/
































































































































































































































Автор: Рамсундар Б. Босаг Заде Р.
Теги: искусственный интеллект компьютерные технологии программирование машинное обучение язык программирования python
ISBN: 978-5-9775-4014-8
Год: 2019




Текст
O'REILLY
ОТ ЛИНЕЙНОЙ РЕГРЕССИИ ДО ОБУЧЕНИЯ С МАКСИМИЗАЦИЕЙ ПОДКРЕПЛЕНИЯ
bhv®
Бхарат Рамсундар Реза Босаг Заде
TensorFlow for Deep Learning
From Linear Regression to Reinforcement Learning
Bharath Ratnsundar and Reza Bosagh Zadeh
Beijing • Boston • Farnham • Sebastopol • Tokyo
O’REILLY
TensorFlow
для глубокого обучения
Бхарат Рамсундар Реза Босаг Заде
Санкт-Петербург « БХВ-Петербург» 2019
УДК 004.85
ББК 32.973.26-018
Р21
Рамсундар, Б.
Р21 TensorFlow для глубокого обучения: Пер. с англ. / Б. Рамсундар,
Р. Б. Заде. — СПб.: БХВ-Петербург, 2019. — 256 с.: ил.
ISBN 978-5-9775-4014-8
Книга знакомит с основами программной библиотеки TensorFlow и принципами глубокого обучения, начиная с нулевого уровня. В книге рассмотрены базовые вычисления в библиотеке TensorFlow, простые обучающиеся системы и их построение, полносвязные глубокие сети, прототипы и превращение прототипов в высококачественные модели, сверхточные нейронные сети и обработка изображений, рекуррентные нейронные сети и наборы естественно-языковых данных, способы обучения с максимизацией подкрепления на примере известных игр, приемы тренинга глубоких сетей с помощью графических и тензорных процессоров.
Для разработчиков систем машинного обучения
УЖ 004.85
ББК 32.973.26-018
Группа подготовки издания:
Руководитель проекта Зав. редакцией Перевод с английского Компьютерная верстка Оформление обложки
Евгений Рыбаков
Екатерина Сависте
Андрея Логунова Ольги Сергиенко Карины Соловьевой
©2019BHV
Authorized Russian translation of the English edition of TensorFlow for Deep Learning ISBN 978-1-491-98045-3 ©2018 Reza Zadeh, Bharath Ramsundar
This translation is published and sold by permission of O'Reilly Media, Inc., which owns or controls all rights to publish and sell the same.
Авторизованный русский перевод английской редакции книги TensorFlow for Deep Learning
ISBN 978-1-491-98045-3 © 2018 Reza Zadeh, Bharath Ramsundar.
Перевод опубликован и продается с разрешения O'Reilly Media, Inc., собственника всех прав на публикацию и продажу издания.
Подписано в печать 04.02.19.
Формат 70х1001/16. Печать офсетная. Усл. печ. л. 20,64.
Тираж 1000 экз. Заказ №8426.
"БХВ-Петербург", 191036, Санкт-Петербург, Гончарная ул., 20.
Отпечатано с готового оригинал-макета
ООО "Принт-М", 142300, М.О., г. Чехов, ул. Полиграфистов, д. 1
ISBN 978-1-491-98045-3 (англ.)
ISBN 978-5-9775-4014-8 (рус.)
©2018 Reza Zadeh, Bharath Ramsundar
© Перевод на русский язык, оформление ООО "БХВ-Петербург",
ООО "БХВ", 2019
Оглавление
Об авторах.................................................................11
Предисловие................................................................13
Условные обозначения, принятые в этой книге................................13
Использование примеров программ............................................14
Признательности............................................................14
Комментарии переводчика....................................................15
Исходный код...........................................................16
Протокол установки библиотек...........................................17
Установка библиотек Python из whl-файлов...............................17
Глава 1. Введение в глубокое самообучение..................................19
Машинное самообучение "питается" информатикой..............................19
Глубоко обучающиеся примитивы..............................................21
Полносвязный слой......................................................21
Сверточный слой........................................................22
Слои рекуррентной нейронной сети.......................................22
Ячейки долгой краткосрочной памяти.....................................23
Глубоко обучающиеся архитектуры............................................24
LeNet..................................................................24
AlexNet................................................................24
ResNet.................................................................25
Нейронная модель титрования изображений................................26
Нейронный машинный перевод Google......................................27
Однократные модели.....................................................27
AlphaGo................................................................29
Генеративно-состязательные сети........................................31
Нейронные машины Тьюринга..............................................31
Вычислительные каркасы для глубокого самообучения..........................32
Ограничения вычислительной среды TensorFlow............................33
Резюме.....................................................................34
Глава 2. Введение в примитивы TensorFlow...................................35
Введение в тензоры.........................................................35
Скаляры, векторы и матрицы.............................................36
Матричная математика...................................................39
Тензоры................................................................41
Тензоры в физике.......................................................42
Математические ремарки.................................................44
5
Базовые вычисления в TensorFlow.............................................44
Установка TensorFlow и начало работы....................................45
Инициализация константных тензоров......................................45
Отбор случайных значений для тензоров...................................47
Сложение и шкалирование тензоров........................................48
Матричные операции......................................................49
Типы тензоров...........................................................50
Обработка форм тензоров.................................................51
Введение в операцию транслирования......................................52
Императивное и декларативное программирование...............................53
Графы TensorFlow........................................................55
Сеансы TensorFlow.......................................................55
Переменные TensorFlow...................................................56
Резюме......................................................................58
Глава 3. Линейная и логистическая регрессия с помощью TensorFlow............. 59
Математический обзор........................................................59
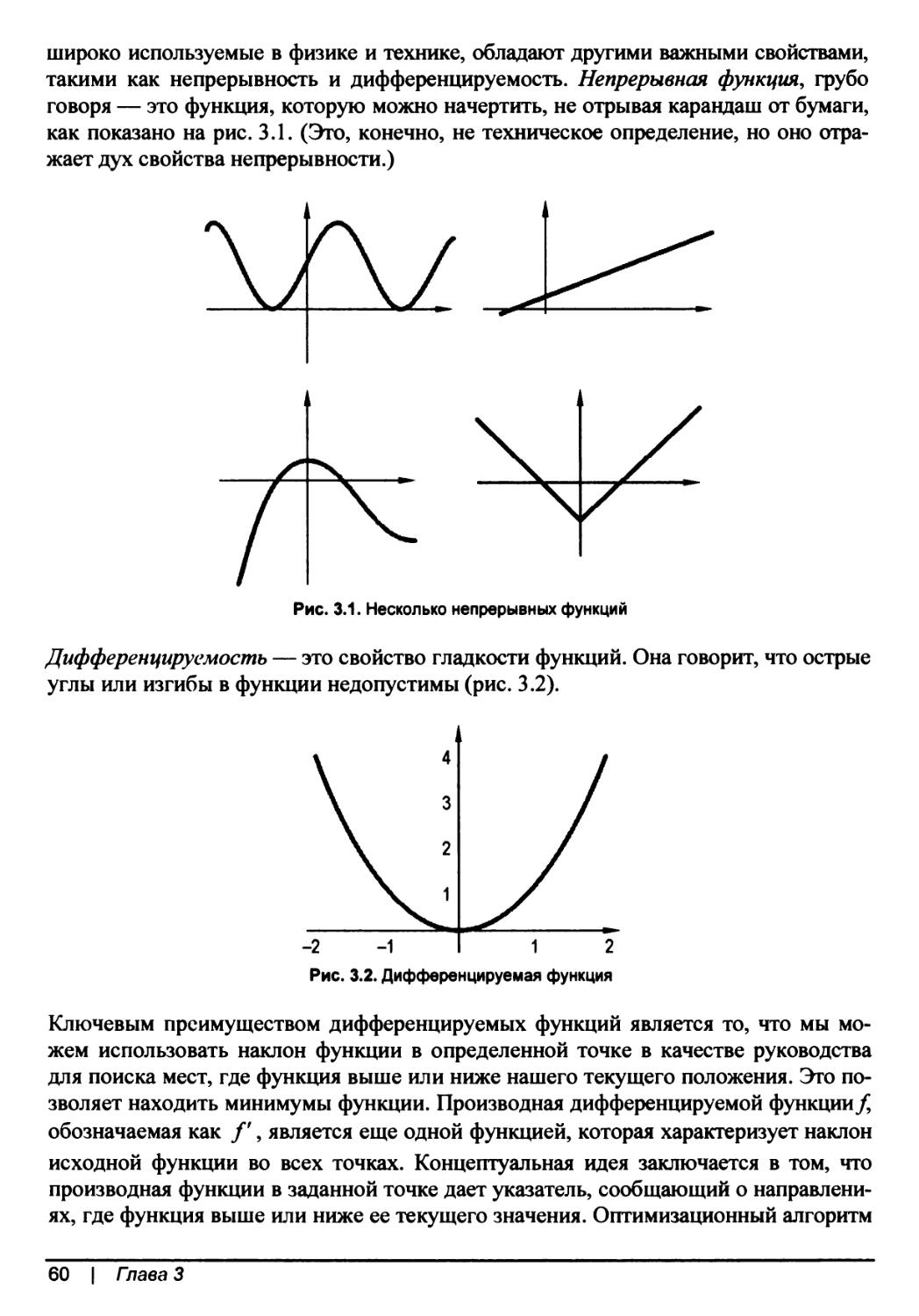
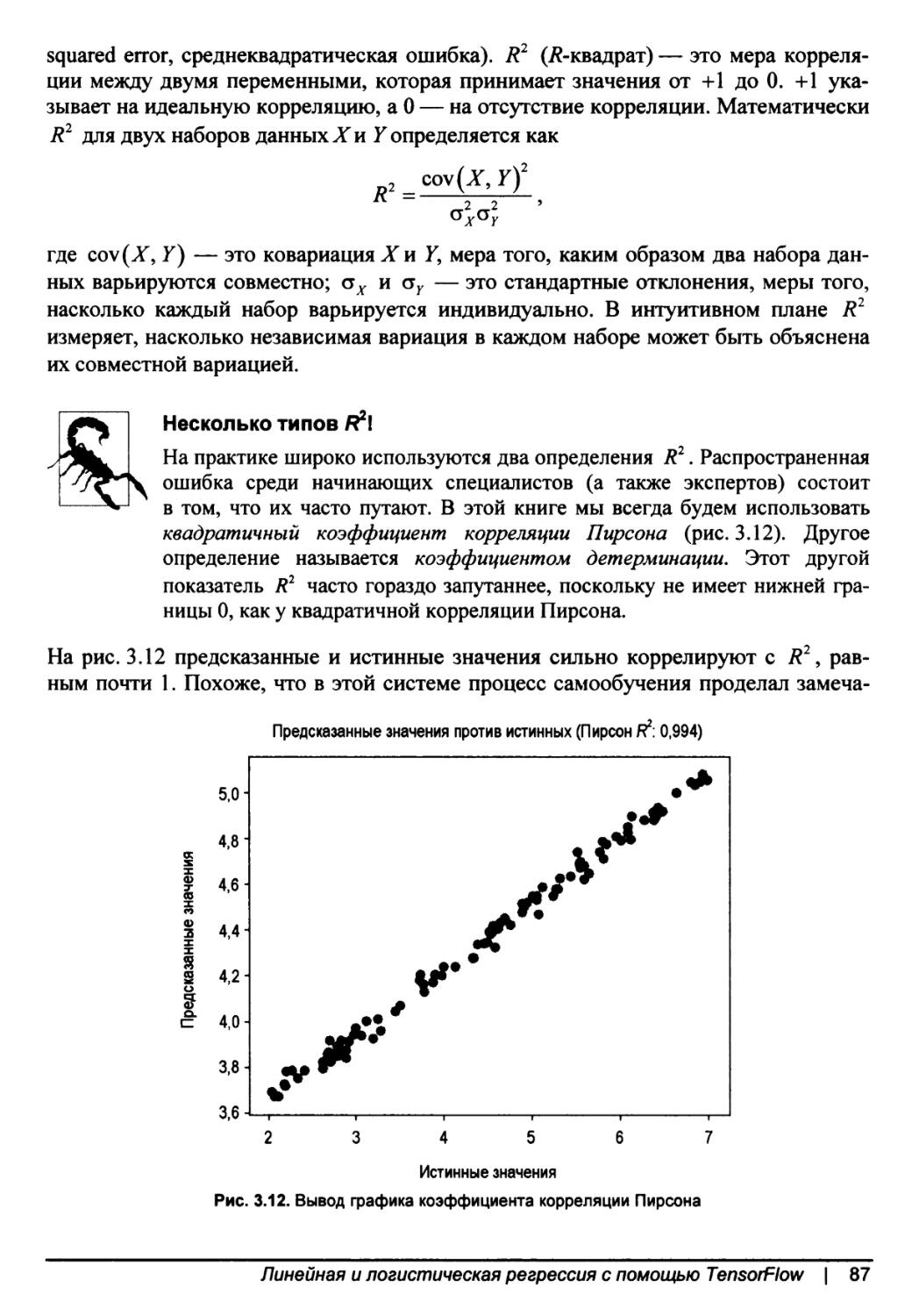
Функции и дифференцируемость............................................59
Функции потерь..........................................................61
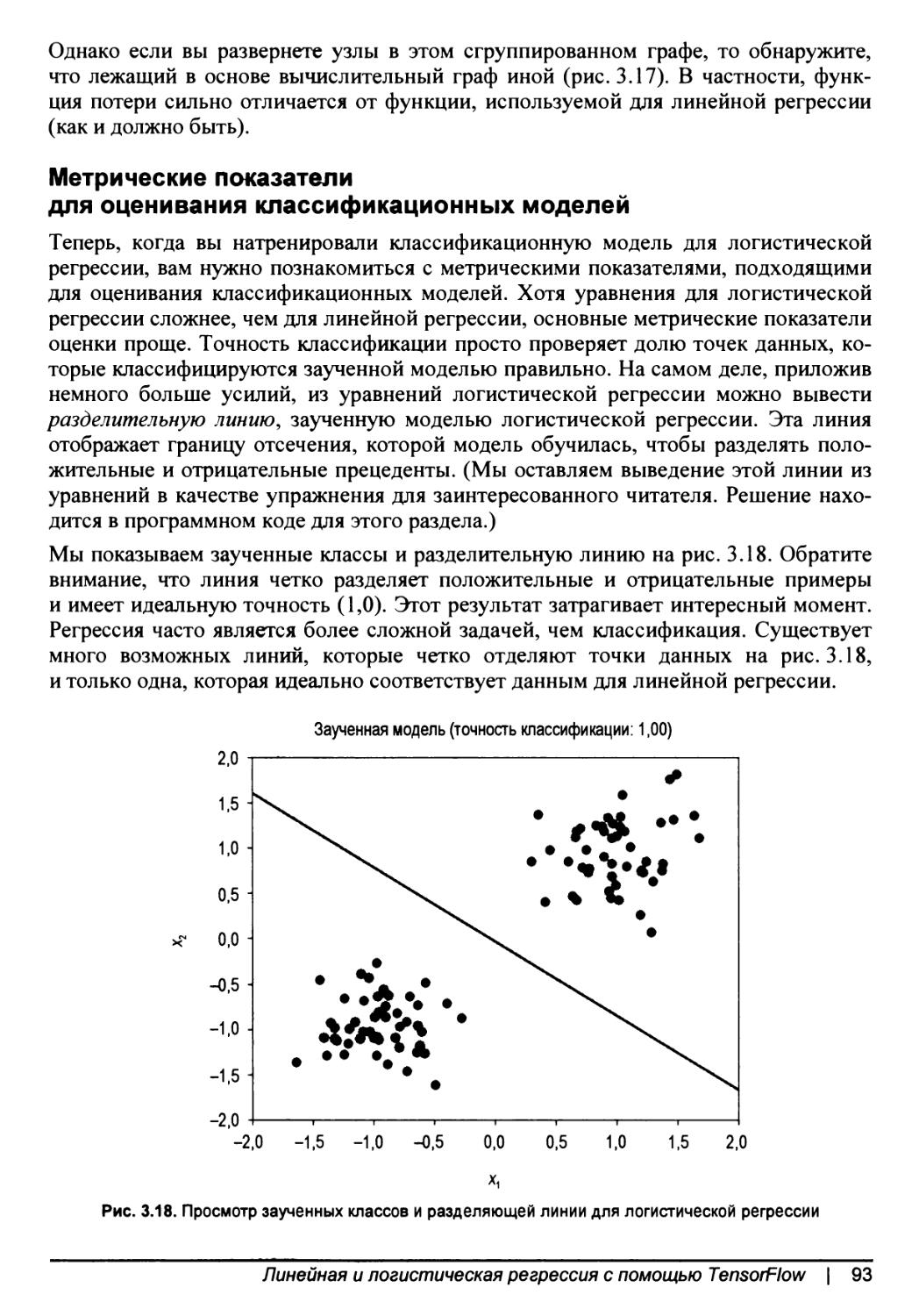
Классификация и регрессия...........................................62
£2-потеря...........................................................63
Режимы сбоя функции £2-потери.......................................63
Распределения вероятностей..........................................64
Перекрестно-энтропийная потеря......................................65
Градиентный спуск.......................................................66
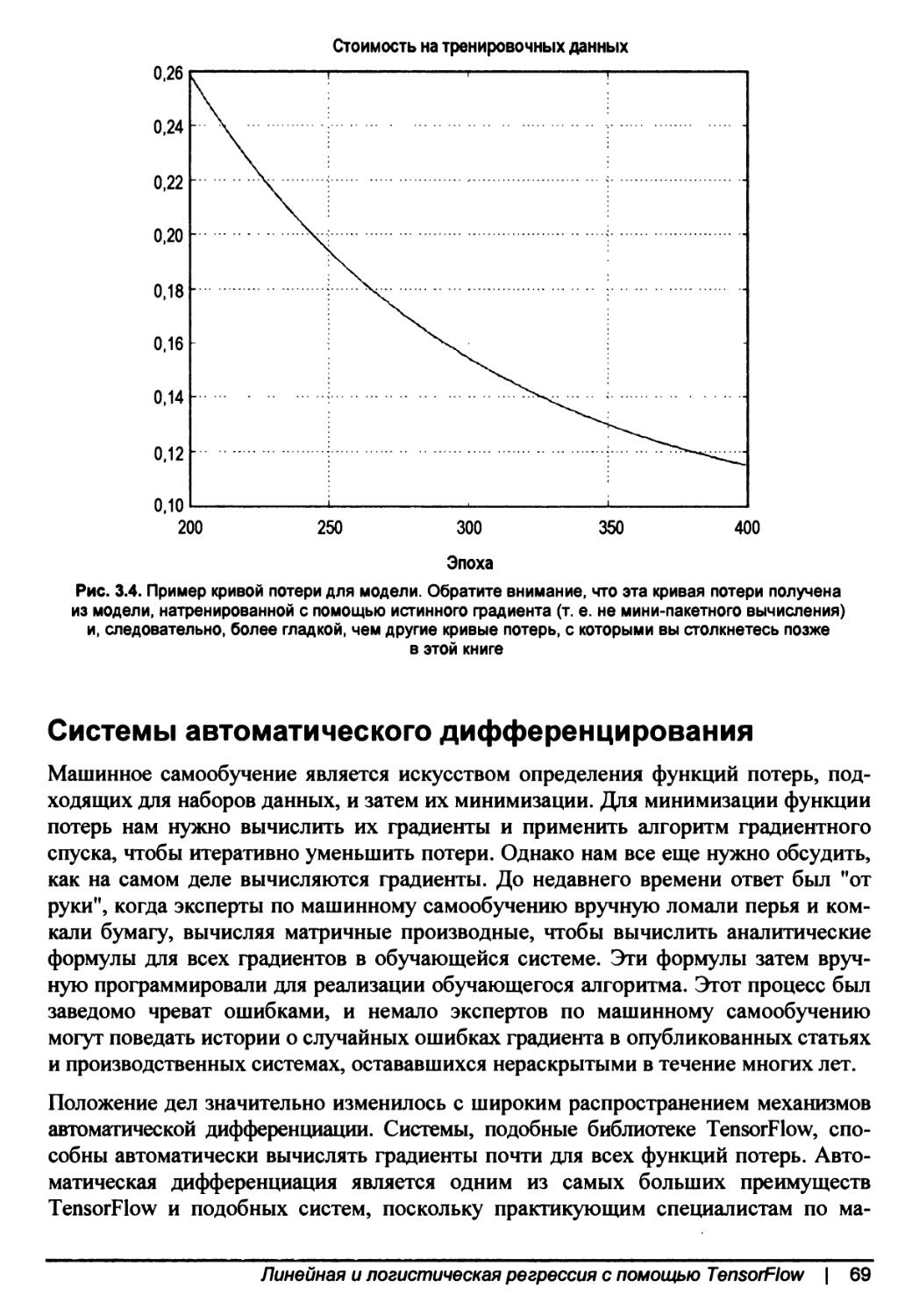
Системы автоматического дифференцирования...............................69
Самообучение с помощью TensorFlow...........................................70
Создание игрушечных наборов данных......................................71
Чрезвычайно краткое введение в NumPy................................71
Почему важны игрушечные наборы данных?..............................71
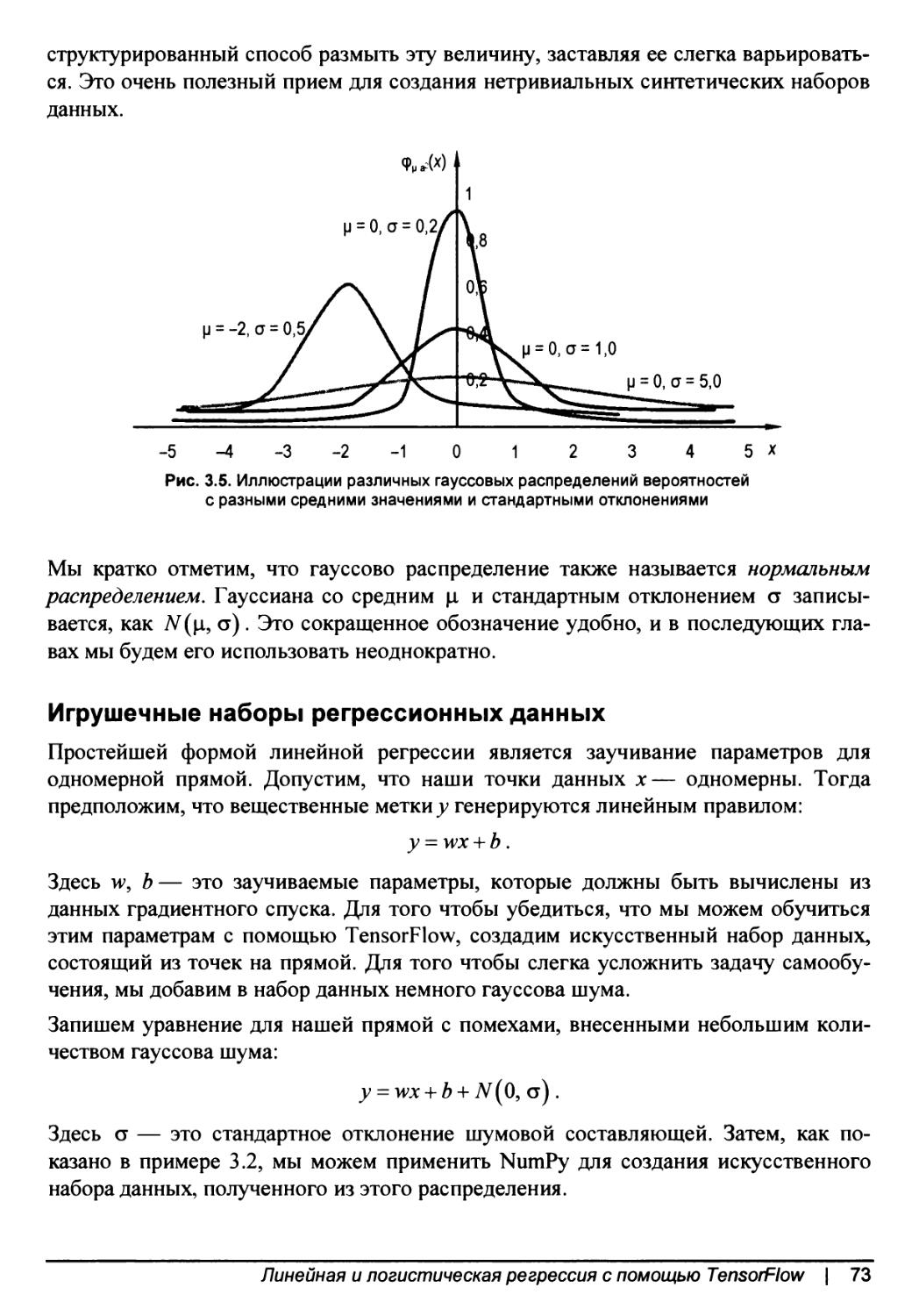
Добавление шума с помощью гауссиан..................................72
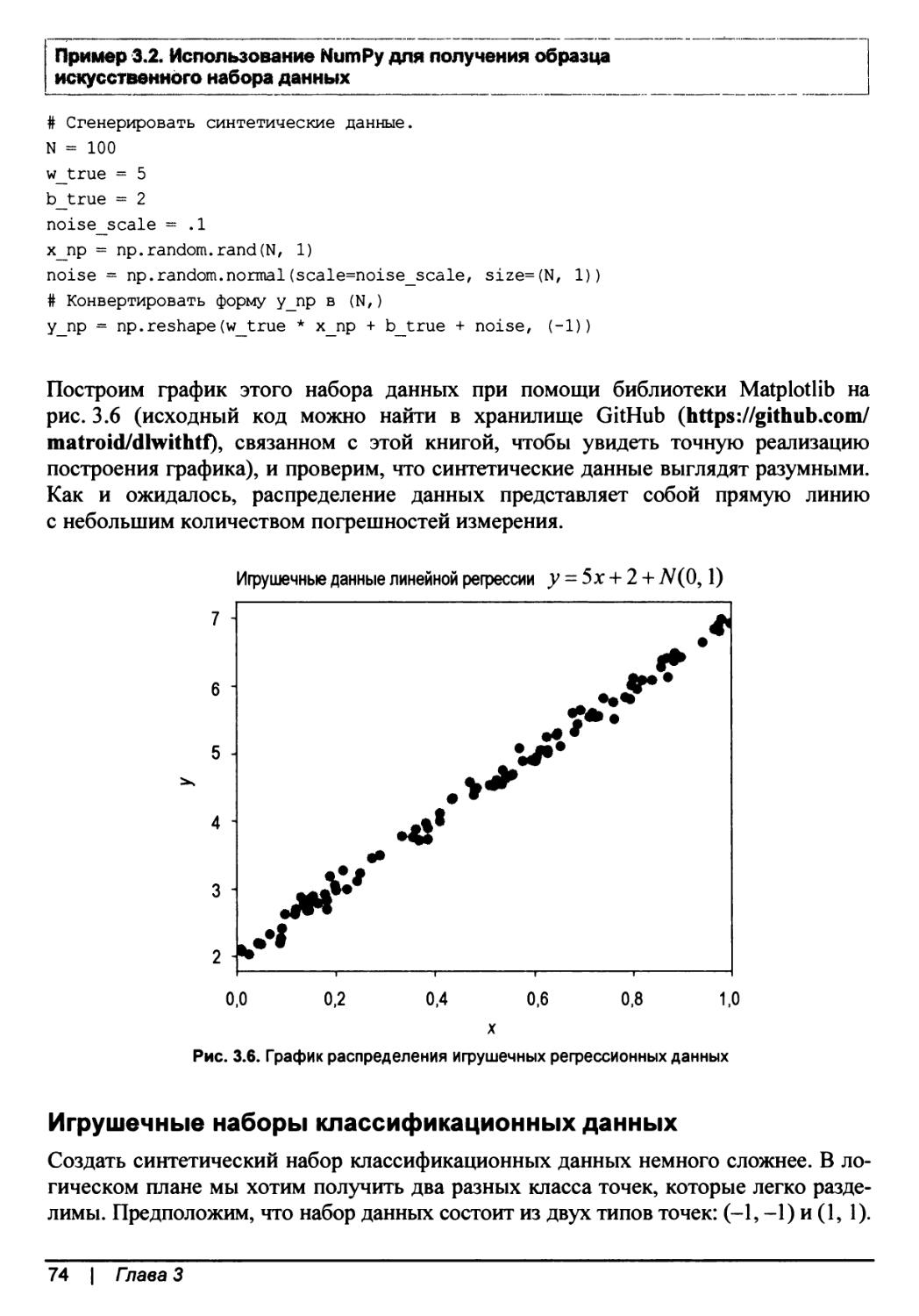
Игрушечные наборы регрессионных данных..............................73
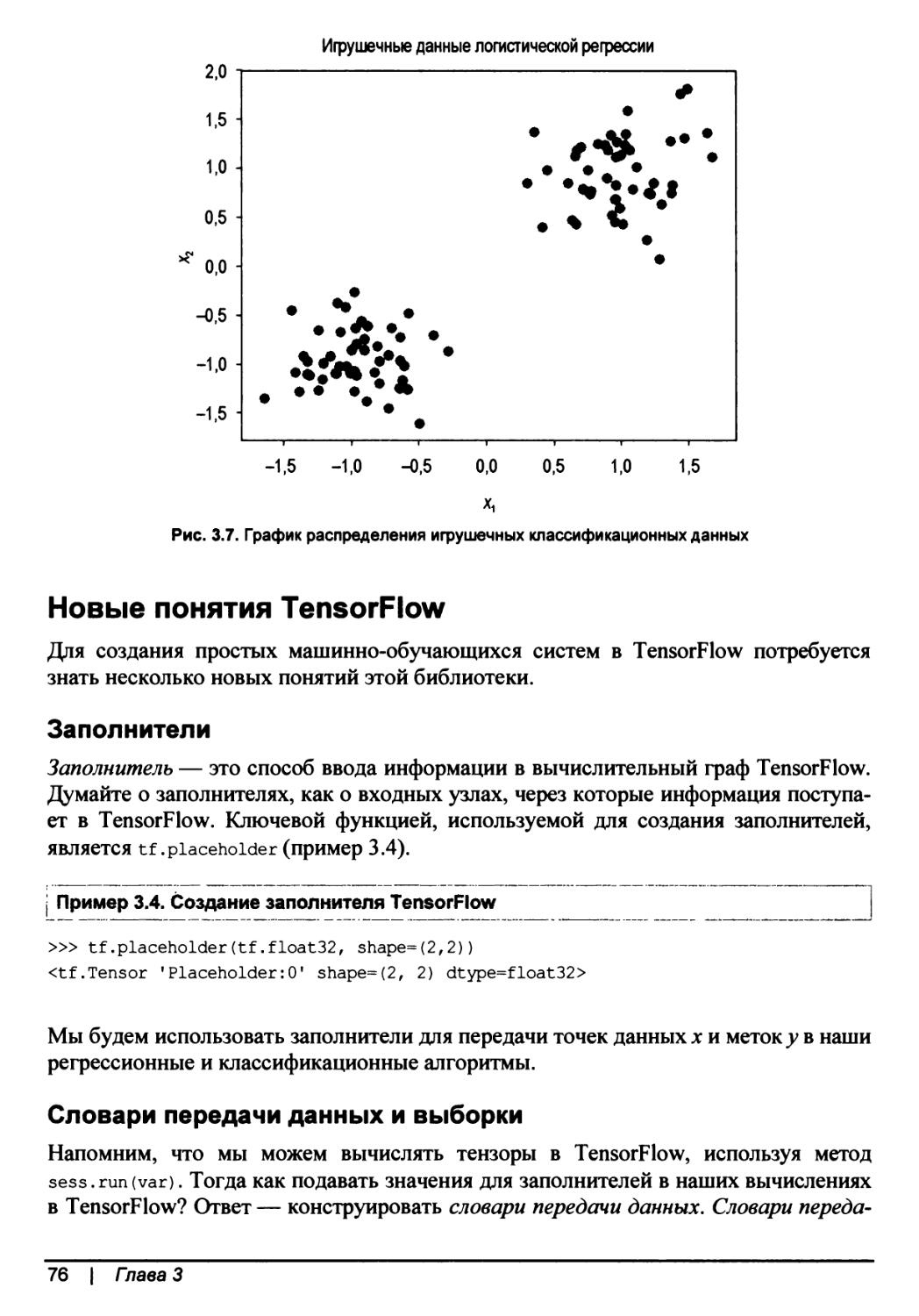
Игрушечные наборы классификационных данных..........................74
Новые понятия TensorFlow................................................76
Заполнители.........................................................76
Словари передачи данных и выборки...................................76
Области имен........................................................77
Оптимизаторы........................................................77
Взятие градиентов с помощью TensorFlow..............................78
Сводки и пишущие объекты для TensorBoard............................79
Тренировка моделей с помощью TensorFlow.............................80
Тренировка линейной и логистической моделей в TensorFlow....................80
Линейная регрессия в TensorFlow.........................................80
Определение и тренировка линейной регрессии в TensorFlow............81
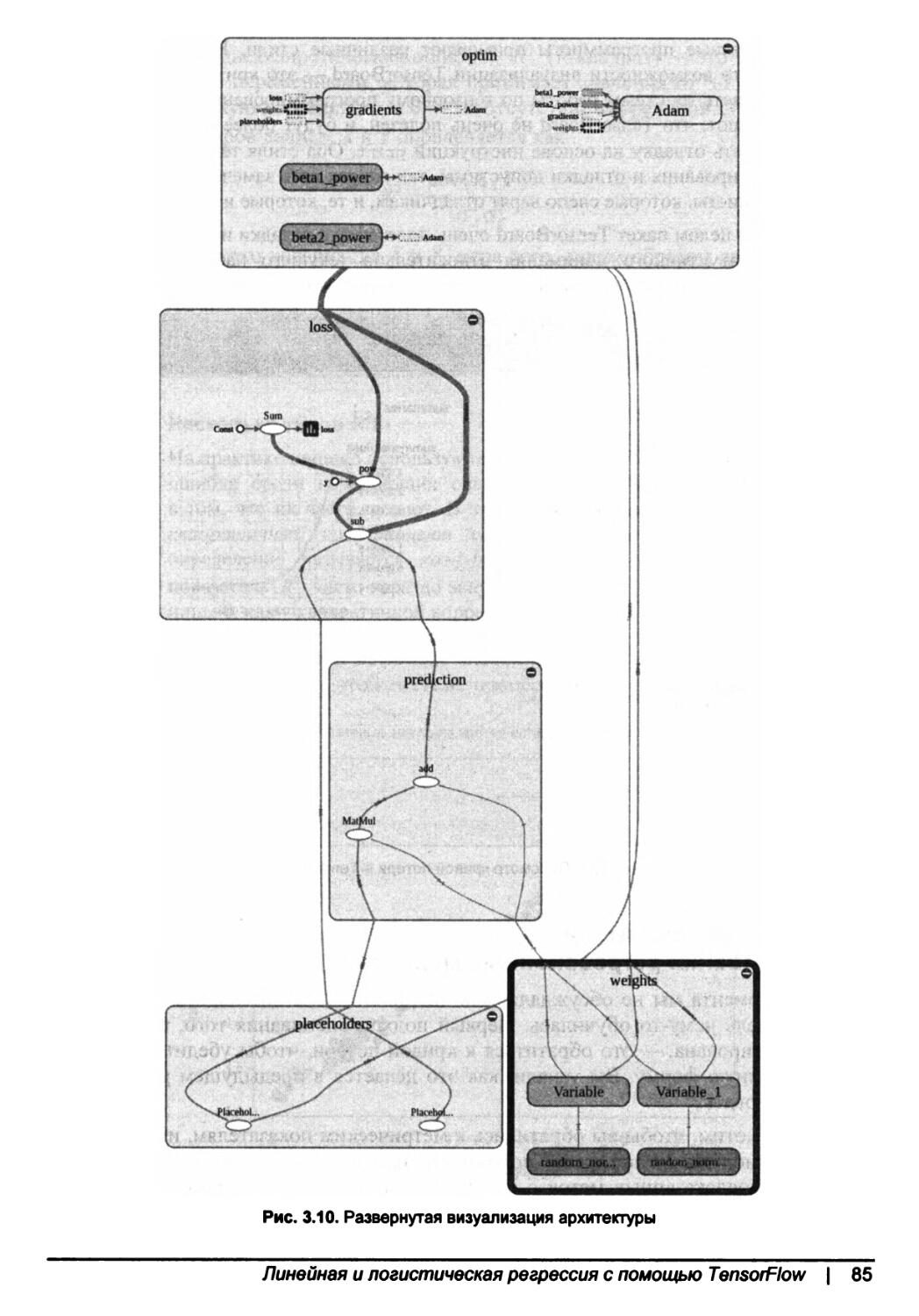
Визуализация линейных регрессионных моделей с помощью TensorBoard...83
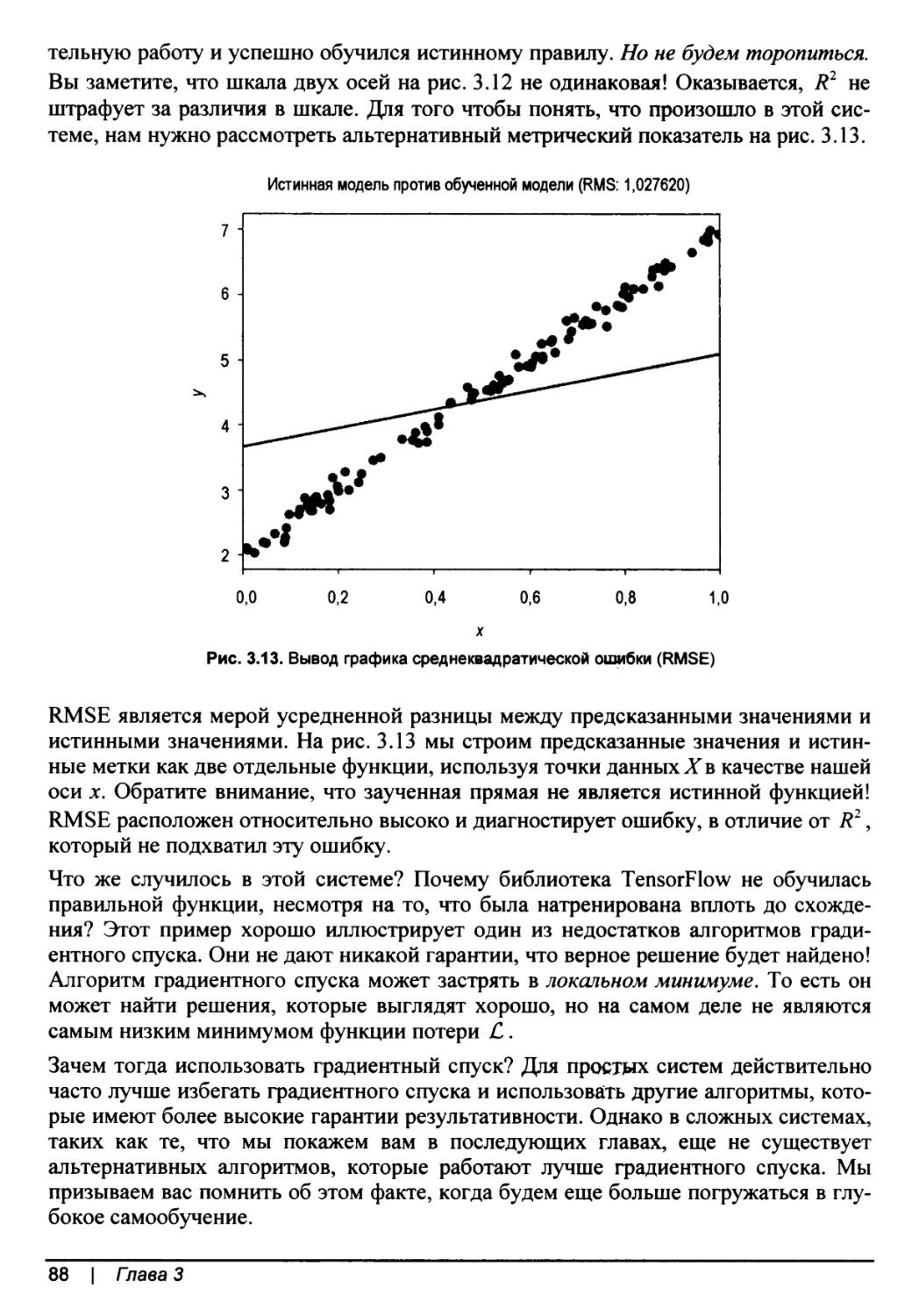
Метрические показатели для оценивания регрессионных моделей.........86
Логистическая регрессия в TensorFlow....................................89
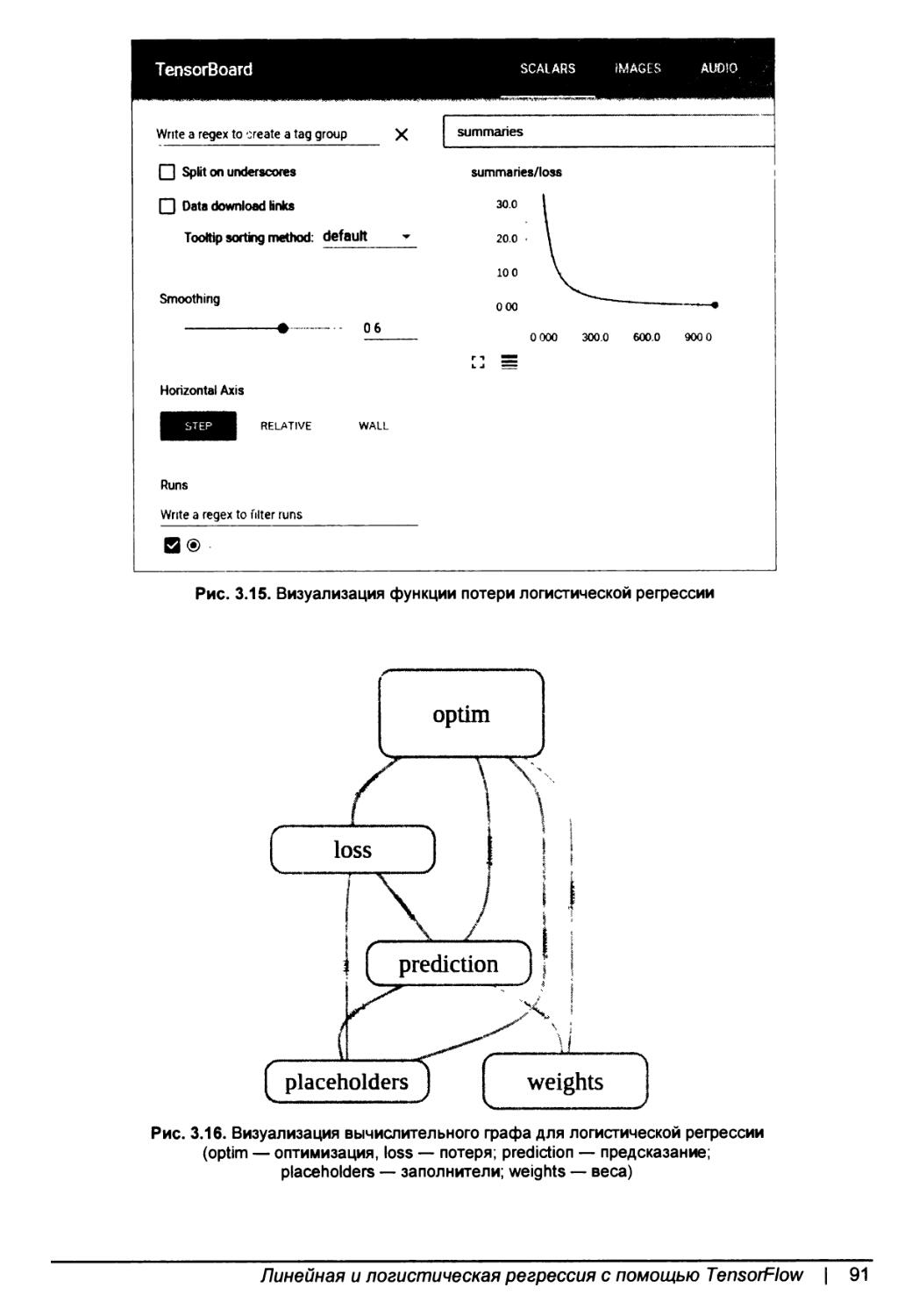
Визуализация логистических регрессионных моделей с помощью TensorBoard.90
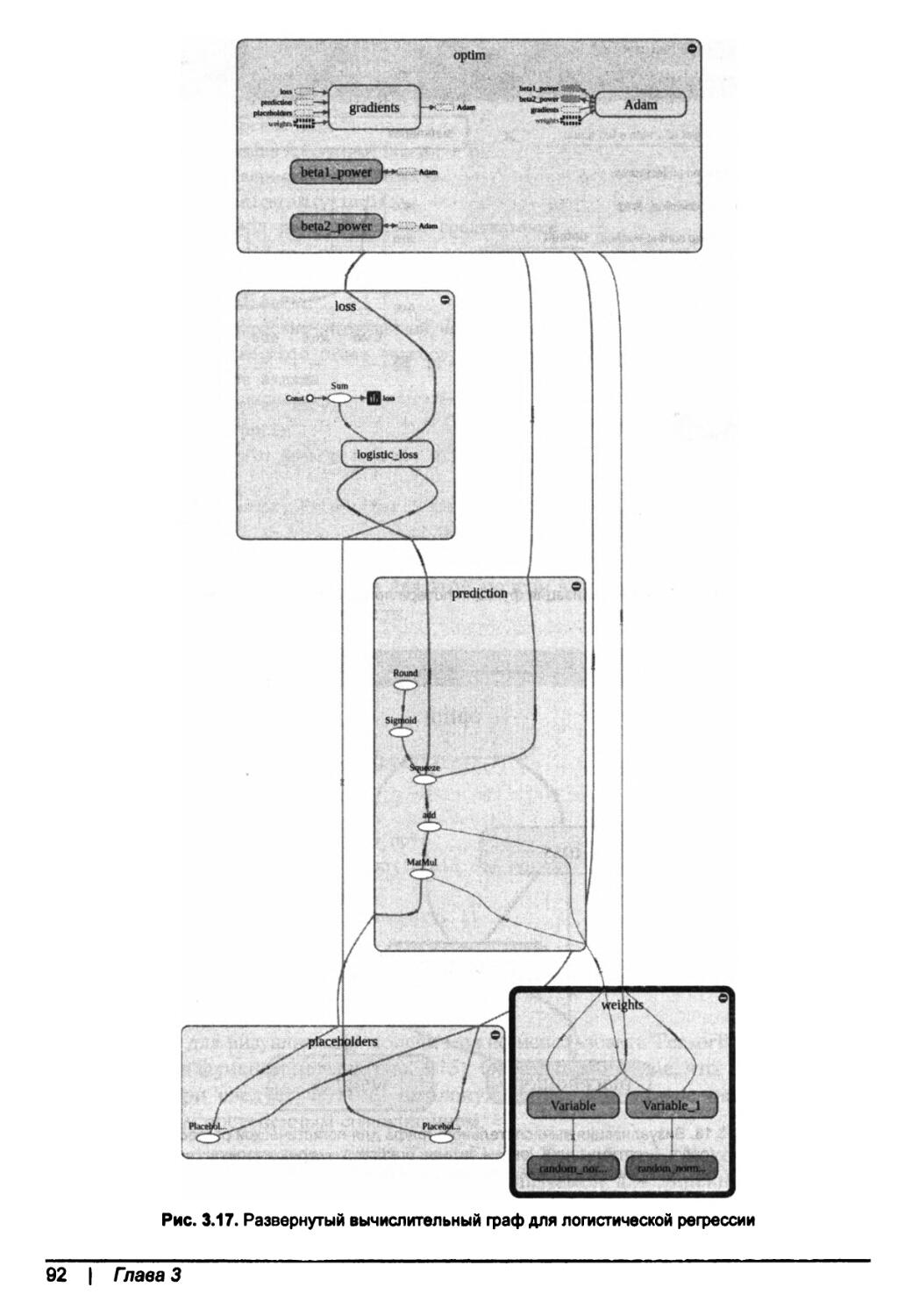
Метрические показатели для оценивания классификационных моделей.....93
Резюме......................................................................94
6 | Оглавление
Глава 4. Полносвязные глубокие сети.........................................95
Что такое полносвязная глубокая сеть?.......................................95
"Нейроны” в полносвязных сетях..............................................97
Обучающиеся полносвязные сети с обратным распространением...............99
Теорема об универсальной сходимости....................................100
Почему именно глубокие сети?...........................................102
Тренировка полносвязных нейронных сетей....................................102
Заучиваемые представления..............................................102
Активации..............................................................103
Полносвязные сети запоминают...........................................104
Регуляризация..........................................................104
Отсев..............................................................105
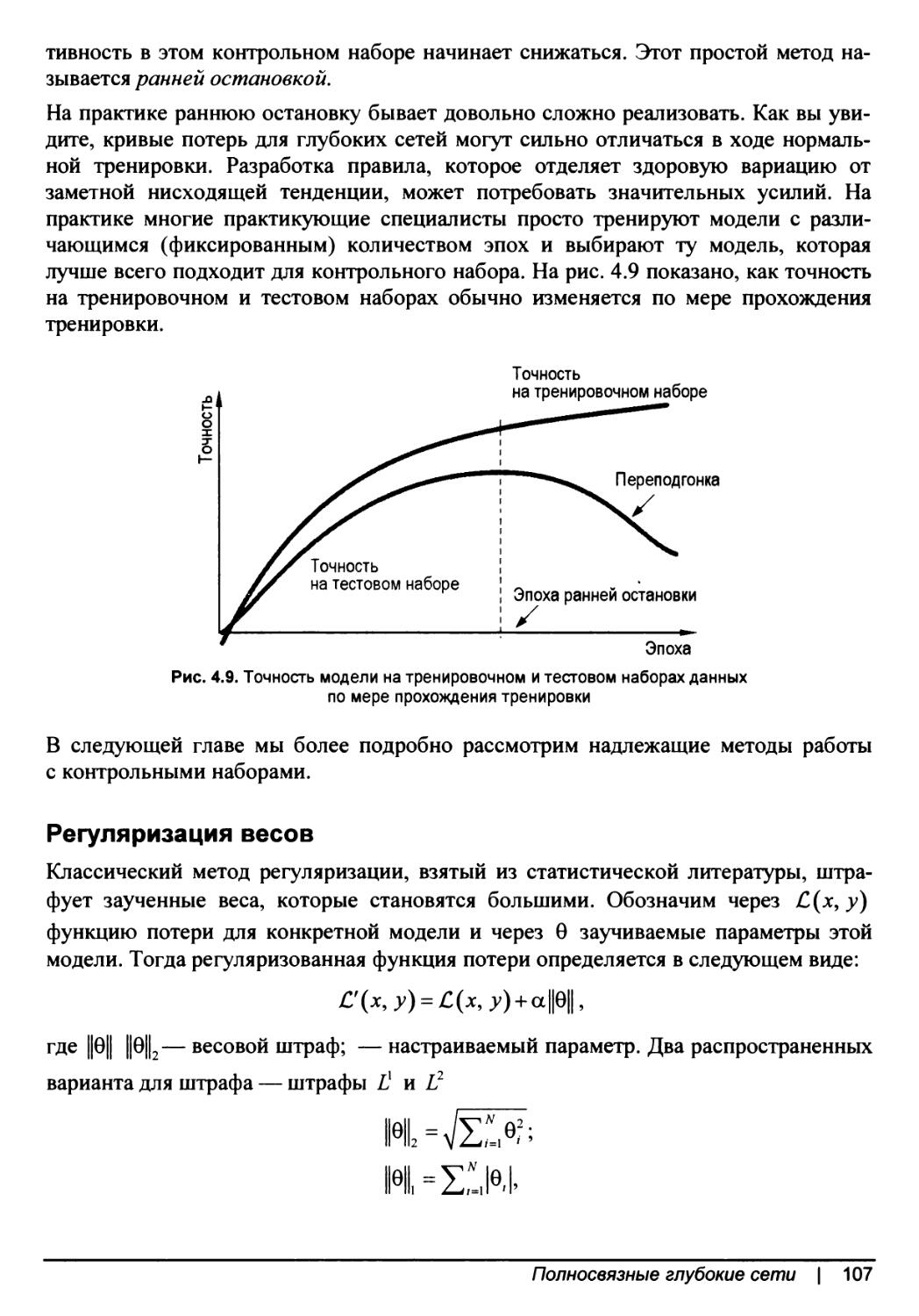
Ранняя остановка...................................................106
Регуляризация весов................................................107
Тренировка полносвязных сетей..........................................108
Мини-пакетирование.................................................108
Скорости заучивания................................................108
Реализация в TensorFlow....................................................109
Инсталляция DeepChem...................................................109
Набор данных Тох21.....................................................109
Принятие мини-пакетов заполнителей.....................................110
Реализация скрытого слоя...............................................111
Добавление отсева в скрытый слой.......................................112
Реализация мини-пакетирования..........................................113
Оценивание точности модели.............................................113
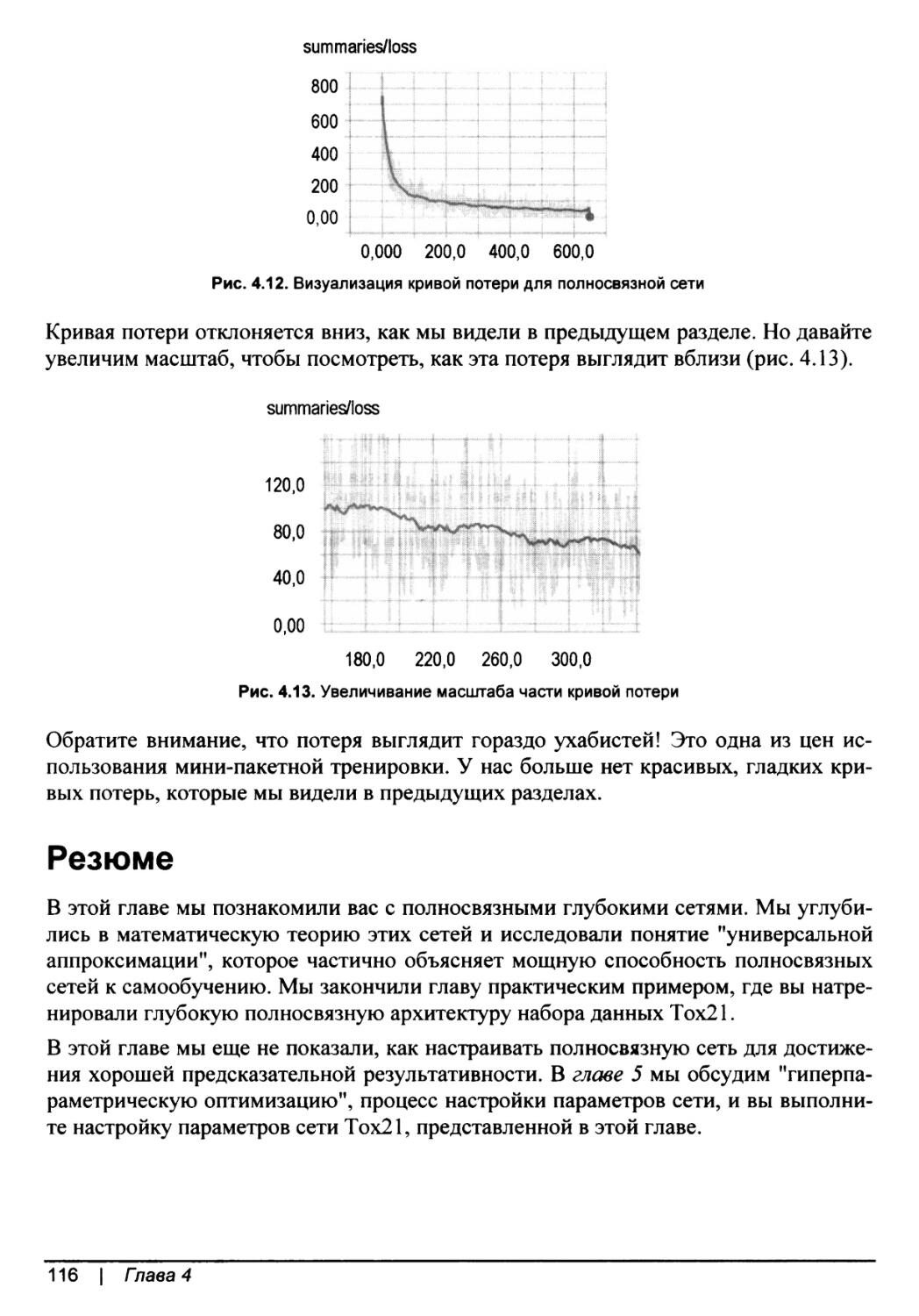
Использование пакета TensorBoard для отслеживания схождения модели.....114
Резюме.....................................................................116
Глава 5. Гнперпараметрнческая оптимизация..................................117
Оценивание модели и гиперпараметрическая оптимизация.......................118
Метрики, метрики, метрики..................................................120
Бинарно-классификационные показатели...................................120
Метрические показатели мультиклассовой классификации...................123
Регрессионные метрические показатели...................................124
Алгоритмы оптимизации гиперпараметров......................................125
Установление ориентира.................................................126
Спуск студента магистратуры............................................128
Решеточный поиск гиперпараметров.......................................129
Случайный поиск гиперпараметров........................................130
Задание для читателя...................................................132
Резюме.....................................................................132
Глава 6. Сверточные нейронные сети.........................................133
Введение в сверточные архитектуры..........................................134
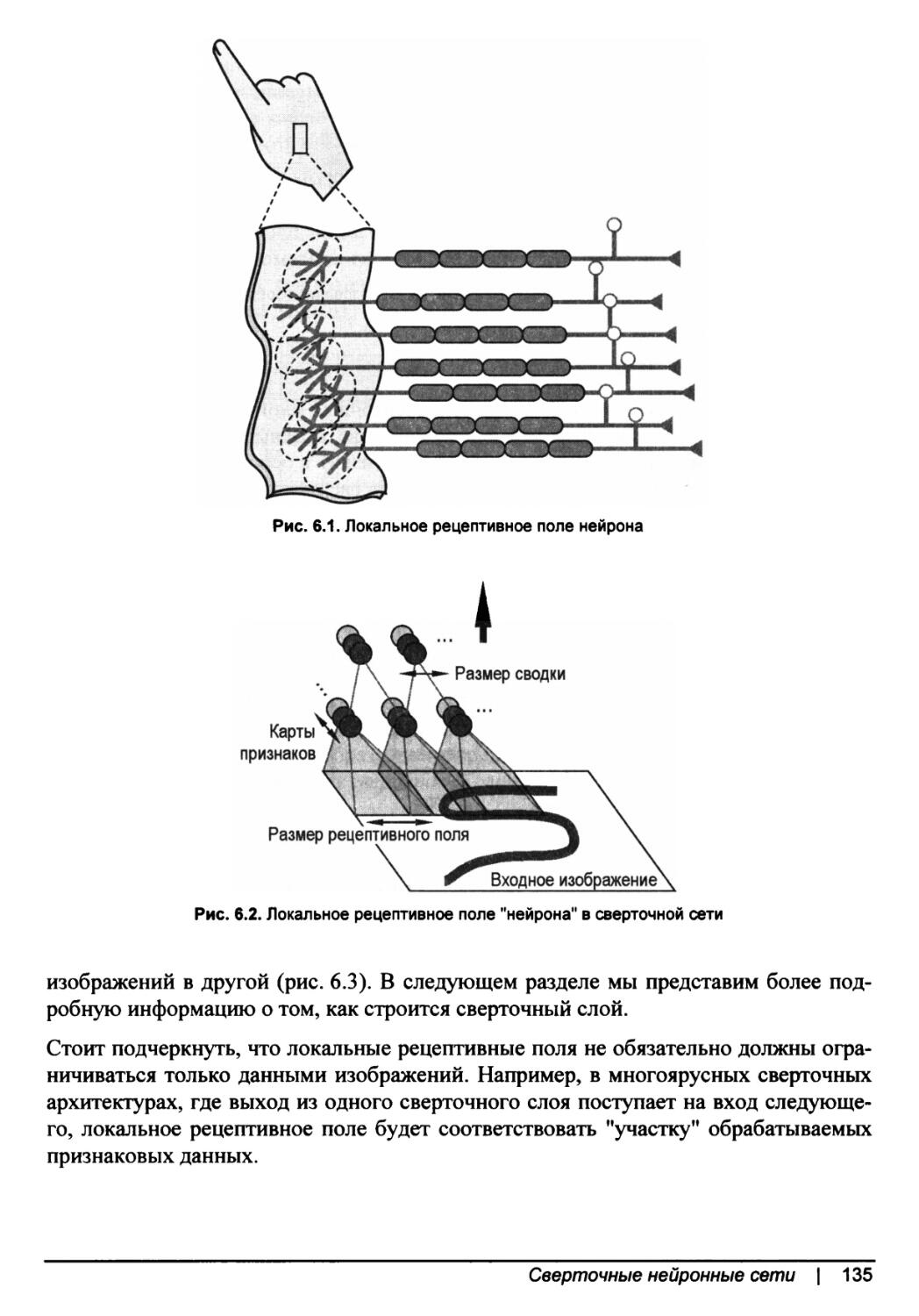
Локальные рецептивные поля.............................................134
Сверточные ядра........................................................136
Редуцирующие слои......................................................138
Конструирование сверточных сетей.......................................139
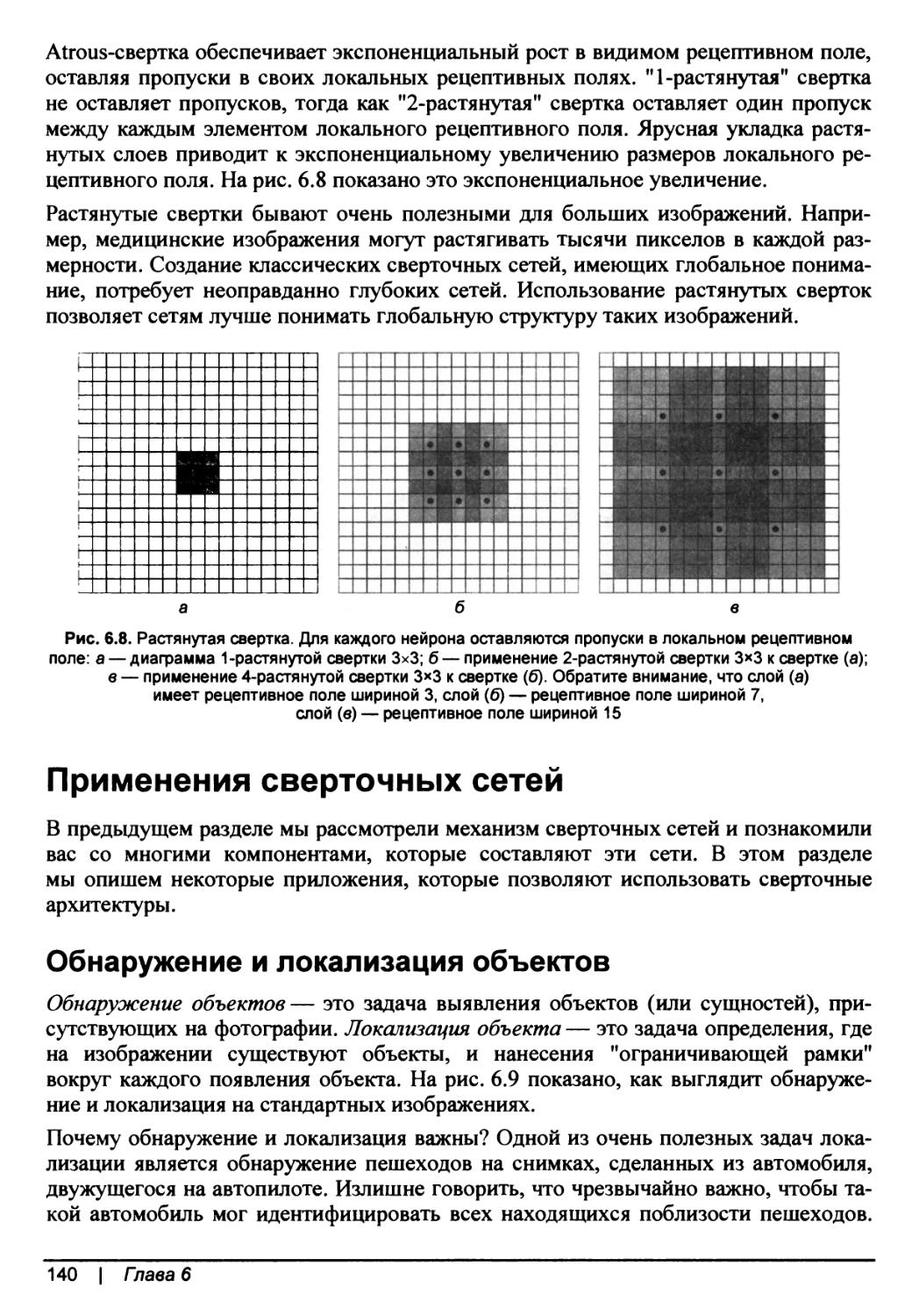
Растянутые свертки.....................................................139
Оглавление | 7
Применения сверточных сетей...............................................140
Обнаружение и локализация объектов....................................140
Сегментация изображений...............................................141
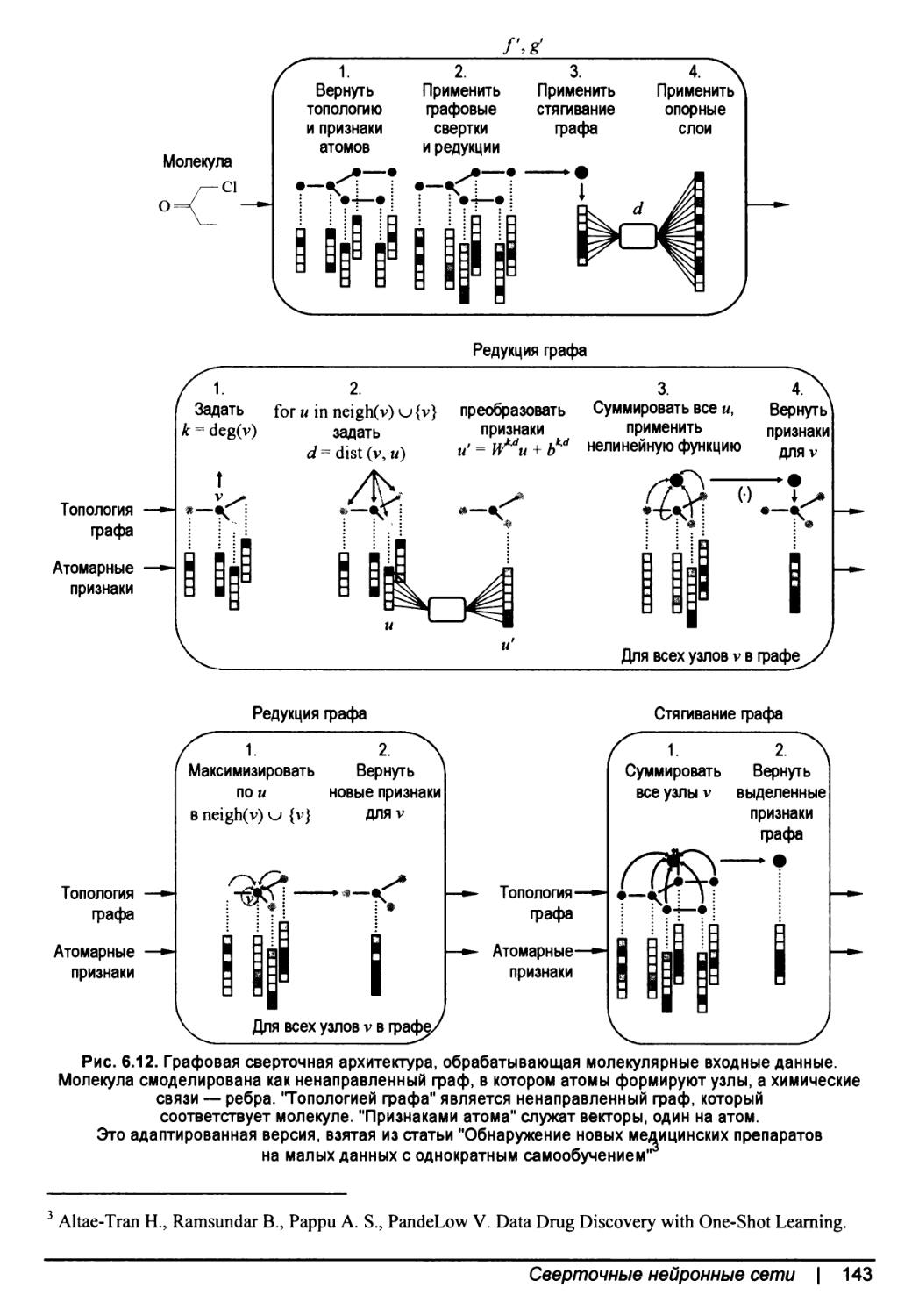
Графовые свертки......................................................142
Генерирование изображений с помощью вариационных автокодировщиков.....144
Состязательные модели.............................................146
Тренировка сверточной сети в TensorFlow...................................147
Набор данных MNIST....................................................147
Скачивание набора данных MNIST........................................148
Сверточные примитивы TensorFlow.......................................152
Сверточная архитектура................................................153
Оценивание натренированных моделей....................................158
Задание для читателя..................................................160
Резюме....................................................................160
Глава 7. Рекуррентные нейронные сети......................................161
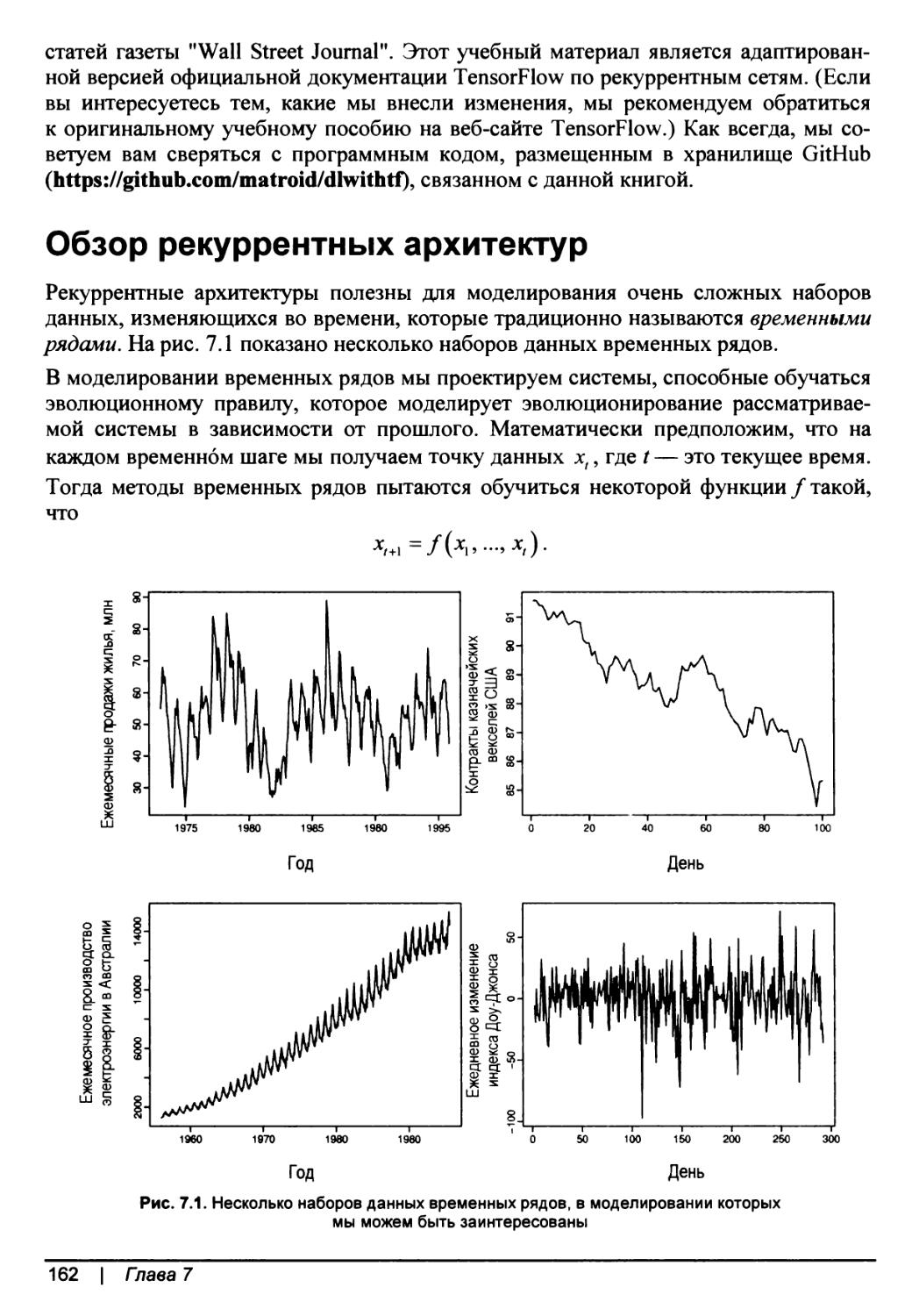
Обзор рекуррентных архитектур.............................................162
Рекуррентные ячейки.......................................................164
Долгая краткосрочная память...........................................164
Вентильные рекуррентные блоки.........................................166
Применение рекуррентных моделей...........................................166
Получение образцов из рекуррентных сетей..............................167
Модели Seq2seq........................................................167
Нейронные машины Тьюринга.................................................169
Работа с рекуррентными нейронными сетями на практике......................171
Обработка корпуса Penn Treebank.......................................171
Программный код для предобработки.....................................173
Загрузка данных в TensorFlow..........................................175
Базовая рекуррентная архитектура......................................177
Задание для читателя..................................................179
Резюме....................................................................179
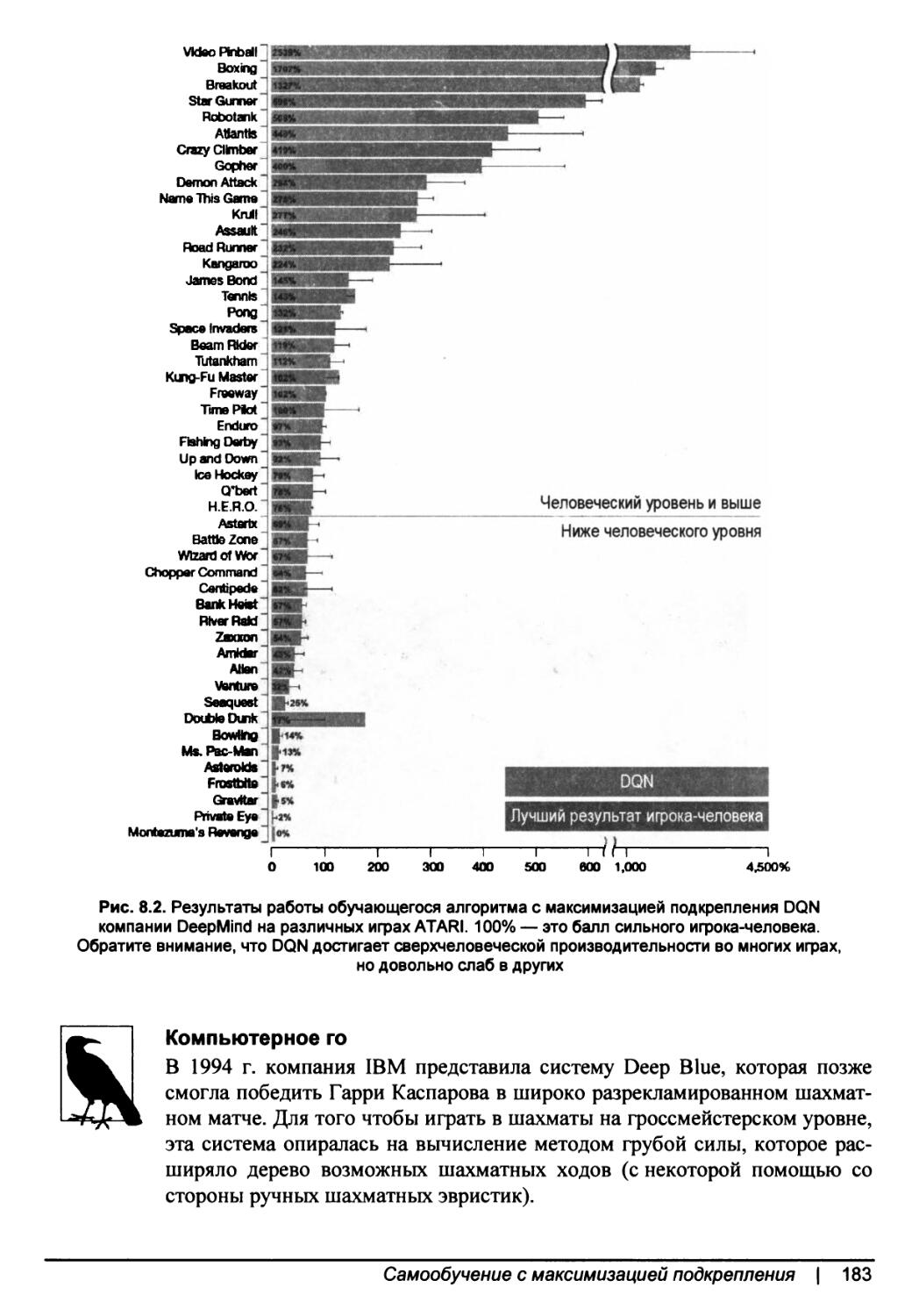
Глава 8. Самообучение с максимизацией подкрепления........................181
Марковские процессы принятия решений......................................185
Алгоритмы для самообучения с максимизацией подкрепления...................187
0-заучивание..........................................................188
Заучивание стратегии..................................................189
Асинхронная тренировка................................................191
Ограничения самообучения с максимизацией подкрепления.....................191
Игра крестики-нолики......................................................193
Объектная ориентированность...........................................194
Абстрактная среда.....................................................194
Среда игры крестики-нолики............................................195
Слоевая абстракция....................................................198
Определение графа слоев...............................................201
Алгоритм АЗС..............................................................206
Функция потери........................................................211
Определение рабочих процессов.........................................213
Разворачивание игровой ситуации в рабочих процессах...................214
Тренировка стратегии..................................................217
8 | Оглавление
Задание для читателя.......................................................218
Резюме.....................................................................218
Глава 9. Тренировка крупных глубоких сетей.................................219
Специальное аппаратное обеспечение для глубоких сетей......................219
Тренировка на CPU..........................................................220
Тренировка на GPU......................................................221
Тензорные процессоры...................................................222
Программируемые пользователем вентильные матрицы.......................224
Нейроморфные чипы......................................................224
Распределенная тренировка глубоких сетей...................................225
Параллелизм данных.....................................................226
Параллелизм моделей....................................................227
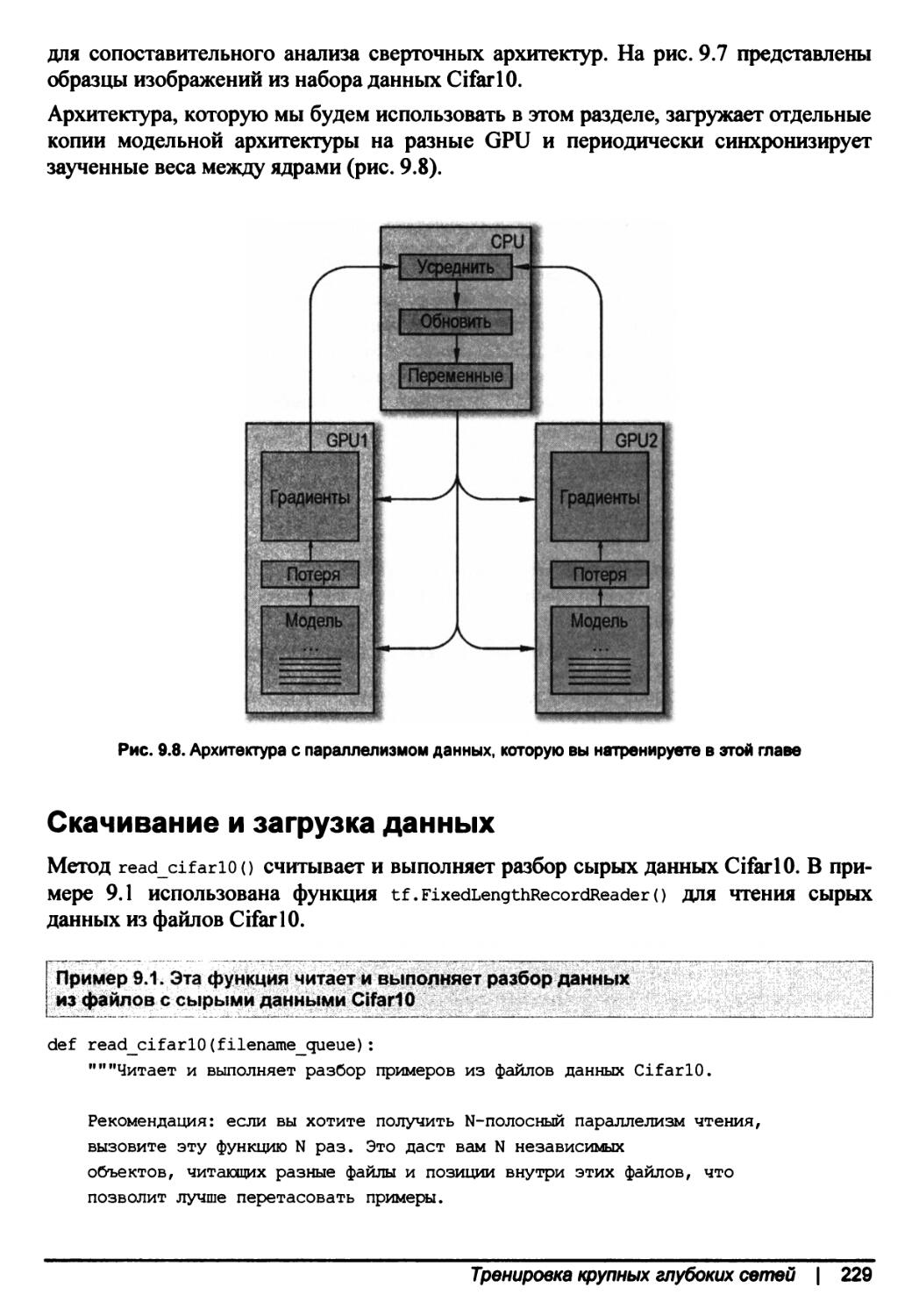
Параллельная тренировка на данных CifarlO с использованием многочисленных GPU.228
Скачивание и загрузка данных...........................................229
Глубокое погружение в архитектуру......................................231
Тренировка на многочисленных GPU.......................................234
Задание для читателя.......................................................237
Резюме.....................................................................237
Глава 10. Будущее глубокого самообучения...................................239
Глубокое самообучение вне технологической индустрии........................240
Глубокое самообучение в фармацевтической промышленности................241
Глубокое самообучение в юстиции........................................241
Глубокое самообучение для робототехники................................242
Глубокое самообучение в сельском хозяйстве.............................242
Этическое использование глубокого самообучения.............................243
Действительно ли универсальный искусственный интеллект неизбежен?..........245
Куда направиться дальше?...................................................246
Предметный указатель.......................................................247
Оглавление | 9
Об авторах
Бхарат Рамсундар (Bharath Ramsundar) получил степень бакалавра гуманитарных и естественных наук по электротехнике, компьютерным наукам и математике в институте Беркли Калифорнийского университета, с отличием закончил выпускной класс по математике. В настоящее время он является аспирантом в области вычислительной техники в Стэнфордском университете в лаборатории Панде. Его исследовательская работа лежит в сфере применения глубокого обучения при создании медицинских препаратов. В частности, Бхарат является ведущим разработчиком DeepChem.io— пакета с открытым исходным кодом, основанного на библиотеке TensorFlow, который ориентирован на демократизацию использования глубокого обучения при создании медицинских препаратов. Он стипендиат аспирантуры Герца, самой избирательной аспирантуры в данной области наук.
