C0: B0 00 00 00 00 99 99 99 99 00 00 99 99 00 00 00 |
1D0: |Э0 00 00 00 09 99 99 99 99 99 99 00 00 00 00 00 |
Рис. 8.12. Направленный ответ DHCP (продолжение)
iEO: lee 00 00 00 00 00 00 00 00 00 00 00 ее 00 00 0011
iF0: lee 00 00 00 00 00 00 00 00 00 00 00 00 00 00 eel 1
200: pe 00 00 00 00 00 00 00 00 00 00 00 00 00 00 eel | ►options
210: 100 00 00 00 00 00 00 00 00 00 00 00 00 00 00 001 |
220: Ю0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 001 |
230: be 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00] I
240: pe 00 00 00 00 00 00 00 00 00 00 00 00 00J I
Рис. 8.12. Направленный ответ DHCP (продолжение)
Трассировка сообщений DHCP с широковещательным
ответом от сервера
На рис. 8.13 и 8.14 представлены широковещательный запрос от клиента DHCP
и ответ сервера DHCP. Тем не менее, в отличие от предыдущего раздела, ответ
сервера DHCP пересылается в широковещательном режиме. Направленный
ответ был невозможен, поскольку данная реализация сервера DHCP не заносит
данные в кэш ARP.
Широковещательный запрос DHCP имеет следующие параметры:
О ор - 1;
О htype - 1;
О Ыеп = 6;
О hops - 0;
О xid - 826E7769 (шести.);
О sees = 0;
О flags - 0;
О ciaddr - 0.0.0.0;
О yiaddr - 0.0.0.0;
О siaddr - 0.0.0.0;
О giaddr - 0.0.0.0;
О chaddr = 00A024ABD1E6 0000000000000000000;
О sname e 0 F4 октета);
О file = 0 A28 октетов);
О options = 0 C12 октетов).
Широковещательный ответ DHCP имеет следующие параметры:
О ор = 2;
О htype - 1;
О Ыеп = 6;
Packet Number : 6 7:28:11 PM
Length : 346 bytes
ether: ============в8====« Ethernet Datalink Layer ====««============
Station: 66-A6-24-AB-D1-E6 > FF-FF-FF-FF-FF-FF
Type: 9x0806 (IP)
ip: ssssssssssssssssssrssss Internet PrOtOCOl ======sss=sssss==s===s=
Stat ion:0.0.0.0 >255.255.255.255
Protocol: UDP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay. Normal Throughput. Normal Reliability
Total length: 328
Identification: 256
Fragmentation allowed, Last fragment
Fragment Offset: 0
Time to Live: 128 seconds
Checksum: 0x38A6(Valid)
udp: ===================== User Datagram Protocol ====================
Source Port: BOOTPC
Destination Port: BOOTPS
Length = 308
Checksum: 0x8EB0(Valid)
Data:
0: 01 01 06 00 01 4E AB 33 00 00 00 00 00 00 00 00 | N.3
10: 00 00 00 00 00 00 00 00 00 00 00 00 00 A0 24 AB | S.
20: Dl E6 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
30: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 60 00 |
40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
56: 00 60 00 00 00 06 00 60 06 00 00 00 00 00 06 00 |
60: 00 60 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
70: 00 60 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
80: 00 60 00 00 00 00 06 60 00 00 00 06 66 66 66 66 |
96: 06 66 66 66 66 66 60 00 00 00 00 00 00 00 00 00 |
A0: 00 60 00 00 00 00 00 00 00 66 66 66 66 66 66 66 |
B6: 60 00 00 00 00 00 06 00 00 00 00 66 66 66 66 66 |
C6: 66 66 66 66 66 66 66 66 66 66 .66 66 66 66 66 66 |
D6: 66 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
EO: 00 00 00 00 00 00 00 00 00 00 00 00 63 82 53 63 | c.Sc
F0: 35 01 03 3D 07 01 00 A0 24 AB Dl E6 32 04 C7 F5 |5..= $...2...
100: B4 29 36 04 C7 F5 B4 0A 0C 06 54 50 4E 54 57 00 |.N TPNTW.
110: 37 07 01 0F 03 2C 2E 2F 06 FF 00 00 00 00 00 00 |7 /
120: 00 00 00 00 00 00 00 00 00 00 00 00 |
UDP UDP HtJpe Ethernet
Source Deetination UDP Ethernet f Type _.. ,.
Port Port Header Header OP Hlen A jfJJJJJJJ
t t t M О t . IP
0: FF FF FF FF FF FF 00 A0 24 AS И ЕбДЗГбЭ 45 00 | $ E. " Header
10: 01 48 ek 00 0a00 80 11 38 A6 бГв[00 00 00)(fFFF |.H 8 ^So^e
20: FF FF)fi04?te0 43H1 34 8Г B9 ШХбШЭГёаббГТ! J...D.C.4 N А^ПМ
36: ab 33)fee еЮСео eelee ее ее 60100 00 00 еёдее ее i.з w
40: 00 eeXeojee eeleeXee леЬд ab pi E6 ее oa ее ее | $
1 " C- ►chaddr
5в: ее ее ре ее ее eefee eelee ее ее eelee eel ее еэ| |
66: fee 66 be lee eelee 00 00 00 00 00 ее ее ed ее ed 1
||| I It I *8name
I sees flags ciaddr yiaddr hops
T
giaddr
Рис. 8.13. Широковещательный запрос DHCP
70: lOO 0© 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
I I > sname
80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00]|
90: loe 00 00 00 00 00 jfeo 00 00 00 00 00 00 00 00 ool I
A0: [00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 001j
B0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
C0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
►file
D0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 001|
E0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 001 |
F0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
100: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00]|
110: [©0 00 00 00 00 0pjp82 53 63K5 01 03 3D 07 01^ j c.Sc5..=..
/ I * I > magic cookie
120: [00 A0 24 AB Dl E6 32 04 C7 F5 B4 29 36 04 C7 F5 |..S...2 N...
130: B4 0A 0C 06 54 50 4E 54 57 00 37 07 01 0F 03 2C |....TPNTW.7
I I > options
140: 2E 2F 06 FF 00 00 00 00 00 00 00 00 00 00 00 00 |./
150: 00 00 00 00 00 00 I I
Рис. 8.13. Широковещательный запрос DHCP (продолжение)
О hops = 0;
О xid - 826Е7769 (шести.);
О sees = 0;
О flags = 0;
О ciaddr = 0.0.0.0;
О yiaddr = 0.0.0.0;
О siaddr= 199.245.180.10;
О giaddr = 0.0.0.0;
О chaddr = 00A024ABD1E6 0000000000000000000;
О sname = 0 F4 октета);
О file = 0 A28 октетов);
О options = «волшебное число» 63 82 53 63 (шести.).
Packet Number : 7 7:28:11 PM
Length : 594 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-00-C0-DD-14-5C > FF-FF-FF-FF-FF-FF
Type: 0x0800 (IP)
ip: ======================= internet Protocol =======================
Stat ion:199.245.180.10 >255.255.255.255
Protocol: UDP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput, Normal Reliability
Total length: 576
Identification: 47445
Fragmentation allowed, Last fragment
Fragment Offset: 0
Time to Live: 128 seconds
Checksum: 0x0358(Valid)
udp: ===================== User Datagram Protocol ====================
Source Port: BOOTPS
Destination Port: BOOTPC
Length = 556
Checksum: 0x0000(checksum not used)
Data:
0: 02 01 06 00 01 4E AB 33 00 00 00 00 00 00 00 00 | N.3
10: 00 00 00 00 C7 F5 B4 0A 00 00 00 00 00 A0 24 AB | $.
20: Dl E6 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
30: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
60: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
70: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
90: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
A0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
B0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
C0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
D0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
E0: 00 00 00 00 00 00 00 00 00 00 00 00 63 82 53 63 | С. Sc
F0: 35 01 06 FF 00 00 00 00 00 00 00 00 00 00 00 00 15
100: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
110: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
120: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
130: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
140: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
150: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
160: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
170: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
180: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
190: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1A0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1B0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1C0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1D0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1E0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
1F0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
200: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 j
210: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 I
220: 00 00 00 00 |
Рис. 8.14. Широковещательный ответ DHCP
I b© 00 00 00 00 GO 00 00 00 00 00 00 00 00 00 ©©I :©0T
I b© 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :0ЭХ
I bo 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :09I
I BO 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :0VT
I Ю0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :06T
I bo 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :08T
I bo 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 -QLI
suoijdo < I I
I feo 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :©9T
I bO 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :0ST
I bO 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 -Obi
I bO 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :0€I
I во ©о 00 ©о ©о oo oo о© 00 op 00 op 00 op op eej :©гт
eptooo oj6eui M 1 I
s^so i bo oo jj 90 xo se ks cs zs tern oo 00 00 00 00] :©n
I Ю0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 :O0T
I p© 00 00 00 00 00 ©0 00 00 00 00 00 00 00 00 00 :©d
I b© 00 ©0 00 00 00 90 00 00 00 00 00 00 Q© 00 0© :©3
I |б0 99 00 09 90 00 00 90 00 00 00 09 00 00 00 6© :©0
л ^ 1 [О© 0© ©9 00 0© 00 00 00 0© 0© 00 00 0© 00 00 00 :©Э
eltf ^ I I
I Ь© 00 00 00 00 00 0© 00 00 00 00 00 00 90 00 00 :09
eujeus < I . I
I Ю0 00 00 0© б© 00 00 09 ©0 ©9 QQ б© 90 9© 9©| 0©J :0V
jppeie^ 1 —I '
I pe ©e ее ее ее ее ее е© ее eojfee 00 ©0 ©a ©0 001 :©6
soes *< * == ,
I b© 00 00 ©0 00 ©0 00 ©9 ©0 00 09 99 99 9ft 00 09 :©8
s6eu 4 1
I Ю0 00 ©9 00 Q© 0© 00 00 00 00 99 99 99 0G| ©9 99 -01
jppej40«< 1 1 I I
I Ю0 99 99 99 99 99 99 90 09 99 99 99 9© 061 QQ 0©) :©9
JppeiA 4 1 I
I be ее ее ее lee ее ее ее ее eeJteeiee eel ее] ее ее :©s
jppeqo ^ -1 _ 111
$ I ее ее ©е ©е 93 to av м ©у 00X00 00 00 Щ(Уо »g :ot
jppets rf I I I I
£l Sd ZDIQQ 00 00 00X00 00 00 00100 OQjjQQQ^jii 8V 'Qi
oojP|X n аэ •••! з» тож)рУ0)(?©)е9 о© эг го (ьУЩ[ы oqcdd d d 'qz
w*^ iji I i I
«^^ X П'§-1 Id ddfffr fr8 Sd ф89 £9 It 08 09 Ю9 SS 98 0* ZQ -Ql
jepeeH^-J'X 1 ©0 Sfr 08 88 Ы1 П 00 0Э 00 ©0 dd Ld dd M Ы id :©
т I f | j | f у
S^s^S T ue'H dO J9P**H лрвен POd VX)d
^ ed*i X »вшвфЗ dan uoftBURsea «unos
)8шеч)Э ьдМн dan dan
dl/cDl еииоахэен венневос1иеи±еио1а\/ '8 eeei/j ggj
1Е0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0011
1F0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
200: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0011 > °ptK>ns
210: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
220: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
230: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00j |
240: lee 00 00 00 00 00 00 00 00 00 00 00 00 oej I
Рис. 8.14. Широковещательный ответ DHCP (продолжение)
Итоги
Протоколы ВООТР и DHCP решают важную проблему автоматической
настройки параметров IP (в частности, IP-адресов и масок подсети) для отдельных
сетевых устройств. Оба протокола основаны на архитектуре «клиент-сервер»
и используют одинаковые номера портов UDP. Протокол DHCP проектировался
в качестве замены старого протокола ВООТР, а его сообщения представляют
собой расширение формата сообщений ВООТР.
Главное преимущество DHCP заключается в том, что этот протокол
позволяет арендовать IP-адреса на временной основе. Тем самым обеспечивается
более гибкое управление IP-адресами в ситуациях, когда IP-адреса не обязаны
жестко ассоциироваться с конкретным компьютером по аппаратному адресу.
Механизм назначения IP-адресов в ВООТР менее гибок, поскольку IP-адрес
связывается с аппаратным адресом сетевого интерфейса.
9 Обзор семейства
протоколов IP
Марк А. Спортак (Mark A. Sportack)
Каранжит С. Сиян (Karanjit S. Siyan)
Термин «TCP/IP» постоянно используется при описании IP-коммуникаций.
Несмотря на его популярность, лишь немногие понимают, что в действительности речь
идет о целом семействе протоколов, каждый из которых обладает своими
достоинствами и недостатками. В этой главе рассматривается архитектура,
функциональные возможности и область применения различных протоколов из семейства IP.
Данная глава закладывает фундамент для дальнейшего обсуждения TCP/IP.
В дальнейших главах компоненты семейства протоколов TCP/IP будут описаны
более подробно. Хотя часть представленного материала уже встречалась ранее,
этот обзор поможет составить общее представление о протоколе TCP/IP.
Модель TCP/IP
Протокол TCP/IP обычно рассматривается в контексте эталонной модели,
определяющей структурное деление его функций. Однако модель TCP/IP
разрабатывалась значительно позже самого комплекса протоколов, поэтому она
никак не могла быть взята за образец при проектировании протоколов.
Эталонная модель TCP/IP описана в главе 1.
Семейство протоколов TCP/IP
Семейство протоколов IP состоит из нескольких протоколов, часто
обозначаемых общим термином «TCP/IP»:
О IP — протокол межсетевого уровня;
О TCP — протокол межхостового уровня, обеспечивающий надежную доставку;
О UDP — протокол межхостового уровня, не обеспечивающий надежной доставки;
О ICMP — многоуровневый протокол, упрощающий контроль, тестирование
и управление в сетях IP. Различные протоколы ICMP распространяются на
межхостовой и прикладной уровень.
Связи между этими протоколами изображены на рис. 9.1.
ПРИМЕЧАНИЕ
Вообще говоря, приложения, работающие на прикладном уровне (Telnet, FTP и многие другие),
также должны считаться компонентами семейства протоколов IP. Но так как они все же являются
приложениями, а не протоколами, в этой главе они не рассматриваются.
I Протоколы I | Протоколы I
прикладного прикладного
уровня уровня (TFTP,
I (FTP, HTTP и т. д.) I J DNS, NFS и т. д.) |
Ж Ж
X J
TCP ICMP UDP
I I I
IP
X
I
Механизмы канального и физического уровней
Рис. 9.1. Термин TCP/IP в действительности обозначает
не один протокол, а целое семейство протоколов
Протокол IP
Протокол IP (Internet Protocol) является самым распространенным межсетевым
протоколом в мире. Все его конкуренты — OSI, AppleTalk и даже IPX — в
конечном счете, проиграли IP из-за его открытости. Несмотря на столь выдающийся
успех, протокол IP часто воспринимается неправильно. Функциональность
протокола определяется объемом данных, хранящихся в заголовках. Структура
заголовков IP, а следовательно и его возможности первоначально определялись
в серии RFC и других общедоступных документов, которые были
опубликованы еще во времена создания группы IETF. Обычно считается, что базовым
документом для современной версии IP является RFC 791 (дата публикации —
сентябрь 1981 года).
Благодаря неустанной работе IETF протокол IP постоянно развивается. В
последующих RFC были добавлены многочисленные новые возможности. Тем не
менее все они строятся на основе, заложенной в RFC 791. С архитектурной точки
зрения текущая версия IP имеет номер 4 (IPv4). Со временем новая версия
(IPv6) постепенно вытеснит IPv4, но в настоящее время повсеместно
поддерживается стандарт IPv4. Дополнительная информация об IPv6 приведена в главе 12.
Заголовок IPv4
На рис. 9.2 представлена структура заголовка IP с указанием размеров
отдельных полей.
L I I |06щ9я|Уникальный! Г I I , 1^1 I д^ I I
Г"* Длина № Длина иденти- Флаги О^ие Срок £^ 31 Адрес И^ Дополнение
Ьрсим загшшса »«РЫ ***" Ф"«Ч> фрагмен- фрагмента жизни LS^ ^ «яучиив ГЗ, П1£«и3
Ибита) < Ч октет) (два (два (трибита) октет) Октет) «» Д ™) Д
| октета) | октета) | \ | _| _|
Нормаль" H^Wafl Но»ш,|г Заоеэео-
Приоритет ная/низкая ^L-^ ная/высокая ГТ^1
(Збита) задержка Щ Н*™П2З
A6ит) Г^?^ Обит) <26ита)
Рис. 9.2. В структуре заголовков IP определены многие поля, обеспечивающие
те или иные возможности этого протокола
Заголовок IP состоит из следующих полей:
О Версия — первые 4 бита заголовка определяют текущую версию IP
(например, 4 или 6).
О Длина заголовка — следующие 4 бита содержат длину заголовка в двойных
словах (блоках по 32 бита).
О Параметры — следующий октет содержит набор флагов, которые могут
использоваться для определения параметров пакета данных — абсолютного
приоритета по отношению к другим пакетам IP, задержки, пропускной
способности и надежности. Флаг приоритета имеет длину три бита, тогда как
каждый из флагов задержки, пропускной способности и надежности
представлен одним битом. Оставшиеся два бита зарезервированы на будущее.
О Общая длина — 16-разрядное поле, содержащее общую длину пакета IP в
октетах. Максимальная допустимая длина составляет 65 535 октетов.
О Идентификатор — каждому пакету IP присваивается уникальный
16-разрядный идентификатор, используемый для идентификации фрагментов
дейтаграммы.
О Флаги фрагментации — следующее поле содержит три 1-битовых флага,
которые указывают, разрешена ли фрагментация пакета и завершает ли пакет
серию фрагментов. Первый бит зарезервирован и всегда равен 0. Второй бит
указывает, разрешена ли фрагментация для данного пакета. Если бит равен 0,
то содержимое пакета может фрагментироваться, а если бит равен 1, то
пакет не фрагментируется. Значение третьего бита учитывается только в том
случае, если второй бит был равен 0. Если фрагментация разрешена (то есть
данные могут быть разбиты на несколько сегментов), этот бит показывает,
завершает ли данный пакет серию фрагментов, или приложение-получатель
должно ожидать поступления дополнительных фрагментов. Значение 0
указывает на то, что пакет является последним в серии фрагментов.
О Смещение фрагмента — 8-разрядное поле определяет смещение фрагменти-
рованного содержимого по отношению к началу всего пакета (в блоках
размером 64 бита).
О Срок жизни — пакеты IP не могут бесконечно блуждать в глобальных сетях,
их срок жизни необходимо ограничить. 8-разрядное поле срока жизни
увеличивается на 1 для каждого перехода (hop). После достижения счетчиком
максимальной величины считается, что пакет доставить не удалось. При этом
генерируется и передается отправителю сообщение ICMP, а пакет
уничтожается.
О Протокол — 8-разрядное поле определяет тип протокола, данные которого
следуют за заголовком IP: VINES, TCP, UDP и т. д.
О Контрольная сумма — 16-разрядное значение, используемое для выявления
ошибок. Получатель, а также все шлюзовые узлы сети производят с
заголовком пакета такие же математические вычисления по той же формуле, как на
отправителе. Если пересылка данных прошла успешно, результаты двух
вычислений будут идентичны.
О IP-адрес отправителя — IP-адрес компьютера, с которого был отправлен пакет.
О IP-адрес получателя — IP-адрес компьютера, которому должен быть
доставлен пакет.
О Дополнение — поле заполняется нулями, чтобы длина заголовка IP была
кратна 32 битам.
Анализ полей заголовка показывает, что межсетевой уровень IPv4 не
ориентирован на соединение: устройства, пересылающие пакет в сети, по своему
усмотрению выбирают идеальный маршрут для каждого пакета. Кроме того, IP не
обладает средствами подтверждения, управления передачей или упорядочения
пакетов, присутствующими в высокоуровневых протоколах (таких, как TCP).
Протокол IP также не может использоваться для передачи данных,
содержащихся в дейтаграмме IP, конкретному приложению. Эти функции обеспечиваются
протоколами более высокого уровня (в частности, TCP и UDP).
Задачи протокола IP
Заголовок пакета IP содержит всю информацию, необходимую для выполнения
основных сетевых операций. К числу таких операций относятся:
О адресация и маршрутизация;
О фрагментация и повторная сборка;
О выявление и исправление данных, поврежденных в процессе пересылки.
Адресация и маршрутизация
Одна из самых очевидных возможностей IP — наличие информации о
компьютере, которому следует доставить данный пакет. IP-адрес получателя
используется маршрутизаторами и коммутаторами в сети, отделяющей отправителя от
получателя, для определения оптимального маршрута в сети.
В пакетах IP также хранится IP-адрес отправителя. Следовательно, при
необходимости получатель сможет связаться с отправителем.
Фрагментация и повторная сборка
Иногда сегменты данных приложения не помещаются в одном пакете IP,
максимальный размер которого определяется параметром MTU (Maximum Transmission
Unit) сети. В этом случае пакет IP фрагментируется, то есть разбивается на два
и более пакета. Протокол IP должен обеспечивать восстановление исходного
сегмента данных независимо от того, сколько фрагментов потребовалось для его
доставки к месту назначения.
Важно, чтобы отправитель и получатель поддерживали общую процедуру
фрагментирования сегментов данных и придерживались ее. В противном случае
сборка данных, фрагментированных на несколько пакетов для доставки по сети,
станет невозможной. В результате успешной сборки данные восстанавливаются
в точно таком же виде, как на исходном компьютере до фрагментации. Для
идентификации фрагментированных сегментов данных используются флаги
фрагментации в заголовках IP.
ПРИМЕЧАНИЕ
Процесс сборки фрагментированных сегментов данных существенно отличается от
восстановления нарушенного порядка пакетов, который относится к функциям TCP.
Поврежденные пакеты
Последняя из важных функций IP — выявление и исправление дейтаграмм,
содержимое которых было повреждено или потеряно в процессе пересылки.
Повреждение пакетов происходит по разным причинами, чаще всего под
воздействием радио- и электромагнитных помех. Пакет считается поврежденным, если
при получении пакета содержащиеся в нем данные отличаются от тех, которые
были переданы с отправителем.
Потери пакетов также объясняются разными причинами. Во-первых,
чрезмерный объем трафика может привести к истечению срока жизни пакетов.
Маршрутизатор, обнаруживший пакет с превышенным сроком жизни, просто уничтожает
его. Возможен и другой вариант — в результате воздействия помех содержимое
пакета может быть искажено настолько, что информация заголовка станет
абсолютно бессмысленной. Такие пакеты тоже обычно уничтожаются.
О том, что пакет IP не удалось доставить или он непригоден к
использованию, необходимо уведомить отправителя. Для подобных оповещений в
заголовок включается IP-адрес отправителя. Таким образом, хотя протокол IP не
обладает собственными средствами координации пересылки, он играет важную
роль в оповещении отправителя о необходимости повторной пересылки.
Заключение
Несмотря на перечисленные возможности, следует признать, что пакет IP
является всего лишь межсетевым протоколом. Для реального практического
использования он должен быть дополнен как транспортным протоколом (уровень 4
эталонной модели OSI), так и канальным протоколом (уровень 2 эталонной
модели OSI). Канальные архитектуры выходят за рамки настоящей книги, а
оставшаяся часть главы будет посвящена двум транспортным протоколам,
использующим IP для обеспечения межсетевого обмена данными: TCP и UDP.
Протокол TCP
Протокол TCP (Transmission Control Protocol) пользуется сервисом IP для
обеспечения надежной доставки прикладных данных. TCP создает между двумя
или более хостами сеанс, ориентированный на соединение. Он обладает такими
возможностями, как поддержка нескольких потоков данных, координация
потока и контроль ошибок и даже восстановление нарушенного порядка пакетов.
Протокол TCP также разрабатывался посредством публикации общедоступных
документов RFC группой IETF. Результатом стал документ RFC 793,
опубликованный в сентябре 1981 года. За прошедшие 18 лет стандарт RFC 793, как и
стандарт IP (RFC 791), был усовершенствован, но так и не подвергся полной замене.
Таким образом, базовая модель TCP по-прежнему определяется содержимым
этого RFC.
Структура заголовка TCP
Функциональность TCP, как и функциональность IP, ограничивается объемом
информации, пересылаемой в заголовке. Следовательно, для понимания общей
механики и круга возможностей TCP необходимо хорошо разобраться в
содержимом заголовка. На рис. 9.3 представлена структура заголовка TCP с
указанием размеров отдельных полей.
Заголовок протокола TCP состоит минимум из 20 октетов и содержит
следующие поля:
О Порт TCP отправителя — 16-разрядный номер порта, инициировавшего
соединение. Совокупность номера порта и IP-адреса отправителя определяет
«обратный адрес» данного пакета.
О Порт TCP получателя — 16-разрядный номер порта, на который направляется
данный пакет. Порт определяет интерфейсный адрес приложения, которому
будет передан пакет на компьютере-получателе.
О Порядковый помер — 32-разрядный порядковый номер используется
получателем при восстановлении исходной формы фрагментированных пакетов. В сети
с динамической маршрутизацией фрагменты вполне могут передаваться по
разным маршрутам, что приведет к нарушению их исходного порядка. Передача
порядкового номера позволяет восстановить правильную последовательность
пакетов.
I I II I I I I I I I I Допол- I
ПортТСР ПортТСР "J* ^П^Г- Смещение Зарвэвр«- ф L»M*«i "J* иеиие
отравителя получателя """ "*Г данных роаано .... . окна срочности ,.__,£_, (перемен-
(гаоета) <2«жтета) ИД ,*£,, D6ита) (ббит, <66"> Ьо-оета р^ Р«^& ^
I URG I АСК I PSH I RST SYN FIN
I A бит) I A6ит) A6т) Aбит) I A бит) I Aбит)
Рис. 9.3. Поля, определенные в структуре заголовков TCP, определяют разнообразные
возможности этого протокола
О Номер для подтверждения (АСК) — 32-разрядный номер первого октета
данных, содержащегося в следующем ожидаемом сегменте. На первый взгляд
подтверждение «того, чего еще нет» выглядит нелогично, однако при
получении подтверждения хост-отправитель TCP/IP знает, что были получены все
данные до заданного сегмента (но не включая его). Идентификация сигналов
АСК производится по порядковому номеру подтверждаемого пакета. Данное
поле действительно только при установленном флаге АСК (см. ниже
описание поля флагов).
О Смещение данных — размер заголовка TCP в 32-разрядных блоках.
О Зарезервировано — это 6-разрядное поле всегда заполняется нулями. Оно
зарезервировано для будущего использования, и на сегодняшний день его
смысл еще не определен.
О Флаги — 6-разрядное поле содержит шесть 1-битных флагов,
активизирующих интерпретацию поля срочности, подтверждения, немедленной отправки,
сброса соединения, синхронизации порядковых номеров и завершения
отправки данных; по порядку следования в строке эти флаги обозначаются
URG, АСК, PSH, RST, SYN и FIN.
О Размер окна — 16-разрядное поле используется получателем для передачи
отправителю информации о том, какой объем данных он готов принять в
одном сегменте TCP.
О Контрольная сумма — в заголовок TCP также включается 16-разрядная
контрольная сумма, предназначенная для выявления ошибок. Отправитель
производит математические вычисления по данным сегмента, затем те же самые
вычисления производятся получателем. Если результаты совпадают, значит,
данные были переданы без искажения.
О Указатель точности — 16-разрядный указатель на последний октет срочных
данных в сегменте. Значение поля действительно только при установленном
флаге URG. Если флаг не установлен, поле не интерпретируется. Сегменты
данных, снабженные признаком срочности, в первую очередь обрабатываю!< я
всеми устройствами TCP/IP, находящимися между отправителем и получи
телем.
О Параметры — поле переменной длины, состоящее минимум из одного октечл,
определяет параметры сегмента TCP. При отсутствии параметров поле состо
ит из 1 октета и содержит 0 (признак конца списка параметров). Значение 1
в этом октете означает отсутствие дополнительных операций. Значение 2
указывает на то, что следующие 4 октета содержат максимальный размер
сегмента (MSS, Maximum Segment Size) для отправителя. MSS определяет
максимальное количество октетов в поле данных, согласованное между
отправителем и получателем.
О Данные — формально данные не являются частью заголовка TCP, однако
необходимо понимать, что данные следуют за указателем срочности и/или полем
параметров, но предшествуют полю дополнения. Максимальный размер поля
данных определяется значением MSS, согласованным между получателем и
отправителем. Сегменты могут быть меньше MSS, но никогда не превышают его.
О Дополнение — в области коммуникационных технологий дополнение всегда
используется для обеспечения единства размеров блоков данных, интервалов
и т. д. В заголовке TCP это поле заполняется нулями и обеспечивает
выравнивание заголовка TCP по 32-разрядной границе.
Задачи протокола TCP
В сеансе связи TCP обеспечивает ряд важных функций, большая часть которых
связана с обеспечением интерфейса между различными приложениями и сетью.
К числу этих функций относятся:
О мультиплексирование данных между приложениями и сетью;
О проверка целостности полученных данных;
О восстановление нарушенного порядка данных;
О подтверждение успешного получения данных;
О регулирование скорости передачи данных;
О измерение временных характеристик;
О координация повторной передачи данных, поврежденных или потерянных
в процессе пересылки.
Мультиплексирование потоков данных
Протокол TCP обеспечивает интерфейс между пользовательскими
приложениями и бесчисленными коммуникационными протоколами, используемыми в сетях.
Пользователи практически никогда не ограничиваются одним приложением,
поэтому протокол TCP должен одновременно принимать данные от нескольких
приложений, делить их на сегменты и передавать эти сегменты протоколу IP.
Аналогичные функции выполняются и в обратном направлении — протокол
TCP должен одновременно принимать данные, предназначенные для
нескольких приложений.
Для определения приложения, которому следует направить тот или иной
входящий пакет, в TCP используются номера портов. Следовательно, было бы
весьма желательно, чтобы оба компьютера, получатель и отправитель,
согласовали бы общий набор портов для своей базы. К сожалению, количество
существующих приложений на базе IP настолько огромно, что обеспечить
сколько-нибудь согласованную схему нумерации портов практически невозможно. По этой
причине в IANA, а позднее — в ICANN было решено регламентировать
использование хотя бы для части доступных портов.
Задача, стоящая перед ICANN, упрощалась тем, что многие приложения были
распространены настолько широко, что могли считаться хорошо известными
(well known). Номера портов, присвоенные таким приложениям, с большой
долей вероятности распознавались любым хостом с поддержкой IP. Примеры
хорошо известных номеров портов:
О порт 80 (протокол HTTP);
О порт 119 (протокол NNTP);
О порт 69 (протокол TFTP).
Мы не будем перечислять все 1024 номера хорошо известных портов (с
номерами от 0 до 1023). Полный список хорошо известных номеров портов для
TCP и UDP приведен в RFC 1700.
Поскольку номер порта определяется 16-разрядным двоичным числом, с
математической точки зрения существует 65 536 возможных номеров портов. Порты
с номерами от 0 до 1023 считаются хорошо известными, а все номера,
превышающие 1023, относятся к категории старших номеров, также называемых
временными или эфемерными. Использование старших номеров портов не
регламентируется правилами ICANN, поэтому любое приложение, не являющееся хорошо
известным, может использовать их для своих коммуникационных потребностей.
Любая программа (как любительская, так и коммерческая) может произвольно
выбрать любой неиспользуемый номер верхнего порта.
В каждом сегменте TCP хранятся номера двух портов — как
приложения-отправителя, так и приложения-получателя. На практике также часто встречается
термин сокет (socket ), хотя в заголовке TCP нет отдельного поля, в котором бы
хранился номер сокета. Сокет представляет собой совокупность IP-адреса хоста
с номером порта конкретного приложения, находящегося на этом хосте. Таким
образом, сокет определяет уникальную пару «хост/приложение». Компоненты
сокета разделяются двоеточием. Например, сокет 10.1.1.9:666 определяет порт 666
(номер порта DOOM) на хосте 10.1.1.9.
ПРИМЕЧАНИЕ
Термин «сокет» также обозначает программную структуру данных, в которой хранится упомянутая
выше пара (IP-адрес и номер порта). Набор системных функций для работы со структурой данных
сокета называется интерфейсом сокетов. Интерфейс сокетов получил широкое распространение
в BSD Unix, поэтому иногда он также называется интерфейсом сокетов BSD. Реализация
интерфейса сокетов для операционной системы Windows называется Windows Sockets, или сокращенно
WinSock. Обычно WinSock реализуется в виде библиотеки динамической компоновки (DLL).
Проверка целостности данных
TCP выполняет математические операции с каждым сегментом данных,
находящимся в сегменте TCP, и помещает результат в поле контрольной суммы
заголовка TCP. После прибытия пакета к заданному месту назначения с
полученными данными выполняется та же математическая операция, а полученный
результат должен совпасть с хранящимся в заголовке TCP. Если числа
совпадают, то можно с достаточно большой вероятностью предположить, что передача
данных произошла без искажений. В противном случае отправителю передается
запрос на повторную передачу этого сегмента данных.
Восстановление порядка данных
На практике сегменты данных достаточно часто приходят к получателю не в том
порядке, в котором они были отправлены. Нарушение порядка может
объясняться разными причинами. Например, при высоком объеме сетевого трафика
протоколы маршрутизации могут выбрать разные маршруты, в результате чего
сегменты придут к получателю в другом порядке. Кроме того, потеря или
повреждение данных в процессе пересылки также приводит к нарушению исходного
порядка. В любом случае модуль TCP на хосте-получателе накапливает
полученные сегменты данных до тех пор, пока не сможет восстановить их в
правильном порядке.
Для решения этой задачи TCP анализирует содержимое поля порядкового
номера в заголовке TCP. Восстановление порядка сводится к математической
сортировке полученных сегментов по значению этого поля.
Управление потоком данных
Отправитель и получатель, участвующие в сеансе TCP, называются
равноправными узлами (peers). Каждый из них обладает возможностью управлять
потоком данных, направляемым в физические буферы ввода. Это делается при
помощи размера окна TCP. Размер окна согласовывается между отправителем и
получателем в заголовке TCP. Получатель, не справляющийся с входным
потоком данных, может снизить скорость передачи данных с отправителя, для этого
достаточно сообщить отправителю новый размер окна. В случае переполнения
буферов адресат получает подтверждение последнего полученного сегмента
данных с новым размером окна, равным 0. Тем самым он фактически блокирует
передачу данных до тех пор, пока перегруженный компьютер не освободит свои
буферы. Для каждого обработанного сегмента получатель должен отправить
подтверждение; при этом он может указать положительный размер окна и
возобновить передачу данных.
Хотя этот простой механизм позволяет эффективно управлять потоком
данных между двумя компьютерами, он всего лишь предотвращает переполнение
конечных систем входящими данными. Сам по себе размер окна не учитывает
загруженности промежуточной сети, а возможные сетевые заторы приводят к тому,
что передаваемые сегменты добираются до места назначения дольше обычного.
Следовательно, при управлении потоком данных также должны учитываться
временные характеристики передачи.
Временные характеристики
Для выполнения ряда важных функций в TCP используются механизмы
измерения временных характеристик. Для каждого передаваемого сегмента
устанавливается таймер. Если до того, как для данного сегмента будет получено
подтверждение, значение таймера уменьшится до 0, сегмент считается
потерянным и передается заново. Таймеры также косвенно используются для борьбы
с сетевыми заторами за счет снижения скорости передачи данных при
возникновении тайм-аутов. Теоретически скорость передачи сегментов снижается
до тех пор, пока тайм-ауты не прекратятся. TCP не может бороться с сетевыми
заторами напрямую, но по крайней мере уменьшает свой вклад в их
возникновение.
Подтверждение приема
Если в заголовке установлен флаг АС К, получатель должен подтвердить
получение конкретного сегмента данных, определяемого порядковым номером.
Протокол TCP почти всегда используется в режиме надежной передачи, поэтому
ситуации, в которых флаг АСК не установлен, встречаются редко.
Сегменты данных, прием которых не подтвержден, считаются потерянными
в процессе передачи и отправляются заново. Процесс повторной отправки
должен быть согласован между отправителем и получателем.
Протокол UDP
Протокол UDP (User Datagram Protocol) является вторым протоколом межхос-
тового уровня (соответствующего транспортному уровню в эталонной модели
OSI). UDP обеспечивает простейшие, требующие минимальных затрат средства
передачи данных в виде так называемых «дейтаграмм» (datagrams). Чтобы
понять, насколько прост механизм UDP, достаточно сравнить RFC 768 (исходная
спецификация с описанием функциональности, структур данных и механизмов
UDP) практически с любым другим RFC. Документ RFC 768 выглядит просто
крошечным — он состоит всего из трех страниц. Во многих других RFC одно
оглавление занимает больше места!
Из-за своей простоты протокол UDP оказывается неподходящим для
некоторых приложений. С другой стороны, он отлично подходит для более сложных
приложений, которые обладают собственными средствами контроля,
ориентированными на соединение. В числе других потенциальных областей
применения UDP — пересылка таблиц маршрутизации, системных сообщений,
данных сетевого мониторинга и т. д. Подобная пересылка не требует управления
потоком, подтверждения, упорядочения и прочих возможностей,
обеспечиваемых TCP.
Как правило, UDP используется в приложениях, ориентированных на
широковещательную рассылку или работу с сообщениями, а также там, где не
требуется полная надежность, обеспечиваемая протоколом TCP. В последнее время
протокол U DP также нашел применение в приложениях реального времени —
таких, как VoIP (Voice over IP), когда присущие TCP повышенная надежность
и повторная пересылка потерянных сегментов оборачиваются лишними
затратами, которые лишь увеличивают общую задержку при передаче пакетов.
Структура заголовка UDP
На рис. 9.4 представлена структура заголовка UDP с указанием размеров
отдельных полей.
Порт1ЮР Порт1ЮР Контрольная Длина
отправителя получателя сумма сообщения
B октета) B октета) B октета) B октета)
Рис 9.4. Структура заголовков UDP демонстрирует предельную простоту
и ограниченные возможности этого протокола
Заголовок UDP содержит следующие поля:
О Порт UDP отправителя — 16-разрядный номер порта, инициировавшего
соединение. Совокупность номера порта и IP-адреса отправителя определяет
«обратный адрес» данного пакета.
О Порт UDP получателя — 16-разрядный номер порта, на который
направляется данный пакет. По номеру порта определяется приложение, которому
будет передан пакет на компьютере-получателе.
О Контрольная сумма — в этом поле хранится 16-разрядное значение,
полученное отправителем в результате математических вычислений с содержимым
сегмента. Затем те же самые вычисления производятся получателем.
Расхождение двух результатов означает, что в процессе пересылки пакета
произошла ошибка.
О Длина сообщения — 16-разрядное поле, в котором получателю передается
размер сообщения. Обеспечивает дополнительную возможность для проверки
правильности сообщения.
ПРИМЕЧАНИЕ
Хотя протоколы TCP и UDP используют 16-разрядные номера портов, они находятся в разных
адресных пространствах. Иначе говоря, порт TCP с номером 2000 не имеет ничего общего с портом
UDP 2000.
Задачи протокола UDP
Протокол UDP намеренно проектировался как эффективный транспортный
протокол с минимальными издержками, что напрямую отражено в структуре
его заголовка. Информации, хранящейся в заголовке, -хватает только для того,
чтобы переслать дейтаграмму нужному приложению (то есть номеру порта) и
выполнить простейшую проверку ошибок.
UDP не обладает ни одной из нетривиальных возможностей,
обеспечиваемых протоколом TCP. В нем не предусмотрены таймеры, средства
управления потоком или регулировки скорости передачи, подтверждения, механизмы
ускоренной доставки срочных данных и т. д. Протокол UDP просто пытается
доставить дейтаграмму. Если попытка по какой-либо причине завершается
неудачей, дейтаграмма теряется без каких-либо попыток повторной передачи
данных.
Сравнение TCP с UDP
TCP и UDP — разные протоколы транспортного уровня, спроектированные для
решения разных задач. Между ними существует только одно заметное сходство:
в качестве протокола сетевого уровня они используют IP. С другой стороны,
главное функциональное различие между TCP и UDP — это надежность
доставки. Протокол TCP гарантирует надежную доставку, а протокол UDP всего
лишь обеспечивает простейший механизм доставки дейтаграмм. Вследствие
этого протокол TCP гораздо более сложен, а его функционирование связано со
значительными затратами, тогда как протокол UDP отличается простотой и
эффективностью.
Протокол UDP часто критикуют за ненадежность, так как в нем не
поддерживается ни одно из средств надежной доставки TCP — подтверждение приема
дейтаграмм, изменение нарушенного порядка дейтаграмм и даже запрос на
повторную передачу поврежденных пакетов. Иначе говоря, ничто не гарантирует,
что дейтаграмма UDP достигнет своего места назначения в исходном виде! По
этой причине протокол UDP лучше подходит для передачи небольших объемов
данных (на уровне отдельных пакетов), a TCP обычно применяется для
управления потоком данных, состоящим из множества пакетов.
Впрочем, говоря о ненадежности UDP, необходимо упомянуть и о
достоинствах этого протокола. UDP — простейший протокол транспортного уровня,
требующий минимальных затрат и способный работать значительно быстрее
TCP. По этой причине он хорошо подходит для приложений, критичных по
времени, — таких, как передача голосовых данных VoIP (Voice over IP) и
видеоконференции в реальном времени.
Протокол UDP также хорошо подходит для выполнения служебных
операций в сети (например, пересылки обновлений маршрутных таблиц между
маршрутизаторами или данных сетевого мониторинга). Такие операции важны для
обеспечения общей работоспособности сети, но вынужденное использование
механизмов надежной доставки TCP при их выполнении может привести к
нежелательным последствиям. Таким образом, ненадежность протокола UDP еще
не означает его бесполезности. Просто этот протокол разрабатывался для другого
класса приложений, нежели протокол TCP.
Итоги
Семейство протоколов TCP/IP (включая UDP и ICMP) удовлетворяло быстро
растущие потребности пользователей и приложений более 20 лет. За это время
протоколы постоянно обновлялись, что объяснялось новыми технологическими
разработками и превращением Интернета из исследовательской среды с
ограниченным кругом пользователей в общедоступную коммерческую инфраструктуру.
Коммерциализация Интернета вызвала бурный рост сообщества пользователей
и изменила его демографическую структуру. В свою очередь, это обусловило
необходимость в новых адресах и поддержки новых типов сервиса на уровне
Интернета. Ограниченные возможности IPv4 привели к разработке совершенно новой
версии протокола. Новой версии IP был присвоен номер 6 (IPv6), но также часто
используется термин IPng (Internet Protocol: Next Generation). Протокол IPv6
подробно рассматривается в главе 12.
1 f\ пр°токол 1Р
Карапжит С. Сиян (Karanjit S. Siyan)
Межсетевой протокол IP (Internet Protocol) реализует первый уровень
абстракции, на котором все сетевые узлы рассматриваются как узлы IP. Таким образом,
IP обеспечивает логическую модель абстрактной сети, обладающей свойствами,
описанными в этой главе.
Протоколы, работающие на более высоком уровне — такие, как TCP и UDP, —
могут считать, что в сети используется только протокол IP. На практике сеть
не обязательно ограничивается IP, она также может поддерживать другие
протоколы. Устройства, подключенные к сетям IP, определяются 32-разрядными
значениями, которые называются IP-адресами. IP предоставляет
высокоуровневым протоколам сервис связи, не ориентированный на соединение. Этот
сервис реализуется с применением дейтаграмм, содержащих IP-адреса
отправителя и получателя, а также другие параметры, необходимые для работы IP.
Данная глава дает серьезное концептуальное представление о работе IP в
реальных сетях.
Абстрактная модель IP
Пересылка данных протоколом IP выполняется средствами сетевого
оборудования нижнего уровня. Это означает, что дейтаграммы IP инкапсулируются в
кадрах базовой сети — например, Ethernet, Token Ring или Х.25.
Протоколы верхнего уровня, к числу которых относятся TCP и UDP, не
обязаны знать обо всех тонкостях инкапсуляции сетевых данных и работы базового
оборудования. Протоколы верхнего уровня могут рассчитывать лишь на
определенные характеристики сетевого сервиса (такие, как пропускная способность
и задержка), называемые параметрами качества предоставляемых услуг (QoS,
Quality of Service). Верхние уровни передают параметры QoS уровню IP
вместе с данными. Уровень IP может попытаться реализовать параметры QoS на
уровне сервиса, предоставляемого базовым сетевым оборудованием, хотя нельзя
гарантировать, что базовое оборудование поддерживает такую возможность.
К процессам верхнего уровня
А Хост I I
Г Логическая сеть IP ^ Ц^^^ш Ш LJ
Уровень IF* I J I
1 ' I/ I Ж X
ШГ\\
Физические различия ^^^ U
^^ между сетями Д-i mm
i j Li rX
^---J ^ p]
N
V( IpsnWpsnI ^\ Сеть
f (pad)\~-Jf—N <; пакетов Х.25
—^^ ' Узел коммутации
• Уровень IP пакетов
-обеспечивает сильную логическую абстракцию;
-маскирует различия, существующие на физическом уровне
• Процессы верхнего уровня работают с логической сетью IP
PAD = сборщик/разборщик пакетов
Рис 10.1. Абстрактная модель IP (с разрешения Learning Tree)
На рис. 10.1 изображен хост IP, имеющий три сетевых подключения: для
Ethernet, Token Ring и Х.25. В этом примере IP работает на каждом из трех
сетевых подключений, каждое из которых определяется уникальным
32-разрядным числом, называемым IP-адресом. Уровень IP предоставляет верхним
уровням абстрактную модель каждой из трех сетей. Абстракция не зависит от
физических атрибутов сети — таких, как размер адреса, максимальная единица
передачи (MTU, Maximum Transfer Unit), пропускная способность сети,
максимальная скорость передачи данных и т. д. Параметр MTU определяет
максимальный размер поля данных в базовой физической сети. Поскольку в поле
данных хранятся дейтаграммы IP в сетях TCP/IP, значение MTU также
определяет максимальный размер дейтаграмм IP, пересылаемых в физической сети.
В сети, изображенной на рис. 10.1, значение MTU для сети Ethernet равно
1500 байт. Для сети IEEE 802.4, Token Ring 4 Мбит/с оно равно 4440, а для сети
IEEE 802.5 16 Мбит/с — 17940. Для сети Х.25 значение MTU проходит
дополнительное согласование и может изменяться в пределах от 64 байт до 4 Кбайт.
Сети IP обязаны обеспечивать обработку дейтаграмм минимального размера
576 байт. Так как минимальный размер дейтаграммы IP, обрабатываемой всеми
маршрутизаторами, составляет 576 байт, при пересылке данных TCP/IP по сети
Х.25 значения MTU, меньшие 576, не используются.
Несмотря на разные значения MTU и разные скорости передачи данных,
уровень IP игнорирует все физические различия и объединяет эти сети в
единую логическую сеть IP.
Абстрактная сеть IP не ориентируется на соединение, каждая дейтаграмма
маршрутизируется независимо от других. Следовательно, возможна ситуация,
когда последовательные дейтаграммы пересылаются по разным маршрутам
(рис. 10.2).
Узел IP Узел IP
I *Г
I ' I
4 ♦ » *—•-
f———^—————-—I А I'
/ | Дейтаграмма 2 г ~ _ 1
Л^%/Дейта- у^^У У^^,'
/'''\Г\ грамма 2!/| / У
/.of"" • ''
*! 1 ♦-
Узел IP Узел IP
Рис. 10.2. Независимая маршрутизация дейтаграмм IP
Из-за разных задержек во времени прохождения маршрутов нельзя
исключать, что дейтаграммы поступят к получателю не в том порядке, в котором они
были отправлены. Уровень IP не пытается решить эту проблему и каким-то
образом обеспечить правильный порядок доставки дейтаграмм. Более того, он
даже не пытается гарантировать их надежную доставку получателю. Проблемы
восстановления порядка и надежной доставки решаются протоколами более
высокого уровня — такими, как TCP.
Отсутствие гарантий порядка и надежной доставки упрощает отображение IP
на разные виды сетевого оборудования. Протоколы верхнего уровня
самостоятельно реализуют дополнительные уровни надежности в соответствии с
потребностями приложений.
Важно понимать, что без поддержки со стороны протоколов верхнего уровня
сети IP в принципе ненадежны. Сеть IP добросовестно пытается доставить
дейтаграмму IP, но не может гарантировать, что доставка состоится. По этой
причине IP почти всегда используется в сочетании с протоколами верхнего уровня,
обеспечивающими дополнительную функциональность.
Сервис IP не ориентирован на соединение, и каждая дейтаграмма
маршрутизируется независимо от других. В каждую дейтаграмму включаются IP-адреса
отправителя и получателя. Адрес получателя используется промежуточными
маршрутизаторами для доставки дейтаграммы IP к нужному месту назначения.
Абстрактная модель IP позволяет пересылать дейтаграммы независимо от
значения MTU базовой сети. Слишком большие дейтаграммы при
необходимости фрагментируются узлами IP. Ниже механизм фрагментации рассматривается
гораздо более подробно.
Размер дейтаграммы IP
Протокол IP проектировался в расчете на поддержку разных типов сетевого
оборудования. Как упоминалось выше, в разных сетях устанавливаются разные
ограничения для максимального размера данных, передаваемых в кадре канального уровня.
В табл. 10.1 приводятся значения MTU для разных типов сетевого оборудования.
Таблица 10.1. Значения MTU для разных типов сетей
Тип сети MTU (в октетах)
Ethernet 1500
IEEE 802.3 1492
Token Ring от 4440 до 17940 (в зависимости от времени удержания маркера)
FDDI 4352
IEEE 802.4 8166
SMDS 9180
Х.25 1007 (ARPANET через DDN X.25), 576 (для открытых сетей, но может
увеличиваться в результате согласования)
Значение MTU в сетях Token Ring зависит от времени удержания маркера
(ТНТ, Token Holding Time), которое составляет примерно 8,58 миллисекунды.
Для скорости передачи 4 Мбит/с максимальный размер кадра Token Ring
вычисляется по следующей формуле:
Максимальный размер кадра в сети Token Ring D Мбит/с) - 8,58 мс х
х 4 Мбит/с = 8,58 х 4 х 1024 х 1024 = 36 000 бит - 36 000/(8 бит/октет) =
= 4500 октетов.
В этих вычислениях 1 Мбит/с = 1024 х 1024 бит/с.
Максимальный размер кадра в сети Token Ring вычисляется следующим
образом:
Заголовок MAC = 15 октетов
Поле маршрутных данных = 30 октетов
Заголовок LLC = 4 октета
Заголовок SNAP = 5 октетов
Завершение MAC = 6 октетов
Общий размер заголовка = 60 октетов
Значение MTU для Token Ring D Мбит/с) = максимальный размер кадра - размер заголовка
кадра Token Ring = 4500 - 60 = 4440 октетов
Максимальный размер кадра Token Ring для скорости 16 Мбит/с
вычисляется следующим образом:
Максимальный размер кадра в сети Token Ring A6 Мбит/с) = 8,58 мс х
х 16 Мбит/с « 8,58 х 16 х 1024 х 1024 = 144 000 бит = 36 000/(8 бит/октет) -
18 000 октетов.
Значение MTU для Token Ring A6 Мбит/с) = максимальный размер кадра - размер заголовка
кадра Token Ring = 18000 - 60 = 17940 октетов
Значение MTU для сети FDDI на рис. 10.1 вычисляется следующим образом:
Максимальный размер кадра FDDI с применением кодировки 4В/5В = 4500
октетов.
Наибольший заголовок кадра FDDI:
Заголовок MAC =16 октетов
Заголовок LLC = 4 октета
Заголовок SNAP = 5 октетов
Завершение MAC = 7 октетов (приближенно)
Общий размер заголовка = 32 октета
Для будущих расширений рекомендовано зарезервировать для заголовка
кадра FDDI 148 октетов.
Значение MTU для FDDI A00 Мбит/с) = максимальный размер кадра - размер заголовка
кадра Token Ring = 4500 - 148 = 4352 октета
Максимальная длина дейтаграммы IP составляет 65 536 байт, что значительно
превышает значения MTU, поддерживаемые большинством сетей. Уровень IP
отправителя обычно ограничивает размер дейтаграмм, чтобы он не превышал
значения MTU локального сегмента сети. Если дейтаграмма IP пересылается между
сетями, то, чтобы дейтаграмма IP была доставлена в виде единого целого, ее
размер не должен превышать значения MTU всех промежуточных сетей. В сетях
IP не существует эффективных средств, которые бы позволяли заранее
определить значения MTU промежуточных сетей. Если бы такие средства существовали,
отправитель мог бы отправить дейтаграмму IP с размером, не превышающим
значения MTU промежуточных сетей. Вместо этого в сетях IP используется
механизм фрагментации, позволяющий передавать дейтаграммы произвольного
размера в любых сетях.
Фрагментация в IP
Если размер дейтаграммы IP оказывается больше значения MTU для сети, в
которой дейтаграмма должна передаваться, передача дейтаграммы в исходном
виде невозможна. Дейтаграмма разбивается на фрагменты, размер которых не
превышает значения MTU для сети. Этот процесс называется фрагментацией.
Каждый фрагмент исходной дейтаграммы пересылается в виде отдельной
дейтаграммы IP. Информации, хранящейся в заголовках IP, достаточно для
идентификации фрагментов. Эта информация используется хостом-получателем при
сборке исходной дейтаграммы из фрагментов.
На рис. 10.3 схематично изображен процесс передачи дейтаграммы IP в сети.
В приведенном примере для сети В установлено значение MTU, меньшее размера
дейтаграммы. Маршрутизатор обнаруживает это обстоятельство и фрагментирует
дейтаграмму IP на несколько дейтаграмм меньшего размера, не превышающего
MTU сети В.
Хост А Маршрутизатор
Фрагментация Фрагментация обязательна:
не нужна: размер размер дейтаграммы > MTU
дейтаграммы = MTU
Рис. 10.3. Фрагментация дейтаграмм IP (с разрешения Learning Tree)
Предположим, что затем дейтаграммы независимо друг от друга прибывают
на хост С. Хотя значение MTU сети С позволяет переслать исходную дейтаграмму,
маршрутизатор на границе между сетями В и С не будет пытаться собрать
дейтаграмму из фрагментов. Сборка выполняется только модулем IP на
хосте-получателе, но не на промежуточных маршрутизаторах.
Что произойдет, когда хосту С потребуется ответить хосту А? Хост С
отрегулирует размер дейтаграммы так, чтобы он не превышал MTU для сети С. От
хоста С к хосту А дейтаграммы передаются без фрагментации. Тем не менее
промежуточные маршрутизаторы не пытаются объединять фрагменты в
дейтаграммы большего размера для повышения эффективности передачи.
Структура дейтаграмм IP
Дейтаграмма IP состоит из заголовка IP и данных IP, полученных от
протоколов верхнего уровня (рис. 10.4). Структура заголовка IP спроектирована таким
образом, чтобы хранящиеся в нем данные обеспечивали выполнение основных
функций уровня IP.
Из описания уровня IP в предыдущем разделе следует, что заголовок IP
должен содержать как минимум следующие данные:
О IP-адреса отправителя и получателя. Протокол IP не ориентирован на
соединение, поэтому с каждой дейтаграммой должна передаваться полная
адресная информация об отправителе и получателе.
О Уровень сервиса, который должен поддерживаться базовой сетью.
О Данные фрагментации. Поскольку дейтаграммы IP могут фрагментироваться
на границах сетей, в заголовке должны присутствовать поля, по которым
можно было бы определить позицию фрагмента в исходной дейтаграмме.
О Размер дейтаграммы. Дейтаграммы IP имеют переменный размер, поэтому
в заголовке должно присутствовать поле, содержащее информацию о общей
длине дейтаграммы IP.
Данные верхнего уровня Уровни 4, 5, 6, 7 модели OSI
"^ I
Заголовок IP Данные IP Уровень 3 модели OSI
. 1^ I .
Заголовок Данные канального уровня Проверочные УР°вень2
канального уровня н ашвпи.и^пл сегменты модели OSI
Рис. 10.4. Формат дейтаграммы IP
О Размер заголовка IP. Дейтаграммы могут содержать необязательные поля
с информацией о безопасности, маршрутизации от источника и т. д. В
результате заголовки IP имеют переменную длину, поэтому в заголовок IP
необходимо включить его реальную длину.
Ниже структура заголовка IP рассматривается более подробно.
Структура заголовка IP
Минимальная длина заголовка IP равна 20 октетам. Если в дейтаграмму
включены параметры, заголовок может оказаться длиннее. На рис. 10.5 изображена
общая структура заголовка IP.
ПРИМЕЧАНИЕ
Структура заголовка IP подробно рассматривается в RFC 791 и RFC 1122. Подробное описание
поля TOS (Type of Service) заголовка IP приведено в RFC 1349.
< 32 бита ►
г—т—г—i—|—I—г—т—I—I—г—т—I—I—I—I—|—I—I—I—i—I—I—I—I—г—т—j—1—I—I—I—|
Длина
Версия заголовка Тип сервиса (ToS) Общая длина
(IHL)
—I—I—I—I—I—I—I—I—I—I—I—l—I—I—I——I—I—I—I—l—I—I—I—I—I—I—I—l—I—I—
Идентификатор ° F F Смещение фрагмента
[-Н—I—I—I—I—I—I—|—I—I—I—нн—I—I——I—I—I—i—I—I—I—I—I—I—i—i—i—I—I—
Срок жизни Протокол Контрольная сумма заголовка
—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—i—I—i—I—I—I—I—i—i—I—I—
Адрес отправителя
—i—I—i—i—i—I—i—i—t—I—i—i—i—i—I—i—i—i—i—i—i—i—1—I—I—i—i—i—i—i—i—
Адрес получателя
—I—l—l—I—I—l—l—I—I—I—I—I—I—I—I—I—I—I—I—i—i—I—i—I—|—I—i—i—I—I—I—
«<^ Параметры Дополнение <<L
V—\—i—i—i—i—i—I—i—i—i—i—I—i—I—i—i—i—i—i—i—i—i—i—i—I—i—i—i—i—i—i—|
ДАННЫЕ
I i i i i ■ » ■ i—i i i i i i i i i ii i ■ ■ » ■ i i « ■ ■ ■ i___J
Рис. 10.5. Заголовок IP
Версия
На рис. 10.5 поле Версия имеет длину 4 бита и определяет формат заголовка IP. Это
позволяет определять новые версии структуры пакетов IP в будущем. Текущей
версии IP присвоен номер 4, и она называется IPv4. Следующая версия IP,
которой будет присвоен номер 6, будет поддерживать 128-разрядную адресацию.
Эта версия обозначается IPv6. Дополнительная информация об IPv6 приведена
в главе 12. В табл. 10.2 перечислены другие допустимые значения поля версии.
ПРИМЕЧАНИЕ
Номера версий 7, 8 и 9 были присвоены экспериментальным версиям протоколов IP, которые
должны были преодолеть ограничения 32-разрядной адресации. В настоящее время эти протоколы
были заменены IPv6.
Таблица 10.2. Номера версий IP
Версия IP Описание
О Зарезервировано
1-3 Значения не присвоены
4 IPv4
5 Stream IP Datagram Mode (экспериментальная версия IP)
6 IPv 6 (также называется IPng)
7 TP/IX: The Next Internet
8 «P» Internet Protocol
9 TUBA
10-14 Значения не присвоены
15 Зарезервировано
Поле версии используется отправителем, получателем и всеми
промежуточными маршрутизаторами для определения формата заголовка IP. Программное
обеспечение IP должно проверить поле версии и убедиться в том, что
заголовок IP имеет поддерживаемый формат. Например, если программное обеспечение
IP обрабатывает только дейтаграммы версии 4, оно отвергнет все дейтаграммы,
у которых значение версии отлично от 4.
Ниже приведены краткие комментарии по поводу содержимого табл. 10.2.
О Экспериментальный протокол Stream IP обеспечивает сквозную
гарантированную доставку данных в объединенных сетях. Он описан в RFC 1819.
О Протоколы TP/IX, «P» Internet Protocol и TUBA в течение некоторого
времени соревновались друг с другом за право заменить IPv4. Сейчас они уже
не являются серьезными конкурентами и представляют чисто исторический
интерес, поскольку в качестве замены IPv4 был принят протокол IPv6.
О Новый протокол «Р» обладал расширенными возможностями и
поддерживал адреса переменной длины. Позднее он был объединен с протоколом SIP
(Simple Internet Protocol), использующим 64-разрядную адресацию.
Протокол SIP был объединен с механизмом IPAE (IP Address Encapsulation),
определяющим преобразование между адресами IPv4 и длинными адресами.
Информация о SIP приведена в RFC 1710.
О Протокол TP/IX (см. табл. 10.2) был заложен в основу архитектуры CATNIP
(Common Architecture for the Internet), интегрирующей IPv4 с протоколами
IPX (Internet Packet Exchange) и OSI CLNP (Connectionless Network Protocol).
Протокол CATNIP представляет в основном исторический интерес.
Информация о нем приводится в документе RFC 1707.
О Сокращение TUBA означает «TCP и UDP с расширенными адресами» («TCP
and UDP with Bigger Addresses»). Протокол TUBA основан на CLNP, а его
описания приводятся в RFC 1347, RFC 1526 и RFC 1561.
Длина заголовка
Поле длины заголовка (IHL, Internet Header Length) содержит длину заголовка
в 32-разрядных блоках. Длина поля равна 4 битам, а его присутствие
необходимо из-за того, что в заголовок IP входит поле параметров переменной длины.
Остальные поля имеют фиксированную длину. При необходимости поле
параметров дополняется до 32-разрядной границы. На практике большинство
заголовков IP не содержит параметров. Длина заголовка IP за вычетом поля
параметров составляет 20 октетов, поэтому поле IHL чаще всего равно 5 (пять
32-разрядных блоков). Максимальная длина заголовка, равная 60 октетам,
задается при помощи параметров IP. В этом случае значение поля IHL будет равно
15 (пятнадцать 32-разрядных блоков).
Тип сервиса
Тип сервиса (ToS, Type of Service) содержит информацию о желательных
параметрах QoS — приоритете, задержке, пропускной способности и
надежности. Интерпретация отдельных битов этого 8-разрядного поля показана на
рис. 10.6.
Биты 0-2 1 1 111
Приоритет Задержка Пропускная Надежность Стоимость MBZ
|—0 = Нормальная
Li = Низкая
Т ,
I I I рО = Нормальная г~ = Нормальная
8? £££L« |Ll= Высокая Ti- Низкая
010 Высокий
011 Срочный
100 Срочный с отменой рО = Нормальная
101 Критический И
110 Межсетевой контроль 1—1= Высокая
111 Сетевой контроль
Рис. 10.6. Интерпретация поля ToS для пакетов IP
Первые три бита определяют параметры приоритета, связанные с
дейтаграммой IP. В приоритете отражено происхождение сетей IP, исследования в области
которых были инициированы Министерством обороны. Ниже расшифрован смысл
некоторых типов приоритета:
О Срочный — немедленная доставка, максимальный приоритет во всех сетях.
О Высокий — доставка в течение четырех часов.
О Повышенный — доставка в тот же день.
О Обычный — доставка в течение суток.
Коды приоритета имеют длину 3 бита. В табл. 10.3 перечислены допустимые
значения и их интерпретация.
Таблица 10.3. Коды приоритета
Код Интерпретация
000 Обычный
001 Повышенный
010 Высокий
011 Срочный
100 Срочный с отменой
101 Критический
110 Межсетевой контроль
111 Сетевой контроль
Поле приоритета предназначалось для применения межсетевых протоколов
в военных областях. Ненулевые значения этого поля выходят за рамки
стандартной спецификации IP. Уровень IP должен предоставить средства, при
помощи которых транспортный уровень мог бы задать содержимое поле ToS
каждой отправляемой дейтаграммы; по умолчанию все биты заполняются нулями.
Уровень IP должен передать полученные значения ToS транспортному уровню.
ПРИМЕЧАНИЕ
Информацию по использованию поля приоритета и его связи с уровнями других протоколов можно
получить в Агентстве по оборонным информационным системам DISA (Defence Information System
Agency). Следует учитывать, что при использовании приоритета его значение должно передаваться
между протокольными уровнями по аналогии с передачей поля ToS.
Четыре бита, следующих за полем приоритета, содержат коды типа сервиса.
Интерпретация кодов приведена в табл. 10.4.
Последний бит поля ToS должен быть равен нулю. Это 1-битное поле MBZ
(Must Be Zero) зарезервировано для использования в будущем. Поле ToS может
быть задействовано в протоколах IP, участвующих в экспериментальных
разработках Интернета. Маршрутизаторы и получатели дейтаграмм игнорируют
значение этого поля. Поле копируется при фрагментации, в результате чего все
фрагменты IP имеют одинаковые параметры типа сервиса.
Таблица 10.4. Коды типа сервиса
Код ToS Интерпретация
1000 Минимальная задержка
0100 Максимальная пропускная способность
0010 Максимальная надежность
0001 Минимальные затраты
0000 Нормальный сервис
Поле ToS игнорируется большинством реализаций IP и протоколов
маршрутизации — RIP, HELLO и т. д. Хотя в прошлом поле ToS почти не
использовалось, предполагается, что в таких протоколах маршрутизации, как OSPF, его
роль возрастет. Ожидается, что поле ToS будет использоваться для управления
двумя аспектами работы маршрутизатора: собственно маршрутизацией и
алгоритмами работы с очередями. Кроме того, поле ToS может отображаться на
совместное использование последовательных линий на канальном уровне со
стороны различных классов трафика TCP.
Алгоритмы маршрутизации могут руководствоваться содержимым поля ToS
для выбора наиболее подходящего маршрута. Если маршрутизатор знает, что
к месту назначения ведут несколько разных маршрутов, он может подобрать
маршрут, который наиболее близко соответствует содержимому поля ToS.
Допустим, маршрутизатору известны два маршрута: первый проходит через
спутниковый канал и обладает высокой задержкой и высокой пропускной способностью,
а второй (выделенная линия) характеризуется низкой задержкой и низкой
пропускной способностью. Если в трафике приложения передается информация
об интерактивных нажатиях клавиш, то основным требованием будет низкая
задержка, а пропускная способность не критична. Соответственно, для таких
целей маршрутизатор выбирает подключение под выделенной линии. Если
приложение требует пересылки большого объема данных, на первый план выходит
пропускная способность, пусть даже сопряженная с высокой задержкой. В этом
случае оптимальный маршрут проходит через спутниковый канал с высокой
пропускной способностью.
ПРИМЕЧАНИЕ
Использование поля ToS подробно описано в RFC 1349.
Общая длина
В поле общей длины хранится суммарная длина заголовка IP и данных (в
байтах). Поле состоит из 16 битов, поэтому максимальный размер дейтаграммы
составляет 65 535 октетов. Максимальное значение, которое может быть
представлено 16 битами, состоит из 16 единиц:
11111111U111111
Это число равно 216 - 1, или 65 535 в десятичном представлении.
Для большинства хостов и сетей дейтаграммы длиной 65 535 октетов не
используются на практике. Во многих сетях устанавливаются значения MTU,
гораздо меньшие 65 535 октетов. Также неэффективно было бы проектировать
коммуникационные буферы, в которых дейтаграммы IP могут достигать 65 535
октетов. Типичный размер дейтаграммы для большинства сетей и хостов редко
превышает 16 Кбайт.
Любой IP-узел должен быть готов принимать дейтаграммы длиной не менее
576 байт, поступающие как в виде единого целого, так и разбитые на фрагменты.
Минимальный размер 576 байт складывается из 512 байт данных и 64 байт
служебной информации протокола.
Дейтаграммы, размер которых превышает MTU базовой сети, проходят
обязательную фрагментацию, поскольку в противном случае их не удалось бы
переслать по базовой сети.
Идентификатор
Поле идентификатора содержит значение, уникальное для каждой дейтаграммы,
и фактически определяет ее номер. Каждая передающая сторона начинает
нумерацию дейтаграмм с некоторой начальной величины (рис. 10.7). В большинстве
реализаций IP используется глобальный счетчик, автоматически
увеличивающийся с каждой отправленной дейтаграммой IP.
Длина поля идентификатора равна 16 битам, что позволяет нумеровать
дейтаграммы в интервале от 0 до 65 535.
Поле идентификатора используется в первую очередь для идентификации
фрагментов, на которые была разбита определенная исходная дейтаграмма.
Идентификатор используется при сборке исходной дейтаграммы вместе с флагами
запрета фрагментации (DF) и наличия дополнительных фрагментов (MF), а
также полем смещения фрагмента. Эти поля описаны в следующем разделе.
Флаги фрагментации и поле смещения фрагмента
Установленный флаг DF (DF=1) запрещает фрагментацию дейтаграммы. В
частности, данная возможность может использоваться в тех случаях, когда получатель
заведомо не обладает средствами для сборки исходной дейтаграммы из
фрагментов. Примером служит программа начальной загрузки в памяти компьютера,
принимающего данные с сервера. Если все данные должны находиться в одной
дейтаграмме, отправитель устанавливает флаг DF. Также флаг DF может
устанавливаться для ликвидации задержки, возникающей при сборке фрагментов на
компьютере-получателе. Если флаг DF равен 0, это означает, что дейтаграмма IP
может маршрутизироваться промежуточными маршрутизаторами или хостами.
Установленный флаг MF (MF=1) сообщает получателю о том, что к нему
должны поступить дополнительные фрагменты. Флаг MF, равный 0, является
признаком последнего фрагмента. У полных (не фрагментированных)
дейтаграмм флаг MF всегда равен 0, что указывает на отсутствие других фрагментов
у текущей дейтаграммы.
В идеальном случае значения MTU всех сетей, по которым пересылаются
дейтаграммы IP, превышают размер наибольшей из передаваемых дейтаграмм.
В этом случае фрагментация не нужна. Но даже если минимальное значение
MTU на маршруте известно заранее, необходимо понимать, что некоторые
дейтаграммы могут быть направлены по другому маршруту и попасть в сеть, в ко-
торой действует другое, меньшее значение MTU (как говорилось выше, каждая
дейтаграмма IP маршрутизируется независимо от других дейтаграмм).
Начальный номер I —^—**«^/^^^ Начальный номер
дейтаграммы = 110 ^"^==::::=::^:::::^^ дейтаграммы = 3007
^^
Рис. 10.7. Изменение поля идентификатора
Как же происходит фрагментация дейтаграмм IP? На рис. 10.8 изображена
ситуация, в которой хост сети А отправляет дейтаграммы IP хосту, находящемуся
в сети С. Передаваемые дейтаграммы проходят через промежуточную сеть В.
Значения MTU для сетей А, В и С составляют 1500, 525 и 4470 октетов
соответственно. Сети А и В связываются маршрутизатором Ra, а сети В и С —
маршрутизатором Re. Как правило, хост А передает дейтаграммы IP, размер которых не
превышает MTU сети А. Предположим, хост А отправляет дейтаграмму с
идентификатором 5 и размером 1500 октетов. Получив эту дейтаграмму,
маршрутизатор Ra фрагментирует ее перед отправкой в сеть В, поскольку MTU в сети В
меньше размера дейтаграммы. Размеры фрагментов выбираются в соответствии
со значением MTU сети В E25 байт). В поле смещения каждого из полученных
фрагментов заносится начало данных этой дейтаграммы по отношению к
исходным, нефрагментированным данным.
| Дейтаграмма IP [-►
( Сеть ^ /^^\ { ^еть Ч /^^\ к ^еть \
С MTU = 1500 лЛ [J yC MTU = 525 Л~~( [J jC MTU = 4470 Л
С октетов у ^^^/ v октетов у ^^^^ v__ октетов <
Фрагменты
дейтафаммы iP
j | Дейтаграмма IP |
г Уровень IP J
/ l""^ [ДейтаФамма IP №~з}>»
/ [Дбйтаграмма IP №~2J-»-
[Дейтаграмма IP № 1|-fr»
Рис. 10.8. Пример фрагментации
Поле смещения фрагмента определяет позицию данных, передаваемых в
текущем фрагменте, по отношению к началу исходной дейтаграммы (ниже
описаны некоторые специфические особенности значения этого поля). Длина поля
смещения фрагмента равна 13 битам. Если присмотреться к структуре
заголовка IP на рис. 10.5, становится видно, что остальные биты этого слова заняты
флагами DF и MF.
Длина дейтаграмм IP может доходить до 65 535 октетов, однако поле
смещения не позволяет представлять значения, большие 8 192. По этой причине поле
смещения дополняется тремя нулевыми битами:
смещение_фрагмента000
Полученное значение кратно 8 байтам. Следовательно, значение поля смещения
всегда задается в количестве 8-байтовых групп, а для получения
непосредственного смещения значение поля необходимо умножить на 8. Также это означает,
что длина всех фрагментов, кроме последнего, должна быть кратна 8 байтам
(и при этом фрагмент должен быть меньше значения MTU, установленного для
сети). В описанном выше примере с дейтаграммой IP, состоящей из 1500
октетов, теоретически может быть выбран следующий вариант фрагментации:
Фрагмент 1 = 525 октетов
Фрагмент 2 = 525 октетов
Фрагмент 3 = 450 октетов
Размер дейтаграммы IP = 1500 октетов
Тем не менее размер 525 байт не кратен 8. Также необходимо учитывать, что
в дейтаграмму должен входить заголовок IP, состоящий минимум из 20 октетов.
При MTU = 525 после вычитания типичного размера заголовка IP на долю
фрагмента остается 505 октетов. Впрочем, это число тоже не кратно 9.
Ближайший размер, меньший 505 и нацело делящийся на 8, равен 504. Таким образом,
размер фрагмента IP можно выбрать равным 504 октетам. На рис. 10.9
изображена исходная дейтаграмма IP, разделенная на следующие фрагменты:
Фрагмент 1 = 504 октета
Фрагмент 2 = 504 октета
Фрагмент 3 = 492 октета
Размер дейтаграммы IP = 1500 октетов
<— 504 октета—W4—504 октета—НЧ—492 октета—>\
Заголовок
I IP I
; Смещение ; Смещение ; Смещение ;
! фрагмента = J фрагмента = ; фрагмента = ;
! 4 октета ! 504 октета ! 1008 октетов !
Заголовок фрагмент 1 ! j
Заголовок фрагмент 2 j
I Заголовок! Фрагмент 3
Рис. 10.9. Фрагментация исходной дейтаграммы IP
Каждый фрагмент снабжается отдельным заголовком IP. Поле
идентификатора в дейтаграммах-фрагментах содержит то значение, которое хранилось в
исходной (фрагментированной) дейтаграмме IP. Содержимое этого поля
идентифицирует фрагменты как принадлежащие конкретной дейтаграмме IP. Ниже
перечислены флаги и смещения фрагментов во фрагментированных
дейтаграммах IP (рис. 10.10).
Фрагмент 1
Общая длина = 504 октета
Идентификатор = 5
Флаг DF =0
Флаг MF =1
Смещение фрагмента = 0
Фрагмент 2
Общая длина = 504 октета
Идентификатор = 5
Флаг DF =0
Флаг MF =1
Смещение фрагмента = 63 блока по 8 октетов E04 октета)
Фрагмент 3
Общая длина = 492 октета
Идентификатор = 5
Флаг DF =0
Флаг MF =0
Смещение фрагмента = 126 блоков по 8 октетов A008 октетов)
Для восстановления фрагментированной дейтаграммы IP получатель должен
собрать фрагменты со всеми смещениями, от нулевого и до максимального.
Получатель использует размер каждого фрагмента (поле общей длины в заголовке
дейтаграммы IP), смещение фрагмента и флаг MF, чтобы определить, были ли
получены все фрагменты. Как получатель узнает о получении последнего
фрагмента? У последнего фрагмента флаг MF равен 0. У первого фрагмента флаг
MF равен 1, а смещение равно 0. У всех остальных промежуточных фрагментов
флаг MF равен I, а смещение положительно.
Отдельные части фрагментированной дейтаграммы IP следуют к месту
назначения, причем возможно — по разным маршрутам. Фрагменты собираются
на компьютере-получателе, но не на промежуточных маршрутизаторах. Из этого
факта можно сделать следующие выводы:
О Фрагменты IP перемещаются от точки фрагментации к получателю.
О Несмотря на то что в других промежуточных сетях может быть установлено
значение MTU, превышающее размер фрагмента, фрагменты все равно пере-
даются в виде пакетов малого размера, что приводит к плохой эффективности
протокола.
О Лишняя фрагментация порождает лишний сетевой трафик.
20 w|^ 504 w|^ 504 ^ 492 .
К" октетов ~*Т* октета И^ октета И^ октета Н
Заголовок 1.1
I I !-*_ I t I ^. «' I
Идентификатор = 5 ^- / „--'"'
DF = 0 *^<t~''*'*
MF = 0 ^i*-'^^
Смещение фрагмента = 0 ^^~' / ""-,
^^ / 20 ^к 504
^'** / Н" октетов >|< октета ►)
уУ\* обетов »Н off!» Н I 3а7рОВ°К I *Ра™ент 1 L>
I Заголовок I фрагмент 2 L* Г
, ' г ' Идентификатор = 5
i DF = 0
v Идентификатор = 5 ™ .
\ DF = 0 Смещение фрагмента = 0
Ч-чч MF = 1
4 v - х Смещение фрагмента = 63
и. 20 »|«'* 492 И
Г^ октетов ^Т4 октета И
I Заголовок I фрагмент з I ►
' Г ^
Идентификатор = 5
DF = 0
MF = 0
Смещение фрагмента = 126
Рис 10.10. Фрагменты дейтаграммы IP
В случае потери одного фрагмента восстановить исходную дейтаграмму не
удастся. Даже если остальные фрагменты будут доставлены успешно, вся
дейтаграмма будет потеряна. Протоколы верхнего уровня (такие, как TCP)
обеспечивают повторную отправку всей дейтаграммы, но она снова будет фрагментиро-
вана в той точке, где ее размер превысит MTU.
При получении первого фрагмента узел-получатель запускает таймер
восстановления. Если заданный интервал времени истечет до получения всех
остальных фрагментов, узел IP удалит полученные фрагменты, даже если они были
переданы правильно. С ростом количества фрагментов также возрастает
вероятность потери дейтаграмм IP, поскольку для потери всей дейтаграммы достаточно
потери всего одного фрагмента. Отправитель извещается о наступлении тайм-аута
при помощи сообщения ICMP (Internet Control Message Protocol). Для
привлечения вашего внимания к этой проблеме могут использоваться специальные
диагностические программы — например, анализаторы протоколов.
Хотя методика с восстановлением дейтаграмм IP на узле-получателе создает
некоторые проблемы, о которых говорилось выше, у нее есть преимущество: она
упрощает реализацию маршрутизаторов, которым не приходится хранить и
восстанавливать фрагментированные дейтаграммы IP. При наличии нескольких сетей
с малыми значениями MTU восстановление фрагментов на промежуточных
маршрутизаторах было бы неэффективным, поскольку восстановленная дейтаграмма
снова фрагментируется перед входом в следующую сеть с малым значением MTU.
Срок жизни (TTL)
Срок жизни (TTL, Time To Live) измеряется в секундах и определяет
максимальное время существования дейтаграммы IP в сети. Поле должно уменьшаться
каждым маршрутизатором на величину времени, затраченного на обработку
пакета. Когда поле TTL уменьшается до 0, срок жизни дейтаграммы истекает.
Подобная схема предназначалась для того, чтобы истечение срока жизни
приводило к удалению дейтаграммы на маршрутизаторах, а не на получателе. Хосты,
выполняющие функции маршрутизаторов, должны следовать правилам
сокращения срока жизни при маршрутизации. Поле TTL решает две задачи:
О Ограничение жизненного цикла сегментов ТСО.
О Прерывание циклической маршрутизации в Интернете.
При истечении таймера TTL отправителю посылается уведомляющее
сообщение ICMP.
Хотя срок жизни измеряется в секундах, маршрутизатору трудно определить
точное время прохождения дейтаграммы IP в сегменте сети. С другой стороны,
он может отслеживать время, проведенное дейтаграммой IP непосредственно на
маршрутизаторе — для этого достаточно зафиксировать время поступления и
отправки дейтаграммы. Но и это сопряжено с дополнительными вычислениями,
поэтому многие маршрутизаторы даже не пытаются оценивать время нахождения
дейтаграммы IP и просто уменьшают содержимое поля TTL на 1. Из-за этого
данное поле превращается в некое подобие счетчика переходов (hops). В
некоторых ранних реализациях в поле срока жизни ошибочно заносилось значение 16,
представляющее бесконечность в протоколе RIP (Routing Information Protocol).
Тем не менее срок жизни дейтаграммы не зависит от метрик RIP.
Кроме того, о сроке жизни дейтаграмм необходимо знать следующее:
О Хост не должен отправлять дейтаграммы с нулевым сроком жизни или
уничтожать дейтаграммы только потому, что при получении их срок жизни был
меньше 2.
О Протоколы верхнего уровня иногда используют поле TTL для реализации
расширенного контекста поиска ресурсов Интернета. Информация используется
некоторыми диагностическими утилитами; предполагается, что она
помогает найти «ближайший» сервер заданного класса — например, посредством
групповой рассылки IP. Конкретный транспортный протокол также может
самостоятельно задать значение TTL, определяющее максимальную
продолжительность жизненного цикла дейтаграммы.
О Минимальное фиксированное значение TTL должно быть по крайней мере
равно интернет-диаметру, то есть длине наибольшего возможного пути.
На практике рекомендуется выбирать значения, вдвое большие диаметра,
с учетом продолжающегося роста Интернета.
О Уровень IP должен предоставить транспортному уровню средства для
задания поля TTL во всех отправляемых дейтаграммах. При использовании
фиксированного значения TTL необходимо предусмотреть возможность его
настройки. К сожалению, в большинстве реализаций настройка начального
значения TTL не поддерживается. На практике очень часто используется
значение по умолчанию C2 или 64).
Тип протокола
Поле типа протокола задает протокол верхнего уровня, который должен
получать данные IP. Содержимое этого поля используется при
мультиплексировании/демультиплексировании данных, передаваемых протоколам верхнего
уровня. Например, протокол TCP представляется кодом 6, протокол UDP —
кодом 17, а протокол ICMP — кодом 1. Когда модуль IP получает дейтаграмму
с типом протокола 6, он знает, что в дейтаграмме инкапсулируются данные
TCP, которые должны быть доставлены модулю TCP. Если в полученной
дейтаграмме поле типа протокола равно 17, значит, ее следует передать модулю UDP.
А если в полученной дейтаграмме поле типа протокола равно 1, значит, эта
дейтаграмма передается модулю ICMP.
В табл. 10.5 перечислены допустимые значения поля типа протокола в
заголовке IP.
Таблица 10.5. Коды протоколов
Код Сокращение Расшифровка
0 (зарезервировано)
1 ICMP Internet Control Message Protocol
2 IGMP Internet Group Management Protocol
3 GGP Gateway-to-Gateway Protocol
4 IP IP в IP (инкапсуляция)
5 ST Stream
6 TCP Transmission Control Protocol
7 UCL UCL
8 EGP Exterior Gateway Protocol
9 IGP Любой протокол внутреннего шлюза
10 BBN-RCC-MON BBN RCC Monitoring
11 NVP-II Network Voice Protocol
12 PUP PUP
13 ARGUS ARGUS
продолжение &
Таблица 10.5 (продолжение)
Код Сокращение Расшифровка
14 EMCON EMC0N
15 XNET Cross Net Debugger
16 CHAOS Chaos
17 UDP User Datagram Protocol
18 MUX Multiplexing
19 DCN-MEAS DCN Measurement Subsystem
20 HMP Host Monitoring Protocol
21 PRM Packet Radio Monitoring
22 XNS-IDP XEROX NSIDP
23 TRUNK-1 Trunk-1
24 TRUNK-2 Trunk-2
25 LEAF-1 Leaf-1
26 LEAF-2 Leaf-2
27 RDP Reliable Data Protocol
28 IRTP Internet Reliable Transaction Protocol
29 ISO-TP4 ISO Transport Protocol Class4
30 NETBLT Bulk Data Transfer Protocol
31 MFE-NSP MFE Network Services Protocol
32 MERIT-INP MERIT Internodal Protocol
33 SEP Sequential Exchange Protocol
34 3PC Third Party Connect Protocol
35 IDPR Inter-Domain Policy Routing Protocol
36 XTP XTP
37 DDP Datagram Delivery Protocol
38 IDPR-CMTP IDPR Control Message Transport Protocol
39 TP++ TP++ Transport Protocol
40 IL IL Transport Protocol
41 SIP Simple Internet Protocol
42 SDPR Source Demand Routing Protocol
43 SIP-SR SIP Source Route
44 SIP-FRAG SIP Fragment
45 IDPR Inter-Domain Routing Protocol
46 RSVP Reservation Protocol
47 GRE General Routing Encapsulation
Код Сокращение Расшифровка
48 MHRP Mobile Host Routing Protocol
49 BNA BNA
50 SIPP-ESP SIPP Encap Security Payload
51 SIPP-AH SIPP Authentication Header
52 I-NLSP Integrated Net Layer Security TUBA
53 SWIPE IP с шифрованием
54 NHRP NBMA Next Hop Resolution Protocol
55-60 (не присвоены)
61 (любой внутренний протокол хоста)
62 CFTP CFTP
63 (любая локальная сеть)
64 SAT-EXPAK SATNET and Backroom EXPAK
65 KRYPTOLAN Kryptolan
66 RVD MIT Remote Virtual Disk Protocol
67 IPPC Internet Pluribus Packet Core
68 (любая распределенная файловая система)
69 SAT-MON SATNET Monitoring
70 VISA VISA Protocol
71 IPCV Internet Packet Core Utility
72 CPNX Computer Protocol Network Executive
73 CPHB Computer Protocol Heart Beat
74 WSN Wang Span Network
75 PVP Packet Video Protocol
76 BR-SAT-MON Backroom SATNET Monitoring
77 SUN-ND SUN ND PROTOCOL-Temporary
78 WB-MON WIDEBAND Monitoring
79 WB-EXPAK WIDEBAND EXPAK
80 ISO-IP ISO Internet Protocol
81 VMTP VMTP
82 SECURE-VMTP SECURE-VMTP
83 VINES VINES
84 TTP TTP
85 NFSNET-IGP NFSNET-IGP
86 DGP Dissimilar Gateway Protocol
продолжение £>
Таблица 10.5 (продолжение)
Код Сокращение Расшифровка
87 TCF TCF
88 IGRP IGRP
89 OSPFIGP 0SPFIGP
90 Sprite-RPC Sprite-RPC Protocol
91 LARP Locus Address Resolution Protocol
92 MTP Multicast Transport Protocol
93 AX.25 AX.25 Frames
94 IPIP IP-within-IP Encapsulation Protocol
95 MICP Mobile Internetworking Control Pro.
96 SCC-SP Semaphore Communications Sec. Pro
97 ETHERIP Ethernet-within-IP Encapsulation
98 ENCAP Encapsulation Header
99 (любая закрытая схема шифрования)
100 GMTP GMTP
101-254 (не присвоены)
255 (зарезервировано)
Контрольная сумма заголовка
Контрольная сумма используется только для проверки целостности заголовка IP.
Сначала суммируются поразрядные дополнения до 1 всех 16-разрядных
величин, входящих в заголовок (за исключением поля контрольной суммы), затем
вычисляется дополнение до 1 полученной величины. Содержимое поля
вычисляется заново на каждом маршрутизаторе, поскольку поле TTL на нем
уменьшается, что должно быть отражено в модификации заголовка IP.
Контрольная сумма вычисляется относительно легко, а экспериментальные
данные показывают, что эта мера с достаточно высокой надежностью выявляет
ошибки в дейтаграммах.
IP-адреса получателя и отправителя
В адресных полях заголовка IP хранятся 32-разрядные IP-адреса двух узлов,
получателя и отправителя. Эти адреса пересылаются с каждой дейтаграммой IP,
поскольку сеть IP не ориентирована на соединение, поэтому каждая дейтаграмма
должна содержать полную информацию об адресах отправителя и получателя.
IP-адрес получателя используется маршрутизаторами для выбора маршрута
каждой дейтаграммы IP.
Параметры IP
В протоколе IP предусмотрены средства передачи информации о безопасности
дейтаграммы, маршрутизации сообщений от источника и временной пометки.
Поскольку эти средства используются относительно редко, они реализованы
в необязательных полях, называемых параметрами IP.
Существуют следующие параметры IP:
О безопасность;
О запись маршрутизации;
О жесткая маршрутизация от источника;
О свободная маршрутизация от источника;
О временная пометка.
Параметры IP должны обрабатываться всеми узлами IP. Они передаются
в необязательных полях, находящихся в конце заголовка. Присутствие
параметров в любом конкретном пакете не обязательно, но их поддержка должна
быть реализована в обязательном порядке. Например, в средах с высоким
уровнем безопасности для всех дейтаграмм IP может потребоваться
соответствующий параметр.
Поле параметров имеет переменную длину, кратную 32 битам. Для
соблюдения этого требования поле может дополняться нулями. Поддерживаются два
формата значений поля параметров IP (рис. 10.11):
О Формат 1: тип параметра (один октет).
О Формат 2: тип параметра (один октет), длина параметра (один октет) и
собственно данные параметра. Длина параметра включает все три поля (то есть
тип, длину и данные).
Тип параметра
1^ ^Длина^Ч J
П Чпараметра/ П
г; ./г I \—|
Тип параметра Длина параметра Данные параметра
1 ' ' \ '
Рис. 10.11. Форматы параметров
Тип параметра определяется первым октетом. В формате 1 параметр состоит
только из октета класса, а в формате 2 за классом следуют другие поля. Тип
параметра состоит из трех полей (рис. 10.12):
О Флаг копирования A бит).
О Класс параметра B бита).
О Номер параметра E бит).
Флаг копирования управляет обработкой поля параметров на
маршрутизаторах при фрагментации пакета. Если флаг равен 1, то параметры исходной дейта-
граммы должны копироваться в каждый фрагмент. Если флаг равен 0, то
параметры копируются только в первый фрагмент.
0 12 3 4 5 6 7
Класс параметра Номер параметра
копирования
Рис. 10.12. Октет типа параметра
Поле класса параметра имеет длину 2 бита и принимает значения от 0 до 3.
Смысл этих значений описан в табл. 10.6.
Таблица 10.6. Значения поля класса параметра в октете типа параметра
Значение Описание
0 Управление сетью
1 Зарезервировано для использования в будущем
2 Отладка и сбор информации
3 Зарезервировано для использования в будущем
Поле класса определяет общую категорию параметра. В настоящее время
определены две категории: управление сетью и отладка. Поле номера
параметра занимает 5 бит и позволяет задать до 32 параметров для каждой
категории. В табл. 10.7 перечислены различные параметры, определенные в
настоящее время.
Таблица 10.7. Параметры IP
Класс Номер Длина Описание
параметра параметра
О 0 Конец списка параметров. Занимает только 1 октет
и не сопровождается октетом длины. Используется
в том случае, если конец списка параметров
не совпадает с концом заголовка
О 1 Нет операции. Занимает только 1 октет и не
сопровождается октетом длины. Используется
для выравнивания октетов в списке параметров
О 2 11 Базовая безопасность
О 3 Перем. Свободная маршрутизация от источника.
Дейтаграмма IP маршрутизируется на основании
данных, предоставленных отправителем
О 5 Перем. Расширенная безопасность
О 7 Перем. Сохранение маршрута. Используется
для отслеживания маршрута, по которому
передается дейтаграмма IP
Класс Номер Длина Описание
параметра параметра
0 8 4 Идентификатор потока. Используется для пересылки
16-разрядного идентификатора потока SATNET
в сетях, не поддерживающих концепцию потоков.
В настоящее время считается устаревшим
0 9 Перем. Жесткая маршрутизация от источника.
Дейтаграмма IP маршрутизируется на основании
данных, предоставленных отправителем
2 4 Перем. Временная пометка. Используется для регистрации
времени прохождения по маршруту. В настоящее
время является единственным параметром,
определенным в категории отладки и сбора
информации
В следующих разделах различные типы параметров IP описаны более
подробно.
Конец списка параметров и выравнивание
Только два из определенных в настоящее время параметров состоят из одного
октета — конец списка параметров и отсутствие операции. Конец списка
параметров (см. табл. 10.7) представляет собой однооктетный параметр,
заполненный нулями (рис. 10.13).
00000000
Тип = 0
Рис. 10.13. Конец списка параметров
Данный параметр обозначает конец списка параметров, который может и не
совпадать с концом заголовка, обозначенным полем длины заголовка (IHL).
Он завершает весь список параметров, но не каждый параметр по отдельности,
и используется только в том случае, если конец списка параметров не приходится
на 32-разрядную границу.
На рис. 10.14 изображена структура однооктетного параметра-заполнителя.
00000001
Тип = 1
Рис. 10.14. Заполнитель
Включение заполнителя между параметрами обеспечивает выравнивание па-
чала следующего параметра по 32-разрядной границе.
Безопасность
Параметр безопасности используется хостами для пересылки информации о
безопасности, дроблении (compartmentation), ограничений доступа и закрытых
пользовательских групп. Существует две разновидности параметра безопасности:
О Базовая безопасность. Используется для обозначения стандартных уровней:
конфиденциальная, секретная, открытая информация и т. д.
О Расширенная безопасность. Определяет дополнительные атрибуты
безопасности в соответствии с потребностями военных организаций.
Ниже эти параметры описаны более подробно.
Базовая безопасность
На рис. 10.15 изображена структура параметра базовой безопасности,
характеризуемого кодом типа 130. Коды соответствуют различным организациям,
устанавливающим разные правила обработки дейтаграмм IP. К числу таких организаций
относятся Агентство национальной безопасности США, Центральное
разведывательное управление и Министерство энергетики.
Тип Ограничения Код
параметра = 130 Длина Безопасность доступа управления
параметра = 11 Дробление передачей
i 1 1—^—i—^—i—^—i—^—i
10000010 00001011 SSS...SSS ССС...ССС ННН...ННН ТСС
Ц4-] ' —I \ '—\ ' \,—' \ '
|| К—16 бит >\< 16 бит—Ж— 16 бит »И 24 бита-Н
Флаг '
копирования
11
Класс '
параметра
I
Номер
параметра
Рис. 10.15. Структура параметра базовой безопасности
Поле безопасности имеет длину 16 бит и определяет один из 16 уровней
безопасности, 8 из которых зарезервированы для использования в будущем. Коды
безопасности перечислены в табл. 10.8. Некоторые из кодов используются только
во внутренней работе организаций, отвечающих за безопасность.
Таблица 10.8. Коды безопасности для параметров IP
Код Описание
00000000 00000000 Открытая информация
11110001 00110101 Конфиденциальная информация
01111000 10011010 EFTO
10111100 01001101 ММММ
Код Описание
01011110 00100110 PROG
10101111 00010011 Информация для служебного пользования
11010111 10001000 Секретная информация
01101011 11000101 Совершенно секретная информация
00110101 11100010 Зарезервировано на будущее
10011010 11110001 Зарезервировано на будущее
01001101 01111000 Зарезервировано на будущее
00100100 10111101 Зарезервировано на будущее
00010011 01011110 Зарезервировано на будущее
10001001 10101111 Зарезервировано на будущее
11000100 11010110 Зарезервировано на будущее
11100010 01101011 Зарезервировано на будущее
Поле дробления имеет длину 16 бит. Если передаваемая информация не
дробится, поле состоит из одних нулей. За информацией о других значениях поля
обращайтесь в Разведывательное управление Министерства обороны США.
Поле ограничений доступа имеет длину 16 бит. Значения представляют
собой алфавитно-цифровые диграфы, определенные в руководстве DIAM 65-19,
«Standard Security Markings».
Поле кода управления передачей ТСС (Transmission Control Code) имеет
длину 24 бита; оно предназначено для разделения трафика и определения
управляемых групп. Значения ТСС представляются в виде триграфов. За
информацией о значениях этого поля обращайтесь в Разведывательное управление
Министерства обороны США.
Расширенная безопасность
Параметр расширенной безопасности используется для определения
дополнительных требований к безопасности (рис. 10.16) и характеризуется кодом типа 133.
Некоторые коммерческие маршрутизаторы не поддерживают параметры
безопасности IP.
Сохранение маршрута
Если отправитель включает в дейтаграмму параметр сохранения маршрута, то
в дейтаграмме сохраняется IP-адрес каждого маршрутизатора, участвующего
в доставке дейтаграммы. Таким образом, вместе с дейтаграммой получатель
принимает список всех маршрутизаторов, «посещенных» дейтаграммой.
Параметр сохранения маршрута начинается с октета, содержащего код типа 131
(рис. 10.17). Во втором октете хранится длина всего параметра. В поле данных
содержится список IP-адресов. Третий октет параметра содержит указатель на
следующий обрабатываемый элемент списка. Смещение указателя определяется
относительно начала параметра, и минимальное значение указателя равно 4.
Если указатель больше длины параметра, хранящейся во втором октете, в поле
данных не осталось пустых элементов; иначе говоря, список IP-адресов полон.
При заполненном списке маршрутизаторы пересылают дейтаграмму без
добавления новых элементов в список.
Тип параметра = 133 Длина параметра Код формата
i 1 г^ 1 ^ 1
10000101 Дополнительная информация
"Т]—;— безопасности
I—и-] 1 1 1 \ 1
Флаг
копирования!,
Класс
параметра I
Номер
параметра
Рис. 10.16. Структура параметра расширенной безопасности
Сохраненные
К 8 бит НИ 8 бит ►К-8бит-Н/^^' Данные ^\^^
I 1 1 Г"и гА/ | |
IP- IP- IP-
Тип параметра = 131 длИНа параметра указатель адрес адрес - адрес
ЦЯЦХЮП, 12 N
I mi 1 L_|_J 1 by_J 1
Флаг
копирования ± | |
Класс
параметра
T
Номер
параметра
Рис. 10.17. Параметр сохранения маршрута
Если значение указателя не превышает длину параметра, значит, список
не заполнен и в нем имеются пустые элементы. Маршрутизатор вставляет свой
IP-адрес в позицию, обозначенную указателем, и увеличивает значение указателя
на 4 (размер IP-адреса в октетах). В дейтаграмме сохраняется IP-адрес сетевого
интерфейса маршрутизатора, через который пересылалась дейтаграмма.
Использование сохраненной информации о маршрутизаторах должно быть
согласовано между отправителем и получателем. Отправитель включает в
дейтаграмму параметр сохранения маршрута с количеством элементов,
достаточных для сохранения адресов маршрутизаторов. Получатель должен быть готов
обработать список IP-адресов, хранящийся в поле данных. Если получатель не
собирается обрабатывать сохраненные данные, он игнорирует накопленную
информацию.
Свободная и жесткая маршрутизация от источника
При использовании маршрутизации от источника отправитель указывает путь,
по которому дейтаграмма должна пересылаться к получателю. Путь представля-
ется в виде списка IP-адресов посещаемых маршрутизаторов. Обычно маршрут
строится маршрутизаторами на основании оптимального пути, определяемого
протоколами маршрутизации. Но маршрутизация от источника жестко диктует
путь дейтаграммы к получателю. Средства маршрутизации от источника могут
пригодиться для тестирования пути даже тогда, когда вы знаете, что в обычной
ситуации маршрутизатор выберет другой путь. Кроме того, они предоставляют
дополнительную свободу действий при маршрутизации дейтаграмм в сетях,
заведомо работающих надежно. К недостаткам маршрутизации от источника
следует отнести то, что топология сети и состав маршрутизаторов, используемых
при пересылке дейтаграммы, должны быть известны заранее. В сложных сетях
определение топологии и реального пути дейтаграмм IP может оказаться
непростой задачей.
Существует две разновидности маршрутизации от источника:
О жесткая маршрутизация от источника;
О свободная маршрутизация от источника.
При установке параметра жесткой маршрутизации от источника (рис. 10.18)
отправитель указывает последовательность IP-адресов, которые обязательно
должны использоваться в процессе пересылки дейтаграммы. Путь между двумя
соседними IP-адресами в списке обязательно должен проходить в границах
одного физического сетевого сегмента. Один физический сегмент включает только
устройства уровней 1 (повторители) и 2 (мосты), но не уровня 3
(маршрутизаторы). Если маршрутизаторы не могут обеспечить жесткое выполнение
последовательности IP-адресов, дейтаграмма отвергается.
Данные жесткой
маршрутизации
Ы 8 бит НИ 8 бит ►+*- 8 бит-Н^"" от источника ^\
i 1 1 г^л Л | |
IP- IP- IP-
ТИП "шш= 1 | Длина паРаметРа Указатель адрес адрес - адрес
Флаг у
копирования
Т
Класс
параметра
Т
Номер
параметра
Рис. 10.18. Жесткая маршрутизация от источника
В режиме свободной маршрутизации от источника (рис. 10.19) отправитель
тоже передает серию IP-адресов, которые должны использоваться при пересылке
дейтаграммы. Тем не менее путь между двумя последовательными IP-адресами
может содержать произвольное количество маршрутизаторов. На рис. 10.20
продемонстрированы различия между жесткой и свободной маршрутизацией от
источника.
Данные свободной
маршрутизации
И 8 бит Ж 8 бит Н<- 8 бит -»/^ от источника \.
i 1 1 г—п—г^-г—п
- I IP- I IP- I I IP- I
Тип параметра - 131 длина параметра Указатель адрес адрес - адрес
„j.Mv.Uyy.lJ 12 N
—+-I—I 1 > 1 1 [ArJ '
Флаг у
копирования
Т
Класс
параметра
Т
Номер
параметра
Рис. 10.19. Свободная маршрутизация от источника
Как при жесткой, так и при свободной маршрутизации от источника
маршрутизаторы перезаписывают исходные адреса в параметре своими локальными
IP-адресами. Когда дейтаграмма добирается до получателя, список адресов
содержит фактически пройденный маршрут. Такой же список был бы получен
при использовании параметра сохранения маршрута. По этой причине
свободная маршрутизация от источника также называется свободной маршрутизацией
от источника с сохранением маршрута (LSRR, Loose Source and Record Route),
а жесткая маршрутизация от источника также называется жесткой
маршрутизацией от источника с сохранением маршрута (SSRR, Strict Source and Record
Route).
Анализируя форматы данных при сохранении маршрута, жесткой и
свободной маршрутизации от источника на рис. 10.17—10.19, обратите внимание на их
сходство. Поле указателя выполняет функции индекса в списке IP-адресов, а поле
длины определяет максимальное количество элементов в списке. Завершая
обработку IP-адреса, маршрутизатор перемещает индекс-указатель к следующему
элементу. Так как длина IP-адреса равна 4 октетам, поле указателя
увеличивается на 4 и тем самым перемещается к следующему элементу.
Если значение указателя превышает длину параметра, значит, список
IP-адресов полностью обработан или его емкость исчерпана. В этом случае
дейтаграмма IP маршрутизируется стандартным образом по содержимому таблицы
маршрутизации, хранящейся на маршрутизаторе; информация в полях параметра
при этом не используется. Если указатель меньше длины параметра либо равен
ей, обработка списка IP-адресов еще не завершена (рис. 10.21). В этом случае
маршрутизатор использует указатель для определения адреса следующего
маршрутизатора, на который следует переслать дейтаграмму. Затем маршрутизатор
записывает IP-адрес сетевого интерфейса, через который дейтаграмма была
направлена, в элемент списка, определяемый значением указателя. Таким образом
сохраняется информация о фактическом маршруте, по которому пересылалась
дейтаграмма. Указатель перемещается к следующему элементу списка
IP-адресов, для чего он увеличивается на 4.
Жесткая маршрутизация
от источника
£ 200.1.1.0 <^ £ 201.1.1.0 <}
7*200.1.1.1 .Х^оТ/1.1.1 >^202.1.1. l\
[Т I I I I ^^ \ I Т\Г 202.1.1.0 <
J™ Длина Указ. 200.1.1.1 201.1.1.1 202.1.1.1 203.1.1.1 204.1.1.1 \Ч_^У^_У
/ "/203.1.1.1
Г 204.1.1.0 j П$ J—Г 203.1.1.0 3 ^^^^^
^-^-^~^ 204.1.1.1 ^С^^^
^^-^Свободная маршрутизация
~^^ от источника
^^^ J? 200.1.1.0 ^ £ 201.1.1.0 «I
^""^ 200.1.1.1 201.1.1.1^^202.1.1.l\
ГГ-п | | | -^-г | Г202.1.1.0З
J™ Длина Указ. 201.1.1.1 202.1.1.1 204.1.1.1 V_^v^--^
/ у/203.1.1.1
Г 204.1.1.0 j ОТ)—Г 203.1.1.0 3
204.1.1.1
Рис. 10.20. Сравнение жесткой и свободной маршрутизации
Поле данных содержит серию IP-адресов, каждый из которых представлен
4 октетами. Если значение указателя больше длины параметра, то исходный
маршрут пуст, а сохраненный маршрут полон. Дальнейшая маршрутизация
выполняется на основании поля адреса получателя в дейтаграмме IP.
Тип Длина Указатель IP-адрес IP-адрес IP-адрес
параметра параметра 15 4 1 2 3
14 1 >|< 1 >|< 1 ь|< 4 ►[< 4 »|< 4 —>|
^ октет октет октет *"'"* октета *"'"* октета *"'"* октета ^\^**
Указатель < длина параметра ^^^^
^__^ I ~\
Тип Длина Указатель IP-адрес IP-адрес IP-адрес
параметра параметра 15 16 1 2 3
L4 ^ ъ|< ^ >|< ^ ь|< 4 ь|^ 4 >|< 4 Ы
октет октет октет *"'"* октета ^'"* октета *"'"*октета *"'
Указатель > длина параметра
Рис. 10.21. Использование полей указателя и длины параметра
Временная пометка Интернета
Параметр временной пометки Интернета (Internet timestamp) используется для
регистрации времени получения дейтаграммы IP на каждом из промежуточных
маршрутизаторов. В дейтаграмме записывается IP-адрес и время получения,
измеряемое в миллисекундах с полуночи по универсальному времени UTC (Universal
Time Coordinated). Время UTC, ранее называвшееся гринвичским временем
(GMT, Greenwich Mean Time), соответствует времени на нулевой долготе.
Кроме собственно времени, параметр временной пометки также позволяет
записывать IP-адреса маршрутизаторов. На рис. 10.22 представлен формат
параметра временной пометки Интернета.
Тип параметра равен 68, а длина определяется суммарным количеством
октетов во всех полях. Каждый элемент в поле данных содержит две 32-разрядные
величины: IP-адрес маршрутизатора и время.
Длина параметра задает размер области, зарезервированной в поле данных
для IP-адресов и временных пометок. Указатель выполняет функции индекса
в поле данных и указывает на следующий свободный элемент. Наименьшее
допустимое значение указателя равно 5. Если значение указателя превышает
длину параметра, значит, область данных полностью заполнена сохраненной
информацией. Отправитель должен создать параметр временной пометки
достаточно большим, чтобы в нем поместились все предполагаемые данные. В про-
цессе пересылки дейтаграммы IP-размер параметра остается неизменным.
Отправитель должен инициализировать область данных нулями.
012345678 9 10 1112 13 14 15 16 17 18 19 20 2122 23 24 25 26 27 28 29 30 31
I i i i i i i i | i i i i i i i i i i i i i i i j ii | i i i i |
I тип параметра F8) | Длина параметра | Указатель [п^еиие1 флаги 1
IP-адрес 1 Т
Время 1
Поле
данных
• • •
I I JL
Рис. 10.22. Параметр временной пометки Интернета
Поле переполнения имеет длину 4 бита; в нем хранится количество
маршрутизаторов, для которых временные пометки не были сохранены из-за
недостаточного размера поля данных. Максимальное значение поля переполнения
равно 15. Если в области данных не хватает места для сохранения полных данных
временной пометки или счетчик переполнения превышает 15, дейтаграмма IP
считается ошибочной и уничтожается. В любом из этих случаев отправителю
посылается сообщение ICMP с информацией о проблеме с параметрами.
Поле флагов управляет форматом поля данных. Оно может содержать три
разных кода, перечисленных в табл. 10.9.
Таблица 10.9. Значения поля флагов в параметре временной пометки
Значение Описание
0 В области данных хранится только время; каждая пометка представлена
32-разрядной величиной. IP-адреса не сохраняются в области данных
1 Перед каждой временной пометкой хранится IP-адрес узла (маршрутизатора),
на котором она была зафиксирована. Этот формат представлен на рис. 10.20
2 Отправитель заносит в область данных IP-адреса. Модуль IP на маршрутизаторе
регистрирует временные пометки только в том случае, если IP-адрес
маршрутизатора совпадает со следующим заданным IP-адресом
Значения временных пометок выравниваются по правому краю и измеряются
в миллисекундах, прошедших с полуночи в формате UTC. Если время в
миллисекундах неизвестно или не может быть вычислено по отношению к полуночи
по UTC, в область данных может быть вставлено произвольное значение
(например, локальное время), но при этом старший бит поля временной пометки
должен быть равен 1. Установка старшего бита является признаком
нестандартного формата времени.
Маршрутизаторы могут быть настроены на местное время, а их часы могут
быть не синхронизированы. Из-за различий в показаниях часов на
маршрутизаторах значения временной пометки следует считать приближенными.
Параметр временной пометки не копируется при фрагментации и переносится
только в первый фрагмент дейтаграммы IP.
Сетевой порядок байтов
Физический уровень передает биты в том порядке, в котором они были
получены от верхних уровней. Однако порядок хранения битов, из которых состоят
передаваемые данные, может отличаться на разных компьютерах. Например, не
все компьютеры хранят 32-разрядные целые величины (такие, как IP-адреса)
в одинаковом формате. На одних компьютерах младшие байты 32-разрядного
числа хранятся в младших адресах памяти. Также встречается и другой вариант,
при котором в младших адресах хранятся старшие байты числа.
На некоторых компьютерах, особенно на более старых 16-разрядных машинах,
данные делятся на 16-разрядные блоки. При этом младшие байты хранятся в
младших адресах памяти, но внутри 16-разрядного слова байты меняются местами.
Из-за потенциальных различий в порядке следования байтов данные не
могут напрямую копироваться между узлами IP. Протоколы TCP/IP определяют
сетевой стандартный порядок байтов, используемый для хранения двоичных
данных в межсетевых пакетах. Каждый узел IP при представлении данных в
пакетах должен использовать сетевой стандартный порядок байтов. Перед
отправкой пакета узел IP приводит локальное представление данных к сетевому порядку
байтов, а при получении пакета IP сетевой порядок преобразуется к локальному
представлению для данного узла. В большинстве реализаций TCP/IP
преобразование между сетевым стандартным порядком байтов и специфическим
представлением конкретного узла выполняется на уровне прикладных интерфейсов
TCP/IP и вспомогательных программных модулей.
В сетевом стандартном порядке байтов сначала передаются старшие байты.
Это означает, что в пересылаемом пакете сначала идут старшие байты целых
чисел, а младшие байты находятся ближе к концу пакета.
Структура заголовков протокола TCP/IP часто представляется с разделением
на 32-разрядные блоки (см. рис. 10.5). Нормальный порядок передачи октетов
заголовка соответствует нормальному порядку чтения (слева направо). Так, на
рис. 10.23 октеты пересылаются в порядке их нумерации.
0 12 3
01234567890123456789012 34 5 6 7 8 9 0 1
I—I—i—i—i—i—i—i—|—I—I—i—i—i—i—ьч—i—i—i—i—i—i—\—\—I—i—i—i—i—i—нЧ
12 3 4
—i—i—i—i—i—i—i——i—i—i—i—i—i—i——i—i—*—i—i—I—i——i—i 1 1—i—i—
5 6 7 8
—I—I—I—I—I—I—I——I—I—I—I—I—I—I——I—I—I—I—i—I—I——I—I 1 1—I—I—
9 10 11 12
I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—|—I—I—I—I—I—I—I—I
Рис. 10.23. Порядок пересылки байтов
Если октет представляет числовую величину, крайний левый бит на диаграмме
соответствует старшему биту числа. Так, на рис. 10.24 изображено двоичное
представление десятичного числа 170.
0 1234567
| I I I I I I I I
10 10 10 10
I I I I I I I I I
Рис. 10.24. Старшинство битов
Во всех представлениях числовых величин, состоящих из нескольких
октетов, крайний левый бит всего поля является старшим. При передаче величины,
состоящей из нескольких октетов, старший октет передается первым.
Трассировка IP
В этом разделе приводится расшифровка пакетов IP, сохраненных при реальной
работе сети. Перед анализом представленных данных стоит кратко просмотреть
предыдущие разделы, в которых описывался смысл полей IP. На рис. 10.25
изображена трассировка первых 50 пакетов сеанса Telnet. В настоящей главе
рассматривается только протокол IP, поэтому ниже будут описаны лишь некоторые
пакеты из приведенной трассировки Telnet.
Обратите внимание: первые три пакета в этом сеансе Telnet являются
пакетами ARP. Применение протокола ARP для разрешения аппаратных адресов
рассматривалось в главе 5.
Заголовок Ethernet во всех дейтаграммах IP содержит значение 800 (шести.),
означающее, что кадр Ethernet инкапсулирует дейтаграмму IP.
Поле протокола в заголовках IP всех дейтаграмм равно 6. Это значение
указывает на то, что в дейтаграмме IP инкапсулируется пакет TCP.
Первая дейтаграмма IP: пакет IP с полем флагов = О, MF = О, DF = О
На рис. 10.26 изображена первая дейтаграмма IP (пакет № 4 на рис. 10.25),
отправленный с адреса 199.245.180.44 на хост Telnet 199.245.180.201. Анализ
заголовка IP показывает следующие значения полей (перевод названий на рисунке
указан в скобках):
О Version (версия): 4;
О Header Length (длина заголовка в 32-разрядных блоках): 5;
О ToS: 0 (приоритет: обычный, нормальная задержка, нормальная пропускная
способность, нормальная надежность);
О Total Length (общая длина): 44;
О Identification (идентификатор): 1;
О Flags (флаги): 0, DF=0, MF=0 (фрагментация разрешена, последний фрагмент);
О Fragment offset (смещение фрагмента): 0;
О Time to Live (срок жизни): 100 секунд;
О Protocol (протокол): 6 (TCP);
No. Source Destination Layer Size Summary
1 0000C024282D FFFFFFFFFFFF arp 0064 Req by 144.19.74.44 for 144.19.74
2 0000C024282D FFFFFFFFFFFF arp 0064 Req by 144.19.74.44 for 144.19.74
3 0000C0A20F8E 0000C024282D arp 0064 Reply 144.19.74.201=0000C0A20F8E
4 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET SYN
5 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK SYN
6 0000C024282D 0000C0A20F8E telnt 0069 Cmd=Do; Code=Echo; Cmd=Do; Code=S
7 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
8 0000C0A20F8E 0000C024282D telnt 0064 Cmd=Do; Code=;
9 0000C024282D 0000C0A20F8E telnt 0064 Cmd=Won't; Code=;
10 0000C0A20F8E 0000C024282D telnt 0067 Cmd=Will; Code=Echo; Cmd=Will; Co
11 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
12 0000C024282D 0000C0A20F8E telnt 0072 Cmd=Do; Code=Suppress Go Ahead; С
13 0000C0A20F8E 0000C024282D telnt 0070 Cmd=Do; Code=Term1nal Type; Cmd=D
14 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
15 0000C024282D 0000C0A20F8E telnt 0072 Cmd=Will; Code=Terminal Type; Cmd
16 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
17 0000C0A20F8E 0000C024282D telnt 0064 Cmd=Subnegotiation Begin; Code=Te
18 0000C024282D 0000C0A20F8E telnt 0071 Cmd=Subnegotiat1on Begin; Code=Te
19 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
20 0000C0A20F8E 0000C024282D telnt 0067 Cmd=Do; Code=Echo; Cmd=W1ll; Code
21 0000C024282D 0000C0A20F8E telnt 0069 Cmd=Won't; Code=Echo; Cmd*Don't;
22 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
23 0000C0A20F8E 0000C024282D telnt 0104 Data»..Linux 1.3.50 (Itreecl.Itre
24 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
25 0000C0A20F8E 0000C024282D telnt 0064 Data»..
26 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
27 0000C0A20F8E 0000C024282D telnt 0073 Data=ltreecl login:
28 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
29 0000C024282D 0000C0A20F8E telnt 0064 Data=u
30 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
31 0000C0A20F8E 0000C024282D telnt 0064 Data=u
32 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
33 0000C024282D 0000C0A20F8E telnt 0064 Data=s
34 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
35 0000C0A20F8E 0000C024282D telnt 0064 Data*s
36 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
37 0000C024282D 0000C0A20F8E telnt 0064 Data=e
38 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
39 0000C0A20F8E 0000C024282D telnt 0064 Data«e
40 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
41 0000C024282D 0000C0A20F8E telnt 0064 Data=r
42 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
43 0000C0A20F8E 0000C024282D telnt 0064 Data*r
44 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
45 0000C024282D 0000C0A20F8E telnt 0064 Data*l
46 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
47 0000C0A20F8E 0000C024282D telnt 0064 Data=l
48 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
49 0000C024282D 0000C0A20F8E telnt 0064 Data»..
50 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
Рис. 10.25. Трассировка сеанса Telnet
О Checksum (контрольная сумма): OxAlAF (правильная);
О Source IP address (IP-адрес отправителя): 144.19.74.44;
О Destination IP address (IP-адрес получателя): 144.19.74.201.
О Поле версии, равное 4, означает, что дейтаграмма IP соответствует стандарту
IPv4.
Длина заголовка равна пяти 32-разрядным блокам B0 октетов). Это
минимальный размер, а следовательно, дейтаграмма не содержит параметров.
Общая длина дейтаграммы равна 44 октетам. Заголовки Ethernet и
контрольная сумма занимают 18 октетов; суммирование этих двух величин дает размер
пакета Ethernet — 62 октета. Чтобы размер кадра Ethernet был выровнен до
64 октетов, к нему добавляются два дополнительных октета.
Packet Number : 4 6:38:38 РМ
Length : 64 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-90-C0-24-28-2D > 00-00-C0-A2-0F-8E
Type: 0x0800 (IP)
ip: «===================== internet Protocol =======================
Station:144.19.74.44 >144.19.74.201
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput, Normal Reliability
Total length: 44
Identification: 1
Fragmentation allowed, Last fragment
Fragment Offset: 0
Time to Live: 100 seconds
Checksum: 0xAlAF(Valid)
tcp: ■«■««■■««■*■■»« Transmission Control Protocol ■■■■■■■■■■■■■■■■■
Source Port: 6295
Destination Port: TELNET
Sequence Number: 2S784320
Acknowledgement Number: 0
Data Offset C2-bit words): 6
Window: 4096
Control Bits: Synchronize Sequence Numbers (SYN)
Checksum: 0x4A87(Valid)
Urgent Pointer: 0
0pt1on:MAXIMUM SEGMENT SIZE
Option Length: 4
Maximum Segment Size : 1024 %/ ,
° Version
Ethernet Header Ethemet Jype |ndjcate§ | IHJ- T?S
T IP encapsulation a ITT
0{ОО 00 CO A2 OF 8E 00 00 C0 24 28 2DF8~ё^1^К99^ | $(-. .E.
10:(QO 2CXO0 0lX®Q QQffiXofoAl AFX90 13 4A 2С)(^Тз | d J...
20: 4A|c9yi8| 97 00 |l7 {01 J89 7g| 00 00 00H0 00 60 |б2^I J p
30 :(l0|0Q 4A|87 Qq|oq|02 [g4 04| 00^0§)| I | I. . J
^ I It * I II Deft,nation
Total Length tti Header Address
1 IT Checksum| у
Identification Protocol (TCP) Source
1 1 Address I
DF*0 Ethemet T
MF«0 Pad TCP
Fragment offset=0
Рис. 10.26. Первая дейтаграмма IP
Поле идентификатора в дейтаграмме IP равно 1, а срок жизни — 100
секундам. Последнее значение используется по умолчанию хостом 199.245.180.44 для
всех отправляемых дейтаграмм.
Поле ToS равно 0; это означает, что дейтаграмма IP должна передаваться
с обычным приоритетом, нормальной задержкой, нормальной пропускной
способностью и нормальной надежностью.
Поле флагов фрагментации равно 0; следовательно, флаги DF и MF тоже
равны 0. Это означает, что дейтаграмма может фрагментироваться, а текущий
фрагмент является последним. Нулевое смещение фрагмента указывает, что
данный фрагмент также является и первым. Дейтаграмма, которая одновременно
является первым и последним фрагментом, не имеет других фрагментов —
следовательно, перед нами полная нефрагментированная дейтаграмма.
В поле типа протокола хранится код 6. Следовательно, дейтаграмма IP
используется для пересылки сообщений TCP.
Контрольная сумма равна A1AF (шести.). Это значение подтверждает
правильность принятых данных.
Вторая дейтаграмма IP: ответный пакет IP с полем флагов = О,
MF = О, DF = О
На рис. 10.27 изображена вторая дейтаграмма IP (пакет № 5 на рис. 10.25),
отправленная в ответ на дейтаграмму IP, описанную в предыдущем разделе.
Дейтаграмма отправляется с хоста Telnet (адрес 199.245.180.201) клиенту Telnet
A99.245.180.44). Анализ заголовка IP показывает следующие значения полей
(перевод см. ранее):
О Version: 4;
О Header Length (в 32-разрядных блоках): 5;
О ToS: 0 (приоритет: обычный, нормальная задержка, нормальная пропускная
способность, нормальная надежность);
О Total Length: 44;
О Identification: 21410;
О Flags: 0, DF=0, MF=0 (фрагментация разрешена, последний фрагмент);
О Fragment offset: 0;
О Time to Live: 64 секунд;
О Protocol: 6 (TCP);
О Checksum: 0x720E (правильная);
О Source IP address: 144.19.74.201;
О Destination IP address: 144.19.74.44.
Поле версии равно 4, а значит, что дейтаграмма IP соответствует стандарту IPv4.
Длима заголовка равна пяти 32-разрядным блокам B0 октетов). Это
минимальный размер, а следовательно, дейтаграмма не содержит параметров.
Общая длина дейтаграммы равна 44 октетам. Заголовки Ethernet и
контрольная сумма занимают 18 октетов; суммирование этих двух величин дает
размер пакета Ethernet — 62 октета. Чтобы размер кадра Ethernet был выровнен
до 64 октетов, к нему добавляются два дополнительных октета.
Поле идентификатора в дейтаграмме IP равно 21410. Обратите внимание:
идентификатор отличен от того, который передавался клиентом Telnet. Он
представлен относительно большим числом, потому что еще до начала текущего
сеанса хост Telnet успел отправить много дейтаграмм IP.
Другая интересная подробность: срок жизни тоже изменился и равен 64
секундам. Это значение используется по умолчанию хостом 199.245.180.201 для всех
отправляемых дейтаграмм IP. Оно отличается от значения, которое
использовалось клиентом 199.245.180.44. В разных реализациях TCP/IP используются
разные исходные значения TTL.
Packet Number : 5 6:38:38 PM
Length : 64 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-00-C0-A2-0F-8E > 00-00-C0-24-28-2D
Type: 0x0800 (IP)
ip: ======================= internet Protocol =======================
Station:144.19.74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput, Normal Reliability
Total length: 44
Identification: 21410
Fragmentation allowed, Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x720E(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: TELNET
Destination Port: 6295
Sequence Number: 1508167651
Acknowledgement Number: 25784321
Data Offset C2-bit words): 6
Window: 30719
Control Bits: Acknowledgement Field is Valid (ACK)
Synchronize Sequence Numbers (SYN)
Checksum: 0xB8AE(Valid)
Urgent Pointer: 0
Option:MAXIMUM SEGMENT SIZE
Option Length: 4
Maximum Segment Size : 1024
Version |HL
T 4
Ethernet Header I T
A Ether Type indicates IP encapsulation I TOS
0:(O0 00 C0 24 28 2D 00 00 C0 A2 0F 8E (g8*0l^]^0) | ...$(- E.
10: @0 2f)(S3 A2J(g0 0(^(jl0)(QG2 0^(90 13 4A C9)(g0 lj) | . ,S. . .@.r. . .J. . .
20: Й/ф<МH 17 18 97 59 E4 CF E3 01 89 70 01 60 \l$\ | J Y p.' .
30: G7 FF B8 AE 00 00 02 04 04 0©jff2 65) |w re
1 I ▼[▼ Г ▼
▼ w I TTL Header I Source
Total Length T 1 Checksum Address
Identification I T I
T Protocol (TCP) 1 f
DF_0 Ethernet Destination
РяН Address
MF=0 Pad
Fragment ofifset=0 X
TCP
Рис. 10.27. Вторая дейтаграмма IP
Поле ToS равно 0; это означает, что дейтаграмма IP должна передаваться
с обычным приоритетом, нормальной задержкой, нормальной пропускной
способностью и нормальной надежностью.
Поле флагов фрагментации равно 0; следовательно, флаги DF и MF тоже
равны 0. Это означает, что дейтаграмма может фрагментироваться, а текущий
фрагмент является последним. Нулевое смещение фрагмента указывает, что
данный фрагмент также является и первым. Дейтаграмма, которая одновременно
является первым и последним фрагментом, не имеет других фрагментов —
следовательно, перед нами полная нефрагментированная дейтаграмма.
Packet Number : б 6:38:38 РМ
Length : 69 bytes
ether: ===ssssssssssssrsssr Ethernet Oatalink Layer =«==«===========«
Station: 00-00-C0-24-28-2D > 00-00-C0-A2-0F-8E
Type: 0x0800 (IP)
ip; sssssssssssssssssssssss internet Protocol ====»===»========«===«=
Station:144.19.74.44 >144.19.74.201
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput. Normal Reliability
Total length: 49
Identification: 2
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 100 seconds
Checksum: 0xAlA9(Valid)
tcp: и«1ш»1«г18квв81 Transmission Control Protocol ■«■•■«»«•■■■■■■
Source Port: 6295
Destination Port: TELNET
Sequence Number: 25784321
Acknowledgement Number: 1508167652
Data Offset C2-b1t words): 5
Window: 4096
Control Bits: Acknowledgement Field 1s Valid (ACK)
Push Function Requested (PSH)
Checksum: 0xl8A9(Val1d)
Urgent Pointer: 0
telnt: ■■■■■■■■■■■■■■■■■■■■■■■■ Telnet Protocol ■■■■■■■■■■■■■««■■■■■■■■
Command: Do
Option Code: Echo
Command: Do
Option Code: Suppress Go Ahead
Command: Will
Option Code:
Ether Type indicates IP encapsulation
* Version
Ethernet Header A IHL
t JtT
0: @0 00 C0 A2 0F 8E 00 00 C0 24 28 2D@8 0O)(j§@0J | $(-..E.
10: @0 3l)@0^2X00 00X64X06%M ASJX98 13 4A 2СХ?еТз | . 1. . . . d J . . .
20: 4AJC9V18 97 88 17 lei [89 78|01 59| E4 CF E4 50118) |J p.Y...P.
30: (l0 00 18 A9 00 00JFF[FD 01 FF FDI 03 FF FB IF lee) |
40: £00! I 1 1 J T ▼ |.
—Г Source Destination
▼ \ I \ 1 AddreM Address
Total Length ▼
"^^ Header Checksum
ТУ 1
Identification Protocol (TCP) TJp
▼ T
DFs° Telnet
MF*0
Fragment offset=0
Рис. 10.28. Третья дейтаграмма IP
В поле типа протокола хранится код 6. Следовательно, дейтаграмма IP
используется для пересылки сообщений TCP.
Контрольная сумма равна 720Е (шести.). Это значение подтверждает
правильность принятых данных.
Третья и четвертая дейтаграммы IP: анализ идентификаторов
На рис. 10.28 и 10.29 показаны две дейтаграммы IP, переданные между
клиентом Telnet по адресу 199.245.180.44 и хостом Telnet по адресу 199.245.180.201.
Packet Number : 7 6:38:38 РМ
Length : 64 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-00-C0-A2-0F-8E > 00-00-C0-24-28-2D
Type: 0x0800 (IP)
Station:144.19 74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput, Normal Reliability
Total length: 40
Identification: 21411
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x7211(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: TELNET
Destination Port: 6295
Sequence Number: 1508167652
Acknowledgement Number: 25784330
Data Offset C2-bit words): 5
Window: 30710
Control Bits: Acknowledgement Field is Valid (ACK)
Checksum: 0xCEB7(Valid)
Urgent Pointer: 0
Ether Type indicates IP encapsulation
T Version
A IHL
Ethernet Header T A TOS
0:@0 00 C0 24 28 20 00 00 C0 A2 0F 8Е(УН=Ю]И^П^ I•••$(- E.
10:f00 28jgTA?^H 00у5У0б)[5ГТ1У90 13 4A~C?)(90 13 | . (S . . .3. r. . . J . . .
20: 4A 2$(ee 17 18 97 59 E4 CF E4 01 89 70 ЮА 50 \l£) |j Y p. P.
30:1G7 F6 CE|B7 00| 00)|02 |04 04 00 p2 65)] J |w re
I ГЛ I~1 ▼ *
▼ тт. Ethernet TCP Destination
identification 1 Pad | Address
T
f Source
Total Length Protocol (TCP) Address
T
у Header Checksum
DF=0
MF=0
Fragment offset=0
Рис. 10.29. Четвертая дейтаграмма IP
Будет полезно проанализировать значения идентификаторов в этих
дейтаграммах. На рис. 10.28 изображена вторая дейтаграмма, отправленная от клиента хосту
Telnet. Поле идентификатора в этой дейтаграмме равно 2, что на единицу больше
идентификатора в дейтаграмме, изображенной на рис. 10.26. На рис. 10.28
показана вторая дейтаграмма, переданная хостом Telnet клиенту. Идентификатор
в этой дейтаграмме равен 21411, что на единицу больше идентификатора в
предыдущей дейтаграмме (см. рис. 10.27). Данный пример наглядно показывает, что
каждая сторона, участвующая в обмене данными, генерирует идентификаторы
независимо от другой стороны.
Packet Number : 8 6:38:39 РМ
Length : 64 bytes
ether: ==================== Ethernet Oatalink Layer ====================
Station: 00-00-C0-A2-0F-8E > 00-00-C0-24-28-2D
Type: 0x0800 (IP)
ip: =======:=:=============== internet Protocol =======================
Station:144 19.74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput, Normal Reliability
Total length: 43
Identification: 21412
Fragmentation not allowed, Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x320D(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: TELNET
Destination Port: 6295
Sequence Number: 1508167652
Acknowledgement Number: 25784330
Data Offset C2-bit words): 5
Window: 30710
Control Bits: Acknowledgement Field is Valid (ACK)
Push Function Requested (PSH)
Checksum: 0xA9AE(Valid)
Urgent Pointer: 0
telnt: ======================== Telnet Protocol ========================
Command: Do
Option Code:
Ether Type indicates IP encapsulation
у Version
Ethernet Header TCP f IHL
f t j \}j
0: @0 00 C0 24 28 2D 00 00 CO A2 0F 8E@8 00)^]@0) | ...$(- E.
10: (O0 2В)фЗ A4^40 00)^0^6Y32 0DY90 13 4A СЭХЭЭ 13 | .+S.@.@. 2. . . J . . .
20: 4A|2C)@0| 17 1в| 97 5э| E4| CF E4| 01 89 70 |0A 50|18) |j Y p. P.
30: G7JF6 A9 AE 00 00^ Fd| 25)фо| 72 65) J |w %.re
I I 1 I I I Destination
T I T-n I ▼ I Address
Total Length Y Header
I Checksum J
| Teinet Source
Identification 1 Address
▼ Protocol (TCP)
DF=1 I
^F=0 я Ethernet
Fragment offset=0 pad
Рис. 10.30. Пятая дейтаграмма IP
Пятая дейтаграмма IP: DF = 1
На рис. 10.30 показана дейтаграмма IP, отправленная с хоста Telnet 199.245.180.201
клиенту Telnet 199.245.180.44. Анализ заголовка IP показывает следующие
значения полей (перевод см. ранее):
О Version: 4;
О Header Length (в 32-разрядных блоках): 5;
О ToS: 0 (приоритет: обычный, нормальная задержка, нормальная пропускная
способность, нормальная надежность);
О Total Length: 43;
О Identification: 21412;
О Flags: 0, DF=1, MF=0 (фрагментация не разрешена, последний фрагмент);
О Fragment offset: 0;
О Time to Live: 64 секунды;
О Protocol: 6 (TCP);
О Checksum: 0x320D (правильная);
О Source IP address: 144.19.74.201;
О Destination IP address: 144.19.74.44.
Значения большинства полей рассматривались выше для других дейтаграмм IP.
Отличается только поле флагов фрагментации, в котором флаг DF равен 1.
Установка флага говорит о том, что хост Telnet запрещает фрагментацию дейтаграммы.
Итоги
Протокол IP обеспечивает логическое представление сети, которое не зависит
от конкретных сетевых технологий, использовавшихся при построении
физической сети. Логическая сеть независима от адресов физического уровня, размера
MTU и других различий. Протоколы верхнего уровня (такие, как TCP и UDP)
абстрагируются от физического уровня и рассматривают сеть исключительно
как сеть IP. Сеть IP предоставляет верхнему уровню сервис обмена данными, не
ориентированный на соединение. При этом используются дейтаграммы,
содержащие IP-адреса получателя и отправителя и прочие параметры, необходимые
для работы IP. Одна из важных особенностей протокола IP заключается в том,
что передаваемые дейтаграммы фрагментируются маршрутизаторами по мере
необходимости, чтобы обеспечить размер дейтаграммы соответствовал
ограничениям на размер пакета в базовой сети. При использовании фрагментации IP
получатель отвечает за восстановление исходной дейтаграммы из фрагментов.
«f 4 Транспортные
JL JL протоколы
Караижит С. Сияй (Karanjit 5. Siyan)
Транспортные протоколы TCP/IP соответствуют транспортному уровню модели
OSL В семействе протоколов TCP/IP определены два стандартных
транспортных протокола: TCP и UDP. Протокол TCP (Transmission Control Protocol)
обеспечивает надежную пересылку данных, а протокол UDP (User Datagram Protocol)
успешной доставки не гарантирует.
Оба транспортных протокола, TCP и UDP, работают поверх протокола IP
и используют предоставляемый им сервис (рис. 11.1). Протокол IP
обеспечивает обмен дейтаграммами между двумя компьютерами, не ориентированный
на соединение. Протоколы TCP и UDP позволяют доставить данные не только
удаленному компьютеру, но и прикладному процессу, работающему на этом
компьютере. Прикладные процессы идентифицируются по номерам портов.
Протокол TCP ориентируется на соединение и обеспечивает надежную доставку
данных к месту назначения. С другой стороны, протокол UDP не ориентирован
на соединение и не обеспечивает надежной доставки. Тем не менее протокол
UDP также приносит пользу во многих ситуациях — например, при передаче
данных конкретному приложению, работающему на компьютере, а также при
широковещательной или групповой рассылке данных.
Хотя некоторые общие сведения о протоколах TCP и UDP приводились в
главе 3, в настоящей главе материал будет представлен гораздо более подробно.
Протокол TCP
Протокол TCP выполняет очень важные функции в семействе TCP/IP, поскольку
он предоставляет стандартизированные средства надежной доставки данных.
Вместо того чтобы изобретать свои собственные транспортные протоколы,
приложения обычно пользуются средствами TCP для обеспечения надежной доставки
данных, так как TCP прошел существенный путь развития и был дополнен
многими усовершенствованиями, повышающими его быстродействие и надежность.
Протокол TCP гарантирует надежную сквозную передачу данных между
прикладными процессами, работающими в разных компьютерных системах (рис. 11.2).
Надежность обеспечивается наращиванием новых функциональных возможно-
стей на основе IP. Протокол IP не ориентируется на соединение и не гарантирует
доставки пакетов; TCP, зная о принципиальной ненадежности IP, добавляет
новые средства для обеспечения сквозной доставки данных. Поскольку
протокол TCP почти не делает никаких предположений относительно сервиса,
предоставляемого сетью, он может работать на широком спектре оборудования.
Фактически TCP требует лишь одного: простых средств ненадежной доставки
дейтаграмм, реализованных на нижнем уровне. Такие сети, как Х.25, иногда
предоставляют нетривиальные средства, ориентированные на соединение, на
сетевом уровне. В этом случае дейтаграммы IP передаются в виртуальном
канале Х.25, а пакеты протокола TCP инкапсулируются в дейтаграммах IP.
С Приложения TCP 5 С Приложения UDP -5
TCP UDP
t l
IP
Канал передачи данных
Рис. 11.1. Протоколы TCP и UDP
Протокол TCP является основным транспортным протоколом, используемым
для поддержки надежных дуплексных соединений в виртуальных сетях. Чаще
всего TCP работает на базе IPv4 и IPv6, хотя в некоторых экспериментальных
проектах он работал на базе других протоколов сетевого уровня.
Если протокол IP реализуется на хостах и маршрутизаторах, то TCP обычно
реализуется только на хостах для обеспечения надежной доставки при сквозной
передаче. В наши дни многие маршрутизаторы не ограничиваются одной
маршрутизацией и предоставляют ряд других функций, упрощающих их настройку
и управление. Например, многие коммерческие маршрутизаторы также
реализуют TCP и UDP для поддержки удаленного входа и управления сетью.
Впрочем, несмотря на реализацию TCP и UDP в маршрутизаторах, транспортные
протоколы не используются сервисом маршрутизации и обработки сообщений.
Протокол TCP описан в RFC 792 (STD 7), «Transmission Control Protocol».
Протокол UDP описан в RFC 768 (STD 6), «User Datagram Protocol». Документ
RFC 1122 (STD 3), «Requirements for Internet Hosts — Communication Layers»
содержит ряд важных дополнений. Статус обоих протоколов, TCP и UDP,
определяется всего лишь на уровне рекомендаций. Тем не менее на практике все
устройства TCP/IP (за исключением «чистых» маршрутизаторов) реализуют TCP
и UDP. В большинстве реализаций логика UDP инкапсулируется в модуле TCP
и не отделяется от реализации TCP.
Ниже рассматриваются основные возможности TCP.
г Приложения <J г Приложения ^
i i
i i
i i
Надежность сквозной передачи
тер k- ->\ tcp
ip ip ip ip
Канальный Канальный Канальный Канальный
Физический Физический Физический Физический
(^^адежность\ (^мадежностьХ (^^адежностьГ\
q сквозной ^ q сквозной J q сквозной J
Х_^ передачи у \_^ передачи у Х_^ передачи у
Рис. 11.2. Надежность сквозной передачи с применением TCP
Возможности TCP
Следующие возможности протокола TCP заслуживают особого внимания:
О базовая пересылка данных;
О надежность;
О управление потоком данных;
О мультиплексирование;
О соединения;
О приоритет и безопасность.
Базовая пересылка данных
Под базовой пересылкой дачных понимается возможность пересылки
непрерывного потока октетов в обоих направлениях. Октеты пересылаются между
прикладными процессами, работающими в удаленных системах с поддержкой TCP.
Прикладные процессы группируют отправляемые/принимаемые байты в сегменты
(также называемые сообщениями). Сегмент может иметь произвольную длину.
В конечном счете сегменты должны пересылаться в дейтаграммах IP, размер
которых ограничивается значением MTU сетевого интерфейса. Тем не менее на
уровне TCP размер сегментов реально не ограничивается, поскольку задача
размещения сегментов в дейтаграммах IP относится к уровню IP. Впрочем, по со-
ображенпям эффективности соединения TCP обычно согласовывают
максимальный размер сегмента.
Сегменты, передаваемые TCP, имеют потоковую ориентацию (рис. 11.3).
Протокол TCP отслеживает каждый отправленный/полученный октет. В нем
отсутствует концепция блоков данных, и этим он отличается от других
транспортных протоколов, которые обычно отслеживают номера TPDU (Transport
Protocol Data Unit) вместо номера октета. Протокол TCP позволяет создать
несколько виртуальных каналов между двумя хостами TCP.
I Последний октет I
-|шшшш— Должен быть обозначен
[^^ДДИРдД^ специальным признаком
•Потоковая ориентация.
Концепция блока
TCP TCP данных в явном
виде не поддерживается
IP ,P
Рис. 11.3. Потоковая ориентация протокола TCP (с разрешения Learning Tree)
Прикладные процессы, использующие TCP, отправляют данные в сегментах
размера, удобного для отправки. Размер отправляемых данных может изменяться
в пределах от одного октета до нескольких килооктетов. Октеты доставляются
прикладному процессу на получателе в том порядке, в котором они были
отправлены. Этот процесс называется упорядочением октетов.
Приложение может передавать данные TCP по нескольку октетов за раз.
TCP накапливает данные в буфере и отправляет эти октеты в виде одного
большого сегмента или нескольких сегментов меньшего размера. При этом
гарантируется лишь поступление сегментов к получателю в порядке их отправки.
Например, если приложение за 10 секунд отправляет 1024 октета данных, эти
данные могут быть переданы в виде одного пакета TCP, содержащего все 1024
октета, в виде четырех пакетов TCP по 256 октетов каждый или в виде
произвольной комбинации октетов.
Поскольку TCP передает данные в виде потока октетов, поток данных не
содержит фактического маркера, обозначающего конец сообщения. Для обеспече-
ния отправки всех данных, переданных модулю TCP, должна быть реализована
функция активной отправки (push), которая заставляет TCP немедленно
отправить все данные, полученные от приложения до настоящего момента.
Данные, передаваемые протоколом TCP, рассматриваются как
неструктурированный поток октетов. В TCP не предусмотрены средства для отображения
структуры, специфической для конкретного приложения, на полученные данные.
Например, вы не можете приказать TCP интерпретировать данные как набор
записей базы данных и передавать записи по одной. Вся структуризация должна
выполняться прикладными процессами, которые обмениваются данными через TCP.
Надежность
Надежная сквозная доставка данных является одной из ключевых
особенностей TCP. Чтобы обеспечить надежную доставку, протокол TCP должен уметь
восстанавливать поврежденные, потерянные, повторяющиеся или доставленные
с нарушением исходного порядка данные. Для обеспечения надежности в TCP
используется схема повторной передачи с позитивным подтверждением PAR
(Positive Acknowledgement Retransmission). На рис. 11.4 показано, как работает
схема PAR, когда все данные и подтверждения поступают без ошибок. Новые
данные отправляются лишь после того, как будет подтверждено получение
предыдущих данных. На рис. 11.5 показано, как схема PAR используется при
восстановлении потерянных данных.
Отправитель Получатель
I £"№"""'"""*\ || || / .;"ч |
[lUHIHHHIHIHUWH E~rrrJ J lllHIMIIHIMIIIIIIIIMI Е~~Э1
I -—^__L^^77
r-—^^S^^—г "
ч- - - - -U— "
Рис. 11.4. Схема PAR при передаче данных без ошибок
Отправитель Получатель
[lumnuttmtiuuuu Eb===d j [iiiuttiintttmmtuii Е~гз J
. ^о^55^^--^Ч
Данные 2 >^>^/\t^y//
- -г — ► «^Ошибка ^^ j - Данные не
Т ^^V\P^ получены,
| подтверждение
Тайм-аут не отправлено
1 \Повторная г-_
^^—л
Рис. 11.5. Схема PAR при восстановлении после сбоя
Реализация схемы PAR в TCP основана на последовательной нумерации всех
передаваемых октетов и ожидании подтверждения (АСК) от модуля TCP,
получающего данные. Если до истечения интервала тайм-аута не будет получено
подтверждение, данные передаются заново. Модуль TCP, получающий данные,
использует нумерацию для правильного упорядочения сегментов, поступивших
с нарушением исходного порядка, и для удаления дубликатов. Искажение
переданных данных обнаруживается проверкой поля контрольной суммы в
заголовке пакета TCP. Сегменты данных, полученные с нарушением контрольной
суммы, уничтожаются. При отсутствии физических нарушений, препятствующих
работе сетевого канала, TCP обеспечивает восстановление после большинства
ошибок в коммуникационных системах Интернета.
Управление потоком данных
Получение и отправка сегментов данных TCP на разных компьютерах TCP может
производиться с разной скоростью из-за различий в вычислительной мощности
процессора и пропускной способности сети. В такой ситуации нельзя исключать
того, что скорость передачи данных отправителем будет заметно превышать
скорость их обработки получателем. В TCP реализован механизм управления
потоком данных, который позволяет контролировать объем данных, передаваемых
отправителем, — так называемое скользящее окно. На рис. 11.6
продемонстрировано применение скользящего окна в TCP. Поток данных в TCP нумеруется
на уровне октетов; номер, присвоенный октету, называется порядковым номером.
Окно
J^J°" ► 1 2 3 |~4 5 6 7 8 ; 9 10 111 12 13 14
октетов I ! I
Ч X ► < X ►
Отправленные Отправленные, Не отправленные Октеты, которые
и подтвержденные но не октеты, которые могут быть
октеты подтвержденные могут быть отправлены
октеты отправлены только после
в любой момент смещения окна
Рис. 11.6. Управление потоком данных в TCP с использованием
скользящего окна (с разрешения Learning Tree)
Модуль TCP, получающий данные, передает отправителю подтверждение
с указанием диапазона допустимых порядковых номеров, следующих за
успешно полученным последним сегментом. Диапазон допустимых порядковых
номеров называется окном. Таким образом, окно определяет количество октетов,
которые могут быть переданы отправителем до получения очередного разрешения.
На рис. 11.6 в окно включены октеты с порядковыми номерами от 4 до 11.
В приведенном примере октеты 1-3 были отправлены и подтверждены. Октеты
с 4 по И, входящие в окно, уже были отправлены или ожидают отправки, но
еще не были подтверждены. Модуль TCP на стороне отправителя не обязан
отправлять сегменты TCP, размер которых точно равен размеру окна. Окно
определяет лишь максимальное количество октетов, которые могут передаваться
без подтверждения. На рис. 11.6 октеты с 4 по 8 уже были отправлены; октеты
с 9 по 11, хотя и входят в окно, еще не были отправлены, но могут быть
отправлены в любой момент. Отправка октета 12 и далее пока невозможна, поскольку
эти октеты не входят в диапазон окна. Итак, механизм управления потоком
данных TCP обладает следующими свойствами:
О Октеты, находящиеся в потоке данных слева от окна, уже были отправлены
и подтверждены.
О Октеты, находящиеся в диапазоне окна, могут быть отправлены в любой
момент. Возможно, некоторые из этих октетов уже были отправлены, но еще не
были подтверждены. Другие октеты могут ожидать отправки.
О Октеты, находящиеся справа от окна, еще не были отправлены. Отправка
разрешена только для октетов, входящих в окно.
Левый край окна совпадает с октетом, имеющим минимальный номер, для
которого еще не было получено подтверждение. Окно смещается в потоке данных;
при подтверждении получения отправленных данных левый край окна двигается
вправо. Пакет TCP, содержащий подтверждение, содержит информацию о размере
окна, который должен использоваться отправителем.
Размер окна соответствует объему области буфера, свободной для приема новых
данных на стороне получателя. Если объем свободной части буфера уменьшается
из-за того, что получатель не успевает обрабатывать получаемые данные,
получатель приказывает уменьшить размер окна. В крайнем случае получатель может
установить размер окна равным одному октету; в этом случае отправитель после
отправки каждого октета должен дождаться подтверждения. Подобная ситуация
называется синдромом мелкого окна, и в большинстве реализаций TCP
предпринимаются специальные меры для ее предотвращения. За дополнительной
информацией обращайтесь к разделу «Борьба с синдромом мелкого окна» настоящей главы.
Передавая подтверждение с нулевым размером окна, модуль TCP сообщает
отправителю о том, что его буферы заполнены, а отправку данных следует
временно прекратить. В TCP предусмотрены средства как для уменьшения
размеров окна при накоплении необработанных данных на стороне получателя, так и
для его увеличения по мере решения проблем.
Основная цель механизма скользящего окна — обеспечение максимальной
загрузки канала данными и сокращение задержек при ожидании подтверждений.
Мультиплексирование
Протокол TCP позволяет нескольким процессам, работающим на одном
компьютере, одновременно использовать средства связи TCP; это называется
мультиплексированием. Поскольку процессы обычно используют один и тот же сетевой
интерфейс, им соответствует один и тот же IP-адрес сетевого интерфейса. Тем
не менее для идентификации процесса одного IP-адреса недостаточно, поскольку
все процессы, работающие на одном сетевом интерфейсе, обладают одинаковым
IP-адресом.
Приложения, использующие TCP, идентифицируются дополнительным
числом — номером порта. Из-за этого на компьютере могут одновременно
существовать несколько соединений, установленных разными прикладными процессами, —
каждое соединение характеризуется своей парой номеров портов. На рис. 11.7
показано, как организуется мультиплексирование нескольких соединений в TCP.
Привязка прикладных процессов к портам производится на каждом
компьютере независимо от других. Во многих системах специальный процесс
(регистратор пли супердемон) следит за номерами портов, идентифицированными или
считающимися хорошо известными для других систем.
Соединения
Чтобы прикладной процесс мог передавать данные через TCP, он должен сначала
создать соединение. Соединение устанавливается между определенной парой
портов на отправителе и получателе. Таким образом, соединение TCP требует
идентификации конечных точек, между которыми устанавливается связь. Конечная точка
(рис. 11.8) формально определяется как совокупность IP-адреса и номера порта:
(IP-адрес, номер-порта)
где IP-адрес — межсетевой адрес сетевого интерфейса, через который
обмениваются данными приложения TCP/IP, а номер порта — номер порта TCP,
определяющий приложение. Конечная точка должна включать как IP-адрес, так и номер
порта, потому что номера портов выбираются независимо каждой реализацией
TCP, а их уникальность не гарантируется. Объединение уникального IP-адреса
с номером порта обеспечивает уникальность определения конечной точки.
Порты
I 1 ТСР I 1
Прикладной уровень J vj Прикладной уровень
О О- -<5—Г Т-Ь- -<D CD
| TCP I ! I TCP i ;
I IP ! I i IP ! !
i Каналь- j j ; Каналь- j j
! НЬ1Й III I ' ныи ! !
; уровень' ' I • уровень! •
! Физи- ; ; ; Физи- ; ;
Её \ ческий ; | / ! ческий | |
If ; • I ! УР°вень• ' [I [ 1 ! уровень! •
нптнжиипинн *~ * J I , , [HiHHiiHHrniMiirtii ЬтггтгН J i i
«' ! ! Канал TCP 1 ; ! !
! ! Канал TCP 2 J J !
; Канал TCP 3
Рис. 11.7. Мультиплексирование в TCP
у Прикладной ^ ^Прикладной \ С^ Прикладной ^
^^^ процесс *"? процесс р ^т^ процесс р
Конечная точка \ Конечная точка! Конечная точка |
A97.12.5.8,80); A97.12.5.8,87); A97.12.5.8,2002);
< ? * ? < "г*
CljKL^> d 87 D <Q002^
! TCP ! I
p„ l ,p I I I
|щишп; ! 1
Ъшяшм^ IP-адрес
liMtiiMiHiitiimnlin &=l I 197.12.5.8 i ■ i
Сетевой ч-_ ч-_ ч-_
интерфейс
Рис. 11.8. Конечные точки в TCP
Соединение TCP устанавливается между двумя конечными точками (рис. 11.9)
и определяется параметрами обеих конечных точек:
AР-адрес-1, номер-порта-1, 1Р-адрес-2, номер-порта-2)
Это позволяет нескольким прикладным процессам установить соединпшг
с одной удаленной конечной точкой. На рис. 11.9 изображены прикладные про
цессы, соединенные с удаленной точкой A99.11.21.1, 2001). Модуль TCP на х<>
сте 199.11.23.1 различает разные соединения, так как в TCP соединение
определяется как локальной, так и удаленной конечной точкой. На рис. 11.9 конечная
точка A99.11.21.1, 2001) остается одной и той же, но точки на другом конце
соединения имеют разные параметры, благодаря чему TCP различает эти
соединения.
k^jLp~b Номер kf ц[р~^} Номер
Гу~^щГпорта pJ3i]4nopTa
П Полная ГТ
ассоциация I
ляшшт— с номером порта — юшшйч
IpMgwa TCP (top. 199.21.32.2, TCP JfagH
^^Ш^л'Фшй^Ж^Ш^ 1QQ 91 *\0 9 HQfi CO 109 л 1Щ'Г*«й^^шс14Ж»ш1ш« J
\\_ Г Сеть IP J J]
Рис. 11.9. Соединение TCP между конечными точками (с разрешения Learning Tree)
Рисунок 11.9 также показывает, что TCP может поддерживать несколько
параллельных соединений. Данные этих соединений мультиплексируются через
один сетевой интерфейс.
Соединение полностью определяется парой конечных точек. Локальная
конечная точка может участвовать в нескольких соединениях с разными
удаленными конечными точками. Соединения TCP поддерживают пересылку данных
в обоих направлениях; такие соединения называются дуплексными.
Говоря о соединениях TCP, будет полезно определить понятия половинной
и полной ассоциации. Половинная ассоциация состоит из определения конечной
точки и имени транспортного протокола:
(транспортный протокол, IP-адрес, номер порта)
Следовательно, на рис. 11.9 присутствуют половинные ассоциации
(tcp, 199.21.32.2, 1400)
(tcp, 196.62.132.1, 21)
Полная ассоциация состоит из двух половинных ассоциаций и записывается
в следующем формате:
(транспортный протокол, IP-адрес-1, номер порта-1, 1Р-адрес-2, номер порта-2)
Транспортный протокол указывается только один раз, потому что он должен
быть одним и тем же для обеих половинных ассоциаций. Понятия полных и
половинных ассоциаций удобны при описании разных транспортных протоколов.
Например, полная ассоциация на рис. 11.9 записывается в виде
(tcp, 199.21.32.2, 1400, 196.62.132.1, 21)
Полная ассоциация, включающая IP-адреса отправителя и получателя, а также
номера портов отправителя и получателя, однозначно определяет соединение TCP.
Программная среда хостов TCP
Протокол TCP реализуется в виде модуля, взаимодействующего с
операционной системой компьютера. Во многих операционных системах обращение к
сервису TCP имеет много общего с обращением к сервису файловой системы. В
частности, модель файловой системы заложена в основу интерфейса сокетов BSD,
реализованного в системах семейства Unix, и более нового интерфейса Winsock,
реализованного в операционных системах Microsoft.
Работа модуля TCP зависит от других функций операционной системы,
обеспечивающих управление его структурами данных и выполнение служебных
операций. Интерфейс с сетью обычно находится под управлением модуля драйвера
устройства. TCP не взаимодействует с модулем драйвера устройства напрямую.
Вместо этого TCP обращается к модулю IP, который, в свою очередь, обращается
к модулю драйвера устройства (рис. 11.10).
Также возможен вариант с размещением модулей стека протоколов TCP/IP
на отдельной станции, называемой фронтальным процессором (front-end processor).
Фронтальный процессор действует как специализированное коммуникационное
устройство, обеспечивающее работу модулей протоколов (рис. 11.11). Должен
существовать механизм, обеспечивающий взаимодействие хоста с фронтальным
процессором. Как правило, этот механизм работает через интерфейс файловой
системы.
С абстрактной точки зрения приложения взаимодействуют с модулем TCP
при помощи следующих системных функций:
О OPEN — открытие соединения;
О CLOSE — закрытие соединения;
О SEND — отправка данных по открытому соединению;
О RECEIVE — получение данных по открытому соединению;
О STATUS — получение информации о соединении.
Эти системные функции реализуются по аналогии с функциями
операционной системы, вызываемыми пользовательскими программами. Например, функ-
ции открытия/закрытия соединений можно рассматривать как аналоги
функций открытия/закрытия файлов, а функции отправки/приема данных — как
аналоги функций чтения/записи файлов.
С Модуль < Транспортный уровень
( TCP ^
С Модуль 2 сетевой уровень
С Драйвер 2
л" устройства J
Ч Канальный уровень
А Интерфейс J
у к сетевому л
С оборудованию \
Рис. 11.10. Взаимодействие модуля TCP с сетью
Системные функции TCP могут взаимодействовать с другими модулями TCP,
находящимися на любом узле объединенной сети. Системным функциям TCP
при вызове передаются соответствующие параметры: IP-адреса, тип сервиса,
приоритет, безопасность, номер порта приложения и т. д.
Компьютер, на котором г J £&
работают приложения у Приложения 'S ^
\. чч -! ТСР i
\ * лшътжк |Р :
т. ^^шяМ^п^ш '
Фронтальный
процессор
Рис. 11.11. Удаленное выполнение модулей TCP
Открытие и закрытие соединений TCP
Открываемое соединение передается при вызове OPEN для локального порта.
Параметры, передаваемые при вызове, определяют вторую конечную точку.
Системная функция возвращает манипулятор (handle) соединения — короткое
целое число, используемое для ссылки на соединение при дальнейших
вызовах. Информация о соединении хранится в структуре данных, называемой ТСВ
(Transmission Control Block); для обращения к информации из ТСВ используется
манипулятор.
В TCP определены две разновидности вызовов OPEN:
О Активный вызов OPEN.
О Пассивный вызов OPEN.
В первом случае соединение устанавливается в активном режиме. Активный
вызов OPEN преобразуется в сообщение TCP, которое отправляется другой
конечной точке.
Пассивный вызов OPEN сигнализирует об ожидаемом приеме уведомления
об активном установлении соединения; сегменты TCP в этом случае не
генерируются. Пассивный вызов OPEN означает, что процесс предпочитает принять
входящий запрос на соединение, нежели пытаться инициировать соединение
самостоятельно. Довольно часто процесс, выполнивший пассивный вызов OPEN,
принимает запрос на соединение от любой обратившейся стороны. Также при
пассивном вызове OPEN можно указать, что запрос на соединение должен
приниматься только от конкретной конечной точки.
TCP информирует процессы, которые выдают пассивные запросы OPEN и
ожидают поступления активных вызовов OPEN от других процессов, об
установлении соединения (рис. 11.12).
TCP TCP
Пассивный вызов со
'~ стороны получателя '"
If \\\Р 1 ---_.. I If \\ IP
: L I """""Л^'Н'-■ h '
V—■■ __ _ i—ir
[nmiimiinimuuiii Errrrd J [Hiiinmiiiiiiniiinii EE==J J
"""""" -———^wl Получатель
^ в состоянии
Л «п прослушивания
L4 Соединение TCP открыто >J
Рис. 11.12. Создание соединения TCP с использованием активного и пассивного запросов OPEN
Два процесса, одновременно выдавшие активные запросы OPEN, также будут
успешно соединены (рис. 11.13). Создание соединений TCP при помощи двух
активных вызовов OPEN часто применяется в распределенных средах, где
компоненты могут действовать асинхронно по отношению друг к другу.
Структура пакета TCP
На рис. 11.14 изображена структура пакета TCP. Заголовок TCP, как и в
большинстве протоколов семейства TCP/IP, делится на 32-разрядные блоки.
Ниже приводятся более подробные описания отдельных полей заголовка TCP.
Номера портов отправителя и получателя
Номера портов отправителя и получателя (см. рис. 11.14) используются для
идентификации конечных процессов, связанных виртуальным каналом TCP. Таким
образом, номера портов определяют связи между процессами. Некоторые номера
портов считаются хорошо известными (то есть фиксируются), другие
назначаются динамически.
TCP TCP
If^V^ll ,Р [( ' ' ll ,P
1 I:-"- *:'■''.:■■':■:*:"+: J I I I I V ,';, | ..",,~. и,/ I
|н|Ц|нн|тини«щ L==r=d) [iiimiHHimmiHwi hard J
L4 Соединение TCP открыто -- w
Рис. 11.13. Создание соединения TCP с использованием двух активных запросов OPEN
< 32 бита ►
I—i—i—i—i—»—1—1—1—1—1—1—1—\—i—i—[—i—i—i—i—i—i—i—i—i—i—i—i—i—i—i—j
Порт отправителя Порт получателя
I 1 1 h-Ч 1 1—1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Порядковый номер
—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—!—I—I—I—I—I—I—I—I—I—I—I—I—I—I—
Номер для подтверждения (АСК)
—i—i—i—I—i—i—'—i—'—IuIaIpIrIsI р\—'—'—'—'—'—'—'—'—'—'—'—'—'—'—'—
Смещение Зарезервиро- Ш *
данных вано г Ьг м т м м
—I—i—I—I—i—i—i—I—i—1°1ЧП1 ' \"\п\—i—I—i—i—I—I—i—i—i—I—i—I—I—I—l—
Контрольная сумма Указатель срочности
—I—I—I—I—I—I—I—!—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—I—
<<! Параметры Дополнение <ц^
Ьч—I—I—I—I—I—I—i—I—I—i—i—i—i—i—i—i—i—i—i—i—i—i—I—I—i—i—i—i—i—i—|
<i Данные <i
С L—l 1—J 1 1 1 > I 1 1 1 1 1 I I l__J 1,1 I I I I I—-I I I I l_J 1
Рис. 11.14. Структура пакета TCP
Список назначенных номеров, содержащий описания ряда хорошо
известных портов, периодически публикуется в RFC (под разными номерами).
ПРИМЕЧАНИЕ
Номера портов в диапазоне 0-1 023 относятся к категории хорошо известных номеров, а их
администрирование осуществляет IANA. Номера портов, превышающие 1023, могут
регистрироваться, но не находятся под контролем IANA. Эти номера портов называются зарегистрированными.
Не все порты с номерами от 1024 и выше относятся к категории зарегистрированных. Некоторые
номера портов, называемые временными номерами, переназначаются по мере надобности.
Назначение временных номеров портов производится модулем TCP no алгоритму, специфическому для
конкретной реализации.
Модули TCP могут по своему усмотрению ассоциировать номера портов с
любыми прикладными процессами (за исключением того, что хорошо известные
номера портов резервируются для конкретных приложений). Во многих
операционных системах прикладные процессы могут «захватывать» порты. Номера
таких портов выбираются случайным образом (при этом они должны быть
больше 1023. В некоторых реализациях используется алгоритм хэширования,
который выделяет номера портов в зависимости от имени процесса. Как правило,
имя процесса определяет значения старших битов номера порта.
Порядковый номер и номер для подтверждения
Надежность передачи данных в TCP обеспечивается двумя специальными
полями — порядковым номером и номером для подтверждения. На концептуальном
уровне каждому октету данных присваивается порядковый номер. Порядковый
номер первого октета данных в сегменте сообщения передается в заголовке TCP
этого сегмента и называется порядковым номером сегмента.
Сегменты, отправляемые получателем, также содержат номер для
подтверждения, который совпадает с порядковым номером следующего ожидаемого
октета данных. Передача данных по протоколу TCP является дуплексной. В
любой момент времени модуль TCP выполняет как функции отправителя для
передаваемых им данных, так и функции получателя для данных, принимаемых от
других отправителей.
Когда модуль TCP желает отправить сегмент, он заносит копию сегмента в
очередь передачи и запускает таймер. Если подтверждение получения данных
приходит до истечения таймера, сегмент удаляется из очереди. Если же
получение данных не подтверждается, то сегмент отправляется заново (из копии,
хранящейся в очереди).
32-разрядный порядковый номер (см. рис. 11.4) определяет номер первого
байта данных в текущем сообщении. Если флаг SYN равен 1, то поле определяет
начальный порядковый номер (ISN, Initial Sequence Number) для текущего сеанса,
а первое смещение данных должно быть равно ISN+1. Тем самым предотвращается
использование старых порядковых номеров, которые могли быть ранее назначены
данным, пересылаемым в сети.
Поле номера для подтверждения определяет порядковый номер следующего
байта, ожидаемого получателем. Подтверждения TCP носят накопительный
характер. Другими словами, одно подтверждение может подтверждать
получение сразу нескольких переданных сегментов TCP.
Подтверждения TCP означают лишь факт приема данных модулем TCP.
Подтверждения не гарантируют, что данные были доставлены приложению,
использующему сервис TCP для пересылки данных. Ответственность за доставку
данных приложению лежит на модуле TCP, работающем на стороне получателя.
Ошибки в работе модуля TCP или прикладного интерфейса могут привести
к тому, что данные не будут доставлены приложению.
Смещение данных
Поле смещения данных определяет размер заголовка TCP в 32-разрядных блоках
(см. рис. 11.14). Оно должно присутствовать в заголовке, потому что поле
параметров может иметь переменную длину. Без параметров TCP поле смещения
данных равно 5 B0 октетов). Длина заголовка TCP, даже если он содержит
параметры, всегда кратна 32 битам.
В настоящее время определен только один параметр TCP — максимальный
размер сегмента (MSS, Maximum Segment Size). При наличии этого параметра
поле смещения данных равно 6 B4 октета).
Зарезервированное поле, следующее за полем смещения данных, должно быть
равно 0.
Флаги
Следующее поле в заголовке TCP (см. рис. 11.4) содержит набор флагов.
О Установка флага АСК указывает на то, что поле номера для подтверждения
содержит действительное значение.
О Флаг SYN обозначает открытие виртуального канала.
О Флаг FIN используется для закрытия соединения.
О Флаг RST сбрасывает виртуальный канал при возникновении неисправимых
ошибок. При получении сегмента TCP с установленным флагом RST
получатель должен ответить немедленным закрытием соединения. В случае сброса
обе стороны должны немедленно освободить соединение и все его ресурсы.
При этом пересылка данных в обоих направлениях прекращается, что может
привести к потере передаваемых данных. Сброс с использованием флага TCP
RST применяется только в аварийных ситуациях. Для нормального закрытия
соединений TCP следует использовать флаг FIN. Например, сброс может
производиться из-за сбоя на хосте или отложенном получении дубликатного
пакета SYN.
О Установка флага PSH означает, что протокол TCP должен немедленно
доставить данные полученного сегмента процессу верхнего уровня.
О Флаг URG обеспечивает экстренную отправку данных без ожидания
обработки получателем октетов, уже находящихся в потоке.
При открытии соединений TCP используется процедура согласования,
основанная на обмене тремя пакетами со следующими значениями флагов SYN и АСК:
SYN=1 и АСК=0 — открытие соединения
SYN=1 и АСК=1 — подтверждение открытия соединения
SYN=0 и АСК=1 — пакет данных или пакет АСК
Процедура открытия соединения TCP, использующая управляющий флаг
синхронизации SYN, изображена на рис. 11.15.
Пользователь
Пассивное
ТСВ ^ открытие
ТСВ = Блок управления передачей
Рис. 11.15. Использование флага TCP SYN (с разрешения Learning Tree)
Соединение инициируется получением сегмента с установленным флагом SYN,
для которого имеется ожидающий блок ТСВ. Прибывающий сегмент TCP
генерируется активным вызовом OPEN, а ожидающий блок TCP появляется в
результате пассивного вызова OPEN. При наличии парных вызовов OPEN (для
активного и пассивного) создается соединение. Установленный флаг SYN (SYN=1)
является признаком синхронизации порядковых номеров в обоих направлениях.
На рис. 11.15 активный вызов OPEN генерирует сегмент TCP со следующими
значениями флагов:
SYN = 1, АСК = О
Когда модуль TCP на стороне получателя, выполнивший пассивный вызов
OPEN, получает активный вызов OPEN, он подтверждает его передачей пакета
со следующими флагами TCP:
SYN - 1, АСК - 1
Такое подтверждение активного пакета OPEN иногда называется пассивным
пакетом OPEN. Установленный флаг АСК (АСК=1) означает, что поле номера
для подтверждения содержит действительные данные.
Общая последовательность трехфазного открытия соединения
проиллюстрирована на рис. 11.16.
Фаза 1 Фаза 2 Фаза 3
Отправитель Получатель Отправитель
I Можно ли открыть? I I Да, можно I SEQ = X+1+Z I
SEQ=X SEQ = Y ACK = Y + 1
ACK=0 ACK = X+1+Z
Передача Продолжение
необязательных отправки
данных данных
Отправка
Z октетов
Рис. 11.16. Трехфазное согласование при открытии соединения (с разрешения Learning Tree)
На шаге 1 (см. рис. 11.16) отправляется активный вызов OPEN с порядковым
номером X. Вместе с активным пакетом OPEN отправитель может переслать
дополнительные данные. Например, эти данные, состоящие из Z октетов, могут
содержать атрибуты аутентификации (имя и пароль) для запрашиваемого
сервиса. В большинстве приложений TCP/IP атрибуты аутентификации передаются
после открытия соединения. Тем не менее в некоторых сетях (например, при
использовании TCP/IP в сетях Х.25) атрибуты аутентификации могут
пересылаться вместе с запросом OPEN. Значения полей порядкового номера и номера
для подтверждения задаются следующим образом:
порядковый номер = X
номер для подтверждения = О
На шаге 2 получатель отвечает пакетом, в котором номер для подтверждения
равен X+1+Z — следующему ожидаемому номеру октета. Также задается
начальный порядковый номер (Y), используемый получателем. Поля порядкового
номера и номера для подтверждения задаются следующим образом:
порядковый номер = Y
номер для подтверждения = X + 1 + Z
На шаге 3 отправитель подтверждает получение порядкового номера от
получателя. Поля порядкового номера и номера для подтверждения задаются
следующим образом:
порядковый номер = X + 1 + Z
номер для подтверждения = Y + 1
Зачем нужна третья фаза в трехфазном процессе? Этот вопрос часто
становится причиной недоразумений. Третья фаза завершает согласование и
информирует получателя о том, что его исходный порядковый номер был принят источ-
ником, открывшим соединение TCP. Без этого подтверждения получатель не
может быть уверен в том, что отправитель знает правильный начальный
порядковый номер. Ниже приведена краткая сводка трехфазного согласования:
О Фаза 1. Отправитель посылает свой начальный порядковый номер (ISS, Initial
SEND Sequence Number).
О Фаза 2. Получатель подтверждает получение ISS; для этого он отправляет ответ
с номером для подтверждения, на 1 большим ISS (и дополнительных данных,
которые могли быть переданы отправителем). Получатель отправляет свой
исходный порядковый номер (IRS, Initial RECEIVE Sequence Number).
О Фаза 3. Отправитель передает номер для подтверждения, чтобы получатель
мог быть уверен в успешной доставке отправленных им данных.
Для предотвращения возможной отправки сегментов с порядковым номером,
совпадающим с порядковым номером другого, старого сегмента, в TCP
используется концепция максимального срока жизни сегмента (MSL, Maximum Segment
Lifetime). MSL определяет время, которое должно пройти перед назначением
любых порядковых номеров при запуске или восстановлении после сбоя (при
котором информация о ранее использовавшихся порядковых номерах теряется).
В спецификации TCP указано значение MSL, равное двум минутам. Если
реализация TCP может обеспечить хранение информации об использовавшихся
порядковых номерах, то она может обойтись без ожидания в течение MSL и
немедленно начать использовать порядковые номера, большие тех, которые
использовались ранее.
Нумерация всех октетов в TCP приводит к быстрому расходованию
порядковых номеров. Если октеты передаются со скоростью 2 Мбит/с, 232 порядковых
номеров октетов будут израсходованы за 4,5 часа. Поскольку максимальный срок
жизни сегмента в сети вряд ли превысит десятые доли секунды, это время
обеспечивает достаточную защиту для скоростей, измеряемых десятками мегабит в
секунду. На скорости 100 Мбит/с порядковые номера расходуются за 5,4 минуты, что
все равно больше двух минут, определяемых в спецификации TCP (RFC 793).
Как выбирается значение ISN? В RFC 792 для выбора нового 32-разрядного
ISN рекомендуется использовать генератор — например, связанный с
32-разрядными показаниями часов, увеличивающимися примерно каждые 4 микросекунды.
В этом случае циклическое повторение ISN происходит примерно каждые 4,55
часа. Маловероятно, чтобы сегменты оставались в сети более 4,55 часа;
следовательно, можно с полным основанием считать, что значения ISN уникальны.
После установления соединения TCP флаг АСК всегда равен 1, что
указывает на действительность содержимого поля номера для подтверждения. Далее
обе стороны начинают обмениваться сообщениями и происходит дуплексный
обмен данными, который продолжается до того момента, когда соединение TCP
потребуется закрыть.
Когда соединение TCP будет готово к закрытию, передается пакет с
установленным управляющим флагом FIN. В TCP отправка флага FIN не приводит
к автоматическому закрытию соединения — обе стороны должны отправить флаг
FIN и тем самым согласиться на закрытие соединения. Такой способ закрытия
называется корректным закрытием и предотвращает неожиданный выход одной
из сторон из соединения. Попробуем представить, что произойдет, если одна
сторона закроет соединение, не поставив об этом в известность другую сторону.
Другая сторона продолжит передавать данные, не получая подтверждений,
поскольку соединение уже разорвано. Это приведет к потере данных. Механизм
корректного закрытия, изображенный на рис. 11.17, предотвращает потерю
данных вследствие преждевременного выхода из соединения TCP.
TCP ULP
ULP TCP
Отправка""► —^ ^_ АСК
^ -^^
о w 44г^~*~~^^ FIN = 1 ^
Закрытие -->► ► --■>
^^^~ <— Отправка
^^^^\~ Ч--- Отправка Не готов
^—-^ ^— ^ к к закрытию
^--—--~" —~*"~"~~^ ^^-_-^- Ч— Отправка
АСК ---► -^^^^
•<— Закрытие
Закрытие «<-- -4г-"~"
АСК --> ►
Готов к закрытию
ULP = протокол верхнего уровня
(Upper Layer Protocol)
Рис. 11.17. Использование флага корректного закрытия FIN (с разрешения Learning Tree)
Говоря об использовании флагов TCP при отправке сообщений, также
следует уделить внимание флагу PSH. Флаг PSH первоначально предназначался
для оповещения TCP о немедленной обработке полученных данных. Если
приложение выдает серию вызовов SEND без установки флага PSH, модуль TCP
может накапливать данные в своем внутреннем буфере без отправки.
Аналогично, при получении серии сегментов без флага PSH модуль TCP может ставить
данные во внутреннюю очередь вместо того, чтобы передать их
соответствующему приложению. Бит PSH не используется для пометки записей и не зависит
от границ сегментов. Тем не менее некоторые реализации ошибочно
воспринимают PSH как метку записи. При пакетировании данных для отправки
наибольшего возможного сегмента передающая сторона должна объединять
последовательные установленные флаги PSH, заменяя их одним флагом.
Модуль TCP может реализовать поддержку флагов PSH для вызовов SEND.
Если поддержка PSH не реализована, то работа отправляющего модуля TCP
должна подчиняться следующим правилам:
1. Данные не должны храниться в буфере в течение неограниченного времени.
2. Модуль TCP должен установить флаг PSH в последнем буферизованном
сегменте (например, если в очереди нет других данных, ожидающих отправки).
В RFC 793 ошибочно утверждается, что полученный флаг PSH должен
передаваться прикладному уровню. Сейчас передача полученного флага PSH
прикладному уровню не обязательна.
Прикладная программа должна установить флаг PSH в вызове SEND
каждый раз, когда потребуется выполнить принудительную доставку данных для
предотвращения взаимных блокировок. Тем не менее для повышения
эффективности передачи модуль TCP должен по возможности отправлять сегменты
максимального размера. Отсюда следует, что на стороне отправителя PSH
установка флага PSH не обязательно приводит к немедленной отправке сегмента.
Если флаг PSH не реализован в вызовах TCP SEND (или если в интерфейсе
«приложение/TCP» используется чисто потоковую модель), ответственность
за объединение мелких фрагментов данных в сегменты нормального размера
частично возлагается на прикладной уровень. Как правило, протоколы
интерактивных приложений должны устанавливать флаг PSH — по крайней мере, в
последнем вызове SEND каждой команды или ответа. Протоколы массовой
передачи данных (такие, как FTP) должны устанавливать флаг PSH в последнем
сегменте файла или по мере необходимости для предотвращения блокировки
буфера. Рисунок 11.18 поясняет использование флага PSH.
Модуль TCP Модуль TCP
отправителя получателя
о о ч-
^ ^ ^ При установке
<л со со I I флага PSH
^ I ^ I °; I I I данные в буфере
ПП fSl fSl т4 принудительно
шшш доставляются
I °° J I Iе0 J Ll °° I приложениям
I 1^1 1^1 1^ к
Буферы TCP Буферы TCP
| SEG11 SEG2|SEG3| ~"j | | ~]
v м / ж р=;
у -г-
A SEG, PSH = 1
| I I
Установленный флаг PSH
приказывает немедленно
отправить сегменты,
накопленные в буферах TCP
Рис. 11.18. Использование флага TCP PSH (с разрешения Learning Tree)
На стороне получателя бит PSH форсирует немедленную доставку
буферизованных данных приложению (даже если полученные данные не заполняют
буфер). И наоборот, отсутствие PSH помогает обойтись без лишних обращений
к прикладному процессу, что может существенно повысить производительность
работы на крупных хостах с разделением времени.
В TCP также предусмотрены средства экстренной отправки данных с
использованием флага URG. Флаг URG используется в сочетании с полем
указателя срочности для обхода очереди и немедленной отправки важного
сообщения для получателя. Благодаря механизму экстренной передачи отправитель
может передавать сигналы прерывания и отмены, которые при поступлении к
получателю не ставятся в стандартную очередь данных.
Посмотрим, что могло бы произойти без такого механизма. Предположим, вы
хотите отменить обработку передаваемых пользовательских данных. Если
экстренное сообщение будет ставиться получателем в обычную очередь данных TCP,
оно может оказаться бесполезным, поскольку такое сообщение будет прочитано
лишь после обработки всех данных, предшествующих экстренному сообщению
в очереди. Как правило, в этих случаях экстренное сообщение будет
обрабатываться слишком поздно. А если прикладной процесс, которому адресовано
экстренное сообщение, «зависнет» после чтения неверных данных, то это
сообщение вообще не будет прочитано.
Установка флага URG означает, что поле указателя срочности содержит
действительные данные (рис. 11.19). В RFC 1122 говорится, что указатель
срочности ссылается на порядковый номер последнего октета LAST (не LAST+1)
в последовательности срочных данных, а в RFC 793 приводится неправильная
ссылка на LAST+1.
Реализация TCP должна поддерживать передачу экстренных данных
произвольной длины. Уровень TCP асинхронно информирует прикладной
уровень о получении указателя срочности без необработанных срочных данных или
о том, что срочный указатель вызывает смещение текущей позиции в потоке
данных. При этом должен существовать механизм, при помощи которого
приложение могло бы узнать, сколько экстренных данных ожидает чтения из
соединения или по крайней мере — существуют ли такие данные. Хотя область
применения механизма срочности не ограничена, обычно он используется для
отправки команд прерывания в программе Telnet. Асинхронное оповещение
позволяет приложению перейти в режим экстренного чтения данных из
соединения TCP. Таким образом, приложение может получать управляющие команды
даже в том случае, если его стандартные буферы ввода заполнены
необработанными данными.
Окно
Поле окна используется получателем для управления потоком данных.
Модуль TCP на стороне получателя сообщает модулю TCP на стороне отправителя
размер «окна», то есть количество октетов (начиная с номера для
подтверждения), которое в настоящий момент готов принять модуль TCP на стороне
получателя.
Ф Используется
для внеочередной
отправки данных.
Обрабатывается получателем
немедленно, без ожидания
обработки предшествующих
октетов потока
• Имеет смысл только при URG = 1
. _—, > TELENET 5
Ж ^—>
l^n^1^^! > тср р
Заголовок TCP Экстренное
<URG> urg = 1 сообщение
t t
SEQ SEQ + URGPTR - 1
• Указатель срочности
обозначает последний
октет срочного сообщения
Рис. 11.19. Флаг TCP URG (с разрешения Learning Tree)
Контрольная сумма
Поле контрольной суммы содержит дополнение до 1 суммы дополнений до 1
всех 16-разрядных слов пакета TCP. Для вычисления контрольной суммы перед
заголовком TCP подставляется 96-разрядный псевдозаголовок (рис. 11.20),
который позволяет убедиться в том, что пакет прибыл к правильному месту
назначения. Псевдозаголовок обеспечивает защиту от ошибок маршрутизации
сегментов. В нем присутствует идентификатор протокола F для TCP), IP-адреса
отправителя и получателя. Поскольку заголовок TCP содержит номера портов
отправителя и получателя, совокупность данных в заголовках описывает
соединение между конечными точками, то есть задает полную ассоциацию,
образованную соединением TCP.
Поле длины TCP в псевдозаголовке содержит суммарную длину заголовка
TCP и данных в октетах (значение не передается в явном виде, а вычисляется).
В значении поля не учитываются 12 октетов псевдозаголовка.
Параметры
Поле параметров TCP может находиться в конце заголовка TCP, а его длина
должна быть кратна 8 битам. Значение поля параметров учитывается при вычис-
лении контрольной суммы. Параметры могут начинаться с произвольной
границы октета.
Существует два формата параметров:
О Тип параметра (один октет).
О Тип параметра (один октет), длина параметра (один октет) и собственно
данные параметра.
О 8 16 24 31
i ' ' ' '—п
IP-адрес отправителя
I Псевдо-
Г заголовок
IP-адрес получателя
О I Про™ол I Длина TCP
Заголовок TCP
^С^ Данные <у,
Рис. 11.20. Псевдозаголовок при вычислении контрольной суммы TCP
В поле длины параметра учитываются первые два октета (тип и длина) и
собственно октеты данных. Фактическая длина списка параметров может быть
меньше указанной в поле смещения данных, в этом случае оставшаяся часть
заголовка после параметра с типом 0 заполняется нулями.
В настоящее время определены следующие параметры:
Тип Длина Описание
0 - Конец списка параметров
1 - Нет операции
2 4 Максимальный размер сегмента
Параметры типа 0 и 1 являются представителями первого формата.
Структура параметров TCP показана на рис. 11.21.
Параметр типа 0 обозначает конец списка параметров, который может не
совпадать с концом заголовка TCP, определяемым полем смещения данных. Он
находится в конце всего списка параметров (а не каждого параметра по
отдельности!). Присутствие этого параметра обязательно только в том случае,
если список параметров не совпадает с концом заголовка.
I oooooooo ~|
Тип = 0
I 00000001 ~]
Тип = 0
I 00000010 | 00000100 | MSS ~|
Тип = 0 Длина = 4
Рис. 11.21. Параметры TCP
Параметр типа 1 может находиться между параметрами для того, чтобы
начало следующего параметра было выровнено по границе слова. Использование
этого параметра отправителем TCP не гарантировано, поэтому получатели TCP
должны быть готовы обрабатывать параметры даже в том случае, если они не
начинаются с границы слова.
В настоящее время только параметр типа 2 несет полезную информацию —
максимальный размер сегментов (MSS). Значение MSS согласовывается только
в начале соединения TCP, при синхронизации порядковых номеров (при
установленном флаге SYN). Обычно каждая сторона соединения TCP отправляет
свой параметр MSS, сообщая его используемое значение другой стороне. Если
параметр MSS не используется, разрешаются сегменты любого размера.
Накопительные подтверждения в TCP
По сравнению с транспортными протоколами в других семействах протоколов
в TCP принята несколько необычная интерпретация порядковых номеров. В
большинстве транспортных протоколов порядковый номер относится к номеру
пакета. В TCP дело обстоит иначе — порядковые номера назначаются отдельным
октетам. TCP передает октеты в сегментах переменной длины. Если получатель
не подтвердил получение сегмента, эти сегменты передаются заново. Не
существует гарантии того, что повторно передаваемый сегмент будет в точности
совпадать с исходным, потому что с момента отправки исходного пакета
приложение-отправитель могло сгенерировать дополнительные данные.
Следовательно, номер для подтверждения не может относиться к отправленному сегменту.
В TCP номер для подтверждения определяет позицию в потоке данных, до
которой данные были получены и подтверждены удаленным модулем TCP. Один
номер для подтверждения может подтверждать получение октетов, переданных
в разных сегментах данных. На рис. 11.22 изображены три сегмента, переданные
отправителем, которые подтверждаются всего одним номером для подтверждения.