Реза Босаг Заде (Reza Bosagh Zadeh) — основатель и генеральный директор компании Matroid и адъюнкт-профессор в Стэнфордском университете. Его профессиональная деятельность лежит в области машинного обучения, вычислительной и дискретной прикладной математики. Реза получил докторскую степень по вычислительной математике под руководством Гуннара Карлссона в Стэнфордском университете. Его награды включают премию KDD Best Paper Award в области открытия знаний в базах данных и премию Gene Golub Outstanding Thesis Award за выдающуюся дипломную работу. Он работал в технических консультативных советах Microsoft и Databricks.
В рамках своего исследования Реза занимался построением машинно-обучающихся алгоритмов, лежащих в основе системы Twitter "кого-читать", которая стала первым продуктом с использованием машинного обучения в этой социальной сети. Реза является инициатором создания линейно-алгебраического пакета в Apache Spark, и его работа была включена в промышленные и академические кластерные вычислительные среды. В дополнение к исследованиям, Реза разработал и преподает два класса уровня докторантуры в Стэнфордском университете: распределенные алгоритмы и оптимизация (СМЕ 323) и дискретная математика и алгоритмы (СМЕ 305).
11
Предисловие
Эта книга познакомит вас с фундаментальными принципами машинного обучения с использованием TensorFlow— новой программной библиотеки компании Google для глубокого обучения, которая значительно облегчает инженерам работу по проектированию и внедрению сложных глубоко обучающихся архитектур. Вы познакомитесь с тем, как использовать библиотеку TensorFlow для построения систем, способных обнаруживать объекты на изображениях, понимать человеческий текст и предсказывать свойства потенциальных лекарств. Кроме того, вы получите интуитивное понимание возможностей TensorFlow как системы для выполнения тензорного исчисления и узнаете, как использовать ее для задач, лежащих за пределами традиционной сферы машинного обучения.
Важно отметить, что эта книга является одной из первых книг по глубокому обучению, написанных для практикующих специалистов. Она обучает фундаментальным понятиям на практических примерах и развивает понимание основ машинного обучения, начиная с нулевого уровня. Целевая аудитория этой книги — практикующие разработчики, которые не испытывают проблем с проектированием программных систем, но отнюдь не всегда справляются с созданием обучающихся систем. По ходу изложения мы лишь изредка будем использовать элементарную линейную алгебру и математический анализ, но при этом рассмотрим все необходимые фундаментальные принципы. Мы также ожидаем, что наша книга окажется полезной для ученых и других специалистов, которые не испытывают проблем с написанием сценариев, но отнюдь не всегда — с проектированием обучающихся алгоритмов.
Условные обозначения, принятые в этой книге
В книге используются следующие типографические условные обозначения:
♦ курсивный шрифт указывает новые термины;
♦ полужирный шрифт служит для выделения интернет-адресов, элементов интерфейса программных продуктов;
♦ моноширинный шрифт используется для листингов программ, а также внутри абзацев для отсылки на элементы программ, такие как переменные или имена функций, базы данных, типы данных, переменные среды, инструкции и ключевые слова;
♦ полужирный моноширинный шрифт показывает команды либо другой текст, который должен быть напечатан непосредственно пользователем;
13
♦ курсивный моноширинный шрифт показывает текст, который должен быть заменен на предоставленные пользователем значения либо на значения, определяемые контекстом.
Данный элемент обозначает общее замечание.
Данный элемент обозначает подсказку или совет.
Данный элемент обозначает предупреждение или предостережение.
Использование примеров программ
Дополнительные материалы (примеры кода, упражнения и т. д.) доступны для скачивания по адресу https://github.com/matroid/dlwithtf.
У нас есть веб-страница для этой книги, где мы размещаем опечатки, примеры и любую дополнительную информацию. Вы можете получить доступ к этой странице по адресу http://bit.ly/tensorflowForDeepLearmng.
Признательности
Бхарат благодарен своему научному руководителю по докторской диссертации за то, что он дал ему возможность работать над этой книгой по ночам и в выходные дни, и особо благодарен своей семье за их неизменную поддержку в течение всего процесса.
Реза благодарен сообществам разработчиков открытого программного обеспечения, на которых основывается подавляющая часть программного обеспечения и исследований в области информатики. Программное обеспечение с открытым исходным кодом является одной из крупнейших концентраций человеческих знаний, когда-либо созданных, и эта книга была бы невозможна без всего сообщества.
14 | Предисловие
Комментарии переводчика
В центре внимания машинного самообучения и глубокого самообучения как подобластей информатики находятся алгоритмы, модели и системы, способные обучаться. Обучающаяся система — это система, способная с течением времени улучшать свою работу, используя поступающую информацию1. В зарубежной специализированной литературе по данной теме в отличие от русского языка для передачи знаний и приобретения знаний существуют отдельные термины — train (обучить, натренировать) и learn (обучиться). Приведенное ниже предложение из главы 7 настоящей книги четко это демонстрирует.
Neural Turing machine can be trained end-to-end to learn to perform arbitrary computations.
Нейронная машина Тьюринга может быть натренирована в сквозном порядке, чтобы обучиться производить любые вычисления.
Тренировка (training)— это работа, которую выполняет исследователь-проектировщик для получения работающей самообучающейся модели или системы. В основе такой модели или системы лежит обучающийся алгоритм, который представляет собой "не что иное, как искателя минимумов (или максимумов) для надлежащим образом сформулированных функций". Самообучение (learning)— это работа, которую выполняет алгоритм-ученик, это процесс приобретения новых или изменения и закрепления существующих знаний, поведения, навыков, ценностей или предпочтений2.
Итак, русский термин "обучение" несет в себе двусмысленность, потому что под ним может подразумеваться и передача знаний, и получение знаний. С другой стороны, появление термина learning в любом виде подразумевает исключительно второе — работу, выполняемую обучающимся алгоритмом, т. е. самообучение, заучивание алгоритмом весов и параметров. Поэтому в отличие от русского термина "машинное обучение", который может означать и тренировку машин, и способность машин обучаться, в своей основе английский термин machine learning обозначает именно машинное приобретение знаний.
По этому поводу следует особо отметить следующий момент. С начала 1960-х до середины 1980-х годов в ходу был термин "обучающиеся машины". Проблематика обучающихся и самопроизводящихся машин изучалась в работах А. Тьюринга "Может ли машина мыслить?", 1960 г. (обучающиеся машины), К. Шеннона "Работы по теории информации и кибернетике" (самовоспроизводящиеся машины), Н. Винера, "Кибернетика, или управление и связь в животном и машине" (1961), Н. Нильсона "Обучающиеся машины" (1974) и Я. 3. Цыпкина "Основы теории обучающихся систем" (1970).
1 См. https://ru.wikipedia.org/wiki/06y4aioiuancn_CHCTeMa, а также https://bigenc.ru/mathematics/text/1810335. — Прим. пер.
2 См. http://www.basicknowledgel01.eom/subjects/learningstyles.html#diy. —Прим. пер.
Предисловие | 15
В сухом остатке, английский термин machine learning более точно передается термином "машинное самообучение" или "технология обучающихся машин". Интересный факт: в испанском языке он переводится как aprendizaje automatico, т. е. автоматическое самообучение.
В настоящем переводе далее за основу принят зарубежный подход, который неизбежно заставил подкорректировать терминологию. Вот несколько таких корректировок. Соответствующие области информатики переведены как машинное самообучение и глубокое самообучение. Применяемые в этих областях алгоритмы, модели и системы переведены как обучающиеся, машинно-обучающиеся и глубоко обучающиеся. То есть акцент делается не на классификации алгоритма в соответствующей иерархии, а на его характерном свойстве. Далее, методы, которые реализуются в обучающихся алгоритмах, переведены как методы самообучения (ср. методы обучения). Как известно, эти методы делятся на три широкие категории. Следуя принципу бритвы Оккама, они переведены как методы контролируемого самообучения (ср. обучение с учителем), методы неконтролируемого самообучения (ср. обучение без учителя) и методы самообучения с максимизацией подкрепления (ср. обучение с подкреплением). Последний термин обусловлен особенностью лежащего в его основе алгоритма — "учиться максимизировать некое понятие вознаграждения", получаемого за правильное действие3. Среди многих гиперпараметров, которые позволяют настроить работу обучающегося алгоритма, имеется rate of (earing, который переведен как скорость заучивания (ср. темп обучения).
Исходный код
Перевод книги снабжен пояснениями и ссылками, размещенными в сносках. Данная книга действительно является полезным ресурсом из разряда "все, что вам нужно знать о глубоком самообучении" на профессиональном уровне.
Элементарная кодовая база книги протестирована в среде Windows 10. При тестировании исходного кода за основу взят Python версии 3.6.4 (время перевода — апрель 2018 г.).
В ЭТОЙ книге используются библиотеки tensorflow, numpy, matplotlib, scikit-learn И deepchem (https://deepchem.io). В обычных условиях библиотеки Python можно скачать и установить из каталога библиотек Python PyPi (https://pypi.python.org/) при помощи менеджера пакетов pip. Однако следует учесть, что в ОС Windows для работы некоторых библиотек, в частности scipy, scikit-learn и scikit-image, требуется, чтобы в системе была установлена библиотека Numpy+MKL. Библиотека Numpy+MKL привязана к библиотеке Intel* Math Kernel Library и включает в свой состав необходимые динамические библиотеки (DLL) в каталоге numpy.core. Библиотеку Numpy+MKL следует скачать из хранилища whl-файлов на веб-странице Кристофа Голька из Лаборатории динамики флуоресценции Калифорнийского университета в г. Ирвайн (http://www.lfd.uci.edu/~gohlke/pythonlibs/) и установить при
3 См. https://en.wikipedia.org/wiki/Reinforcement_learning. — Прим. пер.
16 | Предисловие
помощи менеджера пакетов pip как whl (соответствующая процедура установки пакетов в формате WHL описана далее). Например, для 64-разрядной операционной системы Windows и среды Python 3.6 команда будет такой:
pip install numpy-1.14.2+mkl-cp36-cp36m--win_amd64 .whl
Стоит также отметить, что эти особенности установки не относятся к ОС Linux и Mac OS X.
Протокол установки библиотек
Далее предлагается список команд установки библиотек, скачанных с хранилища whl-файлов.
python -m pip install —upgrade pip
pip install numpy-1.14.2+mkl-cp36-cp36m-win_amd64 .whl
pip install scikit_learn-0.19.1-cp36-cp36m-win_aind64.whl
Библиотеки tensorflow и matpiotiib устанавливаются стандартным образом:
pip install tensorflow
pip install matpiotiib
Примечание
В зависимости от базовой ОС, версий языка Python и версий программных библиотек устанавливаемые вами версии whl-файлов могут отличаться от приведенных выше, где показаны последние на май 2018 г. версии для 64-разрядной ОС Windows и Python 3.6.4.
Установка библиотек Python из whl-файлов
Библиотеки для Python можно разрабатывать не только на чистом Python. Довольно часто библиотеки программируются на С (динамические библиотеки), и для них пишется обертка Python, или же библиотека пишется на Python, но для оптимизации узких мест часть кода пишется на С. Такие библиотеки получаются очень быстрыми, однако библиотеки с вкраплениями кода на С программисту на Python тяжелее установить ввиду банального отсутствия соответствующих знаний либо необходимых компонентов и настроек в рабочей среде (в особенности в Windows). Для решения описанных проблем разработан специальный формат (файлы с расширением whl) для распространения библиотек, который содержит заранее скомпилированную версию библиотеки со всеми ее зависимостями. Формат WHL поддерживается всеми основными платформами (Mac OS X, Linux, Windows).
Установка производится с помощью менеджера библиотек pip. В отличие от обычной установки командой pip install <имя_библиотеки>, вместо имени библиотеки указывается путь к whl-файлу: pip install <путь_к_иЬ1-файлу>. Например,
pip install C:\temp\scipy-1.0.l-cp36-cp36m-win_amd64.whl
Предисловие | 17
Откройте окно командой строки и при помощи команды cd перейдите в каталог, где размещен ваш whl-файл. Просто скопируйте туда ваш whl-файл. В этом случае полный путь указывать не понадобится. Например,
pip install scipy-1.О.l-cp36-cp36m-win_amd64.whl
При выборе библиотеки важно, чтобы разрядность устанавливаемой библиотеки и разрядность интерпретатора совпадали. Пользователи Windows могут брать whl-файлы с веб-сайта Кристофа Голька. Библиотеки там постоянно обновляются, и в архиве содержатся все, какие только могут понадобиться.
18 | Предисловие
ГЛАВА 1
Введение в глубокое самообучение
Глубокое самообучение произвело революцию в технологической индустрии. Современный машинный перевод, поисковые системы и компьютерные помощники работают на основе глубокого самообучения. Эта тенденция будет только продолжаться по мере того, как глубокое самообучение будет распространяться на робототехнику, фармацевтические препараты, энергетику и другие области современных технологий. Для специалиста в области разработки программного обеспечения приобретение практических навыков в сфере глубокого самообучения быстро становится первостепенной необходимостью.
В этой главе мы познакомим вас с историей глубокого самообучения и с его более широким влиянием на исследовательские и деловые сообщества. Далее мы рассмотрим несколько самых знаменитых приложений глубокого самообучения. Они будут включать как выдающиеся машинно-обучающиеся архитектуры, так и фундаментальные глубоко обучающиеся примитивы. В конце мы представим краткий обзор направлений, по которым пойдет развитие глубокого самообучения в течение последующих нескольких лет, после чего в следующих нескольких главах мы погрузимся в TensorFlow.
Машинное самообучение "питается" информатикой
До недавнего времени будущие инженеры-программисты посещали лекции в специализированных учебных заведениях, чтобы изучить ряд базовых алгоритмов (поиск в графах, сортировку, запросы к базам данных и т. д.). По окончании учебы эти инженеры применяли полученные знания в конкретной работе. Подавляющая часть современной цифровой экономики построена на сложных цепочках базовых алгоритмов, кропотливо склеенных поколениями инженеров. И большая часть этих систем не приспособлена к адаптации. Все конфигурации и перенастройки должны выполняться высококвалифицированными инженерами, что делает такие системы хрупкими.
Машинное самообучение обещает изменить область разработки программного обеспечения, позволяя системам динамически адаптироваться. Развернутые машинно-обучающиеся системы способны обучаться желаемому поведению из баз данных с примерами. Кроме того, такие системы могут регулярно тренироваться по мере поступления новых данных. Очень сложные программные системы, приводи-
19
мые в движение машинным самообучением, способны кардинально изменить свое поведение без существенных модификаций программного кода (только в тренировочных данных). Эта тенденция, скорее всего, лишь ускорится по мере упрощения и внедрения средств машинного самообучения.
В ходе изменения линий поведения программных систем меняются и роли инженеров-программистов. В некотором роде эта трансформация будет аналогична трансформации, последовавшей за развитием языков программирования. Первые компьютеры тщательно программировались. Провода объединялись в сложную взаимосвязанную сеть. Затем были придуманы перфокарты, позволившие создавать новые программы без аппаратных изменений в компьютерах. После эпохи перфокарт появились первые языки ассемблера. Потом языки более высокого уровня, такие как Fortran или Lisp. Последующие уровни разработки создавали языки очень высокого уровня, такие как Python, со сложными экосистемами предварительно запрограммированных алгоритмов. Современная информатика во многом уже опирается на автогенерируемый программный код. Современные разработчики приложений используют инструменты, например Android Studio, для автогенерации большей части программного кода, который они хотели бы создать. Таким образом, каждая последующая волна упрощения расширяла сферу информатики, снижая барьеры для доступа.
Машинное самообучение обещает снизить барьеры еще больше; программисты скоро смогут менять поведение систем путем изменения тренировочных данных, возможно, без написания кода. На стороне пользователя системы, построенные на понимании естественного языка, такие как Alexa и Siri. дадут непрограммистам возможность выполнять сложные вычисления. Более того, системы со встроенным машинным самообучением, вероятно, станут более устойчивыми к ошибкам. Способность многократно тренировать модели будет означать, что кодовые базы могут сократиться, а удобство сопровождения повысится. Иными словами, машинное самообучение, судя по всему, полностью перевесит роль инженеров-программистов. Сегодняшние программисты должны понимать, каким образом машинно-обучающиеся системы учатся, и знать классы ошибок, которые возникают в обычных машинно-обучающихся системах. Кроме того, им нужно будет понять шаблоны проектирования, лежащие в основе машинно-обучающихся систем (сильно разнящихся по стилю и форме от классических шаблонов проектирования программного обеспечения). И им нужно будет в достаточной мере разбираться в тензорном исчислении, чтобы понимать, почему сложная глубокая архитектура может вести себя ненадлежащим образом во время самообучения. Не будет преуменьшением сказать, что понимание (теории и практики) машинного самообучения станет фундаментальным навыком, который каждый компьютерный ученый и инженер-программист должен будет приобрести в течение следующего десятилетия.
Далее в этой главе мы проведем экскурсию по основам современного глубокого самообучения. В остальных главах этой книги мы более подробно рассмотрим темы, которые здесь только затронем.
20 | Гпава 1
Глубоко обучающиеся примитивы
Большинство глубоких архитектур строятся путем группирования и перегруппирования ограниченного набора архитектурных примитивов. Такие примитивы, обычно называемые слоями нейронных сетей, являются основополагающими строительными блоками глубоких сетей. В остальной части этой книги мы предоставим подробные вводные сведения о таких слоях. Однако в этом разделе мы дадим краткий обзор общих модулей, которые находятся во многих глубоких сетях. Данный раздел не предназначен для подробного ознакомления с этими модулями. Скорее, мы стремимся акцентировавать ваше внимание на строительных блоках сложных глубоких архитектур, чтобы подогреть ваш интерес. Искусство глубокого самообучения заключается в группировании и перегруппировании таких модулей, и мы хотим направить вас по правильному пути к специальным знаниям в области глубокого самообучения.
Полносвязный слой
Полносвязная сеть преобразует список входов в список выходов. Такое преобразование называется полносвязным, поскольку любое входное значение может повлиять на любое выходное значение. Такие слои будут иметь много заучиваемых параметров, даже для относительно небольших входных данных, но эти слои обладают большим преимуществом, т. к. они допускают отсутствие структуры во входных данных. Эта концепция проиллюстрирована на рис. 1.1.
Рис. 1.1. Полносвязный слой. Входящие стрелки представляют входные данные, а исходящие стрелки — выходные данные. Толщина взаимосвязанных линий представляет собой величину заученных весов. Полносвязный слой преобразует входные данные в выходные посредством заученного правила
Введение в глубокое самообучение | 21
Сверточный слой
Сверточная сеть исходит из особой пространственной структуры во входных данных. В частности, она принимает допущение, что входные данные, близкие друг к другу пространственно, семантически связаны. Это допущение имеет наибольший смысл для изображений, т. к. пикселы, близкие друг к другу, скорее всего, семантически связаны. В результате такого подхода сверточные слои нашли широкое применение в глубоких архитектурах обработки изображений. Эта концепция проиллюстрирована на рис. 1.2.
Так же как в случае с полносвязными слоями, которые преобразуют списки в списки, сверточные слои преобразуют изображения в изображения. Поэтому сверточные слои могут использоваться для выполнения сложных преобразований изображений, таких как применение художественных фильтров к изображениям в приложениях по обработке фотографий.
Рис. 1.2. Сверточный слой. Фигура слева представляет входные данные, фигура справа — выходные данные. В этом конкретном случае входные данные имеют форму (32, 32, 3), т. е. входные данные представляют собой изображение 32x32 пиксела с тремя цветовыми каналами RGB. Выделенная область на входе (слева) — это "локальное рецептивное поле", группа входных данных, которые обрабатываются вместе, чтобы создать выделенную область в выходных данных (справа)
Слои рекуррентной нейронной сети
Слои рекуррентной нейронной сети (recurrent neural network, RNN) являются примитивами, которые позволяют нейронным сетям обучаться на последовательностях входных данных. Этот слой исходит из того, что входные данные изменяются от шага к шагу, следуя четко сформулированному правилу обновления, которому можно обучиться из данных. Это правило обновления представляет собой предсказание следующего состояния в последовательности с учетом всех состояний, которые поступали ранее. RNN-сеть показана на рис. 1.3.
RNN-слой способен обучиться этому правилу обновления из данных, благодаря чему RNN-сети очень полезны для таких задач, как моделирование языка, где инженеры пытаются строить системы, способные предсказывать следующее слово, которое пользователи напечатают, исходя из накопленных данных.
22 | Гпава 1
Рис. 1.3. Рекуррентная нейронная сеть. Входы поступают в сеть снизу, а выходы извлекаются сверху. IV представляет собой заученное преобразование (общее для всех временных шагов). Сеть представлена концептуально слева и развернута справа, чтобы продемонстрировать, как обрабатываются входные данные из разных временных шагов
Ячейки долгой краткосрочной памяти
RNN-слои, представленные в предыдущем разделе, в теории способны обучаться произвольным правилам обновления для работы с последовательностью. На практике, однако, такие слои неспособны обучаться влияниям из отдаленного прошлого. Такие отдаленные влияния имеют решающее значение для надежного моделирования языка, поскольку значение составного предложения может зависеть от связи между отдаленными словами. Ячейка долгой краткосрочной памяти (long short-term memory, LSTM) является модификацией RNN-слоя, которая позволяет сигналам пробиваться из более глубокого прошлого в настоящее. LSTM-ячейка показана на рис. 1.4.
Рис. 1.4. Ячейка долгой кратковременной памяти. На внутреннем уровне LSTM-ячейка имеет набор специально спроектированных операций, которые обеспечивают значительную часть обучающей способности классической RNN-сети, сохраняя при этом влияния из прошлых данных. На рисунке показан один вариант LSTM-ячейки из многих
Введение в глубокое самообучение | 23
Глубоко обучающиеся архитектуры
Существуют сотни различных глубоко обучающихся моделей, которые сочетают глубоко обучающиеся примитивы, представленные в предыдущем разделе. Одни из этих архитектур важны исторически. Другие были первыми демонстрациями новейших подходов к проектированию, которые повлияли на восприятие того, что может делать глубокое самообучение.
В этом разделе мы представим подборку различных глубоко обучающихся архитектур, которые повлияли на исследовательское сообщество. Мы хотим подчеркнуть, что это изложение является эпизодическим и не претендует на то, чтобы быть исчерпывающим. Безусловно, в профессиональной литературе содержатся важные модели, которые здесь не представлены.
LeNet
Архитектура LeNet— пожалуй, первая видная ’’глубокая” сверточная архитектура, которая была представлена в 1988 г. Она использовалась для выполнения оптического распознавания символов (optical character recoginition, OCR) в документах. Хотя она превосходно выполняла свою задачу, вычислительная емкость LeNet была экстремальной для компьютерного оборудования, доступного в то время, поэтому этот подход к проектированию пребывал в (относительной) неизвестности в течение нескольких десятилетий после его создания. Эта архитектура показана на рис. 1.5.
связь
Рис. 1.5. Архитектура LeNet для обработки изображений. Представленная в 1988 г., она была, пожалуй, первой глубокой сверточной моделью для обработки изображений
AlexNet
Конкурсная инициатива ImageNet по созданию и сопровождению массивной базы данных аннотированных изображений (Large Scale Visual Recognition Challenge, ILSVRC) была впервые организована в 2010 г. для демонстрации успеха, достигнутого в системах визуального распознавания. Организаторы использовали Amazon Mechanical Turk— онлайновую платформу для подключения работников к заявителям с целью каталогизации большой коллекции изображений со связанными с ними списками присутствующих на изображении объектов. Использование плат
24 | Гпава 1
формы Mechanical Turk позволило создать коллекцию данных, значительно превышающую собранные ранее.
Первые два года, пока проводился конкурс, торжествовали более традиционные машинно-обучающиеся системы, которые опирались на такие системы, как HOG и SIFT (ручные методы извлечения визуальных признаков). В 2012 г. архитектура AlexNet, опирающаяся на модификацию LeNet, выполняемая на мощных графических процессорах (GPU-процессорах), стала доминировать в проекте с частотой ошибок вдвое меньше, чем у ближайших конкурентов. Эта победа резко оживила (уже зарождающуюся) тенденцию к глубоко обучающимся архитектурам в области компьютерного зрения. Архитектура AlexNet проиллюстрирована на рис. 1.6.
96 Максимально Максимально
Максимально редуцирующий редуцирующий
Шаг редуцирующий слой слой
слой
Рис. 1.6. Архитектура AlexNet для обработки изображений. Эта архитектура стала победителем в конкурсе ILSVRC 2012 и способствовала возрождению интереса к сверточной архитектуре
ResNet
С 2012 г. сверточные архитектуры последовательно выигрывали в конкурсе ILSVRC (наряду со многими другими конкурсами в области компьютерного зрения). С каждым годом проведения конкурса в архитектуре-победителе увеличивалась глубина и сложность. Архитектура ResNet, победитель конкурса ILSVRC 2015 г., стала особо заметной: она была расширена до 130 слоев в глубину, в отличие от 8-слойной архитектуры AlexNet.
Очень глубокие сети обучались с большим трудом; когда сети вырастают до такой глубины, они сталкиваются с проблемой исчезающих градиентов. Сигналы ослабляются по мере продвижения по сети, что приводит к ослаблению самообучения. Это затухание можно объяснить математически, но эффект заключается в том, что каждый дополнительный слой мультипликативно уменьшает силу сигнала, приводя к ограничению эффективной глубины сетей.
В ResNet было внедрено новшество, которое контролирует затухание — обходное соединение (рис. 1.7). Эти связи позволяют пропускать часть сигнала из более глубоких слоев без затухания, давая возможность эффектно тренировать значительно более глубокие сети.
Введение в глубокое самообучение | 25
Тождественное отображение х
Рис. 1.7. Ячейка ResNet. Обходное соединение (тождественное отображение) с правой стороны допускает пропускание немодифицированной версии входного сигнала через ячейку. Эта модификация позволяет эффективно тренировать очень глубокие сверточные архитектуры
Нейронная модель титрования изображений
По мере того как практикующие специалисты перестали испытывать проблемы с использованием глубоко обучающихся примитивов, они начали экспериментировать, смешивая и сопоставляя модули примитивов для создания систем более высокого порядка, которые могли бы выполнять более сложные задачи, чем элементарное обнаружение объектов. Нейронные системы титрования автоматически генерируют титры для содержимого изображений. Они делают это путем объединения сверточной сети, которая извлекает информацию из изображений, с LSTM-слоем, который генерирует описательное предложение для изображения. Вся система тренируется в сквозном порядке. То есть тренировка сверточной сети и LSTM-сети осуществляется вместе, чтобы достичь желаемой цели создания описательных предложений для предоставленных изображений.
Такая сквозная тренировка является одной из ключевых инноваций, приводящих в движение современные глубоко обучающиеся системы, поскольку она уменьшает
1. Входное изображение
2. Сверточное извлечение признаков (карта признаков 14x14)
3. RNN с вниманием 4. Пословная
на изображении
генерация
Рис. 1.8. Архитектура нейронного титрования. Соответствующие входные признаки извлекаются из входного изображения при помощи сверточной сети. Затем для создания описательного предложения используется рекуррентная сеть
26 | Гпава 1
потребность в сложной предобработке входных данных. Модели титрования изображений, которые не используют глубокое самообучение, должны применять сложные методы обработки изображений, такие как SIFT, которые не могут быть натренированы вместе с генератором титров.
Нейронная модель титрования показана на рис. 1.8.
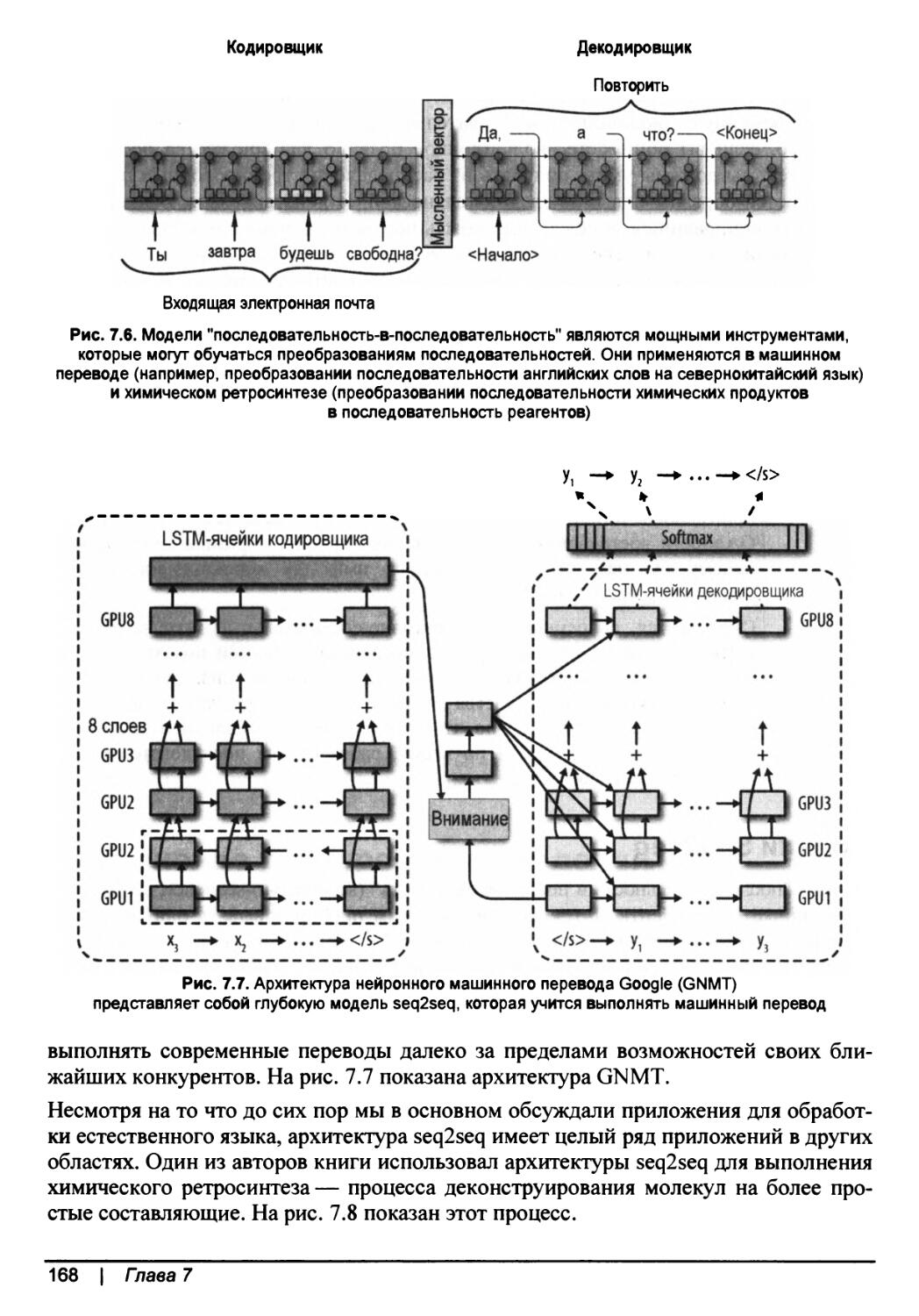
Нейронный машинный перевод Google
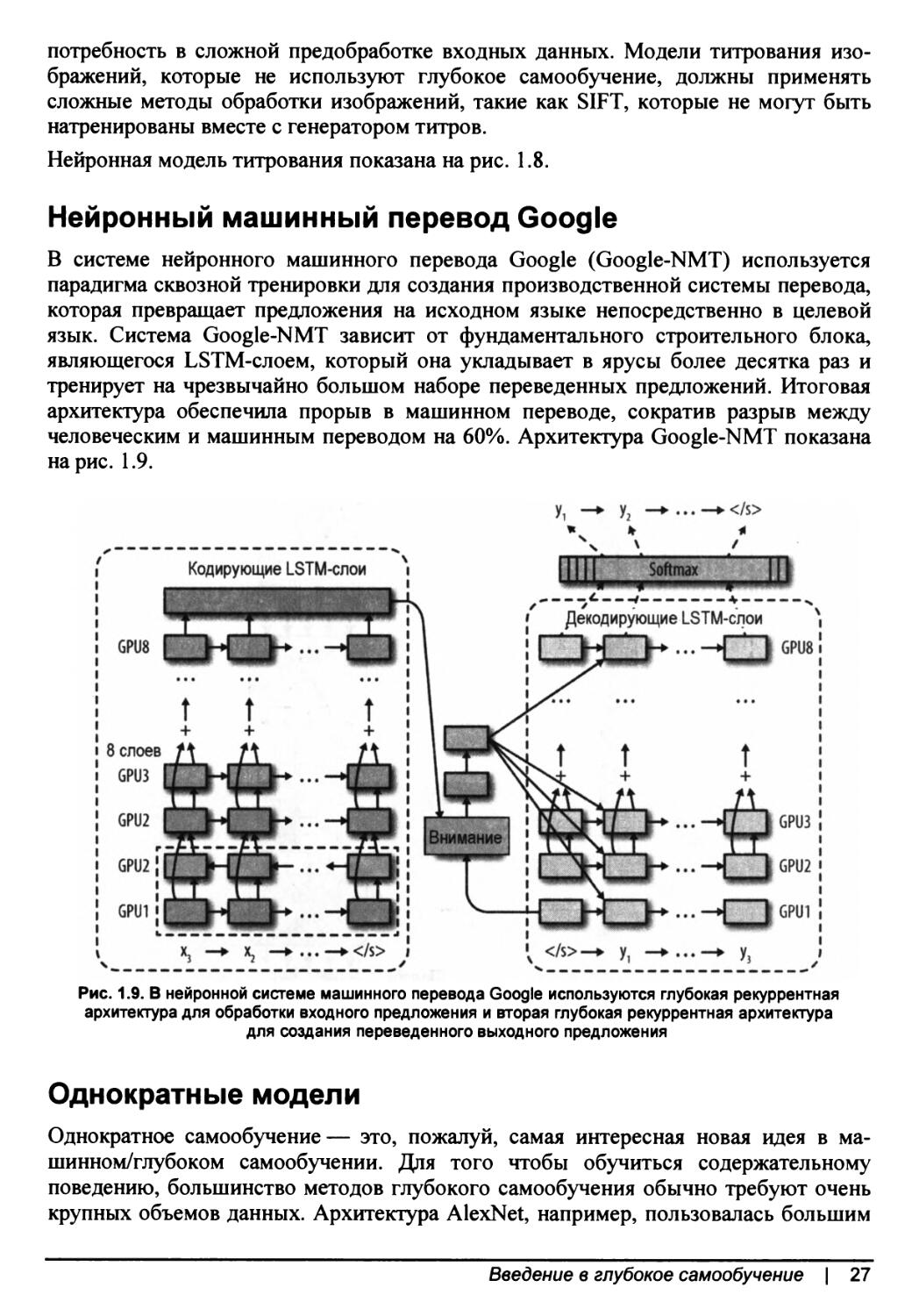
В системе нейронного машинного перевода Google (Google-NMT) используется парадигма сквозной тренировки для создания производственной системы перевода, которая превращает предложения на исходном языке непосредственно в целевой язык. Система Google-NMT зависит от фундаментального строительного блока, являющегося LSTM-слоем, который она укладывает в ярусы более десятка раз и тренирует на чрезвычайно большом наборе переведенных предложений. Итоговая архитектура обеспечила прорыв в машинном переводе, сократив разрыв между человеческим и машинным переводом на 60%. Архитектура Google-NMT показана на рис. 1.9.
Рис. 1.9. В нейронной системе машинного перевода Google используются глубокая рекуррентная архитектура для обработки входного предложения и вторая глубокая рекуррентная архитектура для создания переведенного выходного предложения
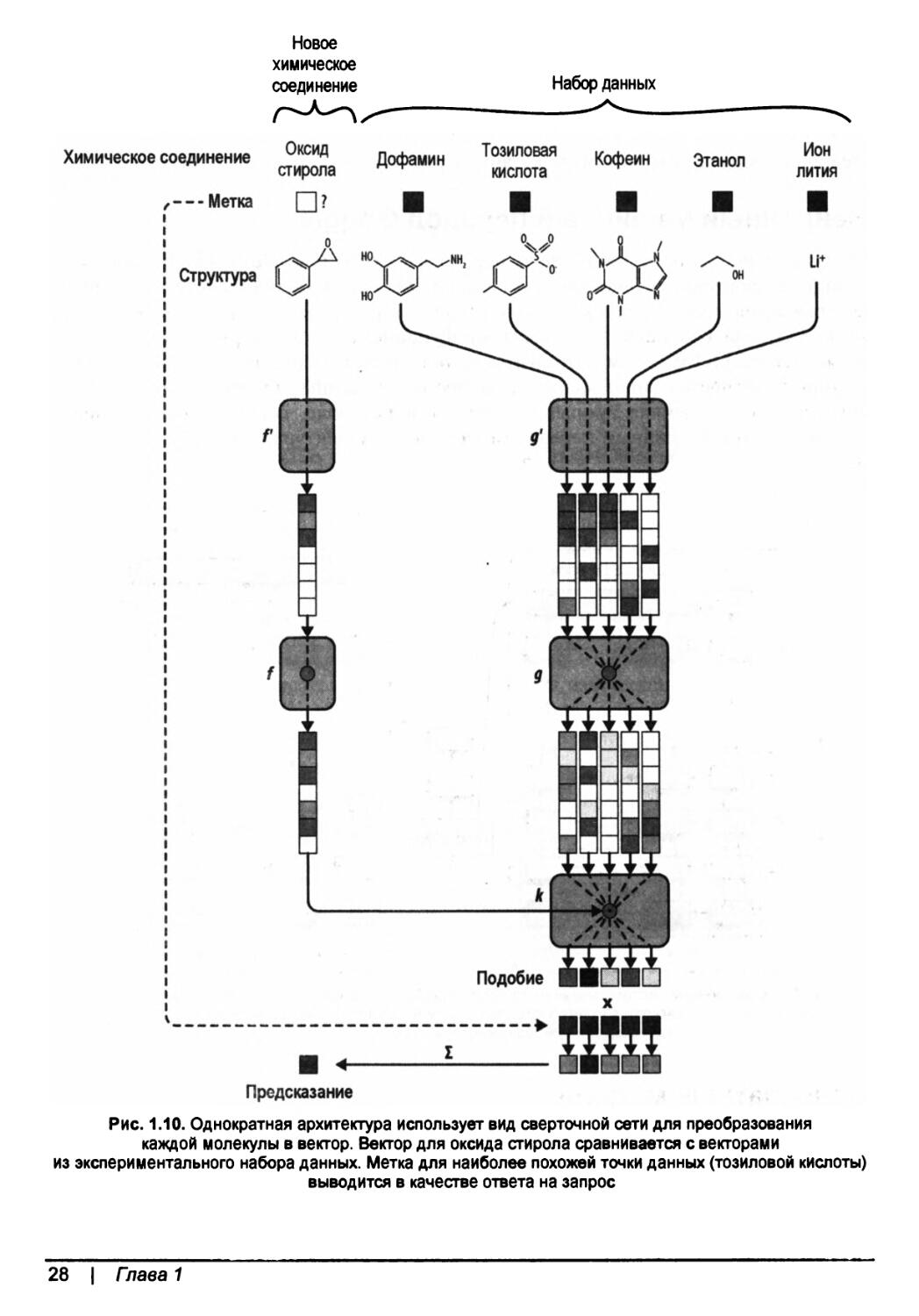
Однократные модели
Однократное самообучение— это, пожалуй, самая интересная новая идея в ма-шинном/глубоком самообучении. Для того чтобы обучиться содержательному поведению, большинство методов глубокого самообучения обычно требуют очень крупных объемов данных. Архитектура AlexNet, например, пользовалась большим
Введение в глубокое самообучение | 27
Новое химическое соединение
Набор данных
Химическое соединение
-- Метка
Структура
Оксид стирола
Дофамин
Тозиловая кислота
Кофеин Этанол
Ион лития
Предсказание
Рис. 1.10. Однократная архитектура использует вид сверточной сети для преобразования каждой молекулы в вектор. Вектор для оксида стирола сравнивается с векторами из экспериментального набора данных. Метка для наиболее похожей точки данных (тозиловой кислоты) выводится в качестве ответа на запрос
28 | Гпава 1
набором данных ILSVRC, чтобы обучиться визуальному обнаружению объектов. Вместе с тем большая работа в когнитивной науке показала, что люди могут обучаться сложным понятиям всего на нескольких примерах. Возьмите хоть ребенка, узнающего о жирафах в первый раз. Ребенок, которому в зоопарке показали одного жирафа, с тех пор может научиться распознавать всех жирафов, которых он увидит.
Недавний прогресс в глубоком самообучении проявился в изобретении архитектур, способных к аналогичным достижениям в самообучении. При наличии лишь нескольких примеров того или иного понятия (но при наличии обильных источников дополнительной информации) такие системы могут научиться делать содержательные предсказания с очень небольшим количеством точек данных. В одной недавней статье (автора этой книги) эта идея использовалась для демонстрации того, что однократные архитектуры могут обучаться в контекстах, в которых не способны обучаться дети, например в обнаружении медицинских препаратов. Однократная архитектура для обнаружения препаратов показана на рис. 1.10.
AlphaGo
Го — это древняя настольная игра, очень популярная в Азии. С конца 1960-х годов компьютерное го представляет собой серьезную задачу для информатики. Приемы, позволившие компьютерной шахматной системе Deep Blue обыграть гроссмейстера Гарри Каспарова в 1997 г., не масштабируются на игру го. Одна из причин этого — го имеет гораздо более крупную доску, чем шахматы; доски для го имеют разлиновку 19x19 клеток (рис. 1.11), в отличие от 8x8 клеток для шахмат. Поскольку за один шаг можно делать гораздо больше ходов, игровое дерево возможных ходов расширяется гораздо быстрее, что делает поиск методом грубой силы даже с помощью современного компьютерного оборудования недостаточным для адекватного игрового процесса.
Рис. 1.11. Иллюстрация игровой доски для игры го. Игроки поочередно размещают белые и черные фигуры на поле размером 19x19 клеток
Введение в глубокое самообучение | 29
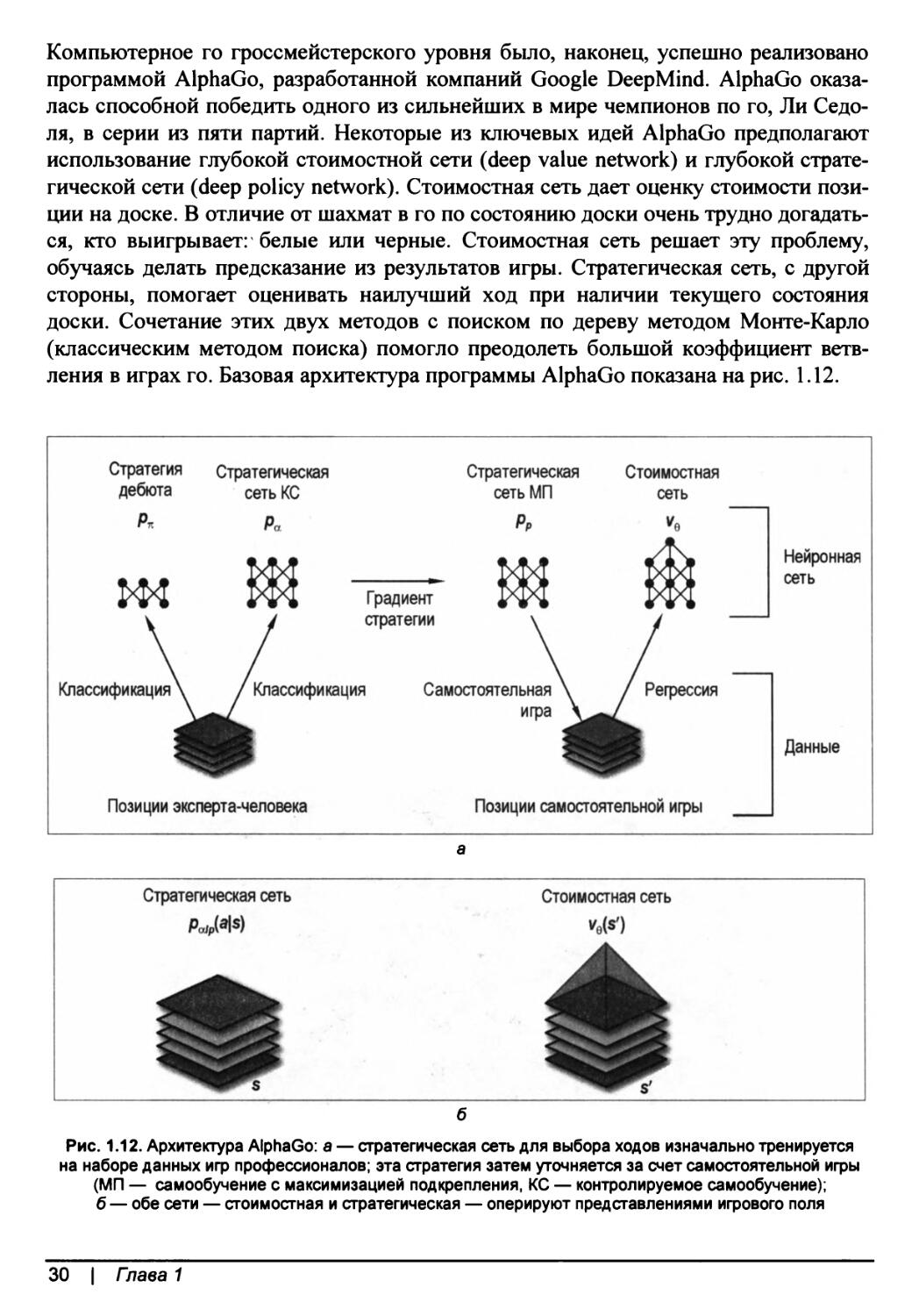
Компьютерное го гроссмейстерского уровня было, наконец, успешно реализовано программой AlphaGo, разработанной компаний Google DeepMind. AlphaGo оказалась способной победить одного из сильнейших в мире чемпионов по го, Ли Седо-ля, в серии из пяти партий. Некоторые из ключевых идей AlphaGo предполагают использование глубокой стоимостной сети (deep value network) и глубокой стратегической сети (deep policy network). Стоимостная сеть дает оценку стоимости позиции на доске. В отличие от шахмат в го по состоянию доски очень трудно догадаться, кто выигрывает: белые или черные. Стоимостная сеть решает эту проблему, обучаясь делать предсказание из результатов игры. Стратегическая сеть, с другой стороны, помогает оценивать наилучший ход при наличии текущего состояния доски. Сочетание этих двух методов с поиском по дереву методом Монте-Карло (классическим методом поиска) помогло преодолеть большой коэффициент ветвления в играх го. Базовая архитектура программы AlphaGo показана на рис. 1.12.
Стратегия Стратегическая дебюта сеть КС
Стратегическая
Стоимостная
сеть МП сеть
Нейронная сеть
Градиент
Позиции эксперта-человека
Позиции самостоятельной игры
Данные
Стратегическая сеть Pojp(a|s)
б
Рис. 1.12. Архитектура AlphaGo: а — стратегическая сеть для выбора ходов изначально тренируется на наборе данных игр профессионалов; эта стратегия затем уточняется за счет самостоятельной игры (МП — самообучение с максимизацией подкрепления, КС — контролируемое самообучение); б — обе сети — стоимостная и стратегическая — оперируют представлениями игрового поля
30 | Гпава 1
Генеративно-состязательные сети
Генеративно-состязательные сети (generative adversarial networks, GAN)— это новый тип глубокой сети, в которой используются две конкурирующие нейронные сети: генератор и дискриминатор (так называемая соперничающая сеть), которые сходятся в поединке друг против друга. Генератор пытается извлечь образцы из тренировочного распределения (например, пытается сгенерировать реалистичные изображения птиц). Дискриминатор работает над установлением различия образцов, извлеченных генератором, и истинных образцов данных. (Является ли конкретная птица реальным изображением или же она создана генератором?) Такая ’’состязательная” тренировка GAN-сетей, по всей видимости, способна генерировать образцы изображений значительно более высокой точности, чем другие методы, и может быть полезна для тренировки эффективных дискриминаторов с помощью ограниченных данных. Архитектура GAN-сети показана на рис. 1.13.
Латентная
случайная величина
Рис. 1.13. Концептуальное изображение генеративно-состязательной сети
GAN-сети оказались способными генерировать очень реалистичные изображения и, судя по всему, приведут в действие следующее поколение инструментов компьютерной графики. Качество образцов из таких систем сейчас приближается к фотореалистичному. Вместе с тем, относительно этих систем еще предстоит разработать многие теоретические и практические оговорки, и многое еще необходимо исследовать.
Нейронные машины Тьюринга
Подавляющая часть глубоко обучающихся систем, представленных до сих пор, заучивали сложные функции с ограниченными областями применения; например, обнаружение объектов, титрование изображений, машинный перевод или процесс игры в го. Но можно ли вообще иметь глубокие архитектуры, которые заучивают универсальные алгоритмические концепции, такие как сортировка, сложение или умножение?
Введение в глубокое самообучение | 31
Нейронная машина Тьюринга (НМТ)— это первая попытка создать глубоко обучающуюся архитектуру, способную обучаться произвольным алгоритмам. Эта архитектура предусматривает добавление внешнего банка памяти в LSTM-подобную систему, что позволяет глубокой архитектуре использовать вспомогательное пространство для вычисления более изощренных функций. На данный момент НМТ-подобные архитектуры все еще довольно ограничены и способны обучаться лишь простым алгоритмам. Тем не менее, методы НМТ остаются активной областью исследований, и будущие достижения могут превратить эти предварительные демонстрации в практические обучающиеся инструменты. Архитектура НМТ концептуально проиллюстрирована на рис. 1.14.
Рис. 1.14. Концептуальное изображение нейронной машины Тьюринга. В ней добавлен внешний банк памяти, в котором глубокая архитектура выполняет операции чтения и записи
Вычислительные каркасы для глубокого самообучения
На протяжении десятилетий исследователи реализовывали программные пакеты для облегчения построения нейронно-сетевых (глубоко обучающихся) архитектур. До недавнего времени эти системы имели в основном специальное назначение и использовались только в академических кругах. Нехватка стандартизированного, промышленного программного обеспечения затрудняет неэкспертам широкое использование нейронных сетей.
Данная ситуация резко изменилась за последние несколько лет. В 2012 г. компания Google реализовала систему DistBelief и использовала ее для создания и внедрения многих более простых глубоко обучающихся архитектур. Появление DistBelief и подобных пакетов, в частности Caffe, Theano, Torch, Keras, MxNet и др., широко стимулировало их внедрение в информационной индустрии.
32 | Гпава 1
Библиотека TensorFlow опирается на эту богатую интеллектуальную историю и строятся на основе некоторых из этих пакетов (Theano, в частности) ради принципов проектирования. В TensorFlow (и Theano), например, используется понятие гензоров как положенный в основу фундаментальный примитив, приводящий в действие глубоко обучающиеся системы. Акцент на тензоры отличает эти пакеты от таких систем, как DistBelief или Caffe, которые не допускают подобную гибкость в построении сложных моделей.
Несмотря на то что в оставшихся главах книги мы сосредоточимся на библиотеке TensorFlow, понимание положенных в основу принципов должно позволять вам учитывать полученные знания и применять их почти без труда в альтернативных вычислительных каркасах для глубокого самообучения.
Ограничения вычислительной среды TensorFlow
Одним из основных текущих недостатков библиотеки TensorFlow является то, что построение новой глубоко обучающейся архитектуры происходят относительно медленно (порядка несколько секунд на то, чтобы инициализировать архитектуру). Поэтому в TensorFlow неудобно строить некоторые сложные глубокие архитектуры, которые динамически изменяют свою структуру. Одна из таких архитектур — TreeLSTM (рис. 1.15), в которой используется синтаксический разбор деревьев английских предложений для выполнения задач, требующих понимания естественного языка. Поскольку каждое предложение имеет собственное дерево разбора, каждое предложение требует немного другой архитектуры.
Рис. 1.15. Концептуальное изображение архитектуры TreeLSTM. Форма дерева различается для каждой точки входных данных, поэтому для каждого примера необходимо строить отдельный вычислительный граф
Хотя такие модели в принципе могут быть реализованы в TensorFlow, однако это требует значительной изобретательности из-за ограничений текущего API TensorFlow. Новые вычислительные каркасы, например Chainer, DyNet и PyTorch, обещают
Введение в глубокое самообучение | 33
снять эти барьеры, достаточно облегчив конструирование новых архитектур, чтобы такие модели, как TreeLSTM, можно было конструировать без труда. К счастью, разработчики TensorFlow уже трудятся над расширениями базового API TensorFlow (например, Tensorflow Eager), которые облегчат построение динамических архитектур.
Один из выводов состоит в том, что прогресс в вычислительных каркасах для глубокого самообучения является быстрым, и новая сегодняшняя система может стать старыми завтрашними новостями. Вместе с тем фундаментальные принципы положенного в основу тензорного исчисления уходят корнями в столетия и послужат читателям добрую службу, независимо от будущих изменений в моделях программирования. В этой книге будет сделан упор на использование библиотеки TensorFlow в качестве инструмента для развития интуитивного понимания положенного в основу тензорного исчисления.
Резюме
В этой главе мы объяснили, почему глубокое самообучение является вопросом первостепенной значимости для современного инженера-программиста, и привели краткий обзор ряда глубоких архитектур. В следующей главе мы начнем изучать TensorFlow — программную инфраструктуру Google для построения и тренировки глубоких архитектур. В последующих главах мы подробно разберем ряд практических примеров глубоких архитектур.
Машинное самообучение (и, в частности, глубокое самообучение), как и значительная часть информатики, является весьма эмпирической дисциплиной. Понять глубокое самообучение действительно можно, только накопив значительный практический опыт. По этой причине в оставшуюся часть этой книги мы включили ряд углубленных практических примеров. Мы рекомендуем вам разобраться в них и заняться черной работой, экспериментируя со своими собственными идеями при помощи TensorFlow. Никогда не достаточно понимать алгоритмы только теоретически!
34 | Гпава 1
ГЛАВА 2
Введение в примитивы TensorFlow
В этой главе вы познакомитесь с фундаментальными аспектами библиотеки TensorFlow. Вы узнаете, как выполнять базовые вычисления с ее помощью. Подавляющая часть этой главы посвящена введению понятия тензоров и обсуждению гого, как тензоры представлены и обрабатываются в TensorFlow. Рассмотрение этого вопроса потребует краткого обзора некоторых математических концепций, лежащих в основе тензорной математики. В частности, мы кратко рассмотрим элементарную линейную алгебру и продемонстрируем, как выполнять основные линейные алгебраические операции с помощью TensorFlow.
Изложение элементарной математики мы будем сопровождать рассмотрением различий между декларативными и императивными стилями программирования. В отличие от многих языков программирования библиотека TensorFlow в значительной степени декларативна. В результате вызова ее операций она добавляет описание вычисления в ’’вычислительный граф” TensorFlow. В частности, программный код TensorFlow лишь ’’описывает” вычисления и фактически их не выполняет. Для того чтобы выполнять программный код TensorFlow, пользователи должны создавать объекты tf. Session. Мы введем понятие сеансов и опишем, каким образом пользователи должны выполнять с ними вычисления в TensorFlow.
Мы завершим эту главу обсуждением понятия переменных. Переменные в TensorFlow содержат тензоры и позволяют выполнять вычисления, модифицирующие переменные, с отслеживанием состояний. Мы продемонстрируем, как создавать переменные и обновлять их значения с помощью TensorFlow.
Введение в тензоры
Тензоры являются фундаментальными математическими конструкциями в таких областях, как физика и техника. Однако в историческом плане тензоры совершили гораздо меньше набегов на информатику, которая традиционно была больше связана с дискретной математикой и логикой. Такое положение дел начало значительно меняться с появлением машинного самообучения и его опорой на непрерывную, векторную математику. Современное машинное самообучение основано на обработке и исчислении тензоров.
35
Скаляры, векторы и матрицы
Для начала приведем несколько простых примеров тензоров, с которыми вы, возможно, знакомы. Простейшим примером тензора является скаляр — одиночное постоянное значение, получаемое из вещественных чисел. (Напомним, что вещественные числа являются десятичными числами произвольной точности, причем допускаются как положительные, так и отрицательные числа.) Математически мы обозначаем вещественные числа буквой R . Более формально мы называем скаляр тензором нулевого ранга.
Ремарка о полях
Математически искушенные читатели возразят, что совершенно допусти-мо определять тензоры на комплексных числах или с помощью двоичных чисел. В более общем случае достаточно, чтобы числа исходили из поля — математической совокупности чисел, где определены 0, 1, сложение, умножение, вычитание и деление. Общепринятые поля включают вещественные числа R, рациональные числа Q, комплексные числа С и конечные поля, такие как Z2. Для простоты в большей части изложения мы примем за основу вещественные тензоры, но подстановка значений из других полей совершенно разумна.
Если скаляры являются тензорами нулевого ранга, что же представляет собой тензор 1-го ранга? Формально, тензор 1-го ранга является вектором, или списком вещественных чисел. Традиционно векторы записываются как векторы-столбцы
а b
или как векторы-строки
[a />].
Совокупность всех векторов-столбцов длины 2 обозначается как R2xl, а множество всех векторов-строк длины 2— как Rlx2. В более вычислительном плане можно сказать, что форма вектора-столбца есть (2, 1), а форма вектора-строки— (1,2). Если мы не хотим конкретизировать, является ли вектор вектором-строкой или вектором-столбцом, то можем сказать, что он принадлежит множеству R2 и имеет форму (2). Это понятие формы тензора очень важно для понимания вычислений в библиотеке TensorFlow, и мы вернемся к нему позже в этой главе.
Простейшим способом использования векторов является представление координат в реальном мире. Предположим, что мы определяем исходную точку (скажем, местоположение, в котором вы сейчас находитесь). Тогда любое местоположение в мире может быть представлено тремя значениями смещения от вашего текущего местоположения (смещение влево-вправо, смещение вперед-назад, смещение вверх-вниз). Следовательно, множество векторов (векторное пространство) R3 может представлять любое местоположение в мире.
36 | Гпава 2
В качестве другого примера предположим, что кошку можно описать ее ростом, весом и окрасом. Тогда кошка из видеоигры может быть представлена в виде вектора
рост
вес
окрас
в пространстве R3. Этот тип представления часто называется хешированием признаков (конвертацией признаков в индексы векторов, featurization). То есть хеширование признаков заключается в представлении реального объекта в виде вектора (или, в более общем плане, как тензора). Почти все машинно-обучающиеся алгоритмы работают с векторами или тензорами. Следовательно, процесс хеширования признаков в вектор является важной частью любого конвейера машинного самообучения. Часто система хеширования признаков в вектор может быть самой сложной частью машинно-обучающейся системы. Предположим, у нас есть молекула бензола (рис. 2.1).
Рис. 2.1. Представление молекулы бензола
Как преобразовать эту молекулу в вектор, подходящий для запроса к машинно-обучающейся системе? Существует ряд потенциальных решений этой задачи, подавляющая часть которых используют идею маркировки присутствия подфрагментов молекулы. Наличие или отсутствие конкретных подфрагментов маркируется путем назначения индексам двоичного вектора ({0,1}") соответственно значений 1/0. Этот процесс показан на рис. 2.2.
Обратите внимание, что этот процесс выглядит (и является) довольно сложным. На самом деле, один из самых сложных аспектов построения машинно-обучающейся системы заключается в принятии решения о том, как преобразовывать данные в тензорный формат. Для некоторых типов данных это преобразование очевидно. Для других (например, молекул) требуемое преобразование может быть довольно тонким. Практикующему специалисту по машинному самообучению, как правило, не нужно изобретать новый метод хеширования признаков, поскольку научная литература обширна, но нередко требуется прочитать исследовательские работы, чтобы понять лучшие практические приемы преобразования нового потока данных.
Введение в примитивы TensorFlow | 37
Рис. 2.2. Отбор подфрагментов молекулы для создания признаков (тех, которые содержат ОН). Эти фрагменты хешируются в индексы вектора фиксированной длины. Эти позиции имеют значение 1, а все остальные — значение О
Теперь, когда мы установили, что тензоры нулевого ранга являются скалярами (R), а тензоры 1-го ранга— векторами (R”), нужно выяснить, что же такое тензор 2-го ранга? Традиционно тензор 2-го ранга является матрицей'.
а b
с d
Эта матрица состоит из двух строк и двух столбцов. Множество всех таких матриц обозначается R2x2. Возвращаясь к нашему понятию формы тензора, форма этой матрицы составляет (2, 2). Матрицы традиционно используются для представления преобразований векторов. Например, поворот вектора на плоскости на угол а может быть выполнен такой матрицей:
cos a -sin а sin а cos а
Для того чтобы увидеть это, обратите внимание, что единичный вектор [1 0] преобразуется матричным умножением в вектор [cos a sin а]. (Мы рассмотрим подробное определение матричного умножения далее в этой главе, но на текущий момент просто покажем результат.)
-sinal [*1
О
cos а sin а
cos а
sin а cos а
38 | Гпава 2
Рис. 2.3. Положения на единичной окружности параметризуются косинусом и синусом
Это преобразование также можно визуализировать графически. На рис. 2.3 показано, как итоговый вектор соответствует повороту исходного единичного вектора.
Матричная математика
Существует ряд стандартных математических операций над матрицами, которые машинно-обучающиеся программы используют многократно. Мы кратко рассмотрим некоторые наиболее фундаментальные из этих операций.
Транспонирование матрицы — это удобная операция, которая переворачивает матрицу относительно своей диагонали. Пусть А — некоторая матрица. Тогда транспонированная матрица Аг определяется соотношением a]-ajtx. Например, транспонированная матрица поворота Ra такова:
cos a sin а
-sin а cos а
Сложение матриц определяется только для матриц одинаковой формы и выполняется поэлементно. Например,
1 21 Г1 11Г2 3
3 4 + 1 1 “ 4 5
Точно так же матрицы можно умножать на скаляры. В этом случае каждый элемент матрицы умножается на рассматриваемый скаляр:
1 21_Г2 4
3 4 " 6 8
1 Здесь ay — элемент матрицы А в /-й строке и j-м столбце. — Прим. ред.
Введение в примитивы TensorFlow | 39
Иногда можно непосредственно перемножить две матрицы. Понятие матричного умножения, вероятно, является наиболее важным математическим понятием, связанным с матрицами. Матричное умножение — не то же самое, что поэлементное умножение матриц! Предположим, что у нас есть матрица А формы (т, п)ст строками и п столбцами. Тогда А можно умножить справа на любую матрицу В формы (и, к) (где к — любое положительное целое число), чтобы сформировать матрицу АВ формы (т, к). В целях фактического математического описания предположим, что А — это матрица формы (ш, и), а В — матрица формы (п, к). Тогда произведение матриц АВ определяется следующим соотношением:
(ab)v • к
Ранее мы показали уравнение матричного умножения. Имея формальное определение, давайте этот пример теперь расширим:
cosa -sina 1 cosal-sinaO sin a cosa 0 sinal + cosa-0
cosa sina
Основное правило матричного умножения заключается в том, что строки одной матрицы умножаются на столбцы другой матрицы.
Это определение скрывает ряд тонкостей. Обратите внимание, что матричное умножение не является коммутативным. То есть, в общем случае АВ ВА . На самом деле, АВ может существовать, когда ВА не возможно. Предположим, например, что А — это матрица формы (2, 3), а В — матрица формы (3, 4). Тогда АВ — это матрица формы (2, 4). Однако ВА не определена, поскольку соответствующие размерности (4 и 2) не совпадают. В качестве еще одной тонкости отметим, что, как и в примере поворота, матрицу формы (т, п) можно умножить в правой части на матрицу формы (п, 1). Однако матрица формы (п, 1)— это просто вектор-столбец. Поэтому имеет смысл умножать матрицы на векторы. Матрично-векторное умножение является одним из фундаментальных строительных блоков универсальных машинно-обучающихся систем.
Одно из самых приятных свойств стандартного умножения заключается в том, что оно является линейной операцией. Функция f называется линейной, если f (х + у) = f (х) + f (у) и f (ex) = cf (х), где с — это скаляр. Для того чтобы продемонстрировать, что скалярное умножение линейно, предположим, что a, b, с, d являются вещественными числами. Тогда мы имеем:
а(с + d) = ac + a- d.
Здесь мы используем коммутативные и дистрибутивные свойства скалярного умножения. Теперь предположим, что А, С, D — теперь матрицы, где С и D имеют одинаковый размер, и можно умножить А справа на С или D (Ь остается вещественным числом). Тогда матричное умножение является линейным оператором:
40 | Гпава 2
A(Z>C) = 6(AC); A (C + D) = AC +AD.
Другими словами, матричное умножение является дистрибутивным и коммутирует со скалярным умножением. Можно показать, что любое линейное преобразование на векторах соответствует матричному умножению. В качестве аналогии с информатикой подумайте о линейном преобразовании как об абстрактном методе в суперклассе. Тогда стандартное умножение и матричное умножение являются конкретными реализациями этого абстрактного метода для различных подклассов (соответственно вещественных чисел и матриц).
Тензоры
В предыдущих разделах мы ввели понятие скаляров как тензоров нулевого ранга, векторов как тензоров 1-го ранга и матриц как тензоров 2-го ранга. Что же такое тогда тензор 3-го ранга? Прежде чем перейти к общему определению, поразмыслите над общими чертами скаляров, векторов и матриц. Скаляры — это одиночные числа. Векторы — это списки чисел. Для того чтобы выбрать какой-либо элемент вектора, необходимо знать его индекс. Следовательно, нам нужен один индексный элемент в вектор (тензор 1-го ранга). Матрицы — это таблицы чисел. Для того чтобы выбрать какой-либо конкретный элемент матрицы, необходимо знать его строку и столбец. Значит, нам нужны два индексных элемента (тензор 2-го ранга). Из этого естественно следует, что тензор 3-го ранга представляет собой набор чисел, где есть три обязательных индекса. Целесообразно представить тензор 3-го ранга в виде параллелепипеда (рис. 2.4).
Рис. 2.4. Тензор 3-го ранга может быть визуализирован в виде параллелепипеда
Показанный на рисунке тензор 3-го ранга Т имеет форму их их и. Произвольный элемент тензора выбирается путем задания тройки чисел (/, у, к) в качестве индексов.
Существует связь между тензорами и формами. Тензор 1-го ранга имеет форму размерности 1, тензор 2-го ранга— форму размерности 2 и тензор 3-го ранга — форму размерности 3. Вы можете возразить, что это противоречит нашему предыдущему обсуждению векторов-строк и векторов-столбцов. По нашему определе
Введение в примитивы TensorFlow | 41
нию, вектор-столбец имеет форму (и, 1). Разве это не сделает вектор-столбец тензором 2-го ранга (или матрицей)? Именно так и произошло. Напомним, что вектор, который не задан как вектор-строка или вектор-столбец, имеет форму (л). Когда мы указываем, что вектор является вектором-строкой или вектором-столбцом, мы фактически задаем метод преобразования базового вектора в матрицу. Этот тип расширения размерности является распространенным приемом обработки тензоров.
Обратите внимание, что есть еще один способ представить тензор 3-го ранга — это список матриц с одинаковой формой. Предположим, что W есть матрица с формой (и, и). Тогда тензор = [W] ... W„] состоит из п копий матрицы W.
Стоит отметить, что черно-белое изображение может быть представлено тензором 2-го ранга. Предположим, у нас есть черно-белое изображение размером 224x224 пикселов. Тогда элемент (/,/) равен соответственно 1 или 0, тем самым кодируя черно-белый пиксел. Отсюда следует, что черно-белое изображение может быть представлено в виде матрицы формы (224, 224). Теперь рассмотрим цветное изображение размером 224 х 224. Цвет в том или ином пикселе обычно представлен тремя отдельными каналами RGB. То есть пиксел (i,j) представлен в виде кортежа чисел (г, g, b), которые кодируют количество соответственно красного, зеленого и синего в пикселе. Значения г, g,b — это обычно целые числа от 0 до 255. Из этого следует, что цветное изображение может быть закодировано как тензор 3-го ранга формы (224, 224, 3). Продолжая аналогию, рассмотрим цветное видео. Предположим, что каждый кадр видео является цветным изображением размера 224 х 224. Тогда минута видео (при 60 кадрах в секунду) будет тензором 4-го ранга формы (224, 224, 3, 3600). Коллекция из 10 таких видео затем сформирует тензор 5-го ранга формы (10, 224, 224, 3, 3600). В целом тензоры обеспечивают удобное представление числовых данных. На практике не принято видеть тензоры выше 5-го ранга, но разумно проектировать программное обеспечение для любых тензоров, позволяющее использовать произвольные тензоры, поскольку находчивые пользователи всегда придумают варианты применения, которые проектировщики не учитывают.
Тензоры в физике
Тензоры широко используются в физике для кодирования фундаментальных физических величин. Например, тензор напряжений обычно используется в материаловедении для задания напряжения в точке внутри материала. Математически тензор напряжений является тензором 2-го ранга формы (3, 3):
bi
,Т31
Т12 Т13
а22 Т23
т32 о33
Далее предположим, что п является вектором формы (3), который кодирует направление. Напряжение Т“ в направлении п задается вектором Т“=Т п (обратите
42 | Гпава 2
Рис. 2.5. Трехмерное изображение компонентов напряжения
внимание на матрично-векторное умножение). Эта взаимосвязь изображена на рис. 2.5.
В качестве еще одного физического примера приведем уравнение поля общей теории относительности Эйнштейна. Оно обычно выражается в тензорном формате:
р ' р , а _ гт
Кцу 2 + A&pv — ^4 ’
где — тензор кривизны Риччи; Rg^ — метрический тензор; Tgv — тензор энергии-импульса материи; оставшиеся физические величины — это скаляры. Вместе с тем обратите внимание, что есть важная тонкость, отличающая эти тензоры от других тензоров, которые мы обсуждали ранее. Такие величины, как метрический тензор, представляют собой отдельный тензор (в смысле множества чисел) для каждой точки в пространстве-времени (в математическом смысле, метрический тензор — это тензорное поле). То же самое соблюдается и для ранее рассмотренного тензора напряжений, и для других тензоров в этих уравнениях. В заданной точке пространства-времени каждая из этих физических величин с использованием нашего обозначения становится симметричным тензором 2-го ранга формы (4, 4).
Часть мощи современных систем тензорного исчисления, таких как TensorFlow, заключается в том, что некоторые математические механизмы, давно используемые для классической физики, теперь могут быть адаптированы для решения прикладных задач обработки изображений и понимания языка. В то же время современные системы тензорного исчисления по-прежнему ограничены по сравнению с математическим аппаратом в области физики. Например, при использовании TensorFlow нет простого способа говорить о такой величине, как метрический тензор. Мы надеемся, что эта ситуация изменится, поскольку тензорное исчисление становится
Введение в примитивы TensorFlow | 43
более фундаментальным для информатики, и такие системы, как TensorFlow, будут служить мостом между физическим и вычислительным мирами.
Математические ремарки
До сих пор вы знакомились с тензорами неофициально на примерах и иллюстрациях. В нашем определении тензор— это просто массив чисел. Часто удобно рассматривать тензор как функцию. Наиболее распространенное определение вводит тензор как полилинейную функцию-отображение из произведения векторных пространств в вещественные числа:
Т: v, XV, х---х v„ —> R. 1 Z п
В этом определении используется ряд терминов, которые вы не встречали. Векторное пространство — это просто совокупность векторов. Вы встречали несколько примеров векторных пространств, таких как R3 или в общем случае R". Мы не потеряем универсальность, утверждая, что v, = RJ‘. Как мы определили ранее, функция f линейна, если /(* + >>) = /(*) + /(у) и /(сх) = </(*). Полилинейная функция— это просто функция, линейная в каждом аргументе. Эту функцию можно рассматривать как назначение отдельных значений ячейкам многомерного массива, если в качестве аргументов указаны индексы массива.
В этой книге мы больше не будем использовать это математическое определение, но оно послужит полезным мостом для соединения концепций глубокого самообучения, с которыми вы познакомитесь, с многовековыми математическими исследованиями, которые предпринимались на тензорах физико-математическими сообществами.
Ковариация и контравариация
Наше определение здесь скрыло много деталей, которым следовало бы уделить пристальное внимание для формального обращения. Например, мы не затрагиваем понятия ковариантных и контравариантных индексов. То, что мы называем тензором и-го ранга, лучше описать как тензор ранга (р, q\ или (р, #)-тензор, где п = p + q,p — число контравариантных индек-
сов, q— число ковариантных индексов. Например, матрицы— это (1,1)-тензоры. И еще один нюанс — существуют тензоры 2-го ранга, которые не являются матрицами! Мы не будем углубляться в эти темы подробно, поскольку они не часто появляются в машинном самообучении, но мы рекомендуем вам разобраться в том, как ковариация и контравариация влияют на машинно-обучающиеся системы, которые вы строите.
Базовые вычисления в TensorFlow
Мы потратили некоторое время на математические определения различных тензоров. Настал момент рассказать, как создавать тензоры и манипулировать ими, используя TensorFlow. В этом разделе мы рекомендуем попутно использовать
44 | Гпава 2
интерактивный сеанс Python (с IPython). Во многих базовых понятиях библиотеки TensorFlow легче всего разобраться, экспериментируя с ними напрямую.
Установка TensorFlow и начало работы
Прежде чем продолжить изложение, необходимо установить библиотеку TensorFlow на компьютер. Детали установки будут варьировать в зависимости от вашего конкретного оборудования, поэтому мы отсылаем вас к официальной документации TensorFlow (https://www.tensorflow.org/api_docs/) за более подробной информацией2.
Хотя интерфейсы для библиотеки TensorFlow существуют на нескольких языках программирования, в оставшейся части этой книги мы будем использовать программный интерфейс TensorFlow исключительно для языка Python. Рекомендуется установить дистрибутив Anaconda Python (https://anaconda.org/anaconda/python), который поставляется в комплекте с множеством полезных числовых библиотек вместе с базовым исполняемым файлом Python.
После установки библиотеки TensorFlow рекомендуется во время изучения базового API вызывать ее в интерактивном режиме (пример 2.1). Во время экспериментирования с TensorFlow в интерактивном режиме удобно использовать инструкцию tf.InteractiveSessionо. Ее вызов в интерактивной оболочке IPython заставит TensorFlow вести себя почти императивно, облегчая возможность начинающим специалистам экспериментировать с тензорами. Вы узнаете об императивном и декларативном стиле более подробно далее в этой главе.
। Пример 2.1. Инициализация интерактивного сеанса TensorFlow |
»> import tensorflow as tf »> tf.InteractiveSession() <tensorflow.python.client.session.InteractiveSession>
В остальной части программного кода в этом разделе предполагается, что интерактивный сеанс загружен.
Инициализация константных тензоров
До сих пор мы обсуждали тензоры как абстрактные математические сущности. Однако такая система, как библиотека TensorFlow, должна работать на реальном компьютере, поэтому для того чтобы быть полезными для компьютерных программистов, любые тензоры должны существовать в оперативной памяти компьютера. Библиотека TensorFlow предоставляет ряд функций, реализующих основные тензоры в памяти. Самые простые из них— tf. zeros о и tf.onesO. Функция tf. zeros о принимает форму тензора (представленную в виде кортежа Python) и возвращает
2 См. https://www.tensorflow.org/install/install_windows. — Прим. пер.
Введение в примитивы TensorFlow | 45
тензор данной формы, заполненный нулями. Попробуем вызвать эту команду в оболочке (пример 2.2).
Пример 2.2. Создание тензора нулей
»> tf. zeros (2)
<tf.Tensor ’zeros:O' shape=(2,) dtype=float32>
TensorFlow возвращает не значение самого тензора, а ссылку на желаемый тензор. Для того чтобы принудительно вернуть значение тензора, будем использовать метод tf. Tensor, eval о тензорных объектов (пример 2.3). Поскольку мы инициализировали tf. interactiveSession (), этот метод вернет нам значение тензора нулей.
I Пример 2.3. Вычисление значения тензора
»> а = tf .zeros (2)
»> а. eval ()
array([ 0., 0.], dtype=float32)
Обратите внимание, что вычисленное значение тензора TensorFlow само является объектом Python. В частности, a.eval о — это объект numpy.ndarray. NumPy представляет собой сложную числовую систему в виде программной библиотеки Python. Здесь мы не будем углубляться в обсуждение библиотеки NumPy помимо замечания, что библиотека TensorFlow спроектирована так, чтобы быть в значительной степени совместимой с принятыми в NumPy обозначениями.
Мы можем вызвать методы tf. zeros о и tf.oneso для создания и вывода на экран тензоров различных размеров (пример 2.4).
Пример 2.4. Вычисление и вывод тензоров на экран
>» а = tf. zeros ((2, 3))
»> а. eval ()
array([[ 0., 0., 0. ], [ 0., 0., 0.]], dtype=float32)
»> b = tf .ones ((2,2,2))
»> b. eval () array([[[ 1., 1.], [ 1., 1.]],
[[ 1., 1.],
[ 1., 1.]]], dtype=float32)
А если нам нужен тензор, заполненный некоторой величиной, помимо 0/1? Функция tf .fill о предоставляет для этого хорошую краткую форму (пример 2.5).
46 | Гпава 2
Пример 2.5. Заполнение тензоров произвольными значениями
»> Ь = tf .fill ((2, 2), value=5.)
>» b.eval () array([[ 5., 5.],
[ 5., 5.]], dtype=float32)
tf .constant o — это еще одна функция, похожая на tf .fillо, позволяющая конструировать тензоры, которые не должны изменяться во время исполнения программы (пример 2.6).
I Пример 2.6. Создание константных тензоров
»> а = tf .constant (3)
»> a.eval ()
3
Отбор случайных значений для тензоров
Хотя работа с константными тензорами удобна для тестирования идей, гораздо чаще принято инициализировать тензоры случайными значениями. Наиболее распространенный способ сделать это — отбирать каждое значение в тензоре из случайного распределения. Функция tf. random normal о позволяет отобрать каждое значение в тензоре заданной формы из нормального распределения с заданным средним значением и стандартным отклонением (пример 2.7).
Нарушение симметрии
Многие машинно-обучающиеся алгоритмы обучаются, выполняя обновле-ния набора тензоров, содержащих веса. Эти уравнения обновления обычно подчиняются свойству, что веса, инициализированные одинаковым значением, будут продолжать эволюционировать вместе. Следовательно, если начальный набор тензоров инициализируется постоянным значением, то модель не сможет многому обучиться. Для того чтобы исправить ситуацию, требуется нарушить симметрию. Самый простой способ нарушить симметрию — отбирать значения для каждой записи в тензоре случайным образом.
I Пример 2.7. Отбор случайных значений для тензора из нормального распределения
»> а = tf.random_normal((2, 2), mean=0, stddev=l) »> a. eval ()
array([[-0.73437649, -0.77678096],
[ 0.51697761, 1.15063596]], dtype=float32)
Следует отметить, что машинно-обучающиеся системы часто используют очень большие тензоры, которые имеют десятки миллионов параметров. Когда мы отби
Введение в примитивы TensorFlow | 47
раем десятки миллионов случайных значений из нормального распределения, почти наверняка окажется, что некоторые отобранные значения будут далеки от среднего. Такие большие выборки могут привести к числовой неустойчивости, поэтому общепринято вместо функции tf. random nomai () выполнять отбор с использованием функции tf .truncated normai о. Эта функция в терминах API ведет себя так же, как функция tf. random nomai (), но при этом она отбрасывает и повторно отбирает все значения, которые больше двух стандартных отклонений от среднего.
Функция tf .random_uniform() ведет себя как функция tf .random_normai() за исключением того, что случайные значения отбираются из равномерного распределения в заданном диапазоне (пример 2.8).
Пример 2.8. Отбор случайных значений для тензора из равномерного распределения
»> а = tf.random_uniform((2, 2), minval=-2, maxval=2)
»> a.eval () array([[-1.90391684, 1.4179163 ], [ 0.67762709, 1.07282352]], dtype=float32)
Сложение и шкалирование тензоров
В библиотеке TensorFlow используется перегрузка операторов Python, чтобы упростить базовую тензорную арифметику с помощью стандартных операторов Python (пример 2.9).
^Пример 2.9. Сложение тензоров
>» с = tf.ones((2, 2))
»> d = tf.ones((2, 2))
»> е = с + d
>» e.eval () array([[ 2., 2.], [ 2., 2.]], dtype=float32)
»> f = 2 * e
»> f.evalO array([[ 4., 4.], [ 4., 4.]], dtype=float32)
Таким же образом тензоры можно умножать. Обратите внимание, что при умножении двух тензоров мы получаем не матричное умножение, а поэлементное умножение, что можно наглядно увидеть в примере 2.10.
[ Пример 2.10. Поэлементное умножение тензоров (----------------------------------------------
»> с = tf .fill ((2,2), 2.)
»> d = tf .fill( (2,2), 7.) »> e = c * d
48 | Гпава 2
»> e.eval () array([[ 14., 14.], [ 14., 14.]], dtype=float32)
Матричные операции
Библиотека TensorFlow предоставляет целый ряд удобств для работы с матрицами. (Матрицы на сегодняшний день являются наиболее распространенным типом тензоров, используемых на практике.) В частности, TensorFlow предоставляет краткие формы для создания определенных типов часто используемых матриц. Пожалуй, наиболее широко используемой является единичная матрица. Единичная матрица— это квадратная матрица, элементы которой равны 0 везде, кроме главной диагонали, где они равны 1. Функция tf.eyeo позволяет быстро конструировать единичные матрицы желаемого размера (пример 2.11).
Пример 2.11. Создание единичной матрицы
»> а = tf.eye(4)
»> а. eval ()
array([[ 1., 0., 0., 0.],
[ 0., 1., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]], dtype=float32)
Диагональные матрицы — еще один распространенный тип матриц. Как и единичные матрицы, диагональные матрицы являются ненулевыми по диагонали. В отличие от единичных матриц, они могут принимать по диагонали произвольные значения. Построим диагональную матрицу с восходящими значениями по диагонали (пример 2.12). Для начала нам понадобится метод построения вектора возрастающих значений в TensorFlow. Самый простой способ сделать это — вызвать функцию tf.range(начало, граница, дельта). Обратите внимание, ЧТО значение границы исключается из диапазона, а дельта — это размер шага для обхода диапазона. Полученный вектор затем может быть передан на вход функции tf.diag(диагональ), которая построит матрицу с заданной диагональю.
Пример 2.12. Создание диагональной матрицы
»> г = tf.range(1, 5, 1)
»> г.eval () array([1, 2, 3, 4], dtype=int32) »> d = tf.diag(г)
»> d.evalO
array([[l, 0, 0, 0],
[0, 2, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 4]], dtype=int32)
Введение в примитивы TensorFlow | 49
Теперь предположим, что у нас в TensorFlow имеется точно определенная матрица. Как получить транспонированную матрицу? Функция tf .matrix transposeO сработает безупречно (пример 2.13).
Пример 2.13. Получение транспонированной матрицы
»> а = tf.ones((2, 3))
»> a.eval ()
array([[ 1., 1., 1.], [ 1., 1., 1.]], dtype=float32)
»> at = tf .matrix_transpose (а)
»> at .eval () array([[ 1., 1.], [ l.z 1.], [ 1., 1.]], dtype=float32)
Теперь предположим, что у нас есть пара матриц, которые мы хотели бы перемножить с помощью матричного умножения. Самый простой способ сделать это — вызвать функцию tf .matmui о (пример 2.14).
। Пример 2.14. Выполнение матричного умножения
»> а = tf.ones((2, 3))
»> a.eval ()
array([[ 1., 1., 1.], [ 1., 1., 1.]], dtype=float32)
»> b = tf.ones((3, 4))
»> b.eval ()
array([[ 1., 1., 1., 1.], [ 1., 1., 1., 1.], [ 1., 1., 1., 1.]], dtype=float32)
»> c = tf.matmui (a, b)
»> c.evalO
array([[ 3., 3., 3., 3.], [ 3.f 3., 3., 3.]], dtype=float32)
Вы можете проверить, что этот ответ соответствует математическому определению матричного умножения, которое мы предоставили ранее.
Типы тензоров
Возможно, вы заметили обозначение dtype в предыдущих примерах. Тензоры в TensorFlow бывают различных типов, таких как tf.float32, tf.float64, tf.int32, tf.int64. Тензоры точно заданного типа можно создавать, назначая тип dtype в функции конструирования тензора. Более того, при заданном тензоре можно из
50 | Гпава 2
менять его тип при помощи функции приведения типов, таких как tf .to_double(), tf. to_float (), tf.to_int32 (), tf. to_int64 () И др. (пример 2.15).
| Пример 2.15. Создание тензоров различных типов
»> а = tf .ones ((2,2), dtype=tf.int32) >» a.eval () array([[0, 0], [0, 0]], dtype=int32)
»> b = tf. to_float (a)
»> b.eval () array([[ 0., 0.], [ 0., 0.]], dtype=float32)
Обработка форм тензоров
В TensorFlow тензоры — это просто коллекции чисел, записанных в памяти, а различные формы — это представления лежащего в основе набора чисел. Они обеспечивают различные способы взаимодействия с этим набором чисел. В разное время может быть полезно взглянуть на тот же самый набор чисел как формирующий тензоры с разными формами. Функция tf.reshape() позволяет конвертировать тензоры в тензоры другой формы (пример 2.16).
Пример 2.16. Манипуляции с формами тензоров
»> а = tf.ones(8)
»> a.eval ()
array([ 1., 1., 1., 1., 1., 1., 1., 1.], dtype=float32) »> b = tf.reshape(а, (4, 2)) »> b.eval () array([[ 1., 1.], [ 1., 1.], [ 1., 1.], [ 1., 1.]], dtype=float32)
»> с = tf. reshape (а, (2, 2, 2))
»> c.eval ()
array([[ [ 1., 1.], [ 1., 1.]], [[ 1., 1.], [ 1., 1.]]], dtype=float32)
Обратите внимание на то, как с помощью функции tf. reshape о можно превратить исходный тензор 1-го ранга в тензор 2-го ранга, а затем в тензор 3-го ранга. Хотя все необходимые манипуляции с формами можно выполнять с помощью tf. reshape о, иногда может быть удобно осуществить более простые манипуляции с формой, используя такие функции, как tf.expand_dims() или tf.squeezeо. Функ
Введение в примитивы TensorFlow | 51
ция tf .expand_dims о добавляет в тензор новую размерность размера 1. Это полезно для увеличения ранга тензора на единицу (например, во время конвертации вектора 1-го 0анга в вектор-строку 2-го ранга или вектор-столбец). Функция tf. squeeze о удаляет из тензора все размерности размера 1. Этот способ полезен, когда нужно конвертировать вектор-строку или вектор-столбец в плоский вектор.
Таким образом, появляется удобная возможность познакомиться с методом tf .Tensor.get shape о (пример 2.17). Этот метод позволяет пользователям запрашивать форму тензора.
Пример 2.17. Получение формы тензора
>» а = tf .ones (2) »> а. get_shape () TensorShape([Dimension(2) ]) »> a.eval () array([ 1., 1.], dtype=float32) »> b = tf .expand_dims (a, 0) »> b. get_shape ()
TensorShape([Dimension(1), Dimension(2)]) »> b.eval () array([[ 1., 1.] ], dtype=float32) >» c = tf .expand_dims (a, 1) »> c.get_shape () TensorShape([Dimension(2), Dimension(1)]) »> c.eval () array([[ 1.], [ 1.]], dtype=float32) »> d = tf .squeeze (b) >» d.get_shape () TensorShape([Dimension(2)]) »> d.eval () array([ 1., 1.], dtype=float32)
Введение в операцию транслирования
Транслирование — это термин (введенный в библиотеке NumPy), который применяется для операций, позволяющих складывать между собой матрицы тензорной системы и векторы разных размеров. Правила транслирования допускают такие удобства, как добавление вектора в каждую строку матрицы. Эти правила могут быть довольно сложными, поэтому мы не будем погружаться в их формальное обсуждение. Часто легче поэкспериментировать и увидеть, как транслирование работает на практике (пример 2.18).
52 | Гпава 2
Пример 2.18. Примеры транслирования
»> а = tf.ones((2, 2))
»> a.eval ()
array([[ 1., 1.],
[ 1., 1.]], dtype=float32)
»> b = tf. range (0, 2, 1, dtype=tf. float32)
»> b.eval ()
array([ 0., 1.], dtype=float32)
»> c = a + b
»> c.eval () array([[ 1., 2.],
[ 1., 2.]]r dtype=float32)
Обратите внимание, что вектор ь добавляется в каждую строку матрицы а. Также обратите внимание на еще одну тонкость: мы явно задаем тип dtype для ь. Если dtype не задан, то TensorFlow сообщит об ошибке типа. Давайте посмотрим, что бы произошло, если бы мы не задали dtype (пример 2.19).
Пример 2.19. TensorFlow не выполняет неявное приведение типов, выводя сообщение о несоответствии типов
»> b = tf. range (0, 2, 1) »> b.eval ()
array([0 r 1], dtype=int32) »> c = a + b
ValueError: Tensor conversion requested dtype float32 for Tensor with dtype int32: 'Tensor("range_2:0", shape=(2,), dtype=int32)
В отличие от таких языков, как С, библиотека TensorFlow не выполняет неявное приведение типов за кадром. Нередко во время выполнения арифметических операций необходимо выполнять явные приведения типов.
Императивное и декларативное программирование
Большинство ситуаций в информатике связано с императивным программированием. Рассмотрим простую программу на Python (пример 2.20).
Пример 2.20. Программа на Python, императивно выполняющая сложение J
»> а = 3 »> Ь = 4 »> с = а + b »> с 7
Введение в примитивы TensorFlow | 53
Эта программа при переводе в машинный код предписывает машине выполнить примитивные операции сложения двух регистров, где один содержит 3, а другой — 4. Результат равен 7. Этот стиль программирования называется императивным. поскольку программа явным образом сообщает компьютеру, какие действия выполнять.
Альтернативный стиль программирования— декларативный. В декларативной системе компьютерная программа представляет собой высокоуровневое описание вычислений, которые необходимо выполнить. Это описание не указывает компьютеру, как именно выполнять вычисления. Пример 2.21 является эквивалентом примера 2.20 в TensorFlow.
, Пример 2.21. Программа TensorFlow декларативно выполняет сложение I
L . _ _____ . . _ . __ ______________________________________ ___________—___I
»> а = tf .constant (3)
»> b = tf .constant (4)
>» c = a + b
»> c
<tf.Tensor 'add_l:0' shape=() dtype=int32> »> c.evalO
7
Обратите внимание, что значение с не равно 7! Напротив, оно представляет собой символический тензор. Этот фрагмент кода определяет вычисление сложения двух значений между собой для создания нового тензора. Фактическое вычисление не выполняется до тех пор, пока мы не вызовем метод с.eval о. В предыдущих разделах для моделирования императивного стиля в TensorFlow мы использовали метод eval (), т. к. поначалу декларативное программирование может показаться сложным для понимания.
Однако декларативное программирование отнюдь не является неизвестным понятием для программной инженерии. Реляционные базы данных и SQL служат примером широко используемой декларативной системы программирования. Такие команды, как select и join, могут быть реализованы произвольным образом за кадром при условии, что их базовая семантика соблюдена. Программный код в TensorFlow лучше рассматривать, как аналог программ SQL; программный код TensorFlow задает вычисление, которое будет выполнено, а их подробности отданы на усмотрение TensorFlow. Разработчики TensorFlow за кадром задействуют это отсутствие подробностей, чтобы адаптировать стиль исполнения программного кода к используемому аппаратному обеспечению будь то CPU (central processing unit — центральный процессор), GPU (graphics processing unit — графический процессор) или мобильное устройство.
Важно отметить, что главная слабость декларативного программирования заключается в том, что эта абстракция нередко довольно дырява. Например, без ясного понимания лежащей в основе реализации реляционной базы данных длинные SQL-программы могут стать невыносимо неэффективными. Аналогичным образом,
54 | Гпава 2
большие программы TensorFlow, реализованные без понимания лежащих в основе обучающихся алгоритмов, вряд ли будут работать хорошо. В остальной части этого раздела мы начнем разбирать эту абстракцию, процесс, который мы продолжим выполнять на протяжении всей остальной части книги.
Модуль TensorFlow Eager
Команда разработчиков TensorFlow недавно добавила новый экспериментальный модуль— TensorFlow Eager, который позволяет пользователям выполнять вычисления TensorFlow императивно. Со временем этот модуль, скорее всего, станет предпочтительным для привлечения новых программистов, изучающих TensorFlow. Тем не менее, на момент написания данной книги этот модуль по-прежнему остается довольно сырым со многими недоработками. По этой причине мы не будем знакомить вас с режимом Eager, но рекомендуем обратиться к нему самостоятельно.
Важно подчеркнуть, что подавляющая часть TensorFlow останется декларативной даже после того, как модуль Eager сформируется, поэтому независимо ни от чего стоит изучать декларативный TensorFlow.
Графы TensorFlow
Любое вычисление в TensorFlow представляется как экземпляр вычислительного графа tf .Graph. Такой граф состоит из множества экземпляров объектов tf .Tensor и tf.Operation. Мы рассмотрели объект tf.Tensor, но что же такое объекты tf.Operation? Вы уже встречали их в этой главе. Вызов такой операции, как tf .matmui, создает экземпляр tf .Operation, чтобы отметить необходимость выполнения операции матричного умножения.
Когда граф tf.Graph не задан явно, TensorFlow добавляет тензоры и операции в скрытый глобальный экземпляр tf .Graph. Этот экземпляр может быть извлечен при ПОМОЩИ функции tf .get_default_graph() (пример 2.22).
Г----------------------------------------------------------------------------------1
Пример 2.22. Получение принятого по умолчанию графа TensorFlow J
»> tf. get_default_graph ()
<tensorflow.python.framework.ops.Graph>
Существует возможность указывать, что операции TensorFlow должны выполняться в графах, отличных от заданного по умолчанию. Мы продемонстрируем такие примеры в последующих главах.
Сеансы TensorFlow
В TensorFlow объект tf. Session о хранит контекст, в котором выполняется вычисление. В начале этой главы мы использовали tf.interactiveSessionо, чтобы настроить среду для всех вычислений TensorFlow. Этот вызов создал скрытый гло
Введение в примитивы TensorFlow | 55
бальный контекст для всех выполняемых вычислений. Затем для выполнения наших ДеКЛараТИВНО ОПИСаННЫХ вычислений МЫ ИСПОЛЬЗОВаЛИ МеТОД tf. Tensor, eval о. За кадром этот вызов вычисляется в контексте скрытого глобального объекта tf. Session о. Нередко вместо скрытого контекста вычисления может быть удобно (и часто необходимо) использовать явный контекст (пример 2.23).
: Пример 2.23. Обработка сеансов TensorFlow явным образом
»> sess = tf. Session () »> а = tf.ones((2, 2)) »> b = tf .matmul (а, a) »> b.eval (session=sess) array([[ 2., 2.],
[ 2., 2.]], dtype=float32)
Этот фрагмент кода вычисляет ь в контексте sess вместо скрытого глобального сеанса. Фактически мы можем сделать это более явным при помощи альтернативной формы записи (пример 2.24).
| Пример 2.24. Выполнение вычисления в сеансе
»> sess.run(b) array([[ 2., 2.],
[ 2., 2.]], dtype=float32)
На самом деле, вызов метода b.eval (session=sess) представляет собой синтаксический сахар для вызова sess. run (b).
Вся эта информация порой может походить на софистику. Какая разница, какой сеанс в игре, учитывая, что все различные методы, судя по всему, возвращают один и тот же ответ? Явно заданные сеансы не проявляют свое значение до тех пор, пока вы не начнете выполнять вычисления, имеющие состояние, о чем вы узнаете в следующем разделе.
Переменные TensorFlow
Во всех примерах программного кода этого раздела использовались константные тензоры. Хотя мы могли комбинировать и рекомбинировать эти тензоры любым способом, мы никак не могли изменять значение самих тензоров (только создавать новые тензоры с новыми значениями). До этого момента стиль программирования был функциональным и не отслеживал состояния. Хотя функциональные вычисления очень полезны, машинное самообучение часто сильно зависит от вычислений с отслеживанием состояния. Обучающиеся алгоритмы, по сути, представляют собой правила обновления хранящихся тензоров для объяснения предоставляемых данных. Если нет возможности обновлять эти хранящиеся тензоры, то будет трудно обучиться.
56 | Гпава 2
Объект tf. variable о предоставляет оболочку вокруг тензоров, которая позволяет выполнять вычисления с отслеживанием состояния. Объекты-переменные служат контейнерами для тензоров. Создать переменную достаточно просто (пример 2.25).
Пример 2.25. Создание переменной TensorFlow
»> а = tf .Variable (tf. ones ( (2, 2))) »> a
<tf.Variable 'Variable:O' shape=(2, 2) dtype=float32_ref>
Что происходит, когда мы пытаемся вычислить переменную а в качестве тензора, как в примере 2.26?
I Пример 2.26. Сбой вычисления неинициализированной переменной ! с ошибкой ’’попытка использовать неинициализированную переменную"
»> a.eval ()
FailedPreconditionError: Attempting to use uninitialized value Variable
Вычисление не выполняется, поскольку переменные должны быть явным образом инициализированы. Самый простой способ инициализации всех переменных — вызвать функцию tf.global_variabies-initializerо. Выполнение этой операции в сеансе инициализирует все переменные в программе (пример 2.27).
i Пример 2.27. Вычисление инициализированных переменных
»> sess = tf.Session()
»> sess.run(tf.global_variables_initializer())
»> a.eval (session=sess)
array([[ 1., 1.],
[ 1., 1.]], dtype=float32)
После инициализации мы можем получить значение, хранящееся в переменной, как если бы это был обычный тензор. До сих пор переменные ненамного отличались от простых тензоров. Переменные становятся интересными только тогда, когда мы можем их присваивать. Функция tf. assign о позволяет это делать. При помощи функции tf. assign о мы можем обновить значение существующей переменной (пример 2.28).
| Пример 2.28. Присвоение значений переменным
»> sess.run(a.assign(tf .zeros ( (2,2))) ) array([[ 0., 0. ], [ 0., 0.]], dtype=float32)
»> sess.run (a) array([[ 0., 0. ], [ 0., 0.]], dtype=float32)
Введение в примитивы TensorFlow | 57
Что произойдет, если попытаться присвоить значение переменной а, не имеющей форму (2, 2)? Давайте разберемся в примере 2.29.
'Пример 2.29. Присвоение терпит неудачу, когда формы не равны j
»> sess.run (a.assign (tf .zeros ((3,3))))
ValueError: Dimension 0 in both shapes must be equal, but are 2 and 3 for 'Assign_3' (op: ’Assign') with input shapes: [2,2], [3,3].
Вы видите, что TensorFlow жалуется. Форма переменной фиксируется при инициализации и должна сохраняться во время обновлений. А вот еще одно интересное замечание: функция tf. assign о сама по себе является частью базового глобального экземпляра вычислительного графа tf .Graph. Это позволяет программам TensorFlow обновлять свое внутреннее состояние при каждом выполнении. Мы будем активно использовать это функциональное средство в последующих главах.
Резюме
В этой главе мы ввели математическое понятие тензоров и кратко рассмотрели ряд математических понятий, связанных с тензорами. Затем мы продемонстрировали, как создавать тензоры в TensorFlow и выполнять те же самые математические операции в TensorFlow. Мы также кратко представили некоторые лежащие в основе TensorFlow структуры, такие как вычислительный граф, сеансы и переменные. Если вы еще не полностью разобрались в понятиях, обсуждаемых в этой главе, то не переживайте. Мы будем неоднократно использовать их на протяжении оставшейся части книги, поэтому у вас будет много возможностей для того, чтобы усвоить эти идеи.
В следующей главе мы научим вас строить простые обучающиеся модели для линейной и логистической регрессии с использованием TensorFlow. Последующие главы будут строиться на этом фундаменте, чтобы научить вас выполнять тренировку более сложных моделей.
58 | Гпаеа 2
ГЛАВА 3
Линейная и логистическая регрессия с помощью TensorFlow
В этой главе мы покажем, как построить простые, но нетривиальные примеры обучающихся систем в TensorFlow. В начале этой главы обсуждаются математические основы построения обучающихся систем, и, в частности, будут рассмотрены функции, их непрерывность и дифференцируемость. Мы введем понятие функций потерь, а затем обсудим то, как машинное самообучение по сути сводится к способности находить минимальные точки сложных функций потерь. Затем мы рассмотрим понятие градиентного спуска и объясним, как его использовать для минимизации функций потерь. Мы закончим изложение кратким обсуждением алгоритмической идеи автоматического дифференцирования. Второй раздел посвящен введению понятий TensorFlow, подкрепленных математическими идеями. Эти понятия включают заполнители, области имен, оптимизаторы и пакет визуализации TensorBoard и создают условия для практического построения и анализа обучающихся систем. В заключительном разделе приведены практические примеры тренировки линейной и логистической регрессионных моделей в TensorFlow.
Глава 3 длинная, и в ней представлено много новых идей. Вполне нормально, если вы не поймете все тонкости идей при первом прочтении. Мы рекомендуем двигаться вперед и возвращаться, чтобы позже свериться с приведенными здесь понятиями по мере необходимости. Мы будем многократно использовать фундаментальные принципы в оставшейся части книги, чтобы дать вам возможность постепенно усвоить эти идеи.
Математический обзор
В данном разделе рассматриваются математические инструменты, необходимые для концептуального понимания машинного самообучения. Мы попытаемся минимизировать количество требуемых греческих символов и вместо этого сосредоточимся прежде всего на построении концептуального понимания, а не на технических манипуляциях.
Функции и дифференцируемость
В этом разделе предоставлен краткий обзор понятий функций и дифференцируемости. Функция f— это правило, которое превращает данные на входе в данные на выходе. Функции имеются во всех языках программирования, и математическое определение функции не сильно отличается. Однако математические функции,
59
широко используемые в физике и технике, обладают другими важными свойствами, такими как непрерывность и дифференцируемость. Непрерывная функция, грубо говоря — это функция, которую можно начертить, не отрывая карандаш от бумаги, как показано на рис. 3.1. (Это, конечно, не техническое определение, но оно отражает дух свойства непрерывности.)
Рис. 3.1. Несколько непрерывных функций
Дифференцируемость — это свойство гладкости функций. Она говорит, что острые углы или изгибы в функции недопустимы (рис. 3.2).
Рис. 3.2. Дифференцируемая функция
Ключевым преимуществом дифференцируемых функций является то, что мы можем использовать наклон функции в определенной точке в качестве руководства для поиска мест, где функция выше или ниже нашего текущего положения. Эго позволяет находить минимумы функции. Производная дифференцируемой функции/, обозначаемая как /', является еще одной функцией, которая характеризует наклон исходной функции во всех точках. Концептуальная идея заключается в том, что производная функции в заданной точке дает указатель, сообщающий о направлениях, где функция выше или ниже ее текущего значения. Оптимизационный алгоритм
60 | Гпава 3
может следовать этому указателю, чтобы приближаться к минимумам. На минимумах функция будет иметь нулевую производную.
Мощь оптимизации под управлением производной сначала не очевидна. Поколения студентов, штудирующих математический анализ, с трудом продирались через отупляющие упражнения минимизации крошечных функций на бумаге. Эти упражнения неполезны тем, что нахождение минимумов функции с небольшим количеством входных параметров является тривиальным упражнением, которое лучше всего выполнять графически. Мощь оптимизации под управлением производной становится очевидной только при наличии сотен, тысяч, миллионов или миллиардов переменных. В этих масштабах понимание функции аналитически почти невозможно, и все визуализации являются сложными упражнениями, чреватыми непреднамеренным пропуском ключевых атрибутов функции. В этих масштабах градиент функции V/, обобщение f на многомерные функции, вероятно, является самым мощным математическим инструментом для понимания функции и ее поведения. Мы углубимся в градиенты позже в этой главе. (Концептуально это так, однако в данной книге мы не будем освещать технические подробности градиентов.)
На очень высоком уровне машинное самообучение — это просто процесс минимизации функций: обучающиеся алгоритмы — это не что иное, как искатели минимумов для функций, сформулированных надлежащим образом. Это определение имеет преимущество математической простоты. Но каковы же эти особые дифференцируемые функции, которые кодируют полезные решения в своих минимумах и как их можно найти?
Функции потерь
Для того чтобы решить ту или иную задачу машинного самообучения, аналитик данных должен найти способ построения функции, минимумы которой кодируют решения текущей задачи реального мира. К счастью для нашего горемычного аналитика данных, литература по машинному самообучению накопила богатый архив функций потерь, которые выполняют такие кодирования. Практическое машинное самообучение сводится к пониманию различных типов имеющихся функций потерь и пониманию того, какая функция потери должна применяться к тем или иным задачам. Другими словами, функция потери — это механизм, с помощью которого проект в области науки о данных преобразовывается в математику. Все машинное самообучение, и большая часть искусственного интеллекта, сводится к созданию правильной функции потери для решения текущей задачи. Мы предоставим вам краткий обзор некоторых широко используемых семейств функций потерь.
Начнем с того, что функция потери £, чтобы иметь содержательное значение, должна удовлетворять некоторым математическим свойствам. Во-первых, С должна использовать как точки данных х, так и метки у. Мы обозначим это, записав функцию потери как £(х, у) . Если использовать понятия из предыдущей главы, то можно сказать, что х и у являются тензорами, а С — это отображение из
Линейная и логистическая регрессия с помощью TensorFlow | 61
пар тензоров в скаляры. Какой должна быть функциональная форма функции потери? Общепринято делать функции потерь аддитивными. Предположим, что (х,, у,) — это данные, имеющиеся в прецеденте i, и в общей сложности существует У прецедентов. После этого функцию потери можно разложить, как
1=1
(На практике Ct одинакова для каждой точки данных.) Это аддитивное разложение позволяет получить много полезных преимуществ. Во-первых, производные факторизуются через сложение, поэтому вычисление градиента общих потерь упрощается следующим образом:
V£(x, y) = fvz;(x„y,).
1=1
Этот остроумный математический прием означает, что при условии, если более мелкие функции £, дифференцируемы, значит, то же самое будет и с функцией полной потери. Из этого следует, что задача проектирования функций потерь сводится к задаче проектирования более мелких функций £. (х,, у,) . Прежде чем мы погрузимся в проектирование £., будет полезно сделать небольшое отступление, которое объяснит разницу между классификационными и регрессионными задачами.
Классификация и регрессия
Машинно-обучающиеся алгоритмы могут быть разбиты на широкие категории: контролируемые задачи (с учителем) и неконтролируемые задачи (без учителя). Контролируемые задачи — это такие задачи, для которых имеются как точки данных х, так и метки у, в то время как неконтролируемые задачи имеют только точки данных х без меток у. В общем случае контролируемое машинное самообучение намного сложнее и менее четко сформулировано. (Что значит "понимать" точки х?) Пока мы не будем углубляться в функции неконтролируемых потерь, поскольку на практике большинство неконтролируемых потерь умно переиначиваются в контролируемые потери.
Контролируемое машинное самообучение можно разбить на две подзадачи: классификационную задачу и регрессионную задачу. Классификационная задача — это задача, в которой вы пытаетесь спроектировать машинно-обучающуюся систему, которая присваивает дискретную метку, скажем 0/1 (или в более общем случае 0,..., п), конкретной точке данных. Регрессия — это задача проектирования машинно-обучающейся системы, которая прикрепляет вещественную метку (в пространстве R ) к конкретной точке данных.
На высоком уровне эти проблемы могут показаться несопоставимыми. Дискретные и непрерывные объекты обычно трактуются по-разному математикой и здравым смыслом. Однако часть хитрости, используемой в машинном самообучении, заключается в применении непрерывных дифференцируемых функций потерь для
62 | Гпава 3
кодирования как классификационных, так и регрессионных задач. Как мы уже упоминали ранее, подавляющая часть машинного самообучения представляет собой не что иное, как искусство превращения сложных систем реального мира в достаточно простые дифференцируемые функции.
В следующих разделах мы познакомим вас с парой математических функций, которые окажутся очень полезными для преобразования классификационных и регрессионных задач в подходящие функции потерь.
/Лпотеря
Потеря Z2 (произносится как "эль два") обычно используется для регрессионных задач. Потеря Z2 (или Z2 -норма, как ее обычно называют в других местах) обеспечивает меру величины вектора:
н,=Ж?-
Здесь а — вектор длины N. Норма L2 обычно используется для определения расстояния между двумя векторами:
Эта идея с £2 в качестве меры расстояния оказалась очень полезной для решения регрессионных задач в контролируемом машинном самообучении. Предположим, что х есть набор данных, а у — это метки. Пусть f есть некоторая дифференцируемая функция, которая кодирует нашу машинно-обучающуюся модель. Тогда, чтобы побудить f предсказывать у, мы создаем функцию Z2 -потери:
£(x’>z)=I|/(x)->'L
В качестве краткого примечания, на практике общепринято использовать Z2 -потерю не напрямую, а скорее ее квадрат:
||а-Ь|Б=±(^-^)2,
/=1
чтобы не заниматься членами вида 1/4х в градиенте. Мы будем многократно использовать квадратичную 1} -потерю в оставшейся части этой главы и всей книги.
Режимы сбоя функции /Лпотери
Потеря Z2 резко штрафует крупномасштабные отклонения от истинных меток, но не делает большой работы по вознаграждению точных совпадений для реальных меток. Мы можем понять это расхождение математически, изучая поведение функций х2 и х вблизи начала координат (рис. 3.3).
Линейная и логистическая регрессия с помощью TensorFlow | 63
Рис. 3.3. Сравнение квадратных и тождественных функций вблизи начала координат
Обратите внимание на то, как х2 уменьшается до 0 при малых значениях х. Как результат, небольшие отклонения штрафуются Z2-потерей не сильно. В низкоразмерной регрессии это не является серьезной проблемой, но в многомерной регрессии L2 становится плохой функцией потери, поскольку может иметься много небольших отклонений, которые вместе делают результат регрессии плохим. Например, при предсказании изображения Z2-потеря создает размытые изображения, которые визуально не привлекательны. Недавний прогресс в машинном самообучении привел к разработке способов обучаться функциям потерь. Эти заученные функции потерь, часто стилизованные в виде генеративно-состязательных сетей (GAN-сетей), гораздо больше подходят для многомерной регрессии и способны генерировать неразмытые изображения.
Распределения вероятностей
Прежде чем вводить функции потерь для классификационных задач, полезно сделать небольшое отступление и познакомиться с распределениями вероятностей. Для начала следует ответить на вопросы: что такое вероятность и почему мы должны быть в ней заинтересованы для целей машинного самообучения? Вероятность является обширной темой, поэтому мы погрузимся в нее достаточно глубоко, чтобы вы всё поняли. На высоком уровне распределения вероятностей реализуют остроумный математический прием, который позволяет смягчить дискретное множество вариантов выбора, переведя его в бесконечное множество. Предположим, что вам нужно спроектировать машинно-обучающуюся систему, которая предсказывает, упадет монета орлом вверх или вниз. Не похоже, что падение орлом вверх/вниз можно закодировать как непрерывную функцию, а тем более дифференцируемую. Тогда как воспользоваться механизмом математического анализа или библиотекой TensorFlow, чтобы решать задачи, связанные с дискретным выбором?
64 | Гпава 3
Следует внести распределение вероятностей. Вместо трудных вариантов выбора заставить классификатор предсказывать шанс получать орла вверх или вниз. Например, классификатор может научиться предсказывать, что монета орлом вверх имеет вероятность 0,75, а монета, упавшая решкой вверх, — вероятность 0,25. Обратите внимание, что вероятности непрерывно меняются! Следовательно, работая с вероятностями дискретных событий, а не с событиями как таковыми, вы можете аккуратно обойти проблему, связанную с тем, что математический анализ на самом деле не работает с дискретными событиями.
Распределение вероятностей р — это просто список вероятностей для располагаемых возможных дискретных событий. В этом случае р = (0,75; 0,25). Обратите внимание, что в качестве альтернативы можно рассматривать р\ {0; 1} —> R, как отображение из множества, состоящего из двух элементов, в вещественные числа. Такой взгляд время от времени будет полезен в плане обозначения.
Вкратце отметим, что техническое определение распределения вероятностей будет сложнее. Существует практическая возможность назначать распределения вероятностей реальным событиям. Мы обсудим такие распределения позже в этой главе.
Перекрестно-энтропийная потеря
Перекрестная энтропия — это математический метод измерения расстояния между двумя распределениями вероятностей:
н (р> я)="Е р (х) 1ое я (*) •
Здесь р и q — это два распределения вероятностей. Форма записи р(х) обозначает, что вероятность р соответствует событию х. Это определение стоит тщательно обсудить. Как и норма Z2, Н дает понятие расстояния. Обратите внимание, что в случае, когда p = q,
н (р, р)=-£р(х)1оеИх) • X
Эта величина представляет собой энтропию р и обычно записывается просто, как Н (р). Это мера того, насколько распределение является беспорядочным; энтропия максимальна, когда все события равновероятны. Н(р) всегда меньше или равна Я(р, ?) • самом деле, чем дальше распределение q отр, тем больше становится перекрестная энтропия. Мы не будем углубляться в точные значения этих утверждений, но интуитивное понимание перекрестной энтропии как механизма расстояния стоит запомнить.
Обратите внимание, что в отличие от нормы Z2, Н— асимметрична! То есть, Я(р, q) Н(ц, р). По этой причине рассуждения с перекрестной энтропией могут быть немного заковыристыми, и лучше всего их делать с некоторой осторожностью.
Возвращаясь к конкретным вопросам, теперь предположим, что р = (у, 1 - у) является истинным распределением данных для дискретной системы с двумя исходами,
Линейная и логистическая регрессия с помощью TensorFlow | 65
a Я ~(КреДск’ 1 “ Упредск) — это то> что предсказывается машинно-обучающейся системой. Тогда перекрестно-энтропийная потеря равна
Н (р, q) = у log + (1 - у) log (1 - упредск) .
Эта форма потери широко используется в машинно-обучающихся системах для тренировки классификаторов. Эмпирически минимизация Н(р, q), судя по всему, создает классификаторы, которые хорошо воспроизводят предоставленные тренировочные метки.
Градиентный спуск
Итак, к этому моменту вы познакомились с понятием минимизации функции как косвенным показателем для машинного самообучения. Напомним: для того чтобы научиться решать желаемую задачу, зачастую достаточно минимизации подходящей функции. Использование этого математического каркаса подразумевает необходимость применять подходящие функции потерь, такие как потеря £2 или перекрестная энтропия H(p,q), с тем, чтобы преобразовать классификационные и регрессионные задачи в подходящие функции потерь.
Заучиваемые веса
До сих пор в этой главе мы объясняли, что машинное самообучение явля-ется действием по минимизации надлежаще сформулированной функции потери £(х, у) . То есть мы пытаемся найти такие аргументы функции потери £, которые ее минимизируют. Однако внимательные читатели вспомнят, что (х, у) являются фиксированными величинами, которые нельзя изменить. Какие же аргументы функции £ мы меняем во время самообучения?
Внесем заучиваемые веса FT. Предположим, что f (х) является дифференцируемой функцией, подгонку которой мы хотим выполнить с помощью нашей машинно-обучающейся модели. Определим, что f параметризуется выбором W. То есть наша функция фактически имеет два аргумента f (И\ х). Фиксация значения W приводит к функции, которая зависит исключительно от точек данных х. Такие заучиваемые веса представляют собой величины, которые фактически выбираются путем минимизации функции потери1. Позже в этой главе мы увидим, каким образом библиотека TensorFlow может использоваться для кодирования заучиваемых весов при ПОМОЩИ tf.Vartable.
Теперь предположим, что мы закодировали нашу задачу самообучения подходящей функцией потери. Каким образом можно найти минимумы этой функции потери на
1 Иными словами, когда говорится, что величина (вес, параметр) является заучиваемой, имеется в виду, что она вычисляется обучающимся алгоритмом путем минимизации функции потери, которая зависит от тренировочных данных. — Прим. пер.
66 | Гпава 3
1рактике? Ключевой прием, который мы будем использовать, — это минимизация фадиентного спуска. Предположим, что f есть функция, которая зависит от некоторых весов W. Тогда VFF обозначает изменение направления в W, которое максимально увеличит / Из этого следует, что шаг в противоположном направлении лриблизит нас к минимумам f
Обозначение для градиентов
Мы записали градиент для заучиваемого веса W, как VFF. Иногда удобно использовать альтернативное обозначение градиента:
VFF = —.
dW
Это уравнение следует трактовать так, что градиент VJV кодирует направление, которое изменяет потерю £ в максимальной степени.
Идея градиентного спуска— отыскать минимум функции, неоднократно следуя в направлении отрицательного градиента. Это правило можно выразить алгоритмически следующим образом:
где а является размером шага и предписывает, сколько веса следует придать новому градиенту VW . Идея состоит в том, чтобы выполнять много маленьких шажков в сторону VJV. Обратите внимание, что градиент VJV как таковой является функцией W, поэтому фактический шаг меняется на каждой итерации. Каждый шаг делает небольшое обновление весовой матрицы W. Итеративный процесс выполнения обновлений обычно называется заучиванием весовой матрицы W.
Эффективное вычисление градиентов с помощью мини-пакетов
Одна из проблем заключается в том, что вычисление VFF может быть очень медленным. Неявно VFF зависит от функции потери С. Поскольку С зависит от всего набора данных, вычисление может стать очень медленным для больших наборов данных. На практике специалисты обычно вычисляют VFF на части набора данных, называемого мини-пакетом. Каждый мини-пакет, как правило, состоит из 50-100 элементов данных. В глубоко обучающемся алгоритме размер мини-пакета является гиперпараметром. Размер а каждого шага— это еще один гиперпараметр. Глубоко обучающиеся алгоритмы обычно имеют кластеры гиперпараметров, которые как таковые не заучиваются посредством стохастического градиентного спуска.
Эта напряженность между заучиваемыми параметрами и гиперпараметрами является одной из слабых и сильных сторон глубоких архитектур. Наличие гиперпараметров дает много возможностей для использования мощной интуиции эксперта, в то время как заучиваемые параметры позволяют данным говорить самим за себя. Однако эта гибкость быстро становится слабостью, а поведение гиперпараметров выглядит как черная магия, что
Линейная и логистическая регрессия с помощью TensorFlow | 67
создает начинающим специалистам препятствия для широкого внедрения глубокого самообучения. Мы потратим значительные усилия на обсуждение гиперпараметрической оптимизации позже в этой книге.
Мы заканчиваем этот раздел введением понятия эпохи. Эпоха — это полный проход алгоритма градиентного спуска по данным х. Говоря конкретнее, эпоха состоит из множества шагов градиентного спуска, необходимых для просмотра всех данных в мини-пакете заданного размера. Например, предположим, что набор данных имеет 1000 точек данных, и в процессе тренировки используется мини-пакет размером 50 элементов. Тогда эпоха будет состоять из 20 обновлений градиентного спуска. Каждая эпоха тренировки увеличивает объем полезных знаний, полученных моделью. В математическом смысле это будет соответствовать сокращениям в значении функции потери в тренировочном наборе.
Ранние эпохи будут вызывать резкое падение функции потери. Этот процесс часто называют заучиванием априорной информации на том или ином наборе данных. Хотя кажется, что модель учится быстро, на самом деле она лишь приспосабливается к пребыванию в той части параметрического пространства, которая имеет отношение к решаемой задаче. Более поздние эпохи будут соответствовать гораздо меньшим падениям в функции потери, но нередко именно в этих более поздних эпохах произойдет содержательное самообучение. Несколько эпох, как правило, дают слишком мало времени для нетривиальной модели на то, чтобы обучиться чему-нибудь полезному; модели обычно тренируют, используя от 10 до 1000 эпох, или до тех пор, пока не наступит схождение. Хотя это количество кажется большим, важно отметить, что количество требуемых эпох обычно не масштабируется вместе с размером текущего набора данных. Следовательно, градиентный спуск масштабируется вместе с размером данных линейно, а не квадратично! Это одна из самых сильных сторон метода стохастического градиентного спуска по сравнению с другими обучающимися алгоритмами. Более сложные обучающиеся алгоритмы могут требовать только один проход по набору данных, но могут использовать тотальное вычисление, которое масштабируется квадратично с числом точек данных. В наше время больших наборов данных квадратичное время работы является фатальным недостатком.