Многие реализации TCP стремятся свести к минимуму количество
отдельных сегментов подтверждений. Например, реализация TCP может постараться
отправлять одно подтверждение для каждых двух полученных сегментов данных.
Поскольку сегменты TCP в конечном счете инкапсулируются в
дейтаграммах IP, нельзя гарантировать того, что они поступят к получателю в
определенном порядке. Модуль TCP на стороне получателя использует порядковые номера
для формирования непрерывного потока октетов. Получатель подтверждает
самую длинную непрерывную последовательность октетов, принятую до настоя-
щего момента. Если в потоке октетов имеется пробел, представляющий
потерянные данные, модуль TCP на стороне получателя подтверждает только данные,
предшествующие пробелу.
Отправитель Получатель
Ф ^^X — Одно подтверждение
^Л^-^^^ для трех предыдущих
^itf№>^^ сегментов данных
Рис. 11.22. Одно подтверждение для нескольких сегментов данных
Преимущество накопительных подтверждений заключается в том, что потеря
подтверждений не означает необходимости повторной пересылки.
Следовательно, даже если одно подтверждение было потеряно в процессе передачи,
последующие подтверждения подтвердят ранее все данные, которые были получены
до настоящего момента. С другой стороны, накопительные подтверждения
становятся неэффективными при потере части принимаемых данных. Данные,
находящиеся после пробела, могут быть подтверждены только после того, как будут
приняты отсутствующие данные. Отправитель не получает информации об
успешном приеме данных после пробела, потому что получатель может подтвердить
только данные, предшествующие пробелу. Рисунок 11.23 поясняет ситуацию.
На этом рисунке сегменты SEG2 и SEG3 были приняты успешно, а сегмент SEG1
был потерян во время передачи.
Хотя сегменты SEG2 и SEG3 были приняты успешно, потерянный сегмент
SEG1 образует пробел в потоке данных, принимаемом на стороне получателя.
Отправитель не может сместить окно, так как он еще не получил
подтверждения для SEG1. Получатель не располагает средствами, которые позволили бы
сообщить отправителю об успешном приеме сегментов SEG2 и SEG3. На этой
стадии возможны две ситуации:
1. Отправитель дожидается тайм-аута и заново передает сегменты SEG1, SEG2
и SEG3. В этом случае пересылка сегментов SEG2 и SEG3 оказывается лишней,
поскольку эти сегменты уже были успешно приняты получателем. Повторная
пересылка SEG2 и SEG3 лишь порождает избыточный сетевой трафик.
• Подтверждения
- Относятся к позиции байта
в строке, а не к номеру пакета
- Имеют накопительный характер
Достоинство: потеря подтверждений
не приводит к вынужденной
повторной передаче
Недостаток: отправитель не знает
об успешно принятых данных
после потерянного фрагмента
SEQ= 101
\<— Размер окна—> SEG 2 SEG 3
I i_ Буфер Буфер . ? Ш////Ш////1
I Г отправки получения П ; Ш//Ш/////1
Потерян
[SEG 1|SEG 21SEG 3| ^ ^^ Ч^
1 ( |SEG1J X Л
f |SEG 2J [SEG 3| )
< ^~~\Л уч^_^
АСК = 101 Ч -^
Рис. 11.23. Отправитель не может получить информацию об успешно
принятых данных (с разрешения Learning Tree)
2. Отправитель дожидается тайм-аута, отправляет только сегмент SEG 1 и
ожидает подтверждения, прежде чем принимать решение о пересылке
дополнительных данных. Когда получатель принимает SEG1, он отправляет пакет с
накопительным подтверждением, которое подтверждает принятие сегмента SEG1
и ранее переданных сегментов SEG2 и SEG3. Хотя этот сценарий кажется более
эффективным, следует учитывать, что отправитель должен дождаться
подтверждения SEG1 перед тем, как передавать SEG2 и SEG3. Следовательно,
отправитель не использует преимущества большого окна и передает данные
только по одному сегменту.
Адаптивный тайм-аут в TCP
Протокол TCP изначально проектировался для работы в глобальных сетях
(WAN); позднее он был адаптирован для локальных сетей. По этой причине
TCP обладает рядом преимуществ перед протоколами, которые разрабатывались
только для локальных сетей. В частности, в TCP предусмотрены нетривиальные
алгоритмы, которые автоматически подстраиваются под широкий диапазон
задержек, возникающих при отправке сообщений в глобальных сетях. Для
локальных сетей такое разнообразие задержек не характерно.
Протокол IP обладает одним интересным свойством: даже если уровень IP
дважды передает одно сообщение по одному маршруту, время прибытия
сообщения к конечной точке будет различаться из-за следующих факторов:
О В глобальных сетях сообщения обычно передаются последовательно, то есть
по одному. Если канал глобальной сети занят отправкой других данных,
сообщению придется ждать в очереди, что вносит в задержку элемент
неопределенности.
О Маршрутизаторы, разделяющие сегменты глобальных сетей, могут быть
перегружены пиковым трафиком. Возможно, дейтаграммам IP, принимаемым
маршрутизатором, придется ждать в очереди, пока маршрутизатор не сможет
определить маршрут для дейтаграммы. Но даже после определения маршрута
дейтаграммам иногда приходится ждать в очереди, пока не освободится
сетевой интерфейс, открывающий доступ к маршруту. Наконец, в худшем случае
дейтаграммы поступают с такой скоростью, что они заполняют всю свободную
память маршрутизатора, и последнему приходится удалять дейтаграммы, не
помещающиеся в памяти. Такая ситуация возможна из-за того, что в сетях
IP не предусмотрена возможность предварительного выделения памяти для
отдельных соединений TCP.
Уровень IP спроектирован таким образом, что каждая дейтаграмма IP
маршрутизируется независимо от других дейтаграмм. Последовательные сегменты
TCP в соединении могут передаваться по разным маршрутам, что создает
разные задержки при прохождении по разным маршрутизаторам и каналам.
Когда модуль TCP отправляет сообщение, он ждет подтверждения, чтобы
сместить окно. Но как долго следует ждать? Время ожидания называется
интервалом тайм-аута. Из-за существенных различий в задержке при передаче
пакетов TCP используется механизм адаптивного тайм-аута. В основу его работы
заложен адаптивный алгоритм повторной передачи, описанный ниже.
1. Измерить время между отправкой октета с конкретным порядковым номером
и получением подтверждения, включающего этот номер. Измеренное время
называется периодом кругового обращения (RTT, Round-Trip Time). На
основании RTT вычисляется величина сглаженного периода кругового обращения
(SRTT, Smoothed RTT) по формуле:
SRTT = (а х SRTT) + ((l-a)xRTT)
где а — весовой коэффициент в интервале от 0 до 1 @ < a < 1). SRTT
составляет оценку тайм-аута. Таким образом, новое значение SRTT представляет
собой взвешенную сумму старого значения SRTT и нового значения RTT.
Если a = 0,5, SRTT представляет собой среднее арифметическое старого
SRTT и нового RTT:
SRTT - (SRTT + RTT)/2, при a = 0,5
Если коэффициент а меньше 0,5, больший вес назначается фактическому
периоду кругового обращения (RTT). Если же а больше 0,5, то больший вес
назначается предыдущему сглаженному периоду кругового обращения (SRTT).
В двух крайних случаях коэффициент а равен 0 или близок к 1. При a = 0
значение SRTT всегда совпадает с RTT, а если коэффициент а близок к 1,
используется фиксированное значение SRTT, практически не учитывающее
реально измеренное значение RTT. Не стоит и говорить, что два крайних
случая редко используются на практике, но они помогают лучше понять
природу взвешенной суммы.
2. Значение SRTT используется для вычисления тайм-аута повторной
передачи (RTO, Retransmission Time-Out) по формуле:
RTO - min[UBOUND,max[LBOUND,(PxSRTT)]]
где UBOUND — верхняя граница тайм-аута (например, 1 минута), a LBOUND —
нижняя граница тайм-аута (например, 1 секунда). Присутствие этих
значений гарантирует, что RTO будет принадлежать интервалу между LBOUND
и UBOUND. Коэффициент разброса времени задержки р изменяет
чувствительность задержки. Если р = 1, то значение RTO будет равно SRTT, если
только значение SRTT не выходит из интервала (LBOUND,UBOUND). При
использовании значения р = 1 протокол TCP чувствителен к потере пакетов,
а ожидание перед повторной передачей будет иметь минимальную
продолжительность. Тем не менее слишком малые задержки могут стать
причиной лишней повторной пересылки данных. Чтобы протокол TCP был менее
восприимчив к потере пакетов, следует использовать большие значения р.
В RFC 793 рекомендуются значения от 1,3 до 2,0.
В 1987 году Карн (Кагп) и Партридж (Partridge) в процессе работы группы
ACM SIGCOMM'87 опубликовали документ «Improving Round-Trip Estimates
in Reliable Transport Protocols». Хотя этот документ и не был оформлен как
RFC, он повлиял на разработку некоторых реализаций TCP и особенно — на
реализацию TCP для BSD Unix. С тех пор этот алгоритм называется
алгоритмом Карпа. В RFC 1122 рекомендуется использовать алгоритм Карна в
сочетании с алгоритмом замедленного старта в перегруженных сетях Ван Джейкобсона
(Van Jacobson), описанным ниже в разделе «Снижение последствий перегрузки
сети в TCP». Алгоритм Карна, учитывающий повторную передачу сегментов,
описан ниже.
При повторной передаче данных по алгоритму Карна значение SRTT не
изменяется. Вместо этого используется стратегия регулировки тайм-аута путем
применения масштабного коэффициента. Смысл заключается в том, что при
повторной передаче данных в сети происходит нечто непредвиденное, поэтому
тайм-аут также следует резко увеличить для предотвращения повторной
передачи в будущем. Изменение тайм-аута производится по простой формуле вида:
новый тайм-аут = у х тайм-аут
Формула применяется до тех пор, пока не будет достигнута заранее
установленная верхняя граница. Обычно коэффициент у устанавливается равным 2;
в этом случае алгоритм ведет себя как экспоненциальный алгоритм с
двукратным увеличением. Новый тайм-аут не влияет на значение SRTT, используемое
в обычных вычислениях. При получении подтверждения для сегмента, не
требующего повторной передачи, TCP изменяет RTT и использует это значение
для вычисления SRTT и RTO.
Снижение последствий перегрузки сети в TCP
Протокол TCP способен реагировать на перегрузку сети TCP, для чего он
регулирует интервал тайм-аута и повторно пересылает данные в том случае, если
подтверждение не было получено до истечения интервала. Тем не менее повторная
передача лишь увеличивает объем данных, обрабатываемых сетью, и усугубляет
проблемы с перегруженностью. Если в результате многочисленных повторных
передач объем повторно передаваемых данных достигнет общей
информационной емкости сети, это неизбежно приведет к коллапсу. В условиях
перегруженной сети необходимы средства для замедления или полной остановки запуска
новых данных в сеть.
В 1988 году в процессе работы группы ACM SIGCOMM'88 Ван Джейкобсон
опубликовал документ «Congestion Avoidance and Control». В этом документе
кратко описаны принципы реагирования на перегруженность сети посредством
снижения объема данных, передаваемых отправителем. Маршрутизаторы,
обнаруживающие перегруженность сети, передают отправителю сообщение ICMP
Source Quench; отправитель передает это сообщение модулю TCP, тем самым
уведомляя его о перегруженности сети.
ПРИМЕЧАНИЕ
Такое средство, как алгоритм замедленного старта Ван Джейкобсона, помогает бороться с
перегруженностью сети за счет динамической регулировки размеров окна.
Алгоритм замедленного старта Ван Джейкобсона пытается уменьшить
перегруженность сети посредством регулировки размера окна TCP. Он поддерживается
всеми современными реализациями TCP. Более того, алгоритм Ван
Джейкобсона наряду с алгоритмом Карна должен быть обязательно реализован в
соответствии с требованиями RFC 1122
В алгоритме Ван Джейкобсона реализация TCP отслеживает дополнительное
предельное значение, называемое размером окна при перегрузке. Реально
используемый размер окна совпадает с меньшим из двух значений: размером окна
при перегрузке и размером окна TCP, установленным получателем:
фактический размер окна = min {размер окна при перегрузке, размер окна TCP}
В обычных условиях, когда сеть не перегружена, размер окна при перегрузке
совпадает с размером окна TCP; это означает, что фактический размер окна
равен размеру окна TCP. При обнаружении условий перегруженности (например,
при потере сегмента) алгоритм Ван Джейкобсона сокращает размер окна при
перегрузке в два раза. При каждой последующей потере сегмента размер окна
при перегрузке снова уменьшается вдвое. Этот процесс приводит к быстрому
экспоненциальному уменьшению размера окна. Если потеря данных
продолжается, размер окна TCP уменьшается до одного сегмента; это означает, что за
один раз передается только одна дейтаграмма. В то же время алгоритм Карна
удваивает интервал тайм-аута перед повторной передачей. Процесс
кардинального сокращения объема передаваемых данных называется экспоненциальным
откатом или мультипликативным сокращением.
В алгоритме Ван Джейкобсона для выхода из перегрузки сети используется
замедленный старт. При получении подтверждения для каждого сегмента
алгоритм увеличивает размер окна при перегрузке на один сегмент. Поскольку
начальный размер окна при перегрузке при сильно перегруженной сети равен 2,
при получении подтверждения он увеличивается до 2. Таким образом, далее
TCP может переслать два сегмента. Если для этих сегментов возвращаются
подтверждения, размер окна при перегрузке становится равным 4, что позволяет
TCP передать четыре сегмента. При подтверждении приема этих сегментов
размер окна становится равным 8. Окно продолжает увеличиваться до тех пор,
пока размер окна при перегрузке не сравняется с размером окна,
установленным получателем. Вследствие экспоненциального возрастания размера окна при
перегрузке отправка N сегментов становится возможной после log2(N) успешно
переданных сегментов.
Если размер окна при перегрузке растет слишком быстро, это может
привести к возрастанию сетевого трафика перед тем, как сеть полностью
восстановится после перегрузки. Если же перегрузка возникнет снова, размер окна при
перегрузке быстро уменьшится. Все эти увеличения и уменьшения приводят
к частым колебаниям размеров окна. Алгоритм Ван Джейкобсона
предотвращает слишком быстрое увеличение размера окна при перегрузке при помощи
методики предотвращения перегрузки. Когда размер окна при перегрузке дости^
гает половины исходного размера окна TCP, далее он увеличивается на один
сегмент только в том случае, если были подтверждены все сегменты,
отправленные до настоящего момента.
Борьба с синдромом мелкого окна
Ранним реализациям TCP было присуще патологическое состояние, которое
называлось синдромом мелкого окна (SWS, Silly Window Syndrome). В этом
состоянии при некоторых условиях данные TCP передаются всего по одному октету,
то есть сегмент TCP состоит только из одного октета, а каждый октет
подтверждается по отдельности. Синдром мелкого окна возникает при выполнении
любого из следующих условий:
О Приложение на стороне получателя читает данные по одному октету из
заполненного буфера, а модуль TCP на стороне получателя передает
отправителю подтверждения TCP с размером окна, равным 1 (рис. 11.24).
О Приложение на стороне отправителя генерирует данные по одному октету,
а модуль TCP на стороне отправителя немедленно передает эти данные
(рис. 11.25).
На рис. 11.24 получатель указывает размер окна, равный одному октету,
поэтому отправитель передает данные только по одному октету. Сразу же после
приема этого октета получающее приложение читает один октет данных, и
модуль TCP снова объявляет окно размера 1. Далее все продолжается в цикле.
На рис.11.25 отправитель передает только один октет данных. Модуль TCP
на стороне отправителя не ждет дальнейшего накопления данных, а немедленно
отправляет этот октет. Приложение-отправитель продолжает генерировать октеты
по одному, и каждый октет немедленно отправляется получателю.
Г Приложение Л
г" получающее J
V данные )
д Чтение по одному
• октету
I Буфер TCP
Will II III III ■ 1
Л -г,-ч« ' J ;1 октет
Окно TCP ;
i I
i .,-■■. i ,.- i , i
ОКНО i
TCP = 1 Получатель | к ;
^г-7 1 («Jg——^s=n ^
^ [ [тнинпшштнтв сгг=гз J I
I I
*- - J -J
Рис. 11.24. Синдром мелкого окна, вызванный действиями получателя
В обеих ситуациях возникают огромные непроизводительные затраты на
пересылку данных, что объясняется следующими причинами:
О В процессе передачи данных генерируется огромное количество мелких пакетов.
О Каждый пакет обрабатывается отдельно на канальном уровне, уровнях IP
и TCP отправителя и получателя. Промежуточные маршрутизаторы должны
обрабатывать пакеты на канальном уровне и уровне IP.
О На каждом из протокольных уровней выполняется огромное количество лишних
вычислений — для каждого пакета приходится по отдельности выполнять
маршрутизацию, проверку контрольной суммы и инкапсуляцию/декапсуляцию.
Кроме того, для каждого пакета вычисляется порядковый номер и номер для
подтверждения, а также производится его обработка в буферах приема/передачи.
О Отношение объема протокольных заголовков к объему полезных данных
чрезвычайно велико; следовательно, эффективность протокола низка. Это
приводит к снижению реальной скорости передачи данных.
О Так как каждый сегмент подтверждается по отдельности, суммарные задержки
накапливаются до значительной величины, что также снижает скорость
передачи. При пересылке 1000 октетов в канале с задержкой 50 мс
суммарная задержка составит 1000 х 50 мс = 5 секунд. Если предположить, что
время передачи пакета по каналу относительно мало по сравнению с
задержкой, суммарная скорость передачи составит всего 1000 октетов х 8 бит/октет/
5 секунд = = 1600 бит/с.
С Приложение, Ч
г отправляющее^
V данные J
• Запись по одному
I октету
i
Окно TCP [///] | Буфер TCP
Отправитель , Кднал
Д = I
^"""—--J Размер сегмента
рг^^ш^^™гт1 • TCP равен 1 октету
T I .=!?■
Рис. 11.25. Синдром мелкого окна, вызванный действиями отправителя
Для предотвращения синдрома мелкого окна на стороне получателя в
реализациях TCP используются следующие средства:
О Отложенное объявление размера окна. Если размер окна получателя меньше
заданного размера, получатель откладывает объявление размера окна до тех
пор, пока размер окна получателя не достигнет величины
min@,5 х размер буфера получателя, максимальный размер сегмента)
О Отложенное подтверждение. Отправка подтверждений с размером окна
получателя, вычисленным в соответствии с предыдущим пунктом списка,
откладывается. Такая задержка уменьшает объем сетевого трафика за счет
уменьшения количества подтверждений. Как говорилось выше, подтверждения
TCP имеют накопительный характер, поэтому более позднее подтверждение
подтверждает все данные, полученные до настоящего момента. При этом
возникает риск того, что из-за задержки с подтверждением на стороне
отправителя произойдет тайм-аут, и он перешлет сегменты повторно. Чтобы этого не
произошло, подтверждения откладываются не более чем на 500 миллисекунд.
Во многих реализациях максимальная задержка с отправкой подтверждений
ограничивается 200 миллисекундами. С другой стороны, подтверждение
сегментов данных необходимо для того, чтобы отправитель располагал
достаточной статистикой по периодам круговых обращений для работы адаптивного
алгоритма тайм-аута.
Вместо задержки подтверждений также можно использовать другой способ:
подтверждения не откладываются, а отправляются немедленно, но размер окна
в них не объявляется до тех пор, пока он не достигнет заранее заданного порога.
Тем не менее применять такой подход в TCP не рекомендуется.
Для предотвращения синдрома мелкого окна на стороне отправителя в
реализациях TCP используется алгоритм Нейгла (Nagle), основанный на
следующих принципах:
О Отправитель передает первый сегмент данных. После первого сегмента
данных отправитель не выполняет немедленную отправку коротких сегментов,
даже если приложение-получатель устанавливает флаг PSH.
О Данные передаются только при выполнении следующих условий:
1. Объем накопленных данных достаточен для заполнения сегмента
максимального размера.
2. Во время ожидания отправки данных поступает подтверждение.
3. Происходит тайм-аут.
Приложение, быстро генерирующее данные, быстро заполнит буфер TCP на
стороне отправителя до максимального размера сегмента. TCP отправляет
сегмент максимального размера без задержек. Кроме того, при получении
подтверждения хранящиеся в буфере данные отправляются немедленно даже в том
случае, если их суммарный размер меньше максимального размера сегмента.
Если приложение медленно генерирует данные, сегменты будут отправляться
при получении подтверждений. Тем временем в буфере TCP на стороне
отправителя будут накапливаться новые данные.
Для приложений реального времени, требующих минимальной задержки и
отправляющих большой объем данных за один раз, применение алгоритма Нейгла
можно запретить.
Разрыв соединений TCP
При сбое на удаленном компьютере или в сетевом канале пересылка данных по
соединению TCP прекращается. Как TCP узнает, что соединение не работает,
а выделенные ему ресурсы следует освободить? На хост может прийти
сообщение ICMP, которое сообщает TCP о том, что получатель недоступен. Прежде
чем сообщить приложению о разрыве соединения, TCP несколько раз пытается
переслать сегменты заново. А если TCP не получит сообщения ICMP, потому
что они потеряны во время передачи? В этом случае после достижения первого
порогового числа повторных передач TCP приказывает IP узнать, не связана ли
проблема с неработоспособностью маршрутизатора или маршрута. IP пытается
заново вычислить маршрут к получателю. Тем временем TCP продолжает
попытки повторной передачи до тех пор, пока не будет достигнут второй порог,
после чего соединение объявляется разорванным. Обнаружив разорванное
соединение, модуль TCP должен освободить все связанные с ним ресурсы (например,
буферы ТСВ).
Если ни одна из конечных точек соединения в течение долгого времени не
передает данных, соединение поддерживается в пассивном состоянии.
Пассивное соединение расходует ресурсы даже при выходе из строя сетевого канала
или другой конечной точки. Некоторые реализации TCP периодически
передают проверочное сообщение TCP, чтобы убедиться в сохранении связи. При
отправке проверочного сообщения от получателя должно прийти подтверждение.
Периодичность отправки проверочных сообщений выбирается таким образом,
чтобы она имела смысл для большинства приложений, работающих на хосте
TCP. Если сообщения будут отправляться слишком часто, это породит лишний
трафик, тогда как слишком большой интервал между сообщениями не позволит
TCP своевременно узнать о разрыве соединения.
Конечный автомат TCP
На рис. 11.26 изображена диаграмма поведения TCP, представленная в виде
конечного автомата — логической модели поведения системы, внутреннее
состояние которой изменяется в результате наступления некоторых событий. Блоки
представляют состояния автомата, а стрелки — переходы из одного состояния
в другое. Надписи на стрелках указывают, какое событие вызвало данный
переход (над чертой), а также ответ TCP на это событие (под чертой). «X» вместо
ответа означает отсутствие специального ответа.
[CLOSED)< —у \ Активное открытие
Пассивное открытие га CLOSE \ \ create ТС
create ТСВ I delete TCB \\ **т
Пассивное ^Щ \\
открытие у^у CLOSE | ]
rcvSYN SEND delete TCB I I
( L sndSYN.ACK J [ sndSYN wf—^k
SYN И ' «J: П SYN 1
I RCVD J< ffS, ==j SENT I
rcvACKofSYN rev SYN, ACK Активное открытие
X I I sndACK
CLOSE данных iKIABySHEDj Пассивное закрытие
r~"l CLOSE" T\ rev FIN . 1
i \^Г). ™>m \ \\ sndACK i ЬГШГ) i
! I WAiT-ip ~ ч ; H wai J ;
; I rev ACK of FIN rev FIN \ ; CLOSE I 1
I X sndACK I i , sndRNX ;
• jm т » < t ▼ ,
! ( ШГЛ Одновременное ( C[DmG Y. \ lLAST-АСк) i
I l. WAJTB- J закрытие I i. ' U_™J !
I rev ACK of FINI ; , rev ACK of FIN ;
; ЩШ> X 1 Тайм-аут = 2MSL^ ? -I---'
! sndACK / *—TdeleteTfjr- , ▼ч
; * И TIME WATT U J CLOSED )
\,■,■,,■,м,;л;■;J^Wл■■.^л^:^^^^.;^F: i У.л.мА. .,■..,■ ■.■.■■.■,.......w,<!5;
\ J
Активное закрытие
Рис. 11.26. Диаграмма состояний TCP в виде конечного автомата
Каждая из конечных точек соединения TCP первоначально находится в
закрытом состоянии (CLOSED). Стрелки, ведущие из блока CLOSED, указы-
вают, что соединение может произойти в результате как активного, так и
пассивного открытия (OPEN).
При активном открытии TCP создает ТСВ, отправляет сегмент с флагом SYN
и входит в состояние SYN SENT. Когда другая конечная точка отправляет ответ
с флагами SYN и АСК, TCP передает подтверждение для завершения трехфазного
согласования и входит в состояние установленного соединения (CONNECTION
ESTABLISHED).
При пассивном открытии конечная точка создает ТСВ и входит в состояние
прослушивания (LISTEN). Получив в этом состоянии флаг SYN (запрос на
активное открытие), TCP отправляет сегмент с порядковым номером, флагами SYN
и АСК и входит в состояние SYN RCVD. При получении флагов АСК или SYN
от другой конечной точки TCP входит в состояние установленного соединения.
Состояние TIME WAIT активизируется при закрытии соединения; оно
гарантирует задержку продолжительностью минимум в 2 MSL (Maximum Segment
Lifetime). Задержка предотвращает дублирование номеров сегментов (эта тема
обсуждалась выше в разделе «Флаги»).
Состояния FIN WAIT-1 и FIN WAIT-2 относятся к механизму корректного
закрытия соединений. Соединение закрывается лишь после того, как обе стороны
согласятся его закрыть.
Трассировка TCP
Протокол Telnet работает на базе TCP, и его трассировка хорошо подходит для
изучения поведения TCP. На рис. 11.27 приведена полная трассировка сеанса
Telnet при выполнении пользователем следующих действий:
1. Вход на сервер Telnet.
2. Выполнение различных команд на сервере Telnet.
3. Выход с сервера Telnet.
No. Source Destination Layer Size Summary
1 0000C024282D FFFFFFFFFFFF arp 0064 Req by 144.19.74.44 for 144.19.74
2 0000C024282D FFFFFFFFFFFF arp 0064 Req by 144.19.74.44 for 144.19.74
3 0000C0A20F8E 0000C024282D arp 0064 Reply 144.19.74.201=0000C0A20F8E
4 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET SYN
5 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK SYN
6 0000C024282D 0000C0A20F8E telnt 0069 Cmd=Do; Code=Echo; Cmd=Do; Code=S
7 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
8 0000C0A20F8E 0000C024282D telnt 0064 Cmd=Do; Code=;
9 0000C024282D 0000C0A20F8E telnt 0064 Cmd=Won't; Code=;
10 0000C0A20F8E 0000C024282D telnt 0067 Cmd=Will; Code=Echo; Cmd=Will; Co
11 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
12 0000C024282D 0000C0A20F8E telnt 0072 Cmd=Do; Code=Suppress Go Ahead;
13 0000C0A20F8E 0000C024282D telnt 0070 Cmd=Do; Code=Terminal Type; Cmd=D
14 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
15 0000C024282D 0000C0A20F8E telnt 0072 Cmd=Will; Code=Terminal Type; Cmd
16 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
17 0000C0A20F8E 0000C024282D telnt 0064 Cmd=Subnegotiation Begin; Code=Te
18 0000C024282D 0000C0A20F8E telnt 0071 Cmd=Subnegotiation Begin; Code=Te
19 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
20 0000C0A20F8E 0000C024282D telnt 0067 Cmd=Do; Code=Echo; Cmd=Will; Code
21 0000C024282D 0000C0A20F8E telnt 0069 Cmd=Won't; Code=Echo; Cmd=Don't;
22 0000C0A20F8E 0000C024282D tcp 0064 Port.TELNET ---> 6295 ACK
23 0000C0A20F8E 0000C024282D telnt 0104 Data=..Linux 1.3.50 (Itreecl.Itre
24 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
25 0000C0A20F8E 0000C024282D telnt 0064 Data=..
26 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
Рис. 11.27. Трассировка трафика Telnet
27 O000C0A20F8E 0000C024282D telnt 0073 Data=ltreecl login:
28 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
29 0000C024282D 0000C0A20F8E telnt 0064 Data=u
30 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
31 0000C0A20F8E 0000C024282D telnt 0064 Data=u
32 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
33 0000C024282D 0000C0A20F8E telnt 0064 Data=s
34 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
35 0000C0A20F8E 0000C024282D telnt 0064 Data=s
36 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
37 0000C024282D 0000C0A20F8E telnt 0064 Data=e
38 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
39 0000C0A20F8E 0000C024282D telnt 0064 Data=e
40 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
41 0000C024282D 0000C0A20F8E ' telnt 0064 Data=r
42 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
43 0000C0A20F8E 0000C024282D telnt 0064 Data=r
44 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
45 0000C024282D 0000C0A20F8E telnt 0064 Data=l
46 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
47 0000C0A20F8E 0000C024282D telnt 0064 Data=l
48 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
49 0000C024282D 0000C0A20F8E telnt 0064 Data=..
50 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
51 0000C0A20F8E 0000C024282D telnt 0064 Data=..
52 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
53 0000C0A20F8E 0000C024282D telnt 0068 Data=Password:
54 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
55 0000C024282D 0000C0A20F8E telnt 0064 Data=u
56 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
57 0000C024282D 0000C0A20F8E telnt 0064 Data=s
58 0000C0A2OF8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
59 0000C024282D 0000C0A20F8E telnt 0064 Data=e
60 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
61 0000C024282D 0000C0A20F8E telnt 0064 Data=r
62 0000C0A20F8E 0O00C024282D tcp 0064 Port:TELNET ---> 6295 ACK
63 0000C024282D 0000C0A20F8E telnt 0064 Data=l
64 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
65 0000C024282D 0000C0A20F8E telnt 0064 Data=p
66 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
67 0000C024282D 0000C0A20F8E telnt 0064 Data=w
68 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
69 0000C024282D 0000C0A20F8E telnt 0064 Data=..
70 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
71 0000C0A20F8E 0000C024282D telnt 0064 Data=
72 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
73 0000C0A20F8E 0000C024282D telnt 0113 Data=Last login: Wed May 28 18:33
74 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
75 0000C0A20F8E 0000C024282D telnt 0073 Data=Linux 1.3.50...
76 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
77 0000C0A20F8E 0000C024282D telnt 0064 Data=..
78 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
79 0000C0A20F8E 0000C024282D telnt 0069 Data=Power, n:..
80 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
81 0000C0A20F8E 0000C024282D telnt 0119 Data=.The only narcotic regulated
82 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
83 0000C0A20F8E 0000C024282D telnt 0064 Data=..
84 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
85 0000C0A20F8E 0000C024282D telnt 0069 Data=ltreecl:-$
86 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
87 0000C024282D 0000C0A20F8E telnt 0064 Data=l
88 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
89 0000C0A20F8E 0000C024282D telnt 0064 Data=l
90 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
91 0000C024282D 0000C0A20F8E telnt 0064 Data=s
92 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
93 0000C0A20F8E 0000C024282D telnt 0064 Data=s
94 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
95 0000C024282D 0000C0A20F8E telnt 0064 Data=
96 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
97 0000C0A20F8E 0000C024282D telnt 0064 Data=
98 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
99 0000C024282D 0000C0A20F8E telnt 0064 Data=-
100 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
101 0000C0A20F8E 0000C024282D telnt 0064 Data=-
102 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
Рис. 11.27. Трассировка трафика Telnet (продолжение)
103 0000C024282D 0000C0A20F8E telnt 0064 Data=a
104 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
105 0000C0A20F8E 0000C024282D telnt 0064 Data=a
106 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
107 0000C024282D 0000C0A20F8E telnt 0064 Data=l
108 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
109 0000C0A20F8E 0000C024282D telnt 0064 Data=l
110 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
111 0000C024282D 0000C0A20F8E telnt 0064 Data=..
112 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
113 0000C0A20F8E 0000C024282D telnt 0064 Data=..
114 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
115 0000C0A20F8E 0000C024282D telnt 0067 Data=total 7..
116 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
117 0000C0A20F8E 0000C024282D telnt 0130 Data=drwxr-xr-x 3 userl user
118 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
119 0000C0A20F8E 0000C024282D telnt 0131 Data=drwxr-xr-x 19 root root
120 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
121 0000C0A20F8E 0000C024282D telnt 0138 Data=-rw-r--r-- 1 userl user
122 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
123 0000C0A20F8E 0000C024282D telnt 0132 Data=-rw-r--r-- 1 userl user
124 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
125 0000C0A20F8E 0000C024282D telnt 0130 Data=-rw-r--r-- 1 userl use
126 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
127 0000C0A20F8E 0000C024282D telnt 0132 Data=-rw-r--r-- 1 userl use
128 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
129 0000C0A20F8E 0000C024282D telnt 0134 Data=drwxr-xr-x 2 userl use
130 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
131 0000C0A20F8E 0000C024282D telnt 0064 Data=l
132 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
133 0000C0A20F8E 0000C024282D telnt 0068 Data=treecl:~$
134 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
135 0000C024282D 0000C0A20F8E telnt 0064 Data=p
136 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
137 0000C0A20F8E 0000C024282D telnt 0064 Data=p
138 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
139 0000C024282D 0000C0A20F8E telnt 0064 Data=s
140 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
141 0000C0A20F8E 0000C024282D telnt 0064 Data=s
142 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
143 0000C024282D 0000C0A20F8E telnt 0064 Data=
144 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
145 0000C0A20F8E 0000C024282D telnt 0064 Data=
146 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
147 0000C024282D 0000C0A20F8E telnt 0064 Data=-
148 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
149 0000C0A20F8E 0000C024282D telnt 0064 Data=-
150 0000C024282D 0000C0A20F8E tcp 0064 Porti6295 ---> TELNET ACK
151 0000C024282D 0000C0A20F8E telnt 0064 Data=a
152 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
153 0000C0A20F8E 0000C024282D telnt 0064 Data=a
154 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
155 0000C024282D 0000C0A20F8E telnt 0064 Data=l
156 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
157 0000C0A20F8E 0000C024282D telnt 0064 Data=l
158 0000C024282D 0000C0A20F8E tcp 0064 Porti6295 ---> TELNET ACK
159 0000C024282D 0000C0A20F8E telnt 0064 Data=x
160 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
161 0000C0A20F8E 0000C024282D telnt 0064 Data=x
162 0000C024282D 0000C0A20F8E tcp 0064 Porti6295 ---> TELNET ACK
163 0000C024282D 0000C0A20F8E telnt 0064 Data=..
164 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
165 0000C0A20F8E 0000C024282D telnt 0064 Data=..
166 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
167 0000C0A20F8E 0000C024282D telnt 0133 Data= F UID PID PPIO PRI N1
168 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
169 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 1 0 30 15
170 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
171 0000C0A20F8E 0000C024282D telnt 0143 Data= 0 0 2 1 30 15
172 0000C024282D 0000C0A20F8E tcp 0064 Porti6295 ---> TELNET ACK
173 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 8 1 30 15
174 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
175 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 24 1 30 15
176 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
177 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 38 1 30 15
178 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
Рис. 11.27. Трассировка трафика Telnet (продолжение)
179 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 40 1 30 15
180 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
181 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 1 42 1 30 15
182 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
183 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 44 1 30 15
184 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
185 0000C0A20F8E 0000C024282D telnt 0139 Data= 0 0 46 1 30 15
186 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
187 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 49 1 30 15
188 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
189 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 51 1 30 15
190 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
191 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 53 1 30 15
192 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
193 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 57 1 30 15
194 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
195 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 61 1 30 15
196 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
197 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 62 1 30 15
198 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
199 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 63 1 30 15
200 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
201 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 64 1 30 15
202 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
203 0000C0A20F8E 0000C024282D telnt 0140 Data= 0 0 65 1 30 15
204 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
205 0000C0A20F8E 0000C024282D telnt 0131 Data= 0 0 145 1 30 15
206 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
207 0000C024282D 0000C0A20F8E telnt 0064 Data=.
208 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
209 0000C0A20F8E 0000C024282D telnt 0136 Data= 0 0 258 44 29 15
210 0000C0A20F8E 0000C024282D telnt 0064 Cmd=;
211 0000C024282D 0000C0A20F8E telnt 0064 Data=.
212 0000C0A20F8E 0000C024282D telnt 0064 Data=.
213 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
214 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
215 0000C0A20F8E 0000C024282D telnt 0071 Data=..ltreecl:~$
216 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
217 0000C024282D 0000C0A20F8E telnt 0064 Data=l
218 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
219 0000C0A20F8E 0000C024282D telnt 0064 Data=l
220 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
221 0000C024282D 0000C0A20F8E telnt 0064 Data=o
222 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
223 0000C0A20F8E 0000C024282D telnt 0064 Data=o
224 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
225 0000C024282D 0000C0A20F8E telnt 0064 Data=g
226 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
227 0000C0A20F8E 0000C024282D telnt 0064 Data=g
228 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
229 0000C024282D 0000C0A20F8E telnt 0064 Data=o
230 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
231 0000C0A20F8E 0000C024282D telnt 0064 Data=o
232 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
233 0000C024282D 0000C0A20F8E telnt 0064 Data=u
234 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
235 0000C0A20F8E 0000C024282D telnt 0064 Data=u
236 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
237 0000C024282D 0000C0A20F8E telnt 0064 Data=t
238 0000C0A20F8E 0000C024282D tcp 0064 Port:TELNET ---> 6295 ACK
239 0000C0A20F8E 0000C024282D telnt 0064 Data=t
240 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK
241 0000C024282D 0000C0A20F8E telnt 0064 Data=..
242 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
243 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK FIN
244 0000C024282D 0000C0A20F8E tcp 0064 Port:6295 ---> TELNET ACK FIN
245 0000C0A20F8E 0000C024282D tcp 0064 PortiTELNET ---> 6295 ACK
Рис. 11.27. Трассировка трафика Telnet (продолжение)
Щкеты 1-3 на рис. 11.27 относятся к разрешению адресов ARP (эта тема
рассматривалась в главе 5). Собственно трафик Telnet начинается с пакета 4.
В дальнейшем анализе трафика Telnet, изображенного на рис. 11.27, будут
рассматриваться только аспекты, относящиеся к TCP, но не сами данные Telnet.
Номера пакетов, упоминаемые в тексте, соответствуют номерам пакетов на рис. 11.27.
По этой причине выше была приведена полная трассировка сеанса Telnet, хотя
листинг получился довольно большим.
Трехфазное согласование при открытии соединения TCP
На рис. 11.28-11.30 изображены три пакета TCP, участвующие в процессе
трехфазного согласования, используемого при открытии соединения TCP.
Packet Number : 4 6:38:38 РМ
Length : 64 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-00-C0-24-28-2D > 00-00-C0-A2-0F-8E
Type: 0x0800 (IP)
ip: ======================= internet Protocol =======================
Station:144.19.74.44 >144.19.74.201
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput, Normal Reliability
Total length: 44
Identification: 1
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 100 seconds
Checksum: 0xAlAF(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: 6295
Destination Port: TELNET
Sequence Number: 25784320
Acknowledgement Number: 0
Data Offset C2-bit words): 6
Window: 4096
Control Bits: Synchronize Sequence Numbers (SYN)
Checksum: 0x4A87(Valid)
Urgent Pointer: 0
Option:MAXIMUM SEGMENT SIZE
Option Length: 4
Maximum Segment Size : 1024
Ethernet Type
Ethernet Header a
i T
(I т^и^^ w IP Header
00 00 C0 A2 0F 8E 00 00 C0 24 28 2P@80^L5 00 | $(-. .E.
^ Destination
10: 09 2C 00 01 08 00 64 06 Al AF(90 13 4A 2фС90 13 | . .d J. . . IP Address
20: 4A C9)A8 97)^?Т7)@Ге9 70 0^00 00 00 0ф((рГ03) | J p ' .
30: fi0 00)^АЛ87)Г00 00)(^(б4У04 00)@0 961 I | . . J
▼ Ill TIT Source I I
Checksum Option- Ethernet ,p
T ▼ 1 Length A Pad Address
Window Urgent Option- Option-
Pointer Kjnd Data
(MSS)
У ▼ ▼
Destination Sequence Data
Port B3) Number Offset
T T ▼
Source Port Acknowledgment Flags
F295) Number SYN=1
Рис. 11.28. Запрос на открытие соединения TCP: отправка
начального порядкового номера отправителя (ISS)
Перевод обозначений на этих и последующих рисунках данного типа
приведен в следующем списке:
О Ethernet Header — заголовок Ethernet;
О Ethernet Type — тип Ethernet;
О IP Header — заголовок IP;
О Destination IP Address — IP-адрес получателя;
О TCP Header — заголовок TCP;
О Window — окно;
О Checksum — контрольная сумма;
О Urgent Pointer — указатель срочности;
О Option-Kind (MSS) — тип параметра (MSS);
О Source Port F295) — порт отправителя F295);
О Destination Port B3) — порт получателя B3);
О Option Length — длина параметра;
О Ethernet Pad — дополнение Ethernet;
О Source IP Address — IP-адрес отправителя;
О Data Offset — смещение данных;
О Flags — флаги;
О Acknowledgement Number — номер для подтверждения;
О Option-Data — данные параметра;
О Sequence Number — порядковый номер.
Пакет TCP, инициирующий открытие соединения и представляющий фазу 1
трехфазного согласования, содержит следующие значения порядкового номера
и флагов:
ISS = 25784320
номер для подтверждения = 0 (недействителен, поскольку АСК=0)
Также обратите внимание на то, что поле смещения данных равно 6, что
указывает на наличие параметра TCP. В данном случае используется параметр MSS
(тип параметра равен 2) с шестнадцатеричным кодом
02 04 04 00
Код расшифровывается следующим образом:
О параметр: MSS (максимальный размер сегмента);
О длина параметра: 4;
О максимальный размер сегмента: 1 024.
В исходный пакет входят порты отправителя и получателя и размер окна:
О порт отправителя: 6295;
О порт получателя: 23 (стандартный порт сервера Telnet);
О размер окна: 4 096.
Порт отправителя задает номер порта, по которому клиент Telnet готов
принимать данные от сервера Telnet. Порт получателя задает номер порта сервера
Telnet, к которому обращается клиент для открытия соединения. Размер окна
определяет количество октетов, которые готов принять клиент Telnet;
фактически он совпадает с размером приемного буфера на клиентском узле TCP.
Packet Number : 5 6:38:38 РМ
Length : 64 bytes
ether: ==--.==-=-•-=--.---.----■ Ethernet Datalink Layer ====================
Station: 00-00-C0-A2-0F-8E > 00-00-C0-24-28-2D
Type: 0x0800 (IP)
1p: ======================= Internet Protocol =======================
Station:144.19.74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay. Normal Throughput, Normal Reliability
Total length: 44
Identification: 21410
Fragmentation allowed, Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x720E(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: TELNET
Destination Port: 6295
Sequence Number- 1508167651
Acknowledgement Number: 25784321
Data Offset C2-bit words): 6
Window: 30719
Control Bits: Acknowledgement Field is Valid (ACK)
Synchronize Sequence Numbers (SYN)
Checksum: 0xB8AE(Valid)
Urgent Pointer: 0
Option:MAXIMUM SEGMENT SIZE
Option Length: 4
Maximum Segment Size : 1024
Ethernet Type
Ethernet Header a
t t
/I > li ^ > IP Header
0: @0 00 C0 24 28 2D 00 00 C0 A2 0F 8E @8 00Д4$ 00 | ...$(- E. "
fr noctinatinn
10: 90 2C 53 A2 00 09 40 96 72 9£ @0Ш 4А С9)(9в 13 [ . , S. . .@. r. . . J . . . *" \p Address
28: 4A 20$НГ7)(ГГ1^Е9 E4^^ 1 J Y p.'. w
_____ j' ^_"_f_ ^————»___«_«_r- .-*—mm—m———j—■—•—'' w*m_«____________——^. yQp НбвйбГ
30: |7 fF)fe8 UeN9 p)^?^^4ra^7l5J I |w re
▼ I I I T ▼ I I T ISource
JChecksum Option- Ethernet IP
T TW 1епЯ^ W Pa0* Address
Window Urgent I ~ J li . II
J(mss, | M
Destination Sequence Data
Port F295) Number Offset
T T T
Source Port Acknowledgment Flags
B3) Number SYN=1
ACK=1
Рис. 11.29. Подтверждение запроса на открытие соединения: передача
начального порядкового номера получателя (IRS)
На рис. 11.29 приведен пакет TCP, который передается получателем для
подтверждения запроса на соединение. Этот пакет представляет вторую фазу
трехфазного согласования:
О SYN - 1;
О АСК - 1;
О остальные флаги TCP равны 0;
О порядковый номер = 1508167651 (IRS);
О номер для подтверждения - 25784321 (ISS +1).
Пакет, изображенный на рис. 11.29, передается сервером Telnet с целью
синхронизации порядкового номера и содержит начальный порядковый номер,
установленный сервером. Также следует заметить, что поле смещения данных
равно 6, что указывает на наличие параметра TCP. В данном случае используется
параметр MSS (тип параметра равен 2) с шестнадцатеричным кодом
02 04 04 00
Код расшифровывается следующим образом:
О параметр: MSS (максимальный размер сегмента);
О длина параметра: 4;
О максимальный размер сегмента: 1 024.
В данном примере клиент и сервер Telnet используют одинаковые значения
MSS, но это условие выполняется далеко не всегда. В пакет подтверждения
запроса на открытие соединения также входят порты отправителя и получателя
и размер окна:
О порт отправителя: 23 (стандартный порт сервера Telnet);
О порт получателя: 6295;
О размер окна: 30 719.
Порт отправителя задает номер порта, по которому сервер Telnet готов
принимать данные от клиента Telnet. Порт получателя задает номер порта клиента
Telnet, с которого поступил запрос на открытие соединения. Размер окна
определяет количество октетов, которые готов принять сервер Telnet; фактически он
совпадает с размером приемного буфера на серверном узле TCP. Обратите
внимание — это число больше того, которое использовалось клиентом Telnet.
На рис. 11.30 представлена последняя фаза трехфазного согласования:
клиент подтверждает порядковый номер, полученный от сервера Telnet. Пакет
содержит следующие флаги и значения полей:
О АСК - 1;
О PSH = 1;
О остальные флаги TCP равны 0;
О порядковый номер = 25784321 (ISS+1);
О номер для подтверждения = 1508167652 (IRS+1).
Предполагается, что флаг PSH сообщит TCP о необходимости отправить
данные. Для предотвращения синдрома мелкого окна применяется алгоритм
Нейгла (роль алгоритма Нейгла рассматривается в разделе «Борьба с
синдромом мелкого окна» настоящей главы).
Packet Number : 6 6:38:38 РМ
Length : 69 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-00-C0-24-28-2D > 00-00-C0-A2-0F-8E
Type: 0x0800 (IP)
ip: ======================= Internet Protocol =======================
Station:144.19.74.44 >144.19.74.201
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput. Normal Reliability
Total length: 49
Identification: 2
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 100 seconds
Checksum: 0xAlA9(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: 6295
Destination Port: TELNET
Sequence Number: 2S784321
Acknowledgement Number: 1508167652
Data Offset C2-bit words): 5
Window: 4096
Control Bits: Acknowledgement Field is Valid (ACK)
Push Function Requested (PSH)
Checksum: 0xl8A9(Valid)
Urgent Pointer: 0
telnt: ======================== Telnet Protocol ========================
Command: Do
Option Code: Echo
Command: Do
Option Code: Suppress Go Ahead
Command: Will
Option Code:
Ethernet Type
Ethernet Header a
_f t
/—■ j I i4 w IP Header
0:@0 98 CO A2 0F 8E 00 88 C8 24 28 2D E>8 G8J45 00. | $(-..E.
^ r w Destination
10: 08 31 08 02 00 00 64 06 Al AS $9 13 4A 2CJ#0 13 % |. 1 d J ,. . IP Address
20: 4A €9N^97)^9 17)^1 89 78 91)^9 €4|СР ^jflfffi |J p.Y...P.
30: Ш 88)(ША9)&0 ee)f F FD 01 FF IfD 83 IFF FB llFJ |
40: || f| I M T I |.
IChecksuml II у II у II
у I у I $ео<иег,од X I Source I I
Window Urgent Number Telnet IP Address
Pointeij Data
Y T
DestinaUon I *£
± J ±
c«.T^« Acknowledgment _, T
PSH=1
Рис. 11.30. Подтверждение начального порядкового номера получателя (IRS)
Поле смещения данных равно 5, что указывает на отсутствие параметров TCP.
Номера портов и размер окна имеют следующие значения:
О порт отправителя: 6295;
О порт получателя: 23 (стандартный порт сервера Telnet);
О размер окна: 4 096.
Порт отправителя представляет конечную точку соединения TCP на клиенте
Telnet. Порт получателя представляет конечную точку соединения TCP на сервере
Telnet. Размер окна определяет количество октетов, которые готов принять клиент
Telnet, то есть фактически размер приемного буфера на клиентском узле TCP.
Трассировка нормальных данных TCP
В пакете 6 (см. рис. 11.30), завершающем трехфазное согласование и
подтверждающем IRS получателя, передаются 9 октетов данных Telnet:
FF FD 01 FF FD 03 FF FB IF
Как определить, что передаются именно 9 октетов данных Telnet? Сначала
мы узнаем размер дейтаграммы IP по значению соответствующего поля
заголовка IP (см. рис. 11.30). Размер дейтаграммы равен 49 октетам. Из них 20 октетов
(длина заголовка равна 5 блокам) занимает заголовок TCP. Для данных Telnet
остается 49 - 29 - 20 = 9 октетов.
Пакет 6 открывает режим пересылки данных в сеансе Telnet. Пакет 7 (рис. 11.31)
подтверждает прием этих данных от сервера. Сервер Telnet на этой стадии еще
не имеет данных для передачи и поэтому ограничивается отправкой
подтверждения.
Пакет содержит следующие флаги и значения полей:
О АСК - 1;
О остальные флаги TCP равны 0;
О порядковый номер = 1508167652;
О номер для подтверждения = 25784330.
Обратите внимание: возвращаемый номер для подтверждения подтверждает
прием 9 октетов клиентских данных Telnet:
О ISN от клиента Telnet - 25784321;
О размер данных Telnet = 9;
О подтверждение - ISN от клиента Telnet + размер данных Telnet = 25784321 + 9 =
- 25784330.
Через секунду после отправки подтверждения сервер Telnet отправляет
ответ клиенту в пакете 8 (рис. 11.32). Если бы сервер Telnet был готов отправить
ответ немедленно, он бы включил эти данные в пакет 7. Чтобы предотвратить
отправку большого количества мелких пакетов, TCP откладывает отправку
подтверждений, но в соответствии со стандартом TCP максимальная задержка не
превышает 500 миллисекунд (за подробностями обращайтесь к разделу «Борьба
с синдромом мелкого окна»). Между пакетами 7 и 8 прошла одна секунда; об
этом можно узнать по временным пометкам, выводимым в первой строке рас-
шифровки пакета. Временная пометка определяет момент сохранения пакета
анализатором протокола.
Packet Number : 7 6:38:38 РМ
Length : 64 bytes
ether: ==================== Ethernet Oatalink Layer ====================
Station: 00-00-C0-A2-0F-8E > 00-00-C0-24-28-2D
Type: 0x0800 (IP)
ip: ======================= Internet Protocol =======================
Station:144.19.74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput, Normal Reliability
Total length: 40
Identification: 21411
Fragmentation allowed, Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x7211(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: TELNET
Destination Port: 6295
Sequence Number: 1508167652
Acknowledgement Number: 25784330
Data Offset C2-bit words): 5
Window: 30710
Control Bits: Acknowledgement Field is Valid (ACK)
Checksum: 0xCEB7(Valid)
Urgent Pointer: 0
Ethernet Type
Ethernet Header a
/—1 I >■ IP Header
0:@0 00 C0 24 28 2D 00 00 C0 A2 0F 8E (88 00^45 60 |. . .$(- E.
4 — — —^ w Destination
10: 00 28 53 A3 00 00 40 96 72 11 ;j&8. 13 4A СЭ)фв 13 ; |. (S. . .§. r. . . J . . . ^* IP Address
20: 4A 2<3 |6 17H,8 97X59 E4 CF tifel «9 70 6^($)TIS) [J Y p.P.
30: G7 F6)fcE 87Y00 te^(&2 04 |04 00 72 |б5) 1 |w re
▼ III III Source
Checksum IP Address
▼ ▼ T
Window Urgent Ethernet
Pointer Pad
7 ▼ M
Destination Sequence Data
Port Number Offset
T T T
Source Acknowledgment Flags
Port Number ACK=1
Рис. 11.31. Пакет подтверждения
Объем данных, переданных в пакете 8, вычисляется по уже известной формуле:
размер дейтаграммы IP - длина заголовка IP - смещение данных TCP =
= 43 - 20 - 20 = 3 октета
Packet Number : 243 6:39:12 PM
Length : 64 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-e0-Ce-A2-0F-8E > 00-00-C0-24-28-2D
Type: 0x0800 (IP)
ip: ======================= Internet Protocol =======================
Station:144.19.74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput. Normal Reliability
Total length: 40
Identification: 21533
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x7197(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: TELNET
Destination Port: 6295
Sequence Number: 1508170215
Acknowledgement Number: 25784420
Data Offset C2-bit words): 5
Window: 30719
Control Bits: Acknowledgement Field is Valid (ACK)
No More Data from Sender (FIN)
Checksum: 0xC450(Valid)
Urgent Pointer: 0
Ethernet Type
Ethernet Header д
/—I- / I ^ ► IP Header
0:100 00 C0 24 28 2D 00 00 C0 A2 0F 8E F8 00J4S 69 |...$(- E.
v— _— Zw > Destination
10: 00 28 $4 ID 09 90 49.0$ 71; $7 §3 1% 4A C9)&0 13 1.(T...§.q...J . . . IP Address
20: 4A 20рТт)^Г97)ф9 €4 D9 1^Ш^;^ в4)^]^Тз) [J Y pdP.
". ' j "}"" • ^————* г ' I ]| l ™^^~^^^^^^^ш^^^шш^^ TCP Header
30: ft? ?У)(&4 $ф(&0ШЗ)^4 QA|6C 74 72 |б5) 1 |w..P..t.ltre
will Source
Checksum IP Address
▼ ▼ T
Window Urgent Ethernet
Pointer Pad
V ▼ ▼
Destination Sequence Datal
Port Number Offsed
T T T
Source Acknowledgment Flags
Port Number ACK=1
FIN=1
Рис. 11.32. Передача данных TCP
Корректное закрытие соединений TCP
В пакетах 217-242 (см. рис. 11.27) клиент передает серверу команду завершения
сеанса Telnet. Команда пересылается по одному символу. Пакеты 243-245
демонстрируют работу механизма корректного закрытия соединений. В пакете 243
(рис. 11.33) сервер Telnet, получивший команду выхода, выдает запрос на завер-
шение соединения TCP установкой флага FIN. Флаг означает, что у сервера
Telnet нет больше данных для отправки.
Packet Number : 243 6:39:12 РМ
Length : 64 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 09-00-C0-A2-0F-8E > 00-00-C0-24-28-2O
Type: 0x0800 (IP)
1p: ======================= Internet Protocol =======================
Station:144.19.74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput. Normal Reliability
Total length: 40
Identification: 21533
Fragmentation allowed. Last fragment
Fragment Offset 0
Time to Live: 64 seconds
Checksum: 0x7197(Valid)
tcp: ================= Transmission Control Protocol =================
Source Port: TELNET
Destination Port: 6295
Sequence Number 1508170215
Acknowledgement Number: 25784420
Data Offset C2-bit words): 5
Window: 30719
Control Bits: Acknowledgement Field is Valid (ACK)
No Ноге Data from Sender (FIN)
Checksum: 0xC450(Valid)
Urgent Pointer: 0
Ethernet Type
Ethernet Header a
/-J- ^L^ ,, ► IP Header
0:f 00 00 C0 24 28 2D 00 00 C0 A2 0F 8E 08 00Д45 06 \ . . .$(- E.
4 ■ ^ . .....,;: w Destination
10: 00 28 54 ID S0 60 40 06 71 Э7 (98 U 4A С9)&в Ш|. (Т. . .g.q. . . J . .. IP Address
20: ДА 2Q£e 17)A8 97)g?l4 D9 E7}flTw 78 M(s]f79 IJ Y pdP.
30: fr7 FF)g4 $6)fe0]00)^4 0А|бС 74 72 [65) I |w. .P. . t.Ure
I T III I Source I
Checksum IP Address
I I t I III
Window Urgent Ethernet
Pointer Pad
Destination Sequence I Date I
Port Number Offset
T T T
Source Acknowledgment Flags
Port Number ACK=1
FIN=1
Рис. 11.33. Запрос на корректное закрытие, выданный сервером Telnet
В пакете 244 (рис. 11.34) клиент Telnet отвечает установкой флага FIN со
своей стороны, сообщая тем самым, что клиент готов закрыть соединение и у него
нет больше данных для отправки. Данная реализация устанавливает размер
окна равным 9, указывая тем самым, что модуль TCP на стороне клиента
прекращает прием данных.
Packet Number : 244 6:39:12 РМ
Length : 64 bytes
ether: ss5SsraStsssssssss=s Ethernet Datalink Layer ===============«=*=
Station: 99-06-08-24-28-20 > e0-09-Ce-A2-0F-8E
Type: 0x0800 (IP)
1p: sssssssssssssssssssrsrs Internet ProtOCOl ==========*===:=========
Station:144.19.74.44 >144.19.74.201
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay. Normal Throughput, Normal Reliability
Total length: 40
Identification: 117
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 100 seconds
Checksum: 0xA13F(Valid)
tcp: *«=s===s==s====== Transmission Control Protocol =================
Source Port: 6295
Destination Port: TELNET
Sequence Number: 25784420
Acknowledgement Number: 1508170216
Data Offset C2-bit words): 5
Window: 0
Control Bits: Acknowledgement Field is Valid (ACK)
No More Data from Sender (FIN)
Checksum: 0x3C4F(Valid)
Urgent Pointer: 0 _
Ethernet Type
A
Ethernet Header
I I
/—' м I 4V . >» IP Header
0:100 09 C0 A2 0F 8E 00 00 C0 24 28 2D |8~eejL5 00 | $(-..E.
4 .. ""■"^. •■•■: Destination
10: 00 2$ 00 75 00 00 «4 06 Al 3E $B 13 4A 2C)g& 13 |. (.u..d.. ?. . J ,. . ^IP Address
20:ЖЩ^ЯЩ^В1^§Г 89 70 64){jjj f4 D9 p)^| Щ M pdY...P. ^TCP НваЬвГ
зо: @0 ee)Cc|4F)(e8|ee)^e 00 00 00 fe bs\ I |..<o
I T I I I II I Source I
[Checksum] IP Address
▼ ▼ T
Window Urgent Ethernet
Pointer Pad
▼ ▼ n*
Destination Sequence D?*3
Port Number olfset
T T T
Source Acknowledgment Flags
Port Number ACK=1
FIN=1
Рис. 11.34. Клиент Telnet соглашается корректно закрыть соединение
На рис. 11.35 сервер Telnet подтверждает получение флага FIN от клиента
Telnet. На этой стадии модули TCP на стороне клиента и сервера Telnet
освобождают ресурсы, связанные с соединением TCP.
Packet Number : 245 6:39:12 PM
Length : 64 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 0e-00-C8-A2-0F-8E > 00-00-C0-24-28-2D
Type: 0x0800 (IP)
ip: ======================= Internet Protocol =======================
Station:144.19.74.201 >144.19.74.44
Protocol: TCP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay. Normal Throughput, Normal Reliability
Total length: 40
Identification: 21534
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live 64 seconds
Checksum: 0x7196(Valid)
tcp: ================= Transmission Control Protocol ===■=============
Source Port: TELNET
Destination Port: 6295
Sequence Number: 1508170216
Acknowledgement Number: 25784421
Data Offset C2-bit words): 5
Window: 30718
Control Bits: Acknowledgement Field is Valid (ACK)
Checksum: 0xC450(Valid)
Urgent Pointer: 0
Ethernet Type
Ethernet Header a
^_L I w IP Header
0:( 00 00 C0 24 28 2D 00 00 C0 A2 0F 8E Ю800М5 00 | . . .$(- E.
4 ; ^~^ w Destination
10: 00 28 54 Ц 00 00 40 66 7*96 {jjj 13 4A C9)fo 13 | . (T. . .g.q. .. J.. . IP Address
20: 4A 3$@iTl?)fr* gflgJT 64 E9 g$)fcl ^S#g[6S)|5)fT5) | J Y peP.
:':' ",",.,'■' .1 i •• • t '•'! ' • jJJ '"■■-■■] ■ л J W TCP Header
30: fr7 FBNtp0)fe0 ee)G4 0A |6C 74 72 [65 ) | w. P. . t. Ure
Checksum *
▼ I ▼ I W Source
Window Urgent EthJrnet IP
Pointer Pad Address
T ▼ T
Destination Sequence Data
Port Number Offset
T T T
Source Acknowledgment Flags
Port Number ACK=1
Рис. 11.35. Подтверждение запроса на корректное закрытие от клиента Telnet
Протокол UDP
В некоторых приложениях надежность и устойчивость TCP оказываются
излишними. В таких приложениях вполне достаточно транспортного протокола, который
бы обеспечивал идентификацию приложений на двух компьютерах и обладал
простейшими средствами проверки ошибок. Такими возможностями обладает
протокол UDP (User Datagram Protocol).
В отличие от протокола TCP, ориентированного на соединение, протокол UDP
работает в режиме простой передачи дейтаграмм. UDP не пытается создать
соединение. Данные инкапсулируются в заголовках UDP и передаются
уровню IP. Уровень IP пересылает пакет UDP в одной дейтаграмме IP, если
пересылка не требует фрагментации. UDP не пытается обеспечивать упорядоченный
прием данных, поэтому порядок принятых данных может отличаться от порядка,
использовавшегося при отправке. Приложения, требующие сохранения порядка
приема, должны либо реализовать механизм упорядочения самостоятельно, либо
использовать протокол TCP вместо UDP. Во многих локальных сетях
вероятность нарушения исходного порядка пакетов невелика, что объясняется
небольшими, легко прогнозируемыми задержками и простой топологией сети.
Протокол UDP особенно удобен в приложениях, работающих по схеме
«команда/ответ», в которых команды и ответы могут пересылаться в одной
дейтаграмме. В этом случае приложение не тратит ресурсы на открытие и закрытие
соединений для пересылки малого объема данных. Другое преимущество UDP
проявляется при широковещательной и групповой рассылке. При использовании
TCP для рассылки сообщений по 1000 узлов отправитель должен создать 1000
соединений, передать данные по каждому соединению по отдельности, а затем
закрыть 1000 соединений. Непроизводительные затраты на открытие соединений,
их поддержание и закрытие слишком велики. При использовании протокола
UDP отправитель может передать данные модулю IP с запросом на
широковещательную или групповую рассылку. В этом случае отправка данных может
осуществляться средствами широковещательной/групповой рассылки базовой сети.
Протокол UDP поддерживает простейшую проверку целостности данных.
Если базовая сеть заведомо надежна, то для ускорения обработки UDP проверку
контрольных сумм UDP можно запретить.
Основные особенности UDP можно охарактеризовать следующим образом:
О протокол UDP обладает средствами идентификации прикладных процессов
по номерам портов UDP;
О протокол UDP ориентируется на передачу дейтаграмм без затрат на
открытие, поддержание и закрытие соединений;
О протокол UDP эффективно работает при широковещательной/групповой
рассылке;
О порядок пересылаемых данных не сохраняется, а их доставка не
гарантирована;
О в UDP поддерживается необязательная проверка контрольных сумм,
которая ограничивается данными;
О по быстроте, простоте и эффективности протокол UDP превосходит TCP, но
при этом он уступает ему по надежности.
Протокол UDP обеспечивает ненадежный и не ориентированный на
соединение сервис доставки данных. Он относится к протоколам транспортного уровня,
что выглядит несколько странно, так как транспортный уровень должен обеспе-
чивать целостность при сквозной передачи данных, a UDP этого не делает.
Но несмотря на этот недостаток, на базе UDP построено достаточно много
популярных приложений, в том числе:
О TFTP (Trivial File Transfer Protocol);
О DNS (Domain Name System);
О NFS (Network File System) версии 2;
О SNMP (Simple Network Management Protocol);
О RIP (Routing Information Protocol);
О многие службы широковещательной рассылки, включая WHOD (демон Who
на серверах Unix).
Ниже протокол UDP будет описан более подробно.
Структура заголовка UDP
Заголовок UDP имеет фиксированную длину, равную 8 октетам. Структура
заголовка UDP представлена на рис. 11.36.
О 7 8 1516 23 24 31
• 1 1 1 1
Порт Порт
отправителя получателя
Дяииа | ХТмГ
Октеты
данных
Рис. 11.36. Структура заголовка UDP
Порт отправителя имеет длину 16 бит и является необязательным. Если
поле содержит действительные данные, оно определяет номер порта
процесса-отправителя; этот номер должен использоваться для отправки ответов при
отсутствии дополнительной информации. Если поле заполнено нулями, то номер
порта отправителя не используется.
Поле порта получателя идентифицирует процесс на приемном IP-адресе,
которому передаются данные UDP. Как и TCP, протокол UDP распределяет
данные разных процессов-получателей по номерам портов. Если UDP получает
дейтаграмму с неиспользуемым номером порта (то есть номером, с которым не
связано приложение UDP), он генерирует сообщение ICMP о недоступности
порта и отвергает дейтаграмму.
Поле длины содержит длину пакета UDP в октетах, с учетом как длины
заголовка UDP, так и длины данных. Минимальное значение поля длины равно 8
и указывает на то, что поле данных имеет нулевой размер.
Поле контрольной суммы содержит 16-разрядное дополнение до 1 суммы
дополнений до 1 псевдозаголовка с данными IP, заголовка UDP и данных, ко-
торые при необходимости выравниваются нулями до 16-разрядной границы.
Контрольная сумма проверяется по тем же правилам, что и в TCP.
Псевдозаголовок, подставляемый перед заголовком UDP, содержит адреса
отправителя и получателя, идентификатор протокола (для UDP он равен 17)
и длину дейтаграммы UDP (рис. 11.37). Содержимое псевдозаголовка
обеспечивает защиту от неправильной маршрутизации дейтаграмм. Псевдозаголовок
имеет фиксированный размер, равный 12 октетам. Информация псевдозаголовка
полностью определяет половинную ассоциацию для получателя, даже несмотря
на отсутствие соединения.
О 7 8 15 16 23 24 31
Порт отправителя
Порт получателя
| Ноль | Протокол | дейта^НмаыиРР |
Рис. 11.37. Псевдозаголовок UDP, используемый при вычислении контрольной суммы
Если вычисленная контрольная сумма равна 0, передаваемое поле
заполняется единицами (дополнение до 1). Следовательно, нулевая контрольная сумма
никогда не может быть получена в результате вычислений и используется для
обозначения особого условия. Если передаваемое поле контрольной суммы
состоит из одних нулей, это означает, что контрольная сумма не используется.
Приложения, работающие в надежных сетях IP (например, в локальных сетях),
могут запретить вычисление контрольных сумм при передаче и их проверку при
получении дейтаграмм UDP.
Протокол UDP работает на базе IP. Контрольная сумма IP вычисляется только
для заголовка, тогда как контрольная сумма UDP охватывает как заголовок UDP,
так и данные и обеспечивает гарантии целостности содержимого поля.
Иерархия UDP и инкапсуляция
Как видно из рис. 11.38, протокол UDP работает на базе IP. Приложения,
использующие UDP, идентифицируются по номеру порта UDP. Нумерация
портов UDP и TCP производится в разных адресных пространствах. Следовательно,
вы можете использовать порт TCP с номером 1017 и порт UDP с номером 1017,
ссылающиеся на разные прикладные процессы.
На рис. 11.39 показано, как данные UDP инкапсулируются в заголовке IP,
который, в свою очередь, инкапсулируется канальным уровнем. Протокол UDP
обозначается кодом 17.
Между UDP и IP существует достаточно тесная связь, поскольку уровень
UDP должен знать IP-адрес для заполнения псевдозаголовка. Как говорилось
выше, псевдозаголовок является частью контрольной суммы UDP. Отсюда
следует, что модуль UDP должен уметь получать IP-адреса и код в поле протокола
из заголовка IP. Один из возможных интерфейсов UDP/IP возвращает всю
дейтаграмму IP вместе со всеми данными заголовка IP в ответ на операцию
RECEIVE, инициированную приложением UDP. Такой интерфейс позволит
UDP передавать IP полную дейтаграмму IP вместе с заголовком. Уровень IP
проверяет целостность некоторых полей и вычисляет контрольную сумму
заголовка IP.
UDP
IP
Канальный
уровень
Физический
уровень
Рис. 11.38. Иерархия протокола UDP
Заголовок Данные
UDP UDP
. Л у .- !
Заголовок Данные
IP IP
**" ^
. !t,.v „i ..•*'* .
., - n - Контрольная
Канальный Дейтаграмма последовательность
заголовок IP кадра
Рис. 11.39. Инкапсуляция данных UDP
Трассировка UDP
На рис. 11.40 и 11.41 изображены два пакета UDP. Первый пакет сгенерирован
демоном WHOD (Who Daemon) системы Unix, а второй — протоколом RIP.
WHOD использует порты UDP отправителя и получателя с номерами 513.
У протокола RIP номера портов отправителя и получателя равны 520. В обоих
приведенных пакетах контрольная сумма отлична от нуля, а следовательно,
используется при проверке данных.
Packet Number : 2 19:57:22 РМ
Length : 130 bytes
ether: ==================== Ethernet Oatalink Layer 8»г.ккик«ккк
Station: 00-00-C0-BB-E8-73 > FF-FF-FF-FF-FF-FF
Type: 0x0800 (IP)
1p; ssssssssxsssssssssssssx Internet PrOtOCOl =======================
Station:199.245.180.15 >199.245.180.255
Protocol: UDP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay, Normal Throughput. Normal Reliability
Total length: 112
Identification: 296
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x805B(Valid)
udp: ===================== user Datagram Protocol ====================
Source Port: WHO
Destination Port: WHO
Length = 92
Checksum: 0x086A(Valid)
Data:
0: 01 01 00 00 31 ЕЕ А4 F5 00 00 00 00 67 61 74 65 | 1 gate
10: 6B 65 65 70 65 72 00 00 00 00 00 00 00 00 00 00 |keeper
20: 00 00 00 00 00 00 00 90 00 00 00 00 00 00 00 00 |
30: 00 00 00 00 00 00 00 00 31 ЕЕ 7F 85 63 6F 6E 73 | l...cons
40: 6F 6C 65 00 72 6F 6F 74 00 00 00 00 31 ЕЕ 80 10 |ole.root 1...
50: 00 00 24 36 |..$6
Ethernet Type
Ethernet Header A ,p Header
A It
0:(FF FF FF FF FF FF 00 00 C0 BB E8 73 §800J45 00 I S..E.
4 v—==y Destination
10: 00 78 01 28 № M 48 11 80 5В%* F5 B4 0F)t7 F5 I. p. (. .@.. [ ^ IP Address
Header 20: B4 f%& 0l)fe2 0lXft8 SC)fe8 6a)@1 01 Io0 00 31 EE^| \ . j. . . . 1.
30:Га4 F5 00 Io0 00|©0 6?|61 74 1б5 6В 65 65 70 65 72 | gatekeeper
40: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ||
50: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
60: 00 00 31 ЕЕ 7F 85 63 6F 6E 73 6F 6C 65 00 72 6F |..1...console.ro
70:l6F 74 00 00 00 00 31 ЕЕ 80 10 00 00 24 36 J|ot....l $6
I I T I
Length
▼ 1 <92> T
UDP Data T Checksum
(Who Data) Destination >(Г
Port E13) Source
Y IP Address
Source Port
E13)
Рис. 11.40. Пакет UDP для процесса WHOD
Packet Number : 4 10:57:57 PM
Length : 70 bytes
ether: ==================== Ethernet Datalink Layer ====================
Station: 00-00-C0-A2-0F-8E > FF-FF-FF-FF-FF-FF
Type: 0x0800 (IP)
ip: ======================= Internet Protocol =======================
Station:144.19.74.201 >144.19.255.255
Protocol: UDP
Version: 4
Header Length C2 bit words): 5
Precedence: Routine
Normal Delay. Normal Throughput. Normal Reliability
Total length: 52
Identification: 30
Fragmentation allowed. Last fragment
Fragment Offset: 0
Time to Live: 64 seconds
Checksum: 0x0FAC(Valid)
udp: ===================== User Datagram Protocol ====================
Source Port: ROUTER
Destination Port: ROUTER
Length = 32
Checksum: 0xFE96(Valid)
rip: ================== Routing Information Protocol =================
Command: Response
Version: 1
Family ID: IP
IP Address: 144.19.0.0
Distance: X Ethernet Type
A IP Header
Ethernet Header I л
A JL t
0 :f FF FF FF FF FF FF 00 00 CO A2 0F 8E &8 O0J4S 00 I E.
^- — :— ^ ^ . Destination
10: 00 34 00 IE 00 00 40 11: ёГ AC $0 13 6X C9)fee 13 • 1.4 e J .. . IP Address
UDP < ;■ -• ' • - • -■-" •;• ' ЧХ±ЯК -y\
Header 20: FF FF)fe2 08)^2 ОЩЭ .20)(р1^ОД[02 01 00 00 00 02 ||
r I I I I —' I I
30: 00 00 90 13 00 00 00 00 00 00 00 00 00 00 00 00)\
4e:[o0 61J I I J I '
I Length I
C2)
T T I
▼ Doe!??fom Checksum SouTce
UDP Data Port E20) |pA(jdress
(RIP Data) X
Source Port
E20)
Рис. 11.41. Пакет UDP для процесса RIP
Также обратите внимание на то, что поле протокола IP равно 17, что
указывает на инкапсуляцию данных UDP.
Итоги
ТсР и UDP — стандартные протоколы транспортного уровня для сетей IP.
Протокол TCP обязательно реализуется всеми устройствами (кроме
маршрутизаторов), реализующими семейство протоколов TCP/IP. «Эталонные» маршру-
тизаторы не реализуют TCP и UDP. Тем не менее многие коммерческие
маршрутизаторы поддерживают функции управления сетью и удаленного входа.
Для этих служб необходима реализация транспортных протоколов TCP и UDP.
Во многих реализациях TCP протокол UDP реализуется в составе модуля TCP,
хотя на концептуальном уровне он работает независимо от TCP.
Протоколы TCP и UDP не только позволяют доставить данные на удаленный
компьютер, но и направить их конкретному прикладному процессу, работающему
на этом компьютере. Прикладные процессы идентифицируются по номерам
портов. TCP обеспечивает надежную доставку данных, а предоставляемый им
сервис ориентирован на соединение. С другой стороны, протокол UDP не
ориентируется на соединение и не обеспечивает надежной доставки, но он также
может пригодиться во многих ситуациях — например, при широковещательной
или групповой рассылке данных.
Ч *% IPv6
На момент разработки IP версии 4 (то есть текущей версии IP) казалось, что
32-разрядных IP-адресов будет вполне достаточно для предполагаемого
развития Интернета. Однако ускоренные темпы роста Интернета показали, что
32-разрядная адресация создает немало проблем. Для преодоления этого препятствия
была начата разработка спецификации IP следующего поколения — IP версии 6
(IPv6), или IP Next Generation.
Перед принятием окончательной формы IPv6 был проанализирован ряд
альтернатив. Самыми популярными альтернативными решениями были TUBA (TCP
and UDP with Bigger Addresses), CATNIP (Common Architecture for the Internet)
и SIPP (Simple Internet Protocol Plus). Ни один из трех проектов не
удовлетворял требованиям, выдвинутым к новой версии протокола, но они послужили
основой для поиска компромиссов и внесения изменений в основную
спецификацию.
Какими же возможностями обладает IP следующего поколения? Ниже
приведен краткий список его основных особенностей.
О 128-разрядные сетевые адреса вместо 32-разрядных.
О Более эффективная структура заголовков IP с возможностью расширения
и включения новых параметров.
О Возможность добавления необязательных заголовков с необязательными
полями после фиксированного базового заголовка.
О Использование потоковых меток для идентификации требований к качеству
сервиса.
О Предотвращение промежуточной фрагментации дейтаграмм.
О Улучшенная поддержка мобильных станций.
О Автоматическое назначение адресов IPv6 на основании адресов MAC.
О Встроенные средства аутентификации и шифрования.
В этой главе протокол IPv6 будет рассмотрен более подробно. Особое
внимание уделяется изменениями, а также аспектам, представляющим интерес для
разработчиков, занимающихся сетевым программированием, и администраторов
сетей. Следующий раздел посвящен структуре заголовка IPv6.
Дейтаграмма IPv6
Как упоминалось выше, в IP версии 6 структура заголовков изменилась.
Изменения в основном связаны с поддержкой новых, длинных 128-разрядных
адресов и перемещением необязательных полей в заголовки расширения. Базовая
структура заголовка IPv6 изображена на рис. 12.1. Для сравнения на рис. 12.2
изображена структура старых заголовков версии 4.
Поле номера версии в заголовке дейтаграммы IP имеет длину 4 бита и равно 6
для IPv6. Поле приоритета тоже состоит из 4 бит и содержит числовой
показатель приоритета дейтаграммы. Приоритет, используемый при определении
порядка передачи, сначала задается на уровне общей классификации, а затем
уточняется внутри каждого класса (за дополнительной информацией
обращайтесь к разделу «Классификация приоритетов» настоящей главы).
версии Приоритет Потоковая метка
Длина полезных Следующий Переходной
данных заголовок предел
IP-адрес отправителя
Адрес получателя
Рис. 12.1. Структура заголовка IPv6
Номер Длина Тип Длина
версии заголовка сервиса дейтаграммы
Идентификатор DF MF Смещение фрагмента
Срок жизни РпоотоколЫИ Контрольная сумма заголовка
IP-адрес отправителя
IP-адрес получателя
Параметры и дополнение
Рис. 12.2. Структура заголовка IPv4
Поле потоковой метки имеет длину 24 бита. В сочетании с IP-адресом
отправителя оно используется для идентификации потока данных в сети. Например
если в сети используется рабочая станция Unix, ее потоковая метка будет отлична
от потоковой метки другого компьютера (скажем, рабочей станции Windows).
Поле может использоваться для идентификации характеристик потока данных
и регулировки передачи. Кроме того, оно помогает идентифицировать приемные
узлы при пересылке больших объемов данных, что повышает эффективность
кэширования при маршрутизации между отправителем и получателем. Тема
идентификации потоков более подробно рассматривается в разделе «Потоковые метки».
16-разрядное поле длины полезных данных определяет общую длину
дейтаграммы IP в байтах. Сам заголовок IP при вычислении общей длины не
учитывается. Использование 16-разрядного поля ограничивает максимальную длину
дейтаграммы 65 535 байтами, но существует возможность пересылки
дейтаграмм большего размера с использованием заголовков расширения (см. раздел
«Заголовки расширения IP» настоящей главы).
Поле следующего заголовка имеет длину 8 бит и определяет тип заголовка,
следующего сразу же после базового заголовка IPv6; оно используется в тех
случаях, когда другие приложения используют IP для пересылки своих данных.
Некоторые значения, определенные для поля следующего заголовка, приведены
в табл. 12.1. Значение этого поля идентифицирует транспортный протокол (код 6
для TCP или 17 для UDP) или содержит признак заголовка расширения IPv6.
Заголовки расширения IPv6 используются для передачи параметров IPv6 и
других данных.
Таблица 12.1. Значения поля следующего заголовка в IPv6
Значение Описание
О Параметры уровня переходов
4 IP
6 TCP
17 UDP
43 Маршрутизация
44 Фрагмент
45 Междоменная маршрутизация
46 Резервирование ресурсов
50 Атрибуты безопасности
51 Аутентификация
58 ICMP
59 Следующий заголовок отсутствует
60 Параметры для получателя
На рис. 12.3 приведены примеры использования поля следующего заголовка
для сообщения TCP и для заголовков расширения. Значение 59 указывает на
отсутствие следующего заголовка, то есть инкапсуляции других протоколов или
данных.
Заголовок I pv6
Л™^Т-Й TCP заголовок*данные
заголовок =
TCP F)
Базовый заголовок IPv6 с инкапсулированным сегментом TCP
I Заголовок IPv6 I 3аголовок I I
Cлeлvюший маршрутизации
заголовок = Следующий TCP заголовок + данные
кл~~...п~ 1лъ\ заголовок =
Маршрут D3) TCP F)
Базовый заголовок IPv6, заголовок маршрутизации и инкапсулированный сегмент TCP
I Заголовок IPv6 Заголовок Заголовок
Следующий маршрутизации фрагмента Фрагмент TCP
заголовок = ^пУйЮпТ-И SSSJT- заголовок .данные
Маршрут D3) заголовок- заголовок =
I I Фрагмент D4) | TCP F) |
Базовый заголовок IPv6, заголовок маршрутизации, заголовок фрагментации
и инкапсулированный сегмент TCP
Рис. 12.3. Примеры использования поля следующего заголовка
Поле переходного предела определяет максимальное количество переходов
(hops), на которые может переместиться дейтаграмма. При каждой пересылке
значение этого поля уменьшается на 1. Когда оно падает до 0, дейтаграмма
уничтожается. Ограничение количества переходов предотвращает бесконечные
перемещения старых дейтаграмм в сети, возникающие из-за циклической
маршрутизации. Начальное значение переходного предела задается отправителем.
Данное поле является аналогом поля срока жизни (TTL) в заголовках IPv4.
Основное различие заключается в том, что в IPv4 срок жизни измеряется в
секундах, а в IPv6 он измеряется в переходах. Впрочем, даже в IPv4 поле TTL
фактически выполняло функции счетчика переходов, потому что маршрутизаторы
уменьшали его на 1 вместо того, чтобы вычитать время обработки дейтаграммы.
На практике такие протоколы, как TCP, используют для борьбы со старыми
пакетами большие значения порядковых номеров (см. главу 11).
Заголовок завершается полями, в которых хранятся IP-адреса отправителя
и получателя в 128-разрядном формате. Новый формат IP-адресов подробно
описан ниже, в разделе «128-разрядные IP-адреса».
Классификация приоритетов
Поле приоритета в заголовке IPv6 сначала относит дейтаграмму к одной из двух
категорий: управляемые (имеется в виду управление перегруженностью сети)
и неуправляемые. Неуправляемые дейтаграммы всегда маршрутизируются перед
управляемыми. Для неуправляемых дейтаграмм существует дополнительная
субклассификация с приоритетами от 8 до 15.
Управляемые дейтаграммы реагируют на проблемы с перегруженностью сети.
Если сеть перегружена, пересылка дейтаграммы замедляется, и она временно
хранится в кэшах до решения проблемы. В широкой категории управляемых
дейтаграмм существует несколько подклассов, уточняющих приоритет
дейтаграмм. Субкатегории управляемого приоритета перечислены в табл. 12.2.
Таблица 12.2. Дополнительная классификация управляемых дейтаграмм
Приоритет Описание
0 Приоритет не задан
1 Фоновая пересылка данных
2 Необслуживаемая пересылка данных
3 Не используется
4 Обслуживаемая массовая пересылка данных
5 Не используется
6 Интерактивная пересылка данных
7 Пересылка управляющих данных
Приоритетам неуправляемого трафика выделены приоритеты от 8 до 15.
Такие дейтаграммы не реагируют на перегруженность сети — например, они
могут использоваться для пересылки в реальном времени пакетов,
генерируемых с постоянной скоростью.
Практические примеры основных субкатегорий помогут вам лучше понять,
как назначаются приоритеты. Трафику маршрутизации и управления сетью,
считающемуся наиболее приоритетным, присваивается категория 7.
Интерактивные приложения (например, сеансы Telnet и Remote X) относятся к категории
интерактивного трафика (категория 6). Пересылка данных, не критичная по
времени (в отличие от Telnet), но проходящая под управлением интерактивных
приложений типа FTP, относится к категории 4. Электронной почте обычно
назначается категория 2, тогда как низкоприоритетный трафик — например,
передача новостей — относится к категории 1.
Потоковые метки
Как упоминалось выше, в заголовках IPv6 появилось новое поле потоковой метки,
упрощающее идентификацию отправителя и получателя в сериях дейтаграмм IP.
Применение кэшей при управлении потоком данных позволяет более
эффективно организовать маршрутизацию дейтаграмм. Не все приложения будут
поддерживать обработку потоковых меток; в этом случае полю присваивается ноль.
Использование потоковых меток проще всего пояснить на простом примере.
Предположим, компьютер с системой Windows подключается к серверу Unix,
находящемуся в другой сети, и пересылает большое количество дейтаграмм.
Если всем дейтаграммам в контексте этой передачи будет задано определенное
значение потоковой метки, промежуточные маршрутизаторы могут включить
в свои кэши маршрутизации запись, которая указывает, по какому маршруту
должны передаваться все дейтаграммы с этой меткой. При получении
дальнейших дейтаграмм с тем же значением метки маршрутизатору не приходится иы-
числять маршрут заново; он просто обращается к кэшу и извлекает хранящуюся
в нем информацию маршрутизации. Тем самым ускоряется прохождение дсч'Нл
грамм через маршрутизатор.
Чтобы предотвратить чрезмерное разрастание кэшей и хранение устаревших
данных, спецификация IPv6 указывает, что содержимое кэшей на устройствах
маршрутизации не должно храниться более шести секунд. Если новая дейтаграмма
с той же потоковой меткой не принимается в течение шести секунд, запись
удаляется из кэша. Чтобы метки не повторялись, отправитель должен выждать шесть
секунд, прежде чем использовать ту же метку для другого получателя.
IPv6 позволяет использовать потоковые метки для резервирования
маршрутов в приложениях, критичных по времени. Предположим, приложение
реального времени должно передавать большое количество дейтаграмм по одному
и тому же маршруту, причем передача должна осуществляться как можно
быстрее (скажем, передача видео- или аудиоинформации). Такое приложение может
установить маршрут, отправляя дейтаграммы заранее; при этом оно должно
следить за тем, чтобы не превысить шестисекундный интервал тайм-аута на
промежуточных маршрутизаторах.
128-разрядные IP-адреса
Вероятно, самой важной особенностью IPv6 все же следует считать поддержку
более длинных IP-адресов. В версии 6 длина IP-адреса увеличена с 32 до 128
битов. Тем самым количество возможных IP-адресов увеличивается с
экспоненциальной скоростью.
Новый механизм адресации поддерживает три категории IP-адресов:
направленные, групповые и альтернативные.
О Направленный адрес (unicast address) определяет сетевой интерфейс
конкретного компьютера. Один компьютер может использовать несколько разных
протоколов, каждый из которых обладает собственным адресом. Например,
сообщение может быть направлено по адресу интерфейса IP, но не по адресу
интерфейса NetBEUI.
О Групповой адрес (multicast address) определяет группу сетевых интерфейсов
и позволяет получить пакет всем компьютерам, входящим в группу.
Групповая адресация может рассматриваться как аналог групповой рассылки в IP
версии 4, однако групповые адреса обладают большей гибкостью при
определении групп. В частности, интерфейсы одного компьютера могут
принадлежать к разным группам.
О Альтернативный адрес (anycast address) определяет группу интерфейсов для
одного группового адреса. Иначе говоря, дейтаграмма может быть получена
несколькими интерфейсами на одном компьютере.
Все три типа адресов более подробно описываются ниже, в разделе
«Направленные, групповые и альтернативные адреса».
Заголовки IP в версии 6 существенно изменились; они содержат гораздо
больше информации и стали более гибкими. Изменения в области
фрагментации и повторной сборки расширили возможности IP. Также для IPv6
предложена схема аутентификации и шифрования, которая гарантирует, что данные не
были испорчены во время пересылки, а получатель и отправитель являются
именно теми, за кого они себя выдают.
ПРИМЕЧАНИЕ
Схема аутентификации и шифрования является частью предложения IPSec (IP Security).
Заголовки расширения IP
В IPv6 предусмотрена возможность присоединения дополнительных заголовков
к заголовку IP. Например, это может понадобиться, если к месту назначения не
существует простого маршрута или если дейтаграмма требует особой обработки
(например, аутентификации). Дополнительная информация упаковывается в
заголовок расширения и присоединяется к заголовку IP.
IPv6 определяет несколько типов заголовков расширения. Тип заголовка
задается числовым кодом, хранящимся в поле следующего заголовка в
заголовке IP. Значения, принятые в настоящий момент, и их интерпретация приводятся
в табл. 12.1. К заголовку IP может быть присоединено несколько заголовков
расширения, при этом поле следующего заголовка в каждом расширении
обозначает тип следующего расширения. Заголовки расширения присоединяются
в следующем порядке:
1. Заголовок IPv6.
2. Заголовок переходных параметров.
3. Заголовок параметров получателя.
4. Заголовок маршрутизации.
5. Заголовок фрагментации.
6. Заголовок аутентификации.
7. Заголовок ESP.
8. Заголовок параметров получателя.
9. Заголовок верхнего уровня.
Упорядочение заголовков упрощает обработку дейтаграмм на
маршрутизаторах и позволяет прекратить анализ после просмотра расширений, относящихся
к маршрутизации.
Переходные заголовки
Расширение с типом 0 используется для передачи параметров IP всем
компьютерам, через которые проходит дейтаграмма. Параметры, включаемые в
переходные заголовки, имеют стандартный формат, состоящий из признака типа, длины
и данных (за исключением параметра Padl, который состоит из одного нулевого
значения и не содержит полей длины или данных). Длина полей типа и длины
равна одному байту, а поле данных имеет переменную длину, которая указана
в предыдущем поле.
В настоящее время определены три переходных параметра: Padl, PadN и Jumbo
Payload. Параметр Padl состоит из одного байта с нулевым значением, не имеет
полей длины и данных. Он используется для изменения порядка и положения
других параметров в заголовке, что обычно определяется нуждами приложения.
Параметр PadN устроен аналогично, но его поле данных заполнено N нулями,
а значение поля длины вычисляется по размеру данных.
Параметр Jumbo Payload используется при обработке дейтаграмм с размером
более 65 635 байт. Из-за ограничения поля длины в заголовке IP 16 битами
максимальный размер дейтаграмм не может превысить 65 535. При обработке
дейтаграмм большего размера поле длины в заголовке IP равно нулю; это
означает, что за правильным значением длины маршрутизатор должен обратиться
к расширению. Поле длины в заголовке расширения содержит до 32 бит, что
позволяет создавать дейтаграммы размером свыше 4 миллиардов байт!
Заголовки переходных параметров в формате IPv6 представлены нулевым кодом
следующего заголовка. Структура переходных параметров изображена на рис. 12.4.
0 12 3
01234567890123456789012345678901
I I II I I I I I I I М М I М I I—I I I I—I > I I I—НН—Н-Н
_ v Длина
Следующий заголовка
заголовок расшире„ия
1 i i i i i i i—I i i > i i i i ' -|-
Параметры |
I I I I I I I I—I—I I < I I I I t I t I I I I I—I I I I I—h-H-H—\-
Рис. 12.4. Заголовок переходных параметров в IPv6
Поля в заголовках переходных параметров имеют следующий смысл:
О Следующий заголовок. 8-разрядный селектор, который определяет тип заголовка,
следующего непосредственно за переходным заголовком.
О Длина заголовка расширения. 8-разрядное целое без знака. Длина переходного
заголовка в 8-октетных единицах, за вычетом первых 8 октетов.
О Параметры. Поле переменной длины, при которой полная длина заголовка
кратна 8 октетам. Параметры кодируются в формате TLV
(тип-длина-значение).
Кроме параметров Padl и PadN для заголовков переходных параметров также
определен параметр Jumbo Payload (рис. 12.5).
Параметр Jumbo Payload должен выравниваться по границе 4п + 2. Это
означает, что начало параметра должно начинаться с границы 4 октетов плюс 2 октета
от начала заголовка.
Параметр Jumbo Payload используется для пакетов IPv6, у которых полезная
нагрузка превышает 65 535 октетов. Данные параметра хранятся в
32-разрядном поле и представляют длину пакета в октетах, за вычетом заголовка IPv6, но
с заголовком переходных параметры; значение должно быть больше 65 535. При
получении пакета с параметром Jumbo Payload, меньшим либо равным 65 535,
отправителю пакета отправляется сообщение ICMP с кодом 0 (недопустимые
параметры), указывающее на старший октет недействительного поля данных.
2 3
6789012345678901
-]—I—I—I 1 > I I—»—I—I—*—I—НН—Н-1-
Длина
194 данных
0 1 I параметра =
0123456789012349 4
I i i—> i i i i—i—iii<—nil—iii iiii—I—«—iii lit—у
Увеличенная длина
I l I I I l l I I—I I i I I I i i l l l iiii—l—l—l—fH—H+-H—L
Рис. 12.5. Параметр Jumbo Payload
Кроме того, поле длины полезных данных в заголовке IPv6 должно быть равно
нулю для всех пакетов, содержащих параметр Jumbo Paylod. Если принятый
пакет содержит ненулевую длину полезных данных IPv6 с допустимым
значением параметра Jumbo Payload, отправителю пакета отправляется сообщение
ICMP с кодом 0 (недопустимые параметры), указывающее на поле типа
параметра Jumbo Payload.
Заголовки маршрутизации
Заголовки маршрутизации присоединяются к заголовкам IP в тех случаях, когда
отправитель хочет сам управлять маршрутизацией дейтаграммы вместо того, чтобы
доверить принятие решений маршрутизаторам. Такой тип маршрутизации
называется маршрутизацией от источника. Описание маршрута передается в
заголовке маршрутизации, содержащего перечень всех промежуточных IP-адресов.
В заголовке маршрутизации IPv6 (рис. 12.6) перечисляются
промежуточные маршрутизаторы, через которые должна пройти дейтаграмма IPv6 на пути
к месту назначения. Этот заголовок реализует идею маршрутизации от источника,
также присутствовавшую в IPv4. Заголовки расширения IPv6 идентифицируются
кодом 43 в поле следующего заголовка базового заголовка IPv6.
0 12 3
012345678901234567890 12345678901
—| 1 1 1 h—Н 1 1 1 1 1 Ь-Ч 1 1—-1 J—I Н—I 1 h—I 1 1—i 1—I 1 1 1—I 1~
Следующий заголовка Тип Длина остаточного
заголовок расширения маршрутизации маршрута
— 1 h—I 1 1 1 1 1—I 1 1 1 1 1 1——I 1 У—I 1 »—I 1 1—1 1 1 1—1 1 1
Специализированные данные
Iiii—1—н—н—i i i i—i—i—i—i—i i i i i i i i—i 1 t i t—i i i—i I
Рис. 12.6. Заголовок маршрутизации IPv6
Поля в заголовках маршрутизации имеют следующий смысл:
О Следующий заголовок. 8-разрядный селектор, который определяет тип
заголовка, следующего непосредственно за заголовком маршрутизации. Это
может быть другой заголовок расширения IPv6, входящий в цепочку
заголовков расширения IPv6, или же заголовок транспортного протокола верхнего
уровня.
О Длина заголовка расширения. 8-разрядное целое без знака. Длина заголовка
маршрутизации в 8-октетных единицах, за вычетом первых 8 октетов.
О Тип маршрутизации. 8-разрядный идентификатор, определяющий
используемую разновидность заголовка. В настоящее время в спецификации IPv6
(RFC 1883) определена маршрутизация типа 0. Возможно, в будущем также
появятся другие форматы заголовков маршрутизации.
О Длина остаточного маршрута. 8-разрядное целое без знака, определяющее
количество оставшихся сегментов маршрута — то есть количество явно
перечисленных промежуточных узлов, которые должны принять дейтаграмму
перед тем, как она достигнет места назначения.
О Специализированные данные. Поле переменной длины, формат которого
определяется содержимым поля типа маршрутизации. Длина поля должна быть
такой, чтобы полная длина заголовка маршрутизации была кратна 8 октетам.
Если узел обнаруживает заголовок маршрутизации с неизвестным кодом
типа маршрутизации, он обрабатывает пакет, руководствуясь значением поля
длины остаточного маршрута. Если поле равно нулю, узел игнорирует
заголовок маршрутизации и переходит к следующему заголовку пакета,
идентифицируемому полем следующего заголовка IPv6. Если поле длины остатка маршрута
отлично от нуля, узел должен отвергнуть пакет и отправить получателю (адрес
которого берется из поля IP-адреса отправителя в заголовке) сообщение ICMP
с кодом 0 (недопустимые параметры) с сообщением о неопознанном типе
маршрутизации.
На рис. 12.7 изображена структура заголовка маршрутизации для типа 0.
Обратите внимание на совпадение первых 32 бит этого заголовка с изображенным
на рис. 12.6. Поле специализированных данных содержит список адресов
маршрутизаторов, который используется вместо маршрута, выбираемого
протоколом маршрутизации на маршрутизаторе.
0 12 3
012345678901234567890 12345678901
| t 1 У-—■ Н—-« 1 Н—I 1 1—1 1 Н—Н 1 1 1 I—« 1—1 1 j 1 1—H 1 lilt
Следующий за^ловка Тип Длина остаточного
заголовок расширения маршрутизации = 0 маршрута
Н—I—i t i—i i i [—I—I—>—и 1—I—I 1—н—•—н 1 1—I—I 1—I 1—(—i 1 i i к
Зяоезеовиоовано Карта жесткой/свободной
Зарезервировано маршрутизации
I 1 1 I I I 1 1 1 I I 1 I I 1 I I I I 1 Н-Н \—Н »—I 1 1 1 »—» 1 I
Рис. 12.7. Заголовок маршрутизации IPv6 для типа 0
Поля в заголовке маршрутизации IPv6 имеют следующий смысл:
О Следующий заголовок. 8-разрядный селектор, который определяет тип заголовка,
следующего непосредственно за заголовком маршрутизации.
О Длина заголовка расширения. 8-разрядное целое без знака. Длина заголовка
маршрутизации в 8-октетных единицах, за вычетом первых 8 октетов. Для
заголовка маршрутизации типа 0 длина вдвое больше количества адресов
в заголовке; это должно быть четное число, меньшее либо равное 46.
О Длина остаточного маршрута. 8-разрядное целое без знака, определяющее
количество оставшихся сегментов маршрута. Максимальное допустимое
значение для типа 0 равно 23.
О Зарезервировано. 8-разрядное поле обнуляется при передаче и игнорируется
при получении.
О Карта жесткой/свободной маршрутизации. 24-разрядная карта, биты
которой слева направо нумеруются от 0 до 23. Каждый бит соответствует
некоторому сегменту маршрута и указывает, должен ли следующий адрес быть
прямым соседом предыдущего адреса. Бит, равный 1, означает жесткую
маршрутизацию от источника, то есть следующий адрес должен
непосредственно соседствовать с текущим. Бит, равный 0, означает свободную
маршрутизацию от источника, то есть следующий адрес может быть отделен от
текущего промежуточными узлами.
О Адрес [1..п]. Вектор 128-разрядных адресов, пронумерованных от 1 до п.
Заголовки фрагментации
Заголовки фрагментации присоединяются к дейтаграммам IP для того, чтобы
большие дейтаграммы могли разбиваться на более мелкие части.
Проектирование IPv6 было отчасти направлено на сокращение фрагментации, но в
некоторых случаях фрагментация абсолютно необходима, чтобы дейтаграммы могли
передаваться по сети.
В отличие от IPv4 фрагментация IPv6 выполняется только
узлом-отправителем, но не маршрутизаторами на пути доставки пакета. Отправитель IPv6
знает размер MTU на пути к получателю; способы определения MTU описаны
в RFC 1191, раздел «Path MTU Discovery».
Собираясь передавать пакеты, размер которых превышает MTU на пути к
получателю, отправитель IPv6 вставляет в них заголовок фрагментации. Заголовок
фрагментации определяется кодом 44 в поле следующего заголовка, находящемся
в предыдущем заголовке. Структура заголовка фрагментации изображена на
рис. 12.8.
Поля в заголовке фрагментации IPv6 имеют следующий смысл:
О Следующий заголовок. 8-разрядный селектор, который определяет тип
заголовка, следующего непосредственно за заголовком фрагментации. Это может быть
другой заголовок расширения IPv6, входящий в цепочку заголовков
расширения IPv6, или же заголовок транспортного протокола верхнего уровня.
О Зарезервировано. 8-разрядное поле обнуляется при передаче и игнорируется
при получении.
0 12 3
012345678901234567890 12345678901
I I I 1 1 > I 1 1 1 1—I 1 1 1 1 (—I 1 1 1 1 1 1 1 1 1 1 1 1 j 1 H
Следующий зарезервировано £"!Щ!НИ! Результат М
заголовок к г г фрагмента 7
II ill ii—I—i—i—i—i i i—i—I—i—i—i—i i i i—I i i—i—i—i—I—i—U
Идентификатор
—I 1 I I I Н—Н 1 I I Н-Н 1 Н-Н 1 »—I 1 1 I I I 1 1 1 1 »—< I—-Н 1 I—
Рис. 12.8. Заголовок фрагментации в IPv6
О Смещение фрагмента. 13-разрядное целое без знака, определяющее смещение
данных, следующих за заголовком (в 8-октетных единицах). Смещение
измеряется относительно начала фрагментируемой части исходного пакета.
О Результат. 2-разрядное поле обнуляется при передаче и игнорируется при
получении.
О Флаг М. Если существуют другие фрагменты, флаг равен 1, а если их не
существует — флаг равен 0.
О Идентификатор. 32-разрядное поле. Для каждого фрагментируемого пакета
узел-отправитель генерирует идентификатор, отличный от идентификатора
всех фрагментированных пакетов, отправленных недавно с теми же адресами
отправителя и получателя.
Заголовки аутентификации
Заголовки аутентификации гарантируют, что в содержимое дейтаграммы не были
внесены изменения, а сама дейтаграмма была отправлена с узла, указанного в
заголовке IP. По умолчанию IPv6 использует схему аутентификации Message Digest 5
(MD5). Также возможно использование других схем аутентификации,
согласованных между обоими концами соединения.
Заголовок аутентификации состоит из индекса параметров защиты (SPI),
который в сочетании с IP-адресом получателя определяет схему
аутентификации. За SPI следуют данные аутентификации, которые в схеме MD5 имеют длину
16 байт. MD5 берет ключ (при необходимости дополненный до 128 бит) и
присоединяет к нему всю дейтаграмму. Результат обрабатывается по алгоритму MD5. Для
предотвращения проблем с изменением счетчиков переходов и самого заголовка
аутентификации, при вычислении проверочной величины эти поля обнуляются.
Алгоритм MD5 генерирует 128-разрядное значение и включает его в заголовок
аутентификации. На стороне получателя эти действия повторяются. Разумеется,
для того чтобы эта схема работала, обе стороны должны иметь одинаковые ключи.
Перед построением проверочных величин содержимое дейтаграммы может быть
зашифровано по стандартной схеме шифрования IPv6, которая называется СВС
(Cipher Block Chaining) и является частью стандарта DES (Data Encryption Standard).
Поля в заголовке аутентификации IPv6 имеют следующий смысл (рис. 12.9):
О Следующий заголовок. 8-разрядный селектор, который определяет тип
заголовка, следующего непосредственно за заголовком аутентификации.
О Длина. Поле имеет длину 8 бит и определяет длину поля данных
аутентификации в 32-разрядных блоках. Минимальное значение равно 0 и используется
только в особом случае, когда алгоритм аутентификации не используется.
О Зарезервировано. 16-разрядное поле зарезервировано для использования в
будущем. Должно быть заполнено нулями отправителем. Значение включается
в вычисление проверочной величины, но в остальном игнорируется
получателем.
О Индекс параметров защиты (SPI). 32-разрядное псевдослучайное число,
идентифицирующее систему защиты для данной дейтаграммы. Значение 0
означает отсутствие системы защиты. Значения от 1 до 255 зарезервированы для
IANA (Internet Assigned Numbers Authority). IANA обычно не назначает
зарезервированные значения SPI, если только использование этого конкретного
значения не оговорено в RFC.
О Данные аутентификации. Поле имеет переменную длину, но всегда
содержит целое число 32-разрядных блоков и содержит вычисленные данные
аутентификации для этого пакета.
0 12 3
01234567890123456789012345678901
1 1 ~t ' Г"
Следующий Длина Зарезервировано
заголовок
Индекс параметров защиты
1 ' ' ' г
Данные аутентификации
(переменное число 32-разрядных блоков)
\ 1 1 1 г-
Рис. 12.9. Заголовок аутентификации в IPv6
Заголовки ESP
Заголовки ESP (Encrypted Security Payload) обеспечивают целостность и
конфиденциальность содержимого дейтаграмм IP. Иногда они также могут
использоваться для аутентификации (в зависимости от того, какая схема используется).
ESP не защищает от анализа трафика и ложных отказов в подтверждении. При
использовании с некоторыми аутентификационными алгоритмами заголовки
аутентификации IPv6 могут обеспечивать защиту от ложных отказов на
подтверждение.
Заголовки ESP могут использоваться в сочетании с заголовками
аутентификации для предоставления аутентификации. Приложение, нуждающееся в
проверке целостности и аутентификации без конфиденциальности, должно
использовать заголовок аутентификации вместо ESP.
ESP шифрует защищаемые данные и размещает их в области данных. Этот
механизм может использоваться для шифрования как сегментов транспортного
уровня, так и целых дейтаграмм IP.
ESP работает в двух режимах, туннельном и транспортном. В туннельном
режиме исходная дейтаграмма IP помещается в зашифрованную часть ESP, а весь
кадр ESP помещается в дейтаграмму с незашифрованными заголовками IP.
Данные незашифрованных заголовков используются для маршрутизации
защищенных дейтаграмм от отправителя к получателю. Между заголовком IP и
заголовком ESP может присутствовать незащищенный заголовок маршрутизации IP.
В транспортном режиме заголовок ESP вставляется в дейтаграмму IP
непосредственно перед заголовком протокола транспортного уровня. Это повышает
эффективность передачи данных, поскольку дейтаграмма не содержит
шифрованные заголовки или параметры IP.
Заголовок ESP может находиться в любом месте после заголовка IP и перед
последним заголовком протокола транспортного уровня. Заголовок,
непосредственно предшествующий ему, должен содержать в поле следующего заголовка
значение 50. ESP состоит из незашифрованного заголовка, за которым следуют
зашифрованные данные. Эти данные включают как защищенную информацию
заголовка ESP, так и защищенные данные — полную дейтаграмму IP или пакет
протокола транспортного уровня. Примерное строение защищенной
дейтаграммы IP представлено на рис. 12.10.
Структура заголовка ESP
U Открытые данные >\< Шифрованные данные —W
Заголовок IP ДРУГОЙ Шифрованные
W ЗаГОЛОВОК IP waiwiiwBun йог ДЭННЫв
Формат заголовка ESP
\ ' j ' Ь
SPI, 32 бита
I ' ' ' 1
Данные непрозрачного преобразования
(переменная длина)
i 1 1 1 Ь
Рис. 12.10. Структура заголовка ESP в IPv6
Алгоритмы шифрования и аутентификации, а также точный формат
связанных с ними данных непрозрачного преобразования называются
трансформациями (transforms). Формат ESP спроектирован таким образом, чтобы в будущем
он поддерживал возможность использования новых трансформаций для
поддержки новых или дополнительных криптографических алгоритмов.
Поле SPI (см. рис. 12.10) представляет собой 32-разрядное псевдослучайное
число, идентифицирующее систему защиты для данной дейтаграммы.
Значение 0 означает отсутствие системы защиты. SPI является аналогом
идентификатора SAID (Security Association Identifier), используемого в других протоколах
защиты данных. Значения от 1 до 255 зарезервированы для IANA (Internet
Assigned Numbers Authority). IANA обычно не назначает зарезервированные
значения SPI, если только использование этого конкретного значения не
оговорено в RFC. SPI является единственным обязательным полем, независимым от
трансформаций.
Хосты с несколькими IP-адресами
Если не считать потенциальной проблемы исчерпания IP-адресов, стоило ли
изобретать принципиально новую структуру заголовков IP? Как нетрудно
заметить при изучении структуры заголовков, новая версия наделена множеством
новых возможностей, среди которых важное место занимает использование
нескольких IP-адресов на одном хосте.
В современных системах TCP/IP почти все хосты ограничиваются одним
IP-адресом. Исключение составляют компьютеры, выполняющие функции
шлюзов, маршрутизаторов, брандмауэров, прокси-серверов и преобразователей сетевых
адресов (NAT, Network Address Translators). Одноадресные компьютеры
обладают некоторыми преимуществами: например, подсчитав количество IP-адресов
в сети, можно узнать количество подключенных компьютеров. Поддержка одного
IP-адреса на хосте упрощает настройку сети по сравнению с многоадресными
хостами. Пользователю, работающему в FTP и Telnet, проще запомнить один
IP-адрес, чем несколько разных адресов. Наконец, при внедрении IPv6 придется
вносить изменения в DNS и другие службы, в которых имена отображаются на
один IP-адрес. Однако переход на модель многоадресного хоста в IPv6
обусловлен рядом веских причин.
Преимущества многоадресной модели особенно очевидно проявляются на
многопользовательских компьютерах. Например, если вы работаете на машине
одновременно с четырьмя пользователями (которые могут использовать
бездисковые рабочие станции или другие устройства), было бы удобно назначить
каждому пользователю собственный IP-адрес; подобное распределение адресов
упрощает подключение к файловым системам, наблюдение за использованием
ресурсов и сбор аналитической информации. Назначение каждому пользователю
собственного IP-адреса позволит применять в схемах шифрования,
поддерживаемых в IPv6, разные ключи для разных пользователей, что сделает защиту
данных более надежной.
Другое важное преимущество многоадресных хостов — шифрование.
Большинство современных серверов доступно по некоторой разновидности доменного
имени (например, ftp.microsoft.com для демонов FTP или http://www.microsoft.com
для World Wide Web), причем все эти службы работают на одном хосте с
одинаковыми средствами защиты, встроенными в IP. IPv6 позволяет назначить
каждой службе собственный IP-адрес, при этом в зависимости от IP-адреса будут
использоваться разные методы шифрования и аутентификации. Например, один
адрес может отображаться на http://www.microsoft.com с минимальным уровнем
шифрования и аутентификации, а другой адрес, отображаемый на ftp.microsoft.com,
может требовать жесткой аутентификации, поскольку пересылка файлов должна
быть разрешена только доверенным системам. Хотя применение разных уровней
обработки в зависимости от типа службы реализуется и в современной версии IP,
IPv6 обладает гораздо большими возможностями. С другой стороны, это
значительно увеличит количество адресов, отображаемых на имена.
По сравнению с текущей версией IP, IPv6 также упрощает добавление номеров
портов TCP. Например, чтобы обратиться на сервере к порту TCP с номером 14,
необходимо указать IP-адрес вместе с именем порта (например, 205.150.89.1:14).
В результате пользователю приходится запоминать номер порта. Поддержка
множественных адресов в IPv6 позволяет легко организовать разрешение
портов TCP. Например, один адрес может указывать на порт FTP с более высоким
уровнем защиты, нежели другой адрес, указывающий на другой FTP-порт.
Множественные адреса также удобны при слиянии подсетей. Предположим,
в вашей организации установлены две локальные сети: для научного персонала
и для управления. Если вы управляете работой научно-исследовательской
лаборатории, ваш компьютер должен иметь IP-адреса в обеих сетях. В некоторых
ситуациях компьютер может работать как своего рода маршрутизатор, и вам
придется часто указывать, в какой сети вы хотите работать в настоящий момент.
IPv6 позволяет назначить адреса таким образом, что информация может
пересылаться сразу по обеим локальным сетям, или же данные будут без особых
трудностей перемещаться из одной сети в другую (при этом потребность в
маршрутизаторе фактически пропадает).
Направленные, групповые
и альтернативные адреса
Направленные адреса существуют в нескольких разновидностях: глобальные,
локальные и совместимые. Спецификация IPv6 позволяет в будущем добавлять
другие типы направленных адресов по мере необходимости.
Глобальные направленные адреса используются для установления связи с
любым поставщиком в Интернете. Формат глобального направленного адреса
показан на рис. 12.11.
На рис. 12.11 первые три бита 010 определяют тип направленного адреса.
Поле REG ID определяет реестр адресов Интернета, назначающий
идентификатор поставщика (PROV ID), который, в свою очередь, назначает адреса клиентам
(в большинстве случаев PROV ID определяет поставщика услуг Интернета).
Поле SUBSC ID идентифицирует подписчиков (клиентов) в сети поставщика,
а поле SUBNET ID позволяет использовать конкретный адрес. Наконец, поле
INTF ID содержит идентификатор интерфейса, который может использоваться
для идентификации нужного интерфейса подписчика.
nm Dcr^m PR0V SUBSC SUBNET INTF
010 REG ID |D ID ID ">
Рис 12.11. Структура глобального направленного адреса
Локальный направленный адрес используется только в сети или подсети,
поэтому для него требуется меньше информации. Заголовок локального
направленного адреса изображен на рис. 12.12. Поле INTF ID содержит идентификатор
интерфейса сети или подсети. У локальных направленных адресов существует
разновидность, при которой идентификатор подсети включается в заголовок
с сокращением поля INTF ID. Поле INTF ID также может использоваться для
идентификации конкретной подсети заданной сети.
1111111010 0 INTF ID
Рис. 12.12. Структура локального направленного адреса
Наконец, на рис. 12.13 представлена разновидность направленных адресов,
содержащих встроенные адреса IPv4. Адрес IPv4 находится в конце адреса IPv6
и может использоваться старыми реализациями IP.
80 бит 16 бит 32 бита
000...000 0 Адрес IPv4
Рис. 12.13. Структура совместимого направленного адреса,
содержащего встроенный адрес IPv4
Альтернативные адреса используют ту же структуру, что и направленные
адреса, и в большинстве случаев не отличаются от направленных адресов,
используемых при широковещательной рассылке.
Структура групповых адресов изображена на рис. 12.14.
1111111 <п™1 Область Идентификатор
1 1 флаТов) 1 **™* 1 ГРУ™Ы 1
Рис. 12.14. Структура группового адреса
Единицы в старших 8 битах являются признаком группового адреса. Поле
флагов состоит из четырех битов, начинается с трех нулей (зарезервированы
для использования в будущем) и завершающего бита, который может быть
равен либо 0 для постоянно назначаемого группового адреса, либо 1 для
временного группового адреса. 4-разрядное поле области действия ограничивает
групповую рассылку. Допустимые значения этого поля перечислены в табл. 12.3.
Наконец, идентификатор группы определяет конкретную группу, в которой
производится рассылка.
Таблица 12.3, Допустимые значения области действия групповой рассылки
Значение Описание
0 Зарезервировано
1 Рассылка уровня узла
2 Рассылка уровня канала
3, 4 Не присвоено
5 Рассылка уровня подразделения
6, 7 Не присвоено
8 Рассылка уровня организации
9, А, В, С, D Не присвоено
Е Глобальная рассылка
F Зарезервировано
Переход с IPv4 на IPv6
С технической точки зрения IPv6 превосходит текущую версию IP (IPv4),
однако реализация IPv6 в мировом масштабе порождает определенные проблемы.
Переключение со старой версии IP на новую требует определенного времени,
поэтому переход следует организовать так, чтобы в течение этого срока
поддерживалась совместимость с обеими версиями. Предполагается, что повсеместное
внедрение IPv6 займет несколько лет, поэтому проблемы перехода чрезвычайно
важны.
Одна из проблем с переходом на IPv6 заключается в том простом факте, что
протокол IPv4 жестко встроен во многие уровни семейства протоколов TCP/IP
и во многие приложения. Чтобы переключиться на IPv6, необходимо
преобразовать все приложения, все драйверы и все компоненты стека TCP,
использующие IP. Это потребует изменения сотен и тысяч программ в миллионах строк
исходных текстов. Маловероятно, чтобы тысячи поставщиков аппаратного и
программного обеспечения успели изменить свою программную базу в заданный
промежуток времени. И снова приходится сделать вывод, что IPv4 и IPv6
придется сосуществовать в течение некоторого времени.
Все современные компьютеры (хосты, маршрутизаторы, мосты и т. д.)
используют IPv4. По мере перехода на IPv6 (за счет обновления аппаратной или
программной базы) всем этим компьютерам придется поддерживать два
комплекта программного обеспечения IP: для старой и для новой версии. В
некоторых случаях реализация таких решений будет сильно затруднена ограниченным
объемом памяти или производительностью, поэтому на некоторых устройствах
придется поддерживать только одну версию IP (или заменить их более мощными
устройствами).
Если обновить приложение до IPv6 невозможно (или нежелательно), для
него придется разработать программный преобразователь. Например, при взаи-
модействии с IPv6 устройств и приложений на базе IPv4 взаимодействующие
стороны разделяются дополнительным модулем, который обеспечивает
преобразование. Скорость и эффективность работы системы при этом снижается, но
в некоторых случаях нет другого способа обеспечить работу старых программ
и оборудования.
На первый взгляд переход от IPv4 к IPv6 не вызывает особых сложностей,
но на практике трудностей хватает. Главная проблема связана с преобразованием
заголовков, где даже минимальное упущение приводит к потере данных.
Протокол IPv6 основан на IPv4, но заголовки этих протоколов сильно различаются.
Любая информация в заголовке IPv6, не поддерживаемая IPv4 (в частности,
классификация приоритета), будет потеряна при преобразовании. И наоборот,
преобразование в IPv6 пакетов, выходящих с хостов IPv4, приведет к тому, что
большая часть данных, многие из которых могут оказаться очень важными, будет
отсутствовать в заголовках.
Отображение адресов (преобразование IP-адресов IPv4 в IPv6, и наоборот)
также требует особого внимания. Если хост имеет несколько IP-адресов IPv6
и только один адрес IPv4, то на преобразователях, маршрутизаторах и других
устройствах, осуществляющих преобразование между версиями IP, придется
хранить большие таблицы отображений. В крупных организациях подобное
решение неприемлемо, и преобразование IPv4 в IPv6 может привести к
ошибочному вычислению места назначения. Адреса IPv4 могут внедряться в заголовки
IPv6, однако это может породить проблемы в системах на базе IPv6.
Переход на IPv6 потребует радикальной переработки некоторых служб TCP/IP.
Например, DNS содержит информацию о преобразовании имен в IP-адреса. На
стадии перехода серверам DNS придется поддерживать обе версии IP, а также
обеспечивать разрешение нескольких IP-адресов для каждого хоста — скажем,
IPv6 позволяет назначить одному компьютеру 10 разных адресов (например,
разные службы могут быть представлены разными адресами). С
широковещательной рассылкой тоже возникают проблемы, потому что IPv4 достаточно часто
используется для широковещательной рассылки в масштабах локальной или
глобальной сети (например, ARP использует средства широковещательной
рассылки канального уровня). В IPv6 используется система групповой рассылки,
которая спроектирована таким образом, чтобы дейтаграмма пересылалась в
локальной или глобальной сети только один раз. Согласование двух систем
широковещательной рассылки также вызывает проблемы.
При переводе всей сетевой инфраструктуры с IPv4 на IPv6 приходится
учитывать гораздо больше факторов, чем упоминалось выше. Для обеспечения
максимальной гибкости по мере перехода компаний и сетей с одной версии IP на
другую необходимо решить множество технических вопросов. Процесс перехода
отнюдь не прост. Предполагается, что он займет несколько лет, но его конечным
результатом должна стать сеть, работающая исключительно на базе IPv6 (хотя
не исключено, что многие старые устройства не удастся обновить до IPv6, а их
работа будет обеспечиваться дополнительными преобразователями). Тем, чья
работа непосредственно связана с администрированием сети, переход с IPv4 на
IPv6 принесет массу незабываемых впечатлений.
Итоги
На повсеместное внедрение IPv6 потребуется несколько лет, но рано или поздно
это произойдет. Собираетесь ли вы осуществить переход за короткий
промежуток времени или пойдете по пути постепенных изменений, когда-нибудь вам
придется реализовать IPv6 в своей сети. Для большинства пользователей
(особенно тех, кто пользуется услугами поставщиков Интернета) это дело
отдаленного будущего. С другой стороны, для многих компаний те преимущества,
которыми обладает IPv6, ускорят процесс перехода. В IPv6 заложены встроенные
средства совместимости с IPv4, поэтому работа старых систем на базе IP будет
поддерживаться еще достаточно долго.
■i *Э Маршрутизация
ХЭ в сетях IP
Марк А. Спартак (Mark A. Sportack)
Маршрутизация принадлежит к числу важнейших операций в объединенных
сетях IP. Маршрутизацией называется процесс построения, сравнения и выбора
маршрута в сети к произвольному IP-адресу. Обычно эти функции выполняются
специализированными устройствами, которые называются маршрутизаторами.
Тем не менее технологический прогресс быстро стирает различия между
традиционными маршрутизаторами, коммутаторами локальных сетей и даже
обычными хостами, подключенными к сети. В наши дни все три типа устройств
способны строить, сравнивать и выбирать маршруты, поэтому маршрутизацию следует
рассматривать как функцию, а не как физическое устройство.
Сущность маршрутизации воплощена в форме специализированных сетевых
протоколов, которые позволяют маршрутизаторам (независимо от типа
физического устройства) выполнять свои жизненно важные функции. К числу таких
функций относятся:
О обмен информацией о локально подключенных хостах и сетях;
О сравнение альтернативных путей;
О согласование топологии сети.
Хорошее понимание механики выполнения этих базовых функций в сетях IP
закладывает основу для углубленного изучения трех самых распространенных
протоколов динамической маршрутизации, описанных в главах 14-16.
Основы маршрутизации
Маршрутизаторы выполняют свои функции в двух основных режимах: они
либо используют заранее запрограммированные статические маршруты, либо
строят маршруты с использованием протоколов динамической маршутизации.
Статические маршрутизаторы не способны строить маршруты и не обладают
средствами обмена данными с другими маршрутизаторами. Статический
маршрутизатор может только передавать пакеты по маршрутам, определенным
сетевым админинистратором.
В свою очередь, протоколы динамической маршрутизации делятся на две
категории: дистанционно-векторные и топологические протоколы. Основное раз-
личие между этими типами динамических протоколов маршрутизации
заключается в алгоритме поиска и построения новых маршрутов к месту назначения.
ПРИМЕЧАНИЕ
Существует несколько вариантов классификации протоколов маршрутизации. Одни из них основаны
на рабочих характеристиках — области применения, количеству потенциальных маршрутов для
каждого возможного места назначения и т. д. В этой книге протоколы маршрутизации
классифицируются по способу поиска и построения маршрутов. Тем не менее классификация по области
применения (то есть по их роли в объединенной сети) тоже встречается на практике. Например,
существует два функциональных класса протоколов динамической маршрутизации: протоколы
внутреннего шлюза IGP (Interior Gateway Protocol) и протоколы внешнего шлюза EGP (Exterior
Gateway Protocol).
Вероятно, проще всего эта классификация объясняется так: протоколы IGP используются внутри
автономных систем (таких, как интрасети), тогда как протоколы EGP используются между
автономными системами. Автономная система представляет собой самостоятельную совокупность
сетей, обычно находящихся под управлением одного администратора или группы администраторов.
Для построения маршрутов в Интернете используется пограничный межсетевой протокол BGP
(относящийся к категории EGP). С точки зрения маршрутизации Интернет представляет собой не что
иное, как магистральный транспорт для глобальной совокупности автономных систем, находящихся
в частном владении и управляемых частным образом.
Для каждого протокола, описанного в книге, указано, к какой категории он относится — IGP или EGP.
Статическая маршрутизация
Простейшая форма маршрутизации основана на использовании статических,
то есть заранее запрограммированных маршрутов. За построение маршрутов
и их распространение в сети отвечают администраторы межсетевого объединения.
Маршрутизатор, использующий статическую маршрутизацию, отправляет
пакеты с заранее определенных портов. После настройки связи между адресом
получателя и портом маршрутизатора последнему нет необходимости пытаться искать
маршруты и даже распространять информацию о маршрутах, ведущих к этому
месту назначения. Тем не менее маршрутизатор может использовать
статическую маршрутизацию для одних получателей и динамическую — для других.
Статическая маршрутизация обладает многими преимуществами. В
частности, она повышает надежность сети: существует только один вход (и выход)
в сеть, связь с которой осуществляется через статически определенный маршрут
(разумеется, если на маршрутизаторе не определено несколько статических
маршрутов для одного получателя).
Другое преимущество заключается в том, что статическая маршрутизация
гораздо эффективнее расходует ресурсы. Она сводит к минимуму
дополнительный трафик, не расходует вычислительные мощности маршрутизатора на
построение маршрута и требует меньше памяти. В некоторых сетях статическая
маршрутизация даже позволяет использовать менее мощные, а следовательно —
более дешевые маршрутизаторы. Несмотря на эти преимущества, статическая
маршрутизация обладает рядом принципиальных недостатков, о которых следует
помнить.
Статические маршруты иногда используются в малых сетях с редко
изменяемой топологией. Примером может послужить сеть из двух узлов, соединенных
каналом «точка-точка».
Статическая маршрутизация также может применяться для диагностики
и временного исправления проблем, связанных с маршрутизацией. Например,
если вы знаете, что содержимое таблицы маршрутизации было испорчено, можно
переопределить ошибочные записи и заменить их статическими маршрутами.
Как правило, использовать статическую маршрутизацию одновременно с
динамической не рекомендуется, так как это может привести к конфликтам между
статическими и динамически вычисляемыми маршрутами. Статические
маршруты будут использоваться даже в том случае, если динамические маршруты
более эффективны.
Недостатки статической маршрутизации
В случае сбоя сетевого канала или изменения топологии сети администратору
приходится вручную изменять статические маршруты. Ситуация
проиллюстрирована на рис. 13.1.
Г СетьЮ ^
/Маршрутизатор А\
Маршрутизатор В Маршрутизатор с\
£ Сеть 172.16 3 \ $192.168.125 ")
Маршрутизатор D
Сеть 192.168.126
Рис. 13.1. Простая объединенная сеть со статическими маршрутами
В этом простом примере администраторы сети выработали согласованную
схему распределения маршрутных данных, которая, как предполагается,
упростит их работу и снизит сетевой трафик. Объединенная сеть относительно мала;
она состоит из трех разных сетей, каждая из которых относительно мала и
изолирована. Каждая сеть использует собственное адресное пространство и свой
протокол динамической маршрутизации. С учетом несовместимости трех
протоколов динамической маршрутизации, администраторы решили не
перераспределять маршрутные данные между сетями и определили статические маршруты.
В табл. 13.1 приведено содержимое маршрутных таблиц для трех шлюзов.
Маршрутизатор D соединяет небольшую сеть с другими сетями, а
последовательный порт этого маршрутизатора выполняет функции шлюза для всех пакетов,
предназначенных для IP-адресов, не входящих в сеть 192.168.126.
Таблица 13.1. Статические маршруты
Маршрутизатор Получатель Следующий переход
А 172.16.0.0 В
А 192.168.125.0 С
А 192.168.126.0 С
В 10.0.0.0 А
В 192.168.125.0 С
В 192.168.126.0 С
С 10.0.0.0 А
С 172.16.0.0 В
С 192.168.126.0 О
В этом сценарии маршрутизатор А пересылает все пакеты, адресованные хостам
в адресном пространстве сети 172.16, маршрутизатору В. Маршрутизатор А также
пересылает все пакеты» адресованные хостам в сетях 192.168.125 и 192.168.126,
маршрутизатору С. Маршрутизатор В пересылает все пакеты, адресованные
хостам в сетях 192.168.125 и 192.168.126, маршрутизатору С. Маршрутизатор В
пересылает пакеты, адресованные хостам в сети 10, маршрутизатору А.
Маршрутизатор С пересылает все пакеты, предназначенные для сети 10,
маршрутизатору А. а пакеты, предназначенные для сети 172.16, — маршрутизатору В. Кроме
того, маршрутизатор С пересылает пакеты, предназначенные для сети 192.168.126,
маршрутизатору D, в концевую сеть. Сеть называется концевой (stub),
поскольку она буквально образует «тупик» в сетевой иерархии; она связана с
объединенной сетью одним входом и одним выходом. Весь обмен данными с хостами
объединенной сети полностью зависит от канала, ведущего к маршрутизатору С,
и от самого маршрутизатора С.
В этом примере сбой сетевого канала приведет к тому, что некоторые
получатели станут недоступными, несмотря на существование альтернативного
маршрута. На рис. 13.2 сбой произошел в сетевом канале между маршрутизаторами А и С.
Г Сеть 10 !?
/Маршрутизатор А\
/ Маршрутизатор В Маршрутизатор С \ ^ч.
£ Сеть 172.16 !) \ $192.168.125 J)
Маршрутизатор D ]
Сеть 192.168.126
Рис. 13.2. В результате сбоя канала в сети сю статическими маршрутами
часть сети может стать недоступной
В результате сбоя хосты сетей 10 и 192.168 не смогут связаться друг с
другом, несмотря на существование альтернативного пути через маршрутизатор В!
Таблица 13.2 поясняет, как подобные сбои отражаются на работе таблиц
маршрутизации.
Таблица 13.2. Статические маршруты при сбое в канале связи
Маршрутизатор Получатель Следующий переход
А 172.16.0.0 В
А 192.168.125.0 С — недостижим
А 192.168.126.0 С —недостижим
В 10.0.0.0 А
В 192.168.125.0 С
В 192.168.126.0 С
С 10.0.0.0 А — недостижим
С 172.16.0.0 В
Из-за отсутствия динамических механизмов маршрутизаторы А и С не
распознают сбой в канале. Они не используют протоколы маршрутизации, которые
бы обнаружили факт сбоя и проверили качество связи с известными
получателями. Соответственно, маршрутизаторы А и С не могут обнаружить
альтернативный путь через маршрутизатор В. Хотя этот путь вполне работоспособен,
жестко запрограммированные маршруты не позволяют обнаружить или
использовать его. Ситуация останется без изменений до тех пор, пока администраторы
сети не внесут необходимые исправления вручную.
Преимущества статической маршрутизации
Возможно, после всего сказанного возникает вопрос — какая польза от
статического определения маршрутов? Статическая маршрутизация пригодна только
для очень малых сетей, в которых к любому узлу ведет только один путь. Как
правило, механизм статической маршрутизации обладает наибольшей
эффективностью, поскольку он не тратит ресурсы на попытки построения путей или
взаимодействие с другими маршрутизаторами.
По мере роста сетей и добавления альтернативных путей статическая
маршрутизация начинает требовать все большего объема работы. Любые изменения
в доступности маршрутизаторов или каналов связи в глобальных сетях
приходится обнаруживать и программировать вручную. Глобальные сети со сложными
топологиями, подразумевающими наличие альтернативных маршрутов,
неизбежно требуют применения динамической маршрутизации. Попытки
использования статической маршрутизации в сложных глобальных сетях противоречат
самой идее наличия альтернативных маршрутов.
В некоторых ситуациях применение статических маршрутов оправдано даже
в крупных и сложных сетях. Например, статические маршруты могут повысить
уровень защиты. Подключение компании к Интернету может связываться
статическим маршрутом с сервером безопасности. Любой доступ к сети будет возможен
лишь после прохождения процедуры аутентификации, обеспечиваемой сервером.
Кроме того, статически определяемые маршруты исключительно полезны при
организации экстрасетевых подключений на базе IP к другим компаниям,
интенсивно работающим с вашей компанией. Наконец, статические маршруты могут
оказаться оптимальным способом подключения небольших участков с концевыми
сетями к глобальной сети. Короче говоря, статические маршруты тоже приносят
пользу. Вы лишь должны хорошо понимать, когда их следует применять.
Дистанционно-векторная маршрутизация
При маршрутизации на базе дистанционно-векторных алгоритмов, также
иногда называемых алгоритмами Беллмана—Форда, копии таблиц маршрутизации
периодически передаются узлам, находящимся в непосредственном соседстве.
Каждый получатель добавляет в таблицу значение дистанции и передает его
своим непосредственным соседям. Процесс повторяется по всем направлениям
между соседними маршрутизаторами. В результате этой многошаговой процедуры
каждый маршрутизатор получает сведения о других маршрутизаторах и
накапливает информацию о сетевых «расстояниях».
Накопленная информация используется для обновления таблиц
маршрутизации на каждом маршрутизаторе. После его завершения каждый маршрутиза-
тор узнает примерные «расстояния» между сетевыми ресурсами. Он не знает
ничего конкретного о других маршрутизаторах и о фактической топологии сети.
Недостатки дистанционно-векторной маршрутизации
В некоторых обстоятельствах дистанционно-векторная маршрутизация создает
проблемы с маршрутизацией. Например, в случае сбоя или изменений в сети
требуется некоторое время на согласование (то есть распространение новых
представлений о сетевой топологии между маршрутизаторами). В процессе
согласования сеть может страдать от непоследовательной и даже циклической
маршрутизации. Специальные защитные меры позволяют ограничить многие из
этих опасностей, но даже в этом случае в процессе согласования
производительность сети оказывается под угрозой. Из-за этого старые
дистанционно-векторные протоколы с медленным распространением изменений оказываются
неподходящими для больших, сложных глобальных сетей.
Даже в сетях меньшего масштаба дистанционно-векторные протоколы
маршрутизации порождают проблемы (в худшем случае) или оказываются
неоптимальными (в лучшем случае). Дело в том, что простота, которая является одной из
сильных сторон этого механизма маршрутизации, оборачивается его слабостью.
Например, на рис. 13.3 представлена объединенная сеть с несколькими филиалами.
Нью-Йорк
Филадельфия
£ 10.0.0.0 р ^192.168.125.0 }
Маршрутизатор А / Маршрутизатор С
/ Стоимость = 1
Маршрутизатор В Маршрутизатор D
ч. Сеть S С. Сеть j
Ч 172.16.0.0 р <>192.168.123.0 р
Сиэтл Миннеаполис
Рис 13.3. Объединенная сеть с использованием дистанционно-векторного
протокола маршрутизации
В данном примере сеть 1 находится в Нью-Йорке, сеть 2 — в Сиэтле, сеть 3 —
в Филадельфии, а сеть 4 — в Миннеаполисе. Дистанционно-векторный
протокол маршрутизации использует для каждого перехода статически
назначенную стоимость 1, независимо от протяженности канала и даже его пропускной
способности. В табл. 13.3 приведена сводка количества по всем остальным сетям.
Из таблицы видно, что маршрутизаторы не обязаны создавать в таблице
отдельную запись для каждой конечной системы. Сеть может выполнять подобную
маршрутизацию на уровне хостов, но, скорее всего, она будет работать гораздо
эффективнее, если ограничиться маршрутизацией на уровне сети. В сетевых
маршрутах используется только сетевая часть IP-адреса; идентификатор хоста
отсекается.
Теоретически для всех хостов и конечных систем любой конкретной сети
может использоваться один и тот же маршрут. Следовательно, создание отдельной
записи для каждого хостового адреса ничего не дает.
Таблица 13.3. Количество переходов в дистанционно-векторном протоколе
Маршрутизатор Приемник Следующий переход Длина пути в переходах
А 172.16.0.0 В 1
А 192.168.125.0 С 1
А 192.168.253.0 В или С 2
В 10.0.0.0 А 1
В 192.168.125.0 С 1
В 192.168.253.0 D 1
С 10.0.0.0 А 1
С 172.16.0.0 В 1
С 192.168.253.0 D 1
D 10.0.0.0 В или С 2
D 172.16.0.0 В 1
D 192.168.125.0 С 1
В любой сети с альтернативными маршрутами дистанционно-векторные
протоколы удобнее статических маршрутов, поскольку они позволяют
автоматически обнаруживать и исправлять многие сетевые сбои. К сожалению,
дистанционно-векторные протоколы тоже не идеальны. Для примера рассмотрим записи
маршрутизации для маршрутизатора А (нью-йоркский шлюз). С его точки
зрения шлюз D (Миннеаполис) удален на два перехода независимо от пути
следования пакета (через Филадельфию или Сиэтл). С точки зрения маршрутизатора
оба пути равноправны.
При одинаковых сетевых характеристиках (включая уровни трафика,
пропускные способности каналов и даже технологию передачи) самый короткий
в географическом отношении путь обеспечивает минимальную задержку.
Следовательно, логика подсказывает, что при пересылке из Нью-Йорка в Миннеа-
полис следует использовать кратчайший путь через Филадельфию. На практике
такая логика выходит за границы возможностей простых
дистанционно-векторных протоколов. Впрочем, это нельзя считать недостатком
дистанционно-векторных протоколов, поскольку задержка передачи часто является наименее
существенным фактором, определяющим эффективность маршрута.
Пропускная способность каналов и уровни трафика оказывают гораздо большее влияние
на эффективность.
Преимущества дистанционно-векторной маршрутизации
Как правило, дистанционно-векторные протоколы устроены очень просто; такие
протоколы легко понять, настроить, сопровождать и использовать. Таким
образом, эти протоколы приносят несомненную пользу в очень мелких сетях с
минимальным количеством альтернативных путей и отсутствием жестких
требований к производительности сети. Основные принципы дистанционно-векторной
маршрутизации воплощены в протоколе RIP (Routing Information Protocol),
который определяет оптимальный путь для любого конкретного пакета по
единственной метрике — стоимости. Протокол RIP широко использовался в течение
десятилетий, и только недавно возникла необходимость в его обновлении. За
дополнительной информацией о протоколе RIP обращайтесь к главе 15.
Топологическая маршрутизация
Алгоритмы топологической маршрутизации, часто объединяемые термином SPF
(Shortest Path First, то есть «предпочтительный выбор кратчайшего пути»),
ведут сложную базу данных, описывающую топологию сети. В отличие от
дистанционно-векторных протоколов, топологические протоколы располагают
полной информацией о маршрутизаторах сети и о способах их соединения. Задача
решается посредством обмена сообщениями LSA (Link-State Advertisement) с
другими маршрутизаторами в сети.
Каждый маршрутизатор, участвующий в обмене сообщениями LSA, строит
топологическую базу данных на основании всей полученной информации, после
чего доступность сетевых узлов оценивается по алгоритму SPF. Полученная
информация используется для обновления таблиц маршрутизации. Этот процесс
позволяет обнаруживать изменения в сетевой топологии, вызванные сбоями
отдельных компонентов или расширением сети.
Обмен сообщениями LSA не производится на периодической основе, а
инициируется событиями в сети. Тем самым существенно ускоряется процесс
распространения изменений в сети, поскольку маршрутизаторам не приходится
ожидать завершения целой серии произвольно выставленных интервалов тайм-аута.
Если бы в объединенной сети, изображенной на рис. 13.3, использовался
протокол топологической маршрутизации, то все проблемы с выбором пути
между Нью-Йорком и Миннеаполисом автоматически отпали бы. В зависимости
от выбора протокола и метрик весьма вероятно, что протокол маршрутизации
найдет два альтернативных маршрута и попытается выбрать лучший.
Обобщенная сводка содержимого таблиц маршрутизации приведена в табл. 13.4.
Таблица 13.4. Данные топологической маршрутизации
Маршрутизатор Приемник Следующий переход Длина пути в переходах
А 172.16.0.0 В 1
А 192.168.125.0 С 1
А 192.168.253.0 В 2
А 192.168.253.0 С 2
В 10.0.0.0 А 1
В 192.168.125.0 С 1
В 192.168.253.0 D 1
С 10.0.0.0 А 1
С 172.16.0.0 В 1
С 192.168.253.0 D 1
D 10.0.0.0 В 2
D 10.0.0.0 С 2
D 172.16.0.0 В 1
D 192.168.125.0 С 1
Анализ таблиц маршрутизации очевидно показывает, что для пути из Нью-
Йорка в Миннеаполис топологический протокол запомнит оба маршрута.
Некоторые топологические протоколы даже могут оценить эффективность этих двух
маршрутов и выбрать оптимальный вариант. Если в оптимальном маршруте
(например, ведущем через Филадельфию) возникнут какие-либо проблемы,
включая перегруженность сети или сбой отдельных компонентов, топологический
протокол обнаружит эти изменения и начнет пересылать пакеты через Сиэтл.
Недостатки топологической маршрутизации
Несмотря на широту возможностей и гибкость, топологическая маршрутизация
обладает двумя потенциальными недостатками:
О На стадии исходного сбора информации протоколы топологической
маршрутизации передают по сети большой объем информации, существенно снижая
возможности сети по пересылке данных. Это снижение производительности
является временным, но оно может быть очень заметным. Влияние
трафика на эффективность работы сети зависит от двух факторов: пропускной
способности и количества маршрутизаторов, обменивающихся
маршрутными данными. В больших сетях с относительно слабыми каналами (например,
в малопроизводительных каналах DLCI в сетях Frame Relay) это влияние
будет гораздо заметнее, чем в мелкомасштабных сетях с производительными
каналами (например, ТЗ).
О Топологическая маршрутизация требует больших затрат памяти и
процессорных ресурсов. Следовательно, для обеспечения топологической
маршрутизации требуются более мощные компьютеры, чем для дистанционно-векторной,
что приводит к повышению стоимости маршрутизаторов.
Вряд ли эти недостатки топологического подхода к маршрутизации можно
считать фатальными. Проблемы с потенциальным снижением быстродействия в
обоих случаях решаются посредством планирования, прогнозирования и
технического оснащения.
Преимущества топологической маршрутизации
Топологический подход к динамической маршрутизации приносит пользу в сетях
любого размера. В хорошо спроектированной сети топологическая
маршрутизация позволяет корректно адаптироваться к эффектам неожиданных
топологических изменений. Применение событий для обновления данных маршрутизации
(вместо таймеров с фиксированными интервалами) значительно ускоряет начало
распространения информации о топологических изменениях.
Кроме того, топологическая маршрутизация обходится без частых,
периодических обновлений, присущих дистанционно-векторной маршрутизации. В
результате повышается доля ресурсов сети, расходуемых на пересылку полезных
данных, а не на служебные операции (при условии, что сеть была правильно
спроектирована).
Из повышенной эффективности протоколов топологической маршрутизации
в отношении пропускной способности сети вытекает другое, дополнительное
преимущество: эти протоколы упрощают масштабирование сети по сравнению
со статическими маршрутами или дистанционно-векторными протоколами.
Принимая во внимание ограничения статических маршрутов и
дистанционно-векторных протоколов, нетрудно убедиться, что топологическая маршрутизация
лучше работает в больших сетях со сложной структурой, а также в сетях,
которые должны обладать высокой степенью масштабируемости. Исходная
настройка топологической маршрутизации в большой сети — задача непростая, но
в конце концов эти усилия окупятся. За дополнительной информацией о
топологической маршрутизации обращайтесь к главе 16.
Согласование в сетях IP
Одним из самых замечательных аспектов маршрутизации является согласование.
Другими словами, при каждом изменении топологии или размеров сети все
маршрутизаторы, входящие в сеть, должны согласовать друг с другом новые
данные об изменившейся топологии сети. В процессе согласования
маршрутизаторы обмениваются информацией друг с другом, однако каждый из них должен
самостоятельно определить воздействие топологических изменений на
маршрутные данные. Поскольку маршрутизаторы должны независимо прийти к единому
представлению о новой топологии с разных позиций, этот процесс называется
согласованием.
Согласование необходимо из-за того, что маршрутизаторы являются
интеллектуальными устройствами, способными самостоятельно принимать решения
о маршрутизации. В этом одновременно кроется их сила и слабость. В обычных
условиях механизм независимого распределенного сбора информации обладает
огромными преимуществами. С другой стороны, при изменении топологии сети
процесс согласования может породить временную нестабильность и проблемы
с маршрутизацией.
Адаптация к топологическим изменениям
К сожалению, самостоятельность маршрутизаторов создает проблемы при
изменении сетевой топологии. Рисунок 13.4 показывает, как разрыв одного сегмента
сети фактически приводит к изменению в ее топологии.
£ 10.0.0.0 р $192.168.125.0 }
Маршрутизатор А Маршрутизатор С
Маршрутизатор В Маршрутизатор D
Компьютер
Сервер 192.168.253.2 пользователя
Рис. 13.4. Объединенная сеть с четырьмя шлюзами
На рис. 13.4 представлена довольно простая объединенная сеть из четырех
узлов с альтернативными маршрутами. Обобщенная сводка содержимого
таблиц маршрутизации приведена в табл. 13.5. В целях нашего примера
приведенные данные отражают содержимое таблиц маршрутизации до начала
согласования.
Таблица 13.5. Содержимое таблиц маршрутизации перед согласованием
Маршрутизатор Приемник Следующий переход Длина пути в переходах
А 172.16.0.0 В 1
А 192.168.125.0 С 1
А 192.168.253.0 В или С 2
В 10.0.0.0 А 1
В 192.168.125.0 АилиР 2
В 192.168.253.0 D 1
С 10.0.0.0 А 1
С 172.16.0.0 Аилий 2
С 192.168.253.0 D 1
D 10.0.0.0 В или С 2
D 172.16.0.0 В 1
D 192.168.125.0 С 1
Если пакеты, передаваемые маршрутизатором С на сервер 192.168.253.2, вдруг
перестают доставляться, скорее всего, где-то в сети произошел сбой. Существует
огромное количество разных причин, из которых самыми распространенными
являются следующие:
О полный отказ сервера (аппаратный, программный или сбой питания);
О сбой подключения сервера к локальной сети;
О общий сбой на маршрутизаторе D;
О сбой интерфейсного порта на маршрутизаторе D;
О сбой канала между маршрутизаторами С и D;
О сбой интерфейсного порта на маршрутизаторе С.
Разумеется, определение новой топологии сети возможно лишь после точной
идентификации места сбоя. Кроме того, маршрутизаторы не смогут пытаться
обойти сбойный участок до тех пор, пока не будет определено его
местонахождение. В первых двух случаях из приведенного списка сервер 192.168.253.2
становится полностью недоступным для всех пользователей объединенной сети,
независимо от наличия альтернативных маршрутов.
Аналогично, полный отказ маршрутизатора D изолирует все ресурсы,
подключенные к его локальной сети, от остальной части сети. Но если
маршрутизатор сохранил частичную работоспособность или сбой произошел в другом
месте, возможно, хосты сети 192.168.255 остаются доступными. При поиске
нового маршрута к сети 192.168.255 маршрутизаторы должны распознать сбойный
компонент сети и согласовать общую информацию о нем. Исключение этого
компонента из сети фактически изменяет сетевую топологию.
Продолжая наш пример, допустим, что сбой произошел в интерфейсном порте
маршрутизатора D к каналу, ведущему к маршрутизатору С. Новая топология
сети изображена на рис. 13.5.
£ 10.0.0.0 р ^192.168.125.0 р
Маршрутизатор А Маршрутизатор С
ж
Маршрутизатор В Маршрутизатор D
с Свть < №&ЖШ':ч:^г^™м'^"" \ РЩ
V 172.16.0.0 р ^MI«V^^ISS^Zb^J
Компьютер
Сервер 192.168.253.2 пользователя
Рис. 13.5. Канал между маршрутизаторами С и D стал недоступным
Маршрутизаторы, использующие протокол динамической маршрутизации,
быстро определяют, что сервер 192.168.253.2 стал недоступным через текущий
маршрут. Ни один из маршрутизаторов сам по себе не может определить, где
произошел сбой и сохранились ли возможные альтернативные маршруты. Тем
не менее, обмениваясь информацией друг с другом, они совместно создают новое
представление сетевой топологии.
ПРИМЕЧАНИЕ
В примерах этой главы намеренно используется обобщенная методика согласования. Специфика
согласования в каждом из протоколов маршрутизации описана в главах 14-16.
В этой объединенной сети используется относительно простой протокол
маршрутизации. Каждый маршрутизатор обменивается маршрутными данными
только со своими непосредственными соседями, хотя при этом для каждой
конечной точки поддерживается возможность записи нескольких маршрутов.
В табл. 13.6 приведена сводка связей между парами маршрутизаторов,
представленных на рис. 13.5.
Таблица 13.6. Маршрутизаторы, обменивающиеся маршрутными данными
с непосредственными соседями
Маршрутизатор ABC D
А — Да Да Нет
В Да — Нет Да
С Да Нет — Да
D Нет Да Да —
Ячейки таблицы со словом «Да» обозначают пары маршрутизаторов, которые
являются непосредственными соседями и обмениваются маршрутными данными.
Ни один маршрутизатор не может соседствовать сам с собой, такие ячейки
помечены прочерком. Наконец, ячейки со словом «Нет» обозначают несмежные
пары маршрутизаторов, которые не могут напрямую обмениваться маршрутными
данными. Для обновления информации друг о друге они используют
информацию, полученную от непосредственных соседей.
Из таблицы становится ясно, что маршрутизаторы А и D, не соединенные
друг с другом напрямую, получают информацию друг о друге на основании
данных, полученных от маршрутизаторов В и С. С другой стороны,
маршрутизаторы В и С обмениваются информацией друг о друге через
маршрутизаторы А и D.
На рис. 13.6 обмен информацией через непосредственных соседей
представлен в графическом виде.
У такого сценария есть один важный аспект: поскольку не все
маршрутизаторы непосредственно соседствуют друг с другом, для распространения новой
информации о сбойном канале может потребоваться несколько обновлений.
Следовательно, адаптация к топологическим изменениям является
итеративным процессом, в котором участвуют все стороны.
Простоты ради допустим, что в нашем примере согласование выполняется за
два обновления таблиц маршрутизации. При первой итерации маршрутизаторы
начинают согласовывать новые представления о топологии сети.
Маршрутизаторы С и D из-за сбоя в канале не могут обмениваться маршрутной
информацией. Соответственно, они исключают из своих таблиц этот маршрут и все пути,
в которых он используется. Содержимое таблиц маршрутизации во время
процесса согласования приведено в табл. 13.7. Обратите внимание: в некоторых
таблицах может сохраняться ошибочное представление о том, что канал между
маршрутизаторами С и D по-прежнему остается рабочим.
Как видно из табл. 13.7, маршрутизаторы С и D обнаружили, что
соединяющий их канал неработоспособен. Тем не менее маршрутизаторы А и С все еще
полагают, что маршруты, проходящие через этот канал, остаются
действительными. Они узнают об изменении топологии сети лишь после обновления
маршрутных данных на маршрутизаторах С и D.
Ъ* Автономная система № 1 ) Ъ* Автономная система № 3 )
\у Сеть 10.0.0.0 S V. Сеть 192.168.125.0 "S
Маршрутизатор А Маршрутизатор С
I А I А
| Т | Т
Маршрутизатор В Маршрутизатор D
>■ Автономная система № 1 ) (^mw^£ww>-vwrv v.../.-.-Ц? v-ч^.'ш^
с сеть 172.16.0.0 ^ШШЁШШШштт
li ||Ш I ИМИ I IbWfll
ИЕДи шш|. ! f
1 /шШ™\~~
Компьютер
Сервер 192.168.253.2 пользователя
Ч ► Обмен маршрутными данными
Рис. 13.6. Обмен маршрутными данными между непосредственными соседями
Таблица 13.7. Содержимое таблиц маршрутизации во время согласования
Маршрутизатор Приемник Следующий переход Длина пути в переходах
А 172.16.0.0 В 1
А 192.168.125.0 С 1
А 192.168.253.0 В или С 2
В 10.0.0.0 А 1
В 192.168.125.0 АилиР 2
В 192.168.253.0 D 1
С 10.0.0.0 А 1
С 172.16.0.0 Только A (D не отвечает) 2
продолжение ё
Таблица 13.7 (продолжение)
Маршрутизатор Приемник Следующий переход Длина пути в переходах
С 192.168.253.0 D — недействительный Не работает
маршрут
D 10.0.0.0 В или С 2
D 172.16.0.0 В 1
D 192.168.125.0 С — недействительный Не работает
маршрут
В табл. 13.8 приведено содержимое таблиц на всех четырех маршрутизаторах
после согласования новой топологии. Не забывайте, что это описание процесса
согласования было намеренно обобщено и из него были исключены все
специфические механизмы конкретных протоколов.
Таблица 13.8. Содержимое таблиц маршрутизации после завершения согласования
Маршрутизатор Приемник Следующий переход Длина пути в переходах
А 172.16.0.0 В 1
А 192.168.125.0 С 1
А 192.168.253.0 Только В 2
В 10.0.0.0 А 1
В 192.168.125.0 Только А 2
В 192.168.253.0 D 1
С 10.0.0.0 А 1
С 172.16.0.0 Только А 2
С 192.168.253.0 А 3
D 10.0.0.0 Только В 2
D 172.16.0.0 В 1
D 192.168.125.0 Только В 3
Как следует из табл. 13.8, все маршрутизаторы объединенной сети в
конечном счете приходят к выводу, что канал между С и D не может использоваться,
но конечные узлы каждой автономной системы по-прежнему доступны через
альтернативные маршруты.
Время согласования
Изменение топологии сети не может быть обнаружено всеми маршрутизаторами
сети одновременно. В зависимости от выбранного протокола маршрутизации,
а также множества других факторов согласование новой топологии на всех
маршрутизаторах сопровождается существенной задержкой, которая называется
временем согласования. Следует помнить, что согласование не наступает
мгновенно; единственное, чего нельзя сказать заранее, — сколько времени на него
потребуется.
Следующие факторы влияют на продолжительность задержки при
согласовании:
О расстояние от маршрутизатора до точки изменений (в переходах);
О количество маршрутизаторов в сети, использующих протоколы
динамической маршрутизации;
О пропускная способность и загруженность коммуникационных каналов;
О загруженность маршрутизатора;
О закономерности распределения трафика на участке, где произошли
топологические изменения;
О выбор протокола маршрутизации.
Отрицательное воздействие некоторых факторов может быть
скомпенсировано тщательным планированием работы сети. Например, сеть может
проектироваться с расчетом на минимальную загрузку маршрутизаторов и
коммуникационных каналов. Другие факторы — такие, как количество маршрутизаторов
в сети — воспринимаются как неизбежный риск, присущий самой структуре сети.
Тем не менее сеть можно спроектировать так, чтобы в процессе согласования
участвовало меньшее количество маршрутизаторов. В частности, для этого можно
подключать концевые сети через статические маршруты. Результат — прямое
уменьшение времени согласования. Учитывая сказанное, становится ясно, что
ключевую роль в минимизации времени согласования играют два фактора:
О выбор протокола маршрутизации, обеспечивающего эффективное построение
маршрутов;
О правильное проектирование сети.
Построение маршрутов в сетях IP
Приведенные в предыдущем разделе примеры наглядно показывают, что время
согласования играет важнейшую роль в способности сети реагировать на
изменяющиеся условия ее работы. В целом согласование сводится к обмену данными
между маршрутизаторами сети, за который отвечают протоколы маршрутизации.
А именно, эти протоколы должны проектироваться так, чтобы маршрутизаторы
могли обмениваться информацией о маршрутах, ведущих к разным узлам сети.
К сожалению, протоколы маршрутизации не равноценны. Один из лучших
способов оценить пригодность протокола — воспользоваться его средствами для
вычисления маршрутов и определения времени согласования, а затем сравнить
полученные данные с другими протоколами. Однако из приведенного выше
списка факторов очевидно, что время согласования трудно определить с
достаточной степенью уверенности. Возможно, в этом вам поможет поставщик
маршрутизатора, даже если он предоставит лишь общие оценки.
Время согласования также зависит от того, насколько эффективно протокол
строит маршруты. Эффективность построения маршрутов зависит от
нескольких факторов:
О возможность построения и хранения нескольких маршрутов для каждой
конечной точки;
О механизм, инициирующий обновление маршрутных данных;
О метрики, используемые для вычисления расстояний и стоимости.
В нескольких ближайших разделах мы рассмотрим все эти факторы, а также
их вклад в общую эффективность протокола маршрутизации.
Хранение альтернативных маршрутов
Для повышения эффективности своей работы некоторые протоколы
маршрутизации хранят для каждой конечной точки только один маршрут (в идеальном
случае — оптимальный). Недостаток подобного решения заключается в том, что
при изменении топологии сети каждому маршрутизатору приходится строить
новые маршруты для всех точек, которые будут затронуты этим изменением.
Другие протоколы идут на увеличение таблиц маршрутизации и хранят
несколько маршрутов для каждой конечной точки. В нормальном рабочем режиме
наличие нескольких маршрутов позволяет маршрутизатору сбалансировать
трафик по нескольким каналам. При изменении топологии сети маршрутизаторы
уже знают альтернативные маршруты к соответствующим конечным точкам.
Наличие готовых альтернативных маршрутов не обязательно ускоряет
согласование, однако оно помогает сетям более корректно адаптироваться к
изменениям в топологии.
Механизм инициирования обновлений
Некоторые протоколы маршрутизации инициируют обновление маршрутных
данных по прошествии определенного времени. Другие протоколы управляются
событиями, то есть обновление инициируется автоматически при обнаружении
топологических изменений. При неизменности остальных факторов событийное
обновление ускоряет процесс согласования по сравнению с периодическим
обновлением.
Периодическое обновление
Механизм периодического обновления чрезвычайно прост. С течением времени
уменьшаются показания счетчика. После завершения установленного интервала
маршрутные данные обновляются независимо от того, происходили в сети
топологические изменения или нет. Такой способ обновления обладает двумя
недостатками:
О многие обновления выполняются без необходимости, что приводит к
пересылке лишних данных и напрасному расходованию маршрутизатора;
О зависимость построения маршрутов от прохождения времени увеличивает
время согласования.
Периодическое обновление данных обычно используется в протоколах
дистанционно-векторной маршрутизации.
Событийное обновление
Обновление, управляемое событиями, предоставляет гораздо больше
возможностей для инициирования обновления. Вполне логично приступать к обновлению
только в случае изменения топологии сети. Поскольку необходимость в
согласовании возникает только при изменении топологии сети, этот подход
обеспечивает наибольшую эффективность.
Выбирая протокол маршрутизации, вы фактически выбираете механизм
инициирования обновлений; в любом протоколе реализован один из этих двух
вариантов. Следовательно, это еще один фактор, который необходимо учитывать
при выборе протокола маршрутизации.
Событийное обновление обычно используется в протоколах топологической
маршрутизации.
Маршрутные метрики
Выбор протокола маршрутизации также определяет выбор метрик. Наборы
метрик, используемые разными протоколами, заметно различаются — как в
количественном, так и в качественном отношении.
Количество метрик
Простые протоколы маршрутизации ограничиваются одной-двумя метриками.
Более сложные протоколы могут поддерживать пять и более метрик. Чем больше
метрик, тем больше разнообразную и специфичную информацию можно
получить с их помощью. Следовательно, большое количество метрик позволяет лучше
приспособить работу сети под конкретные надобности. Например, простейшие
дистанционно-векторные протоколы используют всего одну эвфемистическую
метрику: расстояние. На практике значение этой метрики совершенно не связано
с географическим расстоянием и еще в меньшей степени зависит от физической
длины кабеля, соединяющего отправителя с получателем. Вместо этого обычно
подсчитывается количество переходов между этими двумя точками.
Топологические протоколы также могут учитывать другие факторы при
вычислении маршрутов:
О уровень трафика;
О занятость канала;
О задержка с распространением;
О сетевая стоимость использования канала (хотя эта метрика носит скорее
приблизительный характер).
Большинство из этих факторов носит динамический характер, то есть
изменяется в зависимости от времени суток, дня недели и т. д. Главное — помнить,
что вместе с этими факторами изменяется общая производительность сети.
Следовательно, метрики динамической маршрутизации позволяют принимать
оптимальные решения относительно выбора маршрута на основании самой свежей
информации.
Статические и динамические метрики
Одни метрики просты и имеют статический характер, другие чрезвычайно сложны
и динамичны. Значения статических метрик обычно настраиваются на стадии
выбора конфигурации. После завершения настройки значения остаются
постоянными до тех пор, пока они не будут изменены вручную.
Динамические метрики позволяют принимать решения, связанные с
выбором маршрута, на основании оперативно собираемых данных о состоянии сети.
Эти метрики поддерживаются только относительно сложными топологическими
или гибридными протоколами маршрутизации.
Итоги
Маршрутизация дает возможность пользователям и конечным системам
обмениваться данными в объединенных сетях IP. Тем не менее существует много
способов построения и сравнения маршрутов. Проблема выбора выходит за чисто
академические и философские рамки — принятое решение напрямую отражается
на производительности и функциональности сети IP. В этой главе представлен
общий обзор разных способов маршрутизации с обсуждением преимуществ и
недостатков каждого варианта. На основе этих общих сведений в трех следующих
главах будут проанализированы специфические особенности протоколов RIP,
OSPF и BGP.
М Шлюзовые протоколы
Тим Паркер (Tim Parker)
Протокол TCP/IP предназначался в первую очередь для поддержки межсетевого
трафика в сети, которая со временем превратилась в Интернет. По этой
причине для TCP/IP была выбрана иерархическая архитектура, особенно хорошо
подходящая для объединенных сетей. При переходе из одной сети в другую
дейтаграмма проходит через компьютеры, выполняющие маршрутизацию для
каждой сети.
Маршрутизатор определяет, предназначена ли дейтаграмма для локальной
сети, подключенной через шлюз. Если проверка дает положительный результат,
дейтаграмма выводится из магистральной пересылки в объединенной сети и
направляется в локальную сеть. Если дейтаграмму необходимо переслать дальше,
то маршрутизатор выполняет эту операцию. Чтобы правильно выбрать
следующий узел в цепочке пересылки, на маршрутизаторе должна храниться таблица
путей, содержимое которой соответствует текущему состоянию сети и
используется программными средствами маршрутизации. В этой главе объясняется,
как организуется обмен данными между маршрутизаторами в объединенных
сетях. Для разных типов маршрутизаторов были разработаны
специализированные протоколы.
Шлюзы, мосты и маршрутизаторы
Получив дейтаграмму из объединенной сети, маршрутизатор выполняет
простую проверку адреса получателя, хранящегося среди данных протокола TCP.
Если сетевая часть IP-адреса получателя совпадает с IP-адресом сети,
маршрутизатор понимает, что дейтаграмма предназначена для одного из компьютеров
подсети, к которой он подключен, и передает дейтаграмму в сеть для доставки.
Если анализ IP-адреса показывает, что дейтаграмма не предназначена для
подсети, обслуживаемой текущим маршрутизатором, она передается
следующему маршрутизатору в объединенной сети.
Организовать пересылку сообщений с компьютера на компьютер в малой сети
несложно, потому что каждый компьютер может знать IP-адреса всех остальных
компьютеров в сети. В крупной сети, а также при слиянии нескольких сетей
в объединенную сеть сложность неимоверно возрастает. В очень больших
объединенных сетях (таких, как Интернет) один маршрутизатор ни при каких
условиях не может хранить IP-адреса всех остальных компьютеров. По этой
причине были разработаны специальные устройства, упрощающие
маршрутизацию между сетями, в объединенной или глобальной сети. Такие устройства
называются шлюзами, мостами и маршрутизаторами. Они различаются по
выполняемым функциям:
О Шлюз (gateway) — компьютер, выполняющий протокольные преобразования.
Шлюзы работают на уровнях OSI с 4 по 7. Обычно шлюзы работают на
уровне 7 (например, шлюзы электронной почты).
О Мост (bridge) — компьютер, соединяющий две и более сетей, использующих
один протокол. Мост работает на уровне 2 модели OSI. В последнее время
появился новый класс устройств, называемых коммутаторами уровня 2,
которые могут использоваться в качестве замены мостов. Мосты работают с
канальными адресами, но не с IP-адресами сетевого уровня.
О Маршрутизатор (router) — компьютер, пересылающий дейтаграммы в сети.
Маршрутизаторы работают на уровне 3 модели OSI. Коммерческие
маршрутизаторы также могут выполнять функции, не относящиеся к уровню 3.
Например, некоторые маршрутизаторы одновременно работают как мосты,
выполняют преобразование сетевых адресов (NAT) или решают задачи,
связанные с безопасностью — скажем, фильтрацию пакетов.
ПРИМЕЧАНИЕ
В ранней литературе, посвященной Интернету, шлюзами обычно назывались устройства, которые
в наши дни называются маршрутизаторами. К сожалению, это иногда вызывает путаницу. В
современной терминологии старые шлюзовые устройства называются маршрутизаторами.
Шлюз
Шлюзом называется устройство, занимающееся преобразованием протоколов.
Такие преобразования необходимы, если шлюз обеспечивает интерфейс между
Интернетом (использующей TCP/IP) и локальной сетью (например,
использующей Novell NetWare). Чтобы эти две сети могли обмениваться данными, шлюз
должен преобразовывать пакеты NetWare IPX/SPX в дейтаграммы TCP/IP,
и наоборот. Шлюзы выполняют преобразования многих разных протоколов и
довольно часто обслуживают сразу несколько протоколов в зависимости от сетевых
подключений. В некоторых сетевых системах шлюзы также занимаются
преобразованиями файловых форматов или шифрованием/расшифровкой данных.
Мост
Мост проще всего представить себе как канал, связывающий две и более сети.
Иногда локальные сети соединяются скоростными выделенными линиями, как
это часто делается в многонациональных компаниях с представительствами
в разных регионах. Обе сети используют один и тот же протокол (например,
TCP/IP), но для скоростного телекоммуникационного канала нужна быстрая
система маршрутизации. Мост выполняет маршрутизацию дейтаграмм из одной
локальной сети в другую. Мосты могут обслуживать сразу несколько локальных
сетей, но все эти сети должны использовать один и тот же протокол.
Маршрутизатор
Большинство функций, выполняемых маршрутизаторами, относится к сетевому
уровню. Основная функция маршрутизаторов — пересылка дейтаграмм к месту
назначения, но при использовании альтернативных маршрутов некоторые
маршрутизаторы, как и шлюзы, могут выполнять преобразования протоколов.
Автономная система
Термин «автономная система» часто встречается при описании сетей,
подключенных к Интернету и другим объединенным сетям. Автономной называется такая
система, в которой структура локальной сети, к которой она подключена, остается
невидимой для остальной объединенной сети. Обычно локальная сеть
подключается через граничный маршрутизатор, через который проходит весь трафик для
этой сети. Внутренняя структура локальной сети изолируется от объединенной
сети, что одновременно упрощает управление дейтаграммами и улучшает защиту.
Знакомство со шлюзовыми протоколами
Как упоминалось выше в этой главе, хранить на одном компьютере таблицу
маршрутизации с информацией обо всем Интернете в принципе невозможно,
поэтому большинство маршрутизаторов обслуживает конкретный участок
объединенной сети и получает информацию о других сетях от соседних шлюзов.
Однако в результате возникает распространенная проблема, когда нехватка
информации не позволяет принять полностью обоснованные решения по выбору
маршрута. В таких ситуациях используются маршруты по умолчанию.
Протоколы маршрутизации обмениваются информацией о маршрутах и
состоянии сети между шлюзами. Существует несколько протоколов маршрутизации,
спроектированных для быстрой и надежной пересылки данных с минимальным
объемом непроизводительных затрат. Но прежде чем переходить к
рассмотрению конкретных протоколов, необходимо различать два типа шлюзов,
используемых в Интернете (и в других объединенных сетях): базовые и не-базовые.
К категории базовых шлюзов относятся компьютеры, администрируемые
центром INOC (Internet Network Operations Center) и являющиеся частью
магистральной структуры Интернета. Как упоминалось выше, хотя эти компьютеры
называются шлюзами, в действительности их следовало бы называть
маршрутизаторами. Базовые шлюзы первоначально разрабатывались для ARPANET.
Не-базовые шлюзы администрируются группами из внешних компаний или
организацией. Как правило, корпорации и образовательные учреждения, представленные
в Интернете, используют не-базовые шлюзы. В эпоху ARPANET шлюзы, не
находящиеся под прямым управлением ARPANET (то есть не-базовые шлюзы в
современной терминологии), назывались не-маршрутизирующими шлюзами.
Изменения в структуре Интернета и увеличение количества базовых шлюзов
потребовали разработки протокола, который бы позволял базовым шлюзам
обмениваться информацией друг с другом. Так появился протокол GGP (Gateway-
to-Gateway Protocol), который обычно используется только между базовыми
шлюзами. Протокол GGP в основном используется для распространения
информации о не-базовых шлюзах, подключенных к каждому базовому шлюзу; на
основании этой информации базовые шлюзы обновляют таблицы маршрутизации.
Некоторые локальные или глобальные сети содержат несколько
маршрутизаторов. Например, в крупной сети объем интернет-трафика может быть таким,
что для его обслуживания потребуется два маршрутизатора. С другой стороны,
если у вас имеется две локальные сети, входящие в глобальную сеть
корпоративного уровня, их можно настроить так, чтобы каждая сеть имела собственный
маршрутизатор. Если в локальной или глобальной сети используются два
маршрутизатора, которые могут общаться друг с другом, они считается соседями
в контексте этой сети. Если маршрутизаторы не могут общаться друг с другом
напрямую, так как принадлежат к разным автономным системам, они называются
внешними шлюзами или граничными маршрутизаторами. При использовании
маршрутов по умолчанию внешние шлюзы отвечают за маршрутизацию
сообщений между автономными системами.
В отдельно взятой локальной или глобальной сети маршрутные данные
обычно передаются между внутренними шлюзами при помощи протокола RIP (Routurm
Information Protocol). В некоторых системах используется менее
распространенный протокол HELLO. Протоколы RIP и HELLO относятся к категории
протоколов внутреннего шлюза IGP (Interior Gateway Protocols), предназначенных для
обмена информацией между соседними маршрутизаторами внутри сети. Обмен
информацией между двумя внешними шлюзами обычно производится с
использованием протокола EGP (Exterior Gateway Protocol).
Работа протоколов RIP, HELLO и EGP зависит от частой пересылки
дейтаграмм с информацией состояния между шлюзами. Передаваемая информация
используется для обновления таблиц маршрутизации. Протокол EGP используется
между шлюзами в автономных системах, тогда как протоколы RIP и HELLO
(принадлежащие к категории IGP) используются внутри сети. Протокол GGP
обеспечивает обмен данными между базовыми шлюзами в Интернете.
Протоколы IGP и EGP
Подробности работы протоколов, используемых для обмена данными между
маршрутизаторами, не представляют особого интереса для пользователей и
разработчиков, поскольку приложения очень редко напрямую работают с
протоколами маршрутизации.
Протокол GGP
Чтобы правильно и эффективно осуществлять маршрутизацию дейтаграмм,
базовые шлюзы должны знать текущее состояние дел в Интернете. Это означает,
они должны обмениваться информацией и сообщать друг другу характеристики
присоединенных подсетей. Например, если один из шлюзов, который является
единственной точкой входа в подсеть, перегружен обработкой большого объема
данных; другие шлюзы сети регулируют трафик, чтобы разгрузить
перегруженный шлюз.
Протокол GGP предназначен, прежде всего, для обмена маршрутными
данными. Маршрутные данные (адреса, топология и информация о задержках) не
следует путать с алгоритмами, используемыми для принятия решений по выбору
маршрута. Алгоритмы маршрутизации обычно фиксируются на уровне шлюза,
и протокол GGP не влияет на их работу. Базовый шлюз общается с другими
базовыми шлюзами, рассылая сообщения GGP, ожидая ответа и затем обновляя
таблицы маршрутизации, если полученный ответ содержит полезную информацию.
Протокол GGP относится к категории дистанционно-векторных протоколов.
Этот термин означает, что в сообщениях протокола передается конечная точка
(вектор) и расстояние до этой конечной точки. Для эффективной работы
дистанционно-векторных протоколов шлюз должен располагать полной
информацией обо всех шлюзах объединенной сети, без которой он не сможет вычислить
эффективный маршрут к конечной точке. По этой причине все базовые шлюзы
поддерживают таблицу с информацией обо всех остальных базовых шлюзах в
Интернете. Список получается относительно небольшим, и шлюзы легко
справляются с его хранением.
ПРИМЕЧАНИЕ
Базовые маршрутизаторы Интернета обмениваются информацией о доступности при помощи
протокола BGP (Border Gateway Protocol). Текущая версия BGP имеет номер 4. Протокол BGP4
необходим для поддержки механизма бесклассовой междоменной маршрутизации CIDR, обобщающего
данные маршрутизации.
Протокол EGP
Протокол EGP (Exterior Gateway Protocol) используется для обмена
информацией между нс-базовыми соседними шлюзами. He-базовые шлюзы содержат
полную маршрутную информацию для своих непосредственных соседей в сети
и компьютеров, подключенных к ним, но не обладают сведениями о других
зонах Интернета.
Протокол EGP в основном ограничивается передачей информации о
локальной и глобальной сети, обслуживаемой шлюзом. Тем самым предотвращается
пересылка чрезмерного объема маршрутных данных в локальных и глобальных
сетях. Протокол EGP ограничивает состав узлов, с которыми не-базовые шлюзы
обмениваются маршрутными данными.
Базовые шлюзы используют протокол GGP, не-базовые шлюзы используют
EGP, однако и те и другие находятся в Интернете; следовательно, должен
существовать механизм взаимодействия между этими категориями шлюзов.
Интернет позволяет любому автономному (пе-базовому) шлюзу отправлять другим
системам информацию о доступности, которая также должна попасть на
минимум один базовый шлюз. В больших автономных сетях обработка информации
о доступности обычно поручается специальному шлюзу.
Протокол EGP, как и GGP, использует механизм опроса (polling), чтобы
шлюзы постоянно располагали информацией о своих соседях и постоянно обменива-
лнсь с ними маршрутной и статусной информацией. EGP относится к
категории протоколов, управляемых состоянием] это означает, что их работа зависит от
таблицы состояния, содержащей информацию о состоянии шлюзов и операциях,
которые должны выполняться при изменении информации в таблице состояния.
Протоколы IGP
В настоящее время используется несколько протоколов IGP. Самыми
популярными являются протоколы RIP и HELLO, упоминавшиеся выше в этой главе,
а также протокол OSPF (Open Shortest Path First). Ни один из протоколов не
является безусловным лидером, хотя на практике чаще встречаются протоколы
RIP и OSPF. Выбор конкретного протокола IGP зависит от сетевой архитектуры.
Протоколы RIP и HELLO вычисляют расстояние до конечной точки, а в их
сообщениях передастся идентификатор компьютера и расстояние до него. В
общем случае сообщения этих протоколов имеют большую длину, потому что они
содержат информацию о данных, нескольких записей таблиц маршрутизации.
Протоколы RIP и HELLO постоянно связываются с соседними шлюзами и
убеждаются в том, что компьютеры активны.
Протокол RIP версии 1 использует технологию широковещательной рассылки.
Это означает, что шлюзы периодически рассылают свои таблицы
маршрутизации другим шлюзам сети. В этом заключается один из недостатков RIP, так
как увеличение сетевого трафика и неэффективный обмен сообщениями
замедляют работу сети. RIP версии 2 рассылает обновления маршрутных данных
с использованием групповой рассылки. Групповая рассылка эффективнее
широковещательной, потому что сообщение обрабатывается только
маршрутизаторами RIP, входящими в определенную группу.
Протокол HELLO отличается от RIP тем, что в качестве маршрутной метрики
в нем выбрано время, а не расстояние. Чтобы этот протокол нормально работал,
шлюз должен обладать относительно точной хронометражной информацией по
каждому маршруту, вследствие чего HELLO зависит от сообщений
синхронизации часов. Протокол HELLO использовался в некоторых университетах, но
широкого распространения в корпоративных сетях он не получил.
Протокол OSPF был разработан группой IETF как более эффективный
протокол IGP. Выражение «кратчайший маршрут» недостаточно точно описывает
принципы маршрутизации этого протокола. С учетом количества критериев,
используемых для выбора лучшего маршрута к заданной точке, правильнее было
бы использовать термин «оптимальный маршрут».
Итоги
Настоящая глава посвящена шлюзовым протоколам. Устройства, которые раньше
назывались шлюзами, а теперь называются маршрутизаторами, играют
важнейшую роль при передаче информации между сетями. В настоящее время
существует несколько основных шлюзовых протоколов, все они были упомянуты в
этой главе. Подробные описания таких протоколов, как RIP и OSPF, будут
приведены в следующих главах.
4 С Протокол RIP
Марк А, Спортак (Mark A. Sportack)
Протокол маршрутной информации RIP (Routing Information Protocol) имеет
одну из самых длинных историй среди всех протоколов маршрутизации. Он
основывается на алгоритмах дистанционно-векторной маршрутизации,
разработанных еще до появления ARPANET. Первые академические описания этих
алгоритмов появились между 1957 и 1962 годами. В 1960-х годах эти алгоритмы
были реализованы многими компаниями и распространялись на рынке под
разными названиями. Конечные продукты имели много общего, но из-за внесения
закрытых (запатентованных) усовершенствований они не обеспечивали полной
совместимости.
В этой главе подробно описан механизм работы и область применения
современных открытых стандартов RIP. Последняя версия RIP имеет номер 2 (RIPv2)
и включает в RIP поддержку подсетей. Кроме того, в RIPv2 применяется
групповая рассылка вместо широковещательной, применявшейся в исходной версии
RIP, которая также называется RIP версии 1 (RIPvl).
RFC 1058
Реализация RIP появилась раньше стандарта RIP, описанного в RFC 1038.
Реализация RIP для TCP/IP создавалась на базе версии RIP для XNS (Xerox
Networking System). Семейство протоколов XNS было разработано фирмой
Xerox и широко использовалось в разных формах разными организациями на
ранних стадиях сетевых технологий. Первая реализация RIP для TCP/IP
впервые появилась в BSD Unix еще до появления стандарта, который описывал ее
работу. В течение нескольких лет считалось, что «стандарт» RIP определяется
исходными текстами BSD.
В июне 1988 года был опубликован документ RFC 1058 с описанием RIP.
Следовательно, версии RIP, появившиеся до выхода RFC 1058, могут оказаться
несовместимыми.
RFC 1058 описывает новую и по-настоящему открытую форму
дистанционно-векторного протокола маршрутизации. Открытый стандарт RIP, как и его
закрытые предшественники, принадлежал к числу простых дистанционно-век-
торных протоколов, предназначенных для выполнения функций протокола IGP
в небольших, простых сетях.
Каждое устройство, использующее RIP, должно иметь по крайней мере один
сетевой интерфейс. Если сеть имеет стандартную архитектуру (Ethernet, Token
Ring или FDDI), протоколу RIP придется строить маршруты только для
устройств, не подключенных к этой локальной сети напрямую. Устройствам,
находящимся в одной локальной сети, для взаимодействия друг с другом вполне
достаточно средств этой локальной сети.
Формат пакета RIP
Протокол RIP использует специальный формат пакета для сбора и
распространения информации о расстояниях до известных конечных точек объединенной
сети. На рис. 15.1 изображен пакет RIP с маршрутными данными для одной
конечной точки.
Команда ^1®Ч Ноль AFI Ноль Me^L®l Ноль Ноль МвтРика
A октет)L <РТ0Т) Bоктета) Bоктета) Bоктета) Dоктета) Dоктета) Dоктета) Dоетета)
Рис. 15.1. Структура пакета RIP
Пакет RIP может содержать до 25 записей с полями AFI, межсетевого адреса
и метрики. Это позволяет использовать один пакет RIP для обновления
нескольких записей в таблицах маршрутизации других маршрутизаторов. В пакетах
RIP с несколькими записями маршрутизации просто многократно повторяется
фрагмент от поля AFI до поля метрики, включая все поля с нулями.
Дополнительные записи присоединяются в конец структуры, изображенной на рис. 15.1.
Пакет RIP с двумя записями изображен на рис. 15.2.
Команда ^J^JM Ноль AFI Ноль Мв^^В° I Ноль Ноль Метрика
A октет) L ^ет) Bоктета) Bоктета) Bоктета) Dо!авга) К4 о^ета) D октета) D оетета)
Мва^Н Ноль Ноль Мвфии
D октета) D октета) D октета) D октета)
Рис. 15.2. Структура пакета RIP с двумя записями
В поле адреса содержится либо адрес отправителя, либо серия IP-адресов из
таблицы маршрутизации отправителя. Пакет запроса содержит одну запись с адресом
отправителя. Пакет ответа содержит до 25 записей из таблицы маршрутизатора RIP.
Общий размер пакета RIP ограничивается 512 октетами. Из-за этого в
больших сетях RIP запрос на полное обновление таблицы маршрутизации может
потребовать передачи нескольких ответных пакетов RIP. По прибытии к месту
назначения пакеты не упорядочиваются. В этом нет необходимости, так как
данные отдельных записей не разбиваются между пакетами RIP. Таким
образом, содержимое любого пакета RIP вполне самостоятельно, даже при том, что
пакет может содержать подмножество записей полной таблицы маршрутизации.
Узел-получатель обрабатывает обновления по мере получения пакетов, не
пытаясь восстанавливать их исходный порядок.
Предположим, таблица маршрутизатора RIP содержит 100 записей. Обмен
маршрутными данными с другим узлом RIP потребует четырех пакетов RIP,
каждый из которых содержит 25 записей. Если первым будет принят четвертый
пакет (содержащий записи с 76 по 100), получатель просто начинает
обновление таблицы с соответствующей части. Никакой порядковой зависимости между
пакетами не существует. Это позволяет при пересылке пакетов RIP обойтись без
затрат, присущих полноценным транспортным протоколам типа TCP.
ПРИМЕЧАНИЕ
В качестве транспортного протокола RIP использует UDP. Сообщения RIP инкапсулируются в
пакетах UDP/IP. Процессы RIP на маршрутизаторах используют порт UDP с номером 520.
Команда
Поле команды указывает тип содержимого пакета RIP — запрос или ответ. В обоих
случаях используется одинаковая структура кадра:
О пакет запроса требует, чтобы маршрутизатор передал содержимое своей
таблицы маршрутизации (частично или полностью);
О пакет ответа содержит записи таблицы маршрутизации, которые должны быть
переданы другим узлам RIP в сети. Ответ генерируется либо в результате
поступления запроса, либо как обновление по инициативе маршрутизатора.
Номер версии
Поле номера версии содержит номер версии RIP, использованной при создании
пакета RIP. Хотя протокол маршрутизации RIP определяется открытым
стандартом, он не стоит на месте. За прошедшее время в RIP вносились изменения,
отраженные в номере версии. Несмотря на появление многочисленных аналогов,
протокол RIP существует всего в двух версиях. Версия 1 использует
широковещательную рассылку для передачи сообщений RIP, а в версии 2 используется
групповая рассылка. Групповая рассылка эффективнее широковещательной, а в случае
RIP версии 2 сообщения групповой рассылки обрабатываются только
маршрутизаторами RIPv2. Протокол RIPv2 использует групповой адрес класса D 224.0.0.9.
Нулевые поля
В каждый пакет RIP входят многочисленные нулевые поля. Это пережитки
прошлого, которые остались от RIP-подобных протоколов, предшествовавших
RFC 1058. Большинство нулевых полей обеспечивает обратную совместимость
со старыми аналогами RIP без поддержки их специфических возможностей.
В качестве примера таких устаревших механизмов можно привести режимы
traceon и traceoff. Они не вошли в RFC 1058, однако открытый стандарт RIP
должен быть совместим с закрытыми аналогами RIP, в которых эти режимы
поддерживались. По этой причине стандарт RFC 1058 сохранил в пакете
соответствующие поля, но потребовал, чтобы эти поля всегда заполнялись нулями.
Полученные пакеты, у которых значение полей отлично от нуля, просто игнорируются.
Но не все нулевые поля появились для обеспечения совместимости. По
крайней мере одно из нулевых полей зарезервировано для использования в будущем.
В RIPv2 первое нулевое поле содержит метку маршрутизации, а второе —
домен маршрутизации. Нулевые записи в формате пакетов RIPvl были заменены
маской подсети и информацией о следующем маршрутизаторе в формате RIPv2.
Версия RIPvl не поддерживала использования масок подсетей в записях
таблицы маршрутизации. На момент создания RIPvl механизм определения масок
подсетей вообще не существовал.