Отслеживание падения в функции потери в зависимости от количества эпох может быть чрезвычайно полезным визуальным обозначением для понимания процесса самообучения. Такие графики часто называются кривыми потерь (рис. 3.4). Со временем опытный практикующий специалист сможет диагностировать общие сбои в самообучении, просто взглянув на кривую потери. В этой книге мы будем уделять значительное внимание кривым потерь для различных глубоко обучающихся моделей. В частности, далее в этой главе мы представим TensorBoard — мощный пакет визуализации, который TensorFlow предоставляет для таких величин, как функции потерь.
68 | Гпава 3
Стоимость на тренировочных данных
Рис. 3.4. Пример кривой потери для модели. Обратите внимание, что эта кривая потери получена из модели, натренированной с помощью истинного градиента (т. е. не мини-пакетного вычисления) и, следовательно, более гладкой, чем другие кривые потерь, с которыми вы столкнетесь позже в этой книге
Системы автоматического дифференцирования
Машинное самообучение является искусством определения функций потерь, подходящих для наборов данных, и затем их минимизации. Для минимизации функции потерь нам нужно вычислить их градиенты и применить алгоритм градиентного спуска, чтобы итеративно уменьшить потери. Однако нам все еще нужно обсудить, как на самом деле вычисляются градиенты. До недавнего времени ответ был "от руки", когда эксперты по машинному самообучению вручную ломали перья и комкали бумагу, вычисляя матричные производные, чтобы вычислить аналитические формулы для всех градиентов в обучающейся системе. Эти формулы затем вручную программировали для реализации обучающегося алгоритма. Этот процесс был заведомо чреват ошибками, и немало экспертов по машинному самообучению могут поведать истории о случайных ошибках градиента в опубликованных статьях и производственных системах, остававшихся нераскрытыми в течение многих лет.
Положение дел значительно изменилось с широким распространением механизмов автоматической дифференциации. Системы, подобные библиотеке TensorFlow, способны автоматически вычислять градиенты почти для всех функций потерь. Автоматическая дифференциация является одним из самых больших преимуществ TensorFlow и подобных систем, поскольку практикующим специалистам по ма
Линейная и логистическая регрессия с помощью TensorFlow | 69
шинному самообучению больше не нужно быть экспертами в матричном исчислении. Тем не менее, по-прежнему есть необходимость в высокоуровневом понимании, каким образом библиотека TensorFlow способна автоматически брать производные сложных функций. Те читатели, которые в свое время продирались сквозь вводный курс математического анализа, возможно, помнят, что взятие производных функций удивительно механическое. Существует ряд простых правил, которые можно применять для получения производных большинства функций. Например,
—хл=пх"-';
dx
d х .
—е =е .
dx
Эти правила могут быть объединены за счет цепного правила:
-у-/($(*)) = f'(g W)g' (*), dx
где f — обозначение производной функции f, g' — обозначение производной функции g. С помощью этих правил легко представить, как можно запрограммировать механизм автоматической дифференциации для одномерного исчисления. Действительно, создание такого механизма дифференциации часто входит в учебный план на первом курсе программирования на занятиях по языку Lisp. (Оказывается, что правильный разбор функций является гораздо более сложной задачей, чем получение производных. Язык Lisp делает тривиальным разбор формул с использованием своего синтаксиса, в то время как на других языках для выполнения этого упражнения нередко проще дождаться, пока вы не пройдете курс по компиляторам.)
Каким образом эти правила могут быть распространены на исчисление более высоких размерностей? Получить правильные математические выкладки сложнее, поскольку приходится учитывать много других факторов. Например, при наличии X - АВ, где X, А, В — это матрицы, формула получается следующей:
VA = — = — Br=(VX)Br.
дк дХ V 7
Такие формулы могут быть объединены, чтобы обеспечить символическую систему дифференцирования для векторного и тензорного исчисления.
Самообучение с помощью TensorFlow
В оставшейся части этой главы мы рассмотрим понятия, которые вам потребуются, чтобы изучить основные машинно-обучающиеся модели с использованием библиотеки TensorFlow. Мы начнем с представления концепции игрушечных наборов данных и объясним, как создавать содержательные игрушечные наборы данных с использованием универсальных библиотек Python. Затем мы обсудим новые идеи TensorFlow, такие как заполнители, словари передача данных, области имен, опти
70 | Гпава 3
мизаторы и градиенты. В следующем разделе будет показано, как использовать эти понятия для тренировки простых регрессионных и классификационных моделей.
Создание игрушечных наборов данных
В этом разделе мы обсудим, как создавать простые, но содержательные синтетические, или игрушечные, наборы данных, которые мы будем использовать для тренировки простых контролируемых классификационных и регрессионных моделей.
Чрезвычайно краткое введение в NumPy
Мы будем активно использовать пакет NumPy для определения полезных игрушечных наборов данных. Пакет Python NumPy позволяет манипулировать тензорами (которые в NumPy называются массивами). В примере 3.1 показаны некоторые основы.
Пример 3.1. Несколько примеров элементарного применения пакета NumPy
»> import numpy as пр »> np. zeros ((2,2)) array([[ 0., 0.],
[ 0., 0.]])
»> пр.еуе(З)
array([[ 1., 0., 0.], [ 0., 1., 0.], [ 0., 0., 1.]])
Вы можете заметить, что манипуляции с массивом NumPy ndarray выглядят удивительно похоже на манипуляции с тензорами в TensorFlow. Это сходство было специально спроектировано архитекторами библиотеки TensorFlow. Многие ключевые сервисные функции TensorFlow имеют аргументы и формы, схожие с аналогичными функциями в NumPy. Именно по этой причине мы не будем пытаться подробно знакомить вас с NumPy и предоставим читателям возможность поэкспериментировать самостоятельно, чтобы разобраться в использовании NumPy. Существует большое количество интернет-ресурсов, предоставляющих учебные материалы по NumPy.
Почему важны игрушечные наборы данных?
В машинном самообучении зачастую важно научиться правильно использовать игрушечные наборы данных. Тренировка алгоритма сопряжена с трудностями, и одна из наиболее распространенных ошибок, которые совершают начинающие специалисты, — слишком поспешные попытки натренировать нетривиальные модели на сложных данных. Эти попытки часто заканчиваются полным провалом, и потенциальный специалист в машинном самообучении уходит удрученным и убежденным, что машинное самообучение не для него.
Линейная и логистическая регрессия с помощью TensorFlow | 71
Настоящий виновник здесь, конечно, не начинающий специалист, а тот факт, что реальные наборы данных имеют много характерных особенностей. Опытные аналитики данных поняли, что реальные наборы данных часто требуют многих преобразований, связанных с очисткой и предобработкой, прежде чем они могут стать пригодными для применения в машинном самообучении. Глубокое самообучение усугубляет эту проблему, поскольку большинство глубоко обучающихся моделей, как известно, чувствительны к погрешностям в данных. Такие проблемы, как широкий диапазон регрессионных меток или залегающие в основе шаблоны сильных шумов, могут сбить методы, опирающиеся на градиентный спуск, даже когда другие машинно-обучающиеся алгоритмы (такие как случайные леса) не будут иметь проблем.
К счастью, с этими проблемами почти всегда можно справиться, но решение может потребовать значительной изощренности со стороны аналитика данных. Такие проблемы чувствительности, пожалуй, являются самым большим препятствием на пути коммерциализации машинного самообучения как технологии. Мы подробно рассмотрим стратегии очистки данных, но пока рекомендуем гораздо более простую альтернативу: использовать игрушечные наборы данных!
Игрушечные наборы данных имеют решающее значение для понимания обучающихся алгоритмов. При наличии очень простых синтетических наборов данных не составит труда точно определить, обучился ли алгоритм нужному правилу или нет. На более сложных наборах данных получить такое суждение может оказаться очень сложным. По этой причине в оставшейся части этой главы по мере освещения фундаментальных принципов самообучения на основе градиентного спуска с помощью TensorFlow мы будем использовать только игрушечные наборы данных. Мы углубимся в практические примеры с использованием реальных данных в последующих главах.
Добавление шума с помощью гауссиан
Ранее мы обсуждали дискретные распределения вероятностей как инструмент для превращения дискретных вариантов в непрерывные значения. Мы также ссылались на идею непрерывного распределения вероятностей, но в нее не погружались.
Непрерывные распределения вероятностей (более точно именуемые как функции плотности вероятности) являются полезным математическим инструментом для моделирования случайных событий, которые могут иметь диапазон исходов. Для наших целей достаточно представить функции плотности вероятности, как полезный инструмент для моделирования некоторой ошибки измерения при сборе данных. Гауссово распределение вероятностей, или гауссиана, широко используется для моделирования шума.
Обратите внимание, что гауссианы могут иметь разные средние значения ц и стандартные отклонения о (рис. 3.5). Среднее гауссианы является средним арифметическим значением, которое она принимает, тогда как стандартное отклонение является мерой разброса вокруг этого среднего значения. В общем случае, добавление гауссовой случайной величины в некоторую величину обеспечивает
72 | Гпава 3
структурированный способ размыть эту величину, заставляя ее слегка варьироваться. Это очень полезный прием для создания нетривиальных синтетических наборов
Рис. 3.5. Иллюстрации различных гауссовых распределений вероятностей с разными средними значениями и стандартными отклонениями
Мы кратко отметим, что гауссово распределение также называется нормальным распределением. Гауссиана со средним ц и стандартным отклонением а записывается, как N(p, п). Это сокращенное обозначение удобно, и в последующих главах мы будем его использовать неоднократно.
Игрушечные наборы регрессионных данных
Простейшей формой линейной регрессии является заучивание параметров для одномерной прямой. Допустим, что наши точки данных х— одномерны. Тогда предположим, что вещественные метки у генерируются линейным правилом:
у = wx + b.
Здесь w, b— это заучиваемые параметры, которые должны быть вычислены из данных градиентного спуска. Для того чтобы убедиться, что мы можем обучиться этим параметрам с помощью TensorFlow, создадим искусственный набор данных, состоящий из точек на прямой. Для того чтобы слегка усложнить задачу самообучения, мы добавим в набор данных немного гауссова шума.
Запишем уравнение для нашей прямой с помехами, внесенными небольшим количеством гауссова шума:
у = wx + Z> + 7V(0, а).
Здесь а — это стандартное отклонение шумовой составляющей. Затем, как показано в примере 3.2, мы можем применить NumPy для создания искусственного набора данных, полученного из этого распределения.
Линейная и логистическая регрессия с помощью TensorFlow | 73
Пример 3.2. Использование NumPy для получения образца искусственного набора данных
# Сгенерировать синтетические данные.
N - 100
w__true = 5
b__true = 2
noise__scale = .1
x__np = np.random.rand(N, 1)
noise = np.random.normal(scale=noise_scale, size=(N, 1))
# Конвертировать форму y_np в (N,)
y_np = np. reshape (w__true * x_np + b__true + noise, (-1))
Построим график этого набора данных при помощи библиотеки Matpiotiib на рис. 3.6 (исходный код можно найти в хранилище GitHub (https://github.com/ matroid/dlwithtf), связанном с этой книгой, чтобы увидеть точную реализацию построения графика), и проверим, что синтетические данные выглядят разумными. Как и ожидалось, распределение данных представляет собой прямую линию с небольшим количеством погрешностей измерения.
Игрушечные данные линейной регрессии у - 5х + 2 + 7V(0,1)
Рис. 3.6. График распределения игрушечных регрессионных данных
Игрушечные наборы классификационных данных
Создать синтетический набор классификационных данных немного сложнее. В логическом плане мы хотим получить два разных класса точек, которые легко разделимы. Предположим, что набор данных состоит из двух типов точек: (-1, -1) и (1, 1).
74 | Гпава 3
Тогда обучающийся алгоритм должен будет обучиться правилу, которое разделяет эти два значения данных.
Уо =(-1.-1); у, =0.1).
Как и раньше, немного усложним задачу, добавив в оба типа точек немного гауссова шума:
у0=(-1,-1) + У(0,о);
у,=(1,1) + ЛГ(0, о).
Вместе с тем здесь есть небольшая хитрость. Наши точки — двумерны, в то время как гауссов шум, который мы внесли ранее, — одномерен. К счастью, существует многомерное обобщение гауссианы. Мы не будем обсуждать здесь тонкости многомерной гауссианы, вам это не нужно, чтобы следить за нашим обсуждением.
Программный код NumPy для создания синтетического набора данных в примере 3.3 немного сложнее, чем для линейной регрессионной задачи, поскольку мы должны использовать функцию укладки np.vstack2, чтобы объединить два разных типа точек данных и связать их с разными метками. (Мы используем связанную функцию пр.concatenate о, чтобы совместить одномерные метки.)
| Пример 3.3. Получение образца игрушечного набора классификационных данных с помощью NumPy
।----------------------------------------------------------------------------------
# Сгенерировать синтетические данные
N = 100
# Нули образуют гауссиану, центрированную в (-1, -1)
# эпсилон равняется .1
x_zeros - np.random.multivariate_normal(
mean=np.array((-1, -1)), cov=.l*np.eye(2), size=(N/2,))
y_zeros = np.zeros((N/2,))
# Нули образуют гауссиану, центрированную в (1, 1)
# эпсилон равняется .1
x_ones = np.random.multivariate_normal(
mean=np.array((1, 1)), cov=.l*np.eye (2), size=(N/2,))
y_ones = np.ones((N/2,))
x_np = np.vstack([x_zeros, x_ones]) y_np = np.concatenate([y_zeros, yones])
На рис. 3.7 показан график данных, сгенерированных приведенным выше программным кодом с помощью библиотеки Matplotlib, для проверки правильности распределения. Мы видим, что данные находятся в двух классах, которые четко разделены.
2 np.vstack () — функция вертикальной укладки массивов в многоярусную последовательность. См. https://docs.scipy.org/doc/numpy/reference/generated/numpy.vstack.html. — Прим. пер.
Линейная и логистическая регрессия с помощью TensorFlow | 75
Рис. 3.7. График распределения игрушечных классификационных данных
Новые понятия TensorFlow
Для создания простых машинно-обучающихся систем в TensorFlow потребуется знать несколько новых понятий этой библиотеки.
Заполнители
Заполнитель — это способ ввода информации в вычислительный граф TensorFlow. Думайте о заполнителях, как о входных узлах, через которые информация поступает в TensorFlow. Ключевой функцией, используемой для создания заполнителей, является tf .placeholder (пример 3.4).
। Пример 3.4. Создание заполнителя TensorFlow
>» tf.placeholder(tf.float32, shape=(2,2))
<tf.Tensor ’Placeholder:0’ shape=(2, 2) dtype=float32>
Мы будем использовать заполнители для передачи точек данных х и меток у в наши регрессионные и классификационные алгоритмы.
Словари передачи данных и выборки
Напомним, что мы можем вычислять тензоры в TensorFlow, используя метод sess.run(var). Тогда как подавать значения для заполнителей в наших вычислениях в TensorFlow? Ответ — конструировать словари передачи данных. Словари переда
75 | Гпава 3
чи данных — это словари Python, которые увязывают тензоры TensorFlow с объектами-массивами NumPy np.ndarray, содержащими конкретные значения для этих заполнителей. Словарь передачи данных лучше всего рассматривать, как входные данные для вычислительного графа TensorFlow. Что же такое выходные данные? В TensorFlow выходные данные называются выборками (fetches). Вы уже встречали выборки. Мы широко использовали их в предыдущей главе, не называя их как таковые; выборка — это тензор (или тензоры), значение которого извлекается из вычислительного графа после завершения вычисления (используя значения заполнителей из словаря передачи данных) (пример 3.5).
Пример 3.5. Использование выборок
»> а = tf.placeholder(tt.floatJ2, shape=(i,jj »> b = tf.placeholder(tf.float32, shape=(lj) »> c = a + b
»> with tf.Session () as sess: c_eval = sess.run(с, {a: [1.], b: [2.]}) print(c_eval)
[ 3.]
Области имен
В сложных программах TensorFlow, безусловно, будет большое количество тензоров, переменных и заполнителей. Функция tf .пате_зсоре(имя) предоставляет простой механизм определения областей видимости для управления этими коллекциями переменных (пример 3.6). Имена всех элементов вычислительного графа, созданных В рамках вызова tf .name scope (имя), ДОПОЛНЯЮТСЯ префиксом имя.
Этот организационный инструмент наиболее полезен в сочетании с пакетом визуализации TensorBoard, поскольку он помогает системе визуализации автоматически группировать элементы графа в пределах одной области имен. Вы узнаете больше о TensorBoard далее в следующем разделе.
^Пример 3.6. Использование областей имен для организации заполнителей
»> N = 5
»> with tf.name_scope("placeholders”) : х = tf.placeholder(tf.float32, (N, 1)) у = tf .placeholder (tf. float32, (NJ)
»> x
<tf.Tensor 'placeholders/Placeholder:0' shape=(5, 1) dtype=float32>
Оптимизаторы
Примитивы, представленные в последних двух разделах, уже намекают на то, как машинное самообучение выполняется в TensorFlow. Вы узнали, как добавлять заполнители для точек данных и меток и как использовать тензорные операции для
Линейная и логистическая регрессия с помощью TensorFlow | 77
определения функции потери. Недостающая часть заключается в том, что вы все еще не знаете, как выполнять градиентный спуск в TensorFlow.
Хотя на самом деле можно определить оптимизационные алгоритмы, такие как градиентный спуск, непосредственно на Python, используя для этого примитивы TensorFlow, библиотека TensorFlow предоставляет коллекцию оптимизационных алгоритмов в модуле tf.train. Эти алгоритмы могут быть добавлены в качестве узлов в вычислительный граф TensorFlow.
Какой оптимизатор я должен использовать?
В tf.train имеется большое число возможных оптимизаторов. В качест-ве краткого предварительного просмотра этот список включает v’Д' w tf.train.GradientDescentOptimizer, tf.train.Momentumoptimizer, tf.train.
AdagradOptimizer, tf.train.AdamOptimizer И многие другие. В чем разница между этими оптимизаторами?
Почти все эти оптимизаторы основаны на идее градиентного спуска. Вспомните простое правило градиентного спуска, которое мы ввели ранее:
В математическом смысле это правило обновления примитивно. Существует целый ряд остроумных математических приемов, обнаруженных исследователями, которые позволяют выполнять оптимизацию быстрее без интенсивного использования избыточных вычислений. В общем случае, хорошим вариантом по умолчанию является оптимизатор tf.train.AdamOptimizer, который относительно надежен. (Многие методы в оптимизаторах очень чувствительны к выбору гиперпараметров. Начинающим специалистам лучше избегать заковыристых методов, пока они в достаточной мере не разберутся в поведении различных оптимизационных алгоритмов.)
В примере 3.7 приведен короткий фрагмент кода, в котором в вычислительный граф добавляется оптимизатор, минимизирующий предопределенную потерю 1.
Пример 3.7. Добавление оптимизатора AdamOptimizer в вычислительный граф TensorFlow
learning_rate = .001
with tf.name_scope("optim"):
train_op = tf.train.AdamOptimizer(learning_rate).minimize(1)
Взятие градиентов с помощью TensorFlow
Ранее мы упоминали, что в TensorFlow можно напрямую реализовывать алгоритмы градиентного спуска. В то время как в большинстве вариантов использования переопределять содержимое модуля tf.train не нужно, может оказаться полезным взглянуть на значения градиента непосредственно для целей отладки. Функция tf .gradients о предоставляет для этого полезный инструмент (пример 3.8).
78 | Гпава 3
Пример 3.8. Прямое взятие градиентов
»> W = tf .Variable ((3,))
»> 1 = tf. reduce_sum (W)
»> gradW = tf .gradients (1, W)
»> gradW
[<tf.Tensor 'gradients/Sum_grad/Tile:O’ shape=(l,) dtype=int32>]
Этот фрагмент кода символически стягивает градиенты потери 1 относительно заучиваемого параметра (tf.variable) w. Функция tf.gradientsо возвращает список желаемых градиентов. Обратите внимание, что градиенты как таковые являются тензорами! TensorFlow выполняет символическое дифференцирование, и это означает, что сами градиенты являются частями вычислительного графа. Один изящный побочный эффект символических градиентов TensorFlow заключается в том, что в TensorFlow имеется возможность укладывать производные в ярусы. Иногда это может быть полезно для более продвинутых алгоритмов3.
Сводки и пишущие объекты для TensorBoard
Получение визуального понимания структуры тензорной программы может быть очень полезным. Для этого команда разработчиков TensorFlow предоставляет пакет TensorBoard. TensorBoard запускает веб-сервер (по умолчанию на localhost), который показывает различные полезные визуализации программы TensorFlow. Однако для того чтобы программы TensorFlow проверялись с помощью TensorBoard, программисты должны вручную писать инструкции журналирования. Метод tf. train. Filewriter о задает каталог журналов для программы TensorBoard, а функция tf .summaryо записывает сводки о различных переменных TensorFlow в заданный каталог журналов. В этой главе мы будем использовать только функцию tf .summary.scalar о, которая резюмирует скалярную величину, чтобы отслеживать значение функции потери. Модуль tf содержит функцию tf.summary.merge aiiо, являющуюся полезным средством ведения журнала, которая для удобства объединяет несколько сводок в одну.
Фрагмент кода в примере 3.9 добавляет сводку о потере и задает каталог журналов.
РПример 3.9. Добавление сводного отчета для функции потери
with tf.name_scope ("summaries”) : tf.summary.scalar("loss", 1) merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter('/tmp/lr-train’, tf.get_default_graph())
3 Например, когда имеется две функции. В этом случае градиентные векторы организуют в матрицу, уложив градиенты один над другим. Когда это делается, получается матрица Якоби. См. http://parrt cs.usfca.edu/doc/matrix-calculus/index.html. — Прим. пер.
Линейная и логистическая регрессия с помощью TensorFlow | 79
Тренировка моделей с помощью TensorFlow
Предположим, что мы определили заполнители для точек данных и меток и опре-делили потерю с помощью тензорных операций. Мы добавили в вычислительный граф узел оптимизатора train op, который можно использовать для выполнения шагов градиентного спуска (несмотря на то, что мы можем использовать другой оптимизатор, для удобства мы будем ссылаться на обновления как градиентный спуск). Каким образом можно итеративно выполнять градиентный спуск, чтобы обучиться на этом наборе данных?
Самый простой ответ— использовать цикл Python for. В каждой итерации мы применяем метод sess. run о, чтобы из вычислительного графа извлечь тренировочную операцию train op вместе с объединенной сводкой merged и потерей 1. Мы передаем все точки данных и метки в метод sess. run о, используя словарь передачи данных.
Фрагмент кода в примере 3.10 демонстрирует этот простой метод самообучения. Обратите внимание, что ради педагогической простоты мини-пакеты мы не применяем. В программном коде последующих глав мини-пакеты будут использоваться во время тренировки на больших наборах данных.
Гпример 3.10. Простой пример тренировки модели
n_steps = 1000
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Натренировать модель
for i in range(n_steps):
feed_dict = {x: x_np, y: y_np}
summary, loss = sess.run([train_op, merged, 1], feed_dict=feed_diet) print("шаг %d, потеря: %f" % (i, loss)) train_writer.add_summary(summary, i)
Тренировка линейной и логистической моделей в TensorFlow
Этот раздел связывает все концепции TensorFlow, представленные в предыдущем разделе, для тренировки линейных и логистических регрессионных моделей на игрушечных наборах данных, которые мы ввели ранее в этой главе.
Линейная регрессия в TensorFlow
В этом разделе мы предоставим программный код для определения линейной регрессионной модели в TensorFlow и обучимся ее весам. Эта задача проста, и вы можете сделать это легко без TensorFlow. Вместе с тем это хорошее упражнение по работе с библиотекой TensorFlow, поскольку оно сведет вместе новые понятия, с которыми мы вас знакомили на протяжении всей главы.
80 | Гпава 3
Определение и тренировка линейной регрессии в TensorFlow
Модель для линейной регрессии простая: у = wx + b.
Здесь w и b — это веса, которым мы хотим обучиться. Мы преобразуем эти веса в объекты tf.variable. Затем мы используем тензорные операции, чтобы сконструировать £2-потерю:
£(x,y) = (y-wx-b)2.
Программный код в примере 3.11 реализует эти математические операции в TensorFlow. Он также использует функцию tf.name scopeo для группировки различных операций и добавляет функцию tf.train.AdamOptimizer о для самообучения и операции tf .summary для использования пакета визуализации TensorBoard.
; Пример 3.11. Определение линейной регрессионной модели
# Сгенерировать граф tensorflow with tf.name_scope("placeholders"):
x = tf.placeholder(tf.float32, (N, 1))
у = tf.placeholder(tf.float32, (N,)) with tf.name_scope("weights"):
# Обратите внимание, что x - это скаляр,
# поэтому W - это одиночный заучиваемый вес.
W = tf .Variable (tf. random__normal ((1, 1)))
b = tf.Variable(tf.random_normal((1,))) with tf.name_scope("prediction"):
yjpred = tf.matmul(x, W) + b with tf .name__scope("loss") :
1 = tf.reduce_sum((y - y_pred)**2)
# Добавить оптимизацию тренировки with tf.name_scope("optim"):
# Задать скорость заучивания .001, как рекомендовано выше.
train_op = tf.train.AdamOptimizer(.001).minimize(1) with tf.name_scope ("summaries") :
tf.summary.scalar("loss", 1) merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter('/tmp/lr-train', tf.get_default_graph())
Далее пример 3.12 тренирует эту модель, как обсуждалось ранее (не используя мини-пакеты).
Линейная и логистическая регрессия с помощью TensorFlow | 81
। Пример 3.12. Тренировка линейной регрессионной модели |
n_steps = 1000
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Натренировать модель
for i in range(n_steps):
feed_dict = {x: x_np, y: y_np}
summary, loss = sess.run([train_op, merged, 1], feed_dict=feed_dict) print (’’шаг %d, потеря: %f’’ % (i, loss)) train_writer.add_summary(summary, i)
Весь программный код этого примера размещен в связанном с книгой хранилище GitHub (https://github.com/matroid/dlwithtf). Мы рекомендуем всем читателям выполнить полный сценарий примера линейной регрессии, чтобы на своем опыте получить представление о том, как функционирует обучающийся алгоритм. Пример мал настолько, что для его выполнения читатели не будут нуждаться в каком-то специализированном вычислительном оборудовании.
Взятие градиентов для линейной регрессии
Уравнение для линейной системы, которую мы моделируем, имеет вид у = wx + Ь , где w, Ь — это заучиваемые веса. Как мы упоминали ранее, потеря для этой системы имеет вид £ = (у - юх - Ь)2. Несколько операций матричного исчисления могут быть использованы для вычисления градиентов заучиваемых параметров непосредственно для w:
Vw = = -2 (у - юх - Ь)хг
дю
и для Ь\
УЬ =
дС дЬ
= -2(у- юх-Ь).
Мы помещаем эти уравнения здесь только в качестве справки для любопытных читателей. Мы не будем пытаться систематически обучать методам взятия производных функций потерь, с которыми мы сталкиваемся в этой книге. Однако отметим, что в случае со сложными системами взятие производной функции потери вручную помогает развить интуитивное понимание того, как глубокая сеть обучается. Это интуитивное понимание может послужить мощным ориентиром для проектировщика, поэтому мы призываем продвинутых читателей продолжить изучение этой темы самостоятельно.
82 | Гпава 3
Визуализация линейных регрессионных моделей с помощью TensorBoard
Модель, определенная в предыдущем разделе, использует пишущий объект tf.summary.Filewriter для записи журналов в каталог журналов /tmp/lr-train. Мы можем вызвать TensorBoard в этом каталоге журналов с помощью команды из примера 3.13. (Локальный веб-сервер TensorBoard устанавливается по умолчанию вместе с TensorFlow.)
1~ Пример 3.13. Запуск веб-сервера TensorBoard
tensorboard —logdir=/tmp/lr-train
Эта команда запустит веб-сервер TensorBoard на порте, закрепленном за localhost. Откройте этот порт в браузере. Экран TensorBoard будет выглядеть примерно так, как на рис. 3.8. (Точный внешний вид может меняться в зависимости от вашей версии TensorBoard.)
Перейдите во вкладку Graphs (Графы), и вы увидите визуализацию архитектуры TensorFlow, которую мы определили (рис. 3.9).
TensorBoard scalaps
Write a regex to create a tag group X summaries
□ Split on underscores
Q Data download links Tooltip sorting method: default *
Smoothing -------------------------— 06
Horizontal Axis RELATIVE WALL
Runs
Write a regex to filter runs
B®
Рис. 3.8. Снимок экрана панели TensorBoard
Линейная и логистическая регрессия с помощью TensorFlow | 83
placeholders j weights
Рис. 3.9. Визуализация архитектуры линейной регрессии в TensorBoard (optim — оптимизация, loss — потеря; prediction — предсказание; placeholders — заполнители; weights — веса)
Обратите внимание, что эта визуализация сгруппировала все элементы вычислительного графа, принадлежащие различным областям имен tf.name scopes. Различные группы связаны в вычислительном графе в соответствии с их зависимостями. Все сгруппированные элементы можно развернуть, чтобы просмотреть их содержимое. На рис. 3.10 показана развернутая архитектура.
Как вы видите, имеется много скрытых узлов, которые внезапно становятся видимыми! Функции TensorFlow, такие как tf. train. AdamOptimizer о, ЧВСТО Имеют МНОГО внутренних переменных в собственной области имен tf .name scope. Разворачивание элементов графа в TensorBoard обеспечивает простой способ заглянуть под капот, чтобы увидеть, что именно система создает в действительности. Хотя визуализация выглядит довольно сложной, подавляющая часть этих деталей находится за кадром, и вам пока не о чем беспокоиться.
Вернитесь во вкладку Ноте (Главная) и откройте раздел Summaries (Сводки). Теперь вы должны увидеть кривую потери, которая выглядит примерно так, как показано на рис. 3.11. Обратите внимание на плавную падающую форму кривой. В начале потеря падает быстро, когда происходит заучивание априорной информации, а затем убывает и стабилизируется.
Визуальные и невизуальные стили отладки
Нужно ли применять такой инструмент, как TensorBoard, чтобы сполна воспользоваться возможностями системы TensorFlow? Все зависит от обстоятельств. Нужно ли использовать графический интерфейс пользователя (GUI) или интерактивный отладчик, чтобы стать профессиональным программистом?
84 | Гпава 3
Рис. 3.10. Развернутая визуализация архитектуры
Линейная и логистическая регрессия с помощью TensorFlow | 65
Разные программисты применяют различные стили. Некоторые найдут, что возможности визуализации TensorBoard — это критическая составная часть их схемы работы по тензорному программированию. Другие посчитают, что TensorBoard не очень полезен, и будут более широко использовать отладку на основе инструкций print. Оба стиля тензорного программирования и отладки допустимы, так же как есть замечательные программисты, которые слепо верят отладчикам, и те, которые их ненавидят.
В целом пакет TensorBoard очень полезен для отладки и развития базового интуитивного понимания относительно текущего набора данных. Мы рекомендуем вам следовать стилю, который лучше всего подходит для вас.
TensorBoard
SCALARS IMAGES AUDIO
Write a regex to create a tag group X
0 Split on underscores
Q] Data download links Tooltip sorting method: default
Smoothing -------------------------------0 6
Horizontal Axis
RELATIVE WALL
STEP
summaries
summaries/loss
2.600e+5
2 200e+5
1.800e+5
1.400e+5
1.000e+5
6.000e+4
2.000e+4
0.000 3.000k 6.000k
Runs
Write a regex to filter runs
B®
Рис. 3.11. Просмотр кривой потери в TensorBoard
Метрические показатели для оценивания регрессионных моделей
До этого момента мы не обсуждали, как оценивать, действительно ли натренированная модель чему-то обучилась. Первый подход оценивания того, была ли модель натренирована, — это обратиться к кривой потери, чтобы убедиться, что она имеет разумную форму. Вы узнали, как это делается в предыдущем разделе. Что еще попробовать?
Теперь мы хотим, чтобы вы обратились к метрическим показателям, имеющим отношение к модели. Метрический показатель, или метрика, — это инструмент для сравнения предсказанных меток с истинными метками. Для регрессионных задач существует два общепринятых метрических показателя: R2 и RMSE (root mean
86 | Гnaea 3
squared error, среднеквадратическая ошибка). R2 (Я-квадрат) — это мера корреляции между двумя переменными, которая принимает значения от +1 до 0. +1 указывает на идеальную корреляцию, а 0 — на отсутствие корреляции. Математически R2 для двух наборов данных / и У определяется как
где cov(Jf, У) — это ковариация Хи У, мера того, каким образом два набора данных варьируются совместно; и aY — это стандартные отклонения, меры того, насколько каждый набор варьируется индивидуально. В интуитивном плане R2 измеряет, насколько независимая вариация в каждом наборе может быть объяснена их совместной вариацией.
Ш Несколько типов R2!
На практике широко используются два определения R2. Распространенная ошибка среди начинающих специалистов (а также экспертов) состоит в том, что их часто путают. В этой книге мы всегда будем использовать квадратичный коэффициент корреляции Пирсона (рис. 3.12). Другое определение называется коэффициентом детерминации. Этот другой показатель R2 часто гораздо запутаннее, поскольку не имеет нижней границы 0, как у квадратичной корреляции Пирсона.
На рис. 3.12 предсказанные и истинные значения сильно коррелируют с R2, равным почти 1. Похоже, что в этой системе процесс самообучения проделал замеча-
Предсказанные значения против истинных (Пирсон R2: 0,994)
Рис. 3.12. Вывод графика коэффициента корреляции Пирсона
Линейная и логистическая регрессия с помощью TensorFlow | 87
тельную работу и успешно обучился истинному правилу. Но не будем торопиться. Вы заметите, что шкала двух осей на рис. 3.12 не одинаковая! Оказывается, R2 не штрафует за различия в шкале. Для того чтобы понять, что произошло в этой системе, нам нужно рассмотреть альтернативный метрический показатель на рис. 3.13.
Истинная модель против обученной модели (RMS: 1,027620)
Рис. 3.13. Вывод графика среднеквадратической ошибки (RMSE)
RMSE является мерой усредненной разницы между предсказанными значениями и истинными значениями. На рис. 3.13 мы строим предсказанные значения и истинные метки как две отдельные функции, используя точки данных X в качестве нашей оси х. Обратите внимание, что заученная прямая не является истинной функцией! RMSE расположен относительно высоко и диагностирует ошибку, в отличие от R2, который не подхватил эту ошибку.
Что же случилось в этой системе? Почему библиотека TensorFlow не обучилась правильной функции, несмотря на то, что была натренирована вплоть до схождения? Этот пример хорошо иллюстрирует один из недостатков алгоритмов градиентного спуска. Они не дают никакой гарантии, что верное решение будет найдено! Алгоритм градиентного спуска может застрять в локальном минимуме. То есть он может найти решения, которые выглядят хорошо, но на самом деле не являются самым низким минимумом функции потери С.
Зачем тогда использовать градиентный спуск? Для простых систем действительно часто лучше избегать градиентного спуска и использовать другие алгоритмы, которые имеют более высокие гарантии результативности. Однако в сложных системах, таких как те, что мы покажем вам в последующих главах, еще не существует альтернативных алгоритмов, которые работают лучше градиентного спуска. Мы призываем вас помнить об этом факте, когда будем еще больше погружаться в глубокое самообучение.
88 | Гпава 3
Логистическая регрессия в TensorFlow
В этом разделе мы определим простой классификатор, используя TensorFlow. Сначала стоит рассмотреть, что собой представляет уравнение для классификатора. Общепринятый математический прием — задействовать сигмоидальную функцию, или сигмоиду. Сигмоида, изображенная на рис. 3.14, которую общепринято обозначать с, является отображением вещественных чисел R в (0, 1). Это свойство удобно тем, что мы можем интерпретировать выход из сигмоиды как вероятность события. (Остроумный прием конвертирования дискретных событий в непрерывные значения является сквозной темой в машинном самообучении.)
Рис. 3.14. Нанесение сигмоидальной функции
Уравнения для предсказания вероятностей дискретной переменной, принимающей значение 0 или 1, представлены далее. Эти уравнения определяют простую логистическую регрессионную модель:
^O=o(wx + Z>); yl = l-c(wx + Z>).
TensorFlow предоставляет сервисные функции для вычисления перекрестноэнтропийных потерь для сигмоидальных значений. Простейшей из этих функций является tf .пп.sigmoid_cross_entropy_with_iogits(). (Математическая операция взятия логарифма (log) обратна сигмоиде. На практике это просто означает передачу аргумента wx + b сигмоиды непосредственно в TensorFlow вместо самого сигмоидального значения с (их + Ь).) Мы рекомендуем вместо ручного определения перекрестной энтропии использовать реализацию TensorFlow, поскольку при вычислении перекрестно-энтропийной потери возникают числовые проблемы.
В примере 3.14 определена простая логистическая регрессионная модель в TensorFlow.
Пример 3.14. Определение простой логистической регрессионной модели ।
# Сгенерировать граф tensorflow with tf.name_scope("placeholders"):
# Обратите внимание, что точки данных х - двумерные х = tf.placeholder(tf.float32, (N, 2))
у = tf.placeholder(tf.float32, (N,))
Линейная и логистическая регрессия с помощью TensorFlow | 89
with tf.name_scope("weights"):
W = tf.Variable(tf.random_normal((2, 1)))
b = tf.Variable(tf.random_normal((1,))) with tf.name_scope("prediction"):
y_logit = tf.squeeze(tf.matmul(x, W) + b)
# Сигмоида дает вероятность класса 1 y_one_prob = tf.sigmoid(y_logit)
# Округление P(y=l) даст правильное предсказание y_pred = tf.round(y_one_prob)
with tf.name_scope("loss"):
# Вычислить перекрестно-энтропийный член для каждой точки данных entropy = tf.nn.sigmoid_cross_entropy_with_logits(logits=y_logit, labels=y)
# Суммировать все вклады
1 = tf.reduce_sum(entropy)
with tf.name_scope("optim"):
train_op = tf. train. AdamOptimizer (. 01) .minimize (1)
train_writer = tf.summary.FileWriter('/tmp/logistic-train', tf.get_default_graph())
Тренировочный программный код для этой модели в примере 3.15 идентичен коду для линейной регрессионной модели.
j Пример 3.15. Тренировка логистической регрессионной модели
n_steps = 1000
with tf.Session() as sess:
sess.run(tf.global—VariableS—initializer())
# Натренировать модель for i in range(n_steps): feed_dict = {x: x_np, y: y_np} _, summary, loss = sess.run([train_op, merged, 1], feed_dict=feed_diet) print("потеря: %f" % loss) train_writer. add_summary (summary, i)
Визуализация логистических регрессионных моделей с помощью TensorBoard
Как и прежде, для визуализации модели можно использовать TensorBoard. Начните с визуализации функции потери (рис. 3.15). Обратите внимание, что, как и раньше, функция потери следует четкому шаблону. Происходит резкое падение потери с последующим постепенным сглаживанием.
Вы также можете просмотреть граф TensorFlow в TensorBoard. Поскольку структура областей имен аналогична структуре, используемой для линейной регрессии, упрощенный граф выглядит почти идентичным (рис. 3.16).
90 | Гпава 3
TensorBoard
SCALARS IMAGES AUDIO
Write a regex to create a tag group X
Q Split on underscores
QJ Data download links Tooltip sorting method: default
Smoothing -------------------.. 0 6
summaries
Horizontal Axis
Runs
Write a regex to filter runs
Рис. 3.15. Визуализация функции потери логистической регрессии
Рис. 3.16. Визуализация вычислительного графа для логистической регрессии (optim — оптимизация, loss — потеря; prediction — предсказание; placeholders — заполнители; weights — веса)
Линейная и логистическая регрессия с помощью TensorFlow | 91
Рис. 3.17. Развернутый вычислительный граф для логистической регрессии
92 | Гпава 3
Однако если вы развернете узлы в этом сгруппированном графе, то обнаружите, что лежащий в основе вычислительный граф иной (рис. 3.17). В частности, функция потери сильно отличается от функции, используемой для линейной регрессии (как и должно быть).
Метрические показатели для оценивания классификационных моделей
Теперь, когда вы натренировали классификационную модель для логистической регрессии, вам нужно познакомиться с метрическими показателями, подходящими для оценивания классификационных моделей. Хотя уравнения для логистической регрессии сложнее, чем для линейной регрессии, основные метрические показатели оценки проще. Точность классификации просто проверяет долю точек данных, которые классифицируются заученной моделью правильно. На самом деле, приложив немного больше усилий, из уравнений логистической регрессии можно вывести разделительную линию, заученную моделью логистической регрессии. Эта линия отображает границу отсечения, которой модель обучилась, чтобы разделять положительные и отрицательные прецеденты. (Мы оставляем выведение этой линии из уравнений в качестве упражнения для заинтересованного читателя. Решение находится в программном коде для этого раздела.)
Мы показываем заученные классы и разделительную линию на рис. 3.18. Обратите внимание, что линия четко разделяет положительные и отрицательные примеры и имеет идеальную точность (1,0). Этот результат затрагивает интересный момент. Регрессия часто является более сложной задачей, чем классификация. Существует много возможных линий, которые четко отделяют точки данных на рис. 3.18, и только одна, которая идеально соответствует данным для линейной регрессии.
Рис. 3.18. Просмотр заученных классов и разделяющей линии для логистической регрессии
Линейная и логистическая регрессия с помощью TensorFlow | 93
Резюме
В этой главе мы показали вам, как построить и натренировать несколько простых обучающихся систем в TensorFlow. Мы начали с рассмотрения некоторых фундаментальных математических понятий, в том числе функции потери и градиентного спуска. Затем мы познакомили вас с несколькими новыми понятиями TensorFlow, такими как заполнители, области имен и пакет визуализации TensorBoard. Мы закончили главу практическими примерами, которые выполнили тренировку линейной и логистической регрессионных систем на игрушечных наборах данных. В этой главе мы рассмотрели довольно много материала, и вполне нормально, если вы пока еще не все усвоили. Основной материал, представленный здесь, будет использоваться на протяжении оставшейся части этой книги.
В главе 4 мы познакомим вас с вашей первой глубоко обучающейся моделью и полносвязными сетями, а также покажем, как определять и тренировать полносвязные сети в TensorFlow. В последующих главах мы рассмотрим более сложные глубокие сети, но все эти архитектуры будут использовать те же самые фундаментальные принципы самообучения, что и в этой главе.
94 | Гпава 3
ГЛАВА 4
Полносвязные глубокие сети
Эта глава познакомит вас с полносвязными глубокими сетями — рабочими лошадками глубокого самообучения, используемыми в тысячах приложений. Основное преимущество полносвязных сетей заключается в том, что они являются ’’структурно агностическими”, т. е. нам не нужно делать никаких специальных допущений о природе входных данных (например, что входные данные состоят из изображений или видео). Мы будем использовать эту универсальность полносвязных глубоких сетей с целью их применения для решения задачи химического моделирования далее в этой главе.
Мы кратко углубимся в математическую теорию, лежащую в основе полносвязных сетей. В частности, мы займемся исследованием идеи, что полносвязные архитектуры являются ’’универсальными аппроксиматорами”, способными обучаться любой функции. Эта идея объясняет универсальность полносвязной архитектуры, но со многими оговорками, которые мы обсудим.
Хотя структурно агностический характер полносвязных сетей позволяет весьма широко их применять на практике, такие сети, как правило, имеют более низкую результативность, чем сети специального назначения, настроенные на структуру предметного пространства. Мы обсудим некоторые ограничения полносвязных архитектур далее в этой главе.
Что такое полносвязная глубокая сеть?
Полносвязная нейронная сеть состоит из серии полносвязных слоев. Полносвязный слой — это отображение из пространства R7” в пространство R". Каждая выходная размерность зависит от каждой входной размерности. В наглядном виде полносвязный слой представляется так, как показано на рис. 4.1.
Давайте немного углубимся в математическую форму полносвязной сети. Пусть х е представляет входные данные для полносвязного слоя, а € R есть z-й выход из полносвязного слоя. Тогда ух g R вычисляется следующим образом:
У1 = n(w1x,+...+ wmxm),
где а — нелинейная функция (пока рассматривайте а как сигмоидальную функцию, введенную в предыдущей главе); — заучиваемые параметры в сети. Полный выход у тогда имеет вид:
95
<т(м'11Х + ... + W. X ) у ill im m j
<т(м',Х + ... + M' X„) у Л1 1 nm m /
Обратите внимание, что имеется возможность укладывать полносвязные сети в ярусы. Сеть с многочисленными полносвязными сетями нередко называется глубокой сетью (рис. 4.2).
Рис. 4.1. Полносвязный слой в глубокой сети
Рис. 4.2. Многослойная глубокая полносвязная сеть
96 | Гпава 4
В качестве краткого примечания к реализации обратите внимание, что уравнение для одного нейрона очень похоже на скалярное произведение двух векторов (вспомните обсуждение основ тензоров). В случае слоя нейронов часто удобно для целей эффективности вычислять у, используя матричное умножение:
у = <r(Wx),
где а — это матрица в пространстве R"xm, и нелинейное преобразование о применяется покомпонентно.
"Нейроны" в полносвязных сетях
Узлы полносвязной сети обычно называются "нейронами". Вследствие этого во всех публикациях полносвязные сети, как правило, принято называть "нейронными сетями". Эта терминология в значительной степени является исторической случайностью.
В 1940-х годах Уоррен С. Мак-Каллок (Warren S. McCulloch) и Уолтер Питтс (Walter Pitts) опубликовали первую математическую модель мозга. В своей работе они утверждали, что нейроны способны вычислять произвольные функции на булевых величинах. Продолжатели этой работы немного усовершенствовали данную логическую модель, сделав математические "нейроны" непрерывными функциями, которые варьировались от нуля до единицы. Если входы этих функций становились достаточно крупными, то нейрон "возбуждался" (принимал значение 1), а в остальных случаях он находился в состоянии покоя. С добавлением адаптируемых весов это описание совпадает с приведенными выше уравнениями.
Разве не так себя ведет настоящий нейрон? Конечно, нет! Реальный нейрон (рис. 4.3) представляет собой чрезвычайно сложный механизм с более чем 100 триллионами атомов и десятками тысяч различных сигнальных белков, способных реагировать на разные сигналы. Микропроцессор является наилучшей аналогией нейрона, чем однострочное уравнение.
Во многих отношениях расхождение между биологическими и искусственными нейронами весьма прискорбно. Непосвященные эксперты читают захватывающие дух пресс-релизы, утверждающие, что были созданы искусственные нейронные сети с миллиардами "нейронов" (в то время как мозг имеет всего 100 млрд биологических нейронов), и думают, что ученые близки к созданию интеллекта на уровне человека. Не приходится и говорить, что современное состояние глубокого самообучения находится на расстоянии десятилетий (если не столетий) от такого достижения.
Погружаясь в чтение о глубоком самообучении, вы можете столкнуться с крикливыми заявлениями об искусственном интеллекте. Не бойтесь опровергать их. Глубокое самообучение в его текущей форме представляет собой набор методов для решения задач исчисления на быстром оборудовании. Это не предшественник Терминатора (рис. 4.4).
Полносвязные глубокие сети | 97
Рис. 4.3. Более биологически точное представление нейрона
Рис. 4.4. К сожалению (или, вполне возможно, к счастью), эта книга не научит вас конструировать Терминатора!
Зимы искусственного интеллекта
Искусственный интеллект (ИИ) прошел через несколько этапов бума и спада в развитии. Такое циклическое развитие характерно для этой области. Каждое новое продвижение в машинном самообучении порождает волну оптимизма, на гребне которой пророки заявляют, что зарождается человекоподобный (или сверхчеловеческий) интеллект. Через пару лет такой интеллект никак себя не проявляет, и разочарованные спонсоры удаляются. Получаемый в результате период называется зимой искусственного интеллекта.
98 | Гпава 4
До настоящего времени было несколько зим искусственного интеллекта. В качестве мысленного упражнения мы рекомендуем вам подумать, когда произойдет следующая такая зима. Нынешняя волна прогресса в глубоком самообучении позволила решить гораздо больше практических задач, чем любая предыдущая волна достижений. Возможно ли, что искусственный интеллект, наконец, поднялся и вышел из цикла бума и спада, или вы думаете, что мы скоро окажемся в "Великой депрессии" ИИ?
Обучающиеся полносвязные сети с обратным распространением
Первой версией полносвязной нейронной сети был перцептрон (рис. 4.5), созданный Фрэнком Розенблаттом (Frank Rosenblatt) в 1950-х годах. Перцептроны идентичны "нейронам", с которыми мы познакомились в предыдущих уравнениях.
Входные Выходные сигналы сигналы
Рис. 4.5. Схематическое представление перцептрона
Перцептроны тренировались на основе специального "правила перцептрона". Несмотря на то что перцептроны были умеренно полезны для решения простых задач, они были принципиально ограничены. Книга "Перцептроны"1 Марвина Мински и Сеймура Пейперта конца 1960-х годов доказала, что простые перцептроны не способны обучиться функции xor. На рис. 4.6 представлено доказательство этого утверждения.
Проблема была преодолена с помощью изобретения многослойного перцептрона (еще одно название глубокой полносвязной сети). Это изобретение было огромным достижением, поскольку ранее простые обучающиеся алгоритмы не позволяли глубоким сетям обучаться эффективно. Проблема "передачи ответственности" ставила их в тупик; каким образом алгоритм решает, какой нейрон обучился и чему он обучился?
1 Minsky М., Papert S. Perceptrons. An Introduction to Computational Geometry. — M.I.T. Press, Cambridge, Mass., 1969. — 258 pp.
Полносвязные глубокие сети | 99
Рис. 4.6. Линейное правило перцептрона не может обучиться функции XOR
Полное решение этой проблемы требует применения обратного распространения. Обратное распространение — это обобщенное правило для заучивания весов нейронных сетей. К сожалению, сложные объяснения метода обратного распространения в публикациях сродни настоящей эпидемии. Эта ситуация вызывает сожаление, поскольку обратное распространение — это просто еще одно обозначение автоматической дифференциации.
Давайте предположим, что f (0, х) — это функция, представляющая собой глубокую полносвязную сеть. Здесь х — это входы в полносвязную сеть, а 0 — заучиваемые веса. Тогда алгоритм обратного распространения просто вычисляет 5/750. Практические сложности возникают при реализации обратного распространения для всех возможных функций/ которые возникают на практике. К счастью для нас, библиотека TensorFlow уже об этом позаботилась!
Теорема об универсальной сходимости
Предыдущее обсуждение затронуло идеи о том, что глубокие полносвязные сети являются мощными аппроксимациями. Мак-Каллок и Питтс показали, что логические сети могут кодировать (почти) любую булеву функцию. Перцептрон Розенблатта являлся непрерывным аналогом логических функций Мак-Каллока и Питтса, но был фундаментально ограничен, и этот факт доказан Мински и Пейпертом. Многослойные перцептроны пытались разрешить ограниченность простых перцептронов и эмпирически казались способными обучаться сложным функциям. Однако теоретически не было ясно, имеет ли эта эмпирическая способность какие-то нераскрытые ограничения. В 1989 г. американский ученый Джордж Цыбенко продемонстрировал, что многослойные перцептроны способны представлять произвольные функции. Эта демонстрация придала веское обоснование утверждениям об универсальности полносвязных сетей как обучающейся архитектуры, частично объяснив их сохраняющуюся популярность.
Вместе с тем, если в конце 1980-х годов были поняты и теория обратного распространения, и теория полносвязных сетей, почему тогда ’’глубокое” самообучение не стало популярным еще тогда? Значительная часть этой неспособности была вызвана вычислительными ограничениями; тренировка полносвязных сетей занимала
100 | Глава 4
непомерный объем вычислительной мощности. Кроме того, глубокие сети было очень сложно тренировать из-за отсутствия понимания того, какие гиперпараметры являются наиболее подходящими. Поэтому большую популярность получили альтернативные обучающиеся алгоритмы, такие как машины опорных векторов (SVM), которые имели более низкие вычислительные потребности. Недавний всплеск популярности глубокого самообучения частично объясняется повышением доступности более производительного вычислительного оборудования, позволяющего выполнять вычисления быстрее, и частично благодаря применению хороших схем тренировки, обеспечивающих стабильное самообучение.
Неужели универсальная аппроксимация настолько удивительна?
Свойства универсальной аппроксимации встречаются в математике чаще, чем можно было бы ожидать. Например, теорема Вейерштрасса — Стоуна доказывает, что любая непрерывная функция на замкнутом интервале может быть приближена многочленной функцией. Если ослабить наши критерии далее, можно использовать ряды Тейлора и ряды Фурье, предлагающие некоторые возможности универсальной аппроксимации (в пределах их областей схождения). Тот факт, что универсальная сходимость — довольно обычное явление в математике, дает частичное обоснование эмпирического наблюдения, что существует много малых вариантов полносвязных сетей, которые, судя по всему, дают свойство универсальной аппроксимации.
Универсальная аппроксимация не означает универсальное самообучение!
В теореме об универсальной аппроксимации существует критическая тонкость. Тот факт, что полносвязная сеть может представлять любую функцию, не означает, что обратное распространение может обучиться любой функции! Одним из основных ограничений обратного распространения является то, что нет никакой гарантии ’’сходимости” полносвязной сети, т. е. отыскания наилучшего доступного решения задачи самообучения. Когда речь шла о нейронных сетях, этот критический теоретический разрыв вызывал настоящую тошноту у целых поколений специалистов в области информатики. Даже сегодня многие ученые предпочитают работать с альтернативными алгоритмами, которые дают более сильные теоретические гарантии.
Эмпирические исследования дали много практических приемов, которые позволяют обратному распространению находить хорошие решения задач. Мы подробно рассмотрим многие из этих приемов в оставшейся части главы. Для практикующего аналитика данных теорема об универсальной аппроксимации не является чем-то слишком серьезным. Она обнадеживает, но искусство глубокого самообучения заключается в освоении практических приемов, которые заставляют самообучение работать.
Полносвязные глубокие сети | 101
Почему именно глубокие сети?
Тонкость в теореме об универсальной аппроксимации заключается в том, что она на самом деле справедлива для полносвязных сетей только с одним полносвязным слоем. Какой тогда смысл в использовании ’’глубокого” самообучения с многочисленными полносвязными слоями? Оказывается, в академических и практических кругах этот вопрос до сих пор остается достаточно спорным.
На практике, судя по всему, более глубокие сети могут иногда обучаться более сложным моделям на больших наборах данных. (Правда, это только эмпирическое правило; у каждого практикующего специалиста есть множество примеров, когда глубокие полносвязные сети справляются не очень хорошо.) Это наблюдение заставило исследователей строить гипотезы, что более глубокие сети могут представлять сложные функции ’’эффективнее”, т. е. более глубокая сеть способна обучиться более сложным функциям, чем более мелкие сети с таким же количеством нейронов. Например, архитектура ResNet, кратко упомянутая в главе 7, со 130 слоями, судя по всему, превосходит своих более мелких конкурентов, таких как AlexNet. В общем случае, при фиксированном бюджете нейронов более глубокая ярусная укладка приводит к лучшим результатам.
В публикациях приводится ряд ошибочных ’’доказательств” этого ’’факта”, но все они имеют уязвимости. Судя по всему, вопрос глубины в сопоставлении с шириной затрагивает фундаментальные концепции теории сложности (которая изучает минимальное количество ресурсов, необходимых для решения конкретных вычислительных задач). В настоящее время похоже, что теоретическое доказательство (или опровержение) превосходства глубоких сетей лежит далеко за пределами возможностей наших математиков.
Тренировка полносвязных нейронных сетей
Как мы уже упоминали ранее, теория полносвязных сетей не соответствует практике. В этом разделе мы познакомим вас с рядом эмпирических наблюдений о полносвязных сетях, которые помогают практикующим специалистам. Мы настоятельно рекомендуем вам использовать наш программный код (представленный далее в этой главе), чтобы самим проверить наши утверждения.
Заучиваемые представления
Одна из точек зрения на полносвязную сеть заключается в том, что каждый полносвязный слой осуществляет преобразование признакового пространства, в котором расположена задача. Идея преобразования представления задачи для придания ей большей податливости очень стара в технике и физике. Отсюда неудивительно, что методы глубокого самообучения иногда называют методами ’’заучивания представлений”2. (Интересный и мало примечательный факт — одна из важнейших конфе
2 Заучивание представлений (representation learning) — набор методов, позволяющий системе автоматически обнаруживать представления, необходимые для обнаружения или классификации признаков
в сырых данных. См. https://en.wikipedia.org/wiki/Feature_lcarning. — Прим. пер.
102 | Глава 4
ренций по глубокому самообучению называется Международной конференцией по заучиванию представлений3.)
Поколения аналитиков использовали преобразования Фурье, Лежандра, Лапласа и др., чтобы свести сложные уравнения и функции к формам, более приближенным для рукописного анализа. Одна из точек зрения на глубоко обучающиеся сети состоит в том, что они осуществляют управляемое данными преобразование, соответствующее решаемой задаче.
Способность выполнять преобразования, характерные для той или иной задачи, может быть чрезвычайно мощной. Стандартные методы преобразования не могли решать задачи анализа изображения или речи, в то время как глубокие сети способны решать эти задачи с относительной легкостью из-за присущей им гибкости заученных ими представлений. Эта гибкость имеет свою цену: преобразования, заученные глубокими архитектурами, как правило, гораздо менее универсальные, чем математические преобразования, такие как преобразование Фурье. Тем не менее, наличие глубоких преобразований в аналитическом инструментарии может быть мощным инструментом решения задач.
Имеется разумный аргумент, что глубокое самообучение— это просто первый метод заучивания представлений, который работает. В будущем вполне могут появиться альтернативные методы, которые вытеснят методы глубокого самообучения.
Активации
Ранее мы ввели нелинейную функцию а в качестве сигмоидальной функции. В то время как сигмоидальная активационная функция является в полносвязных сетях классическим нелинейным преобразованием, в последние годы исследователи обнаружили, что другие активационные блоки, в частности выпрямленная линейная активация (обычно сокращенно ReLU или relu от англ, rectified linear unit) а(х) = max(x, 0) работает лучше, чем сигмоидальный блок. Это эмпирическое наблюдение может быть связано с проблемой исчезающего градиента в глубоких сетях. Для сигмоидальной функции наклон равен нулю почти для всех ее входных значений, поэтому в случае более глубоких сетей градиент будет стремиться к нулю. Для активационной функции ReLU наклон не равен нулю для гораздо большей части входного пространства, что позволяет распространять ненулевые градиенты. На рис. 4.7 представлены сигмоидальные и ReLU-активации.
3 International Conference on Learning Representations (https://iclr.cc/). В кратком обзоре конференции записано следующее: результативность методов машинного самообучения в значительной степени зависит от выбора представления данных (или признаков), к которым они применяются. Быстро развивающаяся область заучивания представлений связана с вопросами о том, каким образом мы лучше всего сможем обучаться значимым и полезным представлениям данных. — Прим. пер.
Полносвязные глубокие сети | 103
Насыщенная
Насыщенная
1 /
Полносвязные сети запоминают
Одним из поразительных аспектов полносвязных сетей является то, что они, как правило, запоминают тренировочные данные полностью при условии, что предоставлено достаточно времени. Поэтому тренировка полносвязной сети до "схождения" на самом деле не является содержательным метрическим показателем. Сеть будет продолжать тренироваться и обучаться до тех пор, пока пользователь готов ждать.
В случае достаточно больших сетей довольно часто потеря на тренировочных данных4 стремится к нулю. Это эмпирическое наблюдение — практический пример возможностей универсальной аппроксимации полносвязных сетей. Вместе с тем обратите внимание, что стремящаяся к нулю потеря на тренировочных данных не означает, что сеть обучилась более мощной модели. Весьма вероятно, что модель начала просто запоминать особенности тренировочного набора, которые не применимы к любым другим точкам данных.
Здесь стоит разобраться, что именно мы подразумеваем под особенностями. Одним из интересных свойств многомерной статистики является то, что при наличии достаточно большого набора данных будет иметься обильное множество паразитных корреляций и шаблонов, которые можно подхватить. На практике полносвязные сети вполне способны находить и использовать эти ложные корреляции. В целях успешного моделирования критически важно контролировать сети и предотвращать их неправильное поведение.
Регуляризация
Регуляризация — это общий статистический термин для математической операции, которая ограничивает запоминание, способствуя самообучению, поддающемуся обобщению. Существует много различных типов регуляризации, и некоторые из них мы рассмотрим в нескольких следующих разделах.
4 Имеется в виду показатель потери на тренировочных данных. — Прим. пер.
104 | Глава 4
Совсем не та регуляризация, которая используется в статистике
Регуляризация имеет долгую историю в статистической литературе, с целыми стопками статей, написанных на эту тему. К сожалению, только часть этого классического анализа переносится на глубокие сети. Линейные модели, широко используемые в статистике, могут вести себя совершенно иначе, чем глубокие сети, и многое из интуитивного опыта, накопленного в той среде, может быть совершенно неправильным для глубоких сетей.
Первое правило для работы с глубокими сетями, в особенности для читателей с предшествующим опытом статистического моделирования, заключается в доверии эмпирическим результатам по сравнению с прошлым интуитивным опытом. Не исходите из того, что прошлые знания о таких методах, как LASSO-регуляризация (Least Absolute Shrinkage and Selection Operator), имеют большое значение для моделирования глубоких архитектур. Наоборот, подготовьте эксперимент, чтобы методично протестировать предложенную вами идею. В следующей главе мы вернемся к этому процессу методического экспериментирования и рассмотрим его подробнее.
Отсев
Отсев, или прореживание, — это форма регуляризации, которая случайным образом сбрасывает какую-то часть узлов, поступающих в полносвязный слой (рис. 4.8). Здесь сбрасывание узла означает, что его вклад в соответствующую активационную функцию равняется 0. Поскольку вклад активации отсутствует, градиенты для обнуленных узлов также падают до нуля.
Рис. 4.8. Отсев случайным образом обнуляет нейроны сети во время тренировки: а — стандартная нейронная сеть; б — после применения отсева. Эмпирически этот метод часто обеспечивает мощную регуляризацию для тренировки сети
Подлежащие отсеву узлы выбираются случайным образом на каждом шаге градиентного спуска. Базовый принцип этой формы регуляризации заключается в том, что сети будут вынуждены избегать "коадаптации". Вкратце мы объясним, что такое коадаптация и как она возникает в нерегуляризуемых глубоких архитектурах.
Полносвязные глубокие сети | 105
Предположим, что один нейрон в глубокой сети обучился полезному представлению. Тогда другие нейроны глубже в сети быстро обучатся информативно зависеть от этого конкретного нейрона. Этот процесс сделает сеть хрупкой, поскольку она будет чрезмерно зависеть от заученных этим нейроном признаков, которые могут представлять собой специфическую особенность набора данных, вместо того чтобы обучиться универсальному правилу.
Отсев предотвращает этот тип коадаптации, потому что больше не будет возможности зависеть от наличия одиночных мощных нейронов (поскольку этот нейрон может случайным образом выпасть во время тренировки). Как результат, другие нейроны будут вынуждены ’’подменить собой выбывшего бойца” и обучиться полезным представлениям. Из этого теоретически следует, что такой процесс должен привести к более прочным заученным моделям.
На практике отсев имеет пару эмпирических эффектов. Во-первых, он не позволяет сети запоминать тренировочные данные; с отсевом потеря на тренировочных данных больше не будет быстро стремиться к 0, даже для очень больших глубоких сетей. Во-вторых, отсев, как правило, немного повышает предсказательную способность модели на новых данных. Этот эффект часто имеет место для широкого спектра наборов данных, отчасти по той причине, что отсев признан мощным изобретением, а не просто простым статистическим приемом.
Следует отметить, что во время выполнения предсказаний отсев должен быть отключен. Если забыть отключить отсев, то это может привести к предсказаниям, намного более шумным и менее полезным, чем они были бы в противном случае. Позже в этой главе мы обсудим, как правильно обращаться с отсевом для тренировки и предсказаний.
Как большие сети избегают переподгонки?
Неожиданным результатом для статистиков с классической подготовкой является то, что глубокие сети обычно могут иметь внутренних степеней свободы больше, чем в тренировочных данных. В классической статистике наличие этих дополнительных степеней свободы сделало бы модель бесполезной, поскольку больше не будет гарантии того, что заученная модель ’’реальна” в классическом смысле.
Тогда каким образом глубокая сеть с миллионами параметров может обучиться содержательным результатам на наборах данных всего из тысяч примеров? Отсев может иметь здесь большое значение и предотвратить грубое запоминание. Но есть также более глубокая необъяснимая тайна, которая заключается в том, что глубокие сети будут стремиться обучаться полезным фактам даже при отсутствии отсева. Эта тенденция может быть следствием некой особенности метода обратного распространения или же самой полносвязной сетевой структуры, которую мы еще не понимаем.
Ранняя остановка
Как уже упоминалось, полносвязные сети, как правило, запоминают все, что перед ними находится. На практике часто бывает полезно отслеживать результативность сети на отложенном ’’контрольном” наборе и останавливать сеть, когда результа
106 | Глава 4
тивность в этом контрольном наборе начинает снижаться. Этот простой метод называется ранней остановкой.
На практике раннюю остановку бывает довольно сложно реализовать. Как вы увидите, кривые потерь для глубоких сетей могут сильно отличаться в ходе нормальной тренировки. Разработка правила, которое отделяет здоровую вариацию от заметной нисходящей тенденции, может потребовать значительных усилий. На практике многие практикующие специалисты просто тренируют модели с различающимся (фиксированным) количеством эпох и выбирают ту модель, которая лучше всего подходит для контрольного набора. На рис. 4.9 показано, как точность на тренировочном и тестовом наборах обычно изменяется по мере прохождения тренировки.
Рис. 4.9. Точность модели на тренировочном и тестовом наборах данных по мере прохождения тренировки
В следующей главе мы более подробно рассмотрим надлежащие методы работы с контрольными наборами.
Регуляризация весов
Классический метод регуляризации, взятый из статистической литературы, штрафует заученные веса, которые становятся большими. Обозначим через £(х, у) функцию потери для конкретной модели и через 0 заучиваемые параметры этой модели. Тогда регуляризованная функция потери определяется в следующем виде:
С(х, у) = £(х, y) + a||0||,
где ||0|| ||0||2—весовой штраф; —настраиваемый параметр. Два распространенных варианта для штрафа — штрафы Z1 и L2
Полносвязные глубокие сети | 107
где ||0||2 и ЦОЦ, обозначают соответственно штрафы Z,1 и Г. Из личного опыта эти штрафы, как правило, менее полезны для глубоких моделей, чем отсев и ранняя остановка. Некоторые практикующие специалисты по-прежнему используют регуляризацию веса, поэтому, безусловно, стоит разобраться в том, как применять эти штрафы при настройке глубоких сетей.
Тренировка полносвязных сетей
Тренировка полносвязной сети требует нескольких приемов, помимо тех, которые вы встречали до сих пор в этой книге. Во-первых, в отличие от предыдущих глав, мы будем тренировать модели на больших наборах данных. С учетом этих наборов данных мы покажем вам, как использовать мини-пакеты для ускорения градиентного спуска. Во-вторых, мы вернемся к теме настройки скоростей заучивания.
Мини-пакетирование
В случае больших наборов данных (которые могут даже не поместиться в оперативной памяти) отсутствует возможность вычислять градиенты на полном наборе данных на каждом шаге. Вместо этого практикующие специалисты часто выбирают небольшой фрагмент данных (обычно 50-500 точек данных) и вычисляют градиент на этих точках данных. Этот небольшой фрагмент данных традиционно называется мини-пакетом.
На практике мини-пакетирование, судя по всему, способствует схождению, поскольку может быть предпринято больше шагов градиентного спуска с тем же количеством вычислений. Правильный размер мини-пакета— это эмпирический вопрос, который нередко решается с помощью гиперпараметрической настройки.
Скорости заучивания
Скорость заучивания определяет степень важности каждого шага градиентного спуска. Установка правильной скорости заучивания может представлять сложность. Многие начинающие специалисты по глубоким сетям устанавливают скорости заучивания неправильно и с удивлением обнаруживают, что их модели не обучаются или начинают возвращать значения NaN (не определено). Эта ситуация значительно улучшилась с развитием таких методов, как ADAM5, которые значительно упрощают выбор скорости заучивания. Однако если модели ничему не обучаются, то стоит заняться тонкой настройкой скорости заучивания.
5 Adam (Adaptive Moment Estimation, метод адаптивной оценки момента градиента) представляет собой обновление оптимизатора RMSProp. В этом оптимизационном алгоритме используются скользящие средние как градиентов, так и вторых моментов градиентов. RMSProp (метод адаптивного скользящего среднего градиентов) — это метод адаптивного самообучения без сжатия скорости заучивания. См. Википедию https://en.wikipedia.Org/wiki/Stochastic_gradient_descent#Adam. — Прим. пер.
108 | Глава 4
Реализация в TensorFlow
В этом разделе мы покажем, как реализовать полносвязную сеть в TensorFlow. Здесь нам не придется вас знакомить со многими новыми примитивами TensorFlow, поскольку мы уже рассмотрели подавляющую часть требующихся основ.
Инсталляция DeepChem
В этом разделе для своих экспериментов вы будете использовать набор инструментальных средств машинного самообучения DeepChem (один из авторов книги был создателем DeepChem). Подробные указания по установке DeepChem можно найти в Интернете (https://deepchem.io), но заметим, что инсталляция дистрибутива Anaconda с помощью инструмента conda, вероятно, будет наиболее удобной.
Набор данных Тох21
Для нашего примера моделирования мы будем использовать химический набор данных. Токсикологи очень заинтересованы в использовании машинного самообучения в целях предсказания, будет ли то или иное химическое соединение токсичным или нет. Эта задача чрезвычайно сложна, т. к. современная наука имеет лишь ограниченное представление о метаболических процессах, происходящих в организме человека. Однако биологи и химики разработали ограниченный набор экспериментов, которые дают показания по токсичности. Если химическое соединение в одном из этих экспериментов ’’попадает в цель”, то оно, вероятно, будет для человека токсичным при внутреннем употреблении. Вместе с тем эти эксперименты нередко являются дорогостоящими, поэтому аналитики данных стремятся построить машинно-обучающиеся модели, которые могут предсказывать результаты этих экспериментов на новых молекулах.
Одна из наиболее важных коллекций токсикологических данных называется Тох21. Она была выпущена Национальными институтами здоровья (NIH) и Агентством по защите окружающей среды (ЕРА), США, в рамках инициативы в области науки о данных и использовалась в качестве набора данных в конкурсе построения модели. Победитель этого конкурса использовал многозадачные полносвязные сети (вариант полносвязных сетей, где каждая сеть предсказывает несколько величин для каждой точки данных). Мы проанализируем один из наборов данных коллекции Тох21. Этот набор данных состоит из 10 тыс. молекул, протестированных на взаимодействие с рецептором андрогена. Конкурсная задача в области науки данных — предсказать, будут ли новые молекулы взаимодействовать с рецептором андрогена.
Обработка этого набора данных может представлять сложность, поэтому мы будем использовать коллекцию наборов данных MoleculeNet, курируемую в рамках проекта DeepChem. Каждая молекула в Тох21 переработана проектом DeepChem в бит-вектор длиной 1024. Загрузка набора данных, таким образом, представляет собой несколько простых обращений в DeepChem (пример 4.1).
Полносвязные глубокие сети | 109
Пример 4.1. Загрузка набора данных Тох21
import deepchem as de
(train, valid, test), _ = dc.molnet.Ioad_tox21() train_X, train_y, train_w = train.X, train.y, train.w valid_X, valid_y, valid_w = valid.X, valid.y, valid.w test_X, test_y, test_w = test.X, test.y, test.w
Здесь переменные x содержат обработанные признаковые векторы, переменные у — метки, а переменные w— веса прецедентов. Метки являются бинарными 1/0 для химических соединений, которые взаимодействуют или не взаимодействуют с рецептором андрогена. Тох21 содержит несбалансированные наборы данных, где положительных прецедентов гораздо меньше, чем отрицательных. Переменные w содержат рекомендуемый вес для каждого прецедента, в которых больше внимания уделяется положительным прецедентам (увеличение важности редких прецедентов является распространенным методом обработки несбалансированных наборов данных). Для простоты мы не будем использовать эти веса во время тренировки. Все эти переменные являются массивами NumPy.
В Тох21 имеется больше наборов данных, чем мы здесь будем анализировать, поэтому нам нужно удалить метки, связанные с этими лишними наборами данных (пример 4.2).
Пример 4.2. Удаление лишних наборов данных из Тох21
# Удалить лишние задачи train_y = train_y[:, 0] valid_y = valid_y[:, 0] test_y = test_y[:, 0] train_w = train_w[:, 0] valid_w = valid_w[:, 0] test_w = test_w[:, 0]
Принятие мини-пакетов заполнителей
В предыдущих главах мы создавали заполнители, которые принимали аргументы фиксированного размера. Во время работы с мини-пакетными данными часто удобно иметь возможность подавать пакеты переменного размера. Предположим, что набор данных содержит 947 элементов. Тогда с размером мини-пакета, равным 50 элементам, последний пакет будет иметь 47 элементов. Это приведет к фатальному сбою программного кода из главы 3. К счастью, TensorFlow позволяет запросто исправить ситуацию: использование None в качестве размерного аргумента для заполнителя дает возможность заполнителю принимать тензоры с произвольным размером в конкретной размерности (пример 4.3).
110 | Глава 4
Пример 4.3. Определение заполнителей, которые принимают мини-пакеты разных размеров
d = 1024 with tf.name_scope("placeholders"):
x = tf.placeholder(tf.float32, (None, d))
у = tf.placeholder(tf.float32, (None,))
Обратите внимание, что d равняется 1024, т. e. размерности наших признаковых векторов.
Реализация скрытого слоя
Программный код для реализации скрытого слоя очень похож на тот код, который мы встречали в предыдущей главе для реализации логистической регрессии, как показано в примере 4.4.
i Пример 4.4. Определение скрытого слоя I
with tf.name_scope("hidden-layer"):
W = tf.Variable(tf.random_normal((d, n_hidden)))
b = tf.Variable(tf.random_normal((n_hidden,)))
x_hidden = tf.nn.relu(tf.matmul(x, W) + b)
Мы применяем функцию tf .name scope о для группировки введенных переменных. Обратите внимание, что мы используем матричную форму полносвязного слоя. Мы выбрали форму xW вместо Wx для того, чтобы удобнее справляться поочередно с каждым мини-пакетом входных данных. (В качестве упражнения попробуйте разработать соответствующие размерности, чтобы понять, почему это именно так.) Наконец, мы применяем нелинейное преобразование ReLU с помощью встроенной аКТИВаЦИОННОЙ фуНКЦИИ t f. nn . relu ().
Оставшаяся часть программного кода для полносвязного слоя очень похожа на код, используемый для логистической регрессии в предыдущей главе. Для полноты в примере 4.5 мы привели полный программный код, используемый для определения сети. Напоминаем, что полный программный код для всех моделей доступен в связанном с этой книгой хранилище GitHub. Мы настоятельно рекомендуем вам попробовать выполнить этот код самостоятельно.
i Пример 4.5. Определение полносвязной архитектуры I
with tf.name_scope("placeholders"):
x - tf.placeholder(tf.float32, (None, d))
у = tf.placeholder(tf.float32, (None,)) with tf.name_scope("hidden-layer"):
W = tf.Variable(tf.random_normal((d, n_hidden)))
b - tf.Variable(tf.random_normal((n_hidden,)))
x_hidden - tf.nn.relu(tf.matmul(x, W) + b)
Полносвязные глубокие сети | 111
with tf.name_scope("output"):
W = tf.Variable(tf.random_normal((n_hidden, 1)))
b = tf.Variable(tf.random_normal ((1,)))
y_logit = tf.matmul(x_hidden, W) + b # Сигмоида дает вероятность класса 1 y_one_prob = tf.sigmoid(y_logit) # Округление P(y=l) даст правильное предсказание y_pred = tf.round(y_one_prob) with tf.name_scope("loss"):
# Вычислить перекрестно-энтропийный член для каждой точки данных y_expand = tf.expand_dims(у, 1) entropy = tf.nn.sigmoid_cross_entropy_with_logits(logits=y_logit, 1abe1s=y_expand)
# Суммировать все вклады
1 = tf.reduce_sum(entropy)
with tf.name_scope("optim"):
train_op = tf.train.AdamOptimizer(learning_rate).minimize(1)
with tf.name_scope("summaries"): tf.summary.scalar("loss", 1) merged = tf.summary.merge_all()
Добавление отсева в скрытый слой
Библиотека TensorFlow берет на себя реализацию отсева за нас во встроенном примитиве tf . nn.dropout (х, keep prob), где keep prob— ЭТО вероятность ТОГО, ЧТО любой заданный узел остается. Напомним из нашего предыдущего обсуждения, что мы хотим включить отсев во время тренировки и отключить его во время выполнения предсказаний. Для того чтобы справиться с этим правильно, мы введем новый заполнитель для keep probe, как показано в примере 4.6.
' Пример 4.6. Добавление заполнителя для вероятности отсева <
keep_prob = tf.placeholder(tf.float32)
Во время тренировки мы передаем желаемое значение, часто 0,5, но во время тестирования мы назначаем keep prob значение 1,0, т. к. хотим, чтобы предсказания делались всеми заученными узлами. При такой настройке добавление отсева в полносвязную сеть, определенную в предыдущем разделе, представляет собой всего одну дополнительную строку кода (пример 4.7).
। Пример 4.7. Определение скрытого слоя с отсевом
with cf.name_scope("hidden-layer"):
W = tf.Variable(tf.random_normal((d, n_hidden)))
b = tf.Variable(tf.random_normal((n_hidden,)))
112 | Глава 4
x_hidden = tf.nn.relu(tf.matmul(x, W) + b)
# Применить отсев
x_hidden = tf.nn.dropout(x_hidden, keep_prob)
Реализация мини-пакетирования
Для того чтобы реализовать мини-пакетирование, нам нужно вытаскивать данные в размере мини-пакета всякий раз, когда мы вызываем метод sess.run. К счастью для нас, наши признаки и метки уже находятся в массивах NumPy, и мы можем использовать удобный синтаксис NumPy для нарезки частей массивов (пример 4.8).
Пример 4.8. Тренировка на мини-пакетах
step = О
for epoch in range(n_epochs):
pos = 0
while pos < N:
batch_X = train_X[pos:pos+batch_size]
batch_y = train_y[pos:pos+batch_size]
feed_dict = {x: batch_X, y: batch_y, keepjDrob: dropout_prob} _, summary, loss = sess.run([train_op, merged, 1], feed—dict=feed_diet)
print("эпоха %d, step %d, потеря: %f" % (epoch, step, loss)) train_writer.add_summary(summary, step)
step += 1
pos += batch—size
Оценивание точности модели
Для оценки точности модели стандартная практика требует измерения точности модели на данных, не используемых для тренировки (а именно, на контрольном наборе). Правда, тот факт, что данные не сбалансированы, вносит свою сложность. Метрический показатель точности классификации, которую мы использовали в предыдущей главе, просто измеряет долю точек данных, которые были помечены правильно. Однако 95% данных в нашем наборе помечены как 0 и только 5% помечены как 1. В результате этого модель "с одними нулями" (которая все помечает отрицательно) достигнет 95% точности! Это не то, чего мы хотим.
Более приближенным вариантом было бы увеличить вес положительных прецедентов, чтобы они получили большее значение. Для этой цели мы используем рекомендуемые веса для каждого прецедента из MoleculeNet для вычисления взвешенной точности классификации, где положительные образцы в 19 раз больше веса отрицательных образцов. При такой взвешенной точности модель "с одними нулями" будет иметь точность 50%, что кажется гораздо более разумным.
Полносвязные глубокие сети | 113
Для вычисления взвешенной ТОЧНОСТИ МЫ используем функцию accuracyscore (true, pred, sample_weight=given_sample_weight) ИЗ ПОДМОДУЛЯ sklearn.metrics. Она имеет именованный аргумент sampie_weight, который позволяет нам задавать желаемый вес для каждой точки данных. Мы используем эту функцию для вычисления взвешенного метрического показателя как на тренировочном, так и на контрольном наборах данных (пример 4.9).
Пример 4.9. Вычисление взвешенной точности
train_weighted_score accuracy_score(train_y, train_y_pred,
sample_weight=train_w)
print("Тренировочная взвешенная точность классификации: %f" % train_weighted_score)
valid_weighted_score = accuracy_score(valid_y, valid_y_pred,
sample_weight=valid_w)
print("Контрольная взвешенная точность классификации: %f" % valid_weighted_score)
Хотя мы могли бы переопределить эту функцию сами, иногда проще (и менее подвержено ошибкам) использовать стандартные функции из программной инфраструктуры Python для науки о данных. Осведомленность об этой инфраструктуре и имеющихся функциях является частью обязанностей практикующего аналитика данных. Теперь мы можем натренировать модель (для 10 эпох в принятых по умолчанию настройках) и измерить ее точность:
Тренировочная взвешенная точность классификации: 0.742045
Контрольная взвешенная точность классификации: 0.648828
В главе 5 мы покажем вам методы систематического повышения этой точности и более тщательной настройки нашей полносвязной модели.
Использование пакета TensorBoard
для отслеживания схождения модели
Теперь, когда мы определили нашу модель, давайте воспользуемся пакетом визуализации TensorBoard для обследования модели. Сначала проверим структуру графа в TensorBoard (рис. 4.10).
Граф похож на граф логистической регрессии с одним исключением— добавлен новый скрытый слой. Давайте развернем скрытый слой, чтобы увидеть, что внутри (рис. 4.11).
Вы видете, как здесь представлены новые тренируемые переменные и операция отсева. Кажется, все на своем месте. Теперь давайте закончим, посмотрев на кривую потери во времени (рис. 4.12).
114 | Глава 4
Рис. 4.10. Визуализация вычислительного графа для полносвязной сети (optim — оптимизация, loss — потеря; output — выход; hidden-layer — скрытый слой; placeholders — заполнители)
Рис. 4.11. Визуализация развернутого вычислительного графа для полносвязной сети
Полносвязные глубокие сети | 115
summaries/loss
800
600
400
200
0,00
Рис. 4.12. Визуализация кривой потери для полносвязной сети
Кривая потери отклоняется вниз, как мы видели в предыдущем разделе. Но давайте увеличим масштаб, чтобы посмотреть, как эта потеря выглядит вблизи (рис. 4.13).
summaries/loss
180,0 220,0 260,0 300,0
Рис. 4.13. Увеличивание масштаба части кривой потери
Обратите внимание, что потеря выглядит гораздо ухабистей! Это одна из цен использования мини-пакетной тренировки. У нас больше нет красивых, гладких кривых потерь, которые мы видели в предыдущих разделах.
Резюме
В этой главе мы познакомили вас с полносвязными глубокими сетями. Мы углубились в математическую теорию этих сетей и исследовали понятие ’’универсальной аппроксимации”, которое частично объясняет мощную способность полносвязных сетей к самообучению. Мы закончили главу практическим примером, где вы натренировали глубокую полносвязную архитектуру набора данных Тох21.
В этой главе мы еще не показали, как настраивать полносвязную сеть для достижения хорошей предсказательной результативности. В главе 5 мы обсудим ’’гиперпараметрическую оптимизацию”, процесс настройки параметров сети, и вы выполните настройку параметров сети Тох21, представленной в этой главе.
116 | Глава 4
ГЛАВА 5
Г иперпараметрическая оптимизация
Тренировка глубокой модели и тренировка хорошей глубокой модели — это две разные вещи. Достаточно легко скопировать и вставить программный код TensorFlow из Интернета и запустить первый прототип, но гораздо сложнее преобразовать этот прототип в высококачественную модель. Процесс превращения прототипа в высококачественную модель связан со множеством шагов. Мы рассмотрим один из таких шагов — гиперпараметрическую оптимизацию.
В первом приближении гиперпараметрическая оптимизация представляет собой процесс настройки всех тех параметров модели, которые градиентный спуск не заучивает. Эти величины называются гиперпараметрами. Рассмотрим полносвязные сети из предыдущей главы. В то время как весы полносвязных сетей могут быть заучены из данных, к другим настройкам сети это не относится. Такие гиперпараметры включают в свой состав количество скрытых слоев, количество нейронов в расчете на скрытый слой, скорость заучивания и многое другое. Каким образом можно систематически находить хорошие значения для этих величин? Ответ на этот вопрос обеспечивают методы оптимизации гиперпараметров.
Ранее мы уже упоминали, что результативность модели отслеживается на отложенном "контрольном" наборе. Методы гиперпараметрической оптимизации систематически пробуют несколько вариантов параметров на контрольном наборе. Наиболее результативный набор значений гиперпараметров затем оценивается на втором отложенном "тестовом" наборе, чтобы точно измерить истинную результативность модели. Различные методы гиперпараметрической оптимизации отличаются алгоритмом, который они используют, чтобы предложить новые настройки гиперпараметров. Эти алгоритмы варьируются от очевидных до довольно сложных. В последующих главах мы рассмотрим некоторые более простые методы, поскольку более сложные методы гиперпараметрической оптимизации, как правило, требуют очень больших вычислительных мощностей.
В качестве практического примера мы настроим введенную в главе 4 полносвязную сеть токсичности Тох21 с целью достичь хорошей результативности. Мы настоятельно рекомендуем вам (как всегда) выполнить методы гиперпараметрической оптимизации самостоятельно, используя программный код в хранилище GitHub (https://github.com/matroid/dlwithtf), связанном с этой книгой.
117
Гиперпараметрическая оптимизация не только для глубоких сетей!
Стоит подчеркнуть, что гиперпараметрическая оптимизация предназначена не только для глубоких сетей. Большинство форм машинно-обучающихся алгоритмов имеют параметры, которые не могут быть заучены с помощью принятых по умолчанию методов самообучения. Эти параметры также называются гиперпараметрами. Далее в этой главе вы увидите некоторые примеры гиперпараметров для случайных лесов (другого распространенного метода машинного самообучения).
Однако стоит отметить, что глубокие сети, как правило, более чувствительны к выбору гиперпараметра, чем другие алгоритмы. В то время как случайный лес при наличии вариантов гиперпараметров, взятых по умолчанию, снижает свою результативность лишь слегка, глубокие сети могут не обучиться и вовсе. По этой причине для будущего специалиста по глубокому самообучению чрезвычайно важно надлежащим образом освоить методы оптимизации гиперпараметров.
Оценивание модели и гиперпараметрическая оптимизация
В предыдущих главах мы лишь кратко затронули вопрос о том, как определять, является ли машинно-обучающаяся модель хорошей или нет. Любой анализ результативности модели должен включать точное измерение способности модели к обобщению. То есть, может ли модель выполнять предсказания на точках данных, которые она никогда не встречала раньше? Лучшим тестом результативности модели является создание модели, а затем перспективное оценивание данных, которые становятся доступными после построения модели. Однако этот вид тестирования громоздок и поэтому не пригоден для выполнения на регулярной основе. Во время фазы проектирования практикующий аналитик данных может принять решение выполнить оценивание многих других типов моделей или обучающихся алгоритмов, чтобы выяснить, который из них лучший.
Решение этой дилеммы состоит в том, чтобы ’’отложить" часть имеющегося набора данных в качестве контрольного набора. Этот контрольный набор будет использоваться для измерения результативности различных моделей (с разными вариантами гиперпараметров). Также рекомендуется иметь второй отложенный набор (тестовый набор) для точного замера результативности конечной модели, выбранной методами отбора гиперпараметров.
Допустим, что у вас есть 100 точек данных. Простая процедура заключается в использовании 80 этих точек данных для тренировки перспективных моделей и 20 отложенных точек данных для контрольной проверки выбранной модели. Качество предложенной модели может отслеживаться по ее "оценке" на отложенных 20 точках данных. Модели могут итеративно улучшаться благодаря предложению новых проектов моделей и принятию только тех, которые улучшают результативность на отложенном наборе.
118 | Глава 5
Однако на практике эта процедура приводит к переподгонке. Практикующие специалисты быстро начинают разбираться в характерных особенностях структуры отложенного набора и донастраивают модель так, что она начинает давать искусственно завышенные оценки на отложенном наборе. Для того чтобы бороться с этим, практикующие специалисты обычно разбивают отложенный набор на две части: одну часть для контрольной проверки гиперпараметров, а другую — для окончательной контрольной проверки модели. В этом случае, допустим, вы резервируете 10 точек данных для контрольной проверки и 10 для окончательного тестирования. Это называется расщеплением данных в соотношении 80:10:10.
г—А-i Зачем нужен тестовый набор?
Важный момент, который стоит отметить, — методы гиперпараметриче-ской оптимизации как таковые сами являются формой обучающегося алго-ритма. В частности, они представляют собой обучающийся алгоритм для * настройки недифференцируемых величин, которые нелегко поддаются исследованию на основе математического анализа. ’’Тренировочный набор” для алгоритма заучивания гиперпараметров — это отложенный контрольный набор.
В общем случае не имеет особого смысла производить точный замер результативности модели на ее тренировочных наборах. Как всегда, заученные величины должны уметь обобщать, и поэтому необходимо протестировать результативность на другом наборе. Поскольку тренировочный набор используется для заучивания весов на основе градиента, а контрольный набор применяется для заучивания гиперпараметров, тестовый набор необходим, чтобы точно измерить, насколько хорошо заученные гиперпараметры обобщаются на новые данные.
Обучающиеся алгоритмы по принципу черного ящика
Обучающиеся алгоритмы, работающие по принципу черного ящика, не исходят из какой-то структурной информации о системах, которые они пытаются оптимизировать. Большинство гиперпараметрических методов представляют собой черный ящик, т. е. закрытое устройство; они работают для любого типа глубоко обучающегося и машинно-обучающегося алгоритмов.
Методы по принципу черного ящика в целом не масштабируются так же хорошо, как и методы по принципу белого ящика (такие как градиентный спуск), поскольку они, как правило, теряются в многомерных пространствах. Из-за отсутствия направленной информации от градиента методы по принципу черного ящика могут заблудиться даже в 50-размерных пространствах (оптимизация 50 гиперпараметров на практике представляет довольно большую сложность).
Для того чтобы понять, почему, давайте предположим, что существует 50 гиперпараметров, каждый с тремя потенциальными значениями. Тогда алгоритм по принципу черного ящика должен слепо выполнить поиск в пространстве размером 3 . Это выполнимо, но поиск потребует большой вычислительной мощности в целом.
Гиперпараметрическая оптимизация | 119
Метрики, метрики, метрики
При выборе гиперпараметров следует выбирать те, которые делают проектируемые модели точнее. В машинном самообучении метрический показатель, или метрика, — это функция, которая измеряет точность предсказаний натренированной модели. Гиперпараметрическая оптимизация выполняется для оптимизации тех гиперпараметров, которые максимизируют (или минимизируют) этот метрический показатель в контрольном наборе. Хотя на первый взгляд это кажется простым, понятие точности на самом деле может быть довольно тонким. Предположим, у вас есть бинарный классификатор. Будет ли более важным никогда не помечать неправильно ложные образцы как истинные или же истинные образцы как ложные? Как выбрать модельные гиперпараметры, удовлетворяющие потребностям ваших приложений?
Ответом окажется подбор правильного метрического показателя. В этом разделе мы обсудим ряд различных метрических показателей для классификационных и регрессионных задач. Мы дадим рекомендации по качественным характеристикам, которые подчеркивают каждый метрический показатель. Лучший показатель не существует, но для разных приложений есть более подходящие и менее подходящие показатели.
Ш Метрические показатели — это не замена здравому смыслу!
Метрические показатели ужасно слепы. Они оптимизируют всего одну-единственную величину. Вследствие этого слепая оптимизация метрических показателей может привести к совершенно неподходящим результатам. Медийные сайты в веб часто принимают решение оптимизировать показатель кликабельности, т. е. число нажатий пользователями на рекламе и других элементах содержимого веб-страниц. Какой-то предприимчивый молодой журналист или рекламодатель затем понял, что такие названия, как "Вы никогда не поверите, что произошло, когда X" побуждают пользователей нажимать с большей частотой. Как и следовало ожидать, родились клик-наживки — кликбейты. В то время как "кликбейтовые" заголовки действительно побуждают читателей нажимать, они также отталкивают пользователей и приводят к тому, что те избегают тратить время на сайты, заполненные кликбейтами. Оптимизация кликабельности привела к снижению вовлеченности и доверия пользователей.
Урок здесь общий: оптимизация одного метрического показателя часто происходит за счет отдельной величины. Убедитесь, что величина, которую вы хотите оптимизировать, действительно является "правильной" величиной. Не правда ли, интересно, как машинное самообучение по-прежнему требует человеческого суждения?
Бинарно-классификационные показатели
Прежде чем познакомить вас с метрическими показателями для бинарных классификационных моделей, считаем, что вам будет полезно узнать о некоторых вспомогательных величинах. Когда бинарный классификатор строит предсказания на
120 | Глава 5
наборе точек данных, вы можете разделить все эти предсказания на четыре категории (табл. 5.1).
Таблица 5.1. Категории предсказаний
Категория Значение
Истинноположительный исход (true positive, TP) Предсказание истинно, метка истинная
Ложноположительный исход (false positive, FP) Предсказание истинно, метка ложная
Истинноотрицательный исход (true negative, TN) Предсказание ложное, метка ложная
Ложноотрицательный исход (false negative, FN) Предсказание ложное, метка истинная
Мы также считаем полезным ввести обозначения, приведенные в табл. 5.2.
Таблица 5.2. Положительные и отрицательные исходы
Категория Значение
Р Количество положительных меток
N Количество отрицательных меток
Крайне желательно минимизировать количество ложноположительных и ложноотрицательных исходов. Вместе с тем, часто невозможно минимизировать как ложноположительные, так и ложноотрицательные исходы любого конкретного набора данных из-за ограничений в присутствующем сигнале. Вследствие этого существует целый ряд метрических показателей, которые обеспечивают различные компромиссные соотношения между ложноположительными и ложноотрицательными исходами. Эти компромиссные соотношения могут быть очень важны для приложений. Предположим, вы проектируете медицинскую диагностику рака молочной железы. Тогда ложноположительный исход будет означать, что здоровой пациентке будет диагностирован рак молочной железы. Ложноотрицательный исход отметит пациентку, страдающую от рака груди, как не имеющую этого заболевания. Ни один из этих результатов не является желательным, и проектирование правильного баланса является сложным вопросом биоэтики.
Теперь мы покажем вам ряд различных метрических показателей, которые уравновешивают ложноположительные и ложноотрицательные исходы в разных соотношениях (табл. 5.3). Каждое из этих соотношений оптимизируется для разного баланса, и мы рассмотрим некоторые из них более подробно.
Точность — самый простой показатель. Он просто подсчитывает долю предсказаний, которые были сделаны классификатором правильно. В простых приложениях точность должна быть наипервейшим, дежурным метрическим показателем для практикующего специалиста. Прецизионность и полнота являются наиболее часто измеряемыми метрическими показателями после точности. Прецизионность — это мера того, сколько точек данных в долевом выражении, предсказанных положи-
Гиперпараметрическая оптимизация | 121
Таблица 5.3. Таблица бинарных метрических показателей
Метрический показатель Формула расчета
Точность (TP + TN)/(P + N)
Прецизионность TP/(TP + FP)
Полнота TP/(TP + FN) = TP/P
Специфичность TN/(FP + TN) = TN/N
Доля ложноположительных исходов (false positive rate, FPR) FP/(FP + TN) = FP/N
Доля ложноотрицательных исходов (false negative rate, FNR) FN/(TP + FN) = FN/P
тельно, оказались положительными на самом деле. Полнота, в свою очередь, измеряет долю положительно помеченных точек данных, которые классификатор пометил положительно. Специфичность измеряет долю точек данных, помеченных как отрицательные, которые были классифицированы правильно. Доля ложноположительных исходов измеряет долю точек данных, помеченных как отрицательные, но которые были классифицированы неправильно как положительные. Доля ложноотрицательных исходов — это доля точек данных, помеченных как положительные, но которые были ошибочно помечены как отрицательные.
Все эти показатели подчеркивают различные аспекты работы классификатора. Они также могут быть полезны при построении более сложного анализа результативности бинарного классификатора. Например, предположим, что бинарный классификатор выводит вероятности классов, а не только сырые предсказания. Тогда встает вопрос о выборе порога отсечения. То есть, при какой вероятности положительного исхода вы помечаете результат, как фактически положительный? Наиболее распространенный ответ— 0,5. Однако, выбирая более высокие или более низкие пороги, часто можно вручную варьировать баланс между прецизионностью, полнотой, долей ложноположительных исходов (false positive rate, FPR) и долей истинноположительных исходов (true positive rate, TPR). Эти компромиссные соотношения часто представляются графически.
Кривая рабочей характеристики приемника (receiver operating characteristic, ROC) показывает компромиссное соотношение между .уолей истинноположительных исходов и долей ложноположительных исходов п& мере изменения пороговой вероятности (рис. 5.1).
Площадь под кривой (area under curve, AUC) рабочей характеристики приемника (ROC-AUC) является общепринятым измеряемым метрическим показателем. Метрический показатель ROC-AUC полезен тем, что он обеспечивает глобальную картину бинарного классификатора для всех вариантов порога отсечения. Идеальный метрический показатель будет иметь ROC-AUC 1.0, поскольку доля TRP всегда будет максимизированной. Для сравнения, случайный классификатор будет иметь ROC-AUC 0.5. Показатель ROC-AUC часто полезен для несбалансированных наборов данных, поскольку глобальное представление частично учитывает дисбаланс в наборе данных.
122 | Глава 5
Доля ложно положительных исходов (специфичность)
Рис. 5.1. Кривая рабочей характеристики приемника (ROC-кривая)
Метрические показатели мультиклассовой классификации
Многие распространенные задачи машинного самообучения требуют, чтобы выводимые моделями классификационные метки были не только бинарными. К примеру, задача конкурса ImageNet (ILSVRC) требовала от участников строить модели, которые должны распознавать, какой из тысячи потенциальных классов объектов имелся в предоставленных изображениях. Или в более простом примере, вполне возможно, что вы захотите предсказать завтрашнюю погоду, где предусмотрены классы ’’солнечно”, ’’дождливо” и ’’облачно”. Каким образом измеряется результативность такой модели?
Самый простой метод — использовать прямое обобщение точности, которое измеряет долю точек данных, помеченных правильно (табл. 5.4).
Таблица 5.4. Метрические показатели мультиклассовой классификации
Метрический показатель Определение
Точность Количество правильно помеченных/количество точек данных
Стоит отметить, что существуют мультиклассовые обобщения величин, в частности точности, полноты и ROC-AUC, и, если это интересно, мы рекомендуем вам изучить эти определения. На практике существует более простая визуализация — матрица ошибок (или матрица несоответствий), которая хорошо работает. Для мультиклассовой задачи с к классами матрица ошибок является матрицей ккк . (/, у)-я ячейка представляет количество точек данных, помеченных как класс i с истинным классом меток j. На рис. 5.2 показана матрица ошибок.
Не стоит недооценивать мощь человеческого глаза в отлавливании шаблонов систематических неудач на простых визуализациях! Взгляд на матрицу ошибок может дать быстрое понимание того, что могут пропустить десятки более сложных муль-тиклассовых метрических показателей.
Гиперпараметрическая оптимизация | 123
Предсказанная метка
Рис. 5.2. Матрица ошибок для однополосного классификатора
540
480
420
360
300
240
180
120
60
0
Регрессионные метрические показатели
Вы познакомились с метрическими регрессионными показателями несколько глав назад. Заметим, что R2 Пирсона и RMSE (среднеквадратическая ошибка) являются хорошими вариантами по умолчанию.
Ранее мы лишь вкратце рассмотрели математическое определение показателя R2. но сейчас мы рассмотрим его подробнее. Пусть xt представляет предсказания, а yt — метки. Пусть х и у представляют среднее значение соответственно предсказанных значений и меток. Тогда R Пирсона (обратите внимание на отсутствие квадрата) имеет следующий вид:
Это уравнение может быть переписано как
cov(x, у) о(х)о(у)’
124 | Глава 5
где cov — ковариация; и — стандартное отклонение. В интуитивном плане R2 Пирсона измеряет совместные колебания предсказаний и меток от их средних значений, нормализованных своими соответствующими диапазонами колебаний. Если предсказания и метки различаются, то эти колебания будут происходить в разных точках и иметь тенденцию к взаимному погашению, делая R2 меньше. Если предсказания и метки согласуются (как правило, так и есть), то колебания будут происходить вместе и делать R2 больше. Отметим, что показатель R2 ограничен диапазоном от 0 до z.
RMSE измеряет абсолютную величину ошибки (погрешности) между предсказаниями и истинными величинами. Эта аббревиатура означает квадратный корень из среднеквадратической ошибки, что примерно аналогично абсолютному значению ошибки между истинной величиной и предсказанной величиной. Математически RMSE определяется следующим образом (с использованием того же обозначения, что и раньше):
RMSE = ~У)_.
V N
Алгоритмы оптимизации гиперпараметров
Как мы уже упоминали ранее в этой главе, методы гиперпараметрической оптимизации — это обучающиеся алгоритмы поиска значений гиперпараметров, оптимизирующих выбранный метрический показатель в контрольном наборе. В общем случае эта целевая функция не может быть дифференцирована, поэтому любой оптимизационный метод обязательно должен быть черным ящиком. В этом разделе мы покажем вам несколько простых обучающихся алгоритмов по принципу черного ящика для выбора значений гиперпараметров. В качестве примера мы будем использовать набор данных Тох21 из главы 4 для демонстрации этих оптимизационных методов по принципу черного ящика. Набор данных Тох21 достаточно мал, чтобы сделать эксперимент легким, и вместе с тем достаточно сложен, чтобы процесс гиперпараметрической оптимизации был нетривиальным.
Прежде чем начать, отметим, что ни один из этих алгоритмов по принципу черного ящика не работает идеально. Как вы вскоре увидите, гиперпараметрическая оптимизация на практике требует большого вмешательства человека.
Можно ли автоматизировать оптимизацию гиперпараметров?
Давней мечтой машинного самообучения является автоматизация процесса отбора модельных гиперпараметров. Авторы таких проектов, как "автоматизированное рабочее место статистика" и другие, стремились удалить из процесса отбора гиперпараметров часть тяжелой работы и сделать построение модели более доступным для неэкспертов. Однако на практике за добавленное удобство, как правило, приходилось платить крутую цену в результативности.
Гиперпараметрическая оптимизация | 125
В последние годы наблюдается всплеск работы, направленной на совершенствование алгоритмических основ настройки моделей. Гауссовы процессы, эволюционные алгоритмы и самообучение с максимизацией подкрепления были использованы для заучивания модельных гиперпараметров и архитектур с очень ограниченным участием человека. Недавняя работа показала, что при больших объемах вычислительной мощности эти алгоритмы могут превышать результативность эксперта при настройке модели! Но накладные расходы серьезны, и требуется в десятки и сотни раз больше вычислительной мощности.
На данный момент автоматическая настройка модели по-прежнему остается непрактичной. Все алгоритмы, которые мы рассмотрим в этом разделе, требуют значительной ручной настройки. Вместе с тем, поскольку качество оборудования совершенствуется, мы ожидаем, что заучивание гиперпараметров станет все более автоматизированным. Мы настоятельно рекомендуем всем практикующим специалистам в ближайшем будущем обязательно освоить тонкости настройки гиперпараметров. Прочное умение выполнять гиперпараметрическую настройку является тем самым умением, которое отличает эксперта от новичка.
Установление ориентира
Первый шаг в гиперпараметрической настройке— найти ориентир. Ориентир — это результативность, достижимая надежным (обычно неглубоко обучающимся) алгоритмом. Вообще, случайные леса являются превосходным вариантом для установления ориентиров. Как показано на рис. 5.3, случайные леса представляют собой ансамблевый метод, который тренирует большое количество моделей дерева принятия решений на подмножествах входных данных и входных признаков. Затем эти отдельные деревья выбирают исход на основе голосования.
Рис. 5.3. Иллюстрация случайного леса. Здесь v — это входной признаковый вектор
126 | Глава 5
Случайные леса, как правило, являются достаточно надежными моделями. Они устойчивы к шуму и не беспокоятся о масштабе входных признаков. (Несмотря на то что нам не нужно беспокоиться об этом с наборами данных Тох21, поскольку все наши признаки — бинарные, в целом глубокие сети довольно чувствительны к своему входному диапазону. Для хорошей результативности полезно выполнять нормализацию или иным образом шкалировать диапазон входных данных. Мы вернемся к этому вопросу в последующих главах.) Они также, как правило, имеют устойчивую способность к обобщению и для запуска не требуют большой гиперпараметрической настройки. Для некоторых наборов данных преодоление глубокой сетью результативности случайного леса может потребовать значительной изощренности.
Как создать и натренировать случайный лес? К счастью для нас, библиотека Python scikit-learn обеспечивает высококачественную реализацию случайного леса. Библиотеке scikit-learn посвящен целый ряд учебных пособий и ознакомительных материалов, поэтому мы просто покажем программный код тренировки и предсказания, необходимый здесь для создания модели случайного леса на основе наборов данных Тох21 (пример 5.1).
; Пример 5.1. Определение и тренировка случайного леса на наборе данных Тох21
from sklearn.ensemble import RandomForestClassifier
# Сгенерировать граф tensorflow
sklearn_model = RandomForestClassifier( class_weight=”balanced”, n_estimators=50) print("Все готово для подгонки модели на тренировочном наборе.") sklearn_model.fit(train_X, train_y)
train_y_pred = sklearn_model.predict(train_X) valid_y_pred = sklearn_model.predict(valid_X) test_y_pred = sklearn_model.predict(test_X)
weighted_score = accuracy_score(train_y, train_y_pred, sample_weight=train_w) print("Тренировочная взвешенная точность классификации: %f" % weighted_score)
weighted_score = accuracy_score(valid_y, valid_y_pred, sample_weight=valid_w) print("Контрольная взвешенная точность классификации: %f" % weighted_score) weighted_score = accuracy_score(test_y, test_y_pred, sample_weight=test_w) print("Тестовая взвешенная точность классификации: %f" % weighted_score)
print("Тренировочная взвешенная точность классификации: %f" % train_weighted_score)
valid_weighted_score = accuracy_score(valid_y, valid_y_pred, sample_weight=valid_w) print("Контрольная взвешенная точность классификации: %f" % valid_weighted_score)
Гиперпараметрическая оптимизация | 127
Здесь train x, train y и другие являются сегментами набора данных Тох21, определенного в предыдущей главе. Напомним, что все эти величины являются массивами NumPy. Именованный аргумент n estimators обозначает число деревьев принятия решений в нашем лесу. Задание 50 или 100 деревьев часто обеспечивает достойную результативность. Библиотека scikit-learn предлагает простой объектно-ориентированный API с методами fit (х, у) и predict (X). Эта модель достигает следующей точности по отношению к нашему взвешенному метрическому показателю точности:
Тренировочная взвешенная точность классификации: 0.989845
Контрольная взвешенная точность классификации: 0.681413
Напомним, что полносвязная сеть из главы 4 достигла результативности:
Тренировочная взвешенная точность классификации: 0.742045
Контрольная взвешенная точность классификации: 0.64882
Похоже, что данный ориентир показывает более высокую точность, чем наша глубоко обучающаяся модель! Самое время засучить рукава и приступить к работе.
Спуск студента магистратуры
Самый простой способ испытать хорошие гиперпараметры — просто попробовать вручную несколько разных вариантов гиперпараметров, чтобы увидеть, какой из них работает. Эта стратегия может быть удивительно эффективной и поучительной. Практикующий специалист по глубокому самообучению обязан развить интуитивное понимание структуры глубоких сетей. Учитывая очень слабое состояние теории, эмпирическая работа— лучший способ научиться строить глубоко обучающиеся модели. Мы настоятельно рекомендуем самостоятельно попробовать многочисленные варианты полносвязной модели. Будьте последовательны и педантичны; записывайте свои варианты и результаты в электронную таблицу и систематически исследуйте гиперпараметрическое пространство. Попробуйте разобраться в эффектах различных гиперпараметров. Что делает тренировку сети быстрее, а что медленнее? Какие диапазоны настроек совершенно нарушают процесс самообучения? (К сожалению, их довольно легко найти.)
Есть несколько остроумных приемов программной инженерии, которые могут упростить этот поиск. Создайте функцию, аргументом которой является подлежащий исследованию гиперпараметр, и пусть она выводит точность на печать. Тогда испытание новых гиперпараметрических комбинаций потребует только одного вызова функции. Пример 5.2 показывает, как будет выглядеть сигнатура такой функции для нашей полносвязной сети из примера Тох21.
। Пример 5.2. Функция, выводящая на экран гиперпараметры I разных полносвязных сетей для данных Тох21
def eval_tox21_hyperparams(n_hidden=50, n_layers=l, learning_rate=.001, dropout_prob=0.5, n_epochs=45, batch_size=100, weight_positives=True):
128 | Глава 5
Давайте пройдемся по каждому из этих гиперпараметров. Итак, n_hidden управляет количеством нейронов в каждом скрытом слое сети, a n iayers— количеством скрытых слоев. Гиперпараметр learning rate контролирует скорость заучивания, используемую в градиентном спуске, dropout prob является вероятностью, что нейроны не сброшены во время шагов тренировки, n epochs управляет количеством проходов по всем данным, a batch size является количеством точек данных в каждом пакете.
Единственный новый гиперпараметр здесь— это weight positives. Для несбалансированных наборов данных часто бывает полезно взвешивать прецеденты обоих классов, чтобы иметь одинаковый вес. Для набора данных Тох21 проект DeepChem предоставляет для использования веса. Для того чтобы выполнить взвешивание, мы просто умножаем перекрестно-энтропийные члены прецедента на эти веса (пример 5.3).
; Пример 5.3. Взвешивание положительных образцов для Тох21
entropy = tf.nn.sigmoid_cross_entropy_with_logits(logits=y_logit,
1abe1s=y_expand)
# Умножить на веса if weight_positives: w_expand = tf.expand_dims(w, 1) entropy = w_expand * entropy
Почему метод подбора значений гиперпараметров называется спуском студента магистратуры? Машинное самообучение до недавнего времени было преимущественно академической областью. Проверенный на практике метод проектирования нового машинно-обучающегося алгоритма состоит в том, чтобы описать метод, который желают получить от нового студента магистратуры и поручить ему проработать детали. Этот процесс слегка смахивает на обряд посвящения и часто требует от студента усердно перепробовать множество проектных вариантов. В целом это очень поучительный опыт, т. к. единственный способ приобрести эстетику проектирования — это укрепить память о настройках, которые работают и не работают.
Решеточный поиск гиперпараметров
После опробования несколько ручных гиперпараметрических настроек, процесс кажется очень утомительным. Опытные программисты захотят просто написать цикл for, который будет выполнять итеративный обход вариантов желаемых гиперпараметров. Этот процесс до известной степени является методом поиска в решетке гиперпараметров. Суть метода — для каждого гиперпараметра выбрать список значений, которые могут оказаться хорошими для гиперпараметра, написать вложенный цикл for, который пробует все комбинации этих значений, чтобы найти их контрольные точности, и отследить наилучших исполнителей.
Гиперпараметрическая оптимизация | 129
Однако в этом процессе есть одна тонкость. Глубокие сети могут быть довольно чувствительны к выбору начального случайного значения, используемого для инициализации сети. По этой причине стоит повторить каждый вариант гиперпараметрических настроек несколько раз и усреднить результаты, чтобы заглушить дисперсию.
Программный код для этой процедуры прост, как показано в примере 5.4.
Пример 5.4. Выполнение поиска в решетке гиперпараметров на полносвязной сети Тох21
scores = {}
n_reps = 3
hidden_sizes = [50]
epochs = [10]
dropouts = [.5, 1.0]
num_layers = [1, 2]
for rep in range(n_reps):
for n_epochs in epochs:
for hidden_size in hidden_sizes:
for dropout in dropouts:
for n_layers in num_layers:
score = eval_tox21_hyperparams(n_hidden=hidden_size, n_epochs=n_epochs, dropout_prob=dropout, n_layers=n_layers)
if (hidden_size, n_epochs, dropout, n_layers) not in scores: scores[(hidden_size, n_epochs, dropout, n_layers)] = []
scores[(hidden_size, n_epochs, dropout, n_layers)].append(score)
print("Все оценки")
print(scores)
avg_scores = {}
for params, param_scores in scores.iteritems():
avg_scores[params] = np.mean(np.array(param_scores))
print("Оценки, усредненные на %d повторах" % n_reps)
Случайный поиск гиперпараметров
Для опытных практикующих специалистов нередко будет очень заманчивым повторно использовать магические гиперпараметрические настройки или поисковые решетки, которые работали в предыдущих приложениях. Эти настройки могут иметь свою ценность, но они также могут привести нас в заблуждение. Каждая задача машинного самообучения немного отличается, и оптимальные настройки
130 | Глава 5
могут лежать в области параметрического пространства, которое мы ранее не рассматривали. По этой причине зачастую стоит попробовать случайные гиперпараметрические настройки (где случайные значения выбираются из разумного диапазона).
Существует также более веская причина, почему следует попробовать случайные поиски. В многомерных пространствах регулярные решетки могут пропускать много информации, в особенности если интервал между точками сетки не велик. Выбор случайных вариантов для точек решетки может помочь нам не попасть в ловушку неконтролируемых решеток. На рис. 5.4 проиллюстрирован этот факт.
Решеточная схема размещения
Важный параметр
Случайная схема размещения
Важный параметр
Рис. 5.4. Иллюстрация того, почему случайный гиперпараметрический поиск может превосходить поиск в решетке
Как реализовать случайный гиперпараметрический поиск в программе? Остроумный программный прием — отобрать случайные значения, желаемые с самого начала, и сохранить их в списке. Затем случайный гиперпараметрический поиск просто превращается в поиск в решетке этих случайно отобранных списков. Приведем пример. В случае скоростей заучивания часто полезно испытать широкий диапазон от 0,1 до 0,000001 или около того. В примере 5.5 для отбора нескольких случайных скоростей заучивания используется библиотека NumPy.
Гпример 5.5. Отбор случайных образцов скоростей заучивания
n_rates = 5
learning_rates = 10**(-np.random.uniform(low=l, high=6, size=n_rates))
Здесь мы используем остроумный математический прием. Обратите внимание, что 0,1 = 10-1 и 0,000001 = 10"6 . Отбор вещественных чисел между такими диапазонами, как 1 И 6, выполняется просто С ПОМОЩЬЮ функции np. random.uniform. Мы можем возвести эти отобранные значения в степень, чтобы восстановить наши скорости заучивания. Тогда learning rates будет содержать список значений, которые мы можем использовать в нашем программном коде решеточного гиперпараметрического поиска из предыдущего раздела.
Гиперпараметрическая оптимизация | 131
Задание для читателя
В этой главе вы познакомились с основами настройки гиперпараметров, но эти рассмотренные инструменты достаточно мощные. В качестве задания попробуйте настроить полносвязную глубокую сеть, чтобы достигнуть контрольной результативности, которая будет выше, чем у случайного леса. Для этого потребуется немного потрудиться, но ради получения опыта работа стоит того.
Резюме
В этой главе мы рассмотрели основы гиперпараметрической оптимизации, процесс отбора значений модельных параметров, которые не могут быть заучены автоматически на тренировочных данных. В частности, мы показали вам случайный и решеточный гиперпараметрический поиск и продемонстрировали использование такого программного кода для оптимизации моделей на наборе данных Тох21, представленном в предыдущей главе.
В главе 6 мы вернемся к нашему обзору глубоких архитектур и познакомим вас со сверточными нейронными сетями, одним из фундаментальных строительных блоков современных глубоких архитектур.
132 | Гпава 5
ГЛАВА 6
Сверточные нейронные сети
Сверточные нейронные сети позволяют глубоким сетям обучаться функциям на структурированных пространственных данных, таких как изображения, видео и текст. В математическом смысле сверточные сети обеспечивают инструменты для эффективного использования локальной структуры данных. Изображения удовлетворяют определенным естественным статистическим свойствам. Предположим, мы представляем изображение в виде двумерной пиксельной решетки. Части изображения, близкие друг к другу в пиксельной решетке, могут изменяться вместе (например, все пикселы, соответствующие таблице в изображении, вероятно, являются коричневыми). Сверточные сети учатся использовать эту естественную ковариационную структуру с целью эффективного самообучения.
Сверточные сети — старое изобретение. Первые версии сверточных сетей предлагались в публикациях, начиная с 1980-х годов. Хотя проекты этих старых сверточных сетей часто были довольно надежными, они требовали ресурсов, которые превышали возможности имевшегося в то время аппаратного обеспечения. Как результат, сверточные сети томились в относительной безвестности, прозябая на страницах научной литературы.
Эта тенденция резко изменилась после 2012 г., когда стал проводиться конкурс ILSVRC на лучшие проекты по обнаружению объектов в изображениях, где сверточная AlexNet-сеть достигла частот ошибок вдвое меньше, чем у ее ближайших конкурентов. Сеть AlexNet смогла использовать графические процессоры (graphics processing unit, GPU) для тренировки старых сверточных архитектур с помощью значительно более крупных наборов данных. Такое сочетание старых архитектур с новым оборудованием позволило AlexNet значительно превзойти уровень технологий в области обнаружения объектов в изображениях. Эта тенденция продолжилась, и развитие сверточных нейронных сетей приобрело огромное ускорение по сравнению с другими технологиями обработки изображений. Без преувеличений, почти все современные конвейеры обработки изображений теперь приводятся в движение сверточными нейронными сетями.
Кроме того, произошел ренессанс в проектировании сверточных сетей, который продвинул сверточные сети далеко за пределы элементарных моделей из 1980-х годов. В первую очередь сети становятся гораздо глубже, при этом мощные современные сети достигают сотен слоев. Еще одной популярной тенденцией стало обобщение сверточных архитектур для работы на новых типах данных. Например, графовые архитектуры позволяют применять сверточные сети к молекулярным данным, таким как набор данных Тох21, с которым мы столкнулись несколько глав
133
назад! Сверточные архитектуры также оставляют свой след в геномике и в обработке текста и даже в переводе с одного языка на другой.
В этой главе мы представим основные понятия сверточных сетей. Они будут включать основные сетевые компоненты, которые составляют сверточные архитектуры, и введение в принципы проектирования, определяющие, каким образом эти части соединяются вместе. Мы также приведем подробный пример, который продемонстрирует, как использовать TensorFlow для тренировки сверточной сети. Пример программного кода для этой главы является адаптированной версией учебного руководства по сверточным нейронным сетям в документации по TensorFlow. Если вам интересно узнать об изменениях, которые мы внесли, рекомендуем вам обратиться к оригинальному учебному руководству (https://www.tensorflow.org/ tutorials/deep_cnn) на сайте TensorFlow. Как всегда, рекомендуем вам проработать сценарии для данной главы, размещенные в хранилище GitHub (https://github.com/ matroid/dlwithtf), связанном с этой книгой.
Введение в сверточные архитектуры
Большинство сверточных архитектур состоят из ряда базовых примитивов. Эти примитивы включают такие слои, как сверточные и редуцирующие. Существует также набор связанных с ними терминов, в том числе размер локального рецептивного поля, размер шага и количество фильтров. В этом разделе мы кратко рассмотрим базовые термины и концепции, положенные в основу сверточных сетей.
Локальные рецептивные поля
Концепция локального рецептивного поля берет свое начало в нейробиологии, где рецептивное поле нейрона является частью чувственного восприятия тела, которое влияет на возбуждение нейрона. Когда нейроны обрабатывают чувственный стимул, они имеют определенное поле "обзора", видимое мозгу. Такое поле обзора традиционно называется локальным рецептивным полем. Этот "обзор" может соответствовать участку кожи человека или сегменту его поля зрения. На рис. 6.1 проиллюстрировано локальное рецептивное поле нейрона.
Сверточные архитектуры заимствуют последнее понятие с вычислительным переосмыслением "локальных рецептивных полей". На рис. 6.2 наглядно представлена концепция локального рецептивного поля, применяемая к данным изображений. Каждое локальное рецептивное поле соответствует пиксельному участку в изображении и обрабатывается отдельным "нейроном". Эти "нейроны" аналогичны тем, которые находятся в полносвязных слоях. Как и в случае с полносвязными слоями, к входящим данным (которые исходят из локального рецептивного участка изображения) применяется нелинейное преобразование.
Слой таких "сверточных нейронов" может быть реорганизован в сверточный слой. Этот слой можно рассматривать как преобразование одной пространственной области в другую. В случае изображений сверточный слой преобразует один пакет
134 | Глава 6
Рис. 6.1. Локальное рецептивное поле нейрона
Рис. 6.2. Локальное рецептивное поле "нейрона" в сверточной сети
изображений в другой (рис. 6.3). В следующем разделе мы представим более подробную информацию о том, как строится сверточный слой.
Стоит подчеркнуть, что локальные рецептивные поля не обязательно должны ограничиваться только данными изображений. Например, в многоярусных сверточных архитектурах, где выход из одного сверточного слоя поступает на вход следующего, локальное рецептивное поле будет соответствовать ’’участку” обрабатываемых признаковых данных.
Сверточные нейронные сети | 135
Рис. 6.3. Сверточный слой выполняет преобразование изображения
Сверточные ядра
В предыдущем разделе мы упомянули, что сверточный слой применяет нелинейную функцию к локальному рецептивному полю во входных данных. Такое локально применяемое нелинейное преобразование лежит в основе сверточных архитектур, но это не единственная часть. Вторая часть свертки называется сверточным ядром. Сверточное ядро — это просто матрица весов, во многом подобная весам, ассоциированным с полносвязным слоем. На рис. 6.4 схематически показано, как сверточное ядро применяется к входным данным1.
0 0 0 0 0 0
0 0 21 0 0 0 0
0 85 71 0 0 0 0
0 250 231 127 63 3 0
0 250 252 250 209 56 0
0 250 252 250 250 83 0
0 0 0 0 0 0 0
Изображение
О _o__L
О 1 О
1 О О
Ядро
Карта признаков
Рис. 6.4. Сверточное ядро применяется к входным данным. Ядерные веса перемножаются поэлементно с соответствующими числами в локальном рецептивном участке, и получившиеся произведения суммируются. Обратите внимание, что это соответствует сверточному слою без нелинейного преобразования
Ключевая идея сверточных сетей заключается в том, что одно и то же (нелинейное) преобразование применяется к каждому локальному рецептивному полю в изображении. Визуально изобразите локальное рецептивное поле как скользящее окно, перетаскиваемое поверх изображения. В каждой позиции локального рецептивного поля нелинейная функция применяется для получения одного числа, соответствующего конкретному участку изображения. Как показано на рис. 6.4, это преобра
1 См. интуитивно понятную демонстрацию и объяснение (на англ, яз.) работы сверточной сети на странице https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/ — Прим. пер.
136 | Гпава 6
зование превращает одну решетку чисел в другую решетку чисел. Для графических данных принято обозначать размер локального рецептивного поля в терминах количества пикселов на каждом размере рецептивного поля. Например, в сверточных сетях обычно встречаются размеры локальных рецептивных полей 5x5 и 7x7.
Что делать, если мы хотим указать, что локальные рецептивные поля не должны перекрываться? Это можно сделать, изменив размер шага сверточного ядра. Размер шага управляет перемещением рецептивного поля над входными данными. На рис. 6.4 показано одномерное сверточное ядро с шагами 1 и 2 соответственно. На рис. 6.5 представлено, как изменение размера шага меняет перемещение рецептивного поля по входным данным.
Это яснее всего видно на одномерном входе. Сеть слева имеет шаг 1, в то время как та, что справа, имеет шаг 2. Обратите внимание, что каждое локальное рецептивное поле вычисляет максимум своих входных данных
Теперь обратите внимание, что сверточное ядро, которое мы определили, преобразует решетку чисел в другую решетку чисел. Что делать, если мы хотим получить более одной решетки чисел на выходе? Это достаточно легко: нам просто нужно добавить для обработки изображения больше сверточных ядер. Сверточные ядра также называются фильтрами, поэтому количество фильтров в сверточном слое управляет количеством преобразованных решеток, которые мы получаем. Коллекция сверточных ядер образует сверточный слой.
Сверточные ядра на многомерных входных данных
В этом разделе мы описали сверточные ядра преимущественно как преобразование решеток чисел в другие решетки чисел. Ссылаясь на наш тензорный язык из предыдущих глав, свертки преобразуют матрицы в матрицы.
Что делать, если ваши входные данные имеют больше размерностей? Например, изображение с цветовой схемой RGB обычно имеет три цветных канала, поэтому такое изображение по праву является тензором 3-го ранга. Самый простой способ обработки данных RGB — указать, что каждое локальное рецептивное поле содержит все цветные каналы, связанные с пикселами в этом участке. Тогда можно сказать, что для локального рецептивного поля размером 5x5 пикселов в трех цветных каналах локальное рецептивное поле имеет размер 5x5x3.
В общем случае можно обобщить выводы на тензоры более высокой размерности, соответствующим образом расширив размерность локального
Сверточные нейронные сети | 137
рецептивного поля. Такое действие также может потребовать многомерных шагов, в особенности если разные размерности должны обрабатываться по отдельности. Детали просты в разработке, и мы оставляем вам исследование многомерных сверточных ядер в качестве упражнения.
Редуцирующие слои
В предыдущем разделе мы ввели понятие сверточных ядер. Такие ядра применяют заучиваемые нелинейные преобразования к локальным участкам входных данных. Эти преобразования поддаются заучиванию и по теореме об универсальной аппроксимации способны обучаться на локальных участках произвольно сложным входным преобразованиям. Такая гибкость придает сверточным ядрам значительную часть их мощи. Но в то же время наличие большого количества заучиваемых весов в глубокой сверточной сети может замедлить процесс ее тренировки.
Вместо использования заучиваемого преобразования можно использовать фиксированное нелинейное преобразование, тем самым уменьшив вычислительные затраты на тренировку сверточной сети. Популярным фиксированным нелинейным преобразованием является максимально редуцирующий слои1. Такие слои отбирают и передают на выход максимально активирующиеся входные данные в пределах каждого локального рецептивного участка. Этот процесс показан на рис. 6.6. Редуцирующие слои полезны для структурированного уменьшения размерности входных данных. В более математическом смысле они принимают локальное рецептивное поле и заменяют нелинейную активационную функцию в каждой части поля функцией max (либо min, либо average).
Редуцирующие слои стали менее полезны по мере совершенствования оборудования. Хотя редукция по-прежнему эффективна в качестве метода уменьшения раз-
Одиночный срез глубины
1 1 2 4
5 6 7 со
3 2 1 0
1 2 3 4
Максимальная редукция с фильтрами 2x2 и шагом 2
6 со
3 4
У
Рис. 6.6. Иллюстрация максимально редуцирующего слоя. Обратите внимание на то, как на выход передается максимальное значение в каждой цветной области (каодом локальном рецептивном поле)
2 Максимально редуцирующий слой (max pooling) берет максимальное значение участка/окна окрестных признаков для уменьшения количества активаций и приводит к инвариантности сдвига в изображении. В отечественной литературе термин pooling layer часто переводится как субдискретизирую-щий, или подвыборочный, слой. — Прим. пер.
138 | Глава 6
мерности, новейшие исследования, как правило, избегают использования редуцирующих слоев из-за присущей им теряемости данных (из редукции данных невозможно вычленить, какой пиксел на входе породил сообщенную активацию). Тем не менее редукция появляется во многих стандартных сверточных архитектурах, поэтому ее стоит понимать.
Конструирование сверточных сетей
В простой сверточной архитектуре к входным данным применяется серия сверточных и редуцирующих слоев, чтобы обучить ее сложной функции на данных входного изображения. В формировании этих сетей существует много деталей, но в своей основе архитектурная конструкция представляет собой не что иное, как сложную форму компоновки по принципу LEGO. На рис. 6.7 показано, как сверточная архитектура строится из составных блоков.
связь
Рис. 6.7. Простая сверточная архитектура, сконструированная из многоярусных сверточных и редуцирующих слоев
Растянутые свертки
Растянутые свертки, или atrous-свертки, — это новый популярный вид сверточного слоя. Оригинальная идея здесь состоит в том, чтобы оставлять пропуски в локальном рецептивном поле для каждого нейрона (a trous на французском языке означает "с дырами"). В его основе лежит старая концепция из цифровой обработки сигналов, которая недавно вошла в оборот в сверточной литературе.
Основным преимуществом atrous-свертки является увеличение видимой области для каждого нейрона. Рассмотрим архитектуру свертки, первый слой которой является классическим сверточным слоем с локальными рецептивными полями 3x3. Затем нейрон на один слой глубже в архитектуре во втором классическом сверточном слое имеет рецептивную глубину 5x5 (каждый нейрон в локальном рецептивном поле второго слоя сам имеет локальное рецептивное поле в первом слое). Затем нейрон на два слоя глубже имеет рецептивный обзор 7 х 7. В общем случае, нейрон N слоев внутри сверточной архитектуры имеет рецептивный обзор размером (2N +l)x(2N + l). Этот линейный рост в рецептивном обзоре хорош для небольших изображений, но быстро становится помехой для крупных изображений.
Сверточные нейронные сети | 139
Atrous-свертка обеспечивает экспоненциальный рост в видимом рецептивном поле, оставляя пропуски в своих локальных рецептивных полях. ”1-растянутая” свертка не оставляет пропусков, тогда как ”2-растянутая” свертка оставляет один пропуск между каждым элементом локального рецептивного поля. Ярусная укладка растянутых слоев приводит к экспоненциальному увеличению размеров локального рецептивного поля. На рис. 6.8 показано это экспоненциальное увеличение.
Растянутые свертки бывают очень полезными для больших изображений. Например, медицинские изображения могут растягивать тысячи пикселов в каждой размерности. Создание классических сверточных сетей, имеющих глобальное понимание, потребует неоправданно глубоких сетей. Использование растянутых сверток позволяет сетям лучше понимать глобальную структуру таких изображений.
Рис. 6.8. Растянутая свертка. Для каодого нейрона оставляются пропуски в локальном рецептивном поле: а — диаграмма 1-растянутой свертки 3x3; б — применение 2-растянутой свертки 3x3 к свертке (а); в — применение 4-растянутой свертки 3x3 к свертке (6). Обратите внимание, что слой (а) имеет рецептивное поле шириной 3, слой (6) — рецептивное поле шириной 7, слой (а) — рецептивное поле шириной 15
Применения сверточных сетей
В предыдущем разделе мы рассмотрели механизм сверточных сетей и познакомили вас со многими компонентами, которые составляют эти сети. В этом разделе мы опишем некоторые приложения, которые позволяют использовать сверточные архитектуры.
Обнаружение и локализация объектов
Обнаружение объектов— это задача выявления объектов (или сущностей), присутствующих на фотографии. Локализация объекта — это задача определения, где на изображении существуют объекты, и нанесения ’’ограничивающей рамки" вокруг каждого появления объекта. На рис. 6.9 показано, как выглядит обнаружение и локализация на стандартных изображениях.
Почему обнаружение и локализация важны? Одной из очень полезных задач локализации является обнаружение пешеходов на снимках, сделанных из автомобиля, двужущегося на автопилоте. Излишне говорить, что чрезвычайно важно, чтобы такой автомобиль мог идентифицировать всех находящихся поблизости пешеходов.
140 | Глава 6
Рис. 6.9. Объекты, обнаруженные и локализованные ограничительными рамками на нескольких демонстрационных изображениях
Другие приложения обнаружения объектов могут использоваться для поиска всех появлений друзей на фотографиях, загруженных в социальную сеть. Еще одним приложением может быть выявления потенциальных опасностей столкновения с беспилотником.
Эта масса применений привела к тому, что задача обнаружения и локализации стала во главу угла огромного количества исследовательских работ. Конкурс ILSVRC, упомянутый несколько раз в этой книге, сосредоточен на обнаружении и локализации объектов, которые можно найти в коллекции ImagetNet.
Сегментация изображений
Сегментация изображения — это задача по маркировке каждого пиксела изображения объектом, которому он принадлежит. Сегментация связана с локализацией объектов, но значительно сложнее, т. к. требует точного понимания границ между
Рис. 6.10. Объекты на изображении "сегментированы" на разные категории. Ожидается, что сегментация изображений окажется очень полезной для таких применений, как беспилотные автомобили и робототехника, т. к. оно позволит достигать подробнейшего понимания сцен
Сверточные нейронные сети | 141
объектами на изображениях. До недавнего времени сегментация изображений часто выполнялась с помощью графических моделей, т. е. альтернативной формы машинного самообучения (в отличие от глубоких сетей), но в последнее время сверточные сегментации стали более заметными и позволили алгоритмам сегментации изображений достичь новых рекордов точности и скорости. На рис. 6.10 показан пример сегментации изображения применительно к данным визуальной информации самоходных автомобилей.
Графовые свертки
Сверточные алгоритмы, которые мы показали вам к этому моменту, ожидают в качестве своих входных данных прямоугольные тензоры. Такие входы могут быть в виде изображений, видео или даже предложений. Можно ли обобщить свертки для применения к нерегулярным входным данным?
Фундаментальной идеей, положенной в основу сверточных слоев, является понятие локального рецептивного поля. Каждый нейрон выполняет вычисление на входных данных в своем локальном рецептивном поле, которые обычно составляют смежные пикселы на входном изображении. Что касается нерегулярных входных данных, таких как ненаправленный (неориентированный) граф на рис. 6.11, то это простое понятие локального рецептивного поля не имеет смысла; смежные пикселы отсутствуют. Если мы сможем определить более общее локальное рецептивное поле для ненаправленного графа, то мы будем в состоянии определять сверточные слои, которые принимают ненаправленные графы.
Как показано на рис. 6.11, граф состоит из множества узлов, соединенных ребрами. Одним из потенциальных определений локального рецептивного поля может быть его определение как содержащего узел и его коллекцию соседей (где два узла считаются соседями, если они соединены ребром). Используя это определение локальных рецептивных полей, можно сформулировать обобщенные понятия сверточного и редуцирующего слоев. Эти слои могут быть собраны в графовые сверточные архитектуры.
Рис. 6.11. Иллюстрация ненаправленного графа, состоящего из узлов, связанных ребрами
142 | Гпава б
Молекула
1. Задать
к - deg(v)
Топология —*-графа
Атомарные — признаки
L
' Вернуть топологию и признаки атомов
2. 3.
Применить Применить
графовые стягивание
свертки графа
и редукции
4. > Применить опорные слои
Редукция графа
2.
for и in neigh(v) <j{v} задать d = dist (v, w)
преобразовать признаки и' = и + bkd
3. Суммировать все и, применить нелинейную функцию
4. \ Вернуть признаки для V
Рис. 6.12. Графовая сверточная архитектура, обрабатывающая молекулярные входные данные. Молекула смоделирована как ненаправленный граф, в котором атомы формируют узлы, а химические связи — ребра. 'Топологией графа" является ненаправленный граф, который соответствует молекуле. "Признаками атома" служат векторы, один на атом.
Это адаптированная версия, взятая из статьи "Обнаружение новых медицинских препаратов на малых данных с однократным самообучением"3
3 Altae-Tran Н., Ramsundar В., Pappu A. S., PandeLow V. Data Drug Discovery with One-Shot Learning.
Сверточные нейронные сети | 143
Где могут быть полезными такие графовые сверточные архитектуры? Оказывается, что в химии молекулы могут быть смоделированы как ненаправленные графы, где атомы образуют узлы, а химические связи — ребра. Поэтому графовые сверточные архитектуры особенно полезны в химическом машинном самообучении. Например, на рис. 6.12 показано, как можно применить графовую сверточную архитектуру к обработке молекулярных входных данных.
Генерирование изображений
с помощью вариационных автокодировщиков
Все приложения, которые мы описали к этому моменту, представляют собой задачи контролируемого самообучения. Иными словами, имеются четко сформулированные входные и выходные данные, и задача по-прежнему (используя сверточную сеть) остается в том, чтобы узнать сложную функцию, которая преобразует вход в выход. Существуют ли задачи неконтролируемого самообучения, которые могут решаться с помощью сверточных сетей? Напомним, что неконтролируемое самообучение требует ’’понимания” структуры точек входных данных. Если говорить о моделировании изображений, то здесь хорошим показателем понимания структуры входных изображений является возможность ’’получать образцы” новых изображений из входного распределения.
Что означает "получение образца” изображения? Давайте для начала предположим, что у нас есть набор данных с изображениями собак. Получение образца нового изображения собаки требует генерирования нового изображения собаки, которого нет в тренировочных данных* Идея заключается в том, что мы хотим иметь фотографию собаки, которая могла бы быть обоснованно включена в тренировочные данные, но туда не попала. Как можно решить эту задачу с помощью сверточных сетей?
Наверное, мы могли бы натренировать модель, принимающую словарные метки, например ’’собака”, и предсказывающую изображения собак. И вполне возможно, что для решения этой предсказательной задачи мы сможем натренировать контролируемую модель, но проблема остается по-прежнему в том, что при наличии входной метки "собака” наша модель сможет генерировать только одну фотографию собаки. Предположим, что теперь за каждой собакой мы можем закрепить случайный тег, скажем, "собака3422" или ”собака9879”. Тогда все, что от нас потребуется, чтобы получить новое изображение собаки, — это прикрепить новый случайный тег, скажем, "собака2221", и получить эту новую фотографию собаки.