Поле AFI
Поле AFI (Address Family Identifier) задает семейство адресов, представленное
полем межсетевого адреса. Хотя стандарт RFC 1058 создавался группой IETF,
что подразумевало использование протокола IP, он проектировался с расчетом
на обеспечение обратной совместимости с предыдущими версиями RIP. Из этого
следовало, что протокол должен был поддерживать передачу маршрутных данных
для разнообразных архитектур межсетевых адресов. Соответственно, открытому
стандарту RIP требовался механизм определения типа адреса, передаваемого в его
пакетах. В стандарте RIP поле AFI равно 2.
Межсетевой адрес
Поле межсетевого адреса состоит из 4 октетов, может содержать адрес хоста,
сети или даже код адреса основного шлюза. Следующие примеры показывают,
насколько сильно может различаться содержимое поля:
О в пакете запроса, рассчитанном на одну запись, это поле содержит адрес
отправителя пакета;
О в пакете ответа, рассчитанном на несколько записей, это поле содержит
IP-адреса, хранящиеся в таблице маршрутизации отправителя.
Метрика
Последнее поле пакета RIP — поле метрики — содержит счетчик метрики для
данного пакета. Значение увеличивается при проходе через маршрутизатор.
Допустимые значения метрики для этого поля лежат в интервале от 1 до 15.
Вообще говоря, метрика может быть увеличена до 16, но это значение связано
с недействительными маршрутами. Соответственно, значение поля метрики,
равное 16, является кодом ошибки и не входит в диапазон допустимых значений.
Оно означает, что конечная точка недостижима.
Таблица маршрутизации RIP
В предыдущем разделе был рассмотрен формат пакетов, при помощи которых
хосты RIP обмениваются информацией. На хостах эта информация хранится
в таблицах маршрутизации. Для каждой известной и доступной на данный мо-
мент конечной точки в таблицу включается одна запись, которая определяет
маршрут с минимальной стоимостью, ведущий к заданной точке.
ПРИМЕЧАНИЕ
Количество записей, хранящихся для каждой конечной точки, зависит от разработчика
маршрутизатора. Разработчики могут придерживаться опубликованных спецификаций или «улучшать» их
так, как сочтут нужным. Вполне вероятно, что вам попадется какая-нибудь разновидность
маршрутизаторов, которая позволяет хранить до четырех маршрутов с равной стоимостью для каждой
конечной точки сети.
Каждая запись в таблице маршрутизации содержит следующие поля:
О IP-адрес конечной точки;
О дистанционно-векторная метрика;
О IP-адрес следующего маршрутизатора;
О флаг изменения маршрута;
О маршрутные таймеры.
ПРИМЕЧАНИЕ
Хотя открытый стандарт RFC 1058 поддерживает различные схемы межсетевой адресации, он
разрабатывался группой IETF для использования в автономных системах в Интернете. При этом
подразумевалось, что данная форма RIP будет использоваться в сочетании с межсетевым протоколом IP.
IP-адрес конечной точки
Самой важной информацией в любой таблице маршрутизации следует считать
IP-адреса всех известных конечных точек. Получив пакет, маршрутизатор RIP
ищет указанный в заголовке IP-адрес получателя в своей таблице
маршрутизации и по результатам поиска определяет, куда следует переслать этот пакет.
Метрика
Метрика, хранящаяся в таблице маршрутизации, представляет общие затраты
на пересылку дейтаграммы от точки отправления до заданной конечной точки.
В поле метрики хранится сумма всех затрат, присвоенных сетевым каналам,
образующим сквозной путь между маршрутизатором и конечной точкой.
IP-адрес следующего маршрутизатора
Поле содержит IP-адрес следующего интерфейса маршрутизации в сетевом пути,
ведущем к конечному IP-адресу. Поле заполняется только в том случае, если
IP-адрес конечной точки принадлежит к сети, не подключенной напрямую к
текущему маршрутизатору.
Флаг изменения маршрута
Флаг изменения маршрута показывает, изменялся ли в последнее время маршрут
к данному IP-адресу. Предполагалось, что эта информация важна, поскольку
в таблицах маршрутизации RIP хранится только один маршрут для каждого
IP-адреса.
Маршрутные таймеры
С каждым маршрутом связаны два интервала времени: тайм-аута и удаления
маршрута. Таймеры, измеряющие эти маршруты, совместно определяют
действительность маршрутов, хранящихся в таблице маршрутизации. Процесс
ведения таблицы маршрутизации более подробно описан в разделе «Обновление
таблицы маршрутизации» этой главы.
Механика работы RIP
Как объяснялось в главе 13, маршрутизаторы, использующие
дистанционно-векторные протоколы маршрутизации, должны периодически пересылать копии
своих таблиц маршрутизации своим непосредственным соседям по сети. Таблица
маршрутизации содержит данные о расстояниях между маршрутизатором и
известными ему конечными точками — хостами, принтерами и даже сетями.
Каждый получатель добавляет в таблицу свое значение расстояния и
пересылает измененную таблицу своим непосредственным соседям. Этот процесс
происходит в обе стороны между всеми соседними маршрутизаторами. На
рис. 15.3 изображена простая объединенная сеть RIP, на примере которой будет
продемонстрирована концепция обмена маршрутными данными между
непосредственными соседями.
Шлюзовый
маршрутизатор
Маршрутизатор А ; ! Маршрутизаторе
Маршрутизатор В
Рис. 15.3. Каждый узел RIP рассылает содержимое своей таблицы
маршрутизации своим непосредственным соседям
На рис. 15.3 показаны четыре маршрутизатора. Шлюзовый маршрутизатор
связан с каждым из трех маршрутизаторов и должен обмениваться с ними
маршрутными данными. Маршрутизаторы А, В и С подключены только к шлюзу,
поэтому каждый из них может напрямую обмениваться информацией только со
шлюзом. Они узнают друг о друге через информацию, распространяемую через
шлюз. В табл. 15.1 приведено сокращенное содержимое таблиц маршрутизации
на всех трех маршрутизаторах. Этими данными маршрутизаторы обмениваются
со шлюзом.
Таблица 15.1. Содержимое таблиц маршрутизации
Маршрутизатор Хост Следующий узел
А 192.168.130.10 Локальный
192.168.130.15 Локальный
В 192.168.125.2 Локальный
192.168.125.9 Локальный
С 192.68.254.5 Локальный
192.68.254.20 Локальный
На основе полученных данных шлюзовый маршрутизатор строит свою
собственную таблицу маршрутизации. Сокращенное содержимое этой таблицы
приведено в табл. 15.2.
Таблица 15.2. Содержимое таблицы маршрутизации на шлюзовом маршрутизаторе
Хост Следующий узел Количество переходов
192.168.130.10 А 1
192.168.130.15 А 1
192.168.125.2 В 1
192.168.125.9 В 1
192.68.254.5 С 1
192.68.254.20 С 1
Маршрутные данные из табл. 15.2 рассылаются в пакетах обновления
маршрутных данных всем остальным маршрутизаторам в сети. Маршрутизаторы
используют полученную информацию для построения собственных таблиц. В табл. 15.3
приведено сокращенное содержимое таблицы маршрутизатора А после обмена
маршрутными данными со шлюзовым маршрутизатором.
Таблица 15.3. Содержимое таблицы маршрутизации на шлюзовом маршрутизаторе
Хост Следующий узел Количество переходов
192.168.130.10 Локальный 0
192.168.130.15 Локальный 0
192.168.125.2 Шлюз 2
192.168.125.9 Шлюз 2
192.68.254.5 Шлюз 2
192.68.254.20 Шлюз 2
Маршрутизатор А знает, что шлюзовый маршрутизатор расположен на
расстоянии одного перехода. Получив информацию о том, что хосты 192.168.125.x
и 192.68.254.x тоже находятся на расстоянии одного перехода от этого шлюза,
он складывает два числа и определяет, что эти компьютеры находятся на
расстоянии двух переходов.
Подобное описание чрезвычайно упрощено, но оно дает представление о том,
как каждый маршрутизатор узнает о других маршрутизаторах, постепенно
формирует свое представление о сети и о расстояниях между отправителем и
получателем.
Вычисление расстояний
Дистанционно-векторные протоколы маршрутизации используют метрики для
измерения расстояния, отделяющего маршрутизатор от всех известных
конечных точек. Маршрутные данные позволяют маршрутизатору определить точку
следующего перехода с максимальной эффективностью.
В RFC 1058 определена всего одна дистанционно-векторная метрика:
количество переходов. По умолчанию в RIP используется метрика, равная 1. Таким
образом, для каждого маршрутизатора, получающего и пересылающего пакет,
количество переходов в поле метрики пакета RIP увеличивается на 1.
Полученные дистанционные метрики используются при построении таблиц
маршрутизации. В этих таблицах хранятся данные о следующем узле, которому следует
переслать пакет для того, чтобы он прибыл к месту назначения с минимальными
затратами.
В предыдущих, закрытых аналогах RIP каждому переходу обычно
назначалась фиксированная стоимость, равная 1. В RIP стандарта RFC 1058 это правило
было сохранено (по умолчанию расстояние равно количеству переходов), но
у администратора появилась возможность установить более высокую стоимость.
Увеличение стоимости помогает различать каналы с разными характеристиками
быстродействия — такими, как пропускная способность сетевого канала
(например 56 кбит/с в сравнении с линией Т1) или даже различия в быстродействии
старой и новой модели маршрутизатора.
Обычно каждому порту маршрутизатора, подключенному к другой сети,
назначается стоимость 1. Разумеется, этот пережиток сохранился с времен,
предшествовавших появлению RFC 1058, когда стоимость каждого перехода была
равна 1 и оставалась неизменной. В относительно небольшой сети,
использовавшей однородные средства передачи, присваивание стоимости 1 всем портам было
вполне логично. Пример изображен на рис. 15.4.
Администратор маршрутизатора может изменить метрику, используемую по
умолчанию. Например, медленным каналам к другим маршрутизаторам можно
назначить более низкую стоимость. Но даже если повышенная стоимость более
адекватно представляет затраты или расстояние до указанной конечной точки,
поступать подобным образом не рекомендуется. Дело в том, что значения,
большие 1, повышают риск того, что счетчик переходов превысит пороговое
значение 161 Рисунок 15.5 показывает, как быстро становятся недействительными
маршруты в результате увеличения маршрутных метрик.
Сеть 172.31.1
Шлюзовый
Стоимость = 1 у маршрутизатор ч стоимость = 1
Сеть / \ Сеть
192.168.130/ \192.68.254
Маршрутизатор А Маршрутизатор с\
Стоимость = 1 \
1_ I Сеть /^ ^ч
О^т— Ethernet —pL ) | 192.168.125 / \
^ШШШШШШ^ ( Token Ring j
РЯД ЩЯ Маршрутизаторе yS *\
\^^*\ [ШШ I sQ \
192.168.130.10 192.168.130.15 ВВ |ДД
J 192.68.254.20 [ИШ]
|) —.— EtHeitiet | )
U — ' 192.168.254.5
ш в
192.168.125.2 192.168.125.9
Рис. 15.4. Однородная сеть с одинаковой стоимостью каналов
На рис. 15.5 представлен слегка измененный вариант глобальной сети,
изображенной на рис. 15.4. В исходную топологию добавлены избыточные связи
с низкой пропускной способностью. Чтобы альтернативные маршруты
использовались только при недоступности основного маршрута, сетевой
администратор присваивает им метрику 10. Повышение стоимости приводит к тому, что
основная нагрузка сохраняется за скоростным каналом Т1. В случае сбоя одной из
линий Т1 объединенная сеть продолжает нормально работать, хотя пониженная
пропускная способность резервного канала 56 кбит/с может привести к
снижению общей производительности. На рис. 15.6 показано, как сеть реагирует на
сбой канала Т1 между шлюзом и маршрутизатором А.
Сеть 172.31.1
' /' Ш^^^^ШШШЯШШш\ ч
// I I \ \
Сеть // Шлюзовый \\ Сеть
192.168.130 /У маршрутизатор \\ 192.68.254
Маршрутизатор А ; ! Маршрутизатор CN.
192.168.130.10 192.168.130.15 ИВ ШШ
192.68.254.20 ШШ
192.168.125.2 192.168.125.9
Условные
обозначения
Линия Т1
Стоимость = 1
Линия 56 кбит/с
Рис. 15.5. Назначение каналам повышенной стоимости для того, чтобы при маршрутизации
различались основные и альтернативные маршруты
Альтернативный канал 56 кбит/с остается единственной линией, через
которую маршрутизатор А может обмениваться данными с прочими узлами сети.
Содержимое таблицы маршрутизации узла А после того, как маршрутизаторы
согласуют общее представление о новой топологии сети, приведено в табл. 15.4.
Хотя повышение стоимости маршрута более точно отражает низкую пропускную
способность альтернативных маршрутов, оно может вызвать нежелательные
проблемы маршрутизации. На рис. 15.7 произошел сбой сразу двух каналов Т1,
вследствие чего одновременно активизировались сразу два альтернативных маршрута.
Сеть 172.31.1
Сеть >/ ^^^^^^^^ ч\ч Сеть
192.168.130 //' Шлюзовый \\ 192.68.254
^^ШШШйЯ^^ маршрутизатор ЛЙЩ[^
Маршрутизатор А Маршрутизатор С\
L_ Сеть у^~^\
, Ethernet |-L- ) \ 192.68.125 / \
^ШШШШ^^Ъ I Token Ring J
L ' ■. щ L . щ Маршрутизатор В / \
[ЯИВВИв] | II lg~j :*•:••;:;•::: Ш: h1.1'" 'jj'' I' —г|
192.168.130.10 192.168.130.15 НН ВШИ
192.68.254.20 МД
О—I— Ethernet , ) 192.168.254.5
ВС ЩЯ
рн||'1'11'1||иИ'ип|| Hl^flliffilHtilil *
192.168.125.2 192.168.125.9
Условные
обозначения
Линия Т1
Стоимость = 1
Линия 56 кбит/с
Стоимость = 1
Рис. 15.6. Стоимость маршрута резко увеличивается, но сеть продолжает работать
Таблица 15.4. Содержимое таблицы маршрутизации на маршрутизаторе А после сбоя канала
Хост Следующий узел Количество переходов
192.168.130.10 Локальный 0
192.168.130.15 Локальный 0
192.168.125.2 Шлюз 11
продолжение £
Таблица 15.4 (продолжение)
Хост Следующий узел Количество переходов
192.168.125.9 Шлюз 11
192.68.254.5 Шлюз И
192.68.254.20 Шлюз 11
Сеть 172.31.1
192.168.130 //' Шлюэовый \\ 192.68.254
Маршрутизатор А ! I Маршрутизатор с\
l_^ ! ; Сеть у^ ^\
(Q ■ Ethernet г-1- ) jj 192 168.125 / \
I. в| !•' ""ш! Маршрутизатор В у^ \
192.168.130.10 192.168.130.15 \Ш\^'"! jGeSmI;
192.68.254.20 |№'-\li
О 1 Ethernet , ) 192.168.254.5
ющ Si:
I* ш1 • ш
192.168.125.2 192.168.125.9
Условные
обозначения
Линия Т1
Стоимость = 1
_ _ Линия 56 кбит/с
Стоимость = 1
Рис. 15.7. Стоимость маршрута быстро накапливается, но сеть продолжает работать
Поскольку у обоих альтернативных каналов метрика стоимости равна 10, их
одновременная активизация приводит к тому, что стоимость маршрута превышает 16.
Допустимые значения счетчика переходов RIP лежат в интервале от 0 до 16, при
этом код 16 представляет недействительный маршрут. Таким образом, если
метрика (суммарная стоимость) маршрута превышает 16, маршрут объявляется
недействительным, с рассылкой оповещения по всем соседним маршрутизаторам.
Очевидно, сохранение стоимости по умолчанию, равной 1, помогает
избежать этой проблемы. Если увеличение метрики стоимости некоторого перехода
абсолютно необходимо, к выбору нового значения следует подходить очень
внимательно. Сумма метрик для любой пары адресов получателя и отправителя
в сети никогда не должна быть больше 15. В табл. 15.5 показано, как сбой второго
канала изменяет содержимое таблицы маршрутизации на узле А.
Таблица 15.5. Содержимое таблицы маршрутизации на маршрутизаторе А после двух сбоев каналов
Хост Следующий узел Количество переходов
192.168.130.10 Локальный 0
192.168.130.15 Локальный 0
192.168.125.2 Шлюз 11
192.168.125.9 Шлюз И
192.68.254.5 Шлюз 16
192.68.254.20 Шлюз 16
Как видно из табл. 15.5, стоимость маршрута между А и С превысила 16,
поэтому записи всех маршрутов между этими точками объявлены
недействительными. Маршрутизатор А по-прежнему может обмениваться данными с В, потому
что суммарная стоимость этого маршрута равна 11.
Обновление таблицы маршрутизации
Протокол RIP хранит в таблице маршрутизации только одну запись для каждой
конечной точки, поэтому ему приходится активно поддерживать целостность
таблицы маршрутизации. Для этого протокол требует, чтобы все активные
маршрутизаторы RIP рассылали содержимое своих таблиц маршрутизации.
Получаемые обновления автоматически замещают предыдущее содержимое таблиц
маршрутизации.
Для ведения таблицы маршрутизации в протоколе RIP используются три
таймера:
О Таймер обновления.
О Таймер тайм-аута маршрута.
О Таймер удаления маршрута.
Таймер обновления инициирует обновление таблицы маршрутизации на
узловом уровне. На каждом узле RIP используется только один таймер обновления.
С другой стороны, для каждого маршрута поддерживаются отдельные таймеры
тайм-аута и удаления.
По этой причине в каждую запись таблицы маршрутизации включаются
отдельные таймеры тайм-аута и удаления. При помощи этих таймеров узлы RIP
проверяют целостность маршрутов, а также активно восстанавливают
маршрутные данные после сетевых сбоев, инициируя обновление по прошествии
определенного времени. В нескольких следующих разделах описываются основные
операции по ведению таблиц маршрутизации.
Периодическое обновление таблиц
Обновление таблиц инициируется каждые 30 секунд. Этот интервал времени от-
считывается таймером обновления. По истечении заданного времени узел RIP
генерирует серию пакетов с полным содержимым своей таблицы маршрутизации.
Пакеты рассылаются между соседними узлами. Таким образом, каждый
маршрутизатор RIP примерно через 30 секунд должен получать обновленную
информацию от своих соседей по RIP.
ПРИМЕЧАНИЕ
В больших автономных системах на базе RIP периодические обновления могут порождать
неприемлемо большой объем трафика. Следовательно, обновление для каждого узла желательно
инициировать с небольшой случайной задержкой. RIP делает это автоматически; при каждой
инициализации интервал обновления увеличивается на небольшую случайную величину.
Если обновление не происходит в предполагаемое время, это указывает на сбой
или ошибку в объединенной сети. Диапазон причин очень широк, от элементарных
сбоев вроде потери пакета, содержащего обновленную информацию, до очень
серьезных (отказ маршрутизатора). Разумеется, дальнейшие действия зависят от
конкретной причины сбоя. Было бы нелогично объявлять недействительными целую
серию маршрутов из-за потери одного пакета с обновлением (вспомните: для
повышения эффективности пакеты с обновленными данными RIP пересылаются
с использованием ненадежного транспортного протокола). Итак, одно
пропущенное обновление не должно стать причиной для серьезных исправительных
операций. Чтобы протокол RIP лучше понимач, насколько серьезна та или иная ошибка,
для идентификации недействительных маршрутов в нем используются таймеры.
Идентификация недействительных маршрутов
Маршруты становятся недействительными по одной из двух причин:
О истечение срока жизни маршрута;
О получение информации о недоступности маршрута от другого маршрутизатора.
В обоих случаях маршрутизатор RIP должен обновить свои таблицы
маршрутизации, чтобы в них отражалась информация о недействительных маршрутах.
Если маршрутизатор не получает обновленных данных о доступности
маршрута в течение заданного времени, срок жизни маршрута истекает. Интервал
тайм-аута для маршрутов обычно устанавливается равным 180 секундам. Отсчет
времени начинается с момента активизации или очередного обновления маршрута.
За 180 секунд маршрутизатор обычно получает до шести обновлений
маршрутных данных от своих соседей (если предположить, что они обновляют таблицы
каждые 30 секунд). Если по истечении 180 секунд маршрутизатор RIP не
получает обновления для данного маршрута, считается, что IP-адрес конечной точки
стал недоступным. Соответственно, маршрутизатор помечает эту запись в своей
таблице как недействительную, для этого он заносит в поле метрики значение 16
и устанавливает флаг изменения маршрута. Далее эта информация
распространяется среди соседей при периодических обновлениях таблиц маршрутизации.
ПРИМЕЧАНИЕ
Для узлов RIP код 16 означает бесконечность. Таким образом, присваивание 16 полю метрики
фактически объявляет маршрут недействительным.
Получив оповещение о недоступности маршрута, соседние узлы используют
полученную информацию для обновления своих таблиц маршрутизации. Это
второй из двух вариантов появления недействительных записей в таблице
маршрутизации.
Недействительная запись остается в таблице маршрутизации очень недолго,
пока маршрутизатор решает, следует ли ее удалить. Даже несмотря па
присутствие записи в таблице, отправка дейтаграмм на IP-адрес данной записи
невозможна: протокол RIP не может маршрутизировать дейтаграммы по
недействительным маршрутам.
Удаление недействительных маршрутов
Когда маршрутизатор признает запись недействительной, он запускает второй
таймер — таймер удаления записи. Таким образом, таймер удаления записи
запускается через 180 секунд после последнего перезапуска таймера тайм-аута.
Обычно он устанавливается на 90 секунд.
Если и через 270 секунд для маршрута не будет получено обновление A80
секунд на тайм-аут + 90 секунд на удаление), маршрут удаляется из таблицы.
Таймеры удаления играют важную роль в механизме восстановления после
сетевых сбоев.
ПРИМЕЧАНИЕ
Важно помнить, что для правильной работы объединенных сетей RIP необходимо участие всех
шлюзов в сети. Участие может быть активным или пассивным, но участвовать должны все.
Активными называются узлы, которые активно участвуют в обмене маршрутными данными. Они
получают обновления от соседних узлов и рассылают копии своих таблиц маршрутизации соседям.
Пассивные узлы получают обновления от соседей и используют их для модификации своих таблиц
маршрутизации. С другой стороны, пассивные узлы не занимаются активным распространением
копий своих таблиц.
Пассивное поддержание таблиц маршрутизации было чрезвычайно полезно в эпоху,
предшествующую появлению аппаратных маршрутизаторов, когда маршрутизация выполнялась демоном routed
в системах Unix. Пассивный режим сводил к минимуму затраты на маршрутизацию на хосте Unix.
Проблемы адресации
Группа IETF позаботилась о совместимости протокола RIP со всеми известными
разновидностями RIP и routed. Так как ранние реализации были относительно
закрытыми, открытый стандарт RIP не мог жестко определять тип адресации.
По этой причине поле адреса в пакете RIP может содержать:
О адрес хоста;
О идентификатор подсети;
О идентификатор сети;
О 0 (признак маршрута по умолчанию).
Из этого разнообразия вариантов следует, что RIP позволяет строить
маршруты как к отдельным хостам, так и к сетям, содержащим множество хостов.
Чтобы реализовать эту гибкость адресации на практике, узлы RIP используют
при пересылке дейтаграмм наиболее конкретные из имеющихся данных.
Например, когда маршрутизатор RIP получает пакет IP, он анализирует адрес
получателя и пытается найти его в своей таблице маршрутизации. Если найти запись с
указанным адресом не удается, маршрутизатор проверяет, не входит ли этот
адрес в одну из известных ему сетей или подсетей. Если и на этом уровне
совпадение не найдено, маршрутизатор RIP использует маршрут по умолчанию.
Маршрутизация на шлюз
До настоящего момента подразумевалось, что записи в таблице маршрутизации
RIP относятся к отдельным хостам. Это упрощенное предположение в большей
степени относится к исходному механизму работы маршрутизации. В наши дни
сети стали слишком большими и содержат слишком много хостов, что сделало
маршрутизацию на уровне хостов непрактичной. Хостовая маршрутизация
приводит к излишнему увеличению размеров таблиц и замедляет маршрутизацию
в объединенных сетях.
В реальных сетях маршруты строятся для адресов сетей, а не для адресов
хостов. Например, если все хосты заданной сети (или подсети) доступны через
один и тот же шлюз (или шлюзы), таблица маршрутизации может просто
определить этот шлюз в качестве IP-адреса получателя. Все дейтаграммы,
адресованные хостам этой сети или подсети, будут пересылаться шлюзу. Далее шлюз
отвечает за доставку дейтаграмм их конечному месту назначения. Ситуация
представлена на рис. 5.8; мы сохраняем топологию сети из нескольких
предыдущих примеров, но используем более традиционные IP-адреса.
На рис. 15.8 хост 172.31.254.4 должен передать пакет IP хосту 192.168.125.10.
Маршрутизатору С этот адрес неизвестен. Маршрутизатор проверяет маску
подсети 255.255.255.0 и находит идентификатор подсети 192.168.125. Маршрут
к этой подсети ему известен. Предполагается, что шлюзовый маршрутизатор
подсети знает, как связаться с нужным хостом. Соответственно, маршрутизатор С
пересылает пакет на шлюз. При таком подходе хосты должны быть известны
только ближайшему маршрутизатору, а остальные маршрутизаторы не обязаны
их знать. Пунктирная линия на рис. 15.8 обозначает два этапа перемещения
дейтаграммы IP. На первом этапе дейтаграмма пересылается с маршрутизатора С
на маршрутизатор А, а затем — с маршрутизатора А на хост 192.168.125.10.
ПРИМЕЧАНИЕ
Протокол RIPvl не поддерживает масок подсетей переменной длины (VLSM). Соответственно, для
каждой сети может быть назначена только одна маска подсети. Вполне вероятно, что сеть будет
содержать несколько подсетей, каждая из которых обладает собственным адресом с постоянной длиной
маски. RIP также относится к категории «классовых» протоколов маршрутизации, поскольку он
поддерживает только классовые адреса IPv4. Версия RIPv2 поддерживает как VLSM, так и бесклассовую
междоменную маршрутизацию QDR. Механизм QDR, описанный в предыдущих главах, позволяет
объединять записи таблиц маршрутизации в блоки адресов, ассоциируемые с одной записью таблицы.
\ !
! Сеть 172.31.1
| х.—..-~-- — ---„ Автономная
п *'' 11ШШШШШШ п^^ Сеть 172.31
Сеть ^ у<^Ш^штШШ Сеть ч-ч
192.168.125 / |~! '\ \ 172.31.254 Ч
/ , Шлюзовыи X
Маршрутизатор А \ \ Маршрутизатор с\ \
D 1 j Ethernet —pi- )' Сеть 172.31.12 f^\ \
' ' J^^''m'^H^Zh ( Token ^'n9 ] l
\* *'m\\ •""""" m | Маршрутизатор В у/ \ \
|'~^Ш~Аj L |;^=Ш^-. ; • m\ I, J на
192.168.125.10 192.168.125.15; |jj||j||| . m\
\ I 172.31.254.20 | Z\
! @ i Ethernet - i )
j u — ' 172.31.254.5
! Цг^пД; ll ГД fill
! !• m\ • m\
i 172.31.12.2 172.31.12.9
Рис. 15.8. Узлы RIP могут пересылать дейтаграммы на шлюзы
Маршрутизация между шлюзами
Пример, представленный в предыдущем разделе, создает потенциальную проблему
маршрутизации. Если маршрутизатор С не знает маску подсети для IP-адреса
получателя, а хостовая часть адреса отлична от нуля, маршрутизатор не сможет
определить, содержит ли адрес идентификатор подсети или номер хоста. В итоге
пакет будет отвергнут из-за невозможности доставки.
Во избежание этой двойственности маршруты, ведущие в подсеть, не
распространяются за пределами сети, содержащей эту подсеть. Маршрутизатор на
границе подсети выполняет функции шлюза; каждая подсеть рассматривается как
отдельная сеть. Обновления RIP выполняются между непосредственными сосе-
дями внутри каждой подсети, но сетевой шлюз распространяет только
идентификатор сети между соседними шлюзами в других сетях.
На практике это означает, что граничный шлюз рассылает разную
информацию среди своих соседей. Непосредственные соседи внутри сети получают
обновления со списками всех подсетей, напрямую подключенных к шлюзу. В
записях таблицы маршрутизации перечисляются идентификаторы подсетей.
Непосредственные соседи вне сети получают всего одно обновление, в
котором объединяются все хосты подсетей, находящихся внутри сети. Передаваемая
метрика задает расстояние только до входа в сеть, без учета переходов внутри
сети. В результате удаленные маршрутизаторы RIP считают, что любой хост в
подсети известен граничному шлюзовому маршрутизатору сети и доступен через него.
Маршруты по умолчанию
1Р-адрес 0.0.0.0 используется для определения маршрута по умолчанию. По
аналогии с группировкой подсетей при маршрутизации на сетевой шлюз, маршрут
по умолчанию может использоваться для маршрутизации в несколько сетей без
их явного определения и описания. Единственное требование заключается в том,
чтобы между этими сетями существовал как минимум один шлюз, готовый
обработать сгенерированный трафик.
Для определения маршрута по умолчанию в RIP создается запись с адресом
0.0.0.0. Этот специальный адрес обрабатывается по тем же правилам, что и
обычные IP-адреса. В поле следующего маршрутизатора указывается IP-адрес
соседнего шлюзового маршрутизатора. Запись маршрута по умолчанию используется
так же, как и остальные записи, с одним важным исключением: маршрут по
умолчанию используется для маршрутизации всех дейтаграмм, у которых адрес
получателя не подходит ни под одну запись в таблице.
В табл. 15.6 приведено сокращенное содержимое таблицы маршрутизации
узла А с маршрутом по умолчанию. В этой таблице явно определены только два
локальных хоста. Все остальные локальные запросы автоматически передаются
на шлюзовый маршрутизатор.
Таблица 15.6. Содержимое таблицы маршрутизации с маршрутом по умолчанию на узле А
Хост Следующий узел
192.168.125.10 Локальный
192.168.125.15 Локальный
0.0.0.0 Шлюз
Топологические изменения
До настоящего момента основные механизмы и спецификации RIP
рассматривались в относительно статической ситуации. Тем не менее для получения
более глубокого понимания механики RIP следует разобраться в том, как
происходит взаимодействие этих механизмов при изменении топологии сети.
Согласование
Самым важным последствием топологических изменений в объединенной сети
RIP следует считать изменение маршрутных данных на соседних узлах.
Изменение также может привести к тому, что при следующем построении
дистанционных векторов будут получены другие результаты. Таким образом, новые группы
соседних узлов должны прийти к общему представлению о новой сетевой
топологии, начиная с разных отправных точек. Процесс разработки общего
представления о топологии сети называется согласованием.
Процесс согласования изображен на рис. 15.9. На рисунке представлены два
возможных маршрута к маршрутизатору D от маршрутизатора А и сети 192.168.125.
Маршрутизатор D является шлюзовым. Основной маршрут к сети
маршрутизатора D проходит через маршрутизатор С. Если внутри этого маршрута
произойдет сбой, маршрутизаторам потребуется некоторое время на согласование новой
топологии, не содержащей связи между маршрутизаторами С и D.
Сеть 172.31.1
Стоимость = 10 /™^ИИЯ\ Стоимость = 1
/ Маршрутизатор D \
Сеть / \ Сеть
192.168.130^/ B.D \ 192.68.254
Маршрутизатор В \ / Маршрутизатор С
Стоимость = 1^1^168^125^ / д Q N.
\ ^Ш11Ш|1ШшШ/ Стоимость = 1 /^^^Х
I Ethernet -р1 ) |^^^^|^Ш / \
ьшсрщищ, (Token Ring)
1 1 Маршрутизатор А V I
i и' г ei ^^ \
192.168.130.2 192.168.130.9 jjjjjjjj L^J^J
192.68.254.20 [гЁЙ]
f] I Ethernet ■ i I
4 — ' 192.68.254.5
L^SS ||с~пИ|
{• ш\ }• ш\
192.168.125.10 192.168.125.15
Рис. 15.9. Два возможных пути от маршрутизатора D к маршрутизатору А
Канал C-D перестает работать сразу же после сбоя, но на то, чтобы
информация об этом распространилась в сети, может потребоваться некоторое время.
Согласование начинается с того, что маршрутизатор D узнает о недоступности С.
Предполагается, что таймер обновления на маршрутизаторе D истекает раньше
таймера на маршрутизаторе С. Поскольку обновления от D к С передавались
именно по тому каналу, на котором произошел сбой, их пересылка прекращается.
Соответственно, маршрутизатор С (а также А и В) еще не знает о том, что канал
C-D не работает. Все маршрутизаторы объединенной сети продолжают
передавать через этот канал дейтаграммы, предназначенные для сети D. Первая стадия
согласования изображена на рис. 15.10.
Сеть 172.31.1
.,.. .,4.л,..л..л у Автономная
ШМЩтШ^Ш^М система
рШШ^ЩЩу Сеть 172.31
/ Маршрутизатор D \ _ _
/ у \ Стоимость = 1
Стоимость = 10/ _„-.-*'' B_D \ j^S
Маршрутизатор В ' д-В / / Маршрутизатор С
Стоимость = 1192^68Ь125/ / \
0~Т~ Ethemet | ) jHlllCTOHM^bH (CenRir^
I .1 Маршрутизатор А V J
• m\ • m „v^L \
192.168.130.2 192.168.130.9 'ВИН! L' m\
192.68.254.20 |ШШш{
(P i Ethernet i ~H
* — } 192.68.254.5
I* И • KB;
192.168.125.10 192.168.125.15
Рис. 15.10. Только маршрутизатор D знает о сбое канала
После истечения таймера обновления маршрутизатор D попытается передать
соседям свое представление об изменившейся топологии сети. Единственным
непосредственным соседом, с которым ему удастся связаться, будет
маршрутизатор В. Получив обновление, маршрутизатор В обновляет свою таблицу
маршрутизации и устанавливает для маршрута от В к D (через С) бесконечную
метрику. Это позволяет ему продолжить обмен данными с D через канал B-D.
После обновления своей таблицы узел В распространяет информацию об
изменившейся топологии сети среди своих соседей — А и С.
ПРИМЕЧАНИЕ
Помните, что узлы RIP объявляют маршрут недействительным, присваивая ему метрику 16 — в RIP
этот код обозначает бесконечность.
Как только А и С получат обновления и пересчитают стоимости, они могут
заменить свои устаревшие маршруты, использовавшие канал C-D, каналом B-D.
Маршрут B-D раньше отвергался всеми узлами, включая В, как более дорогой
по сравнению с C-D. Присвоенная ему метрика 10 уступала метрике C-D,
равной 1. Теперь, после сбоя канала C-D, наименьшей стоимостью обладает канал
B-D. В результате новый маршрут заменяет старый, ставший недействительным
в результате тайм-аута, в таблицах соседних маршрутизаторов.
Когда все маршрутизаторы придут к выводу, что самый эффективный
маршрут к D ведет через В, согласование завершается (рис. 15.11).
Период времени, в течение которого будет производиться согласование,
определить нелегко. Он сильно зависит от многочисленных факторов, в том числе
от ошибкоустойчивости маршрутизаторов и средств передачи данных, объема
трафика и т. д.
Проблема бесконечного отсчета
В примере из предыдущего раздела единственный сбой произошел в канале,
соединяющем узлы С и D. Маршрутизаторы смогли согласовать новую
топологию, вследствие чего доступ к сети маршрутизатора D был восстановлен по
альтернативному маршруту. Но если бы сбой произошел на самом
маршрутизаторе D, ситуация была бы гораздо более серьезной. Процесс согласования
в предыдущем примере начался с того, что маршрутизатор D смог оповестить В
о сбое в сети. Если работать перестанет сам маршрутизатор D, а не канал связи
с С, то маршрутизаторы В и С не получат обновлений и не узнают от
изменившейся топологии.
Согласование новой топологии при сбоях такого рода порождает явление,
называемое проблемой бесконечного отсчета. Если сеть становится совершенно
недоступной, обновления между оставшимися маршрутизаторами могут привести
к устойчивому увеличению метрик маршрутизации до недоступной конечной
точки; при этом каждый маршрутизатор ошибочно полагает, что другой
маршрутизатор может получить доступ к потерянной конечной точке. Если не
вмешаться в происходящее, маршрутизаторы буквально начинают отсчет до
бесконечности (в интерпретации RIP)
Сеть 172.31.1
^!Y,^,t,j; ? ^ Автономная
И|^^Ш^й система
/^^^ggfegv Сеть 172.31
Гтлмм^ _ 1П /^Маршрутизатор D C-D
Стоимость - 1Су, 4 v Стоимость = 1
Сеть // ? ч. V Сеть
192168130// | ^B-D /\ 192.68.254
Маршрутизатор В ' д.^^ х / Маршрутизатор С
Стоимость =1 192.168.125 / \
\ ^Ш1^^^85Э^ Стоимость = 1 /^~~^\
I I Маршрутизатор А V 7
192.168.130.2 192.168.130.9 j^^^ L' ,
192.68.254.20 |рШШ|
(Г^— Ethernet ■ )
« — ' 192.68.254.5
•,,-•:■:;:;■•,■ • га
192.168.125.10 192.168.125.15
Рис. 15.11. Маршрутизаторы согласовали новый маршрут B-D
Чтобы лучше понять опасность подобных фатальных сбоев по отношению
к механизму маршрутизации, вернемся к знакомой топологии, на примере
которой пояснялся процесс согласования. На рис. 15.12 на маршрутизаторе D
произошел сбой.
Сбой маршрутизатора D приводит к тому, что внешний доступ к хостам,
входящим в его сеть, становится невозможным. Не получив шесть
последовательных обновлений от D, маршрутизатор С объявляет маршрут C-D
недействительным и рассылает информацию о его недоступности (рис. 15.13).
Маршрутизаторы А и В не знают о сбое маршрута до тех пор, пока их не известит об
этом маршрутизатор С.
Сеть 172.31.1 Автономная
^^^;^;";-,;ж;;;^^<^ СИСТвМа
yl^^S^^S Сеть 172.31
/ Маршрутизатор d\ Стоимость = 1
B-D „--' ^Vn£ Сеть
Стоим^эсть = 10/ - - " * ' в-D | ^Aw-jwJ[92.68.254
Маршрутизатор В « * / / Маршрутизатор С
Стоимость =1 192.168.125/ / N,
\ шШш1жС# Стоимость = 1 /^ "Х
ж^тжуштш^т (Token Ring)
I l Маршрутизатор А V 7
U вв| [* ав | х \
192.168.130.2 192.168.130.9 Щрр! L'T' ■
192.68.254.20 |^^^|
Cl Ethernet 1 )
— ' 192.68.254.5
||{—]Д| ||г~]^|
* в U щ
192.168.125.10 192.168.125.15
Рис 15.12. Сбой на маршрутизаторе D
На этой стадии А и С полагают, что к D можно обратиться через узел В. Они
пересчитывают маршруты и включают в них повышенную стоимость обходного
пути (рис. 15.14).
Маршрутизаторы отправляют очередные обновления В — непосредственному
соседу обоих маршрутизаторов. Маршрутизатор В после наступления тайм-аута
для маршрута к D полагает, что он все еще может обратиться к D через А или С.
Разумеется, на самом деле это невозможно, поскольку эти маршрутизаторы
используют канал, который узел В только что объявил недействительным.
Фактически между А, В и С возникает цикл, порожденный ошибочным
представлением о том, что А и С могут связаться с недоступным маршрутизатором D через
друг друга. Это объясняется тем, что они оба связаны с маршрутизатором В,
который в, свою очередь, связан с D.
Сеть 172.31.1 Автономная
^яж^.Щ5^}да|^ система
/fei^ll^^gfx Сеть 172.31
/ N^mp>nn^TopD\ стоимость = 1
"В"^ .// B-D ><С Сеть
^!^l3—. Стоимость = 1 ^Д_Д92.68;254
Маршрутизатор В 'А-В р ^/Маршрутизатор С
Стоимость =1 g1 у Ч
О —I— Ethernet —Н ) |^^^И|1Н8| Стоимость =1 / \
ч _ 1 шш^шш^ш^^т Token Rjngj
, I,,, I Маршрутизатор А V 7
192.168.130.2 192.168.130.9 Sjjjj| LSH
| 192.68.254.20 [ДВВ)
0~ I Ethernet i ^П
— ' 192.68.254.5
192.168.125.10 192.168.125.15
Рис. 15.13. Маршрутизатор С объявляет канал C-D недействительным
При каждой итерации обновлений стоимость метрики возрастает с учетом
дополнительного перехода, добавленного к уже построенному циклу. Причиной
зацикливания является задержка, присущая независимому согласованию с
передачей обновлений по соседним узлам.
Теоретически узлы рано или поздно поймут, что узел D недоступен. Тем
не менее практически невозможно предсказать, сколько времени им для этого
потребуется. Данный пример убедительно объясняет, почему в RIP был
выбран такой низкий порог бесконечности. Когда сеть становится недоступной,
наращивание метрик вследствие стандартных обновлений необходимо
остановить как можно раньше. К сожалению, это означает ограничение
продолжительности отсчета узлов, после которого конечная точка объявляется недоступ-
ной. Любое ограничение такого рода напрямую ограничивает максимальный
размер диаметра маршрутизируемой сети. Разработчики RIP решили, что 15
переходов для автономной системы будет более чем достаточно. В системах
больших масштабов можно воспользоваться более сложным протоколом
маршрутизации.
Сеть 172.31.1 А
s. ^ ^ ^" Автономная
Шж^Ш^^Ш система
у^ЩП Сеть 172.31
/ Маршрутизатор D \ C"D
/ \ Стоимость = 1
B-D / d n О/ Сеть
CT0ll£ii^<- -°™^-ь- - -1- - - ^§Ы111254
Маршрутизатор В I \ \^ /Маршрутизатор С
Стоимость = 1 \l92.168.125 / Nv
(Ш^!^у£;У'-.-!',:г ..!^Й^^^.. ^ТТ^ЙЛ-3 |^^^H[lm| Стоимость = 1 ( \
" 'Г"'"''""""'**'"'™ '""'''*'\ гу^шмрйииг™ (Token Ring)
вив в|а | V 7
р"' '"'] [^^Sj Маршрутизатор A J^^^_^^\
Sail § Ш
192.168.130.2 192.168.130.9 bgd \^Ш^\
ЛТР! :". J
192.68.254.20 ЩП
^^^^^^^^Щр^ 192.68.254.5
IhJh | КЗ
ПШИ|1 LIHJ
ЛТП. JBEl
192.168.125.10 192.168.125.15
Рис. 15.14. Маршрутизаторы А и С полагают, что они могут обратиться к D через В
В RIP предусмотрены три способа решения проблемы бесконечного отсчета:
О асимметричное распространение;
О асимметричное распространение с обратным исправлением;
О экстренные обновления.
Асимметричное распространение
Проблема зацикливания, описанная в предыдущем разделе, решается с
применением специальной логической схемы, которая обычно называется
асимметричным распространением. Хотя протокол RIP не поддерживает асимметричного
распространения «в чистом виде», понимание этого механизма поможет вам
лучше понять его более сложную разновидность — асимметричное
распространение с обратным исправлением (split horizon with poisoned reverse).
Механизм асимметричного распространения основан на предположении, что
узел RIP не передает информацию о маршруте конкретному соседу, если
изначально информация об этом маршруте была получена именно от этого соседа.
Рисунок 15.15 поясняет ситуацию.
Сеть 172.31.1
.. гО^Ч*4 Обновления только
Маршрутизатор D ^ч дляД.ВиС!
Обновления только для D! чч^\Ч
Сеть „ s\4x Сеть
192.168.130 Обновления только N>\4l9Z68.254
Г:,,,,,:,:,,^:,,::,,:,,.,:^.™Г - ОбНОВЛвНИЯ ТОЛЬКО Р^^ЩШ23&Ш*
Маршрутизатор В Для А и в' Маршрутизатор С
Чч\\ Обновления только * /*''
\\\ Для А, С и D! '//
ч\ чх Обновления только/ V/1-
\\ ч af»i / / * Обновления только
\\ \ для А и В! //' ^пи»,«п"л iwjww
Обновления только ч>\\ //''' для В, С и D!
для В, С и D! Чч\Ч\ Сеть ///
ч\\ \ 192.168.125 ///
Маршрутизатор А
Рис. 15.15. Асимметричное распространение
На рис. 15.15 маршрутизаторы поддерживают логику асимметричного
распространения. Маршрутизатор С (поддерживающий единственный путь к
маршрутизатору D) не может получать от А обновления, касающиеся сети D, поскольку
при получении этой информации А зависит от С (и даже В). Маршрутизатор А
должен исключить из распространения информацию о маршрутах, полученных
от С. Этот простой способ предотвращения циклов относительно эффективен,
но у него есть серьезный функциональный недостаток: отказ из
распространения обратных маршрутов приводит к тому, что узлам приходится дожидаться
тайм-аута для каждого недоступного маршрута.
В протоколе RIP тайм-аут происходит только после пропуска шести
сообщений об обновлении маршрута. Следовательно, неправильно информированный
узел может до пяти раз передать другим узлам неправильную информацию о
недоступной конечной точке. Именно эта задержка создает возможность
зацикливания неправильных маршрутных данных. Из-за этого ограничения в RIP
используется слегка измененная схема, называемая асимметричным распространением
с обратным исправлением.
Асимметричное распространение
с обратным исправлением
Простая схема асимметричного распространения пытается предотвратить
зацикливание посредством отказа от возвращения информации тому узлу, от
которого она была получена. Хотя в некоторых ситуациях этот способ помогает,
существуют более эффективные средства предотвращения циклов.
Асимметричное распространение с обратным исправлением использует гораздо более
радикальный способ: для разрыва циклических маршрутов их метрики «портятся»
присваиванием бесконечного значения. Пример представлен на рис. 15.16.
Сеть172 31 1
T--w-wmr--^miirrTT|%N^ч ^ ОбНОВЛвНИЯ ТОЛЬКО
Маршрутизатор D ч>\4 для А, В и С!
Обновления только для D! ччЧ?4ч
Сеть 4nNN Сеть
192.168.130 Обновления только для А и В! чХ>ч 192.68.254
t^ilu^n,^ Маршруты к D испорчены tf=JSl!3iib
Маршрутизаторов Маршрутизатор С
\ \ * / / *'
\ Обновления только для А и С! / / /
Маршруты к D испорчены '//
чч\ \ Обновления только для А и В! '/
\\ \ Маршруты к D испорчены
Обновления только ч\\\ Сеть У/*''
для А и С! \\\ 192 168 125 '//
Маршруты к D испорчены \\ V—^^—L—^'V/ Обновления только
^^ШШ^Ш/ШШ'' для • и
Маршрутизатор А
Рис. 15.16. Асимметричное распространение с обратным исправлением
Как видно из рис. 15.16, маршрутизатор А может предоставить
маршрутизатору В информацию о том, как достичь маршрутизатора D, но этот маршрут
содержит метрику 16. Следовательно, В не может обновить свою таблицу мар-
шрутизации информацией о том, как лучше достичь D. В сущности, А сообщает
о том, что он не может напрямую связаться с D, и это действительно так.
Подобная форма распространения маршрутных данных быстро и эффективно
разрывает циклы;
Как правило, в дистанционно-векторных сетях асимметричное
распространение с обратным исправлением гораздо надежнее простого асимметричного
распространения. И все же ни один из вариантов не идеален. Асимметричное
распространение с обратным исправлением эффективно предотвращает
зацикливание в топологиях, ограничивающихся двумя шлюзами, но в более крупных
сетях протокол RIP по-прежнему страдает от проблемы бесконечного отсчета.
Чтобы бесконечные циклы обнаруживались как можно раньше, RIP
поддерживает механизм экстренного обновления.
Экстренные обновления
Топологии с тремя шлюзами к общей сети по-прежнему подвержены проблеме
зацикливания, возникающей при «взаимном обмане» шлюзов. Пример
представлен на рис. 15.17. На рисунке изображены три шлюза А, В и С, ведущих к
маршрутизатору D.
Сеть
172.31.1
/ Маршрутизатор D \
192.168.130/ \ 192.68.254
Маршрутизатор В Маршрутизатор С
Маршрутизатор А
Сеть
192.168.125
Рис. 15.17. Три шлюза, связанных с D
Если на маршрутизаторе D произойдет сбой, маршрутизатор А может
считать, что маршрутизатор В все еще может работать с D. Маршрутизатор В
считает, что С по-прежнему работает с D, а маршрутизатор С думает то же самое
о маршрутизаторе А. В результате возникает знакомая ситуация зацикливания.
Ситуация представлена на рис. 15.18.
Сеть
172.31.1
/ Маршрутизатор D \
Сеть / Стоимость = \ Сеть
192.168.130/ Стоимость + 1 \ 192.68.254
Маршрутизатор В Стоимость = Маршрутизатор С
\Стоимость + 1 Стоимость = / /
\ \ Стоимость + 1\/
Маршрутизатор А
Сеть
192.168.125
Рис. 15.18. Проблема бесконечного отсчета с тремя шлюзами
Логика асимметричного распространения в этом сценарии неэффективна,
что объясняется задержкой перед объявлением недействительных маршрутов.
Для ускорения согласования протокол RIP использует другой механизм,
называемый экстренным обновлением. В соответствии с правилом экстренного
обновления при изменении маршрутной метрики шлюз должен немедленно разослать
информацию об этом независимо от того, сколько времени осталось до
истечения 30-секундного таймера обновления.
Как показывает предыдущий раздел, время является ахиллесовой пятой
асимметричного распространения, с обратным исправлением или без него.
Экстренное обновление призвано преодолеть этот недостаток за счет сведения задержки
до абсолютного минимума.
Таймеры временного отказа от приема
Тем не менее экстренное обновление — не панацея. Обновления в сети не
распространяются мгновенно, поэтому возможно (хотя и маловероятно), что другой
шлюз выполнит периодическое обновление до получения экстренного
обновления от другого шлюза. В этом сценарии устаревший (недействительный)
маршрут может получить дальнейшее распространение в сети. Хотя вероятность
такого события чрезвычайно мала, нельзя утверждать, что экстренные обновления
полностью исключают зацикливание в сетях RIP.
Одно из решений потенциальной проблемы основано на использовании
таймеров временного отказа. Таймер временного отказа используется в сочетании с
механизмом экстренного обновления. Сразу же после экстренного обновления
на маршрутизаторе запускается таймер. Пока счетчик не достигнет нуля, мар-
шрутизатор не принимает обновления от соседей для указанного маршрута или
конечной точки.
В результате маршрутизатор RIP не принимает обновления
недействительного маршрута в течение заданного интервала времени. Это сделано для того,
чтобы маршрутизатор не пришел к ошибочному выводу, что другому
маршрутизатору известен действительный путь к недоступной точке.
Недостатки RIP
Несмотря на свою долгую историю существования, протокол RIP не лишен
недостатков. Он прекрасно подходил для построения маршрутов на ранних порах
развития объединенных сетей, но технологические достижения радикально
изменили принципы построения и использования объединенных сетей. Из-за этого
в современных объединенных сетях протокол RIP быстро уходит в прошлое.
Среди главных недостатков RIP необходимо выделить следующие:
О отсутствие поддержки маршрутов, длина которых превышает 15 переходов;
О использование фиксированных метрик при построении маршрутов;
О высокий уровень трафика при обновлении таблиц;
О относительно медленное согласование;
О отсутствие поддержки динамического распределения нагрузки.
Ограничение количества переходов
Протокол RIP разрабатывался для относительно небольших автономных систем,
поэтому максимальная длина маршрута в нем жестко ограничивается 15
переходами. При пересылке пакета маршрутизатор увеличивает его счетчик переходов
на величину стоимости канала, через который этот пакет передается. Если
счетчик переходов достигает 15, а пакет еще не добрался до положенной конечной
точки, эта точка считается недоступной, а пакет уничтожается.
Ограничение длины маршрута фактически ограничивает максимальный
диаметр сети 15 переходами. При грамотном проектировании этого достаточно для
построения довольно большой сети, однако возможности RIP серьезно
ограничены по сравнению с масштабируемостью других, более современных
протоколов маршрутизации. Таким образом, если ваша сеть не относится к
категории самых мелких, RIP вряд ли можно считать правильным выбором протокола
маршрутизации.
Фиксированные метрики
От ограничения количества переходов будет логично перейти к следующему
принципиальному ограничению RIP: фиксированным стоимостным метрикам. Хотя
метрики могут настраиваться администратором, они имеют статическую
природу. Протокол RIP не может обновлять их в реальном времени в соответствии
с изменениями, обнаруженными в сети. Стоимостные метрики, определенные
администратором, сохраняют фиксированные значения до того момента, когда
они будут обновлены вручную.
Отсюда следует, что протокол RIP плохо подходит для динамичных сетей,
в которых маршруты строятся в реальном времени в ответ на изменения в
состоянии сети. Например, если в сети поддерживаются приложения, критичные
по времени, будет разумно выбрать протокол маршрутизации, который бы строил
маршруты на основании измерений задержек в каналах связи или даже текущей
нагрузки каналов. RIP использует фиксированные метрики и поэтому
принципиально не поддерживает построение маршрутов в реальном времени.
Высокий уровень трафика при обновлении таблиц
Через каждые 30 секунд узел RIP производит широковещательную рассылку
таблиц маршрутизации. В больших сетях с большим количеством узлов это
может породить заметный объем трафика.
Медленное согласование
С точки зрения пользователя 30-секундное ожидание обновления не создает
особых проблем. Тем не менее маршрутизаторы и компьютеры работают гораздо
быстрее людей, а ожидание обновлений в течение 30 секунд имеет ярко
выраженные негативные последствия (см. выше раздел «Топологические изменения»
этой главы).
Но 30-секундное ожидание обновлений — далеко не самое неприятное. Гораздо
хуже то, что для обновления маршрута недействительным приходится ждать
целых 180 секунд, причем по истечении этого времени один маршрутизатор всего
лишь начинает согласование. В зависимости от количества маршрутизаторов
и топологии объединенной сети полное согласование может потребовать
многократных обновлений. Низкая скорость согласования маршрутных данных
маршрутизаторами RIP создает массу возможностей для ложного распространения
маршрутов, которые успели стать недействительными. Разумеется, это ухудшает
производительность сети как в целом, так и в субъективном восприятии
конкретного пользователя.
В этой главе были наглядно продемонстрированы отрицательные
последствия медленного согласования, характерного для RIP.
Отсутствие распределения нагрузки
Еще один существенный недостаток RIP — отсутствие средств динамического
распределения нагрузки. На рис. 15.19 изображен маршрутизатор с двумя
последовательными соединениями с другим маршрутизатором объединенной сети.
В идеальном случае этот маршрутизатор должен стараться как можно
равномернее распределять трафик по двум соединениям для поддержания минимальной
загрузки обоих каналов и оптимизации скорости передачи данных.
К сожалению, протокол RIP не обладает средствами динамического
распределения нагрузки. Он просто использует первое из двух известных ему
физических соединений. RIP направляет весь трафик по этому соединению, несмотря
на наличие второго свободного соединения. Ситуация изменится только в том
случае, если маршрутизатор на рис. 15.19 получит обновление маршрутных
данных, извещающее об изменении метрик к любой заданной конечной точке. Если
в результате обновления второй канал станет путем с минимальной стоимостью,
RIP переходит на второй канал и перестает использовать первый.
Стоимость = 1
„ - ** "*"''■»
,''* Нет трафика N
Сеть *' \ Сеть
192.168.130 / \ 192.68.254
EEESSE™|SS£1 ВеСЬ ТрафИК ESZS3Z£SEE3£ID
Маршрутизатор А \
7, Г (Token Ring
m Щ ИЗ \
гтйвигН Г'йям"! I [ ЩШШЩ
I СшЦ I LJuSsh—J LZ_I_LIIZJ hE» I
) HT ^ Jhi.т l т д^ I I ВШ5Э I
hatd
192.168.130.2 192.168.130.9 tmd [—II]
иЩ-] I ' i
192.68.254.20 f|||j
192.68.254.5
Рис. 15.19. Проблема бесконечного отсчета с тремя шлюзами
Принципиальное отсутствие средств распределения нагрузки в RIP лишь
подтверждает то, что этот протокол изначальо предназначался для простых сетей.
Такие сети по своей природе ограничиваются минимум альтернативных
маршрутов (или обходятся вообще без них), поэтому распределение нагрузки не входит
в число целей проектирования, а его поддержка не развивалась.
Итоги
Благодаря простоте настройки, гибкости и удобству использования протокол
маршрутизации RIP пользовался большим успехом. С момента его разработки
в компьютерных, сетевых и межсетевых технологиях появились огромные
достижения, отразившиеся на популярности RIP. В наши дни используется множество
других протоколов, превосходящих RIP с технической точки зрения. Но несмотря
на успех этих протоколов, RIP остается весьма полезным протоколом
маршрутизации для тех, кто понимает практические следствия его недостатков и
использует его соответствующим образом. В этой главе также были рассмотрены
усовершенствования новой версии RIP — RIPv2.
"I 4% пР°токол OSPF
Марк А. Спортак (Mark A. Sportack)
В конце 1980-х годов принципиальные недостатки дистанционно-векторной
маршрутизации становились все более очевидными. Одна из попыток
улучшения масштабируемости сетей была основана на том, чтобы решения по выбору
маршрута принимались на основании состояния каналов, а не на количестве
переходов или других дистанционных метриках. Каналом называется соединение
между двумя маршрутизаторами сети. К состоянию канала причисляются такие
атрибуты, как скорость передачи и задержка.
В этой главе дается подробное описание версии открытого протокола
предпочтительного выбора кратчайшего пути OSPF (Open Shortest Path First).
Протокол был разработан группой IETF, а его первая спецификация содержалась
в RFC 1131. Эта недолговечная спецификация быстро ушла в прошлое с
выходом RFC 1247. Различия между двумя спецификациями OSPF были достаточно
значительными, поэтому версия OSPF из RFC 1247 получила название OSPF
версии 2. Протокол OSPF версии 2 продолжал развиваться и совершенствоваться.
Последующие модификации были описаны в RFC 1583, 2178 и 2328 (текущая
версия). Текущей версии OSPF по-прежнему присвоен номер 2. Интернет и IP
быстро развиваются, и вполне вероятно, что OSPF будет совершенствоваться
наравне с ними.
Происхождение OSPF
В соответствии с растущей потребностью в построении крупномасштабных
IP-сетей в IETF была сформирована рабочая группа по разработке открытого
топологического протокола маршрутизации, предназначенного для больших
разнородных сетей IP. Новый протокол маршрутизации создавался на базе более или
менее успешных запатентованных протоколов маршрутизации SPF, в большом
количестве представленных на рынке. Все протоколы маршрутизации SPF,
включая OSPF, непосредственно основаны на математическом алгоритме, известном
как алгоритм Дейкстры. Вместо дистанционно-векторных метрик этот алгоритм
выбирает маршрут на основании состояния каналов.
Протокол маршрутизации OSPF был разработан в IETF в конце 1980-х
годов. Он представлял собой открытую версию семейства протоколов
маршрутизации SPF. Исходный вариант OSPF был описан в RFC 1131. Эта первая версия
вскоре была заменена существенно улучшенной версией, документированной
в RFC 1247. За новой версией было закреплено название «OSPF версии 2», что
должно было явно обозначить существенные улучшения в ее устойчивости и
функциональности. В эту версию были внесены многочисленные улучшения,
каждое из которых воплощалось в форме открытого стандарта с обсуждением
на форуме IETF. Последующие спецификации публиковались в RFC с номерами
1583, 2178 и 2328.
Вместо того чтобы анализировать путь постепенного развития текущей
версии OSPF, в этой главе основное внимание будет уделено основным
возможностям, специфике и области применения последней версии OSPF.
Принципы работы OSPF
Протокол OSPF разрабатывался как протокол маршрутизации IP,
предназначенный для использования в автономных системах. По этой причине он не
способен пересылать дейтаграммы других маршрутизируемых сетевых протоколов
(таких, как IPX или AppleTalk). Если ваша сеть должна поддерживать несколько
разных протоколов маршрутизации, подумайте над использованием другого
протокола маршрутизации вместо OSPF.
Протокол OSPF строит маршруты на основании IP-адреса получателя,
указанного в заголовке дейтаграммы IP; поддержка построения маршрутов для
получателей, не являющихся узлами IP, не предусмотрена. Сообщения OSPF
инкапсулируются в IP напрямую, их доставка не требует применения других
протоколов (TCP, UDP и т. д.).
Одной из целей, поставленных при разработке OSPF, было быстрое
обнаружение топологических изменений в автономных системах и быстрое согласование
новой топологии после обнаружения изменений. Решения по выбору
маршрутов учитывают состояние каналов, связывающих маршрутизаторы в автономной
системе. На каждом из маршрутизаторов хранится идентичная копия базы
данных с информацией о состоянии каналов в сети. В базу данных включены
данные о состоянии маршрутизатора, в том числе о его интерфейсах, доступных
соседях и состоянии каналов связи.
Обновления таблицы маршрутизации, называемые сообщениями LSA (Link-
State Advertisements), передаются непосредственно всем остальным соседям в зоне
маршрутизатора. В технической терминологии такой механизм обновления
называется лавиной (flooding), но этот термин несет отрицательный подтекст и создает
неверное представление о реальных характеристиках быстродействия OSPF.
На практике согласование в сетях OSPF происходит очень быстро. Все
маршрутизаторы сети используют один и тот же алгоритм маршрутизации и
пересылают обновления таблицы маршрутизации непосредственно друг другу. На
основании этой информации строится образ сети и ее каналов. На каждом мар-
шрутизаторе сеть представляется в виде древовидной структуры, в которой сам
маршрутизатор является корневым узлом. Это дерево, называемое деревом
кратчайших путей, содержит информацию о кратчайшем маршруте к каждой
конечной точке автономной системы. Доступ к конечным точкам за пределами
автономной системы осуществляется через граничные шлюзы внешних сетей, которые
представляются листовыми узлами на дереве кратчайших путей. Данные о
состоянии каналов для таких конечных точек и/или сетей не могут храниться
просто потому, что они находятся за пределами сети OSPF и не могут
отображаться в виде ветвей на дереве кратчайших путей.
Зоны OSPF
Среди причин, объясняющих быстроту согласования в протоколе OSPF, одно
из ключевых мест занимает использование зон. Стоит напомнить, что при
разработке OSPF группа IETF выдвинула две основные цели:
О улучшение масштабируемости сети;
О ускорение согласования.
Ключом к достижению обеих целей является разделение сети на области
меньшего размера, называемые зонами. Зона представляет собой совокупность
конечных систем, маршрутизаторов и каналов связи, объединенных в сеть. Каждая зона
характеризуется уникальным номером, настраиваемым на уровне
маршрутизатора. Интерфейсы маршрутизаторов, которым назначены одинаковые номера
зоны, становятся частью одной зоны. В идеальном варианте зоны определяются
не произвольно, а так, чтобы свести к минимуму объем межзонного трафика.
Разбиение на зоны производится с учетом реальных закономерностей трафика,
а не географических или политических границ. Конечно, это идеальный случай,
который может оказаться непрактичным для вашей конкретной среды.
Количество зон, поддерживаемых сетью OSPF, ограничивается размером поля
идентификатора зоны. Поле представляет собой 32-разрядное двоичное число,
потому теоретическое максимальное количество сетей определяется 32-разрядным
двоичным числом, у которого все биты равны 1. В десятичном представлении
это число равно 4 294 967 295. Разумеется, реальное количество
поддерживаемых зон значительно ниже теоретического максимума. На практике
максимальное количество зон в сети зависит от того, насколько правильно была
спроектирована сеть. На рис. 16.1 изображена относительно простая сеть OSPF с тремя
зонами, которым присвоены номера 0, 1 и 2.
Типы маршрутизаторов
Не забывайте, что протокол OSPF относится к категории топологических
протоколов. По этой причине каналы и интерфейсы маршрутизаторов, к которым
они подключаются, относятся к определенной зоне. В зависимости от зонной
принадлежности в сетях OSPF различаются три типа маршрутизаторов:
О внутренние маршрутизаторы;
О граничные маршрутизаторы;
О магистральные маршрутизаторы.
/ Маршрутизатор! Зона 0 Маршрутизатор \.
Маршрутизатор Маршрутизатор | Маршрутизатор Маршрутизатор
Маршрутизатор ! Маршрутизатор
Рис. 16.1. Небольшая сеть OSPF с тремя зонами
На рис. 16.2 изображены все три типа маршрутизаторов для сети из
предыдущего примера.
.Маршрутизатор | Магистральные Маршрутизатор
/ маршрутизаторы \
Маршрутизатор ч"^% Маршрутизатор » ; /Маршрутизатор ,'' Маршрутизатор
Маршрутизатор ч" *. '• ' ■'.*'' Маршрутизатор
w Граничные ^
\ маршрутизаторы /
ч /
""---_ _. - Внутренние .. _ _ ,.. ~ ~'
маршрутизаторы
Рис. 16.2. Внутренние, граничные и магистральные маршрутизаторы в сети OSPF
Как показано на рис. 16.2, маршрутизатор с несколькими интерфейсами
может принадлежать к двум и более зонам. Такие маршрутизаторы называются
граничными. К категории магистральных относятся маршрутизаторы, у которых
как минимум один интерфейс определен как принадлежащий к зоне 0. Любой
граничный маршрутизатор, подключенный к зоне с номером 0, одновременно
является и граничным, и магистральным.
Внутренний маршрутизатор содержит интерфейсы, принадлежащие к одной
зоне, но не к зоне 0. Использование трех базовых типов маршрутизаторов
позволяет строить эффективные, масштабируемые сети OSPF.
Типы маршрутизации
Наряду с тремя типами маршрутизаторов, представленными на рис. 16.2,
протокол OSPF поддерживает два типа маршрутизации:
О внутризонная маршрутизация;
О межзонная маршрутизация.
Смысл терминов не требует объяснений. Внутризонная маршрутизация
ограничивается внутренними маршрутизаторами одной зоны. На рис. 16.3
представлен пример межзонных коммуникаций в сети OSPF, изображенной на
рис 16.1.
/М а рш рути затор \ Зона О I Маршрутизатора
Маршрутизатор \ \ Маршрутизатор ! Маршрутизатор / Маршрутизатор
\ \ Зона 1 | Зона 2 /
ШЧ {Маршрутизатор • Маршрутизатор
Сервер \ ;
иДДвэ
Рабочая станция
Рис. 16.3. Внутризонные коммуникации в сети OSPF
Межзонная маршрутизация требует обмена данными между зонами. Вся
межзонная маршрутизация должна осуществляться через зону с номером 0.
Зонам с номерами, отличными от 0, не разрешено напрямую взаимодействовать
друг с другом. Это иерархическое ограничение обеспечивает корректное
масштабирование сетей OSPF без хаотического переплетения каналов и
маршрутизаторов. Подобные иерархические механизмы иногда называются иерархической
маршрутизацией.
На рис. 16.4 показано, как выглядит правильная организация межзонных
коммуникаций в сетях OSPF.
/Маршрутизатор! Маршрутизатору
Маршрутизатору / Маршрутизатор ! Маршрутизатор \ / Маршрутизатор
[дч Маршрутизатор i Маршрутизатор ',
°~ Ш_
1ИМП Т'Ж'1
Рабочая станция
Рис. 16.4. Межзонные коммуникации в сетях OSPF
Предыдущие примеры показывают, как на высоком уровне организуется
обмен данными в сетях OSPF. Тем не менее протокол OSPF также может
применяться для обмена маршрутными данными между сетями OSPF, а не только
между зонами одной сети. Использование OSPF продемонстрировано в
следующем разделе.
Межсетевая маршрутизация
Протокол OSPF может использоваться для объединения сетей, независимо от
того, используют ли они OSPF или работают на базе совершенно других
протоколов маршрутизации. Стыковка сети OSPF с другим протоколом
маршрутизации — сложная задача, основанная на использовании механизма
перераспределения маршрутов. Маршрутные данные сети, работающей на базе другого
протокола, обобщаются и перераспределяются в сети OSPF.
В сети OSPF все маршруты, полученные подобным образом, помечаются как
внешние. Объединить две сети OSPF проще, поскольку это не требует
преобразования затратных метрик одного протокола к формату, понятному для другого
протокола. Протокол OSPF также используется при создании автономных сие-
тем. Автономной системой (AS, Autonomous System) называется замкнутая сеть,
обслуживаемая одним сетевым администратором или группой администраторов
и использующая один протокол маршрутизации.
Подобное определение автономной системы выглядит недостаточно четко,
но это, в общем-то, несущественно. Важно другое — что OSPF позволяет
присваивать сетям номера AS. Одна очень большая сеть OSPF может быть
сегментирована на две и более автономные системы. Эти системы связываются через
маршрутизатор OSPF четвертого типа — граничный маршрутизатор
автономной системы ASBR (Autonomous System Border Router). ASBR обобщает всю
маршрутную информацию для своей автономной системы и пересылает
обобщенные данные парному ASBR в соседней автономной системе. В этом
отношении ASBR работают практически так же, как зонные граничные
маршрутизаторы. Разумеется, главное различие состоит в том, что граница проходит между
автономными системами, а не зонами, входящими в одну автономную систему
или сеть.
На рис. 16.5 продемонстрировано объединение автономных систем через
ASBR.
/ Граничный ! Граничный \
/ маршрутизатор ! маршрутизатор \
-—У автономной системы | автономной системы \ ^—^
> Автономная ) | > Автономная )
V, система 1 \ \ \. система 2 \
Рис. 16.5. Объединение автономных систем на базе OSPF
Обновление маршрутных данных
Одна из причин хорошей масштабируемости OSPF кроется в механизме
обновления маршрутных данных. Для распространения маршрутных данных между
узлами OSPF используются сообщения LSA. Данные распространяются
полностью внутри зоны, но не выходят за ее пределы.
Таким образом, каждому маршрутизатору известна топология той зоны, в
которой он находится, но за пределами зоны информация о ее топологии не
распространяется. Поскольку существуют четыре типа маршрутизаторов OSPF
(внутренние, граничные, ASBR и магистральные), становится ясно, что каждый
тип маршрутизатора связывает конечные точки разных типов, обменивающиеся
сообщениями LSA.
Внутренние маршрутизаторы
Внутренние маршрутизаторы обмениваются сообщениями LSA непосредственно
со всеми остальными маршрутизаторами зоны — как внутренними, так и
граничными, которые также входят в эту зону. На рис. 16.6 изображена
последовательность лавинной пересылки LSA в зоне 1 для сети OSPF, представленной
в предыдущих примерах главы. Важно заметить, что для обмена информацией
LSA маршрутизаторы OSPF не обязательно должны быть соединены напрямую.
Маршрутизатор OSPF напрямую адресует пакеты LSA каждому известному
маршрутизатору в этой области и пересылает их по любым доступным каналам.
Лавинная рассылка LSA осуществляется на базе групповой рассылки,
которая эффективнее широковещательной. Только процессы маршрутизации OSPF,
присоединившиеся к группе 224.0.0.5, получают сообщения LSA. Кроме того,
эффективность групповой рассылки OSPF повышается еще и тем, что сообщения
пересылаются непосредственно в дейтаграммах IP с кодом протокола 89. Протокол
OSPF не использует транспортные протоколы (такие, как TCP и UDP), и этим
он отличается от протокола RIP, использующего порт UDP с номером 520.
/Маршрутизатор! Маршрутизатор \
Маршрутизатор W- ► Маршрутизатор ; Маршрутизатор / Маршрутизатор
Маршрутизатор • Маршрутизатор
Рис. 16.6. Лавинная рассылка сообщений LSA внутри зоны 1
В схеме, показанной на рис. 16.6, идея заключается в том, что согласование
в ней происходит довольно быстро. Это объясняется двумя причинами.
Во-первых, маршрутизаторы OSPF напрямую адресуют и одновременно передают LSA
всем маршрутизаторам в этой зоне (лавинная рассылка). Этим они существенно
отличаются от согласования RIP, основанного на распространении данных
среди непосредственных соседей. В результате новая топология практически
одновременно распространяется в масштабах зоны.
Согласование также ускоряется определением и использованием зон.
Топологические данные не распространяются за границы зоны, поэтому в согласовании
участвуют не все маршрутизаторы автономной системы, а только
маршрутизаторы соответствующей зоны. Эта особенность ускоряет процесс согласования
и одновременно повышает устойчивость сети, поскольку нестабильность,
присущая процессу согласования, проявляется только среди части маршрутизаторов
автономной системы.
Граничные маршрутизаторы
Граничные маршрутизаторы хранят в своих базах данных топологическую
информации обо всех зонах, с которыми они связаны. Следовательно, если
граничный маршрутизатор связывает две зоны, он должен обмениваться
сообщениями LSA с конечными точками в обеих сетях. Как и в случае с внутренними
маршрутизаторами, данные LSA адресуются и передаются напрямую
одноранговым узлам в каждой зоне, как показано на рис. 16.7.
/ Маршрутизатору Зона О Т Маршрутизатор \\
Маршрутизатору «< ►Маршрутизатор | Маршрутизатор Ч—►Маршрутизатор
\ \ Зона 1 / ; Зона 2 \ \
Маршрутизатор • Маршрутизатор
Рис. 16.7. Межзонная лавинная рассылка LSA граничными маршрутизаторами в сети OSPF
Другая особенность, повышающая производительность OSPF, — обобщение
маршрутов. Топологическая информация о зоне не распространяется среди
маршрутизаторов, находящихся за ее пределами. Вместо этого граничный
маршрутизатор собирает сводную информацию обо всех адресах в зонах, к которым он
подключен. Затем эти обобщенные данные передаются в пакетах LSA
одноранговым маршрутизаторам в каждой зоне, к которой этот маршрутизатор
подключен. В OSPF используется несколько типов LSA, выполняющих разные
функции. Сообщения LSA, используемые для обмена обобщенными маршрутными
данными, называются LSA типа 3. Остальные типы LSA в OSPF будут описаны
в оставшейся части главы.
На рис. 16.7 граничный маршрутизатор передает обобщенные данные
напрямую всем маршрутизаторам в зоне 0. OSPF не позволяет зонам с номерами,
большими или равными 1, напрямую общаться друг с другом. Все такие
взаимодействия должны осуществляться через зону 0. Таким образом, граничный
маршрутизатор соединяет зону 0 минимум с одной зоной, номер которой отличен
от нуля.
Магистральные маршрутизаторы
Магистральные маршрутизаторы отвечают за поддержание топологической
информации, определяющей основу сети, а также за распространение обобщенной
топологической информации внутри всех остальных зон автономной системы.
Обмен сообщениями LSA между магистральными маршрутизаторами
изображен на рис. 16.8.
2 Маршрутизатор ! Маршрутизатор Маршрутизатор
Зона 1 | Зона 2 \ \
Маршрутизатор ■ Маршрутизатор
Рис. 16.8. Межзонная лавинная рассылка LSA магистральными маршрутизаторами в сети OSPF
Хотя различия между магистральными, граничными и внутренними
маршрутизаторами кажутся четкими и наглядными, возможность подключения к
другим маршрутизаторам через несколько портов ввода/вывода иногда создает
недоразумения. Теоретически все порты могут быть подключены к разным зонам,
и тогда маршрутизатор находится на границе разных зон, с которыми его
связывают интерфейсные порты.
Знакомство со структурами данных OSPF
OSPF — весьма сложный протокол маршрутизации, который обладает
многочисленными возможностями, повышающими его быстродействие и надежность.
Не приходится удивляться тому, что этот протокол использует множество
служебных структур данных. Каждая структура (или тип сообщения) предназначена
для выполнения определенной задачи. Во все структуры включается общий
заголовок, который называется заголовком OSPF. Заголовок OSPF состоит из
24 октетов и содержит следующие поля:
О Номер версии — в первом октете заголовка OSPF хранится номер версии
протокола.
О Тип — второй октет определяет, какой из пяти типов пакетов OSPF следует
после заголовочной структуры. Тип пакета OSPF (HELLO, описание базы
данных, запрос о состоянии канала, обновление состояния канала и
подтверждение состояния канала) задается числовым кодом.
О Длина пакета — в двух следующих октетах заголовка OSPF узлу,
получающему пакет, передается его общая длина. В общей длине учитывается как
заголовок, так и полезные данные пакета.
О Идентификатор маршрутизатора — каждому маршрутизатору в зоне
присваивается уникальный идентификатор, состоящий из четырех октетов.
Маршрутизатор OSPF сохраняет свой идентификатор в поле заголовка перед
отправкой сообщения OSPF другим маршрутизаторам.
О Идентификатор зоны — следующие четыре октета заголовка определяют
номер зоны.
О Контрольная сумма — каждый заголовок OSPF содержит поле контрольной
суммы, состоящее из двух октетов. Контрольная сумма используется для
выявления порчи данных во время пересылки. Отправитель обрабатывает каждое
сообщение по определенному математическому алгоритму и сохраняет
полученный результат в этом поле. Получатель выполняет те же действия с
полученным сообщением и сравнивает полученный результат с величиной,
хранящейся в поле контрольной суммы. Если сообщение не изменилось, два
результата совпадут. Расхождение означает, что пакет OSPF был поврежден
в процессе передачи. Поврежденные пакеты просто отвергаются получателем.
О Тип аутентификации — OSPF обеспечивает защиту от злонамеренных
действий, которые могут привести к распространению ложной маршрутной
информации, посредством проверки отправителя каждого сообщения OSPF.
Поле типа аутентификации состоит из двух октетов и определяет, какая из
различных форм аутентификации используется для данного сообщения.
О Аутентификация — последние девять октетов заголовка используются для
пересылки данных, необходимых получателю для аутентификации
отправителя сообщения. Протокол OSPF позволяет администратору сети определять
различные уровни аутентификации, от NONE и SIMPLE до мощного механизма
аутентификации MD5.
Заголовок содержит всю информацию, на основании которой узел OSPF может
определить, следует ли принять пакет для дальнейшей обработки или отвергнуть
его. Пакеты, поврежденные в процессе пересылки (и обнаруженные при
помощи контрольной суммы), а также не прошедшие аутентификацию, отвергаются.
В OSPF используются пакеты пяти типов, каждый из которых выполняет
в сети свою, узкоспециализированную функцию:
О пакеты HELLO (тип 1);
О пакеты описания базы данных (тип 2);
О пакеты запроса состояния канала (тип 3);
О пакеты обновления состояния канала (тип 4);
О пакеты подтверждения состояния канала (тип 5).
На типы пакетов иногда ссылаются по номерам, а не по именам (то есть под
пакетом OSPF типа 5 понимается пакет подтверждения состояния канала). Все
пять типов пакетов используют заголовок OSPF.
ПРИМЕЧАНИЕ
Пять базовых структур данных OSPF существуют в множестве вариантов, поэтому подробное
описание этих структур и размеров их полей выходит за рамки книги. Данная глава ограничивается
описанием области применения и правил использования каждой структуры данных.
Пакет HELLO
В OSPF входит протокол HELLO, предназначенный для установления и
поддержания отношений между соседними узлами. Такие отношения называются
отношениями смежности. Отношения смежности заложены в основу обмена
маршрутными данными в OSPF.
Именно этот протокол и пакеты этого типа позволяют узлам OSPF
обнаруживать другие узлы OSPF в этой зоне. Протокол HELLO использует
специальную структуру субпакета, присоединяемого к стандартному 24-октетному
заголовку OSPF. Комбинация этих структур образует пакет HELLO.
Все маршрутизаторы в сети OSPF должны соблюдать некоторые правила,
распространяющиеся на всю сеть. К числу этих правил относятся:
О маска сети;
О интервал рассылки пакетов HELLO {интервал HELLO)',
О период времени, по истечении которого неотвечающий маршрутизатор
объявляется недоступным другими маршрутизаторами сети {интервал
недоступности маршрутизатора).
Все маршрутизаторы в сети OSPF должны использовать одинаковые
значения для каждого из перечисленных параметров, в противном случае сеть может
работать неправильно. Обмен значениями параметров осуществляется при
помощи пакетов HELLO. В сочетании эти параметры образуют основу для
взаимодействия смежных узлов. Единство их значений гарантирует, что
отношения между соседями (отношения смежности) не будут формироваться между
маршрутизаторами разных сетей и что все узлы сети связываются друг с другом
с одинаковой частотой.
Пакет HELLO также включает список других маршрутизаторов (с
уникальными идентификаторами), с которыми недавно связывался
маршрутизатор-отправитель. Эта информация облегчает поиск соседей. Пакет HELLO содержит
еще несколько полей, в том числе отмеченный (designated) маршрутизатор,
резервный отмеченный маршрутизатор и т. д. Информация, хранящаяся в этих
полях, обеспечивает поддержание отношений смежности и функционирование
сети OSPF в периоды стабильной работы и согласования. Назначение полей
отмеченного маршрутизатора и резервного отмеченного маршрутизатора будет
описано ниже в настоящей главе.
Пакет описания базы данных
Во время инициализации отношений смежности два маршрутизатора OSPF
обмениваются пакетами описания базы данных (DD). Пакеты этого типа
используются для описания (но не для фактической передачи) содержимого базы
состояния каналов. Поскольку эта база данных может быть довольно большой,
для описания всего содержимого может потребоваться несколько пакетов. В
пакетах описания базы данных предусмотрено специальное иоле, определяющее
последовательность пакетов описания базы данных. Сохранение исходной
последовательности пакетов гарантирует точное воспроизведение переданного
описания базы данных на стороне получателя.
Процесс обмена DD также основан на схеме «опрос/ответ», в которой один
маршрутизатор назначается ведущим, а другой — подчиненным. Ведущий
маршрутизатор отправляет содержимое своей таблицы маршрутизации
подчиненному. Подчиненный обязан подтвердить получение пакетов DD. Разумеется,
роли ведущего и подчиненного меняются с каждым обменом DD. Любой
маршрутизатор сети в разные моменты времени выступает в роли как ведущего, так
и подчиненного.
Пакет запроса состояния канала
К третьему типу пакетов OSPF относятся пакеты запроса состояния канала.
Пакеты этого типа используются для запроса конкретных данных из базы данных
состояния каналов соседнего маршрутизатора. После получения обновления
маршрутизатор OSPF может обнаружить, что информация соседа является
более новой или более полной, чем его собственная. В этом случае маршрутизатор
посылает пакет (или пакеты) запроса состояния канала своему соседу,
располагающему более свежими данными, чтобы получить более достоверную
информацию топологической маршрутизации.
Запрос дополнительной информации должен быть предельно точным.
Запрашиваемые данные определяются в нем по следующим критериям:
О номер типа состояния капала (LS) от 1 до 5;
О идентификатор LS;
О маршрутизатор, передающий информацию.
Набор этих критериев определяет логическое подмножество базы данных
OSPF, но не его конкретный экземпляр (то есть постоянную совокупность
данных во временном интервале). Помните, что протокол OSPF является
динамическим протоколом маршрутизации и может автоматически обновлять данные
о топологии сети в соответствии с изменениями в состоянии каналов. Таким
образом, запрос LS считается относящимся к последней итерации маршрутной
базы данных.
Пакет обновления состояния канала
Пакеты обновления состояния канала используются для непосредственной
пересылки данных LSA соседним узлам. Обновления генерируются в ответ на
запросы LSA. Существуют пять типов пакетов LSA. Тип пакета определяется
числовым кодом в интервале от 1 до 5.
Типы пакетов и соответствующие им коды LSA перечислены ниже.
О Маршрутный пакет LSA (тип 1) — описывает состояние и стоимости
каналов, связывающих маршрутизатор с зоной. Все каналы должны описываться
одним пакетом LSA. Кроме того, маршрутизатор должен сгенерировать
маршрутный пакет LSA для каждой зоны, к которой он принадлежит.
Следовательно, граничный маршрутизатор должен сгенерировать несколько
маршрутных пакетов LSA, а внутреннему маршрутизатору достаточно одного
такого пакета.
О Сетевой пакет LSA (тип 2) — как и маршрутный пакет LSA, описывает
состояние каналов и стоимости всех маршрутизаторов, соединенных с сетью.
Различие между маршрутным и сетевым пакетами LSA заключается в том,
что сетевой пакет LSA содержит информацию о состоянии и стоимости всех
каналов сети. Только отмеченный маршрутизатор (designated router) сети
отслеживает эту информацию и генерирует сетевой пакет LSA.
О Сводный пакет LSA-IP (тип 3) — этот тип пакетов LSA может генерироваться
в сетях OSPF только граничными маршрутизаторами. Он используется для
распространения сводной маршрутной информации о зоне в смежных зонах
сети OSPF. Обычно считается более желательным обобщать информацию
о маршрутах по умолчанию, нежели распространять обобщенную
информацию OSPF в других сетях.
О Сводный пакет LSA-ASBR (тип 4) — близкий аналог пакета LSA типа 3.
Главное различие между двумя типами пакетов заключается в том, что тип 3
описывает межзонные маршруты, а тип 4 описывает маршруты, внешние по
отношению к сети OSPF.
О Пакет LSA AS-внешняя система (тип 5) — как следует из названия, эти
пакеты LSA используются для описания конечных точек, находящихся за
пределами сети OSPF — как отдельных хостов, так и внешних сетей. Узел OSPF,
выполняющий ASBR по отношению к внешней автономной системе,
отвечает за распространение внешних маршрутных данных среди всех зон OSPF,
к которым он принадлежит.
Перечисленные типы сообщений LSA используются для описания различных
аспектов домена маршрутизации OSPF. Они напрямую адресуются каждому
маршрутизатору в зоне OSPF и передаются одновременно. Механизм лавинной
рассылки гарантирует, что все маршрутизаторы в зоне OSPF будут располагать
одинаковой информацией о пяти разных аспектах своей сети (соответствующих
пяти типам LSA). Маршрутизатор хранит полный набор данных LSA в базе
данных состояния канала. В результате обработки содержимого этой базы
данных по алгоритму Дейкстры генерируется содержимое таблицы маршрутизации
OSPF. Различия между таблицей и базой данных заключаются в том, что база
данных содержит полный набор необработанных данных, а таблица
маршрутизации содержит список кратчайших путей к известным конечным точкам через
интерфейсные порты конкретного маршрутизатора.
Мы не будем подробно рассматривать структуру каждого типа пакетов LSA
и ограничимся их заголовками.
Заголовок LSA
Все пакеты LSA используют общий формат заголовка. Заголовок имеет длину
20 октетов и присоединяется к стандартному 24-октетному заголовку OSPF.
Заголовок LSA предназначен для однозначной идентификации каждого пакета
LSA, поэтому в нем хранится код типа LSA, идентификатор состояния канала
и идентификатор маршрутизатора, распространяющего информацию. Ниже
перечислены поля заголовка LSA.
О Возраст пакета LSA — в первых двух октетах заголовка хранится возраст LSA,
то есть количество секунд, прошедших с момента создания пакета.
О Параметры OSPF — следующий октет содержит набор флагов, описывающих
необязательные возможности, которые могут поддерживаться сетью OSPF.
О Тип LS — поле типа LS состоит из одного октета и определяет один из пяти
возможных типов, к которым может относиться пакет LSA. Пакеты разных
типов различаются по формату, поэтому важно знать, данные какого типа
следуют после заголовка.
О Идентификатор состояния капала — поле из четырех октетов,
определяющее конкретную часть сетевой среды, описываемую сообщением LSA. Поле
тесно связано с предыдущим полем заголовка (типом LS). Более того, его
содержимое напрямую зависит от типа LS. Например, в маршрутном LSA
в поле идентификатора состояния канала хранится идентификатор
распространителя — маршрутизатора OSPF, сгенерировавшего пакет.
О Распространитель — поле содержит идентификатор маршрутизатора OSPF,
сгенерировавшего пакет LSA. Поскольку длина идентификатора
маршрутизатора OSPF равна 4 октетам, размер поля также должен быть равен 4 октетам.
О Порядковый номер LS — маршрутизаторы OSPF постоянно увеличивают
порядковые номера сгенерированных ими пакетов LSA. Таким образом,
маршрутизатор, получивший два экземпляра одних и тех же данных LSA, может
выбрать более новый пакет одним из двух способов. Поле порядкового номера
имеет длину 4 октета; проверяя его, можно определить, какой из двух
пакетов был сгенерирован позже. Также можно проверить поле возраста пакета,
но теоретически возраст нового пакета LSA может быть больше возраста
старого пакета LSA, особенно в больших и сложных сетях. По этой причине
проверка основывается на порядковом номере LS; тот пакет, у которого этот
номер больше, был сгенерирован позже. Этот механизм избавлен от
превратностей динамической маршрутизации и потому обеспечивает более надежное
средство определения новизны пакетов LSA.
О Контрольная сумма — поле контрольной суммы, состоящее из трех октетов,
предназначено для обнаружения возможных повреждений пакетов LSA в
процессе пересылки. Вычисление контрольной суммы производится по простому
математическому алгоритму. Результат зависит только от исходных
данных, поэтому такой механизм проверки отличается высокой надежностью.
Передавая алгоритму одни и те же входные данные, вы всегда получите один
и тот же результат. Величина, хранящаяся в поле контрольной суммы,
вычисляется на основании части содержимого пакета LSA (включая заголовок,
кроме полей возраста и контрольной суммы). Узел-отправитель выполняет
вычисления по специальному алгоритму, называемому алгоритмом Флетчера,
и сохраняет результат в поле контрольной суммы. Узел-получатель
выполняет те же математические действия и сравнивает результат с содержимым
поля контрольной суммы. Если значения различаются, можно достаточно
уверенно утверждать, что в процессе пересылки пакет был поврежден. В этом
случае генерируется запрос на повторную пересылку.
В оставшейся части пакета LSA содержится список записей LSA. Каждая
запись описывает один из пяти аспектов сети OSPF (в соответствии с числовым
кодом). Таким образом, маршрутный пакет LSA распространяет информацию
о маршрутизаторах этой зоны, о которых ему известно.
Выполнение обновлений LSA
OSPF существенно отличается от других протоколов маршрутизации тем, что
его обновления не используются узлами-получателями напрямую. Обновление,
полученное от другого маршрутизатора, содержит информацию о сети в
представлении этого маршрутизатора. Прежде чем интерпретировать или
использовать эти данные, маршрутизатор должен обработать полученные данные LSA
по алгоритму Дейкстры и преобразовать их к своему представлению.
Предполагается, что данные LSA были переданы из-за того, что
маршрутизатор обнаружил изменения в состоянии канала или каналов. Следовательно,
после получения LSA любого типа маршрутизатор OSPF должен сравнить
содержимое LSA с соответствующей частью своей маршрутной базы данных. Это
молено сделать лишь после того, как маршрутизатор использует новые данные
для формирования нового представления сети по алгоритму SPF. Результат
обработки представляет собой новое сетевое представление данного
маршрутизатора. Полученные данные сравниваются с существующей маршрутной базой
данных OSPF, и маршрутизатор проверяет, повлияло ли изменение состояния
сети на какие-либо из его маршрутов.
Если изменение состояния сети привело к изменению каких-либо
существующих маршрутов, маршрутизатор строит новую маршрутную базу данных на
основе новой информации.
Дублирование LSA
Из-за лавинной рассылки данных LSA в зонах возникает вероятность того, что
одни данные LSA будут существовать в нескольких экземплярах. Следовательно,
для надежной работы сети OSPF маршрутизатор должен уметь выбирать самый
последний экземпляр дублированных данных LSA. Маршрутизатор, получивший
два и более экземпляра с одинаковым типом LSA, анализирует поля возраста,
порядкового номера и контрольной суммы в заголовках LSA. Маршрутизатор
принимает только информацию, содержащуюся в самом новом пакете, и
обрабатывает ее так, как описано в предыдущем разделе.
Пакет подтверждения состояния канала
К пятому типу пакетов OSPF относятся пакеты состояния канала. В OSPF
реализовано надежное распространение пакетов LSA. Под этим термином понимается
то, что получение пакета должно быть подтверждено получателем. В противном
случае отправитель не может быть уверен в том, что данные LSA добрались до
предполагаемого адресата. Следовательно, протоколу OSPF необходим механизм
подтверждения получения пакетов LSA, и этот механизм использует пакеты
подтверждения состояния канала.
Пакет подтверждения состояния канала однозначно идентифицирует
пакет LSA, получение которого он подтверждает. Идентификация производится
на основе данных, содержащихся в заголовке LSA, включая порядковый номер
LS и маршрутизатор, распространяющий информацию. Между пакетами LSA
и подтверждениями не обязательно должно существовать однозначное соот-
ветствие; один пакет подтверждения может подтверждать получение сразу
нескольких пакетов LSA.
Построение маршрутов
Несмотря на свою относительную сложность, протокол OSPF вычисляет
стоимость маршрута одним из двух простых способов:
О для каждого интерфейса OSPF может использоваться значение по
умолчанию, независимо от пропускной способности канала;
О OSPF может автоматически вычислять стоимость использования отдельных
интерфейсов маршрутизации.
Независимо от выбора способа стоимость любого конкретного маршрута
вычисляется суммированием стоимости всех интерфейсов, входящих в этот
маршрут. Вычисленная стоимость маршрутов к известным конечным точкам
хранится в дереве кратчайших путей OSPF.
Автоматическое вычисление
Протокол OSPF умеет автоматически вычислять стоимость интерфейса.
Алгоритм вычисления основан на различной пропускной способности,
поддерживаемой разными типами интерфейсов. Сумма вычисленных стоимостей всех
интерфейсов по заданному маршруту образует основу для принятия решений
маршрутизации в OSPF. Благодаря этим данным OSPF может строить
маршруты, руководствуясь как минимум пропускной способностью каждого канала
в альтернативных маршрутах. На рис. 16.9 изображена простая сеть, на примере
которой будет поясняться процесс автоматического вычисления.
На рис. 16.9 стоимость маршрута между хостом в сети 193.1.3.0 и конечной
системой в сети 193.1.4.0 равна 138. Она складывается из стоимости двух каналов Т1,
связывающих эти сети (каждому каналу присвоена стоимость 64), и стоимости
интерфейса Ethernet к сети 193.1.4.0. Стоимость интерфейсов Ethernet в точках
отправки и получения не включается в расчет стоимости OSPF, потому что
OSPF учитывает только стоимости интерфейсов внешних маршрутизаторов.
В табл. 16.1 приведена сводка значений, используемых при автоматическом
вычислении стоимости интерфейсов сети, представленной на рис. 16.9.
Таблица 16.1. Зависимость стоимости от типа интерфейса
Тип интерфейса Вычисляемая стоимость
FDDI 100 Мбит/с 1
Ethernet 10 Мбит/с 10
Последовательный канал Т1 1,544 Мбит/с 64
Последовательный канал 56 кбит/с 1 768
193 .V\.0 Стоимость = 1 193.1^0
Т1 Маршрутизатор 1 '\ Зона 0 Маршрутизатор 2 \ к итс
Стоимость =/ Т1 Т1 \ Стоимость =
/ Стоимость = 64 | Стоимость = 64 \
Маршрутизатор 3 Маршрутизатор 4 « Маршрутизатор 5 Маршрутизатор 6
| Стоимость-10
I ! I Зона 2 II
193.1.3.0 193.1.4.0 | 193.1.5.0 193.1.6.0
Рис. 16.9. Автоматическое вычисление стоимости каналов
Использование стоимости маршрутов
по умолчанию
Автоматическое вычисление стоимости маршрутов в OSPF весьма удобно, но
такая возможность существует не всегда. Например, старые маршрутизаторы могут
не поддерживать механизм автоматического вычисления. В таких случаях всем
интерфейсам присваивается одинаковая стоимость OSPF, и канал Т1 не будет
отличаться по стоимости от выделенной линии 56 кбит/с. Естественно, эти две
линии сильно различаются по быстродействию. Это различие должно быть
заложено в основу для принятия обоснованных решений по маршрутизации.
Тем не менее в некоторых ситуациях использование стоимости по умолчанию
оказывается приемлемо. Например, если сеть состоит из относительно однородных
каналов передачи данных, значения по умолчанию дают адекватное представление
об относительной стоимости пересылки. Кроме того, стоимостные метрики
конкретных интерфейсов могут настраиваться вручную. Это позволяет вам
организовать распределение трафика в критических участках сети OSPF по своему
усмотрению, сохранив стоимостные метрики по умолчанию во всех остальных случаях.
Однородные сети
В однородных сетях все каналы передачи обладают одинаковыми
характеристиками. Например, все подключения к локальной сети осуществляются через ин-
терфейсы Ethernet 10 Мбит/с, а последовательные интерфейсы глобальной сети
относятся к типу Т1. В таких ситуациях использование стоимости по
умолчанию не вызывает проблем с маршрутизацией, особенно при минимальном
количестве альтернативных маршрутов.
Рисунок 16.10 наглядно иллюстрирует это утверждение.
Т1 /^Маршрутизатор \ I Маршрутизатор \Т1
Стоимость = / Т1 Т1 \Стоимость =
1768 / Стоимость = 1768 Зона 0 Стоимость == 1768 \ 1768
Маршрутизатор Маршрутизатор • Маршрутизатор Маршрутизатор
Зона 1 ; Зона 2
Стоимость = 1768 Стоимость = 1768 •
Рис. 16.10. Возможный вариант использования стоимостных метрик по умолчанию
Каждому интерфейсу, изображенному на рис. 16.10, присваивается стоимость
по умолчанию 1768. Все значения равны, поэтому вы можете использовать
любую числовую величину по своему усмотрению — 1, 128, 1768 или 1 000 000.
Решения по маршрутизации в однородных сетях сводятся к простому подсчету
и сравнению количества переходов (хотя и кратного стоимости по умолчанию).
Это правило выполняется независимо от количества альтернативных
маршрутов в сети.
Разумеется, в сложной сети со значительным количеством альтернативных
маршрутов и разнообразием используемых технологий передачи данных
значения по умолчанию не позволят выбрать оптимальный маршрут к любой
заданной конечной точке.
Ручная настройка значений
В некоторых сетях бывает удобнее принять стоимости по умолчанию, а затем
вручную настроить значения для тех каналов, у которых наблюдаются наиболее
серьезные отличия. Предположим, по умолчанию каналам вашей сети присваи-
вается стоимость 1768 — значение, вычисленное для последовательного канала
56 кбит/с.
Если все каналы сети, кроме одного или двух, обладают одинаковой
пропускной способностью, вы можете принять значения по умолчанию и
отредактировать стоимость этих конкретных каналов.
С точки зрения узлов OSPF неважно, как именно была получена стоимость
маршрута —вычислена автоматически, получена по умолчанию или настроена
вручную. Узел принимает любое значение и использует его при построении
представления сети в виде дерева кратчайших путей.
Дерево кратчайших путей
Различные механизмы LSA в конечном счете предназначены для того, чтобы
каждый маршрутизатор мог построить собственное представление топологии
сети, оформленное в виде дерева. Корнем этого дерева является маршрутизатор
OSPF. Дерево содержит полные пути ко всем известным адресам получателей
(как сетей, так и хостов), даже несмотря на то, что для непосредственной
маршрутизации дейтаграмм используется только следующий переход. Причина
проста: отслеживание полных путей позволяет сравнить альтернативные пути
и выбрать лучший из них для каждой конечной точки. Если существует
несколько путей с равной стоимостью, все они будут обнаружены протоколом
OSPF и использованы для распределения нагрузки. Динамическое
распределение трафика по всем доступным каналам повышает общую пропускную
способность канала.
Дерево кратчайших путей для маршрутизатора 3
Принципы построения дерева кратчайших путей лучше пояснить на
конкретном примере. На рис. 16.11 изображена небольшая сеть OSPF.
Администратор разрешил автоматическое вычисление стоимости маршрутов. Обратите
внимание: канал Ethernet, проходящий между маршрутизаторами 5 и 6, создает
альтернативный маршрут для сетей 193.1.5.0 и 193.1.6.0. Ему присваивается
автоматически вычисленная стоимость 10, тогда как остальным сетям Ethernet
в этом примере аналогичная стоимость не присваивается.
Вид дерева кратчайших путей для сети, представленной на рис. 16.10,
зависит от маршрутизатора. Например, на рис. 16.12 представлено дерево
кратчайших путей для маршрутизатора 3.
Как видно из рис. 16.12, древовидная структура заметно упрощает
вычисление стоимости маршрута к любой конечной точке. Корневой
маршрутизатор (в данном примере это маршрутизатор 3 с адресом 193.1.3.0) может быстро
просуммировать стоимости всех интерфейсов, входящих в маршрут к заданной
точке. Данные о стоимости маршрутизации для разных сетей с точки зрения
маршрутизатора 3 приведены в табл. 16.2. Для конечных точек, находящихся
на расстоянии более одного перехода, в круглых скобках приводится формула
вычисления стоимости маршрута. Это поможет вам проанализировать
различные варианты путей в сети, изображенной на рис. 16.12.
Стоимость = 1
193.1.1.0 & Ч 193.1.2.0
Т1 .Маршрутизатор l'\ зона 0 Маршрутизатор 2 \ 56 кбит/с
64 / Стоимость = 64 Стоимость = 64 \ 1768
Маршрутизатор 3 Маршрутизатор 4 | Маршрутизатор 5 Маршрутизатор 6
| Стоимость-10
! Зона 2 II
193.1.3.0 193.1.4.0 | 193.1.5.0 193.1.6.0
Рис. 16.11. Возможный вариант использования стоимостных метрик по умолчанию
Корневой узел:
маршрутизатор 3
Стоимость = 64
193.1.1.0
Стоимость = 1 / \ Стоимость = 64
193.1.2.0 193.1.4.0
Стоимость = 64 / \ Стоимость = 1768
193.1.5.0 193.1.6.0
Стоимость = 10
Рис. 16.12. Дерево кратчайших путей для маршрутизатора 3
Таблица 16.2. Маршруты от узла 3 к известным сетям
Сеть Длина маршрута в переходах Суммарная стоимость
193.1.3.0 - 0
193.1.1.0 1 64
193.1.2.0 2 65 F4+1)
193.1.4.0 2 128F4+64)
193.1.5.0 3 129 F4+1+64)
193.1.6.0 3 1833 F4+1+1768)
193.1.6.0 4 139F4+1+64+10)
В этом примере существует два возможных маршрута к сети 193.1.60. Один
маршрут содержит меньше переходов, но обладает более высокой стоимостью
из-за медленного канала между маршрутизаторами 2 и 6. Альтернативный
маршрут содержит больше переходов, но с гораздо меньшей суммарной стоимостью.
В этой ситуации OSPF игнорирует маршрут с высокой стоимостью и
использует только маршрут с меньшей стоимостью, несмотря на большее количество
переходов. Если два маршрута имеют одинаковую стоимость, OSPF хранит их
в разных записях таблицы маршрутизации и старается как можно более
равномерно распределять трафик между ними.
Дерево кратчайших путей для маршрутизатора 2
Каждый маршрутизатор использует свое, отличное от других представление сети.
Изучать все представления было бы несколько однообразно, однако один
дополнительный пример лучше продемонстрирует зависимость структуры дерева
кратчайших путей от представления конкретного маршрутизатора. На рис. 16.13
изображено дерево кратчайших путей для маршрутизатора 2.
Корневой узел:
маршрутизатор 2
Стоимость = 1 / \ Стоимость = 1768
/ Стоимость = 64
193.1.1.0 193.1.6.0
Стоимость = 64/ \ 193.1.5.0 Стоимость =10
/ Стоимость = 64\
193.1.3.0 193.1.4.0
Рис. 16.13. Дерево кратчайших путей для маршрутизатора 3
В табл. 16.3 приведена сводка стоимости маршрутов ко всем известным
конечным точкам в представлении маршрутизатора 2.
Таблица 16.3. Маршруты от узла 2 к известным сетям
Сеть Длина маршрута в переходах Суммарная стоимость
193.1.2.0 — 0
193.1.5.0 1 64
193.1.6.0 1 1 768
193.1.6.0 2 74 F4+10)
193.1.1.0 1 1
193.1.3.0 2 65F4+1)
193.1.4.0 2 65 F4+1)
Сравнение табл. 16.2 и 16.3 показывает, что суммарные расстояния между
отправителем и получателем в сети изменяются в зависимости от начальной
точки. Дерево полностью зависит от перспективы, поэтому для построения
собственной перспективы сети маршрутизаторы OSPF используют данные,
полученные от других маршрутизаторов через LSA, вместо того чтобы напрямую
обновлять свои маршрутные таблицы этой информацией.
Итоги
OSPF — один из самых мощных и функциональных открытых стандартов
протоколов маршрутизации. Сложность протокола также является одной из его
слабых сторон, поскольку проектирование, построение и управление объединенной
сети OSPF требует больше опыта и усилий, чем при использовании любых других
протоколов маршрутизации. Назначение стоимости по умолчанию существенно
упрощает проектирование сети OSPF. По мере освоения OSPF и появления новой
информации о рабочих характеристиках сети вы сможете постепенно настроить
производительность сети посредством модификации переменных OSPF.
Проектирование зон и общей топологии сети требует тщательного
планирования. Правильно спроектированная сеть OSPF вознаградит ваши усилия
хорошей скоростью работы и быстрым согласованием.
4| "J Протокол IPP
Тим Паркер (Tim Parker)
Протокол печати в объединенной сети IPP (Internet Printing Protocol)
принадлежит к числу новых разработок в семействе протоколов TCP/IP. Он
проектировался для упрощения процедуры печати в больших объединенных сетях
с использованием IP-адресов. Такие компании, как Hewlett-Packard, уже
выпускают устройства с поддержкой стандарта IPP, который пока существует на
уровне предложения. Предполагается, что по мере продвижения IPP до уровня
принятого стандарта количество таких устройств возрастет.
В этой главе объясняется, что представляет собой протокол IPP и как он
работает. Хотя этот протокол вряд ли понадобится тем пользователям, у которых
принтер подключен непосредственно к компьютеру, знакомство с IPP поможет
лучше понять принципы организации печати в объединенных сетях.
История IPP
IPP — последнее название целой серии конкурентных разработок. История IPP
начинается в 1996 году, когда компания Novell (разработчик NetWare) обратилась
к ведущим производителям принтеров с предложением о разработке нового
протокола печати, который бы работал по Интернету и поддерживал IP. Некоторые
компании (в том числе Xerox) присоединились к Novell. Совместными усилиями
они создали проект и план разработки. Проект, находившийся под руководством
Novell, получил название LDPA (Lightweight Document Printing Application).
Тем временем в IBM разрабатывайся аналогичный протокол НТРР (Hypertext
Printing Protocol). Название было выбрано не случайно — протокол работал
в Web по аналогии с HTTP. Аналогичные проекты также вели Hewlett-Packard
и фирма Microsoft, которая разрабатывала новый протокол печати для
операционной системы Windows 2000. Для координации конкурирующих проектов
и ведении разработок под эгидой IETF — организации, контролирующей все
протоколы Интернета — была создана рабочая группа PWG (Printer Working
Group). Группа состояла из нескольких компаний, производителей принтеров
и разработчиков операционных систем. В результате объединения лучших
аспектов LDPA и HTTP был разработан протокол IPP.
Основной целью PWG являлось формирование единого стандарта печати,
который бы не ограничивался IP и работал с другими протоколами. Тем не
менее основное внимание уделялось поддержке печати в Интернете на базе IP.
Вместо разработки принципиально нового протокола, работающего поверх IPP,
используется протокол НТРР, который работает в сочетании со следующей
версией HTTP, называемой HTTP 1.1. Такой подход упрощает реализацию для
фирм-производителей, поскольку большинство из них очень хорошо знакомо
с HTTP. IPP использует новый тип расширений MIME «application/ipp».
Группа PWG планирует включить в спецификацию IPP ряд дополнительных
возможностей, в том числе:
О проверка возможностей принтера, поддерживающего IPP;
О отправка заданий печати на принтер IPP;
О получение информации о состоянии задания печати;
О отмена заданий, находящихся в очереди на печать.
Эти четыре возможности, ориентированные на конечного пользователя,
включают практически все операции, выполняемые при печати, от получения
информации о доступных принтерах до управления и отмены запросов на печать по
Интернету, локальной или глобальной сети. Кроме того, протокол позволяет
быстро найти доступные принтеры в сети или межсетевом объединении,
обеспечивает безопасность запросов на печать и самих принтеров.
В идеальном варианте IPP реализуется как протокол, работающий на стороне
клиента. Серверная сторона может быть реализована разными способами —
например, в виде выделенного сервера печати или принтера, подключенного через IP.
Тем не менее это не должно привести к изменению спулеров печати и систем,
используемых в настоящее время, — таких, как Ipr и Ipd в системе Unix или
подсистемы печати в Windows. Протокол IPP дополняет существующие
возможности, но не заменяет их.
В долгосрочной перспективе в протоколе IPP должны появиться средства
управления принтером, поддержка сбора учетной информации и даже
возможность проведения коммерческих транзакций.
Другой целью, поставленной разработке IPP, была возможность
преобразования протокола LPR (Line Printer) в IPP, и наоборот. Впрочем, клиенты LPR
не получат доступа к новым возможностям IPP, а требования к преобразованию
расширений LPR в IPP ограничиваются возможностями, доступными в
реализации LPR для BSD Unix 4.2.
ПРИМЕЧАНИЕ
Дополнительную информацию о IPP можно найти в нескольких документах RFC, присутствующих
в любом архиве RFC. Список таких RFC приведен в приложении А. Кроме того, группа PWG ведет
web-сайт с общей информацией о IPP и данными о текущем состоянии проекта. Сайт находится по
адресу http://www.ietf.org/html.charters/ipp-charter.html.
Протокол IPP с точки зрения пользователя
Широкое применение IPP открывает перед пользователями принципиально
новый уровень возможностей, связанных с печатью. В документе RFC,
посвященном IPP, новые возможности разбиты на шесть категорий:
О поиск принтера;
О создание локального экземпляра принтера;
О получение информации о состоянии и возможностях принтера;
О отправка задания на печать;
О получение информации о состоянии печати;
О модификация заданий печати.
IPP позволит вывести список доступных принтеров в браузере или другом
приложении, способном находить IPP-совместимые принтеры. Протокол
проектируется так, чтобы поиск можно было производить разными способами, в том
числе по имени, по географическому местонахождению или атрибутам принтера.
Возможность поиска по атрибутам пригодится в крупных организациях.
Предположим, вы хотите напечатать страницы размера 11x17 дюймов; IPP поможет
найти принтер, который обладает такой возможностью. Кроме того, вы можете
искать принтеры с поддержкой цветной печати, с лотками для бумаги
определенного размера, с поддержкой брошюровки и любыми другими поддерживаемыми
атрибутами. А при некотором уточнении условий поиска можно проводить
поиск по дополнительным критериям — скажем, по максимальному удалению от
вашего офиса или принадлежности к определенному домену (даже в масштабах
страны или континента). Такие возможности поиска не входят в спецификацию
IPP, но неизбежно появятся в результате эволюции.
Итак, вы нашли принтер, которому будет передан запрос на печать. Далее
необходимо сообщить локальному компьютеру информацию о принтере и о том,
как к нему обращаться. Эта операция называется созданием локального
экземпляра принтера. Конкретная последовательность действий зависит от
операционной системы, но в результате выбранный принтер включается в список
доступных принтеров вашего компьютера.
Иногда при создании локального экземпляра требуется загрузить драйверы
для принтера. В настоящее время такая необходимость существует при сетевой
печати в Windows 95/98/ME. В некоторых операционных системах (таких, как
Unix, Linux и Windows NT/2000) процесс создания локального экземпляра
обладает большей гибкостью. Например, вы можете разместить очередь печати на
другом компьютере или выбрать конфигурацию с локальным хранением
драйверов и очереди. Протокол IP обладает достаточной гибкостью, чтобы
удовлетворять всем этим требованиям при создании экземпляра принтера.
После создания локального экземпляра все выглядит так, словно принтер
подключен непосредственно к компьютеру. Например, в системе Windows принтер
(независимо от того, где он на самом деле находится) отображается в
приложении Принтеры (Printers) панели управления, присутствует во всех диалоговых
окнах и всех остальных приложениях, получающих информацию о доступных
принтерах. Удаленный принтер используется точно так же, как если бы он был
подключен к компьютеру через параллельный порт.
Перед тем как использовать принтер с поддержкой IPP, желательно
проверить его конфигурацию и определить, занят ли принтер в настоящий момент,
какая бумага в нем загружена, сколько памяти на нем установлено,
поддерживается ли конкретный язык описания страниц (например, PostScript и PCL), и по-
лучить другую информацию о состоянии. Протокол IPP предоставляет средства,
при помощи которых пользователь может получить информацию о состоянии
и возможностях принтера. В частности, пользователь может узнать, включен ли
принтер в настоящий момент, получить его параметры по умолчанию и т. д.
Спецификация IPP не регламентирует конкретные способы отображения
информации на экране и выполнения операций с принтерами на уровне
приложения. Вместо этого IPP регламентирует механизм передачи сообщений и тип
передаваемой информации. Тем не менее при правильной работе клиентского
приложения пользователь должен иметь возможность получить информацию
о текущем состоянии доступного принтера, находящегося в любой точке мира,
а также о состоянии очереди печати.
После создания локального экземпляра принтера можно переходить к
отправке запросов на печать. Главное преимущество протокола IPP заключается
в том, что он позволяет печатать на любом принтере, для которого имеется
локальный экземпляр, так, как если бы он был физически подключен к
компьютеру. Например, приложения Windows отображают принтеры с поддержкой IPP
в диалоговых окнах печати — как локальные, так и удаленные. Некоторые аспекты
печати на удаленном принтере реализуются на других уровнях; например, выбор
интерпретатора языка описания страниц обычно автоматически выполняется
принтером, а за выбор драйвера обычно отвечает операционная система.
После постановки задания печати в очередь IPP позволяет запросить у
принтера или сервера печати информацию о текущем состоянии очереди, а также
удалить задания из очереди.
Реализация IPP от HP
Фирма Hewlett-Packard уже предоставила своим клиентам доступ к IPP при
помощи программного продукта Internet Printer Connection. Программа Internet
Printer Connection предназначена для настройки и печати на принтерах HP
(и других принтерах с поддержкой IPP) по Интернету или интрасети
(локальной или глобальной). В этой программе протокол IPP реализован как
транспорт для данных, выводимых на печать, и информации о состоянии принтера.
Internet Printer Connection устанавливается как обновление существующего
программного обеспечения, что упрощает ее интеграцию с существующими сетями.
Для работы с ней необходим компьютер с системой Windows NT (управляющий
хост) и сервер печати HP JetDirect с поддержкой IPP. Пользователям также
потребуется браузер. Не все серверы печати JetDirect работают с Internet Printer
Connection; подходят только микропрограммы версий Х.07.16 и выше. К счастью,
обновления микропрограмм для сервера печати JetDirect имеются на web-сайте
HP. Процесс установки Internet Printer Connection прост: запустите принятый
файл и выполните настройку принтеров, доступ к которым будет
предоставляться через Internet Printer Connection.
После установки Internet Printer Connection позволяет любому
пользователю, обладающему необходимыми привилегиями, печатать на любом принтере
с поддержкой IPP. Для этого пользователь должен указать IP-адрес принтера,
имя хоста (если поддерживается разрешение имен через DNS) или URL
принтера. Прелесть Internet Printer Connection заключается в том, что при наличии
необходимых привилегий вы можете работать с принтером, расположенным в
любой точке мира. Например, находясь в гостиничном номере в Германии, можно
отправить запрос на печать на принтере, находящемся в вашем офисе в Сан-
Франциско. Маршрутизация заданий печати с использованием IPP
осуществляется средствами Интернета. С точки зрения пользователя удаленный принтер
ничем не отличается от любого другого принтера, подключенного к компьютеру
или сети.
Итоги
Протокол IPP еще не получил широкого распространения в Интернете. Тем не
менее достигнутые результаты и появление таких реализаций, как Internet Printer
Connection (Hewlett-Packard), внушают надежды на будущее. Ожидается, что
протокол IPP войдет в состав стандартных служб TCP/IP и значительно
упростит удаленную печать в сетях TCP/IP.
ft Протоколы
АО удаленного доступа
Марк Кадрич (Mark Kadrich)
С ростом Интернета возрастает и потребность в подключении к нему из любого
места. Такой тип доступа называется удаленным. Когда-то удаленный доступ
осуществлялся с терминалов, подключенных к большой ЭВМ или
мини-компьютеру. Такое решение оставалось приемлемым лишь до тех пор, пока доступ
производился из определенного помещения — например, из офиса. С сокращением
численности технического персонала стало очень важно, чтобы системный
администратор мог подключиться к корпоративной сети из дома. Так появился
удаленный доступ. Сначала он осуществлялся по медленным модемам того
времени, обычно со скоростью 110 бод (скорость в бодах достаточно близка к
скорости в битах в секунду, поэтому в контексте излагаемого материала эти две
единицы будут считаться эквивалентными). Системные администраторы
следили за работой сети и управляли ей из относительно комфортных домашних
условий. Для организаций это означало, что важнейшие системы фактически
круглосуточно обслуживались людьми, которые могли принять экстренные меры
в аварийной ситуации (естественно, при условии, что терминалы продолжали
нормально работать!)
В результате технического прогресса конца 70-х и начала 80-х годов
скорость модемов за каждые два года возрастала примерно в два раза.
Современные модемы обычно работают на скорости 56 кбит/с, а их фактическая
пропускная способность определяется архаичной инфраструктурой коммутируемой
телефонной сети. Старая инфраструктура в сочетании с повышением
требований к надежности и безопасности данных потребовала разработки протоколов,
которые бы обеспечивали эффективный прием и передачу цифровых данных.
Удаленное подключение
Как уже сказано выше, главным компонентом механизмов удаленного доступа
является модем (МОдулятор/ДЕМодулятор). Существует много типов
устройств, причисляемых к этой категории. Основная функция модема —
преобразование цифровых сигналов, сгенерированных компьютером, к аналоговой
форме, которая может передаваться по коммутируемой телефонной сети. Чтобы
этот механизм пересылки данных работал правильно, на обоих концах
соединения должны быть установлены совместимые модемы (рис. 18.1). На стороне
получателя аналоговые сигналы демодулируются в цифровую форму и передаются
компьютеру.
ъ. Телефонная j
Удаленный ^С ^ Сервер
[ragnl Модему^ Телефонная Телефонная\м0дем [%Щ
—ЗВВИЙДГ... — У......].,.,1„1
И У«*"Щ • ' fciafadK-i
"' w1 Последовательный Последовательный рДр|
канал канал /""l:"fi':V'i'k
Рис. 18.1. Модемы в коммутируемой сети
ISDN
Не все устройства, относящиеся к категории модемов, совместимы друг с
другом. Стандартный модем может использоваться только для связи по каналам
ISDN, a NT-1 не позволяет соединиться ни по каким линиям, кроме ISDN. С
другой стороны, технология ISDN обладает рядом существенных преимуществ.
Интерфейс BRI (Basic Rate Interface) позволяет подписчику использовать
аналоговый телефон наряду с чисто цифровой передачей данных. В США BRI состоит
из двух каналов 64 кбит/с и одного канала 16 кбит/с, мультиплексируемых с
временным разделением каналов до суммарной скорости 144 кбит/с.
Универсальность ISDN обусловлена тем фактом, что в любой момент
времени все три канала могут использоваться по отдельности или два канала 64 кбит/с
могут использоваться вместе для обеспечения суммарной пропускной
способности 128 кбит/с. В числе преимуществ ISDN следует упомянуть возможность
использования двухпроводного телефонного кабеля, имеющегося в большинстве
организаций и домов (рис. 18.2). Данный фактор сыграл важную роль как для
бизнеса, так и для телефонных компаний, которые должны были поддерживать
ISDN, поскольку дорогостоящая замена существующей телефонной сети
становилась излишней. Хотя это решение как нельзя лучше подходило с позиций
продления срока эксплуатации существующей телефонной сети, в результате
бурного развития Интернета к сети стали подключаться миллионы новых
пользователей. Дни ISDN были сочтены.
Кабельные модемы
Кабельные модемы начали использоваться несколько лет назад (рис. 18.3). В их
работе используется тот факт, что в домах многих пользователей уже имеется
широкополосный канал передачи данных в виде кабельного телевидения.
Канал В f¥^\ \
Канал D W_J ISDN BRI
Канал В ^ J ) I
Телефон
Мультиплексор |
*,-г - Линия ISDN BRI
NT-1
1ЯИ Ш '
Компьютер
Рис. 18.2. Конфигурация BRI в ISDN
Телевизор
П
Кабельный
модем
I 1 I гп Кабельное телевидение
ЯН ' ] 1 Разветвитель
^а= i ' ' ^ Компьютер
Рис. 18.3. Кабельный модем
За счет использования свободной части полосы пропускания, а также
применения нетривиальной модуляции кабельные модемы обеспечивают скорость
передачи данных около 1 Мбит/с, весьма впечатляющую для домашних условий.
Недавние разработки в области программного обеспечения и операционных
систем позволяют нескольким компьютерам использовать общую точку доступа.
Кабельный модем подключает компьютер к кабельной линии по тому же
принципу, как в архитектуре Ethernet компьютеры подключаются к коаксиаль-
ному кабелю. Все данные передаются по одной шине. Это означает, что соседи
теоретически могут получить доступ к вашему компьютеру, для
предотвращения которого необходимо принять особые меры. Один из вариантов основан на
преобразовании сетевых адресов NA T (Network Address Translation).
Методика NAT, описанная в RFC 1918, «Address Allocation Techniques for
Private Networks», позволяет обеспечить доступ к Интернету и безопасность
для каждого компьютера домашней сети.
DSL
Относительно новая технология DSL (Digital Subscriber Loop) существует в
нескольких интересных вариантах. Уровень сервиса напрямую зависит от цены, то
есть более высокая цена обеспечивает повышение пропускной способности.
Самая популярная разновидность DSL — ADSL (Asymmetric DSL) —
использует тот факт, что типичный пользователь принимает больше информации, чем
отправляет. Так, во время работы в Web большинство пользователей принимает
большой объем графики и кода HTML, тогда как отправка данных
ограничивается простыми ответами на запросы Web. Щелкая на кнопке, находящейся на
web-странице, вы передаете серверу простое сообщение с требованием
выполнить некоторую операцию — например, вернуть графическое изображение или
текст. При работе с электронной почтой картина меняется, но даже с учетом
электронной почты общий объем принимаемых данных обычно на порядок
превышает объем отправляемых данных.
Технология DSL разрабатывалась для решения ряда специфических проблем,
обусловленных бурным развитием Интернета, и прежде всего — проблем
пропускной способности. Существующая телефонная сеть строилась на предположении,
что большинство разговоров продолжается около 10 минут, при этом в доме
проведено в среднем две телефонные линии. С учетом этого технические
мощности АТС определялись с учетом средней ожидаемой загрузки. Иначе говоря,
если в любой момент времени только 10 процентов абонентов использует
телефон, количество коммутаторов на стендах АТС рассчитывается на поддержку
этого числа абонентов.
ПРИМЕЧАНИЕ
Технология DSL не лишена недостатков. Например, если линия DSL входит в кабельный комплекс,
включающий линию ISDN, существенные затраты на граничную передачу данных снижают
эффективность DSL. Обсудите возможные технические проблемы с фирмой-поставщиком, прежде чем
принимать решение об установке линии DSL
Интересное преимущество DSL перед кабельными модемами — постоянная
пропускная способность. Поскольку сегмент кабельной сети используется
совместно с соседними компьютерами, установка кабельных модемов у соседей
снижает фактическую пропускную способность канала. Технология DSL создает
соединение типа «точка-точка» с поставщиком службы, поэтому она избавлена
от этого недостатка. Тем не менее DSL зависит от пропускной способности
канала к Интернету, а максимальное расстояние от точки подключения DSL
до АТС ограничено. В настоящее время это ограничение равно примерно 4,5 км,
но с развитием технологии оно может измениться.
Радиосети
Радиосети строятся на базе разных технологий беспроводной связи, от сотовых
сетей до «классических» радиомодемов наподобие предлагаемых фирмами Ricochet
и Metricom. Радиомодемы Ricochet связываются с приемо-передающими
устройствами, закрепляемыми на фонарных столбах, и обеспечивают беспроводную
связь с Интернетом. Пользователь может подключаться к Интернету из любого
места, как при использовании сотовых телефонов или пейджеров. Хотя этот
способ связи чрезвычайно удобен, он не обеспечивает достаточной безопасности.
RADIUS
Протокол RADIUS (Remote Authentication Dial-In User Service), описанный
в RFC 2138, был разработан фирмой Livingston Enterprises в 1992 году. Он
относится к классу протоколов «клиент-сервер» и предоставляет пользователям
сервис удаленного подключения. Разработка протокола была обусловлена
потребностью в усовершенствованном механизме аутентификации пользователей.
Протокол RADIUS стал важным инструментом в работе системных
администраторов, стремящихся сделать процесс аутентификации более надежным.
В конфигурацию RADIUS обычно входит центральный сервер базы данных
и один или несколько серверов удаленного доступа (рис. 18.4).
Клиенты RADIUS ^^" ^Ч" ^
(, . -) £ Интернет J
Г^Х Внутренний | ^1 Маршрутизаторы
f a^v , . ^ г—-^^-i маршрутизатор Rgba R Интернета
1^^У..Ы."""" : ' '.::■:."J L bj.'::»:..".:.!»:.»».:;* L"JI£l£jJ
i I ЭВЗ
Внутренние клиенты /v ' Л
I Сервер RADIUS
Рис. 18.4. Примерная конфигурация RADIUS
Аутентификация RADIUS
Механизм обмена данными на базе RADIUS весьма прямолинеен. После того
как пользователь установит связь с сервером удаленного доступа, сервер
запрашивает у пользователя имя и пароль с использованием протоколов РАР или CHAP.
Протокол РАР
Старый протокол РАР (Password Authentication Protocol), документированный
в RFC 1334, основан на использовании имен и паролей. После удаленного
подключения имя пользователя и пароль передаются серверу RADIUS. Как показано
на рис. 18.5, сервер удаленного доступа многократно посылает введенное имя
и пароль серверу аутентификации до тех пор, пока не произойдет тайм-аут.
Если вы уделяете внимание безопасности, протокол РАР вам вряд ли подойдет,
поскольку пароли передаются «в открытую». Другими словами, имя
пользователя и пароль не шифруются. Следовательно, злоумышленник может
перехватить передаваемые пакеты, узнать имя пользователя с паролем или просто
переслать сохраненные пакеты для получения доступа к критическим ресурсам
системы. Протокол РАР обычно используется в качестве резервного, если
попытка использования протокола CHAP завершилась неудачей.
Клиенты RADIUS,^—^—л.—-.
использующие РАР (^ <.
< д^..„—j £ Интернет J
Внутренний ^Щ
маршрутизатор l««l«jHi
ЙДЧ Брандмауэр
Сервер RADIUS, аутентификацию
использующий РАР
Рис. 18.5. Принцип работы протокола РАР
Протокол CHAP
В отличие от РАР протокол CHAP предоставляет более сильный механизм
аутентификации пользователя. Подробное описание CHAP приведено в RFC 1994.
Аутентификация CHAP проводится в три этапа. После установления связи
сервер посылает клиенту специальный пакет — «вызов». Клиент вычисляет ответ
с использованием одностороннего алгоритма хэширования (например, MD5).
Клиент посылает результат серверу, который уже вычислил предполагаемый
ответ. Если ответ от клиента совпадает с ответом, вычисленным сервером,
клиенту разрешается доступ к сети. Если ответы не совпадают, доступ запрещается.
Для предотвращения атак типа «перехват сеанса» протокол CHAP можно
настроить на периодическое проведение повторной аутентификации клиента. В
отличие от РАР сторона, проводящая аутентификацию, контролирует все
происходящие события, и повторные попытки допускаются редко.
Подобная схема аутентификации предотвращает атаки с воспроизведением
сохраненных пакетов (вроде упомянутой в предыдущем разделе). Поскольку
каждый вызов отличается от предыдущих, вычисленные ответы тоже будут
различаться. Следует учитывать, что работа протокола зависит от общего ключа,
используемого при хэшировании (рис. 18.6), поэтому ключ необходимо хранить
в секрете. Вызов должен удовлетворять двум критериям: он должен быть
уникальным и непредсказуемым.
Ключ
Т
Вызов J ~
или ответ
Т
Хэш-код
фиксированной
длины
Рис. 18.6. Применение хэширования в протоколе CHAP
Метод аутентификации CHAP следует использовать в тех случаях, если
вы собираетесь обратиться к важным сетевым ресурсам или просто заботитесь
о безопасности. Как указано в CHAP RFC 1994, применение протокола РАР
для проверки пароля при использовании РРР считается нежелательным.
Учетные данные
Существует много разновидностей учетных данных: имя пользователя, пароль,
ограничения доступа по времени, данные авторизации и аудита.
Всем хорошо известны классические учетные данные — имя пользователя
и пароль. RADIUS дополняет их расширенной информацией, при помощи
которой можно узнать, когда пользователь пытается выйти за пределы своих полно-
мочий. Например, можно задать время, в течение которого пользователю
разрешается доступ к сети. Если секретарь работает с 9 до 17 часов, включите этот
интервал в его учетную запись. Любые попытки доступа за пределами этого
интервала автоматически отвергаются. Подобное ужесточение внешнего доступа
к сети повышает ее безопасность.
Аналогичный эффект дает ограничение доступа к службам. Явно
перечисляя службы, разрешенные для конкретного пользователя, вы запрещаете доступ
к остальным службам. Если пользователь обращается к службе, к которой ему
обращаться не положено, сервер RADIUS пресекает сто попытку. В этой
стратегии управления доступом используется централизованная база данных с
информацией о пользователях, легко обновляемая в случае необходимости.
Транспортировка дейтаграмм IP
в протоколах SLIP, CSLIP и РРР
Существует несколько протоколов, предназначенных для передачи дейтаграмм IP
по телефонным линиям. Выбор протокола зависит от того, какие из его
возможностей вы собираетесь использовать. Ниже кратко описана история протоколов
удаленного доступа и современное положение дел.
Протокол SLIP
SLIP (Serial Line Internet Protocol) — ранний протокол, предназначенный для
подключения удаленных пользователей к хостам. Документ RFC 1055 содержал
только информативную спецификацию, поскольку на момент написания этого
документа протокол SLIP уже превратился в фактический стагщарт. SLIP стал
одним из первых по-настоящему полезных протоколов удаленного доступа,
поскольку он обеспечивал подключение IP к удаленным сетям, которые начали
появляться в начале 1980-х годов. На рис. 18.7 показано, как протокол SLIP
использовался и операционных системах Berkeley и Sun Microsystems.
Маршрутизатор
с поддержкой SLIP
/1^™™/\ TCP/IP
Удаленный SLIP ^ — ^ Сервер
клиент / \. Корпоративный Е§ЭЯ
1 ьцум^яи"] Модем / Телефонная Линия Т-1 \маршрутизатор [«йдд
i^^— R.,.,...J...... ,i ГТ^ПтН
1 ===** Последовательный Сеть [ ТП \
канал /"' -'-''А
Рис. 18.7. Протокол SLIP
Протокол SLIP весьма тривиален, поскольку он разрабатывался во времена
простых сетевых технологий, а решаемая проблема сводилась к простой передаче
дейтаграмм IP по телефонным линиям. Весь документ RFC вместе с
программным кодом занимал всего пять страниц. В сущности, протокол SLIP всего лишь
определяет механизм формирования кадра для последовательного канала. Он не
обладает средствами обнаружения и исправления ошибок, адресации,
идентификации пакетов или сжатия данных. У него есть только одна задача — отправка
пакетов по последовательному каналу.
ПРИМЕЧАНИЕ
Следует понимать, что протоколы последовательных каналов (такие, как SLIP и РРР) являются
протоколами канального уровня (уровень 2 модели OSI). Необходимость в таких протоколах
связана с тем, что последовательные каналы не имеют собственных протоколов канального уровня.
В этом отношении они отличаются от протоколов локальных сетей (таких, как Ethernet и Token
Ring), имеющих определенную структуру кадра канального уровня. Во многих
последовательных каналах на физическом уровне используются асинхронные коммуникации, когда символьный
кадр формируется с использованием стоповых битов и необязательных битов контроля четности.
Возможно, вы знакомы с правилами формирования кадров на физическом уровне асинхронных
коммуникаций с описаниями вида «N,8,2», означающими «отсутствие контроля четности, 8 бит
данных, 2 стоповых бита». Описания вида «N,8,2» относятся к физическому уровню передачи
данных в последовательных каналах. Но какой протокол канального уровня должен использоваться
для последовательных каналов? Другими словами, как должны группироваться символы в кадре
информации и как должен выглядеть формат пакета канального уровня? При попытках найти
ответ на этот вопрос становится ясно, что последовательные каналы не имеют собственного
протокола канального уровня, а формат кадра для последовательных каналов выбирается
разработчиком протокола. Раньше в качестве протокола канального уровня для последовательных
каналов использовался протокол SLIP, описанный выше. Ниже рассматривается современный
протокол РРР, заменивший SLIP.
Из-за своей простоты протокол SLIP обладает рядом недостатков, делающих
нежелательным его применение в широкомасштабных сетях. Самый серьезный
недостаток заключается в том, что в сеансах SLIP обе стороны должны знать
IP-адреса друг друга, без чего невозможно выполнить маршрутизацию. В
современных сетях это может вызвать проблемы, особенно при использовании средств
автоматической конфигурации DHCP. С другой стороны, примитивность
протокола SLIP упрощает его реализацию.
Размер дейтаграммы обычно поддерживается меньше 1006 байт, что
существенно ниже предельного размера MTU большинства каналов. Также
ограничивается максимальная скорость модема. В соединениях SLIP не рекомендуется
превышать скорость 19,2 кбит/с. При больших скоростях возникает потребность
в средствах проверки ошибок, поддерживаемых РРР.
Протокол CSLIP
Протокол CSLIP (Compressed SLIP) сокращает непроизводительные затраты
на транспортировку за счет применения сжатия заголовков TCP по алгоритму
Ван-Джейкобсона, вследствие чего размер объединенных заголовков TCP и IP
сокращается с 40 до 3-7 байт. В большинстве пакетов содержимое заголовков
TCP и IP остается практически одинаковым, что позволяет использовать
алгоритмы сжатия — такие, как кодирование длин серий (RLE), при котором
последовательная серия одинаковых элементов заменяется одним символом и числом
его повторений. Сжатие дает особенно существенный выигрыш при отправке
большого количества мелких пакетов, как при использовании протоколов типа
Telnet.
Протокол РРР
Многочисленные ограничения и недостатки протокола SLIP наглядно показали,
что нужен новый протокол. Так на замену SLIP появился протокол РРР.
Исходная спецификация RFC 1134 с описанием РРР была написана в 1989 году
Дрю Перкинсом (Drew Perkins) из университета Карнеги Меллон. Протокол РРР
отличается высокой универсальностью, он поддерживает передачу дейтаграм по
последовательным каналам «точка-точка» и по Интернету. Дейтаграммой
называется блок данных, по своей природе сходный с пакетом. Инкапсуляция
дейтаграмм позволяет РРР сохранить независимость от среды передачи и
поддерживать протоколы, отличные от IP. РРР используется с такими протоколами, как
UDP/IP, IPX/SPX и даже AppleTalk.
Режимы работы РРР
Чтобы протокол РРР поддерживал практически любые типы пользовательских
сеансов, в него была включена поддержка нескольких режимов работы. При
получении запроса на установление связи РРР может перейти в один из трех
режимов:
О прямой канал РРР;
О режим автоматического распознавания;
О интерактивный режим.
Прямой канал
Как нетрудно предположить по названию, в режиме прямого канала после
ответа на запрос создается канал связи РРР. Вся аутентификация должна
выполняться средствами самого протокола РРР. Данный способ соединения весьма
рискован из-за возможности отключения аутентификации, что позволит любому
желающему подключиться к вашей сети.
Автоматическое распознавание
В режиме автоматического распознавания сервер выбирает между РРР, SLIP,
интерактивным режимом и другими протоколами в соответствии с настройкой
системы. В данном случае ключевым преимуществом является универсальность.
Благодаря поддержке широкого спектра протоколов для сети теперь могут
эффективно решаться проблемы обновления и миграции. Вместо принудительного
перевода на РРР можно осуществить постепенную миграцию пользователей
и служб. Одновременный перевод всех систем на новую технологию сильно
испортил жизнь многим системным администраторам, потому что
преобразование не всегда идет гладко и неизменно сопровождается непредвиденными
проблемами.
Интерактивный режим
Другое преимущество — поддержка неинтеллектуальных терминалов и
терминальной эмуляции. Некоторым программам, работающим с базами данных,
по-прежнему необходим доступ к унаследованным системам, поэтому об этой
возможности следует помнить.
В начале сеанса РРР проверяет тип сеанса — активный или пассивный.
Активный узел начинает передавать кадры в попытке согласовать установление связи
с другой стороной. Пассивный узел ожидает, пока процесс согласования будет
инициирован другой стороной. Как правило, узлы с исходящим доступом
настраиваются на активный режим, тогда как узлы с входящим доступом могут
быть как активными, так и пассивными. Для определения протокола линии
передачи данных удаленного узла сервер удаленного доступа с автоматическим
распознаванием должен работать в пассивном режиме.
Чтобы протокол РРР приступил к процессу согласования, один из узлов
должен быть активным. Учтите, что не все программное обеспечение
поддерживает выбор режима. Например, сервер удаленного доступа NT является
пассивным, а сервер РРР для Solaris работает только в активном режиме. При
использовании РРР 2.3 вам будет предоставлен выбор между активным и пассивным
режимом.
РРР поддерживает шифрование в форме протокола ЕСР (Encrypting Control
Protocol), описанного в RFC 1962 и RFC 1968. Возможно применение
различных алгоритмов шифрования, в том числе DES. Обе стороны должны
поддерживать шифрование и согласовать общий алгоритм. Будьте внимательны,
шифрование поддерживается не всеми программными продуктами, поскольку оно
относится к числу расширений РРР.
В отличие от SLIP протокол РРР обладает многими полезными
возможностями:
О одновременная поддержка нескольких протоколов;
О настройка канала связи;
О обнаружение ошибок;
О сжатие;
О шифрование;
О получение информации о сети;
О аутентификация.
Как показано на рис. 18.8, РРР находится в стеке протоколов на канальном
уровне и взаимодействует с физическим и сетевым уровнями.
Подобное использование стека позволяет РРР поддерживать несколько
протоколов. Так, на рис. 18.9 показано, как дейтаграммы IP инкапсулируются
в кадрах РРР.
Прикладной уровень
Представительский уровень
Другие
Сеансовый уровень ТСР/|Р („g^p, ,PX)
Транспортный уровень
Сетевой уровень
Канальный уровень РРР
^ ^ Интерфейс последовательной
Физический уровень | передачи данных |
Рис. 18.8. Место протокола РРР в стеке TCP/IP
Данные приложения
перемещаются по стеку
сверху вниз
I
Дейтаграмма IP
Кадр РРР
у
I Форматирование на I
| физическом уровне |
Кадр направляется
в линию последовательной
I передачи данных
Рис. 18.9. Инкапсуляция дейтаграмм IP для пересылки в канале
Точно так же инкапсулируются данные IPX — вместо дейтаграммы IP
канальному уровню с поддержкой РРР передается дейтаграмма IPX. Подобная схема
сохраняет логическую целостность стека и одновременно обеспечивает гибкость,
столь необходимую в современных сетевых средах с поддержкой нескольких
протоколов.
О гибкости РРР также свидетельствуют возможности модификации рабочих
параметров этого протокола. Для обеспечения максимальной э(})фективности работы
канала РРР позволяет задать целый ряд параметров конфигурации, в том числе:
О максимальная единица приема (MRU);
О асинхронная карта управляющих символов (АСММ);
О протокол аутентификации;
О протокол контроля качества;
О «волшебное число»;
О сжатие поля протокола;
О сжатие поля адреса и управления;
О альтернативная контрольная последовательность кадра.
Максимальная единица приема
Максимальная единица приема (MRU) сообщает другому узлу, что получатель
способен работать с единицами MTU, размер которых отличен от стандартного
A500 байт). Следует заметить, что все реализации должны при любых
обстоятельствах поддерживать передачу данных РРР объемом 1500 байт независимо
от того, какие значения были согласованы на стадии подключения. Вычисление
MRU считается довольно сложным процессом из-за протоколов сжатия,
которые могут увеличивать объем некоторых данных из-за специфики алгоритмов
подстановки. В некоторых реализациях РРР параметр MRU вычисляется на
основании скорости подключения.
Асинхронная карта управляющих символов
Асинхронная карта управляющих символов АССМ (Async Control Character Map),
описанная в RFC 1662, указывает другой стороне, какие символы в потоке данных
должны «экранироваться» для предотвращения порчи данных. Это делается для
разрешения или запрета использования управляющих символов ASCII с кодами
в интервале от 18 до IF. Некоторые управляющие последовательности (такие,
как Ctrl+S и Ctrl+A — XON и XOFF), обычно используемые для остановки и
возобновления передачи, иногда весьма странным и удивительным образом портят
данные.
Протокол аутентификации
Параметр протокола аутентификации описан в RFC 1661. Выдавая запрос на
аутентификацию, отправитель сообщает другой стороне, что перед дальнейшим
обменом данными она должна передать информацию о себе. По умолчанию
аутентификация не используется. Получатель может ответить отказом, запрашивая
тем самым другой протокол (рис. 18.10).
I I Запрос (с указанием | I
протокола аутентификации)
<< Отказ
q (протокол неизвестен) £,
s Запрос (с указанием другого fe
го протокола аутентификации) >,
Е §
I EZ I
О Подтверждение
(протокол известен)
Отправка
1 ' идентификационных ' '
данных
Рис. 18.10. Последовательность аутентификации
Получив отказ, отправитель может завершить сеанс или повторить попытку
с другим протоколом. Допустимые протоколы аутентификации — PAP (RFC 1334),
MD5 CHAP (RFC 1994), MS CHAP, EAP и SPAP. После того как другая сторона
передаст подтверждение, она должна сообщить информацию о себе с
использованием одного из перечисленных протоколов.
Протоколы CHAP и РАР были описаны выше. В оставшейся части этого
раздела приводится краткая сводка других протоколов аутентификации и
перечислены остальные поля РРР.
ЕАР
Протокол ЕАР (Extensible Authentication Protocol), описанный в RFC 2284 и 2484,
рекомендован для использования в качестве протокола аутентификации РРР.
РРР создает подключение, а выбор алгоритма откладывается до фазы
управления каналом (LCP, Link Control Phase). Затем во время фазы аутентификации
ЕАР запрашивает у клиента дополнительные сведения о конкретных протоколах
аутентификации. Основным преимуществом ЕАР является поддержка
использования вспомогательных систем для шифрования и аутентификации, что
существенно упрощает интеграцию РРР с серверами RADIUS и другими аппаратными
и программными средствами безопасности.
Shiva PAP
Shiva PAP тоже использует аппаратные средства безопасности, но, похоже, Shiva
не собирается делать свой протокол общественным достоянием и предоставляет
лицензии избранным производителям. Найти свободно распространяемую
документацию по этой теме нелегко.
MS CHAP
Протокол MS CHAP фактически представляет собой обычный CHAP с
измененным алгоритмом хэширования. Вместо обычного алгоритма MD5 в MS CHAP
используется DES или MD4 в зависимости от того, используется ли
LAN-версия (DES) или NT-версия (MD4). В обоих случаях при построении ответа
используется DES.
Протокол контроля качества
Еще одна интересная особенность РРР — возможность измерения параметров
качества сервиса (QoS, Quality of Service). Сообщив другой стороне о своем
желании получать информацию QoS, вы сможете отслеживать потерю данных
и процент ошибок. По умолчанию этот параметр принимает значение «нет
протокола», а предоставляемая информация ограничивается простой статистикой
о состоянии канала.
«Волшебное число»
«Волшебное число» используется в запросах QoS, а также в запросах на
исключение данных и в пакетах с информацией о качестве связи. Оно выбирается
случайным образом, используется для взаимной идентификации узлов, а также
упрощает выявление ошибок и «петель». По умолчанию «волшебное число» не
используется.
Сжатие поля протокола
При включении сжатия поля протокола 16-разрядное поле протокола
заменяется 8-разрядным значением. Чтобы сжатие работало, старший октет должен быть
равен 0; передается только младший октет. По умолчанию сжатие поля протокола
не используется.
Сжатие поля адреса и управления
Включение сжатия поля адреса и управления сообщает другой стороне, что
фиксированные значения HDLC Oxff и 0x03, связанные с этим полем, можно
игнорировать. По умолчанию сжатие поля адреса и управления не используется.
В приложениях, критичных по задержке (например, в приложениях реального
времени), этот параметр позволяет игнорировать неиспользуемые части поля
и сэкономить несколько байт при передаче пакетов.
Альтернативная последовательность передачи кадра
Последний из рассматриваемых параметров — альтернативная
последовательность передачи кадра — сообщает другой стороне, что узел желает получать
нестандартное поле контрольной последовательности кадра. Этот параметр LCP
обычно не используется, поскольку он по-разному интерпретируется в разных
реализациях РРР. Включение альтернативной последовательности передачи
кадра позволяет сторонам согласовать использование 32-разрядных
контрольных сумм вместо обычных 16-разрядных.
Существуют и другие параметры и расширения, поддерживаемые РРР, но они
считаются либо устаревшими, либо дефектными. Применяйте их только в
крайнем случае, а там, где это возможно — рассмотрите другие варианты. Описания
этих параметров приводятся в RFC 1570, RFC 1663, RFC 1976 и RFC 1990.
Туннелирование удаленного доступа
Перемещение данных между сетями нередко требует применения специальных
приемов. Иногда проблема решается простой инкапсуляцией одного протокола
в другом, как это делается при передаче пакетов IPX в каналах IP (рис. 18.11).
Завершитель Заголовок
канального Пакет IPX Заголовок UDP Заголовок IP канального
уровня уровня
Рис. 18.11. Передача IPX в пакетах IP
Основной протокол (в данном случае IPX) может не обладать возможностями
перемещения данных между объединенными сетями IP. Для решения этой
проблемы к пакету IPX присоединяется заголовок IP с информацией,
необходимой для маршрутизации пакета к месту назначения. Эта стандартная методика
используется с первых дней существования AppleTalk и доказала свою
эффективность.
Впрочем, у подобных решений есть свои недостатки. Некоторые приложения
рассчитаны на прямую работу с базовыми протоколами, в данном случае Novell
NetWare. Во многих реализациях IP присутствуют свои особенности, сильно
усложняющие их использование. Для примера можно снова привести протокол
IPX в сетях Microsoft. В некоторых реализациях IPX для сетей MS наблюдаются
странные проблемы с тайм-аутом, а сетевые ресурсы случайным образом
появляются и исчезают. Чаще всего эти проблемы возникают с принтерами и
объясняются неправильным взаимодействием драйвера принтера с сетевыми драйверами.
В этом и заключается суть проблемы. Инкапсуляция требует особого
внимания ко всем мелочам, поскольку в ней фактически задействованы два и более
сетевых протоколов. Всего один неправильно установленный или устаревший
драйвер создает проблемы, которые крайне трудно выявить и устранить. Что
еще важнее, такие проблемы создают впечатление общей ненадежности сети,
а это крайне нежелательно.
В прошлом были предложены некоторые решения, оказавшиеся весьма
эффективными. Во-первых, существуют специальные продукты удаленного
администрирования, при помощи которых системные администраторы устанавливают
удаленные узлы и управляют их работой. Продукты таких компаний, как Vector Networks
(www.vector-networks.com) и Traveling Software (www.travelingsoftware.com) обладают
дополнительными возможностями, не поддерживаемыми стандартными
рабочими средами. В них реализованы средства удаленного управления и
администрирования и средства сбора информации о программах и оборудовании,
предназначенные для формирования надежной сетевой среды. Впрочем, не стоит
считать подобные продукты панацеей. При неправильной настройке они могут
предоставить несанкционированный доступ к конфиденциальной информации.
Позаботьтесь о том, чтобы пароли были сильными, а административный доступ
предоставлялся только тем, кому он действительно нужен. Программа ZENWorks
for Desktop для сетей Novell обладает встроенными средствами защиты
удаленного доступа.
В некоторых случаях обычного уровня безопасности оказывается
недостаточно. В таких особых случаях приходится использовать протоколы
шифрования — такие, как РРТР и L2TP.
Протокол РРТР (Point-to-Point Tunneling)
Протокол РРТР является результатом сотрудничества между Ascend
Communications ECI Telematics, Microsoft, 3Com и US Robotics. Данная группа получила
название форума РРТР. Предполагалось, что протокол РРТР откроет новые
возможности для пользователей и производителей оборудования. При поддержке
этого стандарта пользователи смогут подключиться по модему к местному
поставщику услуг Интернета и создать защищенный туннель к корпоративной
сети. В результате корпорациям не придется тратить силы и средства на
создание и сопровождение собственных средств контроля удаленного доступа.
Протокол должен был сблизить корпорации с существующими структурами
Интернета. Поставщикам услуг Интернета (ISP) оставалось делать то, что они
умеют — подключать отдельных пользователей к Интернету. Корпорациям
оставалось лишь приобрести оборудование, подключаемое к региональным
сетям (MAN) и местные линии связи для демультиплексирования входящих
подключений удаленного доступа. С их точки зрения внешнее подключение
выглядело как связь с обычным сайтом Интернета. На рис. 18.12 проиллюстрированы
различия в двух архитектурных моделях.
ШРЩХВ Мультиплексный канал от ISP
Н№|||§9' Маршрутизатор
ЖЙЁЁИ: \ мультиплексного канала
^^ДД^^^Интернет <^ пь^Л
/ \ г'РЙН
Удаленные ЖЩЕЗД Точка доступа к Интернету, предоставленная ISP I /■■ 'Т!.,,'Ь
РНШ1, Маршрутизатор
' ■ /"""£1— мультиплексного канала
q Интернет J I ЦД |
^ШШШШгУ^. Корпоративная
^£^S Уцаленные [ЯРРШ]
Рис. 18.12. Два варианта архитектуры удаленного подключения к корпоративной сети
Агрегирование сеансов РРР
Протокол РРТР, работающий по схеме «клиент-сервер», проектировался
специально для поддержки туннелирования в сетях IP с использованием РРР и
уровня 2. В нем предусмотрена такая интересная возможность, как поддержка несколь-
ких подключений РРР по одному туннелю РРТР. Она хорошо работает в модели
с поставщиком услуг Интернета, в которой несколько удаленных пользователей
подключаются к корпоративной точке входа (рис. 18.13). Такие туннели обычно
называются виртуальными частпьши сетями (VPN, Virtual Private Networks).
С^^^П Агрегатный канал РРТР
KKK ^S^f:;^^ Интернет Ц шяж
Клиенты ^ I ]
W ••--fH Сервер
&п та=г| удаленного
U^sJ доступа
Рис. 18.13. РРТР с многопользовательской поддержкой
Для работы РРТР необходимо дополнительное управление через порт TCP
1723 с использованием протокола GRE (General Routing Encapsulation). Тем не
менее протокол GRE не получил такого распространения, как TCP или
родственный ему UDP, поэтому он не поддерживается многими поставщиками услуг
Интернета. Без поддержки GRE протокол РРТР работать не будет.
Самый распространенный способ реализации основан на обслуживании
удаленных точек присутствия (POP, Point of Presence). В этом случае поставщик
услуг Интернета просто предоставляет сервис IP, а клиенты согласовывают
свои каналы РРТР с частными маршрутизаторами. Следует учитывать, что не
все программные средства РРР поддерживают РРТР, поскольку этот протокол
не является стандартным. В качестве примера клиента и сервера,
поддерживающих РРТР, можно привести реализацию РРР от Microsoft в операционных
системах Windows 98 и NT.
После установления физического соединения и проверки пользователя
дейтаграммы создаются средствами РРР. Далее РРТР инкапсулирует пакеты РРР
для передачи по туннелю IP.
Отдельный управляющий канал
Как упоминалось выше, в РРТР подключение производится по двум каналам:
каналу данных и управляющему каналу. Управляющий канал работает на порте
TCP 1723. По нему передается информация, относящаяся к состоянию связи,
а также управляющие сообщения для создания, управления и завершения
туннелей РРТР. Именно управляющий канал позволяет регулировать скорость
передачи данных РРТР, что может быть полезно при высоком уровне помех в линии
или сильной перегрузке сети, приводящей к потере пакетов.
Данные передаются между узлами в потоке данных, инкапсулированном
в «оболочке» IP; для управления маршрутизацией используется протокол GRE.
Следует еще раз напомнить, что GRE не поддерживается некоторыми
поставщиками услуг Интернета, поэтому создание туннелей может потребовать
непосредственного согласования между клиентом и сервером.
Поддержка других протоколов
Другая интересная особенность РРТР — поддержка таких протоколов, как
NetBEUI, IPX и даже AppleTalk (для тех, кто еще продолжает им пользоваться).
Поскольку РРТР относится к протоколам второго уровня, он также включает
заголовок носителя, что позволяет ему работать через Ethernet или
подключения РРР.
Аутентификация и защита
Шифрование и управление ключами не входят в спецификацию РРТР.
Протокол РРТР использует средства аутентификации и шифрования,
предоставляемые протоколом РРР. Для повышения надежности защиты данных в паре
РРР/РРТР фирма Microsoft реализовала новый механизм шифрования —
алгоритм Microsoft Point-to-Point Encryption, основанный на стандарте RSA RC4.
Для выполнения аутентификации РРТР использует протоколы CHAP, PAP,
ЕАР и MS-CHAP, поддерживаемые РРР.
Типы туннелей РРТР
Протокол РРТР поддерживает несколько базовых конфигураций туннельных
подключений. Тип туннеля зависит от нескольких условий. Первое и самое
главное — это выполнение требования о поддержке GRE поставщиком услуг
Интернета. Второе условие — возможность поддержки подключений РРТР самим
клиентом. Конечной точкой туннеля является либо сервер удаленного доступа
(RAS) поставщика услуг Интернета, либо компьютер пользователя. Туннели этих
двух видов называются соответственно добровольными и принудительными.
Добровольный туннель
При создании добровольного туннеля пользователь создает подключение РРТР
к корпоративному компьютеру. Однако в этом случае на его компьютере
должен работать полноценный клиент РРТР (такие клиенты имеются в
операционных системах Windows 9x и NT). В этом случае от поставщика услуг Интернета
не требуется ничего, кроме предоставления базового сервиса IP (рис. 18.14).
Если сервер удаленного доступа предоставляется поставщиком услуг
Интернета, присутствие клиента РРТР на компьютере пользователя не
обязательно; необходим только клиент РРР. В принудительных туннелях пользователь
подключается к серверу удаленного доступа поставщика услуг Интернета и не
может управлять туннелем (рис. 18.15). Как правило, пользователь вообще не
знает о существовании туннеля РРТР.
Каналы /^ С Корпоративная}
РРТР / ^ .—. > сеть \ J
ЛУ г Интернет <^ ^^-—г~~-^Лл
Клиенты fh^S- «^j* Сервер удаленного
РРТР \ШЩ Ш доступа РРТР
Рис. 18.14. Туннель РРТР «пользователь-сервер» через Интернет
Агрегатный канал
Г#5ё«»*йП а/ РРТР к сети
жЙИб^П^ч Г ^^ Корпоративная!)
4=^даГ J^>. jf -*У ^\^--«~Л-—Хг- сеть и
j^|i^||^^^ Интернет | <^ I Т&зШ
Клиенты / ^—-^\^_^У^ Я I ри^ЕС]
ррр X / pzd
^__ J7 Обратный выход I
['Ш^йй I в Интернет через Hfc^-l
г§Ш|$я корпоративную сеть I ЬрИч
Ч "''< '^warH Сервер
| да п ч^^ удаленного
s=a^ доступа
Рис. 18.15. Принудительный туннель
Принудительный туннель
Принудительные туннели делятся на две категории: статические и
динамические. Статические туннели работают на специально выделенном
оборудовании, их также называют туннелями иа базе областей (realm-based tunnels).
Область (realm) является частью имени пользователя и может ассоциироваться
с пользовательским доменом. Эта информация используется сервером RAS для
определения конечной точки подключения РРТР. Поддержание соединений
такого рода требует ручной настройки сервера RAS. Преимущество статических
туннелей состоит в том, что корпорации могут контролировать работу своих
пользователей в Интернете. Пользователь подключается к корпоративной сети
и пользуется корпоративным сервисом, а его выход в Интернет производится
через корпоративную сеть и полностью подчиняется корпоративным
требованиям (см. рис. 18.15).
Динамические туннели более эффективны, потому что туннель создается только
в случае необходимости. Для получения информации о пользователе сервер
RAS связывается с сервером RADIUS. Туннель создается на основе сведений
о пользователе. Информация об использовании туннеля и контроле доступа
хранится на сервере RADIUS и запрашивается сервером RAS по мере
необходимости.
Другое преимущество принудительных туннелей — возможность
агрегирования трафика. Несколько клиентов РРР могут быть объединены в одно
подключение РРТР к корпоративной интрасети, что обеспечивает сокращение объема
трафика и экономию затрат.
С другой стороны, у принудительных туннелей имеется недостаток,
связанный с безопасностью: канал от клиента к серверу RAS остается незащищенным.
Тем не менее то же самое можно сказать и о добровольном туннеле, поскольку
ничто не мешает пользователю подключиться к Интернету, загрузить
вредоносную программу, а затем подключиться к корпоративной сети.
Туннельный протокол уровня 2 (L2TP)
Протокол L2TP (Layer 2 Tunneling Protocol) имеет много общего с РРТР. Он
объединяет РРТР с протоколом Cisco L2F (Layer 2 Forwarding). Преимущество
L2F перед РРТР заключается в том, что он не зависит от GRE, а, следовательно,
совместим с другими средствами передачи данных (например, ATM и другими
пакетными сетями, включая Х.25 и Frame Relay). С другой стороны, это означает,
что в спецификации должны быть определены правила обработки пакетов L2F.
L2F
По аналогии с РРТР, протокол L2F использовал РРР в качестве базового
протокола, обеспечивающего подключение и вспомогательные функции
(например, аутентификацию). Но в отличие от РРТР L2F с самого начала
использовал TACACS (Terminal Access Controller Access-Control System) —
запатентованный протокол, разработанный Cisco Systems. TACACS обеспечивает сервис
аутентификации, авторизации и сбора данных для маршрутизаторов Cisco.
Протокол TACACS обладает некоторыми ограничениями, которые рассматриваются
ниже в этой главе.
L2F также использует туннельные подключения, что позволяет ему
поддерживать несколько туннелей в одном подключении L2F. Стремясь к повышению
уровня безопасности, L2F поддерживает дополнительный уровень
аутентификации. Кроме простой аутентификации на уровне РРР, в L2F была добавлена
аутентификация на уровне корпоративного шлюза или брандмауэра.
Главные преимущества L2F были перенесены в спецификацию L2TP. В L2TP
используется тот же способ подключения удаленных пользователей через РРР;
также был позаимствован и туннельный протокол L2TP. Эта особенность важна,
если учесть тенденцию перехода на сети ATM и Frame Relay, наблюдающуюся за
последние несколько лет.
Аутентификация
В L2TP, как и в РРТР, аутентификация выполняется средствами РРР. L2TP
использует PAP, CHAP и ЕАР для подключения к серверам RADIUS и но
эффективности не уступает РРТР. Наряду с этим уровнем эффективности в L2TP
используется сервис PACACS, TACACS+ и IPSec.
Поддержка IPSec
Основное отличие IPSec от других аналогичных служб заключается в том, что
эта открытая спецификация поддерживает не только аутентификацию, но и
защиту данных. В IPSec реализованы гораздо более сильные средства
безопасности, чем в простой модели РРР. Как видно из рис. 18.16, в L2TP предусмотрена
возможность поддержки PKI (Public Key Infrastructure) за счет применения
LDAP и сильных средств аутентификации. PKI является средством
управления открытыми ключами и теми сертификатами, которые ими поддерживаются.
В IPSec используется несколько различных механизмов аутентификации и
шифрования, включая асимметричные алгоритмы шифрования, на базе которых
работает PKI. Но хотя ниже мы поговорим о некоторых из этих механизмов, тема
PKI выходит за рамки настоящей главы и далее не рассматривается.
Клиенты RADIUS ^>^-—^ ч.—^
f .л.» i ,,„,,.•"] С Интернет J
Внутренние клиенты |Щ Внутренний ^* Маршрутизаторы
п маршрутизатор l^Um Интернета
серверы ииииввя
сертификатов Р*?Н Сервер РРТР
и LDAP ГИГ11 на брандмауэре
щ
| Сервер RADIUS
Рис. 18.16. L2TP и PKI
L2TP, как и РРТР, создает подключение средствами РРР. L2TP ожидает, что
РРР установит физическое соединение, выполнит начальную аутентификацию,
создаст дейтаграммы РРР, а по завершении сеанса — закроет подключение. На
этом сходство завершается. L2TP «переговаривается» с другим узлом и
определяет, разрешено ли подключение и собирается ли другая сторона поддерживать
L2TP. Если проверка дает отрицательный результат, сеанс на этом завершается.
Как и в РРТР, в L2TP определены два типа сообщений: управляющие и
данные. Управляющие сообщения предназначены для создания и поддержания
туннелей, а также для управления передачей и приемом данных. В отличие от
протокола РРТР, использующего два раздельных канала, L2TP объединяет
каналы управления и данных в один поток данных. В сети IP такое объединение
выглядит как упаковка данных и управляющей информации в одной дейтаграмме
UDP (рис. 18.17).
Заголовок Заголовок Заголовок Полезная
UDP L2TP РРР нагрузка IP
Рис. 18.17. Дейтаграмма в пакете UDP
Полезная нагрузка фактически состоит из пакета РРР за вычетом элементов
формирования кадра, зависящих от канала передачи. Поскольку L2TP относится
к протоколам второго уровня, он должен включать заголовок носителя, который
передает следующему уровню информацию о том, как должен передаваться пакет.
Возможны различные варианты: Ethernet, Frame Relay, X.25, ATM или исходный
канал РРР. Как видите, схема получается достаточно гибкой.
Для борьбы с перегрузкой сети в L2TP поддерживается управление потоком
данных. Оно реализуется между концентратором доступа L2TP LAC (L2TP
Access Concentrator) и сервером сетевого доступа L2TP LNS (L2TP Network
Access Server), предоставляющим доступ к корпоративной сети. Управляющие
сообщения содержат информацию о скорости передачи и параметрах
буферизации. Обмениваясь этой информацией, LAC и LNS регулируют поток данных,
а следовательно, способствуют разгрузке сети (рис. 18.18).
[ ЦЩ&шГ] Подключение через Интернет
ррр jXs-aBrassssB^^v У LHS
Д^^^^^ЁЮ Интернет | ■< ^
Рис. 18.18. LAC и LNS
В L2TP применяется и такой способ снижения объема трафика, как сжатие
заголовков пакетов. Как говорилось выше, такая возможность существует и в РРТР.
L2TP, как и РРТР, также поддерживает два типа классов подключений и
добровольные и принудительные туннели.
В добровольном туннеле подключение L2TP инициируется с компьютера
пользователя. Тем не менее это означает, что на этом компьютере должен быть
установлен действующий клиент L2TP. От поставщика услуг Интернета в этом
случае не требуется ничего, кроме предоставления базового сервиса связи
(рис. 18.19).
Каналы /^ С Корпоративная j
L2TP / ТЬ^Г СвТЬ \ ?
/ г" Интернет А? ^t
■в М — / w
[ии—j u~w / •••
'ЕттшЯЯШг' [ ■вгтч-:т-а5, уу У I I —;_"■- I
КРРТРЫ ||Ш|Н; L2TPLNS
Рис. 18.19. Добровольный туннель L2TP между пользователем и сервером
Если LAC предоставляется поставщиком услуг Интернета, присутствие
клиента L2TP на компьютере пользователя не обязательно; нужен только клиент
РРР. В принудительном туннеле пользователь подключается к LAC поставщика
услуг Интернета и не контролирует работу туннеля (рис. 18.20). Как правило,
пользователь вообще не знает о существовании туннеля L2TP.
Принудительные туннели делятся на две категории: статические и
динамические. Статические туннели работают на специально выделенном оборудовании.
В общем случае они неэффективно используют оборудование, поскольку оно
остается занятым даже в то время, пока туннель не используется. Кроме того,
поддержание соединений такого рода требует ручной настройки LAC.
Динамические туннели более эффективны, потому что туннель создается
только в случае необходимости. LAC получает информацию о пользователях от
сервера аутентификации (например, от сервера RADIUS или TACACS).
Использование принудительного динамического туннеля в сочетании с сервером
аутентификации имеет большие преимущества: туннели создаются с учетом
информации о пользователе (например, телефонного номера и метода аутентификации).
Аутентификация может производиться с использованием биометрических
признаков или смарт-карт, получающих все более широкое распространение. Кроме
того, в процессе аутентификации может производиться аудит и сбор статистики.
На основании накопленной информации выставляются счета за обслуживание
и выбирается скорость передачи данных в арендуемом канале.
■Н |™li Агрегатный канал L2TP
/iJILHHJ"8K^" Чуч г КорпоративнаяГ)
fefffliBffl}iRi^ \ s*r- -^^{ ^ч^. i.^^ ^ сеть )
РРР Ъ»-«—я^^^- У LNS
ЙШЭ|ЁР^ Интернет [ < ^
Клиенты / ^ 'V___^/Ss ^ 1г»»'",И1
|ИП| &^», •••:?• "J^
ИИ КЗ: *":-::; 1'"ч
Доступ к внутреннему |* а!
сервису | ■■ |
Рис. 18.20. Принудительный туннель через LAC поставщика услуг Интернета
Преимущества такого подхода уже упоминались в предыдущем разделе.
Пользователи подключаются к корпоративной интрасети для работы с
корпоративным сервисом и доступа к Интернету через корпоративную сеть, если он
разрешен (рис. 18.21).
_.. . Агрегатный канал L2TP
[ уимт-шу Выход в Интернет I [_^J
Клиенты НИШ через корпоративную сеть | ЩЦ
^г:';-;>ГГтгН Сервер
доступа
Рис. 18.21. Принудительное подключение к Интернету через L2TP
Другим преимуществом принудительных туннелей является агрегирование
трафика. Объединение нескольких подключений в один туннель L2TP к
корпоративной интрасети повышает эффективность использования ресурсов канала
и снижает затраты.
Не следует забывать и о недостатках принудительных туннелей. Канал от
клиента к серверу LAC не защищен, так как это простой канал РРР. Впрочем,
выше уже говорилось о том, что этот недостаток присущ и добровольным
туннелям. Ничто не мешает пользователю подключиться к Интернету, загрузить
вредоносную программу, а затем подключиться к корпоративной сети.
Как и в случае с реализацией РРТР, вопросы безопасности приходится
решать на системном уровне. Невозможно обеспечить безопасность, опираясь
только на технологические решения. Забывая о культурных особенностях и
процессах, вы сами создаете угрозу для безопасности системы.
Аутентификация L2TP через поставщика услуг Интернета сложнее той,
которая используется РРТР. При исходном контакте поставщик предоставляет
один из трех признаков, идентифицирующих пользователя:
О номер телефона, с которого поступил вызов;
О номер телефона, на который поступил вызов;
О имя пользователя или идентификатор.
После этого LAC поставщика услуг Интернета генерирует новый
идентификатор вызова, по которому данный сеанс будет определяться в туннеле, и
передает эту информацию LNS корпоративной сети (рис. 18.22).
Пользователь подключается ^
к поставщику услуг Интернета
Поставщик передает ^
информацию LNS
^ LNS возвращает подтверждение
поставщику
Пользователь создает
канал РРР с LNS
^ LNS запрашивает данные
аутентификации пользователя
Пользователь передает ^
данные аутентификации
Рис. 18.22. Последовательность аутентификации L2TP
Корпоративная сеть анализирует предоставленную информацию и решает,
принять или отвергнуть запрос на подключение. Если запрос будет принят,
наступает следующая фаза — аутентификация РРР. Хотя конечные точки были
определены и аутентифицированы, следует заметить, что сообщения
по-прежнему передаются в незашифрованном виде. Любой желающий с протокольным
анализатором может перехватить ваши данные. Кроме того, в поток пакетов
могут быть вставлены посторонние пакеты в попытке нарушить логику работы
получателей. Для предотвращения подобных попыток применяется механизм
IPSec.
Вспомните, что протокол РРР обеспечивает шифрование данных, но при этом
используется общий ключ. Чтобы процесс работал, ключ должен быть известен
обеим сторонам; следовательно, необходимо предусмотреть средства передачи
ключей по дополнительному каналу. То же самое относится и к
аутентификации туннелей L2TP. Но даже при использовании шифрования РРР протокол
L2TP не защищает управляющую информацию. IPSec может помочь и в этом.
IPSec
Протокол TCP/IP не обеспечивает сколько-нибудь надежной защиты. За
прошедшие годы было разработано немало механизмов, пытающихся заполнить этот
пробел. Тем не менее эти решения не обладали межплатформенной
совместимостью и работали недостаточно надежно. Для решения этой проблемы группа
IETF разработала набор протоколов, известных под общим названием IPSec.
Хотя эта тема скорее относится к виртуальным частным сетям (VPN),
некоторые функции IPSec достаточно эффективно используются L2TP, поэтому ниже
приводится краткий обзор возможностей IPSec.
В 1995 году были опубликованы документы RFC 1825-1829 с описаниями
механизмов аутентификации и шифрования дейтаграмм IP, первоначально
предназначавшиеся для нового стандарта IPv6. Вскоре эти механизмы были
адаптированы для текущей схемы адресации Интернета IPv4. В спецификациях IPSec
концепции решений разделены на две категории:
О Аутентификация.
О Шифрование.
Аутентификация обеспечивается элементом АН (Authentication Header), а
шифрование — элементом ESP (Encapsulating Security Payload). Каждая из этих
возможностей представлена заголовком, присоединяемым к пакету IP (рис. 18.23).
Стандарты шифрования
В отличие от других механизмов аутентификации, упоминавшихся до
настоящего момента, IPSec наряду с аутентификацией и шифрованием также
обеспечивает проверку целостности данных. Иначе говоря, IPSec проверяет, не были
ли данные изменены в процессе пересылки.
Для обеспечения совместимости стандарт IPSec использует несколько
криптографических стандартов:
О D-H (алгоритм Даффи—Хеллмана) — для обмена ключами;
О алгоритм шифрования с открытым ключом — для сертификации операций
D-H;
О шифрование DES;
О MD5, SHA и НМАС (Hash-based Message Authentication Code) —
хэширование с ключом;
О цифровые сертификаты.
IPv4 с ESP
Заголовок Заголовок T~D nauUufl Завершитель Аутент.
IP ESP TCP ДаННЫв ESP ESP
|Ч Шифрование Н
|< Аутентификация ►]
IPv6 с ESP
Заголовок Данные Заголовок тгр л Завершитель Аутент.
IP маршрутизации ESP и манные Esp ESp
|< Шифрование w
|Ч Аутентификация Н
IPv4 с АН
Заголовок Заголовок тср Данные
|< Аутентификация ►)
IPv6 с АН
Заголовок Данные Заголовок Спецификации Данные
IP маршрутизации АН адресата iv*r данные
(Ч Аутентификация ►)
Рис. 18.23. Структура заголовков пакета IPSec
Основным достоинством такого подхода является его универсальность. По мере
разработки новые алгоритмы также могут внедряться с стандарт IPSec (рис. 18.24).
Создание ассоциации безопасности
В самом начале обе стороны должны установить ассоциацию безопасности (SA,
Security Association). Хотя для установления защищенных каналов связи
существуют значения по умолчанию, IPSec дает возможность согласовать значения
ключей, используемые алгоритмы и временные характеристики. Для удобства
работы с многочисленными параметрами в IPSec используется концепция домена
интерпретации (DOI, Domain of Interpretation), упрощающая стандартизацию
этих элементов и значительно упрощающая создание SA. SA определяет
следующие атрибуты:
О режим алгоритма аутентификации и ключи, используемые в АН;
О режим алгоритма шифрования и ключи, используемые в ESP;
О параметры криптографической синхронизации;
О протокол, алгоритм и ключ, используемый для аутентификации;
О протокол, алгоритм и ключ, используемый для шифрования;
Протокол Протокол
I AH ESP I
1 ▼ Т1 1 ▼ I
Алгоритмы Алгоритмы
И аутентификации шифрования И
I * М DOI U * 1
J
Управление
ключами
Рис. 18.24. Архитектура IPSec
О частота обмена ключами аутентификации и шифрования;
О алгоритм аутентификации, режим, преобразование и ключи, используемые
ESP;
О срок действия ключа;
О срок действия SA;
О исходный адрес SA.
Аутентификация
АН позволяет выполнить сильную аутентификацию отправителя пакета и
содержащейся в нем информации. Криптографические хэш-функции используются
для вычисления контрольной суммы, а полученная информация вставляется
вместе с другими управляющими данными между заголовком IP и другими
заголовками (см. рис. 18.23).
ESP
АН всего лишь доказывает, что пакет действительно поступил от указанного
отправителя, а его содержимое не изменялось в процессе пересылки, однако
это не мешает злоумышленнику просмотреть содержимое пакетов. Защита
конфиденциальности данных осуществляется ESP. Информация ESP вставляется
между заголовком IP и оставшейся частью пакета, зашифрованной методом,
указанным в индексе SPI (Security Parameter Index). Некоторые режимы ESP
обладают интересными возможностями. Например, одним из режимов является
режим туппелироваиия (рис. 18.25).
IPv4 с ESP туннельного режима
I , Н™„ |заголовок|^ЭДн"Й| тгр Lhh J Завершитель I Аутент.I
заголовок „D заголовок TCP Данные £ео ' D
IP tor |р ь "^
|*< Шифрование ►]
|< Аутентификация ►]
IPv4 с ESP туннельного режима
Новый Новый L Исходный исх°Дныв
заголовок расширенный PQD заголовок
расширен- тср даННЫв завершитель Аутент.
| и» | заголовок | | IP \^ZJ I II I
|< Шифрование >|
|^ Аутентификация м
Рис. 18.25. Туннелирование в IPSec
Туннелирование
В режиме туннелирования весь пакет шифруется, аутентифицируется и
снабжается префиксом адреса промежуточного шлюза (например, брандмауэра). Тем
самым предотвращается раскрытие конечной точки маршрута в случае перехвата
пакета. Поскольку весь пакет вместе с заголовком зашифрован, он выглядит как
данные с другим заголовком IP. Этот заголовок содержит IP-адреса
отправителя и получателя конечных точек туннеля и используется для пересылки пакета
к месту назначения.
Как видите, стандарт IPSec обладает заметными преимуществами перед
стандартными средствами безопасности РРТР и L2TP и широко используется
продуктами построения VPN.
Итоги
Существует много способов удаленного подключения пользователей к
локальной сети. Протоколы SLIP, PPP, РРТР и L2TP обладают разными
возможностями и обеспечивают разную степень защиты.
Протокол РРР предоставляет базовый сервис подключения к серверу, но по
своим возможностям он значительно превосходит более ранний протокол SLIP.
Благодаря средствам управления каналом и поддержке нескольких протоколов
РРР быстро вытеснил SLIP. Возможно, протокол SLIP с его простыми
возможностями подходит для терминальных подключений по выделенным линиям, но
на фоне мощи и универсальности РРР он явно проигрывает.
Протокол РРТР расширяет возможности РРР и позволяет корпорациям более
эффективно использовать Интернет в своих целях. Благодаря поддержке
дополнительных протоколов в РРТР сервис интрасетей становится доступным для
домашних и портативных компьютеров удаленных пользователей. Применение
механизмов удаленной аутентификации (таких, как PAP, CHAP и RADIUS)
обеспечивает дополнительный контроль над использованием сетевых ресурсов.
Протокол L2TP также расширяет список возможностей удаленного доступа.
В L2TP объединены лучшие аспекты многих протоколов и используется
потенциал Интернета. Поддержка сильной модели безопасности IPSec повышает
надежность работы клиентов в удаленном режиме. Внедрение новых возможностей
в сетевую инфраструктуру должно сопровождаться разработкой новых методов,
предотвращающих их неправильное или злонамеренное применение.
Предполагается, что протокол L2TP предоставит такие гарантии, особенно если он будет
использоваться в сочетании с IPv6.
1 О Брандмауэры
Тим Паркер (Tim Parker)
Каждый раз, когда речь заходит о сетях, межсетевых объединениях и
Интернете, рано или поздно упоминаются такие термины, как «брандмауэр», «шлюз»
или «прокси-сервер». Читатель уже знает, что такое шлюз и как он работает, но
брандмауэры и прокси-серверы в книге еще не рассматривались. Хотя
брандмауэры и прокси-серверы не имеют прямого отношения к TCP/IP, они
повсеместно используются в сетях на базе TCP/IP и в Интернете.
А значит, стоит потратить немного времени и разобраться в том, как работают
брандмауэры и прокси-серверы и какие функции они выполняют в сетях TCP/IP.
Настоящая глава (а также глава 21) посвящена вопросам защиты сети,
маскировке и предотвращению порчи данных.
Безопасность сети
Брандмауэры и прокси-серверы, а также механизмы шифрования и
аутентификации, которые будут рассматриваться в следующей главе, призваны
обеспечивать безопасность данных. Но зачем беспокоиться о защите, если вы уверены,
что в ваших сообщениях электронной почти или на шлюзе нет ничего ценного?
Очень просто: если ваш компьютер подключен к Интернету, то и Интернет
подключен к вашему компьютеру. Это означает, что любой пользователь Интернета
теоретически может войти в вашу сеть, если не принять специальных мер. Если
система безопасности на шлюзовом компьютере не настроена, любой
пользователь с подключением к Интернету может использовать TCP/IP, чтобы пройти
через шлюз и получить доступ к любому компьютеру сети. Вероятно, где-нибудь
в сети у вас имеются данные, не предназначенные для посторонних глаз, а
значит, необходимо позаботиться о блокировке внутреннего доступа к сети для
пользователей Интернета.
Настраивая систему безопасности для сети, вы в действительности
стремитесь защитить данные, хранящиеся в сети, и оборудование, подключенное к ней.
Если хакер сможет пользоваться вашим оборудованием, он может испортить
его. То же самое относится к данным. Ведь вы не хотите, чтобы ваша конфиден-
циальная информация распространялась по всему Интернету с сообщениями
электронной почты, не правда ли? Наконец, система безопасности также косвенно
защищает репутацию — вашу личную или репутацию вашей компании. Если
вся служебная документация крупной компании (такой, как IBM или Hewlett-
Packard) станет доступна для всех желающих, вряд ли это пойдет ей на пользу.
Самый распространенный тип проблем безопасности уже упоминался выше —
доступ к сети через Интернет. Подобные несанкционированные вторжения и
являются основной причиной для принятия мер безопасности. Злоумышленники
или хакеры могут войти в сеть, найти любые данные, внести в них любые
изменения и даже вызвать физические повреждения системы. Злоумышленник
может проникнуть в сеть разными способами, от использования известных
дефектов в системе безопасности операционной системы и приложений, до прямого
шпионажа. Главной задачей системы безопасности, а еще точнее — брандмауэров,
является предотвращение несанкционированного доступа.
Другая категория проблем из области безопасности называется отказом от
обслуживания, или DoS (Denial of Service). Такая ситуация возникает в том
случае, если вмешательство хакера не позволяет вам нормально использовать ваши
собственные компьютеры. Существует много форм отказа от обслуживания.
Типичный пример, часто встречающийся в Интернете, — затопление службы
(электронной почты, сайта FTP или web-сервера). Иначе говоря, служба начинает
получать так много данных, что не может с ними справиться и либо аварийно
завершает свою работу, либо тратит время на обработку фиктивных данных и
отказывает в обслуживании нормальным пользователям. Хакеры часто применяют
эту методику к электронной почте, когда ежечасно па почтовый сервер адресата
отправляются многие тысячи сообщений. Сервер не справляется с поступающими
сообщениями, и служба электронной почты парализуется. Аналогичный прием
может использоваться с большинством служб TCP/IP, включая FTP, Telnet
и Web. Другой аспект отказа от обслуживания связан с повторной
маршрутизацией — вместо обращения к нужной службе на одном компьютере ваш запрос
перенаправляется на другой сайт. В частности, это может произойти при
вмешательстве в работу серверов DNS, в результате которого действительные имена
DNS ассоциируются с неправильными (или недействительными) IP-адресами.
Существует несколько способов защитить сеть, ее данные и службы. Многие
администраторы полагаются на анонимность и нераспространение информации.
Предполагается, что если никто не знает о вашей сети и ее содержимом, то сеть
надежно защищена. Разумеется, подобная «безопасность» ни от чего не защищает,
потому что многочисленные способы получения информации в Интернете не
позволяют прятаться слишком долго. Наивно полагать, что хакеры не
заинтересуются вашим сайтом, потому что там нет ничего особенно интересного. Для
большинства хакеров вполне достаточно самого процесса получения доступа к данным.
Самая распространенная форма безопасности — хостовая безопасность —
основана на защите каждого компьютера в сети по отдельности. В частности,
хостовая безопасность используется при настройке прав доступа в системе
Windows и при настройке разрешений файловой системы в Unix. Хотя хостовая
безопасность может защитить отдельные компьютеры, было бы неправильно
полагать, что сеть, состоящая из защищенных компьютеров, автоматически стаио-
вится защищенной. Нужно лишь найти одну «брешь», и вся сеть станет открытой
для хакеров. Кроме того, поскольку уровень защиты на разных компьютерах
может различаться, использование средств плохо защищенного компьютера
позволит без проблем получить доступ к хорошо защищенному компьютеру.
Функции брандмауэров
Большинству из нас следует ориентироваться на уровень сетевой безопасности.
Под этим термином подразумевается защита всех точек доступа к сети с
применением хостовой безопасности внутри нее. Ключевым компонентом сетевой
безопасности является брандмауэр (firewall) — компьютер, который обеспечивает
взаимодействие сети и Интернетом, уделяя основное внимание безопасности.
Брандмауэр выполняет несколько функций:
О Сокращение количества точек доступа к сети до минимума.
О Предотвращение несанкционированного доступа к сети.
О Принудительная отправка трафика в Интернет через защищенные точки.
О Предотвращение атак типа отказа от обслуживания.
О Ограничение возможных действий в сети со стороны пользователей
Интернета.
Брандмауэры не ограничиваются подключениями сети к Интернету, они также
используются на серверах удаленного (модемного) доступа и при объединении
сетей. Принцип работы брандмауэра заключается в направлении всего
входящего и исходящего трафика по каналу, настройка которого обеспечивает контроль
за службами и доступом.
Использование брандмауэров
Многие полагают, что брандмауэр представляет собой отдельный компьютер,
и в некоторых сетях это действительно так. Существуют готовые конфигурации,
которые не делают ничего, кроме выполнения шлюзовых функций в системе
безопасности. Кроме того, администратор сети может создать отдельный хост,
на котором будет работать только программное обеспечение брандмауэра. Тем
не менее термин брандмауэр в большей степени относится к выполняемым
функциям, нежели к физическому устройству. Брандмауэр может состоять из
нескольких компьютеров, совместная работа которых обеспечивает управление
взаимодействием сети с Интернетом. Для выполнения этих функций существует
множество различных программ. Однако возможности брандмауэров отнюдь не
ограничиваются простым отслеживанием обращений к сети.
Брандмауэры не обеспечивают стопроцентной гарантии. Довольно часто в них
обнаруживаются дефекты, которые могут использоваться хакерами. Вдобавок
брандмауэры весьма дороги, а на их установку и настройку уходит немало
времени. И все же преимущества, получаемые большинством сетей от применения
брандмауэров, значительно превышают проблемы.
Брандмауэры способны на многое. Они обеспечивают единую точку для
реализации всех мер безопасности в сети, благодаря чему изменения вносятся в одном
месте, а не на каждом компьютере в сети (например, можно запретить
анонимный доступ FTP). Брандмауэры обеспечивают соблюдение политики
безопасности на уровне сети — например, запретить доступ к службам Интернета для
всех, кто находится внутри сети. Впрочем, брандмауэры не всесильны, и вы
должны понимать, чего они сделать не смогут. Брандмауэр никак не помешает
пользователю, находящемуся внутри сети, сделать что-либо с другим
компьютером сети. Брандмауэр не защитит сеть от вторжения с другого подключения —
например, если компьютер с системой Windows подключится к Интернету по
модему через поставщика (если пересылка данных не проходит через
брандмауэр, вся безопасность, предоставляемая брандмауэром, будет фактически
обойдена). Наконец, брандмауэр не спасает от многих напастей, распространяемых
через Интернет, таких как вирусы и троянские программы.
Существует два варианта реализации брандмауэра в сети:
О самостоятельное построение на основе базовых сетевых служб;
О приобретение коммерческого продукта.
Второй вариант проще, но он обходится достаточно дорого. Например,
типичный пакет программного обеспечения брандмауэра для Unix в небольшой сети
стоит от $10 000 и выше. С увеличением размеров сети стоимость программного
обеспечения брандмауэра может возрасти более чем в 10 раз! Преимущества
коммерческих пакетов просты: большая часть работы уже выполнена за вас.
Остается лишь воспользоваться меню для выбора служб, доступ к которым
нужно разрешить или запретить, а пакет сделает все остальное. При
самостоятельном построении брандмауэра для решения тех же задач приходится
настраивать компьютер, находящийся между сетью и Интернетом. Разрешение или запрет
доступа требует ручной настройки каждой службы. Например, на компьютерах
с системой Unix для блокировки некоторых типов запросов приходится
редактировать файлы конфигурации сети и такие файлы, как /etc/services.
Самостоятельное построение брандмауэра занимает много времени, требует опыта и
долгих экспериментов. С другой стороны, вам не придется тратить много денег на
покупку коммерческого пакета.
При установке брандмауэра вам будет предоставлена возможность настроить
несколько аспектов защиты. Захотите ли вы реализовывать их все — решайте
сами. Однако при этом необходимо знать, что означают некоторые понятия, в том
числе «прокси-сервер» и «пакетный фильтр». Ниже смысл этих терминов
объясняется более подробно.
Прокси-серверы
Прокси-сервер находится между сетью и Интернетом, принимает запросы к
службам, анализирует их и, если сочтет запрос допустимым, — передает для
дальнейшей обработки. Фактически прокси-сервер предоставляет промежуточную точку,
через которую должно производиться подключение к службе. Например, если
вы находитесь внутри сети и хотите воспользоваться службой Telnet для
подключения к интернет-хосту, прокси-сервер примет запрос, решит, стоит ли
разрешить такое подключение, и затем создаст сеанс Telnet между собой и сервером
Telnet. Прокси-сервер находится между пользователем и сервером Telnet,
скрывает часть информации от пользователя, а все взаимодействие со службой
осуществляется через него. Прокси-серверы работают со службами и
приложениями, поэтому их часто называют «шлюзами уровня приложения».
Для чего нужны прокси-серверы? Представьте, что вы работаете над
секретным проектом и хотите скрыть от Интернета всю информацию, относящуюся к
вашей сети, — IP-адреса, учетные данные пользователей и т. д. При создании
сеанса Telnet с удаленным хостом по Интернету ваш IP-адрес будет передан в
пакетах. По адресу хакер может определить размер сети, особенно если мимо него
проходят пакеты с разными IP-адресами. Прокси-сервер заменяет ваш IP-адрес
своим собственным и использует внутреннюю таблицу для распределения
входящего и исходящего трафика между нужными сторонами. За пределами сети
виден только один IP-адрес, принадлежащий прокси-серверу. Иначе говоря,
из-за специфики своей работы прокси-сервер также выполняет функции
преобразования сетевых адресов (NAT).
Прокси-серверы всегда реализуются на программном уровне. Они не обязаны
быть частью программного обеспечения брандмауэра, но обычно выбирается
именно этот вариант. Многие коммерческие брандмауэры также обладают
функциями прокси-сервера. С другой стороны, многие программные прокси-серверы
не ограничиваются выполнением посреднических функций; они также
контролируют состав используемых приложений и блокируют некоторые
входящие/исходящие данные.
Если вы предпочитаете строить брандмауэр самостоятельно, существует ряд
пакетов, упрощающих эту задачу. Наибольшее распространение получил пакет
SOCKS. Другой популярный пакет, TIS FWTK (Trusted Information Systems
Internet Firewall Toolkit), содержит готовые прокси-серверы, написанные для
многих приложений TCP/IP, в том числе FTP и Telnet.
Пакетные фильтры
Система фильтрации пакетов (пакетный фильтр) обеспечивает избирательное
прохождение пакетов из сети в Интернет, и наоборот. Иначе говоря, он
отфильтровывает некоторые пакеты, предотвращая их дальнейшее прохождение, и
беспрепятственно пропускает другие. Пакеты различаются по типу приложения,
которым они были сгенерированы. Соответствующая информация берется из
заголовков. Как было показано в предыдущих главах, заголовок пакета TCP/IP
содержит IP-адреса отправителя и получателя, номера портов отправителя и
получателя (также используемые для идентификации приложения), тип
протокола (TCP, UDP или ICMP) и прочие данные. Например, если вы решили
полностью заблокировать весь входящий и исходящий трафик FTP в своей сети,
пакетный фильтр обнаруживает все пакеты с номерами портов 20 и 21 и не
пропускает их. Фильтрация пакетов может выполняться программным
обеспечением брандмауэра или маршрутизатора. Во втором варианте маршрутизатор
называется экранирующим.
Экранирующий маршрутизатор отличается от обычного только способом
обработки пакетов. Обычный маршрутизатор просто анализирует IP-адреса и
пересылает пакеты по правильному маршруту к получателю. Экранирующий мар-
шрутизатор анализирует заголовок и не только строит маршрут к получателю,
но и на основании заданного набора правил решает, нужно ли пересылать
данный пакет. Иначе говоря, экранирующий маршрутизатор не ограничивается
выполнением функций уровня 3.
Напрашивается мысль, что система фильтрации пакетов обходится
изменением номера порта, и до некоторой степени это действительно возможно. Тем
не менее, поскольку пакетный фильтр работает в вашей сети, он также может
вычислить, какому интерфейсу будет передан пакет и откуда он поступил.
Следовательно, даже при изменении номеров портов TCP пакетным фильтрам
иногда удается правильно блокировать трафик.
Существует несколько вариантов использования пакетных фильтров. В самом
распространенном варианте фильтр используется для простой блокировки
отдельных служб (например, FTP или Telnet). Также можно указать отдельные
компьютеры, для которых следует запретить или разрешить трафик. Например, если
некоторая сеть создает слишком много проблем, можно приказать пакетному
фильтру на основании IP-адреса игнорировать все пакеты, поступающие из этой
сети. В особых случаях фильтр может блокировать все службы или
ограничиваться минимальным набором служб (например, пересылкой электронной почты).
Защита служб
Одним из ключевых аспектов настройки брандмауэра является принятие
решений о том, какие службы следует пропускать через интерфейс сети с
Интернетом, а какие следует запретить. Хотите ли вы разрешить подключения из сети
к внешним компьютерам через FTP? А как насчет запросов web-страниц?
В этом разделе приведены очень краткие описания основных служб,
используемых через брандмауэр, и присущих им проблем безопасности.
Администратор разрешает или запрещает отдельные службы, руководствуясь требованиями
безопасности своей сети.
Многие брандмауэры по умолчанию разрешают прохождение шести служб:
О электронная почта (SMTP);
О HTTP (доступ к World Wide Web);
О FTP;
О Telnet (удаленный доступ);
О Usenet (NNTP);
О DNS (разрешение имен хостов).
Как будет показано ниже, эти шесть служб не лишены проблем, связанных
с безопасностью.
Электронная почта (SMTP)
Электронная почта используется чаще всех остальных служб Интернета, поэтому
прохождение ее через брандмауэр ограничивается крайне редко. У почтовых
программ, широко распространенных в Интернете (например, sendmail), были
свои проблемы с безопасностью, но этим проблемам уделялось пристальное
внимание, и они были решены. Современные почтовые программы хорошо
защищены от хакеров, однако передаваемые сообщения могут содержать вирусы.
Большинство систем электронной почты использует протокол SMTP (Simple
Mail Transfer Protocol). При обработке почты сервер SMTP часто использует
привилегии суперпользователя или учетной записи, которой адресовано
сообщение. Умный хакер может воспользоваться сменой привилегий. Самый
распространенный сервер SMTP sendmail работает в системе Unix. Чтобы хакеры не
могли пользоваться дефектами sendmail, необходимо установить все последние
обновления этой программы.
Другая проблема заключается в том, что протокол SMTP не поддерживает
аутентификации заголовков сообщения, что позволяет хакерам и программам
массовой рассылки фальсифицировать заголовки. Программа sendmail должна
быть настроена на проверку действительности адресов электронной почты и имен
DNS, используемых в заголовках сообщений. Последние обновления sendmail
находятся по адресу http://www.sendmail.org.
ПРИМЕЧАНИЕ
В последнее время объектами атаки все чаще становятся почтовые клиенты Microsoft (такие, как
Outlook и Outlook Express). Вредоносное действие большинства атак основано на простоте доступа
к Outlook из сценарных языков (в частности, VBScript). Как правило, злоумышленник обманным
путем заставляет почтового клиента выполнить некоторый сценарий. Сценарий читает адресную
книгу и рассылает себя всем лицам, перечисленным в книге.
HTTP: World Wide Web
В наши дни практически любая сеть имеет выход в Интернет. Весьма вероятно,
что вам не потребуется ограничивать доступ из внутренней сети через
брандмауэр. Разрешение доступа в Web с компьютеров сети не создает особой угрозы
для безопасности, если не считать загрузки вредоносных апплетов Java, но эта
проблема решается при помощи программ обнаружения вирусов на
компьютерах-получателях.
Другая, более серьезная проблема — обращения пользователей Интернета
к web-серверам внутренней сети. При этом создаются серьезные проблемы
безопасности. Одно из лучших решений этой проблемы заключается в вынесении
хостов, предоставляющих сервис Web, за брандмауэр. Большинство современных
web-серверов достаточно безопасны, хотя известны некоторые дефекты,
которые могут использоваться хакерами. Например, Internet Information Server (IIS)
фирмы Microsoft известен своими многочисленными дефектами безопасности,
для исправления которых приходилось устанавливать специальные
обновления. Также обязательно проследите за тем, чтобы все расширения,
загружаемые на сервер для CGI (Common Gateway Interface) и других подобных вещей,
тщательно защищались посредством назначения соответствующих прав доступа.
FTP
Протокол FTP (File Transfer Protocol) широко используется в Интернете. Тем
не менее возможность пересылки любого файла из Интернета в сеть означает,
что входящие файлы могут содержать вредоносный код (например, вирусы
и троянские программы), передающий информацию о сети хакеру. Служба FTP
сама по себе достаточно хорошо защищена, но и в ней существуют хорошо
известные дефекты безопасности, которые должны исправляться системными
администраторами в зависимости от версии FTP.
Впрочем, еще более серьезная проблема — анонимный доступ FTP, при котором
любой желающий может войти на сервер FTP с гостевого входа. Привилегии
доступа на анонимный сервер FTP должны тщательно контролироваться; в противном
случае квалифицированный хакер легко сможет использовать сервер в своих целях.
ПРИМЕЧАНИЕ
В системах семейства Unix, включая Linux, по умолчанию создается анонимная учетная запись
«ftp» с домашним каталогом /home/ftp. Системный вызов chroot ограничивает анонимный доступ
этим домашним каталогом и не позволяет анонимным пользователям выходить за его пределы.
В качестве меры безопасности следует запретить системным администраторам использовать свои
стандартные учетные записи при регистрации на сервере FTP. Дело в том, что FTP передает
информацию о пароле пользователя в виде обычного текста, который может быть перехвачен
программами-шпионами. Чтобы привилегированные пользователи не могли использовать для входа
данные своих учетных записей, включите их имена в файл /etc/ftpusers. Также следует подумать
об использовании ssh (Secure Shell) для сеансов telnet и ftp. Ssh создает между клиентом и
службой виртуальную частную сеть (VPN). В системах Unix при этом должен работать демон shhd
(Secure Shell Daemon). Бесплатные реализации ssh можно найти на web-сайте www.ssh.com.
Наконец, не разрешайте использовать протокол TFTP (Trivial FTP) через
интерфейс сети с Интернетом. Лишь немногие приложения используют TFTP,
и они обычно не выходят за пределы сети. Дело в том, что TFTP не требует
никакой аутентификации пользователя. Также проследите за тем, чтобы доступ
TFTP ограничивался определенной областью. В семействе Unix TFTP но
умолчанию ограничивается каталогом /tftpboot.
ПРИМЕЧАНИЕ
В системах Unix использование протокола TFTP можно запретить. Для этого следует
закомментировать записи службы TFTP в файлах /etc/inetd.conf или /etc/xinetd.conf и перезапустить демона
inetd или xinetd.
Telnet
Популярная служба Telnet дает возможность пользователю подключиться к
удаленному компьютеру и работать так, словно он подключен напрямую. У Telnet
есть очень существенный недостаток: вся информация передается в
незашифрованном виде. Если Telnet передает имя и пароль для входа в систему, эти
данные пересылаются в виде обычного текста; хакер может перехватить эту
информацию и воспользоваться ей. С этой проблемой можно бороться при помощи
протоколов аутентификации, но на практике Telnet все равно используется
достаточно часто.
Вместо Telnet нередко применяются берклиевские утилиты (rlogin, rsh, exec
и т. д.). В основу их работы заложена концепция доверенного хоста,
неприменимая к Интернету. Берклиевские средства удаленного доступа крайне ненадежны
и легко подвержены атакам хакеров, поэтому их трафик не должен пропускаться
через брандмауэр.
ПРИМЕЧАНИЕ
Вместо Telnet также можно воспользоваться утилитой ssh, позволяющей создавать шифрованные
сеансы между клиентами и серверами.
Usenet: NNTP
Протокол NNTP (Network News Transfer Protocol) является самым
распространенным механизмом отправки и приема материалов Usenet. Если вы собираетесь
принимать новости в свою сеть, использование NNTP потребует тщательного
планирования в сфере безопасности. Протокол NNTP легко может
использоваться хакерами для получения доступа к внутренней сети. К счастью, защитить
NNTP относительно легко, поскольку в каждом сеансе коммуникации между
хостами NNTP почти всегда остаются одинаковыми.
Более важная проблема для пользователей Usenet, особенно в крупных
организациях, — предотвращение отправки материалов внутренних (закрытых)
конференций в Интернет. Возможно, также стоит ограничить состав принимаемых
конференций. Протокол NNTP можно настроить так, чтобы разрешить или
запретить прием практически любых конференций.
DNS
DNS является неотъемлемым компонентом больших сетей и использует
Интернет-хосты для разрешения имен. Проблемы безопасности возникают не столько
из-за самой службы DNS, сколько из-за протоколов, на основе которых она
работает. Установка специальных средств аутентификации помогает убедиться
в подлинности запросов и отсутствии перенаправлений. Впрочем, в целом служба
DNS достаточно хорошо защищена.
Построение собственного брандмауэра
Как уже было сказано, брандмауэр можно построить самостоятельно, хотя для
этого потребуется очень хорошее знание операционной системы и TCP/IP.
Установить качественный брандмауэр в Windows 95 и 98 практически невозможно, что
связано с архитектурой этих операционных систем. В Unix и Windows NT/2000
дело обстоит лучше, хотя настроить брандмауэр в Windows NT/2000 сложнее,
чем в Unix.
Описание процедуры настройки брандмауэра в Windows NT/2000 и Unix
выходит далеко за рамки этой книги. Существует несколько книг, посвященных
только этой теме (для разных операционных систем). В основном настройка
брандмауэра включает блокировку всех служб, которые не должны проходить
в сеть, и настройку брандмауэра для предотвращения доступа к нему со
стороны хакеров. Самостоятельное построение брандмауэра занимает много
времени, даже если вы точно знаете, что нужно сделать.
ПРИМЕЧАНИЕ
Информацию о самостоятельной настройке брандмауэров можно найти на следующих сайтах:
http://www.linux-mag.com/1999-08/guru_01.htm
http://www.linuxgazette.eom/issue26/kunz.html#fire
http://www.hotwired.lycos.com/webmonkey/01/31/index2a_page4.html
http://tech.irt.org/articles/jsl49/
http://www.practicailynetworked.com/serving/firewall_config.htm
http://www.linuxworld.com. au/article.php3?tid=8&aid=160
http://www.isaac.cs.bereley.edu/simple-firewall.html
http://www.ncmag.com/2001_05/ifolder51/settingup.html
Использование коммерческих брандмауэров
На рынке представлено много программных пакетов для установки
брандмауэров, причем все они обычно довольно дороги. Примером коммерческого
брандмауэра может послужить программа Cyberguard от Cyberguard Corporation.
Также стоит упомянуть брандмауэры BorderManager от Novell, Checkpoint от Check
Point Software Trchnologies и Eagle от Raptor Systems. Названия других
коммерческих продуктов можно найти на сайте http://www.thegild.com/firewall/.
Программа Cyberguard существует для платформ Windows NT/2000 и Unix.
Первоначальный вариант был написан для системы Unix, и лишь недавно
программа была адаптирована для Windows NT/2000. Популярность Cyberguard
связана с тем, что это один из самых надежных брандмауэров, который к тому
же чрезвычайно прост в установке, настройке и сопровождении.
ПРИМЕЧАНИЕ
Информацию о Cyberguard можно найти на web-сайте компании http://www.cyberguard.com. Здесь
имеется описание пакета, а также ряд официальных документов. За дополнительной
информацией о брандмауэрах и проблемах безопасности, связанных с их использованием, обращайтесь на
сайт CERT (Computer Emergency Response Team) по адресу http://www.cert.org.
Cyberguard особенно легко устанавливается и настраивается на серверах
Windows NT/2000; для простых сетевых конфигураций эта процедура занимает
не более 15 минут. Программа предназначена для работы на хостах с двумя
подключениями, к внутренней сети и к Интернету (напрямую или через
поставщика услуг Интернета). При установке пакета Cyberguard предлагает выбрать
одну из трех стандартных конфигураций безопасности (рис. 19.1).
Выбрав один из стандартных вариантов, вы можете проверить все параметры,
зависящие от этого выбора. Для этого следует просмотреть последовательно
отображаемые окна и проверить варианты. На рис. 19.2 изображено окно,
которое показывает, как выбранный вариант влияет на учетные записи и пароли
Windows NT/2000.
Далее Cyberguard перезагружает сервер Windows NT/2000, и с этого момента
начинает действовать защита. Администратор может изменить настройку любого
аспекта брандмауэра. На рис. 19.3 изображено окно фильтрации пакетов; с его
помощью администратор выбирает, какие пакеты пропускаются брандмауэром,
а какие должны быть отвергнуты. Как видно из иллюстраций, Cyberguard
использует диалоговые окна Windows для упрощения сложного процесса настройки.
Select a Preset !
\ Choose a Security Preset thai matches your site's security . ;
j policy and your system's requirements.
You may select an Environment Preset that matches your needs, S elect4 View D etaite4' io
examine the specftc security settings sand make fnocSficatiom to the preset S elect' "Skip
to Finish" to proceed to the finish page where you may eppJy your selection.
• Security Pieset* ~- —-^.—-„^..,...- _..„ t
Example Utage: • j I
Г* High Security Dedicatecl Fireweb j
: Г Medium Security ftewals that are Domain Gontiolet* " Sky to Trash j
P* Standard Security Firewal* that are database server? 1
<Iack ]#**'Petals >j ";:': CanceJ |
Рис. 19.1. Три стандартные конфигурации Cyberguard поддерживают большинство
вариантов настройки брандмауэров в Windows NT/2000
'■■ Accounts and Passwords . ;. I
\.\ Select Measures that control user accounts and user ;
4 passwords pi
J,, n.jiM.uin^r^MMnn.ilMm?!^?^.^^!? nmfn V-i м--- ц ■ -- ■ ■ j
IP: rJD Disable Guest account _ :
Enable Strong Password Filtering
Г: F [S Tighten User Rights i
: P m Disallow blank passwords
Description: ТЫ* security measure disables'theguest account.
. <fi«* :.| jjjext> | Caned |
Рис. 19.2. Выбор конфигурации Cyberguard определяет настройку отдельных
параметров, отображаемых в диалоговых окнах
MS System 2 Cpnliguietian Ш Exports $ Iacls Oifi^ndow ? Help j
||^ ••■--—■ И
HI JO deny AU EVERYONE EVERYONE Ш^# Jl
гт^ ■ ■ ■ i ■ ***** j—■,:,,,!:';;:'; ■;■ d .в r-<.- ,,^-/ |.
h «$► г ?ъщ , ;;,;••--у,-,;—;— «„. p ■.-,,>,, .,..<.., I
;* rpt0sy \ . —-- . и г*^.^.-*. jJ
MA Г Den* ' РайкеЮейллюп J ll Ml
HI ; ; _.••• • >>• г^-<.:,*■■->■ ~.:**.с \ .
[I 1 -. : 1 ' ■•^.:ift:1--: • • " r:-..,;:-...-^;:.^W.r^ .Ц
|госКе^р|«$п =:...:H.; ■..■■.■■..jrZJS^l".: -1
Рис. 19.3. Диалоговое окно для определения критериев фильтрации входящих и исходящих пакетов
Функциональность прокси-сервера настраивается так же просто. На рис. 19.4
изображено диалоговое окно настройки прокси-сервера в программе Cyberguard.
Выбор протоколов сводится к простому выделению строк в списке. На рисунке
настраивается прокси-сервер FTP.
^System J Configuration В ВерогЦ $ Ipole OYtfndow ? fcleip \
\ '■■ Tr* ED -1ч ;S' П Sft V <"* Hotiefwi/Oomen Relcom j 0 ;j
jl «~ Inbound-.~; }'Outbound —< -~Ш
11 [ Sm-ytPtoweg | a ,.,,~ i ll.. ■'■,ui'i.i,ililp?i^ft^rP^ i I TofiteweB ] T^oughFrewaS JToFyewaS | Thtoyffij ||
rlftp L^*Jj^ks£'.2*«=5L. _....1.„.05LJ. r~; Г.. 1 JTL , И IL-Ilt II
j HTTP~ Hypertext Truster Protocol ® S *" ~P "' """"' Г '*"G ~ *" P '~'~ ~ P jl]
LDE LoadEquafcei ® V Г Г Ш Г Р, j
||.IWNTP N«KwrkN*mTr*n<™rr Prnrnr.nl (Ь \'l: P Г P P Г ]|j
||] HideOptions I .П? Updatepdck^Hftenngidfts •'•:;' j|j
: Serup jusers |'M««ag«i CVPSe^up] :;.. ":'•. j|J
11 j 17 Atewinbound atrtherticatedFTP Server.) |||
jjl P Afiowinbe*jr*iartor>ymou«FTP Serve» j^ " V:..::"- •'. . . 11;
HI inactiveSessionTimeout(iecGnds} |ЗСЮ |i
ll] p Authent«4tehbound II
||M -;f J ^1
LfaHelpipressFl _ ^.'^Cl.. - ...... I'.^^l'Z'^M
Рис. 19.4. Простое и удобное окно настройки прокси-серверов в Cyberguard
Cyberguard также превосходно справляется с таким аспектом настройки
брандмауэра, как использование DNS. Как видно из рис. 19.5, программа позволяет
легко настроить параметры DNS и даже определить зоны в сети.
Hi System S Configuration Ш Вэро-rtsj; 3 Tools C3 Window 7 Help i
Mi -*►' £3 Зк Ф '■ PS IR ? M « ■;''^fe*i*w '.'Otwire'lpdcMB • jj j r.T 0 ' • *• . • •j
Setup Severs | Zone» | Hwts | ,11
j j [Server 1 bye 1 Interface* :- ■■ 1 Privileged Addresses I Towardc?? I ||
II! HI
II •••• 111
•: i ..,...._......... • i
^fr**0* 1 ''flw< 1 &№**»^\ШлШ\ Сору 1 Fo*eJ Delete j jjj J^j • |
Swver | "'' " Y jtj
ill TVP« Г Irtemal """^t Г external Ш
InMaces . • p205T5O837 • • I ]3
I
Privileged Addiesmj 4|1
\\\<\ : . •, ••■,;,•■•• \; ,• ,,':-r- • : - •••; . J 2O
|faH<jp.pt»ttn ^ _ J.::-j£iiz ..,..,..,......■..,.., ,..,... А~''Щ*Г''''"'...А
Рис. 19.5. Настройка DNS через графический интерфейс Cyberguard
Существует много других коммерческих пакетов, выполняющих функции
брандмауэров. Многие журналы, посвященные сетевым технологиям, регулярно
проводят сравнительное тестирование. Если вы решили приобрести
коммерческий брандмауэр, начните со сбора информации, потому что качество и цена
коммерческих реализаций очень сильно различаются.
Итоги
В этой главе объясняется, что такое брандмауэр, как он работает и какие
основные функции им выполняются. Также вы узнали, как работают прокси-серверы
и пакетные фильтры. Тема безопасности IP продолжена в следующей главе,
где мы рассмотрим некоторые сопутствующие темы, в том числе криптографию
и аутентификацию.
Т1'Л Сетевая и системная
Шш\3 безопасность
Тим Паркер (Tim Parker)
В предыдущей главе рассматривались принципы работы брандмауэров, прокси-
серверов и пакетных фильтров. Брандмауэр играет важную роль в обеспечении
сетевой безопасности, предотвращая вторжения извне и несанкционированный
доступ к конфиденциальным данным. Тем не менее предотвращение доступа
нарушителей к сети является лишь одним из факторов безопасности. Необходимо
позаботиться о решении других проблем — например, убедиться в том, что
пересылаемые по Интернету данные не могут быть прочитаны посторонними; что
лицо, которому вы посылаете почту (или от которого ее принимаете), является
именно тем, за кого себя выдает; наконец, реализовать дополнительные меры
безопасности в сети на тот случай, если злоумышленнику все же удастся
проникнуть через брандмауэр.
Определить нужный уровень безопасности в объективных показателях
нелегко. Хотя большинство операционных систем предоставляет базовую защиту
файлов и каталогов, вам могут понадобиться механизмы шифрования или
другие методы предотвращения постороннего доступа. Не существует единой
системы оценок уровней безопасности, хотя Министерство обороны США
попыталось назначать разные уровни безопасности своим компьютерам (работающим
в основном под управлением Unix или специализированных операционных
систем). Ниже эти уровни перечисляются в порядке возрастания безопасности:
О D: отсутствие мер безопасности или защиты данных.
О С1: пользователи идентифицируются по данным, указанным при входе в
систему; возможен контроль доступа к файлам и каталогам.
О С2: уровень С1 в сочетании со средствами аудита (регистрация системной
активности) и назначением административных привилегий.
О В1: уровень С2 в сочетании со средствами управления доступом, которые не
могут переопределяться пользователями.
О В2: уровень В1 в сочетании с безопасностью всех устройств, поддержкой
доверенных хостов и управлением доступом на уровне приложений
О ВЗ: уровень В2 в сочетании с возможностью группировки системных
объектов с управлением доступом на уровне этих групп.
О А1: уровень ВЗ в сочетании с проверенной и заведомо надежной системной
архитектурой аппаратного и программного обеспечения.
Уровень безопасности А1 обычно считается недостижимым. В настоящее
время не существует ни одной операционной системы, которая бы его
обеспечивала (по крайней мере, открытая информация на этот счет отсутствует).
Большинство разновидностей Unix и Windows NT может обеспечивать безопасность
уровня С2, некоторые операционные системы были сертифицированы на
соответствие уровню В1, но более высокие уровни ограничения, накладываемые
требованиями безопасности, слишком сильно отражаются на работе системы.
Но что же делать с существующими системами на базе Windows, Macintosh
и Linux, подключенными к локальной сети? Вы должны предпринять ряд
действий по защите этих систем, а также работающих на них приложений от
вторжения извне. Если подключение к Интернету производится через TCP/IP,
необходимо знать о проблемах безопасности, связанных с этим протоколом и его
практическими применениями.
Мы начнем эту главу со знакомства с шифрованием — одного из
механизмов, обеспечивающих защиту данных даже в случае их перехвата. Далее будут
рассмотрены вопросы безопасности сети и приложений TCP/IP.
Шифрование
В наши дни трудно найти правительственные организации или коммерческие
предприятия, которые бы не заботились о безопасности своих данных —
особенно при виде ежедневно появляющихся сообщений о проникновении хакеров
в корпоративные сети, промышленном шпионаже и саботаже со стороны
бывших работников. Многие работники работают в корпоративных сетях в режиме
удаленного доступа, подключаясь из дома, гостиниц или прямо в пути по
средствам сотовой связи. В таких условиях очень важно обеспечить высокий
уровень защиты данных. Также следует подумать о защите данных, передаваемых
по Интернету и телефонным линиям, чтобы в случае перехвата злоумышленник
не смог бы прочитать эти данные. Единственным эффективным и относительно
дешевым способом защиты этих данных является шифрование.
Шифрование данных стало одной из крупных и выгодных отраслей. К
нескольким ведущим компаниям, развивавшим средства шифрования в течение
десятилетий, прибавляются новые фирмы, специализирующиеся на технологиях
шифрования. Всего пару лет назад найти хорошие средства шифрования было нелегко,
потому что спецслужбы пытались предотвратить появление сильных алгоритмов
шифрования (что затруднило бы их собственную работу). До последнего времени
в США считалось незаконным применение любых технологий с более чем
40-разрядным шифрованием — системы шифрования считались оружием. Впрочем,
с распространением бесплатных и условно-бесплатных продуктов шифрования
в Интернете, а также под давлением разработчиков приложений и операционных
систем ограничение было снято, и теперь продукты с 128-разрядным
шифрованием разрешается распространять практически во всех странах (за редкими
исключениями). В отдельных странах разрешены еще более сильные методы
шифрования.
В общих чертах алгоритмы шифрования при помощи ключа преобразуют
данные к виду, который может быть прочитан лишь стороной, обладающей
ключом для расшифровки. Чем длиннее ключ, тем больше времени требуется на
раскрытие шифра. Простое шифрование с применением паролей успешно
работает, потому что пароль должен быть известен обеим сторонам. Если сообщение
было зашифровано с использованием пароля, оно может быть расшифровано
только с тем же паролем.
Если вам нужны простые средства шифрования с применением паролей,
опробуйте программу CodedDrag по адресу http://www.fim.uni-linz.ac.at/codeddrag/
codedrag.htm. Пробная копия CodedDrag бесплатна, а ее регистрация для
неограниченного использования требует лишь небольшого пожертвования в фонд
данного сайта. В программе CodedDrag, разработанной университетом Линца
(Австрия), реализован очень быстрый вариант алгоритма шифрования DES (Data
Encryption Standard). Точнее, CodedDrag предоставляет на выбор пользователя
алгоритмы DES, Triple-DES и BlowFish; два последних алгоритма взломать
гораздо сложнее, чем DES. CodedDrag подключается к рабочему столу
Windows 95/98 и Windows NT и добавляет команды шифрования и расшифровки
в контекстные меню. После однократного ввода пароля файлы шифруются и
расшифровываются так быстро, что процесс остается незаметным для
пользователя. В Windows 2000 файловая система NTFS версии 5 позволяет зашифровать
содержимое любого файла или папки, для чего достаточно соответствующим
образом пометить этот файл или папку. Расшифровать файлы может только
пользователь или агент восстановления (с административными правами). Файлы
автоматически расшифровываются при использовании и шифруются при закрытии.
Шифрование с парными ключами
Схема шифрования с парными ключами пользуется гораздо большей
популярностью среди пользователей Интернета, поскольку она позволяет
расшифровывать сообщения без ввода отдельного пароля для каждого сообщения. Принцип,
по которому работает система шифрования с парными ключами, прост: имеются
два строковых ключа, один из которых (открытый) доступен для всех желающих;
другой ключ (закрытый) известен только вам. Чтобы отправить зашифрованное
сообщение, другой стороне нужен открытый ключ. Программа шифрования
шифрует сообщение с использованием открытого ключа. После того как
сообщение будет получено, оно может быть расшифровано только с закрытым
ключом, поэтому только обладатель закрытого ключа сможет прочитать сообщение.
Открытый ключ не может использоваться для расшифровки сообщений. Для
отправки сообщения другой стороне вам потребуется ее открытый ключ. Чтобы
содействовать распространению подобного способа шифрования, многие
пользователи присоединяют открытые ключи к своей электронной почте.
RSA
Проект RSA Data Security (http://www.rsa.com), основанный в 1977 году тремя
учеными из Массачусетсского технологического института, был одним из пер-
вых коммерческих проектов, обеспечивающих средства шифрования с парными
ключами. Алгоритм RSA продолжает широко использоваться в наши дни; он
требует относительно малых ресурсов, обладает очень высокой надежностью
и прост в использовании. Программное обеспечение RSA существует в разных
формах для разных операционных систем; в простейшем варианте оно
добавляет несколько новых команд меню в программы просмотра типа Проводника
Windows. Если выделить файл и выполнить команду Encrypt, файл
автоматически шифруется после ввода пароля. При расшифровке соответствующая
команда меню отображает окно для ввода пароля, и если введенный пароль
правилен — пользователь получает доступ к восстановленному файлу. Для
упрощения процесса пароли могут сохраняться в системе.
PGP
Одним из самых знаменитых средств шифрования стала система PGP (Pretty
Good Privacy) Фила Циммермана (Phil Zimmermann). За свободное
распространение PGP в Интернете правительство США выдвинуло обвинение против
Циммермана. В конце концов дело было закрыто, но эта история практически
гарантировала широкое распространение PGP, особенно в других странах.
Реализации PGP имеются на многих web-сайтах, и ключи PGP нередко прилагаются
к сообщениям электронной почты.
Шифрование с симметричным закрытым ключом
Базовая форма шифрования называется шифрованием с симметричным
закрытым ключом. При шифровании с симметричным закрытым ключом используется
подстановка, при которой каждая буква заменяется другой буквой: например, все
вхождения а заменяются на х, все вхождения b заменяются на d и т. д. В
простейшем варианте выбирается постоянная величина сдвига, и все замены
осуществляются с соответствующим смещением позиции (а заменяется на d, b — на с,
с — на f и т. д.).
Более гибкие схемы с симметричным ключом обеспечивают случайный
подбор пар, а иногда для расшифровки сообщения необходимо знать пароль.
Шифрование с симметричным ключом легко реализуется и быстро работает. К
сожалению, простые схемы с симметричным ключом также обладают наименьшей
надежностью. Причина проста: при достаточно большом объеме текста по
относительному распределению частот символов можно вычислить соответствие
между буквами. Например, самой распространенной буквой в английском языке
является «е»; если в зашифрованном тексте буква «х» встречается чаще других
символов, можно предположить, что буквы «е» в исходном тексте в процессе
шифрования были заменены на «х». После подбора нескольких пар остальные
пары легко подбираются по фрагментам слов. «Симметричность» означает, что
один и тот же ключ используется как для шифрования, так и для расшифровки.
Для повышения надежности алгоритмов шифрования с симметричным ключом
были разработаны дополнительные схемы, вносящие дополнительный
случайный сдвиг в зависимости от позиции в тексте.
DES, IDEA и другие
Фирма IBM в 1976 году разработала стандарт DES для правительства США.
Алгоритм DES использует 56-разрядный ключ шифрования, что позволяет
использовать 72 057 594 037 927 936 разных ключей. Один и тот же ключ
используется как для шифрования, так и для расшифровки сообщений. DES не является
простой схемой шифрования с симметричным закрытым ключом — подстановка,
то есть соответствие между парами букв, изменяется в зависимости от позиции
символа. Теоретически DES всегда можно взломать. Для этого необходимо
проверить 72 квадриллиона возможных комбинаций, но нашлись люди, которые
справились с этой задачей (и выиграли $10 000 за свою работу) и доказали,
что DES не обеспечивает абсолютной надежности. Дополнительная информация
о раскрытии шифра DES приведена по адресу http://www.cryptography.com/des.
ПРИМЕЧАНИЕ
Для проведения быстрого подбора ключей DES использовался компьютер, построенный Cryptography
Research, Advanced Wireless Technologies и EFF. В проекте DES Key Search было задействовано
специальное оборудование и программы, обеспечивающие перебор около 90 миллиардов ключей
в секунду. В результате после 56 часов работы ключ был успешно подобран.
В ходе работы семинара DIMACS в 1995 году был опубликован документ, в котором описывалось
применение молекулярной электроники для подбора ключа DES примерно за 4 месяца работы.
Кроме того, в документе было показано, что при некоторых условиях и предварительной обработке
текста ключ DES может быть подобран за один день. Этот метод обобщается для взлома любой
криптографической системы, использующей ключи с длиной более 64 бит.
Алгоритм Triple DES CDES) представляет собой модификацию базового
алгоритма с увеличенным ключом, что значительно затрудняет взлом шифра.
Вероятно, самым надежным из всех современных алгоритмов шифрования
является алгоритм IDEA (International Data Encryption Algorithm),
разработанный Швейцарским федеральным технологическим институтом. Для повышения
надежности алгоритм IDEA использует 64-разрядный блок в 128-разрядном
ключе с обратной связью. Уже появилась усовершенствованная версия IDEA,
которая называется Triple IDEA. Полный алгоритм IDEA работает относительно
медленно, поэтому был разработан ряд упрощенных версий, в том числе
популярный вариант Tiny IDEA. Считается, что IDEA превосходит по надежности
как DES E6-разрядный ключ), так и Triple-DES A12-разрядный ключ). Ниже
перечислены некоторые характеристики Tiny IDEA:
О Файлы обрабатываются «на месте» (то есть с замещением оригинала).
О Использование 8-проходного алгоритма IDEA в режиме обратной связи.
О Заполнение вектора инициализации нулями.
О Обратная связь осуществляется 8-байтовыми блоками.
О Ключ IDEA представляет собой пользовательский ключ, дополненный
символом '\г' и нулями.
О Алгоритм оптимизирован по затратам памяти, а не по скорости, но работает
все равно быстро.
За дополнительной информацией о Tiny IDEA обращайтесь по адресу http://
www.cypherspace.org/~adam/rsa/idea.html. Здесь же можно загрузить бесплатную
копию программы.
Алгоритм CAST получил свое название по именам разработчиков — Карлайла
Адамса (Carlisle Adams) и Стаффорда Тавареса (Stafford Tavares). В нем
используется 64-разрядный ключ и 64-разрядный блок. Подробности не столь
существенны, поскольку на их объяснение потребовалась бы отдельная книга. Алгоритм
CAST до настоящего времени еще не был взломан, но как и IDEA, он несколько
замедляет шифрование и расшифровку данных. За дополнительной
информацией о CAST обращайтесь по адресу http://www.cs.wm.edu/~hallyn/des/sbox.html.
Система шифрования Skipjack была разработана Агентством национальной
безопасности США специально для чипа Clipper, который правительство США
планировало установить во всех устройствах связи. До практической
реализации этого плана так и не дошло, но система Skipjack существует. Подробная
информация засекречена; известно, что в Skipjack используется 80-разрядный
ключ с 32-проходной обработкой. В работе Skipjack задействованы два ключа:
закрытый и главный ключ, находящийся в распоряжении правительства.
Теоретически на взлом Skipjack с использованием лучшего современного
оборудования потребуется около 400 миллиардов лет.
В RSA Data Security были разработаны секретные алгоритмы RC2 и RC4.
К сожалению, исходные тексты алгоритмов были опубликованы в Интернете, так
что особого секрета не получилось. Алгоритм RC4 считался достаточно хорошо
защищенным и использовался Netscape в экспортных версиях Navigator. Шифр
был одновременно взломан двумя разными группами, на решение этой задачи
потребовалось около восьми дней.
Какие же из упомянутых алгоритмов шифрования быстрее и надежнее
остальных? С надежностью однозначного фаворита нет; алгоритмы Triple DES,
IDEA и Skipjack достаточно хорошо защищены и взломать их практически
невозможно. Тем не менее дополнительная защита требует значительных затрат
на шифрование и расшифровку. Если предположить, что шифрование или
расшифровка документа с применением DES занимает одну секунду, то Triple DES
на выполнение этой операции потребуется 3 секунды, IDEA — 2,5 секунды,
и Triple IDEA — 4 секунды. На первый взгляд затраты не так уж велики, но при
обработке множества больших файлов задержки, присущие более защищенным
алгоритмам, становятся более заметными. Теоретически Skipjack не уступает DES
по скорости, но кто рискнет доверить ключ к своим секретам правительству?
Из всех систем шифрования с парными ключами в наши дни чаще всего
используется алгоритм RSA, названный по фамилиям разработчиков (Ривест, Ша-
мир и Адельман, если вы вдруг захотите поразить окружающих своей
эрудицией). Его ближайшим конкурентом является алгоритм PGP Фила Циммермана.
RSA и PGP используют очень длинные ключи, нередко их длина равна 100
битам и более. Чем длиннее ключ, тем больше времени требуется на шифрование
и расшифровку и тем труднее вскрыть шифр без ключа. На практике нередко
встречаются 1024-разрядные ключи. На сайте RSA (http://www.rsa.com/rsalabs/)
обсуждается зависимость надежности шифрования от длины ключа. Для взлома
512-разрядных ключей потребуются серьезные вычислительные мощности, но
эта задача вполне реальна. Ключи большей длины G68- или 1024-разрядные)
требуют вычислительных мощностей, недоступных для большинства
злоумышленников. Теоретически любая система, основанная на использовании ключей,
может быть вскрыта простым перебором или при помощи удачной догадки,
основанной на знании зашифрованного текста, но на практике алгоритмы RSA
и PGP достаточно надежны при использовании длинных ключей.
Система Диффи—Хеллмана (Diffie—Hellman) относится к категории
алгоритмов, генерирующих ключи для открытого распространения. Она не шифрует
и не расшифровывает сообщения, а используется исключительно для создания
надежных ключей. Процесс прост, но требует участия обеих взаимодействующих
сторон (отправителя и получателя) для построения ключа с использованием
простых чисел.
Аутентификация с применением
цифровых подписей
Кроме шифрования данных, для обеспечения безопасного обмена информацией
необходимо решить другую важную проблему — проверки подлинности
отправителя (или получателя) сообщения. Для аутентификации отправителей и
получателей используется система так называемых цифровых подписей. Цифровые
подписи основаны на шифровании с парными ключами, при этом открытый
ключ предоставляется любому, кто пожелает проверить подлинность
отправителя, а сообщение шифруется с применением закрытого ключа.
Правительство США разработало и приняло к использованию систему DSS
(Digital Signature Standard), которая, как следует из ее названия, обеспечивает
аутентификацию с использованием цифровых подписей. Впрочем, у системы
DSS имеется один крупный недостаток: если одно и то же случайное число,
используемое при шифровании, будет выбрано дважды и хакер имеет доступ
к обоим сообщениям, он сможет легко получить доступ к ключу. Что еще хуже,
содержимое зашифрованных сообщений иногда достаточно легко
расшифровывается.
Алгоритмы SHA (Secure Hash Algorithm) и SHS (Secure Hash Standard) также
были разработаны правительством США, но они превосходят DSS по надежности,
В SHS используется алгоритм хэширования с 160-разрядным ключом. К
сожалению, SHS относительно медленно работает. Если принять во внимание скорость
работы RSA и PGP, трудно найти доводы в пользу применения SHS.
Другая разновидность цифровых подписей — алгоритмы профилирования
сообщений. Из них в широком обращении находятся три алгоритма (MD2,
MD4 и MD5). Алгоритмы категории MD обрабатывают блок входных данных
и генерируют 128-разрядный цифровой профиль. Теоретически два сообщения
никогда не обладают одинаковыми профилями. Наиболее защищенным из
перечисленных алгоритмов является алгоритм MD5, разработанный RSA с
применением специального алгоритма хэширования. Фирма Microsoft использует MD4
в своих файлах пользователей Windows NT для шифрования паролей.
ПРИМЕЧАНИЕ
Алгоритм MD4 неоднократно вскрывался. В Web легко находятся программы для вскрытия файлов
паролей Windows NT (например, http://js-it-true.org/nt/atips/atips92.shtml и http://www.atstake.com/
research/lc3index.html). Вскрытие паролей в Windows 2000 рассматривается в статье 9186 на сайте
http://www.windowsitsecurity.com/Articles. Квалифицированный администратор может
воспользоваться этими программами для проверки безопасности в сетях Windows. Хакеры уже знают об
этом дефекте, поэтому публикация этих сведений не сделает вашу систему более уязвимой.
Серверы сертификации управляют ключами, выдаваемыми компаниям и
организациям, и обычно легко доступны через Интернет. Существует несколько
коммерческих серверов сертификации для платформ Windows и Unix. Одна из
лучших реализаций принадлежит Netscape. Кроме того, Netscape публикует
список FAQ (http://home.netscape.com/certificate), который объясняет, для чего нужны
серверы сертификации, а также описывает возможности продукта.
Говоря об аутентификации, невозможно не упомянуть о Kerberos. Каждый,
кто когда-либо занимался установкой серверов или сопровождением программного
обеспечения Web, наверняка сталкивался с этим названием. Пакет Kerberos
обеспечивает сетевую безопасность посредством контроля доступа к сетевым
службам на уровне пользователей. Серверы Kerberos работают в сети (обычно
на защищенном компьютере) и иногда называются центрами распределения
ключей (KDC, Key Distribution Centers). Каждый раз, когда пользователь пытается
воспользоваться некоторой сетевой службой, сервер Kerberos проверяет, что
пользователь является именно тем, за кого он себя выдает и что служба работает
на соответствующем хосте. Безопасность системы Kerberos основана на
использовании системы шифрования с закрытым ключом, которая, в свою очередь,
основана на алгоритме DES. Каждому клиенту и каждому серверу в сети выдается
закрытый ключ, который проверяется при любых операциях, находящихся под
управлением Kerberos. Kerberos работает на выделенном сервере и поэтому
обычно используется в больших сетях, а также в сетях, требующих усиленных
мер безопасности.
Раскрытие шифров
Наука (а по мнению некоторых — искусство) взлома криптографических систем
называется криптоанализом. Конечная цель криптоанализа — прочитать
зашифрованное сообщение без знания ключа, который использовался при шифровании.
Некоторые факторы уменьшают объем работы по взлому кодов; самый
распространенный прием основан на знании части сообщения или ключа. Например,
если заранее известно, что в сообщении говорится об акциях компании ABC,
вам будет гораздо проще выдвинуть обоснованные предположения относительно
некоторых слов в зашифрованном сообщении, а это способствует ускорению
расшифровки.
Иногда закрытые ключи случайно или преднамеренно попадают в руки
посторонних. Знание части ключа или его особенностей также ускоряет
расшифровку. Например, если вы знаете, что некоторое лицо часто выбирает в качестве
ключа имена своих детей, которые нетрудно узнать, вы существенно
приблизитесь к раскрытию шифра. Получение ключей обычно не вызывает особых
трудностей, особенно если сообщения пересылаются в Интернете. Существует много
способов перехвата пакетов IP; иногда из перехваченной информации удается
получить представление о ключах пользователя. Если хакеру известна хотя бы
часть ключа или он знает открытые ключи обеих сторон, шансы на расшифровку
всего сообщения заметно повышаются.
Если эти полезные приемы не работают, криптоанализ продолжает
действовать методом «грубой силы». Существует много подходов к расшифровке
сообщений; выбор зависит от методики, которую предпочитает использовать хакер,
предположений относительно сообщений и ключа, а также сообразительности
хакера и имеющихся в его распоряжении вычислительных ресурсов. Если
никакой информации, кроме текста сообщения, не имеется, используется метод
перебора. Компьютер пытается расшифровать сообщение с разными ключами,
иногда с помощью хакера, который пытается угадать отдельные слова в
сообщении. Поскольку большинство сообщений имеет стандартный формат (сколько
вы знаете разных вариантов структуры деловых писем?), часть зашифрованного
текста иногда помогает определить ключ для расшифровки всего сообщения.
Если известен алгоритм шифрования, хакер может попытаться шифровать
другое сообщение по тому же алгоритму (но с другим ключом). Повторяя этот
процесс с разными сообщениями и ключами, можно получить представление о
ключе, использовавшемся для шифрования исходного сообщения. Данная
методика работает на удивление эффективно.
Также существуют сложные математические способы расшифровки
сообщений, основанные на тонкостях алгоритма с парными ключами. Между ключами
и зашифрованным сообщением существует связь, которую можно
проанализировать при достаточно больших вычислительных мощностях. Математики
написали целые книги, посвященные теории раскрытия шифров. Многие приемы,
описанные в этих книгах, используются учеными и инженерами, работающими
в области национальной безопасности.
Защита сети
Локальные сети редко рассматриваются как угроза для безопасности, однако
именно они открывают один из самых простых путей в систему. Если хотя бы
один узел сети имеет плохо защищенную точку доступа, то все остальные узлы
становятся доступными через сетевые службы этого компьютера.
PC и Macintosh обычно слабо защищены (особенно при внешнем
подключении по модему), поэтому через них злоумышленник может получить доступ
к сетевым службам. Основное правило безопасности в локальных сетях гласит,
что защищенный компьютер не может существовать в одной сети с
незащищенными компьютерами. Следовательно, любые решения в области
безопасности, примененные на одном компьютере, должны быть реализованы на всех
машинах сети.
Вход в систему и пароли
Самый распространенный способ несанкционированного входа в систему по сети,
модемному подключению или через терминал основан на использовании
слабых паролей. Слабые (а значит, легко подбираемые) пароли встречаются очень
часто. Если пользователи системы используют слабые пароли, даже лучшая
система безопасности не защитит от вторжения.
Если под вашим управлением находится система с несколькими
пользователями, установите политику безопасности, в соответствии с которой пользователи
будут регулярно изменять свои пароли (рекомендуемый срок составляет от
шести до восьми недель), причем в качестве пароля не могут использоваться
английские слова. Лучшими паролями считаются комбинации букв и цифр,
отсутствующие в словарях.
Однако в некоторых случаях одних правил защиты от слабых паролей
оказывается недостаточно. Рассмотрите возможность использования общедоступных
или коммерческих программ, проверяющих потенциальные пароли на
допустимость. Коммерческие и условно-бесплатные утилиты проверки паролей
существуют во многих операционных системах.
Если вы работаете в операционной системе Unix или Linux, уделите особое
внимание файлам /etc/passwd и /etc/group. Неиспользуемые записи в этих
файлах необходимо заблокировать, а пароли должны быть назначены всем учетным
записям — как активным, так и временно неиспользуемым.
ПРИМЕЧАНИЕ
В системе Unix следует воспользоваться утилитой pwconv, которая использует «теневые» файлы
для хранения данных паролей. В отличие от обычного файла паролей, теневой файл не может
быть прочитан любым желающим.
Учетные записи пользователей Windows NT/2000 должны быть правильно
созданы в User Manager for Domains или Active Directory (Users and Computers),
где могут создаваться учетные записи уровня рабочих групп и доменов. С
пользователями Windows 95 и 98 дело обстоит сложнее, поскольку в этих
операционных системах не существует полноценной безопасности учетных записей.
Любой пользователь, находящийся за компьютером, может создать новую
учетную запись. Если компьютеры с Windows 95/98 не входят в домен,
находящийся под контролем Windows NT, слабым местом сети всегда будут клиенты
Windows 95/98.
Разрешения доступа к файлам и каталогам
Безопасность начинается на уровне файловых разрешений, назначение которых
требует тщательного планирования. Чтобы защитить файл от доступа со стороны
злоумышленника или другого пользователя, хорошо продумайте структуру
файловых разрешений, чтобы она обеспечивала максимальную безопасность.
Способ настройки разрешений доступа к файлам и каталогам зависит от
операционной системы. В системах Unix и Linux для этой цели используется команда
chmod, а в Windows 95/98 и NT/2000 — списки управления доступом ACL (Access
Control List).
Самым распространенным внешним интерфейсом к любой системе является
модем (за исключением полностью автономной работы или замкнутых сетей).
Модемы обеспечивают удаленный доступ пользователей к сети и Интернету.
Защита линий модемного подключения к вашей системе является простой и
эффективной мерой, вполне достаточной для того, чтобы преградить путь простым
любопытствующим.
Самая надежная методика предотвращения несанкционированного доступа
по модему заключается в использовании модема с обратным вызовом. Такой
модем позволяет пользователю подключиться к системе обычным способом;
затем он разрывает связь, проверяет список допустимых пользователей и их
телефонных номеров и перезванивает пользователю. Модемы с обратным
вызовом довольно дороги, поэтому в большинстве систем такое решение не
оправдано с экономической точки зрения.
Кроме того, у модемов с обратным вызовом есть свои проблемы, особенно
если пользователи часто перемещаются с места на место. Наконец, модемы с
обратным вызовом открывают возможности для злоупотреблений из-за
возможностей динамического перенаправления вызовов современных телефонных
коммутаторов.
Обычный модем тоже может стать источником проблем, если он не
разорвет связь после завершения сеанса. Чаще всего подобные проблемы возникают
из-за неправильного подключения модема или параметров конфигурации.
Фраза «неправильное подключение» может показаться странной, однако в
некоторых системах встречается модемы с самодельными кабелями, которые не
обеспечивают полноценного управления всеми контактами. В результате система
может остаться в состоянии, когда сеанс модемного подключения не был
должным образом закрыт с выходом пользователя из системы. Любой, кто
подключится к этому модему, продолжит работу с того момента, на котором ее закончил
предыдущий пользователь. Для предотвращения подобных проблем убедитесь
в том, что модем связан с компьютером нормальным кабелем. Замените все
самодельные кабели, в которых вы не уверены, нормальными промышленными
изделиями. Также понаблюдайте за тем, как ведет себя модем после завершения
сеанса, и убедитесь в том, что он правильно разрывает связь.
Доверительные отношения
Если два компьютера связаны доверительными отношениями, одни компьютер
разрешает пользователям другого компьютера доступ к ресурсам без повторного
входа в систему. Предполагается, что «законные» пользователи одного
компьютера автоматически пользуются доверием на другом компьютере. Система
доверительных отношений была разработана много лет назад для того, чтобы
упростить доступ пользователя к сетевым ресурсам. Предположим, вы
зарегистрировались на одном компьютере и хотите получить доступ к файлу или
приложению, находящемся на другом компьютере. Каждый раз вводить имя и
пароль было бы весьма неудобно, поэтому доверительные отношения позволяют
обращаться к ресурсам без регистрации на каждом компьютере. Не путайте
доверительные отношения со службами типа NIS (Network Information Service)
или YP (Yellow Pages), использующими централизованный файл с
информацией о пользователях.
Возможность настройки доверительных отношений предусмотрена в
большинстве операционных систем, включая Windows NT, Unix и Linux. Основная
проблема с доверительными отношениями вполне очевидна: если
злоумышленник взломает один компьютер, он получит доступ ко всем остальным
компьютерам, связанным с ним доверительными отношениями.
Доверительные отношения могут быть как двусторонними (оба компьютера
доверяют друг другу), так и односторонними (первый компьютер доверяет
второму, но не наоборот). Кроме того, они могут устанавливаться для целых сетей.
Предположим, в вашей компании используются три подсети, одна из которых
содержит хорошо защищенную информацию; в двух других подсетях работают
обычные пользователи. Чтобы при обращении к ресурсам пользователям не
приходилось регистрироваться в каждой подсети, между подсетями можно
установить доверительные отношения. Вероятно, защищенная сеть не должна
доверять незащищенным (но при этом защищенной подсети следует разрешить
доступ к любым ресурсам незащищенных подсетей). Две незащищенные подсети
могут быть связаны двусторонними доверительными отношениями, а между
защищенной и незащищенными подсетями устанавливаются односторонние
отношения. Windows NT и Unix позволяют легко установить подобные отношения.
С точки зрения безопасности необходимо проследить за тем, чтобы
доверительные отношения сводили к минимуму ущерб от проникновения на
доверенный компьютер или сеть. Компьютер с конфиденциальной информацией
никогда не должен доверять компьютерам, доступным для всех желающих.
UUCP в системах Unix и Linux
Программа UUCP для системы Unix проектировалась с учетом требований
безопасности. Однако с тех пор прошло много времени, и требования безопасности
существенно изменились. За годы существования UUCP было обнаружено много
проблем безопасности, многие из которых решались посредством модификации
и установки исправлений в системе. И все же надежная и безопасная работа
UUCP требует внимания со стороны системного администратора.
Если вы не собираетесь использовать UUCP, исключите пользователя uucp
из файла /etc/passwd или назначьте сильный пароль, который невозможно легко
подобрать (замена первого символа пароля в файле /etc/passwd фактически
блокирует учетную запись). В системе Linux удаление пользователя uucp из файла
/etc/passwd больше ни на что не повлияет.
Для всех каталогов UUCP (обычно это каталоги /usr/lib/uucp, /usr/spool/uucp
и /usr/spool/uucppublic/) следует установить как можно более жесткие
ограничения. В большинстве систем доступ к этим каталогам предоставляется весьма
либерально; воспользуйтесь командами chown, chmod и chgrp и ограничьте доступ
учетной записью uucp. Регулярно проверяйте файловые разрешения.
Для управления доступом UUCP используются конфигурационные файлы
(такие, как /usr/lib/uucp/Systems и /usr/lib/uucp/Permissions). Они должны принад-
лежать и быть доступными только для учетной записи uucp. Тем самым
предотвращается модификация файла со стороны злоумышленников, вошедших в
систему под другим именем.
Каталог /usr/spool/uucppublic часто становится объектом нападения, поскольку
чтение и запись в него должны быть разрешены для всех систем, которые
работают с этим каталогом. Чтобы организовать защиту каталога, создайте два
подкаталога: для получения и отправки файлов. При желании можно создать
подкаталоги следующего уровня для всех систем, входящих в список разрешенных
пользователей.
Приготовьтесь к худшему
Предположим, кто-то все же проник в вашу сеть и учинил в ней погром. Что
делать? Разумеется, в таких случаях пригодятся резервные копии системы,
позволяющие восстановить любые поврежденные или удаленные файлы. Возможны
ли какие-то другие меры?
Прежде всего определите, как злоумышленник получил доступ к системе,
и предотвратите его использование в будущем. Если способ проникновения в
систему неизвестен, закройте все модемы и терминалы и тщательно проверьте
конфигурационные файлы на предмет дефектов безопасности. Такой дефект
должен существовать, иначе проникновение в систему было бы невозможно. Также
проверьте списки пользователей и паролей на предмет существования плохо
защищенных или устаревших данных.
Если ваша систем подвергается периодическим атакам, подумайте об
установлении системы аудита, которая бы следила за входом в систему и выполняемыми
операциями. Как только вы увидите, что злоумышленник вошел в систему,
примите необходимые меры.
Наконец, если атаки продолжаются, обратитесь к органам правопорядка.
В большинстве стран проникновение в компьютерные системы (как крупные
корпоративные, так и домашние) является незаконным, а злоумышленников
обычно удается отследить до того места, откуда осуществляется взлом.
Посягательства на безопасность вашей системы не должен оставаться безнаказанными!
Итоги
В этой главе рассматриваются механизмы шифрования и аутентификации, а также
некоторые простейшие меры предосторожности. Тема безопасности TCP
чрезвычайно широка, и эта глава лишь дает начальное представление о ней. Если вы
захотите больше узнать о компьютерах и сетевой безопасности, обратитесь к
специализированной литературе.
*Ъ 4 Общая конфигурация
Курт Хадсон (Kurt Hudson)
Протокол TCP/IP является самым распространенным сетевым протоколом, но
он также вызывает наибольшие трудности с конфигурацией. Соответственно,
возможности ошибиться в процессе настройки конфигурации чрезвычайно
широки. В этой главе рассматривается базовый процесс установки и настройки
сетевой платы и сетевых служб. Обязательные параметры конфигурации IP
рассматриваются наряду с характерными ошибками, допускаемыми в процессе
настройки. Также рассматривается туннелирование других протоколов в
каналах IP. В качестве примера в настоящей главе выбрана система Windows 98.
Настройка сетевых средств в других операционные системах будет подробно
описана в следующих главах. Система Windows 98 используется потому, что
она знакома большинству пользователей. Еще не все перешли на систему
Windows ME, которая не пользуется особой популярностью, а переход на
Windows NT/2000 и ХР не всегда возможен из-за возросших аппаратных
требований этих операционных систем.
Установка сетевой платы
Чтобы ваш компьютер мог связываться с другими компьютерами и обмениваться
с ними данными по сети, необходимо правильно настроить сетевую плату.
Существует несколько типов сетевых плат, которые к тому же по-разному
настраиваются. Тем не менее любая сетевая плата должна быть физически установлена на
компьютере и логически настроена при помощи программных драйверов.
ПРИМЕЧАНИЕ
Если на компьютере установлено две и более сетевые платы, используемые в обмене данными
TCP/IP, каждой плате должен быть назначен собственный IP-адрес и набор параметров
конфигурации TCP/IP.
Чтобы установить сетевую плату, следует отключить компьютер, снять кожух
и закрепить плату в одном из слотов. На портативных компьютерах физическая
установка устройства может сводиться к простой вставке устройства в слот
PCMCIA. Фаза физического подключения устройства к компьютеру
присутствует независимо от типа системы.
После физической установки устройства сетевой плате необходимо
выделить системные ресурсы. Одни сетевые платы получают свои ресурсы
автоматически, другие приходится настраивать вручную.
Сетевые платы
Прежде чем устанавливать сетевую плату на компьютер, следует сначала узнать
правильный тип платы, а для этого нужно знать тип аппаратных слотов вашего
компьютера. На обычных настольных компьютерах чаще всего используются
сетевые платы для слотов ISA (Industry Standard Architecture) и PCI (Peripheral
Component Interconnect). В документации системной платы должно быть
указано, какие слоты на ней установлены. Найдите свободный слот и установите
в нем сетевую плату.
После выяснения типа слота также необходимо узнать тип сети, к которой
будет подключено устройство. Тип физического интерфейса сетевой платы с сетью
обычно называется типом траисивера. На практике чаще всего используются
стандартные трансиверы RJ-45, BNC (British Naval Connector) и AVI (Attachment
Unit Interface). Интерфейс RJ-45 предназначен для подключения сетевой платы
к сети на базе витой пары. Коннектор BNC используется при подключении к
тонкому коаксиальному кабелю (сети 10Base-2). Интерфейс AUI позволяет
подключить адаптер к толстому коаксиальному кабелю A0Base-5). Вы должны заранее
узнать тип сети, к которой будет подключена сетевая плата, чтобы выбрать
устройство с правильным типом интерфейса.
Многие сетевые платы поддерживают несколько типов трансиверов. Иногда
тип траисивера выбирается перед установкой сетевой платы в системе —
обычно при помощи конфигурационной программы, предоставленной
производителем, или перемычек на плате. Обязательно ознакомьтесь с документацией перед
тем, как устанавливать устройство. Впрочем, большинство сетевых плат с
несколькими типами трансиверов настраивается автоматически, посредством
распознавания подключения на стадии инициализации.
После того как сетевая плата будет вставлена в соответствующий слот и
задания типа траисивера (если это потребуется), фаза физического подключения
устройства завершается. Следующая задача — настройка ресурсов. Однако
перед тем, как переходить к настройке, следует упомянуть другие типы сетевых
адаптеров: устройства PCMCIA, модемы и адаптеры для параллельных портов.
Устройства PCMCIA
Устройства стандарта PCMCIA (Personal Computer Memory Card International
Association) обычно используются в портативных компьютерах. Чаще всего
интерфейс PCMCIA используется при подключении сетевых плат, модемов и
внешних жестких дисков. Обычно сетевые платы PCMCIA подключаются к сетевому
кабелю через переходник.
Сетевые платы PCMCIA используют типичные сетевые ресурсы (как
правило, один номер IRQ и диапазон адресов ввода/вывода). Тем не менее для
работы устройств PCMCIA также необходимы специальные программные
интерфейсы, предоставляемые системами с поддержкой этих устройств.
Модемы
При подключении к удаленной сети или Интернету модемы выполняют те же
функции, что и сетевые адаптеры. Конфигурация модема несколько отличается
от конфигурации сетевых плат, поскольку модемы обычно используют
последовательные коммуникационные порты СОМ1, COM2, COM3 и COM4. На многих
модемах имеются собственные СОМ-порты, в таких случаях СОМ-порты
системной платы приходится отключать в параметрах CMOS/BIOS. Модемы также
используют номера IRQ, присвоенные соответствующим СОМ-портам. По
умолчанию порты СОМ1 и COM3 работают с IRQ 4, а порты COM2 и COM4 — с IRQ.
Адаптеры для параллельных портов
Некоторые модемы и другие сетевые устройства (например, маршрутизаторы)
могут подключаться к параллельным портам (вместо последовательных СОМ-
портов). Обычно эти устройства содержат специальный кабель или переходник
для параллельного порта, к которому подключается устройство. Процесс
настройки аналогичен настройке СОМ-портов, поскольку параллельным портам
тоже назначаются номера IRQ и диапазоны ввода/вывода по умолчанию.
Сетевые устройства, работающие на параллельных портах, часто используют
стандартные значения этих параметров.
Настройка ресурсов
Для любой сетевой платы, установленной на компьютере, необходимо задать
параметры — номер линии IRQ и диапазон адресов ввода/вывода. Как правило,
в документации производителя указываются значения этих параметров,
используемые по умолчанию. Чтобы сетевая плата работала с операционной системой,
необходимо проверить, свободны ли указанные номера линий IRQ и диапазоны
адресов ввода/вывода. Если необходимые ресурсы доступны, у вас не будет
проблем с настройкой сетевой платы. Но если ресурсы заняты, вам придется найти
другие свободные значения.
Новые сетевые платы и другие устройства поддерживают стандарт Plug and
Play (PnP), а это означает, что ресурсы (IRQ и диапазон ввода/вывода)
настраиваются автоматически в процессе загрузки. Технология РпР должна
поддерживаться на уровне операционной системы; в частности, ее поддержка реализована
в Windows 95, Windows 98 и Windows 2000. Во время загрузки операционная
система и устройство РпР согласовывают ресурсы, доступные для устройства.
Если сетевая плата не поддерживает РпР, вам придется найти свободные ресурсы
и закрепить их за устройством.
ПРИМЕЧАНИЕ
При настройке ISDN (Integrated Services Digital Network) или другого подключения, использующего
шину USB, достаточно выделить устройству свободный диапазон адресов ввода/вывода.
В Windows 98 свободные ресурсы определяются легко — для этого достаточно
открыть Диспетчер устройств. В диалоговом окне свойств компьютера
отображаются используемые номера IRQ и диапазоны адресов ввода/вывода (рис. 21.1).
;;• View Resources j Reserve fliieii^J;/:" J
?••'" f* J?JJ!?.^Щ^?ШЭД! ^::СШ>^.Д!?Ц!ДОу*CCe$$(PMAj;! .::.. j
W :Г• InpU^tpUtA/0} V-'Л:-:Р%1^^""'••'•;-".:" .;:•""
• j Settingh;Hefdy^eusing^'M^.::.:.: : • y'"; ';1*»j I
тЩОО System timer *;j""'|
. Щ& 01 Standard 101/102-Key or Microsoft Natural Keyboard rf• J
' Ш02 Prc^rammable interrupt controller- ill! In
• ЫоЗ Communjcatbnj Port [COM2] Й| Г
: ьУ04 Communfcdtiorw Port {COM3) :|ffi i
•; & 05 Creative Sound Blaster 1Б Plug and Play ЙЙ1Ш
K&06 Standard Floppy Disk Controller ЙЧ1Й
U? 07 Printer Port [LPT1) ^Щ
| OK | Cancel Щ j
Рис. 21.1. Поиск свободных ресурсов в Диспетчере устройств
Диалоговое окно свойств компьютера в Windows 98 открывается следующим
образом:
1. Щелкните правой кнопкой мыши на значке Мой компьютер (My Computer).
2. Выберите в контекстном меню команду Свойства (Properties).
3. Перейдите на вкладку Диспетчер устройств (Device Manager).
4. Щелкните на кнопке Свойства (Properties).
Чтобы найти неиспользуемый номер IRQ или диапазон адресов, установите
соответствующий переключатель в верхней части окна. После определения
свободных ресурсов проверьте по документации своего сетевого адаптера,
поддерживаются ли эти ресурсы устройством. Возможно, для настройки правильных
ресурсов сетевой платы вам придется установить перемычки на плате, изменить
положение переключателей или воспользоваться программой, предоставленной
фирмой-производителем.
Установка программного обеспечения
сетевой платы
После того как сетевая плата будет настроена на использование свободных
ресурсов операционной системы, необходимо установить драйверы сетевой платы.
Некоторые операционные системы включают подборку стандартных
драйверов для различных сетевых плат, но большинство сетевых плат поставляется
с собственными драйверами. Вы можете использовать драйверы операционной
системы, взять их с диска, предоставленного производителем (если он есть), или
обратиться на web-сайт производителя в Интернете.
Установка программного обеспечения сетевой платы в Windows 98
выполняется следующим образом:
1. Щелкните правой кнопкой мыши на значке Сетевое окружение (Network
Neighborhood).
2. Выберите в контекстном меню команду Свойства (Properties).
3. На вкладке Конфигурация (Configuration) диалогового окна Сеть (Network)
щелкните на кнопке Добавить (Add).
4. Выберите в диалоговом окне Выбор типа компонента (Select Network Component
Туре) строку Адаптер (Adapter) и щелкните на кнопке Добавить (Add) (рис. 21.2).
5. В следующем диалоговом окне выводится список производителей
оборудования и моделей сетевых плат. Выберите нужную комбинацию или вставьте
в дисковод диск, предоставленный производителем, и щелкните на кнопке
Установить с диска (Have Disk).
6. Щелкните на кнопке ОК. Возможно, вам придется ввести информацию о
ресурсах, используемых сетевой платой (номер IRQ и диапазон адресов
ввода/вывода).
7. После того как программное обеспечение будет успешно установлено, закройте
диалоговое окно Сеть (Network) кнопкой ОК, и если потребуется —
перезагрузите компьютер.
Click the type of network c^ponenS^u want to irma8:.
ГШ№& !__ Li :: ^ I
pjAdapter
NrProlocol Cancel j |
Ш} Service I
Рис. 21.2. Установка программной поддержки сетевой платы
После установки драйвера сетевой платы можно переходить к установке и
настройке программных компонентов сети — редиректора, сетевых служб и
семейства протоколов TCP/IP.
Редиректоры и API
Редиректором (redirector) называется программный компонент стека протоколов,
который перенаправляет локальные запросы сетевым ресурсам. Иначе говоря,
редиректор — компонент операционной системы, при помощи которого
компьютер получает доступ к сетевым ресурсам и службам. Иногда редиректор
называется клиентской службой, поскольку он выполняет соответствующие функции.
Редиректор должен быть совместим с типом сети, в которой он будет
использоваться. Редиректоры, созданные разными разработчиками, редко бывают
совместимыми. В разнородной сети это часто приводит к тому, что клиентские
системы приходится настраивать с несколькими редиректорами.
Чтобы упростить поддержку нескольких редиректоров и отделить работу
стека протоколов от разработки приложения, производители сетевого
оборудования создают специальные интерфейсы внутри стека протоколов. Например,
Microsoft использует интерфейс NetBIOS для отделения стека протоколов от
кода операционной системы. Многие протоколы и редиректоры интегрируются
через этот интерфейс. NetBIOS представляет собой программный интерфейс
приложений (API), поскольку он отделяет приложения от сетевых компонентов.
Это позволяет разработчику приложений сосредоточить основное внимание на
создаваемом приложении, не беспокоясь о специфических особенностях базовой
сети, в которой приложение может использоваться.
Установка редиректора в операционной системе Windows 98 выполняется так:
1. Щелкните правой кнопкой мыши на значке Сетевое окружение (Network
Neighborhood).
2. Выберите в контекстном меню команду Свойства (Properties).
3. На вкладке Конфигурация (Configuration) диалогового окна Сеть (Network)
щелкните на кнопке Добавить (Add).
4. Выберите в диалоговом окне Выбор типа компонента (Select Network Component
Туре) строку Клиент (Client) и щелкните на кнопке Добавить (Add).
5. В следующем диалоговом окне выводится список производителей
оборудования и сетевых клиентов (а фактически — редиректоров). Выберите нужную
комбинацию и щелкните на кнопке ОК.
6. Подтвердите или введите путь к установочным файлам и щелкните на
кнопке ОК.
7. После того как программное обеспечение будет успешно установлено, закройте
диалоговое окно Сеть (Network) кнопкой ОК, и если потребуется —
перезагрузите компьютер.
Службы
Службы, как и редиректоры, обычно реализуются на прикладном (то есть
верхнем) уровне стека протоколов. В частности, такие известные службы, как FTP
(File Transfer Protocol), HTTP (Hypertext Transfer Protocol) и Telnet, работают
на прикладном уровне TCP/IP. Службы также выигрывают от использования
API стека протоколов, поскольку процесс их разработки не зависит от структуры
базовой сети.
Службы совместного использования файлов и принтеров обычно зависят от
типа сети. Например, в сетях NetWare используются не такие службы, как в
сетях Microsoft. В операционной системе Windows 98 предусмотрена поддержка
служб совместного использования файлов и принтеров как для Microsoft, так
и для NetWare, а процесс ее установки очень похож на установку редиректора.
Единственное различие заключается в том, что в диалоговом окне Выбор типа
компонента (Select Network Component Type) вместо строки Клиент (Client)
выбирается строка Служба (Service).
Сетевые интерфейсы
На первых порах существования сетей стеки протоколов не обладали модульной
структурой. Вместо того чтобы использовать отдельные редиректоры, службы
и протоколы, стек протоколов оформлялся в виде единого монолитного
программного компонента, который обладал весьма ограниченными возможностями.
Каждая фирма-производитель выпускала программные продукты, рассчитанные
на определенный тип сети.
Один из первых и наиболее очевидных недостатков такого подхода заключался
в том, что он не позволял использовать разные транспортные протоколы. Чтобы
справиться с подобными ограничениями, фирмы-производители сетевого
оборудования и организации, занимающиеся выработкой стандартов (такие, как ISO),
направили свои усилия на развитие модульной структуры стека протоколов.
Так появились два интерфейса, которые продолжают использоваться в
наши дни — ODI (Open Datalink Interface) и NDIS (Network Driver Interface
Specification). Интерфейс ODI был разработан фирмой Novell для того, чтобы
ее сетевые компоненты могли использовать разные протоколы с одной или
несколькими сетевыми платами. NDIS является частью стека протоколов Microsoft
и позволяет организовать работу нескольких протоколов с несколькими
сетевыми платами на одном компьютере.
Сетевые и транспортные протоколы
Чтобы компьютер мог обмениваться данными с другими компьютерами, кроме
программного обеспечения сетевой платы, редиректора и служб также
необходима программная реализация протокола. Устанавливаемый протокол зависит
от типа сети и других систем, с которыми будет связываться ваш компьютер.
Вы должны заранее убедиться в том, что устанавливаемый протокол
поддерживается сетью. Чтобы две системы могли обмениваться данными, они должны
поддерживать общие протоколы.
Книга посвящена семейству протоколов TCP/IP, поэтому в этом разделе
будут рассматриваться вопросы конфигурации TCP/IP.
Обязательные параметры конфигурации IP
Минимальные требования к конфигурации TCP/IP включают два параметра:
IP-адрес и маску подсети. Возможно, это все, что вам потребуется для работы
в локальной сети через TCP/IP.
Чтобы компьютер участвовал в обмене данными, ему должен быть присвоен
правильный IP-адрес в локальном сегменте сети. При настройке системы ей
присваивается уникальный IP-адрес и соответствующая маска подсети, котрая
должна совпадать с маской других систем той же подсети, чтобы эти компьютеры
могли взаимодействовать. Кроме того, IP-адрес должен быть уникальным в
границах подсети, он должен содержать правильный идентификатор сети и
идентификатор подсети (если он используется). Идентификатор сети определяется
маской подсети. Например, маска подсети 255.255.0.0 означает, что первые два
октета IP-адреса определяют сегмент сети (то есть адрес подсети). Если первые
два октета определяют сеть, то два других октета должны однозначно
определять хост в этом сегменте. Рассмотрим пример, приведенный в табл. 21.1.
Таблица 21.1. IP-адрес и маска подсети
Хост/1Р-адрес Маска подсети
HostA/192.168.1.12 255.255.0.0
HostB/192.168.2.17 255.255.255.240
HostC/192.168.1.250 255.255.0.0
HostD/192.168.2.30 255.255.255.240
HostE/192.168.2.33 255.255.255.240
В приведенном примере хосты HostA и HostC принадлежат одной логической
сети (идентификатор 192.168.0.0). Хосты HostB и HostD тоже принадлежат одной
логической подсети (идентификатор 192.168.1.16). Хост HostE находится в другой
логической сети (идентификатор 192.168.1.32). Если бы все хосты были
подключены к одному физическому кабелю, хосты HostA и HostC смогли бы
взаимодействовать друг с другом, как и хосты HostB и HostD. Во всех остальных комбинациях
взаимодействие было бы невозможно из-за различий в логических подсетях.
ПРИМЕЧАНИЕ
Возможно, тот факт, что HostE не входит в одну подсеть с хостами HostB и HostD, не является
очевидным. Тем не менее, если просмотреть главу 4, вы увидите, что идентификатор подсети для
маски 255.255.255.240 определяется каждым 16-м числом, начиная с 16 и заканчивая 224. Ниже
перечислены действительные идентификаторы и диапазоны для адреса 192.168.1.0 с маской
подсети 255.255.255.240:
192.168.1.16, адреса хостов 192.168.1.17-192.168.1.30
192.168.1.32, адреса хостов 192.168.1.33-192.168.1.46
192.168.1.48, адреса хостов 192.168.1.49-192.168.1.62
192.168.1.64, адреса хостов 192.168.1.65-192.168.1.78
192.168.1.80, адреса хостов 192.168.1.81-192.168.1.94
192.168.1.96, адреса хостов 192.168.1.97-192.168.1.110
192.168.1.112, адреса хостов 192.168.1.113-192.168.1.126
192.168.1.128, адреса хостов 192.168.1.129-192.168.1.142
192.168.1.144, адреса хостов 192.168.1.145-192.168.1.158
192.168.1.160, адреса хостов 192.168.1.161-192.168.1.174
192.168.1.176, адреса хостов 192.168.1.177-192.168.1.190
192.168.1.192, адреса хостов 192.168.1.193-192.168.1.206
192.168.1.208, адреса хостов 192.168.1.209-192.168.1.222
192.168.1.224, адреса хостов 192.168.1.225-192.168.1.238
Таким образом, создаются 14 логических подсетей, каждая из которых содержит 14 хостов. В этой
схеме адреса 192.168.1.33 и 192.168.1.30 принадлежат разным подсетям.
Чтобы хосты одной локальной сети могли обмениваться данными, они должны
обладать уникальными идентификаторами хостов и идентичными
идентификаторами сети/подсети. Чтобы хосты могли взаимодействовать с другими хостами
в удаленных сегментах (через маршрутизатор), на каждом из них должен быть
настроен адрес основного шлюза.
Настройка адреса основного шлюза
Чтобы система могла взаимодействовать с удаленными сетями или с другими
сегментами локальной сети, отделенными маршрутизатором, в ней необходимо
настроить адрес основного шлюза. Как правило, адрес основного шлюза
является IP-адресом локального маршрутизатора. Тем не менее при наличии в
локальном сегменте сети нескольких маршрутизаторов обмен данными с
удаленными сетями желательно производить через основной шлюз.
На основании маски подсети хост определяет, с каким сегментом сети он
должен взаимодействовать — локальным или удаленным. Если идентификатор
подсети получателя совпадает с идентификатором локального сегмента, пересылка
производится внутри локального сегмента. Но если идентификаторы отличаются,
данные передаются основному шлюзу. Как правило, основным шлюзом является
маршрутизатор, который пересылает пакет соответствующему получателю или
в следующую точку маршрута на пути к конечному получателю.
Чтобы локальный хост мог правильно взаимодействовать с основным шлюзом,
на нем должны быть заданы некоторые параметры: действительный уникальный
IP-адрес, правильная маска подсети и адрес основного шлюза. Если какие-либо
из этих параметров будут заданы неверно, у хоста возникнут проблемы. Адрес
основного шлюза должен быть задан в локальном сегменте сети. Иначе говоря,
удаленный хост не может использоваться вашей системой в качестве основного
шлюза.
Если система нормально связывается с локальными хостами, но не может
связаться с удаленными хостами, проблема обычно связана с основным шлюзом
или его конфигурацией. Среди потенциальных проблем с основным шлюзом
можно назвать следующие:
О Основной шлюз временно недоступен.
О Кабель или интерфейс, связывающий основной шлюз с локальным
сегментом, не работает.
О На клиенте неверно задан адрес основного шлюза.
О На клиенте не настроен адрес основного шлюза.
О Запись кэша ARP (Address Resolution Protocol) для маршрутизатора содержит
неверную информацию. Проблема обычно решается перезагрузкой клиента,
если только клиент не использует статическую загрузку данных в кэш ARP.
Многие конфигурационные проблемы легко распознаются и решаются. Тем
не менее проблема с неправильными данными в кэше ARP не столь очевидна.
Следует помнить, что весь обмен данными в локальном сегменте в конечном
счете проводится между аппаратными адресами MAC (Media Access Control).
Если сетевой интерфейс основного шлюза изменился, а все клиенты
продолжают использовать аппаратный адрес старого Интернета, они не смогут связаться
с основным шлюзом. Обычно перезагрузка клиентской системы обновляет кэш
ARP и заставляет клиента заново разрешить адрес MAC. Но если операционная
система была настроена на загрузку статической записи ARP для основного
шлюза, проблема не решается простой перезагрузкой — необходимо
отредактировать файл, из которого в кэш ARP загружается статическая запись.
Настройка адреса сервера имен
Другой важный параметр хоста TCP/IP — IP-адрес сервера имен. Существует
два основных типа серверов имен: серверы DNS (Domain Name System) и
серверы WINS (Windows Internet Name Service). Серверы DNS преобразуют имена
хостов, обычно используемые в Интернете, в IP-адреса. Такое преобразование
обеспечивает возможность взаимодействия между хостами TCP/IP. Серверы
WINS преобразуют имена NetBIOS, используемые в сетях Microsoft, в
IP-адреса. Серверы DNS подробно описаны в главе 6, а серверы WINS — в главе 7.
При настройке хостов IP следует задать правильный адрес соответствующего
сервера имен. Для правильного разрешения имен (то есть преобразования их
в IP-адреса) при настройке клиентов Microsoft иногда приходится задавать
IP-адреса как сервера DNS, так и сервера WINS. Если вы можете связаться с
хостом по IP-адресу, но не по имени, значит, где-то в процессе разрешения имени
происходит ошибка. Ниже перечислены некоторые распространенные причины.
О На клиенте неверно задан адрес сервера имен.
О Сервер имен недоступен.
О Маршрутизатор между сервером имен и вашей системой недоступен (что не
позволяет связаться с сервером имен), но хост, с которым вы пытаетесь
связаться, находится по одну сторону от маршрутизатора с вашей системой.
О Где-то между вашей системой и сервером существует физическая ошибка
связи, тогда как канал связи с другим хостом работает нормально.
О Имя системы, к которой вы пытаетесь подключиться, не настроено на сервере
имен (или настроено неверно).
Настройка адреса почтового сервера
Чтобы локальный хост мог отправлять и получать электронную почту, следует
задать в почтовой программе адрес почтового сервера. Для передачи
сообщений в сетях TCP/IP обычно используется протокол SMTP (Simple Mail Transfer
Protocol). Клиенты, как правило, принимают почту с использованием протокола
POP (Post Office Protocol) или IMAP (Internet Message Access Protocol). При
настройке входящей почты обычно указываются данные одного из серверов POP
или IMAP, но не обоих сразу.
Многие почтовые приложения Интернета позволяют указать как имя хоста
почтового сервера, так и его IP-адрес. Например, в данных почтового сервера
можно ввести имя mail.server.com или адрес 192.168.1.50. Некоторые поставщики
услуг Интернета используют один и тот же почтовый сервер как для входящей,
так и для исходящей почты, но иногда для этих целей используются разные
серверы. Чтобы ваша система могла как принимать, так и отправлять почту,
необходимо правильно задать адрес почтового сервера (или серверов).
Регистрация доменного имени
Если вы собираетесь использовать в Интернете конкретное доменное имя типа
domaJn.com, это имя необходимо зарегистрировать в InterNIC. Обычно
регистрация доменных имен выполняется через поставщика услуг Интернета, который
берет на себя все формальности, связанные с регистрацией. Тем не менее вся
необходимая информация о регистрации доменных имен приведена на сайте
InterNIC по адресу http://www.internic.net.
Разновидности конфигурации IP
Некоторые устройства и операционные системы обладают интегрированной
поддержкой TCP/IP, которая должна настраиваться в процессе настройки этого
устройства или операционной системы. Настройка осуществляется по тем же
принципам, что и выше; различается только конкретная процедура. В качестве
примера устройств, в процессе настройки которых настраивается IP, можно
привести маршрутизатор (например, Cisco). Поскольку маршрутизаторы
обладают несколькими интерфейсами, настройка выполняется на уровне отдельного
интерфейса. Во время автоматизированной настройки Cisco вам предлагается
произвести настройку IP для каждого интерфейса. Также можно обойти
соответствующее диалоговое окно и настроить интерфейсы непосредственным
вводом команд Cisco IOS в режиме командной строки.
Между процедурами настройки IP-адресов и масок подсетей в разных
системах также существуют различия. Например, при настройке маски подсети IP
для маршрутизатора Cisco не нужно вводить всю 32-разрядную маску, поскольку
маска по умолчанию вычисляется по типу сети. Например, если интерфейсу
маршрутизатора Cisco назначается IP-адрес 192.168.1.1, вам не придется вводить
маску подсети 255.255.255.0. Поскольку адрес относится к классу С,
предполагается, что ему соответствует маска 255.255.255.0. Вам будет предложено
ввести только количество дополнительных битов. Например, для маски подсети
255.255.255.240 вводится число 4, поскольку эта маска на 4 разряда превышает
маску подсети по умолчанию.
Кроме того, в настройках IP некоторых устройств не всегда используются
десятичные маски подсетей — также часто встречается двоичный формат маски
подсети и формат CIDR (Classless InterDomain Routing). В двоичном формате
числа остаются прежними, изменяется только система счисления — например,
255.255.240.0 превращается в 11111111.11111111.11110000.00000000. В формате
CIDR за IP-адресом указывается количество бит в маске. Например, адрес
192.168.1.1 с маской подсети 255.255.255.240 представляется в виде 192.168.1.1/28,
поскольку маска подсети содержит 28 двоичных цифр.
Настройка таблицы маршрутизации
Ошибки в таблицах маршрутизации создают проблемы со связью в сетях IP.
Многие маршрутизаторы автоматически настраиваются динамическими протоколами
маршрутизации — такими, как RIP (Routing Information Protocol) и OSPF (Open
Shortest Path First). Однако когда маршруты вводятся администратором вручную,
возможные опечатки увеличивают вероятность появления ошибок в таблицах
маршрутизации. Наряду с опечатками в таблицах маршрутизации также часто
встречается и такая проблема, как неправильное указание интерфейса для следующего
перехода. Рассмотрим сетевую конфигурацию, изображенную на рис. 21.3.
| 1192.168.3.2 192.168.2.1 i 1
RouterY p^^ J RouterQ
^^-^J92.168.3.1 s^ oj
I I уГ ^
RouterX F192.168.2.2 Щ
^^-^92.168.4.1 Щ
RouterZ r"""^
I 1192.168.4.2
Таблица маршрутизации RouterX
Сеть Маска Интерфейс
192.168.4.0 255.255.255.0 192.168.4.1
192.168.3.0 255.255.255.0 192.168.3.1
192.168.2.0 255.255.255.0 192.168.2.2
I 192.168.1.0 I 255.255.255.0 J 192.168.2.2 |
Рис. 21.3. Диагностика проблем с настройкой таблиц маршрутизации
Ошибка, допущенная при настройке таблицы маршрутизации RouterX,
незаметна на первый взгляд, однако она вызывает проблемы в сети. Последняя строка
таблицы RouterX указывает на то, что трафик для сети 192.168.1.0 должен
пересылаться через интерфейс 192.168.2.2, но это неправильно. Маршрутизатор
должен направлять трафик в точку следующего перехода. С точки зрения RouterX
следующим переходом к сети 192.168.1.0 является интерфейс RouterQ с
IP-адресом 192.168.2.1. Если не исправить эту ошибку, то пакеты, предназначенные
для сети 192.168.1.0, не пройдут через маршрутизатор RouterX.
Поскольку маршрутизатор RouterX связан со всеми сегментами, указанными
в его таблице маршрутизации, он взаимодействует с этими сегментами через
свои интерфейсы. Только если маршрутизатор не связан напрямую с сегментом,
он использует интерфейс другого маршрутизатора для пересылки данных
удаленному сегменту.
Чтобы исправить ошибку, представленную на рис. 21.3, необходимо ввести
правильный адрес интерфейса, которому RouterX пересылает пакеты для сети
192.168.1.0. Исправленная запись выглядит так:
192.168.1.0 255.255.255.0 192.168.2.1
Инкапсуляция внешних протоколов
Протокол IP часто используется для инкапсуляции пакетов других протоколов
сетевого уровня и их последующей передачи в сетях IP. Примером может
послужить пересылка пакетов IPX в туннелях IP. Сети Novell NetWare работают
на базе протокола IPX/SPX. Если потребуется связать две локальные сети Novell
NetWare через Интернет, достаточно организовать пересылку пакетов IPX через
туннельный канал IP.
Слово туннель (tunnel) описывает ситуацию на концептуальном уровне.
После того как данные протоколов верхнего уровня инкапсулируются в пакетах
IPX, весь набор инкапсулируется в пакетах IP и пересылается в удаленную сеть
IPX. Ситуация представлена на рис. 21.4.
IPX/SPX LAN IPX/SPX LAN
| •_ m\ L « I
f IPX ) *1 * f IPX )
V—L_—/ Передача пакетов V /
в обоих направлениях
GD Г ) CZD
► Сеть Интернет TCP/IP ►
Рис. 21.4. В результате пересылки пакетов IPX в туннеле IP
фактически формируется глобальная сеть IPX
Серверы на обеих сторонах канала TCP/IP должны быть настроены на
упаковку/распаковку данных IPX из пакетов IP. На серверах NetWare,
выполняющих эти функции, используется драйвер IP Tunnel, для чего в файл NET.CFG
сервера NetWare обычно включаются следующие строки:
Link Driver IPTUNNEL
Gateway 192.168.1.50
Protocol IPXODI
Bind #2
Первая часть указывает на то, что распаковка пакетов на другом конце канала
будет осуществляться шлюзом. Вторая часть привязывает IPXODI ко второму
определенному драйверу, которым является драйвер IP Tunnel. Кроме внесения
этих изменений в NET.CFG, на сервере должна быть установлена и загружена
программная поддержка TCP/IP (tcpip), а также драйвер IP Tunnel (iptunnel).
ПРИМЕЧАНИЕ
Серверы Unix и Linux также поддерживают туннелирование IPX в сетях IP. Туннелирование чаще
используется при выполнении приложений IPX no Интернету, нежели при пересылке данных между
локальными сетями. Поддержка туннелирования обеспечивается приложением ipxtunnel, которое
можно загрузить с сайта sunsite.unc.edu и с множества других сайтов Интернета.
Инкапсуляция внешних протоколов не ограничивается пересылкой IPX в сетях
TCP/IP — в пакетах IP могут передаваться пакеты других протоколов. Фирма
Microsoft использует протокол РРТР (Point-to-Point Tunneling Protocol) для
шифрования обмена данными между хостами, подключенными к Интернету.
Для создания безопасных туннелей также применяется протокол L2TP в
сочетании с IPSec. Туннели такого типа защищают пересылку данных в Интернете.
Многие брандмауэры используют аналогичную методику шифрования для
инкапсуляции трафика специализированных протоколов между двумя удаленными
точками в Интернете. Это позволяет компаниям создавать в Интернете
защищенные соединения или виртуальные локальные сети (VLAN). Инкапсуляция
затрудняет (а по мнению некоторых — полностью исключает) перехват данных,
передаваемых в соединениях VLAN, со стороны хакеров.
Итоги
Включение нового хоста в сеть IP сопровождается настройкой многочисленных
параметров. Если на компьютере еще не была установлена и настроена сетевая
плата, настройка начинается с анализа аппаратных ресурсов. Возможно, вам
придется проверить линии IRQ и диапазоны адресов ввода/вывода и найти значения,
не используемые другими устройствами. Настройка сетевых плат часто
выполняется программными драйверами, предоставленными производителем
устройства. Впрочем, операционная система Windows содержит драйверы для
множества сетевых плат.
После установки сетевой платы и настройки драйвера обычно
устанавливается редиректор и дополнительные службы. Конкретный тип редиректора и служб
зависит от типа сети, к которой подключается компьютер, и сервиса,
предоставляемого но сети.
Чтобы организовать обмен данными в сети IP, необходимо либо использовать
устройство с интегрированной поддержкой IP, либо установить семейство
протоколов TCP/IP. Если устройство обладает интегрированной поддержкой IP,
конфигурация протокола обычно задается во время настройки. Для работы
хоста IP в сети IP абсолютно необходимы два параметра: IP-адрес и маска
подсети. Если вы хотите, чтобы система взаимодействовала с хостами IP в
удаленных сетях, также необходимо задать адрес основного шлюза — приемника
пакетов, пересылаемых в удаленные сегменты. Адрес основного шлюза представляет
собой IP-адрес маршрутизатора в локальном сегменте сети, занимающегося
пересылкой пакетов в удаленные сети и/или другим маршрутизаторам. Чтобы
хост мог обращаться к другим хостам по хостовым именам, на нем должна быть
настроена одна из схем разрешения имен. Для получения доступа к сервису
разрешения имен в конфигурации клиента задается адрес сервера имен.
*J *% Настройка TCP/IP
ЖшЖшЪ Windows 95
и Windows 98
Курт Хадсои (Kurt Hudson)
В этой главе рассматривается настройка сетевых компонентов Windows 98.
Основное внимание уделяется двум аспектам: конфигурации сетевых драйверов и
настройке TCP/IP. Также приводятся общие сведения о сетевой архитектуре
Windows 98 и рассматриваются такие специфические области конфигурации, как
статические файлы TCP/IP и некоторые ключи системного реестра Windows 98.
ПРИМЕЧАНИЕ
В Windows 95 и Windows 98 используются практически одинаковые процедуры настройки сетевых
компонентов. Информация, приведенная в этой главе, применима к любой из этих операционных
систем.
Сетевая архитектура Windows 98
В основу сетевой архитектуры Windows 98 заложены два основных интерфейса:
NetBIOS (Network Basic Input/Output System) и NDIS (Network Device Interface
Specification). Кроме того, на верхних уровнях сетевой поддержки систем от
Microsoft используется протокол SMB (Service Message Blocks). Базовое
строение стека протоколов Windows 98 по сравнению с сетевой моделью OSI
изображено на рис. 22.1.
Из рисунка видно, какие места занимают эти компоненты в стеке протоколов
TCP/IP. Там, где на графике находятся протоколы TCP, UDP и IP, можно было
бы разместить еще несколько транспортных и сетевых протоколов, потому что
уровень NDIS позволяет привязать несколько протоколов к одной или
нескольким сетевым платам. Уровень NetBIOS обеспечивает независимость
приложений NetBIOS от протокола. Проектировщики сетевой архитектуры Microsoft
стремились к тому, чтобы процесс разработки сетевых приложений как можно
меньше зависел от используемого протокола. Это делалось для того, чтобы
разработчики могли сосредоточить внимание на создаваемом приложении и не
беспокоиться о том, какой протокол из сетевого стека при этом используется.
Прикладной уровень
— SMB
Представительский уровень
Сеансовый уровень NetBIOS WinSocks
Транспортный уровень TCP UDP
Сетевой уровень IP
Канальный уровень Драйверы локальной сети
Физический уровень Сетевая плата
Рис. 22.1. Специфические компоненты реализации TCP/IP от Microsoft
находятся на канальном уровне и выше транспортного уровня
Также обратите внимание на добавление интерфейса WinSocks (Windows
Sockets) к сеансовому уровню модели. Интерфейс WinSocks был разработан
фирмой Microsoft для того, чтобы существующие приложения и утилиты TCP/IP
могли использоваться клиентами Microsoft. Например, такие утилиты, как ping
и tracert, обращаются к стеку протоколов через интерфейс Windows Sockets.
Из всего стека протоколов Windows 98 администратор или пользователь
может настраивать только драйверы локальной сети, сетевые и транспортные
протоколы, а также выбирать тип сетевой платы. SMB, NetBIOS и NDIS
являются постоянными компонентами сетевой поддержки Windows 98. Кроме того,
при установке реализации TCP/IP от Microsoft автоматически добавляется
интерфейс Windows Sockets.
Основными компонентами, добавляемыми пользователем, являются
драйверы сетевой платы, протоколы и сетевые службы (клиентские и серверные
компоненты). На рис. 22.2 изображено диалоговое окно Сеть (Network) системы
Windows 98 с перечнем компонентов. В этой главе все компоненты будут
рассмотрены более подробно.
Установка сетевой платы
В главе 22 был описан процесс установки устройства сетевой платы, а также
процесс настройки ресурсов и драйверов в Windows 98. В этом разделе различные
варианты установки и настройки сетевых плат будут рассмотрены более подробно.
ПРИМЕЧАНИЕ
Предполагается, что сетевая плата уже установлена на компьютере. Кроме того, следует узнать
название фирмы-производителя, адрес web-сайта и номер модели сетевой платы.
Как сказано в предыдущей главе, перед установкой программного
обеспечения сетевой платы следует узнать номера свободных прерываний (IRQ) и
доступных адресов ввода/вывода. Для получения этой информации можно
воспользоваться диспетчером устройств (за подробным описанием обращайтесь
к главе 22). Возможно, перед началом работы потребуется настроить нужные
номера IRQ и адреса ввода/вывода на сетевой плате при помощи утилиты,
предоставленной производителем.
Configuration j Identification | Access Control j
• The folov^neKvwk components ate installed 11
2J Client for Microsoft Networks j j
. ^N£2000 Compatible '
: . [Г TCP/IP ■;.:. J
Ш} File and printer sharing for Microsoft Networks j J
Primary Network ^одоп: : , I
| Client for Microsoft Network? 3 11
ffteartf Print Sharing.,. II
: Oescripbon j j
OK | Cancel | j
Рис. 22.2. Диалоговое окно Сеть (Network) системы Windows 98 используется для
централизованной настройки большинства сетевых параметров в Windows 98
Мастер установки нового оборудования
Для установки программного обеспечения сетевой платы можно воспользоваться
мастером установки нового оборудования. Откройте панель управления
командой Пуск ► Настройка ► Панель управления (Start ► Settings ► Control panel).
1. Дважды щелкните на значке Установка оборудования (Add New Hardware).
2. Мастер установки нового оборудования сначала предлагает закрыть все
остальные открытые приложения. Последуйте его совету и щелкните на кнопке
Далее (Next).
3. В следующем окне выводится сообщение о том, что Windows выполняет
поиск устройств Plug and Play. Если устанавливаемая сетевая плата
соответствует стандарту Plug and Play, система найдет ее и автоматически настроит
номер IRQ и диапазон адресов. В противном случае ресурсы, используемые
платой, придется задать вручную.
4. Щелкните на кнопке Далее (Next).
5. Если установленная сетевая плата присутствует в списке, выделите ее,
щелкнув на соответствующем значке в окне Устройства (Devices).
6. Установите переключатель Да, устройство присутствует в списке (Yes, the Device
is In the List) и щелкните на кнопке Далее (Next). Это должно привести к
автоматической установке и настройке сетевой платы Plug and Play.
7. Если сетевая плата не входит в список, установите переключатель Нет,
устройства нет в списке (No, the Device Isn't In the List) и щелкните на кнопке Далее
(Next). Если вам пришлось выбрать этот вариант, значит, ваша сетевая плата
не поддерживает стандарт Plug and Play.
8. Для устройств, не соответствующих стандарту Plug and Play, в следующем
окне вам будет предложено поручить поиск сетевой платы системе Windows.
К сожалению, процедура поиска может привести к «зависанию» компьютера;
в этом случае систему придется перезагрузить. С другой стороны, если
Windows 98 успешно обнаружит сетевую плату, вам не придется выбирать ее в
списке устройств.
9. Если вы хотите провести автоматический поиск сетевой платы, установите
переключатель Да (рекомендуется) (Yes(Recommended)) и щелкните на кнопке
Далее (Next). Если поиск будет успешным, вы сможете подтвердить его
результаты и перейти к дальнейшей настройке.
10. С другой стороны, если вы точно знаете модель устанавливаемой сетевой
платы или у вас имеется диск от производителя оборудования, который бы
вы хотели установить, установите переключатель Нет, выбрать из списка (No,
I Want to Select the Hardware from a List) и щелкните на кнопке Далее (Next).
11. Если устройство не было обнаружено (или если вы пропустили фазу поиска),
на экране появляется диалоговое окно с предложением выбрать устройство
из списка допустимых устройств.
12. Найдите в списке строку Сетевые платы (Network Adapters), выделите ее и
щелкните на кнопке Далее (Next).
13. В следующем окне слева выводится список производителей, а справа —
список моделей.
14. Выберите производителя сетевой платы и модель. Например, если
устанавливается устройство 3COM ЗС509 ISA, выберите в списке производителей
строку «3COM», прокрутите второе окно и найдите в списке моделей строку
«3COM Etherlink III ISA CC509/3C509b) in ISA mode».
15. Щелкните на кнопке ОК.
Существует и другая возможность — кнопка Установить с диска (Have Disk)
позволяет установить драйвер, предоставленный производителем оборудования.
Далее вам будет предложено вставить гибкий диск, CD-ROM или ввести путь
к драйверам, после чего процесс установки продолжится. Также система может
предложить выбрать один из драйверов, найденных на диске. За информацией
о выборе драйвера обращайтесь к документации, предоставленной
производителем сетевой платы.
ПРИМЕЧАНИЕ
Возможно, перед продолжением установки вам будет предложено выбрать ресурсы, используемые
сетевой платой. Введите необходимые значения и щелкните на кнопке Далее (Next).
После того как мастер установки нового оборудования Windows 98 найдет
и установит драйвер, на экране появляется диалоговое окно с информацией об
успешном завершении установки. Вам предлагается завершить процесс
установки, щелкнув на кнопке Готово (Finish). Систему можно перезагрузить
немедленно или подождать. Драйвер сетевой платы появится в системе только
после перезагрузки.
Ручная установка сетевой платы
Процесс ручной установки сетевой платы в Windows 98 подробно описан в
главе 22 (подробные инструкции по установке драйвера здесь не повторяются).
В этом случае вместо использования мастера установки нового оборудования
следует воспользоваться значком Сеть (Network) на панели управления. На экране
появляется диалоговое окно Сеть (Network). Далее следует щелкнуть на кнопке
Добавить (Add), выбрать сетевую плату и установить соответствующий драйвер.
После щелчка на кнопке Добавить (Add) процесс практически не отличается от
установки сетевой платы, не поддерживающей стандарт Plug and Play, с помощью
мастера нового оборудования.
16-разрядные сетевые драйверы
Если в системе Windows 98 устанавливается старая сетевая плата, возможно,
вам придется использовать старые 16-разрядные драйверы. Такое решение не
оптимально и его следует по возможности избегать. Тем не менее в Windows 98
поддерживаются старые конфигурационные файлы (такие, как autoexec.bat,
config.sys и system.ini), что позволяет использовать старое оборудование и
программы, существовавшие до появления Windows 95.
Процесс настройки старой сетевой платы достаточно прост. Сначала
запустите программу установки, предоставленную производителем сетевой платы.
Программа устанавливает драйвер и обновляет старые конфигурационные файлы.
Если конфигурационные файлы потребуется обновить вручную, проще всего
воспользоваться программой sysedit Программа запускается из диалогового окна
Пуск ► Выполнить (Start ► Run); она автоматически открывает все старые
конфигурационные файлы в окнах текстового редактора. Далее вы можете внести
необходимые изменения.
Изменение параметров конфигурации
сетевой платы
Ресурсы, используемые сетевой платой, можно изменить в диспетчере устройств
Windows 98. После установки сетевой платы значок этого устройства появляется
в окис диспетчера устройств.
1. Чтобы вызвать диспетчера устройств, щелкните на значке Система (System)
панели управления или щелкните правой кнопкой мыши на значке Мой
компьютер (My Computer) и выберите команду Свойства (Properties).
2. Щелкните на вкладке Устройства (Device Manager).
3. Щелкните на значке + рядом с категорией Сетевые платы (Network Adapters).
В окне появляется список сетевых плат, установленных в системе.
4. Дважды щелкните на значке сетевой платы, настройки которой требуется
изменить.
Количество вкладок, отображаемых для конкретной сетевой платы, зависит
от его модели и возможностей настройки. Впрочем, для большинства устройств
отображаются три вкладки:
О Общие (General) — информация о текущем состоянии устройства (например,
устройство работает нормально, или в системе существует конфликт ресурсов).
О Драйвер (Driver) — изменение и обновление драйвера сетевой платы.
О Ресурсы (Resources) — изменение параметров конфигурации сетевой платы.
Если Windows 98 не загружается
Если установка сетевой платы вызывает конфликт ресурсов, возможно, у вас
возникнут трудности с перезагрузкой системы. Драйверы некоторых устройств
вызывают «зависание» системы Windows 98 в процессе загрузки. В этом случае
следует попытаться загрузить Windows 98 в безопасном режиме. Как правило,
этот режим активизируется автоматически, когда Windows 98 обнаруживает
неудачную попытку загрузки. Тем не менее, если потребуется активизировать
безопасную загрузку вручную, нажмите клавишу F8 в процессе загрузки.
ПРИМЕЧАНИЕ
Время, в течение которого воспринимается нажатие клавиши F8, ограничено, поэтому эту
клавишу обычно нажимают многократно в начале загрузки системы. Если на экране появляется
заставка Windows 98, значит, вы не успели вовремя нажать клавишу.
При нажатии клавиши F8 во время загрузки открывается меню, состоящее
из нескольких команд. Вероятно, проще всего загрузиться в безопасном режиме
и сбросить настройки сетевой платы.
Интерфейс безопасного режима очень похож на стандартный интерфейс
Windows 98, в котором производилась первоначальная настройка сетевой платы.
Воспользуйтесь этим режимом для выявления проблем с ресурсами сетевой платы.
Если проблема обусловлена 16-разрядным драйвером, отредактируйте
конфигурационные файлы программой SYSEDIT. Если проблема возникла из-за
32-разрядных драйверов, измените настройку ресурсов в диспетчере устройств.
Если вам не удается выявить и исправить проблему в безопасном режиме,
попробуйте сохранить журнал загрузки в файле bootlog.txt. Возможно, вы
установили не тот драйвер устройства. Журнал загрузки создается так:
1. Выберите в меню запуска Windows 98 команду Logged....
2. Перезагрузите систему и подождите, пока загрузка завершится неудачей.
3. Загрузите систему в безопасном режиме или в режиме командной строки.
Найдите файл bootlog.txt в корневом каталоге диска С:.
4. Откройте файл в текстовом редакторе (например, в DOS-редакторе edit или
в Блокноте Windows). Вероятно, вам удастся определить причину
возникающих сбоев по последней строке — в ней выводится информация о последнем
драйвере, который система попыталась загрузить перед «зависанием».
Если выяснится, что драйвер сетевой платы не загружается, найдите
нормальный драйвер. Убедитесь в том, что содержимое файла драйвера не испорчено.
Проверьте диск программой ScanDisk — возможно, драйвер был испорчен из-за
дефектов поверхности диска. За сведениями об известных проблемах с
конфигурацией устройства следует обращаться на сайт фирмы-производителя или
в службу технической поддержки.
Если в процессе диагностики будет обнаружен конфликт ресурсов, сбросьте
настройки ресурсов сетевой платы или другого конфликтующего устройства.
Если оба устройства обязательно используют одни и те же аппаратные ресурсы,
для разрешения конфликта придется выбрать одно из этих устройств и убрать
другое устройство из системы. После того как все необходимые исправления
будут внесены, перезагрузите систему — она должна работать правильно.
Настройка TCP/IP в Windows 98
Основная настройка TCP/IP в Windows 98 достаточно проста и выполняется
через удобный графический интерфейс. Тем не менее некоторые параметры
конфигурации можно изменить только правкой реестра Windows 98 и/или
конфигурационных файлов. В этом разделе мы рассмотрим оба варианта.
Сбор предварительной информации
Прежде чем устанавливать TCP/IP в системе Windows 98, необходимо собрать
основные сведения о текущем сегменте сети. В процессе настройки следует
использовать IP-адрес и маску подсети данного сегмента, если вы не собираетесь
использовать сервер DHCP. При использовании DHCP необходимо определить,
какие параметры будут автоматически настраиваться сервером DHCP.
Если вы собираетесь связываться с хостами, находящимися в удаленных
сегментах, то кроме IP-адреса и маски подсети вам потребуется адрес основного
шлюза (также называемого локальным маршрутизатором). При использовании
HDCP необходимо узнать, будет ли производиться автоматическая настройка
IP-адреса маршрутизатора, и если не будет — вручную добавить адрес в
локальную конфигурацию TCP/IP.
Если связь с хостами в сети будет осуществляться по именам, вам также
потребуется адрес сервера DNS, который будет обеспечивать разрешение имен.
Без сервера DNS придется создать файл HOSTS с перечнем списком всех
IP-адресов и имен хостов, к которым вы будете подключаться. Также потребуется
механизм разрешения имен NetBIOS — сервер WINS или файл LMHOSTS. Адреса
серверов DNS и WINS могут предоставляться сервером DHCP, если он
используется в локальной сети.
Когда вы будете располагать всеми перечисленными сведениями, можно
переходить к установке семейства протоколов TCP/IP. Держите под рукой компакт-
диск или установочные файлы Windows 98, они понадобятся при установке
протокола.
Установка TCP/IP
В Windows 98 семейство протоколов TCP/IP устанавливается из диалогового
окна Сеть (Network), которое вызывается при помощи значка Сетевое окружение
(Network Neighborhood), находящегося на рабочем столе, или из панели управления.
Чтобы вызвать диалоговое окно с рабочего стола, щелкните правой кнопкой
мыши на значке Сетевое окружение (Network Neighborhood) и выберите команду
Свойства (Properties). Чтобы вызвать его из панели управления, выполните команду
Пуск ► Настройка ► Панель управления (Start ► Settings ► Control Panel) и дважды
щелкните на значке Сеть (Network). Далее выполните следующие действия:
1. Щелкните на кнопке Добавить (Add).
2. Выберите в диалоговом окне Выбор типа компонента (Select Network Component
Туре) строку Протокол (Protocol) и щелкните на кнопке Добавить (Add). В окне
появляется список протоколов.
3. Выберите в списке производителей строку Microsoft, а в списке протоколов —
строку TCP/IP. Щелкните на кнопке Добавить (Add).
4. Вероятно, система запросит путь к установочным файлам Windows 98.
Введите путь вручную или щелкните на кнопке Обзор (Browse) и найдите файлы.
Щелкните на кнопке ОК — протокол добавляется в список установленных
протоколов.
5. Щелкните на кнопке ОК в диалоговом окне Сеть (Network). Вам будет
предложено перезагрузить систему. Подтвердите перезагрузку, чтобы завершить
установку.
В процессе установки семейства протоколов TCP/IP система Windows 98 не
спрашивает, нужно ли настраивать DHCP; служба настраивается по умолчанию.
Следовательно, если в вашем сегменте IP протокол DHCP не используется,
необходимо перезагрузить систему и изменить настройку параметров TCP/IP.
Настройка реализации TCP/IP от Microsoft
Настройка параметров Microsoft TCP/IP (IP-адрес, маска подсети, основной
шлюз и т. д.) также производится в диалоговом окне Сеть (Network).
Установленный протокол TCP/IP появляется на вкладке Конфигурация (Configuration). Если
в системе установлено несколько сетевых плат или даже служба модемного
подключения, TCP/IP автоматически привязывается ко всем доступным
устройствам. Если вы захотите «отвязать» протокол от какого-либо адаптера, найдите
строку, изображающую привязку протокола TCP/IP к устройству, и щелкните
на кнопке Удалить (Remove). Данные привязки изменяются после того, как вы
закроете диалоговое окно Сеть (Network) кнопкой ОК. Если в окне будет нажата
кнопка Отмена (Cancel), внесенные изменения теряются.
Чтобы вручную настроить протокол TCP/IP для сетевого адаптера, дважды
щелкните в строке списка, изображающей привязку TCP/IP к сетевой плате
(кроме того, можно выделить строку и нажать кнопку Свойства (Properties)). На
экране появляется диалоговое окно свойств TCP/IP (рис. 22.3).
tl'DNS Conflgurdtion. J Шщгу I.-VANS &x^№$. '/ *Pj№ess J I
1 An IP address can be automatical assigned to this eonputer. j 1
^:::. ify^fle*¥rok<ioe£r«taUuma6c^ J j
Ш• •'' your network administrator tor an addte$i and then type km : j j
P;:: the space beiow. j j
W : jsrC::. Speedy an JP address: ~- •...^^.l-.:t.:,:1:_ • j!
|, j' $$г?,-л^<Ф.: \ .-...• l:-;.-.^K .;[•• ••;.. j. • ;j J
Г •' j , OK • j?:':|УЬпЬе1 |:j
Рис. 22.3. Диалоговое окно настройки параметров TCP/IP
По умолчанию диалоговое окно Свойства TCP/IP (TCP/IP Properties)
открывается на вкладке IP-адрес (IP Address ). На этой вкладке можно либо настроить
систему на использование DHCP, либо вручную настроить IP-адрес и маску
подсети. Дело в том, что минимальный набор данных, предоставляемых
сервером DHCP, включает IP-адрес и маску подсети. Конечно, при соответствующей
настройке сервер DHCP также может предоставлять дополнительные
параметры — например, адрес основного шлюза.
Настройка шлюза
Чтобы настроить основной шлюз вручную, перейдите на вкладку Шлюз (Gateway).
На этой вкладке можно задать один или несколько адресов шлюзов для вашего
компьютера. Адрес в начале списка используется по умолчанию, а остальные
адреса шлюзов используются только при недоступности основного шлюза.
Порядок обращения к шлюзам определяется порядком перечисления адресов в
списке (сверху вниз).
Настройка WINS
На компьютере с системой Windows 98 также следует по возможности ввести
данные сервера WINS. Сервер WINS преобразует имена NetBIOS в IP-адреса.
Служба WINS была обязательным сетевым интерфейсом в операционных
системах Microsoft до появления Windows 2000. При использовании Windows 98 с
семейством протоколов TCP/IP необходим механизм разрешения имен NetBIOS.
Механизмы разрешения имен NetBIOS, WINS и файл LMHOSTS
рассматриваются в главе 7.
На вкладке Конфигурация WINS (WINS Configuration) диалогового окна свойств
TCP/IP включается разрешение имен WINS и вводятся IP-адреса серверов
WINS (рис. 22.4). Если настроить разрешение имен WINS, компьютер с
системой Windows 98 будет использовать первый доступный сервер WINS для
разрешения имен NetBIOS. Если первый сервер WINS в списке недоступен, система
пытается связаться со вторым сервером. Обращение к каждому серверу WINS
в списке производится только в том случае, если предыдущий сервер WINS был
недоступен. Если какой-либо сервер ответил (даже если в ответе говорится, что
имя отсутствует в базе данных), связь с другими серверами WINS не
устанавливается.
• c©nfgureybi«cc^pui«lor.^NS. I j
К; '}■; •':; :Cj Й$ф1е WINS Яе$окШщ|.:, ". •
h • ■' |о:Щмш8 йвгокшшлл; щу
, ]<•• .] .£••. ']'. $Щ&& I '• v'. ' 1.1
•••;.^цЩ^Ш^Щ^' '■ •'•;'•'Щ/- ,M,ui,im^i,iiii","":,|:•••••! |
•; '.'•;'-''. ^Ш|.:--' 'ОК.•■'.•;.}•• '.Сапов! •■ |J
Рис. 22.4. На вкладке WINS вводятся адреса серверов WINS
или включается использование DHCP для разрешения имен
На вкладке Конфигурация WINS (WINS Configuration) также присутствует
текстовое поле Код области (Scope ID), которое обычно оставляется пустым. Поле
предназначено для ввода суффикса NetBIOS — произвольной комбинации
алфавитно-цифровых символов, присоединяемых к имени компьютера NetBIOS.
Например, если ввести в поле символы 123АВС, а компьютеру в системе присвоено
имя NetBIOS Server2, то полное имя системы имеет вид Server2.123ABC. Системы
Microsoft, использующие TCP/IP, могут общаться только с другими системами
Microsoft, имеющими тот же суффикс. Более того, поскольку суффикс изменяет
имя компьютера, в сети может существовать другой компьютер с тем же именем
Server2, но с другим суффиксом. Суффиксы NetBIOS создают путаницу с
именами и подключениями, поэтому на практике они используются редко.
По умолчанию в окне устанавливается переключатель Использовать DHCP для
распознавания WINS (Use DHCP for WINS Resolution). Это означает, что сервер DHCP
совмещен с сервером WINS и выполняет обе функции. Если в вашей ситуации
это т так, введите IP-адрес сервера WINS в текстовом поле.
Разрешение имен WINS можно отключить. В частности, это уместно в тех
случаях, когда служба WINS не используется в сети для разрешения имен. При
отключении WINS система не будет пытаться искать сервер WINS в сети. Если
разрешение WINS включено, а в сети нет ни одного сервера WINS, клиент лишь
зря потратит время на поиски сервера WINS.
Конфигурация DNS
Вероятно, кроме имен NetBIOS вам также потребуется разрешение имен хостов
вида www.informIT.com. Это особенно важно при подключении к Интернету или
при наличии в сети хостов, не использующих системы Microsoft. Чтобы
настроить разрешение имен хостов в системе, перейдите на вкладку Конфигурация DNS
(DNS Configuration) — рис. 22.5.
Г-0Ш0Йдиг^оп j Gateway ] WIWS Солй^г^с^ j• IP^tMeis |
x; ,; ::;^,Р^5Ш1 : . . . :
■i:;• jif %nabJe DNS ••::;:-.f :;:;-;v; ::•■•-" ;"::-"] ■
:V j ;•;.:.:: I %**£$■?$ j ; j j ]
Г..-:- • * ;-:'::::-'.|:.:J i \ ]
г • I * 11
Рис 22.5. На вкладке DNS можно разрешить или запретить использование DNS,
а также настроить различные параметры
Если щелкнуть на кнопке Включить DNS (Enable DNS), вы сможете ввести имена
хоста и домена для своего компьютера с Windows 98. Обычно хостовое имя
компьютера совпадает с именем NetBIOS. Использование другого имени NetBIOS
усложняет отладку, поскольку одни программы пытаются связываться с
компьютерами по хостовому имени, а другие используют имя NetBIOS.
На этой вкладке также задаются адреса серверов DNS, обеспечивающих (таре-*
образование имен хостов в IP-адреса. Адреса используются по тем же правилам,
что и адреса серверов WINS на вкладке Конфигурация WINS — если первый
сервер DNS ответил, то система не пытается связываться с остальными серверами
DNS даже в том случае, если первый сервер не располагает адресом для данного
имени. Обращение к каждому серверу в списке производится только в том
случае, если предыдущий сервер недоступен.
Если сервис DNS в сети не поддерживается, то разрешение имен DNS
желательно отключить. Если сеть подключена к Интернету, то DNS понадобится
клиенту для разрешения web-адресов вида http://www.miaosoft.com. Тем не менее,
если подключение по доменным или хостовым именам не обязательно или не
желательно, использование DNS можно запретить. Во внутренних сетях,
использующих только системы Microsoft, сервис DNS не нужен (если в сети не
используются внутренние web-серверы с доменными или хостовыми именами).
Настройка привязки
Вкладка Привязка (Bindings) определяет, с какими службами может
взаимодействовать тот или иной протокол. Например, если протокол TCP/IP должен
использоваться для работы с сетевыми службами, но не для совместного доступа к
файлам, настройка привязок показана на рис. 22.6.
L^ ib"N$ С!ютйзыиййп'J" GTatewasn':| 'WINS Corrfiguation j IP Address I 1
Bincfings j: Advanced j NetBIOS |
Oick the network components lhat wiB communicate using this j j
protocol To improve your computer's speed, click ordy the 11
;• components that need to usethts protocol. j I
|[#j Client for Microsoft Networks j j
В Re and printer sharing lor Microsof t Network? j. j
W-' If
W ■■■ Л
'•■/ [. OK I ^^ 1 1
Рис. 22.6. Если протокол не должен использоваться для совместного доступа
к файлам, отключите привязку соответствующей службы к TCP/IP
Флажок Служба доступа к файлам и принтерам сетей Microsoft (File and printer
sharing) снят, а флажок Клиент для сетей Microsoft (Client for Microsoft Networks)
установлен. Это означает, что TCP/IP может использоваться для подключения
к другим системам Microsoft с общими файлами и принтерами, но эти системы
не могут воспользоваться TCP/IP для подключения к вашим локальным
файлам и принтерам.
Установка службы совместного доступа к файлам
и принтерам для сетей Microsoft
Если служба совместного доступа к файлам и принтерам не установлена, она не
будет присутствовать на вкладке Привязка (Binding) и другие клиенты Microsoft
не смогут подключиться к вашей системе для работы с общими файлами и
принтерами. Чтобы установить службу доступа к файлам и принтерам для сетей
Microsoft, выполните следующие действия:
1. Откройте диалоговое окно Сеть (Network) — щелкните правой кнопкой мыши
на значке Сетевое окружение (Network Neighborhood) и выберите команду
Свойства (Properties) в контекстном меню.
2. Щелкните на кнопке Добавить (Add).
3. Выделите строку Служба (Service), затем щелкните на кнопке Добавить (Add).
4. Выберите в списке производителей строку Microsoft и убедитесь в том, что в
списке Сетевые службы (Network Services) появилась строка Служба доступа к файлам
и принтерам (File and Printer Sharing).
5. Щелкните на кнопке OK и введите путь к установочным файлам, если система
запросит его.
6. Щелкните на кнопке ОК, чтобы подтвердить введенный путь, и затем еще раз —
для подтверждения установки.
7. Перезагрузите систему.
Дополнительная настройка
На вкладке Дополнительно (Advanced) имеется только одна полезная
возможность — флажок Использовать данный протокол по умолчанию (Set This Protocol to
Be the Default Protocol). Если выбрать этот флажок, клиентская система пытается
использовать TCP/IP перед всеми остальными настроенными протоколами.
Если в системе установлен только протокол TCP/IP, он автоматически
назначается протоколом по умолчанию.
NetBIOS
Вкладка NetBIOS в действительности не позволяет настраивать параметры. У
клиентов сетей Microsoft, предшествующих Windows 2000, служба NetBIOS была
важной частью сетевой поддержки, использующей семейство протоколов TCP/IP.
Флажок отключения NetBIOS через TCP/IP заблокирован и всегда остается
установленным. Поддержку NetBIOS можно разрешить или запретить для
IPX/SPX-совместимых протоколов, но не для TCP/IP.
Статические конфигурационные файлы
Файлы HOSTS и LMHOSTS.SAM (см. главу 7) находятся в корневом каталоге Windows.
ПРИМЕЧАНИЕ
Помните, что корневой каталог системы Windows не всегда называется «Windows». Чтобы
определить имя корневого каталога Windows, введите команду %windir% в диалоговом окне выполнения
Выполнить. Окно вызывается командой Пуск ► Выполнить (Start ► Run).
В корневом каталоге Windows также находится другой статический
конфигурационный файл с именем SERVICES (обратите внимание на отсутствие
расширения). Содержимое файла SERVICES соответствует списку хорошо известных
номеров портов служб TCP и UDP, приведенному в RFC 1700 (в самом файле
говорится, что он соответствует RFC 1060, но этот RFC был пересмотрен в RFC
1700 — см. http://www.ietf.org/rfc/rfcl700.txt). В файле SERVICES перечислены
различные службы, номера портов и протоколов, назначенные хорошо известным
службам в RFC. В частности, в файле указаны номера портов команд и данных
FTP B1/TCP и 20/ТСР соответственно). По содержимому этого файла
встроенный клиент FTP от Microsoft определяет, какие порты должны использоваться
для коммуникаций FTP. Модификация файла приводит к изменению порта
по умолчанию, используемому программой FTP режима командной строки. Тем
не менее файл SERVICES используется не всеми программами TCP/IP. Более
того, некоторые программы обращаются к файлу SERVICES лишь после
специальной настройки параметров. Многие программы независимых фирм и даже
браузер Microsoft Internet Explorer не используют файл SERVICES.
Настройка реестра
Многие важные параметры настройки TCP/IP отсутствуют в диалоговом окне
свойств TCP/IP и находятся только в реестре Windows 98. В этом разделе
будут рассмотрены основные параметры конфигурации TCP/IP, настройка
которых производится на уровне реестра.
ПРИМЕЧАНИЕ
Другие параметры конфигурации TCP/IP в реестре Windows 98 более подробно описаны в статье
Knowledge Base Q158474 на сайте www.microsoft.com/support или в технической документации
Microsoft Tech Net.
Все параметры, описанные в этом разделе, настраиваются в разделе HKEY_
LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP (рис. 22.7).
Редактирование реестра Windows 98 производится следующим образом:
1. Выполните команду Пуск ► Выполнить (Start ► Run).
2. Введите команду REGEDIT и щелкните на кнопке ОК.
3. Команда REGEDIT может вводиться как прописными, так и строчными
буквами. В Windows 98 имена подавляющего большинства команд вводятся без
учета регистра символов.
ПРИМЕЧАНИЕ
Модификация реестра может привести к сбою системы вплоть до того, что систему не удастся
нормально перезапустить. Соответственно, изменяйте только те параметры реестра, в которых вы
твердо уверены, и не экспериментируйте в системе, которая выполняет особенно важные
функции. Перед редактированием рекомендуется создать резервную копию реестра. Экспортирование
реестра выполняется следующим образом:
1. Выполните команду Пуск ► Выполнить (Start ► Run).
2. Введите в диалоговом окне команду REGEDIT.
3. В открывшемся окне редактора реестра откройте меню Реестр (Registry) и выберите команду
Экспорт файла реестра (Export Registry).
4. Введите имя файла (например, RegSave).
5. Задайте каталог, в котором будет сохраняться файл.
6. Щелкните на кнопке Сохранить (Save).
7. Закройте редактор реестра. Файл архива (RegSave.reg) появляется в том каталоге, в котором
он был сохранен.
Если после редактирования реестра система перестает нормально работать, дважды щелкните на
сохраненном файле, чтобы вернуться к старой конфигурации.
Если вы хотите заархивировать физические файлы, образующие реестр, найдите файлы system.dat
и user.dat в каталоге Windows и скопируйте их в другое место. Если после внесения изменений
система не загружается, скопируйте файлы system.dat и user.dat обратно в каталог Windows.
■ ДедЫу £d* yiew jjslp '\ '' ; = • •/ '• :=;:-.-\ '';':'.'.[■■. . .•• ..-. • :
I! ) Г+: LJ RemoteAccess3 l Waime^__.____J^L^.iLL™w.^^^.^.L~~~—* J
II ; p UPDATE j|»||Deiault) "(value not self ~ ~ \
I Й-О VxD IgjEnableDNS " J
I] I CJ AFVXD J*b]LMHo$tFile TAWINDOWSXImhosls" |
:- !■ OJ ASPIENUM 1
II K^B,os i I
i-CJ BIOSXLAT l
II ;■ CJ CnrApiEng 11 j
Г) i-Cl COMBUFF j
J : Ж p CQNFIGMG U j
1 • "CJ CyberKm :| j
: I D DFS
i It) О DHCP
I : S) CJ DHCPOptions
:-Cj dosmgr j
: p IFSMGR :j
Q I0S
\\ •■ ^ D ISAPNP J I
• ! p JAVAS„UP 1 J
j [+1 CJ Parameters j I
I • ■ О Se-rviceProvider ▼]|< \ '.'.''"'•''•:,:. ''.: ':'••"'"■'•''• ■'' I ►)[
;My Cc^'a^ •.•?••:' , }
Рис. 22.7. Для изменения параметров конфигурации TCP/IP в реестре
используется программа regedit.exe
Включение маршрутизации
Если компьютер с Windows 98 должен использоваться в качестве статического
маршрутизатора, внесите соответствующие настройки в реестр Windows 98. Для
этого следует найти в реестре ключ MSTCP и добавить в него строковый
параметр с именем EnableRouting и значением 1. Это делается так:
1. Выполните команду Пуск ► Выполнить (Start ► Run).
2. Введите в диалоговом окне команду REGEDIT.
3. Последовательно щелкая на значках +, раскройте нужную ветвь реестра и
выберите ключ MSTCP (рис. 22.7).
4. Откройте меню Правка (Edit) и выберите команду Создать ► Строковый
параметр (New ► String Value).
5. На правой панели редактора появляется новый параметр. Введите имя
EnableRouting и нажмите клавишу Enter.
6. Дважды щелкните в строке EnableRouting.
7. Введите в поле Значение (Value Data) строку 1.
8. Щелкните на кнопке ОК и закройте редактор реестра.
Чтобы убедиться в том, что в результате изменений в реестре действительно
была включена маршрутизация, воспользуйтесь программой winipcfg. Запустите
WINPCFG из диалогового окна Выполнить; щелкните на кнопке Сведения (More
Info). Вы увидите, что флажок Маршрутизация IP (IP Routing Enabled) установлен
(рис. 22.8).
г- Host Information ^Vlbrjx^ww:.".":- ::;:;:•; у :■-/:-: г •
1 • • НоайШр" KURT ч
; DNS ServerЛ ^20470.123.1
NodeTypef Broadcast
; ... NdBlOSScopf jd|: :; !
.' IP Routing ЕпаЬЙ £/ • WINS Proxy Enabled
] NetBIOS Resolution UsesDfef"
r Ethernet Adapter Information —,- •'- r :..:.:...;.r
i I:; JPPPAdapter.2j\
I Adapter Addresif" 4445'5>54-00-00
; IP Addre^ Г ' : 1£5.1 Vs. 138 203
Subnet Mask f ""'255 255 00
• ; Default Gatewayi'7 " 165.113.156.203
[ DHCP Server f "'Ж.255\ 25&2S5
I Primary WINS Sever p™ "
5 Secondary WINS Server Г
. Lease Obtained f: 0101801200:00 AM ll
■ t \
\\ tease EspjfesS . 0101801200.00AM ]
Г I- — "^l r'kj?;^- I ■*'■■■■"■ I Re^eAll j RenewАЯ |
Рис. 22.8. Включение маршрутизации IP в реестре
проверяется при помощи программы WINIPCFG
В Windows 98 и реализацию TCP/IP от Microsoft не входят протоколы
маршрутизации (такие, как RIP или OSPF). Следовательно, таблицы
маршрутизации Windows 98 придется обновлять вручную. Чтобы разместить статические
маршруты на новом маршрутизаторе, следует выполнить команду route:
1. Откройте приглашение командной строки.
2. Введите команду route /?.
3. Нажмите клавишу Enter для получения дополнительной информации.
При включении маршрутизации также можно задать размер буфера
маршрутизации, по умолчанию равный 73 216. Если вы хотите изменить буфер
маршрутизации, добавьте в раздел MSTCP строковый параметр RoutingBufSize и задайте
нужное значение. Также можно задать числовой параметр RoutingPackets,
определяющий количество одновременно маршрутизируемых пакетов (по умолчанию
равное 50).
Случайный выбор сетевого адаптера
Параметр реестра Random Adapter предназначен для компьютеров Windows 98,
оснащенных несколькими сетевыми платами. При включении этого параметра
система Windows 98 возвращает случайно выбранный адрес из набора своих
IP-адресов независимо от того, какая сетевая плата приняла запрос. Такой
режим может пригодиться для распределения нагрузки между несколькими
сетевыми адаптерами. Чтобы настроить этот режим, добавьте в раздел MSTCP
строковый параметр RandomAdapter и задайте ему значение 1. По умолчанию сетевые
платы Windows 98 возвращают адрес, получивший запрос.
Тайм-аут при разрешении имен
Когда клиент WINS с системой Windows 98 пытается преобразовать имя
компьютера NetBIOS в IP-адрес, он обращается к серверу WINS до трех раз с интервалом
750 миллисекунд, прежде чем пытаться использовать другой метод разрешения
имен. Включение строковых параметров NameSrvQueryCount и NameSrvQueryTimeout
в раздел MSTCP реестра позволяет изменить стандартную процедуру разрешения
имен в Windows 98. Параметр NameSrvQueryCount определяет, сколько раз клиент
Windows 98 попытается связаться с сервером WINS перед наступлением тайм-
аута. Параметр NameSrvQueryTimeout определяет период времени, по истечении
которого клиент Windows 98 либо попытается снова связаться с сервером WINS,
либо откажется от дальнейших попыток.
Если клиент Windows 98 не настроен на использование сервера WINS или не
получает от него ответа, он пытается преобразовать имя компьютера NetBIOS
в IP-адрес посредством широковещательной рассылки. По умолчанию система
производит три рассылки с интервалом 750 миллисекунд, после чего прекращает
дальнейшие попытки. Эти количественные характеристики по умолчанию
определяются параметрами BcastNameQueryCount и BcastNameQueryTimeout раздела MSTCP.
Срок жизни пакетов по умолчанию
По умолчанию срок жизни пакетов IP, отправляемых системой Windows 98,
равен 32. Чтобы изменить срок жизни пакетов IP в Windows 98, следует
добавить строковый параметр DefaultTTL в раздел MSTCP реестра. Значение параметра
определяется максимальным количеством переходов, после которого пакет
должен прекратить свое существование.
Размер окна TCP
По умолчанию размер окна TCP в Windows 98 равен 8192. Чтобы изменить это
значение, включите в раздел MSTCP реестра Windows 98 строковый параметр
DefaultRcvWindow. Значение параметра определяет количество байт, которые
могут быть переданы отправителем без предварительного подтверждения
предыдущей отправки.
Тестирование TCP/IP
В комплект поставки Windows 98 входит несколько утилит, предназначенных для
тестирования конфигурации TCP/IP после ее установки. В число основных
утилит немедленной проверки конфигурации входят утилиты ping, tracer! и WINIPCFG.
После установки семейства протоколов TCP/IP вы можете проверить
конфигурацию при помощи программы WINIPCFG. Если настройка системы
осуществлялась с применением протокола DHCP, программа WINIPCFG покажет параметры,
переданные сервером DHCP. Если параметры настраивались вручную, WINIPCFG
поможет убедиться в правильности введенных данных.
Утилита ping проверяет наличие связи с другими системами. Проверку
настройки протокола следует начать с адреса обратной связи.
1. Откройте приглашение командной строки — введите команду command в
диалоговом окне Выполнить (Run) и нажмите Enter. На экране появляется окно
с приглашением командной строки.
2. Введите команду ping 127.0.0.1 и нажмите клавишу Enter.
Вы должны получить ответ от вашей системы. Если ответа не будет,
переустановите семейство протоколов TCP/IP. Если ответ будет получен, произведите
опрос по своему IP-адресу (как говорилось выше, для получения IP-адреса
можно воспользоваться программой WINIPCFG).
Если адрес обратной связи и адрес локальной системы работают нормально,
попробуйте проверить локальный основной шлюз. Если шлюз ответит, проверьте
хост в удаленной сети. Если и эта проверка завершится успешно, значит, TCP/IP
работает нормально. Если на компьютере были настроены службы
разрешения имен (такие, как DNS и WINS), опросите эти серверы и убедитесь в их
доступности.
При возникновении проблем с получением ответа от удаленного хоста
воспользуйтесь утилитой tracer! Программа tracert запускается из командной строки
и предназначается для отслеживания маршрута к удаленному хосту от
локальной системы. Tracert последовательно генерирует сообщения ICMP с постоянно
увеличивающимся сроком жизни. Это позволяет проследить путь запроса от
локальной системы к удаленной и получать информацию о его прохождении.
Если запрос останавливается где-то на своем пути, вы будете знать, где в сети
следует искать проблемы.
Для проверки конфигурации разрешения имен DNS воспользуйтесь
программой ping или tracert с именами хостов. Попробуйте связать диск с именем
сервера Microsoft, чтобы убедиться в правильности работы разрешения имен
NetBIOS. Если при выполнении какой-либо из этих операций возникнут
проблемы, проверьте конфигурацию соответствующего сервера и своей системы.
NBTSTAT
Программа NBTSTAT (NetBIOS over TCP/IP Status) предназначена для
получении информации о работе NetBIOS на базе TCP/IP. Чтобы запустить эту
программу, откройте приглашение командной строки и введите команду NBTSTAT /?.
В окне выводится список ключей команды NBTSTAT.
Команда NBTSTAT -С выводит информацию о состоянии кэша имен NetBIOS.
По умолчанию сведения о связи имен NetBIOS с IP-адресами хранятся в кэше
имен в течение 360 000 миллисекунд (то есть 6 минут). Чтобы изменить
продолжительность хранения информации в кэше, добавьте параметр CacheTimeout
в раздел реестра MSTCP и задайте другое число. Команда NBTSTAT -R очищает
и инициализирует кэш имен NetBIOS. Если в системе имеется файл LMHOSTS,
содержащий записи с тегом #PRE, в результате выполнения команды NBTSTAT -R
эти записи будут загружены в кэш.
ПРИМЕЧАНИЕ
Содержимое файла LMHOSTS описано в файле LMHOSTS.SAM, находящемся в корневом каталоге
Windows. Чтобы получить дополнительную информацию, откройте файл LMHOSTS.SAM в Блокноте
или в другом текстовом редакторе.
Еще одна полезная возможность утилиты NBTSTAT — получение таблицы
имен локального или удаленного хоста. Введите команду NBTSTAT -А с
IP-адресом компьютера, для которого следует получить таблицу имен. Если вы
предпочитаете использовать имя удаленного компьютера, введите команду NBTSTAT -a
с именем удаленного компьютера. Также можно ввести имя или IP-адрес вашей
системы, чтобы проверить содержимое ее таблицы имен. Команда также
выводит адрес MAC удаленной системы.
NETSTAT
Полезная утилита NETSTAT предназначена для проверки соединений TCP и UDP.
Например, команда NETSTAT -р TCP используется для проверки состояния
протокола TCP; вы получите список используемых портов TCP. Команда NETSTAT -s
выводит полную информацию о текущем состоянии всех протоколов.
ARP
Все локальные IP-адреса должны преобразовываться в адреса MAC. Программа
ARP используется для просмотра адресов MAC локальных систем, находящихся
в локальном кэше ARP. Если IP-адрес был разрешен один раз, но не
использовался снова, соответствующая запись остается в кэше ARP в течение двух
минут. Если адрес был снова использован в течение двух минут, срок жизни записи
ARP равен десяти минутам. В кэш ARP также можно добавить статические
данные, которые остаются в нем до перезагрузки системы. Статические записи
позволяют уменьшить количество широковещательных запросов ARP для
адресов MAC в локальном сегменте. Чтобы получить информацию о синтаксисе
добавления статических записей ARP, введите команду ARP /? в командной
строке Windows 98.
Итоги
Фирма Microsoft разработала собственную реализацию семейства протоколов
TCP/IP для операционной системы Windows 98. Реализация TCP/IP от Microsoft
включает поддержку интерфейсов NetBIOS и Windows Sockets для поддержки
программ, ориентированных на NetBIOS и Unix (например, ping и tracert). Кроме
того, стек IP от Microsoft поддерживает спецификацию NDIS, что позволяет
привязать несколько протоколов к одной или нескольким сетевым платам.
Установка и настройка семейства протоколов TCP/IP производится в
диалоговом окне Сеть (Network). Протоколы устанавливаются кнопкой Добавить (Add).
Чтобы изменить конфигурацию протоколов после установки, вызовите
диалоговое окно Сеть (Network) и найдите строку нужного протокола. Дважды щелкните
на ней — открывается диалоговое окно свойств TCP/IP. Нужные параметры
настраиваются на вкладках этого окна.
Если нужные параметры отсутствуют в окне свойств TCP/IP, вероятно, вам
придется настраивать их в редакторе реестра Windows. Настройка параметров
TCP/IP в реестре Windows 98 описана в статье Microsoft Knowledge Base Q158474
(http://support.microsoft.eom/support/kb/articles/ql58/4/74.asp).
Следующая глава посвящена настройке Windows 98 для модемного
подключения к Интернету. Многие концепции этой главы в равной степени относятся
и к следующей главе, но процесс настройки модема несколько отличается от
процесса настройки сетевой платы для локальной сети.
*к ^* Настройка TCP/IP
4Jb Windows 2000
Kapawicum С. Сияй (Karanjit S.Siyan)
Глава посвящена вопросам установки и настройки сетевых компонентов и
протоколов TCP/IP в Windows. Также рассматривается процесс настройки рабочих
станций Windows 2000. Обычно протокол TCP/IP устанавливается вместе с
другими сетевыми средствами во время установки операционной системы. Впрочем,
иногда автономный компьютер требуется подключить к сети после добавления
соответствующего сетевого оборудования. В таких случаях поддержку TCP/IP
приходится устанавливать вручную.
В этой главе вы также научитесь настраивать стек TCP/IP для
использования сетевых служб WINS и DNS.
Установка TCP/IP
Программа установки Windows 2000 автоматически включает поддержку стека
протоколов TCP/IP при установке любых сетевых служб. В этой главе описана
процедура установки и настройки стека протоколов TCP/IP Windows 2000.
Необходимость в ручной установке TCP/IP возникает только в том случае, если
поддержка стека была удалена ранее, но теперь ее потребовалось установить
заново. Выполните следующие действия:
1. Зарегистрируйтесь на компьютере с системой Windows 2000 с правами
администратора.
2. Выполните команду Пуск ► Настройка ► Сетевые подключения (Start ► Settings ►
Network and Dial-Up Connections). Щелкните правой кнопкой мыши на команде
Подключение по локальной сети (Local Area Network) и выберите команду
Свойства (Properties). На экране появляется диалоговое окно свойств подключения
по локальной сети (рис. 23.1). Его также можно открыть другим способом —
щелкните правой кнопкой мыши на значке Сетевое окружение (My Network
Neighborhood) и выберите команду Свойства (Properties). Затем щелкните правой
кнопкой мыши на значке Подключение по локальной сети (Local Area Network)
и выберите команду Свойства (Properties).
3. Чтобы переустановить стек протоколов TCP/IP, щелкните на кнопке
Установить (Install). Появляется диалоговое окно Выбор типа сетевого компонента
(Select Network Component Type) (рис. 23.2). Выберите строку Протокол (Protocol)
и щелкните на кнопке Добавить (Add). В диалоговом окне Выбор сетевого
протокола (Select Network Protocol) отображается перечень протоколов для установки.
4. Выберите строку Протокол TCP/IP и щелкните на кнопке ОК.
5. Завершите процедуру установки по отображаемым инструкциям.
После установки протокола TCP/IP наступает следующий этап — настройка
основных параметров TCP/IP.
. General | Sharing | /ШШГ
Connect ushg I I
j m 3Com EtherLinkШ0Л 00 Pd NIC (X905*TX) ~
: I Configure } j j
Components checked are i&&i by this connection:
| i^TNWLink NetBIOS 3
J l?<) "Г" ЫЧ^гшк IPX/SPK/NetBIOS Compatible Transparr Proto
ШT*Network Monitor Drive* _J
l.iJ-■..•.....;..;,,. _*. 12Г
г Description- : I I
; E^ablelorhet Windows comput«s to access NetWare • I
. servers witl^t ruir^ NetWare Client Software. !
P Show ben in ta^bar when connected II
OK | Caned ||
Рис. 23.1. Диалоговое окно свойств подключения по локальной сети
Dck the type of network component you want to install:
jMhHI ^v
ШЦ Service i
ПГ Protocol Щ
rDesertion —— - - —• ~i
: A client provide» access to computer* and files on j ]
. ! the network you are connecting to. -Ш j
| Add.. | Cancet j j
Рис. 23.2. Диалоговое окно выбора типа сетевого компонента
Настройка IP-адреса
Каждый сетевой интерфейс, обслуживаемый стеком протоколов TCP/IP,
описывается набором параметров IP. К числу таких параметров относится IP-адрес,
маска подсети, шлюз по умолчанию и IP-адреса серверов имен. Как минимум
для каждого сетевого интерфейса должен быть задан IP-адрес и маска подсети.
Настройка параметров IP может производиться двумя способами: вручную
или автоматически. При ручной (статической) настройке параметров IP
необходимо вести учет IP-адресов всех компьютеров, а также назначить уникальный
IP-адрес каждому сетевому интерфейсу. Из-за невнимательности часто
происходят ошибки настройки IP, которые обходятся довольно дорого из-за времени,
затрачиваемого на отладку. По этой причине во многих сетях используется
механизм автоматической настройки параметров IP с центрального сервера
(например, сервера DHCP).
Если вы не используете протокол DHCP для динамического назначения
IP-адресов в Windows 2000 Server, на экране появляется диалоговое окно свойств
TCP/IP (рис. 23.3).
General I
You can ge* IP settings assigned automatical if you network supports
this сараЫШу. Otherwise, you пъъй. to. ask your network асЫпЫга1ог for j
the appropriate IP settings;
Г Obtain anIP address aufoinaticaJjy
:■■■(• U^theto|fowr^lPadAes?:r""™ ;
\ IP address:. : ;:.: j 10 . 0 . 0 . 102 \
\ Subnet rrtask: . \.\/-:-.j 255 . 0.0.0 !
\ Default gateway: :./• J 10 0 0 .114 j
г-*? Use the following DNS server addresses: ; jj
| Preferred DNS server: ::, ;j 10 . 0 . 0 .102 j
: | Alternate DNS server: . j 63 24 . 13 Л18 j
I [ _ ...,.,'. •■■■■,■'■■•„■■■,,.• „. Л i I j
Advanced., j j j
j OK ] СапЫ'" |
Рис. 23.3. Диалоговое окно свойств TCP/IP
Диалоговое окно также можно вызвать другим способом — выбрать строку
Протокол Интернета (TCP/IP) (Internet Protocol TCP/IP) в диалоговом окне свойств
подключения по локальной сети. В этом диалоговом окне задается IP-адрес,
маска подсети и адрес основного шлюза для сетевого интерфейса. IP-адрес,
маска подсети и настройки основного шлюза должны соответствовать
параметрам сети, к которой подключен компьютер с Windows 2000. Например, если эта
сеть описывается сетевым адресом 192.120.12.0/255.255.255.255, то значения
IP-адресов компьютеров, принадлежащих этой сети, должны находиться в
интервале 192.120.12.1 - 192.12.12.254 с маской подсети 255.255.255.0.
IP-адрес основного шлюза также должен входить в этот интервал, поскольку
шлюз должен находиться в той же сети.
Настройка IP-адреса производится следующим образом:
1. Если в сети уже работает сервер DHCP и вы хотите использовать его для
настройки компьютера с Windows 2000, установите переключатель Получить
IP-адрес автоматически (Obtain an IP address automatically). Сервер DHCP
содержит сведения о конфигурации TCP/IP, используемые другими хостами
TCP/IP. При запуске хост TCP/IP запрашивает свои конфигурационные
данные у сервера DHCP.
2. При автоматическом получении IP-адреса компьютер принимает IP-адрес
и маску подсети с сервера. Если ввести значения IP-адреса и маски подсети,
работа клиента DHCP блокируется и он не принимает никакой информации
с сервера DHCP.
3. Если сервер DHCP не работает в сети или его функции должны выполняться
сервером Windows 2000, IP-адрес и маска подсети вводятся вручную в
соответствующих полях (см. рис. 23.3).
4. Если сеть подключена к другим сетям или подсетям TCP/IP, следует
заполнить поле Основной шлюз (Default Gateway), чтобы вы могли связаться с другими
сетями. TCP/IP определяет, что адрес получателя относится к другой сети,
и направляет пакет основному шлюзу (а точнее говоря, основному
маршрутизатору — термин «основной шлюз» продолжает использоваться, поскольку
устройства, называемые маршрутизаторами, раньше назывались шлюзами).
5. Если на компьютере установлено несколько сетевых плат, каждая из них
настраивается по отдельности. Задайте параметры конфигурации IP (IP-адрес,
маска подсети, основной шлюз, использование сервера DHCP) для каждого
адаптера с привязкой к протоколу TCP/IP, последовательно выбирая сетевые
платы в списке.
6. Щелкните на кнопке Дополнительно (Advanced), если потребуется настроить
несколько IP-адресов или несколько основных шлюзов для одной сетевой
платы, а также для настройки параметров безопасности. Учтите, что параметры
конфигурации IP в этом диалоговом окне относятся только к выбранной
ранее сетевой плате. Процедура настройки WINS/DNS будет описана ниже
в этой главе.
7. Чтобы задать несколько IP-адресов и масок подсети для выбранной сетевой
платы, введите нужные значения в соответствующих полях диалогового окна
Дополнительные параметры TCP/IP (Advanced TCP/IP Settings), изображенного на
рис. 23.4, и щелкните на кнопке Добавить (Add).
8. Возможность определения нескольких IP-адресов и масок подсетей особенно
полезна в ситуациях, когда одна физическая система должна выглядеть как
несколько логических систем. Например, почтовому серверу назначается адрес
199.245.180.1, серверу DNS - адрес 200.1.180.2, а серверу FTP - 203.24.10.3.
Кроме того, использование нескольких IP-адресов и масок подсетей упрощает
переход на другую схему назначения IP-адресов в сети. Множественные
IP-адреса также используются в сетях, состоящих из нескольких логических
сетей IP.
• IP Settings ] от j WINS | Options | .:.
■!. : IP addfesses
I I IP address ] Si&net mask j :
I j i o.'o.'o.'i 02 255.o.ab !
' I Addl> j; j | Edit.. | Remove j j
г Default gateway's:
i I Gateway j Metric _ •
! mciaiu: "T """ Л ~ i
Add.'.. j Edit... | Remove j !
I rA erfac© metric: у II
1 °K 1 CanCd 1
Рис. 23.4. Диалоговое окно дополнительных свойств TCP/IP
9. Если потребуется настроить дополнительные шлюзы, введите их IP-адреса
в поле Основные шлюзы (Default Gateways) и щелкните на кнопке Добавить (Add).
10. В этом поле задаются IP-адреса маршрутизаторов в локальной сети. При
отправке пакета по IP-адресу, отсутствующему в локальной сети и не
включенному в локальную таблицу маршрутизации компьютера с Windows 2000,
используется основной шлюз. Если в системе определено несколько
основных шлюзов, они последовательно перебираются в порядке перечисления
(обращение к следующему шлюзу производится только в том случае, если
попытка связаться с предыдущим шлюзом оказалась безуспешной).
ПРИМЕЧАНИЕ
Чтобы удалить IP-адрес с маской подсети или данные шлюза, выделите соответствующую строку
в списке и щелкните на кнопке Удалить (Remove).
Назначение IP-адресов при отказе сервера DHCP
Если найти сервер DHCP не удается, клиент DHCP для Windows 2000 решает
проблему назначения IP-адресов несколько иначе. Если на компьютере с
Windows 2000 настроен режим автоматического получения IP-адресов, происходит
следующее:
1. При установке клиент пытается обнаружить сервер DHCP. Во многих сетях
TCP/IP используются серверы DHCP, настроенные администратором для
предоставления в аренду IP-адресов и назначения других конфигурационных
данных.
2. Если попытка обнаружить сервер DHCP завершается неудачей, Windows 2000
автоматически настраивает клиента DHCP с IP-адресом из
зарезервированной IANA сети класса В с адресом 169.254.0.0 и маской подсети 255.255.0.0.
Этот частный адрес зарегистрирован за Microsoft. Клиент DHCP при помощи
протокола ARP проверяет, не используется ли выбранный IP-адрес в
настоящее время. Если адрес используется, клиент выбирает другой IP-адрес и
делает новую попытку (до десяти раз). Когда клиенту DHCP удается найти
неиспользуемый IP-адрес, он настраивает интерфейс с этим адресом, но
продолжает в фоновом режиме обращаться к серверу DHCP через каждые пять
минут. Если сервер DHCP снова начнет работать, автоматически выбранные
данные заменяются сведениями, предоставленными сервером DHCP.
Если клиент DHCP ранее получил от сервера арендованный адрес,
последовательность событий выглядит несколько иначе:
1. Если во время загрузки срок аренды еще не истек, клиент пытается продлить
аренду у сервера DHCP. Если при этом клиенту не удается найти сервер DHCP,
клиент при помощи ping опрашивает основной шлюз, указанный в аренде. Если
шлюз отвечает, клиент приходит к выводу, что он все еще находится в сети,
где был получен текущий арендуемый адрес, но сервер DHCP по какой-то
причине временно недоступен; в этом случае клиент продолжает использовать
арендованный адрес. После истечения половины срока аренды клиент в
фоновом режиме пытается возобновить аренду. Попытки возобновления аренды по
прошествии половины интервала является частью стандартной операции DHCP.
2. Если попытка опроса основного шлюза завершается неудачей, клиент считает,
что он был перемещен в сеть, не поддерживающую сервиса DHCP. Далее
клиент производит автоматическую настройку описанным выше способом
для сети 169.254.0.0/24. После этого он продолжает свои попытки связаться
с сервером DHCP каждые 5 минут.
Настройка параметров DNS
Пользователи обычно идентифицируют хосты по именам DNS. Компьютер с
системой Windows 2000 должен разрешить имя DNS, то есть преобразовать его в
соответствующий IP-адрес. В Windows 2000 имеется клиент DNS, также
называемый резолъвером, который выдает запросы к серверу DNS на разрешение имен.
На компьютере с Windows 2000 должен быть задан IP-адрес как минимум одного
сервера DNS. Поскольку сервис разрешения имен имеет критическое значение
для работы Windows 2000, в сети следует поддерживать дополнительный сервер
DNS на случай отказа основного сервера.
Адреса серверов DNS в Windows 2000 настраиваются на вкладке DNS в
диалоговом окне Дополнительные параметры TCP/IP (Advanced TCP/IP Settings). DNS
является самым распространенным механизмом разрешения имен в Интернете
и в сетях на базе Unix. При включении разрешения имен DNS в сети должен
работать сервер DNS, с которым может связаться клиент Windows 2000. Адрес
сервера указывается на вкладке DNS. В этом разделе рассматривается
клиентская часть DNS.
Если настройка параметров IP осуществляется при помощи сервера DHCP,
то последний также может использоваться для настройки параметров DNS
клиента Windows.
Непосредственное обращение к другим хостам TCP/IP в сети производится
по IP-адресам. Пользователи обычно предпочитают запоминать и использовать
символические имена вместо IP-адресов. В системе DNS имена узлов TCP/IP
(как компьютеров с Windows 2000, так и хостов Unix) имеют иерархическую
структуру вида wksl.kinetics.com или wk2.cello.org. DNS является наиболее
распространенной системой формирования имен для хостов Unix и Интернета. Если
вы планируете использовать компьютер с системой Windows 2000 в сети Unix
или в Интернете, настройте Windows 2000 на использование DNS. Приложения
TCP/IP, написанные для программного интерфейса Windows Sockets (например,
Internet Explorer, FTP и Telnet), производят разрешение символических имен
при помощи DNS или по локальному файлу HOSTS.
При установке TCP/IP на компьютере с системой Windows 2000 также
устанавливается клиент DNS. Помимо динамического разрешения имен, клиент DNS
также используется для разрешения имен компьютеров NetBIOS на серверах
WINS. Настройка DNS на компьютере с Windows 2000 относится ко всем
сетевым платам, установленным на компьютере.
Ниже описана процедура настройки клиента DNS на компьютере с
Windows 2000.
1. Перейдите на вкладку DNS диалогового окна Дополнительные параметры TCP/IP
(Advanced TCP/IP Settings), изображенного на рис. 23.4. Внешний вид вкладки
показан на рис. 23.5.
2. Чтобы добавить в список IP-адрес сервера DNS, щелкните на кнопке Добавить
(Add). Редактирование IP-адреса производится при помощи кнопки Изменить
(Edit). Чтобы удалить адрес из списка, щелкните на кнопке Удалить (Remove).
Клиент DNS пытается разрешить имена DNS, связываясь с первым сервером
в списке. Если разрешить имя не удается, клиент пытается обратиться ко
второму серверу и т. д. до тех пор, пока не будут опробованы все серверы.
Порядок перебора серверов DNS изменяется при помощи кнопок со стрелками
справа от списка.
Следующие три параметра относятся ко всем подключениям TCP/IP и
используются для разрешения неполных доменных имен.
IP Settings DNS jv/INS j Option |
DNS server addresses, in order of u$e:
]63 224 13.11^^^^^^^^^^^^^^^^^ JLl
Add... j Edit... j Remove |
f The following three settings are applied to ail connections with ТСРУ1Р j j
;:: enabled f- or resolution of unquaSfied пагле?:
И (• Append primary and connection specific DNS suffixes
■ Г" Append parent suffixes of the primary DNS suffix ] j
: Г Append these DNS suflwes.fa order):
[ и
DNS suffix for this connection: jsiyan.com
. P Register tHs connection's addresses in DNS j
Г" Use this connection's DNS suffix in DNS registration j
| OK \ Cancel |
Рис. 23.5. Вкладка DNS диалогового окна дополнительных параметров TCP/IP
Переключатель Дописывать основной DNS-суффикс и суффикс подключения (Add
Primary and connection specific DNS suffixes) указывает на то, что к неполному
доменному имени должно присоединяться название родительского домена DNS.
Например, для компьютера NTWS1, находящегося в родительском домене
KINETICS.COM, будет производиться поиск имени NTWS1.KINETICS.COM.
При установке этого переключателя поиск ограничивается родительским
доменом. Если разрешить имя не удается, дальнейший поиск на этом прекращается.
Переключатель Дописывать следующие DNS-суффиксы (по порядку) (Append these
DNS suffixes (in order)) используется для задания списка суффиксов DNS,
которые будут присоединяться к неполному доменному имени в процессе
разрешения. Чтобы изменить порядок поиска доменных суффиксов, выделите
суффикс имени и переместите его в нужную позицию при помощи кнопок
со стрелками. Чтобы удалить суффикс, выделите его в списке и щелкните
на кнопке Удалить (Remove). Чтобы отредактировать суффикс, выделите его
и щелкните на кнопке Изменить (Edit).
В поле DNS-суффикс подключения (DNS suffix for this connection) можно задать
суффикс DNS, используемый для текущего подключения. При установке
флажка Зарегистрировать адреса этого подключения в DNS (Register this connection's
address in DNS) на сервере DNS создается запись для IP-адреса и доменного
имени текущего подключения. При регистрации имени можно использовать
имя хоста с суффиксом DNS, для чего устанавливается флажок Использовать
DNS-суффикс подключения при регистрации в DNS (Use this connection's DNS suffix
in DNS registration).
ПРИМЕЧАНИЕ
На серверах DNS хранится информация о соответствии между IP-адресами и именами хостов.
Берклиевские средства удаленного доступа (такие, как rep, rsh и гехес) используют для
аутентификации хостовые имена, в которых запрещено использование некоторых символов, разрешенных
в именах компьютеров Windows 2000 (прежде всего символа подчеркивания). При подключении
к Интернету следует использовать зарегистрированные имена DNS.
На рис. 23.6 представлен пример настройки DNS для хоста NTS. В этом примере
используется локальное доменное имя SIYAN.COM и серверы DNS с адресами
10.0.0.102 и 63.224.13.118. Сначала с запросом на разрешение имени клиент
обращается к серверу DNS с IP-адресом 10.0.0.102. Если этот сервер не может
преобразовать имя в IP-адрес, используется сервер DNS с адресом 63.224.13.118.
При поиске доменные суффиксы перебираются в порядке SIYAN.COM, KINETICS.
СОМ и SCS.COM. В ряде старых клиентов Windows (Windows 95 без Winsock2,
Windows NT до выхода SP5) резольвер DNS связывается со вторым
сервером DNS только в том случае, если первый сервер DNS не ответил на запрос.
Если первый сервер DNS не может разрешить имя, такие клиенты не
пытаются обратиться с запросом на разрешение имени ко второму серверу DNS.
у ONS server dddresiei/jri order of use:
ШШЕШШШ^ШШШШШИШШШШШШШШ -'•*> I
; 163.224.13.118 :_J
I .: ,„:..,„вд„ст„_ _Д±]
.• The fotowtng three'settbgs are applied to sA comectton* with TCP/IP
h enabled. For re^oUicrj of oiqualined name$:
г С Append primary and connection specific DNS suffixes jj
П Append р£Ш^и&&>: .6Ь.&й ^аду DNS. &#«. ]
h С Append theie DNS suffixes ftn order): jj
N nunetics.com :—LJ j
h jsce.com i i
k; • 1.,.... . ...,,,,,.,,:.,,, iULj '■
Щ:.-. • ■ •");:; •' -: АоШ;.. ''$£.;:' Edit!: f •••.•' RehroveV': j
%■: РЩ. ^u№k *°f №* connect^:-jsiyanxom ;. • :-•:
k;. jf? {Register this; сопгшсЙопЧ iSdoVe$$e$ in ONS . . I
Шг Г^ Use this connection's DNS «ifa in DNS reoifctration 1.
:':iv--/'-:^';.:';\-/-'-: 'j/'';Q^'' 'jv!':'::''''Canc^ : [j
Рис 23.6. Пример настройки параметров DNS в диалоговом окне дополнительных параметров TCP/IP
3. Завершив настройку параметров DNS, щелкните на кнопке ОК.
В Windows 2000 DNS использует негативное кэширование. Если сервер DNS
не может разрешить некоторое имя, то на последующие запросы к этому имени
дается отрицательный ответ в течение интервала, заданного параметром реестра
NegativeCacheTime (по умолчанию — 300 секунд).
Настройка адресов WINS
Если в сети установлены серверы WINS (Windows Internet Name Service), для
разрешения имен компьютеров могут использоваться серверы WINS в
сочетании с широковещательными запросами. Сервер WINS является примером
сервера NNBS (NetBIOS Name Server), используемым для разрешения имен
NetBIOS в соответствии с правилами, определенными в RFC 1001 и 1002.
Клиенты Windows 2000 и Windows NT, Windows 95 и Windows 98 с
установленным обновлением Active Directory не нуждаются в использовании
пространства имен NETBIOS. Служба WINS остается необходимой для того, чтобы
старые клиенты могли находить серверы, и наоборот. Если в сети не осталось
старых клиентов, серверы WINS можно отключить. К категории старых
относятся клиенты для Windows 95, Windows 98 и Windows NT.
Если данные сервера WINS отсутствуют, то компьютер с системой
Windows 2000 использует широковещательные запросы и локальный файл LMHOSTS
для разрешения компьютерных имен в IP-адреса. Широковещательное
разрешение производится только внутри локальной сети.
Процедура настройки адресов WINS описана ниже.
1. Чтобы указать, что вы собираетесь использовать серверы WINS, введите
IP-адреса основного и вторичных серверов WINS па вкладке WINS диалогового
окна дополнительных параметров TCP/IP (рис. 23.7). Вторичные серверы
WINS используются в качестве резервных на случай, если первичный сервер
WINS не ответит. IP-адреса WINS добавляются кнопкой Добавить (Add), а
порядок поиска серверов WINS изменяется при помощи кнопок со стрелками.
2. Разрешение имен компьютеров NetBIOS в сетях Windows может выполняться
на основании содержимого файла LMHOSTS. Режим использования файла
LMHOSTS включается установкой флажка Включить просмотр LMHOSTS (Enable
LMHOSTS lookup). Кнопка Импорт LMHOSTS (Import LMHOSTS) позволяет
импортировать имена и IP-адреса из существующих файлов LMHOSTS. Например,
если вы создали файл LMHOSTS с именами компьютеров вашей сети и теперь
хотите продублировать введенную информацию на всех компьютерах сети,
воспользуйтесь кнопкой импортирования.
3. Если компьютер настроен на использование DHCP, вы можете установить
переключатель Использовать параметры NetBIOS, полученные с DHCP-сервера (Use
NetBIOS settings from the DHCP sen/er).
4. Смысл переключателей Включить NetBIOS через TCP/IP (Enable NetBIOS over TCP/IP)
и Отключить NetBIOS через TCP/IP (Disable NetBIOS over TCP/IP) не требует
комментариев. Работа NetBIOS через TCP/IP описывается в RFC 1001 и 1002.
Приложения, использующие интерфейс Winsock, не нуждаются в NetBIOS.
Новые приложения работают непосредственно на уровне TCP/IP, а это
означает, что они используют стек TCP/IP напрямую без участия NetBIOS. Службы
Windows 2000 разрешают имена при помощи DNS и не нуждаются в услугах
разрешения имен в NetBIOS. В «чистой» сети Windows 2000, в которой
отсутствуют приложения, зависящие от NetBIOS, использование NetBIOS
через TCP/IP можно отключить. Такое отключение уменьшает объем сетевого
трафика NetBIOS, а компьютеру с Windows 2000 не приходится тратить
ресурсы на поддержку протокола NetBIOS.
IP Setting*| DNS WINS | Option*] ..
г WINS addresses, in order cfr usee— :~~—~i' . j j
|i.. j.
j ' **•• 1;;^; 1 j— 1 [
К LMHQSTS lookup is enabled й applies to зй connection* for which I
TCP/IP is enabled
\? Enable LMHQSTS lookup/:. : Import LMHQSTS. |
Г Enable NetBIOS over TCP/IP
Г Disable NetBIOS over TCP/I£,
<* UseN«BIDS setting fromIheOHCP server
| OK | Cancel j
Рис. 23.7. Вкладка WINS диалогового окна дополнительных параметров TCP/IP
ПРИМЕЧАНИЕ
По умолчанию файл LMHOSTS находится в каталоге \%SystemRoot%\SYSTEM32\DRIVERS\ETC. При
использовании сервера WINS обращение к файлу LMHOSTS происходит только после обращения
к серверу WINS. Файлы LMHOSTS хорошо работают в сетях Windows с небольшим количеством
компьютеров, а также в сетях, топология которых остается относительно постоянной. С другой
стороны, в больших, динамично изменяющихся сетях использование файлов LMHOSTS весьма
проблематично. Синхронизация копий LMHOSTS на разных компьютерах — непростая задача, при этом
слишком легко создать ситуацию, при которой два компьютера (даже находящиеся вблизи друг
от друга) располагают разной информацией о сети. А если IP-адреса назначаются при помощи
DHCP, то содержимое файла LMHOSTS может оказаться недействительным для хоста,
относящегося к другой подсети.
Безопасность и фильтрация TCP/IP
В Windows 2000 предусмотрены средства обеспечения безопасности и фильтрации
трафика TCP/IP. Настройка этих средств производится на вкладке Параметры
(Options) диалогового окна дополнительных параметров TCP/IP (рис. 23.8),
вызываемого кнопкой Дополнительно (Advanced) в диалоговом окне свойств
протокола TCP/IP. Чтобы вызвать это окно, выделите строку Протокол Интернета
(TCP/IP) (Internet Protocol (TCP/IP)) в свойствах подключения по локальной сети
и щелкните на кнопке Свойства (Properties).
. IP Settings] DNS | WINS • Optbrw: |
к Optional settings; 11
fipiecuri^'j '.. I J
:; TCP/IP Filtering |
Г I Pmpettles | 1
k : p Description: ~т: ■•;• p';1: •:: ггг^фуг^— - '-у; 11
• i IP security protects the confidemtia6<y, integrity and authenticity of IP j I
U ! pockets bet ween two computers on a network I P security settings \ 1!
;. ! apply to afi connections for which TCP/IP is enabled j; II
г I -II
: | i
• °fej Cancel |
Рис. 23.8. Вкладка Параметры в диалоговом окне дополнительных параметров TCP/IP
Система безопасности обеспечивает конфиденциальность, целостность и
аутентичность пакетов IP, передаваемых между двумя компьютерами сети. Параметры
безопасности относятся ко всем подключениям, использующим TCP/IP. Выделите
строку Безопасность IP (IP Security), щелкните на кнопке Свойства (Properties),
затем в открывшемся диалоговом окне Безопасность IP (IP Security), изображенном
на рис. 23.9, установите переключатель Use this IP security policy. Выберите в списке
нужную политику безопасности: Клиент (только ответ) (Client (Respond Only)),
Сервер безопасности (требуется безопасность) (Secure Server (Request Security)) или
Сервер (запрос безопасности) (Server (Request Security)).
ПРИМЕЧАНИЕ
Если сервер Windows NT/2000, подключенный к нескольким сетям, выполняет важные функции
(например, является web-сервером) и вы не хотите тратить процессорное время на выполнение
других задач, для которых существуют специализированные серверы, отключите маршрутизацию.
Маршрутизацию также следует отключать на брандмауэрах и прокси-серверах. Пакеты не должны
обходить программное обеспечение брандмауэра или прокси-сервера, обрабатывающее эти пакеты
с учетом политики безопасности системы. При включенной маршрутизации пакеты пересылаются
маршрутизатором независимо от ограничений, установленных в конфигурации
брандмауэра/прокси-сервера.
IP security settings; apply to «I connections for which TCP/IP к enabled I
. *V Use фЫР secwty ройсу: .
(Client (Respond Only] ~" 3 1
Selected IP secisily po&oy description: I
jCommunicate normally jtwsec^red^Ueetnedebuitre^on&emleb I
jnegotiatewith.serversthat request $ешй^ QNy the requested 1
jpiotocol and port ЬаШс with that server is secured I
'.':• ' ' j ГЖ J 'Щ0Ы ' ,[ J
Рис. 23.9. Параметры безопасности IP
Политика Клиент (только ответ) (Client (Respond Only)) обеспечивает обычный
обмен данными в незащищенных сеансах. Если от сервера поступает запрос на
безопасность IP, то клиент переходит на защиту трафика для указанного
протокола и номера порта.
При политике Сервер безопасности (требуется безопасность) (Secure Server
(Request Security)) трафик IP обязательно защищается протоколом Kerberos.
Небезопасный обмен данными с незащищенными клиентами запрещается. Поскольку
многие хосты Интернета не поддерживают проверку подлинности с
применением Kerberos, выбор этой политики фактически блокирует связь с
большинством хостов Интернета.
При политике Сервер (запрос безопасности) (Server (Request Security)) сервер
запрашивает у клиента защиту трафика IP с применением Kerberos. Для
клиентов, не ответивших на запрос, разрешается небезопасный обмен данными.
Чтобы настроить средства фильтрации TCP/IP, выделите строку Фильтрация
TCP/IP (TCP/IP Filtering) в диалоговом окне дополнительных параметров TCP/IP
и щелкните на кнопке Свойства (Properties). На экране появляется диалоговое
окно Фильтрация TCP/IP (TCP/IP Filtering) — рис. 23.10. Установите флажок
Задействовать фильтрацию TCP/IP (все адаптеры) (Enable TCP/IP Filtering (All adapters)). По
умолчанию разрешаются все порты TCP/UDP, а также протоколы IP. Чтобы
разрешить трафик только для конкретных номеров портов TCP/UDP или про-
токолов IP, установите соответствующий переключатель Только (Permit Only),
щелкните на кнопке Добавить (Add) и включите в список нужные порты или
протоколы.
ГдЕпаЫе TCP/IP Filtering (АЯ «daptets)
<• Permit A8 <? Permit AI <? Р&гЫМ
1:"гГ;"РвшЛ0л!у 1 г Г PermitOnly < rC Perm* Only ;
i. Ш^^*'ГЛ | J jjjbpE»b„l .1 • !..IP Protocols j !
M '■] ■' i .".." ! \ \\
:!: \ I :■■■ j ■■"■ ' i 1 M
Ml ■ ! I •• I X] I M
f "I " ■ • I
•::| Add., | 1 :; j Л Add.. | J j Add | \
Г > с | ! ' I ■ Л" j I ,. I M
| OK I Cancel |
Рис. 23.10. Диалоговое окно Фильтрация TCP/IP
Механизм фильтрации особенно полезен в ситуации, когда принимается
только трафик хорошо известных служб с конкретными номерами портов. Перечень
официально утвержденных номеров портов и протоколов приводится в RFC 1700,
«Assigned Numbers». По умолчанию разрешено прохождение пакетов для всех
портов TCP и UDP и протоколов IP, то есть Windows 200 принимает пакеты IP,
предназначенные для любых портов TCP и UDP. Чтобы изменить значения по
умолчанию, установите переключатель Только (Permit Only) и измените критерии
фильтрации при помощи кнопок Добавить (Add) и Удалить (Remove).
Настройка служб разрешения имен
Из предыдущих разделов вы узнали, как настраиваются данные серверов WINS
и DNS в параметрах конфигурации IP на компьютерах Windows 2000. Серверы
WINS и DNS обеспечивают разрешение имен в сетях Windows. Кроме того, в
разрешении имен задействованы два дополнительных файла, LMHOSTS и HOSTS.
Они часто применяются в малых сетях, не имеющих серверов WINS pi DNS,
поскольку информация о связях имен с IP-адресами хранится в текстовом виде
и легко изменяется в текстовом редакторе.
Также стоит заметить, что механизм разрешения имен NetBIOS на базе WINS
не нужен в «чистых» сетях Windows 2000, в которых разрешение имен
осуществляется через DNS. Тем не менее в смешанных сетях, содержащих компьютеры
с Windows 2000 и Windows NT, приходится обеспечивать разрешение имен
NetBIOS для старых клиентов. Именно это обстоятельство является главной
причиной для рассмотрения средств разрешения имен NetBIOS в этой главе.
Службы NetBIOS
NetBIOS предоставляет службы имен, службы дейтаграмм и службы сеансов
(табл. 23.1). Когда NetBIOS работает на базе TCP, службы имен и дейтаграмм
используют порты 137 и 138 протокола транспортного уровня UDP. Службы
сеансов используют порт 139 протокола TCP. Использование протокола UDP
службами имен и дейтаграмм объясняется тем, что трафик этих служб по своей
природе ориентируется на схему «запрос-ответ». Кроме того, службы имен часто
используют в своей работе широковещательную рассылку, a UDP подходит для
этой цели лучше, чем TCP. В больших сетях широковещательная рассылка
создает проблемы из-за чрезмерного роста трафика, поэтому многие
маршрутизаторы по умолчанию настраиваются на блокировку широковещательных
рассылок. Процедура настройки зависит от конкретного маршрутизатора.
Таблица 23.1. Службы NetBIOS
Название Порт Протокол Сокращенное название
Служба имен NetBIOS 137 UDP nbname
Служба дейтаграмм NetBIOS 138 UDP Nbdatagram
Служба сеансов NetBIOS 139 TCP Nbsession
Служба сеансов NetBIOS использует TCP. Протокол TCP гарантирует
доставку данных, тогда как UDP таких гарантий не дает. Кроме того, сеансовая
модель TCP более точно воспроизводит сущность сеансов NetBIOS. И TCP,
и NetBIOS генерируют специальные примитивы для открытия и закрытия сеанса.
На любом конкретном компьютере работает несколько процессов. Процессы,
предоставляющие некоторый сервис, называются службами приложений.
Некоторые службы приложений регистрируются под именами NetBIOS. Windows 2000
позволяет зарегистрировать на компьютере до 250 имен NetBIOS. Ниже
приводятся примеры служб приложений на компьютерах с системой Windows:
О Служба сервера — идентифицирует выполняемую службу приложения; обычно
относится к службе, обеспечивающей совместное использование файлов и
принтеров на компьютере.
О Служба рабочей станции — позволяет рабочей станции выполнять функции
клиента и использовать сервис, предоставляемый службой сервера на другом
компьютере.
О Служба сообщений — получает и отображает сообщения для имен,
зарегистрированных на компьютере.
Максимальная длина имен NetBIOS равна 16 символам. Первые 15
символов определяют имя NetBIOS, а последний символ (байт) содержит код типа
имени NetBIOS. Значения этого однобайтового идентификатора лежат в интер-
вале от 0 до 255. Ниже перечислены имена некоторых регистрируемых служб
(число в квадратных скобках представляет шестнадцатеричный код
однобайтового идентификатора):
О компьютер[0х00] — служба рабочей станции, зарегистрированная для
компьютера.
О компьютер\0\03] — служба сообщении, зарегистрированная для компьютера.
О компьютер[0\06] — служба сервера удаленного доступа, зарегистрированная
для компьютера.
О компыотер\Ох\¥] — служба NetDDE, зарегистрированная для компьютера.
О компъютер\ 0x20] — служба сервера, зарегистрированная для компьютера.
О компъютер[0х2\] — служба клиента удаленного доступа, зарегистрированная
для компьютера.
О компьютер\0хВЕ] — служба агента сетевого монитора, зарегистрированная
для компьютера.
О компъютер[0хВ¥] — служба приложения сетевого монитора,
зарегистрированная для компьютера.
О домен [0x00] — регистрация принадлежности к домену или рабочей группе.
О домен [OxIE] — используется для упрощения выбора браузера.
О домен [0x1В] — регистрация компьютера в качестве главного браузера домена.
ПРИМЕЧАНИЕ
Раньше в NetBIOS использовались только имена компьютеров. На каждом компьютере работал
всего один пользователь; он получал все сообщения, отправляемые этому компьютеру.
По мере роста сетей и количества пользователей появились имена NetBIOS для пользователей
и доменов. Имена пользователей позволяли передавать сообщения конкретному пользователю.
Если имя пользователя существовало в нескольких экземплярах (из-за того, что пользователь
зарегистрировался в системе несколько раз), сообщение передавалось только тому имени, которое
было зарегистрировано первым.
Поддержка доменных имен появилась для того, чтобы разные системы можно было группировать
под общим именем для упрощения получения информации, выполнения управляющих операций и
настройки безопасности в доменной модели Windows NT. Эти групповые имена регистрировались
в сети как имена NetBIOS.
В Windows 2000 имена NetBIOS продолжают использоваться в смешанных доменах, содержащих
домены и компьютеры под управлением Windows NT. Именно поэтому мы рассматриваем NetBIOS
в этой главе.
В «чистых» доменах Windows 2000 настраивать NetBIOS не нужно, поскольку разрешение имен
выполняется через DNS.
О домен [0x1 С] — регистрация компьютера в качестве контроллера домена.
О домен [0x1 D] — регистрация компьютера в качестве главного браузера
локальной подсети.
О пользователь [0x03] — имя, зарегистрированное службой сообщений для
заданного пользователя.
О группа — имя группы.
О \\-_MSBROWSE_l01h] - главный браузер.
Допустим, пользователь Phylos на рабочей станции WS1 с системой
Windows 2000 Professional, находящейся в домене KINETD, хочет принять файлы
с сервера ADS с системой Windows 2000, используя имя в стандартном
формате UNC (Universal Naming Convention) \\ADS\sharename. Имя пользователя
«Phylos[0x03]» сначала использует службу рабочей станции с именем NetBIOS
«WSl[0x00]» для аутентификации контроллером домена с именем NetBIOS
«KINETD[0xlC ]». После аутентификации служба рабочей станции «WSl[0x00]»
связывается со службой сервера «ADS[0x20]» для приема файлов.
Механизмы разрешения имен
Механизмы разрешения имен Windows 2000 делятся на следующие категории:
О стандартное разрешение (также называемое разрешением имен хостов);
О специализированное разрешение (также называемое разрешением имен NBT
NetBIOS).
Ниже эти механизмы рассматриваются более подробно.
Стандартное разрешение имен
Стандартное разрешение имен используется в системах семейства Unix и в
программном обеспечении, перенесенном из Unix в среду Windows. При
стандартном разрешении проверка производится в следующей последовательности:
1. Локальный хост.
2. Файл HOSTS.
3. DNS.
4. Разрешение имен NetBIOS (если попытка использования DNS завершилась
неудачей).
Сначала проверяется, не совпадает ли разрешаемое имя с именем локального
компьютера.
ПРИМЕЧАНИЕ
В Windows 2000 разрешение имен DNS выполняется клиентской службой DNS. Служба реализует
резольвер DNS, который вызывает сокетные функции Windows gethostbynameQ и getnamebyhost().
Если разрешаемое имя не совпадает с именем локального компьютера, на
следующем этапе проверяется файл HOSTS. В этом файле хранится информация
о соответствии между именами хостов и IP-адресами. Формат файла HOSTS
позаимствован из BSD (Berkeley Software Distribution) Unix 4.3. В частности,
файл HOSTS используется такими приложениями, как Telnet, FTP и ping.
Файл HOSTS не является централизованным ресурсом — каждый
компьютер должен поддерживать собственный вариант файла HOSTS. В случае
изменений в сети содержимое файла должно быть изменено на всех компьютерах.
Если разрешаемое имя отсутствует в файле HOSTS, запрос на разрешение
имени посылается серверу DNS. Серверы DNS хранят распределенную базу
данных с информацией о соответствии между именами хостов и IP-адресами.
Большинство серверов DNS в Интернете работает на базе Unix, хотя
реализации DNS существуют и на других платформах, включая Windows 2000.
Специализированное разрешение имен
Механизм специализированного разрешения имен применяется только в сетях
Windows. Он представляет собой комбинацию следующих механизмов:
О локальная широковещательная рассылка;
О WINS;
О файл LMHOSTS.
Под «локальной широковещательной рассылкой» подразумевается
пересылаемый по локальной сети запрос на получение IP-адреса, соответствующего
разрешаемому имени. Компьютер, распознающий указанное в запросе имя как
свое собственное, передает свой IP-адрес. Если такого компьютера не найдется,
ответ на широковещательную рассылку не приходит и система приходит к
выводу о невозможности разрешения имени посредством широковещательной
рассылки. Этот способ также называется «b-узловым разрешением имен».
Служба WINS является примером сервера имей NetBIOS (NBNS). Самый
распространенный пример NBNS — реализация WINS в серверах Windows NT и
Windows 2000. Спецификация разрешения имен NBNS приведена в RFC 1001 и 1002.
ПРИМЕЧАНИЕ
Файлы хостов обычно используются лишь в очень мелких сетях. В приложениях TCP/IP
разрешение имен чаще выполняется при помощи DN5.
ПРИМЕЧАНИЕ
Перед полным разрешением имен система проверяет, не совпадает ли разрешаемое имя NetBIOS
с локальным именем; в этом случае разрешение имен выполнять не нужно.
Результаты предыдущих запросов сохраняются в кэше имен. Прежде чем разрешать имя, система
проверяет, не присутствует ли ответ в кэше имен, и если поиск окажется успешным, разрешение
на этом прекращается.
Файл LMHOSTS содержит таблицу соответствия между именами NetBIOS и IP-
адресами. По своей структуре файл LMHOSTS напоминает файл HOSTS, однако
в его синтаксисе предусмотрены дополнительные директивы, упрощающие
настройку разрешения имен. Windows 2000 обращается к файлу LMHOSTS только
в том случае, если все остальные способы завершились неудачен.
Конкретный порядок действий при специализированном разрешении имен
зависит от настройки методов разрешения имен на компьютере с Windows 2000.
К числу таких методов относятся b-узловое, р-узловое, m-узловое и h-узловое
разрешение имен. Ниже приведены краткие описания всех четырех методов.