Вариационные автокодировщики формализуют эти интуитивные подходы и состоят из двух сверточных сетей: кодировщика и декодировщика. Сеть кодировщика используется для преобразования изображения в плоский "встроенный” вектор. Сеть декодировщика отвечает за преобразование встроенного вектора в изображения. Для того чтобы гарантировать способность декодировщика получать образцы разных изображений, добавляется шум. На рис. 6.13 показан вариационный автокодировщик.
144 | Глава 6
Латентное пространство
Рис. 6.13. Схематическая иллюстрация вариационного автокодировщика. Вариационный автокодировщик состоит из двух сверточных сетей — кодировщика и декодировщика
Фактическая реализация вариационных автокодировщиков влечет за собой еще больше деталей, но они действительно обладают способностью получать образцы изображений. Вместе с тем наивные вариационные кодировщики, судя по всему, порождают размытые образцы (рис. 6.14). Эта размытость может быть вызвана тем, что А2 -потеря не накладывает строгий штраф на размытость изображения (вспомните наше обсуждение £2 -потери, которая не штрафует небольшие отклонения). Для создания четких образцов изображений нам понадобятся другие архитектуры.
Рис. 6.14. Образцы изображений, полученных из вариационного автокодировщика, натренированного на наборе лиц. Обратите внимание, что образцы изображений довольно размытые
Сверточные нейронные сети | 145
Состязательные модели
1} -потеря строго штрафует крупные локальные отклонения, но не сильно штрафует много малых локальных отклонений, вызывая размытость. Как спроектировать альтернативную функцию потери, которая строже штрафует размытость изображений? Оказывается, довольно сложно написать функцию потери, которая реализует этот прием. В то время как наши глаза могут быстро обнаруживать размытость, наши аналитические инструменты не настолько быстры, чтобы ухватить проблему.
А можно ли каким-то образом "обучиться" функции потери? Сначала эта идея звучит немного бессмысленно, поскольку не понятно, где получить тренировочные данные? Но оказывается, что существует блестящая идея, которая делает это возможным.
Предположим, мы можем натренировать отдельную сеть, которая заучивает потерю. Назовем эту сеть дискриминатором. Давайте назовем сеть, которая создает изображения, генератором. Генератор может быть настроен так, чтобы он соперничал с дискриминатором до тех пор, пока генератор не научится производить изображения, которые являются фотореалистичными. Эта форма архитектуры обычно называется генеративно-состязательной сетью, или GAN-сетью.
Лица, генерируемые GAN-сетью (рис. 6.15),— гораздо четче, чем те, которые порождает наивный вариационный автокодировщик (см. рис. 6.14)! Кроме того,
Рис. 6.15. Образцы изображений, полученные из генеративно-состязательной сети (GAN), натренированной на наборе лиц. Обратите внимание, что полученные образцы изображений менее расплывчатые, чем образцы изображений из вариационного автокодировщика
146 | Глава 6
GAN-сети достигли ряда других многообещающих результатов. Например, сеть CycleGAN, судя по всему, способна обучаться сложным преобразованиям изображений, таким как превращение лошадей в зебр и наоборот. На рис. 6.16 показано несколько преобразований изображений CycleGAN.
Зебры Лошади
Рис. 6.16. Сеть CycleGAN способна выполнять сложные преобразования изображений, такие как преобразование изображений лошадей в изображения зебр (и наоборот)
К сожалению, на практике генеративно-состязательные сети по-прежнему с трудом поддаются тренировке. Для того чтобы заставить генераторы и дискриминаторы обучаться разумным функциям, требуется большой запас хитроумных приемов. Поэтому, хотя и существует много будоражащих демонстраций GAN-сетей, пока что они еще не дозрели до состояния, когда их можно широко внедрять в промышленных приложениях.
Тренировка сверточной сети в TensorFlow
В этом разделе мы рассмотрим образец программного кода для тренировки простой сверточной нейронной сети. В частности, наш образец кода продемонстрирует, как тренировать сверточную архитектуру LeNet-5 на наборе данных MNIST, используя библиотеку TensorFlow. Как всегда, мы рекомендуем вам сверяться, попутно выполняя полный образец программного кода, размещенный в хранилище GitHub (https://github.com/matroid/dlwithtf), связанном с этой книгой.
Набор данных MNIST
Набор данных MNIST состоит из изображений рукописных цифр. Задача машинного самообучения, связанная с MN1ST, состоит в создании модели, натренированной на тренировочном наборе цифр, которая обобщается на контрольный набор. На рис. 6.17 показано несколько изображений, полученных из набора данных MNIST.
Сверточные нейронные сети | 147
3 9 г \ ?SiX/g
470/ G 3 И 7 0
5 / -' ? 4 i / а 27343^
I SЯ % 3 * Я 7 33
° 3 \ Я > 3 i О
1
4'704,' " 5 4- 3 Я ? 1 О 4> Я 4» з
Рис. 6.17. Несколько изображений рукописных цифр из набора данных MNIST.
Задача самообучения состоит в том, чтобы научиться идентифицировать цифру на изображении
Набор данных MNIST имел большое значение для разработки методов машинного самообучения для компьютерного зрения. Этот набор данных настолько сложен, что очевидные необучающиеся методы, как правило, справляются не очень хорошо. В то же время MNIST настолько мал, что эксперименты с новыми архитектурами не требуют больших вычислительных мощностей.
Вместе с тем набор данных MNIST, в основном, устарел. Лучшие модели достигают почти 100-процентной точности на тестовом наборе. Обратите внимание, что этот факт не означает, что задача распознавания рукописных цифр решена! Скорее всего, исследователи плотно подогнали архитектуру под набор данных MNIST и воспользовались его характерными особенностями для достижения очень высокой предсказательной точности. Вследствие этого использовать MNIST для разработки новых глубоких архитектур больше не рекомендуется. С учетом сказанного, MNIST по-прежнему остается превосходным набором данных для педагогических целей.
Скачивание набора данных MNIST
Кодовая база MNIST доступна онлайн на сайте Яна Лекуна (Yann LeCun) (http;//yannJecunxom/exdb/mnist/). Загрузочный сценарий скачивает сырой файл с веб-сайта. Обратите внимание на то, как этот сценарий кэширует скачанные данные, чтобы повторные вызовы функции download () не тратили силы впустую.
В качестве более общего замечания, наборы данных для машинного самообучения вполне нормально хранить в облаке и извлекать их пользовательским кодом перед обработкой для ввода в обучающийся алгоритм. Набор данных Тох21, к которому мы обращались через библиотеку DeepChem в главе 4, следовал тому же шаблону проектирования. В общем случае, если вы хотите разместить большой набор данных для анализа в облаке, то хранение его в облаке и загрузка на локальный ком
148 | Глава 6
пьютер по мере необходимости для обработки считается хорошей практикой. (Однако этот прием не работает для очень больших наборов данных, где время передачи по сети становится непомерно дорогим.) См. пример 6.1.
| Пример 6.1. Эта функция скачивает набор данных MNIST
def download(filename):
’’’’’’Скачать данные с веб-сайта Яна Лекуна, если это еще не было сделано.””’’
if not os.path.exists(WORK_DIRECTORY):
os.makedirs(WORK_DIRECTORY)
filepath = os.path.join(WORK_DIRECTORY, filename)
if not os.path.exists(filepath):
filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename,
filepath)
size = os.stat(filepath).st_size
print(’Успешно скачан’, filename, size, ’байт.’)
return filepath
Приведенная функция проверяет наличие рабочего каталога work directory. Существование этого каталога воспринимается так, что набор данных MNIST уже скачан. В противном случае этот сценарий использует библиотеку Python urllib, чтобы скачать данные, и выводит сведения о количестве скачанных байтов.
Набор данных MNIST хранится в виде сырой строки байтов, в которой закодированы значения пикселов. Для того чтобы легко обработать эти данные, нам нужно конвертировать их в массив NumPy. Удобство функции np.frombuffer состоит в том, что она позволяет преобразовывать сырой байтовый буфер в числовой массив (пример 6.2). Как мы уже отмечали в других разделах этой книги, глубокие сети могут быть дестабилизированы входными данными, занимающими широкие диапазоны. Для стабильного градиентного спуска часто необходимо сократить рамки входных данных, чтобы они охватывали ограниченный диапазон. Исходный набор данных MNIST содержит значения пикселов в диапазоне от 0 до 255. Для стабильности этот диапазон должен быть смещен, чтобы иметь нулевое среднее и единичный диапазон (от -0,5 до +0,5).
Пример 6.2. Извлечение изображений из скачанного набора данных в массивы NumPy
def extract_data(filename, num_images) :
’’’’’’Извлечь изображения в 4-мерный тензор [индекс изображения, у, х, каналы] .
Значения перешкалируются из [0, 255] вплоть до [-0.5, 0.5]. »» п п
print(’Извлечение’, filename)
with gzip.open(filename) as bytestream:
bytestream.read(16)
Сверточные нейронные сети | 149
buf = bytestream.read(IMAGE_SIZE * IMAGE_SIZE * num_images * NUM_CHANNELS) data = numpy.frombuffer(buf, dtype=numpy.uint8).astype(numpy.float32) data = (data - (PIXEL_DEPTH / 2.0)) / PIXEL_DEPTH
data = data.reshape(num_images, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS) return data
Метки хранятся в простом файле в виде строки байтов. Данные содержат заголовок, состоящий из 8 байт, а оставшиеся данные содержат метки (пример 6.3).
.. ----- — ----------------------------— - ------------- - - • 1
Пример 6.3. Функция, извлекающая метки из скачанного набора данных в массив меток i
def extract_labels(filename, num_images):
'"’"Извлечь метки в вектор идентификаторов меток с типом int64."""
print('Извлечение', filename)
with gzip.open(filename) as bytestream:
bytestream.read(8)
buf = bytestream.read(1 * num_images) labels = numpy.frombuffer(buf, dtype=numpy.uint8).astype(numpy.int64) return labels
Учитывая функции, определенные в предыдущих примерах, теперь можно скачать и обработать тренировочные и тестовые наборы данных MNIST (пример 6.4).
Пример 6.4. Использование функций, определенных в предыдущих примерах. |
। Этот фрагмент кода скачивает и обрабатывает тренировочные и тестовые наборы I
данных MNIST I
. ______________________________________________ j
# Получить данные
train_data_filename = download('train-images-idx3-ubyte.gz') train_labels_filename = download('train-labels-idxl-ubyte.gz') test_data_filename = download('tl0k-images-idx3-ubyte.gz') test_labels_filename = download('tlOk-labels-idxl-ubyte.gz')
# Извлечь их в массивы NumPy
train_data = extract_data(train_data_filename, 60000)
train_labels = extract_labels(train_labels_filename, 60000)
test_data = extract_data(test_data_filename, 10000) test_labels = extract_labels(test_labels_filename, 10000)
Набор данных MNIST не определяет контрольный набор данных для гиперпараметрической настройки явным образом. По этой причине в качестве контрольных данных мы вручную назначаем последние 5000 точек данных тренировочного набора данных (пример 6.5).
150 | Гпава 6
Гпример 6.5. Извлечение заключительных 5000 элементов тренировочных данных ^для контроля гиперпараметров
VALIDATION_SIZE = 5000 # размер контрольного набора
# Сгенерировать контрольный набор
validation_data = train_data[:VALIDATION_SIZE, ...] validation_labels = train_labels[:VALIDATION_SIZE] train_data = train_data[VALIDATION_SIZE:, ...] train_labels = train_labels[VALIDATION_SIZE:]
Получение образца правильного контрольного набора
В примере 6.5 в качестве контрольного набора для измерения результативности наших методов самообучения мы используем заключительный фрагмент тренировочных данных. В этом случае такой метод относительно безвреден. Распределение данных в тестовом наборе хорошо представлено распределением данных в контрольном наборе.
Однако в других ситуациях такой тип простого определения контрольного набора может быть катастрофическим. В молекулярном машинном самообучении (приложении машинного самообучения для предсказания свойств молекул) почти всегда тестовое распределение резко отличается от тренировочного распределения. Ученые больше всего заинтересованы в перспективном предсказании, т. е. они хотели бы предсказывать свойства молекул, которые никогда не испытывались для рассматриваемого свойства. В этом случае использование последнего фрагмента тренировочных данных для контроля или даже случайной подвыборки тренировочных данных приведет к ошибочно высокой точности. Довольно часто молекулярная машинно-обучающаяся модель имеет точность 90% на контрольных данных и, к примеру, 60% на тестовых.
Для того чтобы исправить эту ошибку, необходимо спроектировать методы получения образца контрольного набора, которые прилагают все усилия, чтобы сделать контрольный набор непохожим на тренировочный. Для молекулярного машинного самообучения разработан целый ряд таких алгоритмов, подавляющая часть которых используют разные математические оценки различия графов (рассматривая молекулу как математический граф с атомами в качестве узлов и химическими связями в качестве ребер).
Эта проблема возникает и во многих других областях машинного самообучения. В медицинском или в финансовом машинном самообучении опора на исторические данные для выполнения предсказаний может быть катастрофической. В каждом приложении машинного самообучения важно критически рассуждать о том, является ли результативность полученного образца контрольного набора на самом деле хорошим косвенным показателем истинной результативности.
Сверточные нейронные сети | 151
Сверточные примитивы TensorFlow
Начнем с введения примитивов TensorFlow, которые используются для построения сверточных сетей (пример 6.6).
i Пример 6.6. Определение двухмерной свертки в TensorFlow
tr.nn.conv2d( input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None
)
Функция tf.nn.conv2d() — это встроенная в TensorFlow функция, которая определяет сверточные СЛОИ. Здесь ВВОДИТСЯ тензор формы (пакет, высота, ширина, каналы) , где пакет — это количество изображений в мини-пакете.
Обратите внимание, что определенные ранее функции преобразования считывают данные MNIST в этот формат. Аргумент filter— это тензор формы (высо-та_фильтра, ширина_фильтра, каналы, выходные_каналы), КОТОрЫЙ задает заучиваемые веса для нелинейного преобразования, заученного в сверточном ядре. Аргумент strides содержит шаги фильтра и представляет собой список длиной 4 (по одному для каждой входной размерности).
Аргумент padding управляет дополнением входных тензоров лишними нулями (рис. 6.18), тем самым гарантируя, что данные на выходе из сверточного слоя имеют ту же форму, что и данные на входе. Если padding=”SAME”, то входные данные input дополняются нулями, обеспечивая из сверточного слоя вывод тензора той же формы, что и оригинальный входной тензор изображения. Если padding=”VALiD”, то дополнение нулями не используется.
Рис. 6.18. Дополнение нулями для сверточных слоев гарантирует, что выходное изображение имеет ту же форму, что и у входного изображения
152 | Гпава 6
Фрагмент кода в примере 6.7 определяет в TensorFlow максимально редуцирующий слой.
| Пример 6.7. Определение максимально редуцирующего слоя в TensorFlow
tf.nn.maxjDool( value, ksize, strides, padding, data_format='NHWC', name=None
Функция tf .nn.max pool о выполняет редукцию на основе функции max. Здесь value имеет ту же форму, ЧТО И ВХОД input ДЛЯ tf .nn.conv2d(пакет, высота, ширина, каналы). Аргумент ksize — это размер окна редукции и представляет собой список длиной 4. Аргументы strides и padding ведут себя так же, как для tf .nn.conv2d.
Сверточная архитектура
Определенная в этом разделе архитектура будет близко напоминать LeNet-5 — оригинальную архитектуру, используемую для тренировки сверточных нейронных сетей на наборе данных MNIST. В то время когда была изобретена архитектура LeNet-5, она была непомерно ресурсоемкой в вычислительном плане, требуя для завершения тренировки нескольких недель вычислений. В наши дни, чтобы тренировать модели LeNet-5, к счастью, более чем достаточно современного ноутбука. На рис. 6.19 представлена структура архитектуры LeNet-5.
Вход 32x32
С1: карты S2: карты СЗ: карты
признаков признаков признаков
6@28х28 6@14х14 16@10х10
S4: карты С5: слой F6: слой Выход признаков 120 84 10
16@5х5
связь связи
Рис. 6.19. Сверточная архитектура LeNet-5
Где больший объем вычислений имеет реальное значение?
Возраст архитектуры LeNet-5 насчитывает десятилетия, но она по существу является правильной архитектурой для задачи распознавания цифр. Тем не менее вычислительные потребности этой архитектуры оставляли ее в относительной неизвестности в течение десятилетий. Тогда вызывает инте-
Сверточные нейронные сети | 153
pec следующий вопрос: какие исследовательские задачи сегодня решаются аналогичным образом, но ограничиваются исключительно отсутствием адекватной вычислительной мощности?
Одним из сопоставимых претендентов является обработка видео. Сверточные модели достаточно хороши в обработке видеоданных. Однако они громоздки в хранении и тренировке моделей на больших наборах видеоданных, поэтому большинство научных работ молчат о результатах на видеоданных. Вследствие этого наспех скомпоновать хорошую систему обработки видеоданных не так просто.
Эта ситуация, вероятно, изменится по мере увеличения вычислительных возможностей, и вполне вероятно, что системы обработки видеоданных станут гораздо более распространенным явлением. Вместе с тем существует одно критическое различие между сегодняшними улучшениями в аппаратных средствах и теми, которые происходили в прошлые десятилетия. В отличие от прошлых лет выполнение закона Мура резко замедлилось. Это явилось результатом того, что улучшения в оборудовании требуют более чем естественного сжатия транзисторов и часто значительной изобретательности в проектировании архитектур. Мы вернемся к этой теме в последующих главах и обсудим архитектурные потребности глубоких сетей.
Давайте определим веса, необходимые для тренировки нашей сети LeNet-5. Мы начнем с определения нескольких основных констант, которые используются для задания наших весовых тензоров (пример 6.8).
|пример 6.8. Определение основных констант для модели LeNet-5 |
NUM_CHANNELS = 1
IMAGE_SIZE =28
NUM_LABELS =10
Определяемая нами архитектура будет использовать два сверточных слоя вперемешку с редуцирующими слоями, заканчиваясь двумя полносвязными слоями. Напомним, что в редуцирующем слое заучиваемые веса не требуются, поэтому нам нужно создать веса только для сверточных и полносвязных слоев. Для каждой функции tf.nn.conv2d() нам нужно создать тензор с заучиваемыми весами, соответствующий аргументу filter для tf ,nn.conv2d.() В этой конкретной архитектуре мы также добавим сверточное смещение, по одному для каждого выходного канала (пример 6.9).
| Пример 6.9. Определение заучиваемых весов для сверточных слоев |
convl_weights = tf.Variable(
tf.truncated_normal([5, 5, NUM_CHANNELS, 32], # фильтр 5x5, # глубина 32. stddev=0.1, seed=SEED, dtype=tf.float32))
154 | Глава 6
convl_biases = tf.Variable(tf.zeros([32], dtype=tf.float32)) conv2_weights = tf.Variable(tf.truncated_normal(
[5, 5, 32, 64], stddev=0.1,
seed=SEED, dtype=tf.float32))
conv2_biases = tf.Variable(tf.constant(0.1, shape=[64], dtype=tf.float32))
Обратите внимание, что сверточные веса являются тензорами 4-го ранга, а смещения— тензорами 1-го ранга. Первый полносвязный слой конвертирует выходы сверточного слоя в вектор размера 512. Входные изображения начинаются с размера image_size=28. После двух редуцирующих слоев (каждый из которых уменьшает входные данные в 2 раза) мы в итоге получаем изображения размером image_size//4. Мы создаем форму полносвязных весов, учитывая эти размеры.
Второй полносвязный слой используется для обеспечения 10-полосного классификационного выхода, поэтому, как показано в примере 6.10, он имеет форму весов (512, 10) и форму смещения (10).
' Пример 6.10. Определение заучиваемых весов для полносвязных слоев
fcl_weights = tf.Variable( # полносвязный, глубина 512.
tf.truncated_norrnal( [IMAGE_SIZE // 4 * IMAGE_SIZE // 4 * 64, 512],
stddev=0.1,
seed=SEED, dtype=tf.float32))
fcl_biases = tf.Variable(tf.constant(0.1, shape=[512], dtype=tf.float32))
fc2_weights = tf.Variable(tf.truncated_normal([512, NUM_LABELS],
stddev=0.1, seed=SEED, dtype=tf.float32))
fc2_biases = tf.Variable(tf.constant(
0.1, shape=[NUM_LABELS], dtype=tf.float32))
Вычислив все веса, мы теперь можем определить архитектуру сети. Архитектура имеет шесть слоев по схеме “свертка — редукция — свертка — редукция — полная связь — полная связь” (пример 6.11).
| Пример 6.11. Определение архитектуры LeNet-5. Вызов функции, определенной в этом примере, создаст экземпляр архитектуры
def model(data, train=False):
”””Определение модели.”””
# Двухмерная свертка с заполнением ’SAME' (т. е. выходная карта # признаков имеет тот же размер, что и вход).
# Примечание: {strides} - это четырехмерный массив,
# форма которого соответствует конфигурации данных: # [индекс изображения, у, х, глубина].
Сверточные нейронные сети | 155
conv = tf.nn.conv2d(data, convl_weights, strides=[l, 1, 1, 1], padding=’SAME’)
# Смещение и нелинейное преобразование ReLU.
relu = tf.nn.relu(tf.nn.bias_add(conv, convl_biases))
# Максимальная редукция. Спецификация размера ядра {ksize} также
# соответствует конфигурации данных. Здесь мы имеем окно редукции # размером 2 и шаг размером 2. pool = tf.nn.max_pool(relu, ksize=[l, 2, 2, 1], strides=[l, 2, 2, 1], padding=’SAME’) conv = tf.nn.conv2d(pool, conv2_weights, strides=[l, 1, 1, 1], padding=’SAME’)
relu = tf.nn.relu(tf.nn.bias_add(conv, conv2_biases)) pool = tf.nn.max_pool(relu, ksize=[l, 2, 2, 1], strides=[l, 2, 2, 1], padding=’SAME’)
# Реформировать кубоид с картой признаков в двухмерную матрицу, # чтобы подать ее в полносвязные слои. pool_shape = pool.get_shape().as_list() reshape = tf.reshape( pool, [pool_shape[0], pool_shape[1] * pool_shape[2] * pool_shape[3]]) # Полносвязный слой. Примечание: операция автоматически # транслирует смещения.
hidden = tf.nn.relu(tf.matmul(reshape, fcl_weights) + fcl_biases) # Добавить 50% отсев только во время тренировки.
# Отсев также шкалирует активации, что позволяет обходиться # без перешкалирования во время оценивания модели, if train:
hidden = tf.nn.dropout(hidden, 0.5, seed=SEED) return tf.matmul(hidden, fc2_weights) + fc2_biases
Как отмечалось ранее, базовая архитектура сети перемежает слои tf.nn.conv2d, tf .nn.max_pooi с нелинейными преобразованиями и конечным полносвязным слоем. В целях регуляризации отсеивающий слой применяется после конечного полносвязного слоя, но только во время тренировки. Обратите внимание, что мы передаем входные данные в функцию model () в качестве аргумента data.
Единственная часть сети, которая должна быть определена,— это заполнители (пример 6.12). Нам нужно определить два заполнителя для ввода тренировочных изображений и тренировочных меток. В этой конкретной сети мы также определя
156 | Глава 6
ем отдельный заполнитель для оценивания, который позволяет нам вводить большие пакеты во время оценивания.
Пример 6.12. Определение заполнителей для архитектуры
BATCH_S1ZE = 64
EVAL_BATCH_SIZE = 64 train_data_node = tf.placeholder( tf.float32, shape=(BATCH_SIZE, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS)) train_labels_node = tf.placeholder(tf.int64, shape=(BATCH_SIZE,)) eval—data = tf.placeholder( tf.float32, shape=(EVAL-BATCH-SIZE, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS))
Располагая этими определениями, теперь мы имеем обработанные данные, конкретизированные входы и веса, а также построенную модель. Сейчас мы готовы натренировать сеть (пример 6.13).
j Пример 6.13. Тренировка архитектуры LeNet-5
# Создать локальный сеанс для выполнения тренировки, start—time = time.time() with tf.Session() as sess:
# Выполнить все инициализаторы, чтобы подготовить # тренируемые параметры.
tf.global—variables—initializer().run() # Пройти тренировочные шаги в цикле, for step in xrange(int(num_epochs * train_size) // BATCH_SIZE): # Вычислить сдвиг текущего мини-пакета в данных.
# Примечание: здесь можно было применить более оптимальную # рандомизацию по всем эпохам, offset = (step * BATCH_SIZE) % (train_size - BATCH_SIZE) batch_data = train_data[offset:(offset + BATCH_SIZE), . ..] batch_labels = train_labels[offset:(offset + BATCH_SIZE)] # Этот словарь отображает пакетные данные (в виде массива NumPy) # на узел в графе, в который они должны быть поданы. feed_dict = {train_data_node: batch_data, train_labels—node: batch_labels}
# Выполнить оптимизатор, чтобы обновить веса, sess.run(optimizer, feed_dict=feed_dict)
Структура этого программного кода подгонки очень похожа на другой код подгонки, который мы встречали ранее в этой книге. На каждом шаге мы создаем словарь передачи данных в вычислительный граф, а затем запускаем шаг оптимизатора. Обратите внимание: как и раньше, мы используем мини-пакетную тренировку.
Сверточные нейронные сети | 157
Оценивание натренированных моделей
Теперь у нас есть натренированная модель. Как оценить точность натренированной модели? Простой метод— определить метрический показатель ошибки. Как и в предыдущих главах, для измерения точности мы будем использовать простой классификационный метрический показатель (пример 6.14).
Пример 6.14. Оценивание ошибки натренированной архитектуры j
def error_rate(predictions, labels):
"""Вернуть частоту появления ошибок, опираясь на плотные предсказания и разряженные метки.""" return 100.0 - (
100.0 *
numpy.sum(numpy.argmax(predictions, 1) == labels) /
predictions.shape[0])
Приведенную выше функцию можно использовать для оценивания ошибки сети по мере тренировки. Введем дополнительную вспомогательную функцию, которая вычисляет предсказания для любого набора данных в пакетах (пример 6.15). Необходимость этой вспомогательной функции обусловлена тем, что наша сеть может справляться с входными данными только с пакетами фиксированных размеров.
I Пример 6.15. Оценивание одного пакета данных за один раз j
L..... . ____ . __ ______ . . _________ . __ ______________J
def eval_in_batches(data, sess):
"""Получить предсказания для набора данных путем выполнения этой функции малыми пакетами.""" size = data.shape[0] if size < EVAL_BATCH_SIZE:
raise ValueError("размер пакета для eval больше набора данных: %d" % size)
predictions = numpy.ndarray(shape=(size, NUM_LABELS), dtype=numpy.float32)
for begin in xrange(0, size, EVAL_BATCH_SIZE): end = begin + EVAL_BATCH_SIZE if end <= size: predictions[begin:end, :] = sess.run( eval_prediction, feed_dict={eval_data: data[begin:end, ...]}) else:
batch—predictions = sess.run( eval_prediction, feed_dict={eval_data: data[-EVAL_BATCH_SIZE:, ...]}) predictions[begin:, :] = batch_predictions[begin - size:, :] return predictions
158 | Глава 6
Теперь мы можем добавить небольшой измерительный функционал (во внутренний цикл тренировки), который периодически оценивает точность модели в контрольном наборе. Тем самым мы можем закончить тренировку, получив оценку точности на тестовом наборе. В примере 6.16 представлен полный программный код подгонки весов с добавленным измерительным функционалом.
Пример 6.16. Полный программный код тренировки сети с добавленным измерительным функционалом
# Создать локальный сеанс для выполнения тренировки. start_time = time. time () with tf.Session() as sess:
# Выполнить все инициализаторы, чтобы подготовить
# тренируемые параметры.
tf.global—variables_initializer().run()
# Пройти тренировочные шаги в цикле.
for step in xrange(int(num_epochs * train_size) // BATCH_SIZE):
# Вычислить сдвиг текущего мини-пакета в данных.
# Примечание: здесь можно было применить более оптимальную # рандомизацию по всем эпохам.
offset = (step * BATCH_SIZE) % (train_size - BATCH_SIZE) batch—data = train_data[offset:(offset + BATCH_SIZE), ...] batch—labels = train_labels[offset:(offset + BATCH_SIZE)] # Этот словарь отображает пакетные данные (в виде массива NumPy) # на узел в графе, в который они должны быть поданы, feed—diet = {train_data_node: batch_data, train_labels—node: batch_labels}
# Выполнить оптимизатор, чтобы обновить веса, sess.run(optimizer, feed_dict=feed_dict) # Напечатать немного дополнительной информации # после достижения частоты оценивания if step % EVAL_FREQUENCY = 0: # fetch some extra nodes' data
1, Ir, predictions = sess.run([loss, learning_rate, train_prediction], feed_dict=feed_dict) elapsed—time = time.time () - start_time start—time = time. time () print('Шаг %d (epoch %.2f), %.If mc' %
(step, float(step) * BATCH_SIZE / train_size, 1000 * elapsed—time / EVAL_FREQUENCY))
print('Мини-пакетная потеря: %.3f, скорость заучивания: %.6f % (l,lr))
print('Мини-пакетная ошибка: %.lf%%' % error_rate(predictions, batch_labels))
Сверточные нейронные сети | 159
print('Контрольная ошибка: %.lf%%* % error_rate( eval_in_batches(validation_data, sess), validation_labels)) sys.stdout.flush()
# В заключении напечатать результат!
test_error = error_rate(eval_in_batches(test_data, sess), test_labels)
print('Тестовая ошибка: %.lf%%' % test_error)
Задание для читателя
Попробуйте натренировать эту сеть самостоятельно. Вы должны достичь тестовой ошибки менее 1%!
Резюме
В этой главе мы познакомили вас с основными понятиями проектирования сверточных сетей. Эти понятия включают сверточные и редуцирующие слои, которые составляют основные строительные блоки сверточных сетей. Затем мы обсудили применения сверточных архитектур, такие как обнаружение, сегментирование и генерирование изображений. Мы закончили главу углубленным практическим примером, который продемонстрировал, как тренировать сверточную архитектуру на наборе данных рукописных цифр MNIST.
В главе 7 мы рассмотрим рекуррентные нейронные сети — еще одну глубоко обучающуюся архитектуру. В отличие от сверточных сетей, предназначенных для обработки изображений, рекуррентные архитектуры хорошо подходят для обработки последовательных данных, таких как естественно-языковые наборы данных.
160 | Глава 6
ГЛАВА 7
Рекуррентные нейронные сети
К настоящему моменту в этой книге мы познакомили вас с использованием глубокого самообучения для обработки различных видов входных данных. Мы начали с простой линейной и логистической регрессии на векторах признаков фиксированных размерностей, а затем продолжили обсуждение полносвязных глубоких сетей. Эти модели принимают произвольные векторы признаков с фиксированными, предустановленными размерами и не делают никаких допущений о типе данных, закодированных в этих векторах. С другой стороны, сверточные сети принимают серьезные допущения относительно структуры своих данных. Входы в сверточные сети должны удовлетворять условию локальности, которое позволяет определять локальное рецептивное поле.
Как использовать сети, которые мы описали ранее, для обработки данных, таких как предложения естественного языка? Предложения имеют некоторые свойства локальности (соседние слова обычно связаны), и действительно, для обработки данных естественно-языковых предложений можно использовать одномерную сверточную сеть. Вместе с тем, для обработки последовательностей данных большинство практикующих специалистов прибегают к другому типу архитектуры — рекуррентной нейронной сети.
Рекуррентные нейронные сети (RNN-сети) изначально спроектированы для того, чтобы глубокие сети могли обрабатывать последовательности данных. RNN-сети исходят из того, что поступающие данные принимают форму последовательности векторов или тензоров. Если мы преобразуем каждое слово в предложении в вектор (подробнее о том, как это сделать, изложим позже), предложения могут подаваться в RNN-сети. Точно так же и с видео (рассматриваемое как последовательность изображений), которое может обрабатываться RNN-сетью аналогичным образом. К каждой позиции последовательности RNN-сеть применяет произвольное нелинейное преобразование. Это нелинейное преобразование является общим для всех шагов последовательности.
Описание в предыдущем абзаце немного абстрактно, но оказывается чрезвычайно мощным. В этой главе вы более подробно познакомитесь с тем, каким образом структурированы RNN-сети, и с тем, как можно реализовать RNN-сеть в библиотеке TensorFlow. Мы также обсудим, каким образом RNN-сети можно использовать на практике для выполнения таких задач, как получение образцов новых предложений или генерация текста для таких приложений, как чат-боты.
Практический пример для этой главы тренирует рекуррентную нейронно-сетевую модель языка на корпусе Penn Treebank, собрании предложений, извлеченных из
161
статей газеты ’’Wall Street Journal”. Этот учебный материал является адаптированной версией официальной документации TensorFlow по рекуррентным сетям. (Если вы интересуетесь тем, какие мы внесли изменения, мы рекомендуем обратиться к оригинальному учебному пособию на веб-сайте TensorFlow.) Как всегда, мы советуем вам сверяться с программным кодом, размещенным в хранилище GitHub (https://github.com/matroid/dlwithtf), связанном с данной книгой.
Обзор рекуррентных архитектур
Рекуррентные архитектуры полезны для моделирования очень сложных наборов данных, изменяющихся во времени, которые традиционно называются временными рядами. На рис. 7.1 показано несколько наборов данных временных рядов.
В моделировании временных рядов мы проектируем системы, способные обучаться эволюционному правилу, которое моделирует эволюционирование рассматриваемой системы в зависимости от прошлого. Математически предположим, что на каждом временном шаге мы получаем точку данных xt , где t — это текущее время. Тогда методы временных рядов пытаются обучиться некоторой функции f такой, что
Л+i — ,..., xt).
Год День
I960 1970 1980 1980 0 50 100 150 200 250 300
Год День
Рис. 7.1. Несколько наборов данных временных рядов, в моделировании которых мы можем быть заинтересованы
162 | Глава 7
Идея заключается в том, что f хорошо кодирует базисную динамику системы, и ее заучивание на данных позволит обучающейся системе предсказывать будущее рассматриваемой системы. На практике обучиться функции, которая зависит от всех прошлых входов,— слишком обременительный процесс, поэтому обучающиеся системы часто исходят из того, что вся информация о последних точках данных хх, ..., xt_x может быть закодирована в некий фиксированный вектор h,. Тогда уравнение обновления упрощается в формат
^+1»Ь,+1=/(х„Ь,).
Обратите внимание, что мы принимаем допущение, что та же самая функция f здесь применяется для всех временных шагов t. То есть мы исходим из того, что временные ряды являются стационарными (рис. 7.2). Это допущение нарушается для многих систем, в особенности для фондового рынка, где сегодняшние правила не обязательно будут соблюдаться завтра.
Рис. 7.2. Математическая модель временного ряда со стационарным эволюционным правилом. Напомним, что стационарная система — это такая система, чья базисная динамика не смещается во времени
Какое отношение данное уравнение имеет к рекуррентным нейронным сетям? Основной ответ вытекает из теоремы об универсальной аппроксимации, которую мы ввели в главе 4, Функция f может быть сколь угодно сложной, поэтому использование полносвязной глубокой сети для заучивания f кажется разумной идеей. Этот интуитивный подход, по сути, определяет RNN-сеть. Простую рекуррентную сеть можно рассматривать как полносвязную сеть, которая многократно применяется к каждому временному шагу данных.
На самом деАе рекуррентные нейронные сети действительно становятся интересными только для сложных многомерных временных рядов. Для более простых систем существуют классические методы обработки сигналов на основе временных рядов, которые часто хорошо справляются с моделированием временной динамики. Однако для сложных систем, таких как речь (см. спектрограммы речи на рис. 7.3), RNN-сети проявляют себя в полной мере и предлагают возможности, которые другие методы не могут предложить.
Рекуррентные нейронные сети | 163
Время
Рис. 7.3. Спектрограмма речи, представляющая частоты, находящиеся в речевом образце
Рекуррентные ячейки
Градиентная неустойчивость
Рекуррентные сети, как правило, с течением времени ухудшают сигнал. Представьте это, как ослабление сигнала мультипликативным множителем на каждом временном шаге. Как результат, после 50 шагов сигнал довольно сильно деградирует.
Вследствие этой неустойчивости было сложно тренировать рекуррентные нейронные сети на более длинных временных рядах. Для борьбы с этой неустойчивостью был разработан ряд методов, которые мы обсудим в оставшейся части этого раздела.
Существует несколько концепций простой рекуррентной нейронной сети, которые в практических приложениях оказались значительно успешнее. В этом разделе мы кратко рассмотрим некоторые ее варианты.
Долгая краткосрочная память
Часть проблемы, связанной со стандартной рекуррентной ячейкой, заключается в том, что сигналы из далекого прошлого быстро ослабляются. В результате RNN-сети могут не справиться с заучиванием моделей сложных зависимостей. Эта неспособность становится особенно заметной в таких приложениях, как моделирование языка, где слова могут иметь сложные зависимости от более ранних фраз.
Одно из возможных решений этой проблемы заключается в том, чтобы позволить состояниям из прошлого проходить без изменений. Архитектура долгой краткосрочной памяти (long short-term memory, LSTM) предлагает механизм, позволяющий прошлому состоянию проходить в настоящее с минимальными изменениями. В эмпирическом плане использование ’’ячейки” LSTM (показанной на диаграмме 7.4), судя по всему, предлагает превосходную результативность самообучения
164 | Глава?
zr =о(и;[л,_1, xr])
г, =о(^[л/1,х,])
h, = tanh(lF[r,A,_1, x,J)
А/ =(1-гг>Л/-1+г,-Л/
Рис. 7.4. Ячейка долгой краткосрочной памяти (LSTM). LSTM-ячейки демонстрируют результативность, превосходящую стандартные рекуррентные нейронные сети в удержании долгосрочных зависимостей во входных данных. В результате LSTM-ячейки нередко становятся предпочтительнее для сложных последовательных данных, таких как естественный язык
по сравнению с простыми рекуррентными нейронными сетями, использующими полносвязные слои.
Так много уравнений!
Уравнения LSTM содержат много сложных членов. Если вам интересно строгое математическое доказательство, лежащее в основе LSTM, которое здесь представлено на интуитивном уровне, мы рекомендуем вам вооружиться карандашом и бумагой и попробовать взять производные LSTM-ячейки.
Вместе с тем, что касается других читателей, которые в первую очередь заинтересованы в использовании рекуррентных архитектур для решения практических задач, мы считаем, что им не обязательно углубляться в детали того, как работают LSTM. Лучше всего, если вы просто закрепите на уровне интуиции, что прошлое состояние разрешается пропускать без изменений, и углубленно проработаете пример программного кода для этой главы.
Оптимизация рекуррентных сетей
В отличие от полносвязных сетей или сверточных сетей, LSTM предусматривают некоторые сложные математические операции и операции потока управления. В результате задача крупномасштабной тренировки больших рекуррентных сетей оказалась сложной, даже с современным GPU-оборудованием.
Значительные усилия были вложены в оптимизацию реализаций RNN-сетей с целью ускорить их выполнение на GPU-оборудовании. В частности, компания NVIDIA включила RNN-сети в свою библиотеку CuDNN, которая предоставляет программный код, специально оптимизированный для тренировки глубоких сетей на GPU. К счастью для пользователей TensorFlow, интеграция с библиотеками, такими как CuDNN, выполняется в самой библиотеке TensorFlow, поэтому вам не нужно слишком беспоко
Рекуррентные нейронные сети | 165
иться об оптимизации программного кода (если, конечно, вы не работаете с крупномасштабными наборами данных). Мы обсудим аппаратные потребности для глубоких нейронных сетей более детально в главе 9,
Вентильные рекуррентные блоки
Сложность, как концептуальная, так и вычислительная, LSTM-ячеек побудила ряд исследователей попытаться упростить уравнения LSTM, сохранив при этом прирост результативности и моделирующие возможности исходных уравнений.
Существует несколько претендентов на замену LSTM, но одним из лидеров является вентильный рекуррентный блок (gated recurrent units, GRU)1, показанный на рис. 7.5. GRU-блок удаляет один из подкомпонентов LSTM, но эмпирически, судя по всему, достигает результативности, аналогичной LSTM. GRU-блоки могут быть подходящей заменой LSTM-ячеек в проектах моделирования последовательностей.
а б
Рис. 7.5. Долгая краткосрочная память (а) и вентильный рекуррентный блок (6). GRU-блоки сохраняют многие достоинства LSTM с более низкими вычислительными затратами
Применение рекуррентных моделей
Хотя рекуррентные нейронные сети являются полезными инструментами для моделирования наборов данных временных рядов, существует множество других приложений рекуррентных сетей. К ним относятся такие приложения, как моделирование естественного языка, машинный перевод, химический ретросинтез и произвольные вычисления с помощью нейронных машин Тьюринга. В этом разделе мы предлагаем краткий обзор некоторых из этих захватывающих приложений.
1 Вентильный рекуррентный блок (gated recurrent unit) — это вентильный механизм в рекуррентных нейронных сетях, введенный в 2014 г. Было показано, что его результативность по моделированию полифонической музыки и моделированию речевого сигнала аналогична результативности с долгой краткосрочной памятью. Вместе с тем было показано, что GRU-блоки демонстрируют более высокую результативность на меньших наборах данных. — Прим. пер.
166 | Глава?
Получение образцов из рекуррентных сетей
До сих пор мы знакомили вас с тем, как рекуррентные сети могут учиться моделировать временную эволюцию последовательностей данных. Логично предположить, что, если вы понимаете эволюционное правило для множества последовательностей, вы должны уметь получать из распределения тренировочных последовательностей образцы новых последовательностей. И действительно, оказывается, что из натренированных моделей могут быть получены хорошие образцы последовательностей. Самое интересное применение RNN-сетей на сегодняшний момент находится в области моделирования языка. Способность генерировать реалистичные предложения является очень полезным инструментом, который используется, например, системами автозаполнения и чат-ботами.
Почему для последовательностей не используются GAN-сети?
В главе 6 мы обсудили проблему генерирования новых изображений. Мы обсудили модели, в частности вариационные автокодировщики, которые производят только размытые изображения, и познакомились с технологией генеративно-состязательных сетей, которая демонстрирует способность производить четкие изображения. Однако вопрос остается открытым: если GAN-сети востребованы для получения хороших образцов изображений, почему бы нам не воспользоваться ими для хороших естественноязыковых предложений?
Оказывается, современные генеративно-состязательные модели при попытке получения из них образцов последовательностей показывают слабые результаты. Причина этого явления не совсем ясна. Теоретическое понимание GAN-сетей остается очень низким (даже по стандартам теории глубокого самообучения), но что-то связанное с выявлением теоретикоигрового равновесия, судя по всему, работает для последовательностей хуже, чем для изображений.
Модели Seq2seq
Модели ’’последовательность в последовательность” (sequence-to-sequence, seq2seq) — это мощные инструменты, позволяющие моделям преобразовывать одну последовательность в другую. Основная идея модели ’’последовательность в последовательность” заключается в использовании кодирующей рекуррентной сети, которая встраивает (включает) входные последовательности в векторные пространства, и декодирующей сети, которая позволяет получать образцы выходных последовательностей в соответствии с описанием в предыдущих предложениях. На рис. 7.6 показана модель seq2seq.
Самое интересное начинается, если учесть, что слои кодировщика и декодировщика сами по себе могут быть глубокими. (RNN-слои могут быть естественным образом уложены в ярусы.) Система нейронного машинного перевода Google (Google neural machine translation, GNMT) имеет многоярусные кодирующие и декодирующие слои. В результате этого мощного репрезентативного потенциала она способна
Рекуррентные нейронные сети | 167
Кодировщик
Декодировщик
Повторить
Входящая электронная почта
Рис. 7.6. Модели "последовательность-в-последовательность" являются мощными инструментами, которые могут обучаться преобразованиям последовательностей. Они применяются в машинном переводе (например, преобразовании последовательности английских слов на севернокитайский язык) и химическом ретросинтезе (преобразовании последовательности химических продуктов в последовательность реагентов)
Рис. 7.7. Архитектура нейронного машинного перевода Google (GNMT) представляет собой глубокую модель seq2seq, которая учится выполнять машинный перевод
выполнять современные переводы далеко за пределами возможностей своих ближайших конкурентов. На рис. 7.7 показана архитектура GNMT.
Несмотря на то что до сих пор мы в основном обсуждали приложения для обработки естественного языка, архитектура seq2seq имеет целый ряд приложений в других областях. Один из авторов книги использовал архитектуры seq2seq для выполнения химического ретросинтеза — процесса деконструирования молекул на более простые составляющие. На рис. 7.8 показан этот процесс.
168 | Глава 7
Н3С-ОН + ОН’
Н3С-ОН
Рис. 7.8. Модель seq2seq для химического ретросинтеза преобразует последовательность химических продуктов в последовательность химических реагентов
Нейронные машины Тьюринга
Мечта об обучающихся машинах заключалась в том, чтобы продвинуться дальше по стеку абстракций: перейти от способности обучаться коротким механизмам сопоставления с образцом к способности обучаться выполнению произвольных вычислений. Нейронная машина Тьюринга является мощным шагом в этой эволюции.
Машина Тьюринга была конструктивным вкладом в математическую теорию вычислений. Это была первая математическая модель машины, способная выполнять любые вычисления. Машина Тьюринга содержит ’’ленту”, которая обеспечивает память для выполняемых вычислений. Вторая часть машины представляет собой ’’головку записи-чтения”, которая на отдельных ячейках ленты осуществляет преобразования. Оригинальная идея машины Тьюринга заключалась в том, что для выполнения сколь угодно сложных вычислений сама ’’головка” не обязательно должна быть очень сложной.
Нейронная машина Тьюринга (НМТ)— это очень умная попытка преобразовать саму машину Тьюринга в нейронную сеть. Математический прием в этой трансмутации заключается в том, чтобы превратить дискретные действия в мягкие непрерывные функции (этот остроумный прием неоднократно появляется в глубоком самообучении, поэтому возьмите его на заметку!)
Головка машины Тьюринга весьма схожа с RNN-клеткой! Как результат, НМТ-машина может быть натренирована в сквозном порядке, чтобы обучиться производить любые вычисления, по крайней мере в принципе (рис. 7.9). На практике существуют серьезные ограничения на диапазон вычислений, которые НМТ-машина может выполнять. Неустойчивость градиентного потока (как всегда) ограничивает то, чему она может обучиться. Для разработки потомков НМТ-машины, способных обучаться более полезным функциям, потребуются дополнительные исследования и эксперименты.
Рекуррентные нейронные сети | 169
ь ь а а а а
... Лента входа-выхода
Конечное управление
Рис. 7.9. Нейронная машина Тьюринга (НМТ) — это способная обучаться версия машины Тьюринга. Она содержит ленту, на которой может сохранять результаты промежуточных вычислений. Хотя машины НМТ имеют много практических ограничений, вполне возможно, что их интеллектуальные потомки будут способны обучаться мощным алгоритмам
Полнота по Тьюрингу
Полнота по Тьюрингу в информатике является важным понятием. Язык программирования считается полным по Тьюрингу, если он способен выполнять любые вычисления, которые могут быть выполнены машиной Тьюринга. Машина Тьюринга как таковая была изобретена, чтобы обеспечить математическую модель того, что значит для функции быть ’’вычислимой”. Эта машина предоставляет возможность читать, писать и хранить в памяти различные инструкции, т. е. абстрактные примитивы, которые лежат в основе всех вычислительных машин.
Со временем большой объем работ показал, что машина Тьюринга моделирует диапазон вычислений, близких к выполняемым в физическом мире. В первом приближении, если можно показать, что машина Тьюринга не способна выполнять вычисления, то и любое другое вычислительное устройство не способно это делать. С другой стороны, если можно показать, что вычислительная система может выполнять основные операции машины Тьюринга, тогда она является ’’полной по Тьюрингу” и способна выполнять в принципе любые вычисления, которые могут быть выполнены вообще. Ряд удивительных систем являются полными по Тьюрингу. Мы рекомендуем вам подробнее почитать литературу по этой теме, если вы интересуетесь.
Рекуррентные сети являются полными по Тьюрингу
Пожалуй, не удивительно, что НМТ-машины способны выполнять любые вычисления, которые может выполнять машина Тьюринга и, следовательно, являются полными по Тьюрингу. Однако менее известный факт заключается в том, что классические рекуррентные нейронные сети сами по себе
170 | Глава?
являются полными! Иными словами, рекуррентная нейронная сеть способна обучаться выполнять произвольные вычисления.
Основная идея заключается в том, что оператор перехода может научиться выполнять основные операции чтения, записи и хранения. Развертывание рекуррентной сети во времени позволяет выполнять сложные вычисления. В каком-то смысле этот факт не должен быть слишком удивительным. Теорема об универсальной аппроксимации уже демонстрирует, что полносвязные сети способны обучаться произвольным функциям. Сцепление произвольных функций во времени приводит к произвольным вычислениям. (Правда, технические детали, необходимые для официального подтверждения этого утверждения, архисложны.)
Работа с рекуррентными нейронными сетями на практике
В этом разделе вы познакомитесь с использованием рекуррентной нейронной сети для моделирования языка на корпусе Penn Treebank — естественно-языковом наборе данных, созданном из статей газеты "Wall Street Journal”. Мы представим примитивы TensorFlow, необходимые для выполнения этого моделирования, а также проведем вас по шагам работы с данными и их предобработки, необходимым для подготовки данных к тренировке. Мы рекомендуем вам сверяться с программным кодом в хранилище GitHub (https://github.com/matroid/dlwithtf), связанном с этой книгой, и попробовать его выполнить самостоятельно.
Обработка корпуса Penn Treebank
Корпус Репп Treebank содержит коллекцию статей газеты "Wall Street Journal", состоящую из миллиона слов. Этот корпус может использоваться для моделирования на уровне символов или слов (задачи предсказания следующего символа или слова в предложении при наличии предыдущих). Эффективность моделей измеряется с помощью перплексии натренированных моделей (подробнее об этом метрическом показатели позже).
Корпус Penn Treebank состоит из предложений. Каким образом преобразовать предложения в форму, которая может быть подана в машинно-обучающиеся системы, такие как рекуррентные языковые модели? Напомним, что машинно-обучающиеся модели принимают в качестве входных данных тензоры (а рекуррентные модели принимают последовательности тензоров). Следовательно, нам нужно преобразовать слова в тензоры, пригодные для машинного самообучения.
Самый простой способ преобразования слов в векторы — использовать кодирование "с одним активным состоянием"2. Предположим, что наш языковой набор дан
2 Словосочетание кодирование с одним активным состоянием (англ, one-hot encoding) пришло из терминологии цифровых интегральных микросхем, где оно описывает конфигурацию микросхемы, в которой допускается, чтобы только один бит был положительным (активным). В отечественной специализированной литературе для данного типа кодировщика нередко используется альтернативный термин — прямой унитарный кодировщик. — Прим. пер.
Рекуррентные нейронные сети | 171
ных использует словарь из |Г| слов. Тогда в этом кодировании каждое слово преобразуется в вектор формы (|К|). Все элементы этого вектора равняются нулю, кроме одного элемента, в индексе, соответствующем текущему слову. Пример такого встраивания см. на рис. 7.10.
Кодирование с одним активным состоянием v = {роза, куст, школа, монета}
v(posa) = [1, 0, 0, 0]
у(куст) = [0, 1, 0, 0]
v(школа) = [0, 0, 1, 0]
v(монета) = [0, 0, 0, 1]
Рис. 7.10. Кодирование с одним активным состоянием преобразует слова в векторы только с одним отличным от нуля элементом (которому, как правило, назначается 1). Различные индексы в векторе уникально представляют слова из языкового корпуса
Также можно использовать более сложные встраивания. Основная идея аналогична идее кодирования с одним активным состоянием. Каждое слово ассоциируется с уникальным вектором. Однако ключевое различие заключается в том, что в данной системе кодирования можно обучиться вектору непосредственно из данных, получив для указанного слова его "словарное встраивание"3, которое имеет содержательный смысл для текущего набора данных. Мы покажем вам, как обучаться словарным встраиваниям позже в этой главе.
Для того чтобы обработать данные корпуса Penn Treebank, нам нужно найти словарь слов, используемых в корпусе, а затем преобразовать каждое слово в связанный с ним словарный вектор. Затем мы покажем, как передавать обработанные данные в модель TensorFlow.
Ограничения корпуса Репп Treebank
Корпус Penn Treebank является очень полезным набором данных для моделирования языка, но он больше не представляет сложной проблемы для современных языковых моделей; исследователи уже научились плотно подгонять модели под характерные особенности этой коллекции. В самых современных исследованиях используются более крупные наборы данных,
3 Встраивание, или включение, слов (word embedding) — это собирательный термин для набора методов моделирования языка и заучивания признаков в области обработки естественного языка, где словам или фразам словаря ставятся в соответствие векторы реальных чисел. Концептуально оно связано с математическим включением из пространства с одной размерностью в расчете на слово в непрерывное векторное пространство с гораздо более высокой размерностью. См. https://en.wikipeclia.org/wiki/ Word_embedding, а также https://ru.wikipedia.org/wiki/RnoMeHHe. На веб-сайте платформы TensorFlow имеется хорошее руководство по данной теме (https://www.tensorflow.org/tutorials/word2vec) с описанием построения модели, получающей векторные представления слов. — Прим. пер.
172 | Глава 7
такие как эталон модели языка с корпусом из одного миллиарда слов4. Однако для наших исследовательских целей вполне будет достаточно корпуса Penn Treebank.
Программный код для предобработки
Фрагмент кода в примере 7.1 считывает сырые файлы, связанные с корпусом Репп Treebank. Данный корпус хранится в формате одного предложения на строку. Небольшая обработка строк выполняется средствами Python для замены маркеров новой строки ”\п" на фиксированный маркер ”<eos>" и затем разбивки файла на список лексем.
Пример 7.1. Функция считывания сырого файла корпуса Репп Treebank |
def _read_words(filename):
with tf.gfile.GFile(filename, ”r”) as f:
if sys.version_info[0] >= 3:
return f.read().replace("\n", "<eos>").split() else:
return f.readO .decode("utf-8").replace("\n", "<eos>").split()
Определив функцию read words о, мы можем построить словарь, связанный с данным файлом, используя функцию _build_vocab(), определенную в примере 7.2. Мы просто читаем слова в файле и подсчитываем количество уникальных слов в нем, используя встроенную в Python библиотеку collections. Для удобства мы конструируем объект-словарь, отображающий слова на их уникальные целочисленные идентификаторы (их позиции в словаре). Связывая все это вместе, функция file to word ids о преобразует файл в список идентификаторов слов (пример 7.3).
i Пример 7.2. Функция построения словаря, состоящего из всех слов в заданном файле
def _build_vocab(filename):
data = _read_words(filename)
counter = collections.Counter(data)
count_pairs = sorted(counter.items(), key=lambda x: (-x[l], x[0]))
words, _ = list(zip(*count_pairs)) word_to_id = diet(zip(words, range(len(words))))
return word_to_id
4 Cm. http://www.statmt.org/lm-benchmark/. — Прим. nep.
Рекуррентные нейронные сети | 173
j Пример 7.3. Функция преобразования слова из файла в числовые идентификаторы |
def _file_to_word_ids(filename, word_to_id):
data = _read_words(filename)
return [word_to_id[word] for word in data if word in word_to_id]
Располагая этими сервисными функциями, мы можем обработать корпус Репп Treebank функцией ptb raw data () (пример 7.4). Обратите внимание, что тренировочный, контрольный и тестовый наборы данных заданы заранее, поэтому нам остается только прочитать каждый файл в список уникальных индексов.
Пример 7.4. Функция загрузки данных корпуса Penn Treebank из заданного местоположения
def ptb_raw_data(data_path=None):
""’’Загрузить сырые данные РТВ из каталога данных "data_path".
Читает текстовый файл РТВ, конвертирует строковые значения в целочисленные идентификаторы и выполняет мини-пакетирование входных данных.
Набор данных РТВ взят с веб-страницы Томаса Миколова: http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
Аргументы: data_path: строковый путь к каталогу, куда был извлечен архив simple-examples.tgz.
Возвращаемые значения: tuple (train_data, valid_data, test_data, vocabulary), где каждый объект данных может быть передан в PTBIterator. п п п
train_path == os.path.join(data_path, "ptb.train.txt") valid_path = os.path.join(data_path, "ptb.valid.txt") test_path = os.path.join(data_path, "ptb.test.txt")
word__to__id = _build_vocab (train_path)
train_data = _file_to_word_ids (train_path, word__to_id) valid_data =* _file_to_word_ids(valid_path, word_to_id) test_data = _file_to_word__ids (test_path, word_to__id) vocabulary = len (word__to_id)
return train_data, valid_data, test_data, vocabulary
Объекты tf .GFile И tf.Flags
TensorFlow — это крупный проект, в котором содержится много фрагментов и компонентов. Хотя подавляющая часть библиотеки посвящена машинному самообучению, также имеется значительная часть, которая относится к загрузке и массированию данных. Некоторые из этих функций
174 | Глава 7
предоставляют полезные возможности, которых нет нигде. Однако другие части загрузочного функционала менее полезны.
Обертка tf.GFile для операций ввода-вывода без блокировки потока и маршрутизатор импорта tf.Flags предоставляют функционал, который более или менее идентичен стандартной для Python обработке файлов и встроенной библиотеке argparse. Происхождение этих инструментов историческое. В Google в соответствии с внутренними стандартами программирования требуются собственные обработчики файлов и обработка флагов. Однако для остальных из нас по возможности лучше придерживаться стандартных инструментов Python для удобочитаемости и стабильности.
Загрузка данных в TensorFlow
В этом разделе мы рассмотрим программный код, необходимый для загрузки наших обработанных индексов в TensorFlow. Для этого мы познакомим вас с новым механизмом TensorFlow. До сих пор мы использовали специальные словари для передачи данных в TensorFlow. В то время как словари передачи данных хороши для небольших игрушечных наборов данных, они часто не являются удачным вариантом для больших наборов данных, поскольку Python добавляет весомые накладные расходы, связанные с упаковкой и распаковкой словарей. Для получения более производительного программного кода лучше использовать очереди TensorFlow.
Объект tf.Queue позволяет загружать данные асинхронно. Это дает возможность отделить вычислительный поток GPU от потока предобработки данных, ограниченного возможностями CPU. Это разъединение особенно полезно для больших наборов данных, где мы хотим оставить GPU максимально активным.
Объекты tf .Queue можно подавать в заполнители TensorFlow для тренировки моделей и достижения большей производительности. Далее в этой главе мы продемонстрируем, как это делается.
Функция ptb_producer, представленная в примере 7.5, преобразует сырые списки индексов в очереди tf .Queue, которые могут передавать данные в вычислительный граф TensorFlow. Давайте начнем со знакомства с некоторыми вычислительными примитивами, которые мы будем использовать. Функция tf.train.range_input_ producer о — это удобная операция, которая создает очередь tf. Queue из входного тензора. Метод tf. Queue, dequeue о извлекает тензор из очереди для тренировки. Функция tf .strided sliceo извлекает срез этого тензора, который соответствует данным текущего мини-пакета.
Пример 7.5. Функция загрузки данных корпуса Penn Treebank из заданного местоположения
def ptb_producer(raw_data, batch_size, num_steps, name=None): """Выполнить итеративный обход сырых данных РТВ.
Этот программный код нарезает сырые данные raw_data на пакеты примеров и возвращает тензоры, взятые из этих пакетов.
Рекуррентные нейронные сети | 175
Аргументы:
raw_data - одна часть сырых данных, получаемых из ptb_raw_data.
batch_size - целочисленный размер пакета.
num_steps - целочисленное количество разверток.
паше - имя этой операции (необязательный).
Возвращаемые значения:
Пара тензоров, каждый с формой [batch_size, num_steps].
Второй элемент кортежа - это те же данные, сдвинутые во времени вправо на одну позицию.
Вызов исключений:
tf.errors.InvalidArgumentError: если размер пакета batch_size или количество шагов num_steps слишком большое.
м»»»»
with tf.name_sсоре (name, "PTBProducer",
[raw_data, batch_size, num_steps]):
raw_data = tf .convert_to__tensor (raw_data, name="raw_data",
dtype=tf.int32)
data_len = tf.size(raw_data)
batch_len = data_len // batch_size
data = tf.reshape(raw_data[0 : batch_size * batch_len], [batch_size, batch_len])
epoch_size = (batch_len - 1) // num_steps
assertion = tf.assert_positive(
epoch_size,
message="epoch_size == 0, уменьшить batch_size или num_steps") with tf.control-dependencies([assertion]):
epoch_size = tf.identity(epoch_size, name=”epoch_size")
i = tf.train.range_input_producer(epoch_size,
shuffle=False).dequeue()
x = tf.strided_slice(data, [0, i * num_steps], [batch_size, (i + 1) * num_steps])
x.set_shape([batch_size, num_steps])
у = tf.strided_slice(data, [0, i * num_steps + 1], [batch_size, (i + 1) * num_steps + 1])
y.set_shape([batch_size, num_steps])
return x, у
Модуль tf .data
TensorFlow (начиная с версии 1.4) поддерживает новый модуль tf.data с новым классом tf.data.Dataset, который обеспечивает специальный API для представления потоков данных. Вполне вероятно, что tf.data в конеч
176 | Глава?
ном итоге заменит очереди в качестве предпочтительного механизма ввода, тем более что они имеют хорошо продуманный функциональный API.
На момент написания книги модуль tf.data был только что выпущен и оставался относительно сырым по сравнению с другими частями API, поэтому для наших примеров мы решили придерживаться очередей. Вместе с тем мы рекомендуем вам обязательно ознакомиться с модулем tf.data самостоятельно.
Базовая рекуррентная архитектура
Мы будем использовать LSTM-ячейку для моделирования данных корпуса Репп Treebank, поскольку LSTM часто предлагают превосходную результативность для задач моделирования языка. Функция tf.contrib.rnn.BasicLSTMCeiiо реализует для нас базовую LSTM-ячейку, поэтому нет необходимости создавать подобный код самостоятельно (пример 7.6).
I Пример 7.6. Функция обертывания LSTM-ячейки из tf .contrib I
L_________. ___________ _______________________ _ _ . _ !
def lstm_cell():
return tf.contrib.rnn.BasicLSTMCeii(
size, forget_bias=0.0, state_is_tuple=True, reuse=tf.get_variable_scope().reuse)
Нормально, если используется программный код из TensorFlow contrib?
Обратите внимание, что реализация LSTM, которую мы используем, взята из модуля tf.contrib. Допустимо ли использовать программный код из tf.contrib для промышленных проектов? Единого мнения на этот счет пока нет. Из нашего личного опыта программный код в tf .contrib более шаткий, чем код в основной библиотеке TensorFlow, но вместе с тем он обычно довольно устойчивый. Нередко многие полезные библиотеки и сервисные функции доступны только в рамках tf .contrib. Мы рекомендуем использовать фрагменты из tf.contrib по мере необходимости, но возьмите за привычку заменять используемые вами фрагменты их эквивалентами из TensorFlow, если такие появляются в основной библиотеке.
Фрагмент кода в примере 7.7 предписывает TensorFlow обучиться словарному встраиванию для каждого слова в нашем словаре. Ключевой функцией для нас является функция tf .nn. embeddingJ.ookup(), которая позволяет выполнять правильную операцию тензорного поиска. Обратите внимание, что нам нужно определить матрицу встраиваний embedding вручную как переменную TensorFlow.
Пример 7.7. Обучение словарному встраиванию для каждого слова в словаре
with tf.device("/cpu:0"):
embedding = tf.get_variable(
"embedding", [vocab_size, size], dtype=tf.float32)
inputs = tf.nn.embedding_lookup(embedding, input_.input_data)
Рекуррентные нейронные сети | 177
Имея на руках словарные векторы, нам остается только применить LSTM-ячейку (используя функцию istm ceiio) к каждому словарному вектору в последовательности. Для этого мы применяем цикл Python for, в котором конструируется необходимый набор вызовов cell о. Здесь имеется всего один хитрый прием: нам нужно убедиться, что в каждом временном интервале мы используем одни и те же переменные, т. к. LSTM-ячейка должна выполнять одну и ту же операцию в каждом временном интервале. К счастью, метод reuse variables о для областей переменных позволяет сделать это без особых усилий (пример 7.8).
Пример 7.8. Применение LSTM-ячейки к каждому словарному вектору во входной последовательности
outputs = []
state = self._initial_state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables() (cell_output, state) = cell(inputs[:, time_step, :], state) outputs.append(cell_output)
Теперь остается только определить связанную с графом потерю, для того чтобы этот граф натренировать. И удобно, что библиотека TensorFlow в tf .contrib предлагает потерю на тренировочных данных языковых моделей. Нужно лишь вызвать tf.contrib.seg2seq.sequence loss (пример 7.9). За кадром эта потеря оказывается формой перплексии.
Пример 7.9. Добавление потери для последовательности j
# Использовать функцию потери для последовательности из contrib # и усреднить по всем пакетам.
loss = tf.contrib.seq2seq.sequence_loss( logits, input_.targets, tf.ones([batch_size, num_steps], dtype=tf.float32), average_across_timesteps=False, average_ across_batch=True
# Обновить переменные стоимости.
self, cost = cost tf.reduce sum(loss)
Перплексия
Метрический показатель перплексии часто используется для задач моделирования языка. Этот показатель представляет собой вариант бинарной перекрестной энтропии, который используется для измерения того, насколько близким является заученное распределение данных к истинному распределению. Эмпирически показатель перплексии оказался полезным для
178 | Глава?
многих задач моделирования языка, и мы используем его здесь в этом качестве (поскольку sequence loss как раз реализует перплексию, приспособленную для последовательностей, находящихся внутри).
Затем мы можем натренировать этот граф с помощью стандартного метода градиентного спуска. Мы опустили некоторые запутанные детали базового программного кода, но предлагаем вам обратиться к GitHub, если вам интересно. Оценка качества натренированной модели также оказывается простой, поскольку перплексия используется как потеря на тренировочных данных и как метрический оценочный показатель. В результате, чтобы отслеживать процес тренировки модели, мы можем просто показывать self. cost. Рекомендуем вам натренировать модель самостоятельно!
Задание для читателя
Попробуйте снизить перплексию на данных корпуса Penn Treebank, экспериментируя с различными модельными архитектурами. Обратите внимание, что без GPU эти эксперименты могут занимать много времени.
Резюме
Эта глава познакомила вас с рекуррентными нейронными сетями (RNN-сетями) — мощной архитектурой, обучающейся на последовательных данных. RNN-сети способны обучаться лежащему в основе эволюционному правилу, которое управляет последовательностью данных. Хотя RNN-сети можно использовать для моделирования простых временных рядов, они наиболее эффективны при моделировании сложных последовательных данных, таких как речь и естественный язык.
Мы познакомили вас с рядом вариантов RNN-сетей, таких как LSTM-ячейки и GRU-блоки, которые лучше работают с данными со сложными долгосрочными взаимодействиями, а также сделали краткое отступление, чтобы обсудить захватывающую перспективу нейронных машин Тьюринга. Мы закончили главу углубленным практическим примером, в котором LSTM-ячейки были применены для моделирования корпуса Penn Treebank.
В главе 8 мы познакомим вас с мощным методом самообучения с максимизацией подкрепления, который позволяет глубоким системам обучаться играть в игры.
Рекуррентные нейронные сети | 179
ГЛАВА 8
Самообучение с максимизацией подкрепления
Методы самообучения, которые мы рассмотрели, относятся к категориям контролируемого или неконтролируемого самообучения. В обоих случаях поставленная задача требует от аналитика данных проектировать глубокую архитектуру, которая манипулирует и обрабатывает входные данные, и соединять выход из архитектуры с функцией потери, которая подходит для решения поставленной задачи. Такой математический каркас широко применим, но не все приложения безупречно укладываются в этот стиль мышления. Давайте рассмотрим задачу тренировки машин-но-обучающейся модели для того, чтобы она победила в шахматной игре. Кажется разумным рассматривать шахматную доску как пространственный вход, используя сверточную сеть, но с какой функцией потери это будет сопряжено? Ни одна из наших стандартных функций потерь, таких как перекрестная энтропия или Z,2 -потеря, не применима.