О При b-узловом разрешении для регистрации и разрешения имен используются
только широковещательные пакеты. Поскольку широковещательные рассылки
быстро приводят к перегрузке сети, этот способ лучше всего подходит для
мелких локальных сетей, не имеющих сервера WINS. Чтобы настроить сеть
для использования этого режима, убедитесь в том, что в сети отсутствуют
серверы WINS, а компьютеры Windows не настроены на использование WINS.
Другими словами, убедитесь в том, что на клиентских компьютерах Windows
не указан IP-адрес сервера WINS.
О При р-узловом разрешении используются только серверы WINS. Если имя
не удается разрешить средствами WINS, остальные методы разрешения имен
не применяются.
О М-узловое разрешение представляет собой комбинацию первых двух
методов. Сначала делается попытка применить b-узловое разрешение. Если эта
попытка завершается неудачей, клиент переходит к р-узловому разрешению.
Таким образом, данный метод сначала генерирует широковещательный
трафик, а затем применяет средства WINS. Он хорошо подходит для мелких
сетей с сервером WINS, база данных которого не обновлялась в течение
некоторого времени данными новых хостов.
ПРИМЕЧАНИЕ
В-узловое разрешение работает только в границах локальной подсети, если только
маршрутизаторы, ведущие к другим сетям, не настроены на пересылку широковещательного трафика.
ПРИМЕЧАНИЕ
Если при р-узловом или b-узловом разрешении основной метод завершается неудачей,
применяются другие методы (такие, как поиск в файле LMHOSTS).
ПРИМЕЧАНИЕ
М-узловое разрешение обычно применяется в маленьких региональных филиалах, подключенных
к глобальной сети через медленный канал. В таких ситуациях разрешение логично начинать с
обращения к локальным ресурсам и серверам.
О Н-узловое разрешение также является комбинацией b-узлового и р-узлового
разрешения, однако на этот раз сначала применяется р-узловое разрешение.
Если попытка завершается неудачей, клиент переходит к b-узловому
разрешению. Этот метод генерирует широковещательный трафик только в крайнем
случае, после попытки связаться с сервером WINS. Этот способ обладает
наибольшей эффективностью и подходит для больших сетей с надежными
серверами WINS, своевременно обновляемыми информацией о новых хостах.
Настройка кэша имен NetBIOS
Обработка запроса на разрешение имени в системе Windows 2000 начинается
с обращения к специальной области памяти — кэшу имен NetBIOS. В кэше
имен хранится список имен компьютеров и их IP-адресов. Хранение этих
данных в памяти обеспечивает быструю выборку найденной информации. Данные
кэша имен берутся из двух источников:
О результаты успешного разрешения имен;
О предварительная загрузка данных из файла LMHOSTS no директиве #PRE.
Все элементы кэша, за исключением предварительно загруженных, устаревают
по тайм-ауту и удаляются из кэша. По умолчанию интервал тайм-аута равен
10 минутам. Читатели, знакомые с протоколом ARP, заметят, что кэш имен
NetBIOS работает аналогичным образом.
Очистка и повторная загрузка кэша имен осуществляется командой
Nbtstat -R
Обратите внимание на регистр символа в параметре -R. Параметр -г
используется для других целей, а именно для вывода статистики разрешения имен.
Характеристики кэша имен настраиваются при помощи двух параметров
реестра, находящихся в разделе
HKEY_LOCAL_MACHINE\SYSTEM\CuгrentControlSet\Services\NetBT\Parameters
ПРИМЕЧАНИЕ
В малых сетях с низким трафиком (и при отсутствии квалифицированных администраторов) вполне
подойдет b-узловой метод разрешения имен.
В крупных сетях самым эффективным оказывается метод h-узлового разрешения, который
начинается с попытки прямого разрешения имен при помощи WINS (р-узловое разрешение). Только если
WINS не удастся разрешить имя, применяется b-узловой метод. При наличии правильно
настроенного сервера WINS h-узловой метод порождает наименьший уровень сетевого трафика.
Речь идет о следующих параметрах:
О Size/Small/Medium/Large. Параметр определяет максимальное количество имен,
хранящихся в кэше. Существуют три допустимых значения,
соответствующие малому, среднему и большому размеру кэша. Если параметр равен 1,
в кэше помещается до 16 имен. Если параметр равен 2, кэш позволяет
хранить до 64 имен. Наконец, если параметр равен 3, в кэше помещается до 128
имен. По умолчанию используется значение 1, что вполне допустимо для
многих сетей. Параметр относится к типу REG_DWORD.
О CacheTimeout. Максимальная продолжительность хранения данных в кэше
(в секундах). Значение по умолчанию равно 0х927с0 F00 000 секунд, то есть
10 минут), оно вполне нормально подходит для большинства сетей. Параметр
относится к типу REG_DWORD.
Эти и другие параметры NetBT изображены на рис. 23.11. Для параметров
реестра, значения которых не указаны, используются значения по умолчанию.
Настройка широковещательных запросов
на разрешение имен
Если имя, подлежащее разрешению, отсутствует в кэше имен, то при
использовании b-, m- и h-узлового метода разрешения имен будет разослан
широковещательный запрос на разрешение имени. NetBIOS рассылает пакеты в локальный
сегмент сети через порт UDP с номером 137 (см. табл. 23.1).
Широковещательный пакет обрабатывается каждым компьютером локальной подсети. Если
компьютер сети настроен на использование протокола NetBIOS через TCP/IP
(NetBT), широковещательный запрос принимается модулем NetBIOS, который
ищет имя, указанное в запросе, с зарегистрированными именами NetBIOS. При
обнаружении совпадения модуль NetBIOS отправляет пакет с положительным
ответом на разрешение имени.
и" IЛ 1Щ|IjjikiMиШЛИГ^»\Wm\m\m Im\*У\Ш ч\км)ШШШШШЯШШЯШШШЯШШШШШШШШШШШШШИШ I''''i" I
Щ Registry ;;.$cSfe: :Tpg9 . Vtew ■■$<$*** •! Орфг» ^tyndw» : *«p . _' . . \ »1Д|Х1
I I pCDmitsumi ^JlBcastNameQueiyCount: REG_DWORD :0x3 |
f-QmkecrSxx ^J BcastQueryTimeout: REG_DWORD : 0x2ee
I f-GDmnmdd CacheTimeout REG_DWORD: 0x92?c0
L&mnmsrvc EnableLMHOSTS : REGJDWORD : 0x1
кШ Modem EnableProxy:REG_DWORD:0
hODMouclass NameServerPort. REG_DWORD 0x89 I
hSDMountWgr NameSivQueiyCount: REGJDWORD: 0x3
kCt)mraid35x NameSrvQueiyTimeout: REG.DWORD: 0x5dc I
hdlMRxSmb NbProvider: REG SZ : tcp
kSDMSDTC NodeType REG DWORD: 0x8
L&Msfs ScopelD: REG.SZ:
k©MSFTPSVC SessionKeepAlive: REGJDWORD: 0x36ee80
H(±] MSIServer Size/Small/Medium/Large : REG.DWORD : 0x1
kSMSKSSRV TransportBindName : REG_SZ: \Device\
L-GJMSPCLOCK
hQDMSPQM :|J
I kQ]Mup ill
kDNcr53c9x ill
L(£)ncr77c22
hDNcrc700
k-QNcfc710
k(±)NDIS
J-ODNdisTapi
k&NdisWan
I kSNDProxy I
I J-GDneo20xx
кф NetBIOS
f-QNetBT
I l-CDEnum
I [-CD Linkage I
I ИР?ТЙ№МЙШ11 II I
|| *-Ш Interfaces I
*-CD Security ;*«
Рис. 23.11. Раздел параметров NetBT
Получение нескольких ответов свидетельствует о дублировании имен NetBIOS,
о чем выводится информация на консоль компьютера, получившего ответ.
Интересно заметить, что широковещательный запрос на разрешение имени
обрабатывается на каждом компьютере вплоть до сеансового уровня независимо от
того, располагает ли данный компьютер ответом или нет. Следовательно,
широковещательный запрос не только увеличивает трафик, но pi приводит к лишним
затратам процессорного времени на многих компьютерах.
Характеристики широковещательных запросов на разрешение имен
настраиваются при помощи двух параметров реестра, находящихся в разделе
HKEY_L0CAL_MACHINE\5YSTEM\CurrentControlSet\Services\NetBT\Parameters
О BcastNameQueryCount. Параметр определяет, сколько раз система попытается
разослать широковещательный запрос на разрешение имени. Значение по
умолчанию, равное 3, хорошо подходит для сетей с низким и средним
уровнем трафика. Параметр относится к типу REG_DWORD.
О BcastQueryTimeout Интервал между отправками широковещательных запросов.
Значение по умолчанию равно 7,5 секунды и задается в сотых долях секунды.
Параметр относится к типу REG_DWORD.
Настройка файла LMHOSTS
В малых сетях Windows 2000, содержащих до 30 компьютеров и использующих
NetBIOS через TCP/IP, разрешение имен компьютеров обычно производится с
использованием b-узлового метода или файла LMHOSTS. Если в сети работают
серверы WINS, использовать файл LMHOSTS не обязательно (разве что для
дополнительной страховки). Разрешение имен на базе LMHOSTS хорошо подходит
для малых сетей, в которых поддержание файла LMHOSTS не вызывает
трудностей. С другой стороны, в больших сетях обновление LMHOSTS требует слишком
больших усилий, и администратору следует рассмотреть другие средства
разрешения имен — например, DNS или WINS.
ПРИМЕЧАНИЕ
Если уровень трафика в сети постоянно находится на высоком уровне и вы часто сталкиваетесь
с повторениями одного и того же неразрешенного запроса NetBIOS, попробуйте увеличить
значения параметров BcastNameQueryCount и BcastQueryTimeout. Увеличьте параметр BcastQueryTimeout
с 0,5 до 1 секунды, а параметр BcastNameQueryCount следует повысить на 1. Наблюдение за
сетевым трафиком осуществляется при помощи анализаторов протоколов и системных программ —
например, Монитор сети (Network Monitor) из комплекта Windows 2000 Server и SMS (System
Management Server).
Синтаксис файла LMHOSTS
Файл LMHOSTS в Windows 2000 содержит информацию о соответствии между
именами NetBIOS и IP-адресами. Файл находится в каталоге %SystemRoot%\SYSTEM32\
DRIVERS\ETC, а его синтаксис совместим с синтаксисом файла LMHOSTS,
используемым в Microsoft LAN Manager 2.x.
Ниже приведен пример файла LMHOSTS, устанавливаемого на компьютерах
Windows 2000.
# Copyright (с) 1993-1999 Microsoft Corp.
#
#
# Это образец файла LMHOSTS, использующегося Microsoft TCP/IP для
# Windows.
#
# Этот файл содержит таблицу соответствия IP-адресов и обычных (NetBIOS)
# имен компьютеров. Каждый элемент должен располагаться в отдельной
# строке. IP-адрес должен начинаться с первой позиции строки, а за ним
# следует соответствующее имя компьютера. IP-адрес и имя компьютера должны
# быть отделены друг от друга хотя бы одним пробелом или символом табуляции.
# Знак "#" используется обычно для указания на начало комментария
# (Исключения из этого правила будут перечислены ниже).
#
# Этот файл совместиим с файлами Microsoft LAN Manager 2.x TCP/IP Imhosts,
# и в нем можно использовать следующие дополнительные операторы:
#
# #PRE
# #Э0М:<домен>
# #INCLUDE <имя_файла>
# #BEGIN_ALTERNATE
# #END_ALTERNATE
# \0xnn (поддержка специальных символов)
#
# Если дополнить любую из строк символами "#PRE", то соответствующий
# элемент будет предварительно загружен в буфер имен. По умолчанию
# элементы этого списка не загружаются предварительно, а весь список
# просматривается только в том случае, если динамическое разрешение
# соответствий имен не привело к успеху.
#
# Если дополнить любую из строк символами "#D0M:<домен>", то
# соответствующий элемент будет связан с указанным доменом.
# Это влияет на поведение служб обзора и регистрации в среде TCP/IP.
# Для того чтобы обеспечить предварительную загрузку имени, связанного
# со строкой #DOM, необходимо также добавить #PRE к этой строке.
# Имя такого домена будет предварительно загружено, хотя и не будет
# отображаться при просмотре буфера имен.
#
# Если дополнить любую из строк символами "#INCLUDE <имя_файла>", то
# это приведет к тому, что RFC NetBIOS (NBT) произведет поиск указанного
# файла и выполнит его просмотр так, словно он является локальным файлом.
# Обычно <имя_файла> задается в формате UNC, что позволяет хранить
# централизованный файл LMH0STS на сервере. Учтите, что в таком случае
# строка соответствия IP-адреса для используемого сервера ОБЯЗАТЕЛЬНО
# должна предшествовать его использованию в директиве #INCLUDE.
# Это соответствие также должно исползовать директиву #PRE.
# Кроме того, общий ресурс "public" из приведенного ниже примера должен
# присутствовать в списке "NullSessionShares" на LanManServer для того,
# чтобы клиенты смогли успешно прочитать файл LMH0ST5.
# Этот параметр хранится в системном реестре по адресу
# \machine\system\currentcontrolset\services\lanmanserver\parameters\
nullsessionshares.
# Нужно просто добавить строку "public" к имеющемуся там списку.
#
# Ключевые слова #BEGIN_ и #END_ALTERNATE позволяют группировать вместе
# несколько директив #INCLUDE. Хотя бы одно успешное выполнение директивы
# "include" считается успешным выполнением всей группы.
#
# Наконец, можно использовать специальные символы при сопоставлении имен
# с помощью заключения соответствующего имени в кавычки, а затем
# использования шестнадцатеричного кода символа с помощью записи \0xnn.
#
# В следующем примере используются все перечисленные выше дополнительные
# операторы:
#
# 102.54.94.97 rhino #PRE #D0M:networking #домен группы
# 102.54.94.102 "appname \0xl4" Специальный сервер
приложений
# 102.54.94.123 popular #PRE Предварительно
загружаемое имя
# 102.54.94.117 localsrv #PRE #сервер, используемый
в "INCLUDE"
#
# #BEGIN_ALTERNATE
# #INCLUDE \\localsrv\public\lmhosts
# #INCLUDE \\rhino\public\lmhosts
# #END_ALTERNATE
#
# В приведенном выше примере в имени сервера "appname" содержится специальный
# символ, имена серверов "popular" и "localsrv" будут предварительно загружены,
# имя сервера "rhino" будет использоваться для получения централизованного
# файла LMH0STS в том случае, если система "localsrv" будет недоступна.
#
# Учтите, что весь файл LMHOSTS, включая комментарии, будет просматриваться
# при каждом его использовании, так что имеет смысл минимизировать количество
# используемых комментариев. По этой причине не следует просто дополнять
# данный файл нужными строками таблицы соответствия, а лучше будет
# создать новый файл.
Комментарии начинаются с символа #. Если несколько первых символов,
следующих после #, совпадают с ключевыми словами из табл. 23.2, эти символы
интерпретируются как команды, которые должны обрабатываться особым
образом. Поскольку ключевые слова начинаются с символа комментария, синтаксис
LMHOSTS совместим с синтаксисом файла HOSTS, используемым приложениями
Unix и Windows Sockets.
Таблица 23.2. Директивы в файле LMHOSTS
Директива Описание
#PRE Запись файла LMHOSTS, в конце которой находится ключевое слово
#PRE, заранее загружается в кэш имен. Записи без директивы #PRE
не загружаются в кэш имен и обрабатываются только в том случае,
если имя не удается разрешить средствами WINS и широковещательных
запросов на разрешение имен. Записи, добавленные директивой
#INCLUDE, должны загружаться заранее. Следовательно, директива
#PRE должна быть включена в записи файлов, указанных в директиве
#INCLUDE; в противном случае записи игнорируются
#DOM:домен Определение имени компьютера, выполняющего функции контроллера
домена. В аргументе передается имя домена Windows 2000,
по отношению к которому компьютер является контроллером домена.
Директива #DOM влияет на работу служб в сети, состоящей из
нескольких сегментов, соединенных маршрутизаторами
#INCLUDE файл Из заданного файла извлекается информация о соответствии имен
и адресов. Имя файла может быть задано в формате UNC, что позволяет
подгружать файлы с удаленных компьютеров. Если компьютер,
указанный в имени UNC, не входит в локальную зону широковещательной
рассылки, то ассоциация для имени компьютера должна находиться
в файле LMHOSTS. В отображение для имени компьютера может
быть включена директива #PRE, гарантирующая его предварительную
загрузку в кэш имен. Записи, подгружаемые из файла, должны
быть предварительно загружены директивой #PRE; в противном
случае эти записи игнорируются
#BEGIN_ALTERNATE Директива отмечает начало группы директив #INCLUDE. Резольвер
пытается использовать команды #INCLUDE в порядке их перечисления.
Успех при использовании одной из директив #INCLUDE автоматически
приводит к успеху всей группы, в этом случае остальные директивы
#INCLUDE, входящие в группу, не обрабатываются. Если все файлы,
указанные в директиве #INCLUDE, оказались недоступны, в журнал
событий включается информация о том, что попытка включения
завершилась неудачей. Для просмотра журнала событий можно
воспользоваться программой Event Viewer
Директива Описание
#END_ALTERNATE Директива отмечает конец группы директив #INCLUDE. У каждой
директивы #BEGIN_ALTERNATE должна существовать парная директива
#END_ALTERNATE
\0xnn Служебная последовательность для включения непечатаемых символов
в имена NetBIOS. Имена NetBIOS, содержащие коды символов,
должны заключаться в кавычки. Коды символов используются только
в специальных именах устройств и в нестандартных приложениях.
При использовании этого синтаксиса помните, что заключенное
в кавычки имя NetBIOS дополняется пробелами, если оно содержит
менее 16 символов
Обратите внимание на следующую запись в приведенном выше примере
файла LMHOSTS:
# 102.54.94.102 "appname \0xl4" Специальный сервер приложений
Имя приложения отделено от специального символа восемью пробелами;
таким образом, общая длина имени равна 16 символам.
Код 0x14 представляет собой 1-байтовый идентификатор службы
приложения.
Правила обработки файла LMHOSTS
Файл LMHOSTS особенно удобен в тех случаях, когда в сетевом сегменте, в
котором находится клиент Windows 2000, отсутствует сервер WINS. В таких
ситуациях используется механизм широковещательного разрешения имей, основанный
на рассылке широковещательных пакетов уровня IP; обычно такие пакеты
блокируются маршрутизаторами. Следовательно, широковещательное разрешение
имен никогда не выходит за границы маршрутизаторов. Для решения этой
проблемы механизм разрешения имен Windows 2000 при отсутствии сервера WINS
работает так:
1. Windows 2000 ведет локальный кэш имен, инициализируемый во время
загрузки системы. Разрешение имен начинается с обращения к кэшу. Загрузка
данных из LMHOSTS в кэш имен осуществляется директивой #PRE (см. выше).
2. Если в кэше имен данные не найдены, Windows 2000 рассылает
широковещательный запрос на разрешение имени. Этот механизм разрешения имен,
называемый b-узловым методом разрешения, документирован в RFC 1001
и 1002.
3. Если попытка широковещательного разрешения имени завершается
неудачей, резольвер просматривает файл LMHOSTS и использует любые
совпадающие записи.
4. Если просмотр файла LMHOSTS не приносит результатов, попытка
разрешения имени завершается неудачей и выдается сообщение об ошибке.
На рис. 23.12 показана последовательность действий при разрешении имен
с использованием файла LMHOSTS.
С Кэш имен <^
> L 144.19.74.2 zadkiel I ) s-^
( ^ 144.19.74.5 michael |*^ И) Просмотр кэша имен
/ / у <^
|LMHOSTTS\ / / G\ ... J> к
л ' I \^J Широковещательное <Г к g
144.19.74.1 uziel / V' разрешение имен <^> | & о
144.19.74.2 zadkiel #PRE \ , .,.,.,....„ t ' ^> g | о
144.19.74.3 gabriel / \ | ДДИI /^X^\ S> & о 8
144.19.74.4 Uriel / / I Ш§Я I ' > ( () ) <Г 15?
144.19.74.5 michael #PRE / ЗДНЩ V*V <Г о 2 ^
| 144.19.74.6 chamuel / ^uil^^SIH ^p ^> g § |.
\ / l Компьютер <C> о.
с системой <^
©Windows 2000 ^
Просмотр файла LMHOSTS I I
Рис. 23.12. Разрешение имен с использованием LMHOSTS
Кэш имен инициализируется записями файла LMHOSTS, помеченными
директивой #PRE. Ниже приведен фрагмент файла LMHOSTS, в котором только часть
записей помечена для предварительной загрузки.
144.19.74.1 uziel
144.19.74.2 zadkiel #PRE
144.19.74.3 gabriel
144.19.74.4 uriel
144.19.74.5 michael #PRE
144.19.74.6 chamuel
Предварительная загрузка обычно используется для данных серверов и
других хостов, которые должны постоянно оставаться доступными. В результате
предварительной загрузки имена сохраняются в кэше, тем самым
предотвращается повторное чтение LMHOSTS в процессе разрешения имен.
В приведенном фрагменте файла LMHOSTS данные хостов zadkiel и michael
автоматически загружаются в кэш в процессе запуска системы. Если компьютеру
с Windows 2000 потребуется разрешить имена zadkiel и michael, он не будет
генерировать широковещательные пакеты, поскольку необходимая информация берется
из кэша имен. При разрешении имен uziel, gabriel, uriel и chamuel будет
использоваться широковещательный запрос. Если попытка широковещательного
разрешения завершается неудачей, имена ищутся в файле LMHOSTS. Если имя, не
прошедшее предварительную загрузку, было успешно разрешено в процессе просмотра
LMHOSTS, оно кэшируется в течение некоторого времени для будущих запросов.
Имена, разрешенные в результате широковещательных запросов, также
сохраняются в кэше вплоть до истечения интервала тайм-аута.
Объем данных, предварительно загружаемых в кэш, не может превышать 100
записей. Если в файле LMHOSTS директивой #PRE помечено более 100 записей,
предварительно загружаются только первые 100 записей. Остальные записи не
загружаются в кэш и используются в процессе стандартного просмотра файла
LMHOSTS.
При добавлении или удалении директив #PRE в файле LMHOSTS следует
очистить и перезагрузить кэш имен командой
nbtstat -R
Одним из достоинств программы nbtstat является возможность перезагрузить
кэш имен, не перезапуская компьютер с Windows 2000.
Вызов nbtstat с параметром -RR приводит к обновлению имен NetBIOS,
зарегистрированных компьютером:
nbtstat -RR
Стратегия использования общего файла LMHOSTS
Файл LMHOSTS хранится на локальных компьютерах с системой Windows 2000
в каталоге \%SystemRoot%\SYSTEM32\DRIVERS\ETC. При частых модификациях
LMHOSTS ведение локальных копий этого файла на всех компьютерах сети
вызывает немало проблем.
Директива #INCLUDE упрощает сопровождение файла LMHOSTS. Предположим,
основные данные хранятся в файле LMHOSTS на сервере Windows 2000 с именем
AKS. В файлы LMHOSTS на остальных компьютерах сети с системой Windows 2000
включается следующая ссылка:
#INCLUDE \\AKS\ETC\LMHOSTS
В этом примере ETC является общим именем каталога \%SystemRoot%\SYSTEM32\
DRIVERS\ETC на компьютере AKS. Преимущество такого решения заключается
в том, что все предварительно загружаемые общие имена хранятся в одном файле.
Если компьютер AKS не входит в область широковещательной рассылки, для
него необходимо создать специальную запись. Например, если хосту AKS присвоен
IP-адрес 134.21.22.13, то файл LMHOSTS может содержать следующий фрагмент:
134.21.22.13 AKS #PRE
#INCLUDE \\AKS\ETC\LMH0STS
Чтобы общий файл LMHOSTS всегда оставался доступным, его можно
реплицировать на другие компьютеры с Windows 2000 при помощи службы
репликации. Общий файл LMHOSTS должен находиться на сервере Windows 2000
(то есть в системе Windows 2000 Server или Windows 2000 Advanced Server),
поскольку только серверы Windows 2000 могут выполнять функции экспортного
сервера при репликации.
Если в сети имеются дублирующие серверы, следует указать, что файл LMHOSTS
также можно взять с любого из этих серверов. Для этой цели существуют удобные
команды #BEGIN_ALTERNATTVE и #END_ALTERNATTVE. Как было указано в табл. 23.1,
эти директивы предназначены для определения блоков #INCLUDE, в которых
может использоваться любая из перечисленных директив.
Рассмотрим следующий пример со списком альтернативных файлов LMHOSTS
на компьютерах с системой Windows 2000 в текущем сегменте сети:
134.21.22.13 AKS #PRE
134.21.22.14 АС1 #PRE
134.21.22.15 АС2 #PRE
#BEGIN_ALTERNATIVE
#INCLUDE \\AKS\ETC\LMH05TS # Основная копия файла LMHOSTS
#INCLUDE \\AC1\ETC\LMH0STS # Резервная копия 1
#INCLUDE \\AC2\ETC\LMH0STS # Резервная копия 2
#END_ALTERNATIVE
Предполагается, что файл LMHOSTS на сервере AKS реплицируется на резервные
хосты АС1 и АС2. На всех компьютерах Windows 2000 каталог \%SystemRoot%\
SYSTEM32\DRIVERS\ETC обозначается общим именем ETC. Включение блока
оказывается успешным лишь в том случае, если доступен хотя бы один из файлов
LMHOSTS на трех хостах. Если файл недоступен (например, если все хосты
отключены или указан неверный путь), в журнал событий Windows 2000 заносится
соответствующее событие.
Настройка файла HOSTS
Файл HOSTS используется утилитами TCP/IP, разработанными для системы
Unix (в частности, ping и netstat), для преобразования имен хостов в IP-адреса.
Синтаксис файла HOSTS близок к синтаксису LMHOSTS. Более того, файл HOSTS
хранится в одном каталоге с LMHOSTS (\%SystemRoot%\SYSTEM32\DRIVERS\ETC).
Ниже перечислены различия между синтаксисом двух файлов.
О В файле HOSTS не могут использоваться специальные директивы (такие, как
#PRE и #DOM).
О Для одного IP-адреса в файле HOSTS можно определить несколько
псевдонимов (альтернативных имен). Псевдонимы перечисляются в одной строки
и разделяются пробелами.
Существует два варианта обобщенного синтаксиса каждой строки файла HOSTS:
IP-адрес имя1 [имя2 ... имяИ] # Комментарий
# Комментарий
Имя2 и гашЫ — необязательные псевдонимы для имени имя1. Как и в файле
LMHOSTS, все символы после # интерпретируются как комментарий.
Ниже приведен пример файла LMHOSTS:
# (С) Корпорация Майкрософт (Microsoft Corp.), 1993-1999
#
# Это образец файла HOSTS, используемый Microsoft TCP/IP для Windows.
#
# Этот файл содержит сопоставления IP-адресов именам узлов.
# Каждый элемент должен располагаться в отдельной строке. IP-адрес должен
# находиться в первом столбце, за ним должно следовать соответствующее имя.
# IP-адрес и имя узла должны разделяться хотя бы одним пробелом.
#
# Кроме того, в некоторых строках могут быть вставлены комментарии
# (такие, как эта строка), они должны следовать за именем узла и отделяться
# от него символом '#'.
#
# Например:
#
# 102.54.94.97 rhino.acme.com # исходный сервер
# 38.25.63.10 х.acme.com # узел клиента х
127.0.0.1 localhost
199.245.180.1 ntwsl
199.245.180.2 ntws2
199.245.180.3 ntws3
199.245.180.4 ntws4
199.245.180.5 ntws5
199.245.180.6 ntws6 phylos anzimee
ntsmain ntc ntcontroller
Другие служебные файлы TCP/IP
Как упоминалось выше в этой главе, файл HOSTS определяет конфигурацию
многих Unix-служб, адаптированных для Windows 2000. Кроме файла HOSTS,
адаптированные версии служб Unix для Windows 2000 используют еще три
файла - NETWORKS, PROTOCOL и SERVICES, находящиеся в каталоге \%SystemRoot%\
SYSTEM32\ DRIVERS\ETC. Обычно содержимое этих файлов не изменяется — разве
что если вы захотите определить символические имена для своих сетей или
занимаетесь адаптацией новых служб и протоколов для среды Windows.
Файл NETWORKS
Файл NETWORKS используется для идентификации сетей, входящих в
объединенную сеть (то есть сеть, состоящую из нескольких сетей, обычно связанных
через маршрутизаторы). Файл NETWORKS на концептуальном уровне похож на
файл HOSTS. В файле HOSTS хранится информация о соответствии между
адресами и именами хостов, а в файле NETWORKS — информация о соответствии между
адресами и именами сетей.
Каждая строка в текстовом файле NETWORKS содержит информацию в
следующем формате:
имя_сети идентификатор_сети[/маска_подсети] псевдонимы # Комментарий
Здесь имя_сети — идентификатор, представляющий данную сеть, а иденти-
фикатпор_сети — сетевая часть IP-адреса сети. Имя сети не может содержать
пробелов, символов табуляции и знаков # и должно быть уникальным в
границах файла NETWORKS.
Маска ^подсети записывается в десятичной или шестнадцатиричной системе,
компоненты разделяются точками. Квадратные скобки ([]) в приведенном выше
описании синтаксиса NETWORKS указывают на то, что присутствие маски подсети
не обязательно. Если маска подсети не указана, то по умолчанию считается, что
маска не используется.
Необязательные псевдонимы определяют другие имена, которые могут
использоваться для ссылок на данную сеть. Обычно имя сети записывается строчными
буквами, а псевдонимы — прописными.
Все символы от знака # до конца строки игнорируются и интерпретируются
как комментарии, содержащие справочную информацию. Комментарий может
занимать всю строку.
Имена сетей, указанные в файле NETWORKS, используются в конфигурационных
утилитах и командах — например, имя сети может указываться вместо сетевого
адреса. Файл NETWORKS обычно редактируется сетевыми администраторами,
чтобы вместо трудно запоминаемых сетевых адресов в командах и утилитах
использовались более удобные символические имена.
ПРИМЕЧАНИЕ
Файл NETWORKS также приносит пользу при выводе сетевых данных в символическом
представлении — например, при выводе таблиц маршрутизации при помощи route или других аналогичных
команд.
Ниже приведен пример файла NETWORKS.
# (С) Корпорация Майкрософт (Microsoft Corp.), 1993-1999
#
# Этот файл содержит сопоставления сетевых имен/номеров сети для
# локальных сетей. Номера сети задаются в десятичном формате с точками.
#
# Формат:
#
# <сетевое имя> <номер сети> [псевдонимы...] [#<комментарий>]
#
# Например:
#
# loopback 127
# campus 284.122.107
# london 284.122.108
loopback 127
Kinet 199.245.180
SCSnet 200.24.4.0
MyNet 144.19
Файл PROTOCOL
Файл PROTOCOL предназначен для идентификации имен протоколов и
соответствующих им номеров. Номер протокола в семействе протоколов Интернета
совпадает со значением идентификатора протокола в заголовке IP. Поле
идентификатора протокола используется протоколами верхних уровней, работающих
с протоколом IP.
Файл PROTOCOL дополняет модуль TCP/IP и содержит определения
основных протоколов; не изменяйте его содержимое без крайней необходимости.
Каждая строка в текстовом файле PROTOCOL содержит информацию в
следующем формате:
имя_протокола номер_протокола [псевдонимы] # Комментарий
Здесь имя_протокола — идентификатор, представляющий данный протокол,
а помер_протокола — числовой код, используемый для идентификации
протокола в заголовках IP. Имя сети не может содержать пробелов, символов
табуляции и знаков # и должно быть уникальным в границах файла PROTOCOL.
Необязательные псевдонимы определяют другие имена, которые могут
использоваться для ссылок на данный протокол. Обычно имя протокола записывается
строчными буквами, а псевдонимы — прописными.
ПРИМЕЧАНИЕ
Файл PROTOCOL часто используется приложениями, адаптированными из среды Unix.
Некоторые программы с интерфейсом BSD Sockets берут номера транспортных протоколов из файла
PROTOCOL, тогда как в других программах TCP/IP используется «жесткое» кодирование номеров
протоколов.
Все символы от знака # до конца строки игнорируются и интерпретируются
как комментарии, содержащие справочную информацию. Комментарии может
занимать всю строку.
Ниже приведен пример файла PROTOCOL для Windows 2000.
# (С) Корпорация Майкрософт (Microsoft Corp.), 1993-1999
#
# Этот файл содержит протоколы Интернета, определенные
# в документе RFC 1700 (назначенные номера).
#
# Формат:
#
# <протокол> «^назначенный номер> [псевдонимы...] [#<комментарий>]
ip 0 IP # Internet protocol
icmp 1 ICMP # Internet control message protocol
ggp 3 GGP # Gateway-gateway protocol
tcp 6 TCP # Transmission control protocol
egp 8 EGP # Exterior gateway protocol
pup 12 PUP # PARC universal packet protocol
udp 17 UDP # User datagram protocol
hmp 20 HMP # Host monitoring protocol
xns-idp 22 XNS-IDP # Xerox N5 IDP
rdp 27 RDP # "reliable datagram" protocol
rvd 66 RVD # MIT remote virtual disk
Файл SERVICES
В файле SERVICES определяются:
О названия служб;
О транспортные протоколы;
О номера портов, используемых службами.
Службы представляют собой программы, работающие на прикладном уровне
модели TCP/IP, — Telnet, FTP, SMTP, SNMP и т. д. Каждая служба работает на
базе определенного транспортного протокола (TCP или UDP). Информация
о том, какой транспортный протокол используется той или иной службой,
хранится в конфигурационном файле SERVICES. Некоторые службы доступны как
через TCP, так и через UDP. В этом случае служба представлена в файле двумя
записями: для TCP и для UDP.
Файл SERVICES дополняет модуль TCP/IP и содержит определения основных
служб TCP/IP; не изменяйте его содержимое без крайней необходимости.
Каждая строка в текстовом файле SERVICES содержит информацию в
следующем формате:
имя_службы порт/транспорт [псевдонимы] # Комментарий
Здесь имя_служ6ы — идентификатор, представляющий название службы: telnet,
ftp, ftp-data, smtp и т. д. Имя службы не может содержать пробелов, символов
табуляции и знаков # и должно быть уникальным в границах файла SERVICES.
Необязательные псевдонимы определяют другие имена, которые могут
использоваться для ссылок на данную службу.
Все символы от знака # до конца строки игнорируются и интерпретируются
как комментарии, содержащие справочную информацию. Комментарий может
занимать всю строку.
Ниже приведен пример файла SERVICES операционной системы Windows 2000.
# (С) Корпорация Майкрософт (Microsoft Corp.), 1993-1999
#
# Этот файл содержит номера портов для стандартных служб,
# определенные IANA
#
# Формат:
#
# <служба> <номер порта>/<протокол> [псевдонимы...] [#<комментарий>]
#
echo 7/tcp
echo 7/udp
discard 9/tcp sink null
discard 9/udp sink null
systat 11/tcp users #Active users
systat 11/tcp users #Active users
daytime 13/tcp
daytime 13/udp
qotd 17/tcp quote #Quote of the day
qotd 17/udp quote #Quote of the day
chargen 19/tcp ttytst source #Character generator
chargen 19/udp ttytst source #Character generator
ftp-data 20/tcp #FTP, data
ftp 21/tcp #FTP. control
telnet 23/tcp
smtp 25/tcp mail #Simple Mail Transfer Protocol
time 37/tcp timserver
time 37/udp timserver
rip 39/udp resource #Resource Location Protocol
nameserver 42/tcp name #Host Name Server
nameserver 42/udp name #Host Name Server
nicname 43/tcp whois
domain 53/tcp #Domain Name Server
domain 53/udp #Domain Name Server
bootps 67/udp dhcps #Bootstrap Protocol Server
bootpc 68/udp dhcpc #Bootstrap Protocol Client
tftp 69/udp #Trivial File Transfer
gopher 70/tcp
finger 79/tcp
http 80/tcp www www-http #World Wide Web
kerberos 88/tcp krb5 kerberos-sec #Kerberos
kerberos 88/udp krbS kerberos-sec #Kerberos
hostname 101/tcp hostnames #NIC Host Name Server
iso-tsap 102/tcp #IS0-TSAP Class 0
rtelnet 107/tcp #Remote Telnet Service
pop2 109/tcp postoffice #Post Office Protocol - Version 2
рорЗ 110/tcp #Post Office Protocol - Version 3
sunrpc 111/tcp rpcbind portmap #SUN Remote Procedure Call
sunrpc 111/udp rpcbind portmap #SUN Remote Procedure Call
auth 113/tcp ident tap identification Protocol
uucp-path 117/tcp
nntp 119/tcp usenet #Network News Transfer Protocol
ntp 123/udp #Network Time Protocol
epmap 135/tcp loc-srv #DCE endpoint resolution
epmap 135/udp loc-srv #DCE endpoint resolution
netbios-ns 137/tcp nbname #NETBI0S Name Service
netbios-ns 137/udp nbname #NETBI0S Name Service
netbios-dgm 138/udp nbdatagram #NETBI0S Datagram Service
netbios-ssn 139/tcp nbsession #NETBI0S Session Service
imap 143/tcp imap4 #Internet Message Access Protocol
pcmail-srv 158/tcp #PCMait Server
snmp 161/udp #SNMP
snmptrap 162/udp snmp-trap #SNMP trap
print-srv 170/tcp #Network PostScript
bgp 179/tcp #Border Gateway Protocol
ire 194/tcp #Internet Relay Chat Protocol
ipx 213/udp #IPX over IP
Idap 389/tcp #Lightweight Directory Access
Protocol
https 443/tcp MCom
https 443/udp MCom
microsoft-ds 445/tcp
microsoft-ds 445/udp
kpasswd 464/tcp # Kerberos (v5)
kpasswd 464/udp # Kerberos (v5)
isakmp 500/udp ike #Internet Key Exchange
exec 512/tcp #Remote Process Execution
biff 512/udp comsat
login 513/tcp #Remote Login
who 513/udp whod
cmd 514/tcp shell
syslog 514/udp
printer 515/tcp spooler
talk 517/udp
ntalk 518/udp
efs 520/tcp #Extended File Name Server
router 520/udp route routed
timed 525/udp timeserver
tempo 526/tcp newdate
courier 530/tcp rpc
conference 531/tcp chat
netnews 532/tcp readnews
netwall 533/udp #For emergency broadcasts
uucp 540/tcp uucpd
klogin 543/tcp #Kerberos login
kshell 544/tcp kremd #Kerberos remote shell
new-rwho 550/udp new-who
remotefs 556/tcp rfs rfs_server
rmonitor 560/udp rmonitord
monitor 561/udp
Idaps 636/tcp sldap #LDAP over TL5/SSL
doom 666/tcp #Doom Id Software
doom 666/udp #Doom Id Software
kerberos-adm 749/tcp #Kerberos administration
kerberos-adm 749/udp #Kerberos administration
kerberos-iv 750/udp #Kerberos version IV
kpop 1109/tcp #Kerberos POP
phone 1167/udp #Conference calling
ms-sql-s 1433/tcp #Microsoft-SQL-Server
ms-sql-s 1433/udp #Microsoft-SQL-Server
ms-sql-m 1434/tcp #Microsoft-SQL-Monitor
ms-sql-m 1434/udp #Microsoft-SQL-Monitor
wins 1512/tcp #Microsoft Windows Internet
Name Service
wins 1512/udp #Microsoft Windows Internet
Name Service
ingreslock 1524/tcp ingres
12tp 1701/udp #Layer Two Tunneling Protocol
pptp 1723/tcp #Point-to-point tunnelling protocol
radius 1812/udp #RADIUS authentication protocol
radacct 1813/udp #RADIUS accounting protocol
nfsd 2049/udp nfs #NFS server
knetd 2053/tcp #Kerberos de-multiplexor
man 9535/tcp #Remote Man Server
ПРИМЕЧАНИЕ
Если вы устанавливаете в Windows 2000 новую службу, напрямую адаптированную из Unix, новая
служба может брать определения портов и транспортных протоколов из файла SERVICES. Если
устанавливаемая служба не сохраняет свое описание в файле SERVICES, вероятно, в файл SERVICES
придется добавить строку с информацией о новой службе.
Установка и настройка службы сервера FTP
Серверы Windows 2000 (Windows 2000 Server и Windows 2000 Advanced Server),
а также рабочие станции с Windows 2000 Professional могут выполнять
функции серверов FTP и предоставлять клиентам FTP доступ к файлам. Клиентами
FTP могут быть другие компьютеры с системами Windows 2000, Unix, DOS или
Windows, Macintosh или VMS.
Служба сервера FTP в Windows 2000 поддерживает все клиентские команды
FTP, реализуется в виде многопоточиого приложения Win32 и соответствует
спецификациям протоколов и служб FTP, приведенным в RFC 959, «File Transfer
Protocol (FTP)» и 1123, «Requirements for Internet Hosts».
Серверы FTP используют учетные записи пользователей операционной
системы. В случае с Windows 2000 учетные записи FTP состоят из доменных
учетных записей, созданных на компьютере FTP, и учетной записи анонимного
доступа FTP.
Сервер FTP является частью Microsoft Internet Information Server (IIS). В
следующем разделе приводятся общие сведения об установке и использовании
сервера FTP.
Установка и настройка службы сервера FTP
на сервере Windows 2000
Служба сервера FTP и другие службы Интернета могут устанавливаться в
процессе исходной установки Windows 2000. Выберите строку Internet Information
Server при выборе компонентов Windows во время установки. Сервер FTP
автоматически устанавливается как часть IIS.
Если вы уже установили Windows 2000 Server без Internet Information Server,
IIS можно установить и позднее. Поскольку служба сервера FTP использует
протокол TCP/IP, поддержка TCP/IP должна быть установлена перед
установкой сервера FTP.
ПРИМЕЧАНИЕ
В Windows 2000 большинство параметров сервера FTP настраивается в консоли IIS в программе
Управление компьютером (Computer Management) и в Диспетчере служб Интернета. В Windows NT
некоторые нетривиальные параметры приходится настраивать при помощи реестра. В Windows 2000
использовать реестр не обязательно.
Все параметры сервера FTP находятся в разделе реестра HKEYJ_OCAl_MACHINE\SYSTEm\
CurrentControlSet\Services\MSFTPSRV\Parameters.
Если сервер FTP не установлен, установите IIS и выполните следующие
действия по настройке FTP-сайта:
1. Войдите в систему с правами администратора.
2. Выполните команду Пуск ► Настройка ► Панель управления (Start ► Settings ► Control
Panel).
3. Дважды щелкните на значке Установка и удаление программ (Add/Remove
Programs). Выберите значок Установка компонентов Windows (Add/Remove Windows
Components). Запускается Мастер компонентов Windows.
4. Установите флажок в строке Internet Information Services и щелкните на кнопке
Состав (Details). Убедитесь в том, что флажок Служба FTP (FTP Server) установлен.
5. Щелкните на кнопке ОК. Щелкните на кнопках Далее (Next) в следующих
окнах (не забудьте вставить компакт-диск с дистрибутивом Windows 2000
в дисковод) и завершите установку при помощи кнопки Готово (Finish).
6. Перезагрузите Windows 2000. Просмотрите список служб и убедитесь в том,
что служба FTP была успешно запущена. Чтобы вызвать список служб,
выберите значок Управление компьютером (Computer Management) в приложении
Администрирование (Administrative Tools) панели управления. Откройте папку
Службы и приложения (Services and Applications).
7. Дважды щелкните на значке Службы (Services) на правой панели и убедитесь
в том, что служба FTP готова к работе.
8. В окне приложения Управление компьютером (Computer Management) откройте
папку Службы и приложения\1^еп^ Information Services.
9. Щелкните правой кнопкой мыши на строке FTP-узел по умолчанию (Default FTP
Site) и выберите в контекстном меню команду Свойства (Properties). На экране
появляется диалоговое окно свойств FTP-узла по умолчанию.
10. Введите справочную информацию в поле Описание (Description) или
измените существующее описание. В поле IP-адрес (IP Address) выберите IP-адрес
компьютера с системой Windows 2000. Оставьте в поле TCP-порт (TCP Port)
значение 21 — стандартный номер управляющего порта, через который
устанавливается связь с сервером FTP.
11. В рамке Подключение (Connection) задайте допустимое количество
одновременных подключений FTP к серверу. Количество подключений может быть
ограниченным или неограниченным. Ограничение количества подключений
используется для распределения нагрузки. На практике для предотвращения
перегрузки сервера FTP обычно устанавливается' верхняя граница от 50 до
250 одновременных подключений.
12. Содержимое поля Время ожидания подключения (Connection Timeout) указывает
продолжительность периода бездействия, после которого пользователь FTP
будет отключен от сервера. По умолчанию этот срок составляет 900 секунд
A5 минут). Нулевое значение запрещает отключение пользователей по тайм-
ауту. Тайм-аут обычно используется в целях безопасности для уменьшения
потенциальной угрозы со стороны бездействующих сеансов FTP.
13. Флажок Вести журнал (Enable Logging) управляет протоколированием сеансов
FTP и выбором формата текущего журнала (файл журнала Microsoft IIS,
журнал ODBC, расширенный формат файла журнала W3C).
14. На вкладке Безопасные учетные записи (Security Accounts) указываются
пользователи, которым разрешен доступ к серверу FTP.
15. Установите флажок Разрешить анонимные подключения (Allow Anonymous
Connections), чтобы разрешить вход на сервер FTP под именем anonymous или ftp.
При анонимном входе пользователь не обязан вводить пароль, хотя ему
предлагается ввести свой адрес электронной почты.
16. В поле Пароль (Password) вводится пароль для учетной записи, указанной в поле
Пользователь (Username).
17. Установите флажок Разрешить только анонимные подключения (Allow Only
Anonymous Connections), чтобы пользователи не использовали при подключении к
серверу FTP свои имена и пароли в Windows 2000. Помните, что пароли FTP не
шифруются, и их использование в сети может привести к нарушению
безопасности. По умолчанию этот флажок снят. Если установить флажок Разрешить
управление паролем из IIS (Allow IIS to control password), на узле FTP
осуществляется автоматическая синхронизация пароля анонимного пользователя с
паролем Windows.
18. В рамке Операторы FTP-узла (FTP Site Operators) можно предоставить
пользователям Windows операторские привилегии. По умолчанию операторами
являются члены локальной административной группы.
19. На вкладке Сообщения (Messages) вводится текст сообщений, отображаемых
при подключении и отключении пользователя, а также при превышении
максимально разрешенного количества клиентских подключений.
20. На вкладке Домашний каталог (Home Directory) задается каталог, к которому
подключается пользователь при входе в систему. Домашний каталог может
находиться на локальном компьютере или в общей папке другого компьютера.
Для домашнего каталога устанавливаются права чтения, записи и записи в
журнал, а также стиль вывода содержимого каталога (Unix или MS-DOS).
21. На вкладке Безопасность каталога (Directory Security) устанавливаются
ограничения доступа TCP/IP для заданного IP-адреса и маски подсети.
ПРИМЕЧАНИЕ
Имя пользователя anonymous зарезервировано на компьютерах с системой Windows 2000 для
анонимного входа в систему. Следовательно, вы не сможете использовать учетную запись
пользователя с именем anonymous. В поле Пользователь (Username) следует ввести имя учетной записи
пользователя Windows 2000, которая будет назначаться пользователям при анонимном
подключении. Права доступа для анонимных пользователей FTP определяются правами пользователя с
указанным именем. По умолчанию анонимному пользователю назначается учетная запись с именем
«IUSR_nMflj<oMnbiOTepa».
Настройка TCP/IP для печати
из Windows 2000 на принтерах Unix
Windows 2000 поддерживает возможность печати на принтерах Unix по сети. Для
пересылки заданий печати используется протокол TCP/IP. Поддержка печати
йа принтерах Unix из Windows 2000 соответствует спецификации RFC 1179,
«Line Printer Daemon Protocol».
Для печати на компьютере Unix достаточно одного хоста с системой
Windows 2000 (рабочей станции или сервера), на котором установлена и настроена
служба печати Microsoft TCP/IP. Этот хост выполняет функции шлюза печати
для других клиентов Microsoft (рис. 23.13). Чтобы другие клиенты Microsoft могли
использовать шлюз печати, на них даже не обязательно устанавливать
поддержку TCP/IP. На рис. 23.13 показано, что на компьютере AKS с
установленной поддержкой печати TCP/IP определены общие принтеры \\AKS\Unix|__PRl
и \\AKS\Unixl_PR2. Один принтер подключен непосредственно к сети, а другой —
к хосту Unix. Другие клиенты Microsoft подключаются к общим принтерам так,
словно они являются устройствами печати Microsoft. Задания печати,
отправляемые на общие принтеры \\AKS\Unix_PRl и \\AKS\Unix_PR2, передаются AKS на
соответствующий принтер Unix.
Установка и настройка сетевой печати TCP/IP
Поддержка печати через TCP/IP устанавливается вместе с другими компонентами
в категории Другие службы доступа к файлам и принтерам в сети (Other Network File
and Print Services) во время установки Windows 2000. Если этот компонент не был
установлен, выполните следующие действия:
1. Войдите в систему с правами администратора.
2. Выполните команду Пуск ► Настройка ► Панель управления (Start ► Settings ► Control
Panel).
3. Дважды щелкните на значке Установка и удаление программ (Add/Remove
Programs). Выберите значок Установка компонентов Windows (Add/Remove Windows
Components). Запускается Мастер компонентов Windows.
Windows 2000
с установленной поддержкой
сетевой печати TCP/IP
I | pro. Принтер
|[ :: II 25 Unix
... |1 1| \\AKS\Unix_PR1 Ущ \\AKS\Unix_PR2-. v_,
I Хост ! |AKS \ i
Unix ! 41 PR2
* • 1 4 ♦-f-^ ±+
J : L— -
Windows 2000 DOS/Windows Micintosh
Рис. 23.13. Печать TCP/IP в Windows 2000
4. Установите флажок в строке Другие службы доступа к файлам и принтерам в сети
(Other Network File and Print Services) и щелкните на кнопке Состав (Details).
Убедитесь в том, что флажок Службы печати для Unix (Print Services for Unix)
установлен.
5. Щелкните на кнопке ОК. Щелкните на кнопках Далее (Next) в следующих окнах
(не забудьте вставить компакт-диск с дистрибутивом Windows 2000 в
дисковод) и завершите установку при помощи кнопки Готово (Finish).
Ниже кратко описан процесс настройки печати TCP/IP на компьютере
Windows 2000 для использования служб печати Unix, работающих на другом
компьютере Windows 2000, или эквивалентной службы демона построчной печати на
компьютере Unix:
1. Войдите в Windows 2000 (Server или Workstation) с правами администратора.
2. Выполните команду Пуск ► Настройка ► Принтеры (Start ► Settings ► Printers).
3. Дважды щелкните на значке Установка принтера (Add Printer). Когда на экране
появится окно мастера установки принтеров, щелкните на кнопке Далее (Next).
4. В следующем окне выберите тип устанавливаемого принтера (локальный или
сетевой) и щелкните на кнопке Далее (Next). Если выбрать локальный
принтер, мастер попытается автоматически определить и установить принтер Plug-
and-Play. Если попытка завершится неудачей, выберите принтер из списка.
5. Мастер установки принтеров выводит список доступных портов. Установите
переключатель Создать новый порт (Create a New Port), выберите в списке Тип
порта (Туре) порт LPR и щелкните на кнопке Далее (Next).
6. На экране появляется диалоговое окно Добавление LPR-совместимого принтера
(Add LPR compatible printer).
7. В поле Имя или адрес LPD-сервера (Name or address of server providing LPD) введите
имя DNS или IP-адрес устройства Unix (хоста или сетевого принтера), на
котором работает служба LPD — демон построчной печати, выполняющий
функции сервера печати Unix.
ПРИМЕЧАНИЕ
При печати на сетевом принтере с поддержкой LPR устанавливать службу не обязательно. Она
необходима только в том случае, если очередь принтера находится на обычном хосте Unix.
8. В поле Имя принтера или очереди печати на сервере (Name of printer or print queue
on that server) введите имя принтера Unix в системе.
9. Завершив ввод данных в диалоговом окне Добавление LPR-совместимого принтера
(Add LPR compatible printer), щелкните на кнопке ОК. Если служба LPD не
поддерживается, будет выведено соответствующее сообщение. Щелкните на кнопке ОК.
10. В следующем окне мастера установки принтеров выберите производителя
оборудования в списке Изготовитель (Manufacturers) и модель принтера в
списке Принтеры (Printers). Щелкните на кнопке Далее (Next).
11. Мастер установки принтеров отображает имя принтера и спрашивает,
должен ли этот принтер использоваться по умолчанию. Выберите нужный ответ
и щелкните на кнопке Далее (Next).
12. Далее мастер установки принтеров предлагает указать, будет ли этот принтер
совместно использоваться в сети. Установите переключатель Имя общего
ресурса (Share as) или Нет общего доступа к этому принтеру (Do not share this
printer). По умолчанию имя общего принтера совпадает с именем принтера,
введенным ранее. Щелкните на кнопке Далее (Next).
13. В следующем диалоговом окне находятся поля Размещение (Location) и
Комментарий (Comment) для ввода информации о местонахождении и
возможностях принтера. Щелкните на кнопке Далее (Next).
14. При желании напечатайте тестовую страницу, чтобы убедиться в
правильности выбранной конфигурации. Щелкните на кнопке Далее (Next) и завершите
установку принтера кнопкой Готово (Finish).
15. Если тестовая страница напечатана успешно, щелкните на кнопке ОК, а если
нет — провепьте настройки принтера. Для этого следует щелкнуть правой
кнопкой мыши на значке нового принтера и выбрать в контекстном меню
команду Свойства (Properties).
16. На вкладке Параметры устройства (Device Settings) выбираются такие
параметры, как тип и источник бумаги, объем памяти и т. д. Внесенные изменения
сохраняются кнопкой ОК.
Настройка принтера TCP/IP завершена. Закройте окно Принтеры.
Печать в Windows 2000 из клиентов Unix
В предыдущем разделе рассматривается процедура настройки печати на
принтерах Unix из клиентов Microsoft. В смешанных сетях, содержащих клиентов Unix
и Microsoft, иногда возникает необходимость в печати из клиента Unix на
принтере Windows 2000.
Для печати из клиента Unix на компьютере с системой Windows 2000 на
последнем должна работать служба печати TCP/IP. Клиенты печати Unix
используют службу Unix LPD. В Windows 2000 запускается служба LPDSVC, которая
эмулирует демона построчной печати Unix. На рис. 23.14 показано, как
организуется печать из клиентов Unix в Windows 2000.
Г LPDSVC ^
I ^ \Ь^г^,,;^г Устройство печати
' \ ^ЯШВ& Windows 2000
Windows 2000
? ^ »■■ ч»^ •
kS Pi г~"л
I > _ LPR «^ I Г_ LPR ^ I f _ LPR •?
nLJ HUJ Q_^^_/
i»j^!!!!I!!I!II!f^^[! PiiSl!I!!IIIIT^3) f^^^JUJiJU^^^^^^j
liHttF^ ijj|piT^i| /MlBM^
Клиенты Unix
Рис. 23.14. Печать из клиентов Unix на компьютере с системой Windows 2000
Запуск, остановка, продолжение и завершение службы Windows 2000 LPDSVC
осуществляются следующими командами NET:
О NET START LPDSVC,
О NET PAUSE LPDSVC,
О NET CONTINUE LPDSVC,
О NET STOP LPDSVC.
Кроме того, эти операции могут выполняться при помощи значка Службы
(Services) панели управления. Служба LPDSVC называется сервером печати
TCP/IP в диалоговом окне, изображенном на рис. 23.15. По умолчанию эта служба
запускается автоматически. Чтобы изменить способ запуска службы, выберите
нужную строку в списке Тип запуска (Startup type).
Отправка задания печати в Windows 2000 из клиента Unix выполняется
соответствующей командой Unix (обычно используется команда Ipr). За
дополнительной информацией о команде Ipr обращайтесь к документации Unix.
Обобщенный синтаксис команды Ipr:
Ipr -s хост -Р принтер файл
Здесь хост — имя DNS компьютера с системой Windows 2000, на котором
работает LPDSVC; принтер — имя принтера Windows 2000, определенного в
Windows 2000; файл — имя файла Unix, выводимого на печать.
Программы командной строки TCP/IP
Комплект поставки Windows 2000 содержит ряд служебных программ TCP/IP,
работающих в режиме командной строки. В основном эти программы созданы
на базе прототипов, написанных для системы Unix. Они хорошо знакомы всем,
кто уже пользовался инструментарием TCP/IP для Unix.
Tfee | 1 Name / j tescnptipn [Status|. 5tat1xip,T>3?e fbag^OnAs 1 Al
№i Sfervice$(LotaO' :j^g&Remote Registry Service Allows rem... Started Automatic LoealSystem
I ]<%Removable Storage Manaoes f... Started Automatic LocalSystem
I J ^Routing and Remote Access tflffiOESSSIiSBSIZES
I ;;|%RunAs Service En. } 1 j
:]%Security Accounts Manager Stc Ge^dt IL^ °" I ****** I Depended*» \
I I ^u Server Pre 111
II^SfenpbMalTransportProto... Tr*. *"*•"■"«■ >^VC • |
№s«npleTCPAP Services Sut 0^^- УёАЫа,1Ш>ЦЦ|
№ Smart Card Ma * •■ ::, I
I -I$&Smart Card Hefcer Pre Оевсф^юл; {Provides a TCP/IP-based printing service that uses the I j ]
I :№SNMP Service Inc . ill
:№SNMP Trap Service Re ^towepujaWer
%System Event Notification Tr< ;iC;^SNNT\SyJt^2Mcpsvcieie~ ~"'
I I % Task Scheduler En. ; |j
;]%TCP/IP NetBIOS Helper Ser... En. Startup t^P*- |Automatic 3 I
|^1iOWI^5»>^.:.:;,. ^i; Pr<
I ::|^b Telephony Pre • 1 j
I I та Telnet Alk ; Sav«e tfattw Started 1 j
I y& Terminal Services Pre ♦ . , I j I 1
^: %UmnterruptWe Power Supply Ma yr 1 Stop I Pau?e 1 :""'/'• 1 j 1
I ]%Utiflty Manager Stc ,. , ' , . , , , . _L j I
I IJr Youcari spec «j< the s*ai»paf6melets»-«lappjy when you s»a*» ihe serwee I j I
№ Windows Installer Ins fomhwe . j 1
I :№ Windows Internet Name Se... Pre . | J
I | <f»> Windows Management Inst... Pre U- :-- o: ••-':. .; j II 1
I «^Windows Management Inst... Pre 111
^Windows Time Set J j j
^Workstation Pre , Г r5F~~| Cancel | • :, f J
та World Wide Web Publishing... Pre ^__ i » » * j *^f
|^Start|;j g -S НИ ^ jj t-JMUSERSfr... | ^NovellOnfo.,, j jjjftecjtstrvm..\\^Services .'^'"^'"""i'loi'pM |
Рис. 23.15. Окно свойств сервера печати TCP/IP
Помимо программ командной строки, в Windows 2000 также включены
простые службы TCP/IP, работающие на большинстве хостов Unix (например, ECHO,
DAYTIME, CHARGEN и DISCARD). Впрочем, в Windows 2000 эти службы
устанавливаются отдельно в категории Простые службы TCP/IP.
В Windows 2000 включены следующие программы командной строки.
arp tracert
hostname finger
ipconfig rep
Ipq rexec
Ipr rsh
nbtstat ftp
netstat tftp
ping telnet
route pathping
Хотя программы ftp, rexec и telnet требуют аутентификации, пароли перед
отправкой не шифруются. Следовательно, использование этих программ создает
потенциальную угрозу для безопасности системы. Для работы с этими
программами рекомендуется создавать дополнительные учетные записи, чтобы
предотвратить несанкционированный доступ к паролям. В Windows 2000 Telnet
поддерживает механизм шифрованной аутентификации. Используйте его, если
имеется сколько-нибудь существенный риск перехвата данных учетных записей
Telnet.
В этом разделе описан процесс установки простых служб TCP/IP, а также
рассматриваются основные программы командной строки.
Простые службы TCP/IP входят в категорию сетевых служб Windows,
устанавливаемых в процессе основной установки системы. Ниже описана процедура
установки простых служб TCP/IP, если они почему-либо не были установлены
ранее.
1. Войдите в систему с правами администратора.
2. Выполните команду Пуск ► Настройка ► Панель управления (Start ► Settings ► Control
Panel).
3. Дважды щелкните на значке Установка и удаление программ (Add/Remove
Programs). Выберите значок Установка компонентов Windows (Add/Remove Windows
Components). Запускается Мастер компонентов Windows.
4. Выберите категорию Сетевые службы (Network Services) и щелкните на кнопке
Состав (Details). Установите флажок Простые службы TCP/IP (Simple TCP/IP Services)
(рис. 23.16).
То add or remove a component, click the checfc box. A shaded box means that only part
of the cornponerrt w! be hstalMЛ^ I
Subcomponents of Metworking Sefvlce^ :{:: I
Internet Services Proxy 0.0 MB "+J 1
P |SJ Domain Ndrne System (DNS) 1.1MB ^1
D $ Dynamic Host Configuration Protocol (DHCP) 0.0 MB I I
IG JUI nternet Authentication S ervice 0.0MB I . ■ J
iG (j^QoS Admission Control Service 0.0 MB -J I
JD JUSite Server ILS Services 1 6 MB zl: J
[ Description: Supports the fofiov^^gT^/IP se^rces: CrwadefGer^ratoi.Daytffne, I
Discard, Echo, and Qudteof She Day
Total disk space lequeedf; ;; U9;&8 П^-filj |
Space available on di$lc 667ДМ8 ~~ •
• ' - J OK | Cancel |
Рис. 23.16. Установка простых служб TCP/IP
5. Щелкните на кнопке ОК. Щелкните на кнопках Далее (Next) в следующих
окнах (не забудьте вставить компакт-диск с дистрибутивом Windows 2000
в дисковод) и завершите установку при помощи кнопки Готово (Finish).
ПРИМЕЧАНИЕ
В категорию простых служб TCP/IP входят службы CHARGEN, DAYTIME, DISCARD, ECHO и QUOTE,
часто применяемые в диагностических целях.
Служба CHARGEN работает на порте TCP с номером 19. При подключении к этому порту через Telnet
на экране выводится циклическая последовательность из 95 печатаемых символов в кодировке ASCII.
Следующая команда Telnet подключается к службе CHARGEN на удаленном компьютере remote:
telnet remote 19
Служба CHARGEN может использоваться как средство диагностики, позволяющее убедиться в
нормальной работе удаленного компьютера вплоть до уровня TCP.
Служба DAYTIME работает на порте TCP с номером 13. При подключении к этому порту через
Telnet выводится представление текущего времени на удаленном компьютере в кодировке ASCII.
Следующая команда Telnet подключается к службе DAYTIME на удаленном компьютере remote:
telnet remote 13
Команда позволяет узнать время на удаленном компьютере и убедиться в нормальной работе
канала связи вплоть до уровня TCP на удаленном компьютере.
Служба DISCARD работает на порте TCP с номером 9. При подключении к этому порту через Telnet
все передаваемые данные игнорируются. Это своего рода «черная дыра», в которой бесследно
пропадают любые данные. Следующая команда Telnet подключается к службе DISCARD на
удаленном компьютере remote:
telnet remote 9
Порт TCP с номером 9 часто используется в качестве фиктивного порта для тестирования программ.
Например, службе DISCARD можно передавать тестовые сообщения TCP, которые не содержат
важной информации и потому могут уничтожаться.
Служба ECHO работает на порте TCP с номером 7. При подключении к этому порту через Telnet
все передаваемые данные возвращаются отправителю. Служба используется как средство
диагностики, позволяющее убедиться в том, что передаваемые сообщения доходят до адресата и
возвращаются обратно без искажений. Следующая команда Telnet подключается к службе ECHO на
удаленном компьютере remote:
telnet remote 7
Служба QUOTE работает на порте TCP с номером 17. При подключении к этому порту через Telnet
выводится «цитата дня», случайным образом выбранная из файла %SystemRoot%\System32\Drivers\
Etc\Quotes. Служба используется для проверки приема сообщений с удаленного компьютера.
Следующая команда Telnet подключается к службе QUOTE на удаленном компьютере remote:
telnet remote 17
После успешной установки связи на экране выводится «цитата дня».
Итоги
В процессе настройки TCP/IP в Windows 2000 задаются значения таких
базовых параметров, как IP-адрес, маска подсети, основной шлюз и серверы имен.
Чтобы выйти за пределы текущей сети, компьютер с системой Windows 2000
должен располагать данными по крайней мере одного основного шлюза. Если
сеть состоит только из компьютеров на базе Windows 2000, для разрешения
имен хватит данных сервера DNS. Тем не менее, если потребуется обеспечить
совместимость со старыми клиентами и серверами Windows, на компьютерах
Windows 2000 необходимо настроить параметры WINS. В сетях Windows 2000
механизм разрешения имен NetBIOS по-прежнему играет важную роль при
обеспечении обратной совместимости.
Хотя работа службы Active Directory в Windows 2000 зависит от TCP/IP, стек
протоколов TCP/IP практически не требует специальной настройки — достаточно
указать сервер DNS, обеспечивающий разрешение имен.
2 А Поддержка IP
&l? в Novell NetWare
Джо Девлии (Joe Devlin), Эмили Берк (Emily Berk)
Многие считают систему NetWare фирмы Novell предком всех современных
сетевых операционных систем. Это надежный продукт, который развивался в
течение 18 лет. В наши дни NetWare работает на 5 миллионах серверов и 81
миллионе рабочих станций по всему миру.
Novell и TCP/IP
Поддержка TCP/IP в продуктах Novell внедрялась медленно и постепенно.
Версия NetWare 3.11 была выпущена в 1987 году с интегрированной встроенной
поддержкой туннелирования IP, поддержкой стека TCP/IP и прикладных служб
TCP/IP (таких, как FTP и NFS). С того времени фирма Novell включила в свои
сетевые операционные системы широкий спектр решений на базе TCP/IP. Многие
из этих старых решений до сих пор продолжают использоваться. Novell создает
надежные операционные системы, и в мире NetWare старые серверы обычно
оставляют обслуживать сети отделов, филиалов и т. д., тогда как новые серверы
назначаются на решение более масштабных задач или управление Интернетом.
IP и NetWare 4
Система NetWare 4 стала первой серьезной попыткой Novell в создании
операционной системы, обладающей полноценной поддержкой Интернета. В NetWare 4
появилась служба NDS (Novell Directory Services), упрощающая управление
широким спектром сетевых ресурсов в глобальной сети, содержащей серверы
NetWare, NT и Unix. Служба NDS привлекла внимание сетевых
администраторов и лишь укрепила репутацию Novell как разработчика практичных решений,
выходящих за рамки технических возможностей Microsoft.
Попытка внедрения основных средств интернет-разработки в NetWare 4 была
несколько менее успешной. Версия NetWare 4.11 (прозванная Intranet Ware),
выпущенная в октябре 1996 года, содержала собственный набор интернет-средств,
в том числе NetWare Web Server, NetWare FTP Server и NetWare Internet Access
Services (NIAS). Фирма Novell также добавила инструменты для подключения
серверов и клиентов NetWare к интернет-устройствам, работающим на базе TCP/IP.
Служба NDS пользовалась огромным успехом. Тем не менее одного сервера
Novell 4.x с NDS было вполне достаточно для управления большим
конгломератом серверов Novell 3.x, NT и Unix. Корпорации хотели использовать поддержку
TCP/IP на своих серверах Novell, но эта задача решалась многими способами
с использованием серверов NetWare 3.x и 4.x. Не было никаких убедительных
доводов в пользу перехода на NetWare 4.x. Такие доводы появились с выходом
NetWare 5 и Pure IP.
Версия NetWare 6, выпущенная в 2001 году, базируется на возможностях
NetWare 5 и дополняет их такими новыми возможностями, как iPrinter, SAN
(Storage Are Network), Remote Management, встроенными средствами
кластеризации и рядом других служб. Тем не менее базовая поддержка протокола
TCP/IP осталась на том же уровне, что и в NetWare 5. По этой причине
описание сервиса TCP/IP в NetWare 5 в этой главе в равной степени относится
к NetWare 6.
NetWare 5 и NetWare 6
В версии NetWare 5 произошли принципиальные изменения в отношении Novell
к IP. IPX, старый коммуникационный протокол Novell, элегантен, надежен и прост
в использовании. Тем не менее повсеместное распространение получил
протокол IP. Фирма Novell вовремя поняла, что происходит, и переработала NetWare
так, что главным коммуникационным протоколом системы стал протокол IP
(вместо IPX).
Версия NetWare 5 была выпущена в сентябре 1998 года как решение на базе
«чистого IP»; версия NetWare 6, выпущенная в 2001 году, также использует
«чистый IP». Термин «чистый IP» означает, что надобность в инкапсуляции
IPX отпала. Протокол прикладных служб NCP (NetWare Core Protocol)
работает исключительно через TCP/IP.
NetWare 5 использует средства IP для поиска, адресации и пересылки
данных. По сравнению с маршрутизацией NetBIOS в Windows NT или
инкапсуляцией IPX, использовавшейся в прежних версиях NetWare, «чистый IP»
обеспечивает прямой, беспрепятственный доступ к другим сетям на базе IP, включая
платформы Unix и Интернет. Тем самым обеспечивается улучшенное
быстродействие, снижение затрат и простота управления для компаний, полагающихся
на IP в коммуникациях.
Фирма Novell хорошо справилась с расширением знакомых средств типа NDS
и их адаптацией к миру TCP/IP. Кроме того, некоторые стандартные
технологии (такие, как SLP, DHCP и DNS) в NetWare были расширены для поддержки
сетей IP, IPX и смешанных сетей. При этом фирма Novell не забыла об
огромной существующей базе серверов NetWare 3.x и 4.x, работающих на базе IPX.
Хотя стандартным коммуникационным протоколом NetWare теперь является IP,
система NetWare 5 полностью совместима со старыми версиями NetWare,
построенными на базе IPX.
Традиционные решения: IP в NetWare 3.x-4.x
Протокол IPX/SPX (часто сокращается до IPX) был отдаленным аналогом
TCP/IP в сетях Novell. Он является базовым коммуникационным протоколом
во всех серверах NetWare 3.x и 4.x. Протокол IPX отличается надежностью и
стабильностью, но по популярности он значительно уступает TCP/IP. Фирма Novell
стала включать в NetWare интерфейс IPX-TCP/IP, начиная с 1987 года. С того
времени было разработано немало продуктов, связывающих IPX с TCP/IP,
каждый из которых обладает своими специфическими возможностями. В табл. 24.1
приведена краткая сводка основных продуктов с указанием областей
применения по каждому продукту.
Таблица 24.1. Основные технологии, связывающие IPX с TCP/IP
Название Характеристика Область применения Недостатки
IP Tunneling Сервер снабжает Обеспечение связи между Не обеспечивает
каждый исходящий двумя сетями Novell связи TCP/IP между
пакет IPX заголовком на базе IPX, связанных по рабочими станциями.
TCP/IP магистральному каналу TCP/IP Не подходит для
и автоматически или через Интернет. Хорошо соединения большого
восстанавливает подходит для небольшого количества серверов
входящие пакеты количества серверов
IP Relay Обмен данными IPX Технология оптимизирована Технология обладает
инкапсулируется для постоянных соединений теми же достоинствами
в пакетах TCP/IP, (выделенных линий и т. д.); и недостатками, что
которые могут ретрансляция IP обычно и туннелирование IP,
передаваться применяется при создании но лучше подходит
по магистральному виртуальных частных сетей для использования
каналу IP (VPN) в больших сетях
LAN Предоставление Клиентская часть предоставляет Для использования
Workspace доступа к ресурсам доступ к ресурсам TCP/IP этого продукта
TCP/IP и NetWare IPX на компьютерах, не сетевые
за счет предоставления подключенных к локальной администраторы
клиентским сети. Серверная часть должны хорошо
приложениям поддерживает разбираться как
TCP/IP возможности централизованную в IPX, так и в TCP/IP
чтения/записи установку, настройку и
в стеках TCP/IP и IPX сопровождение ресурсов IP
IPX-IP Шлюз преобразует Поскольку все назначение Необходима установка
Gateway данные IPX в данные IP-адресов ограничивается как серверной, так
TCP/IP и направляет адресом шлюза, обычные и клиентской части,
их нужному пользователи IPX, Рабочие станции
получателю подключенные через шлюз, общаются с хостами
могут использовать стандартные IP через шлюз,
web-браузеры или другие что увеличивает
WinSock-совместимые программы непроизводительные
TCP так, как если бы поддержка затраты ресурсов во
TCP/IP была настроена на их всех сеансах связи
локальном компьютере
Название Характеристика Область применения Недостатки
NetWare/IP Инкапсуляция всего Поскольку поддержка IPX На клиенте и сервере
трафика IPX в IP остается доступной на каждой необходимо
рабочей станции, старые установить несколько
IPX-приложения могут компонентов,
взаимодействовать напрямую взаимодействующих
независимо друг
от друга
IP Tunneling
Для установления связи между двумя IPX-сетями Novell, связанными
магистральными каналами TCP/IP или через Интернет, лучше всего подойдет технология
тунпелировапия IP (IP Tunneling), поддерживаемая во всех версиях NetWare,
начиная с 3.11. В этой технологии рабочие станции на базе IPX отправляют
стандартные пакеты IPX локальному или удаленному туннельному серверу. Сервер, на
котором работает соответствующая программная поддержка, ожидает
поступления пакетов IPX. Получив такой пакет, сервер снабжает его заголовком TCP/IP
и маршрутизирует в сети TCP/IP к заданному адресу. Обычно туннелирование
реализуется загружаемым модулем NetWare IPTUNNEL.NLM. Драйвер IPTUNNEL на
сервере инкапсулирует пакеты IPX/NCP в кадрах IP, добавляет заголовок UDP,
заголовок IP и поле контрольной суммы IP для проверки целостности данных.
Туннельные серверы используют стандартные IP-адреса, что позволяет
организовать маршрутизацию пакетов между серверами через Интернет или
магистральный канал TCP/IP. При получении пакета на другом конце канала другой
туннельный сервер IPX удаляет заголовок TCP/IP и передает «чистый» пакет
IPX в точку приема.
Главное преимущество туннелирования IP заключается в том, что оно
позволяет организовать межсетевое взаимодействие IP/IPX с минимальными
неудобствами для сетевых администраторов и пользователей. Например, для
реализации туннелирования на рабочей станции не придется устанавливать
специальные клиентские програмы. Более того, рабочая станция вообще не знает
о том, что пакеты данных IP будут инкапсулироваться. В результате все
существующие приложения IPX работают точно так же, как в обычной сети IPX.
Главный недостаток туннелирования IP заключается в том, что оно не
обеспечивает связи TCP/IP между рабочими станциями. Тем не менее это
надежное и дешевое решение, которое достаточно хорошо справляется со своими
задачами, особенно при связывании небольшого количества серверов. С другой
стороны, инкапсуляция пакетов снижает эффективность пересылки, а
необходимость в дополнительном управлении и диагностике затрудняет сопровождение
сети. По этой причине туннелирование не подходит для объединения большого
количества серверов.
IP Relay
Технология ретрансляции IP (IP Relay) обладает более широкими возможностями,
чем технология туннелирования IP. В ней также используется серверная
инкапсуляция данных IPX в пакетах TCP/IP, которые затем передаются по каналу IP.
Отличие заключается в том, что ретрансляция IP оптимизирована для постоянно
действующих каналов — таких, как выделенные линии, широко используемые
для связи филиалов с основными представительствами фирм. Ретрансляция
часто используется для создания виртуальных частных сетей, не требующих
установки и сопровождения дорогостоящих программ на стороне клиента. В остальных
отношениях ретрансляция IP обладает теми же достоинствами и
недостатками, что и туннелирование. Продукт IP Relay от Novell является частью NetWare
Multiprotocol Router (MPR) версии 2.0 и выше, а также интегрируется с WAN-
версией NetWareLink Services Protocol.
Ретрансляция IP также использует инкапсуляцию, но ее применение для
архитектур «точка-точка» в глобальных сетях значительно упрощает ее настройку
и администрирование по сравнению с туннелированием IP. Сети IP Relay лучше
всего реализуются в архитектурах типа «звезда». Центральный сервер
располагает таблицей IP-адресов всех периферийных серверов. Периферийные серверы
не обязаны знать IP-адрес центрального сервера, они могут работать в режиме
прослушивания и ждать момента, когда центральный сервер откроет
коммуникационную линию.
Технология ретрансляции IP, спроектированная для архитектур
«точка-точка», порождает существенно меньше трафика, чем туннелирование, а также
упрощает процессы установки и администрирования. В конечном счете она также
обладает лучшим потенциалом масштабирования.
LAN Workplace
Продукты Novell LAN Workplace предоставляют пользователям Windows NT/2000
и DOS доступ к ресурсам как TCP/IP, так и NetWare IPX. В этих продуктах
дейтаграммы IPX не инкапсулируются в заголовках TCP/IP. Вместо этого на
стороне клиента используются программные средства, поддерживающие чтение
и запись в стеках TCP/IP и IPX. Таким образом, LAN Workplace позволяет
рабочим станциям DOS и Windows получить доступ к хостам Unix и дискам
NetWare через TCP/IP.
LAN Workplace устанавливается на уровне рабочей станции или сервера.
После установки LAN Workplace предоставляет доступ к ресурсам TCP/IP
даже компьютеру, не имеющему прямого подключения. При установке на сервере
LAN Workplace дает возможность всем пользователям сети работать с ресурсами
TCP/IP. Кроме того, серверная установка также позволяет администраторам
сети NetWare централизованно решать задачи установки, настройки (включая
назначение IP-адресов рабочих станций) и сопровождения.
Недостатком LAN Workplace можно считать то, что сеть IPX не
преобразуется в сеть TCP/IP. Вместо этого поддержка TCP/IP существует отдельно и
независимо от поддержки IPX. Следовательно, управление сетью LAN Workplace
требует всех навыков, необходимых для управления сетями IPX и TCP/IP.
IPX-IP Gateway
Фирма Novell включила свой продукт IPX-IP Gateway в NetWare 4.0 в 1996 году.
Данное решение требует установки компонентов как на сервере (шлюз), так
и на клиенте (редиректор). Тем не менее IP-адреса необходимы только шлюзам.
Затем шлюз автоматически обеспечивает адресацию TCP/IP и IPX и
маршрутизацию сообщений, отправляемых и получаемых клиентом.
IPX-IP Gateway — изящное решение, которое избавляет сетевых
администраторов от хлопот с адресацией IP (поскольку IP-адреса нужны только шлюзам).
Маршрутизация через шлюз реализована достаточно полно, поэтому каждая
подключенная рабочая станция IPX может использовать стандартный браузер или
другую WinSock-совместимую программу TCP так, словно протокол TCP/IP
настроен непосредственно на ней.
Маршрутизация всего трафика IP через шлюз означает новые
непроизводительные затраты в сеансах связи. С другой стороны, шлюз может выполнять
функции простого брандмауэра. В сочетании с программой Novell NDS, продукт
IPX-IP Gateway предоставляет в распоряжение сетевого администратора
централизованную консоль для определения и сопровождения всей информации о
правах доступа пользователей и групп.
NetWare/IP
Продукт NetWare/IP, впервые появившийся как дополнение к NetWare 3.1x
и NetWare 4.x в 1993 году, предназначался для интеграции сервиса NetWare
в среду TCP/IP. Он также поставлялся в качестве компонента Novell Multi-
Protocol Router.
NetWare/IP обеспечивает более полную интеграцию сервиса NetWare 3.x
и 4.x в среду TCP/IP, чем любое из представленных выше решений. В его работе
используется как инкапсуляция, так и передача стандартных пакетов IP.
Впрочем, это решение также потребует больших усилий со стороны администратора.
Например, для NetWare/IP придется установить несколько независимых
компонентов на стороне клиента и сервера.
Клиентская поддержка NetWare/IP состоит из файла TCPIP.EXE (стек TCP),
модуля NWIP.EXE и одного из виртуальных загрузочных модулей оболочки NetWare
(NETX.EXE) или NetWare DOS Requester. Клиентская архитектура NetWare/IP
соответствует традиционной клиентской архитектуре NetWare на физическом,
канальном и прикладном уровнях. Впрочем, транспортный уровень изменился —
вместо традиционной схемы адресации IPX используется стек UDP-TCP/IP
(TCPIP.EXE).
NetWare/IP также расширяет возможности стандартных средств
управления IP. Например, распределенная служба разрешения имен DNS
используется для централизованного хранения информации о соответствии имен хостов
и IP-адресов. Служба DSS (Domain SAP Server) ведет базу данных,
используемую для хранения и предоставления информации IPX SAP среди клиентов
и серверов NetWare/IP.
Такие службы NetWare 3.x и 4.x, как службы файлов, печати и каталогов,
распространяют информацию о себе при помощи протокола Novell SAP (Service
Advertising Protocol). Каждые 60 секунд эти службы производят
широковещательную рассылку пакета, в котором указывается имя, тип службы и адресная
информация. Во время загрузки сервер NetWare/IP сообщает о себе остальным
узлам сети, посылая запись SAP ближайшему серверу DSS с использованием
протокола UDP.
В NetWare/IP весь трафик IPX инкапсулируется в IP. Поскольку стек IPX
остается доступным на каждой рабочей станции, старые приложения на базе
IPX по-прежнему могут общаться напрямую на уровне этого стека. Так как стек
работает под инкапсуляцией IP, к тем же приложениям IPX пользователи могут
обращаться и через TCP/IP. Естественно, существуют некоторые ограничения
того, что можно сделать при помощи эмуляции TCP/IP. Например,
приложения, использующие механизм широковещательной рассылки IPX, не будут
нормально работать при передаче пакетов через маршрутизатор IP.
NetWare 5/NetWare 6 — IP и все
удобства Novell
Полноценная поддержка TCP/IP в NetWare 5 и NetWare 6 была действительно
эффектным новшеством. Фирма Novell полностью переработала архитектуру
операционной системы и средства управления, входившие в ее поставку, что
позволило настроить NetWare для «чистой» сети IP, для «чистой» сети IPX или
для смешанной сети, поддерживающей оба протокола одновременно. Из ядра
операционной системы были исключены все старые зависимости от IPX. Там,
где это было уместно, были добавлены связи между NCP и TCP/IP. В результате
весь сервис NetWare, присутствующий в предыдущих версиях, теперь доступен
и через TCP/IP.
Полноценная поддержка IP
Операционные системы NetWare 5 и NetWare б, а также связанные с ними
вспомогательные средства типа NDS, теперь обладают полноценной поддержкой
TCP/IP. Операционная система, зарегистрированные в ней клиенты и
приложения, работающие в этой операционной системе, могут взаимодействовать друг
с другом, не выходя за рамки стека протоколов TCP/IP. Им уже не приходится
прибегать к инкапсуляции IPX, маршрутизации, туннелированию или шлюзам.
Эти технологии справлялись со своими задачами в ранних версиях IP и
продолжают использоваться большинством других (не входящих в семейство Unix)
операционных систем, однако они порождают лишний трафик и приводят к
лишним затратам аппаратных ресурсов. Использование только трафика IP в канале
снижает требования к программной и аппаратной поддержке маршрутизации,
повышает фактическую пропускную способность сети, освобождает от
необходимости поддерживать несколько сетевых протоколов и расширяет
возможности удаленного подключения к Интернету и корпоративным интрасетям.
Поддержка нескольких протоколов
Хотя протокол IP стал стандартным коммуникационным протоколом NetWare,
фирма Novell не стала разрывать связи с миллионами пользователей NetWare
3.x, 4.x и традиционного инструментария на базе IPX. В NetWare 5 и NetWare 6
осталась поддержка IPX, которую можно активизировать в случае необходимости.
NetWare 5 и NetWare 6 позволяют перейти на работу в среде IP без
преобразования всех существующих IPX-приложений и без нарушения работы
корпоративных систем. С другой стороны, вы можете выбрать IPX в качестве стандартного
протокола и полностью избежать всех вопросов, которые приходится решать
при переходе на IP. Наконец, возможен третий вариант — работать в смешанной
среде и постепенно переходить с IPX на IP по мере возникновения новых
потребностей или роста квалификации.
Варианты установки
При установке NetWare 5 или NetWare 6 выбирается один из трех режимов:
О IP;
О IP/IPX;
О IPX.
Выбранный вариант определяет способы привязки NetWare к стекам
протоколов и сетевым платам, но не сказывается на том, какие стеки протоколов
загружаются в системе. Например, в первом варианте установки («только IP»)
загружаются оба стека, TCP/IP и IPX, но к сетевой плате привязывается только
стек TCP/IP. В этом случае протокол IP является основным, а стек IPX
загружается только для того, чтобы система могла выполнять приложения IPX и
связываться с другими системами IPX при помощи Novell Migration Agent.
Системы, установленные со смешанной поддержкой IP и IPX, позволяют
создавать подключения NCP как через стек TCP/IP, так и стек IPX.
Предоставляя одновременный доступ к IPX и TCP/IP, NetWare 5 и NetWare 6
обеспечивают поддержку существующих IPX-приложений, а также всю
маршрутизацию IP и IPX. В NetWare 5 и NetWare 6 также предусмотрен режим
совместимости (подробности см. ниже), который может использоваться для управления
IPX-приложениями в тех случаях, когда при установке сети был выбран вариант
«чистой» сети IP. Другое средство, входящее в поставку системы — NetWare
Migration Agent, — обеспечивает связь между двумя сетями, одна из которых
устанавливалась как «чистая» сеть IP, а другая работает на базе протокола IPX.
Разные варианты установки IP/IPX представлены на рис. 24.1.
Установка NetWare 5 и NetWare 6 для IP
Вариант установки NetWare 5 и NetWare 6 «только для IP» сильно упростит
жизнь клиентам, активно использующим IP-коммуникации, устранит
необходимость в сопровождении нескольких протоколов и снизит загрузку сети. В этой
конфигурации сервер напрямую обменивается данными с любым клиентом или
сервером, использующим стек TCP/IP. Стек IPX загружается, но не
привязывается к сетевой плате. Для запуска IPX-приложений можно воспользоваться
встроенным режимом совместимости, но сначала необходимо установить Migration
Agent для подключения к IPX-серверам и клиентам. Этот вариант установки
обладает многими преимуществами: сопровождение одного протокола требует
меньше аппаратных и программных ресурсов, повышает эффективность
управления и использования сети, повышает производительность и снижает затраты.
В очень больших сетях он оказывается наиболее эффективным.
fi^^ss) Шзш fnni ysi рив
щЭШщ^—7 1 111 Шш
— 11 ИПШПГ сеть IP I I jSL
Чистый клиент IP ен±э f^ki ^^^
ЖИНИ О \m\ mi
т Тит T ,,px Ш. ^ т пг,'Т'|Т' и
Сеть IPX u ^ ' ™ „ Сеть IP JSL
щзэ п=±=э Клиент с поддержкой rzfci гц£щ
(Я) P^l обоих стеков [fff] PflH
JssmL Нт «see. TriH scmd Щшт\SCMD ^p >& Js. ЧН f__^
li iJffi СеТЬ|РХ Клиент в режиме Сеть [i] i
\Щ \Щ совместимости в режиме \Ш\ Щ]
шЯШЬт шЯШЁт СОВМеСТИМОСТИ иЛИЙи -Я£.
i i 1 [ы!
т ' 1 ' ' ^ BHlCSsi
Сеть IPX ,, «aese
Ejfa pnii Чистый клиент IPX
н и
Рис. 24.1. Варианты установки IP/IPX в NetWare 5
Что необходимо знать перед установкой
При установке NetWare 5 и NetWare 6 с поддержкой TCP/IP вам будет
предложено ввести стандартный IP-адрес сервера. В память загружаются оба стека,
TCP/IP и IPX, но к сетевой плате привязывается только стек TCP/IP. Стек IPX
обеспечивает нормальную работу приложений, написанных для IPX, а также дает
возможность Novell Migration Agent обслуживать пользователей,
подключающихся из сетей IPX.
Установка NetWare 5 и NetWare 6 для IPX
В малых (и даже некоторых средних) сетях протокол IPX по-прежнему остается
вполне достойным решением. Административные затраты на организацию и
сопровождение малой сети IPX гораздо ниже, чем для сети TCP/IP аналогичного
масштаба. В NetWare используется механизм динамических обновлений,
избавляющий от многих хлопот по администрированию IPX. В частности,
администратор может без труда добавить новые устройства и сетевые сегменты.
Достаточно включить имя нового устройства в локальный файл AUTOEXEC.NCF, а все
остальное сделает сервер. Широковещательные обновления IPX, происходящие
через каждые 60 секунд, распространяют по всем серверам и маршрутизаторам
сети информацию, на основании которой они обновляют свои внутренние
таблицы и узнают о том, как связаться с новым устройством.
Вся эта информация требует дополнительных ресурсов. С ростом количества
подключений увеличиваются и затраты ресурсов на обновления. По этой
причине в очень больших сетях TCP/IP бесспорно обеспечивает более высокую
эффективность. Тем не менее при более скромных потребностях стоит подумать,
нужно ли отказываться от IPX.
Разумеется, сервер NetWare 5 и NetWare 6, установленный в режиме IPX,
эффективно и без лишних преобразований обменивается данными с другими
серверами и клиентами IPX. Кроме того, он может (хотя и менее эффективно)
взаимодействовать с серверами и клиентами TCP/IP при содействии Novell
Migration Agent (подробности см. ниже).
Что необходимо знать перед установкой
Если будет выбран вариант установки «только для IPX», вам будет предложено
выбрать для сервера внутренний IPX-адрес, как это требовалось в NetWare 3.x
и NetWare 4.x.
Смешанная установка IPX/IP
Novell уже давно занимается решениями, позволяющими организовать обмен
данными TCP и IPX в одной сети. Любой администратор, сталкивавшийся с
непростой задачей управления смешанными сетями, убедится в том, что в NetWare 5
и NetWare 6 эта задача заметно упростилась.
Серверы и клиенты NetWare 5 и NetWare 6, установленные в смешанном
варианте IP/IPX, могут взаимодействовать по любому из протоколов. Такой
подход позволяет серверу с NetWare 5 или NetWare 6 свободно обмениваться
сообщениями с любым нормально настроенным сервером или клиентом IP или IPX.
На сервере также могут выполняться приложения, написанные для IPX.
Смешанную установку усложняет тот факт, что пользователи получают
большую свободу выбора в отношении схем адресации IP и IPX, поддерживаемых
их сетями. Как и следует ожидать, увеличение количества вариантов приводит
к возрастанию затрат. Из-за этого многие сетевые администраторы
устанавливают только те средства, которые с наибольшей вероятностью будут регулярно
использоваться в их сетях.
При попытках установить связь между двумя смешанными серверами
NetWare 5 или NetWare 6, настроенных разными людьми в разное время, неизбежно
возникают проблемы. Например, трудности могут возникнуть при пересылке
сообщений от одного IP-клиента NetWare, настроенного на использование
«чистой» схемы адресации IP, на другой сервер, соединенный с клиентами NetWare,
признающими только адресацию IPX. Подобные расхождения легко исправляются
утилитой Migration Agent, входящей в комплект поставки NetWare 5 и NetWare 6.
Migration Agent автоматически преобразует межпротокольный обмен данными
по мере необходимости. Применение Migration Agent не приводит к
дополнительным затратам ресурсов. Ключом к эффективной установке является
конфигурация сети, которая включает все регулярно используемые средства, а
относительно редкие преобразования IP/IPX перенаправляются вспомогательным
компонентам типа Migration Agent.
Что необходимо знать перед установкой
Если в процессе установки будет выбран вариант с одновременной
поддержкой IP и IPX, система настраивается на использование подключений NCP через
стек TCP/IP или стек IPX. Для сервера необходимо задать внутренний адрес
IPX и стандартный IP-адрес.
Средства, упрощающие переход на IP
Фирма Novell хорошо понимает, что переход с IPX на TCP/IP для большой части
пользователей окажется достаточно серьезным шагом. Она постаралась по
возможности упростить эту задачу, включив в NetWare 5 и NetWare 6
многочисленные средства преобразования и миграции. Некоторые из них представляют
собой обновленные версии средств, существовавших ранее. Например, служба
NDS была переработана так, что теперь она может отслеживать ресурсы TCP/IP
наряду с ресурсами IPX. Область действия NDS была расширена за счет
создания связей между NDS и другими стандартными средствами IP, входящими
в поставку NetWare. К их числу относятся реализации DNS, DDNS и DHCP,
разработанные Novell. Протокол SLP также был переработан для среды NetWare
IP/IPX. Наконец, режим совместимости и Migration Agent поддерживают
функции, обеспечивающие оперативные преобразования между IPX и TCP/IP.
NDS
NDS (NetWare Directory Service) — глобальная каталоговая служба с
возможностью расширения. Она предоставляет в распоряжение сетевого администратора
центральную консоль для просмотра и управления всевозможными сетевыми
ресурсами, распределенными в одной сети или в смешанном конгломерате сетей
NT/2000, NetWare и Unix, объединенных в глобальную сеть. База данных NDS,
впервые появившаяся в NetWare 4, содержит полную информацию обо всех поль-
зователях, объектах и других ресурсах, находящихся в ее ведении. В NetWare 5
область действия NDS была расширена так, что теперь NDS позволяет
управлять смешанными наборами устройств и сеансов IP и IPX.
DNS
Служба DNS обычно используется для сопоставления пользовательских имен
систем с уникальными адресами в сетях IP или в Интернете. Сервер DNS в
NetWare может быть объединен с другим (разработанным не в NetWare) сервером
DNS в качестве основного или вторичного. Предусмотрены средства
организации двустороннего обмена данными между основным и вторичным серверами.
Возможность подобной пересылки информации существенно снижает стоимость
реализации NetWare 5 в больших корпоративных сетях.
DHCP
Протокол DHCP (Dynamic Host Configuration Protocol) автоматически
назначает и отслеживает IP-адреса, а также другие параметры конфигурации сетевых
устройств. Параметры DHCP могут задаваться на уровне предприятия, подсети
или клиента. Например, вы можете задать промежуток времени, в течение
которого клиентам DHCP будет разрешено использовать некоторый IP-адрес.
Частое перераспределение ресурсов IP помогает освободить неиспользуемые ресурсы
и тем самым обеспечить использование ограниченного пула IP-адресов большим
числом клиентов.
DDNS
Служба DDNS (Dynamic DNS) в NetWare 5 и NetWare 6 помогает
координировать функции реализаций DNS и DNCP в Novell. Например, DDNS оперативно
обновляет информацию DNS в соответствии с изменениями адресов,
произведенными через DHCP. Служба DHCP в NetWare также предоставляет
клиентам конфигурационные данные NDS, включая начальный контекст, имя сервера
NDS и т. д.
SLP
На смешанных серверах IP/IPX NetWare 5 и NetWare 6 используют
стандартный протокол Интернета SLP (Service Location Protocol) для распространения
информации о структуре сети. Протокол SLP не занимается разрешением имен,
как DNS или NDS. Он предназначен для передачи информации о серверах NDS,
серверах DNS, серверах DHCP, серверах регистрации NDPS и шлюзах разных
протоколов.
Протокол SLP совместим со службами и приложениями SAP (старый агент
Novell для распространения информации об IPX). В «чистых» сетях IP, не
требующих обратной совместимости, поддержка SLP не обязательна. Сети IPX могут
продолжать использовать SAP; возможно, SLP им не понадобится.
Режим совместимости
Режим совместимости предоставляет поддержку IPX тогда, когда в ней
возникнет потребность в «чистых» сетях NetWare 5 и NetWare 6. Для этого
дейтаграммы IPX инкапсулируются в стеке UDP, чтобы их можно было пересылать в
сетях TCP/IP, а запросы RIP и SAP обрабатываются при помощи SLP.
Клиентские и серверные драйверы режима совместимости устанавливаются
автоматически при «чистой» IP-установке NetWare 5 и NetWare 6. Когда режим
совместимости не используется, его драйверы (модуль SCMD.NLM) находятся
в пассивном ожидании, не оказывая воздействия на сетевой обмен данными.
Инкапсуляция выполняется только тогда, когда возникает необходимость в
поддержке IPX. Весь трафик, не требующий поддержки IPX, автоматически
передается через IP без инкапсуляции.
Режим совместимости хорош прежде всего тем, что он позволяет организовать
поэтапный переход на IP. Вы можете выбрать нужный темп перехода, точно зная,
что режим совместимости исправит все возникающие расхождения в протоколах.
Драйверы режима совместимости начинают работать в тот момент, когда любой
из подключенных клиентов или серверов захочет передать данные протокола IPX
через канал, предназначенный для обмена данными TCP/IP. Например, это
может произойти при поступлении на вход брандмауэра сообщения в формате
IPX, которое должно быть доставлено пользователю в сети IP. Режим
совместимости также может обеспечивать поддержку магистральной передачи данных —
например, две сети IPX, не связанные друг с другом напрямую, могут
обмениваться информацией через IP-сеть. Режим совместимости также поддерживает
работу со службами Bindery NetWare 3.x.
Migration Agent
Migration Agent решает две основные задачи: преобразование между IP и IPX и
создание «моста» между старыми и новыми службами распространения сетевой
информации (SLP и SAP в NetWare 4).
Необходимость в Migration Agent возникает только тогда, когда вам
потребуется связать две разнородные логические структуры IP и IPX. Migration Agent
обеспечивает эмуляцию, позволяющую семейству протоколов IPX общаться с
миром IP, и заменяет пакеты SAP и RIP для клиентов IPX. На основании адресов
IP и IPX и маршрутной информации, содержащейся в пакетах IPX, Migration
Agent пересылает каждый пакет в соответствующую конечную точку.
Серверы NetWare 5 и NetWare 6, установленные с поддержкой Migration
Agent, могут общаться напрямую с любой системой независимо от того, какой
вариант установки был выбран для этой системы. Кроме того, они
обеспечивают маршрутизацию сетевого трафика между системами IP и IPX.
Стратегии перехода
Вероятно, для большинства пользователей оптимальным вариантом окажется
постепенный переход, возможный благодаря стремлению Novell по поддержке
существующих сетей IPX. Тем не менее появление систем NetWare 5 и NetWare 6,
построенных на базе инфраструктуры «чистого IP», лишний раз доказывает, что
дни IPX сочтены, а TCP/IP быстро занимает ведущее положение даже в мире
сетей NetWare. Теперь перед пользователями NetWare возникает другой вопрос:
с какой скоростью переходить на TCP/IP? К счастью, Novell предоставляет
достаточно богатый выбор вариантов. Переход может осуществляться постепенно
или одним мощным рывком. Главное — заранее обдумать стратегию перехода.
Тестовая платформа
Не проводите эксперименты с переходом в сети, выполняющей жизненно
важные функции. Большинство сетей Novell в результате постепенного развития
превратилось в комбинацию старых и новых программных и аппаратных средств,
в которой трудно разобраться одному человеку. Решение проблем перехода в
рабочей сети — неудачная мысль. Использование тестовой платформы избавит вас
от многих проблем. Симптомы «ухода от IPX» лучше изолировать и вылечить
в лабораторных условиях, не давая им распространиться на пользователей,
занимающихся важными делами. Тестирование рекомендуется начать с установки
NetWare в режиме «чистого IP» (без установки стека IPX). Посмотрите, как
ваши старые приложения будут работать без модификаций или после установки
бесплатных или недорогих обновлений. Попробуйте запустить неработающие
приложения на тестовой платформе, установленной в смешанном режиме IPX/IP.
Возможные сценарии перехода
Если на тестовой платформе IP все работает нормально, скорее всего, вы
предпочтете вариант резкого и полного перехода на IP. Но обычно дело обстоит
подобным образом только в небольших сетях, потребности которых
ограничиваются организацией простого совместного доступа к файлам и принтерам.
Более крупные сети лучше переводить на IP медленно и постепенно. Следует
выявить небольшие сегменты сети, которые могут работать автономно.
Например, в одном из вариантов переход начинается с вывода трафика IPX из сетевой
магистрали и его заменой на IP. Такой подход хорош тем, что магистральный
трафик избавлен от влияния специфических приложений IPX и переход обычно
производится относительно легко.
Магистральный IP-канал может соединять серверы на базе IPX; для этого
необходимо лишь чтобы во всех точках соприкосновения сегментов IP с IPX был
установлен Novell Migration Agent. Migration Agent выполняет инкапсуляцию
и прочие преобразования данных, необходимые для пересылки сообщений IPX
по каналам IP. Если повезет, перевод магистрали на IP приведет к существенному
снижению административных затрат, связанных с поддержанием магистрального
трафика IPX, и создаст условия для перевода следующего сегмента на IP.
Другая стратегия может заключаться в переводе на IP тех сегментов сети,
которые в наибольшей степени выиграют от этого — например, интернет-сервера
вашей компании. Отчет о достигнутых успехах станет лишним доводом в пользу
перехода на IP. Недостатком такого подхода можно считать то, что он не влияет
на работу магистрального канала, поэтому темпы снижения административных
издержек будут не столь впечатляющими.
Самый трудный этап перехода связан с настройкой сети IP для запуска
старых IPX-приложений. Хотя NetWare 5 и NetWare 6 спроектированы так, что
все базовые протоколы могут обслуживаться на уровне IP, многие старые
приложения напрямую записывают данные IPX или используют старые технологии
IPX (такие, как SAP и Novell Bindery). Такие приложения необходимо по
возможности заменить новыми версиями, написанными с учетом поддержки IP.
К сожалению, многие полезные унаследованные приложения жестко привязаны
к IPX и не существуют в версиях с поддержкой IP. Обычно такие программы
работают в режиме совместимости с IPX, но следует помнить, что режим
совместимости сопряжен с некоторым снижением эффективности. Например, работа
драйверов режима совместимости требует правильной настройки
инфраструктуры SLP, а на это требуется время. С другой стороны, протокол SLP является
интернет-стандартом, который играет все более важную роль; чем больше
приложений будет пользоваться предоставляемыми им услугами, тем больше
практической пользы он принесет.
Итоги
Глава начинается с рассмотрения различных режимов работы серверов NetWare
на базе IPX (NetWare 3.x и 4.x) в мире, быстро переходящем на протокол IP. Во
второй части, посвященной NetWare 5 и NetWare 6, обсуждаются механизмы
перевода сетей NetWare 3.x и 4.x, работающих на базе IPX, на «чистый»
протокол IP в NetWare 5 и 6. Также описаны вспомогательные средства фирмы Novell,
обеспечивающие взаимодействие между сетями IP и IPX. В частности,
рассматриваются некоторые компоненты и служебные программы, включенные в комплект
поставки NetWare 5 и NetWare 6, упрощающие переход на IP. Глава завершается
описанием некоторых стратегий, которые могут применяться при переходе от
IPX к IP.
2ЩГ Настройка TCP/IP
Э в системе Linux
Тим Паркер (Tim Parker)
Linux — популярная, свободно распространяемая версия Unix, создававшаяся
для систем на базе Intel. Позднее система Linux была адаптирована для других
платформ, включая SPARC, Alpha, Motorola 6800, Power PC, ARM, Hitachi
SuperH, ISM S/390, MIPS, HPPA-RISC, Intel IA-64, DEC-VAX, AMD x86-64
и для других архитектур.
Система Linux состоит из центрального компонента (ядра), системных
программ и приложений. Ядро Linux находится под управлением Линуса Торвальдса
и небольшой группы программистов. Тем не менее существует много разных
вариантов поставки Linux, использующих стандартное ядро Linux, но
различающихся по составу системных и прикладных программ. Ядро Linux ориентировано
на соответствие спецификациям POSIX и SUS (Single Unix Specification). Многие
системные программы создавались в рамках проекта GNU, который породил
немало самых качественных программ в истории — и притом распространяемых
с открытыми исходными текстами. Дополнительную информацию о
распространении программ с открытыми исходными текстами можно найти на сайте
http://www.eff.org и других сайтах аналогичной направленности.
Поскольку система Linux принадлежит к семейству Unix, она может
выполнять функции клиента и сервера в системах TCP/IP.
В этой главе мы не будем вдаваться в подробное описание операционной
системы Linux, а ограничимся методикой настройки компьютера с системой Linux
в роли клиента и сервера в сетях TCP/IP, а также предоставлением поддержки
РРР и SLIP.
В примерах этой главы используется поставка Slackware Linux на компакт-
диске. Впрочем, описанная процедура подойдет и для RedHat, и для многих
других поставок. Предполагается, что на вашем компьютере уже установлена
система Linux с сетевыми компонентами.
ПРИМЕЧАНИЕ
Система Linux обладает бесконечными возможностями настройки; некоторые поставки также
различаются по составу устанавливаемых и автоматически запускаемых служб. Ядру Linux присваивается
номер версии — например, 2.0, 2.2, 2.4 и т. д. Первая цифра обозначает принципиальные
изменения по сравнению с предыдущей версией, а вторая — второстепенные модификации. Четными
значениями дополнительного номера версии обозначаются стабильные версии ядра Linux.
ПРИМЕЧАНИЕ
Нечетные значения дополнительного номера обозначают версии ядра с экспериментальными
возможностями, которые еще не прошли полное тестирование. Следовательно, ядра версий 2.1 и 2.3
являются «экспериментальными». Применять экспериментальные версии ядра в среде реальной
эксплуатации обычно не рекомендуется.
Последние версии ядра Linux можно загрузить с сайта http://www.kernel.org и с его зеркальных
сайтов.
В различных поставках (RedHat, Debian, Mandrake, Slackware и т. д.) ядро Linux дополняется
системными программами, приложениями и сценариями запуска. В частности, поставки различаются
и по механизмам добавления и настройки этих дополнительных программ. Например, RedHat 7.0
использует ядро Linux версии 2.2, тогда как в RedHat 7.2 используется ядро версии 2.4.
Подготовка системы к настройке TCP/IP
Прежде чем переходить к настройке TCP/IP в системе Linux, следует
выполнить ряд дополнительных проверок и обеспечить выполнение всех требований.
Сначала необходимо убедиться в том, что в системе были установлены сетевые
компоненты. Пакет сетевой поддержки устанавливается из программы установки
системы (рис. 25.1). В категории Networking устанавливаются приложения,
необходимые для использования TCP/IP в Linux.
ПРИМЕЧАНИЕ
В других поставках (прежде всего, в RedHat) имеются графические программы, упрощающие
установку Linux для новичков.
Вероятно, после установки сетевых компонентов систему придется
перезагрузить.
Д^^^ИДВ^^ИнёТйогкЛпд (TCP/IP, UUCP, flail, Неи7ТДДДДДДцДД^Д|Д
Рис. 25.1. Выбор сетевых компонентов в программе установки Linux
В некоторых версиях Linux (в первую очередь использующих ядро 2.0 и
многие последующие версии) для нормального функционирования сети необходима
файловая система /proc. В большинстве версий ядра Linux с интегрированной
сетевой поддержкой файловая система /ргос автоматически создается при
установке операционной системы, поэтому вам останется лишь убедиться в том, что
она правильно монтируется ядром (файловая система /ргос обеспечивает простой
интерфейс для получения сетевых данных ядром, а также используется ядром
для хранения служебных таблиц, обычно находящихся в каталоге /proc/net).
Чтобы убедиться в том, что в вашей версии Linux используется файловая
система /ргос, попробуйте перейти в каталог /ргос командой cd /ргос. Результат
выполнения команды показан на рис. 25.2.
merlin:~# cd /proc
merlin:/proc# Is
1/ 46/ 73/ 80/ kcore pci
174/ 49/ 74/ cpuinfo kmsg self/
24/ 51/ 75/ devices ksyms stat
38/ 55/ 76/ dma loadavg uptime
40/ 6/ 77/ filesystems meminfo versions
42/ II 78/ interrupts module
44/ 72/ 79/ ioports net/
merlin:/proc#
Рис. 25.2. Если вам удалось перейти в каталог /ргос и получить список его содержимого,
значит, файловая система готова к настройке TCP/IP
Если перейти в каталог /ргос не удается, скорее всего, он не существует
(предполагается, что у вас имеются соответствующие права доступа). Если файловая
система /ргос не была создана автоматически в процессе установки Linux, вам
придется построить ядро заново с поддержкой /ргос. Перейдите в каталог с
исходными текстами Linux (например, /usr/src/Linux) и запустите процедуру
конфигурации ядра командой
make config
Если в системе работает среда X Window, можно запустить графическую
программу конфигурации:
make xconfig
На вопрос о поддержке procfs ответьте положительно. Если программа
конфигурации не задает вопросов о поддержке /ргос, а каталог /ргос не создается
в файловой системе, обновите ядро до версии с поддержкой сети.
Файловая система /ргос должна монтироваться автоматически при загрузке
системы Linux. Если этого не происходит, отредактируйте файл /etc/fstab и
включите в него строку вида
none /proc proc defaults
Перед настройкой TCP/IP также следует задать имя хоста. Задача решается
командой вида
hostname имя
где имя — имя, назначаемое локальному компьютеру. Если у компьютера имеется
полное доменное имя, вы можете задать его в своей системе. Например, если
компьютер с системой Linux spinnaker входит в домен yacht.com, полное
доменное имя задается командой
hostname spinnaker.yacht.com
Убедитесь в том, что в файле /etc/hosts появилась запись с именем хоста.
Также необходимо заранее узнать уникальный IP-адрес, назначенный
компьютеру. Эта информация будет использоваться в процессе конфигурации.
Если вы собираетесь передавать информацию в нескольких сетях, возможно,
вам также придется отредактировать файл /etc/networks. В этом файле хранится
список всех имен и IP-адресов сетей, которые должны быть известны вашему
компьютеру. Приложения используют этот файл для определения адресов сетей
по их именам. Записи файла /etc/networks состоят из двух полей: символического
имени удаленной сети и ее IP-адреса. Многие файлы /etc/networks содержат
по крайней мере одну запись для адреса обратной связи, который должен
присутствовать в каждой установке Linux (адрес обратной связи используется по
умолчанию некоторыми приложениями Linux, подробности будут приведены
ниже). Примерный файл /etc/networks выглядит так:
Toopback 127.0.0.0
merlin-net 147.154.12.0
BNR 47.0.0.0
В приведенном фрагменте определяются имена и IP-адреса двух сетей. В этих
адресах указывается только сетевая часть IP-адреса, а хостовая часть
заполняется нулями.
Доступ к сетевому интерфейсу
На следующем этапе необходимо предоставить операционной системе доступ
к сетевому интерфейсу и его вспомогательным средствам. Задача решается при
помощи команды ifconfig. Команда ifconfig организует работу сетевого уровня
ядра с сетевым интерфейсом, для чего передает ядру IP-адрес и выдает команду
активизации интерфейса. Активный интерфейс может использоваться ядром
для приема и передачи данных.
Для компьютера необходимо настроить ряд интерфейсов, в том числе
интерфейс обратной связи и интерфейс Ethernet (впрочем, вместо Ethernet могут
использоваться и другие интерфейсы). Команда ifconfig последовательно
выполняется для всех сетевых интерфейсов. Синтаксис команды ifconfig выглядит так:
ifconfig тип_интерфейса ip_aflpec
где тип_интерфейса — имя драйвера устройства интерфейса (например, 1о для
интерфейса обратной связи, ррр для РРР или eth для Ethernet). В поле ip_adpec
указывается IP-адрес, используемый данным интерфейсом.
После выполнения команды ifconfig и активизации интерфейса
воспользуйтесь командой route для добавления или удаления маршрутов из таблицы мар-
шрутизации ядра. Это необходимо для того, чтобы локальный компьютер мог
находить другие компьютеры в сети. Синтаксис команды route:
route add|del 1р_адрес
Аргумент add или del используется для включения или удаления маршрута
из таблицы маршрутизации ядра, а аргумент гр_адрес определяет маршрут.
Чтобы отобразить текущее содержимое таблицы маршрутизации ядра,
введите команду route без аргументов. Например, если в системе установлен только
драйвер обратной связи, результаты выполнения этой команды будут
выглядеть так:
$ route
Kernel Routing Table
Destination Gateway Genmask Flags MSS Window Use Iface
loopback * 255.0.0.0 U 1936 0 16 lo
ПРИМЕЧАНИЕ
Таблица маршрутизации также отображается командой
netstat -rn
Ключ -г является признаком вывода таблицы маршрутизации, а ключ -п означает, что вместо
символических имен должны отображаться IP-адреса.
Нас интересуют, прежде всего, поля с именем приемника (в данном случае
loopback), маска (Genmask) и интерфейс (Iface, в нашем примере — /dev/lo). Чтобы
вместо символических имен отображались IP-адреса, передайте команде ключ -п:
$ route -n
Kernel Routing Table
Destination Gateway Genmask Flags MSS Window Use Iface
127.0.0.1 * 255.0.0.0 U 1936 0 16 lo
Как упоминалось выше, типичная сетевая конфигурация Linux содержит
интерфейс обратной связи (который должен присутствовать на любом хосте) и
сетевой интерфейс — например, Ethernet.
Настройка интерфейса обратной связи
Интерфейс обратной связи должен присутствовать на любом компьютере. Он
используется некоторыми приложениями, для правильной работы которых
необходим IP-адрес (а если в системе Linux не настроена сетевая поддержка, этого
адреса может не быть). Драйвер обратной связи также используется в
диагностических целях некоторыми приложениями TCP/IP. Интерфейс обратной связи
ассоциируется с IP-адресом 127.0.0.1, поэтому файл /etc/hosts должен содержать
запись для этого интерфейса.
ПРИМЕЧАНИЕ
Для обратной связи может использоваться любой адрес вида 127.х.х.х, где х — число от 0 до 255.
По историческим причинам обычно выбирается адрес 127.0.0.1 — формат, в котором адрес
обратной связи задавался в файле /etc/hosts в семействе Unix.
Драйвер обратной связи может быть создан ядром в процессе установки,
поэтому поищите в файле /etc/hosts строку вида
localhost 127.0.0.1
Если такая строка существует, значит, драйвер обратной связи уже
установлен и вы можете переходить к интерфейсу Ethernet. Если у вас возникнут
сомнения насчет файла /etc/hosts, воспользуйтесь утилитой ipconfig для вывода
информации о драйвере обратной связи. Введите команду
ifconfig lo
На экране должны появиться несколько строк с информацией. Если вы
получите сообщение об ошибке, драйвер обратной связи не существует.
Если запись интерфейса обратной связи отсутствует в файле /etc/hosts,
создайте ее при помощи ifconfig. Следующая команда включает необходимую строку
в файл /etc/hosts:
ifconfig lo 127.0.0.1
Просмотрите подробную информацию о только что созданном драйвере
обратной связи. Следующая команда выводит типичную конфигурацию драйвера
обратной связи:
$ ifconfig lo
lo Link encap: Local Loopback
inet addr 127.0.0.1 Beast {NONE SET} Mask 255.0.0.0
UP BROADCAST LOOPBACK RUNNING MTU 2000 Metric 1
RX packets:© errors:© dropped:© overruns:©
TX packets:© errors:© dropped:© overruns:©
Если информация о драйвере обратной связи присутствует в выходных
данных команды Ifconfig, значит, с этим интерфейсом все в порядке. После проверки
драйвер обратной связи включается в таблицы маршрутизации ядра одной из
следующих команд:
route add 127.0.0.1
route add localhost
Подойдет любая из двух команд. Чтобы быстро проверить правильность
настройки драйвера обратной связи, воспользуйтесь утилитой ping. Введите
следующую команду:
ping localhost
Результат выглядит примерно так:
PING localhost: 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0. 111=255 time=l ms
64 bytes from 127.0.0.1: icmp_seq=l. ttl=255 time=l ms
64 bytes from 127.0.0.1: icmp_seq=2. ttl=255 time=l ms
64 bytes from 127.0.0.1: icmp_seq=3. ttl=255 time=l ms
64 bytes from 127.0.0.1: icmp_seq=4. ttl=255 time=l ms
64 bytes from 127.0.0.1: icmp_seq=5. ttl=255 time=l ms
64 bytes from 127.0.0.1: icmp_seq=6. ttl=255 time=l ms
64 bytes from 127.0.0.1: icmp_seq=7. ttl=255 time=l ms
лс
localhost PING Statistics
7 packets transmitted, 7 packets received, 0% packet loss
round-trip (ms) min/avg/max = 1/1/1
Выполнение утилиты ping было прервано нажатием клавиш Ctrl+C Если вы
не получите от ping никаких результатов, значит, имя localhost не опознано
системой. Проверьте содержимое конфигурационных файлов и запись маршрута,
затем повторите попытку.
Настройка интерфейса Ethernet
Процедура настройки драйвера Ethernet аналогична описанной выше. Сначала
утилита ifconfig передает информацию об интерфейсе ядру, затем в таблицу
маршрутизации включаются маршруты к удаленным компьютерам сети. Если
компьютер подключен к сети, подключение можно немедленно проверить при
помощи утилиты ping.
Интерфейс активизируется командой ifconfig, которой передается имя
устройства Ethernet (обычно ethO) и IP-адрес компьютера. Например, следующая
команда настраивает интерфейс Ethernet с IP-адресом 147.123.20.1:
ifconfig eth0 147.123.20.1
Задавать маску сети не нужно, поскольку ifconfig вычислит правильное
значение по IP-адресу. Если вы предпочитаете задать маску сети в явном виде,
включите ее в командную строку с ключевым словом netmask:
ifconfig ethO 147.123.20.1 netmask 255.255.255.0
Для проверки введите команду ifconfig с именем интерфейса Ethernet:
$ ifconfig eth0
eth0 Link encap 10Mps: Ethernet Hwaddr
inet addr 147.123.20.1 Beast 147.123.1.255 Mask 255.255.255.0
UP BROADCAST RUNNING MTU 1500 Metric 1
RX packets:© errors:0 dropped:© overruns:©
TX packets:© errors:0 dropped:© overruns:©
Обратите внимание: адрес широковещательной рассылки задается на
основании IP-адреса локального компьютера. Он используется TCP/IP для
одновременного обращения ко всем машинам локальной сети. Параметру MTU (Maximum
Transfer Unit) обычно присваивается максимальное значение 1500 (для сетей
Ethernet).
Далее необходимо добавить в таблицы маршрутизации ядра запись, которая
сообщит ядру сетевой адрес локального компьютера. Для этого в команде route
указывается адрес сети в целом, без локального идентификатора. Адрес всей
локальной сети задается с ключом -net. Для IP-адресов из приведенного выше
примера команда выглядит так:
route add -net 147.123.20.0
Все узлы локальной сети, определяемой сетевым адресом 147.123.20,
добавляются в список доступных компьютеров, поддерживаемый ядром. Без опреде-
ления сетевого адреса вам пришлось бы вручную вводить IP-адреса всех
компьютеров в сети.
Альтернативное решение основано на использовании файла /etc/networks для
задания сетевых частей IP-адресов. Файл /etc/networks содержит список имен
сетей и их IP-адресов. Например, если в нем присутствует запись сети с именем
foobar_net, то включение всей сети в таблицы маршрутизации выполняется
командой
route add foobar_net
Впрочем, решение с файлом /etc/networks создает проблемы безопасности —
доступ предоставляется ко всем компьютерам сети. В некоторых ситуациях это
может оказаться нежелательным.
После того как маршрут будет включен в таблицу маршрутизации ядра,
проверьте работу интерфейса Ethernet. Чтобы проверить связь с другим компьютером
при помощи утилиты ping (естественно, при наличии связи по кабелю Ethernet),
необходимо знать его IP-адрес или имя, которое разрешается по файлу /etc/hosts
или службами типа DNS. Команда и результат ее работы выглядят так:
tpci_scol-45> ping 142.12.130.12
PING 142.12.130.12: 64 data bytes
64 bytes from 142.12.130.12: icmp_seq=0. time=20. ms
64 bytes from 142.12.130.12: icmp_seq=l. time=10. ms
64 bytes from 142.12.130.12: icmp_seq=2. time=10. ms
64 bytes from 142.12.130.12: icmp_seq=3. time=20. ms
64 bytes from 142.12.130.12: icmp_seq=4. time=10. ms
64 bytes from 142.12.130.12: icmp_seq=5. time=10. ms
64 bytes from 142.12.130.12: icmp_seq=6. time=10. ms
AC
142.12.130.12 PING Statistics
7 packets transmitted, 7 packets received, 0% packet loss
round-trip (ms) min/avg/max = 10/12/20
Если удаленный компьютер не отвечает, убедитесь в том, что он правильно
подключен и использует указанный IP-адрес. Если все нормально, проверьте
правильность конфигурационных файлов и команд route. Если и это не
поможет, попробуйте опросить другой компьютер.
После настройки интерфейса ваш компьютер с системой Linux сможет
обратиться к любому компьютеру локальной сети через TCP/IP. Если вы работаете
в малой сети, ничего больше делать не придется. В больших сетях, а также при
использовании специальных протоколов и при наличии шлюзов необходимо
выполнить ряд дополнительных действий по настройке. Все эти действия будут
описаны ниже.
Если вы хотите разрешить доступ к компьютеру с системой Linux с других
компьютеров, входящих в сеть TCP/IP, внесите их имена и IP-адреса в файл
/etc/hosts. На рис. 25.3 приведен пример файла /etc/hosts с сокращенными и
полными именами (например, godzilla и godzilla.tcpi.com) и IP-адресами. Эти
компьютеры, работающие под управлением любой операционной системы с
поддержкой TCP/IP, теперь смогут подключиться к вашей системе Linux при помощи
telnet, ftp или другой аналогичной программы. Разумеется, это произойдет только
в том случае, если вы создали на своем компьютере учетную запись для
удаленного пользователя. Если имя удаленного компьютера присутствует в файле /etc/hosts,
вы также сможете связаться с ним по имени или IP-адресу при помощи
программ типа telnet или ftp.
merlin:/etc# cat hosts
#
# hosts This file describes a number of hostname-to-address
# mappings for the TCP/IP subsystem. It is mostly
# used at boot time, when no name servers are running.
# On small systems, this file can be used instead of a
|# "named" name server. Just add the names, addresses.
# and any aliases to this file...
# By the way, Arnt Gulbrandsen <agulbra@nvg.unit.no> says that 127.0.0.1
# should NEVER be named with the name of the machine. It causes problems
# for some (stupid) programs, ire and reputedly talk. :A)
#
# For loopbacking.
127.0.0.1 localhost
147.120.0.1 merlin.tpci.com merlin
147.120.0.2 pepper pepper.tcpi.com
147.120.0.3 megan megan.tcpi.com
147.120.0.4 godzilla godzilla.tcpi.com
# End of hosts,
merlin:/etc#
Рис. 25.3. Файл /etc/hosts позволяет удаленным компьютерам подключаться к серверу Linux
Служба имен
Простейшее преобразование символических имен в IP-адреса в Linux
осуществляется при помощи файла /etc/hosts. Например, если в команде указано имя
компьютера darkstar, TCP/IP просмотрит файл /etc/hosts, найдет это имя и затем
прочитает соответствующий ему IP-адрес. Если поиск окажется неудачным,
связаться с компьютером не удастся.
Но если вы работаете в большой сети, связь приходится устанавливать с
многими компьютерами. Включение информации об этих компьютерах в файл /etc/
hosts становится утомительным и сложным делом, а модификация этих файлов
при изменении структуры сети приносит еще больше хлопот. Впрочем, в тех
редких случаях, когда ваш компьютер связывается с десятком других машин,
файла /etc/hosts вполне достаточно.
Для решения общей проблемы преобразования имен удаленных компьютеров
в IP-адреса была разработана служба BIND (Berkeley Internet Name Domain),
которая позднее превратилась в DNS. В большинстве поставок Linux реализована
служба BIND, хотя уже появилось несколько версий с поддержкой DNS. BIND
и DNS — сложные темы, отягощенные множеством технических деталей,
которые не представляют особого интереса для многих пользователей Linux. Если
в вашей сети уже имеется сервер DNS или вы будете пользоваться сервером DNS
поставщика услуг Интернета, производить настройку BIND не нужно. Тем не
менее в системе необходимо по крайней мере ввести данные сервера DNS,
поскольку перечисление всех хостов в файле /etc/hosts — дело крайне утомительное.
Клиент DNS называется резольвером (resolver); в случае Linux он
представляет собой набор библиотечных процедур, которые вызываются при запросе на
разрешение имен через DNS. Конфигурация резольвера определяется в файле
/etc/resolv.conf.
В типичном варианте этот файл состоит из директив search и nameserver.
Директива search имеет следующий формат:
search домен! домен2 доменИ
Аргументы домен1, домен2 и доменЫ заменяются доменными суффиксами,
которые присоединяются резольвером к имени хоста, не заданного в форме
полностью определенного доменного имени (FQDN). В качестве примера
рассмотрим следующую директиву search:
search xyz.com us.xyz.com europe.xyz.com
Имена вида www.abc.com уже находятся в формате FQDN — за именем хоста
www следует полное имя домена abc.com. В этом случае директива search не
используется. Но если службе TCP/IP будет передано неполное имя www, в
соответствии с директивой search сначала будет сделана попытка разрешить его
в виде www.xyz.com, затем — в виде www.us.xyz.com и www.europe.xyz.com. Если
хотя бы одно из этих имен будет правильно разрешено, остальные варианты не
проверяются.
Сервер DNS, используемый сервером имен, задается директивой nameserver:
nameserver 1р_адрес
Аргумент ipjadpec определяет IP-адрес сервера DNS. Например, если
первому серверу DNS назначен IP-адрес 199.231.13.10, то директива будет
выглядеть так:
nameserver 199.231.13.10
Файл resolv.conf определяет до трех серверов DNS, каждый из которых задается
отдельной директивой nameserver. Например, если IP-адреса второго и третьего
сервера DNS равны 199.231.13.20 199.231.13.15, то полный набор директив с
именами серверов выглядит так:
nameserver 199.231.13.10
nameserver 199.231.13.20
nameserver 199.231.13.15
Ниже приведен окончательный вариант файла /etc/resolv/conf в нашем примере:
search xyz.com us.xyz.com europe.xyz.com
nameserver 199.231.13.10
nameserver 199.231.13.20
nameserver 199.231.13.15
Вы также можете указать, в каком порядке должно производиться
разрешение имен — должен ли резольвер сначала просматривать файл /etc/hosts, а затем
обращаться к серверу DNS, или наоборот. Порядок разрешения определяется
в файле /etc/nsswitch.conf.
В больших системах, а также для предоставления компьютеру с системой
Linux полного доступа к службам Интернета необходимо правильно настроить
службу BIND. К счастью, настройка BIND обычно выполняется только один
раз, после чего о ней можно забыть. Вам понадобится программное обеспечение
BIND, которое обычно входит в поставку системы. Пакет BIND содержит все
конфигурационные и исполняемые файлы, а также руководство оператора BIND
с информацией о настройке файлов базы данных BIND.
Шлюзы
Объединение двух и более локальных сетей производится при помощи шлюзов.
Шлюзом (gateway) называется компьютер, который обеспечивает связь между
сетями и маршрутизирует данные между ними на основании IP-адреса
получателя. Если локальный компьютер будет использовать шлюз (или использоваться
в качестве шлюза, вам придется внести ряд изменений в сетевые
конфигурационные файлы.
Чтобы использовать другой компьютер как шлюз, необходимо внести в
таблицы маршрутизации сведения о шлюзе и тех сетях, к которым он подключен.
Простейший вариант использования шлюза — подключение к глобальной
внешней сети (например, к Интернету). Для этого используется команда route
следующего вида:
route add default gw шлюз
где шлюз — имя компьютера локальной сети, выполняющего функции шлюза.
Ключевое слово default означает, что через этот шлюз можно связаться с любой
сетью, и этот факт должен быть отражен в таблицах маршрутизации ядра.
Если шлюз настраивается для связи с другой локальной сетью, имя этого
шлюза должно храниться в файле /etc/networks. Например, если шлюзовый
компьютер с именем gate_serv связывает вашу локальную сеть с соседней сетью big_corp
(и в файле /etc/networks существует запись с IP-адресом сети big_corp), то
настройка таблиц маршрутизации на локальном компьютере, обеспечивающая
доступ к big_corp через gate_serv, производится следующей командой:
route add big_corp gw gate_serv
В таблице маршрутизации удаленной сети должна присутствовать запись
с адресом вашей сети; в противном случае вы сможете только отправлять
данные, но не получать их.
Если сам.локальный компьютер должен выполнять функции шлюза, следует
ввести информацию о соединяемых сетевых подключениях. Обычно это некая
комбинация двух сетевых плат, подключений РРР или SLIP. Предположим,
ваш компьютер будет выполнять функции простого шлюза между сетями small_
net и big_net и на компьютере установлены два адаптера Ethernet. Интерфейсы
Ethernet настраиваются по отдельности с соответствующими сетевыми 1Р-адре-
сами (например, в сети big_net шлюзовому компьютеру может быть присвоен
IP-адрес 163.12.34.36, а в сети small__net он обладает адресом 147.123.12.1).
Чтобы упростить разрешение имен, включите два сетевых адреса в файл
/etc/hosts. Для упомянутых выше сетей и IP-адресов файл /etc/hosts будет
содержать следующие записи:
163.12.34.36 merlin.big_net.com merlin-ifacel
147.123.12.1 merlin.small_net.com merlin-iface2
В данном примере файла /etc/hosts приведены полностью определенные
доменные имена (предполагается, что в каждой сети шлюзу присвоено имя merlin,
что вполне допустимо). Также возможно использование сокращенных имен
(merlin, merljn.big_.net и т. д.). Для удобства в записи также включены имена
интерфейсов (то есть merlin-ifacel — первый интерфейс на компьютере merlin,
a merlin-iface2 — второй).
Далее команда ifconfig связывает интерфейсы Ethernet с именами, указанными
в файле /etc/hosts:
ifconfig ethO merlin-ifacel
ifconfig ethl merlin-iface2
Предполагается, что адаптер Ethernet /dev/ethO подключен к сети big_net, а
адаптер /dev/ethl подключен к сети smalijiet.
Остается лишь обновить таблицы маршрутизации ядра и включить в них имена
сетей. В нашем примере для этой цели используются следующие команды:
route add big_net
route add small_net
После завершения всех перечисленных действий компьютер может
использоваться компьютерами, входящими в любую из соединяемых сетей, в качестве
межсетевого шлюза.
Графические программы настройки
сетевых интерфейсов
В предыдущем разделе было показано, как происходит настройка сетевых
интерфейсов в режиме командной строки. Обычно при запуске системы Linux
вам не придется выполнять эти команды, поскольку они выполняются
автоматически в стартовых сценариях Linux. Стартовые сценарии представляют
собой сценарии командного интерпретатора bash и различаются в зависимости от
поставки. В одних поставках (например, в Slackware) используются стартовые
сценарии в стиле BSD Unix, в других (таких, как RedHat) — стартовые
сценарии в стиле System VR4. Содержимое стартовых сценариев зависит от поставки,
но даже в разных версиях одной поставки стартовые сценарии иногда радикально
отличаются друг от друга.
Во многие поставки включены графические программы, упрощающие процедуру
настройки сети. Эти программы автоматически вносят изменения в системные
стартовые сценарии Linux и включают в них соответствующие параметры TCP/IP.
Ниже рассматривается процедура настройки TCP/IP в Linux с
использованием графических программ netcfg и linuxconf.
Программа netcfg
Программа netcfg стала одним из первых графических инструментов настройки
Linux. Запустите программу netcfg в режиме командной строки и исследуйте
ее структуру. На рис. 25.4 изображено начальное меню netcfg. Программа может
использоваться для настройки имен, хостов, интерфейсов и маршрутов.
1 -^^^ •; Nsy j
|L;Wames:;i Hosts Interfaces Routing I
I Hostname: . [itreei Itreexom . •::X'; ^.™™^._^_^
I Domain: ptree,com .-j- ■■-»**^^.-«ш.-^J;.^.u.. ^,.
J Search for hostnames in additional domains: jj
I • - ' ••.'••:•:.:••'••■•••:•; Лщ
j Hameservers: f^TJOO г?^- '■ " ~" ■•?^-г:Ж:-™""Я
204.147 80.1 fl j
1 III
1 j 1 \>л Ы
Save I Quit J i
Рис. 25.4. Графическая программа netcfg
Программа linuxconf
Программа linuxconf, обладающая исключительно мощными возможностями,
предназначена для настройки сети и выполнения большинства операций по
администрированию системы. Время, потраченное на освоение этой программы, не
пропадет — вы сможете быстро выполнять как повседневные, так и довольно
сложные операции. Запустите linuxconf из командной строки. В программах
рабочего стола X-Window (таких, как KDE или GNOME) программа linuxconf
может входить в одну из программных групп; в этом случае программу можно
выбрать и запустить мышью. На рис. 25.5 изображено исходное окно linuxconf.
Чтобы изменить имена хостов, раскройте ветвь дерева Config ► Networking ►
Client Tasks ► Basic host information (рис. 25.6).
Настройка резольвера производится в ветви Config ► Networking ► Client Tasks ►
Name server specification (DNS) (рис. 25.7).
г-—~^ : ^ г3^<~|
.JEh-Config С;
У Вт Networking I г I
| [ф—Client tasks г
§1 [—Basic host information H
I И— Name server specification (DNS) 1 I
I ф-Routing and gateways j I
I I I—Set Defaults ! •
|] M—Set other routes to networks J *
I U-Set other routes to hosts 1 i I
|| [—Set routes to alternate locai nets j, I
I M—Configure the routed daemon I . I
M [—Host name search path I I
h] [—Network Information System (NIS) !..! I
I [—IPX interface setup j • I
I Lppp/SLIP/PLIP Г ^
| ф-Server tasks I \
И I—Exported file systems (NFS) \,[
i И—IP aliases for virtual hosts 1 : I
I EH Apache Web server j
H I Ill-Defaults I/**
Quit 1 AcyChan9e$ I Help |
Рис. 25.5. Графическая программа linuxconf
ЮЙшИпд Fj ™*** basic con^on]
Ш №-Client tasks I You ar* allowed to control the parameters
, П-Basic host information j -^^ are ^ t0 m h0§t and ^m
У [-Name server specrficat.on (DNS) to its «am connection to the local network
Ш-Routing and gateways H _:,..:.:... I
I Tl—Set Defaults | . if I i I
I U-Set other routes to networks ; p :Ho$t name | Adaptor! |2j3J4| M
[—Set other routes to hosts I : r—— II
Uset routes to alternate local nets '. :,Hostname jltree1.lUee.corn
I—Configure the routed daemon I : j I
\~ Host name search path : II
\-Network Information System (NIS) I • --. I I
U-IPX interface setup I | j I
I Lppp/sLiP/PUP l : N
ф-Server tasks I 1 I
|—Exported file systems (NFS) 11
H UIP aliases for virtual hosts . j \ I
S-Apache Web server • II
I—Defaults : II
1—Virtual domains j I I
i [— Sub-directory specs , ^,:v |
• I I—Files specs ; •;.'•_':■':.' II
N [-Modules .• \.[„/. ' —m!,,,,,,,,",m!!!,",,,!!!'M\,\,M,,,,,!!:!!!!!':!,!!!!!!!',!!!""!,"!\',,,,,\;,!,,l"".,i |
^-Performance [ ! 1 J i I
.! M-mod_SS| configuration j Accept) Cancel] Help]
И I |r*l~nnmsin N.ar»\P Sorwer <Г\ЫЪ\ j/ - I
Quit | Act/Changes | Help |
Рис. 25.6. Основная информация о хостах в программе linuxconf
Чтобы настроить основной шлюз, раскройте ветвь Config ► Networking ► Client
Tasks ► Routing and gateways ► Set Defaults (рис. 25.8).
I l^Nerwarklna I• •Pils.lfl0$tb^° configuralioft .Revolver configuration >;:::::
j в-Client tasks = you can specify which name server will be used Г
I I- Basic host information •.. to resQ|v host, numljef Usj ^ DNS j5
J-Name server specification (DNS) i t0 hand)e mis on a TCP/IP ne^K The others
. (^Routing and gateways U; are the local/etc/hosts tile
:j П-Set Defaults \ : . (see "information about other hosts" menu
;] П-Set other routes to networks I . or the NIS system
1 k-Set other routes to hosts '
::j П-Host name search path L | . i default domain | it
■j U Network Information System (NIS) j "!.tP of name server 1 J204.147.80.5 — i
I] UIPX Interface setup f : i I
;] I—ppp/SLIP/PLIP •: I tP Of name Server 2 (Opt) J204.147.80 Л I
[•] B-Server tasks ; • i IP of name server 3 (opt) J i j
T U Exported file systems (NFS) j j seafch domaJn 1 ■ ■ rj^^; . j.
•1 I—IP aliases for virtual hosts [: ;■ !_______ _ - Г j
; гк-Apache Web server • | search domain 2 (opt) -| ; I
:•] I-Defaults Mi search domain 3 (opt) | '[
I h-Virtual domains I ; , ^ . , „ \ : j 1
Esub-directory specs ; . |,$earch *»**4 <0^ ■!
И [-Files specs i' • | search domain S (opt) | i I
::J [-Modules ; | search domain 6 (opt) [j I 1
И [—Performance j '.:":::.:.::..::...:::..■...: . ...':...■.■..:.: ..Mi.r.t.:. I
j I—mod ssl configuration I I л j Л »J ,. , j I
■ i-DomaTn Name Server (DNS) 'j *cc***\ Cancel] Jjelpj ::.,:, Г _ j
Quit) AcvChanges j Help | J
Рис. 25.7. Настройка разрешения имен в программе linuxconf
I] Вт Networking И' i I
[;. \т- Client tasks . Enter foe IP number of the main gateway
У m-Basic host information . And indicate If this machine Is allowed to
N [-Name server specification (DNS) : route ip packets \\
::| в-Routing and gateways \\ -.:".л .':., '.-..-.•: 1
J hSet Defaults : ; 0вйЛщ gateway h44.19.74.254] I ^
I [—Set other routes to networks : 3 1 ■ <—' j
J П-Set other routes to hosts \ J Enable routing
M—Set routes to alternate local nets : I
•1 M-Configure the routed daemon ; Accept | Cancel | Help j
: И—Host name search path : —*«—J __i |
II U Network Information System (NIS) : j
I i,p* interface setup : 1
I j L_ PPP/SLIP/PLIP \
II в-Server tasks .; I
t] T|— Exported file systems (NFS) . I
[i M—IP aliases for virtual hosts : j
HI в-Apache Web server [:: j
I T \~Defaults : I
hi p Virtual domains : I
1 [—Sub-directory specs ; j
ij [-Files specs \ \ 11
N [—Modules : I
Г [—Performance :. 11
I L-mod_ssl configuration j ! I
ij в-Domain Name Server (DNS) :j II
pi I ITrh r™^ I/; >
Quit | Act/Changes j Help j I
Рис. 25.8. Настройка основного шлюза в программе linuxconf
Чтобы задать порядок действий при разрешении имен, раскройте ветвь Config ►
Networking ► Client Tasks ► Host name search path (рис. 25.9).
iJ^NrtSorklng И ДЩ1Ш1^ N*** ****?****** \^y I
I й-Client tasks Jlvi You «lust tell th$$y$»mti» which ordw
\ ^-Basic host information I Jj; :v.^:^0UJ name «еМее*гошШ probed : ; |
I M—Name server specification (DNS) j |; ...v^•:••:.; : I
^Routing and gateways ЦI. -9>* «ЯП /ete/ho$t$ I* pfOtoxT <
U ГI . 1 . ♦ . -. Pi ''&$&**** ** N«*brk IntormaUdn Syrstem •,: •.
| m-Set other routes to networks Щ^Йй'!^
•1 и—Set other routes to hosts p ■■ :t J
1 1 '—Configure the routed daemon |^;";чфу;;...лл.::.:..:......,:.:....;...:. •..:........:. •....;.•:..«...-. j j
If h-Host name search path | Ы;• :Щу Ш%, NIS, dn* • v !*>«*, NJS v hosts, dn$, NJS : j
H II [-Network Information System (NIS) pr-tei;::-,' 7 . ! I
| UlPX Interface setup КГЙК^?^^С> ''-г'*-**?*--:.: , v: ^ ^ host*, dM \"\\
Ц Ш-ppp/sup/PUP fehlfevws/fwflt'•; •".•: v Nis#da*, ho«fr 'vN!S/dh» :. :
M \m-Server tasks Щ|^МЖ::;Р':;-Ж--.•'•':':': "■" •:*: i
W Jl-Exporled file systems (NFS) ft;J#$#*&-:' ■■"^ ' .:• V«.b^t*. / v *•,**•: :> |: •
I J- IP aliases for virtual hosts j|[; >1р^"<Ц; N15, ho$t* . >,dn$,NIS . . : ^ dn* | j
LI ShApache Web server ||:!/:Ж^;^;.;1,.:.^л. ,...:..::...: :.-л*...-л.-...; «.;...,..- ! j j
LI [-Sub-directory specs fe?-'^€ii^::5:'i'V.!;:-- II
hi rFiles specs Ш'-ШШ^УА '' II
I r~Modu,BS Ы\' -ШШу^
I I Pen*ormance М^^!^:-й:':-'-:
H mod_ssl configuration f||f ЖЖ-".: v-':'.:
N MP"DomaJn Name Server (DNS) Kj .Й:.^4.:-:^ I
Guttj AcVChanges| и»» | :'Щ)^-\/ I
Рис. 25.9. Определение последовательности поиска при разрешении имен в программе linuxconf
Программа linuxconf даже позволяет настроить BIND — для этого следует
раскрыть ветвь Config ► Networking ► Server Tasks ► Domain Name Server (DNS) ► Config
(рис. 25.10). Тем не менее, если вы намерены серьезно освоить настройку BIND,
вам придется изучить синтаксис стартового файла BIND (/etc/named.boot для
BIND 4 и /etc/named.conf для BIND 8 и 9) и синтаксис файлов зонных данных
и научиться напрямую редактировать эти файлы.
Настройка SLIP и РРР
Настройка протоколов SLIP (Serial Line Internet Protocol) и РРР (Point-to-Point
Protocol) выполняется после общей настройки TCP/IP, рассмотренной в
предыдущем разделе. Протоколы SLIP и РРР работают по модему; сначала с удаленной
системой устанавливается модемная связь, а затем на базе установленного
соединения начинает работать протокол SLIP или РРР. Вы можете настроить SLIP и РРР
во время общей настройки файлов TCP/IP или отложить настройку до того
момента, когда потребуется организовать доступ SLIP или РРР для пользователей.
Поддержка SLIP и РРР задействована не во всех установках, хотя многие
поставщики услуг Интернета используют ее для организации доступа из малых систем.
Щ I I I I—Set routes to alternate locat nets Щ\ primaries! I
щ L-Configure the routed daemon { ! i I
kj [—Host name search path j j= You are allowed to ediVadd/remave primaries I
A UNetworK information System (WIS) I i I I
: П-IPX Interface setup : Select [Add) to define a new pnmary
Щ L-ppp/sLlP/PLIP j.j; -::p-..::-.::..A.i?- - :
j;j в-Server tasks Ui':^i-": ^m?'ft:. Revision date Revision count • . . 1
Щ [[-Exported file systems (NFS) И; л "jt^aro I - I 2 Г
[I Ь- IP aliases for virtual hosts \{\ •: s .'...jl.'. V..'..1..1.1:"..'.■.'■. ..'/v.'1 ч'::::..: ■.?...= j
•1 В-Apache Web server \ ] ■■',.{■ ж.. i ,, , < I
H U-Dttoih K;-^_2!SLI J522J
|| U Virtual domains II::.;.:х.::.л ,:::.:.. . I]
II к-Sub-directory specs щ\••'•••,: I
H r"p,l6S8Pecs "l^r- I
Я [-Modules ||:;j J
•I U-Performance 1-4 . I
II L—mod_ssl configuration I < II
Щ B-Domain Name ServBr (DNS) 1=1: I
Fl Тф-Conflg ,fjl: . .11
•1 T |~ Configure domains lp|: I
\i\ I— Configure IP reverse mappings |-Si .... 1
fcl I— Configure secondaries F\ " I
:.] i- Configure forward zones ьЛ]. -I
•1 N— Configure forwarders l{\ ..,-.... ]
rl r-Configure features [If: :-'::'\!';'." I
p;j M—Configure IP allocation space [e;!:.: ё- =•' I
H ф-Add/Edit M^','-^,, '.'• j
К Quit| AcyChangesl H»ip| V I
Рис. 25.10. Настройка BIND в программе linuxconf
Настройка фиктивного интерфейса
Фиктивный интерфейс предоставляет вашему компьютеру IP-адрес, с которым
он может работать при использовании только интерфейсов SLIP и РРР.
Фиктивный интерфейс решает проблему автономного компьютера, единственным
действительным IP-адресом которого является адрес драйвера обратной связи
A27.0.0.1). Хотя протоколы SLIP и РРР связывают компьютер с внешним
миром, в то время пока интерфейс не активен, у компьютера нет внутреннего
IP-адреса, который мог бы использоваться приложениями.
Создать фиктивный интерфейс несложно. Если в файле /etc/hosts вашему
компьютеру уже назначен IP-адрес, от вас потребуется лишь настроить
интерфейс и создать маршрут. Задача решается следующими командами:
ifconfig dummy имя_хоста
route add имя__хоста
где имя_хоста — имя локального компьютера. В результате выполнения этих
команд создается ссылка на IP-адрес самого компьютера. Если в файле /etc/hosts
еще нет записи с IP-адресом вашего компьютера, создайте ее перед созданием
фиктивного интерфейса. Добавьте строку и укажите в ней имя компьютера,
псевдонимы и IP-адрес:
147.120.0.34 merlin merlin.tpci.com
Настройка SLIP
Протокол SLIP используется многими поставщиками услуг Интернета,
применяющими модемную связь, а также при организации связи с другими
компьютерами. После установления модемной связи SLIP управляет дальнейшим ходом
сеанса. Драйвер SLIP обычно настраивается как часть ядра. Драйвер SLIP для
Linux также обеспечивает поддержку CSLIP — сжатой версии SLIP,
поддерживаемой некоторыми реализациями. Обычно драйвер SLIP встраивается в ядро
Linux по умолчанию, но в некоторых версиях Linux необходимо построить ядро
заново и ответить положительно на вопрос об использовании SLIP и CSLIP.
Протокол CSLIP может использоваться только в том случае, если он
поддерживается на обоих концах соединения. Многие поставщики услуг Интернета
поддерживают как SLIP, так и CSLIP, но вопрос о поддержке CSLIP следует
выяснить заранее. CSLIP передает в пакетах больше полезной информации, чем SLIP,
что повышает фактическую скорость обмена данными.
В системе Linux под протокол SLIP выделяется последовательный порт,
который не может использоваться для других целей. Программа SLIPDISC управляет
портом SLIP и блокирует попытки его использования другими приложениями.
В простейшем способе выделения порта для SLIP используется программа
slattach. В качестве аргумента ей передается имя устройства
последовательного порта. Например, чтобы выделить под SLIP второй последовательный порт
(/dev/cual), введите команду
slattach /dev/cual &
Знак & означает, что команда должна выполняться в фоновом режиме. Если
этого не сделать, терминал или консоль, с которой была введена команда, не
сможет использоваться до завершения процесса. Команда slattach может
выполняться в стартовом сценарии.
После успешного выделения порт связывается с первым устройством SLIP
/dev/slO. По умолчанию большинство систем Linux разрешает использование CSLIP
в порте SLIP. Если вы захотите переопределить этот режим, включите в команду
ключ -р и имя slip:
slattach -p slip /dev/cual &
Убедитесь в том, что на обоих концах соединения используется одна и та же
форма SLIP. Например, вы не сможете настроить порт на CSLIP и
обмениваться данными с другим компьютером, настроенным на поддержку SLIP. Если
версии SLIP не совпадают, попытки выполнения команд типа ping завершаются
неудачей.
После настройки последовательного порта на использование SLIP сетевой
интерфейс настраивается так же, как при обычных сетевых подключениях.
Например, если ваш компьютер merlin подключается к системе с именем arthur,
введите следующие команды:
ifconfig s!0 merlin-slip pointtopoint arthur
route add arthur
Команда ifconfig настраивает интерфейс merlin-slip (локальный адрес
интерфейса SLIP) для соединения класса «точка-точка» с системой arthur. Rjvfylf route
включает удаленный компьютер arthur в таблицы маршрутизации. Кроме того,
при помощи команды route можно назначить arthur основным шлюзом:
route add default gw arthur
Если порт SLIP будет использоваться для доступа к Интернету, он должен
иметь IP-адрес и запись в файле /etc/hosts.
После выполнения команд ifconfig и route проверьте, как работает канал SLIP.
Если в будущем потребуется исключить интерфейс SLIP из системы, удалите
запись из таблицы маршрутизации, отключите интерфейс SLIP командой ifconfig
и завершите процесс slattach. Первые два действия выполняются следующими
командами:
route del arthur
ifconfig sl0 slO down
Чтобы завершить процесс slattach, определите его идентификатор (PID) при
помощи команды ps и введите команду kill.
В некоторые версии Linux входит утилита dip (Dial-up IP), которая помогает
автоматизировать перечисленные действия, а также предоставляет
интерпретируемый язык для линии SLIP. В настоящее время существует много версий dip.
Настройка РРР
Протокол РРР по своим возможностям превосходит SLIP. Обычно
предпочтение отдается именно этому протоколу, если только он поддерживается
соединением. В Linux функции РРР делятся на две части: протокол HDLC (High-level
Data Link Control) помогает определить правила пересылки дейтаграмм РРР
между двумя компьютерами, а демон РРР pppd управляет работой протокола
после того, как система HDLC установит параметры связи. Кроме того, в Linux
используется программа chat, которая вызывает удаленную систему. Как и в
случае с протоколом SLIP, сначала между двумя компьютерами устанавливается
модемная связь, а затем управление линией передается протоколу РРР.
Для оптимизации защиты протокол РРР желательно использовать со
специальной учетной записью пользователя. Вообще говоря, это не обязательно, и
протокол РРР может использоваться с любой учетной записью, но для повышения
уровня безопасности следует создать в системе учетную запись пользователя РРР.
Сначала данные нового пользователя включаются в файл /etc/passwd. Примерная
запись /etc/passwd для учетной записи РРР (с UID=201 и GID=51) выглядит так:
ррр:*:201:51:РРР account:/tmp:/etc/ppp/pppscript
В приведенном примере учетная запись создается без пароля. Создавать файлы
не нужно, поэтому пользователю РРР назначается домашний каталог /tmp. В
качестве стартового сценария указывается файл /etc/ppp/pppscript, который
выглядит примерно так:
#!/bin/sh
mesg n
stty -echo
exec pppd-detach silent modem crtscts
Первая строка обеспечивает выполнение сценария в командном
интерпретаторе Bourne. Вторая строка подавляет все попытки записи на терминал учетной
записи РРР. Команда stty отключает эхо-вывод. Наконец, команда exec запускает
демона pppd, управляющего всем трафиком РРР. Демон ррр и параметры его
запуска рассматриваются ниже.
Чтобы протокол РРР мог получить управление, с удаленным компьютером
необходимо предварительно установить связь по модему. Существует несколько
программ для решения этой задачи; на практике чаще всего используется chat.
Для работы программы chat необходимо составить командную строку,
которая управляет взаимодействием с модемом и подключением к удаленной системе.
Например, следующая команда устанавливает связь с удаленным компьютером
через Hayes-совместимый модем (с использованием набора команд AT) по
номеру 555-1234:
chat "" ATZ OK ATDT5551234 CONNECT "" ogin: ppp word: secretl
Команды задаются в формате «запрос-ответ»: сначала вы указываете, какие
данные должны поступить от удаленного компьютера, а затем — какие данные
отправляются в ответ. Сценарий chat всегда начинается с пустой строки,
поскольку без получения команды никакие данные от модема не поступят. После
«получения» пустой строки мы выдаем команду ATZ (сброс), ожидаем ответа
«ОК» (признак успешного выполнения команды) и затем передаем команду
набора номера. При получении сообщения «CONNECT» выполняется сценарий
входа в удаленную систему. Мы отправляем «пустой символ», ожидаем
приглашения ogin:, передаем имя ррр, ожидаем приглашения word: и передаем пароль.
После завершения процедуры входа программа chat завершается, оставляя
линию открытой.
ПРИМЕЧАНИЕ
Почему вместо обычных слов «login» и «password» в сценарии используются «ogin» и «word»?
Прежде всего из-за возможных различий в регистре символов приглашения удаленной системы,
чтобы «login» и «Login» интерпретировались одинаково. Сокращение слова «password» допускает
потерю некоторых символов без зависания сеанса.
Если другая сторона подключения после ответа модема не запускает
сценарий входа в систему, можно «встряхнуть» ее командой BREAK:
chat -v "" ATZ OK ATDT5551234 CONNECT ""
ogin:-BREAK-ogin: ppp word: secretl
Сеанс РРР открывается запуском демона pppd. Демон запускается после
установления модемной связи и регистрации на удаленном компьютере с
данными учетной записи РРР. Если на локальном компьютере для подключения
РРР используется устройство /dev/cual на скорости 38 400 бод, то демон pppd
запускается командой
pppd /dev/cual 38400 crtscts defaultroute
Команда приказывает ядру Linux переключить интерфейс /dev/cual на РРР
и установить связь IP с удаленным компьютером. Аргумент crtscts, обычно ис-
пользуемый для всех подключений РРР на скорости свыше 9600 бод,
переключается на аппаратное подтверждение установления связи.
Поскольку перед запуском pppd необходимо установить связь программой
chat, вызов chat при желании можно включить в командную строку pppd. При
этом сценарий chat желательно загружать из файла (ключ -f). В этом случае
команда запуска pppd может выглядеть так:
pppd connect "chat -f chat_fileH /dev/cual 38400
-detach crtscts modem defaultroute
Файл chatjlle содержит следующую строку:
и" ATZ OK ATDT5551234 CONNECT "" ogin: ppp word: secretl
Кроме заключенного в кавычки вызова chat в глаза бросаются еще несколько
параметров. Параметр connect определяет сценарий подключения, с которого
должна начаться работа pppd, а ключ -detach указывает, что демон pppd не
отсоединяется от консоли. Ключевое слово modem означает, что демон pppd
должен следить за состоянием порта модема (на случай преждевременного разрыва
связи) и дать отбой после завершения сеанса.
Сначала демон pppd согласовывает параметры подключения с удаленным
компьютером и обменивается IP-адресами. Затем он настраивает сетевой
уровень ядра Linux на Интернет /dev/pppO (если это первый активный канал РРР
на компьютере). Наконец, pppd заносит в таблицу маршрутизации ядра ссылку
на компьютер, находящийся на другом конце канала РРР.
У демона pppd имеются и параметры, файлы и процедуры аутентификации,
которые могут потребоваться при подключении к некоторым удаленным
системам. Подробное описание заняло бы слишком много места, поэтому за
дополнительной информацией читателю следует обратиться к специализированной
литературе.
Итоги
После выполнения всех действий, описанных в этой главе, на вашем
компьютере будет успешно настроена поддержка TCP/IP. Теперь компьютер с системой
Linux сможет выполнять функции клиента при подключении к другим
компьютерам TCP/IP или предоставлять им доступ в роли сервера. В этой главе также
кратко рассматривались РРР и SLIP — модемные протоколы, используемые
при подключении к Интернету.
*Э 4% Whois и Finger
Нил С. Джеймисон (Neal S.Jamison)
Для упрощения поиска информации в Интернете были созданы многочисленные
поисковые системы, метапоисковые системы, интеллектуальные агенты и т. д.
Тем не менее количество пользователей, хостов и доменов постоянно растет
и найти информацию о них становится все сложнее. На помощь приходят два
протокола TCP/IP прикладного уровня: Whois и Finger. Протокол Whois
используется для получения информации о хостах и доменах, а протокол Finger
предназначен для поиска информации о конкретных людях. Оба протокола будут
подробно рассмотрены в этой главе.
Протокол Whois
Whois — служба и протокол TCP/IP для получения информации о хостах и
доменах Интернета. Протокол Whois, задуманный как «белые страницы»
Интернета, использовался (а в отдельных случаях — продолжает использоваться) в
сочетании с большими базами данных кадров. Однако из-за стремительного роста
Интернета поддерживать такие базы данных стало невозможно, поэтому сейчас
информация Whois ограничивается хостами и доменами. В наши дни
популярные базы данных Whois содержат сведения о контактных лицах хостов и
доменов, организациях и адресах. Данные Whois также используются при
регистрации доменов для проверки того, не был ли домен с таким именем создан ранее.
Протокол Whois работает на хорошо известном порте TCP с номером 43, а его
спецификация приводится в RFC 954. Дополнительная информация о Whois
и родственном протоколе Finger приводится в следующих RFC:
О RFC 2167 - «Referral Whois (RWhois) Protocol V1.5», S. Williamson, M. Kosters,
D. Blacka, J. Singh, K. Zeistra, июнь 1997.
О RFC 1834 — «Whois and Network Information Lookup Service, Whois++»,
J. Gargano, K. Weiss, 1995.
О RFC 1835 - «Architecture of the WHOIS++ service», P. Deutsch, R. Schoultz,
P. Faltstrom, C. Weider, 1995.
О RFC 1913 - «Architecture of the Whois++ Index Service», C. Weider, J. Full-
ton& S. Spero, 1996.
О RFC 1914 - «How to Interact with a Whois++ Mesh», P. Faltstrom, R. Schoultz
& С Weider, 1996.
О RFC 1288 — «The Finger User Information Protocol», D.Zimmerman, 1991.
Регистрация имен в Интернете
Регистрация имен в Интернете иногда сопряжена с определенными сложностями,
поскольку ни одна организация не обладает полным контролем над Интернетом
(дополнительная информация об основных организациях, выполняющих
административные функции в Интернете, приведена в главе 2). Эта путаница
отразилась и на структуре традиционной службы Whois, поскольку каждый
регистратор поддерживает собственную базу данных.
ПРИМЕЧАНИЕ
Доменные имена Интернета имеют многоуровневую структуру. Самыми распространенными
доменами верхнего уровня являются домены .com, .edu, .gov, .mil, .net и .org. Также существуют домены
верхнего уровня для отдельных стран — us (США), са (Канада), nl (Нидерланды), de (Германия)
и int (международный домен — см. RFC 1591). Домены второго уровня уточняют домен верхнего
уровня — например, ibm.com, mit.edu, nasa.gov и army.mil. На третьем уровне логическое деление
продолжается — например, whois.nic.mil и www.internic.net.
Совет регистраторов CORE (Council of Registrars) также представил дополнительные домены
верхнего уровня, называемые родовыми доменами верхнего уровня:
.firm — коммерческие предприятия;
.shop — торговля;
.web — организации, деятельность которых связана с World Wide Web;
.arts — культура и досуг;
.гее — развлечения;
.info — информационные услуги;
.name — персоналии;
.biz — бизнес;
.tv — телевидение;
.coop — кооперативы;
.museum — музеи;
.pro — профессиональная деятельность (бухгалтеры, адвокаты, врачи);
.aero — воздушный транспорт.
За дополнительной информацией об этой инициативе обращайтесь на сайт http://www.icann.org/.
Информационный центр InterNIC (деятельность которого осуществляется
Network Solutions, Inc.) был основным регистратором доменов верхнего уровня
с 1993 года. Надзор за деятельностью InterNIC осуществляет Национальная
администрация в области телекоммуникаций и информации NTIA (National
Telecommunications and Information Administration), входящая в Министерство торговли.
Часть полномочий InterNIC была делегирована другим официальным
регистраторам — таким, как Информационный центр Министерства обороны или Азиатско-
Тихоокеанский информационый центр. Недавно были разработаны новые
инициативы, которые могут привести к дальнейшему дроблению полномочий NIC.
Одна из таких инициатив, известная как SRS (Shared Registry System), стремится
внести в процесс регистрации доменов элементы честной и открытой
конкуренции. Среди ведущих конкурентов следует отметить Register.com
(дополнительная информация приводится на сайте http://www.register.com).
Конечно, честная конкуренция и делегирование полномочий положительно
влияют на процессе регистрации, но они приводят к усложнению службы Whois.
Как упоминалось выше, каждый регистратор ведет собственную базу данных
зарегистрированных организаций. Например, база данных Whois центра InterNIC
не содержит информации о доменах, относящихся к Министерству обороны,
и наоборот. Из этого следует, что пользователь должен знать, какая база данных
с наибольшей вероятностью содержит искомую информацию, и адресовать свой
запрос этой базе данных.
ПРИМЕЧАНИЕ
InterNIC присваивает всем лицам, зарегистрированным в качестве доменных контактов,
неформальные имена.
Например, мне присвоили неформальное имя NJ1181. Запрос к базе данных Whois центра InterNIC
по этому имени выдает следующую информацию:
Jamison, Neal (NJ1181) jamisonn@ANVI.COM
AnviCom, Inc.
7921 Jones Branch Dr.
Suite G-10
McLean, VA 22102
Базы данных Whois
Информация Whois хранится в нескольких базах данных. Как упоминалось
выше, большинство крупных баз данных Whois содержит только информацию
о зарегистрированных хостах и доменах Интернета. Впрочем, некоторые базы
данных содержат более подробные сведения.
InterNIC
Основным источником информации о зарегистрированных доменах и хостах
в США является центр InterNIC (деятельность которого осуществляется
Network Solutions, Inc.). InterNIC обладает полномочиями для регистрации всех
доменов верхнего уровня в США, поэтому его база данных содержит информацию
об огромном количестве доменов.
За дополнительной информацией об InterNIC обращайтесь к главе 2 и на
сайт http://www.internic.net.
Сервер Whois InterNIC находится по адресу whois.internic.net.
Министерство обороны США
Информационный центр Министерства обороны (DoD) поддерживает
регистрационные данные всех хостов домена .mil. В настоящее время деятельность центра
осуществляется корпорацией Boeing. Дополнительная информация имеется на
сайте http://whois.nJc.mil.
Сервер Whois DoD находится по адресу whois.nic.mil.
Федеральное правительство США
Информационный центр Федерального правительства США поддерживает
регистрационные данные всех хостов доменов .gov и .fed. В настоящее время
деятельность центра осуществляется Администрацией общих служб GSA (General
Services Administration). За дополнительной информацией обращайтесь на сайт
http://whois.nic.gov.
Сервер Whois Федерального правительства США находится по адресу whois.
nic.gov.
RIPE
Дополнительная информация о Европейском координационном сетевом центре
RIPE (Reseaux IP Europeens) приведена на сайте http://www.ripe.net/.
Сервер Whois RIPE находится по адресу whois.ripe.net.
APNIC
APNIC (Asia Pacific Network Information Center) является регистратором в
Азиатско-Тихоокеанском регионе. За дополнительной информацией о APNIC
обращайтесь на сайт http://www.apnic.net/.
Сервер Whois APNIC находится по адресу whois.apnic.net.
Другие серверы Whois
В Интернете существует множество других баз данных Whois, содержащих
информацию о корпорациях, университетах и других организациях. Полный список
серверов Whois, собранный Мэттом Пауэром (Matt Power) из Массачусетсского
технологического института, размещается по адресу ftp://sipb.mit.edu/pub/whois/
whois-servers.list
Сервис Whois в Web
Хотя протокол и служба Whois появились гораздо раньше Web, для обращения
с запросами к базам данных Whois и поиска нужной информации был
разработан ряд web-интерфейсов.
Некоторые клиенты Whois на базе Web перечислены в табл. 26.1.
Таблица 26.1. Основные web-интерфейсы к Whois
База данных URL
InterNIC http://www.networksolutions.com/cgi-bJn/whois/whois/
IANA http://www.isi.edu:80/in-notes/usdnr/rwhois.html
RIPE (Европа) http://www.ripe.net/db/whois.html
APNIC (Азиатско-Тихоокеанский регион) http://www.apnic.net/apnic-bin/whois.pl
Министерство обороны США http://www.nic.mil/cgi-bin/whois
Правительство США http://www.nic.gov/cgi-bin/whois
Allwhois.com
При таком количестве баз данных иногда бывает трудно понять, где именно
следует искать информацию. Впрочем, иногда это неважно. В Web имеется сайт
с именем Allwhois.com (http://www.allwhois.com), позволяющий проводить
поиск одновременно во всех крупных базах данных Whois. Домашняя страница
Allwhois.com изображена на рис. 26.1.
I ^g^tew Mlttnnt.XC-г "-■-": N- * .WJI
дай» Alwttots » com тшлнж ц
|iim0miiiiiii|i|||||[|WiMii||||-]|||| | " :•••<:'-•. .. JW ■ K.ji
ИШШЩШЯ"Я th* mo9t complete whoii service on the internet |:|
I Afjjn-Pjoifie к.:; ^^ЩЦщщЩщ^^^ТддщЗщДЦ! ЯИЕиЯшЕшНЕцЩЁмШ Ш
\: iyourdomain ". ^Щ ^Ascension Island (ас) Щ,.• Я
ША ;j-'=- ■ = •'• ••■•• '•••>•:••$: J American Samoa (as) Щ- :...••• hi
I .usoomjinj ' |сот "'.'..-'."у 1Э8М1НЯМИИИИИИИвША*'^ |gj
тК™.. ^--/-1 :/:! lArgentina (ar) ^^^^ ... |J
ripe мое Valid Character: .:.;. iAustria (at) Щ
ip*.eutop.jr, •. Letters,Numbers.Dash"-*. ,•..;:? 1 Belgium (be)
"••!*; '• ШШ.сшМ*. ti&pf ftwgin '..% |вгагн(ь»)
M5^ iK^SifiOS . >:: jBritish Indian Ocean Territory (io)
.-У. .jCanada(ca) . M■■■■■■■'■
Ьмпшмпмиттгитг Enhanced to search аЛ corn/net/org
РШШУ Registrars! 4 Щ>Г ._ ..,.,,.:.:...::,...: J.;. • ' -
'•■'"•.'" Ш^::\'"."::' ^:^^рЖП#1 '
lfrfofcf'.ffln..nit. • Thi«M*rohw«l«rt<lh«>»h.oyd4Ul>att<«»tb«'"% . .. '"•'. .'.••. ]
jiu£* р*гисч1»»4««тц(л л|Т1» jutf 0>*p]«ytbe output ]
Д1Ыш1а13 p*rtk«iU*<J«*mift*jrr.t tht outputwffl <e1um
аК&ш ■.••»«•«•«••'-•«»*"•-. :, £3-V.
к*> ,Л output
uuisjiirftja . •• ..■.-...... .4..........
|&M£iil*l) . I Щ\
Afiau:ii»r»i4 •" I ""*] 1
Рис. 26.1. Домашняя страница Allwhois.com
Как будет показано ниже, для упрощения поиска также существует
специальное расширение службы Whois, называемое RWhois (Referral Whois).
Клиенты Whois режима командной строки
Хотя у клиентов Whois, работающих в режиме командной строки, появился
конкурент в лице Web, такие клиенты по-прежнему включаются в большинство
современных операционных систем и реализаций TCP/IP. В этом разделе
описана команда whois и ее разновидности.
Команда whois для Unix
Стандартным клиентом Whois для системы Unix является команда whois. Команда
имеет следующий синтаксис:
whois [-h хост] идентификатор
Параметры:
-h - сервер Whois
Некоторые метасимволы, находящиеся в начале идентификатора, позволяют
ограничить круг поиска. Например, чтобы поиск производился только по
именам, идентификатор должен начинаться с точки (.). В табл. 26.2 перечислены
допустимые метасимволы и их влияние на поиск. Идентификатор может
начинаться с нескольких метасимволов.
Таблица 26.2. Символы, используемые для ограничения поиска командой whois
Метасимвол Смысл
Поиск только по именам
! Поиск только по неформальным именам
* Поиск только по группам или организациям
Примеры использования символов управления поиском приводятся ниже
в разделе «Примеры».
fwhois
Fwhois (Finger Whois) — клиент Whois для систем BSD Unix, распространяемый
с открытыми текстами — был написан Крисом Каппучио (Chris Cappuccio).
Fwhois свободно распространяется в Интернете, и вы можете легко включить его
в свою систему. Команда fwhois имеет следующий синтаксис:
fwhois пользователь [@<сервер.whois>]
Примеры
В первом примере команда Unix whois используется для поиска по именам —
допустим, мы хотим найти человека с именем «neal» и фамилией «Jamison».
Если не указывать конкретный сервер Whois, по умолчанию whois ищет данные
в базе InterNIC. Выходные данные команды whois выглядят так:
% whois Jamison, n
[rs.internic.net]
The Data in Network Solutions' WHOIS database is provided by Network
Solutions for information purposes, and to assist persons in obtaining
information about or related to a domain name registration record.
Network Solutions does not guarantee its accuracy. By submitting a
WHOIS query, you agree that you will use this Data only for lawful
purposes and that, under no circumstances will you use this Data to:
A) allow, enable or otherwise support the transmission of mass
unsolicited, commercial advertising or solicitations via e-mail
(spam); or B) enable high-volume, automated, electronic processes
that apply to Network Solutions (or its systems). Network Solutions
reserves the right to modify these terms at any time. By submitting
this query, you agree to abide by this policy.
Jamison, Neal (NJ795) iamisonn@PATRIOT.NET
Jamison, Neal (NJ1181) jamisonn@ANVI.COM
To single out one record, look it up with "!xxx", where xxx is the
handle, shown in parenthesis following the name, which comes first.
Далее команда Unix whois позволяет выбрать ту запись, по которой вы хотите
получить дополнительную информацию. Обратите внимание на использование
метасимвола «!», экранированного символом «\», чтобы он не обрабатывался
командным интерпретатором Unix:
% whois \!NJU81
[rs.internic.net]
The Data in Network Solutions' WHOIS database is provided by Network
Solutions for information purposes, and to assist persons in obtaining
information about or related to a domain name registration record.
Network Solutions does not guarantee its accuracy. By submitting a
WHOIS query, you agree that you will use this Data only for lawful
purposes and that, under no circumstances will you use this Data to:
A) allow, enable or otherwise support the transmission of mass
unsolicited, commercial advertising or solicitations via e-mail
(spam); or B) enable high-volume, automated, electronic processes
that apply to Network Solutions (or its systems). Network Solutions
reserves the right to modify these terms at any time. By submitting
this query, you agree to abide by this policy.
Jamison, Neal (NJ1181) jamisonn@ANVI.COM
AnviCom, Inc.
7921 Jones Branch Dr.
Suite G-10
McLean, VA 22102
Record last updated on 20-Feb-99.
Database last updated on 20-Aug-99 04:31:00 EDT.
Так выглядит моя запись в базе данных InterNIC.
Аналогичный результат можно получить и при помощи команды fwhois. В
следующем примере мы запрашиваем информацию об известном агентстве NASA,
занимающемся космическими программами США:
% fwhois nasa.gov
[rs.internic.net]
The Data in Network Solutions' WHOIS database is provided by Network
Solutions for information purposes, and to assist persons in obtaining
information about or related to a domain name registration record.
Network Solutions does not guarantee its accuracy. By submitting a
WHOIS query, you agree that you will use this Data only for lawful
purposes and that, under no circumstances will you use this Data to:
A) allow, enable or otherwise support the transmission of mass
unsolicited, commercial advertising or solicitations via e-mail
(spam); or B) enable high-volume, automated, electronic processes
that apply to Network Solutions (or its systems). Network Solutions
reserves the right to modify these terms at any time. By submitting
this query, you agree to abide by this policy.
No match for "NASA.GOV".
Оказывается, в команде не был указан сервер Федерального правительства
США, на котором должен производиться поиск. Следующая попытка приводит
к желаемому результату:
% fwhois nasa.gov@whois.nic.gov
[nic.gov]
National Aeronautics and Space Administration (NASA-DOM)
NASA Marshall Space Flight Center
MSFC. AL 35812
Domain Name: NASA.GOV
Status: Active
Administrative Contact:
Pirani, Joseph L. (JLP1)
JOSEPH.PIRANI@MSFC.NASA.GOV
Domain servers in listed order:
E.ROOT-SERVERS.NET 192.203.230.10
NS1.J PL.NASA.GOV 137.78.160.9
NS.GSFC.NASA.GOV 128.183.10.134
MX.NSI.NASA.GOV 128.102.18.31
%
Whois на базе Telnet
Раньше на многих серверах Whois поддерживался интерфейс Telnet. Теперь при
попытке подключиться к серверу Whois Информационного центра Министерства
обороны (whois.nic.mil) выдается следующее сообщение:
% telnet whois.nic.mil
Trying 207.132.116.6...
Connected to is-l.nic.mil.
Escape character is ,A]'.
The telnet service to nic.mil has been discontinued.
For WHOIS usage, please use the online web form at
http://nic.mil.
On Unix platforms, you can also use the WHOIS client service,
included with most operating systems.
$ whois -h nic.mil 'keyword'
Connection closed by foreign host.
Впрочем, серверы Whois, доступные через Telnet, еще существуют. Один
из таких серверов находится по адресу whois.ripe.net. Пример использования
Telnet-интерфейса к Whois:
% telnet whois.ripe.net
Trying 193.0.0.200...
Connected to joshua.ripe.net.
Escape character is ,A]'.
* RIPE NCC
* Telnet-Whois interface to the RIPE Database
*
* Most frequently used keys are: IP address or prefix (classless).
* network name, persons last, first or complete name, NIC handle,
* and AS<number>.
* Use 'help' as key to get general help on the RIPE database.
* Contact <ripe-dbm@ripe.net> for further help or to report problems.
Enter search key [q to quit]:
Расширения Whois
Протокол и служба Whois предоставляют в распоряжение пользователя богатый
сервис для обращения к конкретным базам данных Whois с запросами
информации о зарегистрированных хостах, доменах, а в отдельных случаях — и людей.
Тем не менее у Whois есть свои недостатки. Например, иногда бывает трудно
выбрать правильную базу данных для запроса, что может существенно
усложнить поиск необходимой информации. Существует два протокола, являющихся
расширениями WHOIS++:
О RWhois (Referral Whois);
О WHOIS++.
Краткие описания этих протоколов приводятся ниже.
RWhois
Вследствие огромных размеров Интернета поддерживать единую базу данных
с информацией обо всех хостах, доменах и пользователях немыслимо. Чтобы
сократить размеры базы данных и сложность ее сопровождения до разумных
пределов, необходима децентрализация.
Каталоговый протокол и служба RWhois расширяют концепцию Whois для
передачи запроса любому количеству децентрализованных баз данных Whois.
В RWhois эта задача решается примерно по тому же принципу, что и в DNS.
Если база данных RWhois не содержит информации, необходимой для ответа на
запрос, она может переадресовать запрос другой базе данных. Процесс
повторяется до обнаружения нужной базы данных и получения ответа на запрос.
За дополнительной информацией о RWhois обращайтесь к RFC 2167 или на
сайт http://www.rwhois.net.
WHOIS++
WHOIS++ представляет собой расширение традиционного протокола и службы
Whois. Задействованные в нем серверы аналогичны Whois, но предоставляют
более подробную и структурированную информацию.
Описание WHOIS++ приводится в RFC 1834, 1835, 1913 и 1914.
Finger
Finger — название протокола и программы, предназначенных для получения
информации о состоянии хостов или пользователей в Интернете. Обычно Finger
используется для получения информации о том, подключен ли пользователь
к Интернету, а также для получения адресов электронной почты и имен. Finger
работает на порте TCP с номером 79.
Finger относится к числу простых служб TCP/IP. Сеанс между клиентом
и сервером проходит по следующему сценарию:
О Клиент Finger отправляет запрос серверу Finger.
О Сервер открывает подключение для клиента.
О Клиент передает однострочный запрос.
О Сервер ищет информацию в локальных файлах «учетных записей» и
возвращает результаты.
О Сервер закрывает подключение.
Ниже приведен простейший пример использования Finger с применением
команды telnet:
% telnet host.mydomain.com 79
Trying...
Connected to host.mydomain.com
Escape character is ,A]'
jamisonn
Login: jamisonn Name: Neal Jamison
Directory: /users/home/jamisons Shell: /bin/tcsh
On since Mon Aug 16 19:20 (EOT) in ttyp4 from poo!180-128
No mai1.
No plan.
Connection closed by foreign host.
%
Спецификация Finger приводится в RFC 1288.
ПРИМЕЧАНИЕ
Концепция базы данных «электронного телефонного справочника» CSO была разработана
отделом средств связи и вычислительной техники Иллинойсского университета. На сервере CSO
хранятся данные телефонной книги и выполняется программа qi (интерпретатор запросов)/ которая
получает запросы и возвращает информацию. Клиент запускает программу рп, которая отправляет
запросы серверу. Программа рп была адаптирована для большинства основных платформ; кроме
того, клиент рп интегрирован во многие программные продукты (в том числе Eudora и Mosaic).
За дополнительной информацией обращайтесь к списку FAQ, посвященному рп, по адресу http://
www.landfield.com/faqs/ph-faq/.
Команда finger
Команда finger предназначена для поиска информации о локальных и удаленных
пользователях. В этом разделе основное внимание сосредоточено на
применении finger для сбора информации об удаленных пользователях.
Команда finger для Solaris
В операционной системе Solaris для работы с протоколом Finger используется
клиентская команда finger. Команда finger запрашивает у сервера подключение
и после установления связи передает однострочный запрос. Синтаксис команды
finger для Solaris:
finger [ -bfhilmpqsw ] [ пользователь... ]
finger [ - 1 ][ пользователь@хост1[@хост2...@хостп]
finger [ - 1 ][ @хост1 [@хост2. . .@хостп] ... ]
ПРИМЕЧАНИЕ
При использовании finger для поиска удаленных пользователей поддерживается только ключ -I.
Параметры:
О -b — подавление длинного формата вывода.
О -f — подавление заголовка.
О -h — не выводить файл .project.
О -j — аналог короткого формата, но с выводом только имени пользователя,
терминала, времени входа в систему и времени бездействия.
О -I — принудительное использование длинного формата вывода.
О -т — поиск только по системному имени пользователя (но не по имени или
фамилии).
О -р — не выводить файл .plan.
О -q — ускоренный вывод (аналог короткого формата, но с выводом только
имени пользователя, терминала и времени входа в систему).
О -s — короткий формат вывода.
О -w — не выводить полное имя.
Пример:
$finger jamisonn@mydomain.com
Login name: jamisonn In real life: Neal Jamison
Directory: /www/home/jamisonn Shell: /bin/csh
On since Aug 3 13:21:37 on pts/1 from hostnamel
No unread mail
Project: AlphaBeta Project
Plan: To finish this AlphaBeta project.
$
Команда finger для Linux
Версия finger для Linux напоминает реализацию для Solaris. Синтаксис команды
finger для Linux:
finger [ -Imsp ] [ пользователь... ] [пользователь@хост ... ]
Параметры:
О -s — вывести системное имя пользователя, реальное имя, имя терминала и
состояние записи (в виде * после имени терминала при запрете записи), время
бездействия, время входа в систему, местонахождение организации и номер
телефона.
О -I — вывести всю информацию, выводимую для параметра -s, а также
домашний каталог пользователя, домашний номер телефона, командный
интерпретатор, состояние почтового ящика и содержимое файлов .plan, .project и .forward
из домашнего каталога пользователя.
О -р — не выводить содержимое файлов .plan и .project при использовании
параметра -I.
О -т — предотвратить поиск по реальным именам. Пользователь обычно
идентифицируется по системному имени, указываемому при входе в систему, но
без параметра -т в поиск также будет включено реальное имя пользователя.
При поиске команда finger не учитывает регистр символов.
Если параметры не заданы, то при наличии аргументов finger по умолчанию
использует длинный формат вывода (-1); в противном случае используется
формат -s. Следует учитывать, что в обоих форматах вывода могут отсутствовать
некоторые поля, если для них отсутствует информация в базе данных.
При отсутствии аргументов finger выводит информацию обо всех
пользователях зарегистрированных в системе в настоящий момент.
Пример:
$finger jamisonn@domain.com
Login name: jamisonn In real life: Neal Jamison
Directory: /www/home/jamisonn Shell: /bin/csh
On since Aug 3 13:21:37 on pts/1 from hostnamel
No unread mail
Project: AlphaBeta Project
Plan: To finish this AlphaBeta project.
S
Демоны Finger
Демоны fingerd и in.fingerd, прослушивающие запросы finger, автоматически
запускаются демоном inetd. Иногда Finger (и демоны) отключаются
администратором по соображениям «конфиденциальности». Попытка обращения к серверу
с отключенной службой Finger приводит к следующему результату:
$ finger jamisonn@host.mydomain.com
[host.mydomain.com]
Connection refused.
$
Демон in.fingerd для Solaris
in.fingerd — демон Finger для системы Solaris. Он находится под управлением inetd
и прослушивает запросы на подключение. При поступлении запроса in.fingerd
передает его команде finger, которая ищет запрашиваемую информацию среди
системных файлов. Демон in.fingerd возвращает ответ клиенту и закрывает
подключение. Демон in.fingerd запускается командой
/usr/sbin/in.fingerd
Параметры: нет.
В табл. 26.3 приводится список файлов/команд, связанных с in.fingerd.
Таблица 26.3. Команды и файлы, связанные с in.fingerd
Файл/команда Описание
.plan Пользовательский файл
.project Пользовательский файл с информацией о проектах
/var/adm/utmp Сведения о пользователях
/etc/passwd Системный файл паролей, содержащий информацию о пользователе
/var/adm/lastlog Время последнего входа в систему
Демон fingerd для Linux
Демон fingerd в системе Linux похож на демона in.fingerd для Solaris. Демон
fingerd запускается командой
fingerd [-wul] [-pl_ путь]
Параметры:
О -w — вывод заголовка с информацией о состоянии системы.
О -и — отвергать запросы вида finger @xocm.
О -I — вести журнал запросов к finger.
О -р — передача альтернативного каталога, в котором находится локальная
команда finger.
Finger в других системах
Служба Finger, как и большинство команд и программ TCP/IP, родилась в среде
Unix. Тем не менее некоторые фирмы разработали реализации Finger для других
операционных систем. В табл. 26.4 представлены две реализации Finger и адреса,
по которым можно получить дополнительную информацию.
Таблица 26.4. Программное обеспечение Finger для других платформ
Производитель URL
Hummingbird Communications LTD http://arctic.www.hummingbird.com/products/nc/nfs/index.html
Trumpet Winsock http://www.trumpet.com.au/
В Интернете также существует несколько web-интерфейсов (шлюзов) к службе
Finger. В частности, в своей работе я встречал следующие шлюзы Finger:
http://www.es.indiana.edu/finger/
http://webrunner.webabc.com/egi-bin/finger
На рис. 26.2 изображен шлюз Web/Finger в действии.
Необычное применение Finger
Время от времени инструментарий TCP/IP используется в целях, которые вряд ли
были предусмотрены его разработчиками. В следующем примере умные (и не
лишенные чувства юмора) студенты приспособили Finger для получения
информации о работе автомата, продающего охлажденные напитки. Выходные данные
слегка сокращены для экономии места.
% finger coke@cs.wisc.edu
[cs.wisc.edu]
[coke@lime.es.wisc.edu]
Login name: coke In real life: Coke
Directory: /var/home/coke Shell: /var/home/cokead/bin/coke
On since Aug 10 11:47:46 on term/a 3 hours 6 minutes Idle time
Plan:
This Coke (tm) machine is computer operated. It is available to SACM
members, Computer Sciences personnel, and CS&S building support staff.
(Plus anyone who asks really nice :-)
If you do not have an account set up or your account is below $.40,
then you can leave a check made out to SACM in a sealed envelope in
the SACM mailbox (fifth floor) with your email address and an initial
password. The Coke machine will email you when your account has been
created/updated.
Contents of the Coke machine:
Coke, Diet Coke, Mendota Springs Lemon (sparkling mineral water),
Sprite, Barq's Root Beer, Cherry Coke, Nestea Cool
%
This page generated by the )U finger gateway Щ
nasanews@space.mit.edu Ш
nasanews: [space] Mon Aug 16 20:44:11 1999
MIT Center for Space Research Щ
This NasaNews service is brought to you by the Microwave Subnode of \
NASA*a Planetary Data System. It is also available via World Ride ЯеЬ
at "http: //space.mit. edu/nasanews. html". AOL users can receive this
bulletin as: keyword "Gopher" > Aerospace and Astronomy > Nasa News.
We also maintain an email listserver for planetary microwave
information at "pds-listserver@space.mit.edu", an anonymous ftp server at
"delcano.mit.edu", and a WWW home page at "http://delcano.mit.edu/".
I If you have any suggestions for how we might improve our services,
I please mail them to "pds-requests@space.mit.edu".
I NASA press releases and other information are available automatically J
bv sendina an Internet electronic mail messaae to "domoOha.nasa.aov", Щ
И*Ь >-..АЬшт&Шт. , л ч 3.л..^.Г ^,,ЗЗЖ2,31^3,^,^^.,,Ъ:^ Д„titijba^fl
Рис. 26.2. Обращение к NASA News через шлюз Finger университета штата Индиана
Другой (и вероятно, более полезный) пример использования Finger можно
найти в сети Тихоокеанской Северо-Западной сейсмографической лаборатории.
Как и в предыдущем примере, выходные данные приводятся в сокращении.
% finger quake@geophys.washington.edu
[geophys.washington.edu]
Earthquake Information (quake)
Plan:
The following catalog is for earthquakes (M>2) in Washington and Oregon
produced by the Pacific Northwes Seismograph Network, a member of the
Council of the National Seismic System. PNSN support comes from the
US Geological Survey. Department of Energy, and Washington State.
Additional catalogs and information for the PNSN (as well as other
networks) are available on the World-Wide-Web at
URL:*http'V/www.geophys.washington.edu/'
For specific questions regarding our network send E-mail to:
seis_info@geophys.washington.edu
DATE-TIME is in Universal Time (UTC) which is PST + 8 hours. Magnitudes are
reported as duration magnitude (Md). QUAL is location quality A-excellent,
B-good, C-fair, D-poor, *-from automatic system and may be in error.
Updated as of Tue Sep 18 09:00:12 PDT 2001
DATE-(UTC)-TIME LAT(N) LON(W) DEP MAG QUAL COMMENTS
yy/mm/dd hh:mm:ss deg. deg. km Ml
01/07/31 05:07:32 47.73N 117.44W 0.6 2.2 AC FELT 7.4 km NNW of Spokane.
01/08/01 14:29:48 47.71N 117.44W 0.6 2.2 AD FELT 5.9 km NNW of Spokane.
01/08/02 15:35:23 47.72N 122.38W 27.0 2.2 BA 14.3 km WNW of Kirkland, WA
01/08/13 11:47:28 48.25N 120.02W 7.2 2.3 CD 35.3 km WSW of Okanogan. WA
01/08/15 00:37:29 47.66N 122.41W 26.1 2.2 BA 9.6 km NW of Seattle, WA
01/08/19 06:17:32 48.25N 121.61W 1.7 3.0 CC FELT 1.0 km WSW of Darringt
01/08/20 06:14:09 45.29N 120.14W 8.8 2.1 BD 6.8 km NNE of Condon, OR
01/08/25 17:52:34 48.23N 121.60W 2.7 2.1 CC FELT 2.1 km S of Darringt
01/08/30 03:47:31 48.23N 121.62W 4.8 2.7 CC FELT 2.9 km SW of Darringt
Итоги
В этой главе описаны два основных протокола и набора команд,
предназначенных для поиска информации о хостах, доменах и пользователях.
Служба/протокол Whois раньше использовалась для сбора информации о зарегистрированных
хостах и доменах. Обычно эта информация ограничивается сведениями об
организации-регистраторе, контактных лицах и почтовых адресах. Протокол Whois
первоначально задумывался как информационная служба для получения данных
обо всех пользователях Интернета, однако из-за стремительного развития
Интернета эта задача стала невыполнимой. RWhois и WHOIS++ расширяют
традиционные возможности Whois и пытаются превратить Whois в более полную
информационную службу. Во многих организациях, включая корпорации и
учебные заведения, Whois эффективно используется для реализации каталогового
сервиса.
Служба/протокол Finger используется для сбора информации о хостах
Интернета и их пользователях. Как показано выше, при помощи Finger можно
узнать, подключен ли в настоящий момент пользователь к системе, а также
получить различные сведения, включая время входа в систему, номер телефона
и описание его «рабочих планов». Finger также может применяться для
получения другой информации — например, прогнозов погоды, текущих новостей
и даже для проверки состояния автомата по продаже напитков.
*% "Т Протоколы пересылки
Жт Ш файлов
Энн Карасик (Anne Carasik)
Пересылка файлов из одной системы в другую считается одной из важнейших
задач в работе сети. Вообще говоря, файлы можно пересылать во вложениях
электронной почты, однако это косвенный способ, уступающий по
эффективности прямой пересылке файлов. Если вы хотите немедленно добиться желаемого
результата, следует воспользоваться протоколом пересылки файлов. К этой
категории относятся интернет-протоколы FTP (File Transfer Protocol) и TFTP
(Trivial FTP). Процесс удаленного копирования рассматривается в главе 32.
Роль FTP и TFTP в современном мире
В наши дни многие пользователи используют протокол HTTP для пересылки
данных между серверами, поэтому приложения FTP и TFTP не так
распространены, как раньше. Тем не менее web-серверы работают не во всех системах, поэтому
для пересылки файлов независимо от наличия web-сервера все равно необходимы
протоколы FTP и TFTP. Также следует заметить, что при пересылке файлов
протокол HTTP уступает FTP по эффективности. Если адрес URL, внедренный
в тег HTML, подразумевает пересылку по FTP (например, ftp://ftp.xyz.com), то
система переадресует запрос на пересылку клиенту FTP.
Впрочем, даже при использовании Web пересылка файлов по-прежнему
затруднена. В целом команды Web уступают по своим возможностям командам
FTP и не обладают таким количеством режимов и функций.
Приложения пересылки файлов, работающие в режиме командной строки,
позволяют передавать файлы без установки web-сервера. В большинстве систем
Unix и Linux поддержка FTP устанавливается по умолчанию.
Поскольку большинство таких команд работает в текстовом режиме (хотя
существуют программы, выполняющие те же операции через графический
интерфейс), работу FTP лучше всего продемонстрировать на примере клиентов
командной строки, входящих в поставку Unix. Тем не менее, независимо от того, в каком
режиме работает клиент FTP — графическом или в режиме командной строки,
во внутренних операциях всех клиентов используются базовые команды FTP.
Хотя протокол TFTP используется в гораздо меньшем масштабе, чем FTP,
в этой главе рассматриваются оба протокола.
Пересылка файлов через FTP
Протокол FTP является стандартным средством пересылки файлов в Интернете
и в сетях IP. На ранней стадии развития Интернета, до повсеместного
распространения World Wide Web, для пересылки файлов использовались
приложения командной строки. Одним из самых популярных средств решения этой
задачи наряду с электронной почтой (SMTP) стал протокол FTP.
FTP относится к категории приложений TCP/IP, а это означает, что
протокол работает на прикладном уровне — седьмом в модели OSI и четвертом в
модели TCP. Спецификация FTP приводится в RFC 959. В качестве транспортного
протокола FTP использует TCP (рис. 27.1).
Прикладной уровень —► FTP
Представительский уровень
Сеансовый уровень
Прикладной уровень [—►FTP Транспортный уровень
Транспортный уровень Сетевой уровень
Сетевой уровень Канальный уровень
Физический уровень Физический уровень
Модель TCP Модель OSI
Рис. 27.1. Место FTP в моделях OSI и TCP
Первоначально FTP проектировался как протокол пересылки файлов между
компьютерами ARPANET, предшественника Интернета. Старая сеть ARPANET
поддерживалась Министерством обороны США с 1960-х по 1980-е годы прошлого
века. В те времена главной функцией FTP считалась эффективная и надежная
пересылка файлов между хостами. Сейчас FTP по-прежнему обеспечивает
надежную пересылку, а также удаленное хранение файлов, то есть возможность
работать в одной системе и хранить файлы где-то в другом месте. Например,
если вы поддерживаете работу web-сервера и хотите загрузить файлы HTML
и программы CGI для правки на локальном компьютере, вам достаточно
загрузить эти файлы с сайта, на котором они хранятся (то есть с удаленного web-
сервера).
После внесения изменений файлы передаются обратно на web-сервер через
FTP. В этом случае вам не придется регистрироваться и работать на удаленном
компьютере, как при использовании Telnet.
Подключения FTP
Подключение FTP устанавливается сразу с двумя портами: 20 и 21. Эти два
порта выполняют разные функции — порт 20 используется для обмена данными,
а порт 21 предназначен для управляющих команд.
На рис. 27.2 показано, как клиент FTP подключается к демону FTP на
удаленном сервере.
Любой порт с номером п 21
1024 и выше : И
Управляющий порт
Любой порт с номером Р 2q
1024 и выше z И р
Порт данных
Клиент FTP Сервер FTP
Рис. 27.2. Подключение клиента FTP к серверу
Управляющий порт
Управляющий порт FTP предназначен для передачи команд и ответов на них.
Например, при отправке команды вида get thisfile будет получен примерно такой
ответ:
200 PORT command successful
150 Opening ASCII mode data connection for .message A27 bytes).
256 Transfer complete.
local: .message remote: .message
135 bytes received in 1,4 seconds @,09 Kbytes/s)
Обратите внимание: команды, передаваемые через управляющий порт 21,
обозначаются префиксом PORT. В некоторых реализациях FTP вместо
управляющего порта (PORT) допускается передача команд через порт данных
командами пассивного режима (PASV).
В выходных данных команды указывается состояние данных, текущий режим,
состояние пересылки и объем принятых данных. Подключение использует
протокол Telnet, спецификация которого приведена в RFC 495.
В некоторых реализациях команда PASV допускает «низкоуровневое»
подключение FTP, при котором не используются знакомые пользователю команды. Это
позволяет пересылать файлы с использованием единственного порта 20 вместо
двух портов 20 и 21.
ПРИМЕЧАНИЕ
Истинное предназначение команды PASV — обеспечить нормальное прохождение FTP через
брандмауэры. В обычном режиме клиент FTP посылает серверу команду PORT,
идентифицирующую конечную точку, с которой сервер FTP должен установить подключение для передачи
данных. Такой способ часто называется обратным подключением. Точка на стороне клиента
представляет собой временный порт, лежащий в интервале от 1024 до 65 535, однако брандмауэру
об этом неизвестно, и он не может разрешить доступ к заданному порту, не зная заранее его
номера. Проблема решается выдачей команды PASV сервером FTP, в результате чего сервер
переводится в «пассивный режим». Команда PASC идентифицирует для клиента FTP конечную
точку для передачи данных на стороне сервера. Затем клиент FTP осуществляет активное
подключение к конечной точке данных на стороне сервера. Поскольку брандмауэры обычно разрешают
исходящие подключения по любому номеру порта, работа FTP через брандмауэр проходит
нормально.
При подключениях PASV в распоряжении пользователя находится полный
набор команд; тем не менее подключение с использованием управляющих
команд гораздо надежнее и лучше контролируется, так как администратор может
выбрать команды, доступные для пользователя.
Порт данных
Через порт данных информация FTP (файлы) передается серверу FTP (ftpd).
ПРИМЕЧАНИЕ
Серверный демон FTP ftpd (или in.ftpd) предназначен для системы Unix. В других операционных
системах сервер FTP может быть реализован иначе.
Не путайте порт данных с управляющим портом, через который посылаются
команды, вводимые пользователем. При пересылке файлов через порт 20 (порт
данных) передаются сами файлы, а не команды.
Подключения к порту данных называются пассивными. Все, что известно при
подключении к порту данных, — это режим пересылки и тип файла, а также
количество передаваемых файлов. Кроме того, существует возможность отправки
фрагмента файла, хотя практические применения для этого находятся довольно редко.
При ожидании подключений сервер прослушивает порт данных (порт 20)
в ожидании запросов, по которым открывается подключение данных. Пассивное
подключение открывается одновременно с управляющим подключением. В этом
случае команды передаются через управляющий порт, однако вы можете
напрямую управлять портом данных при помощи пассивных команд FTP.
ПРИМЕЧАНИЕ
Команда PASV не вводится пользователями; пользовательский интерфейс обеспечивается
командой PORT. Серверы FTP должны поддерживать пассивные команды (RFC 1123), хотя на практике
это делается не всегда.
Для ввода команд в пассивном режиме следует подключиться к порту 21 через Telnet:
tigerlair:/home/stripes- telnet localhost 21
Примерный результат выглядит так:
Trying 1.2.3.4...
Connected to localhost.
Escape character is ,Л]'
220 mysystem.tigerlalr.com FTP server (SunOS 5.6) ready.
Далее все вводимые команды будут восприниматься как пассивные.
Команда PWD выводит информацию о текущем каталоге:
PWD
257 7home/stripesH is current directory.
Команда CDUP осуществляет переход в родительский каталог:
CDUP
250 CWD command successful.
Повторный ввод команды PWD выводит информацию о новом текущем каталоге:
PWD
257 "/home" is current directory.
Команды не снабжаются префиксом PORT, поскольку управляющий порт при этом не
используется — вместо этого вы работаете с портом данных напрямую.
Подключение с использованием клиентов FTP
Чтобы открыть подключение через FTP, выполните команду ftp с именем хоста.
Синтаксис команды ftp:
ftp [параметры] [хост]
Например, для подключения к серверу ftp.example.org выполняется
следующая команда:
tigerlair:/home/stripes- ftp ftp.example.org
Если вы хотите изменить обычный режим работы клиента FTP,
воспользуйтесь параметрами командной строки, перечисленными в табл. 27.1.
Таблица 27.1. Параметры командной строки клиента ftp
Параметр Назначение
-d Включение отладки
-i Отключение подтверждений
-п Запрет автоматического входа в систему
-v Вывод ответов от удаленного сервера
-д Запрет метасимволов (глобов)
Например, чтобы запретить автоматический вход в систему (когда клиент FTP
автоматически запрашивает имя пользователя и пароль) и не запрашивать
подтверждения при пересылке нескольких файлов, следует ввести следующую команду:
ftp -i -n ftp.example.org
Но вернемся к исходному примеру запуска клиента FTP без параметров:
tigerlaiг:/home/stripes- ftp ftp.exampTe.org
Следующее сообщение выглядит так:
Connected to ftp.example.org
220 ftp.example.org FTP Server (Version wu-2.4.2-VR16(l)
Wed Apr 7 15:59:03 PDT 1999) ready.
Name (ftp.example.org:stripes):
По умолчанию FTP использует для входа на удаленный сайт имя вашей
локальной учетной записи (в данном случае — stripes). Если нужно использовать
другое имя, введите его:
Connected to ftp.example.org
220 ftp.example.org FTP Server (Version wu-2.4.2-VR16(l)
Wed Apr 7 15:59:03 PDT 1999) ready.
Name (ftp.example.org:stripes): ahc
Password:
Вам предлагается ввести пароль; будьте внимательны и введите его без
ошибок. Во время ввода символы не отображаются на экране и даже не
маскируются звездочками.
ПРИМЕЧАНИЕ
Не используйте example.org для экспериментов с FTP, здесь этот адрес используется только в
качестве примера. Если вы хотите поэкспериментировать с FTP, не создавая угрозы для удаленной
системы, воспользуйтесь локальной системой и запустите клиента FTP с подключением к локальному
хосту. В этом случае предполагается, что сервер FTP работает на одном компьютере с клиентом.
На экране появляется приглашение FTP, которое выглядит так:
ftp>
В этом режиме, называемом интерактивным режимом, вводятся команды на
пересылку файлов.
Интерактивный режим FTP
Интерактивный режим позволяет вводить и интерпретировать команды в
клиенте FTP. В частности, вы можете отправлять клиентские команды на открытие
и закрытие подключений, пересылку файлов, изменение типа пересылки и т. д.
прямо из клиента FTP.
В табл. 27.2 перечислены команды интерактивного режима FTP.
Таблица 27.2. Команды FTP
Команда Описание
!<локальная команда> Выполнение командного интерпретатора в локальной системе
$<макрос> Выполнение макроса
account [пароль] Использование другого имени/пароля для получения расширенного
доступа к удаленной системе
ascii Выбор ASCII-режима пересылки файла
append локальный Присоединение локального файла к удаленному (файла на удаленном
файл [удаленный файл] компьютере)
bell Подача звукового сигнала после завершения пересылки
binary Выбор двоичного режима пересылки файла
bye, exit Завершение удаленного подключения
case Переключение режима учета регистра символов
close, disconnect Закрытие удаленного подключения
cd <каталог> Смена текущего каталога в удаленной системе
cdup Переход к родительскому каталогу
debug <уровень> Установка уровня отладки
dir Вывод содержимого каталога
delete <файл> Стирание файла на удаленном компьютере
get <файл> Загрузка файла с удаленного компьютера в локальную систему
glob Разрешение/запрет использования метасимволов при пересылке файлов
Команда Описание
hash Вывод символа # после передачи каждых 1024 байт
help Вывод справки
led <каталог> Смена текущего каталога в локальной системе
Is Вывод содержимого каталога на удаленном компьютере
Ipwd Вывод содержимого рабочего каталога на локальном компьютере
macdef <макрос> Определение макроса
mdel <файл(ы)> Удаление нескольких файлов
mdir <файл(ы)> Вывод содержимого нескольких каталогов
mget <файл(ы)> Загрузка нескольких файлов из удаленной системы на локальный
компьютер
mkdir <каталог> Создание каталога на удаленном компьютере
mput <файл(ы)> Пересылка нескольких файлов на удаленный компьютер
open < сайт> Открытие подключения к сайту
prompt Управление режимом интерактивного ввода команд
put <файл> Пересылка файла на удаленный компьютер
pwd Вывод текущего рабочего каталога
user [пользователь] Вход в удаленную систему
[пароль]
verbose Разрешение/запрет расширенного вывода
При таком количестве команд протокол FTP способен на многое. Чтобы вы
лучше поняли, как используются эти команды, в следующем разделе будет
рассмотрен пример сеанса FTP.
Пример сеанса FTP
Большинство сеансов FTP проще того, что описан ниже — этот пример
разработан специально для демонстрации некоторых возможностей, доступных при
использовании FTP. Прежде всего необходимо открыть подключение к удаленному
сайту FTP:
tigerlair:/home/stripes- ftp ftp.example.org
Connected to ftp.example.org
220 ftp.example.org FTP Server (Version wu-2.4.2-VR16(l)
Wed Apr 7 15:59:03 PDT 1999) ready.
Name (ftp.example.org:stripes): ahc
Password:
230 User ahc logged in.
ftp>
Получив доступ к удаленному сайту, мы хотим получить список имеющихся
файлов. В FTP существует две команды для решения этой задачи: Is и dir. Сле-
дует учитывать, что в нашем примере подключение FTP производится к
системе Unix. Выходные данные команды Is выглядят примерно так:
ftp> Is
200 PORT command successful.
150 ASCII data connection for /bin/Is A.2.3.4,52262) @ bytes).
ISS-SOLARIS.TAR
Mail
ar203sol.tar.Z
c-files.tar.gz
debug.ssh
deshadow.c
e205-pdf.pdf
226 ASCII Transfer complete.
468 bytes received in 0.0077 seconds E9.35 Kbytes/s)
ftp>
Команда dir выдает следующий результат:
ftp> dir
200 PORT command successful.
150 ASCII data connection for /bin/Is A.2.3.4,52263) @ bytes).
total 56220
drwrx-xr-x 16 ahc users 1536 May 25 09:22 .
drwrx-xr-x 6 root others 512 Oct 27 1998 ..
-rw 1 ahc users 168 May 7 11:26 .Xauthority
-rw-r--r-- 1 ahc users 424 Dec 2 14:43 .alias
-rw-r--r-- 1 ahc users 313 Jun 2 1998 .cshrc
drwxr-xr-x 11 ahc users 512 May 7 11:27 .dt
-rwxr-xr-x 1 ahc users 5111 Nov 2 1998 .dtprofile
drwx 2 ahc users 512 Jan 27 15:04 .elm
-rw-r--r-- 1 ahc users 174 Dec 2 14:45 .login
-rw-r--r-- 1 ahc users 556 Dec 2 15:32 .tcshrc
-rw 1 ahc users3655680 Jan 4 08:27 ISS-SOLARIS.TAR
drwx 2 ahc users 512 Dec 8 16:01 Mail
-rw-r--r-- 1 ahc users5919933 Nov 3 1998 ar302sol.tar.Z
-rw 1 ahc users 14605 May 13 10:43 c-files.tar.gz
-rw 1 ahc users 1818 Mar 8 12:09 debug.ssh
-rw-r--r-- 1 ahc users 2531 Jan 7 10:07 deshadow.c
-rw-r--r-- 1 ahc users 54532 Nov 19 1998 e205-pdf.pdf
-rw-r--r-- 1 ahc users 898279 Jan 6 09:50 neotrl22.zip
226 ASCII Transfer complete.
3830 bytes received in 0.047 seconds G9.06 Kbytes/s)
ftp>
Команда dir не только выводит более подробную информацию о файлах, чем
команда Is, но и отображает скрытые файлы Unix (имена таких файлов
начинаются с символа «точка»).
ПРИМЕЧАНИЕ
В Unix список файлов выводится командами Is и dir, но команда dir выводит более подробную
информацию, включая дату последней модификации, владельца, привилегии и размер файла. При
подключении через FTP к системе Windows NT/2000 или Windows 9x команда Is работает несколько
иначе, и для получения списка файлов рекомендуется использовать команду dir.
После получения списка файлов наступает очередь следующей операции —
загрузки файла из удаленной системы на локальный компьютер. Сначала
желательно проверить локальный каталог и убедиться в том, что файл будет
сохранен в нужном месте:
ftp> Ipwd
/home/stripes
ftp>
Загруженные файлы будут храниться в домашнем каталоге, который
является текущим. Загрузка файлов выполняется командой get:
ftp> get notes
200 PORT command successful.
150 ASCII data connection for notes A.2.3.4,52264) B10 bytes).
226 ASCII Transfer complete.
local: notes remote: notes
226 bytes received in 0.019 seconds A1.81 Kbytes/s)
ftp>
Файл из удаленной системы сохраняется в локальной системе под тем же
именем, если только новое имя файла не было включено в команду get Для
этой цели используется следующий синтаксис:
get имя_удаленного_файла имя_локального_файла
Следовательно, если потребуется принять другой файл с именем notes, один
из файлов придется переименовать. После появления в локальной системе файла
notes переименовывается либо этот файл, либо удаленный файл на стадии
загрузки в локальную систему. В нашем примере второму загружаемому файлу
будет присвоено имя notes2. Имена локального и удаленного файлов
указываются в выходных данных FTP.
ftp> get notes notes2
200 PORT command successful.
150 ASCII data connection for notes A.2.3.4,52264) B10 bytes).
226 ASCII Transfer complete.
local: notes2 remote: notes
226 bytes received in 0.019 seconds A1.81 Kbytes/s)
ftp>
Файлы notes являются текстовыми. Из выходных данных видно, что FTP по
умолчанию использует пересылку данных в формате ASCII, то есть в текстовом
формате. А если потребуется переслать двоичный файл? Для этого следует
отдать FTP команду на изменение типа файла.
ftp> bin
200 Type set to I.
Двоичный формат обозначается кодом типа I, а текстовый формат — кодом
типа А. В частности, к категории двоичных файлов относятся исполняемые,
сжатые и библиотечные файлы. Двоичные файлы, в отличие от текстовых, не
предназначены для чтения.
После переключения типа можно переходить к пересылке двоичных файлов.
ftp> get vr40a.exe windowsfile.exe
200 PORT command successful.
150 Binary data connection for vr40a.exe A.2.3.4,52265) B338635 bytes).
226 Binary Transfer complete.
local: windowsfile.exe remote:vr40a.exe
2338635 bytes received in 1,4 seconds A593.23 Kbytes/s)
ftp>
В выходных данных FTP указано, в каком режиме происходит пересылка
данных — в двоичном или в режиме ASCII. Чтобы вернуться к текстовому типу
файла, введите команду ascii.
ftp> ascii
200 Type set to A.
ПРИМЕЧАНИЕ
Текстовые файлы следует пересылать в режиме ASCII, поскольку при этом учитываются
обозначения конца строки, действующие в разных операционных системах, с автоматическим выполнением
соответствующих преобразований. Например, в системах семейства Unix конец строки
обозначается одним символом <LF> (перевод строки). С другой стороны, в системах Windows
используется последовательность символов <CR><LF>, где <CR> — символ возврата курсора, a <LF> —
символ перевода строки. При пересылке файла из системы Unix в Windows в текстовом режиме
в конец каждой строки автоматически добавляется символ возврата курсора. И наоборот, при
пересылке файла в текстовом режиме из Windows в Unix лишние символы перевода строки в конце
строк удаляются.
Большие компьютеры используют кодировку EBCDIC вместо ASCII, поэтому для них вместо команды
ascii следует использовать команду ebcdic.
Пересылка двоичного файла в текстовом режиме приводит к ошибкам, поскольку она
сопровождается дополнительными преобразованиями строк, что может привести к появлению или удалению
символов возврата курсора в переданном файле. В результате подобных модификаций двоичные
файлы становятся неработоспособными.
Если вы ограничиваетесь пересылкой одного файла, все нормально работает.
Но что, если потребуется загрузить несколько файлов? Например, для загрузки
всех файлов, имена которых начинаются с символа «s», интуитивно хочется
воспользоваться командой get s*. К сожалению, результат будет следующим:
ftp> get s*
550 s*: No such file or directory
Чтобы протокол FTP распознавал метасимволы (также называемые
универсальными и подстановочными символами) в именах файлов, следует
воспользоваться командой mget:
ftp> mget s*
mget s3-Solaris.tar?
По умолчанию при каждом запросе на загрузку или пересылку нескольких
файлов клиент FTP запрашивает подтверждение. Чтобы принять все найденные
файлы, необходимо ввести у при каждом запросе на загрузку файла:
mget s3-Solaris.tar? у
200 PORT command successful.
150 ASCII data connection for s3-5olaris.tar B338635 bytes)
A27.0.0.1,52452) @ bytes).
226 ASCII Transfer complete.
mget sendmai1.8.9.2.tar.gz? у
200 PORT command successful.
150 ASCII data connection for sendmai1.8.9.2.tar.gz
A27.0.0.1.52453) @ bytes).
226 ASCII Transfer complete.
mget solsniffer.с? у
200 PORT command successful.
150 ASCII data connection for solsniffer.c
A27.0.0.1,52454) @ bytes).
226 ASCII Transfer complete.
mget spadell0.exe? y
200 PORT command successful.
150 ASCII data connection for spadell0.exe
A27.0.0.1,52455) (8192 bytes).
226 ASCII Transfer complete.
mget sun-sniff.с? у
200 PORT command successful.
150 ASCII data connection for sun-sniff.с
A27.0.0.1,52456) (8192 bytes).
226 ASCII Transfer complete.
ftp>
Однако постоянно отвечать у на все запросы утомительно, особенно при
большом количестве файлов. Чтобы пересылка осуществлялась автоматически,
введите команду prompt:
ftp> prompt
Interactive mode off.
Если теперь ввести ту же команду, пересылка выполняется без
подтверждений — а значит, будет выполнена гораздо быстрее:
mget s3-Solaris.tar? у
200 PORT command successful.
150 ASCII data connection for s3-Solaris.tar B338635 bytes)
A27.0.0.1,52458) @ bytes) .
226 ASCII Transfer complete.
200 PORT command successful.
150 ASCII data connection for sendmai1.8.9.2.tar.gz
A27.0.0.1,52459) @ bytes).
226 ASCII Transfer complete.
200 PORT command successful.
150 ASCII data connection for solsniffer.c
A27.0.0.1,52460) @ bytes).
226 ASCII Transfer complete.
200 PORT command successful.
150 ASCII data connection for spadell0.exe
A27.0.0.1,52461) (8192 bytes).
226 ASCII Transfer complete.
200 PORT command successful.
150 ASCII data connection for sun-sniff.с
A27.0.0.1,52462) (8192 bytes).
226 ASCII Transfer complete.
ftp>
Такой режим гораздо быстрее и удобнее, чем режим с интерактивным
подтверждением.
ПРИМЕЧАНИЕ
Если загрузка приводит к перезаписи ранее существовавшего файла, FTP не предупреждает вас
заранее.
От загрузки файлов мы переходим к пересылке файлов на удаленный сервер
FTP. Задача решается командой put:
ftp> mput h2obg.jpg
200 PORT command successful.
150 Binary data connection for h2obg.jpg A.2.3.4,52270)
226 Transfer complete.
local: h2obg.jpg remote: h2obg.jpg
1194 bytes sent in 0.019 seconds F0.82 Kbytes/s)
ftp>
Команда put пересылает локальный файл в удаленную систему. Для отправки
нескольких файлов используется команда mput:
ftp> mput dd*
mput debug.ssh? у
200 PORT command successful.
150 ASCII data connection for debug.ssh A.2.3.4,52266).
226 Transfer complete.
mput deshadow.c? у
200 PORT command successful.
150 ASCII data connection for deshadow.c A.2.3.4,52267).
226 Transfer complete.
ftp>
Как и в случае команды mget, следует выполнить команду prompt, чтобы вам
не пришлось отдельно подтверждать пересылку каждого передаваемого файла:
ftp> prompt
Interactive mode off.
ftp> bin
200 Type set to I.
ftp> mput k*
200 PORT command successful.
150 Binary data connection for kayaking.jpg A.2.3.4,52268).
226 Transfer complete.
200 PORT command successful.
150 Binary data connection for kay.tar A.2.3.4,52269).
226 Transfer complete.
ftp>
ПРИМЕЧАНИЕ
Чтобы операция выполнялась с несколькими файлами, достаточно поставить префикс «т» в начало
соответствующей команды (get, put или delete).
ПРИМЕЧАНИЕ
Перед тем как передавать файлы через FTP на удаленный сервер, необходимо получить право
копирования файлов. При входе на удаленный сервер FTP использует систему аутентификации этого
сервера. Таким образом, если вы регистрируетесь в системе под именем linda, на удаленном
сервере FTP должна существовать учетная запись linda. Чтобы пересылать файлы на сервер, этот
пользователь должен обладать правом записи в соответствующий каталог.
На серверах TFTP также необходимо позаботиться о том, чтобы файл с указанным именем уже
существовал и был перезаписан соответствующим файлом. Пользователь должен иметь доступ
к удаленной системе с привилегиями, достаточными для создания пустого файла. В системах Unix
пустой файл создается командой touch:
touch файл
Некоторые средства разработчика (например, компилятор Borland С ++ для Windows) также
включают Windows-версию утилиты touch.
Если вы хотите удалить файл в удаленной системе (и обладаете для этого
достаточными привилегиями), воспользуйтесь командой delete (допускается
сокращение команды до del):
ftp:> del h2obj.jpg
250 DELE command successful.
ftp>
Удаление нескольких файлов выполняется командой mdel. Как и в случае с
mget и mput, команда prompt отменяет интерактивное подтверждение удаления
по каждому файлу:
ftp> mdel s*
250 DELE command successful.250 DELE command successful.
250 DELE command successful.
ftp>
ПРИМЕЧАНИЕ
Как и при перезаписи файлов, FTP не предупреждает пользователя о стирании файлов в
удаленной системе.
Помимо перемещения файлов между удаленной и локальной системами, вы
также можете создавать и удалять каталоги. Каталоги создаются командой mkdir:
ftp> mkdir morestuff
257 MKD command successful.
Если вы забыли, какой каталог удаленной системы является текущим,
введите команду pwd:
ftp> pwd
257 Vhome/ahc/morestuff" is current directory.
При пересылке очень больших файлов рекомендуется включить
вспомогательный вывод. Взглянув на экран, вы будете знать, что пересылка идет
нормально, даже если ее результатов приходится дожидаться несколько минут или
часов. Вспомогательный вывод включается командой hash:
ftp> hash
Hash mark printing on (8192 bytes/hash mark)
Теперь при пересылке файла командой put или get вы сможете следить за
ходом процесса:
ftp> put sendmail.8.9.2.tar.gz
200 PORT command successful.
150 Binary data connection for sendmai1.8.9.2.tar.gz A.2.3.4,52271).
#################################################################
226 Transfer complete.
local: sendmail.8.9.2.tar.gz remote: sendmail.8.9.2.tar.gz
106534 bytes sent in 0.56 seconds A870.03 Kbytes/s)
ftp> pwd
Если вы завершили работу с сайтом, но не хотите выходить из клиента FTP,
достаточно просто закрыть подключение. Команда close разрывает связь с
удаленной системой, но оставляет клиента FTP в режиме интерпретации команд:
ftp> close
221 Goodbye.
ftp>
Приглашение ftp> по-прежнему готово к работе, поэтому вы можете открыть
подключение к другому хосту командой open:
ftp> open another-example.org
Connected to another-example.org
220 another-example.org FTP Server (SunOS 5.6) ready.
Name (localhost:ahc):
331 Password required for ahc.
Password:
230 User ahc logged in.
ftp>
На этот раз подключение устанавливается с совершенно другой системой.
В вашем распоряжении остаются те же команды, но состав файлов не имеет
ничего общего с первой системой.
После окончательного завершения работы с FTP следует ввести команду quit
или bye:
ftp> quit
221 Goodbye.
Безопасность при использовании FTP
Хотя служба FTP предназначается для работы с файлами, никто не хочет, чтобы
злоумышленники учинили хаос в его системе. Протокол FTP обладает базовыми
средствами управления доступом, но это не решает фундаментальных проблем
безопасности, связанных с использованием FTP.
Протокол FTP всегда использует аутентификацию на базе открытого
текста, то есть пароли пересылаются в сети в незашифрованном виде. Это создает
очень большие проблемы с безопасностью. Проблемы безопасности FTP также
обусловлены неправильной настройкой среды FTP с анонимным доступом,
когда посетители могут проникать в неположенные места, а также наличие двух
открытых портов на сервере FTP вместо одного, как в большинстве сетевых
служб TCP/IP.
Другой важный аспект безопасности FTP — применение для
аутентификации имени пользователя и пароля в локальной операционной системе (кроме
анонимного доступа). Передача пароля в виде открытого текста может привести
к тому, что данные учетной записи попадут в чужие руки.
Файл /etc/ftpusers
Файл /etc/ftpusers позволяет контролировать доступ к серверу FTP. В нем хранится
список пользователей, которые не могут использовать FTP (хотя это не мешает
пользователям работать с другими приложениями, включая rsh, telnet и ssh).
Типичный файл /etc/ftpusers выглядит примерно так:
tigerlaiг:/home/stripes- cat /etc/ftpusers
root
uucp
bin
После настройки файла /etc/ftpusers административные учетные записи, а
также нежелательные пользователи не смогут использовать FTP.
Файл .netrс
Файл .netrc предназначен для автоматизации входа на удаленный хост в
подключениях FTP. Файл находится в домашнем каталоге пользователя и
используется для подключения к различным системам без ввода имени и пароля. Файлу
.netrc должны быть присвоены права доступа 700 (чтение и запись файла не
разрешаются никому, кроме владельца).
Записи файла .netrc имеют следующий формат:
machine <компьютер> login <пользователь> password <пароль>
Следовательно, запись для example.org будет выглядеть примерно так:
tigerlair:/home/stripes- cat .netrc
machine example.org login ahc password stuff
Поскольку файл .netrc часто используется для регистрации в удаленных
системах, он может использоваться и для анонимных FTP-сайтов, которые в качестве
пароля принимают адреса электронной почты. Впрочем, анонимные FTP-сайты
предоставляют только общедоступную информацию — ничего такого, к чему
следовало бы допускать без пароля.
ВНИМАНИЕ
В современных условиях использовать файл .netrc не рекомендуется. Содержащиеся в нем пароли
могут быть прочитаны, что приводит к нарушению конфиденциальности данных учетной записи.
Другие клиенты FTP
В предыдущем примере рассматривался стандартный клиент FTP, входящий
в поставку таких операционных систем, как Unix, Windows и VMS. В этих
системах клиенты работают более или менее одинаково, но все же существуют
некоторые различия, рассматриваемые ниже.
Unix
Для системы Unix написаны два клиента FTP, превосходящие по своим
возможностям «базового» клиента FTP: Ncftp и xftp.
Клиент Ncftp автоматизирует анонимный вход на серверы FTP, поэтому
пользователю не приходится вводить пароль (адрес электронной почты) или
беспокоиться о конфиденциальности файла .netrc. Клиент обеспечивает
псевдографическое оформление со строкой состояния пересылки файла, а также дополнительные
удобства, в том числе редактирование командной строки. Ncftp можно загрузить
с сайта http://www.ncftp.com.
Программа xftp обеспечивает графический интерфейс к клиенту FTP.
Пользователь работает с клиентом, обходясь без прямого ввода команд в
интерактивном режиме. Окно программы xftp изображено на рис. 27.3. Программа xftp
загружается со страницы http://www.llnl.gov/ia/xdir_xftp/xftp.html.
laura III iiiyi* phoenbcxcfJlnl.gov i
connect Wr Select Ops,:-': j ||nnr Connect DJr Select Ops I 1
Otn llntxftpg.O -j |:.;уд:^|||[у ; Pin smith,'„j [ j
~8и.^>-,.^;:.'.'."■■■"..:, ,wiu ^ -?:'xferops ' -.. -jvjzz
[шашшпвиввн 11ш:>>*т>> 1 ] • 1|й|^ШШ^ммш# I
^ШШ^'Ш'Х^^Ш^ 1:1 ' г XfeVMode №^^.):^^^ "И
|~!?:?rf:-::i- f:?i?: ''•■■&. '' '"Н:'*"■"'■'■?'*''$*'>% 11 $ '■•'W Л%Я*11 j j ''"•\"_i'\x ■' $:*Z'&'.-: У УУ'\у '■ "..'-. =Г.::..'*.-*-*Г : •'•■';'■:■.'.' .:': }*?? ф\
l-vxSx'l.v/'•• • !-.<. ..:•....-.•. ■•:!'-"'••. . ..Л" ":'••!••!••!<! \ I : : I•"MfJV i.'v"".'.!'! ,>':,!-Л; '" I '"' |:J
еГ~~ **.*>"" "" iJ^' Л-Д. ■ , .PI ■ '"~%1а^-Л53 ' _|
| > 1 «w**..•■^:'.",:: :";"'—:—-::"M. r:1:-.1"-'":"? :':"'"" " ■"• ■—rrrr.—:':n i","""",":."• /u -.' • <"**' Щ
Рис. 27.3. Программа xftp с окном активного сеанса
Клиенты FTP для Windows и Macintosh
На платформах Windows и Macintosh тоже существуют свои клиенты FTP.
Многие из них имеют графический интерфейс, сходный с интерфейсом xftp и
позволяющий перемещать файлы между локальным и удаленным компьютерами
простым перетаскиванием мышью.
В некоторые реализации Windows входят клиенты FTP, работающие в режиме
командной строки. В других системах для работы с FTP используется программа
Internet Explorer, обладающая урезанными возможностями.
В табл. 27.3 приведен выборочный список клиентов FTP для Windows и
Macintosh.
Таблица 27.3. Клиенты FTP для Windows и Macintosh
Клиент FTP Web-сайт
WS-FTP Pro http://www.ipswitch.com
fetch http://www.dartmouth.edu/pages/softdev/fetch.html
CuteFTP http://www.cuteftp.com
FTPPro2000 http://www.ftppro.com
Электронная почта
Как ни странно, доступ FTP может работать даже по электронной почте. FTPmail
позволяет работать с FTP даже пользователям, имеющим доступ к Интернету
только по электронной почте. Любой пользователь может получать файлы с сайта
FTP, даже если он не может использовать FTP напрямую.
Некоторые серверы Интернета предоставляют пользователям сервис FTPmail.
На таких серверах создается учетная запись FTPmail, а пользователи включают
запросы FTP в сообщения электронной почты, адресованные этой учетной
записи (в запросах используются команды, аналогичные командам интерактивного
режима FTP).
При получении почтового запроса инициируется сеанс FTP, результаты
которого передаются пользователю по электронной почте. Если службе FTPMail не
удалось подключиться к серверу FTP, отправляется сообщение с объяснением причин.
Сервис FTPmail поддерживается многими серверами и доступен для всех
пользователей, работающих с электронной почтой.
В табл. 27.4 приведен список некоторых серверов FTPmail с указанием их
географического местонахождения.
Таблица 27.4. Серверы FTPmail
Сервер FTPmail Страна
ftpmail@grasp.insalyon.fr Франция
ftpmail@doc.ic.ac.uk Великобритания
ftpmail@decwrl.dec.com США
Серверы и демоны FTP
От клиентских программ FTP мы переходим к рассмотрению серверов FTP
и принципов их работы. Поскольку весь сервис FTP должен контролироваться
сервером, необходимо учитывать ряд основных правил, относящихся к работе
сервера FTP.
Unix и Linux
В Unix и Linux демон FTP in.ftpd обычно запускается супердемоном Интернета
inetd. Вместо in.ftpd подключения прослушиваются демоном inetd, тем самым
повышается безопасность управления подключениями. Дополнительная
информация о inetd приведена к главе 39.
В файл /etc/inetd.conf включается строка следующего вида:
ftp stream tcp nowait root /usr/sbin/in.ftpd. in.ftpd
Эта строка запускает in.ftpd. При вызове in.ftpd могут передаваться различные
параметры, в том числе -d (отладочный режим), -I (ведение журнала с
использованием syslogd) и -t (изменение продолжительности тайм-аута).
Windows NT/2000
В системах Windows 95/98 и NT/2000 также существуют свои серверы FTP.
К их числу относится сервер Serv-U (http://www/ftpserv-u.com) и демон War FTP
(http://www.jgaa.com/tftpd.htm).
Анонимный доступ FTP
Несмотря на популярность Web в современном мире, анонимные FTP-сайты
остаются важной частью Интернета. В Интернете существует бесчисленное
множество анонимных сайтов, на которых хранится различная информация, файлы
и программное обеспечение. Одним из самых популярных анонимных FTP-сай-
тов является сайт wuarchlve.wustl.edu.
Многие анонимные сайты предоставляют свободный доступ к файлам,
потому что они пытаются организовать распространение информации без хлопот,
связанных с назначением имен и паролей постоянно увеличивающемуся
количеству пользователей в Интернете.
Анонимные серверы FTP
Анонимный сервер FTP представляет собой общедоступное хранилище файлов.
Перед тем как основной движущей силой Интернета стала служба World Wide
Web, поиск файлов и информации в Интернете осуществлялся при помощи
gopher (интернет-приложение на базе меню) и FTP.
В результате анонимный сервис FTP стал чрезвычайно популярным и
продолжает широко использоваться в наши дни. Анонимные серверы FTP должны
функционировать в отдельной среде и дисковом пространстве, полностью
отделенной от системных файлов.
Например, в системе Unix существуют каталоги /usr и /etc. Такие же каталоги
существуют и на анонимном сервере FTP в системе Unix, однако каталоги /etc
системы Unix и анонимного сервера содержат разные файлы. Дело в том, что
доступ клиентов FTP ограничивается домашним каталогом учетной записи
пользователя ftp; обычно это каталог /home/ftp. Файлы каталогов /etc и /public сервера
FTP расположены внутри каталога /home/ftp и называются /home/ftp/etc и /home/
ftp/public.
Из этого следует, что системные файлы не хранятся в каталоге анонимного
сервера FTP. Этот участок файловой системы специально выделяется для соз-
дания среды, полностью отделенной от жизненно важных компонентов
операционной системы.
Анонимные клиенты FTP
При входе на анонимный сервер FTP пользователь обычно регистрируется под
именем «anonymous» или «ftp», а в качестве пароля вводится адрес электронной
почты (например, stripes@tigerlair.com).
Для анонимного сервиса FTP также устанавливаются ограничения доступа.
Обычно по соображениям безопасности пользователям разрешается обращаться
только к общедоступным файлам, а доступ к системным и конфигурационным
файлам блокируется.
Ниже приведен пример анонимного сеанса FTP с выдачей заставки
анонимного FTP-сайта.
tigerlair:/home/stripes- ftp wuarchive.wustl.edu
Connected to wuarchive.wustl.edu
220 wuarchive.wustl.edu FTP server (Version wu-2.4.2-academ[BETA-16]
A) Wed Apr 1 08:28:10 CST 1998) ready.
Name (wuarchive.wustl.edu:stripes): anonymous
331 Guest login ok, send your complete e-mail address as password.
Password:
230- If your FTP client crashes or hangs shortly after login please try
230- using a dash (-) as the first character of your password. This
230- will turn off the informational messages that may be confusing your
230- FTP client.
230-
230- This system may be used 24 hours a day, 7 days a week. The local
230- time is Wed May 26 12:02:37 1999. You are user number 23 out of a
230- possible 500. All transfers to and from wuarchive are logged. If
230- you don't like this then please disconnect.
230-
230- Wuarchive is currently a Sun Ultra Enterprise 2 Server.
230-
230- Wuarchive is connected to the Internet over a T3 D5 Mb/s) line from
230- STARnet and MCI. Thanks to both of these groups for their support.
230-
230- Welcome to wuarchive.wustl.edu, a public service of Washington
230- University in St.Louis, Missouri USA.
230-
230-
230-
230 Guest login ok, access restirctions apply.
Remote system type is Unix.
Using binary mode to transfer files.
ftp>
Из-за широкого распространения Web для работы с анонимными сайтами
вместо клиента FTP часто используется браузер.
ХЭВЕТ
В качестве пароля не обязательно вводить весь адрес электронной почты, достаточно ввести
первую часть (имя@). Например, вместо stripes@tigerlair.com достаточно ввести stripes®.
TFTP
Протокол TFTP (Trivial FTP) может использоваться для пересылки файлов
в локальной сети. Он использует транспортный протокол UDP и передает
данные через порт UDP с номером 69.
Поскольку TFTP не поддерживает никакой проверки регистрационных данных
пользователя, он создает немалое количество проблем безопасности. В
современных сетях он чаще всего применяется для пересылки списков доступа с рабочих
станций на маршрутизаторы и для настройки маршрутизаторов. Кроме того, TFTP
применяется для загрузки бездисковых систем посредством загрузки образа
системы с сервера TFTP. По сравнению с FTP этот протокол устроен проще
(хотя и обладает меньшими возможностями) и легче встраивается в ПЗУ
сетевых плат на бездисковых рабочих станциях.
ВНИМАНИЕ
Не используйте TFTP, если это не объясняется абсолютной необходимостью. При малейшей
невнимательности со стороны администратора этот протокол создает большие проблемы
безопасности, включая доступ к файлам паролей. По умолчанию доступ TFTP ограничивается каталогом
/tftpboot, что считается рудиментарной формой безопасности. Если отменить это ограничение,
клиент TFTP получит доступ к остальным частям файловой системы без прохождения
аутентификации. Это крайне опасная ситуация!
В настоящее время существует версия 2 протокола TFTP, ее спецификация
приведена в RFC 1350. В отличие от протокола FTP, использующего
транспортный протокол TCP, TFTP использует протокол UDP, поэтому он отличается
простотой и компактностью. Как и FTP, TFTP запускается через inetd.
Каждый обмен пакетами между клиентом и сервером начинается с
клиентского запроса к серверу на чтение или запись файла. Другие операции в TFTP
не поддерживаются.
Пересылка файлов производится в текстовом или в двоичном режиме. В
текстовом режиме строки данных представляют собой последовательность ASCII-
символов, завершенную символами возврата курсора и перевода строки (CR/LF).
Отличия TFTP от FTP
TFTP не обладает многими возможностями, поддерживаемыми FTP. В
частности, TFTP не позволяет использовать метасимволы, создавать или удалять
каталоги и даже отдельные файлы. Кроме того, TFTP не запрашивает имя
пользователя и пароль; следовательно, ограничение доступа должно производиться
другими средствами.
Благодаря своей простоте протокол TFTP используется маршрутизаторами
для пересылки списков доступа и конфигурационных данных маршрутизации.
Поскольку регистрация пользовательских данных на маршрутизаторах не
применяется (при отсутствии контроля доступа с применением TACACS+ или
RADIUS).
Команды TFTP
Тот, кто хорошо понимает принципы работы FTP, без труда разберется в TFTP.
Количество команд TFTP невелико, все команды перечислены в табл. 27.5. У
многих команд существуют прямые аналоги в протоколе FTP.
Таблица 27.5. Команды EFTP
Команда Описание
ascii Выбор текстового режима пересылки
binary Выбор двоичного режима пересылки
connect Подключение к удаленному серверу TFTP
mode Выбор режима пересылки файлов
put Пересылка файла на удаленный сайт
get Загрузка файла с удаленного сайта
quit Завершение работы с TFTP
rexmt <значение> Установка интервала тайм-аута пакетного уровня
status Вывод информации о состоянии сервера
timeout <секунды> Установка тайм-аута пересылки (в секундах)
trace Включение трассировки пакетов
verbose Разрешение/запрет расширенного вывода
Итоги
Протоколы пересылки файлов играют важную роль в обмене информацией между
системами в сетях TCP/IP. Двумя основными протоколами, используемыми
для пересылки файлов в сетях TCP/IP, являются протоколы FTP и TFTP.
Протокол FTP использует в качестве транспортного протокола TCP и
открывает два порта: порт 20 (порт данных) и порт 21 (управляющий порт). Порт
данных используется только для пересылки файлов, а управляющий порт
используется для отправки команд и сообщений.
Протокол TFTP, использующий транспортный протокол UDP,
ограничивается открытием одного порта с номером 69. Протокол TFTP гораздо проще FTP
и не поддерживает многие из его возможностей. Тем не менее TFTP часто
применяется для передачи списков доступа и конфигурационных данных на
маршрутизаторы. Кроме того, он используется для загрузки бездисковых систем.
Следующая глава посвящена протоколу Telnet. В ней вы познакомитесь с
другой разновидностью интерактивных сетевых служб TCP/IP.
*ЪО Telnet
Нил С. Джеймисон (Neal S.Jamison)
Хотя эмуляция терминала в наши дни уже не пользуется такой популярностью,
как раньше, она остается необходимым средством для работы в
многопользовательских системах. Telnet также является базой для других протоколов —
например, для X-Window при установке сеанса с клиентом X. Telnet относится
к категории «тонких клиентов», поскольку все выполнение происходит на
сервере Telnet. Кроме того, Telnet часто используется в качестве диагностического
средства. В настоящей главе рассматриваются средства эмуляции терминала
в Интернете: протокол TCP/IP Telnet и сопутствующие программы.
Знакомство с протоколом Telnet
Telnet — один из самых ранних протоколов TCP/IP. Достаточно интересную
информацию по этой теме можно найти в RFC 15 (документ написан в 1969 году!).
Текущая спецификация Telnet приводится в RFC 854.
Протокол Telnet предназначался для упрощения подключений к удаленным
хостам. Например, для подключения к мэйнфрейму IBM требовались терминалы
IBM, а если мэйнфрейм был выпущен фирмой DEC — приходилось
использовать терминалы DEC. Рисунок 28.1 поясняет ситуацию.
Возникла необходимость в службе эмуляции терминала, которая бы заменила
все специализированные языки управления терминалами. В этом случае
пользователь мог бы находиться за одним терминалом и подключаться к разным
удаленным хостам. Так появился протокол Telnet.
Telnet — стандартный прикладной протокол Интернета, предназначенный
для входа на удаленные хосты. Он обеспечивает механизм шифрования и
другой сервис, необходимый для подключения пользовательской системы к
удаленному хосту.
Telnet использует надежный транспорт TCP, поскольку он должен
поддерживать надежную, стабильную связь. По умолчанию сервер TCP/IP прослушивает
хорошо известный порт TCP с номером 23. Клиент Telnet может быть настроен
на подключение к любому другому порту, на котором работает другая служба.
Это позволяет использовать клиента Telnet для передачи команд конкретным
службам приложений и для целей диагностики.
Терминал ^
IBM 1 J
Терминал И Мэйнфрейм IBM
IBM I J
Терминал И
IBM
Терминал П
HFC] I J
Терминал П Мэйнфрейм DEC
DFC| 1 J
Терминал П
DEC
Терминал П
XY7 I J
Терминал П Мэйнфрейм XYZ
XY7 I J
Терминал \
XYZ
Рис. 28.1. Жесткая структура распределения терминалов до создания Telnet
Telnet может работать в следующих режимах:
О полудуплексный;
О посимвольный;
О построчный;
О локальный.
Полудуплексный режим считается устаревшим.
В посимвольном режиме каждый вводимый символ немедленно передается
удаленному хосту для обработки, а затем возвращается клиенту. В медленных
сетях этот режим создает раздражающие задержки, но во многих реализациях
он используется по умолчанию.
В построчном режиме текст проходит локальный эхо-вывод, а законченные
строки передаются удаленному хосту для обработки.
В локальном режиме обработка символов производится в локальной системе
под контролем удаленной системы.
Дополнительная информация о Telnet приведена в следующих RFC:
О RFC 15, «Network subsystem for time sharing hosts», C.S. Carr, 1969 r.
О RFC 854, «Telnet Protocol Specification», J. Postel, J.K. Reynolds, 1983 r.
О RFC 855, «Telnet Option Specifications», J. Postel, J.K. Reynolds, 1983 r.
О RFC 856, «Telnet Binary Transmission», J. Postel, J.K. Reynolds, 1983 r.
О RFC 857, «Telnet Echo Option», J. Postel, J.K. Reynolds, 1983 r.
О RFC 858, «Telnet Suppress Go Ahead Option», J. Postel, J.K. Reynolds, 1983 r.
О RFC 859, «Telnet Status Option», J. Postel, J.K. Reynolds, 1983 r.
О RFC 860, «Telnet Timing Mark Option», J. Postel, J.K. Reynolds, 1983 r.
О RFC 861, «Telnet Extended Options: List Option», J. Postel, J.K. Reynolds, 1983 r.
О RFC 1123, «Requirements for Internet hosts — application and support»,
R.T. Braden, 1989 r.
О RFC 1184, «Telnet Linemode Option», D.A. Borman, 1990 r.
О RFC 1205, «Telnet Interface», P. Chmielewski, 1991 r.
О RFC 1372, «Telnet Remote Flow Control Option», С Hedrick, D. Borman, 1992 r.
О RFC 1408, «Telnet Environment Option», D. Borman, 1993 r.
О RFC 1411, «Telnet Authentication: Kerberos Version 4», D. Borman, 1993.
О RFC 1412, «Telnet Authentication: SPX», K. Alagappan, 1993 r.
О RFC 1416, «Telnet Authentication Option», D. Borman, 1993 r.
О RFC 1571, «Telnet Environment Option Interoperability Issues», D. Borman, 1994 r.
О RFC 1572, «Telnet Environment Option», S. Alexander, 1994 r.
О RFC 2066, «TELNET CHARSET Option», R. Gellens, 1997 r.
О RFC 2217, «Telnet Com Port Control Option», G. Clark, 1997 r.
Некоторые RFC, посвященные Telnet, содержат менее серьезную информацию:
О RFC 748, «Telnet randomly-lose option», M.R. Crispin, 1978 r.
О RFC 1097, «Telnet subliminal-message option», B. Miller, 1989 r.
Виртуальный терминал
В повседневной работе используется множество разнотипных компьютеров с
разными клавиатурами и другими устройствами ввода данных, поэтому Telnet
приходится решать нетривиальную задачу. Устройства ввода и компьютеры говорят
на разных «языках», от различных диалектов ASCII до EBCDIC, что существенно
затрудняет взаимодействие между ними. Для упрощения этой задачи была
разработана концепция виртуального термина (NVT, Network Virtual Terminal).
Структура логических связей между клиентами, серверами и соответствующими
виртуальными терминалами представлена на рис. 28.2.
Виртуальный терминал получает данные, вводимые в клиентской системе,
и переводит их на универсальный «язык». Получаемые данные переводятся с
универсального языка на специализированный язык, воспринимаемый хостом.
J Мэйнфрейм IBM
Хост с Telnet \>^
I NVT I N. """"""" 4 Мэйнфрейм DEC
N Мэйнфрейм XYZ
Рис. 28.2. Telnet и NVT упрощают подключение терминалов к различным хостам
Виртуальные терминалы позволяют любому специализированному клиенту
взаимодействовать с любым специализированным хостом.
Демон Telnet
Как и другие службы TCP/IP, работающие по схеме «клиент-сервер», для
обработки клиентских запросов в системе должен быть запущен демон Telnet.
В семействе Unix этим демоном является сервер Telnet, обрабатывающий запросы
клиента Telnet. По умолчанию демон Telnet работает на порте 23.
Ниже приведено описание синтаксиса и параметров in.telnetd,
позаимствованное из электронной документации операционной системы Linux. За
дополнительной информацией, относящейся к конкретной реализации, обращайтесь к
печатной или электронной документации вашей операционной системы.
/usr/sbin/in.telnetd [-hns] [-а режим_аутен] [-D режим_отладки]
[-L прог_журнал] [-S tos] [-X тип_аутен] [-е debug] [-debug порт]
Параметры:
О -а режим_аутен — режим, используемый при аутентификации. Параметр
используется только в том случае, если демон telnetd был откомпилирован с
поддержкой аутентификации. Параметр режим jxymen может принимать
следующие значения:
□ debug — отладка процедуры аутентификации;
□ user — подключение осуществляется только в том случае, если удаленный
пользователь предоставляет действительную информацию, необходимую
для идентификации, и обладает правом доступа к указанной учетной
записи без предоставления пароля;
□ valid — подключение осуществляется только в том случае, если удаленный
пользователь предоставляет действительную информацию, необходимую
для идентификации;
□ other — подключение осуществляется только в том случае, если
удаленный пользователь предоставляет некоторую информацию, необходимую
для идентификации;
□ попе — используется по умолчанию. Предоставление данных для
аутентификации не обязательно;
□ off — код аутентификации полностью блокируется.
О -D режим_отладки — используется в отладочных целях. Параметр позволяет
telnetd выводить отладочную информацию о подключении, по которой
пользователь может следить за работой telnetd. Параметр режим_отладки может
принимать следующие значения:
□ options — вывод информации о согласованных параметрах Telnet;
□ report — вывод сведений о параметрах, а также дополнительной
информации о том, что происходит в системе;
□ netdata — вывод потока данных, принимаемого telnetd;
□ ptydata — вывод информации, выводимой на псевдотерминал.
О -е debug — включение отладки шифрования.
О -h — подавление вывода информации о хосте перед завершением входа в
систему.
О -L прог__журнал — параметр может использоваться для смены программы
ведения журнала (по умолчанию используется /bin/login).
О -п — запрет поддержания соединений TCP. В обычной ситуации telnetd
позволяет механизму поддержания соединений TCP «зондировать»
подключения, у которых в течение некоторого времени отсутствовал обмен данными.
Такая проверка выполняется для того, чтобы из системы своевременно
удалялись бездействующие подключения от «зависших» или недоступных
компьютеров.
О -s — параметр доступен только в том случае, если демон telnetd был
откомпилирован с поддержкой карт SecurlD. Параметр -s передается login и реально
используется только в том случае, если login поддерживает флаг -s,
указывающий, что вход в систему допускается только при проверке SecurlD. Обычно
эта возможность используется для управления удаленными подключениями
из-за брандмауэра.
О -S tos — параметру типа службы IP (Type of Service) для подключения Telnet
присваивается заданное значение.
О -X munjxymen — параметр используется только в том случае, если демон
telnetd был откомпилирован с поддержкой аутентификации. Он запрещает
применение аутентификации заданного типа и может использоваться для
временного подавления без необходимости перекомпилировать telnetd.
Использование Telnet
Протокол Telnet очень прост в работе. Его применение состоит из трех очень
простых этапов:
О Запуск клиента Telnet (инициирование сеанса).
О Ввод имени пользователя и пароля.
О Завершение сеанса после выполнения всех необходимых действий.
Telnet работает в двух режимах: в режиме ввода и в командном режиме.
Впрочем, в большинстве случаев взаимодействие пользователя с Telnet
ограничивается запуском/завершением сеанса и работой с удаленной операционной
системой или программой в режиме ввода.
Команда telnet в системе Unix
Ниже рассматривается синтаксис и параметры реализации telnet в
операционной системе Linux. Многие реализации очень похожи на нее, однако за
подробной информацией о команде telnet для вашей системы следует обращаться к
печатной или электронной документации. Синтаксис команды telnet:
telnet [-8ELadr] [-S tos] [-e экран_символ] [-1 пользователь]
[-n файл_трас] [хост [порт]]
Параметры:
О -8 — запрос на использование 8-разрядного режима.
О -Е — запрет использования экранирующих символов.
О -L — 8-разрядные выходные данные.
О -а — попытка автоматического входа в систему при подключении. Имя
пользователя передается в переменной USER, если такая возможность
поддерживается удаленным хостом.
О -d — флаг отладки инициализируется значением TRUE.
О -г — эмуляция rlogin.
О -S tos — параметру типа службы IP (Type of Service) для подключения Telnet
присваивается заданное значение.
О -е экрап_символ — заданный символ используется в качестве
экранирующего.
О -I пользователь — имя пользователя, используемое при входе в удаленную
систему. Параметр сходен с параметром -а.
О -п файл_трас — заданный файл открывается для записи трассировочных
данных.
О хост — хост, с которым устанавливается связь по сети.
О порт — номер порта или имя службы для установки связи. Если значение не
задано, используется хорошо известный порт с номером 23.
Графические клиенты Telnet
Графические клиенты упрощают работу с Telnet на других платформах. В среде
Windows широко распространены программы Microsoft Telnet и CRT. Microsoft
Telnet входит в комплект поставки операционных систем Microsoft Windows
(Windows NT/2000, Windows 98 и т. д.). Программа CRT (VanDyke Technologies)
распространяется условно-бесплатно и присутствует на многих сайтах с
условно-бесплатным программным обеспечением Windows.
Два этих приложения в действии изображены на рис. 28.3 и 28.4.
У ' дШ - ^-МнаоЙ$©?:.• i: • • 1 j
р •■•^^^ов^ j J
| ^'■ ■ У^Щ^Щ^^^^^^ 1 I
I х;/^ ] j
:; 1,,^ т., liiHiiiiiriniЛимитна;! I :]
Рис. 28.3. Распространенное приложение Microsoft Telnet
ЙШ*1-1Д -■?-::.Г:-;7 ;•
1 * 11
| Ь&:Й: Ш:к:^ {:\;::^"Mww.y^c|vkeLCom' I 11
| ХШр@(ккА^Ъег^ей^о:цШ':'.-:<:.:/ I II
I •; ■; ш иш;..v-isй}}>Ш&Ш, . •. • . :.= I]
II ▼ ] 1
[Ready; У.';'-у .;::;/, , '•".•.••.• 6::.':^.?Щ^ЩЩ-$^^
Рис. 28.4. Другая популярная программа эмуляции терминала CRT
(разработчик — Van Dyke Technologies, Inc.)
Команды Telnet
Благодаря простому пользовательскому интерфейсу Telnet типичному
пользователю обычно не приходится вводить команды, приведенные ниже. Как
упоминалось выше, большая часть сеанса Telnet (а то и весь сеанс) проходит в режиме
ввода, то есть за непосредственным взаимодействием с удаленной операционной
системой или программой. Некоторые команды (такие, как TOGGLE) пригодятся
опытным пользователям и системным администраторам при диагностике проблем.
Чтобы получить список команд Telnet, введите команду HELP в режиме
командной строки. Пример:
$ telnet
telnet> help
Commands may be abbreviated. Commands are:
close close current connection
logout forcibly logout remote user and close the connection
display display operating parameters
mode try to enter line or character mode ('mode ?' for more)
open connect to a site
quit exit telnet
send transmit special characters ('send ?' for more)
set set operating parameters ('set ?' for more)
unset unset operating parameters ('unset ?' for more)
status print status information
toggle toggle operating parameters ('toggle ?' for more)
sic set treatment of special characters
z suspend telnet
environ change environment variables ('environ ?' for more)
telnet>
Чтобы получить справку по конкретной команде, введите имя команды и
вопросительный знак, как показано ниже:
telnet> mode ?
format is: 'mode Mode', where 'Mode' is one of:
character Disable LINEMODE option
(or disable obsolete line-by-line mode)
line Enable LINEMODE option
(or enable obsolete line-by-line mode)
These require the LINEMODE option to be enabled
isig Enable signal trapping
-isig Disable signal trapping
edit Enable character editing
-edit Disable character editing
softtabs Enable tab expansion
-softtabs Disable tab expansion
litecho Enable literal character echo
-litecho Disable literal character echo
? Print help information
telnet>
В табл. 28.1 приведен полный набор команд Telnet.
ПРИМЕЧАНИЕ
Описания команды и параметров Telnet, приведенные в табл. 28.1—28.3, взяты из электронной
документации telnet операционной системы Linux. За информацией, специфической для вашей
реализации, обращайтесь к печатной или электронной документации операционной системы.
Таблица 28.1. Команды Telnet
Команда Описание
CLOSE Закрытие подключения к удаленному хосту
DISPLAY Вывод заданных параметров работы
ENVIRON Изменение переменных окружения
HELP (или ?) Вывод справочной информации (для получения справки по отдельным
командам используется запись команда ?)
LOGOUT Принудительное отключение удаленного пользователя с закрытием
подключения. Аналог команды CLOSE
MODE Запрос на переход в построчный или посимвольный режим
OPEN Открытие подключения к удаленному хосту
QUIT Закрытие сеанса с выходом из Telnet
SEND Передача служебной последовательности символов (см. табл. 28.3)
SET Установка рабочих параметров. См. также UNSET
SLC Назначение определения и/или интерпретации специальных символов
STATUS Вывод текущей информации состояния — имени хоста, режима и т. д.
TOGGLE Переключение рабочих параметров. Список основных параметров приведен
в табл. 28.2
UNSET Сброс рабочих параметров. См. также SET
Z Приостановка Telnet (выполнение продолжается командой fg)
! [команда] Выполнение заданной команды в командном интерпретаторе. Если команда
не указана, запускается новый экземпляр интерпретатора
Некоторые команды Telnet — такие, как TOGGLE и SEND — требуют
дополнительных параметров. В табл. 28.2 перечислены некоторые распространенные параметры
команды TOGGLE, а в табл. 28.3 приводится список параметров команды Telnet SEND.
Команда TOGGLE переключает заданный параметр в противоположное
логическое состояние (из TRUE в FALSE, и наоборот).
Таблица 28.2. Некоторые распространенные параметры команды Telnet TOGGLE
Параметр Описание
debug Переключение режима отладки уровня сокетов. Начальное значение
параметра равно FALSE
skiprc Если параметр skiprc равен TRUE, Telnet не читает файл .telnetrc.
Начальное значение параметра равно FALSE
? Вывод списка допустимых параметров TOGGLE
Команда SEND используется для передачи команд и параметров удаленному
хосту. В табл. 28.3 перечислены параметры команды SEND.
Таблица 28.3. Параметры команды Telnet SEND
Параметр Описание
EOF Конец файла
SUSP Приостановка текущего процесса
ABORT Отмена процесса
EOR Конец записи
SE Конец подпараметра
NOP Нет операции
DM Метка данных
BRK Прерывание
IP Прерывание процесса
АО Отмена вывода
AYT Проверка связи
ЕС Экранирующий символ
EL Стирание строки
GA Вперед
SB Начало подпараметра
WILL Согласование параметра
WONT Согласование параметра
DO Согласование параметра
DONT Согласование параметра
IAC Байт данных 255
Примеры использования Telnet
Следующий пример демонстрирует процедуру согласования, которая обычно
проходит незаметно для пользователя. Расширенный вывод обеспечивается
командой TOGGLE OPTIONS:
% telnet
telnet> toggle options
Will show option processing.
telnet> open hostl.mydomain.com
Trying...
Connected to hostl.mydomain.com.
Escape character is ,Л]'.
SENT DO SUPPRESS GO AHEAD
SENT WILL TERMINAL TYPE
SENT DO SUPPRESS GO AHEAD
SENT WILL NAWS
SENT WILL TSPEED
SENT WILL LFLOW
SENT WILL LINEMODE
SENT WILL NEW-ENVIRON
SENT DO STATUS
RCVD DO TERMINAL TYPE
RCVD DO TSPEED
RCVD DO XDISPLOC
RCVD WONT XDISPLOC
RCVD DO NEW-ENVIRON
RCVD WILL SUPPRESS GO AHEAD
RCVD DO NAWS
SENT IAC SB (terminated by -1 -16, not IAC SE!) NAWS 0 95 (95) 0 29 B9)
RCVD DO LFLOW
RCVD DON'T LINEMODE
RCVD WILL STATUS
RCVD IAC SV (terminated by -1 -16. not IAC SE!) TERMINAL-SPEED SEND
RCVD IAC SV (terminated by -1 -16, not IAC SE!) ENVIRON SEND
RCVD IAC SV (terminated by -1 -16. not IAC SE!) ENVIRON IS
RCVD IAC SV (terminated by -1 -16, not IAC SE!) TERMINAL-TYPE SEND
RCVD DO ECHO
RCVD WONT ECHO
RCVD WILL ECHO
SENT DO ECHO
Access to this system is restricted to authorized users only,
login:
Дополнительные возможности Telnet
В этом разделе рассматриваются некоторые интересные аспекты Telnet —
безопасность, приложения на базе Telnet и использование Telnet для работы с
другими популярными службами TCP/IP.
Безопасность
Telnet, как и все программы и приложения TCP, создает определенные проблемы
в области безопасности. Тем не менее существует целый ряд инструментов,
которые помогают обезопасить использование Telnet или заменить его другими
средствами.
TCP Wrappers
Пакет TCP Wrappers (иногда называемый tcpd) представляет собой набор
инструментов, работающих на базе демонов TCP (таких, как in.telnetd) и
обеспечивающих сервис мониторинга и фильтрации в программах TCP. При помощи
TCP Wrappers систему можно настроить таким образом, чтобы она отвечала
только на запросы Telnet, поступающие от заданных компьютеров или доменов.
Автором TCP Wrappers является Витце Венема (Wietse Venema).
В некоторых операционных системах функциональность TCP Wrappers
реализуется на внутреннем уровне. В других системах вам придется загрузить и
установить TCP Wrappers самостоятельно. В следующем подразделе описан
процесс настройки файлов /etc/hosts.allow и /etc/hosts.deny для TCP Wrappers.
Настройка файлов /etc/hosts.allow и /etc/hosts.deny
Файлы /etc/hosts.allow и /etc/hosts.deny используются при организации доступа
к хосту, в том числе и программой TCP Wrappers, для определения того, кому
разрешено или запрещено выполнение некоторых команд на компьютере.
Например, файл hosts.deny может содержать запись
In.telnetd: AU
тогда как в файле hosts.allow будет находиться запись
in.telnetd: *.mydomain.com
В этом примере запись в файле hosts.deny запрещает доступ к Telnet всем
пользователям, а запись в файле hosts.allow разрешает доступ с хостов домена
mydomain.com.
За дополнительной информацией о TCP Wrappers обращайтесь по адресу
ftp://ftp.porcupine.org/pub/security/index.html.
Secure Shell
Secure Shell (SSH) является безопасной альтернативой для Telnet. Благодаря
использованию механизмов шифрования типа DES (Data Encryption Standard)
и механизма аутентификации хостов RSA SSH защищает хосты от некоторых
стандартных атак — таких, как фальсификация IP и перехват паролей. SSH
создает между клиентом и сервером виртуальную частную сеть (VPN).
Для некоммерческого использования SSH распространяется бесплатно. За
дополнительной информацией о SSH обращайтесь по адресам http://www.ssh.fi/
sshprotocols2/ и www.openssh.org.
Приложения Telnet
Telnet часто используется для работы с удаленными приложениями. В индексе
Hytelnet хранится информация о библиотеках и других ресурсах, доступных
через Telnet. Хотя по популярности и простоте использования на первое место
вышла служба World Wide Web, многие из этих сайтов по-прежнему доступны
для пользователей.
На рис. 28.5 и 28.6 показана программа Hytelnet 6.9 для Windows.
С Hytelnet также можно работать через Web по адресу http://www.ljghts.com/
hytelnet.
Среди других приложений Telnet можно упомянуть интерфейсы для Whois
и Finger. Дополнительная информация приведена в главе 26.
|8ВН5ЕСД!Е5!Ш
gte &fc Search $&*** Ф*,.;;! .,';• £ * Л,'^"','•••.,'■■■:--!"'■■■••' •;:•••-'' Vr^v^'iC ' ;-'У:
|ss.:- '• • • • ,. /:::. ,f •: • ••• •:!:.!. K)gE^^«^i»ft • ;6^^; ■ • ^i ;• 4 ■ • .а Щ1^.|ЙЙ A.|fij
г " • C* dfesiWi to. ***te£f'U8o^
indorsation «it©* 4ltp&*2A*t, specifically tbo*« ««»**» who? j
I •■ •■ «cces* Teloot ш^IМм or tbe «tMMwt-f«**••£%:.-IBH^r-'•• J I
Г compatible personajLso^pufcerv.. :/..'; ••. Jvf^.:;, \.{-'\ \
I : When loaded* НУТЕЬНШ i* «mrwrj^residettt. Once loaded hitj 1
' Control* JB*etep«wi^;^tl4***- tl».,|^«r*»* T«^S3««v^'il»S j
• • ЙЫЧТ- while in• t^;:|^^w*». . :::.::'::::у I j
[ . : ■ t>or indorsation on см*Ш№Щ( the pMhriM* •••^'ffjf^fr -^fofefov.:::: ] j
I . For «ccessible tih*mx#M'&Wb catalog* ... "• Y<MTBW>"---^£?-:;\^»l j
[ .'" .For other in£eJW*tlonj*^^J:^:f;; 7",<">',.^it«2>™^^s^:-%?1,^.j j
. - Fa* extra information on ifladiftjr the pro#rdiq and bow :Ы#£:Ь^:У| 1
.;• • oonta*^tb» authorf^^ j
! £revio«* item ^йщ Hytelnet for Windows $*>*9хИ
I <<Jg^ck«w*d1 '—*-"-—j FaqeiAj^iJj * p".w:.^... 1
Рис. 28.5. Справочная информация о Hytelnet для Windows
jfo £drt jeartth gptiom #ф •,.■■" ,; Ч:Щ;^ :; ' '■ .■' / ' ■'■ 2\ : I
j" — - -....,, T-^'[4ix^'iM'fi»^J^7"'''" y;:;:T''-'™ -"""M ~~|>j|
teelnet vtls*vt.ed« or %&:*Х&'ф±Ь*?-?:*Щ$$£г/<Г- :.:-;:" ;U-M
Hit: <KHTUHH> one* or -twi^ey. • . ^ 1Шж Щ 1
I It о exit, |||ИИ1РуР»1ТЦ|1 i и^^^^^^^^^^^^^^^^^^^^^^^^^^^^д l ^i | j|
L:h£- -= 1 ЗЙЙft~l>>1*15Г#SiielM'jj ;:T '. "" """T7":,'Hi
I • •;. .• ;• ]4.4 BSD UNIX (artewis.cc.vt.edu) <16) '"""Ц j
|:<::'':':^::'::й:;Ш:*%-;::||* * j
ЬЗ:'Щ^Я|« Welcome to VTLS « j
hbSSlSI* {Release 1999) * j
ШШМ$*£Ш* VTLS is e proprietary library software product * j
Ш:|Щ1Щ|* of VTLS, Inc., Blacksburg, Virginia 24060, USA. • j
||Щ||||||||* Copyright <c> 1984, VTLS Inc. fill rights reserved. « J
M :•' 1* * ,:i
I ft^Ilfll WELCOME to Addison Щ
v '<.< fi.a«i«w| Virginia Tech Libraries Online Catalog щ1
p .':'.:1i;:t|l Please enter '/QUIT' to exit... 'Щ
| LOCATION is NEWMAN ЦЛ
|] Enter уН||
||/HELP.......General help HELP...About this screen Any new command *~1 J
!l 3
Рис. 28.6. Обращение к электронной библиотеке при помощи
программ Hytelnet для Windows и CRT
Работа с другими службами TCP/IP через Telnet
Хотя для выполнения своих основных функций Telnet использует порт TCP
с номером 23, демон Telnet прослушивает и отвечает на запросы, поступающие
на другие хорошо известные порты TCP. Это позволяет использовать Telnet в
сочетании с другими службами TCP/IP. В табл. 28.4 приведены номера портов
для некоторых стандартных служб TCP/IP, доступных через Telnet.
Таблица 28.4. Порты основных служб, доступных через Telnet
Служба Порт
FTP 21
SMTP 25
Whois 43
Finger 79
HTTP 80
Для подключения к этим службам через Telnet используется команда вида
telnet хост порт
или
telnet хост служба
Во втором случае вместо номера порта указывается имя службы — например,
SMTP вместо номера 25. Сервер Telnet на хосте находит номер службы в
системном файле (в большинстве реализаций Unix это файл /etc/services) и открывает
подключение к порту, соответствующему заданной службе. В следующем разделе
процедура открытия порта по имени службы поясняется конкретным примером.
Отправка почты через Telnet
Telnet может использоваться для подключения к хорошо известному порту SMTP
с номером 25. Администраторы и лица, ответственные за работу почты, часто
поступают подобным образом для диагностики проблем с электронной почтой.
В следующем примере Telnet используется для подключения к порту SMTP
и выполнения команды VRFY. За дополнительной информацией о SMTP
обращайтесь к главе 35.
$ telnet host.mydomain.com SMTP
Trying...
Connected to host.mydomain.com.
Escape character is ,A]'.
220 host.mydomain.com ESMTP Sendmail 8.8.8+Sun/8.8.8; 8 Aug 1999 17:14
vrfy jamisonn
250 Neal Jamison <jamisonn@host.mydomain.com>
qui t
221 host.mydomain.com closing connection
Connection closed by foreign host.
Выполняя нужные команды SMTP, вы даже сможете отправлять сообщения.
Finger
Протокол Telnet также позволяет подключиться к порту Finger G9) удаленного
хоста, как это сделано в следующем примере:
$ telnet hostl.mydomain.com 79
Trying...
Connected to hostl.mydomain.com.
Escape character is ,Л]'.
jamisonn
Login: jamisonn Name: Neal Jamison
Directory: /users/home/jamisonn Shell: /bin/tcsh
On since Sun Aug 8 17:16 (EDT) on ttyp7 from роо118Э-68
No mail.
No Plan.
Connection closed by foreign host.
После создания подключения вводится однострочный запрос (jamisonn).
Сервер Finger отвечает на полученный запрос. Подключение через Telnet может
пригодиться в том случае, если вам придется работать в среде без клиента Finger.
За дополнительной информацией о Finger обращайтесь к главе 29.
Работа в Web через Telnet
Как показывает следующий пример, Telnet также может использоваться для
подключения к порту HTTP (80) web-сервера.
$ telnet mywebserver.com 80
Trying...
Connected to mywebserver.com.
Escape character is ,Л]'.
GET /
<HTML>
<HEAD>
<TITLE>Makoa Corporation</TITLE>
</HEAD>
<BODY>
<Hl>Welcome to the Makoa Corporation</Hl>
<p>
This is the homepage of Makoa Corporation.
<br><br>
</BODY>
</HTML>
Connection closed by foreign host.
После установления связи вводится команда HTTP GET /, запрашивающая
корневой документ web-сервера. Если вы не умеете интерпретировать код HTML
так же хорошо, как ваш браузер, вряд ли вам удастся применить полученный
результат на практике. В данном случае он приводится только для пояснения
материала, а также для проверки того, что сервер HTTP нормально работает на
порте TCP с номером 80. За дополнительной информацией о HTTP
обращайтесь к главе 26.
Итоги
В этой главе подробно описан протокол эмуляции терминала Telnet, входящий
в семейство протоколов TCP/IP. Протокол Telnet решил проблему
несовместимости терминалов, столь распространенную на стадии становления Интернета.
Благодаря Telnet и концепции виртуального терминала научные работники и
студенты обходились одним компьютерным терминалом, который при
необходимости подключался к разным хостам.
Далее был рассмотрен синтаксис и параметры запуска стандартного клиента
и сервера Telnet для системы Unix. Также были приведены описания команд
Telnet (которые, впрочем, редко применяются конечными пользователями).
Глава завершается кратким описанием проблем безопасности и приложений
Telnet. Читатель узнает, как использовать Telnet для подключения к другим
службам TCP/IP (таким, как почта SMTP, Finger и HTTP) и работы с ними.
Глава также содержит полный список документов RFC, относящихся к Telnet,
включая исходную спецификацию: RFC 15 от 1969 года.
^%С| Инструментарий
•■ *г удаленного доступа
Нил С. Джеймисои (Neal S.Jamison)
Как вы уже знаете, термин TCP/IP объединяет целое семейство протоколов,
обеспечивающих обмен информацией между компьютерами. Тем не менее для
построения объединенной сети одних коммуникационных протоколов
недостаточно. В дополнение к ним необходимы программы прикладного уровня, которые
используют протоколы и службы TCP/IP и обеспечивают обмен данными на
высоком уровне. В этой главе рассматривается конкретное семейство программ,
используемых при различных типах взаимодействия с удаленными компьютерами.
R-команды
Набор утилит с префиксом «г» (далее — «r-команды») был создан в сообществе
BSD Unix для того, чтобы программисты и пользователи могли работать на
удаленных компьютерах. В наши дни r-команды продолжают использоваться
в сообществе Unix и TCP/I и по-прежнему успешно справляются со своими
задачами. R-команды позволяют копировать файлы из одной системы в другую,
выполнять команды на удаленных компьютерах и даже создавать рабочие
сеансы с входом в удаленную систему. Однако в отличие от Telnet и FTP эти
команды могут настраиваться на работу без участия пользователя (то есть без
ввода имени и пароля).
Основные r-команды перечислены в табл. 29.1.
Таблица 29.1. R-команды в системах семейства Unix
Команда Описание
rsh Remote Shell: выполнение программы на удаленном компьютере. В некоторых
дистрибутивах Unix команда называется rshell, remsh или rcmd)
гср Remote Copy: копирование файла с одного компьютера на другой.
Функциональный аналог FTP
rlogin Remote Login: вход в систему на удаленном компьютере. Функциональный
аналог Telnet
Команда Описание
rup Remote Uptime: вывод информации о состоянии удаленного компьютера
ruptime Remote Uptime: вывод информации о состоянии удаленного компьютера (аналог rup)
rwho Remote Who: вывод текущего списка пользователей удаленного компьютера
rexec Remote Execution: Аналог rsh, но с обязательным вводом пароля
R-команды и безопасность
Работа r-команд основана на концепции «эквивалентности хостов». Компьютеры
настраиваются таким образом, чтобы некоторые «доверенные» хосты могли в
прозрачном режиме подключаться и запускать команды. Такой подход обладает
рядом недостатков. Во-первых, уровень защиты системы падает до уровня защиты
слабейшего доверенного хоста, а ошибка в настройке параметров может
предоставить несанкционированный доступ к системе. Во-вторых, если пользователь
не является доверенным и должен ввести пароль, этот пароль пересылается по
сети в виде простого, незашифрованного текста. Перехватив передаваемую
информацию, злоумышленник может получит доступ к сети.
Из-за проблем безопасности, создаваемых r-командам, многие эксперты
рекомендуют запретить их использование. Тем не менее, поскольку эти команды
продолжают широко использоваться на практике, в этой главе будут рассмотрены
основные принципы их настройки и использования. Кроме того, в ней будут
представлены альтернативные средства на тот случай, если вы последуете
рекомендациям и откажетесь от использования г-команд (см. «Альтернативы для
r-команд» ниже в этой главе).
Дополнительная информация о параметрах конфигурации приведена в
разделе «Справочник г-команд» настоящей главы.
ПРИМЕЧАНИЕ
Существует множество разнообразных диалектов операционной системы Unix; в этой главе
рассматривается реализация r-команд для системы Linux. Впрочем, основные концепции и принципы
использования этих команд остаются одинаковыми и практически не зависят от операционной
системы. За подробным описанием команд и их параметров обращайтесь к документации ОС.
Запрет использования г-команд
Чтобы запретить использование r-команд, следует закомментировать все
соответствующие строки в конфигурационном файле /etc/inetd.conf (то есть поставить
символ # в начало строки). Ниже приведен пример файла /etc/inetd.conf с
закомментированными строками (листинг слегка сокращен для экономии места).
#
# inetd.conf Файл содержит описания служб, предоставляемых
# через суперсервер TCP/IP INETD.
# Чтобы изменить конфигурацию рабтающего процесса INETD,
# отредактируйте файл и отправьте процессу INETD сигнал SIGHUP.
# Версия: @(#)/etc/inetd.conf 3.10 05/27/93
# Авторы: Оригинал позаимствован из BSD Unix 4.3/TAHOE.
# Фред Н. ван Кемпен, <waltje@uwalt.nl.mugnet.org>
# Модификация для Debian Linux: Ян А.Мердок <imurdock@shell.portal.com>
# Модификация для RHS Linux: Марк Эвинг <marc@redhat.com>
# <имя_службы> <тип_сокета> <протокол> <флаги> <польз> <путь_серв> <аргум>
# Службы echo, discard, daytime и chargen используются в основном
# для целей тестирования.
#
# Стандартные службы
#
ftp stream tcp nowait root /usr/sbin/tcpd in.ftpd -1 -a
telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd
#
# Shell, login, exec, comsat и talk - протоколы BSD.
#
#shell stream tcp nowait root /usr/sbin/tcpd in.rshd
#login stream tcp nowait root /usr/sbin/tcpd in.rlogind
#exec stream tcp nowait root /usr/sbin/tcpd in.rexecd
#
В приведенном листинге строки, запускающие in.rshd, in.rlogind и in.rexecd,
начинаются с символа #.
ПРИМЕЧАНИЕ
Для редактирования файлов и выполнения команд, упоминаемых в этой главе, необходимо
обладать привилегиями суперпользователя.
После того как демоны г-команд будут закомментированы, необходимо
перезапустить демона inetd. Задача решается следующей командой:
killall -HUP inetd
ПРИМЕЧАНИЕ
В системе Unix «демоном» называется программа, которая работает в фоновом режиме и ожидает
наступления некоторых событий. Как известно, в мифологии демон является посредником между
человеком и сверхъестественным существом. В мире Unix демон является посредником между двумя
событиями или процессами. Например, демон in.rlogind ожидает поступления запросов rlogin.
Получив такой запрос, in.rlogind пытается выполнить аутентификацию пользователя. Если запрос
поступил от доверенного пользователя, ему предоставляется доступ в систему. В противном случае
in.rlogind отклоняет запрос.
Защита г-команд
Если вы решите, что r-команды абсолютно необходимы вам для работы, по
крайней мере постарайтесь обеспечить их максимальную защиту. Ниже
описаны некоторые средства:
О TCP Wrappers.
О Аутентификация Kerberos.
О DES (Data Encryption Standard).
TCP Wrappers
Механизм управления доступом TCP Wrappers (tcpd) представляет собой
интерфейсную «оболочку» для демона TCP, обеспечивающую отслеживание и
фильтрацию программ TCP. При помощи TCP Wrappers систему можно настроить
так, чтобы запросы r-команд принимались только от сетевых компьютеров или
доменов из заданного списка.
В большинстве дистрибутивов Linux поддержка TCP Wrappers обычно
устанавливается автоматически (за дополнительной информацией обращайтесь по
адресу htф://hovЛo.tucowsxom/LDP/LDP/LG/issue46/pollman/tфwгappel3.html или к тап-
странице host_accessE)). В некоторых операционных системах пакет TCP Wrappers
приходится загружать и устанавливать самостоятельно.
Содержимое файлов /etc/hots.allow и /etc/hosts.deny используется средствами
доступа хостового уровня и программой TCP Wrappers для определения того,
кому разрешено или запрещено выполнение некоторых команд на вашем
компьютере. Записи этих файлов имеют следующий синтаксис:
демон : клиент
Предположим, файл hosts.deny содержит запись
All: All
Файл hosts.allow содержит следующий фрагмент:
in.telnetd: All
in.ftpd: All
in.rshd: *.mydomain.com
in.rlogind: *.mydomain.com
in.rexecd: *.mydomain.com
В приведенном примере запись All: All в файле hosts.deny означает, что всем
пользователям закрыт доступ ко всем демонам. На первый взгляд это
ограничение выглядит чрезмерно жестким, но оно переопределяется в файле hosts.allow.
Последний указывает, что доступ к системе через интерактивные программы
Telnet и FTP разрешен для всех желающих, однако выполнение защищенных
r-команд разрешено только хостам доверенного домена mydomain.com.
За дополнительной информацией о возможностях TCP Wrappers
обращайтесь к документации операционной системы.
ПРИМЕЧАНИЕ
Фальсификация IP (IP spoofing) основана на «обмане» компьютерной системы, которая полагает,
что входящий запрос поступил от доверенного компьютера, хотя на самом деле это не так.
Объектом фальсификации обычно становятся доверенные системы — такие, как используемые г-коман-
дами и TCP Wrappers.
Подробное описание методики фальсификации выходит за рамки настоящей книги. В общих чертах
злоумышленник модифицирует заголовки сетевых пакетов и придает им такой вид, словно пакеты
поступили из доверенной сети.
Аутентификация Kerberos
Стремясь повысить надежность r-команд, многие поставки теперь используют
версии rsh, rep и rlogin с поддержкой аутентификации Kerberos.
Kerberos — система аутентификации, которая позволяет двум сторонам
обмениваться защищенной информацией по незащищенной сети. Каждый из двух
сторон выдается билет (ticket), который встраивается в сообщения и
используется вместо пароля для идентификации отправителя.
Дополнительная информация о Kerberos приведена на сайте http://web.mit.edu/
kerberos/www/.
DES
В некоторых поставках команда rsh может настраиваться для использования
мощного стандарта шифрования DES, разработанного в 1970-е годы и
обеспечивающего высокую надежность шифрования.
За дополнительной информацией о DES обращайтесь по адресу http://www.itl.
nist.gov/fipspubs/fip46-3.htm.
Альтернативы для г-команд
Учитывая, сколько проблем для безопасности создает применение г-команд,
возникает вопрос — не существует ли альтернативы? Да, существует: это Secure
Shell (SSH).
Secure Shell — защищенная программа, обеспечивающая вход на удаленный
компьютер, выполнение команд в удаленном режиме и копирование удаленных
файлов. SSH обладает теми же возможностями, что и менее защищенные
утилиты rlogin, rsh и rep.
Защита SSH основана на использовании таких средств шифрования, как
DES (Data Encryption Standard) и RSA. При помощи этих механизмов SSH
защищает систему от нескольких видов распространенных атак, в том числе:
О фальсификация IP;
О перехват паролей, пересылаемых в виде простого текста;
О манипуляции с данными.
ПРИМЕЧАНИЕ
Алгоритм RSA, получивший свое название по фамилиям разработчиков (Ривест, Шамир и Адель-
ман), обеспечивает шифрование с открытым и закрытым ключом. Основной принцип заключается
в том, что данные, зашифрованные с открытым ключом, могут быть расшифрованы только с
применением закрытого ключа. В случае аутентификации хостов отправитель шифрует случайную
строку данных с использованием открытого ключа получателя (удаленного хоста). Если
удаленному хосту удается успешно расшифровать сообщение, используя свой закрытый ключ, каждый
хост может быть уверен в подлинности другой стороны.
За дополнительной информацией о RSA обращайтесь на сайт http://www.rsa.com. Хорошее введение
в методы шифрования с открытыми и закрытыми ключами находится по адресу http://www.rsa.com/
rsalabs/pkcs.
SSH версий 1 и 2 распространяется бесплатно для некоммерческого
использования. За дополнительной информацией о SSH обращайтесь по адресу http://
www.ssh.fi/sshprotocols2/.
Справочник r-команд
В этом разделе рассматривается синтаксис r-команд и приводятся примеры их
использования. Как упоминалось выше, описание относится к операционной
системе Linux. За информацией о параметрах и особенностях использования
команд в вашей операционной системе обращайтесь к электронной или печатной
документации.
Демоны г-команд
В табл. 29.2 перечислены демоны, которые должны выполняться на сервере (или
запускаться по запросу inetd) для нормальной работы г-команд. За
дополнительной информацией обращайтесь к электронной или печатной документации.
Таблица 29.2. Демоны г-команд
Демон Описание
rshd Сервер удаленной работы с командным интерпретатором.
Обеспечивает возможность удаленного выполнения
без аутентификации
rlogind Сервер удаленного входа. Обеспечивает возможность
удаленного выполнения без аутентификации
rwhod Сервер состояния системы
rstatd (или rcp.rstatd) Сервер состояния удаленного хоста
rsh
Утилита rsh позволяет выполнять команды в удаленной системе. Синтаксис
использования rsh:
ПРИМЕЧАНИЕ
В некоторых поставках Unix утилита rsh может называться rshell, remsh или rcmd.
rsh [-Kdnx] [-к область] [-1 пользователь] хост [команда]
Параметры
О -К — запрет аутентификации Kerberos.
О -d — разрешение отладки на уровне сокетов.
О -п — перенаправление ввода.
О -к — билет Kerberos выдается для заданной области (вместо области
удаленного хоста).
О -I — определение имени пользователя для удаленного хоста (вместо
использования текущего имени).
О -х — включение шифрования DES (если оно доступно).
Если команда не указана, пользователю предоставляется сеанс rlogin. Пример
использования команды rsh:
%rsh hostnamel who
jamisonn pts/1 Jul 26 09:13 (hostname2)
evanm pts/13 Jul 25 12:30 (hostname3)
На удаленном хосте hostnamel выполняется команда who. Выходные данные
показывают, что в настоящий момент на hostnamel работают два пользователя.
гср
Утилита rep (Remote Copy) копирует файлы с одного компьютера на другой. Ее
можно рассматривать как не-интерактивную разновидность FTP. Синтаксис
использования гср:
гср [-рх] [-к область] файл1 файл2
гср [-рх] [-к область] файл ... каталог
Имена файлов и каталогов задаются в формате полъзователъ@хост:путъ.
Параметры:
О -г — рекурсивное копирование (приемником должен быть каталог).
О -р — попытка сохранения времени модификации и режимов исходных файлов.
О -к — билет Kerberos выдается для заданной области (вместо области
удаленного хоста)
О -х — включение шифрования DES (если оно доступно).
Пример использования команды гср:
%rcp /home/jamisonn/report jamison@hostname2:report
Файл report копируется из локального домашнего каталога в домашний
каталог на удаленном хосте hostname2.
rlogin
Запуск терминального сеанса на удаленном хосте. Синтаксис использования rlogin:
rlogin [-8EKLdx] [-e символ] [-к область] [-1 пользователь] хост
Параметры
О -8 — восьмиразрядный путь входных данных.
О -Е — запрет использования символа отключения.
О -К — запрет аутентификации Kerberos.
О -L — проведение сеанса rlogin в режиме «буквального вывода» (litout).
О -d — разрешение отладки на уровне сокетов.
О -е — определение символа отключения (по умолчанию — «-»).
О -к — билет Kerberos выдается для заданной области (вместо области
удаленного хоста).
О -х — включение шифрования DES (если оно доступно).
Пример использования команды rlogin:
%rlogin -I jamisonn hostnamel
Команда создает для пользователя jamisonn сеанс на удаленном хосте hostnamel.
На удаленном хосте должен работать демон rlogind.
rup
Вывод информации о состоянии удаленной системы. Если хост ие указан, rup
возвращает информацию о состоянии всех хостов в сети. Синтаксис использования rup:
rup [-dhlt] [хост ...]
Параметры
О -d — отображение локального времени для хоста.
О -h — алфавитная сортировка выходных данных по имени хоста.
О -I — сортировка выходных данных по средней нагрузке.
О -t — сортировка выходных данных по продолжительности работы.
Пример:
% rup hostnamel
hostnamel up 15 days. 11:13, load average: 0.21, 0.26, 0.19
%rup -d hostnamel
hostnamel 4.08pm up 15 days. 11:13, load average: 0.21, 0.26, 0.19
Для работы rup на удаленном хосте должен быть запущен демон rstatd (или
rpc.rstatd).
ruptime
Команда ruptime по выполняемым функциям близка к rup. Синтаксис
использования ruptime:
rup [-alrtu]
Параметры
О -а — вывод информации о хостах, бездействовавших в течение часа и более.
О -I — сортировка выходных данных по средней нагрузке.
О -г — обратный порядок сортировки.
О -t — сортировка выходных данных но продолжительности работы.
О -и — сортировка выходных данных по количеству пользователей.
Для работы ruptime на удаленном хосте должен быть запущен демон rwhod.
rwho
Вывод списка пользователей, зарегистрированных в удаленной системе.
Выходные данные rwho близки к выходным данным команды Unix who. По умолчанию
rwho отображает только тех пользователей, которые работали с системой за
последний час. Синтаксис использования rwho:
rwho [-a]
Параметры
О -а — вывод информации обо всех пользователей, включая тех, которые
простаивали в течение часа и более.
Для работы rwho на удаленном хосте должен быть запущен демон rwhod.
rexec
Команда rexec по выполняемым функциям близка к rsh, но требует ввода
пароля. Синтаксис использования гехес:
гехес [пользователь@хост] [-DNn] [-1 пользователь] [-р пароль] команда
rexec [-DNn] [-1 пользователь] [-р пароль] [пользователь@хост] команда
Параметры
О -D — разрешение отладки на уровне сокетов для сокетов TCP, используемых
для взаимодействия с удаленным хостом. При передаче этого параметра
также выводится имя пользователя, переданное службе (или демону) rexecd.
О -I пользователь — имя пользователя, с правами которого выполняется команда.
Также может задаваться включением секции пользователь@хост в
командную строку.
О -N — запрет создания отдельного выходного потока для ошибок. Все
выходные данные передаются в стандартный вывод. Параметр используется при
выполнении интерактивных команд. Пример:
гехес -N localhost cmd
rexec -N localhost sh -i
О -n — перенаправление ввода.
О -р пароль — пароль заданного пользователя на удаленном хосте.
О Если пароль не указан, комбинация хоста, имени пользователя и пароля
ищется в файле ~/.netrc. Если пароль не найден, пользователю предлагается
ввести его вручную.
Другие файлы
Для правильной работы r-команд необходимо настроить несколько файлов, в том
числе:
О /etc/hosts
О /etc/hosts.equiv
О .rhosts
О /etc/hosts.allow и /etc/hosts.deny
Перечисленные файлы кратко рассматриваются ниже.
/etc/hosts
Хосты, участвующие в обмене данными, должны знать о друг друге. Задача
решается внесением соответствующей информации в файл /etc/hosts. Если хост hosnamel
хочет разрешить хосту hostname2 выполнение r-команд, на хосте hostnamel файл
/etc/hosts должен содержать запись для хоста hostname2, и наоборот.
/etc/hosts.equiv
Файл hosts.equiv содержит информацию о хостах и пользователях, которым
разрешены (или запрещены) доверительные привилегии при выполнении г-команд.
Неправильная настройка файла hosts.equiv откроет вашу систему для всех желающих.
Основной формат записи файла /etc/hosts.equiv выглядит так:
[+ | -] [хост][пользователь]
Префикс «+» перед именем хоста или пользователя предоставляет
доверенный доступ этому хосту или пользователю. Префикс «-» отменяет доверенный
доступ для хоста или пользователя. В табл. 29.3 приведено несколько примеров
записей с краткими пояснениями.
Таблица 29.3. Примеры записей hosts.equiv
Запись Результат
Hostnamel Разрешает доверенный доступ всем пользователям Hostnamel
-Hostnamel Запрещает доверенный доступ всем пользователям Hostnamel
Hostname2 -root Запрещает доверенный доступ пользователю root с хоста Hostname2
Hostname2 +admin Разрешает доверенный доступ пользователю admin с хоста Hostname2
-root Запрещает доступ пользователя root из любой системы
+admin Разрешает доступ пользователя admin из любой системы
+ Разрешает доверенный доступ для всех пользователей (опасно!)
Запрещает доверенный доступ для всех пользователей
ПРИМЕЧАНИЕ
В некоторых поставках в файл hosts.equiv включается запись «+». Она сообщает вашей системе,
что любой другой хост является доверенным, и создает очень большую угрозу для безопасности.
Если в файле hosts.equiv присутствует запись «+», удалите ее.
.г hosts
Файл .rhosts по своей структуре идентичен файлу hosts.equiv. Тем не менее файлы
.rhosts используются для разрешения или запрета доступа на уровне конкретной
пользовательской записи, тогда как файл hosts.equiv относится к системе в целом.
Файл .rhosts часто используется для предоставления пользователю
доверенного доступа к нескольким системам, в которых у него имеются учетные записи.
Предположим, у пользователя есть учетная запись на хосте hostnamel с именем
Jamison. На другом хосте, hostname2, он может иметь учетную запись с именем
jamisonn. Создание файла .rhosts для каждой записи позволит вам получить
доверенный доступ к другой системе.
Файл .rhosts в домашнем каталоге Jamison на хосте hostnamel может
выглядеть так:
hostname2 +jamisonn
На хосте hostname2 в домашнем каталоге jamisonn файл содержит запись
hostnamel +jamison
Эти два файла .rhosts позволяют получить привилегии доверенного доступа
в обеих системах.
Один из недостатков системы доверенных хостов и пользователей в г-коман-
дах заключается в том, что систему можно «обмануть», чтобы она приняла
другую сторону за кого-то другого. Например, если в предыдущем примере
злоумышленник получит доступ к первой системе hostnamel как пользователь Jamison
или суперпользователь, он автоматически получает беспрепятственный доступ
к hostname2. Этот прием называется фальсификацией на уровне пользователей.
Фальсификация IP или фальсификация на уровне имен хостов (имитация
обращения с доверенного хоста) менее прямолинейна, но, к сожалению, она часто
встречается на практике при использовании доверенных систем.
Файлы /etc/hosts.allow и /etc/hosts.deny
Файлы /etc/hosts.allow и /etc/hosts.deny используются при контроле доступа на
хостовом уровне и программой TCP Wrappers для определения того, кому из
пользователей разрешено или запрещено выполнение тех или иных команд на
вашем компьютере. За более подробным описанием этих файлов и их
синтаксиса обращайтесь к разделу «TCP Wrappers» настоящей главы. Ниже
приведены примеры использования файлов hosts.allow и hosts.deny:
Файл /etc/hosts.deny запись
AU: All
Файл /etc/hosts.allow:
in.telnetd: All
in.ftpd: All
in.rshd: *.mydomain.com
in.rlogind: *.mydomain.com
Сначала файл hosts.deny запрещает доступ всем и для всего. Это полезная
привычка, повышающая уровень безопасности вашей системы. Затем файл hosts.allow
открывает доступ к Telnet и FTP для всех желающих и разрешает выполнение
r-команд хостам, входящим в доверенный домен mydomain.com.
Функциональность г-команд
на других платформах
R-команды создавались специально для платформы Unix. Тем не менее они
начинают появляться и в других продуктах TCP/IP — например, в компонентах
Microsoft TCP/IP систем Windows NT/2000. Существует ряд продуктов незави-
симых фирм, позволяющих использовать функциональные возможности г-команд
в других системах.
В табл. 29.4 приведены примеры фирм-разработчиков и URL, по которым
. следует обращаться за дополнительной информацией. Если вместо
фирмы-разработчика указано имя автора, программа является условно-бесплатной.
Таблица 29.4. Реализации r-команд, разработанные независимыми фирмами
Фирма-разработчик URL
Hummingbird Communications LTD http://www.hummingbird.com/products/nc/inetd/
Denicomp Systems http://www.denicomp.com/products.htm
Дидье Кассеро http://www.loa.espci.fr/winnt/rshd/rshd.htm
Маркус Фишер http://www.uni-paderborn.de/StaffWeb/getin
Итоги
В этой главе были представлены r-команды системы Unix, предназначенные для
входа на удаленный компьютер, удаленного копирования файлов и выполнения
других удаленных команд. Следует учитывать, что работа этих команд и служб
создает существенные проблемы для безопасности, поэтому в главе были
представлены альтернативные решения — такие, как SSH (Secure Shell). В конце
главы обсуждается использование r-команд на других платформах. В главе
встречаются многочисленные URL, по которым читатель сможет самостоятельно
обратиться за дополнительной информацией.
Приведенные описания команд относятся к системе Linux. За информацией
по другим версиям Unix обращайтесь к электронной и печатной документации
вашей операционной системы.
*Э>Л Протоколы
*Э w совместного доступа
к файловой системе:
NFS и SMB/CIFS
Нил С. Джеймисоп (Neal S.Jamison)
Протокол TCP/IP заложен в основу служб и протоколов, обеспечивающих
совместный доступ к данным, находящихся на других компьютерах. Именно эта
возможность когда-то стала первопричиной интернет-революции, плодами
которой мы пользуемся сегодня. Одним из самых полезных приложений TCP/IP
является сетевая файловая система, чаще обозначаемая сокращением NFS
(Network File System).
Что такое NFS?
NFS — распределенная файловая система, позволяющая организовать совместный
доступ к ресурсам в сетях TCP/IP. С точки зрения клиентского приложения
NFS операции чтения и записи файлов, находящихся на серверах NFS,
выполняются прозрачно. До появления NFS совместный доступ к данным
организовывался посредством дублирования, централизации данных или их распространения
в сети, состоящей из однородных компьютеров. Конечно, у всех перечисленных
вариантов имеются очевидные недостатки — дублирование данных приводит
к лишним расходам дискового пространства и может вызвать проблемы с
логической согласованностью копий; централизация подразумевает использование
дорогих больших компьютеров и неинтеллектуальных терминалов; да и кому
захочется ограничиваться однородными сетями?
Так появилась система NFS, которая позволяла организовать совместный
доступ к данным независимо от платформы. Все проблемы были решены.
ПРИМЕЧАНИЕ
В контексте этой главы под «файловой системой» понимается набор файлов данных,
сгруппированных в иерархии каталога. Например, в системе Unix /usr является файловой системой.
Серверы NFS предоставляют совместный доступ к ресурсам для клиентов
сети. Как будет показано ниже, NFS работает как в локальных, так и
глобальных сетях. Одной из целей проектирования системы NFS была независимость
от операционных систем и оборудования, чтобы совместный доступ к ресурсам
мог предоставляться по возможности более широкому кругу компьютеров.
Базовый сервис NFS включает два протокола: Mount и NFS.
Краткая история NFS
Система NFS была представлена Sun Microsystems в 1984 году. Сначала она была
реализована в системе Sun 4.2BSD (более известной как SunOS). Благодаря
широкому распространению и очевидной потребности в подобном сервисе система NFS
скоро была адаптирована для широкого круга рабочих платформ. В 1986 году
NFS обслуживала 16 аппаратных платформ с пятью разными операционными
системами. В наши дни система NFS работает на многих аппаратных платформах
и операционных системах и даже была усовершенствована для работы в Web.
Почему NFS?
Система NFS создавалась для организации совместного доступа к ресурсам.
В период разработки (начало 1980-х годов) компьютерная индустрия быстро
изменялась. Появление дешевых процессоров и технологий «клиент-сервер»
создало условия для децентрализации компьютерных сред. Тем не менее, хотя
процессоры дешевели, системы массового хранения большой емкости оставались
относительно дорогими. Возникла потребность в решении, которое бы позволяло
компьютерам использовать общие средства храпения данных, но при этом
сохранить максимальный уровень вычислительной мощности отдельных машин.
Так появилась система NFS.
Реализация — как работает NFS
NFS использует службы и протоколы семейства TCP/IP. Как показано в табл. 30.1,
NFS работает на прикладном уровне модели OSI.
Таблица 30.1. Место NFS в многоуровневой модели OSI
Номер Название Функция
1 Прикладной уровень NFS
2 Представительский уровень XDR
3 Сеансовый уровень RPC
4 Транспортный уровень UDP, TCP
5 Сетевой уровень IP
6 Канальный уровень Много
7 Физический уровень Много
Поскольку утилитарный транспортный протокол UDP обладает более
высоким быстродействием, система NFS первоначально ориентировалась на UDP,
а не на TCP. Тем не менее, хотя протокол UDP хорошо работает в локальных
сетях, в менее надежных глобальных сетях (таких, как Интернет) он обладает
рядом недостатков. Последние достижения в области TCP позволяют NFS
достаточно эффективно работать при использовании надежного транспортного
протокола. Начиная с Solaris 2.6, NFS работает на базе TCP/IP. Поддержка TCP
появилась еще в NFS версии 2, но не была оптимизирована. В NFS версии 3
поддержка TCP была оптимизирована, а также было снято искусственное
ограничение размера блока (8 Кбайт). Последняя версия NFS имеет номер 4.
ПРИМЕЧАНИЕ
За дополнительной информацией о UDP и TCP обращайтесь к главе 9.
RPC и XDR
Полная платформенная независимость NFS основана на использовании средств
нижних уровней OSI. Механизмы сеансового уровня RPC (Remote Procedure
Call) и представительского уровня XDR (external Data Representation)
обеспечивают сетевые подключения NFS и формат данных, передаваемых по этим
подключениям. Эти механизмы позволяют NFS работать на широком спектре
разных платформ.
RPC
Механизм процедур RPC работает на сеансовом уровне стека OSI. Он позволяет
вызывать удаленные процедуры так, как если бы они находились на
локальном компьютере. При помощи RPC локальные компьютеры или приложения
могут работать со службами на удаленных компьютерах. Благодаря библиотеке
процедур RPC приложения высокого уровня не обязаны знать все
низкоуровневые подробности реализации удаленных систем. Именно этот уровень
абстракции обеспечивает платформенную независимость NFS на прикладном уровне.
XDR
Библиотека XDR обеспечивает преобразование данных RPC между
разнородными компьютерными системами. XDR определяет стандартное представление
данных, «понятное» для всех компьютеров.
В сочетании RPC и XDR формируют отношения между клиентом и
сервером, необходимые для NFS.
Жесткое и мягкое монтирование
Поскольку NFS не обладает состоянием, клиенты и клиентские приложения
могут восстанавливаться после периодов недоступности сервера. Поведение
клиентов и клиентских приложений в случае недоступности сервера определяется
типом монтирования. Мы вернемся к рассмотрению типов монтирования в
разделе «Распространенные проблемы NFS и их решения» настоящей главы.
Жесткое монтирование
Жесткое монтирование ресурса приводит к тому, что в случае недоступности
сервера NFS или ресурса повторные вызовы RPC будут продолжаться до
бесконечности. Когда от сервера будет получен ответ, вызов RPC завершится успехом
и будет выполнена следующая процедура. При возникновении серьезных
проблем с сервером или сетью жестко смонтированный ресурс переходит в
хроническое состояние ожидания, а клиентское приложение NFS «зависает». Естественно,
повторные обращения увеличивают объем сетевого трафика. Существует
параметр, который запрещает прерывание ожидания при жестком монтировании.
Мягкое монтирование
При мягком монтировании ресурса многократные неудачи при вызовах RPC
приведут к сбою в клиентском приложении, что может привести к появлению
ненадежных данных. Такие данные не должны использоваться в файловых системах с
записью, а также при чтении критически важных данных и исполняемых программ.
ПРИМЕЧАНИЕ
Материал следующего раздела содержит примерно ту же информацию, которая приводится в
электронной документации Unix. За более подробными сведениями обращайтесь к руководствам по
конкретным файлам и программам.
Файлы и команды NFS
В этом разделе представлены демоны, программы и файлы, используемые NFS.
Поскольку система NFS тесно связана с Unix, ниже будет описана процедура
организации совместного доступа и использования ресурсов NFS в двух
популярных операционных системах семейства Unix: Sun Solaris 2.x и Linux.
Комментарии по поводу других реализаций, в том числе для клиентов на базе PC,
приведены ниже, в разделе «Другие протоколы и продукты».
ПРИМЕЧАНИЕ
В системе Unix «демоном» называется программа, которая работает в фоновом режиме и ожидает
наступления некоторых событий. Как известно, в мифологии демон является посредником между
человеком и сверхъестественным существом. В мире Unix демон является посредником между двумя
процессами. Например, демон печати ожидает поступления заданий в очередь, а демон NFS ждет
обращения к файловой системе со стороны клиента.
Демоны NFS
Функционирование NFS обеспечивается совместной работой нескольких
серверных демонов. Ниже приведены описания этих демонов для операционных
систем Solaris и Linux.
Solaris 2.x
Следующие демоны используются в системе Solaris для прослушивания и
обработки запросов NFS. Серверные демоны Solaris запускаются сценарием /etc/init.d/
nfs.server.
nfsd
Демон nfsd ожидает и принимает клиентские запросы NFS. Синтаксис запуска
демона nfsd:
/usr/Tib/nfs/nfsd [ -a ] [ -с подключ ] [ -1 очередь ] [ -р протокол ]
[ -t устройство ] [ число_запросов 3
Параметры:
О -а — демон NFS запускается для всех доступных транспортных протоколов,
ориентированных или не ориентированных на соединение, включая UDP и TCP.
О -с подключ — максимальное количество подключений, разрешенных сервером
NFS для транспортных протоколов, ориентированных на соединение. По
умолчанию количество подключений не ограничивается.
О -I — длина очереди NFS TCP. По умолчанию длина очереди равна 32.
О -р протокол — демон NFS запускается для заданного протокола.
О -t устройство — демон NFS запускается для транспорта, определяемого
заданным устройством.
О число ^запросов — максимальное количество одновременно обрабатываемых
запросов.
Другие файлы: /etc/init.d/nfs.server; сценарий, запускающий nfsd.
mountd
Демон mountd получает информацию о доступе NFS и монтировке файловых
систем. Доступность файловых систем определяется чтением /etc/dfs/sharetab.
Синтаксис запуска демона mountd:
/usr/lib/nfs/mountd [ -v ] [ -г ]
Параметры:
О -v — режим расширенного вывода.
О -г — отклонение клиентских запросов.
Другие файлы: /etc/dfs/sharetab/.
statd
Демон statd работает в сочетании с lockd и обеспечивает восстановление
блокировки файлов после сбоев. Statd работает на стороне клиента. Синтаксис запуска
демона statd:
/usr/lib/nfs/statd
Другие файлы: lockd.
lockd
Демон lockd является частью системы блокировки файлов NFS. Lockd работает
на стороне клиента. Синтаксис запуска демона lockd:
/usr/lib/nfs/lockd [ -g интервал ] [ -t тайм-аут ] [ число_потоков ]
Параметры:
О -g интервал — интервал, в течение которого клиент должен восстановить
блокировку после перезагрузки сервера (задается в секундах). Значение по
умолчанию — 45.
О -t тайм-аут — продолжительность ожидания перед повторной отправкой
запроса на блокировку (в секундах). Значение по умолчанию — 15.
О число_потоков — количество программных потоков, обрабатывающих запросы
на блокировку. Значение по умолчанию — 20.
Другие файлы: statd.
Linux
Следующие демоны используются в системе Linux для прослушивания и
обработки запросов NFS. По своему синтаксису и основным принципам
использования они близки к демонам Solaris.
rpc.nfsd
Демон rpc.nfsd обрабатывает запросы NFS. Синтаксис запуска демона rpc.nfsd:
/usr/sbin/rpc.nfsd [ -f файл ] [ -P порт ] [ -R каталог ]
[ -Fhlnprstv ] [ -- exports-fi1е=файл] [ --foreground j
[ --help ] [ --allow-nn-root ] [ --re-export ]
[ --public-root каталог ] [ --no-spoof-trace ] [ --port порт ]
[ --log-transfers ] [ --version ] [ число_серверов ]
Параметры:
О -f или -exports-file — файл экспорта. По умолчанию используется файл /etc/
exports.
О -h или -help — краткая справка.
О -I или -log-transfers — регистрация всех операций пересылки файлов.
О -п или -allow-non-root — разрешить обслуживание входящих запросов NFS
даже в том случае, если они не поступили с зарезервированных портов IP.
О -Р порт или -port порт — демон nfsd прослушивает порт с заданным номером
вместо используемого по умолчанию порта 2049 или порта, указанного в файле
/etc/services.
О -р или -promiscuous — серверу разрешается обслуживать любые хосты в сети.
О -v или -version — вывод номера версии программы.
О число_серверов — параллельный запуск нескольких экземпляров nfsd.
Другие файлы: exports, mountd.
rpc.mountd
Демон rpc.mountd получает запросы на монтирование и проверяет доступность
файловой системы NFS, указанной в /etc/exports. Если запрашиваемый ресурс
доступен, rpc.mountd создает идентификатор файла и включает запись в /etc/
rmtab. При получении запроса UMOUNT демон rpc.mountd удаляет информацию
из /etc/rmtab. Синтаксис запуска демона rpc.mountd:
/usr/sbin/rpc.mountd [ -f файл ] [ -P порт ] [ -Dhnprv ]
[ -- exports-fПе=файл] [ --help ] [ --allow-nn-root ]
[ --re-export ] [ --no-spoof-trace J [ --version ]
Параметры.
См. описание демона rpc.nfsd.
Другие файлы: /etc/exports, /etc/rmtab.
rpc.statd
См. описание демона statd для Solaris.
rpc.lockd
См. описание демона lockd для Solaris.
biod
Команда biod запускает указанное количество демонов асинхронного блочного
ввода/вывода на клиенте NFS. Эти демоны выполняют операции опережающего
чтения и обратной записи в файловой системе NFS, помогающие повысить
быстродействие NFS. Синтаксис запуска демона biod:
/usr/etc/biod [ количество_демонов ]
Служебные файлы NFS
Чтобы успешно организовать совместный доступ и монтирование файловых
систем NFS, необходимо отредактировать несколько файлов на сервере и клиенте.
Solaris 2.x
Ниже перечислены файлы, используемые в системе Solaris для определения
ресурсов NFS и отслеживания их состояния.
/etc/dfs/dfstab
В файле dfstab хранятся команды share, управляющие экспортом файловых
систем NFS. За дополнительной информацией о команде share обращайтесь к
разделу «Серверные команды NFS» настоящей главы.
Пример:
share -F nfs -о rw-engineering -d "home dirs" /export/home2
/etc/dfs/sharetab
Файл sharetab содержит информацию обо всех файловых системах, заявленных
для совместного доступа в командах share. Этот файл автоматически
генерируется системой. Записи файла sharetab содержат следующие поля:
О Путь — путь к общему ресурсу.
О Ресурс — имя, по которому удаленные системы обращаются к ресурсу.
О Тип — тип общего ресурса.
О Параметры — параметры, использовавшиеся при предоставлении совместного
доступа к ресурсу.
О Описание — описание общего ресурса.
Пример:
/export/home2 - nfs rw=engineering "Engineering home"
/etc/rmtab
Файл rmtab содержит список файловых систем NFS, смонтированных
клиентами в настоящее время. Этот файл также генерируется системой и содержит
строки в формате
хост:файловая_система
/etc/vfs/vfstab
Файл vfstab, хранящийся на стороне клиента, используется для описания
монтируемых локальных и удаленных систем. Запись файла vfstab состоит из
следующих полей:
О Монтируемое устройство.
О Устройство для fsck.
О Точка монтирования.
О Тип файловой системы.
О Проход fsck.
О Монтирование при загрузке.
О Параметры монтирования (описание параметров приводится ниже в разделе
«Клиентские команды NFS»).
Пример:
servername:/export/home2 - /export/home NFS у
Linux
Ниже перечислены файлы, используемые в системе Linux для определения
ресурсов NFS и отслеживания их состояния.
/etc/exports
Файл exports представляет собой список управления доступом для файлов,
экспортируемых клиентам NFS. В каждой строке файла exports указывается ресурс
NFS и хосты, которым разрешено его монтировать. Параметры доступа
перечисляются в круглых скобках (хотя их наличие не обязательно). Существует
обширный список ключей и параметров, управляющих доступом к ресурсам; за
подробностями обращайтесь к документации.
Пример:
/users/home host.mydomain.com(го)
Приведенная запись означает, что хосту host.mydomain.com разрешено
монтировать файловую систему /users/home в режиме только для чтения.
/etc/rmtab
Файл rmtab содержит перечень файловых систем NFS, в настоящее врем^
смонтированных клиентами. Содержимое файла генерируется системой. Фа#л имеет
следующий формат:
хост:ресурс
Пример
datahouse.anvi.com:/users/home
/etc/fstab
Файл /etc/fstab содержит информацию обо всех файловых системах, которые
могут использоваться системой. Он является аналогом vfstab для Linux. Запись
файла fstab состоит из следующих полей:
О Удаленная файловая система.
О Точка монтирования удаленного ресурса.
О Тип удаленного ресурса (например, nfs).
О Параметры монтирования.
О Признак создания резервной копии. По умолчанию равен 0 (резервная
копия не создается).
О Проход, на котором файловая система должна проверяться fsck. Значение
по умолчанию, равное 0, означает, что файловая система не проверяется
fsck.
За полным списком параметров и другой информацией о файле fstab
обращайтесь к электронной или печатной документации.
Пример
solaris:/www /mnt nfs rsize=1024,wsize=1024,hard,1ntr 0 0
Серверные команды NFS
После запуска всех необходимых демонов и редактирования
конфигурационных файлов операции создания общих ресурсов NFS и их монтирования
решаются просто.
Создание общих ресурсов
Чтобы ресурсы NFS могли использоваться клиентами вашей сети, они должны
быть экспортированы сервером NFS. В следующем разделе рассматриваются
команды Solaris и Linux, используемые при экспортировании ресурсов.
Solaris 2.x
Следующие команды Solaris обеспечивают совместный доступ и сбор
информации о состоянии ресурсов NFS.
share
Команда share предоставляет клиентам доступ к указанной файловой системе.
Синтаксис команды share:
share [ *F тип ] [ -о параметры ] [ -d описание ] [ путь ]
Параметры:
О -F тип — тип файловой системы.
О -о параметры — управление доступом к общему ресурсу. Поддерживаются
следующие значения:
□ rw- доступ для чтения/записи.
□ гн-клиеит\\клиепт\ — доступ для чтения/записи предоставляется только
указанным клиентам.
□ Ro — доступ только для чтения.
□ Ro=клиеит[:клиент] — доступ только для чтения предоставляется только
указанным клиентам.
О -d описание — описание общего ресурса.
Пример:
share -F nfs -о rw=Engineering -d "home dirs" /export/home2
shareall
Команда shareall предоставляет совместный доступ к ресурсам из заданного файла,
стандартного ввода или файла dfstab. Синтаксис команды shareall:
shareall [ -F тип [,тип...]] [ - | файл ]
Параметры:
О -F тип — тип файловой системы.
О [ - | файл ] — если указан параметр -, команда shareall получает входные
данные из стандартного ввода. Если указано имя файла, команда shareall
загружает входные данные из этого файла. Если параметр не указан, shareall по
умолчанию использует файл dfstab (/etc/dfs/dfstab).
showmount
Команда showmount выводит список всех клиентов, смонтировавших
файловые системы с сервера, на котором выполняется команда. Синтаксис команды
showmount:
/usr/sMn/showmount [ -ade ] [ хост ]
Параметры:
О -а — вывод информации обо всех файловых системах, смонтированных
удаленными клиентами.
О -d — вывод информации о каталогах, смонтированных удаленными
клиентами.
О -е — вывод списка общих файловых систем.
Linux
Следующие команды Linux обеспечивают совместный доступ и сбор
информации о состоянии ресурсов NFS.
exportfs
Команда exportfs заставляет систему заново загрузить файл /etc/exports. В
некоторых поставках Linux команда exportfs не поддерживается, но в этом случае
можно воспользоваться коротким сценарием, который выполняет ту же
операцию:
#!/bin/sh
ki Hall -HUP /usr/sbin/rpc.mountd
ki Hall -HUP /usr/sbin/rpc.nfsd
ПРИМЕЧАНИЕ
В RedHat версии 7 и выше также можно перезапустить службу nfs, выполнив следующий сценарий:
/etc/rc.d/init.d/nfs restart
Перезапуск службы автоматически приводит к повторной загрузке файла /etc/exports.
Кроме аргумента restart, сценарий также может вызываться с аргументами start и stop. Смысл этих
аргументов понятен без комментариев.
showmount
Команда showmount запрашивает у демона монтирования на сервере NFS
информацию о файловых системах, смонтированных в настоящий момент. Синтаксис
команды showmount:
/usr/sbin/showmount [ -adehv ] [ --all ] [ --directories ]
[ --exports ] [ --help ] [ --version ] [ хост ]
Параметры:
О -а или -all — вывод имен клиентских хостов и смонтированных каталогов
в формате хост'.каталог.
О -d или —directories — вывод списка каталогов, смонтированных клиентами.
О -е или -exports — вывод списка экспортируемых файловых систем.
О -h или -help — вывод справочной информации.
О -v или -version — вывод версии программы.
О -no-headers — исключение заголовков из выходных данных.
Отключение общих ресурсов
Рано или поздно наступит момент, когда вы захотите запретить
монтирование той или иной файловой системы. Для этого можно воспользоваться
ключом -г команды mount (см. выше) или просто отменить объявление общего
ресурса.
Solaris 2.x
Следующие команды Solaris отменяют объявление общих ресурсов NFS.
unshare
Команда unshare делает общую файловую систему недоступной для клиентов.
Синтаксис команды unshare:
unshare [ -F тип ] [ -о параметры 3 [ путь | ресурс ]
Если аргумент -F тип не задан, команда unshare по умолчанию использует
тип первой записи в файле /etc/dfs/dfstab. Аргумент -о параметры зависит от типа
файловой системы. За дополнительной информацией обращайтесь к
документации.
unshareall
Команда unshareall отменяет объявления всех общих ресурсов заданного типа.
Синтаксис команды unshareall:
unshareall [-F тип[,тип . . . ]]
Если команда вызывается без указания конкретного типа, отменяются
объявления всех общих ресурсов.
Проверка командой showmount
Чтобы убедиться в том, что файловая система не смонтирована ни одним
клиентом, воспользуйтесь командой showmount. Синтаксис команды описан в
предыдущем разделе.
Linux
В системе Linux не существует официальных команд, отменяющих объявления
общих ресурсов. Задача проще всего решается редактированием файла /etc/exports
и исключением из него файловых систем, совместный доступ к которым вы
хотите запретить. После этого следует выполнить команду exportfs, чтобы система
заново прочитала файл /etc/exports. Если команда exportfs не поддерживается
в вашей версии Linux, воспользуйтесь эквивалентным сценарием:
#!/bin/sh
killall -HUP /usr/sbin/rpc.mountd
killall -HUP /usr/sbin/rpc.nfsd
Клиентские команды NFS
В этом разделе описаны клиентские команды, используемые для монтирования
и демонтирования ресурсов NFS.
ПРИМЕЧАНИЕ
Следует помнить, что точка монтирования (пустой каталог), которая будет использоваться для
монтирования ресурсов, должна создаваться заранее.
Монтирование ресурсов NFS
Следующие команды предназначены для монтирования общих ресурсов.
mount (Solaris/Linux)
Монтирование удаленных файловых систем NFS осуществляется командой mount
Solaris
Синтаксис команды mount:
mount [ -р | -v ]
mount [ -F тип ) [ общие_параметры ] [ -о специальные_параметры ] [ -0 ]
точка_монтирования
mount [ -F тип ] [ -V ] [ общие_параметры j [ -о специальные_параметры ]
[точка_монтирования...]
Linux
mount [ -hV]
mount [ -fnrsvw ] [ -о параметры [....]] устройство | каталог
mount [ -fnrsvw ] [ -t тип ][ -о параметры ] устройство каталог
Версии команды mount для Solaris и Linux выполняют сходные функции, но
различаются по используемым параметрам. За дополнительной информацией
обращайтесь к печатной или электронной документации по операционной системе.
В простейшем варианте монтирования ресурса точка монтирования или
устройство указывается в файле vfstab или fstab.
Предположим, в файле vfstab системы Solaris присутствует запись
remotehost:/export/home2 - /export/myhome NFS у
В этом случае файловая система легко монтируется любой из следующих
команд:
# mount /export/myhome
# mount remotehost:/export/home2
mountall (Solaris)
Команда mountall монтирует все ресурсы, указанные в файле vfstab. Синтаксис
команды mountall:
mountall [ -F тип ] [ -11 - г ] [ список_файловых_систем ]
Параметры:
О -F тип — в данном случае NFS.
О -I — монтирование всех локальных файловых систем.
О -г — монтирование всех удаленных файловых систем.
О список_файловых_систем — по умолчанию /etc/vfstab.
ПРИМЕЧАНИЕ
Специальный демон NFS может отслеживать появление запросов к удаленной файловой системе.
Этот процесс называется автомонтированием. Когда приложение или пользователь обращается
с запросом к несмонтированной удаленной файловой системе, эта система автоматически
монтируется на сервере NFS. Если удаленная файловая система не используется, она автоматически
демонтируется. Технология автомонтирования обладает многими преимуществами; в частности,
она повышает эффективность использования сети и упрощает администрирование.
Поддержка автомонтирования присутствует в Solaris и Linux, а также на большинстве других
платформ семейства Unix. За дополнительной информацией обращайтесь к печатной или
электронной документации операционной системы.
Демонтирование ресурсов NFS
В этом разделе описаны команды демонтирования общих ресурсов.
umount (Solaris/Linux)
Команда umount демонтирует смонтированный ресурс.
Solaris
Синтаксис команды umount:
umount [ -V ] [ -о параметры ] спец | точка_монтирования
umount -а [ -V ] [ -о параметры ] [ точка_монтирования...]
Linux
Синтаксис команды umount:
umount [ -hV]
umount -a [ -nrv ] [ -t тип ]
umount [ -nrv ] устройство | каталог [ ... ]
Как и в случае с командой mount, команды umount для Linux и Solaris в целом
похожи, но обладают специфическими наборами параметров. За
дополнительной информацией обращайтесь к электронной или печатной документации.
По аналогии с mount, для выполнения команды umount достаточно указать
точку монтирования или устройство из файла vfstab или fstab.
Предположим, в файле fstab системы Linux присутствует запись
remotehost:/export/home2 /export/myhome nfs
rsize=1024,wsize=1024,hard.intr 0 0
В этом случае файловая система легко демонтируется любой из следующих
команд:
# umount /export/myhome
# umount remotehost:/export/home2
umountall (Solaris)
Команда umountall демонтирует все смонтированные файловые системы.
Параметры команды позволяют ограничиться демонтированием удаленных
файловых систем и даже систем, смонтированных с определенного хоста. Синтаксис
команды umountall:
umountall [ -k ] [ -s ] [ -F тип ] [ -1|-г ]
umountall [ -k ] [ -s ] [ -h хост ]
Параметры:
О -к — попытка принудительного закрытия всех процессов, использующих
файловую систему.
О -s — запрет параллельного демонтирования файловых систем.
О -F тип — демонтирование файловых систем заданного типа (в данном
случае NFS).
О -I — демонтирование только локальных файловых систем.
О -г — демонтирование только удаленных файловых систем.
О -h хост — демонтирование только удаленных файловых систем для
заданного хоста.
Пример: организация совместного доступа
и монтирование файловой системы NFS
В этом разделе мы применим на практике то, о чем говорилось выше: файловая
система из системы Solaris 2.6 будет смонтирована в системе Linux (RedHat 6.0).
Прежде всего необходимо отредактировать файл /etc/dfs/dfstab и включить
в него запись экспортируемой файловой системы. Запись выглядит примерно
так:
share -F nfs -d "WWW Directory" /www
Экспортируется файловая система /www.
После включения строки в файл dfstab и выполнения команды shareall
файловая система /www готова к удаленному монтированию.
#shareall
Команда share поможет убедиться в том, что файловая система была успешно
экспортирована.
#share
/www "WWW Directory"
Теперь нужно убедиться в том, что в системе работают необходимые демоны;
на сервере Solaris это демоны nfsd и mountd. Состояние демонов проверяется
командой Unix ps:
#ps -ef
Команда ps выводит список всех активных процессов, среди которых
присутствуют демоны NFS:
root 27282 1 0 08:10:59 ? 0:00 /usr/lib/nfs/nfsd -a 16
root 27280 1 0 08:10:59 ? 0:00 /usr/lib/nfs/mountd
Если в выходных данных ps демоны NFS отсутствуют (а значит, не работают
в системе), их можно запустить процедурой NFS init:
#/etc/init.d/nfs.server start
Теперь можно перейти к клиенту Linux и смонтировать общий ресурс.
На компьютере с Linux для этого выполняется команда mount:
mount -о rsize=1024,wsize=1024 solaris:/www /mnt
Команда демонтирования файловой системы выглядит так:
umount /mnt
Если монтирование должно выполняться достаточно часто, включите в файл
/etc/fstab следующую запись:
Solaris:/www /mnt nfs rsize=024,wsize=1024,hard,intr 0 0
Запись означает, что файловая система NFS /www должна монтироваться с
сервера Solaris в точке монтирования /mnt. Параметры hard, intr означают, что
файловая система монтируется жестко и с возможностью прерывания (более надежно
при возникновении серверных проблем).
Как видите, в теории все очень просто. К сожалению, на практике не
обходится без проблем, и NFS не является исключением. В следующем разделе
описаны некоторые проблемы, часто встречающиеся на практике, и представлены
возможные решения этих проблем.
Распространенные проблемы NFS
и их решения
В этом разделе представлены некоторые затруднения, возникающие при
использовании NFS в среде Unix. Мы рассмотрим несколько стандартных проблем
и способы их решения. Поскольку работа NFS зависит от нескольких демонов
и конфигурационных файлов, правильная настройка системы может оказаться
непростым делом. На первых порах основные проблемы связаны с
монтированием ресурсов.
Ошибки при монтировании ресурсов
Проблемы с монтированием чаще всего вызваны неправильной конфигурацией
или проблемами с функционированием сети.
Если вы не имеете ни малейшего представления о возможных причинах
(например, если вы попытались настроить файл vfstab, не ознакомившись с
инструкциями и т. д.), обычно стоит начинать с верхнего уровня.
Прежде всего убедитесь в том, что вы можете установить связь с сервером
NFS. Для этого можно воспользоваться командой ping, однако в этом случае вы
проверите лишь доступность хоста на уровне IP.
Если сервер доступен, убедитесь в том, что необходимые демоны
выполняются в системе. За подробностями обращайтесь к разделу «Демоны NFS» настоящей
главы. Проверьте правильность экспортирования ресурсов при помощи команды
share или ее аналога. Если ресурс не экспортируется, проверьте
конфигурационные файлы сервера (dfstab или exports). Дополнительная информация приведена
в разделе «Служебные файлы NFS» настоящей главы. Убедитесь в том, что
сервер знает о существовании клиента. Хостовое имя клиента должно находиться
в файле /etc/hosts в той же форме, в какой оно задается в конфигурационном
файле. Например, если сервер указывает, что системе loco разрешается
монтировать ресурс, убедитесь в присутствии данных loco в файле hosts. Система NFS
иногда бывает весьма требовательной — даже если в файле присутствуют
данные loco.mydomaJn.com, в нем также должны быть данные loco.
Если сервер недоступен, обратитесь за помощью к системному
администратору.
Если конфигурация сервера задана правильно, настало время проверить
конфигурацию клиента. Снова убедитесь в том, что в системе работают
необходимые демоны, а конфигурационные файлы (fstab или vfstab) были правильно
настроены. Проверьте, совпадают ли имена в файле hosts и в конфигурационных
файлах NFS.
Ошибки при демонтировании ресурсов
При возникновении проблем с демонтированием ресурсов прежде всего
необходимо убедиться в том, что ресурс не используется. Иногда труднее всего
заметить самые простые и очевидные случаи использования ресурсов. Итак, вы
получили невразумительное сообщение о том, что файловая система занята.
Проверьте все открытые сеансы командного интерпретатора и терминалы;
убедитесь в том, что файловая система не просматривается в открытых «диспетчерах
файлов». Также проверьте, чтобы файлы, находящиеся в файловой системе, не
были открыты в редакторах. Обнаружив подобные случаи, исправьте их и
повторите попытку. Не забудьте проверить командный интерпретатор, в котором
вы работаете!
Жесткое и мягкое монтирование
Файловые системы NFS монтируются в жестком или мягком режиме. Как
упоминалось выше, жесткое монтирование обеспечивает максимальную надежность
и поэтому обычно используется при монтировании ресурсов для записи,
чтении критически важных данных и исполняемых программ. С другой стороны,
если при жестком монтировании ресурса произойдет сбой на сервере или
сетевое подключение будет нарушено по другим причинам, все программы,
работающие с этим ресурсом, «зависнут», а это может оказаться нежелательно. По
умолчанию ресурсы NFS монтируются жестко.
При другом способе монтирования — мягком — прерывание обмена данными
между клиентом и сервером приводит к сбою в программах, использующих
ресурсы NFS. Следует помнить, что мягкое монтирование в ненадежных сетях
приводит к ненадежным результатам.
Проблема решается монтированием ресурсов NFS с параметрами hard и intr.
Эти параметры команды mount обеспечивают жесткое монтирование,
реагирующее на команды прерывания и завершения.
Другие протоколы и продукты
Вследствие популярности NFS и необходимости в использовании общих
ресурсов на разных компьютерных платформах было создано много программ,
работающих на базе NFS. В этой главе приведены некоторые примеры,
заслуживающие внимания.
WebNFS
Фирма Sun Microsystems недавно представила WebNFS — усовершенствованную
версию протокола NFS. WebNFS превосходит своего предшественника по
масштабируемости, надежности и эффективности работы по Интернету. WebNFS
также работает через брандмауэры — в системе NFS, базирующейся на RPC, это
было непросто. WebNFS требует установки NFS версии 3 и выше. WebNFS
поддерживается всеми основными разработчиками, включая Netscape, Novell, Apple,
IBM и т. д. WebNFS 1.2 включает компонент JavaBean, для работы которого
требуется Java 2 SDK.
За дополнительной информацией обращайтесь на сайт http://www.sun.com/
webnfs/.
PC-NFS и другие клиентские программы
Клиентская программа PC-NFS, разработанная в Sun Microsystems,
предназначена для компьютеров, не входящих в семейство Unix. Работа PC-NFS зависит
от демона pcnfsd, входящего в комплект поставки нескольких продуктов Sun.
ПРИМЕЧАНИЕ
Если демон pcnfsd отсутствует на вашем сервере NFS, вероятно, вам придется найти исходные
тексты в Интернете, откомпилировать и установить его самостоятельно. В системе Linux демон
pcnfsd называется rpc.pcnfsd.
Также существует много других клиентских программ NFS. В табл. 30.2
перечислены некоторые клиенты и приведены адреса, по которым следует
обращаться за дополнительной информацией.
Таблица 30.2. Клиентские программы NFS
Продукт Разработчик URL
Solstice NFS Client Sun Microsystems http://www.sun.com/netclient/nfs-client/
Reflection NFS Connection WRQ http://www.irq.com/
NFS Maestro Hummingbird http://www.hcl.com/products/nc/nfs/
Communications, Ltd.
Omni-NFS Xlink Technology http://www.xlink.com/
SMB и CIFS
SMB (Service Message Block) — стандарт, разработанный IBM, Microsoft и
рядом других компаний, предназначенный для организации совместного доступа
к файловым системам, принтерам и другим ресурсам. В настоящее время
поддержка SMB интегрирована в Windows NT, OS/2 и Linux, а во многих других
системах она обеспечивается продуктами независимых фирм.
За дополнительной информацией о SMB обращайтесь по адресу http://www.
samba.org/cifs/docs/what-is-smb.html.
Открытая версия протокола SMB CIFS (Common Internet File System)
создается группой разработчиков (Microsoft, SCO и др.). Предполагается, что
первоначальная реализация будет очень близка к NT LM (компонент LAN Manager
в Microsoft NT) с улучшенной поддержкой совместного доступа к ресурсам по
Интернету.
За дополнительной информацией о CIFS посетите сайт http://www.microsoft.com/
library и проведите поиск по строке CIFS.
Ниже перечислены некоторые продукты с поддержкой SMB:
О Samba.
О Windows NT, 95/98/ME/2000/XP.
О LAN Manager.
ПРИМЕЧАНИЕ
Samba — продукт класса «клиент-сервер», распространяемый с открытыми исходными текстами и
поддерживающий протоколы SMB и CIFS. Распространяется на условиях общедоступной лицензии
GNU (GNU Public License).
Samba позволяет легко организовать совместное использование сетевыми клиентами серверных
ресурсов — таких, как файловые системы и принтеры.
За дополнительной информацией обращайтесь на сайт http://www.samba.org.
Другие продукты
Кроме NFS и SMB существуют и другие продукты, предназначенные для
организации совместного доступа к ресурсам. Впрочем, большинство из них
специализируется на относительно узком круге платформ. В качестве примеров таких
протоколов можно упомянуть AppleTalk, Decnet, NetWare и т. д.
Итоги
В этой главе рассматривается протокол NFS, его история и принципы работы.
Мы познакомились с демонами и конфигурационными файлами, используемыми
NFS, а также разобрали практический пример экспортирования и монтирования
файловой системы NFS. Также были описаны другие программы и протоколы,
включая клиентские программы NFS и протокол SMB.
Из-за большого количества демонов, конфигурационных файлов и
параметров, задействованных в работе системы NFS и ее команд, в этой главе также
были кратко рассмотрены некоторые проблемы, возникающие при
использовании NFS, и приведены ссылки на источники дополнительной информации.
*J Интеграция TCP/IP
О JL с прикладными
службами
Бернард МакКарго (Bernard McCargo)
Семейство протоколов TCP/IP имеет многоуровневую структуру. Чтобы вы лучше
поняли, что это значит, рассмотрим конкретный пример — отправку электронной
почты. Непосредственные операции с почтой выполняются при помощи
специального протокола, который определяет набор команд, передаваемых с одного
компьютера на другой. Команды определяют отправителя сообщения, адресата,
текст сообщения и т. д. Однако этот протокол предполагает, что между двумя
компьютерами существует надежная связь. Протокол электронной почты, как
и другие протоколы прикладного уровня, просто определяет набор
передаваемых команд и сообщений. Он спроектирован так, что его работа основана на
использовании TCP и IP.
Протокол TCP отвечает за надежную доставку команд на другой конец
соединения. Он следит за отправленными данными и посылает заново все данные,
потерянные на пути к получателю. Если какой-либо блок данных оказывается
слишком большим для одной дейтаграммы (например, текст сообщения), он
разбивается протоколом IP на несколько дейтаграмм.
Протокол IP обеспечивает фрагментацию и восстановление дейтаграмм,
размер которых превышает значение MTU промежуточной сети. Тем не менее
правильная сборка дейтаграмм в точке приема относится к функциям TCP.
Поскольку сервис надежной доставки используется многими приложениями,
эти функции выделяются в отдельный протокол вместо того, чтобы быть
включенными в спецификацию отправки почты. Можно считать, что TCP
предоставляет библиотеку функций, используемых приложениями при необходимости
произвести надежный обмен данными с другим компьютером. В свою очередь,
TCP пользуется сервисом IP. Хотя услуги, предоставляемые TCP, используются
многими приложениями, в отдельных случаях сервис надежной передачи
оказывается излишним; в таких приложениях обычно используется протокол UDP.
Тем не менее некоторые функции необходимы каждому приложению, и эти
функции были объединены в протокол IP. С точки зрения TCP протокол IP может
рассматриваться как библиотека функций, вызываемых TCP, однако эти
функции доступны и для приложений, не использующих TCP. В результате образу-
ется многоуровневая структура протоколов. Прикладные программы типа
клиентов электронной почты, протоколы TCP и IP находятся на разных уровнях,
при этом каждый уровень пользуется услугами нижних уровней. В общем
случае приложения TCP/IP используют четыре уровня:
О прикладные протоколы (например, электронная почта);
О протоколы, функции которых используются многими приложениями (TCP);
О протокол IP, обеспечивающий базовые средства доставки дейтаграмм к месту
назначения;
О протоколы, необходимые для управления физическими средствами передачи
информации (например, Ethernet или канал «точка-точка»).
В следующих разделах каждый из этих уровней рассматривается более подробно.
Применение браузера
на представительском уровне
Представительский уровень выполняет некоторые функции, достаточно часто
используемые приложениями. Из-за частоты использования для этих функций
стоит поискать общее решение, чтобы пользователю не приходилось каждый
раз решать проблемы самостоятельно. В отличие от нижних уровней, основная
задача которых сводится к надежному перемещению битов с одного компьютера
на другой, представительский уровень учитывает синтаксис и семантику
передаваемой информации.
Типичным примером сервиса представительского уровня служил кодировка
данных в стандартном, согласованном виде. Многие пользовательские программы
передают не произвольные последовательности битов, а различные
информационные объекты — имена, даты, денежные суммы и т. д. Передаваемая информация
представляется символьными строками, целыми и вещественными числами, а
также структурами данных, состоящих из нескольких полей простых типов. В разных
системах используются разные форматы представления символьных строк, целых
чисел и т. д. Чтобы компьютеры с разным представлением данных могли
взаимодействовать друг с другом, должен существовать способ абстрактного определения
передаваемых структур данных и стандартный формат, используемый при
передаче данных в канале. Задачи управления этими абстрактными структурами
данных и преобразования представлений, используемых внутри компьютеров, в
стандартное сетевое представление, решаются на представительском уровне.
Представительский уровень также учитывает другие аспекты представления
информации. Например, для уменьшения объема передаваемой информации
может применяться сжатие данных, а для обеспечения конфиденциальности
и при аутентификации часто используется шифрование.
ПРИМЕЧАНИЕ
Хотя шифрование относят к представительскому уровню, оно не является исключительной
функцией этого уровня. Во многих стандартах (например, IPSec) шифрование реализуется в составе
сетевого уровня (IPv6) или на отдельном подуровне, находящимся между сетевым и транспортным
уровнями (IPv4).
Анализируя возможности использования браузера на представительском уровне,
следует учитывать некоторые особенности, относящиеся к специфике
представления данных в браузере — например, фреймы. В работе сервера (в том числе
и сервера HTTP) наличие фреймов не учитывается. Сервер всего лишь получает
информацию по заданному URL и помещает ее туда, куда потребует браузер.
Интеграция TCP/IP с унаследованными
приложениями
Интеграция TCP/IP с унаследованными приложениями превращается в обыденное
явление. Некоторые фирмы-производители интегрируют TCP/IP в стандартные
протоколы, как видно на примере таких продуктов, как NetWare 5 и NetWare 6.
Другие компании обеспечивают интеграцию TCP/IP с другими протоколами
при помощи специальных преобразователей (также называемых шлюзами).
Интегрированная поддержка TCP/IP в приложениях обладает рядом
преимуществ, в том числе:
О упрощение выбора TCP/IP за счет полной интеграции выбора протокола в
процесс установки приложения;
О упрощение управления IP-адресами через серверы DHCP/BootP за счет
предоставления постоянного пула IP-адресов, автоматически назначаемых
пользователям по мере необходимости;
О мобильные пользователи, подключающиеся к Интернету через SLIP или РРР,
могут работать с серверами приложений, находящимися в любой точке
земного шара;
О повышение эффективности работы глобальной сети за счет ликвидации
лишнего широковещательного трафика, разгрузка каналов и повышение реальной
пропускной способности;
О возможность использования сетевых устройств на базе IP (например,
принтеров, подключенных к хостам Unix);
О возможность предоставления полного доступа к сетевым ресурсам для
широкого круга настольных клиентов, включая DOS, Windows 3.1, Windows for
Workgroups, Windows 9x, Windows NT/2000 Server и Workstation.
Использование TCP/IP в других сетях
В некоторых сетях TCP/IP является лишь одним из используемых протоколов.
В таких случаях очень важно правильно организовать взаимодействие TCP/IP
(и других протоколов этого семейства) с другими протоколами. Уровни
протокола TCP/IP проектировались независимыми друг от друга, что обеспечивало
их смешанное использование. При пересылке сообщения по сети на удаленный
компьютер каждый уровень протокола получает информационный пакет от
верхнего уровня, добавляет к нему собственный заголовок и передает пакет еле-
дующему нижнему уровню. Получив пакет по сети (в формате, определяемом
требованиями сети), получатель передает его по уровням стека протоколов в
обратном порядке, последовательно удаляя из него служебные заголовки.
Во время передачи пакета по уровням информация протоколов нижних
уровней определяет, каким протоколом верхнего уровня должен обрабатываться пакет.
При замене любого уровня в стеке протоколов новый протокол должен
работать со всеми остальными уровнями, а также выполнять все обязательные
функции этого уровня (в частности, воспроизводить функциональность
замененного протокола). Процесс начинается с получения сообщения от протокола
верхнего уровня, который в свою очередь передает сообщение от приложения,
расположенного еще выше. Получив сообщение, TCP включает в него
собственный заголовок и передает протоколу IP, который делает то же самое. Когда
сообщение IP передается уровню Ethernet, последний добавляет собственную
информацию в начало и конец сообщения и передает сообщение по сети. При
работе с другими операционными системами или сетевыми архитектурами часто
требуется заменить один или несколько уровней структуры TCP/IP уровнями
другой системы.
Ниже приведены примеры служб, использующих разные уровни сети.
NetBIOS и TCP/IP
Служба NetBIOS расположена в иерархии уровней над протоколами TCP и UDP,
хотя обычно она прочно связана с ними (поэтому четко разделить эти два уровня
не удается). NetBIOS обеспечивает логическую связь приложений на верхних
уровнях, предоставляет сервис обмена сообщениями и распределения ресурсов.
Для работы NetBIOS выделяются три порта: для службы имен NetBIOS
(порт 137), для службы дейтаграмм (порт 138) и для сеансовой службы (порт
139). Также поддерживается механизм отображения имен DNS (Domain Name
Service) и сервером имен NetBIOS NBNS (NetBIOS Name Server). Сервер имен
NetBIOS предназначен для идентификации компьютеров, работающих в зоне
NetBIOS. В интерфейсе NetBIOS/TCP отображение имен используется для
формирования имен DNS.
На компьютерах с системой Windows протокол IP можно настроить так, чтобы
он работал на базе NetBIOS, с полным исключением TCP и UDP и работой
NetBIOS в режиме, не ориентированном на соединение. В этом случае NetBIOS
берет на себя функции уровня TCP/IP, а задачи обеспечения целостности данных,
соблюдения порядка пакетов и управления потоком данных должны решаться
протоколами верхнего уровня. В этой архитектуре NetBIOS инкапсулирует
дейтаграммы IP. Чтобы в пакетах NetBIOS отражались IP-адреса, необходимо
наличие жесткого соответствия между IP-адресами и именами NetBIOS (для чего
в NetBIOS кодируются имена вида lP.nnn.nnn.nnn.nnn).
В сетях такого типа вся необходимая функциональность протокола TCP
эмулируется протоколами верхнего уровня, однако у такой сетевой архитектуры
есть свои преимущества — простота и эффективность. В некоторых сетях такой
подход работает достаточно хорошо, хотя иногда возникают проблемы с
разработкой подходящих протоколов верхнего уровня.
ПРИМЕЧАНИЕ
С другой стороны, работа сети на базе NetBIOS создает свои трудности. На протокольном уровне
NetBIOS часто реализуется в контексте протокола NetBEUI. Протокол NetBEUI не
маршрутизируется, а это значит, что он плохо масштабируется при построении больших сетей. Другая
проблема — чрезмерное применение широковещательной рассылки. Широковещательная рассылка
снижает фактическую пропускную способность сети, а многие маршрутизаторы по умолчанию
блокируют широковещательные пакеты. В случае доменов Windows NT из-за блокировки
широковещательных пакетов на маршрутизаторах появилось правило, согласно которому каждая подсеть
должна иметь свой главный браузер (лишние сложности). Начиная с Windows 2000, фирма Microsoft
отказалась от использования NetBIOS. Протоколы SMB (Server Message Block) и MS-RPC (Microsoft
Remote Procedure Call) можно настроить на работу в «чистой» сети IP, не использующей NBT
(NetBIOS over TCP/IP). В сетях Windows 2000 протокол NetBIOS нужен только для поддержки
клиентов предыдущего поколения, включая Windows NT и Windows 9x.
IPX и UDP
В сетевом продукте Novell NetWare имеется сходный с IP протокол IPX (Internet
Packet Exchange), основанный на протоколе Xerox XNS. Для обмена данными,
не ориентированного на соединение, IPX обычно использует UDP, хотя в
сочетании с LLC типа 1 может использоваться протокол TCP.
Вертикальная иерархия уровней (работа IPX на базе UDP) означает, что
заголовки UDP и IP остаются без изменений, а информация IPX инкапсулируется
как часть стандартного процесса обработки сообщений. Как и в случае с
другими сетевыми протоколами, необходима схема отображения между адресами IP
и адресами IPX. В IPX идентификаторы сети и хоста занимают четыре и шесть
байт соответственно. При передаче UDP эти идентификаторы автоматически
преобразуются.
Сеть IPX можно перенастроить таким образом, чтобы вместо UDP в ней
использовался протокол TCP, с заменой протокола LLC типа 1, не
ориентированного на соединение. При использовании подобной архитектуры отображение
адресов IP выполняется средствами ARP.
Итоги
Многим приложениям приходится решать типовые задачи — открывать
подключение к заданному компьютеру, регистрироваться в системе, запрашивать
файлы и управлять их пересылкой. Эти задачи решаются при помощи
прикладных протоколов, которые работают на базе TCP/IP. Иначе говоря, когда
приложению требуется отправить некоторое сообщение, оно передает это сообщение
протоколу TCP, который обеспечивает его надежную доставку на другой конец
подключения. Поскольку TCP и IP берут на себя все технические детали
сетевого обмена данными, прикладные протоколы могут интерпретировать
межсетевое подключение как простой поток байтов (по аналогии с терминалом или
модемным подключением).
*Э *% Почтовые протоколы
*■} ёы Интернета
Нил С. Джеймисоп (Neal S.Jamison)
Несомненно, электронная почта остается самой популярной службой Интернета.
Без всякого преувеличения можно сказать, что электронная почта изменила
стандарты общения между людьми в современном мире.
Электронная почта
Все мы ежедневно общаемся с другими людьми — членами семьи, друзьями и
коллегами. Одной из важнейших технологий, появившихся в информационную
эпоху, стала электронная почта. Когда вы читаете эти строки, в Интернете
передаются бесчисленные сообщения, содержащие деловую и личную информацию
на компьютеры миллионов пользователей.
В этом разделе кратко описаны концепции электронной почты и пути ее
эволюции к современному состоянию. Читатель познакомится со стандартами, на
основе которых работает электронная почта, и группами, которые вырабатывают
эти стандарты.
История электронной почты
Интернет предназначался для повышения качества связи между
правительственными учеными и технологами, работавшими над проектом. И хотя появлению
электронной почты предшествовали другие механизмы обмена данными, сейчас
электронная почта считается наиболее часто используемой службой Интернета.
Впрочем, за это время Интернет давно вырос за рамки простой среды
транспортировки электронной почты.
Первые системы электронной почты представляли собой простые программы,
предназначенные для копирования сообщений в почтовые ящики пользователей.
В то время электронная почта обслуживала только локальных пользователей:
один пользователь многопользовательского компьютера отправлял сообщения
другим пользователям, работающим на том же компьютере. Этим все и
ограничивалось. С появлением таких продуктов, как cc:Mail, и других специализированных
решений для работы с электронной почтой обмен сообщениями вышел в
локальную сеть. Через некоторое время появились так называемые почтовые шлюзы,
при помощи которых пользователь одного сервера электронной почты мог
отправлять и принимать сообщения от других серверов. Шлюзы обеспечивали
взаимодействие разнотипных почтовых систем. Например, пользователи cc:Mail
использовали шлюзы для отправки сообщений пользователям Microsoft Mail из
других организаций. Впрочем, шлюзы продолжали отправлять и получать
сообщения в специализированных форматах. Появилась необходимость в стандарте.
Стандарты и их разработчики
На самом деле в области электронной почты существует два основных стандарта.
Стандарт Х.400 был разработан группой ITU-TSS (International
Telecommunications Union-Telecommunications Standards Sector) и Международной
организацией по стандартизации ISO. Протокол SMTP (Simple Mail Transfer Protocol)
был создан в ходе ранних исследований и разработок в области Интернета, а его
стандартизация производилась группой IETF. В следующих разделах оба
стандарта рассматриваются более подробно.
Х.400
Первая спецификация протокола Х.400 появилась в 1984 году и была обновлена
в 1988 году Х.400 — сложный, обладающий широкими возможностями протокол
обмена сообщениями. Тем не менее из-за своей сложности и недостаточной
поддержки со стороны фирм-производителей он не получил такого широкого
распространения, как SMTP. По этой причине в этой главе Х.400 лишь
представлен в общих чертах, а фактический стандарт электронной почты Интернета
SMTP рассматривается гораздо подробнее.
ПРИМЕЧАНИЕ
В мире электронной почты используются специальные термины, описывающие компоненты систем
электронной почты:
Пользовательский агент UA (User Agent) — клиентская программа, работающая на компьютере
пользователя и предназначенная для создания и чтения сообщений электронной почты.
Агент передачи сообщений МТА (Message Transfer Agent) — сервер электронной почты. МТА
хранит и пересылает сообщения.
Хранилище сообщений MS (Message Store) — хранит сообщения до того, как они будут прочитаны
или иным образом обработаны получателем.
Сообщения Х.400 могут содержать структурированную информацию и
вложения. Они обладают атрибутами, определяющими условия доставки и
дополнительные характеристики сообщения. Примерами таких атрибутов являются:
О важность;
О приоритет;
О срок жизни;
О подтверждение доставки;
0 предельный срок ответа.
Схема адресации Х.400, как и структура сообщений, относительно сложна.
В табл. 32.1 перечислены основные атрибуты, входящие в адреса Х.400.
Таблица 32.1. Основные атрибуты Х.400
Атрибут Описание
G Имя
1 Инициал
S Фамилия
Q Поколение (Jr., Sr.)
CN Общее имя
О Организация
OU Отдел
Р Частный домен
А Административный домен
С Страна
Для примера рассмотрим следующий адрес:
C=US;A=XXX;P=Acme;0=Acme;OU=IT'S=Jamison;G=Neal
В приведенном адресе указана страна США (C=US); административный
домен (или компания, предоставляющая сервис Х.400) XXX (А=ХХХ); частный
домен Acme (P=Acme); организация или работодатель Acme @=Acme) и отдел
информационных технологий (OU=IT). Имя в пояснениях не нуждается.
Сравните с адресом SMTP jamisonn@company.com.
ПРИМЕЧАНИЕ
Одной из сложностей стандарта Х.400 является его схема адресации. В отличие от адресов SMTP
(пользователь@домен.сот) адреса Х.400 бывают достаточно сложными. На помощь приходят
службы каталогов Х.500 и LDAP, протоколы которых определяют стандартный формат
структуры глобальных каталогов. Почтовые системы Х.400 могут использовать эти каталоги для поиска
адресатов.
За дополнительной информацией о Х.500 и LDAP обращайтесь к главе 18, RFC 2256 или на сайт
ITU (http://www.itu.int/).
Сложная структура адресов Х.400 обладает как очевидными достоинствами,
так и недостатками.
Достоинства:
О схема адресации прекрасно подходит для приложений, работающих со
сложными и/или защищенными данными (например, электронных магазинов);
О хорошая защищенность данных;
О надежный механизм оповещения о невозможности доставки;
О международная стандартизация.
Недостатки:
О высокая стоимость реализации;
О большие затраты на настройку и администрирование;
О недостаточная поддержка со стороны фирм-производителей;
О многие замечательные возможности Х.400 (например, защита данных) еще
не используются приложениями.
За дополнительной информацией о Х.400 обращайтесь на сайт ITU http://
www.itu.int/.
SMTP
Стандартом электронной почты в Интернете является протокол SMTP (Simple
Mail Transfer Protocol). Это протокол прикладного уровня, обеспечивающий
сервис доставки сообщений в сетях TCP/IP. Протокол SMTP был разработан
в 1982 году группой IETF; в настоящее время его спецификация содержится
в RFC 821 и 822.
SMTP использует порт TCP с номером 25.
ПРИМЕЧАНИЕ
Хотя SMTP является самым распространенным протоколом электронной почты, он не обладает
некоторыми нетривиальными возможностями X .400. Главным недостатком стандартного варианта
SMTP является то, что он поддерживает только текстовые сообщения.
MIME и SMTP
Стандарт MIME (Multipurpose Internet Mail Extensions) дополняет SMTP и
позволяет включать в стандартные сообщения SMTP мультимедийные (то есть не
текстовые) данные. Для преобразования двоичных файлов в ASCII используется
кодировка Base64.
MIME — относительно новый стандарт. Хотя в настоящее время он
поддерживается практически всеми клиентскими приложениями, нельзя полностью
исключать того, что он не будет поддерживаться вашей почтовой программой.
В таких случаях обычно используются другие способы кодировки двоичных
данных (BinHex или uuencode), описанные ниже.
Стандарт MIME описан в RFC 2045-2049.
S/MIME
Существует новая спецификация MIME, которая позволяет передавать
шифрованные сообщения. S/MIME использует технологию шифрования с открытым
ключом RSA и предотвращает перехват и фальсификацию сообщений.
Текущая спецификация S/MIME приведена в RFC 2311 и 2312.
ПРИМЕЧАНИЕ
Название RSA составлено из первых букв фамилий его разработчиков — Ривест (Rivest), Шамир
(Shamir) и Адельман (Adelman). Алгоритм RSA обеспечивает шифрование с открытым ключом.
Базовый принцип шифрования с открытым ключом основан на том, что данные, зашифрованные
с открытым ключом, могут быть расшифрованы только с использованием закрытого ключа. В
стандарте S/MIME пользовательский агент отправителя шифрует произвольную строку данных с
использованием открытого ключа получателя. Затем пользовательский агент получателя
расшифровывает сообщение, используя закрытый ключ.
За дополнительной информацией о RSA обращайтесь на сайт http://www.rsa.com/.
Другие стандарты кодировки двоичных данных
Наряду с MIME существуют и другие стандарты кодировки сообщений.
Наибольшей известностью пользуются BinHex и uuencode.
BinHex (сокращение от «Binary Hexadecimal») некоторые считают версией
MIME для Macintosh. Стандарт uuencode (сокращение от «Unix-to-Unix
Encoding») первоначально создавался для системы Unix, но в наше время он
поддерживается на множестве других платформ. Хотя между MIME, uuencode и BinHex
существует ряд принципиальных различий, все эти стандарты решают общую
задачу — пересылку произвольных двоичных данных в текстовых сообщениях.
Выбор механизма кодировки зависит от того, какие пользовательские агенты
используются на вашем компьютере и на компьютерах получателей. К счастью,
большинство современных агентов автоматически кодируют и декодируют
двоичные данные.
Команды SMTP
Простота SMTP отчасти обусловлена малым количеством используемых команд.
Команды SMTP перечислены в табл. 32.2.
Таблица 32.2. Команды SMTP (по спецификации RFC 821)
Команда Описание
НЕЮ Используется для идентификации отправителя на стороне получателя. Команда
сопровождается именем хоста-отправителя. В расширенной версии протокола
(ESMTP) используется команда EHLO. Дополнительная информация приведена
в разделе «Расширение SMTP»
MAIL Начинает операцию по пересылке почты. Аргументы команды включают поле
«From», то есть отправителя сообщения
RCPT Идентифицирует получателя сообщения
DATA Сообщает о начале пересылаемых данных (основного текста сообщения).
Данные содержат произвольные ASCII-коды и завершаются отдельной строкой,
состоящей из символа «точка» (.)
RSET Отменяет текущую операцию
VRFY Используется для проверки получателя
NOOP Команда не выполняет никаких действий
Команда Описание
QUIT Закрывает подключение
SEND Сообщает хосту-получателю о том, что сообщение должно быть отправлено
на другой терминал
Следующие команды определены в RFC 821, но не являются обязательными
SOML Send OR Mail. Сообщает хосту-получателю о том, что сообщение должно быть
отправлено на другие терминалы или почтовые ящики
SAML Send OR Mail. Сообщает хосту-получателю о том, что сообщение должно быть
отправлено на другие терминалы или почтовые ящики
EXPN Используется для расширения списка рассылки
HELP Запрашивает справочную информацию с хоста-получателя
TURN Требует, чтобы хост-получатель принял на себя роль отправителя
Как видно из следующего примера, команды SMTP имеют простой синтаксис:
220 receivingdomain.com
Server E5MTP Sendmail 8.8.8+Sun/8.8.8; Fri. 30 Jul 1999 09:23:01
HELO host.sendingdomain.com
250 receivingdomain.com Hello host, pleased to meet you
MAIL FROM:<username@sendi ngdomai n.com>
250 <username@sendingdomain.com> Sender ok.
RCPT TO:<username@receivi ngdomai n.com>
250 <username@receivingdomain.com> Recipient ok.
DATA
354 Enter mail, end with '.' in a line by itself
Here goes the message
250 Message acepted for delivery
QUIT
221 Goodbye host.snedingdomain.com
Полученное сообщение выглядит примерно так:
From username@sendingdomain.com Fri Jul 30 09:23:39 1999
Date: Fri. 30 Jul 1999 09:23:15 -0400 (EDT)
From: useгname@sendingdomain.com
Message-Id:<199907301326.JAA137 34@mai1.receivingdomain.com>
Content-Length: 23
Here goes the message.
Коды состояния SMTP
Когда МТА-отправитель передает команды SMTP МТА-получателю,
последний возвращает специальные коды состояния, по которым отправитель узнает
о результатах выполнения операций. В табл. 32.3 перечислены коды состояния
SMTP в соответствии со спецификацией RFC 821. Коды группируются по
признаку состояния, определяемому первой цифрой кода (lxx-Зхх — успех, 4хх —
временные затруднения, 5хх — неудача).
Таблица 32.3. Коды состояния SMTP
Код Описание
211 Справочный ответ, статус системы
214 Справочное сообщение
220 Служба готова к работе
221 Закрытие подключения
250 Запрашиваемая операция разрешена
251 Пользователь не является локальным, перенаправление по заданному пути
354 Начало ввода почты
421 Служба недоступна
450 Операция не выполнена, почтовый ящик занят
451 Операция отменена, локальная ошибка
452 Операция не выполнена из-за нехватки места
500 Неопознанная команда (или синтаксическая ошибка)
501 Синтаксическая ошибка в параметрах или аргументах
502 Команда не поддерживается
503 Нарушена последовательность команд
504 Параметр не поддерживается
550 Операция не выполнена, почтовый ящик недоступен
551 Пользователь не является локальным
552 Отмена: превышение объема выделенного блока
553 Операция не выполнена, недопустимое имя почтового ящика
554 Сбой при выполнении операции
Числовые коды определены в RFC. С другой стороны, хотя в RFC
рекомендуется примерный вид сопроводительного текста, окончательный выбор остается
за администратором МТА. Иногда администраторы дают волю фантазии.
Расширение SMTP
Протокол SMTP на практике доказал свою силу и полезность. Тем не менее
возникла потребность в расширениях стандартной версии SMTP. В RFC 1869
определены средства добавления новых расширений SMTP. Документ не
содержит списка конкретных расширений, а описывает механизм добавления
нужных команд. Примером может послужить команда SIZE, при помощи которой
хост-получатель ограничивает размер входящих сообщений. Без применения
ESMTP это было бы невозможно.
При подключении к МТА система может передать команду EHLO —
расширенную версию команды HELO. Если МТА поддерживает расширение SMTP
(ESMTP), он отвечает списком поддерживаемых команд. Если ESMTP не
поддерживается, МТА выдает код ошибки E00: неопознанная команда), а
хост-отправитель возвращается к SMTP. Ниже приведен пример транзакции SMTP.
220 esmtpdomain.com
Server ESMTP Sendmail 8.8.8+Sun/8.8.8; Thu, 22 Jul 1999 09:43:01
EHLO host.sendingdomain.com
250-mail.esmtpdomain.com Hello host, pleased to meet you
250-EXPN
250-VERB
250-8BITMIME
250-SIZE
250-&SN
250-ONEX
250-ETRN
250-XUSR
250 HELP
QUIT
221 Goodbye host.sendingdomain.com
В табл. 32.4 приведены основные команды ESMTP.
Таблица 32.4. Основные команды ESMTP
Команда Описание
EHLO Расширенная версия НЕЮ
8ВГГМ1МЕ 8-разрядная кодировка MIME
SIZE Определение предельного размера сообщения
Заголовки SMTP
Внимательное изучение заголовков SMTP приносит достаточно обширную
информацию. Вы можете узнать не только имя отправителя, тему, дату отправки
и предполагаемого получателя, но и просмотреть все промежуточные точки на
пути сообщения к вашему почтовому ящику. В RFC 822 указано, что заголовок
сообщения должен содержать как минимум данные отправителя (поле From),
дату и адресата (поля ТО, СС или ВСС).
Достоинства и недостатки SMTP
Протокол SMTP, как и Х.400, обладает специфическими достоинствами и
недостатками.
Достоинства:
О Чрезвычайная популярность протокола SMTP.
О Поддержка со стороны многих производителей на многих платформах.
О Низкие затраты на реализацию и администрирование.
О Простая схема адресации.
ПРИМЕЧАНИЕ
С технической точки зрения поля ТО и СС идентичны. Термин СС (Carbon Copy, то есть «копирка»)
остался с тех времен, когда при печати на пишущих машинках для создания копий применялась
копировальная бумага.
В поле заголовка Received хранится список узлов, на которых побывало сообщение перед
доставкой в ваш почтовый ящик. Содержимое поля Received существенно упрощает диагностику
возникающих проблем. Рассмотрим следующий пример:
From someone@mydomain.COM Sat Jul 31 11:33:00 1999
Received: from hostl.mydomain.com by host2.mydomain.com (8.8.8+Sun/8.8.8)
with ESMTP id LAA21968 for <jamisonn@host2.mydomain.com>;
Sat, 31 Jul 1999 11:33:00 -0400 (EDT)
Received: by hostl.mydomain.com with Internet Mail Service E.0.1460.8)
id <KNJ6NT2Q>; Sat, 31 Jul 1999 11:34:39 -0400
Message-ID: <C547FF20D6E3DUlB4BF0020AFF588113101AF@hostl.mydomain.com>
From: "Your Friend" <someone@mydomain.COM>
To: ",jamisonn(a)host2.mydomain.com'" <jamisonn@host2.mydomain.com>
Subject: Hello There
Date: Sat, 31 Jul 1999 11:34:36 -0400
Анализ заголовка показывает, что сообщение было отправлено с адреса someone@mydomain.com.
Из домена mydomain.com оно было доставлено на хост hostl. После hostl сообщение было
получено хостом host2, на котором оно было доставлено адресату. На каждой промежуточной остановке
хост-получатель обязан включить в сообщение свой заголовок с пометкой даты/времени.
Интересно заметить, что в приведенном примере в этих пометках существуют расхождения. Хост host2
(получатель) сообщает, что сообщение было получено в 11:33:00. С другой стороны, хост hostl
указывает, что сообщение было принято в 11:34:36, то есть через минуту после его получения.
Расхождения объясняются десинхронизацией часов на двух хостах.
Недостатки:
О Отсутствие некоторых нетривиальных функций.
О Недостаточный уровень безопасности по сравнению с Х.400.
О Простота протокола ограничивает возможности его практического применения.
Получение почты с применением POP и IMAP
На ранних порах существования электронной почты Интернета пользователям
приходилось подключаться к серверу, чтобы прочитать свои сообщения.
Почтовые программы обычно работали в текстовом режиме и не обладали
элементарными удобствами, привычными для многих пользователей. Были разработаны
протоколы, которые позволяли доставлять сообщения электронной почты
прямо на рабочие станции пользователей. Эти протоколы также оказались очень
удобными для «блуждающих» пользователей, работающих за разными
компьютерами.
В настоящее время чаще всего применяются протоколы POP (Post Office
Protocol) и ШЛР (Internet Mail Access Protocol).
Протокол POP
Протокол POP позволяет локальным пользовательским агентам подключаться
к МТА и загружать сообщения на локальный компьютер для чтения и
составления ответов. Первая спецификация POP появилась в 1984 году, а в 1988 году
вышла обновленная версия РОР2. Текущим стандартом протокола является РОРЗ.
Пользовательские агенты РОРЗ подключаются к серверу через TCP/IP (обычно
с использованием порта 110). Пользовательский агент указывает имя и пароль,
которое хранится в служебных данных (более удобный вариант) или каждый
раз вводится пользователем заново (более безопасный вариант). После
прохождения авторизации пользовательский агент выдает команды РОРЗ,
предназначенные для чтения и удаления сообщений.
Протокол РОРЗ предназначен только для принятия сообщений. Для отправки
почты на сервер пользовательские агенты используют протокол SMTP.
Спецификация РОРЗ приведена в RFC 1939.
Список команд РОРЗ приведен в табл. 32.5.
Таблица 32.5. Команды РОРЗ
Команда Описание
USER Передача имени пользователя
PASS Передача пароля
STAT Запрос информации о состоянии почтового ящика (количество и размер сообщений)
LIST Вывод списка сообщений
RETR Прием заданных сообщений
DELE Удаление заданных сообщений
NOOP Нет операции
RSET Отмена удаления сообщений (откат)
QUIT Закрепление изменений и отключение от сервера
Протокол IMAP
Протокол РОРЗ чрезвычайно прост и удобен для приема сообщений
пользовательским агентом. Тем не менее его простота иногда оборачивается отсутствием
нужных возможностей. Например, РОРЗ работает только в автономном режиме,
то есть сообщения загружаются пользовательским агентом и удаляются с сервера.
ПРИМЕЧАНИЕ
В некоторых реализациях РОРЗ поддерживается режим «псевдоподключения», который позволяет
оставлять сообщения на сервере.
Протокол ШАР (Internet Mail Access Protocol) стремится заполнить пробелы,
присущие РОРЗ. Протокол ШАР был разработан в 1986 году в Стэнфордском
университете, а первая реализация IMAP2 появилась в 1987 году. Последняя
версия IMAP4 была принята в качестве стандарта Интернета в 1994 году (а ее спе-
цификация определена в RFC 2060). Протокол IMAP4 работает на порте TCP
с номером 143.
В табл. 32.6 приведен список команд IMAP4 в соответствии с RFC 2060.
Таблица 32.6. Команды IMAP4
Команда Описание
CAPABILITY Запрос списка поддерживаемых возможностей
AUTHENTICATE Определение механизма аутентификации
LOGIN Передача имени пользователя и пароля
SELECT Выбор почтового ящика
EXAMINE Просмотр содержимого почтового ящика в режиме «только для чтения»
CREATE Создание почтового ящика
DELETE Удаление почтового ящика
RENAME Переименование почтового ящика
SUBSCRIBE Включение почтового ящика в активный список
UNSUBSCRIBE Исключение почтового ящика из активного списка
LIST Вывод списка почтовых ящиков
LSUB Вывод списка почтовых ящиков в активном списке
STATUS Запрос информации о состоянии почтового ящика (количество
сообщений и т. д.)
APPEND Включение сообщения в почтовый ящик
CHECK Запрос контрольной точки для почтового ящика
CLOSE Подтверждение удалений и закрытие почтового ящика
EXPUNGE Подтверждение удалений
SEARCH Поиск в почтовом ящике сообщений, удовлетворяющих заданному критерию
FETCH Выборка частей заданного сообщения
STORE Модификация данных указанных сообщений
COPY Копирование сообщений в другой почтовый ящик
NOOP Нет операции
LOGOUT Закрытие подключения
Сравнение РОРЗ с IMAP4
Между протоколами POP 3 и IMAP4 существует ряд принципиальных
различий. В зависимости от пользовательского агента, МТА и ваших конкретных
потребностей можно использовать один из двух протоколов и даже оба сразу.
Главными протоколами протокола РОРЗ являются:
О чрезвычайная простота;
О широкая поддержка.
Однако из-за своей простоты протокол РОРЗ часто обладает ограниченными
возможностями. Например, он может работать только с одним почтовым
ящиком, а загруженные сообщения должны удаляться с сервера (хотя во многих
реализациях поддерживается режим «псевдоподключения», который позволяет
оставлять сообщения на сервере.
У IMAP4 есть свои премущества:
О усиленная аутентификация;
О поддержка нескольких почтовых ящиков;
О улучшенная поддержка автономного и подключенного режимов работы.
Поддержка подключенного режима в ШАР4 позволяет принять с сервера
часть сообщений, проводить поиск и загружать сообщения по определенным
критериям и т. д. IMAP4 также позволяет пользователям и пользовательским
агентам перемещать сообщения между папками на сервере и удалять некоторые
сообщения. IMAP4 лучше подходит для мобильных пользователей, работающих
за несколькими компьютерами, и для пользователей с несколькими почтовыми
ящиками.
Главный недостаток IMAP4 — то, что он не получил широкого
распространения среди поставщиков услуг Интернета, хотя в наши дни существует немало
клиентов и серверов IMAP4.
Нетривиальные возможности
электронной почты
С увеличением количества пользователей электронной почты расширяется и круг
вопросов, связанных с ее применением. В этом разделе освещены некоторые
темы, представляющие интерес для пользователей электронной почты —
безопасность, спам и новые виды почтового сервиса.
Безопасность
Безопасность играет важную роль при работе с электронной почтой — как,
впрочем, и в любой области, относящейся к компьютерным сетям. А в обеспечении
безопасности очень важную роль играют механизмы надежной и
конфиденциальной доставки сообщений.
Шифрование
Как упоминалось выше, стандарт S/MIME позволяет шифровать данные в
сообщениях электронной почты. Шифрование защищает данные и гарантирует, что
сообщения не будет искажены в процессе передачи.
На практике также часто используется механизм шифрования сообщений
PGP (Pretty Good Privacy). В PGP для шифрования и расшифровки сообщений
используются пары, состоящие из открытого и закрытого ключа. Отправитель
шифрует сообщение с открытым ключом получателя, а получатель расшифро-
вывает сообщение с закрытым ключом. За дополнительной информацией о PGP
обращайтесь на сайт http://www.pgp.com.
Цифровые подписи позволяют убедиться в том, что сообщение действительно
исходит от указанного отправителя. Механизм цифровых подписей также
основан на шифровании с парными ключами. Дополнительная информация о
цифровых подписях приводится по адресу http://www.verisign.com/client/index.html.
Вопросы конфиденциальности электронной почты и шифрования
рассматриваются в RFC 1421-1424.
Фильтры
Фильтры электронной почты работают по тому же принципу, что и
брандмауэры. Входящие и исходящие сообщения сканируются на соответствие критериям,
установленным администраторами и лицами, ответственными за работу почтовой
системы. Подобные средства часто применяются в организациях, занимающихся
передовыми научными исследованиями и следящими за тем, чтобы данные не
попали в руки конкурентов. Организация устанавливает фильтр электронной
почты и блокирует отправку некоторых типов вложений (например, чертежей,
схем или проектной документации). Фильтрация также применяется для
блокировки оскорбительных сообщений (определяемых по ключевым словам) и спа-
ма, а также блокировки вложений, зараженных вирусами или недопустимых по
другим причинам.
Вирусы
С появлением многочисленных компьютерных и почтовых вирусов эта тема
стала весьма актуальной. Хотя переслать вирус в обычном ASCII-тексте
сообщения электронной почты невозможно, вирусы могут внедряться во вложения.
Многие почтовые вирусы используют поддержку макросов в почтовых
клиентах — например, клиентах от Microsoft (Outlook и Outlook Express).
ПРИМЕЧАНИЕ
Вирус Melissa наглядно убедил многих пользователей электронной почты в необходимости
сканировать сообщения в поисках вирусов.
За дополнительной информацией о вирусах обращайтесь на сайт ISOC по
адресу http://www.isoc.org/internet/issues/viruses.
Фальсификация
Из-за слабой защищенности протокола SMTP злоумышленник может подделать
сообщение электронной почты или придать ему такой вид, словно оно было
отправлено кем-то другим. Например, для подключения к порту SMTP можно
воспользоваться командой SMTP. После подключения фальсификатор вводит те же
команды, которые обычно вводит МТА. Рассмотрим следующий сеанс SMTP:
% telnet mail.mydomain.com 25
Trying...
Connected to mail.mydomain.com.
Escape character is ,л] ' .
220 host.mydomain.com ESMTP Sendmail 8.8.8+Sun/8.8.8;
Fri, 30 Jul 1999 09:23:01
help
214-This is Sendmail version 8.8.8+Sun
214-Topics
214- HELO EHLO MAIL RCPT DATA
214- RSET NOOP QUIT HELP VRFY
214- EXPN VERB ETRN DSN
214-For more info use "HELP <topic>".
help mail
214-MAIL FROM: <sender> [ <parameters> ]
214- Specifies the sender. Parameters are ESMTP extensions.
214- See "HELP DSN" for details.
214 End of HELP info
helo fakedomain.com
250 mail.mydomain.com Hello realhost.mydomain.com, pleased to meet you
mail from:<charlatan@fakedomain.com>
250 <charlatan@fakedomain.com>... Sender ok
rcpt to:jamisonn
250 jamisonn... Recipient ok
data
354 Enter mail, end with "." on a line by itself
This is not really from charlatan@fakedomain.com.
250 MAA07012 Messsage accepter for delivery
quit
221 mail.mydomain.com closing connection
Connection closed by foreign host.
$
Обратите внимание: настоящее имя хоста известно и указано в ответе 250 на
команду HELO. В итоге пользователю jamisonn будет отправлено следующее
сообщение:
From charlatan@fakedomain.com Sun Aug 1 12:18:08 1999
Date: Sun, 1 Aug 1999 12:17:43 -0400 (EDT)
From: charlatan@fakedomain.com
Message-Id: <199908011617.MAA07012@realhost.mydomain.com>
Content-Length: 50
This is not really from charlatan@fakedomain.com.
Хотя на первый взгляд кажется, что сообщение было отправлено с адреса
charlatan@fakedomain.com, внимательное изучение заголовка обнаруживает
настоящее имя хоста в строке Message-Id.
Предупреждение для тех, кому захочется опробовать эту возможность на
практике: квалифицированные администраторы используют хитроумные
системы инкапсуляции данных и ведения журналов, которые обнаружат личность
настоящего отправителя или даже сделают фальсификацию невозможной.
Фальсификация электронной почты — нехорошее дело, и приведенный выше пример
всего лишь демонстрирует теоретическую возможность.
Спам и другие нежелательные сообщения
В последнее время между электронными и «железными» почтовыми ящиками
возникло одно раздражающее сходство: и те и другие быстро заполняются
рекламным мусором.
Рекламные сообщения электронной почты (на сетевом жаргоне называемые
спамом) в последнее время стали серьезной проблемой. На наши почтовые ящики
обрушивается шквал объявлений о распродажах, схемах быстрого обогащения
и других ненужных и раздражающих объявлений. Наши адреса электронной
почты становятся объектом купли-продажи или обмена наряду с обычными
адресами. Результат — заполнение почтовых ящиков электронной макулатурой.
Интересный способ блокировки этих раздражающих сообщений основан на
использовании «фильтрации от идиотов» и «убойных файлов». Эти инструменты
с устрашающими названиями интегрируются в некоторые почтовые агенты и
обеспечивают блокировку сообщений, удовлетворяющих некоторым условиям. Самая
распространенная реализация просматривает заголовок SMTP входящего
сообщения и ищет адрес отправителя или ключевые слова темы в «файле идиотов».
Если фильтр не находит никаких нарушений, сообщение пропускается дальше.
Но если сообщение было отправлено «идиотом» или содержит «идиотскую»
тему, оно либо удаляется, либо перемещается в специальный «мусорный»
почтовый ящик на случай, если вы хотите что-нибудь с ним сделать в будущем.
Меры борьбы со спамом не ограничиваются фильтрацией, однако эта тема
выходит за рамки настоящей главы. За дополнительной информацией
обращайтесь на сайт http://spam.abuse.net или на страницу ISOC, посвященную борьбе со
спамом, по адресу http://www.isoc.org/internet/issues/spamming/.