Самообучение с максимизацией подкрепления обеспечивает математический каркас, который хорошо подходит для решения игровых задач. Центральная математическая концепция — это марковский процесс принятия решений, инструмент для моделирования агентов ИИ, которые взаимодействуют со средами, предлагающими вознаграждение по завершении определенных действий. Этот каркас доказал свою гибкость и универсальность, и в последние годы он нашел ряд применений. Стоит отметить, что самообучение с максимизацией подкрепления как область исследования является довольно зрелой и существует в узнаваемой форме с 1970-х годов. Тем не менее до недавнего времени большинство обучающихся систем с максимизацией подкрепления были способны решать только игрушечные задачи. Последние исследования показали, что эти ограничения, судя по всему, существовали по причине отсутствия сложных механизмов приема данных; для многих игр или роботизированных сред часто было недостаточно вручную конструируемых признаков. Судя по всему, извлечения глубоких представлений, натренированных в сквозном порядке на современном оборудовании, в последние годы пробились через барьеры более ранних обучающихся систем с максимизацией подкрепления и достигли значительных результатов.
Пожалуй, первый прорыв в глубоком самообучении с максимизацией подкрепления был осуществлен на аркадных играх ATARI. Аркадные игры ATARI традиционно были представлены в игровых залах и предлагали пользователям простые игры, которые обычно не требуют выработки сложных стратегий, но могут потребовать хороших рефлексов. На рис. 8.1 показан снимок экрана из популярной игры
181
ATARI Breakout. В последние годы, благодаря разработке хорошего программного обеспечения для эмуляции ATARI, игры ATARI стали тестовой площадкой для алгоритмов игрового процесса. На первом этапе обучающимся алгоритмам с максимизацией подкрепления, применительно к ATARI, не удавалось достичь превосходных результатов; техническое требование, которое заключалось в том, чтобы алгоритм понимал состояние видеоигры, провалило большинство попыток. Однако по мере взросления сверточных сетей исследователи в компании DeepMind поняли, что сверточные сети могут сочетаться с существующими методами самообучения с максимизацией подкрепления и тренироваться в сквозном порядке.
Рис. 8.1. Снимок экрана аркадной игры ATARI Breakout. Игроки должны использовать ракетку внизу экрана, чтобы отбивать мяч, который разбивает плитки вверху экрана
Получившаяся в результате система достигла превосходных результатов и научилась играть во многие игры ATARI (в особенности те, которые зависят от быстрых рефлексов) на уровне сверхчеловеческих стандартов. На рис. 8.2 показаны баллы ATARI, полученные алгоритмом DQN компании DeepMind в разных играх. Этот прорыв стимулировал огромный рост в области глубокого самообучения с максимизацией подкрепления и вдохновил легионы исследователей заняться разведкой потенциала соответствующих методов. В то же время результаты компании DeepMind на играх ATARI показали, что методы самообучения с максимизацией подкрепления способны решать задачи, зависящие только от краткосрочных ходов. Эти результаты не продемонстрировали, что глубоко обучающиеся системы способны выигрывать игры, которые требуют большего стратегического планирования.
182 | Глава 8
Рис. 8.2. Результаты работы обучающегося алгоритма с максимизацией подкрепления DQN компании DeepMind на различных играх ATARI. 100% — это балл сильного игрока-человека. Обратите внимание, что DQN достигает сверхчеловеческой производительности во многих играх, но довольно слаб в других
Компьютерное го
В 1994 г. компания IBM представила систему Deep Blue, которая позже смогла победить Гарри Каспарова в широко разрекламированном шахматном матче. Для того чтобы играть в шахматы на гроссмейстерском уровне, эта система опиралась на вычисление методом грубой силы, которое расширяло дерево возможных шахматных ходов (с некоторой помощью со стороны ручных шахматных эвристик).
Самообучение с максимизацией подкрепления | 183
Специалисты в области информатики попытались применить аналогичные методы к другим играм, таким как го. К несчастью для ранних экспериментаторов, игровая доска го с разлиновкой 19x19 значительно больше шахматной доски 8x8 . В результате, деревья возможных ходов показывают взрывной рост гораздо быстрее, чем для шахмат, а простые, не требующие сложных расчетов вычисления показали, что закон Мура займет очень много времени, прежде чем позволит выработать решение методом грубой силы в стиле Deep Blue для задачи игры в го. Ситуация усложнялась отсутствием простой эвристики для оценки того, кто выигрывает в середине партии го (определение того, кто впереди — белые или черные, заведомо является предметом шумной дискуссии лучших аналитиков). Именно поэтому до самого недавнего времени многие известные специалисты в области информатики считали, что на разработку сильного компьютерного го уйдет по крайней мере десятилетие.
Для того чтобы продемонстрировать мастерство своих обучающихся алгоритмов, компания DeepMind приняла вызов обучиться играть в го — игру, которая требует сложного стратегического планирования. В своей изобретательной работе компания DeepMind показала собственный механизм глубокого самообучения с максимизацией подкрепления — AlphaGo, который объединил сверточные сети с древесным поиском, чтобы победить гроссмейстера Ли Седола (рис. 8.3).
Рис. 8.3. Чемпион по го Ли Седол сражается с AlphaGo. Ли Седол в конечном счете проиграл матч со счетом 1:4, но ему удалось выиграть одну игру. Маловероятно, что эта победа может повториться в отношении значительно усовершенствованных потомков AlphaGo, таких как AlphaZero
Программа AlphaGo убедительно продемонстрировала, что методы глубокого самообучения с максимизацией подкрепления способны обучаться распутывать сложные стратегические игры. Суть прорыва заключалась в осознании того, что сверточные сети могут научиться оценивать, кто ведет в середине игры — черные
184 | Гпава 8
или белые, что позволило подрезать игровые деревья до разумных глубин. (Программа AlphaGo также оценивает, какие ходы являются наиболее выгодными, что позволяет подрезать пространство игрового дерева во второй раз.) Победа программы AlphaGo действительно вывела глубокое самообучение с максимизацией подкрепления в первые ряды, и масса исследователей теперь работают над тем, чтобы трансформировать системы в стиле AlphaGo в практическую реализацию.
В этой главе мы обсудим обучающиеся алгоритмы с максимизацией подкрепления и, в частности, глубоко обучающиеся архитектуры на их основе. Затем мы покажем читателям, как успешно применять самообучение с максимизацией подкрепления в игре крестики-нолики. Несмотря на простоту игры, тренировка успешного ученика для крестиков-ноликов требует значительной изощренности, в чем вы вскоре убедитесь сами.
Программный код для этой главы является адаптированной версией библиотеки DeepChem для самообучения с максимизацией подкрепления, и в частности примера кода, созданного Питером Истманом (Peter Eastman) и Карлом Лесвингом (Karl Leswing). Спасибо Питеру за помощь в отладке и настройке примера кода этой главы.
Марковские процессы принятия решений
Перед тем как начать обсуждение обучающихся алгоритмов с максимизацией подкрепления, будет полезно точно определить семейство задач, которые пытаются решать методы самообучения с максимизацией подкрепления. Математический каркас марковских процессов принятия решений (Markov decision processes, MDP) очень полезен для формулирования методов самообучения с максимизацией подкрепления. Традиционно MDP-процессы сопровождаются целым арсеналом греческих символов, но вместо этого мы попытаемся продолжить предоставлять некоторое базовое интуитивное понимание.
В центре MDP-процессов находится пара, состоящая из среды и агента. Среда кодирует ’’мир”, в котором агент пытается действовать. Примеры сред могут включать игровые миры. Например, доска го с сидящим напротив гроссмейстером Ли Седолом является допустимой средой. Еще одной потенциальной средой может быть среда, окружающая небольшого робота-вертолета. В раннем выдающемся успешном эксперименте самообучения с максимизацией подкрепления команда исследователей из Стэнфорда во главе с Эндрю Hr (Andrew Ng) натренировала вертолет летать в перевернутом положении, используя самообучение с максимизацией подкрепления (рис. 8.4).
Агент — это обучающаяся сущность, которая действует в среде. В нашем первом примере программа AlphaGo как таковая является агентом. Во втором примере агентом является робот-вертолет (точнее, алгоритм управления в роботе-вертолете). Каждый агент имеет набор действий, которые он может выполнять в среде. Для программы AlphaGo они представляют собой допустимые ходы игры го. Для вертолета-робота они включают управление главным и вторичным винтами.
Самообучение с максимизацией подкрепления | 185
Рис. 8.4. Команда исследователей Эндрю Нг из Стэнфорда (2004-2010) натренировала робот-вертолет летать в перевернутом положении, используя самообучение с максимизацией подкрепления. Эта работа потребовала сконструировать изощренный физически точный симулятор
Предполагается, что действия агента оказывают влияние на среду. В случае с программой AlphaGo это влияние имеет детерминированный характер (решение программы AlphaGo поставить фишку приводит к размещению фишки на доске). В случае с вертолетом эффект — вероятностный (изменение положения вертолета может зависеть от ветровых условий, которые нельзя эффективно смоделировать).
Последняя часть модели — это понятие вознаграждения. В отличие от контролируемого самообучения, где присутствуют явно заданные метки, на которых алгоритм обучается, или неконтролируемого самообучения, где задача состоит в том, чтобы обучиться лежащей в основе структуре данных, самообучение с максимизацией подкрепления работает в обстановке частичных, нечастых вознаграждений. В го вознаграждения достигаются в конце игры по факту победы или поражения в игре, тогда как в полете вертолета вознаграждения могут представляться за успешные полеты или завершение фигур пилотажа.
Трудность разработки функции вознаграждения
Одна из самых больших проблем в самообучении с максимизацией подкрепления— это проектирование вознаграждений, которые побуждают агентов обучаться желаемому поведению. Даже для простых игр с выиг-рышем/проигрышем, таких как го или крестики-нолики, эта задача может быть удивительно сложной. Как должен штрафоваться проигрыш и как должен вознаграждаться выигрыш? Хороших ответов пока не существует.
186 | Глава 8
Для более сложных линий поведения эта задача может быть чрезвычайно трудной. Ряд исследований показали, что простое вознаграждение может привести к неожиданному и даже потенциально опасному поведению агентов. Эти системы подстегивают опасения в отношении будущих агентов с большой автономией, связанные с тем, что, если их натренируют оптимизировать плохие функции вознаграждения, они начнут сеять хаос, когда будут выпущены в реальный мир.
В общем случае самообучение с максимизацией подкрепления является менее зрелым, чем методы контролируемого самообучения, и мы предостерегаем, что решения о внедрении самообучения с максимизацией подкрепления в производственных системах должны приниматься с большой осторожностью. Учитывая неопределенность в отношении заученного поведения, любая развернутая обучающаяся система с максимизацией подкрепления должна быть тщательно протестирована.
Алгоритмы для самообучения с максимизацией подкрепления
Теперь, когда мы познакомили вас с ключевыми математическими структурами, лежащими в основе самообучения с максимизацией подкрепления, давайте рассмотрим проектирование алгоритмов, которые заучивают интеллектуальные линии поведения для обучающихся агентов. На высоком уровне обучающиеся алгоритмы с максимизацией подкрепления могут быть разделены на две группы: модельноориентированные и безмоделъные алгоритмы. Основное различие между ними состоит в том, пытается ли алгоритм обучиться внутренней модели того, как действует его среда, или нет. Для более простых сред, таких как крестики-нолики, динамика модели тривиальна. Для других сред, таких как полет вертолета или даже игры ATARI, положенная в основу среда, судя по всему, чрезвычайно сложная. Отказ от построения явной модели среды в пользу неявной модели, которая консультирует агента как действовать, вполне может быть более прагматичным.
Симуляции и самообучение с максимизацией подкрепления
Любой обучающийся алгоритм с максимизацией подкрепления требует итеративного улучшения результативности текущего агента путем оценки текущего поведения агента и его изменения для улучшения получаемых вознаграждений. Эти обновления структуры агента часто связаны с некоторым обновлением градиентного спуска, как мы увидим в последующих разделах. Однако, как вы знаете из предыдущих глав, градиентный спуск является медленным тренирующим алгоритмом! Для того чтобы обучиться эффективной модели, могут потребоваться миллионы или даже миллиарды шагов градиентного спуска.
Это создает проблему, если среда самообучения находится в реальном мире; каким образом агенту взаимодействовать миллионы раз с реальным миром? В большинстве случаев это невозможно. В результате подавляю
Самообучение с максимизацией подкрепления | 187
щая часть изощренных обучающихся систем с максимизацией подкрепления критически зависит от симуляторов, которые позволяют взаимодействовать с имитационной вычислительной версией среды. Для среды полета вертолета одной из самых трудных задач, с которыми исследователи столкнулись, было создание точного симулятора физики вертолета, который позволял бы вычислительно обучиться эффективным стратегиям полета.
Q-заучивание
В математическом каркасе марковских процессов принятия решений агенты осуществляют действия в среде и получают вознаграждения, которые (предположительно) связаны с действиями агентов. Функция Q предсказывает ожидаемое вознаграждение за выполнение конкретного действия в определенном состоянии среды. Эта концепция кажется очень простой, но загвоздка возникает, когда ожидаемое вознаграждение включает дисконтированные вознаграждения от будущих действий.
Дисконтирование вознаграждений
Понятие дисконтированного вознаграждения широко распространено и часто вводится в контексте финансов. Предположим, знакомый говорит, Ж что он заплатит вам 10 долларов на следующей неделе. Эти будущие 10 долларов для вас стоят меньше, чем 10 долларов в вашем кармане прямо сейчас. (К примеру, что будет, если оплата никогда не произойдет?) Поэтому в математическом смысле распространена практика введения коэффициента дисконтирования у (как правило, между 0 и 1), который снижает ’’текущую стоимость” будущих платежей. Скажем, ваш знакомый несколько ненадежен. Вы можете решить установить у = 0,5 и оценить обещание вашего знакомого, как 10у = 5 долларов сегодня, чтобы учесть неопределенность в вознаграждениях.
Вместе с тем эти будущие вознаграждения зависят от действий, предпринимаемых агентом в будущем. В результате функция Q должна быть сформулирована рекурсивно в терминах самой себя, поскольку ожидаемые вознаграждения для одного состояния зависят от вознаграждений для другого состояния. Это рекурсивное определение делает заучивание функции Q запутанным. Такая рекурсивная зависимость может быть сформулирована явным образом для простых сред с дискретными пространствами состояний и решена методами динамического программирования. В случае более универсальных сред до недавнего времени методы 0-заучи-вания не были особо полезными.
Недавно компания DeepMind представила глубокие g-сети (deep 0-networks, DQN), которые использовались для распутывания игр ATARI, как упоминалось ранее. Ключевая оригинальная идея, лежащая в основе DQN, опять-таки является теоремой об универсальной аппроксимации; поскольку функция Q может быть сколь угодно сложной, мы должны моделировать ее с помощью универсального аппрок
188 | Глава 8
симатора, такого как глубокая сеть. Хотя использование нейронных сетей для моделирования Q выполнялось и ранее, компания DeepMind для этих сетей также ввела понятие воспроизведения опыта, которое позволило им эффективно тренировать модели DQN-сети в масштабе. Воспроизведение опыта позволяет хранить наблюдавшиеся исходы игр и переходы из состояния в состояние из прошлых игр и выполнять их повторный отбор во время тренировки (в дополнение к тренировке на новых играх), тем самым гарантируя, что уроки прошлого не будут сетью забыты.
t Катастрофическое забывание
i Нейронные сети быстро забывают прошлое. На самом деле, это явление, У>/9***\ которое носит название катастрофического забывания, может происхо-1—- X ‘ дить очень быстро; несколько пакетных обновлений может быть достаточно, чтобы сеть забыла сложное поведение, которое она знала ранее. И без таких методов, как воспроизведение опыта, которые гарантируют, что сеть всегда тренируется на эпизодах из прошлых матчей, было бы невозможно обучиться сложному поведению.
Проектирование тренирующего алгоритма для глубоких сетей, которые не страдают от катастрофического забывания, сегодня по-прежнему остается серьезной открытой задачей. Примечательно, что люди не страдают от катастрофической амнезии; даже если вы не ездили на велосипеде в течение многих лет, скорее всего, вы по-прежнему помните, как это делается. Создание нейронной сети с похожей устойчивостью может включать добавление долгосрочной внешней памяти, по аналогии с нейронной машиной Тьюринга. К сожалению, до сих пор ни одна из попыток проектирования устойчивых архитектур не работала хорошо.
Заучивание стратегии
В предыдущем разделе вы познакомились с (2-заучиванием, которое пытается получать ожидаемые вознаграждения за выполнение определенных действий в конкретных состояниях среды. Заучивание стратегии является альтернативным математическим каркасом для поведения обучающегося агента. Оно вводит функцию стратегии л, которая назначает вероятность каждому действию, которое агент может выполнить в данном состоянии.
Обратите внимание, что стратегии вполне хватает, чтобы определить поведение агента. При наличии стратегии агент может действовать просто путем получения образца подходящего действия для текущего состояния среды. Заучивание стратегий удобно тем, что стратегии могут быть заучены напрямую посредством алгоритма, который называется стратегическим градиентом. Этот алгоритм использует несколько остроумных математических приемов, позволяющих вычислять стратегические градиенты непосредственно методом обратного распространения для глубоких сетей. Ключевым понятием является разворачивание (rollout) игровой ситуации: дать агенту действовать в среде в соответствии со своей текущей стратегией и отмечать все поступающие вознаграждения; затем распространять в обратном
Самообучение с максимизацией подкрепления | 189
направлении, чтобы увеличить вероятность тех действий, которые привели к более выгодным вознаграждениям. Это описание является точным на высоком уровне, но позже мы увидим более подробные детали его реализации.
Стратегия часто связана с функцией стоимости V1. Эта функция возвращает ожидаемое дисконтированное вознаграждение за выполнение стратегии я, начиная с текущего состояния среды. Функции V и Q тесно связаны, т. к. обе предоставляют оценки будущих вознаграждений, начиная с текущего состояния, но V не задает действие, которое должно быть выполнено, и, напротив, исходит из того, что образцы действия отбираются из я .
Еще одной универсально определяемой функцией является функция преимущества А, Она определяет разницу между ожидаемым вознаграждением за выполнение конкретного действия а в заданном состоянии среды s и вознаграждением за соблюдение базовой стратегии я . Математически А определяется в терминах Q и V\
A(s, a) = Q(s, a)-V(s).
Это преимущество полезно в алгоритмах заучивания стратегии, т. к. оно позволяет алгоритму количественно определять, насколько конкретное действие подходит лучше, чем текущая рекомендация стратегии.
Стратегический градиент вне самообучения с максимизацией подкрепления
Несмотря на то что в качестве обучающегося алгоритма с максимизацией подкрепления мы ввели стратегический градиент, он также может рассматриваться как инструмент для обучающихся глубоких сетей с недифференцируемыми подмодулями. Что это значит в переводе с математического жаргона?
Предположим, что у нас есть сеть, которая вызывает внешнюю программу внутри самой сети. Эта внешняя программа является черным ящиком; это может быть сетевой вызов либо вызов подпрограммы COBOL 1970-х годов. Каким образом остальная часть глубокой сети может обучиться, когда этот модуль не имеет градиента?
Оказывается, стратегический градиент можно переориентировать на оценку ’’эффективного” для системы градиента. Простой интуитивный подход заключается в том, что можно выполнять несколько "разворачиваний” ситуации, которые используются для вычисления градиентов. Можно ожидать, что в течение последующих нескольких лет мы увидим исследования, расширяющие эту идею для создания больших сетей с недифференциальными модулями.
1 См. https://ru.wikipedia.org/wiki/4HCKOHTHpoBaHHafl_CTOHMOCTb. — Прим. пер.
190 | Глава 8
Асинхронная тренировка
Недостатком методов стратегического градиента, представленных в предыдущем разделе, является то, что выполнение операций разворачивания требует вычисления оценки поведения агента в некоторой (вероятно, смоделированной) среде. Большинство симуляторов— это сложные компоненты программы, которые не могут выполняться на GPU. В результате прохождение одного шага самообучения требует продолжительных расчетов, ограниченных возможностями CPU. А это может привести к неоправданно медленной тренировке.
Методы самообучения с асинхронной максимизацией подкрепления пытаются ускорить этот процесс, используя несколько асинхронных потоков CPU для выполнения независимых разворачиваний игровых ситуаций. Эти рабочие потоки разворачивают игру, локально вычисляют обновления стратегического градиента, а затем периодически синхронизируются с глобальным набором параметров. В эмпирическом плане асинхронная тренировка, судя по всему, значительно ускоряет самообучение с максимизацией подкрепления и позволяет обучаться довольно сложным стратегиям на ноутбуках. (Без GPU-процессоров! Подавляющая часть вычислительной мощности используется на разворачивание, поэтому шаги обновления градиента часто не являются ограничивающим аспектом самообучения с максимизацией подкрепления.) Наиболее популярным алгоритмом самообучения с асинхронной максимизацией подкрепления в настоящее время является алгоритм асинхронной критики стратегии с учетом преимущества (asynchronous advantage actor-critic, АЗС).
CPU или GPU?
GPU-процессоры необходимы для большинства крупных глубоко обу-чающихся приложений, но в настоящее время самообучение с максимиза-цией подкрепления является исключением из этого общего правила. Опора обучающихся алгоритмов с максимизацией подкрепления на многочисленные разворачивания игровой ситуации в настоящее время, судя по всему, смещает реализации самообучения с максимизацией подкрепления в сторону систем с многоядерными CPU. Вполне вероятно, что в конкретных приложениях отдельные симуляторы могут быть портированы для более быстрой работы на GPU, однако в ближайшем будущем моделирование на основе CPU, скорее всего, будет продолжать доминировать.
Ограничения самообучения с максимизацией подкрепления
Математический каркас марковских процессов принятия решений чрезвычайно универсальный. Например, ученые-бихейвиористы регулярно используют марковские процессы принятия решений для понимания и моделирования принятия решений человеком. Математическая универсальность этого каркаса побудила ученых утверждать, что решение задачи самообучения с максимизацией подкрепления мо
Самообучение с максимизацией подкрепления | 191
жет стимулировать создание искусственных универсальных разумов (artificial general intelligences, AGI). Ошеломляющий успех программы AlphaGo против Ли Седола усилил это убеждение, и поэтому исследовательские группы, такие как OpenAI и DeepMind, направленные на создание AGI, сосредотачивают подавляющую часть своих усилий на разработке новых методов самообучения с максимизацией подкрепления.
Тем не менее имеются серьезные слабые стороны в самообучении с максимизацией подкрепления в том виде, в котором оно существует сегодня. Тщательный сопоставительный анализ на основе эталонов показал, что методы самообучения с максимизацией подкрепления очень восприимчивы к выбору гиперпараметров (даже по стандартам глубокого самообучения, которое уже намного лучше отшлифовано до мелочей, чем другие методы, такие как случайные леса).
Как мы уже упоминали, конструирование функций вознаграждения очень незрелое — люди способны внутренне проектировать собственные функции вознаграждения или эффективно учатся копировать функции вознаграждения из наблюдений. Несмотря на то, что были предложены алгоритмы ’’обратного самообучения с максимизацией подкрепления”, которые непосредственно обучаются функциям вознаграждения, эти алгоритмы имеют много ограничений на практике.
Помимо фундаментальных ограничений, есть еще много практических вопросов масштабирования. Люди способны играть в игры, в которых высокоуровневая стратегия совмещается с тысячами ”микро”-ходов. Например, для профессиональной игры в стратегическую игру StarCraft (рис. 8.5) требуются сложные стратегические хитрости в сочетании с тщательным контролем за сотнями юнитов (боевых
“Tvlove to Веас%$
“'Collect Minerals and Gas ,
-Build Marines
Collect Mineral1 Shards
Рис. 8.5. Коллекция подзадач, необходимых для игры в стратегию StarCraft в реальном времени.
В этой игре игроки должны создать армию, которую они могут использовать, чтобы победить противостоящую силу. Успешная игра в StarCraft требует мастерства планирования ресурсов, разведки и сложной стратегии. Лучшие компьютерные агенты StarCraft остаются на любительском уровне
192 | Глава 8
единиц). Игры могут потребовать тысяч локальных ходов, чтобы довести игру до завершения. Кроме того, в отличие от го или шахмат, StarCraft имеет "туман войны" (ухудшение видимости на поле боя), где игроки не могут видеть все состояние игры целиком. Это сочетание обширного игрового состояния и неопределенности сорвало попытки обучиться максимизировать подкрепления на игре StarCraft. По этой причине команды исследователей искусственного интеллекта в DeepMind и других исследовательских группах сосредотачивают серьезные усилия на решении задачи StarCraft с помощью методов глубокого самообучения с максимизацией подкрепления. Несмотря на некоторые серьезные усилия, лучшие боты StarCraft пока остаются на любительском уровне.
В целом существует широкий консенсус в отношении того, что самообучение с максимизацией подкрепления является полезным методом, который, судя по всему, будет иметь большое влияние в течение нескольких следующих десятилетий, но также ясно и другое: многие практические ограничения методов самообучения с максимизацией подкрепления будут означать, что в ближайшей перспективе подавляющая часть работы будет происходить в исследовательских лабораториях.
Игра крестики-нолики
Крестики-нолики — это простая игра для двух игроков. Игроки ставят крестики и нолики на игровом поле размером 3 х 3 до тех пор, пока одному игроку не удастся разместить три свои фигуры в ряд. Первый игрок, который это сделает, выигрывает. Если ни одному из игроков не удается поставить три фигуры в ряд до того, как игровое поле заполнится, игра заканчивается вничью. На рис. 8.6 показано игровое поле игры в крестики-нолики.
Рис. 8.6. Игровое поле игры в крестики-нолики
Крестики-нолики — это хорошая испытательная площадка для методов самообучения с максимизацией подкрепления. Игра проста настолько, что для тренировки эффективных агентов не требуется непомерного объема вычислительной мощности. В то же время, несмотря на простоту игры крестики-нолики, заучивание эффективного агента требует значительной изощренности. Программный код TensorFlow данного раздела, возможно, будет самым сложным примером в этой книге. В оставшейся части этого раздела мы проведем вас по процессу проектирования агента TensorFlow, опирающегося на самообучение с асинхронной максимизацией подкрепления.
Самообучение с максимизацией подкрепления | 193
Объектная ориентированность
Программный код, с которым мы знакомили до настоящего момента в этой книге, в основном состоял из сценариев, дополненных небольшими вспомогательными функциями. Однако в этой главе мы перейдем к объектно-ориентированному стилю программирования, который может быть для вас новым, в особенности если вы родом из научного мира, а не из мира технологий. Вкратце, объектно-ориентированная программа определяет объекты, моделирующие аспекты мира. Например, вы можете определить объекты среды Environment или агента Agent, или вознаграждения Reward, которые непосредственно соответствуют этим математическим понятиям. Класс — это шаблон для объектов, который используется для создания экземпляров многих новых объектов. Например, вы вскоре увидите определение класса Environment, которое мы будем использовать для определения многих конкретных объектов среды Environment.
Объектная ориентированность особенно эффективна для построения сложных систем, поэтому мы будем применять ее для упрощения проекта нашей обучающейся системы с максимизацией подкрепления. На практике ваши реальные глубоко обучающиеся системы (или обучающиеся с максимизацией подкрепления), вероятно, тоже должны быть объектно-ориентированными, поэтому мы рекомендуем потратить некоторое время на освоение объектно-ориентированного проектирования. Существует много превосходных книг, в которых раскрыты фундаментальные принципы объектно-ориентированного проектирования, и мы рекомендуем вам по мере необходимости с ними сверяться.
Абстрактная среда
Начнем с определения абстрактного класса Environment, который кодирует состояние системы в списке объектов NumPy (пример 8.1). Объект Environment является довольно универсальным (это адаптированная версия механизма самообучения с максимизацией подкрепления проекта DeepChem), поэтому он может легко служить шаблоном для других проектов самообучения с максимизацией подкрепления, которые вы, возможно, попытаетесь реализовать.
। Пример 8.1. Этот класс определяет шаблон для конструирования новых сред J
class Environment(object):
"""Среда, в которой актор выполняет действия для решения задачи.
Среда имеет текущее состояние, которое представлено либо как
один массив NumPy, либо как список массивов NumPy. Когда действие совершается, оно заставляет состояние обновиться. Что именно имеется в виду под "действием", определяется каждым подклассом. Что касается интерфейса, то это просто произвольный объект.
Среда также вычисляет вознаграждение за каждое действие и сообщает о завершении задачи (имея в виду, что больше не может быть выполнено никаких действий). л л л
194 | Глава 8
def _init__(self, state_shape, reactions, state_dtype=None):
"""Подклассы в дополнение к собственной инициализации должны вызывать конструктор надкласса, п и и self.state_shape = state_shape self.n_actions = n_actions if state_dtype is None:
# Принимается, что все массивы имеют тип float32.
if isinstance(state_shape[0], collections.Sequence): self.state_dtype = [np.float32] * len(state_shape) else:
self.state_dtype = np.float32 else:
self.state_dtype = state_dtype
Среда игры крестики-нолики
Нам нужно конкретизировать класс Environment, чтобы создать среду TicTacToeEnvironment, подходящую для наших нужд. Для этого мы создаем подкласс класса Environment, который добавляет больше возможностей, сохраняя при этом основную функциональность исходного надкласса. В примере 8.2 мы определяем среду TicTacToeEnvironment как подкласс класса Environment, которая добавляет детали, характерные для игры в крестики-нолики.
Пример 8.2. Класс TicTacToeEnvironment определяет шаблон для конструирования новых сред игры в крестики-нолики
class TicTacToeEnvironment(de.rl.Environment): и и и
Играть в крестики-нолики против случайно действующего противника и и и
X = пр.array([1.0, 0.0])
О = пр.array([0.0, 1.0])
EMPTY = пр.array([0.0, 0.0])
ILLEGAL—MOVE_PENALTY = -3.0
LOSS_PENALTY = -3.0
NOT—LOSS =0.1
DRAW_REWARD =5.0
WIN_REWARD =10.0
def __init__(self):
super(TicTacToeEnvironment, self).___init__([(3, 3, 2)], 9)
self.terminated = None
self.reset()
Самообучение с максимизацией подкрепления | 195
Первый интересный момент, который здесь следует отметить, заключается в том, что мы определяем состояние игрового поля, как массив NumPy формы (3, 3, 2). Мы используем кодирование с одним активным состоянием, состоящее из х и о. (Кодирование с одним активным состоянием полезно не только для обработки естественного языка!)
Второй важный момент, который стоит отметить, состоит в том, что среда явно определяет функцию вознаграждения, устанавливая штрафы за недопустимые ходы и проигрыши, а также вознаграждения за ничьи и победы. Этот фрагмент кода мощно иллюстрирует произвольный характер конструирования функции вознаграждения. Почему именно эти числа?
Эмпирически эти варианты, судя по всему, приводят к стабильному поведению, но мы рекомендуем вам поэкспериментировать с альтернативными настройками вознаграждения, чтобы понаблюдать за результатами. В этой реализации мы указываем, что агент всегда играет крестиками х, но рандомизируем, кто будет ходить первым: х или о. Функция get_o_move() помещает о на случайную открытую клетку игрового ПОЛЯ. Подкласс TicTacToeEnvironment Кодирует противника, КОТОрыЙ Играет ноликами о, при этом всегда выбирая случайный ход. Функция reseto очищает игровое поле и помещает фигуру о в случайную клетку, если во время этой игры о ходит первым (пример 8.3).
Пример 8.3. Еще пара методов ИЗ класса TicTacToeEnvironment J
def reset(self):
self.terminated = False
self.state = [np.zeros(shape=(3, 3, 2), dtype=np.float32)]
# Рандомизировать, кто будет ходить первым, if random.randint(0, 1) == 1: move = self.get_0_move() self.state[0][move[0]][move[1]] = TicTacToeEnvironment.0
def get_0_move(self): empty_squares = [] for row in range(3): for col in range(3): if np.all(self.state[0][row][col] == TicTacToeEnvironment.EMPTY): empty_squares.append((row, col)) return random.choice(empty_squares)
Сервисный метод game overO сообщает, что игра закончилась, если все клетки заполнены. Метод check winner о проверяет, не выставил ли указанный игрок три фигуры подряд и выиграл игру (пример 8.4).
196 | Глава 8
Пример 84. Служебные методы из класса TicTacToeEnvironment для обнаружения, когда игра закончилась и кто победил
def check_winner(self, player):
for i in range(3):
row = np.sum(self.state[0][i][:], axis=0)
if np.all(row == player * 3): return True
col = np.sum(self.state[0][:][i], axis=0)
if np.all(col == player * 3): return True
diagl = self.state[0][0][0] + self.state[0][1][1] + self.state[0][2][2]
if np.all(diagl = player * 3): return True
diag2 = self.state[0][0][2] + self.state[0][1][1] + self.state[0][2][0]
if np.all(diag2 == player * 3): return True
return False
def game_over(self):
for i in range(3):
for j in range(3):
if np.all(self.state[0][i][j] == TicTacToeEnvironment.EMPTY): return False
return True
В нашей реализации действие — это просто число от 0 до 8, определяющее клетку, на которую помещается фигура х. Метод step о проверяет, занята ли эта клетка (возвращает штраф, если клетка занята), затем помещает фигуру. Если х выиграл, возвращается вознаграждение. Иначе случайный противник о может сделать ход. Если выиграл о, то будет возвращен штраф. Если игра закончилась вничью, возвращается вознаграждение. В противном случае игра продолжается с вознаграждением notloss (пример 8.5).
Пример 8.5. Этот метод выполняет шаг симуляции
def step(self, action):
self.state = copy.deepcopy(self.state)
row = action // 3
col = action % 3
# Недопустимый ход - клетка занята.
if not np.all(self.state[0][row][col] == TicTacToeEnvironment.EMPTY):
Самообучение с максимизацией подкрепления | 197
self.terminated = True
return TicTacToeEnvironment.ILLEGAL_MOVE_PENALTY
# Ход X.
self.state[0][row][col] = TicTacToeEnvironment.X
# X выиграл?
if self.check_winner(TicTacToeEnvironment.X): self.terminated = True return TicTacToeEnvironment.WIN_REWARD
if self.game_over(): self.terminated = True return TicTacToeEnvironment.DRAW_REWARD
move = self.get—0—move()
self.state[0][move[0]][move[1]] = TicTacToeEnvironment.0
# О выиграл?
if self.check_winner(TicTacToeEnvironment.0): self.terminated = True
return TicTacToeEnvironment.LOSS_PENALTY
if self.game_over(): self.terminated = True return TicTacToeEnvironment.DRAW_REWARD
return TicTacToeEnvironment.NOT_LOSS
Слоевая абстракция
Выполнение обучающегося алгоритма с асинхронной максимизацией подкрепления, такого как АЗС, требует, чтобы каждый поток имел доступ к отдельной копии стратегической модели. Для продолжения процесса тренировки эти копии модели должны периодически синхронизироваться друг с другом. Как проще всего сконструировать несколько копий графа TensorFlow, которые можно распределять по каждому потоку?
Одной из простых возможностей является создание функции, которая формирует копию модели в отдельном графе TensorFlow. Этот подход работает хорошо, но становится немного запутанным, в особенности для сложных сетей. Применение небольшой объектной ориентированности может значительно упростить этот процесс. Поскольку наш программный код самообучения с максимизацией подкрепления является адаптированной версией библиотеки DeepChem, мы используем упрощенную версию вычислительного каркаса TensorGraph из DeepChem (см. https:// deepchem.io для подробной информации и документации). Этот вычислительный
198 | Глава 8
каркас похож на другие высокоуровневые вычислительные каркасы TensorFlow, такие как Keras. Основной абстракцией во всех таких моделях является введение объекта Layer, который содержит часть глубокой сети.
Объект Layer— это часть графа TensorFlow, которая принимает список входных слоев in layers. В этой абстракции глубокая архитектура состоит из направленного графа слоев. Направленные графы похожи на ненаправленные графы, которые вы видели в главе 6, но в отличие от них имеют направления на своих ребрах. В данном случае in layers образуют ребра в сторону нового слоя Layer с направлением, указывающим на новый слой. Вы познакомитесь с подробностями данной концепции в следующем разделе.
Мы используем сервисную функцию tf.register_tensor_conversion_function(), которая позволяет произвольным классам регистрироваться как конвертируемые в тензоры. Эта регистрация будет означать, что слой может быть конвертирован в тензор TensorFlow посредством вызова функции tf.convert_to_tensor. Приватный метод get input tensors () — это сервисный метод, использующий функцию tf .convert to tensor о для преобразования входных слоев во входные тензоры. Каждый слой отвечает за реализацию методу create tensor о, который определяет операции для добавления в вычислительный граф TensorFlow (пример 8.6).
। Пример 8.6. Объект Layer является фундаментальной абстракцией
: в глубоких объектно-ориентированных архитектурах. Он инкапсулирует часть сети,
I такую как полносвязный слой или сверточный слой.
В этом примере определяется общий надкласс для всех таких слоев
class Layer(object):
def __init___(self, in_layers=None, **kwargs):
if "name" in kwargs: self.name = kwargs["name"] else: self.name = None
if in_layers is None: in_layers = list()
if not isinstance(in_layers, Sequence): in_layers = [in_layers] self.in_layers = in_layers self.variable_scope = "" self.tb_input = None
def create_tensor(self, in_layers=None, **kwargs):
raise NotlmplementedError("Подклассы должны реализовывать себя")
def _get_input_tensors(self, in_layers):
"""Получить входные тензоры для этого слоя.
Самообучение с максимизацией подкрепления | 199
Параметры
in_layers: список слоев Layers или тензоров; входы, переданные в create_tensor(). Если None, то вместо этого будут использоваться входы этого слоя, w н н
if in_layers is None: in_layers = self.in_layers if not isinstance(in_layers, Sequence): in_layers = [in_layers] tensors = [] for input in in_layers:
tensors.append(tf.convert_to_tensor(input)) return tensors
def _convert_layer_to_tensor(value, dtype=None, name=None, as_ref=False):
return tf.convert_to_tensor(value.out_tensor, dtype=dtype, name=name)
tf.register_tensor_conversion_function(Layer, _convert_layer_to_tensor)
Приведенное выше описание является абстрактным, но на практике простым в использовании. В примере 8.7 приведен слой сжатия Squeeze, который обертывает функцию tf. squeeze о со слоем Layer (позже вы отметите для себя удобство этого класса). Обратите внимание, что squeeze является подклассом класса Layer.
^Пример 8.7. Слой Squeeze сжимает свой вход |
class Squeeze(Layer): def ______init__(self, in_layers=None, squeeze_dims=None, **kwargs):
self .squeeze_dims = squeeze_dims super(Squeeze, self).__init__(in_layers, **kwargs)
def create_tensor(self, in_layers=None, **kwargs): inputs = self._get_input_tensors(in_layers) parent_tensor = inputs[0] out_tensor = tf.squeeze(parent_tensor, squeeze_dims=self.squeeze_dims) self.out_tensor = out_tensor return out_tensor
Входной слой input для удобства обертывает заполнители (пример 8.8). Обратите внимание, что метод Layer.create_tensorо должен вызываться для каждого слоя, который мы используем для построения вычислительного графа TensorFlow.
200 | Гпава 8
. Пример 8.8. Входной слой input добавляет заполнители в вычислительный граф
class Input(Layer):
def __init__(self, shape, dtype=tf.float32, **kwargs):
self. _shape = tuple(shape) self.dtype = dtype super(Input, self).__init__(**kwargs)
def create_tensor(self, in_layers=None, **kwargs): if in_layers is None: in_layers = self.in_layers out_tensor = tf.placeholder(dtype=self.dtype, shape=self,_shape) self,out_tensor = out_tensor return out—tensor
МОДУЛИ tf .keras И tf .estimator
Вычислительный каркас TensorFlow теперь интегрировал популярный объектно-ориентированный интерфейс Keras в основную библиотеку TensorFlow. Keras включает определение класса Layer, близко соответствующее объектам Layer, о которых вы только что узнали в этом разделе. На самом деле здесь объекты Layer являются адаптированной версией библиотеки DeepChem. В свою очередь объекты DeepChem были взяты из более ранней версии Keras.
Стоит отметить, что модуль tf.keras еще не стал стандартным высокоуровневым интерфейсом к библиотеке TensorFlow. Модуль tf.estimator предоставляет альтернативный (хотя и менее богатый) высокоуровневый интерфейс к сырому коду TensorFlow.
Независимо от того, какой интерфейс в конечном итоге станет стандартным, мы считаем, что понимание принципов проектирования для создания собственного интерфейса является поучительным и целесообразным. Возможно, вам понадобится создать новую систему для вашей организации, которая требует альтернативного проектирования, поэтому четкое понимание принципов проектирования сослужит вам хорошую службу.
Определение графа слоев
В предыдущем разделе мы вкратце упомянули, что глубокая архитектура может быть представлена как направленный граф объектов Layer. В этом разделе мы применим данный интуитивный подход к объекту TensorGraph. Эти объекты отвечают за построение базового вычислительного графа TensorFlow.
Объект TensorGraph отвечает за поддержание объектов tf .Graph, tf .Session и списка слоев (self.layers) на внутреннем уровне (пример 8.9). Направленный граф представлен неявно, при помощи списка входных слоев in iayers, принадлежащих каждому объекту Layer. Объект TensorGraph также содержит сервисные функции для сохранения этого экземпляра tf .Graph на диск и, следовательно, присваивает себе
Самообучение с максимизацией подкрепления | 201
каталог (используя функцию tempfile.mkdtempo, если другая не указана) для хранения контрольных точек весов, связанных с базовым графом TensorFlow.
Пример 8.9. Тензорный граф содержит граф слоев; объекты TensorGraph можно рассматривать, как ’’модельный" объект, содержащий глубокую архитектуру, которую вы хотите натренировать
class TensorGraph(object):
def __init__(self,
batch_size=100, random_seed=None, graph=None, learning_rate=O.001, model_dir=None, **kwargs): II II II
Параметры
batch_size: целочисленный; размер пакета по умолчания для тренировки и оценивания, graph: tens orflow.Graph
граф Graph, в котором создаются объекты Tensorflow. Если None, то создается новый Graph.
learning_rate: вещественный или LearningRateSchedule; скорость заучивания, используемая для оптимизации, kwargs именованные аргументы, и и и
# Управление слоем, self.layers = diet() self.features = list() self.labels = list() self.outputs = list() self.task_weights = list() self.loss = None self.built = False self.optimizer = None self.learning_rate = learning_rate
# Отдельное место для хранения тензорных объектов, которые # не сериализуются.
# См. TensorGraph._get_tf() для получения подробностей # ленивого конструирования, self.tensor_objects = { ’’Graph”: graph, #”train_op”: None, }
202 | Гпава 8
self.global_step = 0
self.batch_size = batch_size
self.random_seed = random_seed
if model_dir is not None:
if not os.path.exists(model_dir):
os.makedirs(model_dir)
else:
model_dir = tempfile.mkdtemp() self.model_dir_is_temp = True self.model_dir = model_dir self.save_file = ”%s/%s" % (self.model_dir, "model") self.model_class = None
Приватный метод add layer () выполняет служебную работу для добавления нового объекта Layer В TensorGraph (например, 8.10).
I Пример 8.10. Метод _add_layer () добавляет новый объект Layer
def _add_layer(self, layer):
if layer.name is None:
layer.name = "%s_%s" % (layer.___class__.__name__, len(self.layers) + 1)
if layer.name in self.layers:
return
if isinstance(layer, Input):
self.features.append(layer) self.layers[layer.name] = layer for in_layer in layer.in_layers:
self._add_layer(in_layer)
Слои в TensorGraph должны образовывать направленный ациклический граф (в таком графе не может быть циклов). В результате мы можем отсортировать эти слои топологически. В интуитивном смысле топологическая сортировка "упорядочивает" СЛОИ В графе так, ЧТО входящие СЛОИ in layers каждого объекта-слоя Layer предшествуют ему в упорядоченном списке. Такая топологическая сортировка необходима для того, чтобы убедиться, что все входные слои конкретного слоя добавлены в граф перед этим слоем (пример 8.11).
F Пример 8.11. Метод topsortO упорядочивает слои в TensorGraph I
def topsort(self):
def add_layers_to_list(layer, sorted_layers): if layer in sorted_layers:
return
Самообучение с максимизацией подкрепления | 203
for in_layer in layer.in_layers:
add_layers_to_list(in_layer, sorted_layers) sorted_layers.append(layer)
sorted_layers = []
for 1 in self.features + self.labels + self.task_weights +
self.outputs:
add_layers_to_list(1, sorted_layers) add_layers_to_list(self.loss, sorted_layers) return sorted—layers
Метод build о берет на себя ответственность за заполнение экземпляра tf. Graph путем вызова метода iayer.create_tensor() для каждого слоя в топологическом порядке (пример 8.12).
Пример 8.12. Метод build о заполняет лежащий в основе граф TensorFlow |
def build(self): if self.built: return
with self,_get_tf("Graph”),as_default():
self._training_placeholder = tf.placeholder(dtype=tf.float32, shape=())
if self,random_seed is not None:
tf.set_random_seed(self.random_seed)
for layer in self.topsort():
with tf,name_scope(layer.name):
layer.create_tensor(training=self._training_placeholder) self.session = tf.Session()
self.built = True
Метод set loss () добавляет в граф потерю за счет тренировки. Метод add outputo указывает, что рассматриваемый слой может быть извлечен из графа. Метод set optimizer () задает оптимизатор, используемый для тренировки (пример 8.13).
i Пример 8.13. Методы, добавляющие в вычислительный граф необходимые потери, : выходы и оптимизаторы
def set_loss(self, layer):
self,_add_layer(layer)
self.loss = layer
def add_output(self, layer):
self._add_layer(layer)
self.outputs.append(layer)
204 | Гпава 8
def set_optimizer(self, optimizer):
"""Назначить оптимизатор, который будет использоваться для подгонки.'""' self.optimizer = optimizer
Метод get layer variabieso используется для извлечения заучиваемых объектов-переменных tf .variable, созданных слоем. Приватный метод get tf о применяется для извлечения экземпляров tf .Graph и оптимизатора, лежащих в основе объекта TensorGraph. Метод get global step () — ЭТО вспомогательный Метод ДЛЯ Выборки текущего шага в тренировочном процессе (начиная с 0 при конструировании). См. пример 8.14.
Пример 8.14. Выбор заучиваемых переменных, связанных с каждым слоем J
def get_layer_variables(self, layer):
'""'Получить список тренируемых переменных в слое графа.'""' if not self.built:
self.build()
with self,_get_tf("Graph"),as_default() : if layer.variable_scope == return [] return tf,get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES, scope=layer.variable_scope)
def get_global_step(self):
return self,_get_tf("GlobalStep”)
def _get_tf(self, obj):
'""'Выбирает лежащие в основе примитивы TensorFlow.
Параметры
obj: строковый.
Если "Graph”, то возвращает экземпляр tf.Graph. Если "Optimizer", то возвращает оптимизатор. Если "train_op", то возвращает тренировочную операцию. Если "GlobalStep”, то возвращает глобальный шаг.
Возвращаемое значение
Объект TensorFlow п п п
if obj in self.tensor_objects and self.tensor_objects[obj] is not None: return self.tensor_objects[obj]
if obj == "Graph":
self,tensor_objects["Graph"] = tf.GraphO
Самообучение с максимизацией подкрепления | 205
elif obj == "Optimizer":
self.tensor_objects["Optimizer"] = tf.train.AdamOptimizer( learning_rate=self.learning_rate, betal=0.9, beta2=0.999, epsilon=le-7) elif obj == "GlobalStep":
with self._get_tf("Graph").as_default():
self.tensor_objects["GlobalStep"] = tf.Variable(0, trainable=False) return self._get_tf(obj)
Наконец, метод restore () восстанавливает сохраненный объект TensorGraph с диска (пример 8.15). (Как вы увидите позже, TensorGraph автоматически сохраняется во время тренировки.)
Пример 8.15. Восстановление натренированной модели с диска
def restore(self):
"""Перезагрузить значения всех переменных из файла самой последней контрольной точки.""" if not self.built:
self.build()
last_checkpoint = tf.train.latest_checkpoint(self.model_dir)
if last_checkpoint is None:
raise ValueError("No checkpoint found")
with self._get_tf("Graph").as_default():
saver = tf.train.Saver()
saver.restore(self.session, last_checkpoint)
Алгоритм АЗС
В этом разделе вы научитесь реализовывать АЗС — обучающийся алгоритм с асинхронной максимизацией подкрепления, который вы встречали ранее в этой главе. АЗС является значительно более сложным обучающимся алгоритмом, чем те, которые вы встречали ранее2. Он требует выполнения градиентного спуска в нескольких потоках, перемежающегося с кодом разворачивания игровой ситуации и асинхронного обновления заученных весов. В результате этой дополнительной сложности мы определим алгоритм АЗС в объектно-ориентированном стиле. Начнем с определения объекта азс.
Класс азс реализует алгоритм АЗС (пример 8.16). В основной алгоритм включено несколько дополнительных танцев с бубном, чтобы стимулировать самообучение,
2 См. https.7/medium.com/emergent-future/simpie-reinforcement-iearning-with-tensorflow-part-8-asynchronous-actor-critic-agents-a3c-c88f72a5e9f2 с подробным описанием формализации алгоритма. — Прим. пер.
206 | Гпава 8
в частности энтропийный член и поддержка обобщенного оценивания преимуществ. Мы не будем раскрывать все эти детали, но для того чтобы получше в них разобраться, рекомендуем вам перейти по ссылкам на исследовательскую литературу (перечисленную в описании класса в коде).
| Пример 8.16. Определить класс АЗС, инкапсулирующий тренировку алгоритма । с асинхронной максимизацией подкрепления АЗС
class АЗС(object): п п п
Реализует алгоритм асинхронной критики стратегии с учетом преимущества (АЗС).
Алгоритм описан в Mnih V. et al. "Asynchronous Methods for Deep Reinforcement Learning” ("Асинхронные методы глубокого самообучения с максимизацией подкрепления”, см. https://arxiv.org/abs/1602.01783). Этот класс требует, чтобы стратегия выводила две величины: вектор, дающий вероятность выполнения каждого действия, и оценку функции стоимости для текущего состояния. Он оптимизирует оба выходных значения одновременно, используя потерю, которая представляет собой сумму трех слагаемых.
1. Потеря стратегии; она пытается максимизировать дисконтированное вознаграждение за каждое действие.
2. Потеря стоимости; она пытается подогнать оценку стоимости под фактическое дисконтированное вознаграждение, которое было достигнуто на каждом шаге.
3. Энтропийный член для стимулирования обследования.
Этот класс поддерживает среды только с дискретными (не непрерывными) пространствами действий. Аргумент "action”, передаваемый в среду, является целочисленным индексом выполняемого действия.
Этот класс поддерживает обобщенное оценивание преимуществ, как описано в Schulman et al. "High-Dimensional Continuous Control Using Generalized Advantage Estimation” ("Многомерное непрерывное управление с использованием обобщенного оценивания преимуществ”, см. https://arxiv.org/abs/1506.02438).
Это метод нахождения компромиссного соотношения между смещением и дисперсией в оценке преимуществ, который иногда может приводить к улучшению скорости схождения. Для настройки компромисса используйте параметр advantage_lambda. п it и
self._env = env
self.max_rollout_length = max_rollout_length self.discount_factor = discount-factor
Самообучение с максимизацией подкрепления | 207
self.advantage_lambda = advantage_lambda
self.value_weight = value_weight
self.entropy_weight = entropy_weight
self.-Optimizer = None
(self._graph, self.-features, self._rewards, self._actions,
self._actionjprob, self._value, self.-advantages) = self.build_graph(
None, ’’global”, model_dir)
with self ._graph._get_tf (’’Graph”) .as_default() :
self._session = tf.SessionO
В самом центре класса азс находится метод build graph () (пример 8.17), создающий экземпляр TensorGraph (внутри которого лежит вычислительный граф TensorFlow), кодирующий заученную моделью стратегию. Обратите внимание на то, насколько сжато это определение по сравнению с другими, которые вы видели ранее! Использование объектной ориентированности имеет много преимуществ.
i Пример 8.17. Этот метод строит вычислительный граф для алгоритма АЗС.
Обратите внимание, что стратегическая сеть здесь определяется на основе слоевой абстракции Layer, которую вы встречали ранее
def build_graph(self, tf_graph, scope, model_dir):
’’’’’’Сконструировать TensorGraph, содержащий вычисления стратегии и потери.”””
state_shape = self._env.state_shape
features = []
for s in state_shape:
features.append(Input(shape=[None] + list(s), dtype=tf.float32))
dl = Flatten(in_layers=features)
d2 = Dense(
in_layers=[dl],
activation_fn=tf.nn.relu,
normalizer_fn=tf.nn.12_normalize,
normalizer_params={ ’’dim”: 1}, out_channels=64)
d3 = Dense(
in_layers=[d2],
activation_fn=tf.nn.relu,
normalizer_fn=tf.nn.12_normalize,
normalizerjparams={ ’’dim”: 1}, out_channels=32)
d4 = Dense(
in_layers=[d3],
activation_fn=tf.nn.relu,
normalizer_fn=tf.nn.12_normalize,
normalizer_params= {’’dim”: 1}, out_channe1s=16)
208 | Гпава 8
d4 = BatchNorm(in_layers=[d4])
d5 = Dense(in_layers=[d4], activation_fn=None, out_channels=9)
value = Dense(in_layers=[d4], activation_fn=None, out_channels=l)
value = Squeeze(squeeze_dims=l, in_layers=[value])
action_prob = SoftMax(in_layers=[d5])
rewards = Input(shape=(None,))
advantages = Input(shape=(None,))
actions = Input(shape=(None, self._env.n_actions)) loss = A3CLoss(
self.value_weight,
self.entropy_weight,
in_layers=[rewards, actions, actionjorob, value, advantages])
graph = TensorGraph(
batch_size=self.max_rollout_length,
graph=tf_graph, mode l_di r=mode l_di r) for f in features:
graph._add_layer(f)
graph.add_output(actionjorob)
graph.add_output(value)
graph.set_loss(loss)
graph.set—optimi zer(self.—Optimizer)
with graphget_tf("Graph”).as_default():
with tf.variable_scope(scope):
graph.buildO
return graph, features, rewards, actions, action_prob, value, advantages
В этом примере много программного кода. Давайте разберем его на несколько примеров и обсудим подробнее. Пример 8.18 принимает кодировку среды TicTacToeEnvironment в виде массива и передает ее непосредственно в экземпляры input для графа.
Пример 8.18. Этот фрагмент из метода build_graph() передает кодировку среды TicTacToeEnvironment в виде массива
state_shape = self._env.state_shape features = [] for s in state_shape:
features.append(Input(shape=[None] + list(s), dtype=tf.float32))
В примере 8.19 показан фрагмент кода, используемый с целью конструирования входов input для вознаграждений из среды, наблюдаемых преимуществ и выполняемых действий.
Самообучение с максимизацией подкрепления | 209
Пример 8.19. Этот фрагмент из метода build_graph() определяет объекты input для вознаграждений, преимуществ и действий
rewards = Input(shape=(None,)) advantages = Input(shape=(None,)) actions = Input(shape=(None, self._env.n_actions))
Стратегическая сеть отвечает за заучивание стратегии. В примере 8.20 входное состояние игрового поля сначала сглаживается в простой входной вектор признаков. К сглаженному игровому полю применяется ряд полносвязных (или Dense) преобразований. В самом конце используется слой Softmax для предсказания вероятностей действий из d5 (обратите внимание, что аргументу out channeis присвоено значение 9, по одному для каждого возможного хода на игровом поле крестиков-ноликов).
Пример 8.20. Этот фрагмент из метода build_graph() определяет стратегическую сеть
dl = Flatten(in_layers=features)
d2 = Dense(
in_layers=[dl],
activation_fn=tf.nn.relu,
normalizer_fn=tf.nn.12_normalize,
normalizer_params={"dim": 1}, out_channels=64)
d3 = Dense(
in_layers=[d2],
activation_fn=tf.nn.relu,
normalizer_fn=tf.nn.12_normalize,
normalizer_params={"dim": 1}, out_channels=32)
d4 = Dense(
in_layers=[d3],
activation_fn=tf.nn.relu,
normalizer_fn=tf.nn.12_normalize,
normalizer_params={"dim": 1}, out_channels=16)
d4 = BatchNorm(in_layers=[d4])
d5 = Dense(in_layers=[d4], activation_fn=None, out_channels=9) value = Dense(in_layers=[d4], activation_fn=None, out_channels=l) value = Squeeze(squeeze_dims=l, in_layers=[value])
action_prob = SoftMax(in_layers=[d5])
210 | Глава 8
Конструирование признаков действительно мертво?
В этом разделе мы передаем сырое игровое поле крестиков-ноликов в TensorFlow, чтобы натренировать стратегию. Вместе с тем важно отме-Ж тить, что для более сложных, чем крестики-нолики, игр это может не дать удовлетворительных результатов. Одним из менее известных фактов о программе AlphaGo является то, что для облегчения программе AlphaGo самообучения компания DeepMind выполняет сложное конструирование признаков для извлечения ’’интересных” позиций го на доске. (Этот факт спрятан в информации, прилагаемой к исследовательской работе компании DeepMind.)
Факт остается фактом, но самообучение с максимизацией подкрепления (и методы глубокого самообучения в целом) часто по-прежнему нуждаются в человеко-ориентированном конструировании признаков для извлечения содержательной информации, прежде чем обучающиеся алгоритмы будут способны обучаться эффективным стратегиям и моделям. Вполне вероятно, что с ростом вычислительных мощностей, доступных благодаря совершенствованию аппаратного обеспечения, эта потребность в конструировании признаков будет уменьшаться, но в ближайшем будущем планируйте вручную извлекать информацию о ваших системах, необходимую для повышения результативности.
Функция потери
Теперь объектно-ориентированный механизм находится на своем месте, и все готово для определения потери в стратегической сети АЗС. Данная функция потери будет реализована как объект Layer (удобная абстракция— все части глубокой архитектуры являются просто слоями). Объект A3CLoss реализует математическую потерю, состоящую из суммы трех членов: policy loss, value loss и entropy (пример 8.21).
Пример 8.21. Слой, реализующий функцию потери для АЗС
class A3CLoss(Layer):
’’’’’’Это слой вычисляет функцию потери для АЗС.’"”’
def __init__(self, value_weight, entropy_weight, **kwargs):
super(A3CLoss, self).___init__(**kwargs)
self.value_weight = value_weight self,entropy_weight = entropy_weight
def create_tensor(self, **kwargs):
reward, action, prob, value, advantage = [ layer.out_tensor for layer in self.in_layers
]
prob = prob + np.finfo(np.float32).eps
log_prob = tf.log(prob)
Самообучение с максимизацией подкрепления | 211
policy_loss = -tf.reduce_mean(
advantage * tf.reduce_sum(action * log_prob, axis=l)) value_loss = tf.reduce_mean(tf.square(reward - value)) entropy = -tf.reduce_mean(tf.reduce_sum(prob * log_prob, axis=l)) self.out_tensor = policy_loss + self.value_weight * value_loss \
- self.entropy_weight * entropy return self.out tensor
В приведенном выше определении есть много частей, поэтому давайте вытащим фрагменты кода и обследуем их. Слой A3CLoss принимает слои reward, action, prob, value, advantage в качестве входных данных. Для математической устойчивости мы конвертируем вероятности в логарифмические вероятности (это численно гораздо более стабильно). См. пример 8.22.
Пример 8.22. Этот фрагмент кода из слоя АЗсьозз принимает вознаграждение, действие, вероятность, стоимость, преимущество как входные слои |
и вычисляет логарифмическую вероятность j
reward, action, prob, value, advantage = [ layer.out_tensor for layer in self.in_layers
prob = prob + np.finfo(np.float32).eps log_prob = tf.log(prob)
Функция потери для стратегии вычисляет сумму всех наблюдаемых преимуществ, взвешенную на логарифмическую вероятность выполняемого действия. (Напомним, что преимуществом является разница между вознаграждением за выполнение конкретного действия и ожидаемым вознаграждением сырой стратегии для данного состояния.) Идея здесь заключается в том, что poiicy ioss дает сигнал о том, какие действия были выгодными, а какие нет (пример 8.23).
Пример 8.23. Этот фрагмент кода из слоя АЗсьозз определяет стратегическую потерю |
policy_loss = -tf.reduce_mean(
advantage * tf.reduce_sum(action ★ log_prob, axis=l))
Потеря стоимости вычисляет разницу между нашей оценкой вознаграждения V (reward) и фактическим наблюдаемым значением V (value). Обратите внимание на применение здесь I? -потери (пример 8.24).
Пример 8.24. Этот фрагмент кода из слоя АЗСЬозз определяет потерю стоимости |
value_loss = tf.reduce_mean(tf.square(reward - value))
Энтропийный член является дополнением, которое побуждает стратегию исследовать дальше, добавляя небольшой шум. Этот член фактически является формой
212 | Глава 8
регуляризации для АЗС-сетей. Окончательная потеря, вычисляемая функцией A3CLoss, представляет собой линейную комбинацию потерь этих компонентов (пример 8.25).
Пример 8.25. Этот фрагмент кода из слоя дзсьозз определяет энтропийный член, j добавленный в потерю
entropy = -tf.reduce_mean(tf.reduce_sum(prob * log_prob, axis=l))
Определение рабочих процессов
К настоящему времени вы узнали, как строится стратегическая сеть, но еще не увидели, как реализуется процедура асинхронной тренировки. Концептуально асинхронная тренировка состоит из отдельных рабочих процессов, выполняющих градиентный спуск на локально симулируемых разворачиваниях игровой ситуации и периодически возвращающих полученные знания в глобальный набор весов. Продолжая наше объектно-ориентированное проектирование, давайте представим класс Worker.
Каждый экземпляр класса worker содержит копию модели, которая тренируется асинхронно в отдельном потоке (пример 8.26). Обратите внимание, что a3c.buiid_grapho используется для конструирования локальной копии вычислительного графа TensorFlow для рассматриваемого потока. Здесь обратите особое внимание на locai vars и giobai vars. Нам нужно обеспечить тренировку только тех переменных, которые связаны с копией стратегии этого рабочего процесса, а не с глобальной копией переменных (которая используется для обмена информацией между рабочими потоками). Как следствие, градиенты используют функцию tf. gradients о, которая берет градиенты потери относительно только локальных переменных.
Пример 8.26. Класс Wbrker реализует вычисление, выполняемое каждым потоком
class Worker(object):
"""Объект Worker создается для каждого тренировочного потока."""
def __init___(self, аЗс, index):
self.a3c = аЗс self.index = index self.scope = "worker%d" % index self.env = copy.deepcopy(a3c._env) self.env.reset() (self.graph, self.features, self.rewards, self-actions, self.action_prob, self.value, self.advantages) = a3c.build_graph( a3c._graph._get_tf("Graph"), self.scope, None)
Самообучение с максимизацией подкрепления | 213
with a3c._graph._get_tf ("Graph").as_default(): local_vars = tf.get_collection(
tf.GraphKeys.TRAI NABLE_VARI ABLES, self.scope) global_vars = tf.get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES, "global")
gradients = tf.gradients(self.graph.loss.out_tensor, local_vars)
grads_and_vars = list(zip(gradients, global_vars)) self.train_op = a3c._graph._get_tf(
"Optimizer").apply_gradients( grads_and_vars) self.update_local_variables = tf.group(
* [tf.assign(vl, v2) for vl, v2 in zip(local_vars, global_vars)]) self.global_step = self.graph.get_global_step()
Разворачивание игровой ситуации в рабочих процессах
Каждый рабочий процесс отвечает за симулирование разворачивания игровой ситуации локально. Метод create_rollout() использует session.run для выборки из графа TensorFlow вероятностей действий (пример 8.27). Затем он получает образец действия из этой стратегии, используя функцию NumPy np.random.choice о, взвешенную на вероятности каждого класса. Вознаграждение за выполняемое действие вычисляется ИЗ среды TicTacToeEnvironment посредством ВЫЗОВа self .env. step(action).
Пример 8.27. Метод create_roilout симулирует локальное разворачивание игровой ситуации
def create_rollout(self):
"""Сгенерировать разворачивание игровой ситуации."""
n_actions = self.env.n_actions
session = self.a3c._session states = [] actions = [] rewards = [] values = []
# Генерация разворачивания.
for i in range(self.a3c.max_rollout_length): if self.env.terminated:
break
state = self.env.state
214 | Глава 8
states.append(state)
feed_dict = self,create_feed_dict(state) results = session.run(
[self,action_prob.out_tensor, self.value.out_tensor], feed_dict=feed_dict)
probabilities, value = results[:2]
action = np.random.choice(np.arange(n_actions), p=probabilities[0]) actions.append(action)
values.append(float(value))
rewards.append(self.env.step(action))
# Вычислить оценку вознаграждения для остального эпизода, if not self.env.terminated:
feed_dict = self,create_feed_dict(self.env.state)
final_value = self,a3c.discount-factor * float( session.run(self.value.out_tensor, feed_dict)) else:
final_value =0.0 values.append(final_value) if self.env.terminated:
self.env.reset()
return states, actions, np.array(rewards), np.array(values)
Метод process_rollouts() выполняет предобработку, необходимую для вычисления дисконтированных вознаграждений, стоимостей, действий и преимуществ (пример 8.28).
Пример 8.28. Метод processjrollouts() вычисляет вознаграждения, стоимости, действия и преимущества и затем делает шаг градиентного спуска относительно потери
def process_rollout(self, states, actions, rewards, values, step_count): ’’’’’’Натренировать сеть на основе разворачивания.”””
# Вычислить дисконтированные вознаграждения и преимущества, if len(states) == 0:
# В многопоточной среде создать разворачивание иногда не удается.
# Не обрабатывать, если испорчено.
print(’’Создать разворачивания не получилось. Пропускаю”) return
discounted_rewards = rewards.copy()
discounted_rewards[-1] += values[-1] advantages = rewards - values[:-l] +
self,a3c.discount-factor * np.array(values[1:])
Самообучение с максимизацией подкрепления | 215
for j in range(len(rewards) - 1, 0, -1):
discounted_rewards[j-1] += self.a3c.discount_factor * \ discounted_rewards[j]
advantages[j-1] += (
self.a3c.discount_factor *
self.a3c.advantage_lambda * advantages[j])
# Конвертировать действия в кодировку с одним активным состоянием.
n_actions = self.env.n_actions actions_matrix = [] for action in actions:
a = np.zeros(n_actions) a[action] = 1.0 actions_matrix.append(a)
# Перераспределить состояния в соответствующий набор массивов. state_arrays = [[] for i in range(len(self.features))] for state in states:
for j in range(len(state)): state_arrays[j].append(state[j])
# Построить словарь передачи данных и применить градиенты. feed_dict = {}
for f, s in zip(self.features, state_arrays): feed_dict[f.out_tensor] = s
feed_dict[self.rewards.out_tensor] = discounted_rewards feed—diet[self.actions.out—tensor] = actions_matrix feed_dict[self.advantages.out_tensor] = advantages feed_dict[self.global_step] = step_count
self.a3c._session.run(self.train_op, feed_dict=feed_dict)
Метод Worker, run о выполняет тренировочный шаг для объекта worker, опираясь на то, что метод process_rollout() за кадром сделает фактический вызов метода self.аЗс._session.run() (пример 8.29).
; Пример 8.29. Метод run О является высокоуровневой активацией объекта Worker
def run(self, step_count, total_steps):
with self.graph._get_tf("Graph").as_default():
while step_count[0] < total_steps:
self.a3c.—Session.run(self.update_local_variables) states, actions, rewards, values = self.create_rollout() self.process_rollout(states, actions, rewards, values, step_count[0])
step_count[0] += len(actions)
216 | Глава 8
Тренировка стратегии
Метод азс. fit о объединяет все разрозненные части, созданные для тренировки модели. Метод fit о берет на себя ответственность за порождение рабочих потоков Worker, используя ДЛЯ ЭТОГО библиотеку Python threading. Поскольку каждый рабочий процесс worker берет на себя ответственность за тренировку как таковую, метод fit о просто отвечает за периодическое сохранение на диск состояния натренированной модели в контрольной точке (пример 8.30).
' - - - - .
, Пример 8.30. Метод fit() объединяет все вместе
[и выполняет тренировочный алгоритм АЗС
def fit(self,
total_steps,
max_checkpoints_to_keep=5, checkpoint_interval=600, restore=False):
’’’’’’Натренировать стратегию.
Параметры
tоtal_s teps: целочисленный;
общее количество временных шагов, выполняемых в среде, по всем разворачиваниям во всех потоках.
max_checkpoints_to_keep: целочисленный;
максимальное количество хранимых файлов контрольных точек.