Анонимный сервис электронной почты
и пересылка
Анонимность в Интернете создает некоторые вопросы этического плана. Одни
пользователи настаивают на том, что анонимность должна поддерживаться,
другие полагают, что любые действия пользователей должны отслеживаться.
Разумеется, когда речь заходит о личном общении (таком, как электронная почта),
споры становятся еще более ожесточенными.
В Интернете существуют программы и службы анонимной отправки
электронной почты. Простейшие из таких служб используют программы, которые
удаляют из сообщения заголовки SMTP и отправляют оставшуюся информацию
указанному получателю. Проследить путь полученного таким образом
сообщения невозможно, а получатель не сможет ответить отправителю; это может быть
как хорошо, так и плохо (все зависит от того, к чему вы стремитесь).
Более совершенные службы ведут базу данных своих анонимных
пользователей. Каждому пользователю назначается идентификатор, позволяющий
отправлять анонимную почту (разумеется, при условии конфиденциальности базы
данных). Информация о связи идентификатора с фактическим адресом
электронной почты пользователя позволяет получателю ответить на анонимное
сообщение.
Другая разновидность анонимного почтового сервиса предоставляется
специализированными поставщиками онлайнового сервиса и электронной почты.
Недавно появившиеся «бесплатные» почтовые службы (Hotmail, Yahoo!, Usanet
и т. д.) предлагают пользователю выбрать идентификатор, то есть имя, под
которым будет отправляться почта. Не стоит и говорить, что идентификатор не
обязан совпадать с настоящим именем (полностью или частично). Используя
идентификатор, отличный от настоящего имени, можно отправлять электронную
почту практически анонимно.
Итоги
В этой главе подробно рассматривается основной протокол электронной почты
в Интернете: SMTP. Краткий курс истории электронной почты позволяет лучше
понять, какой значительный путь развития прошла эта служба. Внимание также
уделяется Х.400 — мощному, но не получившему достаточно широкого
распространения протоколу для работы с электронной почтой. Знакомясь с
протоколом SMTP, мы рассмотрели его набор команд, коды ответов и способы
кодировки двоичных данных. Также были упомянуты два протокола приема сообщений
от агента передачи сообщений (МТА) или хранилища сообщений (MS):
упрощенный РОРЗ и более мощный IMAP4.
Также был рассмотрен ряд вопросов, относящихся к работе с электронной
почтой. При обсуждении вопросов безопасности особое внимание уделялось
шифрованию, фильтрации сообщений и вирусам. Мы обсудили проблемы спама
и привели некоторые рекомендации по поводу того, как с ним бороться.
Наконец, в главе неоднократно приводятся ссылки на документы RFC, содержащие
спецификации электронной почты в Интернете, и упоминаются сайты и группы,
ответственные за разработку современных почтовых протоколов.
*J ** Служба HTTP
Нил С, Джеймисои (Neal S.Jamison)
World Wide Web часто называют технологическим прорывом 1990-х годов. Ни
одна другая технология или программа не открыла столько новых
возможностей. Благодаря Web огромные объемы информации оказались буквально на
расстоянии вытянутой руки. Феноменальный рост Web лишний раз доказывает
важность и огромный потенциал интернет-технологий.
World Wide Web
Всемирная паутина. Информационная супермагистраль. Сеть. Как ни называй,
бесспорно, Web стала величайшим достижением с первых дней революции,
произведенной широким внедрением персональных компьютеров. За свою
короткую жизнь Web прошла долгий путь — от небольшой физической лаборатории
в начале 1990-х годов до 200 с лишним миллионов пользователей в наши дни.
В 1995 году мы слепо блуждали среди нескольких тысяч web-сайтов и полагали,
что это большое достижение. В наши дни умные поисковые системы помогают
ориентироваться в Сети, находить нужную информацию, заказывать товары
и даже платить за них. И это — лишь начало!
В этом разделе рассматривается краткая, но бурная история World Wide Web.
Краткая история Web
Концепция World Wide Web разрабатывалась в Европейской лаборатории по
ядерным исследованиям (CERN) для упрощения совместного доступа к файлам
и обмена информацией между учеными-физиками. В 1993 году в Национальном
центре по использованию суперкомпьютеров (NCSA) был разработан первый
графический браузер Mosaic. С разработки этого web-клиента началась World
Wide Web в том виде, в котором она существует сегодня.
Создатели и попечители Web
Честь изобретения Web принадлежит Тиму Бернерсу-Ли (Tim Berners-Lee),
работнику CERN. Именно он написал первый web-сервер и тем самым определил языки
и протоколы Web. Кроме того, он разработал первого простейшего клиента WWW.
Автором первого популярного web-сервера (NCSA HTTPd) является Роб
Мак-Кул (Rob McCool) из NCSA. Co временем этот сервер был заложен в
основу web-сервера Apache, самого распространенного сервера в современной Web.
Первый графический браузер был также создан в NCSA Марком Андриссеном
(Mark Andreessen), который позднее основал корпорацию Netscape
Communications, создавшую Netscape Navigator.
Тим Бернерс-Ли сейчас возглавляет консорциум World Wide Web (W3C) —
организацию, которая несет основную ответственность за дальнейшее
совершенствование Web, ее протоколов и стандартов. За дополнительной информацией
о консорциуме W3C и его важной работе обращайтесь на сайт http://www.w3c.org.
В истории WWW важную роль также сыграла Проблемная группа
проектирования Интернета IETF (Internet Engineering Task Force). Как сказано в
уставе, «IETF — неформальная самоорганизующаяся группа людей, вносящих
технический и иной вклад в проектирование и развитие Интернета и его технологий»
(источник: http://www.ietf.org/tao.html). IETF играет важную роль в эволюции Web
вообще и протокола HTTP в частности. За дополнительной информацией о роли
IETF обращайтесь на сайт http://www.ics.uci.edu/pub/ietf/http/.
В текущей работе и в стандартизации Интернета и Web также принимает
участие ряд других организаций. Среди них следует особо упомянуть
Координационный совет Интернета IAB (Internet Activities Board), Общество Интернета
ISOC (Internet Society) и Проблемную группу Интернета IRTF (Internet Research
Task Force).
Стремительное развитие Web
В середине 1994 года в Web работало около трех миллионов человек, а сама
структура Web содержала около 3000 сайтов. В июле 2001 года по оценкам
Nielsen/NetRatings (http://www.njelsen-netratings.com/) население Интернета
превысило 257 миллионов.
ПРИМЕЧАНИЕ
В приведенных выше цифрах речь идет не о людях, а о хостах. Подсчитать количество людей,
работающих в Web, очень трудно; задача подсчета хостов решается проще, а на каждый хост
приходится как минимум один пользователь.
Из незрелой, хотя и перспективной среды, используемой немногочисленными
учеными и инженерами, Web превратилась в надежную, защищенную среду,
пригодную для электронной коммерции и решения других важных задач. По мере
улучшения сетевых и компьютерных технологий можно ожидать, что круг
пользователей расширится, а для Web найдется много новых практических применений.
Унифицированные указатели ресурсов
Чтобы найти нужную информацию в Web, необходимо знать, как в серверах
и браузерах определяются ссылки на серверы и файлы. Идентификация
страниц и других ресурсов в Web осуществляется при помощи унифицированных
указателей информационных ресурсов, или URL (Uniform Resource Locators).
Пример адреса URL:
http://www.w3c.org/Protocols/index.html
Этот адрес, ведущий на web-сайт Консорциума World Wide Web, делится на
следующие компоненты:
протокол:// сервер.домен / каталог/ файл
В приведенном выше примере URL определяет:
О протокол http.
О полное доменное имя www.w3c.org.
О каталог Protocols.
О файл index.html.
ПРИМЕЧАНИЕ
Большинство web-серверов настраивается таким образом, чтобы обращения на сайт
автоматически перенаправлялись на страницу по умолчанию. Как правило, страница по умолчанию называется
index.html, однако встречаются и другие варианты — home.html, default.html и index.htm. Таким
образом, URL http://www.w3c.org/Protocols/ вернет файл index.html, находящийся в каталоге Protocols.
Примеры других распространенных разновидностей URL:
ftp://сервер/каталог/файл
ftp://пользователь@сервер/каталог/файл
telnet://сервер
news://сервер/группа
Первые два примера запрашивают документ через FTP, соответственно через
анонимный вход и с указанием имени пользователя. Третий URL запрашивает
доступ к серверу Telnet, а в четвертом примере запрашивается доступ к
конференции Usenet.
URL может содержать данные, используемые сервером. Наиболее
характерным примером является передача параметров функции, работающей на стороне
сервера, например:
http://сервер/каталог/file.html?username=Jamison&uid=300
Приведенный URL передает странице file.html две пары «ключ-значение»:
имя пользователя (username) Jamison и идентификатор (uid) 300.
Иногда в URL требуется включить специальный символ — например, пробел
или косую черту (/). В этом случае специальные символы «кодируются», чтобы
предотвратить возникновение проблем на стороне сервера. В результате
кодирования (иногда называемого шестнадцатеричным кодированием) специальные
символы заменяются их шестнадцатеричными эквивалентами. Предположим,
в URL должно передаваться полное имя пользователя:
http://сервер/каталог/file.html?name=Neal%20Jami son
В приведенном примере пробел между словами «Neal» и «Jamison»
заменяется своим шестнадцатеричным эквивалентом 20. Передача данных в URL часто
используется в программах CGI (Common Gateway Interface). Дополнительная
информация о CGI приводится ниже, в разделе «Языки Web» настоящей главы.
Web-серверы и браузеры
Web-сервсры служат поставщиками информационного содержимого Web.
Получив запрос от клиента, web-сервер предоставляет запрошенные данные в той или
иной форме. В большинстве случаев данные представляются в форме страницы
HTML (Hypertext Markup Language), однако серверы могут предоставлять
информацию в других форматах — графические изображения, звуки, файлы
приложений и даже видеоданные. Клиентские функции в Web выполняются браузерами.
Браузеры содержат программные средства, необходимые для взаимодействия
с web-серверами, а также преобразования и отображения информации,
возвращаемой сервером. В табл. 33.1 приведены примеры хорошо известных серверов
Web, а в табл. 33.2 перечислены основные браузеры.
Таблица 33.1. Популярные web-серверы
Сервер URL
Apache http://www.apache.org
Microsoft IIS (Internet http://www.mJcrosoft.com/ntserver/techresources/webserv/default.asp
Information Server)
Netscape Enterprise Server http://home.netscape.com/enterprise/
Таблица 33.2. Популярные браузеры
Браузер URL
Netscape Navigator http://home.netscape.com/browsers/
Microsoft Internet Explorer http://www.microsoft.com/windows/ie/
Opera http://opera.nta.no/
Обмен данными между web-сервером и браузерами осуществляется па базе
протокола HTTP (Hypertext Transfer Protocol).
ПРИМЕЧАНИЕ
Основной web-сервер в Интернете распространяется бесплатно, и удивляться этому не
приходится. Интернет появился в результате усилий хакеров и ученых, выступавших за свободу мысли
и свободное распространение программного обеспечения. Как показали исследования,
проведенные в октябре 2001 года, свыше 57 процентов серверов в Web работают на базе Apache. Второе
место принадлежит web-серверу Microsoft IIS C0 процентов).
Успех Apache и других бесплатных программных продуктов (таких, как язык программирования Perl
и операционная система Unix) вдохнул новую жизнь в движение Open Source в пользу свободного
распространения программ. К числу продуктов, распространяемых на условиях Open Source,
относятся Netscape Navigator (http://www.mozilla.org/) и AOL Web server (http://www.aolserver.com).
К этой инициативе присоединились такие компании, как Sun Microsystems и IBM.
За дополнительной информацией о философии свободного распространения программ
обращайтесь на сайт http://www.gnu.org/philosophy/.
Дополнительная информация о Apache приведена на сайте http://www.apache.org/, а информация
о системе Linux — на сайте http://www.linux.org/.
Протокол HTTP
Протокол HTTP обеспечивает обмен данными между web-серверами и
браузерами. Он строится на схеме «запрос/ответ»; иначе говоря, сервер ожидает
запросы со стороны и отвечает на них. HTTP не поддерживает собственных
соединений с клиентом и использует надежные соединения TCP, чаще всего на
порте TCP с номером 80. Операция обмена данными между клиентом и
сервером делится на четыре основных этапа:
1. Браузер подключается к серверу.
2. Браузер запрашивает документ с сервера.
3. Сервер передает браузеру запрошенные данные.
4. Связь разрывается.
Протокол HTTP не обладает состоянием, то есть не хранит информацию
о состоянии текущего подключения.
В этом разделе рассматривается версия HTTP, которая в настоящее время
считается стандартной.
НТТР/1.1
Чтобы сделать возможным обмен данными между сервером и клиентом, в
спецификации HTTP определяется язык Web, основанный на запросах и ответах.
ПРИМЕЧАНИЕ
Спецификация НТТР/1.1 определяется в документе RFC 2616, который можно найти по адресам
http://www.w3c.org/Protocols и http://www.rfc-editor.org.
Клиентский запрос
Клиентский запрос содержит следующую информацию:
О Метод запроса.
О Заголовок запроса.
О Данные запроса.
Метод запроса определяет операцию, выполняемую с заданным URL или web-
страницей. Допустимые методы перечислены в табл. 33.3.
Таблица 33.3. Методы запросов HTTP
Метод Описание
GET Запрашивает указанный документ
HEAD Запрашивает только заголовок документа
POST Сервер должен интерпретировать указанный документ как исполняемую программу
и передать ему некоторые данные
PUT Заменяет содержимое указанного документа данными, полученными от клиента
DELETE Запрашивает удаление указанной страницы
Метод Описание
OPTIONS Используется клиентом для получения информации о возможностях
и требованиях сервера
TRACE Используется при тестировании для передачи клиенту информации о том,
как было получено сообщение
Необязательный заголовок передает серверу дополнительную информацию
о клиенте. Типы заголовков перечислены в табл. 33.4.
Таблица 33.4. Заголовки запросов HTTP
Заголовок Описание
Accept Тип данных, принимаемых клиентом
Authorization Аутентификационные данные (например, имя пользователя и пароль)
User-Agent Тип клиентской программы
Referer Web-страница, с которой пришел клиент
Если для выполнения метода необходимы дополнительные данные (как,
например, для метода POST), они передаются после заголовка. В остальных
случаях клиент переходит к ожиданию ответа от сервера.
Ответы сервера
Ответ сервера также содержит важную информацию:
О Код состояния.
О Заголовок ответа.
О Данные ответа.
В HTTP определено несколько групп кодов состояния, возвращаемых
браузеру. Эти коды перечислены в табл. 33.5.
Таблица 33.5. Коды состояния HTTP
Информационные коды Aхх)
100 Continue
101 Switching Protocols
Успешные коды Bхх)
200 ОК
201 Created
202 Accepted
203 Non-Authoritative Information
204 No Content
продолжение ё>
Таблица 33.5 (продолжение)
Информационные коды Aхх)
205 Reset Content
206 Partial Content
Коды перенаправления (Зхх)
300 Multiple Choices
301 Moved Permanently
302 Moved Temporarily
303 See Other
304 Not Modified
305 Use Proxy
Ошибки клиента Dхх)
400 Bad Request
401 Unauthorized
402 Payment Required
403 Forbidden
404 Not Found
405 Method Not Allowed
406 Not Acceptable
407 Proxy Authentication Required
408 Request Timeout
409 Conflict
410 Gone
411 Length Required
412 Precondition Failed
413 Request Entity Too Large
414 Request URI Too Long
415 Unsupported Media Type
Ошибки сервера Eхх)
500 Internal Server Error
501 Not Implemented
502 Bad Gateway
503 Service Unavailable
504 Gateway Timeout
505 HTTP Version Not Supported
В заголовках ответов сервер передает клиенту информацию о себе и/или
запрашиваемом документе. Заголовки, перечисленные в табл. 33.6, завершаются
пустой строкой.
Таблица 33.6. Заголовки ответов HTTP
Метод Описание
Server Информация о web-сервере
Date Текущая дата/время
Last Modified Дата/время последней модификации запрашиваемого документа
Expires Дата/время, когда запрашиваемый документ становится недействительным
Content-type Тип MIME данных
Content-length Размер данных (в байтах)
WWW-authenticate Передача клиенту информации, необходимой для выполнения
аутентификации (например, имени или пароля)
Если клиент запросил данные, то сервер переходит к передаче данных. В
противном случае связь с сервером завершается.
MIME и Web
Стандарт MIME (Multipurpose Internet Mail Extensions) используется в Web для
классификации блоков данных (например, файлов или web-страниц). MIME
позволяет передавать данные в форматах, отличных от простого текста.
Благодаря Mime можно передавать и принимать web-страницы, содержащие двоичную
информацию — звуки, видео, изображения, приложения и т. д.
В процессе обмена данными браузер и сервер согласовывают типы MIME.
Браузер передает информацию о типах MIME, которые он готов принять, в
заголовке запроса. Сервер сообщает клиенту тип MIME данных, которые он
собирается передать.
В табл. 33.7 перечислены некоторые типы MIME, часто встречающиеся в Web.
Таблица 33.7. Распространенные типы MIME в Web
Тип MIME Описание
text/plain Простой ASCII-текст
text/html Текст HTML
image/gif Графическое изображение GIFF
image/jpeg Графическое изображение JPEG
application/msword Microsoft Word
video/mpeg Видео в формате MPEG
audio/wave Аудио
application/x-tar Сжатые данные в формате TAR
Пример сеанса HTTP
Теперь, когда вы знаете, какая информация и какие типы данных передаются
между клиентом и сервером, мы рассмотрим пример использования HTTP в
действии.
Запрос
В этом примере браузер запрашивает документ с URL http://www.hostname.com/
jndex.html. Все запросы завершаются одной пустой строкой:
GET /index.html НТТР/1.1
Accept: text/plain
Accept: text/html
User-Agent: Mozilla/4.5(WInNT)
(пустая строка)
Браузер запрашивает документ /index.html методом GET. Он указывает, что
ответ может содержать только простой текст и данные HTML и что браузер
использует платформу Mozilla/4.5(Netscape).
Ответ
В ответе сервер передает код состояния, заголовки (за которыми следует пустая
строка) и, если потребуется — запрошенные данные. В первом примере
предполагается, что данные были успешно найдены:
НТТР/1.1 200 ОК
Date Sunday, 15-Jul-99 12:18:03 GMT
Server: Apache/1.3.6
MIME-version: 1.0
Content-type: text/html
Last-modified: Thursday, 02-Jun-99 20:43:56 GMT
Content-length: 1423
(пустая строка)
<HTML>
<HEAD>
<title>Example Server-Browser Communication</title>
</HEAD>
<BODY>
Во втором примере запрошенный документ не обнаружен:
НТТР/1.1 404 NOT FOUND
Date Sunday, 15-Jul-99 12:18:03 GMT
Server: Apache/1.3.6
Нетривиальные возможности Web
В этом разделе кратко упоминаются некоторые нетривиальные темы,
относящиеся к Web: средства, работающие на стороне сервера, и механизмы защиты
информации.
Средства, работающие на стороне сервера
Web-серверы передают браузерам разнообразные данные, включая страницы
HTML, видео, аудио и графику. Эти данные берутся из статических страниц
и файлов или генерируются динамически на момент запроса. Динамически!!
контент позволяет строить страницы, ориентированные на конкретный запрос.
Например, при запросе к гипотетическому телефонному справочнику
генерируется конкретная страница с найденной информацией. При подготовке
динамических данных часто используются следующие технологии:
О CGI (Common Gateway Interface).
О API (Application Programming Interface).
О Сервлеты Java.
О Код JavaScript на стороне сервера.
О Включения па стороне сервера.
Дополнительная информация об этих технологиях приводится ниже, в
разделе «Языки Web» настоящей главы.
SSL и S-HTTP
Протоколы SSL (Secure Sockets Layer) и S-HTTP (Secure HTTP) используются
для передачи конфиденциальной информации в Web.
Протокол SSL, разработанный корпорацией Netscape Communications,
использует шифрование с закрытым ключом для безопасной пересылки данных по
защищенному соединению. Серверы SSL отличаются по префиксу протокола —
вместо http в URL используется префикс https.
За дополнительной информацией о SSL обращайтесь по адресу http://home.
netscape.com/secunty/techbriefs/ssl.html.
Протокол S-HTTP является усовершенствованной версией HTTP и
обеспечивает пересылку защищенных сообщений. Не все браузеры и серверы
поддерживают S-HTTP.
Языки Web
Спецификация HTTP определяет конкретный набор правил, по которым
организуется обмен данными между web-сервером и браузером. Тем не менее именно
языки Web наполняют эти коммуникации реальным содержанием и предоставляют
нам, пользователям Web, искомую информацию. Самым распространенным
языком Web является язык HTML, однако существуют и другие языки, используемые
самостоятельно или в сочетании с HTML для расширения возможностей
информационного наполнения. Некоторые из этих языков кратко описаны ниже.
HTML
Стандартный язык HTML (Hypertext Markup Language) поддерживается всеми
браузерами. Он состоит из тегов, определяющих внешний вид web-страницы.
HTML является платформенно-независимым языком и поэтому чрезвычайно
легко переносится из одной среды в другую. Данная особенность позволила
HTML с полным правом называться главным языком Web.
ПРИМЕЧАНИЕ
HTML является специализированным вариантом языка SGML (Standard Generalized Markup
Language) — международного стандарта разметки электронного текста. На SGML можно создавать
определения типов документов (DTD, Document Type Definition) — такие, как HTML.
Представление информации в HTML описывается при помощи тегов. Теги
имеют следующий синтаксис:
<те г информация </те г >
<Тег> начинает определение, a </tag> является признаком его конца.
Допускается использование вложенных тегов.
Пример страницы HTML:
<html>
<head>
<title>Sample page</title>
</head>
<body>
<hl>Hello World</hl>
<bl>Bold text</bl>
<i>Italics</i>
<u>Underlined text</u>
<li>List Item l</li>
<Ii>List Item 2</li>
</body>
</html>
Приведенный пример показывает, насколько прост HTML. Информация
заключается в теги, определяющие начертание текста, тип шрифта, цвет и т. д. За
дополнительной информацией о HTML обращайтесь на сайт http://www.builder.com/.
XML
Язык XML (Extensible Markup Language) является подмножеством SGML,
позволяющим предоставлять в Web информацию в формате SGML. XML можно
представить себе как SGML без некоторых сложных и относительно редко
используемых спецификаций. Простой документ XML выглядит так:
<?xml version=,,1.0n standalone="yes"?>
<conversation>
<greeting>Hello, world!</greeting>
<response>Hello to you too!</response>
</conversation>
Хотя язык XML появился относительно недавно, он обретает популярность.
В частности, XML поддерживается Internet Explorer 5 и Mozilla (браузер Netscape,
распространяемый на условиях Open Source).
DocZilla, браузер на базе Mozilla (http://www.doczilla.com), поддерживает HTML,
XML и SGML. DocZilla содержит дополнительные компоненты, обеспечивающие
оперативный разбор и отображение документов SGML/XML без этапа
предварительной компиляции.
За дополнительной информацией о XML обращайтесь по адресам http://www.
w3.org/XML/, www.xml.org и к списку FAQ Питера Флинна (Peter Flynn) по адресу
http://www.ucc.ie/xml/.
CGI
Стандарт CGI (Common Gateway Interface) обеспечивает передачу данных от web-
сервера CGI-программам. CGI-программы могут быть написаны практически на
любом языке, хотя чаще всего для этой цели используются С и Perl. Как правило,
сценарии CGI получают данные от web-страницы, обрабатывают полученную
информацию и возвращают некий результат пользователю.
За дополнительной информацией о CGI обращайтесь по адресу http://www.
w3.org/CGI/.
Perl
Язык программирования Perl распространяется с открытыми текстами и очень
часто используется в Web. Perl предназначен для обработки текстов. В
исходном варианте он предназначался для системных администраторов Unix и
должен был упростить выполнение некоторых повседневных задач. Его средства
работы с текстами хорошо подходят для написания CGI-программ для Web.
Пример сценария Perl, генерирующего информацию для пользователя:
#!/usr/local/bin/perl
#
# helloworld.pl: CGI output sample program.
#
# Вывод заголовка ответа CGI, необходимого для всего выходного кода HTML
# Заголовок завершается дополнительным символом \п
# для передачи пустой строки,
print "Content-type: text/html\n\n";
# Вывод простого кода HTML в STDOUT
print <<EOF;
<html>
<head><title>CGI Results</title></head>
<body>
<hl>Hello, world.</hl>
</body>
</html>
EOF
exi t;
За дополнительной информацией обращайтесь на сайт Perl Institute no адресу
http://www.perl.org/perl.html.
Java
Объектно-ориентированный язык Java, созданный в Sun Microsystems,
напоминает язык C++. Проектировщики стремились к тому, чтобы Java был проще
и надежнее C++, и благодаря своей архитектуре Java идеально подходит для
web-разработок. За дополнительной информацией о Java обращайтесь на сайт
http://java.sun.com/.
Существует два основных варианта применения Java в Web: на стороне клиента
или на стороне сервера. Клиентские программы Java (так называемые апплеты)
загружаются с сервера на компьютер клиента и выполняются в специальной
защищенной среде. Поскольку размеры апплетов иногда довольно велики,
процесс загрузки тоже бывает относительно долгим. По соображениям безопасности
апплеты также ограничиваются по составу операций, выполняемых в клиентской
системе. В частности, апплету никогда не разрешается записывать какие-либо
данные на клиентский компьютер и запускать локальные программы.
Другой вариант — выполнение кода Java на сервере в виде приложений,
называемых сервлетами. Хотя сервлеты повышают вычислительную нагрузку на
web-сервер, они радикально уменьшают время, необходимое для получения
данных клиентом, и обходят некоторые ограничения безопасности, установленные
для апплетов. Благодаря более высокому быстродействию сервлетам часто
отдается предпочтение перед программами CGI. После выполнения сервлеты
остаются в памяти, что ускоряет их последующее выполнение. Программы CGI
в памяти не остаются.
JavaScript
Язык JavaScript был разработан корпорацией Netscape Communications для того,
чтобы web-программисты могли включать в свои страницы интерактивный
контент. Самые распространенные примеры применения JavaScript в
web-страницах — счетчики посещений, кнопки с изменяемыми изображениями и другие
формы интерактивного контента. JavaScript также может выполнять некоторые
функции, обычно выполняемые программами CGI. К числу таких функций
относится проверка заполнения web-форм: вместо того чтобы отправлять данные
серверу для проверки их полноты и/или правильности, более эффективно
выполнить те же самые операции на клиентском компьютере при помощи JavaScript.
Следующий пример показывает, как это делается:
<html>
<head>
<script language=HJavaScript">
<!--Hide
function testsomething(form) {
if (form.something.value == ,,M)
alert("I said something!")
else
alert("Thank you!");
}
// -->
</script>
</head>
<body>
<form name="example">
Enter something:<br>
<input type=,,text" name="somethingH><br>
<input type="button" name="button" value="Test input"
onCLick=Mtestsomething(this.form)">
<P>
</body>
</html>
У JavaScript существует разновидность, называемая серверным кодом
JavaScript. Серверный JavaScript работает на web-сервере и выполняет примерно те
же функции, что и CGI. Netscape Enterprise Server обладает мощной встроенной
поддержкой серверного JavaScript. За дополнительной информацией о
JavaScript (и о многих других web-технологиях) обращайтесь по адресу http://developer.
netscape.com/tech/.
ASP
Технология Microsoft Active Server Pages (ASP) представляет собой несколько
упрощенный способ включения CGI-подобной функциональности в
web-страницы. В отличие от технологии CGI, требующей определенных навыков
программирования, при программировании страниц ASP используются более
простые сценарные языки типа JScript, VBScript и Visual Basic.
За дополнительной информацией о технологии ASP и языках, которые в ней
используются, обращайтесь по адресу http://msdn.microsoft.com/workshop/server/asp/
ASPover.asp.
Будущее Web
Несмотря на относительно короткую историю, World Wide Web
продемонстрировала невероятные темпы роста. Однако за этим ростом скрывается еще более
невероятный потенциал для дальнейшего развития и расширения. Наряду со
статистическими показателями увеличиваются и возможности Web.
Дальнейший прогресс Web будет обеспечиваться такими инициативами, как HTTP-ng,
IPv6 и НОР. На сегодняшний день возможности развития Web безграничны.
НТТР-пд
Следующая версия протокола HTTP, названная HTTP-ng (от слов «Next
Generation», то есть «следующее поколение»), станет более защищенной и быстрой
заменой для HTTP. HTTP-ng обладает более широкими возможностями и
поэтому лучше подходит для коммерческих приложений. Ниже перечислены лишь
некоторые усовершенствования:
О улучшенная модульность;
О улучшенная эффективность сетевых взаимодействий;
О улучшенная безопасность и аутентификация;
О простая структура.
За дополнительной информацией о HTTP-ng обращайтесь по адресу http://
www.w3.org/Protocols/HTTP-NG/.
ПОР
Протокол HOP (Internet Inter-ORB Protocol) обещает предоставить
пользователям гораздо более эффективные средства для работы с данными через Web.
В отличие от протокола HTTP, позволяющего передавать только текстовые
данные, ПОР поддерживает передачу более сложных данных — таких, как массивы
и другие объекты. Протокол ПОР реализует архитектуру CORBA (Common
Object Request Broker Architecture) на базе Web. Архитектура CORBA позволяет
программистам создавать платформенно-независимые приложения, подходящие
для многократного использования.
За дополнительной информацией о ПОР и CORBA обращайтесь на сайт
Object Management Group по адресу http://www.omg/org/.
IPv6
Интернет постепенно готовится перейти на качественно новую ступень.
Протокол IP версии 6 (IPv6), также известный под названием IPng, вносит в текущую
версию IPv4 (появившуюся более 20 лет назад) множество усовершенствований,
в том числе:
О расширенное адресное пространство;
О улучшенная безопасность/конфиденциальность данных;
О улучшенная поддержка параметров качества и класса предоставляемых услуг
передачи данных QoS (Quality of Service).
За дополнительной информацией о IPv6 обращайтесь на сайт http://www.
ipv6.org/.
ipp
Протокол IPP (Internet Printing Protocol) был предложен на концептуальном
уровне фирмами Novell и Xerox, а его разработкой занималась группа IETF.
Интересно заметить, что протокол IPP базируется на HTTP/1.1. IPP предоставляет
в распоряжение пользователей средства для выполнения ряда стандартных
функций печати:
О получение информации о доступных принтерах;
О отправка и отмена заданий печати;
О получение информации о состоянии заданий печати.
За дополнительной информацией о IPP обращайтесь на сайт IETF по адресу
http://www.ietf.org/html.charters/ipp-charter.html.
XML
Язык XML (extensible Markup Language) стал одним из самых интересных
направлений развития программных средств Web. XML обеспечивает
представление структурированных данных: электронных таблиц, адресных книг, параметров
конфигурации, данных финансовых транзакций, технических проектов и т. д.
XML позволяет определить набор правил для проектирования текстовых
форматов, обеспечивающих структурирование данных. XML не является языком
программирования, это язык представления данных. Он поддерживает стандарт
Юникод, помогает решать задачи построения/чтения данных и обеспечивает
однозначную интерпретацию структуры данных.
Язык XML, как и HTML, основан на использовании тегов — ключевых слов,
заключенных между символами «<» и «>», и атрибутов в формате имя="зиаче-
ние". В HTML теги определяют параметры отображения текста в браузере. В XML
теги используются только для разграничения данных, а интерпретация этих
данных полностью определяется тем приложением, которое читает эти данные.
Например, тег <р> в файле XML вовсе не обязательно является признаком абзаца.
В зависимости от контекста он может обозначать параметр, цену, человека и т. д.
XML — слишком обширная тема, чтобы ее можно было рассмотреть в этой
главе. За дополнительной информацией о XML обращайтесь на сайт www.xml.org.
Итоги
В этой главе вы познакомились с «Всемирной паутиной» World Wide Web и
технологиями, на основе которых она работает. Мы рассмотрели структуру
унифицированных указателей ресурсов (URL) и возможности их применения для
получения информации из Web. Также были упомянуты основные web-серверы,
браузеры и коммуникационные протоколы, позволяющие им обмениваться
информацией. Протокол НТТР/1.1 был рассмотрен достаточно подробно. Глава
завершается краткими сведениями о некоторых языках Web (таких, как HTML,
Perl и Java), а также HTTP-ng, ПОР и других революционных технологиях,
которые обещают изменить Web к лучшему. В этой главе часто встречаются
ссылки на web-ресурсы; при желании читатель может посетить эти сайты и
больше узнать о замечательных технологиях, благодаря которым произошла
информационная революция.
^1Л Служба сетевых
^■Этг новостей
и протокол NNTP
Дэниел Бейкер (Daniel Baker)
В настоящей главе рассматриваются различные вопросы, связанные с
функционированием системы сетевых новостей Usenet. Usenet — одна из самых старых
форм распространения информации в Интернете, которая продолжает работать
в наши дни. Кроме того, в этой главе показано, как напрямую работать с
сервером NNTP (Network News Transfer Protocol).
Хотя протокол NNTP был не первым протоколом, предназначенным для
передачи материалов Usenet, после его появления все предшествующие средства
(такие, как UUCP — Unix-to-Unix Copy Protocol) практически вышли из
употребления.
Usenet
Система распространения новостей Usenet, созданная в 1979 году двумя
аспирантами университета Дьюк, в наши дни стала одной из самых старых и
популярных служб Интернета. Usenet позволяет вести дискуссии, доступные для
всех желающих; информация распространяется в текстовом формате. В каком-то
смысле Usenet напоминает электронную почту, адресуемую всем
заинтересованным лицам.
Информация Usenet распространяется не в реальном времени; иногда
пересылка материалов между сайтами сопровождается задержками. Тем не менее
эти задержки обычно невелики и не отражаются на возможности пользователей
Интернета участвовать в обсуждении.
За последние годы растущая популярность и расширение Интернета
привели к тому, что рост Usenet стал испытывать определенные проблемы. Много лет
назад для обеспечения работы сервера новостей требовалось только
непостоянное подключение к Интернету, один компьютер и от 20 до 100 мегабайт
свободного места на диске. Сейчас многие поставщики услуг Интернета поддерживают
несколько серверов Usenet; как правило, пара магистральных накопителей
обеспечивает обмен данными с другими новостными сайтами Интернета, а также
несколько клиентских серверов, поставляющих материалы Usenet конечным
пользователям. Для предоставления качественного сервиса Usenet клиентский
сервер Usenet теперь должен иметь постоянное подключение к Интернету на
мегабитной скорости, по крайней мере полгигабайта памяти, 50 гигабайт
дискового пространства и несколько мощных процессоров.
Однако проблемы Usenet не исчерпываются чисто техническими
ограничениями. Отсутствие централизованного управления, назойливая коммерческая
информация, а также нехватка культуры и образования у многих пользователей
затрудняют масштабирование Usenet до нужных размеров.
ПРИМЕЧАНИЕ
Новое воплощение Usenet — Usenetll — пытается решить многие из перечисленных проблем за
счет установки ограничений и контрольных мер для наведения порядка. Web-сайт Usenetll
находится по адресу www,usenet2.org.
Хотя ничего лучшего еще не предложено, в целом все согласны с тем, что
в Usenet используется неэффективный метод хранения и пересылки статей.
Сейчас каждый сервер Usenet получает копии всех статей, опубликованных в
поддерживаемой им иерархии.
Передача статей между серверами осуществляется при помощи механизма,
называемого равноправным обменом (peering). Администраторы новостей
согласовывают параметры равноправного обмена между сайтами и решают,
какие иерархии Usenet должны участвовать в обмене. Как правило, сервер
новостей имеет от 1 до 200 партнеров. Для каждой полученной статьи сервер
подключается к одному из своих партнеров (за исключением того, с которого
статья была отправлена) и предлагает ему новую статью при помощи команды
NNTP ihave.
ПРИМЕЧАНИЕ
Подобный способ хранения информации приводит к тому, что даже небольшая статья Usenet
занимает невероятный объем. Например, если предположить, что в Интернете работает 1500
серверов Usenet, то средняя статья объемом 2500 байт в масштабах Интернета займет 3,75 мегабайта
B500 байт х 1500 серверов), причем эта цифра относится только к затратам дискового
пространства на серверах и не учитывает клиентов, читающих статью. Одна песня в формате МРЗ (около
3,5 мегабайта), отправленная в Usenet, займет 5,25 гигабайта, а суммарные затраты на хранение
фильма (около 1,2 гигабайта) составят 1,95 терабайта.
Конференции и иерархии
Дискуссионные группы Usenet делятся на десятки тысяч конференций,
которые традиционно объединяются в иерархическую структуру по категориям.
Существует несколько «корневых» иерархий верхнего уровня, обычно
называемых «большой семеркой».
В табл. 34.1 перечислены иерархии «большой семерки» с краткими
характеристиками их тематики. Другие иерархии, активно используемые в Usenet,
указаны в табл. 34.2.
Таблица 34.1. Иерархии Usenet верхнего уровня
Название Описание
сотр Вычислительная техника
misc Разное
news Администрирование Usenet
гее Развлечения
sci Наука
soc Общество
talk Разговоры на общие темы
Таблица 34.2. Другие популярные иерархии
Название Описание
alt Неконтролируемая иерархия с «альтернативными» конференциями
bionet Биология
clari Последние новости от Reuters, Associated Press и т. д.
Для уменьшения путаницы разные языки обычно принято относить к
разным иерархиям. По этой причине многие страны имеют собственные иерархии;
несколько примеров приведено в табл. 34.3.
Таблица 34.3. Иерархии языков и стран
Название Описание
ch Швейцария
fr Франция
de Германия
Для большинства иерархий верхнего уровня установлены ограничения,
гарантирующие, что операции создания и удаления конференций могут выполняться
только уполномоченными администраторами. Впрочем, в самой крупной
иерархии alt какие-либо официальные средства контроля отсутствуют. Тем не менее
администратор сервера новостей должен решить, собирается ли он обеспечить
выполнение ограничений для соответствующих иерархий, и настроить свой сервер
соответствующим образом. Тем не менее конфликты между решениями
администраторов серверов новостей часто вызывают логические нестыковки в
иерархиях. Например, одни серверы могут распространять материалы конференции,
а другие — не подозревать о ее существовании из-за разного отношения админи-
страторов к соблюдению правил иерархий. Такие противоречия озадачивают
пользователей и затрудняют администрирование Usenet.
ПРИМЕЧАНИЕ
Прежде чем отправлять управляющие сообщения, следует хорошо разобраться в политике
управления конференциями в данной иерархии. «Управляющими сообщениями» называются сообщения
Usenet, обрабатываемые сценариями управления конференциями сервера Usenet. Управляющее
сообщение может приказать серверу создать новую конференцию (newgroup), удалить существующую
конференцию (rmgroup), отменить отправку (cancel) и выполнить другие управляющие операции.
Разнообразие тем, входящих в иерархию Usenet, позволит найти
конференции для обсуждения любых, даже самых специализированных вопросов.
Например, в названиях более чем 350 конференций присутствует слово «unix».
Наибольшей популярностью пользуются comp.unix.solaris и comp.unlx.aix.
Подобная структура имен четко определяет основную тему конференции. Компонент
сотр указывает на то, что конференция входит в иерархию вычислительной
техники, а компонент unix — что данная иерархия второго уровня посвящена
операционной системе Unix. Наконец, уточнение Solaris относится к системе Solaris
фирмы Sun Microsystems. Следовательно, можно с первого взгляда определить,
что конференция comp.unix.solaris посвящена компьютерной тематике и
обсуждению системы Solaris из семейства Unix.
По иерархическим именам также можно судить о том, какого рода информация
публикуется в конференции. Например, все конференции иерархии alt.binaries
предназначены для публикации двоичных данных — компьютерных программ,
звуковых файлов, графики и т. д. Если в названии конференции прямо не
указано обратное, можно смело предполагать, что конференция предназначена для
публикации английского текста в кодировке ASCII.
ПРИМЕЧАНИЕ
Публикация двоичных данных в текстовых конференциях считается крайне нежелательной.
Например, отправка аудиоклипа в конференцию alt.tv.seinfeld создает существенные неудобства для
администраторов и нарушит те цели, для которых создавалась многоуровневая иерархия. С другой
стороны, отправка того же файла в alt.binaries.sounds.tv не вызовет нареканий и будет наиболее
эффективным способом распространения файла в Usenet.
После рассмотрения принципов устройства Usenet и ее организации мы
займемся механизмом пересылки данных в Usenet.
Протокол NNTP
Протокол NNTP (Network News Transfer Protocol) является наиболее
распространенным механизмом пересылки данных статей Usenet между серверами
и клиентами. NNTP пересылает информацию в кодировке ASCII и обычно
работает на порте TCP с номером 119. Хотя пользователь может напрямую
работать с сервером новостей (пример приводится ниже в этом разделе), обычно все
операции NNTP — отправка, чтение и т. д. — выполняются пользовательским
агентом. Примерами клиентов NNTP для Unix являются tin и trn, а пользователи
Windows обычно работают в Netscape, Forte Free Agent и Microsoft Outlook Express.
В этом разделе рассматривается выполнение различных операций, связанных
с NNTP, в том числе:
О получение списка конференций;
О получение конкретных статей Usenet;
О отправка сообщений в Usenet.
Этот материал обеспечит прочное понимание базовой структуры
функциональных средств NNTP.
Получение списка конференций
Чтобы получить от сервера NNTP список конференций, необходимо подключиться
к серверу NNTP, активизировать режим чтения и запросить «активный» список.
Подключение создается следующей командой:
unixbox% telnet news.utb.edu 119
Результат выглядит так:
200 news.utb.edu DNEWS Version 5.5c6, S0, posting OK
Далее введите команду
MODE reader
Команда выводит строку
200 DNews is in reader mode - posting ok.
После появления этой строки введите команду получения списка
конференций Usenet:
LIST active
Сервер NNTP перечисляет все конференции Usenet, материалы которых на
нем хранятся.
215 list of newsgroup follows
alt. test 0000000967 0000000947 у
comp.unix 0000000343 0000000343 у
сотр.unix.admin 000094331 0000094080 у
сотр.unix.advocacy 0000068422 0000068413 у
сотр.unix.aix 0000162768 0000162368 у
сотр.unix.amiga 000019141 000019132 у
comp.unix.aux 0000023507 0000023502 у
сотр.unix.bsd.bsdi.announce 0000000090 00000091 m
сотр.unix.bsd.bsdi.misc 0000009195 0000009192 у
comp.unix.bsd.freebsd 000000201 000000197 у
сотр.unix.bsd.freebsd.announce 0000000955 0000000955 m
После получения списка введите команду
QUIT
Сервер NNTP завершает сеанс:
205 closing connection - goodbye!
ПРИМЕЧАНИЕ
Большинство серверов новостей передает материалы огромного количества конференций. На
практике нередко встречается ситуация, когда активный файл сервера содержит от 30 000 до 60 000
конференций. Получив команду List active, сервер может выдать большой файл объемом в
несколько мегабайт. Постарайтесь свести прием списка конференций к минимуму, чтобы избежать
порождения лишнего трафика на обоих концах подключения.
Сервер выводит информацию о конференциях в формате «название стар-
ший_номер младший_номер флаги». Старший и младший номера определяют
локальный диапазон статей, которые сервер NNTP готов предложить клиентам
NNTP. Флаги содержат информацию о состоянии конференции; флаг «т»
означает, что конференция модерируется, а флаг «у» является признаком немодери-
руемых конференций.
ПРИМЕЧАНИЕ
В этой главе упоминается лишь часть доступных команд NNTP. Чтобы получить информацию о
других командах, введите команду HELP после подключения к серверу NNTP. Большинство клиентских
серверов выдает список доступных команд и сведения об их аргументах.
Прием сообщений
Чтобы принять сообщение Usenet с сервера NNTP, следует подключиться к
серверу, выбрать конференцию и запросить статью по идентификатору. После
приема статьи пользователь продолжает принимать следующие статьи по
идентификатору или командой next.
Подключение создается следующей командой:
unixbox% telnet news.utb.edu 119
Результат выглядит так:
200 news.utb.edu DNEWS Version 5.5c6. S0, posting OK
Далее введите команду
MODE reader
Команда выводит строку
200 DNews is in reader mode - posting ok.
После появления этой строки введите команду, которая сообщает серверу
новостей, к какой конференции вы хотите подключиться:
GROUP alt.test
Сервер выдает информацию об указанной конференции:
211 386 603537 603922 alt.test selected
Второе число обозначает количество статей указанной конференции,
хранящихся на сервере в настоящее время. Третье и четвертое числа определяют на-
чальный и конечный номера статей в диапазоне. Количество хранимых статей
будет отличаться от длины интервала, поскольку некоторые сообщениям могут
отменяться после их получения сервером. Таким статьям выделяются номера,
но на сервере они не хранятся.
Далее следует выбрать номер статьи, входящий в полученный диапазон, и
запросить статью с сервера:
ARTICLE 603922
Результат выглядит примерно так:
220 603922 <3c0d06c5@newsreader.utb.edu> article retrieved - head and body f
ws
From: "Gary Kercheck" <gary.kercheck@aei.com>
Newsgroups: alt.test
Subject: test
Date: Tue, 4 Dec 2001 09:31:36 -0800
Lines: 3
Organization: Sekidenko
X-Priority: 3
X-MSMail-Priority: Normal
X-Newsreader: Microsoft Outlook Express 5.50.4807.1700
X-MimeOLE: Produced by Microsoft MileOLE V5.50.4807.1700
NNTP-Posting-Host: 65.162.27.214
X-Original-NNTP-Posting-Host: 65.162.27.214
Message-ID: <3c0d06c5@newsreader.utb.edu>
X-Trace: newsreader.utb.edu 1007486661 65.162.27.214 D Dec 2001 11:24:21 -0
Path: newsreader.utb.edu
Xref: newsreader.utb.edu alt.test:603922
Далее пользователь продолжает сеанс NNTP или завершает его командой QUIT.
Как показано выше, для приема статьи достаточно указать номер
конференции и номер статьи.
Заголовок Path показывает, по какому маршруту сообщение перемещалось
к клиенту NNTP. Узлы, входящие в маршрут, перечисляются справа налево;
имена имен хостов или псевдонимы разделяются восклицательными знаками.
Заголовок NNTP-Posting показывает, какой клиент подключался к
клиентскому серверу NNTP при отправке статьи. В приведенном выше примере хост
65.162.27.214 отправил статью 4 декабря 2001 года в 11:24:21.
Команда next приказывает серверу перейти к следующему номеру статьи
и вывести заголовок и тело нового сообщения.
Отправка сообщений
Чтобы отправить сообщение в Usenet, следует подключиться к серверу NNTP,
включить режим чтения и ввести команду POST. После этого текст статьи
вводится как обычно. Только заголовки From, Newsgroups и Subject являются строго
обязательными. Впрочем, существуют и другие заголовки, которые считаются
стандартными и используются клиентами, работающими с новостями.
unixbox% telnet news.utb.edu 119
200 news.utb.edu DNEWS Version 5.5c6, S0, posting OK
MODE reader
200 Dnews is in reader mode - posting ok.
Далее необходимо перевести сервер NNTP в режим отправки сообщений:
POST
Сервер подтверждает полученный запрос следующим сообщением:
340 OK, recommended ID 3c0d21df@newsreader.utb.edu
Приступайте к вводу сообщения Usenet. Перед данными статьи необходимо
ввести заголовок, который в минимальном варианте должен включать поля From,
Newsgroups и Subject.
From: Karanjit
Newsgroups: alt.test
Subject: Updated test!
This is a generic test!
.Karanjit
240 article posted ok
Сообщение завершается вводом точки в отдельной строке:
Если сервер NNTP не обнаруживает никаких проблем с введенной статьей,
он подтверждает успешную отправку:
240 article posted ok
Далее сеанс можно завершить:
QUIT
Как видите, для отправки сообщения Usenet достаточно минимального набора
сведений.
Обратите внимание: завершающая точка является признаком конца
сообщения. Чтобы сервер NNTP понял, что точка не входит в сообщение, а завершает
его, она должна находиться в отдельной строке.
В следующем разделе описаны некоторые проблемы современного Usenet.
Само устройство Usenet подразумевает отсутствие официальных
администраторов, распоряжающихся всей инфраструктурой в целом; администрированием
занимаются администраторы отдельных иерархий, что подразумевает отсутствие
единого подхода к возникающим проблемам.
Спам и блокировка
Одной из самых серьезных проблем Usenet стали массовые рассылки
рекламных материалов («спам»). Неразборчивые в средствах фирмы используют
бесплатную информационную среду и рассылают рекламу, не обращая внимания
на тематику групп. Это приводит к серьезным затратам ресурсов на серверах
новостей и раздражает конечных пользователей, которым приходится
фильтровать огромное количество рекламы, чтобы добраться до полезной информации.
Некоторые администраторы новостей пытаются решить эту проблему путем
блокировки (игнорирования) сайтов, которые допускают спам в Usenet, создают
его или участвуют в пересылке спама. Любой сайт, соблюдающий правила
блокировки, игнорирует все заблокированные сайты. Из-за этого сайты вынуждены
бороться со спамом; если сервер новостей, принадлежащий некоторому
поставщику услуг Интернета, не примет мер к нарушителю, он может попасть в
«черный список».
Другой способ борьбы со спамом основан на отмене неподходящих статей.
Специальная программа ищет коммерческие сообщения, а обнаружив их —
рассылает управляющее сообщение, которое требует у серверов Usenet удалить
соответствующую статью.
Описанные правила и методы получают все более широкое распространение.
Можно надеяться, что со временем они практически полностью искоренят
попытки спам еров рассылать рекламу в Usenet.
ПРИМЕЧАНИЕ
Одной из самых крупных организаций, обеспечивающих блокировку спама, является MAPS RBL
(http://mail-abuse.org/rbl/).
Итоги
За прошедшие годы ведения публичных дискуссий в Usenet был накоплен
огромный объем полезной информации, доступной для любого пользователя
Интернета. Сайт Deja (приобретен Google — http://groups.google.com/googlegroups/
deja_announcement.html/) архивирует все материалы Usenet и позволяют
производить поиск в данных, которые накапливались буквально годами. С учетом
широты спектра тем, рассматриваемых в Usenet, вы найдете в архивах Deja
информацию буквально по любой возможной теме. Относительно новые проекты —
такие, как Deja — укрепляют уверенность в том, что Usenet по-прежнему
приносит реальную пользу.
Usenet — замечательная служба, обладающая огромным потенциалом. Тем не
менее для обеспечения масштабируемости и управляемости Usenet необходимо
решить целый ряд важных вопросов. Бесспорно, эти вопросы могут быть решены
таким образом, чтобы служба Usenet процветала и в полной мере проявила свой
потенциал.
В следующей главе рассматриваются административные вопросы, связанные
с поддержанием работы web-сайта. В частности, в ней будут представлены web-
серверы Apache, Netscape Enterprise Server и Microsoft IIS.
*Э Щ" Установка и настройка
*ЭЭ web-сервера
Нил С. Джеймисоп (Neal S.Jamison)
World Wide Web занимает первое место по популярности среди служб
Интернета, значительно опережая своих конкурентов. Множество людей отправляется
в Web для того, чтобы получить нужную информацию, в поисках работы, за
покупками и даже данными биржевых котировок. Коммерция идет в Web, чтобы
удовлетворить растущие потребности клиентов. В этой главе рассматривается
установка, настройка и сопровождение самого популярного web-сервера в
Интернете — Apache.
Принципы работы web-серверов
Функционирование World Wide Web в значительной степени зависит от
протокола HTTP, работающего на базе TCP/IP. Протокол HTTP работает по схеме
«запрос/ответ» и обеспечивает обмен информацией между клиентами
(браузерами) и web-серверами. Web-сервер представляет собой программу, которая
прослушивает запросы от браузера и передает данные в формате HTML с
использованием HTTP. Типичный сеанс HTTP состоит из следующих действий:
О Браузер подключается к серверу.
О Браузер запрашивает файл или другие данные.
О Сервер выдает ответ и закрывает подключение.
Предположим, браузер отправляет запрос HTTP GET на получение файла
с именем index.html:
GET /index.html HTTP/1.1
Accept: text/plain
Accept: text/html
User-agent: MoziUa/4.5 (WinNT)
(пустая строка)
Сервер выдает ответ HTTP, включающий запрошенный файл:
HTTP/1.1 200 OK
Date Sunday, 15-Jul-99 12:18:03 GMT
Server: Apache/1.3.6
MIME-version: 1.0
Content-type: text/html
Last-modified: Thursday, 02-Jun-99 20:43:56 GMT
Content-length: 1423
(пустая строка)
<HTML>
<HEAD>
<title>Example Server-Browser Communication</title>
</HEAD>
<B0DY>
После передачи файла подключение закрывается. Протокол HTTP не имеет
состояния; это означает, что сервер не сохраняет никакой информации о
браузере или сеансе (не считая данных, записываемых в журнальный файл).
По умолчанию HTTP работает на хорошо известном порте TCP с номером 80.
Терминология web-серверов
В этом разделе объясняются некоторые термины, связанные с работой
web-серверов и встречающиеся как в этой главе, так и в другой документации по
web-серверам.
Web-сервер
Web-сервером называется компьютер, который предоставляет документы (web-
страницы) по Интернету с использованием протокола HTTP. Термин
«web-сервер» может использоваться как для обозначения компьютера (совокупности
оборудования и программ), так и самого программного пакета (например, «web-
сервер Apache»).
Браузер
Браузер — клиентская программа для работы в Web. Наибольшее распространение
получили браузеры Lynx, Netscape Communicator, Opera и Microsoft Internet
Explorer.
URL
URL — универсальная схема адресации, используемая для ссылок на
web-страницы (например, http://www.apache.org/). Дополнительная информация приведена
во врезке на с. 715.
Корневой каталог сервера
Корневым каталогом сервера называется каталог на том компьютере, на котором
работает web-сервер. По умолчанию в корневом каталоге сервера хранятся все
журнальные и конфигурационные файлы, все демоны и вспомогательные документы.
Примеры корневых каталогов — /usr/local/apache и c:\netscape\suitespot\ https-myserver.
Корневой каталог документов
Корневым каталогом документов называется каталог на web-сервере, в котором
находятся web-страницы, предоставляемые клиентам. Именно этот каталог
просматривается при указании URL вида http://www.yourserver.com/.
Порт
Службы TCP/IP используют порты для создания подключений и передачи
информации. По умолчанию протокол HTTP использует порт с номером 80, хотя
он может быть настроен на любой не используемый номер порта от 1 до 65535.
Многие службы тоже работают на стандартных портах: Telnet B3), электронная
почта SMTP B5), FTP B1).
Виртуальный хост (или виртуальный сервер)
Многие web-серверы способны представлять сразу несколько доменов. Для этой
цели используется концепция виртуальных хостов, при которой один
web-сервер обслуживает несколько сайтов. Виртуальные хосты обычно используются
поставщиками услуг Интернета как дешевая альтернатива предоставления
отдельного web-сервера каждому клиенту.
SSL (Secure Sockets Layer)
Протокол SSL был разработан фирмой Netscape для безопасной пересылки
данных в Web. SLL использует технологию шифрования с открытым ключом для
защиты данных, передаваемых по соединению.
MIME (Multipurpose Internet Mail Extensions)
Стандарт MIME позволяет web-серверам и браузерам передавать файлы, не
ограниченные форматами HTML и ASCII — например, графику или документы
Microsoft Word.
За дополнительной информацией о HTTP и web-серверах обращайтесь к
главе 36.
ПРИМЕЧАНИЕ
Для идентификации web-страниц и других ресурсов в Web используется схема адресации,
построенная на использовании унифицированных указателей ресурсов (URL).
Пример URL:
http://www.apache.org/docs/index.html
Данный адрес URL, относящийся к странице документации Apache Group, делится на несколько
сегментов:
протокол:// сервер.домен/ каталог/ файл
Таким образом, приведенный пример делится на следующие компоненты:
- протокол: http
- полное доменное имя: www.apache.org
- каталог: docs
- файл: lndex.html
Популярные web-серверы
В прессе часто пишут о борьбе за контроль над Интернетом. Тем не менее в
номинации web-серверов первое место по популярности принадлежит вовсе не
продуктам от Microsoft и Netscape. Более того, самый популярный web-сервер вообще
не является коммерческим продуктом. Большая часть World Wide Web
обслуживается бесплатным сервером Apache, распространяемым с открытыми текстами.
ПРИМЕЧАНИЕ
На первых порах своего существования Интернет базировался на философии свободы и
бескорыстия. Идеи были бесплатными. Помощь оказывалась бесплатно. Даже программы были
бесплатными! Такой подход обусловил начальный рост и прогресс. Инженеры и программисты
пользовались плодами совместного труда великих умов, объединившихся для решения общей проблемы.
Но по мере развития Сети расширялись возможности ее использования в коммерческих целях.
Однако коммерческий инструментарий призван обеспечивать конкурентное преимущество, а его
бесплатное распространение обычно не входит в планы фирм. Корпоративная культура быстро
поглотила философию свободы. Тем не менее ряд проектов по-прежнему существует и
создается совместными усилиями энтузиастов. Один из главных принципов распространения программ
с открытыми текстами заключается в том, что тысячи программистов Сети лучше справятся с
развитием и совершенствованием программы, чем маленькая группа корпоративных программистов.
Ниже перечислены некоторые популярные программные проекты, распространяемые с открытыми
текстами:
- Web-сервер Apache: самый популярный web-сервер Интернета.
- Linux: операционная система, популярность которой непрерывно растет.
- Perl: язык программирования Web (также используемый многими системными администраторами
Unix и некоторыми системными администраторами Windows в качестве мощного сценарного языка).
За дополнительной информацией о распространении программ с открытыми исходными текстами
обращайтесь на сайт http://www.opensource.org/.
Фирма Netcraft. Ltd, (http://www.netcraft.com), занимающаяся сетевой
аналитикой, регулярно анализирует состав программного обеспечения web-серверов,
работающего в Web. В табл. 35.1 приведены результаты одного из последних
исследований Netcraft.
В категорию iPlanet входят сайты, на которых работают iPlanet-Enterprise,
Netscape-Enterprise, Netscape-FastTrack, Netscape-Commerce,
Netscape-Communications, Netsite-Commerce и Netsite-Communications. В категорию Microsoft
входят сайты с программными продуктами Microsoft Internet Information Server,
Microsoft HS-W, Microsoft-PWS-95 и Microsoft PWS.
Таблица 35.1. Рыночная доля различных web-серверов по состоянию на август 2001 г.
(по результатам анализа 30 775 624 сайтов)
Сервер Процент использования
Apache 60,33%
Microsoft 28,29%
iPlanet 4,29%
Zeus 1,53%
Установка и запуск web-сервера Apache
Web-сервер Apache, занимающий первое место по популярности в Web,
распространяется с открытыми текстами и базируется на некогда популярном сервере
NCSA httpd. Apache надежен, обладает богатыми возможностями и при этом
распространяется бесплатно! Не приходится удивляться тому, что Apache в
настоящее время обеспечивает работу более половины web-серверов в Интернете.
Загрузка, установка и настройка Apache
В этом разделе кратко рассматривается процесс загрузки, установки и настройки
web-сервера Apache в среде Linux.
ПРИМЕЧАНИЕ
Поскольку сервер Apache первоначально разрабатывался для Unix и сейчас используется в
основном в системах семейства Unix, материал этого раздела ориентируется на установку и настройку
Apache в среде Unix (конкретно — в системе Linux). На момент написания книги существовала
реализация Apache 1.3.22 для Win32, но по стабильности работы она уступала Unix-версии. В конце
главы приведен очень краткий обзор установки Apache для Windows. Тем не менее, если ваш web-
сервер должен работать в среде Windows, подумайте об использовании более надежного
продукта — например, Microsoft Internet Information Server, O'Reilly Website или Netscape Enterprise Server.
Если вы работаете в операционной системе Linux, вполне вероятно, что web-
сервер Apache был установлен по умолчанию. Если это так — замечательно,
можно двигаться дальше. Тем не менее было бы лучше удалить Apache и
установить его заново по двум причинам:
1. Версия, включенная в установку, может оказаться устаревшей или
неправильно настроенной.
2. Загрузка, компиляция и установка Apache поможет лучше разобраться в том,
как работает сервер.
Итак, приступим к делу. Для начала следует убедиться в выполнении
следующих требований:
О Свободное место на диске — для установки Apache понадобится по крайней
мере 12 Мбайт временного дискового пространства. После установки Apache
будет занимать примерно три мегабайта плюс все пространство, занимаемое
web-страницами.
О Компилятор ANSI С — на компьютере должен быть установлен и правильно
настроен компилятор ANSI С. Рекомендуется использовать компилятор GNU
(http://www.gnu.org/).
Загрузка Apache
Apache можно загрузить с основного сайта (http://www.apache.org) или с любого
зеркального сайта.
ПРИМЕЧАНИЕ
Для ускорения загрузки рекомендуется выбрать зеркальный сайт, расположенный как можно
ближе. Список зеркальных сайтов публикуется по адресу http://www.apache.org/mirrors/.
Далее следует решить, хотите ли вы загрузить полный набор исходных
текстов и откомпилировать сервер самостоятельно или пропустите этап
компиляции и загрузите двоичные файлы.
ПРИМЕЧАНИЕ
Если вы решите загрузить предварительно откомпилированные двоичные файлы, убедитесь в том,
что они находятся на официальном сайте Apache или одном из его зеркальных сайтов. Файлы,
находящиеся на других сайтах, могут быть неправильно откомпилированы или даже могут содержать
дефекты в системе безопасности.
Следующий пример наглядно поясняет процесс загрузки исходных текстов.
Зайдите на сайт http://www.apache.org/dist/httd/. В окне браузера отображается
список доступных файлов. Выберите нужную версию и щелкните на ней, чтобы
приступить к загрузке. Ниже приведен примерный список предлагаемых файлов.
Announcement.html 03-Oct-2002 13:37 8.0К Apache 1.3 Release Note
Announcement.txt 03-Oct-2002 13:37 7.2K Apache 1.3 Release Note
Announcement2.html 02-Apr-2003 11:11 6.6K Apache 2.0 Release Note
Announcement2.txt 02-Apr-2003 11:11 5.8K Apache 2.0 Release Note
CHANGESJL.3 03-Oct-2002 11:51 404K List of changes in 1.3
CHANGES_2.0 01-Apr-2003 20:03 560K List of changes in 2.0
CURRENT-IS-2.0.45 20-Jan-2003 02:32 0 HTTP Server project
HEADER.html 20-Jan-2003 07:23 702 HTTP Server project
KEYS 01-Apr-2003 15:36 130K Developer PGP/GPG keys
README.html 01-Apr-2003 15:36 2.6K HTTP Server project
apache-docs-1.3.23.pdf.zip 24-Jan-2002 08:25 1.6M Documentation
in PDF - pkzipped
apache_L3.27-win32-src.zip 03-Oct-2002 19:13 2.9M Current Release
1.3.27
apache_1.3.27-win32-src.zip.asc 03-Oct-2002 19:13 477 PGP signature
apache_1.3.27-win32-src.zip.md5 03-Oct-2002 19:13 69 MD5 hash
apache_l.3.27.tar.Z 03-Oct-2002 11:51 3.5M Current Release
1.3.27
apache_l.3.27.tar.Z.asc 03-Oct-2002 11:51 175 PGP signature
apache_l.3.27.tar.Z.mdS 03-Oct-2002 11:53 61 MD5 hash
apache_l.3.27.tar.gz 03-Oct-2002 11:51 2.2M Current Release
1.3.27
ПРИМЕЧАНИЕ
Контрольная сумма MD5 поможет убедиться в том, что содержимое пакета не изменялось
после его создания. Это особенно важно при загрузке предварительно откомпилированных
двоичных файлов. Конкретная процедура проверки зависит от особенностей рабочей среды. В системе
Linux можно выполнить следующую команду:
# md5sum apache_1.3.6.gz
b4114ed78f296bfe424c4ba05dccc643apache_1.3.6.tar.gz
Сравните результат с содержимым файла md5 на сайте Apache (в данном примере это файл
apache_1.3.6.gz.md5). Если данные совпадают, значит, все нормально. Если между ними
существуют какие-либо различия, попробуйте загрузить файл снова.
После того как пакет Apache будет загружен во временный каталог, распакуйте
его утилитами gzip или uncompress (в зависимости от формата загрузки) и tar.
ПРИМЕЧАНИЕ
Программа gzip (GNU zip) — бесплатная утилита сжатия данных, распространяемая на условиях
общедоступной лицензии GNU. Благодаря своим хорошим показателям сжатия она очень популярна
в Интернете и в сообществе Unix.
За дополнительной информацией об этой популярной программе обращайтесь на сайт http://
www.gzip.org/.
Компиляция и установка Apache
Простейший способ компиляции и установки Apache основан на использовании
интерфейса APACI (Apache AutoConf-style Interface), появившегося в Apache
версий 1.3 и выше. Интерфейс APACI позволяет выполнить установку в
автоматизированном режиме.
ПРИМЕЧАНИЕ
Вы также можете откомпилировать и установить Apache старым способом. Соответствующие
инструкции приведены в файле INSTALL, находящемся в каталоге src.
Чтобы установить Apache при помощи APACI, перейдите во временный
каталог с файлами Apache. Обычно вам не придется редактировать файл Configuration,
если только вы не собираетесь устанавливать специальные модули кроме тех,
которые устанавливаются по умолчанию. Тем не менее, если в процессе
установки возникнут ошибки, прочитайте документацию в файле Configiration.
Обратите особое внимание на флаги EXTRAJZFLAGS, LIBS, LDFLAGS, INCLUDES и СС.
Дополнительная информация приведена в файле INSTALL
Процесс установки запускается следующей командой:
# ./configure -pref1х=каталог
где каталог — корневой каталог web-сервера (например, /usr/iocal/apache).
Затем постройте пакет Apache командой make:
# make
ПРИМЕЧАНИЕ
Если при вводе команды make отображается сообщение «command not found», необходимо
добавить ссылку на соответствующий каталог (вероятно, /usr/bin или /usr/ccs/bin) в переменную PATH.
Конкретная процедура зависит от того, какой командный интерпретатор используется в вашей
системе. Например, для интерпретатора bash необходимо выполнить следующие команды:
# PATH=$PATH:/usr/ccs/bin/
# export PATH
Выполнение make займет несколько минут (в зависимости от скорости вашей
системы). После того как команда будет успешно выполнена, можно переходить
к установке Apache. Введите команду
# make install
Команда устанавливает web-сервер Apache и соответствующие файлы в
каталог, указанный на первом этапе. После завершения установки переходите к
настройке Apache для вашей конкретной рабочей среды.
Настройка Apache
Настройка Apache определяется тремя основными конфигурационными файлами:
О access.conf — управление доступом к ресурсам web-сервера.
О httpd.conf — основной конфигурационный файл с параметрами работы Apache.
О srm.conf — информация о ресурсах, предоставляемых сайтом.
На первых порах вам практически не придется вносить изменения в эти файлы.
Некоторые параметры или директивы, которые могут потребовать редактирования,
описаны в следующих разделах. Конфигурационные файлы хорошо
документированы, и редактируемые параметры легко определяются простым просмотром
файла. За дополнительной информацией о настройке Apache обращайтесь по
адресу http://httpd.apache.org/docs/misc/perf-tuning.html.
ПРИМЕЧАНИЕ
В последней версии Apache три конфигурационных файла объединены в файл httpd.conf,
рассмотренный в следующем подразделе.
Файл httpd.conf
Файл httpd.conf содержит основные рабочие параметры Apache. Ниже
перечислены основные параметры, на которые следует обратить особое внимание.
О ServerName — имя web-сервера.
ServerName www.mydomain.com
О ServerType — тип сервера. Допустимые значения — standalone и inetd.
Автономный сервер (standalone) работает постоянно. Сервер с типом inetd начинает
работать только после получения запроса на запуск. По соображениям
быстродействия рекомендуется использовать значение standalone.
ServerType standalone
О Port — по умолчанию серверы HTTP работают на порте с номером 80.
Впрочем, в некоторых ситуациях сервер переводится на нестандартный порт —
например, для того, чтобы «скрыть» его от посторонних. Если сервер работает
на нестандартном порте, то для обращения к web-страницам пользователь
должен знать номер порта и включить его в URL. Допустимыми считаются
номера портов в интервале 1-65535, хотя обычно первые 1024 номера
резервируются.
Port 80
О User — пользователь, с правами которого работает сервер Apache. При
выборе значения этого параметра следует учитывать возможные проблемы
безопасности, поскольку Apache обладает привилегиями управляющего
пользователя. Во многих системах Unix для подобных целей создается
пользователь с именем «nobody». Если в вашей системе отсутствует учетная запись
непривилегированного пользователя, создайте ее.
User nobody
О ServerAdmin — имя администратора. Если в процессе работы возникнут
проблемы, Apache сообщает о них указанному пользователю.
ServerAdmin root
О ServerRoot — корневой каталог установки Apache. Все конфигурационные
и журнальные файлы хранятся в корневом каталоге, если обратное не будет
указано в настройках Apache.
ServerRoot /usr/local/apache
О ErrorLog — местонахождение и имя файла, используемого для регистрации
ошибок.
ErrorLog logs/error.log
О TransferLog — местонахождение и имя файла, используемого для регистрации
обращений.
TransferLog logs/access.log
О Timeout — продолжительность интервала (в секундах), после истечения которого
при отсутствии ответа от браузера web-сервер принимает решение о закрытии
подключения. По умолчанию интервал тайм-аута равен 300 секундам.
Timeout 300
Следующие параметры управляют ресурсами Apache. Традиционно они
хранились в файле srm.conf, хотя в новых версиях Apache они переместились в файл
httpd.conf. Ниже перечислены самые важные из этих параметров.
О DocumentRoot — корневой каталог дерева документов, предоставляемых web-
сервером.
DocumentRoot /usr/local/apache/htdocs/
О Directorylndex — если пользователь запрашивает с сервера URL,
завершающийся именем каталога, web-сервер пытается предоставить документ с
указанным именем. Например, при обращении по адресу http://www.apache.org/
браузеру будет предоставлен файл index.html.
Directorylndex index.html
О Indexlgnore — если пользователь запрашивает с сервера URL, завершающийся
именем каталога, но файл index.html при этом недоступен, web-сервер
предоставляет пользователю список файлов в указанном каталоге. Некоторые
файлы (например, .htaccess или README) отображать в таких списках
нежелательно. Сервер исключает из отображаемого списка файлы, указанные в
параметре Indexlgnore.
Indexlgnore .>>* *- *# HEADER* README* RCS CVS *,v *,t
Правила, регулирующие доступ к web-серверу в целом или к его отдельным
компонентам, настраиваются в файле access.conf. В последних версиях Apache
эти параметры перемещены в файл httpd.conf.
Рассмотрим следующий блок:
<Directory /><Directory />
Options FollowSymLinks
AllowOverride None
</Directory></Di rectory>
Похожий блок присутствует в любом типичном файле access.conf. Тег
<Directory /> открывает контейнер. Все содержимое файла перед тегом </Directory>
относится к каталогу /. Параметры в приведенном примере означают, что Apache
должен следовать символическим ссылкам на этот каталог и запрещать
переопределение параметров в других управляющих файлах.
За дополнительной информацией об управлении доступом к сайту с
использованием файла access.conf обращайтесь к документации Apache, прилагаемой
к web-серверу.
Запуск и остановка Apache
После того как сервер Apache будет откомпилирован, установлен и настроен,
все готово к работе. Apache запускается следующей командой:
# каталог/bin/apachectl start
где каталог — корневой каталог сервера.
Просмотр списка процессов показывает, что Apache успешно запущен:
# ps -ax | grep http
3514 ? S 0:00 /usr/local/apache/bin/httpd
16201 ? S 0:00 /usr/local/apache/bin/httpd
16635 ? S 0:00 /usr/local/apache/bin/httpd
16661 ? S 0:00 /usr/local/apache/bin/httpd
16662 ? S 0:00 /usr/local/apache/bin/httpd
Введите в браузер URL, указанный в параметре ServerName (http://www.
yourdomain.com/ или http://localhost/). Если настройка Apache выполнена
правильно, вы увидите тестовую страницу, изображенную на рис. 35.1.
Работа Apache останавливается командой
# каталог/bin/apachectl stop
/etc/ red
Система red позволяет организовать автоматический запуск Apache. В некоторых
разновидностях Unix и Linux файл httpd.init создается автоматически (например,
/etc/rc.d/init.d/httpd.init в Red Hat Linux). В таких случаях необходимо
отредактировать этот файл и включить в него информацию о местонахождении
исполняемого файла httpd.
В большинстве систем достаточно включить в файл /etc/rc.drc.local простую
запись вида
/usг/local/apache/bin/apachectl start
IE*» £<* ¥*** ЁР £«f*nuiicator Йф\ !.'.":_.: :-'.:л :•:":::!
Щ • ^|Г8ооктдк$' ^ GotejhKpV/focabost/ j»j {j^T What's Rdat«xi jgj
It Worked! The Apache Web Server is Installed on this Web
Site!
II you can see this page, then the peopte who own this domain have just installed the Apache Web server software successfully.
They now have to add content to this directory and replace this placeholder page, or else point the server at their real content.
I If you are seeing this page instead of the site you expected, please contact the administrator of the site 1
involved. (Try sending mail to <Mebmb3tez%do2aa±a>.) Although this site is running the Apache software it
I almost certainly has no other connection to the Apache Group, so please do not send mail about this site or its
contents to the Apache authors. If you do, your message will be ignored.
The Apache documentation has been included with this distribution.
The Webmaster of this site is free to use the image befow on an Apache-powered Web server. Thanks for using Apache!
^juiniirir*^'^'* *у
^M щ APAC *~i Ш
Рис. 35.1. Тестовая страница Apache
Загрузка двоичных файлов Apache
Если вы предпочитаете загрузить предварительно откомпилированные двоичные
файлы, введите адрес http://www.apache.org/dist/httpd/binaries/. В браузере
отображается список доступных платформ. Ниже приведена примерная структура
каталога с двоичными файлами Apache для различных операционных систем.
aix/ 12-Jul-2002 06:25 - Binary distributions
aux/ 06-May-2000 12:56 - Binary distributions
beos/ 02-Nov-2000 02:17 - Binary distributions
bs2000-osd/ 21-Jun-2002 03:31 - Binary distributions
bsdi/ 18-Oct-2000 00:22 - Binary distributions
cygwin/ 19-Nov-2002 09:07 - Binary distributions
darwin/ 28-Nov-2002 12:14 - Binary distributions
dgux/ 12-Jun-2000 03:47 - Binary distributions
digitalunix/ 12-Jun-2000 03:47 - Binary distributions
freebsd/ 12-Aug-2002 12:28 - Binary distributions
hpux/ 12-Aug-2002 12:27 - Binary distributions
irix/ 13-Oct-2000 04:57 - Binary distributions
linux/ 13-Oct-2002 23:58 - Binary distributions
macosx/ 28-Nov-2002 12:14 - Binary distributions
macosxserver/ 30-Oct-2000 17:42 - Binary distributions
netbsd/ 12-Jun-2000 03:47 - Binary distributions
netware/ 01-Apr-2003 16:23 - Binary distributions
openbsd/ 13-Oct-2000 04:59 - Binary distributions
os2/ 04-Apr-2O03 22:42 - Binary distributions
os390/ 14-Aug-2002 12:50 - Binary distributions
osfl/ 12-Jun-2000 03:47 - Binary distributions
qnx/ 31-May-2001 01:22 - Binary distributions
reliantunix/ 03-Oct-2002 23:59 - Binary distributions
rhapsody/ 30-Oct-2000 17:42 - Binary distributions
sinix/ 03-Oct-2O02 23:59 - Binary distributions
Solaris/ 17-Oct-2002 03:56 - Binary distributions
sunos/ 24-Feb-2000 18:27 - Binary distributions
unixware/ 13-Oct-2000 04:58 - Binary distributions
Win32/ 02-Apr-2003 04:13 - Binary distributions
Откройте каталог, соответствующий вашей платформе. В браузере появляется
список форматов и версий следующего вида:
apache_1.3.1-sparc-whatever-linux.README 06-Apr-2000 14:05 522
apache_1.3.1-sparc-whatever-linux.tar.gz 06-Apr-2000 14:05 1.3M
apache_1.3.12-i686-whatever-linux2.README 06-Apr-2000 14:05 1.8K
apache_1.3.12-i686-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.6M
apache_1.3.14-i686-whatever-linux2.README 13-Oct-2000 04:57 1.8K
apache_1.3.14-i686-whatever-linux2.tar.gz 13-Oct-2000 03:21 2.8M
apache_1.3.14-i686-whatever-linux2.tar.gz.asc 13-Oct-2000 03:10 292
PGP signature
apache_1.3.20-i686-whatever-linux22.README 20-Jun-2001 11:36 1.9K
apache_1.3.20-i686-whatever-linux22.tar.gz 20-Jun-2001 11:36 3.1M
apache_l.3.20-i686-whatever-linux22.tar.gz.asc 20-Jun-2001 11:36 477
PGP signature
apache_1.3.20-ia64-whatever-linux22.README 21-Aug-2001 08:15 2.IK
apache_1.3.20-ia64-whatever-linux22.README.asc 21-Aug-2001 08:18 293
PGP signature
apache_1.3.20-ia64-whatever-linux22.tar.gz 21-Aug-2001 08:16 3.4M
apache_l.3.20-ia64-whatever-linux22.tar.gz.asc 21-Aug-2001 08:17 293
PGP signature
apache_l.3.20-ia64-whatever-linux22. tar.gz.md5 21-Aug-2001 08:16 84
MD5 hash
apache_1.3.22-i686-whatever-linux22.README 15-Oct-2001 10:37 1.9K
apache_1.3.22-i686-whatever-linux22.tar.gz 15-Oct-2001 10:25 3.4M
apache_l.3.22-i686-whatever-linux22.tar.gz.asc 15-Oct-2001 10:26 477
PGP signature
apache_1.3.24-i686-whatever-linux22.README 16-May-2002 13:00 1.9K
apache_l.3.24-i686-whatever-linux22.tar.gz 16-May-2002 13:00 3.5M
apache_l.3.24-i686-whatever-linux22.tar.gz. asc 16-May-2002 13:00 232
PGP signature
apache_1.3.24-s390-whatever-linux22.README 14-May-20O2 13:57 1.9K
apache_l.3.24-s390-whatever-linux22.tar.gz 14-May-2002 13:57 3.6M
apache_1.3.24-s390-whatever-linux22.tar.gz.asc 14-May-2002 13:57 232
PGP signature
apache_1.3.26-ppc-whatever-linux22.README 19-Jun-2002 14:41 1.9K
apache_1.3.26-ppc-whatever-linux22.tar.gz 19-Jun-2002 14:50 3.6M
apache_l.3.26-ppc-whatever-linux22.tar.gz.asc 19-Jun-2002 14:50 232
PGP signature
apache_1.3.26-ppc-whatever-linux22.tar.gz.md5 19-Jun-2002 14:50 76
MD5 hash
apache_1.3.6-armv41-whatever-linux2.README 06-Apr-2000 14:05 1.9K
apache_1.3.6-armv41-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.2M
apache_1.3.6-i586-whatever-linux2.README 06-Apr-2000 14:05 1.9K
apache_1.3.6-i586-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.1M
apache_1.3.6-i686-whatever-linux2.README 06-Apr-2000 14:05 1.9K
apache_1.3.6-i686-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.1M
apache_1.3.6-mips-whatever-linux2.README 06-Apr-2000 14:05 1.9K
apache_1.3.6-mips-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.2M
apache_1.3.6-sparc-whatever-linux2.README 06-Apr-2000 14:05 1.9K
apache_1.3.6-sparc-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.1M
apache_1.3.9-alpha-whatever-linux2.README 06-Apr-2000 14:05 1.8K
apache_1.3.9-alpha-whatever-linux2.tar.gz 06-Apr-2000 14:05 3.5M
apache_1.3.9-alpha-whatever-linux2.tar_gz.asc 06-Apr-2000 14:05 286
PGP signature
apache_1.3.9-i586-whatever-linux2.README 06-Apr-2000 14:05 1.8K
apache_1.3.9-i586-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.3M
apache_l.3.9-i586-whatever-1 inux2.tar_gz.asc 06-Apr-2000 14:05 286
PGP signature
apache_1.3.9-i686-whatever-linux2.README 06-Apr-2000 14:05 1.8K
apache_1.3.9-i686-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.3M
apache_l.3.9-i686-whatever-linux2.tar_gz.asc 06-Apr-2000 14:05 286
PGP signature
apache_1.3.9-mips-whatever-linux2.README 06-Apr-2000 14:05 1.8K
apache_1.3.9-mips-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.5M
apache_1.3.9-sparc-whatever-linux2.README 06-Apr-2000 14:05 1.8K
apache_1.3.9-sparc-whatever-linux2.tar.gz 06-Apr-2000 14:05 2.7M
apache_l.3.9-sparc-whatever-linux2.tar_gz.asc 06-Apr-2000 14:05 286
PGP signature
Выберите нужную версию и загрузите ее во временный каталог своей системы.
Установка и настройка Apache
в двоичном формате
После загрузки пакета можно переходить к установке и настройке Apache. Прежде
всего распакуйте принятый пакет во временный каталог (утилитами uncompress
или gzip и tar).
Чтобы установить Apache, запустите сценарий install-bindist.sh. Если Apache
устанавливается в каталог, отличный от каталога по умолчанию (/usr/local/apache/),
укажите имя каталога (ServerRoot) в командной строке. Дополнительная
информация приведена в файле INSTALL
# ./install-bindist.sh [каталог]
После установки web-сервера Apache операции настройки, запуска и остановки
производятся так же, как описано в предыдущих разделах.
Использование Apache для Windows
В этом разделе рассказано, как загрузить, установить и настроить Apache для
работы на платформе Microsoft Windows.
ПРИМЕЧАНИЕ
Версия Apache для Windows менее надежна, чем Unix-версия. Она не оптимизирована по
производительности и может содержать ошибки, создающие дефекты в безопасности вашей системы.
Если ваш web-сервер должен работать на платформе Microsoft, лучше воспользоваться Microsoft
IIS или другим сервером, предназначенным для Windows.
Полный список web-серверов приведен в разделе «Другие web-серверы» в конце главы.
Загрузка Apache для Windows
Предварительно откомпилированная версия Apache для Win32 доступна по
адресу http://www.apache.org/dist/httpd/binaries/win32/.
Загрузите файл во временный каталог или разместите его на рабочем столе.
Установка Apache для Windows
Чтобы начать установку, запустите только что принятый исполняемый файл. Вам
будет предложено ввести каталог, в который будет устанавливаться Apache. Либо
подтвердите предложенный вариант, либо укажите другой каталог по своему
усмотрению. Если каталог еще не существует, программа установки создаст его за вас.
Далее программа установки запрашивает имя, под которым Apache будет
отображаться в меню Пуск (Start). Как и на предыдущем шаге, подтвердите
значение по умолчанию или введите другое имя по своему усмотрению.
Выберите тип установки. При типичной установке (Typical) устанавливается
все, кроме исходных текстов программы. При минимальной установке (Minimal)
не устанавливаются руководства и исходные тексты. При выборочной (Custom)
установке вы сможете выбрать состав устанавливаемых компонентов
(руководства, исходные тексты и т. д.).
Настройка Apache для Windows
После установки Apache для Windows обычно вносятся изменения в
конфигурационные файлы. В версии Apache для Windows, как и в Unix-версии,
используются три конфигурационных файла:
О access.conf;
О httpd.conf;
О srm.conf.
Файлы снабжены подробными комментариями. Внимательно прочитайте их,
и вы поймете, какие параметры необходимо настроить. За дополнительной
информацией обращайтесь к разделу «Настройка Apache» настоящей главы.
Запуск Apache для Windows
Существует несколько вариантов запуска Apache для Windows:
О из меню Пуск (Start) системы Windows;
О из окна DOS (в режиме командной строки);
О в виде службы NT.
Запуск Apache из меню и окна DOS
При запуске Apache из меню Пуск (Start) открывается окно DOS, которое остается
открытым в течение всего времени, пока работает Apache. Чтобы остановить или
перезапустить Apache, откройте другое консольное окно и введите команду
apache -k shutdown
или
apache -к restart
Apache также можно запустить из консоли DOS командой
apache -k start
Консольное окно остается активным в течение всей работы Apache.
Запуск Apache в виде службы NT
Прежде чем запускать Apache как службу NT, необходимо установить его в этом
формате. Введите в окне DOS команду
apache -I -n "Apache Webserver"
Чтобы удалить поддержку запуска Apache в виде службы, выполните команду
apache -u -n "Apache Webserver"
После того как Apache будет установлен в виде службы NT, для настройки,
запуска и остановки сервера можно использовать приложение Службы (Services)
панели управления Windows.
Другие web-серверы
Хотя основная доля рынка web-серверов принадлежит Apache, существует
немало альтернативных программных продуктов. Ниже приведен краткий список
самых распространенных web-серверов.
О Netscape Enterprise Server — мощный сервер Netscape (также см. FastTrack).
Платформа: HP-UX, Solans, NT (http://www.iplanet.com/products).
О Netscape FastTrack — сервер Netscape начального уровня (также см. Enterprise).
Платформа: Unix, Windows 95/98, NT (http://www.iplanet.com/products).
О Microsoft Internet Information Server (IIS) — популярный сервер для
Windows NT. Платформа: NT Server (http://www.microsoft.com/).
О Microsoft Personal Web Server (PWS) — web-сервер начального уровня; не
рекомендуется для сайтов с высоким трафиком. Платформа: Windows (входит
в NT 4.0 Option Pack) (http://www.microsoft.com).
О AOLserver — компактный, бесплатный сервер с поддержкой средств
разработки web-приложений. Платформа: Unix, Linux (http://www.aolserver.com).
О Zeus — полнофункциональный web-сервер с поддержкой защищенных
виртуальных серверов. Платформа: Unix (http://www.zeus.co.uk/products/zws/).
О O'Reilly WebSitePro — полнофункциональный сервер, прекрасно
подходящий для разработки web-приложений. Платформа: Windows 95/98, NT (http://
website.ora.com/).
О Stronghold — коммерческая версия Apache с улучшенной защитой.
Платформа: Unix (https://www.c2.net/products/sh3/).
О WebSTAR — полнофункциональный web-сервер для платформы Macintosh
(http://www.webstar.com/).
За дополнительной информацией об этих и многих других web-серверах
обращайтесь по адресам, включенным в приведенные выше описания, или
посетите следующие сайты:
О Webserver Compare — данные спецификаций серверов HTTP:
http://webcompare.internet.com/
О Server Watch — авторитетный ресурс, посвященный серверам Интернета:
http://serverwatch.internet.com/
Итоги
World Wide Web ежегодно удваивается в размерах, и конца этому росту не
предвидится. Однако эксперты сходятся в том, что мы не используем и малой
доли тех возможностей, которые открываются благодаря Интернету и Web.
За короткое время World Wide Web прошла путь от небольшого количества
«сугубо информационных» сайтов до миллионов сайтов, предлагающих
разнообразную информацию и услуги. Люди используют Web для выполнения таких
повседневных дел, как получение информации, оформление покупок,
проведение банковских операций и т. д.
Функционирование Web обеспечивают web-серверы. Более половины сайтов
в Web работает на базе Apache — web-сервера, наиболее подробно
представленного в этой главе. Приведенный материал поможет читателю загрузить,
установить, настроить и запустить самый популярный web-сервер Интернета. Глава
завершается кратким обзором web-серверов, распространенных на момент
написания книги. Хочется верить, что материал, приведенный в книге (и особенно
в этой главе), будет применен на практике и поможет читателю включиться
в самое динамичное технологическое направление, наиболее заметно
изменяющее нашу жизнь — World Wide Web.
*%£Z Настройка
*ЭО и оптимизация
протоколов
в системах
семейства Unix
Энн Карасик (Anne Carasik)
При работе с любой системой необходимо знать, как проходит процесс
инициализации и где находятся конфигурационные файлы. Эта информация помогает
оптимизировать конфигурацию сети и упрощает диагностику. В процессе
настройки и оптимизации параметров сети также приходится учитывать
некоторые аспекты, не связанные напрямую с сетевой поддержкой, но обусловленные
спецификой самой системы.
Инициализация системы
При загрузке системы Unix или Linux необходимо учитывать ряд факторов,
многие из которых относятся к сетевым демонам — когда и кем запускается тот
или иной демон и какие демоны работают в системе.
В любой разновидности Unix существует процесс-«предок» init. Он запускает
все остальные процессы в системе Unix, включая командные интерпретаторы,
в которых работают пользователи, и сетевые процессы.
Процесс init и /etc/inittab
Говорят, что система Unix состоит из двух основных компонентов: файлов и
процессов. В Unix все процессы порождаются от init — в конечном счете любой
процесс связывается с init через своих родителей. На рис. 36.1 изображена связь init
с другими процессами.
init
ftpd tty mountd
tesh
xterm
Рис. 36.1. Процесс init и его потомки
Процесс init выполняется на последнем этапе загрузки, после проверки
файловых систем и монтировки дисков, поэтому он может определить, в каком режиме
(однопользовательском или многопользовательском) должна работать система.
В некоторых системах семейства Unix init использует конфигурационный
сценарий /etc/inittab. Пример такого сценария приводится ниже.
# inittab Файл определяет параметры настройки системы
# процессом INIT для определенных уровней исполнения
# Автор: Михель ван Сморенбург, <miquels@drinkel.nl.mugnet.org>
# Файл изменен для RHS Linux Марком Эвингом и Донни Барнсом
# Уровень выполнения по умолчанию. В RHS используются следующие уровни:
# 0 - остановка (НЕ ПРИСВАИВАЙТЕ initdefault!)
# 1 - однопользовательский режим
# 2 - многопользовательский режим без NFS (то же, что и 3,
# но без сетевой поддержки)
# 3 - полный многопользовательский режим
# 4 - не используется
# 5 - XII
# 6 - перезагрузка (НЕ ПРИСВАИВАЙТЕ initdefault!)
id: 3:initdefault;
# Инициализация системы
si::sysinit:/etc/rc.d/rc.sysinit
10:0:wait:/etc/rc.d/rc 0
U:l:wait:/etc/rc.d/rc 1
12:2:wait:/etc/rc.d/rc 2
13:3:wait:/etc/rc.d/rc 3
14:4:wait:/etc/rc.d/rc 4
15:5:wait:/etc/rc.d/rc 5
16:6:wait:/etc/rc.d/rc 6
# Операции, выполняемые на всех уровнях
ud::once:/sbin/update
# Перехват CTRL-ALT-DELETE
са: :ctrlaltde"l:/sbin/shutdown -t3 -г now
# При получении от UPS сообщения о сбое питания предполагается, что
# запаса аккумуляторов хватит еще на несколько минут работы.
# Запланировать отключение системы через 2 минуты.
# Разумеется, для этого в системе должен быть установлен^ демон
# powerd с подключенным и правильно работающим UP5.
pf::powerfail:/sbin/shutdown -f -h +2
"Power failure; System Shutting Down"
# Если питание восстанавливается до отключения, отменить отключение,
рг:12345:powerokwait:/sbin/shutdown -с
"Power Restored; Shutdown Cancelled"
# Запуск getty на стандартных уровнях
1:2345:respawn:/sbin/mingetty ttyl
2:2345:respawn:/sbin/mingetty tty2
3:2345:respawn:/sbin/mingetty tty3
4:2345:respawn:/sbin/mingetty tty4
5:2345:respawn:/sbin/mingetty tty5
6:2345:respawn:/sbin/mingetty tty6
# Запуск xdm на уровне 5
# Xdm теперь представляет собой отдельную службу,
х:5:respawn:/etc/Xll/prefdm -nodaemon
В приведенном файле /etc/inittab для Red Hat Linux сетевая поддержка
начинается с уровня 3. В большинстве диалектов Unix на уровне 3 запускаются
сетевые процессы, включая демона Интернета (inetd), NFS, DNS и Sendmail.
Сценарии re
Чтобы инициировать выполнение процессов-потомков, init запускает
стартовые сценарии, называемые сценариями гс. Эти сценарии запускают сетевые
процессы, в результате чего система Unix готовится к взаимодействию с другими
системами.
В Red Hat Linux и других системах на базе System V (таких, как HP-UX) init
запускает все сетевые стартовые сценарии, находящиеся в каталоге /etc/rc.d/rc3.d.
В других системах также могут вызываться сетевые сценарии из rc.M («M»
означает «Multiuser», то есть многопользовательский) или rc.inet Конкретная
процедура полностью зависит от операционной системы.
Для сохранения логической последовательности мы будем ориентироваться
на Red Hat Linux. Поскольку эта книга посвящена сетям, просмотрим
содержимое каталога /etc/rc.d/rc3.d/:
[root@tigerlair stripes]# Is /etc/rc.d/rc3.d/
K05innd K20rwalld K45arpwatch
K80random S40atd S85sound
K08autofs K20rwhod K45named K85netfs
S40crond S90xfsK10xntpd K25squid
K50snmpd K88ypserv S50inet
S99linuxconf K15postgresql K30mcserv K55routed
K89portmap 555sshd S99local
K20bootparamd K30sendmail K6011pd
K96pcmcia S72amdK20nfs K34yppasswdd K60mars-new S05apmd
S75keytableK20rstatd K35dhcpd K75gated S10network
585gpm
K20rusersd K35smb K80nscd
S30syslog S85httpd
Каждый из этих файлов запускает определенную службу. На уровне 3,
помимо сетевой поддержки, запускается много других процессов. Что касается сети,
запускаемых демонов можно идентифицировать по символам, следующим за
S## и К## (К = Kill, S = Start). Числовые номера определяют
последовательность запуска и остановки демонов.
Сценарии гс также определяют параметры, используемые сетевыми демонами
при первом запуске.
Обратите внимание: в сценарии запуска или остановки не обязательно
существует парный сценарий. Например, у сценария S50inet нет парного сценария K50inet.
Файл SSOinet выглядит так:
#!/bin/sh
#
# inet Запуск сетевых служб TCP/IP. Сценарий определяет имя хоста,
# создает маршруты, запускает сетевого демона Интернета
# и RPC postmapper.
# Автор: Михель ван Сморенбург, <miquels@drinkel.nl.mugnet.org>
# Другие участники проекта Red Hat
#
# chkconfig: 345 50 50
# Описание: Суперсерверный демон Интернета (обычно называемый inetd) \
# запускает другие службы Интернета по мере необходимости. \
# Он отвечает за запуск многих служб, включая telnet, ftp, \
# rsh и rlogin. Отключение inetd приводит к отключению \
# всех служб, за которые он отвечает.
# processname: inetd
# pidfile: /var/run/inetd.pid
# config: /etc/sysconfig/network
# config: /etc/inetd.conf
# Библиотека функций
. /etc/rc.d/init.d/functions
# Конфигурация
. /etc/sysconfig/network
# Проверить сетевую поддержку
if [ ${NETWORKING} = "no" ]
then
exit 0
fi
[ -f /usr/sbin/inetd ] || exit 0
# Проверить параметр вызова
case "$1" in
start)
echo -n "Starting INET services: "
daemon inetd
echo
touch /var/lock/subsys/inet
stop)
echo -n "Stopping INET services: "
killproc inetd
echo
rm -f /var/lock/subsys/inet
status)
status inetd
restart|reload)
killall -HUP inetd
*)
echo "Usage: inet {start|stop|status|restart|reload}"
exit 1
esac
exi t 0
Сценарий остановки K45named выглядит так:
#!/bin/sh
#
# named
# Сценарий обеспечивает запуск и остановку named (сервер DNS BIND)
#
# chkconfig: 345 55 45
# Описание: named (BIND) - сервер DNS (Domain Name System),
# обеспечивающий преобразование хостовых имен в IP-адреса.
# probe: true
# Библиотека функций
. /etc/rc.d/init.d/functions
# Сетевая конфигурация
. /etc/sysconfig/network
# Проверить сетевую поддержку
if [ ${NETWORKING} = "no" J && exit 0
[ -f /usr/sbin/named ] || exit 0
[ -f /etc/named.conf ] || exit 0
# Проверить параметр вызова
case "$1" in
start)
# Запуск демонов
echo -n "Starting named: "
daemon named
echo
touch /var/lock/subsys/inet
stop)
# Остановка демонов
echo -n "Shutting down named: "
killproc named
rm -f /var/lock/subsys/named
echo
status)
/usr/sbin/ndc status
exit $?
restart)
/usr/sbin/ndc restart
exit $?
reload)
/usr/sbin/ndc reload
exit $?
probe)
/usr/sbin/ndc reload >/dev/null 2>&1 || echo start
exit 0
*)
echo "Usage: named {start|stop|status|restart}"
exi t 1
esac
exit 0
ПРИМЕЧАНИЕ
Следует помнить, что не все реализации Unix хранят стартовые сценарии в одном месте. В
некоторых системах они могут храниться в каталогах /etc, /etc/rc и т. д.
Большинство сценариев, относящихся к различным уровням выполнения
и находящихся в каталогах с именами типа /etc/rc.d/rc3.d, представляют собой
символические ссылки на сценарии из каталога /etc/rc.d/init.d. Например,
сценарий /etc/rc.d/rc3.d/S50inet содержит символическую ссылку на файл
. . /init.d/inet
При запуске S50inet вызывается файл сценария ../in.it.d/inet с аргументом start.
Файл /etc/rc.d/rc3.d/S53named содержит символическую ссылку на сценарий
../init.d/named. При запуске S53named вызывается сценарий ../init.d/named с
аргументом start. При отключении системы выполняется сценарий K45named, который
также содержит символическую ссылку на сценарий ../init.d/named, но на этот
раз ../init.d/named передается аргумент stop. Теперь понятно, почему в каждом из
этих сценариев присутствует логика обработки условий start, stop и всех
остальных аргументов, которые могут передаваться сценарию. С учетом этого факта
сценарии /etc/rc.d/initd могут использоваться для запуска и остановки различных
служб. Например, следующая команда останавливает службу BIND:
/etc/rc.d/init.d/named stop
Если служба BIND в данный момент не работает, ее можно запустить командой
/etc/rc.d/init.d/named start
После внесения изменений в файлы базы данных BIND (named) служба
перезапускается командой
/etc/rc.d/init.d/named restart
Конфигурационные файлы
Для нормальной работы сети необходимо обратить особое внимание на
содержимое конфигурационных файлов. В некоторых реализациях Unix особенно
важны следующие конфигурационные файлы:
О /etc/inetd.conf;
О /etc/services;
О /etc/protocols;
О /etc/hosts.equiv;
О /etc/resolv.conf;
О /etc/exports.
В других системах семейства Unix используются другие конфигурационные
файлы.
Определение сетевых протоколов в /etc/protocols
Сетевые протоколы, работающие в системе Unix, определяются в файле /etc/
protocols. Вводить информацию вручную вам не придется — настройка
протоколов должна осуществляться автоматически на стадии установки.
Обратите внимание: все перечисленные протоколы являются протоколами IP.
Другие протоколы (такие, как AppleTalk, NetWare или SNA) в списке отсутствуют.
Ниже приведен пример файла /etc/protocols.
# /etc/protocols:
# Межсетевые протоколы (IP)
#
# Источник: @(#)protocols 5.1 (Berkeley) 4/17/89
#
# Обновлено для NetBSD на основании RFC 1340,
# "Assigned Numbers"(июль 1992 г.)
Ip 0 IP # Internet Protocol (фиктивный номер)
icmp 1 ICMP # Internet Control Message Protocol
igmp 2 IGMP # Internet Group Management Protocol
ggp 3 GGP # Gateway-Gateway Protocol
ipencap 4 IP-ENCAP # Инкапсуляция IP в IP (официально - ''IP'1)
st 5 ST # Режим дейтаграмм ST
tcp 6 TCP # Transmission Control Protocol
egp 8 EGP # Exterior Gateway Protocol
pup 12 PUP # PARC Universal Packet Protocol
udp 17 UDP # User Datagram Protocol
hmp 20 HMP # Host Monitoring Protocol
xns-idp 22 XNS-IDP # Xerox NS IDP
rdp 27 RDP # Reliable Datagram Protocol
iso-tp4 29 IS0-TP4 # ISO Transport Protocol class 4
xtp 36 XTP # Xpress Transport Protocol
ddp 37 DDP # Datagram Delivery Protocol
idpr-cmtp 39 IDPR-CMTP # IDPR Control Message Transport
rspf 73 RSPF # Radio Shortest Path First
vmtp 81 VMTP # Versatile Message Transport
ospf 89 OSPFIGP # Open Shortest Path First IGP
ipip 94 IPIP # Yet Another IP encapsulation
encap 98 ENCAP # Yet Another IP encapsulation
Имена хостов в /etc/hosts
В некоторых локальных системах имена части хостов должны разрешаться без
использования DNS. Информация о таких хостах хранится в файле /etc/hosts.
Минимальный файл /etc/hosts выглядит так:
127.0.0.1 localhost loopback
Приведенная запись определяет адрес локального хоста (или адрес обратной
связи), который используется для обозначения IP-адреса текущего хоста. По
умолчанию имя localhost ассоциируется с адресом 127.0.0.1.
При добавлении в файл новых записей используется следующий синтаксис:
IP-адрес хост псевдоним
Каждая запись содержит IP-адрес хоста, ассоциированное с этим хостом
имя и назначаемые все псевдонимы. Файл /etc/hosts выглядит примерно так:
# Пример файла /etc/hosts
127.0.0.1 localhost loopback
1.2.3.4 wednesday.addams.com mymachine
1.2.3.5 pugsley.addams.com yourmachine
1.2.3.6 gomez.addams.com hismachine
1.2.3.7 cousinit.addams.com istmachine
1.2.3.8 morticia.addams.com hermachine
Таким образом, при подключении через Telnet к компьютеру yourmachine связь
будет установлена с компьютером pugsley.addams.com. Наличие псевдонима
позволяет обойтись без ввода полного имени домена.
ПРИМЕЧАНИЕ
Если система, указанная в файле /etc/hosts, находится в локальной сети, вводить полное имя
домена не обязательно.
Файл /etc/nsswitch.conf управляет порядком разрешения имен. Например, вы
можете указать, что поиск по файлу /etc/hosts должен выполняться до поиска
DNS, или наоборот — что поиск DNS должен предшествовать обращению к /etc/
hosts. Для настройки разрешения имен в Linux проще всего воспользоваться
конфигурационной утилитой linuxconf.
TCP/IP и файл /etc/services
Сервис TCP/IP, поддерживаемый системой Unix, определяется составом служб,
работающих в системе. Запускаемые службы настраиваются в двух местах: в файле
/etc/services и конфигурационном файле inetd.conf демона inetd, рассматриваемом
ниже в этой главе.
Файл /etc/services распределяет номера портов между сетевыми службами
(FTP, Telnet, сервер времени, сервер имен, SSH, Finger и т. д.).
Многие службы обычно всегда ассоциируются с одним стандартным портом;
такие порты называются хорошо известными. К их числу относятся все службы,
работающие на портах с номерами, не превышающими 1024.
В файл /etc/services также включается информация о других службах, гораздо
менее распространенных. Синтаксис записи файла /etc/services выглядит
следующим образом:
служба порт/1:ср_или_ис1р
В первом поле определяется имя сетевой службы (Telnet, echo, SMTP и т. д.),
а во втором — номер порта. После номера порта указывается, какой
транспортный протокол используется службой, TCP или UDP.
Ниже приведен пример файла /etc/services.
# /etc/services:
#
# Сетевые службы Интернета
#
# В настоящее время IANA присваивает один хорошо известный номер
# порта как для TCP, так и для UDP; по этой причине большинство
# служб представлено двумя записями, даже если протокол не поддерживает
# работы через UDP.
# Обновлено на основании RFC 1700, "Assigned Numbers"(октябрь 1994 г.).
# В список включены не все порты, а лишь наиболее распространенные.
pcpmux 1/tcp # Мультиплексор портов TCP
echo 7/tcp
echo 7/udp
discard 9/tcp sink null
discard 9/udp sink null
systat 11/tcp users
daytime 13/tcp
daytime 13/udp
netstat 15/tcp
qotd 17/tcp quote
msp 18/tcp # Message Send Protocol
msp 18/udp # Message Send Protocol
chargen 19/tcp ttystat source
chargen 19/udp ttystat source
ftp-data 20/tcp
fsp 21/udp fspd
ssh 22/tcp # SSH Remote Login Protocol
ssh 22/udp # SSH Remote Login Protocol
telnet 23/tcp
# 24 - зарезервирован
smtp 25/tcp mail
# 26 - не используется
time 37/tcp timserver
nameserver 42/tcp name # IEN 116
whois 43/tcp nicname
domain 53/tcp nameserver # сервер имен
domain 53/udp nameserver
bootps 67/tcp # Сервер В00ТР
bootpc 68/tcp # Клиент В00ТР
ttfp 69/udp
gopher 70/tcp # Gopher
finger 79/tcp
www 80/tcp http # WorldWideWeb HTTP
www 80/udp # HyperText Transfer Protocol
link 87/tcp ttylink
kerberos 88/tcp kerberos krb5 # Kerberos v5
kerberos 88/udp kerberos krb5 # Kerberos v5
supdup 95/tcp
# 100 - зарезервирован
pop-3 110/tcp # POP version 3
sunrpc 111/tcp portmapper # RCP 4.0 portmapper TCP
sunrpc 111/udp portmapper # RCP 4.0 portmapper UDP
auth 113/tcp authentication tap ident
sftp 115/tcp
nntp 119/tcp readnews untp # USENET News Transfer Protocol
ntp 123/tcp
netbios-ns 137/tcp # NetBIOS Name Service
netbios-dgm 138/tcp # NetBIOS Datagram Service
netbios-ssn 139/tcp # NetBIOS session service
imap2 143/tcp imap # Interim Mail Access Proto v2
imap2 143/udp imap
snmp 161/udp # Simple Net Mgmt Proto
snmp-trap 162/udp snmptrap # Traps for SNMP
cmip-man 163/tcp # ISO Mgmt over IP (CMOT)
bgp 179/tco # Border Gateway Proto.
ire 194/tcp # Internet Relay Chat
qmtp 209/tcp # Quick Mail Transfer Protocol
#
# Специфические службы Unix
#
exec 512/tcp
biff 512/udp comsat
login 513/tcp
who 513/udp whod
shell 514/tcp cmd # Пароли не используются
syslog 514/udp
printer 515/tcp spooler # Спулер построчной печати
talk 517/udp
ntalk 518/udp
route 520/udp router routed # RIP
#
# Сервис Kerberos (Project Athena/MIT)
#
kerberos4 750/udp kerberos-iv kdc # Kerberos (server) udp
kerberos4 750/tcp kerberos-iv kdc # Kerberos (server) tcp
kerberos_master 751/udp # Аутентификация Kerberos
kerberos_master 751/tcp # Аутентификация Kerberos
passwd__server 752/udp # Сервер паролей Kerberos
krb_prop 754/tcp
krbupdate 760/tcp kreg # Регистрация Kerberos
kpasswd 761/tcp kpwd # Kerberos "passwd"
#
# Службы, добавленные для поставки Debian GNU/Linux
poppassd 106/tcp # Eudora
poppassd 106/udp # Eudora
ssmtp 465/tcp # SMTP через SSL
rsync 873/tcp # rsync
rsync 873/udp # rsync
simap 993/tcp # IMAP через SSL
spop3 995/tcp # POP-3 через SSL
socks 1080/tcp # Прокси-сервер socks
socks 1080/udp # Прокси-сервер socks
icp 3130/tcp # Internet Cache Protocol (Squid)
icp 3130/udp # Internet Cache Protocol (Squid)
ircd 6667/tcp # Internet Relay Chat
ircd 6667/udp # Internet Relay Chat
inetd и /etc/inetd.conf
В системе Unix многие сетевые службы запускаются супердемоном Интернета
inetd. Информация о запускаемых службах берется из файла inetd.conf, обычно
расположенного в каталоге /etc
ПРИМЕЧАНИЕ
Из-за возможности запуска других сетевых демонов из inetd возникает искушение постоянно
использовать inetd. Тем не менее в некоторых ситуациях это может оказаться нежелательным из-за
снижения быстродействия. Например, необходимость генерировать криптографические ключи в Secure
Shell серьезно сказывается на быстродействии.
В некоторых версиях Linux вместо демона inetd используется его усовершенствованный вариант
xinetd. Конфигурация этого демона хранится в файле /etc/xinetd.conf.
Большинству сетевых демонов взаимодействовать с другими демонами через
inetd достаточно удобно. Демоны прибегают к услугам inetd, поскольку inetd
может вести прослушивание на всех сокетах; в противном случае демонам
придется организовывать такое прослушивание самостоятельно.
Работа через inetd предотвращает ожидание привязки к сокету со стороны
многих демонов, а также случайное распределение доступа к сокетам между
демонами. В каком-то смысле inetd выполняет функции охранника на входе: он
пропускает только тех, у кого на это есть право, и направляет посетителей по
нужному пути. Тем самым упрощается обеспечение безопасности и управление
трафиком.
На рис. 36.2 показано, какие функции inetd выполняет во взаимодействии
между сетевыми процессами.
Сервер Клиент
inetd
Прослушивает подключения
по Интернету от клиента . .
< ftP
I '. . . I . I Г I Клиент запрашивает
I inetd Г 1 Пр 1 подключение ftp
inetd получает запрос на
подключение ftp от клиента
и передает его демону ftp
I ! I Возвращается к прослушиванию
| ' I других сокетов
inetd М W ftp
I I Между демоном ftp и клиентом I . 1
устанавливается связь
inetd
I inetd U -/ / W ftp
Даже после закрытия подключения
ftp inetd продолжает прослушивание
Рис. 36.2. Управление процессом inetd
Поскольку inetd не знает, каких сетевых демонов следует запустить,
информацию о запускаемых демонах необходимо определить в файле /etc/inetd.conf.
Записи /etc/inetd.conf имеют следующий формат:
служба тип_сокета протокол флаги пользователь путь аргументы
Таким образом, для демона ftp используется запись вида
ftp stream tcp nowait root /usr/sbin/tcpd in.ftpd -I -a
После расшифровки становится ясно, что речь идет о демоне FTP с типом
сокетов stream, работающем с привилегиями root. Сервер находится в каталоге
/usr/sbin/tcpd, при вызове ему передаются аргументы in.ftpd -I -а. Обратите внимание:
флаги в этой записи отсутствуют (в этом случае поле флагов полностью
пропускается). Интерфейсный демон TCP /usr/sbin/tcpd управляет доступом к
службе, передаваемой в аргументе при вызове tcpd. Контроль за доступом к службе
осуществляется при помощи файлов /etc/hosts.deny и /etc/hosts.allow.
Использование интерфейсного демона позволяет задать политику безопасности,
управляющую доступом к заданной службе.
Ниже приведен фрагмент типичного файла inetd.conf.
# Авторы: Оригинал позаимствован из BSD Unix 4.3/TAHOE.
# Фред Н.ван Кемпен, <waltje@uwalt.nl.mugnet.org>
#
echo stream tcp nowait root internal
echo dgram udp wait root internal
discard stream tcp nowait root internal
discard dgram udp wait root internal
daytime stream tcp nowait root internal
daytime dgram udp wait root internal
chargen stream tcp nowait root internal
chargen dgram udp wait root internal
time stream tcp nowait root internal
time dgram udp wait root internal
# Стандартные службы
#
ftp stream tcp nowait root /usr/bin/tcpd in.ftpd -I -a
telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd
#
# Shell, login, exec, comsat и talk -- протоколы BSD.
#
shell stream tcp nowait root /usr/bin/tcpd in.rshd
login stream tcp nowait root /usr/bin/tcpd in.rlogind
#exec stream tcp nowait root /usr/bin/tcpd in.rexecd
#comsat dgram udp wait root /usr/bin/tcpd in.comsat
talk dgram udp wait root /usr/bin/tcpd in.talkd
ntalk dgram udp wait root /usr/bin/tcpd in.ntalkd
#dtalk stream tcp wait nobody /usr/bin/tcpd in.dtalkd
#
# Pop.imap и другие почтовые службы
#
#рор2 stream tcp nowait root /usr/bin/tcpd ipop2d
pop2 stream tcp nowait root /usr/bin/tcpd ipop3d
imap stream tcp nowait root /usr/bin/tcpd imapd
#
# Служба UUCP
#
#uucp stream tcp nowait uucp /usr/bin/tcpd
/usr/lib/uucp/uucico -1
#
# Служба Tftp предназначена в основном для загрузки. На большинстве
# сайтов эта служба запускается только на компьютерах, выполняющих
# функции "серверов загрузки". Не снимайте комментарии, если
# запуск этих служб не является *абсолютно* необходимым.
#
#tftp dgram udp wait root /usr/bin/tcpd in.tftpd
#bootps dgram udp wait root /usr/bin/tcpd bootpd
#
# Службы finger, systat и netstat выдают информацию о пользователях,
# которая может пригодиться потенциальным взломщикам систем. Многие
# сайты для улучшения безопасности отключают эти службы
# (полностью или частично).
#
finger stream tcp nowait root /usr/bin/tcpd in.fingerd
#cfinger stream tcp nowait root /usr/bin/tcpd in.cfingerd
#systat stream tcp nowait guest /usr/bin/tcpd /bin/ps -auwwx
#netstat stream tcp nowait guest /usr/bin/tcpd
/bin/netstat -f inet
#
# Аутентификация
#
auth stream tcp nowait nobody
/usr/sbin/in.identd in.identd -1 -e -o
#
# Конец файла inetd.conf
Обратите внимание: по умолчанию команды запуска многих сетевых
демонов закомментированы знаком #. Это означает, что эти команды должны
выполняться только в том случае, если вы абсолютно твердо уверены в их
необходимости. Считается, что эти команды создают угрозу для безопасности системы,
так как злоумышленник может использовать их для получения доступа или
выведения системы из строя.
ПРИМЕЧАНИЕ
Демоны обычно запускаются с правами пользователя nobody или user. Пользователь nobody
использует гостевой вход с ограниченными привилегиями. Будьте особенно внимательны при запуске
демонов с правами root, поскольку пользователь root обладает полным доступом ко всей системе.
При внесении изменений в файл /etc/inetd.conf (например, при отключении
существующих или запуске новых сетевых демонов) следует перезапустить inetd,
отправив ему сигнал HUP:
# killall -HUP inetd
Информация о сетях в файле /etc/networks
Хотя на практике данная возможность используется довольно редко, вы можете
создавать собственные определения сетей в файле /etc/networks. Это помогает
упорядочить информацию о сетях, к которым подключена ваша сеть.
Клиент DNS и файл /etc/resolv.conf
Для нормальной работы механизма разрешения имен DNS необходимо правильно
настроить клиента DNS. Задача решается при помощи файла /etc/resolv.conf.
В файле /etc/resolv.conf указываются имена доменов, серверы имен (только
основные или основные с дополнительными) и дополнительные директивы,
используемые в процессе поиска.
Содержимое файла /etc/resolv.conf используется в процессе разрешения имен,
то есть преобразования имен вида www.example.com в IP-адреса. Например,
фрагмент файла может выглядеть так:
search exampTe.com sub.example.com
nameserver 200.1.1.1
nameserver 200.1.1.2
nameserver 200.1.1.3
Директива search указывает, какие доменные суффиксы должны
использоваться при попытке разрешения неполных имен. Например, при попытке
обратиться к серверу по имени slOO DNS сначала попытается разрешить имя вида
slOO.example.com, а затем — имя вида slOO.sub.example.com. Директива nameserver
используется для определения до трех серверов DNS. Серверы опрашиваются
в порядке их перечисления в директиве nameserver.
ПРИМЕЧАНИЕ
Хотя содержимое файла относится к специфике DNS, вы должны проследить за правильностью
настройки. Проверьте работу DNS при помощи nslookup, dig, dnsquery или любых других
подручных средств.
Если этого не сделать, в работе сети часто возникают необъяснимые проблемы, внешне не
связанные с DNS.
Итоги
К числу важнейших аспектов сетевого администрирования относятся
инициализация сети, сопровождение конфигурационных файлов и внесение
правильных изменений при их редактировании.
Администратор должен знать, с какой отправной точки начинает работать
сетевая поддержка в системе. Системы семейства Unix могут работать на
нескольких уровнях выполнения; состав служб, работающих в системе, зависит от
текущего уровня. Следовательно, вы должны знать, на каком уровне запускаются
средства сетевой поддержки в вашей системе. В некоторых системах это
происходит на уровне 3, хотя в других случаях сетевая поддержка может запускаться
на других уровнях, в том числе и на многопользовательских. Конфигурация
уровней выполнения обычно определяется в файле /etc/inittab.
Правильная настройка конфигурационных файлов также играет важную роль
в обеспечении пропускной способности сети и безопасности системы. В системе
Unix конфигурация супердемона Интернета inetd хранится в файле /etc/inetd.conf,
конфигурация клиента DNS — в файле /etc/resolv.conf, информация о доступных
сетях — в файле /etc/networks, информация о хостах — в файле /etc/hosts, а
информация о сетевых службах — в файле /etc/services.
От настройки сетевых служб TCP/IP мы переходим к следующей теме —
управлению разрешением имен с использованием DNS, управлению сетью и
протоколу SNMP, а также вопросам безопасности и отладки в сетях TCP/IP.
*2Т1 Реализация DNS
Тим Паркер (Tim Parker)
Было бы крайне неудобно запоминать и вводить IP-адреса всех хостов сети,
предоставляющих тот или иной сервис. Вместо этого мы работаем с именами
хостов в системе DNS (Domain Name System). При осмысленном назначении
имена хостов легко запоминаются и удобны в использовании.
Система DNS делит пространство имен Интернета на домены, которые, в свою
очередь, могут делиться на субдомены. Домены первой группы называются
доменами верхнего уровня; они хорошо знакомы всем, кто когда-либо просматривал
web-страницы или работал в Интернете. На практике чаще всего используются
семь доменов верхнего уровня:
О агра — организации, деятельность которых связана с Интернетом;
О com — коммерческие организации;
О edu — образовательные учреждения;
О gov — правительственные учреждения;
О mil — военные организации;
О net — поставщики сетевых услуг;
О org — некоммерческие организации.
Кроме перечисленных доменов верхнего уровня также существуют домены
верхнего уровня для отдельных стран. Обычно такие домены обозначаются
сокращенным названием страны — например, .са (Канада) или .uk
(Великобритания). Внутри домена верхнего уровня создаются субдомены отдельных
организаций (Jbm.com, Nnux.org и т. д.). Имена доменов регистрируются в центре NIC
и являются уникальными для каждой сети.
Серверы имен DNS
Каждый сервер имен DS обслуживает отдельный участок сети (или весь домен,
если размеры сети невелики). Домены, в которых серверу имен предоставлены
такие полномочия, образуют зону. Один сервер может обслуживать несколько
зон, каждая из которых состоит из одного или нескольких доменов. Внутри
каждой зоны почти всегда существует вторичный (резервный) сервер имен. Два
сервера имен (первичный и вторичный) содержат одинаковые данные. Серверы
имен внутри зоны взаимодействуют при помощи протокола зонной передачи
данных.
Работа DNS основана на концепции вложенности зон. Сервер имен
взаимодействует с другими серверами и знает адрес по крайней мере одного сервера
имен. В каждой зоне имеется по крайней мере один сервер имен, ответственный
за получение адресной информации для каждого компьютера в этой зоне.
Когда пользовательскому приложению требуется преобразовать
символическое имя в сетевой адрес, оно обращается с запросом к резольверу, который
переадресует запрос серверу имен. Сервер имен просматривает свои таблицы
и возвращает сетевой адрес, соответствующий символическому имени. Если
сервер имен не располагает необходимой информацией, он передает запрос
другому серверу. Серверы имен и резольверы поддерживают таблицы и кэши с
информацией о компьютерах локальной зоны и наиболее часто запрашиваемых
данных внешних зон.
При получении от резольвера запроса на разрешение имени сервер имен
выполняет одну из нескольких операций. Операции по разрешению имен делятся
на две категории: рекурсивные и итеративные (не рекурсивные).
Рекурсивными называются операции, при которых на запрос на разрешение
имени выдается ответ с затребованной информацией или сообщением об ошибке.
Сервер, получивший запрос от резольвера, может обратиться за информацией
к другим серверам DNS. Последние находят (или не находят) затребованные
данные и возвращают запрос стороне, от которой он поступил. Итеративные
операции выдают полный ответ на запрос резольвера, ссылку на другой сервер
имен (к которому должен обратиться резольвер) или сообщение об ошибке.
При необходимости выполнить рекурсивную операцию сервер имен
связывается с другим сервером по запросу резольвера. Удаленный сервер имен
возвращает сетевой адрес или сообщение с кодом ошибки. При рекурсивных операциях
правила DNS запрещают удаленному серверу возвращать ссылки на другие
серверы имен.
Ресурсные записи
Информация, необходимая для разрешения символических имен, хранится на
сервере DNS в виде базы данных с ресурсными записями.
ПРИМЕЧАНИЕ
Ресурсные записи вводятся из текстовых файлов, называемых «зонными файлами данных».
Информация DNS, загруженная из текстовых файлов, хранится в памяти сервера DNS в виде таблиц,
обеспечивающих ускоренную выборку данных. Обычно используется некоторая разновидность
хэш-таблиц с индексной выборкой элементов.
Структура ресурсных записей уже рассматривалась выше, поэтому здесь эта
информация повторяться не будет
В адресных данных DNS (например, в адресных ресурсных записях)
используется специальный формат, называемый IN-ADDR-ARPA. Он обеспечивает
как преобразование имен хостов в адреса, так и обратное преобразование
адресов в имена хостов. Чтобы лучше понять IN-ADDR.ARPA, полезно рассмотреть
типичную ресурсную запись. Одной из простейших разновидностей ресурсных
записей являются адресные записи (тип А). Ниже приведен небольшой
фрагмент из адресного файла:
TPCI_HPWS1 IN A 143.12.2.50
TPCI_HPWS2 IN A 143.12.2.51
TPCI_HPWS3 IN A 143.12.2.100
IN A 144.23.56.2
MERLIN IN A 145.23.24.1
SMALLWOOD IN A 134.2.12.75
Каждая строка файла представляет одну ресурсную запись. В приведенном
примере используются простые записи, содержащие символическое имя хоста,
класс (IN = Интернет), признак адресной ресурсной записи (А) и адрес хоста
в Интернете, компьютеру TPCI_GATEWAY назначены два адреса, поскольку он
выполняет функции шлюза между двумя сетями. В разных сетях шлюзу
назначаются разные адреса, этим и объясняется присутствие двух ресурсных записей
в одном файле.
Подобные файлы упрощают процедуру преобразования между именами
хостов и адресами. Сервер имен просто ищет строку с символическим именем,
переданным в запросе приложения, и возвращает интернет-адрес, указанный
в конце строки. Базы данных индексируются по именам, поэтому поиск
выполняется очень быстро.
С преобразованием адреса в имя дело обстоит сложнее. Если бы файлы
ресурсных записей были невелики, небольшая задержка с поиском была бы
приемлема, однако большие зоны могут содержать тысячи и десятки тысяч записей.
Файлы индексируются по именам, поэтому поиск по адресу выполняется
медленно. Для разрешения проблемы обратного разрешения имен был разработан
механизм IN-ADDR.ARPA, индексирующий данные ресурсных записей по адресу
хоста. Из найденной ресурсной записи извлекается символическое имя.
В IN-ADDR.ARPA адреса ассоциируются с именами при помощи ресурсных
записей типа PTR. Ниже приведен пример файла, связывающий числовые адреса
с именами:
23.1.45.143.IN-ADDR.ARPA. PTR TPCI_HPWS_4.TPCI.COM
1.23.64.147.IN-ADDR.ARPA. PTR TPCI_SERVER.MERLIN.COM
3.12.6.123.IN-ADDR.ARPA. PTR BEAST.BEAST.COM
143.23.IN-ADDR.ARPA PTR MERLINGATEWAY.MERLIN.COM
Интернет-адреса в файле IN-ADDR.ARPA записываются в обратном порядке.
Как видно из примера, указывать полный адрес шлюза не обязательно, поскольку
имя домена предоставляет достаточно информации для маршрутизации.
Резольвер
Клиент DNS называется резольвером. С точки зрения пользовательского
приложения разрешение символических имен, то есть их преобразование в сетевые
адреса, выполняется достаточно просто. Приложение посылает запрос процессу,
называемому резольвером (который иногда находится на другом компьютере).
Иногда резольверу удается разрешить имя напрямую; в этом случае он
возвращает приложению ответное сообщение. Если резольвер не может определить
сетевой адрес для указанного имени, он связывается с сервером имен (который,
в свою очередь, может связаться с другим сервером).
Резольвер должен заменить существующие механизмы разрешения имен
(такие, как файл /etc/hosts). Эта замена полностью прозрачна для пользователя,
хотя администратор должен знать, какой механизм разрешения имен будет
использоваться на каждом компьютере («родная» система разрешения или DNS).
Когда резольвер получает информацию с сервера имен, он сохраняет ее в своем
кэше, чтобы избежать порождения лишнего сетевого трафика при повторном
запросе на разрешение того же символического имени (как часто бывает в
сетевых приложениях). Продолжительность хранения записей в кэше резольвера
определяется значением поля срока жизни (TTL) в ресурсных записях или
значением по умолчанию, установленным в системе.
Если серверу не удается разрешить имя, он может отправить резольверу
сообщение с адресом другого сервера имен (в случае итеративного запроса).
Резольвер адресует сообщение другому серверу в надежде разрешить имя.
Резольвер может потребовать, чтобы сервер имен самостоятельно переслал запрос, для
чего в сообщение устанавливается бит рекурсивности. Сервер имен может
принять или отклонить это требование.
При обработке запроса резольвер использует протокол UDP. Тем не менее
при пересылке больших объемов данных (например, внутризонные пересылки)
может возникнуть необходимость в более надежном протоколе TCP.
В операционных системах семейства Unix, где берет свое начало система
DNS, используются несколько разных реализаций резольвера. Особенно
ограниченными возможностями обладал резольвер, входивший в исходные
поставки BSD, — в нем не поддерживался кэш и отсутствовали возможности
итеративного поиска. Для решения этих проблем в BSD Unix 4.2 был включен сервер
BIND (Berkeley Internet Name Domain). BIND поддерживает кэширование и
итеративные запросы в трех режимах: первичного сервера, вторичного сервера и кэ-
ширующего сервера (который не обладает собственной базой данных и
ограничивается ведением кэша). Применение BIND в системах BSD позволяет возложить
задачи разрешения имен на другой процесс, который может находиться на
другом компьютере.
ПРИМЕЧАНИЕ
Текущая разработка и развитие BIND находятся под управлением консорциума ISC (www.isc.org).
Реализации BIND существуют в Unix и в операционных системах семейства MS Windows.
Настройка сервера DNS в Unix и Linux
Настройка сервера DNS требует модификации и создания ряда файлов и баз
данных. Процесс занимает довольно много времени, но к счастью, он
выполняется всего один раз для каждого сервера. В большинстве конфигураций DNS
используются следующие файлы:
О named.hosts — официальная информация о домене и преобразование имен
хостов в IP-адреса.
О named.rev — преобразование IP-адресов в имена хостов через IN-ADDR.ARPA.
О named.local — разрешение для драйвера обратной связи.
О named.са — список корневых серверов домена.
О named.boot (BIND 4) и named.conf (BIND 8 и выше) — информация о
местонахождении файлов и баз данных.
Имена этих файлов (кроме named.boot или named.conf) не являются
обязательными; вы можете выбрать их по своему вкусу. Самая важная информация
хранится в файле named.boot (BIND 4) или named.conf (BIND 8 и выше); этот
файл читается при загрузке системы и содержит информацию об остальных
файлах, в том числе о новых именах переименованных файлов. Каждый файл
в приведенном списке представляет собой базу данных с ресурсными записями.
Ввод ресурсных записей
В типичной конфигурации сервера используются стандартные имена и структуры
сетей. DNS позволяет определять очень сложные конфигурации, но для
знакомства с файлами и типами ресурсных записей лучше воспользоваться простым
примером.
Ресурсная запись SOA находится в файле named.hosts. Символы,
следующие после точки с запятой, используются для оформления комментариев. Для
большей наглядности каждое поле ресурсной записи выводится в отдельной
строке, хотя это и не обязательно. Следующая ресурсная запись означает, что
в домене tpci.com хост server.tpci.com выполняет функции первичного сервера
имен, а с администратором, отвечающим за работу домена, можно связаться по
адресу root@merlin.tpci.com. Смысл остальных полей понятен из комментариев.
tpci.com. IN SOA server.tpci.com
root.merlin.tpci.com. (
2 ; Порядковый номер
7200 ; Период обновления B часа)
3600 ; Период повтора A час)
151200 ; Период актуальности A неделя)
86400 ); Срок жизни
Обратите внимание: все поля, начиная с порядкового номера и завершая
сроком жизни, заключены в круглые скобки. Скобки являются частью синтаксиса
команды и определяет порядок параметров.
Кроме ресурсной записи SOA файл named.hosts содержит адресные записи
(тип А) с информацией об отображении имен хостов в IP-адреса. Следующий
фрагмент поясняет формат этих записей:
artemis IN A 143.23.25.7
merlin IN A 143.23.25.9
pepper IN A 143.23.25.72
Имена хостов обычно не задаются в формате FQDN, поскольку сервер может
вычислить полное имя. Если в файле указывается полностью определенное
доменное имя, за ним должен следовать символ «.». Если заменить имена хостов
в приведенном выше фрагменте полностью определенными доменными именами,
фрагмент принимает следующий вид:
artemis.tpci.com. IN A 143.23.25.7
merlin.tpci.com. IN A 143.23.25.9
pepper.tpci.com. IN A 143.23.25.72
Ресурсная запись типа PTR связывает IP-адреса с именами с использованием
механизма IN-ADDR.ARPA. Простой пример ресурсной записи PTR объясняет,
как работает механизм обратного разрешения. Следующая запись указывает на
то, что компьютеру merlin присвоен IP-адрес 147.120.0.7:
7.0.120.147.in-addr.arpa IN PTR merlin.tpci.com
Ресурсная запись типа NS определяет сервер имен, обслуживающий
заданную зону. Записи типа NS используются в больших сетях, состоящих из
нескольких подсетей, каждая из которых обладает собственным сервером имен. Запись
типа NS выглядит следующим образом:
tpci.com. IN A merlin.tpci.com
Она означает, что домен tpci.com обслуживается сервером DNS merlin.tpci.com.
Остальные файлы DNS
Как вы знаете, в DNS ресурсные записи, содержащие информацию о зонах,
хранятся в нескольких файлах. Первый из этих файлов, named.hosts, содержит
ресурсные записи типов SO A, NS и А. Все записи файла named.hosts должны начинаться
с первой позиции каждой строки. Ниже приведен примерный файл named.hosts
с комментариями:
; Файл named.hosts
; Ресурсная запись SOA (Start of Authority)
tpci.com. IN SOA merlin.tpci.com.
root.merlin.tpci.com. (
2 ; Порядковый номер
7200 ; Период обновления B часа)
3600 ; Период повтора A час)
151200 ; Период актуальности A неделя)
86400 ); Срок жизни
; Ресурсные записи NS (Name Server)
tpci.com. IN NS merlin.tpci.com.
subnetl.tpci.com IN NS goofy.subnetl.tpci.com.
; Адресные ресурсные записи
artemis IN A 143.23.25.7
merlin IN A 143.23.25.9
Windsor IN A 143.23.25.12
reverie IN A 143.23.25.23
bigcat IN A 143.23.25.43
pepper IN A 143.23.25.72
В первой части определяется запись типа SOA с параметрами срока жизни,
периода актуальности, периодичности обновления и т. д. В ней также указано, что
домен tpci.com обслуживается сервером имен merlin.tpci.com. Во второй части файла
записи типа NS определяют для домена tpci.com сервер имен merlin.tpci.com
(как и в записи SOA), а субдомену tpci с именем subnetl назначается сервер
goofy.subnetl.tpci.com. Третья часть состоит из адресных записей, определяющих
соответствие между именами и IP-адресами. Каждый компьютер в сети
представлен одной из записей этого раздела.
Файл named.rev обеспечивает обратное преобразование IP-адресов в имена
хостов и состоит из записей типа PTR. По формату записей он близок к файлу
named.hosts, если не считать перестановки имен и IP-адресов, а также
преобразования IP-адресов в стиле IN-ADDR.ARPA. Файл named.rev, соответствующий
приведенному выше файлу named.hosts, выглядит так:
; Файл named.rev
; Ресурсная запись SOA (Start of Authority)
23.143.in-addr.arpa. IN SOA merlin.tpci.com.
root.merlin.tpci.com. (
2 ; Порядковый номер
7200 ; Период обновления B часа)
3600 ; Период повтора A час)
151200 ; Период актуальности A неделя)
86400 ); Срок жизни
; Ресурсные записи NS (Name Server)
23.143.in-addr.arpa. IN NS merlin.tpci.com.
100.23.143.ih-addr.arpa. IN NS goofy.subnetl.tpci.com.
; Адресные ресурсные записи
9.25.23.143.in-addr.arpa. IN PTR merlin.tpci.com.
12.25.23.143.in-addr.arpa. IN PTRwindsor.tpci.com.
23.25.23.143.in-addr.arpa. IN PTR reverie.tpci.com.
43.25.23.143.in-addr.arpa. IN PTR bigcat.tpci.com.
72.25.23.143.in-addr.arpa. IN PTR pepper.tpci.com.
Для каждой зоны или субдомена сети создается отдельный файл named.rev.
Файлы должны различаться по именам или находиться в разных каталогах.
Если вы используете только одну зону, достаточно одного файла named.rev.
Файл named.local содержит сведения об интерфейсе обратной связи (которому
обычно присваивается IP-адрес 127.0.0.1, хотя подойдет любой адрес в форме
127.х.х.х). Файл должен содержать данные обратного разрешения в формате
IN-ADDR.ARPA для драйвера обратной связи, а также информацию о сервере
имен (поскольку файл named.rev не распространяется на сеть 127). Файл named,
local выглядит примерно так:
; Файл named.local
; Ресурсная запись SOA (Start of Authority)
0.0.127.in-addr.arpa. IN
SOA merlin.tpci.com.
root.merlin.tpci.com. (
2 ; Порядковый номер
7200 ; Период обновления B часа)
3600 ; Период повтора A час)
151200 ; Период актуальности A неделя)
86400 ); Срок жизни
; Ресурсная запись NS (Name Server)
0.0.127.in-addr.arpa. IN NS merlin.tpci.com.
; Адресная ресурсная запись
1.0.0.127.in-addr.arpa. IN localhost.
IP-адрес 127.0.0.1 ассоциируется с именем localhost.
Файл named.ca определяет имена корневых серверов домена. Хосты,
указанные в файле named.ca, должны быть стабильными и не подверженными частым
изменениям. Типичный файл named.ca выглядит примерно так:
; named.ca
; Корневые серверы домена
99999999 IN NS ns.nic.ddn.mil.
99999999 IN NS ns.nasa.gov.
99999999 IN NS ns.internic.net
; Адреса серверов
ns.nic.ddn.mil. 99999999 IN A 192.112.36.3
ns.nasa.gov. 99999999 IN A 192.52.195.10
ns.internic.net. 99999999 IN A 198.41.0.4
В этом файле определены всего три сервера DNS. В некоторых файлах named.ca
определяется по десять и более серверов, в зависимости от их близости к вашей
системе.
Требования к работе корневых серверов описаны в RFC 2870. Ниже приведен
полный список тринадцати корневых серверов домена ROOT-SERVERS.NET
с обозначениями от A.ROOT-SERVERS.NET до M.ROOT-SERVERS.NET. В
таблице также приводятся данные об их физическом местонахождении.
Восточное побережье США
A.ROOT-SERVERS.NET NSF-NSI. Херндон, штат Вирджиния
С. ROOT-SERVERS.NET PSI. Херндон, штат Вирджиния
D.ROOT-SERVERS.NET UMD, Колледж-Парк, штат Мэриленд
G.ROOT-SERVERS.NET DISA, Боинг, штат Вирджиния
Н.ROOT-SERVERS.NET Министерство обороны США. Абердин, штат Мэриленд
J.ROOT-SERVERS.NET NSF-NSI, Херндон, штат Вирджиния
Западное побережье США
E.ROOT-SERVERS.NET NASA, Моффет-Филд, штат Калифорния
F-ROOT-SERVERS.NET ISC, Вудсайд, штат Калифорния
B.ROOT-SERVERS.NET DISA-USC, Марина дель Рей, штат Калифорния
LROOT-SERVERS.NET DISA-USC, Марина дель Рей, штат Калифорния
Европа
K.ROOT-SERVERS.NET LINX/RIPE, Лондон, Великобритания
I.ROOT-SERVERS.NET NORDU, Стокгольм, Швеция
Азия
M.ROOT-SERVERS.NET WIDE, Кейо, Япония
Текущая версия списка корневых серверов доступна по адресу ftp://ftp.rs.internic.
net.domain/named.root. Ниже приводится файл зонных данных для корневых
серверов.
; Ранее NS.INTERNIC.NET
3600000 IN NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET. 3600000 А 198.41.0.4
; Ранее NS1.ISI.EDU
! 3600000 NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET. 3600000 A 128.9.0.107
; Ранее CPSI.NET
3600000 NS С.ROOT-SERVERS.NET.
CROOT-SERVERS.NET. 3600000 A 192.33.4.12
; Ранее TERP.UMD.EDU
3600000 NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET. 3600000 A 128.8.10.90
; Ранее NS.NASA.GOV
! 3600000 NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10
; Ранее NS.ISC.ORG
3600000 NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241
; Ранее NS.NICDDN.MIL
3600000 NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4
; Ранее AOS.ARL.ARMY.MIL
3600000 NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET. 3600000 A 128.63.2.53
; Ранее NIC.NORDU.NET
3600000 NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17
; Управляется VeriSign, Inc.
3600000 NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET. 3600000 A 192.58.128.30
; Находится в LINX, управляется RIPE NCC
3600000 NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129
; Управляется IANA
3600000 NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET. 3600000 A 198.32.64.12
; Находится в Японии, управляется WIDE
3600000 NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33
Содержимое этого файла можно вставить в named.ca. Каждый сервер
представлен в файле named.ca двумя записями: первая задает корневой домен
(точка) и имя сервера имен, а вторая — IP-адрес сервера имен. Срок жизни задан
очень большим, поскольку эти серверы всегда должны быть доступны.
Файл named.boot (или named.conf) инициирует загрузку демонов DNS, а также
содержит информацию о первичном и вторичном серверах имен в сети. Ниже
приведен примерный файл named.boot.
; named.boot
directory /usr/lib/named
primary tpci.com named.hosts
primary 25.143.in-addr.arpa named.rev
primary 0.0.127.in-addr.arpa named.local
cache named.ca
Первая строка файла named.boot содержит ключевое слово directory, за
которым указывается имя каталога с конфигурационными файлами DNS.
Последующие строки с ключевым словом primary передают DNS информацию о файлах,
содержащих конфигурационные данные. Например, первая строка указывает, что
информация о первичном сервере имен для tcpi.com хранится в файле named.hosts.
Информация IN-ADDR.ARPA для подсети 13.25 хранится в файле named.rev.
Данные локального хоста хранятся в файле named.local, а данные серверов и кэша
имен — в файле named.ca.
Конфигурация вторичного сервера задается практически так же. Отличается
только файл named.boot, в который включается ссылка на первичный сервер.
Запуск демонов DNS
В завершение настройки DNS необходимо проследить за тем, чтобы демон DNS
named загружался в процессе загрузки системы. Обычно эта задача решается при
помощи стартовых сценариев гс. В большинстве версий Unix и Linux процедуры
запуска DNS автоматически включаются в стартовые сценарии; обычно при
этом проверяется существование файла named.boot. Если файл существует,
запускается демон DNS named. Код проверки выглядит примерно так:
# Если файл named.boot существует, запустить сервер DNS
if [ -f /etc/inet/named.boot -a -x /usr/sbin/in.named ]
then
/usr/sbin/in.named
fi
В вашем сценарии гс могут использоваться другие пути и параметры, но
принцип остается тем же: команда проверяет, существует ли файл named.boot,
и если существует — запускает named.
Настройка клиента
Настройка данных первичного сервера DNS на компьютере с системой Unix
или Linux происходит быстро. Сначала адрес первичного сервера включается
в файл /etc/resolv.conf. Например, файл resolv.conf может выглядеть так:
domain tcpi.com
nameserver 143.25.0.1
nameserver 143.25.0.2
Первая строка задает имя домена, за которым следуют IP-адреса серверов
имен. Директиву domain можно заменить более гибкой директивой search,
которая, как было показано выше, позволяет задать несколько доменных суффиксов.
В приведенном примере файл определяет два сервера имен в подсети 143.25.
Windows и DNS
Чтобы системы Windows NT, Windows 95 и Windows 98 использовали
серверы DNS, достаточно ввести IP-адреса этих серверов на вкладке DNS окна Сеть
(Network). В окне можно ввести данные нескольких серверов DNS, поиск на
которых производится в порядке их перечисления. Серверы DNS находятся
внутри вашей сети или предоставляются поставщиком услуг Интернета
(разумеется, в этом случае сервер DNS не будет обладать информацией о внутренней
сети вашей организации).
Также предусмотрена возможность настройки Windows на выполнение
функций сервера DNS при помощи дополнительных приложений, но в сетях Windows
DNS настраивается сложнее, чем WINS и DHCP. В разнородных сетях,
содержащих компьютеры с системами Windows и Unix, гораздо проще установить
сервер DNS на компьютере Unix — как по соображениям производительности,
так и из-за более подходящей архитектуры этой операционной системы.
ПРИМЕЧАНИЕ
В Windows 2000 DNS работает в сочетании с Active Directory. В Windows 2000 используется
динамическая система DNS, но нестандартный способ обновления записей вызывает многочисленные
проблемы при попытке интегрировать Windows 2000 с серверами Unix.
Итоги
Настройка DNS на сервере требует немалой квалификации, но с клиентами дело
обстоит гораздо проще. С учетом преимуществ DNS затраты времени и усилий
на установки и настройку системы быстро окупаются. Компьютеры с системами
Unix и Linux идеально подходят на роль серверов DNS, а компьютеры на базе
Windows неплохо справляются с функциями клиентов.
^ О Управление сетью
О О tcp/ip
Бернард МакКарго (Bernard McCargo)
В те времена, когда весь сетевой комплекс поставлялся одним производителем,
этот производитель отвечал за его поддержку. AT&T и местная телефонная
компания отвечали за работу телекоммуникационных линий; фирма IBM
обеспечивала работу большого компьютера, используемого при финансовых
расчетах, а фирма DEC занималась мини-компьютерами в конструкторском отделе.
Администратору сети оставалось лишь определить, где именно произошел сбой,
и обратиться к фирме-производителю за ее решением.
Управление современными объединенными сетями сильно затрудняется двумя
обстоятел ьствам и:
О На смену централизованной обработке данных пришли распределенные
системы.
О Экономический бум в области коммуникационных технологий радикально
увеличил количество фирм, работающих в этом секторе рынка.
В результате фирмы-производители стали все чаще перекладывать
ответственность друг на друга.
Организации, занимающиеся выработкой стандартов, и фирмы-производители
предложили свои решения этих проблем. В широко распространенном
стандарте ISO 7498-4 определены пять функциональных областей управления:
О Управление сбоями — обнаружение, диагностика и исправление сетевых сбоев.
О Управление расходами — распределение расходов среди ответственных сторон.
О Управление конфигурацией — поддержание текущего состояния всех
элементов сети.
О Управление производительностью — сбор и хранение статистической
информации, описывающей производительность системы.
О Управление безопасностью — защита сетевых ресурсов и контроль доступа
к сети.
Некоторые разработчики стандартов создали протоколы для поддержки этих
стандартов. Тем не менее самым популярным протоколом управления сетью
остается протокол SNMP (Simple Network Management Protocol), разработанный
сообществом Интернета. Его популярность во многом объясняется простотой:
в исходной версии SNMP было определено всего пять команд/ответов. Таким
образом, протокол по возможности упрощал управление сетью за счет
минимизации объема данных, передаваемых между элементами сети и консолью
управления. В последующих версиях появились дополнительные команды, которые
упрощали сбор информации управляющими станциями SNMP от других
управляющих станций.
Наконец, фирмы, работающие в области телекоммуникаций, разработали
системы управления сетью, в которых стандартные протоколы типа SNMP
внедрялись в закрытые архитектуры. Среди основных представителей этого направления
можно назвать AT&T (Unified Network Management Architecture — UNMA); DEC,
часть фирмы Compaq, которая собирается объединиться с Hewlett-Packard
(Management Control Center — DECmcc); Hewlett-Packard (OpenView Network
Management); Bay Networks (Optivity); Cisco Systems (Cisco Works) и IBM
(NetView). С ростом сложности объединенных сетей следует ожидать
дальнейшего развития в этой области.
В этой главе рассматривается процесс разработки плана управления сетью
и описаны инструменты, используемые при управлении; при этом SNMP
подробно не рассматривается. Формальное описание SNMP и его протоколов
приводится в главе 39.
Разработка плана сетевого мониторинга
В результате воздействия многочисленных факторов — перехода от
централизованных вычислительных архитектур к распределенным, появления
широкополосных средств передачи данных, использования специализированных рабочих
станций, различных протоколов, новых механизмов взаимодействия локальных
и глобальных сетей и разнородных систем управления сетью — создаются весьма
интересные смеси. В объединенной сети могут быть задействованы различные
типы кабелей, включая витые пары, коаксиальные и оптоволоконные каналы.
Оборудование, используемое в локальной сети, может включать несовместимые
механизмы доступа — например, CSMA/CD (IEEE 802.3) и передачу маркера
(IEEE 802.5). Промежуточные устройства (такие, как мосты) могут
использовать разные алгоритмы — например, алгоритм связующего дерева (IEEE 802.3)
и маршрутизацию от источника (IEEE 802.5). Пакет для работы с электронной
почтой от одной сетевой операционной системы может отказаться
взаимодействовать с пакетом, выпущенным конкурентом. И как же проанализировать эту
межсетевую мешанину и убедиться в том, что сеть нормально работает?
Для начала следует определить, что же понимается под «нормальной
работой» сети. На этот вопрос можно дать разные ответы. Вероятно, с точки зрения
конечного пользователя это означает время отклика меньше секунды. Для
администратора это почти наверняка означает сеть, работа которой не требует
постоянного вмешательства. С точки зрения сетевого инженера критерий оценки
определяется пропускной способностью, скоростью пересылки, задержкой и т. д.
Начальной точкой при проектировании системы сбора данных о сети должны
стать ожидания пользователей и организационные ограничения. Задача проек-
тировщика заключается в том, чтобы выработать набор компромиссов и
построить систему, удовлетворяющую разумным ожиданиям. Несомненно, выражение
«прочность цепи определяется прочностью ее слабейшего звена» в полной мере
применимо к сетям. Оптимальная производительность обеспечивается
балансировкой всех компонентов.
К числу факторов, непосредственно влияющих на производительность сети
и заслуживающих первоочередного внимания проектировщика, относятся
пропускная способность сети, возможности оборудования и приложений. Эти
факторы играют ключевую роль в реализации «точки отсчета» — зафиксированного
состояния нормально работающей сети, которое может использоваться для
сравнительного анализа при возникновении проблем.
Анализ и диагностика сетевых проблем
С ростом степени распределенности, повышения пропускной способности и
количества поддерживаемых протоколов в объединенных сетях, сетевые
администраторы должны быть готовы к изменениям в работе отделов поддержки сети и
приобретению новых аналитических средств
Специфика распределенных сетей заставляет вносить изменения в структуру
централизованного управления информационными системами. Отдельным
филиалам нужны свои специалисты по управлению сетью, которые занимаются
проблемами на уровне пользователей, тогда как центральная организация может
специализироваться на анализе межсетевых проблем.
Появление средств связи с высокой пропускной способностью сократило
экономический срок жизни существующих средств сетевого анализа и управления.
Например, прежде в глобальных сетях использовались преимущественно
аналоговые каналы; если сетевой администратор считал, что в сети происходит что-то
неладное, он проверял канал на соответствие параметрам аналоговой передачи —
уровню импульсных помех, искажению огибающей и дрожанию фазы. Но
современные цифровые каналы с высокой скоростью передачи требуют совершенно
иной методики анализа совершенно иных параметров передачи. Например,
каналы Т1/ТЗ должны проверяться на правильность формирования кадра и
генерирования сигналов. А если в качестве передающей среды вместо витой пары или
коаксиального кабеля используется оптоволоконный канал, анализатор должен
иметь оптический интерфейс вместо электрического.
Ниже приведены некоторые общие рекомендации, которые помогут вам найти
правильный подход к проблеме.
О Сформулируйте суть проблемы. Чтобы исправить проблему, сначала ее нужно
четко описать.
О Разработайте решение. Тщательно и методично разработайте решение
проблемы.
О Документируйте свою работу. Возможно, описания прошлых ошибок
пригодятся вам в будущем.
О Сообщите о результатах. Ваш опыт может пригодиться другим.
Средства управления сетью
Средства управления сетью весьма сложны, а возрастание количества
отслеживаемых протоколов приводит к их дальнейшему усложнению. Для
многопротокольных объединенных сетей нужны более совершенные анализаторы. Анализаторы,
которые раньше обрабатывали одно семейство протоколов (например, SNA),
теперь должны обрабатывать несколько протоколов — например, SNA, DECnet
и TCP/IP. Чтобы лучше разобраться в происходящем, необходимо немного
разбираться в принципах работы анализаторов и направлениях их развития.
Анализаторы протоколов
Анализатор подключается к объединенной сети в пассивном режиме и
перехватывает информацию, передаваемую между разными устройствами. Собираемая
информация делится на две категории:
О данные пользовательских процессов (например, сообщения электронной почты);
О управляющие данные, обеспечивающие пересылку данных по стандартам
протоколов.
По этой причине управляющие данные часто называются управляющей
информацией протокола (PCI, Protocol Control Information); они уникальны для
каждого протокола. Таким образом, если некоторая функция объединенной сети
ассоциируется с семью протоколами, для них потребуются семь уникальных
элементов PCI. Эти элементы, называемые заголовками, передаются вместе с
данными в кадрах канального уровня. Передаваемые данные создаются на
прикладном уровне и поэтому называются прикладными данными (AD, Application Data).
К данным присоединяется прикладной заголовок (АН, Application Header), и
полученная комбинация (AH+AD) передается следующему (представительскому)
уровню. Прикладной уровень интерпретирует эту информацию (AH+AD) как
данные и присоединяет к ним собственный представительский заголовок (РН,
Presentation Header). Результат описывается формулой PH+AH+AD. Процесс
продолжается до тех пор, пока не будет сконструирован весь кадр, включающий
управляющие заголовки с каждого уровня.
Задача анализатора заключается в том, чтобы извлечь из пакета
управляющие данные и отобразить их в формате, удобном для администратора. Тем не
менее, как объясняется выше, процесс извлечения управляющей информации
может быть весьма сложным.
Возможности анализаторов протоколов не стоят на месте. Анализаторы
первого поколения просто декодировали поток данных и выводили шестнадцате-
ричный дамп на экране монитора; они не обладали сколько-нибудь удобным
пользовательским интерфейсом. В анализаторах второго поколения были
добавлены средства анализа вплоть до третьего уровня OSI. Они декодировали
бит-ориентированные протоколы и могли программироваться пользователями
на выполнение различных тестов в зависимости от специфических требований.
Например, анализ можно ограничить трафиком от одной конкретной рабочей
станции или конкретным протоколом (скажем, IP). Анализаторы третьего
поколения позволяют декодировать и обрабатывать протоколы до 7 уровня OSI
включительно и обладают удобным пользовательским интерфейсом,
упрощающим программирование и построение отчетов.
Анализаторы четвертого поколения лучше подходят для работы с
объединенными сетями, имеющими сложную топологию и состоящими из локальных,
региональных и глобальных сетей. Некоторые анализаторы четвертого уровня обладают
искусственным интеллектом, выявляющим проблемы и предлагающим их
возможные решения. В региональных и глобальных сетях задействуются уровни OSI 1-3,
хотя также может присутствовать информация более высокого уровня
(например, передача сигналов или информации, используемой при управлении сетью).
В локальных сетях используются уровни OSI 1-7 (рис. 38.1). Анализатор для
локальных и глобальных сетей должен обеспечивать декодирование управляющей
информации на физическом, канальном и сетевом уровнях. Он проверяет, как
пакеты проходят в коммуникационной подсети (уровни 1-3), но не
расшифровывает содержащуюся в них информацию, поскольку эта информация представляет
интерес лишь для пользователей рабочих станций локальной сети. Сетевые
операционные системы, установленные на рабочих станциях (например, Novell NetWare
или Windows NT/2000), поддерживают протоколы до 7 уровня включительно.
Сеть А Сглобальная S Сеть В
У_^ сеть р
НИ Й НИ ™ / t \ КШЫЙ\ Ш\
х / / I \ ^йЯвЁяКк 111 ННИ Шт\
/ Р^ЙЙг BSS IH3B I -ЗцйЕ' I j
I -ыщр\\ Ч^цдаг* j|gggt a
• raj
Анализ протоколов Анализ протоколов Анализ протоколов
в локальной сети, в глобальной сети, в локальной сети,
уровни OSI 17 уровни OSI 13, плюс уровни OS! 17
данные локальной сети
Рис. 38.1. Анализ локальных и глобальных сетей
Чтобы правильно выявить проблему между рабочей станцией в сети А и
сервером в сети В, соединенных по глобальной сети, анализатор локальной сети
должен декодировать данные высоких уровней модели OSI.
Требования к тестированию в локальных и глобальных сетях также
различаются из-за различий в типах характерных сбоев. Сбои в локальных сетях
обычно повторяются многократно, тогда как сбои в глобальных сетях могут
быть однократными. Последнее различие заключается в способе физического
подключения анализатора к локальной, региональной или глобальной сети.
Анализаторы региональных и глобальных сетей обычно используются в
специальных лабораториях или центральных представительствах в условиях
ограниченного пространства (вследствие чего они часто проектируются с возможностью
как вертикального, так и горизонтального размещения). Анализаторы локальных
сетей обычно работают на обычных настольных компьютерах.
Экспертные системы
Чтобы сетевые анализаторы могли поддерживать хорошую производительность
в сложных объединенных сетях, они должны становиться все более разумными.
Все анализаторы содержат достаточно обширную информацию о
характеристиках интерфейсов, протоколах и взаимодействии между ними и т. д. На основе
этих сведений отображаются экраны со справочной информацией, запускаются
серии тестов или служебная информация одного протокола анализируется в
сочетании с информацией, полученной от другого протокола. Но самые
интеллектуальные анализаторы (в частности, анализаторы четвертого поколения)
используют в своей работе экспертные системы.
Экспертная система использует набор правил в сочетании со своими знаниями
о сети и принципах ее работы для диагностики и решения сетевых проблем.
Знания экспертных систем берутся из различных источников, в том числе из
общетеоретической базы данных (например, стандартов IEEE, на основе
которых должна работать сеть), из базы данных по конкретной сети (топологическая
информация о сетевых узлах), а также из прошлых результатов и опыта
пользователя. На основании этой информации строится гипотеза о причинах
возникшей проблемы и план ее решения. Например, аномально высокий процент
коллизий в сети Ethernet приведет к тестированию магистрального кабеля и
терминаторов, и на основе проведенных тестов будет принято решение.
LAN Analyzers фирмы Hewlett-Packard удовлетворяет критериям экспертной
системы. У Network General имеется экспертная система Expert Sniffer, которая
автоматически выявляет проблемы в реальном времени и вырабатывает
рекомендации на основе применения нескольких экспертных технологий.
Разработки в области экспертных систем проводят и другие производители локальных
сетей — например, Bytex и Wandel & Goltermann.
Фирма Hewlett-Packard разработала экспертную систему Fault Finder.
Пользователь анализатора сообщает Fault Finder симптом сбоя, а анализатор
разрабатывает гипотезу на основании оценки текущей ситуации в сети и/или
результатов тестов, проведенных анализатором. Процесс продолжается до тех пор,
пока анализатор не придет к определенному заключению. Если достичь оконча-
тельного решения не удается, анализатор выдает пользователю список
потенциальных проблем и симптомов для продолжения диагностики. Автоматизация
цикла формирования гипотез/тестирования в экспертных системах позволяет
свести к минимуму время простоя сети.
Из-за сложной природы протоколов глобальных сетей (например, ISDN и
Signaling System 7-SS7) анализаторы глобальных сетей третьего поколения
обладают чрезвычайно мощными аналитическими средствами. Например, анализаторы
третьего поколения проводят статистический анализ входного потока данных.
Сводка накопленной статистики на уровне кадров (уровень 2 модели OSI) или
пакетов (уровень 3 модели OSI) дает некоторое представление о состоянии
канала; низкий процент кадров с ошибками контрольной суммы или отвергнутых
пакетов означает, что канал работает хорошо. При возникновении ошибок
анализаторы протоколов глобальных сетей помогут найти причину посредством
избирательного анализа информации, передаваемой в скоростном канале; этот
процесс называется фильтрацией. Например, если проблема возникает только
на одной рабочей станции, аналитик устанавливает фильтр для отслеживания
данных, относящихся к этой станции.
Анализаторы на базе PC
Микропроцессоры Intel Pentium наделили обычные персональные компьютеры
мощью мини-компьютеров 1980-х годов. Эти устройства, обладающие высокой
вычислительной мощностью при относительной компактности, стали идеальной
платформой для построения тестового оборудования. Портативные компьютеры
позволяют легко доставить анализатор на удаленную площадку. Благодаря
стандартизированным шинам (ISA,EISA, Micro Channel или PCI) вы можете легко
добавить другие устройства (например, модем). В результате многие
производители анализаторов выбрали PC в качестве своей основной аппаратной платформы.
Производители анализаторов локальных сетей традиционно поддерживали
системы на базе PC из-за их сходства с сетевыми рабочими станциями.
Анализаторы глобальных сетей сейчас тоже базируются на PC.
При рассмотрении анализаторов, построенных на платформе PC, необходимо
задать себе два вопроса: как производитель определяет понятие «на базе PC»
и как реализуются эти возможности? Существуют принципиальные различия
между использованием PC в качестве платформы для анализатора и включением
возможностей PC в сам анализатор. Целый ряд производителей, включая CXR/
Digilog и ProTools, базируют свои изделия на портативных, переносных и
настольных персональных компьютерах. У Cabletron Systems имеется анализатор на базе
Apple Macintosh. Такие устройства могут использоваться для других целей
(например, подготовки документов или работы с электронными таблицами), когда
они не используются для анализа сетевого трафика. Другие производители
(например, Wandel & Goltermann) используют многопроцессорные системы: один
процессор для приложений PC, а другой — для анализа сети. Третий вариант —
программное обеспечение GN Navtel — позволяет любому PC проанализировать
данные, сохраненные анализатором. Другие продукты позволяют хранить
данные на стандартных дисковых устройствах DOS и выводить их на монитор или
принтер. Таким образом, вы должны узнать, что имеет в виду производитель,
снабжая свое изделие пометкой «на базе PC».
Второй вопрос связан с реализацией: как превратить PC в анализатор? В
данном случае у вас также имеются три варианта. Например, LAN Analyzer от FTP
Software — автономный программный продукт, который можно установить на
любом компьютере, оснащенном сетевой платой. FTP Software предлагает версии
своей программы для разных интерфейсных плат — таких, как 3Com Etherlink,
Proteon ProNET и т. д. Второй вариант — приобретение аппаратно-программного
комплекса и установка его в PC. Такой подход используется в анализаторах
глобальных сетей от Frederick Engineering и Progressive Computing. Третья
альтернатива — полностью укомплектованная система — выпускается многими
фирмами, включая CXR/Digilog, Inc., Hewlett-Packard, Network General Corporation
и TTC/LP COM. Такие решения обычно обеспечиваются более качественной
поддержкой, поскольку за всю систему отвечает только один производитель.
Кроме того, в Интернете можно найти бесплатные анализаторы
протоколов и их исходные тексты. Среди качественных анализаторов,
адаптированных для платформ Unix и Windows, стоит упомянуть Ethereal. За
дополнительной информацией о бесплатных анализаторах протоколов обращайтесь на сайт
www.ethereal.com.
Поддержка протоколов управления сетью
О необходимости стандартов управления сетью, облегчающих централизованное
управление сложными объединенными сетями, были написаны целые тома. Для
выполнения этих функций рассматривались два основных кандидата, SNMP
и CMIP. Протокол SNMP широко используется в сообществе TCP/IP, а
протокол CMIP (Common Management Information Protocol) является протоколом
управления сетью OSI. Протокол SNMP занимает доминирующее положение.
Хотя CMIP все еще поддерживается (Tekelec поддерживает CMIP для
глобальных сетей, a AR/Telenex поддерживает IBM NetView), в наши дни реализации
СМР встречаются крайне редко.
Возможность декодирования протоколов управления сетью, которой обладает
SNMP, служит нескольким целям. Разработчики агентов или диспетчеров SNMP
могут тестировать свой код, сохраняя обмен данными между агентом и
диспетчером. Анализатор также может определять задержки с откликом между
сообщением агента и соответствующим ответом диспетчера. Поскольку управляющие
данные занимают ресурсы сети, анализатор также может сравнивать процент
загрузки сети управляющей информацией с пользовательским трафиком.
Протокол SNMP декодируется продуктами Micro Technology, Novell для
локальных сетей, Kamputech, Wandel & Goltermann и Network General для
локальных и глобальных сетей.
Фирма Novell первоначально внедрила поддержку SNMP в сетевой зонд
LANtern. Программа LANtern подключалась к сети Ethernet/IEEE 802.3 и
использовала SNMP для обмена данными с SNMP-совместимой консолью сетевого
управления. Прохождение данных между зондом и консолью обеспечивалось
самой сетью, а зонд выполнял функции агента SNMP. Поскольку программа
LANtern была сетевым монитором Ethernet, а не анализатором протоколов, она
собирала всевозможную сетевую статистику — данные о коллизиях, ошибки
контрольных сумм и кадров, но не декодировала кадры. Опыт работы над LANtern
пригодился Novell в разработках в области удаленного мониторинга (RMON).
Другой разработчик анализаторов локальных сетей, FTP Software, предлагает
интересный продукт SNMP Tools, созданный на базе популярного продукта FTP
PC/TCP. SNMP Tools работает на любом компьютере с системой DOS и
поддерживается многими сетевыми платами. Кроме того, в него включен
инструментарий для построения нестандартных приложений SNMP.
Интеграция со средствами сетевого
моделирования
Когда сети обслуживались единым хостом и ограничивались одним
географическим местонахождением, было гораздо проще вычислить время задержки и
отклика. Распределение сетевых ресурсов заметно усложнило прогнозирование
сетевых метрик. Анализ топологии объединенной сети может помочь в
прогнозировании такого рода.
Анализаторы всегда замечательно справлялись со сбором данных. Но что
делать с накопленной информацией? Первые анализаторы выдавали на печать
листинг сохраненных данных в формате ASCII. Более совершенные
анализаторы могли преобразовать данные в электронную таблицу или базу данных для
последующего анализа. Например, электронная таблица могла отсортировать
данные о трафике в локальной сети по адресу отправителя и выставить счет
соответствующей организации за использование сети.
В большинстве современных продуктов на рынке локальных сетей
анализатор локальной сети интегрируется со средствами моделирования типа BONeS
(ComDisco Systems, Inc., Фостер-Сити, Калифорния) или LANSIM (InternetiX,
Inc., Верхнее Мальборо, Мэриленд). Фирма Quintessential Solutions, Inc. (Сан-
Диего, Калифорния), разработчик средств имитации и моделирования
глобальных сетей, предлагает продукты, способные получать данные от анализаторов
глобальных сетей. Типичным применением таких продуктов является
моделирование времени отклика в протестированном сегменте. На основании
экспериментальных данных, полученных от анализатора, программы QSI прогнозируют
изменения в этих переменных в результате возрастания трафика, установки
новых приложений и т. д.
Программы моделирования применяются во многих ситуациях, в том числе
при первоначальном проектировании сети, изменении конфигурации и
нагрузочных испытаний. Для модели задаются значения многочисленных переменных
(количество которых может превышать 100, в зависимости от типа
анализируемой сети): количество и тип рабочих станций, серверов, протоколов, уровней
нагрузки и т. д. Результат моделирования существенно зависит от значений
этих переменных. Например, время отклика в сети зависит как от количества
серверов, так и от количества пользователей, логически подключенных к каждому
серверу. При уменьшении времени отклика администратору стоит подумать
о перераспределении пользователей или установке новых серверов. Вместо
выдвижения гипотез о параметрах сетевого трафика, использование фактических
данных, полученных от анализатора, позволяет получить гораздо более точное
представление характеристик сети. Такой подход упрощает интерактивное
проектирование сети, ее расширение и изменение архитектуры.
Возможность экспорта данных в упомянутые средства сетевого
моделирования поддерживается такими разработчиками, как Bytex, Network General и Spider
Systems. В будущем средства имитации/моделирования будут встроены
напрямую в анализаторы локальных сетей.
Настройка SNMP
SNMP позволяет сетевым администраторам производить удаленную отладку
и наблюдение за концентраторами, маршрутизаторами и другими устройствами.
При помощи SNMP можно получить информацию об удаленных устройствах,
не находясь поблизости от этих устройств.
Правильное понимание и использование протокола SNMP делает его весьма
полезным инструментом. Вы можете собирать различные объемы информации
по широкому спектру устройств; состав получаемой информации зависит от
типа устройства. Ниже приведены примеры сведений, которые могут быть
получены при помощи SNMP:
О IP-адрес маршрутизатора;
О количество открытых файлов;
О объем свободного места на жестком диске;
О версия программы, работающей на хосте.
В SNMP используется распределенная архитектура. Это означает, что
компоненты SNMP распределены в сети для выполнения функций по сбору
информации и обработке данных, заложенных в основу удаленного управления.
Поскольку SNMP является распределенной системой, управление может
выполняться из разных точек. Тем самым предотвращается чрезмерная нагрузка
на одну систему, а также обеспечиваются резервные возможности управления.
Реализация SNMP от Microsoft позволяет компьютеру с системой Windows
NT/2000 передать информацию о своем состоянии компьютеру, на котором
работает система управления SNMP. Впрочем, в данном случае речь идет всего лишь
о выполнении агентских функций, а не о средствах управления.
Для управления используются специальные программы, не входящие в
Windows NT/2000, в том числе:
О IBM NetView;
О Sun Net Manager;
О Hewlett-Packard OpenView.
Настройка SNMP в системе Windows
Служба SNMP обычно устанавливается для того, чтобы вы могли:
О следить за работой TCP/IP в Системном мониторе;
О следить за работой системы на базе Windows NT/2000 из внешней программы.
Следующее описание процедуры установки SNMP предполагает, что в системе
уже установлена и настроена поддержка TCP/IP, а вы обладаете
административными привилегиями для установки и использования SNMP.
Установка службы SNMP
Чтобы установить службу SNMP, выполните следующие действия:
1. Откройте диалоговое окно Сеть (Network), перейдите на вкладку Службы (Services)
и щелкните на кнопке Добавить (Add). На экране появляется диалоговое окно
Выбор сетевой службы (Select Network Service).
2. Выберите службу SNMP и щелкните на кнопке ОК.
3. Задайте местонахождение установочных файлов Microsoft Windows NT.
4. После того как файлы будут скопированы, на экране появится диалоговое окно
свойств Microsoft SNMP. Заполните поля Имя сообщества (Community Name)
и Trap Destination.
5. Закройте диалоговое окно свойств кнопкой ОК. Закройте диалоговое окно Сеть
(Network) кнопкой Закрыть (Close) и подтвердите перезагрузку компьютера.
Установка протокола
Работа с SNMP начинается с установки протокола. Протокол устанавливается
следующим образом:
1. Откройте диалоговое окно Сеть (Network) и перейдите на вкладку Службы
(Services).
2. Щелкните на кнопке Добавить (Add), выберите строку Агент SNMP (SNMP Agent)
и введите путь к установочным файлам.
3. Закройте диалоговое окно кнопкой Закрыть (Close) и подтвердите перезагрузку
компьютера.
Проверка работы SNMP утилитой SNMPUTIL
Для проведения следующей проверки понадобится утилита SNMPUTIL из пакета
Windows NT Resource Kit. Если у вас нет пакета Resource Kit, найдите SNMPUTIL
в Интернете (тем не менее рекомендуется использовать SNMPUTIL из комплекта
Windows NT/2000 Resource Kit).
Перед проведением проверки желательно увеличить количество строк в окне
командной строки. Щелкните на значке системного меню в левом верхнем углу
окна и выберите команду Свойства (Properties). На вкладке Расположение (Layout)
введите большее значение (например, 300).
Выполните следующие действия:
1. Откройте окно режима командной строки.
2. Введите следующие команды:
SNMPUTIL get 127.0.0.1 public
.1.3.6.1.4.1.77.1.2.2.0
SNMPUTIL get 127.0.0.1 public
.1.3.6.1.4.1.77.1.2.24.0
3. Проверьте введенные числа. Чтобы проверить первое число, щелкните на
значке Службы (Services) панели управления и подсчитайте количество запу-
щенных служб (или введите команду NET START в приглашении командной
строки и подсчитайте количество запущенных служб).
4. Чтобы проверить второе число, откройте Диспетчер пользователей и
подсчитайте количество пользователей.
5. Создайте нового пользователя в Диспетчере пользователей. Переключитесь
в режим командной строки и повторите вторую команду SMPUTIL
(воспользуйтесь клавишей Т).
6. Убедитесь в том, что количество пользователей увеличилось, и введите
следующую команду:
SNMPUTIL walk 127.0.0.1 public
.1.3.6.1.4.1.77.1.2.25
7. Команда выводит список имен всех пользователей.
8. Снова щелкните на значке Службы (Services) на панели управления.
Остановите службу Server. Система выдает предупреждение, что это приведет к
остановке службы Computer Browser; так и должно быть.
9. Снова введите команду
SNMPUTIL get 127.0.0.1 public
.1.3.6.1.4.1.77.1.2.2
10. Убедитесь в том, что завершенные службы не работают, и введите команду:
SNMPUTIL walk 127.0.0.1 public
.1.3.6.1.4.1.77.1.2.3.1.1
11. Команда выводит список работающих служб. Завершенные службы
отсутствуют в этом списке.
ПРИМЕЧАНИЕ
Даже после остановки службы сервера информация остается доступной через интерфейс сокетов.
Поскольку взаимодействие производится непосредственно через сокеты, вы можете использовать
агента SNMP, напрямую работающего с портом UDP 161.
12. Перезапустите службы Server и Computer Browser.
13. Чтобы отобразить всю информацию из управляющей базы LAN Manager,
введите следующую команду:
SNMPUTIL walk 127.0.0.1 public
.1.3.6.1.4.1.77
Настройка SNMP в системе Unix
В системе Unix включение/отключение протоколов и задание их параметров
осуществляется протокольными командами. Протокольные команды определены для
SNMP, RIP, Hello, ICMP Redirect, EGP и BGP. Существуют две разновидности
структуры команд: для внутренних и для внешних протоколов. Протокол SNMP
является единственным исключением. Команда snmp имеет следующий формат:
snmp yes | no | on | off
Команда управляет регистрацией демоном SNMP информации gated. SNMP
не является протоколом маршрутизации и не запускается этой командой — он
должен быть запущен отдельно. Команда всего лишь управляет тем, будет ли
gated оповещать управляющую программу об изменениях своего состояния.
Выдача информации включается аргументами yes или on (любым из двух) и
отключается аргументами по или off.
Параметры безопасности SNMP
В процессе настройки также задаются значения параметров, влияющих на
безопасность агента SNMP. По умолчанию агент отвечает любому диспетчеру,
используя имя сообщества «public». Поскольку запрос может поступить как из вашей
организации, так и извне, вы должны по крайней мере сменить имя сообщества.
Ниже кратко описаны основные параметры безопасности SNMP.
Посылка ловушки проверки подлинности
Флажок Посылать ловушку проверки подлинности (Send Authentication Trap) посылает
ловушку станции управления при попытке использования SNMP от диспетчера,
не принадлежащего к числу допустимых сообществ или не входящему в список
Принимать пакеты SNMP только от этих узлов (Only Accept SNMP Packets From These
Hosts).
Допустимые имена сообществ
Список Допустимые имена сообществ (Accepted Community Names) содержит список
имен сообществ, которым будет отвечать агент. Когда диспетчер отправляет
запрос, он включает в него имя сообщества.
Прием пакетов SNMP от любого узла
Переключатель Принимать пакеты SNMP от любого узла (Accept SNMP Packets from
Any Host) отвечает на любые запросы, передаваемые любой системой управления
из любого сообщества.
Прием пакетов SNMP от определенных узлов
Если установить переключатель Принимать пакеты SNMP только от этих узлов (Only
Accept SNMP Packets From These Hosts), агент будет отвечать только хостам из
списка, что позволит следить за указанными хостами и игнорировать данные от
других хостов.
Управление сетью и агенты SNMP
Двумя основными сторонами в протоколе SNMP являются станция управления
и агент.
О Станция управления — централизованный узел, с которого осуществляется
управление SNMP.
О Агент работает на оборудовании, с которого собираются данные.
Каждая из этих частей рассматривается в следующих разделах.
Станция управления SNMP
Станция управления является ключевым компонентом для получения
информации от клиента; служба SNMP может использоваться только при наличии хотя
бы одной станции управления. Основная функция станции управления — запрос
информации у устройств. Как упоминалось выше, у разных устройств в
зависимости от их типов может запрашиваться разная информация. Станция
управления представляет собой компьютер, на котором работает один из упоминавшихся
выше программных пакетов (рис. 38.2).
PS БЩ
г." "'.as'i K'."i'.".iП
pg^fe] r^^. v^| ^ Запрос get, get-next, set «—;——■'■■i |'.№""|
^^^^jgj^ Ответ или ловушка iv ^Г|„ РтРл
Агент SNMP Диспетчер SNMP
Рис. 38.2. Обмен данными между агентом и станцией управления
обычно инициируется станцией управления
Станция управления также поддерживает несколько общих команд:
О get — запрос указанного значения. Например, станция управления может
запросить количество активных сеансов.
О get-next — запрос значения следующего объекта. Например, после первого
запроса к клиентскому кэшу ARP можно запросить данные следующей записи.
О set — изменение значения объекта с возможностью чтения/записи. Команда
используется относительно редко, что объясняется соображениями
безопасности и тем фактом, что большинство объектов допускает только чтение.
Обычно группа хостов обслуживается одной станцией управления, на которой
работает служба SNMP. Такая группа называется сообществом (community).
Тем не менее в некоторых ситуациях одной станции оказывается недостаточно:
О Разные станции управления отслеживают разные подсистемы одних и тех же
агентов.
О В сообществе существует несколько точек управления.
О По мере расширения и усложнения сети возникает необходимость в
раздельном анализе разных аспектов работы сообщества.
Агенты SNMP для Windows
Итак, мы знаем, за что отвечает управляющая сторона протокола SNMP и как
именно она выполняет свои функции. Как правило, управляющая сторона
активно запрашивает и принимает информацию.
С другой стороны, агент SNMP отвечает за предоставление затребованной
информации и ее передачу диспетчеру SNMP. Обычно агентом является
маршрутизатор, сервер или концентратор. Агент работает в пассивном режиме и
отвечает только на прямые запросы.
Впрочем, в одном конкретном случае агент инициирует передачу данных и
действует по собственной инициативе без прямого запроса. Речь идет о так
называемых ловушках (traps). Ловушка устанавливается диспетчером на стороне агента,
но чтобы узнать, поступила ли в ловушку нужная информация, диспетчер не
обращается с запросом к агенту. Агент сам посылает сигнал управляющей
стороне и передает ей информацию о наступлении события.
Иногда настраиваются другие параметры агента SNMP, которые определяют
типы устройств, передающих информацию, и лиц, ответственных за работу системы.
О Контактное лицо (Contact) — имя лица, которое должно оповещаться о
различных ситуациях на данной станции (обычно это пользователь компьютера).
О Размещение (Location) — краткое описание компьютера. Упрощает
идентификацию системы, отправившей сигнал.
О Службы (Service) — типы подключений и устройств, отслеживаемые агентом:
□ Физическая (Physical) — используются при управлении физическими
устройствами (такими, как репитеры и концентраторы).
□ Приложения (Applications) — приложения TCP/IP. Флажок всегда должен
находиться в установленном состоянии.
□ Канал данных и подсети (Datalink/Subnetwork) — установка флажка означает,
что система управляет мостовым соединением.
□ Интернет (Internet) — флажок устанавливается, если компьютер с системой
Windows NT выполняет функции маршрутизатора IP.
□ Узел-узел (End-to-End) — флажок устанавливается, если компьютер с
системой Windows NT/2000 использует TCP/IP. Естественно, флажок всегда
должен находиться в установленном состоянии.
Ошибки SNMP сохраняются в системном журнале, в котором
регистрируются все операции SNMP. Программа Event Viewer позволяет просмотреть список
ошибок, выявить проблемы и найти возможные решения.
Инструментарий и команды SNMP
После краткого знакомства с системой управления и агентами мы познакомимся
с различными базами данных, к которым можно обращаться при помощи команд
SNMP.
Данные, запрашиваемые диспетчером у агента, хранятся в базе управляющей
информации (Management Information Base). База представляет собой набор
значений, выдаваемых по запросу диспетчера (конкретный состав списка зависит
от того, к какому устройству адресован запрос).
База MIB, поддерживаемая клиентом SNMP, как и реестр Windows, имеет
иерархическую структуру. Базы MIB являются источником информации,
доступ к которому предоставляется как агенту, так и управляющей стороне.
Служба SNMP является дополнительным компонентом программной
поддержки TCP/IP в Windows NT/2000. Она включает четыре разновидности баз
Ml В, реализованных в виде библиотеки динамической компоновки (DLL) и
загружаемых/выгружаемых по мере необходимости. Служба SNMP предоставляет
сервис агента SNMP любому хосту TCP/IP, на котором работают управляющие
программы SNMP. Кроме того, она выполняет следующие функции:
О уведомление хостов об особых ситуациях (например, о ловушках);
О обработка запросов на получение информации от хостов;
О создание в Системном мониторе счетчиков, используемых для анализа
производительности подсистемы TCP/IP;
О идентификация хостов, получающих и запрашивающих информацию, по
именам и IP-адресам.
Управляющая программа SNMP не входит в комплект поставки Windows NT/
2000, но присутствует в системе Unix и включается в пакет Windows NT/2000
Resource Kit. Она реализована в виде системной утилиты, работающей в режиме
командной строки. Программа SNMPUTIL проверяет настройку и правильность
работы службы SNMP; она также может использоваться для выполнения некоторых
команд. Программа SNMPUTIL не поддерживает некоторые возможности
управления SNMP, но как вы вскоре убедитесь, ее синтаксис и без этого достаточно сложен.
Обобщенный синтаксис команды SNMPUTIL выглядит так:
snmputil команда агент сообщество идентификатор_объекта_(ОЮ)
Поддерживаются следующие команды:
О walk — перемещение по ветви MIB, определяемой идентификатором объекта.
О get — выборка значения элемента, определяемого идентификатором объекта.
О getnext — выборка значения элемента, следующего за элементом,
определяемым командой get.
Например, чтобы узнать время запуска сервера WINS, обратитесь к WINS
MIB следующей командой (естественно, для этого необходима установленная
служба WINS и работающий агент SNMP):
C:\snmputil getnext localhost public
.1.3.6.1.4.1.311.1.1.1.1
В этом примере первая часть идентификатора определяет ветвь Microsoft
.1.3.6.1.4.1.311 (или iso.org.dod.internet.private.enterprise.microsoft). Вторая часть
определяет конкретную базу Ml В и объект, к которому адресован запрос: .1.1.1.1 (или
.software.Wins.Par.ParWinsStartTime). Полученное значение выглядит примерно так:
Value = OCTER STRING ' 01:17:22 on 11: 23:1997.<0xa>
RMON и другие модули MIB
Все объекты и события RMON содержатся в пяти модулях MIB (табл. 38.1).
В общей сложности модули RMON определяют свыше 900 объектов. Это
довольно много. В дополнение к модулям RMON MIB, в документе «Remote
Network Monitoring MIB Protocol Identifiers» (RFC 2074) содержится
определение языка спецификаций для идентификаторов протоколов и первая версия
списка протоколов. Следует помнить, что для применения RMON в сети не
обязательно знать все эти объекты.
Таблица 38.1. RFC, относящиеся к RMON
Модуль MIN Описание
RMON-MIB RFC 1757: Remote Network Monitoring Management Information Base (RMON1;
определяет 203 объекта и 2 события)
TOKEN-RING- RFC 1513: Token Ring Extensions to the Remote Network Monitoring MIN (Token
RMON-MIB Ring Extensions for RMON1; определяет 181 объект)
RMON2-MIB RFC 2021: Remote Network Monitoring Management Information Base Version 2
(RMON2, включает расширения для RMON1; определяет 268 объектов)
HC-RMON-MIB Интернет-проект: Remote Network Monitoring Management Information Base
for High Capacity Networks (HC-RMON, содержит расширения для RMON1
и RMON2, определяет 184 объекта)
SMON-MIB Интернет-проект: Remote Network Monitoring MIB Extensions for Switched Networks
(SMON или SWITCH-RMON; определяет 52 объекта)
Выработка требований
В этом разделе представлена конкретная последовательность действий по
выработке требований к управлению сетевыми компонентами и функциями.
Построение подробного списка информации
Сначала необходимо построить список информационных свойств, которые
будут запрашиваться у каждого управляемого объекта. Подробно распишите все
информационные объекты — назначение каждого элемента данных и тип
реализации (счетчик, целое число, текстовое сообщение).
Передача списка в службу поддержки
Передайте список в службу поддержки, отвечающую за работу устройства. Пусть
специалисты этой службы решат, какие данные понадобятся для выполнения их
служебных функций. Основное внимание следует сосредоточить на информации,
которая позволит лучше и проще выполнять эти функции.
Формулировка стратегии построения отчетов
Сформулируйте стратегию составления отчетов о работе устройства.
Определение показателей, используемых
для оповещения об экстренных ситуациях
(в реальном времени)
Система оповещения об экстренных ситуациях включает следующие элементы:
О Выбор пороговых значений (например, три срабатывания за один час).
О Выбор приоритетов и пороговых значений, определяющих нарастание
серьезности ситуации.
О Выбор диагностических процессов, запускаемых автоматически или службой
поддержки для упрощения ее работы.
О Выбор частоты сбора информации (каждые пять минут, каждые десять
минут, ежечасно и т. д.).
Выбор информации для составления
ежемесячных отчетов
В ежемесячный отчет включаются следующие факторы:
О Доступность устройств и служб.
О Средняя загруженность.
Выбор информации для оптимизации
Какие показатели действительно важны для оптимизации производительности
сетевых компонентов и функций?
Рассмотрите различные варианты комбинирования показателей или их
обработки, чтобы с полученной информацией было удобнее работать службе
поддержки.
Обратная связь
Наличие обратной связи гарантирует, что предлагаемое вами решение
удовлетворяет реально существующие потребности вашей организации.
Общаясь с руководством организации, вы должны объяснить функции и цели
системы управления сетью. В частности, особо подчеркните следующие
факторы:
О повышение эффективности работы службы поддержки;
О сокращение средней наработки до ремонта при исправлении проблем;
О профилактический подход к выявлению и локализации проблем;
О возможность сотрудничества и обмена информацией среди служб поддержки.
Следующий список поможет вам выработать требования, которые будут
поняты вашим руководством:
О соберите требования, предъявляемые ко всем функциям, существенным для
коммерческой стороны дела;
О не ограничивайтесь функциями, присущими только устройствам,
управляемым через SNMP;
О если устройство, связанное с некоторой функцией, не обладает даже базовым
«интеллектом», позднее обратитесь к руководству с предложением о его
обновлении.
Реализация требований
Реализуйте все собранные требования. Каждая реализация должна
ориентироваться на конкретное требование, однако реализации должны складываться не
в разрозненный набор, а в интегрированную систему. О том, как решить эту
задачу, будет рассказано ниже.
Оповещение служб поддержки
После того как все требования будут реализованы, оповестите службы поддержки,
связанные с управляемыми объектами или системами, о запуске системы
управления сетью.
Повторный анализ требований
Чтобы убедиться в том, что исходные требования не потеряли своей
актуальности на протяжении жизненного цикла сети, следует периодически возвращаться
к ним. Ниже приводятся некоторые рекомендации по повторному анализу
требований.
О При наступлении первого отчетного периода вернитесь к исходным
требованиям и проанализируйте их вместе со всеми службами поддержки и
руководством.
О Если потребуется — внесите изменения в формулировку требований.
О Помните, что содержимое отчетов и типы представленных данных будут
изменяться по мере того, как службы поддержки будут осваиваться с новой
системой.
Информирование технической службы
На стадии реализации направляйте сообщения о любых неожиданных ситуациях
в техническую службу. Хорошая информированность персонала технической
службы имеет первостепенное значение для успешного запуска системы
управления сетью.
Пробные проверки
Проводите пробные оповещения о неожиданных ситуациях и диагностику,
направленную на быстрое и эффективное решение проблемы. Задействуйте
соответствующие службы поддержки, чтобы можно было идентифицировать и включить
все диагностические действия. Не забывайте об оповещении руководства, если
в этом возникнет необходимость.
Обучение технической службы
Обучите специалистов из технической службы и позаботьтесь о том, чтобы они
вводили информацию о всех неполадках и проблемах в таблицу диагностики.
К этой категории может относиться все, что угодно — от простого обращения
пользователя, у которого возникли проблемы с приложением (например, MS
Word), до заполнения заявок на предоставление особого сервиса.
Документирование диагностических процедур
Сбор информации о диагностических процедурах позволяет собрать полезную
информацию и использовать ее в масштабах предприятия. Диагностические
процедуры составляют базу знаний о различных проблемах и средствах,
применяемых для их решения. Наличие готовой информации такого рода расширяет
возможности персонала технической службы, помогая быстро реагировать на
возникающие проблемы. Система управления сетью является полностью
интегрированной системой, поэтому она должна иметь модульную структуру и легко
наращиваться или сокращаться по мере возникновения новых требований.
Упрощение систем управления элементами
Системы управления элементами (EMS, Element Management Systems) — как
реализованные в виде продуктов независимых фирм типа SunNet Manager, HP
OpenView, NetView 6000, NetView, NetMaster, 3M TOPAZ, Larsecom Integra-T
или средства собственной разработки — должны легко интегрироваться в систему.
Следует понимать, что в архитектуре ни одна система EMS не знает о
существовании других подобных систем. Согласование потребностей EMS должно
выполняться на более высоком уровне, чтобы отдельная система могла заниматься
только той областью, которой она управляет.
Использование искусственного интеллекта
Такие функции, как корреляция оповещений, диагностика между системами EMS
и т. д., могут быть реализованы с применением принципов искусственного
интеллекта к реляционной базе данных. Почти во всех диспетчерских продуктах
используется оценка риска возможного сбоя компонентов, которая часто выполняется
компонентами экспертных систем. Наличие компонентов экспертных систем
повышает стоимость программного обеспечения из-за возрастания его
сложности. Подобные решения должны приниматься при участии служб поддержки,
поскольку им местная рабочая среда известна лучше, чем кому-либо другому.
Не будет ли приложение лучше выполнять свои функции, если оно будет более
тесно интегрировано с бизнес-логикой?
Отличным примером использования технологии экспертных систем
является Network General DSS (Distributed Sniffer Servers). Анализируя связи между
протоколами, трафиком, подключениями и механизмами управления локальной
сетью, DSS использует экспертные системы для выявления проблем на очень
низком уровне, еще до того, как они отразятся на работе пользователей и
вызовут снижение производительности или простои.
Кроме того, искусственный интеллект может использоваться для выявления
эвристических закономерностей поведения сети и упрощения диагностики. В сие-
тему должна быть включена информация о проблемах подобного рода,
возникавших в прошлом, и о мерах по их идентификации и исправлению.
Итоги
В этой главе рассматривается протокол SNMP и его место в управлении сетью.
Как было показано, SNMP — очень простой протокол, предназначенный для
получения информации из баз MIB. Это позволяет управляющим программам
(таким, как HP Open View) читать информацию из систем Windows NT /2000 и Unix.
Чтобы использовать SNMP в своей сети, вам придется приобрести
управляющую программу SNMP. Агентская поддержка SNMP может устанавливаться
независимо от того, используется она или нет; в частности, она устанавливается
для правильного функционирования счетчиков Системного монитора при
использовании Windows NT/2000.
Ниже приведена краткая сводка основных положений настоящей главы.
О Агент SNMP в Windows NT/2000 — только агент, и ничего более. Система
поддерживает только API диспетчера SNMP, но не содержит программной
реализации диспетчера.
О Диспетчер может передавать агенту три команды: set, get и get-next.
О Вы должны знать, что такое ловушка (оповещение о событии) и что такие
оповещения отправляются агентом.
О Вы должны знать пять областей, отслеживаемых агентом, и области их
применения: физические устройства, приложения, каналы данных и подсети,
Интернет и взаимодействия «узел-узел».
О Вы должны знать, как установить агента.
О Вы должны знать, как настроить ловушку проверки подлинности.
О Вы должны уметь задавать имена сообществ и адреса станций, которые будут
выполнять функции диспетчеров.
О Вы должны понимать структуру баз MIB и знать четыре базы MIB,
входящие в Windows NT/2000: LAN Manager MIB II, Internet MIB II, DHCP MIB
и WINS MIB.
О Агент SNMP должен быть установлен для работы счетчиков в Системном
мониторе.
В настоящее время существует много замечательных продуктов,
позволяющих управлять не только оборудованием, но и службами и приложениями. При
выборе системы следует обращать особое внимание на ее реализацию, поскольку
в таких системах каждая управляющая возможность должна соответствовать
некоторой практической потребности. Кроме того, для достижения
максимальной эффективности эти разнородные системы должны хорошо интегрироваться
друг с другом и с рабочей средой служб поддержки.
^Q Протокол управления
*3Z7 сетьюSNMP
Тим Паркер (Tim Parker)
В предыдущей главе обсуждались основные принципы и инструментарий
управления сетью. Настоящая глава содержит более подробный обзор протокола
SNMP (Simple Network Management Protocol), предназначенного для
администрирования сетевых устройств и получения информации о периферийном
оборудовании. Протокол SNMP используется во многих сетях TCP/IP — особенно
в больших, поскольку он существенно упрощает администрирование.
Интеллектуальные периферийные устройства передают специальной программе (серверу
SNMP) информацию о своем состоянии, а также обо всех ошибках и проблемах,
возникающих в процессе работы. Используя SNMP, сетевой администратор
изменяет конфигурацию и собирает статистику по разным узлам из одной
централизованной точки.
Что такое SNMP?
Протокол SNMP первоначально разрабатывался для управления
маршрутизаторами в сетях. Хотя протокол SNMP принадлежит к семейству протоколов
TCP/IP, он не зависит от уровня IP. SNMP проектировался в расчете на
независимость от базовых протоколов, поэтому он с таким же успехом может
работать на базе протокола IPX из семейства Novell IPX/SPX (хотя большинство
установок SNMP работает на базе IP).
Протокол SNMP состоит из трех компонентов:
О база управляющей информации (MIB, Message Information Base) — база
данных с информацией о текущем состоянии;
О структура и описание управляющей информации (SMI, Structure and
Identification of Management Information) — спецификация, определяющая
формат данных MIB;
О собственно SNMP (Simple Network Management Protocol) — механизм обмена
данными между управляемыми устройствами и серверами.
На периферийных устройствах со встроенной поддержкой SNMP работает
агентская программа, загружаемая на стадии загрузки или внедренная в устрой-
ство на уровне микрокода. Фирмы-производители выбирают разные названия для
устройств с агентами SNMP, но в общем случае используется термин «SNMP-
управляемое устройство».
SNMP-управляемые устройства взаимодействуют с сервером SNMP,
работающим в сети. Существует два основных механизма взаимодействия с сервером:
опрос и прерывание. В первом случае сервер связывается с устройством и
запрашивает у него информацию о текущем состоянии или статистику. Опросы часто
проводятся с определенной периодичностью, при этом сервер связывается со всеми
управляемыми устройствами в сети. Основные недостатки опроса заключается
в том, что полученная информация может оказаться устаревшей, а возрастание
количества управляемых устройств и частоты опроса увеличивает сетевой трафик.
В системе SNMP, основанной на прерываниях, управляемое устройство
посылает сообщение серверу при выполнении некоторого условия. Таким образом,
сервер немедленно узнает обо всех проблемах — за исключением сбоя устройства
(в этом случае оповещение должно поступить от другого устройства, которое
попыталось связаться с неработающим устройством). Впрочем, у схемы с
прерываниями тоже имеются свои недостатки. Главный недостаток заключается в том,
что на подготовку сообщения для сервера нужно процессорное время, которое
отнимается от нормальной работы устройства. Это может привести к нехватке
ресурсов и другим проблемам в работе устройства. Отправка больших
сообщений (например, содержащих большой объем статистической информации)
снижает эффективность работы сети в процессе сбора и пересылки данных.
Если в сети происходит серьезный сбой (например, потеря напряжения с
автоматическим подключением источников бесперебойного питания), все SNMP-
управляемые устройства могут попытаться одновременно отправить серверу
сообщения о возникших проблемах. В результате может произойти переполнение
пропускной способности сети, и сервер получит неверную информацию.
Для решения этих проблем часто применяется комбинированное решение,
в котором задействуются оба механизма (опрос и прерывания). В этой схеме,
называемой опросом с применением ловушек, сервер собирает статистику с
заданными интервалами, по запросу системного администратора или при получении
сообщения от ловушки SNMP. Кроме того, каждое SNMP-управляемое устройство
может сгенерировать сообщение прерывания при выполнении определенных
условий, но такие условия обычно определяются более жестко, чем в традиционных
системах с прерываниями. Например, при использовании схемы SNMP,
основанной на прерывания, маршрутизатор может сообщать об увеличении загрузки
на каждые 10 процентов. Но если использовать опрос с применением ловушек,
уровень загрузки будет известен в процессе регулярного опроса; в этом случае
маршрутизатор обычно настраивается так, чтобы прерывание отправлялось только
при существенном возрастании загрузки. Получив сообщение прерывания при
опросе с применением ловушек, сервер при необходимости может запросить
у устройства дополнительную информацию.
Программное обеспечение сервера SNMP взаимодействует с агентами SNMP
и передает или запрашивает различную информацию. Обычно сервер запрашивает
у агента всевозможную статистику, включая количество обработанных пакетов,
текущее состояние устройства, специальные условия для устройства данного
типа (например, отсутствие бумаги в принтере или разрыв связи в модеме) и
уровень загрузки процессора.
Сервер также может приказать, чтобы агент изменил записи своей базы
данных (MIB), или послать пороговые значения и условия, при достижении
которых агент SNMP должен сгенерировать сообщение прерывания (например,
когда загрузка процессора достигнет 90 процентов).
Взаимодействие между сервером и агентом организуется достаточно
прямолинейно, хотя содержимое сообщений должно подчиняться стандарту ASN.1
(Abstract Syntax Notation Rev 1). Например, сервер отправляет сообщение
«Сообщи свой текущий уровень загрузки» и получает ответ «75 %». Агент посылает
данные серверу только при возникновении прерывания или при проведении
опроса. Следовательно, сервер SNMP может не знать о проблемах, существующих
в сети, просто потому, что он не проводил опросов и не получал прерывания.
MIB
Каждое SNMP-управляемое устройство поддерживает базу данных со
статистикой и другими сведениями. Такая база данных называется базой управляющей
информации, или MIB (Management Information Base). Записи MIB содержат
четыре поля: тип объекта, синтаксис, уровень доступа и состояние. Обычно
элементы MIN стандартизируются протоколом и следуют жестким правилам
форматирования, определяемым стандартом ASN.1 (Abstract Syntax Notation 1).
Тип объекта определяет имя записи (обычно в качестве имени используется
простая строка). Синтаксис определяет тип значения (например, строковое или
целочисленное значение). Значение присутствует не во всех записях МШ.Поле
доступа определяет уровень доступа к записи и обычно принимает значения
«только чтение», «чтение/запись», «только запись» и «недоступно». Поле
состояния указывает, является ли запись MIB обязательной (то есть должна
всегда реализовываться управляемым устройством), необязательной (управляемое
устройство может реализовать запись по своему усмотрению), нежелательной
(находящейся на пути к устареванию) или устаревшей (не используемой).
На практике используются два типа MIB: MIB-1 и MIB-2. Они имеют
разную структуру. Структура MIB-1 используется с 1988 года; таблица содержит
114 записей, разделенных на группы. Чтобы управляемое устройство могло
претендовать на совместимость с MIB-1, оно должно обязательно поддерживать все
группы, относящиеся к его типу. Например, управляемый принтер не обязан
реализовывать все записи, относящиеся к протоколу EGP (Exterior Gateway
Protocol), которые обычно реализуются только маршрутизаторами и другими
аналогичными устройствами. Чтобы быть MIB-1-совместимым, он должен
поддерживать только записи, которые должны поддерживаться всеми принтерами.
Спецификация MIB-2, появившаяся в 1990 году, представляет собой
усовершенствованный вариант MIB-1; она состоит из 171 записи и 10 групп. MIB-2
расширяет некоторые базовые группы MIB-1 и добавляет к ним три новые
группы. Как и в случае с MIB-1, устройство SNMP, претендующее на совместимость
с М1В-2, должно реализовывать все группы, относящиеся к данному типу
устройства. Существует много устройств, совместимых с MIB-1, но не совместимых
с MIB-2.
Кроме MIB-1 и MIB-2 существует несколько экспериментальных версий
MIB, добавляющих различные группы и записи в базу данных. Ни одна из этих
версий не получила широкого распространения, хотя некоторые из них
выглядят перспективно. Некоторые версии MIB были разработаны отдельными
корпорациями для собственного использования; ряд фирм-производителей
предлагает совместимость с этими версиями MIB. Например, фирма Hewlett-Packard
разработала собственную версию MIB, которая поддерживается некоторыми
SNMP-управляемыми устройствами и серверными пакетами.
Использование SNMP
Протокол SNMP прошел несколько стадий развития. Обычно он работает в
режиме асинхронного приложения «клиент-сервер», то есть как управляемое
устройство, так и программа-сервер SNMP могут передать другой стороне
сообщение и ждать ответа (если он предполагается). Сообщения упаковываются
и обрабатываются сетевым программным обеспечением (например, уровнем IP),
как и любые другие пакеты. Для транспортировки сообщений SNMP использует
протокол UDP. Все сообщения, кроме ловушек, передаются через порт UDP 161
(сообщения ловушек передаются через порт UDP 162). Агенты получают
сообщения от диспетчера через порт UDP 161 в агентской системе.
Первая крупная версия SNMP — SNMP vl — проектировалась для
выполнения относительно простых операций, была рассчитана на относительно простые
реализации и хорошо адаптировалась к разным операционным системам. SNMP vl
поддерживает только пять типов операций между сервером и агентом:
О get — выборка одной записи MIB;
О get-next — перебор записей MIB;
О get-response — ответ на get;
О set — модификация записей MIB;
О trap — передача информации о прерываниях.
При отправке запроса некоторые поля записи SNMP остаются пустыми.
Клиент заполняет их и возвращает запись. Такой способ позволяет эффективно
передать запрос и ответ в одном блоке и обойтись без сложных алгоритмов
поиска, определяющих, к какому запросу относится полученный ответ.
Например, при отправке команды get поля типа и значения равны NULL
Клиент возвращает аналогичное сообщение, в котором эти два поля заполнены
(конечно, если содержимое полей относится к клиенту — иначе возвращается
сообщение об ошибке).
Во второй версии SNMP (SNMP v2) протокол SNMP был наделен новыми
возможностями. Одна из таких возможностей предназначена для серверов —
новая операция get-bulk позволяет переслать в одном сообщении несколько
записей MIB (в SNMP vl для этого приходилось многократно выполнять запросы
get-next). Кроме того, более совершенная защита SNMP v2 предотвращает
получение информации о состоянии управляемых устройств посторонними. SNMP v2
поддерживает шифрование и аутентификацию. Разумеется, SNMP v2 гораздо
сложнее и используется не так широко, как SNMP vl. Из-за политических
проблем с разработкой SNMP v2 эта версия так и не получила широкого
распространения. Текущая версия SNMP имеет номер 3 и включает поддержку IP
версии 6, а также улучшенные возможности безопасности и администрирования.
SNMP поддерживает опосредованное управление; иначе говоря, устройство
с агентом SNMP и MIB может взаимодействовать с другими устройствами, не
имеющими полноценных агентских программ SNMP. Механизм опосредованного
управления позволяет управлять другими устройствами через подключенный
компьютер, при этом MIB устройства размещается в памяти агента. Например,
принтер может управляться с агентской рабочей станции, на которой также
имеется агент опосредованного управления и MIB принтера. Опосредованное
управление помогает освободить устройства, находящиеся под интенсивной
загрузкой.
Несмотря на широкое распространение, протокол SNMP обладает некоторыми
недостатками, главным из которых является зависимость от UDP. Протокол
UDP не ориентирован на соединение, поэтому обмен сообщениями между
сервером и агентом принципиально не может быть надежным. Другая проблема
заключается в том, что SNMP обеспечивает только простой механизм обмена
сообщениями и не позволяет фильтровать сообщения; тем самым повышается
нагрузка на программы-получатели. Наконец, SNMP почти всегда использует те
или иные разновидности опроса, порождающего существенный объем трафика.
Диспетчер SNMP управляет обменом данными между устройствами при
помощи коммуникационного протокола SNMP. Вспомогательные программы
обеспечивают пользовательский интерфейс, через который администратор сети
может получить информацию о состоянии всей системы и ее отдельных
компонентов, а также проследить за любым конкретным сетевым устройством.
Unix и SNMP
При работе в очень большой сети SNMP часто оказывается единственным
средством, при помощи которого администратор узнает, что происходит в сети, а также
получает предупреждения о возникающих проблемах. Поддержка SNMP
включается во все версии Unix, легко настраивается, а после основательных усилий
по ее изучению — эффективно используется для управления сетями,
содержащими тысячи устройств. Естественно, все сказанное в равной степени относится
к системе Linux.
Данный раздел посвящен настройке SNMP в типичной системе семейства
Unix. Как нетрудно догадаться, управляющие пакеты SNMP с графическим ин-
терфейсом гораздо удобнее текстовых, поэтому во многие поставки Unix входят
дополнительные приложения для администрирования SNMP.
Настройка SNMP в Unix и Linux
Во многих версиях Unix программное обеспечение клиента и сервера является
частью операционной системы. Клиентская часть выполняется демоном snmpd,
который обычно работает в течение всего времени использования SNMP в сети.
Обычно демон snmpd запускается автоматически при загрузке системы; команда
запуска включается в стартовый сценарий гс. При запуске SNMP демон snmpd
читает ряд конфигурационных файлов. В большинстве агентов SNMP читаются
следующие файлы:
/еtc/inet/snmpd.conf
/etc/inet/snmpd.comm
/etc/inet/snmpd.trap
В некоторых версиях Unix эти файлы могут находиться в других каталогах;
проверьте файловую систему и определите их правильное расположение.
Файл snmpd.conf содержит описания четырех системных объектов MIB. Обычно
эти объекты настраиваются во время установки SNMP, но иногда бывает
полезно проверить их содержимое. Ниже приведено примерное содержимое файла
snmpd.conf:
descr=SC0 TCP/IP Runtime Release 2.0.0
objid=SC0.1.2.0.0
contact=Tim Parker tparker@tpci.com
location=TPCI Infl HQ, Richmond
Во многих файлах snmpd.conf вам придется вводить значения полей contact и
location самостоятельно, но поля descr и objid следует оставить без изменений.
Переменные, определяемые в файле snmpd.conf, соответствуют переменным MIB.
descr sysDescr
objid sysObjectID
contact sysContact
location sysLocation
Файл snmpd.comm содержит данные аутентификации и список хостов,
которым предоставляется доступ к локальной базе данных. Чтобы предоставить
удаленному компьютеру доступ к локальным данным SNMP, включите его имя
в файл snmpd.conf. Пример файла snmpd.conf:
accnting 0.0.0.0 READ
r_n_d 147.120.0.1 WRITE
public 0.0.0.0 read
interop 0.0.0.0 read
Каждая строка файла snmpd.conf состоит из трех полей: имени сообщества,
IP-адреса удаленного компьютера и привилегий, предоставляемых сообще-
ству. Если IP-адрес равен 0.0.0.0, разрешен доступ для любого члена
указанного сообщества. Допустимые значения привилегий: READ (доступ только для
чтения), WRITE (доступ для чтения и записи) и NONE (запрет доступа).
Доступ для чтения и записи позволяет изменять данные MIB, но не файловые
системы.
Файл snmpd.trap определяет имена хостов, которым направляются сообщения
ловушек при обнаружении критического события. Пример файла snmpd.conf:
superduck 147.120.0.23 162
Каждая строка файла snmpd.trap состоит из трех полей: имени сообщества,
IP-адреса и порта UDP, используемого для отправки ловушек.
Команды SNMP
В системе Unix существуют команды на базе SNMP, при помощи которых
сетевые администраторы получают информацию из MIB или от SNMP-совмес-
тимых устройств. Конкретный список команд зависит от реализации, однако
в большинстве разновидностей SNMP поддерживаются команды,
перечисленные в табл. 39.1.
Таблица 39.1. Команды SNMP
Команда Описание
getone Получение значения переменной с использованием команды SNMP get
getnext Получение значения следующей переменной с использованием команды SNMP
getnext
getid Получение значений sysDescr, sysObjectID и sysUpTime
getmany Получение значений группы переменных MIB
snmpstat Получение содержимого структуры данных SNMP
getroute Получение данных маршрутизации
setany Присваивание значения переменной с использованием команды SNMP set
Большинство команд SNMP вызывается с аргументами, определяющими
присваиваемое или получаемое значение. Ниже приведены результаты выполнения
некоторых команд из табл. 39.1 для компьютера SNMP в небольшой локальной
сети.
$ getone merlin udpInDatagrams.0
Name: udpInDatagrams.0
Value: 6
$ getid merlin public
Name: sysDescr.0
Value: UNIX System V Release 4.3
Name: sysObjectID.0
Value: Lachman.1.4.1
Name: sysUpTime.0
Value: 62521
Команды SNMP нельзя назвать удобными для пользователей — их выходные
данные слишком кратки, что затрудняет их анализ. Из-за этого обрели
популярность системы управления сетью SNMP с графическим интерфейсом,
упрощающим выполнение функций SNMP и представление собранной информации.
Графические программы SNMP строят цветные диаграммы, отображающие
сетевую статистику в реальном времени. Эти программы часто сложны, а их
реализация обходится довольно дорого, но они оказывают неоценимую помощь
в управлении сетью и устройствами.
Одна из самых полезных возможностей SNMP связана с сообщениями об
ошибках и проблемах в работе устройств. Управляющие станции с графическим
интерфейсом позволяют графически отображать эту информацию на
топологических схемах сети.
Windows и SNMP
Все основные системы Microsoft — Windows NT/2000/XP, Windows 9x/ME — в той
или иной степени поддерживают SNMP. Во всех операционных системах имеются
драйверы для выполнения агентских функций по сбору информации в сетях SNMP,
а в некоторых операционных системах (Windows NT/ 2000/XP и Windows 9x/ME)
поддерживаются административные агенты. Ниже мы вкратце познакомимся с
уровнем поддержки SNMP во всех операционных системах семейства Windows.
Windows NT/2000
Windows NT/2000 содержит средства сбора информации SNMP, которые
устанавливаются в виде стандартной службы. Запустите приложение Сеть (Network)
на панели управления и перейдите на вкладку Службы (Services). Если службы
SNMP отсутствуют в списке, щелкните на кнопке Добавить (Add), найдите в
списке соответствующую строку и установите поддержку SNMP в системе. После
загрузки драйверов из установочных файлов на экране появляется страница
с тремя вкладками, на которых вводятся конфигурационные данные.
На первой вкладке свойств SNMP (рис. 39.1) вводятся контактные данные
администратора SNMP. Два текстовых поля содержат данные об имени и
местонахождении администратора. Заполнять эти поля необязательно, но наличие
контактных данных поможет быстрее узнать, кто является администратором
SNMP. В нижней части вкладки перечислены типы подключений и устройств,
находящихся под управлением SNMP. Для большинства сетей лучше всего
подходят значения по умолчанию.
На вкладке Ловушки (Traps), изображенной на рис. 39.2, вводятся имена
сообществ SNMP. Во всех перечисленных сообществах отслеживается
срабатывание ловушек. Обычно все компьютеры сети являются членами сообщества public.
Если заполнить эту вкладку, вы сможете задать IP-адреса устройств
наблюдения SNMP для всех сообществ. Например, ловушки SNMP для сообщества
research могут передаваться в аналитическую службу SNMP.
Ар** |Ti*pi | $яф{ ... . , г* \
MIB'* $y^ero group 0#iorwi€&*act and Uc*J^fieJ& «hogW [j
beprovWtatt&eoinprtei; $«уюе Horatio» *hputif*e«* j J
Ihenetv^;temper^ovkiftdfcythitcompu^, •:' ||
£<a*aefc |Tim Parker < "A, J I
.' .'... .Ml r , ,, . . . %. >^*\\. '11
УхШжих. (National HQ '^VMI
t'vV''$I 1
I Г Ehyscel I? Apj&ajiQra Г" £*tatok/SufenM*& ll?>|>]
■ & internet F £fl*k-£nd ' ^ Л: \^;Дт]
jr....... ••-'-. , ч ч //vA?i^1 j
' """" ' Ътъ I
OK I Cancel ( ' £pp*TiH
Рис. 39.1. Свойства агента SNMP
A*** Tit» )$ec^J3 • ";> ^ :^;-Й^;йЩ|
The SNMP $efvk*.#ovid«.*#¥^ ey* ТЙЖСг Ш
art IFWPX #©&**& If йар*«ше^*4 one 0*100» \ Г'л^лЗ-П
community name» murtbe specified ?raj> destination*яздЬе ЪШ£ j
r«ime«JPa^es«e5rurJI^«tteMe$; • .. <:>: ^»%fM
f Community Name; • ■•.■•■*■-:*■"* •;••:•:'• т^-г-.-'^^^^Й^И
jld ^fejf|
) ' .-• ;':•• > ••■••. •••'•.^Ч;^-^«mJ
I IiepDertndtora: ••■■■■•: • .■--• »• *.**ея$ж|-1
| __^ ^-^.ад^!-
I ;Ш|
:'••'•'.:." ' . ;■&&•,&$&$*!■*',,■ I j
• OK'" 1л,;'С^гюе1::1л?!1^^Лг''|
Рис. 39.2. Свойства ловушек SNMP
Последняя вкладка свойств SNMP — Безопасность (Security) — изображена на
рис. 39.3. Она предназначена для ограничения доступа к сервису SNMP на уровне
сообществ и консолей. Переключатели в нижней части вкладки позволяют
ограничить доступ к SNMP и принимать запросы только от перечисленных хостов.
ГШ&!1*й£ ': "^W;|I3IS•••: • • ■
j: И:г|й^е^ _,.. г^™ j
IJBS9HBBBBHHHBHHBBHBBI
• j :• -: k\\
■ : ." | \ j j
"•:.b:.v- :^^^Ш^:::.:1 ■ ^--" 1 j
'• • ;-::'|;:;g;j€i|ig;:-:■■ j';> • С№* j &ppb> |
Рис. 39.3. Свойства безопасности 5NMP
После завершения настройки происходит перезагрузка Windows NT с
активизацией служб SNMP.
Windows 9x/ME
В настоящее время существует целый рад агентов SNMP для Windows 9x/ME.
Большей частью это бесплатные или условно-бесплатные программы, которые легко
находятся при помощи поисковых систем WWW. Агенты SNMP для Windows
позволяют следить за работой сетей, получать информацию о возникающих
проблемах, а в некоторых случаях даже управлять сетью из системы Windows.
Одна из самых популярных программ SNMP для Windows 9х/МЕ — Net-
Guardian — была разработана в Лиссабонском университете. Для работы Net-
Guardian необходим стек TCP/IP или Trumpet Winsock. Программа обычно
распространяется в виде ZIP-файла, который распаковывается в отдельный
каталог и не требует компоновки с ядром Windows или загрузки специальных
драйверов. Благодаря такому решению с программой очень удобно работать
(и игнорировать ее, когда она не нужна). Среди сильных сторон NetGuardian
стоит упомянуть ее интерфейс — настолько простой и удобный, насколько это
возможно в такой сложной области, как SNMP.
Главное окно NetGuardian изображено на рис. 39.4. В нем представлена
схема сети со всеми компьютерами, известными NetGuardian. Если значок
компьютера перечеркнут, это означает, что NetGuardian не может с ним связаться (что
вполне понятно — на рисунке изображена конфигурация, включенная в пакет
NetGuardian по умолчанию). Чтобы программа NetGuardian провела поиск в
вашей сети, откройте меню Net и выберите команду Discover. На экране появляется
окно, в котором вводится диапазон IP-адресов для поиска (рис. 39.5).
Stoclcholm-EBS.Ebone.NET
19#Т21.156.34
Paris-EBS.Ebjy*£NET VIENNA-EBS1.Ebone.NET
192.121.15&$£ 192.121.156.18
Cern^BSI. Ebone.NET Dante.NET
щ Щ
194.41.0.50 194.41.0.49 А
Рис. 39.4. Окно NetGuardian со схемой сети
ftom;;}^ [If
. -То: J205.150.89.25 |||
.ICommuRl^j***^ "|||
. ^ ,, ,,, ^^У:^.-р.,, ...^ . щ|:|
[. ■■ /.'Г- ' J :^;Ш.|,/5 ^^^|.4':'v^'vSt::: S
Г;;:"" "W^^
Рис. 39.5. При поиске в сети NetGuardian запрашивает диапазон IP-адресов
После проверки всех компьютеров в заданном диапазоне NetGuardian
отображает результаты поиска на новой схеме. На рис. 39.6 изображена простая сеть,
в которой только три компьютера сообщили о себе. NetGuardian обнаруживает
компьютеры сети последовательным опросом (pinging) всех адресов в заданном
диапазоне.
i ^. - - j——^т j
§—л—* Ч
j 205.150.89.1 205.150.89.3 205.150.89.10 |
V 1
V I
I
ЬЦ-' л, ... ■ '■ -. ■ ::,^Ш:.:.:,:::,. ■ ■ ;,■ ,„• ; ; ^ лД
Рис. 39.6. Схема сети в NetGuardian с тремя компьютерами, заявившими о своей активности
Рис. 39.7. График сетевой активности в NetGuardian
Используя простой интерфейс NetGuardian, администратор (или
любознательный пользователь) может проверить активные компьютеры в сети, добавить
или исключить элементы из схемы сети или изменить ее внешний вид. Пакет
NetGuardian очень легко осваивается, он прост в работе и обладает многими
специальными возможностями, не поддерживаемыми в других пакетах
(например, вывод графика сетевой активности — рис. 39.7).
ПРИМЕЧАНИЕ
Копию NetGuardian можно найти на различных web-сайтах или на анонимном FTP-сайте ftp.fc.ul.pt
в файле /pub/networking/snmp/netgXXX.zip, где XXX — номер версии.
Итоги
Протокол SNMP — простой и эффективный механизм управления сетевыми
устройствами. С момента своего появления в 1988 году он был дополнен новыми
возможностями, получил широкое распространение и в настоящее время
занимает основное место в области управления сетями. Одним из главных
преимуществ SNMP является его простота, поскольку производители периферийного
оборудования легко внедряют поддержку SNMP в свои устройства. С другой
стороны, для администратора сети SNMP — по меньшей мере замечательный
инструмент.
Л(\ Безопасность
Нг w передачи
данных TCP/IP
Энн Карасий (Anne Carasik)
Конечно, главная задача сетей — предоставление доступа, но в современном мире
безопасность играет ничуть не менее важную роль. Администратор разрешает
приложениям доступ к сетевым службам по номерам используемых портов
TCP. Кроме того, TCP/IP можно защитить при помощи виртуальных
частных сетей (VPN) и создать защищенный туннельный канал без защиты самого
приложения.
\
Планирование сетевой безопасности
В процессе планирования политики сетевой безопасности администратор
определяет, каким сетевым службам и приложениям следует разрешить вход и
выход из сети. Не разрешайте прием входящих сетевых пакетов, если это не
объясняется стопроцентной необходимостью (а если такая необходимость есть, она
должна быть достаточно четко определена). Слишком много развелось
«вундеркиндов», которые загружают программы с хакерских сайтов и получают доступ
к вашей сети, если вы не приняли защитных мер.
Разрешая входной трафик, необходимо внимательно следить за работой
программ на входном порте и устанавливать исправления сразу же после их
публикации.
Существует и другой вариант — криптографические приложения Secure Shell,
SSL (Secure Sockets Layer) и продукты VPN, обладающие улучшенной поддержкой
аутентификации и шифрования с открытым ключом. Данное решение также
хорошо подходит и для исходящего трафика — вряд ли вы хотите, чтобы
конфиденциальная информация (например, пароли) пересылались на внешние сайты
в незащищенном виде.
Что такое сетевая безопасность?
В простейшем понимании под сетевой безопасностью понимается определение
того, какой сетевой трафик может входить в сеть и выходить из нее. При этом
сеть может представлять собой сегмент локальной сети (LAN) или
распространяться на целый регион (глобальные сети, WAN).
Один из способов реализации сетевой безопасности основан на
сегментировании сети и включении контрольных точек (таких, как брандмауэры и
маршрутизаторы). Настройка брандмауэра или маршрутизатора определяет, каким
типам сетевого трафика и сетевым приложениям разрешено прохождение через
контрольную точку.
Таким образом, контрольная точка фильтрует сетевой трафик и пропускает
только некоторые типы пакетов (входящих, исходящих или и тех и других).
Например, электронная почта очень важна для любой коммерческой
деятельности. В очень простой политике сетевой безопасности разрешается входящий
и исходящий трафик электронной почты на порте 25 для протокола SMTP (Simple
Mail Transfer Protocol). Остальной трафик блокируется и не пропускается через
контрольную точку.
На рис. 40.1 показаны примеры контрольных точек.
г Интернет 5 г Интернет 5
I Маршрутизатор I I FW I с Web-серверы 5
С^ Сеть S у Сеть S
^организации организации р
(Экстрасеть (сеть, <v
\ используемая j
( совместно Л
7^ с партнерами) J
^__^-^_^ ^\ FW [ ^-^--У^-^
у Сеть ^
^организации Д^
| FW [^
г Интернет -2
Рис. 40.1. Разделение сетей контрольными точками
Почему важна сетевая безопасность?
С увеличением количества пользователей Интернета растет необходимость в
безопасности. Все больше пользователей и организаций становятся жертвами атак.
Атаки происходят по разным причинам, в том числе:
О злоумышленник желает получить конфиденциальную информацию о вас
или вашей организации;
О злоумышленник проверяет свои навыки по проникновению в системы и
использует вашу систему для экспериментов;
О просто потому, что это интересно.
Уровни безопасности
Сетевая безопасность также зависит от прав доступа — от того, кто из
пользователей обладает или не обладает такими правами. В плане сетевой безопасности
некоторым пользователям предоставляются административные привилегии, а
рядовые пользователи обладают стандартным уровнем привилегий, единым для всех.
Между администраторами и рядовыми пользователями существует много
промежуточных уровней безопасности. Одни администраторы могут пользоваться
ограниченным доступом к одной системе, тогда как другие получают доступ
к нескольким системам. Например, один администратор обслуживает системы
разработки, другой занимается брандмауэрами и т. д.
Во многих операционных системах — таких, как Unix и Windows NT/2000 —
поддерживаются учетные записи администраторов (root в Unix) и учетные записи
пользователей. Эти два уровня представляют два крайних состояния сетевой
безопасности. Существуют и другие уровни безопасности — скажем, пользователи,
обладающие частью административных привилегий, и гостевые учетные записи.
ПРИМЕЧАНИЕ
Будьте крайне осторожны с «гостевыми» учетными записями, по умолчанию создаваемыми в
некоторых системах Unix и Windows NT/2000. Перед подключением системы к сети гостевые учетные
записи рекомендуется заблокировать.
В некоторых операционных системах — например, HP-UX CMW (Compart-
mented Mode Workstation), используемой в HP-UX Virtual Vault — применяется
разделенная схема безопасности. В этой схеме определены четыре уровня доступа
без единой административной учетной записи; привилегии администратора
делятся между несколькими учетными записями. Четыре уровня, о которых идет
речь — высокий, низкий, внешний и внутренний, — показаны на рис. 40.2.
ПРИМЕЧАНИЕ
В некоторых операционных системах (например, Windows NT/2000) группе, объединяющей всех
пользователей системы, присваиваются полные права чтения, записи, удаления и исполнения
файлов. Администратору следует отменить неограниченный доступ к важнейшим системным и
сетевым файлам.
Высокий
^организации 1 Внутренний Внешний S Интернет 2
Низкий
Рис. 40.2. Разделенный доступ в HP-UX CMW
Пользователь не может производить запись на более высоком уровне, но
может читать на более низком уровне. Чтение и запись на одном уровне разрешены.
Например, администратор, использующий свою учетную запись на низком
уровне, не может записывать на высоком уровне.
ПРИМЕЧАНИЕ
За дополнительной информацией о Virtual Vault обращайтесь по адресу http://www.hp.com/securlty/
products/virtualvault.
Пароли и файлы паролей
Проверка пользовательского доступа к учетной записи обычно осуществляется
при помощи паролей. Существуют и другие средства, в том числе
биометрические (основанные на проверке физических атрибутов пользователя) и
использующие шифрование с открытым ключом, однако большинство сетевых
протоколов аутентификации продолжает использовать пароли.
Главный недостаток паролей заключается в том, что они не гарантируют
полной защиты. В одних схемах с использованием паролей применяются
недостаточно надежные средства шифрования, в других проверку пароля вообще
удается обойти. Тем не менее даже при качественной реализации механизма
проверки пароля возникают другие проблемы.
Пароли часто легко подбираются, потому что пользователи хотят, чтобы их
пароль легко запоминался. Многие выбирают пароли из словаря или
используют дату своего рождения, номер телефона, кличку собаки или другие личные
данные, которые относительно легко узнать.
По этой причине многие администраторы требуют, чтобы пользователи
выбирали «сильные» пароли. Существуют специальные программы, которые
выбирают сильные пароли или заставляют пользователей применять их.
Сильный пароль содержит:
О алфавитно-цифровые символы (цифры и буквы);
О символы смешанного регистра (прописные и строчные буквы);
О специальные символы (!@#$%А&*_-=+\1?/><-/":~).
Выполнение этих условий не позволит подобрать пароль за достаточно
короткое время.
Пример сильного пароля:
%Ji92a*jpeijAjdkkjw
Однако у такого пароля появляется другой недостаток — он очень плохо
запоминается. Его придется записывать, а это создает угрозу для безопасности.
Вместо этого можно выбрать фразу и записать ее с чередованием регистра символов:
i Luv2c0mputePrimez!
Такой пароль не подбирается обычным перебором словаря.
СОВЕТ
Пробелы в паролях также повышают их защищенность.
Через определенный промежуток времени пароли обязательно должны
меняться. На большинстве защищенных сайтов смена пароля обычно происходит
каждые 90 дней. Повторное использование паролей запрещено, поскольку оно
также создает риск для системы безопасности.
Чтобы проверить устойчивость сильных паролей, выделите тестовый
компьютер (не содержащий ценной информации и отключенный от сети) и создайте
на нем фиктивные учетные записи с разной защитой паролей — одни пароли
должны легко подбираться, другие должны обладать разными уровнями защиты.
Существуют специальные программы, проверяющие продолжительность подбора
пароля. В табл. 40.1 приведены некоторые бесплатные программы-взломщики,
предназначенные для проверки качества паролей.
Таблица 40.1. Взломщики паролей
Программа Адрес
Crack http://www.cs.purdue.edu/COAST
LOphtchrack http://www.IOpht.com
John the Ripper http://www.openwall.com/john/
Ограничение доступа к паролям
Пароли должны храниться в зашифрованном файле или базе данных, чтобы
пользователи не могли читать пароли других пользователей и входить в систему
под их именами.
Пароли хранятся в различных местах в зависимости от операционной системы.
Примеры приведены в табл. 40.2.
Таблица 40.2. Способы хранения паролей в разных операционных системах
Операционная система Место хранения паролей
Windows NT Системный реестр
Unix /etc/passwd или/etc/shadow
Файл паролей необходимо защитить соответствующей настройкой
разрешений и принадлежности. Например, в Unix файл паролей должен быть доступен
только для суперпользователя root, а если пароли хранятся в теневом файле —
чтение этого файла должно быть разрешено только root и запрещено всем
остальным пользователям.
В более защищенных версиях Unix — таких, как HP-UX CMW и Bl Solaris —
пароли хранятся в базах данных или в разных файлах. Это сделано для того,
чтобы злоумышленник, получивший доступ к одному файлу, не смог получить
все пароли одновременно.
Сетевая безопасность
Повседневная работа по обеспечению сетевой безопасности всегда вызывает
наибольшие трудности, поскольку пользователи должны усвоить правила
безопасности и соблюдать их. К сожалению, многие пользователи нарушают эти правила,
хотя сами только выигрывают от них. Впрочем, существуют приемы,
позволяющие обеспечить необходимый уровень безопасности и даже повысить его.
Типы атак
Классификация, принятая в области сетевой безопасности, включает несколько
типов атак, которые рассматриваются в следующих разделах.
Троянские программы
Троянские программы имитируют полезные функции, но в действительности
они собирают информацию для хакера. Например, злоумышленник может
установить троянскую программу входа в сеть; программа запрашивает имя
пользователя и пароль и выдает сообщение об ошибке. Полученная информация
отправляется по электронной почте злоумышленнику.
Троянские программы не ограничиваются сбором информации — они
причиняют реальный вред, хотя и маскируются под «добропорядочные» программы.
Троянские программы не размножаются, поэтому с технической точки зрения
они не относятся к вирусам.
Черные входы
«Черные входы» скрываются в программах и операционных системах. Обычно
их существование остается неизвестным для широкой публики.
Злоумышленник получает доступ к системе через «черный вход», обходя действующие меры
безопасности.
Отказ от обслуживания
Атаки отказа от обслуживания (DoS, Denial of Service) либо полностью выводят
из строя сетевую службу (например, web-сервер), либо значительно замедляют
ее работу, вызывая крайнее раздражение у пользователей.
Сетевые атаки
К числу сетевых атак относится сканирование открытых портов. Например,
порт 5641 в Windows NT/2000 и Windows 9x используется PCAnywhere для по-
лучения имени пользователя и пароля. Злоумышленник может методом
«грубой силы» подобрать имя пользователя и пароль или воспользоваться «черным
входом» PCAnywhere.
Фальсификация
Используя прием фальсификации (spoofing), злоумышленник пытается выдать
себя за пользователя или хост, которым он в действительности не является.
Одним из самых серьезных недостатков берклиевских r-команд была их
«легковерность». R-команды полностью доверяли имени хоста и не пытались убедиться
в том, что обращение исходит именно от того компьютера.
Однако имя хоста и пользователя было нетрудно сфальсифицировать.
Например, имя внешнего хоста заменялось именем доверенной внутренней системы.
К сожалению, не существовало средств, которые бы позволяли убедиться в том,
что подключение действительно исходит от доверенной системы.
Злоумышленники фальсифицировали имена хостов и обманывали г-команды.
ПРИМЕЧАНИЕ
Современные маршрутизаторы обладают средствами проверки IP-адресов, предотвращающими
подобные атаки, но на имена хостов проверка не распространяется. В системе безопасности
можно определить правила, запрещающие входящие подключения к г-командам.
Взлом паролей
Если нападающему удастся заполучить файл паролей или копию реестра NT/2000,
он может найти в Интернете бесплатные программы для взлома паролей.
Располагая достаточным запасом времени, рано или поздно он вскроет хотя бы один
пароль и получит доступ к компьютеру.
Дефекты программ и переполнение буфера
Один из распространенных методов атаки основан на использовании дефектов
программ, позволяющих получить права суперпользователя или администратора.
Для этого программе передается слишком большой объема данных, в результате
чего программа «давится» и выдает дамп памяти. Такой прием называется
переполнением буфера.
Многие сетевые программы (таких, как sendmail и NFS) содержат
многочисленные дефекты и относятся к категории небезопасных сетевых приложений.
ПРИМЕЧАНИЕ
Кроме sendmail существуют и другие программы для работы с SMTP — например, защищенный
почтовый сервер qmail. За дополнительной информацией обращайтесь на сайт http://www.qmail.org/.
Система NFS также недостаточно хорошо защищена, но у нее имеется альтернатива — AFS (Andrew
File System). За дополнительной информацией о AFS обращайтесь по адресу http://www.faqs.org/
faqs/afs-faq/.
Ошибки при назначении разрешений
При неправильно назначенных разрешениях файлов в Unix и Windows NT/2000
злоумышленник может запустить программу с правами root (или администратора),
устроить сбой системы или использовать дефект программы. Запуск
приложения с неправильными разрешениями также позволяет использовать систему или
получить особые привилегии.
Если суперпользователю или администратору принадлежит файл, запись в
который может осуществляться другими пользователями, злоумышленник может
изменить содержимое файла и предоставить локальному или удаленному
пользователю особые привилегии без ведома администратора.
Вирусы
Вирусом называется программа, которая тайно внедряется в другие программы.
Единственной целью вируса обычно является причинение вреда компьютеру —
перепрограммирование раскладки клавиатуры, уничтожение содержимого
жесткого диска или стирание файлов определенного типа.
Многие компании выпускают антивирусные программы. Эффективная
работа антивирусных программ требует регулярного (по крайней мере ежемесячного)
обновления баз данных с информацией о вирусах.
Впрочем, в последнее время вирусы вызвали настоящее массовое
помешательство в интернет-сообществе. Практически любая проблема немедленно
приписывается воздействию вируса. Многие программы (например, Netbus и Back
Orifice), относящиеся к классу троянских программ и «черных входов», также
считаются вирусами. Хотя с технической точки зрения эти программы не
являются вирусами, производители антивирусных программ своевременно
обнаруживают их и предотвращают многочисленные проблемы, способные парализовать
работу системы. Некоторые организации используют сразу несколько программ-
детекторов в надежде, что если вирус не будет обнаружен одной программой, то
с ним справятся другие программы.
Социотехника
Из всех видов сетевых атак сложнее всего бороться с приемами социотехники,
использующими самое слабое звено сетевой безопасности — человека.
Например, злоумышленник может позвонить в службу поддержки, притвориться
пользователем и уговорить администратора сообщить пароль по телефону.
К социотехнике также относится подкуп или обман работников, в результате
которого они предоставляют злоумышленнику свои данные доступа или
оставляют его наедине со своим компьютером. Иногда для получения доступа к
компьютерам злоумышленник может прикинуться курьером, уборщиком и т. д. Хорошие
примеры использования социотехники для получения доступа к сети
встречаются в фильмах «Тихушники», «Миссия невыполнима» и др.
Меры, обеспечивающие сетевую безопасность
В этом разделе даны некоторые рекомендации по обеспечению сетевой
безопасности. Помните, что уровень безопасности зависит от многих факторов, но в
первую очередь от времени, людей и вашего желания обеспечить себе спокойную
жизнь в роли администратора.
Обучение и переподготовка пользователей
Хотите — верьте, хотите — нет, но обучение персонала вносит самый заметный
вклад в обеспечение сетевой безопасности. Вы должны позаботиться о том, чтобы
все работники (и новые, и старые) знали правила сетевой безопасности и
соблюдали их. Если соблюдение этих правил станет одним из принципов
корпоративной культуры, вы сможете заняться и такими вещами, как защита паролей,
хранение смарт-карт и личных ключей в надежных местах и предотвращение
обмена конфиденциальными данными среди пользователей.
Сторожевые системы
Сторожевые системы обнаруживают подозрительный сетевой трафик, помогают
выявить атаки отказа в обслуживании и нестандартные пакеты типа Windows
ООВ (Out of Bounds), приводящие к сбою системы. Сторожевые пакеты
помогают выявить атаки на вашу систему. В табл. 40.3 приведены примеры
сторожевых пакетов.
Таблица 40.3. Сторожевые системы
Система Адрес
Network Flight Recorder http://www.nfr.com
RealSecure http://www.iss.net
NetProwler http://www.symantec.com
Проверка на проникновение
Проверкой на проникновение называется попытка проникнуть в систему через
известные дефекты в системе безопасности. Это самый эффективный способ
убедиться в безопасности сети; консультирующие фирмы, занимающиеся
проверкой систем на проникновение, обычно прибегают к услугам тех же хакеров.
Даже если вы не пользуетесь услугами таких фирм, обязательно проведите хотя
бы минимальную проверку на проникновение и убедитесь в отсутствии
очевидных дефектов в системе безопасности.
В Интернете можно найти многочисленные программы, выполняющие
проверку на проникновение. На многих web-сайтах представлен хакерский код,
который вы можете загрузить и откомпилировать в своей системе.
Эксперты в области безопасности также предлагают коммерческие и
бесплатные программы. Примеры приведены в табл. 40.4.
Таблица 40.4. Программы для проверки на проникновение
Программа Адрес
Internet Security Scanner http://www.iss.net
SATAN http://www.fish.com/satan/
Nessus http://www.nessus.org
Cybercop http://www.nai.com
Проверка целостности файлов
Один из базовых способов выявления постороннего проникновения в систему
основан на проверке изменений файлов. Существуют многочисленные
программы, выявляющие изменения в файловой системе или отдельных файлах. Такие
программы помогут узнать, что именно было изменено и кто внес изменения —
системный администратор или злоумышленник, проводящий атаку на систему.
В табл. 40.5 приведены примеры программ для проверки целостности файлов.
Таблица 40.5. Программы для проверки целостности файлов
Программа Адрес
Tripwire http://www.tripwiresecurity.com
COPS http://www.cerias.purdue.edu/coast/
Tiger http://www.cerias. purdue.edu/coast/
System Scanner http://www.iss.net
Отслеживание журналов
Самый простой и дешевый способ выявления атак — отслеживание журналов
и поиск сведений о подозрительных операциях. К сожалению, это исключительно
долгое и утомительное занятие. Другая проблема с проверкой журналов
заключается в том, что вы не сможете доказать, что журналы не были изменены. Если
злоумышленник получил привилегированный доступ к компьютеру, он сможет
внести изменения в журналы и замести следы.
Настройка приложений
Правильная настройка сетевых приложений играет важную роль в обеспечении
общей безопасности сети. В частности, следует твердо запомнить ряд важных
советов:
О Используйте только те приложения, которые вам абсолютно необходимы.
О Отключите все, без чего можно обойтись.
О Как можно лучше защитите выполняемые приложения.
О Главная функция сетей — предоставление доступа. Любое обращение к
вашей сети приподнимает «железный занавес» и создает опасность
постороннего проникновения в сеть.
Демон Интернета и файл /etc/inetd.conf
Многие сетевые приложения Unix могут быть отключены в файле /etc/inetd.conf.
Файл /etc/inetd.conf определяет, какие демоны сетевых приложений запускаются
супердемоном Интернета inetd.
ПРИМЕЧАНИЕ
Демон inetd и файл /etc/inetd.conf также рассматриваются в главе 39.
В только что установленной системе файл /etc/inetd.conf выглядит примерно так:
#
# Авторы: Оригинал позаимствован из BSD Unix 4.3/TAHOE.
# Фред Н.ван Кемпен, <waltje@uwalt.nl.mugnet.org>
#
echo stream tcp nowait root internal
echo dgram udp wait root internal
discard stream tcp nowait root internal
discard dgram udp wait root internal
daytime stream tcp nowait root internal
daytime dgram udp wait root internal
chargen stream tcp nowait root internal
chargen dgram udp wait root internal
time stream tcp nowait root internal
time dgram udp wait root internal
# Стандартные службы
#
ftp stream tcp nowait root /usr/sbin/tcpd in.ftpd -1 -a
telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd
#
# Shell, login, exec, comsat и talk -- протоколы BSD.
#
shell stream tcp nowait root /usr/sbin/tcpd in.rshd
login stream tcp nowait root /usr/sbin/tcpd in.rlogind
#exec stream tcp nowait root /usr/sbin/tcpd in.rexecd
#comsat dgram udp wait root /usr/sbin/tcpd in.comsat
talk dgram udp wait root /usr/sbin/tcpd in.talkd
ntalk dgram udp wait root /usr/sbin/tcpd in.ntalkd
#dtalk stream tcp wait nobody /usr/sbin/tcpd in.dtalkd
#
# Pop,imap и другие почтовые службы
#
#рор2 stream tcp nowait root /usr/sbin/tcpd ipop2d
pop2 stream tcp nowait root /usr/sbin/tcpd ipop3d
imap stream tcp nowait root /usr/sbin/tcpd imapd
#
В этом фрагменте любая строка, не начинающаяся с символа комментария #,
определяет активное сетевое приложение, запускаемое демоном inetd. Если вы
хотите, чтобы из всех демонов сетевых приложений в системе запускались только
демоны FTP и Telnet, файл /etc/inetd.conf принимает следующий вид:
#
# Авторы: Оригинал позаимствован из BSD Unix 4.3/TAHOE.
# Фред Н.ван Кемпен, <waltje@uwalt.nl.mugnet.org>
#
#echo stream tcp nowait root internal
#echo dgram udp wait root internal
#discard stream tcp nowait root internal
#discard dgram udp wait root internal
#daytime stream tcp nowait root internal
#daytime dgram udp wait root internal
#chargen stream tcp nowait root internal
#chargen dgram udp wait root internal
#time stream tcp nowait root internal
#time dgram udp wait root internal
# Стандартные службы
#
ftp stream tcp nowait root /usr/sbin/tcpd in.ftpd -1 -a
telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd
#
# Shell, login, exec, comsat и talk -- протоколы BSD.
#
#shell stream tcp nowait root /usr/sbin/tcpd in.rshd
#login stream tcp nowait root /usr/sbin/tcpd in.rlogind
#exec stream tcp nowait root /usr/sbin/tcpd in.rexecd
#comsat dgram udp wait root /usr/sbin/tcpd in.comsat
#talk dgram udp wait root /usr/sbin/tcpd in.talkd
#ntalk dgram udp wait root /usr/sbin/tcpd in.ntalkd
#dtalk stream tcp wait nobody /usr/sbin/tcpd in.dtalkd
#
# Pop.imap и другие почтовые службы
#
#рор2 stream tcp nowait root /usr/sbin/tcpd ipop2d
#pop2 stream tcp nowait root /usr/sbin/tcpd ipop3d
#imap stream tcp nowait root /usr/sbin/tcpd imapd
#
После того как все лишние строки будут закомментированы, из всех сетевых
приложений остаются работать только FTP и Telnet. Все заведомо
небезопасные службы (echo, login, shell, finger и т. д.) отключаются, и никто не сможет
проникнуть через них на ваш компьютер.
ПРИМЕЧАНИЕ
Учтите, что Telnet и FTP не являются защищенными протоколами. Они пересылают пароли в
текстовом виде, и эта информация может быть легко перехвачена программой-шпионом.
Программы шифрования
Один из способов защиты передачи данных TCP/IP основан на применении
программ шифрования. К этой категории относится программное обеспечение SSL
(Secure Sockets Layer) для шифрования трафика HTTP; SSH (Secure Shell) для
шифрования терминального трафика и трафика X; VPN (Virtual Private Network)
для создания туннельных каналов между двумя удаленными сайтами в Интернете
или клиентом, подключающимся к основному сайту организации через Интернет.
Технологии SSL и SSH используются для создания защищенных туннелей,
по которым передается трафик других приложений, в том числе РОРЗ, ШАР
и FTP. Аутентификация в SSL и SSH обычно основана на применении
шифрования с открытым ключом (например, RSA или DSA), а шифрование
осуществляется при помощи симметричных шифров (DES, Triple DES и IDEA).
Виртуальные частные сети (VPN) обычно обеспечивают безопасную пересылку
незащищенного трафика между двумя точками. Например, процедура
совместного доступа к файлам, крайне ненадежная по своей природе, защищается при
помощи VPN, при этом вам не приходится заново переписывать сетевое
приложение в защищенном варианте.
ПРИМЕЧАНИЕ
Дополнительную информацию о SSH можно найти по адресу http://www/employees.org/~satch/
ssh/faq. За информацией о SSL обращайтесь по адресу http://psych.psy.uq.oz.au/~ftp/Crypto/, а за
информацией о виртуальных частных сетях (VPN) — по адресу http://www.vpnc.org/.
TCP Wrappers
Для защиты сетевых приложений также применяется технология TCP Wrappers,
предназначенная для отслеживания и ограничения доступа к сетевым
приложениям, запущенным inetd.
Прежде чем использовать демонов сетевых приложений с TCP Wrappers,
необходимо сначала убедиться в том, что пакет установлен в системе и правильно
настроен.
Чтобы установить TCP Wrappers, распакуйте архив tar и выполните команду
make:
# gzip -de tcp_wrappers-7.6.tar.gz | tar -xvf -
#cd tcp_wrappers-7.6
#make
Далее следуйте инструкциям по установке TCP Wrappers в вашей системе.
После завершения установки следует настроить файлы /etc/inetd.conf, /etc/
hosts.deny и /etc/hosts.allow. Два последних файла используются TCP Wrappers
для контроля доступа. Чтобы использовать TCP Wrappers, следует запустить
демонов сетевых приложений программой tepd.
Типичная запись сетевого приложения в файле /etc/inetd.conf выглядит так:
netappd stream tcp nowait root /usr/sbin/tcpd netappd
При каждом запросе SSH (Secure Shell) для netappd порождается новый процесс.
Допустим, в соответствии с условиями предыдущего примера вы хотите
ограничиться запуском FTP и Telnet. В исходном варианте демон FTP запускался
следующей командой:
ftp stream tcp nowait root /usr/sbin/in.ftpd in.ftpd -1 -a
Чтобы демон FTP запускался под управлением TCP Wrappers, команда должна
выглядеть так:
ftp stream tcp nowait root /usr/sbin/tcpd in.ftpd -1 -a
Файл /etc/hosts.deny настраивается таким образом, чтобы никто не мог
получить доступ к системе через приложения TCP Wrappers (тем самым
предотвращается доступ со всех хостов, не перечисленных в файле /etc/hosts.allow).
Соответствующая запись /etc/hosts.deny выглядит так:
ALL : ALL
После создания /etc/hosts.deny необходимо добавить новые записи в /etc/hosts,
allow. Простой файл /etc/hosts.allow для запуска демонов FTP и Telnet под
контролем TCP Wrappers выглядит примерно так:
in.ftpd: example.com: allow
in.telnetd: example.com: allow
Доступ предоставляется только клиентам из домена example.com.
Базовый формат записи /etc/hosts.allow и /etc/hosts.deny выглядит так:
демоны: клиенты: allow/deny
В следующем примере мы не доверяем клиентам из домена evil.org. В файл
/etc/hosts.deny включается следующая запись:
in.fingerd: evil.org: deny
ПРИМЕЧАНИЕ
За дополнительной информацией о TCP Wrappers обращайтесь на сайт ftp://ftp.porcupine.org/
pub/security.
Порты
Порты используются службами Unix и Windows NT/2000 для приема запросов.
Если злоумышленник ищет в системе открытые порты, он обычно проверяет,
какой тип приложения работает на соответствующем порте. Через
незащищенный порт можно получить несанкционированный доступ к системе или
«затопить» ее пакетами и устроить атаку отказа в обслуживании.
Брандмауэры
Брандмауэром называется контрольная точка сети, фильтрующая сетевой
трафик по типам сетевых приложений. Большинство брандмауэров работает только
в сетях TCP/IP, хотя некоторые продукты могут работать и в других сетях
(например, в сетях IPX).
Информация о фильтруемом трафике регистрируется в журнале.
Администратор всегда может узнать, какие приложения работают в настоящий момент
и какие пакеты были отвергнуты или не выпущены брандмауэром из сети. Во
многих брандмауэрах имеются встроенные определения типов трафика,
пропускаемых брандмауэром.
ПРИМЕЧАНИЕ
Брандмауэр может пропускать трафик незащищенных служб (таких, как NFS и берклиевские г-ко-
манды), однако при настройке конфигурации эти службы рекомендуется отключить.
Брандмауэр обеспечивает лишь тот уровень безопасности, который вы сами
определите. Проследите за тем, чтобы незащищенные приложения были
заблокированы — прохождение незащищенного трафика противоречит основным
целям установки брандмауэра.
Пакетные фильтры
Пакетный фильтр проверяет пакет и убеждается в том, что он передается
допустимому порту. Содержимое пакета при этом не проверяется. Например,
маршрутизатор может фильтровать пакеты и разрешать входной и выходной трафик
для заданного набора портов. Хотя пакетные фильтры игнорируют содержимое
пакетов, они обладают превосходным быстродействием.
Шлюзы приложений
Шлюз приложения не ограничивается проверкой порта и проверяет все
содержимое пакета, в том числе и тип приложения, для которого предназначается
пакет. Увеличение объема проверяемой информации приводит к тому, что шлюзы
приложений работают значительно медленнее пакетных фильтров и хуже
масштабируются.
Многие шлюзы приложений обладают дополнительными возможностями —
поддержкой VPN, интеграцией со сторожевыми системами и управлением
маршрутизаторами.
Шлюзы приложений не могут выяснить, какому приложению передаются
зашифрованные пакеты SSH (Secure Shell) и SSL (Secure Sockets Layer). В этом
случае функции шлюза приложения фактически сводятся к простой
фильтрации пакетов.
Приложения-фильтры
В продуктах Checkpoint, Novell Board Manager и Cisco PIX используется
механизм проверки с состоянием (stateful inspection), которая представляет собой
гибрид шлюза приложения и пакетного фильтра. Этот механизм анализирует
содержимое пакета, но не так подробно, как шлюзы приложений.
ПРИМЕЧАНИЕ
Брандмауэры рассматриваются в главе 20.
Итоги
Защита пересылки данных TCP/IP в значительной мере зависит от четкого
определения того, какой трафик должен считаться допустимым. Ключевым
фактором защиты является контрольная точка, ограничивающая входной и выходной
трафик по определенному критерию.
В процессе настройки системы защиты администратор выбирает сетевые
службы, которые должны работать в системе.
Хотя многие сетевые приложения считаются незащищенными, существуют
специальные технологии, обеспечивающие безопасность пересылки данных —
SSH, SSL и VPN. Применение этих технологий защищает от программ-шпионов
и перехвата сеансов.
Л 4 Инструментарий
Тг JL и методы диагностики
Бернард Мак-Карго (Bernard McCargo)
Большинство проблем возникает из-за простых причин, поэтому четкое
понимание проблемы часто приводит к ее решению. К сожалению, это не всегда так,
поэтому в этой главе будут описаны некоторые средства, помогающие в
решении особо трудных проблем. Существует множество диагностических программ,
от коммерческих систем со специализированным оборудованием и программами
стоимостью в несколько тысяч долларов до бесплатных утилит,
распространяемых через Интернет. В этой главе в основном рассматриваются бесплатные или
«встроенные» средства диагностики.
Наш выбор объясняется несколькими причинами. Во-первых, дорогие
коммерческие системы должны содержать полную документацию. Во-вторых, для
многих администраторов коммерческие решения слишком дороги, а бесплатные
программы доступны для всех. Наконец, бесплатные диагностические программы
решают многие сетевые проблемы. Вероятно, для больших сетей понадобятся
коммерческие программы TDR (Time Domain Reflectometer), но в малой сети
вполне достаточно общедоступных диагностических программ.
Инструменты, упоминаемые в этой главе (а также многие другие), описаны
в RFC 1147.
Наблюдение за состоянием сети
Чтобы правильно подойти к решению проблемы, необходимо в общих чертах
представлять себе, как отслеживается состояние сети. Без системы сетевого
мониторинга (встроенной или внешней) диагностика сетевых проблем будет
занимать очень много времени.
Наблюдение за состоянием сети иногда позволяет выполнять упреждающие
операции сопровождения еще до появления проблемы. А если проблема все же
возникнет, у администратора будет подробная и точная информация о
происходящем. Получив сообщение о проблеме, просмотрите журналы системы сетевого
мониторинга. Выясните, какое приложение вызвало сбой. Узнайте имя и IP-адрес
удаленного хоста и данные пользователя. Как выглядело сообщение об ошибке?
Пусть пользователь попытается снова запустить проблемное приложение на своем
компьютере. Если возможно, воспроизведите проблему в тестовой системе.
Стандартные утилиты
В этой главе (а также на страницах книги) рассматриваются следующие
стандартные утилиты:
О ifconfig. Информация о базовой конфигурации интерфейса. Используется для
обнаружения неправильных IP-адресов, масок подсетей и адресов
широковещательной рассылки. Утилита входит в комплект поставки операционной
системы Unix. В Windows NT/2000 аналогичная утилита называется ipconfig,
а в Windows 9х — winipcfg.
О агр. Информация о преобразования адресов Ethernet/IP. Используется для
обнаружения в локальном сегменте сети систем с неправильными
IP-адресами. Утилита существует в системах Windows и Unix.
О netstat. Разнообразная информация о сети. Обычно используется для вывода
подробной статистики о сетевых интерфейсах, сокетах и таблицах
маршрутизации. Утилита существует в системах Windows и Unix.
О ping. Проверка связи с удаленным хостом. Кроме того, утилита выводит
статистику о потере пакетов и времени доставки.
О nslookup. Вывод информации о службе имен DNS.
О dig. Вывод информации о службе имен, аналог nslookup. Утилита dig доступна
на анонимном сайте FTP venera.isi.edu в файле pub/dig.2.0.tar.Z.
О ripquery. Вывод информации о содержимом пакетов обновления RIP,
получаемых или передаваемых системой. Входит в пакет gated, но не требует запуска
демона gated. Работает в любой системе, использующей RIP.
О traceroute. Трассировка маршрута к удаленной системе с выводом информации
о каждом переходе. Утилита доступна на анонимном сайте FTP ftp.ee.lbl.gov
в файле traceroute.tar.Z. Версия для Windows NT/2000 называется tracer!
О etherfind. Анализатор протокола TCP/IP с возможностью просмотра
содержимого пакетов и заголовков. Чрезвычайно полезен для диагностики проблем,
связанных с работой протоколов. Версия для SunOS называется tcpdump и
распространяется с анонимного сайта FTP ftp.ee.lbl.gov.
О ethereal. Высококачественный анализатор протокола TCP/IP с возможностью
просмотра содержимого пакетов и заголовков. Программа была
адаптирована для Windows и большинства операционных систем семейства Unix. За
дополнительной информацией обращайтесь на сайт www.ethereal.com.
В этой главе будут рассмотрены примеры использования всех перечисленных
программ, включая те, которые встречались ранее на страницах книги. Начнем
с утилиты ping, которая используется чаще любой другой диагностической
программы.
Проверка базового соединения
Команда ping проверяет, может ли ваш компьютер связаться с удаленным хостом.
Эта простая функция чрезвычайно полезна для проверки сетевых соединений
независимо от того, в каком сетевом приложении возникла исходная проблема.
Ping помогает выяснить, где следует искать проблему — на уровне сетевого
соединения (нижний уровень) или на уровне приложений (верхний уровень).
Если утилита ping показывает, что пакеты успешно передаются в удаленную
систему и обратно, вероятно, проблема обусловлена работой верхних уровней.
Если пакету не удается пройти туда и обратно, скорее всего, в этом виноваты
нижние уровни.
Пользователи довольно часто сообщают о сетевых проблемах, утверждая, что
им не удается связаться через telnet (ftp, по электронной почте и т. д.) с
удаленным хостом. Естественно, при этом «раньше все работало нормально». В
ситуациях, когда возникает сомнение в самой возможности связи с удаленным хостом,
утилита ping приносит несомненную пользу.
Выполните команду ping с указанием имени хоста, сообщенного
пользователем. Если команда ping работает нормально, предложите выполнить ее
пользователю. Если попытка окажется успешной, дальнейшие усилия следует
направить на анализ конкретного приложения, с которым работает пользователь.
Может быть, пользователь пытается связаться через telnet с хостом,
поддерживающим только анонимный доступ ftp, или хост был недоступен в тот момент.
Пусть пользователь попробует еще раз, пока вы внимательно следите за всем,
что он делает. Если все делается правильно, но приложение все равно не
работает, проанализируйте трафик приложения при помощи etherfind. Возможно,
к работе придется привлечь администратора удаленной системы.
Если на вашем компьютере ping работает нормально, а на компьютере
пользователя происходит сбой, проверьте конфигурацию пользовательской системы
и другие различия на пути от пользовательской системы к удаленному хосту
(по сравнению с путем от вашей системы).
Если на вашем компьютере команда ping тоже не работает, обратите особое
внимание на сообщения об ошибках. Сообщения об ошибках, выводимые ping,
содержат полезную информацию для планирования дальнейших тестов.
Подробности изменяются в зависимости от реализации, но базовых типов ошибок немного.
О unknown host. Имя удаленного хоста не удается преобразовать в IP-адрес.
Возможные причины — сбой на сервере имен (локальном или на сервере
удаленной системы), ошибка в имени или сбои в сети между вашей системой
и удаленным хостом. Если IP-адрес удаленного хоста известен, попробуйте
связаться с ним утилитой ping. Если связь с хостом по IP-адресу
устанавливается, значит, проблема связана со службой имен. Проверьте локальный
и удаленный серверы имен утилитами nslookup и dig и убедитесь в
правильности хостового имени, предоставленного пользователем.
О network unreachable. Локальной системе неизвестен маршрут к удаленной
системе. Если в командной строке ping вводился числовой IP-адрес, повторите
команду ping с хостовым именем. Тем самым исключается вероятность ошибок
при вводе IP-адресов (а также того, что IP-адрес был сообщен вам неверно).
Если в системе используется протокол маршрутизации, убедитесь в том, что
он работает, и проверьте таблицу маршрутизации командой netstat. Если
используется протокол RIP, проверьте содержимое обновлений RIP командой
ripquery. Если используется статический маршрут по умолчанию, попробуйте
перезагрузить его. Если на хосте все выглядит нормально, переходите к
поиску проблем с маршрутизацией на основном шлюзе.
О по answer. Удаленная система не отвечает. Сообщение в том или ином
варианте присутствует в большинстве сетевых утилит. Некоторые реализации ping
выводят сообщение 100% packet loss; telnet выводит сообщение Connection timed
out, a sendmail — сообщение error cannot connect. Все эти ошибки означают одно
и то же: локальная система знает маршрут к удаленной системе, но не
получает ответа от удаленной системы ни на один отправленный пакет.
О Проблема возникает по разным причинам — из-за недоступности удаленного
хоста, неправильной настройки локального или удаленного хоста,
недоступности шлюза или сбоя канала между удаленным и локальным хостом,
проблем с маршрутизацией на удаленном хосте и т. д. Только дополнительное
тестирование может выявить причины проблемы. Тщательно
проанализируйте локальную конфигурацию при помощи netstat и ifconfig. Проверьте
маршрут к удаленной системе командой traceroute. Свяжитесь с
администратором удаленной системы и сообщите ему о возникшей проблеме.
Утилиты, упомянутые в этом разделе, будут рассмотрены ниже. Но прежде
чем переходить к другим утилитам, давайте поближе познакомимся с командой
ping и той статистикой, которую она выводит.
Команда ping
Общий синтаксис командной строки ping выглядит так:
ping хост [размер_пакета] [счетчик]
Аргумент хост содержит хостовое имя или IP-адрес проверяемого удаленного
хоста. Обычно указывается имя или адрес, занесенные пользователем в отчет
о неисправностях.
Аргумент размерjnaxema определяет размер тестовых пакетов в байтах и
является обязательным только при использовании поля счетчик. По умолчанию
размер пакета равен 56 байтам.
Аргумент счетчик определяет количество пакетов, передаваемых в процессе
тестирования. Если значение поля счетчик окажется слишком большим, команда
ping будет пересылать тестовые пакеты до тех пор, пока ее работа не будет
прервана (обычно комбинацией клавиш Ctrl+C). Излишек тестовых пакетов
приводит к неэффективному использованию пропускной способности канала и
системных ресурсов. Обычно для проверки достаточно пяти пакетов.
Чтобы убедиться в том, что хост uunet.uu.net доступен с рабочей станции
bernard, мы передаем пять 56-байтовых пакетов следующей командой:
% ping -s uunet.uu.net 56 5
PING uunet.uu.net: 56 data bytes
64 bytes from uunet.UU.NET A37.39.1.2): icmp_seq=0. Time=14. ms
64 bytes from uunet.UU.NET A37.39.1.2): icmp_seq=0. Time=14. ms
64 bytes from uunet.UU.NET A37.39.1.2): icmp_seq=0. Time=14. ms
64 bytes from uunet.UU.NET A37.39.1.2): icmp_seq=0. Time=14. ms
64 bytes from uunet.UU.NET A37.39.1.2): icmp_seq=0. Time=14. ms
uunet.UU.NET PING Statistics
5 packets transmitted. 5 packets received, 0% packet loss
round-trip (ms) min/avg/max=12/13/15
Хост bernard является рабочей станцией Sun, и мы хотим получить
статистику на уровне отдельных пакетов, поэтому в командную строку включен
параметр -s. Без него команда ping в Sun-версии выведет только сводную строку
uunet.uu.net is alive. Другие реализации ping по умолчанию выводят полную
статистику и не требуют ключа -s.
Проверка показывает наличие быстрой связи с хостом uunet.uu.net по
глобальной сети, без потери пакетов и с быстрым откликом. Цикл «запрос/ответ» между
хостами bernard и uunet.uu.net в среднем занимает всего 13 миллисекунд. Для
глобальной сети обычно более характерен небольшой процент потери пакетов
с примерно на порядок большим временем отклика. Статистика, выводимая
командой ping, помогает выявить низкоуровневые сетевые проблемы. В нее
включаются следующие основные показатели:
О Последовательность получения пакетов, определяемая порядковым номером
ICMP (icmp_seq) для каждого пакета.
О Время отклика (указывается в миллисекундах после строки time=).
О Процент потери пакетов (выводится в строке сводной информации в конце
выходных данных ping).
Если процент потери пакетов велик, время отклика очень велико, а пакеты
прибывают с нарушением исходного порядка, это может свидетельствовать о
физических сбоях сети. Если такие условия наблюдаются при попытке установить
связь на огромных расстояниях в глобальной сети, беспокоиться не о чем.
Протокол TCP/IP проектировался для работы в условиях ненадежных сетей, а для
некоторых глобальных сетей характерен высокий процент потери пакетов. Но
если подобные симптомы возникают в локальной сети, значит, происходит что-то
неладное.
В пределах кабельного сегмента локальной сети время отклика должно быть
близко к нулю, процент потери пакетов должен быть минимальным или
нулевым, а пакеты должны прибывать с сохранением исходного порядка.
Нарушение этих условий свидетельствует о проблемах в работе сетевого оборудования.
В сети Ethernet это может быть неправильное завершение кабеля, дефектный
сегмент кабеля или сбой в работе «активного» оборудования (например, репитера
или трансивера). Начните с проверки завершения кабеля, это просто —
завершающий резистор (терминатор) либо есть, либо его нет. Отсутствие терминатора
встречается весьма часто, особенно если кабель завершается в рабочей области,
доступной для пользователей.
Полезным средством выявления аппаратных проблем является рефлектометр
(TDR, Time Domain Reflectometer). Рефлектометр посылает сигнал по кабелю
и прослушивает вызванные им эхо-отклики. Информация выводится на
небольшом экране перед специалистом, выполняющим тестирование. На нормальном
графике небольшие пики отображаются только в местах подключения трансиве-
ров к сети. Рефлектометр заметно упрощает поиск дефектов в кабелях.
Результаты простого тестирования ping, даже если связь будет установлена
успешно, помогут локализовать наиболее вероятную причину возникших
проблем. Но для более подробного анализа и выяснения непосредственных причин
понадобятся более совершенные средства диагностики.
ПРИМЕЧАНИЕ
В некоторых системах (например, в Linux) команда ping выполняет обратное разрешение целевого
IP-адреса. Если DNS не работает, выполнение DNS займет много времени из-за ожидания тайм-
аута. В этом случае результаты выполнения ping лишь дезинформируют пользователя из-за долгой
задержки при тайм-ауте DNS. Чтобы этого не происходило, запускайте ping с ключом -п,
подавляющим разрешение имен.
Диагностика проблем на сетевом уровне
Сообщения no answer и cannot connect свидетельствуют об ошибках на нижнем
уровне сетевых протоколов. Если предварительная проверка указывает на
существование проблем, поиски следует сосредоточить на маршрутизации и на
сетевом уровне. В процессе диагностики на сетевом уровне используются команды
ifconfig, netstat и агр.
При вызове с одним аргументом, определяющим имя интерфейса, команда
ifconfig выводит текущие значения, назначенные этому интерфейсу. Например,
проверка интерфейса 1е0 для компьютера bernard дает следующий результат:
%ifconfig 1е0
1е0: flags-63<UP,BROADCAST,NOTRAILERS,RUNNING>
inet 128.66.12.2 netmask ffff0000 broadcast 128.66 0.0
Команда ifconfig выводит две строки. В первой строке отображается имя
интерфейса и его характеристики. Обратите особое внимание на следующие поля:
О UP — интерфейс активен и готов к использованию. Если интерфейс не активен,
активизируйте его командой ifconfig с правами суперпользователя (ifconfig leO
up). Если интерфейс не активизируется, замените сетевой кабель и повторите
попытку. Если новая попытка тоже завершается неудачей, проверьте
интерфейсное оборудование.
О RUNNING — интерфейс работает. Если интерфейс не работает, возможно, это
связано с неправильной установкой драйвера интерфейса. Системный
администратор должен проанализировать всю последовательность действий
по установке интерфейса и найти в ней ошибки или пропущенные операции.
Во второй строке выходных данных ifconfig отображается IP-адрес, маска
подсети (в шестнадцатеричном формате) и адрес широковещательной рассылки.
Проверьте содержимое этих полей и убедитесь в правильности конфигурации
сетевого интерфейса.
Команда агр
Команда агр предназначена для анализа проблем, связанных с преобразованием
IP-адресов в адреса Ethernet. В процессе диагностики особенно часто
применяются три ключа ipconfig:
О -а — вывод всех записей ARP в таблице.
О -d хост — удаление записи из таблицы ARP.
О -s хост адрес_ethernet — включение новой записи в таблицу ARP.
Ключи позволяют просмотреть текущее содержимое таблицы ARP, удалить
ошибочные записи и заменить их правильными. Возможность оперативного
исправления экономит время при поиске долгосрочных решений.
Если вы подозреваете, что таблица разрешения адресов содержит
неправильные данные, воспользуйтесь командой агр. Одним из верных признаков ошибок
в таблице ARP является сообщение о том, что на некоторую команду (ftp, telnet
и т. д.) ответил другой хост. Нерегулярно возникающие и исчезающие проблемы,
присущие только определенным хостам, также могут свидетельствовать о порче
содержимого таблицы ARP. Самая распространенная ошибка — назначение
одного IP-адреса двум системам. Хаотичный характер ошибок объясняется тем,
что запись в таблице ARP относится к хосту, быстрее ответившему на
последний запрос ARP. В некоторых случаях правильный хост отвечает быстрее.
Если вы предполагаете, что две системы используют один и тот же IP-адрес,
выведите содержимое таблицы ARP командой агр -а. Пример:
% агр -а
bernard A28.66.12.2) at 8:0:20:b:4a:71
annette A28.66.12.1) at 8:0:20:e:aa:40
bernadette A28.66.12.3) at 0:0:93:e0:80:bl
Проверка соответствия между IP-адресами и адресами Ethernet упрощается,
если у вас имеется информация о правильных адресах Ethernet всех хостов. По
этой причине администратору рекомендуется сохранять адреса Ethernet и IP
всех новых хостов, добавляемых в сеть. При наличии таких записей вы сможете
быстро найти любые ошибки в таблице.
Если таких записей нет, в диагностике проблемы вам помогут первые три байта
адреса Ethernet, определяющие производителя оборудования. Список префиксов
приведен в RFC 1340 «Assigned Numbers», раздел «Ethernet Vendor Address
Components».
В табл. 41.1 перечислены некоторые производители оборудования и
назначенные им префиксы. Например, из этой таблицы можно узнать, что первые две
записи ARP в нашем примере относятся к системам Sun (8:0:20). Если хост
bernadette тоже должен быть станцией Sun, префикс Proteon 0:0:93 укажет на то,
что маршрутизатор Proteon был ошибочно настроен с IP-адресом bernadette.
Таблица 41.1. Префиксы производителей оборудования Ethernet
Префикс Производитель Префикс Производитель
00:00:0С Cisco 08:00:0В Unisys
00:00:0F NeXT 08:00:10 AT&T
00:00:10 Sytek 08:00:11 Tektronix
00:00: ID Cabletron 08:00:14 Excelan
00:00:65 Network General 08:00:1A Data General
00:00:6B MIPS 08:00:1B Data General
00:00:77 MIPS 08:00: IE Apollo
00:00:89 Cayman Systems 08:00:20 Sun
00:00:93 Proteon 08:00:25 CDC
00:00:A2 Wellfleet 08:00:2B DEC
продолжение &
Таблица 41.1 (продолжение)
Префикс Производитель Префикс Производитель
00:00:А7 NCD 08:00:38 Bull
00:00:А9 Network Systems 08:00:39 Spider Systems
00:00:C0 Western Digital 08:00:46 Sony
00:00:C9 Emulex 08:04:47 Sequent
00:80:2D Xylogics Annex 08:00:5A IBM
00:AA:00 Intel 08:00:69 Silicon Graphics
00:DD:00 Ungermann-Bass 08:00:6E Excelan
00:DD:01 Ungermann-Bass 08:00:86 Imagen/QMS
02:07:01 MICOM/Interlan 08:00:87 Xyplex terminal servers
02:60:8C 3Com 08:00:89 Kinetics
08:00:02 3Com(Bridge) 08:00:8B Pyramid
08:00:03 ACC 08:00:90 Retix
08:00:05 Symbolics AA:00:03 DEC
08:00:08 BBN AA:00:04 DEC
08:00:09 Hewlett-Packard
Если ни проверка правильности записей, ни префиксы производителей так
и не помогут выявить источник ошибок ARP, попробуйте подключиться к
IP-адресу, указанному в записи ARP, через telnet. Если устройство поддерживает
telnet, возможно, вам удастся определить неправильно настроенный хост по
заставке, выводимой при подключении.
Проверка интерфейса командой netstat
Если тестирование наводит на мысль, что подключение к локальной сети
работает ненадежно, команда netstat -i может предоставить ценную информацию.
В следующем примере приведены выходные данные команды netstat -i:
% netstat -i
Name Mtu Net/Dest Address Ipkts Ierrs Opkts Oerrs Collis Queue
leO 1500 family.com annette 442697 2 633524 2 '50679 0
lo0 1536 loopback localhost 53040 0 53040 0 0 0
На строку интерфейса обратной связи 1о0 можно не обращать внимания.
Важна только строка «полноценного» сетевого интерфейса, причем
информация, полезная для диагностики, содержится только в пяти последних полях.
Начнем с последнего поля. Очередь (Queue) не должна содержать
неотправленных пакетов. Если интерфейс нормально работает, а система не
может доставить пакеты в сеть, можно заподозрить дефект в ответвительном кабеле
или сетевом интерфейсе. Замените кабель и проверьте, не исчезнет ли
проблема. Если проблема осталась, свяжитесь с поставщиком оборудования насчет
ремонта интерфейса.
Количество входных (Ierrs) и выходных (Oerrs) ошибок должно быть близко
к нулю. Независимо от объема трафика, проходящего через интерфейс, 100
ошибок в любом из этих полей — это слишком много. Высокое количество
выходных ошибок является признаком переполнения локального сегмента сети или
дефекта физического соединения между хостом и сетью. Высокое количество
входных ошибок указывает на переполнение сети, перегруженность локального
хоста или физический дефект сети. Физические дефекты выявляются при помощи
статистики ping или рефлектометра. Переполнение локальной сети Ethernet можно
оценить по частоте коллизий.
Высокое значение в поле количества коллизий (Collis) является обычным
явлением, но слишком большой процент выходных пакетов, приводящих к
коллизиям, указывает на переполнение сети. Если частота коллизий превышает 5
процентов, на ситуацию следует обратить пристальное внимание. Если во многих
системах, входящих в сеть, хронически наблюдаются высокие частоты коллизий,
возможно, сеть следует разделить для сокращения потоковой нагрузки.
Частота коллизий вычисляется в процентах от количества выходных
пакетов. При подсчете используется не общее количество принятых и отправленных
пакетов, а значения Opkts и Collis. Например, в выходных данных netstat из
предыдущего примера показаны 50 679 коллизий из 633 424 выходных пакетов. Таким
образом, частота коллизий составляет 8 процентов. Возможно, сеть в этом примере
подвергается чрезмерной нагрузке; проверьте статистику по другим хостам. Если
в других системах также наблюдается высокий процент коллизий, подумайте
о дальнейшем делении сети.
Проверка маршрутов
Сообщение network unreachable недвусмысленно указывает на проблемы с
маршрутизацией. Ошибки в таблице маршрутизации локального хоста легко
обнаруживаются и исправляются. Сначала команды netstat -nr и grep проверяют наличие
конечной точки в таблице маршрутизации. Следующий пример проверяет наличие
маршрута к сети 128.0.0.0:
% netstat -nr | grep '1284.84.04.0'
128.8.0.0 26.20.0.16 UG 0 37 std0
Если маршрут отсутствует в таблице маршрутизации, результат выполнения
команды будет пустым. Предположим, пользователь не может связаться через
Telnet с хостом nic.ddn.mil, а команда ping возвращает следующий результат:
% ping -s nic.ddn.m1l 56 2
PING n1c.ddn.mil: 56 data bytes
sendto: Network is unreachable
ping: wrote nic.ddn.mil 64 chars, ret=-l
sendto: Network is unreachable
ping: wrote nic.ddn.mil 64 chars, ret=-l
n1c.ddn.mil PING Statistics
2 packets transmitted, 0 packets reeived, 100% packet loss
Сообщение network unreachable означает, что мы должны проверить
таблицу маршрутизации пользователя. В данном примере ищется маршрут к хосту
nic.ddn.mil. Хосту nic.ddn.mil назначен IP-адрес 192.112.36.5, относящийся к
классу С. Помните, что маршруты состоят из адресов сетей, поэтому мы проверяем
маршрут к сети 192.112.36.0:
% netstat -nr | grep '192\.112\.36\.0'
%
Проверка показывает, что маршрут к сети 192.112.36.0 отсутствует в таблице.
Если бы маршрут был найден, утилита дгер отобразила бы его. При отсутствии
явно заданного маршрута следует произвести поиск маршрута по умолчанию.
В следующем примере этот маршрут найден успешно:
% netstat -nr | grep def
default 128.66.12.1 UG 0 101277 le0
Если netstat правильно отображает явно заданный маршрут или маршрут по
умолчанию, значит, проблема кроется не в таблице маршрутизации. В этом
случае следует проанализировать маршрут к конечной точке при помощи утилиты
traceroute, описанной ниже в этой главе.
Если netstat вопреки ожиданиям не возвращает предполагаемый маршрут,
значит, проблемы объясняются локальной ошибкой маршрутизации. Существует
два подхода к диагностике локальных ошибок маршрутизации в зависимости
от того, какой тип маршрутизации используется в системе (статическая или
динамическая маршрутизация). При использовании статической маршрутизации
отсутствующий маршрут создается командой route add. Помните, что многие
системы со статической маршрутизацией используют маршруты по умолчанию,
поэтому отсутствующий маршрут может быть маршрутом по умолчанию.
Проследите за тем, чтобы нужный маршрут включался в таблицу из стартовых
файлов при перезагрузке системы.
При использовании динамической маршрутизации проверьте, работает ли
программная поддержка маршрутизации. Например, следующая команда
проверяет работу демона gated:
% ps 'cat /etc/gated.pid'
PID TT STAT TIME COMMAND
27711 ? S 304:59 gated tep /etc/log/gated.log
Если демон маршрутизации не работает, перезапустите его и включите
режим трассировки. Трассировка позволяет выявить проблемы, приводящие к
аварийному завершению работы демона. В следующих двух разделах
рассматриваются обновления RIP и трассировка маршрутов.
Проверка обновлений RIP
Если демон маршрутизации работает нормально и локальная система
получает обновления маршрутных данных через протокол RIP (Routing Information
Protocol), проверьте обновления, получаемые от поставщиков RIP, утилитой
ripquery. Например, чтобы проверить обновления RIP, получаемые от annette
и bernadette, администратор bernard вводит следующую команду:
% ripquery -n -r annette bernadette
44 bytes from annette.family.comA28.66.12.1):
0.0.0.0, metric 3
26.0.0.0, metric 0
264 bytes from bernadette.family.comA28.66.12.3):
128.66.5.0, metric 2
128.66.3.0, metric 2
128.66.12.0, metric 2
128.66.13.0, metric 2
После первой строки с данными шлюза ripquery выводит содержимое
входящих пакетов RIP, по одной строке на каждый маршрут. Первая строка отчета
указывает, что утилита ripquery получила ответ от annette. За этой строкой следуют
еще две строки с маршрутами, полученными от annette. Хост annette
распространяет маршрут по умолчанию @.0.0.0) с метрикой 3 и свой прямой маршрут
к Milnet B6.0.0.0) с метрикой 0. Далее выводятся маршруты к другим подсетям,
полученные от хоста bernadette.
В приведенном примере утилита ripquery вызывается с двумя параметрами:
О -n — ripquery выводит все результаты в числовом виде. При вызове без
ключа -п утилита пытается преобразовать все IP-адреса в имена. Как правило,
утилиту стоит вызывать с ключом -п — выходные данные выглядят более
четко, и экономится время на разрешение имен.
О -г — для запроса данных у поставщика RIP утилита ripquery использует
команду RIP REQUEST вместо команды RIP POLL. Команда RIP POLL
поддерживается не всеми поставщиками. Вызов ripquery с ключом -г повышает
вероятность успешного ответа.
Маршруты, содержащиеся в этих обновлениях, должны соответствовать
имеющейся информации о структуре сети. В противном случае (или если утилита вообще
не возвращает информации) проверьте конфигурацию поставщиков данных RIP.
В результате ошибок в настройке маршрутизации поставщики данных RIP
начинают передавать неверную информацию. Проблемы такого рода выявляются
только посредством анализа доступной информации о конфигурации сети. Чтобы
найти ошибку, необходимо знать, как выглядят правильные данные. Не
надейтесь получить очевидные признаки типа сообщения об ошибках или явно
искаженных маршрутов.
Трассировка маршрутов
Если локальная таблица маршрутизации и поставщики данных RIP содержат
правильную информацию, вероятно, проблема возникает на некотором расстоянии
от локального хоста. Удаленные проблемы маршрутизации обычно
сопровождаются сообщениями no answer или network unreachable, однако сообщение network
unreachable не всегда свидетельствует о проблемах маршрутизации. Возможно,
удаленная сеть недоступна из-за сбоя где-то на участке между локальным и
удаленным хостом. Программа traceroute помогает находить ошибки такого рода.
Утилита traceroute трассирует маршруты пакетов UDP от локального к
удаленному хосту. Она выводит имена (если их удается определить) и IP-адреса
всех маршрутизаторов на пути к удаленному хосту.
Для отслеживания маршрута пакета к месту назначения traceroute использует
два приема: малые значения срока жизни (TTL, Time-To-Live) и
недействительный номер порта. Для обнаружения промежуточных маршрутизаторов traceroute
передает пакеты UDP с малым сроком жизни. Значение счетчика начинается с 1
и увеличивается с единичным приращением для каждой группы из трех пакетов
UDP. Получая пакет, маршрутизатор уменьшает поле TTL. Если значение падает
до нуля, пакет не пересылается дальше и отправителю возвращается сообщение
ICMP Time Exceeded. Утилита traceroute выводит одну строку выходных данных
для каждого маршрутизатора, от которого было получено сообщение Time Exceeded.
Когда приемный хост получает пакет от traceroute, он возвращает сообщение
ICMP Unreachable Port. Это происходит из-за того, что traceroute намеренно
использует недопустимый номер порта C3434) для принудительного вызова ошибки.
Когда утилита traceroute получает сообщение о недопустимом номере порта, она
знает, что пакет добрался до конечного хоста, и завершает трассировку. Таким
образом, traceroute строит список промежуточных маршрутизаторов, начиная с
расстояния в один переход и заканчивая хостом-получателем.
Следующий пример показывает результат трассировки к хосту nic.ddn.mil.
Утилита traceroute посылает три пакета с каждым значением TTL. Если пакет
остается без ответа, traceroute выводит символ *. При получении ответа traceroute
выводит имя и адрес ответившего маршрутизатора вместе с временем отклика
в миллисекундах.
% traceroute n1c.ddn.m1l
traceroute to n1c.ddn.m1l A92.112.36.5). 30 hops max, 40 byte packets
1 * pgw A29.6.80.254) 4 ms 3 ms
2 129.6.1.242 A29.6.1.242) 4 ms 4 ms 3 ms
3 129.6.2.252 A29.6.2.252) 5 ms 5 ms 4 ms
4 128.167.122.1 A28.167.122.1) 50 ms 6 ms 6 ms
5 * 192.80.214.247 A92.80.214.247) 96 ms 18 ms
6 129.140.9.10 A29.140.9.10) 18 ms 25 ms 15 ms
7 nsn.sura.net A92.80.214.253) 21 ms 18 ms 23 ms
8 GSI.NSN.NASA.GOV A28.161.252.2) 22 ms 34 ms 27 ms
9 NIC.DDN.MIL A92.112.36.5) 37 ms 29 ms 34 ms
Трассировка показывает, что маршрут включает восемь промежуточных
шлюзов, что пакеты успешно передаются до конечной цели, а время прохождения
пакетов от текущего хоста до nic.dd.mil и обратно составляет примерно 33 миллисекунды.
Из-за различий и ошибок в реализации ICMP на разных типах
маршрутизаторов, а также непредсказуемой природы перемещения дейтаграммы в сети
traceroute иногда выдает весьма странные результаты. По этой причине не стоит
слишком подробно анализировать данные traceroute. Основное внимание стоит
обратить на следующее:
О Добрался ли пакет до места назначения?
0 А если не добрался, то где он остановился?
Ниже приведена другая трассировка пути до хоста nic.ddn.mil. На этот раз
пакет не дошел до NIC.
% traceroute nic.ddn.mil
traceroute to nic.ddn.mil A92.112.36.5), 30 hops max, 40 byte packets
1 * pgw A29.6.80.254) 4 ms 3 ms
2 129.6.1.242 A29.6.1.242) 4 ms 4 ms 3 ms
3 129.6.2.252 A29.6.2.252) 5 ms 5ms 4ms
4 128.167.122.1 A28.167.122.1) 6 ms 6 ms 10 ms
5 enss.sura.net A92.80.214.247) 9 ms 6 ms 8 ms
6 t3-l.cnss58.t3.nsf.net A40.222.58.2) 10 ms 15 ms 13 ms
7 t3-0.nssl42.t3.nsf.net D02.222.142.1) 13 ms 12 ms 12 ms
8 GSI.N5N.NASA.GOV A28.161.252.2) 22 ms 26 ms 21 ms
g * * *
10* * *
29* * *
30* * *
Если программе traceroute не удается доставить пакеты в конечную систему,
трассировка обрывается и в каждой строке выводятся три звездочки до тех пор,
пока счетчик не достигнет 30. Если это произойдет, свяжитесь с
администратором удаленного хоста, с которым вы хотите связаться, и администратором
последнего шлюза, включенного в маршрут. Изложите суть проблемы; возможно,
им удастся вам помочь. В приведенном примере последний отклик на пакет был
получен от GSI.NSN.NASA.GOV. Вероятно, стоит связаться с системным
администратором этой системы и администратором nic.ddn.mjl.
Проверка службы имен
Сообщение unknown host error, возвращаемое пользователем приложения,
свидетельствует о проблемах на сервере. Проблемы серверов имен обычно выявляются
при помощи утилит nslookup и dig. По своим функциональным возможностям
утилита dig сходна с nslookup. Но прежде чем знакомиться с dig, давайте вернемся
к nslookup и посмотрим, как эта программа применяется при отладке службы имен.
При диагностике проблем с удаленными серверами имен особенно важны
следующие три основные возможности nslookup:
О поиск авторитетных серверов для удаленного домена с использованием
запроса NS;
О получение всей информации об удаленном хосте с применением запроса ANY;
О просмотр всех записей удаленной зоны командами nslookup Is и view.
Во время поиска проблем с удаленным сервером обратитесь с прямым
запросом к авторитетным серверам, возвращенным запросом NS. Не полагайтесь на
информацию, возвращаемую не-авторитетными серверами. Если проблемы имеют
нерегулярный характер, последовательно опросите все авторитетные серверы
и сравните их ответы. Возвращение удаленными серверами разных ответов на
один запрос иногда порождает хаотические проблемы разрешения имен. .
Запрос ANY возвращает все записи, относящиеся к хосту, и поэтому
предоставляет самый широкий интервал диагностической информации. Даже если вы
просто знаете, какая информация доступна (или недоступна), это поможет в
решении многих проблем. Например, если запрос возвращает запись MX, но не
возвращает запись А, нетрудно понять, почему пользователь не может связаться
с хостом через Telnet! Многие хосты доступны для электронной почты, но
недоступны для других сетевых служб. В этом случае пользователь просто
пытается связаться с удаленным хостом неподходящим способом.
Если вам не удается найти никакой информации о хосте, имя которого было
сообщено пользователем, возможно, в имени допущена ошибка. В этом случае
найти правильное имя не проще, чем найти иголку в стоге сена. К счастью, на
помощь приходит утилита nslookup. Команда nslookup Is выводит сведения об
удаленной зоне и перенаправляет листинг в файл. Затем команда nslookup view ищет
в файле имена, похожие на имя, указанное пользователем. На практике многие
проблемы возникают из-за ошибок в написании имени хоста.
Вместо nslookup для выполнения запросов к службе имен также можно
воспользоваться утилитой dig. Запросы dig обычно вводятся в виде однострочных команд,
тогда как nslookup обычно работает в интерактивном режиме. Но в целом команда
dig выполняет практически те же функции, что и nslookup, и выбор зависит в
основном от личных предпочтений. Обе программы справляются со своими задачами.
Допустим, вы хотите запросить у корневого сервера aggie.nca&t.edu записи NS
для домена jhu.edu. Введите следующую команду:
% dig @aggie.nca&t.edu jhu.edu ns
В этом примере @aggie.nca&t.edu — сервер, которому адресуется запрос.
Сервер задается по имени или IP-адресу. Если вы занимаетесь поиском проблем в
удаленном домене, укажите авторитетный сервер для этого домена. В
приведенном примере запрашиваются имена серверов домена верхнего уровня (jhu.edu),
поэтому мы обращаемся к корневому серверу.
Диагностика сетевого интерфейса
Хотя на этом уровне происходит не так уж много содержательных операций,
проблемы обычно встречаются в нижней части стека. Проблемы, возникающие
на этом уровне, делятся на четыре типа:
О Физические соединения. Сети TCP/IP, как и любые другие сети, лучше
работают при подключенных кабелях. Всегда начинайте с проверки кабеля.
О Клиенту DHCP не назначен IP-адрес. Этот факт должен быть очевиден для
пользователя, поскольку на экране выводится большое сообщение. IP-адрес
может быть получен двумя способами: либо он назначается статически, либо
динамически получается с сервера DHCP (Dynamic Host Configuration
Protocol). Полученные адреса проверяются утилитой ifconfig в Unix, winipcfg в
Windows 9х или ipconfig в Windows NT/2000.
О Проблемы ARP. При ошибках в работе протокола ARP IP-адрес не удастся
преобразовать в физический адрес MAC. Утилита агр, упоминавшаяся выше
в этой главе, проверяет правильность разрешения адресов.
О Дублирование IP-адресов в сети. Другая проблема, с которой вы также
можете столкнуться, — назначение одинаковых IP-адресов двум системам в сети.
Такого быть не должно, но если все же произойдет, при разных попытках
разрешения могут быть получены разные адреса MAC.
Проблемы ARP обычно возникают только в одном случае — при добавлении
статических записей в кэш ARP по соображениям быстродействия. При измене-
нии сетевого адаптера в системе, IP-адрес которой был введен в таблицу,
статическая загрузка данных ARP вызовет проблемы. Чтобы выявить эти проблемы,
воспользуйтесь утилитой агр.
Диагностика на сетевом уровне (IP)
Как говорилось выше, сетевой уровень отвечает за маршрутизацию пакетов. На
нем вам придется тщательно проверить IP-адрес, маску подсети и данные
основного шлюза. Помимо конфигурации также возможны проблемы с таблицами
маршрутизации и маршрутизаторами где-то между вашей системой и той
системой, с которой вы пытаетесь связаться.
Параметры конфигурации TCP/IP
Конфигурация TCP/IP определяется тремя основными параметрами: IP-адресом,
маской подсети и основным шлюзом, который обычно соответствует интерфейсу
маршрутизатора к сегменту вашей сети. В среде Windows эти параметры
настраиваются на вкладке Протоколы (Protocols) в диалоговом окне Сеть (Network),
а в системе Unix они вводятся в командной строке ifconfig. Хотя IP-адрес может
быть получен от сервера DHCP, на данный момент описание ориентируется на
значения, вводимые вручную.
Если хотя бы один из трех основных параметров TCP/IP будет введен
неправильно, связь через TCP/IP станет невозможной. Ошибки конфигурации
часто происходят из-за обычных опечаток; неверно указанный IP-адрес, маска
подсети или основной шлюз приведет к тому, что связь будет работать с
ошибками или не будет работать вообще.
Ошибки в разных конфигурационных параметрах приводят к возникновению
разных проблем. Процедуры идентификации и исправления ошибок будут
рассмотрены в нескольких следующих разделах.
Ошибки конфигурации
Иногда неверно заданный адрес TCP/IP не вызывает особых проблем. Если
адрес принадлежит к правильной подсети и не дублируется, но использует
неверно заданный идентификатор хоста, вполне вероятно, что обмен данными
с клиентом будет происходить нормально. Но если правильный IP-адрес был
введен в статический файл или базу данных, по которым имена хостов
преобразуются в IP-адреса (например, файл LMHOSTS или файл базы данных DNS),
возникнут неизбежные проблемы. Таким образом, в общем случае
неправильный IP-адрес мешает работе TCP/IP.
Неправильная конфигурация параметров TCP/IP характеризуется различными
симптомами в зависимости от конкретного параметра. Ниже кратко описаны
последствия от ошибок, допущенных в разных параметрах TCP/IP.
1Р-адрес
Адрес TCP/IP содержит два или три компонента, однозначно определяющих
сетевое подключение, которому назначен этот адрес. IP-адрес определяет как
минимум адрес сети и адрес хоста в этой сети. Кроме того, при использовании
подсетей, третья часть адреса определяет адрес подсети.
На рис. 41.1 показано, к каким последствиям приводит ошибка в сетевом адресе.
В этом примере клиенту был назначен адрес 143.168.2.9, тогда как правильный
адрес должен иметь вид 133.168.2.9. Неправильный адрес содержит
идентификатор сети 143.168.x.х, тогда как идентификатор сети правильного адреса
должен выглядеть как 133.168.х.х.
Неправильный адрес 143.168.3.9 не позволит клиенту общаться с другими
хостами TCP/IP. Поскольку идентификатор сети задан ошибочно, все пакеты,
отправляемые этим клиентом, будут передаваться по неверному маршруту.
Если хост с неправильным адресом 143.168.3.9 отправит сообщение
локальному клиенту A33.168.3.20), из конфигурации TCP/IP хоста-отправителя будет
следовать, что этот адрес является удаленным, поскольку идентификатор сети
получателя отличается от идентификатора сети отправителя. Пакет даже не
доберется до локального клиента, поскольку адрес 133.168.3.20 интерпретируется
как удаленный адрес.
Если локальный клиент A33.168.3.6) отправляет сообщение хосту с
неправильным адресом A43.168.3.9), это сообщение также не дойдет до получателя.
Оно либо маршрутизируется (если локальный клиент отправляет сообщение по
неправильному IP-адресу), либо остается в локальной подсети (если локальный
клиент отправляет сообщение по правильному адресу 133.168.3.9). В случае
маршрутизации клиент с неправильным адресом не получит сообщение,
поскольку он находится в одном сегменте сети с локальным клиентом. Если
сообщение не маршрутизируется, оно все равно не доберется до клиента, потому что
IP-адрес получателя A33.168.3.9) не совпадает с адресом, указанным в
конфигурации клиента A43.168.3.9).
yS yS 133.168.3.10 >v
/ /С^язь невозможна \ Удаленный
/ yS из-за несовпадения \ ^
Н'""""\/г идентификаторов сетей Маршрутизатор [Sjffffi^l
. ими Л Связь невозможна, ЩЩ^щшЩЩшШт t ™y*75Sffi J
1^ПТ*ШГ= поскольку локальный 133168 31 |^ГЯДЩд
L^Mlm..;.; --^^ маршрутизатор ' 'BHihiHumllw
133.168.3.9v не найдет клиента У
133.168.3.8
Рис. 41.1. Последствия неправильного назначения IP-адреса
На рис. 41.2 приведен другой пример ошибочного IP-адреса. На этот раз
используется адрес класса А (ЗЗ.х.х.х). Маска подсети B55.255.0.0) указывает на
то, что второй октет используется для определения подсети. Хотя
идентификатор сети клиента совпадает с идентификаторами сетей других клиентов,
идентификаторы подсети различаются из-за ошибки при вводе адреса.
На этот раз неправильный адрес определяет неправильный номер подсети.
Клиент 33.5.8.4 принадлежит подсети 5, тогда как остальные клиенты подсети
имеют адреса 33.4.х.х. Если клиент 33.5.8.4 пытается связаться с другими
клиентами той же подсети, сообщение будет маршрутизироваться, потому что
идентификатор подсети не совпадает с идентификатором подсети хоста-отправителя.
Если клиент 33.5.8.4 пытается отправить сообщение удаленному хосту,
сообщение маршрутизируется, однако ответа клиент не получит — маршрутизатор
обслуживает только подсеть 4, но не подсеть 5.
/г yS 33.4.8.5 ^Ч
/ у/ Связь невозможна, поскольку \ Удаленный
/ у^ трафик маршрутизируется \ х^>ст
^^лт1у Связь невозможна, поскольку ^^ffrWF^
IpM | j-_4==j] маршрутизатор не вернет 33.4.8.1 \ШШ\\ , .' \
33.5.8.4 v ответ клиенту в ЗЗ.б.х.х. У
33.4.8.3
Рис. 41.2. Последствия ошибки в идентификаторе подсети
Если локальный клиент попытается отправить сообщение по адресу 33.5.8.4,
сообщение не достигнет получателя. Если адрес используется в том виде, в
котором он задан в конфигурации, сообщение маршрутизируется, а это нежелательно,
поскольку предполагаемый хост-получатель является локальным. Если
локальный клиент посылает сообщение по правильному IP-адресу, хост 33.5.8.4 также
не получит это сообщение, поскольку его IP-адрес отличается от указанного.
Последний компонент IP-адреса, который может стать причиной проблем со
связью, — идентификатор хоста. Впрочем, ошибка в идентификаторе хоста не
всегда мешает нормальной связи. На рис. 41.3 локальному клиенту назначен
неправильный IP-адрес, в котором ошибка допущена только в идентификаторе
хоста. Идентификаторы сети и подсети соответствуют идентификаторам других
клиентов подсети.
Подсеть ЗЗ.х.х.х
с неправильной
маской подсети
255.255.0.0
/ Г 33.4.8.5 \
/ / _ \ Удаленный
/ / Связь невозможна, поскольку \ Vrt„
/ grzzzzfi / . * \ ХОСТ I^SSI
I •13111/ трафик маршрутизируется I (———, |||И
Ml lIFji из-за ошибки Маршрутизатор МШ |pf|
■^^В 'В11 В 0ПРеДелении ПОДСеТИ ДШ;,ДйА | Я^В I ЯЙ!
/™jjjf^[fiC СВЯЗЬ НеВОЗМОЖНа, ПОПКПЛЫсуШШШжШШшк JsaSSSSmC '
шШШЩЛь маршрутизатор не вернет 33.4.8.1 ЖШМгШШк
33 5 8 4\ ответ клиенту в ЗЗ.б.х.х. /
33.4.8.3
Рис. 41.3. Последствия ошибки в идентификаторе хоста
В этом случае сообщение, отправленное клиенту по неправильному адресу,
будет доставлено успешно. С другой стороны, попытка связаться с клиентом по
правильному адресу завершится неудачей. Более того, она может привести к
установлению связи с другим хостом, адрес которого должен был назначаться
исходному хосту.
Если в результате ошибки настройки исходному хосту будет присвоен
IP-адрес, совпадающий с IP-адресом другого хоста, первый клиент начнет работать,
но второй клиент при запуске может обнаружить конфликт адресов и отказаться
от загрузки стека TCP/IP. В этом случае второй клиент не сможет участвовать
в коммуникациях TCP/IP.
Другая проблема возникает в том случае, если правильный адрес
зарегистрирован в статических файлах (например, LMHOSTS или в базе данных DNS). В
подобных ситуациях никто не сможет связаться с клиентом по имени, поскольку
в результате разрешения имени для хоста всегда будет возвращаться
правильный адрес, по которому связаться с хостом не удастся из-за ошибки,
допущенной при вводе адреса.
Проблемы, возникающие при неверном вводе адресов хостов, обычно носят
нерегулярный характер. Но если хост был настроен как клиент WINS (в опера-
ционных системах семейства Windows), то имя хоста будет зарегистрировано
с неправильным адресом. Другой клиент WINS, пытающийся связаться с ;гшм
хостом, получит IP-адрес, зарегистрированный для заданного имени
(неправильный, но работающий!).
Маска подсети
Маска подсети указывает, каким образом октеты IP-адреса разделяются на
идентификаторы сети и хоста. Кроме того, маска подсети может использоваться для
разрешения идентификатора хоста на подсети. Если при настройке маски
подсети допущена ошибка, клиенты либо вообще не смогут взаимодействовать,
либо связь будет сопровождаться хроническими проблемами.
На рис. 41.4 изображена подсеть сети TCP/IP, использующей адрес класса В
138.13.X.X. Третий октет в данном случае используется для формирования
подсетей, поэтому все клиенты на рисунке должны принадлежать подсети 4, на что
указывает общая часть адреса 138.13.4.x.
1Р-адрес 138.13.4.6
Маска подсети 255.255.255.0
/ yS Маска подсети указывает \ даленныи
/ yS на принадлежность к одной \
■ \s подсети, что в данном Маршрутизатор [,:У^РИ||
;; случае соответствует истине ^жж;жжж»а жВ$Ш\
у г ■■; '^BmrrJ Маска подсети указывает И™Д^М1«^8 i, Мтшии, I
r^B'IT^fe^l на принадлежность к одной 138.13.4.1 l^^Tf^^f^gg]
'■'■■"'■■■■'■'■"'и"^ подсети, поэтому трафик у '■' '■ ■
IP-адрес 138.13.4.5 не маршрутизируется. Сообщение У 138.13.3.26
Маска подсети 255.255.0.0 не доходит до получателя ^У
IP-адрес 138.13.4.4
Маска подсети 255.255.255.0
Рис. 41.4. Даже если IP-адрес задан правильно, ошибка в маске подсети приводит
к использованию неправильного идентификатора подсети
Но по ошибке одному из клиентов была назначена маска подсети 255.255.0.0.
Когда клиент пытается связаться с другими хостами той же подсети, он
связывается с ними нормально — маска указывает, что они принадлежат к одной
подсети, что соответствует действительности. Но попытка связаться с хостом
другой подсети — например, 138.13.3.x — завершается неудачей.
В этом случае маска подсети по-прежнему указывает на то, что
хост-получатель находится в одной подсети с отправителем, поэтому сообщение не
маршрутизируется. Но так как на самом деле получатель находится в другой подсети,
сообщение не попадает к предполагаемому получателю. Маска подсети
используется при маршрутизации исходящего трафика, поэтому клиент с
неправильной маской может получать входящие сообщения. Но когда он попытается на
них ответить и при этом находится в разных подсетях с получателем,
сообщение не маршрутизируется.
Таким образом, клиент с неправильной маской подсети может участвовать
только в одностороннем обмене данными. Связь с хостами за пределами
локального сегмента сети продолжает работать нормально, поскольку они требуют
маршрутизации.
На рис. 41.5 изображена маска подсети, содержащая лишние биты. В данном
случае маска подсети равна 255.255.255.0, однако проектировщики сети
предполагали использование маски 255.255.240.0; первые четыре бита третьего октета
определяют подсеть, а оставшиеся четыре бита являются частью идентификатора хоста.
Подсеть 138.13.16-31.х
IP-адрес 138.13.19.1
Маска подсети 255.255.240.0
/ /"Трафик маршрутизируется. \ удаленный
/ / Согласно маске подсети \ хост
( , / . л у/ адрес интерпретируется, \ f .,_,_••• _. 1
\ШЛш\ как принадлежащий Маршрутизатор ЯКЁёН
[Я^^^Н маршрутизируется 138.13.16.1 [мщЬ^1^
IP-адрес 138.13.18.1 / 138.13.32.1
Маска подсети 255.255.255.0 ./
g—|П LSS3|
IP-адрес 138.13.17.1
Маска подсети 255.255.240.0
Рис. 41.5. Проблемы со связью будут возникать и в том случае,
если маска подсети содержит лишние биты
Если правильно настроенный клиент попытается отправить сообщение
локальному хосту с одинаковым значением третьего октета, сообщение не маршрута-
зируется и достигает клиента. Но если адрес локального клиента отличается
в последних четырех битах третьего октета, то сообщение передается на
маршрутизацию и не попадает в точку назначения. Если неправильно настроенный
клиент пытается отправить сообщение другому клиенту в другой подсети, это
сообщение будет маршрутизировано из-за различий в третьем октете.
Проблемы с маской подсети также приводят к нерегулярным сбоям
соединений: связь то работает, то не работает. Проблемы возникают в тех случаях, когда
IP-адрес получателя приводит к маршрутизации пакета там, где она не нужна,
или к локальной передаче пакета там, где он должен маршрутизироваться.
Основной шлюз
Адрес основного шлюза определяет адрес маршрутизатора — окна во внешний
мир, лежащий за пределами локальной подсети. Если адрес основного шлюза
клиента задан неверно, клиент сможет связываться с локальными хостами, но
сеть за пределами локального сегмента станет для него полностью недоступной.
Возможно, неправильно настроенный клиент сможет принимать сообщения,
поскольку основной шлюз используется только для передачи пакетов другим
хостам. Но как только такой клиент попытается ответить на полученное
сообщение, адрес основного шлюза не сработает, и ответ не достигнет хоста,
отправившего исходное сообщение.
Диагностика проблем TCP и UDP
На транспортном уровне проблемы возникают крайне редко. Если вам удается
установить связь через ping, значит, транспортный уровень работает нормально.
Единственная проблема, встречающаяся на этом уровне, связана с размером окна
TCPWindowSize (см. главу 9).
Обычно эта проблема приводит к низкой скорости обмена данными (как на
110-бодовых терминалах 1970-х и 80-х годов). Но если вы проверили все
остальное, чтобы быстро проверить TCPWindowSize (например, в Windows NT/2000),
откройте реестр и поищите в нем параметр Window Size. Если параметр существует,
запомните его и удалите значение. Размер окна вернется к прежнему значению.
Проблемы с сокетами
Даже если на хосте задан правильный IP-адрес и настроена программная
поддержка протокола, даже если он успешно находит маршрут к удаленному
компьютеру, на последнем должны работать необходимые службы на правильных
сокетах. Если вы предоставляете сетевые службы для внешнего доступа или
наоборот, пытаетесь подключиться к ним, вы в любом случае должны знать номера
используемых портов.
Стандартные номера портов (сокетов) присваиваются агентством IANA (Internet
Assigned Numbers Authority); тем не менее в некоторых случаях службы могут
использовать другие порты. Правильность выбора используемого порта можно
проверить по специальному служебному файлу (см. ниже). После проверки
выполните команду netstat и убедитесь в том, что порт готов к приему данных.
Файл SERVICES
Файл SERVICES в системе Windows NT/2000 находится в каталоге system32\
drivers\etc и используется большинством системных служб, инициализирующих
сокеты на стадии собственной инициализации. Ниже приведен небольшой
фрагмент файла SERVICES.
# Этот файл содержит номера портов для стандартных служб,
# определенные IANA
#
# Формат:
#
# <служба> <номер порта>/<протокол> [псевдонимы...] [#<комментарий>]
#
echo 7/tcp
echo 7/udp
discard 9/tcp sink null
discard 9/udp sink null
systat 11/tcp users #Active users
systat 11/tcp users #Active users
daytime 13/tcp
daytime 13/udp
qotd 17/tcp quote #Quote of the day
qotd 17/udp quote #Quote of the day
chargen 19/tcp ttytst source #Character generator
chargen 19/udp ttytst source #Character generator
ftp-data 20/tcp #FTP, data
ftp 21/tcp #FTP. control
telnet 23/tcp
smtp 25/tcp mail #Simple Mail Transfer
Protocol
time 37/tcp timserver
time 37/udp timserver
rip 39/udp resource #Resource Location
Protocol
nameserver 42/tcp name #Host Name Server
nameserver 42/udp name #Host Name Server
nicname 43/tcp whois
Если у вас возникают проблемы с конкретными службами, проверьте,
присутствуют ли имена этих служб в файле, и убедитесь в правильности номеров
назначенных портов. Если служба отсутствует в файле, возможно, ее придется
добавить вручную, чтобы система знала, на каком порте должна
инициализироваться служба (файл SERVICES имеет обычный текстовый формат и
редактируется в таких программах, как Edit или Блокнот).
Диагностика на прикладном уровне
Наконец мы добрались до прикладного уровня. Проблемы, возникающие на этом
уровне, делятся на две основные категории: проблемы NetBIOS и проблемы
разрешения имен. На практике чаще всего встречаются проблемы разрешения
имен, влияющие на работу как сокетных приложений, так и приложений NetBIOS.
В этом разделе кратко рассматриваются основные проблемы разрешения имен.
Проблемы разрешения имен
Если поддержка TCP/IP была правильно настроена, если протокол установлен
и работает в системе, то проблемы связи, вероятно, обусловлены ошибками
разрешения хостовых имен. При проверке связи на уровне адресов TCP/IP
одновременно проверяется более низкий уровень, на котором обычно работают
пользователи.
Когда пользователь желает связаться с сетевым ресурсом (например,
подключить диск с сервера или загрузить web-сайт), он обычно указывает имя сервера
или web-сайта вместо его IP-адреса. Более того, IP-адреса отдельных серверов
обычно остаются неизвестными для пользователей. Однако для этого имена,
используемые для установления связи, должны быть преобразованы в IP-адреса,
используемые сетевыми программами для установления связи.
После проверки связи на уровне IP следующим логичным шагом станет
проверка разрешения имен в IP-адреса. Если имя не преобразуется в IP-адрес или
преобразуется неправильно, пользователи не смогут обращаться к сетевым
ресурсам по этому имени, даже если ресурс доступен через IP-адрес.
Как известно, при обмене данными в сети используются два типа имен. Имя
NetBIOS присваивается компьютеру с поддержкой NetBIOS (например, серверу
Windows NT/2000 или системе Windows 9x); хостовое имя присваивается всем
компьютерам, включая серверы Unix. В общем случае при организации
совместного доступа к файлам, принтерам и приложениям в сетях Microsoft обычно
используются имена NetBIOS. Однако при выполнении специфических команд
TCP/IP (например, через FTP или браузер) указываются хостовые имена
компьютеров.
Итоги
Проблемы гораздо чаще возникают из-за ошибок конфигурации TCP/IP, нежели
из-за ошибок реализации протокола TCP/IP. Большинство таких проблем
выявляется анализом с применением простых утилит, о которых говорилось выше.
Но в отдельных случаях не обойтись без анализа протокольного трафика между
двумя системами, а в худшем случае приходится анализировать пакеты потока
данных на уровне отдельных битов.
A RFC и стандарты
Тим Паркер (Tim Parker)
Большая часть информации о семействе протоколов TCP/IP публикуется в виде
запросов на комментарии, или RFC (Request for Comments). RFC определяют
различные аспекты протоколов, их области применения и управления
протоколом в неформально связанных документов.
RFC содержат много бесполезной информации (в основном специфической
для конкретных систем или заметно устаревшей), но также в них можно найти
массу полезных деталей. Как ни удивительно, в RFC встречаются
занимательные и юмористические статьи, включая такие классические работы, как «Twas
the Night Before Start-up» (RFC 968), «ARPAWOCKY» (RFC 527) и «TELNET
Randomly-Lose Option» (RFC 748).
В настоящем приложении перечислены наиболее важные или интересные RFC,
заслуживающие внимания читателей. Также приводится информация о том, где
найти RFC. Список не полон; из него исключены старые и неактуальные RFC.
Информационные ресурсы
RFC можно получить несколькими способами, проще всего — в электронном виде.
Также распространяются бумажные копии, но для этого требуется специальный
запрос. Электронные версии обычно распространяются в формате ASCII, хотя
некоторые из них хранятся в формате PostScript и для их вывода требуется
интерпретатор PostScript. Большинство электронных RFC не содержат диаграмм,
рисунков и чертежей.
World Wide Web
Подборки RFC имеются на многих сайтах World Wide Web. Чтобы найти их,
проще всего воспользоваться поисковой системой и ввести строку «RFC». На
большинстве сайтов RFC перечисляются в виде простого списка, упорядоченного
по номерам, но в отдельных случаях производится группировка документов по
самым интересным темами (хотя списки обычно получаются неполными).
Официальный перечень RFC представлен на сайте http://www.rfc-editor.org.
FTP
RFC можно загрузить через FTP с сайта NIC (Network Information Center) или
других сайтов FTP. Через клиента FTP обратитесь к архиву NIC NIC.DDN.MIL,
введите имя guest и пароль anonymous. Далее RFC загружаются командой FTP
get следующего формата:
<RFC>RFC527.txt
Вместо 527 подставляется номер нужного RPC. Загрузка материалов из архива
NIC через FTP возможна только с компьютера, подключенного к Интернету.
Электронная почта
Тексты RFC также рассылаются по электронной почте. NIC и информационный
центр NFSNET поддерживают службы автоматизированной рассылки текстов.
Обе службы ищут во входящем сообщении ключевые слова, определяющие
запрашиваемый документ, и адрес электронной почты отправителя, после чего
отправляют запрашиваемый RFC.
Чтобы получить RFC от NIC, отправьте по адресу service@nic.ddn.mil
сообщение, у которого в поле темы указан нужный документ. Если потребуется
дополнительная информация о работе службы электронной рассылки NIC, отправьте
сообщение с темой help.
Чтобы получить RFC от информационного центра NFSNET, отправьте
сообщение, у которого первые две строки текста выглядят так:
REQUEST: RFC
TOPIC: 527
Первая строка определяет тип запрашиваемого документа (RFC), а во второй
строке указывается номер RFC. Сообщение отправляется по адресу info-server@
sh.cs.net. Чтобы получить дополнительную информацию, укажите в строке TOPIC
слово help.
Бумажные копии
При отсутствии доступа к электронной связи можно запросить бумажную
копию RFC. Для этого обратитесь в NIC по телефону 1 —800—235—3155.
Нехорошо заставлять персонал NIC ожидать, пока вы найдете нужный
документ. Подготовьте список заранее, чтобы разговор был кратким и деловым.
Операторы ежедневно отвечают на множество звонков и обычно сильно загружены.
Тематический список полезных RFC
В следующем списке перечислены многие RFC, содержащие подробную
информацию о протоколах и их использовании или более общую информацию по
конкретным темам, относящимся к TCP/IP. Многие RFC не вошли в список
либо потому, что они были заменены и потеряли актуальность, либо потому, что
их содержимое не имеет отношения к TCP/IP. RFC отбирались автором книги
на основании его личных предпочтений, поэтому если вы не найдете
интересующей вас информации, обратитесь к полному списку RFC.
Общие сведения
RFC1340 «Assigned Numbers», Reynolds, J.К; Postel, J.В.; 1992
RFC1360 «IAB Official Protocol Standards», Postel, J.B.; 1992
RFC1208 «Glossary of Networking Terms», Jacobsen, O.J.; Lynch, D.C.; 1991
RFC1180 «TCP/IP Tutorial», Socolofsky, T.J.; Kale, CJ.; 1991
RFC1178 «Choosing a Name For Your Computer», Libes, D.; 1990
RFC1175 «FYI on Where to Start: A Bibliography of Internetworking Information», Bowers, K.L.;
LaQuey, T.L; Reynolds, J.K.; Roubicek, K.; Stahl, M.K.; Yuan, A.; 1990
RFC1173 «Responsibilities of Host and Network Managers: A Summary of the 'oral tradition' of the
Internet», VanBokkelen, J.; 1990
RFC1166 «Internet Numbers», Kirkpatrick, S.; Stahl, M.K.; Recker, M.; 1990
RFC1127 «Perspective on the Host Requirements RFCs», Braden, R.T.; 1989
RFC1123 «Requirements for Internet Hosts — Application and Support», Braden, R.T.; ed.; 1989
RFC1122 «Requirements for Internet Hosts — Communication Layers», Braden R.T.; ed.; 1989
RFC1118 «Hitchhiker's Guide to the Internet», Krol, E.; 1989
RFC1011 «Official Internet Protocols», Reynolds, J.R.; Postel, J.B; 1987
RFC1009 «Requirements for Internet Gateways», Braden, R.T.; Postel, J.В.; 1987
RFC980 «Protocol document order information», Jacobsen, O.X; Postel, J.В.; 1986
TCP и UDP
RFC1072 «TCP Extensions for Long-Delay Paths», Jacobson, V.; Braden, R.T.; 1988
RFC896 «Congestion Control in 1РДСР Internetworks», Nagle, J.; 1984
RFC879 «TCP Maximum Segment Size and Related Topics», Postel, J.B; 1983
RFC813 «Window and Acknowledgement Strategy in TCP», Clark, D.D.; 1982
RFC793 «Transmission Control Protocol», Postel J.B; 1981
RFC768 «User Datagram Protocol», Postel J.В.; 1980
IP и ICMP
RFC1219 «On the Assignment of Subnet Numbers», Tsuchiya, P.F.; 1991
RFC1112 «Host Extensions for IP multicasting», Deering, S.E.; 1989
RFC1088 «Standard for the Transmission of IP Datagrams over NetBIOS Networks»,
McLaughlin, L.J.; 1989
RFC950 «Internet Standard Subnetting Procedure», Mogul, J.C.; Postel, J.В.; 1985
RFC932 «Subnetwork Addressing Scheme», Clark, D.D.; 1985
RFC922 «Broadcasting Internet Datagrams in the Presence of Subnets», Mogul, J.C.; 1984
RFC919 «Broadcasting Internet Datagrams», Mogul, J.C.; 1984
RFC886 «Proposed Standard for Message Header Munging», Rose, M.T.; 1983
RFC815 «IP Datagram Reassembly Algorithms», Clark, D.D.; 1982
RFC814 «Name, Addresses, Ports, and Routes», Clark, D.D.; 1982
RFC792 «Internet Control Message Protocol», Postel, J.B; 1981
RFC791 «Internet Protocol», Postel, J.B; 1981
RFC781 «Specification of the Internet Protocol (IP) Timestamp Option», Su, Z.; 1981
Нижние уровни
RFC1236 «IP to X.121 Address Mapping for DDN», Morales, L; Hasse, P.; 1991
RFC1220 «Point-to-Point Protocol Extensions for Bridging», Baker, F.; 1991
RFC1209 «Transmission of IP Datagrams over the SMDS Service», Piscitello, D.M.; Lawrence, J.; 1991
RFC1201 «Transmitting IP Traffic over ARCNET Networks», Provan, D.; 1991
RFC1188 «Proposed Standard for the Transmission of IP Datagrams over FDDI Networks», Katz, D.;
1990
RFC1172 «Point-to-Point Protocol (PPP) Initial Configuration Options», Perkins, D.; Hobby, R.; 1990
RFC1171 «Point-to-Point Protocol for the Transmission of Multi-Protocol Datagrams over
Point-to-Point Links», Perkins, D.; 1990
RFC1149 «Standard for the Transmission of IP datagrams on Avian Carriers», Waitzman, D.; 1990
(первоапрельская шутка!)
RFC1055 «Nonstandard for Transmission of IP Datagrams over Serial Lines: SUP», Romkey, J.L; 1988
RFC1044 «Internet Protocol on Network System's HYPERchannel: Protocol Specification»,
Hardwick, K.; Lekashman, J.; 1988
RFC1042 «Standard for the Transmission of IP Datagrams over IEEE 802 Networks», Postel, J.;
Reynolds, J.K.; 1988
RFC1027 «Using ARP to Implement Transparent Subnet Gateways», Carl-Mitchell, S.;
Quarterman, J.S.; 1987
RFC903 «Reverse Address Resolution Protocol», Finlayson, R.; Mann, Т.; Mogul, J.C.; Theimer, M.;
1984
RFC895 «Standard for the Transmission of IP Datagrams over Experimental Ethernet Networks»,
Postel, J.B; 1984
RFC894 «Standard for the Transmission of IP Datagrams over Ethernet Networks», Hornig, C; 1984
RFC893 «Trailer encapsulations», Leffler, S.; Karels, M.J.; 1984
RFC877 «Standard for the Transmission of IP Datagrams over Public Data Networks», Korb, IT.; 1983
Загрузка
RFC1084 «BOOTP Vendor Information Extensions», Reynolds, J.K.; 1988
RFC951 «Bootstrap Protocol», Croft, W.J.; Gilmore, J.; 1985
RFC906 «Bootstrap Loading Using TFTP», Finlayson, R.; 1984
DNS
RFC1035 «Domain Names — Implementation and Specification», Mockapetris, P.V.; 1987
RFC1034 «Domain Names — Concepts and Facilities», Mockapetris, P.V.; 1987
RFC1033 «Domain Administrators Operations Guide», Lottor, M.; 1987
RFC1032 «Domain Administrators Guide», Stahl, M.K.; 1987
RFC1101 «DNS Encoding of Network Names and Other Types», Mockapetris, P.V.; 1989
RFC974 «Mail Routing and the Domain System», Partridge, C; 1986
RFC920 «Domain Requirements», Postel, J.B.; Reynolds, J.K.; 1984
RFC799 «Internet Name Domains», Mills, D.L.; 1981
Пересылка и доступ к файлам
RFC1094 «NFS: Network File System Protocol Specification», Sun; 1989
RFC1068 «Background File Transfer Program (BFTP)», DeSchon, A.L.; Braden, R.T.; 1988
RFC959 «File Transfer Protocol», Postel, J.B.; Reynolds, J.K.; 1985
RFC949 «FTP Unique-Named Store Command», Padlipsky, M.A.; 1985
RFC783 «TFTP Protocol (Revision 2)», Sollins, K.R.; 1981
RFC775 «Directory Oriented FTP Commands», Mankins, D.; Franklin, D.; Owen, A.D; 1980
Электронная почта
RFC1341 «MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying and Describing
the Format of Internet Message Bodies», Borenstein, N.; Freed, N.; 1992
RFC1143 «The Q Method of Implementing TELNET Option Negotiation», Bernstein, DJ.; 1990
RFC1090 «SMTP on X.25», Ullmann, R.; 1989
RFC1056 «PCMAIL: A Distributed Mail System for Personal Computers», Lambert, M.L.; 1988
RFC974 «Mail Routing and the Domain System», Partridge, C; 1986
RFC822 «Standard for the Format of ARPA Internet Text Messages», Crocker, D.; 1982
RFC821 «Simple Mail Transfer Protocol», Postel, J.В.; 1982
Протоколы маршрутизации
RFC1267 «Border Gateway Protocol 3 (BGP-3)», Lougheed, K.; Rekhter, Y.; 1991
RFC1247 «OSPF Version 2», Moy, X; 1991
RFC1222 «Advancing the NSFNET Routing Architecture», Braun, H.W.; Rekhter, Y.; 1991
RFC1195 «Use of OSIIS-IS for Routing in TCP/IP and Dual Environments», Callon, R.W.; 1990
RFC1164 «Application of the Border Gateway Protocol in the Internet», Honig, J.C.; Katz, D.;
Mathis, M.; Rekhter, Y.; Yu, J.Y.; 1990
RFC1163 «Border Gateway Protocol (BGP)», Lougheed, K.; Rekhter, Y.; 1990
RFC1074 «NSFNET Backbone SPF Based Interior Gateway Protocol», Rekhter, J.; 1988
RFC1058 «Routing Information Protocol», Hedrick, C.L; 1988
RFC904 «Exterior Gateway Protocol Formal Specification», Mills, D.L.; 1984
RFC827 «Exterior Gateway Protocol (EGP)», Rosen, E.C.; 1982
RFC823 «DARPA Internet Gateway», Hinden, R.M.; Sheltzer, A.; 1982
RFC1136 «Administrative Domains and Routing Domains: A Model for Routing in the Internet»,
Hares, S.; Katz, D.; 1989
RFC9U «EGP Gateway under Berkeley UNIX 4.2», Kirton, P.; 1984
RFC888 «STUB Exterior Gateway Protocol», Seamonson, L; Rosen, E.C.; 1984
Политика и производительность маршрутизации
RFC1254 «Gateway Congestion Control Survey», Mankin, A.; Ramakrishnan, K.; 1991
RFC1246 «Experience with the OSPF Protocol», Moy, J.; 1991
RFC1245 «OSPF Protocol Analysis», Moy, 3.; 1991
RFC1125 «Policy requirements for Inter-Administrative Domain Routing», Estrin, D.; 1989
RFC1124 «Policy Issues in Interconnecting Networks», Leiner, B.M.; 1989
RFC1104 «Models of Policy Based Routing», Braun, H.W.; 1989
RFC1102 «Policy Routing in Internet Protocols», Clark, D.D.; 1989
Терминальный доступ
RFC1205 «5250 Telnet Interface», Chmielewski, P.; 1991
RFC1198 «FYI on the X Window System», Scheifler, R.W.; 1991
RFC1184 «Telnet Linemode Option», Borman, DA; 1990
RFC1091 «Telnet Terminal-Type Option», VanBokkelen, X; 1989
RFC1080 «Telnet Remote Flow Control Option», Hedrick, C.L.; 1988
RFC1079 «Telnet Terminal Speed Option», Hedrick, C.L.; 1988
RFC1073 «Telnet Window Size Option», Waitzman, D.; 1988
RFC1053 «Telnet X.3 PAD Option», Levy, S.; Jacobson, Т.; 1988
RFC1043 «Telnet Data Entry Terminal Option: DODIIS Implementation», Yasuda, A.;
Thompson, Т.; 1988
RFC1041 «Telnet 3270 Regime Option», Rekhter, Y.; 1988
RFC1013 «X Window System Protocol, version 11: Alpha Update», Scheifler, R.W.; 1987
RFC946 «Telnet Terminal Location Number Option», Nedved, R.; 1985
RFC933 «Output Marking Telnet Option», Silverman, S.; 1985
RFC885 «Telnet End Of Record Option», Postel, IB; 1983
RFC861 «Telnet Extended Options: List Option», Postel, IB.; Reynolds, IK; 1983
RFC860 «Telnet Timing Mark Option», Postel, IB.; Reynolds, J.K.; 1983
RFC859 «Telnet Status Option», Postel, J.B.; Reynolds, J.K.; 1983
RFC858 «Telnet Suppress Go Ahead Option», Postel, J.В.; Reynolds, J.K.; 1983
RFC857 «Telnet Echo Option», Postel, J.В.; Reynolds, J.K.; 1983
RFC856 «Telnet Binary Transmission», Postel, J.В.; Reynolds, J.K.; 1983
RFC855 «Telnet Option Specifications», Postel, J.B.; Reynolds, J.K.; 1983
RFC854 «Telnet Protocol Specification», Postel, J.B.; Reynolds, J.K.; 1983
RFC779 «Telnet Send-Location Option», Killian, E.; 1981
RFC749 «Telnet SUPDUP-Output Option», Greenberg, В.; 1978
RFC736 «Telnet SUPDUP Option», Crispin, M.R.; 1977
RFC732 «Telnet Data Entry Terminal Option», Day, J.D.; 1977
RFC727 «Telnet Logout Option», Crispin, M.R.; 1977
RFC726 «Remote Controlled Transmission and Echoing Telnet Option», Postel, J.B; Crocker, D.; 1977
RFC698 «Telnet Extended ASCII Option», Mock, Т.; 1975
Другие приложения
RFC1196 «Finger User Information Protocol», Zimmerman, D.P.; 1990
RFC1179 «Line Printer Daemon Protocol», McLaughlin, L; 1990
RFCU29 «Internet Time Synchronization: The Network Time Protocol», Mills, D.L.; 1989
RFC1119 «Network Time Protocol (Version 2) Specification and Implementation», Mills, D.L.; 1989
RFC1057 «RPC: Remote Procedure Call Protocol Specification: Version 2», Sun Microsystems, 1988
RFC1014 «XDR: External Data Representation standard», Sun Microsystems, 1987
RFC954 «NICNAME/WHOIS», Harrenstien, K.; Stahl, M.K.; Feinler, E.J.; 1985
RFC868 «Time Protocol», Postel, J.B.; Harrenstien, K.; 1983
RFC867 «Daytime Protocol», Postel, J.B.; 1983
RFC866 «Active Users», Postel, J.B.; 1983
RFC865 «Quote of the Day Protocol», Postel, IB.; 1983
RFC864 «Character Generator Protocol», Postel, J.B.; 1983
RFC863 «Discard Protocol», Postel, J.В.; 1983
RFC862 «Echo Protocol», Postel, J.B.; 1983
Управление сетью
RFC1271 «Remote Network Monitoring Management Information Base», Waldbusser, S.; 1991
RFC1253 «OSPF Version 2 Management Information Base», Baker, F.; Coitun, R.; 1991
RFC1243 «AppleTalk Management Information Base», Waldbusser, S.; 1991
RFC1239 «Reassignment of Experimental MIBs to Standard MIBs», Reynolds, J.K.; 1991
RFC1238 «CLNS MIB for Use with Connectionless Network Protocol (ISO 8473) and End System to
Intermediate System (ISO 9542)», Satz, G.; 1991
RFC1233 «Definitions of Managed Objects for the DS3 Interface Type», Сох, Т.А.; Tesink, K.; 1991
RFC1232 «Definitions of Managed Objects for the DS1 Interface Type», Baker, F.; Kolb, СР.; 1991
RFC1231 «IEEE 802.5 Token Ring MIB», McCloghrie, K.; Fox, R.; Decker, E.; 1991
RFC1230 «IEEE 802.4 Token Bus MIB», McCloghrie, K.; Fox, R.; 1991
RFC1229 «Extensions to the Generic-Interface MIB», McCloghrie, K.; 1991
RFC1228 «SNMP-DPI: Simple Network Management Protocol Distributed Program Interface»,
Carpenter, G.; Wijnen, В.; 1991
RFC1227 «SNMP MUX protocol and MIB», Rose, M.T.; 1991
RFC1224 «Techniques For Managing Asynchronously Generated Alerts», Steinberg, L; 1991
RFC1215 «Convention for Defining Traps for Use with the SNMP», Rose, M.T.; 1991
RFC1214 «OSI Internet Management: Management Information Base», LaBarre, L; 1991
RFC1213 «Management Information Base for Network Management of
TCP/IP-based Internets: MIB-II», McCloghrie, K.; Rose, M.T.; 1991
RFC1212 «Concise MIB Definitions», Rose, M.T.; McCloghrie, K.; 1991
RFC1187 «Bulk Table Retrieval with the SNMP», Rose, M.T.; McCloghrie, K.; Davin, J.R.; 1990
RFC1157 «Simple Network Management Protocol (SNMP)», Case, J.D.; Fedor, M.;
Schoffstall, M.L.; Davin, C; 1990
RFC1156 «Management Information Base for Network Management of TCP/IP-based Internets»,
McCloghrie, K.; Rose, M.T.; 1990
RFC1155 «Structure and Identification of Management Information for TCP/IP-based Internets»,
Rose, M.T.; McCloghrie, K.; 1990
RFC1147 «FYI on a Network Management Tool Catalog: Tools for Monitoring and Debugging
TCP/IP Internets and Interconnected Devices», Stine, R.H.; 1990
RFC1089 «SNMP over Ethernet», Schoffstall, M.L; Davin, C; Fedor, M.; Case, J.D.; 1989
Туннелирование
RFC1241 «Scheme for an Internet Encapsulation Protocol: Version 1»; 1991
RFC1234 «Tunneling IPX Traffic Through IP Networks», Provan, D.; 1991
RFC1088 «Standard for the Transmission of IP Datagrams over NetBIOS Networks»,
McLaughlin, L.J.; 1989
RFC1002 «Protocol Standard for a NetBIOS Service on a TCP/UDP Transport: Detailed
Specifications», NetBIOS Working Group; 1987
RFC1001 «Protocol Standard for a NetBIOS Service on a TCP/UDP Transport: Concepts
and Methods», NetBIOS Working Group; 1987
OSI
RFC1240 «OSI Connectionless Transport Services on Top of UDP: Version 1», Shue, C; Haggerty, W.;
Dobbins, K.; 1991
RFC1237 «Guidelines for OSI NSAP Allocation in the Internet», Colella, R.; Gardner, E.; Callon, R.; 1991
RFC1169 «Explaining the Role of GOSIP», Cerf, V.G.; Mills, K.L.; 1990
Безопасность
RFC1244 «Site Security Handbook»
RFC1115 «Privacy Enhancement for Internet Electronic Mail: Part in — Algorithms, Modes,
and Identifiers [Draft]», Linn, J.; 1989
RFC1114 «Privacy Enhancement for Internet Electronic Mail: Part II — Certificate-Based Key
Management», Kent, ST.; Linn, J.; 1989
RFC1113 «Privacy Enhancement for Internet Electronic Mail: Part I — Message Encipherment and
Authentication Procedures», Linn, J.; 1989
RFC1108 «Security Options for the Internet Protocol», 1991
Разное
RFC1251 «Who's Who in the Internet: Biographies of IAB, IESG and IRSG Members», Malkin, G.; 1991
RFC1207 «FYI on Questions and Answers: Answers to Commonly Asked 4experienced Internet
user* questions», Malkin, G.S.; Marine, A.N.; Reynolds, J.K.; 1991
RFC1206 «FYI on Questions and Answers: Answers to Commonly Asked 4New Internet User*
Questions», Malkin, G.S.; Marine, A.N.; 1991
Список RFC по номерам
Последняя обновленная версия списка всех RFC, упорядоченных по номерам,
находится на сайте http://www.rfc-editor.org.
Б Сокращения
и акронимы1
Тим Паркер (Tim Parker)
ABI Application Binary Interface
ACB Access Control Block
ACIA Asynchronous Communications
Interface Adapter
ACK Acknowledgement Подтверждение
AD Active Directory
AF Address Family
AFP AppleTalk Filing Protocol
AFS Andrew File System
AIX Advanced Interactive Executive
(IBM Unix)
ANSI American National Standards Institute Национальный институт стандартизации США
АОСЕ Apple Open Collaborative
Environment
API Application Programming Interface Программный интерфейс приложения
APPC Advanced Program-to-Program Усовершенствованный интерфейс связи
Communications между программами
APPN Advanced Peer-to-Peer Networking Улучшенный протокол одноранговых сетей
ARA AppleTalk Remote Access
ARPA Advanced Research Projects Agency Управление перспективного планирования
научно-исследовательских работ
AS Anonymous System
ASA American Standards Association Американская ассоциация стандартов
ASCII American National Standard Code Американский стандартный код обмена
For Information Interchange информацией
1 В последней графе приведены только устоявшиеся русские переводы. — Примеч. ред.
ASN. 1 Abstract Syntax Notation One
ASPI Advanced SCSI Programming Усовершенствованный интерфейс
Interface программирования SCSI
ATM Adobe Type Manager
ATM Asynchronous Transfer Mode Асинхронный режим передачи
AUI Attached Unit Interface
A/UX Apple Unix
BBLT Bus Block Transfer
BBN Bolt, Beranek, and Newman,
Incorporated
BER Basic Encoding Rules Базовые правила кодировки
BER Bit Error Rate Частота ошибок по битам
BGP Border Gateway Protocol Пограничный межсетевой протокол
BIOS Basic Input/Output System Базовая система ввода/вывода
BISDN Broadband ISDN (Integrated Широкополосная цифровая сеть
Services Digital Network) комплексных услуг
BITBLT Bit Block Transfer Пересылка битового блока
BITNET Because It's Time Network
BSD Berkeley Software Distribution
CAMMU Cache/Memory Management Unit
CBLT Character Block Transfer Пересылка символьного блока
ССГТТ Consultative Committee Совещательный комитет по международной
for International Telephone телефонии и телеграфии
and Telegraphy
CDE Common Desktop Environment Коллективная среда настольных
вычислительных средств
CDMA Code Division Multiple Access Множественный доступ с кодовым
разделением каналов
CLI Call-Level Interface Интерфейс уровня вызовов
CLI Command-Line Interpreter Интерпретатор командной строки
CMC Common Messaging Calls Набор стандартных вызовов
CMIP Common Management Information Протокол общей управляющей информации
Protocol
CMIS Common Management Information Служба общей управляющей информации
Services
СМОТ Common Management Information Служба и протокол общей управляющей
Services and Protocol over TCP/IP информации по TCP/IP
CORBA Common Object Request Broker
Architecture
COSE Cbmmon Open Software Environment Общая открытая среда программных средств
CPU Central Processing Unit Центральный процессор
CRC Cyclic Redundancy Check Контроль с помощью циклического
избыточного кода
CREN Consortium for Research and Консорциум по организации
Educational Networking научно-исследовательских
и образовательных сетей
CSMA/CD Carrier Sense Multiple Access with Множественный доступ с контролем несущей
Collision Detection и обнаружением конфликтов
CSNET Computer Science Network
CUA Common User Access Общий пользовательский доступ
DARPA Defense Advanced Research Управление перспективных
Projects Agency исследовательских программ
DARPANET Defense Advanced Research Сеть управления перспективных
Projects Agency Network исследовательских программ
DAT Digital Audio Tape Цифровая аудиокассета
DBMS Database Management System Система управления базами данных
DCA Defense Communications Agency Управление связи Министерства обороны США
DCE Data Circuit-Terminating Equipment Оконечное оборудование передачи данных
(Data Communications Equipment) (аппаратура передачи данных)
DCE Distributed Computing Environment Среда распределенных вычислений
DDBMS Distributed DBMS Распределенная СУБД (система управления
базами данных)
DDE Dynamic Data Exchange Динамический обмен данными
DDN Defense Data Network Оборонная сеть передачи данных
DES Data Encryption Standard Стандарт шифрования данных
DFS Distributed File Service Распределенная файловая служба
DHCP Dynamic Host Configuration Protocol Протокол динамической конфигурации хоста
DIF Data Interchange Format Формат информационного обмена
DIME Dual Independent Map Encoding
DISA Defense Information System Agency Агентство по оборонным информационным
системам
DIX Digital, Intel, and Xerox Ethernet
Protocol
DLL Dynamic Link Library Динамически подсоединяемая библиотека
DLP Data Link Protocol Протокол передачи данных
DME Distributed Management Распределенная среда управления
Environment
DNS Domain Name System Система имен доменов
DOE Distributed Objects Everywhere
DSA Directory System Agent Агент системы каталогов
DSAP Destination Service Access Point
DTE Data Terminal Equipment Терминальное оборудование
DTMF Dual-Tone Multi-Frequency Двухтональный многочастотный набор
DUA Directory User Agent
DVI Digital Video Interactive Интерактивное цифровое видео
EBCDIC Extended Binary Coded Decimal Расширенный двоично-десятичный код
Interchange Code обмена информацией
ECC Error Correction Code Код исправления ошибок
ECM Error Correction Mode Режим исправления ошибок
EGP Exterior Gateway Protocol Внешний шлюзовой протокол
ENS Enterprise Network Services Сетевое обеспечение предприятия
EOF End of File Конец файла
EOR End of Record Конец записи
ERLL Enhanced Run Length Limited Расширенный код с ограничением
по длине серий
ESDI Enhanced Small Device Interface Улучшенный интерфейс малых устройств
FAT File Allocation Table Таблица размещения файлов
FCS Frame Check Sequence Контрольная последовательность кадра
FDDI Fiber Distributed Data Interface Распределенный интерфейс передачи
данных по оптоволоконным каналам
FIN Final Segment Завершающий сегмент
FTAM File Transfer, Access, and Передача, доступ и управление файлами
Management
FTAM Rle Transfer Access Method Метод пересылки и обеспечения
доступа к файлам
FTP Rle Transfer Protocol Протокол передачи файлов
GGP Gateway-Gateway Protocol Межшлюзовой протокол
GIF Graphics Interchange Format Формат графического обмена
GOSIP Government OSI Profile Спецификации протоколов OSI,
поддерживаемые государством
GPF General Protection Fault Общее нарушение защиты
GPI Graphics Programming Interface Графический программный интерфейс
GTF Generalized Trace Facility
GUI Graphical User Interface Графический интерфейс пользователя
HAL Hardware Abstraction Layer Уровень аппаратных абстракций
HDLC High-level Data Link Control Высокоуровневый протокол управления
каналом
HDX Half-Duplex Полудуплексный
HFS Hierarchical File System Иерархическая файловая система
HIPPI High-Performance Parallel Interface Высокоскоростной параллельный интерфейс
(также HPPI)
НОВ High Order Byte Старший байт
HPFS High Performance File System Высокопроизводительная файловая система
HPPI High-Performance Parallel Interface Высокоскоростной параллельный интерфейс
(также HIPPI)
HTTP Hypertext Transfer Protocol Протокол передачи гипертекста
IAB Internet Activities Board Координационный совет Интернета
IAB Internet Architecture Board Координационный совет по архитектуре
Интернета
IAC Interapplication Communication Связь между приложениями
IAC Interpret as Command Интерпретируется как команда
IAIMA Internet Assigned Numbers Authority Агентство по выделению имен и параметров
протоколов Интернета
ICMP Internet Control Message Protocol Межсетевой протокол управляющих сообщений
ID Identifier Идентификатор
IDE Integrated Drive Electronics Интегрированный интерфейс накопителей
IEEE Institute of Electrical and Electronics Институт инженеров по электротехнике
Engineers и электронике
IEN Internet Experiment Note Экспериментальный рабочий документ
Интернета
IESG Internet Engineering Steering Group Исполнительный комитет IETF
IETF Internet Engineering Task Force Проблемная группа проектирования
Интернета
IFF Interchange File Format
IGMP Internet Group Management Protocol Межсетевой протокол управления группами
IGP Interior Gateway Protocol Протокол внутреннего шлюза
IMAP Interactive Mail Access Protocol Протокол интерактивного доступа
к электронной почте
INT Interrupt Прерывание
IP Internet Protocol Межсетевой протокол
IPC Interprocess Communication Межпроцессное взаимодействие
IPX/SPX Internet Packet Exchange/
Sequenced Packet Exchange
IRC Interrupt Request Controller Контроллер прерываний
IRQ Interrupt Request Запрос на прерывание
IRTF Internet Research Task Force Проблемная группа Интернета
ISDN Integrated Services Digital Network
IS-IS Intermediate System to Intermediate Связь между промежуточными системами
System
ISN Initial Sequence Number
ISO International Organization for Международная организация
Standardization по стандартизации
ISODE ISO Development Environment Среда разработки, отвечающая
требованиям ISO
JPEG Joint Photography Experts Group
LAN Local Area Network Локальная сеть
LAPB Link Access Procedures Balanced
LAPD Link Access Procedures on the D
channel
LLC Logical Link Control Управление логическим соединением
LOB Low Order Byte Младший байт
LSB Least Significant Bit/Byte Младший бит/байт
LSD Least Significant Digit Младший разряд
MAC Media Access Control Протокол управления доступом
к (передающей) среде
MAN Metropolitan Area Network Региональная сеть
MAPI Messaging API Интерфейс прикладного программирования
для обмена сообщениями
MAU Medium Access Unit
MFC Microsoft Foundation Classes
MFS Macintosh File System
MHS Message Handling Service Служба управления сообщениями
MIB Management Information Base База управляющей информации
MILNET Military Network
MIME Multipurpose Internet Mail Многоцелевые расширения электронной
Extensions почты Интернета
MNP Microcom Networking Protocol
MSB Most Significant Bit/Byte Старший бит/байт
MSS Maximum Segment Size Максимальный размер сегмента
MTA Message Transfer Agent Агент передачи сообщений
MTU Maximum Transfer Unit Максимальная единица передачи
MX Mail Exchanger
NAU Network Access Unit
NDIS Network Driver Interface Спецификация стандартного интерфейса
Specification сетевых адаптеров
NDS NetWare (Novell) Directory Service Служба каталогов NetWare (Novell)
NETBIOS Network Basic Input/Output System Сетевая базовая система ввода/вывода
NETBEUI NetBIOS Extended User Interface
NFS Network File System Сетевая файловая система
NIC Network Information Center Сетевой информационный центр
NIS Network Information Service Сетевая информационная служба
NIST National Institute of Standards Национальный институт стандартов
and Technology и технологий
NIU Network Interface Unit
NLM NetWare Loadable Module Загружаемый модуль NetWare
NMI Nonmaskable Interrupt Немаскируемое прерывание
NNTP Network News Transfer Protocol Сетевой протокол передачи новостей
NOS Network Operating System Сетевая операционная система
NREN National Research and Education Национальная научно-исследовательская
Network и образовательная сеть
NSAP Network Service Access Point Точка доступа к сетевому сервису
NSF National Science Foundation Network Сеть Национального научного фонда
NVT Network Virtual Terminal Виртуальный терминал сети
ODAPI Open Database API
ODI Open Data-link Interface Открытый канальный интерфейс
ONC Open Network Computing Открытая сетевая обработка
OSF Open Software Foundation Фонд открытого программного обеспечения
OSI Open System Interconnection Взаимодействие открытых систем
OSPF Open Shortest Path First Первоочередное открытие кратчайших
маршрутов
PAD Packet Assembler / Disassembler Сборщик/разборщик пакетов
PCMCIA Personal Computer Memory Card Международная ассоциация производителей
International Association плат памяти для персональных компьютеров
PDU Protocol Data Unit Протокольная единица обмена
PI Protocol Interpreter Интерпретатор протокола
PING Packet Internet Groper Отправитель пакетов Интернета
POP Post Office Protocol Почтовый протокол
POTS Plain Old Telephone Service Обычная телефонная сеть
PPP Point-to-Point Protocol Протокол передачи от точки к точке
QIC Quarter-Inch Cartridge Четвертьдюймовый картридж
RARP Reverse Address Resolution Protocol Протокол определения (сетевого) адреса
по местоположению (узла)
RFC Request for Comments Запрос на комментарии
RFS Remote File System Удаленная файловая система
RIP Routing Information Protocol Протокол маршрутной информации
RMON Remote Network Monitor
RPC Remote Procedure Call Удаленный вызов процедуры
RST Reset Сброс
RTT Round-Trip Time Период кругового обращения
SAP Service Access Point Точка доступа к службе
SDLC Synchronous Data Link Control Синхронное управление передачей данных
SLIP Serial Line Internet Protocol Межсетевой протокол для последовательного
канала
SMDS Switched Multimegabit Data Service
SMTP Simple Mail Transfer Protocol Простой протокол электронной почты
SNA Systems Network Architecture Системная сетевая архитектура
SNMP Simple Network Management Простой протокол сетевого управления
Protocol
SONET Synchronous Optical Network Синхронная оптическая сеть
SPF Shortest Path First Предпочтительный выбор кратчайшего пути
SSAP Source Service Access Point
SSCP System Services Control Point
SYN Synchronizing Segment Синхронизирующий сегмент
TCB Transmission Control Block Блок управления передачей
TCP Transmission Control Protocol Протокол управления передачей
TCP/IP Transmission Control Протокол управления передачей/
Protocol/Internet Protocol Межсетевой протокол
TCU Trunk Coupling Unit
TELNET Terminal Network
TFTP Trivial File Transfer Protocol Тривиальный протокол передачи файлов
TLI Transport Layer Interface Интерфейс транспортного уровня
TP4 OSI Transport Class 4
TSAP Transport Service Access Point Точка доступа к услугам транспортного уровня
TTL Time-to-Live Срок жизни
UA User Agent Пользовательский агент
UART Universal Asynchronous Универсальный асинхронный
Receive^ransmitter приемопередатчик
UDP User Datagram Protocol Протокол пользовательских дейтаграмм
ULP Upper Layer Protocol Протокол верхнего уровня
URL Uniform Resource Locator Унифицированный указатель
информационного ресурса
UUCP Unix to Unix Copy
WAN Wide Area Network Глобальная сеть
WWW World Wide Web Всемирная паутина
XDR External Data Representation
XNS Xerox Network Systems
Алфавитный указатель
А
А, записи, 132
А, тип записей, 128
АССМ, 425
АСК, управляющий бит, 60
ADSL, 416
AFI, поле RIP, 354
allwhois.com, 588
AOLserver, 727
Apache, 689
APACI, 719
API, 138,475
APNIC, 587
AppleShare, 68
AppleTalk, 68
ARP, протокол, 104, 478, 510
arp, команда, 122
RARP, 118
кэш, 104
тайм-аут, 111
ARPA, 43
AS, автономные системы, 391
ASCII, 37
ASN.l, 779
ASP, 701
В
BBN, 44
BCC, поле, 679
BGP, 351
BGP, протокол, 327
BIND, 571,747
biod, демон, 654
BITNET, 45
ВООТР, протокол, 162
формат сообщений, 166
В-узлы, 142
С
Caldera, 68
CAST, шифрование, 462
CATNIP, 306
СВС, 317
СС, поле, 679
CERN, 45, 688
CERT, 453
CGI, 690,699
CHAP, 419
ciaddr, поле, 168
CIDR, 88,368
CIFS, 666
Clipper, чип, 462
CMIP, 763
CMW, 792
CNAME, 132
Coded Drag, схема шифрования, 459
CORE, 585
CSLIP, 69,421
CSNET, 45
Cyberguard, брандмауэр, 453
D
Debian, 68
DECnet, 101
DefaultRcvWindow, параметр, 502
DefaultTTL, параметр, 501
DES, шифрование, 461, 631
DF, флаг, 62,216
DHCP, 170
ВООТР, сообщения, 166
NetWare, 558
TCP/IP, конфигурация, 171
серверы, 157
dig, 806
DNS
Linux, 748
NetWare, 559
DNS (продолжение)
WINS, 156
демоны, 753
иерархии, 124
клиенты, 742
разрешение имен, 124
резольвер, 745
ресурсные записи, 745
серверы имен, 479, 526, 742, 744
файлы, 748
DOS, 538
DSL, 69
DSS, 463
DTD, 698
E
EBCDIC, 37
EGP, протокол, 327,779
EMS, 775
ESP, 318
Ethereal, 763
Ethernet
кадры, 102
префиксы, 811
exec, команда, 582
Expert Sniffer, 761
exportfs, команда, 658
F
file, поле, 168
FIN, управляющий бит, 60
Finger, 48,545,592
FTP, 64,545,599
fwhois, команда, 589
G
GGP, 350
giaddr, поле, 168
GMT, 236
GRE, протокол, 430
GSA, 587
gzip, 725
H
HDLC, 581
HELLO, протокол, 350
HINFO, записи, 133
hlen, поле, 168
hops, поле, 168
HTML, 691,696
HTTP, 54,689,693
S-HTTP, 697
Telnet, 634
httpd.conf, файл, 720
HTTP-ng, 701
htype, поле, 168
Н-узлы, 142
I
12 (Internet2), 53
IANA, 54,91
ICANN, 54,93
IDEA, 461,462
IEEE 802.3, 207
IESG, 46
IETF, 53,689
ifconfig, 806
ihave, команда, 705
HOP, протокол, 702
IMAP, 479,681
IN-ADDR-ARPA, формат, 746
InterNIC, 55,73,480
IP, 190, 198, 204
CIDR, 88
IPv4, заголовки, 192
NetWare, 548
TUBA, 212
UDP, 299
адрес отправителя, 62
адрес получателя, 63
адресация, 70, 103
дейтаграммы, 209
заголовки расширения, 312
контрольная сумма, 62
конфигурация, 476
параметры, 507
срок жизни, 62
туннелирование, 548
флаги, 62
IPP, 54,408,702
IPSec, 312,434
ESP, 439
SPI, 442
аутентификация, 439
туннелирование, 442
IPv6, 307
адресация, 96, 311
альтернативные адреса, 311
IPv6 {продолжение)
групповые адреса, 311
заголовки расширения, 312
направленные адреса, 311
переход с IPv4, 323
IRTF, 689
ISDN, 414
ISDN, записи, 134
ISOC, 53,689
3
Java, 699
JavaScript, 700
К
KDC, 464
Kerberos, 464,639
kill, команда, 581
L
LANtern, 763
LDAP, 674
LDPA, 408
Linux, 68
Apache, 689
DNS, 748
FTP, 616
PPP, 578
TCP/IP, 563
демоны, 653
загрузка, 729
клиенты, 754
поддержка туннелирования, 483
linuxconf, 575
LMHOSTS
настройка, 522
разрешение имен NetBIOS, 158
lockd, демон, 652
LPR, протокол, 409
LSA, 334
OSPF, 386
LSAP, 101
м
М, флаг (заголовки расширения IPv6), 317
MAC, 101
Macintosh, клиенты FTP, 614
Mandrake, 68
MB, записи, 134
MBZ, поле, 214
MD, алгоритмы, 463
MF, флаг, 62,216
MG, записи, 135
MIB, 67,770
RMON, 771
SNMP, 779
Microsoft Outlook, 450
Microsoft TCP/IP, конфигурация, 485
Migration Agent, 560
MIME, 675,695
MINFO, записи, 135
Mosaic, 45
mount, команда, 660
mountall, команда, 660
mountd, демон, 652
MR, записи, 135
MRU, 425
MSS, 264
MSTCP, ключ, 501
MTA, 673
MTU, 194,206
MX, записи, 135
М-узлы, 142
N
NAT, 92
NBNS, 522
NCP, 44
NCSA, 688
NDIS, 476
NDS, 548
NetBIOS, 138
TCP/IP, 670
WINS, 144
имена, 139
конфигурация, 503
кэш, 522
разрешение, 159
netcfg, программа, 575
NetGuardian, 786
Netscape, 689
web-сайт, 464
web-серверы, 714
netstat, 806,812
NetWare
DDNS, 559
DHCP, 559
DNS, 559
NetWare (продолжение)
IP, 550
IPX, 671
SLP, 559
режим совместимости", 560
установка, 555
NETWORKS, файл, 533
NFS, 36,66,648
клиентские команды, 659
монтирование, 654
приложения, 660
протоколы, 664
серверные команды, 656
nfsd, демон, 652
NGI, 52
NNTP, 49,707
команды, 708
конференции, 705
сообщения, 708
Novell, 34,548
NS, записи, 132
nslookup, 806
NTIA, 55,585
NVT, 622
О
ODI, 476
OSI, эталонная модель, 32
OSPF, 385
заголовки, 394
зоны, 387
обновления маршрутов, 391
построение маршрутов, 401
структуры данных, 394
OUI, 100
Р
РАР, протокол, 418
PCAnywhere, порты, 795
PCI, 759
PCMCIA, 471
Perl, 699
PGP, 460,683
PID, 581
POP, протокол, 479, 681
PPP, протокол, 45, 69
Linux, 578
дейтаграммы, 423
РРТР, протокол, 428
PROTOCOL, файл, 534
PSH, управляющий бит, 60
PSH, флаг, 264,291
PTR, записи, 133
PWG, 408
PWS, 716
Р-узлы, 142
Q
qi, 593
QoS
PPP, 426
параметры, 213
QUIT, команда, 710
R
RADIUS, 417
аутентификация, 418
модель клиент-сервер, 417
RARP, протокол, 118
гс, сценарии, 731
RC2/RC4, шифрование, 462
гср, команда, 642
RedHat Linux, 68
гехес, команда, 644
RFC, 46,805
RIP, протокол, 334, 350
адреса, 358
недостатки, 382
обновление, 814
топология, 362
RIPE, 587
ripquery, 806,814
rlogin, команда, 642
RMON, 771
RP, записи, 136
RPC, 650
rpc.lockd, демон, 654
rpc.mountd, демон, 653
rpc.nfsd, демон, 653
rpc.statd, демон, 654
RSA
web-сайт, 640
общие сведения, 640
rsh, команда, 545, 641
RST, бит, 264
RST, управляющий бит, 60
RT, записи, 136
rup, команда, 643
ruptime, команда, 643
rwho, команда, 643
RWhois, 588
r-команды, 636
альтернативы, 640
безопасность, 637
демоны, 641
список, 641
файлы, 644
функциональность, 646
S
S/MIME, 675
Samba, 666
SAP, протокол, 553
SERVICES, файл, 498,535
SGML, 698
SHA, алгоритм, 463
SHS, стандарт, 463
S-HTTP, 697
SIPP, 306
Skipjack, система шифрования, 462
SLIP, 69
Linux, 578
транспорт, 420
SMB, 485
SMDS, 207
SMTP, 49,449
sname, поле, 168
SNMP, 37,67,756
MIB, 779
Unix, 781
установка, 766
snmpd.conf, файл, 782
snmpd.trap, файл, 783
SOA, записи, 127
SOCKS, 448
Solaris
демоны, 651
команды, 658
файлы, 654
ssh, команда, 451, 631
SSL, 697
stty, команда, 582
SYN, управляющий бит, 60
т
ТСВ, 260
TCP, 58,59,223,248
АСК, 60
TCP (продолжение)
UDP, 200
адаптивный тайм-аут, 275
контрольная сумма, 60
заголовки, 195
мультиплексирование, 255
надежность, 252
реализация, 281
сегменты, 250
смещение данных, 264
управляющие биты, 60
флаги, 264
TCP/IP
NetBIOS, 670
Telnet, 633
архитектура, 58
клиенты, 114
командная строка, 544
модели, 190
настройка, 162
параметры, 819
применение, 68
протоколы, 58
серверы, 114
уровни, 58
установка, 505
эталонные модели, 40
Telnet, 43,49,620
TCP Wrappers, 630
команды, 627
трассировка, 284
TFTP, 65, 168, 545
Tiny IDEA, 461
Token Ring, 36, 207
TOS, 211
коды, 213
пакеты IP, 213
TUBA, 212
TXT, записи, 136
и
UDP, 58,200,299,671
TCP, 200
заголовок, 300
инкапсуляция, 301
трассировка, 302
функции, 200
umount, команда, 661
unshare, команда, 659
unshareall, команда, 659
URG, управляющий бит, 60
URL, 714
Usenet, 49,704
спам, 711
UUCP, 468
V
vBNS, 52
VLSM, 77,87
VPN, 801
PPTP, 439
w
W3C, 690
WebNFS, 665
WebSTAR, 728
web-серверы
AOLserver, 727
Apache, 722
Netscape, 727
Stronghold, 728
WebSTAR, 728
Whois, протокол, 48, 631
WHOIS++, 592
Windows, 68
Apache, 725
Ethereal, 763
SNMP, 784
TCP, 58, 198
winipcfg, программа, 500
WINS
DHCP, 157
NetBIOS, 144
адреса, 514
конфигурация, 493
WKS, записи, 137
World Wide Web, 49,688
X
X.25
MTU, 207
X.400, 673
X25, записи, 137
XDR, 36,650
XML, 698,702
Y
yiaddr, поле, 168
A
адаптивный алгоритм повторной
передачи, 276
адаптивный тайм-аут, 275
администрирование
IP-адреса, 171
WINS, 149
Интернет, 53
адреса
ARP, дублирование, 114
CIDR, 88
IP, 70, 103
IP, специальные, 77
IPv6, 96,311
MAC, 101
URL, 689
Whois, протокол, 584
WINS, 514
двоичная запись, 70
класс А, 73
класс В, 74
класс D, IPv4, 75
класс С, IPv4, 74
основной шлюз, 479
отправителя, 207
физические, 100
активные иерархии Usenet, 706
алгоритмы
TCP, 275
Нейгла, 282
анонимная электронная почта, 686
анонимный доступ FTP, 616
апплеты, 700
архитектура
TCP/IP, 58
адресация IP, 70
атаки, 795
DoS, 795
вирусы, 797
подбор паролей, 794
троянские программы, 795
черный вход, 795
атрибуты, Х.400, 673
аутентификация
РРТР, 431
RADIUS, 417
цифровые подписи, 463
Б
базы данных
Whois, 584
распределенные, 127
безопасность, 444, 456
CERT, сайт, 453
FTP, 612
IP, 516
IPSec, 312,434
Kerberos, 464
r-команды, 637
SNMP, 768
Telnet, 630
атаки, 795
аутентификация, 425
брандмауэры, 444, 803
доверительные отношения, 467
модемы, 469
порты, 795
приложения, 799
файлы, 802
цифровые подписи, 463
шифрование, 459, 793
электронная почта, 683
Бернерс-Ли, Тим, 45
Бернерс-Ли, тип, 688
билеты Kerberos, 640
брандмауэры, 444
браузер, 668, 691
в
версии
IP, 62,71
вирусы, 684, 797
г
глобальные сети, 56, 275, 482, 760, 791
граничные шлюзы (OSPF), 387
Д
Дейкстры, алгоритм, 385, 398
дейтаграммы
IP, 209
IPv6, 307
заголовки, 210
транспортировка, 420
фрагментация, 209
демоны, 112
DNS, 753
демоны (продолжение)
finger, 595
FTP, 616
NFS, 651
Solaris, 651
Telnet, 623
Unix, 638
WHOD, 302
динамическое разрешение имен
NetBIOS, 143
директивы, LMHOSTS, 159
дистанционно-векторная
маршрутизация, 331, 358
Диффи—Хеллмана, алгоритм, 463
доверительные отношения, 468
домены
BIND, 747
CIDR, 368
верхнего уровня, 586
имена, 585
ж
жесткое монтирование, 651, 664
з
заголовки, 759
HTTP, 693
IP, 61
IPv4, 192
IPv6, 307
LSA, 398
OSPF, 394
TCP, 57, 59, 195
загрузка, в Linux/Unix, 729
записи
A, 132
CNAME, 132
HINFO, 133
ISDN, 134
MB, 134
MG, 135
MINFO, 135
MR, 135
MX, 135
NS, 132
PTR, 133
RP, 136
RT, 136
TXT, 136
записи (продолжение)
WKS, 137
Х25, 137
ресурсные (RR), 745
запросы
имена, 145
итеративные, 124
обратное разрешение имен, 129
рекурсивные, 124
зарегистрированные порты TCP, 263
зоны, 387
и
иерархии
DNS, 124
подсети, 81
имена
BIND, 747
DNS, 123
NetBIOS, 139
Usenet, 707
возобновление, 145
домены, 585
запросы, 145
резольвер, 747
серверы, 100, 479
сообществ, 768
широковещательная рассылка, 522
инициализация
Unix/Linux, 729
инкапсуляция, 301
интеграция
DNS/WINS, 156
сетевое моделирование, 764
унаследованные приложения, 669
Интернет
администрирование, 53
будущее, 52
демон, 799
история, 43
регистрация, 584
службы, 48
интерфейсы
APACI, 719
API, 138
Ethernet, 569
интрасети, 47, 68
искусственный интеллект, 775
итеративные запросы, 129
итеративные операции, 747
к
кабельные модемы, 69, 414
кадры
Ethernet, 102
размер, 208
сети, 102
канал, 385
канальный уровень, 34, 59, 64
каталоговые службы, 674
класс А, адреса, 73
класс В, адреса, 74
класс С, адреса, 74
класс D, адреса, 75
класс Е, адреса, 76
клиенты
ВООТР, 162
DHCP, 171
FTP, 65,599
Linux, 754
NFS, 648
NNTP, 707
RARP, 119
TCP/IP, 114
Unix, 754
ключи, 640
команды
arp, 122,806
CLOSE, 628
exec, 582
finger, 593
ftp, 603
fwhois, 589
GET, 67
GETNEXT, 67
HELP, 628,709
ifconfig, 566,806
kill, 581
make, 719
mount, 660
mountall, 660
netstat, 812
next, 709
ping, 568,806
rep, 642
rexec, 644
rlogin, 642
route, 566
rsh, 641
rup, 643
команды (продолжение)
ruptime, 643
rwho, 643
r-команды, 636
SEND, 628
SET, 67
share, 657
shareall, 657
showmount, 657
SMTP, 676
SNMP, 67,771
Telnet, 625
TRAP, 67
umount, 661
umountall, 661
VRFY, 633
компиляция, Apache, 722
контактные лица (Whois), 584
контрольная сумма, 399
IP, заголовок, 62
OSPF, заголовок, 395
TCP, 60,271
UDP, 300
конференции, 705
конфигурация
/etc/hosts.allow, 631
/etc/hosts.deny, 631
Apache, 720
BOOTP, 162
DHCP, 171
FTP, 539
HOSTS, 532
IP-адреса, 95
LMHOSTS, 522
SLIP, 578
TCP/IP, 171
Windows, 112
WINS, 514
безопасность, 803
интерфейс обратной связи, 567
интерфейсы Ethernet, 569
сети, 476
физические адреса, 100
корректное завершение, 267
кэш
ARP, 112
DNS, 128
NetBIOS, 522
Л
логическая смежность, 31
локальные сети, 791
TCP, 275
VLAN, 483
анализ, 760
м
маршрут по умолчанию, 360
маршрутизаторы, 323, 326, 348
ARP, 109,479
SNMP, 67
адаптивный тайм-аут, 275
отмеченные, 398
сетевой уровень, 34
маршрутизация, 309, 326
CIDR, 88,368
от источника, жесткая, 233
от источника, свободная, 233
маски подсетей
CIDR, 480
VLSM, 368
диагностика, 823
настройка, 477
методы
запросы HTTP, 692
разрешение имен, 520
миграция NetWare, 558, 560
сценарии, 561
тестирование, 561
многоадресные хосты, 117
модели
OSI, эталонная, 32
TCP/IP, 40, 190
модемы, 413
безопасность, 469
кабельные, 414
монтирование
NFS, 654
жесткое/мягкое, 650
ресурсы, 659
мосты, 348
ARP, ИЗ
IPX-TCP/IP, 560
мультиплексирование
TCP, 255
потоки данных, 197
мягкое монтирование, 651
н
Нейгла, алгоритм, 282
о
однородные сети, 402
октеты, 70
адреса IPv4 класса А, 73
адреса IPv4 класса В, 74
адреса IPv4 класса С, 74
адреса IPv4 класса D, 75
адреса IPv4 класса Е, 76
операционные системы, 68
оптимизация
NetBIOS, 144
производительность, 773
основной сервер RARP, 121
основной шлюз, 825
открытые сети, 29
многоуровневая структура, 30
эталонная модель OSI, 32
открытые стандарты, 30
п
пакеты
АСК, 293
DHCP, 176
TCP, 261
UDP, 302
транспортный уровень, 35
фильтрация, 448
форматы, 354
параметры
IP, 507
SNMP, 768
TCP/IP, 819
пароли, 466
безопасность, 792
надежность, 468
переполнение буфера, 796
переходы, 377
планирование сети, 757
порт данных FTP, 601
порты, 715
FTP, 613
PCAnywhere, 795
TCP, 195
трехфазное согласование, 288
порядковый номер, 59, 263, 273
почтовые службы, SMTP, 66
представительский уровень, 37, 668
прерывание, 778
префиксы Ethernet, 811
привилегии, 792
прикладной уровень, 37, 58, 826
приложения
FTP, 599
Linux, 563
NFS, 648
RFC, 805
TCP, 195
безопасность, 799
фильтры, 804
шифрование, 793
прокси-серверы, 444, 455
протоколы
ARP, 104,524
CHAP, 419
CSLIP, 69,421
EGP, 779
FTP, 64,633
GRE, 430
HELLO, 396
HTTP, 689
HOP, 702
ШАР, 479, 681
IP, 61, 190
IPP, 408,702
IPSec, 434
L2TP, 433
LDAP, 674
NetWare, 555
NFS, 664
NNTP, 707
OSPF, 386
PAP, 418
POP, 479,681
PPP, 69
PPTP, 428
SLIP, 69
SMTP, 66,673
SNMP, 67,756
SPF, 334,386
TCP, 223,248
TCP/IP, 58, 190
Telnet, 620
TFTP, 65, 168, 599
TUBA, 212
протоколы (продолжение)
UDP, 200,299,671
Whois, 584
Х.400, 673
анализаторы, 759
верхнего уровня, 670
дистанционно-векторные, 351
маршрутизации, 327
процессы
ink, 729
взаимодействие, 31
управление, 740
р
разрешение
DNS, 124
NetBIOS, 143
физические адреса, 104
регистрация
имен, 144
протокол Whois, 584
редиректор, 474
реестр, 498
WINS, 142
режим совместимости, 560
режимы
двоичный, 618
дуплексный, 36
полудуплексный, 36
совместимости, 560
текстовый, 618
установка NetWare, 555
резольвер, 745
рекурсивные запросы, 128
рекурсивные операции, 745
репликация
WINS, 155
ресурсы
NFS, 648
демонтирование, 661
монтирование, 659
ретрансляция
IP, 551
С
сеансовый уровень, 35
сеансы, 592, 636
серверы
AOLserver, 727
Apache, 689
серверы (продолжение)
ВООТР, 162
DHCP, 171
DNS, 124,754
Finger, 593
FTP, 65,600,616
HTTP, 693
Kerberos, 464
NBNS, 522
NetWare, 548
NFS, 663
NNTP, 706
PWS, 727
RARP, 118
Stronghold, 728
Telnet, 64
WebSTAR, 728
Whois, 586
WINS, 491
имен, 100
типы, 720
сетевой уровень, 34, 59, 64
сетевые платы
модемы, 472
настройка, 470
службы, 475
установка, 470
сети
ARP, 121
IP, 70
OSPF, 386
ping, 806
атаки, 795
автономные системы, 349
глобальные, 482
доступ, 807
интрасети, 68
кадры, 102
маршрутизация, 813
мосты, 348
протоколы, 735
разнородные, 44
хосты, 736
эволюция открытых сетей, 30
сжатие
баз данных WINS, 150
синдром мелкого окна, 279
синтаксис, LMHOSTS, 526
системы
Linux/Unix, 729
экспертные, 761
скользящее окно, 254
службы, 475
Finger/Whois, 48
FTP, 539
NetBIOS, 519
NNTP, 704
SNMP, 766
Telnet, 49
Usenet, 49
WWW, 49
анонимная почта, 686
безопасность, 449
электронная почта, 49
смещение фрагмента, поле, 218
согласование, 336
сокеты
TCP, 198
WinSocks, 139
сообщения
ARP, запросы, 106
ВООТР, 166
TCP, форматы, 261
управляющие, 707
спам, 686, 711
средства моделирования, 764
стандарты
шифрование, 683
электронная почта, 667, 672
статическая маршрутизация, 327
статические записи (WINS), 149
сценарии
гс, 731
т
тайм-аут
ARP, 111
TCP, 275
интервалы, 276
типы
MIME, 695
топология
RIP, 362
изменение, 336
транспортный уровень, 35, 59, 63
трехфазное согласование, 266
троянские программы, 795
туннели, 427
IPSec, 434
L2TP, 433
РРТР, 428
У
удаленный доступ, 413
RADIUS, 417
передача IPX в IP, 427
транспорт, 420
туннелирование, 427
узлы
В, 142
Н, 142
М, 142
Р, 142
уровни
TCP/IP, 58
UDP, 301
канальный, 34
межсетевой, 41
межхостовой, 41
представительский, 37, 668
прикладной, 37, 40, 826
сеансовый, 35
сетевого доступа, 41
сетевой, 34
транспортный, 35
физический, 33
установка
Apache, 717
FTP, 539
NetWare, 555
TCP/IP, 505
Ф
файловые системы
Linux, 565
NFS, 661
файлы
/etc/ftpusers, 613
/etc/hosts, 645
/etc/hosts.allow, 646
/etc/hosts.deny, 646
/etc/hosts.equiv, 645
/etc/inetd.conf, 739, 799
/etc/inittab, 730
/etc/networks, 742
/etc/protocols, 735
файлы (продолжение)
/etc/red, 722
/etc/resolv.conf, 742
/etc/services, 737
HOSTS, 142
LMHOSTS, 142,526
NETWORKS, 533
SERVICES, 535
snmpd.conf, 782
snmpd.trap, 783
фальсификация, 646, 796
физические адреса, 100
arp, команда, 122
RARP, 118
дублирование, 100
кэш, 104
тайм-аут, 111
физический уровень, 33
фиксированные метрики, 382
фильтрация
IP, 516
пакетов, 804
Флетчера алгоритм, 399
форматы
IN-ADDR-ARPA, 746
IPv4, адреса, 70
TCP, сообщения, 261
UDP, заголовки, 300
фрагментация, 194
х
хосты
/etc/hosts, файл, 736
/etc/services, файл, 737
TCP, 249
Telnet, 620
Whois, протокол, 586
конфигурация, 532
хэш-таблицы, 745
ц
централизация (NFS), 648
демоны, 651
команды, 651
монтирование, 654
реализация, 648
серверные команды, 656
центры распределения ключей, 464
ш
широковещательная рассылка
IP-адреса, 78
имена, 522
шифрование, 459
3DES, 461
CAST, 462
СВС, 317
CodeDrag, 459
DES, 461
IDEA, 461
Skipjack, 462
электронная почта, 683
шлюзы, 348
IPX-IP, 550
диагностика, 825
и маршрутизаторы, 348
протоколы, 348
удаление, 509
э
эволюция открытых сетей, 30
экстрасети, 56
электромагнитные помехи, 194
электронная почта, 49, 667, 672
ШАР, 681
POP, 681,682
SMTP, 66,673
безопасность, 683
Т. Паркер, К. Сиян
TCP/IP. Для профессионалов
3-е издание
Перевел с английского Е. Матвеев
Главный редактор Е. Строганова
Заведующий редакцией И. Корнеев
Руководитель проекта Ю. Суркис
Научные редакторы Е. Матвеев
Литературный редактор А. Пасечник
Художник Н. Биржаков
Корректор В. Листова
Верстка Р. Гришанов
Лицензия ИД № 05784 от 07.09.01.
Подписано в печать 23.10.03. Формат 70X100/16. Усл. п. л. 69,66.
Тираж 4000 экз. Заказ № 897.
ООО «Питер Принт». 196105, Санкт-Петербург, ул. Благодатная, д. 67в.
Налоговая льгота - общероссийский классификатор продукции
ОК 005-93, том 2; 953005 - литература учебная.
Отпечатано с готовых диапозитивов в ФГУП «Печатный двор» им. А. М. Горького
Министерства РФ по делам печати, телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловский пр., 15.