Когда достигается это число, более старые файлы удаляются, checkpoint-interval: вещественный;
временной интервал в секундах, в котором нужно сохранять контрольные точки restore: булевый;
если True, то восстановить модель из самой последней контрольной точки и продолжить тренировку оттуда. Если False, то натренировать модель заново.
И !! !!
with self._graph._get_tf("Graph").as_default(): step_count = [0] workers = [] threads = [] for i in range(multiprocessing.cpu_count()): workers.append(Worker(self, i))
self. —Session.run(tf.global_variables_initializer()) if restore:
self.restore() for worker in workers:
thread = threading.Thread( name=worker.scope, target=lambda: worker.run(step_count, total_steps))
Самообучение с максимизацией подкрепления | 217
threads.append(thread) thread.start()
variables = tf.get_collection(tf.GraphKeys.GLOBAL-VARIABLES, scope=’’global")
saver = tf.train.Saver(variables,
max_to_keep=max_checkpoints—to_keep) checkpoint-index = 0 while True:
threads = [t for t in threads if t.isAlive()] if len(threads) > 0:
threads[0].j oin(checkpoint-interval) checkpoint-index += 1 saver.save(
self.—Session, self._graph.save_file, global_s tep=checkpoint_index) if len(threads) == 0:
break
Задание для читателя
Мы настоятельно рекомендуем вам попробовать натренировать модель игры крестики-нолики самостоятельно! Обратите внимание, что этот пример более запутан, чем другие примеры в книге, и потребует большей вычислительной мощности. Рекомендуется использовать компьютер с несколькими ядрами CPU. Это техническое требование не особо обременительно; хорошего ноутбука должно быть достаточно. Попробуйте использовать такой инструмент, как htop, чтобы удостовериться, что программный код действительно многопоточный. Убедитесь в качестве модели, которую вы тренируете! Подавляющую часть времени вы должны будете одерживать верх над случайным ориентиром, но эта элементарная реализация не даст вам модель, которая всегда выигрывает. Мы рекомендуем изучить публикации по самообучению с максимизацией подкрепления и расширить базовую реализацию, чтобы посмотреть, насколько хорошо вы можете это сделать.
Резюме
В этой главе мы познакомили вас с основными понятиями самообучения с максимизацией подкрепления. Мы провели вас через некоторые недавние успехи методов самообучения с максимизацией подкрепления на аркадных играх ATARI, в полете вертолета в перевернутом положении и в компьютерном го. Затем мы рассказали вам о математическом каркасе марковских процессов принятия решений. Мы рассмотрели его с учетом подробного практического примера, проведя вас по процессу конструирования агента игры крестики-нолики. В этом алгоритме применяется сложный метод тренировки АЗС, который для ускорения процесса тренировки использует несколько ядер процессора.
В главе 9 вы подробнее познакомитесь с тренировкой моделей с помощью нескольких графических процессоров.
218 | Глава 8
ГЛАВА 9
Тренировка крупных глубоких сетей
Итак, теперь вы знаете, как можно полностью натренировать небольшие модели на хорошем ноутбуке. Все эти модели могут успешно выполняться на оснащенном графическими процессорами (GPU) оборудовании с заметным повышением скорости (за исключением моделей на основе самообучения с максимизацией подкрепления по причинам, рассмотренным в предыдущей главе). Однако тренировка более крупных моделей по-прежнему требует значительной доработки. В этой главе мы обсудим различные типы оборудования, которые могут быть использованы для тренировки глубоких сетей, в том числе графические процессоры (GPU), тензорные процессоры (TPU) и нейроморфные чипы. Мы также кратко рассмотрим принципы распределенной тренировки для более крупных глубоко обучающихся моделей. А закончим главу углубленным практическим примером, взятым и адаптированным из одного из учебных пособий TensorFlow, демонстрирующим метод тренировки сверточной нейронной сети CIFAR-10 на многопроцессорном сервере для GPU-вычислений. Мы рекомендуем вам попробовать выполнить этот программный код самостоятельно, но с готовностью признаем, что получить доступ к многопроцессорному серверу для GPU-вычислений сложнее, чем найти хороший ноутбук. К счастью, доступ к многопроцессорным серверам для GPU-вычислений в облаке становится возможным и, судя по всему, является наилучшим решением для промышленных потребителей TensorFlow, пытающихся тренировать большие модели.
Специальное аппаратное обеспечение для глубоких сетей
Как вы смогли убедиться на протяжении всей книги, тренировка глубокой сети требует цепочек тензорных операций, выполняемых неоднократно на мини-пакетах данных. Тензорные операции обычно преобразуются в операции матричного умножения с помощью программного обеспечения, поэтому скорость тренировки глубоких сетей принципиально зависит от способности быстро выполнять операции матричного умножения. В то время как центральные процессоры (central processing unit, CPU) прекрасно справляются с реализацией матричных умножений, универсальность оборудования CPU означает, что много усилий будет потрачено на ненужные для математических операций накладные расходы.
Инженеры аппаратного обеспечения отмечали этот факт многие годы, и существует целый ряд альтернативного аппаратного обеспечения для работы с глубокими
219
сетями. Такое оборудование можно в целом подразделить на две категории: только вывод и тренировка и вывод. Аппаратное обеспечение только для вывода не может применяться для тренировки новых глубоких сетей, но может использоваться для внедрения натренированных моделей в производственной среде, что позволяет потенциально увеличить производительность на порядок. Оборудование для тренировки и вывода позволяет тренировать модели исходно. В настоящее время GPU-оборудование компании NVIDIA занимает доминирующее положение на рынке аппаратного обеспечения для тренировки и вывода из-за значительных инвестиций в программное обеспечение и образовательно-информационной деятельности команд разработчиков NVIDIA, но ряд других конкурентов уже начинают "наступать на пятки" GPU. В этом разделе мы кратко рассмотрим некоторые из этих новых аппаратных средств. Помимо GPU и CPU, подавляющая часть этих альтернативных форм аппаратного обеспечения еще не получили широкую доступность, поэтому значительная часть этого раздела ориентирована на будущее.
Тренировка на CPU
Хотя тренировка на CPU ни в коем случае не является последним словом в тренировке глубоких сетей, она часто довольно хорошо подходит для небольших моделей (как вы убедились на своем личном опыте, читая эту книгу). Для задач самообучения с максимизацией подкрепления многоядерный CPU может даже превосходить тренировку на GPU.
CPU также пользуются широкой популярностью для приложений глубоких сетей категории "только вывод". Большинство компаний вложили значительные средства в разработку облачных серверов, построенных в основном на серверах Intel. Весьма вероятно, что первое поколение глубоких сетей, развернутых повсеместно (за пределами технологических компаний), будет в основном внедрено в производственной среде на таких серверах Intel. Несмотря на то что внедрение на базе CPU не является достаточным для высокопроизводительного развертывания обучающихся моделей, его нередко достаточно для первых потребностей клиентов. На рис. 9.1 показан стандартный процессор Intel.
Рис. 9.1. CPU от Intel. Центральные процессоры по-прежнему являются доминирующей формой компьютерного оборудования, которая присутствует во всех современных ноутбуках, настольных компьютерах, серверах и телефонах. Подавляющая часть программного обеспечения написана для работы на CPU. Числовые вычисления (такие как тренировка нейронной сети) могут исполняться на CPU, но при этом могут быть медленнее, чем на специальном аппаратном обеспечении, оптимизированном для численных методов
220 | Глава 9
Тренировка на GPU
GPU (graphics processing unit — графический процессор) изначально были спроектированы для выполнения вычислений, требующихся графическому сообществу. По случайному стечению обстоятельств оказалось, что примитивы, используемые для определения графических шейдеров, могут быть перепрофилированы для глубокого самообучения. В своих математических основах графика и машинное самообучение опираются на матричные умножения. В эмпирическом плане матричные умножения на GPU предлагают ускорения, на порядок или два порядка превышающие реализации CPU. Каким образом GPU добились такого успеха? Хитрость в том, что GPU используют тысячи идентичных потоков. Умные хакеры преуспели в разложении матричного умножения на параллельные операции, которые могут предложить резкое ускорение. На рис. 9.2 представлена архитектура GPU.
Рис. 9.2. Архитектура GPU от компании NVIDIA. GPU обладают намного большим количеством ядер, чем CPU, и хорошо подходят для выполнения численных линейно-алгебраических методов, которые подходят для графических вычислений и вычислений, связанных с машинным самообучением. Графические процессоры проявили себя в качестве доминирующей аппаратной платформы для тренировки глубоких сетей
Хотя сегодня существует ряд поставщиков GPU, в настоящее время на рынке GPU доминирует компания NVIDIA. Подавляющая часть мощности GPU этой компании связана с собственной библиотекой CUDA (compute unified device architecture, про
Тренировка крупных глубоких сетей | 221
граммно-аппаратной архитектурой параллельных вычислений), которая предлагает примитивы, облегчающие написание программ на GPU. Компания NVIDIA предлагает расширение CUDA под названием CUDNN, предназначенное для ускорения глубоких сетей (см. рис. 9.2). TensorFlow имеет встроенную поддержку расширения CUDNN, поэтому для ускорения ваших сетей вы также можете использовать CUDNN посредством TensorFlow.
Насколько важны размеры транзисторов?
В течение многих лет полупроводниковая промышленность отслеживала рост скоростей чипов, наблюдая за размерами транзисторов. По мере того как транзисторы становились все меньше, все больше чипов могло быть упаковано в стандартную микросхему, и алгоритмы могли работать быстрее. На момент написания этой книги компания Intel оперирует с 10-нано-метровыми транзисторами и работает над переходом на 7 нм. В последние годы темп сжатия размеров транзисторов значительно замедлился, поскольку в таких масштабах возникают огромные проблемы с рассеиванием тепла.
GPU компании NVIDIA частично преодолели эту тенденцию. В них, как правило, используются размеры транзисторов с отставанием на одно-два поколения от лучших транзисторов Intel, и эти GPU ориентированы на решение проблем, связанных с узкими местами в архитектурах и программном обеспечении, а не на проектировании транзисторов. До настоящего времени стратегия компании NVIDIA приносила дивиденды, и компания достигла доминирования на рынке в сегменте чипов для машинного самообучения.
Пока не ясно, как далеко могут зайти архитектурные и программные оптимизации. Столкнутся ли вскоре оптимизации GPU с теми же препятствиями закона Мура, что и CPU? Или же умные архитектурные инновации позволят годами ускорять работу GPU? Покажет только время.
Тензорные процессоры
Тензорный процессор (tensor processing unit, TPU) — это специализированная интегральная микросхема (application specific integrated circuit, ASIC), разработанная компанией Google для того, чтобы увеличить рабочие нагрузки глубокого самообучения, предусмотренные в TensorFlow. В отличие от GPU, TPU-блок имеет урезанную конфигурацию и реализует только абсолютный минимум ’’on-die”1, требуемый для выполнения необходимых операций матричного умножения. В отличие от GPU, TPU-блок зависит от смежного CPU, который выполняет для него подавляющую часть предобработки. Такой сжатый подход позволяет TPU-блоку достигать более высоких скоростей, чем GPU, при более низких энергетических затратах.
1 On-die termination (ODT) — это технология, где резистивный терминатор размещается внутри полупроводникового чипа, а не на печатной плате.
См. https://en.wikipedia.org/wiki/On-die_termination. — Прим. пер.
222 | Гпава 9
Первая версия TPU допускала вывод только на натренированных моделях, но самая последняя версия (TPU2) уже допускает тренировку (определенных) глубоких сетей. Вместе с тем, компания Google опубликовала не так уж много подробностей о TPU, и доступ ограничен сотрудниками Google, при этом имеются планы включить доступ к TPU через облако Google. Компания NVIDIA приняла к сведению TPU, и вполне вероятно, что будущие выпуски ее GPU будут напоминать TPU, поэтому пользователи на первых этапах производственного цикла, скорее всего, выиграют от инноваций Google независимо от того, кто одержит победу в борьбе за потребительский рынок глубокого самообучения: Google или NVIDIA.
На рис. 9.3 показан архитектурный проект TPU.
Внекристалльный в/в г——*, | । Буфер данных
Не в масштабе
; Вычисление
j Ц Управление
Рис. 9.3. Архитектура тензорного процессора (TPU) компании Google.
TPU — это специализированные чипы, спроектированные компанией Google в целях ускорения рабочих нагрузок глубокого самообучения. TPU представляет собой сопроцессор и не является автономной частью аппаратного обеспечения
Что такое микросхемы ASIC?
И CPU, и GPU являются универсальными чипами. CPU обычно поддерживают наборы инструкций в скомпонованном блоке и спроектированы так, чтобы быть универсальными. Особое внимание уделяется обеспечению широкого спектра применений. GPU менее универсальны, но по-прежнему
Тренировка крупных глубоких сетей | 223
позволяют реализовывать широкий спектр алгоритмов на таких языках, как CUDA.
Специализированные интегральные микросхемы (Application specific integrated circuits, ASIC) пытаются отойти от универсальности в пользу концентрации на потребностях конкретного применения. Исторически сложилось так, что микросхемы ASIC добились лишь ограниченного проникновения на рынок. Барабанная дробь закона Мура означала, что универсальные CPU отставали всего на дыхание или два от специализированных ASIC, и поэтому накладные расходы, связанные с аппаратным проектированием, часто не стоили усилий.
Такое положение дел начало меняться в последние несколько лет. Замедление сжатия транзисторов привело к расширению использования ASIC. Например, майнинг биткойнов полностью зависит от специализированных микросхем ASIC, которые реализуют специализированные криптографические операции.
Программируемые пользователем вентильные матрицы
Программируемые пользователем вентильные матрицы (field programmable gate arrays, FPGA) являются подвидом "программируемых на месте" микросхем ASIC. Стандартные FPGA часто можно перенастроить с помощью языков описания аппаратных средств, таких как Verilog, для динамической реализации новых проектов ASIC. FPGA обычно менее эффективны, чем специализированные ASIC, но их совершенствование может значительно повысить скорость обработки данных по сравнению с реализациями на основе CPU. Компания Microsoft, в частности, использовала FPGA для реализации вывода глубокого самообучения и заявляет, что достигла значительного роста скорости их развертывания. Однако этот подход пока еще не завоевал широкую популярность за пределами Microsoft.
Нейроморфные чипы
"Нейроны" в глубоких сетях математически моделируют понимание нейрональной биологии 1940-х годов. Излишне говорить, что биологическое понимание нейронального поведения с тех пор значительно продвинулось. Прежде всего теперь известно, что нелинейные активации, используемые в глубоких сетях, не являются точными моделями нейронной нелинейности. "Импульсные цепи" (spike trains) — более оптимальная модель (рис. 9.4), в которой нейроны активируются в виде кратковременных всплесков (пиков), но чаще всего падают на задний план.
Инженеры аппаратного обеспечения потратили значительные усилия на изучение возможности создания импульсно-цепных микросхем, отличающихся от существующей схемотехники (CPU, GPU, ASIC). Эти разработчики утверждают, что современные конструкции чипов страдают от фундаментальных ограничений мощности; мозг потребляет энергии на много порядков меньше, чем компьютерные чипы, и умные проекты должны стремиться учиться на архитектуре мозга.
224 | Гпава 9
Рис. 9.4. Нейроны часто активируются в виде кратковременных всплесков, которые называются импульсными цепями (а). В нейроморфных чипах предпринята попытка смоделировать поведение импульсных цепей в вычислительном аппаратном оборудовании. Биологические нейроны представляют собой сложные сущности (6), поэтому такие модели по-прежнему остаются лишь приблизительными
Ряд проектов в этой области привел к построению больших импульсно-цепных чипов, в которых предпринята попытка развить этот ключевой тезис. Проект TrueNorth компании IBM преуспел в создании импульсно-цепных процессоров с миллионами "нейронов" и продемонстрировал, что это оборудование может выполнять элементарное распознавание изображений со значительно меньшими потребностями к питанию, чем у существующих конструкций микросхем. Однако, несмотря на эти успехи, пока непонятно, каким образом транслировать современные глубокие архитектуры на импульсно-цепные чипы. Без возможности "компилировать" модели TensorFlow на импульсно-цепное оборудование маловероятно, что такие проекты получат широкое распространение в ближайшем будущем.
Распределенная тренировка глубоких сетей
В предыдущем разделе мы рассмотрели различные варианты аппаратного обеспечения для тренировки глубоких сетей. Вместе с тем большинство организаций, скорее всего, будут иметь доступ только к CPU и, возможно, к GPU. К счастью, существует возможность выполнять распределенную тренировку глубоких сетей, где несколько CPU или GPU совместно используются для тренировки моделей быстрее и эффективнее. На рис. 9.5 показаны две основные парадигмы тренировки глубоких сетей с многочисленными CPU/GPU, а именно тренировка с параллелизмом данных и тренировка с параллелизмом моделей. Вы узнаете об этих методах более подробно в следующих двух разделах.
Тренировка крупных глубоких сетей | 225
Параллелизм данных
Рис. 9.5. Параллелизм данных и параллелизм моделей — два главных режима распределенной тренировки глубоких архитектур. Тренировка с параллелизмом данных разбивает большие наборы данных по многочисленным вычислительным узлам, в то время как тренировка с параллелизмом моделей разбивает по многочисленным узлам большие модели
Параллелизм модели
Параллелизм данных
Параллелизм данных является наиболее распространенным типом тренировки многоузловой глубокой сети. Модели с параллелизмом данных распределяют большие наборы данных по разным машинам. Большинство узлов являются рабочими и имеют доступ к фрагментам общих данных, используемых для тренировки сети. Каждый рабочий узел имеет полную копию тренируемой модели. Один узел назначается в качестве супервизора, который через регулярные промежутки времени собирает обновленные веса от рабочих узлов и передает усредненные версии весов назад рабочим узлам. Обратите внимание, что в этой книге вы уже встречали пример с параллелизмом данных; реализация алгоритма АЗС, представленная в главе 8, является простым примером тренировки глубокой сети с параллелизмом данных.
В качестве исторической справки: предшественник TensorFlow компании Google, DistBelief, был основан на тренировке с параллелизмом данных на серверах для CPU-вычислений. Эта система была способна достигать распределенных скоростей CPU (используя 32-128 узлов), которые соответствовали или превышали скорости тренировки на GPU. На рис. 9.6 представлен метод тренировки с параллелизмом данных, реализованный в DistBelief. Однако успех таких систем, как DistBelief, как правило, зависит от наличия сетевых соединений с высокой пропускной способностью, которые обеспечивают быстрый обмен модельными параметрами. Во многих организациях отсутствует сетевая инфраструктура, обеспечивающая эффективную многоузловую тренировку с параллелизмом данных на CPU. Однако, как показывает пример АЗС, существует возможность выполнять тренировку с параллелизмом данных на одном узле, используя различные ядра CPU. В случае современных серверов также имеется возможность выполнять тренировку с параллелизмом данных с помощью многочисленных GPU, которыми оборудован один-единственный сервер, как мы покажем вам позже.
226 | Гпава 9
Параметрический
сервер и7 = и’ - r|Aw
Рис. 9.6. Поточный метод стохастического градиентного спуска (SGD) поддерживает многочисленные точные копии модели и тренирует их на разных подмножествах набора данных. Заученные веса от этих сегментов периодически синхронизируются с глобальными весами, хранящимися на параметрическом сервере
Параллелизм моделей
Человеческий мозг является единственным известным примером универсального интеллектуального аппаратного обеспечения, поэтому, естественно, были проведены сравнения между сложностью глубоких сетей и сложностью мозга. Простые аргументы говорят о том, что мозг имеет около 100 млрд нейронов; будет ли построение глубоких сетей с таким количеством ’’нейронов” достаточным для достижения универсального интеллекта? К сожалению, такие аргументы упускают из виду то, что биологические нейроны значительно сложнее, чем ’’математические нейроны". Поэтому простые сравнения дают мало пользы. Тем не менее создание более крупных глубоких сетей было основным направлением исследований в течение последних нескольких лет.
Главная трудность тренировки очень больших глубоких сетей заключается в том, что GPU, как правило, имеют ограниченную память (обычно десятки гигабайт). Нейронные сети с несколькими сотнями и более миллионов параметров, даже если их программировать тщательнейшим образом, невозможно натренировать на одном GPU из-за требований к объему памяти. Тренировочные алгоритмы с параллелизмом моделей пытаются это ограничение обойти, храня крупные глубокие сети в памяти многочисленных GPU. Несколько команд разработчиков успешно реализовало эти идеи на массивах GPU, натренировав глубокие сети с миллиардами параметров. К сожалению, эти модели до сих пор не показали улучшения в производительности, которые оправдывали бы дополнительные трудности. На данный момент, судя по всему, повышение экспериментальной легкости от использования более мелких моделей перевешивает выгоды от параллелизма моделей.
Тренировка крупных глубоких сетей | 227
Межсоединения памяти и аппаратного обеспечения
Внедрение параллелизма моделей требует наличия очень высокой пропускной способности соединений между вычислительными узлами, т. к. каждое обновление градиента в силу объективных причин требует межузлового обмена данными. Обратите внимание, что в то время как параллелизм данных требует эффективных межсоединений, операции синхронизации должны выполняться только спорадически после нескольких локальных обновлений градиента.
Несколько групп разработчиков использовали межсоединения InfiniBand (InfiniBand — это высокопроизводительный сетевой стандарт с низкой задержкой) или проприетарные межсоединения NVLINK компании NVIDIA, чтобы попытаться построить такие большие модели. Однако результаты экспериментов до сих пор были неоднозначными, и требования к оборудованию для таких систем, как правило, являются дорогостоящими.
Параллельная тренировка на данных CifarlO с использованием многочисленных GPU
В этом разделе мы дадим вам подробное пошаговое руководство по тренировке параллельной сверточной сети на эталонном наборе CifarlO. Набор данных CifarlO состоит из 60 тыс. изображений размером 32x32. Этот набор часто используется
Самолет
Автомобиль
Птица
Кошка
Олень
Собака
Лягушка
Лошадь
Корабль
Грузовик
Рис. 9.7. Набор данных CifarlO состоит из 60 тыс. изображений, взятых из 10 классов. Некоторые образцы изображений из различных классов приведены здесь
228 | Гпава 9
для сопоставительного анализа сверточных архитектур. На рис. 9.7 представлены образцы изображений из набора данных CifarlO.
Архитектура, которую мы будем использовать в этом разделе, загружает отдельные копии модельной архитектуры на разные GPU и периодически синхронизирует заученные веса между ядрами (рис. 9.8).
Рис. 9.8. Архитектура с параллелизмом данных, которую вы натренируете в згой главе
Скачивание и загрузка данных
Метод read cifarioo считывает и выполняет разбор сырых данных CifarlO. В примере 9.1 использована функция tf .FixedLengthRecordReaderO ДЛЯ чтения сырых данных из файлов CifarlO.
Пример 9.1. Эта функция читает и выполняет разбор данных из файлов с сырыми данными CifarlO
def read_cifarlO(filename_queue):
””"Читает и выполняет разбор примеров из файлов данных CifarlO.
Рекомендация: если вы хотите получить N-полосный параллелизм чтения, вызовите эту функцию N раз. Это даст вам N независимых объектов, читающих разные файлы и позиции внутри этих файлов, что позволит лучше перетасовать примеры.
Тренировка крупных глубоких сетей | 229
Аргументы: filename_queue: очередь строковых значений с именами файлов для чтения.
Возвращаемые значения:
Объект, представляющий одиночный пример, со следующими полями:
height: количество строк в результате (32) width: количество столбцов в результате (32) depth: количество цветных каналов в результате (3) key: скалярный строковый тензор, описывающий имя файла
и номер записи для этого примера.
label: целочисленный (int32) тензор с меткой в диапазоне 0..9. uint8image:: целочисленный (uint8) тензор в формате [height, width, depth] с данными изображений и и it
class CIFARlORecord(object): pass
result = CIFARlORecord()
# Размерности изображений в наборе данных CifarlO.
# См. http://www.cs.toronto.edu/~kriz/cifar.html по поводу описания # входного формата. label_bytes =1 #2 для CifarlOO
result.height = 32 result.width = 32 result.depth = 3 image_bytes = result.height * result.width * result.depth
# Каждая запись состоит из метки, после которой идет изображение # с фиксированным количеством байтов. record_bytes = label_bytes + image_bytes
# Прочитать запись, получив имена файлов из очереди filename_queue.
# В формате CifarlO верхний и нижний колонтитулы отсутствуют, поэтому # оставляем header_bytes и footer_bytes с их значениями по умолчанию, # равными 0.
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes) result.key, value = reader.read(filename_queue)
# Конвертировать из строкового типа в вектор из uint8, который имеет # длину record_bytes. record_bytes = tf.decode_raw(value, tf.uint8)
# Прочитать запись, получив имена файлов из очереди filename_queue.
# В формате CifarlO верхний и нижний колонтитулы отсутствуют, # поэтому мы оставляем header_bytes и footer_bytes с их значениями # по умолчанию, равными 0.
230 | Гпава 9
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes) result.key, value = reader.read(filename_queue)
# Конвертировать из строкового типа в вектор из uint8, который имеет # длину record_bytes.
record_bytes = tf.decode_raw(value, tf.uint8)
# Первые байты представляют метку, которую мы конвертируем # из uint8->int32.
result.label = tf.cast(
tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
# Остальные байты после метки представляют изображение, которое мы # реформируем из [depth * height * width] в [depth, height, width]. depth_maj or = tf.reshape(
tf.strided_slice(record_bytes, [label_bytes], [label_bytes + image_bytes]), [result.depth, result.height, result.width])
# Конвертировать из [depth, height, width] в [height, width, depth]. result.uint8image = tf.transpose(depth_major, [1, 2, 0]) return result
Глубокое погружение в архитектуру
Архитектура данной сети — стандартная многослойная сверточная сеть, похожая на усложненный вариант архитектуры LeNet5, который вы встречали в главе 6. Метод inference () создает архитектуру (пример 9.2). Данная сверточная архитектура соответствует относительно стандартной архитектуре со сверточными слоями, перемежающимися с локальными нормализующими слоями.
Пример 9.2. Эта функция строит архитектуру CifarlO
def inference(images):
'""'Построить модель CifarlO.
Аргументы: images: изображения, возвращаемые из distorted_inputs() либо inputs().
Возвращаемые значения: логиты. н н н
# Мы создаем экземпляры всех переменных, применяя tf .get_variable () # вместо tf.Variable() для того, чтобы использовать переменные
# совместно во всех тренировочных прогонах на многочисленных GPU.
Тренировка крупных глубоких сетей | 231
# Если выполнять эту модель только на одном GPU, то функцию
# можно упростить, заменив все экземпляры
# tf.get_variable() на tf.Variable().
#
# convl
with tf.variable_scope('convl') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 3, 64], stddev=5e-2, wd=0.0)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME') biases = _variable_on_cpu('biases', [64], tf.constant-initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
convl = tf.nn.relu(pre_activation, name=scope.name) _activation_summary(convl)
# pooll
pooll = tf.nn.max_pool(convl, ksize=[l, 3, 3, 1], strides=[l, 2, 2, 1], padding='SAME', name='pooll') # norml
norml = tf.nn.lrn(pooll, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=' norml')
# conv2
with tf.variable_scope('conv2') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 64, 64], stddev=5e-2, wd=0.0)
conv = tf.nn.conv2d(norml, kernel, [1, 1, 1, 1], padding='SAME') biases = _variable_on_cpu('biases', [64], tf.constant-initializer(0.1))
pre_activation = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(pre_activation, name=scope.name) _activation_summary(conv2)
# norm2
norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=' norm2')
# pool2
pool2 = tf.nn.max_pool(norm2, ksize=[l, 3, 3, 1], strides=[l, 2, 2, 1], padding='SAME', name='pool2')
232 | Гпаев 9
# 1оса13
with tf.variable_scope('loca!3') as scope:
# Переместить все в глубину, чтобы можно было выполнить # одно-единственное матричное умножение.
reshape = tf.reshape(роо!2, [FLAGS.batch_size, -1]) dim = reshape.get_shape()[1].value
weights = _variable_with_weight_decay('weights', shape=[dim, 384], stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [ 384], tf.constant-initializer(0.1)) local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)
_activation_summary(local3)
# local4
with tf.variable_scope('local4') as scope:
weights = _variable_with_weight_decay('weights', shape=[384, 192], stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [192],
tf.constant-initializer(0.1)) local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name=scope.name)
_activation_summary(local4)
# Линейная layer(WX + b).
# Здесь мы не применяем softmax, потому что
# tf.nn.sparse_softmax_cross_entropy_with_logits принимает
# нешкалированные логиты и выполняет softmax внутренне # для эффективности.
with tf.variable_scope('softmax_linear') as scope: weights = _variable_with_weight_decay('weights',
[192, CifarlO.NUM_CLASSES], stddev=l/192.0, wd=0.0)
biases = _variable_on_cpu('biases', [cifarlO.NUM_CLASSES], tf.constant-initializer(0.0))
softmaX-linear = tf.add(tf.matmul(local4, weights), biases, name=scope.name)
_activation_summary(softmax_linear)
return softmax_linear
Нет объектной ориентированности?
Сравните программный код модели, приведенный в этой архитектуре, с кодом стратегии из предыдущей архитектуры. Обратите внимание на то, как введение объекта Layer позволяет значительно упростить код с сопутствующими улучшениями в удобочитаемости. Это резкое улучшение читаемости является одной из причин, по которой большинство разработ
Тренировка крупных глубоких сетей | 233
чиков на практике предпочитают использовать объектно-ориентированное наложение поверх TensorFlow.
Тем не менее в этой главе мы используем сырой код TensorFlow, поскольку создание таких классов, как TensorGraph, с учетом многочисленных GPU потребует значительных дополнительных затрат. В целом сырой код TensorFlow предоставляет максимальную гибкость, но объектная ориентированность обеспечивает удобство. Подберите себе абстракцию, которая подходит для решаемой вами задачи.
Тренировка на многочисленных GPU
Мы создаем отдельный экземпляр модели и архитектуры на каждом GPU. Затем мы используем CPU для усреднения весов для отдельных узлов GPU (пример 9.3).
1 Пример 9.3. Эта функция тренирует модель CifarlO |
def train():
"""Натренировать CifarlO за несколько шагов."""
with tf.Graph().as_default(), tf.device('/cpu:0’):
# Создать переменную для подсчета количества вызовов train().
# Оно равняется количеству обработанных пакетов * FLAGS.num_gpus. global_step = tf.get_variable(
'global_step’, [],
initializer=tf.constant-initializer(0)r trainable=False)
# Рассчитать план скоростей заучивания.
num_batches_per_epoch = (cifarlO .NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN /
FLAGS.batch_s i ze) decay_steps = int(num_batches_per_epoch * cifarlO.NUM_EPOCHS_PER_DECAY)
# Гасить скорость заучивания экспоненциально с учетом
# количества шагов.
Ir = tf.train.exponential—decay(cifarlO.INITIAL—LEARNING—RATE, global_step, decay_steps, cifarlO. LEARNING—RATE—DECAY—FACTOR, staircase=True)
# Создать оптимизатор, который выполняет градиентный спуск.
opt = tf.train.GradientDescentOptimizer(Ir)
# Получить изображения и метки для CifarlO.
images, labels = cifarlO.distorted_inputs()
batch_queue = tf.contrib.slim.prefetch_queue.prefetch_queue(
[images, labels], capacity=2 * FLAGS.num_gpus)
234 | Гпава 9
Программный код в примере 9.4 выполняет ключевую тренировку на многочисленных GPU. Обратите внимание на то, как разные пакеты исключаются из очереди ДЛЯ каждого GPU, НО обмен весами посредством tf.get_variable_scoreQ.reuse_ variables о позволяет выполнять тренировку правильно.
Пример 9.4. Этот фрагмент реализует тренировку на многочисленных GPU I
# Вычислить градиенты для каждого модельного блока.
tower_grads = []
with tf.variable_scope(tf.get_variable_scope()):
for i in xrange(FLAGS.num_gpus): with tf.device('/gpu:%d' % i):
with tf.name_scope('%s_%d' % (cifarlO.TOWER_NAME, i)) as scope:
# Исключить из очереди один пакет для GPU.
image_batch, label_batch = batch_queue.dequeue()
# Рассчитать потерю для одного блока модели Cifar.
# Эта функция конструирует полную модель Cifar, но
# делится переменными между всеми блоками.
loss = tower_loss(scope, image_batch, label_batch)
# Использовать переменные повторно
# для следующего блока.
tf.get_variable_scope().reuse_variables()
# Сохранить сводки из последнего блока.
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
# Рассчитать градиенты для пакета данных
# на этом блоке Cifar.
grads = opt.compute_gradients(loss)
# Отслеживать градиенты во всех блоках. tower_grads.append(grads)
# Мы должны рассчитать среднее значение каждого градиента.
# Обратите внимание, что это точка синхронизации между всеми блоками.
grads = average_gradients(tower_grads)
Мы заканчиваем тем, что применяем совместную тренировочную операцию и по мере необходимости записываем контрольные точки со сводной информацией, как показано в примере 9.5.
Тренировка крупных глубоких сетей | 235
Пример 9.5. Этот фрагмент кода группирует обновления и» различных GPU й по мере необходимости записывает сводные контрольные точки
# Добавить сводку для отслеживания скорости заучивания.
summaries.append(tf.summary.scalar(’learning_rate’t lr))
# Добавить гистограммы для градиентов.
for grad, var in grads:
if grad is not None:
summaries.append(tf.summary.histogram(var.op.name + ’/gradients’, \grad))
# Применить градиенты для корректировки совместных переменных.
apply_gradient_op == opt.apply_gradients(grads,
global_step^global_step)
# Добавить гистограммы для тренируемых переменных.
for var in tf.trainable_variables():
summaries.append(tf.summary.histogram(var.op.name, var))
# Отследить скользящие средние всех тренируемых переменных.
variable_averages = tf.train.ExponentialMovingAverage(
cifarlO.MOVINGJWERAGE_DECAY, global_step)
variables_averages_op =
variable_averages.apply(tf.trainable_variables())
# Сгруппировать все обновления в единственную тренировочную операцию. train_op = tf.group(apply_gradient_op, variables_averages_op)
# Создать средство сохранения.
saver = tf.train.Saver(tf.global_variables())
# Создать сводную операцию из последних сводок, поступивших из блоков summary_op = tf. summary, merge (summaries)
# Создать операцию инициализации, чтобы выполнить ниже.
init - tf.global_variables_initializer()
# Начать выполнение операции на графе. Именованный аргумент
# allow_soft_jplacement должен иметь значение True, чтобы создавать
# блоки на GPU, т. к. некоторые операции не имеют реализации на GPU.
sess = tf.Session(config=tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=FLAGS. log_device_jplacement)) sess.run(init)
# Запустить исполнителя очередей.
tf.train.start_queue_runners(sess=sess)
236 | Гпаев 9
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
for step in xrange(FLAGS.max_steps):
start_time = time.time()
_t loss_value = sess.run([train_op, loss]) duration = time.time() - start_time
assert not np.isnan(loss_value),
'Модель отклонилась с потерей = NaN'
if step % 10 == 0:
num_examples_per_step = FLAGS.batch_size * FLAGS.num_gpus examples_per_sec = num_examples_per_step / duration sec_per_batch = duration / FLAGS.num_gpus
format_str = ('%s: шаг %d, потеря = %.2f (%.If примеров/с; %.3f ' 'с/пакет)')
print (format_str % (datetime.now(), step, loss_value, examples_per_sec, sec_per_batch))
if step % 100 == 0:
summary_str = sess.run(summary_op)
summary_writer .add_summary (summary_str, step)
# Периодически сохранять контрольную точку модели.
if step % 1000 == 0 or (step + 1) == FLAGS.max_steps: checkpoint_path = os.path.join(FLAGS.train_dir, 'model.ckpt') saver.save(sess, checkpoint_path, global_step=step)
Задание для читателя
Теперь у вас есть все фрагменты, необходимые для тренировки этой модели на практике. Попробуйте выполнить ее на подходящем сервере с вычислениями на GPU! Вы можете использовать такие инструменты, как nvidia-smi, чтобы убедиться, что все GPU действительно используются.
Резюме
В этой главе вы познакомились с различными типами оборудования, обычно используемого для тренировки глубоких архитектур. Вы также изучили режимы работы с параллельностью данных и параллельностью моделей для тренировки глубоких архитектур на многочисленных CPU или GPU. Мы закончили главу практическим примером реализации тренировки с параллельностью данных, в котором выполняется тренировка сверточной сети в TensorFlow.
В главе 10 мы обсудим будущее глубокого самообучения и то, как эффективно и корректно использовать навыки, которые вы получили в этой книге.
Тренировка крупных глубоких сетей | 237
ГЛАВА 10
Будущее глубокого самообучения
В этой книге мы рассмотрели основы современного глубокого самообучения. Мы обсудили широкий спектр алгоритмов и углубились в ряд сложных тематических исследований. Читатели, которые работали с примерами, описанными в этой книге, теперь хорошо подготовлены к использованию глубокого самообучения на работе и к чтению широкой исследовательской литературы по методам глубокого самообучения.
Стоит подчеркнуть, насколько уникален этот набор навыков. Глубокое самообучение уже оказало огромное влияние на технологическую отрасль, но глубокое самообучение начинает кардинально менять состояние практически всех нетехнических отраслей и даже смещать глобальный геополитический баланс. Ваше понимание этой эпохальной технологии откроет многие двери, которые вы, возможно, даже не пытались рисовать в своем воображении. В последней главе мы кратко рассмотрим несколько важных приложений глубокого самообучения за пределами индустрии программного обеспечения.
Мы также будем использовать эту главу, чтобы помочь вам ответить на вопрос о том, как эффективно и этически использовать ваши новые знания. Глубокое самообучение — это технология такой мощи, что практикующим специалистам важно подумать о том, как правильно использовать свои навыки. Уже имелись многочисленные злоупотребления глубокого самообучения, поэтому практикующим специалистам пойдет только на пользу сделать паузу, прежде чем приступить к построению сложных глубоко обучающихся систем, чтобы задаться вопросом, соблюдают ли системы, которые они строят, этические нормы. Мы попытаемся провести краткое обсуждение передовой этической практики, но предостерегаем, что область этики программного обеспечения настолько сложна, что краткие обсуждения вряд ли отдадут этой теме должное.
Наконец, мы рассмотрим, где происходит глубокое самообучение. Является ли глубокое самообучение первым шагом к созданию универсальных искусственных интеллектов, вычислительных сущностей, которые имеют полный спектр способностей человека? Мы сделаем обзор широкого диапазона экспертных заключений по этому вопросу.
239
Глубокое самообучение вне технологической индустрии
Технологические компании, такие как Google, Facebook, Microsoft и другие, инвестировали крупные средства в инфраструктуру глубокого самообучения. Большинство этих компаний уже знакомы с машинно-обучающимися системами, вероятно, из прошлого опыта работы, например с рекламными предсказательными или поисковыми системами. Как результат, их переход к глубокому самообучению от старых машинно-обучающихся систем потребовал лишь небольшого концептуального сдвига. Кроме того, успех прошлых приложений машинного самообучения убедил технологический менеджмент в том, что глубокое самообучение может шире применяться в компаниях. По этим причинам в ближайшем будущем компании-разработчики программного обеспечения, вероятно, останутся основными пользователями глубокого самообучения. Если вы собираетесь найти работу, используя глубокое самообучение в течение следующих нескольких лет, вполне возможно, вы в итоге окажетесь в технологической компании.
Однако в то же время назревает более широкий сдвиг, в котором глубокое самообучение начинает проникать в отрасли, где исторически машинное самообучение особо не использовалось. В отличие от более простых методов машинного самообучения, глубокое самообучение уменьшает потребность в сложной предобработке признаков и позволяет напрямую вводить перцептивные, текстовые и молекулярные данные. Как результат, ряд отраслей обращают внимание на новые тенденции, и во многих инновационных стартапах уже начались масштабные работы по перестройке этих отраслей. Теперь мы кратко обсудим некоторые изменения, происходящие в граничных отраслях, и отметим, что в ближайшем будущем может появиться много новых рабочих мест для экспертов по глубокому самообучению.
Приложения являются синергетическими
Далее вы познакомитесь с рядом глубоко обучающихся приложений в различных отраслях промышленности. Поразительно, но факт: во всех них используются одни и те же фундаментальные глубоко обучающиеся алгоритмы. Методы, которые вы встречали, такие как полносвязные сети, сверточные сети, рекуррентные сети и самообучение с максимизацией подкрепления, широко применяются в любой из этих областей. В частности, это означает, что ключевые улучшения в конструкции сверточной сети принесут плоды в фармацевтических, сельскохозяйственных и робототехнических приложениях. И напротив, инновации в области глубокого самообучения, обнаруженные инженерами-робототехниками, в свою очередь отфильтруют и укрепят основополагающие принципы глубокого самообучения. Этот творческий цикл, когда фундаментальные принципы совершенствуют приложения, которые совершенствуют фундаментальные принципы, означает, что глубокое самообучение является силой, призванной остаться всерьез и надолго.
240 | Гпава 10
Глубокое самообучение в фармацевтической промышленности
Глубокое самообучение показывает признаки широкомасштабного взлета в области разработки медицинских препаратов, которая подразделяется на многочисленные этапы. Есть доклиническая фаза разработки, когда эффекты от потенциальных лекарств опосредованно тестируются в пробирках и на животных, а затем клиническая фаза, в которой лекарственный препарат тестируется непосредственно на добровольцах. Лекарство, которое проходит обе фазы испытаний не на людях и на людях, допускается к продаже потребителям.
Исследователи начали строить модели, которые оптимизируют каждую часть процесса разработки медицинских препаратов. Например, молекулярное глубокое самообучение было применено к таким задачам, как предсказание потенциальной токсичности предполагаемых лекарственных препаратов, а также к химическим задачам, связанным с синтезом и конструированием лекарственных молекул. Другие исследователи и компании используют глубокие сверточные сети для разработки новых экспериментов, которые тесно отслеживают клеточное поведение в огромных масштабах, чтобы получить более глубокое понимание неизведанной биологии. Эти практики оказали определенное воздействие на фармацевтический мир, но пока ничего драматического не произошло ввиду того, что отсутствует возможность построить единую модель, которая "конструирует" новейшее лекарственное средство. Однако по мере продолжения усилий по сбору данных и разработке глубоко обучающихся биологических и химических моделей такое положение дел может резко измениться в ближайшие несколько лет.
Глубокое самообучение в юстиции
Юридическая сфера в большой степени опирается на прецедент в правовой литературе, для того чтобы аргументировать законность или незаконность новых судебных дел. Традиционно легионы параюридических исследователей нанимались крупными юридическими фирмами для выполнения необходимого поиска в правовой литературе. В последние годы юридические поисковые системы стали стандартными издержками для большинства современных фирм.
Такие алгоритмы поиска все еще относительно незрелые, и вполне вероятно, что глубоко обучающиеся системы для нейролингвистической обработки (neurolinguistic processing, NLP) смогут предложить значительные улучшения. Например, ряд стартапов работают над созданием глубоких систем NLP, которые предлагают более оптимальные формы запрашивания юридического прецедента. Другие стартапы работают над предсказательными методами, которые используют машинное самообучение для предсказания исхода судебного разбирательства, в то время как некоторые даже экспериментируют с методами автоматизированной генерации юридических аргументов.
В целом, эти сложные применения глубоких моделей потребуют времени, чтобы созреть, но волна инноваций в области юридического искусственного интеллекта, вероятно, предвещает драматический сдвиг в юридической профессии.
Будущее глубокого самообучения | 241
Глубокое самообучение для робототехники
Индустрия робототехники традиционно избегает внедрения машинного самообучения, поскольку нелегко обосновать, что внедрение машинно-обучающихся систем в этой области не несет опасности. Это отсутствие гарантий безопасности может стать основным сдерживающим фактором при создании систем, развертывание которых не должно создавать опасность вокруг операторов-людей.
Однако в последние годы стало очевидным, что глубоко обучающиеся системы в сочетании с методами самообучения с низкими потребностями в данных могут предложить значительные улучшения в задачах управления роботами. Компания Google продемонстрировала, что самообучение с максимизацией подкрепления может быть развернуто, чтобы обучаться управлять роботами-манипуляторами, используя фабрику роботов-манипуляторов с целью обеспечения возможности широкомасштабной тренировки на реальных роботах (рис. 10.1). Вполне вероятно, что такие усовершенствованные методы самообучения для роботов начнут находить применение в более крупной робототехнической индустрии в течение следующих нескольких лет.
Рис. 10.1. Компания Google обеспечивает работу нескольких роботов-манипуляторов, которые она использует, чтобы протестировать методы глубокого самообучения с максимизацией подкрепления для роботизированного управления. В ближайшие несколько лет это фундаментальное исследование, судя по всему, найдет свой путь в фабричные цеха
Глубокое самообучение в сельском хозяйстве
Промышленное сельское хозяйство уже в большой степени механизировано, а сложные тракторы используются для посадки и даже сбора урожая. Достижения в области робототехники и компьютерного зрения ускоряют эту тенденцию в сторону автоматизации. Сверточные сети уже используются для выявления сорняков,
242 | Глава 10
которые можно удалять с меньшим количеством пестицидов. Другие компании экспериментировали с самоходными тракторами, автоматизированным сбором фруктов и алгоритмической оптимизацией урожайности. На данный момент эти усилия в основном являются исследовательскими проектами, но в течение следующего десятилетия они, по всей видимости, перерастут в крупные внедренческие проекты.
Этическое использование глубокого самообучения
Подавляющая часть этой книги была посвящена эффективному использованию глубокого самообучения. Мы рассмотрели множество методов построения глубоких моделей, которые хорошо обобщают различные типы данных. Вместе с тем, также стоит потратить немного времени на размышления о социальных последствиях систем, которые мы строим как инженеры. Глубоко обучающиеся системы могут инициировать множество потенциально опасных приложений.
Прежде всего, сверточные сети позволят широко применять технологии распознавания лиц. Китай вышел в лидеры по внедрению таких систем для применения в реальных условиях (рис. 10.2).
Рис. 10.2. Китайское правительство широко внедряет алгоритмы распознавания лиц, основанные на сверточных сетях. Способность этих систем отслеживать людей, скорее всего, будет означать, что анонимность в общественных местах в Китае останется в прошлом
Будущее глубокого самообучения | 243
Обратите внимание, что вездесущее обнаружение лиц будет означать, что общественная анонимность канет в Лету. Любые действия, предпринимаемые в публичной сфере, будут регистрироваться и отслеживаться корпорациями и правительствами. Это видение будущего должно показаться тревожным для всех, кто обеспокоен этическими последствиями глубокого самообучения.
Более того, когда алгоритмы смогут понимать визуальную и перцептивную информацию, почти все аспекты человеческой жизни подпадут под алгоритмическое влияние. Эта тенденция является макроскопической, и не очевидно, что найдется какой-то инженер, который сможет предотвратить это будущее. Тем не менее инженеры сохраняют способность ’’голосовать ногами”. Ваши навыки ценны и востребованы; не работайте для компаний, которые следуют неэтичным практикам и строят потенциально опасные системы.
Смещение в искусственном интеллекте
Машинное самообучение и глубокое самообучение предоставляют возможность без особых усилий обучаться интересным моделям на данных. Этот основательно проработанный математический процесс может создавать мираж объективности. Стоит решительно отметить, что в такой анализ могут проникнуть всякого рода смещения и даже предубеждения. Смещения в базовых данных, взятые из исторических, смещенных записей, могут привести к тому, что модели будут обучаться принципиально несправедливым моделям. В компании Google, не в обиду ей будет сказано, однажды обнаружили, что ошибочная визуальная предсказательная модель помечала потребителей-афроамериканцев как горилл, вероятно, из-за смещенных тренировочных данных, которым не хватало адекватного представления людей с разным цветом кожи. Несмотря на то, что эта система была быстро исправлена, как только эта ошибка была доведена до сведения Google, такие сбои вызывают глубокую тревогу и символизируют более фундаментальные проблемы социальной изоляции в технологической индустрии.
По мере того как искусственный интеллект все чаще используется в таких приложениях, как процедуры условно-досрочного освобождения заключенных и утверждения займов в кредитных организациях, для нас становится все более важным обеспечить, чтобы наши модели не принимали расистских допущений или не обучались смещениям, уже присутствующим в исторических данных. Если вы работаете с конфиденциальными данными, делая предсказания, которые могут изменить ход человеческих жизней, проверьте дважды, а то и трижды, чтобы убедиться, что ваши системы не становятся жертвой смещений в данных.
244 | Гпава 10
Действительно ли универсальный искусственный интеллект неизбежен?
Широко обсуждается вопрос о том, появится ли в скором времени универсальный искусственный интеллект или нет. Эксперты не согласны с тем, что стоит серьезно рассчитывать на появление универсального ИИ. Мы считаем, что, хотя нет никакого вреда в проведении исследований по "выравниванию ценностей ИИ" и "безопасной функции вознаграждения", системы искусственного интеллекта сегодня и в обозримом будущем вряд ли быстро достигнут разумности. Как вы узнали на личном опыте, большинство глубоко обучающихся систем — это просто сложные численные механизмы, подверженные многим тонким проблемам числовой стабильности. Вероятно, потребуются десятилетия фундаментальных достижений, прежде чем универсальный разум станет реальностью. В то же время, как мы обсуждали в предыдущем разделе, искусственный интеллект уже оказывает значительное влияние на человеческие сообщества и промышленные отрасли. Поэтому, безусловно, нужно беспокоиться о влиянии ИИ, но без придумывания безумных страшилок.
Заблуждение о суперинтеллекте
Книга "Искусственный интеллект. Этапы, Угрозы, Стратегии" Ника Бост-рома1 (издательство Оксфордского университета) оказала глубокое влияние на дискурс вокруг ИИ. Основная предпосылка книги состоит в том, что взрыв интеллекта может произойти, когда модели станут способными улучшать себя рекурсивно. Сама по себе данная идея не особо радикальная. Если бы универсальный ИИ должен был появиться, нет никакой причины предположить, что ему не удалось бы быстро самосовершенство-
ваться.
В то же время, эксперт по глубокому самообучению Эндрю Hr (Andrew Ng) пошел на рекорд, заявив, что беспокоиться о суперинтеллекте— это все равно, что беспокоиться о перенаселении на Марсе. Однажды человечество, скорее всего, достигнет Марса. Когда люди высадятся на красной планете, вполне вероятно будет существовать перенаселенность, которая даже может стать очень серьезной проблемой. Но ничто из этого не меняет факта, что Марс сегодня — это пустыня. Таково и состояние литературы по созданию универсального ИИ!
Так вот, это последнее заявление гиперболическое. Солидный прогресс в самообучении с максимизацией подкрепления и генеративном моделировании имеет много перспектив для создания более интеллектуальных агентов. Но подчеркивание возможности появления сверхразумных сущностей отвлекает от реальных задач автоматизации, встречающихся на нашем пути. Безусловно, здесь даже не упоминаются другие серьезные проблемы, с которыми мы сталкиваемся, такие как глобальное потепление.
1 Bostrom N. Superintelligence: Paths, Dangers, Strategies. — Oxford University Press, 2014. — 352 p. (Востром И. Искусственный интеллект. Этапы. Угрозы. Стратегии. — М.: Манн, Иванов и Фербер, 2016, —496 с.).
Будущее глубокого самообучения | 245
Куда направиться дальше?
Если вы внимательно прочитали эту книгу и потратили усилия на работу с нашими образцами программного кода в соответствующем хранилище GitHub, тогда поздравляем! Вы уже освоили фундаментальные принципы практического машинного самообучения. Вы сможете тренировать эффективные машинно-обучающиеся системы на практике.
Однако машинное самообучение— это очень быстро развивающаяся область. Взрывной рост данной области означает, что каждый год открываются десятки перспективных моделей. Практикующие специалисты по машинному самообучению должны постоянно находиться в поиске новых моделей. При рассмотрении новых моделей полезным способом оценки их полезности является попытка подумать о том, как применить модель к задачам, которые волнуют вас или вашу организацию. Эта проверка— хороший способ организовать большой приток моделей из исследовательского сообщества, она даст вам инструмент для определения приоритетов в изучении методов, которые действительно для вас важны.
Как ответственный специалист по машинному самообучению, обязательно подумайте о том, для чего используются ваши научные модели данных. Спросите себя, используется ли ваша работа по машинному самообучению для улучшения благосостояния людей? Если ответ — "нет”, поймите, что с вашими навыками у вас есть прекрасная возможность найти работу там, где вы сможете использовать свои суперспособности по машинному самообучению для добра, а не для зла.
Наконец, мы надеемся, что вы получите большое удовольствие. Глубокое самообучение — это невероятно бурлящая область человеческой деятельности, наполненная захватывающими новыми открытиями, блестящими людьми и возможностью серьезного воздействия. Нам было приятно поделиться с вами нашими волнением и страстью к этой области, и мы надеемся, что вы приумножите наши усилия, поделившись своими познаниями в глубоком самообучении с окружающим миром.
246 | Глава 10
Предметный указатель
А
AlexNet 24, 133
AlphaGo 30, 184, 185, 192,211
Anaconda Python 45, 109
Application specific integrated circuit (ASIC ) 222
argparse 174
Artificial general intelligences (AGI) 192
Asynchronous Advantage Actor-Critic (A3C) 206
c
Central Processing Unit (CPU) 54, 219
CifarlO 228
0 загрузка данных 229
0 многослойная сверточно-сетевая архитектура 231
0 тренировка на многочисленных GPU 234
Compute unified device architecture (CUDA) 221
CuDNN 165
CycleGAN 147
D
Deep Blue 183
Deep Q-networks (DQN) 188
DeepChem 109
0 инсталляция 109
0 самообучение с максимизацией подкрепления 185
DeepMind 211
DistBelief 32
dtype 50, 53
F
Field programmable gate arrays (FPGA) 224
G
GAN-сетьЗ!, 167
Gated recurrent units (GRU) 166
Google neural machine translation (GNMT) 167
Graphics Processing Unit (GPU) 54, 221
InfiniBand 228
Intel 222
J
JOIN 54
L
Ь2-потеря 146
Layer 199
LeNet 24
LeNet-5 153
Long short-term memory (LSTM) 164
M
Markov decision processes (MDP) 185
MNIST 147
MoleculeNet 109
N
ndarray 46, 71
NumPy 46,71
NVIDIA 165, 220-223, 228
NVLINK 228
247
р
Penn Treebank 161, 171
О базовая рекуррентная архитектура 177
О загрузка данных в TensorFlow 175
О ограничения 172
О предобработка 173
Python API 45
Q
Q-самообучение 188
R
ResNet 25
Root mean squared error (RMSE) 87
s
SELECT 54 skleam.metrics 114
T
Tensor processing unit (TPU) 222 TensorBoard:
О визуализация логистической регрессионной модели 90
0 области имен 77
TensorFlow 44, 70
0 графы 56
0 документация 45
0 матричные операции 49
0 ограничения 33
0 переменные 56
0 преимущества 13
0 сеанс 55
0 тренировка модели 80
0 установка 45
0 фундаментальные примитивы 33
TensorFlow Eager 55
TensorGraph 201
tf.contrib 177
tf.data 176
tf.estimator 201
tf.FLags 174
tf.float32 50
tf.float64 50
tf.GFile 174
tf.Graph 55, 58, 201
tf. InteractiveSession 45
tf.keras 201
tf.matmul 55
tf.name scopes 84
tf.nn.max_pool 156
tf.Operation 55
tf.Queue 175
tf.Session 55,201
tf.Tensor 55
tf.train 78
tf.truncated normal 48
tf.Variable 57
Tox21 117, 125
train op 80
TrueNorth 225
248 | Предметный указатель
A
Автокодировщик вариационный 167
Агент 185
О игры в крестики-нолики 193
° абстрактная среда 194
° объектная ориентированность 194
° определение графа слоев 201
° слоевая абстракция 198
° среда игры 195
Активация 103
0 выпрямленная линейная 103
Алгоритм:
0 АЗС 206
0 Q-самообучение 188
0 асинхронной критики стратегии 206
0 безмодельный 187
0 для самообучения с максимизацией подкрепления 187
0 заучивание стратегии 189
0 катастрофическое забывание 189
0 модельно-ориентированный 187
0 обучающийся, принцип черного ящика 119
0 оптимизационный 77
0 решеточный поиск 129
0 случайный поиск гиперпараметров 130
0 тренировка асинхронная 191
Аппроксиматор универсальный 95, 104
Б
Блок вентильный рекуррентный 166
в
Вес:
0 заучиваемый 66, 82, 154
0 сверточный 155
Видеоданные 133, 142
Вознаграждение 181, 186
0 будущее 188
0 дисконтированное 188
Встраивание словарное 172
Выборка 77
Гиперпараметр 67, 117
Градиент 60, 67, 78
Граф 55
0 направленный 199, 201
графовые свертки 142
д
Данные:
0 входные многомерные 137
0 классификационные, набор синтетический 74
Действие 181
Дифференцируемость 60
Доля истинноположительных исходов 122
3
Забывание катастрофическое 189
Задача:
0 классификационная 62
0 регрессионная 62
Заполнитель 76, 159
Заучивание 68
0 стратегии 189,210
Значение случайное 47
и
Игра:
0 аркадная:
° ATARI 181
° Breakout 182
0 крестики-нолики 193
0 стратегическая StarCraft 192
Изображение RGB 137
Индекс:
0 ковариантный 44
0 контравариантный 44
Инструкция журналирования 79
Интеллект:
0 искусственный, цикл подъема и спада 98
0 универсальный искусственный 191, 245
к
Класс заученный 93
Коадаптация 105
Кодирование с одним активным состоянием 171
Конструирование признаков 211
Концепция развертывания игровой
ситуации 189
Предметный указатель | 249
Корреляции ложные 104
Коэффициент:
0 детерминации 87
0 корреляции Пирсона, квадратичный 87
Кривая рабочей характеристики приемника
122
л
Лес случайный 126
Линия разделительная 93
Локализация объекта 140
м
Максимизация подкрепления асинхронная 206
Матрица 38
0 вентильная, программируемая пользователем (FPGA) 224
0 диагональная 49
0 единичная 49
0 ошибок 123
0 сложение с матрицей 39
0 транспонирование 39
0 умножение:
° на матрицу 40
° на скаляр 39
° поэлементное 40
Машина Тьюринга 169
0 нейронная 32, 169
Межсоединения устройств памяти 228
Метод:
0 A3C.fit217
0 add output 204
0 build 204
0 build_graph 208
0 c.eval 54
0 eval 54
0 fit 217
0 get_global_step 205
0 getinputtensors 199
0 get layer variables 205
0 read cifarlO 229
0 restore 206
0 reuse variables 178
0 sess.run 76, 80, ИЗ
0 set loss 204
0 set optimizer 204
0 tf.lnteractiveSession 55
0 tf.Tensor.eval 46, 56
О tf.Tensor.get shape 52
О tf.train.FileWriter 79
О решеточного поиска 129
Метрика 86, 120
Мини-макет 108
Минимумы 67
Мини-пакет 67
Моделирование:
О временных рядов 162
О на уровне символов 171
0 на уровне слов 171
0 языка 167
Модель:
0 глубокая 117
0 настройка автоматическая 125
0 натренированная 158
0 оценивание 118
0 последовательность-в-
последовательность (seq2seq) 167
0 состязательная 146
0 точность 113
н
Набор:
0 контрольный 151
0 тестовый 119
Нарушение симметрии 47
Неустойчивость градиентная 164
о
Обнаружение объекта 140
Оборудование:
0 для тренировки и вывода 220
0 только для вывода 220
Обучение:
0 глубокое:
° альтернативные применения 240
° этическое использование 243
0 машинное:
° быстрая эволюция 245
° потенциальное смещение 244
Ограничение вычислительное 100
Операция управления потоком 169
Оптимизация:
0 гиперпараметрическая 117
° автоматизация 125
0 под управлением производных 61
0 слепая 120
250 | Предметный указатель
Ориентир 126
Ориентированность объектная 194
Остановка ранняя 107
Отладка в визуальном и невизуальном стиле 84
Отсев 105
Ошибка среднеквадратическая 86, 124
п
Память долгая краткосрочная 164
Параллелизм:
0 данных 226
0 моделей 227
Параметр заучиваемый 67
Параметризация 66
Перевод Google нейронный машинный 27, 167
Перегрузка операторов 48
Переменная 56
0 заучиваемая 205
Переподгонка 106, 119
Перплексия 178
Перцептрон 99
Показатель метрический 86, 120
Поле локальное рецептивное 134, 142
Полнота 121
0 по Тьюрингу 170
Полупроводник 222
Порог отсечения 122
Потеря перекрестно-энтропийная 65, 89
Правило стационарное эволюционное 162
Предсказание перспективное 151
Представление заучиваемое 102
Преобразование:
0 Лапласа 103
0 Лежандра 103
0 полносвязное 21
0 Фурье 103
Прецизионность 121
Приведение типов, неявное 53
Примитив:
0 TensorFlow 35
0 глубокое самообучение 21
Проблема исчезающего градиента 103
Программирование:
0 декларативное 54
0 императивное 53
0 с отслеживанием состояний 56
0 функциональное 56
Проект автоматизированного рабочего
места, статистика 125
Производная 60
Прореживание 105
Пространство векторное 36, 44, 167
Процесс принятия решений, марковский
181, 185
Процессор тензорный 222
р
Размер:
0 транзисторов 222
0 шага 137
Распознавание символов оптическое 24
Распределение:
0 вероятностей 64
0 нормальное 73
Распространение обратное 100, 101
Регрессия линейная 80
Регуляризация 104
0 весов 107
Ряд:
0 Тейлора 101
0 Фурье 101
с
Самообучение:
0 глубокое 19
° примитивы 21
0 машинное:
° молекулярное 151
° скорость чипов 222
0 однократное 27
0 с максимизацией подкрепления 181
° агент игры в крестики-нолики 193
° алгоритм АЗС 206
° алгоритмы 187
° марковский процесс принятия решений 185
° ограничения 191
° симуляция 187, 191
Свертка растянутая 139
Сеанс 55
Сегментация изображения 141
Сеть:
0 генеративно-состязательная 31
0 глубокая 96
0 крупная глубокая:
° обзор тренировки 219
° параллельная тренировка на данных CifarlO с использованием многочисленных GPU 228
Предметный указатель | 251
° специальное аппаратное обеспечение 219
° тренировка на CPU 220
° тренировка распределенная 225
0 полносвязная 21
° глубокая, компоненты 95
° тренировка 108
0 рекуррентная нейронная 22
° машина Тьюринга 169
° оптимизация 165
° полнота по Тьюрингу 170
° применение 166
° рекуррентные архитектуры 162
0 сверточная 22
° нейронная, конструирование 139
0 структурно-агностическая 95
Симуляция 187
0 на основе CPU 191
Скаляр 36
Скорость:
0 заучивания 108
0 чипов 222
Словарь:
0 передачи данных 77
0 построение 173
Слой:
0 максимально редуцирующий 138, 153
0 полносвязный 21
0 сверточный 22, 137
° преобразование 134
Спектрограмма речи 163
Специфичность 122
Спуск:
0 градиентный 67, 179
° стохастический, поточный 226
0 студента магистратуры 129
Среда 181, 185
Среднее значение 72
Стандартное отклонение 72
Суперинтеллект 245
т
Тензор:
0 в физике 42
0 второго ранга 38
0 вычисление значения 46
0 константный, инициализация 45
0 матричные операторы 49
0 нулевого ранга 36
0 обработка формы 51
0 отбор случайных значений 47
0 первого ранга 36
0 сложение и шкалирование 48
0 создание и обработка 44
0 типы 50
0 третьего ранга 41, 51
0 четвертого ранга 42
Теорема:
0 Вейерштрасса-Стоуна 101
0 об универсальной сходимости 100
Технология обнаружения лиц 243
Точность 121
0 обобщение 123
Транслирование 52
Тренировка:
0 асинхронная 191
0 глубокой сети, распределенная 225-227
0 на графическом процессорном устройстве 221
0 на центральном процессорном устройстве:
° нейроморфные чипы 224
° преимущества 220
° программируемые пользователем вентильные матрицы 224
° против тренировки на GPU 220
° тренировка на TPU 222
0 сквозная 26
У
Узел оптимизационный 80
ф
Фильтр 137
Форма, обработка 51
Функция 59
0 accuracy score 114
0 tf.assign57
0 tf.constant 47
0 tf.convert to tensor 199
0 tf.diag49
0 tf.expand dims 52
0 tf.eye49
0 tf.fill 46
0 tf.FixedLengthRecordReader 229
0 tf.get default_graph 55
0 tf.global-Variables initializer 57
0 tf.gradients 78
252 | Предметный указатель
0 tf.matmul 50
О tf.matrixtranspose 50
О tf.namescope 77, 1И
О tf.nn.conv2d 152, 154
О tf.nn.embeddinglookup 177
О tf.nn.max_pool 153
О tf.nn.relu 111
О tf.ones45
О tf.randnormal 48
О tf.randuniform 48
О tf.randomnormal 47
О tf.range49
О tf.registertensorconversionfunction 199
О tf.reshape 51
О tf.squeeze 52
О tf. summary 79
0 tf.summary.merge all 79
0 tf.summary.scalar 79
0 tf.to double 51
0 tf.to float 51
0 tf.to_int32 51
0 tf.to_int64 51
0 tf.train.AdamOptimizer 81
0 tf.zeros45
О градиент 61
О минимизации 61, 67
О минимум и производная 61, 67
О многомерная 61
О непрерывная 60
О полилинейная 44
О потерь 145, 211
О превосходства 190
О приведения типов 50
О сигмоидальная 89, 103
О стоимости 190
X
Хеширование признаков 37
ц
Цепь импульсная 224
ч
Чип нейроморфный 224
ш
Шахматы профессиональные 183
э
Энтропия перекрестная 65
Эпоха 68
я
Ядро сверточное 136
Ячейка долгой краткосрочной памяти 23
177
Предметный указатель | 253
O'REILLY’
TensorFlow для глубокого обучения Книга позволяет освоить TensorFlow — новую революционную программную библиотеку Google для глубокого обучения. Для освоения достаточно иметь базовые знания по линейной алгебре и математическому анализу. Вы на практике познакомитесь с основами машинного обучения и научитесь решать как типичные, так и нестандартные задачи. Книга покажет, как проектировать системы, способные обнаруживать объекты на изображениях, понимать текст и даже предсказывать свойства потенциальных лекарств.
Книга содержит множество практических примеров и дает прочные знания фундаментальных принципов глубокого обучения, начиная с нулевого уровня. Она идеально подходит практикующим разработчикам с опытом проектирования программных систем и будет полезна тем специалистам, которые не испытывают проблем с написанием сценариев, но не всегда справляются с проектированием обучающихся алгоритмов.
Это фантастическая книга для специалистов-практиков по машинному обучению, желающих начать работу в новой области глубокого обучения. Широта охватываемых тем делает эту книгу настоящим справочником, к которому вы будете неоднократно возвращаться, чтобы вывести свои навыки на следующий уровень.
Марвин Бертин, инженер-исследователь по машинному обучению, компания Freenome
В этой книге вы:
познакомитесь с фундаментальными принципами библиотеки TensorFlow, включая выполнение базовых вычислений;
построите простые обучающиеся системы, чтобы понять их математические основы;
погрузитесь в полносвязные глубокие сети, применяемые в тысячах приложений; .. |
превратите прототипы в высококачественные модели с помощью гиперпараметрической оптимизации;
обработаете изображения с помощью сверточных нейронных сетей;
научитесь справляться с наборами естественно-языковых данных | с помощью рекуррентных нейронных сетей;
примените обучение с максимизацией подкрепления на примере таких игр, как крестики-нолики;
натренируете глубокие сети с помощью оборудования, включая графические и тензорные процессоры.
191036, Санкт-Петербург, Гончарная ул., 20 Тел.: (812) 717-10-50, 339-54-17, 339-54-28
E-mail: mail@bhv.ru Internet: www.bhv.ru
Бхарат Рамсундар (Bharath Ramsundar)—аспирант в области вычислительной техники и глубокого обучения в Стэнфордском университете, является ведущим разработчиком пакета с открытым исходным кодом DeepChem.io, основанного на библиотеке TensorFlow.
Реза Босаг Заде (Reza Bosagh Zadeh) — основатель и генеральный директор компании Matroid и адъюнкт-профессор в Стэнфордском университете. Его профессиональная деятельность находится в области машинного обучения, вычислительной и дискретной прикладной математики. Работал в технических консультативных советах Microsoft, а также занимался построением машинно-обучающихся алгоритмов, лежащих в основе системы Twitter. Разработал и преподает два класса уровня докторантуры в Стэнфордском университете: распределенные алгоритмы и оптимизация и дискретная математика и алгоритмы.